
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ci418/A1_atronomical_imaging_2020
|
https://github.com/ci418/A1_atronomical_imaging_2020
|
48c4b001140944d1c9b178b36ac19c3f7f72209c
|
39efb410a8ea25e35cb23dfd9bd537a15afd1ba8
|
b70f9db536250aaac122d9db5de9d295bbbeac91
|
refs/heads/main
| 2023-01-06T07:49:50.449289 | 2020-11-02T17:07:53 | 2020-11-02T17:07:53 | 309,432,540 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5939376354217529,
"alphanum_fraction": 0.6225336194038391,
"avg_line_length": 26.543306350708008,
"blob_id": "26951014496e672e7e6937a5571cbd54b3e367cb",
"content_id": "6707e8467a547b608de4f2336c32ac16fe40d461",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3497,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 127,
"path": "/aperture_test.py",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 13 09:33:19 2020\n\n@author: Charalambos Ioannou\n\nModule testing the discovery and masking of sources\nby using a square expanding aperture.\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n#%%\n\n#Determine the brightest point in a 2d array\ntest_data = np.random.rand(10,15) #random data set\npos = np.where(test_data == np.max(test_data))\nprint(pos[0][0], pos[1][0]) #coordinates of highest point\n\n#%%\ncopied_data = np.copy(test_data)\n#print(np.amax(test_data))\n\n\ndef max_value(x):\n 'Returns position of maximum value in 2d array'\n pos = np.where(x == np.max(x))\n row_index = pos[0][0]\n column_index = pos[1][0]\n return row_index, column_index\n\nr = 3 #initial aperture radius\n\ndef aperture(c_index, r_index, radius):\n 'Defines square aperture around maxumum point'\n x1 = c_index - radius\n x2 = c_index + radius\n y1 = r_index - radius\n y2 = r_index + radius\n return x1, x2, y1, y2\n\nm_row, m_column = max_value(copied_data)#\n#print max value and its coordinates\nprint(copied_data[m_row][m_column], m_column, m_row)\n\nx1_test, x2_test, y1_test, y2_test = aperture(m_column, m_row, r)\n#print edges of aperture and its radius\nprint(x1_test, x2_test, y1_test, y2_test, r) \n\n#%%\n \ndef Gaussian(sigma, shape):\n 'Defines a 2D Gaussian to test code'\n r = -10\n l = 10\n mean = 0\n x, y = np.meshgrid(np.linspace(r, l, shape[0]), np.linspace(r, l, shape[1]))\n var = ((x * x) + (y * y))\n z = np.exp(- ((var - mean)**2) / (2 * (sigma * sigma)))\n return z \n\nsigma = 20\nshape = [100, 100]\ngauss1 = Gaussian(sigma, shape)\n\nplt.imshow(gauss1)\nplt.show()\n\n#pixels with value lower than this are considered background\nlow_threshold = 1e-1 \n\nradius = 2 #initial radius\n\n#lists for background and source pixels to be appended\nbackground = []\nsource = []\n\ngauss_loop = gauss1.copy() #copy of data that will not be masked\n\n#lists for the row and collumn coordinates to be appended\nr_list = []\nc_list = []\n\nwhile(True):\n\n r, c = max_value(gauss1) #coordinates of max value\n \n r_list.append(r)\n c_list.append(c) \n \n #if below low threshold break the while loop\n if gauss1[r][c] < low_threshold:\n break\n \n else:\n #condition determining the final size of the aperture \n while len(background) < len(source) + 1:\n \n x1, x2, y1, y2 = aperture(c, r, radius)\n \n box = gauss_loop[y1:y2, x1:x2] #creates aperture\n \n radius += 1\n \n #mask the data corresponding to a source\n gauss1[y1:y2, x1:x2][gauss1[y1:y2, x1:x2] >= low_threshold] = 0\n \n #appends pixel to corresponding list depending on its value\n background = box[box < low_threshold]\n source = box[box >= low_threshold]\n \n #determines true flux of source\n total_flux = sum(source)\n mean_background = np.mean(background)\n total_background = mean_background * len(source)\n true_flux = total_flux - total_background\n# check background and source data to make sure they make sense\n# check gauss1 data to make sure that the source is eliminated\n\n#plots the masked data to check if source is masked\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\ncircle = plt.Circle((r_list[0], c_list[0]), radius, color='r', fill = False)\nax.add_artist(circle)\nplt.scatter(r_list[0], c_list[0], c='r')\nplt.imshow(gauss1)\nplt.show()"
},
{
"alpha_fraction": 0.7751539945602417,
"alphanum_fraction": 0.790554404258728,
"avg_line_length": 56.235294342041016,
"blob_id": "f3a4db46dac9b125e461c3d6f8cec1e3e72be430",
"content_id": "946df99682ba40db66dcce0d17353c3f16dac08f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 974,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 17,
"path": "/README.md",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# A1_atronomical_imaging_2020\nContains code used for Imperial College Physics 3rd year labs experiment A1 'Astronomical imaging' on term 1 cycle 1 in 2020. \nCode produced by Charalambos Ioannou and Ines Belo Ferreira.\n\nThis repository should contain 5 Python scripts. These are\n\n'Histogram' - Python script that produces the initial histogram of the data created to determine the background mean\n\n'aperture_test' - Python script that tests the function of a square aperture on a simulated 2d Gaussian array\n\n'Test_on_image' - Python script that tests our algorithm on a small part of the image\n\n'Circular_aperture_test' - Python script that tests the creation of a circular aperture using artificial data\nand also tests the circular aperture on a small part of the image (same part as in 'Test_on_image')\n\n'Final_count' - Python script that runs the algorithm on the whole image and produces the catalogue. \nAlso produces the plot of number of galaxies brighter than a brightness limit m against m \n"
},
{
"alpha_fraction": 0.5327257513999939,
"alphanum_fraction": 0.6195999383926392,
"avg_line_length": 25.16098976135254,
"blob_id": "008b7df3fa9eb69699dd7aee6f024f45ac594fd6",
"content_id": "028584a2d9c51768560d3f66703186bb27157451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8449,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 323,
"path": "/Final_count.py",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Oct 24 10:11:19 2020\n\n@author: Charalambos Ioannou\n\nModule producing the catalogue for the whole image and analysing the data\n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom astropy.io import fits\nfrom matplotlib.colors import LogNorm\nfrom scipy.optimize import curve_fit\n\n#%%\nhdulist = fits.open(\"mosaic.fits\")\ndata = hdulist[0].data\ntest_data = data\n\n#calibration value and error\nZP = hdulist[0].header[\"MAGZPT\"]\nZP_error = hdulist[0].header[\"MAGZRR\"]\n\n#%%\n\n#Bleed is masked manually at these points\ndata[3000:3400, 1219:1642] = 0 #eliminate the large source\n\ndata[0:, 1425:1453] = 0 #mask vertical bleed from large source\n\ndata[425:433, 1103:1652] = 0 #mask horizontal bleed\ndata[433:442, 1310:1526] = 0 #mask horizontal bleed\ndata[442:471, 1378:1477] = 0 #mask horizontal bleed\n\ndata[314:320, 1019:1702] = 0 #mask horizontal bleed\ndata[320:335, 1309:1535] = 0 #mask horizontal bleed\ndata[335:363, 1397:1474] = 0 #mask horizontal bleed\n\ndata[202:263, 1390:1475] = 0 #mask horizontal bleed\n\ndata[124:128, 1291:1524] = 0 #mask horizontal bleed\ndata[128:129, 1342:1505] = 0 #mask horizontal bleed\ndata[129:130, 1350:1490] = 0 #mask horizontal bleed\ndata[130:153, 1369:1481] = 0 #mask horizontal bleed\ndata[153:161, 1419:1432] = 0 #mask horizontal bleed\n\ndata[117:124, 1390:1467] = 0 #mask horizontal bleed\n\ndata[117:139, 1526:1539] = 0 #mask horizontal bleed\n\ndata[333:354, 1641:1649] = 0 #mask horizontal bleed\n\ndata[424:437, 1027:1043] = 0 #mask vertical bleed\ndata[437:451, 1036:1039] = 0 #mask vertical bleed\n\ndata[1403:1452, 2063:2115] = 0 #mask vertical bleed\ndata[1400:1403, 2089:2092] = 0 #mask vertical bleed\n\ndata[2276:2337, 2105:2157] = 0 #mask vertical bleed\n\ndata[3382:3446, 2440:2496] = 0 #mask vertical bleed\n\ndata[3733:3803, 2102:2164] = 0 #mask vertical bleed\ndata[3706:3803, 2129:2140] = 0 #mask vertical bleed\n\ndata[411:456, 1439:1480] = 0 #mask vertical bleed\n\ndata[4072:4123, 535:587] = 0 #mask vertical bleed - left side\n\ndata[3202:3418, 730:828] = 0 #mask vertical bleed - left side\n\ndata[2737:2836, 934:1020] = 0 #mask vertical bleed - left side\ndata[2702:2737, 969:979] = 0 #mask vertical bleed - left side\n\ndata[2223:2357, 871:937] = 0 #mask vertical bleed - left side\n\ndata[4380:4416, 1295:1331] = 0 #mask vertical bleed - left side\n\ndata[4314:4348, 1348:1383] = 0 #mask vertical bleed - left side\n\n#eliminate edge effects\n\ndata[4511:4611, 0:] = 0 #top horizontal\ndata[0:115, 0:] = 0 #bottom horizontal\n\ndata[0:, 0:100] = 0 #left vertical\ndata[0:, 2470:2570] = 0 #right vertical\n\n#plots the masked image\nplt.imshow(test_data, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\n\n#%%\ndef set_aperture(data, c_index, r_index, radius):\n 'Creates a circular aperture around the a point'\n x_0 = c_index\n y_0 = r_index\n \n x_low = x_0 - radius\n x_high = x_0 + radius\n \n x = np.arange(x_low, x_high)\n \n y_low = y_0 - radius\n y_high = y_0 + radius\n \n y = np.arange(y_low, y_high)\n \n x_indices = []\n y_indices = []\n \n for i in x:\n for j in y:\n \n if ((i - x_0) ** 2) + ((j - y_0) ** 2) <= radius ** 2:\n x_indices.append(i)\n y_indices.append(j)\n \n data = data[(y_indices, x_indices)]\n return data, y_indices, x_indices\n\ndef max_value(x):\n 'Returns position of maximum value in 2d array'\n pos = np.where(x == np.max(x))\n row_index = pos[0][0]\n column_index = pos[1][0]\n return row_index, column_index\n\ndef calibration(ZP, counts):\n 'Calibrates the value of the flux of the source'\n z = ZP - 2.5 * np.log10(counts)\n return z\n\ndef calibration_error(ZP_error, counts, counts_error):\n 'Determines the eror of the flux after calibration'\n error_log = (2.5) * (1 / np.log(10)) * (1 / counts) * (counts_error)\n error_calib = np.sqrt((ZP_error * ZP_error) + (error_log * error_log))\n return error_calib\n\n#%%\ntest_data = data.copy()\n\nshape = np.shape(test_data)\n\nlow_threshold = 3500\n\nbackground = []\nsource = []\n\ntest_data_loop = test_data.copy()\n\nr_list = []\nc_list = []\nradius_list = []\ncatalogue = []\n\nwhile(True):\n\n r, c = max_value(test_data)\n \n radius = 2 #initial radius\n \n source = []\n background = []\n \n if test_data[r][c] < low_threshold:\n break\n \n elif test_data[r][c] >= low_threshold:\n \n while len(background) < len(source) + 1:\n \n aperture, y_indices, x_indices = set_aperture(test_data_loop, c, r, radius)\n \n radius += 1\n \n for i in range(len(x_indices)):\n if test_data[y_indices[i]][x_indices[i]] >= low_threshold:\n test_data[y_indices[i]][x_indices[i]] = 0\n \n background = aperture[aperture < low_threshold]\n source = aperture[aperture >= low_threshold]\n \n total_flux = sum(source)\n flux_error = 0.1 * total_flux\n \n mean_background = np.mean(background)\n mean_error_background = np.std(background)\n total_background = mean_background * len(source)\n error_background = mean_error_background * len(source)\n \n true_flux = total_flux - total_background\n true_flux_error = np.sqrt((flux_error ** 2) + (error_background ** 2))\n \n calibrated_flux = calibration(ZP, true_flux)\n calibrated_error = calibration_error(ZP_error, true_flux, true_flux_error)\n \n #eliminates faint sources from catalogue\n if calibrated_flux > 20:\n continue\n \n catalogue.append([r, c, calibrated_flux, calibrated_error])\n \n r_list.append(r)\n c_list.append(c)\n radius_list.append(radius)\n \n#saves the catalogue\n#np.savetxt('Catalogue', catalogue, delimiter=' , ', fmt='%.2f', \\\n# header = 'Row coord Column coord Brightness')\n\n#%%\nparams = {\n 'axes.labelsize': 18,\n 'font.size': 18, \n} \nplt.rcParams.update(params)\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\n\n\nplt.imshow(test_data)\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\nfor i in range(len(c_list)):\n circle = plt.Circle((c_list[i], r_list[i]), radius_list[i],\n color='r', fill=False)\n ax.add_artist(circle)\nplt.scatter(c_list[0:], r_list[0:], c='r', s=5)\n \nplt.imshow(test_data_loop, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n\n#%%\n#obtain the flux values from the catalogue\nfluxes = []\n\nfor i in catalogue:\n fluxes.append(i[2])\n\nprint(min(fluxes), max(fluxes))\n\nfluxes = np.asarray(fluxes)\n\n#Form arrays based on a magnitude limit\nflux_1 = fluxes[fluxes < 10]\nflux_2 = fluxes[fluxes < 11]\nflux_3 = fluxes[fluxes < 12]\nflux_4 = fluxes[fluxes < 13]\nflux_5 = fluxes[fluxes < 14]\nflux_6 = fluxes[fluxes < 15]\nflux_7 = fluxes[fluxes < 16]\nflux_8 = fluxes[fluxes < 17]\nflux_9 = fluxes[fluxes < 18]\nflux_10 = fluxes[fluxes < 19]\nflux_11 = fluxes[fluxes < 20]\n#%%\n#number of sources with brightness higher then a limit\nn_1 = len(flux_1)\nn_2 = len(flux_2)\nn_3 = len(flux_3)\nn_4 = len(flux_4)\nn_5 = len(flux_5)\nn_6 = len(flux_6)\nn_7 = len(flux_7)\nn_8 = len(flux_8)\nn_9 = len(flux_9)\nn_10 = len(flux_10)\nn_11 = len(flux_11)\n\nN = np.array([n_1, n_2, n_3, n_4, n_5, n_6, n_7, n_8, n_9, n_10, n_11])\n\ndef gal_count_error(x, deg_squared):\n 'determines error of counts'\n error = np.sqrt(x) / deg_squared\n return error\n\ndeg_squared = 0.06 #number of degrees squared that our image covers\n\nN_new = N / deg_squared\nN_error = gal_count_error(N, deg_squared)\n\ndef log_error(N_new, N_error):\n 'determines error of y axis'\n error = (1 / np.log(10)) * (1 / N_new) * (N_error)\n return error\n\nN_error_log = log_error(N_new, N_error)\n\nx_axis = np.array([10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20])\ny_axis = np.log10(N_new)\n\nplt.errorbar(x_axis, y_axis, yerr = N_error_log, fmt = 'x')\n\n#%%\n\n#fits a linear function on the plot\ndef function(x, m, c):\n 'linear function to be fitted'\n n = (m * x) + c\n return n\n\nx_fit = np.linspace(10, 20, 1000)\n\npop, pcov = curve_fit(function, x_axis, y_axis)\n\nplt.errorbar(x_axis, y_axis, yerr = N_error_log, fmt = 'x')\nplt.plot(x_fit, function(x_fit, pop[0], pop[1]))\nprint(pop[0], pcov[0][0], pop[1])\nplt.xlabel('m')\nplt.ylabel('N(m)')\nplt.show()"
},
{
"alpha_fraction": 0.5327380895614624,
"alphanum_fraction": 0.5629960298538208,
"avg_line_length": 24.687898635864258,
"blob_id": "926c1862b0cb48551b9c7c15426b5d3cd773c9fc",
"content_id": "d70418e40b7e8a57fc208780f55163bf9d0aadf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4032,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 157,
"path": "/Test_on_image.py",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 20 09:52:06 2020\n\n@author: Charalambos Ioannou\n\nTests the code on a small part of the image\n\"\"\"\n#%%\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom astropy.io import fits\nfrom matplotlib.colors import LogNorm\n\n#%%\n\nhdulist = fits.open(\"mosaic.fits\")\ndata = hdulist[0].data\ntest_data = data[625:913, 1661:1949]\n\nZP = hdulist[0].header[\"MAGZPT\"] #calibration value\nZP_error = hdulist[0].header[\"MAGZRR\"] #calibration error\n\n#plots data to be tested\nplt.imshow(test_data, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n#%%\ndef max_value(x):\n 'Returns position of maximum value in 2d array'\n pos = np.where(x == np.max(x))\n row_index = pos[0][0]\n column_index = pos[1][0]\n return row_index, column_index\n\nr = 3 #initial aperture radius\n\ndef make_aperture(c_index, r_index, radius):\n 'Defines square aperture around maxumum point'\n x_1 = c_index - radius\n x_2 = c_index + radius\n y_1 = r_index - radius\n y_2 = r_index + radius\n return x_1, x_2, y_1, y_2\n\ndef calibration(ZP, counts):\n 'Calibrates the value of the flux of the source'\n z = ZP - 2.5 * np.log10(counts)\n return z\n\n#%%\n\ntest_data = data[625:913, 1661:1949].copy()\n\nshape = np.shape(test_data)\n\nlow_threshold = 3500\n\nbackground = []\nsource = []\n\ntest_data_loop = test_data.copy()\n\nr_list = []\nc_list = []\nradius_list = []\ncatalogue = []\n\nwhile(True):\n\n r, c = max_value(test_data)\n \n radius = 2 #initial radius\n \n source = []\n background = []\n \n if test_data[r][c] < low_threshold:\n break\n \n elif test_data[r][c] >= low_threshold:\n \n while len(background) < len(source) + 1:\n \n x_1, x_2, y_1, y_2 = make_aperture(c, r, radius)\n \n #stop aperture if it reaches the edge of the data set\n if x_1 < 0 or x_2 > shape[1] or y_1 < 0 or y_2 > shape[0]:\n test_data[y_1:y_2, x_1:x_2][test_data[y_1:y_2, x_1:x_2] \\\n >= low_threshold] = 0\n break\n \n aperture = test_data_loop[y_1:y_2, x_1:x_2]\n \n background = aperture[aperture < low_threshold]\n source = aperture[aperture >= low_threshold]\n \n radius += 1\n \n #mask the detected source\n test_data[y_1:y_2, x_1:x_2][test_data[y_1:y_2, x_1:x_2] \\\n >= low_threshold] = 0\n \n background = aperture[aperture < low_threshold]\n source = aperture[aperture >= low_threshold]\n \n total_flux = sum(source)\n mean_background = np.mean(background)\n total_background = mean_background * len(source)\n true_flux = total_flux - total_background\n \n calibrated_flux = calibration(ZP, true_flux) #calibrates flux\n catalogue.append([r, c, calibrated_flux]) #appends to catalogue\n \n r_list.append(r)\n c_list.append(c)\n radius_list.append(radius)\n\n#%%\n \n#Plots the detected sources on the data to check how accurate the code is\nparams = {\n 'axes.labelsize': 18,\n 'font.size': 18, \n} \nplt.rcParams.update(params)\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\n\nfor i in range(len(c_list)):\n circle = plt.Circle((c_list[i], r_list[i]), radius_list[i],\n color='r', fill=False)\n ax.add_artist(circle)\nplt.scatter(c_list[0:], r_list[0:], c='r', s=5)\n\nplt.imshow(test_data)\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\nfor i in range(len(c_list)):\n circle = plt.Circle((c_list[i], r_list[i]), radius_list[i],\n color='r', fill=False)\n ax.add_artist(circle)\nplt.scatter(c_list[0:], r_list[0:], c='r', s=5)\n \nplt.imshow(test_data_loop, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()"
},
{
"alpha_fraction": 0.6316516995429993,
"alphanum_fraction": 0.6703524589538574,
"avg_line_length": 26.826923370361328,
"blob_id": "c51e5cb1c7386fc031c684412db6c7dec82e551e",
"content_id": "05d9112588bdbcbbed3213bdcdb6dcad2e42bdbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1447,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 52,
"path": "/Histogram.py",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 13 09:06:53 2020\n@author: Charalambos Ioannou\n\nModule producing a histogram with respect to brightness of the data\nand analysing it in order to determine the mean background count.\n\"\"\"\n\nfrom astropy.io import fits\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom scipy.optimize import curve_fit\n\n#%%\nhdulist = fits.open(\"mosaic.fits\")\ndata = hdulist[0].data\n\n#%%\ndata_1d = data.ravel()\n#print(max(data_1d))\n#Plots histogram of data within the range of the background count\nbins = plt.hist(data_1d, bins = 75, range = (3350, 3500), \\\n label = \"number of bins = 100\")\nplt.title(\"Histogram of flux\")\nplt.xlabel(\"Flux\")\nplt.ylabel(\"Count\")\nplt.legend()\nplt.show()\n\ndef Gaussian(x, m, sigma, A):\n \"Defines Gaussian used to fit our histogram\"\n return A * np.exp( - ((x - m) / sigma) ** 2)\n\ncounts = bins[0] #counts per bin\nbin_edges = bins[1] #bin locations\nx_points = []\nfor i in range(len(bin_edges) - 1):\n x = (bin_edges[i+1] + bin_edges[i])/2 #centre of bin\n x_points.append(x)\n\nplt.plot(x_points, counts, 'o', label = 'Data') \n\n#Fits the data points with a gaussian\npopt, pcov = curve_fit(Gaussian, x_points, counts, p0 = [3421, 20, 1200000])\nprint(popt[0], np.sqrt(pcov[0][0]), popt[1], np.sqrt(pcov[1][1]))\nplt.plot(x_points, Gaussian(x_points, *popt), label = 'Fit')\nplt.title(\"Gaussian Fit on background noise\")\nplt.xlabel(\"Flux\")\nplt.ylabel(\"Count\")\nplt.legend()\nplt.show()\n"
},
{
"alpha_fraction": 0.5505142211914062,
"alphanum_fraction": 0.5714861750602722,
"avg_line_length": 23.07281494140625,
"blob_id": "634ae6c59dce354f2e1c3aaa180cca609e9fc4ba",
"content_id": "da0e7fbb52e5b768f0606505b0dbf29e409b7397",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4959,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 206,
"path": "/Circular_aperture_test.py",
"repo_name": "ci418/A1_atronomical_imaging_2020",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Nov 2 15:17:40 2020\n\n@author: Charalambos Ioannou\n\nTests the circular aperture on a part of the image\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom astropy.io import fits\nfrom matplotlib.colors import LogNorm\n\n#%%\ndef set_aperture(data, c_index, r_index, radius):\n 'Creates a circular aperture around the a point'\n x_0 = c_index\n y_0 = r_index\n \n x_low = x_0 - radius\n x_high = x_0 + radius\n \n x = np.arange(x_low, x_high)\n \n y_low = y_0 - radius\n y_high = y_0 + radius\n \n y = np.arange(y_low, y_high)\n \n x_indices = []\n y_indices = []\n \n for i in x:\n for j in y:\n \n if ((i - x_0) ** 2) + ((j - y_0) ** 2) <= radius ** 2:\n x_indices.append(i)\n y_indices.append(j)\n \n data = data[(y_indices, x_indices)]\n return data, y_indices, x_indices\n\n#%%\n#create a 2d array\nx = np.arange(0, 100)\ny = np.arange(0, 100)\n\nX,Y = np.meshgrid(x,y)\n\nplt.imshow(X)\nplt.show()\n\nradius = 10 #radius of aperture\n\n#coordinates of centre of aperture\nc_index = 50 \nr_index = 50\n\ntest, y_indices, x_indices = set_aperture(X, c_index, r_index, radius)\n\n#mask the aperture and plot the data to check its shape\nfor i in range(len(x_indices)):\n X[y_indices[i]][x_indices[i]] = 0\n\nplt.imshow(X)\nplt.show()\n#%%\nhdulist = fits.open(\"mosaic.fits\")\ndata = hdulist[0].data\ntest_data = data[625:913, 1661:1949]\n\nZP = hdulist[0].header[\"MAGZPT\"]\nZP_error = hdulist[0].header[\"MAGZRR\"]\n\n\nplt.imshow(test_data, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\n\n#%%\ndef max_value(x):\n 'Returns position of maximum value in 2d array'\n pos = np.where(x == np.max(x))\n row_index = pos[0][0]\n column_index = pos[1][0]\n return row_index, column_index\n\ndef calibration(ZP, counts):\n 'Calibrates the value of the flux of the source'\n z = ZP - 2.5 * np.log10(counts)\n return z\n\ndef calibration_error(ZP_error, counts, counts_error):\n 'Determines the eror of the flux after calibration'\n error_log = (2.5) * (1 / np.log(10)) * (1 / counts) * (counts_error)\n error_calib = np.sqrt((ZP_error * ZP_error) + (error_log * error_log))\n return error_calib\n#%%\n\nshape = np.shape(test_data)\n\n\nlow_threshold = 3500\n\nbackground = []\nsource = []\n\n\ntest_data_loop = test_data.copy()\n\nr_list = []\nc_list = []\nradius_list = []\ncatalogue = []\n\nwhile(True):\n\n r, c = max_value(test_data)\n \n radius = 2\n \n source = []\n background = []\n \n if test_data[r][c] < low_threshold:\n break\n \n elif test_data[r][c] >= low_threshold:\n \n while len(background) < len(source) + 1:\n \n aperture, y_indices, x_indices = set_aperture(test_data_loop, c, r, radius)\n \n radius += 1\n \n for i in range(len(x_indices)):\n if test_data[y_indices[i]][x_indices[i]] >= low_threshold:\n test_data[y_indices[i]][x_indices[i]] = 0\n \n background = aperture[aperture < low_threshold]\n source = aperture[aperture >= low_threshold]\n \n total_flux = sum(source)\n flux_error = 0.1 * total_flux\n \n mean_background = np.mean(background)\n mean_error_background = np.std(background)\n total_background = mean_background * len(source)\n error_background = mean_error_background * len(source)\n \n true_flux = total_flux - total_background\n true_flux_error = np.sqrt((flux_error ** 2) + \\\n (error_background ** 2))\n \n calibrated_flux = calibration(ZP, true_flux)\n calibrated_error = calibration_error(ZP_error, true_flux, true_flux_error)\n \n #if source is too faint do not catalogue it\n if calibrated_flux > 20:\n continue\n \n catalogue.append([r, c, calibrated_flux, calibrated_error])\n \n r_list.append(r)\n c_list.append(c)\n radius_list.append(radius)\n\n#%%\nparams = {\n 'axes.labelsize': 18,\n 'font.size': 18, \n} \nplt.rcParams.update(params)\n\n#Plot the detected sources on the data\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\n\nfor i in range(len(c_list)):\n circle = plt.Circle((c_list[i], r_list[i]), radius_list[i],\n color='r', fill=False)\n ax.add_artist(circle)\nplt.scatter(c_list[0:], r_list[0:], c='r', s=5)\n\nplt.imshow(test_data)\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n\nfig = plt.figure()\nax = fig.add_subplot(1, 1, 1)\nfor i in range(len(c_list)):\n circle = plt.Circle((c_list[i], r_list[i]), radius_list[i],\n color='r', fill=False)\n ax.add_artist(circle)\nplt.scatter(c_list[0:], r_list[0:], c='r', s=5)\n \nplt.imshow(test_data_loop, norm = LogNorm())\nplt.colorbar()\nax = plt.gca()\nax.set_ylim(ax.get_ylim()[::-1])\nplt.show()\n"
}
] | 6 |
VertPingouin/projectjudge
|
https://github.com/VertPingouin/projectjudge
|
5ff296c3521d322952043e966f6b0fc29e8d5e8f
|
3fd8b9d930b26d47f6f66ce2021203036c393ca6
|
fcdc1fb7439de6e3ff43da2976eb4f9a1d19a602
|
refs/heads/master
| 2020-06-04T14:40:59.552641 | 2014-12-21T16:50:56 | 2014-12-21T16:50:56 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5546467304229736,
"alphanum_fraction": 0.5607379078865051,
"avg_line_length": 32.406978607177734,
"blob_id": "aacccc8ba1e7f928e92103529f7bc62d114141f5",
"content_id": "3fdfd55c9133f8e10ce5342775e004c5ba42ff64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5746,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 172,
"path": "/directory.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "import sqlite3\n\n\nclass Directory:\n def __init__(self):\n self.__con = sqlite3.connect(':memory:')\n self.__cur = self.__con.cursor()\n\n self.__cur.execute('create table objects '\n '(id INTEGER PRIMARY KEY, x INTEGER, y INTEGER, z INTEGER)')\n self.__cur.execute('create table tags (id INTEGER PRIMARY KEY, label STRING)')\n self.__cur.execute('create table objects_tags (object_id INTEGER, tag_id INTEGER, flag BOOLEAN)')\n\n self.__objectidDict = {}\n\n def __getobjectbyid(self, identifier):\n return self.__objectidDict[identifier]\n\n # tags operations\n def disabletag(self, obj, tag):\n identifier = id(obj)\n self.__cur.execute(\n 'update objects_tags set flag = 0 where tag_id in '\n '(select id from tags where label = \"{}\") and object_id = {}'.format(tag, identifier)\n )\n\n def enabletag(self, obj, tag):\n identifier = id(obj)\n self.__cur.execute(\n 'update objects_tags set flag = 1 where tag_id in '\n '(select id from tags where label = \"{}\") and object_id = {}'.format(tag, identifier)\n )\n\n def register(self, obj, *tags):\n # get id from the object\n identifier = id(obj)\n try:\n posx = obj.position[0]\n posy = obj.position[1]\n\n except AttributeError:\n posx, posy = 'null', 'null'\n\n try:\n depth = obj.depth\n except AttributeError:\n depth = 'null'\n\n # insert the id in object table and store correspondance in dictionnary\n self.__cur.execute('insert into objects values ({}, {}, {}, {})'\n .format(identifier, posx, posy, depth))\n self.__objectidDict[identifier] = obj\n\n # insert tags in tags table\n for tag in tags:\n if not self.__cur.execute('select * from tags where label = \"{}\"'.format(tag)).fetchone():\n self.__cur.execute('insert into tags (\"label\") values (\"{}\")'.format(tag))\n\n tagid = self.__cur.execute('select id from tags where label = \"{}\"'.format(tag)).fetchone()[0]\n self.__cur.execute('insert into objects_tags values ({}, {}, 1)'.format(identifier, tagid))\n\n def unregister(self, obj):\n identifier = id(obj)\n\n # removing ref from correspondances\n self.__objectidDict.pop(identifier)\n\n # cleaning base, removing object, object tag reference and not used tags\n self.__cur.execute('delete from objects where id = {}'.format(identifier))\n self.__cur.execute('delete from objects_tags where object_id = {}'.format(identifier))\n self.__cur.execute('delete from tags where id not in (select tag_id from objects_tags)')\n\n def get(self, tag):\n # todo allow to get by update order or draw order, find good way to do it\n self.__cur.execute(\n 'select objects.id from objects \\\n inner join objects_tags on objects_tags.object_id = objects.id \\\n inner join tags on objects_tags.tag_id = tags.id \\\n where tags.label = \"{}\" and flag = 1 order by objects.z'\n .format(tag)\n )\n\n result = self.__cur.fetchall()\n\n for i, elt in enumerate(result):\n result[i] = self.__getobjectbyid(result[i][0])\n\n return result\n\n def get_single(self, tag):\n self.__cur.execute(\n 'select objects.id from objects \\\n inner join objects_tags on objects_tags.object_id = objects.id \\\n inner join tags on objects_tags.tag_id = tags.id \\\n where tags.label = \"{}\" and flag = 1 order by objects.z'\n .format(tag)\n )\n result = self.__cur.fetchone()\n result = self.__getobjectbyid(result[0])\n\n return result\n\n def get_nearest(self, obj, tag):\n posx = obj.position[0]\n\n self.__cur.execute(\n 'select objects.id from objects \\\n inner join objects_tags on objects_tags.object_id = objects.id \\\n inner join tags on objects_tags.tag_id = tags.id \\\n where tags.label = \"{}\" and flag = 1 a,d x > {} order by objects.x'\n .format(tag, posx)\n )\n\n try:\n result = self.__cur.fetchone()\n result = self.__getobjectbyid(result[0])\n except TypeError:\n return None\n\n return result\n\n def get_tags(self, obj):\n identifier = id(obj)\n\n self.__cur.execute(\n 'select label from tags where id in (select tag_id from objects_tags where object_id = {})'\n .format(identifier)\n )\n\n result = self.__cur.fetchall()\n for i, elt in enumerate(result):\n result[i] = str(elt[0])\n\n return result\n\n def update(self):\n pass\n\n\nif __name__ == '__main__':\n from externallibs.gameobjects.gametime import GameClock\n\n clock = GameClock()\n clock.start()\n\n d = Directory()\n\n class MiniObject():\n def __init__(self, d, position, name, *tags):\n self.position = position\n self.name = name\n self.directory = d\n self.directory.register(self, *tags)\n\n def __del__(self):\n self.directory.unregister(self)\n\n def get_nearest(self, tag):\n return self.directory.get_nearest(self, tag)\n\n cat1 = MiniObject(d, (1, 1), 'Kitty', 'cat')\n dog1 = MiniObject(d, (-1, 1, 0), 'Snoopy', 'dog')\n dog1 = MiniObject(d, (3, 1, 0), 'Medor', 'dog', 'zombie')\n dog1 = MiniObject(d, (4, 1, 0), 'Laika', 'dog', 'zombie')\n\n time = 0\n for i in range(100):\n prev = clock.get_real_time()\n print d.get('zombie')\n time += (clock.get_real_time() - prev)\n\n print time\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 21.200000762939453,
"blob_id": "7efec954d94c7c2478bf34c7586cfb0960b4639e",
"content_id": "55904d3012e341f239dfccfe6e83a2ac028c0cf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 5,
"path": "/gameobjects/pawns/__init__.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "__author__ = 'vertpingouin'\n\nfrom blocker import Blocker\nfrom squid import Squid\nfrom fixsquid import FixSquid"
},
{
"alpha_fraction": 0.5569043755531311,
"alphanum_fraction": 0.5576631426811218,
"avg_line_length": 22.96363639831543,
"blob_id": "5290ef7f3b499b51a419f30aaa99195cb417ef37",
"content_id": "3b005d0742d5c21426531f505e8dee96a55b2e05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1318,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 55,
"path": "/assetsmanagement/assetmanager.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "import re\nimport os\nfrom spritesheet import SpriteSheet\nfrom asset import Asset\n\n\nclass AssetFolder(dict, Asset):\n def __init__(self):\n Asset.__init__(self)\n dict.__init__({})\n\n def __getattr__(self, item):\n return self[item]\n\n def load(self):\n Asset.load(self)\n for item in self.values():\n item.load()\n\n def unload(self):\n Asset.unload(self)\n for item in self.values():\n item.unload()\n\n\nclass AssetManager(Asset):\n spritesheet = re.compile(\"spritesheet\")\n\n def __browsefolder(self, folder):\n result = AssetFolder()\n\n for elt in os.listdir(folder):\n if re.match(AssetManager.spritesheet, elt):\n result[elt.split('.')[0]] = SpriteSheet(os.path.join(folder, elt))\n else:\n result[elt] = self.__browsefolder(os.path.join(folder, elt))\n\n return result\n\n def __init__(self, folder):\n Asset.__init__(self)\n self.__root = self.__browsefolder(folder)\n\n def __getattr__(self, item):\n return self.__root[item]\n\n def load(self):\n Asset.load(self)\n for item in self.__root.values():\n item.load()\n\n def unload(self):\n Asset.unload(self)\n for item in self.__root.values():\n item.unload()\n"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 27,
"blob_id": "ea9282f662bf01340e88abcfe8bbfce66e8377f4",
"content_id": "70f8f6460cedc2683557b61892dab4b5a88b51ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 1,
"path": "/locals/__init__.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "__author__ = 'vertpingouin'\n"
},
{
"alpha_fraction": 0.5804311633110046,
"alphanum_fraction": 0.5804311633110046,
"avg_line_length": 19.133333206176758,
"blob_id": "adb79632b8d3567f7e116c579ab37b746a215ec4",
"content_id": "42fa16e3a49827d5a13c712fbe43aad82cf4b0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 30,
"path": "/gameobjects/pawns/fixsquid.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from gameobjects.gameobjects import *\nimport pygame\n\n\nclass FixSquid(GameObject):\n def __init__(self, d, position, frame, depth, *tags):\n GameObject.__init__(self, d, Tags.VISIBLE, Tags.UPDATABLE, Tags.PHYSIC, *tags)\n\n self.__frame = frame\n self.__depth = depth\n\n self.activity = Activity(self, None)\n\n self.position = Position(\n owner=self,\n position=position,\n )\n\n\n def update(self, tick):\n pass\n\n\n @property\n def frame(self):\n return self.__frame\n\n @property\n def depth(self):\n return self.__depth"
},
{
"alpha_fraction": 0.6814159154891968,
"alphanum_fraction": 0.6976401209831238,
"avg_line_length": 28.521739959716797,
"blob_id": "ff5c52818832749748f9a7195d39b2cf54787b64",
"content_id": "36d7b4a545bd10f72aac20a4ff1e56f451e35352",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 23,
"path": "/assetsmanagement/utils.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from OpenGL.GL import *\nimport pygame\n\n\ndef createtexture(pygamesurface):\n rect = pygamesurface.get_rect()\n texturedata = pygame.image.tostring(pygamesurface, \"RGBA\", 1)\n\n textureindex = glGenTextures(1)\n glEnable(GL_BLEND)\n glBindTexture(GL_TEXTURE_2D, textureindex)\n glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA,\n rect.width, rect.height,\n 0, GL_RGBA, GL_UNSIGNED_BYTE, texturedata)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_NEAREST)\n glBindTexture(GL_TEXTURE_2D, 0)\n\n return textureindex\n\n\ndef unloadtexture(id):\n glDeleteTextures(id)"
},
{
"alpha_fraction": 0.6216439604759216,
"alphanum_fraction": 0.635894238948822,
"avg_line_length": 31.072847366333008,
"blob_id": "87d8be62d0bd0cdf00f3fe0df62423472f727402",
"content_id": "540a357796f01124e23e159500a0390c46edfce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4842,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 151,
"path": "/events.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis module provides tools to generate, send and handle events of different types\n\"\"\"\n\nimport re\nfrom locals import EngineError\n\n\nclass _EventType:\n \"\"\"\n Create a new Event Type. Event type consists in an integer code and a dictionnary containing the argument's\n pattern. An event type has two public properties : code and args.\n \"\"\"\n customEventCounter = 1000\n\n def __init__(self, code=None, **kwargs):\n # if code is None we create a custom event type\n if code is None:\n _EventType.customEventCounter += 1\n code = _EventType.customEventCounter\n\n self.__code = code\n self.__argumentPattern = kwargs\n\n def __repr__(self):\n return str(self.__code)\n\n # read only attributes\n\n @property\n def args(self):\n return self.__argumentPattern\n\n @property\n def code(self):\n return self.__code\n\n\nclass EventTypes:\n \"\"\"\n EventTypes provides an abstract class that contains all EventType created.\n An EventType can be added via the add method.\n\n An EventType is formed to match this regexp : '^(E_)[A-Z_]*$'\n \"\"\"\n\n validEventName = re.compile('^(E_)[A-Z_]*$')\n\n # defining default engine events types\n\n # collision events\n E_BODY_COLLIDE_BODY = _EventType(101, gameobjects=(None, None))\n E_BODY_COLLIDE_PHYSIC = _EventType(102, gameobjects=(None, None))\n E_BODY_COLLIDE_WEAPON = _EventType(103, gameobjects=(None, None))\n E_BODY_COLLIDE_WEAKSPOT = _EventType(104, gameobjects=(None, None))\n E_BODY_COLLIDE_SHIELD = _EventType(105, gameobjects=(None, None))\n E_PHYSIC_COLLIDE_PHYSIC = _EventType(106, gameobjects=(None, None))\n E_PHYSIC_COLLIDE_WEAPON = _EventType(107, gameobjects=(None, None))\n E_PHYSIC_COLLIDE_WEAKSPOT = _EventType(108, gameobjects=(None, None))\n E_PHYSIC_COLLIDE_SHIELD = _EventType(109, gameobjects=(None, None))\n E_WEAPON_COLLIDE_WEAPON = _EventType(110, gameobjects=(None, None))\n E_WEAPON_COLLIDE_WEAKSPOT = _EventType(111, gameobjects=(None, None))\n E_WEAPON_COLLIDE_SHIELD = _EventType(112, gameobjects=(None, None))\n E_WEAKSPOT_COLLIDE_WEAKSPOT = _EventType(113, gameobjects=(None, None))\n E_WEAKSPOT_COLLIDE_SHIELD = _EventType(114, gameobjects=(None, None))\n E_SHIELD_COLLIDE_SHIELD = _EventType(115, gameobjects=(None, None))\n\n # activity events\n E_ACTIVITY_START = _EventType(201, activity=None, gameobject=None)\n E_ACTIVITY_END = _EventType(202, activity=None, gameobject=None)\n\n # moving events\n E_MOVING_TOWARD = _EventType(301, gameobjectA=None, gameobjectB=None, distance=None, speed=None, localization=None)\n E_MOVING_AWAY = _EventType(302, gameobjectA=None, gameobjectB=None, distance=None, speed=None, localization=None)\n\n E_IS_STILL = _EventType(303, gameobjectA=None, gameobjectB=None, distance=None)\n\n @staticmethod\n def add(name, **kwargs):\n # add a custom event type\n if EventTypes.validEventName.match(name):\n exec('EventTypes.'+name+'=_EventType(**kwargs)')\n else:\n raise EngineError.BadEventNameError\n\n def __init__(self):\n pass\n\n\nclass Event:\n \"\"\"\n An event is a strucutre with a certain type and certain datas respecting the type pattern.\n \"\"\"\n\n def __init__(self, etype, **kwargs):\n self.__type = etype\n\n # we get the base dict from event type\n self.__arguments = etype.args.copy()\n t1 = len(self.__arguments)\n\n # and update with values passed\n self.__arguments.update(kwargs)\n t2 = len(self.__arguments)\n\n # if a values passed does not fit the event pattern, raise exceptions\n if t1 < t2:\n invalidargs = []\n for key in self.__arguments.keys():\n if key not in etype.args.keys():\n invalidargs.append(key)\n raise EngineError.ArgumentError(invalidargs)\n else:\n if None in self.__arguments.values():\n raise EngineError.MissingArgumentError\n\n def __repr__(self):\n return '<event type: '+str(self.type)+', args: '+str(self.arguments)+'>'\n\n @property\n def type(self):\n return self.__type\n\n @property\n def arguments(self):\n return self.__arguments\n\n\nclass EventHandler():\n \"\"\"\n An EventHandler receive events via the post() public method then handle them in his __handle(event) private method.\n \"\"\"\n\n def __init__(self):\n self._queue = []\n\n def post(self, event):\n # add an event in queue\n self._queue.append(event)\n\n def update(self, tick):\n while self. _queue:\n event = self._queue.pop()\n self.__handle(event)\n\n def __handle(self, event):\n # the magic happen here ! Please override this method\n pass\n\n def __repr__(self):\n return '<EventHandler>'"
},
{
"alpha_fraction": 0.5487805008888245,
"alphanum_fraction": 0.5609756112098694,
"avg_line_length": 25.136363983154297,
"blob_id": "ac836217fb056640987ef2213005c6467160e5fa",
"content_id": "b9dae097e62bf30aa2679473f5308fc4645d5de6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 22,
"path": "/gameobjects/pawns/blocker.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from gameobjects.gameobjects import *\nimport pygame\n\n\nclass Blocker(GameObject):\n def __init__(self, d, position, size, depth, *tags):\n GameObject.__init__(self, d, Tags.PHYSIC, Tags.BLOCKER, *tags)\n\n self.__depth = depth\n\n self.position = Position(\n owner=self,\n position=position,\n )\n\n self.rigidbody = RigidBody(\n owner=self,\n collider=BoxCollider(owner=self, box=pygame.Rect((0, 0), size)),\n gravityscale=1.0,\n lineardrag=0.95,\n iskinematic=True\n )"
},
{
"alpha_fraction": 0.5202078819274902,
"alphanum_fraction": 0.5248267650604248,
"avg_line_length": 25.66153907775879,
"blob_id": "04584d743be0dee8f9403eea9d4b01fb14b3d9c5",
"content_id": "164ceb46ce31eb3c925cfbe951d6f33840dc80f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1732,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 65,
"path": "/activity.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from externallibs.gameobjects.gametime import GameClock\nfrom events import EventHandler\n\nclass Activity(EventHandler):\n \"\"\"This class shouldn't be used as is, child classes should be used instead\"\"\"\n animation = None\n\n def __init__(self, owner):\n EventHandler.__init__(self)\n\n self.__owner = owner\n\n # Activity has its own clock\n self.__clock = GameClock()\n\n self.__cursor = 0\n self.__prevcursor = -1\n self.__advance = 0.0\n self.__ended = False\n\n self.__clock.start()\n self.__prevtime = self.__clock.get_real_time()\n self.__time = self.__prevtime\n\n self._animation = None\n\n def getframe(self):\n if not self.__ended:\n self.__prevtime = self.__time\n self.__time = self.__clock.get_real_time()\n timedelta = self.__time - self.__prevtime + self.__advance\n\n while timedelta > self._animation.getduration(self.__cursor):\n timedelta -= self._animation.getduration(self.__cursor)\n self.__cursor += 1\n\n if self.__cursor > self._animation.length - 1:\n if self._animation.loop:\n self.__cursor = 0\n else:\n self.__cursor -= 1\n self.__ended = True\n\n self.__advance = timedelta\n\n # update target\n # todo return something with cursor value\n\n else:\n # execute something when activity ends\n self._onend()\n\n def __handle(self, event):\n pass\n\n def _onend(self):\n pass\n\n @property\n def isended(self):\n return self.__ended\n\n\nif __name__ == '__main__':\n pass"
},
{
"alpha_fraction": 0.6450839042663574,
"alphanum_fraction": 0.7362110018730164,
"avg_line_length": 22.05555534362793,
"blob_id": "23b69f9c7df63763bf3ddc438e119ec3e91ec582",
"content_id": "26292e329c31ce9b23a2b5b5df09090c263c3c52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 18,
"path": "/locals/Parameters.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from externallibs.gameobjects.vector2 import Vector2\nimport pygame\n\nGRAVITY = Vector2(0, 1500)\n\nGAMETICKS = 30\nAGAMETICKS = 2\nGAMESPEED = 1.0\nFPSLIMIT = 0\nSPEEDCAP = 300 * GAMETICKS\nMINSPEED = 0.1\n\nREFHRES = Vector2(480, 270)\n_multiple = 2\nSSIZE = int(_multiple * REFHRES[0]), int(_multiple * REFHRES[1])\nFLAGS = pygame.OPENGL | pygame.DOUBLEBUF | pygame.HWSURFACE\nSCENESIZE = Vector2(480, 270)\nGRIDRESOLUTION = 32\n\n\n"
},
{
"alpha_fraction": 0.6343283653259277,
"alphanum_fraction": 0.6343283653259277,
"avg_line_length": 15.875,
"blob_id": "420bf99f038ca849a33bf44867755e96dbd2817f",
"content_id": "292d9d5480594a5a11469db10f1c3959e2ec22f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 8,
"path": "/locals/Constants.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "RIGHT = 'c_right'\nLEFT = 'c_left'\nUP = 'c_up'\nDOWN = 'c_down'\n\nSTANDING = 'c_standing'\nFALLING = 'c_falling'\nASCENDING = 'c_ascending'"
},
{
"alpha_fraction": 0.6059989929199219,
"alphanum_fraction": 0.6070157885551453,
"avg_line_length": 32.35593032836914,
"blob_id": "a69a9ed8d46d858b66b57184625da8f00b415d1b",
"content_id": "812f8c67e43ef29f3ac8d7463a9e44f0b31db946",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1967,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 59,
"path": "/gameobjects/components/eventmanager.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from gameobjects.gameobjects import *\nimport events\n\n\nclass EventManager(events.EventHandler, GameObject):\n \"\"\"\n An event manager is a EventHandler that handle events by broadcasting them to other event handlers.\n It has no owner and as it has no owner it should be registered within a directory.\n \"\"\"\n\n def __init__(self, directory):\n events.EventHandler.__init__(self)\n GameObject.__init__(self, directory, Tags.EVENTMANAGER, Tags.UPDATABLE)\n\n self.__listeners = {}\n self.__knownhandlers = []\n self._queue = []\n\n for item in events.EventTypes.__dict__.items():\n if events.EventTypes.validEventName.match(item[0]):\n self.__listeners[item[1]] = []\n\n def update(self, tick):\n # brodcast events to handlers\n while self._queue:\n self.__handle(self._queue.pop())\n\n # empty queue\n self._queue = []\n\n def post(self, event):\n print event\n events.EventHandler.post(self, event)\n\n def __handle(self, evt):\n # if a handler's owner is in event's argument, we post the event to it\n for handler in self.__knownhandlers:\n if handler.owner in evt.arguments.values():\n handler.post(evt)\n\n # if a handler subscribed to the event type, we post the event to it\n for listener in self.__listeners[evt.type]:\n listener.post(evt)\n\n def subscribe(self, handler, eventtype=None):\n # if no eventtype is indicated, we'll send event concerning handler's owner\n if eventtype:\n self.__listeners[eventtype].append(handler)\n else:\n self.__knownhandlers.append(handler)\n\n def unsubscribe(self, handler, eventtype=None):\n if eventtype:\n try:\n self.__listeners[eventtype].remove(handler)\n except ValueError:\n return False\n else:\n self.__knownhandlers.remove(handler)"
},
{
"alpha_fraction": 0.7276995182037354,
"alphanum_fraction": 0.7323943376541138,
"avg_line_length": 52.25,
"blob_id": "8685dd3040ba2ce5393ad1dfa602ce294bd882b0",
"content_id": "00e288aef0b37e620c90cc43fabcef6233dae5e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 4,
"path": "/README.md",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "projectjudge\n============\n\nThis project I started few month ago will be a full featured game. For now it's just a thing that doesn't work and a try to get a generic 2d engine based on python, pyopengl and pygame.\n"
},
{
"alpha_fraction": 0.5695708990097046,
"alphanum_fraction": 0.577373206615448,
"avg_line_length": 22.33333396911621,
"blob_id": "554e634ab90329b5c62016b0b660b9ede29db8ad",
"content_id": "6ed7718870e5a592c61344d0725b4ef93fa75b75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 33,
"path": "/gameobjects/pawns/squid.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from gameobjects.gameobjects import *\nimport pygame\n\nclass Squid(GameObject):\n def __init__(self, d, position, frame, depth, *tags):\n GameObject.__init__(self, d, Tags.VISIBLE, Tags.UPDATABLE, Tags.PHYSIC, *tags)\n\n self.__frame = frame\n self.__depth = depth\n\n self.activity = Activity(self, None)\n\n self.position = Position(\n owner=self,\n position=position,\n )\n\n self.rigidbody = RigidBody(\n owner=self,\n collider=BoxCollider(owner=self, box=pygame.Rect(0, 0, 24, 32)),\n )\n\n def update(self, tick):\n self.rigidbody.update(tick)\n\n\n @property\n def frame(self):\n return self.__frame\n\n @property\n def depth(self):\n return self.__depth"
},
{
"alpha_fraction": 0.5397614240646362,
"alphanum_fraction": 0.5487077832221985,
"avg_line_length": 28.310680389404297,
"blob_id": "f8b6b1f503172cbe1cb5c802058f0c395fc0f69b",
"content_id": "8500397460a0fcbf6988fab08b10043e57b70baa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3018,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 103,
"path": "/assetsmanagement/spritesheet.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from xml.etree import ElementTree\nfrom externallibs.gameobjects.vector2 import Vector2\n\nfrom asset import Asset\nimport pygame\nimport utils\nimport os\n\n\nclass Frame:\n \"\"\"\n A frame combines 2 infos : the texture id in opengl memory and coordinate of the picture to display.\n It can be passed directly to the rendered in order to draw it.\n \"\"\"\n def __init__(self, textureid, coords, size):\n self.__coords = coords\n self.__textureid = textureid\n self.__size = size\n\n @property\n def texid(self):\n return self.__textureid\n\n @property\n def coords(self):\n return self.__coords\n\n @property\n def size(self):\n return self.__size\n\n\nclass FrameSet:\n \"\"\"\n A frameset is a group of frames. It give access to every frame with a __getitem__ method.\n \"\"\"\n def __init__(self, textureid, coords, size):\n self.__frames = []\n\n for coord in coords:\n self.__frames.append(Frame(textureid, coord, size))\n\n def __getitem__(self, item):\n return self.__frames[item]\n\n def __iter__(self):\n return iter(self.__frames)\n\n\nclass SpriteSheet(Asset):\n \"\"\"\n a spritesheet is a group of namesd framesets created after an xml file and a png file.\n \"\"\"\n def __init__(self, path):\n Asset.__init__(self)\n self.__path = path\n self.__framesets = {}\n\n def load(self):\n Asset.load(self)\n xmlfile = ElementTree.parse(os.path.join(self.__path, 'data.xml'))\n image = pygame.image.load(os.path.join(self.__path, xmlfile.findall('./filename')[0].text))\n\n textureid = utils.createtexture(image)\n\n framewidth = int(xmlfile.findall('./framewidth')[0].text)\n frameheight = int(xmlfile.findall('./frameheight')[0].text)\n\n hnb = image.get_width() / framewidth\n vnb = image.get_height() / frameheight\n\n for fs in xmlfile.findall('./animation'):\n name = fs.findall('./name')[0].text\n\n beginframe = int(fs.findall('./beginframe')[0].text)\n endframe = int(fs.findall('./endframe')[0].text)\n\n coords = []\n\n i = 1\n for y in range(1, vnb + 1):\n for x in range(1, hnb + 1):\n if i in range(beginframe, endframe + 1):\n coords.append((\n (x - 1) * 1/float(hnb),\n 1 - (y - 1) * 1/float(vnb),\n x * 1/float(hnb),\n 1 - y * 1/float(vnb)))\n i += 1\n self.__framesets[name] = FrameSet(textureid, coords, Vector2(framewidth, frameheight))\n\n def unload(self):\n if self.loaded:\n Asset.unload(self)\n texid = int(self.__framesets.values()[0][0].texid)\n utils.unloadtexture(texid)\n self.__framesets = {}\n\n def __getattr__(self, item):\n if self.loaded:\n return self.__framesets[item]\n else:\n Asset._missingasset(self)"
},
{
"alpha_fraction": 0.8450704216957092,
"alphanum_fraction": 0.8450704216957092,
"avg_line_length": 27.600000381469727,
"blob_id": "f56926475660bfc5930fb0b6d6bf89148e11e003",
"content_id": "096f3012e1e843ceb5b418b82520c704dfe04a23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 5,
"path": "/gameobjects/components/__init__.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "__author__ = 'vertpingouin'\n\nfrom eventmanager import EventManager\nfrom collisionmanager import CollisionManager\nfrom renderer import Renderer"
},
{
"alpha_fraction": 0.7627118825912476,
"alphanum_fraction": 0.7627118825912476,
"avg_line_length": 14,
"blob_id": "209f44c3c6ed388bc2c4419904c8ba410965b611",
"content_id": "75359aadfcfb0de8e2eb2d689087bc0d31082046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 4,
"path": "/gameobjects/__init__.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "__author__ = 'vertpingouin'\n\nimport components\nimport pawns"
},
{
"alpha_fraction": 0.6317169070243835,
"alphanum_fraction": 0.6317169070243835,
"avg_line_length": 24.433332443237305,
"blob_id": "aa3dee04ed4357edbe8c732f55252d140d6225e2",
"content_id": "ab9ea22e64f4d38400ecf2453e23adbc836db153",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 30,
"path": "/locals/EngineError.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "class ArgumentError(Exception):\n def __init__(self, invalidargs):\n self.message = 'Invalid argument for this EventType : '+str(invalidargs)\n\n def __str__(self):\n return self.message\n\n\nclass MissingArgumentError(Exception):\n def __init__(self):\n self.message = 'Missing argument for this EventType'\n\n def __str__(self):\n return self.message\n\n\nclass BadEventNameError(Exception):\n def __init__(self):\n self.message = 'Event name is not valid, should be the form (E_)[A-Z_]*$'\n\n def __str__(self):\n return self.message\n\n\nclass MissingAssetError(Exception):\n def __init__(self):\n self.message = 'This ressource is either missing or not loaded.'\n\n def __str__(self):\n return self.message\n"
},
{
"alpha_fraction": 0.6165333390235901,
"alphanum_fraction": 0.658133327960968,
"avg_line_length": 23.0256404876709,
"blob_id": "5af7be9a83f7c61d36da9e74c8838329c8e8d857",
"content_id": "88d4f9a7a34d29fa95e759c50b532fce4377f7bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1875,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 78,
"path": "/opengl.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from OpenGL.GL import *\nfrom OpenGL.GLU import *\nfrom locals import Parameters\n\n\ndef applyortho2d(left, right, bottom, top):\n glMatrixMode(GL_PROJECTION)\n glLoadIdentity()\n gluOrtho2D(left, right, bottom, top)\n glPushMatrix()\n glPopMatrix()\n glFlush()\n\n\ndef defineviewport(wi, hi):\n glViewport(0, 0, wi, hi)\n\n\ndef pixelcoord(oglc, scenesize):\n # transform opengl coordinates into pixel coordinates\n return (oglc[0] * float(scenesize[0]))/2, (1 + oglc[1] * float(scenesize[1]))/2\n\n\ndef oglcoord(pixcoord, scenesize):\n # transform pixel coordinates into opengl coordinates\n return 2*(pixcoord[0] / float(scenesize[0])), 2*(pixcoord[1] / float(scenesize[1]))\n\n\ndef oglsize(pixsize, scenesize):\n # transform pixel size into opengl size\n return pixsize[0] / float(scenesize[0]), pixsize[1] / float(scenesize[1])\n\n\ndef clear():\n glClear(GL_COLOR_BUFFER_BIT)\n\n\ndef drawframe(frame, pos, siz, proj=True, r=1.0, g=1.0, b=1.0, alpha=1.0):\n if proj:\n glMatrixMode(GL_MODELVIEW)\n else:\n glMatrixMode(GL_PROJECTION)\n\n pos = oglcoord(pos, Parameters.SCENESIZE)\n siz = oglsize(siz, Parameters.SCENESIZE)\n\n glLoadIdentity()\n glPushMatrix()\n\n glEnable(GL_TEXTURE_2D)\n glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA)\n\n glTranslated(-1, 1, 0)\n glScalef(1, -1, 1)\n glTranslated(pos[0]+siz[0], pos[1]+siz[1], 0)\n glScalef(siz[0], siz[1], 1)\n\n glColor4f(r, g, b, alpha)\n\n glBindTexture(GL_TEXTURE_2D, frame.texid)\n\n glBegin(GL_QUADS)\n\n glTexCoord2f(frame.coords[0], frame.coords[1])\n glVertex2f(-1.0, -1.0)\n\n glTexCoord2f(frame.coords[2], frame.coords[1])\n glVertex2f(1.0, -1.0)\n\n glTexCoord2f(frame.coords[2], frame.coords[3])\n glVertex2f(1.0, 1.0)\n\n glTexCoord2f(frame.coords[0], frame.coords[3])\n glVertex2f(-1.0, 1.0)\n\n glEnd()\n glPopMatrix()\n # glFlush()\n\n"
},
{
"alpha_fraction": 0.7430555820465088,
"alphanum_fraction": 0.7430555820465088,
"avg_line_length": 23.08333396911621,
"blob_id": "c73d70fda68fa23089043919aaa4cf43abb4e0a9",
"content_id": "d1a66c0184f6e37f395b1ff599ce0a67bdcd0482",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 12,
"path": "/locals/Tags.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "UPDATABLE = 't_updatable'\nVISIBLE = 't_visible'\nPHYSIC = 't_physic'\nLOCATABLE = 't_locatable'\n\n# singleton objects\nRENDERER = 't_renderer'\nRESSOURCEMANAGER = 't_ressourcemanager'\nCOLLISIONMANAGER = 't_collisionmanager'\nEVENTMANAGER = 't_eventmanager'\nGRID = 't_grid'\nBLOCKER = 't_blocker'"
},
{
"alpha_fraction": 0.6136919260025024,
"alphanum_fraction": 0.6136919260025024,
"avg_line_length": 17.590909957885742,
"blob_id": "2618892c6a59b3972da5b0f8242f0889c885dc34",
"content_id": "65905b18839854158ca3f3e1efdc7dda1a18c2d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 409,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 22,
"path": "/assetsmanagement/asset.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from locals import EngineError\n\n\nclass Asset:\n \"\"\"\n This is the base class for all assetsmanagement\n \"\"\"\n @staticmethod\n def _missingasset(self):\n raise EngineError.MissingAssetError\n\n def __init__(self):\n self.loaded = False\n\n def load(self):\n self.loaded = True\n\n def unload(self):\n self.loaded = False\n\n def isloaded(self):\n return self.loaded\n"
},
{
"alpha_fraction": 0.6083476543426514,
"alphanum_fraction": 0.6781017780303955,
"avg_line_length": 33.27450942993164,
"blob_id": "e180cedfbd07f5afc7616f3927783c051de0ba96",
"content_id": "5ff39dfc9dab84950903befa779f02ad800f8878",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1749,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 51,
"path": "/main.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "import cpuspinner\nimport directory\nimport gameobjects\nimport assetsmanagement\n\nfrom random import randint\nfrom externallibs.gameobjects.vector2 import Vector2\n\n\nif __name__ == '__main__':\n # first create directory\n d = directory.Directory()\n\n # create an event dispatcher\n gameobjects.components.EventManager(d)\n\n # then create a renderer (an object that draw things in a windows and create opengl context)\n renderer = gameobjects.components.Renderer(d)\n\n # load ressources\n assets = assetsmanagement.AssetManager('ressourcesfiles')\n assets.load()\n\n # create the cpu spinner\n spinner = cpuspinner.CpuSpinner(d, ttl=5)\n\n # create gameobjects\n for i in range(50):\n gameobjects.pawns.Squid(d, Vector2(randint(0, 480-32), randint(0, 270-24)),\n assets.chinesesquid.spritesheet.left[0], 0, 'squidleft')\n\n for squid in d.get('squidleft'):\n squid.rigidbody.push(Vector2(randint(-100, 100), randint(-100, -100)))\n\n\n gameobjects.pawns.FixSquid(d, Vector2(randint(0, 480-32), randint(0, 270-24)),\n assets.chinesesquid.spritesheet.up[0], 0)\n\n gameobjects.pawns.Blocker(d, Vector2(0, -32), Vector2(480, 32), 0)\n gameobjects.pawns.Blocker(d, Vector2(100, 100), Vector2(100, 32), 0)\n gameobjects.pawns.Blocker(d, Vector2(200, 200), Vector2(200, 32), 0)\n gameobjects.pawns.Blocker(d, Vector2(0, 270), Vector2(480, 50), 0)\n\n gameobjects.pawns.Blocker(d, Vector2(-32, 0), Vector2(32, 270), 0)\n gameobjects.pawns.Blocker(d, Vector2(480, 0), Vector2(32, 270), 0)\n\n # create things that have an action on previously defined gameobjects\n gameobjects.components.CollisionManager(d)\n\n # start spinning !\n spinner.start()\n\n"
},
{
"alpha_fraction": 0.6798679828643799,
"alphanum_fraction": 0.6798679828643799,
"avg_line_length": 23.15999984741211,
"blob_id": "613f88c6ecc929a10f697357f752093c5ec0bd33",
"content_id": "9a07b6353ba0dd5e3aa13e8e353cfa6edea69b42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 606,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 25,
"path": "/gameobjects/components/renderer.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from locals import Parameters\nfrom locals import Tags\n\nfrom gameobjects.gameobjects import *\n\nimport pygame\nimport opengl\n\n\nclass Renderer(GameObject):\n def __init__(self, d):\n GameObject.__init__(self, d, Tags.RENDERER)\n\n pygame.init()\n\n pygame.display.set_mode(Parameters.SSIZE, Parameters.FLAGS)\n opengl.clear()\n\n def draw(self, betweenframe):\n opengl.clear()\n\n for sprite in self._directory.get(Tags.VISIBLE):\n opengl.drawframe(sprite.frame, sprite.position.getrenderposition(betweenframe), sprite.frame.size)\n\n pygame.display.flip()\n\n\n"
},
{
"alpha_fraction": 0.5982456207275391,
"alphanum_fraction": 0.6011695861816406,
"avg_line_length": 25.71875,
"blob_id": "96d3b4422335d07bcfc08704db860be091c40cd5",
"content_id": "e82f18799239979a5a96bd5b66a175c544ecdc42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1710,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 64,
"path": "/cpuspinner.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from locals import Tags\n\nfrom externallibs.gameobjects.gametime import GameClock\nfrom pygame.time import Clock\n\nfrom locals import Parameters\n\n\nclass CpuSpinner:\n def __init__(self, directory, ttl=False, gameticks=Parameters.GAMETICKS, gamespeed=Parameters.GAMESPEED):\n self.clock = GameClock(gameticks)\n self.clock.set_speed(gamespeed)\n self.clock.start()\n\n self.limitclock = Clock()\n\n self._running = True\n\n self.__ttl = ttl * Parameters.GAMETICKS\n\n self._directory = directory\n\n self.__aupdatecounter = 0\n\n def __gettick(self):\n return self.clock.game_tick\n\n def __getbetweenframe(self):\n return self.clock.get_between_frame()\n\n def start(self):\n self.__loop()\n\n def __loop(self):\n while self._running:\n for i in self.clock.update():\n self.__update()\n self._draw()\n\n def __update(self):\n if self.__ttl:\n self.__ttl -= 1\n if self.__ttl == 0:\n self._running = False\n\n # regular update done x times by seconds\n for updatable in self._directory.get(Tags.UPDATABLE):\n updatable.update(self.__gettick())\n\n self.__aupdatecounter += 1\n\n if self.__aupdatecounter == Parameters.AGAMETICKS:\n self.__aupdatecounter = 0\n self._aupdate()\n\n def _aupdate(self):\n # alternative (heavy update) every x updates\n self._directory.update()\n # print self.clock.average_fps\n\n def _draw(self):\n self._directory.get_single(Tags.RENDERER).draw(self.__getbetweenframe())\n if Parameters.FPSLIMIT:\n self.limitclock.tick(Parameters.FPSLIMIT)\n"
},
{
"alpha_fraction": 0.6135922074317932,
"alphanum_fraction": 0.6291261911392212,
"avg_line_length": 31.125,
"blob_id": "884a8e8c913cc95087542637ebc34c0fefdc2a4a",
"content_id": "33523466f97dea3a3abe8663e81aebd8e9942db4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 16,
"path": "/gameobjects/components/collisionmanager.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "from gameobjects.gameobjects import *\n\n\nclass CollisionManager(GameObject):\n def __init__(self, d):\n GameObject.__init__(self, d, Tags.COLLISIONMANAGER, Tags.UPDATABLE)\n\n def update(self, tick):\n\n squids = self._directory.get('squidleft')\n blockers = self._directory.get(Tags.BLOCKER)\n\n for o1 in squids:\n for o2 in blockers:\n if o1.rigidbody.collisionbox.colliderect(o2.rigidbody.collisionbox) and o1 != o2:\n o1.rigidbody.conform(o2)\n\n"
},
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 21.33333396911621,
"blob_id": "22978046e07d002818bc2c413b28d2505675552a",
"content_id": "6a9cd2a1b255c9a347620467f85392bbee05e989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 3,
"path": "/assetsmanagement/__init__.py",
"repo_name": "VertPingouin/projectjudge",
"src_encoding": "UTF-8",
"text": "__author__ = 'vertpingouin'\n\nfrom assetmanager import AssetManager\n\n"
}
] | 26 |
funnydman/refactor-this
|
https://github.com/funnydman/refactor-this
|
275e152ce2ef5c1c117a5ffa13c9c48a143e86fb
|
9b30fe13950de1c7d8b29a00e485bd1770494ec0
|
3138d85700ce6c5b06f02088e23ac2c08bfaf881
|
refs/heads/master
| 2020-03-16T14:55:19.092733 | 2018-07-16T15:33:49 | 2018-07-16T15:33:49 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6312684416770935,
"alphanum_fraction": 0.6342182755470276,
"avg_line_length": 29.81818199157715,
"blob_id": "be0406086369c83cf30a216ecf907e4a4a20a16e",
"content_id": "d528a19f0353b2d807a9b9d44a31552ea0aa2170",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/server/main/views.py",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\n\ndef index(request):\n # TODO get data from github\n project_info = {\n 'project_name': 'refactor-this',\n 'project_description': 'Another great project',\n 'keywords': ['django', 'docker', 'python3']\n }\n return render(request, 'index.html', {\"project_info\": project_info})\n"
},
{
"alpha_fraction": 0.7037037014961243,
"alphanum_fraction": 0.7037037014961243,
"avg_line_length": 39.5,
"blob_id": "1b80212dcbaaf2fa05a1e6891c82b0cedab02db3",
"content_id": "47755a5ca30479dc91720392ce7b4a1527da5058",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 2,
"path": "/client/index.js",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "// require('bootstrap/dist/css/bootstrap.css');\nrequire('./app/sass/main.sass');\n"
},
{
"alpha_fraction": 0.4263651371002197,
"alphanum_fraction": 0.43298399448394775,
"avg_line_length": 25.676469802856445,
"blob_id": "358c5bc3f8b27f22ea4981bef5c9bee597da8b3b",
"content_id": "946076bccb20a1a404efce2b88576ec16f1b1042",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1813,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 68,
"path": "/client/webpack.config.js",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "const path = require('path');\nconst ExtractTextPlugin = require('extract-text-webpack-plugin');\nconst UglifyJsPlugin = require('uglifyjs-webpack-plugin');\nconst webpack = require('webpack');\n\nconst WebpackDevServerHost = 'http://0.0.0.0:8000';\n\nmodule.exports = {\n entry: './index.js',\n output: {\n path: path.resolve(__dirname, 'dist'),\n filename: 'main.bundle.js'\n },\n module: {\n rules: [\n {\n test: /\\.html$/,\n use: [\"html-loader\"]\n },\n {\n test: /\\.(sass|css)$/,\n use: ExtractTextPlugin.extract({\n fallback: 'style-loader',\n use: [\n \"css-loader\",\n \"sass-loader\"\n ]\n })\n },\n {\n test: /\\.(png|svg|jpg|gif|jpeg)$/,\n use: [\n {\n loader: 'file-loader',\n options: {outputPath: 'img/'}\n }\n ]\n },\n ]\n },\n plugins: [\n new ExtractTextPlugin({filename: 'main.bundle.css'}),\n new webpack.HotModuleReplacementPlugin()\n\n ],\n optimization: {\n minimize: true,\n minimizer: [new UglifyJsPlugin({\n include: /\\.min\\.js$/\n })]\n },\n devServer: {\n // contentBase: path.join(__dirname, '../server/templates/index.html'),\n publicPath: '/static/',\n compress: true,\n port: 5000,\n hot: true,\n inline: true,\n open: true,\n watchContentBase: true,\n proxy: {\n '/': WebpackDevServerHost,\n secure: false,\n },\n clientLogLevel: 'none',\n stats: 'errors-only'\n }\n};"
},
{
"alpha_fraction": 0.5397727489471436,
"alphanum_fraction": 0.59375,
"avg_line_length": 19.705883026123047,
"blob_id": "2063e3f8426933bd674a07270710895b615d809c",
"content_id": "b882d384eff43d4ccf718ee138b207abdff8f5bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 17,
"path": "/server/main/migrations/0002_auto_20180716_1052.py",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.7 on 2018-07-16 10:52\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('main', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterModelOptions(\n name='repository',\n options={'verbose_name_plural': 'Repositories'},\n ),\n ]\n"
},
{
"alpha_fraction": 0.657575786113739,
"alphanum_fraction": 0.6848484873771667,
"avg_line_length": 24.384614944458008,
"blob_id": "db159fe05ac5bbdf432659873280e6997db846e6",
"content_id": "3c19720c0441a51118fbbbc2cb523120693c7227",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 13,
"path": "/server/main/models.py",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Repository(models.Model):\n title = models.CharField(max_length=120, blank=False)\n description = models.CharField(max_length=256)\n author = models.CharField(max_length=200)\n\n class Meta:\n verbose_name_plural = \"Repositories\"\n\n def __str__(self):\n return self.title\n"
},
{
"alpha_fraction": 0.3749253749847412,
"alphanum_fraction": 0.3761194050312042,
"avg_line_length": 37.09090805053711,
"blob_id": "cd2c0111d8978b645ae3238d2b303aeea4ed534a",
"content_id": "056ea4f0d6b2983ee67fb9149e582694c5e0d98f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1705,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 44,
"path": "/server/templates/index.html",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n{% load static %}\n{% block home %}\n <section class=\"getting-started\">\n <div class=\"container\">\n <div class=\"row\">\n <h1>Делитесь своими проектами</h1>\n <form method=\"POST\" name=\"get-github-url\">\n {% csrf_token %}\n <label for=\"github-url\">\n <input type=\"text\" name=\"github-url\" id=\"github-url\">\n </label>\n <input type=\"submit\" value=\"+\" class=\"btn btn-action\">\n </form>\n </div>\n </div>\n </section>\n <section class=\"last-added\">\n <div class=\"container\">\n <div class=\"row\">\n <div class=\"project\">\n <div class=\"user-photo\">\n <img src=\"https://ukla.org/images/icons/user-icon.svg\" alt=\"user photo\">\n </div>\n <div class=\"project-info\">\n <div class=\"description\">\n <p>{{ project_info.project_name }}</p>\n </div>\n <div class=\"keywords\">\n <ul>\n {% for keyword in project_info.keywords %}\n <li><a href=\"#\">{{ keyword }}</a></li>\n {% endfor %}\n </ul>\n </div>\n </div>\n </div>\n </div>\n </div>\n <div class=\"show-all text-center\">\n <a href=\"#\" class=\"btn btn-action\">Перейти</a>\n </div>\n </section>\n{% endblock %}"
},
{
"alpha_fraction": 0.4833333194255829,
"alphanum_fraction": 0.4833333194255829,
"avg_line_length": 19.11111068725586,
"blob_id": "e15fe4973821815ae6efe417d85578be2b4a0efb",
"content_id": "6406d80fd7f9821da7a4d5fd92284e5b4b4c8210",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 9,
"path": "/server/templates/auth/login.html",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n{% block login %}\n <div class=\"auth\">\n <p>\n We're going to now talk to the GitHub API. Ready?\n\n </p>\n </div>\n{% endblock %}"
},
{
"alpha_fraction": 0.7635933756828308,
"alphanum_fraction": 0.7706855535507202,
"avg_line_length": 83.5999984741211,
"blob_id": "5d228f48e25d27f8a30f2787deb87e4bf638c9b3",
"content_id": "6d09e0f5f158d3d5544f596b97aeb96bb34c52f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 5,
"path": "/README.md",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "[](https://requires.io/github/FUNNYDMAN/refactor-this/requirements/?branch=develop)\n[](https://saythanks.io/to/FUNNYDMAN)\n[](http://hits.dwyl.io/FUNNYDMAN/refactor-this)\n\n# refactor-this\n"
},
{
"alpha_fraction": 0.5135135054588318,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 17.75,
"blob_id": "b70830c6b681eda43ae29194c6309a2a7de31432",
"content_id": "707cf41eb0a8edfdb9ad608e2ac289eff324f06b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "funnydman/refactor-this",
"src_encoding": "UTF-8",
"text": "django==2.0.7\nmysqlclient==1.3.13\ndjango_jenkins==0.110.0\nrequests==2.19.1"
}
] | 9 |
radekska/ESL
|
https://github.com/radekska/ESL
|
7d198331d07eac32295e776033d6fe8043856c77
|
a5656e43c2afb5d049f1e860a314d471ae197add
|
310734752d71bdf1686328999b74bf9b37ef3d8e
|
refs/heads/master
| 2023-01-19T16:31:21.403619 | 2020-11-24T22:33:13 | 2020-11-24T22:33:13 | 315,433,665 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5133057236671448,
"alphanum_fraction": 0.5340035557746887,
"avg_line_length": 20.96103858947754,
"blob_id": "0ff3b31e99644a4b0508018c6e1351c394e10f3c",
"content_id": "7b5b6f30e70d7e107e45fca437abf69eabb4dd61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1691,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 77,
"path": "/t05_fsms_without_monsters/advanced_counter.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef counter_en_rst(clk_i, en_i, rst_i, cnt_o):\n cnt = Bus(len(cnt_o))\n\n # The next state logic now includes a reset input to clear the counter\n # to zero, and an enable input that only allows counting when it is true.\n @seq_logic(clk_i.posedge)\n def next_state_logic():\n if rst_i:\n cnt.next = 0\n elif en_i:\n cnt.next = cnt + 1\n else:\n pass\n\n @comb_logic\n def output_logic():\n cnt_o.next = cnt\n\n\ndef cntr_tb(clk, en, rst):\n '''Test bench for the counter with a reset and enable inputs.'''\n\n # Enable the counter for a few cycles.\n rst.next = 0\n en.next = 1\n for _ in range(4):\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n # Disable the counter for a few cycles.\n en.next = 0\n for _ in range(2):\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n # Re-enable the counter for a few cycles.\n en.next = 1\n for _ in range(2):\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n # Reset the counter.\n rst.next = 1\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n # Start counting again.\n rst.next = 0\n for _ in range(4):\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n clk = Wire(name='clk')\n rst = Wire(1, name='rst')\n en = Wire(1, name='en')\n cnt = Bus(3, name='cnt')\n counter_en_rst(clk_i=clk, rst_i=rst, en_i=en, cnt_o=cnt)\n\n simulate(cntr_tb(clk, en, rst))\n show_text_table()\n"
},
{
"alpha_fraction": 0.6730158925056458,
"alphanum_fraction": 0.6761904954910278,
"avg_line_length": 18.6875,
"blob_id": "7073690093e590e86bf874d22d0cb418ef36d5a1",
"content_id": "6f27940e8501532755dd18abc517ce577601cf61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 16,
"path": "/t02_hierarchy_abstraction_ursidae/counter.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom .register import register\nfrom .adder import adder\n\n\n# defining counter from adder and register\n@chunk\ndef counter(clk_i, cnt_o):\n length = len(cnt_o)\n\n one = Bus(length, init_val=1)\n next_cnt = Bus(length)\n\n adder(one, cnt_o, next_cnt)\n\n register(clk_i, next_cnt, cnt_o)\n"
},
{
"alpha_fraction": 0.5745095014572144,
"alphanum_fraction": 0.586670994758606,
"avg_line_length": 40.9523811340332,
"blob_id": "612e98e954bb888cc04088f381884fcb10003c13",
"content_id": "6291a977b038b8039776f2789608591b93a84117",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6167,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 147,
"path": "/t04_ram_party/demo.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom t04_ram_party.optimized_ram import optimized_simple_ram\n\n@chunk\ndef gen_reset(clk_i, reset_o):\n '''\n Generate a reset pulse to initialize everything.\n Inputs:\n clk_i: Input clock.\n Outputs:\n reset_o: Active-high reset pulse.\n '''\n cntr = Bus(1) # Reset counter.\n\n @seq_logic(clk_i.posedge)\n def logic():\n if cntr < 1:\n # Generate a reset while the counter is less than some threshold\n # and increment the counter.\n cntr.next = cntr.next + 1\n reset_o.next = 1\n else:\n # Release the reset once the counter passes the threshold and\n # stop incrementing the counter.\n reset_o.next = 0\n\n\n@chunk\ndef sample_en(clk_i, do_sample_o, frq_in=12e6, frq_sample=100):\n '''\n Send out a pulse every so often to trigger a sampling operation.\n Inputs:\n clk_i: Input clock.\n frq_in: Frequency of the input clock (defaults to 12 MHz).\n frq_sample: Frequency of the sample clock (defaults to 100 Hz).\n Outputs:\n do_sample_o: Sends out a single-cycle pulse every 1/frq_sample seconds.\n '''\n # Compute the width of the counter and when it should roll-over based\n # on the master clock frequency and the desired sampling frequency.\n from math import ceil, log2\n rollover = int(ceil(frq_in / frq_sample)) - 1\n cntr = Bus(int(ceil(log2(frq_in / frq_sample))))\n\n # Sequential logic for generating the sampling pulse.\n @seq_logic(clk_i.posedge)\n def counter():\n cntr.next = cntr + 1 # Increment the counter.\n do_sample_o.next = 0 # Clear the sampling pulse output except...\n if cntr == rollover:\n do_sample_o.next = 1 # ...when the counter rolls over.\n cntr.next = 0\n\n\n@chunk\ndef record_play(clk_i, button_a, button_b, leds_o):\n '''\n Sample value on button B input, store in RAM, and playback by turning LEDs on/off.\n Inputs:\n clk_i: Clock input.\n button_a: Button A input. High when pressed. Controls record/play operation.\n button_b: Button B input. High when pressed. Used to input samples for controlling LEDs.\n Outputs:\n leds_o: LED outputs.\n '''\n\n # Instantiate the reset generator.\n reset = Wire()\n gen_reset(clk_i, reset)\n\n # Instantiate the sampling pulse generator.\n do_sample = Wire()\n sample_en(clk_i, do_sample)\n\n # Instantiate a RAM for holding the samples.\n wr = Wire()\n addr = Bus(11)\n end_addr = Bus(len(addr)) # Holds the last address of the recorded samples.\n data_i = Bus(1)\n data_o = Bus(1)\n optimized_simple_ram(clk_i, wr, addr, data_i, data_o)\n\n # States of the record/playback controller.\n state = Bus(3) # Holds the current state of the controller.\n INIT = 0 # Initialize. The reset pulse sends us here.\n WAITING_TO_RECORD = 1 # Getting read to record samples.\n RECORDING = 2 # Actually storing samples in RAM.\n WAITING_TO_PLAY = 3 # Getting ready to play back samples.\n PLAYING = 4 # Actually playing back samples.\n\n # Sequential logic for the record/playback controller.\n @seq_logic(clk_i.posedge)\n def fsm():\n\n wr.next = 0 # Keep the RAM write-control off by default.\n\n if reset: # Initialize the controller using the pulse from the reset generator.\n state.next = INIT # Go to the INIT state after the reset is released.\n\n elif do_sample: # Process a sample whenever the sampling pulse arrives.\n\n if state == INIT: # Initialize the controller.\n leds_o.next = 0b10101 # Light LEDs to indicate the INIT state.\n if button_a == 1:\n # Get ready to start recording when button A is pressed.\n state.next = WAITING_TO_RECORD # Go to record setup state.\n\n elif state == WAITING_TO_RECORD: # Setup for recording.\n leds_o.next = 0b11010 # Light LEDs to indicate this state.\n if button_a == 0:\n # Start recording once button A is released.\n addr.next = 0 # Start recording from beginning of RAM.\n data_i.next = button_b # Record the state of button B.\n wr.next = 1 # Write button B state to RAM.\n state.next = RECORDING # Go to recording state.\n\n elif state == RECORDING: # Record samples of button B to RAM.\n addr.next = addr + 1 # Next location for storing sample.\n data_i.next = button_b # Sample state of button B.\n wr.next = 1 # Write button B state to RAM.\n # For feedback to the user, display the state of button B on the LEDs.\n leds_o.next = concat(1, button_b, button_b, button_b, button_b)\n if button_a == 1:\n # If button A pressed, then get ready to play back the stored samples.\n end_addr.next = addr + 1 # Store the last sample address.\n state.next = WAITING_TO_PLAY # Go to playback setup state.\n\n elif state == WAITING_TO_PLAY: # Setup for playback.\n leds_o.next = 0b10000 # Light LEDs to indicate this state.\n if button_a == 0:\n # Start playback once button A is released.\n addr.next = 0 # Start playback from beginning of RAM.\n state.next = PLAYING # Go to playback state.\n\n elif state == PLAYING: # Show recorded state of button B on the LEDs.\n leds_o.next = concat(1, data_o[0], data_o[0], data_o[0], data_o[0])\n addr.next = addr + 1 # Advance to the next sample.\n if addr == end_addr:\n # Loop back to the start of RAM if this is the last sample.\n addr.next = 0\n if button_a == 1:\n # Record a new sample if button A is pressed.\n state.next = WAITING_TO_RECORD\n\n\nif __name__ == '__main__':\n toVerilog(record_play, clk_i=Wire(), button_a=Wire(), button_b=Wire(), leds_o=Bus(5))\n"
},
{
"alpha_fraction": 0.6058981418609619,
"alphanum_fraction": 0.6206434369087219,
"avg_line_length": 20.941177368164062,
"blob_id": "cc17faee332d6a73da2bc1bf2875772fce4cb6b0",
"content_id": "d84f2b3c36177c1898b91eb64050889f4aee4ff8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 746,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 34,
"path": "/t01_led_blinker/main.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n# initialize the module\ninitialize()\n\n\n# defining core blinking function\n@chunk\ndef blinker(clk_i, led_o, length):\n cnt = Bus(length, name='cnt')\n\n @seq_logic(clk_i.posedge)\n def counter_logic():\n cnt.next = cnt + 1\n\n @comb_logic\n def output_logic():\n led_o.next = cnt[length - 1]\n\n\nif __name__ == '__main__':\n # defining signals\n clk = Wire(name='clk')\n led = Wire(name='led')\n\n blinker(clk_i=clk, led_o=led, length=3)\n\n # simulation\n clk_sim(clk, num_cycles=16) # Pulse the clock input 16 times.\n show_text_table()\n\n # converting script to verilog and vhdl\n toVerilog(blinker, clk_i=clk, led_o=led, length=22)\n toVHDL(blinker, clk_i=clk, led_o=led, length=22)\n"
},
{
"alpha_fraction": 0.4492753744125366,
"alphanum_fraction": 0.6908212304115295,
"avg_line_length": 14.923076629638672,
"blob_id": "33288a0a4b343a97ab8025c34095e2875ce4c0f2",
"content_id": "a247714d9f758d8c6e449fb66119e640b28b2ea1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "byteplay3==3.5.0\ncertifi==2020.6.20\nfuture==0.18.2\nmyhdl==0.11\nmyhdlpeek==0.0.8\nnbwavedrom==0.2.0\nnumpy==1.18.5\npandas==0.25.3\npygmyhdl==0.0.3\npython-dateutil==2.8.1\npytz==2020.4\nsix==1.15.0\ntabulate==0.8.7\n"
},
{
"alpha_fraction": 0.5592011213302612,
"alphanum_fraction": 0.5891583561897278,
"avg_line_length": 25,
"blob_id": "454ef3b8e7f5de3abfcd37b51cfb3b3cfa2bac15",
"content_id": "7bc20aab015fdca829fb61a2614fb39a84250054",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 27,
"path": "/t03_pwm/test_glitches.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom t03_pwm.less_simple_pwm import pwm_less_simple\n\n\ndef test_bench(num_cycles, clk_, threshold_):\n clk_.next = 0\n threshold_.next = 3 # Start with threshold of 3.\n yield delay(1)\n for cycle in range(num_cycles):\n clk_.next = 0\n # Raise the threshold to 8 after 15 cycles.\n if cycle >= 14:\n threshold_.next = 8\n yield delay(1)\n clk_.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n clk = Wire(name='clk')\n pwm = Wire(name='pwm')\n threshold = Bus(4, name='threshold')\n pwm_less_simple(clk, pwm, threshold, 10)\n\n simulate(test_bench(20, clk, threshold))\n show_text_table()"
},
{
"alpha_fraction": 0.559268593788147,
"alphanum_fraction": 0.5844892859458923,
"avg_line_length": 29.5,
"blob_id": "22bcb84fac729c17fcd0a0447c84cdfd4a86712a",
"content_id": "d0a279c5ea44af66290d809a7ab44165c4d92ee2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1586,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 52,
"path": "/t03_pwm/demo.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom t03_pwm.simple_pwm import pwm_simple\n\n\n@chunk\ndef ramp(clk_i, ramp_o):\n \"\"\"\n Inputs:\n clk_i: Clock input.\n Outputs:\n ramp_o: Multi-bit amplitude of ramp.\n \"\"\"\n\n # Delta is the increment (+1) or decrement (-1) for the counter.\n delta = Bus(len(ramp_o))\n\n @seq_logic(clk_i.posedge)\n def logic():\n # Add delta to the current ramp value to get the next ramp value.\n ramp_o.next = ramp_o + delta\n\n # When the ramp reaches the bottom, set delta to +1 to start back up the ramp.\n if ramp_o == 1:\n delta.next = 1\n\n # When the ramp reaches the top, set delta to -1 to start back down the ramp.\n elif ramp_o == ramp_o.max - 2:\n delta.next = -1\n\n # After configuring the FPGA, the delta register is set to zero.\n # Set it to +1 and set the ramp value to +1 to get things going.\n elif delta == 0:\n delta.next = 1\n ramp_o.next = 1\n\n\n@chunk\ndef wax_wane(clk_i, led_o, length):\n rampout = Bus(length, name='ramp') # Create the triangle ramp counter register.\n ramp(clk_i, rampout) # Generate the ramp.\n pwm_simple(clk_i, led_o, rampout.o[length:length - 4]) # Use the upper 4 ramp bits to drive the PWM threshold\n\n\nif __name__ == '__main__':\n initialize()\n clk = Wire(name='clk')\n led = Wire(name='led')\n wax_wane(clk, led, 6) # Set ramp counter to 6 bits: 0, 1, 2, ..., 61, 62, 63, 62, 61, ..., 2, 1, 0, ...\n\n clk_sim(clk, num_cycles=180)\n show_text_table()\n toVerilog(wax_wane, clk, led, 23)\n"
},
{
"alpha_fraction": 0.5687386989593506,
"alphanum_fraction": 0.5829249620437622,
"avg_line_length": 37.39603805541992,
"blob_id": "37e761e153dc31ed9017d81256362d7b08c4135d",
"content_id": "3a58ea2e9b7effdb0069052ef2496df84fca8c1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3877,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 101,
"path": "/t05_fsms_without_monsters/classic_fsm.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef classic_fsm(clk_i, inputs_i, outputs_o):\n '''\n Inputs:\n clk_i: Main clock input.\n inputs_i: Two-bit input vector directs state transitions.\n outputs_o: Four-bit output vector.\n '''\n\n # Declare a state variable with four states. In addition to the current\n # state of the FSM, the state variable also stores a complete list of its\n # possible values to use for comparing what state the FSM is in and for\n # assigning a new state.\n fsm_state = State('A', 'B', 'C', 'D', name='state')\n\n # This counter is used to apply a reset to the FSM for the first few clocks upon startup.\n reset_cnt = Bus(2)\n\n @seq_logic(clk_i.posedge)\n def next_state_logic():\n if reset_cnt < reset_cnt.max - 1:\n # The reset counter starts at zero upon startup. The FSM stays in this reset\n # state until the counter increments to its maximum value. Then it never returns here.\n reset_cnt.next = reset_cnt + 1\n fsm_state.next = fsm_state.s.A # Set initial state for FSM after reset.\n elif fsm_state == fsm_state.s.A: # Compare current state to state A.\n # If the FSM is in state A, then go forward to state B if inputs_i[0] is active,\n # otherwise go backward to state D if inputs_i[1] is active.\n # Stay in this state if neither input is active.\n if inputs_i[0]:\n fsm_state.next = fsm_state.s.B # Update state to state B.\n elif inputs_i[1]:\n fsm_state.next = fsm_state.s.D # Update state to state D.\n elif fsm_state == fsm_state.s.B:\n # State B operates similarly to state A.\n if inputs_i[0]:\n fsm_state.next = fsm_state.s.C\n elif inputs_i[1]:\n fsm_state.next = fsm_state.s.A\n elif fsm_state == fsm_state.s.C:\n # State C operates similarly to states A and B.\n if inputs_i[0]:\n fsm_state.next = fsm_state.s.D\n elif inputs_i[1]:\n fsm_state.next = fsm_state.s.B\n elif fsm_state == fsm_state.s.D:\n # State D yada, yada...\n if inputs_i[0]:\n fsm_state.next = fsm_state.s.A\n elif inputs_i[1]:\n fsm_state.next = fsm_state.s.C\n else:\n # If the FSM is in some unknown state, send it back to the starting state.\n fsm_state.next = fsm_state.s.A\n\n @comb_logic\n def output_logic():\n # Turn on one of the outputs depending upon which state the FSM is in.\n if fsm_state == fsm_state.s.A:\n outputs_o.next = 0b0001\n elif fsm_state == fsm_state.s.B:\n outputs_o.next = 0b0010\n elif fsm_state == fsm_state.s.C:\n outputs_o.next = 0b0100\n elif fsm_state == fsm_state.s.D:\n outputs_o.next = 0b1000\n else:\n # Turn on all the outputs if the FSM is in some unknown state (shouldn't happen).\n outputs_o.next = 0b1111\n\n\ndef fsm_tb(clk, inputs):\n nop = 0b00 # no operation - both inputs are inactive\n fwd = 0b01 # Input combination for moving forward.\n bck = 0b10 # Input combination for moving backward.\n\n # Input sequence of 3 forwards and 3 backwards transitions.\n # The four initial NOPs are for the FSM's initial reset period.\n ins = [nop, nop, nop, nop, fwd, fwd, fwd, bck, bck, bck]\n\n # Apply each input combination from the list and then pulse the clock.\n for inputs.next in ins:\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n\n inputs = Bus(2, name='inputs')\n outputs = Bus(4, name='outputs')\n clk = Wire(name='clk')\n classic_fsm(clk, inputs, outputs)\n\n simulate(fsm_tb(clk, inputs))\n show_text_table()"
},
{
"alpha_fraction": 0.760869562625885,
"alphanum_fraction": 0.760869562625885,
"avg_line_length": 45,
"blob_id": "7905b9bb979ff3d88029b885737057d13b99d3ac",
"content_id": "08de9d78c5466b185c1f93e141e07cec3c8a99de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/README.md",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "# ESL Course Repository - All Required Tasks.\n"
},
{
"alpha_fraction": 0.5876777172088623,
"alphanum_fraction": 0.6054502129554749,
"avg_line_length": 27.133333206176758,
"blob_id": "906c2c8ea0f45309410055aa8fac786dedaf3695",
"content_id": "bfa5ef7daa7dc5981a304ef35969afca6480767f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 30,
"path": "/t03_pwm/less_simple_pwm.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nimport math\n\n\n@chunk\ndef pwm_less_simple(clk_i, pwm_o, threshold, duration):\n length = math.ceil(math.log(duration, 2))\n cnt = Bus(length, name='cnt')\n\n # Augment the counter with a comparator to adjust the pulse duration.\n @seq_logic(clk_i.posedge)\n def cntr_logic():\n cnt.next = cnt + 1\n # Reset the counter to zero once it reaches one less than the desired duration.\n # So if the duration is 3, the counter will count 0, 1, 2, 0, 1, 2...\n if cnt == duration - 1:\n cnt.next = 0\n\n @comb_logic\n def output_logic():\n pwm_o.next = cnt < threshold\n\n\nif __name__ == '__main__':\n initialize()\n clk = Wire(name='clk')\n pwm = Wire(name='pwm')\n pwm_less_simple(clk, pwm, threshold=3, duration=5)\n clk_sim(clk, num_cycles=15)\n show_text_table()\n"
},
{
"alpha_fraction": 0.555323600769043,
"alphanum_fraction": 0.5636743307113647,
"avg_line_length": 25.61111068725586,
"blob_id": "4436eae761ebc5e78c450976003fb70bb2c12431",
"content_id": "4da43dfb11c1299c8b6acc83167aef75bb652be9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 18,
"path": "/t04_ram_party/optimized_ram.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n# removed en_i signal\n@chunk\ndef optimized_simple_ram(clk_i, wr_i, addr_i, data_i, data_o):\n mem = [Bus(len(data_i)) for _ in range(2 ** len(addr_i))]\n\n @seq_logic(clk_i.posedge)\n def logic():\n if wr_i:\n mem[addr_i.val].next = data_i\n else:\n data_o.next = mem[addr_i.val]\n\n\nif __name__ == '__main__':\n toVerilog(optimized_simple_ram, clk_i=Wire(), wr_i=Wire(), addr_i=Bus(8), data_i=Bus(8), data_o=Bus(8))\n"
},
{
"alpha_fraction": 0.6304023861885071,
"alphanum_fraction": 0.6453055143356323,
"avg_line_length": 28.173913955688477,
"blob_id": "3e7192e9b39e37026af2a0dfcba2a625a301451d",
"content_id": "820aebd2c2aa39270ba93a82b07e316dfbb187a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 23,
"path": "/t02_hierarchy_abstraction_ursidae/blinker.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom t02_hierarchy_abstraction_ursidae.counter import counter\n\n\n@chunk\ndef blinker(clk_i, led_o, length):\n cnt = Bus(length, name='cnt')\n counter(clk_i, cnt)\n\n @comb_logic\n def output_logic():\n led_o.next = cnt[length - 1]\n\n\nif __name__ == '__main__':\n initialize() # Initialize for simulation.\n clk = Wire(name='clk') # Declare the clock input.\n led = Wire(name='led') # Declare the LED output.\n blinker(clk, led, 3) # Instantiate a three-bit blinker and attach I/O signals.\n clk_sim(clk, num_cycles=16) # Apply 16 clock pulses.\n show_text_table()\n\n toVerilog(blinker, clk_i=clk, led_o=led, length=22)\n"
},
{
"alpha_fraction": 0.5248525738716125,
"alphanum_fraction": 0.5408592820167542,
"avg_line_length": 25.377777099609375,
"blob_id": "06b4c63e2e71520a8c6fb9547b29e6912b8430d3",
"content_id": "1e7b5159323fe8306e879c1af17420506172ec6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 45,
"path": "/t04_ram_party/dual_port_ram.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef dual_port_ram(clk_i, wr_i, wr_addr_i, rd_addr_i, data_i, data_o):\n mem = [Bus(len(data_i)) for _ in range(2 ** len(wr_addr_i))]\n\n @seq_logic(clk_i.posedge)\n def logic():\n if wr_i:\n mem[wr_addr_i.val].next = data_i\n data_o.next = mem[rd_addr_i.val]\n\n\ndef ram_test_bench(clk_i, wr_i, wr_addr_i, rd_addr_i, data_i):\n for i in range(10):\n wr_addr_i.next = i\n data_i.next = 3 * i + 1\n wr_i.next = 1\n\n rd_addr_i.next = i - 3\n\n clk_i.next = 0\n yield delay(1)\n clk_i.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n\n clk = Wire(name='clk')\n wr = Wire(name='wr')\n wr_addr = Bus(8, name='wr_addr')\n rd_addr = Bus(8, name='rd_addr')\n data_in = Bus(8, name='data_i')\n data_out = Bus(8, name='data_o')\n\n dual_port_ram(clk, wr, wr_addr, rd_addr, data_in, data_out)\n\n simulate(ram_test_bench(clk, wr, wr_addr, rd_addr, data_in))\n\n show_text_table('clk wr wr_addr data_i rd_addr data_o')\n toVerilog(dual_port_ram, clk_i=Wire(), wr_i=Wire(), wr_addr_i=Bus(8), rd_addr_i=Bus(8), data_i=Bus(8),\n data_o=Bus(8))\n"
},
{
"alpha_fraction": 0.5552855134010315,
"alphanum_fraction": 0.5710813999176025,
"avg_line_length": 20.076923370361328,
"blob_id": "fcc6b85256dbf8c27b2c77330b67c3da13547471",
"content_id": "77020c44aeb8452e79d3120aaf5c650f5eda9779",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 39,
"path": "/t02_hierarchy_abstraction_ursidae/register.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\nfrom random import randint\n\n\n# defining D flip-flop\n@chunk\ndef dff(clk_i, d_i, q_o):\n @seq_logic(clk_i.posedge)\n def logic():\n q_o.next = d_i\n\n\n# defining a register\n@chunk\ndef register(clk_i, d_i, q_o):\n for k in range(len(d_i)):\n dff(clk_i, d_i.o[k], q_o.i[k])\n\n\ndef test_bench(clk_i, d_i):\n for i in range(10):\n d_i.next = randint(0, 256)\n clk_i.next = 0\n yield delay(1)\n clk_i.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n # create clock signal and 8-bit register input and output buses.\n clk = Wire(name='clk')\n data_in = Bus(8, name='data_in')\n data_out = Bus(8, name='data_out')\n\n register(clk_i=clk, d_i=data_in, q_o=data_out)\n\n simulate(test_bench(clk, data_in))\n show_text_table()\n\n"
},
{
"alpha_fraction": 0.5346638560295105,
"alphanum_fraction": 0.5472689270973206,
"avg_line_length": 22.799999237060547,
"blob_id": "b221dd305a2dc094727eed007143206e3c9124c2",
"content_id": "40b47da34340f21c69c6a042aa4f99e4d9059296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 40,
"path": "/t02_hierarchy_abstraction_ursidae/adder.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n# defining adder\n@chunk\ndef full_adder_bit(a_i, b_i, c_i, s_o, c_o):\n @comb_logic\n def logic():\n # defining XOR\n s_o.next = a_i ^ b_i ^ c_i\n c_o.next = (a_i & b_i) | (a_i & c_i) | (b_i & c_i)\n\n\n@chunk\ndef adder(a_i, b_i, s_o):\n c = Bus(len(a_i) + 1)\n c.i[0] = 0\n\n for k in range(len(a_i)):\n full_adder_bit(a_i=a_i.o[k], b_i=b_i.o[k], c_i=c.o[k], s_o=s_o.i[k], c_o=c.i[k + 1])\n\n\n\n\nif __name__ == '__main__':\n initialize() # Once again, initialize for a new simulation.\n\n # Declare 8-bit buses for the two numbers to be added and the sum.\n a = Bus(8, name='a')\n b = Bus(8, name='b')\n s = Bus(8, name='sum')\n\n # Instantiate an adder and connect the I/O buses.\n adder(a, b, s)\n\n # Simulate the adder's output for 20 randomly-selected inputs.\n random_sim(a, b, num_tests=20)\n\n # Show a table of the adder output for each set of inputs.\n show_text_table()\n"
},
{
"alpha_fraction": 0.5061460733413696,
"alphanum_fraction": 0.5234996676445007,
"avg_line_length": 23.210525512695312,
"blob_id": "cf471075a05c2b02c60a4f66a888ff85abc0d515",
"content_id": "5cb4f4cb0766a1887549f3c7508a947d6f0e6d1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1383,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 57,
"path": "/t04_ram_party/simple_ram.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n# defining block ram instance\n@chunk\ndef simple_ram(clk_i, en_i, wr_i, addr_i, data_i, data_o):\n mem = [Bus(len(data_i)) for _ in range(2 ** len(addr_i))]\n\n @seq_logic(clk_i.posedge)\n def logic():\n if en_i:\n if wr_i:\n mem[addr_i.val].next = data_i\n else:\n data_o.next = mem[addr_i.val]\n\n\ndef ram_test_bench(clk_i, en_i, wr_i, addr_i, data_i):\n en_i.next = 1\n wr_i.next = 1\n\n for i in range(10):\n addr_i.next = i\n data_i.next = 3 * i + 1\n\n clk_i.next = 0\n yield delay(1)\n clk_i.next = 1\n yield delay(1)\n\n wr_i.next = 0\n for i in range(10):\n addr_i.next = i\n\n clk_i.next = 0\n yield delay(1)\n clk_i.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n\n clk = Wire(name='clk')\n en = Wire(name='en')\n wr = Wire(name='wr')\n addr = Bus(8, name='addr')\n data_in = Bus(8, name='data_i')\n data_out = Bus(8, name='data_o')\n\n simple_ram(clk_i=clk, en_i=en, wr_i=wr, addr_i=addr, data_i=data_in, data_o=data_out)\n\n simulate(ram_test_bench(clk_i=clk, en_i=en, wr_i=wr, addr_i=addr, data_i=data_in))\n\n show_text_table('en clk wr addr data_i data_o')\n\n # toVerilog(simple_ram, clk_i=Wire(), en_i=Wire(), wr_i=Wire(), addr_i=Bus(8), data_i=Bus(8), data_o=Bus(8))\n\n\n\n"
},
{
"alpha_fraction": 0.5437598824501038,
"alphanum_fraction": 0.5633491277694702,
"avg_line_length": 31.295917510986328,
"blob_id": "b4ac30d8c36082695d47b7429bca4975d5221c88",
"content_id": "f9bdbe5ed44af91a70c32b1c7a67c1a8702ec036",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3165,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 98,
"path": "/t05_fsms_without_monsters/classic_fsm_v2.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef classic_fsm_v2(clk_i, inputs_i, outputs_o):\n fsm_state = State('A', 'B', 'C', 'D', name='state')\n reset_cnt = Bus(2)\n\n # Variables for storing the input values during the previous clock\n # and holding the changes between the current and previous input values.\n prev_inputs = Bus(len(inputs_i), name='prev_inputs')\n input_chgs = Bus(len(inputs_i), name='input_chgs')\n\n # This logic compares the current input values with the negation of the previous values.\n # The output is active only if an input goes from 0 to 1.\n @comb_logic\n def detect_chg():\n input_chgs.next = inputs_i & ~prev_inputs\n\n # This is the same FSM state transition logic as before, except it looks at the\n # input_chgs signals instead of the input_i signals.\n @seq_logic(clk_i.posedge)\n def next_state_logic():\n if reset_cnt < reset_cnt.max - 1:\n reset_cnt.next = reset_cnt + 1\n fsm_state.next = fsm_state.s.A\n elif fsm_state == fsm_state.s.A:\n if input_chgs[0]:\n fsm_state.next = fsm_state.s.B\n elif input_chgs[1]:\n fsm_state.next = fsm_state.s.D\n elif fsm_state == fsm_state.s.B:\n if input_chgs[0]:\n fsm_state.next = fsm_state.s.C\n elif input_chgs[1]:\n fsm_state.next = fsm_state.s.A\n elif fsm_state == fsm_state.s.C:\n if input_chgs[0]:\n fsm_state.next = fsm_state.s.D\n elif input_chgs[1]:\n fsm_state.next = fsm_state.s.B\n elif fsm_state == fsm_state.s.D:\n if input_chgs[0]:\n fsm_state.next = fsm_state.s.A\n elif input_chgs[1]:\n fsm_state.next = fsm_state.s.C\n else:\n fsm_state.next = fsm_state.s.A\n\n prev_inputs.next = inputs_i # Record the current input values.\n\n @comb_logic\n def output_logic():\n if fsm_state == fsm_state.s.A:\n outputs_o.next = 0b0001\n elif fsm_state == fsm_state.s.B:\n outputs_o.next = 0b0010\n elif fsm_state == fsm_state.s.C:\n outputs_o.next = 0b0100\n elif fsm_state == fsm_state.s.D:\n outputs_o.next = 0b1000\n else:\n outputs_o.next = 0b1111\n\n\ndef fsm_tb(clk, inputs):\n nop = 0b00\n fwd = 0b01\n bck = 0b10\n\n ins = [nop, nop, nop, nop, fwd, fwd, fwd, bck, bck, bck]\n for inputs.next in ins:\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n # Interspersed active and inactive inputs.\n ins = [fwd, nop, fwd, nop, fwd, nop, bck, nop, bck, nop, bck, nop]\n for inputs.next in ins:\n clk.next = 0\n yield delay(1)\n clk.next = 1\n yield delay(1)\n\n\nif __name__ == '__main__':\n initialize()\n\n inputs = Bus(2, name='inputs')\n outputs = Bus(4, name='outputs')\n clk = Wire(name='clk')\n classic_fsm_v2(clk, inputs, outputs)\n\n simulate(fsm_tb(clk, inputs))\n show_text_table('clk inputs prev_inputs input_chgs state outputs')\n\n toVerilog(classic_fsm_v2, clk_i=Wire(), inputs_i=Bus(2), outputs_o=Bus(4))\n"
},
{
"alpha_fraction": 0.6493710875511169,
"alphanum_fraction": 0.6564465165138245,
"avg_line_length": 33.4054069519043,
"blob_id": "9982ce5320085f8187aef35cc5a58d5cb2ae5397",
"content_id": "5d2dbb9fef4409d97ad1fabacff09279b8af1f08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 37,
"path": "/t03_pwm/simple_pwm.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef pwm_simple(clk_i, pwm_o, threshold):\n '''\n Inputs:\n clk_i: PWM changes state on the rising edge of this clock input.\n threshold: Bit-length determines counter width and value determines when output goes low.\n Outputs:\n pwm_o: PWM output starts and stays high until counter > threshold and then output goes low.\n '''\n cnt = Bus(len(threshold), name='cnt') # Create a counter with the same number of bits as the threshold.\n\n # Here's the sequential logic for incrementing the counter. We've seen this before!\n @seq_logic(clk_i.posedge)\n def cntr_logic():\n cnt.next = cnt + 1\n\n # Combinational logic that drives the PWM output high when the counter is less than the threshold.\n @comb_logic\n def output_logic():\n pwm_o.next = cnt < threshold # cnt<threshold evaluates to either True (1) or False (0).\n\n\nif __name__ == '__main__':\n initialize()\n\n # Create signals and attach them to the PWM.\n clk = Wire(name='clk')\n pwm = Wire(name='pwm')\n threshold = Bus(3, init_val=3) # Use a 3-bit threshold with a value of 3.\n pwm_simple(clk, pwm, threshold)\n\n # Pulse the clock and look at the PWM output.\n clk_sim(clk, num_cycles=24)\n show_text_table()"
},
{
"alpha_fraction": 0.6056337952613831,
"alphanum_fraction": 0.613458514213562,
"avg_line_length": 22.703702926635742,
"blob_id": "fe1ac4a888d26f57302dc2b2c73525b0fc4aac4d",
"content_id": "66c9e4b80aab4d1f380b3a4cfe14886ef0459b3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 27,
"path": "/t05_fsms_without_monsters/counter.py",
"repo_name": "radekska/ESL",
"src_encoding": "UTF-8",
"text": "from pygmyhdl import *\n\n\n@chunk\ndef counter(clk_i, cnt_o):\n # Here's the counter state variable.\n cnt = Bus(len(cnt_o))\n\n # The next state logic is just an adder that adds 1 to the current cnt state variable.\n @seq_logic(clk_i.posedge)\n def next_state_logic():\n cnt.next = cnt + 1\n\n # The output logic just sends the current cnt state variable to the output.\n @comb_logic\n def output_logic():\n cnt_o.next = cnt\n\n\nif __name__ == '__main__':\n initialize()\n clk = Wire(name='clk')\n cnt = Bus(3, name='cnt')\n counter(clk_i=clk, cnt_o=cnt)\n clk_sim(clk, num_cycles=10)\n\n show_text_table()"
}
] | 19 |
AlinMH/acs-projects
|
https://github.com/AlinMH/acs-projects
|
1527bd0a5eab7a37cc536c1ab0af4653bc606c57
|
1e11b4fd1b96045b4b810d5892b2be73c1d5d886
|
9a087c8fa8bfefc1a33fa57aceb5f6f58da5169e
|
refs/heads/master
| 2023-04-17T22:54:56.832359 | 2021-04-30T17:25:22 | 2021-04-30T17:25:22 | 132,591,940 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7069351077079773,
"alphanum_fraction": 0.7069351077079773,
"avg_line_length": 21.399999618530273,
"blob_id": "bddb9d956f9a488208e49256216b1c5e189b47ec",
"content_id": "eb10dd69907494fb8b5e7ef7ae5c8879db2b1bd3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 447,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 20,
"path": "/shear-sort/pthreads/utils.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <unistd.h>\n#include <pthread.h>\n#include <time.h>\n\nint** matrix;\nint size;\nint num_lines_per_proc;\n\nvoid init_random_matrix();\nint compare_asc(const void* a, const void* b);\nint compare_dsc(const void* a, const void* b);\nvoid* sort_lines(void* start_line);\nvoid* sort_columns(void* arg);\nvoid sort_matrix(int num_cores);\nvoid print_matrix();\nint check_sorted();\nvoid free_memory();"
},
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 15,
"blob_id": "d5c9fef70d895968d85f2fad453349bf8e588ca8",
"content_id": "243baf3a5b72fd30518df4ee899644a5837cf1c1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 63,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 4,
"path": "/http-proxy/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tgcc -Wall httpproxy.c -o httpproxy\nclean:\n\trm httpproxy"
},
{
"alpha_fraction": 0.7300944924354553,
"alphanum_fraction": 0.7327935099601746,
"avg_line_length": 24.586206436157227,
"blob_id": "5a7fb8b4b1d45f39a2e547a26d1a56427f045918",
"content_id": "833557d8c523860327cb2e6412040ec94aef2d0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 741,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 29,
"path": "/cross-platform-hashtable/table.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#ifndef HASH_H\n#define HASH_H\n\n#include <stdio.h>\n#include <stdlib.h>\n#include \"list.h\"\n\n#define HALVE 1\n#define DOUBLE 2\n\nstruct hash {\n\tList** buckets;\n\tunsigned int size;\t\n};\n\ntypedef struct hash Hashtable;\n\nHashtable *create_table (unsigned int size);\nint destroy_table (Hashtable** table);\nint add_to_table (Hashtable* table, char* word);\nint remove_from_table (Hashtable* table, char* word);\nint print_bucket (Hashtable* table, unsigned int index, char* output_file);\nint print_table (Hashtable* table, char* output_file);\nint find_in_table (Hashtable* table, char* word, char* output_file);\nint table_clear (Hashtable* table);\nint table_resize (Hashtable* table, int mode);\n\nvoid execute_command (Hashtable* table, char* line);\n#endif"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 12.933333396911621,
"blob_id": "83d2e9bd2a5d73de812a7a0c7a442578a9165028",
"content_id": "601c7f9e7a6e3ffbba0b3cd935eaeb94059d90aa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 210,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 15,
"path": "/atm/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "all: build\n\nbuild: client server\n\nserver: server.o lib.o\n\tgcc -g server.o lib.o -o server\n\nclient: client.o lib.o\n\tgcc -g client.o lib.o -o client\n\t\n.c.o:\n\tgcc -Wall -g -c $?\n\t\nclean:\n\trm -f *.o server client\t\n"
},
{
"alpha_fraction": 0.6353887319564819,
"alphanum_fraction": 0.6353887319564819,
"avg_line_length": 15.17391300201416,
"blob_id": "bcee22fe4d7fbbc2ca48f235a2fa7e41add270fd",
"content_id": "1505ffdcb4c66ff9fd47ebc46b30c908c2c9f0ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 373,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 23,
"path": "/expression-evaluator/SubNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\n/**\n * Clasa unui nod operator de scadere.\n * \n * @author Alin\n *\n */\npublic class SubNode extends BinaryOpNode {\n\t/**\n\t * Se creaza un nod operator de scadere si i se seteaza semnul operatiei\n\t * corespunzator.\n\t */\n\tpublic SubNode() {\n\t\tsuper.setOperator(\"-\");\n\t}\n\n\t/*\n\t * @see Node#accept(Visitor)\n\t */\n\t@Override\n\tpublic void accept(Visitor v) {\n\t\tv.visit(this);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5615514516830444,
"alphanum_fraction": 0.5733557939529419,
"avg_line_length": 17.53125,
"blob_id": "37e2f120300cb4d36f7880ff4b088dc62f5a48ac",
"content_id": "0722b4df898f857d1c7f9f6890046bec3d9faf79",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 593,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 32,
"path": "/shear-sort/pthreads/shear_sort_pthreads.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nint main(int argc, char** argv) {\n\tif (argc != 2) {\n\t\tprintf (\"Use: %s <size>\\n\", argv[0]);\n\t\treturn 0;\n\t}\n\t\n\tsize = atoi (argv[1]);\n\tint i;\n\t\n\tmatrix = calloc (size, sizeof (int *));\n\tfor(i = 0; i < size; i++) {\n\t\tmatrix[i] = calloc (size, sizeof (int));\n\t}\n\n\tinit_random_matrix();\n\tint num_cores = sysconf(_SC_NPROCESSORS_ONLN);\t\n\tprintf(\"Number of cores = %d\\n\", num_cores);\n\tsort_matrix(num_cores);\n\n\tint check = check_sorted();\n\tif (check == 1) {\n\t\tprintf (\"Is sorted!\\n\");\n\t} else {\n\t\tprintf (\"It is not sorted!\\n\");\n\t}\n\n\tprint_matrix();\n\tfree_memory();\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6082557439804077,
"alphanum_fraction": 0.6159449815750122,
"avg_line_length": 30.69230842590332,
"blob_id": "959f275dbe53de5fe927bc1fa1f4eb4677fd5b08",
"content_id": "408fd98ceeddbae7f8c0f6ccd0fa528cbc41dc09",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2471,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 78,
"path": "/elevator-world/src/agents/Floor.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package agents;\n\nimport jade.domain.FIPANames;\nimport jade.lang.acl.ACLMessage;\nimport jade.lang.acl.MessageTemplate;\nimport jade.proto.AchieveREResponder;\nimport platform.Log;\nimport utils.Command;\nimport utils.Pair;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\npublic class Floor extends Stepper {\n\n /**\n *\n */\n private static final long serialVersionUID = 7921881298666997166L;\n private int floorNr;\n private List<Command> commands = new ArrayList<>();\n\n private static char nameCounter = 'A';\n\n private static final MessageTemplate template = MessageTemplate.and(\n MessageTemplate.MatchProtocol(FIPANames.InteractionProtocol.FIPA_REQUEST),\n MessageTemplate.MatchPerformative(ACLMessage.REQUEST));\n\n public int getFloorNr() {\n return floorNr;\n }\n\n public Floor(int floorNr) {\n super();\n this.floorNr = floorNr;\n }\n\n @Override\n protected void setup() {\n Log.log(this, \"Hello!\");\n\n addBehaviour(new AchieveREResponder(this, template) {\n protected ACLMessage handleRequest(ACLMessage request) {\n //System.out.println(\"[Floor] Agent \" + getLocalName() + \": REQUEST received from \" + request.getSender().getName() + \". Command is \" + request.getContent());\n //System.out.println(\"[Floor] Agent \" + getLocalName() + \": Agree\");\n ACLMessage agree = request.createReply();\n agree.setPerformative(ACLMessage.AGREE);\n return agree;\n }\n\n protected ACLMessage prepareResultNotification(ACLMessage request, ACLMessage response) {\n int from = ((Floor) myAgent).getFloorNr();\n int to = Integer.parseInt(request.getContent());\n char name = Floor.nameCounter;\n Floor.nameCounter++;\n Command command = new Command(from, to, name);\n commands.add(command);\n\n //System.out.println(\"[Floor] Agent \" + getLocalName() + \": Action successfully performed\");\n ACLMessage inform = request.createReply();\n inform.setPerformative(ACLMessage.INFORM);\n return inform;\n }\n });\n\n }\n\n @Override\n protected void takeDown() {\n // Printout a dismissal message\n Log.log(this, \"terminating.\");\n }\n\n @Override\n public Object step() {\n return new Pair<>(getFloorNr(), commands);\n }\n}"
},
{
"alpha_fraction": 0.42384445667266846,
"alphanum_fraction": 0.4315694570541382,
"avg_line_length": 39.03608322143555,
"blob_id": "bf820780fb5897d5b0c0b771a127e451114abb8e",
"content_id": "16b8e31f1637f806297a370ce90b4fddff6f3240",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7767,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 194,
"path": "/atm/client.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <unistd.h>\n#include <sys/types.h> \n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include \"lib.h\"\n\n#define BUFLEN 256\n#define FNAMELEN 20\n\nvoid error(char *msg)\n{\n perror(msg);\n exit(0);\n}\n\nint main(int argc, char *argv[])\n{\n int sockfd, udpsock, n, i;\n int logged = 0; // flag pentru sesiune deja deschisa\n struct sockaddr_in serv_addr;\n \n char* token;\n char* token_aux;\n \n char* current_card; // cardul retinut de la ultimul login\n char* aux;\n char aux_buffer[BUFLEN];\n \n int addr_len = sizeof(serv_addr);\n char client_file[FNAMELEN];\n char buffer[BUFLEN];\n int fdmax;\n FILE* fp;\n\n fd_set read_fds; // multimea de citire folosita in select()\n fd_set tmp_fds; // multime folosita temporar \n\n if (argc < 3) {\n fprintf(stderr,\"Usage %s <IP_server> <port_server>\\n\", argv[0]);\n exit(0);\n }\n\n sprintf(client_file, \"client-%d.log\", getpid()); \n fp = fopen(client_file, \"w\");\n\n FD_ZERO(&read_fds);\n FD_ZERO(&tmp_fds);\n \n // socketul tcp al clientului\n sockfd = socket(AF_INET, SOCK_STREAM, 0);\n if (sockfd < 0) \n error(\"ERROR opening socket\");\n \n //socketul udp al clientului\n udpsock = socket(AF_INET, SOCK_DGRAM, 0);\n if(udpsock < 0)\n error(\"ERROR opening socket\");\n \n serv_addr.sin_family = AF_INET;\n serv_addr.sin_port = htons(atoi(argv[2]));\n inet_aton(argv[1], &serv_addr.sin_addr);\n \n //se introduc socketii udp, tcp (si 0 pentru stdin) in multimea de descriptori\n FD_SET(sockfd, &read_fds);\n FD_SET(udpsock, &read_fds);\n FD_SET(0, &read_fds);\n fdmax = udpsock;\n\n if (connect(sockfd, (struct sockaddr*) &serv_addr, sizeof(serv_addr)) < 0) \n error(\"ERROR connecting\"); \n\n while(1) {\n tmp_fds = read_fds; \n if (select(fdmax + 1, &tmp_fds, NULL, NULL, NULL) == -1) \n error(\"ERROR in select\");\n\n for(i = 0; i <= fdmax; i++) {\n if(FD_ISSET(i, &tmp_fds)) {\n if (i == 0) {\n //citesc de la tastatura\n memset(buffer, 0 , BUFLEN);\n fgets(buffer, BUFLEN - 1, stdin);\n fprintf(fp, \"%s\", buffer);\n token = strtok(strdup(buffer), \" \\n\");\n \n if (!strcmp(token, \"login\")) { // la login se pastreaza ultimul card\n aux = strdup(buffer);\n token_aux = strtok(aux, \" \\n\");\n token_aux = strtok(NULL, \" \\n\");\n current_card = strdup(token_aux);\n }\n\n if (!strcmp(token, \"login\") && logged == 1) { // daca in sesiunea curenta sunt deja logat, trimit de la client eroare coresp.\n printf(\"-2 : Sesiune deja deschisa\\n\");\n fprintf(fp, \"%s\", \"-2 : Sesiune deja deschisa\\n\");\n continue;\n } else if (!strcmp(token, \"unlock\")) { // daca primesc de la tastatura unlock, trimit pe udp unlock <nr_card>\n memset(buffer, 0, BUFLEN);\n sprintf(buffer, \"unlock %s\", current_card);\n \n if(sendto(udpsock, buffer, BUFLEN, 0, (struct sockaddr*)&serv_addr, addr_len) == -1) {\n error(\"err sendto\");\n }\n continue;\n } else if (!strcmp(token, \"logout\")) { // daca primesc logout, verific daca sunt logat deja\n if (logged == 0) {\n printf(\"-1 : Clientul nu este autentificat\\n\");\n fprintf(fp, \"%s\", \"-1 : Clientul nu este autentificat\\n\");\n continue;\n } else { // daca s-a efectuat cu succes, se reseteaza flagul logged\n logged = 0;\n }\n } else if ((!strcmp(token, \"listsold\") || !strcmp(token, \"getmoney\") || !strcmp(token, \"putmoney\")) && logged == 0) {\n // daca trimit o comanda specifica userului si nu sunt logat, trimit eroarea coresp.\n printf(\"-1 : Clientul nu este autentificat\\n\");\n fprintf(fp, \"%s\", \"-1 : Clientul nu este autentificat\\n\");\n continue; \n } else if (!strcmp(token, \"quit\")) { // se trimite mesajul de quit, si se inchid socketele\n n = send(sockfd, buffer, strlen(buffer), 0);\n \n if (n < 0) \n error(\"ERROR writing to socket\");\n \n close(sockfd);\n close(udpsock);\n return 0;\n }\n \n n = send(sockfd, buffer, strlen(buffer), 0);\n if (n < 0) \n error(\"ERROR writing to socket\");\n } else if (i == sockfd) {\n n = recv(sockfd, buffer, sizeof(buffer), 0);\n \n if(n <= 0) { // daca nu mai trimite nimic serverul sau am eroare in recv, inchid socketele si fisierul\n error(\"err recv\");\n \n close(sockfd);\n close(udpsock);\n \n FD_ZERO(&read_fds);\n fclose(fp);\n return 0;\n } else if (n > 0) { // daca primesc mesajul de inchidere al serverului, se inchide la fel.\n if(strstr(buffer, \"Bye\") != NULL) {\n close(sockfd);\n close(udpsock);\n FD_ZERO(&read_fds);\n fclose(fp);\n return 0;\n } else {\n printf(\"%s\", buffer);\n fprintf(fp, \"%s\", buffer);\n }\n }\n \n if (strstr(buffer, \"Welcome\") != NULL) { // daca primesc mesaj de welcome, inseamna ca in sesiunea asta sunt logat\n logged = 1;\n }\n\n } else if (i == udpsock) { \n // primesc pe socketul udp\n memset(buffer, 0, BUFLEN);\n \n if(recvfrom(udpsock, buffer, BUFLEN, 0, (struct sockaddr*)&serv_addr, (socklen_t*)&addr_len) == -1) {\n error(\"recvfrom\");\n }\n \n printf(\"%s\", buffer);\n fprintf(fp, \"%s\", buffer);\n \n if (strstr(buffer, \"Trimite\") != NULL) { // daca trebuie trimisa parola, o citim de la tastatura\n memset(buffer, 0, BUFLEN);\n \n fgets(buffer, BUFLEN - 1, stdin);\n fprintf(fp, \"%s\", buffer);\n \n buffer[strlen(buffer) - 1] = 0; // sterg \\n de la sfarsit\n sprintf(aux_buffer, \"%s %s\", current_card, buffer); // mesajul o sa fie de forma <nr_card> <parola>\n \n if (sendto(udpsock, aux_buffer, BUFLEN, 0, (struct sockaddr*)&serv_addr, addr_len) == -1) {\n error(\"err sendto\");\n }\n }\n }\n }\n } \n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5698663592338562,
"alphanum_fraction": 0.6075333952903748,
"avg_line_length": 46.02857208251953,
"blob_id": "7ea2386c4622f3189d79a05c1b49e3a98bbf870b",
"content_id": "093f24615e58f9db52203c3b8ad33bb28de36f75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3292,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 70,
"path": "/ml/nn/train.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "from keras.preprocessing.image import ImageDataGenerator\nfrom keras.models import Sequential\nfrom keras.layers.convolutional import Conv2D\nfrom keras.layers import MaxPooling2D, Dense, Dropout, Flatten\nfrom keras.callbacks import ModelCheckpoint, TensorBoard\nfrom pandas import read_csv\nfrom matplotlib import pyplot\n\nfrom time import time\n\n\ndef plot_history():\n pyplot.plot(history.history['loss'], label='train')\n pyplot.plot(history.history['val_loss'], label='test')\n pyplot.legend()\n pyplot.show()\n\n\nif __name__ == '__main__':\n # data prep\n df_train = read_csv('MURA-v1.1/train_image_paths.csv')\n df_test = read_csv('MURA-v1.1/valid_image_paths.csv')\n df_train['label'] = ['1' if 'positive' in x else '0' for x in df_train['path']]\n df_test['label'] = ['1' if 'positive' in x else '0' for x in df_test['path']]\n\n train_data_gen = ImageDataGenerator()\n test_data_gen = ImageDataGenerator()\n\n training_set = train_data_gen.flow_from_dataframe(df_train, x_col=\"path\", y_col=\"label\", color_mode=\"grayscale\",\n class_mode=\"binary\", target_size=(244, 244), batch_size=64)\n test_set = test_data_gen.flow_from_dataframe(df_test, x_col=\"path\", y_col=\"label\", color_mode=\"grayscale\",\n class_mode=\"binary\", target_size=(244, 244), batch_size=64)\n\n # design the network\n model = Sequential()\n model.add(Conv2D(filters=128, kernel_size=(7, 7), strides=2, activation='relu', input_shape=(244, 244, 1)))\n model.add(MaxPooling2D((2, 2), 2))\n model.add(Conv2D(filters=256, kernel_size=(5, 5), strides=2, activation='relu'))\n # model.add(Conv2D(filters=128, kernel_size=(5, 5), strides=1, activation='relu')) # added\n model.add(MaxPooling2D((2, 2), 2))\n # model.add(Conv2D(filters=256, kernel_size=(3, 3), strides=1, activation='relu')) # added\n model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=1, activation='relu'))\n model.add(Conv2D(filters=512, kernel_size=(3, 3), strides=1, activation='relu'))\n model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=1, activation='relu'))\n model.add(Conv2D(filters=384, kernel_size=(3, 3), strides=1, activation='relu'))\n model.add(MaxPooling2D((2, 2), 2))\n model.add(Dropout(0.5))\n model.add(Dense(2048, activation='relu'))\n model.add(Dropout(0.5))\n model.add(Flatten())\n model.add(Dense(1, activation='sigmoid'))\n\n model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])\n\n with open(\"model/feature_maps_v2.json\", \"w\") as m:\n m.write(model.to_json())\n\n tensorboard = TensorBoard(log_dir='log/{}'.format(time()))\n checkpointer = ModelCheckpoint(filepath='model/weights/feature_maps_v2_cnn_weights_20ep.hdf5'\n , verbose=0\n , save_best_only=True)\n\n history = model.fit_generator(training_set,\n epochs=20,\n verbose=2,\n steps_per_epoch=576,\n validation_data=test_set,\n validation_steps=50,\n callbacks=[checkpointer, tensorboard])\n plot_history()\n"
},
{
"alpha_fraction": 0.5871953964233398,
"alphanum_fraction": 0.5991399884223938,
"avg_line_length": 18.754716873168945,
"blob_id": "7b2684f92a09b346c5503974e4896310cbf6ad23",
"content_id": "f9d963fe30a19ae0c7c71d81e323bfdda0c6fc3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2093,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 106,
"path": "/atm/lib.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"lib.h\"\n#include <arpa/inet.h>\n#include <poll.h>\n#include <netinet/in.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <unistd.h>\n#include <string.h>\n\n\n// adauga un user cu parola intr-un vector de perechi\nvoid addPair(pair* pairs, user* u, int sock) {\n\tint i;\n\tfor(i = 0; i <= pairs->crt; i++) {\n\t\tif(pairs[i].sock == sock) { // daca are acelasi socket doar se updateaza userul\n\t\t\tpairs[i].user = u;\n\t\t\treturn;\n\t\t}\n\t}\n\tpairs[pairs->crt].sock = sock;\n\tpairs[pairs->crt].user = u;\n\tpairs->crt++; \n}\n\n// delogheaza un user dintr-un vector de perechi\nvoid removePair(pair* pairs, int sock) {\n\tint i;\n\tfor(i = 0; i <= pairs->crt; i++) {\n\t\tif(pairs[i].sock == sock) {\n\t\t\tpairs[i].user->logat = 0;\n\t\t\tbreak;\n\t\t}\n\t}\n}\n\n// returneaza sold-ul din vectorul de perechi corespunzator socketului dat ca parametru\ndouble getSold(pair* pairs, int sock) {\n\tint i;\n\tfor(i = 0; i <= pairs->crt; i++) {\n\t\tif(pairs[i].sock == sock) {\n\t\t\treturn pairs[i].user->sold;\n\t\t}\n\t}\n\treturn 0;\n}\n\n// 0 - success\n// -1 - fonduri insuficiente\nint getMoney(pair* pairs, int sock, int money) {\n\tint i;\n\tfor(i = 0; i <= pairs->crt; i++) {\n\t\tif(pairs[i].sock == sock) {\n\t\t\tdouble sold = pairs[i].user->sold;\n\t\t\tif(sold - money < 0)\n\t\t\t\treturn -1;\n\t\t\tpairs[i].user->sold -= money;\n\t\t\treturn 0;\n\t\t}\n\t}\n\treturn -1;\n}\n\n// adauga suma in contul de pe socketul dat\nvoid putMoney(pair* pairs, int sock, int money) {\n\tint i;\n\tfor(i = 0; i <= pairs->crt; i++) {\n\t\tif(pairs[i].sock == sock) {\n\t\t\tpairs[i].user->sold += money;\n\t\t\treturn;\n\t\t}\n\t}\n}\n\n//-1 card inexistent\n// 0 esuare\n// 1 gasit\nint findCard(user* users, char* nr_card, int no_users) {\n\tint i;\n\tint ok = 0;\n\n\tfor(i = 0; i < no_users; i++) {\n\t\tif(!strcmp(users[i].nr_card, nr_card)) {\n\t\t\tok = 1;\n\t\t\tif(users[i].blocat == 0)\n\t\t\t\treturn 0;\n\t\t\tbreak;\n\t\t}\n\t}\n\tif(!ok)\n\t\treturn -1;\n\treturn 1;\n}\n\n// returneaza indexul userului cu nr. de card dat\nint getUserIndex(user* users, char* nr_card, int no_users) {\n\tint i;\n\tfor (i = 0; i < no_users; i++) {\n\t\tif(!strcmp(users[i].nr_card, nr_card)) {\n\t\t\treturn i;\n\t\t}\n\t}\n\treturn -1;\n\n}"
},
{
"alpha_fraction": 0.5966386795043945,
"alphanum_fraction": 0.5966386795043945,
"avg_line_length": 12.277777671813965,
"blob_id": "7b60ef077454b09ea29f14a2b8f224fdfd7f2f37",
"content_id": "c4749dc370c94b68ce82900894cb9e9986fa6b2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 238,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 18,
"path": "/cross-platform-hashtable/GNUmakefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "CC = gcc\nCFLAGS = -Wall -fPIC\n\nLDFLAGS = -L.\n\nall: main\n\nmain: main.o table.o\n\t$(CC) $(CFLAGS) main.o table.o -o main -L. -lhash\n\nmain.o: main.c\n\t$(CC) $(CFLAGS) -c main.c\n\ntable.o: table.c\n\t$(CC) $(CFLAGS) -c table.c\n\nclean:\n\trm *.o main"
},
{
"alpha_fraction": 0.5790476202964783,
"alphanum_fraction": 0.6095238327980042,
"avg_line_length": 17.75,
"blob_id": "d618473deeeb2066309c3f03cce5c2baee2a4d8a",
"content_id": "8909cbe8615572b7e7061f6d86a6a2eafcb73bf9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 525,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 28,
"path": "/matrix-mul/solver_blas.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Tema 2 ASC\n * 2018 Spring\n * Catalin Olaru / Vlad Spoiala\n */\n#include \"utils.h\"\n#include \"cblas.h\"\n\n/* \n * Add your BLAS implementation here\n */\ndouble* my_solver(int N, double *A) {\n\tprintf(\"BLAS SOLVER\\n\");\n\tdouble *C = calloc(2 * N * N, sizeof(double));\n\tdouble *alpha = calloc(2, sizeof(double));\n\tdouble *beta = calloc(2, sizeof(double));\n\n\talpha[0] = 1;\n\talpha[1] = 0;\n\n\tbeta[0] = 0;\n\tbeta[1] = 0;\n\n\tcblas_zsyrk(CblasRowMajor, CblasUpper, CblasNoTrans, N, N, alpha, A, N, beta, C, N);\n\tfree(alpha);\n\tfree(beta);\n\treturn C;\n}\n"
},
{
"alpha_fraction": 0.6162790656089783,
"alphanum_fraction": 0.6478405594825745,
"avg_line_length": 26.363636016845703,
"blob_id": "e6b8dd9d00c9d870776aa1ae35aaf08e156e6ac1",
"content_id": "28498adb29245141881367a20f5b3f40dc2a4439",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 602,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 22,
"path": "/matrix-mul/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "CC=gcc\nCFLAGS=-Wall -Werror -O0\nOTHER_C_FLAGS=-O3 -funroll-loops -march=native -mfpmath=sse -Wall -Werror \nLIBDIRS=/usr/lib64/atlas/libsatlas.so.3.10\nLIBS=\n\nall: tema2_blas tema2_neopt tema2_opt_m tema2_opt_f\n\ntema2_blas: solver_blas.c main.c\n\t$(CC) $(CFLAGS) $^ $(LIBDIRS) $(LIBS) -o $@\t\n\ntema2_neopt: solver_neopt.c main.c\n\t$(CC) $(CFLAGS) $^ $(LIBDIRS) $(LIBS) -o $@\t\n\ntema2_opt_m: solver_opt.c main.c\n\t$(CC) $(CFLAGS) $^ $(LIBDIRS) $(LIBS) -o $@\t\n\ntema2_opt_f: solver_neopt.c main.c\n\t$(CC) $(OTHER_C_FLAGS) $^ $(LIBDIRS) $(LIBS) -o $@\n\nclean:\n\trm -rf tema2_blas tema2_neopt tema2_opt_m tema2_opt_f\n"
},
{
"alpha_fraction": 0.6838709712028503,
"alphanum_fraction": 0.7419354915618896,
"avg_line_length": 30,
"blob_id": "ea7d605aab2a79d097150896b58528d0e9062748",
"content_id": "f3a4a20d07afe46598e4e3e5ed91032371ccf4d0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 155,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 5,
"path": "/elevator-world/README.md",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "# Multi Agent Systems ACS 2020\n\n## Project Dependencies\n* Jade 4.5\n* JSON Simple - https://cdn.crunchify.com/wp-content/uploads/code/json-simple-1.1.1.jar\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 6.875,
"blob_id": "e60ae706ac52884b69fbb819ac59f1fc0039bf8a",
"content_id": "eb0f78bfb125254c052c97e4ed30682a37e971d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 63,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 8,
"path": "/expression-evaluator/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tjavac *.java\n\nrun:build\n\tjava Main\n\nclean:\n\trm *.class\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 17.11111068725586,
"blob_id": "dc578f1aa67575574aca3a36b0fe5d146bc611cf",
"content_id": "d7af53a2a45d89ee21aacb929dd962c068db962d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 327,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 18,
"path": "/expression-evaluator/NaN_double.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\n/**\n * Clasa unui NaN (Not a Number) de tip double.\n * \n * Clasa este folosita doar pentru a tine evidenta cazului in care rezultatul\n * unei operatii trebuie sa dea rezultatul NaN de tip double.\n * \n * @author Alin\n *\n */\npublic class NaN_double {\n\n\tpublic NaN_double() {\n\t}\n\n\tpublic String toString() {\n\t\treturn \"NaN\";\n\t}\n}\n"
},
{
"alpha_fraction": 0.6206896305084229,
"alphanum_fraction": 0.6206896305084229,
"avg_line_length": 6.25,
"blob_id": "e294fe976b79a3d040eac84b6c4d638bb65ec80a",
"content_id": "a05a411347707de06294d731d8a879ec569449a7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 8,
"path": "/turing-machine/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tgcc main.c -o main\n\nrun:\n\t./main\n\nclean:\n\trm main\n"
},
{
"alpha_fraction": 0.7558348178863525,
"alphanum_fraction": 0.7791741490364075,
"avg_line_length": 64.47058868408203,
"blob_id": "65ec835c796c6f544d7c1e25dd91946b74356963",
"content_id": "9507928e33157b538d1e901f6b790b62f68a8beb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2228,
"license_type": "permissive",
"max_line_length": 169,
"num_lines": 34,
"path": "/ml/sarsa/README.txt",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "Mihaila Alin-Florin\n343C1\n\nRezultate teste:\n\n== Epsilon Greedy vs Softmax ==\nAm testat ambele metode pe hartile empty6x6 si empty8x8 si de fiecare data Epsilon Greedy a invatat mai repede decat\nSoftmax. Pentru hartile empty6x6 si empty8x8 ambele metode converg in 150-200 episoade. Pentru harta empty16x16 nu a reusit\nnicio metoda sa convearga, am lasat pana la 50k episoade, iar castigul mediu ramanea la 0.\n\n== Valori hiperparametrii ==\n\nEpsilon Greedy:\n Prima data am variat constanta (C), pornind de la 0.05 pana la 0.6, si am observat ca daca se mareste constanta, castigul mediu creste\n mai repede, datorita faptului ca marim sansa de a explorare. (se poate vedea in graficele egreedy_var_c_empty6x6 si egreedy_var_c_empty8x8)\n\n La varierea ratei de invatare am observat ca la cresterea parametrului, obtin rezultate din ce in ce mai slabe, am variat rata de invatare intre 0.1 si 0.4.\n (din graficele egreedy_var_lr_empty6x6 si egreedy_var_lr_empty8x8 se poate observa aceasta variatie)\n\n Pentru a testa si initializarea optimista (q0 > 0), am observat ca algoritmul converge mai greu fata de initializarea normala cu 0, deoarece o sa ajunga sa exploreze\n mai mult fata de varianta initiala, si o sa ajunga sa micsoreze valorile de la q0 pana la 0, de aceea o sa ii ia mai mult sa convearga. \n\nSoftmax:\n Pentru metoda softmax, am variat doar rata de invatare si am obtinut rezultate asemanatoare ca la Epsilon Greedy.\n Initializarea optimista nu a mers aici, deoarece beta lua valori foarte mari (numitorul avea la inceput valori de dimensiunea 10^(-4)) si ajungea\n ca exponentul sa fie foarte mare si primeam overflow exception.\n\n== Hartile DoorKey ==\nPentru hartile cu cheie si usa, am intampinat probleme deoarece algortimul nu converge atunci cand harta se schimba, am realizat un grafic si se poate\nobserva ca depinde de ce castig mediu are la inceput, daca are de exemplu 0.3, castigul mediu in continuare o sa se invarta in jurul acestei valori, cu mici\nvariatii.\n\nAm facut testari si pe harti cu seed-ul fixat, si aici agentul a reusit sa invete destul de repede, aproximativ la fel ca pe hartile fara cheie si usa.\n(se poate vedea in directorul doorkey, grafice pentru random seed si seed fixat)\n\n"
},
{
"alpha_fraction": 0.5041025876998901,
"alphanum_fraction": 0.5179487466812134,
"avg_line_length": 16.89908218383789,
"blob_id": "aeeb9e3e1e568bf10f1cde78c6054d4091041d93",
"content_id": "7effcaf27476bbacbded30e985096b49bdcb2993",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1950,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 109,
"path": "/shear-sort/omp/utils.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nvoid init_random_matrix(int** matrix, int size) {\n\tint i, j;\n\tsrand(time(NULL));\n\n\t#pragma omp parallel for private(i, j) collapse(2)\n\tfor (i = 0; i < size; i++) {\n\t\tfor (j = 0; j < size; j++) {\n\t\t\tmatrix[i][j] = rand() % (size * size) + 1; \n\t\t}\n\t}\n}\n\nint compare_asc(const void* a, const void* b) {\n\tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn A - B;\n}\n\nint compare_dsc(const void* a, const void* b) {\n \tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn B - A;\n}\n\nvoid sort_lines(int** matrix, int size) {\n\tint i;\n\t#pragma omp parallel for\n\tfor (i = 0; i < size; i++) {\n\t\tif (i % 2 == 0) {\n\t\t\tqsort(matrix[i], size, sizeof(int), compare_asc);\n\t\t} else {\n\t\t\tqsort(matrix[i], size, sizeof(int), compare_dsc);\n\t\t}\n\t}\n}\n\nvoid sort_columns(int** matrix, int size) {\n\tint i, j;\n\tint col[size];\n\t\n\tfor (j = 0; j < size; j++) {\n\t\t#pragma omp parallel for\n\t\tfor (i = 0; i < size; i++) {\n\t\t\tcol[i] = matrix[i][j];\n\t\t}\n\t\tqsort(col, size, sizeof(int), compare_asc);\n\t\t\n\t\t#pragma omp parallel for\n\t\tfor (i = 0; i < size; i++) {\n\t\t\tmatrix[i][j] = col[i];\n\t\t}\n\t}\n}\n\nvoid sort_matrix(int** matrix, int size) {\n\tint k;\n\t\n\tfor(k = 0; k <= ceil(log2(size)); k++) {\n\t\tsort_lines(matrix, size);\n\t\tsort_columns(matrix, size);\n\t}\n}\n\nvoid print_matrix(int** matrix, int size) {\n\tint i, j;\n\tfor (i = 0; i < size; i++) {\n\t\tfor (j = 0; j < size; j++) {\n\t\t\tprintf(\"%d\\t\", matrix[i][j]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\tprintf(\"\\n\");\n}\n\nint check_sorted(int** matrix, int size) {\n\tint i, j, even;\n\t\n\tfor (i = 0; i < size; i++) {\n\t\tif (i % 2 == 0) {\n\t\t\teven = 1; // even line > ascending\n\t\t} else {\n\t\t\teven = 0; // odd line > descending\n\t\t}\n\t\t\n\t\tfor (j = 0; j < size - 1; j++) {\n\t\t\tif (even) {\n\t\t\t\tif (matrix[i][j] > matrix[i][j + 1])\n\t\t\t\t\treturn 0;\n\t\t\t} else {\n\t\t\t\tif (matrix[i][j] < matrix[i][j + 1])\n\t\t\t\t\treturn 0;\n\t\t\t}\n\t\t}\n\t}\n\t\n\treturn 1;\n}\n\n\nvoid free_memory(int** matrix, int size) {\n\tint i;\n\tfor(i = 0; i < size; i++) {\n\t\tfree (matrix[i]);\n\t}\n\t\n\tfree (matrix);\n}"
},
{
"alpha_fraction": 0.707410454750061,
"alphanum_fraction": 0.707410454750061,
"avg_line_length": 28.256000518798828,
"blob_id": "3f6967a995d06c80998888633b397addbe28e078",
"content_id": "bfa8c38d85fc1f0249996af2f1cf6618af0daba1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3657,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 125,
"path": "/code-interpreter/src/Interpreter.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import java.util.HashMap;\n/*\n * Clasa concreta visitor, care interpreteaza un program. (un arbore de expresie ce tine un program in structura lui).\n */\npublic class Interpreter implements Visitor {\n\t//variabilele sunt tinute intr-un hashmap pentru eficienta\n\tprivate HashMap<String, Integer> variables;\n\t\n\t//flag-uri pentru erori\n\tprivate boolean assertFlag = false;\n\tprivate boolean scopeFlag = false; // la fiecare vizitare de nod acesta va fi actualizat. \n\t\t\t\t\t\t\t\t //(fiind cel mai prioritar, daca se intalneste o eroare de scope, nu se mai evalueaza nimic)\n\tprivate boolean returnFlag = true; //acest flag este true la inceput, iar daca se viziteaza un nod de tip return, devine false.\n\t\n\t//rezultatul final\n\tprivate Integer result;\n\n\tpublic Interpreter() {\n\t\tthis.variables = new HashMap<String, Integer>();\n\t}\n\n\t@Override\n\t// In cazul unui nod sequence, se \"lanseaza\" accept pe stanga si dreapta, cat timp nu avem erori de scope.\n\tpublic void visit(SequenceNode n) {\n\t\tif (n.getLeft() != null && !scopeFlag) {\n\t\t\tn.getLeft().accept(this);\n\t\t}\n\t\tif (n.getRight() != null && !scopeFlag) {\n\t\t\tn.getRight().accept(this);\n\t\t}\n\t}\n\n\t@Override\n\t// In cazul unui nod assign, se adauga variabila cu valoarea corespunzatoare in hashmap.\n\tpublic void visit(AssignNode n) {\n\t\tString v = n.getVariable();\n\t\tString e = n.getExpression();\n\t\tArithmeticExpressionEvaluator eval = new ArithmeticExpressionEvaluator(e, variables);\n\t\tif (eval.isError()) {\n\t\t\tscopeFlag = true;\n\t\t\treturn;\n\t\t}\n\t\tvariables.put(v, eval.getResultValue()); //in cazul in care este o subexpresie, se evalueaza.\n\t}\n\n\t@Override\n\t// In cazul unui nod assert, se evalueaza expresia si se updateaza flag-ul. \n\tpublic void visit(AssertNode n) {\n\t\tString e = n.getExpression();\n\t\tBooleanExpressionEvaluator eval = new BooleanExpressionEvaluator(e, variables);\n\t\tif (eval.isError()) {\n\t\t\tscopeFlag = true;\n\t\t\treturn;\n\t\t}\n\t\tassertFlag = !eval.isResultValue();\n\t}\n\n\t@Override\n\t// In cazul unui nod if, se evalueaza conditia, si daca este true sau false, se viziteaza programul then sau else.\n\tpublic void visit(IfNode n) {\n\t\tString cond = n.getCondition();\n\t\tBooleanExpressionEvaluator eval = new BooleanExpressionEvaluator(cond, variables);\n\t\tif (eval.isError()) {\n\t\t\tscopeFlag = true;\n\t\t\treturn;\n\t\t}\n\t\tif (eval.isResultValue()) {\n\t\t\tn.getThenTree().accept(this);\n\t\t} else {\n\t\t\tn.getElseTree().accept(this);\n\t\t}\n\t}\n\n\t@Override\n\t// In cazul unui nod for, se viziteaza nodul init, apoi se verifica conditia,\n\t//daca este satisfacuta, pentru a stii daca e cazul sa continuam la incrementare\n\tpublic void visit(ForNode n) {\n\t\tn.getInitNode().accept(this);\n\t\t\n\t\tif(!scopeFlag) {\n\t\t\tBooleanExpressionEvaluator eval = new BooleanExpressionEvaluator(n.getCondition(), variables);\n\t\t\tif(eval.isError()) {\n\t\t\t\tscopeFlag = true;\n\t\t\t\treturn;\n\t\t\t}\n\t\t\t\n\t\t\t//cat timp conditia este satisfacuta, se viziteaza programul din for, si se incrementeaza.\n\t\t\twhile(eval.isResultValue() && !scopeFlag) {\n\t\t\t\tn.getProgTree().accept(this);\n\t\t\t\tn.getIncrementNode().accept(this);\n\t\t\t\teval.evaluate();\n\t\t\t}\n\t\t}\n\t}\n\n\t@Override\n\t// In cazul unui nod return, se returneaza valoarea evaluata si se seteaza returnFlag pe false.\n\tpublic void visit(ReturnNode n) {\n\t\tString e = n.getExpression();\n\t\tArithmeticExpressionEvaluator eval = new ArithmeticExpressionEvaluator(e, variables);\n\t\tif (eval.isError()) {\n\t\t\tscopeFlag = true;\n\t\t\treturn;\n\t\t}\n\t\treturnFlag = false;\n\t\tresult = eval.getResultValue();\n\t}\n\t\n\tpublic Integer getResult() {\n\t\treturn result;\n\t}\n\t\n\tpublic boolean isScopeFlag() {\n\t\treturn scopeFlag;\n\t}\n\n\tpublic boolean isAssertFlag() {\n\t\treturn assertFlag;\n\t}\n\t\n\tpublic boolean isReturnFlag() {\n\t\treturn returnFlag;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6548861265182495,
"alphanum_fraction": 0.6921439170837402,
"avg_line_length": 48.86170196533203,
"blob_id": "fa8efc7e37910cab38d0f216935cda486ef5af6d",
"content_id": "406f91fea0bf8a269fe8bf6d87576532a5455c15",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 4697,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 94,
"path": "/ml/nn/README.txt",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "Mihaila Alin-Florin\n343C1\n\nDetalii implementare:\n\n * Preprocesarea datelor:\n Am folosit csv-ul cu caile spre fiecare imagine in parte, am folosit pandas pentru a construi data frame-ul\n si am adaugat inca o coloana pentru label, am pus 1/0 in caz ca am pozitiv sau negativ in calea respectiva a imaginii.\n\n Am folosit din keras ImageDataGenerator si am incarcat toate imaginile cu ajutorul generatorului,\n si am grupat imaginile in cate 64 de batch-uri.\n\n * Construirea retelei\n Am folosit keras cu tensorflow ca backend si am construit 4 arhitecturi diferite pentru aceasta tema,\n prima fiind cea simpla din enuntul temei, a mai fost nevoie sa adaug un strat Flatten inainte de ultimul\n FC, deoarece era nevoie sa se reduca dimensiunea inputului pentru ultimul FC.\n\n A doua arhitectura, este construita pornind de la cea simpla, adaugand inca 2 straturi convolutionale,\n am adaugat un strat dupa al doilea strat din arhitectura initiala, si inca unu dupa al doilea MaxPooling2D.\n\n Ultimele 2 se bazeaza tot pe strutura initiala, doar ca am modificat numarul de filtre,\n a 3-a are 265 in loc de 128 de filtre pe al doilea strat convolutional, si 384 in loc de 256 de filtre pe al 3-lea\n strat convolutional.\n\n A 4-a structura are la toate straturile adaugate 128 de filtre in plus fata de numarul de filtre initial.\n Toate struturile retelei sunt salvate intr-un json al fiecarei retele.\n\n * Antrenarea retelei (train.py)\n Am folosit metota fit_generator, pentru a antrena reteaua direct folosind generatorul obtinut inainte, si am folosit\n callback-uri pentru salvarea celui mai bun model (ModelCheckpointer) si pentru a salva informatiile obtinute pe durata\n antrenarii (Tensorboard), unde se pot vizualiza mai bine graficele.\n Toate ponderile sunt salvate intr-un fisier pentru fiecare model in parte.\n\n * Evaluarea retelei (evaluate.py)\n Pentru evaluare am incarcat modelul cu ponderile acestuia si am folosit metoda predict_generator, pentru a\n obtine labelurile prezise, apoi pentru a stabili acuratetea per imagine, am folosit din sklearn, accuracy_score,\n care calculeaza acuratetea simplu, iar pentru acuratetea per studiu, am folosit un dictionar pentru fiecare pacient si\n studiile acestuia, si am adunat +1 pentru pozitiv si -1 pentru negativ, iar pentru a stabili clasa studiului, daca suma are >0, clasa\n prezisa este pozitiva, daca este <0 este negativa, iar daca suma este 0, se ia random o clasa din cele 2.\n \n * Rezultate obtinute\n Pentru arhitectura din enunt:\n 10 epoci\n Acuratetea per studiu 64,78% (test)\n Acuratetea per imagine 63,43% (test)\n Acuratetea per studiu 70,54% (train)\n Acuratetea per imagine 68,93% (train)\n\n 20 epoci\n Acuratetea per studiu 70,23% (test)\n Acuratetea per imagine 68,25% (test)\n Acuratetea per studiu 78,86% (train)\n Acuratetea per imagine 75,58% (train)\n\n Pentru arhitectura a2a (multi layer):\n 10 epoci\n Acuratetea per studiu 65,37% (test)\n Acuratetea per imagine 63,8% (test)\n Acuratetea per studiu 68,92% (train)\n Acuratetea per imagine 66,79% (train)\n\n 20 epoci\n Acuratetea per studiu 67,65% (test)\n Acuratetea per imagine 66,68% (test)\n Acuratetea per studiu 76,49% (train)\n Acuratetea per imagine 74,44% (train)\n\n Pentru arhitectura a3a (multi feature maps):\n 10 epoci\n Acuratetea per studiu 67,65% (test)\n Acuratetea per imagine 65,93% (test)\n Acuratetea per studiu 72,30% (train)\n Acuratetea per imagine 69,51% (train)\n\n 20 epoci\n Acuratetea per studiu 68,45% (test)\n Acuratetea per imagine 66,59% (test)\n Acuratetea per studiu 75,33% (train)\n Acuratetea per imagine 73,41% (train)\n\n Pentru arhitectura a4a (multi feature maps v2):\n 20 epoci\n Acuratetea per studiu 70,23% (test)\n Acuratetea per imagine 67,59% (test)\n Acuratetea per studiu 77,66% (train)\n Acuratetea per imagine 75,14% (train)\n\n * Concluzii\n Toate arhitecturile ajung la fenomenul de overfitting, daca privim graficile de train loss vs valid loss,\n observam ca train loss-ul scade mereu, iar val loss-ul o sa creasca la un moment dat, de aceea nu am lasat mai\n mult de 20 epoci, o sa se ajunga sa scada mereu train loss-ul, ajungand la o acuratete mare, dar cea de validare\n o sa scada gradual.\n\n Cea mai buna arhitectura a fost cea initiala, (68,25% per imagine, 70,23% per studiu).\n \n"
},
{
"alpha_fraction": 0.5792349576950073,
"alphanum_fraction": 0.5945355296134949,
"avg_line_length": 18.489360809326172,
"blob_id": "1dbd9fa7a5290c5a1c582552b5c849d2641f3837",
"content_id": "19d5b58fd059d28a8976e8aa29c872ad24dc7e6e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 915,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 47,
"path": "/cross-platform-hashtable/main.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdlib.h>\n#include <stdio.h>\n#include <string.h>\n#include <ctype.h>\n#include \"list.h\"\n#include \"utils.h\"\n#include \"table.h\"\n\n#define BUFSIZE 20000\n\nint main(int argc, char const *argv[])\n{\n\tHashtable* table;\n\tFILE* f;\n\tchar buffer[BUFSIZE];\n\tint i, ret;\n\n\tDIE (argc < 2, \"Prea putini parametrii\");\n\n\tfor (i = 0; i < strlen (argv[1]); i++) {\n\t\tDIE (!isdigit(argv[1][i]), \"Lungimea nu este numar\");\n\t}\n\n\ttable = create_table (atoi(argv[1]));\n\n\tif (argc == 2) {\n\t\t/* Se citeste de la tastatura */\n\t\twhile (fgets (buffer, BUFSIZE, stdin) != NULL) {\n\t\t\texecute_command (table, buffer);\n\t\t}\n\t} else {\n\t\tfor (i = 2; i < argc; i++) {\n\t\t\tf = fopen (argv[i], \"r\");\n\t\t\tDIE (f == NULL, \"Eroare deschidere fisier\");\n\n\t\t\twhile (fgets (buffer, BUFSIZE, f) != NULL) {\n\t\t\t\texecute_command (table, buffer);\n\t\t\t}\n\n\t\t\tret = fclose (f);\n\t\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\n\t\t}\n\t}\n\n\tdestroy_table(&table);\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.7069672346115112,
"alphanum_fraction": 0.7069672346115112,
"avg_line_length": 31.600000381469727,
"blob_id": "b3e9a277ec472f298cf264a2fd2c1a09ee6ef534",
"content_id": "41ca7782bc340844354c4b7b6b36a682efb442bb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 488,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 15,
"path": "/shear-sort/omp/utils.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <time.h>\n#include <omp.h>\n\nvoid init_random_matrix(int** matrix, int size);\nint compare_asc(const void* a, const void* b);\nint compare_dsc(const void* a, const void* b);\nvoid sort_lines(int** matrix, int size);\nvoid sort_columns(int** matrix, int size);\nvoid sort_matrix(int** matrix, int size);\nvoid print_matrix(int** matrix, int size);\nint check_sorted(int** matrix, int size);\nvoid free_memory(int** matrix, int size);"
},
{
"alpha_fraction": 0.6904761791229248,
"alphanum_fraction": 0.6972789168357849,
"avg_line_length": 25.81818199157715,
"blob_id": "d917c4cf7ac665bc700981a04b6e40d6dfd4f00e",
"content_id": "467d47a8649dc2cbe61040b33a66c741845ebb8a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 294,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 11,
"path": "/cross-platform-hashtable/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "CC = cl\nCFLAGS = /nologo /W3 /EHsc /Za /DWIN /D_CRT_SECURE_NO_DEPRECATE\n\nmain: main.obj table.obj hash.lib\n\tlink /out:tema1.exe main.obj table.obj hash.lib\n\ntable.obj: table.c\n\t$(CC) /DWIN /D_CRT_SECURE_NO_DEPRECATE /c table.c\n\nmain.obj: main.c\n\t$(CC) /DWIN /D_CRT_SECURE_NO_DEPRECATE /c main.c"
},
{
"alpha_fraction": 0.5530864000320435,
"alphanum_fraction": 0.5679012537002563,
"avg_line_length": 15.875,
"blob_id": "33019f6b823a21b74a1179b449863a49ab308267",
"content_id": "7b54ed9cdc77e37dfcaa8ed34ff34cc9ce4f21b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 405,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 24,
"path": "/shear-sort/serial/shear_sort.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nint main(int argc, char** argv) {\n\tint i;\n\tint** matrix;\n\t\n\tif (argc != 2){\n\t\tprintf(\"Use: %s <size>\\n\", argv[0]);\n\t\treturn 0;\n\t}\n\t\n\tint n = atoi(argv[1]);\n\tmatrix = calloc(n, sizeof (int *));\n\n\tfor (i = 0; i < n; i++) {\n\t\tmatrix[i] = calloc(n, sizeof (int));\n\t}\n\n\tinit_random_matrix(matrix, n);\n\tsort_matrix(matrix, n);\n\tprint_matrix(matrix, n);\n\tfree_memory(matrix, n);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.3617021143436432,
"alphanum_fraction": 0.7021276354789734,
"avg_line_length": 14.666666984558105,
"blob_id": "db1647b77715fe2884b06ebe0257e756e4328c26",
"content_id": "e3c747a9f34509d25d26ae4b3b5b640f21296761",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 47,
"license_type": "permissive",
"max_line_length": 15,
"num_lines": 3,
"path": "/README.md",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "# ACS Projects\n- BSc 2015-2019\n- MSc 2019-2021\n"
},
{
"alpha_fraction": 0.7554585337638855,
"alphanum_fraction": 0.7554585337638855,
"avg_line_length": 27.5,
"blob_id": "e2443c36d198ac6a4e039b31f31af8011996ac72",
"content_id": "665caf2111968a2846b35216cab2d86e3f0d8546",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 229,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 8,
"path": "/code-interpreter/src/Visitor.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\npublic interface Visitor {\n\tpublic void visit(SequenceNode n);\n\tpublic void visit(AssignNode n);\n\tpublic void visit(AssertNode n);\n\tpublic void visit(IfNode n);\n\tpublic void visit(ForNode n);\n\tpublic void visit(ReturnNode n);\n}\n"
},
{
"alpha_fraction": 0.6877697706222534,
"alphanum_fraction": 0.6877697706222534,
"avg_line_length": 15.186046600341797,
"blob_id": "e36a38a38992b9abe03441343125f683bc877d21",
"content_id": "1c7f3419e63a51f79a069e6ce52d5efc9d3c81ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 695,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 43,
"path": "/parallel-snake/main.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#ifndef __MAIN_H__\n#define __MAIN_H__\n\n\nstruct coord\n{\n\tint line;\n\tint col;\n};\n\n\nstruct snake\n{\n\tstruct coord head;\n\tint encoding;\n\tchar direction;\n\tstruct cel* cap;\n\tstruct cel* coada;\n\tstruct coord lastTail;\n\tstruct coord oldHead;\n\n};\n\nstruct cel\n{\n\tstruct cel* prev;\n\tstruct cel* next;\n\tstruct coord poz;\n\t\n};\n\n\n\nvoid print_world(char *file_name, int num_snakes, struct snake *snakes,\n\tint num_lines, int num_cols, int **world);\n\nvoid read_data(char *file_name, int *num_snakes, struct snake **snakes,\n\tint *num_lines, int *num_cols, int ***world);\n\nvoid run_simulation(int num_lines, int num_cols, int **world, int num_snakes,\n\tstruct snake *snakes, int step_count, char *file_name);\n\n#endif"
},
{
"alpha_fraction": 0.6066586971282959,
"alphanum_fraction": 0.6319776773452759,
"avg_line_length": 20.81304359436035,
"blob_id": "81ba5cf5bd7f8401b1aaf4d77a39c1170a3f7f4e",
"content_id": "34d81a57d9292ff8cf2a47bce24358b388fb27fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5016,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 230,
"path": "/turing-machine/main.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n\ntypedef struct {\n\tchar* banda;\n\tint currentPosition;\n}Tape;\n\ntypedef struct {\n\n\tint current_state;\n\tint next_state;\n\tchar* read_symbol;\n\tchar* write_symbol;\n\tchar direction;\n}Tranzitie;\n\ntypedef struct {\n\n\tint terminare; // 1 - se termina, -1 se agata, 0 default;\n\tint stareInitiala;\n\tint stareCrt;\n\tint nrStari;\n\tint nrStariF;\n\tint nrTran;\n\tint* stari;\n\tint* stariFinale;\n\tTranzitie* tranzitii;\n}TM;\n\n\nTape* initTape(char* banda) {\n\tTape* r = malloc(sizeof(Tape));\n\tr->currentPosition = 1;\n\tr->banda = banda;\n\treturn r;\n}\n\nTM* initTM(int stareInitiala, int nrStari, int nrStariF, int nrTran, int* stari, int* stariFinale) {\n\tint i;\n\tTM* t = malloc(sizeof(TM));\n\n\tt->terminare = 0;\n\tt->stareCrt = stareInitiala;\n\tt->stareInitiala = stareInitiala;\n\tt->nrStari = nrStari;\n\tt->nrStariF = nrStariF;\n\tt->nrTran = nrTran;\n\tt->tranzitii = malloc(nrTran * sizeof(Tranzitie));\n\tt->stari = stari;\n\tt->stariFinale = stariFinale;\n\n\tfor(i = 0; i < nrTran; i++) {\n\t\tt->tranzitii[i].read_symbol = malloc(sizeof(char));\n\t\tt->tranzitii[i].write_symbol = malloc(sizeof(char));\n\t}\n\n\treturn t;\n}\n\nint* convertStates(char** states, int nrStari) {\n\n\tint* rez = malloc(nrStari * sizeof(int));\n\tint i;\n\n\tfor(i = 0; i < nrStari; i++) {\n\t\trez[i] = atoi(++states[i]);\n\t}\n\n\treturn rez;\n}\n\nvoid getTransitions(TM* turingMachine, char** tran, int nrTran) {\n\tint i;\n\tchar* aux1 = malloc(100 * sizeof(char));\n\tchar* aux2 = malloc(100);\n\tfor(i = 0; i < nrTran; i++) {\n\t\tturingMachine->tranzitii[i].current_state = atoi(tran[i] + 1);\n\t\tsprintf(aux1, \"%d\", turingMachine->tranzitii[i].current_state);\n\t\tturingMachine->tranzitii[i].next_state = atoi(tran[i] + strlen(aux1)+ 1 + 4);\n\t\tstrncpy(turingMachine->tranzitii[i].read_symbol, tran[i] + 1 + strlen(aux1) + 1, 1);\n\t\tsprintf(aux2, \"%d\", turingMachine->tranzitii[i].next_state);\n\t\tstrncpy(turingMachine->tranzitii[i].write_symbol, tran[i] + 1 + strlen(aux1) + 4 + strlen(aux2) + 1, 1);\n\t\tturingMachine->tranzitii[i].direction = tran[i][strlen(aux1) + 1 + 4 + strlen(aux2) +3];\n\t}\n}\n\nvoid verificare(TM* turingMachine, Tape* tape) {\n\n\tint i, j;\n\tint found1 = 0;\n\tint found2 = 0;\n\tfor(i = 0; i < turingMachine->nrTran; i++) {\n\t\tif(turingMachine->stareCrt == turingMachine->tranzitii[i].current_state)\n\t\t\tif(strncmp(tape->banda + tape->currentPosition, turingMachine->tranzitii[i].read_symbol, 1) == 0) {\n\t\t\t\tfound1 = 1;\n\t\t\t\tj = i;\n\t\t\t}\n\t}\n\tif(found1 == 1) {\n\t\ttape->banda[tape->currentPosition] = *turingMachine->tranzitii[j].write_symbol;\n\t\tturingMachine->stareCrt = turingMachine->tranzitii[j].next_state;\n\t\tfor(i = 0; i < turingMachine->nrStariF; i++) {\n\t\t\tif(turingMachine->stareCrt == turingMachine->stariFinale[i]) {\n\t\t\t\tfound2 = 1;\n\t\t\t}\n\t\t}\n\t\tif(turingMachine->tranzitii[j].direction == 'R') {\n\t\t\ttape->currentPosition++;\n\t\t}\n\t\tif(turingMachine->tranzitii[j].direction == 'L') {\n\t\t\ttape->currentPosition--;\n\t\t}\n\t}\n\n\tif(found2 == 1) {\n\t\tturingMachine->terminare = 1;\n\t\treturn;\n\t}\n\n\tif(found1 == 0) {\n\t\tturingMachine->terminare = -1;\n\t\treturn;\n\n\t}\n}\n\nint main(int argc, char const *argv[]) {\n\n\tchar* buffer = malloc(10000);\n\tchar* p;\n\tchar* tape = malloc(10000* sizeof(char));\n\n\tTape* myTape = initTape(tape);\n\n\tint* rez1, *rez2;\n\tint i = 0;\n\tlong int posFile;\n\n\tint nrStari;\n\tint nrStariF;\n\n\tFILE* fp;\n\tFILE* fptr;\n\tFILE* fout;\n\tfp = fopen(\"tm.in\", \"r\");\n\tfptr = fopen(\"tape.in\", \"r\");\n\tfout = fopen(\"tape.out\", \"w\");\n\n\tfgets(myTape->banda, 10000, fptr);\n\tposFile = ftell(fptr);\n\n\tfor(i = posFile; i < 10000 - posFile; i++) {\n\t\tmyTape->banda[i] = '#';\n\t}\n\n\tprintf(\"TAPE Initial:%s\\n\", myTape->banda);\n\n\tfgets(buffer, 10000, fp);\n\tp = strtok(buffer, \" \");\n\n\tnrStari = atoi(p);\n\n\tchar** stari = malloc(nrStari * sizeof(char*));\n\tfor(i = 0; i < nrStari; i++) {\n\t\tstari[i] = malloc(10);\n\t}\n\n\ti = 0;\n\twhile(p != NULL && i != nrStari) {\n\t\tp = strtok(NULL, \" \");\n\t\tstari[i] = strdup(p);\n\t\ti++;\n\t}\n\n\tfgets(buffer, 10000, fp);\n\tp = strtok(buffer, \" \");\n\tnrStariF = atoi(p);\n\n\n\tchar** stariF = malloc(nrStariF * sizeof(char*));\n\tfor(i = 0; i < nrStariF; i++) {\n\t\tstariF[i] = malloc(10);\n\t}\n\n\ti = 0;\n\twhile(p != NULL && i != nrStariF) {\n\t\tp = strtok(NULL, \" \");\n\t\tstariF[i] = strdup(p);\n\t\ti++;\n\t}\n\n\trez1 = convertStates(stari, nrStari);\n\trez2 = convertStates(stariF, nrStariF);\n\t\n\tfgets(buffer, 10000, fp);\n\tint stareInitiala = atoi(++buffer);\n\n\tfgets(buffer, 10000, fp);\n\tint nrTran = atoi(buffer);\n\n\tTM* turingMachine = initTM(stareInitiala, nrStari, nrStariF, nrTran, rez1, rez2);\n\n\tchar** tran = malloc(nrTran * sizeof(char*));\n\tfor(i = 0; i < nrTran; i++) {\n\t\ttran[i] = malloc(100);\n\t}\n\ti = 0;\n\twhile(fgets(buffer, 10000, fp) && i != nrTran) {\n\t\ttran[i] = strdup(buffer);\n\t\ti++;\n\t}\n\n\tgetTransitions(turingMachine, tran, nrTran);\n\twhile(turingMachine->terminare != 1 && turingMachine->terminare != -1) {\n\t\tverificare(turingMachine, myTape);\n\t}\n\n\tif(turingMachine->terminare == 1)\n\t\tfprintf(fout, \"%s\", myTape->banda);\n\n\tif(turingMachine->terminare == -1)\n\t\tfprintf(fout, \"Se agata!\");\n\t\n\tfclose(fp);\n\tfclose(fptr);\n\tfclose(fout);\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.6736842393875122,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 11,
"blob_id": "c03e72ad1439415dcf43f9ea8fb81c6f9f096d42",
"content_id": "5289e7ca1c9c3cee767d1db3a55707351a2ede04",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 95,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 8,
"path": "/shear-sort/serial/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tgcc shear_sort.c utils.c -o shear_sort -lm\n\nclean:\n\trm shear_sort\n\nrun:\n\t./shear_sort 8"
},
{
"alpha_fraction": 0.7523629665374756,
"alphanum_fraction": 0.757088840007782,
"avg_line_length": 34.266666412353516,
"blob_id": "e1a9676fd008590b2ba822b280e95f08fbfb201a",
"content_id": "0e85ae7a253ae4e27b5b5e261f9d2e7659229165",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1058,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 30,
"path": "/mini-db-engine/Table.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import java.util.ArrayList;\nimport java.util.LinkedHashMap;\nimport java.util.concurrent.Semaphore;\n\n\n\npublic class Table {\n\tString tableName;\n\tLinkedHashMap<String, String> cols; // hash de la numele listelor la tipul lor (este LinkedHashMap pentru a tine ordinea coloanelor)\n\tArrayList<ArrayList<Object>> entries; // intrarile din tabela (tinute ca o lista de linii) \n\tint readCount; // numarul cititorilor\n\tint processesCount; // numarul de procese din tabela\n\tlong transactionThreadId; // id-ul threadului care e facut request la tranzactie\n\tBoolean transactionRunning; // flag pentru a tine evidenta daca este o tranzactie activa in tabela\n\t\n\tSemaphore w = new Semaphore(1); // semafor pentru cititori\n\tSemaphore tranSem = new Semaphore(1); // semafor pentru tranzactii\n\t\n\t\n\tpublic Table(String tableName, LinkedHashMap<String, String> cols) {\n\t\tthis.tableName = tableName;\n\t\tthis.entries = new ArrayList<>();\n\t\tthis.cols = cols;\n\t\tthis.readCount = 0;\n\t\tthis.processesCount = 0;\n\t\tthis.transactionThreadId = -1;\n\t\tthis.transactionRunning = false;\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.510269820690155,
"alphanum_fraction": 0.5227547287940979,
"avg_line_length": 19.520660400390625,
"blob_id": "0a077c6cfb8ad3f825f31ef66f23f6aca678fac9",
"content_id": "2f9feb2adb4b6d562bfaa0085e9af01804db7f21",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2483,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 121,
"path": "/shear-sort/mpi/utils.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nvoid init_random_matrix(int* matrix, int num_lines_per_proc, int size) {\n\tint i, j;\n\tsrand(size);\n\n\tfor(i = 0; i < num_lines_per_proc; i++) {\n\t\tfor(j = 0; j < size; j++) {\n\t\t\tmatrix[i * size + j] = rand() % (size * 2) + 1; \n\t\t}\n\t}\n}\n\nint compare_asc(const void* a, const void* b) {\n\tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn A - B;\n}\n\nint compare_dsc(const void* a, const void* b) {\n \tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn B - A;\n}\n\nvoid sort_lines_start_finish(int* matrix, int remaining_lines, int size) {\n\tint i, j;\n\tint line[size];\n\tint start = size - remaining_lines - 1;\n\tint finish = size;\n\t\n\tfor (i = start; i < finish; i++) {\n\t\tfor (j = 0; j < size ; j++) {\n\t\t\tline[j] = matrix[i * size + j];\n\t\t}\n\t\n\t\tif (i % 2 == 0) {// even lines > ascending\n\t\t\tqsort(line, size, sizeof(int), compare_asc);\n\t\t} else { // odd lines > decending\n\t\t\tqsort(line, size, sizeof(int), compare_dsc);\n\t\t}\n\t\t\n\t\tfor (j = 0; j < size ; j++) {\n\t\t\tmatrix[i * size + j] = line[j];\n\t\t}\n\t}\n}\n\nvoid sort_lines(int* matrix, int num_lines_per_proc, int size) {\n\tint i, j;\n\tint line[size];\n\t\n\tfor (i = 0; i < num_lines_per_proc; i++) {\n\t\tfor (j = 0; j < size ; j++) {\n\t\t\tline[j] = matrix[i * size + j];\n\t\t}\n\t\n\t\tif (i % 2 == 0) {// even lines > ascending\n\t\t\tqsort(line, size, sizeof(int), compare_asc);\n\t\t} else { // odd lines > decending\n\t\t\tqsort(line, size, sizeof(int), compare_dsc);\n\t\t}\n\t\t\n\t\tfor (j = 0; j < size ; j++) {\n\t\t\tmatrix[i * size + j] = line[j];\n\t\t}\n\t}\n}\n\nvoid sort_columns(int* matrix, int size) {\n\tint i, j;\n\tint col[size];\n\t\n\tfor (j = 0; j < size; j++) {\n\t\tfor (i = 0; i < size; i++) {\n\t\t\tcol[i] = matrix[i * size + j];\n\t\t}\n\n\t\tqsort(col, size, sizeof(int), compare_asc);\n\n\t\tfor (i = 0; i < size; i++) {\n\t\t\tmatrix[i * size + j] = col[i] ;\n\t\t}\n\t}\n}\n\nint check_sorted(int* matrix, int num_lines_per_proc, int size) {\n\tint i, j, even, current;\n\t\n\tfor (i = 0; i < size; i++) {\n\t\tif (i % 2 == 0) {\n\t\t\teven = 1; // even line > ascending\n\t\t} else {\n\t\t\teven = 0; // odd line > descending\n\t\t}\n\t\t\n\t\tfor (j = 0; j < size - 1; j++) {\n\t\t\tcurrent = i * size + j;\n\t\t\tif (even) {\n\t\t\t\tif (matrix[current] > matrix[current + 1])\n\t\t\t\t\treturn 0;\n\t\t\t} else {\n\t\t\t\tif (matrix[current] < matrix[current + 1])\n\t\t\t\t\treturn 0;\n\t\t\t}\n\t\t}\n\t}\n\t\n\treturn 1;\n}\n\nvoid print_matrix(int* matrix, int num_lines_per_proc, int size) {\n\tint i, j;\n\tfor (i = 0; i < num_lines_per_proc; i++) {\n\t\tfor (j = 0; j < size; j++) {\n\t\t\tprintf(\"%d\\t\", matrix[i * size + j]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\tprintf(\"\\n\");\n}\n"
},
{
"alpha_fraction": 0.5485208034515381,
"alphanum_fraction": 0.5542375445365906,
"avg_line_length": 16.8040714263916,
"blob_id": "f74ea19555a44a15b0937e6231f0a075030e0906",
"content_id": "5d247a012f228a8419304260320941f7722a52e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6997,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 393,
"path": "/cross-platform-hashtable/table.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <ctype.h>\n#include \"table.h\"\n#include \"list.h\"\n#include \"utils.h\"\n#include \"hash.h\"\n\nHashtable *create_table (unsigned int size)\n{\n\tHashtable *table;\n\tint i;\n\n\tDIE (size < 1, \"Invalid size\");\n\n\ttable = malloc (sizeof(Hashtable));\n\tDIE (table == NULL, \"Eroare malloc\");\n\n\ttable->size = size;\n\n\ttable->buckets = malloc (sizeof(List*) * size);\n\tDIE (table->buckets == NULL, \"Eroare malloc\");\n\n\tfor (i = 0; i < size; i++)\n\t\ttable->buckets[i] = NULL;\n\n\treturn table;\n}\n\nint destroy_table (Hashtable** table)\n{\n\ttable_clear (*table);\n\tfree ((*table)->buckets);\n\tfree (*table);\n\n\treturn 1;\n}\n\nint add_to_table (Hashtable* table, char* word)\n{\n\tList* cell, *p;\n\tchar* aux;\n\tunsigned int index;\n\n\tif (word == NULL)\n\t\treturn -1;\n\n\tindex = hash (word, table->size);\n\t//printf (\"idx : %d\\n\", index);\n\n\tif (table->buckets[index] == NULL) {\n\t\taux = strdup (word);\n\t\tcell = malloc (sizeof(List));\n\t\tDIE (cell == NULL, \"Eroare malloc\");\n\t\tcell->info = aux;\n\t\tcell->next = NULL;\n\n\t\ttable->buckets[index] = cell;\n\t} else {\n\t\tp = table->buckets[index];\n\t\twhile (p != NULL) {\n\t\t\tif (!strcmp (word, p->info)) {\n\t\t\t\t/* Cuvantul deja exista */\n\t\t\t\treturn 2;\n\t\t\t}\n\n\t\t\tif (p->next == NULL) {\n\t\t\t\taux = strdup (word);\n\t\t\t\tcell = malloc (sizeof(List));\n\t\t\t\tDIE (cell == NULL, \"Eroare malloc\");\n\t\t\t\tcell->info = aux;\n\t\t\t\tcell->next = NULL;\n\t\t\t\tp->next = cell;\n\t\t\t}\n\t\t\tp = p->next;\n\t\t}\n\t}\n\n\treturn 1;\n}\n\nint remove_from_table (Hashtable* table, char* word)\n{\n\tunsigned int index;\n\tList *p, *cel_aux;\n\n\tif (word == NULL)\n\t\treturn -1;\n\n\tindex = hash (word, table->size);\n\t//printf (\"\\t -- idx : %d, size : %d -- \\n\", index, table->size);\n\n\t/* Cuvantul nu exista */\n\tif(table->buckets[index] == NULL)\n\t\treturn 2;\n\t\n\tp = table->buckets[index];\n\n\tcel_aux = NULL;\n\n\twhile (p != NULL) {\n\t\tif (!strcmp (word, p->info)) {\n\t\t\tfree (p->info);\n\t\t\tif (cel_aux != NULL) {\n\t\t\t\tcel_aux->next = p->next;\n\t\t\t\tfree (p);\n\n\t\t\t} else {\n\t\t\t\t/* Primul element */\n\t\t\t\ttable->buckets[index] = p->next;\n\t\t\t\tfree (p);\n\t\t\t}\n\t\t\treturn 1;\n\t\t}\n\t\tcel_aux = p;\n\t\tp = p->next;\n\t}\n\n\t/* Cuvantul nu a fost gasit */\n\treturn 2;\n}\n\nint print_bucket (Hashtable* table, unsigned int index, char* output_file)\n{\n\tFILE *f;\n\tList *p;\n\tint ret;\n\n\tif (table->buckets[index] == NULL)\n\t\treturn 1;\n\n\tif (output_file) {\n\t\tf = fopen(output_file, \"a\");\n\t\tDIE (f == NULL, \"Eroare deschidere fisier\");\n\t}\n\n\tp = table->buckets[index];\n\t\n\tfor (; p != NULL; p = p->next) {\n\t\tif(output_file)\n\t\t\tfprintf(f, \"%s \", p->info);\n\t\telse\n\t\t\tprintf(\"%s \", p->info);\n\t}\n\tif (output_file) {\n\t\tfprintf(f, \"\\n\");\n\n\t\tret = fclose(f);\n\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\n\t} else\n\t\tprintf(\"\\n\");\n\n\treturn 1;\n}\n\nint print_table (Hashtable* table, char* output_file)\n{\n\tFILE *f;\n\tList *p;\n\tint i, ret;\n\n\tif (output_file) {\n\t\tf = fopen(output_file, \"a\");\n\t\tDIE (f == NULL, \"Eroare deschidere fisier\");\n\t}\n\n\tfor (i = 0; i < table->size; i++) {\n\t\tp = table->buckets[i];\n\n\t\tif(p == NULL)\n\t\t\tcontinue;\n\n\t\tfor (; p != NULL; p = p->next) {\n\t\t\tif (output_file) {\n\t\t\t\tfprintf (f, \"%s \", p->info);\n\t\t\t} else {\n\t\t\t\tprintf (\"%s \", p->info);\n\t\t\t}\n\t\t}\n\n\t\tif (output_file)\n\t\t\tfprintf (f, \"\\n\");\n\t\telse \n\t\t\tprintf (\"\\n\");\n\t}\n\n\tif (output_file) {\n\t\tret = fclose (f);\n\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\n\t}\n\n\treturn 1;\n}\n\nint find_in_table (Hashtable* table, char* word, char* output_file)\n{\n\tFILE *f;\n\tList *p;\n\tunsigned int index;\n\tint ret;\n\n\tif (word == NULL)\n\t\treturn -1;\n\n\tindex = hash (word, table->size);\n\n\tif (output_file) {\n\t\tf = fopen (output_file, \"a\");\n\t\tDIE (f == NULL, \"Eroare deschidere fisier\");\n\t}\n\n\tif (table->buckets[index] == NULL) {\n\t\tif (output_file) {\n\t\t\tfprintf (f, \"False\\n\");\n\n\t\t\tret = fclose (f);\n\t\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\n\t\t} else\n\t\t\tprintf (\"False\\n\");\n\n\t\treturn 2;\n\t}\n\n\tp = table->buckets[index];\n\n\twhile (p != NULL) {\n\t\tif (!strcmp (word, p->info)) {\n\t\t\tif (output_file) {\n\t\t\t\tfprintf (f, \"True\\n\");\n\n\t\t\t\tret = fclose (f);\n\t\t\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\t\n\t\t\t} else\n\t\t\t\tprintf (\"True\\n\");\n\t\t\treturn 1;\n\t\t}\n\t\tp = p->next;\n\t}\n\tif (output_file) {\n\t\tfprintf (f, \"False\\n\");\n\n\t\tret = fclose (f);\n\t\tDIE (ret < 0, \"Eroare inchidere fisier\");\n\t} else\n\t\tprintf (\"False\\n\");\n\n\treturn 2;\n}\n\nint table_clear (Hashtable* table)\n{\n\tList *p, *cell_aux;\n\tint i;\n\n\tfor (i = 0; i < table->size; i++) {\n\t\tp = table->buckets[i];\n\n\t\tif(p == NULL)\n\t\t\tcontinue;\n\n\t\twhile (p != NULL) {\n\t\t\tcell_aux = p;\n\t\t\tp = p->next;\n\t\t\tcell_aux->next = NULL;\n\t\t\tfree (cell_aux->info);\n\t\t\tfree (cell_aux);\n\t\t\tcell_aux = NULL;\n\t\t}\n\n\t\ttable->buckets[i] = NULL;\n\t}\n\n\treturn 1;\n}\n\nint table_resize (Hashtable* table, int mode)\n{\n\tunsigned int size;\n\tunsigned int i, old_size;\n\tList **buckets;\n\tList **old_buckets;\n\tList *p, *cell_aux;\n\n\told_size = table->size;\n\n\tif (mode == DOUBLE)\n\t\tsize = 2 * table->size;\n\telse\n\t\tsize = table->size / 2;\n\n\told_buckets = table->buckets;\n\ttable->size = size;\n\n\tbuckets = malloc (sizeof(List*) * size);\n\tDIE (buckets == NULL, \"Eroare malloc\");\n\n\tfor (i = 0; i < size; i++) {\n\t\tbuckets[i] = NULL;\n\t}\n\n\ttable->buckets = buckets;\n\n\tfor (i = 0; i < old_size; i++) {\n\t\tp = old_buckets[i];\n\n\t\tif (p == NULL)\n\t\t\tcontinue;\n\n\t\tfor (; p != NULL; p = p->next)\n\t\t\tadd_to_table (table, p->info);\n\t}\n\n\tfor (i = 0; i < old_size; i++) {\n\t\tp = old_buckets[i];\n\n\t\tif(p == NULL) {\n\t\t\tcontinue;\n\t\t}\n\n\t\twhile (p != NULL) {\n\t\t\tcell_aux = p;\n\t\t\tp = p->next;\n\t\t\tcell_aux->next = NULL;\n\t\t\tfree (cell_aux->info);\n\t\t\tfree (cell_aux);\n\t\t\tcell_aux = NULL;\n\t\t}\n\t}\n\n\tfree (old_buckets);\n\treturn 1;\n}\n\nvoid execute_command (Hashtable* table, char* line)\n{\n\tchar* tok, *aux_tok;\n\tint ret, i;\n\ttok = strtok (line, \" \\n\");\n\t\n\tif (tok == NULL)\n\t\treturn;\n\n\tif (!strcmp (tok, \"add\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\tret = add_to_table (table, tok);\n\t\tDIE (ret < 0, \"Eroare in add\");\n\n\t} else if (!strcmp (tok, \"remove\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\tret = remove_from_table (table, tok);\n\t\tDIE (ret < 0, \"Eroare in remove\");\n\t\n\t} else if (!strcmp (tok, \"find\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\taux_tok = strtok (NULL, \" \\n\");\n\t\tret = find_in_table (table, tok, aux_tok);\n\t\tDIE (ret < 0, \"Eroare in find\");\n\t\n\t} else if (!strcmp (tok, \"clear\")) {\n\t\tret = table_clear (table);\n\t\tDIE (ret < 0, \"Eroare in clear\");\n\t\n\t} else if (!strcmp (tok, \"print_bucket\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\t\n\t\t/* Testare input */\n\t\tfor (i = 0; i < strlen (tok); i++) {\n\t\t\tDIE (!isdigit(tok[i]), \"Lungimea nu este numar\");\n\t\t}\n\n\t\taux_tok = strtok (NULL, \" \\n\");\n\t\tret = print_bucket (table, atoi(tok), aux_tok);\n\t\tDIE (ret < 0, \"Eroare in print_bucket\");\n\t\n\t} else if (!strcmp (tok, \"print\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\tret = print_table (table, tok);\n\t\tDIE (ret < 0, \"Eroare in print\");\n\t\n\t} else if (!strcmp (tok, \"resize\")) {\n\t\ttok = strtok (NULL, \" \\n\");\n\t\tDIE (tok == NULL, \"Eroare resize\");\n\n\t\tif ((ret = strcmp (tok, \"double\")) == 0)\n\t\t\ttable_resize (table, DOUBLE);\n\t\telse if ((ret = strcmp (tok, \"halve\")) == 0)\n\t\t\ttable_resize (table, HALVE);\n\t} else {\n\t\tperror (\"Comanda invalida\");\n\t\texit (EXIT_FAILURE);\n\t}\n}\n"
},
{
"alpha_fraction": 0.6572238206863403,
"alphanum_fraction": 0.6770538091659546,
"avg_line_length": 22.566667556762695,
"blob_id": "0dd9ca6ea23c5d0e1223025ae3e8026e32f01982",
"content_id": "e3b865792919fe243cd661773914a05a5f637a7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 706,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 30,
"path": "/atm/lib.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#ifndef LIB\n#define LIB\n\ntypedef struct {\n\tchar nume[13];\n\tchar prenume[13];\n\tchar nr_card[7];\n\tchar pin[5];\n\tchar parola[17];\n\tdouble sold;\n\tint logat; \t\t// 1 - logat, 0 - delogat\n\tint blocat; \t// 1 - blocat, 0 - deblocat\n\tint incercari; \t// de la 0 la 3\n} user;\n\ntypedef struct { \t// pereche (socket, user)\n\tint sock;\n\tuser* user;\n\tint crt;\n\tint len;\n} pair;\n\nvoid addPair(pair* pairs, user* u, int sock);\nvoid removePair(pair* pairs, int sock);\ndouble getSold(pair* pairs, int sock);\nint getMoney(pair* pairs, int sock, int money);\nint getUserIndex(user* users, char* nr_card, int no_users);\nvoid putMoney(pair* pairs, int sock, int money);\nint findCard(user* users, char* nr_card, int no_users);\n#endif"
},
{
"alpha_fraction": 0.7222222089767456,
"alphanum_fraction": 0.7361111044883728,
"avg_line_length": 17.125,
"blob_id": "839f0a8e1ce3073e251d03a82b2e56bf1f410111",
"content_id": "8b4b8729ce506147fb82cd3205aa333987208ef9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 144,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 8,
"path": "/shear-sort/hybrid/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tmpicc -fopenmp shear_sort_hybrid.c utils.c -o shear_sort_hybrid -lm\n\nclean:\n\trm shear_sort_hybrid\n\nrun:\n\tmpirun -n 4 shear_sort_hybrid 8"
},
{
"alpha_fraction": 0.6916666626930237,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 14.125,
"blob_id": "29b173465724fa10cabc95f36383f8284fad2088",
"content_id": "726d05fc230605032d9c12e9c12ac2d7b581f57e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 120,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 8,
"path": "/shear-sort/omp/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tgcc -fopenmp shear_sort_omp.c utils.c -o shear_sort_omp -lm\n\nclean:\n\trm shear_sort_omp\n\nrun:\n\t./shear_sort_omp 8"
},
{
"alpha_fraction": 0.6292428374290466,
"alphanum_fraction": 0.6292428374290466,
"avg_line_length": 14.279999732971191,
"blob_id": "b667224b3946a3f4de7ec9470d0cf2fc6f992af8",
"content_id": "27a41f7a9b6f94c30b51e150a42c65a59482a75a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 383,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 25,
"path": "/expression-evaluator/DivNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\n/**\n * Clasa unui nod operator de impartire.\n * \n * @author Alin\n * \n */\npublic class DivNode extends BinaryOpNode {\n\n\t/*\n\t * Se creaza un nod operator de impartire si i se seteaza semnul operatiei\n\t * corespunzator.\n\t * \n\t */\n\tpublic DivNode() {\n\t\tsuper.setOperator(\"/\");\n\t}\n\n\t/*\n\t * @see Node#accept(Visitor)\n\t */\n\t@Override\n\tpublic void accept(Visitor v) {\n\t\tv.visit(this);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5086677670478821,
"alphanum_fraction": 0.5257658362388611,
"avg_line_length": 28.86524772644043,
"blob_id": "48ce5a8dc70419c12a7c0846a0b47c39d0fdb06a",
"content_id": "dc2b20a2bd6621e15be0dd319079962d27097e52",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4212,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 141,
"path": "/belief-propagation/factor_operations.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "from collections import namedtuple\nfrom copy import deepcopy\n\nFactor = namedtuple(\"Factor\", [\"vars\", \"values\"])\nIdentityFactor = Factor(vars=[], values={(): 1})\n\n\ndef print_factor(phi, indent=\"\\t\"):\n line = \" | \".join(phi.vars + [\"ϕ(\" + \",\".join(phi.vars) + \")\"])\n sep = \"\".join([\"+\" if c == \"|\" else \"-\" for c in list(line)])\n print(indent + sep)\n print(indent + line)\n print(indent + sep)\n for values, p in phi.values.items():\n print(indent + \" | \".join([str(v) for v in values] + [str(p)]))\n print(indent + sep)\n\n\ndef multiply(f1, f2):\n # sanity check\n assert isinstance(f1, Factor) and isinstance(f2, Factor)\n\n all_variables = []\n common_vars = []\n for var in f1.vars:\n all_variables.append(var)\n for var in f2.vars:\n if var not in all_variables:\n all_variables.append(var)\n else:\n common_vars.append(var)\n values = {}\n for line1 in f1.values:\n for line2 in f2.values:\n if len(common_vars) == 0:\n line = line1 + line2\n val = f1.values[line1] * f2.values[line2]\n values[line] = val\n else:\n common_match = True\n for var in common_vars:\n index1 = f1.vars.index(var)\n index2 = f2.vars.index(var)\n if line1[index1] != line2[index2]:\n common_match = False\n break\n\n if common_match:\n line_result = []\n for var in f1.vars:\n line_result.append(line1[f1.vars.index(var)])\n for var in f2.vars:\n if var not in common_vars:\n line_result.append(line2[f2.vars.index(var)])\n values[tuple(line_result)] = f1.values[line1] * f2.values[line2]\n\n result = Factor(vars=all_variables, values=values)\n return result\n\n\ndef reduce(factors):\n if len(factors) == 1:\n return factors[0]\n\n multiplied_factor = factors[0]\n for factor in factors[1:]:\n multiplied_factor = multiply(multiplied_factor, factor)\n\n return multiplied_factor\n\n\ndef condition_factors(factor, Z):\n copy_factor = deepcopy(factor)\n for var in Z:\n for fact in copy_factor:\n if var not in fact.vars:\n continue\n index = fact.vars.index(var)\n deletable = []\n for v in fact.values:\n if v[index] != Z[var]:\n deletable.append(v)\n for v in deletable:\n del fact.values[v]\n return copy_factor\n\n\ndef sum_out(var, factor):\n # sanity check\n assert isinstance(factor, Factor) and var in factor.vars\n values = {}\n delete_idx = factor.vars.index(var)\n\n vars = deepcopy(factor.vars)\n vars.pop(delete_idx)\n\n for key, value in factor.values.items():\n key_list = list(key)\n key_list.pop(delete_idx)\n key_tuple = tuple(key_list)\n if key_tuple not in values:\n values[key_tuple] = value\n else:\n values[key_tuple] += value\n\n return Factor(vars, values)\n\n\ndef divide(phi1, phi2):\n # sanity check\n assert isinstance(phi1, Factor) and isinstance(phi2, Factor)\n\n vars1 = deepcopy(phi1.vars)\n vars2 = deepcopy(phi2.vars)\n\n common_vars = list(filter(lambda x: x in vars1, vars2))\n all_vars = deepcopy(vars1)\n for v in vars2:\n if v not in all_vars:\n all_vars.append(v)\n\n values = {}\n for (vals1, func1) in phi1.values.items():\n for (vals2, func2) in phi2.values.items():\n matching_values = True\n\n for var in common_vars:\n if vals1[vars1.index(var)] != vals2[vars2.index(var)]:\n matching_values = False\n\n if matching_values:\n res = ()\n for var in all_vars:\n if var in vars1:\n res += (vals1[vars1.index(var)],)\n elif var in vars2:\n res += (vals2[vars2.index(var)],)\n\n values[res] = 1.0 * func1 / func2\n\n return Factor(all_vars, values)\n"
},
{
"alpha_fraction": 0.6005627512931824,
"alphanum_fraction": 0.6195289492607117,
"avg_line_length": 19.202104568481445,
"blob_id": "fdcc8c7e56f0e26db77cd7742069a0112214cea0",
"content_id": "5e984cc5458cf5b155abc4288e3f65a8364e846d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9596,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 475,
"path": "/mini-shell/cmd.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/**\n * Operating Systems 2013-2018 - Assignment 2\n *\n *\n *\n */\n#include <stdlib.h>\n#include <string.h>\n#include <stdio.h>\n#include <sys/types.h>\n#include <sys/stat.h>\n#include <sys/wait.h>\n\n#include <fcntl.h>\n#include <unistd.h>\n\n#include \"cmd.h\"\n#include \"utils.h\"\n\n#define READ\t\t0\n#define WRITE\t\t1\n\n/**\n *Functie care salveaza file descriptorii\n */\nstatic void save_fds(int *stdin_copy, int *stdout_copy, int *stderr_copy)\n{\n\tint ret;\n\n\t*stdin_copy = dup(STDIN_FILENO);\n\tDIE(*stdin_copy < 0, \"Error dup\");\n\n\t*stdout_copy = dup(STDOUT_FILENO);\n\tDIE(*stdout_copy < 0, \"Error dup\");\n\n\t*stderr_copy = dup(STDERR_FILENO);\n\tDIE(*stderr_copy < 0, \"Error dup\");\n\n\tret = close(STDIN_FILENO);\n\tDIE(ret < 0, \"Error close\");\n\n\tret = close(STDOUT_FILENO);\n\tDIE(ret < 0, \"Error close\");\n\n\tret = close(STDERR_FILENO);\n\tDIE(ret < 0, \"Error close\");\n}\n\n/**\n * Restaureaza file descriptorii\n */\nstatic void restore_fds(int *stdin_copy, int *stdout_copy, int *stderr_copy)\n{\n\tint ret;\n\n\tret = dup2(*stdin_copy, STDIN_FILENO);\n\tDIE(ret < 0, \"Error dup2\");\n\n\tret = dup2(*stdout_copy, STDOUT_FILENO);\n\tDIE(ret < 0, \"Error dup2\");\n\n\tret = dup2(*stderr_copy, STDERR_FILENO);\n\tDIE(ret < 0, \"Error dup2\");\n\n\tret = close(*stdin_copy);\n\tDIE(ret < 0, \"Error close\");\n\n\tret = close(*stdout_copy);\n\tDIE(ret < 0, \"Error close\");\n\n\tret = close(*stderr_copy);\n\tDIE(ret < 0, \"Error close\");\n}\n\n/**\n * Redirecteaza stdin/stdout/stderr in fisierul dat ca parametru\n */\nstatic void do_redirect(int filedes, const char *filename, int mode)\n{\n\tint rc;\n\tint fd;\n\n\tif (filedes == STDIN_FILENO) {\n\t\tfd = open(filename, O_RDONLY, 0644);\n\t} else {\n\t\tif (mode == IO_REGULAR)\n\t\t\tfd = open(filename\n\t\t\t\t, O_WRONLY | O_CREAT | O_TRUNC, 0644);\n\t\telse\n\t\t\tfd = open(filename\n\t\t\t\t, O_WRONLY | O_CREAT | O_APPEND, 0644);\n\t}\n\n\tDIE(fd < 0, \"Error open\");\n\n\trc = dup2(fd, filedes);\n\tDIE(rc < 0, \"Error dup2\");\n\n\trc = close(fd);\n\tDIE(rc < 0, \"Error close\");\n}\n\n/**\n * Redirectarea in functie de parametrii de redirectare al comenzii.\n */\nstatic void redirect_fds(simple_command_t *s)\n{\n\tint ret;\n\n\t/* daca se cere redirectarea la stderr */\n\tif (s->err) {\n\t\tchar *err_file = get_word(s->err);\n\n\t\tdo_redirect(STDERR_FILENO, err_file, s->io_flags);\n\t\tfree(err_file);\n\t}\n\n\t/* daca se cere redirectarea la stdin */\n\tif (s->in) {\n\t\tchar *in_file = get_word(s->in);\n\n\t\tdo_redirect(STDIN_FILENO, in_file, s->io_flags);\n\t\tfree(in_file);\n\t}\n\n\t/* daca se cere redirectarea la stdout */\n\tif (s->out) {\n\t\tchar *out_file = get_word(s->out);\n\n\t\tdo_redirect(STDOUT_FILENO, out_file, s->io_flags);\n\t\t/* daca se cere si la stderr */\n\t\tif (s->err) {\n\t\t\tchar *err_file = get_word(s->err);\n\n\t\t\tif (!strcmp(out_file, err_file)) {\n\t\t\t\tfree(err_file);\n\t\t\t\tret = dup2(STDOUT_FILENO, STDERR_FILENO);\n\t\t\t\tDIE(ret < 0, \"Error dup2\");\n\t\t\t} else {\n\t\t\t\tdo_redirect(STDERR_FILENO\n\t\t\t\t\t, err_file, IO_OUT_APPEND);\n\t\t\t\tfree(err_file);\n\t\t\t}\n\t\t}\n\t\tfree(out_file);\n\t}\n}\n\n/**\n * Internal change-directory command.\n */\nstatic bool shell_cd(word_t *dir)\n{\n\tint ret = 0;\n\tchar *path;\n\n\t/* Se extrage path-ul */\n\tpath = get_word(dir);\n\n\tif (path != NULL)\n\t\t/* Daca path-ul nu este vid atunci se schimba directorul */\n\t\tret = chdir(path);\n\tfree(path);\n\n\treturn ret;\n}\n\n/**\n * Functie de eliberare a argumentelor unei comenzi.\n */\nstatic void free_argv(char **argv, int size)\n{\n\tint i;\n\n\tfor (i = 0; i < size; i++)\n\t\tfree(argv[i]);\n\n\tfree(argv);\n}\n\n/**\n * Internal exit/quit command.\n */\nstatic int shell_exit(void)\n{\n\treturn SHELL_EXIT;\n}\n\n/**\n * Parse a simple command (internal, environment variable assignment,\n * external command).\n */\nstatic int parse_simple(simple_command_t *s, int level, command_t *father)\n{\n\n\tint size, ret, pid, wait_r, status;\n\tint stdin_copy, stdout_copy, stderr_copy;\n\tchar **argv = get_argv(s, &size);\n\tchar *verb = get_word(s->verb);\n\n\t/* Sanity checks */\n\tDIE(s == NULL, \"Error: null command\");\n\tDIE(father != s->up, \"Error: Bad synthax tree\");\n\n\t/* Daca am exit sau quit, returnez exit status-ul shell-ului */\n\tif (!strcmp(verb, \"exit\") || !(strcmp(verb, \"quit\"))) {\n\t\tfree(verb);\n\t\tfree_argv(argv, size);\n\t\treturn shell_exit();\n\t/* Daca am cd, salvez descriptorii, redirectez,\n\t * apelez cd si restaurez descriptorii\n\t */\n\t} else if (!strcmp(verb, \"cd\")) {\n\t\tsave_fds(&stdin_copy, &stdout_copy, &stderr_copy);\n\t\tredirect_fds(s);\n\n\t\tret = shell_cd(s->params);\n\t\trestore_fds(&stdin_copy, &stdout_copy, &stderr_copy);\n\n\t\tfree(verb);\n\t\tfree_argv(argv, size);\n\n\t\treturn ret;\n\t/* Daca next part nu e null, atunci inseamna ca am\n\t * o comanda de a seta variabila de mediu\n\t */\n\t} else if (s->verb->next_part != NULL) {\n\t\tconst char *name = s->verb->string;\n\t\tconst char *eq = s->verb->next_part->string;\n\n\t\tif (!strcmp(eq, \"=\")) {\n\t\t\t/* Folosesc get_word pentru a expanda valoarea,\n\t\t\t * in caz ca e nevoie.\n\t\t\t */\n\t\t\tchar* value = get_word(s->verb->next_part->next_part);\n\n\t\t\t/* Se seteaza valoarea */\n\t\t\tret = setenv(name, value, 1);\n\t\t\tfree(verb);\n\t\t\tfree(value);\n\t\t\tfree_argv(argv, size);\n\t\t\treturn ret;\n\t\t}\n\t}\n\n\t/* Se creaza procesul copil */\n\tpid = fork();\n\n\tswitch (pid) {\n\tcase -1:\n\t\tDIE(pid < 1, \"fork\");\n\n\tcase 0:\n\t\t/* Se redirecteaza descriptorii in functie de comanda */\n\t\tredirect_fds(s);\n\n\t\t/* Se executa comanda in copil */\n\t\texecvp(verb, (char * const *) argv);\n\t\t/* Daca exec-ul da fail, atunci se va afisa\n\t\t * mesajul de eroare si se va elibera memoria\n\t\t */\n\t\tfprintf(stderr, \"Execution failed for '%s'\\n\", verb);\n\t\tfree(verb);\n\t\tfree_argv(argv, size);\n\t\texit(EXIT_FAILURE);\n\n\tdefault:\n\t\t/* Se asteapta procesul copil */\n\t\twait_r = waitpid(pid, &status, 0);\n\t\tDIE(wait_r < 0, \"Error waitpid\");\n\t\tfree(verb);\n\t\tfree_argv(argv, size);\n\n\t\tif (WIFEXITED(status))\n\t\t\treturn WEXITSTATUS(status);\n\t\telse\n\t\t\treturn EXIT_FAILURE;\n\t}\n}\n\n/**\n * Process two commands in parallel, by creating two children.\n */\nstatic bool do_in_parallel(command_t *cmd1, command_t *cmd2, int level,\n\t\tcommand_t *father)\n{\n\tint pid1, pid2, ret, wait_r;\n\tint status1, status2;\n\n\t/* Se creaza primul copil */\n\tpid1 = fork();\n\n\tswitch (pid1) {\n\tcase -1:\n\t\tDIE(pid1 < 0, \"Error fork\");\n\tcase 0:\n\t\t/* Procesul copil1 va efectual comanda 1 */\n\t\tret = parse_command(cmd1, level + 1, father);\n\t\texit(ret);\n\n\tdefault:\n\t\tbreak;\n\t}\n\n\t/* Se creaza al doilea copil */\n\tpid2 = fork();\n\n\tswitch (pid2) {\n\tcase -1:\n\t\tDIE(pid2 < 0, \"Error fork\");\n\tcase 0:\n\t\t/* Procesul copil2 va efectual comanda 2 */\n\t\tret = parse_command(cmd2, level + 1, father);\n\t\texit(ret);\n\n\tdefault:\n\t\tbreak;\n\t}\n\n\t/* Se asteapta ambii copii */\n\twait_r = waitpid(pid1, &status1, 0);\n\tDIE(wait_r < 0, \"Error waitpid\");\n\n\twait_r = waitpid(pid2, &status2, 0);\n\tDIE(wait_r < 0, \"Error waitpid\");\n\n\tif (WIFEXITED(status1) && WIFEXITED(status2))\n\t\treturn WEXITSTATUS(status1) & WEXITSTATUS(status2);\n\telse\n\t\treturn EXIT_FAILURE;\n}\n\n/**\n * Run commands by creating an anonymous pipe (cmd1 | cmd2)\n */\nstatic bool do_on_pipe(command_t *cmd1, command_t *cmd2, int level,\n\t\tcommand_t *father)\n{\n\tint fd[2], pid1, pid2, ret, wait_r;\n\tint status1, status2;\n\n\t/* Se creaza pipe-ul */\n\tret = pipe(fd);\n\tDIE(ret < 0, \"Error pipe\");\n\n\t/* Se creaza primul copil */\n\tpid1 = fork();\n\n\tswitch (pid1) {\n\tcase -1:\n\t\tDIE(pid1 < 0, \"Error fork\");\n\tcase 0:\n\t\t/* Se inchide capul de citire */\n\t\tret = close(fd[0]);\n\t\tDIE(ret < 0, \"Error close\");\n\n\t\t/* Se redirecteaza output-ul */\n\t\tret = dup2(fd[1], STDOUT_FILENO);\n\t\tDIE(ret < 0, \"Error dup2\");\n\n\t\tret = close(fd[1]);\n\t\tDIE(ret < 0, \"Error close\");\n\n\t\t/* Primul copil va efectua prima comanda */\n\t\tret = parse_command(cmd1, level + 1, father);\n\t\texit(ret);\n\tdefault:\n\t\tbreak;\n\t}\n\n\t/* Se creaza al doilea copil */\n\tpid2 = fork();\n\n\tswitch (pid2) {\n\tcase -1:\n\t\tDIE(pid2 < 0, \"Error fork\");\n\tcase 0:\n\t\t/* Se inchide capul de scriere */\n\t\tret = close(fd[1]);\n\t\tDIE(ret < 0, \"Error close\");\n\n\t\t/* Se redirecteaza inputul */\n\t\tret = dup2(fd[0], STDIN_FILENO);\n\t\tDIE(ret < 0, \"Error dup2\");\n\n\t\tret = close(fd[0]);\n\t\tDIE(ret < 0, \"Error close\");\n\n\t\t/* Al doilea copil va efectua a doua comanda */\n\t\tret = parse_command(cmd2, level + 1, father);\n\t\texit(ret);\n\n\tdefault:\n\t\tbreak;\n\t}\n\n\t/* Se inchid capetele pipe-ului */\n\tret = close(fd[1]);\n\tDIE(ret < 0, \"Error close\");\n\n\tret = close(fd[0]);\n\tDIE(ret < 0, \"Error close\");\n\n\t/* Se asteapta ambii copii */\n\twait_r = waitpid(pid1, &status1, 0);\n\tDIE(wait_r < 0, \"Error waitpid\");\n\n\twait_r = waitpid(pid2, &status2, 0);\n\tDIE(wait_r < 0, \"Error waitpid\");\n\n\tif (WIFEXITED(status2))\n\t\treturn WEXITSTATUS(status2);\n\telse\n\t\treturn EXIT_FAILURE;\n}\n\n\n/**\n * Parse and execute a command.\n */\nint parse_command(command_t *c, int level, command_t *father)\n{\n\tint ret;\n\n\t/* Sanity checks */\n\tDIE(c == NULL, \"Error: null command\");\n\tDIE(father != c->up, \"Error: Bad synthax tree\");\n\n\t/* Comanda simpla */\n\tif (c->op == OP_NONE) {\n\t\tret = parse_simple(c->scmd, level + 1, c);\n\t\treturn ret;\n\t}\n\n\tswitch (c->op) {\n\t/* Comenzi secventiale: cmd1 ; cmd2 */\n\tcase OP_SEQUENTIAL:\n\t\tparse_command(c->cmd1, level + 1, c);\n\t\tret = parse_command(c->cmd2, level + 1, c);\n\n\t\tbreak;\n\t/* Comemzi paralele: cmd1 & cmd2 */\n\tcase OP_PARALLEL:\n\t\tret = do_in_parallel(c->cmd1, c->cmd2, level + 1, c);\n\t\tbreak;\n\n\t/* Comenzi conditionale non-zero: cmd1 || cmd2 */\n\tcase OP_CONDITIONAL_NZERO:\n\t\tret = parse_command(c->cmd1, level + 1, c);\n\n\t\tif (ret != 0)\n\t\t\tret = parse_command(c->cmd2, level + 1, c);\n\n\t\tbreak;\n\n\t/* Comenzi conditionale zero: cmd1 && cmd2 */\n\tcase OP_CONDITIONAL_ZERO:\n\t\tret = parse_command(c->cmd1, level + 1, c);\n\n\t\tif (ret == 0)\n\t\t\tret = parse_command(c->cmd2, level + 1, c);\n\n\t\tbreak;\n\n\t/* Comenzi care comunica printr-un pipe: cmd1 | cmd2 */\n\tcase OP_PIPE:\n\t\tret = do_on_pipe(c->cmd1, c->cmd2, level + 1, c);\n\t\tbreak;\n\n\tdefault:\n\t\treturn SHELL_EXIT;\n\t}\n\n\treturn ret;\n}\n"
},
{
"alpha_fraction": 0.7020785212516785,
"alphanum_fraction": 0.7020785212516785,
"avg_line_length": 32.38461685180664,
"blob_id": "213cca9182c8bddc5fa2ff37756b8c87f5d6f37e",
"content_id": "cc0f404b36f6c9fd420587ec5cc00d42e01da36e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 433,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 13,
"path": "/shear-sort/serial/utils.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <time.h>\n\nvoid init_random_matrix(int** matrix, int size);\nint compare_asc(const void* a, const void* b);\nint compare_dsc(const void* a, const void* b);\nvoid sort_lines(int** matrix, int size);\nvoid sort_columns (int** matrix, int size);\nvoid sort_matrix (int** matrix, int size);\nvoid print_matrix (int** matrix, int size);\nvoid free_memory (int** matrix, int size);"
},
{
"alpha_fraction": 0.5094671249389648,
"alphanum_fraction": 0.5223501920700073,
"avg_line_length": 26.395721435546875,
"blob_id": "bcd979b279d5f2613ac7b1751603dd4caa32fb8c",
"content_id": "570dff5858d26e495b96bf39968271a211befa5f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5123,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 187,
"path": "/belief-propagation/graph_utils.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nfrom graph import Graph\n\n\ndef create_graph(variables, parents):\n G = Graph()\n\n for var in variables:\n G.add_node(var)\n\n for var, ps in parents.items():\n for parent in ps:\n G.add_edge(parent, var)\n\n return G\n\n\ndef create_undirected_graph(G):\n U = deepcopy(G)\n\n for parent, child in G.get_edges():\n U.add_edge(child, parent)\n return U\n\n\ndef moralize_graph(U, parents):\n H = deepcopy(U)\n\n parents_values = parents.values()\n for parent_v in parents_values:\n for parent1, parent2 in [(p1, p2) for p1 in parent_v for p2 in parent_v if p1 != p2]:\n H.add_edge(parent1, parent2)\n return H\n\n\ndef triangualate_graph(H):\n def remove_connected():\n while True:\n remove = False\n for node in H_copy.get_nodes():\n neighbours = node.get_neighbours_names()\n nodes_connected = True\n\n edges = H_copy.get_edges()\n for node1 in neighbours:\n for node2 in neighbours:\n if node1 != node2:\n if (node1, node2) not in edges:\n nodes_connected = False\n break\n if not nodes_connected:\n break\n\n if nodes_connected:\n remove = True\n H_copy.remove_node(node.get_var_name())\n\n if not remove:\n break\n\n H_copy = deepcopy(H)\n H_star = deepcopy(H)\n\n while True:\n remove_connected()\n\n costs_dict = {}\n for node in H_copy.get_nodes():\n neighbours = node.get_neighbours_names()\n\n cost = 0\n edges = H_copy.get_edges()\n for node1 in neighbours:\n for node2 in neighbours:\n if node1 != node2:\n if (node1, node2) not in edges:\n cost += 1\n costs_dict[node.get_var_name()] = cost\n\n if not costs_dict:\n break\n\n node_name_to_be_deleted = min(costs_dict, key=costs_dict.get)\n node_to_be_deleted = H_copy.get_node(node_name_to_be_deleted)\n\n neighbours = node_to_be_deleted.get_neighbours_names()\n\n edges = H_copy.get_edges()\n for node1 in neighbours:\n for node2 in neighbours:\n if node1 != node2:\n if (node1, node2) not in edges:\n H_copy.add_edge(node1, node2)\n H_star.add_edge(node1, node2)\n\n H_copy.remove_node(node_name_to_be_deleted)\n\n return H_star\n\n\ndef bron_kerbosch(G, R, P, X, max_cliques):\n if not P and not X:\n max_cliques.append(tuple(R))\n\n for node_name in P[:]:\n nv = [name for name in G.get_node(node_name).get_neighbours_names()]\n nv = set(nv)\n\n bron_kerbosch(G, R + [node_name], list(set(P).intersection(nv)), list(set(X).intersection(nv)), max_cliques)\n P.remove(node_name)\n X.append(node_name)\n\n\ndef create_graph_of_cliques(maximal_cliques):\n C = []\n\n for c1 in maximal_cliques:\n for c2 in maximal_cliques:\n if c1 != c2:\n n_intersetions = len(set(c1).intersection(set(c2)))\n\n if n_intersetions > 0:\n C.append((c1, c2, n_intersetions))\n\n C.sort(key=lambda c: c[2], reverse=True)\n return C\n\n\ndef kruskal(C, maximal_cliques):\n def find_set(sets, node):\n for i in range(len(sets)):\n for node_set in sets[i]:\n intersect = list(set(node_set).intersection(set(node)))\n\n if len(intersect) == len(node):\n return i\n\n def union(sets, index1, index2):\n sets[index1] += sets[index2]\n sets.pop(index2)\n\n T = Graph()\n for clique in maximal_cliques:\n T.add_node(clique)\n\n sets = [[clique] for clique in maximal_cliques]\n added_edges = 0\n\n cliques_size = len(maximal_cliques)\n for c1, c2, _ in C:\n if added_edges == cliques_size:\n break\n\n i1 = find_set(sets, c1)\n i2 = find_set(sets, c2)\n\n if i1 != i2:\n T.add_edge(c1, c2)\n T.add_edge(c2, c1)\n\n union(sets, i1, i2)\n added_edges += 1\n\n return T\n\n\ndef create_directed_graph(T):\n d_graph = Graph()\n visited = {}\n for node_name in T.get_var_names():\n d_graph.add_node(node_name)\n visited[node_name] = False\n\n root = T.get_var_names()[-1]\n stack = [root]\n\n while stack != []:\n node_name = stack.pop()\n if not visited[node_name]:\n visited[node_name] = True\n for neighbour_name in T.get_node(node_name).get_neighbours_names():\n is_neighbour = node_name in d_graph.get_node(neighbour_name).get_neighbours_names()\n if not is_neighbour:\n d_graph.add_edge(node_name, neighbour_name)\n d_graph.get_node(neighbour_name).parent = node_name\n stack.append(neighbour_name)\n return d_graph\n"
},
{
"alpha_fraction": 0.7268785834312439,
"alphanum_fraction": 0.7268785834312439,
"avg_line_length": 24.629629135131836,
"blob_id": "783cd291a344f79aac5164c429d35927ab4d7f43",
"content_id": "a31a0cb7a485153440af7bfe4bfd179a9aba541f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 692,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 27,
"path": "/code-interpreter/src/ProgramNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Clasa decorator al temei.\n * Este extinsa de fiecare nod concret (AssignNode, AssertNode, etc). \n * Acesta poate sa aiba fiu stanga si dreapta (doar in cazul SequenceNode) sau sa ii aibe pe amandoi pe null (celelalte cazuri).\n */\npublic abstract class ProgramNode implements Visitable {\n\tprivate ProgramNode left;\n\tprivate ProgramNode right;\n\t\n\tpublic ProgramNode(ProgramNode left, ProgramNode right) {\n\t\tthis.left = left;\n\t\tthis.right = right;\n\t}\n\t\n\tpublic ProgramNode getLeft() {\n\t\treturn left;\n\t}\n\tpublic void setLeft(ProgramNode left) {\n\t\tthis.left = left;\n\t}\n\tpublic ProgramNode getRight() {\n\t\treturn right;\n\t}\n\tpublic void setRight(ProgramNode right) {\n\t\tthis.right = right;\n\t}\n}\n"
},
{
"alpha_fraction": 0.7258347868919373,
"alphanum_fraction": 0.7258347868919373,
"avg_line_length": 39.64285659790039,
"blob_id": "1c82ca31be4281f3d5e603fb7dbb9d93ce745bfe",
"content_id": "c33f08a68099c581da98b2ff9d573ef1640e34ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 569,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 14,
"path": "/shear-sort/hybrid/utils.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n#include <mpi.h>\n#include <omp.h>\n\nvoid init_random_matrix(int* matrix, int num_lines_per_proc, int size);\nint compare_asc(const void* a, const void* b);\nint compare_dsc(const void* a, const void* b);\nvoid sort_lines_start_finish(int* matrix, int remaining_lines, int size);\nvoid sort_lines(int* matrix, int num_lines_per_proc, int size);\nvoid sort_columns(int* matrix, int size);\nint check_sorted(int* matrix, int num_lines_per_proc, int size);\nvoid print_matrix(int* matrix, int num_lines_per_proc, int size);\n"
},
{
"alpha_fraction": 0.727979302406311,
"alphanum_fraction": 0.727979302406311,
"avg_line_length": 24.733333587646484,
"blob_id": "3bebc90487142bbee4d9d2f22c6eccdf045f1440",
"content_id": "5896160fb64b7aa4dbfa5afe59b4b5a9bf67d5ac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 386,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 15,
"path": "/code-interpreter/src/SequenceNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Clasa unui nod de tip Sequence.\n * Rolul acestui nod este de tine ca fiu stanga si dreapta cate un program.\n * Acest tip de nod este necesar pentru a construi arborele binar.\n */\npublic class SequenceNode extends ProgramNode {\n\tpublic SequenceNode(ProgramNode left, ProgramNode right) {\n\t\tsuper(left, right);\n\t}\n\t\n\t@Override\n\tpublic void accept(Visitor v) {\n\t\tv.visit(this);\n\t}\n}\n"
},
{
"alpha_fraction": 0.7476922869682312,
"alphanum_fraction": 0.7476922869682312,
"avg_line_length": 19.3125,
"blob_id": "726e23ebaf246b760f055c5dbb7c956adc54e4a2",
"content_id": "d834720929ee8198ea10b5aac6b273d2b96f243f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 325,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 16,
"path": "/code-interpreter/src/VariableNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Clasa unui nod de tip varabila.\n * Utilizat pentru a evalua o expresie aritmetica.\n */\npublic class VariableNode extends ArithmeticNode {\n\tprivate String variableName;\n\t\n\tpublic VariableNode(String variableName) {\n\t\tthis.variableName = variableName;\n\t}\n\t\n\tpublic String getVariableName() {\n\t\treturn variableName;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5245977640151978,
"alphanum_fraction": 0.5369834303855896,
"avg_line_length": 31.84790802001953,
"blob_id": "03ec61d6079be9141fde4cb003ba676823db9834",
"content_id": "3040d8b936c3a7bc4fd877c846e69ccfcfe174ac",
"detected_licenses": [
"MIT",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8639,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 263,
"path": "/ml/sarsa/gym-minigrid/sarsa_skel.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nimport gym\nimport time\nimport math\nimport gym_minigrid\n\nfrom argparse import ArgumentParser\nfrom random import choice\n\n\ndef e_greedy(Q, s, actions, q0, N, const):\n values = np.zeros(len(actions) + 1)\n for a in actions:\n values[a] = Q.get((s, a), q0)\n\n if np.all(values == values[0]):\n return choice(actions)\n\n epsilon = const / N.get(s, 1)\n p2 = epsilon / len(actions)\n p1 = p2 + (1 - epsilon)\n\n probs = np.array([p1, p2])\n probs /= probs.sum()\n return np.random.choice([np.argmax(values), choice(actions)], p=probs)\n\n\ndef beta(ns, actions_to_value, actions):\n log = math.log2(ns)\n\n q_max = -math.inf\n for a1 in actions:\n for a2 in actions:\n if a1 != a2:\n val = abs(actions_to_value[a1] - actions_to_value[a2])\n if q_max < val:\n q_max = val\n\n return log / q_max\n\n\ndef softmax(Q, s, actions, q0, N):\n actions_to_value = {}\n for a in actions:\n actions_to_value[a] = Q.get((s, a), q0)\n\n ok = True\n first = actions_to_value[0]\n for value in actions_to_value.values():\n if first != value:\n ok = False\n break\n\n if ok:\n return choice(actions)\n\n b = beta(N[s], actions_to_value, actions)\n exps = [np.exp(b * Q.get((s, a), q0)) for a in actions]\n sum_of_exps = sum(exps)\n softmax_probs = [exp / sum_of_exps for exp in exps]\n return np.random.choice(a=actions, p=softmax_probs)\n\n\ndef sarsa_softmax(map_file, learning_rate, discount, train_episodes, q0, final_show):\n report_freq = 100\n\n env = gym.make(map_file)\n\n steps, avg_returns, avg_lengths = [], [], []\n recent_returns, recent_lengths = [], []\n crt_return, crt_length = 0, 0\n\n N = {}\n Q = {}\n done = False\n obs = env.reset()\n\n actions = [a for a in env.actions if a != env.actions.done and a != env.actions.drop]\n\n for current_episode in range(1, train_episodes + 1):\n s = (str(obs['image']), obs['direction'])\n action = softmax(Q, s, actions, q0, N)\n\n while not done:\n N[s] = N.get(s, 1) + 1\n obs, reward, done, _ = env.step(action)\n next_s = (str(obs['image']), obs['direction'])\n next_action = softmax(Q, next_s, actions, q0, N)\n qsa = Q.get((s, action), q0)\n Q[(s, action)] = qsa + learning_rate * (reward + discount * Q.get((next_s, next_action), q0) - qsa)\n\n action = next_action\n s = next_s\n\n crt_return += reward\n crt_length += 1\n\n obs = env.reset()\n\n done = False\n recent_returns.append(crt_return)\n recent_lengths.append(crt_length)\n crt_return, crt_length = 0, 0\n\n if current_episode % report_freq == 0:\n avg_return = np.mean(recent_returns)\n avg_length = np.mean(recent_lengths)\n steps.append(current_episode)\n avg_returns.append(avg_return)\n avg_lengths.append(avg_length)\n\n print( # pylint: disable=bad-continuation\n f\"Step {current_episode:4d}\"\n f\" | Avg. return = {avg_return:.2f}\"\n f\" | Avg. ep. length: {avg_length:.2f}\"\n )\n recent_returns.clear()\n recent_lengths.clear()\n\n if final_show:\n renderer = env.render('human')\n s = (str(obs['image']), obs['direction'])\n action = softmax(Q, s, actions, q0, N)\n while not done:\n env.render('human')\n time.sleep(0.5)\n\n if renderer.window is None:\n break\n\n N[s] = N.get(s, 1) + 1\n obs, reward, done, _ = env.step(action)\n next_s = (str(obs['image']), obs['direction'])\n next_action = softmax(Q, next_s, actions, q0, N)\n qsa = Q.get((s, action), q0)\n Q[(s, action)] = qsa + learning_rate * (reward + discount * Q.get((next_s, next_action), q0) - qsa)\n action = next_action\n s = next_s\n return steps, avg_lengths, avg_returns\n\n\ndef sarsa_egreedy(map_file, learning_rate, discount, const, train_episodes, q0, final_show):\n report_freq = 100\n\n env = gym.make(map_file)\n\n steps, avg_returns, avg_lengths = [], [], []\n recent_returns, recent_lengths = [], []\n crt_return, crt_length = 0, 0\n\n N = {}\n Q = {}\n done = False\n obs = env.reset()\n\n actions = [a for a in env.actions if a != env.actions.done and a != env.actions.drop]\n\n for current_episode in range(1, train_episodes + 1):\n s = (str(obs['image']), obs['direction'])\n action = e_greedy(Q, s, actions, q0, N, const)\n\n while not done:\n N[s] = N.get(s, 1) + 1\n obs, reward, done, _ = env.step(action)\n next_s = (str(obs['image']), obs['direction'])\n next_action = e_greedy(Q, next_s, actions, q0, N, const)\n qsa = Q.get((s, action), q0)\n Q[(s, action)] = qsa + learning_rate * (reward + discount * Q.get((next_s, next_action), q0) - qsa)\n\n action = next_action\n s = next_s\n\n crt_return += reward\n crt_length += 1\n\n obs = env.reset()\n done = False\n recent_returns.append(crt_return)\n recent_lengths.append(crt_length)\n crt_return, crt_length = 0, 0\n\n if current_episode % report_freq == 0:\n avg_return = np.mean(recent_returns)\n avg_length = np.mean(recent_lengths)\n steps.append(current_episode)\n avg_returns.append(avg_return)\n avg_lengths.append(avg_length)\n\n print( # pylint: disable=bad-continuation\n f\"Step {current_episode:4d}\"\n f\" | Avg. return = {avg_return:.2f}\"\n f\" | Avg. ep. length: {avg_length:.2f}\"\n )\n recent_returns.clear()\n recent_lengths.clear()\n\n if final_show:\n renderer = env.render('human')\n s = (str(obs['image']), obs['direction'])\n action = e_greedy(Q, s, actions, q0, N, const)\n while not done:\n env.render('human')\n time.sleep(0.5)\n\n if renderer.window is None:\n break\n\n N[s] = N.get(s, 1) + 1\n obs, reward, done, _ = env.step(action)\n next_s = (str(obs['image']), obs['direction'])\n next_action = e_greedy(Q, next_s, actions, q0, N, const)\n qsa = Q.get((s, action), q0)\n Q[(s, action)] = qsa + learning_rate * (reward + discount * Q.get((next_s, next_action), q0) - qsa)\n action = next_action\n s = next_s\n return steps, avg_lengths, avg_returns\n\n\nif __name__ == \"__main__\":\n parser = ArgumentParser()\n\n parser.add_argument(\"--map_file\", type=str, default=\"MiniGrid-Empty-6x6-v0\",\n help=\"File to read map from.\")\n parser.add_argument(\"--method\", type=str, default=\"egreedy\",\n help=\"Method used in sarsa.\")\n\n # Meta-parameters\n parser.add_argument(\"--learning_rate\", type=float, default=0.1,\n help=\"Learning rate\")\n parser.add_argument(\"--discount\", type=float, default=0.99,\n help=\"Value for the discount factor\")\n parser.add_argument(\"--const\", type=float, default=1,\n help=\"Probability to choose a random action.\")\n\n # Training and evaluation episodes\n parser.add_argument(\"--train_episodes\", type=int, default=500,\n help=\"Number of episodes\")\n parser.add_argument(\"--q0\", type=float, default=0.0,\n help=\"q0 value\")\n parser.add_argument(\"--final_show\", dest=\"final_show\",\n action=\"store_true\",\n help=\"Demonstrate final strategy.\")\n\n args = parser.parse_args()\n\n if args.method == \"egreedy\":\n steps, avg_lengths, avg_returns = sarsa_egreedy(args.map_file, args.learning_rate, args.discount, args.const,\n args.train_episodes, args.q0, args.final_show)\n else:\n steps, avg_lengths, avg_returns = sarsa_softmax(args.map_file, args.learning_rate, args.discount,\n args.train_episodes, args.q0, args.final_show)\n\n _fig, (ax1, ax2) = plt.subplots(ncols=2)\n\n ax1.plot(steps, avg_lengths, label=args.method)\n ax1.set_title(\"Average episode length\")\n ax1.legend()\n\n ax2.plot(steps, avg_returns, label=args.method)\n ax2.set_title(\"Average episode return\")\n ax2.legend()\n plt.show()\n"
},
{
"alpha_fraction": 0.6910569071769714,
"alphanum_fraction": 0.707317054271698,
"avg_line_length": 14.5,
"blob_id": "49be60687c04b84873550331be2e0cefd4660125",
"content_id": "babbd1ab1abae5c7d7e6a0f7257f84f85430428e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 123,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 8,
"path": "/shear-sort/mpi/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tmpicc shear_sort_mpi.c utils.c -o shear_sort_mpi -lm\n\nclean:\n\trm shear_sort_mpi\n\nrun:\n\tmpirun -n 4 shear_sort_mpi 8"
},
{
"alpha_fraction": 0.5897114276885986,
"alphanum_fraction": 0.6090338826179504,
"avg_line_length": 18.630542755126953,
"blob_id": "2b03ca00dbad1cea6ebdb7bf8fb3c348f9474f9d",
"content_id": "836140e0ae7665e01351756864f4de20d52e23bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3985,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 203,
"path": "/matrix-mul/main.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Tema 2 ASC\n * 2018 Spring\n * Catalin Olaru / Vlad Spoiala\n * !!! Do not modify this file !!!\n */\n\n#include \"utils.h\"\n#include <stdio.h>\n#include <stdlib.h>\n#include <sys/types.h>\n#include <sys/stat.h>\n#include <unistd.h>\n#include <fcntl.h>\n#include <sys/mman.h>\n#include <string.h>\n\n//used to generate random numbers between [-limit, limit]\n#define RANGE 1000\n\n#define SAFE_ASSERT(condition, message) while(condition) {\t\\\n\tperror(message);\t\t\\\n\tgoto failure;\t\t\t\\\n}\n\n/*\n * Function which reads an input file in a specific format and fills\n * a vector of 'struct test's.\n */\nint read_input_file(char *input_file, int *num_tests, struct test **tests)\n{\n\tFILE *file = NULL;\n\tstruct test *aux = NULL;\n\tint ret = 0, i = 0;\n\n\tfile = fopen(input_file, \"r\");\n\tSAFE_ASSERT(file == 0, \"Failed opening file\");\n\n\tret = fscanf(file, \"%d\\n\", num_tests);\n\tSAFE_ASSERT(ret < 1, \"Failed reading from file\");\n\n\t*tests = malloc(*num_tests * sizeof **tests);\n\tSAFE_ASSERT(*tests == 0, \"Failed malloc\");\n\n\taux = *tests;\n\n\tfor (i = 0; i < *num_tests; i++) {\n\t\tstruct test t;\n\n\t\tret = fscanf(file, \"%d %d %s\\n\", &t.N, &t.seed, t.output_save_file);\n\t\tSAFE_ASSERT(ret == 0, \"Failed reading from file\");\n\n\t\t*aux++ = t;\n\t}\n\n\tfclose(file);\n\treturn 0;\n\nfailure:\n\tif (aux) {\n\t\tfree(aux);\n\t}\n\tif (file) {\n\t\tfclose(file);\n\t}\n\treturn -1;\n}\n\n/*\n * Write a NxN complex number matrix to a binary file\n */\nint write_cmat_file(char *filepath, int N, double *data) {\n\n\tint ret, fd;\n\tsize_t size;\n\tdouble *map = NULL;\n\n\tfd = open(filepath, O_RDWR | O_CREAT | O_TRUNC, (mode_t)0777);\n\tSAFE_ASSERT(fd < 0, \"Error opening file for writing\");\n\n\tsize = N * N * 2 * sizeof(double);\n\n\tret = lseek(fd, size - 1, SEEK_SET);\n\tSAFE_ASSERT(ret < 0, \"Error calling lseek() to stretch file\");\n\n\tret = write(fd, \"\", 1);\n\tSAFE_ASSERT(ret < 0, \"Error writing in file\");\n\n\tmap = (double *)mmap(0, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);\n\tSAFE_ASSERT(map == MAP_FAILED, \"Error mapping the file\");\n\n\tmemcpy(map, data, size);\n\n\tret = msync(map, size, MS_SYNC);\n\tSAFE_ASSERT(ret < 0, \"Could not sync the file to disk\");\n\n\tret = munmap(map, size);\n\tSAFE_ASSERT(ret < 0, \"Error unmapping the file\");\n\n\tclose(fd);\n\treturn 0;\n\nfailure:\n\tif (fd > 0) {\n\t\tclose(fd);\n\t}\n\treturn -1;\n}\n\n/*\n * Generate the test data, based on the number of elements and\n * the seed in the struct test. Allocates the arrays and fills\n * them with random numbers in [-RANGE, RANGE] (see RANGE define\n * above).\n */\nint generate_data(struct test t, double **A)\n{\n\tint N = t.N, i, j;\n\tdouble *aux;\n\n\t*A = malloc(N * N * 2 * sizeof(double));\n\tSAFE_ASSERT(*A == 0, \"Failed malloc\");\n\n\taux = *A;\n\n\tsrand(t.seed);\n\n\tfor (i = 0; i < N; ++i) {\n\t\tfor ( j = 0; j < N; ++j) {\n\t\t\taux[2 * (i * N + j)] = get_rand_double(RANGE); // real\n\t\t\taux[2 * (i * N + j) + 1] = get_rand_double(RANGE); // imaginary\n\t\t}\n\t}\n\n\treturn 0;\n\nfailure:\n\treturn -1;\n}\n\n/*\n * Generates data and runs the solver on the data.\n */\nint run_test(struct test t, Solver solve, float *elapsed)\n{\n\tdouble *A, *res;\n\tint ret;\n\tstruct timeval start, end;\n\n\tret = generate_data(t, &A);\n\tif (ret < 0)\n\t\treturn ret;\n\n\tgettimeofday(&start, NULL);\n\tres = solve(t.N, A);\n\tgettimeofday(&end, NULL);\n\n\tif (res) {\n\t\twrite_cmat_file(t.output_save_file, t.N, res);\n\t}\n\n\t*elapsed = ((end.tv_sec - start.tv_sec) * 1000000.0f + end.tv_usec - start.tv_usec) / 1000000.0f;\n\n\tif (A) {\n\t\tfree(A);\n\t}\n\tif (res) {\n\t\tfree(res);\n\t}\n\n\treturn 0;\n}\n\nint main(int argc, char **argv) {\n\tint num_tests, ret, i;\n\tstruct test *tests;\n\tfloat total_elapsed = 0.0f;\n\n\tif (argc < 2) {\n\t\tprintf(\"Please provide an input file: %s input_file\\n\", argv[0]);\n\t\treturn -1;\n\t}\n\n\tret = read_input_file(argv[1], &num_tests, &tests);\n\tif(ret < 0)\n\t\treturn ret;\n\n\tfor (i = 0; i < num_tests; i++) {\n\t\tfloat current_elapsed = 0.0f;\n\n\t\tret = run_test(tests[i], my_solver, ¤t_elapsed);\n\t\tif (ret < 0){\n\t\t\tfree(tests);\n\t\t\treturn -1;\n\t\t}\n\t\ttotal_elapsed += current_elapsed;\n\n\t\tprintf(\"TEST %d\\n\\tTime: %.6f\\n\", i + 1, current_elapsed);\n\t}\n\n\tfree(tests);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6594969034194946,
"alphanum_fraction": 0.6707984209060669,
"avg_line_length": 27.87368392944336,
"blob_id": "531bbe2c68b18fc230931f009fab39aa04b0ef46",
"content_id": "cf973f96de21e70c4b8ffeb9d53c0b13be9e7d32",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2743,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 95,
"path": "/code-interpreter/src/BooleanExpressionEvaluator.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import java.util.HashMap;\n/*\n * Clasa cu care se evalueaza o expresie booleana.\n */\npublic class BooleanExpressionEvaluator {\n\tprivate String expression;\n\tprivate HashMap<String, Integer> variables; //In hashmap se tin variabilele\n\n\tprivate boolean error;\n\tprivate boolean resultValue;\n\tprivate int pos;\n\n\t//metoda auxiliara pentru a extrage o subexpresie\n\tprivate String getBlock() {\n\t\tint par = 0; //numar de paranteze\n\t\tint end = 0;\n\t\tint index = pos;\n\t\tfor (int i = index; i < expression.length(); i++) {\n\t\t\tif (expression.charAt(i) == '[')\n\t\t\t\tpar++;\n\t\t\telse if (expression.charAt(i) == ']')\n\t\t\t\tpar--;\n\t\t\tif (par == 0) {\n\t\t\t\tend = i + 1;\n\t\t\t\tpos = end; // se actualizeaza pozitia\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\treturn expression.substring(index, end);\n\t}\n\n\tpublic BooleanExpressionEvaluator(String expression, HashMap<String, Integer> variables) {\n\t\tthis.expression = expression;\n\t\tthis.variables = variables;\n\t\tthis.error = false;\n\t\tevaluate();\n\t}\n\n\t//functia care evalueaza expresia data\n\tpublic void evaluate() {\n\t\t//eval1 si eval2 sunt folosite deoarece se poate evalua o expresie de forma [= <expr> <expr>]\n\t\tArithmeticExpressionEvaluator eval1 = null;\n\t\tArithmeticExpressionEvaluator eval2 = null;\n\t\tpos = expression.indexOf(' ') + 1;\n\n\t\t//cazul in care primul operand este tot o expresie se foloseste metoda getBloc pentru a o extrage\n\t\tif (expression.charAt(pos) == '[') {\n\t\t\teval1 = new ArithmeticExpressionEvaluator(getBlock(), variables);\n\t\t\tif (eval1.isError()) {\n\t\t\t\terror = eval1.isError();\n\t\t\t\treturn;\n\t\t\t}\n\t\t//cazul in care este o variabila/valoare\t\n\t\t} else {\n\t\t\tint index = expression.indexOf(' ', pos);\n\t\t\teval1 = new ArithmeticExpressionEvaluator(expression.substring(pos, index), variables);\n\t\t\tpos = index;\n\t\t\tif (eval1.isError()) {\n\t\t\t\terror = eval1.isError();\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\t\t//aceleasi cazuri, doar ca sunt evaluate pentru al doilea operand\n\t\tif (expression.charAt(pos + 1) == '[') {\n\t\t\tpos = pos + 1;\n\t\t\teval2 = new ArithmeticExpressionEvaluator(getBlock(), variables);\n\t\t\tif (eval2.isError()) {\n\t\t\t\terror = eval2.isError();\n\t\t\t\treturn;\n\t\t\t}\n\t\t} else {\n\t\t\teval2 = new ArithmeticExpressionEvaluator(expression.substring(pos + 1, expression.length() - 1), variables);\n\t\t\tif (eval2.isError()) {\n\t\t\t\terror = eval2.isError();\n\t\t\t\treturn;\n\t\t\t}\n\t\t}\n\t\t\n\t\t//cele doua cazuri posibile '<' si '=', se verifica daca valoarea este adevarat sau fals.\n\t\tif (expression.charAt(1) == '<') {\n\t\t\tresultValue = eval1.getResultValue().intValue() < eval2.getResultValue().intValue();\n\t\t} else if (expression.charAt(1) == '=') {\n\t\t\tresultValue = eval1.getResultValue().intValue() == eval2.getResultValue().intValue();\n\t\t}\n\n\t}\n\n\tpublic boolean isError() {\n\t\treturn error;\n\t}\n\n\tpublic boolean isResultValue() {\n\t\treturn resultValue;\n\t}\n}\n"
},
{
"alpha_fraction": 0.7099999785423279,
"alphanum_fraction": 0.7099999785423279,
"avg_line_length": 27.571428298950195,
"blob_id": "1ee38c57755df5a1f09196a7ee2d33fed4985d54",
"content_id": "43d830d44b966c1d340b588a8ec9eafd6b9e71df",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 7,
"path": "/elevator-world/src/other/WakeUpPreference.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package other;\n\npublic class WakeUpPreference {\n public final static String HARD = \"hard\";\n public final static String SOFT = \"soft\";\n public final static String SUPER_SOFT = \"super-soft\";\n}\n"
},
{
"alpha_fraction": 0.7580645084381104,
"alphanum_fraction": 0.7580645084381104,
"avg_line_length": 16.85714340209961,
"blob_id": "df59abf6a96ca2066f9f48e24aee8156475a1c96",
"content_id": "b9167274851b4c5f7db576e1638c9f35504ceea9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 7,
"path": "/elevator-world/src/agents/Stepper.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package agents;\n\nimport jade.core.Agent;\n\npublic abstract class Stepper extends Agent {\n public abstract Object step();\n}"
},
{
"alpha_fraction": 0.5763205885887146,
"alphanum_fraction": 0.5817850828170776,
"avg_line_length": 20.392208099365234,
"blob_id": "8acbfc5a8508993a5787c29386d56e40d589c434",
"content_id": "5a88c2475d3010eb5ea27f5c3038f1908e41e80c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8235,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 385,
"path": "/parallel-snake/parallel_snake.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"main.h\"\n#include <stdio.h>\n#include <stdlib.h>\n\ntypedef struct cel Cell;\ntypedef struct coord Coord;\n\n// aloca o celula pentru lista\nCell* alocaCell(int i, int j) {\n\tCell* cell = (Cell*)malloc(sizeof(Cell));\n\t\n\tcell->prev = NULL;\n\tcell->next = NULL;\n\tcell->poz.line = i;\n\tcell->poz.col = j;\n\n\treturn cell;\n}\n\n//adauga celula la sfarsitul listei\nvoid addCell(struct snake* snake, Cell* el) {\n\tif(snake->coada == NULL && snake->cap == NULL) {\n\t\tsnake->cap = el;\n\t\tsnake->coada = el;\n\t\treturn;\n\t}\n\n\tsnake->coada->next = el;\n\tel->prev = snake->coada;\n\tel->next = NULL;\n\tsnake->coada = el;\n}\n\n//adauga celula din coada in capul listei\nvoid attachHead(struct snake* snake) {\n\tif(snake->cap == snake->coada)\n\t\treturn;\n\n\tsnake->coada->next = snake->cap;\n\tsnake->cap->prev = snake->coada;\n\n\tsnake->coada = snake->coada->prev;\n\tsnake->coada->next = NULL;\n\n\tsnake->cap = snake->cap->prev;\n\tsnake->cap->prev = NULL;\n\n}\n\n\n//completeaza sarpele pornind din coordonatele capului\nvoid completeSnake(struct snake* snake, int **world, int num_lines, int num_cols) {\n\tint crti = snake->head.line;;\n\tint crtj = snake->head.col;\n\n\tint auxi;\n\tint auxj;\n\n\tchar prevDir = snake->direction;\n\n\tsnake->cap = alocaCell(snake->head.line, snake->head.col);\n\tsnake->coada = snake->cap;\n\n\tauxi = crti;\n\tauxj = crtj;\n\n\twhile(1) {\n\t\t// daca directia precedenta este N, atunci nu se va mai cauta sus\n\t\tif(prevDir == 'N') {\n\t\t\tif(auxj == 0)\n\t\t\t\tauxj = num_cols - 1;\n\t\t\telse\n\t\t\t\tauxj--;\n\t\t\t//stanga\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'E';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif(auxj == num_cols - 1)\n\t\t\t\tauxj = 0;\n\t\t\telse\n\t\t\t\tauxj++;\n\t\t\t//dreapta\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'V';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif (auxi == num_lines - 1) {\n\t\t\t\tauxi = 0;\n\t\t\t}\n\t\t\telse {\n\t\t\t\tauxi++;\n\t\t\t}\n\n\t\t\t//jos\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'N';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\t\t\tbreak;\n\n\t\t//daca pozitia precedenta este S, nu se va mai cauta jos\n\t\t} else if (prevDir == 'S') {\n\t\t\tif(auxi == 0)\n\t\t\t\tauxi = num_lines - 1;\n\t\t\telse\n\t\t\t\tauxi--;\n\t\t\t//sus\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'S';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\n\t\t\tif(auxj == 0)\n\t\t\t\tauxj = num_cols - 1;\n\t\t\telse\n\t\t\t\tauxj--;\n\t\t\t//stanga\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'E';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif(auxj == num_cols - 1)\n\t\t\t\tauxj = 0;\n\t\t\telse\n\t\t\t\tauxj++;\n\t\t\t//dreapta\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'V';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\t\t\tbreak;\n\n\t\t//daca pozitia precedenta este E, nu se va mai cauta in dreapta\n\t\t} else if (prevDir == 'E') {\n\t\t\tif(auxi == 0)\n\t\t\t\tauxi = num_lines - 1;\n\t\t\telse\n\t\t\t\tauxi--;\n\t\t\t//sus\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'S';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif (auxi == num_lines - 1)\n\t\t\t\tauxi = 0;\n\t\t\telse\n\t\t\t\tauxi++;\n\t\t\t//jos\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'N';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif(auxj == 0)\n\t\t\t\tauxj = num_cols - 1;\n\t\t\telse\n\t\t\t\tauxj--;\n\t\t\t//stanga\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'E';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\t\t\tbreak;\n\n\t\t//daca pozitia precedenta este V, nu se va mai cauta in stanga\n\t\t} else if (prevDir == 'V') {\n\t\t\tif(auxi == 0)\n\t\t\t\tauxi = num_lines - 1;\n\t\t\telse\n\t\t\t\tauxi--;\n\t\t\t//sus\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'S';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif (auxi == num_lines - 1)\n\t\t\t\tauxi = 0;\n\t\t\telse\n\t\t\t\tauxi++;\n\t\t\t//jos\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'N';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\n\t\t\tif(auxj == num_cols - 1)\n\t\t\t\tauxj = 0;\n\t\t\telse\n\t\t\t\tauxj++;\n\t\t\t//dreapta\n\t\t\tif(world[auxi][auxj] == snake->encoding) {\n\t\t\t\tprevDir = 'V';\n\t\t\t\tCell* cell = alocaCell(auxi, auxj);\n\t\t\t\taddCell(snake, cell);\n\t\t\t\tcrti = auxi;\n\t\t\t\tcrtj = auxj;\n\t\t\t\tcontinue;\n\t\t\t} else {\n\t\t\t\tauxi = crti;\n\t\t\t\tauxj = crtj;\n\t\t\t}\n\t\t\t//daca nu am gasit in cele 3 directii, atunci inseamna ca am dat de coada si ies din loop\n\t\t\tbreak;\n\t\t}\n\t}\n}\n\n\nint checkCollision(struct snake* snake, int** world) {\n\treturn (world[snake->head.line][snake->head.col] != 0);\n}\n\n//calcularea noilor pozitii\nvoid computeMoves(struct snake* snake, int** world, int num_lines, int num_cols) {\n\tsnake->lastTail = snake->coada->poz; //se pastreaza coada anterioara a sarpelui\n\tworld[snake->coada->poz.line][snake->coada->poz.col] = 0; // se sterge coada, pentru ca sarpele o sa se mute\n\n\tsnake->oldHead = snake->head; //se pastreaza ultimul cap al sarpelui\n\tattachHead(snake); //segmentul de coada se ataseaza capului\n\n\n\t//se calculeaza noua pozitia a capului\n\tif(snake->direction == 'N') {\n\t\tif(snake->head.line == 0) {\n\t\t\tsnake->head.line = num_lines - 1;\n\t\t} else {\n\t\t\tsnake->head.line--;\n\t\t}\n\n\t} else if(snake->direction == 'S') {\n\t\tif(snake->head.line == num_lines - 1) {\n\t\t\tsnake->head.line = 0;\n\t\t} else {\n\t\t\tsnake->head.line++;\n\t\t}\n\t} else if(snake->direction == 'V') {\n\t\tif(snake->head.col == 0) {\n\t\t\tsnake->head.col = num_cols - 1;\n\t\t} else {\n\t\t\tsnake->head.col--;\n\t\t}\n\t} else if(snake->direction == 'E') {\n\t\tif(snake->head.col == num_cols - 1) {\n\t\t\tsnake->head.col = 0;\n\t\t} else {\n\t\t\tsnake->head.col++;\n\t\t}\n\t}\n\n\t//actualizare cap\n\tsnake->cap->poz.line = snake->head.line;\n\tsnake->cap->poz.col = snake->head.col;\n}\n\n\nvoid run_simulation(int num_lines, int num_cols, int **world, int num_snakes,\n\tstruct snake *snakes, int step_count, char *file_name) {\n\tint ok = 0;\n\n\tint i, j;\n\n\t//completarea serpilor se face paralel, deoarece este intependent de fiecare sarpe\n\t#pragma omp parallel for\n\tfor(i = 0; i < num_snakes; i++)\n\t\tcompleteSnake(&snakes[i], world, num_lines, num_cols);\n\n\tfor(i = 0; i < step_count; i++) {\n\t\t//calcularea noilor pozitii, tot paralel, din aceiasi cauza\n\t\t#pragma omp parallel for\n\t\tfor(j = 0; j < num_snakes; j++) {\n\t\t\tcomputeMoves(&snakes[j], world, num_lines, num_cols);\n\t\t}\n\n\t\t//testarea de coliziune si mutarea se face in thread-ul master\n\t\tfor(j = 0; j < num_snakes; j++) {\n\t\t\tif(!checkCollision(&snakes[j], world)) {\n\t\t\t\tworld[snakes[j].head.line][snakes[j].head.col] = snakes[j].encoding;\n\t\t\t} else {\n\t\t\t\tok = 1;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\t//daca s-a intalnit o coliziune, trebuie refacuta harta la pasul anterior\n\t\tif(ok) {\n\t\t\t//pana la indicele j (indicele sarpelui care a facut coliziunea), se vor restaura capetele\n\t\t\t#pragma omp parallel for\n\t\t\tfor(i = 0; i < j; i++) {\n\t\t\t\tworld[snakes[i].head.line][snakes[i].head.col] = 0;\n\t\t\t}\n\t\t\t//pentru toti serpii se vor restaura pozitiile capetelor anterioare\n\t\t\t#pragma omp parallel for\n\t\t\tfor(i = 0; i < num_snakes; i++) {\n\t\t\t\tsnakes[i].head = snakes[i].oldHead;\n\t\t\t\tworld[snakes[i].lastTail.line][snakes[i].lastTail.col] = snakes[i].encoding;\n\t\t\t}\n\t\t\t//daca s-a intalnit coliziune trebuie iesit din loop\n\t\t\tbreak;\n\t\t}\n\n\t}\n}"
},
{
"alpha_fraction": 0.7121211886405945,
"alphanum_fraction": 0.7121211886405945,
"avg_line_length": 16.11111068725586,
"blob_id": "73df90fe6fca650644f40be8293984754f4fb857",
"content_id": "cb1bc2ec9f391ce6c9c8b3bd571cd5210e27a58c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 462,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 27,
"path": "/code-interpreter/src/AssignNode.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Clasa unui nod de tip assign.\n */\npublic class AssignNode extends ProgramNode {\n\tprivate String variable;\n\tprivate String expression;\n\n\tpublic AssignNode(String variable, String expression) {\n\t\tsuper(null, null);\n\t\tthis.variable = variable;\n\t\tthis.expression = expression;\n\t}\n\n\tpublic String getVariable() {\n\t\treturn variable;\n\t}\n\n\tpublic String getExpression() {\n\t\treturn expression;\n\t}\n\n\t@Override\n\tpublic void accept(Visitor v) {\n\t\tv.visit(this);\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5587583184242249,
"alphanum_fraction": 0.5688945055007935,
"avg_line_length": 19.506492614746094,
"blob_id": "2bf174209c85b0816bee86efb308b39d9247eaea",
"content_id": "686f752488f2e3a19e991faf622c4198525b3672",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3157,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 154,
"path": "/shear-sort/pthreads/utils.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nint** matrix;\nint size;\nint num_lines_per_proc;\npthread_barrier_t line_barrier;\npthread_barrier_t column_barrier;\n\nvoid init_random_matrix() {\n\tint i, j;\n\tsrand(time(NULL));\n\tfor(i = 0; i < size; i++) {\n\t\tfor(j = 0; j < size; j++) {\n\t\t\tmatrix[i][j] = rand() % (size * size) + 1; \n\t\t}\n\t}\n}\n\nint compare_asc(const void* a, const void* b) {\n\tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn A - B;\n}\n\nint compare_dsc(const void* a, const void* b) {\n \tint A = *(int*)a;\n\tint B = *(int*)b;\n\treturn B - A;\n}\n\nvoid* sort_lines(void* start_line) {\n\tint i, k;\n\tint start = *(int*)start_line;\n\tint finish = start + num_lines_per_proc;\n\tint dif = size - finish;\n\t\n\t// the last process will work with more lines\n\tif (dif <= num_lines_per_proc) {\n\t\tfinish = size;\n\t}\n\t\n\tfor(k = 0; k <= ceil(log2(size)); k++) {\n\t\t\n\t\tpthread_barrier_wait(&column_barrier);\n\t\tfor (i = start; i < finish; i++) {\n\t\t\tif (i % 2 == 0) { // even lines > ascending\n\t\t\t\tqsort(matrix[i], size, sizeof(int), compare_asc);\n\n\t\t\t} else { // odd lines > decending\n\t\t\t\tqsort(matrix[i], size, sizeof(int), compare_dsc);\n\t\t\t}\n\t\t}\n\t\t\n\t\tpthread_barrier_wait(&line_barrier);\n\t}\n\tpthread_barrier_wait(&column_barrier);\n\treturn NULL;\n}\n\nvoid* sort_columns(void* arg) {\n\tint i, j, k;\n\tint col[size];\n\t\t\n\tfor(k = 0; k <= ceil(log2(size)); k++) {\n\t\tpthread_barrier_wait(&line_barrier);\n\t\tfor (j = 0; j < size; j++) {\n\t\t\tfor (i = 0; i < size; i++) {\n\t\t\t\tcol[i] = matrix[i][j];\n\t\t\t}\n\n\t\t\tqsort(col, size, sizeof(int), compare_asc);\n\n\t\t\tfor (i = 0; i < size; i++) {\n\t\t\t\tmatrix[i][j] = col[i] ;\n\t\t\t}\n\t\t}\n\t\tpthread_barrier_wait(&column_barrier);\n\t}\n\treturn NULL;\n}\n\nvoid sort_matrix(int num_cores) {\n\tint i;\n\tnum_lines_per_proc = size / (num_cores - 1);\n\t\n\t// create threads for sorting\n\tpthread_t* threads = calloc(num_cores, sizeof(pthread_t));\n\tint* start_line = calloc(num_cores - 1, sizeof(int));\t\n\n\tpthread_barrier_init(&line_barrier, NULL, num_cores);\n\tpthread_barrier_init(&column_barrier, NULL, num_cores);\n\t\t\n\t// first_thread > sort columns; the others > sort lines\n\tfor (i = 0; i < num_cores - 1; i++) {\n\t\t// the line from with the thread will start working\n\t\tstart_line[i] = i * num_lines_per_proc;\n\t\tpthread_create(&threads[i], NULL, &sort_lines, &start_line[i]);\n\t}\n\t// thread for sorting columns\n\tpthread_barrier_wait(&column_barrier);\n\tpthread_create(&threads[i], NULL, &sort_columns, NULL);\n\t\n\t// wait the threads to complete the work\n\tfor (i = 0; i < num_cores; i++) {\n\t\tpthread_join(threads[i], NULL);\n\t}\n\t\n\tfree(threads);\n\t\n}\n\nint check_sorted() {\n\tint i, j, even;\n\t\n\tfor (i = 0; i < size; i++) {\n\t\tif (i % 2 == 0) {\n\t\t\teven = 1; // even line > ascending\n\t\t} else {\n\t\t\teven = 0; // odd line > descending\n\t\t}\n\t\t\n\t\tfor (j = 0; j < size - 1; j++) {\n\t\t\tif (even) {\n\t\t\t\tif (matrix[i][j] > matrix[i][j + 1])\n\t\t\t\t\treturn 0;\n\t\t\t} else {\n\t\t\t\tif (matrix[i][j] < matrix[i][j + 1])\n\t\t\t\t\treturn 0;\n\t\t\t}\n\t\t}\n\t}\n\t\n\treturn 1;\n}\n\nvoid print_matrix() {\n\tint i, j;\n\tfor (i = 0; i < size; i++) {\n\t\tfor (j = 0; j < size; j++) {\n\t\t\tprintf(\"%d\\t\", matrix[i][j]);\n\t\t}\n\t\tprintf(\"\\n\");\n\t}\n\tprintf(\"\\n\");\n}\n\nvoid free_memory() {\n\tint i;\t\n\tfor(i = 0; i < size; i++) {\n\t\tfree (matrix[i]);\n\t}\n\t\n\tfree (matrix);\n}"
},
{
"alpha_fraction": 0.5789949297904968,
"alphanum_fraction": 0.5876717567443848,
"avg_line_length": 25.714975357055664,
"blob_id": "e8d644ff46c3509b8b474cc7058e646569eba3b1",
"content_id": "b88987ae556638c539bd4cb58a4eae5ef9c84afd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5532,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 207,
"path": "/http-proxy/httpproxy.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <unistd.h>\n#include <sys/types.h> \n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <netdb.h>\n\n#define MAX_CLIENTS\t20\n#define BUFLEN 4096\n#define MAX_LEN 100\n#define HTTP_PORT 80\n\nvoid error(char *msg)\n{\n perror(msg);\n exit(1);\n}\n\n\nvoid parse_command(char* command, char* dname, int* port) {\n\tchar* command_copy = strdup(command);\n\tchar* command_aux = strdup(command);\n\tchar* token;\n\tchar aux[MAX_LEN];\n\tchar* token_aux;\n\t*port = 0;\n\n\ttoken_aux = strtok(command_aux, \"\\n\");\n\ttoken_aux = strtok(NULL, \"\\n\");\n\n\t// cazul in care host-ul este speficiat explicit\n\tif(token_aux != NULL && strstr(token_aux, \"Host:\")) {\n\t\ttoken_aux = strtok(token = strdup(token_aux), \":\\n\");\n\t\ttoken_aux = strtok(NULL, \":\\n\");\n\t\tsscanf(token_aux, \"%s\", dname);\n\t\tfree(command_copy);\n\t\tfree(command_aux);\n\t\tfree(token);\n\t\treturn;\n\t}\n\n\n\ttoken = strtok(command_copy, \" \\n\");\n\ttoken = strtok(NULL, \" \");\n\t\n\tsscanf(token, \"http://%99[^/\\n]\", aux);\n\t\n\tif(strstr(aux, \":\")) { // daca se specifica port-ul in url, se extrage\n\t\ttoken = strtok(aux, \":\\n\");\n\t\tsscanf(token, \"%s\", dname);\n\t\ttoken = strtok(NULL, \":\\n\");\n\t\t*port = atoi(token);\n\t} else { // altfel ne intereseaza doar numele\n\t\tsscanf(aux, \"%s\", dname);\n\t}\n\n\tfree(command_copy);\n\tfree(command_aux);\n}\n\n\nint main(int argc, char *argv[])\n{\n int sockfd, proxy_sock, port, newsockfd, portno, clilen;\n char buffer[BUFLEN];\n char dname[MAX_LEN];\n\n struct sockaddr_in serv_addr, cli_addr, proxy_addr;\n struct hostent* he;\n \n int n, i;\n int yes = 1;\n \n fd_set read_fds;\t//multimea de citire folosita in select()\n fd_set tmp_fds;\t\t//multime folosita temporar \n int fdmax;\t\t\t//valoare maxima file descriptor din multimea read_fds\n\n if (argc < 2) {\n fprintf(stderr,\"Usage : %s <port>\\n\", argv[0]);\n exit(1);\n }\n\n //golim multimea de descriptori de citire (read_fds) si multimea tmp_fds \n FD_ZERO(&read_fds);\n FD_ZERO(&tmp_fds);\n \n proxy_sock = socket(AF_INET, SOCK_STREAM, 0);\n if (proxy_sock < 0) \n \terror(\"ERROR opening socket\");\n \n portno = atoi(argv[1]);\n\n memset((char *) &proxy_addr, 0, sizeof(proxy_addr));\n proxy_addr.sin_family = AF_INET;\n proxy_addr.sin_addr.s_addr = INADDR_ANY;\t// foloseste adresa IP a masinii\n proxy_addr.sin_port = htons(portno);\n \n // optiune pentru reutilizarea adresei socketului tpc\n setsockopt(proxy_sock, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes));\n\n if(bind(proxy_sock, (struct sockaddr *) &proxy_addr, sizeof(struct sockaddr)) < 0) \n \t\terror(\"ERROR on binding\");\n \n listen(proxy_sock, MAX_CLIENTS);\n\n //adaugam noul file descriptor (socketul pe care se asculta conexiuni) in multimea read_fds\n FD_SET(proxy_sock, &read_fds);\n fdmax = proxy_sock;\n\n // main loop\n\twhile(1) {\n\t\ttmp_fds = read_fds; \n\t\tif(select(fdmax + 1, &tmp_fds, NULL, NULL, NULL) == -1) \n\t\t\terror(\"ERROR in select\");\n\t\n\t\tfor(i = 0; i <= fdmax; i++) {\n\t\t\tif(FD_ISSET(i, &tmp_fds)) {\n\t\t\t\n\t\t\t\tif(i == proxy_sock) {\n\t\t\t\t\t// a venit ceva pe socketul inactiv(cel cu listen) = o noua conexiune\n\t\t\t\t\t// actiunea serverului: accept()\n\t\t\t\t\tclilen = sizeof(cli_addr);\n\t\t\t\t\tif((newsockfd = accept(proxy_sock, (struct sockaddr *)&cli_addr, (socklen_t *)&clilen)) == -1) {\n\t\t\t\t\t\terror(\"ERROR in accept\");\n\t\t\t\t\t} \n\t\t\t\t\telse {\n\t\t\t\t\t\t//adaug noul socket intors de accept() la multimea descriptorilor de citire\n\t\t\t\t\t\tFD_SET(newsockfd, &read_fds);\n\t\t\t\t\t\tif (newsockfd > fdmax) { \n\t\t\t\t\t\t\tfdmax = newsockfd;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\tprintf(\"Noua conexiune de la %s, port %d, socket_client %d\\n \", inet_ntoa(cli_addr.sin_addr), ntohs(cli_addr.sin_port), newsockfd);\n\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\telse {\n\t\t\t\t\t// am primit date pe unul din socketii cu care vorbesc cu clientii\n\t\t\t\t\t//actiunea serverului: recv()\n\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\tif((n = recv(i, buffer, sizeof(buffer), 0)) <= 0) {\n\t\t\t\t\t\tif(n == 0) {\n\t\t\t\t\t\t\t//conexiunea s-a inchis\n\t\t\t\t\t\t\tprintf(\"selectserver: socket %d hung up\\n\", i);\n\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\terror(\"ERROR in recv\");\n\t\t\t\t\t\t}\n\t\t\t\t\t\tclose(i); \n\t\t\t\t\t\tFD_CLR(i, &read_fds); // scoatem din multimea de citire socketul pe care \n\t\t\t\t\t} \n\t\t\t\t\t\n\t\t\t\t\telse { //recv intoarce >0\n\n\t\t\t\t\t\t//se parseaza comanda (se extrage numele si port-ul)\n\t\t\t\t\t\tparse_command(buffer, dname, &port);\n\n\t\t\t\t\t\the = gethostbyname(dname);\n\t\t\t\t\t\t\n\t\t\t\t\t\tif(he != NULL) {\n\t\t\t\t\t\t\tif((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) {\n\t\t\t\t\t\t\t\terror(\"Eroare creare socket\");\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t// daca port-ul nu este existent in url\n\t\t\t\t\t\t\t// se seteaza port-ul pe 80\n\t\t\t\t\t\t\tif(port == 0) {\n\t\t\t\t\t\t\t\tport = HTTP_PORT;\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t// se stabileste conexiunea\n\t\t\t\t\t\t\tmemset(&serv_addr, 0, sizeof(serv_addr));\n\t\t\t\t\t\t\tserv_addr.sin_family = AF_INET;\n\t\t\t\t\t\t\tserv_addr.sin_port = htons(port);\n\t\t\t\t\t\t\tserv_addr.sin_addr = *((struct in_addr*)he->h_addr);\n\n\t\t\t\t\t\t\tif(connect(sockfd, (struct sockaddr*) &serv_addr, sizeof(serv_addr)) < 0) {\n\t\t\t\t\t\t\t\terror(\"Eroare conectare\");\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t// se trimite comanda la server \n\t\t\t\t\t\t\tif(send(sockfd, buffer, BUFLEN - 1, 0) < 0) {\n\t\t\t\t\t\t\t\terror(\"Eroare in send\");\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\t// cat timp se primeste pe socket, se trimite inapoi la client (browser)\n\t\t\t\t\t\t\twhile((n = recv(sockfd, buffer, BUFLEN, 0)) > 0) {\n\t\t\t\t\t\t\t\twrite(i, buffer, n);\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t// se intrerupe conexiunea cu serverul\n\t\t\t\t\t\t\tclose(sockfd);\n\t\t\t\t\t\t\tFD_CLR(i, &read_fds);\n\t\t\t\t\t\t\tclose(i);\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t} \n\t\t\t}\n\t\t}\n }\n\n close(sockfd);\n \n return 0; \n}\n\n\n"
},
{
"alpha_fraction": 0.3571428656578064,
"alphanum_fraction": 0.39534884691238403,
"avg_line_length": 22.153846740722656,
"blob_id": "aa6f1d5c8a07b804eb2f0730c11e4c035548c12d",
"content_id": "3b2706150a7291af4e27dba768e0698d0e072819",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 602,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 26,
"path": "/matrix-mul/solver_neopt.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Tema 2 ASC\n * 2018 Spring\n * Catalin Olaru / Vlad Spoiala\n */\n#include \"utils.h\"\n\n/*\n * Add your unoptimized implementation here\n */\ndouble* my_solver(int N, double *A) {\n\tprintf(\"NEOPT SOLVER\\n\");\n\tdouble *C = calloc(2 * N * N, sizeof(double));\n\tint i, j, k;\n\n\tfor (i = 0; i < N; i++) {\n\t\tfor (j = i; j < N; j++) {\n\t\t\tfor (k = 0; k < N; k++) {\n\t\t\t\tC[2 * (i * N + j)] += A[2 * (i * N + k)] * A[2 * (j * N + k)] - A[2 * (i * N + k) + 1] * A[2 * (j * N + k) + 1];\n\t\t\t\tC[2 * (i * N + j) + 1] += A[2 * (i * N + k)] * A[2 * (j * N + k) + 1] + A[2 * (i * N + k) + 1] * A[2 * (j * N + k)];\n\t\t\t}\n\t\t}\n\t}\n\n\treturn C;\n}\n"
},
{
"alpha_fraction": 0.4331165850162506,
"alphanum_fraction": 0.4988388419151306,
"avg_line_length": 46.31867980957031,
"blob_id": "0eb9c9f270975ecbd965eefec19c9ccc5db2ea50",
"content_id": "d9beda75cf8f601813cb1e0106a06881bcd28dbb",
"detected_licenses": [
"BSD-3-Clause",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4306,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 91,
"path": "/ml/sarsa/gym-minigrid/tests.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "from sarsa_skel import *\n\n\ndef plot_egreedy(map):\n c1 = 0.5\n lr1 = 0.1\n d1 = 0.99\n q01 = 0\n steps1, avg_lengths1, avg_returns1 = sarsa_egreedy(map_file=map, learning_rate=lr1,\n discount=d1, const=c1, train_episodes=500, q0=q01,\n final_show=False)\n\n c2 = 0.5\n lr2 = 0.1\n d2 = 0.99\n q02 = 0.2\n steps2, avg_lengths2, avg_returns2 = sarsa_egreedy(map_file=map, learning_rate=lr2,\n discount=d2, const=c2, train_episodes=500, q0=q02,\n final_show=False)\n c3 = 0.5\n lr3 = 0.1\n d3 = 0.99\n q03 = 0.5\n steps3, avg_lengths3, avg_returns3 = sarsa_egreedy(map_file=map, learning_rate=lr3,\n discount=d3, const=c3, train_episodes=500, q0=q03,\n final_show=False)\n c4 = 0.5\n lr4 = 0.1\n d4 = 0.99\n q04 = 1\n steps4, avg_lengths4, avg_returns4 = sarsa_egreedy(map_file=map, learning_rate=lr4,\n discount=d4, const=c4, train_episodes=500, q0=q04,\n final_show=False)\n _fig, (ax1, ax2) = plt.subplots(ncols=2)\n ax1.plot(steps1, avg_lengths1, label=\"egreedy c:\" + str(c1) + \" lr=\" + str(lr1) + \" q0=\" + str(q01))\n ax1.plot(steps2, avg_lengths2, label=\"egreedy c:\" + str(c2) + \" lr=\" + str(lr2) + \" q0=\" + str(q02))\n ax1.plot(steps3, avg_lengths3, label=\"egreedy c:\" + str(c3) + \" lr=\" + str(lr3) + \" q0=\" + str(q03))\n ax1.plot(steps4, avg_lengths4, label=\"egreedy c:\" + str(c4) + \" lr=\" + str(lr4) + \" q0=\" + str(q04))\n ax1.set_title(\"Average episode length\")\n ax1.legend()\n\n ax2.plot(steps1, avg_returns1, label=\"egreedy c:\" + str(c1) + \" lr=\" + str(lr1) + \" q0=\" + str(q01))\n ax2.plot(steps2, avg_returns2, label=\"egreedy c:\" + str(c2) + \" lr=\" + str(lr2) + \" q0=\" + str(q02))\n ax2.plot(steps3, avg_returns3, label=\"egreedy c:\" + str(c3) + \" lr=\" + str(lr3) + \" q0=\" + str(q03))\n ax2.plot(steps4, avg_returns4, label=\"egreedy c:\" + str(c4) + \" lr=\" + str(lr4) + \" q0=\" + str(q04))\n ax2.set_title(\"Average episode return\")\n ax2.legend()\n plt.show()\n\n\ndef plot_softmax(map):\n lr1 = 0.1\n d1 = 0.99\n steps1, avg_lengths1, avg_returns1 = sarsa_softmax(map_file=map, learning_rate=lr1,\n discount=d1, train_episodes=500, q0=0,\n final_show=False)\n\n lr2 = 0.2\n d2 = 0.99\n steps2, avg_lengths2, avg_returns2 = sarsa_softmax(map_file=map, learning_rate=lr2,\n discount=d2, train_episodes=500, q0=0,\n final_show=False)\n lr3 = 0.4\n d3 = 0.99\n steps3, avg_lengths3, avg_returns3 = sarsa_softmax(map_file=map, learning_rate=lr3,\n discount=d3, train_episodes=500, q0=0,\n final_show=False)\n lr4 = 0.8\n d4 = 0.99\n steps4, avg_lengths4, avg_returns4 = sarsa_softmax(map_file=map, learning_rate=lr4,\n discount=d4, train_episodes=500, q0=0,\n final_show=False)\n _fig, (ax1, ax2) = plt.subplots(ncols=2)\n ax1.plot(steps1, avg_lengths1, label=\"softmax lr=\" + str(lr1))\n ax1.plot(steps2, avg_lengths2, label=\"softmax lr=\" + str(lr2))\n ax1.plot(steps3, avg_lengths3, label=\"softmax lr=\" + str(lr3))\n ax1.plot(steps4, avg_lengths4, label=\"softmax lr=\" + str(lr4))\n ax1.set_title(\"Average episode length\")\n ax1.legend()\n\n ax2.plot(steps1, avg_returns1, label=\"softmax lr=\" + str(lr1))\n ax2.plot(steps2, avg_returns2, label=\"softmax lr=\" + str(lr2))\n ax2.plot(steps3, avg_returns3, label=\"softmax lr=\" + str(lr3))\n ax2.plot(steps4, avg_returns4, label=\"softmax lr=\" + str(lr4))\n ax2.set_title(\"Average episode return\")\n ax2.legend()\n plt.show()\n\n\nif __name__ == '__main__':\n plot_softmax(\"MiniGrid-Empty-6x6-v0\")\n"
},
{
"alpha_fraction": 0.5406926274299622,
"alphanum_fraction": 0.5441558361053467,
"avg_line_length": 30.643835067749023,
"blob_id": "63793f2594b0ab75e13e5c84ba27ceb61db67560",
"content_id": "262805789ebed7862084bec17be8ceee7f06ea61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2310,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 73,
"path": "/belief-propagation/main.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom graph_utils import create_graph, create_undirected_graph, create_graph_of_cliques\nfrom graph_utils import moralize_graph, triangualate_graph\nfrom graph_utils import bron_kerbosch, kruskal\n\nfrom factor import FactorWrapper\n\nEPS = 0.0001\nTEST_DIR = 'test_networks'\n\n\ndef read_file(file_path):\n variables = []\n parents = {}\n probabilities = {}\n expected_results = []\n\n with open(file_path) as fp:\n n, m = [int(x) for x in next(fp).split()]\n req_vars = [{} for _ in range(m)]\n req_obs = [{} for _ in range(m)]\n\n for _ in range(n):\n line = next(fp).split(';')\n variable = line[0].strip()\n variables.append(variable)\n parents[variable] = line[1].split()\n probabilities[variable] = [float(i) for i in line[2].split()]\n\n for i in range(m):\n [vars, obs] = next(fp).split('|')\n\n for e in vars.split():\n (lhs, rhs) = e.split('=')\n req_vars[i][lhs] = int(rhs)\n\n for e in obs.split():\n (lhs, rhs) = e.split('=')\n req_obs[i][lhs] = int(rhs)\n\n for _ in range(m):\n expected_results.append(float(next(fp)))\n\n return variables, parents, probabilities, req_vars, req_obs, expected_results\n\n\nif __name__ == '__main__':\n for filepath in os.listdir(TEST_DIR):\n variables, parents, probabilities, req_vars, req_obs, expected_results = read_file(TEST_DIR + '/' + filepath)\n G = create_graph(variables, parents)\n U = create_undirected_graph(G)\n H = moralize_graph(U, parents)\n H_star = triangualate_graph(H)\n\n max_cliques = []\n bron_kerbosch(H_star, [], H_star.get_var_names(), [], max_cliques)\n C = create_graph_of_cliques(max_cliques)\n T = kruskal(C, max_cliques)\n factor_wrapper = FactorWrapper(variables, parents, probabilities, T)\n\n for ro, rv, er in list(zip(req_obs, req_vars, expected_results)):\n result = factor_wrapper.query(ro, rv)\n if not result:\n print('Not implemented')\n continue\n\n if abs(result - er) < EPS:\n print(\"Correct!\")\n else:\n print(\"Wrong!\")\n\n print(\"\\n============================\")\n"
},
{
"alpha_fraction": 0.39375001192092896,
"alphanum_fraction": 0.42250001430511475,
"avg_line_length": 18.071428298950195,
"blob_id": "8ce5e4f14ad45f6629611a7ebb95671919edc1ee",
"content_id": "f0fa4d25842783d55ec7de2c346df8c54341aabc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 800,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 42,
"path": "/matrix-mul/solver_opt.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "/*\n * Tema 2 ASC\n * 2018 Spring\n * Catalin Olaru / Vlad Spoiala\n */\n#include \"utils.h\"\n\n/*\n * Add your optimized implementation here\n */\ndouble* my_solver(int N, double *A) {\n\tprintf(\"OPT SOLVER\\n\");\n\tdouble *C = calloc(2 * N * N, sizeof(double));\n\tint i, j, k;\n\n\tfor (i = 0; i < N; i++) {\n\t\tdouble *orig_a = &A[2 * i * N];\n\t\tdouble *orig_b = &A[2 * i * N + 1];\n\t\tfor (j = i; j < N; j++) {\n\t\t\tdouble *a = orig_a;\n\t\t\tdouble *b = orig_b;\n\t\t\t\n\t\t\tdouble *c = &A[2 * j * N];\n\t\t\tdouble *d = &A[2 * j * N + 1];\n\t\t\tregister double sum_r = 0;\n\t\t\tregister double sum_i = 0;\n\t\t\tfor (k = 0; k < N; k++) {\n\t\t\t\tsum_r += (*a) * (*c) - (*b) * (*d);\n\t\t\t\tsum_i += (*a) * (*d) + (*c) * (*b);\n\n\t\t\t\ta += 2;\n\t\t\t\tb += 2;\n\n\t\t\t\tc += 2;\n\t\t\t\td += 2;\n\t\t\t}\n\t\t\tC[2 * (i * N + j)] = sum_r;\n\t\t\tC[2 * (i * N + j) + 1] = sum_i;\n\t\t}\n\t}\n\treturn C;\n}"
},
{
"alpha_fraction": 0.6455317139625549,
"alphanum_fraction": 0.6665002703666687,
"avg_line_length": 28.455883026123047,
"blob_id": "8027558a183189bba864b4d5d84efc5e6ae0e5cd",
"content_id": "67c2db3ed864ea09e6622c0a88ca27f58f623172",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2003,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 68,
"path": "/mini-db-engine/ScalabilityTestThread.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import java.util.ArrayList;\nimport java.util.concurrent.BrokenBarrierException;\nimport java.util.concurrent.CyclicBarrier;\n\npublic class ScalabilityTestThread extends Thread {\n\tMyDatabase db;\n\tint threadId;\n\tint numThreads;\n\tCyclicBarrier barrier;\n\n\tScalabilityTestThread(MyDatabase db, int threadId, int numThreads, CyclicBarrier barrier) {\n\t\tthis.db = db;\n\t\tthis.threadId = threadId;\n\t\tthis.numThreads = numThreads;\n\t\tthis.barrier = barrier;\n\t}\n\n\tvoid barrierWrapper() {\n\t\ttry {\n\t\t\tbarrier.await();\n\t\t} catch (InterruptedException | BrokenBarrierException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\t}\n\n\tpublic void run() {\n\t\tint jobsPerThread = 4 / numThreads; // each thread has a job\n\t\tbarrierWrapper();\n\t\tbarrierWrapper();\n\t\t// -- multiple clients insert in multiple tables\n\t\tfor (int partialJobId = 0; partialJobId < jobsPerThread; partialJobId++) {\n\t\t\tint jobId = (jobsPerThread * threadId) + partialJobId;\n\t\t\tArrayList<Object> values = new ArrayList<Object>();\n\t\t\tfor (int i = 0; i < 10_000_00; i++) {\n\t\t\t\tvalues.clear();\n\t\t\t\tvalues.add(\"Ion\" + (i * (jobId + 1)));\n\t\t\t\tvalues.add(i * (jobId + 1));\n\t\t\t\tvalues.add(i % 2 == 1);\n\t\t\t\tdb.insert(\"Students\" + jobId, values);\n\t\t\t}\n\t\t}\n\t\tbarrierWrapper();\n\t\tbarrierWrapper();\n\t\t// -- one client update in one table\n\t\tif (threadId == 0) {\n\t\t\tArrayList<Object> values = new ArrayList<Object>();\n\t\t\tvalues.add(\"Ioana\");\n\t\t\tvalues.add(3);\n\t\t\tvalues.add(true);\n\t\t\tdb.update(\"Students2\", values, \"gender == true\");\n\t\t}\n\t\tbarrierWrapper();\n\t\tbarrierWrapper();\n\t\t// -- one client thread selects one table\n\t\tArrayList<ArrayList<Object>> results = null;\n\t\tif (threadId == 0) {\n\t\t\tString[] operations = { \"sum(grade)\" };\n\t\t\tresults = db.select(\"Students0\", operations, \"grade < 10000000\");\n\t\t\tresults = db.select(\"Students1\", operations, \"grade < 10000000\");\n\t\t\tresults = db.select(\"Students2\", operations, \"grade == 3\");\n\t\t\tresults = db.select(\"Students3\", operations, \"grade > 10\");\n\t\t}\n\t\tbarrierWrapper();\n\t\tif (threadId == 0) {\n\t\t\tSystem.out.println(results);\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.538468599319458,
"alphanum_fraction": 0.5494202375411987,
"avg_line_length": 33.718849182128906,
"blob_id": "7a29149eda936b54ea9942f95bf590d4a16210e8",
"content_id": "6d2b8b3d755460f9351e5329e8cd56e3f86c9b99",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 10866,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 313,
"path": "/atm/server.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <unistd.h>\n#include <sys/types.h> \n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include \"lib.h\"\n\n#define MAX_CLIENTS\t20\n#define BUFLEN 256\n\nvoid error(char *msg)\n{\n perror(msg);\n exit(1);\n}\n\nint main(int argc, char *argv[])\n{\n\tint sockfd, udpsock, newsockfd, portno, clilen;\n char buffer[BUFLEN];\n char* token; // auxiliar pentru strtok\n char* nr_card;\n char* parola;\n user* users; // vectorul de useri\n \n struct sockaddr_in serv_addr, cli_addr; // adresa serverului si a clientului\n int n, i, j, k;\n \n int no_users; // numarul de useri din fisier\n \tint idx_usr;\n \tint findRes;\n \tint sold;\n \tint money;\n\tpair* pairs; // perechi de socketi cu useri (adica ce user e logat pe socket) \n\t\n\tFILE* fp;\n int fdmax;\t // valoare maxima file descriptor din multimea read_fds\n\t\n\tfd_set read_fds; // multimea de citire folosita in select()\n fd_set tmp_fds;\t// multime folosita temporar\n\n if (argc < 3) {\n fprintf(stderr, \"Usage : %s <port_server> <user_data_files>\\n\", argv[0]);\n exit(1);\n }\n\n fp = fopen(argv[2], \"r\");\n fscanf(fp, \"%d\\n\", &no_users);\n\n // initializari structuri de date\n users = malloc(no_users * sizeof(user)); \n pairs = malloc(no_users * sizeof(pair));\n\n pairs->len = no_users;\n pairs->crt = 0;\n\n for(i = 0; i < no_users; i++) {\n \tfscanf(fp,\"%s %s %s %s %s %lf\\n\", users[i].nume, users[i].prenume, \n \t\t\tusers[i].nr_card, users[i].pin, users[i].parola, &users[i].sold);\n \tusers[i].blocat = 0;\n \tusers[i].logat = 0;\n \tusers[i].incercari = 0;\n }\n fclose(fp);\n\n FD_ZERO(&read_fds);\n FD_ZERO(&tmp_fds);\n \n //socketul tcp al serverului \n sockfd = socket(AF_INET, SOCK_STREAM, 0);\n if (sockfd < 0) \n \t\terror(\"ERROR opening socket\");\n \t//socketul udp al serverului\n\tudpsock = socket(AF_INET, SOCK_DGRAM, 0);\n \tif(udpsock < 0)\n \t\terror(\"ERROR opening socket\");\n\n portno = atoi(argv[1]);\n memset((char *) &serv_addr, 0, sizeof(serv_addr));\n serv_addr.sin_family = AF_INET;\n serv_addr.sin_addr.s_addr = INADDR_ANY;\n serv_addr.sin_port = htons(portno);\n \n int yes = 1;\n // optiune pentru reutilizarea adresei socketului tpc\n setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes));\n if (bind(sockfd, (struct sockaddr *) &serv_addr, sizeof(struct sockaddr)) < 0) \n \terror(\"ERROR on binding\");\n\n yes = 1;\n // si pentru socketul udp la fel\n setsockopt(udpsock, SOL_SOCKET, SO_REUSEADDR, &yes, sizeof(yes));\n if(bind(udpsock, (struct sockaddr *) &serv_addr, sizeof(struct sockaddr)) < 0)\n \terror(\"ERROR on binding\");\n\n listen(sockfd, MAX_CLIENTS);\n\n //se introduc socketii udp, tcp (si 0 pentru stdin) in multimea de descriptori\n FD_SET(sockfd, &read_fds);\n FD_SET(udpsock, &read_fds);\n FD_SET(0, &read_fds);\n fdmax = sockfd;\n\n // main loop\n\twhile (1) {\n\t\ttmp_fds = read_fds; \n\t\tif (select(fdmax + 1, &tmp_fds, NULL, NULL, NULL) == -1) \n\t\t\terror(\"ERROR in select\");\n\t\n\t\tfor(i = 0; i <= fdmax; i++) {\n\t\t\tif (FD_ISSET(i, &tmp_fds)) {\n\t\t\t\t// daca se citeste de la tastatura din server (doar quit se poate citi de aici)\n\t\t\t\tif(i == 0) {\n\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n fgets(buffer, BUFLEN - 1, stdin);\n \tif(!strcmp(buffer, \"quit\\n\")) { // daca se da comanda de inchidere al serverului\n \t\tfor(k = 1; k <= fdmax; k++) { // se trece prin toti clientii si se trimite mesajul de inchidere al serverului\n if(FD_ISSET(k, &read_fds) && k != sockfd && k != udpsock) {\n \t\t\t\tsprintf(buffer, \"ATM> Bye!\\n\");\n \t\t\t\tsend(k, buffer, BUFLEN, 0);\n \t\t\t\t\n \t\t\t\tclose(k); // se inchide socketul\n \t\t\t}\n \t\t}\n \t\tFD_ZERO(&read_fds);\n \t\t\n \t\tclose(sockfd);\n \t\tclose(udpsock);\n \t\treturn 0;\n \t}\n\n\t\t\t\t} else if (i == sockfd) {\n\t\t\t\t\t// a venit ceva pe socketul inactiv(cel cu listen) = o noua conexiune\n\t\t\t\t\t// actiunea serverului: accept()\n\t\t\t\t\tclilen = sizeof(cli_addr);\n\t\t\t\t\tif ((newsockfd = accept(sockfd, (struct sockaddr *)&cli_addr, (socklen_t*)&clilen)) == -1) {\n\t\t\t\t\t\terror(\"ERROR in accept\");\n\t\t\t\t\t} \n\t\t\t\t\telse {\n\t\t\t\t\t\t//adaug noul socket intors de accept() la multimea descriptorilor de citire\n\t\t\t\t\t\tFD_SET(newsockfd, &read_fds);\n\t\t\t\t\t\tif (newsockfd > fdmax) { \n\t\t\t\t\t\t\tfdmax = newsockfd;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\tprintf(\"Noua conexiune de la %s, port %d, socket_client %d\\n \", inet_ntoa(cli_addr.sin_addr), ntohs(cli_addr.sin_port), newsockfd);\n\t\t\t\t} else if(i == udpsock) { // daca se primeste de pe socketul udp\n\t\t\t\t\tclilen = sizeof(cli_addr);\n\t\t\t\t\tif(recvfrom(udpsock, buffer, BUFLEN, 0, (struct sockaddr*)&cli_addr, (socklen_t*)&clilen) == -1) {\n\t\t\t\t\t\terror(\"err recvfrom\");\n\t\t\t\t\t}\n\t\t\t\t\tprintf (\"Am primit de la clientul de pe socketul %d (UDP), mesajul: %s\\n\", i, buffer);\t\n\n\t\t\t\t\ttoken = strtok(buffer, \" \\n\");\n\t\t\t\t\tif (!strcmp(token, \"unlock\")) { // daca se primeste comanda unlock <nr_card>\n\t\t\t\t\t\ttoken = strtok(NULL, \" \\n\");\n\n\t\t\t\t\t\t// se verifica daca s-a gasit userul si daca este blocat sau nu, si se trimite la client\n\t\t\t\t\t\t// mesajul corespunzator\n\t\t\t\t\t\tif((findRes = findCard(users, strdup(token), no_users)) == 1) {\n\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> Trimite parola secreta\\n\");\n\t\t\t\t\t\t} else if(findRes == -1) {\n\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> -4 : Numar card inexistent\\n\");\n\t\t\t\t\t\t} else if(findRes == 0) {\n\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> -6 : Operatie esuata\\n\");\n\t\t\t\t\t\t}\n\n\t\t\t\t\t\tif(sendto(udpsock, buffer, BUFLEN, 0, (struct sockaddr*)&cli_addr, clilen) == -1) {\n\t\t\t\t\t\t\terror(\"err sendto\");\n\t\t\t\t\t\t}\n\t\t\t\t\t} else { // daca se trimite <nr_card> <parola>\n\t\t\t\t\t\tnr_card = strdup(token);\n\t\t\t\t\t\ttoken = strtok(NULL, \" \\n\");\n\t\t\t\t\t\tparola = strdup(token);\n\n\t\t\t\t\t\t// se cauta indexul userului (in cazul asta stim sigur ca exista)\n\t\t\t\t\t\tidx_usr = getUserIndex(users, nr_card, no_users);\n\n\t\t\t\t\t\t// se verifica daca parola este corecta\n\t\t\t\t\t\t// sau daca nu cumva a fost deblocat in alta sesiune (caz tratat, desi nu este prezentat in tema)\n\t\t\t\t\t\tif(!strcmp(parola, users[idx_usr].parola)) {\n\t\t\t\t\t\t\tif(users[idx_usr].blocat == 0) { // cardul nu este blocat\n\t\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> -6 : Operatie esuata\\n\");\n\t\t\t\t\t\t\t}else { // cardul era blocat, si-l deblocam\n\t\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> Client deblocat\\n\");\n\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\tusers[idx_usr].blocat = 0;\n\t\t\t\t\t\t\t\tusers[idx_usr].incercari = 0;\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t} else { // daca parola nu este corecta\n\t\t\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\t\t\tsprintf(buffer, \"UNLOCK> -7 : Deblocare esuata\\n\");\t\t\t\t\t\t\t\n\t\t\t\t\t\t}\n\t\t\t\t\t\t\n\t\t\t\t\t if (sendto(udpsock, buffer, BUFLEN, 0, (struct sockaddr*)&cli_addr, clilen) == -1) {\n \terror(\"err sendto\");\n \t}\n\n\t\t\t\t\t}\n\t\t\t\t} else {\n\t\t\t\t\tmemset(buffer, 0, BUFLEN);\n\t\t\t\t\tif ((n = recv(i, buffer, sizeof(buffer), 0)) <= 0) {\n\t\t\t\t\t\tif (n == 0) {\n\t\t\t\t\t\t\t//conexiunea s-a inchis\n\t\t\t\t\t\t\tprintf(\"Server: socket %d hung up\\n\", i);\n\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\terror(\"ERROR in recv\");\n\t\t\t\t\t\t}\n\t\t\t\t\t\tclose(i); \n\t\t\t\t\t\tFD_CLR(i, &read_fds); \n\t\t\t\t\t} else { //recv intoarce >0\n\t\t\t\t\t\tprintf (\"Am primit de la clientul de pe socketul %d (TCP), mesajul: %s\", i, buffer);\n\t\t\t\t\t\tint ok1 = 0;\n\t\t\t\t\t\tint ok2 = 0;\n\n\t\t\t\t\t\tchar* tok = strtok(strdup(buffer), \" \\n\");\n\t\t\t\t\t\tif(!strcmp(tok, \"login\")) { // comanda login\n\t\t\t\t\t\t\ttok = strtok(NULL, \" \\n\");\n\t\t\t\t\t\t\tfor(j = 0; j < no_users; j++) {\n\t\t\t\t\t\t\t\tif(!strcmp(users[j].nr_card, tok)) {\n\t\t\t\t\t\t\t\t\tok1 = 1;\n\t\t\t\t\t\t\t\t\tif(users[j].blocat == 1) { // daca este blocat, se trimite mesajul corespunzator\n\t\t\t\t\t\t\t\t\t\tok2 = 1;\n\t\t\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -5 : Card blocat\\n\");\n\t\t\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\t\t\tif(users[j].logat == 1) { // daca este deja logat in alta sesiune\n\t\t\t\t\t\t\t\t\t\tok2 = 1;\n\t\t\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -2 : Sesiune deja deschisa\\n\");\n\t\t\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t\t\t\tbreak;\n\n\t\t\t\t\t\t\t\t\t} else if(!strcmp(tok = strtok(NULL, \" \\n\"), users[j].pin)) { // se verifica pin-ul\n\t\t\t\t\t\t\t\t\t\tok2 = 1;\n\t\t\t\t\t\t\t\t\t\tusers[j].logat = 1;\n\t\t\t\t\t\t\t\t\t\tusers[j].incercari = 0;\n\t\t\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> Welcome %s %s\\n\", users[j].nume, users[j].prenume);\n\t\t\t\t\t\t\t\t\t\taddPair(pairs, &users[j], i);\n\t\t\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t\t\t\tbreak;\n\n\t\t\t\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t\t\t\t// am luat in considerare cazul in care se blocheaza un card, ci nu sesiunea.\n\t\t\t\t\t\t\t\t\t\tif(++users[j].incercari == 3) { // daca nu este bun pin-ul, se incrementeaza contorul de incercari\n\t\t\t\t\t\t\t\t\t\t\tok2 = 1;\n\t\t\t\t\t\t\t\t\t\t\tusers[j].blocat = 1;\n\t\t\t\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -5 : Card blocat\\n\");\n\t\t\t\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t\t}\t\t\t\t\t\t\t\t\t\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tif(!ok1 && !ok2) { // cazul in care nu exista cardul\n\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -4 : Numar card inexistent\\n\");\n\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t\tif(ok1 && !ok2) { // caz in care pin-ul este gresit\n\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -3 : Pin gresit\\n\");\n\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t} else if(!strcmp(tok, \"logout\")) { // comanda logout\n\t\t\t\t\t\t\tremovePair(pairs, i); // se delogheaza userul de pe socket\n\t\t\t\t\t\t\tsprintf(buffer, \"ATM> Deconectare de la bancomat\\n\");\n\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\n\t\t\t\t\t\t} else if(!strcmp(tok, \"listsold\")) { // comanda listsold\n\t\t\t\t\t\t\tsprintf(buffer, \"ATM> %.2lf\\n\", getSold(pairs, i));\n\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\n\t\t\t\t\t\t} else if(!strcmp(tok, \"getmoney\")) { // comanda getmoney\n\t\t\t\t\t\t\ttok = strtok(NULL, \" \\n\");\n\t\t\t\t\t\t\tsscanf(tok, \"%d\", &sold);\n\t\t\t\t\t\t\tif(sold % 10 != 0) { // daca nu este multiplu de 10, se intoarce mesajul coresp.\n\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -9 : Suma nu este multiplu de 10\\n\");\n\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t} else if(getMoney(pairs, i, sold) == 0) {\n\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> Suma %d retrasa cu succes\\n\", sold);\t\n\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t} else {\n\t\t\t\t\t\t\t\tsprintf(buffer, \"ATM> -8 : Fonduri insuficiente\\n\");\n\t\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t} else if(!strcmp(tok, \"putmoney\")) { // comanda putmoney\n\t\t\t\t\t\t\ttok = strtok(NULL, \" \\n\");\n\t\t\t\t\t\t\tsscanf(tok, \"%d\", &money);\n\t\t\t\t\t\t\tputMoney(pairs, i, money);\n\n\t\t\t\t\t\t\tsprintf(buffer, \"ATM> Suma depusa cu succes\\n\");\n\t\t\t\t\t\t\tsend(i, buffer, strlen(buffer), 0);\n\t\t\t\t\t\t} else if(!strcmp(tok, \"quit\")) {\n\t\t\t\t\t\t\tremovePair(pairs, i); // daca se primeste quit de la client, il deloghez\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t} \n\t\t\t}\n\t\t}\n }\n close(sockfd);\n return 0; \n}"
},
{
"alpha_fraction": 0.5759454369544983,
"alphanum_fraction": 0.5784252882003784,
"avg_line_length": 32.60416793823242,
"blob_id": "d01edf649adc1406030b7896db7dadea6fc05a4f",
"content_id": "ec20acecc5e02e1737b1cc4bac8c3262876d8367",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1613,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 48,
"path": "/elevator-world/src/utils/CommandScheduler.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package utils;\n\nimport agents.Simulator;\nimport agents.behaviors.CommandSenderBehavior;\nimport jade.core.Agent;\nimport jade.core.behaviours.OneShotBehaviour;\nimport jade.core.behaviours.WakerBehaviour;\nimport reader.Generator;\n\nimport java.util.List;\n\npublic class CommandScheduler {\n private List<Generator> generatorList;\n private Agent simulator;\n\n public CommandScheduler(List<Generator> generatorList, Agent simulator) {\n this.generatorList = generatorList;\n this.simulator = simulator;\n }\n\n public void schedule() {\n for (Generator generator: generatorList) {\n int start = Math.toIntExact(generator.tFrom);\n int end = Math.toIntExact(generator.tTo);\n int period = Math.toIntExact(generator.period);\n int maxTicks = (end - start + 1) / period;\n\n if (start - 1 == 0) {\n simulator.addBehaviour(new OneShotBehaviour(simulator) {\n @Override\n public void action() {\n myAgent.addBehaviour(new CommandSenderBehavior(myAgent, generator, maxTicks));\n }\n });\n } else {\n int delay = (start - 1) * Simulator.TICK_PERIOD;\n simulator.addBehaviour(new WakerBehaviour(simulator, delay) {\n @Override\n protected void onWake() {\n super.onWake();\n myAgent.addBehaviour(new CommandSenderBehavior(myAgent, generator, maxTicks));\n }\n });\n }\n\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6273525953292847,
"alphanum_fraction": 0.6323713660240173,
"avg_line_length": 31.933883666992188,
"blob_id": "0c5e953c9cb4672d439c765be39f8b5f13f13e4c",
"content_id": "027d2ebcb6e879a551d434f4ba19fe6deb5933ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3985,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 121,
"path": "/elevator-world/src/platform/SingleLauncher.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package platform;\n\nimport agents.Elevator;\nimport agents.Floor;\nimport agents.Simulator;\nimport jade.core.Agent;\nimport jade.core.Profile;\nimport jade.core.ProfileImpl;\nimport jade.core.Runtime;\nimport jade.util.ExtendedProperties;\nimport jade.util.leap.Properties;\nimport jade.wrapper.AgentContainer;\nimport jade.wrapper.AgentController;\nimport jade.wrapper.StaleProxyException;\nimport reader.ConfigReader;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\n/**\n * Launches both containers and associated agents.\n *\n * @author Andrei Olaru\n */\npublic class SingleLauncher {\n static String configFilePath;\n static String scenarioName;\n static float timeScaler;\n\n AgentContainer container;\n\n\n void setupPlatform() {\n Properties mainProps = new ExtendedProperties();\n mainProps.setProperty(Profile.GUI, \"true\"); // start the JADE GUI\n mainProps.setProperty(Profile.LOCAL_HOST, \"localhost\");\n mainProps.setProperty(Profile.LOCAL_PORT, \"1202\");\n mainProps.setProperty(Profile.CONTAINER_NAME, \"Proiect\"); // you can rename it\n mainProps.setProperty(Profile.PLATFORM_ID, \"ami-agents\");\n\n ProfileImpl profile = new ProfileImpl(mainProps);\n\n container = Runtime.instance().createMainContainer(profile);\n }\n\n /**\n * Starts the agents assigned to the main container.\n */\n void startAgents() {\n\n List<Agent> floors = new ArrayList<>();\n List<Agent> elevators = new ArrayList<>();\n ConfigReader configReader = new ConfigReader(configFilePath);\n configReader.parseConfigFile(scenarioName);\n\n int numFloors = Math.toIntExact(configReader.numFloors);\n\n Elevator.T_DOORS = Math.toIntExact(configReader.tDoors);\n Elevator.T_CLOSE = Math.toIntExact(configReader.tClose);\n Elevator.T_TRANSIT = Math.toIntExact(configReader.tTransit);\n Elevator.T_SLOW = Math.toIntExact(configReader.tSlow);\n Elevator.T_ACCEL = Math.toIntExact(configReader.tAccel);\n Elevator.T_FAST = Math.toIntExact(configReader.tFast);\n Elevator.CAPACITY = Math.toIntExact(configReader.capacity);\n Elevator.NUM_FLOORS = numFloors;\n\n for (int i = 0; i < numFloors; i++) {\n try {\n Agent floor = new Floor(i + 1);\n floors.add(floor);\n AgentController floorAgentController = container.acceptNewAgent(\"floor\" + (i + 1), floor);\n floorAgentController.start();\n } catch (StaleProxyException e) {\n e.printStackTrace();\n }\n }\n\n int numElevators = Math.toIntExact(configReader.numElevators);\n for (int i = 0; i < numElevators; i++) {\n try {\n Agent elevator = new Elevator(i + 1);\n elevators.add(elevator);\n AgentController elevatorAgentController = container.acceptNewAgent(\"elevator\" + (i + 1), elevator);\n elevatorAgentController.start();\n } catch (StaleProxyException e) {\n e.printStackTrace();\n }\n }\n\n try {\n Object[] args = new Object[4];\n args[0] = floors;\n args[1] = elevators;\n args[2] = configReader.scenario;\n args[3] = timeScaler;\n\n AgentController simulatorAgentController = container.createNewAgent(\"simulator\", Simulator.class.getName(), args);\n simulatorAgentController.start();\n } catch (StaleProxyException e) {\n e.printStackTrace();\n }\n\n }\n\n public static void main(String[] args) {\n\n if (args.length != 3) {\n System.out.println(\"Invalid number of arguments! Expected 3, got\" + args.length);\n return;\n }\n\n SingleLauncher launcher = new SingleLauncher();\n configFilePath = args[0];\n scenarioName = args[1];\n timeScaler = Float.parseFloat(args[2]);\n\n launcher.setupPlatform();\n launcher.startAgents();\n }\n\n}\n"
},
{
"alpha_fraction": 0.7304964661598206,
"alphanum_fraction": 0.73758864402771,
"avg_line_length": 16.625,
"blob_id": "bd28025627749a0ecb0ed374f6b90ae1208dc052",
"content_id": "357567af8022c5bc6e7a8dd4c5eb7a3b62f8cb7e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 8,
"path": "/shear-sort/pthreads/Makefile",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "build:\n\tgcc shear_sort_pthreads.c utils.c -o shear_sort_pthreads -lm -pthread\n\nclean:\n\trm shear_sort_pthreads\n\nrun:\n\t./shear_sort_pthreads 8 "
},
{
"alpha_fraction": 0.578154444694519,
"alphanum_fraction": 0.5948943495750427,
"avg_line_length": 37.85365676879883,
"blob_id": "a9d1b9fb10a56131cb964aa533ab282702113d66",
"content_id": "202e860f8556bde7ffe6ca22e45b29d5dfbe6a10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4779,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 123,
"path": "/ml/nn/evaluate.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom keras.models import model_from_json\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom sklearn.metrics import accuracy_score\nfrom pandas import read_csv\n\nfrom random import randint\n\n\ndef compute_accuracies_for_test_set(given_set):\n probabilities = best_model.predict_generator(given_set, steps=50)\n predictions = np.where(probabilities > 0.5, 1, 0)\n label_map = given_set.class_indices\n label_map = dict((v, k) for k, v in label_map.items())\n predictions = [label_map[k[0]] for k in predictions]\n i = 0\n\n patient_to_study_dict = {}\n for path in given_set.filepaths:\n patient_idx = path.find('patient')\n study_idx = path.find('study')\n img_idx = path.find('image')\n\n patient = path[patient_idx:study_idx - 1]\n study = path[study_idx: img_idx - 1]\n\n if predictions[i] == '1':\n value = 1\n else:\n value = -1\n\n patient_to_study_dict[patient] = patient_to_study_dict.get(patient, {})\n patient_to_study_dict[patient][study] = patient_to_study_dict[patient].get(study, 0) + value\n i += 1\n studies_counter = 0\n hits = 0\n for patient, study_dict in patient_to_study_dict.items():\n for study, val in study_dict.items():\n if val == 0:\n hits += randint(0, 1)\n if 'positive' in study and val > 0:\n hits += 1\n elif 'negative' in study and val < 0:\n hits += 1\n studies_counter += 1\n\n accuracy = hits / studies_counter\n predictions = list(map(lambda x: int(x), predictions))\n print(\"Test accuracy per study\", accuracy)\n print(\"Test accuracy per image\", accuracy_score(given_set.classes, predictions))\n\n\ndef compute_accuracies_for_train_set(given_set):\n probabilities = best_model.predict_generator(given_set, steps=576)\n predictions = np.where(probabilities > 0.5, 1, 0)\n label_map = given_set.class_indices\n label_map = dict((v, k) for k, v in label_map.items())\n predictions = [label_map[k[0]] for k in predictions]\n i = 0\n\n patient_to_study_dict = {}\n for path in given_set.filepaths:\n patient_idx = path.find('patient')\n study_idx = path.find('study')\n img_idx = path.find('image')\n\n patient = path[patient_idx:study_idx - 1]\n study = path[study_idx: img_idx - 1]\n\n if predictions[i] == '1':\n value = 1\n else:\n value = -1\n\n patient_to_study_dict[patient] = patient_to_study_dict.get(patient, {})\n patient_to_study_dict[patient][study] = patient_to_study_dict[patient].get(study, 0) + value\n i += 1\n studies_counter = 0\n hits = 0\n for patient, study_dict in patient_to_study_dict.items():\n for study, val in study_dict.items():\n if val == 0:\n hits += randint(0, 1)\n if 'positive' in study and val > 0:\n hits += 1\n elif 'negative' in study and val < 0:\n hits += 1\n studies_counter += 1\n\n accuracy = hits / studies_counter\n predictions = list(map(lambda x: int(x), predictions))\n print(\"Train accuracy per study\", accuracy)\n print(\"Train accuracy per image\", accuracy_score(given_set.classes, predictions))\n\n\nif __name__ == '__main__':\n df_train = read_csv('MURA-v1.1/train_image_paths.csv')\n df_test = read_csv('MURA-v1.1/valid_image_paths.csv')\n df_train['label'] = ['1' if 'positive' in x else '0' for x in df_train['path']]\n df_test['label'] = ['1' if 'positive' in x else '0' for x in df_test['path']]\n\n train_data_gen = ImageDataGenerator()\n test_data_gen = ImageDataGenerator()\n\n train_set = train_data_gen.flow_from_dataframe(df_train, x_col=\"path\", y_col=\"label\", color_mode=\"grayscale\",\n class_mode=\"binary\", target_size=(244, 244), batch_size=64,\n shuffle=False)\n\n test_set = test_data_gen.flow_from_dataframe(df_test, x_col=\"path\", y_col=\"label\", color_mode=\"grayscale\",\n class_mode=\"binary\", target_size=(244, 244), batch_size=64,\n shuffle=False)\n\n model_architecture = open('model/feature_maps_v2.json', 'r')\n best_model = model_from_json(model_architecture.read())\n model_architecture.close()\n # Load best model's weights\n best_model.load_weights('model/weights/feature_maps_v2_cnn_weights_20ep.hdf5')\n # Compile the best model\n best_model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])\n # Evaluate on test data\n\n compute_accuracies_for_test_set(test_set)\n compute_accuracies_for_train_set(train_set)\n"
},
{
"alpha_fraction": 0.6304267048835754,
"alphanum_fraction": 0.6374768018722534,
"avg_line_length": 34.46052551269531,
"blob_id": "028345dced4cd2dbace8161ea818baa8ae18c9e0",
"content_id": "00ced08dfda8385732ef3b6e52c56bd5bc85baff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2695,
"license_type": "permissive",
"max_line_length": 163,
"num_lines": 76,
"path": "/elevator-world/src/other/PreferenceAgent.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "package other;\n\nimport jade.core.Agent;\nimport jade.domain.DFService;\nimport jade.domain.FIPAAgentManagement.*;\nimport jade.domain.FIPAException;\nimport jade.domain.FIPANames;\nimport jade.lang.acl.ACLMessage;\nimport jade.lang.acl.MessageTemplate;\nimport jade.proto.AchieveREResponder;\nimport platform.Log;\n\n/**\n * Preference agent.\n */\npublic class PreferenceAgent extends Agent {\n /**\n *\n */\n private static final long serialVersionUID = -3397689918969697329L;\n\n private static final MessageTemplate template = MessageTemplate.and(\n MessageTemplate.MatchProtocol(FIPANames.InteractionProtocol.FIPA_REQUEST),\n MessageTemplate.MatchPerformative(ACLMessage.REQUEST));\n\n @Override\n public void setup() {\n Log.log(this, \"Hello\");\n\n // Register the preference-agent service in the yellow pages\n DFAgentDescription dfd = new DFAgentDescription();\n dfd.setName(getAID());\n\n ServiceDescription sd = new ServiceDescription();\n sd.setType(ServiceType.PREFERENCE_AGENT);\n sd.setName(\"ambient-wake-up-call\");\n dfd.addServices(sd);\n try {\n DFService.register(this, dfd);\n } catch (FIPAException fe) {\n fe.printStackTrace();\n }\n\n // TODO add behaviors\n addBehaviour(new AchieveREResponder(this, template) {\n protected ACLMessage prepareResponse(ACLMessage request) throws NotUnderstoodException, RefuseException {\n System.out.println(\"Agent \" + getLocalName() + \": REQUEST received from \" + request.getSender().getName() + \". Action is \" + request.getContent());\n System.out.println(\"Agent \" + getLocalName() + \": Agree\");\n ACLMessage agree = request.createReply();\n agree.setPerformative(ACLMessage.AGREE);\n return agree;\n }\n\n protected ACLMessage prepareResultNotification(ACLMessage request, ACLMessage response) throws FailureException {\n System.out.println(\"Agent \" + getLocalName() + \": Action successfully performed\");\n ACLMessage inform = request.createReply();\n inform.setPerformative(ACLMessage.INFORM);\n inform.setContent(WakeUpPreference.HARD); // Select one of these : HARD, SOFT, SUPER_SOFT\n return inform;\n }\n });\n }\n\n @Override\n protected void takeDown() {\n // De-register from the yellow pages\n try {\n DFService.deregister(this);\n } catch (FIPAException fe) {\n fe.printStackTrace();\n }\n\n // Printout a dismissal message\n Log.log(this, \"terminating.\");\n }\n}\n"
},
{
"alpha_fraction": 0.6351791620254517,
"alphanum_fraction": 0.6351791620254517,
"avg_line_length": 19.399999618530273,
"blob_id": "897f33c09e20961fd147348658f71659843e83fe",
"content_id": "48c2945abd180297a2359f7b37489670976dc27a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 307,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 15,
"path": "/expression-evaluator/Visitable.java",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\n/**\n * Interfata Visitable, care va fi implementata de orice clasa care va fi\n * \"vizitabila\".\n * \n * @author Alin\n *\n */\npublic interface Visitable {\n\t/**\n\t * Metoda accept nu va face altceva decat sa viziteze obiectul (this).\n\t * @param v\n\t * Visit-orul\n\t */\n\tpublic void accept(Visitor v);\n}\n"
},
{
"alpha_fraction": 0.5519315600395203,
"alphanum_fraction": 0.5634273290634155,
"avg_line_length": 37.56185531616211,
"blob_id": "e4e895f682d3d2b19c8acb36012cf303a72859f4",
"content_id": "772fba21ab97cfa77e116186c6b70605c304ef14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7481,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 194,
"path": "/ml/svm/main.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\nfrom svmutil import *\nfrom argparse import ArgumentParser\nfrom sklearn.metrics import confusion_matrix\n\nTRAIN_PERCENTAGE = 0.7\n\n\ndef plot_confusion_matrix(y_true, y_pred, classes, title,\n cmap=plt.cm.Blues):\n cm = confusion_matrix(y_true, y_pred)\n fig, ax = plt.subplots()\n im = ax.imshow(cm, interpolation='nearest', cmap=cmap)\n ax.figure.colorbar(im, ax=ax)\n ax.set(xticks=np.arange(cm.shape[1]),\n yticks=np.arange(cm.shape[0]),\n xticklabels=classes, yticklabels=classes,\n title=None,\n ylabel='True label',\n xlabel='Predicted label')\n\n plt.setp(ax.get_xticklabels(), rotation=45, ha=\"right\",\n rotation_mode=\"anchor\")\n fmt = 'd'\n thresh = cm.max() / 2.\n for i in range(cm.shape[0]):\n for j in range(cm.shape[1]):\n ax.text(j, i, format(cm[i, j], fmt),\n ha=\"center\", va=\"center\",\n color=\"white\" if cm[i, j] > thresh else \"black\")\n fig.tight_layout()\n fig.savefig(title + \".png\")\n return ax\n\n\ndef classify_skin_nonskin(kernel_type, degree, gamma, C, coef0):\n y, x = svm_read_problem('processed_data/shuffled_skin_nonskin')\n\n # training data\n split_idx = int(TRAIN_PERCENTAGE * len(y))\n y_train = y[:split_idx]\n x_train = x[:split_idx]\n\n # test data\n y_test = y[split_idx:]\n x_test = x[split_idx:]\n\n problem = svm_problem(y_train, x_train)\n param = svm_parameter()\n param.kernel_type = kernel_type\n param.degree = degree\n param.gamma = gamma\n param.C = C\n param.coef0 = coef0\n\n base_title = str.format(\"skin_nonskin_kernel{}_C{}_gamma{}_coef0{}_degree{}\", kernel_type, C, gamma, coef0, degree)\n m = svm_train(problem, param)\n\n pred_labels, p_acc, _ = svm_predict(y_test, x_test, m)\n plot_confusion_matrix(y_test, pred_labels, ['1', '2'], title=base_title + \"_test\")\n (ACC, MSE, _) = p_acc\n print(\"ACC:\", ACC)\n print(\"MSE:\", MSE)\n\n pred_labels, _, _ = svm_predict(y_train, x_train, m)\n plot_confusion_matrix(y_train, pred_labels, ['1', '2'], title=base_title + \"_train\")\n\n\ndef classify_news20(method, kernel_type, degree, gamma, C, coef0):\n y_train, x_train = svm_read_problem('news20')\n y_test, x_test = svm_read_problem('news20.t')\n\n nr_of_classes = 20\n test_probabilities = []\n train_probabilities = []\n\n y_pred_train = np.zeros(len(y_train))\n y_pred_test = np.zeros(len(y_test))\n if method == \"ova\":\n for c in range(1, nr_of_classes + 1):\n train_labels = [0 if y != c else c for y in y_train]\n problem = svm_problem(train_labels, x_train)\n param = svm_parameter(\"-b 1\")\n param.kernel_type = kernel_type\n param.degree = degree\n param.gamma = gamma\n param.C = C\n param.coef0 = coef0\n model = svm_train(problem, param)\n labels, _, pvals = svm_predict(y_test, x_test, model, \"-q -b 1\")\n insert_probabilities(labels, pvals, test_probabilities, y_test)\n\n labels, _, pvals = svm_predict(y_train, x_train, model, \"-q -b 1\")\n insert_probabilities(labels, pvals, train_probabilities, y_train)\n\n ova_predict(nr_of_classes, test_probabilities, y_pred_test, y_test)\n ova_predict(nr_of_classes, train_probabilities, y_pred_train, y_train)\n\n elif method == \"ovo\":\n train_pred_labels = np.zeros((nr_of_classes, nr_of_classes, len(y_train)))\n test_pred_labels = np.zeros((nr_of_classes, nr_of_classes, len(y_test)))\n for i in range(1, nr_of_classes + 1):\n for j in range(i + 1, nr_of_classes + 1):\n train_labels = []\n train_data = []\n for data_idx in range(len(y_train)):\n label = y_train[data_idx]\n if label == i or label == j:\n train_labels.append(label)\n train_data.append(x_train[data_idx])\n problem = svm_problem(train_labels, train_data)\n param = svm_parameter()\n param.kernel_type = kernel_type\n param.degree = degree\n param.gamma = gamma\n param.C = C\n param.coef0 = coef0\n model = svm_train(problem, param)\n\n test_pred_labels[i - 1, j - 1], _, _ = svm_predict(y_test, x_test, model, \"-q\")\n train_pred_labels[i - 1, j - 1], _, _ = svm_predict(y_train, x_train, model, \"-q\")\n\n y_pred_test = np.zeros(len(y_test))\n\n for data_idx in range(len(y_test)):\n y_pred_point = []\n for i in range(1, nr_of_classes + 1):\n for j in range(i + 1, nr_of_classes + 1):\n vote = test_pred_labels[i - 1, j - 1, data_idx]\n y_pred_point.append(vote)\n y_pred_test[data_idx] = max(set(y_pred_point), key=y_pred_point.count)\n\n for data_idx in range(len(y_train)):\n y_pred_point = []\n for i in range(1, nr_of_classes + 1):\n for j in range(i + 1, nr_of_classes + 1):\n vote = train_pred_labels[i - 1, j - 1, data_idx]\n y_pred_point.append(vote)\n y_pred_train[data_idx] = max(set(y_pred_point), key=y_pred_point.count)\n\n classes = [str(i) for i in range(1, nr_of_classes + 1)]\n title = str.format(\"news20_method{}_kernel{}_C{}_gamma{}_coef0{}_degree{}\", method, kernel_type, C, gamma, coef0,\n degree)\n plot_confusion_matrix(y_test, y_pred_test, classes, title=title + \"_test\")\n plot_confusion_matrix(y_train, y_pred_train, classes, title=title + \"_train\")\n acc, mse, _ = evaluations(y_test, y_pred_test)\n print(\"ACC:\", acc)\n print(\"MSE:\", mse)\n\n\ndef ova_predict(nr_of_classes, test_probabilities, y_pred, y_test):\n for i in range(len(y_test)):\n max_prob = 0.0\n predicted_class = 0.0\n for c in range(1, nr_of_classes + 1):\n prob = test_probabilities[c - 1][i]\n if max_prob < prob:\n max_prob = prob\n predicted_class = c\n y_pred[i] = predicted_class\n\n\ndef insert_probabilities(labels, pvals, probabilities, y):\n local_probs = []\n for i in range(len(y)):\n if labels[i] != 0:\n prob = max(pvals[i])\n else:\n prob = min(pvals[i])\n local_probs.append(prob)\n probabilities.append(local_probs)\n\n\nif __name__ == '__main__':\n parser = ArgumentParser()\n\n parser.add_argument(\"--data_file\", type=str, default=\"skin_nonskin\")\n parser.add_argument(\"--method\", type=str, default=\"ova\")\n parser.add_argument(\"--kernel_type\", type=int, default=0, help=\"Kernel type\")\n parser.add_argument(\"--C\", type=int, default=1, help=\"C\")\n parser.add_argument(\"--degree\", type=int, default=3, help=\"Degree\")\n parser.add_argument(\"--gamma\", type=float, default=0.0, help=\"Gamma\")\n parser.add_argument(\"--coef0\", type=float, default=0.0, help=\"Coef0\")\n\n args = parser.parse_args()\n\n if args.data_file == \"skin_nonskin\":\n classify_skin_nonskin(kernel_type=args.kernel_type, degree=args.degree,\n gamma=args.gamma, C=args.C, coef0=args.coef0)\n else:\n classify_news20(method=args.method, kernel_type=args.kernel_type, degree=args.degree,\n gamma=args.gamma, C=args.C, coef0=args.coef0)\n"
},
{
"alpha_fraction": 0.745398759841919,
"alphanum_fraction": 0.745398759841919,
"avg_line_length": 16.052631378173828,
"blob_id": "1ede37bb283f71db9daa258e98742c8a7e8db0c9",
"content_id": "e5787aa5cdd0d5a1853da76a9239bcd50647adf1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 326,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 19,
"path": "/cross-platform-hashtable/hash.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "\n#ifndef HASH_H_\n#define HASH_H_\n\n#ifdef WIN\n#ifdef DLL_IMPORTS\n#define DLL_DECLSPEC __declspec(dllimport)\n#else\n#define DLL_DECLSPEC __declspec(dllexport)\n#endif\n\nDLL_DECLSPEC unsigned int hash(const char *str, unsigned int hash_length);\n\n#else\n\nunsigned int hash(const char *str, unsigned int hash_length);\n\n#endif\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6189956068992615,
"alphanum_fraction": 0.6288209557533264,
"avg_line_length": 23.092105865478516,
"blob_id": "97ea009b65703def7e0f455444536be1ebe2d748",
"content_id": "c6722821c2c124a0be22a7fee6f39ed74998adff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1832,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 76,
"path": "/shear-sort/hybrid/shear_sort_hybrid.c",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#include \"utils.h\"\n\nint main(int argc, char** argv) {\n\tif (argc != 2){\n\t\tprintf (\"Use: %s <size>\", argv[0]);\n\t\treturn 0;\n\t}\n\t\n\tMPI_Init(NULL, NULL);\n\tint world_rank;\n\tMPI_Comm_rank(MPI_COMM_WORLD, &world_rank);\n\tint world_size;\n\tMPI_Comm_size(MPI_COMM_WORLD, &world_size);\n \n\tint size = atoi(argv[1]);\n\tint num_lines_per_proc = size / world_size;\n\tint remaining_lines = size % world_size;\n\tint* matrix;\n\t\n\tmatrix = calloc(size * size, sizeof (int));\n\t\n\tint* local_matrix = calloc(num_lines_per_proc * size, sizeof(int));\n\t\n\tint num_elements = num_lines_per_proc * size;\n\tMPI_Scatter(matrix, num_elements, MPI_INT, \n\t\t\t\tlocal_matrix, num_elements, MPI_INT, \n\t\t\t\t0, MPI_COMM_WORLD);\n\t\t\t\t\n\tinit_random_matrix(local_matrix, num_lines_per_proc, size);\n\t\n\tMPI_Gather(local_matrix, num_elements, MPI_INT, \n\t\t\t\tmatrix, num_elements, MPI_INT, \n\t\t\t\t0, MPI_COMM_WORLD);\n\n\tif (world_rank == 0 && remaining_lines > 0){\t\n\t\tinit_random_matrix(matrix, remaining_lines, size);\n\t}\n\t\n\tMPI_Barrier(MPI_COMM_WORLD);\n\n\tint k;\n\tfor(k = 0; k <= ceil(log2(size)); k++){\n\t\tMPI_Scatter (matrix, num_elements, MPI_INT, \n\t\t\t\t\tlocal_matrix, num_elements, MPI_INT, \n\t\t\t\t\t0, MPI_COMM_WORLD);\n\t\t\n\t\tsort_lines(local_matrix, num_lines_per_proc, size);\n\t\t\n\t\tMPI_Gather(local_matrix, num_elements, MPI_INT, \n\t\t\t\t\tmatrix, num_elements, MPI_INT, \n\t\t\t\t\t0, MPI_COMM_WORLD);\n\t\t\t\t\t\n\t\tif (world_rank == 0 && remaining_lines > 0){\t\n\t\t\tsort_lines_start_finish(matrix, remaining_lines, size);\n\t\t}\n\t\tMPI_Barrier(MPI_COMM_WORLD);\t\t\n\t\tsort_columns(matrix, size);\n\t}\n\t\n\tMPI_Barrier(MPI_COMM_WORLD);\n\tMPI_Finalize();\n\n\tif (world_rank == 0) {\t\n\t\tint check = check_sorted(matrix, num_lines_per_proc, size);\n\t\tif (check == 1) {\n\t\t\tprintf(\"Is sorted!\\n\");\n\t\t} else {\n\t\t\tprintf(\"It is not sorted!\\n\");\n\t\t}\n\t}\n\tif (world_rank == 0) {\n\t\tprint_matrix(matrix, size, size);\n\t}\n\t\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.5086649060249329,
"alphanum_fraction": 0.5147650241851807,
"avg_line_length": 38.631866455078125,
"blob_id": "1d58c69d889fbde95499b2ff34724b5012b0f069",
"content_id": "b8dc5393246533d0d348ee81fa22930977a7a4d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7213,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 182,
"path": "/belief-propagation/factor.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "from itertools import product\nfrom copy import deepcopy\n\nfrom factor_operations import multiply, reduce, condition_factors, sum_out, divide, Factor, IdentityFactor\nfrom graph_utils import create_directed_graph\n\n\nclass FactorWrapper:\n def __init__(self, variables, parents, probabilities, T):\n self.__variables = variables\n self.__parents = parents\n self.__probabilities = probabilities\n self.__factors = None\n self.__T = T\n\n self.__init_factors()\n self.__assign_factors()\n self.__reduce_factors()\n self.__d_graph = create_directed_graph(self.__T)\n\n def __init_factors(self):\n self.__factors = []\n for v in self.__variables:\n _parents = self.__parents[v]\n if not _parents:\n factor = Factor(vars=[v],\n values={(1,): self.__probabilities[v][0], (0,): 1 - self.__probabilities[v][0]})\n else:\n values = {}\n parent_values = list(product([0, 1], repeat=len(_parents)))\n i = 0\n\n for e in parent_values:\n values[(1,) + e] = self.__probabilities[v][i]\n values[(0,) + e] = 1 - self.__probabilities[v][i]\n i += 1\n\n factor = Factor(vars=[v] + _parents, values=values)\n self.__factors.append(factor)\n\n def __assign_factors(self):\n def included():\n return all(var in list(clique_tuple) for var in factor.vars)\n\n self.__factors_assignment = {}\n assigned = {}\n for clique_tuple in self.__T.get_var_names():\n phis = []\n for factor in self.__factors:\n if not tuple(factor.vars) in assigned and included():\n phis.append(factor)\n assigned[tuple(factor.vars)] = True\n self.__factors_assignment[clique_tuple] = phis\n\n def __reduce_factors(self):\n for clique, factors in self.__factors_assignment.items():\n if len(factors) == 0:\n self.__factors_assignment[clique] = IdentityFactor\n else:\n self.__factors_assignment[clique] = reduce(factors)\n\n def query(self, req_obs, req_var):\n # Reducerea factorilor din fiecare nod care corespund obs Z = z (req_obs)\n def calculate_phi0():\n phi_0 = deepcopy(self.__factors_assignment)\n vertices = list(self.__factors_assignment.keys())\n result = condition_factors(list(self.__factors_assignment.values()), req_obs)\n for i in range(len(vertices)):\n phi_0[vertices[i]] = result[i]\n\n return phi_0\n\n # Sunt propagate mesaje de la frunze spre radacina\n # Fiecare nod isi actualizeaza factorul\n def calculate_phi1():\n phi_1 = deepcopy(phi_0)\n leaves = list(filter(lambda x: len(self.__d_graph.get_node(x).get_neighbours_names()) == 0,\n self.__d_graph.get_var_names()))\n recv = {}\n sent = {}\n\n # Initializarea listelor de mesaje trimise/primite\n for node_name in self.__d_graph.get_var_names():\n recv[node_name] = []\n sent[node_name] = []\n\n # Stiva de noduri care sunt gata sa trimita mesaje parintilor\n stack = leaves\n while stack != []:\n node_name = stack.pop()\n parent_name = self.__d_graph.get_node(node_name).parent\n if not parent_name:\n break # root\n\n parent_node = self.__d_graph.get_node(parent_name)\n others = [x for x in phi_1[node_name].vars if\n (x not in list(set(list(node_name)) & set(list(parent_name))))]\n msg = deepcopy(phi_1[node_name])\n for other in others:\n msg = sum_out(other, msg)\n sent[node_name].append(msg)\n recv[parent_name].append(msg)\n\n # Se verifica daca parintele este gata sa primeasca mesajul\n if len(recv[parent_name]) == len(parent_node.get_neighbours_names()):\n phi_1[parent_name] = reduce([phi_1[parent_name]] + recv[parent_name])\n stack.append(parent_name)\n\n return phi_1, deepcopy(sent)\n\n # Propagarea inversa a mesajelor\n # Cand un nod a primit mesaj de la parinte isi actualizeaza factorul si trimite mesaj copiilor\n def calculate_phi2():\n phi_2 = deepcopy(phi_1)\n root = list(filter(lambda x: self.__d_graph.get_node(x).parent == None,\n self.__d_graph.get_var_names()))\n received = {}\n for node_names in self.__d_graph.get_var_names():\n received[node_names] = []\n\n stack = root\n while stack != []:\n id = stack.pop()\n neighbour_names = self.__d_graph.get_node(id).get_neighbours_names()\n if not neighbour_names:\n continue\n\n for node_name in neighbour_names:\n others = [x for x in phi_2[id].vars if (x not in list(set(list(id)) & set(list(node_name))))]\n msg = deepcopy(phi_2[id])\n msg = divide(msg, sent[node_name][0])\n for other in others:\n msg = sum_out(other, msg)\n received[node_name].append(msg)\n\n # Se verifica daca copilul este gata sa primeasca mesajul\n for node_name in neighbour_names:\n if len(received[node_name]):\n phi_2[node_name] = multiply(phi_2[node_name], received[node_name][0])\n stack.append(node_name)\n\n return phi_2\n\n # Calcularea probabilitatilor marginale (prin operatia sum_out)\n def inference():\n req_vars = [x for x in req_var.keys()]\n\n chosen_phi = None\n for _, phi in phi_2.items():\n if set(req_vars).issubset(set(list(phi.vars))):\n chosen_phi = phi\n break\n\n if not chosen_phi:\n return None\n\n final_phi = deepcopy(chosen_phi)\n for var in chosen_phi.vars:\n if var not in req_vars:\n final_phi = sum_out(var, final_phi)\n return final_phi\n\n def compute_final_probability(last_phi):\n _sum = sum(last_phi.values.values())\n last_phi = Factor(vars=last_phi.vars, values={k: v / _sum for (k, v) in last_phi.values.items()})\n\n good_line = ()\n for var in last_phi.vars:\n good_line += (req_var[var],)\n for value, result in last_phi.values.items():\n if value == good_line:\n return result\n return -1\n\n phi_0 = calculate_phi0()\n phi_1, sent = calculate_phi1()\n phi_2 = calculate_phi2()\n last_phi = inference()\n if last_phi:\n result = compute_final_probability(last_phi)\n return result\n return None\n"
},
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 10.769230842590332,
"blob_id": "2d4ba8693ebd85eb1e7f524de59701a3ed578dad",
"content_id": "1acaa3bb4b7f905babc514388fc3d6cc26600c13",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 13,
"path": "/cross-platform-hashtable/list.h",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "#ifndef LIST_H\n#define LIST_H\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstruct cel {\n\tstruct cel* next;\n\tchar* info;\t\n};\n\ntypedef struct cel List;\n#endif"
},
{
"alpha_fraction": 0.5862069129943848,
"alphanum_fraction": 0.587221086025238,
"avg_line_length": 27.579710006713867,
"blob_id": "b5fe6b1ce425d7b636928a70f07ba780f608b155",
"content_id": "db408dd3606ef1f2e93806b6025f4731cce1de75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1972,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 69,
"path": "/belief-propagation/graph.py",
"repo_name": "AlinMH/acs-projects",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self, var_name):\n self.__var_name = var_name\n self.__neighbours_dict = {}\n self.__parent = None\n\n def add_neighbour(self, var_name, cost=0):\n self.__neighbours_dict[var_name] = cost\n\n def remove_neighbour(self, var_name):\n self.__neighbours_dict.pop(var_name, None)\n\n def get_neighbours_names(self):\n return self.__neighbours_dict.keys()\n\n def get_var_name(self):\n return self.__var_name\n\n def get_cost(self, var_name):\n return self.__neighbours_dict[var_name]\n\n def remove_parent_if_exists(self, parent):\n if self.__parent == parent:\n self.__parent = None\n\n @property\n def parent(self):\n return self.__parent\n\n @parent.setter\n def parent(self, parent):\n self.__parent = parent\n\n\nclass Graph:\n def __init__(self):\n self.__nodes = {}\n\n def add_node(self, var_name):\n n = Node(var_name)\n self.__nodes[var_name] = n\n\n def remove_node(self, var_name):\n for neighbour_name in self.__nodes[var_name].get_neighbours_names():\n neighbour_node = self.get_node(neighbour_name)\n\n neighbour_node.remove_neighbour(var_name)\n neighbour_node.remove_parent_if_exists(var_name)\n self.__nodes.pop(var_name)\n\n def get_node(self, var_name):\n return self.__nodes[var_name]\n\n def get_nodes(self):\n return list(self.__nodes.values())\n\n def get_var_names(self):\n return list(self.__nodes.keys())\n\n def add_edge(self, src, dst, cost=0):\n self.__nodes[src].add_neighbour(dst, cost)\n\n def get_edges(self):\n return [(parent, child) for parent in self.__nodes.keys() for child in\n self.__nodes[parent].get_neighbours_names()]\n\n def print_graph(self):\n for n in self.__nodes.values():\n print(str(n.get_var_name()) + \" neighbours:\" + str(list(n.get_neighbours_names())) + \" parent:\", n.parent)\n"
}
] | 73 |
Jaharmi/uvtt2fgu
|
https://github.com/Jaharmi/uvtt2fgu
|
ba4e83716b2475589a706ff3ab57d1cce35d4d03
|
cc9ede6f81dea755656a03f2d65ba5b3fcef7025
|
1df68c6708cf70fc524ecc24c4a3d4acb8d0896f
|
refs/heads/main
| 2023-08-13T03:23:27.731703 | 2021-08-26T02:59:28 | 2021-08-26T02:59:28 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6032131910324097,
"alphanum_fraction": 0.608027994632721,
"avg_line_length": 34.36021423339844,
"blob_id": "37741ed99f8d4367ed4cb712c24d14850b40dacf",
"content_id": "432ae7945264b7a32668ae3b4e9c4c940980db2c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19731,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 558,
"path": "/uvtt2fgu.py",
"repo_name": "Jaharmi/uvtt2fgu",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nimport base64\nimport configparser\nimport errno\nfrom io import BytesIO\nimport json\nimport logging\nfrom math import sin, cos\nfrom os import getenv, remove\nfrom pathlib import Path\nimport platform\nimport sys\nfrom typing import Optional, Tuple\nfrom PIL import Image\nimport xml.etree.ElementTree as ET\nfrom xml.dom import minidom\n\nclass ConfigFileData(object):\n def __init__(self, configFile: str) -> None:\n if not configFile:\n configFile = self.configFilePath() / 'uvtt2fgu.conf'\n\n logging.info('Reading configuration from {}'.format(configFile))\n config = configparser.ConfigParser()\n\n config.read(configFile)\n\n self.xmlpath = None\n self.jpgpath = None\n self.writejpg = True\n self.pngpath = None\n self.writepng = True\n self.forceOverwrite = None\n self.remove = None\n self.alllocaldd2vttfiles = False\n\n for section in config.sections():\n self.xmlpath = config[section].get('xmlpath')\n self.jpgpath = config[section].get('jpgpath')\n self.writejpg = config[section].getboolean('writejpg', True)\n self.pngpath = config[section].get('pngpath')\n self.writepng = config[section].getboolean('writepng', True)\n self.forceOverwrite = config[section].getboolean('force')\n self.remove = config[section].getboolean('remove')\n self.alllocaldd2vttfiles = config[section].getboolean('alllocaldd2vttfiles')\n\n def configFilePath(self) -> Path:\n myPlatform = platform.system()\n\n if myPlatform == 'Windows':\n platformPath = Path(getenv('APPDATA')) / 'uvtt2fgu'\n elif myPlatform == 'Darwin':\n platformPath = Path(getenv('HOME')) / 'Library' / 'Preferences' / 'uvtt2fgu'\n elif myPlatform == 'Linux':\n xdgConfigHome = getenv('XDG_CONFIG_HOME')\n\n if xdgConfigHome:\n platformPath = Path(xdgConfigHome)\n else:\n platformPath = Path(getenv('HOME')) / '.config'\n\n return platformPath\n\nconfigData = None\n\ndef composeId(id: int) -> ET.Element:\n '''Converts an int to an XML element 'id' with the value'''\n elem = ET.Element('id')\n elem.text = str(id)\n return elem\n\n\nclass Point(object):\n def __init__(self, x: float, y: float):\n # FGU only wants 1 decimal point\n self.x = round(x, 1)\n self.y = round(y, 1)\n\ndef translatePortalAdjustment(gridsize: int, adjustment: str) -> float:\n '''Converts from the adjustment value to the actual pixel count\n\n Either ##% of the grid size, or a ##px literal pixels\n '''\n if adjustment[-1] == '%':\n val = max(gridsize * float(adjustment[:-1]) / 100, 1) / 2\n elif adjustment[-2:] == 'px':\n val = float(adjustment[:-2]) / 2\n else:\n raise ValueError('Invalid input: {}'.format(adjustment))\n\n return val\n\n\ndef convertLineToRect(line, width, length, angle):\n '''Essentially turns a line into a fat line'''\n widthModifyX = width * sin(angle)\n widthModifyY = width * cos(angle)\n lengthModifyX = abs(length * cos(angle))\n lengthModifyY = abs(length * sin(angle))\n\n if (line[0].x > line[1].x):\n line[0].x += lengthModifyX\n line[1].x -= lengthModifyX\n else:\n line[0].x -= lengthModifyX\n line[1].x += lengthModifyX\n\n if (line[0].y > line[1].y):\n line[0].y += lengthModifyY\n line[1].y -= lengthModifyY\n else:\n line[0].y -= lengthModifyY\n line[1].y += lengthModifyY\n\n points = []\n\n points.append(Point(line[0].x - widthModifyX, line[0].y - widthModifyY))\n points.append(Point(line[1].x - widthModifyX, line[1].y - widthModifyY))\n points.append(Point(line[1].x + widthModifyX, line[1].y + widthModifyY))\n points.append(Point(line[0].x + widthModifyX, line[0].y + widthModifyY))\n\n return points\n\n\nclass UVTTFile(object):\n class Occluder(object):\n '''Represents a generic Occluder'''\n def __init__(self):\n self.points = []\n\n def xmlElemStart(self, id) -> ET.Element:\n '''Create the initial XML element for an occluder'''\n elem = ET.Element('occluder')\n elem.append(composeId(id))\n return elem\n\n def addPoint(self, coord: Point):\n '''Add a point to this occluder'''\n self.points.append(coord)\n\n class WallOccluder(Occluder):\n '''Represents a Wall Occluder'''\n def xmlElem(self, id) -> ET.Element:\n '''Build up the XML representation of a wall'''\n elem = self.xmlElemStart(id)\n\n logging.debug(' Occluder(Wall) {} {} points'.format(id, len(self.points)))\n pointsElem = ET.Element('points')\n pt = []\n for point in self.points:\n pt.append(str(point.x))\n pt.append(str(point.y))\n pointsElem.text = ','.join(pt)\n elem.append(pointsElem)\n\n return elem\n\n class PortalOccluder(Occluder):\n '''Represents a Portal occluder, could be a door or window'''\n def __init__(self, rotation, widthAdj, lengthAdj):\n super().__init__()\n self.rotation = rotation\n self.widthAdj = widthAdj\n self.lengthAdj = lengthAdj\n\n def addLine(self, point1, point2):\n '''Add a line to this portal'''\n self.points.extend(convertLineToRect(\n (point1, point2), self.widthAdj, self.lengthAdj, self.rotation))\n\n def xmlPoints(self, elem, id) -> None:\n '''Add the points data to the XML representation'''\n logging.debug(' Occluder(Portal) {} {} points'.format(id, len(self.points)))\n pointsElem = ET.Element('points')\n pt = []\n for point in self.points:\n pt.append(str(point.x))\n pt.append(str(point.y))\n pointsElem.text = ','.join(pt)\n elem.append(pointsElem)\n\n toggleAble = ET.Element('toggleable')\n elem.append(toggleAble)\n\n closeElem = ET.Element('closed')\n elem.append(closeElem)\n\n class DoorOccluder(PortalOccluder):\n '''Represents a Door occluder'''\n def xmlElem(self, id) -> ET.Element:\n '''Build up the XML representation of a door'''\n elem = self.xmlElemStart(id)\n\n self.xmlPoints(elem, id)\n\n singleSided = ET.Element('single_sided')\n elem.append(singleSided)\n\n counterclockwise = ET.Element('counterclockwise')\n elem.append(counterclockwise)\n\n return elem\n\n class WindowOccluder(PortalOccluder):\n '''Represents a Window occluder'''\n def xmlElem(self, id) -> ET.Element:\n '''Build up the XML representation of a window'''\n elem = self.xmlElemStart(id)\n\n self.xmlPoints(elem, id)\n\n allowvision = ET.Element('allow_vision')\n elem.append(allowvision)\n\n return elem\n\n def __init__(self, filepath: Path, portalWidthAdjustment: str, portalLengthAdjustment: str, *args, **kwargs):\n self.filepath = filepath\n with self.filepath.open(mode='r') as f:\n self.data = json.load(f)\n\n mapsize = self.data['resolution']['map_size']\n self.originX = self.data['resolution']['map_origin']['x']\n self.originY = self.data['resolution']['map_origin']['y']\n logging.debug(' Origin: {},{}'.format(self.originX, self.originY))\n self.resolution = (mapsize['x'], mapsize['y'])\n self.gridsize = self.data['resolution']['pixels_per_grid']\n self.image = base64.decodebytes(self.data['image'].encode('utf-8'))\n self.portalLengthAdjustmentPixels = translatePortalAdjustment(\n self.gridsize, portalLengthAdjustment)\n logging.debug(' Adding {} pixels to portal length'.format(\n self.portalLengthAdjustmentPixels))\n self.portalWidthAdjustmentPixels = translatePortalAdjustment(\n self.gridsize, portalWidthAdjustment)\n logging.debug(' Adding {} pixels to portal width'.format(\n self.portalWidthAdjustmentPixels))\n\n def translateCoord(self, coord, dimension) -> float:\n '''Translate from a grid coordinate to a pixel coordinate'''\n return round(coord * self.gridsize + (dimension * self.gridsize) // 2, 1)\n\n def translateX(self, x_coord) -> float:\n '''Translate from an X grid coordinate to an X pixel coordinate'''\n return self.translateCoord(x_coord - self.originX, -self.resolution[0])\n\n def translateY(self, y_coord) -> float:\n '''Translate from a Y grid coordinate to a Y pixel coordinate'''\n return self.translateCoord(-(y_coord - self.originY), self.resolution[1])\n\n def translatePoint(self, coord) -> Point:\n '''Translate an x, y element from the uvtt data to a Point'''\n return Point(self.translateX(coord['x']), self.translateY(coord['y']))\n\n def composeGrid(self) -> ET.Element:\n '''Build up the XML representation of the map's grid size'''\n elem = ET.Element('gridsize')\n elem.text = '{},{}'.format(self.gridsize, self.gridsize)\n return elem\n\n def composeWall(self, los) -> Occluder:\n '''Build up an Occluder representation of a wall'''\n wall = self.WallOccluder()\n\n for coord in los:\n wall.addPoint(self.translatePoint(coord))\n\n return wall\n\n def composePortal(self, portal) -> Occluder:\n '''Build up an Occluder representation of one portal\n \n Dungeondraft appears to represent windows as essentially an open door\n '''\n if portal['closed'] == False:\n portalElem = self.WindowOccluder(\n portal['rotation'], self.portalWidthAdjustmentPixels, self.portalLengthAdjustmentPixels)\n else:\n portalElem = self.DoorOccluder(\n portal['rotation'], self.portalWidthAdjustmentPixels, self.portalLengthAdjustmentPixels)\n\n it = iter(portal['bounds'])\n for point1, point2 in zip(it, it):\n portalElem.addLine(self.translatePoint(point1),\n self.translatePoint(point2))\n\n return portalElem\n\n def composeOccluders(self) -> ET.Element:\n '''Build up the XML representation of the line of sight elements'''\n occluders = []\n\n # First the line-of-sight elements, AKA walls\n logging.debug(' {} los elements'.format(\n len(self.data['line_of_sight'])))\n for los in self.data['line_of_sight']:\n occluders.append(self.composeWall(los))\n\n objectsLoS = self.data.get('objects_line_of_sight', [])\n\n logging.debug(' {} object los elements'.format(len(objectsLoS)))\n for los in objectsLoS:\n occluders.append(self.composeWall(los))\n\n # Next the portal elements, which may be doors or windows\n logging.debug(' {} portal elements'.format(len(self.data['portals'])))\n for portal in self.data['portals']:\n occluders.append(self.composePortal(portal))\n\n elem = ET.Element('occluders')\n\n for id, occluder in enumerate(occluders):\n elem.append(occluder.xmlElem(id))\n\n return elem\n\n def composeLights(self) -> ET.Element:\n '''Build up the XML representation of the lights'''\n logging.debug(' {} lights'.format(len(self.data['lights'])))\n\n elem = ET.Element('lights')\n\n for id, light in enumerate(self.data['lights']):\n lightElem = ET.Element('light')\n\n lightElem.append(composeId(id))\n\n position = ET.Element('position')\n position.text = '{},{}'.format(\n self.translateX(light['position']['x']), self.translateY(light['position']['y']))\n lightElem.append(position)\n\n color = ET.Element('color')\n color.text = '#{}'.format(light['color'])\n lightElem.append(color)\n\n range = ET.Element('range')\n range.text = '{},0.75,{},0.5'.format(\n light['range'], light['range'] * 2)\n lightElem.append(range)\n\n on = ET.Element('on')\n lightElem.append(on)\n\n elem.append(lightElem)\n\n return elem\n\n def composeXml(self) -> ET.Element:\n '''Build up the FGU XML representation of the Universal VTT file'''\n root = ET.Element(\n 'root', attrib={'version': '4.1', 'dataversion': '20210302'})\n root.append(self.composeGrid())\n root.append(self.composeOccluders())\n root.append(self.composeLights())\n return root\n\n def writePng(self, filepath: Path) -> None:\n '''Write the image out as a .png file'''\n with filepath.open(mode='wb') as f:\n f.write(self.image)\n\n def writeJpg(self, filepath: Path) -> None:\n '''Write the image out as a .jpg file'''\n imagebytes = BytesIO(self.image)\n pngimage = Image.open(imagebytes)\n jpgimage = pngimage.convert('RGB')\n jpgimage.save(filepath)\n\n def writeXml(self, filepath: Path) -> None:\n '''Write out the FGU .xml file for line-of-sight and lighting'''\n xmlTree = self.composeXml()\n xmlStr = minidom.parseString(\n ET.tostring(xmlTree)).toprettyxml(indent=\" \")\n with filepath.open('w') as f:\n f.write(xmlStr)\n\n\ndef processFile(filepaths: Tuple[Path, Path, Path, Path], portalWidthAdjustment: str, portalLengthAdjustment: str) -> None:\n '''Process an individual Universal VTT file'''\n (uvttpath, pngpath, jpgpath, xmlpath) = filepaths\n\n logging.info('Processing {}'.format(uvttpath))\n uvttfile = UVTTFile(uvttpath, portalWidthAdjustment,\n portalLengthAdjustment)\n\n logging.debug(' Map dimensions: {} grid elements'.format(\n uvttfile.resolution))\n logging.debug(' Grid Size: {} pixels'.format(uvttfile.gridsize))\n\n if configData.writepng:\n logging.info(' Writing {}'.format(pngpath))\n uvttfile.writePng(pngpath)\n\n if configData.writejpg:\n logging.info(' Writing {}'.format(jpgpath))\n uvttfile.writeJpg(jpgpath)\n\n logging.info(' Writing {}'.format(xmlpath))\n uvttfile.writeXml(xmlpath)\n\n if configData.remove:\n remove(uvttpath)\n\n\ndef composeFilePaths(filepath: Path) -> Tuple[Path, Path, Path, Path]:\n '''Take the input filepath and output the full set of input and output paths\n\n The returned tuple is the input uvtt file, the output png path, the output\n jpg path, and the output xml path.\n '''\n vttpath = filepath\n\n pngpath = Path.joinpath(Path(configData.pngpath), filepath.with_suffix('.png').name)\n jpgpath = Path.joinpath(Path(configData.jpgpath), filepath.with_suffix('.jpg').name)\n xmlpath = Path.joinpath(Path(configData.xmlpath), filepath.with_suffix('.xml').name)\n\n return (vttpath, pngpath, jpgpath, xmlpath)\n\n\nclass PortalAdjust(argparse.Action):\n '''Parse the command-line arguments to verify that it is either a percentage, or a pixel count'''\n\n def __init__(self, option_strings, dest, nargs=None, **kwargs):\n if nargs != 1:\n raise ValueError(\"nargs must be 1\")\n super().__init__(option_strings, dest, **kwargs)\n\n def __call__(self, parser, namespace, values, option_string=None):\n if values[-1] == '%':\n pass\n elif values[-2:] == 'px':\n pass\n else:\n raise argparse.ArgumentTypeError('value must be 1-100% or ##px')\n\n setattr(namespace, self.dest, values)\n\n\ndef init_argparse() -> argparse.ArgumentParser:\n '''Set up the command-line argument parser'''\n parser = argparse.ArgumentParser(\n usage='%(prog)s [OPTIONS] [FILES]',\n description='Convert Dungeondraft .dd2vtt files to .jpg/.png/.xml for Fantasy Grounds Unity (FGU)'\n )\n parser.add_argument(\n '-c', '--config', help='Configuration file'\n )\n parser.add_argument(\n '-f', '--force', help='Force overwrite destination files', action='store_true'\n )\n parser.add_argument(\n '-l', '--log', dest='logLevel', choices=['DEBUG', 'INFO', 'WARNING', 'ERROR', 'CRITICAL'], help='Set the logging level'\n )\n parser.add_argument(\n '-o', '--output', help='Path to the output directory'\n )\n parser.add_argument(\n '--portalwidth', help='Width of portals', default='25%'\n )\n parser.add_argument(\n '--portallength', help='Additional length to add to portals', default=\"0px\"\n )\n parser.add_argument(\n '-r', '--remove', help='Remove the input dd2vtt file after conversion'\n )\n parser.add_argument(\n '-v', '--version', action='version', version=f'{parser.prog} version 1.3.0'\n )\n parser.add_argument('files', nargs='*',\n help='Files to convert to .png + .xml for FGU')\n return parser\n\ndef loadConfigData(configFile: str) -> None:\n global configData\n configData = ConfigFileData(configFile)\n\ndef main() -> int:\n parser = init_argparse()\n args = parser.parse_args()\n exitcode = 0\n\n logging.basicConfig(format='%(message)s')\n\n if args.logLevel:\n logging.getLogger().setLevel(getattr(logging, args.logLevel))\n\n loadConfigData(args.config)\n\n # Merge the config file with the command-line arguments\n if args.output:\n configData.xmlpath = args.output\n configData.pngpath = args.output\n configData.jpgpath = args.output\n if not configData.xmlpath:\n configData.xmlpath = '.'\n if not configData.pngpath:\n configData.pngpath = '.'\n if not configData.jpgpath:\n configData.jpgpath = '.'\n if args.force:\n configData.forceOverwrite = args.force\n if not configData.forceOverwrite:\n configData.forceOverwrite = False\n if args.remove:\n configData.remove = args.remove\n if not configData.remove:\n configData.remove = False\n\n # Verify that the destination directories exist (if we are writing that\n # file)\n if not Path(configData.xmlpath).exists():\n logging.error('{}: No such file or directory'.format(configData.xmlpath))\n return errno.ENOENT\n if not Path(configData.pngpath).exists() and configData.writepng:\n logging.error('{}: No such file or directory'.format(configData.pngpath))\n return errno.ENOENT\n if not Path(configData.jpgpath).exists() and configData.writejpg:\n logging.error('{}: No such file or directory'.format(configData.jpgpath))\n return errno.ENOENT\n\n if not args.files:\n if not configData.alllocaldd2vttfiles:\n logging.warning('No files specified')\n return errno.EINVAL\n else:\n cwd = Path('.')\n args.files = list(cwd.glob('*.dd2vtt'))\n\n for filename in args.files:\n filepaths = composeFilePaths(Path(filename))\n\n # Verify that the source file exists, and the destination path exists\n if not filepaths[0].exists():\n logging.error(\n '{}: No such file or directory, skipping'.format(filepaths[0]))\n exitcode = errno.ENOENT\n continue\n\n if not configData.forceOverwrite:\n for filepath in filepaths[1:]:\n if filepath.exists():\n logging.error(\n '{}: file already exists, skipping'.format(filepath))\n exitcode = errno.EEXIST\n continue\n\n if exitcode:\n return exitcode\n\n processFile(filepaths, args.portalwidth, args.portallength)\n\n return exitcode\n\n\nif __name__ == '__main__':\n sys.exit(main())\n"
},
{
"alpha_fraction": 0.7151427268981934,
"alphanum_fraction": 0.7225958704948425,
"avg_line_length": 53.47524642944336,
"blob_id": "d36b55967980b4554f43d34e618f3389b2af9b1d",
"content_id": "087b54cae9dde44c7ca477e00f5917d4cff3015b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5501,
"license_type": "permissive",
"max_line_length": 290,
"num_lines": 101,
"path": "/README.md",
"repo_name": "Jaharmi/uvtt2fgu",
"src_encoding": "UTF-8",
"text": "# uvtt2fgu\nUtility to extract Fantasy Grounds Unity Line-of-sight and lighting files from a Univeral VTT file exported from Dungeondraft\n\nThis program works with Fantasy Grounds Unity v4.1 or higher as that is the version where dynamic lighting effects were added.\nThis was last used with Dungeondraft v1.0.2.1 Beta.\n\n## Requirements\n\nuvtt2fgu.py requires a python3 installation with PIP.\n\n## Usage\n1. Create your map in Dungeondraft\n2. Export the map in Universal VTT format\n - You do not have to use the default \"Best Quality\" Grid Preset. You could use the \"Roll20\" setting as this will make the image files smaller.\n Remember that your players will need to download these images via FGU. The .jpg is also smaller than the .png. The pixel count is encoded\n in the exported file and will be correctly set up in FGU when imported.\n - You should turn off Lighting as you want FGU to draw the lighting effects and not have the underlying image with the lighting\n - You should turn off the Grid as well. The grid size will be correctly set up in FGU so you should only need to turn it on within FGU.\n - These are both \"should\"s and not \"must\"s. If you want your image to have the lighting drawn on it and/or the grid, it won't break anything.\n3. Run the script as `uvtt2fgu.py sampleMap.dd2vtt`. This will emit `sampleMap.png`, `sampleMap.jpg`, and `sampleMap.xml` into your current directory\n4. Copy the `sampleMap.xml` file into your campaign's `images` directory\n5. Import the .png or .jpg in FGU\n\n## Configuration File\nThe configuration file is a standard .INI format file. All of the configuration lives in a \"[default]\" section. This file is found In various places:\n| Platform | Location |\n|----------|----------|\n| Windows | %APPDATA%\\uvtt2fgu\\uvtt2fgu.conf |\n| Mac OS | $HOME/Library/Preferences/uvtt2fgu/uvtt2fgu.conf |\n| Linux | $XDG_CONFIG_HOME/uvtt2fgu.conf<br>$HOME/.config/uvtt2fgu.conf |\n\n The file named in the `-c` command-line parameter overrides this search. For Linux, it uses the XDG_CONFIG_HOME version if that environment variable is set, otherwise use the $HOME version.\n\nExample configuration file:\n```\n[default]\nxmlpath=/home/joesmith/.smiteworks/fgdata/campaigns/TestLight/images\nwritepng=False\njpgpath=out\nforce=True\n```\nThis file will cause the program to write the xml file directly out to joesmith's FGU TestLight campaign's images folder. It will write the jpg to the \"out\" subdirectory of where the script is run. It will overwrite the xml and jpg files if they exist. It will not write out the png file.\n\n### Configuration file parameters\n\n| Parameter | Description | Default |\n|-----------|-------------|---------|\n| alllocaldd2vttfiles | If no files are specified, look for all .dd2vtt files in the current directory and convert them | False |\n| force | Force overwrite destination files | False |\n| jpgpath | Path where the .jpg file will be written | Current working directory |\n| pngpath | Path where the .png file will be written | Current working directory |\n| remove | Remove the source file after conversion | False |\n| writejpg | Write the .jpg file | True |\n| writepng | Write the .png file | True |\n| xmlpath | Path where the .xml file will be written | Current working directory |\n\n## Command-line\n```\nusage: uvtt2fgu.py [OPTIONS] [FILES]\n\nConvert Dungeondraft .dd2vtt files to .jpg/.png/.xml for Fantasy Grounds Unity\n(FGU)\n\npositional arguments:\n files Files to convert to .png + .xml for FGU\n\noptional arguments:\n -h, --help show this help message and exit\n -c CONFIG, --config CONFIG\n Configuration file\n -f, --force Force overwrite destination files\n -l {DEBUG,INFO,WARNING,ERROR,CRITICAL}, --log {DEBUG,INFO,WARNING,ERROR,CRITICAL}\n Set the logging level\n -o OUTPUT, --output OUTPUT\n Path to the output directory\n --portalwidth PORTALWIDTH\n Width of portals\n --portallength PORTALLENGTH\n Additional length to add to portals\n -r REMOVE, --remove REMOVE\n Remove the input dd2vtt file after conversion\n -v, --version show program's version number and exit\n```\n\nParameters specified on the command-line will supersede parameters specified in the configuration file.\n\nBy default, the program will not overwrite destination files. You can use `-f` to force it to overwrite.\n\nBy default, the files are all written into your current directory. You can use `-o /otherdir` to have the files written into `/otherdir`.\n\n`--portalwidth` sets how wide the FGU portals will be. This is specified either as a percentage of a grid width, or as a specific number of pixels. Either `--portalwidth 36%` or `--portalwidth 40px`. The default is 25%.\n\n`--portallength` sets how much extra length for the portals. This is specified just like `--portalwidth`. The default is 0px.\n\n## Acknowledgements\n\n[<img src=\"assets/dungeondraft_icon.png\" width=32 height=32/>](https://dungeondraft.net/) [Dungeondraft](https://dungeondraft.net/) is a map drawing tool. Dungeondraft is produced by Megasploot.\n\n[Fantasy Grounds Unity](https://www.fantasygrounds.com) is a Virtual TableTop program for playing many different table-top Role Playing Games (TTRPG), virtually. FGU is produced by SmiteWorks USA LLC.\n\nuvtt2vtt.py is not endorsed by either of these companies, it is a community-effort to make these two programs interoperable."
},
{
"alpha_fraction": 0.6364914178848267,
"alphanum_fraction": 0.6511104702949524,
"avg_line_length": 42.378047943115234,
"blob_id": "c164e87f891be908af289c7ef70449a265384f94",
"content_id": "4d10e897ceb2d6241dc07cb96293499c01a2b6cd",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3557,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 82,
"path": "/test_uvtt2fgu.py",
"repo_name": "Jaharmi/uvtt2fgu",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pathlib import Path\nimport unittest\nimport uvtt2fgu\n\n\nclass TestComposeFilePaths(unittest.TestCase):\n def setUp(self) -> None:\n uvtt2fgu.loadConfigData(None)\n uvtt2fgu.__dict__['configData'].xmlpath = '.'\n uvtt2fgu.configData.pngpath = '.'\n uvtt2fgu.configData.jpgpath = '.'\n return super().setUp()\n\n def test_fileonly(self) -> None:\n '''Test with a filename, and no output directory specified'''\n (uvttpath, pngpath, jpgpath, xmlpath) = uvtt2fgu.composeFilePaths(\n Path('filename.dd2vtt'))\n self.assertEqual(uvttpath, Path('filename.dd2vtt'))\n self.assertEqual(pngpath, Path('filename.png'))\n self.assertEqual(jpgpath, Path('filename.jpg'))\n self.assertEqual(xmlpath, Path('filename.xml'))\n\n def test_filewithpath(self) -> None:\n '''Test with a filename with a relative path, and no output directory specified'''\n (uvttpath, pngpath, jpgpath, xmlpath) = uvtt2fgu.composeFilePaths(\n Path('abc/filename.dd2vtt'))\n self.assertEqual(uvttpath, Path('abc/filename.dd2vtt'))\n self.assertEqual(pngpath, Path('filename.png'))\n self.assertEqual(jpgpath, Path('filename.jpg'))\n self.assertEqual(xmlpath, Path('filename.xml'))\n\n def test_filewithoutputpath(self) -> None:\n '''Test with a filename, and an output directory specified'''\n uvtt2fgu.configData.xmlpath = 'd1x'\n uvtt2fgu.configData.jpgpath = 'd2x'\n uvtt2fgu.configData.pngpath = 'd3x'\n (uvttpath, pngpath, jpgpath, xmlpath) = uvtt2fgu.composeFilePaths(\n Path('filename.dd2vtt'))\n self.assertEqual(uvttpath, Path('filename.dd2vtt'))\n self.assertEqual(pngpath, Path('d3x/filename.png'))\n self.assertEqual(jpgpath, Path('d2x/filename.jpg'))\n self.assertEqual(xmlpath, Path('d1x/filename.xml'))\n\n def test_filewithpathwithoutputpath(self) -> None:\n '''Test with a filename with a relative path, and an output directory specified'''\n uvtt2fgu.configData.xmlpath = 'd1x'\n uvtt2fgu.configData.jpgpath = 'd2x'\n uvtt2fgu.configData.pngpath = 'd3x'\n (uvttpath, pngpath, jpgpath, xmlpath) = uvtt2fgu.composeFilePaths(\n Path('abc/filename.dd2vtt'))\n self.assertEqual(uvttpath, Path('abc/filename.dd2vtt'))\n self.assertEqual(pngpath, Path('d3x/filename.png'))\n self.assertEqual(jpgpath, Path('d2x/filename.jpg'))\n self.assertEqual(xmlpath, Path('d1x/filename.xml'))\n\nclass TestPortalAdjust(unittest.TestCase):\n def test_percent(self) -> None:\n '''Test the custom argument parser'''\n parser = argparse.ArgumentParser()\n parser.add_argument('--foo', nargs=1, action=uvtt2fgu.PortalAdjust)\n args = parser.parse_args('--foo 25%'.split())\n self.assertEqual(args.foo, '25%')\n\n def test_pixels(self) -> None:\n '''Test the custom argument parser'''\n parser = argparse.ArgumentParser()\n parser.add_argument('--foo', nargs=1, action=uvtt2fgu.PortalAdjust)\n args = parser.parse_args('--foo 99px'.split())\n self.assertEqual(args.foo, '99px')\n\n def test_other(self) -> None:\n '''Test the custom argument parser'''\n parser = argparse.ArgumentParser()\n parser.add_argument('--foo', nargs=1, action=uvtt2fgu.PortalAdjust)\n with self.assertRaises(argparse.ArgumentTypeError):\n args = parser.parse_args('--foo 99'.split())\n\nif __name__ == '__main__':\n unittest.main()\n"
}
] | 3 |
dahlpete/distance-community-network-analysis
|
https://github.com/dahlpete/distance-community-network-analysis
|
744acb27879fa0749cfed30eda98bb598fcd9e90
|
db6d577b3566e26d48c0caa48f6c32de885fd40e
|
467367afcf25dc5bf02c0359c3e775422dfbb65d
|
refs/heads/main
| 2023-08-23T03:53:49.697125 | 2021-11-02T15:33:20 | 2021-11-02T15:33:20 | 423,899,411 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6041225790977478,
"alphanum_fraction": 0.6239280104637146,
"avg_line_length": 41.410682678222656,
"blob_id": "1a7845ced05dd5a9fa2c8def1555f1c5e32ce0bd",
"content_id": "34edf7a0d6e73baf7002ae745f921d9abf89e6b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26003,
"license_type": "no_license",
"max_line_length": 285,
"num_lines": 599,
"path": "/dCNA_through_space_w_nearest_atom.py",
"repo_name": "dahlpete/distance-community-network-analysis",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\n-------------------------------------------------------------------------------------------------------\r\n\r\nDISTANCE COMMUNITY NETWORK ANALYSIS (dCNA) -- Electron Transfer Through Space\r\n\r\nThis script runs a distance analysis on aromatic amino acids from a molecular dynamics trajectory. The\r\nscript takes as an input, a .pdb file containing only aromatic residues (PHE, TYR, TRP, HIS). The \r\ngeometric centers of the residue side chains is computed, and a matrix (Dist_matrix), with entries d_ij\r\nequal to sum(1) or np.exp(-beta*r), is determined (for distinction, see first comment). In the case of the \r\nexponential, these entries are proportional to the probability of electron transfer, as determined by a \r\ntunnelling mechanism. The current version of the code is written for Python 2.7.\r\n\r\nCode written by:\r\n\t\tPeter Dahl (1)(2)\r\n\t\tMalvankar Lab (1)(2)\r\n\t\tBatista Lab (3)\r\n\r\n\t\t(1) Yale University, Department of Molecular Biophysics and Biochemistry, New Haven, CT 06511\r\n\t\t(2) Yale University, Microbial Sciences Institute, West Haven, CT 06516\r\n\t\t(3) Yale University, Department of Chemistry, New Haven, CT 06511\r\n-------------------------------------------------------------------------------------------------------\t\t\r\n\"\"\"\r\n\r\nimport numpy as np\r\nimport csv\r\n\r\nthreshold_mode = True # This will determine how the distance matrix is built. If threshold mode is on\r\ntunneling_mode = False # the distance matrix elements will be a sum of 1's resulting from every instance\r\n # the distance between a pair of residues is less than or equal to the threshold\r\n # value (thresh). If tunnelling mode is on, the distance matrix elements will be\r\n # the mean of exponentials of the form exp(-beta*r), where beta determines the\r\n # rate at which the probability of tunnelling decays, and r is the distance\r\n # between a pair of residues.\r\n\r\nthresh_low = 0.0 # These thresholds are used in threshold mode as the criteria for building the\r\nthresh_high = 10.0 # frequency matrix\r\n\r\nex_thresh = 14 # This threshold is used to compute the exclusion list\r\nbeta = 0.63 # This parameter is used in the exponential function to build the tunneling matrix\r\n\r\nhist_thresh = 10 # This threshold is used as a cutoff when adding distances to the file\r\n # dist_list_for_hist.txt\r\n\r\n#read PDB file\r\naro_pdb = open('/gpfs/loomis/project/fas/batista/pd455/pathogen_work/wt/nm_wt_100ns.pdb')\r\n\r\n\"\"\"\r\nFUNCTIONS FOR DISTANCE CALCULATION\r\n\"\"\"\r\n\r\ndef distance(coord_i,coord_j):\r\n\t\"\"\"\r\n\tPurpose: This function computes the distance between two residues. There is a special case when either\r\n\t\t\t one or both the the residues in the calculation are a TRP residue. In this case, the fucntion\r\n\t\t\t computes the distance between all aromatic rings (TRP has two) and selects the shortest.\r\n\r\n\tInputs:\r\n\t\tcoord_i A list containing the coordinates of the center of the aromatic ring of the i-th \r\n\t\t\t\t\t\tresidue.\r\n\t\tcoord_j A list containing the coordinates of the center of the aromatic ring of the j-th \r\n\t\t\t\t\t\tresidue.\r\n\t\tiTRP\t\t\tA boolean indicating if the i-th residue is a TRP.\r\n\t\tjTRP\t\t\tA boolean indicating if the j-th residue is a TRP.\r\n\r\n\tOutputs:\r\n\t\tdist The distance between the centers of the two aromatic rings.\r\n\t\"\"\"\r\n\tcoord_i = coord_i[0]; coord_j = coord_j[0]\r\n\ti_length = len(coord_i); j_length = len(coord_j)\r\n\r\n\ttabulate_distances = np.zeros([i_length,j_length])\r\n\tfor i in range(0,i_length):\r\n\t\tfor j in range(0,j_length):\r\n\t\t\ttabulate_distances[i,j] = np.sqrt((coord_j[j][0] - coord_i[i][0])**2 + (coord_j[j][1] - coord_i[i][1])**2 + (coord_j[j][2] - coord_i[i][2])**2) \r\n\r\n\tdist = min(min(tabulate_distances))\r\n\r\n\treturn dist\r\n\r\n\r\ndef atom_positions(position,res_identity,type_of_atom,residue):\r\n\t\"\"\"\r\n\tPurpose: This function determines the coordinates of the geometric centers of each of the \r\n\t\t\t aromatic rings. TRP is a special case for which two sets of coordinates are calculated \r\n\t\t\t (one for each of the rings of the residue).\r\n\r\n\tInputs: \r\n\t\tposition A numpy array of the coordinates of each atom\r\n\t\tres_identity An array of integer values indicating the identity of each aromatic residue. \r\n\t\t\t\t\t\t (e.g. PHE 1 chain A = 1; TYR 24 chain A = 2; TYR 27 chain A = 3; ...)\r\n\t\ttype_of_atom An array of values 1 through 6 that are used to assign atoms to particular \r\n\t\t\t\t\t\t positions in the aromatic ring. These are used to compute midpoints to identify \r\n\t\t\t\t\t\t the geometric centers of the rings.\r\n\t\tresidue \t\t A list of residue names (e.g. PHE, TYR, TRP, HIS). This function uses these to \r\n\t\t\t\t\t\t determine by which means it should calculate the center.\r\n\r\n\tOutputs: \r\n\t\tresidue A rewritten list of residue names. Now there is only one instance of the residue \r\n\t\t\t\t\t\t type per actual residue in the stucture (before there was one instance per atom \r\n\t\t\t\t\t\t in the residue).\r\n\t\tcenter_pos A list of coordinates of the centers of the aromatic rings. Since TRP has two \r\n\t\t\t\t\t\t aromatics rings, two sets of coordinates are included for the positions in the \r\n\t\t\t\t\t\t list cooresponding to a TRP residue.\r\n\t\"\"\"\r\n\tresidue = residue[type_of_atom == 1,:]; \r\n\tatomic_positions = np.zeros((int(max(res_identity)),1)); atomic_positions = atomic_positions.tolist()\r\n\tfor i in range(0, int(max(res_identity))):\r\n\t\tres_indices = res_identity == i+1\r\n\t\tres_pos = position[res_indices,:]\r\n\t\tatomic_type = type_of_atom[res_indices]\r\n\t\tif residue[i,0] == 'PHE': \r\n\t\t\tatom_pos_1 = res_pos[atomic_type == 1,:]\r\n\t\t\tatom_pos_2 = res_pos[atomic_type == 2,:]\r\n\t\t\tatom_pos_3 = res_pos[atomic_type == 3,:]\r\n\t\t\tatom_pos_4 = res_pos[atomic_type == 4,:]\r\n\t\t\tatom_pos_5 = res_pos[atomic_type == 5,:]\r\n\t\t\tatom_pos_6 = res_pos[atomic_type == 6,:]\r\n\t\t\tatom_pos_7 = res_pos[atomic_type == 7,:]\r\n\t\t\t\r\n\t\t\tatomic_positions[i] = [atom_pos_1,atom_pos_2,atom_pos_3,atom_pos_4,atom_pos_5,atom_pos_6,atom_pos_7]\r\n\t\telif residue[i,0] == 'TYR':\r\n\t\t\tatom_pos_1 = res_pos[atomic_type == 1,:]\r\n\t\t\tatom_pos_2 = res_pos[atomic_type == 2,:]\r\n\t\t\tatom_pos_3 = res_pos[atomic_type == 3,:]\r\n\t\t\tatom_pos_4 = res_pos[atomic_type == 4,:]\r\n\t\t\tatom_pos_5 = res_pos[atomic_type == 5,:]\r\n\t\t\tatom_pos_6 = res_pos[atomic_type == 6,:]\r\n\t\t\tatom_pos_7 = res_pos[atomic_type == 7,:]\r\n\t\t\tatom_pos_8 = res_pos[atomic_type == 8,:]\r\n\r\n\t\t\tatomic_positions[i] = [atom_pos_1,atom_pos_2,atom_pos_3,atom_pos_4,atom_pos_5,atom_pos_6,atom_pos_7,atom_pos_8]\r\n\r\n\t\telif residue[i,0] == 'TRP':\r\n\t\t\tatom_pos_1 = res_pos[atomic_type == 1,:]\r\n\t\t\tatom_pos_2 = res_pos[atomic_type == 2,:]\r\n\t\t\tatom_pos_3 = res_pos[atomic_type == 3,:]\r\n\t\t\tatom_pos_4 = res_pos[atomic_type == 4,:]\r\n\t\t\tatom_pos_5 = res_pos[atomic_type == 5,:]\r\n\t\t\tatom_pos_6 = res_pos[atomic_type == 6,:]\r\n\t\t\tatom_pos_7 = res_pos[atomic_type == 7,:]\r\n\t\t\tatom_pos_8 = res_pos[atomic_type == 8,:]\r\n\t\t\tatom_pos_9 = res_pos[atomic_type == 9,:]\r\n\t\t\tatom_pos_10 = res_pos[atomic_type == 10,:]\r\n\t\t\t\r\n\t\t\tatomic_positions[i] = [atom_pos_1,atom_pos_2,atom_pos_3,atom_pos_4,atom_pos_5,atom_pos_6,atom_pos_7,atom_pos_8,atom_pos_9,atom_pos_10]\r\n#\t\telif residue[i,0][0] == 'HIS':\r\n#\t\t\tatom_pos_1 = res_pos[atomic_type == 1,:]\r\n#\t\t\tatom_pos_2 = res_pos[atomic_type == 2,:]\r\n#\t\t\tatom_pos_3 = res_pos[atomic_type == 3,:]\r\n#\t\t\tatom_pos_4 = res_pos[atomic_type == 4,:]\r\n#\t\t\tatom_pos_5 = res_pos[atomic_type == 5,:]\r\n#\t\t\tatom_pos_6 = res_pos[atomic_type == 6,:]\r\n#\r\n#\t\t\tatomic_positions[i] = [atom_pos_1,atom_pos_2,atom_pos_3,atom_pos_4,atom_pos_5,atom_pos_6]\r\n\r\n\treturn residue, atomic_positions\r\n\r\ndef distance_matrix(Dist_matrix,lt_thresh,position,res_identity,type_of_atom,residue,frame_num,thresh_low,thresh_high,ex_thresh,beta,tunneling_mode,threshold_mode,dist_list_for_hist,dist_sum,dist_sum_sqr):\r\n\t\"\"\"\r\n\tPurpose: This functions computes the matrix that describes the distance dependent interactions\r\n\t\t\t between each aromatic residue with every other aromatic residue for a single time point.\r\n\t\t\t However, it takes as an input the previous output of the function and adds on the matrix\r\n\t\t\t computed in the curent step. This program computes a proxy for the tunnelling probability\r\n\t\t\t given by np.exp(-beta*r) where r is the distance between the centers of the aromatics.\r\n\r\n\tInputs:\r\n\t\tDist_matrix A matrix that describes the distance dependent relationships of each \r\n\t\t\t\t\t\t\t aromatic residue with every other aromatic residue. Each entry D(i,j)\r\n\t\t\t\t\t\t\t is a sum of terms determined via the exponential relation np.exp(-beta*r),\r\n\t\t\t\t\t\t\t a relation that is proportional to the tunnelling probability. The number\r\n\t\t\t\t\t\t\t of terms summed is equal to the number of time points in the trajectory\r\n\t\t\t\t\t\t\t file. Initially input as a numpy array of a single zero.\r\n\t\tlt_thresh Initially a numpy array of a single zero, but is initialzed to a numpy \r\n\t\t\t\t\t\t\t array of zeros of dimension equal to the number of residues when \r\n\t\t\t\t\t\t\t frame_num is equal to 2. \r\n\t\tposition \t\t\t A numpy array of the coordinates of each atom\r\n\t\tres_identity An array of integer values indicating the identity of each aromatic residue. \r\n\t\t\t\t\t\t (e.g. PHE 1 chain A = 1; TYR 24 chain A = 2; TYR 27 chain A = 3; ...)\r\n\t\ttype_of_atom An array of values 1 through 6 that are used to assign atoms to particular \r\n\t\t\t\t\t\t positions in the aromatic ring. These are used to compute midpoints to identify \r\n\t\t\t\t\t\t the geometric centers of the rings.\r\n\t\tresidue A list of residue names (e.g. PHE, TYR, TRP, HIS).\r\n\t\tframe_num\t\t\t The time point being analyzed in frame numbers (1 frame per 5 ps).\r\n\t\tthresh The distance threshold used to determine the exclusion list (in angstroms)\r\n\t\tbeta The decay factor in the exponential used to determine D(i,j). Beta is a value\r\n\t\t\t\t\t\t\t characteristic of the material being studied.\r\n\r\n\tOutputs:\r\n\t\tDist_matrix A matrix that describes the distance dependent relationships of each \r\n\t\t\t\t\t\t\t aromatic residue with every other aromatic residue. Each entry D(i,j)\r\n\t\t\t\t\t\t\t is a sum of terms dependent on the specified functional form (see first \r\n\t\t\t\t\t\t\t comment). The number of terms summed is equal to the number of time \r\n\t\t\t\t\t\t\t points in the trajectory file.\r\n\t\tresidue Residue remains unchanged; thus, it remains the same as the input of the \r\n\t\t\t\t\t\t\t same name\r\n\t\tlt_thresh Each entry (i,j) of this array indicates whether the given residue pair\r\n\t\t\t\t\t\t\t has ever been within the defined distance threshold (ex_thresh)\r\n\t\"\"\"\r\n\t[residue, atomic_positions] = atom_positions(position,res_identity,type_of_atom,residue)\r\n\tif frame_num == 2:\r\n\t\tDist_matrix = np.zeros((len(atomic_positions),len(atomic_positions)))\r\n\t\tdist_sum = np.zeros((len(atomic_positions),len(atomic_positions)))\r\n\t\tdist_sum_sqr = np.zeros((len(atomic_positions),len(atomic_positions)))\r\n\t\tlt_thresh = np.zeros((len(atomic_positions),len(atomic_positions)))\r\n\t\r\n\tfor i in range(len(atomic_positions)):\r\n\t\tfor j in range(len(atomic_positions)):\r\n\t\t\tif residue[i,0] == 'TRP':\r\n\t\t\t\tiTRP = True\r\n\t\t\telse:\r\n\t\t\t\tiTRP = False\r\n\r\n\t\t\tif residue[j,0] == 'TRP':\r\n\t\t\t\tjTRP = True\r\n\t\t\telse:\r\n\t\t\t\tjTRP = False\r\n\r\n\t\t\tif (residue[i,0] == 'PHE' or residue[i,0] == 'TYR' or residue[i,0] == 'TRP'): # or residue[i,0] == 'HIS'):\r\n\t\t\t\tr = distance(atomic_positions[i],atomic_positions[j])\r\n\t\t\t\tif r <= hist_thresh and r > 0:\r\n\t\t\t\t\tdist_list_for_hist.append(r)\r\n\r\n\t\t\t\tif threshold_mode == True:\r\n\t\t\t\t\tif r >= thresh_low and r <= thresh_high:\r\n\t\t\t\t\t\tDist_matrix[i,j] += 1\r\n\r\n\t\t\t\telif tunneling_mode == True:\r\n\t\t\t\t\tDist_matrix[i,j] += np.exp(-beta*r)\r\n\r\n\t\t\t\tdist_sum[i,j] += r\r\n\t\t\t\tdist_sum_sqr[i,j] += r**2\r\n\r\n\t\t\t\tif r < ex_thresh and lt_thresh[i,j] == 0:\r\n\t\t\t\t\tlt_thresh[i,j] = 1\r\n\r\n\r\n\treturn Dist_matrix, residue, lt_thresh, dist_list_for_hist, dist_sum, dist_sum_sqr\r\n\r\n\r\n\"\"\"\r\nMAIN LOOP\r\n\"\"\"\r\nif tunneling_mode == True:\r\n\tprint('Starting Tunneling Analysis... \\n')\r\nelif threshold_mode == True:\r\n\tprint('Starting Distance Threshold Analysis... \\n')\r\n\r\natom_type = 0\r\nresidue_identity = ['RESNAME', str(0), 'CHAIN']; res_id = 0\r\nframe_num = 0; loop_count = 0\r\nDist_matrix = np.array([0]); lt_thresh = np.array([0])\r\ndist_sum = np.array([0]); dist_sum_sqr = np.array([0])\r\ndist_list_for_hist = []\r\n\r\n#loop through rows of PDB file to generate arrays of required data\r\nfor line in aro_pdb:\r\n\tlist = line.split()\r\n\tid = list[0]\r\n\t\r\n\tif id == 'ATOM' and (list[3] == 'PHE' or list[3] == 'TYR' or list[3] == 'TRP'): # or list[3] == 'HIS'):\r\n\t\tif list[1] == '1':\r\n\t\t\tres_id = 0\r\n\t\t\tloop_count = 0\r\n\t\t\tframe_num += 1\t\r\n\t\t\tif frame_num >= 2:\r\n\t\t\t\tresidue = residue[residue != ['X', 'X', 'X']]; \r\n\t\t\t\tresidue = np.reshape(residue,(len(residue)/3,3))\r\n\t\t\t\ttype_of_atom = type_of_atom[np.isnan(type_of_atom) == False]\r\n\t\t\t\tres_identity = res_identity[np.isnan(res_identity) == False]\r\n\t\t\t\tposition = position[np.isnan(position[:,0]) == False]\r\n\r\n \t if frame_num % 100 == 0:\r\n\t\t\t\t\tprint('Frame Number '+str(frame_num)) \r\n\r\n\t\t\t\t\"\"\"\r\n\t\t\t\tCall function for computation of the distance matrix\r\n\t\t\t\t\"\"\"\r\n\t\t\t\t[Dist_matrix, residue2, lt_thresh, dist_list_for_hist, dist_sum, dist_sum_sqr] = distance_matrix(Dist_matrix,lt_thresh,position,res_identity,type_of_atom,residue,frame_num,thresh_low,thresh_high,ex_thresh,beta,tunneling_mode,threshold_mode,dist_list_for_hist,dist_sum,dist_sum_sqr)\r\n\r\n\t\t\t# re-initialize the data arrays for the next frame\r\n\t\t\tresidue = np.chararray((300000,3), itemsize=3); type_of_atom = np.empty((300000,1))\r\n\t\t\tres_identity = np.empty((300000,1)); position = np.empty((300000,3));\r\n\t\t\tresidue[:,:] = 'X'; \r\n\t\t\ttype_of_atom[:] = np.nan; res_identity[:] = np.nan; position[:,:] = np.nan\r\n\r\n\t\tif [list[3], str(list[5]), list[4]] != residue_identity:\r\n\t\t\tres_id += 1\r\n\t\t\tresidue_identity = [list[3], str(list[5]), list[4]]\r\n\r\n\t\tif residue_identity[0] == 'PHE':\r\n\t\t\tif atom_type < 7:\r\n\t\t\t\tatom_type += 1\r\n\t\t\telse:\r\n\t\t\t\tatom_type = 1\r\n\r\n\t\t\ttype = list[2]\r\n\t\t\tif (type == 'CB'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 7\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\tif (type == 'CG'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 1\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CD1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 2\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CD2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 6\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CE1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 3\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CE2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 5\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CZ'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 4\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\tloop_count += 1\r\n\r\n\t\telif residue_identity[0] == 'TYR':\r\n\t\t\tif atom_type < 8:\r\n\t\t\t\tatom_type += 1\r\n\t\t\telse:\r\n\t\t\t\tatom_type = 1\r\n\r\n\t\t\ttype = list[2]\r\n\t\t\tif (type == 'CB'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 7\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\tif (type == 'CG'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 1\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CD1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 2\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CD2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 6\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CE1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 3\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CE2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 5\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CZ'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 4\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'OH'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 8\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\tloop_count += 1\r\n\r\n\t\telif residue_identity[0] == 'TRP':\r\n\t\t\tif atom_type < 10:\r\n\t\t\t\tatom_type += 1\r\n\t\t\telse:\r\n\t\t\t\tatom_type = 1\r\n\r\n\t\t\ttype = list[2]\r\n\t\t\tif (type == 'CB'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 10\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\tif (type == 'CG'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 1\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CD1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 2\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'NE1'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 3\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CE2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 4\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n\t\t\telif (type == 'CD2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 5\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CE3'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 6\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CZ3'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 7\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CZ2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 9\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\telif (type == 'CH2'):\r\n\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 8\r\n\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n\t\t\tloop_count += 1\r\n\r\n#\t\telif residue_identity[0] == 'HIS':\r\n#\t\t\tif atom_type < 6:\r\n#\t\t\t\tatom_type += 1\r\n#\t\t\telse:\r\n#\t\t\t\tatom_type = 1\r\n#\r\n#\t\t\ttype = list[2]\r\n#\t\t\tif (type == 'CB'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 6\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9] \r\n#\t\t\tif (type == 'CG'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 1\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n#\t\t\telif (type == 'ND1'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 2\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n#\t\t\telif (type == 'CE1'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 3\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n#\t\t\telif (type == 'NE2'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 4\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n#\t\t\telif (type == 'CD2'):\r\n#\t\t\t\tresidue[loop_count,:] = residue_identity; type_of_atom[loop_count] = 5\r\n#\t\t\t\tres_identity[loop_count] = res_id; position[loop_count,:] = list[6:9]\r\n#\t\t\tloop_count += 1\r\n\r\nif tunneling_mode == True:\r\n\tDist_matrix = Dist_matrix / frame_num #average value of np.exp(-r)\r\n\r\nDist_matrix_norm = (Dist_matrix - np.amin(Dist_matrix)) / (np.amax(Dist_matrix) - np.amin(Dist_matrix))\r\nDist_matrix_norm2 = (Dist_matrix - np.amin(Dist_matrix)) / (np.amax(Dist_matrix) - np.amin(Dist_matrix))\r\nDist_matrix_norm[Dist_matrix_norm < 1e-6] = 2.0\r\n\r\ndist_mean = dist_sum / frame_num\r\ndist_variance = dist_sum_sqr / frame_num - dist_mean**2\r\ndist_std = np.sqrt(dist_variance)\r\n\r\nresidue = residue2[residue2 != ['X', 'X', 'X']]; \r\nresidue = np.reshape(residue,(len(residue)/3,3))\r\ntype_of_atom = type_of_atom[np.isnan(type_of_atom) == False]\r\nres_identity = res_identity[np.isnan(res_identity) == False]\r\nposition = position[np.isnan(position[:,0]) == False]\r\n\r\n\"\"\"\r\nCALCULATE EXCLUSION MATRIX\r\n\"\"\"\r\nlength = np.shape(Dist_matrix)[0]\r\ntotal_ix_array = np.arange(1,length+1)\r\nexclusion = np.zeros((length,1)); exclusion = exclusion.tolist()\r\nex_ix = np.zeros(length); ex_ix = ex_ix.tolist()\r\nfor i in range(0,length):\r\n\texclusion[i] = []\r\n\trowlist = exclusion[i]\r\n\tfor j in range(0,length):\r\n\t\tif (lt_thresh[i,j] == 0 or i == j or Dist_matrix_norm[i,j] == 2.0): # A residue j is added to the exclusion matrix if it \r\n\t\t\trowlist.append(j) # has never been within the distance threshold, if i \r\n\tif len(rowlist) == length: # is equal to j (same residue), or if the distance \r\n\t\tex_ix[i] = False # matrix entry is equal to 2.0 (indicates value < 1e-6) \r\n\telse: \r\n\t\tex_ix[i] = True\r\n\r\nex_ix = np.array(ex_ix, dtype=bool)\r\nresidue_exclude = residue[ex_ix,:]\r\ndist_mat_ex = Dist_matrix_norm[ex_ix,:]\r\ndist_mat_ex = dist_mat_ex[:,ex_ix]\r\ndist_mat_ex2 = Dist_matrix_norm2[ex_ix,:]\r\ndist_mat_ex2 = dist_mat_ex2[:,ex_ix]\r\ndist_mean_ex = dist_mean[ex_ix,:]\r\ndist_mean_ex = dist_mean_ex[:,ex_ix]\r\ndist_std_ex = dist_std[ex_ix,:]\r\ndist_std_ex = dist_std_ex[:,ex_ix]\r\nlt_thresh_ex = lt_thresh[ex_ix,:]\r\nlt_thresh_ex = lt_thresh_ex[:,ex_ix]\r\n\r\n# Now recalculate the exclusion list\r\nlength2 = np.shape(dist_mat_ex)[0]\r\nexclusion2 = np.zeros((length2,1)); exclusion2 = exclusion2.tolist()\r\nfor i in range(0,length2):\r\n\texclusion2[i] = []\r\n\trowlist = exclusion2[i]\r\n\tfor j in range(0,length2):\r\n\t\tif (lt_thresh_ex[i,j] == 0 or i == j or dist_mat_ex[i,j] == 2.0):\r\n\t\t\trowlist.append(j)\r\n\r\n\"\"\"\r\nWRITE TEXT FILES\r\n\"\"\"\r\nprint('\\nWriting text files...\\n')\r\n\r\nfilename = 'nottunneling.txt'\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter=' ')\r\n\tcsv_writer.writerows(exclusion2)\r\n\r\nfilename = 'matrix.in'\r\ndist = np.zeros((length2+1,1)); dist = dist.tolist()\r\nfor i in range(0,length2+1):\r\n\tdist[i] = []\r\n\trow = dist[i]\r\n\tif i == 0:\r\n\t\trow.append(length2)\r\n\telse:\r\n\t\tentry = dist_mat_ex[i-1,:]\r\n\t\trow.extend(np.float32(entry))\r\n\r\n\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter=' ')\r\n\tcsv_writer.writerows(dist)\r\n\r\n\r\nfilename = 'dist_matrix_for_centrality.txt'\r\ndist = np.zeros((length2+1,1)); dist = dist.tolist()\r\nfor i in range(0,length2+1):\r\n\tdist[i] = []\r\n\trow = dist[i]\r\n\tif i == 0:\r\n\t\trow.append(length2)\r\n\telse:\r\n\t\tentry = dist_mat_ex2[i-1,:]\r\n\t\trow.extend(np.float32(entry))\r\n\r\n\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter=' ')\r\n\tcsv_writer.writerows(dist)\r\n\r\nfilename = 'dist_means.txt'\r\ndist_means = np.zeros([length2,1]); dist_means = dist_means.tolist()\r\nfor i in range(0,length2):\r\n\tdist_means[i] = []\r\n\trow_mean = dist_means[i]\r\n\tentry_mean = dist_mean_ex[i,:]\r\n\trow_mean.extend(np.float32(entry_mean))\r\n\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter=' ')\r\n\tcsv_writer.writerows(dist_means)\r\n\r\n\r\nfilename = 'dist_stds.txt'\r\ndist_stds = np.zeros([length2,1]); dist_stds = dist_stds.tolist()\r\nfor i in range(0,length2):\r\n\tdist_stds[i] = []\r\n\trow_stds = dist_stds[i]\r\n\tentry_stds = dist_std_ex[i,:]\r\n\trow_stds.extend(np.float32(entry_stds))\r\n\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter=' ')\r\n\tcsv_writer.writerows(dist_stds)\r\n\r\n#residue id list_after exclusion\r\nresidue_numbs = np.arange(0,length2).reshape(length2,1)\r\nresidue_list = np.zeros((length2,1)); residue_list = residue_list.tolist()\r\nresid_conv = np.zeros((length2,2))\r\nfor row in range(0,length2):\r\n\tresidue_list[row] = [row,residue_exclude[row,0],residue_exclude[row,1],residue_exclude[row,2]]\r\n\tfor col in range(0,2):\r\n\t\tif col == 0:\r\n\t\t\tentry2 = residue_numbs[row]\r\n\t\t\tresid_conv[row,col] = int(float(entry2))\r\n\t\telif col == 1:\r\n\t\t\tentry2 = residue_exclude[row,1]\r\n\t\t\tresid_conv[row,col] = int(float(entry2))\r\n\r\nfilename = 'residue_list_ex.txt'\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter = '\\t')\r\n\tcsv_writer.writerows(residue_list)\r\n\r\nfilename = 'residue_list_for_conv.txt'\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f,delimiter = ' ')\r\n\tcsv_writer.writerows(resid_conv)\r\n\r\nfilename = 'dist_list_for_hist.txt'\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter = '\\t')\r\n\tcsv_writer.writerow(dist_list_for_hist)\r\n\r\n\r\n\"\"\"\r\nREFORMAT FOR GNUPLOT\r\n\"\"\"\r\n\r\ndim = ((length**2) + (length-1))\r\ngnu_dist_matrix = np.empty((dim,3),dtype='str')\r\ngnu_dist_matrix[:,:] = ' '; gnu_dist_matrix = gnu_dist_matrix.tolist()\r\nindex = -1; count = 0;\r\nfor j in range(0,length):\r\n\tindex += 1\r\n\tfor i in range(0,length):\r\n\t\tix = count + index\r\n\t\tgnu_dist_matrix[ix][0] = str(i)\r\n\t\tgnu_dist_matrix[ix][1] = str(j)\r\n\t\tgnu_dist_matrix[ix][2] = str(Dist_matrix_norm[i,j])\r\n\r\n\t\tcount += 1\r\n\t\t\r\ngnu_dist_matrix = np.array(gnu_dist_matrix)\r\nfilename = 'tunneling_matrix_gnu_norm.txt'\r\nwith open(filename,'w') as f:\r\n\tcsv_writer = csv.writer(f, delimiter='\\t')\r\n\tcsv_writer.writerows(gnu_dist_matrix)\r\n\r\nprint('Done')\r\n"
},
{
"alpha_fraction": 0.6732548475265503,
"alphanum_fraction": 0.686290979385376,
"avg_line_length": 29.4743595123291,
"blob_id": "aad23395add5ecbbec94565a6ece9c7749bd61a9",
"content_id": "5f0823c37747562c6bd125c95b7aee767a818ac3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2378,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 78,
"path": "/dCNA_aromatics_mpi.py",
"repo_name": "dahlpete/distance-community-network-analysis",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport math\nimport networkx as nx\nimport MDAnalysis as mda\nimport MDAnalysis.analysis.distances as distances\nfrom mpi4py import MPI\nimport time\n\nstructure_file = 'testing/nm_wt_10chains_ph7_wb_ionized.psf'\ndcd_trajectory = 'testing/nm_wt_test.dcd'\n\ncomm = MPI.COMM_WORLD\nrank = comm.Get_rank()\nsize = comm.Get_size()\n\nu = mda.Universe(structure_file,dcd_trajectory)\n\naro_resnames = ['PHE','TYR','TRP']\n\nselection = 'resname ' + ' '.join(aro_resnames)\naro_atomgroup = u.select_atoms(selection).residues\n\nresids = aro_atomgroup.resids\nsegids = aro_atomgroup.segids\nresnames = aro_atomgroup.resnames\natomnames = aro_atomgroup.names\n\nmean_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\nstd_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\ndef pair_distance(res_pair):\n\n\tl = res_pair[0]; m = res_pair[1]\n\n\tsel1 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[l],resids[l],segids[l])\n\tres1 = u.select_atoms(sel1)\n\tpos1 = np.array([res1.atoms.positions for ts in u.trajectory])\n\n\tsel2 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[m],resids[m],segids[m])\n\tres2 = u.select_atoms(sel2)\n\tpos2 = np.array([res2.atoms.positions for ts in u.trajectory])\n\t\n\td = np.array([np.min(distances.distance_array(pos1[k,:,:],pos2[k,:,:])) for k in range(len(u.trajectory))])\n\tdlist = np.array(list(d))\n\tmean_dist = np.mean(dlist)\n\tstd_dist = np.std(dlist)\n\n\treturn (mean_dist,std_dist)\n\n\ndef main():\n\tstart = time.time()\n\n\tresidue_pairs = [(i,j) for i in range(len(aro_atomgroup)) for j in range(i+1,len(aro_atomgroup))]\n\tresidue_pairs = residue_pairs[0:100]\n\n\tm = int(math.ceil(float(len(residue_pairs)) / size))\n\tsep_pairs = residue_pairs[rank*m:(rank+1)*m]\n#\tprint([rank*m,(rank+1)*m])\n\tdist_vals_sep = map(pair_distance,sep_pairs)\n\tdist_vals = comm.allgather(dist_vals_sep)\n\tif rank == 0:\n\t\tdist_vals2 = [list(i) for i in dist_vals]\n\t\t#print(dist_vals2)\n\n\t\tdist_mean_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\t\tdist_std_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\t\tfor k in range(len(residue_pairs)):\n\t\t\ti,j = residue_pairs[k]\n\t\t#\tdist_mean_array[i,j] = dist_vals[k][0]\n\t\t#\tdist_std_array[i,j] = dist_vals[k][1]\n\t\n\t\tstop = time.time()\n\t\twallclock = stop - start\n\t\tprint('\\nWallclock: %.3f seconds' % wallclock)\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6813636422157288,
"alphanum_fraction": 0.6922727227210999,
"avg_line_length": 29.123287200927734,
"blob_id": "66007a9ffad81dbffb6c57cf63289db630545b8b",
"content_id": "f67206c1ad12813d7432d8d9ed3a973436d290c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2200,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 73,
"path": "/dCNA_aromatics_multiproc.py",
"repo_name": "dahlpete/distance-community-network-analysis",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport MDAnalysis as mda\nimport MDAnalysis.analysis.distances as distances\nfrom multiprocessing import Pool, cpu_count\nimport sys\nimport time\n\nstructure_file = 'testing/nm_wt_10chains_ph7_wb_ionized.psf'\ndcd_trajectory = 'testing/nm_wt_test.dcd'\n\nncores = int(sys.argv[1])\n\nu = mda.Universe(structure_file,dcd_trajectory)\n\naro_resnames = ['PHE','TYR','TRP']\n\nselection = 'resname ' + ' '.join(aro_resnames)\naro_atomgroup = u.select_atoms(selection).residues\n\nresids = aro_atomgroup.resids\nsegids = aro_atomgroup.segids\nresnames = aro_atomgroup.resnames\natomnames = aro_atomgroup.names\n\nmean_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\nstd_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\ndef pair_distance(res_pair):\n\n\tl = res_pair[0]; m = res_pair[1]\n\n\tsel1 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[l],resids[l],segids[l])\n\tres1 = u.select_atoms(sel1)\n\tpos1 = np.array([res1.atoms.positions for ts in u.trajectory])\n\n\tsel2 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[m],resids[m],segids[m])\n\tres2 = u.select_atoms(sel2)\n\tpos2 = np.array([res2.atoms.positions for ts in u.trajectory])\n\t\n\td = np.array([np.min(distances.distance_array(pos1[k,:,:],pos2[k,:,:])) for k in range(len(u.trajectory))])\n\tdlist = np.array(list(d))\n\tmean_dist = np.mean(dlist)\n\tstd_dist = np.std(dlist)\n\n\treturn (mean_dist,std_dist)\n\n\ndef main():\n\tstart = time.time()\n\tprint(f'starting computations on {ncores} cores')\n\n\tresidue_pairs = [(i,j) for i in range(len(aro_atomgroup)) for j in range(i+1,len(aro_atomgroup))]\n\n\twith Pool(ncores) as pool:\n\t\tdist_vals = pool.map(pair_distance,residue_pairs)\n\n\tdist_mean_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\tdist_std_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\n\tfor k in range(len(residue_pairs)):\n\t\ti,j = residue_pairs[k]\n\n\t\tdist_mean_array[i,j] = dist_vals[k][0]\n\t\tdist_mean_array[j,i] = dist_vals[k][0]\n\n\t\tdist_std_array[i,j] = dist_vals[k][1]\n\t\tdist_std_array[j,i] = dist_vals[k][1]\n\n\tstop = time.time()\n\twallclock = stop - start\n\tprint('\\nWallclock: %.3f seconds' % wallclock)\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6697324514389038,
"alphanum_fraction": 0.6856187582015991,
"avg_line_length": 30.893333435058594,
"blob_id": "c5394575e7959782ffce1d1b7615f919fea43b04",
"content_id": "001bdf0ccb7e731ab6e28d98f91ce0f97668190f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2392,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 75,
"path": "/dCNA_aromatics.py",
"repo_name": "dahlpete/distance-community-network-analysis",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport networkx as nx\nimport MDAnalysis as mda\nimport MDAnalysis.analysis.distances as distances\nimport csv\nimport time\n\nstart = time.time() \n\nstructure_file = 'testing/nm_wt_10chains_ph7_wb_ionized.psf'\ndcd_trajectory = 'testing/nm_wt_test.dcd'\n\n\nu = mda.Universe(structure_file,dcd_trajectory)\n\naro_resnames = ['PHE','TYR','TRP']\n\nselection = 'resname ' + ' '.join(aro_resnames)\naro_atomgroup = u.select_atoms(selection).residues\n\nresids = aro_atomgroup.resids\nsegids = aro_atomgroup.segids\nresnames = aro_atomgroup.resnames\natomnames = aro_atomgroup.names\n\nprint(len(aro_atomgroup))\n#print((resnames[1],resids[1],segids[1]))\n\nmean_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\nstd_dist_array = np.zeros([len(aro_atomgroup),len(aro_atomgroup)])\nfor i in range(len(aro_atomgroup)):\n\tloop_start = time.time()\n\tfor j in range(i+1,len(aro_atomgroup)):\n\n\t\tsel1 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[i],resids[i],segids[i])\n\t\tres1 = u.select_atoms(sel1)\n\t\tpos1 = np.array([res1.atoms.positions for ts in u.trajectory])\n\t\t#pos1 = res1.atoms.positions\n\t\t#print(np.shape(pos1))\n\n\t\tsel2 = 'resname %s and resid %s and segid %s and not name N C O H* CA CB' % (resnames[j],resids[j],segids[j])\n\t\tres2 = u.select_atoms(sel2)\n\t\tpos2 = np.array([res2.atoms.positions for ts in u.trajectory])\n\t\t#pos2 = res2.atoms.positions\n\t\t#print(np.shape(pos2))\n\n\t\td = np.array([np.min(distances.distance_array(pos1[k,:,:],pos2[k,:,:])) for k in range(len(u.trajectory))])\n\t\t#d = map(lambda k: np.min(distances.distance_array(pos1[k,:,:],pos2[k,:,:])),range(len(u.trajectory)))\n\t\tdlist = np.array(list(d))\n\t\tmean_dist_array[i,j] = np.mean(dlist)\n\t\tstd_dist_array[i,j] = np.std(dlist)\n\t\t#print(d[0:10])\n\n\t#\tmin_dists = np.array([np.min(distances.distance_array(pos1,pos2)) for ts in u.trajectory])\n\t#\tprint(min_dists[100])\n\n\t\t#print(np.shape(pos1))\n\n\tline_time = time.time() - loop_start\n\tprint('line %s: time = %.3d seconds' % (i,line_time))\n\n\n#filename = 'dist_means.txt'\n#with open(filename,'w') as f:\n# csv_writer = csv.writer(f, delimiter=' ')\n# csv_writer.writerows(mean_dist_array)\n#\n#filename = 'dist_means.txt'\n#with open(filename,'w') as f:\n#\tcsv_writer = csv.writer(f, delimiter=' ')\n#\tcsv_writer.writerows(std_dist_array)\n\nstop = time.time()\nwallclock = stop - start\nprint('\\nWallclock: %.3d seconds' % wallclock)\n"
},
{
"alpha_fraction": 0.8277778029441833,
"alphanum_fraction": 0.8277778029441833,
"avg_line_length": 89,
"blob_id": "9fa2127b6a0a4d48317ebfc17e32a924bf0fd02e",
"content_id": "dee756126800f7f01b06e59bf57945857944c315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dahlpete/distance-community-network-analysis",
"src_encoding": "UTF-8",
"text": "# distance-community-network-analysis\ndistance community network analysis (dCNA) - builds a network based on the average distances between aromatic amino acids in a protein system\n"
}
] | 5 |
deltionJP/rfid-raspberry-sounds
|
https://github.com/deltionJP/rfid-raspberry-sounds
|
cddfed0a24a301da3fe0e39accad5444275c084a
|
97456b7d59c2c7681044d8b9c6191ace80201fbf
|
af727dee533a137d812adb20e8924994889fac09
|
refs/heads/master
| 2020-04-12T12:11:57.549650 | 2018-12-19T20:59:09 | 2018-12-19T20:59:09 | 162,484,424 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6907503008842468,
"alphanum_fraction": 0.7010718584060669,
"avg_line_length": 21.491071701049805,
"blob_id": "08ab7d153be7c3aba8042b87db2ca4fa788e0fd7",
"content_id": "1adde6e37244cf572a14139852c78c441b9265e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2519,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 112,
"path": "/SoundPlay.py",
"repo_name": "deltionJP/rfid-raspberry-sounds",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nfrom random import randint\nimport SimpleMFRC522\nimport time\nimport subprocess\nimport os\nimport logging\nimport random\nimport glob\nimport RPi.GPIO as GPIO\n\n\ndef playsound(video, loop = 0):\n\n\tglobal myprocess\n\tglobal directory\n\n\tlogging.debug('linux: omxplayer %s' % video)\n\n\tproccount = isplaying()\n\n\tif proccount == 1 or proccount == 0:\n\n\t\tlogging.debug('No videos playing, so play video')\n\n\telse:\n\n\t\tlogging.debug('Video already playing, so quit current video, then play')\n\t\tmyprocess.communicate(b\"q\")\n\t\t\n\tif loop == 0:\n\t\tmyprocess = subprocess.Popen(['omxplayer',directory + video],stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE, close_fds=True)\n\t\n\telse:\n\t\tmyprocess = subprocess.Popen(['omxplayer','--loop',directory + video],stdin=subprocess.PIPE,stdout=subprocess.PIPE,stderr=subprocess.PIPE, close_fds=True)\n\t\n\ttime.sleep(3)\n\ndef isplaying():\n\n\t\t\"\"\"check if omxplayer is running\n\t\tif the value returned is a 1 or 0, omxplayer is NOT playing a video\n\t\tif the value returned is a 2, omxplayer is playing a video\"\"\"\n\n\t\tprocessname = 'omxplayer'\n\t\ttmp = os.popen(\"ps -Af\").read()\n\t\tproccount = tmp.count(processname)\n\n\t\treturn proccount\n\n\n#program start\n\nlogging.basicConfig(level=logging.DEBUG)\n\nreader = SimpleMFRC522.SimpleMFRC522()\n\ndirectory = '/home/pi/sounds/'\n\nprint(\"Begin Player\")\n\ntry:\n\twhile True: \n\n\t\tproccount = isplaying()\n\n\t\tif proccount == 1 or proccount == 0:\n\n\t\t\tcurrent_sound_id = long(10)\n\t\t\t\n\n\t\t\n\t\tstart_time = time.time()\n\n\t\tlogging.debug(\"Waiting for ID to be scanned\")\n\t\tid, sound_name = reader.read()\n\n\t\tlogging.debug(\"ID: %s\" % id)\n\t\tlogging.debug(\"Sound Name: %s\" % sound_name)\n\n\t\tsound_name = sound_name.rstrip()\n\n\t\tif current_sound_id != id:\n\n\t\t\tlogging.debug('New sound')\n\t\t\t#this is a check in place to prevent omxplayer from restarting video if ID is left over the reader.\n\t\t\t#better to use id than sound_name as there can be a problem reading sound_name occasionally\n\t\t\t\n\n\t\t\tif sound_name.endswith(('.mp3')):\n\t\t\t\tcurrent_sound_id = id \t#we set this here instead of above bc it may mess up on first read\n\t\t\t\tlogging.debug(\"playing: omxplayer %s\" % sound_name)\n\t\t\t\tplaysound(sound_name)\n\n\t\telse:\n\n\t\t\tend_time = time.time()\n\t\t\telapsed_time = end_time - start_time\n\t\t\tproccount = isplaying()\n\n\t\t\tif proccount != 1 and proccount != 0:\n\n\t\t\t\tif elapsed_time > 0.6:\n\t\t\t\t\t#pause, unpause sound\n\n\t\t\t\t\tlogging.debug('Pausing sound - or - Playing sound')\n\t\t\t\t\tmyprocess.stdin.write(\"p\")\n\n\nexcept KeyboardInterrupt:\n\tGPIO.cleanup()\n\tprint(\"\\nAll Done\")\n"
},
{
"alpha_fraction": 0.7322860956192017,
"alphanum_fraction": 0.7436497211456299,
"avg_line_length": 42.34782791137695,
"blob_id": "4405cbcb3183773c06d70c8ba161bc1df1311558",
"content_id": "22cc965eef52e9ced04e3f6236db5c2b81e1b9c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2992,
"license_type": "no_license",
"max_line_length": 257,
"num_lines": 69,
"path": "/README.md",
"repo_name": "deltionJP/rfid-raspberry-sounds",
"src_encoding": "UTF-8",
"text": "# Project leerjaar 3\n\n* Play sounds/videos with NFC RFID RC522 Raspberry Pi\n\nOorspronkelijk een video player, hier is het iets aangepast zodat ik mp3 bestanden kan afspelen.\nVideos werken ook.\n\n\nwat ben je nodig:\n\n* Raspberry Pi 3\n* RFID RC522 Kit\n* RFID 13.56 MHz Cards\n\n### Hieronder staan sites met informatie hoe je je RaspberryPi gebruikt met RC522 NFC reader: \n* [How to setup a Raspberry Pi RFID RC522 Chip - Pi My Life Up](https://pimylifeup.com/raspberry-pi-rfid-rc522/)\n* [RFID (RC522) - piddlerintheroot | piddlerintheroot](https://www.piddlerintheroot.com/rfid-rc522-raspberry-pi/)\n### Belangrijk!!!!\nJe moet je NFC tags (kaarten) wel beschrijven met ```write.py``` en niet met een telefoon, dan wordt de kaart niet goed beschreven en heb je kans dat de kaart niet meer werkt.\n\n### SoundPlay.py:\n* Hieronder staan een paar belangrijke punten over het bestand SoundPlay.py om het te begrijpen.\n\nDe lijn hieronder geeft aan waar de muziek/video fragmenten staan, deze kan je uiteraard aanpassen.\n```\ndirectory = '/home/pi/sounds/'\n```\nHieronder zie je ```id``` en ``` sound_name ```. ```id``` is het id van de NFC tag(kaart) en ```sound_name``` is de naam van het fragment, die je op de kaart gezet hebt met write.py\n```\nid, sound_name = reader.read()\n```\nHieronder wordt sound_name gebruikt en wordt er met ```.rstrip()``` gezorgt dat alle characters achter de ```sound_name``` worden weggehaald(bvb spaties).\n```\nsound_name = sound_name.rstrip()\n```\nHieronder zie je de ```.endswith``` dit zorgt ervoor dat je alleen mp3 bestanden kan aanroepen. je kan hier uiteraard ook mp4 enz. aan toevoegen.\n```\t\t\t\nif sound_name.endswith(('.mp3')):\ncurrent_sound_id = id \t#we set this here instead of above bc it may mess up on first read\n\t\t\t\tlogging.debug(\"playing: omxplayer %s\" % sound_name)\n\t\t\t\tplaysound(sound_name) \n```\n### De Raspberry Pi 3 heeft een video/muziek player ingebouwd die werkt via de terminal : OMXPlayer\n* [OMXPlayer: An accelerated command line media player - Raspberry Pi Documentation](https://www.raspberrypi.org/documentation/raspbian/applications/omxplayer.md)\n\n### Bestanden\n* SoundPlay.py - Dit bestand scant de NFC tag en speeld het bestand af (Video is ook mogelijk)\n* read.py - Testen van NFC tags.\n* write.py - schrijf naam van bestand op NFC tag. Voorbeeld: sound1.mp3\n\nJe kan de verschillende bestanden uitvoeren door:\n```\nsudo python SoundPlay.py\nsudo python read.py\nsudo python write.py\n```\n\nOok kunnen de fragmenten op pauze gezet worden. Als je een tag leest en dus een fragment afspeeld, kan je daarna nog een keer dezelfde tag lezen. Dan wordt het fragment gepauzeerd. Scan je het voor de derde keer dan gaat het weer verder waar je was gebleven\n\n**Code automatisch uitvoeren**\n\nMet het bestand /etc/rc.local kan je, doormiddel van toevoegen van:\n* /ect/rc.local:\n```\npython /home/pi/projectmap/SoundPlay.py\n```\nAutomatisch laten afspelen.\n\n[rc.local - Raspberry Pi Documentation](https://www.raspberrypi.org/documentation/linux/usage/rc-local.md)\n\n"
}
] | 2 |
npk7/PythonDataApplications
|
https://github.com/npk7/PythonDataApplications
|
8fa3870c12d335aa37c0f648a42b07a151cef7bd
|
074ee96ec3b58a65b732dc2a158922033d39738a
|
9a9f9770e5560a337b5136acfd7160988672c588
|
refs/heads/master
| 2022-12-13T15:54:37.752778 | 2020-09-11T04:54:22 | 2020-09-11T04:54:22 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7957317233085632,
"alphanum_fraction": 0.8033536672592163,
"avg_line_length": 39.9375,
"blob_id": "65cac9debdcf71cf58e125d330c6ca638ff2c2ec",
"content_id": "5c35297352e1b1cabdf3754485da7aa4147d822b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 16,
"path": "/README.md",
"repo_name": "npk7/PythonDataApplications",
"src_encoding": "UTF-8",
"text": "Python Portfolio\n\nThanks for visitng. \n\nCoronavirus App - This is built on light weight yet powerful and quick Flask Framework. Also this app has been deployed at Heroku\nMy heroku git is not intergrated with github but you can see the app here:\n\nhttps://serene-eyrie-68676.herokuapp.com/\n\nThis too is work in progress as well.\n\nPython Django App -- this ongoing developement on deploying the full web application using Django framework\n\nThe folder with jupyter notebook contains bunch of test files using Pandas, Numpy, Seaborn, Geopandas, Matplotlib\n\nPlease have a look at the most recent version for good reusable code towards Coronavirus data analysis\n\n"
},
{
"alpha_fraction": 0.7673267126083374,
"alphanum_fraction": 0.7673267126083374,
"avg_line_length": 24.375,
"blob_id": "0e36e5302910757fc0b3366aa92a7995fa469394",
"content_id": "d7963287e802b8285e3a846d1124c7263bd28d7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 8,
"path": "/PythonDjangoApp_DevActive/dashboard/apps/frontend/views.py",
"repo_name": "npk7/PythonDataApplications",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views import generic\n# Create your views here.\n\n\nclass IndexView(generic.TemplateView):\n module = 'indexView'\n template_name = 'frontend/index.html'"
}
] | 2 |
jklre/nagios
|
https://github.com/jklre/nagios
|
13afb7cc2a1364603f1b95690d4f86837f2da9ff
|
072b3927747f51ee40b104156c41b1b30c34d993
|
afa3eccfc6e7f4052caf42a221b1d520b22bcb8d
|
refs/heads/master
| 2021-05-17T19:53:40.586022 | 2019-07-10T21:01:16 | 2019-07-10T21:01:16 | 24,929,286 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6402048468589783,
"alphanum_fraction": 0.6453264951705933,
"avg_line_length": 23.19354820251465,
"blob_id": "a36aed5bf5b5ea9b029a8f15b91f9bc7ee7cc6d2",
"content_id": "0ee1fe4e22bd20d9584ad6d4a0d80d161e420852",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 31,
"path": "/codyDBService.py",
"repo_name": "jklre/nagios",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nimport pymssql\r\n\r\nserver = \"\"\r\nuser =\"\"\r\npassword = \"\"\r\n\r\nconn = pymssql.connect(host=server, user=user, password=password, database='databasename', as_dict=False)\r\nprint \"connecting\"\r\ncursor = conn.cursor()\r\nprint \"next\"\r\n\r\ncursor.execute(\"EXEC msdb.dbo.sysmail_help_status_sp;\")\r\n\r\nprint cursor.fetchone()\r\n\r\nresult = cursor.fetchone()\r\n\r\nif result == 0:\r\n\tprint \"0 status OK\"\r\nif result == 1:\r\n\tprint \"1 status critical\"\r\n\r\nconn.close()\r\n\r\n\r\n\r\n#IF (@MsgWaiting > @MaxMsgWaiting) \r\n# PRINT N'ERROR -- PENDING OUTBOUND MESSAGE. There are '+CAST(@MsgWaiting as nvarchar)+N' Messages waiting to be sent *** System: ' + @@Servername + ':' + DB_NAME()\r\n#ELSE\r\n# PRINT 'NO pending outbound messages *** System: ' + @@Servername + ':' + DB_NAME()\r\n"
},
{
"alpha_fraction": 0.6051844358444214,
"alphanum_fraction": 0.6201395988464355,
"avg_line_length": 19.079999923706055,
"blob_id": "31a9cf7071871a9cb76a151902c4c4e6f3f818b1",
"content_id": "c1d51d4d406b8e674b67958a3881709db7d5030c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1003,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 50,
"path": "/server.py",
"repo_name": "jklre/nagios",
"src_encoding": "UTF-8",
"text": "import socket\nimport time\nimport os\n\n#kinda does nothing at the moment\ndef formatData(data):\n while True:\n #print(data)\n #conn.sendall(data)\n replyBack(data)\n#replys\ndef replyBack(data):\n #print(data)\n if data == \"Fuck You\":\n print(\"Fuck You\")\n client.send(\"No Fuck You\")\n time.sleep(1)\n #s.sendall(\"work\")\n else:\n print(\"Recieved: \" + (data))\n#attempt at making this thing retry connection\ndef connect(host, port):\n s.bind((host, port))\n s.listen(1)\n (client,(ip,port)) = s.accept()\n data = client.recv(1024)\n formatData(data)\n\nhost = 'localhost'\nport = 8080\n\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.bind((host, port))\ns.listen(1)\n(client,(ip,port)) = s.accept()\n\nprint (\"Connection from\", client,ip,port)\ndata = client.recv(1024)\nformatData(data)\n\nif not data:\n connect(host,port)\n#conn.sendall(data)\nclient.close()\n\n\n #response = raw_input(\"Reply: \")\n\n #if response == \"exit\":\n # break"
},
{
"alpha_fraction": 0.598557710647583,
"alphanum_fraction": 0.6048076748847961,
"avg_line_length": 29.985074996948242,
"blob_id": "feea62a82048ac86b57c68cf5d36d291cb031362",
"content_id": "081f85a915b9215a46b17099ea161da781d19dc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2080,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 67,
"path": "/Files.py",
"repo_name": "jklre/nagios",
"src_encoding": "UTF-8",
"text": "import os\nimport datetime\nimport socket\nimport time\n\n#directory = os.listdir(\"/Users/jklre/nagios\")\n#print directory\n\nfrom os import walk\n\n#f = []\n#for (dirpath, dirnames, filenames) in walk(directory):\n# f.extend(filenames)\n # break\n\ndef countFiles (i, myPyfiles):\n for item in myPyFiles:\n i = i+1\n currentTime = int(time.time())\n createTime = os.path.getctime(item)\n #sortedFiles = createTime.sort(key=os.path.getctime)\n timeDays = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(createTime))\n date_time = timeDays\n pattern = '%Y-%m-%d %H:%M:%S'\n epoch = int(time.mktime(time.strptime(date_time, pattern)))\n print item\n print(timeDays)\n print \"Epoch =\", epoch\n print \"The Time is\", currentTime\n timeCompare(currentTime, createTime, item)\n done(i)\n\ndef timeCompare(currentTime, createTime, item):\n timeDif = createTime + 3600\n if currentTime >= timeDif:\n HoursOld = createTime / 3600\n printTime= time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(createTime))\n print \"1 CRIT\", \"file\", item, \"is\", HoursOld, \"Hours Old\"\n else: print(\"0 OK file\", item, \"is\", printTime, \"old\")\n print \" \"\n\ndef done (i):\n print \"filecount =\" , i\n\npath = '.'\n\nfor root, dirs, files in os.walk(path, topdown=True):\n for name in files:\n fileName = os.path.join(root, name)\n print(\"Filename: \" + fileName)\n fileStats = os.stat(fileName)\n print(\" Protection Bits: \" + str(fileStats.st_mode))\n print(\" Last Changed: \" + time.strftime(\"%Z - %Y/%m/%d, %H:%M:%S\", time.localtime(fileStats.st_ctime)))\n # for name in dirs:\n # print(os.path.join(root, name))\n\n# for root, dirs, files in os.walk(path):\n# # do whatever you want to with dirs and files\n# if root != path:\n# # one level down, modify dirs in place so we don't go any deeper\n# del dirs[:]\n\n#myFiles2 = os.listdir('/')\n#myFiles = os.walk('**', True, None, False)\n#myPyFiles = glob.glob('**/*.*')\ni =0\n#countFiles(i, myPyFiles)\n\n\n\n\n"
},
{
"alpha_fraction": 0.6093143820762634,
"alphanum_fraction": 0.6287192702293396,
"avg_line_length": 18.846153259277344,
"blob_id": "4b83cf7bd3047b95c0f9803cdc68211cc708b98c",
"content_id": "36641da62ba2aebdc15aba41420d47ee99209244",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 773,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 39,
"path": "/client.py",
"repo_name": "jklre/nagios",
"src_encoding": "UTF-8",
"text": "import socket\nimport time\nimport os\n\ndef AlwaysTrue(data):\n #print(\"I am in Always True\")\n print(data)\n #response = raw_input(\"Reply: \")\n if data == \"exit\":\n s.sendall(response1)\n time.sleep(1)\n sendReply(data)\n\ndef sendReply(data):\n if data == \"No Fuck You\":\n s.sendall(\"Fuck You\")\n print(data)\n time.sleep(1)\n AlwaysTrue(data)\n else:\n AlwaysTrue(data)\n\ndef newResponse():\n data = s.recv(1024)\n AlwaysTrue(data)\n\nhost = 'localhost'\nport = 8080\n\ns = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\ns.connect((host, port))\nprint(\"Connected to \" + (host) + \" on port \" + str(port))\ninitialMessage = \"Fuck You\"\ns.sendall(initialMessage)\n\ndata = s.recv(1024)\nAlwaysTrue(data)\n#formatData(data)\ns.close()"
}
] | 4 |
pramodith/Vehicle_Speed
|
https://github.com/pramodith/Vehicle_Speed
|
f537e6f647b34e9c8aed27387ebfac84e2d3cd27
|
3eccdd3168aa8e60f4769317d1b4bdb89c4b31a3
|
845baf33fcd555333435afee4ee8cd4d3cefd6b5
|
refs/heads/master
| 2020-05-20T10:18:16.238578 | 2019-05-09T01:20:53 | 2019-05-09T01:20:53 | 185,514,939 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5570518374443054,
"alphanum_fraction": 0.5697985291481018,
"avg_line_length": 41.859031677246094,
"blob_id": "9ca44001e385e3526904927855eb4ff892204a15",
"content_id": "4f2e489bc9d1d1ade908eec98f15da1312363267",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9728,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 227,
"path": "/Model.py",
"repo_name": "pramodith/Vehicle_Speed",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.optim as optim\nfrom DataHandler import DataHandler, TestDataHandler\nfrom torch.utils.data.dataloader import DataLoader\nimport sys\nimport os\nimport argparse\nfrom torch.nn import functional as F\nimport numpy as np\nfrom scipy.ndimage import zoom\nimport cv2\nfrom sklearn.metrics import f1_score, accuracy_score\nfrom torchsummary import summary\nclass Module(nn.Module):\n\n def __init__(self, width=256, height=256, save_dir=None):\n super(Module, self).__init__()\n\n # Directory in which model weights will be saved.\n if save_dir:\n self.save_dir = save_dir\n\n self.width = width\n self.height = height\n self.conv_layers = nn.Sequential(\n nn.Conv2d(3,24,5,2),\n nn.ReLU(),\n nn.Conv2d(24,36,5,2),\n nn.ReLU(),\n nn.Conv2d(36,48,5,2),\n nn.ReLU(),\n nn.BatchNorm2d(48),\n nn.Conv2d(48,64,3),\n nn.ReLU(),\n nn.Conv2d(64,64,3),\n nn.ReLU(),\n nn.BatchNorm2d(64)\n )\n\n self.linear_layers = nn.Sequential(nn.Linear(1152,100),\n nn.ReLU(),\n nn.Linear(100,50),\n nn.ReLU(),\n nn.Linear(50,10),\n nn.ReLU(),\n nn.Linear(10,1))\n\n\n # Initializes convolutional layers with Xavier initialization\n def init_weights(self):\n for m in self.modules():\n if isinstance(m, nn.Conv2d):\n nn.init.xavier_uniform_(m.weight)\n\n # Loads the model with the saved weights file\n def load_model(self, weights_path):\n self.load_state_dict(torch.load(weights_path))\n\n # Implement the forward pass\n def forward(self, input):\n out = self.conv_layers(input)\n out = out.view(out.shape[0],-1)\n score = self.linear_layers(out)\n return score\n\n # Trains the DNN, default parameters suggested by paper.\n def train_model(self, train_dir, gt_file_path, batch_size=16, epochs=5, lr=0.0001, momentum=0.9, weight_decay=0.00005):\n # If a GPU is available transfer model to GPU\n if torch.cuda.is_available():\n self.cuda()\n # Use Cross Entropy Loss\n loss = nn.MSELoss()\n optimizer = optim.Adam(self.parameters(), lr=lr, weight_decay=weight_decay)\n\n # Instantiate data handler and loader to efficiently create batches\n data_handler = DataHandler(train_dir,gt_file_path, mode='train')\n num_workers = 1\n\n # Use the weighted sampler for training\n loader = DataLoader(data_handler, batch_size, True, num_workers=num_workers, pin_memory=True)\n dev_data_handler = DataHandler(train_dir, gt_file_path, mode='val')\n dev_loader = DataLoader(dev_data_handler, batch_size, True, num_workers=num_workers, pin_memory=True)\n\n # Store the loss history and create variables that will store the best loss\n batch_loss_histroy = []\n best_dev_loss = sys.maxsize\n best_loss = sys.maxsize\n\n for epoch in range(epochs):\n print(\"Epoch is \" + str(epoch))\n\n # Model is in train mode so that gradients are computed\n self.train()\n total_loss = 0\n batch_total_loss = 0\n\n for i, batch in enumerate(loader):\n images = batch[0]\n labels = batch[1].float()\n\n # Move all inputs to GPU\n if torch.cuda.is_available():\n images = images.cuda()\n labels = labels.cuda()\n\n # Run the forward pass\n score = self.forward(images)\n\n # Reset the gradients every batch\n optimizer.zero_grad()\n\n # Compute loss, gradients and backprop\n output = loss(score.squeeze(1), labels)\n output.backward()\n optimizer.step()\n\n total_loss += output.item()\n batch_total_loss += output.item()\n\n if i % 50 == 0:\n batch_loss_histroy.append(output.item())\n print(\"Loss: for batch \" + str(i) + \" is \" + str(batch_total_loss))\n batch_total_loss = 0\n # Free GPU memory\n del output\n\n print(\"Training loss is \" + str(total_loss))\n # Store the model corresponding to the least loss\n if total_loss < best_loss:\n best_loss = total_loss\n torch.save(self.state_dict(), os.path.join(self.save_dir, \"weights_epoch_\" + str(epoch) + \".pt\"))\n\n # Test model against the validation set.\n # Check the loss on the validation set, set to eval mode to ensure Dropout, batch norm behaves correctly\n self.eval()\n # Create data handler and data loader for validation set.\n total_dev_loss = 0\n # Ensure that gradients aren't computed since we don't need to back prop every other step is the same\n # as mentioned above\n with torch.no_grad():\n index = 0\n for i, batch in enumerate(dev_loader):\n images = batch[0]\n labels = batch[1].float()\n if torch.cuda.is_available():\n images = images.cuda()\n labels = labels.cuda()\n\n score = self.forward(images).squeeze(1)\n output = loss(score, labels)\n\n total_dev_loss += output.item()\n del output\n index = i\n print(\"Validation loss is \" + str(total_dev_loss/index))\n\n # Store the model corresponding to the best f1 score\n if total_dev_loss < best_dev_loss:\n best_dev_loss = total_dev_loss\n torch.save(self.state_dict(), os.path.join(self.save_dir, \"dev_weights_epoch_\" + str(epoch) + \".pt\"))\n\n # Predict the output label for the test set\n def predict(self, test_dir, batch_size):\n data_handler = TestDataHandler(test_dir)\n num_workers = 1\n loader = DataLoader(data_handler, batch_size, False, num_workers=num_workers, pin_memory=True)\n if torch.cuda.is_available():\n self.cuda()\n self.eval()\n predicted_labels = []\n ground_truth = []\n with torch.no_grad():\n try:\n for batch in loader:\n images = batch[0]\n names = batch[1]\n if torch.cuda.is_available():\n images = images.cuda()\n speed = self.forward(images).squeeze(1)\n predicted_labels.extend(list(speed.cpu().detach().numpy()))\n except Exception as e:\n print(e)\n pass\n with open(\"test.txt\",\"w+\") as f:\n for pred in predicted_labels:\n f.write(str(pred)+\"\\n\")\n\n\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument('--lr', action=\"store\", default=0.0001, type=float,\n help='The learning rate of the network')\n parser.add_argument('--batch_size', action='store', type=int, default=32,\n help=\"The batch size for training.\")\n parser.add_argument('--epochs', action='store', type=int, default=50, help=\"The number of epochs during train time\")\n parser.add_argument('--momentum', action='store', type=float, default=0.9, help=\"The momentum for an optimizer\")\n parser.add_argument('--width', action='store', type=int, default=66, help='Width of the images.')\n parser.add_argument('--height', action='store', type=int, default=220, help='Height of the images.')\n parser.add_argument('--save_dir', action='store', type=str, default='saved_weights',\n help='Directory in which weights will be saved')\n parser.add_argument('--gt_file_path', action='store', type=str, default='data/train.txt',\n help='Directory in which weights will be saved')\n parser.add_argument('--weights_path', action='store', type=str, default='saved_weights/dev_weights_epoch_4.pt',\n help='Path of the weights to be loaded during predict time.')\n parser.add_argument('--train_dir', action='store', type=str, default=\"data/frames_train\",\n help='Directory containing the training images')\n parser.add_argument('--test_dir', action='store', type=str, default=\"data/frames_test\",\n help='Directroy containing the test images')\n parser.add_argument('--ground_truth_masks_dir', action='store', type=str, default='../test256/masks_pngs',\n help='Directory containing the ground truth masks.')\n parser.add_argument('--output_dir', action='store', type=str, default=\"../results\",\n help='Directory that the output activation maps would be saved to')\n parser.add_argument('--mode', action='store', choices=['train', 'predict'], default='predict',\n help='In train mode the network will be trained, in predict mode the network will use'\n 'the default weights to predict the pixel wise classes', required=False)\n\n args = parser.parse_args()\n\n obj = Module(width=args.width, height=args.height, save_dir=args.save_dir)\n if args.mode == 'train':\n obj.train_model(train_dir=args.train_dir, gt_file_path=args.gt_file_path, batch_size=args.batch_size, lr=args.lr, epochs=args.epochs)\n elif args.mode == 'predict':\n obj.load_model(args.weights_path)\n obj.predict(args.test_dir,args.batch_size)"
},
{
"alpha_fraction": 0.5952619910240173,
"alphanum_fraction": 0.6181489825248718,
"avg_line_length": 40.516666412353516,
"blob_id": "51c53fa3e4157f322ad8e880457a859040daec3c",
"content_id": "23cba27036ccd6a71b4861d9bc7b43ad13cbf4d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4981,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 120,
"path": "/DataHandler.py",
"repo_name": "pramodith/Vehicle_Speed",
"src_encoding": "UTF-8",
"text": "from torch.utils.data.dataset import Dataset\nfrom torch.utils.data.dataloader import DataLoader\nimport os\nfrom PIL import Image\nfrom torchvision import transforms\nimport numpy as np\nimport random\nimport torch\nfrom torch.utils.data.sampler import WeightedRandomSampler\nfrom utils import dense_optical_flow\n\nclass TestDataHandler(Dataset):\n\n def __init__(self, root_dir):\n # Root directory that contains the dataset\n self.root_dir = root_dir\n self.dataset_mean = [0.0014861894323434117]\n self.dataset_std = [0.0020256241244931863]\n self.root_dir = root_dir\n self.file_names = sorted(os.listdir(self.root_dir), key=lambda x: int(x[:-4]))\n self.file_names = [os.path.join(self.root_dir, name) for name in self.file_names]\n self.transform = self.create_transformation()\n\n @staticmethod\n def create_transformation():\n transform = transforms.Compose([\n transforms.Resize((66, 200)),\n transforms.ToTensor()\n ])\n return transform\n\n def __len__(self):\n return len(self.file_names)\n\n def __getitem__(self, ind):\n if ind < len(self.file_names)-1:\n img1 = np.asarray(Image.open(self.file_names[ind]).convert('RGB'))\n img2 = np.asarray(Image.open(self.file_names[ind+1]).convert('RGB'))\n img = dense_optical_flow(img1, img2)\n img = Image.fromarray(img, 'RGB')\n names = self.file_names[ind]\n # Apply transformation to image\n if self.transform is not None:\n img = self.transform(img)\n # Label of image\n return img, names\n\n\nclass DataHandler(Dataset):\n '''\n This is the data handler for the train and validation test set.\n '''\n def __init__(self, root_dir, gt_file_path, mode='train'):\n\n # Root directory that contains the dataset\n self.root_dir = root_dir\n self.file_names = sorted(os.listdir(self.root_dir),key=lambda x: int(x[:-4]))\n self.file_names = [os.path.join(self.root_dir,name) for name in self.file_names]\n self.dev_file_indices = list(np.asarray(random.sample(range(0,len(self.file_names)),int(0.2*len(self.file_names)))))\n self.train_file_indices = [i for i in range(len(self.file_names))]\n self.train_file_indices = list(set(self.train_file_indices).difference(set(self.dev_file_indices)))\n self.dev_file_names = [os.path.join(self.root_dir,str(self.dev_file_indices[i])+\".jpg\") for i in range(len(self.dev_file_indices))]\n self.train_file_names = [os.path.join(self.root_dir, str(self.train_file_indices[i]) + \".jpg\") for i in range(len(self.train_file_indices))]\n self.gt_file = np.loadtxt(gt_file_path)\n self.mode = mode\n # Train set mean and standard deviation caluculated before hand.\n self.dataset_mean = [0.0014861894323434117]\n self.dataset_std = [0.0020256241244931863]\n\n # Get the complete paths of all files in the dataset\n if mode == \"train\":\n self.names = self.train_file_names\n self.indices = self.train_file_indices\n # Assign label 0 to negative images and label 1 to positive images\n\n # creating a dev set with 20% of train data containing liver and no liver images\n elif mode == 'val':\n self.names = self.dev_file_names\n self.indices = self.dev_file_indices\n # The type of image transformations that we will try\n self.transform = self.create_transformation()\n\n # Use transformations for image augmentation.\n @staticmethod\n def create_transformation():\n transform = transforms.Compose([\n transforms.Resize((66,200)),\n transforms.ToTensor()\n ])\n return transform\n\n def __len__(self):\n return len(self.names)\n\n def __getitem__(self, ind):\n # Open the image corresponding to the index\n if ind < len(self.file_names):\n try:\n img1 = np.asarray(Image.open(self.file_names[self.indices[ind]]).convert('RGB'))\n img2 = np.asarray(Image.open(self.file_names[self.indices[ind]+1]).convert('RGB'))\n img = dense_optical_flow(img1,img2)\n img = Image.fromarray(img,'RGB')\n names = self.file_names[self.indices[ind]]\n # Apply transformation to image\n if self.transform is not None:\n img = self.transform(img)\n # Label of image\n label = self.gt_file[self.indices[ind]]\n except Exception as e:\n pass\n return img, label, names\n\nif __name__ == \"__main__\":\n data_handler = DataHandler(\"data/frames_train\",\"data/train.txt\",\"train\")\n batch_size = 128\n num_workers = 1\n all_labels = []\n loader = DataLoader(data_handler, batch_size,shuffle=True,num_workers=num_workers, pin_memory=True)\n for i, batch in enumerate(loader):\n print(i)"
},
{
"alpha_fraction": 0.5143129825592041,
"alphanum_fraction": 0.5391221642494202,
"avg_line_length": 35.78947448730469,
"blob_id": "a3a786e74645243e1cfe2cfa2b1fbeedf9bfa9a1",
"content_id": "6c00d39049f38b6c120dc824e8b338a7e0925540",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2096,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 57,
"path": "/utils.py",
"repo_name": "pramodith/Vehicle_Speed",
"src_encoding": "UTF-8",
"text": "import cv2 as cv2\nimport os\nimport numpy as np\nimport argparse\n\ndef extact_frames(video_path=\"data/train.mp4\" ,save_path=\"data/frames_train\", ext = '.jpg'):\n success = True\n img = None\n cnt = 0\n vidcap = cv2.VideoCapture(video_path)\n while success:\n print(cnt)\n success, img = vidcap.read()\n cv2.imwrite(os.path.join(save_path,str(cnt)+ext),img)\n cnt += 1\n\n# This code is from https://docs.opencv.org/3.4/d7/d8b/tutorial_py_lucas_kanade.html\ndef dense_optical_flow(prev_frame,next_frame):\n hsv = np.zeros_like(prev_frame)\n prev_frame = cv2.cvtColor(prev_frame,cv2.COLOR_RGB2GRAY)\n next_frame = cv2.cvtColor(next_frame,cv2.COLOR_RGB2GRAY)\n hsv[..., 1] = 255\n flow_mat = None\n image_scale = 0.5\n nb_images = 1\n win_size = 15\n nb_iterations = 2\n deg_expansion = 5\n STD = 1.3\n extra = 0\n\n # obtain dense optical flow paramters\n flow = cv2.calcOpticalFlowFarneback(prev_frame, next_frame,\n flow_mat,\n image_scale,\n nb_images,\n win_size,\n nb_iterations,\n deg_expansion,\n STD,\n 0)\n mag, ang = cv2.cartToPolar(flow[..., 0], flow[..., 1])\n hsv[..., 0] = ang * 180 / np.pi / 2\n hsv[..., 2] = cv2.normalize(mag, None, 0, 255, cv2.NORM_MINMAX)\n rgb = cv2.cvtColor(hsv, cv2.COLOR_HSV2RGB)\n return rgb\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n parser.add_argument('--save_path', action='store', type=str, default=\"data/frames_test\",\n help='Directory containing the training images')\n parser.add_argument('--video_path', action='store', type=str, default=\"data/test.mp4\",\n help='Directroy containing the test images')\n\n args = parser.parse_args()\n extact_frames(video_path=args.video_path,save_path=args.save_path)"
}
] | 3 |
HidekiTakazawa/TakazawaEmiko
|
https://github.com/HidekiTakazawa/TakazawaEmiko
|
236cef9c4f4705f1ed02080e7df849137382a9a2
|
0bc8061ed0e36569c39cdadf616d5ef8551f6a83
|
c61c5a9548314b381b0ec6811530f9fb91853f62
|
refs/heads/master
| 2022-12-25T14:25:36.805965 | 2019-12-14T02:41:55 | 2019-12-14T02:41:55 | 225,550,643 | 0 | 0 | null | 2019-12-03T06:48:31 | 2019-12-14T02:42:36 | 2022-04-22T22:51:02 |
Python
|
[
{
"alpha_fraction": 0.5407801270484924,
"alphanum_fraction": 0.576241135597229,
"avg_line_length": 23.521739959716797,
"blob_id": "7cd9865832de4bcd041448de6ebb3f3024665ea4",
"content_id": "77e82ded813b4b6832e4bdbb1e6914dceb8c177e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 23,
"path": "/emikoKanri/migrations/0002_auto_20191203_1530.py",
"repo_name": "HidekiTakazawa/TakazawaEmiko",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.5 on 2019-12-03 06:30\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('emikoKanri', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='nurserecord',\n name='urine_time',\n field=models.CharField(max_length=5, null=True),\n ),\n migrations.AddField(\n model_name='nurserecord',\n name='urine_volume',\n field=models.PositiveIntegerField(null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.695652186870575,
"alphanum_fraction": 0.7084980010986328,
"avg_line_length": 33.82758712768555,
"blob_id": "3f509e211059659c8d27fad0d137ef7642bbfa6a",
"content_id": "ca7ff770f7a102e5956cd215e38cab43d8df349d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1012,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 29,
"path": "/emikoKanri/models.py",
"repo_name": "HidekiTakazawa/TakazawaEmiko",
"src_encoding": "UTF-8",
"text": "# Create your models here.\nfrom django.conf import settings\nfrom django.db import models\nfrom django.utils import timezone\n\n\nclass Post(models.Model):\n author = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE)\n title = models.CharField(max_length=200)\n text = models.TextField()\n created_date = models.DateTimeField(default=timezone.now)\n published_date = models.DateTimeField(blank=True, null=True)\n\n def publish(self):\n self.published_date = timezone.now()\n self.save()\n\n def __str__(self):\n return self.title\nclass NurseRecord(models.Model):\n nurse_day = models.DateTimeField(default=timezone.now)\n urine_time = models.CharField(max_length=5, null=True)\n urine_volume = models.PositiveIntegerField(null=True)\n meal_asa = models.CharField(max_length=100)\n meal_hiru = models.CharField(max_length=100)\n meal_yoru = models.CharField(max_length=100)\n memo = models.TextField\n def __str__(self):\n return self.meal_asa\n\n "
},
{
"alpha_fraction": 0.8156424760818481,
"alphanum_fraction": 0.8156424760818481,
"avg_line_length": 24.571428298950195,
"blob_id": "c2f1c508231113938eaf6a49d762d000106b80f7",
"content_id": "fb51f453c8cec5496f3d5f9352c109f032313fc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/emikoKanri/admin.py",
"repo_name": "HidekiTakazawa/TakazawaEmiko",
"src_encoding": "UTF-8",
"text": "# Register your models here.\nfrom django.contrib import admin\nfrom .models import Post\nfrom .models import NurseRecord\n\nadmin.site.register(Post)\nadmin.site.register(NurseRecord)\n"
},
{
"alpha_fraction": 0.4583333432674408,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 15,
"blob_id": "42b0add7a5cffc86d894b15f23d0d8ed87c2bc9d",
"content_id": "9f18aca2d7b09190fcb0a094dcc4b8ff073519f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "HidekiTakazawa/TakazawaEmiko",
"src_encoding": "UTF-8",
"text": "certifi==2019.9.11\nDjango==2.2.5\npsycopg2==2.8.3\npytz==2019.3\nsqlparse==0.3.0\nwincertstore==0.2\n"
}
] | 4 |
prachik26/Boredom_Buster
|
https://github.com/prachik26/Boredom_Buster
|
9b9ca1c2aa2092ed3ef1718a274faaebb13e95f6
|
a657c594c8c07a8d315ba529c3d799ea7e11d4cf
|
c83c9249de9af87f4712a1a3a2d11a3d46857834
|
refs/heads/main
| 2023-06-24T17:39:28.276747 | 2021-07-20T16:15:28 | 2021-07-20T16:15:28 | 387,848,234 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5516669154167175,
"alphanum_fraction": 0.5937547087669373,
"avg_line_length": 32.25839614868164,
"blob_id": "e870c8679c8baa874d85eb84396e034c7690ebd1",
"content_id": "23790b0bc05dc7a3878da71c0287f3a07c3436ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13258,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 387,
"path": "/Main_file.py",
"repo_name": "prachik26/Boredom_Buster",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom tkinter import ttk\r\nfrom tkinter import filedialog\r\nimport os\r\nimport tkinter.messagebox\r\nimport speech_recognition as sr\r\nimport pyttsx3\r\nimport pygame\r\nimport webbrowser\r\nimport random\r\nfrom vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer\r\nrootp=Tk()\r\nrootp.title(\"Welcome Page\")\r\nrootp.geometry(\"600x470\")\r\nrootp.resizable(False,False)\r\nLabel(rootp,text='Welcome',relief='ridge',font='times 25 bold italic',fg='blue').pack()\r\nrootp.config(bg='Light sea green')\r\n\r\n#all functions are listed here\r\ndef music():\r\n rootp.withdraw()\r\n nw1=Tk()\r\n nw1.title(\"Discover Music\")\r\n nw1.geometry(\"697x250+300+220\")\r\n nw1.resizable(False,False)\r\n\r\n pygame.init()\r\n #Initiating Pygame Mixer\r\n pygame.mixer.init()\r\n #Declaring track Variable\r\n track=StringVar()\r\n #Declaring Status Variable\r\n status = StringVar()\r\n\r\n #For playing,pausing and stopping of the song\r\n def play():\r\n try:\r\n # Displaying Selected Song title\r\n track.set(playlist.get(ACTIVE))\r\n # Loading Selected Song\r\n pygame.mixer.music.load(playlist.get(ACTIVE))\r\n except:\r\n tkinter.messagebox.showerror(\"Error\",\"Cannot play any song, not selected\")\r\n pass\r\n \r\n track.set(playlist.get(ACTIVE))\r\n pygame.mixer.music.load(playlist.get(ACTIVE))\r\n # Displaying Status\r\n status.set(\"-Playing\")\r\n \r\n \r\n # Playing Selected Song\r\n pygame.mixer.music.set_volume(0.1)\r\n #print(pygame.mixer.music.get_volume())\r\n pygame.mixer.music.play(-1)\r\n pausebtn['text'] = \"PAUSE\"\r\n\r\n def pause():\r\n # pause\r\n unpause = True\r\n if(unpause):\r\n # Displaying Status\r\n status.set(\"-Paused\")\r\n pausebtn['text'] = \"PAUSED\"\r\n # Paused Song\r\n pygame.mixer.music.pause()\r\n unpause = False\r\n\r\n def stop():\r\n status.set(\"-Stopped\")\r\n \r\n # Stopped Song\r\n pygame.mixer.music.stop()\r\n\r\n def openl():\r\n path = filedialog.askdirectory()\r\n #Changing Directory for fetching Songs \r\n\r\n try:\r\n os.chdir(path)\r\n except:\r\n tkinter.messagebox.showerror(\"Error\",\"You didn't select any folder\")\r\n\r\n #Fetching Songs\r\n songtracks = os.listdir()\r\n # Inserting Songs into Playlist\r\n playlist.delete(0,END)\r\n for track in songtracks:\r\n if track.endswith('.mp3'):\r\n playlist.insert(END, track)\r\n\r\n def homebtn():\r\n nw1.withdraw()\r\n rootp.deiconify()\r\n \r\n # For frame\r\n track_frame = LabelFrame(nw1,text=\"Song Track\",font=(\"times new roman\",15,\"bold\"),bg=\"blue\",fg=\"white\",bd=5,relief=GROOVE) \r\n track_frame.place(x=0,y=0,width=400,height=100)\r\n \r\n songtrack = Label(track_frame, textvariable=track,width=23, font=(\"times new roman\",15,\"bold\"),bg=\"blue\", fg=\"gold\")\r\n songtrack.place(x=0,y=10)\r\n\r\n # Inserting Status Label\r\n trackstatus = Label(track_frame, textvariable=status,width=10, font=(\"times new roman\", 15, \"bold\"), bg=\"blue\",fg=\"gold\")\r\n trackstatus.place(x=280,y=10)\r\n\r\n # Creating Button Frame\r\n buttonframe = LabelFrame(nw1, text=\"Control Panel\", font=(\"times new roman\", 15, \"bold\"), bg=\"blue\",fg=\"white\", bd=5, relief=GROOVE)\r\n buttonframe.place(x=0, y=100, width=400, height=150)\r\n\r\n # Inserting Play Button\r\n playbtn = Button(buttonframe, text=\"PLAY\", command=play, width=8, height=1,font=(\"times new roman\", 12, \"bold\"), fg=\"navyblue\", bg=\"gold\")\r\n playbtn.place(x=20,y=15)\r\n\r\n # Inserting Pause Button\r\n pausebtn = Button(buttonframe, text=\"PAUSE\", command=pause, width=8, height=1,font=(\"times new roman\", 12, \"bold\"), fg=\"navyblue\", bg=\"gold\")\r\n pausebtn.place(x=150,y=15)\r\n\r\n # Inserting Stop Button\r\n stopbtn = Button(buttonframe, text=\"STOP\", command=stop, width=8, height=1,font=(\"times new roman\", 12, \"bold\"), fg=\"navyblue\", bg=\"gold\")\r\n stopbtn.place(x=280,y=15)\r\n\r\n #Inserting Open Button\r\n openbtn=Button(buttonframe, text=\"Open\",command=openl, width=8, height=1,font=(\"times new roman\", 14, \"bold\"), fg=\"black\", bg=\"white\")\r\n openbtn.place(x=80,y=70)\r\n\r\n exitbtn=Button(buttonframe,text=\"Home\",command=homebtn ,width=8,height=1,font=(\"times new roman\", 14, \"bold\"), fg=\"black\", bg=\"white\")\r\n exitbtn.place(x=200,y=70)\r\n\r\n #Creating Playlist Frame\r\n songsframe = LabelFrame(nw1, text=\"Song Playlist\", font=(\"times new roman\", 15, \"bold\"), bg=\"blue\",fg=\"white\", bd=5, relief=GROOVE)\r\n songsframe.place(x=400, y=0, width=300, height=250)\r\n\r\n #Inserting scrollbar\r\n scrol_y=Scrollbar(songsframe, orient=VERTICAL)\r\n\r\n #Inserting Playlist listbox\r\n playlist=Listbox(songsframe,yscrollcommand=scrol_y.set, selectbackground=\"gold\", selectmode=SINGLE, font=(\"times new roman\", 12, \"bold\"),bg=\"silver\",fg=\"navyblue\",bd=5,relief=GROOVE)\r\n\r\n #Applying Scrollbar to listbox\r\n scrol_y.pack(side=RIGHT,fill=Y)\r\n scrol_y.config(command=playlist.yview)\r\n playlist.pack(fill=BOTH)\r\n\r\n nw1.mainloop()\r\n\r\n\r\ndef browser():\r\n rootp.withdraw()\r\n nw2=Toplevel()\r\n nw2.title(\"Welcome to the Browser\")\r\n nw2.geometry(\"400x350\")\r\n nw2.resizable(False,False)\r\n Label(nw2,text='WELCOME TO NP ASSISSTANT',relief='ridge',font='times 18 bold italic',fg='black',bg=\"CadetBlue1\").pack()\r\n photo = PhotoImage(file='microphone.png').subsample(10,10)\r\n btn=StringVar()\r\n def buttonClick():\r\n pygame.init()\r\n pygame.mixer.music.load('chime1.mp3')\r\n pygame.mixer.music.play()\r\n\r\n r = sr.Recognizer()\r\n r.pause_threshold = 0.7\r\n r.energy_threshold = 400\r\n engine = pyttsx3.init()\r\n voices = engine.getProperty('voices')\r\n engine.setProperty('voice', voices[0].id)\r\n def talk(text):\r\n engine.say(text)\r\n engine.runAndWait()\r\n \r\n\r\n with sr.Microphone() as source:\r\n try:\r\n audio = r.listen(source, timeout=10)\r\n message = str(r.recognize_google(audio))\r\n pygame.mixer.music.load('chime2.mp3')\r\n pygame.mixer.music.play()\r\n \r\n if btn.get() == 'google':\r\n webbrowser.open('http://google.com/search?q='+message)\r\n \r\n elif btn.get() == 'you':\r\n webbrowser.open('https://www.youtube.com/results?search_query='+message)\r\n\r\n else:\r\n pass\r\n except sr.UnknownValueError:\r\n talk('Google Speech Recognition could not understand audio')\r\n\r\n except sr.RequestError as e:\r\n talk('Could not request results from Google Speech Recognition Service')\r\n\r\n else:\r\n pass\r\n nw2.withdraw()\r\n rootp.deiconify()\r\n \r\n def homeb():\r\n nw2.withdraw()\r\n rootp.deiconify()\r\n \r\n\r\n r1=Radiobutton(nw2, text='Google', value='google',variable=btn,bg=\"CadetBlue1\")\r\n r1.place(x=90,y=240)\r\n r2=Radiobutton(nw2, text='Youtube', value='you',variable=btn,bg=\"CadetBlue1\")\r\n r2.place(x=230,y=240)\r\n \r\n b6=Button(nw2,image=photo,command=buttonClick,bd=0,activebackground='#c1bfbf', overrelief='groove', relief='sunken',bg=\"CadetBlue1\")\r\n b6.place(x=170,y=100)\r\n Label(nw2,text=\"Click me!!!\", font=\"arial 9 bold\",fg=\"black\",bg=\"CadetBlue1\").place(x=170,y=190)\r\n b11=Button(nw2,text=\"Home\", font=\"arial 9\",command=homeb)\r\n b11.place(x=180,y=285)\r\n nw2.config(bg=\"CadetBlue1\")\r\n btn.set('google')\r\n nw2.mainloop()\r\n\r\n\r\n\r\ndef analyser():\r\n rootp.withdraw()\r\n nw3=Tk()\r\n nw3.title(\"Sentiment Detector\")\r\n nw3.geometry(\"300x325\")\r\n nw3.configure(bg='#00003c')\r\n nw3.resizable(False,False)\r\n\r\n def detect():\r\n sentence=e1.get()\r\n t1.delete(0.0,END)\r\n sid_obj=SentimentIntensityAnalyzer()\r\n sentiment_dict=sid_obj.polarity_scores(sentence)\r\n negative_string=str(sentiment_dict['neg']*100) + \"% Negative\"\r\n t1.insert(END,negative_string+'\\n')\r\n neutral_string=str(sentiment_dict['neu']*100) + \"% Neutral\"\r\n t1.insert(END,neutral_string+'\\n')\r\n positive_string=str(sentiment_dict['pos']*100) + \"% Positive\"\r\n t1.insert(END,positive_string+'\\n')\r\n\r\n if sentiment_dict['compound']>=0.05:\r\n string=\"Positive\"\r\n elif sentiment_dict['compound']<=-0.05:\r\n string=\"Negative\"\r\n else:\r\n string=\"Neutral\"\r\n t1.insert(END,f\"Overall Result : {string}\")\r\n def home22():\r\n nw3.withdraw()\r\n rootp.deiconify()\r\n \r\n e1=Entry(nw3,width=20,font=('arial',14))\r\n e1.place(x=5,y=20)\r\n b10=Button(nw3,text=\"Analyse\",bg='#201d2e',width=6,fg='white',font=('Arial',10),command=detect)\r\n b10.place(x=232,y=20)\r\n\r\n frame2=Frame(nw3,bd=2,relief=RIDGE,bg='#201d2e')\r\n frame2.place(x=10,y=70,height=250,width=280)\r\n\r\n l1=Label(frame2,text=\"Result\",bg='#201d2e',fg='white',font=('arial',12,'bold'))\r\n l1.place(x=10,y=5)\r\n\r\n t1=Text(frame2,bd=2,relief=SUNKEN,font=('Calibri',12,'bold'))\r\n t1.place(x=10,y=30,width=255,height=150)\r\n\r\n b22=Button(frame2, text='HOME',font= ('artal', 10, 'bold'),fg='#ffffff',bg='#201d2e',command=home22)\r\n b22.place(x=110,y=210)\r\n\r\n nw3.mainloop()\r\n\r\n\r\n\r\ndef game():\r\n rootp.withdraw()\r\n nw4=Tk()\r\n nw4.title(\"Game\")\r\n nw4.geometry(\"550x300\")\r\n nw4.resizable(False,False)\r\n nw4.config(bg=\"DeepSkyBlue2\")\r\n computer_value={\"0\":\"Rock\",\"1\":\"Paper\",\"2\":\"Scissor\"}\r\n def reset_game():\r\n b7[\"state\"]=\"active\"\r\n b8[\"state\"]=\"active\"\r\n b9[\"state\"]=\"active\"\r\n l1.config(text=\"Player \")\r\n l3.config(text=\"Computer\")\r\n l4.config(text=\"\")\r\n\r\n def button_disable():\r\n b7[\"state\"]=\"disable\"\r\n b8[\"state\"]=\"disable\"\r\n b9[\"state\"]=\"disable\"\r\n\r\n def isrock():\r\n c_v=computer_value[str(random.randint(0,2))]\r\n if c_v==\"Rock\":\r\n match_result=\"Match Draw\"\r\n elif c_v==\"Scissor\":\r\n match_result=\"Player Win\"\r\n else:\r\n match_result=\"Computer Win\"\r\n l4.config(text=match_result)\r\n l1.config(text=\"Rock \")\r\n l3.config(text=c_v)\r\n button_disable()\r\n\r\n def ispaper():\r\n c_v=computer_value[str(random.randint(0,2))]\r\n if c_v==\"Paper\":\r\n match_result=\"Match Draw\"\r\n elif c_v==\"Scissor\":\r\n match_result=\"Computer Win\"\r\n else:\r\n match_result=\"Player Win\"\r\n l4.config(text=match_result)\r\n l1.config(text=\"Paper \")\r\n l3.config(text=c_v)\r\n button_disable()\r\n\r\n def isscissor():\r\n c_v=computer_value[str(random.randint(0,2))]\r\n if c_v==\"Rock\":\r\n match_result=\"Computer Win\"\r\n elif c_v==\"Scissor\":\r\n match_result=\"Match Draw\"\r\n else:\r\n match_result=\"Player Win\"\r\n l4.config(text=match_result)\r\n l1.config(text=\"Scissor \")\r\n l3.config(text=c_v)\r\n button_disable()\r\n\r\n def homebt():\r\n nw4.withdraw()\r\n rootp.deiconify()\r\n\r\n Label(nw4,text=\"Rock Paper Scissor\",font=\"normal 20 bold\",fg=\"blue\",bg=\"DeepSkyBlue2\").pack(pady=20)\r\n frame=Frame(nw4)\r\n frame.pack()\r\n\r\n l1=Label(frame,text=\"Player \",font=10,bg=\"DeepSkyBlue2\")\r\n l2=Label(frame,text=\"VS \",font=\"normal 10 bold\",bg=\"DeepSkyBlue2\")\r\n l3=Label(frame,text=\"Computer \",font=10,bg=\"DeepSkyBlue2\")\r\n l1.pack(side=LEFT)\r\n l2.pack(side=LEFT)\r\n l3.pack()\r\n\r\n l4=Label(nw4,text=\"\",font=\"normal 20 bold\",width=15,borderwidth=2,relief=\"solid\",bg=\"DeepSkyBlue2\")\r\n l4.pack(pady=20)\r\n frame1=Frame(nw4)\r\n frame1.pack()\r\n\r\n b7=Button(nw4,text=\"Rock\",font=10,width=7,command=isrock,bg=\"DeepSkyBlue2\")\r\n b8=Button(nw4,text=\"Paper\",font=10,width=7,command=ispaper,bg=\"DeepSkyBlue2\")\r\n b9=Button(nw4,text=\"Scissor\",font=10,width=7,command=isscissor,bg=\"DeepSkyBlue2\")\r\n b7.place(x=120,y=190)\r\n b8.place(x=225,y=190)\r\n b9.place(x=330,y=190)\r\n\r\n Button(nw4,text=\"Reset Game\",font=10,fg=\"white\",command=reset_game,bg=\"DeepSkyBlue2\").place(x=145,y=240)\r\n Button(nw4,text=\"Home\",font=8,fg=\"white\",bg=\"DeepSkyBlue2\",command=homebt).place(x=315,y=240)\r\n \r\n nw4.mainloop()\r\n\r\n\r\n\r\ndef exit():\r\n rootp.withdraw()\r\n\r\n\r\n\r\nb1=Button(rootp,text=\"Listen to music\",fg=\"blue\",font='times 13 bold',command=music,overrelief='groove', relief='sunken')\r\nb1.place(x=50,y=85)\r\nb1.config(height=4,width=22)\r\nb2=Button(rootp,text=\"Search on Web Browser\",fg=\"blue\",font='times 13 bold',command=browser)\r\nb2.place(x=320,y=85)\r\nb2.config(height=4,width=22)\r\nb3=Button(rootp,text=\"Get your Text Analysed\",fg=\"blue\",font='times 13 bold',command=analyser)\r\nb3.place(x=50,y=210)\r\nb3.config(height=4,width=22)\r\nb4=Button(rootp,text=\"Bored? Play a Game!\",fg=\"blue\",font='times 13 bold',command=game)\r\nb4.place(x=320,y=210)\r\nb4.config(height=4,width=22)\r\nb5=Button(rootp,text=\"Exit\",fg=\"red\",font='times 10 bold',command=exit)\r\nb5.place(x=250,y=335)\r\nb5.config(height=2,width=10)\r\n\r\nrootp.mainloop()\r\n"
}
] | 1 |
fengqiaogit/MakeUNC
|
https://github.com/fengqiaogit/MakeUNC
|
9d33c94fa0eb4c24c16d3af83bd961f556f4bd3e
|
5278b0d74a8976d27eefa4d0d1a04a8795ae8105
|
beef7ce648b312ec2f48bee6930c923544b65d35
|
refs/heads/master
| 2023-03-19T04:41:45.801607 | 2017-01-12T14:43:05 | 2017-01-12T14:43:05 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.590847909450531,
"alphanum_fraction": 0.5948855876922607,
"avg_line_length": 36.150001525878906,
"blob_id": "14e9fdc2d36ba8e310d74ca3cee9611730725798",
"content_id": "1f422e0f1bb6f47919fc418360a49af6d2aaee89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2972,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 80,
"path": "/CallMC.py",
"repo_name": "fengqiaogit/MakeUNC",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom RunL2genMC import CMCRunner, CBatchManager\n# from MakeUnc import MakeSwfUnc, MakeHMA\nimport argparse\nimport logging\nimport sys\n\n\ndef SetLogger(logger_name, dbg_lvl=False):\n '''\n\n '''\n logfn = '%s.log' % logger_name\n logger = logging.getLogger(logger_name)\n if dbg_lvl:\n logger.setLevel(logging.DEBUG)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -'\n + ' [%(module)s..%(funcName)s..%(lineno)d]'\n + ' - %(message)s')\n else:\n logger.setLevel(logging.INFO)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n fh = logging.FileHandler(logfn)\n fh.setLevel(logging.DEBUG)\n fh.setFormatter(formatter)\n ch = logging.StreamHandler()\n ch.setLevel(logging.ERROR)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n logger.addHandler(fh)\n logger.debug('logging')\n return logger\n\n\ndef ParseCommandLine(args):\n '''\n Returns argparse object with parsed arguments as attributes\n '''\n parser = argparse.ArgumentParser()\n parser.add_argument('-i', '--ifile', help='l1a input file',\n type=str, required='True')\n parser.add_argument('-o', '--opath', help='l2 output main path',\n type=str, required='True')\n parser.add_argument('-s', '--prsil', help='silent param. file',\n type=str, required='True')\n parser.add_argument('-n', '--prnoi', help='noisy param. file',\n type=str, required='True')\n parser.add_argument('-m', '--mcrns', help='number of MC iterations',\n type=int, default=1000)\n parser.add_argument('-w', '--workers', help='process # to allocate',\n type=int, default=1)\n parser.add_argument('-d', '--debug', help='increase output verbosity',\n action='store_true', default=False)\n parser.add_argument('--logName', help='logger name',\n type=str, default='CallMCLog')\n parser.add_argument('-b', '--batch', help='batch processing',\n action='store_true')\n parsedArgs = parser.parse_args(args)\n # TODO parsedArgs = ConsolidateParfile(parsedArgs)\n return parsedArgs\n\n\ndef Main(args):\n pArgs = ParseCommandLine(args)\n mainLogger = SetLogger(logger_name=pArgs.logName, dbg_lvl=pArgs.debug)\n mainLogger.info('Get this?')\n if pArgs.batch:\n mainLogger.info('Initializing batch processor')\n bcr = CBatchManager(pArgs)\n bcr.ProcessL1A()\n else:\n mainLogger.info('Init MCRUnner Object w/ pArgs')\n mcr = CMCRunner(pArgs, mainLogger.name)\n mainLogger.info('Creating task list')\n taskList = mcr.GetCmdList()\n mainLogger.info('Feeding tasklist l2gen runner')\n mcr.Runner(taskList)\n\nif __name__ == '__main__':\n Main(sys.argv[1:])\n"
},
{
"alpha_fraction": 0.47019222378730774,
"alphanum_fraction": 0.49085336923599243,
"avg_line_length": 45.11991500854492,
"blob_id": "548393b51b528753718ffa49d86c0e51819e19c2",
"content_id": "cbdfd2865791cdb17de81ff2e26351b96d171fd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21538,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 467,
"path": "/MakeUnc.py",
"repo_name": "fengqiaogit/MakeUNC",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Nov 2 15:09:44 2015\nscript to run analytic uncertainty analysis of rrs data\n@author: ekarakoy\n\"\"\"\nimport numpy as np\nimport netCDF4 as nc\nimport glob\nimport sys\nimport os\nimport re\nimport argparse\nimport logging\nimport multiprocessing as mp\nimport pickle\nimport shutil\nfrom datetime import datetime as DT\n\n\nclass MakeUnc(object):\n \"\"\"\n Class to get Rrs uncertainties for a given L2 granule. Includes methods to:\n * get baseline from L2 granule\n * calculate uncertainties (as rmse) from corresponding perturbed L2\n files\n * save uncertainty variables in original unperturbed granule\n Inputs:\n *args:\n 1- baselineFile\n 2- noisyDir -- directory where noisy files are located\n\n\n \"\"\"\n def __init__(self, pArgs, parent_logger_name):\n self.logger = logging.getLogger('%s.MakeUnc' % parent_logger_name)\n self.silFile = pArgs.ifile\n self.noisyDir = pArgs.npath\n # Process options\n self.doChla = pArgs.dochl\n self.doNflh = pArgs.doflh\n self.pSafe = pArgs.psafe\n self.doSaniCheck = pArgs.sanity\n self.rrsSilDict = dict.fromkeys(self.bands)\n self.attrRrsUncDict = dict.fromkeys(self.bands)\n self.dimsDict = dict.fromkeys(self.bands)\n self.dTypeDict = dict.fromkeys(self.bands)\n self.rrsUncArrDict = dict.fromkeys(self.bands)\n if self.pSafe:\n self._PlaySafe()\n if self.doSaniCheck:\n self.ltUncArrDict = dict.fromkeys(self.bands)\n self.ltSilDict = dict.fromkeys(self.bands)\n self.attrLtUncDict = dict.fromkeys(self.bands)\n otherProdkeys = []\n if self.doChla:\n self.logger.info('chl_a_unc will be included')\n otherProdkeys.append('chlor_a')\n otherProdkeys.append('chlor_a_unc')\n if self.doNflh:\n self.logger.info('nflh_unc will be included')\n otherProdkeys.append('nflh')\n otherProdkeys.append('nflh_unc')\n if len(otherProdkeys) > 0:\n self.otherProdsDict = dict.fromkeys(otherProdkeys)\n attrUncKeys = [x for x in otherProdkeys if re.search('_unc', x)]\n self.attrOtherProdUncDict = dict.fromkeys(attrUncKeys)\n self.dTypeDict.update(dict.fromkeys(attrUncKeys))\n self.dimsDict.update(dict.fromkeys(attrUncKeys))\n\n def _PlaySafe(self):\n '''\n Method to copy backup of unprocessed silent L2\n This so as not to redo entire processing if a problem arises.\n If a copy already exists, it is assumed this is not the first\n processing attempt and the silent L2 is now tainted. It is removed and\n a clean copy is generated from the backup.\n '''\n orig = self.silFile\n cpy = self.silFile + '.cpy'\n if os.path.exists(cpy): # not the first time - something's wrong\n os.remove(orig) # remove \"original - tainted file\"\n self.logger.info('%s already exists. Removing original %s' % (cpy,\n orig)\n )\n shutil.copy2(cpy, orig)\n self.logger.info('Copying silent from %s' % cpy)\n else:\n shutil.copy2(orig, cpy)\n self.logger.info('No copy for %s. Generating copy' % self.silFile)\n\n def WriteToSilent(self):\n # first create NC variables if necessary\n # save unc in corresponding NC variables.\n with nc.Dataset(self.silFile, 'r+') as dsSil:\n geoGr = dsSil.groups['geophysical_data']\n geoVar = geoGr.variables\n for band in self.bands:\n rrsUncProdName = 'Rrs_unc_' + band\n if rrsUncProdName not in geoVar:\n varRrsUnc = geoGr.createVariable(rrsUncProdName,\n self.dTypeDict[band],\n self.dimsDict[band])\n varRrsUnc.setncatts(self.attrRrsUncDict[band])\n else:\n varRrsUnc = geoVar[rrsUncProdName]\n varRrsUnc[:] = self.rrsUncArrDict[band]\n if self.doSaniCheck:\n ltUncProdName = 'Lt_unc_' + band\n if ltUncProdName not in geoVar:\n varLtUnc = geoGr.createVariable(ltUncProdName,\n self.dTypeDict[band],\n self.dimsDict[band])\n varLtUnc.setncatts(self.attrLtUncDict[band])\n else:\n varLtUnc = geoVar[ltUncProdName]\n varLtUnc[:] = self.ltUncArrDict[band]\n if self.doChla:\n if 'chlor_a_unc' not in geoVar:\n varChloraUnc = geoGr.createVariable('chlor_a_unc',\n self.dTypeDict['chlor_a_unc'],\n self.dimsDict['chlor_a_unc'])\n varChloraUnc.setncatts(self.attrOtherProdUncDict['chlor_a_unc'])\n else:\n varChloraUnc = geoVar['chlor_a_unc']\n varChloraUnc[:] = self.otherProdsDict['chlor_a_unc']\n\n if self.doNflh:\n if 'nflh_unc' not in geoVar:\n self.logger.info('nflh_unc there; creating variable...')\n varNflhUnc = geoGr.createVariable('nflh_unc',\n self.otherProdsDict['nflh_unc'].dtype,\n self.dimsDict['nflh_unc'])\n varNflhUnc.setncatts(self.attrOtherProdUncDict['nflh_unc'])\n else:\n self.logger.info('nflh_unc available, using existing variable...')\n varNflhUnc = geoVar['nflh_unc']\n varNflhUnc[:] = self.otherProdsDict['nflh_unc']\n # self.logger.info(\"%s Processing Complete\" % baseLineFname)\n return None\n\n def BuildUncs(self, noisySfx):\n \"\"\"\"\n Calculates rrs uncertainty as st.dev of rrs. Note that to save time\n I use unperturbed rrs as the rrs baseline for the simulation\n \"\"\"\n fBaseName = self.silFile.split('/')[-1].split('.')[0].split('_')[0]\n matchFilPatt = os.path.join(self.noisyDir, '%s*%s*' % (fBaseName, noisySfx))\n self.logger.info(\"searching for %s...\" % matchFilPatt)\n firstPass = [True] * len(self.bands)\n flis = glob.glob(matchFilPatt)\n lflis = len(flis)\n if lflis == 0:\n self.logger.error('No files to process with pattern %s' % matchFilPatt)\n sys.exit(1)\n else:\n self.logger.info(\"%d files to be processed\" % lflis)\n rrsAggDataDict = dict.fromkeys(self.bands)\n if self.doSaniCheck:\n ltAggDataDict = dict.fromkeys(self.bands)\n if self.doChla:\n chlAggDataArr = np.array([])\n if self.doNflh:\n nflhAggDataArr = np.array([])\n # process noisy data\n for fcount, fname in enumerate(flis):\n prcDone = 100 * fcount / (lflis - 1)\n self.logger.info(\"Loading and reading %s -- %.1f%%\" %\n (fname, prcDone))\n with nc.Dataset(fname) as nds:\n nGeoGr = nds.groups['geophysical_data']\n nGeoVar = nGeoGr.variables\n for i, band in enumerate(self.bands):\n noisyRrs = nGeoVar['Rrs_'+band][:]\n if self.doSaniCheck:\n noisyLt = nGeoVar['Lt_'+band][:]\n if self.doChla:\n noisyChl = nGeoVar['chlor_a'][:]\n if self.doNflh:\n noisyNflh = nGeoVar['nflh'][:]\n if firstPass[i]:\n rrsAggDataDict[band] = (noisyRrs -\n self.rrsSilDict[band]) ** 2\n if self.doSaniCheck:\n ltAggDataDict[band] = (noisyLt -\n self.ltSilDict[band]) ** 2\n if self.doChla:\n chlAggDataArr = (noisyChl -\n self.otherProdsDict['chlor_a']\n ) ** 2\n if self.doNflh:\n nflhAggDataArr = (noisyNflh -\n self.otherProdsDict['nflh']\n ) ** 2\n firstPass[i] = False\n self.logger.debug('First pass complete for band %s' % band)\n else:\n rrsAggDataDict[band] += (noisyRrs -\n self.rrsSilDict[band]) ** 2\n if self.doSaniCheck:\n ltAggDataDict[band] += (noisyLt -\n self.ltSilDict[band]) ** 2\n if self.doChla:\n chlAggDataArr += (noisyChl -\n self.otherProdsDict['chlor_a']\n ) ** 2\n if self.doNflh:\n nflhAggDataArr += (noisyNflh -\n self.otherProdsDict['nflh']\n ) ** 2\n\n for band in self.bands:\n self.logger.debug(\"computing deviation for band %s\" % band)\n self.rrsUncArrDict[band] = np.ma.sqrt(rrsAggDataDict[band] / lflis)\n if self.doSaniCheck:\n self.ltUncArrDict[band] = np.sqrt(ltAggDataDict[band] / lflis)\n self.logger.debug('running sanity check for band %s' % band)\n if self.doChla:\n self.otherProdsDict['chlor_a_unc'] = np.ma.sqrt(chlAggDataArr\n / lflis)\n self.logger.debug('computing deviation for chlor a')\n if self.doNflh:\n self.otherProdsDict['nflh_unc'] = np.ma.sqrt(nflhAggDataArr\n / lflis)\n self.logger.debug('computing deviation for nflh')\n self.logger.info(\"\\nProcessed %d files \" % lflis)\n return None\n\n def ReadFromSilent(self):\n '''Reads Baseline file\n Flags: l2bin default flags, namely ATMFAIL(1), LAND(2), HIGLINT(8),\n HILT(16), HISATZEN(32), STRAYLIGHT(256), CLDICE(512),\n COCCOLITH(1024), HISOLZEN(4096), LOWLW(16384), CHLFAIL(32768),\n NAVWARN(65536), MAXAERITER(524288), CHLWARN(2097152),\n ATMWARN(4194304), NAVFAIL(33554432), FILTER(67108864)\n flagBits = 1 + 2 + 8 + 16 + 32 + 256 + 512 + 1024 + 4096 + 16384 +\n 32768 + 65536 + 524288 + 2097152 + 4194304 + 33554432 + 67108864\n l2flags = geoVar['l2_flags'][:]\n flagMaskArr = (l2flags & flagBits > 0)\n '''\n self.logger.debug('attemping to open silent file %s' % self.silFile)\n with nc.Dataset(self.silFile, 'r') as dsSil:\n geoGr = dsSil.groups['geophysical_data']\n geoVar = geoGr.variables\n for band in self.bands:\n rrs = geoVar['Rrs_%s' % band]\n self.rrsSilDict[band] = rrs[:]\n self.attrRrsUncDict[band] = {'long_name': 'Uncertainty in ' +\n rrs.long_name,\n '_FillValue': rrs._FillValue,\n 'units': rrs.units,\n 'scale_factor': rrs.scale_factor,\n 'add_offset': rrs.add_offset, }\n self.dimsDict[band] = rrs.dimensions\n self.dTypeDict[band] = rrs.dtype\n if self.doSaniCheck:\n self.logger.debug('setting up to run sanity check for band %s' % band)\n lt = geoVar['Lt_'+band]\n self.ltSilDict[band] = lt[:]\n self.attrLtUncDict[band] = {'long_name': 'Uncertainty in '\n + lt.long_name,\n '_FillValue': lt._FillValue,\n 'units': lt.units}\n if self.doChla:\n self.logger.debug('setting up to compute chla uncertainty')\n chla = geoVar['chlor_a']\n self.otherProdsDict['chlor_a'] = chla[:]\n self.attrOtherProdUncDict['chlor_a_unc'] = {'long_name':\n 'Uncertainty in ' +\n chla.long_name,\n '_FillValue':\n chla._FillValue,\n 'units':\n chla.units,\n 'valid_min': 0}\n self.dTypeDict['chlor_a_unc'] = chla.dtype\n self.dimsDict['chlor_a_unc'] = chla.dimensions\n if self.doNflh:\n self.logger.debug('setting up to compute nflh uncertainty')\n nflh = geoVar['nflh']\n self.otherProdsDict['nflh'] = nflh[:]\n self.attrOtherProdUncDict['nflh_unc'] = {'long_name':\n 'Uncertainty in ' +\n nflh.long_name,\n '_FillValue':\n nflh._FillValue,\n 'units': nflh.units,\n 'scale_factor':\n nflh.scale_factor,\n 'add_offset':\n nflh.add_offset}\n self.dimsDict['nflh_unc'] = nflh.dimensions\n self.dTypeDict['nflh_unc'] = nflh.dtype\n return None\n\n\nclass MakeSwfUnc(MakeUnc):\n \"\"\"Uncertainty subclass for SeaWiFS\"\"\"\n def __init__(self, *args, **kwargs):\n self.sensor = 'SeaWiFS'\n self.bands = kwargs.pop(\"bands\",\n ['412', '443', '490', '510', '555', '670',\n '765', '865'])\n self.colDict = {'412': '#001166', '443': '#004488', '490': '#116688',\n '510': '#228844', '555': '#667722', '670': '#aa2211',\n '765': '#770500', '865': '#440000'}\n super(MakeSwfUnc, self).__init__(*args)\n return None\n\n\nclass MakeHMA(MakeUnc):\n \"\"\"Uncertainty engine for HMODISA\"\"\"\n def __init__(self, *args, **kwargs):\n self.sensor = 'HMODISA'\n self.bands = kwargs.pop(\"bands\",\n ['412', '443', '488', '531', '547', '555',\n '645', '667', '678', '748', '859', '869',\n '1240', '1640', '2130'])\n super(MakeHMA, self).__init__(*args)\n self.colDict = {'412': '#001166', '443': '#004488', '488': '#1166FF',\n '531': '#337722', '547': '#557733', '555': '#669922',\n '645': '#883311', '667': '#aa2211', '678': '#dd3300'}\n return None\n\n\ndef PathsGen(matchPattern, l2MainPath):\n # create generator of l2 directory paths\n l2PathsGen = glob.iglob(matchPattern)\n spatt = re.compile('(S[0-9]+)')\n for l2path in l2PathsGen:\n if os.path.isdir(l2path):\n basename = spatt.findall(l2path)[0]\n l2Pa = os.path.join(l2MainPath, basename)\n silFiPa = os.path.join(l2Pa, basename) + '_silent.L2'\n noiDiPa = os.path.join(l2Pa, 'Noisy/')\n else:\n continue\n yield [silFiPa, noiDiPa]\n\n\nclass CBatchManager():\n '''\n Class to manage complete uncertainty generation; from processing of L1As to\n creation of uncertainty from noisy L2 files, to the final packing of new\n uncertainty products into the baseline L2.\n '''\n\n def __init__(self, pArgs):\n '''\n Takes a directory containing L2 directories\n '''\n self.pArgs = pArgs\n self.l2MainPath = pArgs.ipath\n if self.pArgs.sensor == 'SeaWiFS':\n self.matchPattern = os.path.join(self.l2MainPath, 'S*/')\n return None\n\n def _BatchRun(self, sArgs):\n ifile, npath = sArgs\n uncObj = MakeSwfUnc(ifile, npath)\n uncObj.ReadFromSilent()\n uncObj.BuildUncs(self.pArgs.nsfx)\n uncObj.WriteToSilent()\n return uncObj.silFile\n\n def ProcessL2s(self):\n paramGen = (params for params in PathsGen(self.matchPattern,\n self.l2MainPath))\n with mp.Pool() as pool:\n results = pool.map(self._BatchRun, paramGen)\n return results # temporary: should be replaced by log entry\n\n\ndef ParseCommandLine(args):\n parser = argparse.ArgumentParser()\n parser.add_argument('-i', '--ifile', help='Initial L2 file path.',\n type=str)\n parser.add_argument('-j', '--ipath',\n help='Main L2 path for batch processing.', type=str)\n parser.add_argument('-n', '--npath', help='Path to noisy data directory.',\n type=str)\n parser.add_argument('-s', '--nsfx',\n help='Noisy file suffix for pattern matching.',\n type=str, default='_noisy_')\n parser.add_argument('-c', '--dochl', help='Compute chloropyll uncertainty. Default is False',\n action='store_true', default=False)\n parser.add_argument('-f', '--doflh',\n help='Compute normalized fluorescence line height. Default is False',\n action='store_true', default=False)\n parser.add_argument('-p', '--psafe', help='Back source file up. Default is False',\n action='store_true', default=False)\n parser.add_argument('-a', '--sanity', help='Do sanity check. Default is False',\n action='store_true', default=False)\n parser.add_argument('-b', '--batch', help='Batch processing option. Default is False',\n action='store_true', default=False)\n parser.add_argument('-w', '--workers',\n help='Number of concurrent processes. Default is 1',\n type=int, default=1)\n parser.add_argument('-z', '--sensor',\n help='Specify sensor data originates from. Default is SeaWiFS',\n type=str, default='SeaWiFS')\n parser.add_argument('-e', '--debug', help='increase output verbosity',\n action='store_true', default=False)\n parsedArgs = parser.parse_args(args)\n return parsedArgs\n\n\ndef SetLogger(dbg=False):\n '''\n sets logger with more verbose format if dbg_lvl=True\n '''\n logger_name = 'MakeUNC_%s' % str(DT.now())\n logfn = '%s.log' % logger_name\n logger = logging.getLogger(logger_name)\n if dbg:\n level = logging.DEBUG\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -'\n + ' [%(module)s..%(funcName)s..%(lineno)d]'\n + ' - %(message)s')\n else:\n level = logging.INFO\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n logger.setLevel(level)\n fh = logging.FileHandler(logfn)\n fh.setLevel(level)\n fh.setFormatter(formatter)\n ch = logging.StreamHandler()\n ch.setLevel(logging.WARNING)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n logger.addHandler(fh)\n logger.debug('logging')\n return logger\n\n\ndef Main(argv):\n\n pArgs = ParseCommandLine(argv)\n mainLogger = SetLogger(dbg=pArgs.debug)\n if pArgs.batch:\n # min. cmd line is ipath for main L2Path (all L2s should be in a\n # common directory. ) and -b\n mainLogger.info('Initializing batch processor')\n bRunner = CBatchManager(pArgs)\n res = bRunner.ProcessL2s()\n pickle.dump(res, open('L2BatchList.pkl', 'wb'))\n else:\n baseLineFile = pArgs.ifile\n noisyDataDir = pArgs.npath\n noisySfx = pArgs.nsfx\n baseLineFname = baseLineFile.split('/')[-1]\n if noisyDataDir[-1] != '/':\n noisyDataDir += '/'\n if baseLineFname[0] == 'S':\n mainLogger.info('processing SeaWiFS data')\n uncObj = MakeSwfUnc(pArgs, mainLogger.name)\n elif baseLineFname[0] == 'A':\n mainLogger.info('processing MODISA data')\n uncObj = MakeHMA(pArgs)\n uncObj.ReadFromSilent()\n uncObj.BuildUncs(noisySfx)\n uncObj.WriteToSilent()\n\nif __name__ == \"__main__\":\n\n Main(sys.argv[1:])\n"
},
{
"alpha_fraction": 0.5727382302284241,
"alphanum_fraction": 0.5796833038330078,
"avg_line_length": 36.10996627807617,
"blob_id": "6b0dd54ad7aafbc6a801d3a929fdf28ce37792aa",
"content_id": "4938a1341cee648ba7b0b0fea83edb196142f1c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10799,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 291,
"path": "/RunL2genMC.py",
"repo_name": "fengqiaogit/MakeUNC",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python3\n\nfrom subprocess import Popen, DEVNULL, PIPE\nimport glob\nimport re\nimport os\nimport logging\nimport pickle\nimport sys\nimport multiprocessing as mp\nimport argparse\nfrom itertools import islice\nfrom datetime import datetime as DT\n\n__author__ = \"Erdem K.\"\n__version__ = \"0.5\"\n\n\nclass L2genRunner():\n\n def __init__(self, workers):\n maxProcs = (mp.cpu_count() - 1) * 2\n if workers > maxProcs:\n self.workers = maxProcs\n else:\n self.workers = workers\n\n def Runner(self, cmdList):\n '''\n Creates a generator for processes then slices through the iterator\n by the number ofconcurrent processes allowed.\n cmdList is a generator yielding l2gen command lines for each process.\n '''\n status = False\n # create process generator\n processes = (Popen(cmd, shell=True, stderr=DEVNULL, stdout=DEVNULL)\n for cmd in cmdList)\n runningProcs = list(islice(processes, self.workers)) # start new ps\n while runningProcs:\n for i, process in enumerate(runningProcs):\n if process.poll() is not None: # process has finished\n runningProcs[i] = next(processes, None) # start new ps\n if runningProcs[i] is None: # no new processes\n del runningProcs[i]\n status = True\n break\n return status\n\n def GetCmdList(self):\n raise NotImplementedError\n\n\nclass CMCRunner(L2genRunner):\n '''\n Class to run l2gen monte carlo process, by default in parallel.\n Creates silent/noisy files in the appropriate directories for later use\n by the uncertainty computation script.\n '''\n def __init__(self, pArgs, parent_logger_name):\n '''\n Takes pre-parsed command line arguments.\n '''\n\n self.l1path = pArgs.ifile\n self.l2MainPath = pArgs.opath\n self.silParFi = pArgs.prsil\n self.noiParFi = pArgs.prnoi\n self.itNum = pArgs.mcrns\n self.debug = pArgs.debug\n self.filesProcessed = 0\n self.l2SilFname = None\n self.l2NoiPath = None\n self.basename = None\n self.logfname = None\n self.logMeta = None\n super(CMCRunner, self).__init__(pArgs.workers)\n self._GetL2FilePath()\n self._SetLogger(parent_logger_name)\n self.logger.info(\"L1 file: %s\" % self.l1path)\n self.logger.info(\"L2 main path %s\" % self.l2MainPath)\n self.logger.info(\"silent ParFile %s\" % self.silParFi)\n self.logger.info(\"noisy ParFile %s\" % self.noiParFi)\n self.logger.info(\"number of iterations %d\" % self.itNum)\n self.logger.info(\"number of concurrent processes %d\" % self.workers)\n self.logger.info(\"silent L2 file: %s\" % self.l2SilFname)\n self.logger.info(\"noisy L2 path: %s\" % self.l2NoiPath)\n\n def _SetLogger(self, pln):\n '''\n The user is expected to set the logger in the 'main' module and\n pass on its name to this child logger. Otherwise no logging will occurr.\n '''\n self.logger = logging.getLogger('%s.RunL2genMC.CMCRunner' % pln)\n self.logger.info('%s initialized' % self.logger.name)\n\n def _GetL2FilePath(self):\n '''\n Path handling and where necessary directory creation.\n '''\n pattern = '(S[0-9]+).L1A'\n basename = re.findall(pattern, self.l1path)[0]\n l2path = os.path.join(self.l2MainPath, basename)\n if not os.path.exists(l2path):\n os.makedirs(l2path)\n self.l2SilFname = os.path.join(l2path, basename+'_silent.L2')\n self.l2NoiPath = os.path.join(l2path, 'Noisy/')\n if not os.path.exists(self.l2NoiPath):\n os.makedirs(self.l2NoiPath)\n self.basename = basename\n\n def BuildCmdGen(self):\n '''Generator: generates cmdList for subprocess calls'''\n cmdBase = 'l2gen ifile=%s ofile=' % self.l1path\n if os.path.exists(self.l2SilFname):\n self.logger.info('skipping silent L2')\n else:\n # silent L2 does not exist, add it to the tasklist\n cmd = cmdBase + '%s par=%s' % (self.l2SilFname, self.silParFi)\n yield cmd\n\n for it in range(self.itNum):\n l2f = '%s_noisy_%d.L2' % (self.basename, it+1)\n ofile = os.path.join(self.l2NoiPath, l2f)\n if os.path.exists(ofile):\n self.logger.info('skipping noisy file %s' % l2f)\n continue\n cmd = cmdBase + '%s par=%s' % (ofile, self.noiParFi)\n yield cmd\n\n def Runner(self, cmdList):\n '''\n Creates a generator for processes then slices through the iterator\n by the number ofconcurrent processes allowed.\n cmdList is a generator yielding l2gen command lines for each process.\n '''\n status = False\n # create process generator\n processes = (Popen(cmd, shell=True, stdout=DEVNULL, stderr=PIPE)\n for cmd in cmdList)\n runningProcs = list(islice(processes, self.workers)) # start new ps\n while runningProcs:\n for i, process in enumerate(runningProcs):\n if self.debug:\n if process.stderr:\n for line in process.stderr.readlines():\n self.logger.debug('%d %s' % (i, line))\n if process.poll() is not None: # process has finished\n runningProcs[i] = next(processes, None) # start new ps\n if runningProcs[i] is None: # no new processes\n del runningProcs[i]\n status = True\n break\n return status\n\n\nclass CNamespace():\n '''\n Class to replace command line argument parser for IPython calls.\n Usage: args=Namespace(ifile='',opath='',prsil='',prnoi='')\n '''\n\n def __init__(self, **kwargs):\n self.__dict__.update(kwargs)\n return None\n\n\nclass CBatchManager():\n '''\n Class to manage batch processing of multiple L1A files by the MCRunner.\n '''\n\n def __init__(self, bArgs, isdir=True, parent_logger_name=None):\n '''Takes a directory containing L1A or a text file listing\n L1Apaths on each line.'''\n if isdir:\n matchPattern = os.path.join(bArgs.ifile, '*.L1A*')\n self.ifileGen = glob.iglob(matchPattern) # L1AGenerator\n self.pArgs = bArgs\n self.verbose = self.pArgs.verbose\n self.l2MainPath = self.pArgs.opath\n if parent_logger_name is not None:\n self._SetLogger(parent_logger_name)\n\n def _SetLogger(self, parentloggername):\n '''\n The user is expected to set the logger in the 'main' module and\n pass on its name to this child logger. Otherwise no logging will occurr.\n '''\n self.logger = logging.getLogger('%s.RunL2genMC.CMCRunner' % parentloggername)\n self.logger.info('logger initialized')\n\n def ProcessL1A(self):\n '''Calls L1AGenerator to get next file to process'''\n for ifile in self.ifileGen:\n self.pArgs.ifile = ifile\n mcr = CMCRunner(self.pArgs)\n pickle.dump(mcr, open(os.path.join(mcr.l2MainPath, 'mcr_%s.pkl'\n % mcr.basename), 'wb'))\n cmdGen = mcr.BuildCmdGen()\n status = mcr.Runner(cmdGen)\n if status:\n if self.verbose:\n print('\\r%s: Finished processing %s' % (DT.now(), ifile),\n end='', flush=True)\n with open(self.logMeta, 'a') as fmeta:\n print('Finished processing %s' % ifile, file=fmeta)\n del mcr # make room for the next mc set\n return None\n\n def CreateCmdLineArgs(**kwargs):\n pArgs = CNamespace(**kwargs)\n return pArgs\n\n\n# TODO def ConsolidateParfile()\n\ndef SetLogger(dbg_lvl=False):\n '''\n\n '''\n logger_name = 'RL2MC_%s' % DT.strftime(DT.now(), '%Y-%m-%dT%H:%M:%S')\n logfn = '%s.log' % logger_name\n logger = logging.getLogger(logger_name)\n if dbg_lvl:\n logger.setLevel(logging.DEBUG)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s -'\n + ' [%(module)s..%(funcName)s..%(lineno)d]'\n + ' - %(message)s')\n else:\n logger.setLevel(logging.INFO)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n fh = logging.FileHandler(logfn)\n fh.setLevel(logging.DEBUG)\n fh.setFormatter(formatter)\n ch = logging.StreamHandler()\n ch.setLevel(logging.ERROR)\n ch.setFormatter(formatter)\n logger.addHandler(ch)\n logger.addHandler(fh)\n logger.debug('logging')\n return logger\n\n\ndef ParseCommandLine(args):\n '''\n Returns argparse object with parsed arguments as attributes\n '''\n parser = argparse.ArgumentParser()\n parser.add_argument('-i', '--ifile', help='l1a input file',\n type=str, required='True')\n parser.add_argument('-o', '--opath', help='l2 output main path',\n type=str, required='True')\n parser.add_argument('-s', '--prsil', help='silent param. file',\n type=str, required='True')\n parser.add_argument('-n', '--prnoi', help='noisy param. file',\n type=str, required='True')\n parser.add_argument('-m', '--mcrns', help='number of MC iterations',\n type=int, default=1000)\n parser.add_argument('-w', '--workers', help='process # to allocate',\n type=int, default=1)\n parser.add_argument('-d', '--debug', help='increase output verbosity',\n action='store_true', default=False)\n parser.add_argument('-b', '--batch', help='batch processing',\n action='store_true')\n parsedArgs = parser.parse_args(args)\n # TODO parsedArgs = ConsolidateParfile(parsedArgs)\n return parsedArgs\n\n\ndef Main(args):\n\n pArgs = ParseCommandLine(args)\n mainLogger = SetLogger(dbg_lvl=pArgs.debug)\n\n if not os.path.exists(pArgs.ifile):\n sys.exit('\\n %s not found!\\n exiting...' % pArgs.ifile)\n if pArgs.batch:\n mainLogger.info('Initializing batch processor')\n bcr = CBatchManager(pArgs)\n bcr.ProcessL1A()\n else:\n mainLogger.info('Init MCRUnner Object w/ pArgs')\n mcr = CMCRunner(pArgs, mainLogger.name)\n mainLogger.info('Creating task list')\n taskList = mcr.BuildCmdGen()\n mainLogger.info('Feeding tasklist l2gen runner')\n mcr.Runner(taskList)\n\n\nif __name__ == '__main__':\n Main(sys.argv[1:])\n"
},
{
"alpha_fraction": 0.8060678243637085,
"alphanum_fraction": 0.8132064342498779,
"avg_line_length": 239,
"blob_id": "4ac979acc3b5ab7bb64d4d50b760370939db8114",
"content_id": "eb4e4b3c60758851372b6f650bc9150ee24dc311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1681,
"license_type": "no_license",
"max_line_length": 695,
"num_lines": 7,
"path": "/README.md",
"repo_name": "fengqiaogit/MakeUNC",
"src_encoding": "UTF-8",
"text": "Computes Monte-Carlo based uncertainty in ocean color remote sensing radiance to assess the impact of satellite-borne sensor noise and its propagation from at-sensor measurement, through atmospheric correction, to at-ocean-surface remote sensing radiance estimation and from there to derived ocean color products (e.g. as algal chlorophyll) that are vital to such concepts as climate change, fisheries yield, harmful algal blooms. A Monte-Carlo simulation boils down to reprocessing the same [scene](http://oceancolor.gsfc.nasa.gov/cgi/l3) about 1000 times to estimate the uncertainty resulting from of sensor noise and comparing the results to a perturbation-free baseline version of the scene.\n\nContent:\nThe follwoing code can be called from the commandline \n * RunL2genMC calls on [NASA's Ocean Biology Group's](http://oceancolor.gsfc.nasa.gov/cms/) remote sensing processing software l2gen, which is part of a very large code base written in C, to run iterations of a Monte-Carlo process. I added a sensor-based noise model depending on a variety of inputs in l2gen. One issue is that l2gen computes remote sensing data one pixel at a time. This makes for a very long wait when a simulation requires that a scene be reprocessed several hundred times. To mitigate the following, I added the option of running several processes in parallel by spawning concurrent l2gen processes.\nThe output is contained in netCDF4 files.\n * MakeUNC builds Rrs and optionally product uncertainty using data resulting from Monte-Carlo simulation runs by statistically aggregating the results and adding them as uncertainty products to the baseline dataset, also contained in a netCDF4 file. \n"
}
] | 4 |
Fiveside/tftp
|
https://github.com/Fiveside/tftp
|
4003c426f1a336fbf5d6abc387fd99c3316021d8
|
c3ee21889e40aa7975ce68a13829f5a90f19ba5e
|
65526a7c84fc09d5905e86f8b08e1f85b2488199
|
refs/heads/master
| 2022-02-01T13:31:26.118028 | 2019-12-15T18:41:37 | 2019-12-15T18:41:37 | 226,470,373 | 0 | 0 | null | 2019-12-07T07:03:56 | 2019-12-15T18:41:43 | 2022-01-21T20:09:19 |
Python
|
[
{
"alpha_fraction": 0.801369845867157,
"alphanum_fraction": 0.801369845867157,
"avg_line_length": 47.66666793823242,
"blob_id": "3cd81e2f4eb22d0a1111380116fc51cc76bedb54",
"content_id": "93749cbd09249b50072924fc9972ee7b43739e3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Fiveside/tftp",
"src_encoding": "UTF-8",
"text": "# Stupid TFTP\n\nThis is an educational implementation of a TFTP server. It is not feature complete and should not be considered production ready.\n"
},
{
"alpha_fraction": 0.6041588187217712,
"alphanum_fraction": 0.6067894101142883,
"avg_line_length": 29.238636016845703,
"blob_id": "823644b01c1b06434db8700391f0821f0f6df11d",
"content_id": "75fd4a518c5561a3411bcacf239658dd956929cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7983,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 264,
"path": "/main.py",
"repo_name": "Fiveside/tftp",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport asyncio\nimport signal\nimport messages\nimport contextlib\n\n\nclass TFTPStepwiseRetryAdapter:\n def __init__(self, dgram_protocol, retries=5, timeout=3.0):\n self.proto = dgram_protocol\n self.retries = retries\n self.timeout = timeout\n\n async def send(self, buf):\n \"\"\"Send a packet and wait for a response.\"\"\"\n # Write the data\n # Wait for ack before returning to the caller\n loop = asyncio.get_event_loop()\n for _ in range(self.retries):\n try:\n fut = loop.create_future()\n self.proto.set_receiver(fut)\n self.proto.transport.sendto(buf)\n return await asyncio.wait_for(fut, timeout=self.timeout)\n except asyncio.TimeoutError as timeout_error:\n pass\n\n # Failed. Write error message and throw a communication error\n msg = messages.Error.timeout_error()\n self.proto.send(msg.encode())\n self.close()\n\n # TODO: Better exception\n raise timeout_error\n\n def emit(self, buf):\n \"\"\"Send a packet and do not wait for a response.\"\"\"\n self.proto.transport.sendto(buf)\n\n async def close(self):\n self.proto.close()\n\n\nclass TFTPBufferedDataSender:\n def __init__(self, sender):\n self.proto = sender\n self.block_num = 1\n self.send_buffer = bytes()\n\n async def send(self, buf):\n self.send_buffer.write(buf)\n while len(self.send_buffer) > messages.Data.max_data_size:\n block = self.send_buffer[0 : messages.Data.max_data_size]\n self.send_buffer = self.send_buffer[messages.Data.max_data_size :]\n await self._send_block(block)\n\n async def _send_block(self, buf):\n while True:\n msg = messages.Data(self.block_num, buf)\n raw_response = await self.proto.send(msg.encode())\n res = messages.decode(raw_response)\n if res.block_num == self.block_num - 1:\n # Received previous ack instead of the expected one.\n continue\n elif res.block_num == self.block_num:\n # Received expected ack.\n break\n else:\n # Received unexpected ack\n raise Exception(\"Invalid packet received\")\n\n self.block_num += 1\n\n async def close(self):\n # Send the last of the bits inside the send buffer, or an empty data\n # packet if the buffer is empty.\n await self._send_block(self.send_buffer)\n self.send_buffer = bytes()\n\n await self.proto.close()\n\n\nclass TFTPDataReceiver:\n def __init__(self, sender):\n self.proto = sender\n self.block_num = 0\n self.eof_reached = False\n\n def __aiter__(self):\n return self\n\n async def __anext__(self):\n if self.eof_reached:\n raise StopAsyncIteration\n return await self.read()\n\n async def read(self):\n if self.eof_reached:\n return b\"\"\n\n msg = messages.Acknowledgement(self.block_num)\n raw = await self.proto.send(msg.encode())\n res = messages.decode(raw)\n\n assert res.block_num == self.block_num + 1\n self.block_num = res.block_num\n\n print(f\"Read {len(res.data)} bytes of data from client\")\n\n if not res.is_full_block:\n await self.finalize()\n\n return res.data\n\n async def finalize(self):\n print(\"Read EOF detected, finalizing.\")\n self.eof_reached = True\n msg = messages.Acknowledgement(self.block_num)\n self.proto.emit(msg.encode())\n\n async def close(self):\n await self.proto.close()\n\n\[email protected]\nasync def aclosing(thing):\n yield thing\n await thing.close()\n\n\nclass TFTPTransferProtocol(asyncio.DatagramProtocol):\n def __init__(self, addr, port, closer):\n self.addr = addr\n self.port = port\n self.receiver = None\n self.closer = closer\n\n def connection_made(self, transport):\n self.transport = transport\n\n def datagram_received(self, data, addr):\n if self.receiver is None or self.receiver.done():\n print(\n \"Error: Received a message, but no receiver is available. Discarding.\"\n )\n print(f\"Discarded message: {repr(data)}\")\n return\n self.receiver.set_result(data)\n\n def connection_lost(self, exc):\n if exc is None:\n return\n print(f\"Lost connection: {exc}\")\n\n def error_received(self, exc):\n print(f\"Error received: {exc}\")\n self.closer.set_exception(exc)\n\n def set_receiver(self, fut):\n self.receiver = fut\n\n def close(self):\n if not self.closer.done():\n self.closer.set_result(None)\n\n\nasync def send_file_to_client(rrq, ip, port):\n loop = asyncio.get_event_loop()\n closer = loop.create_future()\n transport, protocol = await loop.create_datagram_endpoint(\n lambda: TFTPTransferProtocol(ip, port, closer), remote_addr=(ip, port)\n )\n with contextlib.closing(transport), contextlib.closing(protocol):\n sender = TFTPBufferedDataSender(TFTPStepwiseRetryAdapter(protocol))\n async with aclosing(sender):\n with open(rrq.filename, \"rb\") as fobj:\n for buf in fobj:\n await sender.send(buf)\n\n # Make sure protocol disposition was graceful\n await closer\n\n\nasync def read_file_from_client(wrq, ip, port):\n loop = asyncio.get_event_loop()\n closer = loop.create_future()\n transport, protocol = await loop.create_datagram_endpoint(\n lambda: TFTPTransferProtocol(ip, port, closer), remote_addr=(ip, port)\n )\n with contextlib.closing(transport), contextlib.closing(protocol):\n reader = TFTPDataReceiver(TFTPStepwiseRetryAdapter(protocol))\n async with aclosing(reader):\n with open(wrq.filename, \"wb\") as fobj:\n async for buf in reader:\n fobj.write(buf)\n\n # Make sure protocol disposition was graceful\n await closer\n\n\nclass TFTPServerProtocol(asyncio.DatagramProtocol):\n def __init__(self):\n self.jobs = list()\n self.job_task = asyncio.ensure_future(self.periodically_prune_jobs())\n\n async def periodically_prune_jobs(self):\n with contextlib.suppress(asyncio.CancelledError):\n while True:\n self.jobs = self.running_jobs()\n await asyncio.sleep(5)\n\n def running_jobs(self):\n return [x for x in self.jobs if not x.done()]\n\n def connection_made(self, transport):\n self.transport = transport\n\n def datagram_received(self, data, addr):\n print(f\"Received {repr(data)} from {addr}\")\n msg = messages.decode(data)\n print(f\"Parsed as a {repr(msg)}\")\n if msg.opcode == messages.ReadRequest.opcode:\n job = send_file_to_client(msg, *addr)\n elif msg.opcode == messages.WriteRequest.opcode:\n job = read_file_from_client(msg, *addr)\n else:\n print(f\"Message not appropriate for server port\")\n return\n\n self.jobs.append(asyncio.ensure_future(job))\n\n def connection_lost(self, exc):\n if exc is None:\n return\n print(f\"Lost connection: {exc}\")\n\n def error_received(self, exc):\n print(f\"Received error: {exc}\")\n\n async def close(self):\n self.job_task.cancel()\n await asyncio.gather(*self.running_jobs())\n\n\nasync def main():\n print(\"Starting UDP server\")\n\n loop = asyncio.get_running_loop()\n transport, protocol = await loop.create_datagram_endpoint(\n TFTPServerProtocol, local_addr=(\"127.0.0.1\", 9999)\n )\n\n signal_finisher = loop.create_future()\n\n for sig in [signal.SIGTERM, signal.SIGINT]:\n loop.add_signal_handler(sig, lambda: signal_finisher.set_result(None))\n\n await signal_finisher\n transport.close()\n await protocol.close()\n\n\nasyncio.run(main())\n"
},
{
"alpha_fraction": 0.4153846204280853,
"alphanum_fraction": 0.6461538672447205,
"avg_line_length": 14.25,
"blob_id": "b1fb08341e323d811801a7cf0a2bebfe20bb8c00",
"content_id": "18df64cafe6193e740a1eeeae0b94083c693b645",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "Fiveside/tftp",
"src_encoding": "UTF-8",
"text": "pylint==2.4.4\r\nblack==19.10b0\r\naiofiles==0.4.0\r\nipython==7.10.1\r\n"
},
{
"alpha_fraction": 0.6010506749153137,
"alphanum_fraction": 0.6103214025497437,
"avg_line_length": 21.950355529785156,
"blob_id": "303b3a5e784ee12b60e9a3cc5c3bc0ea78d1f61c",
"content_id": "e9935b75a289825ce240df69dd7dc15f7824a21c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3236,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 141,
"path": "/messages.py",
"repo_name": "Fiveside/tftp",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nimport struct\nfrom collections import namedtuple\n\n\n_RQ = namedtuple(\"RQ\", (\"filename\", \"mode\"))\n\n\ndef _decode_rq(pkt):\n fname, mode = pkt.rstrip(b\"\\0\").split(b\"\\0\", 2)\n return _RQ(fname, mode)\n\n\ndef _encode_rq(rq):\n return rq.filename + b\"\\0\" + rq.mode + b\"\\0\"\n\n\n@dataclass\nclass ReadRequest:\n \"Read Request (RRQ)\"\n opcode = 1\n filename: bytes\n mode: bytes\n\n @classmethod\n def decode(cls, pkt):\n (opcode,) = struct.unpack(\"!h\", pkt[0:2])\n assert opcode == cls.opcode\n\n parsed = _decode_rq(pkt[2:])\n return cls(filename=parsed.filename, mode=parsed.mode)\n\n def encode(self):\n return struct.pack(\"!h\", self.opcode) + _encode_rq(\n _RQ(self.filename, self.mode)\n )\n\n\n@dataclass\nclass WriteRequest:\n \"Write Request (WRQ)\"\n opcode = 2\n filename: bytes\n mode: bytes\n\n @classmethod\n def decode(cls, pkt):\n (opcode,) = struct.unpack(\"!h\", pkt[0:2])\n assert opcode == cls.opcode\n\n parsed = _decode_rq(pkt[2:])\n return cls(filename=parsed.filename, mode=parsed.mode)\n\n def encode(self):\n return struct.pack(\"!h\", self.opcode) + _encode_rq(\n _RQ(self.filename, self.mode)\n )\n\n\n@dataclass\nclass Data:\n \"Data (DATA)\"\n opcode = 3\n block_num: int\n data: bytes\n\n # This is the maximum size of a data packet's data buffer per packet.\n # Note that this number was aquired by looking at the data that the tftp\n # linux utility sends us.\n max_data_size = 512\n\n @property\n def is_full_block(self):\n return len(self.data) == self.max_data_size\n\n @classmethod\n def decode(cls, pkt):\n (opcode, block_num) = struct.unpack(\"!hh\", pkt[0:4])\n assert opcode == cls.opcode\n\n data = pkt[4:]\n return cls(block_num=block_num, data=data)\n\n def encode(self):\n return struct.pack(\"!hh\", self.opcode, self.block_num) + self.data\n\n\n@dataclass\nclass Acknowledgement:\n \"Acknowledgement (ACK)\"\n opcode = 4\n block_num: int\n\n @classmethod\n def decode(cls, pkt):\n (opcode, block_num) = struct.unpack(\"!hh\", pkt)\n assert opcode == cls.opcode\n\n return cls(block_num=block_num)\n\n def encode(self):\n return struct.pack(\"!hh\", self.opcode, self.block_num)\n\n\n@dataclass\nclass Error:\n \"Error (ERROR)\"\n opcode = 5\n error_code: int\n message: bytes\n\n @classmethod\n def decode(cls, pkt):\n (opcode, error_code) = struct.unpack(\"!hh\", pkt[0:4])\n assert opcode == cls.opcode\n\n pkt = pkt[4:].rstrip(b\"\\0\")\n return cls(error_code=error_code, message=pkt)\n\n def encode(self):\n return struct.pack(\"!hh\", self.opcode, self.error_code) + self.message + b\"\\0\"\n\n # Special builders\n @classmethod\n def timeout_error(cls):\n return cls(error_code=0, message=\"Timeout occurred during transport\")\n\n\n_MESSAGES = {\n ReadRequest.opcode: ReadRequest,\n WriteRequest.opcode: WriteRequest,\n Data.opcode: Data,\n Acknowledgement.opcode: Acknowledgement,\n Error.opcode: Error,\n}\n\n\ndef decode(pkt):\n raw_opcode = pkt[0:2]\n (opcode,) = struct.unpack(\"!h\", raw_opcode)\n return _MESSAGES[opcode].decode(pkt)\n"
}
] | 4 |
khofifahitsna27/Metode-Numerik-2021
|
https://github.com/khofifahitsna27/Metode-Numerik-2021
|
1a6f4effc0404c38310ae945ef8df5b08f331688
|
147c8e5a0946e8069d0dbb11c32b30f19d90ae62
|
f8dd613744f1734e027c5c1c62e603851195d38d
|
refs/heads/main
| 2023-05-13T19:22:28.115952 | 2021-06-04T13:39:56 | 2021-06-04T13:39:56 | 373,488,336 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5411179065704346,
"alphanum_fraction": 0.5742289423942566,
"avg_line_length": 35.50926971435547,
"blob_id": "e753a57b5b9c3b27dfa4f3ec2fd88f839496fdcd",
"content_id": "640020e6d5abf3596b36840289b5b78d135c7a20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29547,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 809,
"path": "/Kelompok 9/code/codemetnum9.py",
"repo_name": "khofifahitsna27/Metode-Numerik-2021",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[11]:\n\n\n#TUGAS AKHIR METODE NUMERIK 2021\n#MODUL 2 Akar-Akar Persamaan\n#Oleh: KELOMPOK 9 / OSEANOGRAFI\n\n\"\"\"\nAkar-akar persamaan: Bentuk persamaan-persamaan polinomial sangat sulit atau tidak mungkin diselesaikan secara manual,\nHal ini dikarenakan penyelesaian numerik dilakukan dengan perkiraan yang berurutan (iterasi),\nsehingga setiap hasil hasilnya akan lebih teliti dari perkiraan sebelumnya, yaitu dengan melakukan sejumlah prosedur iterasi\nyang dianggap cukup hingga didapatkan hasil perkiraan yang mendekati hasil eksak dengan toleransi kesalahan yang diijinkan.\n\"\"\"\n\n#~~~METODE SETENGAH INTERVAL~~~\n\"\"\"\nMetode Setengah Interval merupakan metode analisis numerik paling sederhana diantara metode-metode analisis lainnya.\nMetode ini metode iteratif yang digunakan untuk mencari akar persamaan (linier maupun non-linear) yang memiliki akar real.\n\"\"\"\ndef Setengah_Interval(X1,X2,a,b,c,d):\n X1 = X1\n X2 = X2\n a = a\n b = b\n c = c\n d = d\n error = 1\n iterasi = 0\n while(error > 0.0001):\n iterasi +=1\n FXi = (float(a*((X1)**3)))+(float(b*((X1)**2)))+(c*X1)+d\n FXii = (float(a*((X2)**3)))+(float(b*((X2)**2)))+(c*X2)+d\n Xt = (X1+X2)/2\n FXt = (float(a*((Xt)**3)))+(float(b*((Xt)**2)))+(c*Xt)+d\n if FXi*FXt > 0:\n X1 = Xt\n elif FXi*FXt < 0:\n X2 = Xt\n else:\n print(\"Akar Penyelesaian: \", Xt)\n if FXt < 0:\n error = FXt*(-1)\n else:\n error = FXt\n if iterasi > 100:\n print(\"Angka Tak Hingga\")\n break\n print(iterasi, \"|\", FXi, \"|\", FXii, \"|\", Xt, \"|\", FXt, \"|\", error)\n print(\"Jumlah Iterasi: \", iterasi)\n print(\"Akar persamaan adalah: \", Xt)\n print(\"Toleransi Error: \", error)\n\n#~~~METODE INTERPOLASI LINIER~~~#\n\"\"\"\nMetode Interpolasi Linier hampir mirip dengan metode setengah interval. Metode ini dikenal juga dengan \nmetode false position dan ada untuk menutupi kekurangan pada metode setengah interval. Metode ini \ndidasarkan pada interpolasi antara dua nilai dari fungsi yang mempunyai tanda berlawanan.\n\"\"\"\ndef Interpolasi_Linier(X1,a,b,c,d):\n X1 = X1\n X2 = X1+1\n a = a\n b = b\n c = c\n d = d\n error = 1\n iterasi = 0\n while(error > 0.0001):\n iterasi +=1\n FX1 = (float(a*((X1)**3)))+(float(b*((X1)**2)))+(c*X1)+d\n FX2 = (float(a*((X2)**3)))+(float(b*((X2)**2)))+(c*X2)+d\n Xt = X2-((FX2/(FX2-FX1)))*(X2-X1)\n FXt = (float(a*((Xt)**3)))+(float(b*((Xt)**2)))+(c*Xt)+d\n if FXt*FX1 > 0:\n X2 = Xt\n FX2 = FXt\n else:\n X1 = Xt\n FX1 = FXt\n if FXt < 0:\n error = FXt*(-1)\n else:\n error = FXt\n if iterasi > 500:\n print(\"Angka Tak Hingga\")\n break\n print(iterasi, \"|\", FX1, \"|\", FX2, \"|\", Xt, \"|\", FXt, \"|\", error)\n print(\"Jumlah Iterasi: \", iterasi)\n print(\"Akar persamaan adalah: \", Xt)\n print(\"Toleransi Error: \", error)\n\n#~~~METODE NEWTON-RHAPSON~~~\n\"\"\"\nMetode ini paling banyak digunakan dalam mencari akar-akar persamaan, jika perkiraan awal dari akar adalah xi,\nmaka suatu garis singgung dapat dibuat dari titik (xi, f (xi)).\nTitik dari garis singgung tersebut memotong sumbu-x, biasanya memberikan perkiraan yang lebih dekat dari nilai akar.\nSyarat dari metode ini ,syarat yang harus dipenuhi adalah bahwa taksiran awal yang diberikan harus\nsedekat mungkin dengan harga eksaknya.\n\"\"\"\ndef Newton_Rhapson(X1,a,b,c,d):\n X1 = X1\n a = a\n b = b\n c = c\n d = d\n iterasi = 0\n akar = 1\n while (akar > 0.0001):\n iterasi += 1\n Fxn = (float(a*((X1)**3)))+(float(b*((X1)**2)))+(c*X1)+d\n Fxxn = (float((a*3)*X1)**2)+(float((b*2)*X1))+(c)\n xnp1 = X1-(Fxn/Fxxn)\n fxnp1 = (a*(xnp1**3))+(b*(xnp1**2))-(c*xnp1)+d\n Ea = ((xnp1-X1)/xnp1)*100\n if Ea < 0.0001:\n X1 = xnp1\n akar = Ea*(-1)\n else:\n akar = xnp1\n print(\"Nilai akar adalah: \", akar)\n print(\"Nilai error adalah: \", Ea)\n if iterasi > 100:\n break \n print(iterasi, \"|\", X1, \"|\", xnp1, \"|\", akar, \"|\", Ea)\n print(\"Jumlah Iterasi: \", iterasi)\n print(\"Akar persamaan adalah: \", xnp1)\n print(\"Toleransi Error: \", akar)\n\n#~~~METODE SECANT~~~\n\"\"\"\nPada dasarnya metode ini sama dengan metode Newton-Raphson, perbedaannya hanya terletak \npada pendekatan untuk turunan pertama dari f saja. Pendekatan f' pada metode Secant didekati dengan \nungkapan beda hingga yang didasarkan pada taksiran akar sebelumnya (beda mundur).\n\"\"\"\ndef Secant(X1,a,b,c,d):\n X1 = X1\n X2 = X1-1\n a = a\n b = b\n c = c\n d = d\n error = 1\n iterasi = 0\n while(error > 0.0001):\n iterasi +=1\n FX1 = (float(a*((X1)**3)))+(float(b*((X1)**2)))+(c*X1)+d\n FXmin = (float(a*((X2)**3)))+(float(b*((X2)**2)))+(c*X2)+d\n X3 = X1-((FX1)*(X1-(X2)))/((FX1)-(FXmin))\n FXplus = (float(a*((X3)**3)))+(float(b*((X3)**2)))+(c*X3)+d\n if FXplus < 0:\n error = FXplus*(-1)\n else:\n error = FXplus\n if error > 0.0001:\n X2 = X1\n X1 = X3\n else:\n print(\"Selesai\")\n if iterasi > 500:\n print(\"Angka Tak Hingga\")\n break\n print(iterasi, \"|\", FX1, \"|\", FXmin, \"|\", X3, \"|\", FXplus, \"|\", error)\n print(\"Jumlah Iterasi: \", iterasi)\n print(\"Akar persamaan adalah: \", X3)\n print(\"Toleransi Error: \", error)\n\n#~~~METODE ITERASI~~~\n\"\"\"\nMetode tidak langsung atau iterasi, merupakan metode yang berbasiskan terhadap aplikasi dari langkah–langkah/algoritma\nsederhana yang diulang–ulang pada sistem persamaan tersebut hingga sistem persamaan mencapai\nkeadaan konvergen yang merepresentasikan solusi dari sistem persamaan tersebut.\n\"\"\"\ndef Iterasi(X1,a,b,c,d):\n X1 = X1\n a = a\n b = b\n c = c\n d = d\n error = 1\n iterasi = 0\n while (error > 0.0001):\n iterasi +=1\n Fxn = (float(a*((X1)**3)))+(float(b*((X1)**2)))+(c*X1)+d\n X2 = (((float(-b*(X1**2)))-(float(c*X1))-(d))/a)**(1/3)\n Ea = (((X2-X1)/(X2))*100)\n if Ea < error:\n X1 = X2\n if Ea > 0:\n error = Ea\n else:\n error = Ea*(-1)\n else:\n error = Ea\n if iterasi > 100:\n print(\"Angka Tak Hingga\")\n break\n print(iterasi, \"|\", X1, \"|\", X2, \"|\", Ea, \"|\", error)\n print(\"Jumlah Iterasi: \", iterasi)\n print(\"Akar persamaan adalah: \", X2)\n print(\"Toleransi Error: \", error)\n\n#MODUL 3 Sistem Persamaan Linier dan Matriks\n#Oleh: KELOMPOK 9 / OSEANOGRAFI\n\n\"\"\"\nSistem persamaan linier (SPL) merupakan sistem operasi matematis yang terdiri atas dua atau lebih persamaan linier.\nDalam sistem persamaan linear terdapat metode langsung dengan metode tidak langsung (iterasi).\nMatriks adalah susunan angka–angka (sering disebut elemen–elemen) yang diatur menurut baris \ndan kolom, berbentuk persegi panjang atau persegi dan ditulis diantara dua tanda kurung yaitu ( ) atau [ ].\n\"\"\"\n\n#~~~METODE ELEMINASI GAUSS~~~\n\"\"\"\nEliminasi Gauss adalah suatu cara mengoperasikan nilai-nilai di dalam matriks\nmenjadi matriks yang lebih sederhana dan banyak digunakan dalam penyelesaian sistem persamaan linier.\n Metode ini mengubah persamaan linear tersebut ke dalam matriks augmentasi dan mengoperasikannya.\n\"\"\"\nimport numpy as np\ndef Gauss(A, B):\n print(\"Nilai Matriks = \\n\", AB, \"\\n\")\n n = len(B)\n for i in range(n):\n A = AB[i]\n for j in range(i + 1, n):\n B = AB[j]\n m = A[i] / B[i]\n AB[j] = A - m * B\n\n for i in range(n - 1, -1, -1):\n AB[i] = AB[i] / AB[i, i]\n A = AB[i]\n for j in range(i - 1, -1, -1):\n B = AB[j] \n m = A[i]/B[i]\n AB[j] = A-m*B\n x = AB[:, 3]\n print(\"Hasil Matriks = \\n\", AB, \"\\n\")\n print(\"Hasil Akhir Matriks = \\n\", x)\n\n\n#~~~METODE GAUSS JORDAN~~~\n\"\"\"\nEliminasi Gauss-Jordan adalah pengembangan dari eliminasi Gauss yang hasilnya lebih sederhana lagi.\nCaranya adalah dengan meneruskan operasi baris dari eliminasi Gauss sehingga menghasilkan matriks yang Eselon-baris.\nMetode ini digunakan untuk mencari invers dari sebuah matriks.\n\"\"\"\nimport numpy as np\nimport sys\ndef GaussJordan(a,n):\n #Step 1 ===> Looping untuk pengolahan metode Gauss Jordan\n print(\"===============Mulai Iterasi===============\")\n for i in range(n):\n if a[i][i]==0:\n sys.exit(\"Dibagi dengan angka not (Proses tidak dapat dilanjutkan)\")\n for j in range(n):\n if i !=j:\n ratio = a[j][i]/a[i][i]\n #print ('posisi nol di:[',j,i,']', nilai rasio:',ratio)\n \n for k in range (n+1):\n a[j, k]=a[j][k]-ratio*a[i][k]\n print(a)\n print(\"==============\")\n \n #STEP 2 =====> MEMBUAT SEMUA VARIABEL (x1, x2, x3, x4,...)==1\n ax = np.zeros((n, n+1))\n for i in range(n):\n for j in range(n+1):\n ax[i, j]=a[i][j]/a[i][i]\n print(\"======= Akhir Iterasi =======\")\n return ax\n\n#~~~METODE GAUSS SIEDEL~~~\n\"\"\"\nMetode iterasi Gauss-Seidel adalah metode yang menggunakan proses iterasi hingga diperoleh nilai-nilai yang berubah-ubah dan akhirnya\nrelatif konstan. Metode iterasi GaussSeidel dikembangkan dari gagasan metode iterasi pada solusi persamaan tak linier. \nMetode eliminasi gauss-seidel digunakan untuk menyelesaikan SPL yang berukuran kecil.\nMetode ini dapat menghasilkan jumlah iterasi lebih sedikit dibandingkan metode Jacobi.\n\"\"\"\ndef Gauss_Siedel(a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3,r):\n a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3 = a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3\n r = r\n def x1(x2,x3):\n return(D1-(b1*x2)-(c1*x3))/a1\n def x2(x1,x3):\n return(D2-(a2*x1)-(c2*x3))/b2\n def x3(x1,x2):\n return(D3-(a3*x1)-(b3*x2))/c3\n def error(n,o):\n return((n-o)/n)*100\n ax1,ax2,ax3= 0,0,0\n tabel=\"{0:1}|{1:7}|{2:7}|{3:7}|{4:7}|{5:7}|{6:7}\"\n print(tabel.format(\"i\", \"x1\", \"x2\", \"x3\", \"e1\", \"e2\", \"e3\"))\n for i in range(0,r):\n if i == 0:\n print(tabel.format(i, ax1, ax2, ax3, \"-\", \"-\", \"-\"))\n cx1=ax1\n cx2=ax2\n cx3=ax3\n else:\n cx1=eval(\"{0:.3f}\".format(x1(ax2,ax3)))\n cx2=eval(\"{0:.3f}\".format(x2(cx1,ax3)))\n cx3=eval(\"{0:.3f}\".format(x3(cx1,cx2)))\n print(tabel.format(i, cx1, cx2, cx3, \"{0:.2f}\".format(error(cx1, ax1)), \"{0:.2f}\".format(error(cx2, ax2)), \"{0:.2f}\".format(error(cx3, ax3))))\n ax1=cx1\n ax2=cx2\n ax3=cx3\n\n#~~~METODE JACOBI~~~\n\"\"\"\nMetode iterasi Jacobi digunakan untuk menyelesaikan persamaan linier yang proporsi koefisien nol-nya besar.\nKeuntungan metode ini adalah langkah penyelesaiannya yang sederhana, sedangkan kelemahannya adalah proses\niterasinya lambat, terutama untuk persamaan linear serentak dengan ordo tinggi.\n\"\"\"\ndef Jacobi(a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3,r):\n a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3 = a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3\n r = r\n def x1(x2,x3):\n return(D1-(b1*x2)-(c1*x3))/a1\n def x2(x1,x3):\n return(D2-(a2*x1)-(c2*x3))/b2\n def x3(x1,x2):\n return(D3-(a3*x1)-(b3*x2))/c3\n def error(n,o):\n return((n-o)/n)*100\n bx1,bx2,bx3= 0,0,0\n tabel=\"{0:1}|{1:7}|{2:7}|{3:7}|{4:7}|{5:7}|{6:7}\"\n print(tabel.format(\"i\", \"x1\", \"x2\", \"x3\", \"e1\", \"e2\", \"e3\"))\n for i in range(0,r):\n if i == 0:\n print(tabel.format(i, bx1, bx2, bx3, \"-\", \"-\", \"-\"))\n cx1=bx1\n cx2=bx2\n cx3=bx3\n else:\n cx1=eval(\"{0:.3f}\".format(x1(bx2,bx3)))\n cx2=eval(\"{0:.3f}\".format(x2(bx1,bx3)))\n cx3=eval(\"{0:.3f}\".format(x3(bx1,bx2)))\n print(tabel.format(i, cx1, cx2, cx3, \"{0:.2f}\".format(error(cx1, bx1)), \"{0:.2f}\".format(error(cx2, bx2)), \"{0:.2f}\".format(error(cx3, bx3))))\n bx1=cx1\n bx2=cx2\n bx3=cx3\n\n\n#MODUL 4 Integrasi Numerik\n#Oleh: KELOMPOK 9 / OSEANOGRAFI\n\n\"\"\"\nIntegrasi numerik merupakan cara alternatif untuk mengintegrasikan suatu persamaan, disamping integrasi analitis.\nIntegrasi analitis terkadang merupakan cara integrasi yang sulit, khususnya pada persamaan – persamaan\nyang kompleks dan rumit. Disamping itu, juga fungsi-fungsi yang diintegralkan tidak berbentuk analitis\nmelainkan berupa titik-titik data. \n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n#~~~METODE TRAPESIUM SATU PIAS~~~\n\"\"\"\nMetode trapesium merupakan metode pendekatan integral numerik dengan persamaan polinomial order satu. Dalam metode ini\nkurva lengkung dari fungsi f (x) digantikan oleh garis lurus. Pendekatan dilakukan dengan satu pias (trapesium).\n\"\"\"\ndef Trapesium_SatuPias(A,B,a,b,c):\n import numpy as np\n import matplotlib.pyplot as plt\n A = A\n B = B\n a = a\n b = b\n c = c\n x = np.linspace(-10,10,100)\n y = a*(x**3)+b*(x**2)+c\n x1 = A\n x2 = B\n x3 = B/2\n fx1 = a*(x1**3)+b*(x1**2)+c\n fx2 = a*(x2**2)+b*(x2**2)+c\n fx3 = 5\n plt.plot(x,y)\n plt.fill_between([x1,x2],[fx1,fx2])\n plt.xlim([-20,20]); plt.ylim([-20,20]);\n plt.title('Trapesium 1 pias')\n plt.savefig('image\\Trapesium_satu_pias.png')\n L = 0.5*(fx2 + fx1)*(x2 - x1)\n print(\"luas dengan metode trapesium 1 pias:\", L)\n\n#~~~METODE TRAPESIUM BANYAK PIAS~~~\n\"\"\"\nMetode trapesium banyak pias diberikan untuk menutup kekurangan metode trapesium satu pias.\nDiketahui bahwa pendekatan dengan menggunakan satu pias (trapesium) menimbulkan error yang besar.\nUntuk mengurangi kesalahan yang terjadi maka kurve lengkung didekati oleh sejumlah garis lurus,\nsehingga terbentuk banyak pias. Semakin kecil pias yang digunakan, hasil yang didapat menjadi semakin teliti .\n\"\"\"\ndef Trapesium_BanyakPias(A,B,N,a,b,c):\n import numpy as np\n import matplotlib.pyplot as plt\n def trapesium(f,A,B,N):\n x = np.linspace(A,B,N+1)\n y = f(x)\n y_right = y[1:] \n y_left = y[:-1] \n dx = (B-A)/N\n T = (dx/2)*np.sum(y_right + y_left)\n return T\n f = lambda x : ((a*(x**3))+(b*(x**2))+c)\n A = A\n B = B\n N = N\n a = a\n b = b\n c = c\n x = np.linspace(A,B,N+1)\n y = f(x)\n X = np.linspace(A,B+1,N)\n Y = f(X)\n plt.plot(X,Y)\n for i in range(N):\n xs = [x[i],x[i],x[i+1],x[i+1]]\n ys = [0,f(x[i]),f(x[i+1]),0]\n plt.fill(xs,ys,'b',edgecolor='b',alpha=0.2)\n plt.title('Trapesium banyak pias, N = {}'.format(N))\n plt.savefig('image\\Trapesium_banyak_pias')\n L = trapesium(f,A,B,N)\n print(L)\n\n#~~~METODE SIMPSON 1/3~~~\n\"\"\"\nMetode simpson 1/3 adalah metode yang mencocokkan polinomial derajat 2 pada tiga titik data diskrit\nyang mempunyai jarak yang sama. Hampiran nilai integrasi yang lebih baik dapat ditingkatkan\ndengan menggunakan polinominterpolasi berderajat yang lebih tinggi.\n\"\"\"\ndef Simpson_1per3(A,B,a,b,c):\n A = A\n B = B\n a = a\n b = b\n c = c\n def f(x):\n return a*(x**3) + b*(x**2) + c\n def simpson1per3(x0,xn,n):\n h = (xn - x0) / n\n integral = f(x0) + f(xn)\n for i in range(1,n):\n k = x0 + i*h\n if i%2 == 0:\n integral = integral + 2 * f(k)\n else:\n integral = integral + 4 * f(k)\n integral = integral * h/3\n return integral\n hasil = simpson1per3(A, B, 2)\n print(\"nilai integral metode Simpson 1/3:\",hasil )\n\n#~~~METODE SIMPSON 3/8~~~\n\"\"\"\nMetode Simpson 3/8 diturunkan dengan menggunakan persamaan polinomial order tiga yang melalui empat titik.\n\"\"\"\ndef Simpson_3per8(A,B,a,b,c):\n A = A\n B = B\n a = a\n b = b\n c = c\n def simpson():\n import math\n def f(x):\n return a*(x**3)+b*(x**2)+c\n def simpson1per3(x0,xn,n):\n h = (xn-x0)/n\n integral = f(x0) + f(xn)\n for i in range(1,n):\n k = x0 + 1*h\n if i%2 ==0 :\n integral = integral + 2 * f(k)\n else:\n integral = integral + 4 * f(k)\n integral = integral * 3 * h/8\n return integral \n hasil = simpson1per3(A, B, 2)\n print(\"nilai integral metode simpson 3/8:\", hasil)\n\n#MODUL 5 Persamaan Diferensial Biasa\n#Oleh: KELOMPOK 9 / OSEANOGRAFI\n\n\"\"\"\nsuatu persamaan differensial dikategorikan bedasarkan variabel bebasnya (Independent Variable). Pada persamaan differensial \nbiasa atau sering disebut juga dengan Ordinary Differential Equations (ODE) adalah \npersamaan differensial yang hanya memiliki satu variabel bebas.\n\"\"\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom IPython import get_ipython\n\nplt.style.use('seaborn-poster')\nipy = get_ipython()\nif ipy is not None:\n ipy.run_line_magic('matplotlib', 'inline')\n\n#~~~METODE EULER~~~\n\"\"\"\nMetode Euler adalah salah satu dari metode satu langkah yang paling sederhana.\nDi banding dengan beberapa metode lainnya, metode ini paling kurang teliti. Metode Euler dapat \nditurunkan dari Deret Taylor. Metode ini pada dasarnya adalah merepresentasikan solusinya dengan beberapa suku deret Taylor.\n\"\"\"\ndef Euler(h,x0,xn,y0,a,b,c,d):\n h = h\n x0 = x0\n xn = xn\n x = np.arange(x0, xn + h, h)\n y0 = y0\n a = a\n b = b\n c = c\n d = d\n G = a*(x**3) + b*(x**2) + c*x + d\n f = lambda x, y: a*(x**3) + b*(x**2) + c*x + d\n y = np.zeros(len(x))\n y[0] = y0\n \n for i in range(0, len(x) - 1):\n y[i + 1] = y[i] + h*f(x[i], y[i])\n\n Galat = G-y\n print(\"galat yang diperoleh dari metode Euler adalah:\", Galat)\n\n Judul = (\"Grafik Pendekatan Persamaan Differensial Biasa Dengan Metode Euler\")\n plt.figure(figsize = (10, 10))\n plt.plot(x, y, '-b', color='magenta', label='Hasil Pendekatan') \n plt.plot(x, G, 'g--', color='blue', label='Hasil Analitik')\n plt.title(Judul)\n plt.xlabel('x')\n plt.ylabel('y = F(x)')\n plt.grid()\n plt.legend(loc='best')\n plt.savefig('image\\euler.png')\n print(\"hasil pendekatan yang diperoleh dari metode Euler adalah:\", y)\n print(\"hasil analitik yang diperoleh adalah:\", G)\n\n#~~~METODE HEUN~~~\n\"\"\"\nMetode Heun adalah salah satu metode numerik yang dapat digunakan untuk menyelesaikan berbagai persoalan \nmatematika yang mempunyai masalah nilai awal, yaitu masalah penyelesaian suatu persamaan diferensial dengan\nsyarat awal yang telah diketahui. Metode Heun juga merupakan salah satu peningkatan dari metode Euler. Metode ini melibatkan \n2 buah persamaan. Persamaan pertama disebut sebagai persamaan prediktor yang digunakan untuk memprediksi \nnilai integrasi awal dan persamaan kedua disebut sebagai persamaan korektor yang mengoreksi hasil integrasi awal.\n\"\"\"\ndef Heun(h,x0,xn,y0,a,b,c,d):\n h = h\n x0 = x0\n xn = xn\n x = np.arange(x0, xn + h, h)\n y0 = y0\n a = a\n b = b\n c = c\n d = d\n G = a*(x**3) + b*(x**2) + c*x + d\n f = lambda x, y: a*(x**3) + b*(x**2) + c*x + d\n y = np.zeros(len(x))\n y[0] = y0\n\n for i in range(0, len(x) - 1):\n k1 = f(x[i], y[i])\n k2 = f((x[i]+h), (y[i]+(h*k1)))\n y[i+1] = y[i]+(0.5*h*(k1+k2))\n\n Galat = G-y\n print(\"galat yang diperoleh dari metode Heun adalah:\", Galat)\n\n Judul = (\"Grafik Pendekatan Persamaan Differensial Biasa Dengan Metode Heun\")\n plt.figure(figsize = (10, 10))\n plt.plot(x, y, '-b', color='magenta', label='Hasil Pendekatan')\n plt.plot(x, G, 'g--', color='blue', label='Hasil Analitik')\n plt.title(Judul)\n plt.xlabel('x')\n plt.ylabel('y = F(x)')\n plt.grid()\n plt.legend(loc='best')\n plt.savefig('image\\heun.png')\n print(\"hasil pendekatan yang diperoleh dari metode Heun adalah:\", y)\n print(\"hasil analitik yang diperoleh adalah:\", G)\n\n#~~~START~~~\nprint(\"Kode-kode modul: \\n\",\n \"1. Modul Akar-Akar Persamaan \\n\",\n \"2. Modul Sistem Persamaan Linier dan Matriks \\n\",\n \"3. Modul Integrasi Numerik \\n\",\n \"4. Modul Persamaan Diferensial Biasa \\n\")\nsetting = int(input(\"Masukkan kode penggunaan modul: \"))\nif (setting == 1):\n print(\"Kode-kode akar persamaan: \\n\",\n \"1. Metode Setengah Interval \\n\",\n \"2. Metode Interpolasi Linier \\n\",\n \"3. Metode Newton-Rhapson \\n\",\n \"4. Metode Secant \\n\",\n \"5. Metode Iterasi \\n\")\n print(\"Persamaan; ax^3+bx^2+cx+d\")\n setting = int(input(\"Masukkan kode penggunaan akar persamaan: \"))\n if (setting == 1):\n X1 = float(input(\"Masukkan Nilai Pertama Setengah Interval: \"))\n X2 = float(input(\"Masukkan Nilai Kedua Setengah Interval: \"))\n a = float(input(\"Masukkan Nilai a Setengah Interval: \"))\n b = float(input(\"Masukkan Nilai b Setengah Interval: \"))\n c = float(input(\"Masukkan Nilai c Setengah Interval: \"))\n d = float(input(\"Masukkan Nilai d Setengah Interval: \"))\n X = Setengah_Interval(X1,X2,a,b,c,d)\n print(X)\n elif (setting == 2):\n X1 = float(input(\"Masukkan Nilai Pertama Interpolasi Linier: \"))\n a = float(input(\"Masukkan Nilai a Interpolasi Linier: \"))\n b = float(input(\"Masukkan Nilai b Interpolasi Linier: \"))\n c = float(input(\"Masukkan Nilai c Interpolasi Linier: \"))\n d = float(input(\"Masukkan Nilai d Interpolasi Linier: \"))\n X = Interpolasi_Linier(X1,a,b,c,d)\n print(X)\n elif (setting == 3):\n X1 = float(input(\"Masukkan Nilai Pertama Newton-Rhapson: \"))\n a = float(input(\"Masukkan Nilai a Newton-Rhapson: \"))\n b = float(input(\"Masukkan Nilai b Newton-Rhapson: \"))\n c = float(input(\"Masukkan Nilai c Newton-Rhapson: \"))\n d = float(input(\"Masukkan Nilai d Newton-Rhapson: \"))\n X = Newton_Rhapson(X1,a,b,c,d)\n print(X)\n elif (setting == 4):\n X1 = float(input(\"Masukkan Nilai Pertama Secant: \"))\n a = float(input(\"Masukkan Nilai a Secant: \"))\n b = float(input(\"Masukkan Nilai b Secant: \"))\n c = float(input(\"Masukkan Nilai c Secant: \"))\n d = float(input(\"Masukkan Nilai d Secant: \"))\n X = Secant(X1,a,b,c,d)\n print(X)\n else:\n X1 = float(input(\"Masukkan Nilai Pertama Iterasi: \"))\n a = float(input(\"Masukkan Nilai a Iterasi: \"))\n b = float(input(\"Masukkan Nilai b Iterasi: \"))\n c = float(input(\"Masukkan Nilai c Iterasi: \"))\n d = float(input(\"Masukkan Nilai d Iterasi: \"))\n X = Iterasi(X1,a,b,c,d)\n print(X)\nelif (setting == 2):\n print(\"Kode-kode sistem persamaan linier dan matriks: \\n\",\n \"1. Metode Gauss \\n\",\n \"2. Metode Gauss-Jordan \\n\",\n \"3. Metode Gauss-Siedel \\n\",\n \"4. Metode Jacobi\")\n setting = int(input(\"Masukkan kode penggunaan sistem persamaan linier dan matriks: \"))\n if (setting == 1):\n print(\"Matriks: \\n\",\n \"[[a1,a2,a3], [b1,b2,b3], [c1,c2,c3]] \\n\",\n \"[D1,D2,D3]\")\n a1 = int(input(\"Masukkan nilai a1:\"))\n a2 = int(input(\"Masukkan nilai a2: \"))\n a3 = int(input(\"Masukkan nilai a3: \"))\n b1 = int(input(\"Masukkan nilai b1: \"))\n b2 = int(input(\"Masukkan nilai b2: \"))\n b3 = int(input(\"Masukkan nilai b3: \"))\n c1 = int(input(\"Masukkan nilai c1: \"))\n c2 = int(input(\"Masukkan nilai c2: \"))\n c3 = int(input(\"Masukkan nilai c3: \"))\n D1 = int(input(\"Masukkan nilai D1: \"))\n D2 = int(input(\"Masukkan nilai D2: \"))\n D3 = int(input(\"Masukkan nilai D3: \"))\n A = np.array([[a1, a2, a3], [b1, b2, b3], [c1, c2, c3]], dtype=int)\n B = np.array([D1, D2, D3])\n AB = np.hstack([A, B.reshape(-1, 1)])\n X = Gauss(A, B)\n print(X)\n elif (setting == 2):\n print(\"Matriks: \\n\",\n \"[[a1,a2,a3,D1], \\n\",\n \"[b1,b2,b3, D2], \\n\",\n \"[c1,c2,c3, D3]]\")\n n = int(input(\"Masukkan banyaknya jumlah variabel yang akan dicari: \"))\n a1 = int(input(\"Masukkan nilai a1:\"))\n a2 = int(input(\"Masukkan nilai a2: \"))\n a3 = int(input(\"Masukkan nilai a3: \"))\n b1 = int(input(\"Masukkan nilai b1: \"))\n b2 = int(input(\"Masukkan nilai b2: \"))\n b3 = int(input(\"Masukkan nilai b3: \"))\n c1 = int(input(\"Masukkan nilai c1: \"))\n c2 = int(input(\"Masukkan nilai c2: \"))\n c3 = int(input(\"Masukkan nilai c3: \"))\n D1 = int(input(\"Masukkan nilai D1: \"))\n D2 = int(input(\"Masukkan nilai D2: \"))\n D3 = int(input(\"Masukkan nilai D3: \"))\n m = np.array([[a1, a2, a3, D1],\n [b1, b2, b3, D2],\n [c1, c2, c3, D3]],dtype=int)\n print('Matriks Persamaan')\n print(m)\n m = GaussJordan(m,n)\n print(f\"\"\"Hasil Pengelolaan menggunkan metode Gauss Jordan didapatkan matriks:\n {m}\"\"\")\n elif (setting == 3):\n print(\"Persamaan: \\n\",\n \"x1=(Dx1-bx1-cx3)/ax1 \\n\",\n \"x2=(Dx2-bx2-cx2)/bx2 \\n\",\n \"x3=(Dx3-ax3-bx3)/cx3\")\n a1 = float(input(\"Masukkan nilai a1: \"))\n a2 = float(input(\"Masukkan nilai a2: \"))\n a3 = float(input(\"Masukkan nilai a3: \"))\n b1 = float(input(\"Masukkan nilai b1: \"))\n b2 = float(input(\"Masukkan nilai b2: \"))\n b3 = float(input(\"Masukkan nilai b3: \"))\n c1 = float(input(\"Masukkan nilai c1: \"))\n c2 = float(input(\"Masukkan nilai c2: \"))\n c3 = float(input(\"Masukkan nilai c3: \"))\n D1 = float(input(\"Masukkan nilai D1: \"))\n D2 = float(input(\"Masukkan nilai D2: \"))\n D3 = float(input(\"Masukkan nilai D3: \"))\n r = int(input(\"Masukkan range iterasi: \"))\n X = Gauss_Siedel(a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3,r)\n print(X)\n elif (setting == 4):\n print(\"Persamaan: \\n\",\n \"x1=(Dx1-bx1-cx3)/ax1 \\n\",\n \"x2=(Dx2-bx2-cx2)/bx2 \\n\",\n \"x3=(Dx3-ax3-bx3)/cx3\")\n a1 = float(input(\"Masukkan nilai a1 Jacobi: \"))\n a2 = float(input(\"Masukkan nilai a2 Jacobi: \"))\n a3 = float(input(\"Masukkan nilai a3 Jacobi: \"))\n b1 = float(input(\"Masukkan nilai b1 Jacobi: \"))\n b2 = float(input(\"Masukkan nilai b2 Jacobi: \"))\n b3 = float(input(\"Masukkan nilai b3 Jacobi: \"))\n c1 = float(input(\"Masukkan nilai c1 Jacobi: \"))\n c2 = float(input(\"Masukkan nilai c2 Jacobi: \"))\n c3 = float(input(\"Masukkan nilai c3 Jacobi: \"))\n D1 = float(input(\"Masukkan nilai D1 Jacobi: \"))\n D2 = float(input(\"Masukkan nilai D2 Jacobi: \"))\n D3 = float(input(\"Masukkan nilai D3 Jacobi: \"))\n r = int(input(\"Masukkan range iterasi: \"))\n X = Jacobi(a1,a2,a3,b1,b2,b3,c1,c2,c3,D1,D2,D3,r)\n print(X)\nelif (setting == 3):\n print(\"Kode-kode integrasi numerik: \\n\",\n \"1. Metode Trapesium Satu Pias \\n\",\n \"2. Metode Trapesium Banyak Pias \\n\",\n \"3. Metode Simpson 1/3 \\n\",\n \"4. Metode Simpson 3/8\")\n print(\"Persamaan; ax^3+bx^2+c\")\n setting = int(input(\"Masukkan kode penggunaan integrasi numerik: \"))\n if (setting == 1):\n A = int(input(\"Masukkan Nilai Batas Bawah Integral: \"))\n B = int(input(\"Masukkan Nilai Batas Atas Integral: \"))\n a = int(input(\"Masukkan Nilai a: \"))\n b = int(input(\"Masukkan Nilai b: \"))\n c = int(input(\"Masukkan Nilai c: \"))\n X = Trapesium_SatuPias(A,B,a,b,c)\n print(X)\n elif (setting == 2):\n A = int(input(\"Masukkan Nilai Batas Bawah Integral: \"))\n B = int(input(\"Masukkan Nilai Batas Atas Integral: \"))\n N = int(input(\"Masukkan Jumlah Pias: \"))\n a = int(input(\"Masukkan Nilai a: \"))\n b = int(input(\"Masukkan Nilai b: \"))\n c = int(input(\"Masukkan Nilai c: \"))\n X = Trapesium_BanyakPias(A,B,N,a,b,c)\n print(X)\n elif (setting == 3):\n A = int(input(\"Masukkan Nilai Batas Bawah Integral: \"))\n B = int(input(\"Masukkan Nilai Batas Atas Integral: \"))\n a = int(input(\"Masukkan Nilai a: \"))\n b = int(input(\"Masukkan Nilai b: \"))\n c = int(input(\"Masukkan Nilai c: \"))\n X = Simpson_1per3(A,B,a,b,c)\n print(X)\n else:\n A = int(input(\"Masukkan Nilai Batas Bawah Integral: \"))\n B = int(input(\"Masukkan Nilai Batas Atas Integral: \"))\n a = int(input(\"Masukkan Nilai a: \"))\n b = int(input(\"Masukkan Nilai b: \"))\n c = int(input(\"Masukkan Nilai c: \"))\n X = Simpson_3per8(A,B,a,b,c)\n print(X)\nelse:\n print(\"Kode-kode persamaan diferensial biasa: \\n\",\n \"1. Metode Euler \\n\",\n \"2. Metode Heun \\n\")\n print(\"Persamaan; ax^3+bx^2+cx^3+d\")\n setting = int(input(\"Masukkan kode penggunaan persamaan diferensial biasa: \"))\n if (setting == 1):\n h = float(input(\"Masukkan Nilai h Euler: \"))\n x0 = float(input(\"Masukkan Nilai x0 Euler: \"))\n xn = float(input(\"Masukkan Nilai xn Euler: \"))\n y0 = float(input(\"Masukkan Nilai y0 Euler: \"))\n a = float(input(\"Masukkan Nilai a Euler: \"))\n b = float(input(\"Masukkan Nilai b Euler: \"))\n c = float(input(\"Masukkan Nilai c Euler: \"))\n d = float(input(\"Masukkan Nilai d Euler: \"))\n X = Euler(h,x0,xn,y0,a,b,c,d)\n print(X)\n else:\n h = float(input(\"Masukkan Nilai h Heun: \"))\n x0 = float(input(\"Masukkan Nilai x0 Heun: \"))\n xn = float(input(\"Masukkan Nilai xn Heun: \"))\n y0 = float(input(\"Masukkan Nilai y0 Heun: \"))\n a = float(input(\"Masukkan Nilai a Heun: \"))\n b = float(input(\"Masukkan Nilai b Heun: \"))\n c = float(input(\"Masukkan Nilai c Heun: \"))\n d = float(input(\"Masukkan Nilai d Heun: \"))\n X = Heun(h,x0,xn,y0,a,b,c,d)\n print(X)\n\n\n# \n"
},
{
"alpha_fraction": 0.8105975985527039,
"alphanum_fraction": 0.8315432667732239,
"avg_line_length": 103.36743927001953,
"blob_id": "04676a87cd6ca1217384e6b043f649fd9abcadc5",
"content_id": "6420d4e7ba98acadb2113d0e3cfd9dae2dcc1ced",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 22483,
"license_type": "no_license",
"max_line_length": 2698,
"num_lines": 215,
"path": "/README.md",
"repo_name": "khofifahitsna27/Metode-Numerik-2021",
"src_encoding": "UTF-8",
"text": "# Metode-Numerik-2021\n\nAnggota Kelompok 9:\n1. Indah Bella Pratiwi / 26050119130048 / Oseanografi B\n2. Nia Oktaviani Annisa Putri / 26050119130047 / Oseanografi A\n3. Khofifah Itsna Maghfiroh / 26050119130045 / Oseanografi B\n4. Renita Setyowati / 26050119130044 / Oseanografi B\n5. Muhammad Azizi Dirgantara B.N. / 26050119130041 / Oseanografi B\n6. Muhammad Shulhan J. / 26050119130040 / Oseanografi A\n7. M Azka Zahran / 26050119130037 / Oseanografi B\n8. Gamma Haqqul Fikriawan / 26050119130036 / Oseanografi B\n9. Adwitiyadewi Nuraziza A. / 26050119130034 / Oseanografi B\n10. Tia oktavia / 26050119120032 / Oseanografi A\n11. Beltrand Yordan Simangunsong / 26050119120031 / Oseanografi B\n\n\n# KATA PENGANTAR\nAlhamdulillah, puji dan syukur kami panjatkan kepada Tuhan Yang Maha Esa yang telah melimpahkan rahmat serta hidayat Nya, sehingga kami dapat menyelesaikan penyusunan tugas akhir praktikum metode numerik ini dengan semaksimal mungkin. Selama proses penyusunan tugas ini, kami mendapatkan banyak bimbingan dan bantuan dari berbagai pihak. kami menyadari bahwa tanpa bantuan dan dorongan yang tiada henti dari pihak lain rasanya penyusunan tugas ini sulit untuk diselesaikan. Maka dari itu kami ucapkan terima kasih kepada:\n1. Dosen Pengampu Mata kuliah Metode Numerik yang telah memberikan ilmunya\n2. Tim asisten yang telah membimbing serta memberikan ilmunya selama praktikum.\n3. Bapak dan Ibu yang selalu mendo’akan, memotivasi, dan mendukung setiap Langkah kami.\n4. Teman-teman yang selalu memberikan bantuan dan dukungan hingga penyusunan tugas akhir praktikum ini selesai.\nPenyusunan tugas akhir praktikum ini tentunya masih banyak kekurangan. Maka dari itu, kami sangat mengharapkan saran dan kritikan yang bersifat membangun. Kami berharap tugas ini dapat memberikan manfaat kepada pembaca khususnya kami mengenai metode numerik ini.\n\nSemarang, 3 Juni 2021\n\nTim Penulis\n\n\n\n# Library dan Modul yang digunakan\nPada praktikum metode numerik kali ini, digunakan beberapa library seperti matplotlib, numpy, dan lain-lain. Penjelasan dari tiap library dijelaskan sebagai berikut:\n1. Matplotlib\n\nBerdasarkan homepage dari matplotlib (https://matplotlib.org/2.0.2/index.html): “matplotlib adalah library python untuk melakukan plotting 2D yang mana akan menghasilkan gambar berkualitas dalam format yang bervariasi dan dalam lingkungan yang interaktif dalam berbagai platform. Matplotlib dapat digunakan dalam script python, shell python dan Ipython, jupyter notebook, aplikasi web dan lain-lain”. Dalam kata lain, matplotlib dapat dengan mudah membuat plot, histogram, grafik batang, scatterplot, dan hal lainnya hanya dengan menggunakan python dan beberapa baris kode saja. Library ini dapat membantu sehingga dalam melakukan analisis dan explorasi dapat dilakukan lebih cepat (Morgan, 2016).\n\n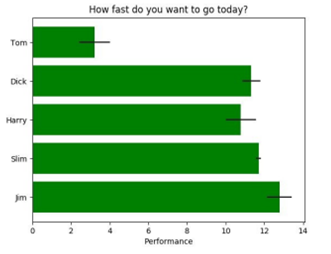\n\nGambar 1. Contoh diagram batang menggunakan matplotlib\n\n(Sumber: Morgan, 2016)\n\n2. Numpy\n\nNumpy merupakan salah satu package primer pada python untuk melakukan komputasi saintifik. Library tersebut mempunyai N-dimensional array, tools untuk melakukan integrasi C/C++ dan kode fortran, aljabar linear, fourier transofrn, dan lain-lain. Numpy juga mendukung broadcasting yang mana merupakan sebuah cara bagi fungsi universal untuk berhubungan dengan input yang tidak mempunyai bentuk yang sama. Selain kemampuan tersebut, kelebihan lain dari NumPy adalah dapat diintegrasikan dalam program python. Dalam kata lain, suatu data dapat diambil dari database, output program lain, file external, atau halaman HTML dan kemudian diproses menggunakan NumPy. NumPy dapat juga digunakan dengan Pygame, yang merupakan sebuah package python untuk membuat games (Asadi, 2016).\n\n3. SYS\n\nModule ini menyediakan akses untuk beberapa variabel yang digunakan atau dimaintain oleh interpreter dan sebagai fungsi yang dapat beriteraksi dengan interpreter. Hal ini sudah tersedia dalam python sehingga tidak perlu mengimport.\n\n4. OS\n\nOS merupakan sebuah library dalam python yang menyediakan suatu cara portable dalam menggunakan fungsi yang bergantung pada operating system.\n\nBeberapa contoh dalam library ini adalah:\n- open(), yang berguna untuk membuka atau memodifikasi suatu files \n- os.path yang berguna untuk memanipulasi path\n- fileinput untuk membaca semua baris dalam semua file pada command line\n- tempfile untuk membuat temporary files dan directories\n\nHal yang harus dicatat dalam ketersediaan fungsi pada library ini:\n- Desain dari semua modul Python bergantung pada sistem operasi bawaan sedemikian rupa sehingga selama fungsionalitas yang sama tersedia, ia menggunakan interface yang sama.\n- Ekstensi khusus untuk sistem operasi tertentu juga tersedia melalui modul os, tetapi menggunakannya tentu saja merupakan ancaman bagi portabilitas.\n- Semua fungsi yang menerima nama path atau file menerima objek byte dan string, dan menghasilkan objek dengan tipe yang sama, jika path atau nama file dikembalikan.\n- Pada VxWorks, os.fork, os.execv dan os.spawn*p* tidak didukung.\n\n5. Ipython\n\nSalah satu dari fitur utama python adalah interpreternya yang interaktif. Hal tersebut memungkinkan untuk testing suatu hal secara cepat tanpa harus membuat test files sebagaimana bahasa pemrograman yang lain. Akan tetapi, interpreter yang didukung oleh distribusi standar python mempunyai Batasan bagi penggunaan yang interaktif.\n\nTujuan dari IPython adalah untuk membuat suatu kondisi atau lingkunagn yang interaktif dalam suatu komputasi. Untuk mendukung hal ini, IPython mempunyai 3 komponen utama:\n\n1. Peningkatan python shell yang lebih interaktif\n2. Model komunikasi dua proses yang dipisahkan, yang memungkinkan beberapa klien untuk terhubung ke kernel komputasi, terutama notebook berbasis web yang menggunakan Jupyter\n3. Arsitektur untuk komputasi interaktif parallel yang menjadi bagian dari package ipyparallel\n\nShell interaktif IPython (ipython), memiliki tujuan sebagai berikut:\n\n1. Memberikan shell interaktif yang lebih unggul dari shell Python default. IPython memiliki banyak fitur untuk penyelesaian tab, introspeksi objek, akses ke system shell, pengambilan riwayat perintah di seluruh sesi, dan sistem perintah khusus untuk menambahkan fungsionalitas saat bekerja secara interaktif. Hal ini menjadi lingkungan yang sangat efisien baik untuk pengembangan kode Python dan untuk eksplorasi masalah menggunakan objek Python (seperti dalam analisis data).\n2. Menjadi interpreter yang siap digunakan dan dapat disematkan dalam suatu program. Shell IPython yang interaktif dapat dibuka dengan satu panggilan dari dalam program lain, menyediakan akses ke namespace saat ini. Hal Ini sangat berguna baik untuk tujuan debugging maupun untuk situasi dimana campuran batch-processing dan eksplorasi interaktif diperlukan.\n3. Menawarkan framework fleksibel yang dapat digunakan sebagai kondisi atau lingkungan dasar untuk bekerja dengan sistem lain, menggunakan Python sebagai bahasa dasar. \n4. Memungkinkan pengujian interaktif toolkit grafis. IPython memiliki dukungan untuk kontrol interaktif dan tidak terblokir dari aplikasi GTK, Qt, WX, GLUT, dan OS X melalui flag threading khusus. Sedangkan shell Python normal hanya dapat melakukan ini untuk aplikasi Tkinter. \n\n\n\n# MODUL 1: PENGENALAN METODE NUMERIK DAN PYTHON\n1.1 Definisi Metode Numerik\n\nMetode numerik adalah teknik untuk menyelesaikan permasalahan yang diformulasikan secara matematis dengan cara operasi hitungan. Dalam metode numerik terdapat beberapa bentuk proses hitungan atau algoritma untuk menyelesaikan suatu tipe persamaan matermatis, seperti operasi dasar hitungan penjumlahan, pengurangan, perkalian dan pembagian. Menurut Sudiarta (2020), terdapat empat bagian utama dalam metode numerik, yaitu:\n1. Teori yang mendasari perhitungan numerik\n2. Algoritma atau langkah-langkah yang dilakukan dalam menyelesaikan masalah atau mendapatkan hasil\n3. Pemograman yang dibutuhkan untuk memberikan instruksi kepada computer dalam melakukan perhitungan numerik\n4. Visualisasi yang merupakan proses menampilkan anka-angka atau data dalam bentuk berbeda sehingga mudah untuk mengenali dalam interpretasi hasil\n\n1.2 Prinsip Kerja dan Cara Pengerjaan Metode Numerik\n\nUntuk menerapkan metode numerik, dibutuhkan berbagai pendekatan-pendekatan matematiss, dan setiap pendekatan memiliki tingkat kesalahan yang berbeda-beda. Metode numerik memberikan solusi yang menghampiri atau mendekati solusi sejati sehingga dinamakan solusi hampiran, tetapi solusi hampiran dapat dibuat seteliti yang diinginkan dan terdapat nilai galat yang tidak sama dengan nol (Faradillah, 2020).\nMetode numerik memberikan cara-cara untuk menyelesaikan bentuk persamaan tersebut secara perkiraan hingga didapat hasil yang mendekati penyelesaian secara besar (eksak). Penyelesaian numerik dilakukan dengan perkiraan yang berurutan (iterasi), maka tiap hasil akan lebih teliti yang dianggap cukup akan didapat hasil perkiraan yang mendekati hasil yang benar (eksak) dengan toleransi yang disesuaikan (Panjaitan, 2017).\nKemudahan dalam pemograman dan banyaknya tambhan modul-modul yang membantu dalam penyelesaian permasalahan matematis serta visualisasi hasil yang baik, menjadikan Phyton sebagai pilihan dalam penerapan metode numerik. Pengerjaan kalkulasi pada dokumen interaktif Jupyter Notebook menghasilkan sebuah dokumen yang menampilkan secara lengkap empat bagian metode numerik. \n\n1.3 Peranan Komputer dalam Metode Numerik\n\nPerhitungan operasi aritmatika dalam metode numerik (jumlah, kali, bagi dan perbandingan) sangat banyak dan sering berulang sehingga akan memerlukan tenaga yang besar untuk mengolah data tersebut dan sering kali timbul berbagai kesalahan. Dengan bantuan computer maka akan mempercepat proses perhitungan dengan hasil yang benar. Penggunaan computer dalam metode numerik antara lain untuk membuat program. Langkah-langkah metode numerik diformulasikan menjadi program komputer dengan Bahasa pemograman tertentu. Selain mempercepat perhitungan metode numerik, dengan penggunaan komputer maka akan dapat menyelesaikan berbagai persoalan yang terjadi akibat perubahan beberapa parameter. Solusi yang diperoleh juga dapat ditingkatkan ketelitiannya dengan mengubah nilai parameter (Rachmad et al., 2017).\n\n1.4 Phyton\n\nBahasa Phyton merupakan bahasa pemograman tingkat tinggi yang mudah digunakan dan memiliki cara penulisan atau syntax yang sederhana, mudah ditulis dan dibaca (dalam bahasa Inggris). Kode bahasa Phyton berupa script, perintah-perintah atau pernyataan-pertanyaan yang tidak memerlukan kompilasi sehingga dapat langsung dijalankan. Hal ini membuat penulisan kode program dapat lebih cepat. Program Phyton merupakan sebuah interpreter seperti program Matlab ataupun yang lainnya, yang dapat menerjemahkan kode Phyton. Program Phyton juga menyediakan fasilitas development environment IDLE. Pada environment ini kita dapat menjalankan atau mengevaluasi perintah-perintah atau kode Phyton secara langsung atau disebut REPL atau Read-Evaluate-Print-Loop (Sudiarta, 2020). Terdapat empat cara untuk menjalankan kode program Phython yaitu:\n1. Menggunakan Phyton Interpreter\n2. Menggunakan aplikasi Phyton IDLE\n3. Menggunakan Phyton pada Command Prompt\n4. Menggunakan Jupyter Notebook\nPerintah-perintah atau pernyataan-pernyataan dengan bahasa Phyton dapat langsung dieksekusi di sel pada sebuah dokumen interaktif Jupyter Notebook. Kode dan hasilnya dapat langsung ditampilkan dalam satu dokumen sehingga membuat Jupyter Notebook menjadi pilihan dalam penerapan metode numerik.\n\n1.5 Jupyter Notebook\n\nJupyter Notebook memungkinkan pengguna bahasa pemograman utama yang lebih beragam yaitu Julia, Python dan R. Jupyter Notebook bersifat opensource sehingga setiap orang dapat mengunduhnya dari internet. Bagi pengguna pemula, cara yang paling mudah adalah dengan mengunduh anaconda dari website. Anaconda memuat lebih dari 300 paket Python terpopuler di bidang matematika, sains, rekayasa dan analisis data termasuk Jupyter Notebook App. Menurut Setiabudidaya (2018), Jupyter Notebook (file yang berekstensi ipynb) adalah dokumen yang dihasilkan oleh Jupyter Notebook App yang berisikan kode komputer dan rich text element seperti paragraph, persamaan matematik, gambar dan tautan (links). Jupyter Notebook dikenal sebelumnya sebagai IPython Notebook dan dalam waktu dekat akan berevolusi menjadi Jupyter Lab\n\n\n\n# MODUL 2: AKAR-AKAR PERSAMAAN\nPada penyelesaian akar- akar persamaan ada lima metode yang dapat digunakan dalam metode numerik. Pertama adalah metode setengah interval yaitu Kelebihan dari metode ini adalah selalu berhasil dalam menentukan akar-akar (solusi) yang dicari atau dengan kata lain selalu konvergen. Selain kelebihan, dalam metode bisection juga terdapat kekurangan, yaitu pada metode biseksi hanya dapat dilakukan apabila ada akar persamaan pada interval yang diberikan. Kedua Metode Interpolasi Linier yang hampir mirip dengan metode setengah interval. Kemiripannya adalah terletak dalam hal diperlukan dua harga taksiran awal pada awal pengurungan akar persamaan. Sedangkan, perbedaannya terletak pada proses pencarian pendekatan akar persamaan selanjutnya setelah pendekatan akar saat ini ditemukan Prinsip pencarian akar persamaan dari metode ini didasarkan pada penggunaan interpolasi linier. Ketiga yaitu Metode Newton-Raphson yang terbukti memiliki laju konvergensi lebih cepat dibandingkan dengan metode bagi dua maupun metode Regula Falsi. Akan tetapi,syarat yang harus dipenuhi adalah bahwa taksiran awal yang diberikan harus sedekat mungkin dengan harga eksaknya. Hal ini untuk mengantisiasi seandainya fungsi nonliniernya tidak seperti yang kita harapkan. Keempat adalah metode iterasi Metode tidak langsung atau iterative, merupakan metode yang berbasiskan terhadap aplikasi dari langkah – langkah/algoritma sederhana yang diulang – ulang pada sistem persamaan tersebut hingga sistem persamaan mencapai keadaan konvergen yang merepresentasikan solusi dari sistem persamaan tersebut. Pada metode iterative, banyaknya langkah – langkah perhitungan yang dilakukan tidak dapat diprediksi, dimana tipikalnya adalah sebanyak N perhitungan per satu kali iterasi. Kekurangan lainnya adalah, jika sistem persamaan tidak berada pada kondisi yang kondusif, maka konvergensi dari suatu sistem persamaan tidak dapat terjamin. Satu – satunya kelebihan dari penggunaan metode iterative adalah sedikitnya memori computer yang digunakan sebagai akibat dari algoritma yang mendesain agar computer hanya menyimpan koefisien – koefisien yang tidak nol. Kelima adalah metode seccant, Pada dasarnya metode ini sama dengan metode Newton-Raphson, perbedaannya hanya terletak pada pendekatan untuk turunan pertama dari f saja.\n\n\n\n# MODUL 3: SISTEM PERSAMAAN LINIER DAN MATRIKS\nSistem persamaan linear merupakan salah satu materi yang memegang peranan penting dalam matematika. Sistem persamaan linear dapat digunakan oleh kehidupan kita sehari-hari. Sistem persamaan linear ini merupakan salah satu materi aljabar yang sangat berguna untuk memecahkan suatu masalah. Salah satu contoh materi dari sistem persamaan linear adalah menentukan koordinat titik potong dua garis, menentukan persamaan garis dan menentukan konstanta-konstanta pada suatu persamaan (Islamiyah et al., 2018).\nTerdapat beberapa materi atau metode yang dapat digunakan untuk menyelesaikan sistem persamaan linear menggunakan matriks. Metode-metode tersebut adalah:\n\n1. Metode Gauss\n\nMetode eliminasi Gauss termasuk dalam metode penyelesaian persamaan linear dengan cara langsung. Inti dari metode ini adalah membawa persamaan ke dalam bentuk matriks dan menyederhanakam matriks tersebut menjadi bentuk segitiga atas. Setelah mendapat bentuk segitiga atas, dilakukan substitusi balik untuk mendapat nilai dari akar persamaan tadi.\n\n2. Metode Gauss-Jordan\n\nMetode ini merupakan pengembangan dari metode eliminasi Gauss. Dimana tujuan kita membuat matriks identitas bukan lagi segitiga atas. Sehingga tidak diperlukan lagi substitusi balik untuk mencari nilai dari akar persamaan.\n\n3. Metode Gauss-Seidel\n\nBerbeda dengan dua metode yang sebelumnya, yaitu eliminasi Gauss dan Gauss-Jordan yang menggunakan matriks untuk menyelesaikan sistem persamaan. Metode Gauss-Seidel menggunakan metode Iterasi dalam menyelesaikan masalahnya. Metode ini dikembangkan dari gagasan penyelesaian masalah tak linear.\n\n4. Metode Iterasi Jacobi\n\nMetode ini merupakan suatu teknik penyelesaian SPL berukuran n x n; AX = b; secara iterative. Proses penyelesaian dimulai dengan suatu hampiran awal terhadap penyelesaian X. Teknik iterative jarang digunakan untuk menyelesaikan SPL dengan ukuran kecil karena metode-metode langsung seperti metode eliminasi Gauss lebih efisien daripada metode iterative. Tetapi, metode ini sangat berguna untuk menyelesaikan SPL dengan ukuran yang besar.\n\n\n\n# MODUL 4: INTEGRASI NUMERIK\nSuatu cara yang digunakan untuk mengintegrasikan suatu persamaan di luar metode analitis. Integrasi numerik digunakan untuk mendapatkan nilai nilai hampiran dari beberapa integral tertentu yang memerlukan penyelesaian numerik sebagai hampirannya.\n\n1.\tMetode Trapesium 1 Pias\n\nMetode yang digunakan pada saat hanya terdapat dua data (f(a), f(b)) karena hanya dapat membentuk satu trapesium\n\n2.\tMetode Trapesium Banyak Pias\n\nMetode yang digunakan apabila tersedia data lebih dari dua, maka dapat dilakukan pendekatan dengan lebih dari satu trapesium dan luas total adalah jumlah dari trapesium – trapesium yang terbentuk\n\n3.\tMetode Simpson 1/3\n\nMengasumsikan bahwa lengkungan dengan tiga ordinat berjarak sama y0, y1, y2 adalah suatu polinomial derajat dua\n\n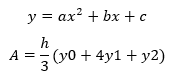\n\n\n\n4.\tMetode Simpson 3/8\n\nMengasumsikan bahwa lengkungan dengan empat ordinat memiliki jarak sama, y0, y1, y2, y3 adalah suatu polinomila berderajat tiga \n\n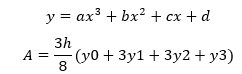\n\n\n\n\n\n# MODUL 5: PERSAMAAN DIFERENSIAL BIASA\nSuatu persamaan disebut dengan persamaan differensial apabila mempunyaai bentuk differensial, misalnya 𝑑𝑦/𝑑𝑡 atau 𝑑𝑦/𝑑𝑥. Persamaan differensial biasa atau sering disebut juga dengan Ordinary Differential Equations (ODE) adalah persamaan differensial yang hanya memiliki satu variabel bebas. Metode yang dikembangkan untuk menyelesaikan persamaan diferensial biasa secara numerik (secara pendekatan karena penyelesaian secara analitis sulit untuk diperoleh), yang antara lain dapat dilakukan dengan dua metode yaitu metode satu-langkah (one-step) dan metode banyak-langkah (multi-step). Metode satu langkah terdiri dari beberapa metode, dimana dua diantaranya adalah metode Euler dan metode Heun..Metode Euler mempunyai ketelitian lebih rendah dari metode Heun namun metode ini cukup sederhana dan mudah pemahamannya. Metode Euler dapat diturunkan dari Deret Taylor. Metode ini pada dasarnya adalah merepresentasikan solusinya dengan beberapa suku deret Taylor. Misal, bentuk persamaan differensial berikut y’= f(x,y). Dengan menggunakan pendekatan nilai awal (x0,y0) maka nilai-nilainya berikutnya dapat diperoleh dengan: yn+1 = yn + h.f(xn, yn). Metode Heun merupakan perbaikan dari metode Euler tetapi memiliki iterasi lebih banyak dibandingkan dengan metode Euler. Metode Heun merupakan bentuk peningkatan dari metode Euler. Metode ini menaksir nilai y(tn+1) yang membutuhkan satu buah taksiran nilai sebelumnya yaitu y(tn). Metode ini melibatkan 2 buah persamaan, yaitu persamaan prediktor untuk memprediksi nilai integrasi awal dan persamaan korektor untuk mengoreksi hasil integrasi awal. Akurasi pada metode ini memang lebih baik karena metode ini melakukan koreksi ulang terhadap suati nilai koreksi menggunakan persamaan selanjutnya. Dari hasilnya dapat dibandingkan dan diamati bahwa metode Heun lebih baik dan efektif digunakan karena hasil perhitungannya lebih mendekati ke nilai asli dibandingkan dengan hasil dari metode Euler. Semua hasil metode Heun lebih mendekati ke hasil analitik dibandingkan dengan hasil dari metode Euler. Dari kurva-kurva yang ada pada kedua grafik juga dapat dilihat bahwa hasil pendekatan metode Heun lebih mendekati hasil analitik dibanding dengan hasil pendekatan metode Euler. Perbedaan keduanya memang cukup tipis, namun tetap saja, hasil metode Heun lebih medekati nilai aslinya. Galat metode Heun lebih kecil daripada metode Euler, berarti hasil perhitungannya semakin baik. Dengan demikian maka dapat disimpulkan bahwa baik dari hasil perhitungan maupun galatnya, metode yang paling baik digunakan adalah metode Heun. Adanya perbedaan hasil perhitungan dan nilai galat (error) ini dapat disebabkan oleh perbedaan prinsip perhitungan pada kedua metode ini.\n\n\n\n\n# DAFTAR PUSTAKA\nAsadi, A. 2016. Python: The Complete Manual: The Essential Handbook for Python User. Imagine Publishing: West Midlands\n\nErmawati, E., Rahayu, P., & Zuhairoh, F. (2017). Perbandingan Solusi Numerik Integral Lipat Dua Pada Fungsi Aljabar Dengan Metode Romberg Dan Simulasi Monte Carlo. Jurnal MSA (Matematika dan Statistika serta Aplikasinya), 5(1), 46.\n\nFaradillah, Ayu. 2020. Metode Numerik. Jakarta: Program Studi Pendidikan Matematika Fakultas Keguruan dan Ilmu Pendidikan UHAMKA.\n\nIslamiyah, A. C., Prayitno, S., & Amrullah, A. (2018). Analisis Kesalahan Siswa SMP pada Penyelesaian Masalah Sistem Persamaan Linear Dua Variabel. Jurnal Didaktik Matematika, 5(1), 66-76.\n\nJami’in, M. A., Hidayat, E. P., Mujiono, U., Julianto, E., & Asmara, I. P. S. (2017, December). Analisa Data Hasil Pelatihan Pengukuran Kapal di Brondong dengan Pendekatan Fungsi Polinomial. In Seminar MASTER PPNS (Vol. 2, No. 1, pp. 181-186).\n\nMorgan, P. 2016. Data Analysis From Scratch With Python. AI Sciences\n\nPanjaitan, Melda. 2017. Pemahaman Meotde Numerik Menggunakan Pemograman MATLAB\t (Studi Kasus: Metode Secant). Jurnal Teknologi Informasi., 1(1).\n\nRachmad, Cahya, Deasy Sandhya E. I. dan Yan W. Syaifudin. 2017. Metode Numerik. Malang:\t Polinema Press.\n\nSetiabudidaya, Dedi. 2018. Penggunaan Piranti Lunak Jupyter Notebook dalam Upaya\tMensosialisasikan Open Science. \n\nSudiarta, I Wayan. 2020. Metode Numerik. Jakarta: Arga Puju Press. \n\nhttps://docs.python.org/3/library/os.html\n\nhttps://docs.python.org/3/library/sys.html\n\nhttps://ipython.readthedocs.io/en/stable/overview.html\n\n\n\n# Saran Praktikum\n1. Sebaiknya diberikan video tutorial agar praktikan lebih memahami\n2. Sebaiknya penjelasan praktikum bisa diberikan dan diterangkan lebih rinci lagi karena materi dari metode numerik sendiri sangat kompleks dan sulit dipahami\n3. Sebaiknya penjelasan mengenai library di phyton lebih diperjelas\n4. Sebaiknya tugas yang telah diberikan dikoreksi bersama agar praktikan lebih mengerti letak kesalahannya\n"
}
] | 2 |
bishoygaid/pharmacy
|
https://github.com/bishoygaid/pharmacy
|
dc253e25ecd2b28e3039903e1c5b15c2f7383f5a
|
77804bebb11a6f1f5e405e3db4fa84cab65362b9
|
a7d789936e877f5a618a00548c51ecab2573ccba
|
refs/heads/master
| 2023-06-10T10:05:12.815497 | 2021-07-02T11:14:15 | 2021-07-02T11:14:15 | 374,797,837 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8097561001777649,
"alphanum_fraction": 0.8097561001777649,
"avg_line_length": 21.77777862548828,
"blob_id": "f83121e5217f1bd4e4507a7d931b44ee65b16266",
"content_id": "d416a81a36e8d3afc228c7adf675827b0aee4451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 9,
"path": "/pharmacies/admin.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom .models import Pharmacy, Branch, Phone, Medicine\n\n\nadmin.site.register(Pharmacy)\nadmin.site.register(Phone)\nadmin.site.register(Branch)\nadmin.site.register(Medicine)\n"
},
{
"alpha_fraction": 0.8095238208770752,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 20,
"blob_id": "d29409914f94a19c70878889edbac38c3f77473c",
"content_id": "8225285f9b64794fe92f40e1fb563746792a1088",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 6,
"path": "/doctors/admin.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom .models import Doctor, Branch\n\nadmin.site.register(Doctor)\nadmin.site.register(Branch)\n"
},
{
"alpha_fraction": 0.7361963391304016,
"alphanum_fraction": 0.7361963391304016,
"avg_line_length": 31.600000381469727,
"blob_id": "5d9f26d0a4107069adad30a19e68cbe8c793fbcb",
"content_id": "a3027a5d1391e4ff34ed3944cacb343ad69e346f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 15,
"path": "/cart/models.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom pharmacies.models import Medicine\nfrom doctors.models import Doctor\nfrom patients.models import Patient\n\n\nclass Cart(models.Model):\n doctor = models.ForeignKey(\n Doctor, related_name='doctors', on_delete=models.CASCADE\n )\n patient = models.ForeignKey(\n Patient, related_name='patients', on_delete=models.CASCADE\n )\n medecines = models.ManyToManyField(Medicine, blank=True)\n summry = models.TextField(blank=True, null=True)\n"
},
{
"alpha_fraction": 0.695716381072998,
"alphanum_fraction": 0.7119645476341248,
"avg_line_length": 34.6315803527832,
"blob_id": "ae1f175b2657525c966bbbb11face194f5b99325",
"content_id": "a5c489c0b1d647bf418af08fc8c9353fa11a1d89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 677,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 19,
"path": "/doctors/models.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n\n\nclass Doctor(models.Model):\n user = models.OneToOneField(\n User, related_name='doctor', on_delete=models.CASCADE\n )\n phone = models.CharField(max_length=20, blank=True, null=True)\n\n\nclass Branch(models.Model):\n doctor = models.ForeignKey(\n Doctor, related_name='branches', on_delete=models.CASCADE\n )\n country = models.CharField(max_length=20, blank=True, null=True)\n city = models.CharField(max_length=20, blank=True, null=True)\n state = models.CharField(max_length=20, blank=True, null=True)\n address = models.CharField(max_length=200, blank=True, null=True)\n"
},
{
"alpha_fraction": 0.5347043871879578,
"alphanum_fraction": 0.5835475325584412,
"avg_line_length": 20.61111068725586,
"blob_id": "97e762c602590b8216aebd59ba1e21c4f5c80bb6",
"content_id": "d6a6406b529e37d23e177b2a1afafdb32dfb2dcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 18,
"path": "/cart/migrations/0003_cart_summry.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-28 20:01\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('cart', '0002_remove_cart_medicine'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='cart',\n name='summry',\n field=models.TextField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.506369411945343,
"alphanum_fraction": 0.5668789744377136,
"avg_line_length": 17.47058868408203,
"blob_id": "decb15848b012bdea82089657716ddb0cffa0cc2",
"content_id": "f061442da44f8e93d4de5f319ddc5cc7fc281cfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/cart/migrations/0002_remove_cart_medicine.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-28 20:00\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('cart', '0001_initial'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='cart',\n name='medicine',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6004140973091125,
"alphanum_fraction": 0.6004140973091125,
"avg_line_length": 25.83333396911621,
"blob_id": "21f9ab83394a8c101658918c488ec69ff5b3e974",
"content_id": "d8fbf58a7f837b480978a7fe56a02d79f4bb9e53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 483,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 18,
"path": "/cart/forms.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Cart, Patient\n\n\nclass PatientForm(forms.ModelForm):\n class Meta:\n model = Patient\n fields = [\"id\", 'full_name', 'phone']\n\nclass CartForm(forms.ModelForm):\n def __init__(self, *args, **kwargs):\n super(CartForm, self).__init__(*args, **kwargs)\n self.fields.pop('doctor')\n self.fields.pop('patient')\n\n class Meta:\n model = Cart\n fields = ['doctor', 'patient', 'medecines', 'summry']\n"
},
{
"alpha_fraction": 0.6654929518699646,
"alphanum_fraction": 0.6654929518699646,
"avg_line_length": 27.399999618530273,
"blob_id": "1f3302d8fe43b8f9f64da9524abdf2f399cae8df",
"content_id": "7e95a9ef07141442e374cadabb505adc6256b3b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 10,
"path": "/core/urls.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\n\nurlpatterns = [\n path('', views.home_page, name=\"home\"),\n path('departments/', views.departments, name=\"departments\"),\n path('doctors/', views.doctors, name=\"doctors\"),\n path('contact/', views.contact, name=\"contact\"),\n]\n"
},
{
"alpha_fraction": 0.684539794921875,
"alphanum_fraction": 0.7033064961433411,
"avg_line_length": 34,
"blob_id": "a5516dee88cbe6a31524bf1d48761a5a7a63a7dd",
"content_id": "560b8f1f9aee271289b86f91395d90e5411c71ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/pharmacies/models.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Pharmacy(models.Model):\n name = models.CharField(max_length=250)\n\n\nclass Branch(models.Model):\n pharmacy = models.ForeignKey(\n Pharmacy, related_name='branches', on_delete=models.CASCADE\n )\n country = models.CharField(max_length=20, blank=True, null=True)\n city = models.CharField(max_length=20, blank=True, null=True)\n state = models.CharField(max_length=20, blank=True, null=True)\n address = models.CharField(max_length=200, blank=True, null=True)\n\nclass Phone(models.Model):\n pharmacy = models.ForeignKey(\n Pharmacy, related_name='phones', on_delete=models.CASCADE\n )\n phone = models.CharField(max_length=20, blank=True, null=True)\n\n\nclass Medicine(models.Model):\n name = models.CharField(max_length=200, blank=True, null=True)\n code = models.CharField(max_length=200, blank=True, null=True)\n price = models.FloatField(default=0)\n # photo = models.ImageField(upload_to=\"/medicine/images/\", blank=True, null=True)\n expire_date = models.DateTimeField(blank=True, null=True)\n\n def __str__(self):\n return self.name"
},
{
"alpha_fraction": 0.6934306621551514,
"alphanum_fraction": 0.7116788029670715,
"avg_line_length": 26.399999618530273,
"blob_id": "a4c24ce3561ec0589f2f89ac7e5a9e428f5371ae",
"content_id": "dd1bb21c5e710d20c2e7c50767131334013d583b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 10,
"path": "/patients/models.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n\n\nclass Patient(models.Model):\n full_name = models.CharField(max_length=250)\n phone = models.CharField(max_length=20, blank=True, null=True)\n\n def __str__(self):\n return self.full_name\n"
},
{
"alpha_fraction": 0.6683937907218933,
"alphanum_fraction": 0.6683937907218933,
"avg_line_length": 23.125,
"blob_id": "bbf6512168ac4ee12b7e305285d32c5227128d73",
"content_id": "fbe26d19e534ee3f308db2ab0e936656df1f0fb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 8,
"path": "/cart/urls.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\n\nurlpatterns = [\n path('cart/', views.create_cart, name=\"create_cart\"),\n path('cart/<int:pk>', views.cart_detail, name=\"cart_detail\"),\n]\n"
},
{
"alpha_fraction": 0.6401006579399109,
"alphanum_fraction": 0.6459731459617615,
"avg_line_length": 35.121212005615234,
"blob_id": "0e839a4adbba5c5aafea67928dd68aeeb7153a41",
"content_id": "6c043f30256a79ef6b6ca417b1003e2aa8e417a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 33,
"path": "/cart/views.py",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "import logging\nfrom django.db.models import Sum\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom .models import Cart\nfrom .forms import CartForm, PatientForm\n\nlogger = logging.getLogger(__name__)\n\ndef create_cart(request):\n if request.method == \"POST\":\n form = CartForm(request.POST or None)\n patient_form = PatientForm(request.POST or None)\n if patient_form.is_valid():\n patient_id = patient_form.save()\n cart = form.save(commit=False)\n cart.patient = patient_id\n cart.doctor = request.user.doctor\n cart.save()\n form.save_m2m()\n return redirect(\"cart_detail\", pk=cart.id)\n else:\n form = CartForm()\n patient_form = PatientForm()\n\n template = \"create_cart.html\"\n context = {\"form\": form, \"patient_form\": patient_form}\n return render(request, template, context)\n\n\ndef cart_detail(request, pk):\n cart = get_object_or_404(Cart, pk=pk)\n total_price = cart.medecines.aggregate(total=Sum(\"price\")).get(\"total\")\n return render(request, \"cart_detail.html\", context={\"cart\": cart, \"total_price\": total_price, \"medecines\": cart.medecines.all()})\n"
},
{
"alpha_fraction": 0.5984252095222473,
"alphanum_fraction": 0.6122047305107117,
"avg_line_length": 23.238094329833984,
"blob_id": "aac2ff3b6f69aec363bd53d94b021991f8cd2d5c",
"content_id": "fb0d3968303ad5f08f0b82353cd840460bf7a822",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 21,
"path": "/templates/account/signup.html",
"repo_name": "bishoygaid/pharmacy",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% load bootstrap5 %}\n\n\n{% block title %}Login{% endblock %}\n\n{% block content %}\n\n\n<form class=\"\" id=\"signup_form\" method=\"post\" action=\"{% url 'account_signup' %}\" style=\"margin-top: 300px; margin-bottom: 100px\">\n {% csrf_token %}\n {% bootstrap_form form %}\n {% buttons %}\n <button type=\"submit\" class=\"btn btn-success\">Sign Up »</button>\n {% endbuttons %}\n <p>Already have an account? Then please <a href=\"{{ login_url }}\">sign in</a>.</p>\n\n</form>\n\n\n{% endblock %}"
}
] | 13 |
Hemangi3598/Chap-9_p4
|
https://github.com/Hemangi3598/Chap-9_p4
|
54f763b1a21a2d10eaaadb836dd0e9d5f2cc112b
|
db8ff8b6202aa200de3b8de3e8e888c6b0eb633b
|
b1bd59d78b9b3e87a0eeb7a02ee613505c16c9d5
|
refs/heads/main
| 2023-08-03T21:50:25.345512 | 2021-09-19T08:50:55 | 2021-09-19T08:50:55 | 408,076,991 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7078651785850525,
"alphanum_fraction": 0.7303370833396912,
"avg_line_length": 43.5,
"blob_id": "c90441ba9b2a0615536b3f856c21dba2fdfd0ddc",
"content_id": "44a43fc2e9194e2534f52f2be9220130c01ee0fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Hemangi3598/Chap-9_p4",
"src_encoding": "UTF-8",
"text": "# Chap-9_p4\n wapp to display id, marks, name, address of student using & superclass\n"
},
{
"alpha_fraction": 0.6054053902626038,
"alphanum_fraction": 0.6126126050949097,
"avg_line_length": 27.157894134521484,
"blob_id": "f8c80461ccc8d63767c2c0c804b8a9566ea49a17",
"content_id": "dba8c579b44842dee85d20ef4f32c4485f994da1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 19,
"path": "/p4.py",
"repo_name": "Hemangi3598/Chap-9_p4",
"src_encoding": "UTF-8",
"text": " # wapp to display id, marks, name, address of student using superclass\r\nclass person:\r\n\tdef __init__(self, id, name, address):\r\n\t\tself.id = id\r\n\t\tself.name = name\r\n\t\tself.address = address\r\n\tdef show(self):\r\n\t\tprint(\"id = \", self.id)\r\n\t\tprint(\"name = \", self.name)\r\n\t\tprint(\"address = \", self.address)\r\nclass student(person):\r\n\tdef __init__(self, id, name, address, marks):\r\n\t\tsuper().__init__(id, name, address)\r\n\t\tself.marks = marks\r\n\tdef show(self):\r\n\t\tsuper().show()\r\n\t\tprint(\"marks = \", self.marks)\r\ns = student(10, \"amit\", \"thane\", 90)\r\ns.show()\r\n"
}
] | 2 |
WouterToering/bynder-python-sdk
|
https://github.com/WouterToering/bynder-python-sdk
|
6b142bc6a27fcd8e0a06922d72c56fdc92ea4437
|
3ea6a964a4135d278b035f13d516728084b93077
|
38c30c1dfc390987b5654798ca3770487e4edc41
|
refs/heads/master
| 2021-07-09T13:02:36.441440 | 2020-12-28T13:37:56 | 2020-12-28T13:37:56 | 220,274,547 | 0 | 0 |
MIT
| 2019-11-07T15:56:51 | 2019-10-25T07:32:09 | 2019-10-25T07:35:09 | null |
[
{
"alpha_fraction": 0.6254599094390869,
"alphanum_fraction": 0.6261957287788391,
"avg_line_length": 29.200000762939453,
"blob_id": "c751a8b3d8bd7f08aeaef2d88bb7adb591c16724",
"content_id": "cdc7d9b4f33df0cd66a5adffba7f4ea06b86b042",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1359,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 45,
"path": "/bynder_sdk/util.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from bynder_sdk.version import VERSION\n\nUA_HEADER = {\n 'User-Agent': 'bynder-python-sdk/{}'.format(VERSION)\n}\n\n\ndef api_endpoint_url(session, endpoint):\n return 'https://{}/api{}'.format(session.bynder_domain, endpoint)\n\n\ndef parse_json_for_response(response):\n try:\n return response.json()\n except ValueError:\n return None\n\n\nclass SessionMixin:\n def wrapped_request(self, func, endpoint, *args, **kwargs):\n endpoint = api_endpoint_url(self, endpoint)\n response = func(endpoint, *args, **kwargs)\n response.raise_for_status()\n\n return parse_json_for_response(response)\n\n def get(self, url, *args, **kwargs):\n return self.wrapped_request(super().get, url, *args, **kwargs)\n\n def post(self, url, *args, **kwargs):\n if url.startswith('https'):\n # Do not send the Authorization header to S3\n kwargs['headers'] = {'Authorization': None}\n return super().post(url, *args, **kwargs)\n\n return self.wrapped_request(super().post, url, *args, **kwargs)\n\n def put(self, url, *args, **kwargs):\n return self.wrapped_request(super().put, url, *args, **kwargs)\n\n def delete(self, url, *args, **kwargs):\n return self.wrapped_request(super().delete, url, *args, **kwargs)\n\n def _set_ua_header(self):\n self.headers.update(UA_HEADER)\n"
},
{
"alpha_fraction": 0.6949179172515869,
"alphanum_fraction": 0.6991792917251587,
"avg_line_length": 21.231578826904297,
"blob_id": "61394dc3007eee5172035d9b944c1025ce961281",
"content_id": "a959178511153460f91a159230ec4429d1ef92e8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6336,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 285,
"path": "/example/app.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "import pprint\n\nfrom bynder_sdk import BynderClient\n\npp = pprint.PrettyPrinter()\n\n# When using Permanent Tokens\n\nbynder_client = BynderClient(\n domain='portal.getbynder.com',\n permanent_token=''\n)\n\n# When using OAuth2\n\ntoken = None\n\"\"\" If we already have a token, it can be passed to the BynderClient\ninitialization.\n\n token = {\n 'access_token': '...',\n 'expires_at': 123456789,\n 'expires_in': 3599,\n 'id_token': '...',\n 'refresh_token': '...',\n 'scope': ['offline'],\n 'token_type': 'bearer'\n }\n\"\"\"\n\n\ndef token_saver(token):\n \"\"\" This function will be called by oauthlib-requests when a new\n token is retrieved, either after the initial login or refreshing an\n existing token. \"\"\"\n print('New token received:')\n pp.pprint(token)\n\n\nbynder_client = BynderClient(\n domain='portal.getbynder.com',\n redirect_uri='',\n client_id='',\n client_secret='',\n scopes=['offline', 'asset:read', 'meta.assetbank:read'],\n token=token, # optional, if we already have one\n token_saver=token_saver, # optional, defaults to empty lambda\n)\n\nif token is None:\n pp.pprint(bynder_client.get_authorization_url())\n\n code = input('Code: ')\n pp.pprint(bynder_client.fetch_token(code))\n\n# Example calls\n\n# Get the asset bank client\nasset_bank_client = bynder_client.asset_bank_client\n\n\n# Get the collections client\ncollection_client = bynder_client.collection_client\n\n\n# Get the workflow client\nworkflow_client = bynder_client.workflow_client\n\n\n# Get the PIM client\npim_client = bynder_client.pim_client\n\n\nprint('\\n> Get brands:')\nbrands = asset_bank_client.brands()\npp.pprint(brands)\n\n\nprint('\\n> Get tags:')\ntags = asset_bank_client.tags()\npp.pprint(tags)\n\n\nprint('\\n> Get metaproperties:')\nmeta_properties = asset_bank_client.meta_properties()\npp.pprint(meta_properties)\n\n\nprint('\\n> Get media list:')\nmedia_list = asset_bank_client.media_list({\n 'count': True,\n 'limit': 2,\n 'type': 'image',\n 'versions': 1\n})\npp.pprint(media_list)\n\n\nprint('\\n> Get media info:')\nmedia_id = media_list.get('media')[0].get('id')\nmedia_info = asset_bank_client.media_info(\n media_id=media_id,\n versions={\n 'versions': 1\n }\n)\npp.pprint(media_info)\n\nprint('\\n Set media description:')\nmedia = asset_bank_client.set_media_properties(\n media_id,\n {'description': 'Description set using SDK'}\n)\n\nprint('\\n> Get download url:')\ndownload_url = asset_bank_client.media_download_url(\n media_id=media_id\n)\npp.pprint(download_url)\n\n\nprint('\\n> Get collections list:')\ncollections = collection_client.collections()\npp.pprint(collections)\n\n\nprint('\\n> Get media ids of a collection:')\ncollection_id = collections[0]['id']\ncollection_media_ids = collection_client.collection_media_ids(\n collection_id=collection_id\n)\npp.pprint(collection_media_ids)\n\n\nprint('\\n> Get workflow users:')\nworkflow_users = workflow_client.users()\nworkflow_user = workflow_users[0]['ID']\npp.pprint(workflow_users)\n\n\nprint('\\n> Create new campaign:')\nnew_campaign = workflow_client.create_campaign(\n name='compaign_name',\n key='CKEY',\n description='campaign_description',\n responsible_id=workflow_user\n)\npp.pprint(new_campaign)\n\n\nprint('\\n> Get campaigns list:')\ncampaigns = workflow_client.campaigns()\npp.pprint(campaigns)\n\n\nprint('\\n> Get campaigns info:')\ncampaign_id = campaigns[0]['ID']\ncampaign_info = workflow_client.campaign_info(campaign_id)\npp.pprint(campaign_info)\n\n\nprint('\\n> Edit a campaign:')\nedited_campaign = workflow_client.edit_campaign(\n campaign_id=new_campaign['id'],\n name='new_compaign_name',\n key='NCKEY',\n description='new_compaign_description',\n responsible_id=workflow_user\n)\npp.pprint(edited_campaign)\n\n\nprint('\\n> Delete campaign:')\nworkflow_client.delete_campaign(\n campaign_id=new_campaign['id']\n)\n\n\nprint('\\n> Get list of PIM metaproperties:')\npim_metaproperties = pim_client.metaproperties()\npim_metaproperty_id = pim_metaproperties[0]\npp.pprint(pim_metaproperties)\n\n\nprint('\\n> Get metaproperty info:')\npim_metaproperty = pim_client.metaproperty_info(\n metaproperty_id=pim_metaproperty_id\n)\npp.pprint(pim_metaproperty_id)\n\n\nprint('\\n> Get list of PIM metaproperty options:')\npim_metaproperty_options = pim_client.metaproperty_options(\n metaproperty_id=pim_metaproperty_id\n)\npim_metaproperty_option_id = pim_metaproperty_options[0]['id']\npp.pprint(pim_metaproperty_options)\n\n\nprint('\\n> Get workflow metaproperties list:')\nworkflow_metaproperties = workflow_client.metaproperties()\nworkflow_metaproperty_id = workflow_metaproperties[0]['ID']\npp.pprint(workflow_metaproperties)\n\n\nprint('\\n> Get workflow metaproperty info:')\nworkflow_metaproperty = workflow_client.metaproperty_info(\n metaproperty_id=workflow_metaproperty_id)\npp.pprint(workflow_metaproperty)\n\n\nprint('\\n> Get workflow groups list:')\nworkflow_groups = workflow_client.groups()\nworkflow_group_id = workflow_groups[0]['ID']\npp.pprint(workflow_groups)\n\n\nprint('\\n> Get workflow group info:')\nworkflow_group = workflow_client.group_info(\n group_id=workflow_group_id\n)\npp.pprint(workflow_group)\n\n\nprint('\\n> Get jobs:')\njobs = workflow_client.jobs()\njob_id = jobs[0]['id']\npp.pprint(jobs)\n\n\nprint('\\n> Get jobs by campaign:')\njobs_by_campaign = workflow_client.jobs(\n campaign_id=campaign_id\n)\npp.pprint(jobs_by_campaign)\n\n\nprint('\\n> Get specific job:')\njob_info = workflow_client.job_info(\n job_id=job_id\n)\npp.pprint(job_info)\n\n\nprint('\\n> Create new job:')\nnew_job = workflow_client.create_job(\n name='new_job_name',\n campaign_id=job_info['campaignID'],\n accountable_id=job_info['accountableID'],\n preset_id=job_info['presetID']\n)\npp.pprint(new_job)\n\n\nprint('\\n> Edit job:')\nedited_job = workflow_client.edit_job(\n job_id,\n name='edited_job_name',\n campaign_id=job_info['campaignID'],\n accountable_id=job_info['accountableID'],\n preset_id=job_info['presetID']\n)\npp.pprint(edited_job)\n\n\nprint('\\n> Delete job:')\nworkflow_client.delete_job(\n job_id=job_id\n)\n\n\nprint('\\n> Get job preset info:')\njob_preset_info = workflow_client.job_preset_info(\n job_preset_id=job_info['presetID']\n)\npp.pprint(job_preset_info)\n\n\nprint('\\n> Upload a file to the asset bank')\nuploaded_file = asset_bank_client.upload_file(\n file_path='example/image.png',\n brand_id=brands[0]['id']\n)\n\npp.pprint(uploaded_file)\n"
},
{
"alpha_fraction": 0.828125,
"alphanum_fraction": 0.828125,
"avg_line_length": 63,
"blob_id": "408605e88211e7aa550710943b6c5179575af917",
"content_id": "eb5e1b39fd1edebb80b6c2c0ba8bfed95dc51989",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 1,
"path": "/bynder_sdk/__init__.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from bynder_sdk.client.bynder_client import BynderClient # noqa\n"
},
{
"alpha_fraction": 0.5552058815956116,
"alphanum_fraction": 0.5583530068397522,
"avg_line_length": 34.30555725097656,
"blob_id": "05302a770184cc54c4bf9ef4141f836ed26460bd",
"content_id": "0625d950f3b8d8274bef487c01a80b53e678176b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3813,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 108,
"path": "/bynder_sdk/client/asset_bank_client.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from bynder_sdk.client.upload_client import UploadClient\n\n\nclass AssetBankClient:\n \"\"\" Client used for all the operations that can be done to the\n Bynder Asset Bank.\n \"\"\"\n def __init__(self, session):\n self.session = session\n self.upload_client = UploadClient(session)\n\n def brands(self):\n \"\"\" Gets list of the brands.\n \"\"\"\n return self.session.get('/v4/brands/')\n\n def tags(self, query: dict = None):\n \"\"\" Gets list of the tags.\n \"\"\"\n return self.session.get('/v4/tags/', params=query or {})\n\n def meta_properties(self, query: dict = None):\n \"\"\" Gets list of the meta properties.\n \"\"\"\n return self.session.get('/v4/metaproperties/', params=query or {})\n\n def media_list(self, query: dict = None):\n \"\"\" Gets a list of media assets filtered by parameters.\n \"\"\"\n return self.session.get('/v4/media/', params=query or {})\n\n def media_info(self, media_id, versions: dict = None):\n \"\"\" Gets all the media information for a specific media id.\n \"\"\"\n return self.session.get(\n '/v4/media/{0}/'.format(media_id),\n params=versions or {}\n )\n\n def media_download_url(self, media_id, query: dict = None):\n \"\"\" Gets the download file URL for a specific media id.\n \"\"\"\n return self.session.get(\n '/v4/media/{0}/download/'.format(media_id),\n params=query or {}\n )\n\n def set_media_properties(self, media_id, query: dict = None):\n \"\"\" Updates the media properties (metadata) for a specific media id.\n \"\"\"\n return self.session.post(\n '/v4/media/{0}/'.format(media_id),\n data=query or {}\n )\n\n def delete_media(self, media_id):\n \"\"\" Deletes a media asset.\n \"\"\"\n return self.session.delete('/v4/media/{0}/'.format(media_id))\n\n def create_usage(self, integration_id, asset_id, query: dict = None):\n \"\"\" Creates a usage record for a media asset.\n \"\"\"\n if query is None:\n query = {}\n query['integration_id'] = integration_id\n query['asset_id'] = asset_id\n\n return self.session.post('/media/usage/', data=query)\n\n def usage(self, query: dict = None):\n \"\"\" Gets all the media assets usage records.\n \"\"\"\n return self.session.get('/media/usage/', params=query or {})\n\n def delete_usage(self, integration_id, asset_id, query: dict = None):\n \"\"\" Deletes a usage record of a media asset.\n \"\"\"\n if query is None:\n query = {}\n query['integration_id'] = integration_id\n query['asset_id'] = asset_id\n\n return self.session.delete('/media/usage/', params=query)\n\n def upload_file(self, file_path: str, brand_id: str,\n media_id: str = '', query: dict = None) -> dict:\n \"\"\" Upload file.\n Params:\n file_path: the local filepath of the file to upload.\n brand_id: the brandid of the brand that belong the asset.\n query: extra dict parameters of information to add to the\n asset. (See api documentation for more information)\n Return a dict with the keys:\n - success: boolean that indicate the result of the upload call.\n - mediaitems: a list of mediaitems created, with at least the\n original.\n - batchId: the batchId of the upload.\n - mediaid: the mediaId update or created.\n \"\"\"\n if query is None:\n query = {}\n query['brandId'] = brand_id\n return self.upload_client.upload(\n file_path=file_path,\n media_id=media_id,\n upload_data=query\n )\n"
},
{
"alpha_fraction": 0.5938435196876526,
"alphanum_fraction": 0.5959811806678772,
"avg_line_length": 34.42424392700195,
"blob_id": "752a89a5db5b03d78200d92bcbf308c5597900e7",
"content_id": "b2adfd7b2908ce6a9cab92c854b025c0a7fb4111",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2339,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 66,
"path": "/bynder_sdk/client/bynder_client.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "\nfrom bynder_sdk.client.asset_bank_client import AssetBankClient\nfrom bynder_sdk.client.collection_client import CollectionClient\nfrom bynder_sdk.client.pim_client import PIMClient\nfrom bynder_sdk.client.workflow_client import WorkflowClient\nfrom bynder_sdk.oauth2 import BynderOAuth2Session\nfrom bynder_sdk.permanent_token import PermanentTokenSession\n\n\nREQUIRED_OAUTH_KWARGS = (\n 'client_id', 'client_secret', 'redirect_uri', 'scopes')\n\n\nclass BynderClient:\n \"\"\" Main client used for setting up the OAuth2 session and\n getting the clients for various Bynder modules.\n \"\"\"\n\n # pylint: disable-msg=too-many-arguments\n def __init__(self, domain, **kwargs):\n if 'permanent_token' in kwargs:\n self.session = PermanentTokenSession(\n domain, kwargs['permanent_token'])\n else:\n missing = [\n kw for kw in REQUIRED_OAUTH_KWARGS\n if kwargs.get(kw) is None\n ]\n if missing:\n raise TypeError(\n 'Missing required arguments: {}'.format(missing)\n )\n\n self.session = BynderOAuth2Session(\n domain,\n kwargs['client_id'],\n scope=kwargs['scopes'],\n redirect_uri=kwargs['redirect_uri'],\n auto_refresh_kwargs={\n 'client_id': kwargs['client_id'],\n 'client_secret': kwargs['client_secret']\n },\n token_updater=kwargs.get('token_saver', (lambda _: None))\n )\n\n if kwargs.get('token') is not None:\n self.session.token = kwargs['token']\n\n self.asset_bank_client = AssetBankClient(self.session)\n self.collection_client = CollectionClient(self.session)\n self.pim_client = PIMClient(self.session)\n self.workflow_client = WorkflowClient(self.session)\n\n def get_authorization_url(self):\n return self.session.authorization_url()\n\n def fetch_token(self, code, *args, **kwargs):\n return self.session.fetch_token(\n code=code,\n *args,\n **kwargs\n )\n\n def derivatives(self):\n \"\"\" Gets the list of the derivatives configured for the current account.\n \"\"\"\n return self.session.get('/v4/account/derivatives/')\n"
},
{
"alpha_fraction": 0.6410256624221802,
"alphanum_fraction": 0.6410256624221802,
"avg_line_length": 25,
"blob_id": "cbfaf49d8d4bd50608fa9fe7428573546976bc53",
"content_id": "a3b3ab396ae1540f6067e208558fa6eccb4895c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 15,
"path": "/bynder_sdk/permanent_token.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from requests import Session\n\nfrom bynder_sdk.util import SessionMixin\n\n\nclass PermanentTokenSession(SessionMixin, Session):\n def __init__(self, bynder_domain, permanent_token):\n super().__init__()\n\n self.bynder_domain = bynder_domain\n self.headers.update({\n 'Authorization': 'Bearer {}'.format(permanent_token),\n })\n\n self._set_ua_header()\n"
},
{
"alpha_fraction": 0.5196343064308167,
"alphanum_fraction": 0.5273218154907227,
"avg_line_length": 32.42361068725586,
"blob_id": "c3749f5921133ea85f0fba6cb51f3f3f194b1a8a",
"content_id": "7a8b328c2ca0666538fbe1cb82f459f5417a8b73",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4813,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 144,
"path": "/bynder_sdk/client/upload_client.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "import math\nimport os\nimport time\n\n\nMAX_CHUNK_SIZE = 1024 * 1024 * 5\nMAX_POLLING_ITERATIONS = 60\nPOLLING_IDLE_TIME = 5\n\n\n# pylint: disable-msg=too-few-public-methods\nclass UploadClient():\n \"\"\" Client to upload asset to Bynder.\n \"\"\"\n def __init__(self, session):\n self.session = session\n\n def upload(self, file_path, media_id, upload_data):\n \"\"\" Handles the upload of the file.\n \"\"\"\n init_data, total_parts = self._run_s3_upload(file_path)\n finalise_data = self._finalise_file(init_data, total_parts)\n return self._save_media(finalise_data['importId'],\n upload_data, media_id)\n\n def _run_s3_upload(self, file_path):\n \"\"\" Uploads the media to Amazon S3 bucket-endpoint.\n \"\"\"\n with open(file_path, 'rb') as f:\n part_nr = 0\n total_parts = math.ceil(\n os.stat(f.fileno()).st_size / MAX_CHUNK_SIZE)\n\n filename = file_path.rsplit('/', 1)[-1]\n build_part_data = self._init_upload(filename, total_parts)\n\n part_bytes = f.read(MAX_CHUNK_SIZE)\n while part_bytes:\n part_nr = part_nr + 1\n part_data = build_part_data(part_nr)\n\n response = self.session.post(\n self.upload_url,\n files={'file': part_bytes},\n data=part_data['multipart_params'],\n )\n response.raise_for_status()\n self._register_part(part_data, part_nr)\n part_bytes = f.read(MAX_CHUNK_SIZE)\n\n return part_data, total_parts\n\n def _init_upload(self, filename, total_parts):\n \"\"\" Gets the URL of the Amazon S3 bucket-endpoint in the region\n closest to the server and initialises a file upload with Bynder\n and returns authorisation information to allow uploading to the\n Amazon S3 bucket-endpoint.\n \"\"\"\n self.upload_url = self.session.get('/upload/endpoint/')\n\n data = self.session.post(\n '/upload/init/',\n data={'filename': filename}\n )\n data['multipart_params'].update({\n 'chunks': total_parts,\n 'name': filename,\n })\n\n key = '{}/p{{}}'.format(data['s3_filename'])\n\n def part_data(part_nr):\n data['s3_filename'] = key.format(part_nr)\n data['multipart_params'].update({\n 'chunk': part_nr,\n 'Filename': key.format(part_nr),\n 'key': key.format(part_nr),\n })\n return data\n\n return part_data\n\n def _register_part(self, init_data, part_nr):\n \"\"\" Registers an uploaded chunk in Bynder.\n \"\"\"\n self.session.post(\n '/v4/upload/',\n data={\n 'id': init_data['s3file']['uploadid'],\n 'targetid': init_data['s3file']['targetid'],\n 'filename': init_data['s3_filename'],\n 'chunkNumber': part_nr\n }\n )\n\n def _finalise_file(self, init_data, total_parts):\n \"\"\" Finalises a completely uploaded file.\n \"\"\"\n return self.session.post(\n '/v4/upload/{0}/'.format(init_data['s3file']['uploadid']),\n data={\n 'id': init_data['s3file']['uploadid'],\n 'targetid': init_data['s3file']['targetid'],\n 's3_filename': init_data['s3_filename'],\n 'chunks': total_parts\n }\n )\n\n def _save_media(self, import_id, data, media_id=None):\n \"\"\" Saves a new media asset in Bynder. If media id is specified\n in the query a new version of the asset will be saved. Otherwise\n a new asset will be saved.\n \"\"\"\n poll_status = self._poll_status(import_id)\n if import_id not in poll_status['itemsDone']:\n raise Exception('Converting media failed')\n\n save_endpoint = '/v4/media/save/{}/'.format(import_id)\n if media_id:\n save_endpoint = '/v4/media/{}/save/{}/'.format(\n media_id, import_id)\n data = {}\n\n return self.session.post(\n save_endpoint,\n data=data\n )\n\n def _poll_status(self, import_id):\n \"\"\" Gets poll processing status of finalised files.\n \"\"\"\n for _ in range(MAX_POLLING_ITERATIONS):\n time.sleep(POLLING_IDLE_TIME)\n status_dict = self.session.get(\n '/v4/upload/poll/',\n params={'items': [import_id]}\n )\n\n if [v for k, v in status_dict.items() if import_id in v]:\n return status_dict\n\n # Max polling iterations reached => upload failed\n status_dict['itemsFailed'].append(import_id)\n return status_dict\n"
},
{
"alpha_fraction": 0.5405476689338684,
"alphanum_fraction": 0.5413375496864319,
"avg_line_length": 30.649999618530273,
"blob_id": "fa51bb8fa1596f97d42cff7ca5276cf261238211",
"content_id": "534b092efe826a303b90a906a384565329237fe8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3798,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 120,
"path": "/bynder_sdk/client/workflow_client.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "class WorkflowClient:\n \"\"\" Client used for all the operations that can be done to the workflow module.\n \"\"\"\n def __init__(self, session):\n self.session = session\n\n def users(self):\n \"\"\" Gets list of users.\n \"\"\"\n return self.session.get('/workflow/users/')\n\n def campaigns(self, query: dict = None):\n \"\"\" Gets list of campaigns.\n \"\"\"\n return self.session.get('/workflow/campaigns/', params=query or {})\n\n def campaign_info(self, campaign_id):\n \"\"\" Gets all the campaign information for a specific campaign id.\n \"\"\"\n return self.session.get(\n '/workflow/campaigns/{0}/'.format(campaign_id)\n )\n\n # pylint: disable=too-many-arguments\n def create_campaign(self, name, key, description, responsible_id,\n query: dict = None):\n \"\"\" Creates a campaign.\n \"\"\"\n if query is None:\n query = {}\n query.update({\n 'name': name,\n 'key': key,\n 'description': description,\n 'responsibleID': responsible_id\n })\n return self.session.post('/workflow/campaigns/', json=query)\n\n def delete_campaign(self, campaign_id):\n \"\"\" Deletes a campaign.\n \"\"\"\n return self.session.delete(\n '/workflow/campaigns/{0}/'.format(campaign_id)\n )\n\n def edit_campaign(self, campaign_id, name, key, description,\n responsible_id, query: dict = None):\n \"\"\" Edits an existing campaign.\n \"\"\"\n if query is None:\n query = {}\n query.update({\n 'name': name,\n 'key': key,\n 'description': description,\n 'responsibleID': responsible_id\n })\n return self.session.put(\n '/workflow/campaigns/{0}/'.format(campaign_id),\n json=query\n )\n\n def metaproperties(self):\n return self.session.get('/workflow/metaproperties/')\n\n def metaproperty_info(self, metaproperty_id):\n return self.session.get(\n '/workflow/metaproperties/{}/'.format(metaproperty_id)\n )\n\n def groups(self):\n return self.session.get('/workflow/groups/')\n\n def group_info(self, group_id):\n return self.session.get('/workflow/groups/{}/'.format(group_id))\n\n def job_preset_info(self, job_preset_id):\n return self.session.get(\n '/workflow/presets/job/{}/'.format(job_preset_id)\n )\n\n def jobs(self, campaign_id: str = None):\n if campaign_id:\n return self.session.get(\n '/workflow/campaigns/{}/jobs/'.format(campaign_id)\n )\n return self.session.get('/workflow/jobs/')\n\n def create_job(self, name, campaign_id, accountable_id,\n preset_id, query: dict = None):\n if query is None:\n query = {}\n query.update({\n 'name': name,\n 'campaignID': campaign_id,\n 'accountableID': accountable_id,\n 'presetID': preset_id\n })\n return self.session.post('/workflow/jobs/', json=query)\n\n def job_info(self, job_id):\n return self.session.get('/workflow/jobs/{}/'.format(job_id))\n\n def edit_job(self, job_id, name, campaign_id, accountable_id,\n preset_id, query: dict = None):\n if query is None:\n query = {}\n query.update({\n 'name': name,\n 'campaignID': campaign_id,\n 'accountableID': accountable_id,\n 'presetID': preset_id\n })\n return self.session.put(\n '/workflow/jobs/{}/'.format(job_id),\n json=query\n )\n\n def delete_job(self, job_id):\n return self.session.delete('/workflow/jobs/{}/'.format(job_id))\n"
},
{
"alpha_fraction": 0.5892314314842224,
"alphanum_fraction": 0.6135475635528564,
"avg_line_length": 33.37313461303711,
"blob_id": "0bc7bc2867b6ab4d618fb2d18878b5edf7f607e0",
"content_id": "80738361c29d16d7d48484c420a6f11f29533a2f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2303,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 67,
"path": "/test/pim_client_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from unittest import mock, TestCase\n\nfrom test import create_bynder_client\n\n\nclass PIMClientTest(TestCase):\n \"\"\" Test the PIM client.\n \"\"\"\n def setUp(self):\n self.bynder_client = create_bynder_client()\n\n self.pim_client = self.bynder_client.pim_client\n self.pim_client.session.get = mock.MagicMock()\n self.pim_client.session.put = mock.MagicMock()\n\n def tearDown(self):\n self.bynder_client = None\n self.pim_client = None\n\n def test_metaproperties(self):\n \"\"\" Test if when we call metaproperties it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.pim_client.metaproperties()\n self.pim_client.session.get.assert_called_with(\n '/pim/metaproperties/'\n )\n\n def test_metaproperty_info(self):\n \"\"\" Test if when we call metaproperty info it will use the correct params\n for the request and returns successfully.\n \"\"\"\n self.pim_client.metaproperty_info(metaproperty_id=1111)\n self.pim_client.session.get(\n '/pim/metaproperties/{}/'.format(1111)\n )\n\n def test_metaproperty_options(self):\n \"\"\" Test if when we call meteproperty options it will use the correct params\n for the request and returns successfully.\n \"\"\"\n self.pim_client.metaproperty_options(metaproperty_id=1111)\n self.pim_client.session.get(\n '/pim/metaproperties/{}/options/'.format(1111)\n )\n\n def test_edit_metaproperty_option(self):\n \"\"\" Test if when we call edit metaproperty option it will use the correct\n params for the request and returns successfully.\n \"\"\"\n self.pim_client.edit_metaproperty_option(\n metaproperty_option_id=1111,\n children=['2222', '3333']\n )\n self.pim_client.session.put.assert_called_with(\n '/pim/metapropertyoptions/{}/'.format(1111),\n json={'children': ['2222', '3333']}\n )\n\n self.pim_client.edit_metaproperty_option(\n metaproperty_option_id='1111',\n children='2222'\n )\n self.pim_client.session.put.assert_called_with(\n '/pim/metapropertyoptions/{}/'.format(1111),\n json={'children': ['2222']}\n )\n"
},
{
"alpha_fraction": 0.5774193406105042,
"alphanum_fraction": 0.5867096781730652,
"avg_line_length": 35.046512603759766,
"blob_id": "66be1814697a976f6d5fe00018a59411e49870e6",
"content_id": "2a0672d8642e93d5c7e4b675642731010902990d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7750,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 215,
"path": "/test/workflow_client_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from unittest import mock, TestCase\n\nfrom test import create_bynder_client\n\n\nclass WorkflowClientTest(TestCase):\n \"\"\" Test the workflow client.\n \"\"\"\n def setUp(self):\n self.bynder_client = create_bynder_client()\n\n self.workflow_client = self.bynder_client.workflow_client\n self.workflow_client.session.get = mock.MagicMock()\n self.workflow_client.session.post = mock.MagicMock()\n self.workflow_client.session.delete = mock.MagicMock()\n self.workflow_client.session.put = mock.MagicMock()\n\n def tearDown(self):\n self.bynder_client = None\n self.workflow_client = None\n\n def test_users(self):\n \"\"\" Test if when we call workflow users it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.workflow_client.users()\n self.workflow_client.session.get.assert_called_with(\n '/workflow/users/'\n )\n\n def test_campaigns(self):\n \"\"\" Test if when we call campaigns it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.campaigns()\n self.workflow_client.session.get.assert_called_with(\n '/workflow/campaigns/',\n params={}\n )\n\n def test_campaign_info(self):\n \"\"\" Test if when we call campaign info it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.campaign_info(campaign_id=1111)\n self.workflow_client.session.get.assert_called_with(\n '/workflow/campaigns/1111/'\n )\n\n def test_create_campaign(self):\n \"\"\" Test if when we call create a campaign it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.workflow_client.create_campaign(\n name='campaign_name',\n key='CKEY',\n description='campaign_description',\n responsible_id='campaign_responsible_id'\n )\n self.workflow_client.session.post.assert_called_with(\n '/workflow/campaigns/',\n json={\n 'name': 'campaign_name',\n 'key': 'CKEY',\n 'description': 'campaign_description',\n 'responsibleID': 'campaign_responsible_id'\n }\n )\n\n def test_edit_campaign(self):\n \"\"\" Test if when we call edit campaign it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.workflow_client.edit_campaign(\n campaign_id='campaign_id',\n name='campaign_name',\n key='ECKEY',\n description='campaign_description',\n responsible_id='campaign_responsible_id'\n )\n self.workflow_client.session.put.assert_called_with(\n '/workflow/campaigns/campaign_id/',\n json={\n 'name': 'campaign_name',\n 'key': 'ECKEY',\n 'description': 'campaign_description',\n 'responsibleID': 'campaign_responsible_id'\n }\n )\n\n def test_delete_campaign(self):\n \"\"\" Test if when we call delete campaign it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.delete_campaign(campaign_id=1111)\n self.workflow_client.session.delete.assert_called_with(\n '/workflow/campaigns/1111/'\n )\n\n def test_metaproperties(self):\n \"\"\" Test if when we call metaproperties it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.workflow_client.metaproperties()\n self.workflow_client.session.get.assert_called_with(\n '/workflow/metaproperties/'\n )\n\n def test_metaproperty_info(self):\n \"\"\" Test if when we call metaproperty info it will use the correct params\n for the request and returns successfully\n \"\"\"\n self.workflow_client.metaproperty_info(metaproperty_id=1111)\n self.workflow_client.session.get.assert_called_with(\n '/workflow/metaproperties/{}/'.format(1111)\n )\n\n def test_groups(self):\n \"\"\" Test if when we call groups it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.groups()\n self.workflow_client.session.get.assert_called_with(\n '/workflow/groups/'\n )\n\n def test_group_info(self):\n \"\"\" Test if when we call group info it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.group_info(1111)\n self.workflow_client.session.get.assert_called_with(\n '/workflow/groups/{}/'.format(1111)\n )\n\n def test_job_preset_info(self):\n \"\"\" Test if when we call job preset info it will use the correct params for\n the request and returns successfully.\n \"\"\"\n self.workflow_client.job_preset_info(job_preset_id=1111)\n self.workflow_client.session.get.assert_called_with(\n '/workflow/presets/job/{}/'.format(1111)\n )\n\n def test_jobs(self):\n \"\"\" Test if when we call jobs it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.jobs(campaign_id=1111)\n self.workflow_client.session.get.assert_called_with(\n '/workflow/campaigns/{}/jobs/'.format(1111)\n )\n self.workflow_client.jobs()\n self.workflow_client.session.get.assert_called_with(\n '/workflow/jobs/'\n )\n\n def test_create_job(self):\n \"\"\" Test if when we call create job it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.create_job(\n name='job_name',\n campaign_id='job_campaign_id',\n accountable_id='job_accountable_id',\n preset_id='job_preset_id'\n )\n self.workflow_client.session.post.assert_called_with(\n '/workflow/jobs/',\n json={\n 'name': 'job_name',\n 'campaignID': 'job_campaign_id',\n 'accountableID': 'job_accountable_id',\n 'presetID': 'job_preset_id'\n }\n )\n\n def test_job_info(self):\n \"\"\" Test if when we call job info it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.job_info(job_id='1111')\n self.workflow_client.session.get.assert_called_with(\n '/workflow/jobs/{}/'.format(1111)\n )\n\n def test_edit_job(self):\n \"\"\" Test if when we call edit job it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.edit_job(\n job_id=1111,\n name='job_name',\n campaign_id='job_campaign_id',\n accountable_id='job_accountable_id',\n preset_id='job_preset_id'\n )\n self.workflow_client.session.put.assert_called_with(\n '/workflow/jobs/{}/'.format(1111),\n json={\n 'name': 'job_name',\n 'campaignID': 'job_campaign_id',\n 'accountableID': 'job_accountable_id',\n 'presetID': 'job_preset_id'\n }\n )\n\n def test_delete_job(self):\n \"\"\" Test if when we call delete job it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.workflow_client.delete_job(job_id=1111)\n self.workflow_client.session.delete(\n '/workflow/jobs/{}/'.format(1111)\n )\n"
},
{
"alpha_fraction": 0.5732010006904602,
"alphanum_fraction": 0.5732010006904602,
"avg_line_length": 31.675676345825195,
"blob_id": "acdbf914fe220cd62786efcf3517e1bb75db639d",
"content_id": "adfab077fd39999b007d5447be90884b3104b527",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1209,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 37,
"path": "/bynder_sdk/client/pim_client.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "class PIMClient:\n \"\"\" Client used for all the operations that can be done to PIM.\n \"\"\"\n def __init__(self, session):\n self.session = session\n\n def metaproperties(self):\n \"\"\" Gets list of metaproperties.\n \"\"\"\n return self.session.get('/pim/metaproperties/')\n\n def metaproperty_info(self, metaproperty_id):\n \"\"\" Get metaproperty info about a specific metaproperty.\n \"\"\"\n return self.session.get(\n '/pim/metaproperties/{}/'.format(metaproperty_id)\n )\n\n def metaproperty_options(self, metaproperty_id, query: dict = None):\n \"\"\" Get list of metaproperty options.\n \"\"\"\n return self.session.get(\n '/pim/metaproperties/{}/options/'.format(\n metaproperty_id),\n params=query or {}\n )\n\n def edit_metaproperty_option(self, metaproperty_option_id, children):\n \"\"\" Edits an existing metaproperty option.\n \"\"\"\n if isinstance(children, str):\n children = [children]\n return self.session.put(\n '/pim/metapropertyoptions/{}/'.format(\n metaproperty_option_id),\n json={'children': children}\n )\n"
},
{
"alpha_fraction": 0.5929431915283203,
"alphanum_fraction": 0.6015490293502808,
"avg_line_length": 27.341463088989258,
"blob_id": "2c11d0619f22f330f6e3efd78a32fcbf6f3a2c06",
"content_id": "4f9fbf0670eef948eab9dd1056c1ce464a826dc8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1162,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 41,
"path": "/bynder_sdk/oauth2.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "import random\nimport string\n\nfrom requests_oauthlib import OAuth2Session\n\nfrom bynder_sdk.util import SessionMixin\n\n\ndef oauth2_url(bynder_domain, endpoint):\n return 'https://{}/v6/authentication/oauth2/{}'.format(\n bynder_domain, endpoint)\n\n\nclass BynderOAuth2Session(SessionMixin, OAuth2Session):\n def __init__(self, bynder_domain, *args, **kwargs):\n self.bynder_domain = bynder_domain\n\n kwargs['auto_refresh_url'] = oauth2_url(self.bynder_domain, 'token')\n\n super().__init__(*args, **kwargs)\n\n self._set_ua_header()\n\n def authorization_url(self):\n state = ''.join([\n random.choice(string.ascii_letters + string.digits)\n for n in range(8)])\n return super().authorization_url(\n oauth2_url(self.bynder_domain, 'auth'),\n state=state\n )\n\n def fetch_token(self, code, *args, **kwargs):\n return super().fetch_token(\n oauth2_url(self.bynder_domain, 'token'),\n client_secret=self.auto_refresh_kwargs['client_secret'],\n include_client_id=True,\n code=code,\n *args,\n **kwargs\n )\n"
},
{
"alpha_fraction": 0.7425780296325684,
"alphanum_fraction": 0.7460256814956665,
"avg_line_length": 24.71921157836914,
"blob_id": "9ffaed556f690381975a87c890e92100bc2ee7ed",
"content_id": "53e780df60659d243adf64d1d583f3b702c0bb8d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5221,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 203,
"path": "/README.md",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "Bynder Python SDK\n=================\n\n\n\n\nThe main goal of this SDK is to speed up the integration of Bynder\ncustomers who use Python. Making it easier to connect to the Bynder API\n(<https://bynder.docs.apiary.io>) and execute requests on it.\n\n_**Note:** As of version 1.0.0 this SDK now uses OAuth 2.0. For the last\nversion using OAuth 1.0a please refer to\n[version 0.0.6](https://github.com/Bynder/bynder-python-sdk/tree/0.0.6)_.\n\nRequirements and dependencies\n-----------------------------\n\nThe Python SDK requires the following in order to fully work:\n\n- `Python >= 3.5`, older versions of Python won't work.\n\nPip should handle all the dependencies automatically.\n\nInstallation\n------------\n\nThis SDK depends on a few libraries in order to work, installing it with\npip should take care of everything automatically.\n\nBefore you install the SDK we recommend you to setup a virtual\nenvironment:\n\n```bash\nvirtualenv -p python3 venv # create virtual environment\nsource venv/bin/activate # activate virtual environment\n```\n\nAfter you have successfully setup a virtual environment you can install\nthe SDK with [pip](https://pip.pypa.io/en/stable/installing/). Run the\nfollowing command while your virtual environment is active.\n\n```bash\npip install bynder-sdk\n```\n\nGetting started\n---------------\n\nThis is a simple example on how to retrieve data from the Bynder asset\nbank. For a more detailed example of implementation refer to the [sample\ncode](https://github.com/Bynder/bynder-python-sdk/blob/master/example/app.py).\n\nFirst import the BynderClient:\n\n```python\nfrom bynder_sdk import BynderClient\n```\n\nWhen using OAuth2, create an instance of the client and use the flow\nto receive a token:\n\n```python\nbynder_client = BynderClient(\n domain='portal.getbynder.com',\n redirect_uri='https://...',\n client_id='',\n client_secret='',\n token_saver=token_saver\n)\n\nprint(bynder_client.get_authorization_url())\ncode = input('Code: ')\nbynder_client.fetch_token(code)\n```\n\nWhen using a permanent token, the client instance can be created like this:\n\n```python\nbynder_client = BynderClient(\n domain='portal.getbynder.com',\n permanent_token=''\n)\n```\n\nFinally call one of the API's endpoints through one of the clients:\n\n```python\nasset_bank_client = bynder_client.asset_bank_client\nmedia_list = asset_bank_client.media_list({\n 'limit': 2,\n 'type': 'image'\n})\n```\n\nA full list of the currently available clients and methods in the SDK\ncan be found below\n\nMethods Available\n-----------------\n\nThese are the methods currently availble on the **Bynder Python SDK**,\nrefer to the [Bynder API Docs](http://docs.bynder.apiary.io/) for more\nspecific details on the calls.\n\n### BynderClient:\n\nGet an instance of the Asset Bank Client or the Collection Client if\nalready with access tokens set up. Also allows to generate and\nauthenticate request tokens, which are necessary for the rest of the\nAsset Bank and Collection calls.\n\n```python\nasset_bank_client\ncollection_client\npim_client\nworkflow_client\nget_authorization_url()\nfetch_token()\nderivatives()\n```\n\n### asset\\_bank\\_client:\n\nAll the Asset Bank related calls, provides information and access to\nMedia management.\n\n```python\nbrands()\ntags()\nmeta_properties()\nmedia_list(query)\nmedia_info(media_id, query)\nmedia_download_url()\nset_media_properties(media_id, query)\ndelete_media(media_id)\ncreate_usage(itegration_id, asset_id, query)\nusage(query)\ndelete_usage(integration_id, asset_id, query)\nupload_file(file_path, brand_id, media_id, query)\n```\n\nWith the `upload_file` method you can do two things. You can upload a\nnew asset, or you can upload a new version of an exising asset. You can\ncontrol this by sending a media\\_id or not.\n\n### collection\\_client:\n\nAll the collection related calls.\n\n```python\ncollections(query)\ncollections_info(collection_id)\ncreate_collection(name, query)\ndelete_collection(collection_id)\ncollection_media_ids(collection_id)\nadd_media_to_collection(collection_id, media_ids)\nremove_media_from_collection(collection_id, meedia_ids)\nshare_collection(collection_id, collection_option, recipients, query)\n```\n\n### pim\\_client:\n\nAll the PIM related calls.\n\n```python\nmetaproperties()\nmetaproperty_info(metaproperty_id)\nmetaproperty_options(metaproperty_id)\nedit_metaproperty_option(metaproperty_option_id, children)\n```\n\n### workflow\\_client:\n\nAll the workflow related calls.\n\n```python\nusers()\ncampaigns(query)\ncampaign_info(campaign_id)\ncreate_campaign(name, key, description, responsibleID, query)\ndelete_campaign(campaign_id)\nedit_campaign(campaign_id, name, key, description, responsibleID, query)\nmetaproperties()\nmetaproperty_info(metaproperty_id)\ngroups()\ngroup_info(group_id)\njob_preset_info(job_preset_info)\njobs(campaign_id)\ncreate_job(name, campaignID, accountableID, presetID, query)\njob_info(job_id)\nedit_job(job_id, name, campaignID, accauntableID, presetID, query)\ndelete_job(job_id)}\n```\n\nTests\n-----\n\nYou can run the tests by using the command below. This will install the\npackages required and execute the tests for all the clients.\n\n```bash\nmake test\n```\n"
},
{
"alpha_fraction": 0.6007705330848694,
"alphanum_fraction": 0.6181073784828186,
"avg_line_length": 36.41441345214844,
"blob_id": "c27f4885edf5ad3ca8a0f403555da87c9b92909b",
"content_id": "2f4dcb6c02e1352ee04904504865dc2e684ce9b7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4153,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 111,
"path": "/test/collection_client_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "import json\nfrom unittest import mock, TestCase\n\nfrom test import create_bynder_client\n\n\nclass CollectionClientTest(TestCase):\n \"\"\" Test the collection client.\n \"\"\"\n def setUp(self):\n self.bynder_client = create_bynder_client()\n\n self.collection_client = self.bynder_client.collection_client\n self.collection_client.session.get = mock.MagicMock()\n self.collection_client.session.post = mock.MagicMock()\n self.collection_client.session.delete = mock.MagicMock()\n\n def tearDown(self):\n self.bynder_client = None\n self.collection_client = None\n\n def test_collections(self):\n \"\"\" Test if when we call collections it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.collection_client.collections()\n self.collection_client.session.get.assert_called_with(\n '/v4/collections/',\n params={}\n )\n\n def test_collection_info(self):\n \"\"\" Test if when we call collection info it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.collection_client.collection_info(collection_id=1111)\n self.collection_client.session.get.assert_called_with(\n '/v4/collections/1111/'\n )\n\n def test_create_collection(self):\n \"\"\" Test if when we call create collections it will use the correct\n params for the request and returns successfully.\n \"\"\"\n collection_name = 'Unit Test'\n self.collection_client.create_collection(\n name=collection_name\n )\n self.collection_client.session.post.assert_called_with(\n '/v4/collections/',\n data={'name': collection_name}\n )\n\n def test_delete_collection(self):\n \"\"\" Test if when we call delete collections it will use the correct\n params for the request and returns successfully.\n \"\"\"\n self.collection_client.delete_collection(collection_id=1111)\n self.collection_client.session.delete\\\n .assert_called_with('/v4/collections/1111/')\n\n def test_collection_media_ids(self):\n \"\"\" Test if when we call collection media ids it will use the correct\n params for the request and returns successfully.\n \"\"\"\n self.collection_client.collection_media_ids(collection_id=1111)\n self.collection_client.session.get.assert_called_with(\n '/v4/collections/1111/media/'\n )\n\n def test_add_media_to_collection(self):\n \"\"\" Test if when we call add media to collection it will use the correct\n params for the request and returns successfully.\n \"\"\"\n media_ids = ['2222', '3333']\n self.collection_client.add_media_to_collection(\n collection_id=1111, media_ids=media_ids)\n self.collection_client.session.post.assert_called_with(\n '/v4/collections/1111/media/',\n data={'data': json.dumps(media_ids)}\n )\n\n def test_remove_media_from_collection(self):\n \"\"\" Test if when we call remove media from collection it will use the correct\n params for the request and returns successfully.\n \"\"\"\n media_ids = ['2222', '3333']\n self.collection_client.remove_media_from_collection(\n collection_id=1111, media_ids=media_ids)\n self.collection_client.session\\\n .delete.assert_called_with(\n '/v4/collections/1111/media/',\n params={'deleteIds': ','.join(map(str, media_ids))}\n )\n\n def test_share_collection(self):\n \"\"\" Test if when we call share collection it will use the correct\n params for the request and returns successfully.\n \"\"\"\n self.collection_client.share_collection(\n collection_id=1111,\n collection_option='view',\n recipients=[]\n )\n self.collection_client.session.post.assert_called_with(\n '/v4/collections/1111/share/',\n data={\n 'collectionOptions': 'view',\n 'recipients': ','.join(map(str, []))\n }\n )\n"
},
{
"alpha_fraction": 0.6735253930091858,
"alphanum_fraction": 0.6769547462463379,
"avg_line_length": 32.906978607177734,
"blob_id": "2279be4a9102468b1379e369167149d7f9ceab8e",
"content_id": "b33e5094ce856bf938596a52229dc02aa89ef06e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1458,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 43,
"path": "/test/bynder_client_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from unittest import mock, TestCase\nfrom bynder_sdk.client.bynder_client import BynderClient\nfrom bynder_sdk.client.asset_bank_client import AssetBankClient\nfrom bynder_sdk.client.collection_client import CollectionClient\nfrom bynder_sdk.client.workflow_client import WorkflowClient\nfrom bynder_sdk.client.pim_client import PIMClient\n\nTOKEN = 'token'\n\n\nclass BynderClientTest(TestCase):\n def setUp(self):\n self.bynder_client = BynderClient(\n domain='test.getbynder.com',\n redirect_uri='https://test.com/',\n client_id='client_id',\n client_secret='client_secret',\n token=TOKEN,\n scopes='offline'\n )\n\n def test_create_bynder_client(self):\n client = self.bynder_client\n\n self.assertIsInstance(client.asset_bank_client, AssetBankClient)\n self.assertIsInstance(client.collection_client, CollectionClient)\n self.assertIsInstance(client.pim_client, PIMClient)\n self.assertIsInstance(client.workflow_client, WorkflowClient)\n\n self.assertEqual(client.session.token, TOKEN)\n\n @mock.patch('bynder_sdk.oauth2.BynderOAuth2Session')\n def test_fetch_token(self, oauth2_mock):\n client = self.bynder_client\n client.session = oauth2_mock\n\n kwargs = {\n 'code': 'code',\n 'timeout': 1,\n }\n\n client.fetch_token(**kwargs)\n client.session.fetch_token.assert_called_once_with(**kwargs)\n"
},
{
"alpha_fraction": 0.5642686486244202,
"alphanum_fraction": 0.5755199193954468,
"avg_line_length": 31.955055236816406,
"blob_id": "f04be456756b25539e54e07500f5dfe9062df1ea",
"content_id": "5936a7e97953bd526d82a980dc3b32a6906c6a8a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5866,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 178,
"path": "/test/asset_bank_client_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from unittest import mock, TestCase\n\nfrom test import create_bynder_client\n\n\nclass AssetBankClientTest(TestCase):\n \"\"\" Test the Asset Bank client.\n \"\"\"\n def setUp(self):\n self.bynder_client = create_bynder_client()\n\n self.asset_bank_client = self.bynder_client.asset_bank_client\n self.asset_bank_client.session.get = mock.MagicMock()\n self.asset_bank_client.session.post = mock.MagicMock()\n self.asset_bank_client.session.delete = mock.MagicMock()\n self.asset_bank_client.upload_client.upload = mock.MagicMock()\n\n def tearDown(self):\n self.bynder_client = None\n self.asset_bank_client = None\n\n def test_brands(self):\n \"\"\" Test if when we call brands it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.brands()\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/brands/'\n )\n\n def test_tags(self):\n \"\"\" Test if when we call tags it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.tags()\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/tags/',\n params={}\n )\n\n query = {\n 'limit': 10\n }\n\n self.asset_bank_client.tags(query)\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/tags/',\n params=query\n )\n\n def test_meta_properties(self):\n \"\"\" Test if when we call meta_properties it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.meta_properties()\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/metaproperties/',\n params={}\n )\n\n def test_media_list(self):\n \"\"\" Test if when we call media_list it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.media_list()\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/media/',\n params={}\n )\n\n query = {\n 'count': True,\n 'limit': 2,\n 'type': 'image',\n 'versions': 1\n }\n\n self.asset_bank_client.media_list(query)\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/media/',\n params=query\n )\n\n def test_media_info(self):\n \"\"\" Test if when we call media_info it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.media_info(media_id=1111)\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/media/1111/',\n params={}\n )\n\n def test_download_url(self):\n \"\"\" Test if when we call download_url it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.media_download_url(media_id=1111)\n self.asset_bank_client.session.get.assert_called_with(\n '/v4/media/1111/download/',\n params={}\n )\n\n def test_set_media_properties(self):\n \"\"\" Test if when we call set_media_properties it will use the\n correct params for the request and returns successfully.\n \"\"\"\n self.asset_bank_client.set_media_properties(media_id=1111)\n self.asset_bank_client.session.post.assert_called_with(\n '/v4/media/1111/',\n data={}\n )\n\n def test_delete_media(self):\n \"\"\" Test if when we call delete_media it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.delete_media(media_id=1111)\n self.asset_bank_client.session\\\n .delete.assert_called_with('/v4/media/1111/')\n\n def test_create_usage(self):\n \"\"\" Test if when we call create_usage it will use the correct params for the\n request and returns successfully.\n \"\"\"\n payload = {\n 'integration_id': 2222,\n 'asset_id': 1111\n }\n self.asset_bank_client.create_usage(\n integration_id=payload['integration_id'],\n asset_id=payload['asset_id']\n )\n self.asset_bank_client.session.post.assert_called_with(\n '/media/usage/',\n data=payload\n )\n\n def test_get_usage(self):\n \"\"\" Test if when we call get_usage it will use the correct params for the\n request and returns successfully.\n \"\"\"\n self.asset_bank_client.usage()\n self.asset_bank_client.session.get.assert_called_with(\n '/media/usage/', params={}\n )\n\n def test_delete_usage(self):\n \"\"\" Test if when we call delete_usage it will use the correct params for the\n request and returns successfully.\n \"\"\"\n payload = {\n 'integration_id': 2222,\n 'asset_id': 1111\n }\n self.asset_bank_client.delete_usage(\n integration_id=payload['integration_id'],\n asset_id=payload['asset_id']\n )\n self.asset_bank_client.session\\\n .delete.assert_called_with(\n '/media/usage/',\n params=payload\n )\n\n def test_upload_file(self):\n \"\"\" Test if when we call upload_file it will use the correct params for the\n requests.\n \"\"\"\n file_path = 'path_to_a_file.png'\n brand_id = 1111\n self.asset_bank_client.upload_file(\n file_path=file_path, brand_id=brand_id)\n self.asset_bank_client.upload_client.upload.assert_called_with(\n file_path=file_path,\n media_id='',\n upload_data={'brandId': brand_id}\n )\n"
},
{
"alpha_fraction": 0.57259601354599,
"alphanum_fraction": 0.5796785354614258,
"avg_line_length": 21.384145736694336,
"blob_id": "959736c1bedc03dd78a0157f621a84c481ee39b1",
"content_id": "23ba9ec771734ac4cb46f8e63b15b756f17f9284",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3671,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 164,
"path": "/setup.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "import logging\nimport re\nimport subprocess\nimport sys\nfrom distutils.core import Command\n\nfrom setuptools import find_packages, setup\n\nwith open('bynder_sdk/version.py', 'r', encoding='utf-8') as version_file:\n version = re.search(\n r'VERSION = [\\'\"]([^\\'\"]+)', version_file.read(), re.MULTILINE\n ).group(1)\n\nwith open(\"README.md\", 'r') as readme:\n LONG_DESC = readme.read()\n\nlog = logging.getLogger(__name__)\nlog.setLevel(logging.INFO)\n\n\ndef _run_linters():\n linters = {\n 'flake8': ['flake8']\n }\n\n if sys.version_info >= (3, 5, 3):\n # https://github.com/PyCQA/pylint/issues/1388\n linters.update({'pylint': ['pylint', '--output-format', 'parseable']})\n\n for linter_name, command in linters.items():\n log.info('Running %s', linter_name)\n\n if subprocess.call(command + ['bynder_sdk', 'test']):\n raise SystemExit('{} failed'.format(linter_name))\n\n\ndef _run_type_linting():\n if subprocess.call(\n ['mypy',\n '--ignore-missing-imports',\n '--follow-imports=skip',\n 'bynder_sdk']):\n raise SystemExit('Type hinting checks failed.')\n\n\ndef _run_tests():\n if subprocess.call(\n ['pytest',\n '--cov-report', 'term-missing:skip-covered',\n '--cov-report', 'xml',\n '--cov', 'bynder_sdk',\n '--cov', 'test',\n 'test']):\n raise SystemExit('Linting failed.')\n\n\ndef _run_listdeps():\n regex = re.compile('.*bynder.*')\n bynder_deps = filter(regex.match, requires)\n print(' '.join(bynder_deps))\n\n\nclass PyTest(Command):\n user_options = []\n\n def initialize_options(self):\n subprocess.call(['pip', 'install'] + requires + test_requires)\n\n def finalize_options(self):\n pass\n\n def run(self):\n _run_tests()\n\n\nclass Linting(Command):\n user_options = []\n\n def initialize_options(self):\n subprocess.call(['pip', 'install'] + requires + test_requires)\n\n def finalize_options(self):\n pass\n\n def run(self):\n _run_linters()\n _run_type_linting()\n\n\nclass ListDeps(Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n _run_listdeps()\n\n\nclass TestDeps(Command):\n user_options = []\n\n def initialize_options(self):\n pass\n\n def finalize_options(self):\n pass\n\n def run(self):\n print(' '.join(test_requires))\n\n\nrequires = [\n 'requests>=2.20.0,<=3.0.0',\n 'requests_oauthlib>=1.1.0,<=2.0.0',\n]\n\ntest_requires = [\n 'pylint',\n 'mypy',\n 'pytest',\n 'pytest-cov',\n 'flake8',\n]\n\ncommands = {\n 'test': PyTest,\n 'lint': Linting,\n 'listdeps': ListDeps,\n 'testdeps': TestDeps,\n}\n\nsetup(\n name='bynder-sdk',\n version=version,\n description=(\n 'Bynder SDK can be used to speed up the'\n ' integration of Bynder in Python'\n ),\n long_description=LONG_DESC,\n long_description_content_type='text/markdown',\n url='https://bynder.com',\n author='Bynder',\n author_email='[email protected]',\n license='MIT',\n cmdclass=commands,\n packages=find_packages(),\n install_requires=requires,\n tests_require=test_requires,\n include_package_data=True,\n keywords='bynder, dam',\n classifiers=[\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: Apache Software License',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n zip_safe=False\n)\n"
},
{
"alpha_fraction": 0.6348314881324768,
"alphanum_fraction": 0.6348314881324768,
"avg_line_length": 22.733333587646484,
"blob_id": "7db87f5a2bcb4399ba35ea3181cd63f54494c71d",
"content_id": "6ec9329f686d3287352a33bed9c4add1e7a31bfd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 356,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 15,
"path": "/test/__init__.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from bynder_sdk.client.bynder_client import BynderClient\n\nTOKEN = 'token'\nTEST_DOMAIN = 'test.getbynder.com'\n\n\ndef create_bynder_client():\n return BynderClient(\n domain=TEST_DOMAIN,\n redirect_uri='https://test.com/',\n client_id='client_id',\n client_secret='client_secret',\n token=TOKEN,\n scopes='offline'\n )\n"
},
{
"alpha_fraction": 0.596258282661438,
"alphanum_fraction": 0.6053107976913452,
"avg_line_length": 31.490196228027344,
"blob_id": "975357f5a4dc4efa95dc2fc98ed066f6a472fbc7",
"content_id": "cf280233a8163f47427cbd4789e1e609de7c95be",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1657,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 51,
"path": "/test/oauth2_session_test.py",
"repo_name": "WouterToering/bynder-python-sdk",
"src_encoding": "UTF-8",
"text": "from unittest import mock, TestCase\n\nfrom bynder_sdk.oauth2 import BynderOAuth2Session, oauth2_url\nfrom bynder_sdk.util import api_endpoint_url, UA_HEADER\n\n\nTEST_DOMAIN = 'test.getbynder.com'\n\n\nclass OAuth2Test(TestCase):\n def setUp(self):\n self.session = BynderOAuth2Session(\n 'test.getbynder.com',\n redirect_uri='https://test.com/',\n client_id='client_id',\n auto_refresh_kwargs={\n 'client_id': 'client_id',\n 'client_secret': 'client_secret'\n },\n )\n\n def test_oauth2_url(self):\n self.assertEqual(\n oauth2_url(TEST_DOMAIN, 'token'),\n 'https://{}/v6/authentication/oauth2/token'.format(TEST_DOMAIN),\n )\n\n def test_api_endpoint_url(self):\n self.assertEqual(\n api_endpoint_url(self.session, '/v4/users/'),\n 'https://{}/api/v4/users/'.format(TEST_DOMAIN)\n )\n\n @mock.patch('requests_oauthlib.OAuth2Session.authorization_url')\n def test_authorization_url(self, mocked_func):\n self.session.authorization_url()\n assert mocked_func.call_count == 1\n\n @mock.patch('requests_oauthlib.OAuth2Session.fetch_token')\n def test_fetch_token(self, mocked_func):\n self.session.fetch_token('code')\n mocked_func.assert_called_with(\n oauth2_url(TEST_DOMAIN, 'token'),\n client_secret='client_secret',\n include_client_id=True,\n code='code',\n )\n\n def test_user_agent_header(self):\n # The UA header is contained within the session headers\n assert UA_HEADER.items() <= self.session.headers.items()\n"
}
] | 19 |
chestnovk/cluster_tools
|
https://github.com/chestnovk/cluster_tools
|
887e82470455230814fc9c2de4846f8dfd3d34a7
|
c2e3586fb0df3637eacfcd660a6d535f9a412d4e
|
402bc50a65b05ecace9fb3ef3fd005980e80eadd
|
refs/heads/master
| 2020-06-03T20:54:03.656567 | 2019-06-18T02:36:30 | 2019-06-18T02:36:30 | 191,727,457 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5468193292617798,
"alphanum_fraction": 0.5506361126899719,
"avg_line_length": 34.727272033691406,
"blob_id": "9187bf1066f81428e7633d15faa5c6c710d131ae",
"content_id": "99d3db0babd1af8c2791080a43be95f260ceb83c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3930,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 110,
"path": "/generators.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport datetime\nimport json\nfrom vm_tools import Vm\n\n\ndef generate_cmdline(**kwargs):\n\n cmdline = \"\"\n\n def append(key, value):\n nonlocal cmdline\n cmdline += (\" \" + key + \"=\" + value)\n\n for k, v in kwargs.items():\n if k == \"iso_name\":\n append(\"inst.stage2=hd:LABEL\", v)\n elif k == \"public_ip\":\n append(\"ip\", v)\n append(k, v)\n else:\n append(k, str(v))\n\n return cmdline\n\n\ndef generate_private_ip(ip):\n # I will extend it for any subnet\n return \"192.168.100.\" + ip[-3:]\n\n\ndef generate_timestamp(base):\n now = datetime.datetime.now()\n name = base + \"-\" + now.strftime(\"%Y%m%d\")\n return name\n\n\ndef generate_config(json_config):\n\n # Create an array to store VMs:\n vms = []\n\n with open(json_config) as f:\n config = json.load(f)\n i = 1\n general_options = {}\n general_options['workdir'] = config['general']['workdir']\n general_options['iso'] = config['general']['iso']\n general_options['ks'] = config['general']['ks']\n general_options['ks_device'] = config['general']['ks_device']\n general_options['name'] = config['cluster']['name']\n general_options['va'] = config['va']\n general_options['storage_ui'] = config['storage_ui']\n\n for vm_public_ip in config['cluster']['public_net']['ips']:\n # the name_generator should be better.\n options = {}\n options['iso_name'] = config['general']['iso']\n options['hostname'] = generate_timestamp(config['cluster']['name']) + \"-\" + str(i)\n options['public_ip'] = vm_public_ip\n options['public_mask'] = config['cluster']['public_net']['mask']\n options['public_gw'] = config['cluster']['public_net']['gw']\n options['public_dns'] = config['cluster']['public_net']['dns']\n options['ks_device'] = config['general']['ks_device']\n options['ks'] = config['general']['ks']\n\n if config['cluster']['private_net']['create'] == \"True\":\n options['private_ip'] = generate_private_ip(vm_public_ip)\n options['private_mask'] = config['cluster']['private_net']['mask']\n\n # Try to create management containers\n # Final decision is made by a kickstart file\n # Depends on given cmdline options\n # In case of troubles check cat /proc/cmdline\n # From anaconda and compare with kickstart\n # For example if you not specify IP address\n # The kickstart will not create VA\n # Same for UI\n # Token should be obtain somehow later.\n # Actually this decision affects future cluster updates.\n # Probably I could write a value \"general\" \"is_created\"\n # So it will not be added later if additional VM should be added to\n # an existed cluster with ui\n\n if i == 1 and not config['general']['is_created']:\n options['includes_va'] = True\n options['va_ip'] = config['va']['ip']\n options['includes_storage_ui'] = True\n options['storage_ui_ip'] = config['storage_ui']['ip']\n # In case there is no such values left blank\n else:\n options['va_ip'] = config['va']['ip']\n options['storage_ui_ip'] = config['storage_ui']['ip']\n options['storage_ui_token'] = config['storage_ui']['token']\n vm = Vm(options, generate_cmdline(**options))\n # I probably need to check VM names and try to create a VM.\n # If it was successfully created I need to create an dumpxml right here.\n # If something goes wrong the script must be stopped.\n vms.append(vm)\n i += 1\n\n return vms, general_options\n\n\ndef main():\n pass\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6481876373291016,
"alphanum_fraction": 0.6492537260055542,
"avg_line_length": 25.05555534362793,
"blob_id": "b0b7be4f4ed0625c5055d8cc568447dc76b31c38",
"content_id": "5f4af3d9a28a31c57df709a534702143217ff8bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 938,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 36,
"path": "/generate_config.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport os\nimport generators\nfrom os_tools_class import IsoTools\nfrom vm_tools import Vm\n\n\n\ndef main():\n\n # Obtain all the parameters from json. It will generate a list of Vm objects + array of general options\n # general option are to be used for mount iso, for example.\n vms, general_options = generators.generate_config(\"/home/kchestnov/Python/cluster_tools/cluster_tools/cluster_config.json\")\n\n # I should mount iso only after I know that vms were created.\n iso = IsoTools(general_options['iso'], os.path.join(general_options['workdir'], \"mounts\"))\n iso.mount()\n\n for vm in vms:\n print(vm.options)\n print(vm.cmdline)\n\n # The VM must be created as well as dumpxml.\n # vm.define\n # vm.start\n # vm.wait\n # vm.define\n # vm.start\n\n\n # After all of the VM have been created, umount ISO\n iso.umount()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6324324607849121,
"alphanum_fraction": 0.6454054117202759,
"avg_line_length": 26.475248336791992,
"blob_id": "de1a632a576503938c98a29c5c02bedb45a2ebc9",
"content_id": "568cb88a1003d6787f736a7865b78e3f215bf04f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2775,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 101,
"path": "/os_tools.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport sys\nimport subprocess\nimport os\n\n# Mount tool assumes that you make precheck if ISO exists and mount dir is created before calling.\n# Otherwise it exits.\n# Probably I can do it in a less number of rows\n\ndef get_mount_dir_name(iso_path, workdir):\n mount_dir_name = os.path.join(workdir, os.path.splitext(os.path.basename(iso_path))[0])\n return mount_dir_name\n\n\ndef create_mount_dir(iso_path, workdir):\n mount_dir = get_mount_dir_name(iso_path, workdir)\n if not os.path.isdir(mount_dir):\n os.mkdir(mount_dir)\n return mount_dir\n\n\ndef mount(iso_path, workdir):\n mount_dir = create_mount_dir(iso_path, workdir)\n try:\n subprocess.run([\"sudo\", \"mount\", \"-o\", \"loop\", iso_path, mount_dir],\n check=True, stderr=True)\n return mount_dir\n except subprocess.CalledProcessError as err:\n sys.exit(\"Cannot mount the {} to the {}. Error: {}\".format(iso_path, mount_dir, err.returncode))\n\n\ndef umount(mount_dir):\n\n try:\n subprocess.run([\"sudo\", \"umount\", mount_dir],\n check=True)\n except subprocess.CalledProcessError as err:\n sys.exit(\"Cannot umount the {}\".format(mount_dir, err.returncode))\n\n\ndef get_vmlinuz(mount_dir):\n vmlinuz = os.path.join(mount_dir, \"images/pxeboot/vmlinuz\")\n if not os.path.isfile(vmlinuz):\n sys.exit(\"Cannot find {} in a {}\".format(vmlinuz, mount_dir))\n else:\n return vmlinuz\n\n\ndef get_initrd(mount_dir):\n initrd = os.path.join(mount_dir, \"images/pxeboot/initrd.img\")\n if not os.path.isfile(initrd):\n sys.exit(\"Cannot find {} in a {}\".format(initrd, mount_dir))\n else:\n return initrd\n\n\n# Check if mount success if there is no ISO\ndef test1():\n iso_path = \"\"\n workdir = \"/tmp/mount\"\n mount(iso_path, workdir)\n umount(iso_path, workdir)\n return \"Passed\"\n\n\n# Check if mount success if there is no mount_dir\ndef test2():\n iso_path = \"/home/kchestnov/ISO/CentOS-7-x86_64-Minimal-1810.iso\"\n workdir = \"/temp/nosuchdir\"\n mount(iso_path, workdir)\n umount(iso_path, workdir)\n return \"Passed\"\n\n\n# Check if mount success if there is already mounted ISO\ndef test3():\n iso_path = \"/home/kchestnov/ISO/CentOS-7-x86_64-Minimal-1810.iso\"\n workdir = \"/tmp/mount\"\n mountdir = mount(iso_path, workdir)\n mountdir = mount(iso_path, workdir)\n umount(mountdir)\n return \"Passed\"\n\ndef test4():\n iso_path = \"/home/kchestnov/ISO/CentOS-7-x86_64-Minimal-1810.iso\"\n workdir = \"/tmp/mount\"\n mount_dir = mount(iso_path, workdir)\n print(get_initrd(mount_dir))\n print(get_vmlinuz(mount_dir))\n umount(mount_dir)\n return \"Passed\"\n\n\ndef main():\n #print(test1())\n #print(test2())\n print(test4())\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.49671250581741333,
"alphanum_fraction": 0.4997011423110962,
"avg_line_length": 29.409090042114258,
"blob_id": "6322efdac342ecd48b260733b5bf65314d7af504",
"content_id": "54f4bf576fed56727c5bf0a4b3d678de278754f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3346,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 110,
"path": "/vm_tools.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport subprocess\n\n\n# Need to make it works\nclass Vm:\n\n def __init__(self, options, cmdline):\n self.options = options\n self.cmdline = cmdline\n\n def create_vm(self):\n name = self.options['name']\n # Need to find a way how to define description\n description = \"\"\n iso = self.options['iso_name']\n\n subprocess.call([\"prlctl\", \"create\", name,\n \"--vmtype\", \"vm\",\n \"--distribution\", \"vzlinux7\"]\n , stdout=False)\n\n subprocess.call([\"prlctl\", \"set\", name,\n \"--description\", description]\n , stdout=False)\n\n subprocess.call([\"prlctl\", \"set\", name,\n \"--device-set\", \"net0\",\n \"--ipfilter\", \"no\",\n \"--macfilter\", \"no\",\n \"--preventpromisc\", \"no\"]\n , stdout=False)\n\n subprocess.call([\"prlctl\", \"set\", name,\n \"--vnc-mode\", \"auto\"]\n , stdout=False)\n\n subprocess.call([\"prlctl\", \"set\", name,\n \"--device-set\", \"cdrom0\",\n \"--connect\", \"--image\", iso]\n , stdout=False)\n\n # Enable support of nested virt\n subprocess.call([\"prlctl\", \"set\", name,\n \"--nested-virt\", \"on\"]\n , stdout=False)\n # define\n # create\n # configure\n # start\n # remove\n\n\n# Rewrite call to run and handle exceptions\n# The best choise is to use Dispatcher and Libvirtd\ndef define_vm(domainxml):\n # This executes virsh define <domainxml>\n subprocess.call([\"virsh\", \"define\", domainxml], stdout=False)\n\n\n# Rewrite to subprocess.run()\n\n\n\ndef generate_dumpxml(workdir, vm_name, vmlinuz, initrd, commandline):\n\n domainxml = os.path.join(workdir, \"configs\", vm_name)\n domainxml_tmp = domainxml + \"_tmp\"\n\n with open(domainxml, 'w') as file:\n subprocess.call([\"virsh\", \"dumpxml\", vm_name], stdout=file)\n\n with open(domainxml) as file:\n tmp = file.readlines()\n\n for index, line in enumerate(tmp):\n if \"<qemu:commandline>\" in line:\n # Need to rewrite for XML\n # This is not cool at all\n tmp.insert(index + 1,\" <qemu:arg value='{}'/>\\n\".format(vmlinuz))\n tmp.insert(index + 1,\" <qemu:arg value='-kernel'/>\\n\")\n tmp.insert(index + 1,\" <qemu:arg value='{}'/>\\n\".format(initrd))\n tmp.insert(index + 1,\" <qemu:arg value='-initrd'/>\\n\")\n tmp.insert(index + 1,\" <qemu:arg value='{}'/>\\n\".format(commandline))\n tmp.insert(index + 1,\" <qemu:arg value='-append'/>\\n\")\n\n with open(domainxml_tmp, 'w') as file:\n for line in tmp:\n file.write(line)\n\n return domainxml_tmp\n\n\ndef start(vm_name):\n # It starts the VM\n subprocess.call([\"prlctl\", \"start\", vm_name], stdout=False)\n\n\ndef remove(vm_name):\n subprocess.call([\"prlctl\", \"stop\", vm_name, \"--force\"], stdout=False)\n subprocess.call([\"prlctl\", \"delete\", vm_name, \"--force\"], stdout=False)\n\n\ndef main():\n # Simple main\n pass\n\n\nif __name__ == \"__main__\":\n main()\n\n"
},
{
"alpha_fraction": 0.4636177718639374,
"alphanum_fraction": 0.4674167037010193,
"avg_line_length": 31.822542190551758,
"blob_id": "89c1cfe148618f44ee0c07b0cb866250c9e550bb",
"content_id": "75c3630b3a6ba676f5b726c25cc2960705df2ce1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13688,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 417,
"path": "/create_vm.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport json\nimport os\nimport sys\nimport subprocess\nimport time\nfrom pprint import pprint\n\n# TODO: user input -> ./create_vm_tmp.py <config_file>\n# TODO: check names of VMs, not add if exist.\n# TODO: rewrite VzVmBaseConfig to get dict on input with **kargs\n# TODO: rewrite add_kernel_options to use Etree XML parser\n# TODO: some output of the script are expected. Need to use some log file\n\nclass VzVmBaseConfig:\n\n def __init__(self, cluster_name, vm_iso_path):\n # Basic settings\n self.vm_iso_path = vm_iso_path\n self.kickstart = \"http://172.16.56.80/ks/create_cluster.cfg\"\n\n self.public_mask = \"255.255.252.0\"\n self.public_gw = \"172.16.56.1\"\n self.public_dns = \"10.30.0.27\"\n\n self.root_dir = \"/root/kchestnov/create_vm\"\n self.mount_dir = self.root_dir + \"/mounts\"\n self.vm_config_dir = self.root_dir + \"/vms\"\n\n # Not sure if I want to put it here\n self.cluster_name = cluster_name\n self.vms = []\n\n\nclass VzVmConfig:\n\n # Some shit went here, if executed with json\n # the __init_ is not able to find va_ip\n # and futher checks failed\n # How to set default if there is no \n # in JSON?\n #\n # I decided to have \"default\" values here\n # which will be overrided by settattr if \n # they are set in \"JSON\"\n\n def __init__(\n self,\n VzVmBaseConfig,\n iso,\n name,\n public_ip,\n private_ip=\"\",\n includes_va=False,\n va_register=False,\n va_ip=\"\",\n includes_storage_ui=False,\n storage_ui_register=False,\n storage_ui_ip=\"\",\n storage_ui_token=\"\",\n **kwargs\n ):\n\n # Assign additional params from extra\n for k, v in kwargs.items():\n print(\"{}: {}\".format(k, v))\n setattr(self, k, v)\n\n # Define name\n self.name = VzVmBaseConfig.cluster_name + \"_\" + name\n self.hostname = name + \"-hostname\"\n self.ips = \"\"\n\n # Kickstart location\n self.ks_device = \"eth0\"\n\n # Public net\n self.public_ip = public_ip\n\n # VNC settings\n self.vnc_mode = \"auto\"\n self.vnc_passwd = \"--vnc-nopasswd\"\n\n # Description for IP\n self.ips = self.ips + self.public_ip\n\n # libvirt specific options\n self.domainxml = os.path.join(VzVmBaseConfig.vm_config_dir, self.name)\n self.domainxml_temp = self.domainxml + \"_temp\"\n\n # Maybe this is not worth thing to do.\n # And I can avoid this check later\n self.iso_path = iso.iso_path\n self.vmlinuz = iso.get_vmlinuz()\n self.initrd = iso.get_initrd()\n\n # kickstart requires the following:\n # \"ksdevice\"\n # \"ip\"\n # \"netmask\"\n # so I TEMPORARY add this\n # to make sure that my\n # example.cfg will be able to run\n\n self.commandline = (\"inst.stage2=hd:LABEL={} \"\n \"ksdevice={} \"\n \"ip={} \"\n \"netmask={} \"\n \"hostname={} \"\n \"ks_device={} \"\n \"public_ip={} \"\n \"public_mask={} \"\n \"public_gw={} \"\n \"public_dns={} \"\n \"ks={} \"\n ).format(\n iso.name,\n self.ks_device,\n self.public_ip,\n VzVmBaseConfig.public_mask,\n self.hostname,\n self.ks_device,\n self.public_ip,\n VzVmBaseConfig.public_mask,\n VzVmBaseConfig.public_gw,\n VzVmBaseConfig.public_dns,\n VzVmBaseConfig.kickstart\n )\n\n # Private net only when needed. Default False\n if private_ip:\n self.private_ip = private_ip\n self.private_net = \"pn_for_\" + VzVmBaseConfig.cluster_name\n self.commandline = self.commandline + (\"private_ip={} \"\n \"private_mask={} \"\n ).format(\n self.private_ip,\n self.private_mask\n )\n\n # VA options if needed. Default False\n # Add related options to commandline\n if includes_va == \"True\" and va_ip:\n self.includes_va = includes_va\n self.va_ip = va_ip\n self.va_register = va_register\n self.ips = self.ips + \" \" + self.va_ip\n self.commandline = self.commandline + (\"includes_va={} \"\n \"va_register={} \"\n \"va_ip={} \"\n ).format(\n self.includes_va,\n self.va_register,\n self.va_ip\n )\n elif va_register == \"True\" and va_ip:\n self.va_register = va_register\n self.va_ip = va_ip\n self.commandline = self.commandline + (\"va_register={} \"\n \"va_ip={} \"\n ).format(\n self.va_register,\n self.va_ip\n )\n # Storage UI options if needed. Default False.\n # Add related options to commandline.\n if includes_storage_ui == \"True\" and storage_ui_ip:\n self.includes_storage_ui = includes_storage_ui\n self.storage_ui_ip = storage_ui_ip\n self.ips = self.ips + \" \" + self.storage_ui_ip\n self.commandline = self.commandline + (\"includes_storage_ui={} \"\n \"storage_ui_ip={} \"\n ).format(\n self.includes_storage_ui,\n self.storage_ui_ip\n )\n\n elif storage_ui_register == \"True\" and storage_ui_ip and storage_ui_token:\n self.storage_ui_register = storage_ui_register\n self.storage_ui_ip = storage_ui_ip\n self.storage_ui_token = storage_ui_token\n self.commandline = self.commandline + (\"storage_ui_register={} \"\n \"storage_ui_ip={} \"\n \"storage_ui_token={} \"\n ).format(\n self.storage_ui_register,\n self.storage_ui_ip,\n self.storage_ui_token\n )\n\n self.description = \"extip:[{}]\".format(self.ips)\n\n def create(self):\n # Create the VM\n subprocess.call([\n \"prlctl\", \"create\", self.name,\n \"--vmtype\", \"vm\",\n \"--distribution\", \"vzlinux7\"\n ], stdout=False)\n # Add some description\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--description\", self.description\n ], stdout=False)\n # Disable filtering\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--device-set\", \"net0\",\n \"--ipfilter\", \"no\",\n \"--macfilter\", \"no\",\n \"--preventpromisc\", \"no\"\n ], stdout=False)\n\n # Add VNC config\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--vnc-mode\", self.vnc_mode,\n self.vnc_passwd\n ], stdout=False)\n\n # Attach cdrom\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--device-set\", \"cdrom0\",\n \"--connect\",\n \"--image\", self.iso_path\n ], stdout=False)\n\n # Enable support of nested virt\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--nested-virt\", \"on\"\n ], stdout=False)\n\n def set_private_net(self):\n # Create private net\n subprocess.call([\n \"prlsrvctl\", \"net\", \"add\",\n self.private_net\n ], stdout=False)\n\n # Add nic to the private net\n subprocess.call([\n \"prlctl\", \"set\", self.name,\n \"--device-add\", \"net\",\n \"--network\", self.private_net\n ], stdout=False)\n\n def add_kernel_options(self):\n\n with open(self.domainxml, 'w') as file:\n subprocess.call([\"virsh\", \"dumpxml\", self.name], stdout=file)\n\n with open(self.domainxml) as file:\n tmp = file.readlines()\n\n for index, line in enumerate(tmp):\n if \"<qemu:commandline>\" in line:\n # Need to rewrite for XML\n # This is not cool at all\n tmp.insert(index + 1,\n \" <qemu:arg value='{}'/>\\n\".format(self.vmlinuz)\n )\n tmp.insert(index + 1,\n \" <qemu:arg value='-kernel'/>\\n\"\n )\n tmp.insert(index + 1,\n \" <qemu:arg value='{}'/>\\n\".format(self.initrd)\n )\n tmp.insert(index + 1,\n \" <qemu:arg value='-initrd'/>\\n\"\n )\n tmp.insert(index + 1,\n \" <qemu:arg value='{}'/>\\n\".format(self.commandline)\n )\n tmp.insert(index + 1,\n \" <qemu:arg value='-append'/>\\n\"\n )\n\n with open(self.domainxml_temp, 'w') as file:\n for line in tmp:\n file.write(line)\n\n def define(self, domainxml):\n # This executes virsh define <domainxml>\n subprocess.call([\"virsh\", \"define\", domainxml], stdout=False)\n\n def start(self):\n # This starts the VM\n subprocess.call([\"prlctl\", \"start\", self.name], stdout=False)\n\n# Need to rename later. \nclass iso:\n\n def __init__(self, iso_path, mount_dir):\n\n if not os.path.isfile(iso_path):\n sys.exit(\"ERROR. Please input correct path for iso \"\n \"current: {}\".format(iso_path))\n if not os.path.isdir(mount_dir):\n os.mkdir(mount_dir)\n\n self.name = os.path.splitext(os.path.basename(iso_path))[0]\n\n self.iso_path = iso_path\n self.mount_dir = os.path.join(\n mount_dir,\n self.name\n )\n self.vmlinuz = os.path.join(self.mount_dir, \"images/pxeboot/vmlinuz\")\n self.initrd = os.path.join(self.mount_dir, \"images/pxeboot/initrd.img\")\n\n if not os.path.isdir(self.mount_dir):\n os.mkdir(self.mount_dir)\n\n def get_vmlinuz(self):\n # Get initrd.img and vzlinuz\n if not os.path.isfile(self.vmlinuz):\n self.mount()\n return self.vmlinuz\n else:\n return self.vmlinuz\n\n def get_initrd(self):\n if not os.path.isfile(self.initrd):\n self.mount(self)\n return self.initrd\n else:\n return self.initrd\n\n def mount(self):\n try:\n subprocess.call([\n \"sudo\", \"mount\", \"-o\", \"loop\",\n self.iso_path, self.mount_dir\n ], stdout=False)\n except:\n sys.exit(\"Cannot mount the {} to the {}\".format(\n self.iso_path,\n self.mount_dir\n ))\n\n def umount(self):\n try:\n subprocess.call([\n \"sudo\", \"umount\",\n self.mount_dir\n ], stdout=False)\n except:\n sys.exit(\"Cannot mount the {} to the {}\".format(\n self.iso_path,\n self.mount_dir\n ))\n\n\ndef my_main():\n \n json_config = sys.argv[1]\n\n with open(json_config) as f:\n o_vms = []\n print(\"Obtaining parameters...\")\n config = json.load(f)\n \n cluster = config.get('cluster')\n iso_path = cluster.get('iso')\n va = config.get('va')\n storage_ui = config.get('storage_ui')\n vms = config.get('vm')\n \n print(\"Creating base config...\")\n o_cluster = VzVmBaseConfig(cluster.get('name'),cluster.get('iso'))\n o_iso = iso(o_cluster.vm_iso_path, o_cluster.mount_dir)\n\n print('''Success. Current objects are:\n o_cluster: {}\n o_iso: {}'''.format(pprint(vars(o_cluster)),pprint(vars(o_iso))))\n \n print(\"Creating VMs...\")\n\n for vm in vms.values():\n print(\"Creating a vm: {}\".format(vm.get('name')))\n o_vm = VzVmConfig(\n o_cluster,\n o_iso,\n vm.pop('name'),\n vm.pop('public_ip'),\n va_ip=va.get('va_ip'),\n storage_ui_ip=storage_ui.get('storage_ui_ip'),\n **vm)\n\n o_vms.append(o_vm)\n\n\n for vm in o_vms:\n pprint(vars(vm))\n vm.create()\n if vm.private_net:\n vm.set_private_net()\n vm.add_kernel_options()\n vm.define(vm.domainxml_temp)\n vm.start()\n while \"running\" in subprocess.getoutput('prlctl status ' + vm.name):\n print(\"Waiting for 30 sec...\")\n time.sleep(30)\n vm.define(vm.domainxml)\n vm.start()\n\n # Cleaning up \n o_iso.umount()\n\n# Need to write some protection from import. Will add later\nmy_main()\n\n# Add \"check for main VM with VA then the rest of VM\n# Add args[]\n# Add output for remote mgmt once a domain was started.\n\n"
},
{
"alpha_fraction": 0.5983263850212097,
"alphanum_fraction": 0.6048349738121033,
"avg_line_length": 33.709678649902344,
"blob_id": "0b933b589c5951ca9caf482be03ff3b1e6432395",
"content_id": "ec5247be2ba9b32ffe7a939d0f2829954c5e6530",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2151,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 62,
"path": "/os_tools_class.py",
"repo_name": "chestnovk/cluster_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport sys\nimport subprocess\nimport os\n\n# Probably I can do it in a less number of rows\n\n\nclass IsoTools:\n\n def __init__(self, iso_path, workdir):\n\n if not os.path.isfile(iso_path) and not os.path.isdir(workdir):\n sys.exit(\"Please specify correct ISO or workdir\")\n\n self.name = os.path.splitext(os.path.basename(iso_path))[0]\n self.iso_path = iso_path\n self.mount_dir = os.path.join(workdir, os.path.splitext(os.path.basename(iso_path))[0])\n if not os.path.isdir(self.mount_dir):\n try:\n os.mkdir(self.mount_dir)\n except OSError as err:\n sys.exit(\"Cannot create \\\"{}\\\". Error: {}\".format (self.mount_dir, err.strerror))\n self.vmlinuz = os.path.join(self.mount_dir, \"images/pxeboot/vmlinuz\")\n self.initrd = os.path.join(self.mount_dir, \"images/pxeboot/initrd.img\")\n\n def mount(self):\n try:\n subprocess.run([\"sudo\", \"mount\", \"-o\", \"ro\", self.iso_path, self.mount_dir], check=True, stderr=True)\n return self.mount_dir\n except subprocess.CalledProcessError as err:\n sys.exit(\"Cannot mount the {} to the {}. Error: {}\".format (self.iso_path, self.mount_dir, err.returncode))\n\n def umount(self):\n try:\n subprocess.run([\"sudo\", \"umount\", self.mount_dir], check=True)\n except subprocess.CalledProcessError as err:\n sys.exit(\"Cannot umount the {}\".format(self.mount_dir, err.returncode))\n\n def get_vmlinuz(self):\n if not os.path.isfile(self.vmlinuz):\n sys.exit(\"Cannot find {} in a {}\".format(self.vmlinuz, self.mount_dir))\n else:\n return self.vmlinuz\n\n def get_initrd(self):\n if not os.path.isfile(self.initrd):\n sys.exit(\"Cannot find {} in a {}\".format(self.initrd, self.mount_dir))\n else:\n return self.initrd\n\n\ndef main():\n IsoTools_v = IsoTools(\"/home/kchestnov/Downloads/vz-platform-2.5.0-1642-1642.iso\", \"\")\n IsoTools_v.mount()\n IsoTools_v.get_initrd()\n IsoTools_v.get_vmlinuz()\n IsoTools_v.umount()\n\n\nif __name__ == \"__main__\":\n main()"
}
] | 6 |
pierrestefani/metaGenBayes
|
https://github.com/pierrestefani/metaGenBayes
|
ece2a481a537b25d8c9639643f4bac3889502fd8
|
9fe3bb86d1fd6d1b1c1002087a661196e7a3d288
|
757d313b7e20979f56bb67e9a8e576132d6fe2e0
|
refs/heads/master
| 2016-09-05T19:45:47.028195 | 2015-10-20T20:47:04 | 2015-10-20T20:47:04 | 32,411,610 | 0 | 1 | null | 2015-03-17T18:16:01 | 2015-04-03T12:10:22 | 2015-04-04T10:17:45 |
Python
|
[
{
"alpha_fraction": 0.8320610523223877,
"alphanum_fraction": 0.8320610523223877,
"avg_line_length": 65,
"blob_id": "8e5d0ac43b9a808fa860103dc07899c538a47822",
"content_id": "04a638dd1b85e8dd94fb58bd1af521d6817cc4e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 2,
"path": "/Generator/__init__.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "#The Generator module lists the generators used to translate the array of \n#instructions compiled by Compiler, in several languages"
},
{
"alpha_fraction": 0.4898882508277893,
"alphanum_fraction": 0.5021287798881531,
"avg_line_length": 40.568180084228516,
"blob_id": "f02a494cb5880cd84e7639b3ee52172df67d109b",
"content_id": "d285b280c23725be510f206ee095193ddada4ab3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3758,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 88,
"path": "/Generator/pyAgrumGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "import time\r\n\r\nclass pyAgrumGenerator: \r\n @classmethod\r\n def nameCpt(self, bn, var):\r\n parents = []\r\n for i in bn.parents(var):\r\n parents.append(str(i))\r\n parents = \"_\".join(parents)\r\n return \"P\"+str(var)+\"sachant\"+parents\r\n \r\n def initCpts(self,bn):\r\n res = \"\"\r\n for i in bn.ids():\r\n res += \"\\tv\"+str(i)+\" = gum.LabelizedVariable('\"+bn.variable(i).name()+\"','\"+bn.variable(i).name()+\"',\"+str(bn.variable(i).domainSize())+\")\\n\"\r\n for i in bn.ids():\r\n\r\n nameCpt = pyAgrumGenerator.nameCpt(bn,i)\r\n res += \"\\t\"+nameCpt+\" = gum.Potential()\\n\"\r\n res += \"\\t\"+nameCpt+\".add(v\"+str(i)+\")\\n\"\r\n ls = bn.cpt(i).var_names\r\n for j in reversed(ls[0:len(ls)-1]):\r\n res += \"\\t\"+nameCpt+\".add(v\"+str(bn.idFromName(j))+\")\\n\"\r\n res += \"\\t\"+nameCpt+\"[:] = np.array(\"+str(bn.cpt(i).tolist())+\")\\n\"\r\n return res\r\n \r\n def creaPot(self,nompot,varPot):\r\n return (\"\\t\"+str(nompot)+\"=gum.Potential()\\n\")\r\n \r\n def addVarPot(self,var,nompot):\r\n return(\"\\t\"+str(nompot)+\".add(\"+str(var)+\")\\n\")\r\n \r\n def addSoftEvPot(self,evid,nompot,index,value):\r\n return(\"\\t\"+str(nompot)+\"[:]=\"+value+\"\\n\")\r\n \r\n def mulPotCpt(self, bn, nompot, var, varPot):\r\n cpt = pyAgrumGenerator.nameCpt(bn,int(var))\r\n res = \"\\t\"+nompot+\".multiplicateBy(\"+cpt+\")\\n\"\r\n return res\r\n \r\n def mulPotPot(self,nompot1,nompot2,varPot1,varPot2):\r\n return(\"\\t\"+str(nompot1)+\".multiplicateBy(\"+str(nompot2)+\")\\n\")\r\n \r\n def margi(self,bn,nompot1,nompot2,varPot1,varPot2): \r\n return(\"\\t\"+str(nompot1)+\".marginalize(\"+str(nompot2)+\")\\n\")\r\n \r\n def norm(self, nompot):\r\n return(\"\\t\"+str(nompot)+\".normalize()\\n\")\r\n \r\n def fill(self, pot, num):\r\n return(\"\\t\"+str(pot)+\".fill(\"+str(num)+\")\\n\")\r\n \r\n def equa(self, nompot1, nompot2):\r\n return \"\\t\"+nompot1+\" = \"+nompot2+\"\\n\"\r\n \r\n def genere(self, bn, targets, evs, comp, nameFile, nameFunc, header):\r\n stream = open(nameFile,'w')\r\n stream.write(\"'''This code was generated for pyAgrum use, compiled by Compiler.py and generated with pyAgrumGenerator.py.\\nIt shouldn't be altered here'''\\n\")\r\n stream.write(\"import pyAgrum as gum\\nimport numpy as np\\n\")\r\n stream.write(\"'''Generated on : \"+time.strftime('%m/%d/%y %H:%M',time.localtime())+\"'''\\n\\n\\n\")\r\n stream.write(header+\"\\n\\n\")\r\n stream.write(\"def \"+nameFunc+\"(evs):\\n\")\r\n stream.write(\"\\tres = {}\\n\")\r\n stream.write(self.initCpts(bn))\r\n for cur in comp:\r\n act = cur[0]\r\n if act == 'CPO':\r\n stream.write(self.creaPot(cur[1],cur[2]))\r\n elif act == 'ADV':\r\n stream.write(self.addVarPot('v'+cur[1],cur[2]))\r\n elif act == 'ASE':\r\n stream.write(self.addSoftEvPot(cur[1],cur[2],cur[3],cur[4]))\r\n elif act == 'MUC':\r\n stream.write(self.mulPotCpt(bn,cur[1],cur[2],cur[3]))\r\n elif act == 'MUL':\r\n stream.write(self.mulPotPot(cur[1],cur[2],cur[3],cur[4]))\r\n elif act == 'MAR':\r\n stream.write(self.margi(cur[1],cur[2],cur[3],cur[4],cur[5]))\r\n elif act == 'NOR':\r\n stream.write(self.norm(cur[1]))\r\n stream.write(\"\\tres['\"+cur[2]+\"']=np.copy(\"+str(cur[1])+\"[:])\\n\")\r\n elif act == 'FIL':\r\n stream.write(self.fill(cur[1],cur[2]))\r\n elif act == 'EQU':\r\n stream.write(self.equa(cur[1],cur[2]))\r\n stream.write(\"\\treturn res\")\r\n\r\n stream.close()\r\n \r\n\r\n"
},
{
"alpha_fraction": 0.48276787996292114,
"alphanum_fraction": 0.5031514167785645,
"avg_line_length": 39.4782600402832,
"blob_id": "a582f8253ff9fc313ba297bbee20463d61d36d5f",
"content_id": "129e34a99217261034bc4faf439165e6a5516a2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7457,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 184,
"path": "/Generator/javascriptGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "import time\n\ndef flatten(liste):\n '''Transforms multidimensional arrays into one'''\n for i in liste:\n if isinstance(i, list) or isinstance(i, tuple):\n for j in flatten(i):\n yield j\n else:\n yield i\n\ndef makeIndexOutOfDict(dictionary, potSize):\n '''From a dictionary of indexes, lenghts, structured in the margi function,\n to the string uses in the potential index of the same function'''\n arr = list()\n size = potSize\n ind=0\n while(ind < len(dictionary)):\n for i in dictionary:\n if(dictionary.get(i)[0] == ind):\n size /= dictionary.get(i)[1]\n arr.append(str(i)+'*'+str(size))\n ind += 1\n return \"+\".join(arr)\n\nclass javascriptGenerator:\n @classmethod\n def nameCpt(self, bn, var):\n parents = []\n for i in bn.parents(var):\n parents.append(str(i))\n parents = \"_\".join(parents)\n return \"P\"+str(var)+\"given\"+parents\n \n def initCpts(self,bn):\n res = \"\"\n for i in bn.ids():\n res += \"\\t\"+javascriptGenerator.nameCpt(bn,i) +\"= new Float32Array(\"+str(list(flatten(bn.cpt(i).tolist())))+\");\\n\"\n return res \n \n \n def creaPot(self, bn, nomPot, varPot):\n dim = []\n res = \"\"\n for i in varPot:\n dim += str(bn.variable(int(i)).domainSize())\n dim = \"*\".join(dim)\n if(nomPot[0:3] == \"Phi\"):\n res += \"\\t\"+nomPot+\"= new Float32Array(\"+str(dim)+\");\\n\"\n res += \"\\tfor(i=0;i<\"+str(dim)+\";i++)\\n\\t\\t\"+nomPot+\"[i] = 1.0;\\n\"\n else:\n res += \"\\t\"+nomPot+\"= new Float32Array(\"+str(dim)+\");\\n\"\n res += \"\\tfor(i=0;i<\"+str(dim)+\";i++)\\n\\t\\t\"+nomPot+\"[i] = 0.0;\\n\" \n return res\n \n \n def addSoftEvPot(self,evid,nompot,index,value):\n return \"\\t\"+str(nompot)+\"= new Float32Array(evs['\"+str(evid)+\"']);\\n\" \n \n def mulPotCpt(self, bn, nompot, var, varPot):\n R = len(varPot)\n res = \"\"\n indexPotList = list()\n indexCptList = list()\n indexPot = \"[\"\n indexCpt = \"[\"\n cpt = javascriptGenerator.nameCpt(bn, int(var))\n sizePot = 1\n sizeCpt = 1\n for i in bn.cpt(int(var)).var_names:\n sizeCpt *= bn.variable(bn.idFromName(i)).domainSize()\n \n for i in range(R):\n res += \"\\tfor (i\"+str(i)+\"=0; i\"+str(i)+\"<\"+str(bn.variable(varPot[i]).domainSize())+\";i\"+str(i)+\"++){\\n\"\n res += \"\\t\"*(i+1)\n indexPotList.append(\"i\"+str(i)+\"*\"+str(sizePot))\n sizePot *= bn.variable(varPot[i]).domainSize()\n indexPot += \"+\".join(indexPotList)+\"]\"\n\n for i in bn.cpt(int(var)).var_names:\n id_var = bn.idFromName(i)\n sizeCpt /= bn.variable(varPot[varPot.index(id_var)]).domainSize()\n indexCptList.append(\"i\"+str(varPot.index(id_var))+\"*\"+str(sizeCpt))\n indexCpt += \"+\".join(indexCptList)+\"]\"\n \n res += \"\\t\"+nompot+indexPot+\" *= \"+str(cpt)+str(indexCpt)+\";\"+\"}\"*(R)+\"\\n\"\n return res\n \n def mulPotPot(self,bn,nompot1,nompot2,varPot1,varPot2):\n R = len(varPot1)\n res = \"\"\n indexPot1List = list()\n indexPot2List = list()\n indexPot1 = \"[\"\n indexPot2 = \"[\"\n sizePot = 1\n for i in range(R):\n res += \"\\tfor (i\"+str(i)+\"=0; i\"+str(i)+\"<\"+str(bn.variable(varPot1[i]).domainSize())+\";i\"+str(i)+\"++){\\n\"\n res += \"\\t\"*(i+1)\n indexPot1List.append(\"i\"+str(i)+\"*\"+str(sizePot))\n sizePot *= bn.variable(varPot1[i]).domainSize()\n indexPot1 += \"+\".join(indexPot1List)+\"]\"\n sizePot = 1\n\n for i in varPot2:\n indexPot2List.append(\"i\"+str(varPot1.index(int(i)))+\"*\"+str(sizePot))\n sizePot *= bn.variable(varPot1[varPot1.index(int(i))]).domainSize()\n indexPot2 += \"+\".join(indexPot2List)+\"]\"\n \n res += \"\\t\"*(R-2)+nompot1+indexPot1+\" *= \"+nompot2+indexPot2+\";\"+\"}\"*(R)+\"\\n\"\n return res\n \n \n def margi(self,bn,nompot1,nompot2,varPot1,varPot2):\n res = \"\"\n R1 = len(varPot1)\n R2 = len(varPot2)\n indexPot1 = \"[\"\n indexPot2 = \"[\"\n indexPot1List = list()\n indexPot2Dict = {}\n sizePot1=1\n sizePot2=1\n varPot3 = list(set(varPot2) - set(varPot1))\n R3 = len(varPot3)\n \n for i in range(R1):\n res += \"\\tfor (i\"+str(i)+\"=0;i\"+str(i)+\"<\"+str(bn.variable(varPot1[i]).domainSize())+\";i\"+str(i)+\"++){\\n\"\n res += \"\\t\"*(i+1)\n indexPot1List.append(\"i\"+str(i)+\"*\"+str(sizePot1))\n sizePot1 *= bn.variable(varPot1[i]).domainSize()\n indexPot2Dict['i'+str(i)] = [R2-1-varPot2.index(int(varPot1[i])), bn.variable(varPot2[varPot2.index(int(varPot1[i]))]).domainSize()]\n sizePot2 *= bn.variable(varPot2[varPot2.index(int(varPot1[i]))]).domainSize()\n indexPot1 += \"+\".join(indexPot1List)+\"]\"\n \n for j in range(R3):\n res += \"\\tfor (j\"+str(j)+\"=0;j\"+str(j)+\"<\"+str(bn.variable(varPot3[j]).domainSize())+\";j\"+str(j)+\"++){\\n\"\n res += \"\\t\"*(j+i+2)\n indexPot2Dict['j'+str(j)] = [R2-1-varPot2.index(int(varPot3[j])), bn.variable(varPot3[j]).domainSize()]\n sizePot2 *= bn.variable(varPot3[j]).domainSize()\n \n indexPot2 += makeIndexOutOfDict(indexPot2Dict, sizePot2)\n res += \"\\t\"+nompot1+indexPot1+\" += \"+nompot2+indexPot2+\"];\"+\"}\"*(R1+R3)+\"\\n\"\n return res\n \n def norm(self, nompot):\n res = \"\\tsum = 0.0\\n\" \n res += \"\\tfor (i0=0; i0 <\"+nompot+\".length;i0++){\\n\"\n res += \"\\t\\tsum +=\"+nompot+\"[i0];}\\n\"\n res += \"\\tfor (i0=0; i0 <\"+nompot+\".length;i0++){\\n\"\n res += \"\\t\\t\"+nompot+\"[i0]/=sum;}\\n\"\n return res\n\n def genere(self, bn, targets, evs, comp, nameFile, nameFunc, header):\n stream = open(nameFile,'w')\n stream.write(\"//This code was generated for javascript use, compiled by Compiler.py and generated with javascriptGenerator.py.\\n//It shouldn't be altered here'''\\n\")\n stream.write(\"//Generated on : \"+time.strftime('%m/%d/%y %H:%M',time.localtime())+\"\\n\\n\\n\")\n stream.write(\"//\"+header+\"\\n\\n\")\n stream.write(\"function \"+nameFunc+\"(evs) {\\n\")\n stream.write(\"\\tres=[];\\n\")\n stream.write(self.initCpts(bn))\n for cur in comp:\n act = cur[0]\n if act == 'CPO':\n stream.write(self.creaPot(bn,cur[1],cur[2]))\n elif act == 'ASE':\n stream.write(self.addSoftEvPot(cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MUC':\n stream.write(self.mulPotCpt(bn,cur[1],cur[2],cur[3]))\n elif act == 'MUL':\n stream.write(self.mulPotPot(bn,cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MAR':\n stream.write(self.margi(cur[1],cur[2],cur[3],cur[4],cur[5]))\n elif act == 'NOR':\n stream.write(self.norm(cur[1]))\n stream.write(\"\\tres['\"+cur[2]+\"']=\"+str(cur[1])+\";\\n\")\n stream.write(\"\\treturn res;\\n}\\n\")\n evsjs = []\n for i in evs:\n ev = \"\\t\\\"\"+str(i)+\"\\\"\"+\" : \"+str(evs[i])\n evsjs.append(ev)\n \n stream.write(\"console.log(\"+nameFunc+\"({\\n\"+\",\\n\".join(evsjs)+\"\\n}));\\n\")\n stream.close()\n \n"
},
{
"alpha_fraction": 0.6054826974868774,
"alphanum_fraction": 0.6078665256500244,
"avg_line_length": 24.28125,
"blob_id": "4f9af599e20187653c95868d351e2dbc334260ac",
"content_id": "990406ca89913eab53eaaa5ddba2636f7620edce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 839,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 32,
"path": "/Generator/AbstractGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "'''Abstract class for the generators'''\r\n\r\nclass AbstractGenerator:\r\n def initCpts(self,bn):\r\n raise(NotImplemented)\r\n \r\n def creaPot(self, potentielName, potentielVariables):\r\n raise(NotImplemented)\r\n \r\n def addVarPot(self,variable, potentielName):\r\n raise(NotImplemented)\r\n \r\n def addSoftEvPot(self,evid,nompot,index,value):\r\n raise(NotImplemented)\r\n \r\n def mulPotCpt(self,sep2,cliq,sep):\r\n raise(NotImplemented)\r\n \r\n def mulPotPot(self,sep2,cliq,sep):\r\n raise(NotImplemented)\r\n \r\n def margi(self,cliq,var):\r\n raise(NotImplemented)\r\n \r\n def norm(self, pot):\r\n raise(NotImplemented)\r\n \r\n def fill(self, pot):\r\n raise NotImplemented\r\n \r\n def genere(prog, nomfichier, nomfonc):\r\n raise(NotImplemented)"
},
{
"alpha_fraction": 0.4712643623352051,
"alphanum_fraction": 0.49088385701179504,
"avg_line_length": 36.94736862182617,
"blob_id": "4f9ed02dbfbdcf4ab4c12865a381d3d6e7b6f725",
"content_id": "30cabe35bdf9352864747ad2064365a03346e416",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5046,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 133,
"path": "/Generator/numpyGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "import time\n\nclass numpyGenerator:\n @classmethod\n def nameCpt(self, bn, var):\n parents = []\n for i in bn.parents(var):\n parents.append(str(i))\n parents = \"_\".join(parents)\n return \"P\"+str(var)+\"sachant\"+parents\n \n def initCpts(self,bn):\n res = \"\"\n for i in bn.ids():\n res += \"\\t\"+numpyGenerator.nameCpt(bn,i) +\"= \"+str(bn.cpt(i).tolist())+\"\\n\"\n return res\n \n def creaPot(self,bn,nomPot,varPot):\n #Create potential evidence (made by addSoftEvPot)\n if (nomPot[0:2] == \"EV\"):\n return \"\"\n \n #Create potential\n dim = []\n \n for i in varPot:\n dim.insert(0,str(bn.variable(int(i)).domainSize()))\n dim = \",\".join(dim)\n if(nomPot[0:3] == \"Phi\"): \n return \"\\t\"+nomPot+\"=np.ones((\"+dim+\"))\\n\"\n return \"\\t\"+nomPot+\"=np.zeros((\"+dim+\"))\\n\"\n\n \n def addSoftEvPot(self,evid,nompot,index,value):\n return \"\\t\"+str(nompot)+\"= evs.get('\"+str(evid)+\"')\\n\"\n \n def mulPotCpt(self, bn, nompot, var, varPot):\n R = len(varPot)\n res = \"\"\n indexPot = \"\"\n indexCpt = \"\"\n cpt= numpyGenerator.nameCpt(bn,int(var))\n \n for i in range(R):\n res += \"\\tfor i\"+str(i)+\" in range(\"+str(bn.variable(varPot[i]).domainSize())+\"): \\n\"\n res += \"\\t\"*(i+1)\n indexPot = \"[i\"+str(i)+\"]\"+indexPot\n\n for i in bn.cpt(int(var)).var_names:\n id_var = bn.idFromName(i)\n indexCpt += \"[i\"+str(varPot.index(id_var))+\"]\"\n\n res += \"\\t\"+nompot+indexPot+\" *= \"+str(cpt)+str(indexCpt)+\"\\n\"\n return res\n \n def mulPotPot(self,bn,nompot1,nompot2,varPot1,varPot2):\n R = len(varPot1)\n res = \"\"\n indexPot1 = \"\"\n indexPot2 = \"\"\n for i in range(R):\n res += \"\\tfor i\"+str(i)+\" in range(\"+str(bn.variable(varPot1[i]).domainSize())+\"):\\n\"\n res += \"\\t\"*(i+1)\n indexPot1 = \"[i\"+str(i)+\"]\"+indexPot1\n\n for i in varPot2:\n indexPot2 = \"[i\"+str(varPot1.index(int(i)))+\"]\"+indexPot2\n \n res += \"\\t\"+nompot1+indexPot1+\" *= \"+nompot2+indexPot2+\"\\n\"\n return res\n \n def margi(self, bn, nompot1,nompot2,varPot1,varPot2):\n res = \"\"\n R1 = len(varPot1)\n R2 = len(varPot2)\n indexPot1 = \"\"\n indexPot2 = ['*']*R2\n varPot3 = list(set(varPot2) - set(varPot1))\n R3 = len(varPot3)\n for i in range(R1):\n res += \"\\tfor i\"+str(i)+\" in range(\"+str(bn.variable(varPot1[i]).domainSize())+\"):\\n\"\n res += \"\\t\"*(i+1)\n indexPot1 = \"[i\"+str(i)+\"]\"+indexPot1\n indexPot2[R2-1-varPot2.index(int(varPot1[i]))] = \"[i\"+str(i)+\"]\"\n \n for j in range(R3):\n res += \"\\tfor j\"+str(j)+\" in range(\"+str(bn.variable(varPot3[j]).domainSize())+\"):\\n\"\n res += \"\\t\"*(j+i+2)\n indexPot2[R2-1-varPot2.index(int(varPot3[j]))] = \"[j\"+str(j)+\"]\"\n indexPot2 = \"\".join(indexPot2)\n res += \"\\t\"+nompot1+indexPot1+\" += \"+nompot2+indexPot2+\"\\n\"\n return res\n \n def norm(self, nompot):\n res = \"\\tsum = 0.0\\n\" \n res += \"\\tfor i0 in range(len(\"+nompot+\")):\\n\"\n res += \"\\t\\tsum +=\"+nompot+\"[i0]\\n\"\n res += \"\\tfor i0 in range(len(\"+nompot+\")):\\n\"\n res += \"\\t\\t\"+nompot+\"[i0]/=sum\\n\"\n return res\n \n def equa(self, nompot1, nompot2):\n return \"\\t\"+nompot1+\" = \"+nompot2+\"\\n\"\n \n def genere(self, bn, targets, evs, comp, nameFile, nameFunc, header):\n stream = open(nameFile,'w')\n stream.write(\"'''This code was generated for python (with the numpy package) use, compiled by Compiler.py and generated with numpyGenerator.py.\\nIt shouldn't be altered here'''\\n\")\n stream.write(\"\\nimport numpy as np\\n\")\n stream.write(\"'''Generated on : \"+time.strftime('%m/%d/%y %H:%M',time.localtime())+\"'''\\n\\n\\n\")\n stream.write(header+\"\\n\\n\")\n stream.write(\"def \"+nameFunc+\"(evs):\\n\")\n stream.write(\"\\tres = {}\\n\")\n stream.write(self.initCpts(bn))\n for cur in comp:\n act = cur[0]\n if act == 'CPO':\n stream.write(self.creaPot(bn,cur[1],cur[2]))\n elif act == 'ASE':\n stream.write(self.addSoftEvPot(cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MUC':\n stream.write(self.mulPotCpt(bn,cur[1],cur[2],cur[3]))\n elif act == 'MUL':\n stream.write(self.mulPotPot(bn,cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MAR':\n stream.write(self.margi(cur[1],cur[2],cur[3],cur[4],cur[5]))\n elif act == 'NOR':\n stream.write(self.norm(cur[1]))\n stream.write(\"\\tres['\"+cur[2]+\"']=np.copy(\"+str(cur[1])+\"[:])\\n\")\n elif act == 'EQU':\n stream.write(self.equa(cur[1],cur[2]))\n stream.write(\"\\treturn res\")\n\n stream.close()"
},
{
"alpha_fraction": 0.481258362531662,
"alphanum_fraction": 0.4986613094806671,
"avg_line_length": 19.342857360839844,
"blob_id": "dbc42eec24971b35f4dab79ba77df37483afa849",
"content_id": "f201720947d41244bb5f9c6fd5054aa0c980a9ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 70,
"path": "/config.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Mar 06 20:03:54 2015\r\n\r\n@author: phw\r\n\"\"\"\r\n\r\nimport yaml\r\n\r\ndef testDoc2Vars():\r\n document = \"\"\"\r\n # configuration file for metaGeneBayes (file.yaml)\r\n\r\n # specification for inference\r\n bayesnet: asia.bif\r\n\r\n evidence:\r\n - x: [2,5] #soft evidence\r\n - y # : 2 hard evidence (number of modality)\r\n - z # 'label' hard evidence (label)\r\n\r\n target:\r\n - a\r\n - b\r\n - c\r\n\r\n\r\n # specification for generation code\r\n language: php\r\n filename: asia\r\n function: getProbaForAsia\r\n header: |\r\n ######################################\r\n # @filename@\r\n # @generationdate@\r\n ######################################\r\n\r\n \"\"\"\r\n print yaml.load(document)\r\n\r\ndef testVars2Doc():\r\n res={\r\n 'language' : 'php',\r\n 'function' : 'getProbaForAsia',\r\n 'filename':'asia',\r\n 'bayesnet': 'asia.bif',\r\n 'target': ['a','b','c'],\r\n 'evidence': ['x:[2,5]','y','z']\r\n }\r\n\r\n print yaml.dump(res)\r\n\r\ndef loadConfig(filename):\r\n print(filename)\r\n with open(filename, 'r') as f:\r\n doc = yaml.load(f)\r\n\r\n print(\"\\n=========================\\nValues in config file\\n=========================\")\r\n for k in doc:\r\n print(\"{0} : {1}\".format(k,doc[k]))\r\n print(\"=========================\\n\\n\\n\")\r\n\r\n return doc\r\n\r\nconfig=loadConfig('config.yaml')\r\nprint(\"Compiling {0} ({1}) in function {2} of file {3}\".format(\r\n config['bayesnet'],\r\n config['language'],\r\n config['function'],\r\n config['filename']))\r\n"
},
{
"alpha_fraction": 0.4355333149433136,
"alphanum_fraction": 0.45699530839920044,
"avg_line_length": 38.227848052978516,
"blob_id": "9ba48a7d53e980a6f9efb865e95e27f5599a5f14",
"content_id": "26758be06d1d29e052985e0c649dcf7f1fdde9b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6197,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 158,
"path": "/Generator/phpGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "import time\n\nclass phpGenerator:\n @classmethod\n def nameCpt(self, bn, var):\n parents = []\n for i in bn.parents(var):\n parents.append(str(i))\n parents = \"_\".join(parents)\n return \"P\"+str(var)+\"sachant\"+parents\n \n def initCpts(self,bn):\n res = \"\"\n for i in bn.ids():\n res += \"\\t$\"+phpGenerator.nameCpt(bn,i) +\"= \"+str(bn.cpt(i).tolist())+\";\\n\"\n return res\n \n def creaPot(self,bn,nomPot,varPot):\n dim = \"\"\n #Create potential evidence (made by addSoftEvPot)\n if (nomPot[0:2] == \"EV\"):\n return \"\"\n #Create potential\n for i in varPot:\n dim = \"array_fill(0,\"+str(bn.variable(int(i)).domainSize())+\",\"+dim\n if (nomPot[0:3] == \"Phi\"):\n return \"\\t$\"+nomPot+\"=\"+dim+\"1.0\"+\")\"*len(varPot)+\";\\n\"\n \n return \"\\t$\"+nomPot+\"=\"+dim+\"0.0\"+\")\"*len(varPot)+\";\\n\"\n \n def addSoftEvPot(self,evid,nompot,index,value):\n return \"\\t$\"+str(nompot)+\"= $evs['\"+str(evid)+\"'];\\n\"\n \n def mulPotCpt(self, bn, nompot, var, varPot):\n R = len(varPot)\n res = \"\"\n indexPot = \"\"\n indexCpt = \"\"\n cpt = phpGenerator.nameCpt(bn,int(var))\n \n for i in range(R):\n res += \"\\tfor($i\"+str(i)+\"=0;$i\"+str(i)+\"<\"+str(bn.variable(varPot[i]).domainSize())+\";$i\"+str(i)+\"++)\\n\"\n res += \"\\t\"*(i+1)\n indexPot = \"[$i\"+str(i)+\"]\"+indexPot\n\n for i in bn.cpt(int(var)).var_names:\n id_var = bn.idFromName(i)\n indexCpt += \"[$i\"+str(varPot.index(id_var))+\"]\"\n \n res += \"\\t\"+\"$\"+nompot+indexPot+\" *= $\"+str(cpt)+str(indexCpt)+\";\\n\"\n return res\n \n def mulPotPot(self,bn,nompot1,nompot2,varPot1,varPot2):\n R = len(varPot1)\n res = \"\"\n indexPot1 = \"\"\n indexPot2 = \"\"\n for i in range(R):\n res += \"\\tfor($i\"+str(i)+\"=0;$i\"+str(i)+\"<\"+str(bn.variable(varPot1[i]).domainSize())+\";$i\"+str(i)+\"++)\\n\"\n res += \"\\t\"*(i+1)\n indexPot1 = \"[$i\"+str(i)+\"]\"+indexPot1\n\n for i in varPot2:\n indexPot2 = \"[$i\"+str(varPot1.index(int(i)))+\"]\"+indexPot2\n \n res += \"\\t\"+\"$\"+nompot1+indexPot1+\" *= $\"+nompot2+indexPot2+\";\\n\"\n return res\n \n def margi(self, bn, nompot1,nompot2,varPot1,varPot2):\n res = \"\"\n R1 = len(varPot1)\n R2 = len(varPot2)\n indexPot1 = \"\"\n indexPot2 = ['*']*R2\n varPot3 = list(set(varPot2) - set(varPot1))\n R3 = len(varPot3)\n for i in range(R1):\n res += \"\\tfor($i\"+str(i)+\"=0;$i\"+str(i)+\"<\"+str(bn.variable(varPot1[i]).domainSize())+\";$i\"+str(i)+\"++)\\n\"\n res += \"\\t\"*(i+1)\n indexPot1 = \"[$i\"+str(i)+\"]\"+indexPot1\n indexPot2[R2-1-varPot2.index(int(varPot1[i]))] = \"[$i\"+str(i)+\"]\"\n \n for j in range(R3):\n res += \"\\tfor($j\"+str(j)+\"=0;$j\"+str(j)+\"<\"+str(bn.variable(varPot3[j]).domainSize())+\";$j\"+str(j)+\"++)\\n\"\n res += \"\\t\"*(j+i+2)\n indexPot2[R2-1-varPot2.index(int(varPot3[j]))] = \"[$j\"+str(j)+\"]\"\n indexPot2 = \"\".join(indexPot2)\n res += \"\\t$\"+nompot1+indexPot1+\" += $\"+nompot2+indexPot2+\";\\n\"\n return res\n \n def phpToPythonRes(self, evs, nameFunc):\n res = \"echo(\\\"{\\\");\\n\"\n res += \"$bb=0;\\n\"\n res += \"foreach(\"+nameFunc+\"(array(\\n\"\n lsEvs = []\n for name, val in evs.items():\n lsEvs.append(\"\\t\"*2+\"\\\"\"+str(name)+\"\\\"=>\"+str(val))\n res += \",\\n\".join(lsEvs)\n res += \"\\n)) as $k=>$v) {\\n\"\n res += \"\\t\"*2+\"if($bb==1) echo(\\\",\\\");\\n\"\n res += \"\\t\"*2+\"$bb=1;\"\n res += \"\\t\"*2+\"echo(\\\"'$k': [[\\\");\\n\"\n res += \"\\t\"*2+\"$b=0;\\n\"\n res += \"\\t\"*2+\"foreach($v as $val) {\\n\"\n res += \"\\t\"*3+\"if ($b==1) echo(\\\",\\\");\\n\"\n res += \"\\t\"*3+\"$b=1;\\n\"\n res += \"\\t\"*3+\"echo(\\\" \\\");\\n\"\n res += \"\\t\"*3+\"echo($val);\\n\"\n res += \"\\t\"*2+\"}\\n\"\n res += \"\\t\"*2+\"echo(\\\"]]\\\");\\n\"\n res += \"}\\n\"\n res += \"echo(\\\"}\\\");\"\n return res\n \n def norm(self, nompot):\n res = \"\\t$sum=0.0;\\n\" \n res += \"\\tfor($i0=0;$i0<count($\"+nompot+\");$i0++)\\n\"\n res += \"\\t\\t$sum+=$\"+nompot+\"[$i0];\\n\"\n res += \"\\tfor($i0=0;$i0<count($\"+nompot+\");$i0++)\\n\"\n res += \"\\t\\t$\"+nompot+\"[$i0]/=$sum;\\n\"\n return res\n def equa(self, nompot1, nompot2):\n return \"\\t$\"+nompot1+\" = $\"+nompot2+\";\\n\"\n \n def genere(self, bn, targets, evs, comp, nameFile, nameFunc, header):\n stream = open(nameFile,'w')\n stream.write(\"<?php\\n\")\n stream.write(\"//This code was generated for php>5.6, compiled by Compiler.py and generated with phpGenerator.py.\\n\")\n stream.write(\"//It shouldn't be altered here\\n\") \n stream.write(\"//Generated on : \"+time.strftime('%m/%d/%y %H:%M',time.localtime())+\"\\n\\n\\n\")\n stream.write(header+\"\\n\\n\")\n stream.write(\"function \"+nameFunc+\"($evs) {\\n\")\n stream.write(\"\\t$res=[];\\n\")\n stream.write(self.initCpts(bn))\n for cur in comp:\n act = cur[0]\n if act == 'CPO':\n stream.write(self.creaPot(bn,cur[1],cur[2]))\n elif act == 'ASE':\n stream.write(self.addSoftEvPot(cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MUC':\n stream.write(self.mulPotCpt(bn,cur[1],cur[2],cur[3]))\n elif act == 'MUL':\n stream.write(self.mulPotPot(bn,cur[1],cur[2],cur[3],cur[4]))\n elif act == 'MAR':\n stream.write(self.margi(cur[1],cur[2],cur[3],cur[4],cur[5]))\n elif act == 'NOR':\n stream.write(self.norm(cur[1]))\n stream.write(\"\\t$res['\"+cur[2]+\"']=$\"+str(cur[1])+\";\\n\")\n elif act == 'EQU':\n stream.write(self.equa(cur[1],cur[2]))\n stream.write(\"\\treturn $res;\\n}\\n\")\n evsphp = []\n for i in evs:\n ev = \"\\t\\\"\"+str(i)+\"\\\"\"+\" => \"+str(evs[i])\n evsphp.append(ev)\n stream.write(self.phpToPythonRes(evs, nameFunc))\n stream.close()"
},
{
"alpha_fraction": 0.6961620450019836,
"alphanum_fraction": 0.6997157335281372,
"avg_line_length": 42.27692413330078,
"blob_id": "7158a96a41f97ace7c698108131166ebb285cab9",
"content_id": "50e90cc31c6f6cb81649b8ea3d6ff53c09a6dce4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2834,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 65,
"path": "/metaGenBayes.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nYAML Config format :\n'language' : 'pyAgrum',\n 'function' : 'getProbaForAsia',\n 'filename':'asia',\n 'bayesnet': 'asia.bif',\n 'target': ['a','b','c'],\n 'evidence': ['x','y','z']\n\"\"\"\n\nimport pyAgrum as gum\nimport yaml\nfrom Compiler import Compiler\nimport config as cg\nimport sys\n\nlanguages = [\"Debug\", \"pyAgrum\", \"numPy\", \"PHP\", \"javascript\"]\n\nif (len(sys.argv)<2):\n print(\"metaGenBayes.py configfile.yaml\")\n sys.exit(0)\n\nprint(\"loading configuration in \"+sys.argv[1])\n\nrequest = cg.loadConfig(sys.argv[1])\nbnpath = request['bayesnet']\nevs= reduce(lambda r, d: r.update(d) or r, request['evidence'], {})\narrayOfInstructions = Compiler.compil(gum.loadBN(bnpath), request['target'][:], evs)\n\n\nif(request['language'].lower() == languages[1].lower()):\n from Generator.pyAgrumGenerator import pyAgrumGenerator\n generator = pyAgrumGenerator()\n generator.genere(gum.loadBN(bnpath), request['target'][:],evs, arrayOfInstructions, request['filename']+'.py', request['function'], request['header'])\n print(\"Génération en pyAgrum effectuée, fichier \"+request['filename']+'.py crée')\n\n\nelif(request['language'].lower() == languages[2].lower()):\n from Generator.numpyGenerator import numpyGenerator\n generator= numpyGenerator()\n generator.genere(gum.loadBN(bnpath), request['target'][:], evs, arrayOfInstructions, request['filename']+'.py', request['function'], request['header'])\n print(\"Génération numpy effectuée, fichier \"+request['filename']+\".py crée\")\n\nelif(request['language'].lower() == languages[3].lower()):\n from Generator.phpGenerator import phpGenerator\n generator = phpGenerator()\n generator.genere(gum.loadBN(bnpath), request['target'][:], evs, arrayOfInstructions, request['filename']+'.php', request['function'], request['header'])\n print(\"Génération PHP effectuée, fichier \"+request['filename']+\".php crée\")\n\nelif(request['language'].lower() == languages[4].lower()):\n from Generator.javascriptGenerator import javascriptGenerator\n generator = javascriptGenerator()\n generator.genere(gum.loadBN(bnpath), request['target'][:], evs, arrayOfInstructions, request['filename']+'.js', request['function'], request['header'])\n print(\"Génération javascript effectuée, fichier \"+request['filename']+'.js crée')\n\nelif(request['language'].lower() == languages[0].lower()):\n from Generator.debugGenerator import debugGenerator\n generator = debugGenerator()\n generator.genere(gum.loadBN(bnpath), request['target'][:], evs, arrayOfInstructions, request['filename']+'.py', request['function'], request['header'])\n print(\"Génération en mode debug effectuée, fichier \"+request['filename']+'.py crée')\n\n\nelse:\n print(\"The language you ask for isn't valid. Languages that have been implemented so far:\\n\"+str(languages))\n\n"
},
{
"alpha_fraction": 0.5490463376045227,
"alphanum_fraction": 0.5585830807685852,
"avg_line_length": 42.979591369628906,
"blob_id": "86a04e5f3960eaa4e7d149d630183dcbd56ca390",
"content_id": "20eb7ed694becfb72a4cbee7b1c3b04304c1c994",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2202,
"license_type": "no_license",
"max_line_length": 241,
"num_lines": 49,
"path": "/Generator/debugGenerator.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "# Code generation API\r\nfrom AbstractGenerator import AbstractGenerator\r\nimport time\r\n\r\nclass debugGenerator(AbstractGenerator): \r\n def creaPot(self,nompot):\r\n return (\"\\tCreation de potentiel :\" + str(nompot)+\"\\n\")\r\n \r\n def addVarPot(self,var,nompot):\r\n return(\"\\tAjout de la variable \"+str(var)+\" au potentiel \"+str(nompot)+\"\\n\")\r\n \r\n def mulPotCpt(self,nompot, var):\r\n return(\"\\tMultiplication du potentiel \"+str(nompot)+\" par la cpt de la variable \"+str(var)+\"\\n\")\r\n \r\n def mulPotPot(self,nompot1,nompot2):\r\n return(\"\\tMultiplication du potentiel \"+str(nompot1)+\" par le potentiel \"+str(nompot2)+\"\\n\")\r\n \r\n def margi(self,nompot1,nompot2):\r\n return(\"\\tMarginalisation de \"+str(nompot1)+ \" par \"+str(nompot2)+\"\\n\")\r\n \r\n def norm(self, nompot):\r\n return(\"\\tNormalisation de \"+str(nompot)+\"\\n\")\r\n \r\n def fill(self, pot, num): \r\n return(\"\\tFill\"+str(num)+\" de \"+str(pot))\r\n \r\n def genere(self, comp, nomfichier, nomfonc, header):\r\n stream = open(nomfichier,'w')\r\n stream.write(\"'''This code was generated to debug (it lists all the instructions to do on the tree to calculate the value of targets), compiled by Compiler.py and generated with debugGenerator.py.\\nIt shouldn't be altered here'''\\n\")\r\n stream.write(\"'''Generated on : \"+time.strftime('%m/%d/%y %H:%M',time.localtime())+\"'''\\n\\n\\n\")\r\n stream.write(header+\"\\n\\n\")\r\n stream.write(\"def \"+nomfonc+\"():\\n\")\r\n for cur in comp:\r\n act = cur[0]\r\n if act == 'CPO':\r\n stream.write(self.creaPot(cur[1]))\r\n elif act == 'ADV':\r\n stream.write(self.addVarPot(cur[1],cur[2]))\r\n elif act == 'MUC':\r\n stream.write(self.mulPotCpt(cur[1],cur[2]))\r\n elif act == 'MUL':\r\n stream.write(self.mulPotPot(cur[1],cur[2]))\r\n elif act == 'MAR':\r\n stream.write(self.margi(cur[1],cur[2]))\r\n elif act == 'NOR':\r\n stream.write(self.norm(cur[1]))\r\n elif act == 'FIL':\r\n stream.write(self.fill(cur[1],cur[2]))\r\n stream.close()"
},
{
"alpha_fraction": 0.69133460521698,
"alphanum_fraction": 0.7071473598480225,
"avg_line_length": 30.26530647277832,
"blob_id": "6d68e62c89f9430502e59f837ca99af814e00f20",
"content_id": "c863ca14127ba8e193108785072d96829c326d34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3170,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 98,
"path": "/testMeta.py",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Apr 22 14:00:38 2015\r\n\r\n@author: Marvin\r\n\"\"\"\r\n\"\"\"FICHIER TEST\"\"\"\r\n\"\"\"\r\nimport Compilator as compilator\r\nfrom debugGenerator import debugGenerator\r\nimport pyAgrum as gum\r\nimport os\r\nos.chdir(\"C:/Users/Marvin/Desktop/Informatique/Projet PIMA/testMetaBaysGen/Recent2\")\r\n\r\nbn = gum.loadBN(\"C:/Users/Marvin/Desktop/Informatique/Projet PIMA/testMetaBaysGen/BNs/Asia.bif\")\r\ntarget = [\"bronchitis?\",\"visit_to_Asia?\"]\r\nevs = {\"smoking?\":[1,0]}\r\n\r\ncomp = compilator.compil(bn, target, evs)\r\ngenerator = debugGenerator()\r\ngenerator.genere(comp, \"test.py\", \"getValue\")\r\n\"\"\"\r\n\r\n\r\nfrom Compiler import Compiler\r\nfrom Generator.pyAgrumGenerator import pyAgrumGenerator\r\nfrom Generator.numpyGenerator import numpyGenerator\r\nfrom Generator.phpGenerator import phpGenerator\r\nfrom Generator.javascriptGenerator import javascriptGenerator\r\n\r\nimport pyAgrum as gum\r\n#import os\r\n#os.chdir(\"C:/Users/Marvin/Desktop/Informatique/Projet PIMA/testMetaBaysGen/Recent2\")\r\n\r\n#Choose the right bn\r\n#bn=gum.BayesNet()\r\n#a,b,c,d,e=[bn.add(gum.LabelizedVariable(s,s,2)) for s in 'abcde']\r\n#bn.addArc(a,b)\r\n#bn.addArc(a,c)\r\n#bn.addArc(b,d)\r\n#bn.addArc(c,d)\r\n#bn.addArc(e,c)\r\n#bn.generateCPTs()\r\n\r\nbn = gum.loadBN(\"/home/ubuntu/metaGenBayes/BNs/hailfinder.bif\")\r\nheader = \"######Testeur rapide#####\"\r\n\r\n#Choose the rights targets\r\n#targets = [\"d\",\"a\"] #Our own bn\r\n#targets = [\"bronchitis?\",\"positive_XraY?\"] #asia\r\n#targets = [\"HYPOVOLEMIA\",\"CATECHOL\"] #alarm1\r\n#targets = [\"ERRCAUTER\",\"HR\",\"HRBP\",\"MINVOLSET\",\"VENTMACH\"] #alarm2\r\ntargets = [\"Boundaries\",\"SynForcng\"] #hailfinder\r\n\r\n#Choose the rigts evs\r\n#evs = {\"e\":[1,0], \"b\":[0.25,0.75]} #Our own bn\r\n#evs = {\"smoking?\":[0.5,0.5]} #asia\r\n#evs = {\"ANAPHYLAXIS\":[0.4,0.6]} #alarm1\r\n#evs = {\"HREKG\":[0.4,0.6,0.0]} #alarm2\r\n#evs = {\"INTUBATION\":[1,0,0]}\r\nevs = {\"AMInstabMt\":[0,1,0]} #hailfinder\r\n\r\nprint(\"** Version aGrUM **\")\r\nie=gum.LazyPropagation(bn)\r\nie.setEvidence(evs)\r\nie.makeInference()\r\nfor t in targets:\r\n print(ie.posterior(bn.idFromName(t)))\r\n\r\nprint(\"** Génération pyAgrum **\")\r\ncomp = Compiler.compil(bn, targets[:], evs)\r\ngenerator = pyAgrumGenerator()\r\ngenerator.genere(bn, targets, evs, comp, \"generated.py\", \"getValue\", header)\r\nfrom generated import getValue\r\nprint(getValue(evs))\r\n\r\n \r\nprint(\"**Génération Python (numpy)**\")\r\ngenerator = numpyGenerator()\r\ngenerator.genere(bn,targets,evs,comp,\"generatedNumpy.py\",\"getValue\", header)\r\nfrom generatedNumpy import getValue\r\nprint(getValue(evs))\r\n\r\nprint(\"** Génération PHP **\")\r\ngenerator = phpGenerator()\r\ngenerator.genere(bn,targets,evs,comp,\"generatedPHP.php\",\"getValue\", header)\r\nimport subprocess\r\nproc = subprocess.Popen(\"php /home/ubuntu/metaGenBayes/generatedPHP.php\", shell = True, stdout = subprocess.PIPE)\r\nscript_response = proc.stdout.read()\r\nprint(script_response)\r\n\r\n\r\nprint(\"** Génération Javascript **\")\r\ngenerator = javascriptGenerator()\r\ngenerator.genere(bn,targets,evs,comp,\"generatedJavascript.js\",\"getValue\", header)\r\nproc = subprocess.Popen('nodejs /home/ubuntu/metaGenBayes/generatedJavascript.js', shell = True, stdout = subprocess.PIPE)\r\nscript_response = proc.stdout.read()\r\nprint(script_response)\r\n"
},
{
"alpha_fraction": 0.7926093339920044,
"alphanum_fraction": 0.7926093339920044,
"avg_line_length": 71.66666412353516,
"blob_id": "6db914821b623ac5d6234e15ebb6a24ffd5f2032",
"content_id": "2d66de10f8b2520dfe93b9d389e6e3060168c172",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1326,
"license_type": "no_license",
"max_line_length": 351,
"num_lines": 18,
"path": "/README.md",
"repo_name": "pierrestefani/metaGenBayes",
"src_encoding": "UTF-8",
"text": "# metaGenBayes Project\r\n\r\n## Presentation\r\n\r\nmetaGenBayes is a student project who computes specific probabilites (targets) given evidences (known probabilities). Using bayesians networks and Shafer-Shenoy inference, it writes in different languages the code that will later calculate the targets.\r\n\r\n## How to Use\r\n\r\nmetaGenBayes uses a yaml configuration file, which follows these guidelines : a *bayesnet*, a list of *evidence* and *target*, a *language*, the *filename* and the *function* you want for the generated code.\r\nLanguages supported so far are python (via numpy), php and Javascript.\r\n\r\nmetaGenBayes.py is the main file. After specifying your inputs in the config.yaml, metaGenBayes.py will create the generated file in the current repository.\r\n\r\n## Components\r\n\r\nIn the [Compiler](https://github.com/pierrestefani/metaGenBayes/tree/master/Compiler) folder you will find the functions that creates an array of instructions that will later be translated in the different languages. In order to have the best results possible, we used barren nodes and the Bayes-Ball algorithm to simplify the given bayesian network. \r\n\r\nThe [Generator](https://github.com/pierrestefani/metaGenBayes/tree/master/Generator) folder lists the different python files used to generate the code from the compiled array of instructions.\r\n"
}
] | 11 |
ykorman/AC-Control
|
https://github.com/ykorman/AC-Control
|
c73d43e8d13f4f723233cc0abec70639d3b6dcd4
|
b895f728c040b1dca397f7282a7869e2f25c75c9
|
3127c6043e40b6404e969d1f96d6033b46b428fa
|
refs/heads/main
| 2023-02-06T07:55:30.569836 | 2020-12-28T20:29:50 | 2020-12-28T20:29:50 | 300,715,236 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7818182110786438,
"alphanum_fraction": 0.7848485112190247,
"avg_line_length": 40.25,
"blob_id": "5fe095e6d5f07557558591da79ab9d14651aeda9",
"content_id": "77fb2f4a5ab7c1c4a5195c058d8e1e0016d3c22b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 8,
"path": "/README.md",
"repo_name": "ykorman/AC-Control",
"src_encoding": "UTF-8",
"text": "The 'broadlink' module must be installed in the python site-packages.\nExample:\npython3 -m venv env\nsource env/bin/activate\npip install broadlink # or 'pip install -r requirements.txt'\n\nThe broadlink-cli is taken from the github repo of the python module.\nAt some future point, it will probably be part of the package but not yey.\n"
},
{
"alpha_fraction": 0.6876310110092163,
"alphanum_fraction": 0.696016788482666,
"avg_line_length": 22.850000381469727,
"blob_id": "16c8e3066dcd460597b235e6093f686e747ef1a8",
"content_id": "9dba5769632f30a12f6894724b7085f52e1d23ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 20,
"path": "/Makefile",
"repo_name": "ykorman/AC-Control",
"src_encoding": "UTF-8",
"text": "SRV = night-script.service\nENV = /etc/default/night_script\nSERVICE_DIR = /etc/systemd/system\n\ninstall:\n\tsed -e \"s|@SCRIPT_PATH@|$(PWD)/night_script.sh|\" \\\n\t\t$(SRV) | sudo tee $(SERVICE_DIR)/$(SRV)\n\tsudo cp night_script.env $(ENV)\n\tsudo systemctl daemon-reload\t\n\tsudo systemctl enable $(SRV)\n\nuninstall:\n\tsudo systemctl disable $(SRV)\n\tsudo rm -f $(SERVICE_DIR)/$(SRV) $(ENV)\n\nwebdbg:\n\tFLASK_ENV=development FLASK_APP=app.py flask run --host=0.0.0.0\n\n\n.PHONY: install uninstall\n"
},
{
"alpha_fraction": 0.5614439249038696,
"alphanum_fraction": 0.578341007232666,
"avg_line_length": 15.074073791503906,
"blob_id": "4972eb80a2295da1ac741ef9a2a865e138cb974b",
"content_id": "cab61cbe67931fb855fba261b7a1e8f08381953f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1302,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 81,
"path": "/night_script.sh",
"repo_name": "ykorman/AC-Control",
"src_encoding": "UTF-8",
"text": "#!/bin/bash -e\n\nDIR=$(dirname $0)\nB=${DIR}/broadlink-cli\nSLEEP_CMD=\"sleep 1m\"\nDEV_CONFIG=${DIR}/device_config\n\nSTART_DELAY=${START_DELAY:-50}\nTIMER_ON=${TIMER_ON:-10}\nTIMER_OFF=${TIMER_OFF:-50}\n\nSTATUS_FILE=/run/$(basename $0).status\n\nif [[ ${EUID} != 0 ]] ; then\n\tSTATUS_FILE=${DIR}/.$(basename $0).status\nfi\n\n# debug\nif [[ -n ${DEBUG} ]] ; then\n\tSLEEP_CMD=\"break\"\nfi\n\nlog() {\n\techo $(date +%H:%M) -- $*\n}\n\nsetup() {\n\tsource ${DIR}/env/bin/activate\n\t${B}/broadlink_discovery | tail -n3 | head -n1 > ${DEV_CONFIG}\n\tlog \"Generated device config:\"\n\tcat ${DEV_CONFIG}\n\techo\n}\n\ncmd() {\n\tif [[ -z ${DEBUG} ]] ; then\n\t\t${B}/broadlink_cli --device @${DIR}/device_config --send $*\n\telse\n\t\tlog \"!DEBUG! Executing cmd with $*\"\n\tfi\n}\n\nmsleep() {\n\tlocal amount=$1\n\tlocal i=0\n\n\tlog \"Sleeping for ${amount} minutes\"\n\twhile [[ ${i} -lt ${amount} ]] ; do\n\t\techo \"$((amount - i)):${2}\" > ${STATUS_FILE}\n\t\techo -n .\n\t\t${SLEEP_CMD}\n\t\tlet i++ || :\n\tdone\n\techo\n}\n\n\nmain() {\n\tsetup\n\n\tmsleep ${START_DELAY}\n\twhile true ; do\n\t\t# turn ac on\n\t\tlog \"Turning AC on (26 degrees)\"\n\t\tcmd @${DIR}/cmds/ac_hot.26\n\t\tmsleep ${TIMER_ON} \"on\"\n\t\tlog \"Turning AC off\"\n\t\tcmd @${DIR}/cmds/ac.off\n\t\tmsleep ${TIMER_OFF}\n\t\tif [[ -n ${DEBUG} ]] ; then\n\t\t\tbreak\n\t\tfi\n\tdone\n}\n\nif [[ \"${1}\" == \"status\" ]] ; then\n\tcat ${STATUS_FILE}\n\texit 0\nfi\n\nmain\n"
},
{
"alpha_fraction": 0.4683544337749481,
"alphanum_fraction": 0.6962025165557861,
"avg_line_length": 14.800000190734863,
"blob_id": "39393c671473cdbe894a5476e09867c66436608b",
"content_id": "d47dabad8accf027142cae6ffb09dc0725416f3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 5,
"path": "/requirement.txt",
"repo_name": "ykorman/AC-Control",
"src_encoding": "UTF-8",
"text": "broadlink==0.15.0\ncffi==1.14.3\ncryptography==3.1.1\npycparser==2.20\nsix==1.15.0\n"
},
{
"alpha_fraction": 0.6368038654327393,
"alphanum_fraction": 0.6416465044021606,
"avg_line_length": 30.769229888916016,
"blob_id": "c70385e19956eea67922f430f871549c44e22fe7",
"content_id": "5d6cddfe014c11061a52350a4bb4ce2824e096ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 13,
"path": "/app.py",
"repo_name": "ykorman/AC-Control",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask, render_template, request, redirect, url_for, send_file, make_response\n\napp = Flask(__name__)\n\[email protected]('/',methods=('GET', 'POST'))\ndef index():\n if request.method == 'POST':\n resp = make_response(redirect(url_for('download')))\n list(map(lambda e: resp.set_cookie(e[0], e[1]), request.form.items()))\n return resp\n\n return render_template('ui.html')\n"
}
] | 5 |
ethicalrushi/recommender_systems
|
https://github.com/ethicalrushi/recommender_systems
|
7130f6fbe2a8572a1d229bee780b7d6aadd57ed5
|
aa0b6e8cf1194ab7c91eb02aef254e409db6de7f
|
636e7aba5f3a6b1a768e46864d2dea3e3d1f975f
|
refs/heads/master
| 2020-03-22T11:37:51.447764 | 2018-07-08T16:36:06 | 2018-07-08T16:36:06 | 139,983,663 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8139534592628479,
"alphanum_fraction": 0.8139534592628479,
"avg_line_length": 33.400001525878906,
"blob_id": "62311777a0bbe972e6c2547aacf9309296b88dd7",
"content_id": "48aa968a3042dbf1f4b6b0fd2d47ad5ae736f7ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 5,
"path": "/README.md",
"repo_name": "ethicalrushi/recommender_systems",
"src_encoding": "UTF-8",
"text": "# recommender_systems\nDifferent types of recommenders\n\nAlso check [Document_Retrieval](https://github.com/ethicalrushi/document_retrieval).\nIt is based on similar concept.\n"
},
{
"alpha_fraction": 0.7320832014083862,
"alphanum_fraction": 0.7413305640220642,
"avg_line_length": 28.43181800842285,
"blob_id": "a4b0b9b2c90ae8c1de56694124bd18ee28c93758",
"content_id": "e6a3c3ab6875e8c8e0c2a7d45437892a017d7bf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3893,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 132,
"path": "/content_based_recommender.py",
"repo_name": "ethicalrushi/recommender_systems",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jul 6 20:02:11 2018\n\n@author: rushikesh\n\"\"\"\n\n\"\"\"\nWe will build recommender which recommends movies based on content i.e plots \nof movies. It will recommend movies similar to a specific movie based on the \npairwise similarity scores.\nThis is similar to my repo called document_retrieval\n\"\"\"\n\n\nimport pandas as pd\nimport numpy as np\n\n\n#Importing the dataset\n\n\"\"\" \nTo avoid the following datatype warning specified low_memory=False\n\nDtypeWarning: Columns (10) have mixed types. Specify dtype option on import \nor set low_memory=False.\ninteractivity=interactivity, compiler=compiler, result=result)\n\n\"\"\"\nmetadata = pd.read_csv('movies_metadata.csv', low_memory=False)\n\nmetadata['overview'].head(10)\n\n#This is the data we are targetting\n\n\"\"\" Since this data containd plain english text it is not suitable for analysis\npurpose. We will use the Tf-Idf vectorizer to convert this text into word vectors.\n\nThis will give us a matrix where each column represents a word in the overview \nof the vocabulary which is essentially collection of all the words and each row \nrepresents a movie.\n\nTf-Idf is the frequency of words generalized to accomodate the fact that some \nless important words like 'the', 'a' occur too many times across all docs\nwhich might give a fale indicative of the similarity of the docs.\n\nTf-Idf's are calculated as follows-\n \n #reminder Put the formula here\n \n\"\"\"\n\n#Using the sklearns tf-idf vectorizer to create desired word_vectors-\n\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\ntfidf = TfidfVectorizer(stop_words='english')\n#Stop words remove words like 'a', 'the' etc which are not useful for analysis\n\n#Replace Nan in the dataset's overview with empty string-\n\nmetadata['overview'] = metadata['overview'].fillna('')\n\n#Constructing a tfidf matrix-\ntfidf_matrix = tfidf.fit_transform(metadata['overview'])\n\n#outputting the shape of tfidf_matrix\ntfidf_matrix.shape\n\n#We have 45,466 movies and 75827 significant and unique words in our vocab\n\n\"\"\" \nWe can use this matrix to calculate the similarity between movies.\n\nThese are the choices for the distance(which basically acts as a similarity score) -\n Euclidean, pearson, cosine_simlarity\n \nYou can try diff scores, we will use cosine_similarity for now since it is \nindependent of magnitude and is relatively easy and fast to calculate\n(especially when used in conjunction with tfidf's)\n\nMathematically-\n \n cosine(x,y) = [(x).dot(y)]/[||x||.||y||]\n \nSince we have used tf-idf vectorizer the resulting vectors for a movie i.e(x and y)\nare unit vectors\nthus we need to calculate only the dot product of x and y.\nWe will use slearn's linear_kernel() instead of cosine_similarities() since it \ndoes the job in this case and is faster.\n\n\"\"\"\n\nfrom sklearn.metrics.pairwise import linear_kernel\n\n#Computing the cosine simiarity-\ncos_sim = linear_kernel(tfidf_matrix, tfidf_matrix)\n\n\"\"\"\nNow we define a function that takes a movie title and returns list of 10\nmovies as output which are closest to the given movie.\nFor this we need a reverse mapping of movie titles and dataframe indices.\nWe need a mechanism to identify the index of movie from its title.\n\n\"\"\"\n\nindices = pd.Series(metadata.index, index=metadata['title']).drop_duplicates()\n\ndef get_recommendations(title, cos_sim):\n \n #get the index of movie\n idx = indices[title]\n \n #Get the pairwise similarity scores of all movies with that movie\n sim_scores = list(enumerate(cos_sim[idx]))\n \n #sort the movies based on sim_scores\n sim_scores = sorted(sim_scores, key= lambda x:x[1], reverse=True)\n \n #Get the top 10\n sim_scores = sim_scores[1:11]\n \n #Get the movie_indices\n movie_indices = [i[0] for i in sim_scores]\n \n return metadata['title'].iloc[movie_indices]\n\n\n\n\nget_recommendations('The Dark Knight Rises')\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7063829898834229,
"alphanum_fraction": 0.7191489338874817,
"avg_line_length": 23.45161247253418,
"blob_id": "5fd947df952bc9cba201fabe62ec52185e75940f",
"content_id": "6ad2804633dbcd4035957344c04709458be1476e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3055,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 124,
"path": "/simple_recommender",
"repo_name": "ethicalrushi/recommender_systems",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jul 6 18:24:19 2018\n\n@author: rushikesh\n\nSimple Recommender:\n Offer generalized recommendations to every user based on movie popularity \n and/or genre. The basic idea behind this system is that the more popular \n and critically acclaimed movie will have a higher probability of being liked \n by the average audience. IMDB top250 is an example of this system\n\"\"\"\n\n\"\"\"\nSteps to build a simple recommender:\n 1) Decide the metric or score to rate movies\n 2) Calculate the score for every movie\n 3) Sort the movies based on the score and output the top results\n \n\"\"\"\n\n\n\n\n\n\n\n\n\n\n\n\n\nimport pandas as pd\nimport numpy as np\n\n\n\n\n#Importing the dataset\n\n\"\"\" \nTo avoid the following datatype warning specified low_memory=False\n\nDtypeWarning: Columns (10) have mixed types. Specify dtype option on import \nor set low_memory=False.\ninteractivity=interactivity, compiler=compiler, result=result)\n\n\"\"\"\nmetadata = pd.read_csv('movies_metadata.csv', low_memory=False)\n\n#printing the first few rows\nmetadata.head()\n\n\n\"\"\"\nOne of the basic metrics you can think of is rating. However, this metric will\nalso favour movies with smaller number of voters with skewed/or extremely \nhigh ratings. As the no of voters increases the rating regularizes and approaches\ntowards a value that is reflective of movies quality.\n\nThus we need a weighting system to weigh the ratings considering the no of voters\n\nWeighted Rating(WR) = (v/(v+m))*R + (m/(v+m))*C\n\nwhere-\nv- no of votes for the movie\nm - min votes req to be listed in the chart\nR- avg rating of movie\nC- mean rating(vote) across the whole report\n\nWe have values of v,R \nC can be easily calculated\nWe need to determine the appropriate value of m. It neglects the movie having \nless than m votes. In this case we are using 90th percentile as our cutoff.\nThus for a movie to be featured it must have more votes than atleast 90% of the\nmovies in list.(Top 10percentile movies in terms of no of votes)\n\n\"\"\"\n\n\n#Calculating the value of C-\n\nC = metadata['vote_average'].mean()\nprint(C)\n\n#Calculate the min number of votes req i.e m-\n\n#quantile() method of pandas is used to calc percentile\nm= metadata['vote_count'].quantile(0.90)\nprint(m)\n\n#Selecting only thse movies having vote_count grater than m-\n\n\n#Creating a copy so that q_movies is independent of og metadata.Changes are ind\nq_movies = metadata.copy().loc[metadata['vote_count']>=m]\n\nq_movies.shape\n\n#In this case only 4555 movies qualify\n\n\ndef weighted_rating(x, m=m, C=C):\n v = x['vote_count']\n R = x['vote_average']\n \n #Calculating weighted rating-\n wr = (v/(v+m)*R) + (m/(v+m)*C)\n return wr\n\n#Adding this wr as new feature 'score' to q_movies\n \nq_movies['score'] = q_movies.apply(weighted_rating, axis=1)\n\n q_movies.apply()\n \n#Sorting the movies based on this score-\n\nq_movies = q_movies.sort_values('score', ascending = False)\n\n#Printing top 10 movies based on score-\nq_movies[['title','vote_count','vote_average','score']].head(10)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
}
] | 3 |
vsel/EVOSummerPythonLab2016CodeExamples
|
https://github.com/vsel/EVOSummerPythonLab2016CodeExamples
|
d970670b2aacda3c91229970d6ce97faf3dc4418
|
bb614434d33969b15cddf5d6207e2f0bbc6ac6e2
|
5d160be1ec4d7e89a397855028ff24438a04489e
|
refs/heads/master
| 2021-01-20T19:30:35.728533 | 2016-08-11T15:57:20 | 2016-08-11T15:57:20 | 64,216,801 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5904139280319214,
"alphanum_fraction": 0.6122004389762878,
"avg_line_length": 34.269229888916016,
"blob_id": "0dc3e806f147f838cdca5b02ad481adeb73bbb12",
"content_id": "cd7ba6bb2adbc20bfdff42c5894f7c0a02448ec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 918,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 26,
"path": "/with/with_class.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "import ctypes\n\n\nclass IntChanger:\n def __init__(self, statement_to_change):\n self.statement_address = id(statement_to_change)\n self.statement_to_change = bytes([statement_to_change])\n\n def __enter__(self):\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] \\\n = b'\\x2A'\n return 'But we had a {}!!!'.format(\n int.from_bytes(self.statement_to_change, byteorder='little')\n )\n\n # Why does this exception_type, exception_value, traceback needed\n # I will tell you later\n def __exit__(self, exception_type, exception_value, traceback):\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] \\\n = self.statement_to_change\n print('Now 112 is {}'.format(112))\n\nif __name__ == \"__main__\":\n with IntChanger(112) as answer:\n print('The 112 is {}'.format(112))\n print(answer)\n\n"
},
{
"alpha_fraction": 0.687960684299469,
"alphanum_fraction": 0.710073709487915,
"avg_line_length": 49.875,
"blob_id": "759ac258a88e7580e8d19f00d6445d8117ed52e8",
"content_id": "49b88cc98d11c81a6ba6ba84f5ec8f9cb4f7e4e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 8,
"path": "/+=/+=.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "original = [1, 2, 3]\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(original))))\ncopy = original\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\ncopy = copy + [1, 2, 3]\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\ncopy += [1, 2, 3]\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\n"
},
{
"alpha_fraction": 0.6678200960159302,
"alphanum_fraction": 0.6724336743354797,
"avg_line_length": 26.935483932495117,
"blob_id": "640088169b8d6d1b21724ee3ce966f45a1c55e23",
"content_id": "0fe23ec63f90899f3759a93c5cadb9f2c2f5bf10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 867,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 31,
"path": "/with_sqlalchemy/sqlalchemy_sqlite_example.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "from sqlalchemy import create_engine, Column, Integer, String\n\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy.orm import sessionmaker\n\n\nBase = declarative_base()\n\n\nclass User(Base):\n __tablename__ = 'users'\n\n id = Column(Integer, primary_key=True)\n name = Column(String)\n fullname = Column(String)\n password = Column(String)\n\n def __repr__(self):\n return \"<User(name='%s', fullname='%s', password='%s')>\" % (\n self.name, self.fullname, self.password\n )\n\nengine = create_engine(\"sqlite:///test.db\")\n# Base.metadata.create_all(engine)\nSession = sessionmaker(bind=engine)\nsession = Session()\ned_user = User(id=1, name='ed', fullname='Ed Jones', password='edspassword')\ned_user2 = User(id=2, name='ed', fullname='Ed Jones', password='edspassword')\nsession.add(ed_user)\nsession.add(ed_user2)\nsession.commit()\n\n"
},
{
"alpha_fraction": 0.5702247023582458,
"alphanum_fraction": 0.5955055952072144,
"avg_line_length": 15.181818008422852,
"blob_id": "854201ad3df794f7a8e5429b965d73f058a8ad72",
"content_id": "fd65bf3a921efd8f142aa4e024d6129922150c9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 356,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 22,
"path": "/else/while_else.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "counter = 0\nresult = 'Not done'\nwhile counter < 10:\n counter += 1\n print(counter, end=', ')\nelse:\n result = 'Done'\n\nprint(result)\n\ncounter = 0\nresult = 'Not done'\nwhile counter < 10:\n counter += 1\n print(counter, end=', ')\n if counter > 2:\n break\nelse:\n # to check that something stoped while\n result = 'Done'\n\nprint(result)\n"
},
{
"alpha_fraction": 0.6330769062042236,
"alphanum_fraction": 0.6399999856948853,
"avg_line_length": 24.490196228027344,
"blob_id": "bde421fd7b578e3081b2aa7a3ba47ac375fab847",
"content_id": "2201e79980c65b3673a394467fc1cf386185a28d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1300,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 51,
"path": "/with_sqlalchemy/with_sqlalchemy.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "from contextlib import contextmanager\n\nfrom sqlalchemy import create_engine, Column, Integer, String\n\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy.orm import sessionmaker\n\n\nBase = declarative_base()\n\n\n@contextmanager\ndef session_scope():\n # __enter__\n engine = create_engine(\"sqlite:///test.db\")\n # Base.metadata.create_all(engine)\n Session = sessionmaker(bind=engine)\n try:\n yield Session()\n # __exit__\n session.commit()\n except Exception as e:\n session.rollback()\n # raise e\n else:\n print('No problem detected')\n finally:\n print('Session closed')\n session.close()\n\n\nclass User(Base):\n __tablename__ = 'users'\n\n id = Column(Integer, primary_key=True)\n name = Column(String)\n fullname = Column(String)\n password = Column(String)\n\n def __repr__(self):\n return \"<User(name='%s', fullname='%s', password='%s')>\" % (\n self.name, self.fullname, self.password\n )\n\nwith session_scope() as session:\n ed_user = User(id=1000, name='ed', fullname='Ed Jones', password='edspassword')\n ed_user2 = User(id=1000, name='ed', fullname='Ed Jones', password='edspassword')\n session.add(ed_user)\nfrom sqlalchemy import inspect\ninsp = inspect(ed_user)\nprint(insp.session)\n"
},
{
"alpha_fraction": 0.5800711512565613,
"alphanum_fraction": 0.5800711512565613,
"avg_line_length": 27.100000381469727,
"blob_id": "ab6fcf26f16927b03416b963ef89ac9b01028bd0",
"content_id": "af5abb5fb525accb1f46245fb3dbc8d460e432a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/else/for_else.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "list_of_desserts = [\"candie\", \"biscuit\", \"ice cream\"]\nfor dessert in list_of_desserts:\n if dessert == \"cake\":\n print(\"{}!!!!\".format(dessert))\n break\n else:\n print('Not a cake')\nelse:\n # to check that something not find\n print('The cake is a lie')\n"
},
{
"alpha_fraction": 0.5913978219032288,
"alphanum_fraction": 0.6272401213645935,
"avg_line_length": 35.39130401611328,
"blob_id": "091829f619cf5b4efb59605703c22c95d6cc3770",
"content_id": "11e2c6ae36a54e663267cca663ac10d35ab6043a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1674,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 46,
"path": "/with/with_class_generator_main_difference.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "import ctypes\n\nfrom contextlib import contextmanager\n\n\n@contextmanager\ndef int_changer(statement_to_change):\n # __init__\n statement_address = id(statement_to_change)\n statement_to_change = bytes([statement_to_change])\n ctypes.cast(statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = b'\\x2A' #42\n # __enter__\n yield 'But we had a {}!!!'.format(int.from_bytes(statement_to_change, byteorder='little'))\n # __exit__\n ctypes.cast(statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = statement_to_change\n print('Now 112 is {}'.format(112))\n\n\nclass IntChanger:\n def __init__(self, statement_to_change):\n self.statement_address = id(statement_to_change)\n self.statement_to_change = bytes([statement_to_change])\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = b'\\x2A' #42\n\n def __enter__(self):\n return 'But we had a {}!!!'.format(int.from_bytes(self.statement_to_change, byteorder='little'))\n\n # Why does this exception_type, exception_value, traceback needed I will tell you later\n def __exit__(self, exception_type, exception_value, traceback):\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = self.statement_to_change\n print('Now 112 is {}'.format(112))\n\n\nif __name__ == \"__main__\":\n try:\n with IntChanger(112) as answer:\n print('The 112 is {}'.format(112))\n 1 / 0\n except:\n print('Except 112 is {}'.format(112))\n try:\n with int_changer(112) as answer:\n print('The 112 is {}'.format(112))\n 1 / 0\n except:\n print('Except 112 is {}'.format(112))\n"
},
{
"alpha_fraction": 0.5962733030319214,
"alphanum_fraction": 0.6211180090904236,
"avg_line_length": 16.88888931274414,
"blob_id": "7f3e5080012411a92f88f17fb87e00761b3e50e8",
"content_id": "e2076633d4de7cdd8c327d37e5e3fe337ae2acfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/else/try_else.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "try:\n # 1/0\n 0/1\nexcept ZeroDivisionError:\n print('Exception, but you can go on')\nelse:\n print('No Exceptions. Done.')\nfinally:\n print('OK then')\n"
},
{
"alpha_fraction": 0.6264367699623108,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 32.14285659790039,
"blob_id": "7f809ff4eef190a9881d18eb0e79dbe6b72c17a1",
"content_id": "6a517b05bd941771ca8fcfad869cce01fb7a7ac9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 21,
"path": "/with/with_generator.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "import ctypes\n\nfrom contextlib import contextmanager\n\n\n@contextmanager\ndef int_changer(statement_to_change):\n # __init__\n statement_address = id(statement_to_change)\n statement_to_change = bytes([statement_to_change])\n ctypes.cast(statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = b'\\x2A'\n # __enter__\n yield 'But we had a {}!!!'.format(int.from_bytes(statement_to_change, byteorder='little'))\n # __exit__\n ctypes.cast(statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = statement_to_change\n print('Now 112 is {}'.format(112))\n\nif __name__ == \"__main__\":\n with int_changer(112) as answer:\n print('The 112 is {}'.format(112))\n print(answer)\n"
},
{
"alpha_fraction": 0.8275862336158752,
"alphanum_fraction": 0.8275862336158752,
"avg_line_length": 57,
"blob_id": "1801711dcfa5920262befb341216f4f346056fbf",
"content_id": "dcd6a41a29ed237297dd8e78416830732e0a42ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 1,
"path": "/README.md",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "Code examples for http://slides.com/volodymyrselyukh/deck\n"
},
{
"alpha_fraction": 0.5945701599121094,
"alphanum_fraction": 0.6199095249176025,
"avg_line_length": 37.034481048583984,
"blob_id": "d493f200c0200e68445280bbe4b01c7fbc7da3f7",
"content_id": "9dcb2cef392edb63227a5716c1e50839523a762e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 29,
"path": "/with/with_class_exception.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "import ctypes\n\n\nclass IntChanger:\n def __init__(self, statement_to_change):\n self.statement_address = id(statement_to_change)\n self.statement_to_change = bytes([statement_to_change])\n\n def __enter__(self):\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = b'\\x2A'\n return 'But we had a {}?'.format(int.from_bytes(self.statement_to_change, byteorder='little'))\n\n def __exit__(self, exception_type, exception_value, traceback):\n print(exception_type)\n print(exception_value)\n print(traceback)\n print('The 112 is {}'.format(112))\n ctypes.cast(self.statement_address, ctypes.POINTER(ctypes.c_char))[3 * 8] = self.statement_to_change\n print('Now 112 is {}'.format(112))\n if exception_type == ZeroDivisionError:\n print('Doing something...')\n # sending signal to interpreter that everything is OK.\n return True\n\nif __name__ == \"__main__\":\n with IntChanger(112) as answer:\n print('In this context The 112 is {}'.format(112))\n 1/0\n print(answer)\n\n\n"
},
{
"alpha_fraction": 0.6820448637008667,
"alphanum_fraction": 0.7206982374191284,
"avg_line_length": 25.733333587646484,
"blob_id": "f0f0620899c9e27ff10251901b402b9ba37e3e3a",
"content_id": "03b79e40e018959f2b531856fa0f6b74475e30cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 30,
"path": "/+=/dis_+=.py",
"repo_name": "vsel/EVOSummerPythonLab2016CodeExamples",
"src_encoding": "UTF-8",
"text": "import dis\nfrom time import sleep\n\noriginal = [1, 2, 3]\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(original))))\ncopy = original\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\n\n\ndef copy_staright_way(copy_from_outer_scope):\n copy_from_outer_scope = copy_from_outer_scope + [4, 5, 6]\ndis.dis(copy_staright_way)\ncopy_staright_way(copy)\nprint(copy)\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\n\n\ndef copy_by_plus_equal(copy_from_outer_scope):\n copy_from_outer_scope += [4, 5, 6]\ndis.dis(copy_by_plus_equal)\ncopy_by_plus_equal(copy)\nprint(copy)\nprint('Address in memory {memory_address}'.format(memory_address=hex(id(copy))))\n\nprint(hex(id(123)))\n\n# sudo gdb -p 31959\n# x/5 0x114ed40\n\n# sleep(1000000)\n"
}
] | 12 |
Fromang/ServicePasquaJove
|
https://github.com/Fromang/ServicePasquaJove
|
5b6015a574c6311e662695cdb7c6cf8ba189125a
|
91271ad4509b09fb97d4d6a360b93ef67a13dd8b
|
19754c67c1f6183bdebee486cc395877fe496bc9
|
refs/heads/master
| 2018-05-02T07:06:13.613047 | 2016-02-28T13:33:10 | 2016-02-28T13:33:10 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.602806568145752,
"alphanum_fraction": 0.6046369671821594,
"avg_line_length": 29.924528121948242,
"blob_id": "94320b460b6cc738ee8d467ee1315e9f8c41b043",
"content_id": "a275a32d895fc4c2d7d6353c340ce26fc6f713c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1639,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 53,
"path": "/src/pasqua/contact.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "import falcon\nfrom db import pascuadb\nfrom framework import *\n\n\nclass ContactModel(PascuaModel):\n def __init__(self, obj=None, errors=[]):\n super(ContactModel, self).__init__(obj, errors)\n\n @staticmethod\n def get_fields():\n return {\n 'name': PascuaString(mandatory=True),\n 'email': PascuaMail(mandatory=True),\n 'comment': PascuaString(mandatory=True)\n }\n\n\n# Falcon follows the REST architectural style, meaning (among\n# other things) that you think in terms of pasqua and state\n# transitions, which map to HTTP verbs.\nclass NewContactResource(BaseResource):\n def __init__(self):\n super(NewContactResource, self).__init__(\n ('\\nNew Contact:\\n'\n ' - Insert a contact into database.\\n'), model=ContactModel)\n\n def process(self, req, resp, data=None, errors=[]):\n contact = ContactModel(data, errors=errors)\n\n insert_contact = contact.copy()\n pascuadb.contact.insert_one(insert_contact)\n contact['_id'] = str( insert_contact['_id'] )\n\n resp.status = falcon.HTTP_201\n return contact\n\n\nclass GetContactsResource(BaseResource):\n def __init__(self):\n super(GetContactsResource, self).__init__(\n ('\\nGet Contacts:\\n'\n ' - Get all contacts from the database. Login needed\\n'), content_type=None)\n\n def process(self, req, resp, data=None, errors=[]):\n users = []\n docs = pascuadb.contact.find()\n for doc in docs:\n user = ContactModel(doc)\n user['_id'] = str ( doc['_id'] )\n users.append(user)\n\n return users\n"
},
{
"alpha_fraction": 0.5793498754501343,
"alphanum_fraction": 0.5855640769004822,
"avg_line_length": 31.184616088867188,
"blob_id": "9a6ac9e9ab3a3f09840fb8ceb1090c95525f9fcb",
"content_id": "ae3648e742886ce11c67e0d83972ab3d84aab95d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2092,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 65,
"path": "/src/pasqua/login.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "# NOT IMPLEMENTED!\nimport falcon\nimport jwt\nimport os\nfrom db import pascuadb\nfrom framework import *\nfrom security import digest\nfrom user import UserModel\n\n\nclass LoginModel(PascuaModel):\n def __init__(self, obj=None, errors=[]):\n super(LoginModel, self).__init__(obj, errors)\n self['timestamp'] = datetime.now().strftime('%d-%m-%Y')\n\n @staticmethod\n def get_fields():\n return {\n 'email': PascuaString(mandatory=True),\n 'password': PascuaString(mandatory=True)\n }\n\n def encode(self):\n return jwt.encode(self, os.environ['PASQUAJOVE_JWT_SECRET'], algorithm='HS256')\n\n\n# Falcon follows the REST architectural style, meaning (among\n# other things) that you think in terms of pasqua and state\n# transitions, which map to HTTP verbs.\nclass LoginResource(BaseResource):\n def __init__(self):\n super(LoginResource, self).__init__(\n ('\\nLogin:\\n'\n ' - Authentication process. It gives you a token.\\n'), model=LoginModel)\n self.version = 0\n self.description = ()\n\n def process(self, req, resp, data=None, errors=[]):\n login = LoginModel(data, errors=errors)\n user = pascuadb.register.find_one( { 'email': login['email'] } )\n if not user:\n errors.append(PascuaError(\n type=pascua_error_types.WRONG_FIELD,\n field='email',\n description='User not found.',\n code=pascua_error_codes['WRONG_PASSWORD']\n ))\n resp.status = falcon.HTTP_403\n return\n\n user = UserModel(user)\n password = digest(user)\n print password\n if not 'password' in user:\n errors.append(PascuaError(\n type=pascua_error_types.WRONG_FIELD,\n field='email',\n description='Non responsable.',\n code=pascua_error_codes['NON_RESPONSABLE']\n ))\n resp.status = falcon.HTTP_403\n return\n\n resp.status = falcon.HTTP_200\n return { 'auth-token' : login.encode() }\n"
},
{
"alpha_fraction": 0.6734693646430969,
"alphanum_fraction": 0.718367338180542,
"avg_line_length": 23.5,
"blob_id": "23600c57127b3971404421d99c5f68b0846fa3fe",
"content_id": "c5990000c5911b5478de65609b4cb76068e2db5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 10,
"path": "/src/pasqua/db/db.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "from pymongo import MongoClient\nimport os\n\ndatabase = 'pasquajove'\nif 'OPENSHIFT_MONGODB_DB_URL' in os.environ:\n url = os.environ['OPENSHIFT_MONGODB_DB_URL']\nelse:\n url = \"mongodb://127.0.0.1:27017/\"\n\npascuadb = MongoClient(url)[database]\n"
},
{
"alpha_fraction": 0.7318255305290222,
"alphanum_fraction": 0.7318255305290222,
"avg_line_length": 29.950000762939453,
"blob_id": "e04b0f5286eb1d158c2cc0e1cc321d0059641e55",
"content_id": "e6b68a41aa8e53cddc5e924aacb3043401e50e81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 20,
"path": "/src/pasqua/__init__.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "from user import NewUserResource, GetUsersResource\nfrom contact import GetContactsResource, NewContactResource\nfrom login import LoginResource\nfrom error_codes import ErrorCodesResource\n\n\ndef init(app):\n # User pasqua\n app.add_route('/api/newUser', NewUserResource())\n app.add_route('/api/getUsers', GetUsersResource())\n\n # Contact pasqua\n app.add_route('/api/newContact', NewContactResource())\n app.add_route('/api/getContacts', GetContactsResource())\n\n # Login pasqua\n app.add_route('/api/login', LoginResource())\n\n # Login pasqua\n app.add_route('/error-codes.js', ErrorCodesResource())\n"
},
{
"alpha_fraction": 0.8519999980926514,
"alphanum_fraction": 0.8519999980926514,
"avg_line_length": 34.71428680419922,
"blob_id": "024b93e61ea3b3becbc6269416fc1d71846a9723",
"content_id": "09f32fe1e4773b9643d552d336209a5e773aba5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 7,
"path": "/src/pasqua/framework/__init__.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "from model import PascuaModel\nfrom fields import *\nfrom errors import PascuaError\nfrom exceptions import PascuaFieldError\nimport error_types as pascua_error_types\nfrom base_error_codes import pascua_error_codes\nfrom base_resource import BaseResource\n"
},
{
"alpha_fraction": 0.668789803981781,
"alphanum_fraction": 0.7197452187538147,
"avg_line_length": 37.75,
"blob_id": "81911a9f5422dd03e87af76787faeb988fbb83bf",
"content_id": "5f31e0607920633836faed7d7809d5cf43ef196b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 4,
"path": "/src/pasqua/framework/base_error_codes.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "\n\npascua_error_codes = dict()\npascua_error_codes['NON_BASIC_ERROR'] = 0x80000\npascua_error_codes['MANDATORY_FIELD'] = 1\npascua_error_codes['WRONG_TYPE'] = 2\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 29.66666603088379,
"blob_id": "d11743e8e2b75b5e41d68cd4f65ad1bf91829dc5",
"content_id": "0271c62676759241d030a345b123aadf9827b9a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 3,
"path": "/src/pasqua/framework/error_types.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "WRONG_FIELD = 'Wrong Field'\nGENERAL_ERROR = 'General Error'\nWRONG_REQUEST = 'Wrong Request'\n"
},
{
"alpha_fraction": 0.6554112434387207,
"alphanum_fraction": 0.6632034778594971,
"avg_line_length": 41.77777862548828,
"blob_id": "39572329d8df966514fcc79e5c45ed697919233d",
"content_id": "409076b1ac1168e7803548edb87858699550e537",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1155,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 27,
"path": "/src/pasqua/error_codes.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "import falcon\nfrom framework import pascua_error_codes\n\npascua_error_codes['INVALID_JSON'] = 1 | pascua_error_codes['NON_BASIC_ERROR']\npascua_error_codes['INVALID_CONTENT_TYPE'] = 2 | pascua_error_codes['NON_BASIC_ERROR']\npascua_error_codes['DUPLICATED_USER_EMAIL'] = 3 | pascua_error_codes['NON_BASIC_ERROR']\npascua_error_codes['NON_RESPONSABLE'] = 4 | pascua_error_codes['NON_BASIC_ERROR']\npascua_error_codes['WRONG_PASSWORD'] = 5 | pascua_error_codes['NON_BASIC_ERROR']\n\n\n# Falcon follows the REST architectural style, meaning (among\n# other things) that you think in terms of pasqua and state\n# transitions, which map to HTTP verbs.\nclass ErrorCodesResource(object):\n def __init__(self):\n self.js_vars = 'var pascua_error_codes={'\n for key in pascua_error_codes:\n value = pascua_error_codes[key]\n self.js_vars += '\"' + key + '\":' + str(value) + \",\"\n\n self.js_vars = self.js_vars[:-1] + \"};\"\n\n def on_get(self, req, resp):\n \"\"\"Handles GET requests\"\"\"\n resp.content_type='text/javascript'\n resp.status = falcon.HTTP_200 # This is the default status\n resp.body = self.js_vars\n"
},
{
"alpha_fraction": 0.748633861541748,
"alphanum_fraction": 0.748633861541748,
"avg_line_length": 25.14285659790039,
"blob_id": "455e169e7cbafa34764bd7704e5d285eacf6e54c",
"content_id": "85cd42cd0654fd08f6634bc08de5faca5f1a8561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "# ServicePasquaJove\nIn order to execute this API you have to setup the environment variables:\n\n```bash\nPASQUAJOVE_MAIL_ADDRESS = '[email protected]'\nPASQUAJOVE_MAIL_PASSWORD = 'mysecretpassword'\n```\n"
},
{
"alpha_fraction": 0.6979166865348816,
"alphanum_fraction": 0.6979166865348816,
"avg_line_length": 18.200000762939453,
"blob_id": "410aa985dfc22f1f152ee8da7cac553a7517e609",
"content_id": "08cd25ed92cc5840546da2850cb3ed9cff7dc984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/start",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nsource __env__/bin/activate\npushd src > /dev/null\ngunicorn app:app\npopd > /dev/null\n"
},
{
"alpha_fraction": 0.6551094651222229,
"alphanum_fraction": 0.6551094651222229,
"avg_line_length": 21.83333396911621,
"blob_id": "4edf0e8c4ce3f25477e27548c51e6aa6ccaf431a",
"content_id": "043b66375009fc1ce7b20ce178575fab71f0009b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 24,
"path": "/src/app.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "# Let's get this party started\nimport falcon\nimport pasqua\n\n\ndef cors_middleware(request, response, params):\n response.set_header(\n 'Access-Control-Allow-Origin',\n '*'\n )\n response.set_header(\n 'Access-Control-Allow-Headers',\n 'Content-Type, Api-Token'\n )\n # This could be overridden in the resource level\n response.set_header(\n 'Access-Control-Expose-Headers',\n 'Location'\n )\n\n\n# falcon.API instances are callable WSGI apps\napp = falcon.API(before=[cors_middleware])\npasqua.init(app)\n"
},
{
"alpha_fraction": 0.5752979516983032,
"alphanum_fraction": 0.5780065059661865,
"avg_line_length": 31.38596534729004,
"blob_id": "a192150886c79c613d0b4a9d97403c93b8eac00f",
"content_id": "b76bb38b102355f8b995964e2f4405b9e46dbbc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3692,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 114,
"path": "/src/pasqua/user.py",
"repo_name": "Fromang/ServicePasquaJove",
"src_encoding": "UTF-8",
"text": "import smtplib\nfrom email.mime.text import MIMEText\n\nimport falcon\nimport os\nfrom db import pascuadb\nfrom framework import *\n\n\nclass UserModel(PascuaModel):\n def __init__(self, obj=None, errors=[]):\n super(UserModel, self).__init__(obj, errors)\n\n @staticmethod\n def get_fields():\n return {\n 'name': PascuaString(mandatory=True),\n 'surname': PascuaString(),\n 'email': PascuaMail(mandatory=True),\n 'birth': PascuaDate(mandatory=True, yearsBefore=0),\n 'phone': PascuaPhone(mandatory=True),\n 'group': PascuaString(mandatory=True),\n 'invitedBy': PascuaString(mandatory=True),\n 'food': PascuaArray(\n PascuaDomain([\"diabetes\", \"celiac\", \"allergies\", \"other\"]),\n mandatory=True\n )\n }\n\n def full_name(self):\n if 'surname' in self:\n return self['name'] + ' ' + self['surname']\n return self['name']\n\n\n# Falcon follows the REST architectural style, meaning (among\n# other things) that you think in terms of pasqua and state\n# transitions, which map to HTTP verbs.\nclass NewUserResource(BaseResource):\n def __init__(self):\n super(NewUserResource, self).__init__(\n ('\\nNew User:\\n'\n ' - Insert a user into database.\\n'), model=UserModel)\n\n def process(self, req, resp, data=None, errors=[]):\n user = UserModel(data, errors=errors)\n\n insert_user = user.copy()\n check_duplied_mail = pascuadb.register.find_one({ 'email': insert_user['email'] })\n if check_duplied_mail is not None:\n errors.append(PascuaError(\n type=pascua_error_types.WRONG_FIELD,\n field='email',\n description='Duplicated email.',\n code=pascua_error_codes['DUPLICATED_USER_EMAIL']\n ))\n resp.status = falcon.HTTP_409\n return\n\n pascuadb.register.insert_one(insert_user)\n user['_id'] = str( insert_user['_id'] )\n\n # Send an email\n self.send_registration_mail(user)\n\n resp.status = falcon.HTTP_201\n return user\n\n @staticmethod\n def send_registration_mail(user):\n # Open a plain text file for reading. For this example, assume that\n # the text file contains only ASCII characters.\n textfile = os.path.dirname(__file__) + '/mails/registro.html'\n toaddrs = user['email']\n\n username = os.environ['PASQUAJOVE_MAIL_ADDRESS']\n password = os.environ['PASQUAJOVE_MAIL_PASSWORD']\n\n # Read mail\n fp = open(textfile, 'rb')\n content = fp.read()\n fp.close()\n\n # Prepare email\n msg = MIMEText(content, 'html')\n msg['Subject'] = 'Registro completado'\n msg['From'] = 'Responsables Pasqua Jove'\n msg['To'] = toaddrs\n\n # Send the message via our own SMTP server, but don't include the\n # envelope header.\n server = smtplib.SMTP('smtp.gmail.com', 587)\n server.ehlo()\n server.starttls()\n server.login(username, password)\n server.sendmail(username, [toaddrs], msg.as_string())\n server.quit()\n\n\nclass GetUsersResource(BaseResource):\n def __init__(self):\n super(GetUsersResource, self).__init__(\n ('\\nGet Users:\\n'\n ' - Get all users from the database. Login needed.\\n'), content_type=None)\n\n def process(self, req, resp, data=None, errors=[]):\n users = []\n docs = pascuadb.register.find()\n for doc in docs:\n user = UserModel(doc)\n user['_id'] = str ( doc['_id'] )\n users.append(user)\n\n return users\n"
}
] | 12 |
DanielEDuan/RCwheel_G29
|
https://github.com/DanielEDuan/RCwheel_G29
|
2667b1ee92075a5df84ff6f78c35e9ccec988eae
|
95450d8615b3cbf170ea0c655fba493661d8528f
|
10caebf984ca780d8fd536a9f6348000fc699b8f
|
refs/heads/master
| 2023-08-11T04:14:32.865868 | 2021-10-11T20:37:24 | 2021-10-11T20:37:24 | 416,078,618 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5871670842170715,
"alphanum_fraction": 0.6452784538269043,
"avg_line_length": 21.953702926635742,
"blob_id": "e893e52fe583ffb8ae1203e790acc88addb004d2",
"content_id": "31f0708e60e05a6aa1a5092685f739c7c50a9481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2478,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 108,
"path": "/venv/Scripts/Steering.py",
"repo_name": "DanielEDuan/RCwheel_G29",
"src_encoding": "UTF-8",
"text": "# Copyright (c) 2019 Diego Damasceno\n#\n# This file is part of pygame-logitechG29_wheel.\n# Documentation, related files, and licensing can be found at\n#\n# <https://github.com/damascenodiego/pygame-logitechG29_wheel>.\n\n\nimport pygame\nimport logitechG29_wheel\nimport struct\nimport serial\n\npygame.init()\n\nser = serial.Serial('COM4',115200)\n\n# define some colors\nBLACK = (0, 0, 0)\nWHITE = (255, 255, 255)\nRED = (255, 0, 0)\nGREEN = (0, 255, 0)\nBLUE = (0, 0, 255)\n\n# window settings\nsize = [600, 600]\nscreen = pygame.display.set_mode(size)\npygame.display.set_caption(\"Steering\")\n\nFPS = 10\n\nclock = pygame.time.Clock()\n\n# make a controller\ncontroller = logitechG29_wheel.Controller(0)\n\n# game logic\nball_pos1 = [100, 290]\nball_pos2 = [200, 290]\nball_pos3 = [300, 290]\nball_pos4 = [400, 290]\n\n# game loop\ndone = False\n\n#sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\nwhile not done:\n # event handling\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n done = True\n\n # handle joysticks\n jsButtons = controller.get_buttons()\n jsInputs = controller.get_axis()\n\n steerPos = controller.get_steer()\n\n throtPos = controller.get_throttle()\n breakPos = controller.get_break()\n clutchPos = controller.get_clutch()\n\n # print(f\"Throttle position {throtPos}\")\n # print(f\"Brake position {breakPos}\")\n\n throtVal = (((-1*throtPos)+1)**4)/4 + (breakPos+1)/4\n if(throtVal>1) : throtVal = 1\n elif(throtVal<0) : throtVal = 0\n\n steerVal = ((steerPos+0.73)/2)\n if(steerVal>1) : steerVal=1\n elif(steerVal<0) : steerVal=0\n\n\n msg = struct.pack('ff',throtVal,steerVal)\n\n # msgX = bytes([126 + int(steerPos * 126)])\n # msgY = bytes([126 + int(throtPos * 126)])\n # msgZ = bytes([126 + int(breakPos * 126)])\n ser.write(msg)\n\n ball1_radius = int((steerPos + 1) * 20)\n ball2_radius = int((clutchPos + 1) * 20)\n ball3_radius = int((breakPos + 1) * 20)\n ball4_radius = int((throtPos + 1) * 20)\n\n if (steerPos >= 0):\n ball_color = RED\n else:\n ball_color = GREEN\n\n # drawing\n screen.fill(BLACK)\n pygame.draw.circle(screen, ball_color, ball_pos1, ball1_radius)\n\n pygame.draw.circle(screen, ball_color, ball_pos2, ball2_radius)\n\n pygame.draw.circle(screen, ball_color, ball_pos3, ball3_radius)\n\n pygame.draw.circle(screen, ball_color, ball_pos4, ball4_radius)\n\n # update screen\n pygame.display.flip()\n clock.tick(FPS)\n\n# close window on quit\npygame.quit()"
},
{
"alpha_fraction": 0.5979381203651428,
"alphanum_fraction": 0.6804123520851135,
"avg_line_length": 13,
"blob_id": "4dcbaadb8d46b7f48b3e564e11741bf58fc37321",
"content_id": "cfa0a7750a9ddaf4aa560697a42e21e4b50344b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 7,
"path": "/venv/Scripts/wheel_config.ini",
"repo_name": "DanielEDuan/RCwheel_G29",
"src_encoding": "UTF-8",
"text": "[G29 Racing Wheel]\nsteering_wheel = 0\ngear = 3\nbrake = 2\nthrottle = 1\nreverse = 5\nhandbrake = 4"
}
] | 2 |
alexey17430/WEB-flask
|
https://github.com/alexey17430/WEB-flask
|
2abf3685f4c7a001a278af32422b0ff0b95dc10c
|
9eeb446f29ae6bcbd70b8604bb722dc56a60caaf
|
07ad10b34f1edd93bf22954eccf70c09b8495a6b
|
refs/heads/master
| 2023-03-16T15:06:19.854362 | 2021-03-07T10:55:44 | 2021-03-07T10:55:44 | 340,642,147 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6155303120613098,
"avg_line_length": 20.1200008392334,
"blob_id": "6a2709dd5f587a7d351e48962ec6bfc7e776e264",
"content_id": "176ad71841b21045ac713d55d27135a6b4408b37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/Тренировки в полёте/main.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import render_template, Flask\n\napp = Flask(__name__)\nTITLE = \"Заготовка\"\n\n\[email protected]('/')\[email protected]('/index')\ndef index():\n global TITLE\n return render_template('base.html', title=TITLE, page=3)\n\n\[email protected]('/training/<prof>')\ndef list_prof(prof):\n global TITLE\n if 'инженер' in prof.lower() or 'строитель' in prof.lower():\n page = 1\n else:\n page = 2\n return render_template('base.html', title=TITLE, page=page)\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.500484049320221,
"alphanum_fraction": 0.5128267407417297,
"avg_line_length": 51.97435760498047,
"blob_id": "5b0337bf82b5c6126f1b731fc0ead9e6e0a96917",
"content_id": "df375160de3333cf49cb6be946a17b4547825f24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4372,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 78,
"path": "/Введение во Flask. Обработка HTML форм/Пейзажи Марса.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask\n\napp = Flask(__name__)\n\n\[email protected]('/')\ndef start():\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Стартовое окно</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <div class=\"alert alert-success\" role=\"alert\" align=\"center\">\n <h4 class=\"alert-heading\">Стартовое окно</h4>\n <p>Уважаемый пользователь, это окно является стратовым</p>\n <hr>\n <p class=\"mb-0\">Чтобы перейти на другую страничку измените ссылку в соответствии с определёнными параметрами</p>\n </div>\n </body>\n </html>\"\"\"\n\n\[email protected]('/index')\ndef index():\n return \"И на Марсе будут яблони цвести!\"\n\n\[email protected]('/carousel')\ndef results():\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Пейзажи Марса</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <h1 align=\"center\">Пейзажи Марса</h1>\n\n <div id=\"carouselExampleIndicators\" class=\"carousel slide\" data-bs-ride=\"carousel\">\n <div class=\"carousel-indicators\">\n <button type=\"button\" data-bs-target=\"#carouselExampleIndicators\" data-bs-slide-to=\"0\" class=\"active\" aria-current=\"true\" aria-label=\"Slide 1\"></button>\n <button type=\"button\" data-bs-target=\"#carouselExampleIndicators\" data-bs-slide-to=\"1\" aria-label=\"Slide 2\"></button>\n <button type=\"button\" data-bs-target=\"#carouselExampleIndicators\" data-bs-slide-to=\"2\" aria-label=\"Slide 3\"></button>\n </div>\n <div class=\"carousel-inner\">\n <div class=\"carousel-item active\">\n <img src=\"static\\img\\mars5.jpg\" class=\"d-block w-100\" alt=\"Фото не найдено\">\n </div>\n <div class=\"carousel-item\">\n <img src=\"static\\img\\mars4.jpg\" class=\"d-block w-100\" alt=\"Фото не найдено\">\n </div>\n <div class=\"carousel-item\">\n <img src=\"static\\img\\mars3.jpg\" class=\"d-block w-100\" alt=\"Фото не найдено\">\n </div>\n </div>\n <button class=\"carousel-control-prev\" type=\"button\" data-bs-target=\"#carouselExampleIndicators\" data-bs-slide=\"prev\">\n <span class=\"carousel-control-prev-icon\" aria-hidden=\"true\"></span>\n <span class=\"visually-hidden\">Previous</span>\n </button>\n <button class=\"carousel-control-next\" type=\"button\" data-bs-target=\"#carouselExampleIndicators\" data-bs-slide=\"next\">\n <span class=\"carousel-control-next-icon\" aria-hidden=\"true\"></span>\n <span class=\"visually-hidden\">Next</span>\n </button>\n </div>\n </body>\n </html>\"\"\"\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.4809619188308716,
"alphanum_fraction": 0.494655966758728,
"avg_line_length": 43.68656539916992,
"blob_id": "dd58a382acb4a97d6e620e042355af0d8d39b976",
"content_id": "8e5aaf78ca87aa608ee661ae5a38e2585372e9be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3337,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 67,
"path": "/Результат отбора.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request\n\napp = Flask(__name__)\n\n\[email protected]('/')\ndef start():\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Стартовое окно</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <div class=\"alert alert-success\" role=\"alert\" align=\"center\">\n <h4 class=\"alert-heading\">Стартовое окно</h4>\n <p>Уважаемый пользователь, это окно является стратовым</p>\n <hr>\n <p class=\"mb-0\">Чтобы перейти на другую страничку измените ссылку в соответствии с определёнными параметрами</p>\n </div>\n </body>\n </html>\"\"\"\n\n\[email protected]('/index')\ndef index():\n return \"И на Марсе будут яблони цвести!\"\n\n\[email protected]('/results/<nickname>/<int:level>/<float:rating>')\ndef results(nickname, level, rating):\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Результаты</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <h1 align=\"center\">Результаты отбора</h1>\n \n <div class=\"alert alert-primary\" role=\"alert\">\n <h2>Претендент на участие в миссии - {nickname}</h2>\n </div>\n \n <div class=\"alert alert-success\" role=\"alert\">\n <h3>Поздравляем ваш рейтинг после {level} этапа отбора выше среднего</h3>\n </div>\n \n <div class=\"alert alert-info\" role=\"alert\">\n <h3>А именно равен {rating} баллам</h3>\n </div>\n \n <div class=\"alert alert-danger\" role=\"alert\">\n <h3>Желаем удачи в дальнейшем прохождении наших испытаний!!!</h3>\n </div>\n </body>\n </html>\"\"\"\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.44396910071372986,
"alphanum_fraction": 0.4499033987522125,
"avg_line_length": 49.31944274902344,
"blob_id": "8a93733045edfa9d9163e7f2133775cb777df386",
"content_id": "ce92e244975a5701e46a9d46d77be615f9f3f2b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7850,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 144,
"path": "/Введение во Flask. Обработка HTML форм/Отбор астронавтов.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, url_for\n\napp = Flask(__name__)\n\n\[email protected]('/')\ndef start():\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Отбор астронавтов</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <h1 align=\"center\">Анкета претендента на участие в миссии</h1>\n <br></br>\n \n <div class=\"mb-3\">\n <label for=\"exampleFormControlInput1\" class=\"form-label\">Фамилия претендента на участие в миссии</label>\n <input type=\"email\" class=\"form-control\" id=\"exampleFormControlInput1\" placeholder=\"Введите фамилию\">\n </div>\n \n <br></br>\n <div class=\"mb-3\">\n <label for=\"exampleFormControlInput1\" class=\"form-label\">Имя претендента на участие в миссии</label>\n <input type=\"email\" class=\"form-control\" id=\"exampleFormControlInput1\" placeholder=\"Введите имя\">\n </div>\n \n <br></br>\n <div class=\"mb-3\">\n <label for=\"exampleFormControlInput1\" class=\"form-label\">Почта претендента на участие в миссии</label>\n <input type=\"email\" class=\"form-control\" id=\"exampleFormControlInput1\" placeholder=\"Введите почту\">\n </div>\n \n <br></br>\n <p>Какое у Вас образование?</p>\n \n <select class=\"form-select form-select-lg mb-3\" aria-label=\".form-select-lg example\">\n <option selected>Среднее общее образование</option>\n <option value=\"1\">Среднее профессиональное образование</option>\n <option value=\"2\">Высшее образование - бакалавриат</option>\n <option value=\"3\">Высшее образование - специалитет, магистратура</option>\n <option value=\"3\">Высшее образование - подготовка кадров высшей квалификации</option>\n </select>\n \n <br></br>\n <p>Какие у Вас есть профессии?</p>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Инженер-строитель\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Инженер-исследователь\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Пилот\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Метеоролог\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Инженер по жизнеобеспечению\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Инженер по радиационной защите\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Врач\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"checkbox\" value=\"\" id=\"flexCheckDefault\">\n <label class=\"form-check-label\" for=\"flexCheckDefault\">\n Биолог\n </label>\n </div>\n \n <br></br>\n <div class=\"form-check form-switch\">\n <input class=\"form-check-input\" type=\"checkbox\" id=\"flexSwitchCheckChecked\">\n <label class=\"form-check-label\" for=\"flexSwitchCheckChecked\">Готовы остаться на Марсе?</label>\n </div>\n \n <br></br>\n <p>Укажите свой пол</p>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"radio\" name=\"flexRadioDefault\" id=\"flexRadioDefault1\">\n <label class=\"form-check-label\" for=\"flexRadioDefault1\">\n Мужской\n </label>\n </div>\n \n <div class=\"form-check\">\n <input class=\"form-check-input\" type=\"radio\" name=\"flexRadioDefault\" id=\"flexRadioDefault1\">\n <label class=\"form-check-label\" for=\"flexRadioDefault1\">\n Женский\n </label>\n </div>\n \n <br></br>\n <div class=\"mb-3\">\n <label for=\"exampleFormControlTextarea1\" class=\"form-label\">Почему Вы хотите поучаствовать в миссии?</label>\n <textarea class=\"form-control\" id=\"exampleFormControlTextarea1\" rows=\"3\"></textarea>\n </div>\n \n <br></br>\n <button type=\"button\" class=\"btn btn-primary\">Отправить</button>\n </body>\n </html>\"\"\"\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.5869565010070801,
"alphanum_fraction": 0.6231883764266968,
"avg_line_length": 17.399999618530273,
"blob_id": "51d171fb2d77ad38e05081054475b18d5ff1fa9d",
"content_id": "35c8893463c69519168f606c966e3f76e08cc43c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/Готовимся к миссии/main.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import render_template, Flask\n\napp = Flask(__name__)\nTITLE = \"Заготовка\"\n\n\[email protected]('/')\[email protected]('/index')\ndef index():\n global TITLE\n return render_template('base.html', title=TITLE)\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.5146792531013489,
"alphanum_fraction": 0.5237404704093933,
"avg_line_length": 37.31944274902344,
"blob_id": "2bc47ff9d498ac9aa95d7a68b14fd4e52dd7d3fe",
"content_id": "af1e0ccfc91be9822d6736c64a1449bc166eed2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3323,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 72,
"path": "/Реклама с картинкой.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, url_for\n\napp = Flask(__name__)\n\n\[email protected]('/')\ndef start():\n return \"Миссия Колонизация Марса\"\n\n\[email protected]('/index')\ndef index():\n return \"И на Марсе будут яблони цвести!\"\n\n\[email protected]('/promotion')\ndef promotion():\n slogan = [\"Человечество вырастает из детства.\", \"Человечеству мала одна планета.\",\n \"Мы сделаем обитаемыми безжизненные пока планеты.\", \"И начнем с Марса!\",\n \"Присоединяйся!\"]\n return '</br>'.join(slogan)\n\n\[email protected]('/image_mars')\ndef image_mars():\n return f'''<title>Привет, Марс!</title>\n <h1>Жди нас, Марс!</h1>\n <img src=\"{url_for('static', filename='img/mars1.jpg')}\" \n alt=\"здесь должна была быть картинка, но не нашлась\">\n <p>Вот она какая, красная планета</p>'''\n\n\[email protected]('/promotion_image')\ndef promotion_image():\n slogan = [\"Человечество вырастает из детства.\", \"Человечеству мала одна планета.\",\n \"Мы сделаем обитаемыми безжизненные пока планеты.\", \"И начнем с Марса!\",\n \"Присоединяйся!\"]\n return f\"\"\"<!doctype html>\n <html lang=\"en\">\n <head>\n <meta charset=\"utf-8\">\n <title>Колонизация</title>\n <link rel=\"stylesheet\" href=\"static/css/style.css\">\n <link href=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css\" rel=\"stylesheet\" integrity=\"sha384-BmbxuPwQa2lc/FVzBcNJ7UAyJxM6wuqIj61tLrc4wSX0szH/Ev+nYRRuWlolflfl\" crossorigin=\"anonymous\">\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-b5kHyXgcpbZJO/tY9Ul7kGkf1S0CWuKcCD38l8YkeH8z8QjE0GmW1gYU5S9FOnJ0\" crossorigin=\"anonymous\"></script>\n </head>\n <body>\n <h1>Жди нас, Марс!</h1>\n <img src=\"{url_for('static', filename='img/mars1.jpg')}\" \n alt=\"здесь должна была быть картинка, но не нашлась\">\n \n <div class=\"alert alert-primary\" role=\"alert\">\n Человечество вырастает из детства.\n </div>\n <div class=\"alert alert-secondary\" role=\"alert\">\n Человечеству мала одна планета.\n </div>\n <div class=\"alert alert-success\" role=\"alert\">\n Мы сделаем обитаемыми безжизненные пока планеты.\n </div>\n <div class=\"alert alert-danger\" role=\"alert\">\n И начнем с Марса!\n </div>\n <div class=\"alert alert-warning\" role=\"alert\">\n Присоединяйся!\n </div>\n </body>\n </html>\"\"\"\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
},
{
"alpha_fraction": 0.6449999809265137,
"alphanum_fraction": 0.6575000286102295,
"avg_line_length": 31,
"blob_id": "ea600b642fc8e286b19eb31b1c1dee59f56a57c1",
"content_id": "4df2845184182e468a3fad1c05a724ebcdeb269f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1022,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 25,
"path": "/Список профессий/main.py",
"repo_name": "alexey17430/WEB-flask",
"src_encoding": "UTF-8",
"text": "from flask import render_template, Flask\n\napp = Flask(__name__)\nTITLE = \"Заготовка\"\nLIST_PROF = ['инженер-исследователь', 'пилот', 'строитель', 'экзобиолог', 'врач',\n 'инженер по терраформированию', 'климатолог', 'специалист по радиационной защите',\n 'астрогеолог', 'гляциолог', 'инженер жизнеобеспечения', 'метеоролог',\n 'опратор марсохода', 'киберинженер', 'штурман', 'пилот дронов']\n\n\[email protected]('/')\[email protected]('/index')\ndef index():\n global TITLE\n return render_template('base.html', title=TITLE)\n\n\[email protected]('/list_prof/<spisok_type>')\ndef list_prof(spisok_type):\n global LIST_PROF\n return render_template('base.html', title=TITLE, spisok_type=spisok_type, spisok=LIST_PROF)\n\n\nif __name__ == '__main__':\n app.run(port=8080, host='127.0.0.1')\n"
}
] | 7 |
saismruthi8/Twitter_Analysis
|
https://github.com/saismruthi8/Twitter_Analysis
|
0d8ca24f17fee0403cc1bcefa3a999a63c5633ae
|
28c41ddd1310678f2b8c6119f6fac824ce066b16
|
583730712ddcdb3d8f3aad64743806e658cc4c20
|
refs/heads/master
| 2020-03-30T08:38:01.239469 | 2018-10-01T03:05:13 | 2018-10-01T03:05:13 | 151,029,623 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6782464981079102,
"alphanum_fraction": 0.7014061212539673,
"avg_line_length": 25.88888931274414,
"blob_id": "f6a4cd0fc9af1864a8de0b1fa002469a52ef3ca7",
"content_id": "e965942871a08609befe3214e3e5cc186c8d1986",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1209,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 45,
"path": "/mosttweeted.py",
"repo_name": "saismruthi8/Twitter_Analysis",
"src_encoding": "UTF-8",
"text": "import string\nimport operator\nimport sys\nimport time\nimport collections\nimport numpy\n\nRead_File = \"C:/Users/user/Desktop/SSDI/BiggBoss.txt\"\n\n#Storing the read file into a Variable - with encoding format - latin-1\nwith open(Read_File, encoding=\"latin-1\") as De_encode_File1:\n hello1 = De_encode_File1.readlines()\n\t\n#using the data from the text file saved in hello1 - variable\n\n#creating a empty array \n\nnames = {}\ncount = 0\nfor dat in hello1:\n file2 = dat.split() \n names[count] = file2[0]\n count = count+1 #count value to increament list of dictionary\nlist_names = names.values()\n\n#list_names\n#len(list_names)\n\n#counting the number of occurences of each name \ncount_names = collections.Counter(list_names)\n\n#displaying the new array\n#count_names\n\n#Taking the top 10 ans storing in array\na = collections.Counter(count_names).most_common(10)\n\n#for i in range(0,10):\n# print(a[i][0])\n \noutputFile = open(r'C:/Users/user/Desktop/SSDI/Most.txt', 'w', encoding=\"utf-8\")\noutputFile.write(\"The top 10 users who have tweeted the for the entire timeline: \\n\",)\nfor i in range(0,10):\n outputFile.write(\"The user \" + a[i][0] + \" tweeted \" + str(a[i][1]) + \" times\" + \"\\n\")\n outputFile.close"
}
] | 1 |
g782373711/WLSSVM_python
|
https://github.com/g782373711/WLSSVM_python
|
e8c1d6a1d4dfbd8dcf1ce3001171c612b11980a6
|
8a11a111267523a931e2a1fef9f78bb626a82099
|
80e37bad1be2c58c68718dec37b00b0a02dcca50
|
refs/heads/master
| 2020-05-05T01:28:45.537311 | 2018-11-24T07:49:24 | 2018-11-24T07:49:24 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 22,
"blob_id": "579476570b1cdc86e9cfeba0c9095519f7a3e8c6",
"content_id": "38fbde615e9db5d71c08a9635205f7b769ec7b98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/README.md",
"repo_name": "g782373711/WLSSVM_python",
"src_encoding": "UTF-8",
"text": "# WLSSVM_python\nWeighted LSSVM for regression\n"
},
{
"alpha_fraction": 0.49176469445228577,
"alphanum_fraction": 0.5157983303070068,
"avg_line_length": 27.522388458251953,
"blob_id": "469ccea095fd673f3ef95c87a34e6228696a54c4",
"content_id": "28b77a4a31daa4c101b054b2cd85c17b89640f73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6856,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 201,
"path": "/wlssvm.py",
"repo_name": "g782373711/WLSSVM_python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jun 5 09:30:24 2018\r\n\r\n@author: lj\r\n\"\"\"\r\nfrom numpy import *\r\n\r\ndef loadDataSet(filename):\r\n '''导入数据\r\n input: filename:文件名\r\n '''\r\n dataMat = []\r\n labelMat = []\r\n fr = open(filename)\r\n for line in fr.readlines():\r\n lineArr = line.strip().split('\\t')\r\n dataMat.append(float(lineArr[0]))\r\n labelMat.append(float(lineArr[1]))\r\n return mat(dataMat).T,mat(labelMat).T\r\n \r\n\r\ndef kernelTrans(X,A,kTup):\r\n '''数据集中每一个数据向量与A的核函数值\r\n input: X--特征数据集\r\n A--输入向量\r\n kTup--核函数参量定义\r\n output: K--数据集中每一个数据向量与A的核函数值组成的矩阵\r\n '''\r\n X = mat(X)\r\n m,n = shape(X)\r\n K = mat(zeros((m,1)))\r\n if kTup[0] == 'lin':\r\n K = X * A.T\r\n elif kTup[0] == 'rbf':\r\n for j in range(m):\r\n deltaRow = X[j] - A\r\n K[j] = deltaRow * deltaRow.T\r\n K = exp(K/(-1 * kTup[1] ** 2))\r\n else: raise NameError('Houston We Have a Problem ,That Kernel is not recognized')\r\n return K\r\n \r\nclass optStruct:\r\n def __init__(self,dataMatIn,classLabels,C,kTup):\r\n self.X = dataMatIn\r\n self.labelMat = classLabels\r\n self.C = C\r\n self.m = shape(dataMatIn)[0]\r\n self.alphas = mat(zeros((self.m,1)))\r\n self.b = 0\r\n self.K = mat(zeros((self.m,self.m))) #特征数据集合中向量两两核函数值组成的矩阵,[i,j]表示第i个向量与第j个向量的核函数值\r\n for i in range(self.m):\r\n self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)\r\n \r\n\r\ndef leastSquares(dataMatIn,classLabels,C,kTup):\r\n '''最小二乘法求解alpha序列\r\n input:dataMatIn:特征数据集\r\n classLabels:分类标签集\r\n C:参数,(松弛变量,允许有些数据点可以处于分隔面的错误一侧)\r\n kTup: 核函数类型和参数选择 \r\n output:b--w.T*x+b=y中的b\r\n alphas:alphas序列 \r\n '''\r\n ##1.参数设置\r\n oS = optStruct(dataMatIn,classLabels,C,kTup)\r\n unit = mat(ones((oS.m,1))) #[1,1,...,1].T\r\n I = eye(oS.m)\r\n zero = mat(zeros((1,1)))\r\n upmat = hstack((zero,unit.T))\r\n downmat = hstack((unit,oS.K + I/float(C)))\r\n ##2.方程求解\r\n completemat = vstack((upmat,downmat)) #lssvm中求解方程的左边矩阵\r\n rightmat = vstack((zero,oS.labelMat)) # lssvm中求解方程的右边矩阵\r\n b_alpha = completemat.I * rightmat\r\n ##3.导出偏置b和Lagrange乘子序列\r\n oS.b = b_alpha[0,0]\r\n for i in range(oS.m):\r\n oS.alphas[i,0] = b_alpha[i+1,0]\r\n e = oS.alphas/C\r\n return oS.alphas,oS.b,e\r\n\r\ndef weights(e):\r\n '''计算权重序列\r\n input:e(mat):LSSVM误差矩阵\r\n output:v(mat):权重矩阵\r\n '''\r\n ##1.参数设置\r\n c1 = 2.5\r\n c2 = 3\r\n m = shape(e)[0]\r\n v = mat(zeros((m,1)))\r\n v1 = eye(m)\r\n q1 = int(m/4.0)\r\n q3 = int((m*3.0)/4.0)\r\n e1 = []\r\n shang = mat(zeros((m,1)))\r\n ##2.误差序列从小到大排列\r\n for i in range(m):\r\n e1.append(e[i,0])\r\n e1.sort()\r\n ##3.计算误差序列第三四分位与第一四分位的差\r\n IQR = e1[q3] - e1[q1]\r\n ##4.计算s的值\r\n s = IQR/(2 * 0.6745)\r\n ##5.计算每一个误差对应的权重\r\n for j in range(m):\r\n shang[j,0] = abs(e[j,0]/s)\r\n for x in range(m):\r\n if shang[x,0] <= c1:\r\n v[x,0] = 1.0\r\n if shang[x,0] > c1 and shang[x,0] <= c2:\r\n v[x,0] = (c2 - shang[x,0])/(c2 - c1)\r\n if shang[x,0] > c2:\r\n v[x,0] = 0.0001\r\n v1[x,x] = 1/float(v[x,0])\r\n return v1\r\n\r\ndef weightsleastSquares(dataMatIn,classLabels,C,kTup,v1):\r\n '''最小二乘法求解alpha序列\r\n input:dataMatIn:特征数据集\r\n classLabels:分类标签集\r\n C:参数,(松弛变量,允许有些数据点可以处于分隔面的错误一侧)\r\n kTup: 核函数类型和参数选择 \r\n output:b--w.T*x+b=y中的b\r\n alphas:alphas序列 \r\n '''\r\n ##1.参数设置\r\n oS = optStruct(dataMatIn,classLabels,C,kTup)\r\n unit = mat(ones((oS.m,1))) #[1,1,...,1].T\r\n #I = eye(oS.m)\r\n gamma = kTup[1]\r\n zero = mat(zeros((1,1)))\r\n upmat = hstack((zero,unit.T))\r\n downmat = hstack((unit,oS.K + v1/float(C)))\r\n ##2.方程求解\r\n completemat = vstack((upmat,downmat)) #lssvm中求解方程的左边矩阵\r\n rightmat = vstack((zero,oS.labelMat)) # lssvm中求解方程的右边矩阵\r\n b_alpha = completemat.I * rightmat\r\n ##3.导出偏置b和Lagrange乘子序列\r\n oS.b = b_alpha[0,0]\r\n for i in range(oS.m):\r\n oS.alphas[i,0] = b_alpha[i+1,0]\r\n e = oS.alphas/C\r\n return oS.alphas,oS.b\r\n\r\n\r\ndef predict(alphas,b,dataMat):\r\n '''预测结果\r\n input:alphas(mat):WLSSVM模型的Lagrange乘子序列\r\n b(float):WLSSVM模型回归方程的偏置\r\n dataMat(mat):测试样本集\r\n output:predict_result(mat):测试结果\r\n '''\r\n m,n = shape(dataMat)\r\n predict_result = mat(zeros((m,1)))\r\n for i in range(m):\r\n Kx = kernelTrans(dataMat,dataMat[i,:],kTup) #可以对alphas进行稀疏处理找到更准确的值 \r\n predict_result[i,0] = Kx.T * alphas + b \r\n return predict_result\r\n\r\ndef predict_average_error(predict_result,label):\r\n '''计算平均预测误差\r\n input:predict_result(mat):预测结果\r\n label(mat):实际结果\r\n output:average_error(float):平均误差\r\n '''\r\n m,n = shape(predict_result)\r\n error = 0.0\r\n for i in range(m):\r\n error += abs(predict_result[i,0] - label[i,0])\r\n average_error = error / m\r\n return average_error\r\n \r\n\r\n\r\nif __name__ == '__main__':\r\n ##1.数据导入\r\n print('--------------------Load Data------------------------')\r\n dataMat,labelMat = loadDataSet('sine.txt')\r\n ##2.参数设置\r\n print('--------------------Parameter Setup------------------')\r\n C = 0.6\r\n k1 = 0.3\r\n kernel = 'rbf'\r\n kTup = (kernel,k1)\r\n ##3.求解LSSVM模型\r\n print('-------------------Save LSSVM Model-----------------')\r\n alphas,b,e = leastSquares(dataMat,labelMat,C,kTup)\r\n ##4.计算误差权重\r\n print('----------------Calculate Error Weights-------------')\r\n v1 = weights(e)\r\n ##5.求解WLSSVM模型\r\n print('------------------Save WLSSVM Model--------------- -')\r\n alphas1,b1 = weightsleastSquares(dataMat,labelMat,C,kTup,v1)\r\n ##6.预测结果\r\n print('------------------Predict Result------------------ -')\r\n predict_result = predict(alphas1,b1,dataMat)\r\n ##7.平均误差\r\n print('-------------------Average Error------------------ -')\r\n average_error = predict_average_error(predict_result,labelMat)\r\n \r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
japeto/SudokuLasVegas
|
https://github.com/japeto/SudokuLasVegas
|
46219930a110315a3c4f6d4ea4ec33008c3851e3
|
79e2d86309f4fb22d2bc30c147bea76a9bcf039e
|
9da0c32ffec8c95f697f25cfdc51be5078255473
|
refs/heads/master
| 2021-01-10T10:32:45.077635 | 2016-03-01T16:28:27 | 2016-03-01T16:28:27 | 52,891,480 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7952314019203186,
"alphanum_fraction": 0.814165472984314,
"avg_line_length": 45,
"blob_id": "9c979492a1f069b954cd07c106a9444ce06d6b62",
"content_id": "43c459db6f3c3e25bf00023c668401dd85becbe5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1452,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 31,
"path": "/README.md",
"repo_name": "japeto/SudokuLasVegas",
"src_encoding": "UTF-8",
"text": "# SudokuLasVegas\n> Algoritmos probabilistas\n\nSudoku es un juego rompecabezas numérico con una o\nvarias soluciones que son combinatoriales, según los números\niniciales en la matriz. El objetivo es llenar la matriz\ngeneralmente 9x9, con dígitos, donde cada columna, fila y\nsubmatriz 3x3 debe tener exactamente la numeración del 1 al 9,\nsin replicación, El planteamiento del proyecto es el de resolver\nun problema Sudoku dado una matriz con ceros y algunos\nvalores válidos preestablecidos en un archivo de texto plano,\ndonde estos ceros indican que esta es una posición que puede\ntomar un número válido según las restricciones del sudoku.\n\nLas restricciones para una malla sudoku de 9x9 son:\n\n0. Cada fila debe tener exactamente un número del [1 -9]\n1. Cada columna debe tener exactamente un número del [1 -9]\n2. Cada bloque o submatriz debe tener exactamente un número del [1 -9]\n\nLa codificación se realizó con el lenguaje de programación\nPython, que permite la comprensión de los algoritmos, dado\nlas características propias del lenguaje.\n\nEste proyecto no busca hallar la solución, más rápida, ni\npresenta una nueva metodología para resolver el rompecabezas\nsudoku, solo establece una estrategia de solución a este\nproblema, basado en un algoritmo probabilista, como Las\nVegas, hallando la solución mediante decisiones aleatorias.\n\nEste es el proyecto de curso 750098M SIMULACIÓN COMPUTACIONAL 2015-II, universidad del valle\n"
},
{
"alpha_fraction": 0.5780274868011475,
"alphanum_fraction": 0.6125676035881042,
"avg_line_length": 21.448598861694336,
"blob_id": "61d2932b205d18baabc6af64874192f9c9eff3c0",
"content_id": "c8523d83d09682279c4a97d0ffb6c28f735ceca8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2403,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 107,
"path": "/filehandle.py",
"repo_name": "japeto/SudokuLasVegas",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"Doc reader.py\n############################################################### \nThis module provides methods to asynchronously read a File\nto obtain the results of these reads.\n###############################################################\n\"\"\"\n\nimport sys\nimport copy\n\nclass filehandle():\n\t\"\"\"\n\tRead a file with sudoku representation\n\tby example\n\n\t0 2 0 6 0 0 0 0 0\n\t0 7 6 1 0 0 9 0 0\n\t0 0 0 7 0 0 2 0 0\n\t8 0 0 0 0 9 0 0 4\n\t2 1 0 0 8 3 0 0 0\n\t4 0 0 0 0 0 0 0 7\n\t0 0 0 0 0 0 0 6 5\n\t0 0 4 0 6 7 0 0 0\n\t0 0 0 0 0 0 0 3 0\n\n\tWhere 0 is permissible change\n\n\t:param debug: debug \n\t:param filename: file path to read\n\t:type debug: boolean\n\t:type filename: String\n\t\"\"\"\n\tdef __init__(self,debug=False,filename=None):\n\t\t\"\"\"\n\t\tClass constructor\n\t\t\"\"\"\n\t\tself.matrix=[]\t\t# matris de numeros. lista de listas\n\t\tself.filename = filename # ruta del archivo\n\t\tself.debug = debug\t# hay depuracion\n\n\tdef setfile_toread(self,filename=None):\n\t\t\"\"\"\n\t\t:param filename: file path to read\n\t\t:type filename: String\n\t\t\"\"\"\n\t\tself.filename = filename\n\n\tdef get_matrix(self):\n\t\t\"\"\"\n\t\tReturns matrix\n \t:returns: list with list inside\n :rtype: list\n\n\t\t\"\"\"\n\t\t# retorno una copia profunda\n\t\treturn copy.deepcopy(self.matrix) \n\n\tdef getfile_path(self):\n\t\t\"\"\"\n\t\tReturns file path\n \t:returns: path file\n :rtype: int\n\n\t\t\"\"\"\n\t\treturn self.filename\n\n\tdef read_file(self):\n\t\t\"\"\"\n\t\tRead filename and create a list with list inside\n\t\t\"\"\"\n\t\tif self.debug:\t\t# muestro mensaje si hay depuracion\n\t\t\tprint \"Leyendo el archivo \"+str(filename)\n\t\t# self.read_file()\t# leo el archivo\n\n\t\tself.file_txt = open(self.filename,'r') # abro como solo lectura\n\t\tline = self.file_txt.readline()\t# linea a linea\n\t\twhile line!=\"\":\t\t# mientras no halla algo que leer\n\t\t\tif self.debug:\t# si hay depuracion muetro la matris\n\t\t\t\tprint map(int, line.split(\" \"))\t\n\t\t\tself.matrix.append(map(int, line.split(\" \")) )\t#agrego esta lista a la lista\n\t\t\tline = self.file_txt.readline()\t# leo la linea \n\t\tself.file_txt.close()\t# cierro el archivo\n\n\t\tif self.debug:\t\t# muestro mensaje si hay depuracion\n\t\t\tprint \"Finalizada lectura ... \"\n\n\n\tdef save_sudoku(self,outputname=\"archivo.txt\",matrix =None):\n\t\t\"\"\"\n\t\tWrite\n\t\t\"\"\"\n\t\tfile_txt = open(outputname,'w')\n\t\tfor rows in matrix:\n\t\t\tfor value in rows:\n\t\t\t\tfile_txt.write(str(value)+\" \")\n\t\t\t\n\t\t\tfile_txt.write(\"\\n\")\n\t\t\n\t\tfile_txt.close()\n\n\n\n# by\n# Jefferson (JAPeTo)\n# Jorge solis\n# Eduardo saavedra\n\n"
},
{
"alpha_fraction": 0.6409099102020264,
"alphanum_fraction": 0.6609496474266052,
"avg_line_length": 27.116750717163086,
"blob_id": "6fd43eebf5e471e39e166c5806b73fb15b0cc394",
"content_id": "03c4f3e036e94b2b7bd36b0b5c20aac9e25e2053",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5539,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 197,
"path": "/sudoku.py",
"repo_name": "japeto/SudokuLasVegas",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"Doc sudoku.py\n############################################################### \nThis module provides methods to asynchronously read a File\nto obtain the results of these reads.\n###############################################################\n\"\"\"\nimport sys\nimport random\nimport copy \n\nfrom filehandle import * #reader module\n\nclass sudoku():\n\t\"\"\"\n\tSolve a sudoku representation\n\tby example\n\t0 2 0 6 0 0 0 0 0\n\t0 7 6 1 0 0 9 0 0\n\t0 0 0 7 0 0 2 0 0\n\t8 0 0 0 0 9 0 0 4\n\t2 1 0 0 8 3 0 0 0\n\t4 0 0 0 0 0 0 0 7\n\t0 0 0 0 0 0 0 6 5\n\t0 0 4 0 6 7 0 0 0\n\t0 0 0 0 0 0 0 3 0\n\n\t:param debug: debug \n\t:param filename: file path to read\n\t:param outputname: file path to save\n\t:type debug: boolean\n\t:type filename: String\n\t:type outputname: String\n\t\"\"\"\n\tdef __init__(self,debug=False,filename=None,outputname=None):\n\t\t\"\"\"\n\t\t\"\"\"\n\t\tself.debug = debug\n\t\t# self.filename = filename\n\t\t# self.outputname = outputname\n\t\tself.matrix = []\n\t\tself.queens = []\n\n\tdef start(self,matrix):\n\t\t\"\"\"\n\t\t\"\"\"\n\n\t\taccum = [0]*10\n\t\tself.readfile = copy.deepcopy(matrix)\n\t\tself.matrix = copy.deepcopy(matrix)\n\n\t\t# create queen vector\n\t\tfor rows in self.matrix:\n\t\t\tfor value in rows:\n\t\t\t\taccum[value] +=1\n\n\t\taccum.pop(0)\n\t\tfor element in range(0,len(accum)):\n\t\t\tnumber = accum.index(max(accum))\n\t\t\tself.queens.append(number+1)\n\t\t\taccum[number] = -1\n\n\t\tif self.debug:\n\t\t\tprint \"Aplicando algoritmo ... \"\n\t\t\n\t\t# print \" self.matrix \",self.matrix\n\t\treturn self.solve(self.matrix)\n\n\t\t# if self.debug:\n\t\t\t# print \"Guardando respuesta en: \"+str(outputname)\n\t\t# self.save_sudoku()\n\n\tdef valid_position(self,matrix=None, row_index=None, col_index=None,value=None):\n\t\t\"\"\"\n\t\tVerify whether given number in row_index, col_index position of matrix\n\t\tits is feasible \n\n\t\t:param matrix: sudoku matrix representation \n\t\t:type matrix: list\n\t\t:param row_index: row index in matrix representation \n\t\t:type row_index: int\n\t\t:param col_index: column index in matrix representation \n\t\t:type col_index: int\n\t\t:param value: value to save in its location\n\t\t:type value: int\n\t\t\"\"\"\n\t\t# dado un valor verifico que no este en la fila\n\t\t# con all, verifico si todos los elementos son true\n\t\t# recorro todos la fila\n\t\trow_valid = all([value != self.matrix[row_index][valid] for valid in range(9)])\n\t\tif row_valid:\n\t\t\t# si es valido en fila\n\t\t\t# dado un valor verifico que no este en la columna\n\t\t\t# con all, verifico si todos los elementos son true\n\t\t\t# recorro todos la fila\n\t\t\tcol_valid = all([value != self.matrix[valid][col_index] for valid in range(9)])\n\t\t\tif col_valid:\n\t\t\t\t# Si es valido en mascara (submatris)\n\t\t\t\trow_mask, col_mask = 3 *(row_index/3), 3 *(col_index/3)\n\t\t\t\tfor posX in range(row_mask, row_mask+3):\n\t\t\t\t\tfor posY in range(col_mask, col_mask+3):\n\t\t\t\t\t\tif self.matrix[posX][posY] == value:\n\t\t\t\t\t\t\treturn False\n\t\t\t\treturn True\n\t\treturn False\n\n\tdef sudoku_candidates(self,matrix=None,row_index=None,queen=None):\n\t\t\"\"\"\n\t\tReturns a random position where set queen in matrix\n\n\t\t:param matrix: sudoku matrix representation \n\t\t:type matrix: list\n\t\t:param row_index: row index in matrix representation \n\t\t:type row_index: int\n\t\t:param queen: queen to evaluate position\n\t\t:type queen: int\n\t\t:return: coordiantes array \n :rtype: array with coordiantes x and y \n\t\t\"\"\"\n\t\t#lista de posibilidades\n\t\tposibities = []\n\t\t# hago validacion en columna ya conozco la fila row_index\n\t\tfor col_index in range(0,len(matrix[row_index])):\n\t\t\t# si esta posicion es modificable\n\t\t\tif self.matrix[row_index][col_index] == 0:\n\t\t\t\t#si esta es valida\n\t\t\t\tif self.valid_position(matrix,row_index,col_index,queen):\n\t\t\t\t\t# agrego esta a la lista de posibilidades\n\t\t\t\t\tposibities.append([row_index,col_index])\n\n\t\t# si no hay posibilidades, pare este no es un camino\n\t\tif len(posibities) == 0:\n\t\t\treturn -1, -1\n\t\t# retorne este opcion factible aleatoria\n\t\tfeasible = random.randrange(0,len(posibities))\n\t\tif self.debug:\n\t\t\tprint \" queen \", queen ,\" in row \",row_index,\" posibities \", posibities , \" feasible \",posibities[feasible]\n\n\t\t#retorno\n\t\treturn posibities[feasible]\n\n\n\n\tdef sudoku_vegas(self,matrix=None):\n\t\t\"\"\"\n\t\tVerify whether if all queen are insert in matrix, else return wront path\n\n\t\t:param matrix: sudoku matrix representation \n\t\t:type matrix: list\n\t\t:return: success or wront path\n :rtype: boolean\n\t\t\"\"\"\n\t\t# arranco sin exito\n\t\tflag_inserted=False\n\t\t# por cada reina en el arreglo\n\t\tfor queen in range(0, len(self.queens)):\n\t\t\t# recorro todas las filas\n\t\t\tfor row_index in range(0,9):\n\t\t\t\t# is existe reina en esta fila\n\t\t\t\tif not self.queens[queen] in self.matrix[row_index]:\n\t\t\t\t\t# escojo un camino valido\n\t\t\t\t\tcoors = self.sudoku_candidates(self.matrix,row_index,self.queens[queen])\n\t\t\t\t\t# si no hay camino falle\n\t\t\t\t\tif coors[0] == -1:\n\t\t\t\t\t\t# empiezo con la matriz nuevamente\n\t\t\t\t\t\tself.matrix = copy.deepcopy(self.readfile)\n\t\t\t\t\t\t# reporto que he fallado\n\t\t\t\t\t\treturn flag_inserted\n\t\t\t\t\t# Si todo va bien, encontre camino, guardo en la matrix\n\t\t\t\t\tself.matrix[ coors[0] ][ coors[1] ]= self.queens[queen]\n\n\t\t# todas reinas han sido insertadas\n\t\tflag_inserted=True\n\t\t# todas las reinas han sido insertadas\n\t\treturn flag_inserted\n\n\n\tdef solve(self,matrix=None):\n\t\t\"\"\"\n\t\t:param matrix: sudoku matrix representation \n\t\t:type matrix: list\n\t\t\"\"\"\n\t\t# estado del algoritmo\n\t\tstate = self.sudoku_vegas(matrix)\n\t\twhile not state:\n\t\t\tif self.debug:\n\t\t\t\tprint \" Fail! \"\n\t\t\t# vuelva a intentar\n\t\t\tstate = self.sudoku_vegas(matrix)\n\t\t\t\n\t\tif self.debug:\n\t\t\tprint \" Success! \"\n\n\t\tprint \" self.matrix \",self.matrix\n\t\treturn self.matrix\n\t\t# for rows in self.matrix:\n\t\t# \tprint str(rows)\n"
},
{
"alpha_fraction": 0.5830774903297424,
"alphanum_fraction": 0.6112816333770752,
"avg_line_length": 30.780487060546875,
"blob_id": "f3ff2b5cf44e712dadf9d79fba0ac0a3745baa3a",
"content_id": "b6b9ae586cf91e1617d8c456e31c0f97b6323a9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5212,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 164,
"path": "/sudokugui.py",
"repo_name": "japeto/SudokuLasVegas",
"src_encoding": "UTF-8",
"text": "#!/bin/python\n\nimport sys, os, random, pygame\nsys.path.append(os.path.join(\"objects\"))\nimport SudokuSquare\nimport SudokuGrid\nfrom GameResources import *\nfrom filehandle import * #reader module\nfrom sudoku import * #sudoku module\n\nif sys.version_info[0] == 2:\n # print (\"Python 2.x\")\n import Tkinter as tk\n from tkFileDialog import asksaveasfilename,askopenfilename\n\n \nif sys.version_info[0] == 3:\n # print (\"Python 3.x\") \n import tkinter as tk \n from tkinter.filedialog import asksaveasfilename,askopenfilename \n\n\n\ndef getSudoku(puzzleNumber=None):\n \"\"\"This function defines the solution and the inital view.\n Returns two lists of lists, inital first then solution.\"\"\"\n inital = SudokuGrid.SudokuGrid()\n current = SudokuGrid.SudokuGrid()\n solution = SudokuGrid.SudokuGrid()\n \n inital.createGrid(27, puzzleNumber)\n current.createGrid(27, puzzleNumber)\n solution.createGrid(81, puzzleNumber)\n\n return inital, current, solution\n\ndef set_matrix(matriz):\n\n\ttheSquares = []\n\tinitXLoc = 10\n\tinitYLoc = 80\n\tstartX, startY, editable, number = 0, 0, \"N\", 0\n\n\t# print matriz\n\n\tfor x in range(len(matriz)):\n\t for y in range(len(matriz[0])):\n\t if x in (0, 1, 2): startX = (x * 41) + (initXLoc + 2)\n\t if x in (3, 4, 5): startX = (x * 41) + (initXLoc + 6)\n\t if x in (6, 7, 8): startX = (x * 41) + (initXLoc + 10)\n\t if y in (0, 1, 2): startY = (y * 41) + (initYLoc + 2)\n\t if y in (3, 4, 5): startY = (y * 41) + (initYLoc + 6)\n\t if y in (6, 7, 8): startY = (y * 41) + (initYLoc + 10)\n\t number = matriz[y][x]\t\n\t if number != None:\n\t editable = \"N\"\n\t # print \"startX \", startX , \"startY \", startY , \"number \", number \n\t theSquares.append(SudokuSquare.SudokuSquare(number, startX, startY, editable, x, y))\n\n\n\tcurrentHighlight = theSquares[0]\n\tcurrentHighlight.highlight()\n\n\treturn theSquares\n\n\ndef main():\n\t# root = tk.Tk(); root.withdraw()\n\t# fileName = askopenfilename(parent=root,title=\"Sudoku solver\",filetypes=[(\"wav files\",\"*.txt\")])\n\t# print os.getcwd()+\"/entradas/taller3.txt\"\n\t# if fileName != \"\":\n\tmat_read = filehandle(False,os.getcwd()+\"/entradas/taller3.txt\")\n\tmat_read.read_file()\n\tmatriz = mat_read.get_matrix()\n\t\n\tpygame.init()\n\tsize = width, height = 400, 500\n\tscreen = pygame.display.set_mode(size)\n\n\tbackground = pygame.Surface(screen.get_size())\n\tbackground = background.convert()\n\tbackground.fill((250, 250, 250))\n\n\tboard, boardRect = load_image(\"board.png\")\n\tboardRect = boardRect.move(10, 80)\n\tlogo, logoRect = load_image(\"about.png\")\n\tlogoRect = logoRect.move(10, 10)\n\n\n\tpuzzleNumber = int(random.random() * 20000) + 1\n\tpygame.display.set_caption(\"Simulacion Computacional 2015-II\")\n\tinital, current, solution = getSudoku(puzzleNumber)\n\n\n\n\ttheSquares = []\n\tinitXLoc = 10\n\tinitYLoc = 80\n\tstartX, startY, editable, number = 0, 0, \"N\", 0\n\n\tfor x in range(len(matriz)):\n\t for y in range(len(matriz[0])):\n\t if x in (0, 1, 2): startX = (x * 41) + (initXLoc + 2)\n\t if x in (3, 4, 5): startX = (x * 41) + (initXLoc + 6)\n\t if x in (6, 7, 8): startX = (x * 41) + (initXLoc + 10)\n\t if y in (0, 1, 2): startY = (y * 41) + (initYLoc + 2)\n\t if y in (3, 4, 5): startY = (y * 41) + (initYLoc + 6)\n\t if y in (6, 7, 8): startY = (y * 41) + (initYLoc + 10)\n\t number = matriz[y][x]\t\n\t if number != None:\n\t editable = \"N\"\n\t # print \"startX \", startX , \"startY \", startY , \"number \", number \n\t theSquares.append(SudokuSquare.SudokuSquare(number, startX, startY, editable, x, y))\n\n\n\tcurrentHighlight = theSquares[0]\n\tcurrentHighlight.highlight()\n\n\tscreen.blit(background, (0, 0))\n\tscreen.blit(board, boardRect)\n\tscreen.blit(logo, logoRect)\n\tpygame.display.flip()\n\n\twhile 1:\n\t for event in pygame.event.get():\n\t if event.type == pygame.QUIT:\n\t return 0\n\t if event.type == pygame.KEYDOWN and event.key == pygame.K_SPACE:\n\t \troot = tk.Tk(); root.withdraw()\n\t \tfileName = askopenfilename(parent=root,title=\"Sudoku solver\",filetypes=[(\"wav files\",\"*.txt\")])\n\t \tif fileName != \"\":\n\t \t\tmat_read = filehandle(False,fileName)\n\t \t\tmat_read.read_file()\n\t \t\tmatriz = mat_read.get_matrix()\n\t \t\ttheSquares = set_matrix(mat_read.get_matrix())\n\n\t if event.type == pygame.KEYDOWN and event.key == pygame.K_F5:\n\t \tsdk = sudoku(True)\n\t \tmatriz = sdk.start(matriz)\n\t \ttheSquares = set_matrix(matriz)\n\t \tfor num in theSquares:\n\t \t\tnum.draw()\n\n\t if event.type == pygame.KEYDOWN and event.key == pygame.K_F9:\n\t \troot = tk.Tk(); root.withdraw()\n\t \tfileName = asksaveasfilename(parent=root,defaultextension=\".txt\")\n\t \tif fileName: \n\t \t\tmat_save = filehandle()\n \t\t\t\tmat_save.save_sudoku(fileName,matriz)\n\n\t\t\tif event.type == pygame.MOUSEBUTTONDOWN:\n\t\t\t\tmousepos = pygame.mouse.get_pos()\n\t\t\t\tfor x in theSquares:\n\t\t\t\t\tif x.checkCollide(mousepos):\n\t\t\t\t\t\tcurrentHighlight.unhighlight()\n\t\t\t\t\t\tcurrentHighlight = x\n\t\t\t\t\t\tcurrentHighlight.highlight()\n\n\t for num in theSquares:\n\t num.draw()\n\t pygame.display.flip()\n\nif __name__ == \"__main__\":\n\tmain()\n"
}
] | 4 |
AtharvaParanjpe/GenderBias
|
https://github.com/AtharvaParanjpe/GenderBias
|
4ad062a4ca2ec83fb8f31263c967da910cf6f29e
|
d52ecf1d673e1a9cf4e07dced6aacbd79269dd74
|
1784e479afd9eeeac816d60675120bede12d270d
|
refs/heads/master
| 2023-07-13T11:46:08.886504 | 2021-08-23T00:25:02 | 2021-08-23T00:25:02 | 322,932,254 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7858861088752747,
"alphanum_fraction": 0.7910986542701721,
"avg_line_length": 58.30952453613281,
"blob_id": "1ce23679a049f7a6c302d1faa9f0b0720e963df9",
"content_id": "63b187e5bbb90d2bedf74933d07d92896b91afe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2494,
"license_type": "no_license",
"max_line_length": 415,
"num_lines": 42,
"path": "/README.md",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "# Suicidal Risk\n\nThe main idea behind the research is to analyse a bias if present by race, gender, or location in people with suicidal tendancies.\nFor this analyses we chose the publically available Synthetic Mass dataset.\n\n\n## 1. Synthea Dataset \n\nData hosted within SyntheticMass has been generated by SyntheaTM, an open-source patient population simulation made available by The MITRE Corporation.\n\nThe data is free from cost, privacy, and security restrictions. It can be used without restriction for a variety of secondary uses in academia, research, industry, and government.\n\n## 2. Data Preparation\n\nThe type of dataset that was used was of CSV format. 8 files contained records of patients and their visits for different reasons. These records were read file by file and filtered by the keywords : \"self harm\" and \"sui\" which were said to indicate the visit being for suicidal patients. These were then matched with the data of the patients in patients.csv using the patient ids and assigned a target value of '1'.\n\nSince the data was large, the entire data was split into 12 different files. As a result, a unique filter was applied. Finally, the data was appended at the end of the patients file.\n\nA similar approach was used to take non suicidal patients randomly and these were appended with a target '0' to account for the negative samples.\n\nAnother major step involved recording the previous visits of patients who were deemed suicidal so as to analyse what factors colud contribute to a persons suicidal tendancy.\n\n## 3. Preparing a model\n\nThe patients dataset was cleaned by removing unnecessary columns like the patient id and the remaining ones were label encoded. \nNow to judge bias, we first chose to evaluate our model on gender. Therefore, the entire data was split into male and female patients. To balance the number of records in each we used the smote library.\n\nWe then evaluated each group of dataset on three different models namely, Linear Regression, Logistic Regression and Support Vector Machines. For each group (male or female), the following scores were computed: \n- True Positive rate , tpr\n- False Positive rate, fpr\n- True Negative rate, tnr\n- False Negative rate, fnr\n- Accuracy\n- Area under curve, auc\n\n## 4. Results\n\nThe \"Final_File_before_label_encoding.xlsx\" represents the resulting data with feature removal.\n\nThe \"Final_File_min13.xlsx\" represents the final data being sent to the model.\n\nThe results can be found in \"Result_with_min_13.xlsx\". \n\n"
},
{
"alpha_fraction": 0.5891693830490112,
"alphanum_fraction": 0.603284478187561,
"avg_line_length": 30.891775131225586,
"blob_id": "4c0e1216212a8a91315dc228f459132e6b57b1d7",
"content_id": "a579c70631443f5fa7efe3e24fca1ac4aee3560f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7368,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 231,
"path": "/comparisonModel.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "## For Generating comparison graphs between datasets\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.utils import shuffle\nimport csv\nimport matplotlib.pyplot as plt \nimport seaborn as sns\n\nfrom sklearn.model_selection import train_test_split \nfrom sklearn.svm import SVC\nfrom sklearn import metrics\nfrom sklearn.metrics import classification_report, confusion_matrix\n\nflag_svm = False\nflag_decision_tree = False\nflag_linear = False\nflag_logistic = False\n\n## Generate a file with min age 10 to proceed\ndf = pd.read_excel('Final_File_min10.xlsx')\ndf2 = pd.read_excel('Final_File_min13.xlsx')\n# print(df.head())\n# input()\ndf = df.groupby(['GENDER'])\ndf2 = df2.groupby(['GENDER'])\n\ndef scatterPlot(x_data,y_data):\n plt.figure()\n for x, y in zip(x_data, y_data):\n color = \"green\" if y == 0 else \"red\"\n plt.scatter(x, y, color = color)\n plt.xlabel('Data points')\n plt.ylabel('Suicidality')\n plt.show()\n\ndef compute_metrics(TP, TN, FP, FN, auc):\n TPR = TP/(TP+FN)\n TNR = TN/(TN+FP) \n FPR = FP/(FP+TN)\n FNR = FN/(TP+FN)\n ACC = (TP+TN)/(TP+FP+FN+TN)\n return [TPR, TNR, FPR, FNR, ACC, auc]\n\ndef compute_svm(data, data2):\n global flag_svm\n \n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n svclassifier = SVC(kernel='rbf')\n svclassifier.fit(X_train, y_train)\n y_pred = svclassifier.predict(X_test)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(flag_svm):\n # flag_svm = False\n plt.figure(0).clf()\n plt.title(\"Support Vector Classifier\")\n # metrics.plot_roc_curve(svclassifier, X_test, y_test) \n plt.plot(fpr,tpr,label=\"For min age 10, Auc=\"+str(round(auc, 4)))\n # plt.show()\n \n \n y = data2['target']\n x = data2\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n svclassifier = SVC(kernel='rbf')\n svclassifier.fit(X_train, y_train)\n y_pred = svclassifier.predict(X_test)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(flag_svm):\n flag_svm = False\n # metrics.plot_roc_curve(svclassifier, X_test, y_test) \n plt.plot(fpr,tpr,label=\"For min age 13, Auc=\"+str(round(auc,4)))\n plt.legend(loc=0)\n plt.show()\n \n return compute_metrics(tp, tn, fp, fn, auc)\n\n################ Linear Model ################\n\nfrom sklearn import linear_model, tree\n\ndef linearRegression(data):\n global flag_linear\n\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n reg = linear_model.LinearRegression()\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n reg.fit(X_train,y_train)\n y_pred = reg.predict(X_test)\n y_pred = np.array(y_pred)\n y_pred = np.where(y_pred<0,0,1)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n return compute_metrics(tp, tn, fp, fn, auc)\n\ndef logisticRegression(data, data2):\n global flag_logistic\n\n plt.figure(0).clf()\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n LR = linear_model.LogisticRegression(max_iter=1000)\n LR.fit(X_train, y_train)\n y_pred = LR.predict(X_test)\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n auc = metrics.auc(fpr, tpr)\n if(flag_logistic):\n # flag_logistic = False\n plt.title(\"Logistic Classifier\")\n plt.plot(fpr,tpr,label=\"For min age 10, Auc=\"+str(round(auc,4)))\n # plt.show()\n\n y = data2['target']\n x = data2\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n LR = linear_model.LogisticRegression(max_iter=1000)\n LR.fit(X_train, y_train)\n y_pred = LR.predict(X_test)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(flag_logistic):\n flag_logistic = False\n # metrics.plot_roc_curve(svclassifier, X_test, y_test) \n plt.plot(fpr,tpr,label=\"For min age 13, Auc=\"+str(round(auc,4)))\n plt.legend(loc=0)\n plt.show()\n\n return compute_metrics(tp, tn, fp, fn, auc)\n\ndef decision_tree(data, data2):\n global flag_decision_tree\n\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n clf = tree.DecisionTreeClassifier()\n clf = clf.fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n \n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(flag_decision_tree):\n plt.figure(0).clf()\n plt.title(\"Decision Tree Classifier\")\n # flag_decision_tree = False\n # metrics.plot_roc_curve(clf, X_test, y_test) \n plt.plot(fpr,tpr,label=\"For min age 10, Auc=\"+str(round(auc,4)))\n # plt.show()\n\n y = data2['target']\n x = data2\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n clf = tree.DecisionTreeClassifier()\n clf = clf.fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(flag_decision_tree):\n flag_decision_tree = False\n # metrics.plot_roc_curve(clf, X_test, y_test) \n plt.plot(fpr,tpr,label=\"For min age 13, Auc=\"+str(round(auc,4)))\n # plt.show()\n plt.legend(loc=0)\n plt.show()\n return compute_metrics(tp, tn, fp, fn, auc)\n \nfinal_list = []\n\nfor (key,group),(key1,group1) in zip(df, df2):\n group = group.drop([\"GENDER\"], axis=1)\n group1 = group1.drop([\"GENDER\"], axis=1)\n print(key1)\n\n a = []\n b = []\n c = []\n d = []\n\n flag_svm = True\n flag_decision_tree = True\n flag_linear = True\n flag_logistic = True\n\n group = shuffle(group)\n group1 = shuffle(group1)\n\n for i in range(100):\n a.append(linearRegression(group))\n b.append(logisticRegression(group, group1))\n c.append(compute_svm(group, group1))\n d.append(decision_tree(group, group1))\n # input()\n \n a = np.average(a, axis=0).tolist()\n b = np.average(b, axis=0).tolist()\n c = np.average(c, axis=0).tolist()\n d = np.average(d, axis=0).tolist()\n\n a = [\"Linear_\"+str(key)] + a\n b = [\"Logistic_\"+str(key)] + b\n c = [\"SVM_\"+str(key)] + c\n d = [\"Decision Tree_\"+str(key)] + d\n\n final_list = final_list+[a]+[b]+[c]+[d]\n \n\ncolumns = [\"Model\", \"TPR\", \"TNR\", \"FPR\", \"FNR\", \"Accuracy\", \"AUC\"]\ndf = pd.DataFrame(data= final_list, columns=columns)\n\n## Uncomment to generate final results\n# df.to_excel('Result_with_min_13.xlsx', index=False, header=True)\n\n"
},
{
"alpha_fraction": 0.652500569820404,
"alphanum_fraction": 0.6594527959823608,
"avg_line_length": 35.097164154052734,
"blob_id": "c6e8f7804ae5aac6f1fef0e680c31b9445fb452c",
"content_id": "524b8f282c3ae992340159c54b0d31181e7729c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8918,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 247,
"path": "/buildDataset.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport csv\nimport pandas as pd\n\ndef readFile(fileName):\n file = pd.read_csv(fileName)\n return file\n\ndef calcPrevOccurences(patientIds, dateOfAtttempt, file, date, columnName):\n prevVisits = []\n for x, y in zip(patientIds, dateOfAtttempt):\n prev = []\n attempt = y.split('-')\n if(len(attempt)==3):\n for w,z in zip(file.get_group(x)[columnName].values,file.get_group(x)[date].values):\n prevDate = z.split('-')\n if(len(prevDate)==3):\n prev.append([w,z])\n prevVisits.append( prev)\n return prevVisits\n\ndef filterBySuicideTendancy(file,columnName, date):\n print(columnName)\n currentFile = file.groupby(['PATIENT'])\n file[columnName] = file[columnName].str.lower()\n file.dropna(subset = [columnName])\n file = file[file[columnName].str.contains('sui', na=False ) ]\n \n patientIds = list(file[\"PATIENT\"].values)\n dateOfAtttempt = list(file[date].values)\n\n prevVisits = calcPrevOccurences(patientIds, dateOfAtttempt, currentFile, date, columnName)\n\n return patientIds, dateOfAtttempt, prevVisits\n\ndef pickRandomData(file,columnName,date):\n currentFile = file.groupby(['PATIENT'])\n file = file[~file[columnName].str.contains('sui', na=False )]\n patientIds = list(file[\"PATIENT\"].values)\n dateOfVisit = list(file[date].values)\n prevVisits = calcPrevOccurences(patientIds, dateOfVisit, currentFile, date, columnName)\n return patientIds, dateOfVisit, prevVisits\n\n\n\n## not needed\n\n## needed\n\nabcd = 1\n\ncsvFileName = 'csv'+str(abcd)\n\nallergiesFile = readFile('./CSV/' + csvFileName +'/allergies.csv')\nimmunizationsFile = readFile('./CSV/' + csvFileName +'/immunizations.csv')\nmedicationsFile = readFile('./CSV/' + csvFileName +'/medications.csv')\nobservationsFile = readFile('./CSV/' + csvFileName +'/observations.csv')\n\ncarePlansFile= readFile('./CSV/' + csvFileName +'/careplans.csv')\nconditionsFile = readFile('./CSV/' + csvFileName +'/conditions.csv')\nencountersFile = readFile('./CSV/' + csvFileName +'/encounters.csv')\nproceduresFile = readFile('./CSV/' + csvFileName +'/procedures.csv')\n\n\n\npatientsColumnNames = [\"ID\",\"BIRTHDATE\",\"DEATHDATE\",\"SSN\",\"DRIVERS\",\"PASSPORT\",\"PREFIX\",\"FIRST\",\"LAST\",\"SUFFIX\",\"MAIDEN\",\"MARITAL\",\"RACE\",\"ETHNICITY\",\"GENDER\",\"BIRTHPLACE\",\"ADDRESS\",'SUICIDE_AGE','SUICIDE_YEAR','PREV_ENCOUNTERS']\n\npatientIdListForSuicide = []\ndatesList = []\nprevOccurences = []\n\ndef appendToExistingData(file,columnName,date):\n global patientIdListForSuicide\n global datesList\n global prevOccurences\n\n ids, dates, prevVisits = filterBySuicideTendancy(file, columnName,date)\n patientIdListForSuicide+= ids\n datesList += dates\n prevOccurences+=prevVisits\n\ndef generate_positive_samples():\n global prevOccurences\n\n appendToExistingData(carePlansFile, \"DESCRIPTION\",'START')\n appendToExistingData(carePlansFile, \"REASONDESCRIPTION\", 'START')\n print(\"Done with 1\")\n\n appendToExistingData(conditionsFile, \"DESCRIPTION\", 'START')\n print(\"Done with 2\")\n\n appendToExistingData(encountersFile, \"DESCRIPTION\", 'DATE')\n appendToExistingData(encountersFile, \"REASONDESCRIPTION\", 'DATE')\n print(\"Done with 3\")\n\n appendToExistingData(proceduresFile, \"DESCRIPTION\",'DATE')\n appendToExistingData(proceduresFile, \"REASONDESCRIPTION\",'DATE')\n print(\"Done with 4\")\n\n appendToExistingData(immunizationsFile, \"DESCRIPTION\",'DATE')\n print(\"Done with 5\")\n\n appendToExistingData(observationsFile, \"DESCRIPTION\",'DATE')\n print(\"Done with 6\")\n\n appendToExistingData(medicationsFile, \"DESCRIPTION\",'START')\n appendToExistingData(medicationsFile, \"REASONDESCRIPTION\",'START')\n print(\"Done with 7\")\n\n appendToExistingData(allergiesFile, \"DESCRIPTION\",'START')\n print(\"Done with 8\")\n\n a = np.unique(patientIdListForSuicide, return_index=True)\n\n finalPatientIds = np.take(patientIdListForSuicide, a[1])\n finalDateList = np.take(datesList, a[1])\n prevOccurences = np.take(prevOccurences,a[1])\n\n dictionary = {}\n prevOccurencesDictionary = {}\n for x,y,z in zip(finalDateList, finalPatientIds, prevOccurences):\n dictionary[y] = x\n prevOccurencesDictionary[y] = z\n\n patientRecords = []\n with open('./CSV/' + csvFileName +'/patients.csv') as csvfile:\n readCSV = csv.reader(csvfile, delimiter=',')\n count = 0\n for row in readCSV:\n if(row and len(row)==17 and row[0]!=\"\" and row[0] in finalPatientIds):\n birthYear = int(row[1].split('-')[0])##,int(row[1].split('-')[1]),int(row[1].split('-')[2])\n suicideYear = int(dictionary[row[0]].split('-')[0])\n row.append(str(suicideYear-birthYear))\n row.append(dictionary[row[0]].split('-'))\n \n prevOccurences = prevOccurencesDictionary[row[0]]\n newListOfOccurences = []\n for x in prevOccurences:\n reason, time = x\n # print(reason,time)\n # input()\n visitYear = int(time.split('-')[0])\n # visitYear, visitMonth, visitDay = int(time.split('-')[0]),int(time.split('-')[1]),int(time.split('-')[2])\n # if(visitYear<birthYear and visitMonth < birthMonth and visitDay < birthDate):\n # continue\n newListOfOccurences.append([reason, str(visitYear-birthYear)])\n row.append(newListOfOccurences)\n patientRecords.append(row)\n\n print(len(patientRecords))\n\n patientRecordsDf = pd.DataFrame(data=patientRecords, columns=patientsColumnNames)\n print(patientRecordsDf.head(100))\n\n patientRecordsDf.to_csv(\"./Modified Outputs/Modified Output \"+str(abcd))\n\npatientIdListForOthers = []\ndatesListForOthers = []\nprevOccurences = []\n\n# generate_positive_samples()\n\ndef appendNegativeSamples(file, columnName, date):\n global patientIdListForOthers\n global datesListForOthers\n global prevOccurences\n\n ids, dates, prevVisits = pickRandomData(file, columnName,date)\n patientIdListForOthers+= ids\n datesListForOthers += dates\n prevOccurences+=prevVisits\n\n\ndef generate_negative_samples():\n global prevOccurences\n\n appendNegativeSamples(carePlansFile, \"DESCRIPTION\",'START')\n appendNegativeSamples(carePlansFile, \"REASONDESCRIPTION\", 'START')\n print(\"Done with 1\")\n \n appendNegativeSamples(conditionsFile, \"DESCRIPTION\", 'START')\n print(\"Done with 2\")\n\n appendNegativeSamples(encountersFile, \"DESCRIPTION\", 'DATE')\n appendNegativeSamples(encountersFile, \"REASONDESCRIPTION\", 'DATE')\n print(\"Done with 3\")\n\n\n appendNegativeSamples(proceduresFile, \"DESCRIPTION\",'DATE')\n appendNegativeSamples(proceduresFile, \"REASONDESCRIPTION\",'DATE')\n print(\"Done with 4\")\n\n appendNegativeSamples(immunizationsFile, \"DESCRIPTION\",'DATE')\n print(\"Done with 5\")\n\n appendNegativeSamples(observationsFile, \"DESCRIPTION\",'DATE')\n print(\"Done with 6\")\n\n appendNegativeSamples(medicationsFile, \"DESCRIPTION\",'START')\n appendNegativeSamples(medicationsFile, \"REASONDESCRIPTION\",'START')\n print(\"Done with 7\")\n\n appendToExistingData(allergiesFile, \"DESCRIPTION\",'START')\n print(\"Done with 8\")\n\n a = np.unique(patientIdListForOthers, return_index=True)\n\n finalPatientIds = np.take(patientIdListForOthers, a[1])\n finalDateList = np.take(datesListForOthers, a[1])\n prevOccurences = np.take(prevOccurences,a[1])\n\n dictionary = {}\n\n prevOccurencesDictionary = {}\n for x,y,z in zip(finalDateList, finalPatientIds, prevOccurences):\n dictionary[y] = x\n prevOccurencesDictionary[y] = z\n\n patientRecords = []\n with open('./CSV/' + csvFileName +'/patients.csv') as csvfile:\n readCSV = csv.reader(csvfile, delimiter=',')\n count = 0\n for row in readCSV:\n if(row and len(row)==17 and row[0]!=\"\" and row[0] in finalPatientIds):\n birthYear = int(row[1].split('-')[0])\n suicideYear = int(dictionary[row[0]].split('-')[0])\n row.append(str(suicideYear-birthYear))\n row.append(dictionary[row[0]].split('-'))\n \n prevOccurences = prevOccurencesDictionary[row[0]]\n newListOfOccurences = []\n for x in prevOccurences:\n reason, time = x\n visitYear = int(time.split('-')[0])\n \n newListOfOccurences.append([reason, str(visitYear-birthYear)])\n row.append(newListOfOccurences)\n patientRecords.append(row)\n \n print(len(patientRecords))\n\n patientRecordsDf = pd.DataFrame(data=patientRecords, columns=patientsColumnNames)\n print(patientRecordsDf.head(100))\n\n patientRecordsDf.to_csv(\"./Negative Samples/neg \"+str(abcd))\n\ngenerate_negative_samples() "
},
{
"alpha_fraction": 0.5749962329864502,
"alphanum_fraction": 0.5920993089675903,
"avg_line_length": 31.69801902770996,
"blob_id": "9ee6d6b6b8fe730a41ad87c682f7bfd3b73e4773",
"content_id": "e208d713b9f878664a06b9e3bec987740fccd0df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6607,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 202,
"path": "/model.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom sklearn.utils import shuffle\nimport csv\nimport matplotlib.pyplot as plt \nimport seaborn as sns\n\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.svm import SVC\nfrom sklearn import metrics\nfrom sklearn.metrics import classification_report, confusion_matrix\n\nflag_svm = False\nflag_decision_tree = False\nflag_linear = False\nflag_logistic = False\n\n\ndf = pd.read_excel('Final_File_min13.xlsx')\ndf = df.groupby(['GENDER'])\n\ndef scatterPlot(x_data,y_data):\n plt.figure()\n for x, y in zip(x_data, y_data):\n color = \"green\" if y == 0 else \"red\"\n plt.scatter(x, y, color = color)\n plt.xlabel('Data points')\n plt.ylabel('Suicidality')\n plt.show()\n\ndef compute_metrics(TP, TN, FP, FN, auc, fpr, tpr):\n TPR = TP/(TP+FN)\n TNR = TN/(TN+FP) \n FPR = FP/(FP+TN)\n FNR = FN/(TP+FN)\n ACC = (TP+TN)/(TP+FP+FN+TN)\n return [TPR, TNR, FPR, FNR, ACC, auc], fpr, tpr\n\ndef compute_svm(data):\n global flag_svm\n \n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n svclassifier = SVC(kernel='rbf')\n svclassifier.fit(X_train, y_train)\n y_pred = svclassifier.predict(X_test)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(len(fpr)==2):\n fpr = [fpr[0], 0.5, fpr[1]]\n tpr = [tpr[0], 0.5, tpr[1]]\n return compute_metrics(tp, tn, fp, fn, auc, fpr, tpr)\n\n################ Linear Model ################\n\nfrom sklearn import linear_model, tree\n\ndef linearRegression(data):\n global flag_linear\n\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n reg = linear_model.LinearRegression()\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n reg.fit(X_train,y_train)\n y_pred = reg.predict(X_test)\n y_pred = np.array(y_pred)\n y_pred = np.where(y_pred<0,0,1)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(len(fpr)==2):\n fpr = [fpr[0], 0.5, fpr[1]]\n tpr = [tpr[0], 0.5, tpr[1]]\n return compute_metrics(tp, tn, fp, fn, auc, fpr, tpr)\n\ndef logisticRegression(data):\n global flag_logistic\n\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n LR = linear_model.LogisticRegression(max_iter=1000)\n LR.fit(X_train, y_train)\n y_pred = LR.predict(X_test)\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n auc = metrics.auc(fpr, tpr)\n if(len(fpr)==2):\n fpr = [fpr[0], 0.5, fpr[1]]\n tpr = [tpr[0], 0.5, tpr[1]]\n return compute_metrics(tp, tn, fp, fn, auc, fpr, tpr)\n\ndef decision_tree(data):\n global flag_decision_tree\n\n y = data['target']\n x = data\n x = x.drop('target', axis = 1)\n X_train, X_test, y_train, y_test = train_test_split(x, y, test_size = 0.15)\n clf = tree.DecisionTreeClassifier()\n clf = clf.fit(X_train, y_train)\n y_pred = clf.predict(X_test)\n \n tn, fp, fn, tp = confusion_matrix(y_test, y_pred).ravel()\n fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred)\n auc = metrics.auc(fpr, tpr)\n if(len(fpr)==2):\n fpr = [fpr[0], 0.5, fpr[1]]\n tpr = [tpr[0], 0.5, tpr[1]]\n return compute_metrics(tp, tn, fp, fn, auc, fpr, tpr)\n \nfinal_list = []\n\ndef showGraph(fpr, tpr, auc, classifier):\n plt.figure()\n plt.plot(fpr, tpr,label= classifier + \", Auc=\"+str(round(auc,4)))\n plt.legend(loc=0)\n plt.show()\n\nfor (key,group) in df:\n group = group.drop([\"GENDER\"], axis=1)\n distribution_list = []\n a, b, c, d = [], [], [], []\n\n flag_svm = True\n flag_decision_tree = True\n flag_linear = True\n flag_logistic = True\n\n group = shuffle(group)\n\n for i in range(1000):\n final_list = []\n\n linear = linearRegression(group)\n logistic = logisticRegression(group)\n svc = compute_svm(group)\n dt = decision_tree(group)\n\n a.append([linear[0]])\n b.append([logistic[0]])\n c.append([svc[0]])\n d.append([dt[0]])\n\n distribution_list.append([linear[0][-2], logistic[0][-2], svc[0][-2], dt[0][-2]])\n # print([linear[0][-2], logistic[0][-2], svc[0][-2], dt[0][-2]]) \n # input()\n\n a_mean = np.average(a, axis=0).tolist()\n b_mean = np.average(b, axis=0).tolist()\n c_mean = np.average(c, axis=0).tolist()\n d_mean = np.average(d, axis=0).tolist()\n \n a_min = np.min(a, axis=0).tolist()\n b_min = np.min(b, axis=0).tolist()\n c_min = np.min(c, axis=0).tolist()\n d_min = np.min(d, axis=0).tolist()\n\n a_max = np.max(a, axis=0).tolist()\n b_max = np.max(b, axis=0).tolist()\n c_max = np.max(c, axis=0).tolist()\n d_max = np.max(d, axis=0).tolist()\n\n a_mean = [\"Linear\"] + a_mean[0]\n b_mean = [\"Logistic\"] + b_mean[0]\n c_mean = [\"SVM\"] + c_mean[0]\n d_mean = [\"Decision Tree\"] + d_mean[0]\n\n a_min = [\"Linear\"] + a_min[0]\n b_min = [\"Logistic\"] + b_min[0]\n c_min = [\"SVM\"] + c_min[0]\n d_min = [\"Decision Tree\"] + d_min[0]\n\n a_max = [\"Linear\"] + a_max[0]\n b_max = [\"Logistic\"] + b_max[0]\n c_max = [\"SVM\"] + c_max[0]\n d_max = [\"Decision Tree\"] + d_max[0]\n\n column_names_for_distribution = [\"Linear\", \"Logistic\", \"SVM\", \"Decision Tree\"]\n columns = [\"Model\", \"TPR\", \"TNR\", \"FPR\", \"FNR\", \"Accuracy\", \"AUC\"]\n \n distribution = pd.DataFrame(data= distribution_list, columns=column_names_for_distribution)\n distribution.to_excel('./Temporary Distribution/Data_Points_For_Accuracy_' + str(key) + '.xlsx', index=False, header=True)\n\n final_list = [a_mean, b_mean, c_mean, d_mean]\n \n mean_distribution = pd.DataFrame(data= final_list, columns=columns)\n mean_distribution.to_excel('./Temporary Distribution/Mean Distibution - ' + str(key) + '.xlsx', index=False, header=True)\n\n final_list = [a_min, b_min, c_min, d_min]\n min_distribution = pd.DataFrame(data= final_list, columns=columns)\n min_distribution.to_excel('./Temporary Distribution/Min Distibution - ' + str(key) + '.xlsx', index=False, header=True)\n\n final_list = [a_max, b_max, c_max, d_max]\n max_distribution = pd.DataFrame(data= final_list, columns=columns)\n max_distribution.to_excel('./Temporary Distribution/Max Distibution - ' + str(key) + '.xlsx', index=False, header=True)\n\n "
},
{
"alpha_fraction": 0.6315120458602905,
"alphanum_fraction": 0.6607369780540466,
"avg_line_length": 27.035715103149414,
"blob_id": "29cd9ca898ce4c005f51c37deed3fd274b3f4907",
"content_id": "c11e477d36ada0d1b37e951582228ac61591f49f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 28,
"path": "/utils.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom sklearn.utils import shuffle\n\nimport csv\n\n\ndef reader(filename):\n df = pd.read_csv(filename)\n df = df[df['SUICIDE_AGE'] < 30] ## replace 30 for upper limit\n ## Uncomment below for applying lower limit\n df = df[df['SUICIDE_AGE'] > 12]\n df = shuffle(df)\n return df\n\n## Do for both positive and negative samples to get the resulting files\ndf = reader('./Filtered Negatives/neg 1')\nfor i in range(2,13):\n df2 = reader('./Filtered Negatives/neg '+str(i))\n df = df.append(df2, ignore_index=False)\n print(\"Done \" + str(i))\n\ndf = df.drop('Unnamed: 0', axis =1)\ndf = df.sample(n=200)\nprint(df.shape)\n# final = pd.ExcelWriter('./For_25.xlsx')\n# input()\ndf.to_excel('./neg/Neg_For_30_min13.xlsx', index=False, header=True)\n \n"
},
{
"alpha_fraction": 0.619515597820282,
"alphanum_fraction": 0.6272376179695129,
"avg_line_length": 28.978946685791016,
"blob_id": "44b43ff2f8fc67fb89fb1e0a3c6a2a4c07c9fb9a",
"content_id": "802cbb0f8b32e88483f8c9cda9e7737b7889f7c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2849,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 95,
"path": "/dataBalancer.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom sklearn.utils import shuffle\nimport csv\nimport matplotlib.pyplot as plt \nimport seaborn as sns\n\ndef cleanData(df):\n df = df.drop(['SSN', 'DRIVERS', 'PREFIX', 'FIRST', 'LAST', 'SUFFIX', 'MAIDEN', 'ADDRESS'], axis=1)\n patientDictionary = {}\n for key,value in enumerate(df['ID'].values):\n patientDictionary[value] = key\n \n #ID\n df['ID'] = df['ID'].replace(patientDictionary)\n\n # DOB\n df[['BIRTH_YEAR', 'BIRTH_MONTH', 'BIRTH_DAY']] = df['BIRTHDATE'].str.split('-', 2, expand=True)\n df = df.drop(['BIRTH_DAY'], axis = 1)\n df = df.drop(['BIRTHDATE'], axis = 1)\n\n # Yes no encoding\n values = []\n for x in df['PASSPORT'].values:\n if(x!=\"false\"):\n values.append(\"Y\")\n else:\n values.append(\"N\")\n df['PASSPORT'] = values\n \n # marital status\n df['MARITAL'] = df['MARITAL'].fillna('NA')\n\n # death date\n df['DEATHDATE'] = df['DEATHDATE'].fillna('None-None-None')\n df[['DEATH_YEAR', 'DEATH_MONTH', 'DEATH_DAY']] = df['DEATHDATE'].str.split('-', 2, expand=True)\n df = df.drop(['DEATH_DAY'], axis =1)\n df = df.drop(['DEATHDATE'], axis =1)\n\n # extract city\n df['BIRTHPLACE'] = df['BIRTHPLACE'].str.split(' ', 0, expand=True)\n \n return df \n\n\ndef getData():\n df_positive = pd.read_excel('./pos/For_30.xlsx')\n df_positive[\"Age\"] = df_positive[\"SUICIDE_AGE\"] \n df_positive = df_positive.drop([\"SUICIDE_AGE\"],axis = 1)\n\n df_negative = pd.read_excel('./neg/Neg_For_30_min13.xlsx')\n df_negative[\"Age\"] = df_negative[\"SUICIDE_AGE\"] \n df_negative = df_negative.drop([\"SUICIDE_AGE\"],axis = 1)\n \n\n df_positive = df_positive.assign(target=1)\n df_negative = df_negative.assign(target=0)\n df = df_positive.append(df_negative, ignore_index=True)\n \n df = shuffle(df)\n df = cleanData(df)\n return df\n\ndf = getData()\ndf.to_excel('Final_File_before_label_encoding.xlsx', index=False, header=True)\n\n## Label Encoding\nfrom sklearn.preprocessing import LabelEncoder\nle = LabelEncoder()\n\ndef preProcessData(df):\n # Categorical boolean mask\n categorical_feature_mask = df.dtypes==object\n # filter categorical columns using mask and turn it into a list\n categorical_cols = df.columns[categorical_feature_mask].tolist()\n df[categorical_cols] = df[categorical_cols].apply(lambda col: le.fit_transform(col))\n return df\n\ndf_labelEncoded = preProcessData(df)\n\n\n############################ SMOTE TO BALANCE THE DATA ###########################\n\nfrom imblearn.over_sampling import SMOTE\n\ndf_equalize_y = df_labelEncoded['GENDER']\ndf_equalize_x = df_labelEncoded.drop('GENDER', axis = 1)\n\nsm = SMOTE(random_state =2)\nx, y = sm.fit_sample(df_equalize_x, df_equalize_y.ravel())\n\nx['GENDER'] = y\ndf = shuffle(x)\n\ndf.to_excel('Final_File_min13.xlsx', index=False, header=True)\n\n"
},
{
"alpha_fraction": 0.5743589997291565,
"alphanum_fraction": 0.6139194369316101,
"avg_line_length": 31.511905670166016,
"blob_id": "43026f9a2cd2eebcf6865a9d7043699a81a057bf",
"content_id": "ff39405e62303fde7faaffe98f2da32206b96fcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2730,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 84,
"path": "/distribution.py",
"repo_name": "AtharvaParanjpe/GenderBias",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport math\nimport matplotlib.pyplot as plt\n\nm = pd.read_excel(\"./Temporary Distribution/Data_Points_For_Accuracy_1.xlsx\")\nf = pd.read_excel(\"./Temporary Distribution/Data_Points_For_Accuracy_0.xlsx\")\n\nminValsMale = m.min()\nminValsFemale = f.min()\nmaxValsMale = m.max()\nmaxValsFemale = f.max()\nmeanValsMale = m.mean()\nmeanValsFemale = f.mean()\n\n## Dataframe objects\ndf_male = pd.concat([minValsMale, maxValsMale, meanValsMale], axis=1)\ndf_female = pd.concat([minValsFemale, maxValsFemale, meanValsFemale], axis=1)\ndf_male.columns = ['Min_Male', 'Max_Male', 'Mean_Male']\ndf_female.columns = ['Min_Female', 'Max_Female', 'Mean_Female']\n\n## Plot distributions Male\nkwargs = dict(alpha=0.5)\nfig, axs = plt.subplots(2, 2)\nfig.suptitle(\"Male\")\nplt.xlim([0.0, 1.0])\naxs[0, 0].hist(m.values[:,0], **kwargs, color=\"g\", bins=15, label=\"Linear\")\naxs[0, 0].set_title('Linear')\naxs[0, 1].hist(m.values[:,1], **kwargs, color=\"r\", bins=15, label=\"Logistic\")\naxs[0, 1].set_title('Logistic')\naxs[1, 0].hist(m.values[:,2], **kwargs, color=\"b\", bins=15, label=\"SVM\")\naxs[1, 0].set_title('SVM')\naxs[1, 1].hist(m.values[:,3], **kwargs, color=\"grey\", bins=15, label=\"Decision Tree\")\naxs[1, 1].set_title('Decision Tree')\n\n# plt.subplots_adjust(left=0.1,\n# bottom=0.1, \n# right=0.9, \n# top=0.9, \n# wspace=0.4, \n# hspace=0.4)\nplt.subplot_tool()\nfor ax in axs.flat:\n ax.set(xlabel='Accuracy', ylabel='Frequency')\n ax.set_xlim(0.0, 1.0)\n\n# Hide x labels and tick labels for top plots and y ticks for right plots.\n# for ax in axs.flat:\n# ax.label_outer()\n\nplt.show()\n\n\n## Plot distributions female\nkwargs = dict(alpha=0.5)\nfig, axs = plt.subplots(2, 2)\nplt.xlim([0.0, 1.0])\nfig.suptitle(\"Female\")\naxs[0, 0].hist(f.values[:,0], **kwargs, color=\"g\", bins=15, label=\"Linear\")\naxs[0, 0].set_title('Linear')\naxs[0, 1].hist(f.values[:,1], **kwargs, color=\"r\", bins=15, label=\"Logistic\")\naxs[0, 1].set_title('Logistic')\naxs[1, 0].hist(f.values[:,2], **kwargs, color=\"b\", bins=15, label=\"SVM\")\naxs[1, 0].set_title('SVM')\naxs[1, 1].hist(f.values[:,3], **kwargs, color=\"grey\", bins=15, label=\"Decision Tree\")\naxs[1, 1].set_title('Decision Tree')\n\n\nfor ax in axs.flat:\n ax.set(xlabel='Accuracy', ylabel='Frequency')\n ax.set_xlim(0.0, 1.0)\n \n# Hide x labels and tick labels for top plots and y ticks for right plots.\n# for ax in axs.flat:\n# ax.label_outer()\n# plt.subplots_adjust(left=0.1,\n# bottom=0.1, \n# right=0.9, \n# top=0.9, \n# wspace=0.4, \n# hspace=0.4)\nplt.subplot_tool()\nplt.show()"
}
] | 7 |
Siketju/Algorithms-in-Python
|
https://github.com/Siketju/Algorithms-in-Python
|
107c5969d9d1f470167301d9e1cfbe8077274e4c
|
7e2a2e436209e75b74c7f0dafbedc625cc7efcd8
|
fdaed75bf36e032eb2f4b15f780ec05f95b53bd0
|
refs/heads/master
| 2020-04-23T01:51:54.480691 | 2019-02-15T08:19:55 | 2019-02-15T08:19:55 | 170,826,833 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7906976938247681,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 29.714284896850586,
"blob_id": "42a130da4b4f6f3507b923f714f387330e8d9e0b",
"content_id": "2a99f5240c365e32c770beecf0502948856c1946",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Siketju/Algorithms-in-Python",
"src_encoding": "UTF-8",
"text": "# Algorithms-in-Python\nExercises of Algorithms in Python (For Education)\n\nThis project is just my exercises for algorithms understanding and Python coding.\nHope I can finish it in 6 months.Good Luck!\n\n1.bubble_sort\n"
},
{
"alpha_fraction": 0.5476190447807312,
"alphanum_fraction": 0.5561224222183228,
"avg_line_length": 38.20000076293945,
"blob_id": "3092cb64301e1a7987513b66f1e98ed2a4d5941c",
"content_id": "d1ed0f06204aaab815b80d6fcf6ff7f82eda341f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 15,
"path": "/bubble_sort.py",
"repo_name": "Siketju/Algorithms-in-Python",
"src_encoding": "UTF-8",
"text": "def bubble_sort(collection):\n length=len(collection)\n for i in range(length-1):\n swapped=False\n for j in range(length-1-i):\n swapped=True\n if collection[j]>collection[j+1]:\n collection[j],collection[j+1]=collection[j+1],collection[j]\n if not swapped:\n break\n return collection\nif __name__=='__main__':\n user_input=input(\"Please input seperated by a comma:\").strip()\n unsorted=[int(item) for item in user_input.split(',')]\n print(*bubble_sort(unsorted),sep=',')\n"
}
] | 2 |
Jack-Hewson/sweepstake_generator
|
https://github.com/Jack-Hewson/sweepstake_generator
|
ba812c6448eda07ef1308ede4cdc036ba006913a
|
2dde4c40c3798c99b92d4b6a24f0d09c9726a9f1
|
5d13a11324d9cf312397277b5e34c9eaffd62a32
|
refs/heads/main
| 2023-05-23T09:39:20.294217 | 2021-06-09T19:00:37 | 2021-06-09T19:00:37 | 375,461,368 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8191489577293396,
"alphanum_fraction": 0.8191489577293396,
"avg_line_length": 46,
"blob_id": "7b201faa15d1670859dcab79a17a11821bc66ef2",
"content_id": "0ef15689b686f9bad5ca3f848792c9b68fdbd147",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Jack-Hewson/sweepstake_generator",
"src_encoding": "UTF-8",
"text": "# sweepstake_generator\nshuffles an array of teams and merges it with an array of participants\n"
},
{
"alpha_fraction": 0.5694736838340759,
"alphanum_fraction": 0.5705263018608093,
"avg_line_length": 12.875,
"blob_id": "4353ddb6b63d3b72c949d89e935dfce65d707d5a",
"content_id": "ca1e6bdb4624e37c7b4fe36cd7e6038e49ba7ca0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 950,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 64,
"path": "/Euro2020_sweepstake.py",
"repo_name": "Jack-Hewson/sweepstake_generator",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport os\r\n\r\ndir_path = os.path.dirname(os.path.realpath(__file__))\r\n\r\nteams = np.array([\r\n\"Belgium\",\r\n\"Italy\",\r\n\"Russia\",\r\n\"Poland\",\r\n\"Ukraine\",\r\n\"Spain\",\r\n\"France\",\r\n\"Turkey\",\r\n\"England\",\r\n\"Czech Republic\",\r\n\"Finland\",\r\n\"Sweden\",\r\n\"Croatia\",\r\n\"Austria\",\r\n\"Netherlands\",\r\n\"Germany\",\r\n\"Portugal\",\r\n\"Switzerland\",\r\n\"Denmark\",\r\n\"Wales\",\r\n\"North\",\r\n\"Hungary\",\r\n\"Slovakia\",\r\n\"Scotland\"])\r\n\r\nparticipants = np.array([\r\n\"Mindy Beaudoin\",\r\n\"Rida Hollin\",\r\n\"Nakisha Bahena\",\r\n\"Lera Mcnealy\",\r\n\"Iesha Sorber\",\r\n\"Molly Nesmith\",\r\n\"Rico Blackburn\",\r\n\"Lorenzo Skiles\",\r\n\"Yvone Musser\",\r\n\"Tatyana Vaillancourt\",\r\n\"Ludie Hotz\",\r\n\"Enniffer Mcginn\",\r\n\"Lasonya Emmert\",\r\n\"Nickole Egner\",\r\n\"Charisse Schwenk\",\r\n\"Joycelyn Lingo\",\r\n\"Victorina Knotts\",\r\n\"Casey Heatwole\",\r\n\"Willia Cantu\",\r\n\"Priscilla Benbow\",\r\n\"Jack Hewson\",\r\n\"Jonathon Gloveman\",\r\n\"Pete Peterson\",\r\n\"The Sidekick\"])\r\n\r\nshuffler = np.random.permutation(len(teams))\r\nteams_shuffled = teams[shuffler]\r\nsweepstake = np.stack((participants,teams_shuffled),axis=1)\r\n\r\nprint(sweepstake)\r\n\r\nnp.savetxt(dir_path + \"\\sweepstake.csv\", sweepstake, fmt='%s', delimiter = ',')"
}
] | 2 |
ivKop/skillbox-chat
|
https://github.com/ivKop/skillbox-chat
|
8b6123e9590c4f9cef0cc85abb9209d48879ec3c
|
4afa2f73cadd23349a6f563ed127d0fcf7ee75cb
|
8d0f8bd938420fbd0690d9ec4c9234666668464a
|
refs/heads/master
| 2020-08-07T12:20:50.734873 | 2019-10-07T19:40:40 | 2019-10-07T19:40:40 | 213,448,751 | 0 | 0 | null | 2019-10-07T17:45:40 | 2019-10-07T17:34:39 | 2019-10-07T15:23:29 | null |
[
{
"alpha_fraction": 0.5865546464920044,
"alphanum_fraction": 0.6336134672164917,
"avg_line_length": 13.512195587158203,
"blob_id": "d02ceb96767c2d72ca2a65b659ea8f261cdb7db9",
"content_id": "9810df035aca08d95000c5ea66e75ff05ac45a7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 41,
"path": "/basic/first/01-intro.py",
"repo_name": "ivKop/skillbox-chat",
"src_encoding": "UTF-8",
"text": "# Created by Artem Manchenkov\n# [email protected]\n#\n# Copyright © 2019\n#\n\n\n# Примеры базового синтаксиса и работа с типами данных\n# Числа, строки, списки, булево значение\n#\n# коментарий Ctrl + /\nsimple = 10\nresult = simple + 10\n\nprint(1 / 2)\nprint(1 // 2)\nprint(1 % 2)\n\nprint(type(simple))\n\ns1 = int(0.8)\ns2 = 10.0\nprint(type(s1))\nprint(type(s2))\nname = \"fJoan\"\nprint(name)\nprint(name + ' ' + name)\nprint(name * 3)\nprint(\"-\"*30)\nname = name.capitalize()\nprint(name)\nname = name.upper()\nprint(name)\n\n\nage = int(input(\"Введите ваш возраст: \"))\nprint(age)\nif age > 10:\n print(\"прівет\")\nelse:\n print(\"Пока\")\n"
}
] | 1 |
Dhruv-Karia/tech-detector
|
https://github.com/Dhruv-Karia/tech-detector
|
1a30d0f36aa093691f6a4aa0bf3949b436660099
|
33ef0ce6c4b28b40d776b60facaa0a0b7d80cf58
|
ae695d0f6c35fc03a3f37c3af16220a3eb856e4b
|
refs/heads/main
| 2023-07-12T11:32:34.400312 | 2021-07-22T22:37:23 | 2021-07-22T22:37:23 | 386,736,123 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4626334607601166,
"alphanum_fraction": 0.49563246965408325,
"avg_line_length": 43.81159591674805,
"blob_id": "fee0892d92d93f960ac7ef701205089b8fac09cf",
"content_id": "e621f0c11d0684b0f0ed53aa8fdd3b5abfe5dfd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 3091,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 69,
"path": "/app/templates/results.html",
"repo_name": "Dhruv-Karia/tech-detector",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html>\n\n<head>\n <link href=\"https://fonts.googleapis.com/css?family=Lexend+Deca&display=swap\" rel=\"stylesheet\" />\n <link rel=\"stylesheet\" href=\"{{ url_for('static', filename='Results.css') }}\" media=\"screen\">\n \n <title>Document</title>\n</head>\n\n<body>\n <div class=\"v87_2\"><span class=\"v87_3\">Results</span>\n <div class=\"v87_4\"></div>\n <div class=\"v87_7\">\n <div class=\"v87_8\"></div>\n <span class=\"v87_9\"><a href=\"{{ url_for('home') }}\">Home</a></span>\n <span class=\"v87_10\"><a href=\"{{ url_for('overview') }}\">Overview</a></span>\n <span class=\"v87_11\"><a href=\"{{ url_for('meet') }}\">Meet the Team</a></span>\n <span class=\"v87_12\"><a href=\"{{ url_for('timeline') }}\">Timeline</a></span>\n <div class=\"v87_13\"></div>\n <div class=\"v87_14\"></div>\n <div class=\"v87_15\"></div>\n </div>\n <div class=\"v87_17\">\n <div class=\"v87_18\"></div>\n <div class=\"v87_19\"></div>\n </div><div class=\"v57_5\">\n<!-- <div class=\"v57_6\"></div> -->\n <div class=\"v57_3\"></div>\n <span class=\"v17_124\">Group Intel AI CAMP</span>\n </div>\n <div class=\"v87_22\" style=\"background-image: url({{ url_for('files', filename=filename) }}); background-size: contain;\"></div>\n <div class=\"u-layout\" >\n <div class=\"u-layout-row\" style=\"\">\n <div class=\"weFound\" style=\"background-image: url({{ url_for('files', filename=filename) }}); background-size: contain;\" data-image-width=\"1280\" data-image-height=\"913\">\n <div class=\"u-container-layout u-container-layout-1\" src=\"\">\n </div>\n </div>\n <div class=\"finalResult u-align-left u-container-style u-layout-cell u-right-cell u-size-30 u-size-xs-60 u-layout-cell-2\">\n <div class=\"topblurb\">\n <h2 class=\"weFound\">We found <strong><span style='text-transform: capitalize;'>{{labels}}!</span></strong></h2>\n\n {% if labels == 'no emotion' %}\n <div>We missed? See why below.</div>\n {% else %}\n <div class=\"lead\"><em>with {{ confidences }} confidence.</em></div>\n {% endif %}\n <!-- button added for uploading a photo -->\n <div class=\"mbr-buttons--left\">\n <div class=\"mbr-section-btn\">\n <a class=\"u-btn u-button-style u-palette-4-dark-2 u-btn-1\" href='https://www.ai-camp.org'>\n Visit AI Camp and see how we did this\n </a>\n\n </div>\n </div>\n </div>\n </div>\n </div>\n </div>\n \n <div class=\"v87_23\"></div><span class=\"v87_24\">Given just three weeks, we only had time to train our model with\n 6377 labeled images. If we have more time, we can improve our model performance!</span>\n </div>\n \n \n</body>\n\n</html>"
},
{
"alpha_fraction": 0.8032258152961731,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 37.875,
"blob_id": "b79d1ccb07b98cb9e3b97bdf7186a1339f9f4827",
"content_id": "d17cbf24f335a20829ed550cac775a3c106dab4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 8,
"path": "/app/pyTest.py",
"repo_name": "Dhruv-Karia/tech-detector",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport numpy as np\nfrom werkzeug.utils import secure_filename\nfrom flask import Flask, flash, request, redirect, url_for, render_template\nfrom flask import send_from_directory\nfrom ai import get_yolo_net, yolo_forward, yolo_save_img\nfrom utils import get_base_url, allowed_file, and_syntax"
}
] | 2 |
denkorzh/tlg
|
https://github.com/denkorzh/tlg
|
5ec9a022feabb62ef2e0c89cf64b0a266afcbc13
|
c22f9947e4f15f0daaa7c68b2a806c6a52eaa910
|
a070cff01afe4362434ff6ea336b7322c0f0b9c9
|
refs/heads/master
| 2021-01-23T01:21:07.597958 | 2017-06-06T11:27:28 | 2017-06-06T11:27:28 | 92,845,377 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5796459913253784,
"alphanum_fraction": 0.5811209678649902,
"avg_line_length": 22.214284896850586,
"blob_id": "80c0ae6464da26efd043c61c325c588048ac890d",
"content_id": "742c0bb1fc9f27cea8d0c108a601bc7e1c9ef338",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 28,
"path": "/utils.py",
"repo_name": "denkorzh/tlg",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport shelve\r\nimport config\r\n\r\n\r\ndef set_user_mode(chat_id, mode):\r\n \"\"\"\r\n Записывает в хранилище режим работы для чата\r\n :param chat_id: id юзера\r\n :param mode: режим для юзера\r\n \"\"\"\r\n with shelve.open(config.mode_shelve_name) as storage:\r\n storage[str(chat_id)] = mode\r\n\r\n\r\ndef get_user_mode(chat_id):\r\n \"\"\"\r\n Возвращает режим, установленный юзером\r\n :param chat_id: id чата\r\n :return: (str or None) режим\r\n \"\"\"\r\n with shelve.open(config.mode_shelve_name) as storage:\r\n try:\r\n answer = storage[str(chat_id)]\r\n return answer\r\n except KeyError:\r\n return None\r\n"
},
{
"alpha_fraction": 0.493537575006485,
"alphanum_fraction": 0.497845858335495,
"avg_line_length": 45.477272033691406,
"blob_id": "f6667afd24826a0a5e2918cfac859c467eb5135f",
"content_id": "5d14a520c7531f95c459b19cfd760ddeacd662ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6386,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 132,
"path": "/bot.py",
"repo_name": "denkorzh/tlg",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\nimport credentials\r\nimport telebot\r\nimport constants\r\nimport utils\r\nfrom telebot import types\r\n\r\nbot = telebot.TeleBot(credentials.token)\r\n\r\n\r\[email protected]_handler(commands=['start'])\r\ndef start_message(message):\r\n bot.send_message(message.chat.id, constants.greeting_md, parse_mode='Markdown')\r\n\r\n\r\[email protected]_handler(commands=['help'])\r\ndef start_message(message):\r\n keyboard = types.InlineKeyboardMarkup()\r\n rep_button = types.InlineKeyboardButton('😜 repeater', callback_data='set_repeater_mode')\r\n nuff_button = types.InlineKeyboardButton('🤐 nuff', callback_data='set_nuff_mode')\r\n keyboard.add(rep_button, nuff_button)\r\n bot.send_message(message.chat.id, constants.help_md, parse_mode='Markdown', reply_markup=keyboard)\r\n\r\n\r\[email protected]_handler(commands=['repeater', 'nuff'])\r\ndef set_mode(message):\r\n hide_keyboard = types.ReplyKeyboardRemove()\r\n utils.set_user_mode(message.chat.id, message.text[1:])\r\n bot.send_message(message.chat.id, \"Bot mode was set to {}.\".format(message.text[1:]), reply_markup=hide_keyboard)\r\n\r\n\r\[email protected]_handler(commands=['advert'])\r\ndef show_ad(message):\r\n keyboard = types.InlineKeyboardMarkup()\r\n bank_button = types.InlineKeyboardButton(text=\"Банк\", url=\"www.tinkoff.ru\")\r\n ins_button = types.InlineKeyboardButton(text=\"Страхование\", url=\"www.tinkoffinsurance.ru\")\r\n loans_button = types.InlineKeyboardButton(text=\"Потребкредиты\", url=\"tinkoff.loans\")\r\n # keyboard.add(bank_button, ins_button, loans_button)\r\n keyboard.row(bank_button)\r\n keyboard.row(ins_button)\r\n keyboard.row(loans_button)\r\n bot.send_message(message.chat.id, 'Немного рекламы', reply_markup=keyboard)\r\n\r\n\r\[email protected]_handler(content_types=[\"text\"])\r\ndef repeat_all_messages(message):\r\n mode = utils.get_user_mode(message.chat.id)\r\n if mode == 'repeater':\r\n bot.send_message(message.chat.id, message.text)\r\n elif mode == 'nuff':\r\n bot.send_message(message.chat.id, constants.nuff_said, parse_mode='Markdown')\r\n\r\n\r\[email protected]_query_handler(func=lambda call: True)\r\ndef callback_inline(call):\r\n if call.message:\r\n if call.data == 'set_repeater_mode':\r\n utils.set_user_mode(call.message.chat.id, 'repeater')\r\n bot.answer_callback_query(call.id, 'repeater mode on')\r\n elif call.data == 'set_nuff_mode':\r\n utils.set_user_mode(call.message.chat.id, 'nuff')\r\n bot.answer_callback_query(call.id, 'nuff mode on', show_alert=True)\r\n\r\n\r\[email protected]_handler(func=lambda query: not len(query.query))\r\ndef empty_query(query):\r\n hint = 'Введи название режима работы'\r\n try:\r\n article = types.InlineQueryResultArticle(id='1',\r\n title='Бот-безделушка',\r\n input_message_content=types.InputTextMessageContent(\r\n message_text='Да введи ж ты наконец!'\r\n ),\r\n description=hint\r\n )\r\n bot.answer_inline_query(query.id, [article])\r\n except Exception as e:\r\n print(e)\r\n\r\n\r\[email protected]_handler(func=lambda query: len(query.query) > 0)\r\ndef advice_inline(query):\r\n repeater_image = 'https://raw.githubusercontent.com/denkorzh/tlg/master/image/echo.png'\r\n nuff_image = 'https://raw.githubusercontent.com/denkorzh/tlg/master/image/silence.jpg'\r\n\r\n repeater_article = types.InlineQueryResultArticle(id='repeater',\r\n title='Repeater mode',\r\n input_message_content=types.InputTextMessageContent(\r\n message_text='/repeater'\r\n ),\r\n description='I will repeat everything',\r\n thumb_url=repeater_image,\r\n thumb_width=48,\r\n thumb_height=48\r\n )\r\n nuff_article = types.InlineQueryResultArticle(id='nuff',\r\n title='Nuff said mode',\r\n input_message_content=types.InputTextMessageContent(\r\n message_text='/nuff'\r\n ),\r\n description='I will say nothing',\r\n thumb_url=nuff_image,\r\n thumb_width=61,\r\n thumb_height=48\r\n )\r\n error_article = types.InlineQueryResultArticle(id='error',\r\n title='I have no such mode',\r\n input_message_content=types.InputVenueMessageContent(\r\n latitude=53.25,\r\n longitude=34.37,\r\n title='Умник, иди-ка отсюда',\r\n address='Random place'\r\n ),\r\n description='Sorry, I have only two modes',\r\n )\r\n\r\n inputed = query.query\r\n length = len(inputed)\r\n\r\n try:\r\n if inputed == 'repeater'[:length]:\r\n bot.answer_inline_query(query.id, [repeater_article], 60)\r\n elif inputed == 'nuff'[:length]:\r\n bot.answer_inline_query(query.id, [nuff_article], 60)\r\n else:\r\n bot.answer_inline_query(query.id, [error_article], 60)\r\n except Exception as e:\r\n print(e)\r\n\r\nif __name__ == '__main__':\r\n bot.polling(none_stop=True)\r\n"
},
{
"alpha_fraction": 0.5684647560119629,
"alphanum_fraction": 0.5726141333580017,
"avg_line_length": 12.29411792755127,
"blob_id": "f52dc7da89327c581c1392b6a83498e828208911",
"content_id": "c5c5d904710369fed2b29fe2d9d8f81306309784",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 17,
"path": "/constants.py",
"repo_name": "denkorzh/tlg",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\ngreeting_md = \"\"\"\r\n*Привет!*\r\n_Это бот-безделушка._\r\nВыбери режим работы.\r\n\"\"\"\r\n\r\nhelp_md = \"\"\"\r\nДа что тут помогать-то?\r\nЭто же _элементарно_, Ватсон.\r\nВыбери режим работы.\r\n\"\"\"\r\n\r\nnuff_said = \"\"\"\r\nNUFF SAID.\r\n\"\"\""
},
{
"alpha_fraction": 0.6571428775787354,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 24.25,
"blob_id": "e2af36151ccc9ef531b5fd456ed9f3bd5f5ebfa7",
"content_id": "1e07b2a203553017272a848175e9933be7371045",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 4,
"path": "/config.py",
"repo_name": "denkorzh/tlg",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\n# хранилище режимов пользователей\r\nmode_shelve_name = 'storage/user_mode.db'\r\n"
}
] | 4 |
tanneeru-vamshi-krishna/sawtooth-blockchain-intkey
|
https://github.com/tanneeru-vamshi-krishna/sawtooth-blockchain-intkey
|
83f62c7d965c5af3024ebb4d8e55b9560241e939
|
1ca5ddc35e08eb2ec58af83793addbf77c60eac9
|
a351af5533b4d9df8b70b7de9ef9e66b09350099
|
refs/heads/master
| 2020-03-24T00:04:45.313150 | 2018-08-01T12:37:18 | 2018-08-01T12:37:18 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.747706413269043,
"alphanum_fraction": 0.752293586730957,
"avg_line_length": 23.33333396911621,
"blob_id": "7167ff9f3a1a8016ff7953dede0f17d758d755eb",
"content_id": "b35b972ef1ae1fdec14bcf587c81e5650f2ca117",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 9,
"path": "/transaction.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_sdk.protobuf.transaction_pb2 import transaction\n\nsignature = signer.sign(txn_header_bytes)\n\ntxn = Transaction(\n header = txn_header_bytes,\n header_signature = signature,\n payload: payload_bytes\n)"
},
{
"alpha_fraction": 0.5850694179534912,
"alphanum_fraction": 0.7604166865348816,
"avg_line_length": 37.46666717529297,
"blob_id": "72bedd850d4b2bc9530253c4910a76c7694cf60f",
"content_id": "41ee5452b7b285c96912bd74255f338caec805da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 576,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 15,
"path": "/transactionheader.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from hashlib import sha512\nfrom sawtooth_sdk.protobuf.transaction_pb2 import TransactionHeader\n\ntxn_header_bytes = TransactionHeader(\n family_name = 'intkey',\n family_version = '1.0',\n inputs = ['1cf1266e282c41be5e4254d8820772c5518a2c5a8c0c7f7eda19594a7eb539453e1ed7']\n outputs = ['1cf1266e282c41be5e4254d8820772c5518a2c5a8c0c7f7eda19594a7eb539453e1ed7']\n signer_public_key = signer.get_public_key().as_hex(),\n\n batcher_public_key = signer.get_public_key().as_hex(),\n\n dependencies = [],\n payload_sha512(payload_bytes).hexdigest()\n).SerializeToString()"
},
{
"alpha_fraction": 0.7613636255264282,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 24.14285659790039,
"blob_id": "d92c45c761e9dcaf12be1097e65ea843cf9aed71",
"content_id": "5c3438e55d6413ceb8e4ebec4cfa44dc9e5da7f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 176,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 7,
"path": "/encodetransaction.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_sdk.protobuf import TransactionList\n\ntxn_list_bytes = TransactionList(\n transactions = [txn1, txn2]\n).SerializeToString()\n\ntxn_bytes = txn.SerializeToString()\n"
},
{
"alpha_fraction": 0.7950819730758667,
"alphanum_fraction": 0.8032786846160889,
"avg_line_length": 40,
"blob_id": "fa14a16520630a85ddaf6144fa6a48eab04954f1",
"content_id": "214a4ed97e5162a9f481a3d494315a2928fdc08a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 3,
"path": "/encodebatch.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_sdk.protobuf.batch_pb2 import BatchList\n\nbatch_list_bytes = BatchList(batches = [batch]).SerializeToString()"
},
{
"alpha_fraction": 0.791304349899292,
"alphanum_fraction": 0.8086956739425659,
"avg_line_length": 37.16666793823242,
"blob_id": "129d5a6fcea0a9d3f4ec635374d920b2b83e2576",
"content_id": "00b086ec781ac4abcbb7aa7a14d28a93526bbbbf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 230,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 6,
"path": "/createkeys.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_signing import create_context\nfrom sawtooth_signing import CryptoFactory\n\ncontext = create_context('secp256k1')\nprivate_key = context.new_random_private_key()\nsigner = CryptoFactory(context).new_signer(private_key)\n\n"
},
{
"alpha_fraction": 0.5403226017951965,
"alphanum_fraction": 0.5564516186714172,
"avg_line_length": 12.777777671813965,
"blob_id": "e20e34ccb2fb60f40ffa8f1c03a2bcf48503f210",
"content_id": "1dd91f8b07138aebd21268809a2d77ac75027e92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 9,
"path": "/encoding.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "import cbor \n\npayload = {\n 'Verb' : 'set',\n 'Name' : 'vamshi',\n 'Value': 22\n}\n\npayload_bytes = cbor.dumps(payload)\n"
},
{
"alpha_fraction": 0.7290640473365784,
"alphanum_fraction": 0.7339901328086853,
"avg_line_length": 21.66666603088379,
"blob_id": "3a72b8883eec011f3777cc3ca7296be784300cfd",
"content_id": "9b5ed6dbf634311e20a9a70e5de0104cfaa21150",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 9,
"path": "/batch.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_sdk.protobuf.batch_pb2 import Batch\n\nsignature = signer.sign(batch_header_bytes)\n\nbatch = Batch(\n header = batch_header_bytes,\n header_signature = signature,\n transactions = txns\n)"
},
{
"alpha_fraction": 0.8396226167678833,
"alphanum_fraction": 0.8396226167678833,
"avg_line_length": 52,
"blob_id": "3f86c654e9747539673dbe5dc9a21d91a8c53753",
"content_id": "91dd380d2494a1312b78c54db7349217279c22f0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 2,
"path": "/README.md",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "# sawtooth-blockchain-intkey\nA Sawtooth Application which creates the basic hyperledger-sawtooth intkey.\n"
},
{
"alpha_fraction": 0.6637681126594543,
"alphanum_fraction": 0.6637681126594543,
"avg_line_length": 25.538461685180664,
"blob_id": "749f5aa883be3feeb3e32417b39e9df5d5a8dd51",
"content_id": "b4e73efb1ef7d850083c9b7def1d9d8b6f4d2d49",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 345,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 13,
"path": "/subbatchvalidator.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "import urlib.request\nfrom urlib.error import HTTPError\n\ntry:\n request=urlib.request.Request(\n 'http://rest.api.domain/batches',\n batch_list_bytes,\n method = 'POST',\n headers = {'Content-Type': 'application/octet-stream'})\n response = urlib.request.urlopen(request)\n\nexcept HTTPError as e:\n response = e.file\n"
},
{
"alpha_fraction": 0.7346938848495483,
"alphanum_fraction": 0.7387754917144775,
"avg_line_length": 29.5,
"blob_id": "b4442a33d03df582ae738bbc68a09fb43141b6c0",
"content_id": "082870be28e7795da455a473800408cfc590ae2c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 8,
"path": "/batchheader.py",
"repo_name": "tanneeru-vamshi-krishna/sawtooth-blockchain-intkey",
"src_encoding": "UTF-8",
"text": "from sawtooth_sdk.protobuf.batch_pb2 import BatchHeader\n\ntxns= [txn]\n\nbatch_header_bytes = BatchHeader(\n signer_public_key = signer.get_public_key().as_hex(),\n transaction_ids=[txn.header_signature for txn om txns],\n).SerializeToString()\n\n"
}
] | 10 |
mgodavar1/Showcase
|
https://github.com/mgodavar1/Showcase
|
8f8a5c6f01f46df8f3dc9e72c47bc1921228aff7
|
06a1b81070883ff2cf7291a57ac610e5eb8db68f
|
3b509397bb1697648e3c3bef39aef19d26056abb
|
refs/heads/master
| 2021-01-22T08:28:06.116273 | 2017-02-14T08:51:08 | 2017-02-14T08:51:08 | 81,901,286 | 0 | 0 | null | 2017-02-14T03:37:33 | 2017-02-10T23:36:13 | 2017-02-10T17:47:06 | null |
[
{
"alpha_fraction": 0.6202531456947327,
"alphanum_fraction": 0.6262099742889404,
"avg_line_length": 41.63492202758789,
"blob_id": "1a28923afb14eb06e6a0f0b12a4b2d6a247fe38f",
"content_id": "39474e485328424ff524de9262e68d28265251d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2686,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 63,
"path": "/db.py",
"repo_name": "mgodavar1/Showcase",
"src_encoding": "UTF-8",
"text": "db = DAL('sqlite://storage.sqlite')\n\n#auth\nfrom gluon.tools import *\nauth = Auth(db)\nauth.define_tables()\ncrud = Crud(db)\n\ndb.define_table('person',\n Field('name', unique=True),\n Field('email'),\n Field('phone'),\n format = '%(person)s')\n\n\n#database for projects\ndb.define_table('project',\n Field('person_id', 'reference person'),\n Field('title'),\n Field('body', 'text'),\n Field('image', 'upload'),\n Field('created_on', 'datetime', default=request.now),\n Field('created_by', 'reference auth_user', default=auth.user_id),\t\tField('category'),\n format='%(title)s')\n\n#db for documents on each project\ndb.define_table('document',\n Field('project_id', 'reference project'),\n Field('name'),\n Field('file', 'upload'),\n Field('created_on', 'datetime', default=request.now),\n Field('created_by', 'reference auth_user', default=auth.user_id),\n format='%(name)s')\n\n#db for posts on each project\ndb.define_table('post',\n Field('project_id', 'reference project'),\n Field('body', 'text'),\n Field('created_on', 'datetime', default=request.now),\n Field('created_by', 'reference auth_user', default=auth.user_id))\n\n#Person validators\ndb.person.name.requires = [IS_NOT_EMPTY(), IS_NOT_IN_DB(db, db.person.name)]\ndb.person.email.requires = [IS_NOT_EMPTY(), IS_EMAIL(error_message='Please enter a valid email!')]\ndb.person.phone.requires = IS_MATCH('^1?((-)\\d{3}-?|\\(\\d{3}\\))\\d{3}-?\\d{4}$', error_message='Please enter in form 1-123-456-7899')\n\n\ndb.project.title.requires = IS_NOT_IN_DB(db, 'project.title')\ndb.project.body.requires = IS_NOT_EMPTY()\ndb.project.person_id.readable = db.project.person_id.writable = False\ndb.project.created_by.readable = db.project.created_by.writable = False\ndb.project.created_on.readable = db.project.created_on.writable = False\ndb.project.category.requires = IS_IN_SET([\"Music\", \"Applications\", \"Games\", \"Movies\", \"Other\"], zero=None)\n\ndb.post.body.requires = IS_NOT_EMPTY()\ndb.post.project_id.readable = db.post.project_id.writable = False\ndb.post.created_by.readable = db.post.created_by.writable = False\ndb.post.created_on.readable = db.post.created_on.writable = False\n\ndb.document.name.requires = IS_NOT_IN_DB(db, 'document.name')\ndb.document.project_id.readable = db.document.project_id.writable = False\ndb.document.created_by.readable = db.document.created_by.writable = False\ndb.document.created_on.readable = db.document.created_on.writable = False\n"
}
] | 1 |
anwala/experiment
|
https://github.com/anwala/experiment
|
c164b930a7f9df39390ebe551613f110297fcbe0
|
e491ae64517d6c38e1b6815ec04f9f6d41e2f7bb
|
018d9ef7dc484864b2c38db531c1e8d9b92351ac
|
refs/heads/master
| 2021-01-22T22:57:33.915967 | 2017-05-03T23:24:17 | 2017-05-03T23:24:17 | 85,595,545 | 1 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7628507614135742,
"alphanum_fraction": 0.7698038220405579,
"avg_line_length": 219.67123413085938,
"blob_id": "56b12bd92d7819df4aa0015d79dd34431fda8b2e",
"content_id": "9e9522fe2f2149e1a68caebdbb555444009ac83b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 16168,
"license_type": "no_license",
"max_line_length": 782,
"num_lines": 73,
"path": "/BoilerplateRM/b6191398572e10059ba8d88aae6b4f46/boilerpipe.CanolaExtractor.html",
"repo_name": "anwala/experiment",
"src_encoding": "UTF-8",
"text": "<table style=\"table-layout: fixed\" width=\"100%\"><tr><td><h3>boilerpipe.CanolaExtractor over gold standard</h3><div><span style=\"background-color: yellow\">Wells</span>\n<span style=\"background-color: yellow\">Fargo</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">Keep</span> <span style=\"background-color: yellow\">Commissions-Based</span> <span style=\"background-color: yellow\">Retirement</span> <span style=\"background-color: yellow\">Accounts</span> <span style=\"background-color: yellow\">Under</span> Fiduciary Rule <span style=\"background-color: yellow\">Bank</span> acknowledges political <span style=\"background-color: yellow\">uncertainty</span> around <span style=\"background-color: yellow\">rule,</span>\nbut plots <span style=\"background-color: yellow\">compliance</span> <span style=\"background-color: yellow\">By</span> Michael Wursthorn Michael Wursthorn <span style=\"background-color: yellow\">The</span> <span style=\"background-color: yellow\">Wall</span> <span style=\"background-color: yellow\">Street</span> Journal Updated Dec. 1,\n<span style=\"background-color: yellow\">2016</span> 4:18 p.m. ET <span style=\"background-color: yellow\">Wells</span> <span style=\"background-color: yellow\">Fargo</span> <span style=\"background-color: yellow\">&</span> <span style=\"background-color: yellow\">Co.</span> <span style=\"background-color: yellow\">will</span> <span style=\"background-color: yellow\">continue</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">allow</span> <span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">savers</span> <span style=\"background-color: yellow\">who</span>\n<span style=\"background-color: yellow\">work</span> <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">its</span> <span style=\"background-color: yellow\">brokerage</span> <span style=\"background-color: yellow\">arm</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">pay</span> <span style=\"background-color: yellow\">commissions</span> <span style=\"background-color: yellow\">for</span> <span style=\"background-color: yellow\">trades,</span> <span style=\"background-color: yellow\">as</span> <span style=\"background-color: yellow\">Wall</span> <span style=\"background-color: yellow\">Street</span> <span style=\"background-color: yellow\">brokerages</span> <span style=\"background-color: yellow\">move</span>\n<span style=\"background-color: yellow\">ahead</span> <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">plans</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">comply</span> <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">new</span> <span style=\"background-color: yellow\">conflict-of-interest</span> <span style=\"background-color: yellow\">rules</span> <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">accounts</span> <span style=\"background-color: yellow\">despite</span> uncertainty <span style=\"background-color: yellow\">surrounding</span>\n<span style=\"background-color: yellow\">their</span> <span style=\"background-color: yellow\">fate.</span> <span style=\"background-color: yellow\">The</span> <span style=\"background-color: yellow\">Labor</span> <span style=\"background-color: yellow\">Department’s</span> <span style=\"background-color: yellow\">so-called</span> <span style=\"background-color: yellow\">fiduciary</span> <span style=\"background-color: yellow\">rule,</span> <span style=\"background-color: yellow\">which</span> <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">set</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">take</span> <span style=\"background-color: yellow\">effect</span> <span style=\"background-color: yellow\">in</span>\n<span style=\"background-color: yellow\">April,</span> <span style=\"background-color: yellow\">aims</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">eliminate</span> <span style=\"background-color: yellow\">conflicts</span> <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">advice</span> <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">requires</span> <span style=\"background-color: yellow\">brokers</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">act</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span>\n<span style=\"background-color: yellow\">best</span> <span style=\"background-color: yellow\">interests</span> <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">their</span> <span style=\"background-color: yellow\">clients.</span> <span style=\"background-color: yellow\">The</span> <span style=\"background-color: yellow\">rule’s</span> <span style=\"background-color: yellow\">fate</span> <span style=\"background-color: yellow\">has</span> become... </div></td><td><h3>gold standard over boilerpipe.CanolaExtractor</h3><div>html\ncode <a href=\"http://archive.is/C0MF6\"> <img style=\"width:300px;height:200px;background-color:white\" src=\"https://archive.is/C0MF6/1c61410150e2af9c590bfc51ef7ed6f42e2a6ced/scr.png\"><br> <span style=\"background-color: yellow\">Wells</span> <span style=\"background-color: yellow\">Fargo</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">Keep</span> <span style=\"background-color: yellow\">Commissions-Based</span> <span style=\"background-color: yellow\">Retirement</span> <span style=\"background-color: yellow\">Accounts</span> <span style=\"background-color: yellow\">Under</span> Fiduc…<br>\narchived 22 Dec <span style=\"background-color: yellow\">2016</span> 17:55:44 UTC </a> wiki code {{cite web | title = <span style=\"background-color: yellow\">Wells</span>\n<span style=\"background-color: yellow\">Fargo</span> <span style=\"background-color: yellow\">to</span> Keep Commissions-Based Retirement Accounts Under Fiduc… | url = http://www.wsj.com/articles/wells-fargo-to-keep-commissions-based-retirement-accounts-under-fiduciary-rule-1480615211 | date =\n2016-12-22 | archiveurl = http://archive.is/C0MF6 | archivedate = 2016-12-22 }} We use cookies <span style=\"background-color: yellow\">and</span> browser\ncapability checks <span style=\"background-color: yellow\">to</span> help us deliver our online services, including <span style=\"background-color: yellow\">to</span> learn if you enabled\nFlash <span style=\"background-color: yellow\">for</span> video or ad blocking. <span style=\"background-color: yellow\">By</span> using our website or by closing this message\nbox, you agree <span style=\"background-color: yellow\">to</span> our use <span style=\"background-color: yellow\">of</span> browser capability checks, and <span style=\"background-color: yellow\">to</span> our use of\ncookies <span style=\"background-color: yellow\">as</span> described <span style=\"background-color: yellow\">in</span> our Cookie Policy . Wi-Fi-Linked Home-Security Gadgets Aren’t Lowering Insurance Premiums\nWi-Fi-Linked Home-Security Gadgets Aren’t Lowering Insurance Premiums Wi-Fi-Linked Home-Security Gadgets Aren’t Lowering Insurance Premiums →Next\nThis copy <span style=\"background-color: yellow\">is</span> for your personal, non-commercial use only. To order presentation-ready copies for distribution\n<span style=\"background-color: yellow\">to</span> your colleagues, clients or customers visit http://www.djreprints.com. ENLARGE Wells Fargo <span style=\"background-color: yellow\">&</span> <span style=\"background-color: yellow\">Co.</span> detailed <span style=\"background-color: yellow\">its</span>\n<span style=\"background-color: yellow\">plans</span> for <span style=\"background-color: yellow\">compliance</span> <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Labor</span> <span style=\"background-color: yellow\">Department’s</span> <span style=\"background-color: yellow\">so-called</span> <span style=\"background-color: yellow\">fiduciary</span> rule <span style=\"background-color: yellow\">despite</span> speculation it <span style=\"background-color: yellow\">will</span> be\ndismantled by Republicans and Donald Trump next year Photo: Reuters 0 COMMENTS Wells Fargo &\nCo. will <span style=\"background-color: yellow\">continue</span> to <span style=\"background-color: yellow\">allow</span> <span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">savers</span> <span style=\"background-color: yellow\">who</span> <span style=\"background-color: yellow\">work</span> <span style=\"background-color: yellow\">with</span> its <span style=\"background-color: yellow\">brokerage</span> <span style=\"background-color: yellow\">arm</span> to <span style=\"background-color: yellow\">pay</span>\n<span style=\"background-color: yellow\">commissions</span> for <span style=\"background-color: yellow\">trades,</span> as <span style=\"background-color: yellow\">Wall</span> <span style=\"background-color: yellow\">Street</span> <span style=\"background-color: yellow\">brokerages</span> <span style=\"background-color: yellow\">move</span> <span style=\"background-color: yellow\">ahead</span> <span style=\"background-color: yellow\">with</span> plans to <span style=\"background-color: yellow\">comply</span> with <span style=\"background-color: yellow\">new</span>\n<span style=\"background-color: yellow\">conflict-of-interest</span> <span style=\"background-color: yellow\">rules</span> <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">accounts</span> despite <span style=\"background-color: yellow\">uncertainty</span> <span style=\"background-color: yellow\">surrounding</span> <span style=\"background-color: yellow\">their</span> <span style=\"background-color: yellow\">fate.</span> <span style=\"background-color: yellow\">The</span> Labor Department’s so-called fiduciary\nrule , <span style=\"background-color: yellow\">which</span> is <span style=\"background-color: yellow\">set</span> to <span style=\"background-color: yellow\">take</span> <span style=\"background-color: yellow\">effect</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">April,</span> <span style=\"background-color: yellow\">aims</span> to <span style=\"background-color: yellow\">eliminate</span> <span style=\"background-color: yellow\">conflicts</span> <span style=\"background-color: yellow\">from</span>\n<span style=\"background-color: yellow\">retirement</span> <span style=\"background-color: yellow\">advice</span> and <span style=\"background-color: yellow\">requires</span> <span style=\"background-color: yellow\">brokers</span> to <span style=\"background-color: yellow\">act</span> in the <span style=\"background-color: yellow\">best</span> <span style=\"background-color: yellow\">interests</span> of <span style=\"background-color: yellow\">their</span> <span style=\"background-color: yellow\">clients.</span> <span style=\"background-color: yellow\">The</span>\n<span style=\"background-color: yellow\">rule’s</span> <span style=\"background-color: yellow\">fate</span> <span style=\"background-color: yellow\">has</span> become unclear as Republicans in Congress and the incoming Trump administration have\nmade it clear that Obama-era regulations are under review for repeal or replacement. <span style=\"background-color: yellow\">The</span> San\nFrancisco bank said that while it is planning for a variety of different scenarios surrounding\nthe fate of the <span style=\"background-color: yellow\">rule,</span> it is preparing as if the rule will be implemented\nin April as scheduled. “While there is a great deal of speculation in the media\non how the election results will affect the DOL <span style=\"background-color: yellow\">rule,</span> none of us can say\nwith certainty what will actually happen,” Wells Fargo said in a memorandum, reviewed by The\n<span style=\"background-color: yellow\">Wall</span> <span style=\"background-color: yellow\">Street</span> Journal, to its more than 15,000 brokers on Thursday. Wells Fargo’s brokerage arm,\nWells Fargo Advisors, which has more $1.5 trillion in total client assets, said it would\nallow its brokers to continue offering individual retirement accounts that charge investors per-transaction commissions, an\napproach toward compliance similar to some brokerages such as Morgan Stanley and Edward Jones. However,\nWells clients in those accounts after April will likely have a slimmer menu of investment\nproducts to choose from, people with knowledge of the matter said, although details weren’t immediately\navailable. Firms still offering commission-based IRAs have had to drop some investment products from them\nto comply with some restrictions within the rule. Edward Jones, for example, won’t allow retirement\nsavers who pay a commission to buy mutual funds next year, while some alternative investments\nwon’t be immediately available in commission-based IRAs at Morgan Stanley. The approach to allow commission\nofferings differs from rivals <span style=\"background-color: yellow\">Bank</span> of America Corp.’s Merrill Lynch and J.P. Morgan Chase &\nCo., among others. Merrill and J.P. Morgan said in recent months that they would ditch\nthe industry’s traditional commission-based sales model for retirement accounts and will effectively offer only IRAs\nthat charge a fee based on a percentage of assets starting next year. The retirement\nrules—which researcher Morningstar Inc. predicts will affect about $3 trillion of commission-based retirement assets in\nthe U.S.—bring a host of changes, including how investors pay for retirement advice, the elimination\nof compensation incentives for brokers and higher investment minimums. But since Republicans took the White\nHouse and retained control of Congress, firms now face the dizzying possibility of an outright\ndismantling of the rule. Congressional Republicans opposing the rule have seized on Donald Trump’s surprise\npresidential win as a chance to stop the regulations ahead of their implementation. Rep. Jeb\nHensarling, the Texas Republican who heads the House Financial Services Committee, and Rep. Ann Wagner\n(R., Mo.), who has been one of the most vocal opponents of the rule, have\nboth said their party will renew the fight to halt it next year. Republicans challenging\nthe rule have said it would cut small retirement savers off from affordable financial advice.\nA recent survey by analytics firm CoreData Research of 552 financial advisers in the U.S.\nfound that 71% plan to no longer service some smaller investors because of the rule.\nWells Fargo and other brokerages are moving ahead with implementation despite the uncertainty. But even\nif the rule is shelved, certain aspects of it, such as heightened oversight of retirement\naccounts, will continue to move forward at Wells Fargo, people familiar with the matter said.\nFor investors, the rule’s halt may not be that apparent if firms choose to keep\nsome of the changes they’ve already made or planned. Some companies will be able to\nimplement the rule’s higher standard of care without the costly compliance requirements, said Kent Mason,\na partner at law firm Davis & Harman LLP who focuses on retirement. “But people\nmay have also lost the option of choice,” Mr. Mason added, referring to some firms’\ndecision to no longer offer commission-based IRAs. “The legacy of the rule may be less\naccess [for small savers] and less choice.” This copy is for your personal, non-commercial use\nonly. Distribution and use of this material are governed by our Subscriber Agreement and by\ncopyright law. For non-personal use or to order multiple copies, please contact Dow Jones Reprints\nat 1-800-843-0008 or visit www.djreprints.com. </div></td></tr></table>"
},
{
"alpha_fraction": 0.6722715497016907,
"alphanum_fraction": 0.7138324975967407,
"avg_line_length": 36.0941162109375,
"blob_id": "ff8bb9d62b5ea4ea4f56d1f29ee59c64686104aa",
"content_id": "4618287c4a91d9dba886c50a89e04d1051fb56f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3152,
"license_type": "no_license",
"max_line_length": 269,
"num_lines": 85,
"path": "/BoilerplateRM/boilerplateRMExpr.py",
"repo_name": "anwala/experiment",
"src_encoding": "UTF-8",
"text": "import os, sys\nimport hashlib\n\n#utility - start\ndef genericErrorInfo():\n\texc_type, exc_obj, exc_tb = sys.exc_info()\n\tfname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]\n\terrorMessage = fname + ', ' + str(exc_tb.tb_lineno) + ', ' + str(sys.exc_info())\n\tprint('\\tERROR:', errorMessage)\n\ndef readTextFromFile(infilename):\n\n\ttext = ''\n\ttry:\n\t\tinfile = open(infilename, 'r')\n\t\ttext = infile.read()\n\t\tinfile.close()\n\texcept:\n\t\tgenericErrorInfo()\n\n\treturn text\n\ndef getURIHash(uri):\n\n\turi = uri.strip()\n\tif( len(uri) == 0 ):\n\t\treturn ''\n\n\thash_object = hashlib.md5(uri.encode())\n\treturn hash_object.hexdigest()\n#utility - end\n\ndef testBoilerplateRM(folderName):\n\n\tprint('\\ntestBoilerplateRM() - start')\n\t\n\tboilerplateRMMethodsOutput = ['beautifulsoup.txt', 'clean_html.txt', 'goose.txt', 'justext.txt', 'boilerpipe.ArticleExtractor.txt', 'boilerpipe.DefaultExtractor.txt', 'boilerpipe.CanolaExtractor.txt', 'boilerpipe.LargestContentExtractor.txt', 'python-readability.txt']\n\t\n\tgoldStandardSet = readTextFromFile(folderName + 'gold-standard.txt')\n\tgoldStandardSet = set(goldStandardSet.split())\n\n\tfor boilerplateMethod in boilerplateRMMethodsOutput:\n\n\t\tboilMethodSet = set( readTextFromFile(folderName + boilerplateMethod).split() )\n\t\t\n\t\tintersection = float(len(goldStandardSet & boilMethodSet))\n\t\tunion = len(goldStandardSet | boilMethodSet)\n\n\t\tscore = intersection/union\n\t\tprint('\\tjaccardIndex:', boilerplateMethod, score)\n\t\n\tprint('testBoilerplateRM() - start\\n')\n\ndef entryPoint():\n\n\tsampleURIs = [\n\t\t\t\t\t\"http://www.wsj.com/articles/indiana-gives-7-million-in-tax-breaks-to-keep-carrier-jobs-1480608461\",\n\t\t\t\t\t\"http://www.cnbc.com/2016/12/01/howard-schultz-stepping-down-as-starbucks-ceo.html\",\n\t\t\t\t\t\"http://www.usatoday.com/story/news/nation-now/2016/12/01/death-toll-tennessee-wildfires-rises-10/94756844/?utm_source=dlvr.it&utm_medium=twitter\",\n\t\t\t\t\t\"https://www.washingtonpost.com/politics/shouting-match-erupts-between-clinton-and-trump-aides/2016/12/01/7ac4398e-b7ea-11e6-b8df-600bd9d38a02_story.html?utm_term=.f17f35b548b4\",\n\t\t\t\t\t\"http://www.telegraph.co.uk/football/2016/12/01/arsenal-should-glad-efl-cup/\",\n\t\t\t\t\t\"http://nymag.com/thecut/2016/12/victorias-secret-angel-jasmine-tookes-diet-workout-routine.html\",\n\t\t\t\t\t\"http://www.nytimes.com/2016/12/19/world/europe/russia-ambassador-shot-ankara-turkey-report.html\",\n\t\t\t\t\t\"http://www.latimes.com/local/lanow/la-me-san-bernardino-terror-probe-20161130-story.html\",\n\t\t\t\t\t\"http://www.wsj.com/articles/wells-fargo-to-keep-commissions-based-retirement-accounts-under-fiduciary-rule-1480615211\",\n\t\t\t\t\t\"http://www.theatlantic.com/entertainment/archive/2016/12/trevor-noah-finds-his-late-night-voice/509318/\"\n\t\t\t\t]\n\n\tshortURIs = [ 'https://archive.is/VWV9j',\n\t\t\t\t 'https://archive.is/NiUZp',\n\t\t\t\t 'https://archive.is/sSTDw',\n\t\t\t\t 'https://archive.is/lhxuj',\n\t\t\t\t 'https://archive.is/rxvyt',\n\t\t\t\t 'https://archive.is/SduYw',\n\t\t\t\t 'https://archive.is/wKOBW',\n\t\t\t\t 'https://archive.is/l1tqE',\n\t\t\t\t 'https://archive.is/C0MF6',\n\t\t\t\t 'https://archive.is/hx6jw'\n\t\t\t\t ]\n\n\tfor uri in sampleURIs:#or shortURIs\n\t\tprint('uri:', uri)\n\t\ttestBoilerplateRM('./' + getURIHash(uri) + '/')\n\nentryPoint()"
},
{
"alpha_fraction": 0.7904680371284485,
"alphanum_fraction": 0.7996994256973267,
"avg_line_length": 90.35294342041016,
"blob_id": "932230574b1184dda06287d2b7f85c754d56af2b",
"content_id": "56dded97d78ce69c24e56d06a8c021a7d3a85143",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 4722,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 51,
"path": "/BoilerplateRM/184d0d06fd8b294326de53faec05e3af/goose.html",
"repo_name": "anwala/experiment",
"src_encoding": "UTF-8",
"text": "<table style=\"table-layout: fixed\" width=\"100%\"><tr><td><h3>goose over gold standard</h3><div>Russian\nAmbassador to Turkey Is Assassinated in Ankara By TIM ARANGO and RICK GLADSTONEDEC. 19, 2016\nContinue reading the main storyShare This Page A man, right, reported by The Associated Press\nto be the gunman, after the shooting of the Russian ambassador, on the floor, on\nMonday at a gallery in Ankara, the capital of Turkey. Credit Yavuz Alatan/Agence France-Presse —\nGetty Images ISTANBUL — Russia’s ambassador to Turkey was assassinated at an Ankara art exhibit\non Monday evening by a lone Turkish gunman shouting “God is great!” and “don’t forget\nAleppo, don’t forget Syria!” in what Russia called a terrorist attack. The gunman, who was\ndescribed by Ankara’s mayor as a policeman, also wounded at least three others in the\nassault, which was captured on Turkish video. Turkish officials said he was killed by other\nofficers in a shootout. The assassination instantly vaulted relations between Turkey and Russia to a\nnew level of crisis over the protracted Syria conflict on Turkey’s southern doorstep. It came\nafter days of protests by Turks angry over Russia’s support for Syria’s government in the\nconflict and the Russian role in the killings and destruction in Aleppo, the northern Syrian\ncity. Andrey Karlov, the Russian ambassador to Turkey, speaking at the gallery in Ankara on\nMonday, moments before he was shot. Credit Burhan Ozbilici/Associated Press The envoy, Andrey G. Karlov,\nwas shot from behind and immediately fell to the floor while speaking at an exhibition,\naccording to multiple accounts from the scene, the Contemporary Arts Center in the Cankaya area\nof Ankara. The gunman, wearing a dark suit and tie, was seen in video footage\nof the assault shouting in Arabic: “God is great! Those who pledged allegiance to Muhammad\nfor jihad. God is great!” Then he switched to Turkish and shouted: “Don’t forget Aleppo,\ndon’t forget Syria! Step back! Step back! Only death can take me from here.” Turkish\nofficials said that the gunman was killed after a shootout with Turkish Special Forces police.\nThe assailant’s identity was not immediately known. People huddle during the shooting in the art\ngallery. Credit Burhan Ozbilici/Associated Press Russia’s Foreign Ministry spokeswoman, Maria Zakharova, told the Rossiya 24\nnews channel that Mr. Karlov had died of his wounds in what she described as\na terrorist attack. Russia news agencies said the ambassador’s wife fainted and was hospitalized after\nlearning of her husband’s death. They also said Russian tourists in Turkey had been advised\nagainst leaving their hotel rooms or visiting public places as a precaution. CNN Turk published\nimages showing several people lying on the floor of the gallery. Russia’s Tass news agency\ninitially quoted witnesses of the attack as saying that there had been an “assassination attempt”\nagainst Mr. Karlov, and that he had been shot from behind while finishing his opening\nremarks at the opening of the exhibition, called “Russia Through Turks’ Eyes.” While the Russian\nand Turkish governments back different sides in the Syria conflict, they had been collaborating in\nrecent days in efforts to evacuate civilians from Aleppo. The gunman gestures after shooting the\nRussian ambassador. Credit Burhan Ozbilici/Associated Press Mr. Karlov, who started his career as a diplomat\nin 1976, worked extensively in North Korea over two decades, before moving to the region\nin 2007, according to a biography on the Russian Embassy’s website. He became ambassador in\nJuly 2013. The attack was a rare instance of an assassination of any Russian envoy.\nHistorians said it might have been the first since Pyotr Voykov, a Soviet ambassador to\nPoland, was shot to death in Warsaw in 1927. For many Russians, the assassination is\nlikely to recall the 19th-century killing in Tehran of Aleksandr Griboyedov, a poet and diplomat\nwho died after a mob stormed the Russian Embassy. That episode is remembered as the\nmost severe insult to Russia’s diplomatic corps in the country’s history. More recently, the Lebanese\nShiite militia Hezbollah, now allied with Russia in Syria, kidnapped four Soviet diplomats in 1985,\nkilling one and releasing three a month later. Correction: December 19, 2016 An earlier version\nof this article misidentified the government that has collaborated with Russia even though it backs\na different side in the Syrian conflict. It is Turkey, not Syria. Tim Arango reported\nfrom Istanbul, and Rick Gladstone from New York. Reporting was contributed by Ivan Nechepurenko, Oleg\nMatsnev and Andrew E. Kramer from Moscow, Safak Timur from Istanbul and Sewell Chan from\nLondon. </div></td><td><h3>gold standard over goose</h3><div></div></td></tr></table>"
},
{
"alpha_fraction": 0.6896551847457886,
"alphanum_fraction": 0.7733989953994751,
"avg_line_length": 67,
"blob_id": "6dd77caa550119e6938bbc1cec46cdb33edca68b",
"content_id": "e26705ad1d067bad53d8dc9b2342ebb23e38c7ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 3,
"path": "/BoilerplateRM/README.md",
"repo_name": "anwala/experiment",
"src_encoding": "UTF-8",
"text": "# Source code to replicate tests from [A survey of 5 boilerplate removal methods]\n\n[A survey of 5 boilerplate removal methods]: <http://ws-dl.blogspot.com/2017/03/2017-03-20-survey-of-5-boilerplate.html>"
},
{
"alpha_fraction": 0.753969669342041,
"alphanum_fraction": 0.7560771703720093,
"avg_line_length": 351.8461608886719,
"blob_id": "77ec28c5d2c663a08fc132b08d49981de4221f98",
"content_id": "520cb4709b9a93fd9793f299ab7b26c88bdf72b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 27613,
"license_type": "no_license",
"max_line_length": 786,
"num_lines": 78,
"path": "/BoilerplateRM/184d0d06fd8b294326de53faec05e3af/boilerpipe.LargestContentExtractor.html",
"repo_name": "anwala/experiment",
"src_encoding": "UTF-8",
"text": "<table style=\"table-layout: fixed\" width=\"100%\"><tr><td><h3>boilerpipe.LargestContentExtractor over gold standard</h3><div><span style=\"background-color: yellow\">Russian</span>\nAmbassador <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">Turkey</span> Is Assassinated <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">Ankara</span> <span style=\"background-color: yellow\">By</span> TIM ARANGO <span style=\"background-color: yellow\">and</span> RICK GLADSTONEDEC. <span style=\"background-color: yellow\">19,</span> <span style=\"background-color: yellow\">2016</span>\n<span style=\"background-color: yellow\">Continue</span> <span style=\"background-color: yellow\">reading</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">main</span> storyShare This <span style=\"background-color: yellow\">Page</span> <span style=\"background-color: yellow\">A</span> man, right, <span style=\"background-color: yellow\">reported</span> <span style=\"background-color: yellow\">by</span> <span style=\"background-color: yellow\">The</span> Associated Press\n<span style=\"background-color: yellow\">to</span> be <span style=\"background-color: yellow\">the</span> gunman, <span style=\"background-color: yellow\">after</span> <span style=\"background-color: yellow\">the</span> shooting <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Russian</span> ambassador, <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">the</span> floor, <span style=\"background-color: yellow\">on</span>\n<span style=\"background-color: yellow\">Monday</span> at <span style=\"background-color: yellow\">a</span> gallery <span style=\"background-color: yellow\">in</span> Ankara, <span style=\"background-color: yellow\">the</span> capital <span style=\"background-color: yellow\">of</span> Turkey. Credit Yavuz Alatan/Agence France-Presse —\nGetty Images ISTANBUL — <span style=\"background-color: yellow\">Russia’s</span> <span style=\"background-color: yellow\">ambassador</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">Turkey</span> <span style=\"background-color: yellow\">was</span> assassinated at <span style=\"background-color: yellow\">an</span> Ankara art exhibit\n<span style=\"background-color: yellow\">on</span> Monday <span style=\"background-color: yellow\">evening</span> <span style=\"background-color: yellow\">by</span> <span style=\"background-color: yellow\">a</span> lone <span style=\"background-color: yellow\">Turkish</span> gunman shouting “God <span style=\"background-color: yellow\">is</span> great!” <span style=\"background-color: yellow\">and</span> “don’t forget\nAleppo, <span style=\"background-color: yellow\">don’t</span> forget Syria!” <span style=\"background-color: yellow\">in</span> what <span style=\"background-color: yellow\">Russia</span> called <span style=\"background-color: yellow\">a</span> terrorist attack. <span style=\"background-color: yellow\">The</span> gunman, <span style=\"background-color: yellow\">who</span> <span style=\"background-color: yellow\">was</span>\ndescribed by Ankara’s mayor <span style=\"background-color: yellow\">as</span> <span style=\"background-color: yellow\">a</span> policeman, also wounded at least three others <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span>\nassault, which <span style=\"background-color: yellow\">was</span> captured <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">Turkish</span> video. <span style=\"background-color: yellow\">Turkish</span> officials <span style=\"background-color: yellow\">said</span> <span style=\"background-color: yellow\">he</span> was killed by other\nofficers <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">a</span> shootout. The assassination instantly vaulted relations <span style=\"background-color: yellow\">between</span> Turkey <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">Russia</span> <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">a</span>\nnew level <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">crisis</span> <span style=\"background-color: yellow\">over</span> <span style=\"background-color: yellow\">the</span> protracted <span style=\"background-color: yellow\">Syria</span> conflict on Turkey’s southern doorstep. <span style=\"background-color: yellow\">It</span> came\nafter days <span style=\"background-color: yellow\">of</span> protests by Turks <span style=\"background-color: yellow\">angry</span> <span style=\"background-color: yellow\">over</span> <span style=\"background-color: yellow\">Russia’s</span> support <span style=\"background-color: yellow\">for</span> Syria’s <span style=\"background-color: yellow\">government</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span>\nconflict <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">the</span> Russian <span style=\"background-color: yellow\">role</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">killings</span> <span style=\"background-color: yellow\">and</span> destruction <span style=\"background-color: yellow\">in</span> Aleppo, <span style=\"background-color: yellow\">the</span> northern <span style=\"background-color: yellow\">Syrian</span>\ncity. Andrey Karlov, <span style=\"background-color: yellow\">the</span> Russian ambassador <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">Turkey,</span> speaking at <span style=\"background-color: yellow\">the</span> gallery <span style=\"background-color: yellow\">in</span> Ankara on\nMonday, moments before <span style=\"background-color: yellow\">he</span> was shot. Credit Burhan Ozbilici/Associated Press The envoy, Andrey G. Karlov,\nwas shot <span style=\"background-color: yellow\">from</span> behind <span style=\"background-color: yellow\">and</span> immediately fell <span style=\"background-color: yellow\">to</span> <span style=\"background-color: yellow\">the</span> floor while speaking at an exhibition,\naccording to multiple accounts <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">the</span> scene, <span style=\"background-color: yellow\">the</span> Contemporary Arts <span style=\"background-color: yellow\">Center</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span> Cankaya area\n<span style=\"background-color: yellow\">of</span> Ankara. The gunman, wearing <span style=\"background-color: yellow\">a</span> dark suit <span style=\"background-color: yellow\">and</span> tie, was seen <span style=\"background-color: yellow\">in</span> video footage\n<span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> assault shouting <span style=\"background-color: yellow\">in</span> Arabic: “God <span style=\"background-color: yellow\">is</span> great! Those <span style=\"background-color: yellow\">who</span> pledged allegiance to Muhammad\n<span style=\"background-color: yellow\">for</span> jihad. God <span style=\"background-color: yellow\">is</span> great!” Then <span style=\"background-color: yellow\">he</span> switched to <span style=\"background-color: yellow\">Turkish</span> <span style=\"background-color: yellow\">and</span> shouted: “Don’t forget Aleppo,\ndon’t forget Syria! Step back! Step back! Only death can take me <span style=\"background-color: yellow\">from</span> here.” Turkish\nofficials said <span style=\"background-color: yellow\">that</span> <span style=\"background-color: yellow\">the</span> gunman was killed after <span style=\"background-color: yellow\">a</span> shootout <span style=\"background-color: yellow\">with</span> Turkish Special Forces police.\nThe assailant’s identity was <span style=\"background-color: yellow\">not</span> immediately known. People huddle <span style=\"background-color: yellow\">during</span> <span style=\"background-color: yellow\">the</span> shooting in <span style=\"background-color: yellow\">the</span> art\ngallery. Credit Burhan Ozbilici/Associated Press Russia’s <span style=\"background-color: yellow\">Foreign</span> Ministry spokeswoman, Maria Zakharova, told <span style=\"background-color: yellow\">the</span> Rossiya 24\nnews channel that <span style=\"background-color: yellow\">Mr.</span> Karlov <span style=\"background-color: yellow\">had</span> died <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">his</span> wounds in what she described <span style=\"background-color: yellow\">as</span>\na terrorist attack. Russia news agencies said <span style=\"background-color: yellow\">the</span> ambassador’s wife fainted <span style=\"background-color: yellow\">and</span> was hospitalized after\nlearning <span style=\"background-color: yellow\">of</span> her husband’s death. They also said Russian tourists in Turkey had <span style=\"background-color: yellow\">been</span> advised\n<span style=\"background-color: yellow\">against</span> leaving their hotel rooms or visiting public places as a precaution. CNN Turk published\nimages showing several people <span style=\"background-color: yellow\">lying</span> on <span style=\"background-color: yellow\">the</span> floor <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> gallery. Russia’s Tass news agency\ninitially quoted witnesses <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">attack</span> as saying that there had been an “assassination attempt”\nagainst <span style=\"background-color: yellow\">Mr.</span> Karlov, <span style=\"background-color: yellow\">and</span> that he had been shot <span style=\"background-color: yellow\">from</span> behind while finishing his opening\nremarks at <span style=\"background-color: yellow\">the</span> opening <span style=\"background-color: yellow\">of</span> the exhibition, called “Russia Through Turks’ Eyes.” While the Russian\nand Turkish governments back <span style=\"background-color: yellow\">different</span> sides in the <span style=\"background-color: yellow\">Syria</span> conflict, they had been collaborating in\nrecent days in efforts to evacuate civilians <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">Aleppo.</span> The gunman gestures after shooting the\nRussian ambassador. Credit Burhan Ozbilici/Associated Press Mr. Karlov, <span style=\"background-color: yellow\">who</span> started his career as a <span style=\"background-color: yellow\">diplomat</span>\nin 1976, worked extensively in North Korea over <span style=\"background-color: yellow\">two</span> decades, before moving to the region\nin 2007, according to a biography on the Russian Embassy’s website. <span style=\"background-color: yellow\">He</span> became ambassador in\nJuly 2013. The attack was a rare instance <span style=\"background-color: yellow\">of</span> an assassination of <span style=\"background-color: yellow\">any</span> Russian envoy.\nHistorians said <span style=\"background-color: yellow\">it</span> might have been the <span style=\"background-color: yellow\">first</span> since Pyotr Voykov, a Soviet ambassador to\nPoland, was shot to death in Warsaw in 1927. <span style=\"background-color: yellow\">For</span> <span style=\"background-color: yellow\">many</span> Russians, the assassination <span style=\"background-color: yellow\">is</span>\nlikely to recall the 19th-century killing in Tehran of Aleksandr Griboyedov, a poet and diplomat\nwho died after a mob stormed the Russian Embassy. That episode <span style=\"background-color: yellow\">is</span> remembered as the\nmost severe insult to Russia’s diplomatic corps in the country’s history. More recently, the Lebanese\nShiite militia Hezbollah, now allied <span style=\"background-color: yellow\">with</span> Russia in Syria, kidnapped four Soviet <span style=\"background-color: yellow\">diplomats</span> in 1985,\nkilling one and releasing three a month later. <span style=\"background-color: yellow\">Correction:</span> <span style=\"background-color: yellow\">December</span> 19, 2016 <span style=\"background-color: yellow\">An</span> <span style=\"background-color: yellow\">earlier</span> <span style=\"background-color: yellow\">version</span>\nof <span style=\"background-color: yellow\">this</span> <span style=\"background-color: yellow\">article</span> <span style=\"background-color: yellow\">misidentified</span> the <span style=\"background-color: yellow\">government</span> that <span style=\"background-color: yellow\">has</span> <span style=\"background-color: yellow\">collaborated</span> <span style=\"background-color: yellow\">with</span> Russia <span style=\"background-color: yellow\">even</span> <span style=\"background-color: yellow\">though</span> it <span style=\"background-color: yellow\">backs</span>\na different <span style=\"background-color: yellow\">side</span> in the <span style=\"background-color: yellow\">Syrian</span> <span style=\"background-color: yellow\">conflict.</span> It <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">Turkey,</span> <span style=\"background-color: yellow\">not</span> <span style=\"background-color: yellow\">Syria.</span> <span style=\"background-color: yellow\">Tim</span> <span style=\"background-color: yellow\">Arango</span> reported\n<span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">Istanbul,</span> and <span style=\"background-color: yellow\">Rick</span> <span style=\"background-color: yellow\">Gladstone</span> <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">New</span> <span style=\"background-color: yellow\">York.</span> <span style=\"background-color: yellow\">Reporting</span> was <span style=\"background-color: yellow\">contributed</span> by <span style=\"background-color: yellow\">Ivan</span> <span style=\"background-color: yellow\">Nechepurenko,</span> <span style=\"background-color: yellow\">Oleg</span>\n<span style=\"background-color: yellow\">Matsnev</span> and <span style=\"background-color: yellow\">Andrew</span> <span style=\"background-color: yellow\">E.</span> <span style=\"background-color: yellow\">Kramer</span> from <span style=\"background-color: yellow\">Moscow,</span> <span style=\"background-color: yellow\">Safak</span> <span style=\"background-color: yellow\">Timur</span> from <span style=\"background-color: yellow\">Istanbul</span> and <span style=\"background-color: yellow\">Sewell</span> <span style=\"background-color: yellow\">Chan</span> from\nLondon. </div></td><td><h3>gold standard over boilerpipe.LargestContentExtractor</h3><div><span style=\"background-color: yellow\">Continue</span>\n<span style=\"background-color: yellow\">reading</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">main</span> story <span style=\"background-color: yellow\">For</span> <span style=\"background-color: yellow\">Turkey,</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Ankara</span> <span style=\"background-color: yellow\">attack</span> resonated <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Turkish</span> collective memory:\n<span style=\"background-color: yellow\">Turkey</span> lost <span style=\"background-color: yellow\">many</span> <span style=\"background-color: yellow\">diplomats</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span> 20th century <span style=\"background-color: yellow\">to</span> Armenian militants <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">a</span> campaign <span style=\"background-color: yellow\">to</span>\navenge <span style=\"background-color: yellow\">the</span> Armenian genocide <span style=\"background-color: yellow\">during</span> World War I. “Turkey <span style=\"background-color: yellow\">is</span> very aware <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> size\n<span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">this</span> failure, <span style=\"background-color: yellow\">and</span> I think <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">government</span> will make every effort <span style=\"background-color: yellow\">to</span> investigate this\nfully,” Sinan Ulgen, <span style=\"background-color: yellow\">a</span> <span style=\"background-color: yellow\">Turkish</span> former <span style=\"background-color: yellow\">diplomat</span> <span style=\"background-color: yellow\">who</span> <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">the</span> chairman <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Center</span> <span style=\"background-color: yellow\">for</span>\nEconomics <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">Foreign</span> Policy Studies, <span style=\"background-color: yellow\">an</span> <span style=\"background-color: yellow\">Istanbul</span> research organization, <span style=\"background-color: yellow\">said</span> <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Russian</span> diplomat’s assassination.\n“I <span style=\"background-color: yellow\">don’t</span> expect <span style=\"background-color: yellow\">any</span> <span style=\"background-color: yellow\">crisis</span> <span style=\"background-color: yellow\">between</span> <span style=\"background-color: yellow\">Turkey</span> <span style=\"background-color: yellow\">and</span> Russia.” Since <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Turkish</span> military incursion into\n<span style=\"background-color: yellow\">Syria</span> <span style=\"background-color: yellow\">in</span> August, <span style=\"background-color: yellow\">Mr.</span> Erdogan’s criticism <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">Russia</span> <span style=\"background-color: yellow\">over</span> <span style=\"background-color: yellow\">Syria</span> <span style=\"background-color: yellow\">had</span> <span style=\"background-color: yellow\">been</span> muted. But <span style=\"background-color: yellow\">Mr.</span>\nErdogan faced <span style=\"background-color: yellow\">a</span> dilemma: Even <span style=\"background-color: yellow\">as</span> <span style=\"background-color: yellow\">he</span> <span style=\"background-color: yellow\">was</span> warming <span style=\"background-color: yellow\">to</span> Russia, <span style=\"background-color: yellow\">he</span> faced <span style=\"background-color: yellow\">a</span> <span style=\"background-color: yellow\">Turkish</span>\npublic, <span style=\"background-color: yellow\">not</span> <span style=\"background-color: yellow\">to</span> mention <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Syrian</span> refugees within <span style=\"background-color: yellow\">Turkey,</span> <span style=\"background-color: yellow\">angry</span> <span style=\"background-color: yellow\">over</span> <span style=\"background-color: yellow\">Russia’s</span> <span style=\"background-color: yellow\">role</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span>\nbombing <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">Aleppo.</span> On <span style=\"background-color: yellow\">Monday</span> <span style=\"background-color: yellow\">evening</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">Istanbul,</span> just <span style=\"background-color: yellow\">after</span> <span style=\"background-color: yellow\">the</span> assassination, <span style=\"background-color: yellow\">a</span> group <span style=\"background-color: yellow\">of</span>\nprotesters gathered outside <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Russian</span> consulate <span style=\"background-color: yellow\">on</span> Istiklal Avenue, <span style=\"background-color: yellow\">the</span> city’s largest pedestrian street. <span style=\"background-color: yellow\">The</span>\ngathering <span style=\"background-color: yellow\">was</span> more street theater than protest, <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">two</span> men <span style=\"background-color: yellow\">lying</span> <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">the</span> street, shrouded\n<span style=\"background-color: yellow\">in</span> bloody sheets <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">Syrian</span> flag, <span style=\"background-color: yellow\">and</span> surrounded <span style=\"background-color: yellow\">by</span> candles, <span style=\"background-color: yellow\">to</span> represent <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">killings</span>\n<span style=\"background-color: yellow\">in</span> Aleppo. Write <span style=\"background-color: yellow\">A</span> Comment Mohammed al-Shibli, <span style=\"background-color: yellow\">a</span> Syrian activist <span style=\"background-color: yellow\">who</span> participated, said, “I felt\nextreme happiness when I heard <span style=\"background-color: yellow\">the</span> news” <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> assassination. <span style=\"background-color: yellow\">He</span> continued: “This <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">the</span>\n<span style=\"background-color: yellow\">first</span> step <span style=\"background-color: yellow\">in</span> getting justice <span style=\"background-color: yellow\">for</span> <span style=\"background-color: yellow\">the</span> Syrian people. <span style=\"background-color: yellow\">The</span> <span style=\"background-color: yellow\">ambassador</span> <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">not</span> innocent. He\nrepresents <span style=\"background-color: yellow\">the</span> foreign policy <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">his</span> murderous state <span style=\"background-color: yellow\">and</span> thus <span style=\"background-color: yellow\">he</span> <span style=\"background-color: yellow\">is</span> <span style=\"background-color: yellow\">a</span> murderer, <span style=\"background-color: yellow\">as</span>\nwell. Now we are waiting for revenge <span style=\"background-color: yellow\">against</span> everyone <span style=\"background-color: yellow\">who</span> shed blood <span style=\"background-color: yellow\">in</span> Syria.” <span style=\"background-color: yellow\">Correction:</span>\n<span style=\"background-color: yellow\">December</span> <span style=\"background-color: yellow\">19,</span> <span style=\"background-color: yellow\">2016</span> <span style=\"background-color: yellow\">An</span> <span style=\"background-color: yellow\">earlier</span> <span style=\"background-color: yellow\">version</span> <span style=\"background-color: yellow\">of</span> this <span style=\"background-color: yellow\">article</span> <span style=\"background-color: yellow\">misidentified</span> <span style=\"background-color: yellow\">the</span> <span style=\"background-color: yellow\">government</span> <span style=\"background-color: yellow\">that</span> <span style=\"background-color: yellow\">has</span> <span style=\"background-color: yellow\">collaborated</span>\n<span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">Russia</span> <span style=\"background-color: yellow\">even</span> <span style=\"background-color: yellow\">though</span> <span style=\"background-color: yellow\">it</span> <span style=\"background-color: yellow\">backs</span> <span style=\"background-color: yellow\">a</span> <span style=\"background-color: yellow\">different</span> <span style=\"background-color: yellow\">side</span> <span style=\"background-color: yellow\">in</span> <span style=\"background-color: yellow\">the</span> Syrian <span style=\"background-color: yellow\">conflict.</span> <span style=\"background-color: yellow\">It</span> <span style=\"background-color: yellow\">is</span>\nTurkey, not <span style=\"background-color: yellow\">Syria.</span> <span style=\"background-color: yellow\">Tim</span> <span style=\"background-color: yellow\">Arango</span> <span style=\"background-color: yellow\">reported</span> <span style=\"background-color: yellow\">from</span> Istanbul, <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">Rick</span> <span style=\"background-color: yellow\">Gladstone</span> <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">New</span> <span style=\"background-color: yellow\">York.</span> <span style=\"background-color: yellow\">Reporting</span>\n<span style=\"background-color: yellow\">was</span> <span style=\"background-color: yellow\">contributed</span> <span style=\"background-color: yellow\">by</span> <span style=\"background-color: yellow\">Ivan</span> <span style=\"background-color: yellow\">Nechepurenko,</span> <span style=\"background-color: yellow\">Oleg</span> <span style=\"background-color: yellow\">Matsnev</span> <span style=\"background-color: yellow\">and</span> <span style=\"background-color: yellow\">Andrew</span> <span style=\"background-color: yellow\">E.</span> <span style=\"background-color: yellow\">Kramer</span> <span style=\"background-color: yellow\">from</span> <span style=\"background-color: yellow\">Moscow,</span> <span style=\"background-color: yellow\">Safak</span> <span style=\"background-color: yellow\">Timur</span>\n<span style=\"background-color: yellow\">and</span> Karam Shoumali <span style=\"background-color: yellow\">from</span> Istanbul, <span style=\"background-color: yellow\">Sewell</span> <span style=\"background-color: yellow\">Chan</span> <span style=\"background-color: yellow\">from</span> London, Gardiner Harris <span style=\"background-color: yellow\">from</span> Washington <span style=\"background-color: yellow\">and</span> Bryant\nRousseau <span style=\"background-color: yellow\">from</span> New York. A version <span style=\"background-color: yellow\">of</span> this article appears <span style=\"background-color: yellow\">in</span> print <span style=\"background-color: yellow\">on</span> December 20,\n2016, <span style=\"background-color: yellow\">on</span> <span style=\"background-color: yellow\">Page</span> A1 <span style=\"background-color: yellow\">of</span> <span style=\"background-color: yellow\">the</span> New York edition <span style=\"background-color: yellow\">with</span> <span style=\"background-color: yellow\">the</span> headline: <span style=\"background-color: yellow\">Russia’s</span> Envoy Gunned\nDown <span style=\"background-color: yellow\">By</span> Lone Turk. Order Reprints | Today's Paper | Subscribe </div></td></tr></table>"
}
] | 5 |
mashrafhemdan1/machine_learning_projects
|
https://github.com/mashrafhemdan1/machine_learning_projects
|
55b6267213addc007601a28edbf351bc6e942cd5
|
33e63f9b4c29dd12c65c885ee77fa90ca3b969ef
|
8a09f06a20d208a8db0f41b2850a6d4ed511c771
|
refs/heads/main
| 2023-02-26T13:17:34.689557 | 2021-02-03T03:24:55 | 2021-02-03T03:24:55 | 328,843,412 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8034993410110474,
"alphanum_fraction": 0.8129205703735352,
"avg_line_length": 91.625,
"blob_id": "5ef5e67b15e4bf1c6b461dbda08b1004887829b5",
"content_id": "de5431092830916b3ae33a8167c35711e178beea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 376,
"num_lines": 8,
"path": "/README.md",
"repo_name": "mashrafhemdan1/machine_learning_projects",
"src_encoding": "UTF-8",
"text": "# Machine Learning Projects\nThis is a set of machine learing projects that was done as part of the MITx 6.86x: Machine Leanring from linear models to deep learning course on Edx. Projects covers a variety of topics including SVM, kernels, Neural Networks, Reinforcement Learning ...etc. The projects doesn't involve sikit-learn functions and libraries. The used ML algorithms is implemented from scratch.\nThe projects are as follows:\n1- Automatic Review Analyzer\n2- Digit Recognition using different algorithms\n3- Movie Rating predictor using Collaborative Learning and EM algorithm\n4- Text-based game using Reinforment Learning\nHere is a link to the MITx course https://www.edx.org/course/machine-learning-with-python-from-linear-models-to\n\n\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5884353518486023,
"avg_line_length": 28.399999618530273,
"blob_id": "a663daf2b7c6fd9fa2a3433ede40c9daf4f94e59",
"content_id": "7acb3c9319771d917bb0e104e69c31d081c26166",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 20,
"path": "/Movie Rating Predictor/my version/main_mine.py",
"repo_name": "mashrafhemdan1/machine_learning_projects",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport kmeans_mine\nimport common_mine\nimport naive_em\nimport em\n\nX = np.loadtxt('toy_data.txt');\nd = X.shape[1]\n# TODO: Your code here\nfor K in [1, 2, 3, 4]:\n min_cost = float('inf')\n mixture = common_mine.GaussianMixture(np.zeros((K, d)), np.zeros((K,)), np.zeros((K,)))\n for seed in [0, 1, 2, 3, 4]:\n post = mixture.init(X, K, seed)\n mixture, post, cost = kmeans_mine.run(X, mixture, post)\n if(cost < min_cost):\n min_cost = cost\n best_mixture = mixture\n best_post = post\n best_mixture.plot(best_post)\n"
},
{
"alpha_fraction": 0.5827620029449463,
"alphanum_fraction": 0.5889650583267212,
"avg_line_length": 30.255102157592773,
"blob_id": "f2ba6936770c45a5ac5084fa5d9e47ccdfa1fb2e",
"content_id": "7380bd2e484b0e25a93c35b09d5b2e39e459af00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3063,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 98,
"path": "/Movie Rating Predictor/my version/kmeans_mine.py",
"repo_name": "mashrafhemdan1/machine_learning_projects",
"src_encoding": "UTF-8",
"text": "\"\"\"Mixture model based on kmeans\"\"\"\nfrom typing import Tuple\nfrom common import GaussianMixture\nimport numpy as np\n\n\ndef estep(X: np.ndarray, mixture: GaussianMixture) -> np.ndarray:\n \"\"\"E-step: Assigns each datapoint to the gaussian component with the\n closest mean\n\n Args:\n X: (n, d) array holding the data\n mixture: the current gaussian mixture\n\n Returns:\n np.ndarray: (n, K) array holding the soft counts\n for all components for all examples\n\n \"\"\"\n # TODO: Add here the implementation of the E step\n n = X.shape[0]\n k = mixture.p.shape[0]\n post = np.zeros(shape=(n, k))\n for i in range(n):\n smallest_dist = float(\"inf\")\n for j in range(k):\n dist = np.linalg.norm(mixture.mu[j, :], X[i, :])\n if dist < smallest_dist:\n smallest_dist = dist\n j_min = j\n post[i, j_min] = 1\n return post\n\n\ndef mstep(X: np.ndarray, post: np.ndarray) -> Tuple[GaussianMixture, float]:\n \"\"\"M-step: Updates the gaussian mixture. Each cluster\n yields a component mean and variance.\n\n Args: X: (n, d) array holding the data\n post: (n, K) array holding the soft counts\n for all components for all examples\n\n Returns:\n GaussianMixture: the new gaussian mixture\n float: the distortion cost for the current assignment\n \"\"\"\n # TODO: Add here the implementation of the M step\n mixture = GaussianMixture\n k = post.shape[1]\n n = post.shape[0]\n d = X.shape[1]\n cost = 0\n mu = np.zeros(k, d)\n var = np.zeros(k)\n p = post.sum(axis=0)\n p = p / n\n for j in range(k):\n cluster_list = X[:, j]\n cluster_list = [i for i, x in enumerate(cluster_list) if x == 1]\n cluster_sum = np.zeros((1, d))\n for i in cluster_list:\n cluster_sum += X[i, :]\n mu[j] = cluster_sum/len(cluster_list)\n cluster_sum = np.zeros((1, d))\n for i in cluster_list:\n cluster_sum += (X[i, :] - mu[j])**2\n cost += (X[i, :] - mixture.mu[j])**2\n var[j] = cluster_sum/(len(cluster_list)*d)\n\n return GaussianMixture(mu, var, p), float(cost)\n\n\ndef run(X: np.ndarray, mixture: GaussianMixture,\n post: np.ndarray) -> Tuple[GaussianMixture, np.ndarray, float]:\n \"\"\"Runs the mixture model\n\n Args:\n X: (n, d) array holding the data\n post: (n, K) array holding the soft counts\n for all components for all examples\n\n Returns:\n GaussianMixture: the new gaussian mixture\n np.ndarray: (n, K) array holding the soft counts\n for all components for all examples\n float: distortion cost of the current assignment\n \"\"\"\n\n # TODO: Add here the implementation of the EM step of the k-means algorithm\n pre_cost = 0\n post_cost = float('inf')\n while abs(pre_cost-post_cost) > 0.0001:\n pre_cost = post_cost\n # E step\n post = estep(X, mixture)\n # M step\n mixture, post_cost = mstep(X, post)\n return mixture, post, post_cost\n"
}
] | 3 |
arturtamborski/goldfinger
|
https://github.com/arturtamborski/goldfinger
|
22819b85797f7f09f30be78432e8eb4d220fb8a0
|
c469b05b31a8bf5dba561b92e3d9ccff5bf3dcdf
|
213317ba2f10aad104a4612112c2fc0a1bbe352b
|
refs/heads/master
| 2022-04-19T18:30:40.867732 | 2020-04-15T13:07:38 | 2020-04-15T13:07:38 | 255,919,473 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5139794945716858,
"alphanum_fraction": 0.5219011902809143,
"avg_line_length": 25.49382781982422,
"blob_id": "a0b55d7abe326eced2deaaf1c2764a004e8feb0a",
"content_id": "4f2f4cc354943efaad62a339fcc8b2138e5c745f",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2154,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 81,
"path": "/goldfinger.py",
"repo_name": "arturtamborski/goldfinger",
"src_encoding": "UTF-8",
"text": "from multiprocessing import get_context\nfrom subprocess import run, PIPE\nfrom sys import argv, exit\nfrom pprint import pprint\nfrom re import search, compile\n\n\n# there's some encoding bug in finger(1)\ntranslation_table = {\n b\"\\xc4M-^E\": \"ę\",\n b\"\\xc4M-^Y\": \"ę\",\n b\"\\xc5M-^[\": \"ś\",\n b\"\\xc5M-^A\": \"Ł\",\n b\"\\xc5M-^B\": \"ł\",\n b\"\\xc5M-^D\": \"ń\",\n b\"\\xc5M-^G\": \"?\",\n b\"\\xc5M-^Z\": \"Ś\",\n b\"\\xc5M-^D\": \"ń\",\n}\n\n\nclass Command:\n def __init__(self, source: str = ''):\n self._source = source\n for k, v in self._patterns.items():\n setattr(self, k, compile(v))\n\n @property\n def _patterns(self) -> str:\n members = self.__class__.__dict__\n members = filter(lambda m: not m.startswith('_'), members)\n return {p: getattr(self, p) for p in members}\n\n\n def __call__(self, *args) -> dict:\n exe = self.__class__.__name__.lower()\n proc = run([exe, *args], stdout=PIPE, stderr=PIPE)\n out, err = proc.stdout, proc.stderr\n\n if proc.returncode or not out or err:\n print(err.decode())\n return dict()\n\n def find(pattern):\n try:\n return pattern.search(self._source).group(1).strip()\n except AttributeError:\n return \"\"\n\n for from_, to in translation_table.items():\n out = out.replace(from_, to.encode())\n\n self._source = out.decode()\n return {k: find(v) for k, v in self._patterns.items()}\n\n\nclass Finger(Command):\n login = \"Login: (.*)\\t\"\n name = \"Name: (.*)\\n\"\n directory = \"Directory: (.*)\\t\"\n shell = \"Shell: (.*)\\n\"\n last_login = \"(?:On|Last login) (.*)\\n\"\n idle = \"(.*) idle\\n\"\n\n\ndef main():\n if len(argv) != 4:\n print(__file__, \"<pattern>\", \"<start index>\", \"<end index>\")\n exit(1)\n\n with get_context('spawn').Pool(processes=4) as pool:\n finger = Finger()\n\n start, end = int(argv[2]), int(argv[3])\n usernames = (argv[1].format(i=i) for i in range(start, end))\n result = pool.map(finger, usernames)\n pprint(result)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6584565043449402,
"alphanum_fraction": 0.7110016345977783,
"avg_line_length": 31.105262756347656,
"blob_id": "e93bd3ebd917573190bceabc1df4d6375c549600",
"content_id": "f9688dfc966163f11c9ae3e3c6e72c0f83482e3d",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 609,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 19,
"path": "/readme.md",
"repo_name": "arturtamborski/goldfinger",
"src_encoding": "UTF-8",
"text": "## goldfinger\n<br>\n\nIt's a multi-processing scraper for `finger(1)`. You can run it like so:\n```\npython3 goldfinger.py \"s{1}\" 1 99999999\n```\n\nwhere `\"s{1}\"` is the username pattern and numbers are used for range. \nThe program will use that to go trough every user named `s<something>` \n(in this case `s1`, `s2`, `s3`, ..., `s99999998`, `s99999999`)\n\n\nIt might be bit overengineered, but hey, it was fun to write it like that. \nOutput is a json list with dictionaries representing users.\n\n\nAlso, there's some weird bug in finger, it can't print unicode characters \ncorrectly, so I'm translating it like so."
}
] | 2 |
RomSnow/DNS-server
|
https://github.com/RomSnow/DNS-server
|
53d3b55be3a3886316ae8504a94ca4716f7e661d
|
71accfa1d5ea207f7123cdedb6fdcf08fd24b734
|
c9cf2dd4525d20d33491776ac6ec4b4b617808ce
|
refs/heads/master
| 2023-04-12T19:54:06.430369 | 2021-05-05T14:08:43 | 2021-05-05T14:08:43 | 362,418,743 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.40480273962020874,
"alphanum_fraction": 0.43224701285362244,
"avg_line_length": 28.897436141967773,
"blob_id": "6c34a2894edd6df1a71c827cd3c61273dfa7111b",
"content_id": "05d69692c4849e8e4fac16b9d2c79865185bc1d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1166,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 39,
"path": "/dns_package/pkg_work.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "from struct import unpack\n\n\nclass PacketWorker:\n def __init__(self, data=None):\n self.data = data\n\n def pack(self, data=None):\n packet = b\"\"\n if data != b'\\xc0\\x0c':\n if data is not None:\n domains = data.split(\".\")\n else:\n domains = self.data.split(\".\")\n\n for domain in domains:\n packet += str(chr(len(domain))).encode(\"utf-8\")\n packet += domain.encode(\"utf-8\")\n packet += str(chr(0)).encode(\"utf-8\")\n else:\n packet += data\n\n return packet\n\n def unpack(self, data, raw):\n domain = \"\"\n while data[0] != 0:\n if data[0] & 192 == 192:\n offset = unpack(\"!H\", data[:2])[0] & 16383\n data = data[2:]\n domain += self.unpack(raw[offset:], raw)[0]\n return domain, data, b\"\\xc0\\x0c\"\n else:\n count = data[0]\n for i in range(1, count + 1):\n domain += chr(data[i])\n domain += '.'\n data = data[count + 1:]\n return domain[:-1], data[1:], b\"\"\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6658614873886108,
"avg_line_length": 23.81999969482422,
"blob_id": "90213f20a5496c79966be2c3a03da3db31c657b2",
"content_id": "b1849814f1e583a4d30a4436f55aa7a59fc4e704",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1487,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 50,
"path": "/README.md",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "# DNS-server\nРеализация кэширующего DNS сервера на Python\n\nАвтор: Ивашкин Роман\n\n## Требования\nДля корректной работы программы необходим выход в интернет или к forward DNS серверу (указывается в параметрах)\n\nИнтерпретатор Python 3\n\n## Параметры\n ```\n server.py [-h] [--forward FORFARD] [--ttl TTL] [--address ADDRESS]\n\n -h, --help справка\n \n --forward FORFARD IP Forward DNS сервера (default: Open Google sever)\n \n --ttl TTL ttl записей в кэше\n \n --address ADDRESS аддресс, по которому можно обратится к серверу\n```\n\n## Пример работы\nВывод утилиты `dig`:\n```\nexampleUSER:~$ dig google.com @127.0.0.1\n\n; <<>> DiG 9.16.6-Ubuntu <<>> google.com @127.0.0.1\n;; global options: +cmd\n;; Got answer:\n;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 40978\n;; flags: qr rd ra; QUERY: 1, ANSWER: 6, AUTHORITY: 0, ADDITIONAL: 0\n\n;; QUESTION SECTION:\n;google.com.\t\t\tIN\tA\n\n;; ANSWER SECTION:\ngoogle.com.\t\t299\tIN\tA\t209.85.233.102\ngoogle.com.\t\t299\tIN\tA\t209.85.233.138\ngoogle.com.\t\t299\tIN\tA\t209.85.233.139\ngoogle.com.\t\t299\tIN\tA\t209.85.233.100\ngoogle.com.\t\t299\tIN\tA\t209.85.233.113\ngoogle.com.\t\t299\tIN\tA\t209.85.233.101\n\n;; Query time: 48 msec\n;; SERVER: 127.0.0.1#53(127.0.0.1)\n;; WHEN: Ср мая 05 17:47:10 +05 2021\n;; MSG SIZE rcvd: 124\n```\n\n"
},
{
"alpha_fraction": 0.6391304135322571,
"alphanum_fraction": 0.6391304135322571,
"avg_line_length": 24.55555534362793,
"blob_id": "c4976325e97b9cfba9b819b04942d2ace40fb564",
"content_id": "6d9b7fecc71b74526ab70888515e007ed7118e8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 18,
"path": "/dns_server/dns_server.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "import asyncio\n\nfrom dns_server.dns_struct import DNS\n\n\nclass DNSServer(asyncio.Protocol):\n def __init__(self, transport=None):\n self.transport = transport\n\n def connection_made(self, transport):\n self.transport = transport\n\n def datagram_received(self, data, addr):\n dns = DNS()\n answer = dns.get_addr(data)\n while answer is None:\n answer = dns.get_addr(data)\n self.transport.sendto(answer, addr)\n"
},
{
"alpha_fraction": 0.5550172924995422,
"alphanum_fraction": 0.5605536103248596,
"avg_line_length": 29.744680404663086,
"blob_id": "c4d506848945648dca3fb4ad690b91e318e69b9d",
"content_id": "a7eaba3fdd168bc2f85a443023c957b2fcd576de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1445,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 47,
"path": "/dns_package/header.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "from struct import pack, unpack\n\n\nclass HeaderQuery:\n def __init__(\n self,\n identification=None,\n flags=None,\n responses_count=0,\n answers_count=0,\n resources_count=0,\n optional_count=0):\n self.identification = identification\n self.flags = flags\n self.responses_count = responses_count\n self.answers_count = answers_count\n self.resources_count = resources_count\n self.optional_count = optional_count\n\n def unpack(self, header_information):\n (self.identification,\n self.flags,\n self.responses_count,\n self.answers_count,\n self.resources_count,\n self.optional_count) = unpack(\"!HHHHHH\", header_information[:12])\n return header_information[12:]\n\n def pack(self):\n header_information = pack(\n \"!HHHHHH\",\n self.identification,\n self.flags,\n self.responses_count,\n self.answers_count,\n self.resources_count,\n self.optional_count)\n return header_information\n\n def __str__(self):\n return \"Header: ID:{} FLAGS:{} NUM_OF_RESP:{} NUM_OF_ANS:{} NUM_OF_VALID:{} NUM_OF_OPT:{}\".format(\n self.identification,\n self.flags,\n self.responses_count,\n self.answers_count,\n self.resources_count,\n self.optional_count)\n"
},
{
"alpha_fraction": 0.6785714030265808,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 27,
"blob_id": "ac84c13dd2de62de8a1c7dc5b552277ef807835e",
"content_id": "d67f3e9605cb3a1f24ca01044ed86b79cf3d68d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/dns_server/dns_errors.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "class DNSError(Exception):\n \"\"\"Ошибка DNS сервера\"\"\"\n"
},
{
"alpha_fraction": 0.5522388219833374,
"alphanum_fraction": 0.5582089424133301,
"avg_line_length": 26.91666603088379,
"blob_id": "26aba0c7605effac60381b2d957bf6b06da84cca",
"content_id": "68866dbad4a00cb264463de7a70deb8041ef1989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 36,
"path": "/dns_package/standart_qry.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "from struct import pack, unpack\n\nfrom dns_package.pkg_work import PacketWorker\n\n\nclass StandartQuery:\n INTERNET_QUESTION_RESPONSE = 1\n DEFAULT_QUESTION_TYPE = 255\n\n def __init__(\n self,\n qname=None,\n qtype=DEFAULT_QUESTION_TYPE,\n qclass=INTERNET_QUESTION_RESPONSE):\n self.type = qtype\n self.qclass = qclass\n self.packer = PacketWorker()\n self.ptr = b\"\"\n if qname != None:\n self.name = PacketWorker.pack(qname)\n\n def unpack(self, data, raw):\n self.name, data, self.ptr = self.packer.unpack(data, raw)\n self.type, self.qclass = unpack(\"!hh\", data[:4])\n return data[4:]\n\n def pack(self):\n if self.ptr != b\"\":\n self.name = self.ptr\n return self.packer.pack(self.name) + pack(\"!hh\", self.type, self.qclass)\n\n def __str__(self):\n return \"QUEST: NAME:{} TYPE:{} CLASS:{}\".format(\n self.name,\n self.type,\n self.qclass)\n"
},
{
"alpha_fraction": 0.591653048992157,
"alphanum_fraction": 0.6047463417053223,
"avg_line_length": 23.93877601623535,
"blob_id": "23faa31c50e9c63ecb3cf957dbfac7bd33050c7b",
"content_id": "652bfcc8cf937cad17861da138a8bfa0bbe98bb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1222,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 49,
"path": "/server.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "import argparse\nimport pickle\nfrom dns_server.dns_errors import DNSError\nfrom dns_server.dns_server import *\n\n\ndef get_args():\n parser = argparse.ArgumentParser(description=\"DNS server\")\n parser.add_argument(\n \"--master\",\n default=\"8.8.4.4\",\n help=\"Master Server IP address (default: Open Google sever)\")\n parser.add_argument(\n \"--ttl\",\n help=\"Time to life data in cache\",\n default=3600, type=int)\n parser.add_argument(\n \"--address\",\n help=\"Address of this DNS server\",\n default='127.0.0.1'\n )\n return parser.parse_args()\n\n\ndef main(arg):\n try:\n cache = pickle.load(open('dump', 'rb'))\n except FileNotFoundError:\n cache = {}\n dns = DNS(arg.master, arg.ttl, cache)\n loop = asyncio.get_event_loop()\n listen = loop.create_datagram_endpoint(\n DNSServer, local_addr=(arg.address, 53))\n transport, protocol = loop.run_until_complete(listen)\n\n try:\n loop.run_forever()\n except DNSError as e:\n print(e)\n except KeyboardInterrupt:\n pickle.dump(dns.cache, open('dump', 'wb'))\n\n transport.close()\n loop.close()\n\n\nif __name__ == \"__main__\":\n args = get_args()\n main(args)\n"
},
{
"alpha_fraction": 0.5395014882087708,
"alphanum_fraction": 0.5445711612701416,
"avg_line_length": 32.33802795410156,
"blob_id": "b3786d51e3a7f7a2c1de5556563887f55629d92a",
"content_id": "44f565cd4a41b3b8fd1642efa28968b47a65be5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2395,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 71,
"path": "/dns_server/dns_struct.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "import datetime\nfrom socket import *\n\nfrom dns_package.dns_msg import DNSMessage\nfrom dns_package.header import HeaderQuery\n\n\nclass Singleton(type):\n \"\"\"Суперкласс, для создание singleton классов\"\"\"\n _instances = {}\n\n def __call__(cls, *args, **kwargs):\n if cls not in cls._instances:\n cls._instances[cls] = super(\n Singleton, cls).__call__(*args, **kwargs)\n return cls._instances[cls]\n\n\nclass DNS(object, metaclass=Singleton):\n def __init__(self, forwarder, ttl, cache):\n self.cache = cache\n self.forwarder = forwarder\n self.err_count = 0\n self.ttl = ttl\n\n def get_addr(self, packet):\n dns_msg = DNSMessage()\n dns_msg.unpack(packet)\n\n for question in dns_msg.query:\n if question.name in self.cache.keys():\n answer, timestamp = self.cache[question.name]\n now = datetime.datetime.now()\n age = now - timestamp\n if age.seconds > self.ttl:\n print('Record is too old, get new data')\n return self._get_addr(question, dns_msg)\n else:\n print(f'Record \"{question.name}\" found in cache')\n return answer.pack()\n else:\n print(f'Record \"{question.name}\" is not found')\n return self._get_addr(question, dns_msg)\n\n def _get_addr(self, question, dns_msg):\n ID = dns_msg.header.identification\n flags = dns_msg.header.flags\n validation = dns_msg.validation\n header = HeaderQuery(\n identification=ID,\n flags=flags,\n responses_count=1,\n answers_count=0,\n resources_count=0,\n optional_count=0)\n msg = DNSMessage(header, [question], [])\n\n try:\n with socket(AF_INET, SOCK_DGRAM) as new_socket:\n new_socket.settimeout(1)\n new_socket.sendto(msg.pack(), (self.forwarder, 53))\n data, addr = new_socket.recvfrom(1024)\n\n answer = DNSMessage()\n answer.unpack(data)\n self.cache[question.name] = (\n answer, datetime.datetime.now())\n print(f'Receiving \"{question.name}\"')\n return data\n except timeout:\n print('DNS server is not reached')\n"
},
{
"alpha_fraction": 0.5173987746238708,
"alphanum_fraction": 0.5225328207015991,
"avg_line_length": 30.303571701049805,
"blob_id": "223284965d7ce8060b74f242e2eea8d79355b27f",
"content_id": "e1d791860305da7551feed4440ce81ca6ad3c2bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1753,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 56,
"path": "/dns_package/record.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\nfrom struct import pack, unpack\nfrom time import time\n\nfrom dns_package.pkg_work import PacketWorker\n\n\nclass ResourceRecord():\n def __init__(\n self,\n all_info=None,\n owner_name=None,\n type=None,\n type_class=None,\n TTL=0):\n self.owner = owner_name\n self.type = type\n self.type_class = type_class\n self.TTL = TTL\n self.length_of_data = None\n self.data = None\n self.expected = int(time()) + TTL\n self.packer = PacketWorker()\n self.used = False\n self.oneOff = TTL == 0\n self.ptr = b\"\"\n self.all_info = all_info\n\n def pack(self):\n data = b\"\"\n if self.ptr != b\"\":\n self.owner = self.ptr\n data += self.packer.pack(self.owner) + pack(\"!h\", self.type) \\\n + pack(\"!h\", self.type_class) + pack(\"!I\", max(0, self.expected - int(time()))) + \\\n pack(\"!H\", self.length_of_data) + self.data\n return data\n\n def unpack(self, data, raw):\n (self.owner, data, self.ptr) = self.packer.unpack(data, raw)\n (self.type, self.type_class, self.TTL, self.length_of_data) = unpack(\"!hhiH\", data[:10])\n self.oneOff = self.TTL == 0\n self.expected = int(time()) + self.TTL\n data = data[10:]\n self.data = data[:self.length_of_data]\n data = data[self.length_of_data:]\n self.all_info = data\n return data\n\n def __str__(self):\n return \"Resource Record: OWNER:{} TYPE:{} CLASS:{} USED:{} EXPECT:{} LENGTH:{}\".format(\n self.owner,\n self.type,\n self.type_class,\n self.used,\n self.expected,\n self.length_of_data)\n"
},
{
"alpha_fraction": 0.5633293390274048,
"alphanum_fraction": 0.5633293390274048,
"avg_line_length": 28.087718963623047,
"blob_id": "90e8bb555fc7d6ec9d66ca1eaa12beb9bd1df463",
"content_id": "a6816274fd82d143c21bb1e288cf479092c60499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1658,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 57,
"path": "/dns_package/dns_msg.py",
"repo_name": "RomSnow/DNS-server",
"src_encoding": "UTF-8",
"text": "from functools import reduce\n\nfrom dns_package.header import HeaderQuery\nfrom dns_package.standart_qry import StandartQuery\nfrom dns_package.record import ResourceRecord\n\n\nclass DNSMessage:\n def __init__(\n self,\n header=HeaderQuery(),\n query=None,\n answers=None):\n self.header = header\n self.query = query\n self.answers = answers\n\n def pack(self):\n data = b\"\"\n data += self.header.pack()\n data += reduce(lambda res, x: res + x.pack(), self.query, b\"\")\n data += reduce(lambda res, x: res + x.pack(), self.answers, b\"\")\n return data\n\n def unpack(self, data):\n raw = data\n data = self.header.unpack(data)\n self.query = []\n self.answers = []\n self.validation = []\n\n for index in range(self.header.responses_count):\n query = StandartQuery()\n data = query.unpack(data, raw)\n self.query.append(query)\n\n for index in range(self.header.answers_count):\n resource_record = ResourceRecord()\n data = resource_record.unpack(data, raw)\n self.answers.append(resource_record)\n\n for index in range(self.header.optional_count):\n resource_record = ResourceRecord()\n data = resource_record.unpack(data, raw)\n self.validation.append(resource_record)\n\n return data\n\n def __str__(self):\n res = \"MESSAGE:\\n\"\n res += str(self.header)\n for q in self.query:\n res += '\\n{}'.format(str(q))\n\n for i in self.answers:\n res += '\\n{}'.format(str(i))\n return res\n"
}
] | 10 |
AleksandarYPetrov/Snake_on_Python3
|
https://github.com/AleksandarYPetrov/Snake_on_Python3
|
4b6966b46ed48ca65328d71f649972f660198518
|
1f2189a1a27af2bf26e2358a159a13e8ac51ad65
|
8b501b3b7b5cf24e47f16cea33dbd73b1734367e
|
refs/heads/master
| 2020-12-07T22:38:03.082158 | 2020-01-09T13:47:16 | 2020-01-09T13:47:16 | 232,818,735 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48266059160232544,
"alphanum_fraction": 0.5224559307098389,
"avg_line_length": 21.240507125854492,
"blob_id": "dc1bbf9206683d76f06bbc787531b837e43277ff",
"content_id": "7a72005562a8031b1b5587fef3b331814d734e4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1759,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 79,
"path": "/snake1.py",
"repo_name": "AleksandarYPetrov/Snake_on_Python3",
"src_encoding": "UTF-8",
"text": "import keyboard\nimport time\nimport multiprocessing\nimport random\n\narea=[]\nfor i in range(25):\n area.append([\"-\"]*20)\n\nrows = len(area)\ncols = len([\"-\"]*20)\n\n\n\nx=10 #ordinata\ny=10 #abcisa\n\nmanager=multiprocessing.Manager()\nshared_list=manager.list()\n\nsnake = [[x, y], [x, y-1], [x, y-2]]\nfood = [random.randint(1,23), random.randint(1,18)]\nshared_list.append(\"\")\n\n\n\ndef printing():\n while True:\n\n for i in snake:\n area[i[0]][i[1]]=\"S\"\n for row in range(25):\n print(area[row])\n area[food[0]][food[1]]=\"F\"\n\n head = snake[0]\n direction = [snake[0][0], snake[0][1] + 1]\n\n\n if shared_list[0] == \"esc\":\n raise Exception(\"Game stopped!\")\n elif shared_list[0] == \"up\":\n direction = [head[0] - 1, head[1]]\n elif shared_list[0] == \"down\":\n direction = [head[0] + 1, head[1]]\n elif shared_list[0] == \"right\":\n direction = [head[0], head[1] + 1]\n elif shared_list[0] == \"left\":\n direction = [head[0], head[1] - 1]\n\n\n new_head = direction\n snake.insert(0,new_head)\n if area[new_head[0]][new_head[1]]==\"S\":\n raise Exception(\"GAME OVER!\")\n\n else:\n area[new_head[0]][new_head[1]]=\"S\"\n\n\n if snake[0][0]==food[0] and snake[0][1]==food[1]:\n snake.append(new_head)\n food[0] = random.randint(1, 23)\n food[1]=random.randint(1, 18)\n else:\n deleted_element=snake.pop()\n area[deleted_element[0]][deleted_element[1]]=\"-\"\n time.sleep(1)\n\n\n\n\n\nif __name__ == '__main__':\n printing=multiprocessing.Process(target=printing)\n\n printing.start()\n while True:\n shared_list[0] = keyboard.read_key()\n\n\n"
}
] | 1 |
pablotoro19/Django-Test
|
https://github.com/pablotoro19/Django-Test
|
cc3664d593df651525108991277df3b792302115
|
df36ca6e7887cd496611cf2c7fe565096b5a0aba
|
6153f527b6b59c5f4cdff0ac2a3cf6a380e27dd9
|
refs/heads/master
| 2022-04-13T11:53:38.917379 | 2020-01-09T02:39:01 | 2020-01-09T02:39:01 | 231,145,473 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.68813556432724,
"alphanum_fraction": 0.698305070400238,
"avg_line_length": 28.5,
"blob_id": "d7e3e1b48a7e91732232bfbf35bad982d48c920d",
"content_id": "aa39331627dbf688a0d9488eb983c1cd5c43f997",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/docker/nginx/Dockerfile",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "FROM nginx:1.13-alpine\n\nCOPY ./docker/nginx/nginx.conf /etc/nginx/nginx.conf\nCOPY ./docker/nginx/entrypoint.sh /entrypoint.sh\n\nRUN ln -sf /dev/stdout /var/log/nginx/access.log && \\\n ln -sf /dev/stderr /var/log/nginx/error.log\n\nCMD [\"nginx\", \"-g\", \"daemon off;\"]\nENTRYPOINT [\"/entrypoint.sh\"]\n"
},
{
"alpha_fraction": 0.6122774481773376,
"alphanum_fraction": 0.6194525361061096,
"avg_line_length": 38.61052703857422,
"blob_id": "71b97d711bbb725ccec54602b0bcd08225237883",
"content_id": "7b19044761c171e728d17a8aea84aa3a0ca44b7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3763,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 95,
"path": "/cornershop-test/user_menu/tests.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from datetime import date, timedelta\n\nimport pytz\nfrom commons.helpers import get_now_cl\n\nimport factory\nfrom menu.factories import MenuFactory, MenuOptionsFactory\nfrom rest_framework import status\nfrom rest_framework.reverse import reverse\nfrom rest_framework.test import APITestCase\nfrom user.factories import UserFactory\nimport random\n\nfrom .factories import OrderFactory\n\n\nclass FakeHttpResponse():\n def __init__(self, status_code=200):\n self.status_code = status_code\n\n def json(self):\n return {}\n\n\nclass UserMenuTestCase(APITestCase):\n\n # def test_create_order(self):\n # menu_date=date.today()\n # menu = MenuFactory(menu_date=menu_date)\n # menu_opt = MenuOptionsFactory(menu=menu)\n # user = UserFactory()\n # order_dict = self.create_order_data(menu_id=menu.id, menu_option=menu_opt.option)\n #\n # with self.settings(LIMIT_TIME=23):\n # response = self.client.post(reverse('create_order', kwargs={\n # 'user_id': user.id}), order_dict, format='json')\n # print(response.data)\n # self.assertEqual(response.status_code, status.HTTP_201_CREATED)\n\n def test_get_ordes_today(self):\n menu_date = get_now_cl().strftime(\"%Y-%m-%d\")\n menu = MenuFactory(menu_date=menu_date)\n menu_opt = MenuOptionsFactory(menu=menu)\n user = UserFactory()\n order = OrderFactory(menu_option=menu_opt, user=user, order_date=menu_date)\n url = reverse('get_orders', kwargs={'user_id': order.user_id})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(response.data[0]['menu_option'], order.menu_option_id)\n\n def test_get_ordes_empty_today(self):\n menu_date=date.today()\n menu = MenuFactory(menu_date=menu_date)\n menu_opt = MenuOptionsFactory(menu=menu)\n user = UserFactory()\n url = reverse('get_orders', kwargs={'user_id': user.id})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(len(response.data), 0)\n\n\n #self.assertEqual(response.data['menu_date'], menu_dict['menu_date'])\n #\n # def test_create_menu_exist(self):\n # menu_date=date.today().strftime(\"%Y-%m-%d\")\n # menu = MenuFactory(menu_date=menu_date)\n # MenuOptionsFactory(menu=menu)\n #\n # menu_dict = self.create_menu_data(menu_date)\n # response = self.client.post(reverse('create_menu', kwargs={\n # 'user_id': 1}), menu_dict, format='json')\n # self.assertEqual(response.status_code, status.HTTP_422_UNPROCESSABLE_ENTITY)\n # self.assertEqual(\n # response.data['menu_date'][0], 'Menu for the date has already been created')\n #\n # def test_update_menu_option(self):\n # menu_date=date.today().strftime(\"%Y-%m-%d\")\n # menu = MenuFactory(menu_date=menu_date)\n # menu_opt = MenuOptionsFactory(menu=menu)\n # description = 'chicken'\n # menu_dict = {'option': menu_opt.option, 'description': description}\n # response = self.client.put(reverse('update_menu', kwargs={\n # 'id': menu.id, 'user_id': 1}), menu_dict, format='json')\n # self.assertEqual(response.status_code, status.HTTP_200_OK)\n # self.assertEqual(response.data['description'], description)\n #\n def create_order_data(self, menu_id, menu_option):\n data = {\n \"menu\": menu_id,\n \"menu_option\": menu_option,\n \"quantity\": random.randint(1, 4),\n \"customizations\": \"tomates sin sal\"\n}\n\n return data\n"
},
{
"alpha_fraction": 0.7659574747085571,
"alphanum_fraction": 0.7735562324523926,
"avg_line_length": 31.899999618530273,
"blob_id": "1e885a9e28ac5946bfc66e77fda20450c6098277",
"content_id": "cf18888f50b4946bdd5e1d17298eba66332e2f18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 658,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 20,
"path": "/cornershop-test/user_menu/factories.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from factory import Faker, SubFactory, LazyAttribute\nfrom factory.django import DjangoModelFactory\nfrom factory.fuzzy import FuzzyInteger\nimport random\nimport pytz\nfrom user.factories import UserFactory\nfrom menu.factories import MenuOptionsFactory\n\nfrom .models import UserMenu\n\n\nclass OrderFactory(DjangoModelFactory):\n class Meta:\n model = UserMenu\n\n user = SubFactory(UserFactory)\n menu_option = SubFactory(MenuOptionsFactory)\n quantity = LazyAttribute(lambda o: random.randint(1, 4))\n customizations = Faker('text', max_nb_chars=300)\n order_date = Faker('date_time_this_year', before_now=False, after_now=True, tzinfo=pytz.utc)\n"
},
{
"alpha_fraction": 0.6229507923126221,
"alphanum_fraction": 0.6352459192276001,
"avg_line_length": 16.428571701049805,
"blob_id": "1f03d068cd4ab95c2fb6a6eb90180cee591cb7a1",
"content_id": "45ab5e8cab8186153e5c8fa9b07c801dbec0c2a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 14,
"path": "/cornershop-test/wait-for.sh",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# wait-for.sh\n\nset -e\n\ncmd=\"$@\"\n\nuntil PGPASSWORD=$DBPASS psql -h \"$DBHOST\" -U \"$DBUSER\" -d \"$DBNAME\" -c '\\q'; do\n >&2 echo \"Postgres is unavailable - sleeping\"\n sleep 1\ndone\n\n>&2 echo \"Postgres is up - executing command\"\nexec $cmd\n"
},
{
"alpha_fraction": 0.5945082902908325,
"alphanum_fraction": 0.5973818898200989,
"avg_line_length": 33.043479919433594,
"blob_id": "23d9167c2e1d6e8016f1adfad807146dcc529a3b",
"content_id": "03b35cc7faa0ad525bcb754ff5ddde597f518e1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3132,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 92,
"path": "/cornershop-test/user_menu/views.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nfrom django.conf import settings\nfrom pytz import timezone\n\nfrom commons.helpers import get_now_cl\nfrom menu.models import Menu, MenuOptions\nfrom rest_framework import status\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.response import Response\nfrom rest_framework.viewsets import ViewSet\nfrom user.models import User\nfrom user_menu.models import UserMenu\n\nfrom .serializers import UserMenuSerializer\n\n\nclass UserMenuViewSet(ViewSet):\n\n def create(self, request, user_id):\n if self.validate_time():\n raise ValidationError({\n 'menu_time': 'You must place orders until 11 AM.'})\n\n order_data = request.data\n order_serializer = UserMenuSerializer(data=order_data)\n\n try:\n user = User.objects.get(id=user_id)\n except User.DoesNotExist:\n raise ValidationError({'user': 'This user is not valid.'})\n\n try:\n if 'menu' not in order_data:\n raise ValidationError({'menu': 'Menu cannot be empty'})\n Menu.objects.get(id=order_data['menu'])\n except Menu.DoesNotExist:\n raise ValidationError({'menu': 'This menu is not valid.'})\n\n try:\n menu_option = MenuOptions.objects.get(\n menu_id=order_data['menu'],\n option=order_data['menu_option'])\n except MenuOptions.DoesNotExist:\n raise ValidationError({\n 'menu_option': 'This menu_option is not valid.'})\n\n if order_serializer.is_valid():\n order = UserMenu.objects.create(\n user=user,\n menu_option=menu_option,\n quantity=order_data['quantity'],\n customizations=order_data['customizations'])\n\n if 'order_date' in order_data:\n order.order_date.add(order_data['order_date'])\n return Response(\n {'message': 'Order created successfully',\n 'order': order.menu_option.description,\n 'customizations': order.customizations,\n 'order_date': order.order_date},\n status=status.HTTP_201_CREATED)\n return Response(\n order_serializer.errors, status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n\n def get(self, request, user_id):\n try:\n User.objects.get(id=user_id)\n except User.DoesNotExist:\n raise ValidationError({\n 'user': 'This user is not valid.'\n })\n\n today = get_now_cl()\n today = today.strftime(\"%Y-%m-%d\")\n\n query = UserMenu.objects\n #Nora(admin) is user_id=1\n if user_id == settings.ADMIN_ID:\n orders = query.filter(order_date=today).all()\n else:\n orders = query.filter(user=user_id, order_date=today).all()\n\n orders_serializer = UserMenuSerializer(orders, many=True)\n return Response(orders_serializer.data)\n\n def validate_time(self):\n now = get_now_cl()\n if now.hour > settings.LIMIT_TIME:\n return True\n\n return False\n"
},
{
"alpha_fraction": 0.5149253606796265,
"alphanum_fraction": 0.7039800882339478,
"avg_line_length": 16.478260040283203,
"blob_id": "768eaabb665616ab67dae70b3b0a410343b4a2e2",
"content_id": "c87386291937347d4722b560e8b3980b9f18b840",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 23,
"path": "/cornershop-test/requirements.txt",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "chardet==3.0.4\ncoreapi==2.3.3\ncoreschema==0.0.4\ncoverage==4.5.2\nDjango==2.0.2\ndjangorestframework==3.9.1\ndocutils==0.14\nfactory-boy==2.11.1\nFaker==1.0.2\ngunicorn==19.9.0\nidna==2.8\nisort==4.3.9\nitypes==1.1.0\npsycopg2-binary==2.8.4\npymongo==3.7.2\npython-dateutil==2.8.0\npython-dotenv==0.10.1\npython-json-logger==0.1.10\npython-slugify==2.0.1\npytz==2018.9\nrequests==2.21.0\nslackclient==1.0.6\ncelery==4.0.2\n"
},
{
"alpha_fraction": 0.7234042286872864,
"alphanum_fraction": 0.7234042286872864,
"avg_line_length": 18.789474487304688,
"blob_id": "979d664b6ecebf418c5a133627586d3e21890799",
"content_id": "901866d35171785a67e50964bdca0b4eb6f2e4d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 19,
"path": "/cornershop-test/user/factories.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import random\n\nimport pytz\n\nfrom factory import Faker, LazyAttribute, SubFactory\nfrom factory.django import DjangoModelFactory\nfrom factory.fuzzy import FuzzyInteger\n\nfrom .models import User\n\n\nclass UserFactory(DjangoModelFactory):\n class Meta:\n model = User\n\n name = Faker('name')\n username = Faker('name')\n email = Faker('email')\n country_code = 'CL'\n"
},
{
"alpha_fraction": 0.4905303120613098,
"alphanum_fraction": 0.5738636255264282,
"avg_line_length": 21.95652198791504,
"blob_id": "a3084c7f01704859f61ffe920f7ff116689cfb6e",
"content_id": "1ad5d972863cf1721547395df598249df717ae9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 23,
"path": "/cornershop-test/menu/migrations/0002_auto_20200107_2113.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2020-01-07 21:13\n\nfrom django.db import migrations, models\nimport uuid\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('menu', '0001_initial'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='menu',\n name='description',\n ),\n migrations.AddField(\n model_name='menu',\n name='uuid',\n field=models.UUIDField(default=uuid.UUID('3f653c77-9625-4552-9a78-d1047753ba1f')),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6618497371673584,
"alphanum_fraction": 0.6618497371673584,
"avg_line_length": 22.066667556762695,
"blob_id": "68d5a0de76fbc97a2e5ed0ccc5c75cd7c3635d59",
"content_id": "bf2116d02f85a12f0520a4380a1c3a6a41e8f794",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 15,
"path": "/cornershop-test/user_menu/urls.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .views import UserMenuViewSet\n\ncreate_order = UserMenuViewSet.as_view({\n 'post': 'create',\n})\n\nget_orders = UserMenuViewSet.as_view({\n 'get': 'get',\n})\n\nurlpatterns = [\n path('user/<int:user_id>', create_order, name='create_order'),\n path('user/<int:user_id>/list', get_orders, name='get_orders'),\n]\n"
},
{
"alpha_fraction": 0.5265456438064575,
"alphanum_fraction": 0.5732015371322632,
"avg_line_length": 13.90068531036377,
"blob_id": "3445700a5ef74f94fb5f21b76a7c5bdc05a584e7",
"content_id": "e48fe004301c3624486ca17ef77e4e35ab2a3c04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4353,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 292,
"path": "/README.md",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "# Cornershop Test\n\n## System requirements\nInstall Docker (Latest stable version)\n\n## Init Project\n```shell\n$ git clone https://github.com/pablotoro19/Backend-Test-Toro.git\n$ cd Backend-Test-Toro/\n```\n\n## Create Docker image and data base (postgresql)\n```shell\n$ make images\n$ make migrate\n```\n\n## In settings.py add configurations\n```python\n\nTOKEN_SLACK = 'token_slack'\nSLACK_CHANNEL = 'default=#almuerzo'\nADMIN_ID = 'default=1'\nLIMIT_TIME = 'default=11'\n```\n\n## Load data\n```shell\n$ make load-data\n```\n\n## Run project\n```shell\n$ make up\n```\n\n## Test\n```shell\n$ make test\n$ make coverage_report\n```\n\n## Components model\n\n\n## Entity–relationship model\n\n\n\n\n# API\nExamples with data loaded previously(Load data) and fake data\n\n\n## Menu\n\n**Create Menu:** https://localhost/menu/user/{user_id}\n\n* method: POST\n\n* Request\n\nhttps://localhost/menu/user/1\n\n```json\n{\n\t\"menu_date\": \"2020-01-09\"\n}\n```\n* Response\n```json\n{\n \"id\": 2,\n \"uuid\": \"51a9bd1d-1896-4174-902e-265da2fcdb33\",\n \"menu_date\": \"2020-01-09\"\n}\n```\n\n**List Menu:** https://localhost/menu\n\n* method: GET\n\n* Request\n\nhttps://localhost/menu\n\n* Response\n```json\n[\n {\n \"id\": 1,\n \"uuid\": \"68be4876-843f-4765-a1c7-8ec2453b2fb5\",\n \"menu_date\": \"2020-01-08\"\n },\n {\n \"id\": 2,\n \"uuid\": \"51a9bd1d-1896-4174-902e-265da2fcdb33\",\n \"menu_date\": \"2020-01-09\"\n }\n]\n```\n\n**Get Menu:** https://localhost/menu/{uuid}\n\n* method: GET\n\n* Request\n\nhttps://localhost/menu/68be4876-843f-4765-a1c7-8ec2453b2fb5\n\n* Response\n```json\n{\n \"id\": 1,\n \"uuid\": \"68be4876-843f-4765-a1c7-8ec2453b2fb5\",\n \"menu_date\": \"2020-01-08\",\n \"options\": [\n {\n \"menu\": 1,\n \"option\": 1,\n \"description\": \"Pure con vienesas y ensalada\"\n },\n {\n \"menu\": 1,\n \"option\": 2,\n \"description\": \"Arroz con pollo y ensalada\"\n },\n {\n \"menu\": 1,\n \"option\": 3,\n \"description\": \"Hamburguesa y papas\"\n },\n {\n \"menu\": 1,\n \"option\": 4,\n \"description\": \"Lentejas y ensalada de tomate\"\n }\n ]\n}\n```\n\n\n## Option\n\n**Create Option:** https://localhost/menu/option/user/{user_id}\n\n* method: POST\n\n* Request\n\nhttps://localhost/menu/option/user/1\n\n```json\n{\n\t\"menu\": 2,\n\t\"option\" : 1,\n\t\"description\": \"Pollo con papas fritas y Ensalada\"\n}\n```\n* Response\n```json\n{\n \"menu\": 2,\n \"option\": 1,\n \"description\": \"Pollo con papas fritas y Ensalada\"\n}\n```\n\n**Update Option:** https://localhost/menu/option/user/{user_id}\n\n* method: PUT\n\n* Request\n\nhttps://localhost/menu/option/user/1\n\n```json\n{\n\t\"menu\": 1,\n\t\"option\" : 1,\n\t\"description\": \"Pastel de choclo y ensalada\"\n}\n```\n* Response\n```json\n{\n \"menu\": 1,\n \"option\": 1,\n \"description\": \"Pastel de choclo y ensalada\"\n}\n```\n\n\n## User\n\n**Create User:** https://localhost/user\n\n* method: POST\n\n* Request\n\nhttps://localhost/user\n\n```json\n{\n\t\"name\": \"Juan\",\n\t\"username\": \"juanito\",\n\t\"email\": \"[email protected]\",\n\t\"country_code\": \"CL\"\n}\n```\n* Response\n```json\n{\n \"id\": 4,\n \"name\": \"Juan\",\n \"username\": \"juanito\",\n \"email\": \"[email protected]\",\n \"country_code\": \"CL\"\n}\n```\n\n**Get User:** https://localhost/user/{user_id}\n\n* method: GET\n\n* Request\n\nhttps://localhost/user/4\n\n* Response\n```json\n{\n \"id\": 4,\n \"name\": \"Juan\",\n \"username\": \"juanito\",\n \"email\": \"[email protected]\",\n \"country_code\": \"CL\"\n}\n```\n\n\n## Order\n\n**Create Order:** https://localhost/order/user/{user_id}\n\n* method: POST\n\n* Request\n\nhttps://localhost/order/user/4\n\n```json\n{\n\t\"menu\": 1,\n\t\"menu_option\": 1,\n\t\"quantity\": 2,\n\t\"customizations\": \"Ensalada solo con limon\"\n}\n```\n* Response\n```json\n{\n \"message\": \"Order created successfully\",\n \"order\": \"Arroz con pollo y ensalada\",\n \"customizations\": \"Ensalada solo con limon\",\n \"order_date\": \"2020-01-08\"\n}\n```\n\n**Get Orders:** https://localhost/order/user/{user_id}\n\n* method: GET\n\n* Request\n\nhttps://localhost/order/user/4\n\n* Response\n```json\n[\n {\n \"customizations\": \"Ensalada solo con limon\",\n \"option\": \"Arroz con pollo y ensalada\",\n \"menu_option\": 2,\n \"quantity\": 2,\n \"order_date\": \"2020-01-08\",\n \"user_name\": \"Juan\",\n \"user_id\": 4\n }\n]\n```\n"
},
{
"alpha_fraction": 0.7263681888580322,
"alphanum_fraction": 0.7330016493797302,
"avg_line_length": 34.47058868408203,
"blob_id": "e83232867a533aa55d362f9ab974c81619c94629",
"content_id": "13d7cf18c35301631a9a6d04cfb5e0cedead7061",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 17,
"path": "/cornershop-test/user_menu/models.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom django.db import models\n\nfrom menu.models import MenuOptions\nfrom user.models import User\nfrom commons.helpers import get_now_cl\n\n\nclass UserMenu(models.Model):\n user = models.ForeignKey(\n \"user.User\", on_delete=models.CASCADE, null=False, blank=False)\n menu_option = models.ForeignKey(\n \"menu.MenuOptions\", on_delete=models.CASCADE, null=False, blank=False)\n quantity = models.IntegerField(default=1)\n customizations = models.CharField(max_length=300, blank=False, null=False)\n order_date = models.DateField(default=get_now_cl().strftime(\"%Y-%m-%d\"))\n"
},
{
"alpha_fraction": 0.6420996785163879,
"alphanum_fraction": 0.6426299214363098,
"avg_line_length": 30.433332443237305,
"blob_id": "9e8050add47fa7f50f23f2acdab4960c3ca38f5e",
"content_id": "75556876eb65c4cc31403b3a5fb9731f3a261083",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1886,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 60,
"path": "/cornershop-test/menu/serializers.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from datetime import date, datetime\n\nfrom pytz import timezone\n\nfrom menu.models import Menu, MenuOptions\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.serializers import ModelSerializer\n\n\nclass MenuSerializer(ModelSerializer):\n\n class Meta:\n model = Menu\n fields = ('id', 'uuid', 'menu_date',)\n\n def validate(self, data):\n if 'menu_date' not in data:\n raise ValidationError({'menu_date': 'Menu date cannot be empty'})\n if Menu.objects.filter(menu_date=data['menu_date']).count() > 0:\n raise ValidationError(\n {'menu_date': 'Menu for the date has already been created'})\n\n return data\n\n def create(self, validated_data):\n dt = datetime.combine(validated_data['menu_date'], datetime.min.time())\n menu_date = (timezone('America/Santiago').localize(dt)).strftime(\"%Y-%m-%d\")\n\n menu = Menu.objects.create(\n menu_date=menu_date)\n\n return menu\n\n\nclass MenuOptionsSerializer(ModelSerializer):\n\n class Meta:\n model = MenuOptions\n fields = ('menu', 'option', 'description')\n\n def validate(self, data):\n if 'menu' not in data:\n raise ValidationError({'Menu': 'Menu cannot be empty'})\n if 'option' not in data:\n raise ValidationError({'option': 'Option cannot be empty'})\n if 'description' not in data:\n raise ValidationError({'description': 'Description cannot be empty'})\n\n return data\n\n def create(self, validated_data):\n option = MenuOptions.objects.create(**validated_data)\n return option\n\n def update(self, instance, validated_data):\n instance.option = validated_data.get('option', instance.option)\n instance.description = validated_data.get('description', instance.description)\n\n instance.save()\n return instance\n"
},
{
"alpha_fraction": 0.687752366065979,
"alphanum_fraction": 0.687752366065979,
"avg_line_length": 23.766666412353516,
"blob_id": "d3a17f9f18e5c2fd065e7862b22558dae3f27b02",
"content_id": "a4dd159ddada8f4214937a5d7352008d46394852",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 745,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 30,
"path": "/cornershop-test/task.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import uuid\n\nfrom django.conf import settings\n\nfrom celery import shared_task\nfrom commons.helpers import generate_uuid\nfrom cornershop-test.celery import app\nfrom secret import TOKEN_SLACK\nfrom slackclient import SlackClient\n\nuuid = generate_uuid()\nurl_menu = \"http://localhost/menu/%s\" % str(uuid)\n\n\n@shared_task\ndef send_slack(options):\n token = settings.SLACK_TOKEN\n sc = SlackClient(slack_token)\n\n menu_options = []\n for o in option:\n menu_options.append(str(o.description))\n\n descriptions = str(menu_options)\n\n sc.api_call(\n \"chat.postMessage\",\n channel=settings.SLACK_CHANNEL,\n text=\"Hola!. \\nDejo el menú de hoy :)\\n\"+ descriptions + \"\\nurl : \"+ url_menu +\" \\nTengan un lindo día! \"\n )\n"
},
{
"alpha_fraction": 0.5979968309402466,
"alphanum_fraction": 0.6057363748550415,
"avg_line_length": 32.280303955078125,
"blob_id": "82232365d58b48e4a2fa1ecc6d2814b94eb7230d",
"content_id": "b7dbe898bae66a6bbfa5866204f39c6e08087af8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4393,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 132,
"path": "/cornershop-test/menu/views.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom django.conf import settings\n\nfrom menu.models import Menu, MenuOptions\nfrom commons.helpers import get_now_cl\nfrom rest_framework import status\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.parsers import JSONParser\nfrom rest_framework.response import Response\nfrom rest_framework.viewsets import ViewSet\nfrom django.shortcuts import render\nfrom .serializers import MenuOptionsSerializer, MenuSerializer\n\n\nclass MenuViewSet(ViewSet):\n\n def index(request):\n return render(request, 'menu/index.html')\n\n #MENU\n\n def create_menu(self, request, user_id):\n #Nora is system admin\n if user_id != settings.ADMIN_ID:\n raise ValidationError(\n {'invalid user': 'the user not permitted to create a menu'})\n\n menu_data = request.data\n menu_serializer = MenuSerializer(data=menu_data)\n\n if menu_serializer.is_valid():\n menu = menu_serializer.save()\n return Response(\n {'id': menu.id,\n 'uuid': menu.uuid,\n 'menu_date': menu.menu_date},\n status=status.HTTP_201_CREATED)\n return Response(\n menu_serializer.errors,\n status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n\n def get_menu(self, request, uuid):\n try:\n menu = Menu.objects.get(uuid=uuid)\n except Menu.DoesNotExist:\n return Response({'Menu not found'}, status=status.HTTP_404_NOT_FOUND)\n\n menu_options = MenuOptions.objects.filter(\n menu=menu.id).all().order_by('option')\n menu_opt_serializer = MenuOptionsSerializer(menu_options, many=True)\n\n return Response(\n {'id': menu.id,\n 'uuid': menu.uuid,\n 'menu_date': menu.menu_date,\n 'options': menu_opt_serializer.data\n })\n\n def list_menu(self, request):\n try:\n menu = Menu.objects.all()\n except Menu.DoesNotExist:\n return Response(\n {'Menus not created'}, status=status.HTTP_404_NOT_FOUND)\n\n menu_serializer = MenuSerializer(menu, many=True)\n\n return Response(menu_serializer.data)\n\n\n\n #OPTIONS\n\n def create_option(self, request, user_id):\n #Nora is system admin\n if user_id != settings.ADMIN_ID:\n raise ValidationError(\n {'invalid user': 'the user not permitted to create a menu'})\n\n option_data = request.data\n\n try:\n Menu.objects.get(id=option_data['menu'])\n except Menu.DoesNotExist:\n return Response({'Menu does not exist'},\n status=status.HTTP_404_NOT_FOUND)\n\n if MenuOptions.objects.filter(option=option_data['option']).count() > 0:\n return Response(\n {'Option already been created'},\n status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n\n option_serializer = MenuOptionsSerializer(data=option_data)\n\n if option_serializer.is_valid():\n option = option_serializer.save()\n return Response(option_serializer.data,\n status=status.HTTP_201_CREATED)\n return Response(\n option_serializer.errors,\n status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n\n def update_option(self, request, user_id):\n #Nora is system admin\n if user_id != settings.ADMIN_ID:\n raise ValidationError(\n {'invalid user': 'the user not permitted to edit a menu'})\n\n option_data = request.data\n\n try:\n Menu.objects.get(id=option_data['menu'])\n except Menu.DoesNotExist:\n return Response(\n {'Menu does not exist'}, status=status.HTTP_404_NOT_FOUND)\n\n try:\n menu_options = MenuOptions.objects.get(\n menu=option_data['menu'], option=option_data['option'])\n except MenuOptions.DoesNotExist:\n return Response(\n {'Option does not exist'}, status=status.HTTP_404_NOT_FOUND)\n\n menu_serializer = MenuOptionsSerializer(\n menu_options, data=option_data, partial=True)\n\n if menu_serializer.is_valid():\n menu_serializer.save()\n return Response(menu_serializer.data)\n return Response(\n menu_serializer.errors, status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 17.399999618530273,
"blob_id": "c547a129fc41b02217f5a723de3b6f42e736dc87",
"content_id": "f1bef1f821ad7aab55b28ca1c59288f59f8e833d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/cornershop-test/user_menu/apps.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass UserMenuConfig(AppConfig):\n name = 'user_menu'\n"
},
{
"alpha_fraction": 0.6352941393852234,
"alphanum_fraction": 0.6352941393852234,
"avg_line_length": 20.25,
"blob_id": "fc5d2a40f7813853cdc50994f0deb072ae2fa65d",
"content_id": "c41a585374250fcd3d618a51e1795890efcfb58d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 16,
"path": "/cornershop-test/user/urls.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .views import UserViewSet\n\ncreate_user = UserViewSet.as_view({\n 'post': 'create_user',\n})\n\nget_user = UserViewSet.as_view({\n 'get': 'get_user',\n})\n\nurlpatterns = [\n path('login', UserViewSet.index),\n path('', create_user, name='create_user'),\n path('<int:id>', get_user, name='get_user'),\n]\n"
},
{
"alpha_fraction": 0.62628573179245,
"alphanum_fraction": 0.62628573179245,
"avg_line_length": 30.25,
"blob_id": "0d7482b4c0ef9c74f5fceda0ffe754a592d27ed5",
"content_id": "3462b6b2a2ccb6a4120feb175333a0c05f3fba67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 875,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 28,
"path": "/cornershop-test/user/serializers.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from user.models import User\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.serializers import ModelSerializer\n\n\nclass UserSerializer(ModelSerializer):\n\n class Meta:\n model = User\n fields = ('id', 'name', 'username', 'email', 'country_code')\n\n\n def validate(self, data):\n if 'username' not in data:\n raise ValidationError({'username': 'Username cannot be empty'})\n if 'country_code' not in data:\n raise ValidationError(\n {'country_code': 'Country Code cannot be empty'})\n return data\n\n def create(self, validated_data):\n user = User.objects.create(\n name=validated_data['name'],\n username=validated_data['username'],\n email=validated_data['email'],\n country_code=validated_data['country_code'])\n\n return user\n"
},
{
"alpha_fraction": 0.7229437232017517,
"alphanum_fraction": 0.7359307408332825,
"avg_line_length": 23.3157901763916,
"blob_id": "93a614c8d5b6a911d1f8abf916bdc99209ddeec5",
"content_id": "13041e48d9eb6302fe7536149dcc01cf2a0c9e27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 19,
"path": "/cornershop-test/cornershop-test/celery.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import, unicode_literals\nimport os\nfrom celery import Celery\n\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'cornershop-test.settings')\n\napp = Celery('celery_app')\n\napp.config_from_object('django.conf:settings', namespace='CELERY')\napp.autodiscover_tasks()\n\n# redis broker\napp.conf.update(\n BROKER_URL='redis://localhost:6379/0',\n)\n\[email protected](bind=True)\ndef debug_task(self):\n print('Request: {0!r}'.format(self.request))\n"
},
{
"alpha_fraction": 0.6226158142089844,
"alphanum_fraction": 0.6314713954925537,
"avg_line_length": 30.913043975830078,
"blob_id": "db0cfe21e8a6add31cd4dd4629fd87f5ec1046f9",
"content_id": "d700a2ad31ac1f1af6e682e4a6ca3e9eae878367",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1468,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 46,
"path": "/cornershop-test/user/tests.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from datetime import date, timedelta\n\nimport factory\nfrom rest_framework import status\nfrom rest_framework.reverse import reverse\nfrom rest_framework.test import APITestCase\n\nfrom .factories import UserFactory\n\n\nclass FakeHttpResponse():\n def __init__(self, status_code=200):\n self.status_code = status_code\n\n def json(self):\n return {}\n\n\nclass UserTestCase(APITestCase):\n\n def test_get_user(self):\n user = UserFactory()\n url = reverse('get_user', kwargs={'id': user.id})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(response.data['username'], user.username)\n\n def test_get_user_empty(self):\n user = UserFactory()\n url = reverse('get_user', kwargs={'id': user.id + 1})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_404_NOT_FOUND)\n\n def test_create_user(self):\n user_dict = self.create_user_data()\n response = self.client.post(reverse('create_user'), user_dict, format='json')\n self.assertEqual(response.status_code, status.HTTP_201_CREATED)\n self.assertEqual(response.data['username'], user_dict['username'])\n\n def create_user_data(self):\n return {\n \"name\": \"Pedro\",\n \"username\": \"pedroo_o\",\n \"email\": \"[email protected]\",\n \"country_code\": \"CL\"\n }\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 29.33333396911621,
"blob_id": "2ae77ee9a6e9ba5773b93004d18fe343ed74a9a2",
"content_id": "6d9be357afc2518f21e806effa550504d09edcb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 6,
"path": "/docker/nginx/entrypoint.sh",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# You need to specify the environment variable of the upstream uwsgi at docker run\n\nsed -i \"s/<GUNICORN_SERVER_IP>/${GUNICORN_SERVER_IP}/\" /etc/nginx/nginx.conf\nexec \"$@\"\n"
},
{
"alpha_fraction": 0.7310924530029297,
"alphanum_fraction": 0.7373949289321899,
"avg_line_length": 33,
"blob_id": "b0b2428ae3e875a0d9e20d29c5dbf330ac961771",
"content_id": "6c0064dea6a9b55474778bb449fb9699feb8b7ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 14,
"path": "/cornershop-test/menu/models.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom commons.helpers import generate_uuid\n\n\nclass Menu(models.Model):\n menu_date = models.DateField(null=False, blank=False)\n uuid = models.UUIDField(default=generate_uuid())\n\n\nclass MenuOptions(models.Model):\n option = models.IntegerField(blank=False, null=False)\n description = models.CharField(max_length=300, blank=False, null=False)\n menu = models.ForeignKey(\n \"Menu\", on_delete=models.CASCADE, null=False, blank=False)\n"
},
{
"alpha_fraction": 0.6785361170768738,
"alphanum_fraction": 0.6874381899833679,
"avg_line_length": 30.59375,
"blob_id": "4e256312abc55d3e81728388e78690f79e03e832",
"content_id": "0867ac626f773e38009caa84b55351afc974062e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1011,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 32,
"path": "/cornershop-test/user/views.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\n\nfrom rest_framework import status\nfrom rest_framework.response import Response\nfrom rest_framework.viewsets import ViewSet\n\nfrom .models import User\nfrom .serializers import UserSerializer\n\n\nclass UserViewSet(ViewSet):\n\n def index(request):\n return render(request, 'user/index.html')\n\n def create_user(self, request):\n user_data = request.data\n user_serializer = UserSerializer(data=user_data)\n if user_serializer.is_valid():\n user = user_serializer.save()\n return Response(user_serializer.data, status=status.HTTP_201_CREATED)\n return Response(\n user_serializer.errors, status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n\n def get_user(self, request, id):\n try:\n user = User.objects.get(id=id)\n except User.DoesNotExist:\n return Response(status=status.HTTP_404_NOT_FOUND)\n user_serializer = UserSerializer(user)\n\n return Response(user_serializer.data)\n"
},
{
"alpha_fraction": 0.6891495585441589,
"alphanum_fraction": 0.7184750437736511,
"avg_line_length": 36.88888931274414,
"blob_id": "0dddd393bb68b9c9d3d127e7a9430aaf328bd7fa",
"content_id": "f3b98c15ebf9b8c473a3dedf583c4c7581b4d213",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/cornershop-test/user/models.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass User(models.Model):\n name = models.CharField(max_length=128, null=False, blank=False)\n username = models.CharField(\n max_length=128, unique=True, null=False, blank=False)\n email = models.CharField(max_length=128)\n country_code = models.CharField(max_length=3, null=False, blank=False)\n"
},
{
"alpha_fraction": 0.5688657164573669,
"alphanum_fraction": 0.5694444179534912,
"avg_line_length": 31.60377311706543,
"blob_id": "8185ed51a26c51122cc61068b5fc9568e3af32b1",
"content_id": "181bcf399963867e0203ecf86cbe5b77a117a128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1728,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 53,
"path": "/cornershop-test/commons/loggers.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom django.conf import settings\n\n\ndef get_json_logger(name=None):\n return JsonLogger(logging.getLogger(name))\n\n\nclass JsonLogger:\n def __init__(self, logger):\n self.logger = logger\n\n def __encode_keys(self, **kwargs):\n reserved_keys = ['stack_info', 'exc_info']\n encoded_keys = {}\n for k, v in kwargs.items():\n if k not in reserved_keys:\n encoded_keys[k] = v\n for k in encoded_keys:\n kwargs.pop(k)\n\n encoded_keys['index'] = getattr(settings, 'LOG_INDEX', None)\n encoded_keys['source'] = getattr(settings, 'LOG_SOURCE', None)\n\n if len(encoded_keys) > 0:\n kwargs['extra'] = encoded_keys\n\n return kwargs\n\n def debug(self, ___msg, *args, **kwargs):\n self.logger.debug(___msg, *args, **self.__encode_keys(**kwargs))\n\n def info(self, ___msg, *args, **kwargs):\n self.logger.info(___msg, *args, **self.__encode_keys(**kwargs))\n\n def warning(self, ___msg, *args, **kwargs):\n self.logger.warning(___msg, *args, **self.__encode_keys(**kwargs))\n\n def warn(self, ___msg, *args, **kwargs):\n self.logger.warn(___msg, *args, **self.__encode_keys(**kwargs))\n\n def error(self, ___msg, *args, **kwargs):\n self.logger.error(___msg, *args, **self.__encode_keys(**kwargs))\n\n def exception(self, ___msg, *args, **kwargs):\n self.logger.exception(___msg, *args, **self.__encode_keys(**kwargs))\n\n def critical(self, ___msg, *args, **kwargs):\n self.logger.critical(___msg, *args, **self.__encode_keys(**kwargs))\n\n def log(self, ___level, ___msg, *args, **kwargs):\n self.logger.log(___level, ___msg, *args, **self.__encode_keys(**kwargs))\n"
},
{
"alpha_fraction": 0.6236559152603149,
"alphanum_fraction": 0.6236559152603149,
"avg_line_length": 25.571428298950195,
"blob_id": "55484046126d012bdce696b4580ab7862ea0d6a8",
"content_id": "bb20efd87614c8eca573ce16f069fbce40e89575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 7,
"path": "/cornershop-test/cornershop-test/urls.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.urls import include, path\n\nurlpatterns = [\n path('menu/', include('menu.urls')),\n path('user/', include('user.urls')),\n path('order/', include('user_menu.urls')),\n]\n"
},
{
"alpha_fraction": 0.6908372044563293,
"alphanum_fraction": 0.6908372044563293,
"avg_line_length": 30.60416603088379,
"blob_id": "c6349c3ef1a6afa8378589c4e8ffe361b1f907d9",
"content_id": "73a5f84c902349143963438ffb20fd63c47f70c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1517,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 48,
"path": "/Makefile",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "SERVICE := cornershop-test\n\nifdef NO_CACHE\n\tBUILD_CACHE_FLAG := --no-cache\nendif\n\nimages:\n\tdocker build ${BUILD_CACHE_FLAG} -t ${SERVICE}:dev -f docker/django/Dockerfile .\n\tdocker build ${BUILD_CACHE_FLAG} -t ${SERVICE}-gateway:dev -f docker/nginx/Dockerfile .\n\n###########################\n####### DEVELOPMENT #######\n###########################\nup:\n\tdocker-compose up\n\nload-data:\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py loaddata menu/fixtures/menu.json'\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py loaddata menu/fixtures/options.json'\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py loaddata user/fixtures/users.json'\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py loaddata user_menu/fixtures/orders.json'\n\nmigrate:\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py migrate'\n\nmakemigrations:\n\tdocker-compose run --rm ${SERVICE} sh -c './wait-for.sh python manage.py makemigrations'\n\nshell:\n\tdocker-compose run --rm ${SERVICE} python manage.py shell\n\ntest:\n\tdocker-compose run ${SERVICE} sh -c './wait-for.sh python manage.py test'\n\nbash:\n\tdocker-compose run --rm ${SERVICE} sh\n\nadd-app:\n\tdocker-compose run --rm ${SERVICE} python manage.py startapp ${APP}\n\nisort:\n\tdocker-compose run --rm ${SERVICE} isort -rc --skip migrations .\n\ncoverage:\n\tdocker-compose run --rm ${SERVICE} coverage run manage.py test\n\ncoverage_report:\n\tdocker-compose run --rm ${SERVICE} coverage report\n"
},
{
"alpha_fraction": 0.6873449087142944,
"alphanum_fraction": 0.6972704529762268,
"avg_line_length": 19.149999618530273,
"blob_id": "1115c844c92c840746ff58b39fcc10127baf1e32",
"content_id": "bc28d9a332e631a9d17761f3e826ff42488c6975",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 20,
"path": "/cornershop-test/commons/helpers.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import uuid\n\n\nfrom datetime import datetime\n\nfrom django.conf import settings\nfrom pytz import timezone\n\n\n#shared space for common functions\n\ndef generate_uuid():\n return uuid.uuid4()\n\ndef get_now_cl():\n try:\n tz = timezone('America/Santiago')\n return datetime.now(tz)\n except Exception as e:\n raise Response({'error': str(e)}, status=status.HTTP_422_UNPROCESSABLE_ENTITY)\n"
},
{
"alpha_fraction": 0.6071175932884216,
"alphanum_fraction": 0.6160735487937927,
"avg_line_length": 38.654205322265625,
"blob_id": "585bdd4999534423d51561aa824a472e6a48cc26",
"content_id": "a59ccb2f79150ed81d8dba18219d892ef1cb4993",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4243,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 107,
"path": "/cornershop-test/menu/tests.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from datetime import date, timedelta\n\nimport factory\nfrom commons.helpers import generate_uuid, get_now_cl\nfrom rest_framework import status\nfrom rest_framework.reverse import reverse\nfrom rest_framework.test import APITestCase\n\nfrom .factories import MenuFactory, MenuOptionsFactory\n\n\nclass FakeHttpResponse():\n def __init__(self, status_code=200):\n self.status_code = status_code\n\n def json(self):\n return {}\n\n\nclass MenuTestCase(APITestCase):\n\n def test_list_menu(self):\n menu_date = get_now_cl().strftime(\"%Y-%m-%d\")\n menu_date_2 = (get_now_cl() + timedelta(days=1)).strftime(\"%Y-%m-%d\")\n MenuFactory(menu_date=menu_date)\n MenuFactory(menu_date=menu_date_2)\n\n url = reverse('list_menu')\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(len(response.data), 2)\n\n def test_list_menu_empty(self):\n url = reverse('list_menu')\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(len(response.data), 0)\n\n def test_get_menu_today(self):\n menu_date = get_now_cl().strftime(\"%Y-%m-%d\")\n menu = MenuFactory(menu_date=menu_date)\n MenuOptionsFactory(menu=menu)\n url = reverse('get_menu', kwargs={'uuid': menu.uuid})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(\n response.data['menu_date'].strftime(\"%Y-%m-%d\"), menu_date)\n\n def test_get_menu_empty_today(self):\n uuid = generate_uuid()\n menu_date = get_now_cl().strftime(\"%Y-%m-%d\")\n MenuFactory(menu_date=menu_date)\n url = reverse('get_menu', kwargs={'uuid': uuid})\n response = self.client.get(f'{url}', format='json')\n self.assertEqual(response.status_code, status.HTTP_404_NOT_FOUND)\n\n def test_create_menu(self):\n menu_date=date.today()\n menu_dict = self.create_menu_data(menu_date.strftime(\"%Y-%m-%d\"))\n response = self.client.post(reverse('create_menu', kwargs={\n 'user_id': 1}), menu_dict, format='json')\n self.assertEqual(response.status_code, status.HTTP_201_CREATED)\n self.assertEqual(response.data['menu_date'], menu_dict['menu_date'])\n\n def test_create_menu_exist(self):\n menu_date=date.today().strftime(\"%Y-%m-%d\")\n menu = MenuFactory(menu_date=menu_date)\n MenuOptionsFactory(menu=menu)\n menu_dict = self.create_menu_data(menu_date)\n response = self.client.post(reverse('create_menu', kwargs={\n 'user_id': 1}), menu_dict, format='json')\n self.assertEqual(response.status_code, status.HTTP_422_UNPROCESSABLE_ENTITY)\n self.assertEqual(\n response.data['menu_date'][0], 'Menu for the date has already been created')\n\n def create_menu_data(self, menu_date):\n data = {\n \"menu_date\": menu_date\n }\n\n return data\n\n\nclass MenuOptionTestCase(APITestCase):\n\n def test_create_option(self):\n menu_date=date.today().strftime(\"%Y-%m-%d\")\n menu = MenuFactory(menu_date=menu_date)\n opt_dict = {'menu': menu.id,\n 'option': 3,\n 'description': 'chicken'}\n response = self.client.post(reverse('options', kwargs={\n 'user_id': 1}), opt_dict, format='json')\n self.assertEqual(response.status_code, status.HTTP_201_CREATED)\n self.assertEqual(response.data['option'], opt_dict['option'])\n\n def test_update_menu_option(self):\n menu_date=date.today().strftime(\"%Y-%m-%d\")\n menu = MenuFactory(menu_date=menu_date)\n menu_opt = MenuOptionsFactory(menu=menu)\n opt_dict = {'menu': menu.id,\n 'option': menu_opt.option,\n 'description': 'chicken'}\n response = self.client.put(\n reverse('options', kwargs={'user_id': 1}), opt_dict, format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(response.data['description'], opt_dict['description'])\n"
},
{
"alpha_fraction": 0.6411985158920288,
"alphanum_fraction": 0.6411985158920288,
"avg_line_length": 29.340909957885742,
"blob_id": "02bba72d216ee90297acd8f9d6022e6ad82612a1",
"content_id": "cb664945186b98cc995bc97d4624847184e133ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 44,
"path": "/cornershop-test/user_menu/serializers.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from menu.models import MenuOptions\nfrom rest_framework import serializers\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.serializers import ModelSerializer\nfrom user.models import User\nfrom user_menu.models import UserMenu\n\n\nclass UserMenuSerializer(ModelSerializer):\n\n option = serializers.SerializerMethodField(read_only=True)\n user_id = serializers.SerializerMethodField(read_only=True)\n user_name = serializers.SerializerMethodField(read_only=True)\n\n class Meta:\n model = UserMenu\n fields = (\n 'customizations',\n 'option',\n 'menu_option',\n 'quantity',\n 'order_date',\n 'user_name',\n 'user_id',\n )\n\n def get_option(self, user_menu):\n mo = MenuOptions.objects.filter(id=user_menu.menu_option.id).first()\n return mo.description\n\n def get_user_id(self, user_menu):\n return user_menu.user.id\n\n def get_user_name(self, user_menu):\n return user_menu.user.name\n\n def validate(self, data):\n if 'menu_option' not in data:\n raise ValidationError(\n {'menu_option': 'Menu option cannot be empty'})\n if 'quantity' not in data:\n raise ValidationError({'quantity': 'Quantity cannot be empty'})\n\n return data\n"
},
{
"alpha_fraction": 0.5870967507362366,
"alphanum_fraction": 0.6709677577018738,
"avg_line_length": 14.5,
"blob_id": "2b7ceaf397b7fd84484a5c2d0cece0a08a4a8dc4",
"content_id": "408dc558c4eb9ba886cfec77737a39217c94f770",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/docker/django/gunicorn.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import os\n\nbind = \"0.0.0.0:4545\"\nbacklog = 2048\nworkers = 2\ndaemon = False\npidfile = \"/tmp/cornershop-test.pid\"\nuser = \"root\"\ngroup = \"root\"\nreload = True\n"
},
{
"alpha_fraction": 0.5712831020355225,
"alphanum_fraction": 0.5987780094146729,
"avg_line_length": 32.86206817626953,
"blob_id": "a1086ec482876509ee3620ab7d150da8426e80d6",
"content_id": "e2288ad5938029e53bf5b848b97926ae3e435b3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 982,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 29,
"path": "/cornershop-test/user_menu/migrations/0001_initial.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.2 on 2020-01-04 14:43\n\nimport datetime\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('user', '0001_initial'),\n ('menu', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='UserMenu',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('quantity', models.IntegerField(default=1)),\n ('customizations', models.CharField(max_length=300)),\n ('order_date', models.DateField(default=datetime.date.today)),\n ('menu_option', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='menu.MenuOptions')),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='user.User')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7420435547828674,
"alphanum_fraction": 0.7453936338424683,
"avg_line_length": 24.95652198791504,
"blob_id": "e8ee707527f1c691dbf1bcf8ab050c76fd70b00e",
"content_id": "f6c721293f54237a7604875fb2e79fa980a967ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 23,
"path": "/cornershop-test/menu/factories.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from factory import Faker, SubFactory, LazyAttribute\nfrom factory.django import DjangoModelFactory\nfrom factory.fuzzy import FuzzyInteger\nimport random\nimport pytz\n\nfrom .models import Menu, MenuOptions\n\n\nclass MenuFactory(DjangoModelFactory):\n class Meta:\n model = Menu\n\n menu_date = Faker('date_time_this_year', before_now=False, after_now=True, tzinfo=pytz.utc)\n\n\nclass MenuOptionsFactory(DjangoModelFactory):\n class Meta:\n model = MenuOptions\n\n description = Faker('text')\n option = LazyAttribute(lambda o: random.randint(1, 4))\n menu = SubFactory(MenuFactory)\n"
},
{
"alpha_fraction": 0.617427408695221,
"alphanum_fraction": 0.6211618185043335,
"avg_line_length": 22.861385345458984,
"blob_id": "31fa85cab5453307265a2410ad224a2bff03fe2a",
"content_id": "b20ab7a08eb44847863904155a9a64b7fb2ee766",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2410,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 101,
"path": "/cornershop-test/cornershop-test/settings.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom dotenv import load_dotenv\n\nif os.environ.get('APP_ENV') == 'DEV':\n load_dotenv()\n\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\nSECRET_KEY = 'x4x^w^%g9zs5=9a20^6r5z4o66e2=o%z*st9eh(f!gtg&km_be'\n\nADMIN_ID=1\n\nLIMIT_TIME = os.environ.get('LIMIT_TIME', 23)\n\nDEBUG = True\n\nALLOWED_HOSTS = {\n 'DEV': lambda: [\"*\"],\n}[os.environ.get('APP_ENV', 'DEV')]()\n\nSLACK_TOKEN = 'xoxp-895727865191-893879730005-885527111649-86318dc6638d972be4d3cdb5617179f4'\nSLACK_CHANNEL = '#almuerzo'\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'commons',\n 'menu',\n 'user',\n 'user_menu',\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n]\n\nROOT_URLCONF = 'cornershop-test.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'cornershop-test.wsgi.application'\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql_psycopg2',\n 'NAME': os.environ.get('DBNAME', ''),\n 'USER': os.environ.get('DBUSER', ''),\n 'PASSWORD': os.environ.get('DBPASS', ''),\n 'HOST': os.environ.get('DBHOST', ''),\n },\n}\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\nSTATIC_URL = '/static/'\n"
},
{
"alpha_fraction": 0.620192289352417,
"alphanum_fraction": 0.620192289352417,
"avg_line_length": 20.517240524291992,
"blob_id": "442bc86819e6858bf66a2c6357187ccc2d599867",
"content_id": "5fa4fe1800987200bfdfbe2bed82ca30c962c99f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 29,
"path": "/cornershop-test/menu/urls.py",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom .views import MenuViewSet\n\nget_menu = MenuViewSet.as_view({\n 'get': 'get_menu',\n})\n\nlist_menu = MenuViewSet.as_view({\n 'get': 'list_menu',\n})\n\ncreate_menu = MenuViewSet.as_view({\n 'post': 'create_menu',\n})\n\noptions = MenuViewSet.as_view({\n 'post': 'create_option',\n 'put': 'update_option',\n})\n\n\nurlpatterns = [\n path('home', MenuViewSet.index),\n path('', list_menu, name='list_menu'),\n path('<uuid:uuid>', get_menu, name='get_menu'),\n path('user/<int:user_id>', create_menu, name='create_menu'),\n path('option/user/<int:user_id>', options, name='options'),\n]\n"
},
{
"alpha_fraction": 0.7331671118736267,
"alphanum_fraction": 0.748129665851593,
"avg_line_length": 21.27777862548828,
"blob_id": "3954500f26db7d4ddc9ab57894bcc4f4f51c7642",
"content_id": "adb49b69bf7ce237f3f1bdfc48cbdbede84b7878",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 401,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 18,
"path": "/docker/django/Dockerfile",
"repo_name": "pablotoro19/Django-Test",
"src_encoding": "UTF-8",
"text": "FROM python:3-alpine\n\nENV PYTHONUNBUFFERED 1\n\nRUN apk add --no-cache gcc postgresql-dev postgresql-client python-dev musl-dev linux-headers\n\nENV DJANGO_ROOT /usr/src/app\nRUN mkdir -p $DJANGO_ROOT\n\nWORKDIR $DJANGO_ROOT\n\nCOPY ./cornershop-test .\nCOPY ./docker/django/gunicorn.py /etc/.\n\nRUN pip install -r requirements.txt\n\nEXPOSE 4545\nCMD [\"gunicorn\", \"cornershop-test.wsgi\", \"-c\", \"/etc/gunicorn.py\"]\n"
}
] | 35 |
yifangd/sesrelay
|
https://github.com/yifangd/sesrelay
|
d509dc1aee67eac90e27e391e6aa89d6358b69cc
|
1d3c683a38b5ed4a1967c30f8c58a5065605d5f7
|
5a77ea86b3565b838177e92b9ab3a955c95f2d5c
|
refs/heads/master
| 2021-06-12T14:36:23.498789 | 2017-03-20T13:34:15 | 2017-03-20T13:34:15 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49025973677635193,
"alphanum_fraction": 0.701298713684082,
"avg_line_length": 16.11111068725586,
"blob_id": "45535429af7d3800995c96eb7f80e1e32675652e",
"content_id": "a4edc7710ca897a1d51eef82d21b48cf8d132f75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 18,
"path": "/requirements.txt",
"repo_name": "yifangd/sesrelay",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.3\nattrs==16.3.0\nAutomat==0.5.0\nboto3==1.4.4\nbotocore==1.5.26\nconstantly==15.1.0\ndocutils==0.13.1\nfutures==3.0.5\nincremental==16.10.1\njmespath==0.9.2\npackaging==16.8\npkg-resources==0.0.0\npyparsing==2.2.0\npython-dateutil==2.6.0\ns3transfer==0.1.10\nsix==1.10.0\nTwisted==17.1.0\nzope.interface==4.3.3\n"
},
{
"alpha_fraction": 0.6986255645751953,
"alphanum_fraction": 0.7013074159622192,
"avg_line_length": 26.620370864868164,
"blob_id": "4325bb1261ba3cc403b07d31bac5d46ebb5e4ba8",
"content_id": "c4b5ef37be562504c7cb9e4ff3f083843a34433b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2983,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 108,
"path": "/sesrelay.py",
"repo_name": "yifangd/sesrelay",
"src_encoding": "UTF-8",
"text": "# Copyright (c) Twisted Matrix Laboratories.\n# See LICENSE for details.\n\n# Based on \n# http://twistedmatrix.com/documents/current/_downloads/emailserver.tac\n# https://github.com/twisted/twisted/blob/trunk/LICENSE\n\n\"\"\"\nsend messages received over smtp via ses api\n\"\"\"\n\nfrom __future__ import print_function\n\nfrom zope.interface import implementer\n\nfrom twisted.internet import defer\nfrom twisted.mail import smtp\nfrom twisted.mail.imap4 import LOGINCredentials, PLAINCredentials\n\nfrom twisted.cred.checkers import InMemoryUsernamePasswordDatabaseDontUse\nfrom twisted.cred.portal import IRealm\nfrom twisted.cred.portal import Portal\n\nimport boto3\nimport logging\nimport os\n\ndef send_message(msg):\n session = boto3.Session()\n client = session.client('ses', region_name=os.environ.get('AWS_DEFAULT_REGION', 'us-east-1'))\n try:\n client.send_raw_email(RawMessage={'Data': msg})\n except Exception as e:\n logging.error(\"Err sending email: %s\" % e)\n return False\n return True\n\n\n@implementer(smtp.IMessageDelivery)\nclass RelayMessageDelivery:\n def receivedHeader(self, helo, origin, recipients):\n return \"Received: MessageDelivery\"\n\n def validateFrom(self, helo, origin):\n # All addresses are accepted\n return origin\n\n def validateTo(self, user):\n return lambda: RelayMessage()\n\n\n@implementer(smtp.IMessage)\nclass RelayMessage:\n def __init__(self):\n self.lines = []\n\n def lineReceived(self, line):\n self.lines.append(line)\n\n def eomReceived(self):\n from twisted.internet import threads\n print(\"New message received:\")\n msg = \"\\n\".join(self.lines)\n self.lines = None\n return threads.deferToThread(send_message, msg)\n\n def connectionLost(self):\n # There was an error, throw away the stored lines\n self.lines = None\n\n\nclass SESRelaySMTPFactory(smtp.SMTPFactory):\n protocol = smtp.ESMTP\n\n def __init__(self, *a, **kw):\n smtp.SMTPFactory.__init__(self, *a, **kw)\n self.delivery = RelayMessageDelivery()\n\n def buildProtocol(self, addr):\n p = smtp.SMTPFactory.buildProtocol(self, addr)\n p.delivery = self.delivery\n p.challengers = {\"LOGIN\": LOGINCredentials, \"PLAIN\": PLAINCredentials}\n return p\n\n\n@implementer(IRealm)\nclass SimpleRealm:\n def requestAvatar(self, avatarId, mind, *interfaces):\n if smtp.IMessageDelivery in interfaces:\n return smtp.IMessageDelivery, RelayMessageDelivery(), lambda: None\n raise NotImplementedError()\n\n\ndef main():\n from twisted.application import internet\n from twisted.application import service\n\n portal = Portal(SimpleRealm())\n checker = InMemoryUsernamePasswordDatabaseDontUse()\n checker.addUser(\"guest\", \"guest\")\n portal.registerChecker(checker)\n\n app = service.Application(\"SES Relay SMTP Server\")\n internet.TCPServer(8080, SESRelaySMTPFactory(portal)).setServiceParent(app)\n\n return app\n\napplication = main()\n"
},
{
"alpha_fraction": 0.7952755689620972,
"alphanum_fraction": 0.7972440719604492,
"avg_line_length": 21.086956024169922,
"blob_id": "f09add77b9b17c55bdc914a184b8637b486cee1a",
"content_id": "0c223bfad323f8b93b8fb8d9b51c6f4bb27d3e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 23,
"path": "/README.md",
"repo_name": "yifangd/sesrelay",
"src_encoding": "UTF-8",
"text": "# SMTP 2 SES Message Relay\n\nTrivial twisted program that provides smtp server\nthat delivers messages via ses api, based on sample\nsmtp server tac.\n\nThis is intended for low volume usage from machines\nwithout direct internet access but can reach ses\napi endpoints via proxy.\n\n\n# Running it\n\n```shell\n\ngit checkout https://github.com/kapilt/sesrelay.git\nvirtualenv sesrelay\nsource sesrelay/bin/activate\npip install -r sesrelay/requirements.txt\ntwistd -y sesrelay/sesrelay.py\n```\n\nrequires mods for port/region\n"
}
] | 3 |
SavvaI/adversarial_autoencoder
|
https://github.com/SavvaI/adversarial_autoencoder
|
5468457435321110556627dbd996ad1eb1a4e099
|
eb24f52dd5343d75099fb797b3ff752472277197
|
8e94f778d1394327568bd930b4a8600bca1e15bd
|
refs/heads/master
| 2021-01-01T15:46:01.818716 | 2017-07-19T09:38:01 | 2017-07-19T09:38:01 | 97,695,253 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 45.29166793823242,
"blob_id": "bd81ca167745778a61d50cff84b5dda12ebadf88",
"content_id": "3e56a9c7b93bbc2bf32bdefd41aba15a52dac6f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 24,
"path": "/main.py",
"repo_name": "SavvaI/adversarial_autoencoder",
"src_encoding": "UTF-8",
"text": "import keras\nfrom keras import datasets\nimport numpy as np\nimport pickle\nimport os\npath_to_py = os.path.dirname(os.path.abspath(__file__))\nx, y_ = pickle.load(open(os.path.join(path_to_py, 'data\\cifar10.pkl'), 'rb'))[0]\n# print(x)\n\nchannels = 3\n\nm = keras.models.Sequential()\n# m.add(keras.layers.Reshape([x.shape[1], x.shape[2], channels], input_shape=[x.shape[1], x.shape[2]]))\nm.add(keras.layers.Conv2D(8, [5, 5], strides=[2, 2], padding='same', activation='relu', input_shape=[x.shape[1], x.shape[2], channels]))\nm.add(keras.layers.BatchNormalization())\nm.add(keras.layers.Conv2D(12, [5, 5], strides=[2, 2], padding='same', activation='relu'))\nm.add(keras.layers.BatchNormalization())\nm.add(keras.layers.Conv2DTranspose(8, [5, 5], strides=[2, 2], padding='same', activation='relu'))\nm.add(keras.layers.BatchNormalization())\nm.add(keras.layers.Conv2DTranspose(channels, [5, 5], strides=[2, 2], padding='same', activation='relu'))\n# m.add(keras.layers.Reshape([x.shape[1], x.shape[2]]))\n\nm.compile('adam', keras.losses.mean_squared_error, metrics=[keras.metrics.mean_squared_error])\nm.fit(x=x, y=x, epochs=2)"
}
] | 1 |
lexjox777/Functions-in-Python
|
https://github.com/lexjox777/Functions-in-Python
|
b72739adaebf87d9db96223c09e234a7b159a0e6
|
36b427f6e6da23ac19d8c242ae3b31ee49b75896
|
dd06c927f4768c757a5a454272e49d0e77bf0c9f
|
refs/heads/master
| 2023-03-24T02:52:21.993237 | 2021-03-13T18:16:40 | 2021-03-13T18:16:40 | 347,445,709 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5858021378517151,
"alphanum_fraction": 0.5930687785148621,
"avg_line_length": 18.670330047607422,
"blob_id": "3078423bfb9eae1729b47b38b35cb74ce945feef",
"content_id": "9ba3926adad1d2360678fdb0ec761ded42dddc25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1789,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 91,
"path": "/main.py",
"repo_name": "lexjox777/Functions-in-Python",
"src_encoding": "UTF-8",
"text": "# def greet():\n# return 'Hello Maria'\n \n# print(greet())\n\n#====================\n\n# '''\n# Functions with parameters\n# '''\n# any functions in a parameter is known as an arguements(name, etc)\n# def greet(name):\n# return f\"Hello {name}, Good morning\"\n\n# print(greet(\"Felix\"))\n# print(greet(\"Maria\"))\n\n#=========================\n# '''\n# Arbitrary parameters\n# '''\n# def fruits(*names):\n\n# # (*name) means the arguements can accept multiple parameters\n# # '''\n# # Accepts unknown number of fruit names and prints each of them \n# # *name: list of fruits\n# # '''\n# for fruit in names:\n# print(fruit)\n# fruits(\"Orange\",\"Banana\")\n\n\n# ================\n# '''\n# Keyword parameters\n# '''\n# def greet(name,msg):\n\n# return f\"Hello {name}, {msg}\"\n \n# # print(greet(\"Kingsley\",\"Good morning\"))\n# # print(greet(\"Maria\",\"Good morning\"))\n# print(greet(name=\"Kingsley\",msg=\"Good morning\"))\n# print(greet(msg=\"Good morning\",name=\"Maria\"))\n\n# ===================\n\n'''\nArbitrary Keyword parameters\n'''\n# ** is used in defining arbitary keywords\n# def person(**student):\n# # print(type(student))\n# # # this is a type of Dict\n# # print(student)\n# for key in student:\n# print(student[key])\n# person(fname=\"Kingsley\",lname=\"Maria\")\n\n\n'''\nDefault parameter values\n'''\n# def greet(name='David'):\n# return f\"Hello, {name}\"\n# print(greet())\n# print(greet('Maria'))\n\n#==================\n'''\npass statement\n'''\ndef greet():\n pass\n\n#==================\n'''\nRecursion\n'''\ndef factorial_recursive(n):\n '''\n multiply a given number by every number by every number less than it down to 1 in a factorial way\n e.g if n is 5 then calculte 5*4*3*2*1=120\n n: is the highest starting number\n '''\n if n==1:\n return True\n else:\n return n * factorial_recursive(n-1)\nprint(factorial_recursive(5))"
}
] | 1 |
jamesalbert/soy
|
https://github.com/jamesalbert/soy
|
eda76be67dc3c08fd1cdefcd132c18c02845cdc4
|
fc4027e0bc2c41ae60b3b0f061644aeefe663abb
|
a833c7c1132bcf3db3ab897111de19e7824d82d2
|
refs/heads/master
| 2021-01-16T18:05:21.281988 | 2013-08-17T21:34:44 | 2013-08-17T21:34:44 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6379716992378235,
"alphanum_fraction": 0.6379716992378235,
"avg_line_length": 18.25,
"blob_id": "940ebae0cdbc63bc5a79352cacdf842e9d6976fc",
"content_id": "a9bae00395882903a9440cbbb50c6d0193c992c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 44,
"path": "/salt/modules/soy_pdns.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom soy.pdns import dns\n\ndef createDomain(name):\n\tkwargs = {'name': name}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.createDomain()\n\ndef reportDomain():\n\tkwargs = {}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.reportDomain()\n\ndef updateDomain(**kwargs):\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.updateDomain()\n\ndef deleteDomain(id):\n\tkwargs = {'id': id}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.deleteDomain()\n\ndef createRecord(**kwargs):\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.createRecord()\n\ndef reportRecord():\n\tkwargs = {}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.reportRecord()\n\n\ndef updateRecord(name, id):\n\tkwargs = {'name': name,\n\t\t\t 'id': id}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.updateRecord()\n\n\ndef deleteRecord(id):\n\tkwargs = {'id': id}\n\tcli = dns(__salt__, **kwargs)\n\treturn cli.deleteRecord()\n\n"
},
{
"alpha_fraction": 0.6075522303581238,
"alphanum_fraction": 0.6075522303581238,
"avg_line_length": 22.539682388305664,
"blob_id": "1948204b15e1ebd6a64885dc42c99e69215c9e4a",
"content_id": "b15dc2b6ee5b1dc3509cb5f2f198200ce4799b13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 63,
"path": "/soy/pdns.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n'''\nsoy powerdns package for creating and maintaining dns tables.\n'''\n\nimport MySQLdb\n\nclass DNS(object):\n\t'''\n\tinit\n\t'''\n\tdef __init__(self, __salt__, **kwargs):\n\t\tself.salt = __salt__\n\t\tself.pillar = __salt__['pillar.raw']\n\t\tself.mysql = {\n\t\t\t'host': self.pillar('mysql.host'),\n\t\t\t'port': self.pillar('mysql.port'),\n\t\t\t'user': self.pillar('mysql.user'),\n\t\t\t'pass': self.pillar('mysql.pass'),\n\t\t\t'db': self.pillar('mysql.db'),\n\t\t\t'unix_socket': self.pillar('mysql.unix_socket')\n\t\t}\n\t\tself.database = self.curs = None\n\t\tself.name = kwargs['name']\n\n\tdef _connect(self, **kwargs):\n\t\t'''\n\t\tconnect to specified database\n\t\t'''\n\t\tself.datebase = MySQLdb.connect(**kwargs)\n\t\tself.curs = self.database.cursor()\n\n\tdef insert_domain(self):\n\t\t'''\n\t\tinsert domain into table domains\n\t\t'''\n\t\tquery = '''INSERT INTO domains\n\t\t\t\t SET `name`=%s, `type`=\"MASTER\", `account`=\"EXTER\"'''\n\t\tself.curs.execute(query, (self.name))\n\n\tdef insert_record(self):\n\t\t'''\n\t\tinsert record into table records\n\t\t'''\n\t\tmail = 'mail.%s' % self.name\n\t\tdns = 'dns.%s' % self.name\n\t\thost = 'hostmaster.%s' % self.name\n\n\t\targs = [(self.name, 'MX', mail),\n\t\t\t\t(mail, 'CNAME', self.name),\n\t\t\t\t(self.name, 'SOA', \". \".join([dns, host]))]\n\t\tquery = \"\"\"INSERT INTO records (`name`, `type`, `content`)\n\t\t\t\t\t\tVALUES (%s, %s, %s)\"\"\"\n\t\tself.curs.executemany(query, args)\n\n\tdef create_domain(self):\n\t\t'''\n\t\tbuild insert tree\n\t\t'''\n\t\tself._connect(**self.mysql)\n\t\tself.insert_domain()\n\t\tself.insert_record()\n"
},
{
"alpha_fraction": 0.6279069781303406,
"alphanum_fraction": 0.6279069781303406,
"avg_line_length": 11.285714149475098,
"blob_id": "16c7c626a900e5bf275af8cb443d93b8d79d0d40",
"content_id": "c8b0e9a08ad58b741564834d1f8ca85839632018",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 14,
"path": "/soy/vsftp.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n'''\nsoy ftp package for file and user editing\n'''\n\nfrom fptlib import FTP\n\nclass User(object):\n\t'''\n\tinit\n\t'''\n\tdef __init__(self, **kwargs):\n\t\tpass\n"
},
{
"alpha_fraction": 0.6761865019798279,
"alphanum_fraction": 0.6770264506340027,
"avg_line_length": 27.011764526367188,
"blob_id": "f1edc314b7a35243e389dbbbab6fb8fa1c87d26d",
"content_id": "72eb818118beb844551a8b7915d843b52dff3bf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2381,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 85,
"path": "/webapi/main.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "from flask import Flask, jsonify, render_template\nfrom gevent.wsgi import WSGIServer\nfrom salt.client import LocalClient\n\nc = LocalClient()\nuser = 'powerdns.com'\napp = Flask(__name__)\n\n'''\n\tCan't use the word 'domains' for placeholders??\n'''\n\[email protected]('/dns', methods=['GET'])\ndef dns():\n\treturn render_template('dns.html')\n\[email protected]('/dns/domain')\ndef dnsdomain():\n\treturn render_template('domains.html')\n\[email protected]('/dns/record')\ndef dnsrecord():\n\treturn render_template('records.html')\n\[email protected]('/dns/create/domain/<name>')\ndef dnscreate(name):\n\tstatus = {}\n\tstatus['domain'] = c.cmd(user, 'soy_pdns.createDomain', [name])\n\tstatus['record'] = c.cmd(user, 'soy_pdns.createRecord', [name])\n\treturn jsonify(status)\n\[email protected]('/dns/report/domain')\ndef dnsreportdomain():\n\tstatus = {}\n\treport = c.cmd(user, 'soy_pdns.reportDomain')\n\tfor domain in report[user]:\n\t\tstatus[domain['name']] = domain\n\treturn jsonify(status)\n\[email protected]('/dns/update/domain/<id>/<name>/<master>/<last_check>/<type>/<notified_serial>/<account>')\ndef dnsupdatedomain(name, id, type, account, last_check, notified_serial, master):\n\tkwargs = {'name':name,\n\t\t\t 'id':id,\n\t\t\t 'type':type,\n\t\t\t 'account':account,\n\t\t\t 'last_check':last_check,\n\t\t\t 'notified_serial':notified_serial,\n\t\t\t 'master':master}\n\tstatus = c.cmd(user, 'soy_pdns.updateDomain', **kwargs)\n\treturn jsonify(status)\n\[email protected]('/dns/delete/domain/<id>')\ndef dnsdeletedomain(id):\n\tstatus = c.cmd(user, 'soy_pdns.deleteDomain', [id])\n\treturn jsonify(status)\n\[email protected]('/dns/report/record')\ndef dnsreportrecord():\n\tstatus = {}\n\treport = c.cmd(user, 'soy_pdns.reportRecord')\n\tfor domain in report[user]:\n\t\tstatus[domain['id']] = domain\n\treturn jsonify(status)\n\[email protected]('/dns/update/record/<name>/<id>/<master>/<last_check>/<type>/<notified_serial>/<account>')\ndef dnsupdaterecord(name, id, master, last_check, type, notified_serial, account):\n\tkwargs = {'name':name,\n\t\t\t 'id': id,\n\t\t\t 'master':master,\n\t\t\t 'last_check':last_check,\n\t\t\t 'type':type,\n\t\t\t 'notified_serial':notified_serial,\n\t\t\t 'account':account}\n\tstatus = c.cmd(user, 'soy_pdns.updateRecord', **kwargs)\n\treturn jsonify(status)\n\[email protected]('/dns/delete/record/<id>')\ndef dnsdeleterecord(id):\n\tstatus = c.cmd(user, 'soy_pdns.deleteRecord', [id])\n\treturn jsonify(status)\n\n\nif __name__ == '__main__':\n\tserver = WSGIServer(('',80),app)\n\tserver.serve_forever()\n"
},
{
"alpha_fraction": 0.6216537952423096,
"alphanum_fraction": 0.6216537952423096,
"avg_line_length": 23.72058868408203,
"blob_id": "960895cbe9c3ee4d3a431642fb0e7cd8d4dfd996",
"content_id": "a61f6c813285a46a6a4ed500d0ba0c94f9884b44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3362,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 136,
"path": "/soy/nginx.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n'''\nsoy nginx package for creating and deleting host configuration files.\n'''\n\nimport soy.utils as soy\n\n\nclass Host(object):\n\t'''\n\tinit\n\t'''\n\tdef __init__(self, __salt__, **kwargs):\n\t\tself.salt = __salt__\n\t\tself.pillar = self.salt['pillar.raw']('nginx')\n\t\tself.host = kwargs['host']\n\t\tself.user = kwargs['user']\n\n\tdef mkconf(self):\n\t\t'''\n\t\twrite and symlink nginx host files from template.\n\t\t'''\n\t\ttry:\n\t\t\tavailable = '%s%s.conf' % (self.pillar['available'], self.host)\n\t\t\tenabled = '%s%s.conf' % (self.pillar['enabled'], self.host)\n\t\t\tsoy.commit(self.pillar['template'], available, **self.__dict__)\n\t\t\tself.salt['file.symlink'](available, enabled)\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\treturn False\n\n\tdef mksource(self, htdocs):\n\t\t'''\n\t\twrite source html template (placeholders)\n\t\t'''\n\t\ttry:\n\t\t\tpath = '%s%s' % (htdocs, 'index.html')\n\t\t\tsoy.commit(self.pillar['index'], path, **self.__dict__)\n\t\t\tself.salt['nginx.signal']('reload')\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\traise OSError\n\n\tdef mkdir(self, htdocs):\n\t\t'''\n\t\tcreate htdocs directory\n\t\t'''\n\t\ttry:\n\t\t\tself.salt['file.mkdir'](htdocs)\n\t\t\tif self.pillar['index']:\n\t\t\t\tself.mksource(htdocs)\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\treturn False\n\n\tdef mklog(self, logdir):\n\t\t'''\n\t\twrite log files in specified log directory\n\t\t'''\n\t\ttry:\n\t\t\tself.salt['file.mkdir'](logdir)\n\t\t\taccess = '%s%s' % (logdir, 'access.log')\n\t\t\terror = '%s%s' % (logdir, 'error.log')\n\t\t\tsoy.prepare(None, access, error)\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\treturn False\n\n\tdef delete(self, user=False):\n\t\t'''\n\t\tremove host tree\n\t\t'''\n\t\ttry:\n\t\t\tenabled = '%s%s.conf' % (self.pillar['enabled'], self.host)\n\t\t\tavailable = '%s%s.conf' % (self.pillar['available'], self.host)\n\t\t\tbase = '%s%s/' % (self.pillar['base'], self.user)\n\t\t\tif user is True:\n\t\t\t\tself.salt['file.remove'](base)\n\t\t\tself.salt['file.remove'](available)\n\t\t\tself.salt['file.remove'](enabled)\n\t\t\tself.salt['file.remove']('%s%s' % (base, self.host))\n\t\t\tself.salt['nginx.signal']('reload')\n\t\t\treturn True\n\t\texcept (OSError, IOError, KeyError):\n\t\t\treturn False\n\n\tdef create(self):\n\t\t'''\n\t\tbuild host tree\n\t\t'''\n\t\troot = '%s%s/%s' % (self.pillar['base'],\n\t\t\t\t\t\t\tself.user,\n\t\t\t\t\t\t\tself.host)\n\t\thtdocs = '%s%s' % (root, self.pillar['htdocs'])\n\t\tlogdir = '%s%s' % (root, self.pillar['logs'])\n\n\t\ttry:\n\t\t\tself.mkdir(htdocs)\n\t\t\tself.mklog(logdir)\n\t\t\tself.mkconf()\n\t\t\tself.salt['nginx.signal']('reload')\n\t\t\treturn True\n\t\texcept (OSError, IOError, KeyError, AttributeError):\n\t\t\treturn self.delete()\n\n\tdef suspend(self):\n\t\t'''\n\t\tsuspend users and their hosts\n\t\t'''\n\t\ttry:\n\t\t\tpath = '%s%s.conf' % (self.pillar['available'], self.host)\n\t\t\tlink = '%s%s.conf' % (self.pillar['enabled'], self.host)\n\t\t\tself.salt['file.remove'](link)\n\t\t\tself.salt['file.remove'](path)\n\t\t\tsoy.commit(self.pillar['susconf'], path, **self.__dict__)\n\t\t\tself.salt['file.symlink'](path, link)\n\t\t\tself.salt['nginx.signal']('reload')\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\treturn False\n\n\tdef unsuspend(self):\n\t\t'''\n\t\tlift suspension\n\t\t'''\n\t\ttry:\n\t\t\tpath = '%s%s.conf' % (self.pillar['available'], self.host)\n\t\t\tlink = '%s%s.conf' % (self.pillar['enabled'], self.host)\n\t\t\tself.salt['file.remove'](link)\n\t\t\tself.salt['file.remove'](path)\n\t\t\tself.mkconf()\n\t\t\tself.salt['nginx.signal']('reload')\n\t\t\treturn True\n\t\texcept (OSError, IOError):\n\t\t\treturn False\n"
},
{
"alpha_fraction": 0.6070640087127686,
"alphanum_fraction": 0.6070640087127686,
"avg_line_length": 19.590909957885742,
"blob_id": "e32a06daf26681e530a84f0876aaf6a4cc555804",
"content_id": "fea4d5c905b699eae58a8ef17b0c51fe859b2e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 22,
"path": "/salt/modules/soy_nginx.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom soy.nginx import Host\n\ndef report():\n return __salt__['pillar.raw']('nginx')\n\ndef create(**kwargs):\n ret = Host(__salt__,**kwargs)\n return ret.create()\n\ndef delete(**kwargs):\n ret = Host(__salt__, **kwargs)\n return ret.delete(user=False)\n\ndef suspend(**kwargs):\n ret = Host(__salt__, **kwargs)\n return ret.suspend()\n\ndef unsuspend(**kwargs):\n ret = Host(__salt__, **kwargs)\n return ret.unsuspend()\n"
},
{
"alpha_fraction": 0.48947927355766296,
"alphanum_fraction": 0.489691823720932,
"avg_line_length": 28.59119415283203,
"blob_id": "d2201055e55047d6d9ee2a482f654aa8e8b44e8a",
"content_id": "d727dbc58c66dc19254b8bb3c179822121e80420",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4705,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 159,
"path": "/soy/tests/test_nginx.py",
"repo_name": "jamesalbert/soy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport nose\nfrom soy.nginx import Host\nfrom nose.tools import raises, ok_\nfrom mock import Mock, patch\n\n\n\nclass Start:\n def start(self, case):\n Pillar_raw = lambda x: {'enabled': '/tmp/',\n 'available': '/tmp/',\n 'base': '/tmp/',\n 'template': '/tmp/test.file',\n 'index': '/tmp/test.file',\n 'indexhtml': 'test.html',\n 'access': 'access.test',\n 'error': 'error.test',\n 'htdocs': '/tmp/',\n 'logs': '/tmp/',\n 'susconf': '/etc/nginx/suspended.conf.tpl',\n 'sushtml': '/etc/nginx/suspended.html.tpl',\n 'sushtdocs': '/var/www/suspended/htdocs/index.html'}\n\n jinja = patch('jinja2.Template')\n jinja.return_value = case\n openfile = patch('__builtin__.open')\n openfile.return_value = case\n prepare = patch('soy.utils.prepare')\n prepare.return_value = case\n commit = patch('soy.utils.commit')\n commit.return_value = case\n\n self.vars = {\n 'user': 'user',\n 'host': 'test.com'\n }\n\n self.__salt__ = {\n 'pillar.raw': Pillar_raw,\n 'file.remove': case,\n 'file.symlink': case,\n 'file.mkdir': case,\n 'nginx.signal': case\n }\n\n\nclass TestCreatePass(Start):\n def setUp(self):\n self.start(lambda *x: True)\n\n def test_mkconf_pass(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mkconf()\n ok_(rv is True, 'returned %s' % rv)\n\n def test_mksource_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mksource('/tmp/')\n ok_(rv is True, 'returned %s' % rv)\n\n def test_mkdir_pass(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mkdir('/tmp/')\n ok_(rv is True, 'returned %s' % rv)\n\n def test_mklog_pass(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mklog('/tmp/')\n ok_(rv is True, 'returned %s' % rv)\n\n def test_create_pass(self):\n t = Host(self.__salt__, **self.vars)\n t.mkconf = lambda: True\n t.mkdir = lambda x: True\n t.mklog = lambda x: True\n rv = t.create()\n ok_(rv is True, 'returned %s' % rv)\n\n\nclass TestCreateFail(Start):\n def setUp(self):\n self.start(Mock(side_effect=OSError))\n\n def test_mkconf_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mkconf()\n ok_(rv is False, 'returned %s' % rv)\n\n @raises(OSError)\n def test_mksource_fail(self):\n t = Host(self.__salt__, **self.vars)\n t.mksource('/tmp/')\n\n def test_mkdir_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mkdir('/tmp/')\n ok_(rv is False, 'returned %s' % rv)\n\n def test_mklog_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.mklog('/tmp/')\n ok_(rv is False, 'returned %s' % rv)\n\n def test_create_fail(self):\n t = Host(self.__salt__, **self.vars)\n t.mkconf = Mock(side_effect=OSError)\n t.mkdir = Mock(side_effect=OSError)\n t.mklog = Mock(side_effect=OSError)\n rv = t.create()\n ok_(rv is False, 'returned %s' % rv)\n\n\nclass TestDeleteFail(Start):\n\n def setUp(self):\n self.start(Mock(side_effect=OSError))\n\n def test_delete_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.delete()\n ok_(rv is False, 'returned %s' % rv)\n\n def test_suspend_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.suspend()\n ok_(rv is False, 'returned %s' % rv)\n\n def test_unsuspend_fail(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.unsuspend()\n ok_(rv is False, 'returned %s' % rv)\n\n def test_delete_user(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.delete(user=True)\n ok_(rv is False, 'returned %s' % rv)\n\n\nclass TestDeleteTrue(Start):\n\n def setUp(self):\n self.start(lambda *x: True)\n\n def test_delete_true(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.delete()\n ok_(rv is True, 'returned %s' % rv)\n\n def test_suspend_true(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.suspend()\n ok_(rv is True, 'returned %s' % rv)\n\n def test_unsuspend_true(self):\n t = Host(self.__salt__, **self.vars)\n rv = t.unsuspend()\n ok_(rv is True, 'returned %s' % rv)\n"
}
] | 7 |
luhn/flatline
|
https://github.com/luhn/flatline
|
f3be7b940152777099c4df0eca42ed900c47f445
|
3b56c911b621f2f7f504d35bea1aca9d53e49cd3
|
67a429a90397a1e20db774a1265874aa36439f93
|
refs/heads/master
| 2021-01-17T06:46:55.245963 | 2016-06-02T23:15:18 | 2016-06-02T23:15:48 | 56,791,312 | 3 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6937860250473022,
"alphanum_fraction": 0.6995515823364258,
"avg_line_length": 34.078651428222656,
"blob_id": "c820b92b99de30b095636e97ce1b2b4a2a4616d8",
"content_id": "836a962814f6073bfa1ba76d9deaa52ff0cfb10d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3122,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 89,
"path": "/flatline/decorator.py",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThe following code is taken from Pyramid (https://github.com/Pylons/pyramid/)\nand is distributed under the following license:\n\nCopyright (c) 2008-2011 Agendaless Consulting and Contributors.\n(http://www.agendaless.com), All Rights Reserved\n\nRedistribution and use in source and binary forms, with or without\nmodification, are permitted provided that the following conditions are met:\n\n1. Redistributions in source code must retain the accompanying copyright\n notice, this list of conditions, and the following disclaimer.\n\n2. Redistributions in binary form must reproduce the accompanying copyright\n notice, this list of conditions, and the following disclaimer in the\n documentation and/or other materials provided with the distribution.\n\n3. Names of the copyright holders must not be used to endorse or promote\n products derived from this software without prior written permission from\n the copyright holders.\n\n4. If any files are modified, you must cause the modified files to carry\n prominent notices stating that you changed the files and the date of any\n change.\n\nDisclaimer\n\nTHIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS ``AS IS'' AND\nANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED\nTO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A\nPARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT\nHOLDERS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL,\nEXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED\nTO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\nDATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON\nANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR\nTORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF\nTHE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\nSUCH DAMAGE.\n\n\"\"\"\n\nfrom functools import update_wrapper\n\n\nclass reify(object):\n \"\"\" Use as a class method decorator. It operates almost exactly like the\n Python ``@property`` decorator, but it puts the result of the method it\n decorates into the instance dict after the first call, effectively\n replacing the function it decorates with an instance variable. It is, in\n Python parlance, a non-data descriptor. An example:\n\n .. testsetup::\n\n from pyramid.decorator import reify\n\n class Foo(object):\n @reify\n def jammy(self):\n print('jammy called')\n return 1\n\n And usage of Foo:\n\n .. doctest::\n\n >>> f = Foo()\n >>> v = f.jammy\n jammy called\n >>> print(v)\n 1\n >>> f.jammy\n 1\n >>> # jammy func not called the second time; it replaced itself with 1\n >>> # Note: reassignment is possible\n >>> f.jammy = 2\n >>> f.jammy\n 2\n \"\"\"\n def __init__(self, wrapped):\n self.wrapped = wrapped\n update_wrapper(self, wrapped)\n\n def __get__(self, inst, objtype=None):\n if inst is None:\n return self\n val = self.wrapped(inst)\n setattr(inst, self.wrapped.__name__, val)\n return val\n"
},
{
"alpha_fraction": 0.5320535898208618,
"alphanum_fraction": 0.5370304584503174,
"avg_line_length": 26.222579956054688,
"blob_id": "342a6ccc5f4d292f1698142ad9fe47543e2bd70d",
"content_id": "214eeae5b2ab92535a32515d77693417891d9120",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8439,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 310,
"path": "/flatline/__init__.py",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "import logging\nimport itertools\nfrom time import sleep\ntry:\n from urllib.parse import urljoin\nexcept ImportError:\n from urlparse import urljoin\n\nimport boto3\nimport requests\n\nfrom .decorator import reify\n\n\nlogger = logging.getLogger('flatline')\nlogging.basicConfig(level=logging.INFO)\n\n\nclass Consul(object):\n \"\"\"\n A simple Consul client.\n\n :param url: The URL of the Consul HTTP API.\n :type url: str\n\n \"\"\"\n def __init__(self, url='http://localhost:8500/'):\n self.url = url\n\n def call(self, method, path, params={}, data={}, retry=False):\n \"\"\"\n Make a call to Consul.\n\n :param method: The HTTP method to use.\n :type method: str\n :param path: The path to query.\n :type path: str\n :param params: The URL parameters to send.\n :type params: dict\n :param data: The data to send in the body.\n :type data: dict\n :param retry: If ``True``, the call will be retried indefinitely if it\n fails.\n :type retry: bool\n\n :returns: A two-tuple of the decoded response body and the\n X-Consul-Index header.\n\n \"\"\"\n url = urljoin(self.url, path)\n while True:\n try:\n logger.debug('Consul request: %s %s', method, url)\n logger.debug('Request body: %s', str(data))\n r = requests.request(\n method,\n url,\n params=params,\n json=data,\n timeout=70,\n )\n r.raise_for_status()\n logger.debug('Consul response: HTTP %s', r.status_code)\n logger.debug('Response body: %s', r.text)\n return r.json(), r.headers.get('X-Consul-Index')\n except requests.RequestException:\n if not retry:\n raise\n logger.warning('Consul error.', exc_info=True)\n logger.debug('Waiting ten seconds before trying again.')\n sleep(10)\n\n def get(self, path, params={}, **kwargs):\n return self.call('GET', path, params, **kwargs)\n\n def post(self, path, data={}, **kwargs):\n return self.call('POST', path, data=data, **kwargs)\n\n def put(self, path, data={}, **kwargs):\n return self.call('PUT', path, data=data, **kwargs)\n\n def delete(self, path, data={}, **kwargs):\n return self.call('DELETE', path, data=data, **kwargs)\n\n\nclass Check(object):\n \"\"\"\n A representation of a Consul health check.\n\n :param blob: The check JSON blob from Consul.\n :type blob: dict\n\n \"\"\"\n def __init__(self, blob):\n self.blob = blob\n self.healthy = blob['Status'] == 'passing'\n self.id = blob['CheckID']\n self.node = blob['Node']\n\n def __eq__(self, other):\n return self.blob == other.blob\n\n\nclass Node(object):\n \"\"\"\n A representation of a node, both as a Consul client and a AWS EC2 instance.\n\n :param consul: The Consul client.\n :type consul: :class:`Consul`\n :param ec2: The EC2 client.\n :type ec2: :class:`boto3.EC2.Client`\n :param asg: The ASG client\n :type asg: :class:`boto3.AutoScaling.Client`\n :param name: The node name.\n :type name: str\n :param checks: The checks associated with the node.\n :type checks: A list of :class:`Check` objects.\n\n \"\"\"\n def __init__(self, consul, ec2, asg, name, checks):\n self.consul = consul\n self.ec2 = ec2\n self.asg = asg\n self.name = name\n self.checks = checks\n\n @property\n def healthy(self):\n \"\"\"\n ``True`` if all health checks are passing.\n\n \"\"\"\n return all(check.healthy for check in self.checks)\n\n @property\n def maintenance(self):\n \"\"\"\n ``True`` if the node is in maintenance mode.\n\n \"\"\"\n return any(check.id == '_node_maintenance' for check in self.checks)\n\n @reify\n def blob(self):\n \"\"\"\n The JSON node representation from Consul.\n\n \"\"\"\n return self.consul.get('v1/catalog/node/{}'.format(self.name))[0]\n\n @property\n def ip(self):\n \"\"\"\n The IP address of the node.\n\n \"\"\"\n return self.blob['Node']['Address']\n\n @reify\n def instance_id(self):\n \"\"\"\n The EC2 instance ID.\n\n \"\"\"\n r = self.ec2.describe_instances(\n Filters=[\n {\n 'Name': 'private-ip-address',\n 'Values': [self.ip],\n },\n ],\n )\n reservations = r['Reservations']\n if len(reservations) == 0:\n return None\n instances = reservations[0]['Instances']\n if len(instances) > 1:\n raise ValueError('Multiple results found.')\n return instances[0]['InstanceId']\n\n @reify\n def is_asg_instance(self):\n \"\"\"\n ``True`` if the instance is part of an autoscaling group.\n\n \"\"\"\n id = self.instance_id\n if id is None:\n return False\n r = self.asg.describe_auto_scaling_instances(\n InstanceIds=[self.instance_id],\n )\n instances = r['AutoScalingInstances']\n return len(instances) > 0\n\n def update_instance_health(self):\n \"\"\"\n Set the autoscaling health check to match the Consul health.\n\n \"\"\"\n self.asg.set_instance_health(\n InstanceId=self.instance_id,\n HealthStatus='Healthy' if self.healthy else 'Unhealthy',\n )\n\n\nclass Worker(object):\n \"\"\"\n\n \"\"\"\n last_index = None\n\n def __init__(self, consul, ec2, asg):\n super(Worker, self).__init__()\n self.consul = consul\n self.ec2 = ec2\n self.asg = asg\n self.prev_nodes = {}\n\n def run(self):\n \"\"\"\n Run :meth:`.update_health` indefinitely.\n\n \"\"\"\n logger.info('Starting worker...')\n while True:\n self.update_health()\n\n def update_health(self):\n \"\"\"\n Query Consul for health checks and update ASG health checks as\n necessary.\n\n \"\"\"\n nodes = self.get_nodes()\n updated = self.diff_nodes(self.prev_nodes, nodes)\n self.prev_nodes = nodes\n for node in updated:\n logging.info(\n '%s is now %s',\n node.name,\n 'Healthy' if node.healthy else 'Unhealthy',\n )\n if node.is_asg_instance:\n node.update_instance_health()\n\n def diff_nodes(self, prev_nodes, nodes):\n \"\"\"\n Compare the a set of nodes to a previous set.\n\n :param prev_nodes: The previous nodes.\n :type prev_nodes: dict\n :param nodes: The current nodes.\n :type nodes: dict\n\n :returns: Nodes that are new or have changed in health.\n :rtype: generator\n\n \"\"\"\n for node in nodes.values():\n prev_node = prev_nodes.get(node.name)\n if prev_node is None or prev_node.healthy is not node.healthy:\n yield node\n\n def get_nodes(self):\n \"\"\"\n Query Consul for health checks and group them into nodes.\n\n :returns: A dictionary with the node name as keys and a corresponding\n :class:`Node` as values.\n\n \"\"\"\n nodes = dict()\n checks = sorted(self.get_checks(), key=lambda x: x.node)\n for name, checks in itertools.groupby(checks, lambda x: x.node):\n node = Node(self.consul, self.ec2, self.asg, name, list(checks))\n if not node.maintenance:\n nodes[node.name] = node\n return nodes\n\n def get_checks(self):\n \"\"\"\n Query Consul for health checks. Blocks for up to 60 seconds while\n waiting for changes.\n\n :returns: A list of :class:`Check` objects.\n\n \"\"\"\n logging.info('Querying Consul for health checks.')\n if self.last_index is None:\n params = {}\n else:\n params = {\n 'wait': '60s',\n 'index': self.last_index,\n }\n r, index = self.consul.get(\n 'v1/health/state/any',\n params,\n )\n self.last_index = index\n return [Check(obj) for obj in r]\n\n\ndef main():\n consul = Consul()\n ec2 = boto3.client('ec2')\n asg = boto3.client('autoscaling')\n worker = Worker(consul, ec2, asg)\n worker.run()\n"
},
{
"alpha_fraction": 0.7572815418243408,
"alphanum_fraction": 0.7572815418243408,
"avg_line_length": 19.600000381469727,
"blob_id": "352d57ace275017e3d99cbbec1982a4c3d9a4567",
"content_id": "43ee9f7d5fee97cafb23898849caadf40cc5a5b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 5,
"path": "/README.rst",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "flatline\n========\n\nA script to watch Consul health checks and update AWS ASG health checks\naccordingly\n"
},
{
"alpha_fraction": 0.5671476125717163,
"alphanum_fraction": 0.5793562531471252,
"avg_line_length": 27.15625,
"blob_id": "324ca91aa5b508d2b4f416d2608bf10e0a8d2ff5",
"content_id": "b2bad47dceca213fb7bc1d7d91ed3523176c7773",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 901,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\n\nsetup(\n name='flatline',\n version='0.1.0',\n description=(\n 'A script to watch Consul health checks and update AWS ASG health ' +\n 'checks accordingly'\n ),\n long_description=open('README.rst').read(),\n author='Theron Luhn',\n author_email='[email protected]',\n url='https://github.com/luhn/flatline',\n install_requires=[\n 'requests>=2,<3',\n 'boto3>=1,<2',\n ],\n packages=['flatline'],\n entry_points={\n 'console_scripts': ['flatline=flatline:main'],\n },\n classifiers=[\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3.5',\n 'Development Status :: 2 - Pre-Alpha',\n 'Environment :: Console',\n 'License :: OSI Approved :: MIT License',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n ],\n)\n"
},
{
"alpha_fraction": 0.4144059121608734,
"alphanum_fraction": 0.42793673276901245,
"avg_line_length": 33.546512603759766,
"blob_id": "a13cb041ffa6d89625812c254f358e4fa0e916f5",
"content_id": "ea8f2bf6ca568364051680bdce84e3acfa96d389",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14855,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 430,
"path": "/test.py",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom datetime import datetime as DateTime\nfrom collections import namedtuple\nimport json\nfrom mock import Mock\nfrom flatline import *\n\n\ndef test_check():\n check = Check({\n \"Node\": \"foobar\",\n \"CheckID\": \"serfHealth\",\n \"Name\": \"Serf Health Status\",\n \"Status\": \"passing\",\n \"Notes\": \"\",\n \"Output\": \"\",\n \"ServiceID\": \"\",\n \"ServiceName\": \"\"\n })\n assert check.healthy is True\n assert check.id == 'serfHealth'\n assert check.node == 'foobar'\n check = Check({\n \"Node\": \"foobar\",\n \"CheckID\": \"service:redis\",\n \"Name\": \"Service 'redis' check\",\n \"Status\": \"critical\",\n \"Notes\": \"\",\n \"Output\": \"\",\n \"ServiceID\": \"redis\",\n \"ServiceName\": \"redis\"\n })\n assert check.healthy is False\n assert check.id == 'service:redis'\n assert check.node == 'foobar'\n\n\ndef test_get_checks_cold():\n check1 = {\n \"Node\": \"foobar\",\n \"CheckID\": \"serfHealth\",\n \"Name\": \"Serf Health Status\",\n \"Status\": \"passing\",\n \"Notes\": \"\",\n \"Output\": \"\",\n \"ServiceID\": \"\",\n \"ServiceName\": \"\"\n }\n check2 = {\n \"Node\": \"foobar\",\n \"CheckID\": \"service:redis\",\n \"Name\": \"Service 'redis' check\",\n \"Status\": \"critical\",\n \"Notes\": \"\",\n \"Output\": \"\",\n \"ServiceID\": \"redis\",\n \"ServiceName\": \"redis\"\n }\n consul = Consul()\n consul.call = Mock(return_value=([check1, check2], '12'))\n worker = Worker(consul, None, None)\n checks = worker.get_checks()\n assert checks == [Check(check1), Check(check2)]\n consul.call.assert_called_once_with(\n 'GET', 'v1/health/state/any', {},\n )\n worker.last_index = '12'\n\n\ndef test_get_checks_warm():\n consul = Consul()\n consul.call = Mock(return_value=([], '13'))\n worker = Worker(consul, None, None)\n worker.last_index = '12'\n assert worker.get_checks() == []\n consul.call.assert_called_once_with('GET', 'v1/health/state/any', {\n 'wait': '60s',\n 'index': '12'\n })\n worker.last_index = '13'\n\n\nMockCheck = namedtuple('MockCheck', ['node', 'id', 'healthy'])\n\n\ndef test_node_healthy():\n node = Node(None, None, None, 'healthy', [\n MockCheck('healthy', '1', True),\n MockCheck('healthy', '2', True),\n ])\n assert node.healthy is True\n\n node = Node(None, None, None, 'unhealthy', [\n MockCheck('unhealthy', '1', True),\n MockCheck('unhealthy', '2', False),\n ])\n assert node.healthy is False\n\n\ndef test_node_maintenance():\n node = Node(None, None, None, 'healthy', [\n MockCheck('healthy', '1', True),\n MockCheck('healthy', '_node_maintenance', False),\n ])\n assert node.maintenance is True\n\n node = Node(None, None, None, 'unhealthy', [\n MockCheck('unhealthy', '1', True),\n MockCheck('unhealthy', '2', False),\n ])\n assert node.healthy is False\n\n\ndef test_node_blob():\n consul = Consul()\n consul.call = Mock(return_value=({'bar': 'foo'}, None))\n node = Node(consul, None, None, 'foobar', [])\n assert node.blob == {'bar': 'foo'}\n assert node.blob == {'bar': 'foo'} # Call twice to verify sure @reify\n consul.call.assert_called_once_with('GET', 'v1/catalog/node/foobar', {})\n\n\ndef test_node_ip(monkeypatch):\n node = Node(None, None, None, 'foobar', [])\n monkeypatch.setattr(Node, 'blob', json.loads(\n \"\"\"\n {\n \"Node\": {\n \"Node\": \"foobar\",\n \"Address\": \"10.1.10.12\",\n \"TaggedAddresses\": {\n \"wan\": \"10.1.10.12\"\n }\n },\n \"Services\": {\n \"consul\": {\n \"ID\": \"consul\",\n \"Service\": \"consul\",\n \"Tags\": null,\n \"Port\": 8300\n },\n \"redis\": {\n \"ID\": \"redis\",\n \"Service\": \"redis\",\n \"Tags\": [\n \"v1\"\n ],\n \"Port\": 8000\n }\n }\n }\n \"\"\"\n ))\n assert node.ip == '10.1.10.12'\n\n\ndef test_node_instance_id(monkeypatch):\n ec2 = Mock()\n ec2.describe_instances = Mock(return_value={\n 'Reservations': [\n {\n 'ReservationId': 'string',\n 'OwnerId': 'string',\n 'RequesterId': 'string',\n 'Groups': [\n {\n 'GroupName': 'string',\n 'GroupId': 'string'\n },\n ],\n 'Instances': [\n {\n 'InstanceId': 'i-1234',\n 'ImageId': 'string',\n 'State': {\n 'Code': 123,\n 'Name': 'running',\n },\n 'PrivateDnsName': 'string',\n 'PublicDnsName': 'string',\n 'StateTransitionReason': 'string',\n 'KeyName': 'string',\n 'AmiLaunchIndex': 123,\n 'ProductCodes': [],\n 'InstanceType': 't1.micro',\n 'LaunchTime': DateTime(2015, 1, 1),\n 'Placement': {\n 'AvailabilityZone': 'string',\n 'GroupName': 'string',\n 'Tenancy': 'default',\n 'HostId': 'string',\n 'Affinity': 'string'\n },\n 'KernelId': 'string',\n 'RamdiskId': 'string',\n 'Platform': 'Windows',\n 'Monitoring': {\n 'State': 'enabled',\n },\n 'SubnetId': 'string',\n 'VpcId': 'string',\n 'PrivateIpAddress': '10.0.1.123',\n 'PublicIpAddress': 'string',\n 'StateReason': {\n 'Code': 'string',\n 'Message': 'string'\n },\n 'Architecture': 'x86_64',\n 'RootDeviceType': 'ebs',\n 'RootDeviceName': 'string',\n 'BlockDeviceMappings': [\n {\n 'DeviceName': 'string',\n 'Ebs': {\n 'VolumeId': 'string',\n 'Status': 'attached',\n 'AttachTime': DateTime(2015, 1, 1),\n 'DeleteOnTermination': True,\n }\n },\n ],\n 'VirtualizationType': 'hvm',\n 'InstanceLifecycle': 'scheduled',\n 'SpotInstanceRequestId': 'string',\n 'ClientToken': 'string',\n 'Tags': [\n {\n 'Key': 'string',\n 'Value': 'string'\n },\n ],\n 'SecurityGroups': [\n {\n 'GroupName': 'string',\n 'GroupId': 'string'\n },\n ],\n 'SourceDestCheck': True,\n 'Hypervisor': 'xen',\n 'NetworkInterfaces': [\n {\n 'NetworkInterfaceId': 'string',\n 'SubnetId': 'string',\n 'VpcId': 'string',\n 'Description': 'string',\n 'OwnerId': 'string',\n 'Status': 'available',\n 'MacAddress': 'string',\n 'PrivateIpAddress': 'string',\n 'PrivateDnsName': 'string',\n 'SourceDestCheck': True,\n 'Groups': [\n {\n 'GroupName': 'string',\n 'GroupId': 'string'\n },\n ],\n 'Attachment': {\n 'AttachmentId': 'string',\n 'DeviceIndex': 123,\n 'Status': 'attached',\n 'AttachTime': DateTime(2015, 1, 1),\n 'DeleteOnTermination': True,\n },\n 'Association': {\n 'PublicIp': 'string',\n 'PublicDnsName': 'string',\n 'IpOwnerId': 'string'\n },\n 'PrivateIpAddresses': [\n {\n 'PrivateIpAddress': 'string',\n 'PrivateDnsName': 'string',\n 'Primary': True,\n 'Association': {\n 'PublicIp': 'string',\n 'PublicDnsName': 'string',\n 'IpOwnerId': 'string'\n }\n },\n ]\n },\n ],\n 'IamInstanceProfile': {\n 'Arn': 'string',\n 'Id': 'string'\n },\n 'EbsOptimized': True,\n 'SriovNetSupport': 'string'\n },\n ]\n },\n ],\n 'NextToken': 'string'\n })\n monkeypatch.setattr(Node, 'ip', '10.0.1.123')\n node = Node(None, ec2, None, 'foobar', [])\n assert node.instance_id == 'i-1234'\n assert node.instance_id == 'i-1234'\n ec2.describe_instances.assert_called_once_with(\n Filters=[\n {\n 'Name': 'private-ip-address',\n 'Values': ['10.0.1.123'],\n },\n ],\n )\n\n\ndef test_node_instance_id_not_found(monkeypatch):\n ec2 = Mock()\n ec2.describe_instances = Mock(return_value={\n 'Reservations': [],\n 'NextToken': 'string'\n })\n monkeypatch.setattr(Node, 'ip', '10.0.1.123')\n node = Node(None, ec2, None, 'foobar', [])\n assert node.instance_id is None\n\n\ndef test_node_is_asg_instance_true(monkeypatch):\n asg = Mock()\n asg.describe_auto_scaling_instances = Mock(return_value={\n 'AutoScalingInstances': [\n {\n 'InstanceId': 'string',\n 'AutoScalingGroupName': 'string',\n 'AvailabilityZone': 'string',\n 'LifecycleState': 'InService',\n 'HealthStatus': 'string',\n 'LaunchConfigurationName': 'string',\n 'ProtectedFromScaleIn': True,\n },\n ],\n })\n monkeypatch.setattr(Node, 'instance_id', 'i-1234')\n node = Node(None, None, asg, 'foobar', [])\n assert node.is_asg_instance is True\n asg.describe_auto_scaling_instances.assert_called_once_with(\n InstanceIds=['i-1234'],\n )\n\n\ndef test_node_is_asg_instance_false(monkeypatch):\n asg = Mock()\n asg.describe_auto_scaling_instances = Mock(return_value={\n 'AutoScalingInstances': [],\n })\n monkeypatch.setattr(Node, 'instance_id', 'i-1234')\n node = Node(None, None, asg, 'foobar', [])\n assert node.is_asg_instance is False\n\n\ndef test_node_is_asg_instance_no_instance_id(monkeypatch):\n monkeypatch.setattr(Node, 'instance_id', None)\n node = Node(None, None, None, 'foobar', [])\n assert node.is_asg_instance is False\n\n\ndef test_node_update_instance_health(monkeypatch):\n asg = Mock()\n monkeypatch.setattr(Node, 'instance_id', 'i-1234')\n node = Node(None, None, asg, 'foobar', [])\n node.update_instance_health()\n asg.set_instance_health.assert_called_once_with(\n InstanceId='i-1234',\n HealthStatus='Healthy',\n )\n\n\ndef test_get_nodes(monkeypatch):\n checks = [\n MockCheck('healthy', '1', True),\n MockCheck('unhealthy2', '2', True),\n MockCheck('healthy', '3', True),\n MockCheck('unhealthy', '4', False),\n MockCheck('unhealthy2', '5', False),\n MockCheck('healthy', '6', True),\n MockCheck('maint', '7', False),\n ]\n monkeypatch.setattr(Worker, 'get_checks', lambda _: checks)\n monkeypatch.setattr(\n Node,\n 'maintenance',\n property(lambda x: x.name == 'maint'),\n )\n worker = Worker('consul', 'ec2', 'asg')\n nodes = worker.get_nodes()\n assert set(nodes.keys()) == {'healthy', 'unhealthy', 'unhealthy2'}\n assert nodes['healthy'].name == 'healthy'\n assert set(nodes['healthy'].checks) == {checks[0], checks[2], checks[5]}\n assert nodes['healthy'].consul == 'consul'\n assert nodes['healthy'].ec2 == 'ec2'\n assert nodes['healthy'].asg == 'asg'\n assert nodes['unhealthy'].name == 'unhealthy'\n assert set(nodes['unhealthy'].checks) == {checks[3]}\n assert nodes['unhealthy2'].name == 'unhealthy2'\n assert set(nodes['unhealthy2'].checks) == {checks[1], checks[4]}\n\n\ndef test_diff_nodes(monkeypatch):\n _Node = namedtuple('Node', ['name', 'healthy'])\n worker = Worker(None, None, None)\n diff = worker.diff_nodes({\n '1': _Node('1', False),\n '2': _Node('2', False),\n '3': _Node('3', True),\n }, {\n '2': _Node('2', True),\n '3': _Node('3', True),\n '4': _Node('4', False),\n })\n assert {x.name for x in diff} == {'2', '4'}\n\n\ndef test_update_healthg(monkeypatch):\n node1 = Mock(is_asg_instance=True)\n node2 = Mock(is_asg_instance=False)\n get_nodes = Mock(return_value='mynodes')\n diff_nodes = Mock(return_value=[node1, node2])\n monkeypatch.setattr(Worker, 'get_nodes', get_nodes)\n monkeypatch.setattr(Worker, 'diff_nodes', diff_nodes)\n worker = Worker(None, None, None)\n worker.prev_nodes = 'prevnodes'\n worker.update_health()\n get_nodes.assert_called_once_with()\n assert worker.prev_nodes == 'mynodes'\n diff_nodes.assert_called_once_with('prevnodes', 'mynodes')\n node1.update_instance_health.assert_called_once_with()\n node2.update_instance_health.assert_not_called()\n"
},
{
"alpha_fraction": 0.45077720284461975,
"alphanum_fraction": 0.6683937907218933,
"avg_line_length": 13.84615421295166,
"blob_id": "68d7c98e91c845e19261b7435b3b7bec2ff457a2",
"content_id": "404f98d7d9997ed6c583d7775f027b3cc9544a6e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 193,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "luhn/flatline",
"src_encoding": "UTF-8",
"text": "boto3==1.3.1\nbotocore==1.4.13\ndocutils==0.12\njmespath==0.9.0\npy==1.4.31\npytest==2.9.1\npython-dateutil==2.5.3\nrequests==2.9.1\nsix==1.10.0\nfuncsigs==1.0.0\nmock==2.0.0\nordereddict==1.1\npbr==1.9.1\n"
}
] | 6 |
hanhongsun/tensorflow_script
|
https://github.com/hanhongsun/tensorflow_script
|
e7752f9682bc9211395e97f8610c455b6acd95a9
|
78ad8b57c3dc4dee6f4f1bfa2a97c9554fcde155
|
a06e2ee58a8ca7d43376e41d7ac12f40716e04d1
|
refs/heads/master
| 2020-04-06T07:00:34.344844 | 2016-08-03T06:22:39 | 2016-08-03T06:22:39 | 56,748,717 | 6 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5610966682434082,
"alphanum_fraction": 0.586449146270752,
"avg_line_length": 45.78850555419922,
"blob_id": "ee87b33349645bf550593ce18b7be41c1fa1593f",
"content_id": "2a8b4e7a0e06ffdfab725a693cb3a62b5c8f1fa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20353,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 435,
"path": "/rl_dgn.py",
"repo_name": "hanhongsun/tensorflow_script",
"src_encoding": "UTF-8",
"text": "# in this file, we are trying to program a naive reinforcement learning deep generated model\n# Author Di Sun\n\n\n# TODO set the train rule\n# TODO tf.stop_gradient(tensor)\n\n# score function\nfrom mt_reward import muscleTorqueScore, muscleDirectTorqueScore\n\nimport tensorflow as tf\nimport numpy as np\nfrom tensorflow.python.ops import control_flow_ops\nimport math, copy\n#??? how to use tensorboard to visualize\n\n# display choice 1\nimport matplotlib.pyplot as plt\n# display choice 0\nimport Image\nimport sys\nsys.path.append('/home/hanhong/Projects/python27/DeepLearningTutorials/code/')\nfrom utils import tile_raster_images\n\n\n# we will try to use tensorboard for display\n\n# we will try to write the python class with tensorflow in order to increase the readablilty\n\n\nnp.random.seed(0)\ntf.set_random_seed(0)\n\ndef scalePosNegOne(vec):\n return tf.add(-1.0, tf.mul(2.0, tf.to_float(vec)))\n\ndef sampleInt(probs):\n return tf.floor(probs + tf.random_uniform(tf.shape(probs), 0, 1))\n\n# Each sample from top level will be used to estimate a probability of generating each of the \n# sample from next level. Sum based on the weight on the previous level.\ndef compute_importance_weight(sp_h, sp, spw_h, w, b_h, batch_size):\n # we use 3d matrices to represent both the tiled input sample and tiled output sample,\n # then we know for each entry of 3d matrix of input sample, the log prob that it would samples a one\n # would be dependent to the parameters.\n # The -log_prob_of_one would be the log_prob for 0\n # The sum over the vector of top sample will be the prob for one top sample generating one bottom.\n\n # TODO double check\n log_prob_of_all_one = tf.matmul(w, sp_h) + tf.tile(b_h, [1, batch_size])\n # supporting only sigmoid function right now\n log_matrix = tf.reduce_sum(tf.tile(tf.expand_dims(log_prob_of_all_one, -1), [1, 1, batch_size]) * \\\n tf.transpose(tf.tile(tf.expand_dims(scalePosNegOne(sp), -1), [1, 1, batch_size]), [0, 2, 1]), 0)\n # sigmoid then unnormalized_weight \n weighted_sigmoid_matrix = tf.sigmoid(log_matrix) * tf.tile(tf.transpose(spw_h), [1, batch_size])\n # weighted mean readuce_mean\n return tf.clip_by_value(tf.reduce_mean(weighted_sigmoid_matrix, 0, True), 1e-35, 1e35)\n\n\n# hope tensor will take this overload form.\ndef derivative_sigmoid_x(sigmoid_x):\n return sigmoid_x * (1 - sigmoid_x)\n\n# input the error: e\n# param weight: W, bias: b\n# data prob1: p, sample from p: s, sample from higher level: s_h\n# control arguement, size low: size_l, last_layer == True then only b_ update\n# return upper level of error: e_1, additive update of W: W_, additive update of b: b_\ndef back_propagate_one_layer(W, p, s, s_h, e, last_layer):\n # e must be the size of (size_l, size_bt)\n delta = tf.mul(tf.mul(e, scalePosNegOne(s)), derivative_sigmoid_x(p))\n # we assert when e[i] != 0 then s[i] == 1 because s[i] was used to compute e[i]\n b_ = tf.reduce_mean(delta, 1, True)\n if last_layer:\n W_ = None\n e_h = None\n else:\n # we need to do a cross product of delta and s_h W_bt_ and mean on the batch to get W_\n # size(W) = (size_l, size_h), size(delta) = (size_l, size_bt), size(s_h) = (size_h, size_bt)\n # delta ==> delta_t with size (size_bt, size_l, 1)\n # s_h ==> s_h_t with size (size_bt, 1, size_h)\n # W_bt_t_ (size_bt, size_l, sizeh) = tf.batch_matmul()\n delta_t = tf.expand_dims(tf.transpose(delta), 2)\n s_h_t = tf.expand_dims(tf.transpose(s_h), 1)\n W_bt_t_ = tf.batch_matmul(delta_t, s_h_t)\n W_ = tf.reduce_mean(W_bt_t_, 0)\n e_h = tf.matmul(tf.transpose(W), delta)\n return b_, W_, e_h\n\nclass ReinforcementLearningDGN(object):\n # Define the network\n # Define the parameter variables\n # Define the value variables\n # Initialize the network\n # Generate by sample Then save to value variables\n # Evaluate marginal p(x) by importance sampling of batched value variables\n # Define the error value with p(x) and with score(x) and with Normalize z\n # Train with backpropogation from the error value\n \n def __init__(self,\n network_architecture=[100, 100, 40],\n transfer_fun=tf.nn.sigmoid,\n learning_rate=0.05, batch_size=100):\n self.sess = tf.Session()\n self.network_architecture = network_architecture\n self.size_x = network_architecture[0]\n self.batch_size = batch_size\n self.learning_rate = learning_rate\n self.transfer_fun = transfer_fun\n # create the tensorflow network\n self._create_network()\n self.exp_norm_const = tf.Variable(10*tf.ones([1] , dtype=tf.float32))\n self.tf_ph_score = tf.placeholder(tf.float32, [1, batch_size])\n # create training algorithm\n self.error_list, self.log_q_x, self.log_p_x= self._create_target_optimizer()\n # initialize\n init = tf.initialize_all_variables()\n self.sess.run(init)\n return\n\n def _create_network(self):\n # Initialize the weights and biases for DGN\n self._initialize_params()\n \n # Initialize the batched samples and weight variables\n self._define_batch_samples()\n \n # Build the forward generate rule with importance sampling p(h) estimation\n self.sample_handle = self._tf_sample_generator()\n\n return\n\n def _initialize_params(self):\n archit = self.network_architecture\n weights_list = []\n bias_list = [tf.Variable(tf.zeros([archit[0], 1], dtype=tf.float32))]\n updt_w_list = []\n updt_b_list = [tf.Variable(tf.zeros([archit[0], 1], dtype=tf.float32))]\n depth = len(archit) - 1\n for i in range(depth):\n n = archit[i]\n m = archit[i+1]\n w = tf.Variable(tf.random_uniform([n, m], -0.05, 0.05, dtype=tf.float32))\n b = tf.Variable(tf.zeros([m, 1], dtype=tf.float32))\n w_updt_v = tf.Variable(tf.zeros([n, m], dtype=tf.float32))\n b_updt_v = tf.Variable(tf.zeros([m, 1], dtype=tf.float32))\n weights_list.append(w)\n bias_list.append(b)\n updt_w_list.append(w_updt_v)\n updt_b_list.append(b_updt_v)\n self.updt_w_list = updt_w_list\n self.updt_b_list = updt_b_list\n self.weights_list = weights_list\n self.bias_list = bias_list\n return\n\n def _define_batch_samples(self):\n archit = self.network_architecture\n samp_prob1_var_list = [tf.Variable(tf.zeros([archit[0], self.batch_size]))]\n samp_var_list = [tf.Variable(tf.zeros([archit[0], self.batch_size]))]\n samp_w_var_list = [tf.Variable(tf.ones([1, self.batch_size]))]\n depth = len(archit) - 1\n for i in range(depth):\n n = archit[i]\n m = archit[i+1]\n pb = tf.Variable(tf.zeros([m, self.batch_size], dtype=tf.float32))\n sp = tf.Variable(tf.zeros([m, self.batch_size])) # binaris eventually, type can be optimized\n spw = tf.Variable(tf.zeros([1, self.batch_size])) # top layer don't have a weight\n samp_prob1_var_list.append(pb)\n samp_var_list.append(sp)\n samp_w_var_list.append(spw)\n self.samp_prob1_var_list = samp_prob1_var_list\n self.samp_var_list = samp_var_list\n self.samp_w_var_list = samp_w_var_list\n return\n\n # The generative model sample from top down.\n # For multiple layers, this requires a batch of samples to estimate the marginal probability\n # of each samples and forward with the weight vector.\n # An alternative would be using a particle filter resampling mechanism. which should be much more\n # acurate but break the auto BP so that we need to provide our own BP.\n def _tf_sample_generator(self):\n archit = self.network_architecture\n depth = len(archit) - 1\n self.samp_prob1_tfhl_list = [tf.tile(self.transfer_fun(self.bias_list[depth]), [1, self.batch_size])] # top layer is just the bias\n self.sample_tfhl_list = [sampleInt(self.samp_prob1_tfhl_list[0])]\n self.samp_w_tfhl_list = [tf.ones([1, self.batch_size])]\n sample_handle = [self.samp_var_list[depth].assign(self.sample_tfhl_list[0]),\\\n self.samp_w_var_list[depth].assign(self.samp_w_tfhl_list[0]),\\\n self.samp_prob1_var_list[depth].assign(self.samp_prob1_tfhl_list[0])]\n # sample from top to the bottom\n for i in range(depth-1, -1, -1): # not include top one\n n = archit[i]\n m = archit[i+1]\n spb = self.transfer_fun(tf.matmul(self.weights_list[i], self.sample_tfhl_list[0]) +\\\n tf.tile(self.bias_list[i], [1, self.batch_size]))\n # we need to save the prob of sample\n sp = sampleInt(spb)\n spb_assign_handle = self.samp_prob1_var_list[i].assign(spb)\n sp_assign_handle = self.samp_var_list[i].assign(sp)\n #compute_importance_weight(Hi+1, Hi, H_wi+1, W, b)\n spw = compute_importance_weight(self.sample_tfhl_list[0],\n sp,\n self.samp_w_tfhl_list[0],\n self.weights_list[i],\n self.bias_list[i],\n self.batch_size)\n spw_assign_handle = self.samp_w_var_list[i].assign(spw)\n sample_handle.extend([sp_assign_handle, spw_assign_handle, spb_assign_handle])\n self.samp_prob1_tfhl_list.insert(0, spb)\n self.sample_tfhl_list.insert(0, sp)\n self.samp_w_tfhl_list.insert(0, spw)\n return sample_handle\n\n\n # the target optimizer will be used in the BP algorithm handled by tenserflow later.\n def _create_target_optimizer(self):\n archit = self.network_architecture\n depth = len(archit) - 1\n # \n self.debug_norm_const = self.exp_norm_const\n log_q_x = self.tf_ph_score - tf.tile(tf.expand_dims(tf.log(self.exp_norm_const), -1), [1, self.batch_size])\n log_p_x = tf.log(self.samp_w_var_list[0])\n error_KLdiv = log_q_x - log_p_x\n # error = [tf.tile(error_KLdiv, [archit[0], 1])]\n # error = [tf.tile(tf.mul(tf.exp(tf.mul(0.5, error_KLdiv)), error_KLdiv), [archit[0], 1])] # top level, with exponential adjustment\n error = [tf.clip_by_value(tf.tile(tf.mul(tf.exp(error_KLdiv), error_KLdiv), [archit[0], 1]), -100.0, 100.0)] # top level, with exponential adjustment\n update_handle = []\n for i in range(depth): # not include top one\n b_, W_, e_h = back_propagate_one_layer(self.weights_list[i], \\\n self.samp_prob1_var_list[i], \\\n self.samp_var_list[i], \\\n self.samp_var_list[i+1],\n error[i], False)\n error.append(e_h)\n update_handle.extend([self.bias_list[i].assign_add(tf.mul(self.learning_rate, b_)), \\\n self.weights_list[i].assign_add(tf.mul(self.learning_rate, W_)), \\\n self.updt_b_list[i].assign(b_),\\\n self.updt_w_list[i].assign(W_)])\n\n [b_, _, _] = back_propagate_one_layer(None, \\\n self.samp_prob1_var_list[depth], \\\n self.samp_var_list[depth], \\\n None,\n error[depth], True)\n # error.append(e_h)\n update_handle.append(self.bias_list[depth].assign_add(tf.mul(self.learning_rate, b_)))\n update_handle.append(self.updt_b_list[depth].assign(b_))\n # this is the update for the norm\n new_exp_norm_const = tf.exp(self.tf_ph_score - log_p_x)\n exp_norm_const_ = tf.reduce_mean(new_exp_norm_const - tf.tile(tf.expand_dims(self.exp_norm_const, -1), [1, self.batch_size]), 1)\n self.update_enc_handle = self.exp_norm_const.assign(tf.clip_by_value(self.exp_norm_const + tf.mul(10.0*self.learning_rate, exp_norm_const_), 1e-35, 1e35))\n update_handle.append(self.update_enc_handle)\n self.update_handle = update_handle\n self.exp_norm_const_ = exp_norm_const_\n return error, log_q_x, log_p_x\n \n def _update(self, side_x, pre_update_enc):\n # check_op = tf.add_check_numerics_ops()\n # run the sample_handle will do a new round of sample and save into variables\n self.sess.run(self.sample_handle)\n # read from the variables the bottom level x and ask for score\n x = self.sess.run(self.samp_var_list[0])\n # score = 10.0 * muscleDirectTorqueScore(side_x*side_x, side_x, x, 0)\n score = 10.0 * muscleTorqueScore(side_x*side_x, side_x, x)\n # feed the optimizer with the score and update the weight and bias and the exp_norm_const\n if pre_update_enc:\n self.sess.run(self.update_enc_handle, feed_dict={self.tf_ph_score: score})\n else:\n self.sess.run(self.update_handle, feed_dict={self.tf_ph_score: score})\n return score\n\ndef display(M, side_i, side_t):\n image = Image.fromarray(tile_raster_images(M,\n img_shape=(side_i, side_i),\n tile_shape=(side_t, side_t),\n tile_spacing=(2, 2)))\n image.show()\n\ndef train(network_architecture, learning_rate,\n batch_size, training_epochs=100, display_step=100):\n # TODO learning rate is wrong, should be defined in loop \n rldgn = ReinforcementLearningDGN(network_architecture,\n tf.nn.sigmoid,\n learning_rate,\n batch_size)\n\n side_b = int(math.sqrt(batch_size)+ 0.1)\n side_x = int(math.sqrt(network_architecture[0])+ 0.1)\n side_h1 = int(math.sqrt(network_architecture[1])+ 0.1)\n side_h2 = int(math.sqrt(network_architecture[2])+ 0.1)\n\n # We need to pre update the norm_const so that it do not explod\n for epoch in range(2):\n print \"norm_const before update\", rldgn.sess.run(rldgn.debug_norm_const)\n score = rldgn._update(side_x, True)\n print \"self.tf_ph_score - log_p_x\", rldgn.sess.run(rldgn.tf_ph_score - rldgn.log_p_x, feed_dict={rldgn.tf_ph_score: score})\n print \"exp_norm_const_\", rldgn.sess.run(rldgn.exp_norm_const_, feed_dict={rldgn.tf_ph_score: score})\n print \"log_p_x\", rldgn.sess.run(rldgn.log_p_x, feed_dict={rldgn.tf_ph_score: score})\n print \"weight_var 0\", rldgn.sess.run(rldgn.samp_w_var_list[0])\n print \"weight_var 1\", rldgn.sess.run(rldgn.samp_w_var_list[1])\n # print \"Epoch:\", '%04d' % (epoch+1), \\\n # \"score=\", score\n\n for epoch in range(training_epochs):\n # update one batch\n rldgn.learning_rate = min(learning_rate, 10.0/(float(epoch + 1)**0.75))\n print \"norm_const before update\", rldgn.sess.run(rldgn.debug_norm_const), \"[learning_rate] \\t\", rldgn.learning_rate\n score = rldgn._update(side_x, False)\n # Display logs per epoch step\n if (epoch + 1) % display_step == 0:\n print \"Epoch:\", '%04d' % (epoch+1), \\\n \"score=\", score\n display(rldgn.sess.run(rldgn.samp_var_list[0]).T, side_x, side_b)\n display(rldgn.sess.run(rldgn.weights_list[0]).T, side_x, side_h1)\n display(rldgn.sess.run(rldgn.weights_list[1]).T, side_h1, side_h2)\n print \"weight_var 0\", rldgn.sess.run(rldgn.samp_w_var_list[0])\n print \"weight_var 1\", rldgn.sess.run(rldgn.samp_w_var_list[1])\n print \"weight_var 2\", rldgn.sess.run(rldgn.samp_w_var_list[2])\n print \"updt weight 0\", rldgn.sess.run(rldgn.updt_w_list[0])\n print \"updt bias 0\", rldgn.sess.run(tf.transpose(rldgn.updt_b_list[0]))\n # print \"updt weight 1\", rldgn.sess.run(rldgn.updt_w_list[1])\n # print \"updt bias 1\", rldgn.sess.run(tf.transpose(rldgn.updt_b_list[1]))\n print \"error 1\", rldgn.sess.run(rldgn.error_list[1], feed_dict={rldgn.tf_ph_score: score})\n print \"log_p_x\", rldgn.sess.run(rldgn.log_p_x, feed_dict={rldgn.tf_ph_score: score})\n print \"log_q_x\", rldgn.sess.run(rldgn.log_q_x, feed_dict={rldgn.tf_ph_score: score})\n # print \"self.tf_ph_score - log_p_x\", rldgn.sess.run(rldgn.tf_ph_score - rldgn.log_p_x, feed_dict={rldgn.tf_ph_score: score})\n # in training display go here as a function.\n print \"epoch \", epoch\n return rldgn\n\ndef main():\n # unit test some functions\n test()\n # train\n train([100, 36, 9], 0.01, 100, training_epochs = 5000, display_step = 100)\n # post display\n\ndef test():\n # test one by one\n\n # test this\n if not test_compute_importance_weight():\n return False\n return\n\ndef sigmoid(x):\n return 1.0 / (1.0 + math.exp(float(-x)))\n\ndef sigmoid_list(X):\n return [sigmoid(x) for x in X ]\n\ndef sigmoid_dlist(X):\n return [sigmoid_list(x) for x in X ]\n\ndef test_back_propagate_one_layer():\n # sizes\n batch_size = 5\n high_size = 3\n low_size = 4\n # tf placeholder\n W = tf.placeholder(tf.float32, [low_size, high_size])\n p = tf.placeholder(tf.float32, [low_size, batch_size])\n s = tf.placeholder(tf.float32, [low_size, batch_size])\n s_h = tf.placeholder(tf.float32, [high_size, batch_size])\n e = tf.placeholder(tf.float32, [low_size, batch_size])\n # actual handle\n bp_true = back_propagate_one_layer(W, p, s, s_h, e, True)\n bp_false = back_propagate_one_layer(None, p, s, None, e, False)\n # session setup\n sess = tf.Session()\n init = tf.initialize_all_variables()\n sess.run(init)\n # test input value setup\n W = [[1, 0, 0], [0, 1, -1], [-1, 0 ,1], [0, -1, 1]]\n P_t = [[0, 0, 1, 0], [0, 1, 0, 0], [1, 0, 0, 1], [1, 1, 0, 1], [0, 1, 1, 0]]\n P = zip(*Sp_t)\n S_t = [[0, 0, 1, 0], [0, 1, 0, 0], [1, 0, 0, 1], [1, 1, 0, 1], [0, 1, 1, 0]]\n S = zip(*Sp_t)\n S_h_t = [ [0, 0, 1], [0, 1, 0], [1, 0, 0], [1, 1, 0], [0, 1, 1]]\n S_h = zip(*Sp_h_t)\n E_t = [[0, 0, 1, 0], [0, 1, 0, 0], [1, 0, 0, 1], [1, 1, 0, 1], [0, 1, 1, 0]]\n E = zip(*Sp_t)\n # test output value setup\n\n # test\n return\n\ndef test_compute_importance_weight():\n # sizes\n batch_size = 5\n high_size = 3\n low_size = 4\n # place holder for test\n sp_h = tf.placeholder(tf.float32, [high_size, batch_size])\n sp = tf.placeholder(tf.float32, [low_size, batch_size])\n spw_h = tf.placeholder(tf.float32, [1, batch_size])\n w = tf.placeholder(tf.float32, [low_size, high_size])\n b_h = tf.placeholder(tf.float32, [low_size, 1])\n # actual handle setup\n spw = compute_importance_weight(sp_h, sp, spw_h, w, b_h, batch_size)\n # set up\n sess = tf.Session()\n init = tf.initialize_all_variables()\n sess.run(init)\n # set up test case value\n Sp_h_t = [ [0, 0, 1], [0, 1, 0], [1, 0, 0], [1, 1, 0], [0, 1, 1]]\n # Sp_h = [[0, 0, 1, 1, 0], [0, 1, 0, 1, 1], [1, 0, 0, 0, 1]]\n Sp_h = zip(*Sp_h_t)\n Sp_t = [[0, 0, 1, 0], [0, 1, 0, 0], [1, 0, 0, 1], [1, 1, 0, 1], [0, 1, 1, 0]]\n Sp = zip(*Sp_t)\n Spw_h = [[1, 1, 1, 1, 1]]\n W = [[1, 0, 0], [0, 1, -1], [-1, 0 ,1], [0, -1, 1]]\n B_h_t = [[0, 0, 0, 0]]\n B_h = zip(*B_h_t)\n # test\n output = sess.run(spw, feed_dict={sp_h: Sp_h, sp: Sp, spw_h: Spw_h, w: W, b_h: B_h})\n print (\"The output\", output)\n true_result_pre_mean = sigmoid_dlist([[1, 0, -2, -2, 1], [-3, 2, 0, 2, -1], [1, -2, 2, 0, -1], [-1, 0, 2, 2, -1], [-1, 2, -2, 0, 1]])\n for i in range(batch_size):\n assert abs(sum(true_result_pre_mean[i])/float(batch_size) - output[0][i]) < 1.0e-5\n # with actual weight\n Spw_h = [[1.0, 0.2, 1.0, 0.2, 1.0]]\n output = sess.run(spw, feed_dict={sp_h: Sp_h, sp: Sp, spw_h: Spw_h, w: W, b_h: B_h})\n print (\"The output\", output)\n true_result_pre_mean = sigmoid_dlist([[1, 0, -2, -2, 1], [-3, 2, 0, 2, -1], [1, -2, 2, 0, -1], [-1, 0, 2, 2, -1], [-1, 2, -2, 0, 1]])\n for i in range(batch_size):\n true_result_pre_mean_weighted = copy.copy(true_result_pre_mean[i])\n for j in range(batch_size):\n true_result_pre_mean_weighted[j] *= Spw_h[0][j]\n assert abs(sum(true_result_pre_mean_weighted)/float(batch_size) - output[0][i]) < 1.0e-5\n return\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.50081866979599,
"alphanum_fraction": 0.5501432418823242,
"avg_line_length": 43.01801681518555,
"blob_id": "e84ced58b06353c5c4d8705ce7b1f2cdd5d1bd8e",
"content_id": "9025de462e3fb7631ac39cb3c9c5c2a4265befe5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4886,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 111,
"path": "/mt_reward.py",
"repo_name": "hanhongsun/tensorflow_script",
"src_encoding": "UTF-8",
"text": "import Image\nimport numpy as np\nimport sys\nsys.path.append('/home/hanhong/Projects/python27/DeepLearningTutorials/code/')\nfrom utils import tile_raster_images\n\ndef muscleTorqueScore(size, side, x):\n # size == side * side\n assert(size == x.shape[0])\n len = x.shape[1] # number of samples\n x = x * 2\n x -= 1\n # print x\n H = side/2 # half the side is the bone in center of the muscle \n tqx = np.zeros((1,len))\n tqy = np.zeros((1,len))\n for i in range(-side + 1, side + 1, 2):\n for j in range(-side + 1, side + 1, 2):\n if i*i + j*j <= size:\n ind = side *(i + side -1)/2 + (j + side -1)/2\n tqx += x[ind, :]*i\n tqy += x[ind, :]*j\n # center of mass is the torque center == 4*r/(3*pi), mass of force = pi*r^2\n # raw score is 2 * 4/3 *r^3, as i, j ranged 2*d instead of d\n # size*side = 8*r^3, \n score = 3 * np.sqrt(tqx*tqx + tqy*tqy)/(size*side)\n return score\n\ndef muscleDirectTorqueScore(size, side, x, theta):\n # size == side * side\n assert(size == x.shape[0])\n # assert(x.shape[1] == theta.shape[0])\n len = x.shape[1] # number of samples\n x = x * 2\n x -= 1\n # print x\n H = side/2 # half the side is the bone in center of the muscle \n tqx = np.zeros((1,len))\n tqy = np.zeros((1,len))\n for i in range(-side + 1, side + 1, 2):\n for j in range(-side + 1, side + 1, 2):\n if i*i + j*j <= size:\n ind = side *(i + side -1)/2 + (j + side -1)/2\n tqx += x[ind, :]*i\n tqy += x[ind, :]*j\n # center of mass is the torque center == 4*r/(3*pi), mass of force = pi*r^2\n # raw score is 2 * 4/3 *r^3, as i, j ranged 2*d instead of d\n # size*side = 8*r^3, \n score_x = 3 * tqx/(size*side)\n score_y = 3 * tqy/(size*side)\n # cos(x - y) = cos(x)cos(y) + sin(x)sin(y)\n # r*cos(x - y)\n direction_score = score_x * np.cos(theta) + score_y * np.sin(theta)\n return direction_score\n\nif __name__ == \"__main__\":\n side_x = 100\n size_x = side_x * side_x\n\n # high score examples should be equal or close to 1\n x_test = np.zeros((size_x, 20))\n # print x_test\n x_test[size_x/2: size_x, 0] = 1 # 0\n logic_index = (np.array(range(0, size_x))/side_x) > (side_x - np.array(range(0, size_x))%side_x)\n x_test[logic_index, 1] = 1 # 1\n logic_index = (np.array(range(0, size_x)) * 2 / side_x)%2 == 1\n x_test[logic_index, 2] = 1 # 2\n logic_index = (np.array(range(0, size_x))/side_x) < (np.array(range(0, size_x))%side_x)\n x_test[logic_index, 3] = 1 # 3\n x_test[0: size_x/2, 4] = 1 # 4\n logic_index = (np.array(range(0, size_x))/side_x) < (side_x - np.array(range(0, size_x))%side_x)\n x_test[logic_index, 5] = 1 # 5\n logic_index = (np.array(range(0, size_x)) * 2 / side_x)%2 == 0\n x_test[logic_index, 6] = 1 # 6\n logic_index = (np.array(range(0, size_x))/side_x) > (np.array(range(0, size_x))%side_x)\n x_test[logic_index, 7] = 1 # 7\n \n # negtive examples, should keep as close to 0 as possible\n x_test[:, 8] = 1.0 * np.ones((size_x))\n x_test[0, 8] = 0\n # 9 is all zeros\n x_test[0:size_x:2, 10] = 1\n logic_index = (np.array(range(0, size_x))/side_x)%2 == 0\n x_test[logic_index, 11] = 1\n x_test[0:size_x:3, 12] = 1\n logic_index = (np.array(range(0, size_x))/side_x)%3 == 0\n x_test[logic_index, 13] = 1\n for i in range(-side_x + 1, side_x + 1, 2):\n for j in range(-side_x + 1, side_x + 1, 2):\n if i*i + j*j <= size_x:\n ind = side_x *(i + side_x -1)/2 + (j + side_x -1)/2\n x_test[ind, 14] = 1\n x_test[:, 15:21] = np.random.randint(2, size=(size_x, 5))\n # Do the test here\n print x_test\n print muscleTorqueScore(size_x, side_x, x_test)\n print \"theta [all]\", muscleDirectTorqueScore(size_x, side_x, x_test, range(20)*3.14159/4)\n print \"theta [0]\", muscleDirectTorqueScore(size_x, side_x, x_test, [0]*20)\n print \"theta 0\", muscleDirectTorqueScore(size_x, side_x, x_test, 0)\n print \"theta pi/4\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159/4)\n print \"theta pi/2\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159/2)\n print \"theta pi*3/4\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159*3/4)\n print \"theta pi\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159)\n print \"theta pi*5/4\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159*5/4)\n print \"theta pi*3/2\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159*3/2)\n print \"theta pi*7/4\", muscleDirectTorqueScore(size_x, side_x, x_test, 3.14159*7/4)\n image = Image.fromarray(tile_raster_images(np.transpose(x_test),\n img_shape=(side_x, side_x),\n tile_shape=(2, 10),\n tile_spacing=(2, 2)))\n image.show()\n"
},
{
"alpha_fraction": 0.573570191860199,
"alphanum_fraction": 0.6026285886764526,
"avg_line_length": 48.17171859741211,
"blob_id": "9a32340c05e13dd2a7e7aedbabdfa7bb42d26fda",
"content_id": "2516d83a1b641656cb920cfb45c692464cd16716",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9739,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 198,
"path": "/rlcd_dir_rbm.py",
"repo_name": "hanhongsun/tensorflow_script",
"src_encoding": "UTF-8",
"text": "from mt_reward import muscleDirectTorqueScore\nimport tensorflow as tf\nimport Image\nimport numpy as np\nimport sys\nsys.path.append('/home/hanhong/Projects/python27/DeepLearningTutorials/code/')\nfrom utils import tile_raster_images\nfrom tensorflow.python.ops import control_flow_ops\nimport matplotlib.pyplot as plt\n\n# size_x is the size of the visiable layer\n# size_h is the size of the hidden layer\nsize_th_raw = 8\nside_h = 10\nside_x = 10\nsize_h = side_h * side_h\nrepeat_th = side_x * 2\nsize_th = repeat_th * size_th_raw\nsize_x = side_x * side_x + size_th\nsize_bt = 10 # batch size ## TODO support only batch == 1\nk = 16\n# helper function\n\ndef sample(probs):\n return tf.to_float(tf.floor(probs + tf.random_uniform(tf.shape(probs), 0, 1)))\n\ndef sampleInt(probs):\n return tf.floor(probs + tf.random_uniform(tf.shape(probs), 0, 1))\n\ndef scalePosNegOne(vec):\n return tf.add(-1.0, tf.mul(2.0, vec))\n\ndef scalePosNegOneInt(vec):\n return tf.add(-1, tf.mul(2, vec))\n\n# define parameters\nb = tf.Variable(tf.random_uniform([size_h, 1], -0.05, 0.05))\nW = tf.Variable(tf.random_uniform([size_x, size_h], -0.05, 0.05))\nc = tf.Variable(tf.random_uniform([size_x, 1], -0.05, 0.05))\nH0 = tf.Variable(tf.zeros([size_h, size_bt], tf.float32))\nX1 = tf.Variable(tf.zeros([size_x, size_bt], tf.float32))\nH1 = tf.Variable(tf.zeros([size_h, size_bt], tf.float32))\nTH = tf.Variable(tf.zeros([size_th_raw, size_bt]), tf.float32)\n\na = tf.placeholder(tf.float32)\ncoldness = tf.placeholder(tf.float32) # coldness is 1/Temperature\n\nsc = tf.placeholder(tf.float32, [1, size_bt]) # place holder for returned score\n# define the Simulated annealing sampling graph\n# cold_target = tf.placeholder(tf.float32)\n# the const number for this\nnorm_const = tf.Variable([20.00])\n\nan_step = tf.constant(0.2)\n\nth_o_const = tf.concat(0, [tf.ones([1, size_bt]), tf.zeros([size_th_raw - 1, size_bt])])\nth_o_raw = tf.random_shuffle(th_o_const)\nth_o_temp = tf.transpose(tf.tile(tf.expand_dims(th_o_raw, -1), [1, 1, repeat_th]), perm=[1, 0, 2])\nth_o = tf.transpose(tf.reshape(th_o_temp, [size_bt, size_th]))\nx_o = tf.concat(0, [sample(tf.ones([size_x - size_th, size_bt]) * 0.5), th_o])\nh_o = sample(tf.sigmoid(tf.matmul(tf.transpose(W)*0, x_o) + tf.tile(b*0, [1, size_bt])))\nql_const = tf.constant(0.2)\ndef simAnnealingGibbs(xx, hh, temp_inv): # W c b size_bt an_step # these are globle values\n xk = tf.concat(0, [tf.slice(sample(tf.sigmoid(tf.matmul(W*temp_inv*ql_const, hh) + \\\n tf.tile(c*temp_inv*ql_const, [1, size_bt]))), \\\n [0, 0], [size_x - size_th, size_bt]), th_o])\n hk = sample(tf.sigmoid(tf.matmul(tf.transpose(W*temp_inv*ql_const), xk) + tf.tile(b*temp_inv*ql_const, [1, size_bt])))\n return xk, hk, temp_inv + an_step\n\ndef isColdEnough(xx, hh, temp_inv):\n return temp_inv < 1.0\n\n[x0, h0, _] = control_flow_ops.While(isColdEnough, simAnnealingGibbs, [x_o, h_o, coldness], 1, False)\n\nx1 = tf.concat(0, [tf.slice(sample(tf.sigmoid(tf.matmul(W, h0) + tf.tile(c, [1, size_bt]))), \\\n [0, 0], [size_x - size_th, size_bt]), th_o])\nh1 = sample(tf.sigmoid(tf.matmul(tf.transpose(W), x1) + tf.tile(b, [1, size_bt])))\n\nsample_data = [H0.assign(h0), X1.assign(x1), H1.assign(h1), TH.assign(th_o_raw)]\n\ndef logMargX(x, h, W, c):\n prob_all1 = tf.matmul(W, h) + tf.tile(c, [1, size_bt])\n # log_matrix has the DIM[0] the position of batch in h and DIM[1] the position of batch in x\n log_matrix = tf.reduce_sum(tf.tile(tf.expand_dims(prob_all1, -1), [1, 1, size_bt]) * \\\n tf.transpose(tf.tile(tf.expand_dims(scalePosNegOne(x), -1), [1, 1, size_bt]), [0, 2, 1]), 1)\n return tf.log(tf.reduce_mean(tf.sigmoid(log_matrix), 0, True))\n\n# define the update rule\nupdt_value = sc - logMargX(X1, H0, ql_const*W, ql_const*c) - tf.tile(tf.expand_dims(norm_const, -1), [1, size_bt])\nupdate_value = tf.minimum(tf.maximum(tf.exp(updt_value / ql_const) - tf.exp(updt_value), - 1), 300)\nupdate_value_norm = tf.minimum(tf.maximum(updt_value, -1), 100)\n\nnorm_const_ = tf.mul(tf.reduce_mean(update_value_norm, 1), 2*a)\n\n# x2 = sample(tf.sigmoid(tf.matmul(W, H1) + tf.tile(c, [1, size_bt])))\n# h2 = sample(tf.sigmoid(tf.matmul(tf.transpose(W), x2) + tf.tile(b, [1, size_bt])))\n\n# the rbmGibbs will let theta value run freely and go wild\ndef rbmGibbs(xx, hh, count, k):\n xk = sampleInt(tf.sigmoid(tf.matmul(W, hh) + tf.tile(c, [1, size_bt])))\n hk = sampleInt(tf.sigmoid(tf.matmul(tf.transpose(W), xk) + tf.tile(b, [1, size_bt])))\n # assh_in1 = h_in.assign(hk)\n return xk, hk, count+1, k\n\ndef lessThanK(xk, hk, count, k):\n return count <= k\n\n# tf.convert_to_tensor(X1, name=\"X1\") tf.convert_to_tensor(H1, name=\"H1\")\n[x2, h2, _, _] = control_flow_ops.While(lessThanK, rbmGibbs, [X1, H1, tf.convert_to_tensor(1), tf.convert_to_tensor(k)], 1, False)\n\n\ndebug_1 = tf.tile(tf.reshape(update_value, [size_bt, 1, 1]), [1, size_x, size_h])\ndebug_2 = tf.batch_matmul(tf.expand_dims(tf.transpose(X1), 2), tf.expand_dims(tf.transpose(H1), 1))\ndebug_3 = tf.batch_matmul(tf.expand_dims(tf.transpose(x2), 2), tf.expand_dims(tf.transpose(h2), 1))\ndebug_4 = tf.tile(tf.reshape(update_value, [size_bt, 1, 1]), [1, size_x, size_h]) * tf.batch_matmul(tf.expand_dims(tf.transpose(X1), 2), tf.expand_dims(tf.transpose(H1), 1))\n\n\nW_ = a/float(size_bt) * tf.reduce_mean(tf.sub(tf.batch_matmul(tf.expand_dims(tf.transpose(X1), 2), tf.expand_dims(tf.transpose(H1), 1)),\\\n tf.batch_matmul(tf.expand_dims(tf.transpose(x2), 2), tf.expand_dims(tf.transpose(h2), 1)))\\\n * tf.tile(tf.reshape(update_value, [size_bt, 1, 1]), [1, size_x, size_h]), 0)\nb_ = a * tf.reduce_mean(tf.mul(tf.sub(H1, h2), tf.tile(update_value, [size_h, 1])), 1, True)\nc_ = a * tf.reduce_mean(tf.mul(tf.sub(X1, x2), tf.tile(update_value, [size_x, 1])), 1, True)\n\n# norm_const\n# TODO not done, add the self engergy function estimation\nupdt = [W.assign_add(W_), b.assign_add(b_), c.assign_add(c_), norm_const.assign_add(norm_const_)]\n\n# run session\n\nsess = tf.Session()\ninit = tf.initialize_all_variables()\nsess.run(init)\n\nnorm_const_history = []\nsample_score_hist = []\nh1_mean_hist = []\n\n# loop with batch\nfor i in range(1, 5002):\n alpha = min(0.05, 100.0/float(i))\n sess.run(sample_data, feed_dict={coldness: 0.0})\n x1_ = sess.run(X1)\n theta = sess.run(tf.to_float(tf.argmax(TH, 0)) * (3.1415926535/4))\n score = 10.0 * sess.run(ql_const) * muscleDirectTorqueScore(size_x - size_th, side_x, x1_[0:size_x - size_th, :], theta)\n sample_score_hist.extend(score.tolist())\n norm_const_history.extend(sess.run(norm_const))\n\n # print sample_score_hist\n # print \"shape of W_\", sess.run(tf.shape(W_), feed_dict={ sc: score, a: alpha, coldness: 0.0}), sess.run(tf.shape(W))\n # print \"shape of b_\", sess.run(tf.shape(b_), feed_dict={ sc: score, a: alpha, coldness: 0.0}), sess.run(tf.shape(b))\n # print \"shape of c_\", sess.run(tf.shape(c_), feed_dict={ sc: score, a: alpha, coldness: 0.0}), sess.run(tf.shape(c))\n # print \"shape of norm_const_\", sess.run(tf.shape(norm_const_), feed_dict={ sc: score, a: alpha, coldness: 0.0}), sess.run(tf.shape(norm_const))\n # print \"logMargX\", sess.run(logMargX(x1, h1, W, c), feed_dict={ sc: score, a: alpha, coldness: 0.00})\n # print \"shape of updt_value\", sess.run(tf.shape(updt_value), feed_dict={ sc: score, a: alpha, coldness: 0.0}), \"value \", sess.run(updt_value, feed_dict={ sc: score, a: alpha, coldness: 0.0})\n sess.run(updt, feed_dict={ sc: score, a: alpha})\n # h1_mean_hist.append(sess.run(tf.reduce_mean(H1))) \n print i, ' mean score ', np.mean(score), ' max score ', np.max(score), ' step size ', alpha, ' norm_const ', sess.run(norm_const)\n # vidualization\n if i % 500 == 1:\n image = Image.fromarray(tile_raster_images(sess.run(W).T,\n img_shape=(side_x + 2*size_th_raw, side_x),\n tile_shape=(side_h, side_h),\n tile_spacing=(2, 2)))\n image.show()\n image = Image.fromarray(tile_raster_images(sess.run(X1).T,\n img_shape=(side_x + 2*size_th_raw, side_x),\n tile_shape=(side_h, side_h),\n tile_spacing=(2, 2)))\n image.show()\n image = Image.fromarray(tile_raster_images(sess.run(c).T,\n img_shape=(side_x + 2*size_th_raw, side_x),\n tile_shape=(1, 1),\n tile_spacing=(2, 2)))\n image.show()\n print 'norm_const ', sess.run(norm_const).T\n print 'W ', sess.run(W).T\n print 'W variant', sess.run(tf.sqrt(tf.reduce_mean(W * W)))\n print 'c ', sess.run(c).T\n print 'update_value', sess.run(update_value, feed_dict={sc: score, a: alpha}).T\n h1_mean_hist.append(sess.run(tf.reduce_mean(H1))) \n # print 'norm_const_history', norm_const_history\n # print 'W update pos side 3d', sess.run(debug_2, feed_dict={sc: score, a: alpha}).T\n # print 'W update neg side re-sample 3d', sess.run(debug_3, feed_dict={sc: score, a: alpha}).T\n # print 'W update neg side weighted 3d', sess.run(debug_4, feed_dict={sc: score, a: alpha}).T\n\n # plt.plot(sample_score_hist)\n # print 'c ', sess.run(c).T\n # print 'b ', sess.run(b).T\n # print 'W ', sess.run(W).T\n \nplt.plot(sample_score_hist)\nplt.show()\n\nplt.plot(norm_const_history)\nplt.show()\n\nplt.plot(h1_mean_hist)\nplt.show()\n\n\n\n"
},
{
"alpha_fraction": 0.539667010307312,
"alphanum_fraction": 0.5675808191299438,
"avg_line_length": 33.59321975708008,
"blob_id": "58d7ba8fa408a95db4dbccf0e723ea946f4bf532",
"content_id": "e8bb0980cd3b9855ffeab8dce746dfc4f6b369ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4084,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 118,
"path": "/rbm.py",
"repo_name": "hanhongsun/tensorflow_script",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport Image\nimport numpy as np\nimport sys\nsys.path.append('/home/hanhong/Projects/python27/DeepLearningTutorials/code/')\nfrom utils import tile_raster_images\nfrom tensorflow.python.ops import control_flow_ops\n\n# size_x is the size of the visiable layer\n# size_h is the size of the hidden layer\nside_h = 10\nsize_x = 28*28\nsize_h = side_h * side_h\nsize_bt = 100 # batch size\n\nk = tf.constant(1)\n\n#### we do the first test on the minst data again\n\nfrom tensorflow.examples.tutorials.mnist import input_data\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot=True)\ntrX, trY, teX, teY = mnist.train.images, mnist.train.labels,\\\n mnist.test.images, mnist.test.labels\n\n\n# helper function\n\ndef sample(probs):\n return tf.to_float(tf.floor(probs + tf.random_uniform(tf.shape(probs), 0, 1)))\n\ndef sampleInt(probs):\n return tf.floor(probs + tf.random_uniform(tf.shape(probs), 0, 1))\n\n# variables and place holder\n\nb = tf.Variable(tf.random_uniform([size_h, 1], -0.005, 0.005))\nW = tf.Variable(tf.random_uniform([size_x, size_h], -0.005, 0.005))\nc = tf.Variable(tf.random_uniform([size_x, 1], -0.005, 0.005))\nx = tf.placeholder(tf.float32, [size_x, size_bt])\na = tf.placeholder(tf.float32)\n\n# define graph/algorithm\n\n# sample h x1 h1 ..\nh = sample(tf.sigmoid(tf.matmul(tf.transpose(W), x) + tf.tile(b, [1, size_bt])))\n\n# CD-k \n# we use tf.while_loop to achieve the multiple (k - 1) gibbs sampling \n\n# set up tf.while_loop()\n\ndef rbmGibbs(xx, hh, count, k):\n xk = sampleInt(tf.sigmoid(tf.matmul(W, hh) + tf.tile(c, [1, size_bt])))\n hk = sampleInt(tf.sigmoid(tf.matmul(tf.transpose(W), xk) + tf.tile(b, [1, size_bt])))\n # assh_in1 = h_in.assign(hk)\n return xk, hk, count+1, k\n\ndef lessThanK(xk, hk, count, k):\n return count <= k\n\nct = tf.constant(1)\n\n[xk1, hk1, _, _] = control_flow_ops.While(lessThanK, rbmGibbs, [x, h, ct, k], 1, False)\n\n# update rule\n[W_, b_, c_] = [tf.mul(a/float(size_bt), tf.sub(tf.matmul(x, tf.transpose(h)), tf.matmul(xk1, tf.transpose(hk1)))),\\\n tf.mul(a/float(size_bt), tf.reduce_sum(tf.sub(h, hk1), 1, True)),\\\n tf.mul(a/float(size_bt), tf.reduce_sum(tf.sub(x, xk1), 1, True))]\n\n# wrap session\nupdt = [W.assign_add(W_), b.assign_add(b_), c.assign_add(c_)]\n\n# stop gradient to save time and mem\ntf.stop_gradient(h)\ntf.stop_gradient(xk1)\ntf.stop_gradient(hk1)\ntf.stop_gradient(W_)\ntf.stop_gradient(b_)\ntf.stop_gradient(c_)\n\n# run session\n\nsess = tf.Session()\ninit = tf.initialize_all_variables()\nsess.run(init)\n\n# loop with batch\nfor i in range(1, 10002):\n tr_x, tr_y = mnist.train.next_batch(size_bt)\n tr_x = np.transpose(tr_x)\n tr_y = np.transpose(tr_y)\n alpha = min(0.05, 100/float(i))\n sess.run(updt, feed_dict={x: tr_x, a: alpha})\n print i, ' step size ', alpha\n # vidualization\n if i % 5000 == 1:\n image = Image.fromarray(tile_raster_images(sess.run(W).T,\n img_shape=(28, 28),\n tile_shape=(side_h, side_h),\n tile_spacing=(2, 2)))\n image.show()\n print 'c ', sess.run(c).T\n print 'b ', sess.run(b).T\n print 'W ', sess.run(W).T\n print 'x ', np.transpose(tr_x)\n print 'h ', sess.run(h, feed_dict={x: tr_x}).T\n # print 'x1 ', sess.run(x1, feed_dict={x: tr_x}).T\n # print 'h1 ', sess.run(h1, feed_dict={x: tr_x}).T \n imagex = Image.fromarray(tile_raster_images(np.transpose(tr_x),\n img_shape=(28, 28),\n tile_shape=(10, 10),\n tile_spacing=(2, 2)))\n imagex.show()\n imagexk = Image.fromarray(tile_raster_images(sess.run(xk1, feed_dict={x: tr_x}).T,\n img_shape=(28, 28),\n tile_shape=(10, 10),\n tile_spacing=(2, 2)))\n imagexk.show()\n\n\n"
}
] | 4 |
waltersharpWEI/udp2server_xc
|
https://github.com/waltersharpWEI/udp2server_xc
|
496c66c57831b61e4cf6f509ed3dbef893e4c2c5
|
dbc15d3d402d98c9d09e7a7ea1a91eccf66c5d17
|
c9d91c1bd084eedc627a686fe73fb9b9a5ea0ce7
|
refs/heads/master
| 2021-03-20T13:30:45.524345 | 2020-03-14T04:17:03 | 2020-03-14T04:17:03 | 247,210,094 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6538461446762085,
"alphanum_fraction": 0.6794871687889099,
"avg_line_length": 14.5,
"blob_id": "0b04f02000fa143cfbaa85e579c60d1175a0c07d",
"content_id": "2f7a985b8d34a77fe5f95de822c5b232089c586e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 10,
"path": "/include/Frame.h",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "\n#ifndef SRC_FRAME_H_\n#define SRC_FRAME_H_\n\nstruct Frame{\n\tlong long timestamp;\n\tunsigned long long dss;\n\tchar content[1400];\n};\n\n#endif /* SRC_FRAME_H_ */\n"
},
{
"alpha_fraction": 0.6646415591239929,
"alphanum_fraction": 0.6780073046684265,
"avg_line_length": 24.71875,
"blob_id": "ab3545f8b494431fd7fd09a45b4601bb80898e63",
"content_id": "8f96221bf26d99f63cee128e90a7865291786479",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 32,
"path": "/scripts/simulator1.py",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport subprocess\nfrom time import sleep\nfrom datetime import datetime\nimport argparse\n\n\ndef change_link(loss = 0,delay = 0,th = 0,target_NIC='ens6'):\n\tos.system(\"sudo tc qdisc change dev \" + target_NIC + \" root netem delay \" + str(delay) + \"ms loss \"+str(loss)+\"%\")\n\n\n\nif __name__ == '__main__':\n\tparser = argparse.ArgumentParser()\n\tparser.add_argument(\"-d\",\"--delay\",help=\"delay of simulator\",type=int)\n\tparser.add_argument(\"-l\",\"--loss\",help=\"loss of simulator(%)\",type=int)\n\targs = parser.parse_args()\n\tdelay = args.delay\n\tloss = args.loss\n\twhile True:\n\t\t#interrupt the link quality every 10s\n\t\tsleep(3)\n\t\t#print('start')\n\t\t#print(datetime.now())\n\t\tchange_link(loss,delay)\n\t\t#the handover takes 2s\n\t\tsleep(1)\n\t\t#print('finish')\n\t\t#print(datetime.now())\n\t\t#the handover finished\n\t\tchange_link(0,0)\n"
},
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.8039215803146362,
"avg_line_length": 24.5,
"blob_id": "4b9779e8ff7d431d90b98b39d53bae62f6bf1fa2",
"content_id": "7dde42476b1f3aab152538b3cf508d2789dc77a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 2,
"path": "/README.md",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "#the mpnext client for exp2 multipath\n# udp2client\n"
},
{
"alpha_fraction": 0.6659528613090515,
"alphanum_fraction": 0.6766595244407654,
"avg_line_length": 23.578947067260742,
"blob_id": "e5c7fa2dbd691dad0e6e8d80c8dd36744c267d0e",
"content_id": "e80a520482af97d49ca1e0bb7ca117347aa1b53b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 19,
"path": "/Makefile",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "CC=g++\nCXXFLAGS=-Wall -std=c++11\n\nINC = -I./include\nLIBS = -L./lib -lpthread\n\nall: udp2\n\nudp2 : build/main.o\n\t$(CC) $(CXXFLAGS) -o tools/udp2server build/main.o build/UDPServer.o $(LIBS)\n\nbuild/main.o : build/UDPServer.o tools/main.cpp \n\t$(CC) $(CXXFLAGS) $(INC) -c tools/main.cpp build/UDPServer.o -o build/main.o \n\t\nbuild/UDPServer.o: src/UDPServer.cpp\n\t$(CC) $(CXXFLAGS) $(INC) -c src/UDPServer.cpp -o build/UDPServer.o\n\nclean:\n\trm -rf tools/mpnext build/* lib/*\n"
},
{
"alpha_fraction": 0.656877875328064,
"alphanum_fraction": 0.671561062335968,
"avg_line_length": 23.41509437561035,
"blob_id": "ebe1cf79d0cc96e5971b83e8df78bc469f28dfa1",
"content_id": "33044da7506de013f5526fffd6d6e3d12455e651",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2588,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 106,
"path": "/src/UDPServer.cpp",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "/*\n * UDPServer.cpp\n *\n * Created on: Dec 23, 2019\n * Author: ubuntu\n */\n\n\n#include <unistd.h>\n#include <string.h>\n#include <stdlib.h>\n#include <stdio.h>\n#include <errno.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <linux/if_packet.h>\n#include <net/ethernet.h> /* the L2 protocols */\n\n#include \"../include/UDPServer.h\"\n\n#define UDPLITE_SEND_CSCOV 10\n#define UDPLITE_RECV_CSCOV 11\n\nUDPServer::UDPServer() {\n\t if((packet_socket = socket(AF_INET, SOCK_DGRAM, 0)) < 0)\n\t {\n\t\t perror (\"packet socket fail\");\n\t\t exit(1);\n\t }\n}\n\nUDPServer::~UDPServer() {\n\tclose(packet_socket);\n}\n\n//initialize the IP and port\nint UDPServer::init(char *IPx, int portx) {\n\tstrcpy(IP,IPx);\n\tport = portx;\n\tmemset(&addr, 0, sizeof(addr));\n\taddr.sin_family = AF_INET;\n\taddr.sin_port = htons(port);\n\taddr.sin_addr.s_addr = inet_addr(IP);\n\tstruct timeval read_timeout;\n\tread_timeout.tv_sec = 0;\n\tread_timeout.tv_usec = 10;\n\tsetsockopt(packet_socket, SOL_SOCKET, SO_RCVTIMEO, &read_timeout, sizeof read_timeout);\n}\n\nint UDPServer::bind_x() {\n\tif(-1 == (bind(packet_socket,(struct sockaddr*)&addr,sizeof(addr)))) {\n\t\tperror(\"UDP Server Bind Failed:\");\n\t\texit(1);\n\t}\n}\n\nssize_t UDPServer::recvfrom_x(void *buf, size_t len, int flags,\n struct sockaddr *src_addr, socklen_t *addrlen) {\n\n\treturn recvfrom(packet_socket, buf, len, flags, src_addr, addrlen);\n}\n\n//clear all UDP options,\n//call before set the UDP-mode\nvoid UDPServer::optclear() {\n\n}\n//set to UDP-Default\nvoid UDPServer::setOptDefault() {\n\tint buffer_size = 0;\n\tsetsockopt(packet_socket, SOL_SOCKET, SO_RCVBUF, (int*)&buffer_size, sizeof(int));\n}\n//set to UDP-Lite\nvoid UDPServer::setOptLite(int cov) {\n\tclose(packet_socket);\n\tif((packet_socket = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDPLITE)) < 0)\n\t{\n\t\tperror (\"UDP-Lite socket\");\n\t\texit(1);\n\t}\n\tint val = 8;\n\tsetsockopt(packet_socket, IPPROTO_UDP, UDPLITE_SEND_CSCOV, &val, sizeof(int));\n}\n//set to UDP-Soomro\nvoid UDPServer::setOptSoomro(int recv_buffer_size){\n\tint buffer_size = 26214400;\n\t//buffer_size = recv_buffer_size;\n\tsetsockopt(packet_socket, SOL_SOCKET, SO_RCVBUF, (int*)&buffer_size, sizeof(int));\n}\n//set the buffer size to size in bytes\nvoid UDPServer::setBuffer(int size){\n\tint ret = 0;\n\tint reuse = 1;\n\tret = setsockopt(packet_socket, SOL_SOCKET, SO_REUSEADDR,(const void *)&reuse , sizeof(int));\n\tif (ret < 0) {\n\t\t\tperror(\"setsockopt\");\n\t\t\t_exit(-1);\n\t}\n\tret = setsockopt(packet_socket, SOL_SOCKET, SO_REUSEPORT,(const void *)&reuse , sizeof(int));\n\tif (ret < 0) {\n\t\tperror(\"setsockopt\");\n\t\t_exit(-1);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5924158692359924,
"alphanum_fraction": 0.6217980980873108,
"avg_line_length": 27.23404312133789,
"blob_id": "61d09b026c2a17ff21948dce7d1e0dd66de83376",
"content_id": "4cabed7d857710ae645ee0d10978bebec0eb456d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3982,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 141,
"path": "/tools/main.cpp",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "\n#include <unistd.h>\n#include <string.h>\n#include <stdlib.h>\n#include <stdio.h>\n#include <errno.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n#include <linux/if_packet.h>\n#include <net/ethernet.h> /* the L2 protocols */\n#include <chrono>\n#include \"../include/UDPServer.h\"\n#include \"Frame.h\"\n\nusing namespace std;\n\n#define ETH_HDR_LEN 14\n#define IP_HDR_LEN 20\n#define UDP_HDR_LEN 8\n#define TCP_HDR_LEN 20\n#define PACKET_LOG_LEN 300\n\n#define MAX_MSG_LEN 1500\n\nlong long gettimestamp() {\n\tchrono::time_point<std::chrono::system_clock> now = chrono::system_clock::now();\n\tauto duration = now.time_since_epoch();\n\tauto millis = std::chrono::duration_cast<std::chrono::milliseconds>(duration).count();\n\treturn millis;\n}\n\nint distractFrame(const void * buf, size_t len, struct Frame* fra) {\n\tint offset = 0;\n\tmemset(fra,0,sizeof(*fra));\n\tmemcpy(&fra->dss, buf, sizeof(fra->dss));\n\toffset += sizeof(fra->dss);\n\tmemcpy(&fra->timestamp, buf + offset, sizeof(fra->timestamp));\n\toffset += sizeof(fra->timestamp);\n\tmemcpy(fra->content,buf+offset, len - offset);\n\treturn len - offset;\n}\n\nstruct packet_log_node {\n\tlong long delay;\n\tstruct packet_log_node *next;\n};\n//pdl, packet_delay_log\nstruct packet_log_node *pdl_head, *pdl_tail;\n\ndouble compute_jitter(struct packet_log_node *head) {\n\tstruct packet_log_node * cursor;\n\tcursor = head;\n\tdouble jitter = 0;\n\tint count = 0;\n\twhile (cursor && cursor->next != nullptr) {\n\t\tjitter += abs(cursor->delay - cursor->next->delay);\n\t\tcursor = cursor->next;\n\t\t++count;\n\t}\n\tif (count == 0) return 0;\n\treturn jitter / count;\n}\n\nint main() {\n\tpdl_head = new struct packet_log_node;\n\tpdl_head->delay = 0;\n\tpdl_head->next = nullptr;\n\tpdl_tail = pdl_head;\n\tUDPServer udpS1;\n\tchar buffer[MAX_MSG_LEN];\n\tint coverage = 10;\n\tint buffer_unit = 1024 * 1024; //1MB\n\tint recv_buffer = 25 * buffer_unit;\n\n\tudpS1.init(\"192.168.6.136\",12345);\n\n\t//udpS1.setOptLite(10);\n\tudpS1.setOptSoomro(200000);\n\tudpS1.setOptDefault();\n\tudpS1.bind_x();\n\n\tstruct sockaddr_in remote_addr;\n\tint sin_size;\n\tmemset(&remote_addr,0,sizeof(sockaddr_in));\n\tstruct Frame fra;\n\tint latest_dss = 0;\n\tlong long loss_count = 0;\n\tlong long packet_count = 0;\n\tdouble current_delay_jitter = 0;\n int ac = 0;\n int dc = 10;\n\twhile (true) {\n ++ac;\n if (ac > 1000) {\n int bsc0 = rand() % 1000000;\n int bsc1 = rand() % 1000;\n int bsc = rand() % 10 > 5? bsc0:bsc1;\n if (ac % 10000 == 0) {\n \t\tudpS1.setOptSoomro(bsc);\n \n }\n printf(\"After:%d===\",bsc);\n }\n\t\tbzero(buffer,MAX_MSG_LEN);\n\t\t//int len = udpS1.recvfrom_x(buffer,MAX_MSG_LEN,0,(struct sockaddr *)&remote_addr, (socklen_t*)sin_size);\n\t\tint len = udpS1.recvfrom_x(buffer,MAX_MSG_LEN,0, NULL, NULL);\n\t\t//non-blocking io\n\t\tif (len < 0) {\n\t\t\t//printf(\"Timeout.\\n\");\n\t\t\tcontinue;\n\t\t}\n\t\t//int slen = sendto(udpS1.packet_socket,buffer,len,0,(struct sockaddr *)&remote_addr,sin_size);\n\t\tint length = distractFrame(buffer, len, &fra);\n\t\t++packet_count;\n\t\tif (fra.dss != latest_dss + 1) {\n\t\t\t++loss_count;\n\t\t}\n\t\tlatest_dss = fra.dss;\n\t\tdouble cumulative_loss = (double)loss_count / packet_count;\n\t\t//printf(\"%d,%d,%s\\n\",len,length,fra.content);\n\t\tlong long this_delay = gettimestamp() - fra.timestamp;\n\t\tcurrent_delay_jitter = compute_jitter(pdl_head);\n\t\tprintf(\"%lld ,%lld,%lld,%f,%f\\n\",fra.dss,fra.timestamp,gettimestamp() - fra.timestamp\n\t\t\t\t, cumulative_loss, current_delay_jitter);\n\t\t//printf(\"1\");\n\t\t//usleep(1000);\n\t\tpdl_tail->next = new struct packet_log_node;\n\t\tpdl_tail->next->delay = this_delay;\n\t\tpdl_tail->next->next = nullptr;\n\t\tpdl_tail = pdl_tail->next;\n\t\tif (packet_count > PACKET_LOG_LEN) {\n\t\t\tstruct packet_log_node * temp = pdl_head;\n\t\t\tpdl_head = pdl_head->next;\n\t\t\tdelete temp;\n\t\t\tpacket_count = 0;\n\t\t\tloss_count = 0;\n\t\t}\n\t}\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5816195607185364,
"alphanum_fraction": 0.6163238883018494,
"avg_line_length": 36.0476188659668,
"blob_id": "1f1bed7b8f82583e196c55fc6d983ab5fbd39117",
"content_id": "a317788afccebd92ea2f3a116854eac6e6366926",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3112,
"license_type": "no_license",
"max_line_length": 353,
"num_lines": 84,
"path": "/scripts/test_mp.py",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport subprocess\nimport time\n\ndef run_flow(flow_size=1000000,exp_mode = 0, loss_x = 0, delay_x = 0, balance_factor = 0):\n\t#handover_num = 4\n\tloss = [0]\n\tdelay = [0]\n\tNIC1ip = '172.31.18.64'\n\tNIC2ip = '172.31.67.209'\n\t#flow_size = 2000000\n\ttime_to_kill = 1\n\tcontent_size = 1024\n\tprotocol1 = 0\n\tprotocol2 = 0\n\tsegments_to_switch = flow_size / 2\n\tsegment_size = 2048\n\tmode_of_running = 0\n\tNIC1 = 'ens5'\n\tNIC2 = 'ens6'\n\ttarget_NIC = 'ens6'\n\tthroughput_log_file = 'log.txt'\n\t\n\tcontent_sizes = [64]\n\t\n\tcmd_start_remote_server = 'ssh ubuntu@' + NIC1ip + ' /home/ubuntu/mpnext2/tools/mpnext' \n\tcmd_kill_remote_server = 'ssh ubuntu@' + NIC1ip + ' killall mpnext'\n\tcmd_start_remote = 'ssh ubuntu@'+ NIC1ip + ' ifstat -b -n -i '+ target_NIC + ' -t 0.1 ' + '>' + throughput_log_file \n\t\n\tremote_monitor = subprocess.Popen(cmd_start_remote, shell=True, stdout=subprocess.PIPE)\n\tprint(cmd_start_remote_server)\n\tprint(cmd_start_remote)\n\t\n\tfor i in range(len(delay)):\n\t for j in range(len(loss)):\n\t os.system(\"sudo tc qdisc change dev \" + target_NIC + \" root netem loss 0% delay 0ms\")\n\t\n\t #time.sleep(6)\n\t content_size = content_sizes[0]\n\t remote_server = subprocess.Popen(cmd_start_remote_server, shell=True, stdout=subprocess.PIPE)\n\t #remote_server.wait()\n\t time.sleep(5)\n\t cmd_simulator = \"python3 simulator1.py\" + \" -l \" + str(loss_x) + \" -d \" + str(delay_x)\n\t jammer = subprocess.Popen(cmd_simulator, shell=True)\n\t os.system(\"sudo tc qdisc change dev \" + target_NIC + \" root netem delay \" + str(delay[i]) + \"ms loss \"+str(loss[j])+\"%\")\n\t cmd = \"../tools/mpnext \" + \" -b \" + str(balance_factor) + \" -e \" + str(exp_mode) + \" -f \" + str(flow_size) + \" -s \" + str(segment_size) + \" -k \" + str(time_to_kill) + ' -m ' + str(mode_of_running) + ' -c ' + str(content_size) + ' -p ' + str(protocol1) + ' -q ' + str(protocol2) + ' -w ' + str(segments_to_switch) + ' -t ' + NIC1ip + ' -u ' + NIC2ip\n\t #os.system(cmd)\n\t os.system(cmd+'>'+'loss'+str(loss[j])+'delay'+str(delay[i])+'.txt')\n\t jammer.kill()\n\t time.sleep(5)\n\t remote_server_killer = subprocess.Popen(cmd_kill_remote_server, shell=True, stdout=subprocess.PIPE)\n\t remote_server_killer.wait()\n\t print(\"killcmd sent\")\n\t time.sleep(5)\n\t print(str(delay[i]) + ':' + str(loss[j]))\n\t print(cmd)\n\t os.system(\"sudo tc qdisc change dev \" + target_NIC + \" root netem loss 0% delay 0ms\")\n\t\n\tremote_monitor.kill()\n\t\n\t#os.system(\"python3 preprocessor.py log.txt\")\n\n\ndef run_exp(delay_x=0,loss_x=0):\n\tflow_size_list = [500000]\n\texp_mode_list = [0,1,2,3]\n\tfor flow_size in flow_size_list:\n\t\tfor exp_mode in exp_mode_list:\n\t\t\trun_flow(flow_size,exp_mode,loss_x,delay_x,70)\n\t\t\tdir_name = \"flow\" + str(flow_size) + \"exp_mode\" + str(exp_mode)\n\t\t\tcmd1 = \"mkdir \" + dir_name\n\t\t\tcmd2 = \"mv *.txt \" + dir_name\n\t\t\tos.system(cmd1)\n\t\t\tos.system(cmd2)\n\nif __name__ == \"__main__\":\n\tfor loss in [0]:\n\t\tfor delay in [100]:\n\t\t\trun_exp(loss,delay)\n\t\t\tfile_name = \"loss\"+str(loss)+\"delay\"+str(delay)+\".zip\"\n\t\t\tos.system(\"zip \" + file_name + \" -r flow*\")\n\t\t\tos.system(\"mv \" + file_name + \" ~\")\n\t\t\tos.system(\"rm -rf flow*\")\n"
},
{
"alpha_fraction": 0.6810506582260132,
"alphanum_fraction": 0.6894934177398682,
"avg_line_length": 19.901960372924805,
"blob_id": "c44135d58e4ac2fbb71d2ae8b1fce65d4960bbd6",
"content_id": "850a289c8676bb4bee09745474fc4c9f342d9d31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 51,
"path": "/include/UDPServer.h",
"repo_name": "waltersharpWEI/udp2server_xc",
"src_encoding": "UTF-8",
"text": "/*\n * UDPServer.h\n *\n * Created on: Dec 23, 2019\n * Author: ubuntu\n */\n\n#ifndef SRC_UDPServer_H_\n#define SRC_UDPServer_H_\n\n#define ADDR_LEN 100\n\nclass UDPServer {\npublic:\n\tint send_buffer_size;\n\tint mss;\n\tint current_delay;\n\tdouble current_loss_event_rate;\n\tint current_througput;\n\tint current_delay_jitter;\n\tdouble current_psnr;\n\tint current_rtt;\n\tint smoothed_rtt;\n\tchar IP[ADDR_LEN];\n\tint port;\n\tint packet_socket,len;\n\tstruct sockaddr_in addr;\npublic:\n\tUDPServer();\n\tvirtual ~UDPServer();\n\t//initialize the IP and port\n\tint init(char *IP, int port);\n\t//bind wrapper\n\tint bind_x();\n\t//recvfrom oop wrapper\n\tssize_t recvfrom_x(void *buf, size_t len, int flags,\n\t struct sockaddr *src_addr, socklen_t *addrlen);\n\t//clear all UDP options,\n\t//call before set the UDP-mode\n\tvoid optclear();\n\t//set to UDP-Default\n\tvoid setOptDefault();\n\t//set to UDP-Lite\n\tvoid setOptLite(int cov);\n\t//set to UDP-Soomro\n\tvoid setOptSoomro(int recv_buffer_size);\n\t//set the buffer size to size in bytes\n\tvoid setBuffer(int size);\n};\n\n#endif /* SRC_UDPServer_H_ */\n"
}
] | 8 |
c1120999164/text-django
|
https://github.com/c1120999164/text-django
|
2353bf8902a1df2a66dd5c583c84c851d096c3f7
|
c4f05ec75622182df7a5389300d00f858991d5a4
|
14cb0cbf9004b093dedc1df162940b43c5b4adca
|
refs/heads/main
| 2022-12-20T01:02:23.196104 | 2020-10-12T10:41:58 | 2020-10-12T10:41:58 | 303,306,455 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.35087719559669495,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 10.600000381469727,
"blob_id": "52c2035ac23b6ca2b361837ff2d67ac39d8e2289",
"content_id": "a5213526a9d0b7af32b42a986e82f73d68cf32a2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 57,
"license_type": "permissive",
"max_line_length": 11,
"num_lines": 5,
"path": "/1.py",
"repo_name": "c1120999164/text-django",
"src_encoding": "UTF-8",
"text": "name = 100\nname2 = 200\nname3 = 300\nname4 = 400\nname5 = 50"
},
{
"alpha_fraction": 0.7931034564971924,
"alphanum_fraction": 0.7931034564971924,
"avg_line_length": 13.5,
"blob_id": "5d000b28799288c49b6f5dc020c3950af2bd2bc8",
"content_id": "1a1fd85b7e5f9080868d16a544a40ba6911e5857",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 29,
"license_type": "permissive",
"max_line_length": 14,
"num_lines": 2,
"path": "/README.md",
"repo_name": "c1120999164/text-django",
"src_encoding": "UTF-8",
"text": "# text-django\ndjango-project\n"
}
] | 2 |
lxa2015/middlemen
|
https://github.com/lxa2015/middlemen
|
a1bf0cf54b4ee8e3fc9f02ceaca37ebd8a5fdf21
|
d5bca7802e721c2df910d10d8ee988aa712f2e0f
|
965951eabd7ec7fe4a1d1c107b95efdf8311259b
|
refs/heads/master
| 2021-01-10T07:43:41.383260 | 2015-11-23T17:55:57 | 2015-11-23T17:55:57 | 46,738,199 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5752255320549011,
"alphanum_fraction": 0.5792526006698608,
"avg_line_length": 35.08720779418945,
"blob_id": "6e153f0134ee61a0c9f55a1086f2f20348ad237e",
"content_id": "e3bd2ace800ff16189fcc5c531504666a8ee766c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6208,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 172,
"path": "/middlemen.py",
"repo_name": "lxa2015/middlemen",
"src_encoding": "UTF-8",
"text": "__author__ = 'Anton Osten'\n\nfrom argparse import ArgumentParser\nfrom collections import Counter, defaultdict\nimport csv\nimport itertools\nimport math\nfrom pathlib import Path\nfrom pprint import pformat, pprint\nimport re\n\n# def find_trigrams_word(word, all_words):\n# indexes = np.where(all_words == word)[0]\n#\n# bigrams = set()\n# for index in indexes:\n# bigram = all_words[index - 1], all_words[index + 1]\n# if bigram not in bigrams:\n# trigram = bigram[0], word, bigram[1]\n# yield trigram, bigram\n\n\ndef get_corpus_bigrams(words):\n bigrams = Counter()\n\n for i in range(1, len(words)):\n bigrams[(words[i - 1], words[i])] += 1\n\n return bigrams\n\ndef find_trigrams(freq_words, all_words):\n trigrams = defaultdict(Counter)\n\n for n, word in enumerate(all_words):\n if word in freq_words:\n try:\n bigram = all_words[n - 1], all_words[n + 1]\n trigrams[word][bigram] += 1\n except IndexError:\n # this is probably a one-off character\n continue\n\n return trigrams\n\n\ndef get_middle_ratios(trigrams, all_bigrams, words, detailed_output=False):\n real_bigrams = {bigram for bigram in itertools.chain.from_iterable(trigrams.values())\n if bigram in all_bigrams}\n\n successful_contexts = Counter()\n num_words = len(words)\n mi_words = {}\n\n detailed_info = defaultdict(list)\n\n # calculate the ratios\n for middle_word, bigrams in trigrams.items():\n\n for bigram, trigram_count in bigrams.items():\n # print('trigram count', trigram_count)\n ratio_with_middle = trigram_count * num_words\n # print('ratio with', ratio_with_middle)\n\n\n bigram_count = all_bigrams[bigram]\n ratio_without_middle = bigram_count * words[middle_word]\n\n try:\n combined_ratio = ratio_with_middle / ratio_without_middle\n if combined_ratio > 1:\n word_frequencies = words[bigram[0]] * words[middle_word] * words[bigram[1]]\n successful_contexts[middle_word] += 1\n\n mutual_information = math.log2(trigram_count / word_frequencies)\n mi_words[middle_word] = mutual_information\n\n if detailed_output:\n trigram = bigram[0], middle_word, bigram[1]\n this_bigram_output = trigram, trigram_count, ratio_with_middle\n this_trigram_output = bigram, bigram_count, ratio_without_middle\n\n detailed_info[middle_word].append((*this_bigram_output,\n *this_trigram_output,\n combined_ratio,\n mutual_information))\n\n\n except ZeroDivisionError:\n # no real bigrams\n #exit('oh no')\n continue\n\n\n middle_ratios = {word: (successes / len(trigrams[word]))\n for word, successes in successful_contexts.items()}\n\n return middle_ratios, real_bigrams, detailed_info\n\n\ndef run(corpus, freq_threshold=10, detailed_output=False):\n all_words = re.findall(r\"\\w+'\\w+|\\w+|[.,;]\", corpus)\n counted_words = Counter(all_words)\n\n print('getting most frequent words...')\n freq_words = {word for word, count in counted_words.items() if count >= freq_threshold}\n\n print('getting all bigrams from the corpus...')\n # we need this to check if the (w1, w3) exists the corpus by itself\n all_bigrams = get_corpus_bigrams(all_words)\n\n print('finding trigrams...')\n trigrams = find_trigrams(freq_words, all_words)\n\n print('finding the middle ratios...')\n middle_ratios, real_bigrams, detailed_info = get_middle_ratios(trigrams, all_bigrams,\n counted_words,\n detailed_output=detailed_output)\n\n return middle_ratios, real_bigrams, detailed_info\n\ndef print_output(corpus_name, ratios, real_bigrams, detailed_info=None):\n results_path = Path('results', corpus_name)\n print('printing results to', results_path)\n if not results_path.exists():\n results_path.mkdir(parents=True)\n\n output_path_ratios = Path(results_path, 'ratios.csv')\n output_path_real_bigrams = Path(results_path, 'real_bigrams.txt')\n\n with output_path_ratios.open('w') as out_file:\n writer = csv.writer(out_file, delimiter=',')\n for item in ratios.items():\n # print('{:15}\\t{:.3f}\\n{}'.format(word, ratio, pformat(bigrams)), file=out_file)\n writer.writerow((item))\n\n with output_path_real_bigrams.open('w') as out_file:\n pprint(real_bigrams, stream=out_file)\n\n if detailed_info:\n print('printing detailed output')\n output_path_words = Path(results_path, 'words')\n if not output_path_words.exists():\n output_path_words.mkdir()\n\n header = ('trigram', 'trigram count', 'count * k',\n 'bigram', 'bigram count', 'count * [word]', 'ratio')\n for word, info in detailed_info.items():\n word_info_path = Path(output_path_words, word + '.csv')\n with word_info_path.open('w') as out_file:\n writer = csv.writer(out_file, delimiter=',')\n writer.writerow(header)\n for row in info:\n writer.writerow(row)\n\n\n\nif __name__ == '__main__':\n arg_parser = ArgumentParser()\n arg_parser.add_argument('corpus', help='corpus file to use for computing the ratios')\n arg_parser.add_argument('--detailed-output', action='store_true',\n help='detailed output on each word')\n args = arg_parser.parse_args()\n\n file = Path(args.corpus)\n\n with file.open() as corpus_file:\n corpus = corpus_file.read().casefold()\n\n ratios, real_bigrams, detailed_info = run(corpus, detailed_output=args.detailed_output)\n\n corpus_name = file.stem\n print_output(corpus_name, ratios, real_bigrams, detailed_info=detailed_info)\n\n"
}
] | 1 |
rick446/pyatl-rest-api
|
https://github.com/rick446/pyatl-rest-api
|
78b2067ca2c78617f32dfad443cedac878c5ab52
|
18f2b3006c042ca6289a51ff0578b58f75a73503
|
82801eb3f7aaf9ec3d73083352f6cdccb43eb268
|
refs/heads/master
| 2021-01-01T17:32:18.248391 | 2013-10-10T22:54:39 | 2013-10-10T22:54:39 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7392405271530151,
"alphanum_fraction": 0.7493671178817749,
"avg_line_length": 22.235294342041016,
"blob_id": "5d54b7469ccb734c37c3b1c81a56260474fa3460",
"content_id": "51917b11bf0058ffe3d3b13d2029d3585269c95a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/simple-pyramid.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.response import Response\n\n\ndef simple_view(request):\n return Response('Got something')\n\n\nconfig = Configurator()\nconfig.add_route('root', '/')\nconfig.add_view(simple_view, route_name='root')\nsimple_app = config.make_wsgi_app()\n\n\nhttpd = make_server('', 8000, simple_app)\nhttpd.serve_forever()\n"
},
{
"alpha_fraction": 0.6566137671470642,
"alphanum_fraction": 0.658730149269104,
"avg_line_length": 22.92405128479004,
"blob_id": "f783470b4d7e0181bbb36728d5d41f00ae1c9e01",
"content_id": "aefa3699c18db3cf9fdec282f6f343517b310243",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1890,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 79,
"path": "/pyramid-resources.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nimport pyramid.httpexceptions as exc\n\n\n# Define our model/resource class\nclass Model(object):\n models = {}\n\n def __init__(self, key, data):\n self.key = key\n self.data = data\n\n @classmethod\n def lookup(cls, request):\n key = request.matchdict['key']\n try:\n return cls.models[key]\n except KeyError:\n raise exc.HTTPNotFound()\n\n def save(self):\n if self.key in self.models:\n raise exc.HTTPConflict()\n self.models[self.key] = self\n\n def update(self, data):\n self.data.update(data)\n\n def delete(self):\n del self.models[self.key]\n\n def __json__(self, request=None):\n return self.data\n\n\n# Define our views\ndef get_models(request):\n return Model.models\n\n\ndef create_model(request):\n model = Model(request.json['key'], request.json['value'])\n model.save()\n return model\n\n\ndef get_model(request):\n return request.context\n\n\ndef put_model(request):\n request.context.update(request.json)\n return request.context\n\n\ndef delete_model(request):\n request.context.delete()\n return exc.HTTPNoContent()\n\n\nconfig = Configurator()\nconfig.add_route('models', '/')\nconfig.add_route('model', '/{key}/', factory=Model.lookup)\nconfig.add_view(\n get_models, route_name='models', request_method='GET', renderer='json')\nconfig.add_view(\n create_model, route_name='models', request_method='POST', renderer='json')\nconfig.add_view(\n get_model, route_name='model', request_method='GET', renderer='json')\nconfig.add_view(\n put_model, route_name='model', request_method='PUT', renderer='json')\nconfig.add_view(\n delete_model, route_name='model', request_method='DELETE')\nsimple_app = config.make_wsgi_app()\n\n\nhttpd = make_server('', 8000, simple_app)\nhttpd.serve_forever()\n"
},
{
"alpha_fraction": 0.5650224089622498,
"alphanum_fraction": 0.5650224089622498,
"avg_line_length": 20.580644607543945,
"blob_id": "0abd0740af5d91462034e3a2dd2e7637dd58a57c",
"content_id": "b6f9ab68acf4615abba942e1a203977d883f6e99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/pyramid_decorators/model.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "import pyramid.httpexceptions as exc\n\n\nclass Model(object):\n models = {}\n\n def __init__(self, key, data):\n self.key = key\n self.data = data\n\n @classmethod\n def lookup(cls, request):\n key = request.matchdict['key']\n try:\n return cls.models[key]\n except KeyError:\n raise exc.HTTPNotFound()\n\n def save(self):\n if self.key in self.models:\n raise exc.HTTPConflict()\n self.models[self.key] = self\n\n def update(self, data):\n self.data.update(data)\n\n def delete(self):\n del self.models[self.key]\n\n def __json__(self, request=None):\n return self.data\n"
},
{
"alpha_fraction": 0.6228070259094238,
"alphanum_fraction": 0.6929824352264404,
"avg_line_length": 14.199999809265137,
"blob_id": "83198020abbc1a7b2511ffbe6b0721888cb3efff",
"content_id": "a9523142c13e150ed5d3840cb25baa676aef28eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 15,
"path": "/supercool.ini",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "[composite:main]\nuse = egg:Paste#urlmap\n/1.0 = v1\n/2.0 = v2\n\n[app:v1]\nuse = call:pyramid_decorators.main:main\n\n[app:v2]\nuse = call:pyramid_decorators.main:main\n\n[server:main]\nuse = egg:pyramid#wsgiref\nhost = 0.0.0.0\nport = 8000\n"
},
{
"alpha_fraction": 0.6094674468040466,
"alphanum_fraction": 0.6360946893692017,
"avg_line_length": 29.727272033691406,
"blob_id": "b271a12a5481f6379ad785ad9fd9228f87d8590c",
"content_id": "44438dd47dea61e60a7ba980e02a2cf9230dfc3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 11,
"path": "/simple-wsgi.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\n\n\ndef simple_app(environ, start_response):\n for k, v in sorted(environ.items()):\n print '%s: %s...' % (k, repr(v)[:40])\n start_response('200 OK', [('Content-type', 'text/plain')])\n return ['WSGI server here\\n']\n\nhttpd = make_server('', 8000, simple_app)\nhttpd.serve_forever()\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 16,
"blob_id": "5e41803bf68ca9530950396da5c2ed3ef421f27d",
"content_id": "5cdd3cef3ad87bc5c336710ac0b33963a95ffa31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 7,
"path": "/pyramid-decorators.ini",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "[app:main]\nuse = call:pyramid_decorators.main:main\n\n[server:main]\nuse = egg:pyramid#wsgiref\nhost = 0.0.0.0\nport = 8000\n"
},
{
"alpha_fraction": 0.6545289158821106,
"alphanum_fraction": 0.6563495397567749,
"avg_line_length": 23.965909957885742,
"blob_id": "bea8cad94c6bd4e94c1d6e4dfd26459601682f45",
"content_id": "cbdc37589b9121f664e1d0ddecfa2d99d50863a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2197,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 88,
"path": "/pyramid-decorators.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nfrom pyramid.view import view_config\nimport pyramid.httpexceptions as exc\n\n\ndef main():\n config = Configurator()\n config.add_route('models', '/')\n config.add_route('model', '/{key}/')\n config.scan()\n simple_app = config.make_wsgi_app()\n return simple_app\n\n\n# Define our model/resource class\nclass Model(object):\n models = {}\n\n def __init__(self, key, data):\n self.key = key\n self.data = data\n\n @classmethod\n def lookup(cls, request):\n key = request.matchdict['key']\n try:\n return cls.models[key]\n except KeyError:\n raise exc.HTTPNotFound()\n\n def save(self):\n if self.key in self.models:\n raise exc.HTTPConflict()\n self.models[self.key] = self\n\n def update(self, data):\n self.data.update(data)\n\n def delete(self):\n del self.models[self.key]\n\n def __json__(self, request=None):\n return self.data\n\n\n# Define our views\n@view_config(route_name='models', request_method='GET', renderer='json')\ndef get_models(request):\n return Model.models\n\n\n@view_config(route_name='models', request_method='POST', renderer='json')\ndef create_model(request):\n model = Model(request.json['key'], request.json['value'])\n model.save()\n return model\n\n\n@view_config(route_name='model', request_method='GET', renderer='json')\ndef get_model(request):\n return request.context.model\n\n\n@view_config(route_name='model', request_method='PUT', renderer='json')\ndef put_model(request):\n request.context.model.update(request.json)\n return request.context.model\n\n\n@view_config(route_name='model', request_method='DELETE', renderer='json')\ndef delete_model(request):\n request.context.model.delete()\n return exc.HTTPNoContent()\n\n\n@view_config(context=exc.HTTPError, renderer='json')\ndef on_error(exception, request):\n request.response.status_int = exception.status_int\n return dict(\n status=exception.status,\n errors=repr(exception))\n\n\nif __name__ == '__main__':\n simple_app = main()\n httpd = make_server('', 8000, simple_app)\n httpd.serve_forever()\n"
},
{
"alpha_fraction": 0.691254734992981,
"alphanum_fraction": 0.6965779662132263,
"avg_line_length": 23.811321258544922,
"blob_id": "28fed4b38d0151208382b2a407d5cc5df024531a",
"content_id": "bfc414ba6ee4418c0fa4ca9270744a31648a4b51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 53,
"path": "/json-pyramid.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\nfrom pyramid.config import Configurator\nimport pyramid.httpexceptions as exc\n\nmodels = {}\n\n\ndef get_models(request):\n return models\n\n\ndef create_model(request):\n key = request.json['key']\n value = request.json['value']\n models[key] = value\n request.response.status_int = 201\n return value\n\n\ndef get_model(request):\n model = models[request.matchdict['key']]\n return model\n\n\ndef put_model(request):\n model = models[request.matchdict['key']]\n model.update(request.json)\n return model\n\n\ndef delete_model(request):\n models.pop(request.matchdict['key'], None)\n return exc.HTTPNoContent()\n\n\nconfig = Configurator()\nconfig.add_route('models', '/')\nconfig.add_route('model', '/{key}/')\nconfig.add_view(\n get_models, route_name='models', request_method='GET', renderer='json')\nconfig.add_view(\n create_model, route_name='models', request_method='POST', renderer='json')\nconfig.add_view(\n get_model, route_name='model', request_method='GET', renderer='json')\nconfig.add_view(\n put_model, route_name='model', request_method='PUT', renderer='json')\nconfig.add_view(\n delete_model, route_name='model', request_method='DELETE')\nsimple_app = config.make_wsgi_app()\n\n\nhttpd = make_server('', 8000, simple_app)\nhttpd.serve_forever()\n"
},
{
"alpha_fraction": 0.720108687877655,
"alphanum_fraction": 0.720108687877655,
"avg_line_length": 25.926828384399414,
"blob_id": "744ec394c0a0c5370f151bea8997de26a06453d3",
"content_id": "7daafafcc8657bdf23c3adec8bd03b792f2a365c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1104,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 41,
"path": "/pyramid_decorators/views.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from pyramid.view import view_config\nimport pyramid.httpexceptions as exc\n\nfrom .model import Model\n\n\n@view_config(route_name='models', request_method='GET', renderer='json')\ndef get_models(request):\n return Model.models\n\n\n@view_config(route_name='models', request_method='POST', renderer='json')\ndef create_model(request):\n model = Model(request.json['key'], request.json['value'])\n model.save()\n return model\n\n\n@view_config(route_name='model', request_method='GET', renderer='json')\ndef get_model(request):\n return request.context\n\n\n@view_config(route_name='model', request_method='PUT', renderer='json')\ndef put_model(request):\n request.context.update(request.json)\n return request.context\n\n\n@view_config(route_name='model', request_method='DELETE', renderer='json')\ndef delete_model(request):\n request.context.delete()\n return exc.HTTPNoContent()\n\n\n@view_config(context=exc.HTTPError, renderer='json')\ndef on_error(exception, request):\n request.response.status_int = exception.status_int\n return dict(\n status=exception.status,\n errors=repr(exception))\n"
},
{
"alpha_fraction": 0.6936416029930115,
"alphanum_fraction": 0.6936416029930115,
"avg_line_length": 27.83333396911621,
"blob_id": "435794995b2257671a75b320ecaa43e5d8d9350c",
"content_id": "e769cab15903a205a06baf86c55b2352df77c125",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 12,
"path": "/pyramid_decorators/main.py",
"repo_name": "rick446/pyatl-rest-api",
"src_encoding": "UTF-8",
"text": "from pyramid.config import Configurator\n\nfrom .model import Model\n\n\ndef main(global_settings, **local_settings):\n config = Configurator()\n config.add_route('models', '/')\n config.add_route('model', '/{key}/', factory=Model.lookup)\n config.scan('pyramid_decorators.views')\n simple_app = config.make_wsgi_app()\n return simple_app\n"
}
] | 10 |
npr96/Stardew
|
https://github.com/npr96/Stardew
|
3f025a769cc3f37207ea92b77029f4be54de4930
|
f309be330bc32aca0372784add0fe2ec5450175d
|
2fc8debd1c09a99b7fce3b6a59b22492d3ec98a1
|
refs/heads/master
| 2021-02-18T21:34:32.182048 | 2020-03-05T20:59:48 | 2020-03-05T20:59:48 | 245,239,866 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5584137439727783,
"alphanum_fraction": 0.5659164190292358,
"avg_line_length": 25.657142639160156,
"blob_id": "f0d463682560f65c1b6e6b6620474d2fb4c4333d",
"content_id": "79084d8ffc5bde59e8023f9cb9bf85867b97f44f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 933,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 35,
"path": "/stardew.py",
"repo_name": "npr96/Stardew",
"src_encoding": "UTF-8",
"text": "from Modules import Settings\nfrom Modules import bones\nfrom Modules import Dict\nfrom Modules import cutscenes\n\nclass Player:\n start = 0\n\n def __init__(self, invent=Settings.inventory, health=Settings.health, wallet=Settings.wallet, name='',\n farm_name=''):\n self.inv = invent\n self.heal = health\n self.wall = wallet\n self.name = name\n self.farm_name = farm_name\n\n def engine(self):\n if Player.start == 0:\n self.name = bones.start()\n Player.start = 1\n else:\n pass\n if Dict.dict_of_flags['Open cutscene'] == 0:\n self.farm_name = cutscenes.open_cutscene(self.name)\n Dict.dict_of_flags['Open cutscene'] = 1\n else:\n pass\n imp = input('-' + self.farm_name + '-')\n bones.interpreter(bones.parser(imp))\n\n\nplayer1 = Player()\n\nif __name__ == \"__main__\":\n player1.engine()\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.4693877696990967,
"avg_line_length": 4,
"blob_id": "6e3e1febdae3f3325a9ad3ad86d15a1b0b9ede9a",
"content_id": "cdc7f78d5bc3a82440e32ca7102e90443b42fdc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 9,
"path": "/Modules/Settings.py",
"repo_name": "npr96/Stardew",
"src_encoding": "UTF-8",
"text": "\nhealth = 10\n\ninventory = {\n\n}\n\nwallet = {\n\n}\n\n\n\n"
},
{
"alpha_fraction": 0.7682926654815674,
"alphanum_fraction": 0.7804877758026123,
"avg_line_length": 12.833333015441895,
"blob_id": "d5d0491c6b2d6e88557066c9821fdc139c84e0ec",
"content_id": "b38e4d269e79ead41108b57832645d44c24c0e17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/Modules/Npc.py",
"repo_name": "npr96/Stardew",
"src_encoding": "UTF-8",
"text": "import stardew\nfrom Modules import Settings\n\n\nclass Npc(stardew.player1):\n pass"
},
{
"alpha_fraction": 0.6568915247917175,
"alphanum_fraction": 0.662756621837616,
"avg_line_length": 16.049999237060547,
"blob_id": "1a95ccd666a97457ad9f4723d8ad05e35aad19e3",
"content_id": "d4bbe3249e9e13fd11ea26f2d3f805d162ddfb5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 20,
"path": "/Modules/bones.py",
"repo_name": "npr96/Stardew",
"src_encoding": "UTF-8",
"text": "from Modules import Dict\nfrom Modules import cutscenes\nimport winsound\n\n\ndef start():\n print(Dict.welcome[1])\n name = input('What is your name?: ')\n print(Dict.welcome[2])\n _ = input('press [enter] to continue')\n return name\n\n\ndef parser(imp):\n parsimp = imp.split()\n return parsimp\n\n\ndef interpreter(parsimp):\n pass\n"
}
] | 4 |
1808467448/pycharm12
|
https://github.com/1808467448/pycharm12
|
208c9074899e3c59ceac91185037347839c48978
|
75750169e09dd04d090397581f36dca443056b0e
|
a96dc238a02be730de2a2ed89d5e5540821179b0
|
refs/heads/master
| 2020-04-03T06:54:03.228843 | 2018-10-28T15:55:15 | 2018-10-28T15:55:15 | 155,087,435 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5706051588058472,
"alphanum_fraction": 0.6023054718971252,
"avg_line_length": 27.94444465637207,
"blob_id": "e23f8eb0a41bbe9f9dc9e7512d80245cb1c0dfa4",
"content_id": "c791fb433bd65c4b1090a1846cb1e9a2afe0535d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 36,
"path": "/maoyan2.py",
"repo_name": "1808467448/pycharm12",
"src_encoding": "UTF-8",
"text": "# coding:utf8\nimport requests\nfrom lxml import etree\nimport json\n\ndef getOnePage(page):\n url = f'http://maoyan.com/board/{page*10}'\n header = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) '\n 'AppleWebKit/537.36 (KHTML, like Gecko) '\n 'Chrome/70.0.3538.67 Safari/537.36'}\n r = requests.get(url, headers=header)\n return r.text\n\ndef parse(text):\n #规范化 标准化\n html = etree.HTML(text)\n names = html.xpath('//div[@class=\"movie-item-info\"]/p[@class=\"name\"]/a/@title')\n print(names)\n releasetimes = html.xpath('//p[@class=\"releasettime\"]/@text()')\n for names, releasetimes in zip(names, releasetimes):\n item = {}\n item[names] = names\n item[releasetimes] = releasetimes\n yield item\n\ndef save2File(data):\n with open('moven.json', 'a', encoding='utf-8')as f:\n data = json.dumps(data, ensure_ascii=float)+ ',/n'\n f.write(data)\n\ntext = getOnePage(4)\n\nitems = parse(text)\n\nfor item in items:\n save2File(item)"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.75,
"avg_line_length": 7,
"blob_id": "9a4c6dcd249e6a5e94ac812301beb1615700182a",
"content_id": "aa5d94f0a5e9ddf4383a6e671576352bbc6b566c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 22,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 2,
"path": "/README.md",
"repo_name": "1808467448/pycharm12",
"src_encoding": "UTF-8",
"text": "# pycharm12\n小爬虫\n"
}
] | 2 |
ItalianScallian/AdventOfCode2017
|
https://github.com/ItalianScallian/AdventOfCode2017
|
ab0a584994edd55a80fcd0710c1b1d3d4774f9b8
|
f9218301f58dcb3dd7c57d3126486e5cb693d422
|
3e53b12de7be6b92b8adab96bb09506c57bba526
|
refs/heads/master
| 2021-08-23T04:09:48.942532 | 2017-12-03T06:20:22 | 2017-12-03T06:20:22 | 112,905,106 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5398058295249939,
"alphanum_fraction": 0.5611650347709656,
"avg_line_length": 22.409090042114258,
"blob_id": "3cc071c658358d0834ee15ba64a7bcf8f93f8abc",
"content_id": "4527dfcd6e0966ceea2ace3a49006844a9939043",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 22,
"path": "/Day2.py",
"repo_name": "ItalianScallian/AdventOfCode2017",
"src_encoding": "UTF-8",
"text": "#found partially on reddit solutions after attempting to do the same thing in Java and failing miserably\n\nimport re\ninp = [i.strip() for i in open('input.txt', 'r').readlines()]\n\ns1 = 0\ns2 = 0\n\nfor line in inp:\n nums = [int(u) for u in re.split('\\s+', line)]\n\n s1 += max(nums) - min(nums)\n\n for i in range(len(nums)):\n for j in range(len(nums)):\n if i == j: continue\n if nums[i] % nums[j] == 0:\n s2 += nums[i] / nums[j]\n\n\nprint \"Part 1:\", s1\nprint \"Part 2:\", s2\n"
},
{
"alpha_fraction": 0.7215189933776855,
"alphanum_fraction": 0.8227847814559937,
"avg_line_length": 38.5,
"blob_id": "07cd4c2e42b3ed4a401564d9b73f3ccfafb62e93",
"content_id": "c751747b22b9fbb322695b00886fc4b472c8659d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ItalianScallian/AdventOfCode2017",
"src_encoding": "UTF-8",
"text": "# AdventOfCode2017\nThe code I wrote to solve the AdventOfCode problems in 2017\n"
},
{
"alpha_fraction": 0.60326087474823,
"alphanum_fraction": 0.6222826242446899,
"avg_line_length": 29.25,
"blob_id": "07c659d32835c58379ebd9ca902e04ff82903844",
"content_id": "e99ee6557b1e06b2e965469aea0c89bbe258fb08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 24,
"path": "/Day3.py",
"repo_name": "ItalianScallian/AdventOfCode2017",
"src_encoding": "UTF-8",
"text": "import math\n\n#returns the distance from the center of a spiral matrix\n#where the bottom left corner is an odd square\n#only works when the number given is on the bottom row\ndef Distance(Num):\n multiplier = []\n my_list = []\n for i in range(1, int(math.sqrt(Num))+1, 2):\n if (i*i) < Num:\n my_list.append(i*i)\n multiplier.append(i)\n multiplier.append(multiplier[-1]+2)\n large_square = multiplier[-1]*multiplier[-1]\n difference = large_square - Num\n if difference > int(math.sqrt(large_square)):\n distance = abs(multiplier[-1]-difference-1)\n else:\n distance = multiplier[-1]-difference-1\n return distance\n \n\nif __name__== \"__main__\":\n print Distance(225)\n\n \n"
}
] | 3 |
tianfeichen/pytorch-human-performance-gec
|
https://github.com/tianfeichen/pytorch-human-performance-gec
|
810c289af6c30e7755fcfe12b3d2b06700498d0d
|
71a15f8b1c3b40c4e6cd42a9fa555cfce0a2a5c3
|
e8439cb176b06a15e3ba448c366920348aeec3f6
|
refs/heads/master
| 2020-04-12T10:07:20.314678 | 2019-05-12T05:22:08 | 2019-05-12T05:22:08 | 162,419,881 | 0 | 0 |
Apache-2.0
| 2018-12-19T10:14:24 | 2018-12-17T00:51:32 | 2018-12-17T00:51:31 | null |
[
{
"alpha_fraction": 0.6183505058288574,
"alphanum_fraction": 0.6208146214485168,
"avg_line_length": 39.345027923583984,
"blob_id": "a01c7e1455e28e67275044a5ceafc9a5e0fd97c5",
"content_id": "45c92a42be1d40706683549c64fee056ecf964d4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6899,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 171,
"path": "/fairseq-scripts/generate-errorgen.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3 -u\n# Copyright (c) 2017-present, Facebook, Inc.\n# All rights reserved.\n#\n# This source code is licensed under the license found in the LICENSE file in\n# the root directory of this source tree. An additional grant of patent rights\n# can be found in the PATENTS file in the same directory.\n\"\"\"\nGenerate boosted training data from error generating model.\n\"\"\"\n\nimport os\nimport torch\n\nfrom fairseq import bleu, data, options, progress_bar, tasks, tokenizer, utils\nfrom fairseq.meters import StopwatchMeter\nfrom fairseq.sequence_generator import SequenceGenerator\nfrom fairseq.sequence_scorer import SequenceScorer\n\nfrom fluency_scorer import FluencyScorer\n\n\ndef main(args):\n assert args.path is not None, '--path required for generation!'\n assert not args.sampling or args.nbest == args.beam, \\\n '--sampling requires --nbest to be equal to --beam'\n assert args.replace_unk is None or args.raw_text, \\\n '--replace-unk requires a raw text dataset (--raw-text)'\n\n if args.max_tokens is None and args.max_sentences is None:\n args.max_tokens = 12000\n print(args)\n\n use_cuda = torch.cuda.is_available() and not args.cpu\n\n # Load dataset splits\n task = tasks.setup_task(args)\n task.load_dataset(args.gen_subset)\n print('| {} {} {} examples'.format(\n args.data, args.gen_subset, len(task.dataset(args.gen_subset))))\n\n # Set dictionaries\n src_dict = task.source_dictionary\n tgt_dict = task.target_dictionary\n\n # Load ensemble\n print('| loading model(s) from {}'.format(args.path))\n models, _ = utils.load_ensemble_for_inference(args.path.split(\n ':'), task, model_arg_overrides=eval(args.model_overrides))\n\n # Optimize ensemble for generation\n for model in models:\n model.make_generation_fast_(\n beamable_mm_beam_size=None if args.no_beamable_mm else args.beam,\n need_attn=args.print_alignment,\n )\n if args.fp16:\n model.half()\n\n # Load alignment dictionary for unknown word replacement\n # (None if no unknown word replacement, empty if no path to align dictionary)\n align_dict = utils.load_align_dict(args.replace_unk)\n\n # Load dataset (possibly sharded)\n itr = task.get_batch_iterator(\n dataset=task.dataset(args.gen_subset),\n max_tokens=args.max_tokens,\n max_sentences=args.max_sentences,\n max_positions=utils.resolve_max_positions(\n task.max_positions(),\n *[model.max_positions() for model in models]\n ),\n ignore_invalid_inputs=args.skip_invalid_size_inputs_valid_test,\n required_batch_size_multiple=8,\n num_shards=args.num_shards,\n shard_id=args.shard_id,\n ).next_epoch_itr(shuffle=False)\n\n # Initialize generator\n gen_timer = StopwatchMeter()\n if args.score_reference:\n translator = SequenceScorer(models, task.target_dictionary)\n else:\n translator = SequenceGenerator(\n models, task.target_dictionary, beam_size=args.beam, minlen=args.min_len,\n stop_early=(not args.no_early_stop), normalize_scores=(not args.unnormalized),\n len_penalty=args.lenpen, unk_penalty=args.unkpen,\n sampling=args.sampling, sampling_topk=args.sampling_topk, sampling_temperature=args.sampling_temperature,\n diverse_beam_groups=args.diverse_beam_groups, diverse_beam_strength=args.diverse_beam_strength,\n )\n\n if use_cuda:\n translator.cuda()\n\n # Initialize fluency scorer (and language model)\n fluency_scorer = FluencyScorer(\n args.lang_model_path, args.lang_model_data, use_cpu=False)\n\n en_filename = os.path.join(args.out_dir, 'errorgen.en')\n gec_filename = os.path.join(args.out_dir, 'errorgen.gec')\n has_target = True\n with progress_bar.build_progress_bar(args, itr) as t, open(en_filename, 'w') as en_file, open(gec_filename, 'w') as gec_file:\n if args.score_reference:\n translations = translator.score_batched_itr(\n t, cuda=use_cuda, timer=gen_timer)\n else:\n translations = translator.generate_batched_itr(\n t, maxlen_a=args.max_len_a, maxlen_b=args.max_len_b,\n cuda=use_cuda, timer=gen_timer, prefix_size=args.prefix_size,\n )\n\n for sample_id, src_tokens, target_tokens, hypos in translations:\n # Process input and ground truth\n has_target = target_tokens is not None\n target_tokens = target_tokens.int().cpu() if has_target else None\n\n # Either retrieve the original sentences or regenerate them from tokens.\n if align_dict is not None:\n src_str = task.dataset(\n args.gen_subset).src.get_original_text(sample_id)\n target_str = task.dataset(\n args.gen_subset).tgt.get_original_text(sample_id)\n else:\n src_str = src_dict.string(src_tokens, args.remove_bpe)\n if has_target:\n target_str = tgt_dict.string(\n target_tokens, args.remove_bpe, escape_unk=True)\n\n # Only consider sentences with at least four words.\n if len(src_tokens) < 5:\n continue\n\n # Calculate the fluency score for the source sentence\n source_fluency = fluency_scorer.score_sentence(src_str)\n\n # Process top predictions\n for i, hypo in enumerate(hypos[:min(len(hypos), args.nbest)]):\n hypo_tokens, hypo_str, alignment = utils.post_process_prediction(\n hypo_tokens=hypo['tokens'].int().cpu(),\n src_str=src_str,\n alignment=hypo['alignment'].int().cpu(\n ) if hypo['alignment'] is not None else None,\n align_dict=align_dict,\n tgt_dict=tgt_dict,\n remove_bpe=args.remove_bpe,\n )\n\n # Skip if this is the original sentence.\n if hypo_str == target_str:\n continue\n\n # Score the hypothesis.\n hypo_fluency = fluency_scorer.score_sentence(hypo_str)\n\n # Save the hypothesis if it is sufficiently disfluent.\n if (source_fluency / hypo_fluency) > 1.05:\n en_file.write('{}\\n'.format(hypo_str))\n gec_file.write('{}\\n'.format(src_str))\n\n\nif __name__ == '__main__':\n parser = options.get_generation_parser()\n # fluency score arguments\n parser.add_argument('--lang-model-data',\n help='path to language model dictionary')\n parser.add_argument('--lang-model-path',\n help='path to language model file')\n parser.add_argument('--out-dir', help='path to the disfluency corpus')\n\n args = options.parse_args_and_arch(parser)\n main(args)\n"
},
{
"alpha_fraction": 0.6134528517723083,
"alphanum_fraction": 0.6176518201828003,
"avg_line_length": 41.85121154785156,
"blob_id": "0c650b5d3025a9e15dda9e0e5de44957be82b2b7",
"content_id": "e7fa993d3be31120fe79c4c1d4f67d120f11ae07",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12384,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 289,
"path": "/fairseq-scripts/transform-CLC_FCE.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "import argparse\nimport os\nimport xml.etree.ElementTree as ET\nfrom nltk.tokenize import sent_tokenize, word_tokenize\n\ndef process(src_dir, out_dir, dataset, src_filenames, dataset_file_paths):\n src_filename = os.path.join(out_dir, 'clc_fce-' + dataset + '.en')\n tgt_filename = os.path.join(out_dir, 'clc_fce-' + dataset + '.gec')\n rtl_src_filename = os.path.join(out_dir, 'clc_fce-' + dataset + '-rtl.en')\n rtl_tgt_filename = os.path.join(out_dir, 'clc_fce-' + dataset + '-rtl.gec')\n\n # clean previous output\n open(src_filename, 'w').close()\n open(tgt_filename, 'w').close()\n open(rtl_src_filename, 'w').close()\n open(rtl_tgt_filename, 'w').close()\n\n filenames_file = os.path.join(src_dir, 'fce-error-detection', 'filenames', src_filenames)\n files = filenames(filenames_file)\n\n for file in files:\n process_file(file, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename, dataset_file_paths)\n\n \ndef process_file(file, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename, dataset_file_paths):\n \"\"\"\"Transform input xml file into tab delimited token sentences\"\"\"\n path_of_file = os.path.join(dataset_file_paths[file], file)\n print(path_of_file)\n with open(path_of_file, 'r') as xml_src:\n tree = ET.parse(xml_src)\n answer1 = tree.getroot().find('./head/text/answer1')\n answer2 = tree.getroot().find('./head/text/answer2')\n\n if answer1 is not None:\n process_answer(answer1, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename)\n\n if answer2 is not None:\n process_answer(answer2, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename)\n\ndef process_answer(answer_xml, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename):\n answer_partitions = list(answer_xml.find('.//coded_answer'))\n\n for elm_p in answer_partitions:\n sentence_permutations = list()\n remaining_text = \"\"\n\n ns_elements = elm_p.findall('./NS')\n\n if elm_p.text is not None:\n get_sentence_permutations(elm_p.text, sentence_permutations, ns_elements, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename)\n\ndef get_sentence_permutations(remaining_text, sentence_permutations, ns_elements, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename):\n should_continue = True\n\n while should_continue:\n\n end_of_sentence_idx = remaining_text.find('.')\n\n # write sentences until we can't find the end of a whole and assumed correct sentence\n while end_of_sentence_idx > 0:\n sentence = remaining_text[:end_of_sentence_idx + 1]\n remaining_text = remaining_text[end_of_sentence_idx + 1:]\n sentence_permutations.append(sentence)\n write_sentences(sentence_permutations, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename)\n end_of_sentence_idx = remaining_text.find('.')\n sentence_permutations = list()\n\n if len(sentence_permutations) == 0:\n sentence_permutations.append(remaining_text)\n\n # abort there is no sentence\n if len(ns_elements) == 0:\n should_continue = False\n continue\n\n elm_ns = ns_elements.pop(0)\n process_correction(sentence_permutations, elm_ns)\n\n #if text is following correction, check for end of sentence\n if elm_ns.tail is not None:\n tail_eos_idx = elm_ns.tail.find('.')\n\n if tail_eos_idx > -1:\n remaining_text = elm_ns.tail[tail_eos_idx + 1:]\n for i in range(0, len(sentence_permutations)):\n sentence_permutations[i] = sentence_permutations[i] + elm_ns.tail[:tail_eos_idx + 1]\n\n write_sentences(sentence_permutations, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename)\n sentence_permutations = list()\n corrections = 0\n if len(remaining_text) == 0 and len(ns_elements) == 0:\n should_continue = False\n elif len(remaining_text) > 0:\n sentence_permutations.append(remaining_text)\n else:\n sentence_permutations.append(\"\")\n\n elif len(ns_elements) == 0:\n should_continue = False\n else:\n for i in range(0, len(sentence_permutations)):\n sentence_permutations[i] = sentence_permutations[i] + elm_ns.tail\n\n elif len(ns_elements) == 0:\n should_continue = False\n\ndef process_correction(sentence_permutations, elm_ns):\n elm_i = elm_ns.find('./i')\n elm_c = elm_ns.find('./c')\n\n if elm_c is not None:\n incorrect_text = \"\"\n if elm_i is not None and elm_i.text is not None:\n incorrect_text = elm_i.text\n\n nested_correction = elm_c.find('./NS')\n if nested_correction is not None:\n preceding_text = \"\"\n if elm_c.text is not None:\n preceding_text = elm_c.text\n\n tailing_text = \"\"\n if nested_correction.tail is not None:\n tailing_text = nested_correction.tail\n\n traverse_corrections(sentence_permutations, incorrect_text, nested_correction, preceding_text, tailing_text)\n\n else:\n add_correction_to_permutations(sentence_permutations, incorrect_text, elm_c.text)\n\n else:\n if elm_i is not None and elm_i.text is not None:\n add_correction_to_permutations(sentence_permutations, elm_i.text, \"\")\n\ndef traverse_corrections(sentence_permutations, incorrect_text, elm_correction, preceding_text, tailing_text):\n elm_i = elm_correction.find('./i')\n elm_c = elm_correction.find('./c')\n\n if elm_i is not None:\n nested_correction = elm_i.find('./NS')\n else:\n nested_correction = None\n\n #base case\n if nested_correction is None:\n if elm_c is not None:\n add_correction_to_permutations_skip_previous(sentence_permutations, incorrect_text, preceding_text + elm_c.text + tailing_text)\n else:\n add_correction_to_permutations_skip_previous(sentence_permutations, incorrect_text, preceding_text + tailing_text)\n else:\n if elm_i.text is not None:\n preceding_text = preceding_text + elm_i.text\n\n if nested_correction.tail is not None:\n tailing_text = nested_correction.tail + tailing_text\n\n #add_correction_to_permutations(sentence_permutations, \"\", preceding_text + elm_c.text + tailing_text)\n add_nested_correction_to_permutations(sentence_permutations, preceding_text + elm_c.text + tailing_text)\n traverse_corrections(sentence_permutations, incorrect_text, nested_correction, preceding_text, tailing_text)\n\ndef add_correction_to_permutations(sentence_permutations, incorrect_text, correct_text):\n sentence_permutations.append(sentence_permutations[0] + correct_text)\n for i in range(0, len(sentence_permutations) - 1):\n sentence_permutations[i] = sentence_permutations[i] + incorrect_text\n\ndef add_correction_to_permutations_skip_previous(sentence_permutations, incorrect_text, correct_text):\n sentence_permutations.append(sentence_permutations[0] + correct_text)\n for i in range(0, len(sentence_permutations) - 2):\n sentence_permutations[i] = sentence_permutations[i] + incorrect_text\n\ndef add_nested_correction_to_permutations(sentence_permutations, correct_text):\n sentence_permutations.append(sentence_permutations[0] + correct_text)\n\ndef write_sentences(sentence_permutations, src_filename, tgt_filename, rtl_src_filename, rtl_tgt_filename):\n with open(src_filename, 'a') as src_out, open(tgt_filename, 'a') as tgt_out, open(rtl_src_filename, 'a') as rtl_src_out, open(rtl_tgt_filename, 'a') as rtl_tgt_out:\n permutations = len(sentence_permutations)\n first_sentence = strip_and_tokenize(sentence_permutations[0])\n first_rtl = \" \".join(reversed(first_sentence.split()))\n if permutations == 1:\n src_out.write(\"{}\\n\".format(first_sentence))\n rtl_src_out.write(\"{}\\n\".format(first_rtl))\n tgt_out.write(\"{}\\n\".format(first_sentence))\n rtl_tgt_out.write(\"{}\\n\".format(first_rtl))\n\n else:\n for i in range(1, permutations):\n src_out.write(\"{}\\n\".format(first_sentence))\n rtl_src_out.write(\"{}\\n\".format(first_rtl))\n ith_sentence = strip_and_tokenize(sentence_permutations[i])\n ith_rtl = \" \".join(reversed(ith_sentence.split()))\n tgt_out.write(\"{}\\n\".format(ith_sentence))\n rtl_tgt_out.write(\"{}\\n\".format(ith_rtl))\n\ndef strip_and_tokenize(sentence):\n tokens = word_tokenize(sentence)\n new_sentence = \"\"\n for token in tokens:\n new_sentence = new_sentence + \" \" + token\n\n return new_sentence.strip()\n\ndef filenames(filenames_file):\n \"\"\"Returns list of files from filenames file\"\"\"\n with open(filenames_file, 'r') as file:\n files = []\n for line in file:\n line = line.strip()\n if(len(line) == 0):\n continue\n \n files.append(line)\n\n return files\n \n\ndef split_file(file, out1, out2, percentage=0.5):\n \"\"\"Splits a file in 2 given the `percentage` to go in the large file.\"\"\"\n with open(file, 'r',encoding=\"utf-8\") as fin, \\\n open(out1, 'w') as fout1, \\\n open(out2, 'w') as fout2:\n \n nLines = sum(1 for line in fin)\n fin.seek(0)\n \n nTrain = int(nLines*percentage) \n nValid = nLines - nTrain\n \n i = 0\n for line in fin:\n if (i < nTrain) or (nLines - i > nValid):\n fout1.write(line)\n i += 1\n else:\n fout2.write(line)\n\ndef get_paths_of_xml_files(src_dir):\n \"\"\"Returns dictionary with xml filenames as keys and paths as their values\"\"\"\n dataset_file_paths = dict()\n dataset = os.path.join(src_dir, 'fce-released-dataset', 'dataset')\n\n for subdir, dirs, files in os.walk(dataset):\n for file in files:\n dataset_file_paths[file] = subdir\n\n return dataset_file_paths\n\n\ndef main(opt):\n dataset_file_paths = get_paths_of_xml_files(opt.src_dir)\n process(opt.src_dir, opt.out_dir, 'train', 'fce-public.train.filenames.txt', dataset_file_paths)\n process(opt.src_dir, opt.out_dir, 'test', 'fce-public.test.filenames.txt', dataset_file_paths)\n \n # rename test file to temp file so that test can be split into validation and test sets\n os.rename(os.path.join(opt.out_dir, 'clc_fce-' + 'test' + '.en'), os.path.join(opt.out_dir, 'clc_fce-' + 'temp' + '.en'))\n os.rename(os.path.join(opt.out_dir, 'clc_fce-' + 'test' + '.gec'), os.path.join(opt.out_dir, 'clc_fce-' + 'temp' + '.gec'))\n os.rename(os.path.join(opt.out_dir, 'clc_fce-' + 'test-rtl' + '.en'), os.path.join(opt.out_dir, 'clc_fce-' + 'temp-rtl' + '.en'))\n os.rename(os.path.join(opt.out_dir, 'clc_fce-' + 'test-rtl' + '.gec'), os.path.join(opt.out_dir, 'clc_fce-' + 'temp-rtl' + '.gec'))\n\n # split\n split_file(\n os.path.join(opt.out_dir, 'clc_fce-' + 'temp' + '.en'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'valid' + '.en'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'test' + '.en')\n )\n split_file(\n os.path.join(opt.out_dir, 'clc_fce-' + 'temp' + '.gec'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'valid' + '.gec'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'test' + '.gec')\n )\n split_file(\n os.path.join(opt.out_dir, 'clc_fce-' + 'temp-rtl' + '.en'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'valid-rtl' + '.en'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'test-rtl' + '.en')\n )\n split_file(\n os.path.join(opt.out_dir, 'clc_fce-' + 'temp-rtl' + '.gec'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'valid-rtl' + '.gec'),\n os.path.join(opt.out_dir, 'clc_fce-' + 'test-rtl' + '.gec')\n )\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description='transform-CLC_FCE.py',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument('-src_dir', required=True, help=\"Path to corpus source files\")\n parser.add_argument('-out_dir', required=True, help=\"Path for transformed data files\")\n\n opt = parser.parse_args()\n main(opt)\n"
},
{
"alpha_fraction": 0.6182902455329895,
"alphanum_fraction": 0.6182902455329895,
"avg_line_length": 28.58823585510254,
"blob_id": "e80672cbf225a67438e552ef6a9b247317623165",
"content_id": "c6551bf80510f7a2aa435e0fbf53c5862342d3f0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 17,
"path": "/opennmt-scripts/compare.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport argparse\n\ndef main(opt):\n with open('../test/translate.txt', 'r') as source_file, open('../test/pred.txt', 'r') as pred_file:\n for source, target in zip(source_file, pred_file):\n print(\"S: {}\\nP: {}\\n\".format(source.strip(), target.strip()))\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description='compare.py',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n\n opt = parser.parse_args()\n main(opt)\n"
},
{
"alpha_fraction": 0.6650485396385193,
"alphanum_fraction": 0.667475700378418,
"avg_line_length": 31.959999084472656,
"blob_id": "9eba67a5a5591c0916916dcda33b88347bf1aad5",
"content_id": "67bea1002787688cad3a12f6341bfe368e08b267",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 824,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 25,
"path": "/fairseq-scripts/eval_fluency.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "\"\"\"\nEvaluate the fluency of a trained language model.\n\"\"\"\n\nimport torch\nimport os\n\nfrom fairseq import options\nfrom fluency_scorer import FluencyScorer\n\ndef main(parsed_args):\n scorer = FluencyScorer(parsed_args.lang_model_path, parsed_args.lang_model_data)\n with open(os.path.join(parsed_args.data, parsed_args.gen_subset)) as f:\n for line in f:\n line = line.strip()\n score = scorer.score_sentence(line)\n print('[{:0.4f}] {}'.format(score, line))\n\nif __name__ == '__main__':\n parser = options.get_eval_lm_parser()\n # fluency score arguments\n parser.add_argument('--lang-model-data', help='path to language model dictionary')\n parser.add_argument('--lang-model-path', help='path to language model file')\n args = options.parse_args_and_arch(parser)\n main(args)\n"
},
{
"alpha_fraction": 0.5699481964111328,
"alphanum_fraction": 0.575129508972168,
"avg_line_length": 37.599998474121094,
"blob_id": "e997f7bf17830983d0982b5e7602770038fa5dde",
"content_id": "3b5510ec04d622037e489747df1aaf77d6fe1f90",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1544,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 40,
"path": "/opennmt-scripts/transform-lang8.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport argparse\nimport os\n\ndef process(src_dir, out_dir, dataset):\n entry_filename = os.path.join(src_dir, 'entries.' + dataset)\n src_filename = os.path.join(out_dir, 'lang8-' + dataset + '-src.txt')\n tgt_filename = os.path.join(out_dir, 'lang8-' + dataset + '-tgt.txt')\n with open(entry_filename, 'r') as entry_file, open(src_filename, 'w') as src_out, open(tgt_filename, 'w') as tgt_out:\n for line in entry_file:\n line = line.strip()\n if (len(line) == 0):\n continue\n\n parts = line.split(\"\\t\")\n sentence = parts[4]\n num_corrections = int(parts[0])\n if num_corrections == 0:\n src_out.write(\"{}\\n\".format(sentence))\n tgt_out.write(\"{}\\n\".format(sentence))\n else:\n for i in range(num_corrections):\n correction = parts[5+i]\n src_out.write(\"{}\\n\".format(sentence))\n tgt_out.write(\"{}\\n\".format(correction))\n\ndef main(opt):\n process(opt.src_dir, opt.out_dir, 'train')\n process(opt.src_dir, opt.out_dir, 'test')\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\n description='transform-lang-8.py',\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument('-src_dir', required=True, help=\"Path to corpus source files\")\n parser.add_argument('-out_dir', required=True, help=\"Path for transformed data files\")\n\n opt = parser.parse_args()\n main(opt)\n"
},
{
"alpha_fraction": 0.7104451656341553,
"alphanum_fraction": 0.7485266327857971,
"avg_line_length": 42.93824768066406,
"blob_id": "e9cfcc21fdd4214ddf873d9e67c6b442f0ff5f8e",
"content_id": "c40a05574a7e21e5531cda699484f64c151cc583",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 22060,
"license_type": "permissive",
"max_line_length": 645,
"num_lines": 502,
"path": "/README.md",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "# pytorch-human-performance-gec\n\nThe goal of this project is to implement a grammatical error correction model from paper [\"Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study\"](https://arxiv.org/abs/1807.01270) using [PyTorch](https://github.com/pytorch/pytorch) and [fairseq](https://github.com/pytorch/fairseq).\n\nWhile the original paper achieves human performance, this implementation is more about an empirical study on applying deep learning in NLP as a university team project.\n\n## Project Team\n\nThis project was completed as the final project for CS 410: Text Information Systems at the University of Illinois at Urbana-Champaign. The team members and their primary areas of responsibility were:\n\n* Tianfei Chen: left-to-right model construction and training, GLEU scoring function, evaluation of test sets, inference, boost inference, web GUI, documentation, and project presentation.\n* Robert Cottrell: framework evaluation and selection, organizing project structure and dependencies, initial prototyping and documentation, boost learning, fluency scoring, and project presentation.\n* Lenny Giannachi: research datasets, acquire alternative datasets, and technology review.\n* Jingwei Li: BPE tokenization, research alignment dictionary generation.\n* Jonathan Montwell: research datasets, right-to-left data generation, technology review.\n\nA [video presentation](https://www.youtube.com/watch?v=n_BHr5RyVdA) is available online and the [slides](doc/Project-Presentation.pdf) are included in this repository. The project [Technology Review](doc/Technology-Review.pdf) is also available.\n\n## What We Learned\n\n### Empirical Study\n\n- Write code quickly\n - Use a framework\n - Don't start from scratch. Use existing library, framework and toolkit.\n - Pre-processing, batching, checkpointing, common models are all included.\n - Tried both OpenNMT and fairseq NLP toolkits.\n - Settled with fairseq which is also what paper used.\n - It is ok to just copy toolkit and components then modify them\n - This is officially recommended way to extending and playing with fairseq.\n - When you copy many times you will naturally learn how to refactor them later.\n- Run experiments\n - Run out of box samples to learn how toolkit works.\n - Run simple models to get a proof of concept and confidence.\n- Keep track of what you tried\n - Keep track of what you ran\n - Source control constructed models and hyper-paramters.\n - Save the scripts so that you can repeat them again with other tweaks and datasets.\n - Keep track of what you got\n - Many frameworks and toolkits will do this for you automatically.\n - Just need to keep folders clear and watch your hard drive free space.\n- Analyze model behavior\n - Feed model with some simplest tests\n - Look at generated values see if that's what you expected.\n - Look at scores and see if they make sense.\n - Evaluate models with proper evaluation metric\n - Loss function for training.\n - Fluency score (cross entropy) and GLEU score etc.\n\n### Completed\n\n- A left-to-right 7-layer convolutional seq2seq model has been implemented using same architecture as the paper suggested.\n- The base convolutional seq2seq model has been trained using mostly same hyper parameters.\n- Fluency score function, which is used for both boost training / learning and boost inference, has been implemented. For example, nature sentences get higher score.\n```\n[0.1977] It is a truth universally acknowledged , that a single man in possession of a good fortune must be in want of a wife . </s>\n[0.1937] I am going to a party tomorrow . </s>\n[0.1902] I am going to the party tomorrow . </s>\n[0.1864] It was the best of times , it was the worst of times , it was the age of wisdom , it was the age of foolishness , it was the epoch of belief , it was the epoch of incredulity , it was the season of Light , it was the season of Darkness , it was the spring of hope , it was the winter of despair , we had everything before us , we had nothing before us , we were all going direct to Heaven , we were all going direct the other way - in short , the period was so far like the present period , that some of its noisiest authorities insisted on its being received , for good or for evil , in the superlative degree of comparison only . </s>\n[0.1654] Yesterday I saw a car . </s>\n[0.1630] Tomorrow I am going to a party . </s>\n[0.1540] I saw the car yesterday . </s>\n[0.1473] Tomorrow I am going to party . </s>\n[0.1383] Tomorrow I go to party . </s>\n[0.1296] Yesterday I see car . </s>\n[0.1280] Yesterday I saw car . </s>\n```\n- GLEU score function, which is used to evaluate JFLEG test set, has been implemented. For example, similar sentences have higher GLEU score.\n```\nThere are several reason|There are several reasons\nO There are several reason\nH There are several reasons -0.029993820935487747\nP -0.0028 -0.0339 -0.0015 -0.0464 -0.0653\nGLEU 100.00\nFor not use car|Not for use with a car\nO For not use car\nH For not use car -0.06429481506347656\nP -0.1332 -0.0239 -0.1537 -0.0102 -0.0006\nGLEU 27.40\nEvery knowledge is connected each other|All knowledge is connected\nO Every knowledge is connected each other\nH Every knowledge is connected to each other -0.17184138298034668\nP -0.1573 -0.0054 -0.0348 -0.0004 -0.9934 -0.0301 -0.0026 -0.1507\nGLEU 18.58\n```\n- An error generation model has been implemented to generates more synthetic data from original training dataset, which will in turn boost training of the base model. For example.\n```\nS-3654 How many languages have you studied ?\nH-3654 How many language have you studied ? -0.19821381568908691\nH-3654 How many languages do you study ? -0.5254995822906494\nH-3654 How much languages have you studied ? -0.5455195903778076\nH-3654 How many languages are you studied ? -0.5917201042175293\n```\n- Basic inference with the base model has been implemented. For example, entered sentence is corrected in multiple ways.\n```\nIn the world oil price very high right now .\n\nIteration\t0\nO\tIn the world oil price very high right now .\nH\tIn the world oil price very high right now .\t0\nFluency Score: 0.1503\n\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil prices very high right now .\t-0.2768438458442688\nFluency Score: 0.1539\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil prices are very high right now .\t-0.31139659881591797\nFluency Score: 0.1831\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil price is very high right now .\t-0.3594667315483093\nFluency Score: 0.1731\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil price very expensive right now .\t-0.4148099422454834\nFluency Score: 0.1434\n\nBest inference \t\"In the world oil prices are very high right now .\"\t(0.1831)\n```\n- Boost inference has been implemented to use both base model and language model. For example, entered sentence is corrected in multiple ways, the best scored one is chosen for multiple rounds of correction, until the score cannot be improved.\n```\nIn the world oil price very high right now .\n\nIteration\t0\nO\tIn the world oil price very high right now .\nH\tIn the world oil price very high right now .\t0\nFluency Score: 0.1503\n\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil prices very high right now .\t-0.2768438458442688\nFluency Score: 0.1539\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil prices are very high right now .\t-0.31139659881591797\nFluency Score: 0.1831\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil price is very high right now .\t-0.3594667315483093\nFluency Score: 0.1731\nIteration\t1\nO\tIn the world oil price very high right now .\nH\tIn the world oil price very expensive right now .\t-0.4148099422454834\nFluency Score: 0.1434\n\nBoost inference from \t\"In the world oil prices are very high right now .\"\t(0.1831)\n\nIteration\t2\nO\tIn the world oil prices are very high right now .\nH\tIn the world oil prices are very expensive right now .\t-0.3672739863395691\nFluency Score: 0.1690\nIteration\t2\nO\tIn the world oil prices are very high right now .\nH\tIn the world oil prices are very high now .\t-0.4246770739555359\nFluency Score: 0.1883\nIteration\t2\nO\tIn the world oil prices are very high right now .\nH\tThe world oil prices are very high right now .\t-0.42579686641693115\nFluency Score: 0.1770\nIteration\t2\nO\tIn the world oil prices are very high right now .\nH\tIn the world oil prices are very high right now ,\t-0.6304754018783569\nFluency Score: 0.1748\n\nBoost inference from \t\"In the world oil prices are very high now .\"\t(0.1883)\n\nIteration\t3\nO\tIn the world oil prices are very high now .\nH\tIn the world oil prices are very expensive now .\t-0.41596412658691406\nFluency Score: 0.1693\nIteration\t3\nO\tIn the world oil prices are very high now .\nH\tThe world oil prices are very high now .\t-0.45905303955078125\nFluency Score: 0.1780\nIteration\t3\nO\tIn the world oil prices are very high now .\nH\tIn world oil prices are very high now .\t-0.47978001832962036\nFluency Score: 0.1718\nIteration\t3\nO\tIn the world oil prices are very high now .\nH\tIn the world oil prices are very high now ,\t-0.6376678347587585\nFluency Score: 0.1780\n\nBest inference\t\"In the world oil prices are very high now .\"\t(0.1883)\n```\n- Evaluation of JFLEG test set using GLEU score.\n - The base model has a GLEU score 48.17 on JFLEG test set when it was trained for 2 epochs.\n - The base model has a GLEU score 48.89 on JFLEG test set when it was trained for 3 epochs.\n - The introduction of boost inference increased GLEU from 48.89 to 49.39. The percentage of increase is consistent with the paper ( ≈ 1% ).\n- An enhanced interactive mode with RESTful API and Web GUI.\n - RESTful API\n - \n - Web GUI\n - \n - Web GUI 2\n - \n\n### Not Completed\n\n- A right-to-left convolutional seq2seq model.\n- Training of the model using new dataset generated by boost learning.\n- BPE tokenization and unknown token replacement.\n- Stemming for raw text / interactive modes.\n- Evaluation of CoNLL-10 test set using F0.5.\n\n### Barriers\n\n- No enough training dataset: we got only Lang-8 corpus, which is about 20% of the dataset used by the paper. We've tried to contact other organizations, but no response was received.\n- Limit time: training big neural network model with large dictionaries is time consuming. We decided to complete the whole process instead of trying to reproduce the score achieved by the paper. We can probably achieve it given more time and datasets.\n\n## Initialize Submodules\n\nAfter checking out the repository, be sure to initialize the included git submodules:\n\n```sh\ngit submodule update --init --recursive\n```\n\nThe reasons of using them as submodules rather than Python package are:\n* some scripts and functions might need be patched in order to work properly.\n* a few scripts are modified based on the original scripts, which is the officially recommended way of using fairseq.\n\n## Install Required Dependencies\n\nThe environment used for the development is Windows 10 64bit + Python 3.6 + CUDA 9.2 + pytorch 0.4.1.\n\n`PyTorch` can be installed by following the directions on its [project page](https://pytorch.org). Conda is recommended as it will install CUDA dependencies automatically. For example,\n\n```sh\nconda install pytorch cuda92 -c pytorch\npip3 install torchvision\n```\n\nThis project also uses the `fairseq` NLP toolkit, which is included as a submodule in this repository. To prepare the library for use, make sure that it is installed along with its dependencies.\n\n```sh\ncd fairseq\npip3 install -r requirements.txt\npython setup.py build develop\n```\n\nSome preprocessing scripts also make use of the NLTK framework, which can be installed with this command:\n\n```sh\npip3 install nltk\n```\n\nOnce the NLTK framework is installed, the `punkt` dataset must also be downloaded. This can be done from the Python REPL:\n\n```sh\npython\n>>> import nltk\n>>> nltk.download('punkt')\n```\n\nOther project dependencies are placed under `fairseq-scripts` folder, which can be installed by running\n\n```sh\ncd fairseq-scripts\npip3 install -r requirements.txt\n```\n\n## Folder Structures\n\n```\n.\n|-- OpenNMT-py The other NLP toolkit we tried early (legacy)\n|-- checkpoints Trained models and checkpoints\n| |-- errorgen-fairseq-cnn An error generation model that takes corrected sentences as input,\n| | uncorrected sentences as output\n| |-- lang-8-fairseq A simple single layer LSTM model for error correction\n| `-- lang-8-fairseq-cnn A 7-layer convolutional seq2seq model for error correction\n|-- corpus Raw and prepared corpus\n| |-- errorgen-fairseq Corpus generated by the error generation model - the result of boost learning.\n| |-- lang-8-en-1.0 Raw Lang-8 corpus\n| |-- lang-8-fairseq Corpus format required by fairseq\n| `-- lang-8-opennmt Corpus format required by OpenNMT\n|-- data-bin Pre-processed and binarized data\n| |-- errorgen-fairseq Binarized synthetic data and dictionaries\n| |-- lang-8-fairseq Binarized Lang-8 data and dictionaries\n| `-- wiki103 Pre-trained WikiText-103 language model and dictionaries\n|-- doc Additional project research and documentation\n|-- fairseq fairseq submodule\n|-- fairseq-scripts fairseq scripts used to implement the model and process proposed by the paper\n|-- opennmt OpenNMT data and model folder (legacy)\n|-- opennmt-scripts OpenNMT scripts folder (legacy)\n`-- test Random test text files can be thrown to here\n```\n\n## fairseq Custom Scripts / Software Usage Tutorial\n\nAll fairseq scripts have been grouped under `fairseq-scripts` folder. The whole process is:\n\n1. Preparing data\n2. Pre-process data\n3. Train the model\n4. Testing the model\n5. Evaluate the model\n6. Interactive mode\n7. Boosting\n\n### Preparing Data\n\nThe first step is to prepare the source and target pairs of training and validation data. Extract original `lang-8-en-1.0.zip` under `corpus` folder. Then create another folder `lang-8-fairseq` under `corpus` folder to store re-formatted corpus.\n\nTo split the Lang-8 learner data training set, use the following command:\n\n```sh\npython transform-lang8.py -src_dir <dataset-src> -out_dir <corpus-dir>\n```\n\nTo split the CLC-FCE data set training set, use the following command:\n\n```sh\npython transform-CLC_FCE.py -src_dir <dataset-src> -out_dir <corpus-dir>\n```\n\nThese scripts will create training, validation, and test sets for both the left-to-right and right-to-left models.\n\n### Pre-process Data\n\nOnce the data has been extracted from the dataset, use fairseq to prepare the training and validation data and create the vocabulary:\n\n```sh\npreprocess-lang8.bat\n```\n\n### Train the Model\n\nTo train the error-correcting model, run the following command:\n\n```sh\ntrain-lang8-cnn.bat\n```\n\nNote that this script may need to be adjusted based on the GPU and memory resources available for training.\n\n### Testing the Model\n\nTo test the model, run the following command to try to correct a list of sentences:\n\n```sh\ngenerate-lang8-cnn.bat\n```\n\nThis command will try to correct all sentences in a file with probabilities and scores in the output. It is a convenient way to peed that the model behaves as expected against lots of test data.\n\n### Evaluate the Model\n\nEvaluate scripts are used to score model using text or pre-processed files in batch.\n\nEvaluate can be done against lang-8 test dataset using\n\n```sh\ngenerate-lang8-cnn-rawtext.bat\n```\n\nThe paper evaluates against JFLEG test dataset, which can be done using\n\n```sh\ngenerate-jfleg-cnn-rawtext.bat\n```\n\nAbove scripts can be modified to test other test dataset easily as they use plain text.\n\nOther scripts such as `generate-lang8.bat or generate-lang8-cnn.bat` can only deal with pre-processed data so it is less convenient.\n\n### Interactive Mode\n\nWhile evaluate scripts are good at batch processing, two interactive scripts are provided to see details of generation / correction.\n\nBelow script will run in console mode:\n```sh\ninteractive-lang8-cnn-console.bat\n```\n\nBelow script will boot a local server to provide a web GUI and RESTful API interface:\n```sh\ninteractive-lang8-cnn-web.bat\n```\n\nInteractive mode allows users to enter a sentence in console, or Web GUI, to see how subtle difference in input are corrected.\n\n### Boosting\n\nTo augment training data to provide more examples of common errors, this project builds an error-generating model that can produce additional lower quality sentences for correct sentences. This uses the same training data as the regular model, but reverses the source and target sentences.\n\nOnce the data has been extracted from the dataset, use fairseq to prepare the training and validation data and create the vocabulary:\n\n```sh\npreprocess-errorgen.bat\n```\n\nTo train the error-correcting model, run the following command:\n\n```sh\ntrain-errorgen-cnn.bat\n```\n\nNote that this script may need to be adjusted based on the GPU and memory resources available for training.\n\nNow the error-generating model can be use to generate additional training data. The generating script will only consider sentences longer than four words that are at least 5% less fluent (as measured by the fluency scorer) than the corrected sentences. This ensures that the new sentences are more likely to showcase interesting corrections while avoiding trivial edits. Notice that in this case we use the latest model checkpoint rather than the most generalized, because in this particular case overfitting to the training data is an advantage!\n\n```sh\ngenerate-errorgen-cnn.bat\n```\n\nThe sentences generated in the corpus\\errorgen directory can then be used as additional data to train or fine tune the error-correcting model.\n\n### Additional Techniques\n\nIn addition to the work describe above, additional datasets and techniques for data preprocessing, model training, and other imporovements were evaluated.\n\nBPE tokenization promises to make more effective use of a limited number of vocabulary tokens by further subdividing words into subword tokens that can be shared by many different words. Additional [documentation](doc/BPE-Documentation) and [notebook](doc/BPE-Notebook.ipynb) showing how to install and tokenize the dataset is available.\n\nAn example of sentences after apply BPE tokenization can be seen below:\n```\nI will introduce my dog , Ti@@ ara .\nShe is a cheerful and plu@@ mp pretty dog , perhaps she is the cu@@ test dog in the world .\nShe 's an 8 year old golden re@@ tri@@ ever\nHer fu@@ r is a beautiful a@@ mber colour and is soft .\nWhen she has had her food , she always pr@@ ances around the living room mer@@ ri@@ ly .\nAnd she loves ba@@ s@@ king too .\n```\n\n### Patching fairseq Environment\n\nIf error `AttributeError: function 'bleu_zero_init' not found` occurs on Windows, modify functions to have `__declspec(dllexport)` then build again. See [Issue 292](https://github.com/pytorch/fairseq/issues/292)\n\nIf error `UnicodeDecodeError: 'charmap' codec can't decode byte` error occurs, modify `fairseq/tokenizer.py` to include `, encoding='utf8'` for all `open` functions.\n\nWhen trying built-in example from `fairseq/examples/translation/prepare-[dataset].sh`, scripts may need to change .py path from `$BPEROOT/[script].py` to `$BPEROOT/subword_nmt/[script].py`.\n\n## OpenNMT (Legacy)\n\nInitial exploration and implentation of this project used the OpenNMT library. Documentation of how to use this library is included below. An [Framework Comparison](doc/Framework-Comparison.pdf) comparing the two frameworks and why we settled on Fairseq is available.\n\n### OpenNMT Scripts\n\nAll OpenNMT scripts have been grouped under `opennmt-scripts` folder.\n\n### Preparing Data\n\nThe first step is to prepare the source and target pairs of training and validation data. Extract original `lang-8-en-1.0.zip` under `corpus` folder. Then create another folder `lang-8-opennmt` under `corpus` folder to store re-formatted corpus.\n\nTo split the Lang-8 learner data training set, use the following command:\n\n```sh\npython transform-lang8.py -src_dir <dataset-src> -out_dir <corpus-dir>\n```\ne.g.\n```sh\npython transform-lang8.py -src_dir ../corpus/lang-8-en-1.0 -out_dir ../corpus/lang-8-opennmt\n```\n\nOnce the data has been extracted from the dataset, use OpenNMT to prepare the training and validation data and create the vocabulary:\n\n```sh\npreprocess-lang8.bat\n```\n\n### Train the Model\n\nTo train the error-correcting model, run the following command:\n\n```sh\ntrain.bat\n```\n\nNote that this script may need to be adjusted based on the GPU and memory resources available for training.\n\n### Testing the Model\n\nTo test the model, run the following command to try to correct a list of sentences:\n\n```sh\ntranslate.bat\n```\n\nAfter the sentences have been translated, the source and target sentence may be compared side to side using the following command:\n\n```sh\npython compare.py\n```\n\n### Patching OpenNMT-py Environment\n\nIf `preprocess.py` fails with a TypeError, then you may need to patch OpenNMT-py.\n\nUpdate `OpenNMT-py\\onmt\\inputters\\dataset_base.py` with the following code:\n\n```python\ndef __reduce_ex__(self, proto):\n \"This is a hack. Something is broken with torch pickle.\"\n return super(DatasetBase, self).__reduce_ex__(proto)\n```\n\nIf `TypeError: __init__() got an unexpected keyword argument 'dtype'` occurs, `pytorch/text` installed by pip may be out of date. Update it using `pip3 install git+https://github.com/pytorch/text`\n\nIf `RuntimeError: CuDNN error: CUDNN_STATUS_SUCCESS` occurs during training, try install pytorch with CUDA 9.2 using conda instead of using default CUDA 9.0.\n\n"
},
{
"alpha_fraction": 0.6042526960372925,
"alphanum_fraction": 0.609207272529602,
"avg_line_length": 37.75199890136719,
"blob_id": "7fefaaa5f901317736293a9ea80f2bc38dac85ec",
"content_id": "a790223769e092e47d61191c4d09ffc06a6c8df4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4844,
"license_type": "permissive",
"max_line_length": 207,
"num_lines": 125,
"path": "/fairseq-scripts/fluency_scorer.py",
"repo_name": "tianfeichen/pytorch-human-performance-gec",
"src_encoding": "UTF-8",
"text": "\"\"\"\nEvaluate the fluency of a trained language model.\n\"\"\"\n\nimport torch\nimport numpy as np\n\nfrom fairseq import data, tasks, tokenizer, utils\nfrom fairseq.sequence_scorer import SequenceScorer\n\nclass FluencyArgs(dict):\n \"\"\"Encapsulate args to build FluencyScorer.\"\"\"\n\n def __init__(self, path, data):\n self['path'] = path\n self['data'] = data\n # Set options to allow line-separate, raw text data files.\n self['task'] = 'language_modeling'\n self['raw_text'] = True\n self['sample_break_mode'] = 'eos'\n # Default fairseq option values.\n self['output_dictionary_size'] = -1\n self['self_target'] = False\n self['future_target'] = False\n self['past_target'] = False\n self['num_shards'] = 1\n self['shard_id'] = 0\n self['max_tokens'] = None\n self['max_sentences'] = None\n self['tokens_per_sample'] = 1024\n\n def __getattr__(self, name):\n if name in self:\n return self[name]\n else:\n raise AttributeError(\"No such attribute: \" + name)\n\n def __setattr__(self, name, value):\n self[name] = value\n\n def __delattr__(self, name):\n if name in self:\n del self[name]\n else:\n raise AttributeError(\"No such attribute: \" + name)\n\nclass FluencyScorer(object):\n \"\"\"Evaluate sentences for fluency.\n\n The FluencyScorer class uses an embedded language model to score candidate\n sentences for according to how likely they would be used by a native\n speaker.\n \"\"\"\n\n def __init__(self, path, data, use_cpu=True):\n # Create the language modeling task.\n self.args = FluencyArgs(path, data)\n self.task = tasks.setup_task(self.args)\n self.use_cuda = torch.cuda.is_available and not use_cpu\n\n # Load language model ensemble.\n models, model_args = utils.load_ensemble_for_inference(self.args.path.split(':'), self.task)\n self.models = models\n self.model_args = model_args\n\n # Optimize ensemble for generation.\n for model in self.models:\n model.make_generation_fast_()\n if self.use_cuda and self.model_args.fp16:\n model.half()\n \n # Create the sequence scorer.\n self.scorer = SequenceScorer(self.models, self.task.target_dictionary)\n if self.use_cuda:\n self.scorer.cuda()\n \n def score_sentence(self, line):\n # Tokenize the input sentence into a batch of size one.\n tokens = tokenizer.Tokenizer.tokenize(line, self.task.dictionary, add_if_not_exist=False).long()\n lengths = np.array([tokens.numel()])\n ds = data.TokenBlockDataset(tokens, lengths, self.args.tokens_per_sample, pad=self.task.dictionary.pad(), eos=self.task.dictionary.eos(), break_mode=self.args.sample_break_mode, include_targets=True)\n\n # Create a batch iterator to wrap the data.\n add_eos_for_other_targets = self.args.sample_break_mode is not None and self.args.sample_break_mode != 'none'\n itr = self.task.get_batch_iterator(\n dataset=data.MonolingualDataset(ds, ds.sizes, self.task.dictionary, self.task.target_dictionary, add_eos_for_other_targets=add_eos_for_other_targets, shuffle=False, targets=self.task.targets),\n max_tokens=self.args.max_tokens or 3000,\n max_sentences=self.args.max_sentences,\n max_positions=utils.resolve_max_positions(*[\n model.max_positions() for model in self.models \n ]),\n num_shards=self.args.num_shards,\n shard_id=self.args.shard_id,\n ignore_invalid_inputs=True,\n ).next_epoch_itr(shuffle=False)\n \n # Evaluate the sentence and return the fluency score.\n results = self.scorer.score_batched_itr(itr, cuda=self.use_cuda)\n for _, _, _, hypos in results:\n for hypo in hypos:\n # Ignore words with infinite probability. This can happen when\n # running low-precision inference on the GPU. \n pos_scores = hypo['positional_scores']\n word_prob = [score for score in pos_scores if score != float('-inf') and score != float('inf')]\n return self._fluency_score(word_prob)\n return 0.0\n\n def _fluency_score(self, word_prob):\n \"\"\"Calculate fluency score.\n\n Given the list of log-probabilities for each token, calculate the\n fluency score of the sentence.\n \"\"\"\n\n # If there were no tokens because they were all filtered out for\n # having infinite probabilites, then give a minimum fluency score.\n if len(word_prob) == 0:\n return 0.0\n\n H = 0.0\n for x in word_prob:\n H -= x\n H = H / len(word_prob)\n score = 1.0 / (1.0 + H)\n return score\n"
}
] | 7 |
loony175/StagesVODList
|
https://github.com/loony175/StagesVODList
|
9cc6145772b9a4dac5c89615a9145cfde8782a9c
|
fe832014a73514342c5cf05c5edb2073fabbf251
|
4874c716113890d33d2aa38c7445a7f9cc7c5bc4
|
refs/heads/master
| 2020-03-08T21:22:36.313520 | 2019-03-03T19:00:38 | 2019-03-03T19:00:38 | 128,405,627 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.516539454460144,
"alphanum_fraction": 0.5383496880531311,
"avg_line_length": 32.54878234863281,
"blob_id": "1a771d7101c5efe42cfeb6de83e94f9f01417624",
"content_id": "48882f610233b5638fd68686769ef64e47fa9beb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2751,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 82,
"path": "/stage48.py",
"repo_name": "loony175/StagesVODList",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nimport bs4\nimport json\nimport logging\nimport multiprocessing\nimport re\nimport requests\nfrom urllib import parse\n\ndef get_review_url(id):\n while True:\n while True:\n try:\n resp=requests.get('https://live.48.cn/Index/invedio/club/1/id/%d'%id)\n break\n except Exception as e:\n logging.warning('[SNH48 Group] %d: %s'%(id,e))\n if resp.status_code==200:\n if len(resp.text)>=36000:\n try:\n review_url=bs4.BeautifulSoup(resp.text,'html.parser').find_all('input',id='chao_url')[0]['value']\n except IndexError:\n review_url=''\n if parse.urlparse(review_url).hostname=='ts.48.cn':\n review_url=review_url.replace('http://','https://')\n break\n else:\n message='Incomplete response'\n elif resp.status_code==502:\n message='502 Bad Gateway'\n else:\n message='HTTP status code not 200 OK'\n logging.warning('[SNH48 Group] %d: %s'%(id,message))\n return id,review_url\n\ndef main():\n parser=argparse.ArgumentParser()\n add=parser.add_argument\n add('-j','--jobs',type=int,default=32)\n args=parser.parse_args()\n logging.basicConfig(level=logging.INFO,format='%(levelname)s: %(message)s')\n while True:\n while True:\n try:\n resp=requests.get('https://live.48.cn/Index/main/club/1')\n break\n except Exception as e:\n logging.warning('[SNH48 Group] Index: %s'%e)\n if resp.status_code==200:\n if len(resp.text)>16:\n ids=[]\n for item in bs4.BeautifulSoup(resp.text,'html.parser').find_all('a',target='_blank'):\n m=re.match(r'^/Index/invedio/club/1/id/(?P<id>\\d+)$',item['href'])\n if m:\n ids.append(int(m.group('id')))\n end_id=max(ids)\n break\n else:\n message='Incomplete response'\n elif resp.status_code==502:\n message='502 Bad Gateway'\n else:\n message='HTTP status code not 200 OK'\n logging.warning('[SNH48 Group] Index: %s'%message)\n pool=multiprocessing.Pool(args.jobs)\n results=pool.map(get_review_url,range(1,end_id+1))\n pool.close()\n pool.join()\n data={}\n for id,review_url in results:\n data[str(id)]=review_url\n output='urls.json'\n f=open(output,'w')\n f.write(json.dumps(data,indent=2))\n f.write('\\n')\n f.close()\n logging.info('[SNH48 Group] %d URLs written in %s'%(end_id,output))\n\nif __name__=='__main__':\n main()\n"
},
{
"alpha_fraction": 0.713178277015686,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 21.764705657958984,
"blob_id": "3c4a3a0fcd0e1f1ff5f118eaa6cdc6cbf6b3ac63",
"content_id": "d9912806ea6c5e54a353aa2fe9c3d2f744bef15e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 651,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 17,
"path": "/README.md",
"repo_name": "loony175/StagesVODList",
"src_encoding": "UTF-8",
"text": "SNH48 Group所有能获取到的公演录播\n\n## Requirement\n```\npip install -U -r requirements.txt\n```\n\n## Usage & Updating manually\n```\nusage: ./stage48.py [-j JOBS]\n\noptional arguments:\n -j JOBS, --jobs JOBS 向*.???48.com发送GET请求时的并发执行数(并发执行数越大,请求效率越高,默认值为32)\n```\n工作原理:执行`./stage48.py`后,首先向*.???48.com发送GET请求以获取原始HTML代码,过滤出单场公演录播的实际URL,并写入normal文件夹下的对应文件中。\n\n本repository中的录播列表我会不定期更新,如需自行手动更新,也可通过执行上述脚本实现。\n"
}
] | 2 |
chinaglia-rafa/PDI
|
https://github.com/chinaglia-rafa/PDI
|
ed294657431768c903d8f5f62df116d62e76ebfb
|
d136c9803f88f9bf21a52c420cc2aa5fa93e79b9
|
fa2fb25c4e5ba8e3fbb3680e23416a93e12a2df5
|
refs/heads/master
| 2021-02-19T09:50:17.271867 | 2020-06-02T05:33:02 | 2020-06-02T05:33:02 | 245,301,246 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.489493191242218,
"alphanum_fraction": 0.4929542541503906,
"avg_line_length": 32.155738830566406,
"blob_id": "fa4512b9a3e15bd1cbe8f36d4020506c01730175",
"content_id": "77e5801e789bffbd8b6c9a1833e67b6ec050dca0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4051,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 122,
"path": "/atividade01/loaders.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nimport re\n\n\nclass ImageLoaderInterface(ABC):\n\n def __init__(self):\n pass\n\n @abstractmethod\n def load(self, filename):\n pass\n\n @abstractmethod\n def write(self, filename):\n pass\n\n\nclass PGMLoader(ImageLoaderInterface):\n \"\"\"Estratégia para carregar uma imagem PGM e retornar um dicionário com os dados\"\"\"\n\n def __init__(self):\n pass\n\n def write(self, matrix, filename):\n \"\"\" Salva os dados de um arquivo .pgm \"\"\"\n print(\"Saving\", filename, \"as PGM\")\n with open(filename, \"w\") as file:\n file.write(str(matrix.get_format()) + \"\\n\")\n file.write(str(matrix.get_size().cols) + \"\\n\")\n file.write(str(matrix.get_size().rows) + \"\\n\")\n file.write(str(matrix.get_limit()))\n for i in range(matrix.get_size().rows):\n file.write(\"\\n\")\n for j in range(matrix.get_size().cols):\n file.write(str(matrix.get_item(i, j)))\n if (j < matrix.get_size().cols - 1):\n file.write(\" \")\n\n def load(self, filename):\n \"\"\" Carrega os dados de um arquivo .pgm e retorna uma lista com o conteúdo relevante \"\"\"\n print(\"Loading\", filename, \"as PGM\")\n data = []\n # TODO: fazer isso direito\n matrix_template = {\n 'format': '',\n 'width': 0,\n 'height': 0,\n 'limit': False,\n 'data': []\n }\n with open(filename, \"r\") as file:\n for line in file:\n content = re.split('\\s', line)\n for element in content:\n if element == '#':\n break\n if element == \"\":\n continue\n data.append(element)\n\n matrix_template['format'] = data.pop(0)\n matrix_template['width'] = data.pop(0)\n matrix_template['height'] = data.pop(0)\n matrix_template['limit'] = data.pop(0)\n matrix_template['data'] = data\n\n return matrix_template\n\n\nclass PPMLoader(ImageLoaderInterface):\n \"\"\"Estratégia para carregar uma imagem PPM e retornar um dicionário com os dados\"\"\"\n\n def __init__(self):\n pass\n\n def write(self, matrix, filename):\n \"\"\" Salva os dados de um arquivo .ppm \"\"\"\n print(\"Saving\", filename, \"as PPM\")\n with open(filename, \"w\") as file:\n file.write(str(matrix.get_format()) + \"\\n\")\n file.write(str(matrix.get_size().cols) + \"\\n\")\n file.write(str(matrix.get_size().rows) + \"\\n\")\n file.write(str(matrix.get_limit()))\n for i in range(matrix.get_size().rows):\n file.write(\"\\n\")\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n for channel in pixel:\n file.write(str(channel) + \"\\n\")\n if (j < matrix.get_size().cols - 1):\n file.write(\" \")\n\n def load(self, filename):\n \"\"\" Carrega os dados de um arquivo .ppm e retorna uma lista com o conteúdo relevante \"\"\"\n print(\"Loading\", filename, \"as PPM\")\n data = []\n # TODO: fazer isso direito\n matrix_template = {\n 'format': '',\n 'width': 0,\n 'height': 0,\n 'limit': False,\n 'data': []\n }\n with open(filename, \"r\") as file:\n for line in file:\n content = re.split('\\s', line)\n for element in content:\n if element == '#':\n break\n if element == \"\":\n continue\n data.append(element)\n\n matrix_template['format'] = data.pop(0)\n matrix_template['width'] = data.pop(0)\n matrix_template['height'] = data.pop(0)\n matrix_template['limit'] = data.pop(0)\n matrix_template['data'] = data\n\n return matrix_template\n"
},
{
"alpha_fraction": 0.5210557579994202,
"alphanum_fraction": 0.5235764980316162,
"avg_line_length": 37.98265838623047,
"blob_id": "3984e1687caa12e206ae5b0984e856cae4da26d2",
"content_id": "7af921b6b76515e7030713ffb5833ab0ec528642",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6754,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 173,
"path": "/atividade01/PPMMatrix.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "import random\nfrom PGMMatrixInterface import PGMMatrixInterface\n\nclass PPMMatrix():\n\n\n def __init__(self):\n # Quantidade de canais por pixel\n self.channels_in_pixel = 3\n\n def __str__(self):\n return self.__class__.__name__\n\n def str(self, matrix):\n if matrix.get_size().rows == matrix.get_size().cols == 0:\n return \"Matrix is empty! (0x0)\"\n s = \" Matrix is %d rows by %d cols\\n\" % (matrix.get_size().rows, matrix.get_size().cols)\n s += \" Matrix has %d channels\\n\\n\" % (self.channels_in_pixel)\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n for channel in range(self.channels_in_pixel):\n s += \" \" + str(pixel[channel])\n s += \"|\"\n s += \"\\n\"\n\n return s\n\n def init(self, matrix):\n \"\"\" Inicializa um vetor de tamanho size x size com zeros \"\"\"\n\n new_items = []\n for i in range(matrix.get_size().rows):\n row = []\n for j in range(matrix.get_size().cols):\n row.append([0] * self.channels_in_pixel)\n new_items.append(row)\n\n matrix.set_all(new_items)\n\n return True\n\n def set_item(self, matrix, i, j, value, debug = False):\n if debug:\n print(\"Verbosing\", i, j, \"with value =\", value, \"having\", matrix.get_size().rows, matrix.get_size().cols)\n if len(value) != self.channels_in_pixel:\n raise NameError(\"WrongChannelsCount\")\n # Limita a range possível de acordo com o tamanho da matriz\n if 0 <= j < matrix.get_size().cols and 0 <= i < matrix.get_size().rows:\n matrix.get_all()[i][j] = value\n return True\n\n raise NameError(\"IndexOutOfRange\")\n return False\n\n def add(self, matrix, added_matrix):\n if matrix.get_size().rows != added_matrix.get_size().rows or matrix.get_size().cols != added_matrix.get_size().cols:\n print(\"Impossível adicionar: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n added_pixel = added_matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n if pixel[channel] + added_pixel[channel] >= matrix.get_limit():\n pixel[channel] = matrix.get_limit()\n else:\n pixel[channel] = pixel[channel] + added_pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def sub(self, matrix, subtracted_matrix):\n if matrix.get_size().rows != subtracted_matrix.get_size().rows or matrix.get_size().cols != subtracted_matrix.get_size().cols:\n print(\"Impossível subtrair: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n subtracted_pixel = subtracted_matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n print(pixel[channel], subtracted_pixel[channel])\n if pixel[channel] - subtracted_pixel[channel] <= 0:\n pixel[channel] = 0\n else:\n pixel[channel] = pixel[channel] - subtracted_pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def noise(self, matrix):\n \"\"\" Preenche a matriz com valores aleatórios \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = []\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel.append((int(random.randint(0, matrix.get_limit()))))\n matrix.set_item(i, j, pixel)\n\n return True\n\n def lighten(self, matrix, ammount):\n \"\"\" Clareia a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] += ammount\n if pixel[channel] > matrix.get_limit():\n has_image_loss = True\n pixel[channel] = matrix.get_limit()\n matrix.set_item(i, j, pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n return True\n\n def darken(self, matrix, ammount):\n \"\"\" Escurece a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] -= ammount\n if pixel[channel] < 0:\n has_image_loss = True\n pixel[channel] = 0\n matrix.set_item(i, j, pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n return True\n\n def invert(self, matrix):\n \"\"\" Inverte as cores de imagem \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] = matrix.get_limit() - pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def black_and_white(self, matrix):\n print(\"HA! IT WAS NEVER IMPLEMENTED FOR COLORED PPM IMAGES! SURPRISE!!!!\")\n return False\n\n def from_template(self, matrix, data):\n \"\"\" Carrega a matrix com os dados do template \"\"\"\n i = j = 0\n pixel = []\n for element in data:\n if len(pixel) == self.channels_in_pixel:\n matrix.set_item(i, j, pixel)\n if j == matrix.get_size().cols - 1:\n i += 1\n j = 0\n else:\n j += 1\n\n pixel = []\n pixel.append(int(element))\n"
},
{
"alpha_fraction": 0.5850746035575867,
"alphanum_fraction": 0.5870646834373474,
"avg_line_length": 26.16216278076172,
"blob_id": "6ca543bcf2feba9f3b201c1c0c370a2cfda5a245",
"content_id": "be913b0e9ef9e1a265661e676bc80831be711700",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1006,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 37,
"path": "/atividade02/ImageLoader.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "from loaders import PGMLoader, PPMLoader\nimport re\n\n\nclass ImageLoader:\n \"\"\"Carrega imagens pgm/ppm/pbm de acordo com sua extensão\"\"\"\n\n def __init__(self):\n pass\n\n def load(self, matrix, filename):\n loader = self.__find_strategy(filename)\n matrix_template = None\n if loader:\n matrix_template = loader.load(filename)\n\n matrix.from_template(matrix_template)\n\n def write(self, matrix, filename):\n loader = self.__find_strategy(filename)\n matrix_template = None\n if loader:\n matrix_template = loader.write(matrix, filename)\n\n def __find_strategy(self, filename):\n filename = filename.lower()\n ext = re.findall(\"\\.(\\w+)$\", filename)\n if not ext:\n raise NameError(\"Malformed Filename\")\n\n if ext[0].lower() == \"pgm\":\n return PGMLoader()\n elif ext[0].lower() == \"ppm\":\n return PPMLoader()\n\n raise NameError(\"Format Unknown\")\n return None\n"
},
{
"alpha_fraction": 0.343137264251709,
"alphanum_fraction": 0.3660130798816681,
"avg_line_length": 14.300000190734863,
"blob_id": "bb8a2677920b8184422b8ec980c8760f96a1e7bd",
"content_id": "9734551347c3458600990f05d04382891c527f95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 20,
"path": "/teste.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "x = int(input(\"Insira a largura \"))\ny = int(input(\"Insira a altura \"))\n\na = 1\nb = 1\n\nwhile b <= y:\n while a <=x:\n\n if b == 1 or b == y or a == 1 or a == x:\n print(\"# \", end = \"\")\n else:\n print (\" \", end =\"\")\n\n a = a + 1\n\n\n b = b + 1\n a = 1\n print ()\n"
},
{
"alpha_fraction": 0.531406581401825,
"alphanum_fraction": 0.533737301826477,
"avg_line_length": 39.66824722290039,
"blob_id": "957b606d1aaba19e3d6a3ade1260056f5b86fc85",
"content_id": "bc4906e2e95029fbee24c645838d60e5cf79b8c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8593,
"license_type": "permissive",
"max_line_length": 188,
"num_lines": 211,
"path": "/atividade02/PPMMatrix.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "import random\nimport copy\nimport re\nfrom PGMMatrixInterface import PGMMatrixInterface\n\nclass PPMMatrix():\n\n\n def __init__(self):\n # Quantidade de canais por pixel\n self.channels_in_pixel = 3\n\n def __str__(self):\n return self.__class__.__name__\n\n def str(self, matrix):\n if matrix.get_size().rows == matrix.get_size().cols == 0:\n return \"Matrix is empty! (0x0)\"\n s = \" Matrix is %d rows by %d cols\\n\" % (matrix.get_size().rows, matrix.get_size().cols)\n s += \" Matrix has %d channels\\n\\n\" % (self.channels_in_pixel)\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n for channel in range(self.channels_in_pixel):\n s += \" \" + str(pixel[channel])\n s += \"|\"\n s += \"\\n\"\n\n return s\n\n def init(self, matrix):\n \"\"\" Inicializa um vetor de tamanho size x size com zeros \"\"\"\n\n new_items = []\n for i in range(matrix.get_size().rows):\n row = []\n for j in range(matrix.get_size().cols):\n row.append([0] * self.channels_in_pixel)\n new_items.append(row)\n\n matrix.set_all(new_items)\n\n return True\n\n def set_item(self, matrix, i, j, value, debug = False):\n if debug:\n print(\"Verbosing\", i, j, \"with value =\", value, \"having\", matrix.get_size().rows, matrix.get_size().cols)\n if len(value) != self.channels_in_pixel:\n raise NameError(\"WrongChannelsCount\")\n # Limita a range possível de acordo com o tamanho da matriz\n if 0 <= j < matrix.get_size().cols and 0 <= i < matrix.get_size().rows:\n matrix.get_all()[i][j] = value\n return True\n\n raise NameError(\"IndexOutOfRange\")\n return False\n\n def add(self, matrix, added_matrix):\n if matrix.get_size().rows != added_matrix.get_size().rows or matrix.get_size().cols != added_matrix.get_size().cols:\n print(\"Impossível adicionar: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n added_pixel = added_matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n if pixel[channel] + added_pixel[channel] >= matrix.get_limit():\n pixel[channel] = matrix.get_limit()\n else:\n pixel[channel] = pixel[channel] + added_pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def sub(self, matrix, subtracted_matrix):\n if matrix.get_size().rows != subtracted_matrix.get_size().rows or matrix.get_size().cols != subtracted_matrix.get_size().cols:\n print(\"Impossível subtrair: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n subtracted_pixel = subtracted_matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n print(pixel[channel], subtracted_pixel[channel])\n if pixel[channel] - subtracted_pixel[channel] <= 0:\n pixel[channel] = 0\n else:\n pixel[channel] = pixel[channel] - subtracted_pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def noise(self, matrix):\n \"\"\" Preenche a matriz com valores aleatórios \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = []\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel.append((int(random.randint(0, matrix.get_limit()))))\n matrix.set_item(i, j, pixel)\n\n return True\n\n def lighten(self, matrix, ammount):\n \"\"\" Clareia a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] += ammount\n if pixel[channel] > matrix.get_limit():\n has_image_loss = True\n pixel[channel] = matrix.get_limit()\n matrix.set_item(i, j, pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n return True\n\n def darken(self, matrix, ammount):\n \"\"\" Escurece a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] -= ammount\n if pixel[channel] < 0:\n has_image_loss = True\n pixel[channel] = 0\n matrix.set_item(i, j, pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n return True\n\n def invert(self, matrix):\n \"\"\" Inverte as cores de imagem \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n # Varre cada canal do pixel\n for channel in range(self.channels_in_pixel):\n pixel[channel] = matrix.get_limit() - pixel[channel]\n matrix.set_item(i, j, pixel)\n\n return True\n\n def black_and_white(self, matrix):\n print(\"HA! IT WAS NEVER IMPLEMENTED FOR COLORED PPM IMAGES! SURPRISE!!!!\")\n return False\n\n def decompose(self, matrix, matrix_template):\n \"\"\" Decompõe os canais de uma imagem PPM em imagens PGM \"\"\"\n channels = []\n for i in range(self.channels_in_pixel):\n channels.append(copy.deepcopy(matrix_template))\n for channel in channels:\n channel.set_format('P2')\n channel.set_limit(matrix.get_limit())\n channel.set_size(matrix.get_size().rows, matrix.get_size().cols)\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = matrix.get_item(i, j)\n for c in range(self.channels_in_pixel):\n channels[c].set_item(i, j, pixel[c])\n\n filename = re.findall(\"(.+)\\.\\w+$\", matrix.get_filename())[0]\n rgb = ['B', 'G', 'R']\n for channel in channels:\n channel.write_to_file(filename + rgb.pop() + \".pgm\")\n\n def compose_from_pgm(self, matrix, matrix_r, matrix_g, matrix_b):\n if not (matrix_r.get_size().rows == matrix_g.get_size().rows == matrix_b.get_size().rows) or not (matrix_r.get_size().cols == matrix_g.get_size().cols == matrix_b.get_size().cols):\n print(\"Imagens PGM são de tamanhos diferentes!\")\n\n matrix.set_format('P3')\n matrix.set_limit(matrix_r.get_limit())\n matrix.set_size(matrix_r.get_size().rows, matrix_r.get_size().cols)\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n pixel = [matrix_r.get_item(i, j), matrix_g.get_item(i, j), matrix_b.get_item(i, j)]\n matrix.set_item(i, j, pixel)\n\n print(\"new PPM composed from \" + matrix_r.get_filename() + \", \" + matrix_g.get_filename() + \", \" + matrix_b.get_filename() + \".\")\n print(\"call write_to_file() to save it\")\n\n def from_template(self, matrix, data):\n \"\"\" Carrega a matrix com os dados do template \"\"\"\n i = j = 0\n pixel = []\n for element in data:\n if len(pixel) == self.channels_in_pixel:\n matrix.set_item(i, j, pixel)\n if j == matrix.get_size().cols - 1:\n i += 1\n j = 0\n else:\n j += 1\n\n pixel = []\n pixel.append(int(element))\n"
},
{
"alpha_fraction": 0.7235188484191895,
"alphanum_fraction": 0.7558348178863525,
"avg_line_length": 29.94444465637207,
"blob_id": "1442684cf94064187f7bf8abf072ccbbfa9cdeb0",
"content_id": "edbbc39452d4f45a071c58fae744b79af97645ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 562,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 18,
"path": "/README.md",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "# PDI\nExercícios para a disciplina de PDI (Processamento Digital de Imagens) na FCT Unesp.\n\n## Atividade01\nReferente a Atividade 01 do Classroom, na pasta `atividade01/`.\n\n### Para testar\nPara testar o processamento de imagens PGM e PPM, execute o seguinte comando na pasta `atividade01/`\n\n```python3 main.py```\n\n## Atividade02\nReferente a Atividade 02 do Classroom, na pasta `atividade02/`.\n\n### Para testar\nPara testar a decomposição e recomposição de imagens PPM em PGM e vice versa, use o seguinte comando na pasta `atividade02/`\n\n```python3 main.py```\n"
},
{
"alpha_fraction": 0.5338797569274902,
"alphanum_fraction": 0.5377049446105957,
"avg_line_length": 37.39160919189453,
"blob_id": "91e6dba41aa1b6adc68f408df5f6aae9286f7388",
"content_id": "34cbace9dc85a854dd8dda65e6bd7db8a9abc24d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5500,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 143,
"path": "/atividade01/PGMMatrix.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "import random\nfrom PGMMatrixInterface import PGMMatrixInterface\n\n\nclass PGMMatrix(PGMMatrixInterface):\n\n\n def __init__(self):\n pass\n\n def __str__(self):\n return self.__class__.__name__\n\n def str(self, matrix):\n if matrix.get_size().rows == matrix.get_size().cols == 0:\n return \"Matrix is empty! (0x0)\"\n s = \" Matrix is %d rows by %d cols\\n\\n\" % (matrix.get_size().rows, matrix.get_size().cols)\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n s += \" %3d\" % matrix.get_item(i, j)\n s += \"\\n\"\n\n return s\n\n def init(self, matrix):\n \"\"\" Inicializa um vetor de tamanho size x size com zeros \"\"\"\n\n new_items = []\n for i in range(matrix.get_size().rows):\n row = []\n for j in range(matrix.get_size().cols):\n row.append(0)\n new_items.append(row)\n\n matrix.set_all(new_items)\n\n return True\n\n def set_item(self, matrix, i, j, value, debug = False):\n if debug:\n print(\"Verbosing\", i, j, \"with value =\", value, \"having\", matrix.get_size().rows, matrix.get_size().cols)\n # Limita a range possível de acordo com o tamanho da matriz\n if 0 <= j < matrix.get_size().cols and 0 <= i < matrix.get_size().rows:\n matrix.get_all()[i][j] = int(value)\n return True\n\n raise NameError(\"IndexOutOfRange\")\n return False\n\n def add(self, matrix, added_matrix):\n if matrix.get_size().rows != added_matrix.get_size().rows or matrix.get_size().cols != added_matrix.get_size().cols:\n print(\"Impossível adicionar: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n if matrix.get_item(i, j) + added_matrix.get_item(i, j) >= matrix.get_limit():\n matrix.set_item(i, j, matrix.get_limit())\n else:\n matrix.set_item(i, j, matrix.get_item(i, j) + added_matrix.get_item(i, j))\n\n return True\n\n def sub(self, matrix, subtracted_matrix):\n if matrix.get_size().rows != subtracted_matrix.get_size().rows or matrix.get_size().cols != subtracted_matrix.get_size().cols:\n print(\"Impossível subtrair: matrizes de tamanhos diferentes!\")\n return False\n\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n if matrix.get_item(i, j) - subtracted_matrix.get_item(i, j) <= 0:\n matrix.set_item(i, j, 0)\n else:\n matrix.set_item(i, j, matrix.get_item(i, j) - subtracted_matrix.get_item(i, j))\n\n return True\n\n def noise(self, matrix):\n \"\"\" Preenche a matriz com valores aleatórios \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n matrix.set_item(i, j, random.randint(0, matrix.get_limit()))\n\n def lighten(self, matrix, ammount):\n \"\"\" Clareia a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n new_value_for_pixel = matrix.get_item(i, j) + ammount\n if new_value_for_pixel > matrix.get_limit():\n has_image_loss = True\n new_value_for_pixel = matrix.get_limit()\n\n matrix.set_item(i, j, new_value_for_pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n def darken(self, matrix, ammount):\n \"\"\" Escurece a imagem de acordo com o valor de ammount \"\"\"\n has_image_loss = False\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n new_value_for_pixel = matrix.get_item(i, j) - ammount\n if new_value_for_pixel < 0:\n has_image_loss = True\n new_value_for_pixel = 0\n\n matrix.set_item(i, j, new_value_for_pixel)\n if has_image_loss:\n print(\"Possível perda de definição da imagem.\")\n\n def black_and_white(self, matrix):\n \"\"\" Transforma a Imagem em Preto e Branco \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n if matrix.get_item(i, j) < matrix.get_limit() // 2:\n new_value_for_pixel = 0\n else:\n new_value_for_pixel = matrix.get_limit()\n\n matrix.set_item(i, j, new_value_for_pixel)\n matrix.set_limit(1)\n\n def invert(self, matrix):\n \"\"\" Inverte as cores de imagem \"\"\"\n for i in range(matrix.get_size().rows):\n for j in range(matrix.get_size().cols):\n new_value_for_pixel = matrix.get_limit() - matrix.get_item(i, j)\n if new_value_for_pixel < 0:\n new_value_for_pixel = matrix.get_limit()\n\n matrix.set_item(i, j, new_value_for_pixel)\n\n def from_template(self, matrix, data):\n \"\"\" Carrega a matrix com os dados do template \"\"\"\n i = j = 0\n for element in data:\n matrix.set_item(i, j, element)\n if j == matrix.get_size().cols - 1:\n i += 1\n j = 0\n else:\n j += 1\n"
},
{
"alpha_fraction": 0.5985401272773743,
"alphanum_fraction": 0.5985401272773743,
"avg_line_length": 16.489360809326172,
"blob_id": "f5112298223bd9f63f0623f8e59fb5ac4232e2f5",
"content_id": "55b0df86ecaad5a554ad0f87997bf601bc5ddd5e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 47,
"path": "/atividade01/PGMMatrixInterface.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\n\nclass PGMMatrixInterface(ABC):\n\n def __init__():\n pass\n\n @abstractmethod\n def init(self, matrix):\n pass\n\n @abstractmethod\n def str(self, matrix):\n pass\n\n @abstractmethod\n def set_item(self, matrix, i, j, value, debug = False):\n pass\n\n @abstractmethod\n def add(self, matrix, added_matrix):\n pass\n\n @abstractmethod\n def sub(self, matrix, subtracted_matrix):\n pass\n\n @abstractmethod\n def noise(self, matrix):\n pass\n\n @abstractmethod\n def lighten(self, matrix, ammount):\n pass\n\n @abstractmethod\n def darken(self, matrix, ammount):\n pass\n\n @abstractmethod\n def black_and_white(self, matrix):\n pass\n\n @abstractmethod\n def invert(self, matrix):\n pass\n"
},
{
"alpha_fraction": 0.5716586112976074,
"alphanum_fraction": 0.5754830837249756,
"avg_line_length": 28.571428298950195,
"blob_id": "0cf63cd508ed33186f286928f4d1abe13a2b875f",
"content_id": "5756d3578ed81cc37c37de5a5aadf96afb15eb67",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4981,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 168,
"path": "/atividade02/Matrix.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "import random\nfrom ImageLoader import ImageLoader\nfrom PGMMatrix import PGMMatrix\nfrom PPMMatrix import PPMMatrix\n\n\nclass Size:\n \"\"\"Representa as dimensões da matriz que armazena os dados da imagem\"\"\"\n\n def __init__(self, rows = 0, cols = 0):\n self.rows = rows\n self.cols = cols\n\n\nclass Matrix:\n \"\"\"Classe que consegue armazenar uma imagem pgm/ppm/pbm e processá-la\"\"\"\n\n def __init__(self, filename = ''):\n self.__filename = filename\n self.__items = []\n self.__size = Size()\n self.__limit = False\n self.__format = 'P2'\n\n # TODO: melhorar o valor-padrão\n self.__strategy = PGMMatrix()\n\n if filename != '':\n self.load_from_file(filename)\n else:\n self.__strategy.init(self)\n\n def __str__(self):\n return self.__strategy.str(self)\n\n def get_all(self):\n \"\"\" Retorna todo o vetor de itens \"\"\"\n return self.__items\n\n def set_all(self, value):\n \"\"\" Seta o valor total para items \"\"\"\n self.__items = value\n\n def get_limit(self):\n return self.__limit\n\n def get_filename(self):\n return self.__filename\n\n def set_limit(self, value):\n self.__limit = int(value)\n\n def set_filename(self, value):\n self.__filename = value\n\n def get_format(self):\n return self.__format\n\n def set_format(self, value):\n self.__format = value\n # Determina qual strategy será usada para processar a imagem\n if value == 'P2':\n self._set_strategy(PGMMatrix());\n elif value == 'P3':\n self._set_strategy(PPMMatrix());\n\n def get_item(self, i, j):\n # Limita a range possível de acordo com o tamanho da matriz\n if 0 <= j < self.__size.cols and 0 <= i < self.__size.rows:\n return self.__items[i][j]\n\n return False\n\n\n def set_item(self, i, j, value, debug = False):\n self.__strategy.set_item(self, i, j, value, debug)\n\n def get_size(self):\n return self.__size\n\n def set_size(self, rows, cols):\n \"\"\"Altera as dimensões da imagem e reseta seus dados\"\"\"\n self.__size.rows = rows\n self.__size.cols = cols\n self.__strategy.init(self)\n\n def _set_strategy(self, strategy):\n print(\"Setting image-processing strategy to\", strategy)\n self.__strategy = strategy\n\n def add(self, matrix):\n self.__strategy.add(self, matrix)\n\n def sub(self, matrix):\n self.__strategy.sub(self, matrix)\n\n def noise(self):\n self.__strategy.noise(self)\n\n def lighten(self, ammount):\n self.__strategy.lighten(self, ammount)\n\n def darken(self, ammount):\n self.__strategy.darken(self, ammount)\n\n def black_and_white(self):\n self.__strategy.black_and_white(self)\n\n def invert(self):\n self.__strategy.invert(self)\n\n def decompose(self):\n # O segundo parâmetro é o modelo de Matrix aque será usado para exportar\n self.__strategy.decompose(self, Matrix())\n\n def compose_from_pgm(self, m1, m2, m3):\n if self.get_format() == 'P3':\n self.__strategy.compose_from_pgm(self, m1, m2, m3)\n\n def rotate(self):\n \"\"\" Rotaciona a imagem 90 graus no sentido horário \"\"\"\n # TODO: criar uma instância melhor de Matrix()\n new_matrix = Matrix()\n new_matrix.set_size(self.get_size().cols, self.get_size().rows)\n new_matrix.set_format(self.get_format())\n if self.get_limit():\n new_matrix.set_limit(self.get_limit())\n\n for i in range(self.get_size().rows):\n for j in range(self.get_size().cols):\n new_matrix.set_item(j, self.get_size().rows - 1 - i, self.get_item(i, j))\n\n self.set_size(new_matrix.get_size().rows, new_matrix.get_size().cols)\n self.set_all(new_matrix.get_all())\n\n def load_from_file(self, filename):\n \"\"\" Carrega os dados de um arquivo usando o loader strategy designado \"\"\"\n\n loader = ImageLoader()\n loader.load(self, filename)\n\n def write_to_file(self, filename):\n \"\"\" Salva os dados em um arquivo usando o loader strategy designado \"\"\"\n\n loader = ImageLoader()\n loader.write(self, filename)\n\n def from_template(self, matrix_template):\n \"\"\"\n Atualiza uma matriz com dados de uma matriz modelo no formato\n matrix_template = {\n 'format': '',\n 'width': 0,\n 'height': 0,\n 'limit': False,\n 'data': []\n }\n \"\"\"\n self.set_format(matrix_template['format'])\n\n if matrix_template['limit']:\n self.set_limit(matrix_template['limit'])\n self.get_size().rows = int(matrix_template['height'])\n self.get_size().cols = int(matrix_template['width'])\n\n # zera a situação da Matrix\n self.__strategy.init(self)\n self.__strategy.from_template(self, matrix_template['data'])\n"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.7352150678634644,
"avg_line_length": 27.615385055541992,
"blob_id": "0b53a31a6a262cd52eae31f40ed21c0a422370d6",
"content_id": "71e563512f9a0cbc5db333db26585f318c0e983b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 749,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 26,
"path": "/atividade02/main.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "from Matrix import *\nimport copy\n\n# Carregando a imagem amarelao.ppm para decomposição\na = Matrix(\"images/amarelao.ppm\")\na.decompose()\n\n# Declara imagem PPM que será reconstruída\nz = Matrix()\n# Seta o formato de z como PPM\nz.set_format('P3')\n\n# Carrega um PGM para cada canal RGB\nr = Matrix(\"images/amarelaoR.pgm\")\ng = Matrix(\"images/amarelaoG.pgm\")\nb = Matrix(\"images/amarelaoB.pgm\")\n\n# Compõe uma imagem PPM usando as PGM como canais\nz.compose_from_pgm(r, g, b)\nz.write_to_file(\"images/recomposed_01.ppm\")\n# Embaralha os canais para ver o que acontece\nz.compose_from_pgm(g, b, r)\nz.write_to_file(\"images/recomposed_02.ppm\")\n# Embaralha os canais para ver o que acontece\nz.compose_from_pgm(b, r, g)\nz.write_to_file(\"images/recomposed_03.ppm\")\n"
},
{
"alpha_fraction": 0.7263279557228088,
"alphanum_fraction": 0.7482678890228271,
"avg_line_length": 27.866666793823242,
"blob_id": "8f3054238bdad15eaa33a6ae280c57a82095c0df",
"content_id": "224f4ba09356baee0291d03f77b7d33976cb834f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 874,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 30,
"path": "/atividade01/main.py",
"repo_name": "chinaglia-rafa/PDI",
"src_encoding": "UTF-8",
"text": "from Matrix import *\nimport copy\n\n# Carregando a imagem lena640x480.pgm para testar arquivos PGM\na = Matrix(\"images/lena640x480.pgm\")\n# Testa a rotação\nfor i in range(4):\n a.rotate()\n# Escurece a imagem\na.darken(50)\n# Clareia a imagem para voltar ao estado anterior\na.lighten(50)\n# Leva os valores dos pixels para os extremos de acordo com a metade do limite\na.black_and_white()\n# Escreve um arquivo pgm\na.write_to_file('images/new.pgm')\n# Carrega um arquivo PPM\nb = Matrix(\"images/amarelao.ppm\")\n# Copia o objeto para ser destruído usando o método noise()\nc = copy.deepcopy(b)\n# Destroi todos os pixels, substituindo todos os valores dos canais por valores aleatórios\nc.noise()\n# Inverte as cores\nb.invert()\n# Adiciona um Noise Filter à imagem PPM\nb.add(c)\n# Rotaciona 90° em sentido horário\nb.rotate()\n# Escreve um arquivo PPM\nb.write_to_file('images/new.ppm')\n"
}
] | 11 |
Nicolae77/even-odd
|
https://github.com/Nicolae77/even-odd
|
07436421ad9edb1633e338660d7e3aa8f0010956
|
ce53e19da4a29b3aaaa6b706baacc81b2c87f786
|
4ac3f84c6e4624ccc247d9b042af048974cbf984
|
refs/heads/main
| 2023-04-20T08:21:44.545069 | 2021-05-10T17:06:07 | 2021-05-10T17:06:07 | 366,117,755 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5446224212646484,
"alphanum_fraction": 0.549199104309082,
"avg_line_length": 31.615385055541992,
"blob_id": "dfbdde71149183a3aadd321d435286af00fd59cf",
"content_id": "50995cfffe15878b25cf66741db65c5507a49393",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 13,
"path": "/even odd number/even odd.py",
"repo_name": "Nicolae77/even-odd",
"src_encoding": "UTF-8",
"text": "\r\nwhile True:\r\n number = int(input(\"Enter the number:\\n\"))\r\n if number % 2 == 0:\r\n print(\"This is even number.\")\r\n else:\r\n print(\"This is odd number\")\r\n continue_check = input(\"Would you like to continue? type 'y', if not 'e' to exit:\\n\")\r\n if continue_check == 'y':\r\n continue\r\n elif continue_check == 'e':\r\n break\r\n else:\r\n print(\"You should type 'y' to continue or 'e' to exit\")"
}
] | 1 |
Spiderixius/SEoMS_Assignments
|
https://github.com/Spiderixius/SEoMS_Assignments
|
44d3be7fcc177cbcaf6003486164f8d21d2b2a4c
|
577ee12002d140af3e466e968986c125d7c62262
|
04e39a0ac40d118be3cc5150bf97d1f9daf4e414
|
refs/heads/master
| 2021-05-08T14:08:02.491960 | 2018-02-03T08:42:07 | 2018-02-03T08:42:07 | 120,069,690 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6580311059951782,
"alphanum_fraction": 0.6717246770858765,
"avg_line_length": 29.704545974731445,
"blob_id": "661acf03baff5c0997e91558e313388822f68631",
"content_id": "41a26c798feedbe1c45e41cc004bc42ba903632f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2702,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 88,
"path": "/SEoMS_Assignment_3/Assignment3_python.py",
"repo_name": "Spiderixius/SEoMS_Assignments",
"src_encoding": "UTF-8",
"text": "import csv\nimport folium\nimport numpy as np\n\n\n# Data types\nwalkingPoints = []\nrunningPoints = []\nbikingPoints = []\ndrivingPoints = []\n\n\n\npath = \"/home/spider/Documents/mobileSystems/Assignment3/mobileCSVData/\"\n\n# Reading from the .csv file\nwith open(path+\"Running.csv\") as csvfile:\n rdr = csv.reader( csvfile )\n for i, row in enumerate( rdr ):\n if i == 0: continue # Skip column titles\n lat, lon= row[3:5]\n runningPoints.append(tuple([float(lat), float(lon)]))\n\nwith open(path+\"Driving.csv\") as csvfile:\n rdr = csv.reader( csvfile )\n for i, row in enumerate( rdr ):\n if i == 0: continue # Skip column titles\n lat, lon= row[3:5]\n drivingPoints.append(tuple([float(lat), float(lon)]))\n\nwith open(path+\"Biking.csv\") as csvfile:\n rdr = csv.reader( csvfile )\n for i, row in enumerate( rdr ):\n if i == 0: continue # Skip column titles\n lat, lon= row[3:5]\n bikingPoints.append(tuple([float(lat), float(lon)]))\n\nwith open(path+\"Walking.csv\") as csvfile:\n rdr = csv.reader( csvfile )\n for i, row in enumerate( rdr ):\n if i == 0: continue # Skip column titles\n lat, lon= row[3:5]\n walkingPoints.append(tuple([float(lat), float(lon)]))\n\nprint (len(walkingPoints))\nprint (walkingPoints)\n\n# Median and mean\nmedianPoints= []\nmeanPoints= []\nfor idx, val in enumerate(walkingPoints):\n range = walkingPoints[idx:idx + 10]\n latAr = [];\n lonAr= [];\n for i,j in range:\n latAr.append(i)\n lonAr.append(j)\n print(latAr)\n latMean = np.mean(latAr);\n lonMean = np.mean(lonAr);\n latMedian = np.median(latAr)\n lonMedian = np.median(lonAr)\n print (latMedian)\n medianPoints.append(tuple([float(latMedian), float(lonMedian)]))\n meanPoints.append(tuple([float(latMean), float(lonMean)]))\nprint (len(medianPoints))\n\nprint(walkingPoints)\nprint(medianPoints)\n\navg_lat = sum(p[0] for p in walkingPoints) / len(walkingPoints)\navg_lon = sum(p[1] for p in walkingPoints) / len(walkingPoints)\n\n# Load map centred on average coordinates\nfmap = folium.Map(location=[avg_lat, avg_lon], zoom_start=14)\n\n# Drawing of lines\nfolium.PolyLine(walkingPoints, color=\"red\", weight=2.5, opacity=1).add_to(fmap)\n# folium.PolyLine(medianPoints, color=\"blue\", weight=2.5, opacity=1).add_to(fmap)\n# folium.PolyLine(pointsMean, color=\"blue\", weight=2.5, opacity=1).add_to(fmap)\n\n# The other data types\nfolium.PolyLine(runningPoints, color=\"yellow\", weight=2.5, opacity=1).add_to(fmap)\nfolium.PolyLine(bikingPoints, color=\"black\", weight=2.5, opacity=1).add_to(fmap)\nfolium.PolyLine(drivingPoints, color=\"purple\", weight=2.5, opacity=1).add_to(fmap)\n\n# Save map\nfmap.save(path+\"allRawDataPlotted.html\")\n"
},
{
"alpha_fraction": 0.8016877770423889,
"alphanum_fraction": 0.8122363090515137,
"avg_line_length": 85.18181610107422,
"blob_id": "d876c83d5f7e922fd1e105ce72ac9fc959b6c1f2",
"content_id": "5578d67659052bba6172bc8d5bdcbbaab94e2cac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 440,
"num_lines": 11,
"path": "/README.md",
"repo_name": "Spiderixius/SEoMS_Assignments",
"src_encoding": "UTF-8",
"text": "# SEoMS_Assignments\n[Software Engineering of Mobile Systems](https://fagbesk.sam.sdu.dk/?fag_id=38402) assignments. Contains only those assignments that required code.\n\n# About\nThis course revolved around advanced topics in software architecture for development of mobile systems. Mobile sensing systems and applications. Methods for addressing energy efficiency and resource adaptability challenges in mobile systems. Methods for incremental and iterative development of mobile systems. Performance testing of mobile systems. In total ten assignments were completed (all approved) that helped understand the course. \n\n# How to Run\n## Android projects (Assignment 1, 4 and 6)\nSimply load the android projects into Android Studio. \n## Python (Assignment 3)\nLoad the Assignment3_python.py file into your favourite editor. You will also have to change the \"path\" variable within the .py file to match with whereever you have extracted the assignment.\n"
},
{
"alpha_fraction": 0.6899695992469788,
"alphanum_fraction": 0.6960486173629761,
"avg_line_length": 25.675676345825195,
"blob_id": "1b1f4e129c69415641a2b8165ab20652dbc8720e",
"content_id": "548f6406d143094a6158666d4029e41a651a3d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 37,
"path": "/SEoMS_Assignment_1/app/src/main/java/com/admur13/spider/assignment_1_admur13/MainActivity.java",
"repo_name": "Spiderixius/SEoMS_Assignments",
"src_encoding": "UTF-8",
"text": "package com.admur13.spider.assignment_1_admur13;\n\nimport android.content.Intent;\nimport android.os.Bundle;\nimport android.support.v7.app.AppCompatActivity;\nimport android.view.View;\n\npublic class MainActivity extends AppCompatActivity {\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_main);\n }\n\n public void accelerometer(View view) {\n Intent intent = new Intent(this, Accelerometer.class);\n startActivity(intent);\n }\n\n public void compass(View view) {\n Intent intent = new Intent(this, Compass.class);\n startActivity(intent);\n }\n\n public void listOfSensors(View view) {\n Intent intent = new Intent(this, ListOfSensors.class);\n startActivity(intent);\n }\n\n public void locationTracker(View view) {\n Intent intent = new Intent(this, RetrieveCurrentLocation.class);\n startActivity(intent);\n }\n\n\n}\n"
}
] | 3 |
pjentsch0/FlyerFlo_Internship_Application
|
https://github.com/pjentsch0/FlyerFlo_Internship_Application
|
cb89fec296c66faa2c40defde12ebfd2147c96d8
|
36ee0e20c5df4674547a7021808dbd353cf39692
|
1d0f50645685ca81c1c6c7c20e3626343ef80556
|
refs/heads/master
| 2020-03-03T12:41:41.548535 | 2013-04-21T03:53:22 | 2013-04-21T03:53:22 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6487376689910889,
"alphanum_fraction": 0.6542261242866516,
"avg_line_length": 31.535715103149414,
"blob_id": "9c86362bc2aab0afc1c10224e34086f205434fc5",
"content_id": "d8d6562b0e4deb6e36364ea144e46063187951ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 28,
"path": "/RedditAlienDownloadScript.py",
"repo_name": "pjentsch0/FlyerFlo_Internship_Application",
"src_encoding": "UTF-8",
"text": "#Reddit Alien Retrieval script by Peter Jentsch for my FlyerFlo application\n#I really like this way of testing students on their technical skills. Thanks for the opportunity.\n\n#Instructions:\n#Run script, enter full url as a string into console, press enter.\n#The image is saved in the local folder with the filename it has on the reddit server.\n#There is only very rudimentary input error handing.\n\nimport urllib\n\npfile = urllib.urlopen(input(\"enter web address:\"))\nf = \"\"\ntag = \"<img id='header-img' src=\"\nfor ln in pfile:\n idx = ln.find(tag)\n if (idx !=-1):\n nextQuote = ln.find(\"\\\"\",idx + len(tag)+1)\n f = ln[idx + len(tag)+1: nextQuote]\n stream = urllib.urlopen(f)\n img = stream.read()\n outfile = open(f[32:],\"wb\")\n outfile.write(img)\n outfile.close()\n stream.close()\n break;\nelse:\n print \"I don't think that was a reddit URL.\"\npfile.close()\n"
}
] | 1 |
DanFeldheim/NBA_playerTracking_analysis
|
https://github.com/DanFeldheim/NBA_playerTracking_analysis
|
953658893a95e7500e3cf44c72b8862fc499a3b7
|
ac9303911543bf37ed20bcfb18cb5f2f2c4dc8fe
|
0027962e79ea3c1114018fe064d40684408e324e
|
refs/heads/master
| 2023-01-23T21:22:00.819531 | 2020-12-07T21:44:39 | 2020-12-07T21:44:39 | 319,452,225 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7877697944641113,
"alphanum_fraction": 0.8039568066596985,
"avg_line_length": 110,
"blob_id": "4593736d143fffc752c11def7638eb3e6af846bc",
"content_id": "9fa594056e57f3facec36bcd6df958142a4b75b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 5,
"path": "/README.md",
"repo_name": "DanFeldheim/NBA_playerTracking_analysis",
"src_encoding": "UTF-8",
"text": "# NBA_playerTracking_analysis\n# These scripts and analysis were generated as part of the interview process for a position in the OKC Thunder \n# data analytics group. The objective was to analyze NBA player tracking data for approximately 500,000 plays\n# and create an algorithm that would predict the likelihood of the offense obtaining a rebound. The logloss\n# of this algorithm was 0.54, which the Thunder indicated was among the best of those received from the job ad. Please read the # reports included in this repository for details of the analysis. \n"
},
{
"alpha_fraction": 0.5670562982559204,
"alphanum_fraction": 0.5808060169219971,
"avg_line_length": 54.90676498413086,
"blob_id": "8926aa770668d27a49b42ec22d8c83efa01fdc82",
"content_id": "fa4cb2dce118ac0d41f95192b121e6f423addae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61165,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 1094,
"path": "/orebound_predictor11.py",
"repo_name": "DanFeldheim/NBA_playerTracking_analysis",
"src_encoding": "UTF-8",
"text": "# This program imports OKC Thunder player tracking rebounding data including player location and position data for >300,000 plays\n# Files are merged and cleaned, and then various parameters are calculated such as player distance and angle from basket,\n# how spread out the players are, how many offensive players are boxing out, number of players in restricted zone, etc.\n# Import file names are entered in the import_files function\n# This program has not been refactored! For a refactored version, see offensive_rebound_predictor_refactored2.py\n\n# Import packages\nimport pandas as pd\nimport numpy as np\nimport csv\nimport math\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn import metrics, cross_validation\nfrom sklearn.metrics import classification_report, confusion_matrix, log_loss\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import ListedColormap \nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import roc_curve\nfrom sklearn.model_selection import cross_val_score\nfrom numpy import median\n\n\nclass rebound:\n \n def __init__(self):\n pass\n \n def import_files(self):\n \n # Import data\n # Location data\n # Full set\n # OKC location data training set\n self.loc_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/training_data_loc.csv\", header = 0)\n \n # Small location development set\n # self.loc_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/10_22_20_loc_test_set.csv\", header = 0)\n \n # Clean up\n self.loc_df = self.loc_df.drop(self.loc_df.columns[0], axis = 1)\n # Change ' ft' to 'ft' in row_type column (i.e., remove the leading space as it prevents an accurate df merge below)\n self.loc_df = self.loc_df.replace(to_replace = \" ft\", value = \"ft\")\n \n # pbp data\n # Full set\n # OKC pbp training set\n self.pbp_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/training_data_pbp.csv\", header = 0)\n \n # Small pbp development set\n # self.pbp_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/10_22_20_pbp_test_set.csv\", header = 0)\n \n # Clean up\n self.pbp_df = self.pbp_df.drop(self.pbp_df.columns[0], axis = 1)\n self.pbp_df = self.pbp_df.drop(self.pbp_df.loc[:, 'reboffensive': 'eventdescription'].columns, axis = 1)\n \n # Change 'final ft' to ft in row_type column \n self.pbp_df = self.pbp_df.replace(to_replace = \"final ft\", value = \"ft\")\n \n # Position data\n self.player_pos_data_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/player_pos_data.csv\", header = 0)\n # Clean up\n self.player_pos_data_df = self.player_pos_data_df.drop(self.player_pos_data_df.columns[[0, 3]], axis = 1)\n \n # Rebounding data\n self.player_reb_data_df = pd.read_csv(\"/Users/danfeldheim/Documents/OKC_project/player_reb_data.csv\", header = 0)\n # Clean up\n self.player_reb_data_df = self.player_reb_data_df.drop(self.player_reb_data_df.columns[0], axis = 1)\n \n return self.loc_df, self.pbp_df, self.player_pos_data_df, self.player_reb_data_df\n \n \n def merge(self):\n \n # Merge self.loc_df and self.pbp_df on playbyplayorder_id\n self.pbp_loc_merged_df = pd.merge(self.loc_df, self.pbp_df, on = [\"playbyplayorder_id\", \"row_type\", \"game_id\"])\n \n \"\"\"\n # Inspect the data\n print (a.info())\n self.pbp_loc_merged_df.hist(bins = 50, figsize = (20, 15))\n plt.show()\n \"\"\"\n \n return self.pbp_loc_merged_df\n \n \n def prep(self):\n\n # Remove rows that have NA in the oreb column. Presumably these are team rebounds, out of bounds, fouls, makes, etc.\n self.pbp_loc_merged_df = self.pbp_loc_merged_df.dropna(subset = [\"oreb\"]).reset_index(drop = True)\n \n # Remove rows in which the shot was a free throw as these are almost never rebounded by the offense and player positions are fixed\n # 174,141 rows remaining\n self.pbp_loc_merged_df = self.pbp_loc_merged_df[~self.pbp_loc_merged_df.row_type.str.contains('ft').reset_index(drop = True)]\n \n # Convert Yes to 1 and No to 0 in oreb column\n self.pbp_loc_merged_df['oreb'] = self.pbp_loc_merged_df['oreb'].str.replace('Yes','1')\n self.pbp_loc_merged_df['oreb'] = self.pbp_loc_merged_df['oreb'].str.replace('No','0')\n \n # Change oreb from string to int\n self.pbp_loc_merged_df['oreb'] = self.pbp_loc_merged_df['oreb'].astype(int) \n \n # Make changes in actiondescription columns\n # If including free throws\n # self.pbp_df[\"actiondescription\"] = self.pbp_df[\"actiondescription\"].apply(lambda x: 'jump_shot' if 'Jump' in x else ('layup' if 'Layup' in x else ('free_throw' if 'Free' in x else ('other'))))\n # No free throws\n self.pbp_loc_merged_df[\"actiondescription\"] = self.pbp_loc_merged_df[\"actiondescription\"].apply(lambda x: 'jump_shot' if 'Jump' in x else ('layup' if 'Layup' in x else ('other'))) \n \n # Convert these to categories\n self.pbp_loc_merged_df[\"actiondescription\"] = self.pbp_loc_merged_df[\"actiondescription\"].astype('category')\n # Convert categories to dummy numbers (adds a new column with codes: other = 2, layup = 1, jumpshot = 0)\n self.pbp_loc_merged_df[\"actiondescription_dummy\"] = self.pbp_loc_merged_df[\"actiondescription\"].cat.codes\n \n \n return self.pbp_loc_merged_df\n \n # Function to add player position data to the df if desired \n def player_pos_data(self):\n \n # Add player position data from self.player_pos_data_df\n # Start a counter to keep track of player column\n self.player_column = 1\n \n # Get column number for playerid_off_player_1 for use as a counter to move through player columns\n self.column_counter = self.pbp_loc_merged_df.columns.get_loc(\"playerid_off_player_1\")\n # Adding 1 for use with itertuples, which counts column index values differently for some reason\n self.column_counter = self.column_counter + 1 \n \n # While loop to move through player columns until all 10 player positions have been found\n while self.player_column <= 10:\n # Use counter to create the appropriate column names for the positions of all 10 players\n # If statement so that when self.player_column > 5, self.player_column is reset to 1 for the defensive players\n # Same when transitioning from offensive to defensive players\n if self.player_column <= 5:\n self.player = 'player_pos_off_player_' + str(self.player_column)\n \n else:\n self.player = 'player_pos_def_player_' + str(self.player_column)\n \n # Create a list for all of the player positions for all players in the current row\n # This list will be appended to self.pbp_loc_merged_df\n self.position_list = []\n \n # Loop through player_id rows\n for row in self.pbp_loc_merged_df.itertuples():\n \n self.player_id = row[self.column_counter]\n \n # Search id column of self.player_pos_data_df for match and return row \n self.player_row = self.player_pos_data_df[self.player_pos_data_df['player_id'] == self.player_id]\n \n # Retreive player position\n self.player_pos = int(self.player_row.iloc[0]['position'])\n \n # Append self.player_pos to self.position_list\n self.position_list.append(self.player_pos)\n \n # Append self.position_list to self.pbp_loc_merged_df\n self.pbp_loc_merged_df[self.player] = self.position_list\n \n # Increment column counters\n self.player_column += 1\n self.column_counter += 1\n \n\n return self.pbp_loc_merged_df\n \n \n def distance_from_hoop(self):\n \n # Calculate the distance of every player from the basket when the shot was taken and when it hit the rim\n # Create a new df \n # Add parameters to this df as desired\n self.pbp_loc_player_distance_df = self.pbp_loc_merged_df[[\"playbyplayorder_id\", \n \"AtRim_loc_x_off_player_1\", \"AtRim_loc_y_off_player_1\", \"AtRim_loc_x_off_player_2\", \"AtRim_loc_y_off_player_2\",\n \"AtRim_loc_x_off_player_3\", \"AtRim_loc_y_off_player_3\", \"AtRim_loc_x_off_player_4\", \"AtRim_loc_y_off_player_4\", \n \"AtRim_loc_x_off_player_5\", \"AtRim_loc_y_off_player_5\", \"AtRim_loc_x_def_player_1\", \"AtRim_loc_y_def_player_1\", \n \"AtRim_loc_x_def_player_2\", \"AtRim_loc_y_def_player_2\", \"AtRim_loc_x_def_player_3\", \"AtRim_loc_y_def_player_3\", \n \"AtRim_loc_x_def_player_4\", \"AtRim_loc_y_def_player_4\", \"AtRim_loc_x_def_player_5\", \"AtRim_loc_y_def_player_5\",\n \"AtShot_loc_x_off_player_1\", \"AtShot_loc_y_off_player_1\", \"AtShot_loc_x_off_player_2\", \"AtShot_loc_y_off_player_2\", \n \"AtShot_loc_x_off_player_3\", \"AtShot_loc_y_off_player_3\", \"AtShot_loc_x_off_player_4\", \"AtShot_loc_y_off_player_4\",\n \"AtShot_loc_x_off_player_5\", \"AtShot_loc_y_off_player_5\", \"AtShot_loc_x_def_player_1\", \"AtShot_loc_y_def_player_1\", \n \"AtShot_loc_x_def_player_2\", \"AtShot_loc_y_def_player_2\", \"AtShot_loc_x_def_player_3\", \"AtShot_loc_y_def_player_3\", \n \"AtShot_loc_x_def_player_4\", \"AtShot_loc_y_def_player_4\", \"AtShot_loc_x_def_player_5\", \"AtShot_loc_y_def_player_5\", \"oreb\", \n 'playerid_off_player_1', 'playerid_off_player_2', 'playerid_off_player_3', 'playerid_off_player_4', 'playerid_off_player_5',\n 'playerid_def_player_1', 'playerid_def_player_2','playerid_def_player_3','playerid_def_player_4','playerid_def_player_5', \n 'actiondescription_dummy']]\n \n # Remove rows with NA in a location row\n # df is now 173744 rows long; still plenty of data\n self.pbp_loc_player_distance_df = self.pbp_loc_player_distance_df.dropna(subset = [\"AtRim_loc_x_off_player_1\", \n \"AtRim_loc_y_off_player_1\", \"AtRim_loc_x_off_player_2\", \"AtRim_loc_y_off_player_2\",\"AtRim_loc_x_off_player_3\", \n \"AtRim_loc_y_off_player_3\", \"AtRim_loc_x_off_player_4\", \"AtRim_loc_y_off_player_4\", \"AtRim_loc_x_off_player_5\", \n \"AtRim_loc_y_off_player_5\", \"AtRim_loc_x_def_player_1\", \"AtRim_loc_y_def_player_1\", \"AtRim_loc_x_def_player_2\", \n \"AtRim_loc_y_def_player_2\", \"AtRim_loc_x_def_player_3\", \"AtRim_loc_y_def_player_3\", \"AtRim_loc_x_def_player_4\", \n \"AtRim_loc_y_def_player_4\", \"AtRim_loc_x_def_player_5\", \"AtRim_loc_y_def_player_5\", \"AtShot_loc_x_off_player_1\", \n \"AtShot_loc_y_off_player_1\", \"AtShot_loc_x_off_player_2\", \"AtShot_loc_y_off_player_2\", \"AtShot_loc_x_off_player_3\", \n \"AtShot_loc_y_off_player_3\", \"AtShot_loc_x_off_player_4\", \"AtShot_loc_y_off_player_4\",\"AtShot_loc_x_off_player_5\", \n \"AtShot_loc_y_off_player_5\", \"AtShot_loc_x_def_player_1\", \"AtShot_loc_y_def_player_1\", \"AtShot_loc_x_def_player_2\", \n \"AtShot_loc_y_def_player_2\", \"AtShot_loc_x_def_player_3\", \"AtShot_loc_y_def_player_3\", \"AtShot_loc_x_def_player_4\", \n \"AtShot_loc_y_def_player_4\", \"AtShot_loc_x_def_player_5\", \"AtShot_loc_y_def_player_5\"])\n \n \n # Calculate distance from basket for every x-y pair (each player) using the pythagorean theorom. \n # Get column index of first x and y positions\n self.x_col = self.pbp_loc_player_distance_df.columns.get_loc(\"AtRim_loc_x_off_player_1\")\n self.y_col = self.pbp_loc_player_distance_df.columns.get_loc(\"AtRim_loc_y_off_player_1\") \n \n # Create counter for keeping track of column positions and naming new columns\n # Could fix this with a try/except, but its unlikely that the first data col will be 0\n self.x_index = 1\n \n # While loop to move through x-y pairs until all distances have been calculated\n # Note the last x column is 39 cols past the first; the last y column is 40 cols past the first (10 off + 10 def)* 2 coords each\n while self.x_index <= 39:\n # If statement to keep track of player numbers based upon self.x_index\n # Calculate player number\n self.player = 0.5*(self.x_index + 1)\n \n # If statement so that when self.x_index > 5, self.player is reset to 1 for the defensive players\n if self.player <= 5:\n self.player = 'AtRim_distance_off_player_' + str(self.player)\n \n elif 5 < self.player <= 10:\n self.player = 'AtRim_distance_def_player_' + str(self.player - 5)\n \n elif 10 < self.player <= 15:\n self.player = 'AtShot_distance_off_player_' + str(self.player - 10)\n \n else:\n self.player = 'AtShot_distance_def_player_' + str(self.player - 15)\n \n # Add the calculated distance for each x-y pair to the df as a new column\n self.pbp_loc_player_distance_df[self.player] = self.pbp_loc_player_distance_df.apply(lambda row: self.pythagorean\n (row[self.x_col], row[self.y_col]), axis = 1)\n \n # Increment x and y index values and columns\n self.x_index += 2\n # self.y_index += 2\n self.x_col += 2\n self.y_col += 2\n \n \n \"\"\"\n # Inspect the data\n # print (self.pbp_loc_player_distance_df.info())\n self.pbp_loc_player_distance_df.hist(bins = 50, figsize = (20, 15))\n plt.show()\n \"\"\"\n \n return self.pbp_loc_player_distance_df\n \n \n \n #---------------------------------------------------------------------------------------------- \n # Function to use with apply to caculate player distance from basket\n # Include 41.75 in the formula to reset the basket as the origin in the x-direction\n def pythagorean(self, a, b):\n \n return math.sqrt((a + 41.75)**2 + b**2)\n \n #----------------------------------------------------------------------------------------------\n \n \n # Functions to calculate the number of offensive and defensive players within x feet of rim (started with x = 6)\n def restricted_players(self):\n \n # Copy self.pbp_loc_rim_distance_df\n self.pbp_loc_player_distance_restricted_zone_df = self.pbp_loc_player_distance_df.copy()\n \n # Add the calculated number of offensive players in restricted zone when ball hits rim as new column\n self.pbp_loc_player_distance_restricted_zone_df['AtRim_restricted_off_players'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.AtRim_off_players_in_restricted_zone\n (row['AtRim_distance_off_player_1.0'], row['AtRim_distance_off_player_2.0'], row['AtRim_distance_off_player_3.0'], row['AtRim_distance_off_player_4.0'], row['AtRim_distance_off_player_5.0']), axis = 1)\n \n # Add the calculated number of defensive players in restricted zone when ball hits rim as new column\n self.pbp_loc_player_distance_restricted_zone_df['AtRim_restricted_def_players'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.AtRim_def_players_in_restricted_zone\n (row['AtRim_distance_def_player_1.0'], row['AtRim_distance_def_player_2.0'], row['AtRim_distance_def_player_3.0'], row['AtRim_distance_def_player_4.0'], row['AtRim_distance_def_player_5.0']), axis = 1)\n \n # Add the calculated number of offensive players in restricted zone when shot is taken as new column \n self.pbp_loc_player_distance_restricted_zone_df['AtShot_restricted_off_players'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.AtShot_off_players_in_restricted_zone\n (row['AtShot_distance_off_player_1.0'], row['AtShot_distance_off_player_2.0'], row['AtShot_distance_off_player_3.0'], row['AtShot_distance_off_player_4.0'], row['AtShot_distance_off_player_5.0']), axis = 1) \n \n # Add the calculated number of defensive players in restricted zone when shot is taken as new column \n self.pbp_loc_player_distance_restricted_zone_df['AtShot_restricted_def_players'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.AtShot_def_players_in_restricted_zone( \n row['AtShot_distance_def_player_1.0'], row['AtShot_distance_def_player_2.0'], row['AtShot_distance_def_player_3.0'], row['AtShot_distance_def_player_4.0'], row['AtShot_distance_def_player_5.0']), axis = 1) \n \n \n # Tested calculations and confirmed\n # self.pbp_loc_player_distance_restricted_zone_df.to_csv('/Users/danfeldheim/Documents/OKC_project/restricted_zone_test_df.csv') \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n \n #----------------------------------------------------------------------------------------------\n # Functions for use with apply in the calculation of number of players in restricted zone\n \n # Do calculation and return number of offensive and defensive players within x feet of rim\n # a-e represent offensive players; j-n represent defensive players\n def AtRim_off_players_in_restricted_zone(self, a, b, c, d, e):\n \n # Create a list of offensive and defensive player distances\n self.AtRim_off_player_dist_list = [a, b, c, d, e]\n \n # Create a counter for number of offensive defensive players in restricted zone\n self.AtRim_off = 0\n \n for entry in self.AtRim_off_player_dist_list:\n if entry < 6:\n self.AtRim_off += 1\n\n \n return float(self.AtRim_off)\n \n def AtRim_def_players_in_restricted_zone(self, j, k, l, m, n):\n \n # Create a list of offensive and defensive player distances\n self.AtRim_def_player_dist_list = [j, k, l, m, n]\n \n # Create a counter for number of offensive defensive players in restricted zone\n self.AtRim_def = 0\n \n for entry in self.AtRim_def_player_dist_list:\n if entry < 6:\n self.AtRim_def += 1\n \n return float(self.AtRim_def)\n \n \n def AtShot_off_players_in_restricted_zone(self, a, b, c, d, e):\n \n # Create a list of offensive and defensive player distances\n self.AtShot_off_player_dist_list = [a, b, c, d, e]\n \n # Create a counter for number of offensive defensive players in restricted zone\n self.AtShot_off = 0\n \n for entry in self.AtShot_off_player_dist_list:\n if entry < 6:\n self.AtShot_off += 1\n\n \n return float(self.AtShot_off)\n \n def AtShot_def_players_in_restricted_zone(self, j, k, l, m, n):\n \n # Create a list of offensive and defensive player distances\n self.AtShot_def_player_dist_list = [j, k, l, m, n]\n \n # Create a counter for number of offensive defensive players in restricted zone\n self.AtShot_def = 0\n \n for entry in self.AtShot_def_player_dist_list:\n if entry < 6:\n self.AtShot_def += 1\n \n return float(self.AtShot_def)\n \n #---------------------------------------------------------------------------------------------- \n \n # Calculate player angles\n def player_angles(self):\n \n # Calculate angle in degrees from basket for every x-y pair (each player) using the tangent formula: tan(theta) = Opposite/Adjacent = y coord/x coord. \n # Create counters to toggle through the x-y pairs (start at an index of 1 for AtRim_loc_x_off_player_1 and 2 for AtRim_loc_y_off_player_1)\n # Calculate distance from basket for every x-y pair (each player) using the pythagorean theorom. \n # Get column index of first x and y positions\n self.x_col = self.pbp_loc_player_distance_restricted_zone_df.columns.get_loc(\"AtRim_loc_x_off_player_1\")\n self.y_col = self.pbp_loc_player_distance_restricted_zone_df.columns.get_loc(\"AtRim_loc_y_off_player_1\")\n \n # Set x index to 1 for use as counter and new column names\n self.x_index = 1\n \n # While loop to move through x-y pairs until all angles have been calculated (note last x col is +39 from first x col)\n while self.x_index <= 39:\n # If statement to keep track of player numbers based upon self.x_index\n # Calculate player number\n self.player = 0.5*(self.x_index + 1)\n \n # If statement so that when self.x_index > 5, self.player is reset to 1 for the defensive players\n # Same when transitioning from offensive to defensive players\n if self.player <= 5:\n self.player = 'AtRim_angle_off_player_' + str(self.player)\n \n elif 5 < self.player <= 10:\n self.player = 'AtRim_angle_def_player_' + str(self.player - 5)\n \n elif 10 < self.player <= 15:\n self.player = 'AtShot_angle_off_player_' + str(self.player - 10)\n \n else:\n self.player = 'AtShot_angle_def_player_' + str(self.player - 15)\n \n \n self.pbp_loc_player_distance_restricted_zone_df[self.player] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.angle_calculator\n (row[self.x_col], row[self.y_col]), axis = 1)\n \n # Increment x and y index values\n self.x_index += 2\n self.x_col += 2\n self.y_col += 2\n \n # Tested and confirmed\n # self.pbp_loc_player_distance_restricted_zone_df.to_csv('/Users/danfeldheim/Documents/OKC_project/angle_test_df2.csv') \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n \n \n #---------------------------------------------------------------------------------------------- \n # Function for use with apply in the calculation of player angles\n \n def angle_calculator(self, a, b):\n \n return math.degrees(math.atan(b/a))\n \n #---------------------------------------------------------------------------------------------- \n \n # Function to calculate the variation coefficient for the distance of every player from the basket\n # Variation coefficient = (STDEV of distance from basket for offensive or defensive players)/mean distance from basket of offense or defense\n # Hypothesis: The ability to get a rebound depends upon the variation in distance of players from the basket\n # The same calculation will be done for player's distance from other players\n def distance_vc_from_basket(self):\n \n # Get first column index \n self.first_col = self.pbp_loc_player_distance_restricted_zone_df.columns.get_loc(\"AtRim_distance_off_player_1.0\")\n self.second_col = self.first_col + 1\n self.third_col = self.first_col + 2\n self.fourth_col = self.first_col + 3\n self.fifth_col = self.first_col + 4\n \n self.x_cntr = 1\n \n while self.x_cntr <= 4:\n \n if self.x_cntr == 1:\n self.header = 'AtRim_off_dis_vc'\n \n # elif self.x_cntr == self.x_cntr + 5:\n elif self.x_cntr == 2:\n self.header = 'AtRim_def_dis_vc' \n \n # elif self.x_cntr + 10 <= self.x_cntr <= self.cntr + 15:\n elif self.x_cntr == 3:\n self.header = 'AtShot_off_dis_vc' \n \n else:\n self.header = 'AtShot_def_dis_vc'\n \n self.pbp_loc_player_distance_restricted_zone_df[self.header] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.vc_calculator\n (row[self.first_col], row[self.second_col], row[self.third_col], row[self.fourth_col], row[self.fifth_col]), axis = 1)\n \n \n self.first_col += 5\n self.second_col += 5\n self.third_col += 5\n self.fourth_col += 5\n self.fifth_col += 5\n self.x_cntr += 1\n \n \n # Tested and calculations confirmed \n # self.pbp_loc_player_distance_restricted_zone_df.to_csv('/Users/danfeldheim/Documents/OKC_project/vc_test2.csv') \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n \n #---------------------------------------------------------------------------------------------- \n # Function for use with apply in the calculation of player distance variation coeficient (vc)\n \n def vc_calculator(self, a, b, c, d, e):\n \n number_list = [a, b, c, d, e]\n \n # Comment out the following and uncomment the section between dashed lines below to delete player distances > x ft.\n # Then remove rows with zeros in any of the vc column using R.\n mean = sum(number_list)/len(number_list)\n variance = sum([((x - mean)**2) for x in number_list])/(len(number_list)-1) \n stdev = variance**0.5\n \n vc = stdev/mean \n \n \"\"\"\n #---------------------------------------------------------------------\n # Tried to improve the model by deleting player distances beyond x ft from rim, but model gets worse as distance is constrained\n # Delete distances > x ft\n number_list = [i for i in number_list if i < 30]\n \n # If statement in case number_list contains one or zero numbers\n if len(number_list) == 0 or len(number_list) == 1: \n vc = 0\n \n else:\n mean = sum(number_list)/len(number_list)\n variance = sum([((x - mean)**2) for x in number_list])/(len(number_list)-1) \n stdev = variance**0.5\n \n vc = stdev/mean \n #---------------------------------------------------------------------\n \"\"\"\n \n return vc\n \n #---------------------------------------------------------------------------------------------- \n \n # Function to calculate the number of offensive players that are in front of or to the side of their closest defensive player.\n # Hypothesis: Players who box out have a better chance of getting a rebound.\n \n def atRim_box_out(self):\n \n # Apply for players atRim (Rows from top to bottom below are x-y off, x-y def)\n self.pbp_loc_player_distance_restricted_zone_df['atRim_no_off_inFrontOf_def'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.box_out_calculator\n (row.AtRim_loc_x_off_player_1, row.AtRim_loc_x_off_player_2, row.AtRim_loc_x_off_player_3, row.AtRim_loc_x_off_player_4, row.AtRim_loc_x_off_player_5, \n row.AtRim_loc_y_off_player_1, row.AtRim_loc_y_off_player_2, row.AtRim_loc_y_off_player_3, row.AtRim_loc_y_off_player_4, row.AtRim_loc_y_off_player_5, \n row.AtRim_loc_x_def_player_1, row.AtRim_loc_x_def_player_2, row.AtRim_loc_x_def_player_3, row.AtRim_loc_x_def_player_4, row.AtRim_loc_x_def_player_5, \n row.AtRim_loc_y_def_player_1, row.AtRim_loc_y_def_player_2, row.AtRim_loc_y_def_player_3, row.AtRim_loc_y_def_player_4, row.AtRim_loc_y_def_player_5), axis = 1) \n \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n \n def atShot_box_out(self): \n \n # Apply for players atShot\n self.pbp_loc_player_distance_restricted_zone_df['atShot_no_off_inFrontOf_def'] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.box_out_calculator\n (row.AtShot_loc_x_off_player_1, row.AtShot_loc_x_off_player_2, row.AtShot_loc_x_off_player_3, row.AtShot_loc_x_off_player_4, row.AtShot_loc_x_off_player_1, \n row.AtShot_loc_y_off_player_1, row.AtShot_loc_y_off_player_2, row.AtShot_loc_y_off_player_3, row.AtShot_loc_y_off_player_4, row.AtShot_loc_y_off_player_5, \n row.AtShot_loc_x_def_player_1, row.AtShot_loc_x_def_player_2, row.AtShot_loc_x_def_player_3, row.AtShot_loc_x_def_player_4, row.AtShot_loc_x_def_player_5, \n row.AtShot_loc_y_def_player_1, row.AtShot_loc_y_def_player_2, row.AtShot_loc_y_def_player_3, row.AtShot_loc_y_def_player_4, row.AtShot_loc_y_def_player_5), axis = 1) \n \n \n \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n #---------------------------------------------------------------------------------------------- \n # Function for use with apply in the calculation of number of players that box out within n ft of the basket (start with n = 10) \n \n def box_out_calculator(self, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t):\n \n # Create lists for off and def x and y coordinates\n self.off_x_coord_list = [a, b, c, d, e]\n self.off_y_coord_list = [f, g, h, i, j]\n self.def_x_coord_list = [k, l, m, n, o]\n self.def_y_coord_list = [p, q, r, s, t]\n \n # Find player distances from the basket\n # Create lists to hold distances from basket\n self.off_dis_from_hoop_list = []\n self.def_dis_from_hoop_list = []\n \n # Calculate distances and populate lists\n for x, y in zip(self.off_x_coord_list, self.off_y_coord_list):\n self.off_distance = ((x + 41.75)**2 + y**2)**0.5\n self.off_dis_from_hoop_list.append(self.off_distance)\n \n for x, y in zip(self.def_x_coord_list, self.def_y_coord_list):\n self.def_distance = ((x + 41.75)**2 + y**2)**0.5\n self.def_dis_from_hoop_list.append(self.def_distance)\n \n # Create dataframe with self.off_x_coord_shifted, self.off_y_coord, self.def_x_coord_shifted, self.def_y_coord, self.off_dis_from_hoop_list, and self.def_dis_from_hoop_list\n self.box_out_df = pd.DataFrame(list(zip(self.off_x_coord_list, self.off_y_coord_list, self.def_x_coord_list, self.def_y_coord_list, self.off_dis_from_hoop_list, \n self.def_dis_from_hoop_list)), columns = ['off_x_coord', 'off_y_coord', 'def_x_coord', 'def_y_coord', 'off_distance_from_hoop', 'def_distance_from_hoop'])\n \n # Start counter for the number of offensive players that are:\n # 1. Within 6 ft of the basket\n # 2. Are equidistant or closer to the basket relative to any and all defensive players that are within 3 ft of the offensive player\n self.box_out_count = 0\n \n # Loop through each offensive player and calculate the number of offensive players that are closer to the basket than any defensive player that is within 3 ft of that offensive player\n for index, row in self.box_out_df.iterrows():\n \n # Get offensive player x-y coords and distance from hoop\n self.x_off_player = row['off_x_coord']\n self.y_off_player = row['off_y_coord']\n self.off_dis_from_hoop = row['off_distance_from_hoop']\n \n # Check to see if offensive player is within 10 ft of the basket\n # If yes continue, otherwise move to next player\n if self.off_dis_from_hoop <= 10:\n # Loop through def x-coord\n for index, row in self.box_out_df.iterrows():\n # Check to see if offensive player is closer to basket than defensive player\n # If yes, calculate distance between players, otherwise move on\n self.x_def_player = row['def_x_coord']\n self.y_def_player = row['def_y_coord']\n if self.x_off_player <= self.x_def_player:\n self.dis_between_players = ((self.x_off_player - self.x_def_player)**2 + (self.y_off_player - self.y_def_player)**2)**0.5\n \n # Check to see if defensive player is within 3 ft of offensive player\n if self.dis_between_players <= 3:\n self.box_out_count += 1\n \n \n return self.box_out_count\n \n \n \n \n #---------------------------------------------------------------------------------------------- \n \n # Calculate average distance between offensive players and average distance between defensive players\n def player_spacing(self):\n \n # Create lists for final AtRim_off, AtRim_def, AtShot_off, and AtShot_def player spacings\n # These will be appended to self.pbp_loc_player_distance_restricted_zone_df\n self.AtRim_off_avgSpacing_list = []\n self.AtRim_def_avgSpacing_list = []\n self.AtShot_off_avgSpacing_list = []\n self.AtShot_def_avgSpacing_list = []\n \n # Calculate player spacing \n for row in self.pbp_loc_player_distance_restricted_zone_df.itertuples():\n # Create temp list of lists for player x and y coord (gets populated with new values for every play)\n self.coordinates_list1 = [row.AtRim_loc_x_off_player_1, row.AtRim_loc_x_off_player_2, row.AtRim_loc_x_off_player_3, row.AtRim_loc_x_off_player_4, row.AtRim_loc_x_off_player_5]\n self.coordinates_list2 = [row.AtRim_loc_y_off_player_1, row.AtRim_loc_y_off_player_2, row.AtRim_loc_y_off_player_3, row.AtRim_loc_y_off_player_4, row.AtRim_loc_y_off_player_5]\n self.coordinates_list3 = [row.AtRim_loc_x_def_player_1, row.AtRim_loc_x_def_player_2, row.AtRim_loc_x_def_player_3, row.AtRim_loc_x_def_player_4, row.AtRim_loc_x_def_player_5]\n self.coordinates_list4 = [row.AtRim_loc_y_def_player_1, row.AtRim_loc_y_def_player_2, row.AtRim_loc_y_def_player_3, row.AtRim_loc_y_def_player_4, row.AtRim_loc_y_def_player_5]\n self.coordinates_list5 = [row.AtShot_loc_x_off_player_1, row.AtShot_loc_x_off_player_2, row.AtShot_loc_x_off_player_3, row.AtShot_loc_x_off_player_4, row.AtShot_loc_x_off_player_5]\n self.coordinates_list6 = [row.AtShot_loc_y_off_player_1, row.AtShot_loc_y_off_player_2, row.AtShot_loc_y_off_player_3, row.AtShot_loc_y_off_player_4, row.AtShot_loc_y_off_player_5]\n self.coordinates_list7 = [row.AtShot_loc_x_def_player_1, row.AtShot_loc_x_def_player_2, row.AtShot_loc_x_def_player_3, row.AtShot_loc_x_def_player_4, row.AtShot_loc_x_def_player_5]\n self.coordinates_list8 = [row.AtShot_loc_y_def_player_1, row.AtShot_loc_y_def_player_2, row.AtShot_loc_y_def_player_3, row.AtShot_loc_y_def_player_4, row.AtShot_loc_y_def_player_5] \n \n # Create dataframe from the lists\n self.spacing_df = pd.DataFrame(list(zip(self.coordinates_list1, self.coordinates_list2, self.coordinates_list3, self.coordinates_list4, self.coordinates_list5, \n self.coordinates_list6, self.coordinates_list7, self.coordinates_list8)), columns = ['AtRim_loc_x_off', 'AtRim_loc_y_off', 'AtRim_loc_x_def', 'AtRim_loc_y_def', \n 'AtShot_loc_x_off', 'AtShot_loc_y_off', 'AtShot_loc_x_def', 'AtShot_loc_y_def'])\n \n # Create column counters\n # Note itertuples columns start with an index column so self.x_cntr must start at 1 here!\n self.x_cntr = 1\n self.y_cntr = 2\n \n # Create temp list of CLOSEST player distances from below; needs to refresh for each play so put inside this outer for loop\n self.closest_player_list = []\n \n while self.x_cntr <= 7:\n \n # Calculate distance between all combinations of all players (e.g., start w/player and calculate distance to all other players)\n for row in self.spacing_df.itertuples():\n \n # Get player x, y-coords\n # Get column names for use with itertuples\n self.player_x = row[self.x_cntr]\n self.player_y = row[self.y_cntr]\n \n # Create temp list of ALL player distances; needs to refresh for each player\n self.player_dis_list = []\n \n # This inner loop calculates all combinations of player spacing \n for row in self.spacing_df.itertuples():\n \n # Calculate distance between players\n self.player_spacing = ((self.player_x - row[self.x_cntr])**2 + (self.player_y - row[self.y_cntr])**2)**0.5\n\n # Append to self.player_dis_list\n self.player_dis_list.append(self.player_spacing)\n \n # Remove 0.0 from list (player's distance from himself). Need to do this outside of the for loop so that the list is not being modified while removing the 0.\n self.player_dis_list.remove(0)\n \n # Find the closest player\n self.closest_dis = min(self.player_dis_list)\n \n # Append self.closest_dis to self.closest_player_list\n self.closest_player_list.append(self.closest_dis)\n \n # Calculate average distance between players and append to master AtRim, AtShot lists at the top of the function\n self.average_distance = sum(self.closest_player_list)/len(self.closest_player_list)\n \n # Append average player distance to final list\n # Need to do this based upon x and y counter numbers to populate the correct master list\n if self.x_cntr == 1:\n self.AtRim_off_avgSpacing_list.append(self.average_distance)\n \n elif self.x_cntr == 3:\n self.AtRim_def_avgSpacing_list.append(self.average_distance)\n \n elif self.x_cntr == 5:\n self.AtShot_off_avgSpacing_list.append(self.average_distance)\n \n else:\n self.AtShot_def_avgSpacing_list.append(self.average_distance)\n \n self.x_cntr += 2\n self.y_cntr += 2\n \n \n # Append final lists to df\n self.pbp_loc_player_distance_restricted_zone_df['AtRim_off_spacing'] = self.AtRim_off_avgSpacing_list\n self.pbp_loc_player_distance_restricted_zone_df['AtRim_def_spacing'] = self.AtRim_def_avgSpacing_list\n self.pbp_loc_player_distance_restricted_zone_df['AtShot_off_spacing'] = self.AtShot_off_avgSpacing_list\n self.pbp_loc_player_distance_restricted_zone_df['AtShot_def_spacing'] = self.AtShot_def_avgSpacing_list\n \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n \n \n # Calculate the median distance between each offensive player and every other defensive player, not just the closer defensive player\n # This needs to be refactored to combine it with the player spacing function!\n def off_def_spacing(self):\n \n # Create lists for final AtRim_off, AtRim_def, AtShot_off, and AtShot_def player spacings\n # These will be appended to self.pbp_loc_player_distance_restricted_zone_df\n self.AtRim_off_def_medianSpacing_list = []\n self.AtShot_off_def_medianSpacing_list = []\n \n # Calculate player spacing \n for row in self.pbp_loc_player_distance_restricted_zone_df.itertuples():\n \n # Create temp list of lists for player x and y coord (gets populated with new values for every play)\n self.coordinates_list1 = [row.AtRim_loc_x_off_player_1, row.AtRim_loc_x_off_player_2, row.AtRim_loc_x_off_player_3, row.AtRim_loc_x_off_player_4, row.AtRim_loc_x_off_player_5]\n self.coordinates_list2 = [row.AtRim_loc_y_off_player_1, row.AtRim_loc_y_off_player_2, row.AtRim_loc_y_off_player_3, row.AtRim_loc_y_off_player_4, row.AtRim_loc_y_off_player_5]\n self.coordinates_list3 = [row.AtRim_loc_x_def_player_1, row.AtRim_loc_x_def_player_2, row.AtRim_loc_x_def_player_3, row.AtRim_loc_x_def_player_4, row.AtRim_loc_x_def_player_5]\n self.coordinates_list4 = [row.AtRim_loc_y_def_player_1, row.AtRim_loc_y_def_player_2, row.AtRim_loc_y_def_player_3, row.AtRim_loc_y_def_player_4, row.AtRim_loc_y_def_player_5]\n self.coordinates_list5 = [row.AtShot_loc_x_off_player_1, row.AtShot_loc_x_off_player_2, row.AtShot_loc_x_off_player_3, row.AtShot_loc_x_off_player_4, row.AtShot_loc_x_off_player_5]\n self.coordinates_list6 = [row.AtShot_loc_y_off_player_1, row.AtShot_loc_y_off_player_2, row.AtShot_loc_y_off_player_3, row.AtShot_loc_y_off_player_4, row.AtShot_loc_y_off_player_5]\n self.coordinates_list7 = [row.AtShot_loc_x_def_player_1, row.AtShot_loc_x_def_player_2, row.AtShot_loc_x_def_player_3, row.AtShot_loc_x_def_player_4, row.AtShot_loc_x_def_player_5]\n self.coordinates_list8 = [row.AtShot_loc_y_def_player_1, row.AtShot_loc_y_def_player_2, row.AtShot_loc_y_def_player_3, row.AtShot_loc_y_def_player_4, row.AtShot_loc_y_def_player_5] \n \n # Create dataframe from the lists\n self.spacing_df = pd.DataFrame(list(zip(self.coordinates_list1, self.coordinates_list2, self.coordinates_list3, self.coordinates_list4, self.coordinates_list5, \n self.coordinates_list6, self.coordinates_list7, self.coordinates_list8)), columns = ['AtRim_loc_x_off', 'AtRim_loc_y_off', 'AtRim_loc_x_def', 'AtRim_loc_y_def', \n 'AtShot_loc_x_off', 'AtShot_loc_y_off', 'AtShot_loc_x_def', 'AtShot_loc_y_def'])\n \n # Create column counters\n # Note itertuples columns start with an index column so self.x_cntr must start at 1 here!\n self.x_cntr = 1\n self.y_cntr = 2\n \n # Create temp list of off-def player distances \n self.off_def_spacing_list = []\n \n while self.x_cntr <= 5:\n \n # Calculate distance between all combinations of all players (e.g., start w/player and calculate distance to all other players)\n for row in self.spacing_df.itertuples():\n \n # Get player x, y-coords\n # Get column names for use with itertuples\n self.player_x = row[self.x_cntr]\n self.player_y = row[self.y_cntr]\n \n # Create temp list of ALL player distances; needs to refresh for each player\n self.player_dis_list = []\n \n # This inner loop calculates all combinations of player spacing \n for row in self.spacing_df.itertuples():\n \n # Calculate distance between players \n # Use self.x_cntr + 2 to get the defensive players x and y coords\n self.player_spacing = ((self.player_x - row[self.x_cntr + 2])**2 + (self.player_y - row[self.y_cntr + 2])**2)**0.5\n \n # Append to self.player_dis_list\n self.player_dis_list.append(self.player_spacing)\n \n # Get median value in self.player_dis_list\n # Note this is the median spacing of one player\n self.median_spacing_perPlayer = median(self.player_dis_list)\n \n # Append to self.off_def_spacing_list\n self.off_def_spacing_list.append(self.median_spacing_perPlayer)\n \n # Get median distance of all offensive players to defensive players\n self.median_spacing_allPlayers = median(self.off_def_spacing_list)\n \n # Append median player distance to final list\n # Need to do this based upon x and y counter numbers to populate the correct master list\n if self.x_cntr == 1:\n self.AtRim_off_def_medianSpacing_list.append(self.median_spacing_allPlayers)\n \n else:\n self.AtShot_off_def_medianSpacing_list.append(self.median_spacing_allPlayers)\n \n \n # Move counter to the 5th column (AtShot_loc_x_off)\n self.x_cntr += 4\n self.y_cntr += 4\n \n # Append final lists to df\n self.pbp_loc_player_distance_restricted_zone_df['AtRim_median_off_def_spacing'] = self.AtRim_off_def_medianSpacing_list\n self.pbp_loc_player_distance_restricted_zone_df['AtShot_median_off_def_spacing'] = self.AtShot_off_def_medianSpacing_list\n \n # Calculations verified to be correct \n # self.pbp_loc_player_distance_restricted_zone_df.to_csv('/Users/danfeldheim/Documents/OKC_project/10_21_20_test_data1.csv') \n \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n # Function to include whether the top offensive and defensive rebounders are in the game and how many are in the game\n def top_rebounders(self):\n \n # Create list of top rebounders\n self.top_rebounders_list = [83, 275, 298, 81, 22, 108, 120, 170, 13, 26, 127, 823, 145, 717, 889, 341]\n \n # Set all NAs to '-' in the playerID columns\n self.pbp_loc_player_distance_restricted_zone_df = self.pbp_loc_player_distance_restricted_zone_df.fillna({'playerid_off_player_1': '-', 'playerid_off_player_2': '-', \n 'playerid_off_player_3': '-', 'playerid_off_player_4': '-', 'playerid_off_player_5': '-'})\n \n \n # Create a master list of lists (This will be converted to a df and merged with self.pbp_loc_player_distance_restricted_zone_df\n self.master_playa_dummy_list = []\n \n # Also get a count of the number of top rebounders in each play \n # Create a list to hold the count\n self.no_top_rebounders_list = []\n\n for row in self.pbp_loc_player_distance_restricted_zone_df.itertuples():\n \n # Create list of playerIDs\n self.playerID_list = [row.playerid_off_player_1, row.playerid_off_player_2, row.playerid_off_player_3, row.playerid_off_player_4, row.playerid_off_player_5]\n \n # Create temp list of 0s and 1s for each player. This will be appended to self.master_playa_dummy_list to create a list of lists.\n self.playa_dummy_list = []\n \n # Start a counter for the number of top rebounders in the play\n self.no_rebounders_inPlay = 0\n \n # Compare self.playerID_list and self.top_rebounders_list for matches\n for rebounder in self.top_rebounders_list:\n \n if rebounder in self.playerID_list:\n self.playa_dummy_list.append(1)\n self.no_rebounders_inPlay += 1\n \n else:\n self.playa_dummy_list.append(0)\n \n # Append to master list to create a list of lists for each player\n self.master_playa_dummy_list.append(self.playa_dummy_list)\n \n # Append number of rebounders count to master list\n self.no_top_rebounders_list.append(self.no_rebounders_inPlay) \n \n # Create dataframe from list of lists\n self.playa_df = pd.DataFrame(self.master_playa_dummy_list, columns = ['player83', 'player275', 'player298', 'player81', 'player22', 'player108', 'player120', 'player170', 'player13', 'player26',\n 'player127', 'player823', 'player145', 'player717', 'player889', 'player341'])\n \n # Reset index values on both of the dataframes before concatenating or blank rows will be inserted\n self.playa_df = self.playa_df.reset_index(drop = True)\n self.pbp_loc_player_distance_restricted_zone_df = self.pbp_loc_player_distance_restricted_zone_df.reset_index(drop = True)\n \n # Concatenate self.playa_df and self.pbp_loc_player_distance_restricted_zone_df\n self.pbp_loc_player_distance_restricted_zone_df = pd.concat([self.pbp_loc_player_distance_restricted_zone_df, self.playa_df], axis = 1)\n \n # Append self.no_top_rebounders_list to df\n self.pbp_loc_player_distance_restricted_zone_df['no_of_top_rebounders_in_play'] = self.no_top_rebounders_list\n \n \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n\n # Function to calculate the variation coefficient for player angles\n def angle_vc(self):\n \n # Get first column index \n self.first_col = self.pbp_loc_player_distance_restricted_zone_df.columns.get_loc(\"AtRim_angle_off_player_1.0\")\n self.second_col = self.first_col + 1\n self.third_col = self.first_col + 2\n self.fourth_col = self.first_col + 3\n self.fifth_col = self.first_col + 4\n \n self.x_cntr = 1\n \n while self.x_cntr <= 4:\n \n if self.x_cntr == 1:\n self.header = 'AtRim_off_angle_vc'\n \n # elif self.x_cntr == self.x_cntr + 5:\n elif self.x_cntr == 2:\n self.header = 'AtRim_def_angle_vc' \n \n # elif self.x_cntr + 10 <= self.x_cntr <= self.cntr + 15:\n elif self.x_cntr == 3:\n self.header = 'AtShot_off_angle_vc' \n \n else:\n self.header = 'AtShot_def_angle_vc'\n \n self.pbp_loc_player_distance_restricted_zone_df[self.header] = self.pbp_loc_player_distance_restricted_zone_df.apply(lambda row: self.vc_calculator\n (row[self.first_col], row[self.second_col], row[self.third_col], row[self.fourth_col], row[self.fifth_col]), axis = 1)\n \n \n self.first_col += 5\n self.second_col += 5\n self.third_col += 5\n self.fourth_col += 5\n self.fifth_col += 5\n self.x_cntr += 1\n \n \n # Tested and calculations confirmed \n # self.pbp_loc_player_distance_restricted_zone_df.to_csv('/Users/danfeldheim/Documents/OKC_project/vc_test2.csv') \n \n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n # Function to calculate the distance difference between every offensive player and their closest defensive player relative to the rim\n # For example, if offensive player is 3 ft from the basket and their closest defensive player is 4 ft from the basket, the difference is +1\n def distance_delta(self):\n \n # Find closest defensive player to each offensive player\n # Create final lists of delta player spacing (will be appended to self.pbp_loc_player_distance_restricted_zone_df)\n self.p1_delta_spacing_list = []\n self.p2_delta_spacing_list = []\n self.p3_delta_spacing_list = []\n self.p4_delta_spacing_list = []\n self.p5_delta_spacing_list = []\n \n for row in self.pbp_loc_player_distance_restricted_zone_df.itertuples():\n \n # Create temp list of lists for player x and y coord (gets populated with new values for every play)\n self.x_coordinates_list = [row.AtRim_loc_x_off_player_1, row.AtRim_loc_x_off_player_2, row.AtRim_loc_x_off_player_3, row.AtRim_loc_x_off_player_4, row.AtRim_loc_x_off_player_5, \n row.AtRim_loc_x_def_player_1, row.AtRim_loc_x_def_player_2, row.AtRim_loc_x_def_player_3, row.AtRim_loc_x_def_player_4, row.AtRim_loc_x_def_player_5]\n self.y_coordinates_list = [row.AtRim_loc_y_off_player_1, row.AtRim_loc_y_off_player_2, row.AtRim_loc_y_off_player_3, row.AtRim_loc_y_off_player_4, row.AtRim_loc_y_off_player_5,\n row.AtRim_loc_y_def_player_1, row.AtRim_loc_y_def_player_2, row.AtRim_loc_y_def_player_3, row.AtRim_loc_y_def_player_4, row.AtRim_loc_y_def_player_5]\n \n # Create dataframe from the lists\n # First 5 rows are offensive players, last 5 are defensive players\n self.spacing_df = pd.DataFrame(list(zip(self.x_coordinates_list, self.y_coordinates_list)), \n columns = ['AtRim_loc_x', 'AtRim_loc_y'])\n \n # Calculate distance from rim for each player\n self.rim_dis = ((self.spacing_df['AtRim_loc_x'] + 41.75)**2 + self.spacing_df['AtRim_loc_y']**2)**0.5\n self.spacing_df['rim_dis'] = self.rim_dis\n \n # Add a column indicating player # from 1-10\n self.spacing_df['player_no'] = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n \n for row in self.spacing_df.itertuples():\n # Create temp dictionary to store closest defensive player number (resets for each offensive player)\n self.closest_player_dict = {}\n # Get offensive player's distance from rim\n self.current_player_rim_dis = row.rim_dis\n \n if row.player_no <= 5: \n self.off_player_no = row.player_no\n self.off_player_x = row.AtRim_loc_x\n self.off_player_y = row.AtRim_loc_y\n \n for row in self.spacing_df.itertuples():\n if row.player_no > 5:\n self.def_player_no = row.player_no\n self.def_player_x = row.AtRim_loc_x\n self.def_player_y = row.AtRim_loc_y\n \n # Calculate distance between the selected offensive player and defensive players\n self.player_dis = (((self.off_player_x + 41.75) - (self.def_player_x + 41.75))**2 + (self.off_player_y - self.def_player_y)**2)**0.5\n # Append player number and spacing to self.closest_player_dict\n self.closest_player_dict.update({self.def_player_no: self.player_dis})\n \n # Find the key (player number) corresponding to the minumum value in self.closest_player_dict\n self.closest_player_number = min(self.closest_player_dict, key = lambda x: self.closest_player_dict[x]) \n \n # Calculate the delta rim distance for each offensive player and their closest defensive player\n # Get rim distance of self.closest_player_number\n self.rim_dis_closest_def_player = self.spacing_df.loc[self.spacing_df['player_no'] == self.closest_player_number, 'rim_dis'].item() \n self.rim_delta = self.current_player_rim_dis - self.rim_dis_closest_def_player\n \n # Append to correct player list\n if self.off_player_no == 1:\n self.p1_delta_spacing_list.append(self.rim_delta)\n \n elif self.off_player_no == 2:\n self.p2_delta_spacing_list.append(self.rim_delta)\n \n elif self.off_player_no == 3:\n self.p3_delta_spacing_list.append(self.rim_delta)\n \n elif self.off_player_no == 4:\n self.p4_delta_spacing_list.append(self.rim_delta)\n \n else:\n self.p5_delta_spacing_list.append(self.rim_delta)\n \n # Append each list to self.pbp_loc_player_distance_restricted_zone_df\n self.pbp_loc_player_distance_restricted_zone_df['p1_delta'] = self.p1_delta_spacing_list\n self.pbp_loc_player_distance_restricted_zone_df['p2_delta'] = self.p2_delta_spacing_list\n self.pbp_loc_player_distance_restricted_zone_df['p3_delta'] = self.p3_delta_spacing_list\n self.pbp_loc_player_distance_restricted_zone_df['p4_delta'] = self.p4_delta_spacing_list\n self.pbp_loc_player_distance_restricted_zone_df['p5_delta'] = self.p5_delta_spacing_list\n \n return self.pbp_loc_player_distance_restricted_zone_df\n \n \n def logistic_reg(self):\n \n # Train \n \n self.X = self.pbp_loc_player_distance_restricted_zone_df[['no_of_top_rebounders_in_play','actiondescription_dummy', 'AtRim_off_dis_vc', 'AtRim_def_dis_vc',\n 'p1_delta', 'p2_delta', 'p3_delta', 'p4_delta', 'p5_delta']] \n self.y = self.pbp_loc_player_distance_restricted_zone_df['oreb']\n self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size = 0.4, random_state = 1)\n \n self.model = LogisticRegression()\n self.model.fit(self.X_train, self.y_train)\n self.probs = self.model.predict_proba(self.X_test)[:, 1]\n # self.class_report = classification_report(self.y_test, self.probs)\n # print ('Classification Report: ')\n # print (self.class_report)\n \n # Print confusion matrix and accuracy\n # self.conf_matrix = confusion_matrix(self.y_test, self.probs)\n # print (\"Confusion Matrix: \")\n # print (self.conf_matrix)\n # print ('Accuracy: ', metrics.accuracy_score(self.y_test, self.probs))\n \n false_positive_rate2, true_positive_rate2, threshold2 = roc_curve(self.y_test, self.probs)\n print('roc_auc_score for Logistic Regression: ', roc_auc_score(self.y_test, self.probs))\n \n fpr, tpr, thresholds = roc_curve(self.y_test, self.probs)\n # plot no skill\n plt.plot([0, 1], [0, 1], linestyle = '--')\n # plot the roc curve for the model\n plt.plot(fpr, tpr)\n # show the plot\n plt.show()\n \n # Calculate logloss\n # self.reb_probs = self.model.predict_proba(self.X_test)\n self.log_loss = log_loss(self.y_test, self.probs)\n print('log loss: ', self.log_loss)\n \n \n \"\"\"\n # Generate a ROC curve (a little nicer looking than the one above)\n logit_roc_auc = roc_auc_score(self.y_test, self.logmodel.predict(self.X_test)[:,1])\n fpr, tpr, thresholds = roc_curve(self.y_test, self.logmodel.predict_proba(self.X_test))\n plt.figure()\n plt.plot(fpr, tpr, label='Logistic Regression (area = %0.2f)' % logit_roc_auc)\n plt.plot([0, 1], [0, 1],'r--')\n plt.xlim([0.0, 1.0])\n plt.ylim([0.0, 1.05])\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title('Receiver operating characteristic')\n plt.legend(loc=\"lower right\")\n plt.savefig('/Users/danfeldheim/Documents/OKC_project/Log_ROC')\n plt.show()\n \"\"\"\n \n # Cross validate\n scores = cross_val_score(self.model, self.X_train, self.y_train, cv = 10)\n print('Cross-Validation Accuracy Scores', scores)\n scores = pd.Series(scores)\n scores.min(), scores.mean(), scores.max()\n \n \n# Call class\nobj1 = rebound()\n\n# Must call\nimports = obj1.import_files()\nmerge = obj1.merge()\n\n# Optional calls\nprepare = obj1.prep()\nposition = obj1.player_pos_data()\n\n# Must call\ndistance = obj1.distance_from_hoop()\nrestricted = obj1.restricted_players()\n\n# Optional calls\nangles = obj1.player_angles()\ndis_variation = obj1.distance_vc_from_basket()\nat_Rim_boxout = obj1.atRim_box_out()\nat_Shot_boxout = obj1.atShot_box_out()\nspacing = obj1.player_spacing()\noff_def_spacing = obj1.off_def_spacing()\nrebounders = obj1.top_rebounders()\nangle_vc = obj1.angle_vc()\ndelta_dis = obj1.distance_delta()\n\n# Logistic regression\nreg = obj1.logistic_reg()\n\n\n\n"
},
{
"alpha_fraction": 0.5755544900894165,
"alphanum_fraction": 0.591516375541687,
"avg_line_length": 47.23829650878906,
"blob_id": "f1423709584b42504efe2985ced264f228d2bacc",
"content_id": "0b3cc5dbcadb7b553a831915b7c3de8345b2186a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22679,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 470,
"path": "/offensive_rebound_predictor_refactored2.py",
"repo_name": "DanFeldheim/NBA_playerTracking_analysis",
"src_encoding": "UTF-8",
"text": "# This program imports OKC Thunder player tracking rebounding data including player location and position data for >300,000 plays\n# Files are merged and cleaned, and then various parameters are calculated such as player distance and angle from basket,\n# how spread out the players are, how many offensive players are boxing out, number of players in restricted zone, etc.\n\n\n# Import packages\nimport pandas as pd\nimport numpy as np\nimport csv\nimport math\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn import metrics, cross_validation\nfrom sklearn.metrics import classification_report, confusion_matrix, log_loss\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import ListedColormap \nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.metrics import roc_auc_score\nfrom sklearn.metrics import roc_curve\nfrom numpy import median\n\n\nclass Calculations:\n \n def __init__(self, loc, pbp, player_pos, player_rebound):\n \n # Import data\n self.loc_df = pd.read_csv(loc, header = 0)\n self.pbp_df = pd.read_csv(pbp, header = 0)\n self.player_pos_df = pd.read_csv(player_pos, header = 0)\n self.player_rebound_df = pd.read_csv(player_rebound)\n \n def reOrder(self):\n \n \"\"\"\n Used on the training and unknown test set, this function re-orders the columns so that distance and angle\n calculations may be performed.\n \"\"\"\n \n # Reorder the columns to prepare for distance from basket calculations below\n self.loc_df = self.loc_df[[\"game_id\", \"playbyplayorder_id\", \"row_type\", \"AtRim_loc_x_off_player_1\", \n \"AtRim_loc_y_off_player_1\", \"AtRim_loc_x_off_player_2\", \"AtRim_loc_y_off_player_2\",\"AtRim_loc_x_off_player_3\", \n \"AtRim_loc_y_off_player_3\", \"AtRim_loc_x_off_player_4\", \"AtRim_loc_y_off_player_4\", \"AtRim_loc_x_off_player_5\", \n \"AtRim_loc_y_off_player_5\", \"AtRim_loc_x_def_player_1\", \"AtRim_loc_y_def_player_1\", \"AtRim_loc_x_def_player_2\", \n \"AtRim_loc_y_def_player_2\", \"AtRim_loc_x_def_player_3\", \"AtRim_loc_y_def_player_3\", \"AtRim_loc_x_def_player_4\", \n \"AtRim_loc_y_def_player_4\", \"AtRim_loc_x_def_player_5\", \"AtRim_loc_y_def_player_5\", \"AtShot_loc_x_off_player_1\", \n \"AtShot_loc_y_off_player_1\", \"AtShot_loc_x_off_player_2\", \"AtShot_loc_y_off_player_2\", \"AtShot_loc_x_off_player_3\", \n \"AtShot_loc_y_off_player_3\", \"AtShot_loc_x_off_player_4\", \"AtShot_loc_y_off_player_4\",\"AtShot_loc_x_off_player_5\", \n \"AtShot_loc_y_off_player_5\", \"AtShot_loc_x_def_player_1\", \"AtShot_loc_y_def_player_1\", \"AtShot_loc_x_def_player_2\", \n \"AtShot_loc_y_def_player_2\", \"AtShot_loc_x_def_player_3\", \"AtShot_loc_y_def_player_3\", \"AtShot_loc_x_def_player_4\", \n \"AtShot_loc_y_def_player_4\", \"AtShot_loc_x_def_player_5\", \"AtShot_loc_y_def_player_5\"]]\n \n \n \n return self.loc_df\n \n def clean_training(self):\n \n \"\"\"\n Clean up the training data sets. A separate testing set cleaning function below is necessary because the sets have\n their own issues that must be dealt with separately.\n \"\"\"\n \n # Clean up loc_df\n self.loc_df = self.loc_df.drop(self.loc_df.columns[0], axis = 1)\n # Change ' ft' to 'ft' in row_type column (i.e., remove the leading space as it prevents an accurate df merge below)\n self.loc_df = self.loc_df.replace(to_replace = \" ft\", value = \"ft\")\n \n # Clean up pbp_df\n self.pbp_df = self.pbp_df.drop(self.pbp_df.columns[0], axis = 1)\n self.pbp_df = self.pbp_df.drop(self.pbp_df.loc[:, 'reboffensive': 'eventdescription'].columns, axis = 1)\n # Change 'final ft' to ft in row_type column \n self.pbp_df = self.pbp_df.replace(to_replace = \"final ft\", value = \"ft\")\n \n # Clean up position data\n self.player_pos_df = self.player_pos_df.drop(self.player_pos_df.columns[[0, 3]], axis = 1)\n \n # Clean up rebounding data\n self.player_rebound_df = self.player_rebound_df.drop(self.player_rebound_df.columns[0], axis = 1)\n \n return self.loc_df, self.pbp_df, self.player_pos_df, self.player_rebound_df\n \n def clean_testing(self):\n \n # Clean up (this isn't needed for the unknown test data\n # self.loc_df = self.loc_df.drop(self.loc_df.columns[0], axis = 1)\n \n # Clean up\n self.pbp_df = self.pbp_df.drop(self.pbp_df.loc[:, 'off_team_id': 'eventdescription'].columns, axis = 1)\n \n # Clean up\n self.player_pos_df = self.player_pos_df.drop(self.player_pos_df.columns[[0, 3]], axis = 1)\n \n # Clean up\n self.player_rebound_df = self.player_rebound_df.drop(self.player_rebound_df.columns[0], axis = 1)\n \n \n \n return self.loc_df, self.pbp_df, self.player_pos_df, self.player_rebound_df\n \n \n def merge(self):\n \n \"\"\"\n Merge the location and pbp data sets.\n \"\"\"\n \n # Merge self.loc_df and self.pbp_df on playbyplayorder_id\n self.pbp_loc_merged_df = pd.merge(self.pbp_df, self.loc_df, on = [\"playbyplayorder_id\", \"row_type\", \"game_id\"])\n \n # Make changes in actiondescription columns to simplify\n self.pbp_loc_merged_df[\"actiondescription\"] = self.pbp_loc_merged_df[\"actiondescription\"].apply(lambda x: 'jump_shot' if 'Jump' in x else ('layup' if 'Layup' in x else ('other'))) \n \n # Inspect the data\n \"\"\"\n print (self.pbp_loc_merged_df.info())\n self.pbp_loc_merged_df.hist(bins = 50, figsize = (20, 15))\n plt.show()\n \"\"\"\n \n \n return self.pbp_loc_merged_df\n \n def purge_oreb(self):\n \n \"\"\"\n Remove all rows in the training set that have NA in the oreb column.\n This can only be called on the training data since the testing data doesn't have oreb.\n \"\"\"\n \n # Remove rows that have NA in the oreb column. Presumably these are team rebounds, out of bounds, fouls, makes, etc.\n self.pbp_loc_merged_df = self.pbp_loc_merged_df.dropna(subset = [\"oreb\"]).reset_index(drop = True)\n \n # Remove rows in which the shot was a free throw as these are almost never rebounded by the offense and player positions are fixed\n # 174,141 rows remaining\n self.pbp_loc_merged_df = self.pbp_loc_merged_df[~self.pbp_loc_merged_df.row_type.str.contains('ft').reset_index(drop = True)]\n \n return self.pbp_loc_merged_df\n \n def purge_shotLoc(self):\n \n \"\"\"\n Remove all rows with NA in a location row.\n This can be used on both the training and testing sets.\n \"\"\"\n \n # Remove rows with NA in a location row\n # df is now 173744 rows long; still plenty of data\n self.pbp_loc_merged_df = self.pbp_loc_merged_df.dropna(subset = [\"AtRim_loc_x_off_player_1\", \n \"AtRim_loc_y_off_player_1\", \"AtRim_loc_x_off_player_2\", \"AtRim_loc_y_off_player_2\",\"AtRim_loc_x_off_player_3\", \n \"AtRim_loc_y_off_player_3\", \"AtRim_loc_x_off_player_4\", \"AtRim_loc_y_off_player_4\", \"AtRim_loc_x_off_player_5\", \n \"AtRim_loc_y_off_player_5\", \"AtRim_loc_x_def_player_1\", \"AtRim_loc_y_def_player_1\", \"AtRim_loc_x_def_player_2\", \n \"AtRim_loc_y_def_player_2\", \"AtRim_loc_x_def_player_3\", \"AtRim_loc_y_def_player_3\", \"AtRim_loc_x_def_player_4\", \n \"AtRim_loc_y_def_player_4\", \"AtRim_loc_x_def_player_5\", \"AtRim_loc_y_def_player_5\", \"AtShot_loc_x_off_player_1\", \n \"AtShot_loc_y_off_player_1\", \"AtShot_loc_x_off_player_2\", \"AtShot_loc_y_off_player_2\", \"AtShot_loc_x_off_player_3\", \n \"AtShot_loc_y_off_player_3\", \"AtShot_loc_x_off_player_4\", \"AtShot_loc_y_off_player_4\",\"AtShot_loc_x_off_player_5\", \n \"AtShot_loc_y_off_player_5\", \"AtShot_loc_x_def_player_1\", \"AtShot_loc_y_def_player_1\", \"AtShot_loc_x_def_player_2\", \n \"AtShot_loc_y_def_player_2\", \"AtShot_loc_x_def_player_3\", \"AtShot_loc_y_def_player_3\", \"AtShot_loc_x_def_player_4\", \n \"AtShot_loc_y_def_player_4\", \"AtShot_loc_x_def_player_5\", \"AtShot_loc_y_def_player_5\"])\n \n \n \n return self.pbp_loc_merged_df\n \n \n \n def distance_from_hoop(self):\n \n \"\"\"\n Calculate distance of every player from basket at time of shot and when ball hits the rim.\n Use on both training and testing sets.\n \"\"\"\n \n # Copy self.pbp_loc_merged_df\n self.pbp_loc_player_distance_df = self.pbp_loc_merged_df.copy()\n \n # One of the locations in the unknown test set is an object instead of float for some reason-convert\n self.pbp_loc_player_distance_df['AtShot_loc_x_off_player_2'] = self.pbp_loc_player_distance_df['AtShot_loc_x_off_player_2'].astype(float)\n \n # Calculate distance from basket for every x-y pair (each player) using the pythagorean theorom. \n # Column order matters here! Must go AtRim_loc_x_off_player1, AtRim_loc_y_off_player1, AtRim_loc_x_off_player2...\n # Must be a block of AtRim followed by a block of AtShot\n # Get column index of first x and y positions\n self.x_col = self.pbp_loc_player_distance_df.columns.get_loc(\"AtRim_loc_x_off_player_1\")\n self.y_col = self.pbp_loc_player_distance_df.columns.get_loc(\"AtRim_loc_y_off_player_1\") \n \n # Create counter for keeping track of column positions and naming new columns\n self.x_index = 1\n \n # While loop to move through x-y pairs until all distances have been calculated\n # Note the last x column is 39 cols past the first; the last y column is 40 cols past the first (10 off + 10 def)* 2 coords each\n while self.x_index <= 39:\n # If statement to keep track of player numbers based upon self.x_index\n # Calculate player number\n self.player = 0.5*(self.x_index + 1)\n \n # If statement so that when self.x_index > 5, self.player is reset to 1 for the defensive players\n if self.player <= 5:\n self.player = 'AtRim_distance_off_player_' + str(self.player)\n \n elif 5 < self.player <= 10:\n self.player = 'AtRim_distance_def_player_' + str(self.player - 5)\n \n elif 10 < self.player <= 15:\n self.player = 'AtShot_distance_off_player_' + str(self.player - 10)\n \n else:\n self.player = 'AtShot_distance_def_player_' + str(self.player - 15)\n \n # Add the calculated distance for each x-y pair to the df as a new column\n self.pbp_loc_player_distance_df[self.player] = self.pbp_loc_player_distance_df.apply(lambda row: self.pythagorean\n (row[self.x_col], row[self.y_col]), axis = 1)\n \n # Increment x and y index values and columns\n self.x_index += 2\n # self.y_index += 2\n self.x_col += 2\n self.y_col += 2 \n \n # Inspect the data\n # print (self.pbp_loc_player_distance_df.info())\n \n # self.pbp_loc_player_distance_df.hist(bins = 50, figsize = (20, 15))\n # plt.show()\n \n \n \n \n return self.pbp_loc_player_distance_df\n \n \n#---------------------------------------------------------------------------------------------- \n # Function to use with apply to caculate player distance from basket\n # Include 41.75 in the formula to reset the basket as the origin in the x-direction\n def pythagorean(self, a, b):\n \n return math.sqrt((a + 41.75)**2 + b**2)\n \n#---------------------------------------------------------------------------------------------- \n \n\n def distance_vc_from_basket(self):\n \n \"\"\"\n Function to calculate the variation coefficient for the distance of every player from the basket\n Variation coefficient = (STDEV of distance from basket for offensive or defensive players)/mean distance from basket of offense or defense\n Hypothesis: The ability to get a rebound depends upon the variation in distance of players from the basket\n \"\"\"\n \n # Get first column index \n self.first_col = self.pbp_loc_player_distance_df.columns.get_loc(\"AtRim_distance_off_player_1.0\")\n self.second_col = self.first_col + 1\n self.third_col = self.first_col + 2\n self.fourth_col = self.first_col + 3\n self.fifth_col = self.first_col + 4\n \n self.x_cntr = 1\n \n while self.x_cntr <= 4:\n \n if self.x_cntr == 1:\n self.header = 'AtRim_off_dis_vc'\n \n elif self.x_cntr == 2:\n self.header = 'AtRim_def_dis_vc' \n \n elif self.x_cntr == 3:\n self.header = 'AtShot_off_dis_vc' \n \n else:\n self.header = 'AtShot_def_dis_vc'\n \n self.pbp_loc_player_distance_df[self.header] = self.pbp_loc_player_distance_df.apply(lambda row: self.vc_calculator\n (row[self.first_col], row[self.second_col], row[self.third_col], row[self.fourth_col], row[self.fifth_col]), axis = 1)\n \n self.first_col += 5\n self.second_col += 5\n self.third_col += 5\n self.fourth_col += 5\n self.fifth_col += 5\n self.x_cntr += 1\n \n \n return self.pbp_loc_player_distance_df\n \n #---------------------------------------------------------------------------------------------- \n # Function for use with apply in the calculation of player distance variation coeficient (vc)\n \n def vc_calculator(self, a, b, c, d, e):\n \n number_list = [a, b, c, d, e]\n \n mean = sum(number_list)/len(number_list)\n variance = sum([((x - mean)**2) for x in number_list])/(len(number_list)-1) \n stdev = variance**0.5\n \n vc = stdev/mean \n \n \n \n return vc\n \n #---------------------------------------------------------------------------------------------- \n \n # Function to include whether the top offensive and defensive rebounders are in the game and how many are in the game\n def top_rebounders(self):\n \n # Create list of top rebounders\n self.top_rebounders_list = [83, 275, 298, 81, 22, 108, 120, 170, 13, 26, 127, 823, 145, 717, 889, 341]\n \n # Set all NAs to '-' in the playerID columns\n self.pbp_loc_player_distance_df = self.pbp_loc_player_distance_df.fillna({'playerid_off_player_1': '-', 'playerid_off_player_2': '-', \n 'playerid_off_player_3': '-', 'playerid_off_player_4': '-', 'playerid_off_player_5': '-'})\n \n \n # Create a master list of lists (This will be converted to a df and merged with self.pbp_loc_player_distance_restricted_zone_df\n self.master_playa_dummy_list = []\n \n # Also get a count of the number of top rebounders in each play \n # Create a list to hold the count\n self.no_top_rebounders_list = []\n\n for row in self.pbp_loc_player_distance_df.itertuples():\n \n # Create list of playerIDs\n self.playerID_list = [row.playerid_off_player_1, row.playerid_off_player_2, row.playerid_off_player_3, row.playerid_off_player_4, row.playerid_off_player_5]\n \n # Create temp list of 0s and 1s for each player. This will be appended to self.master_playa_dummy_list to create a list of lists.\n self.playa_dummy_list = []\n \n # Start a counter for the number of top rebounders in the play\n self.no_rebounders_inPlay = 0\n \n # Compare self.playerID_list and self.top_rebounders_list for matches\n for rebounder in self.top_rebounders_list:\n \n if rebounder in self.playerID_list:\n self.playa_dummy_list.append(1)\n self.no_rebounders_inPlay += 1\n \n else:\n self.playa_dummy_list.append(0)\n \n # Append to master list to create a list of lists for each player\n self.master_playa_dummy_list.append(self.playa_dummy_list)\n \n # Append number of rebounders count to master list\n self.no_top_rebounders_list.append(self.no_rebounders_inPlay) \n \n # Create dataframe from list of lists\n self.playa_df = pd.DataFrame(self.master_playa_dummy_list, columns = ['player83', 'player275', 'player298', 'player81', 'player22', 'player108', 'player120', 'player170', 'player13', 'player26',\n 'player127', 'player823', 'player145', 'player717', 'player889', 'player341'])\n \n # Reset index values on both of the dataframes before concatenating or blank rows will be inserted\n self.playa_df = self.playa_df.reset_index(drop = True)\n self.pbp_loc_player_distance_df = self.pbp_loc_player_distance_df.reset_index(drop = True)\n \n # Concatenate self.playa_df and self.pbp_loc_player_distance_restricted_zone_df\n self.pbp_loc_player_distance_df = pd.concat([self.pbp_loc_player_distance_df, self.playa_df], axis = 1)\n \n # Append self.no_top_rebounders_list to df\n self.pbp_loc_player_distance_df['no_of_top_rebounders_in_play'] = self.no_top_rebounders_list\n \n \n return self.pbp_loc_player_distance_df\n \n \n def build_training_set(self):\n \n # Convert Yes to 1 and No to 0 in oreb column\n self.pbp_loc_player_distance_df['oreb'] = self.pbp_loc_player_distance_df['oreb'].str.replace('Yes','1')\n self.pbp_loc_player_distance_df['oreb'] = self.pbp_loc_player_distance_df['oreb'].str.replace('No','0')\n \n # Change oreb from string to int\n self.pbp_loc_player_distance_df['oreb'] = self.pbp_loc_player_distance_df['oreb'].astype(int) \n \n # One hot encode actiondescription\n self.pbp_loc_player_distance_df = pd.get_dummies(self.pbp_loc_player_distance_df, columns=[\"actiondescription\"])\n \n # Train \n self.X = self.pbp_loc_player_distance_df[['no_of_top_rebounders_in_play','actiondescription_jump_shot', 'actiondescription_layup', 'AtRim_off_dis_vc', 'AtRim_def_dis_vc']] \n self.y = self.pbp_loc_player_distance_df['oreb']\n \n return self.X, self.y\n \n def split_train_test(self):\n \n self.X_train, self.X_test, self.y_train, self.y_test = train_test_split(self.X, self.y, test_size = 0.5, random_state = 1)\n \n self.model = LogisticRegression()\n self.modelFit = self.model.fit(self.X_train, self.y_train)\n self.probs = self.model.predict_proba(self.X_test)[:, 1]\n \n \n false_positive_rate2, true_positive_rate2, threshold2 = roc_curve(self.y_test, self.probs)\n print('roc_auc_score for Logistic Regression: ', roc_auc_score(self.y_test, self.probs))\n \n fpr, tpr, thresholds = roc_curve(self.y_test, self.probs)\n plt.plot([0, 1], [0, 1], linestyle = '--')\n # Plot the roc curve for the model\n plt.plot(fpr, tpr)\n # Show the plot\n plt.show()\n \n \n # Calculate logloss\n self.log_loss = log_loss(self.y_test, self.probs)\n print('log loss: ', self.log_loss)\n \n \n # Process the unknown data files\n # Enter unknown data files in the order location, pbp, player position, and player rebound\n obj2 = Calculations(path + 'okc_testing_data_loc_dev_set.csv', path + 'okc_testing_data_pbp_dev_set.csv', path + 'player_pos_data.csv', path + 'player_reb_data.csv')\n \n # Re-order the columns\n self.reOrderUnk = obj2.reOrder()\n # Clean up and merge the data, and run calculations\n self.clean_up_Unk = obj2.clean_testing()\n self.mergeUnk = obj2.merge()\n self.purgeShotLocUnk = obj2.purge_shotLoc()\n self.distanceUnk = obj2.distance_from_hoop()\n self.varitionUnk = obj2.distance_vc_from_basket()\n self.reboundersUnk = obj2.top_rebounders()\n \n # One hot encode actiondescription in the testUnk_df\n self.reboundersUnk = pd.get_dummies(self.reboundersUnk, columns = [\"actiondescription\"])\n \n # Create the test set\n self.X_test = self.reboundersUnk[['no_of_top_rebounders_in_play','actiondescription_jump_shot', 'actiondescription_layup', 'AtRim_off_dis_vc', 'AtRim_def_dis_vc']]\n \n # Predict the unknown data using the model and self.X_test\n self.probs = self.model.predict_proba(self.X_test)[:, 1]\n \n # Convert to df for export with playbyplayorder_id as one of the columns\n self.play_id = list(self.reboundersUnk['playbyplayorder_id'])\n self.probs_df = pd.DataFrame()\n self.probs_df['playbyplayorder_id'] = self.play_id\n self.probs_df['probability'] = self.probs\n \n \n # Export probability predictions to csv\n self.probs_df.to_csv(\"/Users/danfeldheim/Documents/unknown_prediction_test1.csv\", index = False)\n \n# Call calculations class to process the training data \n# Enter path to csv files\npath = \"/Users/danfeldheim/Documents/OKC_project/\"\n\n# Enter training files in obj1 in the order location, pbp, player position, and player rebound\n# Note unknown files must be entered on line 414.\nobj1 = Calculations(path + '10_22_20_loc_test_set.csv', path + '10_22_20_pbp_test_set.csv', path + 'player_pos_data.csv', path + 'player_reb_data.csv')\n# Any of the df objects in init can be accessed\n# print (obj1.loc_df)\n\n# Re-order the columns\nreOrder = obj1.reOrder\n\n# Clean up the data\nclean_up_training = obj1.clean_training()\n# How to access each returned object separately\n# print (clean_up_training[0])\n\nmerge = obj1.merge()\npurgeOreb = obj1.purge_oreb()\npurgeShotLoc = obj1.purge_shotLoc()\ndistance = obj1.distance_from_hoop()\nvarition = obj1.distance_vc_from_basket()\nrebounders = obj1.top_rebounders()\ntrainSet = obj1.build_training_set()\ntrain_test = obj1.split_train_test()\n\n\n\n\n\n\n\n"
}
] | 3 |
vale-arostica/Arqui
|
https://github.com/vale-arostica/Arqui
|
394ee4f1b6f36fffe1fee573a2760605d0a1b398
|
bb292cf9ab4a0414d551604c8fea4239b603a27d
|
d576664d080e61f99e491fe14a80d00851be8ed9
|
refs/heads/main
| 2023-04-19T04:20:44.308597 | 2021-05-02T04:38:20 | 2021-05-02T04:38:20 | 363,454,594 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.47130340337753296,
"alphanum_fraction": 0.5070623755455017,
"avg_line_length": 36.143836975097656,
"blob_id": "aab78d5dd2880bab2fd485fd7ecd03bcdecfd29a",
"content_id": "3feb7fd49c9b7eb69400f3ca92361e28e9712657",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5622,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 146,
"path": "/Funciones_T1.py",
"repo_name": "vale-arostica/Arqui",
"src_encoding": "UTF-8",
"text": "import math\r\nimport re\r\n\r\nBd={'0':0,'1':1,'2':2,'3':3,'4':4,'5':5,'6':6,'7':7,'8':8,'9':9,\r\n 'a':10,'b':11,'c':12,'d':13,'e':14,'f':15,'g':16,'h':17,'i':18,'j':19,'k':20,'l':21,'m':22,'n':23,'o':24,'p':25,'q':26,'r':27,'s':28,'t':29,'u':30,'v':31,'w':32,'x':33,'y':34,'z':35,\r\n 'A':36,'B':37,'C':38,'D':39,'E':40,'F':41,'G':42,'H':43,'I':44,'J':45,'K':46,'L':47,'M':48,'N':49,'O':50,'P':51,'Q':52,'R':53,'S':54,'T':55,'U':56,'V':57,'W':58,'X':59,'Y':60,'Z':61,\r\n '+':62,'?':63}\r\n\r\n#ER generales para identificar código, números y secuencias alfanuméricas\r\ncodigo = r'bcd|gry|ed3|jsn|par|pbt|ham'\r\nnumerico = r'[0-9]+'\r\nalfanumerico = r'[a-zA-Z0-9?+]+'\r\nnro_binario = r'(0|1)+'\r\n\r\ndef base_to_dec(N, b): # Donde N es el número a convertir y b es la base (0 a 63)\r\n D = 0 # Decinal que será entregado\r\n i = 0 # Contador que recorre N de manera ascendente\r\n pos = ( len(N) - 1 ) # Contador que recorre los índices de N, de manera descendente.\r\n while i < len(N):\r\n if N[i] in Bd:\r\n D = D + Bd[N[i]] * pow(Bd[b] , pos)\r\n i = i + 1\r\n pos = pos - 1\r\n return D #(int)\r\n\r\n\r\ndef dec_to_base(D, t): # Sea D un número decimal y t la base a la cual convertir D\r\n X = [] # Sea X una lista que almacenará los dígitos en base b\r\n R ='' # R será el string de salida\r\n while D != 0:\r\n X.insert(0, ( D % Bd[t] ))\r\n D = math.trunc( D / Bd[t] )\r\n R = \"\".join([str(_) for _ in X])\r\n return R #(str)\r\n\r\n\r\ndef bin_to_dec(X): # Sea X un número binario entregado como str\r\n D = 0 # Sea D un número decimal\r\n i = 0 # Sea i un contador, posición\r\n while i < len(X):\r\n if X[i] == '1':\r\n D = (D + pow(2,i))\r\n i = i+1\r\n return D #(int)\r\n\r\n\r\ndef dec_to_bin(D): # Sea D un número decimal\r\n X = [] # Sea X una lista que almacenará los dígitos en binario\r\n R ='' # R será el string de salida\r\n while D != 0:\r\n X.insert(0, (D%2))\r\n D = math.trunc(D/2)\r\n R = \"\".join([str(_) for _ in X])\r\n return R #(str)\r\n\r\n\r\ndef base_to_bin(N, b)\r\n return dec_to_bin( base_to_dec(N, b) )\r\n\r\n\r\ndef bin_to_base(N, t)\r\n return dec_to_base( bin_to_dec(N) , t)\r\n\r\n\r\ndef bcd_algoritm(binary)\r\n while (len(binary)%4) != 0:\r\n binary = '0' + binary\r\n i = 0 # Contador\r\n largo = 0 # Contador para saber cuando terminé de recorrer el binario\r\n digit = '' # String que contendrá grupos de 4 bits\r\n dec_final = [] # Lista que almacenará el decimal final\r\n while largo < len[binary]\r\n while i < 4:\r\n digit = digit + binary[i]\r\n i += 1\r\n largo += 1\r\n d = bin_to_dec(digit) # Combertir el grupo de 4 bits en un dígito decimal\r\n if d > 9:\r\n return \"Entrada invalida\"\r\n else:\r\n dec_final.append(d) # Agregar el decimal a la lista\r\n digit = '' # Setear el grupo de 4 bits en \"0 bits\"\r\n i = 0 # setear el contador en 0\r\n D = \"\".join([str(_) for _ in dec_final])\r\n return D #(str)\r\n\r\n\r\n\r\n#!OJO ESTE ALG SIRVE CUANDO b ES 2, 10 O BASE HASTA 64 NO PARA CODIGOS!!\"!!!!!!!!!\"\r\ndef apply_bcd(N, b): # N numero (str) y b actual (current) base of number (str)\r\n result = ''\r\n if re.fullmatch(nro_binario, N) and b == '2':\r\n result = bcd_algoritm(N)\r\n if result == \"Entrada invalida\"\r\n return result\r\n elif re.fullmatch(numerico, result) and int(result) > 1000:\r\n return \"Entrada invalida\"\r\n else:\r\n return result\r\n elif re.fullmatch(numerico, N) and b == '10':\r\n result = bcd_algoritm( dec_to_bin(N) )\r\n if result == \"Entrada invalida\"\r\n return result\r\n elif re.fullmatch(numerico, result) and int(result) > 1000:\r\n return \"Entrada invalida\"\r\n else:\r\n return result\r\n elif re.fullmatch(alfanumerico, N) and int(b) > 10 and int(b) <= 64:\r\n result = bcd_algoritm( base_to_bin(N, b) )\r\n if result == \"Entrada invalida\"\r\n return result\r\n elif re.fullmatch(numerico, result) and int(result) > 1000:\r\n return \"Entrada invalida\"\r\n else:\r\n return result\r\n else:\r\n return \"Entrada invalida\"\r\n\r\n\r\ndef cod_filter(line):\r\n num, currbase, endbase = line.split()\r\n if re.fullmatch(codigo, currbase):\r\n if re.fullmatch(alfanumerico, num): # Si el número es un alfanumérico y sólo se entrega un código, no sabemos su base\r\n return \"Entrada invalida\"\r\n elif re.fullmatch(numerico, num): # Se entrega un código y el número de entrada es sólo numérico\r\n if (num[0] == 0):\r\n if re.fullmatch(nro_binario, num):\r\n #!tiene base 2\r\n else:\r\n #!tiene base 10\r\n #todo en cada caso se llama auna fun distinta. Evaluar casos\r\n\r\n\r\n\r\n######### Main #########\r\nprint(\"\\nBienvenido al procesador de codigo de la consola Abyss\\n\\n\")\r\nwhile True:\r\n line = input(\"Ingresar numero valido, base actual y base de destino separados por un solo espacio:\\n\")\r\n if '-' == line:\r\n break\r\n data = line.split()\r\n if len(data) != 3:\r\n print(\"Entrada invalida\")\r\n elif len(data) == 3:\r\n Numero, bactual, bfinal = data\r\n if re.fullmatch(bactual, numerico):\r\n \r\n \r\n\r\n\r\n"
}
] | 1 |
karlfinnerty/auto_send
|
https://github.com/karlfinnerty/auto_send
|
05868f17573fb0b7b8347157cbd760f4db9a9115
|
b83be2b0c834221455bc104245176bf5214b68b8
|
1b731ebf149ffd23dc657d1779846b2ed851406d
|
refs/heads/master
| 2020-08-19T05:27:16.524351 | 2019-10-17T20:53:27 | 2019-10-17T20:53:27 | 215,883,440 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 59.33333206176758,
"blob_id": "ae3a179aa67eeb390917e6fc5ef2c578977dd23a",
"content_id": "04665bda098774a3010eec1ba7fc6b81120755b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 3,
"path": "/README.md",
"repo_name": "karlfinnerty/auto_send",
"src_encoding": "UTF-8",
"text": "#auto_send\n\nThis is a script that automates sending of emails to golf club members. It uses simple mail transfer protocol (SMTP) with secure sockets layer (SSL) for added security. \n"
},
{
"alpha_fraction": 0.6602002382278442,
"alphanum_fraction": 0.6670838594436646,
"avg_line_length": 25.649999618530273,
"blob_id": "c2cb86d7c98781c728df3a637130357f7aad5b61",
"content_id": "142b3e64ee1e637a168b64c0814888b90ac91aa4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1598,
"license_type": "no_license",
"max_line_length": 257,
"num_lines": 60,
"path": "/gui_send.py",
"repo_name": "karlfinnerty/auto_send",
"src_encoding": "UTF-8",
"text": "import sys\nimport smtplib, ssl\n\nclass GUISender():\n\n\tsender = sys.argv[1] #info@nandplinks\n\n\tdef read_recipients(self, filename):\n\t\trecipients = []\n\t\twith open(filename, \"r\") as f:\n\t\t\tfor line in f.readlines():\n\t\t\t\ttokens = line.split(\":\")\n\t\t\t\tentry = (tokens[0], tokens[1])\n\t\t\t\trecipients.append(entry)\n\t\t\treturn recipients\n\n\t# def send_email(self, sender_address, reciever_address, message):\n\t# \tself.server.sendmail(sender_address, reciever_address, message)\n\t# \tprint(\"<Sending email from {} to {}> \\n with message: \\n {}. \\n\".format(sender_address, reciever_address, message))\n\n\n\tdef loop(self):\n\t\ttry:\n\t\t\trecipients = self.read_recipients(sys.argv[2])\n\t\t\tprint(\"Initializing smtp server...\")\n\n\t\t\tpassword = SLogin().get_pass()\n\t\t\tserver = smtplib.SMTP_SSL(\"smtp.gmail.com\", SLogin().port, context = SLogin().context)\n\t\t\tserver.login(self.sender, password)\n\n\t\t\tprint(\"Sending Emails....\")\n\n\t\t\ti = 0\n\t\t\twhile i < len(recipients):\n\t\t\t\tmessage = \"Hi {}, \\n I'm sending you this email to let you know that your GUI card is available for collection in the pro shop. Feel free to call in any day from nine to five. \\n Kind Regards, \\n Karl Finnerty \\n Narin & Portnoo Links\".format(recipients[i][0])\n\t\t\t\tserver.sendmail(self.sender, recipients[i][1], message) #send email from sender to reciever with message\n\t\t\t\ti += 1\n\n\t\t\tserver.quit()\n\n\t\texcept:\n\t\t\twith Exception as e:\n\t\t\t\tprint(e)\n\nclass SLogin():\n\n\tport = 465\n\tcontext = ssl.create_default_context()\n\n\tdef get_pass(self):\n\t\tpassword = input(\"Enter password: \")\n\t\treturn password\n\n\ndef main():\n\tsender = GUISender()\n\tsender.loop()\n\nif __name__ == '__main__':\n\tmain()"
},
{
"alpha_fraction": 0.6741573214530945,
"alphanum_fraction": 0.6797752976417542,
"avg_line_length": 16.899999618530273,
"blob_id": "7c0fcdcd0e14353d3e4f30b8907d910e1c946b39",
"content_id": "4d7f143ddbf5913b572f51e6411912f8a99635a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 10,
"path": "/gui_test1.py",
"repo_name": "karlfinnerty/auto_send",
"src_encoding": "UTF-8",
"text": "from gui_send import GUISender\nimport sys\n\ndef main():\n\tsender = GUISender()\n\treceivers = sender.read_recievers(sys.argv[1])\n\tprint(receivers)\n\nif __name__ == '__main__':\n\tmain()"
}
] | 3 |
crouse0/dotfiles
|
https://github.com/crouse0/dotfiles
|
2a2af42f141cb7725af5df648451a857ceb41a45
|
4c0f6963bc242f4251d9d57be26f7d9f9bf2a493
|
65f355258fe45e368c82583dc5123073ae9db2b7
|
refs/heads/master
| 2018-09-22T20:44:02.786987 | 2018-08-30T19:14:52 | 2018-08-30T19:14:52 | 136,247,599 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8392857313156128,
"alphanum_fraction": 0.8392857313156128,
"avg_line_length": 27,
"blob_id": "3ec3edb623fe1e26a4bf58b037548d7a0fb86d8e",
"content_id": "bad29421492f0f8b3610860372fb0ce7a7a0d7d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 2,
"path": "/README.md",
"repo_name": "crouse0/dotfiles",
"src_encoding": "UTF-8",
"text": "# dotfiles\nConfigurations for my most used applications\n"
},
{
"alpha_fraction": 0.6098748445510864,
"alphanum_fraction": 0.6098748445510864,
"avg_line_length": 27.19607925415039,
"blob_id": "1bf913caee34d03b97bdc8453bbadff35185664c",
"content_id": "101b12ff908c02d16db924adff4eceba4d7fd945",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1438,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 51,
"path": "/create_links.py",
"repo_name": "crouse0/dotfiles",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\n\nVERBOSE = True\nREMOVE_EXISTING = True\n\ndef create_link(link):\n \"\"\"\n Create a symlink from the src file to the current user's home directory.\n \"\"\"\n src = os.path.abspath(link)\n dest = os.path.join(home, link)\n if link in special_cases:\n dest = os.path.join(home, special_cases[link])\n\n # remove link if it exists and remove flag is set\n if os.path.islink(dest) and REMOVE_EXISTING:\n if VERBOSE:\n print 'Removing existing link at \"%s\"' % dest\n os.remove(dest)\n\n # create the destination directory if it does not exist\n dest_parent = os.path.abspath(os.path.join(dest, '..'))\n if not os.path.exists(dest_parent):\n os.makedirs(dest_parent)\n\n # create the link\n if VERBOSE:\n print 'Creating link from \"%s\" to \"%s\"\\n' % (src, dest)\n os.symlink(src, dest);\n\nif __name__ == '__main__':\n # get the home directory\n home = os.path.expanduser('~')\n\n # symlinks to create\n links_to_create = [\n '.astylerc',\n 'nvim/init.vim',\n os.path.join(home, '.local/share/nvim/site/autoload/plug.vim'),\n ]\n\n # add key, value pairs that map a src to a destination\n special_cases = {\n 'nvim/init.vim': '.vimrc',\n os.path.join(home, '.local/share/nvim/site/autoload/plug.vim'): os.path.join(home, '.vim/autoload/plug.vim')\n }\n\n for link in links_to_create:\n create_link(link)\n"
}
] | 2 |
jq2/simple_python_extension
|
https://github.com/jq2/simple_python_extension
|
f4186e160eaede20b8db63e4a73339959bfa2b6a
|
588271915c66ce46ba84ed33d7f167308f7e9739
|
4ccc5d7a12b7bc8f44a71cece8cbe431d1ef20f2
|
refs/heads/master
| 2019-03-20T00:45:36.635985 | 2018-03-16T18:46:05 | 2018-03-16T18:46:05 | 125,557,137 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6544850468635559,
"alphanum_fraction": 0.6578072905540466,
"avg_line_length": 24.799999237060547,
"blob_id": "e12b6202e98e4f87790d98af6a6c0297509c4006",
"content_id": "985aa51b5ec526e7240c823e4aa2430ea9d1e582",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 904,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 35,
"path": "/custom_function.c",
"repo_name": "jq2/simple_python_extension",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <Python.h>\n\nstatic PyObject* my_print_hello(PyObject* self, PyObject* args) {\n printf(\"Saying hello to my_print_hello function :)\\n\");\n return Py_None;\n}\n\nstatic PyObject* my_print_number(PyObject* self, PyObject* args) {\n int number = 0;\n if(!PyArg_ParseTuple(args, \"i\", &number))\n return NULL;\n\n printf(\"%d\\n\", number);\n return Py_BuildValue(\"i\", number);\n}\n\nstatic PyMethodDef custom_function[] = {\n { \"my_print_hello\", my_print_hello, METH_NOARGS, \"Imprime uma mensagem, hello world!\" },\n { \"my_print_number\", my_print_number, METH_VARARGS, \"Imprime números como argumentos\" },\n { NULL, NULL, 0, NULL }\n};\n\nstatic struct PyModuleDef module_array = {\n PyModuleDef_HEAD_INIT,\n \"custom_funcion\",\n \"NOTHING\",\n -1,\n custom_function\n};\n\nPyMODINIT_FUNC PyInit_custom_function(void)\n{\n return PyModule_Create(&module_array);\n}\n"
},
{
"alpha_fraction": 0.7340425252914429,
"alphanum_fraction": 0.7553191781044006,
"avg_line_length": 19.77777862548828,
"blob_id": "8333b956e02b962e87c4e60255c03cec7dceb4eb",
"content_id": "c067256127e407b57687287b7464b65f1d8bf1fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 9,
"path": "/tests/test.py",
"repo_name": "jq2/simple_python_extension",
"src_encoding": "UTF-8",
"text": "#!/bin/python3.6\n\nimport custom_function\nimport sys\n\n\ncustom_function.my_print_hello()\ncustom_function.my_print_number(int(sys.argv[2]))\ncustom_function.my_print_number(int(sys.argv[1]))\n\n"
},
{
"alpha_fraction": 0.7055214643478394,
"alphanum_fraction": 0.7177914381027222,
"avg_line_length": 80.5,
"blob_id": "d8a6658c7f3544b6d7e6c407a376167241a52d4a",
"content_id": "92ea6ac830b7a0bdba0f5e33fdb63e325d4cd575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 2,
"path": "/setup.py",
"repo_name": "jq2/simple_python_extension",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup, Extension\nsetup(name = 'custom_function', version = '0.2', ext_modules = [Extension('custom_function', ['custom_function.c'])])\n"
},
{
"alpha_fraction": 0.6745434999465942,
"alphanum_fraction": 0.6906552314758301,
"avg_line_length": 22.846153259277344,
"blob_id": "9265ecba668e0805e4bcd1246a7e43da28ce0081",
"content_id": "15900fe7f629cb65abe6db2547efb2e7e83b9bb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 931,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 39,
"path": "/README.md",
"repo_name": "jq2/simple_python_extension",
"src_encoding": "UTF-8",
"text": "# Simple Python module written in C Extension\n\nThis repository is for educational purposes and can often be useful for beginners who wish to learn the internal virtual machine of Python (PVM).\nThis project is part of [lptrw](https://github.com/pr1v7/lptrw), see the project [initial issues] (https://github.com/pr1v7/lptrw/issues/1) for more information.\n\n\n# HowTo install\n - Clone the repository:\n```\n $ git clone [email protected]:jq2/simple_python_extension.git\n```\n\n - Change to the working directory:\n```\n $ cd /path/to/simple_python_extension\n```\n\n - Install the module extension:\n```\n $ sudo python setup.py build\n $ sudo python setup.py install\n```\n\n# HowTo test\n - Testing:\n```\n $ python tests/test.py 42 31337\n```\n\n\n# To do\n [x] First's tests.\n [x] Write some simple function.\n [ ] Logging module extension. (WIP)\n [ ] Client administration console CLI.\n\n\n# Contributors\n @jq2 https://github.com/jq2\n\n"
}
] | 4 |
Ledwith94/FYP
|
https://github.com/Ledwith94/FYP
|
80e79276729c663129f87e51101ff6a9d77bba47
|
ec1bd875d7a29b00af8fbc25cb05ef42a8288a74
|
44732dbda8b8dbb3f6fe0eab18d60dc3669f4add
|
refs/heads/master
| 2020-06-11T13:09:44.631327 | 2016-12-13T16:49:25 | 2016-12-13T16:49:25 | 75,657,736 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5718209147453308,
"alphanum_fraction": 0.5780298709869385,
"avg_line_length": 31.339767456054688,
"blob_id": "e19335506a1ab7395ea3e29d236e174235f1438c",
"content_id": "eb66e3bca5a5b4f6860fa8d138b4be1f78be3a84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8375,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 259,
"path": "/diskImageSearch.py",
"repo_name": "Ledwith94/FYP",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# /media/paul/USB DISK/Ubuntu16-Original.vhd\n# /media/paul/USB DISK/Windows7-Original.vhd\nimport argparse\nimport csv\nimport datetime\nimport hashlib\nimport os\nimport time\nimport pytsk3\nimport pyvhdi\n\n\nfrom pymongo import MongoClient\n\n\nclass vhdi_Img_Info(pytsk3.Img_Info):\n def __init__(self, vhdi_file):\n self._vhdi_file = vhdi_file\n super(vhdi_Img_Info, self).__init__(\n url='', type=pytsk3.TSK_IMG_TYPE_EXTERNAL)\n\n def close(self):\n self._vhdi_file.close()\n\n def read(self, offset, size):\n self._vhdi_file.seek(offset)\n return self._vhdi_file.read(size)\n\n def get_size(self):\n return self._vhdi_file.get_media_size()\n\n\nclass ewf_Img_Info(pytsk3.Img_Info):\n def __init__(self, ewf_handle):\n self._ewf_handle = ewf_handle\n self.memory = 0\n super(ewf_Img_Info, self).__init__(\n url=\"\", type=pytsk3.TSK_IMG_TYPE_EXTERNAL)\n\n def close(self):\n self._ewf_handle.close()\n\n def read(self, offset, size):\n self._ewf_handle.seek(offset)\n return self._ewf_handle.read(size)\n\n def get_size(self):\n return self._ewf_handle.get_media_size()\n\n\ndef mongo_insert(insert):\n client = MongoClient()\n db = client['dedupe']\n files = db.files\n file_id = files.insert_one(insert).inserted_id\n\n\ndef acq_insert(insert):\n client = MongoClient()\n db = client['Acquisition']\n files = db.files\n file_id = files.insert_one(insert).inserted_id\n\ndef acquisition_exists(name):\n client = MongoClient()\n db = client['Acquisition']\n files = db.files\n if bool(files.find_one({\"Name\": name})):\n return True\n else:\n return False\n\n\ndef already_exists(hash):\n client = MongoClient()\n db = client['dedupe']\n files = db.files\n if bool(files.find_one({\"SHA1 Hash\": hash})):\n files.update_one({\"SHA1 Hash\": hash}, {'$addToSet': {\"Acquisition\": outname}})\n return True\n else:\n return False\n\ndef blacklisted(hash):\n client = MongoClient()\n db = client['blacklist']\n files = db.files\n if bool(files.find_one({\"SHA1 Hash\": hash})):\n return True\n else:\n return False\n\n\ndef directoryRecurse(directoryObject, parentPath, insert_list):\n for entryObject in directoryObject:\n if entryObject.info.name.name in [\".\", \"..\"]:\n continue\n\n try:\n f_type = entryObject.info.meta.type\n\n except:\n #print \"Cannot retrieve type of\", entryObject.info.name.name\n continue\n\n try:\n\n filepath = '/%s/%s' % ('/'.join(parentPath), entryObject.info.name.name)\n outputPath = './%s/%s/' % (str(partition.addr), '/'.join(parentPath))\n\n if f_type == pytsk3.TSK_FS_META_TYPE_DIR:\n sub_directory = entryObject.as_directory()\n parentPath.append(entryObject.info.name.name)\n insert_list = directoryRecurse(sub_directory, parentPath, insert_list)\n parentPath.pop(-1)\n # print \"Directory: %s\" % filepath\n\n elif f_type == pytsk3.TSK_FS_META_TYPE_REG and entryObject.info.meta.size != 0:\n filedata = entryObject.read_random(0, entryObject.info.meta.size)\n # print \"match \", entryObject.info.name.name\n md5hash = hashlib.md5()\n md5hash.update(filedata)\n sha1hash = hashlib.sha1()\n sha1hash.update(filedata)\n # start_block = None\n # finish_block = None\n # block_length = None\n # for attr in entryObject:\n # for run in attr:\n # start_block = run.addr\n # finish_block = run.addr + run.len\n # block_length = run.len\n\n # wr.writerow([int(entryObject.info.meta.addr), '/'.join(parentPath) + entryObject.info.name.name,\n # datetime.datetime.fromtimestamp(entryObject.info.meta.crtime).strftime(\n # '%Y-%m-%d %H:%M:%S'), int(entryObject.info.meta.size),\n # md5hash.hexdigest(),\n # sha1hash.hexdigest(), filepath])\n\n insert = {\"SHA1 Hash\": sha1hash.hexdigest(),\n \"MD5 Hash\": md5hash.hexdigest(),\n \"inode\": int(entryObject.info.meta.addr),\n \"Name\": '/'.join(parentPath) + entryObject.info.name.name,\n \"Creation Time\": datetime.datetime.fromtimestamp(entryObject.info.meta.crtime).strftime(\n '%Y-%m-%d %H:%M:%S'),\n \"Size\": int(entryObject.info.meta.size),\n \"File Path\": \"Extracted_files/\" + filepath,\n \"Acquisition\": [outname],\n # \"Start Block\": start_block,\n # \"Finish Block\": finish_block,\n # \"Block Length\": block_length\n }\n if args.blacklist and blacklisted(sha1hash.hexdigest()):\n print \"Blacklisted File Found\"\n print insert\n raw_input(\"Press enter to continue\")\n elif already_exists(sha1hash.hexdigest()) is False:\n mongo_insert(insert)\n if not os.path.exists(\"Extracted_files/\" + outputPath):\n os.makedirs(\"Extracted_files/\" + outputPath)\n extractFile = open(\"Extracted_files/\" + outputPath + entryObject.info.name.name, 'w')\n extractFile.write(filedata)\n extractFile.close()\n\n except IOError as e:\n print e\n continue\n\n\nstartTime = datetime.datetime.now()\nargparser = argparse.ArgumentParser(\n description='Hash files recursively from a forensic image and optionally extract them')\nargparser.add_argument(\n '-i', '--image',\n dest='imagefile',\n action=\"store\",\n type=str,\n default=None,\n required=True,\n help='E01 to extract from'\n)\nargparser.add_argument(\n '-t', '--type',\n dest='imagetype',\n action=\"store\",\n type=str,\n default=False,\n required=True,\n help='Specify image type e01 or raw'\n)\nargparser.add_argument(\n '-a', '--acquisition',\n dest='acquisition',\n action=\"store\",\n type=str,\n default=False,\n required=True,\n help='Specify acquisition name'\n)\nargparser.add_argument(\n '--enable-automation',\n dest='blacklist',\n action=\"store\",\n type=bool,\n default=False,\n required=False,\n help='Enable auto file discovery'\n)\nargs = argparser.parse_args()\ndirPath = '/'\ninsert_list = []\n\nif not os.path.exists(\"Extracted_files/\"):\n os.makedirs(\"Extracted_files/\")\n\ni = 0\nwhile acquisition_exists(args.acquisition):\n i += 1\noutname = args.acquisition + \".csv\"\noutfile = open(outname, 'w')\n\noutfile.write('\"Inode\",\"Full Path\",\"Creation Time\",\"Size\",\"MD5 Hash\",\"SHA1 Hash\", \"File Path\\n')\nwr = csv.writer(outfile, quoting=csv.QUOTE_ALL)\nif args.imagetype == \"raw\":\n print \"Raw Type\"\n imagehandle = pytsk3.Img_Info(url=args.imagefile)\nelse:\n print \"Virtual Hard Disk\"\n vhdi_file = pyvhdi.file()\n vhdi_file.open(args.imagefile)\n imagehandle = vhdi_Img_Info(vhdi_file)\n\npartitionTable = pytsk3.Volume_Info(imagehandle)\nfor partition in partitionTable:\n print partition.addr, partition.desc, \"%ss(%s)\" % (partition.start, partition.start * 512), partition.len\n try:\n filesystemObject = pytsk3.FS_Info(imagehandle, offset=(partition.start * 512))\n except:\n print \"Partition has no supported file system\"\n continue\n print \"File System Type Dectected \", filesystemObject.info.ftype\n directoryObject = filesystemObject.open_dir(path=dirPath)\n print \"Directory:\", dirPath\n directoryRecurse(directoryObject, [], insert_list)\n\nrow_count = sum(1 for row in open(outname, \"r\"))\n\ninsert = {\"Name\": outname,\n \"Creation Time\": time.ctime(os.path.getctime(outname)),\n \"File Count\": row_count,\n \"Image Size\": str(pytsk3.Img_Info.get_size(imagehandle)),\n \"MD5 Hash\": \"NULL\",\n \"SHA1 Hash\": \"NULL\",\n \"All Files\": insert_list\n }\nacq_insert(insert)\nprint datetime.datetime.now() - startTime"
}
] | 1 |
jason-neal/convolve_spectrum
|
https://github.com/jason-neal/convolve_spectrum
|
55fd35e6b399b39f8a2b99e89d6b81f17436262c
|
0ebfb6abeae1c6676a4c6f0f06e1da97b4e10923
|
098af2a96b3f4735ce4707b449939aac1f758aee
|
refs/heads/master
| 2023-01-03T20:34:53.545581 | 2022-11-23T00:37:37 | 2022-11-23T00:37:37 | 111,927,365 | 2 | 0 |
MIT
| 2017-11-24T14:32:25 | 2022-02-01T10:32:13 | 2022-12-23T23:22:35 |
Python
|
[
{
"alpha_fraction": 0.6262705326080322,
"alphanum_fraction": 0.6505082249641418,
"avg_line_length": 29.452381134033203,
"blob_id": "d3b234931c5cb8262e9eff86a0dbaddf319f9ba9",
"content_id": "33e873c7e45fc109be0824228684775f477a25bc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1279,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 42,
"path": "/tests/test_utils.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pytest\n\nfrom convolve_spectrum.utils import wav_selector\nfrom hypothesis import given\nfrom hypothesis import strategies as st\n\n\n@given(st.lists(st.floats()), st.floats(allow_nan=False), st.floats(allow_nan=False))\ndef test_wav_selector(wav, wav_min, wav_max):\n y = np.copy(wav)\n wav2, y2 = wav_selector(wav, y, wav_min, wav_max)\n\n assert isinstance(wav2, np.ndarray)\n assert isinstance(y2, np.ndarray)\n assert all(wav2 >= wav_min)\n assert all(wav2 <= wav_max)\n assert len(wav2) == len(y2)\n\n\[email protected](\n \"wav, wav_min, wav_max\", [([np.nan], 1, 2), ([np.inf], 1, 2), ([-1 * np.inf], 3, 4)]\n)\ndef test_wav_selector_with_nans_and_infs(wav, wav_min, wav_max):\n y = np.copy(wav)\n wav2, y2 = wav_selector(wav, y, wav_min, wav_max)\n\n assert isinstance(wav2, np.ndarray)\n assert isinstance(y2, np.ndarray)\n assert all(wav2 >= wav_min)\n assert all(wav2 <= wav_max)\n assert len(wav2) == len(y2)\n assert len(wav2) == 0\n\n\[email protected](\n \"wav, wav_min, wav_max\", [(np.arange(10), np.nan, 2), (range(10), 1, np.nan)]\n)\ndef test_wav_selector_with_nans_inputs(wav, wav_min, wav_max):\n y = np.copy(wav)\n with pytest.raises(AssertionError):\n wav_selector(wav, y, wav_min, wav_max)\n"
},
{
"alpha_fraction": 0.7434036731719971,
"alphanum_fraction": 0.7691292762756348,
"avg_line_length": 55.14814758300781,
"blob_id": "20e469896b087131184f1a07e445fdc1a75f453f",
"content_id": "2bff980e2a35ba4de376627547e14120797f96f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1516,
"license_type": "permissive",
"max_line_length": 590,
"num_lines": 27,
"path": "/README.md",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "# Spectrum Convolution\n\n[](https://travis-ci.org/jason-neal/convolve_spectrum)[](https://www.codacy.com/app/jason-neal/convolve_spectrum?utm_source=github.com&utm_medium=referral&utm_content=jason-neal/convolve_spectrum&utm_campaign=Badge_Grade)[](https://coveralls.io/github/jason-neal/convolve_spectrum?branch=master)\n\n- Convolve a spectrum by a Gaussian instrument profile with a given Resolution `R`.\n- Does not need a equidistant wavelength steps.\n- Uses multiprocessing to speed up the convolution.\n- Calculates the IP for every pixel/wavelength individually (but this is embarrassingly parallel).\n\n## Installation\n```\n git clone https://github.com/jason-neal/convolve_spectrum.git \n cd convolve_spectrum\n pip install -r requirements/requirements.txt\n python setup.py install\n```\n\n## Usage\n```\n from convolve_spectrum import ipconvolution\n convolved_wav, convolved_flux = ip_convolution(wav, flux, wav_limits, R, fwhm_lim=5.0) \n```\nThe wavelength axis is reduced to *wav_limits* due to edge effects in the convolution.\n\n\n## Notes\nThe original version of this code was used for the IP component of [Figueira et. al. 2016](https://arxiv.org/abs/1511.07468) and explained in detail there (page 3).\n"
},
{
"alpha_fraction": 0.6565840840339661,
"alphanum_fraction": 0.67066490650177,
"avg_line_length": 29.196849822998047,
"blob_id": "b8686805acba86409627a232091e71abddf7e08a",
"content_id": "5ca29bda645de4f87867cf0d54f2fd4a70afab70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3835,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 127,
"path": "/convolve_spectrum/ip_convolution.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "# Convolution of spectra to a instrument profile of a given resolution.\n#\n# Unlike PyAstronomy the spectra do not have to be equidistant in wavelength.\n\n# Pixels computed in parallel using multiprocess.\n\n\nfrom __future__ import division, print_function\n\nimport warnings\n\nimport multiprocess as mprocess\nimport numpy as np\nfrom tqdm import tqdm\n\nfrom convolve_spectrum.utils import plot_convolution, unitary_Gauss, wav_selector\n\n\ndef wrapper_fast_convolve(args):\n \"\"\"Wrapper for fast_convolve.\n\n Needed to unpack the arguments for fast_convolve as multiprocess.Pool.map does not accept multiple\n arguments.\n \"\"\"\n return fast_convolve(*args)\n\n\ndef ip_convolution(\n wav,\n flux,\n chip_limits,\n resolution,\n fwhm_lim=5.0,\n plot=True,\n numProcs=None,\n progbar=True,\n):\n \"\"\"Spectral convolution which allows non-equidistant step values.\n\n Parameters\n ----------\n wav:\n Wavelength\n flux:\n Flux of spectrum\n chip_limits: List[float, float]\n Wavelength limits of region to return after convolution.\n resolution:\n Resolution to convolve to.\n fwhm_lim:\n Number of FWHM of convolution kernel to use as edge buffer.\n plot: bool\n Display the spectrum, and convolved result.\n numProcs: int\n NUmber of processes to use. Default=None selects cpu_count - 1.\n progbar: bool\n Enable the tqdm progress bar. Default=True.\n \"\"\"\n\n # Turn into numpy arrays\n wav = np.asarray(wav, dtype=\"float64\")\n flux = np.asarray(flux, dtype=\"float64\")\n\n wav_chip, flux_chip = wav_selector(wav, flux, chip_limits[0], chip_limits[1])\n # We need to calculate the fwhm at this value in order to set the starting\n # point for the convolution\n fwhm_min = wav_chip[0] / resolution # fwhm at the extremes of vector\n fwhm_max = wav_chip[-1] / resolution\n\n # Wide wavelength bin for the resolution_convolution\n wav_min = wav_chip[0] - fwhm_lim * fwhm_min\n wav_max = wav_chip[-1] + fwhm_lim * fwhm_max\n wav_ext, flux_ext = wav_selector(wav, flux, wav_min, wav_max)\n\n # Multiprocessing part\n if numProcs is None:\n numProcs = mprocess.cpu_count() - 1\n\n mprocPool = mprocess.Pool(processes=numProcs)\n\n args_generator = tqdm(\n [[wav, resolution, wav_ext, flux_ext, fwhm_lim] for wav in wav_chip],\n disable=(not progbar),\n )\n\n flux_conv_res = np.array(mprocPool.map(wrapper_fast_convolve, args_generator))\n\n mprocPool.close()\n\n if plot:\n plot_convolution(wav_chip, flux_chip, flux_conv_res, resolution)\n\n return wav_chip, flux_conv_res\n\n\ndef fast_convolve(wav_val, resolution, wav_extended, flux_extended, fwhm_lim):\n \"\"\"IP convolution multiplication step for a single wavelength value.\"\"\"\n fwhm = wav_val / resolution\n # Mask of wavelength range within 5 fwhm of wav\n index_mask = (wav_extended > (wav_val - fwhm_lim * fwhm)) & (\n wav_extended < (wav_val + fwhm_lim * fwhm)\n )\n\n flux_2convolve = flux_extended[index_mask]\n # Gaussian Instrument Profile for given resolution and wavelength\n inst_profile = unitary_Gauss(wav_extended[index_mask], wav_val, fwhm)\n\n sum_val = np.sum(inst_profile * flux_2convolve)\n # Correct for the effect of convolution with non-equidistant positions\n unitary_val = np.sum(inst_profile)\n\n return sum_val / unitary_val\n\n\nif __name__ == \"__main__\":\n # Example usage of this convolution\n wav = np.linspace(2040, 2050, 30000)\n flux = (\n np.ones_like(wav) - unitary_Gauss(wav, 2045, .6) - unitary_Gauss(wav, 2047, .9)\n )\n # Range in which to have the convolved values. Be careful of the edges!\n chip_limits = [2042, 2049]\n\n resolution = 1000\n convolved_wav, convolved_flux = ip_convolution(\n wav, flux, chip_limits, resolution, fwhm_lim=5.0, plot=True\n )\n"
},
{
"alpha_fraction": 0.6618357300758362,
"alphanum_fraction": 0.727053165435791,
"avg_line_length": 17.81818199157715,
"blob_id": "8a410cf727b7cde81435a4772dc76e8a80402055",
"content_id": "eb828ce18570276be23a2f56df2de1447d2dcef6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 414,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 22,
"path": "/CHANGELOG.md",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "# \n\n## 0.3\nOctober 2018\n- Restrict to python 3.6+\n- Remove the single process convolution.\n- Run black\n- Remove convolve a spectrum (and spectrum_overload requirements).\n- Remove depreciated function spelling.\n\n## 0.2\n24-Nov-2017\n- Separate out convolution into separate package.\n\n## 0.1\n## Changes after 1-Nov-2017\n - Convolve a spectrum\n \n \n### October 2017\n - Fix test coverage\n - pin requirements with pyup.io\n"
},
{
"alpha_fraction": 0.5877862572669983,
"alphanum_fraction": 0.7404580116271973,
"avg_line_length": 21,
"blob_id": "857e8afaeede0235616664917f03e9a6e08bc39a",
"content_id": "19e7090b2da6fcd11981a8b77d7771e526a13365",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 6,
"path": "/requirements/test_requirements.txt",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "codacy-coverage==1.3.11\ncodeclimate-test-reporter==0.2.3\nhypothesis==6.58.0\npytest==7.2.0\npytest-cov==4.0.0\npython-coveralls==2.9.3"
},
{
"alpha_fraction": 0.7948718070983887,
"alphanum_fraction": 0.7948718070983887,
"avg_line_length": 51,
"blob_id": "6be0be3730b10d537c4f3699e9d4e920d96cc946",
"content_id": "26ff0b863f8f0f4ad5ba4564c0934694ad75d360",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 3,
"path": "/convolve_spectrum/__init__.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "__all__ = [\"ip_convolution.py\"]\nfrom convolve_spectrum.ip_convolution import ip_convolution\nfrom convolve_spectrum.utils import wav_selector, unitary_Gauss\n"
},
{
"alpha_fraction": 0.6296650767326355,
"alphanum_fraction": 0.6392344236373901,
"avg_line_length": 37.703704833984375,
"blob_id": "34a915f4ebbaad9b9ce305ba4c472711ed8bd3a5",
"content_id": "fc1476c58903342b74bf9dd1fce0489a64242050",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3135,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 81,
"path": "/setup.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nfrom setuptools import find_packages, setup\n\nif sys.version_info < (3, 6):\n error = \"\"\"\nconvolve_spectrum does not support Python 2.x, 3.0, 3.1, 3.2, 3.3, 3.4 or 3.5.\nPython 3.6 and above is required. Attempted with {}.\nThis may be due to an out of date pip.\nMake sure you have pip >= 9.0.1.\n\"\"\".format(\n sys.version\n )\n sys.exit(error)\n\nlong_description = \" \"\nbase_dir = os.path.join(os.path.abspath(os.path.dirname(__file__)))\n\nsetup(\n name=\"convolve_spectrum\",\n version=\"0.3\",\n description=\"Spectrum convolution that handles uneven wavelengths.\",\n long_description=long_description,\n url=\"https://github.com/jason-neal/convolve_spectrum\",\n author=\"Jason Neal\",\n author_email=\"[email protected]\",\n license=\"MIT\",\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n # Indicate who your project is intended for\n \"Intended Audience :: Science/Research\",\n \"Topic :: Scientific/Engineering :: Astronomy\",\n \"Topic :: Scientific/Engineering :: Physics\",\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Natural Language :: English\",\n ],\n # What does your project relate to?\n keywords=[\"astronomy\"],\n # You can just specify the packages manually here if your project is\n # simple. Or you can use find_packages().\n packages=find_packages(exclude=[\"contrib\", \"docs\", \"tests\", \"test\"]),\n # test_suite=[],\n # Alternatively, if you want to distribute just a my_module.py, uncomment\n # this:\n # py_modules=[\"my_module\"],\n # List run-time dependencies here. These will be installed by pip when\n # your project is installed. For an analysis of \"install_requires\" vs pip's\n # requirements files see:\n # https://packaging.python.org/en/latest/requirements.html\n install_requires=[\"numpy\", \"matplotlib\", \"tqdm\", \"multiprocess\"],\n # install_requires=[],\n setup_requires=[\"pytest-runner\"],\n tests_require=[\"pytest\", \"hypothesis\"],\n # List additional groups of dependencies here (e.g. development\n # dependencies). You can install these using the following syntax,\n # for example:\n # $ pip install -e .[dev,test]\n extras_require={\n \"dev\": [\"check-manifest\"],\n \"test\": [\"coverage\", \"pytest\", \"pytest-cov\", \"python-coveralls\", \"hypothesis\"],\n \"docs\": [\"sphinx >= 1.4\", \"sphinx_rtd_theme\"],\n },\n # If there are data files included in your packages that need to be\n # installed, specify them here. If using Python 2.6 or less, then these\n # have to be included in MANIFEST.in as well.\n # package_data={\"spectrum_overload\": [\"data/*.fits\"]},\n package_data={},\n data_files=[],\n # To provide executable scripts, use entry points in preference to the\n # \"scripts\" keyword. Entry points provide cross-platform support and allow\n # pip to create the appropriate form of executable for the target platform.\n entry_points={\n # 'console_scripts': [\n # 'sample=sample:main',\n # ],\n \"console_scripts\": []\n },\n)\n"
},
{
"alpha_fraction": 0.6363211870193481,
"alphanum_fraction": 0.654995322227478,
"avg_line_length": 29.600000381469727,
"blob_id": "cd44759fa6beac20faa530a9bc8522bdf48bc440",
"content_id": "0441a62671b72139e53f856b5f5ed6c0f7c987ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2142,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 70,
"path": "/scripts/IP_compare_single_vs_multiproc.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "# Convolution Code from\n# https://github.com/jason-neal/equanimous-octo-tribble/blob/master/IP_Convolution.py\n# Convolution of spectra to a Instrument profile of given resolution.\n#\n# The spectra does not have to be equidistant in wavelength.\n\n# Multiprocess use and speed timing was contributed by Jorge Martins\n\nfrom __future__ import division, print_function\n\nfrom datetime import datetime as dt\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom convolve_spectrum import unitary_Gauss\nfrom convolve_spectrum.ip_convolution import ip_convolution as multi_ip_convolution\n\nif __name__ == \"__main__\":\n # Example usage of this convolution\n wav = np.linspace(2040, 2050, 20000)\n flux = (\n np.ones_like(wav) - unitary_Gauss(wav, 2045, .6) - unitary_Gauss(wav, 2047, .9)\n )\n\n # range in which to have the convolved values. Be careful of the edges!\n chip_limits = [2042, 2049]\n resolution = 2000\n\n time_init = dt.now()\n single_convolved_wav, single_convolved_flux = multi_ip_convolution(\n wav,\n flux,\n chip_limits,\n resolution,\n fwhm_lim=5.0,\n plot=False,\n verbose=True,\n numProcs=1,\n )\n time_end = dt.now()\n\n multi_convolved_wav, multi_convolved_flux = multi_ip_convolution(\n wav, flux, chip_limits, resolution, fwhm_lim=5.0, plot=False, verbose=True\n )\n time_end_multi = dt.now()\n\n print(\"Time for normal convolution {}\".format(time_end - time_init))\n print(\"Time from multiprocess convolution {}\".format(time_end_multi - time_end))\n\n plt.figure()\n plt.plot(single_convolved_wav, single_convolved_flux, \"ro\", label=\"single\")\n plt.plot(multi_convolved_wav, multi_convolved_flux, \"bo\", label=\"multi\")\n plt.plot(wav, flux, \"k-\", label=\"original\")\n plt.legend(loc=\"best\")\n plt.title(r\"Convolution by an Instrument Profile\")\n\n plt.figure()\n plt.title(r\"single/multi fluxes\")\n plt.plot(\n single_convolved_wav,\n [\n single / multi\n for single, multi in zip(single_convolved_flux, multi_convolved_flux)\n ],\n \"r\",\n label=\"single\",\n )\n\n plt.show()\n"
},
{
"alpha_fraction": 0.565625011920929,
"alphanum_fraction": 0.574999988079071,
"avg_line_length": 25.66666603088379,
"blob_id": "f9880636f4ad863efbdd72dd738df05d2968667e",
"content_id": "a9d1c65305b37c8c8fdf8f753785dd99076fe3c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1600,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 60,
"path": "/convolve_spectrum/utils.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom matplotlib import pyplot as plt\n\n\ndef wav_selector(wav, flux, wav_min, wav_max):\n \"\"\"Wavelength selector.\n\n Slice array to within wav_min and wav_max inclusive.\n \"\"\"\n assert not (np.isnan(wav_min)), \"Lower wavelength band is NaN!\"\n assert not (np.isnan(wav_max)), \"Upper wavelength band is NaN!\"\n\n wav = np.asarray(wav)\n flux = np.asarray(flux)\n\n # Remove NaN wavelengths\n nan_mask = np.isnan(wav)\n wav = wav[~nan_mask]\n flux = flux[~nan_mask]\n assert not np.any(np.isnan(wav))\n mask = (wav >= wav_min) & (wav <= wav_max)\n wav_sel = wav[mask]\n flux_sel = flux[mask]\n return wav_sel, flux_sel\n\n\ndef unitary_Gauss(x, center, fwhm):\n \"\"\"Gaussian_function of area=1.\n\n p[0] = A;\n p[1] = mean;\n p[2] = full with at half maximum (fwhm);\n \"\"\"\n sigma = np.abs(fwhm) / (2 * np.sqrt(2 * np.log(2)))\n Amp = 1.0 / (sigma * np.sqrt(2 * np.pi))\n tau = -((x - center) ** 2) / (2 * (sigma ** 2))\n return Amp * np.exp(tau)\n\n\ndef plot_convolution(wav_chip, flux_chip, flux_conv_res, res):\n plt.figure(1)\n plt.xlabel(r\"Wavelength [ nm ])\")\n plt.ylabel(r\"Normalized Flux [counts] \")\n plt.plot(\n wav_chip,\n flux_chip / np.max(flux_chip),\n color=\"k\",\n linestyle=\"-\",\n label=\"Original\",\n )\n plt.plot(\n wav_chip,\n flux_conv_res / np.max(flux_conv_res),\n color=\"r\",\n linestyle=\"--\",\n label=\"Convolved\",\n )\n plt.legend(loc=\"best\")\n plt.title(r\"Convolution by an Instrument Profile with resolution={0}\".format(res))\n plt.show()\n"
},
{
"alpha_fraction": 0.5123652219772339,
"alphanum_fraction": 0.5884590744972229,
"avg_line_length": 26.189655303955078,
"blob_id": "6e0275f5b3eabf4421471209f739d90296f3a4d6",
"content_id": "7b6ddec00ed23fb5eec15e3cc8c210c77e587952",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3154,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 116,
"path": "/scripts/Test_convolution_between_different_resolutions.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "# Test convolution to different resolutions\n# Test the effect of convolution straight to 20000 and convolution first to an intermediate resolution say 80000.\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom convolve_spectrum import unitary_Gauss\nfrom convolve_spectrum.ip_convolution import ip_convolution\n\n\ndef main():\n # fwhm = lambda/resolution\n fwhm = 2046 / 100000\n # Starting spectrum\n wav = np.linspace(2040, 2050, 20000)\n flux = (\n np.ones_like(wav)\n - unitary_Gauss(wav, 2045, fwhm)\n - unitary_Gauss(wav, 2047, fwhm)\n )\n\n # Range in which to have the convolved values. Be careful of the edges!\n chip_limits = [2042, 2049]\n\n # Convolution to 80k\n resolution = 80000\n wav_80k, flux_80k = ip_convolution(\n wav, flux, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n # Convolution to 50k\n resolution = 50000\n wav_50k, flux_50k = ip_convolution(\n wav, flux, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n wav_80k_50k, flux_80k_50k = ip_convolution(\n wav_80k, flux_80k, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n # Convolution to 20k\n resolution = 20000\n wav_80k_20k, flux_80k_20k = ip_convolution(\n wav_80k, flux_80k, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n wav_50k_20k, flux_50k_20k = ip_convolution(\n wav_50k, flux_50k, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n wav_80k_50k_20k, flux_80k_50k_20k = ip_convolution(\n wav_80k_50k, flux_80k_50k, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n # Convolution straight to 20000\n wav_20k, flux_20k = ip_convolution(\n wav, flux, chip_limits, resolution, fwhm_lim=5.0, plot=False\n )\n\n # Plot the results\n plt.figure(1)\n plt.xlabel(r\"wavelength [nm])\")\n plt.ylabel(r\"flux [counts] \")\n plt.plot(\n wav, flux / np.max(flux), color=\"k\", linestyle=\"-\", label=\"Original spectra\"\n )\n plt.plot(\n wav_80k,\n flux_80k / np.max(flux_80k),\n color=\"r\",\n linestyle=\"-.\",\n label=\"resolution=80k-20k\",\n )\n plt.plot(\n wav_50k,\n flux_50k / np.max(flux_50k),\n color=\"b\",\n linestyle=\"--\",\n label=\"resolution=50k\",\n )\n plt.plot(\n wav_80k_20k,\n flux_80k_20k / np.max(flux_80k_20k),\n color=\"r\",\n linestyle=\"-\",\n label=\"resolution=80k-20k\",\n )\n plt.plot(\n wav_50k_20k,\n flux_50k_20k / np.max(flux_50k_20k),\n color=\"b\",\n linestyle=\"-\",\n label=\"resolution=50k20k\",\n )\n plt.plot(\n wav_80k_50k_20k,\n flux_80k_50k_20k / np.max(flux_80k_50k_20k),\n color=\"m\",\n linestyle=\"-\",\n label=\"resolution=80k-50k-20k\",\n )\n plt.plot(\n wav_20k,\n flux_20k / np.max(flux_20k),\n color=\"c\",\n linestyle=\"-\",\n label=\"resolution=20k\",\n )\n plt.legend(loc=\"best\")\n plt.title(r\"Convolution by different Instrument Profiles\")\n plt.show()\n\n\nif __name__ == \"__main__\":\n # The ip_convolution fails if it is not run inside __name__ == \"__main__\"\n main()\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 8.5,
"blob_id": "f3fbd79946f62a45fe1e072ef0b4126a3a1828dc",
"content_id": "896ae148e6bb5d82b6d72bf23736a0c254815959",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 4,
"path": "/requirements/requirements.txt",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "matplotlib>=2\r\nmultiprocess\r\nnumpy\r\ntqdm\r\n"
},
{
"alpha_fraction": 0.5194805264472961,
"alphanum_fraction": 0.5881261825561523,
"avg_line_length": 30.705883026123047,
"blob_id": "b4893bb5753db04c88731d9375439e0588a80ec6",
"content_id": "88769c20cb11b719f2e38c6d201412a8465a31c4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 34,
"path": "/tests/test_ipconvolution.py",
"repo_name": "jason-neal/convolve_spectrum",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pytest\n\nfrom convolve_spectrum.ip_convolution import fast_convolve, ip_convolution\n\n\ndef test_fast_convolution():\n a = np.linspace(2130, 2170, 1024)\n b = np.linspace(2100, 2200, 1024)\n c = np.ones_like(b)\n resolution = 50000\n for a_val in a:\n assert isinstance(fast_convolve(a_val, resolution, b, c, 5), np.float64)\n assert (\n fast_convolve(a_val, resolution, b, c, 5) == 1\n ) # Test a flat input of 1s gives a flat output of 1s\n assert (\n fast_convolve(a_val, resolution, b, 0 * c, 5) == 0\n ) # Test a flat input of 1s gives a flat output of 1s\n\n\n# TODO: A result that is not just ones.\ndef test_ip_convolution():\n wave = [1, 2, 3, 5, 6, 7, 10, 11]\n flux = [1, 1, 1, 1, 1, 1, 1, 1]\n chip_limits = [2, 9]\n resolution = 100\n new_wav, new_flux = ip_convolution(wave, flux, chip_limits, resolution, plot=False)\n assert np.all(new_flux == [1, 1, 1, 1, 1])\n assert np.all(new_wav == [2, 3, 5, 6, 7])\n\n\nif __name__ == \"__main__\":\n pytest.main(args=[__file__])\n"
}
] | 12 |
kavya199922/Angular-Reactive-Form-Routing
|
https://github.com/kavya199922/Angular-Reactive-Form-Routing
|
9410b8fb1b992deb574033bcc747bf1412bc72cc
|
098746f8304f900385163b341bd02b3aead17a60
|
b05d519d6386fe2a289cdb9a147e71bdec2f0906
|
refs/heads/master
| 2022-12-01T08:47:55.553619 | 2020-08-14T06:43:35 | 2020-08-14T06:43:35 | 285,602,818 | 2 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6071856021881104,
"alphanum_fraction": 0.6179640889167786,
"avg_line_length": 25.507936477661133,
"blob_id": "90049c97686509ae16dad088381c9bee0e2cca1e",
"content_id": "5608a3904745157fab45a5ae06525ab37f40c49e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1670,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 63,
"path": "/src/app/updatsep.py",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "\nfrom flask import Flask, request, jsonify\nfrom flask_restful import Api\nfrom flaskext.mysql import MySQL\nfrom flask_cors import CORS,cross_origin\nimport json\nmysql = MySQL()\napp = Flask(__name__)\nCORS(app)\ncors=CORS(app,resources={\n r\"/*\":{\n \"origins\":'http://localhost:4202',\n \"methods\":['GET','POST','PUT','DELETE']\n }\n})\n\n\nport = 4002\n\n# config = {\n# 'ORIGINS': [\n# 'http://localhost:4002',\n# ]\n# }\n# CORS(app, resources={ r'/*': {'origins': config['ORIGINS']}}, supports_credentials=True)\n\n\n\n# MySQL configurations\napp.config['MYSQL_DATABASE_USER'] = 'root'\napp.config['MYSQL_DATABASE_PASSWORD'] = 'kavya'\napp.config['MYSQL_DATABASE_DB'] ='conference'\napp.config['MYSQL_DATABASE_HOST'] = 'localhost'\n\nmysql.init_app(app)\n\n# Api creation\napi = Api(app)\n\n#post\[email protected]('/<string:name>/<string:email>/<string:password>',methods=['GET','POST'])\ndef update(name,password):\n \n conn = mysql.connect()\n cursor = conn.cursor()\n # id=request.json['id']\n # name=request.json['name']\n insert_query=\"update table customerdata set custpassword=%s where customername=%s\"\n # insert_query = \"insert into departments (dept_id,dept_name) values (\" + \\\n # str(id) + \", '\" + name + \"')\"\n cursor.execute(insert_query,[(password),(name)])\n conn.commit()\n updated_data='select * from customerdata where customername=%s'\n cursor.execute(updated_data,[(name)])\n result=cursor.fetchone()\n conn.close()\n details = {'name': result[0], 'email': result[1],'password':result[2]}\n return details,201\n\n\n\n \n\napp.run(port=port,debug=True)"
},
{
"alpha_fraction": 0.6179487109184265,
"alphanum_fraction": 0.6358974575996399,
"avg_line_length": 25.228069305419922,
"blob_id": "505de735d44a8dd8e3bb647ec8721db10b76fdbe",
"content_id": "0ea15b3e3e0b4f4c9fa3888717e5afb2d2a4f0cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1560,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 57,
"path": "/src/app/flask-api/api.py",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, jsonify\r\nfrom flask_restful import Resource, Api\r\nfrom flaskext.mysql import MySQL\r\nfrom flask_cors import CORS,cross_origin\r\nmysql = MySQL()\r\napp = Flask(__name__)\r\n# cors\r\nCORS(app)\r\n# app.config['CORS_HEADERS'] = 'Content-Type'\r\ncors=CORS(app,resources={\r\n r\"/*\":{\r\n \"origins\":'http://localhost:4202/',\r\n \"methods\":['GET','POST','PUT','DELETE']\r\n }\r\n})\r\nport=4003\r\napp.config['MYSQL_DATABASE_USER'] = 'root'\r\napp.config['MYSQL_DATABASE_PASSWORD']='kavya'\r\napp.config['MYSQL_DATABASE_DB'] = 'kavyaassessment'\r\napp.config['MYSQL_DATABASE_HOST'] = 'localhost'\r\n\r\nmysql.init_app(app)\r\napi = Api(app)\r\n\r\n\r\n\r\n\r\n\r\[email protected]('/login/<string:mobilenumber>',methods=['GET','POST'])\r\ndef login(mobilenumber):\r\n conn = mysql.connect()\r\n cursor = conn.cursor()\r\n check_query='select username,userrole from usersinsystem where phno=%s'\r\n cursor.execute(check_query,[(mobilenumber)])\r\n list_res=cursor.fetchone()\r\n\r\n if list_res[0]=='Kavya_Admin' and list_res[1]=='admin':\r\n return \"admin\",200\r\n elif list_res[1]=='user':\r\n return list_res[0],200\r\n else:\r\n return \"Invalid Login\",200\r\n\r\n\r\[email protected]('/view')\r\ndef viewDeatils():\r\n conn = mysql.connect()\r\n cursor = conn.cursor()\r\n select_query=\"select phno,name,location,loginstatus from userdetails\"\r\n cursor.execute(select_query)\r\n data_list=cursor.fetchall()\r\n if len(data_list)>0:\r\n return data_list,200\r\n else:\r\n return \"no users\",200\r\n\r\napp.run(port=port,debug=True)\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4529324769973755,
"alphanum_fraction": 0.48447510600090027,
"avg_line_length": 23.3125,
"blob_id": "52d5860e0a46d6d89eb900102401cecf0c2fc26b",
"content_id": "fb1d264c4b93fdd62b5fecb9a89e407447c28c68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2029,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 80,
"path": "/src/app/postdata.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { HttpClient } from '@angular/common/http';\r\nimport { Component } from '@angular/core';\r\n\r\n@Component({\r\n selector: 'post-data',\r\n templateUrl:'./post.component.html'\r\n})\r\nexport class PostdataComponent {\r\n url='http://127.0.0.1:4000/'\r\n id:number;\r\n name:string;\r\n jsonData;\r\n deptData;\r\n div1;\r\n \r\n constructor(private http:HttpClient) {\r\n this.div1=false\r\n }\r\n getAllData(){\r\n this.http.get('http://127.0.0.1:4000/getall').toPromise().then((data:any)=>{\r\n this.jsonData=data\r\n console.log(data)\r\n \r\n }) \r\n }\r\n // getData\r\n getData(){\r\n this.url=this.url+this.id\r\n console.log(this.id)\r\n this.http.get(this.url).toPromise().then((data:any)=>{\r\n // this.jsonData=(data.json)\r\n this.jsonData=data\r\n console.log(data)\r\n this.url='http://127.0.0.1:4000/'\r\n this.div1=true\r\n })\r\n }\r\n // create data\r\n postData(){\r\n \r\n \r\n console.log(this.name)\r\n this.http.post('http://127.0.0.1:4000/'+this.id+'/'+this.name,null).toPromise().then((data:any)=>{\r\n // this.jsonData=(data.json)\r\n this.jsonData=data\r\n console.log(data)\r\n \r\n \r\n })\r\n }\r\n //edit data\r\n putData(){\r\n \r\n \r\n console.log(this.name)\r\n this.http.put('http://127.0.0.1:4000/put/'+this.id+'/'+this.name,null).toPromise().then((data:any)=>{\r\n // this.jsonData=(data.json)\r\n this.jsonData=data\r\n console.log(data)\r\n \r\n \r\n })\r\n }\r\n\r\n //delete data\r\n deleteData(){\r\n \r\n \r\n \r\n this.http.delete('http://127.0.0.1:4000/delete/'+this.id,{headers:{'Content-Type': 'application/json;charset=utf-8'}}).toPromise().then((data:any)=>{\r\n // this.jsonData=(data.json)\r\n this.jsonData=data\r\n console.log(data)\r\n \r\n \r\n })\r\n }\r\n\r\n \r\n}\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5792163610458374,
"alphanum_fraction": 0.5928449630737305,
"avg_line_length": 34.6875,
"blob_id": "b7fe640a29076a83ef58d0318fe1a9ce1f805fa6",
"content_id": "2dea4622737d77117fba6f012b36184656424504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 214,
"num_lines": 16,
"path": "/src/app/student.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { Component, OnInit } from '@angular/core';\r\n\r\n@Component({\r\n selector: 'student',\r\n templateUrl: './student.component.html'\r\n // template:`<div>\r\n // <p *ngFor=let a of header>{{a}}</p></div>`\r\n // template:'<h1 *ngFor=\"let a of header\">{{a}}</h1>'\r\n\r\n \r\n})\r\nexport class StudentComponent {\r\nheader=['no','firstname','lastname','handle']\r\n\r\n obj1=[{'no':1,'firstname':'kavya','lastname':'rengaraj','handle':'@kavya_99'},{'no':2,'firstname':'oviya','lastname':'mathi','handle':'@ovi'},{'no':3,'firstname':'jenani','lastname':'sheghal','handle':'@jshegal'}]\r\n}\r\n"
},
{
"alpha_fraction": 0.45968881249427795,
"alphanum_fraction": 0.48797735571861267,
"avg_line_length": 22.180328369140625,
"blob_id": "9b7e31640771259c72286f74c893d94d492528ed",
"content_id": "c96863e6830af3aee4722316b80eb7aec4499148",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1414,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 61,
"path": "/src/app/microservice.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { HttpClient } from '@angular/common/http';\nimport { Component } from '@angular/core';\n\n\n@Component({\n selector: 'micro-service',\n templateUrl: './microservice.component.html'\n\n})\nexport class MicroserviceComponent{\n url='http://127.0.0.1:4000/'\n name:string\n email:string\n password:string\n jsonData;\n constructor(private http:HttpClient) {\n\n }\n \n // getData\n getData(){\n \n this.http.get('http://127.0.0.1:4000/get/'+this.name).toPromise().then((data:any)=>{\n // this.jsonData=(data.json)\n this.jsonData=data\n console.log(data)\n \n \n })\n }\n // create data\n postData(){\n \n \n console.log(this.name)\n this.http.post('http://127.0.0.1:4000/'+this.name+'/'+this.email+'/'+this.password,null).toPromise().then((data:any)=>{\n // this.jsonData=(data.json)\n this.jsonData=data\n console.log(data)\n \n \n })\n }\n //edit data\n // putData(){\n \n \n // console.log(this.name)\n // this.http.put('http://127.0.0.1:4000/put/'+this.id+'/'+this.name,null).toPromise().then((data:any)=>{\n // // this.jsonData=(data.json)\n // this.jsonData=data\n // console.log(data)\n \n \n // })\n //}\n \n \n\n\n}\n"
},
{
"alpha_fraction": 0.6283186078071594,
"alphanum_fraction": 0.6283186078071594,
"avg_line_length": 13.25,
"blob_id": "cfd58912aeedeee0f52e0f078ed0ca1e878a28d4",
"content_id": "9fe5d95f3cb0019ab244ee96b4283416a33a6e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 8,
"path": "/src/app/details.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "export class detail{\n phoneno:string;\n name:string;\n location:string;\n loginstatus:string;\n \n \n}"
},
{
"alpha_fraction": 0.6184210777282715,
"alphanum_fraction": 0.6271929740905762,
"avg_line_length": 16.538461685180664,
"blob_id": "3af9304fffcd7214e2ec174cf8c168dd89b23bbb",
"content_id": "1452560f98bd1eea210480c645caab9ae610244f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/src/app/successreg.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { HttpClient } from '@angular/common/http';\nimport { Component} from '@angular/core';\n\n@Component({\n selector: 'success-reg',\n template:`<h1>Registration Success</h1>`\n})\nexport class Success {\n \n\n \n \n}\n"
},
{
"alpha_fraction": 0.751173734664917,
"alphanum_fraction": 0.8028169274330139,
"avg_line_length": 52.5,
"blob_id": "45c7ba142bdc8b7ff1a7fbdc039b31495624de48",
"content_id": "e888dda83b9b6b19a67e5f9419b8a4a952437592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 4,
"path": "/src/app/tables.sql",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "create table customerdata(customername varchar(20),custemail varchar(50),custpassword varchar(20));\ndesc customerdata;\ninsert into customerdata values('adhvaith','[email protected]','12345adhu');\nselect * from customerdata;"
},
{
"alpha_fraction": 0.7350819706916809,
"alphanum_fraction": 0.735737681388855,
"avg_line_length": 36.125,
"blob_id": "fcf7dad28d1394e9d531c19a059a62496ed6edf8",
"content_id": "5479993f4486940db4f75f33dd60c871b35b4ec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1525,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 40,
"path": "/src/app/app.module.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { ApiService } from './getData.service';\r\n\r\nimport { LoginComponent } from './assessment5.component';\r\nimport { PutmcComponent } from './putmc.component';\r\nimport { MicroserviceComponent } from './microservice.component';\r\nimport { TestComponent } from './test.component';\r\nimport { RouterModule } from '@angular/router';\r\nimport { Success } from './successreg.component';\r\nimport { ValidateFormsComponent } from './validateforms.component';\r\nimport { TodolistComponent } from './todolist.component';\r\nimport { PostdataComponent } from './postdata.component';\r\nimport { StudentComponent } from './student.component';\r\nimport { BrowserModule } from '@angular/platform-browser';\r\nimport { NgModule } from '@angular/core';\r\nimport { HttpClientModule } from '@angular/common/http';\r\nimport {FormsModule} from '@angular/forms'\r\nimport { AppRoutingModule } from './app-routing.module';\r\nimport { AppComponent } from './app.component';\r\nimport {ReactiveFormsModule} from '@angular/forms';\r\n\r\n\r\n\r\n//user-imports\r\n\r\nimport {CheckComponent} from './check.component'\r\nimport { from } from 'rxjs';\r\n\r\n@NgModule({\r\n declarations: [\r\n PutmcComponent, MicroserviceComponent, TestComponent, AppComponent,CheckComponent,StudentComponent,PostdataComponent,TodolistComponent,ValidateFormsComponent,Success,LoginComponent\r\n ],\r\n imports: [\r\n BrowserModule,\r\n FormsModule,ReactiveFormsModule,\r\n AppRoutingModule,HttpClientModule\r\n ],\r\n providers: [ApiService],\r\n bootstrap: [AppComponent]\r\n})\r\nexport class AppModule { }\r\n"
},
{
"alpha_fraction": 0.5615384578704834,
"alphanum_fraction": 0.5615384578704834,
"avg_line_length": 15.25,
"blob_id": "2695b3b2e50d5db0a28d0856eb7fea359275c4da",
"content_id": "50d7527a5392eb89f47aee796eb6c836d47f3f53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/src/app/test.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { Component, OnInit } from '@angular/core';\n\n@Component({\n selector: 'test',\n template:`<input [(ngModel)]='name'><p>{{name}}</p>`\n})\nexport class TestComponent {\n name:string\n constructor() { \n console.log(name)\n }\n \n \n\n \n}\n"
},
{
"alpha_fraction": 0.5442890524864197,
"alphanum_fraction": 0.5559440851211548,
"avg_line_length": 22.83333396911621,
"blob_id": "546cec4be65b136adde6d6a33498c2245f886d53",
"content_id": "d5ad80049e7c231f54d176ee366b9fca5b823956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 858,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 36,
"path": "/src/app/putmc.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { HttpClient } from '@angular/common/http';\nimport { Component} from '@angular/core';\n\n@Component({\n selector: 'put-mc',\n template:`<label>Enter Name</label>\n <input type='text' [(ngModel)]=\"name\" name='name'>\n <label>Enter New Password</label>\n <input type='text' [(ngModel)]=\"password\" name='password'>\n <button (click)=\"putData()\">Update</button>`\n \n \n})\n\nexport class PutmcComponent {\n name:string\n password:string\n jsonData;\n constructor(private http:HttpClient) { }\n putData(){\n \n \n console.log(this.name)\n this.http.put('http://127.0.0.1:4002/'+this.name+'/'+this.password,null).toPromise().then((data:any)=>{\n // this.jsonData=(data.json)\n this.jsonData=data\n console.log(data)\n \n \n })\n }\n\n \n\n \n}\n"
},
{
"alpha_fraction": 0.6594982147216797,
"alphanum_fraction": 0.7204301357269287,
"avg_line_length": 34.064517974853516,
"blob_id": "ec07cb2767b09b0472d50f9f9d17778fe833d1fa",
"content_id": "cf5b5ebf3029311235fea88d036079354fa8fae7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1116,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 31,
"path": "/src/app/flask-api/insertdata.py",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "from connect2db import *\r\nfrom datetime import datetime\r\ncursor=connect2db.cursor()\r\ncursor.execute('use kavyaassessment')\r\n#insert into usersinsystem\r\n# phno bigint not null,username varchar(20),userrole varchar(10),primary key(phno)\r\nusers_in_system=[\r\n (7338908957,'adminuser','admin'),\r\n (9445411598,'Abi','user'),\r\n (9444149885,'martha','user')\r\n\r\n]\r\ninsert_user='insert into usersinsystem(phno,username,userrole) values(%s,%s,%s)'\r\ncursor.executemany(insert_user,users_in_system)\r\nconnect2db.commit()\r\ncursor.execute('select * from usersinsystem')\r\nprint(cursor.fetchall())\r\n\r\n#inserting userdetails\r\n# phno name loc loginstatus\r\n\r\nuser_details=[\r\n (7338908957,'Kavya_Admin','chennai','last login: '+str(datetime.now())),\r\n (9445411598,'ABINAYA','MUMBAI','last login: '+str(datetime.now())),\r\n (9444149885,'Martha','Germany','last login: '+str(datetime.now()))\r\n]\r\ninsert_user='insert into userdetails(phno,name,location,loginstatus) values(%s,%s,%s,%s)'\r\ncursor.executemany(insert_user,user_details)\r\nconnect2db.commit()\r\ncursor.execute('select * from userdetails')\r\nprint(cursor.fetchall())"
},
{
"alpha_fraction": 0.5780346989631653,
"alphanum_fraction": 0.5780346989631653,
"avg_line_length": 20.565217971801758,
"blob_id": "5d573c6085858f5bf3f6fcb536fb753d4cbc9c08",
"content_id": "dd730be2824944534c14978528131852c0f6ef10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 519,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 23,
"path": "/src/app/todolist.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { Component} from '@angular/core';\r\n\r\n@Component({\r\n selector: 'todolist',\r\n templateUrl: './todolist.component.html',\r\n \r\n})\r\nexport class TodolistComponent {\r\n Title='TODO-LIST'\r\n \r\n items_list=[{\r\n 'itemname':'clean the room'},{'itemname':'collect the passes'}]\r\n addItem(x){\r\n this.items_list.push({'itemname':x})\r\n console.log(this.items_list)\r\n\r\n }\r\n RemoveItem(i){\r\n this.items_list=this.items_list.filter(x =>i.itemname!==x.itemname)\r\n }\r\n \r\n\r\n}\r\n"
},
{
"alpha_fraction": 0.7768816947937012,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 60,
"blob_id": "021592bcb19a4f82b7e4978a5465b5c0ecf3eb5c",
"content_id": "734e029754d1d633d36ad47f1c2aa84375ad6606",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 372,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 6,
"path": "/src/app/flask-api/tables.sql",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "create database kavyaassessment;\r\nshow tables;\r\nuse kavyaassessment;\r\ncreate table usersinsystem(phno bigint not null,username varchar(20),userrole varchar(10),primary key(phno));\r\nselect * from usersinsystem;\r\ncreate table userdetails(phno bigint not null,name varchar(20),location varchar(20),loginstatus varchar(100),foreign key(phno) references usersinsystem(phno));\r\n"
},
{
"alpha_fraction": 0.538856029510498,
"alphanum_fraction": 0.5952662825584412,
"avg_line_length": 43.49122619628906,
"blob_id": "a75fcc0e42d590fb10ff91763846b93302a0749b",
"content_id": "284003b349b9acc4a96ce794b9e5d11df6d2d01b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2535,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 57,
"path": "/src/app/insertdata.py",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "from connecttohost import *\ncursor=connect2db.cursor()\ncursor.execute('use AirFone')\n#hashlib\nimport hashlib\nimport random\n#-------------------------------------------Insert data into user table-----------------------------------------------------\n#insert in to usertables(default:3 data)\n# ID, Username,Password,Mobile No,UserRole\n# password='kavya2299'\n# password=password.encode('utf-8')\n# h=hashlib.sha1(password).hexdigest()\n# ------------------------------------>Insert Code starts\n# password_list=[hashlib.sha1('kavya2299'.encode('utf-8')).hexdigest(),\n# hashlib.sha1('Sri1999'.encode('utf-8')).hexdigest(),\n# hashlib.sha1('RamyaSri99'.encode('utf-8')).hexdigest(),\n# hashlib.sha1('Satya100'.encode('utf-8')).hexdigest(),\n# hashlib.sha1('Gowrishankar1999'.encode('utf-8')).hexdigest(),\n# hashlib.sha1('admin'.encode('utf-8')).hexdigest()\n# ]\n#\n# val = [\n#\n# (1,'Kavya', password_list[0],7338908957,'customer'),\n# (2,'SriRanjini',password_list[1],9884242972,'customer'),\n# (3,'Ramya',password_list[2],7339275471,'customer'),\n# (4,'Satya',password_list[3],9177861720,'customer'),\n# (5,'GowriSankar',password_list[4],9080584953,'customer'),\n# (6,'Ebi',password_list[5],8668194659,'admin')\n# ]\n# insert_user='insert into user(ID,username,password,mobilenumber,userrole) values(%s,%s,%s,%s,%s)'\n# cursor.executemany(insert_user,val)\n# connect2db.commit()\n# cursor.execute('select * from user')\n# print(cursor.fetchall())\n# --------------------------------------Plan\n#planID,planName,Amount,PlanData,PlanType,Offer\nlist_of_plans=[\n (1,'4G data Voucher',2599,'740GB:unlimited calling,')\n]\n# --------------------------------------Insert data in conference table------------------------------------------------\n#id,domain,title,dateofevent,location\n# val = [\n#\n# ('ML1','Machine Learning','ML and applns-IIT ','2020-09-22','chennai'),\n# ('BC1', 'Blockchain', 'BC-Ethereum', '2020-10-02', 'chandigarh'),\n# ('ML2', 'Machine Learning', 'ML and AI', '2020-12-12', 'manipal'),\n# ('IoT1', 'Internet of Things', 'IoT', '2022-05-05', 'mumbai'),\n# ('IoT2', 'Internet of Things', 'IoT', '2020-09-09', 'bangalore'),\n# ('BC2', 'Blockchain', 'BC-Bitcoin', '2021-01-01', 'delhi'),\n#\n# ]\n# insert_user='insert into conferencedetails(confid,domain,title,dateofevent,location) values(%s,%s,%s,%s,%s)'\n# cursor.executemany(insert_user,val)\n# connect2db.commit()\n# cursor.execute('select * from conferencedetails')\n# print(cursor.fetchall())"
},
{
"alpha_fraction": 0.7234848737716675,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 35.71428680419922,
"blob_id": "bda71afe6ca38145c52d9e6adc82f5f26fd11281",
"content_id": "b2e720892818ec2e66909f4a1d2af718cbbe787f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1320,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 35,
"path": "/src/app/app-routing.module.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { LoginComponent } from './assessment5.component';\r\nimport { PutmcComponent } from './putmc.component';\r\nimport { MicroserviceComponent } from './microservice.component';\r\nimport { Success } from './successreg.component';\r\nimport { PostdataComponent } from './postdata.component';\r\nimport { ValidateFormsComponent } from './validateforms.component'\r\nimport { TodolistComponent } from './todolist.component';\r\nimport { StaffComponent } from './staff.component';\r\nimport { StudentComponent } from './student.component';\r\n\r\n\r\nimport { AppComponent } from './app.component';\r\nimport { NgModule, Component } from '@angular/core';\r\nimport { Routes, RouterModule } from '@angular/router';\r\nconst routes: Routes =\r\n [\r\n {path:'#',component:AppComponent},\r\n { path:'Student',component:StudentComponent},\r\n {path:'Staff',component:StaffComponent},\r\n {path:'todolist',component:TodolistComponent},\r\n {path:'forms',component:ValidateFormsComponent},\r\n {path:'HTTPmethods',component:PostdataComponent},\r\n {path:'success',component:Success},\r\n {path:'micro',component:MicroserviceComponent},\r\n {path:'micro/put',component:PutmcComponent},\r\n {path:'login2sys',component:LoginComponent}\r\n];\r\n\r\n\r\n\r\n@NgModule({\r\n imports: [RouterModule.forRoot(routes)],\r\n exports: [RouterModule]\r\n})\r\nexport class AppRoutingModule { }\r\n"
},
{
"alpha_fraction": 0.6535947918891907,
"alphanum_fraction": 0.6623093485832214,
"avg_line_length": 19.727272033691406,
"blob_id": "8eadd3b5f16850e42a7bdcc2d446d50e318de370",
"content_id": "0e201018128a00acc6cceaf3d4464b18be9bee69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 22,
"path": "/src/app/getData.service.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "\nimport { Injectable } from '@angular/core';\nimport{HttpClient} from '@angular/common/http'\nimport { Observable } from 'rxjs';\n\n@Injectable({\n providedIn: 'root'\n})\nexport class ApiService {\n url:string=\"http://localhost:4003/\";\n\n constructor(private http:HttpClient) { \n }\n \n public Login(phno:string) {\n return this.http.get(this.url+'login/'+phno);\n } \n public ViewData():Observable<any>{\n return this.http.get(this.url+'/view')\n }\n\n \n}\n\n\n"
},
{
"alpha_fraction": 0.6561514139175415,
"alphanum_fraction": 0.6687697172164917,
"avg_line_length": 22.538461685180664,
"blob_id": "76c4dd277abeb832decee04603bc2504b3500905",
"content_id": "e8a88d11def40892b3081ca4efcc248dc12c09da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 13,
"path": "/src/app/check.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import {Component} from '@angular/core'\r\n@Component({\r\n//similar to css selectors can be used as <courses-component>\r\n selector:'checking',\r\n//render part\r\n//{{}}=>interpolation\r\ntemplate:'<h1>{{property1}}</h1>'\r\n})\r\nexport class CheckComponent{\r\n //property\r\n property1='hello from check component'\r\n \r\n}"
},
{
"alpha_fraction": 0.49626466631889343,
"alphanum_fraction": 0.49626466631889343,
"avg_line_length": 20.159090042114258,
"blob_id": "63bb0a7b912adeeba0e58cd07d76b838cff191d6",
"content_id": "f8bcc5ad06ced209ddd3497d7d209cef6e4d709e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 937,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 44,
"path": "/src/app/assessment5.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "\nimport { Component } from '@angular/core';\nimport { ApiService } from './getData.service';\nimport { detail } from './details';\n@Component({\n selector: 'login',\n templateUrl: './login.component.html',\n \n})\nexport class LoginComponent {\n admin:boolean\n user:boolean\n phno;\n data:detail[]\n constructor(private api:ApiService) { \n this.admin=false\n this.user=false\n }\ncheckLogin(){\n \n \n this.api.Login(this.phno).subscribe((response)=>{\n console.log('response recieve')\n console.log(response)\n\n \n \n })\n \n }\n viewDetails(){\n if \n (this.admin==true){\n this.api.ViewData().subscribe((response)=>{\n console.log('response recieve')\n console.log(response)\n this.data=response\n \n \n \n })\n }\n }\n \n}\n\n \n\n"
},
{
"alpha_fraction": 0.6774193644523621,
"alphanum_fraction": 0.6774193644523621,
"avg_line_length": 9.666666984558105,
"blob_id": "8e779ffb125e9976145243d654320512a8592ad1",
"content_id": "a2ceef2c126a4aa83f8ff91ca90d22992d90c092",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 3,
"path": "/src/app/dataformat.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "export class Dataformat{\n \n}"
},
{
"alpha_fraction": 0.586586594581604,
"alphanum_fraction": 0.5970970988273621,
"avg_line_length": 26.542856216430664,
"blob_id": "d39a5bdba52f92e065aeb86f0dd43b32c34256e9",
"content_id": "1a8f1cb43d7a3a811b5360c676c2400880b0d684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1998,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 70,
"path": "/src/app/flaskbackend.py",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "\r\nfrom flask import Flask, request, jsonify\r\nfrom flask_restful import Api\r\nfrom flaskext.mysql import MySQL\r\nfrom flask_cors import CORS,cross_origin\r\nimport json\r\nmysql = MySQL()\r\napp = Flask(__name__)\r\nCORS(app)\r\ncors=CORS(app,resources={\r\n r\"/*\":{\r\n \"origins\":'http://localhost:4202',\r\n \"methods\":['GET','POST','PUT','DELETE']\r\n }\r\n})\r\n\r\n\r\nport = 4000\r\n\r\n# config = {\r\n# 'ORIGINS': [\r\n# 'http://localhost:4002',\r\n# ]\r\n# }\r\n# CORS(app, resources={ r'/*': {'origins': config['ORIGINS']}}, supports_credentials=True)\r\n\r\n\r\n\r\n# MySQL configurations\r\napp.config['MYSQL_DATABASE_USER'] = 'root'\r\napp.config['MYSQL_DATABASE_PASSWORD'] = 'kavya'\r\napp.config['MYSQL_DATABASE_DB'] ='conference'\r\napp.config['MYSQL_DATABASE_HOST'] = 'localhost'\r\n\r\nmysql.init_app(app)\r\n\r\n# Api creation\r\napi = Api(app)\r\n\r\n#post\r\[email protected]('/<string:name>/<string:email>/<string:password>',methods=['GET','POST'])\r\ndef post(name,email,password):\r\n \r\n conn = mysql.connect()\r\n cursor = conn.cursor()\r\n # id=request.json['id']\r\n # name=request.json['name']\r\n insert_query=\"insert into customerdata(customername,custemail,custpassword) values(%s,%s,%s)\"\r\n # insert_query = \"insert into departments (dept_id,dept_name) values (\" + \\\r\n # str(id) + \", '\" + name + \"')\"\r\n cursor.execute(insert_query,[(name),(email),(password)])\r\n conn.commit()\r\n conn.close()\r\n details = {'name': name, 'email': email,'password':password}\r\n return details,201\r\n#get\r\[email protected]('/get/<string:name>',methods=['GET','POST'])\r\ndef get(name):\r\n conn = mysql.connect()\r\n cursor = conn.cursor()\r\n getall_query='select * from customerdata where customername=%s'\r\n cursor.execute(getall_query,[(name)])\r\n result=cursor.fetchone()\r\n details={'name':result[0],'email':result[1],'password':result[2]}\r\n conn.close()\r\n return details,201\r\n\r\n\r\n \r\n\r\napp.run(port=port,debug=True)"
},
{
"alpha_fraction": 0.6006389856338501,
"alphanum_fraction": 0.6118211150169373,
"avg_line_length": 30.947368621826172,
"blob_id": "e718cccae5e183f31ac49eba759fd6425f2ff18a",
"content_id": "25e19e49b25b1daf650332c674d6945245b06596",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1252,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 38,
"path": "/src/app/validateforms.component.ts",
"repo_name": "kavya199922/Angular-Reactive-Form-Routing",
"src_encoding": "UTF-8",
"text": "import { HttpClient } from '@angular/common/http';\r\nimport { Component } from '@angular/core';\r\nimport {FormGroup,FormControl,FormBuilder,NgForm,Validators} from '@angular/forms';\r\nimport { ReactiveFormsModule } from '@angular/forms';\r\n\r\n@Component({ \r\n selector: 'validateforms',\r\n templateUrl: './validateforms.component.html',\r\n\r\n \r\n})\r\nexport class ValidateFormsComponent {\r\n title='Validation using Reactive Forms'\r\n signupForm:FormGroup;\r\n fname:string='';\r\n password:string='';\r\n email:string='';\r\n \r\n constructor(private frmbuilder:FormBuilder,private http:HttpClient) { \r\n this.signupForm=frmbuilder.group({\r\n \r\n fname:new FormControl('',[Validators.required,Validators.minLength(2),Validators.maxLength(10)]),\r\n password:new FormControl('',[Validators.required,Validators.minLength(8)]),\r\n email:new FormControl('',[Validators.required,Validators.email]),\r\n \r\n\r\n \r\n })\r\n }\r\n postData(){\r\n this.http.post('http://127.0.0.1:5000/'+this.fname+'/'+this.email+'/'+this.password,null).toPromise().then((data:any)=>{\r\n // this.jsonData=(data.json)\r\n \r\n console.log(data)\r\n \r\n })\r\n}\r\n}\r\n"
}
] | 22 |
Narsil-coder/MIT-househunting
|
https://github.com/Narsil-coder/MIT-househunting
|
546380614030945cd4b152d828bba3ce380094d9
|
cfa62dbf7fa4d68411e1f1c727da2a70ca4859c4
|
bccc6a77c206c2178a1cdf4e4a883ab8306071a4
|
refs/heads/main
| 2023-08-04T09:42:27.676815 | 2021-09-08T10:29:00 | 2021-09-08T10:29:00 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7894737124443054,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 18,
"blob_id": "027906a845535a3363e3d071ba3ef6289f1b3fae",
"content_id": "fa6bdb4b7afd36881874e333e82b8d43e9f03656",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Narsil-coder/MIT-househunting",
"src_encoding": "UTF-8",
"text": "# MIT-househunting\n"
},
{
"alpha_fraction": 0.5043150186538696,
"alphanum_fraction": 0.5469255447387695,
"avg_line_length": 35.35293960571289,
"blob_id": "012e6ea6b861e3b19da1245dde064b660e81b73a",
"content_id": "3195ac0835835f838b2734635401b55cf55983e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1854,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 51,
"path": "/ps1cv2.py",
"repo_name": "Narsil-coder/MIT-househunting",
"src_encoding": "UTF-8",
"text": "class House_hunting:\n\n def __init__(self, starting_salary):\n found = False\n max_rate = 100000 #100%\n min_rate = 0 #0%\n r = 0.04\n months = 36\n semi_annual_raise = 0.07\n total_cost = 1000000\n steps = 0\n self.starting_salary = starting_salary\n self.portion_down_payment = total_cost*0.25\n self.bisection_steps = steps\n self.portion_saved = int((max_rate + min_rate) / 2)\n\n while abs(max_rate-min_rate) > 1:\n self.bisection_steps += 1\n annual_salary = self.starting_salary\n monthly_salary = ((annual_salary)/12)*self.portion_saved/10000\n currentsavings = 0.0\n\n for i in range(1, months + 1):\n currentsavings += currentsavings*r/12 + monthly_salary\n if abs(currentsavings-self.portion_down_payment) < 100:\n min_rate = max_rate\n found = True\n break\n elif currentsavings > self.portion_down_payment + 100:\n break\n\n if i % 6 == 0:\n annual_salary += annual_salary*semi_annual_raise\n monthly_salary = (annual_salary/12.0)*self.portion_saved/10000\n\n if currentsavings < self.portion_down_payment - 100:\n min_rate = self.portion_saved\n elif currentsavings > self.portion_down_payment + 100:\n max_rate = self.portion_saved\n\n self.portion_saved = int((max_rate + min_rate)/2)\n\n if found:\n print(\"Best savings rate:\", self.portion_saved / 10000)\n print(\"Steps in bisection search\", self.bisection_steps)\n\n else:\n print(\"Is is not possible to pay the down payment in three years\")\n\na = House_hunting(10000)\nprint(a.starting_salary)\n"
},
{
"alpha_fraction": 0.6158651113510132,
"alphanum_fraction": 0.6627107858657837,
"avg_line_length": 33.80434799194336,
"blob_id": "3ca1439a8a632c37f49ca60294e917fe115485e8",
"content_id": "6b64d403223676fc42f21a9200794f614267cf6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1615,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 46,
"path": "/ps1a.py",
"repo_name": "Narsil-coder/MIT-househunting",
"src_encoding": "UTF-8",
"text": "#Part A: House Hunting\n #1.total_cost\n #2.portion_dow n_payment (assume that portion_down_payment = 0.25 (25%))\n #3.current_savings. You start with a currentsavings of $0.\n #4.current_savings*r/12 (Assume that your investments earn a return of r = 0.04 (4%))\n #5.annual_salary\n #6.portion_saved. (This variable should be in decimal form (i.e. 0.1for 10%))\n #7. monthly salary (annual salary / 12)\n\nclass House_hunting:\n\n def __init__(self, total_cost, portion_saved, annual_salary, semi_annual_raise):\n self.total_cost = total_cost\n self.portion_saved = float(portion_saved)\n self.annual_salary = annual_salary\n self.semi_annual_raise = float(semi_annual_raise)\n\n\n self.portion_down_payment = (self.total_cost)*0.25\n currentsavings = 0\n r = 0.04\n monthly_salary = (self.annual_salary)/12\n self.number_of_months = 0\n months = 0\n\n\n\n while self.portion_down_payment > currentsavings:\n currentsavings += currentsavings*r/12 + monthly_salary*float(self.portion_saved)\n self.number_of_months = self.number_of_months + 1\n if self.number_of_months % 6 == 0:\n monthly_salary += monthly_salary*self.semi_annual_raise\n\n\n\n#create another variable for numbers of months\n#that variable will be equal to the numbers of months divide at six\n#later will be a conditional function that verify if the number is int or float\n\n\na = House_hunting(500000, 0.05, 120000, 0.03)\nb = House_hunting(800000, 0.1, 80000, 0.03)\n\n\nprint(b.number_of_months)\nprint(b.semi_annual_raise)\n"
}
] | 3 |
HuzefaEssaji/invoice-data-extraction
|
https://github.com/HuzefaEssaji/invoice-data-extraction
|
bed9c104103c7a6a55ca0c56714334110690ca6e
|
b5be28648cb6734b01094cee565d3669a7eef4f6
|
b90c341cff7fd25450b1f3e658b5dc3da43d85e2
|
refs/heads/main
| 2023-06-27T13:35:22.157697 | 2021-07-31T09:31:17 | 2021-07-31T09:31:17 | 391,310,952 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4414893686771393,
"alphanum_fraction": 0.640070915222168,
"avg_line_length": 15.090909004211426,
"blob_id": "8b6e4ddeddf1e46bb9304b2085b099c6d28fa6a0",
"content_id": "0744f9032e3a76195fb3251c90cd00ae02172bc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 33,
"path": "/requirements.txt",
"repo_name": "HuzefaEssaji/invoice-data-extraction",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.4\r\nastroid==2.5.6\r\nclick==8.0.1\r\ncolorama==0.4.4\r\nCython==0.29.23\r\ndistlib==0.3.1\r\net-xmlfile==1.1.0\r\nfilelock==3.0.12\r\nFlask==2.0.1\r\nisort==5.8.0\r\nitsdangerous==2.0.1\r\nJinja2==3.0.1\r\nlazy-object-proxy==1.6.0\r\nMarkupSafe==2.0.1\r\nmccabe==0.6.1\r\nnumpy==1.20.3\r\nopencv-python==4.5.2.54\r\nopenpyxl==3.0.7\r\npandas==1.2.4\r\nPillow==8.3.1\r\nprogressbar==2.5\r\npsycopg2-binary==2.8.6\r\npylint==2.8.3\r\npytesseract==0.3.8\r\npython-dateutil==2.8.1\r\npytz==2021.1\r\nsix==1.16.0\r\ntoml==0.10.2\r\nvirtualenv==20.4.7\r\nWerkzeug==2.0.1\r\nwrapt==1.12.1\r\nxlrd==2.0.1\r\nxlwt==1.3.0\r\n"
},
{
"alpha_fraction": 0.7268041372299194,
"alphanum_fraction": 0.7371134161949158,
"avg_line_length": 19.77777862548828,
"blob_id": "50c6b1024d525ccf09085475365f51785bd62073",
"content_id": "02021e88a54f274493140da6b86df1df759d60a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 9,
"path": "/README.md",
"repo_name": "HuzefaEssaji/invoice-data-extraction",
"src_encoding": "UTF-8",
"text": "# ocr-reader\r\n\r\n## please make a python environment and install all dependencies using the command \"pip install -r requirements.txt\"\r\n\r\n1. Activate the virtualenv\r\n2. Run main.py\r\n\r\n\r\n# Thankyou"
},
{
"alpha_fraction": 0.5435435175895691,
"alphanum_fraction": 0.5487987995147705,
"avg_line_length": 22.218181610107422,
"blob_id": "a46cb608ca92e1c22089888e35ebdf4af6655280",
"content_id": "3063fcdf7da6cb1dd641674f165f7186c4ce87ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1334,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 55,
"path": "/main.py",
"repo_name": "HuzefaEssaji/invoice-data-extraction",
"src_encoding": "UTF-8",
"text": "import sys\r\nimport os\r\nimport re\r\nimport json\r\nfrom flask import *\r\nfrom werkzeug.utils import secure_filename\r\nfrom preprocessing import preprocessing\r\n\r\napp = Flask(__name__)\r\n\r\[email protected]('/')\r\ndef index():\r\n return render_template('index.html')\r\n\r\[email protected]('/uploaded', methods = ['GET', 'POST'])\r\ndef upload_file():\r\n if request.method == 'POST':\r\n f = request.files['file']\r\n f.save(secure_filename(f.filename))\r\n image_text = preprocessing(f.filename)\r\n\r\n # trim_from_first = a.index('DESCRIPTION ‘QUANTITY PRICE SALES TAX AMOUNT')\r\n \r\n # trim_from_last = a.index('SUBTOTAL: $10.00')\r\n\r\n # a = a[trim_from_first:]\r\n # a = a[:trim_from_last]\r\n\r\n # headings = str(a[0])\r\n \r\n # headings = list(headings.split(' '))\r\n \r\n # a.pop(0)\r\n \r\n # row = []\r\n # for i in range(len(a)):\r\n \r\n # d = str(a[i])\r\n # row.append(list(d.split(' ')))\r\n \r\n # row = str(a[0])\r\n # row = list(row.split(' '))\r\n\r\n \r\n \r\n\r\n # extract_info = dict(zip(headings, row))\r\n\r\n\r\n\r\n # return render_template('index.html', message = 'upload succesfull',headings = headings,rows=row)\r\n return render_template('index.html', message = 'upload succesfull',result =a)\r\n\r\nif __name__ == '__main__':\r\n app.run(debug=True)\r\n"
},
{
"alpha_fraction": 0.46470892429351807,
"alphanum_fraction": 0.4969088137149811,
"avg_line_length": 26.740739822387695,
"blob_id": "2de0b03cbfa6a96ab4beffd29dc72fcab8120f72",
"content_id": "5c1b68baad152b93a0f91761146c336a590327b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3882,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 135,
"path": "/preprocessing.py",
"repo_name": "HuzefaEssaji/invoice-data-extraction",
"src_encoding": "UTF-8",
"text": "import os\r\nimport cv2\r\nimport numpy as np\r\nimport pytesseract\r\n# from PIL import Image\r\npytesseract.pytesseract.tesseract_cmd = r'H:\\Games\\tesseract.exe'\r\ndef boxes():\r\n img_2 = cv2.imread('./invoice.png')\r\n img_2 = cv2.cvtColor(img_2, cv2.COLOR_BGR2RGB)\r\n hImg,wImg,_ = img_2.shape\r\n boxes = pytesseract.image_to_data(img_2)\r\n row = [[] for i in range(100)]\r\n x = boxes.splitlines()\r\n for y,b in enumerate(x):\r\n b=b.split()\r\n x[y] = b\r\n d=0\r\n\r\n for i in range(len(x)):\r\n \r\n if x[i][0] == '5':\r\n if len(x[i])==12:\r\n row[d].append(x[i][6] +','+ x[i][11])\r\n else:\r\n row[d].append(x[i][6] +','+ x[i][10])\r\n \r\n else:\r\n d=d+1\r\n \r\n rows=[]\r\n for i in range(len(row)):\r\n if len(row[i])!=0:\r\n rows.append(row[i])\r\n row=[]\r\n \r\n\r\n for b in rows:\r\n for l,s in enumerate(b):\r\n s=s.split(',')\r\n b[l] = s\r\n for b in rows:\r\n for l,s in enumerate(b):\r\n print(b[l][0])\r\n # print(int(s[0])-int(b[l][l+1])) \r\n\r\n\r\n print(rows)\r\n # for x,b in enumerate(boxes.splitlines()):\r\n # j=0\r\n # if x!=0:\r\n # b = b.split()\r\n \r\n # # if(len(b)==12):\r\n # # x,y,w,h = int(b[6]),int(b[7]),int(b[8]),int(b[9])\r\n # # cv2.rectangle(img_2,(x,y),(w+x,h+y),(0,0,255),1)\r\n # print(b)\r\n # if b[0]=='5' and len(b)==12:\r\n # row[j].append(b[6]+','+b[11])\r\n # elif b[0]=='5' and len(b)!=12:\r\n # row[j].append(b[6]+','+b[10])\r\n # else:\r\n # j=j+1\r\n # print(j)\r\n\r\n\r\n\r\n # return row\r\n\r\n # cv2.imshow('boxes_making_result',img_2)\r\n # cv2.waitKey(0)\r\n\r\n\r\n\r\n\r\n\r\n\r\ndef preprocessing(filename):\r\n \r\n # Read image using opencv\r\n img_path = './' + filename\r\n img = cv2.imread(img_path)\r\n \r\n items_to_remove = []\r\n\r\n\r\n # img = np.array(img)\r\n # Convert to gray\r\n\r\n img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\r\n #Apply dilation and erosion to remove some noise\r\n kernel = np.ones((1, 1), np.uint8)\r\n # img = cv2.dilate(img, kernel, iterations=1)\r\n img = cv2.erode(img, kernel, iterations=1) # Apply blur to smooth out the edges\r\n # img = cv2.GaussianBlur(img, (5, 5), 0)\r\n # # Apply threshold to get image with only b&w (binarization)\r\n # img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]\r\n \r\n thresh = cv2.adaptiveThreshold(img, 255,cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 21, 4)\r\n # cv2.imshow('hello',thresh)\r\n # cv2.waitKey(0)\r\n # Recognize text with tesseract for python\r\n image_text = pytesseract.image_to_data(thresh, lang=\"eng\")\r\n image_text=image_text.split('\\n')\r\n image_text = image_text\r\n for y,b in enumerate(image_text):\r\n b=b.split()\r\n image_text[y] = b\r\n print(len(image_text))\r\n \r\n \r\n image_text = [n for n in image_text if len(n) == 12]\r\n list_len = len(image_text)\r\n print(list_len)\r\n for i in range(1,list_len):\r\n if i == list_len-1:\r\n break\r\n if (int(image_text[i+1][6])-int(image_text[i][6]))<=40 and (int(image_text[i+1][6])-int(image_text[i][6]))>0:\r\n image_text[i][11] = image_text[i][11] + ' ' + image_text[i+1][11]\r\n items_to_remove.append(i+1)\r\n else:\r\n print('i am %d',i)\r\n image_text.pop(items_to_remove[0])\r\n for i in range(1,len(items_to_remove)):\r\n image_text.pop(items_to_remove[i]-i)\r\n print(items_to_remove[i]-1)\r\n \r\n\r\n for i in range(len(image_text)):\r\n image_text[i] = image_text[i][11]\r\n print(image_text)\r\n return\r\n\r\n# print (preprocessing(\"invoice.png\"))\r\n# print(boxes())\r\nprint(preprocessing('./invoice.png'))\r\n\r\n"
},
{
"alpha_fraction": 0.5997286438941956,
"alphanum_fraction": 0.611940324306488,
"avg_line_length": 25.370370864868164,
"blob_id": "e09f4e3b949f7b43872b666efc99608f007f4fc4",
"content_id": "89bd6bbccfcb5d40cf54a6594a4f6c5c2be52b97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 737,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 27,
"path": "/abc.py",
"repo_name": "HuzefaEssaji/invoice-data-extraction",
"src_encoding": "UTF-8",
"text": "marksheet = []\r\nstudents = []\r\nscorelist = []\r\nfor i in range(int(input())):\r\n a = input()\r\n c = float(input())\r\n scorelist.append(c)\r\n marksheet.append([a,c])\r\n\r\nscorelist = set(scorelist)\r\nmarksheet.sort(key = lambda x: x[1])\r\nsecond_lowest = sorted(list(scorelist))\r\nif len(second_lowest)<=2:\r\n second_lowest = second_lowest[0]\r\nelse:\r\n second_lowest = second_lowest[1]\r\nprint(second_lowest)\r\nfor i in range(len(marksheet)):\r\n if len(scorelist)==2:\r\n if second_lowest==marksheet[i][1]:\r\n students.append(marksheet[i][0])\r\n else:\r\n if second_lowest==marksheet[i][1]:\r\n students.append(marksheet[i][0])\r\nstudents.sort()\r\nfor x in range(len(students)):\r\n print (students[x])"
}
] | 5 |
JerryFox/wiegand_arduino_raspi
|
https://github.com/JerryFox/wiegand_arduino_raspi
|
84b008902a962e13965d6de00799570ab690c98a
|
5908269a7acf27da9e60faf9abe4ebe51cf5762c
|
a06c6c0ba98ee13bbd88238a966f38bd89d70139
|
refs/heads/master
| 2021-01-17T20:01:21.854281 | 2018-01-17T23:21:19 | 2018-01-17T23:21:19 | 63,593,078 | 4 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5571131706237793,
"alphanum_fraction": 0.572429895401001,
"avg_line_length": 21.781064987182617,
"blob_id": "ee2d98e5981618c5570528be277d82f43b27a2af",
"content_id": "5856c2480a90d7ae1db9ca25357facf3f6f8a806",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3852,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 169,
"path": "/wiegand_arduino_raspi.ino",
"repo_name": "JerryFox/wiegand_arduino_raspi",
"src_encoding": "UTF-8",
"text": "/*\nDahua Wiegand keypad with card reader 125 kHz\n1k pullup resistors between D0, D1 and +5V\n*/\n\n#include <Wiegand.h>\n\nconst byte keylockPin = 10;\nconst byte monitorPin = 13;\nint openMillis = 4000; // door open interval ms\n\n#include \"codes.h\"\n\n\nWIEGAND wg;\n\nvoid setup() {\n\tSerial.begin(115200); \n/*\n while (!Serial) {\n ; // wait for serial port to connect. Needed for native USB\n }\n*/\n\n\twg.begin();\n pinMode(2, INPUT_PULLUP);\n pinMode(3, INPUT_PULLUP);\n pinMode(keylockPin, OUTPUT);\n digitalWrite(keylockPin, HIGH);\n pinMode(monitorPin, OUTPUT);\n digitalWrite(monitorPin, LOW); \n listCodes(); \n Serial.println(\"SETUP...\");\n}\n\nbyte wholeCode = false; \nString inCode = \"\"; \nString prefix = \"\";\nunsigned long time = millis(); \nunsigned long beginTime = millis();\n\nvoid loop() {\n // long time since last key\n if (millis() - time > 10000) {\n inCode = \"\";\n wholeCode = false; \n }\n String command = readCommand(50);\n if (command != \"\") {\n Serial.println(\"<= \" + command);\n if (command == \"open\") {\n Serial.println(\"demandOPEN\");\n keyUnlock(keylockPin, openMillis);\n }\n else if (command.startsWith(\"test\")) {\n testCodes(command.substring(4));\n }\n else if (command.startsWith(\"input\")) {\n prefix = command.substring(5, 6);\n inCode = command.substring(6);\n wholeCode = true;\n }\n }\n if(wg.available())\n {\n if(wg.getWiegandType() == 4) {\n prefix = \"k\";\n time = millis();\n String numero = String(wg.getCode(),HEX);\n if (numero == \"d\") {\n inCode = \"\";\n wholeCode = false;\n }\n else {\n inCode += numero;\n }\n if (inCode.length() >= 5) {\n wholeCode = true; \n }\n }\n if(wg.getWiegandType() == 26) {\n prefix = \"c\"; \n inCode = String(wg.getCode(),HEX);\n wholeCode = true; \n }\n }\n //Serial.print(prefix + inCode);\n if (wholeCode) {\n String prac = \"\";\n prac = prefix + inCode;\n if (testCodes(prac)) {\n keyUnlock(keylockPin, openMillis);\n inCode = \"\";\n wholeCode = false; \n }\n }\n}\n\nvoid keyUnlock(byte pin, int time) {\n digitalWrite(pin, LOW); \n digitalWrite(monitorPin, HIGH);\n Serial.println(\"UNLOCKED...\");\n delay(time); \n // if code is in web codes too - kill open command\n while (Serial.available()) {\n byte inByte = Serial.read();\n }\n digitalWrite(pin, HIGH) ; \n digitalWrite(monitorPin, LOW);\n Serial.println(\"LOCKED...\");\n}\n\nvoid listCodes() {\n for (int i =0; i< ARRAYSIZE; i++) { \n Serial.print(\"# \");\n Serial.println(codes[i]); \n }\n}\n\nbyte testCodes(String code) {\n while (Serial.available()) {\n byte inByte = Serial.read();\n }\n byte ok = false; \n Serial.println(code); \n char myCode[128] = \"\"; //create a character array to hold the converted String\n code.toCharArray(myCode,128); //Convert the String to CharArray.\n for (int i =0; i< ARRAYSIZE; i++) {\n //Serial.print(codes[i]);\n //Serial.print(\" \");\n //Serial.println(code);\n if (strcmp(codes[i], myCode) == 0) {\n ok = true;\n Serial.print(\"hardOPEN \");\n Serial.println(code);\n return ok;\n break;\n } \n }\n String command = readCommand(50);\n Serial.print(\"<=\");\n Serial.println(command); \n if (command == \"open\") {\n ok = true; \n Serial.println(\"softOPEN\");\n }\n if (command == \"service\") {\n ok = false;\n wholeCode = false; \n inCode = \"\"; \n }\n return ok;\n}\n\nString readCommand(int delay) {\n String command = \"\";\n char inChar = 0; \n //int delay = 200; \n unsigned long beginTime = millis(); \n while (inChar != 10 && millis() - beginTime < delay) {\n inChar = 0; \n if (Serial.available()) inChar = Serial.read();\n if (inChar != 0 && inChar != 10) {\n command += inChar;\n } \n }\n //Serial.println(command); \n return command;\n}\n\n\n"
},
{
"alpha_fraction": 0.4973745048046112,
"alphanum_fraction": 0.5131275057792664,
"avg_line_length": 28.196319580078125,
"blob_id": "2d3a2823c7a89cdcb32ef842779432d19c228d8f",
"content_id": "8af572303cf56995835bbeecd43080b3dc9c1119",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4761,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 163,
"path": "/access_system.py",
"repo_name": "JerryFox/wiegand_arduino_raspi",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"access system for Mr. Petrik\npython part for raspi\nit communicates with alamode shield (arduino)\nand django web app\n\"\"\"\n\nimport serial, time\nimport json\nimport requests\nimport datetime \nimport os\n\n# download address\nADDRESS = \"http://localhost:8000/access/6eebabbeba3f162859636d349a3e74fd9cbeff5c/dump_codes.json\"\nADDRESS = \"http://vysoky.pythonanywhere.com/access/6eebabbeba3f162859636d349a3e74fd9cbeff5c/dump_codes.json\"\n\nglobal codes_json, codes_list\n\ncodes_json = []\ncodes_list = []\n\n\ntry: \n ser_port = serial.Serial(\"/dev/ttyS0\")\n ser_port.baudrate = 115200\nexcept: \n ser_port = False\n\ndef read_command(ser_port): \n \"\"\"read command from alamode\n as command is considered line without \\r\\n\"\"\"\n if os.path.exists(\"command.txt\"): \n f = open(\"command.txt\")\n c = list(f)\n f.close()\n if c: \n c = c[0].split(\"\\n\")[0]\n #print(c)\n os.remove(\"command.txt\")\n return c\n\n if ser_port: \n command = \"\"\n delay = 0.2 # how long to wait for a command\n # read until new line \n begin_time = time.time()\n inchar = \"\"\n while time.time() < begin_time + delay and inchar != \"\\n\": \n if ser_port.in_waiting: \n inchar = ser_port.read()\n command += inchar\n if \"\\r\\n\" in command and command.index(\"\\r\\n\") == len(command) - 2: \n command = command[:-2]\n return command\n else: \n return \"\" \n\ndef download_codes():\n \"\"\"download codes from web app in json format\"\"\"\n global js\n address = ADDRESS\n try: \n r = requests.get(address)\n except ConnectionError: \n return False\n if r.ok: \n js = r.json()\n json.dump(js, open(\"dump_codes.json\", \"w\"))\n return js\n else: \n return False\n\ndef create_list(js): \n list1 = []\n for i in range(len(js)): \n list1.append(js[i][\"code_input\"] + js[i][\"code_number\"])\n return list1\n\n\ndef load_local_json(file=\"dump_codes.json\"): \n try: \n js = json.load(open(file))\n except IOError: \n js = False\n return js\n\ndef init(): \n global codes_json, codes_list\n istate = False\n js = download_codes()\n if not js: \n js = load_local_json()\n if js:\n codes_json = js\n else: \n istate = \"web\"\n codes_json = js\n if not js: \n print(\"***** no json data *****\")\n else: \n codes_list = create_list(codes_json)\n if not istate: \n istate = \"local\" \n return istate\n\ndef stime(): \n # ansi date + time with milliseconds\n return datetime.datetime.now().strftime(\"%Y-%m-%d %H:%M:%S.%f\")[:-3]\n\n\ndef loop():\n global codes_json, codes_list\n last_download = time.time()\n delay_download = 30 * 60\n f = open(\"logacces.txt\", \"a\", 0)\n f.write(stime() + \" ====== restart\\n\")\n while True:\n if time.time() > last_download + delay_download: \n istate = init()\n last_download = time.time()\n if istate == \"web\": \n imsg = \"downloaded from web ... \"\n elif istate == \"local\":\n imsg = \"refreshed from local ...\"\n else: \n imsg = \"download error ... \"\n print(stime() + \" \" + imsg)\n f.write(stime() + \" \" + imsg + \"\\n\")\n command = read_command(ser_port)\n if command != \"\": \n # command processing\n print(\"=>\" + command)\n if command == \"k135797531\": \n # refresh code list\n init() \n ser_port.write(\"service\\n\") \n f.write(stime() + \" service\" + \"\\n\")\n elif command.startswith(\"hardOPEN\") or command.startswith(\"softOPEN\"): \n f.write(stime() + \" \" + command + \"\\n\")\n elif command.startswith(\"test\") or command.startswith(\"input\"): \n f.write(stime() + \" \" + command + \"\\n\")\n ser_port.write(command + \"\\n\")\n elif command.startswith(\"send\"): \n f.write(stime() + \" \" + command + \"\\n\")\n ser_port.write(command[4:] + \"\\n\")\n elif command[0] in \"kc\": \n # validate keyboard or card code\n f.write(stime() + \" validate \" + command + \" - \")\n if command in codes_list: \n # open\n ser_port.write(\"open\\n\") \n print(codes_json[codes_list.index(command)][\"username\"])\n f.write(\"ok \" + codes_json[codes_list.index(command)][\"username\"]+ \"\\n\")\n else: \n # return ko\n ser_port.write(\"ko\\n\")\n f.write(\"ko\" + \"\\n\")\n \n\ninit()\nloop()\n\n\n"
},
{
"alpha_fraction": 0.47297295928001404,
"alphanum_fraction": 0.6216216087341309,
"avg_line_length": 11.166666984558105,
"blob_id": "023ad2452944ecf66d7a5c8827d74fd187079bfd",
"content_id": "adfefb5945cc74fa04fd2c50b42fc80159759221",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 6,
"path": "/codes.h",
"repo_name": "JerryFox/wiegand_arduino_raspi",
"src_encoding": "UTF-8",
"text": "#define ARRAYSIZE 2\n\nchar* codes[ARRAYSIZE] = { \n\"k12345\", \n\"k98765\" \n};\n\n"
},
{
"alpha_fraction": 0.7806451320648193,
"alphanum_fraction": 0.7806451320648193,
"avg_line_length": 27.090909957885742,
"blob_id": "3ea08578ba2b55d15f3355e290f8940244719691",
"content_id": "9b34a640b31f027e14c09c2216928902ac73c2f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 11,
"path": "/README.md",
"repo_name": "JerryFox/wiegand_arduino_raspi",
"src_encoding": "UTF-8",
"text": "# wiegand_arduino_raspi\n\nClient part for hide bar access system. \n\nhardware parts: \n- wiegand keypad\n- electromagnetic door lock\n- arduino (keypad, lock)\n- raspberry (communication with django web server and arduino)\n\nThe system can use its locally saved access codes and update access codes from web server. \n"
}
] | 4 |
Gaowei-Xu/action-classifier
|
https://github.com/Gaowei-Xu/action-classifier
|
03bd4c4e06d82b60a967a0748fe25ed79afa35b9
|
930a6f1dc80361a11e2964d679772ada631880c1
|
d0dab2490a2d216d4fc0656c78118203047455bc
|
refs/heads/master
| 2022-11-07T08:53:25.087395 | 2020-06-28T01:19:26 | 2020-06-28T01:19:26 | 272,953,127 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5123102068901062,
"alphanum_fraction": 0.5478046536445618,
"avg_line_length": 35.36567306518555,
"blob_id": "4b32c0eaffb529f05d02d8f2456e62f698de9502",
"content_id": "fbaf92970bf15070f42ddaaa490cee95b10b87d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4874,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 134,
"path": "/src/c3d.py",
"repo_name": "Gaowei-Xu/action-classifier",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# -*- coding: utf-8 -*-\nimport tensorflow as tf\n\n\nclass C3DModel(object):\n def __init__(self, config):\n self._config = config\n\n self._input_data = tf.compat.v1.placeholder(\n tf.float32,\n shape=[\n self._config.batch_size,\n self._config.time_dimen,\n self._config.frame_height,\n self._config.frame_width,\n self._config.frame_channels\n ],\n name=\"input_video_segment\")\n\n self._ground_truth = tf.compat.v1.placeholder(\n tf.float32,\n shape=[\n self._config.batch_size,\n self._config.ncls\n ],\n name=\"ground_truth\")\n\n self._global_step = tf.Variable(0, trainable=False)\n self._optimizer, self._summary_op, self._probs = None, None, None\n self._loss, self._accuracy = None, None\n\n self.build_model()\n\n def build_model(self):\n \"\"\"\n build U-Net model\n :return:\n \"\"\"\n def conv3d(x, filters, activation, name):\n return tf.keras.layers.Conv3D(\n filters=filters,\n kernel_size=(3, 3, 3),\n strides=(1, 1, 1),\n padding='SAME',\n data_format='channels_last',\n activation=activation,\n name=name\n )(x)\n\n def pool3d(x, ksize, strides, name):\n return tf.nn.max_pool3d(\n input=x,\n ksize=ksize,\n strides=strides,\n padding='SAME',\n data_format=\"NDHWC\",\n name=name)\n\n with tf.compat.v1.variable_scope(\"C3D-Backbone\"):\n conv1 = conv3d(x=self._input_data, filters=64, activation=tf.nn.relu, name='conv1')\n relu1 = tf.nn.relu(conv1, 'relu1')\n pool1 = pool3d(x=relu1, ksize=(1, 2, 2), strides=(2, 2, 2), name='pool1')\n\n conv2 = conv3d(x=pool1, filters=128, activation=tf.nn.relu, name='conv2')\n relu2 = tf.nn.relu(conv2, 'relu2')\n pool2 = pool3d(x=relu2, ksize=(2, 2, 2), strides=(2, 2, 2), name='pool2')\n\n conv3 = conv3d(x=pool2, filters=256, activation=tf.nn.relu, name='conv3a')\n relu3a = tf.nn.relu(conv3, 'relu3a')\n conv3b = conv3d(x=relu3a, filters=256, activation=tf.nn.relu, name='conv3b')\n relu3b = tf.nn.relu(conv3b, 'relu3b')\n pool3 = pool3d(x=relu3b, ksize=(2, 2, 2), strides=(2, 2, 2), name='pool3')\n\n conv4 = conv3d(x=pool3, filters=512, activation=tf.nn.relu, name='conv4a')\n relu4a = tf.nn.relu(conv4, 'relu4a')\n conv4b = conv3d(x=relu4a, filters=512, activation=tf.nn.relu, name='conv4b')\n relu4b = tf.nn.relu(conv4b, 'relu4b')\n pool4 = pool3d(x=relu4b, ksize=(2, 2, 2), strides=(2, 2, 2), name='pool4')\n\n conv5 = conv3d(x=pool4, filters=512, activation=tf.nn.relu, name='conv5a')\n relu5a = tf.nn.relu(conv5, 'relu5a')\n conv5b = conv3d(x=relu5a, filters=512, activation=tf.nn.relu, name='conv5b')\n relu5b = tf.nn.relu(conv5b, 'relu5b')\n pool5 = pool3d(x=relu5b, ksize=(2, 2, 2), strides=(2, 2, 2), name='pool5')\n\n # Fully connected layer\n flatten = tf.reshape(pool5, shape=(self._config.batch_size, -1))\n fc1 = tf.layers.dense(inputs=flatten, units=1024, activation=tf.nn.relu)\n fc2 = tf.layers.dense(inputs=fc1, units=1024, activation=tf.nn.relu)\n logits = tf.layers.dense(inputs=fc2, units=self._config.ncls, activation=None)\n self._probs = tf.nn.softmax(logits=logits)\n\n with tf.compat.v1.variable_scope(\"Loss\"):\n self._loss = tf.reduce_mean(\n tf.losses.softmax_cross_entropy(onehot_labels=self._ground_truth, logits=logits)\n )\n self._accuracy = tf.reduce_mean(\n tf.cast(tf.equal(tf.argmax(self._ground_truth, 1), tf.argmax(self._probs, 1)), dtype=tf.float32))\n\n tf.compat.v1.summary.scalar('loss', self._loss)\n\n with tf.compat.v1.variable_scope(\"optimization\"):\n train_op = tf.compat.v1.train.AdamOptimizer(self._config.learning_rate)\n self._optimizer = train_op.minimize(self._loss)\n self._summary_op = tf.compat.v1.summary.merge_all()\n\n @property\n def loss(self):\n return self._loss\n\n @property\n def summary_op(self):\n return self._summary_op\n\n @property\n def optimizer(self):\n return self._optimizer\n\n @property\n def ground_truth(self):\n return self._ground_truth\n\n @property\n def input_data(self):\n return self._input_data\n\n @property\n def probs(self):\n return self._probs\n\n @property\n def accuracy(self):\n return self._accuracy\n\n"
},
{
"alpha_fraction": 0.49976733326911926,
"alphanum_fraction": 0.505816638469696,
"avg_line_length": 38.43119430541992,
"blob_id": "bd87a7fc06d1c05f8750fac9fa2a9c9c966ecf28",
"content_id": "9a01ceee95b5487bf7c6fb08fcd05331b4d65e85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4298,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 109,
"path": "/src/train.py",
"repo_name": "Gaowei-Xu/action-classifier",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# -*- coding: utf-8 -*-\nimport tensorflow as tf\nimport numpy as np\nimport os\nfrom c3d import C3DModel\nfrom batch_generator import BatchGenerator\nfrom config import Configuration\n\n\ndef train():\n config = Configuration()\n batch_generator = BatchGenerator(config=config)\n\n # create two list to store cost values\n train_loss = np.zeros(shape=(config.max_epoch, ))\n val_loss = np.zeros(shape=(config.max_epoch, ))\n\n # create folders\n if not os.path.exists(config.train_summary_root_dir):\n os.makedirs(config.train_summary_root_dir)\n\n if not os.path.exists(config.dump_model_para_root_dir):\n os.makedirs(config.dump_model_para_root_dir)\n\n session_config = tf.compat.v1.ConfigProto(allow_soft_placement=True, log_device_placement=True)\n\n with tf.compat.v1.Session(config=session_config) as sess:\n model = C3DModel(config=config)\n print('\\n\\nModel initialized successfully.')\n\n train_writer = tf.compat.v1.summary.FileWriter(config.train_summary_root_dir, sess.graph)\n tf.compat.v1.global_variables_initializer().run()\n saver = tf.compat.v1.train.Saver(max_to_keep=None)\n\n print('Start to train model:')\n train_step = 0\n for e in range(config.max_epoch):\n print('\\n===================================== Epoch {} ====================================='.format(e+1))\n # training phase\n batch_generator.reset_training_batches()\n for batch in range(batch_generator.train_batch_amount):\n input_batch, gt_batch = batch_generator.next_train_batch()\n train_batch_loss, optimizer, summary_op, probs, train_accuracy = sess.run(\n fetches=[\n model.loss,\n model.optimizer,\n model.summary_op,\n model.probs,\n model.accuracy\n ],\n feed_dict={\n model.input_data: input_batch,\n model.ground_truth: gt_batch\n })\n\n # add summary and accumulate stats\n train_writer.add_summary(summary_op, train_step)\n train_loss[e] += train_batch_loss\n train_step += 1\n\n print('[Training] Epoch {}: batch {} / {}: loss = {}, accuracy over batch = {}.'.format(\n e+1, batch, batch_generator.train_batch_amount,\n round(train_batch_loss, 4), round(train_accuracy, 4)))\n\n train_loss[e] /= batch_generator.train_batch_amount\n print('--------------------------------------------------------------------------------------------------')\n\n # validation phase\n batch_generator.reset_validation_batches()\n for batch in range(batch_generator.val_batch_amount):\n input_batch, gt_batch = batch_generator.next_val_batch()\n val_batch_loss, probs, val_accuracy = sess.run(\n fetches=[\n model.loss,\n model.probs,\n model.accuracy\n ],\n feed_dict={\n model.input_data: input_batch,\n model.ground_truth: gt_batch\n })\n\n val_loss[e] += val_batch_loss\n\n print('[Inference] Epoch {}: batch {}: loss = {}, accuracy over batch = {}.'.format(\n e+1,\n batch,\n round(val_batch_loss, 4),\n round(val_accuracy, 4)\n ))\n\n val_loss[e] /= batch_generator.val_batch_amount\n\n # checkpoint model variable\n if (e + 1) % config.save_every_epoch == 0:\n model_name = 'epoch_{}_train_loss_{:3f}_val_loss_{:3f}.ckpt'.format(\n e + 1,\n np.round(train_loss[e], 4),\n np.round(val_loss[e], 4))\n dump_model_full_path = os.path.join(config.dump_model_para_root_dir, model_name)\n saver.save(sess=sess, save_path=dump_model_full_path)\n\n # close writer\n train_writer.close()\n\n\nif __name__ == '__main__':\n train()\n"
},
{
"alpha_fraction": 0.5631321668624878,
"alphanum_fraction": 0.5704057216644287,
"avg_line_length": 40.900001525878906,
"blob_id": "b039cd726c035b88a0acdcd25b69a3a70b628beb",
"content_id": "061a1be7ae09ebff5d50e3371f295e27a3dbf8e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8799,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 210,
"path": "/src/batch_generator.py",
"repo_name": "Gaowei-Xu/action-classifier",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# -*-coding:utf-8-*-\nimport os\nimport numpy as np\nimport json\nimport random\nimport cv2\nimport decord\nimport matplotlib.pyplot as plt\nfrom config import Configuration\n\n\nclass BatchGenerator(object):\n def __init__(self, config):\n self._config = config\n self._samples = self.samples_statistic()\n self.visualize_samples()\n self._label_mapping = dict()\n self._train_samples, self._val_samples = self.split_train_val(train_val_ratio=5.0)\n\n self._train_batch_amount = len(self._train_samples) // self._config.batch_size\n self._val_batch_amount = len(self._val_samples) // self._config.batch_size\n print('Amount of training samples (may be augmented) = {}'.format(len(self._train_samples)))\n print('Amount of validation samples = {}'.format(len(self._val_samples)))\n print('Amount of training batches = {}'.format(self._train_batch_amount))\n print('Amount of validation batches = {}'.format(self._val_batch_amount))\n\n self._train_batch_index, self._val_batch_index = 0, 0\n\n def visualize_samples(self):\n labels_dist = dict()\n for s in self._samples:\n if s['gt'] in labels_dist.keys():\n labels_dist[s['gt']] += 1\n else:\n labels_dist[s['gt']] = 1\n\n by_value = sorted(labels_dist.items(), key=lambda x: -x[1])\n x, y = list(), list()\n for d in by_value:\n x.append(d[0])\n y.append(d[1])\n\n plt.figure(figsize=(12, 8))\n plt.bar(x, y, color='g')\n plt.xlabel('Label', fontdict={'size': 13})\n plt.xticks(x[0:-1:3], rotation=90)\n plt.ylabel('Samples Amount', fontdict={'size': 13})\n plt.title('Samples Distribution (# of classes = {})'.format(len(by_value)),\n fontdict={\n 'size': 16\n })\n plt.savefig('../samples_distribution.png', dpi=300, bbox_inches='tight')\n print('# of Labels = {}'.format(len(by_value)))\n\n def samples_statistic(self):\n samples = list()\n items = json.load(open(os.path.join(self._config.trainval_set_dir, 'lables.json'), 'r'))['lable']\n for item in items:\n video_name = list(item.keys())\n label = list(item.values())\n assert len(video_name) == 1\n assert len(label) == 1\n video_name = video_name[0]\n label = label[0]\n if not os.path.exists(os.path.join(self._config.trainval_set_dir, 'videos', video_name + '.mp4')):\n continue\n\n if {'video_name': video_name, 'gt': label} in samples:\n continue\n\n samples.append(\n {\n 'video_name': video_name,\n 'gt': label\n }\n )\n print('Total samples amount = {}'.format(len(samples)))\n return samples\n\n def split_train_val(self, train_val_ratio=5.0):\n labels = list(set([s['gt'] for s in self._samples]))\n for i, label in enumerate(labels):\n self._label_mapping[label] = i\n\n # dump to local disk for reference\n json.dump(self._label_mapping, open(self._config.mapping_path, 'w'), ensure_ascii=False, indent=True)\n\n random.shuffle(self._samples)\n batch_amount = round(len(self._samples) / self._config.batch_size)\n val_batch_amount = round(batch_amount * 1.0 / (1.0 + train_val_ratio))\n split_index = val_batch_amount * self._config.batch_size\n\n val_samples = self._samples[0:split_index]\n train_samples = self._samples[split_index:]\n\n train_batch_amount = int(np.ceil(len(train_samples) / self._config.batch_size))\n\n print('Training samples amount = {}, batch amount = {} (batch size = {})'.format(len(train_samples), train_batch_amount, self._config.batch_size))\n print('Validation samples amount = {}, batch amount = {} (batch size = {})'.format(len(val_samples), val_batch_amount, self._config.batch_size))\n\n aug_samples_amount = train_batch_amount * self._config.batch_size - len(train_samples)\n aug_part = list()\n for _ in range(aug_samples_amount):\n index = random.randint(0, len(train_samples)-1)\n aug_part.append(train_samples[index])\n\n train_samples.extend(aug_part)\n return train_samples, val_samples\n\n def analyze(self):\n for index, sample in enumerate(self._samples):\n video_path = os.path.join(self._config.trainval_set_dir, 'videos', sample['video_name'] + '.mp4')\n video = decord.VideoReader(video_path)\n print(index + 1, sample['video_name'], len(video), video[0].shape)\n\n frame = video[0]\n frame = frame.asnumpy() # (height, width, channels)\n print(frame.shape)\n resized = cv2.resize(frame, (self._config.frame_width, self._config.frame_height))\n print(resized.shape)\n\n @staticmethod\n def sample_t_dimen(actual_frames, target_frames):\n index = np.linspace(0, actual_frames-1, target_frames)\n return index.astype(np.int)\n\n def next_train_batch(self):\n input_batch = np.zeros(shape=(self._config.batch_size,\n self._config.time_dimen,\n self._config.frame_height,\n self._config.frame_width,\n self._config.frame_channels))\n gt_batch = np.zeros(shape=(self._config.batch_size, self._config.ncls))\n\n for b_idx, sample in enumerate(self._train_samples[\n self._train_batch_index * self._config.batch_size:\n (1+self._train_batch_index) * self._config.batch_size]):\n video_path = os.path.join(self._config.trainval_set_dir, 'videos', sample['video_name'] + '.mp4')\n label = sample['gt']\n video = decord.VideoReader(video_path)\n sampled_frame_index_list = self.sample_t_dimen(len(video), target_frames=self._config.time_dimen)\n for t_idx, index in enumerate(sampled_frame_index_list):\n frame = video[index]\n frame = frame.asnumpy() # (height, width, channels)\n resized_frame = cv2.resize(frame, (self._config.frame_width, self._config.frame_height))\n input_batch[b_idx][t_idx] = resized_frame\n\n gt_batch[b_idx][self._label_mapping[label]] = 1.0\n\n self._train_batch_index += 1\n return input_batch, gt_batch\n\n def next_val_batch(self):\n input_batch = np.zeros(\n shape=(\n self._config.batch_size,\n self._config.time_dimen,\n self._config.frame_height,\n self._config.frame_width,\n self._config.frame_channels))\n gt_batch = np.zeros(shape=(self._config.batch_size, self._config.ncls))\n\n for b_idx, sample in enumerate(self._val_samples[\n self._val_batch_index * self._config.batch_size:\n (1+self._val_batch_index) * self._config.batch_size]):\n video_path = os.path.join(self._config.trainval_set_dir, 'videos', sample['video_name'] + '.mp4')\n label = sample['gt']\n\n video = decord.VideoReader(video_path)\n sampled_frame_index_list = self.sample_t_dimen(len(video), target_frames=self._config.time_dimen)\n for t_idx, index in enumerate(sampled_frame_index_list):\n frame = video[index]\n frame = frame.asnumpy() # (height, width, channels)\n resized_frame = cv2.resize(frame, (self._config.frame_width, self._config.frame_height))\n input_batch[b_idx][t_idx] = resized_frame\n\n gt_batch[b_idx][self._label_mapping[label]] = 1.0\n\n self._val_batch_index += 1\n return input_batch, gt_batch\n\n @property\n def train_batch_amount(self):\n return self._train_batch_amount\n\n @property\n def val_batch_amount(self):\n return self._val_batch_amount\n\n def reset_validation_batches(self):\n self._val_batch_index = 0\n\n def reset_training_batches(self):\n random.shuffle(self._train_samples)\n self._train_batch_index = 0\n\n\nif __name__ == '__main__':\n batch_generator = BatchGenerator(\n config=Configuration()\n )\n\n for _ in range(batch_generator.train_batch_amount):\n train_batch, train_gt = batch_generator.next_train_batch()\n print(train_batch.shape, train_gt.shape)\n\n for _ in range(batch_generator.val_batch_amount):\n val_batch, val_gt = batch_generator.next_val_batch()\n print(val_batch.shape, val_gt.shape)\n"
},
{
"alpha_fraction": 0.5682191848754883,
"alphanum_fraction": 0.5939726233482361,
"avg_line_length": 20.987951278686523,
"blob_id": "0b5a66333b019233213cb6820daf367b1009dcd8",
"content_id": "5ff8a78678e7ea9617956d3650424486d3f3c10f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1825,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 83,
"path": "/src/config.py",
"repo_name": "Gaowei-Xu/action-classifier",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n# -*-coding:utf-8-*-\nimport os\n\n\nclass Configuration(object):\n def __init__(self):\n self._trainval_set_dir = '../dataset/'\n self._mapping_path = '../mapping.json'\n\n self._batch_size = 16\n\n self._time_dimen = 32\n self._frame_height = 720 // 5\n self._frame_width = 1280 // 5\n self._frame_channels = 3\n\n self._ncls = 149\n\n self._learning_rate = 0.0002\n\n self._max_epoch = 250\n self._train_summary_root_dir = '../train/'\n self._dump_model_para_root_dir = '../models/'\n self._save_every_epoch = 1\n\n self._selected_model_name = 'epoch_7_train_loss_348.611500_val_loss_342.913800.ckpt'\n\n @property\n def trainval_set_dir(self):\n return self._trainval_set_dir\n\n @property\n def mapping_path(self):\n return self._mapping_path\n\n @property\n def batch_size(self):\n return self._batch_size\n\n @property\n def time_dimen(self):\n return self._time_dimen\n\n @property\n def frame_height(self):\n return self._frame_height\n\n @property\n def frame_width(self):\n return self._frame_width\n\n @property\n def frame_channels(self):\n return self._frame_channels\n\n @property\n def ncls(self):\n return self._ncls\n\n @property\n def learning_rate(self):\n return self._learning_rate\n\n @property\n def max_epoch(self):\n return self._max_epoch\n\n @property\n def train_summary_root_dir(self):\n return self._train_summary_root_dir\n\n @property\n def dump_model_para_root_dir(self):\n return self._dump_model_para_root_dir\n\n @property\n def save_every_epoch(self):\n return self._save_every_epoch\n\n @property\n def selected_model_name(self):\n return self._selected_model_name\n"
},
{
"alpha_fraction": 0.5652173757553101,
"alphanum_fraction": 0.6304348111152649,
"avg_line_length": 44,
"blob_id": "c39e18c3fd509229accf28ec782146ba5381c3e7",
"content_id": "8a5ff85fb6c0e44f809f914511896af685fb2bcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 1,
"path": "/src/run.sh",
"repo_name": "Gaowei-Xu/action-classifier",
"src_encoding": "UTF-8",
"text": "nohup python3 train.py > ../train.log 2>&1 &\n\n"
}
] | 5 |
gnaixx/keepcode
|
https://github.com/gnaixx/keepcode
|
1b9a786788ecd70356dbcde9fe58fdc483e89807
|
50981dfdd462a717eea2af041a5214049c412115
|
93c2485627a8fae24e8029c9bf16f076cb773623
|
refs/heads/master
| 2023-04-02T21:57:46.742854 | 2021-06-14T13:53:43 | 2021-06-14T13:53:43 | 261,059,143 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5665818452835083,
"avg_line_length": 27.780487060546875,
"blob_id": "fb097bbb9d2e0b8eaa684f4005c540b9b0bd7dd0",
"content_id": "0486764df61721ac52f0f72c1fd0949d45155ade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1221,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 41,
"path": "/python3/linked-list/easy/160.相交链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=160 lang=python3\n#\n# [160] 相交链表\n#\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, x):\n# self.val = x\n# self.next = None\n\nclass Solution:\n # def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:\n # if not headA or not headB: return None\n # # 必须set否则会超时\n # tmpA, tmpB, nodeList = headA, headB, set() \n # while tmpA:\n # nodeList.add(tmpA)\n # tmpA = tmpA.next\n \n # while tmpB:\n # if tmpB in nodeList:\n # return tmpB\n # tmpB = tmpB.next\n # return None\n def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> ListNode:\n if headA is None or headB is None:\n return None\n pa = headA\n pb = headB\n # 非相交最后会一起走到 None\n while pa is not pb:\n pa = headB if pa is None else pa.next\n pb = headA if pb is None else pb.next\n return pa \n# @lc code=end\n\nSolution().getIntersectionNode(createSLink([1, 2, 3]), createSLink([4, 5]))"
},
{
"alpha_fraction": 0.44622424244880676,
"alphanum_fraction": 0.5057207942008972,
"avg_line_length": 19.85714340209961,
"blob_id": "40921a99741d8215700e367742dbf8ba0583ec0c",
"content_id": "600a08ff24d3ee0955486bf7f50970fccc9a8b8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 445,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 21,
"path": "/python3/math/easy/7.整数反转.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=7 lang=python3\n#\n# [7] 整数反转\n#\n\n# @lc code=start\nclass Solution:\n def reverse(self, x: int) -> int:\n if (x < 0):\n string = str(0-x)\n expect = 0 - int(string[::-1])\n else:\n string = str(x)\n expect = int(string[::-1])\n \n return expect if -2**31<expect and expect < 2**31-1 else 0\n\n# @lc code=end\n\nprint(Solution().reverse(1534236469))"
},
{
"alpha_fraction": 0.614535391330719,
"alphanum_fraction": 0.6356945633888245,
"avg_line_length": 21.204082489013672,
"blob_id": "0fa897f445c26ce90ed153b0564cb360356bd5c4",
"content_id": "cdae6e1f3231a83a46370825106f4c6b4ac49edc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1097,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 49,
"path": "/python3/tree/easy/101.对称二叉树.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=101 lang=python3\n#\n# [101] 对称二叉树\n#\n\nfrom typing import List\nfrom python3.aatool.TreeT import preOrder, TreeNode, createBTree, postOrder3, inOrder, postOrder1, postOrder2\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def check(self, s: TreeNode, t: TreeNode) -> bool:\n if not s and not t: \n return True\n if not s or not t:\n return False\n return s.val==t.val and self.check(s.left, t.right) and self.check(s.right, t.left)\n\n def isSymmetric(self, root: TreeNode) -> bool:\n if not root: return True\n return self.check(root.left, root.right)\n# @lc code=end\n\nroot = createBTree([1,2,3,4,5,6,7], 0)\nlist = []\npreOrder(root, list)\nprint(list)\n\nlist = []\ninOrder(root, list)\nprint(list)\n\nlist = []\npostOrder1(root, list)\nprint(list)\n\nlist = []\npostOrder2(root, list)\nprint(list)\n\nlist = []\npostOrder3(root, list)\nprint(list)"
},
{
"alpha_fraction": 0.5662431716918945,
"alphanum_fraction": 0.5831820964813232,
"avg_line_length": 28.51785659790039,
"blob_id": "f93bb1694a74777fdb32370f927904a2b55e91f9",
"content_id": "d109292529454f5e2a258c8a68ab559e789539a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1737,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 56,
"path": "/python3/two-pointers/easy/234.回文链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=234 lang=python3\n#\n# [234] 回文链表\n#\n\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n # head2 需要作为全局变量处理\n def recursion(self, head1: ListNode):\n if head1:\n if not self.recursion(head1.next):\n return False\n if head1.val != self.head2.val:\n return False\n self.head2 = self.head2.next\n return True\n \n def reverseList(self, head: ListNode) -> ListNode:\n if not head or not head.next: return head\n headNode, tailNode, curNode = head, head, head.next\n while curNode:\n tailNode.next, curNode.next = curNode.next, headNode\n headNode, curNode = curNode, tailNode.next\n return headNode\n\n def isPalindrome(self, head: ListNode) -> bool:\n # self.head2 = head\n # return self.recursion(head)\n\n if not head or not head.next: return True\n # 找出中间节点,奇数点归前半段\n slow, fast = head, head\n while fast.next and fast.next.next:\n slow = slow.next\n fast = fast.next.next\n # 反转后续节点\n rehead = self.reverseList(slow.next)\n # 判断回文\n flag, head2 = True, rehead\n while head2 and flag:\n if head.val != head2.val: flag = False\n head, head2 = head.next, head2.next\n # 反转回去\n slow.next = self.reverseList(rehead)\n return flag\n# @lc code=end\n\nSolution().isPalindrome(createSLink([1,2,3,2,1]))\n"
},
{
"alpha_fraction": 0.5165114402770996,
"alphanum_fraction": 0.5292125344276428,
"avg_line_length": 26.465116500854492,
"blob_id": "cde9ea8bf690452dc591b11552bcbc1696989b96",
"content_id": "c240dcfa0ab91aaf9fa90083e70ca67d9f2b3d7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1203,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 43,
"path": "/python3/two-pointers/medium/19.删除链表的倒数第-n-个结点.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=19 lang=python3\n#\n# [19] 删除链表的倒数第 N 个结点\n#\n\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n # def removeNthFromEnd(self, head: ListNode, n: int) -> ListNode:\n # curMap, preMap, preNode, tmp = [], [], None, head\n # while tmp:\n # curMap.append(tmp)\n # preMap.append(preNode)\n # preNode = tmp\n # tmp = tmp.next\n # dIndex = len(curMap) - n\n # curNode = curMap[dIndex]\n # preNode = preMap[dIndex]\n # if preNode:\n # preNode.next = curNode.next\n # else:\n # head = head.next\n # return head\n def removeNthFromEnd(self, head, n):\n def index(node):\n if not node:\n return 0\n i = index(node.next) + 1\n if i > n:\n node.next.val = node.val\n return i\n index(head)\n return head.next\n# @lc code=end\n\nSolution().removeNthFromEnd(createSLink([1,2,3,4,5]), 2)\n"
},
{
"alpha_fraction": 0.5502645373344421,
"alphanum_fraction": 0.5925925970077515,
"avg_line_length": 21.294116973876953,
"blob_id": "e632d67612719769569989e2bd1f5198e05760f5",
"content_id": "8677dff8ab213855b5de62be1bef797d0e2f92c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 386,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 17,
"path": "/python3/math/easy/168.excel表列名称.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=168 lang=python3\n#\n# [168] Excel表列名称\n#\n\n# @lc code=start\nclass Solution:\n def convertToTitle(self, columnNumber: int) -> str:\n ans = ''\n while columnNumber:\n ans = chr((columnNumber-1) % 26 + ord('A')) + ans\n columnNumber = (columnNumber-1) // 26\n return ans\n# @lc code=end\n\nSolution().convertToTitle(701)"
},
{
"alpha_fraction": 0.4328593909740448,
"alphanum_fraction": 0.4612954258918762,
"avg_line_length": 22.481481552124023,
"blob_id": "8cd222c072811e865fcfe45c450548702797fbb9",
"content_id": "e97e79c3ffc39a7af991fdcdb6fc3c32f3e90472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 27,
"path": "/python3/string/easy/38.外观数列.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=38 lang=python3\n#\n# [38] 外观数列\n#\n\n# @lc code=start\nclass Solution:\n def countAndSay(self, n: int) -> str:\n if n == 1: return '1'\n string = self.countAndSay(n -1)\n\n ans, maps, count, pre = '', [], 0, ''\n for c in string:\n if count>0 and list(maps[count-1].keys())[0] == c:\n maps[count-1][c] += 1\n else:\n maps.append({c:1})\n count += 1\n for map in maps:\n key = list(map.keys())[0]\n ans += str(map[key]) + key\n return ans\n \n# @lc code=end\n\nSolution().countAndSay(5)"
},
{
"alpha_fraction": 0.44785276055336,
"alphanum_fraction": 0.4621676802635193,
"avg_line_length": 26.97142791748047,
"blob_id": "189136d58f0ac2712dbee62eacaf9d7c534275ff",
"content_id": "60fbc1657e785b15e3fdfca0579e7bc82d2ae08a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 35,
"path": "/python3/sliding-window/medium/3.无重复字符的最长子串.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=3 lang=python3\n#\n# [3] 无重复字符的最长子串\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def lengthOfLongestSubstring(self, s: str) -> int:\n # maxLen, currStr, currLen, i = 0, {}, 0, 0\n # while i < len(s):\n # if s[i] not in currStr.keys():\n # currLen += 1\n # currStr[s[i]] = i\n # else:\n # i = currStr[s[i]] + 1\n # currLen = 1\n # currStr.clear()\n # currStr[s[i]] = i\n # i += 1\n # maxLen = max(currLen, maxLen)\n # return maxLen\n start, maxLen, useChar = 0, 0, {}\n for i in range(len(s)):\n if s[i] in useChar and start <= useChar[s[i]]:\n start = useChar[s[i]] + 1\n else:\n maxLen = max(maxLen, i - start + 1)\n useChar[s[i]] = i\n return maxLen\n# @lc code=end\n\nSolution().lengthOfLongestSubstring('abcabcbb')"
},
{
"alpha_fraction": 0.4985337257385254,
"alphanum_fraction": 0.5483871102333069,
"avg_line_length": 17.94444465637207,
"blob_id": "f683f0b4d3701626daf25f9d07f5b1615baa5f45",
"content_id": "3476eb12d2a1623eff74babf30628ce1482cf161",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/python3/dynamic-programming/medium/338.比特位计数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=338 lang=python3\n#\n# [338] 比特位计数\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def countBits(self, num: int) -> List[int]:\n dp = [0, 1, 1]\n for i in range(3, num + 1):\n dp.append(dp[i>>1] + i%2)\n return dp[0:num+1]\n \n# @lc code=end\n\nSolution().countBits(5)\n"
},
{
"alpha_fraction": 0.49056604504585266,
"alphanum_fraction": 0.5220125913619995,
"avg_line_length": 20.727272033691406,
"blob_id": "e44d21ad82d21c9b8fdd0b61f71ac44f5493445a",
"content_id": "9e6bfdd21a333b4c28d5aa25e8c2f23b99baafe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 22,
"path": "/python3/binary-search/easy/35.搜索插入位置.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=35 lang=python3\n#\n# [35] 搜索插入位置\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def searchInsert(self, nums: List[int], target: int) -> int:\n start, end = 0, len(nums)-1\n while start <= end:\n mid = int((end + start)/2)\n if nums[mid] < target:\n start = mid + 1\n else:\n end = mid - 1\n return start\n# @lc code=end\n\nSolution().searchInsert([1,3,5,6], 5)"
},
{
"alpha_fraction": 0.5349730849266052,
"alphanum_fraction": 0.5495772361755371,
"avg_line_length": 27.30434799194336,
"blob_id": "6f36fb069caaf9d6c2c0ac2344464f2394753984",
"content_id": "b0d85623ec54c0ab6f12c4e2441438d387b885a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1355,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 46,
"path": "/python3/linked-list/hard/25.k-个一组翻转链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=25 lang=python3\n#\n# [25] K 个一组翻转链表\n#\n\nfrom typing import List\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n # 反转链表的k个节点并返回反转后最后一个节点\n def reverse(self, preNode: ListNode, head: ListNode, k: int) -> ListNode:\n temp, stack = head, []\n for i in range(k):\n if temp:\n stack.append(temp)\n temp = temp.next\n else:\n break\n if len(stack) < k:\n return None\n for i in range(k-1, -1, -1):\n preNode.next = stack[i]\n preNode = preNode.next\n if i == k-1:\n lstNode = stack[i].next\n if i == 0:\n stack[i].next = lstNode\n return preNode\n\n def reverseKGroup(self, head: ListNode, k: int) -> ListNode:\n dummyNode = ListNode(val=0, next=head)\n preNode = dummyNode\n while preNode:\n preNode = self.reverse(preNode, head, k)\n head = preNode.next if preNode else None\n return dummyNode.next\n# @lc code=end\n\nSolution().reverseKGroup(createSLink([1,2,3,4,5]), 1)"
},
{
"alpha_fraction": 0.5085158348083496,
"alphanum_fraction": 0.5498783588409424,
"avg_line_length": 19.600000381469727,
"blob_id": "155fad05857001d5cae06dffc81fb1279f15c3fc",
"content_id": "41641d5573e54481efe38c6b539974cab3e3418b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 20,
"path": "/python3/hash-table/easy/217.存在重复元素.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=217 lang=python3\n#\n# [217] 存在重复元素\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def containsDuplicate(self, nums: List[int]) -> bool:\n list = []\n for i in nums:\n if i in list:\n return True\n else:\n list.append(i)\n return False\n# @lc code=end\nSolution().containsDuplicate([1,1,1,3,3,4,3,2,4,2])"
},
{
"alpha_fraction": 0.5668202638626099,
"alphanum_fraction": 0.599078357219696,
"avg_line_length": 17,
"blob_id": "b0403adb4724280895c872e5a91effa1672c10b9",
"content_id": "71fb19dbe63bf073dce29d7b28e546b043340a77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 12,
"path": "/python3/dynamic-programming/easy/977.有序数组的平方.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=977 lang=python3\n#\n# [977] 有序数组的平方\n#\n\n# @lc code=start\nclass Solution:\n def sortedSquares(self, A: List[int]) -> List[int]:\n return sorted(x*x for x in A)\n \n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4441441297531128,
"alphanum_fraction": 0.4819819927215576,
"avg_line_length": 26.09756088256836,
"blob_id": "1283d262067afd0d8e284b1dba4a5f3433d5ad39",
"content_id": "89f3b17d8886bdd1abfc2ef34a219d8b8bc99bbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1150,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 41,
"path": "/python3/string/medium/8.字符串转换整数_atoi.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=8 lang=python3\n#\n# [8] 字符串转换整数 (atoi)\n#\n\n# @lc code=start\nclass Solution:\n # 根据三种状态决定下一步逻辑\n BEGIN, PM, CONTINUE, STOP = 0, 1, 2, 100\n def check(self, c: str, state:int, num: int, pm: int) -> int:\n if c == ' ' and state == self.BEGIN:\n return self.BEGIN, num, pm\n\n if c in ['-','+'] and state == self.BEGIN:\n pm = -1 if c=='-' else 1\n return self.PM, num, pm\n\n if c.isdigit():\n newNum = num * 10 + int(c) * pm\n if newNum<=2**31-1 and newNum>=-2**31:\n num = newNum\n return self.CONTINUE, num, pm\n else:\n num = 2**31-1 if pm==1 else -2**31\n return self.STOP, num, pm\n\n if not c.isdigit():\n return self.STOP, num, pm\n\n\n def myAtoi(self, s: str) -> int:\n state, num, pm= 0, 0, 1\n for i in range(len(s)):\n state, num, pm = self.check(s[i], state, num, pm)\n if state == self.STOP:\n break\n return num\n# @lc code=end\n\nprint(Solution().myAtoi('21474836460'))"
},
{
"alpha_fraction": 0.5888888835906982,
"alphanum_fraction": 0.6097221970558167,
"avg_line_length": 25.66666603088379,
"blob_id": "f34a6428c29662f2dba55766312583705ff312aa",
"content_id": "e6efdcd14852a26412f3e033f5cc17b16487a392",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 27,
"path": "/python3/linked-list/easy/203.移除链表元素.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=203 lang=python3\n#\n# [203] 移除链表元素\n#\n\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def removeElements(self, head: ListNode, val: int) -> ListNode:\n dummyNode = ListNode(val=0, next=head)\n curNode = dummyNode\n while curNode.next:\n if curNode.next.val == val:\n curNode.next = curNode.next.next\n else:\n curNode = curNode.next\n return dummyNode.next\n# @lc code=end\n\nSolution().removeElements(createSLink([7,7,7,7]), 7)\n"
},
{
"alpha_fraction": 0.47310125827789307,
"alphanum_fraction": 0.5189873576164246,
"avg_line_length": 24.239999771118164,
"blob_id": "da724ba46c2663486c1121095f30aa4dc8cb5b8c",
"content_id": "a14c84593d7a4c024c4354e583091a263fdd9196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 838,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 25,
"path": "/python3/dynamic-programming/easy/1025.除数博弈.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=1025 lang=python3\n#\n# [1025] 除数博弈\n#\n\n# @lc code=start\nclass Solution:\n # 1.最终结果应该是占到 2 的赢,占到 1 的输;\n # 2.若当前为奇数,奇数的约数只能是奇数或者 1,因此下一个一定是偶数;\n # 3.若当前为偶数,偶数的约数可以是奇数,可以是偶数,也可以是 1,因此直接减 1,则下一个是奇数;\n # 4.因此,奇则输,偶则赢\n # return N % 2 ==0;\n def divisorGame(self, N: int) -> bool:\n must = [False] * (N+2)\n must[1], must[2] = False, True\n for i in range(3, N+1):\n for j in range(1, int(N/2)):\n if i%j==0 and not must[i-j]:\n must[i] = True\n break\n return must[N] \n# @lc code=end\n\nSolution().divisorGame(3)\n\n"
},
{
"alpha_fraction": 0.42283299565315247,
"alphanum_fraction": 0.4545454680919647,
"avg_line_length": 19.565217971801758,
"blob_id": "dc7be7f4e9e0d4989909b8ca595ee06ac72b7726",
"content_id": "c271ed9e4f39aa83c326d83bf6be33b7d41c4f2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 23,
"path": "/python3/hash-table/easy/202.快乐数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=202 lang=python3\n#\n# [202] 快乐数\n#\n\n# @lc code=start\nclass Solution:\n def isHappy(self, n: int) -> bool:\n def next_num(n):\n sum = 0\n while n > 0:\n n, digit = divmod(n, 10)\n sum += digit ** 2\n return sum\n seen = set()\n while n!=1 and n not in seen:\n seen.add(n)\n n = next_num(n)\n return n == 1\n# @lc code=end\n\nSolution().isHappy(7)\n"
},
{
"alpha_fraction": 0.49829933047294617,
"alphanum_fraction": 0.5102040767669678,
"avg_line_length": 25.772727966308594,
"blob_id": "df10c9cd6042ba2cc30ed577f499172bfdc53657",
"content_id": "5010a5f71c0f4727cb109e01588433114a9d5e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 22,
"path": "/python3/hash-table/easy/205.同构字符串.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=205 lang=python3\n#\n# [205] 同构字符串\n#\n\n# @lc code=start\nclass Solution:\n def isIsomorphic(self, s: str, t: str) -> bool:\n bitA, bitB = {}, {}\n for i in range(len(s)):\n cs, ct = s[i], t[i]\n if cs not in bitA.keys() and ct not in bitB.keys():\n bitA[cs], bitB[ct] = i, i\n elif cs in bitA.keys() and ct in bitB.keys():\n if bitA[cs] != bitB[ct]: return False\n else:\n return False\n return True\n# @lc code=end\n\nSolution().isIsomorphic('bbbaaaba', 'aaabbbba')"
},
{
"alpha_fraction": 0.39827585220336914,
"alphanum_fraction": 0.4206896424293518,
"avg_line_length": 23.125,
"blob_id": "d8e8282b6d50af0ce9ff0419cf86aafcb3cb5f95",
"content_id": "ac18bbf7d04c381933461b5c59af550b1e69141e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 602,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 24,
"path": "/python3/two-pointers/easy/345.反转字符串中的元音字母.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=345 lang=python3\n#\n# [345] 反转字符串中的元音字母\n#\n\n# @lc code=start\nclass Solution:\n def isVowel(self, c: str) -> bool:\n return c.lower() in ['a', 'e', 'o', 'i', 'u']\n \n def reverseVowels(self, s: str) -> str:\n l, r = 0, len(s)-1\n ss = list(s)\n while l < r:\n if not self.isVowel(s[l]):\n l += 1\n elif not self.isVowel(s[r]):\n r -= 1\n else:\n ss[l], ss[r] = ss[r], ss[l]\n l, r = l+1, r-1\n return ''.join(ss)\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5524817109107971,
"alphanum_fraction": 0.5663141012191772,
"avg_line_length": 29.725000381469727,
"blob_id": "3b1eb275eff32235a47f702569cd1a081fe9af46",
"content_id": "40b725db1700e6a6045c23ad7731410bd949362d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1313,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 40,
"path": "/python3/linked-list/hard/23.合并k个升序链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=23 lang=python3\n#\n# [23] 合并K个升序链表\n#\n\nfrom typing import List\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def mergeKLists(self, lists: List[ListNode]) -> ListNode:\n headNode = None\n dummyNode = ListNode(0, headNode)\n while any(lists):\n minIndex, minValue = 0, float('inf')\n # 找出k个链表中最小值和链表编号\n for i, v in enumerate(lists):\n if not v: continue\n if v.val <= minValue:\n minValue, minIndex = v.val, i\n # 添加最小节点\n if headNode:\n headNode.next = lists[minIndex]\n headNode = headNode.next\n else:\n headNode = lists[minIndex]\n dummyNode.next = headNode\n # 对应的编号的链表往后移一个节点\n if lists[minIndex]: lists[minIndex] = lists[minIndex].next\n return dummyNode.next\n# @lc code=end\n\n# Solution().mergeKLists([createSLink([1,4,5]), createSLink([1,3,4]), createSLink([2,6])])\nSolution().mergeKLists([])\n"
},
{
"alpha_fraction": 0.3978930413722992,
"alphanum_fraction": 0.4294975697994232,
"avg_line_length": 29.121952056884766,
"blob_id": "28b78f56921516bfdc672211fae0ecb3e78ce0da",
"content_id": "a3a3b6a2a2cb9f455a7c528e3cef9d4906fbe59e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 41,
"path": "/python3/array/medium/73.矩阵置零.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=73 lang=python3\n#\n# [73] 矩阵置零\n#\n\nfrom typing import List\n# @lc code=start\nclass Solution:\n def setZeroes(self, matrix: List[List[int]]) -> None:\n \"\"\"\n Do not return anything, modify matrix in-place instead.\n \"\"\"\n # r, c, row, col = len(matrix), len(matrix[0]), [], []\n # for i in range(r):\n # for j in range(c):\n # if matrix[i][j]==0:\n # row.append(i), col.append(j)\n # for i in range(r):\n # for j in range(c):\n # if i in row or j in col:\n # matrix[i][j] = 0\n m, n = len(matrix), len(matrix[0])\n flag_col0 = False\n \n for i in range(m):\n if matrix[i][0] == 0:\n flag_col0 = True\n for j in range(1, n):\n if matrix[i][j] == 0:\n matrix[i][0] = matrix[0][j] = 0\n # 防止第一行被提前修改,倒序遍历\n for i in range(m - 1, -1, -1):\n for j in range(1, n):\n if matrix[i][0] == 0 or matrix[0][j] == 0:\n matrix[i][j] = 0\n if flag_col0:\n matrix[i][0] = 0\n# @lc code=end\n\nSolution().setZeroes([[1,0,1],[1,0,1],[1,1,1]])"
},
{
"alpha_fraction": 0.5367646813392639,
"alphanum_fraction": 0.5514705777168274,
"avg_line_length": 23.25,
"blob_id": "beb300f9bd2366593aad31b8e3be32a34b3d47f3",
"content_id": "e377122b7eb8dee2e172440680b77e01ef3b36de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 28,
"path": "/python3/dynamic-programming/easy/53.最大子序和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=53 lang=python3\n#\n# [53] 最大子序和\n#\n\n# @lc code=start\nclass Solution:\n # 动态规划\n # 计算前一步最大值加上当前值和当前值对比\n # 如果当前值更大,则以当前值为启动\n def maxSubArray(self, nums: List[int]) -> int:\n preSum = maxSum = nums[0]\n for num in nums[1:]:\n preSum = max(preSum + num, num)\n maxSum = max(preSum, maxSum)\n return maxSum\n\n # 动态规划\n # 前一步最大值如果为正数则加上当前值为最大\n # 判断前一步最大值加上当前值的大小\n # def maxSubArray(self, nums: List[int]) -> int:\n # sum, maxSum = 0, nums[0]\n # for num in nums:\n # sum = sum+num if sum > 0 else num\n # maxSum = max(maxSum, sum)\n # return maxSum\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5441176295280457,
"alphanum_fraction": 0.563725471496582,
"avg_line_length": 24.4375,
"blob_id": "a0d61235f13a9283cf52c5a7dac7dd58f6e221d1",
"content_id": "1ed7adddb7d7c0f488649d4b5f1b852e9de087bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 524,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 16,
"path": "/python3/math/easy/453.最小移动次数使数组元素相等.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=453 lang=python3\n#\n# [453] 最小移动次数使数组元素相等\n#\n\n# @lc code=start\nclass Solution:\n # 计算公式\n # sum + m(n-1) = xn sum 为原始数组和,m 为移动步骤,n 为数组大小,x 为最后的相等值\n # m = x - min 移动次数为 x 和 原始数组最小值的差\n # m = sum - (min * n)\n def minMoves(self, nums: List[int]) -> int:\n minNum, sumNum = min(nums), sum(nums)\n return sumNum - (minNum * len(nums)) \n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4988662004470825,
"alphanum_fraction": 0.5192743539810181,
"avg_line_length": 24.97058868408203,
"blob_id": "521b7be7260199d7af30eb5f0d197906f4eeecb9",
"content_id": "c21d643ce2ae47adfaf10371ec11626251701b0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 978,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 34,
"path": "/python3/greedy/medium/55.跳跃游戏.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=55 lang=python3\n#\n# [55] 跳跃游戏\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def canJump2(self, nums: List[int]) -> bool:\n position, step, reach = len(nums)-1, 0, False\n while position:\n reach = False\n # 从后开始找减少耗时\n for i in range(position-1, -1, -1):\n if i+nums[i] >= position:\n step, position, reach = step+1, i, True\n break\n # 如果遍历后找不到能达到当前点,直接返回\n if not reach: break\n return position==0 \n\n def canJump(self, nums: List[int]) -> bool:\n maxPosition = 0\n for i, n in enumerate(nums):\n # 单前节点超过能达到最大节点则失败\n if i > maxPosition:\n return False\n maxPosition = max(maxPosition, i+n)\n return True\n# @lc code=end\n\nSolution().canJump([1, 0, 1,0])"
},
{
"alpha_fraction": 0.5788235068321228,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 24.75757598876953,
"blob_id": "090b2871106b03ccfb69085a191e9b9724df48c7",
"content_id": "76715eef72b7bddf62acf7162a85e8251389032b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 33,
"path": "/python3/linked-list/easy/83.删除排序链表中的重复元素.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=83 lang=python3\n#\n# [83] 删除排序链表中的重复元素\n#\n\nimport sys\nsys.path.append('/Users/xiangqing.xxq/Workspace/Code/tooy/keepcode/python3')\n\nfrom aatool.LinkT import ListNode, createSLink, toList\nfrom typing import List\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def deleteDuplicates(self, head: ListNode) -> ListNode:\n pre, cur, bit = head, head, [False] * 200\n while cur:\n if bit[cur.val]:\n pre.next = cur.next\n else:\n bit[cur.val] = True\n pre = cur\n cur = cur.next\n return head\n# @lc code=end\n\nprint(toList(Solution().deleteDuplicates(createSLink([1,1,2,3,3]))))\n# createDLink([1,2,3])\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.538551390171051,
"avg_line_length": 31.884614944458008,
"blob_id": "de50833e60370a6a5513a774d6b820a99ce5f23e",
"content_id": "3de76b837fbdf9921b7b656710301847a9205b5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 922,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 26,
"path": "/python3/stack/medium/983.最低票价.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=983 lang=python3\n#\n# [983] 最低票价\n#\n\n# @lc code=start\nclass Solution:\n # dp 算法, 计算当天买票花销最优解,无旅行计划则按照最近前一次花费\n # dp[i] = min(dp[i-1]+dailyCosts, dp[i-7]+weeklyCosts, dp[i-30]+monthlyCosts)\n def mincostTickets(self, days: List[int], costs: List[int]) -> int:\n dayCost = [0] * 366\n dayIndex = 0\n for i in range(1, 366):\n if dayIndex >= len(days):\n break\n if i != days[dayIndex]:\n dayCost[i] = dayCost[i-1]\n continue\n costDaily = dayCost[max(i-1, 0)] + costs[0]\n costWeekly = dayCost[max(i-7, 0)] + costs[1]\n costMonthly = dayCost[max(i-30, 0)] + costs[2]\n dayCost[i] = min(costDaily, costWeekly, costMonthly)\n dayIndex += 1\n return dayCost[days[dayIndex - 1]]\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.6240664124488831,
"alphanum_fraction": 0.638174295425415,
"avg_line_length": 26.976743698120117,
"blob_id": "7b8e280168f32f2e46da0ef90a4982195adf85c6",
"content_id": "d2e8dc235c0e3c49d87889173596008e57eec387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 43,
"path": "/python3/tree/easy/572.另一个树的子树.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=572 lang=python3\n#\n# [572] 另一个树的子树\n#\n\nimport sys\nsys.path.append('/Users/xiangqing.xxq/Workspace/Code/tooy/keepcode/python3')\nfrom aatool.TreeT import createBTree\nfrom aatool.TreeT import preOrder1\nfrom aatool.TreeT import levelOrder\nfrom aatool.TreeT import TreeNode\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def isSameTree(self, s: TreeNode, t: TreeNode) -> bool:\n if not s and not t: \n return True\n if not s or not t:\n return False\n return s.val==t.val and self.isSameTree(s.left, t.left) and self.isSameTree(s.right, t.right)\n\n\n def isSubtree(self, s: TreeNode, t: TreeNode) -> bool:\n if not s and not t: \n return True\n if not s or not t:\n return False\n return self.isSubtree(s.left, t) or self.isSubtree(s.right, t) or self.isSameTree(s, t)\n \n# @lc code=end\n\ntreeNode = createBTree([3, 4, 5, 1, 2], 0)\narrays = []\n# preOrder1(treeNode, arrays)\nlevelOrder(treeNode, arrays)\nprint(arrays)\n\n\n"
},
{
"alpha_fraction": 0.4040268361568451,
"alphanum_fraction": 0.43624159693717957,
"avg_line_length": 26.629629135131836,
"blob_id": "a849304511713e47c889a9232dff8e6f776fef25",
"content_id": "e026691ee6e7d357515aefbd2b4511d17bf9f429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 759,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 27,
"path": "/python3/string/medium/12.整数转罗马数字.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=12 lang=python3\n#\n# [12] 整数转罗马数字\n#\n\n# @lc code=start\nclass Solution:\n def intToRoman(self, num: int) -> str:\n K = [1000, 500, 100, 50, 10, 5, 1]\n V = ['M', 'D', 'C', 'L', 'X', 'V', 'I']\n ans, index = '', 0\n while num:\n while index < len(K):\n if num >= K[index]:\n ans += V[index]\n num -= K[index]\n break\n else:\n index += 1\n ans = ans.replace('DCCCC', 'CM').replace('CCCC', 'CD')\n ans = ans.replace('LXXXX', 'XC').replace('XXXX', 'XL')\n ans = ans.replace('VIIII', 'IX').replace('IIII', 'IV')\n return ans\n# @lc code=end\n\nSolution().intToRoman(9)"
},
{
"alpha_fraction": 0.517179012298584,
"alphanum_fraction": 0.5650994777679443,
"avg_line_length": 35.900001525878906,
"blob_id": "b0c6f960be0faf1518cd3a822fd0c2675fab66a1",
"content_id": "dbc7b4b24d384cc971f06c326fcc0e6d45484829",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1140,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 30,
"path": "/python3/dynamic-programming/medium/63.不同路径_ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=63 lang=python3\n#\n# [63] 不同路径 II\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def uniquePathsWithObstacles(self, obstacleGrid: List[List[int]]) -> int:\n if not obstacleGrid or obstacleGrid[0][0]==1: return 0\n dp = [[0 for _ in range(len(obstacleGrid[0]))] for _ in range(len(obstacleGrid))]\n for i in range(0, len(obstacleGrid)):\n for j in range(0, len(obstacleGrid[i])):\n # 判断第一行第一列是否能走到\n if i==0 and 1 not in obstacleGrid[0][0:j]: dp[i][j]=1\n if j==0 and 1 not in list(zip(*obstacleGrid))[0][0:i+1]: dp[i][j]=1\n if obstacleGrid[i][j]==1: \n dp[i][j] = 0\n elif i>0 and j>0:\n dp[i][j] = dp[i-1][j] + dp[i][j-1]\n return dp[i][j]\n# @lc code=end\n\nSolution().uniquePathsWithObstacles([[0,0],[1, 1], [0,0]])\nSolution().uniquePathsWithObstacles([[1, 0]])\nSolution().uniquePathsWithObstacles([[0, 1]])\nSolution().uniquePathsWithObstacles([[0,0],[0,1]])\nSolution().uniquePathsWithObstacles([[0,0,0],[0,1,0],[0,0,0]])"
},
{
"alpha_fraction": 0.5463812351226807,
"alphanum_fraction": 0.5759429335594177,
"avg_line_length": 27.02857208251953,
"blob_id": "58b52a01e82fa884aa313a6a3c90612d00af21d9",
"content_id": "53a6e270e0887274ac9e8040652832f8d35f5ef0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1131,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 35,
"path": "/python3/two-pointers/medium/61.旋转链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=61 lang=python3\n#\n# [61] 旋转链表\n#\n\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def rotateRight(self, head: ListNode, k: int) -> ListNode:\n # 去除k=0,空链表,单链表\n if not k or not head or not head.next: return head\n # 计算链表长度\n cur, p1, p2, s = head, head, head, 1\n while cur.next: s, cur = s+1, cur.next\n # 计算移动长度\n if not (k:=k%s): return head\n # 快指针先走k步,如果走到最后一个节点直接返回\n while k: k, p1 = k-1, p1.next\n if not p1: return head\n # 快慢指针同时移动,快指针走到链尾,慢指针的下个节点为新链表头\n while p1.next:\n if not p2: p2 = head\n p2, p1 = p2.next, p1.next\n p1.next, head, p2.next = head, p2.next, None\n return head\n# @lc code=end\n\nSolution().rotateRight(createSLink([1,2]), 2)\n"
},
{
"alpha_fraction": 0.5711575150489807,
"alphanum_fraction": 0.5743200778961182,
"avg_line_length": 25.788135528564453,
"blob_id": "a3cc467cb985e240c8d1f63708110e209d5082ca",
"content_id": "0fa6507bfc74b28a875ac3dd009bcfb5ea6ccc43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3410,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 118,
"path": "/python3/aatool/TreeT.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "from typing import List\nimport queue\n\nclass TreeNode:\n def __init__(self, val=0, left=None, right=None):\n self.val = val\n self.left = left\n self.right = right\n\n# 创建二叉树\ndef createBTree(array: List, index: int) -> TreeNode:\n treeNode = None\n if index < len(array) and array[index]!=None:\n treeNode = TreeNode(array[index], createBTree(array, 2*index+1), createBTree(array, 2*index+2))\n return treeNode\n\n# 前序遍历\ndef preOrder(root: TreeNode, array: List) -> None:\n if not root: \n return\n array.append(root.val)\n preOrder(root.left, array)\n preOrder(root.right, array)\n\n# 中序遍历\ndef inOrder(root: TreeNode, array: List) -> None:\n if not root: \n return\n inOrder(root.left, array)\n array.append(root.val)\n inOrder(root.right, array)\n\n# 后续遍历\ndef postOrder(root: TreeNode, arrays: List) -> None:\n if not root:\n return\n postOrder(root.left, arrays)\n postOrder(root.right, arrays)\n arrays.append(root.val)\n \n# 前序遍历(非递归)\ndef preOrder1(root: TreeNode, arrays: List) -> None:\n stack = [root]\n while stack:\n node = stack.pop()\n arrays.append(node.val)\n if node.right:\n stack.append(node.right)\n if node.left:\n stack.append(node.left)\n\n# 中序遍历(非递归)\ndef inOrder1(root: TreeNode, arrays: List) -> None:\n stack, node = [], root\n while node or stack:\n while node:\n stack.append(node)\n node = node.left\n node = stack.pop()\n arrays.append(node.val)\n node = node.right\n\n# 后续遍历(非递归)\ndef postOrder1(root: TreeNode, arrays: List) -> None:\n stack = [root]\n while stack:\n node = stack.pop()\n arrays.append(node.val)\n # 采用和先序遍历一样策略,最后反转\n if node.left:\n stack.append(node.left)\n if node.right:\n stack.append(node.right)\n arrays = arrays.reverse()\n\n# 后续遍历(非递归)\ndef postOrder2(root: TreeNode, arrays: List) -> None:\n # temp 保存是第一次访问该节点\n stack, node, temp = [], root, []\n while node or stack:\n while node:\n temp.append(node)\n stack.append(node)\n node = node.left\n node = stack.pop()\n # 如果是第一次访问该节点直接遍历右节点\n if node in temp:\n temp.remove(node)\n stack.append(node)\n node = node.right\n else:\n arrays.append(node.val)\n node = None \n\n# 后续遍历(非递归)\ndef postOrder3(root: TreeNode, arrays: List) -> None:\n stack, node, pre = [], root, None\n while node:\n # 单前节点没有子节点或者子节点被访问过则可以添加\n if (not node.left and not node.right) or (pre and (pre==node.left or pre==node.right)):\n arrays.append(node.val)\n else:\n if node.right:\n stack.append(node.right)\n if node.left:\n stack.append(node.left)\n \n# 层序遍历\ndef levelOrder(root: TreeNode, arrays: List) -> None:\n queues = queue.Queue()\n queues.put(root)\n while not queues.empty():\n node = queues.get()\n arrays.append(node.val)\n if node.left:\n queues.put(node.left)\n if node.right:\n queues.put(node.right)\n\n"
},
{
"alpha_fraction": 0.35374149680137634,
"alphanum_fraction": 0.39727890491485596,
"avg_line_length": 29.58333396911621,
"blob_id": "af84d319669572bd48ae4ab7b372d86c98d47736",
"content_id": "1c30d13a18277e46736f510ed15de0794073020e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 749,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 24,
"path": "/python3/string/easy/13.罗马数字转整数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=13 lang=python3\n#\n# [13] 罗马数字转整数\n#\n\n# @lc code=start\nclass Solution:\n def romanToInt(self, s: str) -> int:\n KV = {'I':1, 'V':5, 'X':10, 'L':50, 'C':100, 'D':500, 'M':1000}\n ansers = KV[s[0]]\n for i in range(1, len(s)):\n if (s[i]=='V' or s[i]=='X') and s[i-1]=='I':\n ansers += KV[s[i]] - 2*KV[s[i-1]]\n continue\n if (s[i]=='L' or s[i]=='C') and s[i-1]=='X':\n ansers += KV[s[i]] - 2*KV[s[i-1]]\n continue\n if (s[i]=='D' or s[i]=='M') and s[i-1]=='C':\n ansers += KV[s[i]] - 2*KV[s[i-1]]\n continue\n ansers += KV[s[i]]\n return ansers\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.44823789596557617,
"alphanum_fraction": 0.4840308427810669,
"avg_line_length": 26.938461303710938,
"blob_id": "0f56dd8b1e98ed1318e3cf10114c343b3fb7af37",
"content_id": "425a7138aa1f7b5c54ad8500baeb83b4712440e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1832,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 65,
"path": "/python3/linked-list/easy/21.合并两个有序链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=21 lang=python3\n#\n# [21] 合并两个有序链表\n#\n\nimport sys\nsys.path.append('/Users/xiangqing.xxq/Workspace/Code/tooy/keepcode/python3')\nfrom aatool.LinkT import ListNode, createSLink, toList\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:\n if l1 is None:\n return l2\n elif l2 is None:\n return l1\n elif l1.val < l2.val:\n l1.next = self.mergeTwoLists(l1.next, l2)\n return l1\n else:\n l2.next = self.mergeTwoLists(l1, l2.next)\n return l2\n\n # def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:\n # if l1==None and l2==None: return None\n # if l1==None: return l2\n # if l2==None: return l1\n\n # if l1.val > l2.val:\n # node = l2\n # l2 = l2.next\n # else:\n # node = l1\n # l1 = l1.next\n # answer = node\n\n # while l1!=None or l2!=None:\n # if l1==None and l2!=None:\n # node.next = l2\n # l2 = l2.next\n # if l2==None and l1!=None:\n # node.next = l1\n # l1 = l1.next\n \n # if l1==None or l2==None:\n # node = node.next\n # continue\n \n # if l1.val > l2.val:\n # node.next = l2\n # l2 = l2.next\n # else:\n # node.next = l1\n # l1 = l1.next\n # node = node.next\n # return answer\n# @lc code=end\n\nprint(toList(Solution().mergeTwoLists(createSLink([-9,3]), createSLink([5,7]))))\n"
},
{
"alpha_fraction": 0.419181764125824,
"alphanum_fraction": 0.44802147150039673,
"avg_line_length": 32.155555725097656,
"blob_id": "8a247e24ffc49fa49ea8f3234f79d6326d114ed4",
"content_id": "c522ee8b855c4b12e5be4f9e02782b0efaf6bab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1533,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 45,
"path": "/python3/binary-search/medium/34.在排序数组中查找元素的第一个和最后一个位置.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=34 lang=python3\n#\n# [34] 在排序数组中查找元素的第一个和最后一个位置\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def binarySearch(self, nums: List[int], target: int, isLeft: bool) -> int:\n l, r = 0, len(nums) - 1\n while l <= r:\n mid = (l + r) // 2\n if nums[mid] < target or (not isLeft and nums[mid]==target):\n l = mid + 1\n else:\n r = mid - 1\n return l if isLeft else r\n \n def searchRange(self, nums: List[int], target: int) -> List[int]:\n l, r = self.binarySearch(nums, target, True), self.binarySearch(nums, target, False)\n return [l, r] if l <= r else [-1, -1]\n\n # def searchRange(self, nums: List[int], target: int) -> List[int]:\n # if not nums: return [-1, -1]\n # l, r, s, e = 0, len(nums)-1, -1, -1\n # while l <= r:\n # mid = (l+r) // 2\n # if nums[mid] == target:\n # s, e = mid, mid\n # while (s-1>=0 and nums[s-1]==target) or (e+1<len(nums) and nums[e+1]==target):\n # if s-1>=0 and nums[s-1]==target:\n # s -= 1\n # if e+1<len(nums) and nums[e+1]==target:\n # e += 1\n # return [s, e]\n # if nums[mid] < target:\n # l = mid + 1\n # else:\n # r = mid - 1\n # return [-1, -1]\n# @lc code=end\n\nSolution().searchRange([5,7,7,8,8,10], 8)"
},
{
"alpha_fraction": 0.4715026021003723,
"alphanum_fraction": 0.5103626847267151,
"avg_line_length": 19.36842155456543,
"blob_id": "12cae1a3fed04d46d652ee2925943f731d104cb8",
"content_id": "7900886eebb59069c72beb5b511136f2fd531131",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 19,
"path": "/python3/bit-manipulation/easy/231.2_的幂.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=231 lang=python3\n#\n# [231] 2的幂\n#\n\n# @lc code=start\nclass Solution:\n def isPowerOfTwo(self, n: int) -> bool:\n # if not n: return False\n # while n:\n # if n==1: return True\n # if n % 2: return False\n # n >>= 1\n # return True\n return (n>0) and (n&(n-1))==0\n# @lc code=end\n\nSolution().isPowerOfTwo(0)"
},
{
"alpha_fraction": 0.6468647122383118,
"alphanum_fraction": 0.669966995716095,
"avg_line_length": 19.133333206176758,
"blob_id": "e64c987af22b65d5ffecd503b2c933abc3065fec",
"content_id": "d23ee76c92b00fb51ba660e816d35bbb707c4ada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 311,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/python3/bit-manipulation/easy/169.多数元素.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=169 lang=python3\n#\n# [169] 多数元素\n#\n\n# @lc code=start\nimport collections\nfrom typing import List\n\nclass Solution:\n def majorityElement(self, nums: List[int]) -> int:\n counts = collections.Counter(nums)\n return max(counts.keys(), key=counts.get)\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5578330755233765,
"alphanum_fraction": 0.569546103477478,
"avg_line_length": 23.428571701049805,
"blob_id": "5a92a53a5932f4484313fc3bc58539a8b5ea0c48",
"content_id": "0dc648a8fa894ec21ff7424287eb69f279ea5eb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 28,
"path": "/python3/backtracking/medium/17.电话号码的字母组合.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=17 lang=python3\n#\n# [17] 电话号码的字母组合\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n ans = []\n table = ['', '', 'abc', 'def', 'ghi', 'jkl', 'mno', 'pqrs', 'tuv', 'wxyz']\n\n def backtrack(self, combination: str, digits: str):\n if not digits: \n self.ans.append(combination)\n return\n for c in self.table[int(digits[0])]:\n self.backtrack(combination + c, digits[1:])\n\n def letterCombinations(self, digits: str) -> List[str]:\n if not digits: return [] \n self.ans = []\n self.backtrack('', digits)\n return self.ans\n# @lc code=end\n\nSolution().letterCombinations('2')"
},
{
"alpha_fraction": 0.5135135054588318,
"alphanum_fraction": 0.5467775464057922,
"avg_line_length": 19.95652198791504,
"blob_id": "c927ebf6b23f0f0f3dd481c9f5a61f9cb1a5f6ac",
"content_id": "04b81e77942550de327c35550993c54c3156491a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 23,
"path": "/python3/two-pointers/easy/26.删除排序数组中的重复项.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=26 lang=python3\n#\n# [26] 删除排序数组中的重复项\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def removeDuplicates(self, nums: List[int]) -> int:\n if len(nums)==0: return 0\n if len(nums)==1: return 1\n\n index = 1\n for i in range(1, len(nums)):\n if nums[i] != nums[i-1]:\n nums[index] = nums[i]\n index += 1\n return index\n# @lc code=end\n\nSolution().removeDuplicates([1,1,2])"
},
{
"alpha_fraction": 0.5388235449790955,
"alphanum_fraction": 0.5505882501602173,
"avg_line_length": 21.421052932739258,
"blob_id": "48597985f488652f8d35545a3e4cbb272bb5884c",
"content_id": "f65640055e4a285dd8fa133953984637ce1f9f23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 19,
"path": "/python3/hash-table/medium/49.字母异位词分组.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=49 lang=python3\n#\n# [49] 字母异位词分组\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def groupAnagrams(self, strs: List[str]) -> List[List[str]]:\n d = {}\n for w in sorted(strs):\n key = tuple(sorted(w))\n d[key] = d.get(key, []) + [w]\n return list(d.values())\n# @lc code=end\n\nSolution().groupAnagrams([\"eat\", \"tea\", \"tan\", \"ate\", \"nat\", \"bat\"])"
},
{
"alpha_fraction": 0.41818180680274963,
"alphanum_fraction": 0.43454545736312866,
"avg_line_length": 21.91666603088379,
"blob_id": "13b154d95926bee1c5753184b58a4382b6792a4c",
"content_id": "b0d6dd8b7c6b0ee2d2c41f8d66c66181c04c8b4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 560,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 24,
"path": "/python3/stack/easy/20.有效的括号.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=20 lang=python3\n#\n# [20] 有效的括号\n#\n\n# @lc code=start\nclass Solution:\n def isValid(self, s: str) -> bool:\n KV = {'(':')', '{':'}', '[':']'}\n stack = [s[0]]\n for i in range(1,len(s)):\n if len(stack)==0:\n stack.append(s[i])\n continue\n x = stack.pop()\n if x not in KV.keys() or KV[x] != s[i]:\n stack.append(x)\n stack.append(s[i])\n return len(stack) == 0\n\n# @lc code=end\n\nprint(Solution().isValid('([)]'))\n"
},
{
"alpha_fraction": 0.4261501133441925,
"alphanum_fraction": 0.4503631889820099,
"avg_line_length": 16.913043975830078,
"blob_id": "f232c10eb104ff42b44697438ad0c59d14abcecc",
"content_id": "42abe61d87dcb9544e1a02654d3cb2ecca03e022",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 23,
"path": "/python3/binary-search/easy/392.判断子序列.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=392 lang=python3\n#\n# [392] 判断子序列\n#\n\n# @lc code=start\nclass Solution:\n \n # 直接按位对比\n def isSubsequence(self, s: str, t: str) -> bool:\n if len(s) == 0:\n return True\n\n index = 0\n for c in t:\n if s[index] == c:\n index += 1\n if index == len(s):\n break\n return index == len(s)\n\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4181034564971924,
"alphanum_fraction": 0.4353448152542114,
"avg_line_length": 27.121212005615234,
"blob_id": "484023a4fd708047f289dde23090ef0e9a781098",
"content_id": "828ee873933def66c7fb9871b04497c481a9bf43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 970,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 33,
"path": "/python3/two-pointers/medium/16.最接近的三数之和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=16 lang=python3\n#\n# [16] 最接近的三数之和\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # 定位一个数后找出每轮最优解\n def threeSumClosest(self, nums: List[int], target: int) -> int:\n nums.sort()\n ans = nums[0] + nums[1] + nums[2]\n for i in range(len(nums)):\n s, e = i+1, len(nums)-1\n while s < e:\n tmp = nums[i] + nums[s] + nums[e]\n if tmp == target:\n return target\n if tmp < target:\n ss = nums[s]\n while s < e and nums[s] == ss:\n s += 1\n if tmp > target:\n ee = nums[e]\n while s < e and nums[e] == ee:\n e -= 1\n ans = tmp if abs(target-tmp) < abs(target-ans) else ans\n return ans\n# @lc code=end\n\nSolution().threeSumClosest([0,1,2], 0)\n"
},
{
"alpha_fraction": 0.5095890164375305,
"alphanum_fraction": 0.5424657464027405,
"avg_line_length": 19.22222137451172,
"blob_id": "9c0a6da4071c3526bb71b2bb48414615d0891e65",
"content_id": "dcbcb7a006c6107d381129fafb8427c55ab0999c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 18,
"path": "/python3/hash-table/easy/350.两个数组的交集-ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=350 lang=python3\n#\n# [350] 两个数组的交集 II\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def intersect(self, nums1: List[int], nums2: List[int]) -> List[int]:\n ans = []\n for i in nums1:\n if i in nums2:\n ans.append(i)\n nums2.remove(i)\n return ans\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.42229729890823364,
"alphanum_fraction": 0.4375,
"avg_line_length": 32.842857360839844,
"blob_id": "3eee2afc9159474f6d96d7b166b40dcafbd4715e",
"content_id": "9080b740f4b8cd9391bebdedf010a1a23a554de7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2478,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 70,
"path": "/python3/two-pointers/medium/18.四数之和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=18 lang=python3\n#\n# [18] 四数之和\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def fourSum2(self, nums: List[int], target: int) -> List[List[int]]:\n if len(nums) < 4:\n return []\n ans, n = [], len(nums)-1\n nums.sort()\n for i in range(n):\n # 重复数直接过滤\n if i>0 and nums[i]==nums[i-1]:\n continue\n for j in range(i+1, n):\n l, r = j+1, n\n while l < r:\n sum = nums[i] + nums[j] + nums[l] + nums[r]\n if sum == target:\n combination = [nums[i], nums[j], nums[l], nums[r]]\n if combination not in ans:\n ans.append(combination)\n l += 1\n if sum < target:\n l += 1\n while l < r and nums[l]==nums[l-1]:\n l += 1\n else:\n r -= 1\n while l < r and nums[r]==nums[r+1]:\n r -= 1\n return ans\n \n def backtrack(self, nums: List[int], target: int, size: int, index: int, combination: List[int], ans: List[List[int]]):\n cSize, cSum = len(combination), sum(combination)\n if cSize==size and cSum==target:\n ans.append(combination.copy())\n return\n for i in range(index, len(nums)):\n # 长度不足\n if len(nums)-i < size - cSize:\n return\n # 连续相同\n if nums[i]==nums[i-1] and i > index:\n continue\n # 之前总和+当前数+下个数*(剩余个数) > 目标值\n if i<len(nums)-1 and cSum + nums[i] + nums[i+1]*(size-cSize-1) > target:\n return\n # 之前总和+当前数+最后一个数*(剩余个数) < 目标值\n if cSum + nums[i] + nums[len(nums)-1]*(size-cSize-1) < target:\n continue\n combination.append(nums[i])\n self.backtrack(nums, target, size, i+1, combination, ans)\n combination.remove(nums[i])\n\n def fourSum(self, nums: List[int], target: int) -> List[List[int]]:\n if len(nums)<4: return []\n nums.sort()\n ans = []\n self.backtrack(nums, target, 4, 0, [], ans)\n return ans\n\n# @lc code=end\n\nSolution().fourSum([-3,-1,0,2,4,5], 0)"
},
{
"alpha_fraction": 0.4197530746459961,
"alphanum_fraction": 0.47325101494789124,
"avg_line_length": 29.41666603088379,
"blob_id": "a255096fdbf1e36690b36bf80d772993a28f3969",
"content_id": "9ff6bae7dd2d984dc1161868a27e16f63a8d9837",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 24,
"path": "/python3/string/medium/43.字符串相乘.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=43 lang=python3\n#\n# [43] 字符串相乘\n#\n\n# @lc code=start\nclass Solution:\n def multiply(self, num1: str, num2: str) -> str:\n ans = [0] * (len(num1) + len(num2))\n for i in range(len(num1)-1, -1, -1):\n carry = 0\n for j in range(len(num2)-1, -1, -1):\n # 计算当前位结果,处理进位及余数\n tmp = (ord(num1[i])-ord('0')) * (ord(num2[j])-ord('0')) + carry\n carry = (ans[i+j+1]+tmp) // 10\n ans[i+j+1] = (ans[i+j+1]+tmp) % 10\n # 计算为倒排,每次计算后最高位为 i\n ans[i] += carry \n ans = ''.join(map(str, ans))\n return '0' if not ans.lstrip('0') else ans.lstrip('0')\n# @lc code=end\n\nSolution().multiply('123', '456')"
},
{
"alpha_fraction": 0.5905673503875732,
"alphanum_fraction": 0.6008202433586121,
"avg_line_length": 28.280000686645508,
"blob_id": "74010c37a77cb6e608723c4373d8ccc45fab40ff",
"content_id": "08f7422c9553edc651ebb13aa9c9a9858eed72c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1633,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 50,
"path": "/python3/linked-list/easy/206.反转链表.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=206 lang=python3\n#\n# [206] 反转链表\n#\n\nfrom typing import List\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n # 递归\n def recursion(self, preNode:ListNode, head: ListNode) -> ListNode:\n if head and head.next: \n # 返回尾部\n tailNode = self.recursion(head, head.next)\n # head.next 保存新的头节点\n preNode.next = head.next\n # 单前节点移到尾部\n tailNode.next, head.next = head, tailNode.next\n return tailNode.next\n else:\n return head\n\n # 迭代\n def iteration(self, head:ListNode) -> ListNode:\n # 空链,单节点链直接返回\n if not head or not head.next: return head\n # 从第二个节点开始遍历\n headNode, tailNode, curNode = head, head, head.next\n while curNode:\n # 当前节点后一个节点移到最新尾部,最新表头移到当前节点后\n tailNode.next, curNode.next = curNode.next, headNode\n # 更新最新节点&单前节点\n headNode, curNode = curNode, tailNode.next\n return headNode\n\n def reverseList(self, head: ListNode) -> ListNode:\n return self.iteration(head)\n # dummyNode = ListNode(val=0, next=head)\n # self.recursion(dummyNode, head)\n # return dummyNode.next\n# @lc code=end\n\nSolution().reverseList(createSLink([1,2,3,4,5]))"
},
{
"alpha_fraction": 0.5401174426078796,
"alphanum_fraction": 0.557729959487915,
"avg_line_length": 24.5,
"blob_id": "161993e83572d49700ca8f762685afd438b23122",
"content_id": "810f410602624d000edd9a38137b5332bacf01e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 20,
"path": "/python3/Unknown/easy/1431.拥有最多糖果的孩子.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=1431 lang=python3\n#\n# [1431] 拥有最多糖果的孩子\n#\n\n# @lc code=start\nclass Solution:\n # 找出最大值\n # 当前点加上额外的是否大于等于最大值\n def kidsWithCandies(self, candies: List[int], extraCandies: int) -> List[bool]:\n res = [False] * len(candies)\n maxNum = max(candies)\n for i in range(len(candies)):\n if candies[i] == maxNum:\n res[i] = True\n continue\n res[i] = candies[i] + extraCandies >= maxNum\n return res\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.568493127822876,
"alphanum_fraction": 0.5835616588592529,
"avg_line_length": 25.10714340209961,
"blob_id": "2571ccc3a996ebb5ee0d59d129128f93c286ddb7",
"content_id": "50f8d73016b0397307706ff93c5fc98cf4b9e895",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 28,
"path": "/python3/backtracking/medium/47.全排列_ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=47 lang=python3\n#\n# [47] 全排列 II\n#\n\n# @lc code=start\nfrom typing import List\n\n\nclass Solution:\n def backtrack(self, nums: List[int], combination:List[int], ans:List[List[int]]):\n if 0==len(nums) and combination not in ans:\n ans.append(combination.copy())\n return\n for i in range(len(nums)):\n combination.append(nums[i])\n self.backtrack(nums[:i]+nums[i+1:], combination, ans)\n # 不能用remove方法会导致第一个重复整数被删除\n combination.pop() \n\n def permuteUnique(self, nums: List[int]) -> List[List[int]]:\n ans = []\n self.backtrack(nums, [], ans)\n return ans\n# @lc code=end\n\nSolution().permuteUnique([2,2,1,1])"
},
{
"alpha_fraction": 0.5570934414863586,
"alphanum_fraction": 0.5882353186607361,
"avg_line_length": 21.30769157409668,
"blob_id": "8f92a13bd9962307262e783b934228ae39c14343",
"content_id": "dcc2190dcb1c69dfaa5a338ca0d88616afcfad81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 13,
"path": "/python3/sort/easy/242.有效的字母异位词.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=242 lang=python3\n#\n# [242] 有效的字母异位词\n#\n\n# @lc code=start\nclass Solution:\n def isAnagram(self, s: str, t: str) -> bool:\n return (lambda x:(x.sort(),x)[1])(list(s)) == (lambda x:(x.sort(),x)[1])(list(t))\n# @lc code=end\n\nSolution().isAnagram('rat', 'car')"
},
{
"alpha_fraction": 0.4243614971637726,
"alphanum_fraction": 0.47347739338874817,
"avg_line_length": 23.285715103149414,
"blob_id": "46c5ca5ba1081ca1be999405768a6b6d0770cf0c",
"content_id": "fdb677f21661348693639a561b635dff4a8faad7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 21,
"path": "/python3/dynamic-programming/medium/91.解码方法.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=91 lang=python3\n#\n# [91] 解码方法\n#\n\n# @lc code=start\nclass Solution:\n # 边界处理太恶心\n def numDecodings(self, s: str) -> int:\n cnt = [1,1] + [0] * len(s)\n s = \"99\" + s #添加虚拟头部,以便不用对头部做特殊处理\n for i in range(2, len(s)):\n if(10 <= int(s[i-1:i+1]) <= 26): #s[i]可与s[i-1]组合\n cnt[i] += cnt[i-2]\n if(s[i] != '0'): #s[i]可单独解码\n cnt[i] += cnt[i-1]\n return cnt[-1]\n# @lc code=end\n\nprint(Solution().numDecodings('112'))"
},
{
"alpha_fraction": 0.48653846979141235,
"alphanum_fraction": 0.5192307829856873,
"avg_line_length": 20.70833396911621,
"blob_id": "4f372e1d1fef010fe78c5648794680ace05ee0cf",
"content_id": "0150337f7a16ea55003e23917a12331fc302235c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 24,
"path": "/python3/two-pointers/easy/283.移动零.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=283 lang=python3\n#\n# [283] 移动零\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def moveZeroes(self, nums: List[int]) -> None:\n \"\"\"\n Do not return anything, modify nums in-place instead.\n \"\"\"\n index = 0\n for i in range(len(nums)):\n if nums[i] != 0:\n nums[index] = nums[i]\n index += 1\n for i in range(index, len(nums)):\n nums[i] = 0\n# @lc code=end\n\nSolution().moveZeroes([0,1,0,3,12])"
},
{
"alpha_fraction": 0.6060255169868469,
"alphanum_fraction": 0.6292004585266113,
"avg_line_length": 27.766666412353516,
"blob_id": "d4eadba15af4d72da0992211a3020b95cc6de6da",
"content_id": "29618df4b4b5f24130c9c3b6174e08c42eb8373a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 889,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 30,
"path": "/python3/tree/easy/108.将有序数组转换为二叉搜索树.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=108 lang=python3\n#\n# [108] 将有序数组转换为二叉搜索树\n#\n\nfrom typing import List\nfrom python3.aatool.TreeT import TreeNode\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def createNode(self, nums: List[int], left: int, right: int) -> TreeNode:\n if left > right:\n return None\n mid = (left+right) // 2\n leftNode = self.createNode(nums, left, mid-1)\n rightNode = self.createNode(nums, mid+1, right)\n return TreeNode(nums[mid], leftNode, rightNode)\n\n def sortedArrayToBST(self, nums: List[int]) -> TreeNode:\n return self.createNode(nums, 0, len(nums)-1)\n# @lc code=end\n\nSolution().sortedArrayToBST([-10,-3,0,5,9])\n"
},
{
"alpha_fraction": 0.4715568721294403,
"alphanum_fraction": 0.5164670944213867,
"avg_line_length": 24.653846740722656,
"blob_id": "d0a387c7331b2bc38d842726e85ba11d32c7468c",
"content_id": "5cc99b99d47b98a6982b5892f13c36e0d0f34a60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 726,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 26,
"path": "/python3/greedy/easy/122.买卖股票的最佳时机-ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=122 lang=python3\n#\n# [122] 买卖股票的最佳时机 II\n#\n\n# @lc code=start\nclass Solution:\n # 动态规划 dp0前一天没股票 dp1前一天有股票\n def maxProfit(self, prices: List[int]) -> int:\n dp0, dp1= 0, -prices[0]\n for i in range(1, range(len(prices))):\n newDp0 = max(dp0, dp1 + prices[i])\n newDp1 = max(dp1, dp0 - prices[i])\n dp0 = newDp0\n dp1 = newDp1\n return dp0\n \n # 贪心算法\n # def maxProfit(self, prices: List[int]) -> int:\n # maxProfit = 0\n # ans = 0\n # for i in range(1, len(prices)):\n # ans += max(0, prices[i]-prices[i-1])\n # return ans\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4962080121040344,
"alphanum_fraction": 0.5417118072509766,
"avg_line_length": 26.176469802856445,
"blob_id": "d95a932798f608d42b7abbcdf55638a9dd05d398",
"content_id": "6b57eee1823dd70007da5807aac5ddb1c6f91d22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 931,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 34,
"path": "/python3/linked-list/medium/2.两数相加.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=2 lang=python3\n#\n# [2] 两数相加\n#\n\nfrom typing import List\nfrom python3.aatool.LinkT import ListNode, createSLink\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n root, pre, x = None, None, 0\n while l1 or l2 or x!=0:\n v1 = l1.val if l1 else 0\n v2 = l2.val if l2 else 0\n x, y = divmod(v1+v2+x, 10)\n node = ListNode(y, None)\n if pre:\n pre.next = node\n else:\n root = node\n pre = node\n l1 = l1.next if l1 else l1\n l2 = l2.next if l2 else l2\n return root\n# @lc code=end\n\nSolution().addTwoNumbers(createSLink([9,9,9,9,9,9,9]), createSLink([9,9,9,9]))"
},
{
"alpha_fraction": 0.5681511759757996,
"alphanum_fraction": 0.5789473652839661,
"avg_line_length": 24.55172348022461,
"blob_id": "6fff0d13892d9ad5117d8e3f5a6467c4e1afc892",
"content_id": "d8c082e4611a280fe4992486a47ecb6a32e2cd51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 747,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 29,
"path": "/python3/backtracking/medium/46.全排列.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=46 lang=python3\n#\n# [46] 全排列\n#\n\n# @lc code=start\nfrom typing import List\n\n\nclass Solution:\n def backtrack(self, nums: List[int], combination:List[int], ans:List[List[int]]):\n if len(combination)==len(nums) and combination not in ans:\n ans.append(combination.copy())\n return\n for i in range(len(nums)):\n if nums[i] in combination:\n continue\n combination.append(nums[i])\n self.backtrack(nums, combination, ans)\n combination.remove(nums[i])\n\n def permute(self, nums: List[int]) -> List[List[int]]:\n ans = []\n self.backtrack(nums, [], ans)\n return ans\n# @lc code=end\n\nSolution().permute([1,2,3])\n"
},
{
"alpha_fraction": 0.4455852210521698,
"alphanum_fraction": 0.47433266043663025,
"avg_line_length": 21.18181800842285,
"blob_id": "2ae0f9bcd0989b06dbda72bb34d5d848876481ba",
"content_id": "36b02ad3b8a0089b380603d9c0bcda4efa03a839",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 22,
"path": "/python3/binary-search/easy/367.有效的完全平方数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=367 lang=python3\n#\n# [367] 有效的完全平方数\n#\n\n# @lc code=start\nclass Solution:\n def isPerfectSquare(self, num: int) -> bool:\n if num == 1: return True\n s, e = 1, num // 2\n while s <= e:\n mid = (s + e) // 2\n tmp = mid * mid\n if tmp == num:\n return True\n if tmp > num: e = mid - 1 \n if tmp < num: s = mid + 1\n return False\n# @lc code=end\n\nSolution().isPerfectSquare(4)"
},
{
"alpha_fraction": 0.452162504196167,
"alphanum_fraction": 0.49279162287712097,
"avg_line_length": 20.77142906188965,
"blob_id": "2548d460b6afd073b5b1faa73d68c5d9b167ebcb",
"content_id": "bf2f2fd868fe0b61ebce6a985b065ee80fba7893",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 35,
"path": "/python3/dynamic-programming/easy/198.打家劫舍.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=198 lang=python3\n#\n# [198] 打家劫舍\n#\n\n# @lc code=start\nclass Solution:\n\n # 存储之前最大值,及单前最大值\n # def rob(self, nums: List[int]) -> int:\n # preMax = 0\n # curMax = 0\n # for num in nums:\n # tmp = curMax\n # curMax = max(preMax+num, curMax)\n # preMax = tmp\n # return curMax\n\n # dp0 表示单前节点不偷,所以最大值可以为前一个节点偷or不偷\n # dp1 表示单前节点偷,必须前一个节点为不偷\n # 比较最终 max(dp0, dp1)\n def rob(self, nums: List[int]) -> int:\n if len(nums) == 0:\n return 0\n\n dp0 = 0\n dp1 = nums[0]\n for i in range(1, len(nums)):\n tmp0 = max(dp0, dp1)\n tmp1 = dp0 + nums[i]\n dp0, dp1 = tmp0, tmp1\n return max(dp0, dp1)\n\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4395161271095276,
"alphanum_fraction": 0.4979838728904724,
"avg_line_length": 18.076923370361328,
"blob_id": "fea79448635f370cfa6be8208b2016ef473891db",
"content_id": "d1ce7558efff9d86fbf773732969f6e44a0a51c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 26,
"path": "/python3/Unknown/easy/1716.按摩师.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=17.16 lang=python3\n#\n# [17.16] 按摩师\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n\n # dp0 表示前一个单子不接情况\n # dp1 表示前一个单子已经接情况\n def massage(self, nums: List[int]) -> int:\n n = len(nums)\n if n == 0:\n return 0\n\n dp0, dp1 = 0, nums[0]\n for i in range(1, n):\n tmp0 = max(dp0, dp1)\n tmp1 = dp0 + nums[i]\n dp0, dp1 = tmp0, tmp1\n return max(dp0, dp1)\n \n\n# @lc code=end\n"
},
{
"alpha_fraction": 0.4968354403972626,
"alphanum_fraction": 0.5348101258277893,
"avg_line_length": 21.5,
"blob_id": "d4023bb5dcf7fc98bd81cd2fb42aa6371698a4ac",
"content_id": "7a692724be82c95dea160f707fa82964de00b771",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 14,
"path": "/python3/array/easy/119.杨辉三角-ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=119 lang=python3\n#\n# [119] 杨辉三角 II\n#\n\n# @lc code=start\nclass Solution:\n def getRow(self, rowIndex: int) -> List[int]:\n row = [1] * (rowIndex + 1)\n for i in range(1, rowIndex):\n row[i] *= int(row[i-1] * (rowIndex - i + 1) / i)\n return row\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5575364828109741,
"alphanum_fraction": 0.5761750340461731,
"avg_line_length": 31.5,
"blob_id": "f3bbaf6a027506f053dd098fbb64604a74f329a8",
"content_id": "3797b8edc23ee92e83f00feb24a70ddc480f96a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1304,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 38,
"path": "/python3/backtracking/medium/40.组合总和_ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=40 lang=python3\n#\n# [40] 组合总和 II\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def backtrack(self, candidates: List[int], target: int, index: int, combination: List[int], ans: List[List[int]]):\n if sum(combination)==target and combination not in ans:\n ans.append(combination.copy())\n return\n for i in range(index, len(candidates)):\n # 连续相同数剪枝\n if candidates[i]==candidates[i-1] and i > index:\n continue\n # 大于目标值剪枝\n if sum(combination) >= target:\n return\n # 当前和+下一个数>target剪枝\n if sum(combination) + candidates[i] > target:\n return\n # 数可重复用i不需要+1\n combination.append(candidates[i])\n self.backtrack(candidates, target, i+1, combination, ans)\n combination.remove(candidates[i])\n\n def combinationSum2(self, candidates: List[int], target: int) -> List[List[int]]:\n if not candidates or target==0: return None\n ans = []\n candidates.sort()\n self.backtrack(candidates, target, 0, [], ans)\n return ans\n# @lc code=end\n\nSolution().combinationSum2([10,1,2,7,6,1,5,2,2], 8)"
},
{
"alpha_fraction": 0.49408283829689026,
"alphanum_fraction": 0.5207100510597229,
"avg_line_length": 24.9743595123291,
"blob_id": "dcef45372463cce0148d64c3e1b1b9cf550b9f58",
"content_id": "59e2ddbf70ed26e6b217e4329db9865c43f5851c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1022,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 39,
"path": "/python3/array/easy/697.数组的度.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=697 lang=python3\n#\n# [697] 数组的度\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Node:\n def __init__(self, degree=0, start=0, end=0):\n self.degree = degree\n self.start = start\n self.end = end\n\nclass Solution:\n def findShortestSubArray(self, nums: List[int]) -> int:\n nodeMap = {}\n maxDegree, minLen = 0, 50000\n for i in range(len(nums)):\n if nums[i] not in nodeMap:\n node = Node(0, 0, 0)\n nodeMap[nums[i]] = node\n node = nodeMap[nums[i]]\n if node.degree == 0:\n node.start = i\n node.end = i\n node.degree += 1\n maxDegree = node.degree if maxDegree < node.degree else maxDegree\n\n for k, v in nodeMap.items():\n if v.degree < maxDegree:\n continue\n minLen = min(minLen, v.end - v.start + 1)\n return minLen\n \n# @lc code=end\n\nSolution().findShortestSubArray([1, 2, 2, 3, 1])\n\n"
},
{
"alpha_fraction": 0.5048543810844421,
"alphanum_fraction": 0.5436893105506897,
"avg_line_length": 20.63157844543457,
"blob_id": "ea122ed4670a3988a067a0fdf8e8138f76f13abd",
"content_id": "fbae4dd9aa5fb155830f2bbfe56fb8c836c6e993",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/python3/two-pointers/easy/27.移除元素.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=27 lang=python3\n#\n# [27] 移除元素\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def removeElement(self, nums: List[int], val: int) -> int:\n index=0\n for i in range(len(nums)):\n if nums[i] != val:\n nums[index] = nums[i]\n index += 1\n return index\n# @lc code=end\n\nSolution().removeElement([0,1,2,2,3,0,4,2], 2)\n\n"
},
{
"alpha_fraction": 0.3940543830394745,
"alphanum_fraction": 0.4117647111415863,
"avg_line_length": 25.779661178588867,
"blob_id": "af1275474b19955d9f3bae007d1c68da39d64cf1",
"content_id": "4501ddad5afb22d4cbb2604b3c3d15eabc93bfd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1697,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 59,
"path": "/python3/dynamic-programming/medium/5.最长回文子串.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=5 lang=python3\n#\n# [5] 最长回文子串\n#\n\n# @lc code=start\nclass Solution:\n\n # 中心扩展,单前字符串往周边扩展\n # 情况1, aba 形式\n # 情况2, abba 形式\n # def longestPalindrome(self, s: str) -> str:\n # if not s:\n # return s\n\n # sLen = len(s)\n # ret = s[0]\n # for i, c in enumerate(s):\n # spread = 1\n # while(i-spread>=0 and i+spread<sLen) and s[i-spread] == s[i+spread]:\n # if spread*2+1 > len(ret):\n # ret = s[i-spread: i+spread+1]\n # spread += 1\n\n # spread = 1\n # while( i-spread+1>=0 and i+spread<sLen) and s[i-spread+1] == s[i+spread]:\n # if spread*2 > len(ret):\n # ret = s[i-spread+1: i+spread+1]\n # spread += 1\n # return ret\n\n # 动态规划\n # l 表示回文长度\n # 当子串为回文是头尾两个字符必须一样\n # P(i,j)=P(i+1,j−1)∧(Si==Sj)\n def longestPalindrome(self, s: str) -> str:\n ret = ''\n sLen = len(s)\n dp = [[False] * sLen for _ in range(sLen)]\n for l in range(sLen):\n for i in range(sLen):\n j = i+l\n if j >= sLen: break\n\n if l == 0:\n dp[i][j] = True\n elif l == 1:\n dp[i][j] = s[i] == s[j]\n else:\n dp[i][j] = s[i]==s[j] and dp[i+1][j-1]\n \n if dp[i][j] and l+1 > len(ret):\n ret = s[i:j+1]\n return ret\n# @lc code=end\n\nret = Solution().longestPalindrome('aaabaaaa')\nprint(ret)\n\n"
},
{
"alpha_fraction": 0.4412265717983246,
"alphanum_fraction": 0.46678024530410767,
"avg_line_length": 21.615385055541992,
"blob_id": "a48d64dda476139d91121d32322c863d5d96fa86",
"content_id": "7ecbbd6c93cffbbcc6df55c56d47e14c369eca7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 26,
"path": "/python3/binary-search/medium/74.搜索二维矩阵.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=74 lang=python3\n#\n# [74] 搜索二维矩阵\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:\n r, c = len(matrix), len(matrix[0])\n s, e = 0, r*c-1\n while s <= e:\n m = (s + e) >> 1\n num = matrix[int(m/c)][int(m%c)]\n if num == target:\n return True\n if target > num:\n s = m + 1\n else:\n e = m - 1\n return False\n# @lc code=end\n\nSolution().searchMatrix([[1,1]], 13)"
},
{
"alpha_fraction": 0.4232258200645447,
"alphanum_fraction": 0.46838709712028503,
"avg_line_length": 23.1875,
"blob_id": "e9c71cfc089d97890052ffc862507f919126331e",
"content_id": "148f3749fa7a59edf15987f2a053b7ddfbd3ad8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 853,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 32,
"path": "/python3/dynamic-programming/medium/967.连续差相同的数字.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=967 lang=python3\n#\n# [967] 连续差相同的数字\n#\n\nfrom typing import List\n# @lc code=start\nclass Solution:\n \n # 动态规划\n # 计算满足差值的少一个位数的全部值,在满足条件下添加一位\n # dp(n) = dp(n-1) + sum(num%10+K<=9 || num%10-K>=0)\n def numsSameConsecDiff(self, N: int, K: int) -> List[int]:\n nums = set(range(1, 10))\n for _ in range(N - 1):\n tmpNums = set()\n for num in nums:\n n1 = num % 10\n if n1 + K <= 9:\n tmpNums.add(num * 10 + n1 + K)\n if n1 - K >= 0:\n tmpNums.add(num * 10 + n1 - K)\n nums = tmpNums\n\n if N == 1:\n nums.add(0)\n return list(nums)\n \n# @lc code=end\n\nprint(Solution().numsSameConsecDiff(4, 4))\n\n"
},
{
"alpha_fraction": 0.4749999940395355,
"alphanum_fraction": 0.5041666626930237,
"avg_line_length": 24.210525512695312,
"blob_id": "a9dc503125044d2d90f5c288e3f02c5ca56d74a6",
"content_id": "84f69d08ed6f03275380f69a6b3c280b556783e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 19,
"path": "/python3/two-pointers/easy/167.两数之和-ii-输入有序数组.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=167 lang=python3\n#\n# [167] 两数之和 II - 输入有序数组\n#\n\n# @lc code=start\nclass Solution:\n def twoSum(self, numbers: List[int], target: int) -> List[int]:\n if len(numbers) < 2: return None\n l, r = 0, len(numbers)-1\n while l < r:\n sum = numbers[l] + numbers[r]\n if sum == target:\n return [l+1, r+1]\n if sum < target: l+=1\n if sum > target: r-=1\n return None\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4565483331680298,
"alphanum_fraction": 0.49816402792930603,
"avg_line_length": 25.387096405029297,
"blob_id": "81933ca7f589d825bd4e66983b33602d7e1aabe3",
"content_id": "12ed9c7528585776b932d60b81d92942a39022ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/python3/array/medium/56.合并区间.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=56 lang=python3\n#\n# [56] 合并区间\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # def sortStart(self, intervals: List[List[int]]) -> List[List[int]]:\n # dict, list = {}, []\n # for i, v in enumerate(intervals):\n # dict[v[0]] = v\n # for i in sorted(dict):\n # list.append(dict[i])\n # return list\n\n def merge(self, intervals: List[List[int]]) -> List[List[int]]:\n ans = []\n for i in sorted(intervals, key=lambda i:i[0]):\n if ans and i[0] <= ans[-1][1]:\n ans[-1][1] = max(i[1], ans[-1][1])\n else:\n ans.append(i)\n return ans\n# @lc code=end\n\n# Solution().merge([[2,6],[1,3],[8,10],[15,18]])\n# Solution().merge([[1,4],[5,6]])\nSolution().merge([[1,4],[2,3]])"
},
{
"alpha_fraction": 0.5656779408454895,
"alphanum_fraction": 0.5932203531265259,
"avg_line_length": 20.409090042114258,
"blob_id": "475969da7cb876d26bd7e4a62c1d1ea4706373de",
"content_id": "e7e500c6125fe2e162076dc753b30f483890207c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 22,
"path": "/python3/dynamic-programming/easy/121.买卖股票的最佳时机.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=121 lang=python3\n#\n# [121] 买卖股票的最佳时机\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def maxProfit(self, prices: List[int]) -> int:\n if not prices:\n return 0\n maxProfit = 0\n minPrice = prices[0]\n for price in prices:\n minPrice = min(minPrice, price)\n maxProfit = max(maxProfit, price-minPrice)\n return maxProfit\n\n# @lc code=end\n\nSolution().maxProfit([7,1,5])\n\n"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6136363744735718,
"avg_line_length": 30.08823585510254,
"blob_id": "25d6a4b26aaeb2823ba3fb4e805295a7c958a3cb",
"content_id": "05c493c8d6bfadd2cfbd3975626835eb223e1cdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 34,
"path": "/python3/tree/easy/112.路径总和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=112 lang=python3\n#\n# [112] 路径总和\n#\n\nfrom python3.aatool.TreeT import TreeNode, createBTree\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def childSum(self, root: TreeNode, targetSum: int, sum: int) -> bool:\n if not root.left and not root.right:\n return sum + root.val == targetSum\n hasLeft, hasRight = False, False\n if root.left:\n hasLeft = self.childSum(root.left, targetSum, sum+root.val)\n if root.right:\n hasRight = self.childSum(root.right, targetSum, sum+root.val)\n return hasLeft or hasRight\n \n def hasPathSum(self, root: TreeNode, targetSum: int) -> bool:\n if not root:\n return False\n return self.childSum(root, targetSum, 0)\n \n# @lc code=end\n\nSolution().hasPathSum(createBTree([5,4,8, 11,None,13,4,7,2,None,None,None,1], 0), 22)"
},
{
"alpha_fraction": 0.44967880845069885,
"alphanum_fraction": 0.5139186382293701,
"avg_line_length": 21.285715103149414,
"blob_id": "bc98f7af86f1997010d21df6a9289c6569dd9e3e",
"content_id": "9e93efcd4da16daedb50a4d8d23f44360d8b9bd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 21,
"path": "/python3/bit-manipulation/easy/190.颠倒二进制位.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=190 lang=python3\n#\n# [190] 颠倒二进制位\n#\n\n# @lc code=start\nclass Solution:\n def reverseBits(self, n: int) -> int:\n # bin, ans = [], 0\n # for i in range(32):\n # bin.append(n>>i & 0x01)\n # for i in range(32):\n # ans = ans<<1 | bin[i]\n # return ans\n oribin = '{0:032b}'.format(n)\n tarbin = oribin[::-1]\n return int(tarbin, 2)\n# @lc code=end\n\nSolution().reverseBits(43261596)"
},
{
"alpha_fraction": 0.5430809259414673,
"alphanum_fraction": 0.5613576769828796,
"avg_line_length": 21.58823585510254,
"blob_id": "163d25d0f3b4a4d00da182ab8b34b040dcfad12c",
"content_id": "7119c12fbdca5ca8144a8d00c148c3f8f6715113",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 17,
"path": "/python3/string/easy/28.实现_str_str.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=28 lang=python3\n#\n# [28] 实现 strStr()\n#\n\n# @lc code=start\nclass Solution:\n def strStr(self, haystack: str, needle: str) -> int:\n n, l = len(haystack), len(needle)\n for start in range(n - l + 1):\n if haystack[start:start+l] == needle:\n return start\n return -1\n# @lc code=end\n\nSolution().strStr('hello', 'll')"
},
{
"alpha_fraction": 0.3664596378803253,
"alphanum_fraction": 0.4021739065647125,
"avg_line_length": 23.730770111083984,
"blob_id": "715ca786de6de9a7c7b42b97ad7fd866f164c45a",
"content_id": "4cdda9e27b3d623a0083f4ceec250d55cf6b8f01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 26,
"path": "/python3/dynamic-programming/medium/279.完全平方数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=279 lang=python3\n#\n# [279] 完全平方数\n#\n\n# @lc code=start\nclass Solution:\n # 动态规划: dp[i] = min(dp[i], dp[i-j*j] + 1)\n # 测试数据比较大,按注释部分会超时\n def numSquares(self, n: int) -> int:\n dp = [float('inf')] * (n+1)\n dp[0], dp[1] = 0, 1\n for i in range(1, n+1):\n j = 1\n while j*j <= i:\n # if j*j == i: \n # dp[i] = 1\n # break\n # dp[i] = min(dp[i], dp[j*j] + dp[i-j*j])\n dp[i] = min(dp[i], dp[i-j*j] + 1)\n j += 1\n return dp[n]\n# @lc code=end\n\nprint(Solution().numSquares(6616))\n\n"
},
{
"alpha_fraction": 0.5845447778701782,
"alphanum_fraction": 0.602142333984375,
"avg_line_length": 30.14285659790039,
"blob_id": "6b9bb6cca4fc188f74ff7fd286ba3bc0f669c886",
"content_id": "493ba22a4f040b22ac503b098a83ba3954a85c00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 42,
"path": "/python3/tree/easy/235.二叉搜索树的最近公共祖先.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=235 lang=python3\n#\n# [235] 二叉搜索树的最近公共祖先\n#\n\nfrom typing import List\nfrom python3.aatool.TreeT import TreeNode, createBTree\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nclass Solution:\n # 找出目标节点的前序节点\n def findAncestor(self, root: TreeNode, target: TreeNode, ancestor: List[TreeNode]) -> bool:\n if not root: return False\n if root==target or self.findAncestor(root.left, target, ancestor) or self.findAncestor(root.right, target, ancestor):\n ancestor.append(root)\n return True\n return False\n \n def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':\n pAncestor, qAncestor = [], []\n self.findAncestor(root, p, pAncestor)\n self.findAncestor(root, q, qAncestor)\n # 找出最接近的公共节点\n i, j = len(pAncestor)-1, len(qAncestor)-1\n while i>-1 and j>-1:\n if pAncestor[i] == qAncestor[j]:\n i, j = i-1, j-1\n else:\n break\n return pAncestor[i+1]\n# @lc code=end\n\nroot = createBTree([6,2,8,0,4,7,9], 0)\nSolution().lowestCommonAncestor(root, root.left, root.left.right)"
},
{
"alpha_fraction": 0.45155394077301025,
"alphanum_fraction": 0.499085932970047,
"avg_line_length": 20.84000015258789,
"blob_id": "57b24c531dfb2cda0459cf34fac86876e8d8140c",
"content_id": "e91059bb962da715924ddc585ef1cec74ae2c3e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 25,
"path": "/python3/greedy/easy/1051.高度检查器.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=1051 lang=python3\n#\n# [1051] 高度检查器\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def heightChecker(self, heights: List[int]) -> int:\n value = [0] * 101\n for height in heights:\n value[height] += 1\n j = 0\n count = 0\n for i in range(len(value)):\n while value[i] > 0:\n value[i] -= 1\n if (heights[j] != i): count += 1\n j += 1\n return count\n\n# @lc code=end\n\nSolution().heightChecker([1,1,4,2,1,3])\n\n"
},
{
"alpha_fraction": 0.5807033181190491,
"alphanum_fraction": 0.5942290425300598,
"avg_line_length": 26.073171615600586,
"blob_id": "0b7b3c36c6be4800529227ee1a9ec7bf7f5d4db7",
"content_id": "1333923f7625906ebb32b40c2927bdad3885a08a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1125,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 41,
"path": "/python3/tree/easy/144.二叉树的前序遍历.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=144 lang=python3\n#\n# [144] 二叉树的前序遍历\n#\n\nfrom python3.aatool.TreeT import TreeNode, createBTree\nfrom typing import List\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def preOrder(self, root: TreeNode, array: List[int]):\n if not root: return\n array.append(root.val)\n self.proOrder(root.left, array)\n self.proOrder(root.right, array)\n\n def preOrder1(self, root: TreeNode, array: List[int]):\n if not root: return\n stack = [root]\n while stack:\n node = stack.pop()\n array.append(node.val)\n if node.right:\n stack.append(node.right)\n if node.left:\n stack.append(node.left)\n\n def preorderTraversal(self, root: TreeNode) -> List[int]:\n array = []\n self.preOrder1(root, array)\n return array\n# @lc code=end\n\nSolution().preorderTraversal(createBTree([1,2,3], 0))"
},
{
"alpha_fraction": 0.3965517282485962,
"alphanum_fraction": 0.42456895112991333,
"avg_line_length": 22.149999618530273,
"blob_id": "bcf9f6c9f74730a37d95ef4028a1379f4048fdb1",
"content_id": "b10d0b38d21cc09ff36d62f63b0be86ea9eac543",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 492,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/python3/math/easy/204.计数质数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=204 lang=python3\n#\n# [204] 计数质数\n#\n\n# @lc code=start\nclass Solution:\n def countPrimes(self, n: int) -> int:\n ans = 0\n pointer = [1 for _ in range(n)]\n for i in range(2, n):\n if pointer[i] == 1:\n ans += 1\n # i 为质数则i的倍数非质数\n if (i*i < n):\n for j in range(i*i, n , i):\n pointer[j] = 0\n return ans\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.46852123737335205,
"alphanum_fraction": 0.5051244497299194,
"avg_line_length": 25.30769157409668,
"blob_id": "6ce6f17bce44c3ea9fcdd785f9c61af5ce786f9b",
"content_id": "0f5d10eb706c0458400f20bcc5be618a89a10455",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 691,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 26,
"path": "/python3/array/easy/228.汇总区间.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=228 lang=python3\n#\n# [228] 汇总区间\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def summaryRanges(self, nums: List[int]) -> List[str]:\n if not nums: return []\n s, e, ans = nums[0], nums[0], []\n for i in range(1, len(nums)):\n if nums[i]-1 > e: \n ans.append(str(s) if s==e else ('%d->%d' % (s, e)))\n s, e = nums[i], nums[i]\n else:\n e = nums[i]\n ans.append(str(s) if s==e else ('%d->%d' % (s, e)))\n return ans\n# @lc code=end\n\nSolution().summaryRanges([-1])\nSolution().summaryRanges([0,2,3,4,6,8,9])\n# Solution().summaryRanges([0,1,2,4,5,7])"
},
{
"alpha_fraction": 0.5204991102218628,
"alphanum_fraction": 0.5811051726341248,
"avg_line_length": 22.33333396911621,
"blob_id": "b83d93c28042db136aef81a4f34f2527dba5070f",
"content_id": "64db6a3dcc9260d4f788e282bc75f3298fbfd9aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 665,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 24,
"path": "/python3/dynamic-programming/easy/746.使用最小花费爬楼梯.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=746 lang=python3\n#\n# [746] 使用最小花费爬楼梯\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n\n # dp0 表示当前楼梯不爬,则前一个楼梯必须是爬过 dp1\n # dp1 表示当前楼梯要爬,则前一个楼梯可以是min(dp0, dp1) + cost[i]\n # 选择 dp0 dp1 最小值\n def minCostClimbingStairs(self, cost: List[int]) -> int:\n dp0, dp1 = 0, cost[0]\n for i in range(1, len(cost)):\n tmp0 = dp1\n tmp1 = min(dp0, dp1) + cost[i]\n dp0, dp1 = tmp0, tmp1\n return min(dp0, dp1)\n \n# @lc code=end\n\nSolution().minCostClimbingStairs([0,0,1,1])\n\n"
},
{
"alpha_fraction": 0.49056604504585266,
"alphanum_fraction": 0.5226414799690247,
"avg_line_length": 64.75,
"blob_id": "a2077058f9c2b5892639d6b4843830ff507b1c71",
"content_id": "a2691ef87930e3eb2b0fc9885a7cb4ce411f15b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 8,
"path": "/zsum.sh",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "echo 'pthon3:'\n# find python3 -type f -name \"*.*.py\" | cut -f3 -d '.'| sort | uniq -c -i\nfind python3 -type f -name \"*.*.py\" | cut -f3 -d '/' | sort | uniq -c\n\neasy=$(find python3 -type f -name \"*.*.py\" | cut -f3 -d '/' | sort | uniq -c | grep easy | tr -cd '[0-9]')\nmedium=$(find python3 -type f -name \"*.*.py\" | cut -f3 -d '/' | sort | uniq -c | grep medium | tr -cd '[0-9]')\nhard=$(find python3 -type f -name \"*.*.py\" | cut -f3 -d '/' | sort | uniq -c | grep hard | tr -cd '[0-9]')\necho 'total: '$(( $easy+$medium+$hard ))\n\n "
},
{
"alpha_fraction": 0.3901869058609009,
"alphanum_fraction": 0.43691587448120117,
"avg_line_length": 24.969696044921875,
"blob_id": "c50caf920bc02679ce74ad3b5f7021f469e25ab2",
"content_id": "47bed8f5156749fdef5a7406569d4b5d627ecd51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 33,
"path": "/python3/array/medium/59.螺旋矩阵_ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=59 lang=python3\n#\n# [59] 螺旋矩阵 II\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # 54 的反向操作\n # [] -> [[9]] -> [[8],[9]] -> [[6,7],[9,8]] -> [[4,5],[9,6],[8,7]] -> [[1,2,3],[8,9,4],[7,6,5]]\n def generateMatrix1(self, n: int) -> List[List[int]]:\n matrix, lo = [], n*n+1\n while lo > 1:\n lo, hi = lo-len(matrix), lo\n matrix = [[i for i in range(lo, hi)]] + list(zip(*matrix[::-1]))\n return matrix\n \n def generateMatrix(self, n: int) -> List[List[int]]:\n A = [[0] * n for _ in range(n)]\n i, j, di, dj = 0, 0, 0, 1\n for k in range(n*n):\n A[i][j] = k + 1\n if A[(i+di)%n][(j+dj)%n]:\n di, dj = dj, -di\n i += di\n j += dj\n return A\n \n# @lc code=end\n\nSolution().generateMatrix(3)"
},
{
"alpha_fraction": 0.4623115658760071,
"alphanum_fraction": 0.49120602011680603,
"avg_line_length": 23.84375,
"blob_id": "73c678b3991ae647d3683f8e65d7fa11d44d336b",
"content_id": "c89891ab824d5874af5309dbad3299fcf7a3300c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 840,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 32,
"path": "/python3/dynamic-programming/medium/322.零钱兑换.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=322 lang=python3\n#\n# [322] 零钱兑换\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # 动态规划\n # 计算总额减去可用领取后最小值\n # fn = min{f(n-k1), f(n-k2) ..., f(n-kn)}\n def coinChange(self, coins: List[int], amount: int) -> int:\n if amount == 0: \n return 0\n\n dp = [float('inf')] * (amount+1)\n for index in range(amount + 1):\n currMin = float('inf')\n for coin in coins:\n if index - coin > 0:\n currMin = min(dp[index - coin]+1, currMin)\n if index == coin:\n currMin = 1\n dp[index] = currMin\n \n return -1 if dp[amount] == float('inf') else dp[amount]\n\n# @lc code=end\n\nprint(Solution().coinChange([2,5,10], 27))\n\n"
},
{
"alpha_fraction": 0.413551390171051,
"alphanum_fraction": 0.43107476830482483,
"avg_line_length": 24.176469802856445,
"blob_id": "1493861d348692b6839b9c3f6068e3130596daf9",
"content_id": "fdc18241a9e1d19ef3deb73863bd3c6fe0dc75ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 34,
"path": "/python3/string/medium/6.z-字形变换.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=6 lang=python3\n#\n# [6] Z 字形变换\n#\n\n# @lc code=start\nclass Solution:\n def format(self, rows):\n s = ''\n for i in range(len(rows)):\n for j in range(len(rows[i])):\n if rows[i][j]:\n s += rows[i][j]\n return s\n\n def convert(self, s: str, numRows: int) -> str: \n if numRows==1:\n return s\n rows = [[] for i in range(numRows)]\n index = 0\n for j in range(1000):\n for i in range(numRows):\n if j%(numRows-1)==0 or (i+j)%(numRows-1)==0:\n rows[i].append(s[index])\n index += 1\n else:\n rows[i].append(None)\n if index >= len(s):\n return self.format(rows)\n\n# @lc code=end\n\nSolution().convert('A', 1)\n"
},
{
"alpha_fraction": 0.43184560537338257,
"alphanum_fraction": 0.46079614758491516,
"avg_line_length": 23.352941513061523,
"blob_id": "03f94cba4195b89c23e1b6ecb5a30b7e734a59d3",
"content_id": "9ff0c7a56f7f1f9121d21271a48cd5097568208e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 34,
"path": "/python3/array/medium/31.下一个排列.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=31 lang=python3\n#\n# [31] 下一个排列\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def nextPermutation(self, nums: List[int]) -> None:\n \"\"\"\n Do not return anything, modify nums in-place instead.\n \"\"\"\n # 从后找出nums[i]<nums[i+1], i后数组为倒序\n i = len(nums)-2\n while i>=0 and nums[i] >= nums[i+1]:\n i -= 1\n if i >= 0:\n # 从后(i,n]找出第一个比 nums[i] 大的数\n j = len(nums)-1\n while j > i and nums[i] >= nums[j]:\n j -= 1\n nums[i], nums[j] = nums[j], nums[i]\n # 正排i后数组\n l, r = i+1, len(nums)-1\n while l < r:\n nums[l], nums[r] = nums[r], nums[l]\n l += 1\n r -= 1\n return \n# @lc code=end\n\nSolution().nextPermutation([4,5,2,6,4,3,1])\n\n"
},
{
"alpha_fraction": 0.5739644765853882,
"alphanum_fraction": 0.5917159914970398,
"avg_line_length": 23.095237731933594,
"blob_id": "bad26a499f4f18e350f823faa948236f3a6cbb75",
"content_id": "6dc541b7b510aaae54c7274716ebef8c2036489d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 21,
"path": "/python3/string/easy/14.最长公共前缀.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=14 lang=python3\n#\n# [14] 最长公共前缀\n#\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # 定一个子串, 从后往前缩减\n def longestCommonPrefix(self, strs: List[str]) -> str:\n if strs is None or len(strs) == 0:\n return ''\n subString = strs[0]\n for s in strs:\n while not s.startswith(subString):\n subString = subString[0: -1]\n return subString\n# @lc code=end\n\nSolution().longestCommonPrefix([\"flower\",\"flow\",\"flight\"])\n\n"
},
{
"alpha_fraction": 0.427730530500412,
"alphanum_fraction": 0.45585349202156067,
"avg_line_length": 34.58139419555664,
"blob_id": "4529d241079f5dde6cc9906ef42612ccacabe807",
"content_id": "20d0b9fb680677490799118a98f35c5072089fde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1605,
"license_type": "no_license",
"max_line_length": 369,
"num_lines": 43,
"path": "/python3/hash-table/medium/36.有效的数独.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=36 lang=python3\n#\n# [36] 有效的数独\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n # 判断数组是否有重复\n def isUnitValid(self, unit: List[str]) -> bool:\n unit = [s for s in unit if s!='.']\n return len(set(unit)) == len(unit)\n\n # 判断行是否有重复\n def isRowValid(self, board: List[List[str]]) -> bool:\n for row in board:\n if not self.isUnitValid(row):\n return False\n return True\n\n # 判断列是否有重复\n def isColValid(self, board: List[List[str]]) -> bool:\n for col in list(zip(*board)):\n if not self.isUnitValid(col):\n return False\n return True\n\n # 判断矩阵是否重复\n def isSquareValid(self, board: List[List[str]]) -> bool:\n for i in (0, 3, 6):\n for j in (0, 3, 6):\n unit = [board[x][y] for x in range(i, i+3) for y in range(j, j+3)]\n if not self.isUnitValid(unit):\n return False\n return True\n\n def isValidSudoku(self, board: List[List[str]]) -> bool:\n return self.isRowValid(board) and self.isColValid(board) and self.isSquareValid(board)\n# @lc code=end\n\nSolution().isValidSudoku([[\"5\",\"3\",\".\",\".\",\"7\",\".\",\".\",\".\",\".\"],[\"6\",\".\",\".\",\"1\",\"9\",\"5\",\".\",\".\",\".\"],[\".\",\"9\",\"8\",\".\",\".\",\".\",\".\",\"6\",\".\"],[\"8\",\".\",\".\",\".\",\"6\",\".\",\".\",\".\",\"3\"],[\"4\",\".\",\".\",\"8\",\".\",\"3\",\".\",\".\",\"1\"],[\"7\",\".\",\".\",\".\",\"2\",\".\",\".\",\".\",\"6\"],[\".\",\"6\",\".\",\".\",\".\",\".\",\"2\",\"8\",\".\"],[\".\",\".\",\".\",\"4\",\"1\",\"9\",\".\",\".\",\"5\"],[\".\",\".\",\".\",\".\",\"8\",\".\",\".\",\"7\",\"9\"]])"
},
{
"alpha_fraction": 0.454033762216568,
"alphanum_fraction": 0.48405253887176514,
"avg_line_length": 21.25,
"blob_id": "7ec55bb6c5b35b02cfca0f7666d2dc8fccc8a631",
"content_id": "b14bbf01c6b21c495aa60baf13fbc3ffcfc87653",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 24,
"path": "/python3/array/easy/118.杨辉三角.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=118 lang=python3\n#\n# [118] 杨辉三角\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def generate(self, numRows: int) -> List[List[int]]:\n rows = []\n for i in range(0, numRows):\n row = []\n for j in range(0, i+1):\n if j==0 or j==i:\n row.append(1)\n else:\n row.append(rows[i-1][j-1] + rows[i-1][j])\n rows.append(row)\n return rows\n# @lc code=end\n\nprint(Solution().generate(5))"
},
{
"alpha_fraction": 0.5653669834136963,
"alphanum_fraction": 0.5745412707328796,
"avg_line_length": 22.594594955444336,
"blob_id": "50953b814f0d63b958bdff2c3b737c5e5a7d4a5d",
"content_id": "6ac88b4954c98ff03c5b8a92de311181b2d5c5c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 898,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 37,
"path": "/python3/aatool/LinkT.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "from typing import List\nimport queue\n\nclass ListNode:\n def __init__(self, val=0, next=None):\n self.val = val\n self.next = next\n \n def __init__(self, val=0, pre=None, next=None):\n self.val = val\n self.pre = pre\n self.next = next\n\n\n# 创建单向链表\ndef createSLink(array: List[int]) -> ListNode:\n head = None\n for i in range(len(array)-1, -1, -1):\n head = ListNode(array[i], next=head)\n return head\n\n# 创建双向链表\ndef createDLink(array: List[int]) -> ListNode:\n head, pre, next = None, None, None\n for i in range(len(array)-1, -1, -1):\n head = ListNode(array[i], pre=pre, next=next)\n if next: next.pre = head\n next = head\n return head\n\n# 转list\ndef toList(node: ListNode) -> List[int]:\n array = []\n while(node != None):\n array.append(node.val)\n node = node.next\n return array"
},
{
"alpha_fraction": 0.5270935893058777,
"alphanum_fraction": 0.5500820875167847,
"avg_line_length": 22.384614944458008,
"blob_id": "e7fe949be918b3eeca0b062d36af425a3eca1962",
"content_id": "1015a4b0c0f1fe3f85d8e21b94551a620ec150fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 629,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 26,
"path": "/python3/dynamic-programming/easy/303.区域和检索-数组不可变.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=303 lang=python3\n#\n# [303] 区域和检索 - 数组不可变\n#\n\n# @lc code=start\nclass NumArray:\n def __init__(self, nums: List[int]):\n self.sum = [0] * len(nums)\n if len(nums) == 0:\n return\n for i in range(len(nums)):\n self.sum[i] = self.sum[i-1] + nums[i] if i > 0 else nums[i]\n\n\n def sumRange(self, i: int, j: int) -> int:\n if i == 0:\n return self.sum[j]\n return self.sum[j] - self.sum[i-1]\n\n\n# Your NumArray object will be instantiated and called as such:\n# obj = NumArray(nums)\n# param_1 = obj.sumRange(i,j)\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5385366082191467,
"alphanum_fraction": 0.5756097435951233,
"avg_line_length": 28.285715103149414,
"blob_id": "5337276f9ef8460757678231869bd68096ffe969",
"content_id": "0240d55095d6b8940027bfdeca1f6cd37af5eb19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 35,
"path": "/python3/binary-search/medium/29.两数相除.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=29 lang=python3\n#\n# [29] 两数相除\n#\n\n# @lc code=start\nclass Solution:\n def div(self, dividend: int, divisor: int) -> int:\n # 除数小于or等于被除数特殊处理\n if dividend < divisor: return 0\n if dividend == divisor: return 1\n # 找出除数翻倍情况下大于被除数的count数\n sum, count = divisor, 1\n while dividend >= sum:\n sum, count = sum<<1, count<<1\n sum, count = sum>>1, count>>1\n # 找出最大的小于被除数翻倍数,进行递归\n return count + self.div(dividend-sum, divisor)\n\n def divide(self, dividend: int, divisor: int) -> int:\n if divisor==1: return dividend\n # 最大值为int32\n if divisor==-1 and dividend==-2**31:\n return 2**31-1\n # 全部转为正数计算\n if dividend>0 and divisor>0:\n return self.div(dividend, divisor)\n elif dividend>0 or divisor>0:\n return -self.div(abs(dividend), abs(divisor))\n else:\n return self.div(abs(dividend), abs(divisor))\n# @lc code=end\n\nSolution().divide(-2147483648, -1)\n"
},
{
"alpha_fraction": 0.522522509098053,
"alphanum_fraction": 0.5379665493965149,
"avg_line_length": 24.09677505493164,
"blob_id": "2238034084becdc50ec1c987dd0404751296774f",
"content_id": "589df62d86cbacb0e140ba526ae4bd8b657e5be0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 797,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 31,
"path": "/python3/backtracking/medium/22.括号生成.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=22 lang=python3\n#\n# [22] 括号生成\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def backtrack(self, ans:List[str], combination:str, l:int, r:int, n:int):\n if l==n and r==n:\n ans.append(combination)\n return\n if l < n:\n combination += '('\n self.backtrack(ans, combination, l+1, r, n)\n combination = combination[:-1]\n # r<l 保证括号有效\n if r < l:\n combination += ')'\n self.backtrack(ans, combination, l, r+1, n)\n combination = combination[:-1]\n\n def generateParenthesis(self, n: int) -> List[str]:\n ans = []\n self.backtrack(ans, '', 0, 0, n)\n return ans\n# @lc code=end\n\nSolution().generateParenthesis(2)"
},
{
"alpha_fraction": 0.5614179968833923,
"alphanum_fraction": 0.5737839937210083,
"avg_line_length": 30.128204345703125,
"blob_id": "ce81dd312d4d9ff7401aebf42f3ac2dbb3ee2d3e",
"content_id": "1d4b13d2a780a6398cbef7fb53113982fa9d121e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1283,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 39,
"path": "/python3/backtracking/medium/39.组合总和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=39 lang=python3\n#\n# [39] 组合总和\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n\n def backtrack(self, candidates: List[int], target: int, index: int, combination: List[int], ans: List[List[int]]):\n if sum(combination)==target and combination not in ans:\n ans.append(combination.copy())\n return\n for i in range(index, len(candidates)):\n # 连续相同数剪枝\n if candidates[i]==candidates[i-1] and i > 0:\n continue\n # 大于目标值剪枝\n if sum(combination) >= target:\n return\n # 当前和+下一个数>target剪枝\n if sum(combination) + candidates[i] > target:\n return\n # 数可重复用i不需要+1\n combination.append(candidates[i])\n self.backtrack(candidates, target, i, combination, ans)\n combination.remove(candidates[i])\n\n def combinationSum(self, candidates: List[int], target: int) -> List[List[int]]:\n if not candidates or target==0: return None\n ans = []\n candidates.sort()\n self.backtrack(candidates, target, 0, [], ans)\n return ans\n# @lc code=end\n\nSolution().combinationSum([2,3,6,7], 7)"
},
{
"alpha_fraction": 0.5599393248558044,
"alphanum_fraction": 0.5705614686012268,
"avg_line_length": 25.31999969482422,
"blob_id": "d2ed9bdf36cf64ff87f4a77189b28bcf73987e10",
"content_id": "19210d87ee49b6c97138bb740d3e0c1d34fca0f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 679,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 25,
"path": "/python3/linked-list/medium/24.两两交换链表中的节点.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=24 lang=python3\n#\n# [24] 两两交换链表中的节点\n#\n\n# @lc code=start\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def swapPairs(self, head: ListNode) -> ListNode:\n dummyNode = ListNode(0, head)\n preNode = dummyNode\n while head:\n nextNode = head.next\n if not nextNode:\n break\n preNode.next, head.next, nextNode.next = nextNode, nextNode.next, head\n preNode = head\n head = head.next\n return dummyNode.next \n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4258706569671631,
"alphanum_fraction": 0.48059701919555664,
"avg_line_length": 28.52941131591797,
"blob_id": "41c6cb6e897e7b4f9eddf91963c8adef4c28d31d",
"content_id": "85d9888085e923b221dc8c751d002966a049e2a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 34,
"path": "/python3/array/medium/57.插入区间.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=57 lang=python3\n#\n# [57] 插入区间\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def insert(self, intervals: List[List[int]], newInterval: List[int]) -> List[List[int]]:\n s, e, ans = newInterval[0], newInterval[1], []\n for val in intervals:\n # 找出最大新增区间\n if val[0]<=s<=val[1] or val[0]<=e<=val[1]:\n s = min(val[0], s)\n e = max(val[1], e)\n # 包含在区间内忽略\n if s<=val[0] and val[1]<=e:\n continue\n # 由于按起始断点排序\n if e<val[0] and [s, e] not in ans:\n ans.append([s, e])\n ans.append(val)\n if [s, e] not in ans: ans.append([s, e])\n return ans\n# @lc code=end\n\n# Solution().insert([[1,3],[6,9]], [2,5])\n# Solution().insert([[1,2],[3,5],[6,7],[8,10],[12,16]], [4,8])\n# Solution().insert([], [5,7])\n# Solution().insert([[1,5]], [2,3])\n# Solution().insert([[1,5]], [2,7])\nSolution().insert([[2,5],[6,7],[8,9]], [0,1])\n\n"
},
{
"alpha_fraction": 0.3718712627887726,
"alphanum_fraction": 0.4052443504333496,
"avg_line_length": 27.965517044067383,
"blob_id": "6a6b9d908baed6faf6c2b66fd872b2e74f6b1543",
"content_id": "8fb5d660409d34544405249cb89a14f2a6fdd85c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 849,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 29,
"path": "/python3/dynamic-programming/medium/64.最小路径和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=64 lang=python3\n#\n# [64] 最小路径和\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def minPathSum(self, grid: List[List[int]]) -> int:\n r, c = len(grid), len(grid[0])\n dp = [[0 for _ in range(c)] for _ in range(r)]\n for i in range(r):\n for j in range(c):\n if i==0 and j>0: \n dp[i][j] = dp[i][j-1] + grid[i][j] \n continue\n if j==0 and i>0: \n dp[i][j] = dp[i-1][j] + grid[i][j]\n continue\n if i>0 and j>0:\n dp[i][j] = min(dp[i-1][j], dp[i][j-1]) + grid[i][j]\n else:\n dp[i][j] = grid[i][j]\n return dp[r-1][c-1] \n# @lc code=end\n\nSolution().minPathSum([[1,3,1],[1,5,1],[4,2,1]])"
},
{
"alpha_fraction": 0.5517970323562622,
"alphanum_fraction": 0.579281210899353,
"avg_line_length": 23.947368621826172,
"blob_id": "fb3994e40333f8ae4a8747dbe5f2735d2c0df398",
"content_id": "44b07095b3c8459df3943a31856ac10c3d4bf3b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/python3/hash-table/easy/290.单词规律.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=290 lang=python3\n#\n# [290] 单词规律\n#\n\n# @lc code=start\nclass Solution:\n def wordPattern(self, pattern: str, s: str) -> bool:\n hash1, hash2 = [], []\n for i, _ in enumerate(pattern):\n hash1.append(pattern.find(pattern[i]))\n sList = s.split()\n for i, v in enumerate(sList):\n hash2.append(sList.index(v))\n return hash1 == hash2\n# @lc code=end\n\nSolution().wordPattern('abba', 'dog cat cat dog')"
},
{
"alpha_fraction": 0.4009740352630615,
"alphanum_fraction": 0.43831169605255127,
"avg_line_length": 19.566667556762695,
"blob_id": "b6b4c247d32ee04b0686dd64af06ef0d7afb8233",
"content_id": "5a7123bb9504ac1d407dfde2334ec9fa83899bca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 30,
"path": "/python3/binary-search/medium/50.pow_x_n.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=50 lang=python3\n#\n# [50] Pow(x, n)\n#\n\n# @lc code=start\nclass Solution:\n # 递归\n def myPow2(self, x: float, n: int) -> float:\n if not n: return 1\n if n < 0:\n return 1 / self.myPow(x, -n)\n if n % 2:\n return x * self.myPow(x, n-1)\n return self.myPow(x*x, n/2)\n\n # 迭代\n def myPow(self, x: float, n: int) -> float:\n if n < 0:\n x, n = 1/x, -n\n pow = 1\n while n:\n if n % 2:\n pow *= x\n x, n = x*x, int(n/2)\n return pow\n# @lc code=end\n\nSolution().myPow(2.000, 10)"
},
{
"alpha_fraction": 0.42658960819244385,
"alphanum_fraction": 0.4485549032688141,
"avg_line_length": 21.789474487304688,
"blob_id": "f267f9bcde6cbdd830cb2de98bf4a5409cc5df9f",
"content_id": "4c85d85356c5f0030151a2f578d2417c4a937b7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 38,
"path": "/python3/greedy/medium/45.跳跃游戏_ii.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=45 lang=python3\n#\n# [45] 跳跃游戏 II\n#\n\n# @lc code=start\nfrom typing import List\n\n\nclass Solution:\n # 反向查找能到达单前位置的点\n def jump2(self, nums: List[int]) -> int:\n position = len(nums) - 1\n step = 0\n while position:\n for i in range(position):\n if i+nums[i] >= position:\n position = i\n step += 1\n break\n return step\n\n # 找出当前边界能跳跃的最大值\n def jump(self, nums: List[int]) -> int:\n n = len(nums)\n maxPos, end, step = 0, 0, 0\n for i in range(n - 1):\n if maxPos >= i:\n maxPos = max(maxPos, i + nums[i])\n # 到达边界增加一步\n if i == end:\n end = maxPos\n step += 1\n return step\n# @lc code=end\n\nSolution().jump([2,3,1,1,4])"
},
{
"alpha_fraction": 0.3501773178577423,
"alphanum_fraction": 0.3705673813819885,
"avg_line_length": 25.880952835083008,
"blob_id": "f929b090056091c81ac2e60d2c26eeb6e99e345c",
"content_id": "16125a3b51ec53eb668fec0e0ebeebee30886502",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1236,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 42,
"path": "/python3/two-pointers/medium/15.三数之和.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=15 lang=python3\n#\n# [15] 三数之和\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def threeSum(self, nums: List[int]) -> List[List[int]]:\n # 排序\n nums.sort()\n list = []\n for i in range(len(nums)):\n # 重复数直接过滤\n if i>0 and nums[i]==nums[i-1]:\n continue\n # 查找剩余数相加是否等于0\n s, e = i+1, len(nums)-1\n while s < e:\n sum = nums[i] + nums[s] + nums[e]\n # 等于0加入, 需要继续查找\n if sum == 0:\n ans = [nums[i], nums[s], nums[e]]\n if ans not in list:\n list.append(ans)\n s += 1\n # 向右查找,过滤重复数\n if sum < 0:\n ss = nums[s]\n while s < e and ss==nums[s]:\n s += 1\n # 向左查找,过滤重复数\n if sum > 0:\n ee = nums[e]\n while s < e and ee==nums[e]:\n e -= 1\n return list\n# @lc code=end\n\nSolution().threeSum([-1,0,1,2,-1,-4])"
},
{
"alpha_fraction": 0.5861148238182068,
"alphanum_fraction": 0.5967957377433777,
"avg_line_length": 28.920000076293945,
"blob_id": "e4f7f2949d37077791e1b210cfebf8109e4c3730",
"content_id": "14c8873e299e46e45a3b13f4565be3095df00f86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 25,
"path": "/python3/depth-first-search/easy/257.二叉树的所有路径.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=257 lang=python3\n#\n# [257] 二叉树的所有路径\n#\n\n# @lc code=start\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\nclass Solution:\n def recursion(self, root: TreeNode, ans:List[str], s:str):\n if root: s = str(root.val) if not s else s +'->'+str(root.val)\n if not root.left and not root.right: ans.append(s)\n if root.left: self.recursion(root.left, ans, s)\n if root.right: self.recursion(root.right, ans, s)\n\n def binaryTreePaths(self, root: TreeNode) -> List[str]:\n ans = []\n self.recursion(root, ans, '')\n return ans\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4554655849933624,
"alphanum_fraction": 0.5020242929458618,
"avg_line_length": 20.434782028198242,
"blob_id": "d0dc9e30741eae3b36a0a8d31fce4bdcf687c34f",
"content_id": "59964c769416cfce97e961ccffa0945eb26e4e2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 23,
"path": "/python3/dynamic-programming/medium/877.石子游戏.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=877 lang=python3\n#\n# [877] 石子游戏\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def stoneGame(self, piles: List[int]) -> bool:\n total = 0\n i, j = 0, len(piles)-1\n dp0, dp1 = 0, 0\n while(i<j):\n total += piles[i] + piles[j]\n dp0 += piles[i] if piles[i] > piles[j] else piles[j]\n i += 1\n j -= 1\n return dp0 > total - dp0 \n# @lc code=end\n\nSolution().stoneGame([5, 3, 4, 5])\n\n"
},
{
"alpha_fraction": 0.4922279715538025,
"alphanum_fraction": 0.5207253694534302,
"avg_line_length": 20.5,
"blob_id": "a23d819d257a01193e88099e4cce88bda7b526a6",
"content_id": "57f62876994ccb45a235211a818a2e69bcfd4145",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 404,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/python3/string/easy/58.最后一个单词的长度.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=58 lang=python3\n#\n# [58] 最后一个单词的长度\n#\n\n# @lc code=start\nclass Solution:\n def lengthOfLastWord(self, s: str) -> int:\n count = 0\n for i in range(len(s)-1, -1, -1):\n if s[i]==' ' and count!=0: break\n if s[i]==' ': continue\n count += 1\n return count\n# @lc code=end\n\nSolution().lengthOfLastWord('b a ')"
},
{
"alpha_fraction": 0.5548387169837952,
"alphanum_fraction": 0.5903225541114807,
"avg_line_length": 18.4375,
"blob_id": "fbc6fb81834c24793a4db700d88bb96e2b233333",
"content_id": "9e5beae188e9e8a826cd4c254e0cfd4b28812a7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 318,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 16,
"path": "/python3/math/easy/171.excel表列序号.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=171 lang=python3\n#\n# [171] Excel表列序号\n#\n\n# @lc code=start\nclass Solution:\n def titleToNumber(self, columnTitle: str) -> int:\n ans = 0\n for c in columnTitle:\n ans = ord(c)-ord('A')+1 + ans*26\n return ans\n# @lc code=end\n\nSolution().titleToNumber('ZY')"
},
{
"alpha_fraction": 0.589595377445221,
"alphanum_fraction": 0.6358381509780884,
"avg_line_length": 22.133333206176758,
"blob_id": "003a70429831e9272a5c3585f7dd973734f0e120",
"content_id": "451f257e12062ecca4523857cced2275c952de85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 354,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 15,
"path": "/python3/array/medium/54.螺旋矩阵.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=54 lang=python3\n#\n# [54] 螺旋矩阵\n#\n\nfrom typing import List\n\n# @lc code=start\nclass Solution:\n def spiralOrder(self, matrix: List[List[int]]) -> List[int]:\n return list(matrix.pop(0)) + self.spiralOrder(list(zip(*matrix))[::-1]) if matrix else []\n# @lc code=end\n\nSolution().spiralOrder([[1,2,3],[4,5,6],[7,8,9]])"
},
{
"alpha_fraction": 0.5348837375640869,
"alphanum_fraction": 0.5953488349914551,
"avg_line_length": 18.454545974731445,
"blob_id": "fa70839b16fb8de771ad280cd33e5610ed17d7e2",
"content_id": "395b40fe7ea196873937860b6c9af09127fe47cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 11,
"path": "/python3/bit-manipulation/easy/342.4-的幂.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=342 lang=python3\n#\n# [342] 4的幂\n#\n\n# @lc code=start\nclass Solution:\n def isPowerOfFour(self, n: int) -> bool:\n return (n>0) and (n&(n-1))==0 and (n&0xaaaaaaaa)==0\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.5618374347686768,
"alphanum_fraction": 0.6007066965103149,
"avg_line_length": 19.214284896850586,
"blob_id": "4ef19513079365bb6e59918d4a1b77261816f50e",
"content_id": "8ac7a608bf0c38b2927b91f9e57869797ab240f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 293,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 14,
"path": "/python3/string/easy/125.验证回文串.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=125 lang=python3\n#\n# [125] 验证回文串\n#\n\n# @lc code=start\nclass Solution:\n def isPalindrome(self, s: str) -> bool:\n x1 = ''.join(list(filter(str.isalnum, s.lower())))\n return x1 == x1[::-1]\n# @lc code=end\n\nSolution().isPalindrome('race a car')\n"
},
{
"alpha_fraction": 0.41137123107910156,
"alphanum_fraction": 0.4648829400539398,
"avg_line_length": 17.625,
"blob_id": "899b23bddbdf0731827b291bce1149320faa9bd6",
"content_id": "bbaa242f489c46158961db369b5b1dc678ee5039",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 16,
"path": "/python3/math/easy/263.丑数.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=263 lang=python3\n#\n# [263] 丑数\n#\n\n# @lc code=start\nclass Solution:\n # n=2^a + 3^b + 5^c\n def isUgly(self, n: int) -> bool:\n if n<=0: return False\n for i in [2, 3, 5]:\n while n%i==0:\n n //= i\n return n==1\n# @lc code=end\n\n"
},
{
"alpha_fraction": 0.4225352108478546,
"alphanum_fraction": 0.4483568072319031,
"avg_line_length": 19.285715103149414,
"blob_id": "fdfe1e7e54f23151f6931d2010c84ca566143982",
"content_id": "5000e4825d423a967edb9cf113630b93deb64f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 21,
"path": "/python3/binary-search/easy/69.x_的平方根.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=69 lang=python3\n#\n# [69] x 的平方根\n#\n\n# @lc code=start\nclass Solution:\n def mySqrt(self, x: int) -> int:\n start, end, ans = 0, x, 0\n while start <= end:\n mid = int((start + end) / 2)\n if mid*mid <= x:\n ans = mid\n start = mid + 1\n else:\n end = mid - 1\n return ans\n# @lc code=end\n\nSolution().mySqrt(1)\n"
},
{
"alpha_fraction": 0.4615384638309479,
"alphanum_fraction": 0.4722222089767456,
"avg_line_length": 21.238094329833984,
"blob_id": "7a96efdcbb6ddafd462f50945343f6cae0e39056",
"content_id": "f99d9faf38c907df1effbbe57b1cf0d00ff6d4aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 21,
"path": "/python3/stack/medium/71.简化路径.py",
"repo_name": "gnaixx/keepcode",
"src_encoding": "UTF-8",
"text": "#\n# @lc app=leetcode.cn id=71 lang=python3\n#\n# [71] 简化路径\n#\n\n# @lc code=start\nclass Solution:\n def simplifyPath(self, path: str) -> str:\n stack = []\n paths = path.split('/')\n for p in paths:\n if not p or p=='.': continue\n if p=='..': \n if stack: stack.pop()\n continue\n stack.append(p)\n return '/' + '/'.join(stack)\n# @lc code=end\n\nSolution().simplifyPath('/a/./b/../../c/')\n\n"
}
] | 108 |
Poorna525/python-lab1
|
https://github.com/Poorna525/python-lab1
|
69a376bc688b4e1bce453ae65f3eeee6e7233302
|
7ef445aefff17b5097607fc73f1dbfeb1ca28eed
|
e01dc496055c2da7c5a1566f586b91926486e58c
|
refs/heads/master
| 2023-01-20T14:34:24.083861 | 2020-12-02T17:48:22 | 2020-12-02T17:48:22 | 291,980,701 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.44736841320991516,
"alphanum_fraction": 0.5592105388641357,
"avg_line_length": 14.105262756347656,
"blob_id": "a1cff6fee1e0afb89d5a834057b31a4b674cf81c",
"content_id": "13af6ad7bdc123bab6da039bb95f05e5a7e8cb05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 19,
"path": "/prog1.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#121910313062\r\n#POORNA CHANDRA\r\n\r\n#reverse array\r\n\r\n#array1\r\na1 = [1,2,3,4,5]\r\nprint(\"Array1 is: \",a1) \r\n\r\n#array2\r\n\r\na2 = [None]*len(a1) #declaring another array2 \r\n #with same length as array1\r\nl = len(a1)\r\n\r\nfor i in range(0,len(a1)):\r\n\ta2[i] = a1[l-i-1] #copying\r\n\r\nprint(\"Array2 is: \",a2)"
},
{
"alpha_fraction": 0.6015200614929199,
"alphanum_fraction": 0.6145493984222412,
"avg_line_length": 18.021739959716797,
"blob_id": "f03a571af00b1939987dc5bc6adc54dd06403db4",
"content_id": "af9ed919c696de49323542755103c6e278612d8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 921,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 46,
"path": "/l8dllinsertnodesinmiddle.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "\r\n#Insert Node at a particular position\r\n#node class\r\nclass node:\r\n\tdef __init__(self,data):\r\n\t\tself.data = data\r\n\t\tself.prev = None\r\n\t\tself.next = None\r\n#linkedlist class\r\nclass LinkedList:\r\n\tdef __init__(self):\r\n\t\tself.head = None\r\n\r\n\t#inserting node in the middle of the list\r\n\tdef atPosition(self,pre,data):\r\n\t\tnew_node = node(data)\r\n\t\tif self.head == None:\r\n\t\t\tself.head = new_node\r\n\t\telse:\r\n\t\t\tcur = self.head\r\n\t\t\twhile cur:\r\n\t\t\t\tif cur.data == pre:\r\n\t\t\t\t\tn = cur.next\r\n\t\t\t\t\tcur.next = new_node\r\n\t\t\t\t\tnew_node.next = n\r\n\t\t\t\t\tnew_node.prev = cur\r\n\t\t\t\tcur = cur.next\r\n\t#printing elements\r\n\tdef display(self):\r\n\t\tele = []\r\n\t\tcur = self.head\r\n\t\twhile cur:\r\n\t\t\tele.append(cur.data)\r\n\t\t\tcur = cur.next\r\n\t\tprint(\"Doubly Linked List: \",ele)\r\n\r\n\r\nDLL = LinkedList()\r\n\r\n#adding nodes\r\nDLL.head = node(10)\r\nDLL.head.next = node(20) \r\nDLL.head.next.next = node(30)\r\nDLL.atPosition(20,8)\r\nDLL.atPosition(10,5) \r\n\\\r\nDLL.display()"
},
{
"alpha_fraction": 0.6049165725708008,
"alphanum_fraction": 0.6224758625030518,
"avg_line_length": 16.25757598876953,
"blob_id": "de70207c5809c6549b7d40daa1e1b2bf29f7bf9b",
"content_id": "91685e6b8b336a3aede1a027e7be4b6700b7be9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 66,
"path": "/l3operationsonarray.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "\n#operations on array\n\n#input of array\nprint(\"Enter length: \")\nn = int(input())\nprint(\"Enter elements: \")\na = []\nfor i in range(0,n):\n\tk = int(input())\n\ta.append(k)\n\n#display\ndef display_element():\n\tprint(\"Array is: \",a)\n\n#copy\ndef copy_element():\n\ta1 = a\n\tprint(\"Copied array: \",a1)\n\n#delete\ndef delete_element():\n\tprint(\"Enter the index: \")\n\ty = int(input())\n\tdel a[y]\n\tprint(\"New Array: \",a)\n\n#search\ndef search_element():\n\tprint(\"Enter the search element: \")\n\tl = int(input())\n\tfor i in range(0,n):\n\t\tif a[i] == l:\n\t\t\tloc = i\n\t\t\tprint(\"Element: \",l,\"is found at index: \",loc)\n\t\t\tbreak\n\telse:\n\t\tprint(\"Element not found!!\")\n\n#removing\ndef remove_duplicate_element():\n\ta1=[]\n\tfor i in a:\n\t\tif i not in a1:\n\t\t\ta1.append(i)\n\tprint(\"New Array is: \",a1)\n\n#choices\nprint(\"Choose: \\n 1:to display \\n 2:to copy \\n 3:to remove duplicates \\n 4:to delete \\n 5:to search\")\n\nprint(\"Enter choice: \")\nq = int(input())\n\n#selection\nif (q == 1):\n\tdisplay_element()\nelif (q == 2):\n\tcopy_element()\nelif (q == 3):\n\tremove_duplicate_element()\nelif (q == 4):\n\tdelete_element()\nelif (q == 5):\n\tsearch_element()\nelse:\n\tprint(\"Enter a right number from 1 to 5!\")"
},
{
"alpha_fraction": 0.49723145365715027,
"alphanum_fraction": 0.5304540395736694,
"avg_line_length": 18.08888816833496,
"blob_id": "2d25f67087eb9ff9023f593c0a68eb95ba5746df",
"content_id": "3771efe0995e96a6cd232341d5c3ba7dbf0ec5e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 45,
"path": "/matrix1.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#POORNA CHANDRA\r\n#121910313062\r\n\r\n#Matrix to SparseMatrix using functions\r\n\r\n#function to print a matrix\r\ndef display_matrix(matrix):\r\n for i in matrix:\r\n for j in i:\r\n print(j, end=\" \")\r\n print()\r\n\r\n#matrix initialization\r\na = ([0,0,0,1],\r\n [1,0,0,2],\r\n [3,0,0,0],\r\n [0,4,0,2])\r\n\r\n#print given matrix\r\nprint(\"Given Matrix:\")\r\ndisplay_matrix(a)\r\n\r\n\r\n#SparseMatrix\r\ndef sparseMatrix(matrix):\r\n\r\n sparsematrix = [] \r\n\r\n for i in range(len(matrix)):\r\n for j in range(len(matrix[0])):\r\n if matrix[i][j] != 0:\r\n\r\n temp=[]\r\n\r\n temp.append(i) #adding row index\r\n temp.append(j) # adding column index\r\n temp.append(matrix[i][j]) \r\n\r\n sparsematrix.append(temp)\r\n\r\n #display sparsematrix\r\n print(\"\\nSparseMatrix:\")\r\n display_matrix(sparsematrix)\r\n\r\nsparseMatrix(a) "
},
{
"alpha_fraction": 0.5331294536590576,
"alphanum_fraction": 0.5433231592178345,
"avg_line_length": 14.948275566101074,
"blob_id": "e12ce4cce677eab6c0de76c7f6067b93382f4f5f",
"content_id": "08be1a9f26a955d59a0c88e399eec165ac943550",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 981,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 58,
"path": "/l5binarysearch2.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#Binary search with user defined function and dynamic inputs\r\n\r\n#dynamic inputs\r\ndef array_input():\r\n\tn = int(input(\"Enter no'of elements: \"))\r\n\tprint(\"Enter elements: \")\r\n\ta = []\r\n\tfor i in range(0,n):\r\n\t\tk = int(input())\r\n\t\ta.append(k)\r\n\treturn a\r\n\r\n#function\r\ndef binarysearch_array(a):\r\n\ta.sort()\r\n\tprint(\"Sorted array is: \",a)\r\n\r\n#search element\r\n\tx = int(input(\"Enter search element: \"))\r\n\r\n\tloc =0\r\n\tlow = 0\r\n\thigh = len(a) - 1\r\n\tmid = (low+high)//2\r\n\r\n#checking\r\n\tif a[mid] == x:\r\n\t\tloc = mid\r\n\t\tf = 1\r\n\r\n\telif x < a[mid]:\r\n\t\tfor i in range(low,mid):\r\n\t\t\tif a[i] == x:\r\n\t\t\t\tloc = i\r\n\t\t\t\tf = 1\r\n\t\t\t\tbreak\r\n\r\n\telif x > a[mid]:\r\n\t\tfor i in range(mid,high+1):\r\n\t\t\tif a[i] == x:\r\n\t\t\t\tloc = i\r\n\t\t\t\tf = 1\r\n\t\t\t\tbreak\r\n\r\n #output\r\n #if found\r\n if f == 1:\r\n print(\"Element\",x,\"is found at index\",loc)\r\n #if not found\r\n else:\r\n print(\"Element not found!!\")\r\n\r\n\r\n\r\n#function calling \r\narr = array_input()\r\nprint(\"Array is: \", arr)\r\nbinarysearch_array(arr)"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6334033608436584,
"avg_line_length": 20.714284896850586,
"blob_id": "e0c7167c593650c8d8c153a4fe44fb0f94e5e45f",
"content_id": "621ced2f175919bba3cebbf770cd1d93b9ed3a79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 952,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 42,
"path": "/l6insertnodeatstart.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#inserting a node at the beigning\r\n\r\n#Node class\r\nclass node:\r\n #Function to initialise the node object\r\n def __init__(self,data):\r\n self.data=data\r\n self.next=None\r\n\r\n#Linked List class contains a Node object\r\nclass LinkedList:\r\n #function to initialize head\r\n def __init__(self):\r\n self.head=None\r\n\r\n #print contents of linked list\r\n def printList(self):\r\n temp=self.head\r\n while temp != None:\r\n print(temp.data)\r\n temp=temp.next\r\n\r\n#to insert new element at start of the list\r\n def AtBegining(self,new_element):\r\n new_node = node(new_element)\r\n# Update the new nodes next val to existing node\r\n new_node.next = self.head\r\n self.head = new_node\r\n\r\n#Code execution starts here\r\n\r\n#starts with empty list\r\nLL=LinkedList()\r\nLL.head=node(10)\r\nsecond=node(20)\r\nthird=node(30)\r\n\r\nLL.head.next=second;\r\nsecond.next=third;\r\nLL.AtBegining(50)\r\n\r\nLL.printList()"
},
{
"alpha_fraction": 0.433529794216156,
"alphanum_fraction": 0.4878847301006317,
"avg_line_length": 18.386667251586914,
"blob_id": "850143dfc304d6db882a4f30ae10d0e3d08e9ae8",
"content_id": "08b35a287d13729b01f95b77504aabc59b219291",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1527,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 75,
"path": "/l5binarysearch3.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#Binary search with test cases\r\n\r\n#function\r\ndef binarysearch_array(a,x):\r\n print(\"Array is: \",a)\r\n a.sort() \r\n print(\"Sorted array is: \",a)\r\n\r\n f = 0\r\n loc =0\r\n low = 0\r\n high = len(a) - 1\r\n mid = (low+high)//2\r\n\r\n #checking with mid value\r\n if a[mid] == x:\r\n loc = mid\r\n f = 1\r\n\r\n #checking with elements lesser than the mid value\r\n elif x < a[mid]:\r\n for i in range(low,mid):\r\n if a[i] == x:\r\n loc = i\r\n f = 1\r\n break\r\n \r\n\r\n #checking with elements greater than the mid value\r\n elif x > a[mid]:\r\n for i in range(mid,high+1):\r\n if a[i] == x:\r\n loc = i\r\n f = 1\r\n break\r\n \r\n \r\n\r\n #output\r\n if f == 1:\r\n print(\"Element\",x,\"is found at index\",loc)\r\n else:\r\n print(\"Element not found!!\")\r\n\r\n\r\n\r\n#test cases\r\n\r\n#1\r\nprint(\"TestCase1: \")\r\na1 = [1,2,4,9,10,12] #sorted list\r\nx1 = 2 \r\n#function calling\r\nbinarysearch_array(a1,x1)\r\n\r\n#2\r\nprint(\"TestCase2: \")\r\na2 = [2,5,11,7,3,15] #unsorted list\r\nx2 = 7 \r\n#function calling\r\nbinarysearch_array(a2,x2)\r\n\r\n#3\r\nprint(\"TestCase3: \")\r\na3 = [3,6,6,3,9,14,23,14,9,10] #repeated elements list\r\nx3 = 9 \r\n#function calling\r\nbinarysearch_array(a3,x3)\r\n\r\n#4\r\nprint(\"TestCase4: \")\r\na3 = [2,5,7,9,10,11,6,9,3,1,2,88] #list\r\nx3 = 4 #element that's not present in the list\r\n#function calling\r\nbinarysearch_array(a3,x3)"
},
{
"alpha_fraction": 0.5402985215187073,
"alphanum_fraction": 0.5850746035575867,
"avg_line_length": 15.230769157409668,
"blob_id": "eb4d0b1d9c22165a4527eb628d3a6644a49d16d7",
"content_id": "ce547b8ef72c771807e5f10f892c00dcc2623db2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 39,
"path": "/matrix.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#POORNA CHANDRA\r\n#121910313062\r\n\r\n#represent a sparse matrix\r\n\r\n#matrix initialization\r\nmatrix = ([0,0,0,2],\r\n\t [8,0,0,4],\r\n\t [2,0,4,0],\r\n\t [0,0,0,2])\r\n#printing initialized matrix\r\nprint(\"Given Matrix: \")\r\nfor i in matrix:\r\n\tfor j in i:\r\n\t\tprint(j, end=\" \")\r\n\tprint()\r\n\r\n#SparseMatrix\r\n\r\nsparsematrix = [] \r\n\r\nfor i in range(len(matrix)):\r\n\tfor j in range(len(matrix[0])):\r\n\t\tif matrix[i][j] != 0:\r\n\r\n\t\t\ttemp=[]\r\n\r\n\t\t\ttemp.append(i) #row index\r\n\t\t\ttemp.append(j) #column index\r\n\t\t\ttemp.append(matrix[i][j]) \r\n\r\n\t\t\tsparsematrix.append(temp)\r\n\r\n#printing SparseMatrix\r\nprint(\"\\nSparseMatrix: \")\r\nfor i in sparsematrix:\r\n\tfor j in i:\r\n\t\tprint(j, end =\" \")\r\n\tprint()"
},
{
"alpha_fraction": 0.4761904776096344,
"alphanum_fraction": 0.5047619342803955,
"avg_line_length": 14.307692527770996,
"blob_id": "d2cb1bb354ae3f8881245123b4ecf1a2474df43f",
"content_id": "72703f63507c9d4696ab980665e7e9831523f456",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/l12iterativeinsertionsort.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#Insertion Sort (iterative)\r\n\r\na=list(map(int,input().split()))\r\n\r\nfor i in range(1,len(a)):\r\n k=a[i] \r\n j=i-1 \r\n\r\n while j>=0 and a[j]>k: \r\n a[j+1]=a[j] \r\n j-=1\r\n a[j+1]=k \r\nprint(\"Sorted Array: \",a)"
},
{
"alpha_fraction": 0.6259351372718811,
"alphanum_fraction": 0.6359102129936218,
"avg_line_length": 16.604650497436523,
"blob_id": "425b66b5629cf0996093d8bda6cc8cfbd39a2bc7",
"content_id": "0295d8847f77f25b3cbe5125cad55f98f7944958",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 43,
"path": "/l8countnodesindll.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "\r\n#Count the number of nodes in a doubly linked list.\r\n#node class\r\nclass node:\r\n\t#constructor\r\n\tdef __init__(self,data):\r\n\t\tself.data = data\r\n\t\tself.prev = None\r\n\t\tself.next = None\r\n\r\n#linkedlist class\r\nclass LinkedList:\r\n\tdef __init__(self):\r\n\t\tself.head = None\r\n\r\n#printing list\r\n\tdef display(self):\r\n\t\tele = []\r\n\t\tcur = self.head\r\n\t\twhile cur:\r\n\t\t\tele.append(cur.data)\r\n\t\t\tcur = cur.next\r\n\t\tprint(\"Doubly LinkedList: \",ele)\r\n\r\n#counting no of elements in the linked list\r\n\tdef countNodes(self):\r\n\t\tcount = 0\r\n\t\tcur = self.head\r\n\t\twhile cur:\r\n\t\t\tcount += 1\r\n\t\t\tcur = cur.next\r\n\t\tprint(\"Count is: \",count)\r\n\r\n#initialization\r\nDLL = LinkedList()\r\n\r\n#creating nodes \r\nDLL.head = node(10) \r\nDLL.head.next = node(20)\r\nDLL.head.next.next = node(30) \r\n\r\n#function calling\r\nDLL.display()\r\nDLL.countNodes()\r\n"
},
{
"alpha_fraction": 0.480701744556427,
"alphanum_fraction": 0.6070175170898438,
"avg_line_length": 12.350000381469727,
"blob_id": "dc8d9c9e6f4df33fa4c4e11cbad59c014ae79eea",
"content_id": "503823fe97d9a67f7d07167aa10a9f95848e60b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 20,
"path": "/Prog2.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#121910313062\r\n#POORNA CHANDRA\r\n\r\n#removing duplicates\r\n\r\n#removing duplicates\r\n\r\n#array1\r\na1 = [1,2,3,4,4,5,5,8,9,8,8,10]\r\nprint(\"Array1 is: \",a1) \r\n\r\n#function\r\ndef remove(a1):\r\n\ta2=[]\r\n\tfor num in a1:\r\n\t\tif num not in a2:\r\n\t\t\ta2.append(num)\r\n\treturn a2\r\n\r\nprint(\"New Array is: \",remove(a1))"
},
{
"alpha_fraction": 0.6398210525512695,
"alphanum_fraction": 0.6487695574760437,
"avg_line_length": 17.478260040283203,
"blob_id": "f8dbcf91230be1ef12ffa15db07d6efedf3e5eaa",
"content_id": "361437e9c56b25000daef45cba5e6896ede889b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 46,
"path": "/l8searchnodeindll.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#Search for an element in a doubly linked list\r\n#node class\r\nclass node:\r\n\t#constructor\r\n\tdef __init__(self,data):\r\n\t\tself.data = data\r\n\t\tself.prev = None\r\n\t\tself.next = None\r\n\r\n#linkedlist class\r\nclass LinkedList:\r\n\tdef __init__(self):\r\n\t\tself.head = None\r\n\r\n#printing list\r\n\tdef display(self):\r\n\t\tele = []\r\n\t\tcur = self.head\r\n\t\twhile cur:\r\n\t\t\tele.append(cur.data)\r\n\t\t\tcur = cur.next\r\n\t\tprint(\"Doubly LinkedList: \",ele)\r\n\r\n#counting no of elements in the linked list\r\n\tdef searchNodes(self,data):\r\n\t\tcur = self.head\r\n\t\twhile cur:\r\n\t\t\tif cur.data == data:\r\n\t\t\t\treturn True\r\n\t\t\tcur = cur.next\r\n\t\telse:\r\n\t\t\treturn False\r\n\r\n#initialization\r\nDLL = LinkedList()\r\n\r\n#creating nodes\r\nDLL.head = node(10)\r\nDLL.head.next = node(20)\r\nDLL.head.next.next = node(30)\r\nDLL.head.next.next.next = node(40)\r\n\r\n#function calling\r\nDLL.display()\r\nx = int(input(\"Enter search element: \"))\r\nprint(DLL.searchNodes(x))"
},
{
"alpha_fraction": 0.47183099389076233,
"alphanum_fraction": 0.47535210847854614,
"avg_line_length": 18.285715103149414,
"blob_id": "384f8f9fbf727d943367ccae4a7aa25db3fcad5a",
"content_id": "a44dc84894379abc4dbfc41a798825cf1b509df3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 14,
"path": "/l12iterativeselectionsort.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#Selection Sort (iterative)\r\n\r\na = list(map(int,input().split()))\r\n \r\nfor i in range(len(a)): \r\n min_num = i \r\n\r\n for j in range(i+1, len(a)):\r\n if a[min_num] > a[j]: \r\n min_num = j \r\n\r\n a[i], a[min_num] = a[min_num], a[i] \r\n\r\nprint (\"Sorted array: \", a) "
},
{
"alpha_fraction": 0.4873417615890503,
"alphanum_fraction": 0.5886076092720032,
"avg_line_length": 15.666666984558105,
"blob_id": "7e3ba19ba9770823324844950e8b18bdd1477268",
"content_id": "fedbcf8868844ac2c75363718190a7476a855223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/prog.py",
"repo_name": "Poorna525/python-lab1",
"src_encoding": "UTF-8",
"text": "#121910313062\r\n#POORNA CHANDRA\r\n\r\n#copying and array into another empty array\r\n\r\n#array1\r\na1 = [1,2,3,4,5]\r\nprint(\"Array1 is: \",a1) \r\n\r\n#array2\r\n\r\na2 = [None]*len(a1) #declaring another array2 \r\n #with same length as array1\r\n\r\nfor i in range(0,len(a1)):\r\n\ta2[i] = a1[i] #copying\r\n\r\nprint(\"Array2 is: \",a2)"
}
] | 14 |
Tatianalarissa/PDEEC0049-Machine-Learning-2018-19
|
https://github.com/Tatianalarissa/PDEEC0049-Machine-Learning-2018-19
|
024ad3084221aa9a0d8c7a899bf75111a758f621
|
8d83ef05d9b17f55fae9aade0eff9240114047e9
|
d12b484a40618ea8a4a736b69ac44bc154b5830c
|
refs/heads/master
| 2021-10-12T00:35:11.197599 | 2019-01-30T22:45:07 | 2019-01-30T22:45:07 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6668726801872253,
"alphanum_fraction": 0.6983931064605713,
"avg_line_length": 36.57143020629883,
"blob_id": "7e9ada5eff547d320c7511d24962576655ce385e",
"content_id": "e77374d5458d8b5f9799cdefcfc5b13e8fd17e72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 42,
"path": "/Classes/kindOfSolutions/myProject04.trainTest - auto - ParaOpt.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.qda import QDA\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.svm import SVC\r\nfrom sklearn.cross_validation import train_test_split\r\nfrom sklearn.cross_validation import KFold\r\nfrom sklearn.grid_search import GridSearchCV\r\nfrom sklearn.metrics import classification_report\r\n\r\n#data = np.genfromtxt('heightWeightData.txt', delimiter=',')\r\ndata = np.genfromtxt('testData.txt', delimiter=';')\r\nNsamples = np.shape(data)[0]\r\nfeatures = data[:,0:2]\r\nlabels = data[:,-1:]\r\nK = np.unique(labels).size\r\n\r\nplt.clf() \r\nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\r\nfor cls in range(K):\r\n idx = (labels == cls+1)\r\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\r\n \r\nprint('Support Vector Machine')\r\ntrainFeatures, testFeatures, trainLabels, testLabels = train_test_split(features, labels, test_size=0.4, random_state=42)\r\nparam_grid = [\r\n {'C': [1, 10, 100, 1000], 'degree':[1, 2, 3], 'kernel': ['poly'], 'coef0': [1.0]},\r\n {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},\r\n ]\r\nmodel = GridSearchCV(SVC(), param_grid, cv=5)\r\nmodel.fit(trainFeatures, trainLabels[:,0])\r\nprint(\"Best parameters set found on development set:\")\r\nprint()\r\nprint(model.best_params_)\r\ny_pred = model.predict(testFeatures)\r\nprint(classification_report(testLabels, y_pred))\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)"
},
{
"alpha_fraction": 0.6336792707443237,
"alphanum_fraction": 0.6833962202072144,
"avg_line_length": 34.1026496887207,
"blob_id": "ade79031b3270396839b83ba4fd2a619858778bb",
"content_id": "de1c8d4fe1534f06fb791e9df96f950c2b334aa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10607,
"license_type": "no_license",
"max_line_length": 512,
"num_lines": 302,
"path": "/Assignments/201819_MachineLearning_HW01/HW1_TiagoGoncalves.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Oct 12 11:37:57 2018\n\n@author: Tiago Filipe Sousa Gonçalves | 5º Ano MIB | UP201607753\n\"\"\"\n\n#Import libraries\nimport numpy as np\nimport random\nimport matplotlib.pyplot as plt\nfrom math import sqrt\nfrom collections import Counter\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.pipeline import make_pipeline\n\n\"\"\"1. Write a Python function to compute the predictions according to the mean Euclidean distance to the sample points of each class.\nThe function should have the following interface function [prediction] = meanPrediction(dataClass1, dataClass2, dataUnknownClass) where dataClass1 is an array N1xd; dataClass2 is an array N2xd; dataUnknownClass is an array Ntxd; and prediction is an array Ntx1. d is the dimension of the features.\n\na)Determine the training error on your samples using only the x1 feature value. Make use of the function meanPrediction you wrote.\n\nb) Repeat but now use two feature values, x1 and x2.\n\nc) Repeat but use all three feature values.\n\nd) Discuss your results. Is it ever possible for a finite set of data that the training error be larger for more data dimensions?\"\"\"\n\n#Implement Euclidean Distance Function First\ndef euclidean_distance(dataClass, dataUnknownClassElement):\n # Computes and returns the Euclidean distance between elements from UnknownDataClass\n #And DataClass\n #Assign temporary distance\n d=np.zeros((dataClass.shape[0],1))\n for index in range(dataClass.shape[0]):\n #In case dataClass has just one column (one feature):\n if dataClass.shape[1]==1:\n d[index]=np.sqrt(np.power((dataUnknownClassElement-dataClass[index]),2))\n \n #For more features \n else:\n d[index]=np.sqrt(sum(np.power((dataUnknownClassElement-dataClass[index]),2)))\n distance = np.mean(d) \n \n return distance \n\n#Implement meanPrediction Function\ndef meanPrediction(dataClass1, dataClass2, dataUnknownClass):\n #Initialize Distance Arrays\n dc1=np.zeros((dataUnknownClass.shape[0],1))\n dc2=np.zeros((dataUnknownClass.shape[0],1))\n predictions = np.zeros((dataUnknownClass.shape[0], 1))\n \n #Iterate from every dataUnknownClass item\n for index in range(dataUnknownClass.shape[0]):\n #Calculate distances from points to every class and assign in variables dc1 and dc2\n dc1[index] = euclidean_distance(dataClass1, dataUnknownClass[index])\n dc2[index] = euclidean_distance(dataClass2, dataUnknownClass[index])\n \n #Evaluate Classes based on the means\n if np.mean(dc1[index]) < np.mean(dc2[index]):\n predictions[index] = 1\n elif np.mean(dc1[index]) > np.mean(dc2[index]):\n predictions[index] = 2\n else:\n #Randomly assign prediction if the means are equal\n predictions[index] = random.randint(1,2)\n \n return predictions\n\n#Let's creat a function to determine the accuracy of our algorithm\ndef accuracy(y_test, y_pred):\n #Number of corrected predictions\n corr = 0\n for index in range(y_test.shape[0]):\n if y_test[index] == y_pred[index]:\n corr +=1 \n #corr = int(np.sum(y_test==y_pred))\n n_samples = int((y_test.shape[0]))\n acc = corr/n_samples\n return acc*100\n\n\n###############################################################################\n#Data\ndataClass1 = np.zeros((10, 4))\n#Assign Values dataClass1\ndataClass1[0, 0] = -5.01\ndataClass1[0, 1] = -8.12\ndataClass1[0, 2] = -3.68\n\ndataClass1[1, 0] = -5.43\ndataClass1[1, 1] = -3.48\ndataClass1[2, 0] = 1.08\ndataClass1[2, 1] = -5.52\ndataClass1[2, 2] = -1.66\n\ndataClass1[3, 0] = 0.86\ndataClass1[3, 1] = -3.78\ndataClass1[3, 2] = -4.11\n\ndataClass1[4, 0] = -2.67\ndataClass1[4, 1] = -0.63\ndataClass1[4, 2] = 7.39\n\ndataClass1[5, 0] = 4.94\ndataClass1[5, 1] = 3.29\ndataClass1[5, 2] = 2.08\n\ndataClass1[6, 0] = -2.51\ndataClass1[6, 1] = 2.09\ndataClass1[6, 2] = -2.59\n\ndataClass1[7, 0] = -2.25\ndataClass1[7, 1] = -2.13\ndataClass1[7, 2] = -6.94\n\ndataClass1[8, 0] = 5.56\ndataClass1[8, 1] = 2.86\ndataClass1[8, 2] = -2.26\n\ndataClass1[9, 0] = 1.03\ndataClass1[9, 1] = -3.33\ndataClass1[9, 2] = 4.33\n\n\n\ndataClass2 = np.zeros((10, 4))\n#Assign Values to dataClass2\ndataClass2[0, 0] = -0.91\ndataClass2[0, 1] = -0.18\ndataClass2[0, 2] = -0.05\n\ndataClass2[1, 0] = 1.30\ndataClass2[1, 1] = -2.06\ndataClass2[1, 2] = -3.53\n\ndataClass2[2, 0] = -7.75\ndataClass2[2, 1] = -4.54\ndataClass2[2, 2] = -0.95\n\ndataClass2[3, 0] = -5.47\ndataClass2[3, 1] = 0.50\ndataClass2[3, 2] = 3.92\n\ndataClass2[4, 0] = 6.14\ndataClass2[4, 1] = 5.72\ndataClass2[4, 2] = -4.85\n\ndataClass2[5, 0] = 3.60\ndataClass2[5, 1] = 1.26\ndataClass2[5, 2] = 4.36\n\ndataClass2[6, 0] = 5.37\ndataClass2[6, 1] = -4.63\ndataClass2[6, 2] = -3.65\n\ndataClass2[7, 0] = 7.18\ndataClass2[7, 1] = 1.46\ndataClass2[7, 2] = -6.66\n\ndataClass2[8, 0] = -7.39\ndataClass2[8, 1] = 1.17\ndataClass2[8, 2] = 6.30\n\ndataClass2[9, 0] = -7.50\ndataClass2[9, 1] = -6.32\ndataClass2[9, 2] = -0.31\n\n#Labels for Each Classes\n#dataClass1 Label is 1\ndataClass1[:, 3] = 1\n#dataClass2 Label is 2\ndataClass2[:, 3] = 2\n\n#dataUnknownClass is the concatenations of both classes:\ndataUnknown = np.concatenate((dataClass1, dataClass2), axis=0)\n\n#Print both datasets\nprint(\"dataClass1 is : \\n\", dataClass1, '\\n')\nprint(\"dataClass2 is : \\n\", dataClass2, '\\n')\n\n#Generate dataUnknownClass\n#dataUnknown = np.random.rand(10,3)\nprint(\"dataUnknown is: \\n\", dataUnknown, '\\n')\n\n#print(dataClass1.shape[0], dataClass2.shape, dataUnknown.shape)\n#print(np.concatenate((dataClass1, dataClass2), axis=0))\n\n#Let's Predict the Unknown Class and check the training error\ny_test = np.array(dataUnknown[:, [-1]] )\n\n#Using Just 1 Feature\ny_pred = meanPrediction(dataClass1[:, [0]], dataClass2[:, [0]], dataUnknown[:, [0]])\nacc_1f = accuracy(y_test=y_test, y_pred=y_pred)\nprint(\"The accuracy with one feature is: \", acc_1f, \" % \" \"with the following predictions: \", y_pred)\n\n#Using Just 2 Feature\n#print(dataUnknown)\ny_pred = meanPrediction(dataClass1[:, 0:2], dataClass2[:, 0:2], dataUnknown[:, 0:2])\nacc_2f = accuracy(y_test=y_test, y_pred=y_pred)\nprint(\"The accuracy with two features is: \", acc_2f, \" % \" \"with the following predictions: \", y_pred)\n\n#Using Just 3 Features\n#Compute function\ny_pred = meanPrediction(dataClass1[:, 0:3], dataClass2[:, 0:3], dataUnknown[:,0:3])\nacc_3f = accuracy(y_test, y_pred)\nprint(\"The accuracy with three features is \", acc_3f, \"% \" \"with the following predictions: \", y_pred)\n\nprint(\"\\nMy thoughts on question d) are:\")\nprint(\"Answer: Actually, that is one of the problems with this algorithm, i.e., the accuracy of k-NN can be severely degraded with high-dimension data because there is little difference between the nearest and furthest neighbour.\\nAlso, one of the suggestions in order to improve the algorithm is to implement dimensionality reduction techniques like PCA, prior to appplying k-NN and help make the distance metric more meaningful.\")\n\n###############################################################################\n\n\"\"\" 2. Peter is a very predictable man. When he uses his tablet, all he does is watch movies. He always watches until his battery dies. He is also a very meticulous man. He has kept logs of every time he has charged his tablet, which includes how long he charged his tablet for and how long he was able to watch movies for afterwards. Now, Peter wants to use this log to predict how long he will be able to watch movies for when he starts so that he can plan his activities after watching his movies accordingly.\nYou will be able to access Peter’s tablet charging log by reading from the file “TabletTrainingdata.txt”. The training data file consists of 100 lines, each with 2 comma-separated numbers. The first number denotes the amount of time the tablet was charged and the second denotes the amount of time the battery lasted.\nRead an input (test case) from the console (stdin) representing the amount of time the tablet was charged and output to the console the amount of time you predict his battery will last.\n\n #example to read test case\n timeCharged = float(input().strip())\n \n #example to output\n print(prediction)\"\"\"\n\n#Regression Model\n#USING OUR OWN IMPLEMENTATION OF LINEAR REGRESSION: Method learned in class\ndef polyRegression(data1D, yy, testData, degree):\n xdata = [data1D**dd for dd in range (degree+1)]\n xdata = np.concatenate(xdata, axis=1)\n \n ww = np.linalg.inv(np.dot(xdata.transpose(),xdata))\n ww = np.dot(ww, xdata.transpose())\n ww = np.dot(ww, yy) \n \n xdata = [testData**dd for dd in range (degree+1)]\n xdata = np.concatenate(xdata, axis=1)\n pred = np.dot(xdata, ww) \n return pred, ww\n \n \n \ndata = np.genfromtxt('TabletTrainingdata.txt', delimiter=',')\n#print (np.shape(data))\n#print (type(data))\n#print (data)\nprint(\"Insert charged time, in hours:\")\ntimeCharged = float(input().strip())\n#I used as input: 5.0\n\n#We have \"virtual feature = 1\"\ntestData = np.array([[1], [timeCharged]])\n\nprediction, model = polyRegression(data[:,[0]], data[:,[-1]], testData, 4)\n#print (np.shape(pred))\n#print (type(pred))\n#plt.plot(testData, pred);\n#plt.plot(data[:,[0]], data[:,[-1]], 'o')\n#print (model)\n\nprint(\"For \", float(timeCharged), \" hours of charging, the battery will last about \", float(prediction[1]), \" hours.\")\n\n#Another way of solving this\n#Depending on the degree of polynome we can make a simple for cycle to use the weights and to multiply by our input:\n#SUM(weight(i)+input**(i))\n#print(model)\npred = 0\nprint(\"Insert charged time, in hours:\")\ntimeCharged = float(input().strip())\n\n#We iterate through all the weights of the model\nfor i in range(int(model.shape[0])):\n pred += model[i]*(timeCharged**i)\n\n#Print prediction\nprint(\"For \", timeCharged, \" hours of charging, the battery will last about \", float(pred), \" hours.\")\n\n#USING SKLEARN\nprint (\"USING sklearn\")\n\ndata = np.genfromtxt('TabletTrainingdata.txt', delimiter=',')\n#print (np.shape(data))\n#print (type(data))\n#print (data)\n\nprint(\"Insert charged time, in hours:\")\ntimeCharged = float(input().strip())\n#I used as input: 5.0\n\n#We have \"virtual feature = 1\"\ntestData = np.array([[1], [timeCharged]])\n\nmodel = make_pipeline(PolynomialFeatures(4), LinearRegression())\nmodel = model.fit(data[:,[0]], data[:,-1])\n\nprediction = model.predict(testData)\n#print (np.shape(pred))\n#print (type(pred))\n#plt.plot(testData, pred);\n#plt.plot(data[:,[0]], data[:,[-1]], 'o')\n#print (model)\n\nprint(\"For \", float(timeCharged), \" hours of charging, the battery will last about \", float(prediction[1]), \" hours.\")"
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 32,
"blob_id": "81cf8cf58da1c64f393cdbea2c8280c6a9b05e96",
"content_id": "46291482108a4ab5c9518b65170d3daa0a4f48f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "# PDEEC0049-Machine-Learning-2018-19\nMachine Learning Assignments\n"
},
{
"alpha_fraction": 0.6909090876579285,
"alphanum_fraction": 0.7028571367263794,
"avg_line_length": 37.28571319580078,
"blob_id": "236e33d10a803b014fe423ce421201613df52ce7",
"content_id": "3cfe8f14b9a52c32cad6b1e79843aa00eb60734f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1925,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 49,
"path": "/Classes/kindOfSolutions/myProject03.trainTest - auto kfold.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.qda import QDA\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.svm import SVC\r\nfrom sklearn.cross_validation import train_test_split\r\nfrom sklearn.cross_validation import KFold\r\n\r\n#data = np.genfromtxt('heightWeightData.txt', delimiter=',')\r\ndata = np.genfromtxt('testData.txt', delimiter=';')\r\nNsamples = np.shape(data)[0]\r\nfeatures = data[:,0:2]\r\nlabels = data[:,-1:]\r\nK = np.unique(labels).size\r\n\r\nplt.clf() \r\nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\r\nfor cls in range(K):\r\n idx = (labels == cls+1)\r\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\r\n \r\nprint('Nearest Neighbour with train test split')\r\ntrainFeatures, testFeatures, trainLabels, testLabels = train_test_split(features, labels, test_size=0.4, random_state=42)\r\nmodel = KNeighborsClassifier(n_neighbors=5, algorithm='brute')\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Nearest Neighbour with 10 fold cross validation')\r\nkf = KFold(Nsamples, n_folds=10)\r\nall_pred, all_y = [], []\r\nfor train_index, test_index in kf:\r\n X_train, X_test = features[train_index], features[test_index]\r\n y_train, y_test = labels[train_index], labels[test_index]\r\n model = KNeighborsClassifier(n_neighbors=5, algorithm='brute')\r\n y_pred = model.fit(X_train, y_train[:,0]).predict(X_test)\r\n y_pred = y_pred[:,np.newaxis]\r\n all_pred.append(y_pred)\r\n all_y.append(y_test)\r\nall_pred=np.vstack(all_pred) \r\nall_y=np.vstack(all_y) \r\naux = (all_pred!=all_y)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/all_y.size\r\nprint (misclassificationRate)\r\n"
},
{
"alpha_fraction": 0.6945366859436035,
"alphanum_fraction": 0.7129489779472351,
"avg_line_length": 38.87654495239258,
"blob_id": "43f2a5905bfc2b42349b8c7c5191153f008765e2",
"content_id": "c0056c4be2adba7132c6ffdccbf0ccfe6e5f3610",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3313,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 81,
"path": "/Classes/kindOfSolutions/myProject02.trainTest - ParamOpt.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.qda import QDA\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.svm import SVC\r\n\r\n#data = np.genfromtxt('heightWeightData.txt', delimiter=',')\r\ndata = np.genfromtxt('testData.txt', delimiter=';')\r\nNsamples = np.shape(data)[0]\r\nfeatures = data[:,0:2]\r\nlabels = data[:,-1:]\r\ntrainFeatures=features[:round(0.6*Nsamples),:] \r\ntrainLabels=labels[:round(0.6*Nsamples),:] \r\ntestFeatures=features[round(0.6*Nsamples):,:] \r\ntestLabels=labels[round(0.6*Nsamples):,:] \r\nprint(np.shape(trainFeatures), np.shape(testFeatures), np.shape(trainLabels), np.shape(testLabels))\r\n\r\nK = np.unique(labels).size\r\n\r\nplt.clf() \r\nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\r\nfor cls in range(K):\r\n idx = (labels == cls+1)\r\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\r\n \r\nprint('Discriminant analysis')\r\nmodel = QDA()\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Logistic Regression')\r\nmodel = LogisticRegression(multi_class = 'multinomial', solver='newton-cg', C=100)\r\n#create extended features\r\nxtrainFeatures = np.concatenate((trainFeatures, trainFeatures[:,0:1]*trainFeatures[:,1:2]), 1)\r\nxtestFeatures = np.concatenate((testFeatures, testFeatures[:,0:1]*testFeatures[:,1:2]), 1)\r\ny_pred = model.fit(xtrainFeatures, trainLabels[:,0]).predict(xtestFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Nearest Neighbour with param opt')\r\nNTrain = np.shape(trainFeatures)[0]\r\nsubtrainFeatures=trainFeatures[:round(0.6*NTrain),:] \r\nsubtrainLabels=trainLabels[:round(0.6*NTrain),:] \r\nvalFeatures = trainFeatures[round(0.6*NTrain):,:] \r\nvalLabels = trainLabels[round(0.6*NTrain):,:] \r\nres = []\r\nfor kk in range(30):\r\n model = KNeighborsClassifier(n_neighbors=kk+1, algorithm='brute')\r\n y_pred = model.fit(subtrainFeatures, subtrainLabels[:,0]).predict(valFeatures)\r\n y_pred = y_pred[:,np.newaxis]\r\n aux = (y_pred!=valLabels)\r\n aux = np.sum(aux.astype(float), 0)\r\n misclassificationRate = aux/valLabels.size\r\n res.append((misclassificationRate, kk+1))\r\nmer,best_k = min(res, key=lambda item: item[0])\r\nprint ('best param', mer, best_k)\r\nmodel = KNeighborsClassifier(n_neighbors=best_k, algorithm='brute')\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Support Vector Machine with C param optimization')\r\n#TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO TODO \r\nmodel = SVC(kernel = 'poly', degree=2, coef0=1.0, C=100)\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\n"
},
{
"alpha_fraction": 0.6503311395645142,
"alphanum_fraction": 0.6728476881980896,
"avg_line_length": 28.038461685180664,
"blob_id": "1e0872a37b95a64ada879dcaa65aedb5deeb5de9",
"content_id": "c22b0557a87798a04a4a582a77af80534e9c347d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1510,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 52,
"path": "/Assignments/regression.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\n#USING OUR OWN IMPLEMENTATION OF LINEAR REGRESSION\ndef polyRegression(data1D, yy, testData, degree):\n xdata = [data1D**dd for dd in range (degree+1)]\n xdata = np.concatenate(xdata, axis=1)\n \n ww = np.linalg.inv(np.dot(xdata.transpose(),xdata))\n ww = np.dot(ww, xdata.transpose())\n ww = np.dot(ww, yy) \n \n xdata = [testData**dd for dd in range (degree+1)]\n xdata = np.concatenate(xdata, axis=1)\n pred = np.dot(xdata, ww) \n return pred, ww\n \n \n \ndata = np.genfromtxt('data_bishop.txt', delimiter=' ')\nprint (np.shape(data))\nprint (type(data))\nprint (data)\ntestData = np.linspace(0, 1, 500).reshape(500,1)\npred, model = polyRegression(data[:,[0]], data[:,[-1]], testData, 3)\nprint (np.shape(pred))\nprint (type(pred))\nplt.plot(testData, pred);\nplt.plot(data[:,[0]], data[:,[-1]], 'o')\nprint (model)\n\n\n#USING SKLEARN\nprint (\"USING sklearn\")\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.pipeline import make_pipeline\n\ndata = np.genfromtxt('data_bishop.txt', delimiter=' ')\nprint (np.shape(data))\nprint (type(data))\nprint (data)\ntestData = np.linspace(0, 1, 500).reshape(500,1)\nmodel = make_pipeline(PolynomialFeatures(9), LinearRegression())\nmodel = model.fit(data[:,[0]], data[:,-1])\npred = model.predict(testData)\nprint (np.shape(pred))\nprint (type(pred))\n\nplt.plot(testData, pred);\nplt.plot(data[:,[0]], data[:,[-1]], 'o')\nprint (model)\n"
},
{
"alpha_fraction": 0.6819843053817749,
"alphanum_fraction": 0.6986945271492004,
"avg_line_length": 31.561403274536133,
"blob_id": "e3740d2a5c0d95cec8c8c1ea438e7b9f493c80b9",
"content_id": "59ae32752a066259bd050b7ca3796bfed6413f89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1915,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 57,
"path": "/Assignments/201819_MachineLearning_HW04/myProject.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom sklearn.qda import QDA\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.svm import SVC\r\n\r\ndata = np.genfromtxt('testData.txt', delimiter=';')\r\nfeatures = data[:,0:2]\r\nlabels = data[:,-1:]\r\n\r\nK = np.unique(labels).size\r\n\r\nplt.clf() \r\nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\r\nfor cls in range(K):\r\n idx = (labels == cls+1)\r\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\r\n \r\nprint('Discriminant analysis')\r\nmodel = QDA()\r\ny_pred = model.fit(features, labels[:,0]).predict(features)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=labels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/labels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Logistic Regression')\r\nmodel = LogisticRegression(multi_class = 'multinomial', solver='newton-cg', C=100)\r\n#create extended features\r\nxfeatures = np.concatenate((features, features[:,0:1]*features[:,1:2]), 1)\r\ny_pred = model.fit(xfeatures, labels[:,0]).predict(xfeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=labels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/labels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Nearest Neighbour')\r\nmodel = KNeighborsClassifier(n_neighbors=1, algorithm='brute')\r\nmodel.fit(features, labels[:,0])\r\ny_pred = model.predict(features)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=labels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/labels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Support Vector Machine')\r\nmodel = SVC(kernel = 'poly', degree=2, coef0=1.0, C=100)\r\ny_pred = model.fit(features, labels[:,0]).predict(features)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=labels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/labels.size\r\nprint (misclassificationRate)\r\n\r\n"
},
{
"alpha_fraction": 0.7077696323394775,
"alphanum_fraction": 0.7255508303642273,
"avg_line_length": 37.769229888916016,
"blob_id": "d08510ffc24bf47213df8e2255d85aea4af6598a",
"content_id": "c53fb72071982f3636432961032fad9b8cdf6889",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2587,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 65,
"path": "/Classes/kindOfSolutions/myProject01.trainTest.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport matplotlib.pyplot as plt\r\n#from sklearn.qda import QDA\r\nfrom sklearn.discriminant_analysis import QuadraticDiscriminantAnalysis\r\nfrom sklearn.neighbors import KNeighborsClassifier\r\nfrom sklearn.linear_model import LogisticRegression\r\nfrom sklearn.svm import SVC\r\n\r\n#data = np.genfromtxt('heightWeightData.txt', delimiter=',')\r\ndata = np.genfromtxt('testData.txt', delimiter=';')\r\nNsamples = np.shape(data)[0]\r\nfeatures = data[:,0:2]\r\nlabels = data[:,-1:]\r\ntrainFeatures=features[:round(0.6*Nsamples),:] \r\ntrainLabels=labels[:round(0.6*Nsamples),:] \r\ntestFeatures=features[round(0.6*Nsamples):,:] \r\ntestLabels=labels[round(0.6*Nsamples):,:] \r\nprint(np.shape(trainFeatures), np.shape(testFeatures), np.shape(trainLabels), np.shape(testLabels))\r\n\r\nK = np.unique(labels).size\r\n\r\nplt.clf() \r\nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\r\nfor cls in range(K):\r\n idx = (labels == cls+1)\r\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\r\n \r\nprint('Discriminant analysis')\r\nmodel = QuadraticDiscriminantAnalysis()\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Logistic Regression')\r\nmodel = LogisticRegression(multi_class = 'multinomial', solver='newton-cg', C=100)\r\n#create extended features\r\nxtrainFeatures = np.concatenate((trainFeatures, trainFeatures[:,0:1]*trainFeatures[:,1:2]), 1)\r\nxtestFeatures = np.concatenate((testFeatures, testFeatures[:,0:1]*testFeatures[:,1:2]), 1)\r\ny_pred = model.fit(xtrainFeatures, trainLabels[:,0]).predict(xtestFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Nearest Neighbour')\r\nmodel = KNeighborsClassifier(n_neighbors=5, algorithm='brute')\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\nprint('Support Vector Machine')\r\nmodel = SVC(kernel = 'poly', degree=2, coef0=1.0, C=100)\r\ny_pred = model.fit(trainFeatures, trainLabels[:,0]).predict(testFeatures)\r\ny_pred = y_pred[:,np.newaxis]\r\naux = (y_pred!=testLabels)\r\naux = np.sum(aux.astype(float), 0)\r\nmisclassificationRate = aux/testLabels.size\r\nprint (misclassificationRate)\r\n\r\n"
},
{
"alpha_fraction": 0.6700000166893005,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 22,
"blob_id": "095f8473d6d5e04d6f108820b5567531de937251",
"content_id": "2eed3fb5e4243ecebe225b7b13d95a5e44581ebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 13,
"path": "/Classes/LogRegCode/testLogReg.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\n#import matplotlib.pyplot as plt\nfrom logReg import logRegF\n \ndata = np.genfromtxt('heightWeightData.txt', delimiter=',')\nprint (np.shape(data))\nxx = data[:,1:]\nprint (np.shape(xx))\nyy = data[:,[0]]-1\nprint (np.shape(yy))\nww = logRegF(xx, yy)\nprint (np.shape(data))\nprint (ww)\n\n"
},
{
"alpha_fraction": 0.6900943517684937,
"alphanum_fraction": 0.7117924690246582,
"avg_line_length": 35.517242431640625,
"blob_id": "2bf421f2a05c47b863eea6a5fecf10a80641ee01",
"content_id": "5f881e58fa47141099a69767e73981a1cf1eb47d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2124,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 58,
"path": "/Assignments/201819_MachineLearning_HW04/HW4_Exc1_TiagoGoncalves.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# 1. Modify the code (script myProject.m / myProject.py) provided in lecture 6. For the SVM model and splitting the given data in suitable subsets:\n# \n# -make sure the kernel is set to RBF.\n# \n# -simultaneously optimize the gamma in the set {0.5, 1, 2} and the C parameter in the set {1/4, 1/2, 1, 2, 4, 8}\n# \n# \n# a. What’s the selected optimal set of parameters {gamma, C}?\n# \n# b. What’s the estimated performance for the chosen parameterization?\n# \n# \n# Provide explicitly the results obtained and the Matlab/Python code supporting your answers.\n\n# In[24]:\n\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn.svm import SVC\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.model_selection import train_test_split\n\ndata = np.genfromtxt('testData.txt', delimiter=';')\nfeatures = data[:,0:2]\nlabels = data[:,-1:].ravel()\n\nK = np.unique(labels).size\n\nplt.clf() \nlineStyle= ['ob', '*g', '+c', 'xr', '>y']\nfor cls in range(K):\n idx = (labels == cls+1)\n plt.plot(features[np.nonzero(idx)[0],0], features[np.nonzero(idx)[0],1], lineStyle[cls])\n \n#Divide in Train and Test Set: GridSearch already performs cross-validations with our train data\nX_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.10, random_state=42)\n\nprint('Support Vector Machine')\n#Parameter to be tested\nparameters = {'kernel':['rbf'], 'gamma':[0.5, 1, 2], 'C':[0.25, 0.5, 1, 2, 4, 8]}\nsvc = SVC()\n#Cross validation folds = 3, classifier is a Support Vector Machine\n#GridSearch will perform a set of for cycles to evaluate the best parameters\nclf = GridSearchCV(svc, parameters,cv=3)\nclf.fit(X_train, y_train)\nprint(\"The selected optimal set of parameters {C, gamma} was: \", clf.best_params_)\n#print(\"Cross Validation results obtained: \", clf.cv_results_)\nprint(\"The estimated performance for the chosen parameterization was: \", clf.best_score_)\n\n#Test on Test Set\ny_pred = clf.predict(X_test)\naux = (y_pred!=y_test)\naux = np.sum(aux.astype(float), 0)\nmisclassificationRate = aux/labels.size\nprint (\"Mislassification Rate, on the test set was: \", misclassificationRate)\n\n"
},
{
"alpha_fraction": 0.4827144742012024,
"alphanum_fraction": 0.601792573928833,
"avg_line_length": 29.31999969482422,
"blob_id": "8a0b38c49c99ae30e428b6dad5df148ec230fb5c",
"content_id": "b71b912ea0e58dacdb52ced360efb6398958e38b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 25,
"path": "/Assignments/201819_MachineLearning_HW05/hmmTest.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\n\r\n#xx = [int(c) for c in '166562663611111122']\r\nxx = [0.7, 0.7, 0.1, 0.2, 0.3, 0.6, 0.2, 0.3, (-0.1), 0.2]\r\nxx = np.array(xx)[:,None]\r\nxx = xx-1 # index starts at 0\r\nprint(xx)\r\n\r\nAA = np.array([[0.95, 0.05], [0.05, 0.95]]) #transition matrix\r\npi0 = np.array([0.5, 0.5])[:,None] #initial probs\r\nPx = np.array([[1/6, 1/6, 1/6, 1/6, 1/6, 1/6], [0.1, 0.1, 0.1, 0.1, 0.1, 0.5]]) # emission probs\r\nT = np.size(xx)\r\n\r\nK = 2 # number of states\r\n\r\n# forward method - slide 31\r\nalpha=pi0*Px[:,xx[0]]\r\nallAlpha=alpha; # only needed for slide 40\r\nfor t in range(1,T):\r\n alpha=Px[:,xx[t]]*np.dot(AA.T,alpha)\r\n allAlpha = np.concatenate((allAlpha,alpha),1) # only needed for slide 40\r\n\r\nprint (allAlpha)\r\nSequenceProbability=np.sum(alpha,0)\r\nprint (SequenceProbability)"
},
{
"alpha_fraction": 0.5980252027511597,
"alphanum_fraction": 0.6363050937652588,
"avg_line_length": 29.781938552856445,
"blob_id": "a9e47ae2dd1354eb574e539da8f035855e46cdb1",
"content_id": "ec3001488f63da7d5523932b654f29ff1d3b9b3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14020,
"license_type": "no_license",
"max_line_length": 293,
"num_lines": 454,
"path": "/Assignments/201819_MachineLearning_HW03/HW3_TiagoGoncalves.py",
"repo_name": "Tatianalarissa/PDEEC0049-Machine-Learning-2018-19",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# 1. Load the height/weight data from the file heightWeightData.txt. The first column is the class label (1=male, 2=female), the second column is height, the third weight. Start by replacing the weight column by the product of height and weight.\n# \n# For the Fisher’s linear discriminant analysis as discussed in the class, send the python/matlab code and answers for the following questions:\n# \n# a. What’s the SB matrix?\n# \n# b. What’s the SW matrix?\n# \n# c. What’s the optimal 1d projection direction?\n# \n# d. Project the data in the optimal 1d projection direction. Set the decision threshold as the middle point between the \n# projected means. What’s the misclassification error rate?\n# \n# e. What’s your height and weight? What’s the model prediction for your case (male/female)?\n\n# In[93]:\n\n\n#Imports\nimport numpy as np\nimport matplotlib.pyplot as plt\nnp.seterr(divide='ignore', invalid='ignore')\n\n#Load Data\ndata = np.genfromtxt(\"heightWeightData.txt\", delimiter=\",\")\n\n#Weight is 3rd Column\nnp.set_printoptions(suppress=True)\nnew_data = np.zeros(data.shape)\nfor i in range(int(new_data.shape[0])):\n new_data[i, 0] = data[i, 0]\n new_data[i, 1] = data[i, 1]\n new_data[i, 2] = np.multiply(data[i, 1], data[i, 2])\n\n\n# In[94]:\n\n\n#Implementing Fisher's Linear Discriminant Analysis\n#Let's group data first\n#Count males (=1) and females (=2)\nnr_males = 0\nnr_females = 0\nfor i in range(int(new_data.shape[0])):\n if new_data[i, 0] == 1:\n nr_males+=1\n elif new_data[i, 0] == 2:\n nr_females+=1\n#print(nr_males, nr_females)\n#Concatenate Class Sizes\nclass_sizes = np.array([nr_males, nr_females])\n\n#Assign Classes\nmales = np.zeros([nr_males, new_data.shape[1]])\nfemales = np.zeros([nr_females, new_data.shape[1]])\nm_index = 0\nf_index = 0\nfor index in range(int(new_data.shape[0])):\n if new_data[index, 0] == 1:\n males[m_index] = new_data[index]\n m_index+=1\n elif new_data[index, 0] == 2:\n females[f_index] = new_data[index]\n f_index+=1\n\n#Calculate means vector for each class\n#Drop Label Column\nf_males = males[:, 1:]\nf_females = females[:, 1:]\n#Calculate mean vector for each class\nmean_males = np.mean(a=f_males, axis=0)\nmean_females = np.mean(a=f_females, axis=0)\n\nprint(\"Mean Vector for Males Class: \\n\", mean_males,\"\\nMean Vector for Females Class: \\n\", mean_females)\n\n\n# a. What’s the SB matrix?\n\n# In[95]:\n\n\n#Calculate Overall Mean\noverall_mean = np.mean(new_data[:, 1:], axis=0)\n#print(\"Overall mean vector is: \", overall_mean)\n\n#Let's Compute Between Class Scatter Matrix S_B\n\"According to the slides: S_B = (m2-m1)(m2-m1).T\"\nS_B = np.multiply((mean_females-mean_males), (mean_females-mean_males).T)\nprint(\"S_B Matrix is: \", S_B)\n\n\n# b. What’s the SW matrix?\n\n# In[96]:\n\n\n#Let's Compute Within Class Scatter Matrix S_W\n#According to Slides\n#Males Class\nscatter_male = sum(np.matmul((f_males-mean_males).T, ((f_males-mean_males).T).T))\nscatter_female = sum(np.matmul((f_females-mean_females).T, ((f_females-mean_females).T).T))\nS_W = scatter_male+scatter_female\nprint(\"S_W Matrix is: \", S_W)\n\n\n# c. What’s the optimal 1d projection direction?\n\n# In[97]:\n\n\n#Optimal Projection or Matrix W\nW = (1/S_W)*(mean_females-mean_males)\nprint(\"Optimal 1D Projection Direction is: \", W)\n\n\n# d. Project the data in the optimal 1d projection direction. Set the decision threshold as the middle point between the \n# projected means. What’s the misclassification error rate?\n\n# In[98]:\n\n\n#Calculate Threshold\ntot = 0\nclass_means = np.array([mean_males, mean_females])\nfor mean in class_means:\n tot += np.dot(W.T, mean)\n #print(tot)\nw0 = 0.5 * tot\nprint(\"Calculated threshold is: \", w0)\n\n\n# In[99]:\n\n\n#Calculate Error\n#For each input project the point\nfeatures = (new_data[:, 1:]).T\nlabels = new_data[:,0]\nprojected = np.dot(W.T, np.array(features))\n#projected\n\n\n# In[100]:\n\n\n#Assign Predictions\npredictions = []\nfor item in projected:\n if item >= w0:\n predictions.append(2)\n else:\n predictions.append(1)\n#predictions\n\n\n# In[101]:\n\n\n#Check Classification\nerrors = (labels != predictions)\nn_errors = sum(errors)\n\nerror_rate = (n_errors/len(predictions) * 100)\nprint(\"Error Rate is: \", error_rate, \"%\")\n\n\n# e. What’s your height and weight? What’s the model prediction for your case (male/female)?\n\n# In[102]:\n\n\n#My case\nmy_height = 164\nmy_weight = 65\nmy_features = np.array([my_height, my_weight*my_height])\nmy_ground_truth = \"Male\"\n\n#My Prediction\nmy_projection = np.dot(W.T, my_features)\nif my_projection >= w0:\n my_pred = \"Female\"\nelse:\n my_pred = \"Male\"\n\nprint(\"In my case I was predicted as: \", my_pred, \" which is \", my_ground_truth==my_pred)\n\n\n# In[103]:\n\n\n#Let's use Sklearn to see if our solution is correct\n#Using sklearn\nfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis\nclf = LinearDiscriminantAnalysis()\nclf.fit(new_data[:, 1:], labels)\nLinearDiscriminantAnalysis(n_components=None, priors=None, shrinkage=None,\n solver='eigen', store_covariance=False, tol=0.0001)\nprint(clf.get_params())\npredictions = clf.predict(new_data[:, 1:])\nprint(predictions)\nerrors = sum(labels!=predictions)\nerror_rate = (n_errors/len(predictions) * 100)\nprint(\"Error Rate is: \", error_rate, \"%\")\nprint(\"\\nAs can be seen, our solution is right!\")\n\n\n# 2. Consider the Logistic Regression as discussed in the class. Assume now that the cost of erring an observation from class 1 is cost1 and the cost of erring observations from class 0 is cost0. How would you modify the goal function, gradient and hessian matrix (slides 11 and 12 in week 5)?\n# \n# Change the code provided (or developed by you) in the class to receive as input the vector of costs. Test your code with the following script:\n# \n# trainC1 = mvnrnd([21 21], [1 0; 0 1], 1000);\n# \n# trainC0 = mvnrnd([23 23], [1 0; 0 1], 20);\n# \n# testC1 = mvnrnd([21 21], [1 0; 0 1], 1000);\n# \n# testC0 = mvnrnd([23 23], [1 0; 0 1], 1000);\n# \n# NA = size(trainC1,1);\n# \n# NB = size(trainC0,1);\n# \n# traindata = [trainC1 ones(NA,1); trainC2 zeros(NB,1)]; %add class label in the last column\n# \n# weights=logReg(traindata(:,1:end-1),traindata(:,end),[NB NA])\n# \n# testC1 = [ones(size(testC1,1),1) testC1]; %add virtual feature for offset\n# \n# testC0 = [ones(size(testC0,1),1) testC0]; %add virtual feature for offset\n# \n# %FINISH the script to compute the recall, precision and F1 score in the test data\n# \n# In this script the cost of erring in C1 is proportional to the elements in C0. Compute the precision, recall and F1 in the test data. Note: if you are unable to modify to account for costs, solve without costs.\n\n# In[104]:\n\n\n#Let's implement Logistic Regression according to the slides\n#First define sigmoid function that will give us our hipothesis\ndef sigmoid(z):\n return 1 / (1 + np.exp(-z))\n\n#Define the log_likelihood\ndef log_likelihood(features,weights,labels):\n z = np.dot(features.T, weights)\n sigmoid_probs = sigmoid(z)\n #Cost 1 is proportional to the elements in C0\n cost1 = len(labels[labels==0])\n l_likell = np.sum((-np.log(sigmoid_probs)*cost1*labels) + ((-np.log(1-sigmoid_probs))*(1-labels)))\n return l_likell\n\n#Functions to predict probabilities and classes\ndef predict_proba(features, weights):\n z = np.dot(features, weights)\n proba = sigmoid(z)\n return proba\n\ndef predictions(features, weights, threshold):\n probs = predict_proba(features, weights)\n return probs >= threshold\n\n#Define Gradient Function to be used in training phase; gradient descent!; Hessian was not taken into account\ndef gradient(features, labels, weights):\n z = np.dot(features, weights)\n sigmoid_probs = sigmoid(z)\n return np.dot(np.transpose(features), (sigmoid_probs - labels))\n\n\n# In[106]:\n\n\ndef logReg(features, labels, learning_rate): \n # Initialize log_likelihood & parameters \n weights = np.zeros((features.shape[1], 1)) \n l = log_likelihood(features, labels, weights) \n # Convergence Conditions \n max_iterations = 1000000 \n for i in range(max_iterations): \n g = gradient(features, labels, weights) \n weights = weights - learning_rate*g \n # Update the log-likelihood at each iteration \n l_new = log_likelihood(features, labels, weights)\n l = l_new \n return weights \n\n\n# In[107]:\n\n\n#Read Data\ntrainC1 = np.random.multivariate_normal([21, 21], [[1, 0], [0, 1]], 1000);\ntrainC0 = np.random.multivariate_normal([23, 23], [[1, 0], [0, 1]], 20);\ntestC1 = np.random.multivariate_normal([21 , 21], [[1, 0], [0, 1]], 1000);\ntestC0 = np.random.multivariate_normal([23, 23], [[1, 0], [0, 1]], 1000);\n\n#Build Train Data and add class label in the last column\nNA = int(trainC1.shape[0]);\nNB = int(trainC0.shape[0]);\nlabels_C1 = np.ones([NA, 1])\noffset_C1 = np.ones((NA, 1))\ntrainC1 = np.concatenate((offset_C1, trainC1, labels_C1), axis=1)\noffset_C0 = np.ones((NB, 1))\nlabels_C0 = np.zeros([NB, 1])\ntrainC0 = np.concatenate((offset_C0,trainC0, labels_C0), axis=1)\ntraindata = np.concatenate((trainC1, trainC0), axis=0)\n\n#Compute Weights\nweights=logReg(traindata[:, :3], traindata[:, 3:], learning_rate=0.001)\nweights\n\n\n# In[108]:\n\n\n#Test Data \n#add virtual feature for offset\nC1_virtualf = np.ones((int(testC1.shape[0]), 1))\ntestC1 = np.concatenate((C1_virtualf , testC1), axis=1);\nC1test_labels = np.ones((int(testC1.shape[0]), 1))\ntestC1 = np.concatenate((testC1, C1test_labels), axis=1)\n#add virtual feature for offset\nC0_virtualf = np.ones((int(testC0.shape[0]), 1))\ntestC0 = np.concatenate((C0_virtualf, testC0), axis=1);\nC0test_labels = np.zeros((int(testC0.shape[0]), 1))\ntestC0 = np.concatenate((testC0, C0test_labels), axis=1)\ntestdata = np.concatenate((testC1, testC0), axis=0)\n\n#FINISH the script to compute the recall, precision and F1 score in the test data\n\n\n# In[109]:\n\n\nfrom sklearn.metrics import confusion_matrix\n#Predict on Test Data with the obtained weights\nlabel_pred = predictions(testdata[:, :3], weights, 0.5)\nlabel_pred = label_pred.astype(int)\nlabels = testdata[:, 3:]\n\ntn, fp, fn, tp = confusion_matrix(labels, label_pred).ravel()\nprecision=tp/(tp+fp)\nrecall=tp/(tp+fn)\nf1=2*((precision*recall)/(precision+recall))\nprint('Precision: ',precision)\nprint('Recall: ', recall)\nprint('F1: ',f1)\n\n\n# In[110]:\n\n\n#Let's check with sklearn\nfrom sklearn.linear_model import LogisticRegression\nclf = LogisticRegression(random_state=0, solver='newton-cg', multi_class='ovr').fit(traindata[:, :3], traindata[:, 3:].ravel())\nlabel_pred = clf.predict(testdata[:, :3])\ntn, fp, fn, tp = confusion_matrix(testdata[:, 3:].ravel(), label_pred).ravel()\nprecision=tp/(tp+fp)\nrecall=tp/(tp+fn)\nf1=2*((precision*recall)/(precision+recall))\nprint('Precision: ',precision)\nprint('Recall: ', recall)\nprint('F1: ',f1)\n\n\n# 3. Several phenomena and concepts in real life applications are represented by\n# angular data or, as is referred in the literature, directional data. Assume the\n# directional variables are encoded as a periodic value in the range [0, 2π].\n# Assume a two-class (y0 and y1), one dimensional classification task over a directional\n# variable x, with equal a priori class probabilities.\n# \n# a) If the class-conditional densities are defined as p(x|y0)= e2cos(x-1)/(2 π 2.2796)\n# and p(x|y1)= e3cos(x+0.9)/(2 π 4.8808), what’s the decision at x=0?\n# \n# b) If the class-conditional densities are defined as p(x|y0)= e2cos(x-1)/(2 π 2.2796)\n# and p(x|y1)= e3cos(x-1)/(2 π 4.8808), for what values of x is the prediction equal\n# to y0?\n# \n# c) Assume the more generic class-conditional densities defined as\n# p(x|y0)= ek0cos(x- μ0)/(2 π I(k0)) and p(x|y1)= ek1cos(x-μ1)/(2 π I(k1)). In these\n# expressions, ki and μi are constants and I(ki) is a constant that depends on ki.\n# Show that the posterior probability p(y0|x) can be written as p(y0|x) =\n# 1/(1+ew0+ w1sin(x- ϴ) ), where w0, w1 and ϴ are parameters of the model (and\n# depend on ki , μi and I(ki) ).\n\n# In[111]:\n\n\n#Imports\nfrom math import exp, cos, pi\n\n#Create functions\n#p(x|y0)= e2cos(x-1)/(2 π 2.2796)\ndef p_x_y0(x):\n result = (exp(2*cos(x-1)))/(2*pi*2.2796)\n return result\n\n#p(x|y1)= e3cos(x+0.9)/(2 π 4.8808)\ndef p_x_y1(x):\n result = (exp(3*cos(x+0.9)))/(2*pi*4.8808)\n return result\n\n\n# In[112]:\n\n\n#a)\n#Compute functions at x=0\nx0_y0 = p_x_y0(0)\nx0_y1 = p_x_y1(0)\n#print(x0_y0, x0_y1)\n\n#Decision at x=0 is equal to argmax(x0_y0, x0_y1), since a priori probabilities are equal!\nif x0_y0 > x0_y1:\n decision = \"y0\"\nelse:\n decision = \"y1\"\n\nprint(\"At x=0, decision is: \", decision)\n\n\n# In[113]:\n\n\n#b\npoints = np.linspace(0, (2*pi), num=100)\n#New p(x|y1)= e3cos(x-1)/(2 π 4.8808) funtion\ndef new_p_x_y1(x): \n result = (exp(3*cos(x-1)))/(2*p*4.8808)\n return result\n\n#Compute values\nx_y0 = []\nfor i in points:\n x_y0.append(p_x_y0(i))\n\nx_y1 = []\nfor i in points:\n x_y1.append(p_x_y1(i))\n\nresults = []\nfor i in range(len(points)):\n if x_y0[i] > x_y1[i]:\n results.append(points[i])\n\n\nprint(\"The prediction of x is equal to y0 for the following points: \\n\")\nfor i in range(len(results)):\n print(results[i])\nprint(\"\\nTotal number of points is: \", len(results))\n\n\n# Tiago Filipe Sousa Gonçalves | MIB | 201607753\n"
}
] | 12 |
fancunjun/python
|
https://github.com/fancunjun/python
|
6549f370f04df04d96652a40794b1dcd47c13191
|
c9f1e1477b06a2c03ae85c93d1fa7d41f3ad00c1
|
50a19ae5256ca8bb1552847e03a6e8e4ef9ddc9f
|
refs/heads/master
| 2020-03-18T21:41:47.596826 | 2018-06-26T12:31:10 | 2018-06-26T12:31:10 | 135,296,351 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6438632011413574,
"alphanum_fraction": 0.6579476594924927,
"avg_line_length": 21.590909957885742,
"blob_id": "069b5df70ed47d14c4bccc0bb255b368c1a65207",
"content_id": "326d6816461afe45e22abe463d2b473675cd184b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 22,
"path": "/git/ex6.py",
"repo_name": "fancunjun/python",
"src_encoding": "UTF-8",
"text": "#--coding:utf-8--\n#%d处取的值是%10中的10\nx = \"There are %d types of people.\" %10\n#赋值\nbinary = \"binary\"\ndo_not = \"don't\"\ny = \"Those who know %s and those who %s.\" % (binary , do_not)\n#打印变量\nprint x \nprint y \n#打印字符串\nprint \"I said:%r\" %x\nprint \"I said:'%s'\" % y \nhilarious = False\njoke_evaluation = \"Isn't that joke so funny?! %r\"\n\nprint joke_evaluation % hilarious \n#拼接字符串\nw = \"This is the left side of ....\"\ne = \"a string with a right side.\"\nprint w + e \n#两个字符串相加是调用了python的apped()方法然后再调用转化成字符串方法,最后把结果返回\n"
},
{
"alpha_fraction": 0.49737533926963806,
"alphanum_fraction": 0.6272965669631958,
"avg_line_length": 19.052631378173828,
"blob_id": "6ab1070ca249acf940e017a4be55807de6e8c5c4",
"content_id": "7545a4c9af68e96247b4ac768b79510c9969d7d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 964,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 38,
"path": "/git/ex3.py",
"repo_name": "fancunjun/python",
"src_encoding": "UTF-8",
"text": "#--coding:utf-8--\nprint \"I will now count my chickens:\"\n#先计算除法,再计算加法\nprint \"Hens \",25 + 30 / 6 \n#计算乘法,取模运算,再计算减法\nprint \"Roosters\", 100 -25 * 3 % 4\n#输入打印信息\nprint \"Now I will count the eggs:\"\n#计算模运算,除法,其他从左到右计算\nprint 3+2 + 1 - 5 + 4 % 2 -1 / 4 + 6\n#输出打印信息\nprint \"Is it true that 3 + 2 < 5 - 7?\"\n#判断3+3是否小于5-7,返回布尔值\nprint 3 + 2 < 5 -7\n#计算3+2\nprint \"What is 3 + 2\",3 + 2\n#计算5-7\nprint \"What is 5 -7?\",5-7\n#输出打印信息\nprint \"Oh,that's why it's False.\"\n#输出打印信息\nprint \"How about some more.\"\n#判断5>-2为真为假\n\nprint \"Is it greater?\", 5 > -2 \n#判断5>=-2为真为假\n\nprint \"Is it greater or equal?\" , 5 >= -2\n#判断5<=2 为真为候\n\nprint \"Is it less or equal?\" ,5 <= -2\n\n#test03 count house value\n\nprint 10798 * 49 - 10798 * 49 * 0.25\n\n#floating point number\nprint 10798.34 * 49.45 - 10000.23 /20.45\n"
},
{
"alpha_fraction": 0.7127753496170044,
"alphanum_fraction": 0.7427312731742859,
"avg_line_length": 25.395349502563477,
"blob_id": "c5260dd1a56966b41a7b46bcb090448417a9f134",
"content_id": "554f8c177da5ecb8595973023cfd5f83ec79ca16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1451,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 43,
"path": "/git/ex4.py",
"repo_name": "fancunjun/python",
"src_encoding": "UTF-8",
"text": "#--coding:utf-8--\n#把100赋值给cars\ncars = 100\n#把4.0赋值给space_in_a_car\nspace_in_a_car = 4.0\n#把30赋值给drivers\ndrivers = 30 \n#把90赋值给passengers\npassengers = 90\n#把cars - drivers 的值赋值给car_not_driver\ncars_not_driver = cars - drivers \n#把drivers 的值赋值给cars_driven\ncars_driven = drivers\n#把car_driven * space_in_a_car的值赋值给carpool_capacity\ncarpool_capacity = cars_driven * space_in_a_car\n#把passengers / cars_driven的赋值给average_passengers_per_car\naverage_passengers_per_car = passengers / cars_driven\n\n#打印输出内容\nprint \"There are\",cars, \"cars available.\"\nprint \"There are only\" ,drivers,\"drivers available.\"\nprint \"There will be\" , cars_not_driver, \"empty cars today.\"\nprint \"We can transport \",carpool_capacity ,\"people today.\"\nprint \"We have\" , passengers, \"to carpool today.\"\nprint \"We need to put about\", average_passengers_per_car, \"in each car\"\n\n\n#expent test \n#运行报错是因为在程序的11行定义的car_not_driver ,而我们在打印中拼写成了car_not_driven,所以报错没有定义\n\n#apace_in_a_car=4.0,如果赋值4,cars_driver * apace_in_a_car 就会是一个整数,赋值4.0,结果是一浮点数\n#浮点数:一种对于实数的近似值数值表现法,由一个有效数字(即尾数)加上幂数来表示,通常是乘以某个基数的整数次指数得到\n\n#test4\n#= equal _ underscore\n\n#test6\n\nx = 100\ny = 2\nj = 50\n\nprint x / y / j * y\n"
},
{
"alpha_fraction": 0.6394193768501282,
"alphanum_fraction": 0.6577540040016174,
"avg_line_length": 25.653060913085938,
"blob_id": "2ef92a437af92090a4bcb42b1477e89f0c09a7a7",
"content_id": "f19d076231afb884b5f88e0f099891edc652f121",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1309,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 49,
"path": "/git/ex5.py",
"repo_name": "fancunjun/python",
"src_encoding": "UTF-8",
"text": "#--coding:utf-8 --\nmy_name = 'Zed A. Shaw'\nmy_age = 35 # not a lie \nmy_height = 74 #inches\nmy_weight = 180 #lbs\nmy_eyes = 'Blue'\nmy_teeth = 'White'\nmy_hair = 'Brown'\n\nprint \"Lte's talk about %s.\" % my_name\nprint \"He's %d pounds heavy\" % my_weight\nprint \"He's %d inches tall.\" % my_height\nprint \"Actually that's not too heavy\"\nprint \"He's got %s eyes and %s hair.\" % (my_eyes,my_hair)\nprint \"His teeth are usually %s depending on the coffee.\" %my_teeth\n\n#this line is tricky,try to get it exactly right \nprint \"If I add %d ,%d,and %d I get %d.\" %(my_age,my_height,my_weight,my_age + my_height + my_weight)\n\nprint 'this is del \"my_\" '\nname = 'Zed A. Shaw'\nage = 35 # not a lie \nheight = 74 #inches\nweight = 180 #lbs\neyes = 'Blue'\nteeth = 'White'\nhair = 'Brown'\n\nprint \"Lte's talk about %s.\" % name\nprint \"He's %d pounds heavy\" % weight\nprint \"He's %d inches tall.\" % height\nprint \"Actually that's not too heavy\"\nprint \"He's got %s eyes and %s hair.\" % (eyes,hair)\nprint \"His teeth are usually %s depending on the coffee.\" % teeth\n\n#this line is tricky,try to get it exactly right \nprint \"If I add %d ,%d,and %d I get %d.\" %(age,height,weight,age + height + weight)\n\n# inches change cm and lbs change kilogram\n\nmid = 2.5\nmid1 = 0.45\ninches = 2\nlbs = 3\n\ncm = inches * mid\nkilogram = lbs * mid1\nprint kilogram\nprint cm\n\n\n\n"
}
] | 4 |
wangui-nganga/integers
|
https://github.com/wangui-nganga/integers
|
f8c6696075b26e830631f6a8274c14360da43484
|
f3a462f5c4435a060d6910071fd738e235b76d8c
|
c0b832dc8cc3711c6a28501350436e5ef87e44dd
|
refs/heads/master
| 2020-08-06T14:02:29.213842 | 2019-10-05T13:48:28 | 2019-10-05T13:48:28 | 213,000,862 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5222222208976746,
"alphanum_fraction": 0.5333333611488342,
"avg_line_length": 17,
"blob_id": "bd290095f77ea2f3be46bc0da86c2f920c624a58",
"content_id": "75e19a111c2a21e20f78094c958470fd5dae027c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 10,
"path": "/test01.py",
"repo_name": "wangui-nganga/integers",
"src_encoding": "UTF-8",
"text": "def maths():\n c= int(input('enter c:'))\n v= int (input('enter v:'))\n x=int(print('enter x:'))\n sum=c+v\n if sum >=50:\n print(\"true \")\n else:\n print (sum)\nprint(maths())\n"
}
] | 1 |
BWfight/zhihu_spider
|
https://github.com/BWfight/zhihu_spider
|
cc67202402be43b156db65a5390b1381d22ac9a4
|
380ef837d7227db656f87bfc48d4d3340434dbca
|
5fd1b7a6061f90951a3145e04ee555350750ba0e
|
refs/heads/master
| 2020-08-12T02:36:53.238193 | 2019-10-27T11:35:37 | 2019-10-27T11:35:37 | 214,672,439 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7426900863647461,
"alphanum_fraction": 0.7514619827270508,
"avg_line_length": 9.6875,
"blob_id": "2ffa030b70229e6e3c649ce97e45232052bd7145",
"content_id": "0a1a7c251b6953ed00ec3b3b1469e8adc2027941",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 540,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 32,
"path": "/README.md",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "# zhihu_spider\n\n\n\n1.\nspider_fig_of_question.py\n\n下载一个问题(或回答)下的图片。需要问题(或回答)的网址。参数:page url\n\n照片保存在 问题+作者+点赞数 的文件夹下\n\n\n\n2.\nspider_ans_of_q_save_excel.py\n\n爬取一个问题下的或回答。参数:question page。保存为excel文件\n\n结果:知乎提问.xlsx\n\n\n\n3.\nanalysis_wordcloud_bar.py\n\n分析爬取的excel文件。参数:excel_path\n\n结果:\n\n词云:title_content-word-cloud.html。\n\n柱状图:title_content-word-agree-bar.html\n"
},
{
"alpha_fraction": 0.5451244115829468,
"alphanum_fraction": 0.5661885142326355,
"avg_line_length": 32.41875076293945,
"blob_id": "d2aeffd386d8e5f8cab9f43ba5713380cbc37530",
"content_id": "a88ac2eae163736ae766f6cc8d4524564c2e899e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5963,
"license_type": "no_license",
"max_line_length": 540,
"num_lines": 160,
"path": "/spider_ans_by_keyword.py",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "import time\r\nimport random\r\nimport requests\r\nimport json\r\nimport jsonpath\r\nimport pandas as pd\r\nimport os\r\n\r\n'''\r\nauthor: BW\r\nvision: 1.0\r\n'''\r\n\r\nheaders={\r\n 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'\r\n }\r\n\r\n\r\ndef spider_by_keyword(keyword, page):\r\n \"\"\"\r\n 根据关键词,爬取搜索结果中的问题\r\n :param keyword: 关键字\r\n :param page: 分页\r\n :return: info_list\r\n \"\"\"\r\n url = 'https://www.zhihu.com/api/v4/search_v3?'\r\n params = {\r\n 't': 'general',\r\n 'q': keyword,\r\n 'correction': '1',\r\n 'offset': str((page)*20), \r\n 'limit': '20', \r\n 'lc_idx': str((page)*20),\r\n 'show_all_topics': '0',\r\n 'search_hash_id': '1105d34171faf880cf9fe08a08ca4319',\r\n 'vertical_info': '0,0,0,0,0,0,0,0,0,1'\r\n }\r\n response = requests.get(url, headers=headers, params=params)\r\n if response.status_code == 200:\r\n print('=====正在爬取第' + str(page+1) + '页=====') \r\n response_json = get_question_id(response.json()) \r\n return response_json\r\n else:\r\n print('=====错误!状态码为' + str(response.status_code) + '。=====')\r\n\r\n\r\ndef get_question_id(response_json):\r\n \"\"\"\r\n 获取回答信息\r\n :param response_json \r\n :return: info_list\r\n \"\"\"\r\n question_id_list = jsonpath.jsonpath(response_json, '$.data[*].object.question.id')\r\n question_name_list = jsonpath.jsonpath(response_json, '$.data[*].object.question.name')\r\n if question_id_list != [] and question_name_list != []:\r\n print('-----相关数据获取成功-----')\r\n return [question_id_list, question_name_list]\r\n else:\r\n print('-----未能获取相关数据-----')\r\n return []\r\n\r\n\r\ndef patch_spider_question_id(keyword, pages):\r\n \"\"\"\r\n 批量爬取\r\n :param keyword: 关键字\r\n :param pages: 共爬取页数\r\n :return: \r\n \"\"\"\r\n # 先清空之前的数据\r\n if os.path.exists(excel_path):\r\n os.remove(excel_path)\r\n # 开始爬取\r\n question_ids_list = []\r\n question_names_list =[]\r\n for page in range(0, pages): \r\n info_list = spider_by_keyword(keyword, page)\r\n time.sleep(random.randint(1, 3))\r\n if info_list != []:\r\n question_ids_list += info_list[0]\r\n question_names_list += info_list[1]\r\n return [question_ids_list, question_names_list]\r\n\r\n\r\ndef data_cleaning(question_ids_names_list):\r\n '''\r\n 清理数据\r\n 1、去除重复,\r\n 2、List 转化为 DataFrame\r\n :param question_ids_names_list = [question_ids_list, question_names_list]\r\n :return data DataFrame \r\n '''\r\n info_dict={\r\n \"id\": question_ids_names_list[0], \r\n \"name\": question_ids_names_list[1]\r\n }\r\n data = pd.DataFrame(info_dict)\r\n data = data.drop_duplicates() # 去重\r\n return data\r\n\r\n\r\ndef spider_ans_id(qus_id, qus_name, num, vote):\r\n '''\r\n 访问各个问题页,爬取高赞回答的id\r\n :param qus_id \r\n :param qus_name \r\n :param num \r\n :param vote \r\n :return ans_list\r\n '''\r\n url = 'https://www.zhihu.com/api/v4/questions/' + qus_id + '/answers?'\r\n print('爬取问题:“' + qus_name + '”的高赞回答')\r\n qvac_list = []\r\n for n in range(num): \r\n params = {\r\n 'include': 'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled,is_recognized,paid_info,paid_info_content;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics',\r\n 'limit': '5',\r\n 'offset': str(5*n),\r\n 'platform': 'desktop',\r\n 'sort_by': 'default'\r\n }\r\n res = requests.get(url, headers = headers, params=params)\r\n time.sleep(random.randint(1, 3))\r\n if res.status_code == 200:\r\n res_json = res.json()\r\n vote_list = jsonpath.jsonpath(res_json, '$.data[*].voteup_count') # 赞 \r\n author_list = jsonpath.jsonpath(res_json, '$.data[*].author.name') # 回答者\r\n content_list = jsonpath.jsonpath(res_json, '$.data[*].content') # 回答\r\n if type(vote_list) != bool: # 回答数不足5条,则 num==2 时,vote_list 是布尔型\r\n for i in range(len(vote_list)):\r\n if int(vote_list[i]) >= vote:\r\n qvac_list.append([qus_name, vote_list[i], author_list[i], content_list[i]])\r\n return qvac_list\r\n \r\n\r\ndef patch_spider_ans_id(data, number, vote):\r\n '''\r\n 批量爬取\r\n :param data DataFrame id name \r\n :param number 每个问题爬取前几条回答,取5的倍数,否则向下取整\r\n :param vote 最低赞数\r\n :return ans_list\r\n '''\r\n num = int(number)//5\r\n all_list = []\r\n for qus_id, qus_name in zip(data['id'], data['name']):\r\n qvac_list = spider_ans_id(qus_id, qus_name, num, vote)\r\n all_list += qvac_list\r\n data = pd.DataFrame(all_list) # 按行合并\r\n data.rename(columns={0:'question',1:'vote',2:'author',3:'answer'},inplace=True)\r\n data.to_excel(excel_path) \r\n\r\nif __name__ == '__main__':\r\n excel_path = '知乎情话.xlsx'\r\n keyword = '情话'\r\n pages = 10 # 爬取10页回答,至多200个问题\r\n df = data_cleaning(patch_spider_question_id(keyword, pages))\r\n number = 10 # 每个问题爬取前10的回答(万赞答案不多,估计前10条足矣)\r\n vote = 10000 # 只保存万赞以上回答\r\n patch_spider_ans_id(df, number, vote)\r\n"
},
{
"alpha_fraction": 0.5356013774871826,
"alphanum_fraction": 0.560136616230011,
"avg_line_length": 42.67231750488281,
"blob_id": "5af66764b7d3cdf961fba55094d364417469cfb4",
"content_id": "eba4f2248c3a08006d68a9e9f32f32bde4f25b08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8529,
"license_type": "no_license",
"max_line_length": 540,
"num_lines": 177,
"path": "/spider_fig_of_question.py",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "import time\r\nimport random\r\nimport re\r\nimport requests\r\nfrom lxml import etree\r\nimport json\r\nimport jsonpath\r\nimport os\r\n\r\n'''\r\nauthor: BWfight\r\nvision: 1.0\r\n'''\r\n\r\n\r\ndef spider_fig_by_url_in_ans(number):\r\n '''\r\n 提取回答页网址\r\n '''\r\n headers = {\r\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\"\r\n } \r\n url = 'https://www.zhihu.com/api/v4/questions/50426133/answers?' # 可更换网址 以 平常人可以漂亮到什么程度?为例\r\n for n in range(number): # 可以从0开始\r\n params = {\r\n 'include': 'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled,is_recognized,paid_info,paid_info_content;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics',\r\n 'limit': '5', # 一个json有5个回答\r\n 'offset': str(5*n), \r\n 'platform': 'desktop',\r\n 'sort_by': 'default',\r\n }\r\n response = requests.get(url, headers = headers, params=params)\r\n data = response.json()\r\n\r\n q_url_list = jsonpath.jsonpath(data, '$.data[*].question.url') \r\n a_url_list = jsonpath.jsonpath(data, '$.data[*].url') \r\n\r\n for q_url, a_url in zip(q_url_list, a_url_list):\r\n q_number = re.findall('\\d+', q_url)[1]\r\n a_number = re.findall('\\d+', a_url)[1]\r\n href = 'https://www.zhihu.com/question/' + q_number + '/answer/' + a_number\r\n \r\n spider_fig_in_one_ans(href)\r\n\r\n\r\ndef spider_fig_in_one_ans(url):\r\n '''\r\n 回答页下载图片\r\n '''\r\n headers = {\r\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\"\r\n } \r\n response = requests.get(url, headers = headers)\r\n html = etree.HTML(response.text) \r\n\r\n title_list = html.xpath('//*[@id=\"root\"]/div/main/div/meta[1]/@content') # 问题\r\n vote_list = html.xpath('//div[@class=\"AnswerItem-extraInfo\"]/span/button/text()') # 赞\r\n\r\n author_list = html.xpath('//div[@class=\"AuthorInfo-content\"]/div/span/div/div/a/text()') # 回答者\r\n if author_list == []:\r\n author = '匿名用户'\r\n else:\r\n author = author_list[0]\r\n \r\n figure_list = html.xpath('//div[@class=\"RichContent-inner\"]/span/figure/img/@data-original') # 图片\r\n if figure_list != []:\r\n coll_name = title_list[0] + author + vote_list[0]\r\n if os.path.exists('D:/' + coll_name) == False: # 若文件夹不存在\r\n os.mkdir('D:/' + coll_name) # 创建目录\r\n else:\r\n os.removedirs('D:/' + coll_name) # 需要以管理者身份运行\r\n os.mkdir('D:/' + coll_name) \r\n \r\n print('=====开始' + url + '的爬取=====')\r\n count = 1\r\n for figure in figure_list:\r\n print(\"正在抓取第\" + str(count) + \"张图片\")\r\n res = requests.get(figure, headers=headers)\r\n # time.sleep(random.randint(1, 2)) \r\n file_name = str(count) + '.jpg'\r\n try:\r\n with open('D:/' + coll_name + '/' + file_name, \"wb\") as f:\r\n f.write(res.content)\r\n except:\r\n print(\"文件名有误\")\r\n count += 1\r\n print('=====' + url + '完成=====')\r\n time.sleep(random.randint(1, 6))\r\n else:\r\n print('该答案无图片')\r\n\r\n\r\n\r\ndef spider_fig_in_quetion(number):\r\n '''\r\n 直接在问题页提取\r\n '''\r\n headers = {\r\n \"User-Agent\": \"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36\"\r\n } \r\n url = 'https://www.zhihu.com/api/v4/questions/34243513/answers?' # 可更换网址 以 你见过最漂亮的女生长什么样?为例\r\n for n in range(number): \r\n params = {\r\n 'include': 'data[*].is_normal,admin_closed_comment,reward_info,is_collapsed,annotation_action,annotation_detail,collapse_reason,is_sticky,collapsed_by,suggest_edit,comment_count,can_comment,content,editable_content,voteup_count,reshipment_settings,comment_permission,created_time,updated_time,review_info,relevant_info,question,excerpt,relationship.is_authorized,is_author,voting,is_thanked,is_nothelp,is_labeled,is_recognized,paid_info,paid_info_content;data[*].mark_infos[*].url;data[*].author.follower_count,badge[*].topics',\r\n 'limit': '5', \r\n 'offset': str(5*n), \r\n 'platform': 'desktop',\r\n 'sort_by': 'default',\r\n }\r\n response = requests.get(url, headers = headers, params=params)\r\n data = response.json()\r\n\r\n title_list = jsonpath.jsonpath(data, '$.data[*].question.title') # 问题\r\n vote_list = jsonpath.jsonpath(data, '$.data[*].voteup_count') # 赞 \r\n author_list = jsonpath.jsonpath(data, '$.data[*].author.name') # 回答者\r\n\r\n content_0 = jsonpath.jsonpath(data, '$.data[0].content')[0] # 只能爬全文内容\r\n content_1 = jsonpath.jsonpath(data, '$.data[1].content')[0]\r\n content_2 = jsonpath.jsonpath(data, '$.data[2].content')[0]\r\n content_3 = jsonpath.jsonpath(data, '$.data[3].content')[0]\r\n content_4 = jsonpath.jsonpath(data, '$.data[4].content')[0]\r\n\r\n pattern = re.compile('data-original=\"(https:.*?jpg)\"') # 非贪婪匹配,返回括号里url # 贪婪匹配出错\r\n fig_list_0 = pattern.findall(content_0) # 返回列表 \r\n figure_list_0 = take_even_index_element_in_list(fig_list_0) # 同一图片重复两遍,所以取偶数下标 \r\n fig_list_1 = pattern.findall(content_1) \r\n figure_list_1 = take_even_index_element_in_list(fig_list_1) \r\n fig_list_2 = pattern.findall(content_2) \r\n figure_list_2 = take_even_index_element_in_list(fig_list_2) \r\n fig_list_3 = pattern.findall(content_3) \r\n figure_list_3 = take_even_index_element_in_list(fig_list_3) \r\n fig_list_4 = pattern.findall(content_4)\r\n figure_list_4 = take_even_index_element_in_list(fig_list_4) \r\n figure_list_list = [figure_list_0, figure_list_1, figure_list_2, figure_list_3, figure_list_4]\r\n\r\n for title, vote, author, figure_list in zip(title_list, vote_list, author_list, figure_list_list):\r\n coll_name = title + author + str(vote) + \"赞\"\r\n if os.path.exists('D:/' + coll_name) == False: \r\n os.mkdir('D:/' + coll_name) # 创建目录\r\n else:\r\n os.remove('D:/' + coll_name) \r\n os.mkdir('D:/' + coll_name) \r\n \r\n print('=====开始' + title + author + '的爬取=====')\r\n count = 1\r\n for figure in figure_list:\r\n print(\"正在抓取第\" + str(count) + \"张图片\")\r\n res = requests.get(figure, headers=headers)\r\n file_name = str(count) + '.jpg'\r\n try:\r\n with open('D:/' + coll_name + '/' + file_name, \"wb\") as f:\r\n f.write(res.content)\r\n except:\r\n print(\"文件名有误\")\r\n count += 1\r\n print('=====' + title + author + '爬取完成=====')\r\n print('=====图片爬取完成=====')\r\n time.sleep(random.randint(1, 6))\r\n\r\ndef take_even_index_element_in_list(list_old):\r\n '''\r\n 取list中所有偶数下标元素\r\n :param list_old\r\n :return list_new\r\n '''\r\n list_new = []\r\n for i in range(len(list_old)//2): # / 得到 float,range 不能处理\r\n list_new.append(list_old[2*i])\r\n return list_new\r\n\r\n\r\nif __name__ == '__main__':\r\n spider_fig_by_url_in_ans(24) # 爬取前24 * 5 = 120条答案 以 平常人可以漂亮到什么程度?为例 \r\n\r\n spider_fig_in_one_ans('https://www.zhihu.com/question/29289467/answer/72898476') # 爬取一条回答的图片 输入网址 生活中你见过的最美女性长什么样? 为例 \r\n\r\n spider_fig_in_quetion(24) # 爬取前120条答案 以 你见过最漂亮的女生长什么样?为例\r\n"
},
{
"alpha_fraction": 0.586718738079071,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 33.55555725097656,
"blob_id": "55579599fb0bf12799eb39b3336c0ad6bb78d0fc",
"content_id": "e1c23901d3bf6747bdc2c97de29819ddfd93597a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4352,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 108,
"path": "/analysis_wordcloud_bar.py",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport pandas as pd\r\nimport jieba.analyse\r\nfrom pyecharts import options as opts\r\nfrom pyecharts.globals import SymbolType\r\nfrom pyecharts.charts import Bar, WordCloud\r\nimport os\r\n\r\n'''\r\nauthor: BW\r\nvision: 1.0\r\n注释:用词云分析文本效果并不好\r\n'''\r\n\r\n\r\nplace_excel_path = '知乎提问.xlsx'\r\nDF = pd.read_excel(place_excel_path)\r\nstop_words_file_path = 'stop_words.txt' \r\n\r\ndef analysis_title_content():\r\n \"\"\"\r\n 词云分析回答的标题+回答\r\n :return:\r\n \"\"\"\r\n # 引入全局数据\r\n global DF\r\n # 数据清洗,去掉无效词\r\n jieba.analyse.set_stop_words(stop_words_file_path)\r\n # 1、词数统计\r\n title_string = ' '.join(DF['标题'])\r\n excerpt_string = ' '.join(DF['回答'])\r\n string = ' '.join([title_string, excerpt_string])\r\n keywords_count_list = jieba.analyse.textrank(string, topK=50, withWeight=True)\r\n print(keywords_count_list)\r\n # 生成词云\r\n word_cloud = (\r\n WordCloud()\r\n .add(\"\", keywords_count_list, word_size_range=[20, 100], shape=SymbolType.DIAMOND)\r\n .set_global_opts(title_opts=opts.TitleOpts(title=\"标题+回答常用词词云TOP50\"))\r\n )\r\n word_cloud.render('title_content-word-cloud.html')\r\n\r\n # 2、回答常用词生成柱状图\r\n # 2.1统计词数\r\n keywords_count_dict = {i[0]: 0 for i in reversed(keywords_count_list[:20])} # 取前20高频的关键词\r\n cut_words = jieba.cut(string)\r\n for word in cut_words:\r\n for keyword in keywords_count_dict.keys():\r\n if word == keyword:\r\n keywords_count_dict[keyword] = keywords_count_dict[keyword] + 1\r\n print(keywords_count_dict)\r\n # 2.2生成柱状图\r\n keywords_count_bar = (\r\n Bar()\r\n .add_xaxis(list(keywords_count_dict.keys()))\r\n .add_yaxis(\"\", list(keywords_count_dict.values()))\r\n .reversal_axis()\r\n .set_series_opts(label_opts=opts.LabelOpts(position=\"right\"))\r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"标题+回答常用词TOP20\"),\r\n yaxis_opts=opts.AxisOpts(name=\"词\"),\r\n xaxis_opts=opts.AxisOpts(name=\"出现数\")\r\n )\r\n )\r\n keywords_count_bar.render('title_excerpt-word-count-bar.html')\r\n\r\n # 3、回答高频关键字与点赞数关系\r\n keywords_sales_dict = analysis_title_keywords(keywords_count_list, '点赞数', 20)\r\n # 生成柱状图\r\n keywords_sales_bar = (\r\n Bar()\r\n .add_xaxis(list(keywords_sales_dict.keys()))\r\n .add_yaxis(\"\", list(keywords_sales_dict.values()))\r\n .reversal_axis()\r\n .set_series_opts(label_opts=opts.LabelOpts(position=\"right\"))\r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"标题+回答高频关键字与点赞数关系TOP20\"),\r\n yaxis_opts=opts.AxisOpts(name=\"词\"),\r\n xaxis_opts=opts.AxisOpts(name=\"点赞数\")\r\n )\r\n )\r\n keywords_sales_bar.render('title_content-word-agree-bar.html')\r\n\r\ndef analysis_title_keywords(keywords_count_list, column, top_num) -> dict:\r\n \"\"\"\r\n 分析标题关键字与其他属性的关系\r\n :param keywords_count_list: 关键字列表\r\n :param column: 需要分析的属性名\r\n :param top_num: 截取前多少个\r\n :return:\r\n \"\"\"\r\n # 1、获取高频词,生成一个dict={'keyword1':agree_number1, 'keyword2':agree_number2,...}\r\n keywords_column_dict = {i[0]: 0 for i in keywords_count_list}\r\n for row in DF.iterrows():\r\n for keyword in keywords_column_dict.keys():\r\n if (keyword in row[1]['标题']) or (keyword in row[1]['回答']):\r\n if row[1]['点赞数'] != '无':\r\n # 2、 将标题包含关键字的属性值放在列表中,dict={'keyword1':[属性值1,属性值2,..]}\r\n keywords_column_dict[keyword] += row[1]['点赞数']\r\n # 3、 根据总点赞数排序,从小到大\r\n keywords_agree_dict = dict(sorted(keywords_column_dict.items(), key=lambda d: d[1], reverse=True))\r\n # 4、截取平均值最高的20个关键字\r\n keywords_agree_dict = {k: keywords_agree_dict[k] for k in list(keywords_agree_dict.keys())[-top_num:]}\r\n print(keywords_agree_dict)\r\n return keywords_agree_dict\r\n\r\nif __name__ == '__main__':\r\n analysis_title_content()\r\n"
},
{
"alpha_fraction": 0.42428719997406006,
"alphanum_fraction": 0.4464470446109772,
"avg_line_length": 31.676616668701172,
"blob_id": "cbad88d74a573c8c2dcd7e03745790755c2214f5",
"content_id": "3bc4afffc85416d816913e63c07982ac1b529519",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7155,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 201,
"path": "/analyse_keyword.py",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\n# from collections import Counter\r\nfrom pyecharts import options as opts\r\nfrom pyecharts.charts import Pie, Bar\r\nfrom pyecharts.globals import ThemeType\r\nfrom pyecharts.commons.utils import JsCode\r\nimport prettytable as pt\r\nimport os\r\n\r\n'''\r\nauthor: BW\r\nvision: 1.0\r\n'''\r\n\r\nexcel_path = '知乎情话.xlsx'\r\ndf = pd.read_excel(excel_path)\r\n\r\n'''\r\n==========各问题下万赞回答的个数==========\r\n'''\r\n# # ------------Counter,已排序\r\n# qus_count = Counter(df['question']) \r\n# q_c = qus_count.most_common() \r\n# q_list = []\r\n# c_list = []\r\n# for i in range(len(q_c)):\r\n# q_list.append(q_c[i][0])\r\n# c_list.append(q_c[i][1])\r\n# # ------------value_counts,已排序\r\n# q_c = pd.value_counts(df['question']) # Series类\r\n# q_list = q_c.index.tolist()\r\n# c_list = q_c.values.tolist() # List类\r\n# --------------未排序\r\nq_list = []\r\nrepeat_bool = df['question'].duplicated() \r\nfor i in range(len(df['question'])):\r\n if repeat_bool[i] == False:\r\n q_list.append(df['question'][i])\r\n\r\nc_list = [0] * len(q_list)\r\nfor i in range(len(q_list)):\r\n for q in df['question']:\r\n if q_list[i] == q:\r\n c_list[i] += 1\r\n\r\nvote_stack_list = [0] * len(q_list)\r\nfor i in range(len(q_list)):\r\n for q, v in zip(df['question'], df['vote']):\r\n if q_list[i] == q:\r\n vote_stack_list[i] += v\r\n'''\r\n直方图\r\n'''\r\nbar = (\r\n Bar() \r\n .add_xaxis(q_list) \r\n .add_yaxis(\"\", c_list) \r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"问题下万赞回答数\"),\r\n yaxis_opts=opts.AxisOpts(name=\"频数\"),\r\n xaxis_opts=opts.AxisOpts(name=\"问题\", axislabel_opts=opts.LabelOpts(rotate=-25)) \r\n )\r\n .set_series_opts(\r\n markpoint_opts=opts.MarkPointOpts(\r\n data=[\r\n opts.MarkPointItem(type_=\"max\", name=\"最大值\") \r\n ]\r\n )\r\n )\r\n .set_series_opts(itemstyle_opts={ \r\n \"normal\": {\r\n \"color\": JsCode(\r\n \"\"\"new echarts.graphic.LinearGradient(\r\n 0, 0, 0, 1, \r\n [\r\n {offset: 0, color: 'rgba(0, 244, 255, 1)'}, \r\n {offset: 1, color: 'rgba(0, 77, 167, 1)'}\r\n ], \r\n false\r\n )\"\"\"\r\n ),\r\n \"barBorderRadius\": [30, 30, 30, 30],\r\n \"shadowColor\": 'rgb(0, 160, 221)',\r\n }\r\n }\r\n )\r\n .render('情话优秀问题柱状图count.html')\r\n )\r\nbar = (\r\n Bar() \r\n .add_xaxis(q_list) \r\n .add_yaxis(\"\", vote_stack_list) \r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"问题下万赞回答的总赞数\"),\r\n yaxis_opts=opts.AxisOpts(name=\"总赞数\"),\r\n xaxis_opts=opts.AxisOpts(name=\"问题\", axislabel_opts=opts.LabelOpts(rotate=-25)) \r\n )\r\n .set_series_opts(\r\n markpoint_opts=opts.MarkPointOpts(\r\n data=[\r\n opts.MarkPointItem(type_=\"max\", name=\"最大值\") \r\n ]\r\n )\r\n )\r\n .set_series_opts(itemstyle_opts={ \r\n \"normal\": {\r\n \"color\": JsCode(\r\n \"\"\"new echarts.graphic.LinearGradient(\r\n 0, 0, 0, 1, \r\n [\r\n {offset: 0, color: 'rgba(0, 244, 255, 1)'}, \r\n {offset: 1, color: 'rgba(0, 77, 167, 1)'}\r\n ], \r\n false\r\n )\"\"\"\r\n ),\r\n \"barBorderRadius\": [30, 30, 30, 30],\r\n \"shadowColor\": 'rgb(0, 160, 221)',\r\n }\r\n }\r\n )\r\n .render('情话优秀问题柱状图vote.html')\r\n )\r\nprint('=====情话优秀问题柱状图完成=====')\r\n'''\r\n玫瑰图\r\n'''\r\npie = (\r\n Pie(init_opts=opts.InitOpts(theme=ThemeType.ROMANTIC)) # 浪漫主题\r\n .add(\"\", [list(z) for z in zip(q_list, c_list)],\r\n radius=[\"20%\", \"75%\"],\r\n center=[\"40%\", \"50%\"],\r\n rosetype=\"radius\")\r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"问题&万赞回答数\"),\r\n legend_opts=opts.LegendOpts(type_=\"scroll\", pos_left=\"80%\", orient=\"vertical\")\r\n )\r\n .set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}: {c}\"))\r\n .render('情话优秀问题玫瑰图count.html')\r\n )\r\npie = (\r\n Pie(init_opts=opts.InitOpts(theme=ThemeType.ROMANTIC)) \r\n .add(\"\", [list(z) for z in zip(q_list, vote_stack_list)],\r\n radius=[\"20%\", \"75%\"],\r\n center=[\"40%\", \"50%\"],\r\n rosetype=\"radius\")\r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"问题下万赞回答赞数和\"),\r\n legend_opts=opts.LegendOpts(type_=\"scroll\", pos_left=\"80%\", orient=\"vertical\")\r\n )\r\n .set_series_opts(label_opts=opts.LabelOpts(formatter=\"{b}: {c}\"))\r\n .render('情话优秀问题玫瑰图vote.html')\r\n )\r\nprint('=====情话优秀问题玫瑰图完成=====')\r\n\r\n'''\r\n==========最佳回答==========\r\n'''\r\ndf_vote = df.sort_values(by='vote', ascending=False) # df.sort_index 有 FutureWarning\r\na_list = df_vote['author'].tolist()[:10]\r\nv_list = df_vote['vote'].tolist()[:10]\r\nans_list = df_vote['answer'].tolist()[:10]\r\nqus_list = df_vote['question'].tolist()[:10]\r\n'''\r\n直方图\r\n'''\r\nbar = (\r\n Bar() \r\n .add_xaxis(a_list) \r\n .add_yaxis(\r\n \"\", \r\n v_list,\r\n itemstyle_opts=opts.ItemStyleOpts(\r\n color=JsCode( # 同问题同色 # 添加注释?\r\n \"\"\"function (params) {\r\n if (params.value > 60000) {return 'red';} \r\n else if (params.value == 56610) {return 'blue';}\r\n else if (params.value == 51240 || params.value == 35316) {return 'gray';}\r\n else if (params.value == 39119) {return 'orange';}\r\n else if (params.value == 31998) {return 'pink';}\r\n else if (params.value == 30562) {return 'purple';}\r\n return 'green';}\r\n \"\"\"\r\n )\r\n )\r\n ) \r\n .set_global_opts(\r\n title_opts=opts.TitleOpts(title=\"万赞回答TOP10\"),\r\n yaxis_opts=opts.AxisOpts(name=\"赞数\"),\r\n xaxis_opts=opts.AxisOpts(name=\"作者\", axislabel_opts=opts.LabelOpts(rotate=-45)) \r\n )\r\n .render('情话优秀回答柱状图.html')\r\n )\r\nprint('=====情话优秀回答柱状图完成=====')\r\n\r\ntb = pt.PrettyTable()\r\ntb.add_column(\"question\", qus_list)\r\ntb.add_column(\"vote\", v_list)\r\ntb.add_column(\"author\", a_list)\r\n# tb.add_column(\"answer\", ans_list)\r\nprint(tb)\r\n"
},
{
"alpha_fraction": 0.46617957949638367,
"alphanum_fraction": 0.4923403263092041,
"avg_line_length": 28.30714225769043,
"blob_id": "95f247571318425e1c37eeeea4048fc3238f515a",
"content_id": "d5a05278ab82f33a381f9aca743868088c87b0a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4723,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 140,
"path": "/spider_ans_of_q_save_excel.py",
"repo_name": "BWfight/zhihu_spider",
"src_encoding": "UTF-8",
"text": "import requests\r\nimport json\r\nimport openpyxl\r\nimport time\r\nimport random\r\n# import re\r\nimport os\r\n\r\n'''\r\nauthor: BW\r\nvision: 1.0\r\n'''\r\n\r\ndef spider_question(question, page):\r\n \"\"\"\r\n 爬取知乎提问网页\r\n :param question: 问题\r\n :param page: 分页\r\n :return: info_list\r\n \"\"\"\r\n headers={\r\n 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'\r\n }\r\n url = 'https://www.zhihu.com/api/v4/search_v3?'\r\n params = {\r\n 't': 'general',\r\n 'q': question,\r\n 'correction': '1',\r\n 'offset': str((page)*20), # 从第几篇文章开始 # 不能从0(第1个答案)开始爬取,有时状态码500,有时爬到空data_list\r\n 'limit': '20', # 一个xhr加载几篇\r\n 'lc_idx': str((page)*20+2),\r\n 'show_all_topics': '0',\r\n 'search_hash_id': '1105d34171faf880cf9fe08a08ca4319',\r\n 'vertical_info': '0,0,0,0,0,0,0,0,0,1'\r\n }\r\n response = requests.get(url, headers=headers, params=params)\r\n if response.status_code == 200:\r\n print('=====正在爬取第' + str(page+1) + '页=====') \r\n info_list = get_answer_info(response.json()) \r\n return info_list\r\n else:\r\n print('=====错误!状态码为' + str(response.status_code) + '。=====')\r\n \r\n\r\ndef get_answer_info(response_json):\r\n \"\"\"\r\n 获取回答信息\r\n :param response_json:\r\n :return: info_list\r\n \"\"\"\r\n data_list = response_json['data']\r\n info_list= []\r\n for i in data_list:\r\n if 'question' in i['object']:\r\n title = i['object']['question']['name'].replace('<em>', '').replace('</em>', '')\r\n else:\r\n title = i['object']['title'].replace('<em>', '').replace('</em>', '')\r\n\r\n if 'excerpt' in i['object']: \r\n excerpt = i['object']['excerpt'].replace('<em>', '').replace('</em>', '')\r\n else:\r\n excerpt = '无'\r\n\r\n if 'author' in i['object']: \r\n author = i['object']['author']['name']\r\n else:\r\n author = '匿名'\r\n \r\n if 'content' in i['object']: \r\n raw_content = i['object']['content']\r\n content = raw_content.replace('<h2>', '').replace('</h2>', '').replace('<p>', '').replace('</p>', '').replace('<hr/>', '').replace('<br/>', '').replace('<b>', '')\r\n # pattern = re.compile(r'[\\u4e00-\\u9fa5 0-9 , 。 ? !]') # re匹配中文,数字等。 \r\n # content_list = pattern.findall(raw_content) # 返回列表 \r\n # content = ''.join(content_list) # 连接为字符串\r\n else:\r\n content = '无' \r\n \r\n\r\n url = i['object']['url']\r\n\r\n if 'voteup_count' in i['object']: \r\n voteup_count = i['object']['voteup_count']\r\n else:\r\n voteup_count = '无'\r\n \r\n info = [title.encode('gbk','ignore').decode('gbk'), author, \\\r\n excerpt.encode('gbk','ignore').decode('gbk'), \\\r\n content.encode('gbk','ignore').decode('gbk'), \\\r\n url, voteup_count]\r\n info_list.append(info)\r\n return info_list\r\n\r\n\r\ndef patch_spider_place(question, page):\r\n \"\"\"\r\n 批量爬取\r\n :param question: 搜索关键字\r\n :return:\r\n \"\"\"\r\n # 写入数据前先清空之前的数据\r\n if os.path.exists(place_excel_path):\r\n os.remove(place_excel_path)\r\n \r\n for i in range(1, page): # 从第21个答案开始爬取\r\n info_list = spider_question(question, i)\r\n save_info_excel(info_list)\r\n # 设置一个时间间隔\r\n time.sleep(random.randint(3, 6))\r\n print('=====爬取完成!=====')\r\n\r\n\r\ndef save_info_excel(info_list):\r\n \"\"\"\r\n 将数据保存成excel文件的准备工作\r\n :param place_list: 数据列表\r\n :return:\r\n \"\"\"\r\n for info in info_list:\r\n sheet.append(info)\r\n\r\n\r\nif __name__ == '__main__':\r\n place_excel_path = '知乎提问.xlsx'\r\n\r\n wb=openpyxl.Workbook() # 创建工作薄\r\n sheet=wb.active # 获取工作薄的活动表\r\n sheet.title=\"Ans\" # 工作表重命名\r\n sheet['A1'] ='标题' # 加表头,给单元格赋值\r\n sheet['B1'] ='作者'\r\n sheet['C1'] ='摘要' \r\n sheet['D1'] ='回答' \r\n sheet['E1'] ='链接' \r\n sheet['F1'] ='点赞数' \r\n \r\n question = '你见过的有些人能漂亮到什么程度?'\r\n page = 21 # 会爬取21-1 * 20 = 400 条,头20条遗漏\r\n patch_spider_place(question, page)\r\n\r\n wb.save(place_excel_path) # 保存\r\n print('=====Excel文件已保存!=====')\r\n"
}
] | 6 |
salomonheimj/HResource
|
https://github.com/salomonheimj/HResource
|
9c0756e32930a75fabb2d062d3fc167511f8d8b7
|
749de88f2082f2a7a1dbe2593629b25d65669c14
|
b2159529bb9e47ce00191eaa88b098cc82c60dcd
|
refs/heads/master
| 2020-03-11T17:34:42.059813 | 2018-04-30T17:50:32 | 2018-04-30T17:50:32 | 130,150,845 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4779950976371765,
"alphanum_fraction": 0.4914425313472748,
"avg_line_length": 20.526315689086914,
"blob_id": "0ed22b8d69075be7ec1fb0dd4f223c5f56f2f91d",
"content_id": "a89d3271f1133bf7fe514561d9ed71366c3f6118",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 819,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 38,
"path": "/HResource-master/templates/resultados.html",
"repo_name": "salomonheimj/HResource",
"src_encoding": "UTF-8",
"text": "{% extends \"layout.html\" %}\n\n{% block body %}\n\n<div id=\"wrapper\">\n\n\n\n <div id=\"page-wrapper\">\n <div class=\"row\">\n <div class=\"col-lg-12\">\n <h1 class=\"page-header\">Resultados</h1>\n <h2>Total resultados: {{entries[0].cantResults}}</h2>\n {% for resultados in entries %}\n <dl>\n <dt>Text tittle: {{resultados.textTittle}}</dt>\n <dd>Main score: {{resultados.mainScore}}</dd>\n <dd>Sentiment label: {{resultados.sentLabel}}</dd>\n <dd>Sentiment score: {{resultados.sentScore}}</dd>\n </dl>\n {% else %}\n <h2>No hay síntomas</h2>\n {% endfor %}\n\n </div>\n <!-- /.col-lg-12 -->\n </div>\n <div class=\"row\">\n\n </div>\n <!-- /.row -->\n </div>\n <!-- /#page-wrapper -->\n\n</div>\n<!-- /#wrapper -->\n\n{% endblock %}\n"
},
{
"alpha_fraction": 0.6326767206192017,
"alphanum_fraction": 0.6633835434913635,
"avg_line_length": 36.5217399597168,
"blob_id": "4f6c62eadba638826a2cb416c5075ee3532a2d02",
"content_id": "f3f626a963357c1ca43d7cbd19591b84e66c701f",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1726,
"license_type": "permissive",
"max_line_length": 302,
"num_lines": 46,
"path": "/HResource-master/connection_backend.py",
"repo_name": "salomonheimj/HResource",
"src_encoding": "UTF-8",
"text": "import requests as requests\nimport json as json\nfrom requests.auth import HTTPBasicAuth\n\ndef cb_get_results(empleados):\n url = 'https://gateway.watsonplatform.net/discovery/api/v1/environments/980ee167-f667-405b-a661-acf3a7d01dc4/collections/949ce21d-4000-4ac4-88d6-38484cccddde/query?version=2017-10-16&count=&offset=&aggregation=&filter=&passages=true&deduplicate=false&highlight=true&return=&natural_language_query='\n for i in range(len(empleados)):\n url+= empleados[i]+'%20'\n r=requests.get(url, auth=('788db5c8-5d33-4998-b0f8-af0ed1d02e1e','4PlZbmbrZ3PL'))\n print(str(r.status_code))\n #print(r.json())\n jso = (r.json())\n cantRes = jso['matching_results']\n resultados = jso['results']\n results =[]\n #results.append(\"Cantidad de resultados: \" + str(cantRes))\n for i in range (len(resultados)):\n res = resultados[i]\n score = res['score']\n metaData = res['extracted_metadata']\n fileName = metaData['filename']\n fileName = fileName.replace('_', ' ')\n enr = res['enriched_text']\n sent = enr['sentiment']\n doc = sent['document']\n sentScore = doc['score']\n sentLabel = doc['label']\n objResultado = Resultado(score,fileName, sentScore, sentLabel,cantRes)\n results.append(objResultado)\n return results\n\nclass Resultado(object):\n mainScore=0\n textTittle=\"\"\n sentScore =0\n sentLabel=\"\"\n cantResults = 0\n def __init__(self, mainScore, textTittle, sentScore, sentLabel,cantResults):\n self.mainScore=mainScore\n self.textTittle=textTittle\n self.sentScore=sentScore\n self.sentLabel=sentLabel\n self.cantResults=cantResults\ndef cb_get_empleados():\n empleados = []\n return empleados\n"
},
{
"alpha_fraction": 0.7290874719619751,
"alphanum_fraction": 0.732889711856842,
"avg_line_length": 24.658536911010742,
"blob_id": "cc7a576b5214243d20dee48878952057c589aebc",
"content_id": "2aea933b2be63c8b0fdbb5f78a71f2756a011700",
"detected_licenses": [
"Apache-2.0",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1052,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 41,
"path": "/HResource-master/README.md",
"repo_name": "salomonheimj/HResource",
"src_encoding": "UTF-8",
"text": "# [HResource](http://hresource-imperative-manslayer.mybluemix.net/)\n\n## Run the app locally\n```\npip install -r requirements.txt\n```\nYou can optionally use a virtual environment to avoid having these dependencies clash with those of other Python projects or your operating system.\n\nRun the app.\n```\npython fms.py\n```\n\n View the app at: http://localhost:8000\n\n## Deploy the app\n\nChoose your API endpoint\n ```\ncf api https://api.ng.bluemix.net\n ```\nLogin to your Bluemix account\n ```\ncf login\n ```\nFrom within the HResource directory push your app to Bluemix\n ```\ncf push\n ```\n\nThis can take a minute. If there is an error in the deployment process you can use the command `cf logs <Your-App-Name> --recent` to troubleshoot.\n\nWhen deployment completes you should see a message indicating that your app is running. View your app at the URL listed in the output of the push command. You can also issue the\n```\ncf apps\n```\ncommand to view your apps status and see the URL.\n\n```\n\nView the app at http://hresource-imperative-manslayer.mybluemix.net/\n"
},
{
"alpha_fraction": 0.6820809245109558,
"alphanum_fraction": 0.7283236980438232,
"avg_line_length": 14.727272987365723,
"blob_id": "b3323248589c04f6af557cd8be06a2ee365f2e22",
"content_id": "73ab4553bfff6c366ca76575d270d83d9cb37a94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 175,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 11,
"path": "/README.md",
"repo_name": "salomonheimj/HResource",
"src_encoding": "UTF-8",
"text": "# HResource\n\nEntrega prototipo pagina web HResource\nMateria: ISIS2007 Diseño, produccion e innovación en TI\nIntegrantes:\n Ivan Arturo Salazar\n Maria Alejandra Abril\n Sebastian Ramos\n Salomón Heim\n \nPuerto: 8000\n"
}
] | 4 |
Andrehoi/inf200_exercises_andreas_hoimyr
|
https://github.com/Andrehoi/inf200_exercises_andreas_hoimyr
|
af0fa586cf1bdc949d5483967154b351b3493b75
|
d94229cdc35f85f746639de14dbbe7732707663c
|
364c5f080f8e84a3a31e232f3f8321aa38d4c876
|
refs/heads/master
| 2020-08-23T02:57:50.128556 | 2019-11-08T07:28:12 | 2019-11-08T07:28:12 | 216,529,098 | 0 | 0 | null | 2019-10-21T09:27:46 | 2019-11-08T07:28:15 | 2019-11-27T09:28:52 |
Python
|
[
{
"alpha_fraction": 0.5506691932678223,
"alphanum_fraction": 0.5745697617530823,
"avg_line_length": 23.034482955932617,
"blob_id": "424440af55e910c94b33598d99032e98f836f27f",
"content_id": "4370aaf908cb95ff3c1d278d04ba704b9852f131",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2092,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 87,
"path": "/src/andreas_hoimyr_ex/ex05/walker_sim.py",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "\n# -*- coding: utf-8 -*-\n\n__author__ = \"Andreas Sandvik Hoimyr\"\n__email__ = \"[email protected]\"\n\n\nimport random\n\n\nclass Walker:\n\n def __init__(self, samfunnet_position, home_position):\n self.student = samfunnet_position\n self.home = home_position\n self.count_steps = 0\n\n def move(self):\n \"\"\" Moves the student either +1 step or -1 step towards home\"\"\"\n step = random.randint(1, 2)\n if step == 2:\n step = -1\n self.student += step\n\n self.count_steps += 1\n\n return\n\n def is_at_home(self):\n \"\"\" Checks if student is at home \"\"\"\n return self.student == self.home\n\n def get_position(self):\n \"\"\" Returns the position of the student\"\"\"\n return self.student\n\n def get_steps(self):\n \"\"\"Returns the number of steps to reach home\"\"\"\n return self.count_steps\n\n\nclass Simulation:\n\n def __init__(self, samfunnet_position, home_position, seed):\n self.start = samfunnet_position\n self.home = home_position\n self.seed = random.seed(seed)\n \"\"\"\n Initialise the simulation\n \"\"\"\n\n def single_walk(self):\n \"\"\"\n Simulate single walk from start to home, returning number of steps.\n\n \"\"\"\n\n walker = Walker(self.start, self.home)\n\n while not walker.is_at_home():\n walker.move()\n\n return walker.get_steps()\n\n def run_simulation(self, num_walks):\n \"\"\"\n Run a set of walks, returns list of number of steps taken.\n\n \"\"\"\n walk_list = []\n for _ in range(num_walks):\n walk_list.append(self.single_walk())\n\n return walk_list\n\n\nif __name__ == '__main__':\n\n for _ in range(2):\n simulation_one = Simulation(0, 10, 12345)\n simulation_two = Simulation(10, 0, 12345)\n print(simulation_one.run_simulation(20))\n print(simulation_two.run_simulation(20))\n\n simulation_three = Simulation(0, 10, 54321)\n simulation_four = Simulation(10, 0, 54321)\n print(simulation_three.run_simulation(20))\n print(simulation_four.run_simulation(20))\n"
},
{
"alpha_fraction": 0.5724248886108398,
"alphanum_fraction": 0.5895922780036926,
"avg_line_length": 25.628570556640625,
"blob_id": "947445bdf8389619a2202c582918d0fb766676f7",
"content_id": "6bcac087b987aa3184f6e533a376809fae675a6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1864,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 70,
"path": "/src/andreas_hoimyr_ex/ex05/bounded_sim.py",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n__author__ = \"Andreas Sandvik Hoimyr\"\n__email__ = \"[email protected]\"\n\nfrom walker_sim import Walker\nfrom walker_sim import Simulation\nimport random\n\n\nclass BoundedWalker(Walker):\n\n def __init__(self, samfunnet_postition, home_position, left_limit,\n right_limit):\n super().__init__(samfunnet_postition, home_position)\n self.student = samfunnet_postition\n self.left_limit = left_limit\n self.right_limit = right_limit\n\n def bounded_move(self):\n \"\"\" Moves the student either +1 step or -1 step towards home\"\"\"\n step = random.randint(1, 2)\n if step == 2:\n step = -1\n self.student += step\n if self.student < self.left_limit:\n self.student = self.left_limit\n\n if self.student > self.right_limit:\n self.student = self.right_limit\n\n self.count_steps += 1\n\n return\n\n\nclass BoundedSimulation(Simulation):\n\n def __init__(self, samfunnet_position, home_position, seed, left_limit,\n right_limit):\n super().__init__(samfunnet_position, home_position, seed)\n self.left = left_limit\n self.right = right_limit\n\n def bounded_sims(self):\n\n walker = BoundedWalker(self.start, self.home, self.left, self.right)\n\n while not walker.is_at_home():\n walker.bounded_move()\n\n return walker.get_steps()\n\n def run_bounded_sims(self, num_walks):\n\n walk_list = []\n for _ in range(num_walks):\n walk_list.append(self.bounded_sims())\n\n return walk_list\n\n\nif __name__ == '__main__':\n\n left_boundary = [0, -10, -100, -1000, -10000]\n\n for boundary in left_boundary:\n bound_sim = BoundedSimulation(0, 20, 7, boundary, 20)\n print(\" Left boundary {0} with these results:\". format(boundary),\n bound_sim.run_bounded_sims(20))\n"
},
{
"alpha_fraction": 0.6705882549285889,
"alphanum_fraction": 0.7882353067398071,
"avg_line_length": 16,
"blob_id": "87802205a71aa2aa4204d139ea1006a876fef88e",
"content_id": "f272ecfce9cb80a47565578febfd3939c2dbfb02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 5,
"path": "/README.md",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "# inf200_exercises_andreas_hoimyr\n\nANDREAS SANDVIK HOIMYR:\n\nExercise repository for inf200 fall 2019\n"
},
{
"alpha_fraction": 0.5091041326522827,
"alphanum_fraction": 0.5273124575614929,
"avg_line_length": 20.123077392578125,
"blob_id": "f33542f854c253853475e5e4b448d3b968a2a072",
"content_id": "73ad2d53c8896e3a03f1e5d8d069d7eb2f5d5223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 65,
"path": "/src/andreas_hoimyr_ex/ex04/walker.py",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\n__author__ = 'andreas sandvik hoimyr'\n__email__ = '[email protected]'\n\nimport random\n\n\nclass Walker:\n\n def __init__(self, samfunnet_position, home_position):\n self.student = samfunnet_position\n self.home = home_position\n self.count_steps = 0\n\n return\n\n def move(self):\n \"\"\" Moves the student either +1 step or -1 step towards home\"\"\"\n step = random.randint(1, 2)\n if step == 2:\n step = -1\n self.student += step\n\n self.count_steps += 1\n\n return\n\n def is_at_home(self):\n \"\"\" Checks if student is at home \"\"\"\n if self.student == self.home:\n return True\n else:\n return False\n\n def get_position(self):\n \"\"\" Returns the position of the student\"\"\"\n return self.student\n\n def get_steps(self):\n \"\"\"Returns the number of steps to reach home\"\"\"\n return self.count_steps\n\n\nif __name__ == '__main__':\n\n progress_home = [1, 2, 5, 10, 20, 50, 100]\n\n for distance in progress_home:\n\n distance_moved = []\n\n for _ in range(5):\n\n walker = Walker(0, distance)\n\n while not walker.is_at_home():\n\n walker.move()\n\n distance_moved.append(walker.get_steps())\n\n print(' Distance: {0} -> path lengths: {1}'.format(\n distance, distance_moved))\n"
},
{
"alpha_fraction": 0.5240083336830139,
"alphanum_fraction": 0.5348643064498901,
"avg_line_length": 20.972476959228516,
"blob_id": "96cc74a6441dc467b96f5c9e5990da80b4b6a1a4",
"content_id": "6379eb7dfa29d2b30450f4b62660c925fa6c53fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2395,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 109,
"path": "/src/andreas_hoimyr_ex/ex05/myrand.py",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n__author__ = \"Andreas Sandvik Hoimyr\"\n__email__ = \"[email protected]\"\n\n\nclass RandIter:\n\n def __init__(self, random_number_generator, length):\n\n self.generator = random_number_generator\n self.length = length\n self.num_generated_numbers = None\n\n def __iter__(self):\n \"\"\"\n Initialise the iterator.\n\n Returns\n -------\n self : RandIter\n\n Raises\n ------\n RuntimeError\n If iter is called twice on the same RandIter object.\n \"\"\"\n if self.num_generated_numbers is not None:\n raise RuntimeError\n\n self.num_generated_numbers = 0\n return self\n\n def __next__(self):\n \"\"\"\n Generate the next random number.\n\n Returns\n -------\n int\n A random number.\n\n Raises\n ------\n RuntimeError\n If the ``__next__`` method is called before ``__iter__``.\n StopIteration\n If ``self.length`` random numbers are generated.\n \"\"\"\n if self.num_generated_numbers is None:\n raise RuntimeError\n\n if self.num_generated_numbers == self.length:\n raise StopIteration\n\n self.num_generated_numbers += 1\n\n return self.generator.rand()\n\n\nclass LCGRand:\n\n def __init__(self, seed):\n self.lcg_value = seed\n return\n\n def rand(self):\n \"\"\"Returns the value given by formula of random values. The formula\n is constant and does not change.\n source:\n https://github.com/yngvem/INF200-2019-Exercises/blob/master/\n exersices/ex04.rst\n \"\"\"\n\n lcg_constant = 7**5\n limit_value = 2**31-1\n\n self.lcg_value = lcg_constant * self.lcg_value % limit_value\n\n return self.lcg_value\n\n def random_sequence(self, length):\n return RandIter(self, length)\n\n def infinite_random_sequence(self):\n \"\"\"\n Generate an infinite sequence of random numbers.\n\n Yields\n ------\n int\n A random number.\n \"\"\"\n while True:\n yield self.rand()\n\n\nif __name__ == '__main__':\n\n generator = LCGRand(1)\n for rand in generator.random_sequence(10):\n print(rand)\n\n i = 0\n while i < 100:\n rand = generator.infinite_random_sequence()\n print(f'The {i}-th random number is {next(rand)}')\n\n i += 1\n"
},
{
"alpha_fraction": 0.5477424263954163,
"alphanum_fraction": 0.5684677958488464,
"avg_line_length": 21.516666412353516,
"blob_id": "566d9c97aa47226afbec0defa0a3bacc034997ef",
"content_id": "bf7097e69770292157ab3a6d9710362685f9806d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1351,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 60,
"path": "/src/andreas_hoimyr_ex/ex04/myrand.py",
"repo_name": "Andrehoi/inf200_exercises_andreas_hoimyr",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\n__author__ = 'andreas sadnvik hoimyr'\n__email__ = '[email protected]'\n\n\nclass LCGRand:\n\n def __init__(self, seed):\n self.counter = 0\n self.lcg_value = seed\n return\n\n def rand(self):\n \"\"\"Returns the value given by formula of random values. The formula\n is constant and does not change.\n source:\n https://github.com/yngvem/INF200-2019-Exercises/blob/master/\n exersices/ex04.rst\n \"\"\"\n\n lcg_constant = 7**5\n limit_value = 2**31-1\n\n self.lcg_value = lcg_constant * self.lcg_value % limit_value\n self.counter += 1\n\n return self.lcg_value\n\n\nclass ListRand:\n\n def __init__(self, list_of_numbers):\n self.numbers = list_of_numbers\n self.counter = 0\n return\n\n def rand(self):\n \"\"\" Returns the first number of input list, then second number if\n called twice, and third if called thrice etc.\"\"\"\n if self.counter > len(self.numbers) - 1:\n raise RuntimeError\n\n number = self.numbers[self.counter]\n self.counter += 1\n\n return number\n\n\nif __name__ == '__main__':\n\n test_lcg = LCGRand(500)\n print(test_lcg.rand())\n print(test_lcg.rand())\n print(test_lcg.rand())\n\n test_list_rand = ListRand([1, 2, 3, 4])\n print(test_list_rand.rand())\n print(test_list_rand.rand())\n"
}
] | 6 |
mfukar/mflib
|
https://github.com/mfukar/mflib
|
5cfee8f9575a52a3bb9aaf325a96dc7b32700e7f
|
1df725616872797f69471d8ebb7b4f2648a2d352
|
f2864ff43ee2a3c92740e251c2a6dd3dd2012cff
|
refs/heads/master
| 2022-05-06T00:14:23.271957 | 2022-04-01T17:21:33 | 2022-04-01T17:21:33 | 25,164,076 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.46943575143814087,
"alphanum_fraction": 0.48746082186698914,
"avg_line_length": 43,
"blob_id": "1488a791d8bac4aed81542a6eea1fc00e740c722",
"content_id": "d5206ae8d6fbb77ec786ef0325581c006a66b943",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1276,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 29,
"path": "/selfdict.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file selfdict.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Tue Oct 14, 2014 13:51 EEST\n# Last Update: Tue Jan 27, 2015 18:38 EET\n#------------------------------------------------------------------------\n# Description: A defaultdict in which the key is also the value.\n#------------------------------------------------------------------------\n# History: First implementation.\n# TODO: Come up with a decent name for it.\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nfrom collections import defaultdict\n\nclass selfdict(defaultdict):\n \"\"\"A selfdict is a defaultdict in which the key is also the value. This has the\n following good properties:\n\n * You can index its values using one of their properties as the key. To index\n objects based on their .name, you implement the __hash__ method to hash .name\n members.\n * If the key is not present, the default factory will be called with the key as\n the only argument.\n \"\"\"\n def __missing__(self, key):\n self[key] = self.default_factory(key)\n return self[key]\n"
},
{
"alpha_fraction": 0.4447852671146393,
"alphanum_fraction": 0.47546011209487915,
"avg_line_length": 43.45454406738281,
"blob_id": "2bb88b6f9f9ded911a03e5755ce9b63117eccbe8",
"content_id": "375eb72b7dd91c56cde10fc7e034e7396c630416",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 978,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 22,
"path": "/plotter.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# @file /Users/mfukar/src/mflib/plotter.py\n# @author Michael Foukarakis\n# @version <+version+>\n# @date Created: Sun Jul 05, 2015 17:02 EEST\n# Last Update: Fri Apr 01, 2022 19:21 W. Europe Daylight Time\n#------------------------------------------------------------------------\n# Description: Various plotting & visualisation routines\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nfrom math import floor\n\ndef plot_counter(collection, width=100):\n \"\"\"Plot a histogram of a collections.Counter in text:\n \"\"\"\n longest_key = max(len(key) for key in collection)\n graph_width = width - longest_key - 2\n widest = collection.most_common(1)[0][1]\n scale = graph_width / floor(widest)\n for k, v in collection.most_common():\n print('{}: {} {}'.format(k, (1 + int(v * scale)) * '=', v))\n"
},
{
"alpha_fraction": 0.5422050952911377,
"alphanum_fraction": 0.5526095032691956,
"avg_line_length": 41.56428527832031,
"blob_id": "083c94d8b5a80dcfc7293b5205e7e9b104a358a6",
"content_id": "b82af83f0dbeb6ad2d373b3aab479e358dcf5305",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5959,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 140,
"path": "/manacher.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file manacher.py\n# @author Michael Foukarakis\n# @version <+version+>\n# @date Created: Thu May 10, 2012 22:28 GTB Daylight Time\n# Last Update: Fri Apr 01, 2022 17:52 W. Europe Daylight Time\n#------------------------------------------------------------------------\n# Description: Manacher's longest palindrome detection\n# algorithm implementation.\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: nothing\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\ndef manacher(seq):\n \"\"\"Returns the longest palindromic substring of a sequence SEQ as a list.\n Works in time linear to the length of the input.\n >>> manacher('opposes')\n [0, 1, 0, 1, 4, 1, 0, 1, 0, 1, 0, 3, 0, 1, 0]\n >>> testcases = ['anttna', 'antiitna', 'opposed', 'defilifed', 'babcbabcbaccba', 'abaaba', 'abababa', 'abcbabcbabcba', 'forgeeksskeegfor', 'caba', 'abacdfgdcaba', 'abacdfgdcabba', 'abacdedcaba']\n >>> expected = ['anttna', 'antiitna', 'oppo', 'defilifed', 'abcbabcba', 'abaaba', 'abababa', 'abcbabcbabcba', 'geeksskeeg', 'aba', 'aba', 'abba', 'abacdedcaba']\n >>> index_max = lambda seq : max(range(len(seq)), key=seq.__getitem__)\n >>> for c, e in zip(testcases, expected):\n ... result = manacher(c)\n ... index = index_max(result)\n ... length = result[index]\n ... start = (index - length) // 2\n ... end = start + length\n ... print(c[start:end])\n anttna\n antiitna\n oppo\n defilifed\n abcbabcba\n abaaba\n abababa\n abcbabcbabcba\n geeksskeeg\n aba\n aba\n abba\n abacdedcaba\n \"\"\"\n seqLen = len(seq)\n l = []\n i = 0\n palLen = 0\n # Loop invariant: seq[(i - palLen):i] is a palindrome.\n # Loop invariant: len(l) >= 2 * i - palLen. The code path that\n # increments palLen skips the l-filling inner-loop.\n # Loop invariant: len(l) < 2 * i + 1. Any code path that\n # increments i past seqLen - 1 exits the loop early and so skips\n # the l-filling inner loop.\n while i < seqLen:\n # First, see if we can extend the current palindrome. Note\n # that the center of the palindrome remains fixed.\n if i > palLen and seq[i - palLen - 1] == seq[i]:\n palLen += 2\n i += 1\n continue\n\n # The current palindrome is as large as it gets, so we append\n # it.\n l.append(palLen)\n\n # Now to make further progress, we look for a smaller\n # palindrome sharing the right edge with the current\n # palindrome. If we find one, we can try to expand it and see\n # where that takes us. At the same time, we can fill the\n # values for l that we neglected during the loop above. We\n # make use of our knowledge of the length of the previous\n # palindrome (palLen) and the fact that the values of l for\n # positions on the right half of the palindrome are closely\n # related to the values of the corresponding positions on the\n # left half of the palindrome.\n\n # Traverse backwards starting from the second-to-last index up\n # to the edge of the last palindrome.\n s = len(l) - 2\n e = s - palLen\n for j in range(s, e, -1):\n # d is the value l[j] must have in order for the\n # palindrome centered there to share the left edge with\n # the last palindrome. (Drawing it out is helpful to\n # understanding why the - 1 is there.)\n d = j - e - 1\n\n # We check to see if the palindrome at l[j] shares a left\n # edge with the last palindrome. If so, the corresponding\n # palindrome on the right half must share the right edge\n # with the last palindrome, and so we have a new value for\n # palLen.\n if l[j] == d: # *\n palLen = d\n # We actually want to go to the beginning of the outer\n # loop, but Python doesn't have loop labels. Instead,\n # we use an else block corresponding to the inner\n # loop, which gets executed only when the for loop\n # exits normally (i.e., not via break).\n break\n\n # Otherwise, we just copy the value over to the right\n # side. We have to bound l[i] because palindromes on the\n # left side could extend past the left edge of the last\n # palindrome, whereas their counterparts won't extend past\n # the right edge.\n l.append(min(d, l[j]))\n else:\n # This code is executed in two cases: when the for loop\n # isn't taken at all (palLen == 0) or the inner loop was\n # unable to find a palindrome sharing the left edge with\n # the last palindrome. In either case, we're free to\n # consider the palindrome centered at seq[i].\n palLen = 1\n i += 1\n\n # We know from the loop invariant that len(l) < 2 * seqLen + 1, so\n # we must fill in the remaining values of l.\n\n # Obviously, the last palindrome we're looking at can't grow any\n # more.\n l.append(palLen)\n\n # Traverse backwards starting from the second-to-last index up\n # until we get l to size 2 * seqLen + 1. We can deduce from the\n # loop invariants we have enough elements.\n lLen = len(l)\n s = lLen - 2\n e = s - (2 * seqLen + 1 - lLen)\n for i in range(s, e, -1):\n # The d here uses the same formula as the d in the inner loop\n # above. (Computes distance to left edge of the last\n # palindrome.)\n d = i - e - 1\n # We bound l[i] with min for the same reason as in the inner\n # loop above.\n l.append(min(d, l[i]))\n\n return l\n"
},
{
"alpha_fraction": 0.49272727966308594,
"alphanum_fraction": 0.5218181610107422,
"avg_line_length": 35.065574645996094,
"blob_id": "35f7217b2d95e213c3fd580b669d56d4f6d3425b",
"content_id": "727e795f903e35f8f202c0c71c1aa0edda3223b5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2201,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 61,
"path": "/mul_xor_shuffle.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file mul_xor_shuffle.py\n# @author Michael Foukarakis\n# @version 0.2\n# @date Created: Fri Jan 06, 2012 15:55 GTB Standard Time\n# Last Update: Tue Jan 27, 2015 18:37 EET\n#------------------------------------------------------------------------\n# Description: A simple obfuscation scheme, just to throw people off or\n# discourage easy tampering of values.\n# Inspired from hbfs.wordpress.com/2011/11/08/mild-obfuscation\n#------------------------------------------------------------------------\n# History: None yet\n# TODO: Implement all ¡magic! methods.\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\n\nclass PerfectShuffledNumber():\n def __init__(self, value=0, mask=None):\n self.mask = mask if mask is not None else 0x1a02f3f12876ce55\n self.sign = -1 if value < 0 else 1\n bitstring = bin(self._modmul(abs(value)) ^ self.mask) [2:]\n if len(bitstring) % 2:\n bitstring = '0' + bitstring\n self.obfuscated_value = perfect_shuffle(bitstring)\n\n def __str__(self):\n return 'mask: {} sign: {} value: {}'.format(self.mask, self.sign, '0b'+''.join(self.obfuscated_value))\n\n def __add__(self, rhs):\n return PerfectShuffledNumber(self.value() + rhs.value())\n\n def __sub__(self, rhs):\n pass\n\n def _modmul(self, x):\n m = 2**64\n a = 2**63 - 1\n return (a * x) % m\n\n def value(self):\n return self.sign * self._modmul(int(''.join((perfect_unshuffle(self.obfuscated_value))), 2) ^ self.mask)\n\ndef perfect_shuffle(seq):\n \"\"\"Returns a list which contains the perfectly shuffled, supplied sequence SEQ.\n Throws AssertionError if list has odd length.\n \"\"\"\n l = len(seq)\n\n if l % 2:\n raise AssertionError\n\n h = l // 2\n\n return [item for pair in zip(seq[:h], seq[h:]) for item in pair]\n\ndef perfect_unshuffle(seq):\n \"\"\"Returns a list containing the perfectly unshuffled supplied sequence SEQ, if\n previously perfectly shuffled.\n \"\"\"\n return seq[::2] + seq[1::2]\n"
},
{
"alpha_fraction": 0.42126622796058655,
"alphanum_fraction": 0.4642857015132904,
"avg_line_length": 43,
"blob_id": "773747b3b93526745ddc6c00aea0a82ce381f49d",
"content_id": "dcf837ea7d84fb91795e5ceb466f2289f1496bc8",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1232,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 28,
"path": "/rolling.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file rolling.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Tue Feb 14, 2012 13:19 GTB Standard Time\n# Last Update: Thu Nov 13, 2014 20:19 SAST\n#------------------------------------------------------------------------\n# Description: Rolling window generator over an iterator.\n#------------------------------------------------------------------------\n# History: 0.1 - First implementation\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nfrom itertools import tee, islice, count\n\ndef rolling_window(iterator, length, step = 1):\n \"\"\"Returns an iterator of length LENGTH over ITERATOR, which advances by STEP after\n each call.\n >>> set(rolling_window(range(10), 3)) == {(0,1,2), (1,2,3), (2,3,4), (3,4,5), (4,5,6), (5,6,7), (6,7,8), (7,8,9)}\n True\n \"\"\"\n streams = tee(iterator, length)\n return zip(*[islice(s, i, None, step) for s,i in zip(streams, count())])\n\ndef rolling_average(sequence, length):\n for win in rolling_window(sequence, length):\n yield sum(win) / length\n"
},
{
"alpha_fraction": 0.4192771017551422,
"alphanum_fraction": 0.4473895728588104,
"avg_line_length": 43.42856979370117,
"blob_id": "ad9e55048d694ee0d0fa093707bc53a062880f69",
"content_id": "449da28becfb811ee0bd4b12a05483c60278cbe1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1245,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 28,
"path": "/wilson_score.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file wilson_score.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Fri Sep 01, 2017 10:19 EEST\n# Last Update: Fri Sep 01, 2017 16:40 EEST\n#------------------------------------------------------------------------\n# Description: Wilson score interval\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nfrom scipy.stats import norm\nfrom math import sqrt\n\ndef ci_lower_bound(positive, n, confidence):\n \"\"\"Returns the lower-bound Wilson score for a given confidence interval.\n positive (int): Number of positive events\n n (int): Total number of trials\n confidence (float): The percentage of confidence that the 'true' value of\n positive events is within this confidence interval\"\"\"\n if n == 0:\n return 0\n z = norm.ppf(1 - (1 - confidence) / 2.0)\n phat = 1.0 * pos / n\n return (phat + z*z / (2 * n) - z * sqrt((phat * (1 - phat) + z * z / (4 * n)) / n)) / (1 + z*z / n)\n\n"
},
{
"alpha_fraction": 0.3308080732822418,
"alphanum_fraction": 0.4375,
"avg_line_length": 27.799999237060547,
"blob_id": "0773447592a270f4505dff7242af2f976a1b2526",
"content_id": "155d3aaf7d43d59672de2908cd3a63d6a077c593",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1585,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 55,
"path": "/goedel.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file goedel.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Thu Oct 16, 2014 10:57 EEST\n# Last Update: Thu Nov 13, 2014 09:25 SAST\n#------------------------------------------------------------------------\n# Description: Implementation of a simple pairing function using Gödel numbering. Code\n# taken from hbfs.wordpress.com/2011/09/27/pairing-functions/\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nfrom math import log\n\ndef godel(x,y):\n \"\"\"\n >>> godel(3, 81)\n 3547411905944302159585997044953199142424\n >>> godel(51, 29)\n 154541870963391800995410345984\n \"\"\"\n return (2**x)*(3**y)\n\ndef degodel_log(z):\n \"\"\"\n >>> degodel_log(3547411905944302159585997044953199142424)\n (3, 81)\n \"\"\"\n x, y = 0, 0\n\n ## \"Galloping\" phase:\n lo_y, hi_y = 0, 1\n while z % 3**hi_y == 0:\n lo_y = hi_y\n hi_y *= 2\n\n # OK, we know it's somewhere lo_y <= y < hi_y:\n while lo_y < hi_y:\n test_y = int((hi_y + lo_y + 1) / 2)\n if z % 3 ** test_y:\n hi_y = test_y - 1\n else:\n lo_y = test_y\n\n z /= 3**lo_y\n # Numerical stability issue here:\n x = int(log(z + 0.01, 2))\n return (x, lo_y)\n\nif __name__ == '__main__':\n import doctest\n fail, total = doctest.testmod()\n"
},
{
"alpha_fraction": 0.32005494832992554,
"alphanum_fraction": 0.35164836049079895,
"avg_line_length": 44.5,
"blob_id": "866058774e8b734ff2849e90f1e8a5f492bfe1c8",
"content_id": "8413a7617a9c1ec03c7c34d3105a395a251eabef",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 728,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 16,
"path": "/view.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file /Users/mfukar/src/mflib/view.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Sat Aug 01, 2015 09:44 EEST\n# Last Update: Sat Aug 01, 2015 09:45 EEST\n#------------------------------------------------------------------------\n# Description: Various ways to view & manipulate sequences\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\ndef rotate(seq, offset):\n return seq[offset:] + seq[:offset]\n"
},
{
"alpha_fraction": 0.4888888895511627,
"alphanum_fraction": 0.49953705072402954,
"avg_line_length": 28.189189910888672,
"blob_id": "7cd211560a4b47d8618c6a99450cb1b8c2b21366",
"content_id": "61c7d9fbce10f6f914fcb8716082975a92659ac5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2160,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 74,
"path": "/logger.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file mflib/logger.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Tue Jan 27, 2015 18:19 EET\n# Last Update: Mon Oct 30, 2017 10:54 CET\n#------------------------------------------------------------------------\n# Description: Useful constructs for logging\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\nimport sys\n\nclass duplicate_stdout():\n \"\"\"Context manager for temporarily duplicating stdout to a file. Like tee, but limited in scope.\n # How to duplicate help() to 'help.txt':\n with duplicate_stdout('help.txt', 'w'):\n help(ord)\n\n Not reusable, and not reentrant.\n \"\"\"\n def __init__(self, path, mode):\n self.path = path\n self.mode = mode\n self.stdout = sys.stdout\n\n def __enter__(self):\n self.fh = open(self.path, self.mode)\n return self\n\n def __exit__(self, *args):\n sys.stdout = self.stdout\n self.fh.flush()\n self.fh.close()\n\n def write(self, buffer):\n self.fh.write(buffer)\n self.stdout.write(buffer)\n\n def flush(self):\n self.fh.flush()\n\nclass duplicate_stderr():\n \"\"\"Context manager for temporarily duplicating stderr to a file. Like tee, but limited in scope.\n\n # How to duplicate sys.stderr.write to 'help.txt':\n with duplicate_stderr('help.txt', 'w'):\n sys.stderr.write(help(ord))\n\n Not reusable, and not reentrant.\n \"\"\"\n def __init__(self, path, mode):\n self.path = path\n self.mode = mode\n self.stderr = sys.stderr\n\n def __enter__(self):\n self.fh = open(self.path, self.mode)\n return self\n\n def __exit__(self, *args):\n sys.stderr = self.stderr\n self.fh.flush()\n self.fh.close()\n\n def write(self, buffer):\n self.fh.write(buffer)\n self.stderr.write(buffer)\n\n def flush(self):\n self.fh.flush()\n"
},
{
"alpha_fraction": 0.4275568127632141,
"alphanum_fraction": 0.4623579680919647,
"avg_line_length": 39.228572845458984,
"blob_id": "3d192894d641717fd9a2a486424dfe5c8dfc0db7",
"content_id": "eef3de93b104c2fbef5bd4ec412bb5cc5a363c82",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1408,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 35,
"path": "/levenshtein.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file levenshtein.py\n# @author Michael Foukarakis\n# @version 0.1\n# @date Created: Thu Oct 16, 2014 10:57 EEST\n# Last Update: Thu Oct 16, 2014 11:01 EEST\n#------------------------------------------------------------------------\n# Description: Levenshtein string distance implementation\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\n\ndef levenshtein(s1, s2):\n \"\"\"Returns the Levenshtein distance of S1 and S2.\n >>> levenshtein('aabcadcdbaba', 'aabacbaaadb')\n 6\n \"\"\"\n if len(s1) < len(s2):\n return levenshtein(s2, s1)\n if not s1:\n return len(s2)\n previous_row = range(len(s2) + 1)\n for i, c1 in enumerate(s1):\n current_row = [i + 1]\n for j, c2 in enumerate(s2):\n insertions = previous_row[j + 1] + 1 # j+1 instead of j since previous_row and current_row are one character longer\n deletions = current_row[j] + 1 # than s2\n substitutions = previous_row[j] + (c1 != c2)\n current_row.append(min(insertions, deletions, substitutions))\n previous_row = current_row\n\n return previous_row[-1]\n"
},
{
"alpha_fraction": 0.5141242742538452,
"alphanum_fraction": 0.5274415016174316,
"avg_line_length": 41,
"blob_id": "6a30af892aa7ee752f4cf6666e6921f8005712cf",
"content_id": "6d3fdbed6524426c14949af6054b21edcd372f64",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2478,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 59,
"path": "/tree_serialize.py",
"repo_name": "mfukar/mflib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# @file tree_serialize.py\n# @author Michael Foukarakis\n# @version 1.0\n# @date Created: Tue Oct 25, 2011 12:46 GTB Daylight Time\n# Last Update: Thu Oct 16, 2014 11:03 EEST\n#------------------------------------------------------------------------\n# Description: Tree serialization routines\n#------------------------------------------------------------------------\n# History: <+history+>\n# TODO: <+missing features+>\n#------------------------------------------------------------------------\n# -*- coding: utf-8 -*-\n#------------------------------------------------------------------------\n\ndef serialize_tree(root):\n \"\"\" Given a tree root node (some object with a 'data' attribute and a 'children'\n attribute which is a list of child nodes), serialize it to a list, each element of\n which is either a pair (data, has_children_flag), or None (which signals an end of a\n sibling chain).\n \"\"\"\n lst = []\n def serialize_aux(node):\n # Recursive visitor function\n if len(node.children) > 0:\n # The node has children, so:\n # 1. add it to the list & mark that it has children\n # 2. recursively serialize its children\n # 3. finally add a \"null\" entry to signal this node has no children\n lst.append((node.data, True))\n for child in node.children:\n serialize_aux(child)\n lst.append(None)\n else:\n # The node is child-less, so simply add it to\n # the list & mark that it has no children:\n lst.append((node.data, False))\n serialize_aux(root)\n return lst\n\ndef deserialize_tree(nodelist):\n \"\"\" Expects a node list of the form created by serialize_tree. Each entry in the list\n is either None or a pair of the form (data, has_children_flag).\n Reconstruct the tree back from it and return its root node.\n \"\"\"\n # The first item in the nodelist represents the tree root\n root = TreeNode(nodelist[0][0])\n parentstack = [root]\n for item in nodelist[1:]:\n if item is not None:\n # This node is added to the list of children of the current parent.\n node = TreeNode(item[0])\n parentstack[-1].children.append(node)\n if item[1]: # has children?\n parentstack.append(node)\n else:\n # end of children for current parent\n parentstack.pop()\n return root\n"
}
] | 11 |
rubenknol/mondo-ForeignCurrencySettle
|
https://github.com/rubenknol/mondo-ForeignCurrencySettle
|
73cd2b5a12e0e5c83c722a661cf89dc12759fd2f
|
571c51ce9857f139e149d20eae1a1ca590279556
|
75a93739c24545673df5f999ee8e9de47b1c6a81
|
refs/heads/master
| 2018-01-10T22:48:29.348886 | 2016-02-26T19:20:21 | 2016-02-26T19:20:21 | 52,602,341 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6402877569198608,
"alphanum_fraction": 0.6402877569198608,
"avg_line_length": 31.115385055541992,
"blob_id": "e7a871bc0d11249dd770e1e5688a9678a6bd8c0a",
"content_id": "90596c214c9f795e35c98046d2698739bc478e44",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 834,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 26,
"path": "/mondo/settle/client.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "import requests\nfrom requests.auth import AuthBase\n\n\nclass MondoAuth(AuthBase):\n def __init__(self, token):\n self.token = token\n\n def __call__(self, r):\n r.headers['Authorization'] = 'Bearer {}'.format(self.token)\n return r\n\n\nclass MondoClient:\n def __init__(self, token):\n self.auth = MondoAuth(token)\n\n def get_all_accounts(self):\n return requests.get('https://api.getmondo.co.uk/accounts', auth=self.auth).json()\n\n def get_all_transactions(self, account_id):\n return requests.get('https://api.getmondo.co.uk/transactions?account_id={}'.format(account_id),\n auth=self.auth).json()\n\n def get_transaction(self, transaction_id):\n return requests.get('https://api.getmondo.co.uk/transactions/{}'.format(transaction_id), auth=self.auth).json()"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.523809552192688,
"avg_line_length": 20,
"blob_id": "8a1f5c771fcb291db58b307f8502eb4a611e798b",
"content_id": "8822f451aaf3923a8c8625aba47d83d1b5a9d842",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 1,
"path": "/mondo/__init__.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "__author__ = 'rknol'\n"
},
{
"alpha_fraction": 0.7456230521202087,
"alphanum_fraction": 0.7476828098297119,
"avg_line_length": 22.707317352294922,
"blob_id": "7bd09ecc292a1229fd8be0301a5c8f7f4a2169fd",
"content_id": "7324291bde4f957422732c8af96d9315c6f75aa6",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 971,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 41,
"path": "/mondo/settle/cli.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "import click\nfrom .client import MondoClient\nfrom .config import MONDO_CLIENT_TOKEN\nfrom .models import Base\nfrom .database import engine, session\nfrom .application import SettledTransactionEngine\nimport sys\n\[email protected]()\ndef cli():\n pass\n\[email protected]()\ndef createdb():\n \"\"\"Create the database if non existing\"\"\"\n Base.metadata.create_all(engine)\n\n\[email protected]()\ndef resetdb():\n \"\"\"Re-create the database from scratch\"\"\"\n Base.metadata.drop_all(engine)\n Base.metadata.create_all(engine)\n\[email protected]()\ndef test():\n client = MondoClient(MONDO_CLIENT_TOKEN)\n application = SettledTransactionEngine(client, session)\n application.get_unsettled_transactions()\n\n\[email protected]()\ndef test2():\n client = MondoClient(MONDO_CLIENT_TOKEN)\n application = SettledTransactionEngine(client, session)\n application.update_transaction_settles()\n\ncli.add_command(test)\ncli.add_command(test2)\ncli.add_command(createdb)\ncli.add_command(resetdb)"
},
{
"alpha_fraction": 0.6308492422103882,
"alphanum_fraction": 0.6412478089332581,
"avg_line_length": 26.4761905670166,
"blob_id": "d6e2e917c1013317dfb00e6bb9f8fff637f6fd0c",
"content_id": "9bfe9a5d9b2ada3414b3fb6881224096d8ece4ec",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 21,
"path": "/setup.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "# Copyright (C) 2016, Gerbil Ltd. - All rights reserved.\n# This file is proprietary and confidential. For more information,\n# see the 'copyright.md' file, which is part of this source code package.\n\n\"\"\"\nSetuptools setup script\n\"\"\"\nfrom setuptools import setup\n\nsetup(name='mondo-settle',\n version='0.1',\n description='Gerbil VPN Node',\n author='Ruben Knol',\n author_email='[email protected]',\n license='Proprietary',\n packages=['mondo.settle'],\n entry_points='''\n [console_scripts]\n cli.py=mondo.settle.cli:cli\n ''',\n zip_safe=False)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.758865237236023,
"avg_line_length": 27.200000762939453,
"blob_id": "a6940502e3b3cb18c00b2b6a8742fe68b12077c7",
"content_id": "fb96711a2bfa55cff04bc950789a0aa91e38ffc9",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "click==6.3\n-e [email protected]:rubenknol/mondo-ForeignCurrencySettle.git@a04f013f8f2af974675197ee495a8df356219262#egg=mondo_settle\nrequests==2.9.1\nSQLAlchemy==1.0.12\nwheel==0.29.0\n"
},
{
"alpha_fraction": 0.6102771162986755,
"alphanum_fraction": 0.6120092272758484,
"avg_line_length": 47.11111068725586,
"blob_id": "f1b4a2e410c59e4969c41ef48cf24266e0020335",
"content_id": "4e9ddc114b754074ed9f9c48899f63d3e872a7e3",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1732,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 36,
"path": "/mondo/settle/application.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "from .models import Transaction\n\n\nclass SettledTransactionEngine:\n def __init__(self, mondo_client, db_session):\n self.mondo_client = mondo_client\n self.db_session = db_session\n\n def get_unsettled_transactions(self):\n accounts = self.mondo_client.get_all_accounts()['accounts']\n for transaction in self.mondo_client.get_all_transactions(accounts[0]['id'])['transactions']:\n if 'local_currency' in transaction and transaction['local_currency'] != 'GBP' \\\n and transaction['settled'] == '' and transaction['amount'] != 0:\n if self.db_session.query(Transaction).filter_by(tx_id=transaction['id']).count() != 0:\n # Don't process again\n continue\n\n self.db_session.add(Transaction(tx_id=transaction['id'], tx_date=transaction['created'],\n pre_settle_amount=transaction['amount'], local_currency_amount=transaction['local_amount'],\n currency=transaction['local_currency'], settled=False))\n\n self.db_session.commit()\n\n def update_transaction_settles(self):\n for transaction in self.db_session.query(Transaction).filter_by(settled=False):\n result = self.mondo_client.get_transaction(transaction.tx_id)['transaction']\n if result['settled'] != '':\n transaction.settled = True\n transaction.post_settle_amount = result['amount']\n transaction.settle_date = result['settled']\n\n print(\"Transaction '{}' has settled\".format(transaction.tx_id))\n else:\n print(\"Transaction '{}' has not settled\".format(transaction.tx_id))\n\n self.db_session.commit()\n"
},
{
"alpha_fraction": 0.7838709950447083,
"alphanum_fraction": 0.7838709950447083,
"avg_line_length": 43.42856979370117,
"blob_id": "693ec2a3ce2be9365d37ffb61b9d86f143eef931",
"content_id": "cd7984018f8dbb1a5de0b4b7a51330c4142124d3",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 7,
"path": "/mondo/settle/database.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "from sqlalchemy import create_engine\nfrom sqlalchemy.orm import sessionmaker\nfrom .config import DATABASE_ENGINE, DATABASE_HOSTNAME, DATABASE_NAME\n\nengine = create_engine('{}://{}/{}'.format(DATABASE_ENGINE, DATABASE_HOSTNAME, DATABASE_NAME), echo=False)\nSession = sessionmaker(bind=engine)\nsession = Session()"
},
{
"alpha_fraction": 0.6873767375946045,
"alphanum_fraction": 0.6962524652481079,
"avg_line_length": 32.83333206176758,
"blob_id": "406ad7e38f6710c76ea0eec398d581a400268cb5",
"content_id": "bb49cc222753f182347fa94a2b0eb35de19d74a3",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1014,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 30,
"path": "/mondo/settle/models.py",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "from sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy import Column, Integer, String, ForeignKey, Boolean, DateTime, Text\nfrom sqlalchemy.orm import relationship\n\nBase = declarative_base()\n\n\nclass Transaction(Base):\n __tablename__ = \"transactions\"\n\n id = Column(Integer, primary_key=True)\n tx_id = Column(Integer)\n tx_date = Column(String(255))\n settle_date = Column(String(255))\n currency = Column(String(255))\n settled = Column(Boolean)\n pre_settle_amount = Column(Integer)\n post_settle_amount = Column(Integer)\n local_currency_amount = Column(Integer)\n\n def get_initial_rate(self):\n return self.local_currency_amount / self.pre_settle_amount\n\n def get_final_rate(self):\n if not self.settled:\n raise Exception('Cannot determine final rate until transaction has settled')\n return self.local_currency_amount / self.post_settle_amount\n\n def __repr__(self):\n return '<Transaction {},{}>'.format(self.tx_id, self.settled)"
},
{
"alpha_fraction": 0.8604651093482971,
"alphanum_fraction": 0.8604651093482971,
"avg_line_length": 85,
"blob_id": "311c2a5e456748dfe29c266aba56b9d51b4c5be1",
"content_id": "9dc4f685e096e30609ebb51b346b61e9f4bcadad",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 172,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 2,
"path": "/README.md",
"repo_name": "rubenknol/mondo-ForeignCurrencySettle",
"src_encoding": "UTF-8",
"text": "# mondo-ForeignCurrencySettle\nExperiment with the Mondo API to capture differences between initial currency conversion rate and post-settled final currency conversion rate\n"
}
] | 9 |
drsteve/SWMFtools
|
https://github.com/drsteve/SWMFtools
|
537afc06ff470382c1c5416f61879951450c4cb8
|
2b0d997cd7d4a5c4110796a3eebdc1d4e65955bc
|
3fa9ac6a69a4c54b33f32b7de01496522e02f1a4
|
refs/heads/master
| 2022-11-27T23:57:29.296073 | 2022-11-22T17:16:51 | 2022-11-22T17:16:51 | 196,270,842 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.607523500919342,
"alphanum_fraction": 0.6489028334617615,
"avg_line_length": 40.97368240356445,
"blob_id": "77c49b4a262323abaaaf293377cfaf4aeba80d15",
"content_id": "e74809ed16dd4a5418997798d4111160ec66060f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3190,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 76,
"path": "/event_selection/stitchIMF.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport datetime as dt\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport spacepy.time as spt\nimport spacepy.toolbox as tb\nimport spacepy.datamodel as dm\nfrom spacepy import pybats\nimport missing # taken from advect1d\n\ndef loadIMFdata(evnum, fform='IMF_rc{:03d}_*.dat', datadir='.'):\n # select file given event number\n datapath = os.path.abspath(datadir)\n gterm = os.path.join(datapath, fform.format(evnum))\n fnl = glob.glob(gterm)[0]\n # load datafile and make time relative to start\n imfdata = pybats.ImfInput(fnl)\n imfdata['time'] = imfdata['time'] - imfdata['time'][0]\n return imfdata\n\n# TODO\n# add argument parser\n# Take event numbers as args and stitch together in order\nif __name__ == '__main__':\n events = [57, 103, 156, 259, 443] # original chrono order\n events = [57, 78, 103, 156, 259] # slow SW substituted, chrono\n events = [1, 57, 103, 156, 259]\n #events = [152, 253, 258, 266, 295] # original chrono order NEK\n #events = [443, 156, 259, 57, 103] # initial random select\n # If we want a random ordering, uncomment next line\n #events = np.random.choice(events, len(events), replace=False)\n\n\n datalist = []\n for ev in events:\n datalist.append(loadIMFdata(ev))\n\n # now loop over events and adjust times\n starttime = dt.datetime(1999, 6, 1)\n f107 = 170 # not using here, but noted for use in PARAM file(s)\n for data in datalist:\n lsttime = data['time'][-1]\n hr6 = dt.timedelta(hours=12)\n trail6 = tb.tOverlapHalf([lsttime-hr6, lsttime], data['time'])\n if data['ux'][trail6[0]] < data['ux'][-1]:\n for key in data:\n data[key] = data[key][:trail6[0]]\n data['time'] = data['time'] + starttime\n starttime = data['time'][-1] + dt.timedelta(hours=3)\n\n # append in order\n imfdata = datalist[0]\n keylist = list(imfdata.keys())\n for data in datalist[1:]:\n for key in keylist:\n imfdata[key] = dm.dmarray.concatenate(imfdata[key], data[key])\n\n # find gaps and fill with badval, then do noisy gap filling\n keylist.pop(keylist.index('time'))\n keylist.pop(keylist.index('pram'))\n newtime = spt.tickrange(imfdata['time'][0], imfdata['time'][-1], dt.timedelta(minutes=1))\n innew, inold = tb.tCommon(newtime.UTC, imfdata['time'], mask_only=True)\n synthdata = pybats.ImfInput(filename=False, load=False, npoints=len(newtime))\n synthdata['time'] = newtime.UTC\n for key in keylist:\n synthdata[key] = dm.dmfilled(len(newtime), fillval=-999)\n synthdata[key][innew] = imfdata[key][inold]\n cval = True if key == 'rho' else False\n # missing.fill_gaps currently adds noise to linear interp.\n # possibly replace with \"sigmoid_like\" interpolation\n # see reddit.com/r/gamedev/comments/4xkx71/sigmoidlike_interpolation/\n synthdata[key] = missing.fill_gaps(synthdata[key], fillval=-999, noise=True, constrain=cval, method='sigmoid')\n synthdata.quicklook()\n plt.savefig('IMF_stitched_{:03d}_{:03d}_{:03d}_{:03d}_{:03d}.png'.format(*events))\n synthdata.write('IMF_stitched_{:03d}_{:03d}_{:03d}_{:03d}_{:03d}.dat'.format(*events))\n"
},
{
"alpha_fraction": 0.6081436276435852,
"alphanum_fraction": 0.6234676241874695,
"avg_line_length": 39.78571319580078,
"blob_id": "3fc8e2138462b3b5a53363e93e416268af4435a5",
"content_id": "2a31df7859c8617b12926b5efe2c6ea458b7ef14",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4568,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 112,
"path": "/perturbedinput/perturbplot.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport spacepy.plot as splot\n\nspace = ' '\n\ndef roundUpTo(inval, onein=10):\n '''Round input value UP to nearest (1/onein).\n \n E.g., to get 0.0795 to nearest 0.01 (above), use roundUpTo(0.0795, 100)\n to get 0.51 to nearest 0.1, use roundUpTo(0.51, 10)'''\n return np.ceil(inval*onein)/onein\n\ndef plotMesh(xx, yy, zz, cmap='plasma', target=None, horiz=False):\n fig, ax = splot.set_target(target)\n orient = 'horizontal' if horiz else 'vertical'\n map_ax = ax.pcolormesh(xx, yy, zz, cmap=cmap)\n cax = fig.colorbar(map_ax, ax=ax, orientation=orient)\n m0 = 0 # colorbar min value\n ntens = 10 if (1/cax.vmax <= 10) else 100\n m5 = roundUpTo(cax.vmax, ntens) # colorbar max value\n num_ticks = 5\n newticks = np.linspace(m0, m5, num_ticks)\n cax.set_ticks(newticks.tolist())\n cax.set_ticklabels(['{:.2f}'.format(x) for x in newticks.tolist()])\n return ax, cax\n\ndef errorHist2D(errors, depend, plotinfo, cmap='plasma'):\n var = plotinfo['var']\n fig = plt.figure()\n ax = fig.add_subplot(111)\n map_ax = ax.hexbin(errors, depend, mincnt=1, cmap=cmap)\n ax.set_xlim(plotinfo['xlimdict'][var])\n ax.set_xlabel(r'$\\varepsilon$' + space + plotinfo['units'][var])\n ax.set_ylim(plotinfo['ylimdict'][var])\n ax.set_ylabel(plotinfo['varlabel'] + space + plotinfo['units'][var])\n cax = fig.colorbar(map_ax)\n caxlabel = 'Count'\n cax.set_label(caxlabel)\n if 'altvar' in plotinfo:\n plt.savefig('Err_hexbin_{}_{}_{}.png'.format(plotinfo['err'], var, plotinfo['altvar']))\n else:\n plt.savefig('Err_hexbin_{}_{}.png'.format(plotinfo['err'], var))\n plt.close(fig)\n\ndef errorJointKDE2D(xx, yy, zz, plotinfo, cmap='plasma'):\n var = plotinfo['var']\n ax, cax = plotMesh(xx, yy, zz, cmap=cmap)\n fig = ax.figure\n ax.set_xlim(plotinfo['xlimdict'][var])\n ax.set_xlabel(r'$\\varepsilon$' + space + plotinfo['units'][var])\n ax.set_ylim(plotinfo['ylimdict'][var])\n ax.set_ylabel(plotinfo['varlabel'] + space + plotinfo['units'][var])\n caxlabel = r'P($\\varepsilon$, '+ plotinfo['varlabel'] +')'\n cax.set_label(caxlabel)\n\n if 'altvar' in plotinfo:\n plt.savefig('Err_joint_distrib_{}_{}_{}.png'.format(plotinfo['err'], var, plotinfo['altvar']))\n else:\n plt.savefig('Err_joint_distrib_{}_{}.png'.format(plotinfo['err'], var))\n plt.close(fig)\n\ndef errorCondKDE2D(xx, yy, zz, plotinfo, cmap='plasma', target=None, save=True):\n var = plotinfo['var']\n hflag = True if (target is not None) else False\n ax, cax = plotMesh(xx, yy, zz, cmap=cmap, target=target, horiz=hflag)\n fig = ax.figure\n if 'annot' in plotinfo:\n ax.text(0.1, 0.9, plotinfo['annot'], fontdict={'color': 'w', 'size': 15}, transform=ax.transAxes)\n ax.set_xlim(plotinfo['xlimdict'][var])\n ax.set_xlabel(r'$\\varepsilon$' + space + plotinfo['units'][var])\n ax.set_ylim(plotinfo['ylimdict'][var])\n ax.set_ylabel(plotinfo['varlabel'] + space + plotinfo['units'][var])\n cax.set_label(r'p($\\varepsilon$|'+ plotinfo['varlabel'] +')')\n if save:\n if 'altvar' in plotinfo:\n plt.savefig('Err_conditional_{}_{}_{}.png'.format(plotinfo['err'], var, plotinfo['altvar']))\n else:\n plt.savefig('Err_conditional_{}_{}.png'.format(plotinfo['err'], var))\n plt.close(fig)\n else:\n return fig, ax, cax\n\ndef plotMarginal(x, marginal, plotinfo):\n var = plotinfo['var']\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.plot(x, marginal)\n ax.set_xlim(plotinfo['ylimdict'][var])\n ax.set_xlabel(plotinfo['varlabel'] + space + plotinfo['units'][var])\n ymax = ax.get_ylim()[1]\n ax.set_ylim([0, ymax])\n ax.set_ylabel('Probability Density')\n plt.title('Marginal Probability, P('+ plotinfo['varlabel'] +')')\n plt.tight_layout()\n if 'altvar' in plotinfo:\n plt.savefig('Err_marginal_{}_{}_{}.png'.format(plotinfo['err'], var, plotinfo['altvar']))\n else:\n plt.savefig('Err_marginal_{}_{}.png'.format(plotinfo['err'], var))\n plt.close(fig)\n\ndef plotSelectionTimestep(x, y, val, plotinfo, run_num, timestep):\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.plot(x, y)\n ax.vlines(val, 0, 1, transform=ax.get_xaxis_transform(), colors='r')\n ax.set_ylim([0, plotinfo['plim']])\n ax.set_xlim(plotinfo['xlimdict'][plotinfo['var']])\n ax.set_xlabel(plotinfo['errlabel']+plotinfo['varlabel'])\n plt.savefig('{}_step{:02d}.png'.format(plotinfo['var'], timestep))\n plt.close(fig)\n"
},
{
"alpha_fraction": 0.6241310834884644,
"alphanum_fraction": 0.6727904677391052,
"avg_line_length": 40.95833206176758,
"blob_id": "a25bf0f42374a93efdf30c1be6604f938907faf3",
"content_id": "2e6c8555993f62f563af756d0b28d9dd9978bf68",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2014,
"license_type": "permissive",
"max_line_length": 162,
"num_lines": 48,
"path": "/dBdt/plot_dBdt.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import datetime as dt\nimport numpy as np\nfrom scipy import linalg\nfrom scipy.signal import decimate\nimport matplotlib.pyplot as plt\nimport spacepy.toolbox as tb\nimport spacepy.plot as splot\nimport spacepy.pybats.bats\nimport supermag_parser\nsplot.style('default')\ntry:\n assert origdata\nexcept:\n origdata = spacepy.pybats.bats.MagFile('magnetometers_e20000812-010000.mag')\n origdata.calc_h()\n origdata.calc_dbdt()\n\nsmdata = supermag_parser.supermag_parser('supermag-20000810-20000812.txt')\n\nstations = ['YKC', 'MEA', 'NEW', 'FRN', 'IQA', 'PBQ', 'OTT', 'FRD', 'VIC']\nstations = [key for key in origdata.keys() if len(key)==3]\n\nfor stat in stations:\n if stat not in smdata.station: continue\n subset = origdata[stat]\n simtime = subset['time'][::6]\n dBdte = decimate(subset['dBdte'], 6)\n dBdtn = decimate(subset['dBdtn'], 6)\n dBdth = np.array([linalg.norm([dBdtn[i], dBdte[i]]) for i in range(len(dBdtn))])\n smstat = smdata.station[stat]\n Bdoth = np.array([linalg.norm(smstat['Bdot'][i,:2]) for i in range(len(smstat['Bdot']))])\n fig = plt.figure(figsize=(10,4))\n ax = fig.add_subplot(111)\n ax.plot(simtime, dBdth, 'b-', alpha=0.4)\n ax.plot(smstat['time'], Bdoth, 'r-', alpha=0.4)\n run20, t20 = tb.windowMean(dBdth, time=simtime, winsize=dt.timedelta(minutes=20), overlap=dt.timedelta(0), st_time=dt.datetime(2000,8,12,1), op=np.max)\n ax.plot(t20, run20, marker='o', color='b', linestyle='none', markersize=3, label='SWMF')\n obs20, t20 = tb.windowMean(Bdoth, time=smstat['time'], winsize=dt.timedelta(minutes=20), overlap=dt.timedelta(0), st_time=dt.datetime(2000,8,12,1), op=np.max)\n ax.plot(t20, obs20, marker='x', color='r', linestyle='none', markersize=3, label='Obs')\n ax.set_ylabel('1-min dB/dt$_{H}$ [nT/s]')\n ax.set_xlabel('2000-08-12')\n splot.applySmartTimeTicks(ax, subset['time'], dolimit=True)\n plt.legend()\n plt.title(stat)\n plt.tight_layout()\n #plt.show()\n plt.savefig('Aug2000_dBdth_{}.png'.format(stat))\n plt.close()\n"
},
{
"alpha_fraction": 0.5901960730552673,
"alphanum_fraction": 0.5954902172088623,
"avg_line_length": 38.238460540771484,
"blob_id": "822249b5a4a6e6853f993877be2e3d104d946665",
"content_id": "f4fcb0fcebf9b0711684ec00a45f231a35bc8897",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5100,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 130,
"path": "/event_selection/scrapeRC.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import requests\nimport re\nimport datetime as dt\nfrom functools import partial\nimport numpy as np\nimport spacepy.datamodel as dm\nfrom bs4 import BeautifulSoup\n\n# first grab the HTML from the website\nrc_url = 'http://www.srl.caltech.edu/ACE/ASC/DATA/level3/icmetable2.htm'\n\n# If the proxies are set correctly in the environment, then\n# the \"get\" request should just work. If having problems,\n# set the proxy explicitly.\n# proxies = {'http': \"http://proxy.goes.here:port\"\n# 'https': \"http://proxy.goes.here:port\"\n# }\n# html = requests.get(rc_url, proxies=proxies)\nhtml = requests.get(rc_url)\n\n# make a parser with BS4 and get header and data rows\nsoup = BeautifulSoup(html.text, 'html.parser')\n# header is first element\ntable_header = soup.find(\"tr\")\n# each data row has a date in the first cell\ndata = [[cell.get_text(strip=True) for cell in row.find_all('td')]\n for row in soup.find_all('tr') if row.find(\"td\", string=re.compile(r'\\d{4}/\\d'))]\n\n\n# Now clean each row to extract dates/times and properties. Replace all '...' with NaN\ndef parse_date(instr):\n \"\"\"input format 'YYYY/MM/DD HHMM'\n \"\"\"\n tstr = instr.split(\"(\")[0]\n time = dt.datetime.strptime(tstr, '%Y/%m/%d %H%M')\n return time\n\n\ndef dvint(instr, value=True):\n \"\"\"get delta-V, or shock marker\"\"\"\n if 'S' in instr:\n shock = 1\n else:\n shock = 0\n vstr = instr.split()[0]\n try:\n val = np.int(vstr)\n except ValueError:\n val = np.nan\n if value:\n return val\n else:\n return shock\n\n\ndef parse_row(jdx, inrow, datadict):\n \"\"\"change formatting/type of each row element\n \"\"\"\n dvshock = partial(dvint, value=False)\n fields = [('Epoch', 0, parse_date),\n ('ICME_start', 1, parse_date),\n ('ICME_end', 2, parse_date),\n ('deltaV', 10, dvint), ('Shock', 10, dvshock),\n ('V_avg', 11, np.float),\n ('V_max', 12, np.float),\n ('B_avg', 13, np.float),\n # 'MC', 'Dst'\n ]\n for finame, idx, func in fields:\n datadict[finame][jdx] = func(inrow[idx])\n\n\n# Organize output for writing to JSON-headed ASCII\nnelem = len(data)\nhcells = table_header.find_all('td')\noutdata = dm.SpaceData(attrs={'DESCRIPTION': soup.find('title').get_text().strip(),\n 'SOURCE': rc_url,\n 'CREATION_DATE': dt.datetime.now().isoformat()})\n# All the time values\noutdata['Epoch'] = dm.dmfilled(nelem, fillval=np.nan, dtype=object,\n attrs={'DESCRIPTION': hcells[0].get_text(strip=True)})\noutdata['ICME_start'] = dm.dmfilled(nelem, fillval=np.nan, dtype=object,\n attrs={'DESCRIPTION': hcells[1].get_text(strip=True)})\noutdata['ICME_end'] = dm.dmfilled(nelem, fillval=np.nan, dtype=object,\n attrs={'DESCRIPTION': hcells[1].get_text(strip=True)})\n# And now the other variables we're interested in\n\n# outdata['Comp_start'] = dm.dmfilled(nelem, fillval=np.nan, dtype=object)\n# outdata['Comp_end'] = dm.dmfilled(nelem, fillval=np.nan, dtype=object)\n# # Offset (hours) from Lepping- or Huttunen-reported times\n# outdata['MC_start_offset'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.int)\n# outdata['MC_end_offset'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.int)\n# # Bidirectional streaming electrons\n# outdata['BDE'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.int)\n# # Bidirectional Ion Flows\n# outdata['BIF'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.int)\n\n# ICME characteristics\noutdata['deltaV'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.float,\n attrs={'DESCRIPTION': 'Increase in V at upstream disturbance',\n 'UNITS': 'km/s'})\noutdata['Shock'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.int,\n attrs={'DESCRIPTION': 'Fast forward shock reported? 1 is True, 0 is False'})\noutdata['V_avg'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.float,\n attrs={'DESCRIPTION': 'Mean ICME speed',\n 'UNITS': 'km/s'})\noutdata['V_max'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.float,\n attrs={'DESCRIPTION': 'Max solar wind speed during ICME',\n 'UNITS': 'km/s'})\noutdata['B_avg'] = dm.dmfilled(nelem, fillval=np.nan, dtype=np.float,\n attrs={'DESCRIPTION': 'Mean magnetic field strength in ICME',\n 'UNITS': 'nT'})\n\n# Parse each row and fill target arrays\nbadrow = []\nfor idx, row in enumerate(data):\n try:\n parse_row(idx, row, outdata)\n except ValueError:\n badrow.append(idx)\n\n# remove bad rows\nodkeys = outdata.keys()\nfor odk in odkeys:\n outdata[odk] = np.delete(outdata[odk], badrow)\n\n# Write to ASCII\nvarorder = ['Epoch', 'ICME_start', 'ICME_end', 'deltaV', 'Shock', 'V_avg',\n 'V_max', 'B_avg']\noutdata.toJSONheadedASCII('richardson_cane_ICME_list.txt', order=varorder)"
},
{
"alpha_fraction": 0.5904186964035034,
"alphanum_fraction": 0.5970012545585632,
"avg_line_length": 34.283870697021484,
"blob_id": "f64241ca6539f9530f8313a2114f8ee3e3c78096",
"content_id": "ff529814d5184f3120f70454e7d622182a801b14",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5469,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 155,
"path": "/viz/BATS2DtoVTP.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import argparse\nfrom collections import OrderedDict\nimport datetime as dt\nimport os\nimport re\nimport sys\nimport numpy as np\nimport spacepy.datamodel as dm\nimport spacepy.pybats.bats as bts\nimport pyvista as pv\nimport vtk\n\n\ndef timeFromFilename(outname):\n '''Get timestamp from SWMF/BATSRUS output file\n\n Supports \"_e\" and \"_t\" naming conventions.\n If both are present, it will use \"_e\" by preference.\n Precision is currently to the nearest second.\n '''\n tsrch = \".*_t(\\d{4})(\\d{2})(\\d{2})(\\d{2})(\\d{2})(\\d{2})\"\n esrch = \".*_e(\\d{4})(\\d{2})(\\d{2})-(\\d{2})(\\d{2})(\\d{2})\"\n if '_t' in outname or '_e' in outname:\n srch = esrch if '_e' in outname else tsrch\n tinfo = re.search(srch, outname).groups()\n tinfo = [val for val in map(int, tinfo)]\n else:\n raise NotImplementedError('Only \"_t\" and \"_e\" format times are supported')\n\n dtobj = dt.datetime(*tinfo)\n return dtobj\n\n\ndef mergeComponents(vecx, vecy, vecz, zeroy=False, zeroz=False):\n '''Return 3-vectors merged from compnents\n\n Parameters\n ----------\n vecx : array\n X-components of vector\n vecy : array\n Y-components of vector\n vecz : array\n Z-components of vector\n \n Other Parameters\n ----------------\n zeroy : bool\n Default False. If True, set Y-components to zero.\n zeroz : bool\n Default False. If True, set Z-components to zero.\n '''\n vecy = vecy if zeroy else np.zeros(len(vecy))\n vecz = vecz if zeroz else np.zeros(len(vecz))\n combined = np.c_[vecx, vecy, vecz]\n return combined\n\n\ndef convertOneFile(fname, triangulate=True, make_vectors=True, keep_components=False):\n '''Convert a single file from BATSRUS 2D to VTP\n\n Parameters\n ----------\n fname : str\n Filename to convert to VTP\n \n Other Parameters\n ----------------\n triangulate : bool\n If True, return a 2D Delaunay triangulation of the data. If False\n just return the point mesh. Default is True.\n make_vectors : bool\n If True, combine vector state variables in VTK vectors. Default is True.\n keep_components : bool\n If True, keep components of vector state variables as scalars in output files.\n Default is False. Warning: Setting this as False while make_vectors is False\n will remove vector quantities from the output VTP files.\n '''\n # load BATSRUS 2D file\n data = bts.Bats2d(fname)\n outname = os.path.splitext(fname)[0]\n # set output filename\n fname = '.'.join((outname, 'vtp'))\n\n # Initialize the VTK object\n # Should work on y=0 and z=0 slices, probably also 3D IDL.\n # Won't work on x=0 or arbitrary slice... (yet)\n xs = data['x']\n vec_dict = {'zeroy': False, 'zeroz': False}\n if 'y' in data and 'z' not in data:\n ys = data['y']\n zs = np.zeros(len(xs))\n vec_dict['zeroz'] = True\n elif 'y' not in data and 'z' in data:\n ys = np.zeros(len(xs))\n zs = data['z']\n vec_dict['zeroy'] = True\n else: # Input data is probably 3D, but this should still work (untested)\n ys = data['y']\n zs = data['z']\n\n points = np.c_[xs, ys, zs]\n point_cloud = pv.PolyData(points)\n\n if 'jx' in data:\n if keep_components:\n point_cloud[\"jx\"] = data[\"jx\"]\n point_cloud[\"jy\"] = data[\"jy\"]\n point_cloud[\"jz\"] = data[\"jz\"]\n if make_vectors:\n point_cloud['jvec_inplane'] = mergeComponents(data[\"jx\"], data[\"jy\"], data[\"jz\"], **vec_dict)\n if 'bx' in data:\n if keep_components:\n point_cloud[\"bx\"] = data[\"bx\"]\n point_cloud[\"by\"] = data[\"by\"]\n point_cloud[\"bz\"] = data[\"bz\"]\n if make_vectors:\n point_cloud['bvec_inplane'] = mergeComponents(data[\"bx\"], data[\"by\"], data[\"bz\"], **vec_dict)\n if 'ux' in data:\n if keep_components:\n point_cloud[\"ux\"] = data[\"ux\"]\n point_cloud[\"uy\"] = data[\"uy\"]\n point_cloud[\"uz\"] = data[\"uz\"]\n if make_vectors:\n point_cloud['uvec_inplane'] = mergeComponents(data[\"ux\"], data[\"uy\"], data[\"uz\"], **vec_dict)\n if 'rho' in data:\n point_cloud[\"rho\"] = data[\"rho\"]\n if 'p' in data:\n point_cloud[\"p\"] = data[\"p\"]\n\n # Convert from points mesh to connected mesh using triangulation\n if triangulate:\n point_cloud.delaunay_2d(tol=1e-05, alpha=0.0, offset=1.0, bound=False, inplace=True, edge_source=None, progress_bar=False)\n\n # write to binary XML output\n point_cloud.save(fname)\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Convert BATS-R-US 2D IDL files to VTP (VTK point data)')\n parser.add_argument('--silent', action='store_true')\n parser.add_argument('inputfiles', nargs='+', help='Input files (can use wildcards, shell will expand)')\n args = parser.parse_args()\n silent = args.silent\n for batlname in args.inputfiles:\n bname, ext = os.path.splitext(batlname)\n if os.path.isdir(batlname):\n if not silent: print('Input file {0} appears to be a directory. Skipping'.format(batlname))\n elif not ext.lower()=='.out':\n if not silent: print('Input file {0} may not be a BATS-R-US file. Skipping'.format(batlname))\n else:\n try:\n convertOneFile(batlname)\n except IOError:\n if not silent: print(\"Unexpected error processing {0}:\".format(batlname), sys.exc_info()[0])\n"
},
{
"alpha_fraction": 0.5818965435028076,
"alphanum_fraction": 0.5917788147926331,
"avg_line_length": 34.49253845214844,
"blob_id": "001605ce2eb5e76078c77a2f464e0e91252d531d",
"content_id": "627f3ace4dacd3d2f9e7f43baa0a75fe2df27018",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9512,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 268,
"path": "/event_selection/SWMFfromOMNI.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "# Standard Lib\nimport re\nimport datetime as dt\n# Scientific Stack\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n# Third-party\nimport spacepy.datamodel as dm\nfrom spacepy import pybats\nimport spacepy.plot as splot\nimport mechanize\n\n\ndef make_imf_input(indata, fname=None, keylist=None):\n \"\"\"Make an SWMF IMF input file from an input SpaceData\"\"\"\n if keylist is None:\n keylist = ['time', 'bx', 'by', 'bz', 'ux', 'uy', 'uz', 'n', 't']\n numpts = indata['time'].shape[0]\n swmfdata = pybats.ImfInput(filename=False, load=False, npoints=numpts)\n naninds = set()\n for key in keylist:\n if key == 'time':\n # convert numpy datetime64 to python datetime\n swmfdata[key] = dm.dmarray(indata['time'].astype('M8[ms]').astype('O'))\n else:\n swmfdata[key] = dm.dmcopy(indata[key])\n naninds.update(np.where(np.isnan(swmfdata[key]))[0])\n # cull rows that have nan entries, SWMF will interpolate between\n # entries linearly. We can revisit this to use a noisy fill method if required\n naninds = np.array(sorted(list(naninds)))\n allkeys = list(swmfdata.keys())\n for key in allkeys:\n swmfdata[key] = np.delete(swmfdata[key], naninds)\n swmfdata.attrs['coor'] = 'GSE'\n if fname is not None:\n swmfdata.write(fname)\n return swmfdata\n\n\ndef clean_OMNI(omarray, varname):\n \"\"\"Given an array of OMNI data, replace the fill values with NaN\n \"\"\"\n if 'velocity' in varname.lower() or varname in ['ux', 'uy', 'uz']:\n thr = 9999\n elif varname.startswith('B') or varname in ['bx', 'by', 'bz']:\n thr = 999\n elif 'density' in varname.lower() or varname.startswith('rho'):\n thr = 999\n elif 'temp' in varname.lower():\n thr = 9999999\n elif varname.lower().startswith('al') or varname.lower().startswith('sym'):\n thr = 99999\n elif 'pressure' in varname.lower() or varname in ['p_dyn']:\n thr = 99\n else:\n thr = None\n if isinstance(omarray, pd.Series) and thr is not None:\n omarray = omarray.mask(omarray >= thr)\n elif isinstance(omarray, dm.dmarray) and thr is not None:\n omarray = omarray.astype(float)\n omarray[omarray >= thr] = np.nan\n\n return omarray\n\n\ndef map_names(indata):\n \"\"\"Change names of variables in record array\"\"\"\n # Copy names for iteration as we can't change something while we're\n # iterating over it\n fieldnames = dm.dmcopy(indata.dtype.names)\n newnames = []\n for name in fieldnames:\n if 'vx' in name.lower():\n newnames.append('ux')\n elif 'vy' in name.lower():\n newnames.append('uy')\n elif 'vz' in name.lower():\n newnames.append('uz')\n elif 'bx' in name.lower():\n newnames.append('bx')\n elif 'by' in name.lower():\n newnames.append('by')\n elif 'bz' in name.lower():\n newnames.append('bz')\n elif 'sym' in name.lower():\n newnames.append('sym-h')\n elif 'density' in name.lower():\n newnames.append('n')\n elif 'temperature' in name.lower():\n newnames.append('t')\n elif 'pressure' in name.lower():\n newnames.append('p_dyn')\n elif name == 'date':\n newnames.append('time')\n else:\n newnames.append(name.lower())\n\n indata.dtype.names = newnames\n\n return indata\n\n\ndef get_OMNI(start_date, end_date, as_pandas=True):\n \"\"\"\n Retrieve OMNI data and format info from omniweb website\n\n Arguments\n ---------\n start_date : string\n Start date for data interval in YYMMDDHH format\n end_date : string\n End date for data interval in YYMMDDHH format\n as_pandas : boolean\n Set True to return pandas dataframe, False returns a SpaceData\n\n Returns\n -------\n dl_fmt : string\n Temporary filename for OMNI format description file\n dl : string\n Temporary filename for OMNI data file\n \"\"\"\n br = mechanize.Browser()\n # set form variables for OMNIWeb\n br.open('https://omniweb.gsfc.nasa.gov/form/omni_min.html')\n br.select_form(name=\"frm\")\n br['activity'] = ['ftp']\n br['res'] = ['min']\n br['start_date'] = start_date\n br['end_date'] = end_date\n br['vars'] = ['22', # Vx Velocity, GSE, km/s\n '23', # Vy Velocity, GSE, km/s\n '24', # Vz Velocity, GSE, km/s\n '14', # Bx, GSE, nT\n '15', # By, GSE, nT\n '16', # Bz, GSE, nT\n '25', # Proton Density, cm^{-3}\n '26', # Proton Temperature, K\n '27', # Flow pressure, nPa\n '38', # AL index, nT\n '41'] # Sym/H, nT\n\n # submit OMNIWeb form\n resp = br.submit()\n\n # Find links to download data and download it\n data_link = br.find_link(text_regex=re.compile(\".lst\")).url\n fmt_link = br.find_link(text_regex=re.compile(\".fmt\")).url\n dl = br.retrieve(data_link)[0]\n dl_fmt = br.retrieve(fmt_link)[0]\n\n # Read column names from .fmt file\n colnames = []\n with open(dl_fmt, 'r') as fh:\n fmt_info = fh.readlines()\n for line in fmt_info[4:]:\n colnames.append(' '.join(line.split()[1:-1]))\n\n # Read data from .lst file, format date\n df = pd.read_table(dl, header=None, delim_whitespace=True, names=colnames, parse_dates=[[0, 1, 2, 3]])\n df['date'] = df['Year_Day_Hour_Minute'].apply(lambda x: dt.datetime.strptime(x, '%Y %j %H %M'))\n if not as_pandas:\n recs = df.to_records()\n # map names to be more useful\n recs = map_names(recs)\n outdata = dm.fromRecArray(recs)\n else:\n outdata = df\n\n # Close browser to clean up temp files\n br.close()\n\n return outdata\n\n\ndef make_plot(plotrange, eventrange, df, show=True):\n \"\"\"\n Make summary plot and either show (default) or save\n\n Arguments\n ---------\n plotrange : tuple of strings\n String timestamps for start and end of data interval\n eventrange : tuple of datetimes\n Datetimes marking iCME interval for highlighting\n \"\"\"\n # TODO: update to use sharex and tidy time axis, labels, etc.\n start_date, end_date = plotrange\n start_datetime, end_datetime = eventrange\n fig, axes = plt.subplots(nrows=4, ncols=1, sharex=True, figsize=(12, 16))\n params_omni = ['BZ, nT (GSM)', 'Vx Velocity,km/s', 'Flow pressure, nPa', 'SYM/H, nT']\n params_sd = ['bz', 'ux', 'p_dyn', 'sym-h']\n labels = ['B$_{Z}^{GSM}$ [nT]', 'V$_{X}$ [km/s]', 'P$_{dyn}$', 'SYM-H [nT]']\n param = params_omni if isinstance(df, pd.DataFrame) else params_sd\n tvar = 'date' if isinstance(df, pd.DataFrame) else 'time'\n for par, cax, lab in zip(param, axes, labels):\n sns.lineplot(x=tvar, y=par, data=df, ax=cax)\n if tvar == 'time':\n cax.set_ylabel(lab)\n cax.axvspan(start_datetime, end_datetime, alpha=0.2, color='yellow')\n dolabel = True if par == 'sym-h' else False\n splot.applySmartTimeTicks(cax, df[tvar].astype('M8[ms]').astype('O'), dolabel=dolabel)\n fig.suptitle('RC event {} - {}'.format(start_date, end_date))\n if show:\n plt.show()\n else:\n plt.savefig('omni_rc_{}_{}.png'.format(start_date, end_date))\n plt.close()\n\n\nif __name__ == '__main__':\n # User defined settings\n generate_plots = True # Make summary plot for each event?\n show_plot = False # True for display, False for save to file\n save_pickle = False # Save a pickle of Pandas dataframes\n save_data = True # Save data to HDF5 and SWMF ImfInput\n subset = 1 # None # Number of events (starting from end) -- None to do everything\n\n # default behavior is to use pandas and save to a pickle\n panda = True if save_pickle else False\n\n # hijack rc data with event range\n rc_data = dm.SpaceData()\n rc_data['ICME_start'] = dm.dmarray([dt.datetime(2017, 5, 27)])\n rc_data['ICME_end'] = dm.dmarray([dt.datetime(2017, 5, 29)])\n n_events = len(rc_data['ICME_start'])\n\n # Empty list to store output data frames if save_pickle is True\n df_list = []\n\n # Loop over all event in the Richardson-Cane list\n for rc_index in range(0, n_events):\n start_datetime = rc_data['ICME_start'][rc_index]\n end_datetime = rc_data['ICME_end'][rc_index]\n start_date = start_datetime.strftime('%Y%m%d%H')\n end_date = end_datetime.strftime('%Y%m%d%H')\n\n # Save data (.lst file) and data format (.fmt file)\n df = get_OMNI(start_date, end_date, as_pandas=panda)\n # And mask fill\n colnames = df.columns if panda else df.keys()\n for colname in colnames:\n df[colname] = clean_OMNI(df[colname], colname)\n\n # process depending on pandas or spacedata output\n if not panda:\n df.attrs['event_id'] = rc_index\n else:\n df['event_id'] = rc_index\n\n # Save per user request\n if save_pickle:\n df_list.append(df)\n elif save_data:\n df.toHDF5('omni_event{:03d}.h5'.format(rc_index))\n swmf = make_imf_input(df, fname='IMF_{:03d}_{}.dat'.format(rc_index, start_date))\n\n if generate_plots:\n fig = make_plot((start_date, end_date), (start_datetime, end_datetime), df, show=show_plot)\n\n print('Finished event %d of %d' % (rc_index, n_events-1))\n\n if save_pickle:\n all_df = pd.concat(df_list)\n all_df.to_pickle('OMNI_rc_dataframe.pkl')\n"
},
{
"alpha_fraction": 0.5217735767364502,
"alphanum_fraction": 0.5724465847015381,
"avg_line_length": 34.11111068725586,
"blob_id": "ec6f630d7be5759a01a3cff0160eca82b9ffcbfd",
"content_id": "e1064a97a10aabe7ccdf2257feb0f764c2fca9b3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1263,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 36,
"path": "/dBdt/plotlog.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import datetime as dt\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport spacepy.plot as splot\n\nsplot.revert_style()\n\ndef read_log(fname):\n with open(fname) as fh:\n lines = fh.readlines()\n head = lines[2][2:]\n nlines = int(lines[1].strip().split()[-2])\n data = np.zeros([nlines, 12]).astype(object)\n for idx, line in enumerate(lines[3:]):\n use = line.strip().split()\n use[1] = dt.datetime.strptime(use[1], '%Y%m%d-%H%M%S')\n for ii, val in enumerate(use):\n if ii == 1:\n data[idx, ii] = val\n else:\n data[idx, ii] = float(val)\n return data\n\nif __name__=='__main__':\n datA2 = read_log('blake_scaledA2_3d.log')\n fig = plt.figure(figsize=(9,4))\n ax = fig.add_subplot(111)\n ax.plot(datA2[30:-30,1], datA2[30:-30,-2], 'r-', alpha=0.9, label='max in RTS-GMLC-GIC-EAST convex hull')\n ax.plot(datA2[30:-30,1], datA2[30:-30,-1], 'k-', alpha=0.5, label='mean in RTS-GMLC-GIC-EAST convex hull')\n splot.applySmartTimeTicks(ax, datA2[30:-30,1])\n ax.axvline(dt.datetime(2004, 11, 9, 4, 35), linestyle='--', color='k')\n ax.set_ylabel('|E$_{H}$| [V/km]')\n ax.set_ylim([0, 5])\n ax.legend()\n\n plt.savefig('rts-gmlc-time_series.png')"
},
{
"alpha_fraction": 0.55078125,
"alphanum_fraction": 0.5768229365348816,
"avg_line_length": 22.838708877563477,
"blob_id": "9761aa2cc929a50ccfbc83a700764d2f5b53fbf8",
"content_id": "836afe1df1bf3c3b88456fc52c3a98016927505a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 768,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 31,
"path": "/viz/anim_xz.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import glob\r\n\r\nimport matplotlib.pyplot as plt\r\nfrom spacepy.pybats import bats\r\n\r\nimport celluloid\r\n\r\n\r\n\r\n\r\ndef makeplot(fname, ax):\r\n data = bats.Bats2d(fn)\r\n data.add_b_magsphere(target=ax, nOpen=10, nClosed=8)\r\n ti_str = '{0}'.format(data.attrs['time'])\r\n ax.set_xlim([-32, 16])\r\n ax.set_ylim([-24, 24])\r\n ax.set_xlabel('X$_{GSM}$ [R$_E$]')\r\n ax.set_ylabel('Z$_{GSM}$ [R$_E$]')\r\n ax.text(0.5, 1.01, ti_str, transform=ax.transAxes)\r\n\r\nif __name__ == '__main__':\r\n fig, ax = plt.subplots()\r\n camera = celluloid.Camera(fig)\r\n files = glob.glob('RESULTS/y*')\r\n files.sort()\r\n\r\n for fn in files[:42]:\r\n makeplot(fn, ax)\r\n camera.snap()\r\n animation = camera.animate()\r\n animation.save('test_anim_x-z-plane.gif')"
},
{
"alpha_fraction": 0.5899460315704346,
"alphanum_fraction": 0.5996401906013489,
"avg_line_length": 34.353355407714844,
"blob_id": "6f2b095d3e7d543c28416aa21e93870e60b05931",
"content_id": "2e6c97edcc9d1f11a0092d8a11692ff3d3d185a5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10006,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 283,
"path": "/event_selection/scrape_OMNI.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "\n\"\"\"\nSome exploratory code for scraping OMNIWeb with desired date ranges and variables.\nStill in progress, need to select correct variables, format output year/day/hour/minute, visualize data.\n\n@author: natalie klein\n\"\"\"\n# Standard Lib\nimport re\nimport datetime as dt\n# Scientific Stack\nimport numpy as np\nimport seaborn as sns\nsns.set(style=\"whitegrid\", font_scale=1.5)\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\n# Third-party\nimport spacepy.datamodel as dm\nfrom spacepy import pybats\nimport spacepy.plot as splot\nimport mechanize\ntry:\n import insitu_inference.code.bursty.readRC as readRC\nexcept ImportError:\n # Local import for running from code directory\n import readRC\n\n\ndef make_imf_input(indata, fname=None, keylist=None):\n \"\"\"Make an SWMF IMF input file from an input SpaceData\"\"\"\n if keylist is None:\n keylist = ['time', 'bx', 'by', 'bz', 'ux', 'uy', 'uz', 'rho', 'temp']\n numpts = indata['time'].shape[0]\n swmfdata = pybats.ImfInput(filename=False, load=False, npoints=numpts)\n naninds = set()\n for key in keylist:\n if key == 'time':\n # convert numpy datetime64 to python datetime\n swmfdata[key] = dm.dmarray(indata['time'].astype('M8[ms]').astype('O'))\n else:\n swmfdata[key] = dm.dmcopy(indata[key])\n naninds.update(np.where(np.isnan(swmfdata[key]))[0])\n # cull rows that have nan entries, SWMF will interpolate between\n # entries linearly. We can revisit this to use a noisy fill method if required\n naninds = np.array(sorted(list(naninds)))\n for key in keylist:\n swmfdata[key] = np.delete(swmfdata[key], naninds)\n swmfdata.attrs['coor'] = 'GSM'\n if fname is not None:\n swmfdata.write(fname)\n return swmfdata\n\n\ndef clean_OMNI(omarray, varname):\n \"\"\"Given an array of OMNI data, replace the fill values with NaN\n \"\"\"\n if 'velocity' in varname.lower() or varname in ['ux', 'uy', 'uz']:\n thr = 9999\n elif varname.startswith('B') or varname in ['bx', 'by', 'bz']:\n thr = 999\n elif 'density' in varname.lower() or varname.startswith('rho'):\n thr = 999\n elif 'temp' in varname.lower():\n thr = 9999999\n elif varname.lower().startswith('al') or varname.lower().startswith('sym'):\n thr = 99999\n elif 'pressure' in varname.lower() or varname in ['p_dyn']:\n thr = 99\n else:\n thr = None\n if isinstance(omarray, pd.Series) and thr is not None:\n omarray = omarray.mask(omarray >= thr)\n elif isinstance(omarray, dm.dmarray) and thr is not None:\n omarray = omarray.astype(float)\n omarray[omarray >= thr] = np.nan\n\n return omarray\n\n\ndef map_names(indata):\n \"\"\"Change names of variables in record array\"\"\"\n # Copy names for iteration as we can't change something while we're\n # iterating over it\n fieldnames = dm.dmcopy(indata.dtype.names)\n newnames = []\n for name in fieldnames:\n if 'vx' in name.lower():\n newnames.append('ux')\n elif 'vy' in name.lower():\n newnames.append('uy')\n elif 'vz' in name.lower():\n newnames.append('uz')\n elif 'bx' in name.lower():\n newnames.append('bx')\n elif 'by' in name.lower():\n newnames.append('by')\n elif 'bz' in name.lower():\n newnames.append('bz')\n elif 'sym' in name.lower():\n newnames.append('sym-h')\n elif 'density' in name.lower():\n newnames.append('rho')\n elif 'temperature' in name.lower():\n newnames.append('temp')\n elif 'pressure' in name.lower():\n newnames.append('p_dyn')\n elif name == 'date':\n newnames.append('time')\n else:\n newnames.append(name.lower())\n\n indata.dtype.names = newnames\n\n return indata\n\n\ndef get_OMNI(start_date, end_date, as_pandas=True):\n \"\"\"\n Retrieve OMNI data and format info from omniweb website\n\n Arguments\n ---------\n start_date : string\n Start date for data interval in YYMMDDHH format\n end_date : string\n End date for data interval in YYMMDDHH format\n as_pandas : boolean\n Set True to return pandas dataframe, False returns a SpaceData\n\n Returns\n -------\n dl_fmt : string\n Temporary filename for OMNI format description file\n dl : string\n Temporary filename for OMNI data file\n \"\"\"\n br = mechanize.Browser()\n # set form variables for OMNIWeb\n br.open('https://omniweb.gsfc.nasa.gov/form/omni_min.html')\n br.select_form(name=\"frm\")\n br['activity'] = ['ftp']\n br['res'] = ['min']\n br['start_date'] = start_date\n br['end_date'] = end_date\n br['vars'] = ['22', # Vx Velocity, GSE, km/s\n '23', # Vy Velocity, GSE, km/s\n '24', # Vz Velocity, GSE, km/s\n '14', # Bx, GSM, nT\n '17', # By, GSM, nT\n '18', # Bz, GSM, nT\n '25', # Proton Density, cm^{-3}\n '26', # Proton Temperature, K\n '27', # Flow pressure, nPa\n '38', # AL index, nT\n '41'] # Sym/H, nT\n\n # submit OMNIWeb form\n resp = br.submit()\n\n # Find links to download data and download it\n data_link = br.find_link(text_regex=re.compile(\".lst\")).url\n fmt_link = br.find_link(text_regex=re.compile(\".fmt\")).url\n dl = br.retrieve(data_link)[0]\n dl_fmt = br.retrieve(fmt_link)[0]\n\n # Read column names from .fmt file\n colnames = []\n with open(dl_fmt, 'r') as fh:\n fmt_info = fh.readlines()\n for line in fmt_info[4:]:\n colnames.append(' '.join(line.split()[1:-1]))\n\n # Read data from .lst file, format date\n df = pd.read_table(dl, header=None, delim_whitespace=True, names=colnames, parse_dates=[[0, 1, 2, 3]])\n df['date'] = df['Year_Day_Hour_Minute'].apply(lambda x: dt.datetime.strptime(x, '%Y %j %H %M'))\n if not as_pandas:\n recs = df.to_records()\n # map names to be more useful\n recs = map_names(recs)\n outdata = dm.fromRecArray(recs)\n else:\n outdata = df\n\n # Close browser to clean up temp files\n br.close()\n\n return outdata\n\n\ndef make_plot(plotrange, eventrange, df, show=True):\n \"\"\"\n Make summary plot and either show (default) or save\n\n Arguments\n ---------\n plotrange : tuple of strings\n String timestamps for start and end of data interval\n eventrange : tuple of datetimes\n Datetimes marking iCME interval for highlighting\n \"\"\"\n # TODO: update to use sharex and tidy time axis, labels, etc.\n start_date, end_date = plotrange\n start_datetime, end_datetime = eventrange\n fig, axes = plt.subplots(nrows=4, ncols=1, sharex=True, figsize=(12, 16))\n params_omni = ['BZ, nT (GSM)', 'Vx Velocity,km/s', 'Flow pressure, nPa', 'SYM/H, nT']\n params_sd = ['bz', 'ux', 'p_dyn', 'sym-h']\n labels = ['B$_{Z}^{GSM}$ [nT]', 'V$_{X}$ [km/s]', 'P$_{dyn}$', 'SYM-H [nT]']\n param = params_omni if isinstance(df, pd.DataFrame) else params_sd\n tvar = 'date' if isinstance(df, pd.DataFrame) else 'time'\n for par, cax, lab in zip(param, axes, labels):\n sns.lineplot(x=tvar, y=par, data=df, ax=cax)\n if tvar == 'time':\n cax.set_ylabel(lab)\n cax.axvspan(start_datetime, end_datetime, alpha=0.2, color='yellow')\n dolabel = True if par == 'sym-h' else False\n splot.applySmartTimeTicks(cax, df[tvar].astype('M8[ms]').astype('O'), dolabel=dolabel)\n fig.suptitle('RC event {} - {}'.format(start_date, end_date))\n if show:\n plt.show()\n else:\n plt.savefig('omni_rc_{}_{}.png'.format(start_date, end_date))\n plt.close()\n\n\nif __name__ == '__main__':\n # User defined settings\n generate_plots = True # Make summary plot for each event?\n show_plot = False # True for display, False for save to file\n save_pickle = False # Save a pickle of Pandas dataframes\n save_data = True # Save data to HDF5 and SWMF ImfInput\n subset = 1 # None # Number of events (starting from end) -- None to do everything\n\n # default behavior is to use pandas and save to a pickle\n panda = True if save_pickle else False\n\n # Read Richardson-Cane data to get date ranges\n rc_data = readRC.read_list()\n n_events = len(rc_data['Epoch'])\n\n # Time period before/after event to extract\n td1 = dt.timedelta(hours=18) # 12\n td2 = dt.timedelta(hours=12) # 12\n\n # Empty list to store output data frames if save_pickle is True\n df_list = []\n\n # Loop over all event in the Richardson-Cane list\n st_at = 0 if subset is None else n_events-subset\n st_at = 103\n for rc_index in range(st_at, st_at + n_events):\n start_datetime = rc_data['ICME_start'][rc_index]\n end_datetime = rc_data['ICME_end'][rc_index]\n start_date = (start_datetime - td1).strftime('%Y%m%d%H')\n end_date = (end_datetime + td2).strftime('%Y%m%d%H')\n\n # Save data (.lst file) and data format (.fmt file)\n df = get_OMNI(start_date, end_date, as_pandas=panda)\n # And mask fill\n colnames = df.columns if panda else df.keys()\n for colname in colnames:\n df[colname] = clean_OMNI(df[colname], colname)\n\n # process depending on pandas or spacedata output\n if not panda:\n df.attrs['event_id'] = rc_index\n else:\n df['event_id'] = rc_index\n\n # Save per user request\n if save_pickle:\n df_list.append(df)\n elif save_data:\n df.toHDF5('omni_rc_event{:03d}.h5'.format(rc_index))\n swmf = make_imf_input(df, fname='IMF_rc{:03d}_{}.dat'.format(rc_index, start_date))\n\n if generate_plots:\n fig = make_plot((start_date, end_date), (start_datetime, end_datetime), df, show=show_plot)\n\n print('Finished RC event %d of %d' % (rc_index, n_events-1))\n\n if save_pickle:\n all_df = pd.concat(df_list)\n all_df.to_pickle('OMNI_rc_dataframe.pkl')\n"
},
{
"alpha_fraction": 0.5320731997489929,
"alphanum_fraction": 0.5523828864097595,
"avg_line_length": 32.829933166503906,
"blob_id": "2d60e0390529374b588405625df743d799954614",
"content_id": "8c814118f227630001f2f9b7e291c7dfe12a4818",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4973,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 147,
"path": "/event_selection/missing.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import random\nimport numpy as np\nimport spacepy.toolbox as tb\nfrom scipy.ndimage.filters import gaussian_filter\n\n\ndef fill_gaps(data, fillval=9999999, sigma=5, winsor=0.05, noise=False, constrain=False,\n method='linear'):\n '''Fill gaps in input data series, using interpolation plus noise\n\n The noise approach is based on Owens et al. (Space Weather, 2014).\n\n data - input numpy ndarray-like\n fillval - value marking fill in the time series\n sigma - width of gaussian filter for finding fluctuation CDF\n winsor - winsorization threshold, values above p=1-winsor and below p=winsor are capped\n noise - Boolean, if True add noise to interpolated region, if False use interp only\n constrain - Boolean, if True\n method - string. Specifies interpolation type, options are 'linear' or 'sigmoid'\n '''\n # identify sequences of fill in data series\n gaps = np.zeros((len(data), 2), dtype=int)\n k = 0\n for i in range(1, len(data)-1):\n # Single space gap/fillval\n if (tb.feq(data[i], fillval)) and (~tb.feq(data[i+1], fillval)) and (~tb.feq(data[i-1], fillval)):\n gaps[k][0] = i\n gaps[k][1] = i\n k += 1\n # Start of multispace gap/fillval\n elif (tb.feq(data[i], fillval)) and (~tb.feq(data[i-1], fillval)):\n gaps[k][0] = i\n # End of multispace gap/fillval\n elif (tb.feq(data[i], fillval)) and (~tb.feq(data[i+1], fillval)):\n gaps[k][1] = i\n k += 1\n gaps = gaps[:k]\n\n # if no gaps detected\n if k == 0:\n return data\n\n # fill gaps with requested interpolation scheme\n interp_dict = {'linear': fill_linear,\n 'sigmoid': fill_sigmoid}\n if method not in interp_dict:\n raise ValueError('Requested interpolation method ({}) not supported'.format(method))\n for gap in gaps:\n data = interp_dict[method](data, gap)\n\n if noise:\n # generate CDF from delta var\n series = data.copy()\n smooth = gaussian_filter(series, sigma)\n dx = series-smooth\n dx.sort()\n p = np.linspace(0, 1, len(dx))\n # \"Winsorize\" - all delta-Var above/below threshold at capped at threshold\n dx[:p.searchsorted(0.+winsor)] = dx[p.searchsorted(0.+winsor)+1]\n dx[p.searchsorted(1.-winsor):] = dx[p.searchsorted(1.-winsor)-1]\n\n # draw fluctuations from CDF and apply to linearly filled gaps\n for gap in gaps:\n for i in range(gap[1]-gap[0]+1):\n series[gap[0]+i] += dx[p.searchsorted(random.random())]\n\n # cap variable if it should be strictly positive (e.g. number density)\n # use lowest measured value as floor\n if constrain and series.min() > 0.0:\n series[series < series.min()] = series.min()\n return series\n\n return data\n\n\ndef fill_linear(data, gap):\n \"\"\"apply linear fill to region of input array\n\n data - input array\n gap - indices marking region for fill\n \"\"\"\n a = data[gap[0] - 1]\n b = data[gap[1] + 1]\n dx = (b - a)/(gap[1] - gap[0] + 2)\n for i in range(gap[1] - gap[0] + 1):\n data[gap[0] + i] = a + dx*(i + 1)\n return data\n\n\ndef fill_sigmoid(data, gap, tr=None, sl=None):\n \"\"\"apply S-shaped (sigmoidal) fill to region of input array\n\n data - input array\n gap - indices marking region for fill\n tr - transition point (0, 1)\n sl - slope term (0, 1). 0 is equivalent to linear interpolation,\n as slope tends to 1 the function tends to a step.\n \n Modified from: reddit.com/r/gamedev/comments/4xkx71/sigmoidlike_interpolation/\n \"\"\"\n a = data[gap[0] - 1]\n b = data[gap[1] + 1]\n def sigfunc(xval, trans=0.5, slope=0.5, up=True):\n cexp = 2/(1 - slope) - 1\n if up:\n if xval <= trans:\n numer = xval**cexp\n denom = trans**(cexp - 1)\n fval = numer/denom\n else:\n numer = (1 - xval)**cexp\n denom = (1 - trans)**(cexp - 1)\n fval = 1 - numer/denom\n else:\n if xval <= trans:\n numer = xval**cexp\n denom = 1 - trans**(cexp - 1)\n fval = 1 - numer/denom\n else:\n numer = (1 - xval)**cexp\n denom = (1 - trans)**(cexp - 1)\n fval = numer/denom\n return fval\n if a > b:\n # slope downward\n if sl is None:\n sl = 0.3\n if tr is None:\n tr = 0.35\n up = False\n hi, lo = a, b\n elif b > a:\n # slope upward\n if sl is None:\n sl = 0.7\n if tr is None:\n tr = 0.5\n up = True\n hi, lo = b, a\n else:\n data = fill_linear(data, gap)\n return data\n gaplen = gap[1] - gap[0] + 1\n for i in range(gaplen):\n fracx = i/gaplen\n data[gap[0] + i] = (hi - lo) * sigfunc(fracx, trans=tr, slope=sl, up=up) + lo\n return data\n"
},
{
"alpha_fraction": 0.5781753063201904,
"alphanum_fraction": 0.5978533029556274,
"avg_line_length": 36.253334045410156,
"blob_id": "77fc425d8b22b5d5f6b1a73018b31d9bf7bdba37",
"content_id": "b45be8c9d560ff3ea0bbb2bcd0f1363279ccde18",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2795,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 75,
"path": "/util.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import glob\nimport os\nimport matplotlib.pyplot as plt\nfrom spacepy.pybats import bats\n\n\ndef load_logs(workdir='.', logtype='log', logbase='log*log', geobase='geo*log'):\n \"\"\"Load and merge all logfiles associated with a run\n\n Will merge multiple logs, e.g., from a sequence of restarts\n If logs overlap, e.g., because a run timed out and was restarted from a \n time before the end of the previous log, then the overlap period is removed\n from the earlier log file.\n \"\"\"\n workdir = os.path.abspath(workdir)\n if logtype == 'log':\n globbase = os.path.join(workdir, logbase)\n loader = bats.BatsLog\n elif logtype == 'geo':\n globbase = os.path.join(workdir, geobase)\n loader = bats.GeoIndexFile\n else:\n raise ValueError('load_logs: logtype must be either \"log\" or \"geo\", not {}'.format(logtype))\n fns = sorted(glob.glob(globbase))\n if not fns:\n raise IOError('No log files found with selected search term ({})'.format(globbase))\n all_logs = [loader(fn) for fn in fns]\n log = all_logs[0]\n if len(all_logs)>1:\n for nlg in all_logs[1:]:\n log = merge_logfiles(log, nlg)\n return log\n\n\ndef merge_logfiles(log1, log2):\n \"\"\"Merge two log files.\n\n If log1 overlaps with log2, the overlapping entries in log1\n are discarded.\n \"\"\"\n first_in_2 = log2['time'][0]\n keep_from_1 = log1['time'] < first_in_2\n for key in log1.keys():\n log1[key] = log1[key][keep_from_1]\n log1.timeseries_append(log2)\n return log1\n\n\ndef results_summary(log, geolog, show=True):\n \"\"\"3-panel summary plot from log and geoindex files\n \"\"\"\n fig, axes = plt.subplots(nrows=3, ncols=1, sharex=True)\n okw = {'c':'purple', 'ls':'--', 'lw':1.5}\n mkw = {'c':'C0', 'ls':'-', 'lw':1.5}\n geolog.add_ae_quicklook(plot_obs=True, target=axes[0], val='AU', obs_kwargs=okw,\n add_legend=False, **mkw)\n okw = {'c':'k', 'ls':'--', 'lw':1.5}\n mkw = {'c':'C1', 'ls':'-', 'lw':1.5}\n geolog.add_ae_quicklook(plot_obs=True, target=axes[0], val='AL', obs_kwargs=okw,\n add_legend=False, **mkw)\n geolog.add_kp_quicklook(plot_obs=True, target=axes[1], add_legend=False)\n log.add_dst_quicklook(plot_obs=True, target=axes[2], add_legend=False)\n axes[0].set_xlabel('')\n axes[1].set_xlabel('')\n axes[0].set_ylabel('AU/AL [nT]')\n axes[2].set_ylabel('Dst [nT]')\n from matplotlib.lines import Line2D\n\n legend_elements = [Line2D([0], [0], color='k', lw=1.5, label='Virtual (solid)'),\n Line2D([0], [0], color='k', lw=1.5, ls='--', label='Observed (dashed)'),\n ]\n axes[2].legend(handles=legend_elements, loc='lower left', ncol=2)\n if show:\n plt.show()\n return fig, axes\n\n"
},
{
"alpha_fraction": 0.5630613565444946,
"alphanum_fraction": 0.582669198513031,
"avg_line_length": 42.43406677246094,
"blob_id": "e857436b9168fbc2a9004f8d7968041a959ea9b9",
"content_id": "7de1272197b9fef1365054708126552ea1116bcc",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7905,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 182,
"path": "/event_selection/pairplots.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import glob\nimport datetime as dt\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport spacepy.datamodel as dm\nimport spacepy.time as spt\nimport spacepy.toolbox as tb\nimport seaborn as sns\nimport pandas as pd\n\n\ndef autoevents(data, n_events=5, bin1d=4, seed=None):\n \"\"\"Select events using equal-weight-bin sampling method\n\n N-d parameter space is broken into a K**N element grid.\n Any bins with no samples are discarded.\n All other bins are weighted equally.\n Each requested event is selected by first choosing a\n random bin (without replacement) and then randomly choosing\n one event from that bin.\n The selected events are therefore distributed across the\n parameter space without being weighted to the probability of\n event occurrence within the region of parameter space.\n\n Parameters\n ----------\n data : pandas.DataFrame\n Dataframe with parameters (each row is one event, each\n column is a parameter)\n n_events : int\n Number of events to select\n bin1d : int\n Number of bins to use in each dimension\n seed : int (or None)\n Random seed. Default None\n \"\"\"\n # Set random seed for reproducible results\n if seed:\n np.random.seed(seed)\n # Standardize all variables and drop events with NaN values\n standardize = lambda x: (x - x.mean())/x.std()\n filt = dframe.dropna()\n try:\n filt = filt.drop(columns=['max(E_sw)'])\n except:\n pass\n filt = filt.apply(standardize)\n ndims = len(filt.columns)\n grid = dict()\n inds = np.empty((filt.shape[0], filt.shape[1])).astype(int)\n # Loop over variables, get limits, set grid\n for var in filt.columns:\n maxval = filt[var].max()\n minval = filt[var].min()\n maxsign = np.sign(maxval)\n roundup = np.ceil(np.abs(maxval)) if maxval > 0 else np.floor(np.abs(maxval))\n roundup *= maxsign\n minsign = np.sign(minval)\n rounddn = np.ceil(np.abs(minval)) if minval < 0 else np.floor(np.abs(minval))\n rounddn *= minsign\n grid[var] = np.linspace(rounddn, roundup, num=bin1d)\n # Now find the bin in this dimension for all events\n inds[:, filt.columns.get_loc(var)] = np.digitize(filt[var], grid[var])\n # Finf \"flattened\" bin for each event and whether bins are used\n cells = set()\n binned_data = dict()\n # For each event ...\n for idx, row in enumerate(inds):\n # Find the flattened index\n bin_num = np.ravel_multi_index(row, [bin1d]*ndims)\n cells.add(bin_num) # Make sure we add this to the set of bins with data\n if bin_num not in binned_data:\n binned_data[bin_num] = []\n binned_data[bin_num].append(idx) # And add the event number to the bin\n cells = np.asarray(list(cells))\n # Choose cells to sample from\n use_cells = np.random.choice(cells, n_events, replace=False)\n # from each cell, find the events and pick one\n use_events = [np.random.choice(binned_data[ind], 1)[0] for ind in use_cells]\n return use_events\n\n\nmakeNew = False\n\nif makeNew:\n # read HDF5 data for each event\n # ensure it's sorted so the event numbers have a chance of lining up\n allh5 = sorted(glob.glob('*.h5'))\n \n # Gather event summary stats\n symh = []\n al = []\n vx = []\n esw = []\n bzhr = []\n evno = []\n stda = []\n \n for idx, h5fn in enumerate(allh5):\n if idx%10 == 0: print('Reading file {} of {}'.format(idx+1, len(allh5)))\n data = dm.fromHDF5(h5fn)\n data['time'] = spt.Ticktock(data['time']).UTC\n symh.append(np.nanmin(np.asarray(data['sym-h'])))\n al.append(np.nanmin(np.asarray(data['al-index, nt'])))\n umask = np.isfinite(data['ux'])\n uxmin = np.nan if data['ux'][umask].size==0 else np.nanmin(data['ux'][umask])\n vx.append(uxmin)\n ey = 1e3 * data['ux'] * data['bz']\n emask = np.isfinite(ey)\n ey[emask][ey[emask]<0] = 0\n eymax = np.nan if ey[emask].size==0 else ey[emask].max()\n esw.append(eymax)\n # hourly avgs of bz\n outd, outt = tb.windowMean(data['bz'], time=data['time'], winsize=dt.timedelta(hours=1),\n overlap=dt.timedelta(0), st_time = data['time'][0].replace(minute=0), op=np.nanmean)\n bzhr.append(np.nanmin(outd))\n evno.append('{:03d}'.format(idx))\n stda.append(data['time'][0].strftime('%Y%m%d%H'))\n \n # make dataframe to pass to seaborn pairplot\n # go via dict-like\n summary = dm.SpaceData()\n summary['min(Sym-H)'] = dm.dmarray(symh)\n summary['min(AL)'] = dm.dmarray(al)\n summary['min(Vx)'] = dm.dmarray(vx)\n summary['max(E_sw)'] = dm.dmarray(esw)\n summary['min(<Bz>)'] = dm.dmarray(bzhr)\n summary['eventNumber'] = dm.dmarray(evno)\n summary['startTime'] = dm.dmarray(stda)\n \n # write summary values and event ID to ASCII\n dm.toJSONheadedASCII('rc_event_summary.txt', summary, order=['eventNumber', 'min(Sym-H)',\n 'min(AL)', 'min(Vx)', 'max(E_sw)',\n 'min(<Bz>)'])\n del summary['eventNumber']\n del summary['startTime']\nelse:\n tmp = dm.readJSONheadedASCII('rc_event_summary.txt')\n summary = dm.SpaceData()\n #summary['min(Sym-H)'] = tmp['min(Sym-H)']\n summary['min(AL)'] = tmp['min(AL)']\n summary['min(Vx)'] = tmp['min(Vx)']\n #summary['max(E_sw)'] = tmp['max(E_sw)']\n summary['min(<Bz>)'] = tmp['min(<Bz>)']\n\n# pair plots\nif True:\n dframe = pd.DataFrame(summary)\n seed = 1405\n selections = [#('SKM', [57, 103, 156, 259, 443], 'maroon', 'd'),\n #('AB2', [47, 124, 240, 266, 360], 'navy', '*'),\n #('ECL', [78, 103, 200, 240, 284], 'gold', 'x'),\n #('AB1', [38, 79, 98, 184, 207], 'black', '2'),\n #('NEK', [152, 253, 258, 266, 295], 'orchid', '.'),\n ('Auto', autoevents(dframe, n_events=15, bin1d=5, seed=seed), 'maroon', 'x'),\n ]\n # Now pass this through to seaborn PairGrid, as it's much more flexible than pairplot\n grid = sns.PairGrid(dframe, height=1.75)\n grid = grid.map_diag(plt.hist, bins='auto')\n grid = grid.map_lower(plt.scatter, marker='.', s=5, color='seagreen')\n grid = grid.map_upper(sns.kdeplot, n_levels=25, cmap='YlGnBu', shade=True, shade_lowest=False)\n axes = grid.axes\n for name, sel, rgb, shape in selections:\n pkw = {'color': rgb, 'linestyle': 'none', 'marker': shape}\n #axes[1][0].plot(summary['min(Sym-H)'][sel], summary['min(AL)'][sel], **pkw)\n #axes[2][0].plot(summary['min(Sym-H)'][sel], summary['min(Vx)'][sel], **pkw)\n #axes[2][1].plot(summary['min(AL)'][sel], summary['min(Vx)'][sel], **pkw)\n #axes[3][0].plot(summary['min(Sym-H)'][sel], summary['max(E_sw)'][sel], **pkw)\n #axes[3][1].plot(summary['min(AL)'][sel], summary['max(E_sw)'][sel], **pkw)\n #axes[3][2].plot(summary['min(Vx)'][sel], summary['max(E_sw)'][sel], **pkw)\n #axes[4][0].plot(summary['min(Sym-H)'][sel], summary['min(<Bz>)'][sel], **pkw)\n #axes[4][1].plot(summary['min(AL)'][sel], summary['min(<Bz>)'][sel], **pkw)\n #axes[4][2].plot(summary['min(Vx)'][sel], summary['min(<Bz>)'][sel], **pkw)\n #axes[4][3].plot(summary['max(E_sw)'][sel], summary['min(<Bz>)'][sel], **pkw)\n axes[1][0].plot(summary['min(AL)'][sel], summary['min(Vx)'][sel], **pkw)\n axes[2][0].plot(summary['min(AL)'][sel], summary['min(<Bz>)'][sel], **pkw)\n axes[2][1].plot(summary['min(Vx)'][sel], summary['min(<Bz>)'][sel], **pkw)\n # grid.fig.suptitle('{} selection\\nEvents {}, {}, {}, {}, {}'.format(name, *select))\n plt.tight_layout()\n #plt.savefig('RC_pairsplot_pointscomparison_AUTO.png', dpi=300)\n plt.savefig('RC_pairsplot_piyush_{}.png'.format(seed), dpi=300)\n plt.close('all')\n"
},
{
"alpha_fraction": 0.5912776589393616,
"alphanum_fraction": 0.6029484272003174,
"avg_line_length": 42.29787063598633,
"blob_id": "3d9910fc1bc1f65031e9f200b810ad18c0d9a92d",
"content_id": "a1246dba7b04dae854622b64445842483db42618",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8140,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 188,
"path": "/viz/BATLtoVTH.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport argparse\nfrom collections import OrderedDict\nimport numpy as np\nimport spacepy.datamodel as dm\ntry:\n import re\n import datetime as dt\n import spacepy.time as spt\n import spacepy.coordinates as spc\n import spacepy.irbempy as ib\n import pyvista as pv\n irb = True\nexcept ImportError:\n irb = False\nimport vtk\n\n\ndef timeFromFilename(outname):\n '''Get timestamp from SWMF/BATSRUS output file\n\n Supports \"_e\" and \"_t\" naming conventions.\n If both are present, it will use \"_e\" by preference.\n Precision is currently to the nearest second.\n '''\n tsrch = \".*_t(\\d{4})(\\d{2})(\\d{2})(\\d{2})(\\d{2})(\\d{2})\"\n esrch = \".*_e(\\d{4})(\\d{2})(\\d{2})-(\\d{2})(\\d{2})(\\d{2})\"\n if '_t' in outname or '_e' in outname:\n srch = esrch if '_e' in outname else tsrch\n tinfo = re.search(srch, outname).groups()\n tinfo = [val for val in map(int, tinfo)]\n else:\n raise NotImplementedError('Only \"_t\" and \"_e\" format times are supported')\n\n dtobj = dt.datetime(*tinfo)\n return dtobj\n\n\ndef convertOneFile(batlname, add_dipole=False):\n '''Convert a single file from BATL HDF5 to VTH\n '''\n # load BATL (HDF5) file\n data = dm.fromHDF5(batlname)\n outname = os.path.splitext(batlname)[0]\n # set output filename (will also create a folder sans extension)\n fname = '.'.join((outname, 'vth')) # vth is expected extension for hierarchical data sets like AMR\n\n # find number of refine levels and Nblocks at each level\n level = OrderedDict()\n nrlev = []\n for idx, lev in enumerate(list(set(data['refine level']))):\n level[lev] = idx\n nrlev.append((data['refine level'] == lev).sum())\n nlevels = len(level)\n levcounter = [0]*nlevels # counter to label each block (per refine level)\n # shortcuts, etc.\n blockcoords = data['coordinates']\n nblocks = blockcoords.shape[0]\n bbox = data['bounding box']\n bx = data['Bx']\n bsize = bx[0].shape[-1] # all blocks have the same dimension (8x8x8 default)\n\n # Initialize the NonOverlappingAMR object\n multiblock = vtk.vtkNonOverlappingAMR()\n multiblock.Initialize(nlevels, nrlev)\n\n # iterate over all blocks\n for idx in range(nblocks):\n dx = ((bbox[idx])[0, 1]-(bbox[idx])[0, 0])/bsize # get resolution\n grid = vtk.vtkUniformGrid() # each block is a uniform grid\n blockcentre = blockcoords[idx]\n blockcentre -= dx*4 # offset from centre to block corner (\"origin\")\n grid.SetOrigin(*blockcentre)\n grid.SetSpacing(dx, dx, dx)\n grid.SetDimensions(bsize+1, bsize+1, bsize+1) # number of points in each direction\n ncells = grid.GetNumberOfCells()\n\n if add_dipole:\n tval = timeFromFilename(outname)\n pvblock = pv.UniformGrid(grid)\n cellcenters = pvblock.cell_centers().points\n bintx1d = np.empty(len(cellcenters))\n binty1d = np.empty(len(cellcenters))\n bintz1d = np.empty(len(cellcenters))\n coords = spc.Coords(cellcenters, 'GSM', 'car')\n tvals = spt.Ticktock([tval]*len(cellcenters), 'UTC')\n Bgeo = ib.get_Bfield(tvals, coords, extMag='0',\n options=[1, 1, 0, 0, 5])['Bvec']\n tmp = spc.Coords(Bgeo, 'GEO', 'car', ticks=tvals)\n Bgsm = tmp.convert('GSM', 'car')\n for ind, xyz in enumerate(Bgsm):\n bintx1d[ind] = xyz.x\n binty1d[ind] = xyz.y\n bintz1d[ind] = xyz.z\n bintarray = vtk.vtkDoubleArray()\n bintarray.SetNumberOfComponents(3)\n bintarray.SetNumberOfTuples(grid.GetNumberOfCells())\n for ind in range(len(bintx1d)):\n bintarray.SetTuple3(ind, bintx1d[ind], binty1d[ind], bintz1d[ind])\n grid.GetCellData().AddArray(bintarray)\n bintarray.SetName('Bvec_int')\n\n # add data [Bx, By, Bz, jx, jy, jz, Rho, P] if present\n if 'jx' in data and 'jy' in data and 'jz' in data:\n jtotarray = vtk.vtkDoubleArray()\n jtotarray.SetNumberOfComponents(3) # 1 for a scalar; 3 for a vector\n jtotarray.SetNumberOfTuples(grid.GetNumberOfCells())\n jx1d = data['jx'][idx].ravel()\n jy1d = data['jy'][idx].ravel()\n jz1d = data['jz'][idx].ravel()\n for ind in range(len(jx1d)):\n jtotarray.SetTuple3(ind, jx1d[ind], jy1d[ind], jz1d[ind])\n grid.GetCellData().AddArray(jtotarray)\n jtotarray.SetName('jvec')\n if 'Ux' in data and 'Uy' in data and 'Uz' in data:\n Utotarray = vtk.vtkDoubleArray()\n Utotarray.SetNumberOfComponents(3) # 1 for a scalar; 3 for a vector\n Utotarray.SetNumberOfTuples(grid.GetNumberOfCells())\n ux1d = data['Ux'][idx].ravel()\n uy1d = data['Uy'][idx].ravel()\n uz1d = data['Uz'][idx].ravel()\n for ind in range(len(ux1d)):\n Utotarray.SetTuple3(ind, ux1d[ind], uy1d[ind], uz1d[ind])\n grid.GetCellData().AddArray(Utotarray)\n Utotarray.SetName('Uvec')\n if 'Bx' in data and 'By' in data and 'Bz' in data:\n Btotarray = vtk.vtkDoubleArray()\n Btotarray.SetNumberOfComponents(3) # 1 for a scalar; 3 for a vector\n Btotarray.SetNumberOfTuples(grid.GetNumberOfCells())\n bx1d = data['Bx'][idx].ravel()\n by1d = data['By'][idx].ravel()\n bz1d = data['Bz'][idx].ravel()\n for ind in range(len(bx1d)):\n Btotarray.SetTuple3(ind, bx1d[ind], by1d[ind], bz1d[ind])\n grid.GetCellData().AddArray(Btotarray)\n Btotarray.SetName('Bvec')\n if 'Rho' in data:\n rhoarray = vtk.vtkDoubleArray()\n rhoarray.SetNumberOfComponents(1) # 1 for a scalar; 3 for a vector\n rhoarray.SetNumberOfTuples(grid.GetNumberOfCells())\n for ind, val in enumerate(data['Rho'][idx].ravel()):\n rhoarray.SetValue(ind, val)\n grid.GetCellData().AddArray(rhoarray)\n rhoarray.SetName('Rho')\n if 'P' in data:\n parray = vtk.vtkDoubleArray()\n parray.SetNumberOfComponents(1) # 1 for a scalar; 3 for a vector\n parray.SetNumberOfTuples(grid.GetNumberOfCells())\n for ind, val in enumerate(data['P'][idx].ravel()):\n parray.SetValue(ind, val)\n grid.GetCellData().AddArray(parray)\n parray.SetName('P')\n\n # add block to multiblock set\n lev = level[data['refine level'][idx]]\n levidx = levcounter[lev]\n multiblock.SetDataSet(lev, levidx, grid)\n levcounter[lev] += 1 # increment block counter for given refine level\n\n # set up writer for binary XML output\n writer = vtk.vtkXMLUniformGridAMRWriter()\n # writer.SetDataModeToAscii()\n writer.SetFileName(fname)\n writer.SetInputData(multiblock)\n writer.Write()\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Convert BATL (HDF5) files to VTH (Hierarchical VTK)')\n parser.add_argument('--silent', action='store_true')\n parser.add_argument('--add-dipole', dest='add_dipole', action='store_true')\n parser.add_argument('inputfiles', nargs='+', help='Input files (can use wildcards, shell will expand)')\n args = parser.parse_args()\n if args.add_dipole and not irb:\n raise ModuleNotFoundError('Dependencies (pyvista, spacepy.irbempy) could not be loaded')\n silent = args.silent\n for batlname in args.inputfiles:\n bname, ext = os.path.splitext(batlname)\n if os.path.isdir(batlname):\n if not silent: print('Input file {0} appears to be a directory. Skipping'.format(batlname))\n elif not ext.lower()=='.batl':\n if not silent: print('Input file {0} may not be a BATL HDF5 file. Skipping'.format(batlname))\n else:\n try:\n convertOneFile(batlname, add_dipole=args.add_dipole)\n except IOError:\n if not silent: print(\"Unexpected error processing {0}:\".format(batlname), sys.exc_info()[0])\n"
},
{
"alpha_fraction": 0.5774629712104797,
"alphanum_fraction": 0.6007726788520813,
"avg_line_length": 42.13888931274414,
"blob_id": "57ae78cce04612658846c5c52974512fbca0d6ef",
"content_id": "3c1b41f02dc51dd7f6921ead63d3310eb08a58b6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7765,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 180,
"path": "/perturbedinput/perturbSWMF.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "#stdlib\nimport os\nimport requests\nimport shutil\nimport itertools\nimport argparse\nimport datetime as dt\n#scientific stack\nimport numpy as np\nimport scipy\nimport scipy.interpolate\nimport spacepy.datamodel as dm\nimport spacepy.time as spt\nimport spacepy.pybats as swmf\nfrom sklearn.neighbors import KernelDensity\n#local\nimport perturbplot as pplot\n\n\ndef get_SC_OMNI(year=2000, bird='ACE', datadir='Data', force=False, verbose=False, **kwargs):\n '''Download S/C specific OMNI file'''\n valid_birds = ['ACE', 'IMP', 'GEOTAIL', 'WIND']\n if bird.upper() not in valid_birds:\n raise ValueError('Invalid satellite selected ({0})'.format(bird))\n targ_fn = '{0}_min_b{1}.txt'.format(bird.lower(), year)\n #now check whether we have this file already\n if not force and os.path.isfile(os.path.join(datadir, targ_fn)):\n if verbose: print('Data already present for {0} in {1} - not downloading'.format(bird, year))\n return os.path.join(datadir, targ_fn)\n #now download the file and save in datadir\n omni_https = 'spdf.gsfc.nasa.gov'\n sc_dir = 'pub/data/omni/high_res_omni/sc_specific/'\n url = 'https://' + omni_https + '/' + sc_dir + '/' + targ_fn\n r = requests.get(url, verify=False, stream=True)\n r.raw.decode_content = True\n with open(os.path.join(datadir, targ_fn), 'wb') as f:\n shutil.copyfileobj(r.raw, f)\n print('Retrieved {0}'.format(targ_fn))\n return os.path.join(datadir, targ_fn)\n\n\ndef load_SC_OMNI(bird, year, outdata=None, **kwargs):\n '''Load satellite specific OMNI data into dict'''\n fname = get_SC_OMNI(year=year, bird=bird, **kwargs)\n dum = np.genfromtxt(fname, usecols=(0,1,2,3,15,16,23,26,28,29,30), \n names=('year','day','hour','minute','By_GSM','Bz_GSM','Vx_GSE','Den_P','X_GSE','Y_GSE','Z_GSE'),\n converters={0: int, 1: int, 2: int, 3: int})\n data = dm.fromRecArray(dum)\n dates = spt.doy2date(data['year'], data['day'], dtobj=True)\n times = [dt.timedelta(hours=x, minutes=y) for x,y in zip(data['hour'],data['minute'])]\n data['DateTime'] = dates + times\n for key in ['year', 'day', 'hour', 'minute']:\n del data[key]\n data['Bz_GSM'][np.abs(data['Bz_GSM'])>20] = np.nan\n data['By_GSM'][np.abs(data['By_GSM'])>20] = np.nan\n data['Vx_GSE'][np.abs(data['Vx_GSE'])>900] = np.nan\n data['X_GSE'][np.abs(data['X_GSE'])>9000] = np.nan\n data['Y_GSE'][np.abs(data['Y_GSE'])>9000] = np.nan\n data['Z_GSE'][np.abs(data['Z_GSE'])>9000] = np.nan\n if outdata:\n for key in ['By_GSM', 'Bz_GSM', 'Vx_GSE', 'DateTime', 'Den_P', 'X_GSE', 'Y_GSE', 'Z_GSE']:\n outdata[key] = np.concatenate([outdata[key], data[key]])\n return outdata\n return data\n\n\n\nif __name__=='__main__':\n #python perturbSWMF.py -p Nov2003 -f IMF.dat -n 6 -s 1977\n parser = argparse.ArgumentParser()\n parser.add_argument('-s', '--seed', dest='seed', type=int, default=1234, help='Specify random seed. Integer. Default=1234')\n parser.add_argument('-n', '--number', dest='Nensembles', type=int, default=8, help='Number of perturbed files to generate. Default=8')\n parser.add_argument('-f', '--file', dest='fname', default='IMF_ev5.dat', help='Input SWMF IMF filename. Default \"IMF_ev5.dat\"')\n parser.add_argument('-p', '--path', dest='path', default='SWMF_inputs', help='Path for input/output')\n options = parser.parse_args()\n\n np.random.seed(options.seed) #set seed for repeatability\n\n #read SWMF ImfInput file\n infilename = os.path.join(options.path, options.fname)\n if os.path.isfile(infilename):\n eventIMF = swmf.ImfInput(filename=infilename)\n else:\n raise IOError('Specified input file does not appear to exist or is not readable')\n\n Ntimes = len(eventIMF['ux']) #3*1440 #N days at 1-min resolution\n generateInputs = True\n saveErrors = False\n\n varlist = ['Vx_GSE', 'Bz_GSM', 'By_GSM']\n Nvars = len(varlist)\n map_dict = {'Vx_GSE': 'ux',\n 'Bz_GSM': 'bz',\n 'By_GSM': 'by'}\n ylimdict = {'Vx_GSE': [-300, -800],\n 'Bz_GSM': [-20, 20],\n 'By_GSM': [-20, 20]}\n xlimdict = {'Vx_GSE': [-60, 60],\n 'Bz_GSM': [-15, 15],\n 'By_GSM': [-15, 15]}\n unitsdict = {'Vx_GSE': '[km/s]',\n 'Bz_GSM': '[nT]',\n 'By_GSM': '[nT]'}\n \n #load ACE data into dict (ups: upstream)\n upsdata = load_SC_OMNI('ace', 1999)\n upsdata = load_SC_OMNI('ace', 2000, outdata=upsdata)\n upsdata = load_SC_OMNI('ace', 2001, outdata=upsdata)\n upsdata = load_SC_OMNI('ace', 2002, outdata=upsdata)\n upsdata = load_SC_OMNI('ace', 2003, outdata=upsdata)\n upsdata = load_SC_OMNI('ace', 2004, outdata=upsdata)\n upsdata = load_SC_OMNI('ace', 2005, outdata=upsdata)\n\n #load GEOTAIL data into dict (nmp: near magnetopause)\n nmpdata = load_SC_OMNI('geotail', 1999)\n nmpdata = load_SC_OMNI('geotail', 2000, outdata=nmpdata)\n nmpdata = load_SC_OMNI('geotail', 2001, outdata=nmpdata)\n nmpdata = load_SC_OMNI('geotail', 2002, outdata=nmpdata)\n nmpdata = load_SC_OMNI('geotail', 2003, outdata=nmpdata)\n nmpdata = load_SC_OMNI('geotail', 2004, outdata=nmpdata)\n nmpdata = load_SC_OMNI('geotail', 2005, outdata=nmpdata)\n\n print(nmpdata['DateTime'][0], nmpdata['DateTime'][-1])\n savedata = dm.SpaceData()\n for var in varlist[::-1]:\n print('Processing {}'.format(var))\n err = 'epsilon'\n varlabel = var[0]+'$_'+var[1]+'$'\n errlabel = r'$\\varepsilon$'\n\n plotinfo = {'var': var,\n 'err': err,\n 'varlabel': varlabel,\n 'errlabel': errlabel,\n 'xlimdict': xlimdict,\n 'ylimdict': ylimdict,\n 'units': unitsdict}\n\n #Get error distrib for var as fn of var and plot\n valid_inds = np.logical_and(np.isfinite(nmpdata[var]), np.isfinite(upsdata[var]))\n err = nmpdata[var]-upsdata[var]\n errors = err[valid_inds]\n savedata[var] = errors\n\n #generate error series with block resampling (cf. moving block bootstrap)\n #use\n error_series = np.empty([options.Nensembles, Ntimes, Nvars])\n blocksize = 60\n n_blocks = 1 + Ntimes//blocksize\n for run_num in range(options.Nensembles):\n #rather than building a 3D array here I should modify an SWMF input file directly\n blockstarts = np.random.randint(0, len(errors)-blocksize, n_blocks)\n for it, bidx in enumerate(blockstarts):\n if Ntimes-it*blocksize>blocksize:\n for vidx, var in enumerate(varlist):\n error_series[run_num, it*blocksize:it*blocksize+blocksize, vidx] = savedata[var][bidx:bidx+blocksize]\n elif Ntimes-it*blocksize>0:\n room = len(error_series[run_num, it*blocksize:, vidx])\n error_series[run_num, it*blocksize:, vidx] = savedata[var][bidx:bidx+room]\n else:\n pass\n #modify SWMF ImfInput and write new file\n outfilename = '.'.join(['_'.join([infilename.split('.')[0],'{0:03d}'.format(run_num)]), 'dat'])\n if generateInputs:\n surrogateIMF = dm.dmcopy(eventIMF)\n for vidx, var in enumerate(varlist):\n\n surrogateIMF[map_dict[var]] += error_series[run_num, :Ntimes, vidx]\n #then write to file\n surrogateIMF.write(outfilename)\n\n\n #save error series if req'd\n if saveErrors:\n out = dm.SpaceData()\n out['errors'] = dm.dmarray(error_series)\n out['errors'].attrs['DEPEND_0'] = 'EnsembleNumber'\n out['errors'].attrs['DEPEND_1'] = 'Timestep'\n out['errors'].attrs['DEPEND_2'] = 'Variable'\n out.toHDF5('MBB_errors.h5'.format(var))\n"
},
{
"alpha_fraction": 0.5532482862472534,
"alphanum_fraction": 0.5986354351043701,
"avg_line_length": 34.29842758178711,
"blob_id": "76339d0a7bdebde816d81fc2c35534e69f297783",
"content_id": "db5aa559280c1c26f140981dbe897948a008e9c3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6742,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 191,
"path": "/perturbedinput/burton_test.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport numpy as np\nimport scipy.optimize as opt\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport spacepy.pybats as bats\nimport spacepy.pybats.kyoto as kyo\nimport spacepy.empiricals as emp\nimport spacepy.toolbox as tb\nimport spacepy.time as spt\nimport spacepy.plot as splot\nsplot.style('spacepy')\nmpl.rcParams.update({'font.size': 15})\n\n\ndef Dst_Burton(initDst, v, Bz, dt=1, alpha=-4.5, tau=7.7):\n '''Advances by timestep dt [hours], adds difference to Dst*'''\n Bsouth = Bz.copy()\n Bsouth[Bz >= 0] = 0 # half-wave rectified\n E = 1e-3 * v * Bsouth\n c1 = alpha*E\n currentDst = initDst\n newDst = np.empty_like(Bz)\n for idx, val in enumerate(c1):\n c2 = currentDst/tau\n deltaDst = (val - c2)*dt\n if not np.isnan(deltaDst):\n currentDst += deltaDst\n newDst[idx] = currentDst\n return newDst\n\n\ndef Dst_OBrien(initDst, v, Bz, dt=1, alpha=-4.4):\n '''Using O'Brien & McPherron formulation.\n doi: 10.1029/1998JA000437\n '''\n Ecrit = 0.49\n Bsouth = Bz.copy()\n Bsouth[Bz >= 0] = 0 # half-wave rectified\n E = 1e-3 * v * Bsouth\n\n def getQ(alpha, E): # nT/h\n mask = E <= Ecrit\n Q = alpha*(E-Ecrit)\n Q[mask] = 0\n return Q\n\n def getTau(E, dt=dt):\n return 2.4*np.exp(9.74/(4.69+E))\n c1 = getQ(alpha, E)\n currentDst = initDst\n newDst = np.empty_like(Bz)\n for idx, val in enumerate(c1):\n c2 = currentDst/getTau(E[idx])\n deltaDst = (val - c2)*dt\n if not np.isnan(deltaDst):\n currentDst += deltaDst\n newDst[idx] = currentDst\n return newDst\n\n\ndef inverseBurton(dst, dt=1, alpha=-4.5, tau=7.7):\n \"\"\"Given a sequence of Dst, get the rectified vBz\n\n Example\n =======\n import numpy as np\n import matplotlib.pyplot as plt\n v = 400*np.ones(24)\n bz = 5*np.sin(np.arange(24))\n vbz = v*bz\n dst = Dst_Burton(0, v, bz)\n recon = inverseBurton(dst)\n plt.plot(recon, 'r-', label='Reconstructed')\n plt.plot(vbz, 'k-', label='Original')\n plt.legend()\n plt.show()\n \"\"\"\n vbz = np.zeros(dst.shape)\n c2 = dst/tau\n deltaDst = dst[1:] - dst[:-1]\n lhs = (deltaDst/dt) + c2[:-1]\n E = lhs/alpha\n vbz[1:] = E/1e-3\n return vbz\n\n\ndef inverseOBrienMcPherron(dst, dt=1, alpha=-4.4):\n \"\"\"\n \"\"\"\n vbz = np.zeros(dst.shape)\n\n def penFunc(E, dst_prev, dst_curr, dt):\n Ecrit = 0.49\n delta_dst = dst_curr - dst_prev\n tau = 2.4*np.exp(9.74 / (4.69 + E))\n guess = alpha*(E - Ecrit) - (dst_curr / tau)\n penalty = np.abs(guess - delta_dst/dt)\n return penalty\n\n for idx, dst_prev, dst_curr in zip(range(len(dst)-1), dst[:-1], dst[1:]):\n # Optimize using bounded Brent's method to find vbz\n res = opt.minimize_scalar(penFunc, args=(dst_prev, dst_curr, dt), bracket=(0, 1e5),\n bounds=(0, 1e7), method='bounded', tol=None, options=None)\n E = res.x\n vbz[idx+1] = E/1e-3\n return vbz\n\n\ndef invert_example():\n \"\"\"Test case for reverse engineering rough solar wind params\n\n We look here at the 1989 storm as studied by Nagatsuma (2015)\n and Boteler (2019)\n \"\"\"\n import datetime as dt\n import spacepy.toolbox as tb\n # fetch doesn't respect the days (it grabs 1 month at a time)\n # but we'll give the days we're inerested in for reference\n st_tup = (1989, 3, 12)\n en_tup = (1989, 3, 15)\n ky_dat = kyo.fetch('dst', st_tup, en_tup)\n st = dt.datetime(*st_tup)\n en = dt.datetime(*en_tup)\n inds = tb.tOverlapHalf([st, en], ky_dat['time'])\n vbz = inverseBurton(ky_dat['dst'][inds])\n vbz_OB = inverseOBrienMcPherron(ky_dat['dst'][inds])\n\n fig, ax = plt.subplots(2, sharex=True, figsize=(10, 4.5))\n ax[0].plot(ky_dat['time'][inds], -vbz, 'r-', label='Burton')\n ax[0].set_ylabel('v.B$_{south}$ [nT.(km/s)$^{2}$]')\n ax[0].plot(ky_dat['time'][inds], -vbz_OB, 'b-', label='O-M')\n ax[0].set_ylabel('v.B$_{south}$ [nT.(km/s)$^{2}$]')\n ax[0].legend()\n ax[1].plot(ky_dat['time'][inds], ky_dat['dst'][inds])\n ax[1].set_ylabel('Dst [nT]')\n plt.show()\n\n\ndef main(infiles=None):\n # read SWMF ImfInput file\n # Originally written to examine data from simulations\n # by Morley, Welling and Woodroffe (2018). See data at\n # Zenodo (https://doi.org/10.5281/zenodo.1324562)\n infilename = 'Event5Ensembles/run_orig/IMF.dat'\n eventIMF = bats.ImfInput(filename=infilename)\n data1 = bats.LogFile('Event5Ensembles/run_orig/GM/IO2/log_e20100404-190000.log')\n\n # #read IMF for 10 events...\n # infiles = ['Event5Ensembles/run_{:03d}/IMF.dat'.format(n)\n # for n in [32,4,36,10,13,17,18,20,24,29]]\n # read IMF files for all ensemble members\n if infiles is None:\n infiles = glob.glob('Event5Ensembles/run_???/IMF.dat')\n subsetlabel = False\n else:\n # got list of run directories from Dst/Kp plotter\n subsetlabel = True\n infiles = [os.path.join(d, 'IMF.dat') for d in infiles]\n nsubset = len(infiles)\n eventlist = [bats.ImfInput(filename=inf) for inf in infiles]\n\n tstart = eventIMF['time'][0]\n tstop = eventIMF['time'][-1]\n sym = kyo.KyotoSym(lines=bats.kyoto.symfetch(tstart, tstop))\n fig = plt.figure(figsize=(10, 5))\n ax1 = fig.add_subplot(211)\n ax2 = fig.add_subplot(212)\n for ev in eventlist:\n gco = '{}'.format(np.random.randint(5, 50)/100.0)\n pred01B = Dst_Burton(sym['sym-h'][0], ev['ux'], ev['bz'], dt=1./60)\n pred01O = Dst_OBrien(sym['sym-h'][0], ev['ux'], ev['bz'], dt=1./60)\n ax1.plot(ev['time'], pred01B, c=gco, alpha=0.5)\n ax2.plot(ev['time'], pred01O, c=gco, alpha=0.5)\n # ax1.plot(sym['time'], sym['sym-h'], lw=1.5, c='crimson', label='Sym-H')\n evtime = spt.Ticktock(eventIMF['time']).RDT\n datime = spt.Ticktock(data1['time']).RDT\n simDst = tb.interpol(evtime, datime, data1['dst'])\n # ax1.plot(eventIMF['time'], simDst+11-(7.26*eventIMF['pram']), lw=1.5, c='seagreen', label='Sym-H (Press.Corr.)')\n # ax2.plot(sym['time'], sym['sym-h'], lw=1.5, c='crimson')\n # ax2.plot(eventIMF['time'], simDst+11-(7.26*eventIMF['pram']), lw=1.5, c='seagreen', label='Sym-H (Press.Corr.)')\n ax1.plot(data1['time'], data1['dst'], linewidth=1.5, color='crimson', alpha=0.65, label='SWMF')\n ax2.plot(data1['time'], data1['dst'], linewidth=1.5, color='crimson', alpha=0.65)\n ax1.legend()\n splot.applySmartTimeTicks(ax1, [tstart, tstop])\n splot.applySmartTimeTicks(ax2, [tstart, tstop], dolabel=True)\n ax1.set_ylabel('Sym-H [nT]')\n ax2.set_ylabel('Sym-H [nT]')\n ax1.text(0.05, 0.05, \"Burton et al.\", transform=ax1.transAxes)\n ax2.text(0.05, 0.05, \"O'Brien et al.\", transform=ax2.transAxes)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7171717286109924,
"avg_line_length": 30,
"blob_id": "41f5dbc432984ebd1417f402ff797e09f4449373",
"content_id": "0840082031454a9584dbea157ccea1e4b1da0f62",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 16,
"path": "/dBdt/cptest.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.gridspec as gridspec\nimport cartopy.crs as ccrs\nimport cartopy.feature as cfeature\n\nfig = plt.figure()\ngs = fig.add_gridspec(3, 3)\n\nax1 = fig.add_subplot(gs[0:2, :], projection=ccrs.PlateCarree())\nax1.set_extent([-180, 180, -90, 90], crs=ccrs.PlateCarree())\nax1.coastlines(resolution='auto', color='k')\nax1.gridlines(color='lightgrey', linestyle='-', draw_labels=True)\n\nax2 = fig.add_subplot(gs[2, :])\nax2.plot([1, 2], [3, 4])"
},
{
"alpha_fraction": 0.5246636867523193,
"alphanum_fraction": 0.5620328783988953,
"avg_line_length": 23.796297073364258,
"blob_id": "fe915b846382e39b6b6b3a353fad0428cdab6a16",
"content_id": "d19326dd86cc42614e9ee33938920f7c0b819a0b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1338,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 54,
"path": "/event_selection/readRC.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "from functools import partial\nimport dateutil.parser as dup\nimport spacepy.datamodel as dm\n\n\ndef read_list(fname='richardson_cane_ICME_list.txt'):\n \"\"\"Read Richardson-Cane ICME list from file\n\n Parameters\n ----------\n fname : str\n filename of Richardson-Cane ICME list\n\n Example\n -------\n >>> import readRC\n >>> data = readRC.read_list()\n \"\"\"\n tfunc = partial(dup.parse, ignoretz=True)\n convdict = {'Epoch': tfunc,\n 'ICME_start': tfunc,\n 'ICME_end': tfunc,\n 'Shock': bool,\n }\n data = dm.readJSONheadedASCII(fname, convert=convdict)\n return data\n\n\ndef get_event(rclist, index=0):\n \"\"\"Get data for a given event number\n\n Parameters\n ----------\n rclist : dict-like\n SpaceData object returned by read_list\n index : int\n Integer index for event\n\n Example\n -------\n >>> import readRC\n >>> data = readRC.read_list()\n >>> readRC.get_event(data, 5)\n {'B_avg': 10.0,\n 'Epoch': datetime.datetime(1996, 12, 23, 16, 0),\n 'ICME_end': datetime.datetime(1996, 12, 25, 11, 0),\n 'ICME_start': datetime.datetime(1996, 12, 23, 17, 0),\n 'Shock': True,\n 'V_avg': 360.0,\n 'V_max': 420.0,\n 'deltaV': 20.0}\n \"\"\"\n evdict = {k: v[3] for k, v in rclist.items()}\n return evdict"
},
{
"alpha_fraction": 0.6420426368713379,
"alphanum_fraction": 0.6499752402305603,
"avg_line_length": 35.672725677490234,
"blob_id": "47d8f89f1900eb816dea6763fe0f4c179218ae74",
"content_id": "613029c91d4ed045bb3652164b2536957c379b80",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2017,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 55,
"path": "/viz/makePVD.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import argparse\nimport glob\nimport os\nimport warnings\nfrom xml.etree import ElementTree\nfrom xml.dom import minidom\n\n\ndef prettify(elem):\n \"\"\"Pretty-print XML string with indents and newlines\n \"\"\"\n rough_string = ElementTree.tostring(elem, 'utf-8')\n reparsed = minidom.parseString(rough_string)\n return reparsed.toprettyxml(indent=\" \")\n\n\ndef genPVD(fnames, outfn):\n \"\"\"Make PVD file with collection of supplied filenames\n \"\"\"\n vtkfile = ElementTree.Element('VTKFile', type='Collection', version='0.1')\n collection = ElementTree.SubElement(vtkfile, 'Collection')\n for idx, fname in enumerate(fnames):\n ElementTree.SubElement(collection, 'DataSet', timestep=f'{idx}', file=fname)\n outstr = prettify(vtkfile)\n with open(outfn, 'w') as fh:\n fh.write(outstr)\n\n\ndef filterFilename(fname, keeppaths=True):\n if keeppaths:\n return fname\n else:\n return os.path.split(fname)[1]\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Generate Paraview data file (.pvd) to group vtp files for multiple times')\n parser.add_argument('-p', '--preservepaths', action='store_true')\n parser.add_argument('-o', '--output', default=\"Bats2d.pvd\", help='Output filename, default is Bats2d.pvd')\n parser.add_argument('inputfiles', nargs='+', help='Input files (can use wildcards, shell will expand)\\n'+\n 'e.g., BBF_3D/GM/y*065[1-9][024]0*vtp')\n args = parser.parse_args()\n\n usefiles = []\n warnings.simplefilter(\"always\")\n \n for fncand in args.inputfiles:\n if not os.path.isfile(fncand):\n tmp = sorted(glob.glob(fncand))\n if not tmp:\n warnings.warn(\"Search pattern '{}' did not match any files. Skipping.\".format(fncand))\n usefiles.extend([filterFilename(fn, args.preservepaths) for fn in tmp])\n else:\n usefiles.append(filterFilename(fncand, args.preservepaths))\n genPVD(usefiles, args.output)\n"
},
{
"alpha_fraction": 0.5689107775688171,
"alphanum_fraction": 0.5805017352104187,
"avg_line_length": 41.268455505371094,
"blob_id": "d7c48dda520b696f8b6f3e7f296c70de551da342",
"content_id": "02de60f781c687b236426c1eef4082acc4efe43c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6298,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 149,
"path": "/scripts/runSWMF.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport errno\nimport sys\nimport shutil\nimport subprocess\nimport time\nimport glob\nimport argparse\nfrom contextlib import contextmanager\n\ndefaults = {'nNodes': 12, #12 node (432 core) default\n 'jobLength': '7:00:00', #default job length in hh:mm:ss\n 'execDir': '/usr/projects/carrington/src/SWMF_grizzly_BATS_Rid_RCM',\n 'noSubmit': False,\n 'ramscb': False\n }\n\n@contextmanager\ndef cd(newdir):\n '''Context-managed chdir; changes back to original directory on exit or failure'''\n prevdir = os.getcwd()\n os.chdir(os.path.expanduser(newdir))\n try:\n yield\n finally:\n os.chdir(prevdir)\n\ndef writeArbitrary():\n '''Manager for distributing work when mixing MPI and OpenMP for RAMSCB'''\n with open('arbitrary.pl', 'w') as fh:\n fh.write(\"#!/usr/bin/perl\\n\")\n fh.write(\"my @tasks = split(',', $ARGV[0]);\\n\")\n #fh.write(\"my @nodes = `scontrol show hostnames $SLURM_JOB_NODELIST`;\\n\")\n fh.write(\"my @nodes = `scontrol show hostnames`;\\n\")\n fh.write(\"my $node_cnt = $#nodes + 1;\\n\")\n fh.write(\"my $task_cnt = $#tasks + 1;\\n\")\n fh.write(\"if ($node_cnt < $task_cnt) {\\n\")\n fh.write(\" print STDERR 'ERROR: You only have $node_cnt nodes, but requested layout on $task_cnt nodes';\\n\")\n fh.write(\" $task_cnt = $node_cnt;\\n\")\n fh.write(\"}\\n\")\n fh.write(\"my $cnt = 0;\\n\")\n fh.write(\"my $layout;\\n\")\n fh.write(\"foreach my $task (@tasks) {\\n\")\n fh.write(\" my $node = $nodes[$cnt];\\n\")\n fh.write(\" last if !$node;\\n\")\n fh.write(\" chomp($node);\\n\")\n fh.write(\" for(my $i=0; $i < $task; $i++) {\\n\")\n fh.write(\" $layout .= ',' if $layout;\\n\")\n fh.write(\" $layout .= $node;\\n\")\n fh.write(\" }\\n\")\n fh.write(\" $cnt++;\\n\")\n fh.write(\"}\\n\")\n fh.write(\"print $layout;\")\n\ndef writeJobScript(runnum, options):\n nNodes = options.nNodes\n timearg = options.jobLength\n with open('job_script.sh', 'w') as fh:\n fh.write(\"#!/bin/tcsh\\n\")\n fh.write(\"#SBATCH --time={0}\\n\".format(timearg))\n fh.write(\"#SBATCH --nodes={0}\\n\".format(nNodes))\n fh.write(\"#SBATCH --no-requeue\\n\")\n fh.write(\"#SBATCH --job-name=SWMF_{0}\\n\".format(runnum))\n fh.write(\"#SBATCH -o slurm%j.out\\n\")\n fh.write(\"#SBATCH -e slurm%j.err\\n\")\n fh.write(\"#SBATCH --qos=standard\\n\")\n # Update allocation name to appropriate SLURM group\n fh.write(\"#SBATCH --account=allocation_name\\n\")\n # Update email to appropriate domain\n fh.write(\"#SBATCH --mail-user={0}@email.provider\\n\".format(os.environ['USER']))\n fh.write(\"#SBATCH --mail-type=FAIL\\n\")\n fh.write(\"\\n\")\n # Update modules for however SWMF was compiled\n fh.write(\"module load gcc/6.4.0 openmpi/2.1.2 idl/8.5.1\\n\")\n if options.ramscb:\n fh.write(\"module load hdf5-parallel/1.8.16 netcdf-h5parallel/4.4.0\\n\")\n fh.write(\"setenv LD_LIBRARY_PATH /usr/projects/carrington/lib:${LD_LIBRARY_PATH}\\n\")\n fh.write(\"\\n\") \n fh.write(\"srun -m arbitrary -n {0} -w `perl arbitrary.pl {1}` ./SWMF.exe\\n\".format(nNodes*36-35,','.join(['1']+['36']*(nNodes-1))))\n writeArbitrary()\n else:\n fh.write(\"\\n\") \n fh.write(\"srun -n {0} ./SWMF.exe\\n\".format(nNodes*36))\n\n\nif __name__=='__main__':\n # Define a command-line option parser and add the options we need\n parser = argparse.ArgumentParser()\n\n parser.add_argument('-v', '--version', action='version', version='%prog Version 0.99 (Jan 14, 2019)')\n\n parser.add_argument('-n', '--nodes', dest='nNodes', type=int,\n help='Sets number of requested nodes for Slurm job. Default is 12.')\n\n parser.add_argument('-l', '--length', dest='jobLength',\n help='Sets requested job length (hh:mm:ss). Default is \"7:00:00\"')\n\n parser.add_argument('-e', '--exec_dir', dest='execDir',\n help='Directory of SWMF installation to use. Default is \"/usr/projects/carrington/src/SWMF_grizzly_BATS_Rid_RCM\"')\n\n parser.add_argument('--ramscb', dest='ramscb', action='store_true', help='Enables RAM-SCB-specific settings')\n\n parser.add_argument('--no_submit', dest='noSubmit', action='store_true',\n help='Disables the job submission feature of the script. Default is to submit the job')\n\n parser.add_argument('runname', help='Run name, used to set location for retrieving run files and setting job name.')\n\n # Parse the args that were (potentially) given to us on the command line\n options = parser.parse_args()\n # set defaults where values aren't provided\n for key in defaults:\n if (not hasattr(options, key)) or (options.__dict__[key] is None):\n options.__dict__[key] = defaults[key]\n user = os.environ['USER']\n\n run_name = 'run_grizzly_{0}'.format(options.runname)\n with cd(options.execDir):\n subprocess.call(['make', 'rundir'])\n\n # Update to refelct location of model input directories\n inloc = '/usr/projects/carrington/modelInputs/{0}'.format(options.runname)\n # Update path to HPC cluster scratch directory\n runloc = '/path/to/scratch/{0}'.format(user)\n shutil.move(os.path.join(options.execDir, 'run'), os.path.join(runloc, run_name))\n inputfiles = glob.glob(os.path.join(inloc,'*'))\n for fname in inputfiles:\n try:\n namepart = os.path.split(fname)[-1]\n shutil.copytree(fname, os.path.join(runloc, run_name, namepart))\n except OSError as exc:\n if exc.errno == errno.ENOTDIR:\n shutil.copy(fname, os.path.join(runloc, run_name))\n else:\n print(fname)\n raise OSError\n\n with cd(os.path.join(runloc, run_name)):\n if os.path.isfile('PARAM.in.start'):\n try:\n os.unlink('PARAM.in')\n except:\n pass\n os.symlink('PARAM.in.start', 'PARAM.in')\n writeJobScript(run_name, options)\n if not options.noSubmit:\n time.sleep(6)\n subprocess.call(['sbatch', 'job_script.sh'])\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 55,
"blob_id": "71b1ceec9407df6e4affd73332d583068e96d096",
"content_id": "080cef693228b2245a8bf36f3a79cebfeceb7ced",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 2,
"path": "/README.md",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "# SWMFtools\nA selection of tools for working with the Space Weather Modeling Framework, its inputs and outputs.\n"
},
{
"alpha_fraction": 0.45970210433006287,
"alphanum_fraction": 0.47816771268844604,
"avg_line_length": 45.23584747314453,
"blob_id": "b8381780e4f182e5cea4619df9253eac1654114e",
"content_id": "0e7d72e66ed32ee1aaf2fbc87291dde0de1bab81",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9802,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 212,
"path": "/dBdt/supermag_parser.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nfrom scipy import interpolate\nfrom scipy import linalg\n\nclass supermag_parser(object): #TODO: inherit from spacepy.datamodel.SpaceData to mirror construction of SWMF MagFile\n \"\"\"\n This class can be used to read data from supermag ascii files and to process the data\n \"\"\"\n\n def __init__(self,fname=None,ncol_time=6,ncol_data=7,deriv_method='difference', legacy=False):\n if not fname is None:\n self.read_supermag_data(fname, ncol_time=ncol_time, ncol_data=ncol_data,\n deriv_method=deriv_method, legacy=legacy)\n \n \n def read_supermag_data(self, filename, ncol_time=6, ncol_data=7,\n legacy=False, critfrac=0.1, badflag=999999.0,\n deriv_method='spectral'):\n \"\"\"\n Read and parse a SuperMAG magnetometer file.\n \n Optional Parameters\n -------------------\n legacy : bool\n For legacy SuperMag files, use True.\n \"\"\"\n data = {}\n time = []\n if legacy:\n # Columns (after IAGA ID) for each param\n bncol = 0\n becol = 1\n bzcol = 2\n mltcol = 3\n mlatcol = 4\n szacol = 5\n declcol = 6\n with open(filename,'r') as f:\n look_for_header = True\n lines=[]\n for i, line in enumerate(f):\n datum = line.strip()\n if look_for_header and legacy:\n istat = 0\n lines.append(datum)\n if len(lines) > 0:\n if len(lines[i]) > 0:\n if lines[i][0] == '=':\n opts=lines[i-1].split()\n for station in opts[-1].split(','):\n data[station] = {'time':[],'data':[]}\n look_for_header=False\n elif look_for_header and not legacy:\n istat = 0\n lines.append(datum)\n # print('Checking header in {}, line {}\\n{}'.format(filename, i, line))\n if datum.startswith('Stations'):\n statlist = datum.split(': ')[1].split(',')\n for station in statlist:\n data[station] = {'time':[],'data':[]}\n if datum.startswith('Param'):\n paramlist = datum.split(': ')[1].split('|')\n paramlist = [prm.strip() for prm in paramlist]\n bncol = paramlist.index('Mag. Field NEZ') - 1\n becol = bncol + 1\n bzcol = bncol + 2\n szacol = paramlist.index('Solar Zenith Angle') - 1\n mlatcol = paramlist.index('Mag. Lat.') - 1\n mltcol = paramlist.index('MLT') - 1\n declcol = paramlist.index('Mag. Declination') - 1\n look_for_header = False\n else:\n line_data = datum.split()\n if istat==0:\n # Line with time data and num. stations\n tstamp = pd.Timestamp(*list(map(int,line_data[:-1])))\n time.append(tstamp)\n nstat = int(line_data[-1])\n else:\n # Line with data for a given station at one time\n stat = line_data[0]\n data[stat]['time'].append(time[-1])\n data[stat]['data'].append(np.array([list(map(float,line_data[1:]))]))\n\n if istat == nstat:\n istat = 0\n else:\n istat+=1\n \n self.time = np.array(time)\n \n # Store data in object unless there is a significant portion missing.\n self.station={}\n for key in data.keys():\n if len(data[key]['time']) > critfrac*len(self.time):\n # Make sure that there is some good data in the time series, \n # otherwise skip this station\n if not all(np.array(data[key]['data']).squeeze()[:,0] == badflag): \n self.station[key] = {} #TODO: do as SpaceData\n # Filter out bad data and interpolate over gaps\n squeeze = lambda x: np.asarray(x).squeeze()\n squeezedB = squeeze(data[key]['data'])\n self.station[key]['B'] = np.c_[self.bad_data_filter(squeezedB[:,bncol], data[key]['time']),\n self.bad_data_filter(squeezedB[:,becol], data[key]['time']),\n self.bad_data_filter(squeezedB[:,bzcol], data[key]['time'])]\n \n B = self.station[key]['B']\n # Calculate the time derivatives of the magnetic field\n Bdot = np.c_[self.get_derivative(B[:,0], deriv_method=deriv_method, dt=60.0),\n self.get_derivative(B[:,1], deriv_method=deriv_method, dt=60.0),\n self.get_derivative(B[:,2], deriv_method=deriv_method, dt=60.0)]\n \n idBmax = linalg.norm(B[:,:2],axis=1).argmax()\n idTmax = linalg.norm(Bdot[:,:2],axis=1).argmax()\n \n # Store the data\n self.station[key]['time'] = self.time\n self.station[key]['Bdot'] = Bdot\n #TODO: interpolate the following onto the correct timebase\n self.station[key]['mlt'] = squeeze(data[key]['data'])[:, mltcol]\n self.station[key]['decl'] = squeeze(data[key]['data'])[:, declcol]\n self.station[key]['mlat'] = squeeze(data[key]['data'])[0, mlatcol]\n self.station[key]['sza'] = squeeze(data[key]['data'])[0, szacol]\n self.station[key]['max_indices'] = [idBmax,idTmax]\n self.station[key]['maxB'] = linalg.norm(B[idBmax,:2])\n self.station[key]['maxBdot'] = linalg.norm(Bdot[idTmax,:2])\n \n return\n \n def filter_window(self,npts,frac=0.05,wid=0.025):\n # A rounded-rectangle function used for FFT windowing\n x=np.linspace(0,1,npts)\n y=0.5*(np.tanh((x-frac)/wid)-np.tanh((x-(1-frac))/wid))\n return y\n\n def get_derivative(self,data,deriv_method,dt=1.0):\n \n if deriv_method == 'spectral':\n # Calculate the derivative of a quantity using a spectral method\n filt = self.filter_window(data.size)\n freq = np.fft.fftfreq(data.size,d=dt)\n dfft = np.fft.fft(filt*data)\n ddot = np.real(np.fft.ifft(2j*np.pi*freq*dfft))\n else: # method = 'difference'\n ddot = np.zeros_like(data)\n ddot[1:-1] = (data[2:]-data[:-2])/(2*dt)\n ddot[0] = (3*data[0]-4*data[1]+data[2])/(2*dt)\n ddot[-1] = -(3*data[-1]-4*data[-2]+data[-3])/(2*dt)\n \n return ddot\n \n def bad_data_filter(self, data, ticks, baddata=999999.0):\n numericticks = np.asarray([tt.timestamp() for tt in ticks])\n # Replace bad data with linear interpolation,\n # applying persistence if bad data is at edge\n if np.all(data==baddata):\n interp_data = np.zeros_like(data)\n elif np.any(data==baddata) or len(ticks)!=len(self.time):\n new_data = np.empty((len(self.time), 3))\n first_good=np.where(data!=baddata)[0][0]\n last_good=np.where(data!=baddata)[0][-1]\n\n #build interpolating func. with good data only\n good_filter = data != baddata\n xvals = np.linspace(self.time[0].timestamp(), self.time[-1].timestamp(),\n len(self.time))\n dinterp = interpolate.interp1d(numericticks[good_filter],\n data[good_filter],\n kind='linear', bounds_error=False,\n fill_value=(data[good_filter][0],data[good_filter][-1]))\n interp_data = dinterp(xvals)\n else:\n interp_data = data.copy()\n\n return interp_data\n \nif __name__ == \"__main__\":\n \n import matplotlib.pyplot as plt\n import glob\n \n # Grab a data file\n data_file = glob.glob('../test_data/2*.txt')[0]\n data_file = '../test_data/supermag-20000810-20000812.txt'\n smp = supermag_parser(data_file)\n \n # Get the GMD peaks for each station\n dbmax=[]\n dtmax=[]\n mlat=[]\n for key,stat in smp.station.items():\n mlat.append(stat['mlat'])\n dbmax.append(stat['maxB'])\n dtmax.append(stat['maxBdot'])\n \n # Plot the latitudinal distribution of peak GMDs\n fig=plt.figure(1,figsize=(12,8))\n ax1,ax2=fig.subplots(2,1,sharex=True)\n ax1.scatter(mlat,dtmax,s=200,alpha=0.5,color='royalblue')\n ax1.set_yscale('log')\n ax1.set_ylim([1e-1,3e1])\n ax1.tick_params(labelsize=16)\n ax1.set_ylabel('Peak $dB/dt$ (nT/s)',fontsize=20)\n ax2.scatter(mlat,dbmax,s=200,alpha=0.5,color='royalblue')\n ax2.set_yscale('log')\n ax2.set_ylim([2e2,5e3])\n ax2.tick_params(labelsize=16)\n ax2.set_xlabel('Magnetic Latitude (Degrees)',fontsize=20)\n ax2.set_ylabel('Peak $\\Delta B$ (nT)',fontsize=20)\n plt.tight_layout()\n plt.show()\n"
},
{
"alpha_fraction": 0.5412330031394958,
"alphanum_fraction": 0.5691486597061157,
"avg_line_length": 39.816993713378906,
"blob_id": "ac160bc74d7c46dc157d04fc570d3aa9e577d302",
"content_id": "966b7cf60fd47edd2e00c17c9b9eb059b101027f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18735,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 459,
"path": "/dBdt/ieee.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import copy\nimport glob\nimport re\nimport os\nimport itertools\nimport datetime as dt\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.colors as mplc\nimport cartopy.crs as ccrs\nimport cartopy.feature as cfea\nimport cartopy.feature.nightshade as night\nimport cartopy.util as cuti\nfrom cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter\nimport spacepy.datamodel as dm\nimport spacepy.toolbox as tb\n\n\ndef discrete_cmap(N, base_cmap=None):\n \"\"\"Create an N-bin discrete colormap from the specified input map\"\"\"\n\n # Note that if base_cmap is a string or None, you can simply do\n # return plt.cm.get_cmap(base_cmap, N)\n # The following works for string, None, or a colormap instance:\n\n base = plt.cm.get_cmap(base_cmap)\n color_list = base(np.linspace(0, 1, N))\n cmap_name = base.name + str(N)\n return base.from_list(cmap_name, color_list, N)\n\n\ndef plotFilledContours(mdata, pdata, addTo=None):\n plotvar = pdata['plotvar']\n try:\n data, lons = cuti.add_cyclic_point(np.transpose(mdata[plotvar]), \n mdata['Lon'])\n except ValueError:\n try:\n data, lons = cuti.add_cyclic_point(mdata[plotvar], mdata['Lon'])\n except:\n data = mdata[plotvar]\n lons = mdata['Lon']\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'],\n extent=[-145.0, 15.0, 30.0, 80.0])\n stn_list = ['FRD', 'OTT', 'PBQ']\n lon_list = [-77.3729, -75.552, -77.745]\n lat_list = [38.2047, 45.403, 55.277]\n ax.plot(lon_list, lat_list, color='k', linestyle='none', marker='o',\n markersize=2, transform=ccrs.PlateCarree())\n for idx, stn in enumerate(stn_list):\n ax.text(lon_list[idx] + 2, lat_list[idx] - 2.5, stn,\n horizontalalignment='left', fontsize='small',\n transform=ccrs.PlateCarree())\n if pdata['shapes'] is not None:\n ax.add_geometries(pdata['shapes'], pdata['plotprojection'], \n edgecolor='black', facecolor='none')\n #ax.gridlines()\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0}'.format(mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n norm = mplc.Normalize()\n clipdata = np.array(data)\n minplotcol = 0.0\n skipPlot = False\n if 'Emag' in plotvar:\n maxplotcol = 2.5 if 'maxplotcol' not in pdata else pdata['maxplotcol']\n norm = mplc.Normalize(vmin=minplotcol, vmax=pdata['maxplotcol'])\n colmap = 'magma_r'\n clabel = '|E| [V/km]'\n elif 'jr' in plotvar:\n minplotcol = -1.\n maxplotcol = 1.\n colmap = 'seismic'\n clabel = 'j$_{R}$ [mA/m$^{2}$]'\n #cmg = ax.contourf(lons, mdata['Lat'], clipdata, np.linspace(-2,2,50),\n # transform=pdata['dataprojection'], cmap=colmap,#'YlOrRd',\n # vmin=minplotcol, vmax=maxplotcol, norm=norm,\n # alpha=0.5)#, extend='max')\n cmg = ax.pcolormesh(lons, mdata['Lat'], clipdata,\n transform=pdata['dataprojection'],\n cmap='seismic')\n skipPlot = True\n elif 'Estd' in plotvar:\n minplotcol = 2e-1\n maxplotcol = 3\n colmap = discrete_cmap(7, 'YlOrBr')\n clabel = '$\\sigma$(|E|) [V/km]'\n clipdata = clipdata + 1e-6\n norm = mplc.LogNorm(vmin=3e-3, vmax=3)\n else:\n maxplotcol = 10#25\n colmap = 'magma_r'\n clabel = '(dB/dt)$_{H}$ [nT/s]'\n #cmg = ax.contourf(lons, mdata['Lat'], np.array(data), np.linspace(0,20,150),\n # transform=pdata['dataprojection'], cmap='magma_r',#'YlOrRd',\n # vmin=0, vmax=maxplotcol,\n # alpha=0.5, extend='max')\n if not skipPlot: \n clipdata[clipdata>maxplotcol] = maxplotcol\n cmap = copy.copy(plt.get_cmap(colmap))\n cmg = ax.contourf(lons, mdata['Lat'], clipdata, np.linspace(0,25,maxplotcol*2),\n transform=pdata['dataprojection'], cmap=cmap,#'YlOrRd',\n vmin=minplotcol, vmax=maxplotcol, norm=norm,\n alpha=0.5)#, extend='max')\n\n cmg.cmap.set_over('k')\n cmg.set_clim(minplotcol, maxplotcol)\n #cmg.cmap.set_under(cmg.cmap(0))\n map_dummy = plt.cm.ScalarMappable(cmap=colmap, norm=norm)\n map_dummy.set_array(np.array(clipdata))\n map_dummy.set_clim(minplotcol, maxplotcol)\n cax = plt.colorbar(map_dummy, ax=ax, extend='max', shrink=0.4, pad=0.04, drawedges=False)\n cax.set_label(clabel)\n return ax\n\n\ndef plotContour(mdata, pdata, addTo=None):\n plotvar = pdata['plotvar']\n data, lons = cuti.add_cyclic_point(np.transpose(mdata[plotvar]), \n mdata['Lon'])\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'])\n\n if pdata['shapes'] is not None:\n ax.add_geometries(pdata['shapes'], pdata['plotprojection'], \n edgecolor='black', facecolor='none')\n #ax.gridlines()\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0}[{1}]\\n{2}'.format(plotvar, \n mdata[plotvar].attrs['units'], \n mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n cax = ax.contourf(lons, mdata['Lat'], np.array(data), [pdata['thresh'], data.max()], \n transform=pdata['dataprojection'], colors=pdata['ccolor'],\n alpha=0.75)\n return ax\n\n\ndef plotVectors(mdata, pdata, addTo=None, quiver=False, maxVec=2.5,\n qstyle=None, sstyle=None):\n '''\n\n Optional arguments\n ------------------\n addTo : Axes or None\n If None (default), then a new figure is created. Otherwise the supplied\n Axes are used to plot the vectors on. The axes are assumed to support\n projections (e.g. cartopy)\n quiver : boolean\n If True makes a quiver plot. If False (default) draws streamlines scaled\n in width by the vector magnitude.\n maxVec : float\n Limit for the linewidth of streamlines.\n qstyle : dict or None\n Dictionary containing plot style kwargs for quiver plots\n '''\n from matplotlib.colors import LogNorm\n plotvar = pdata['plotvec']\n if 'Lat_raw' in mdata:\n if quiver:\n lons = mdata['Lon_raw'][::1]\n lats = mdata['Lat_raw'][::1]\n vec_e = mdata['{0}e_raw'.format(plotvar)][::1]\n vec_n = mdata['{0}n_raw'.format(plotvar)][::1]\n else:\n lons = mdata['Lon_raw']\n lats = mdata['Lat_raw']\n vec_e = mdata['{0}e_raw'.format(plotvar)]\n vec_n = mdata['{0}n_raw'.format(plotvar)]\n else:\n latlon = list(itertools.product(mdata['Lon'], mdata['Lat']))\n lons = np.array(latlon)[:,0]\n lats = np.array(latlon)[:,1]\n vec_e = np.ravel(mdata['{0}e'.format(plotvar)])\n vec_n = np.ravel(mdata['{0}n'.format(plotvar)])\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'])\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0} [{1}]\\n{2}'.format(plotvar, \n 'V/km', \n mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n if quiver:\n def logscl(u, v):\n arr_len = np.sqrt(u*u + v*v)\n len_adj = np.log10(arr_len + 1)/arr_len\n return u*len_adj, v*len_adj\n\n if qstyle is None:\n qstyle = dict()\n qstyle['width'] = 0.004\n qstyle['headlength'] = 4\n qstyle['headaxislength'] = 4\n qstyle['cmap'] = 'plasma' #'inferno'\n mynorm = LogNorm(vmin=1e-2, vmax=5)\n vec_mag = np.linalg.norm(np.c_[vec_e, vec_n], axis=-1)\n pltu, pltv = logscl(vec_e, vec_n)\n qp = ax.quiver(lons, lats, pltu, pltv, vec_mag,\n transform=pdata['dataprojection'], zorder=33,\n norm=mynorm, **qstyle)\n cmap = qp.get_cmap()\n l0 = 5\n l1 = 1\n l2 = 0.5\n l3 = 0.1\n lab0magcol = cmap(mynorm(l0))\n lab1magcol = cmap(mynorm(l1))\n lab2magcol = cmap(mynorm(l2))\n lab3magcol = cmap(mynorm(l3))\n ax.quiverkey(qp, 0.58, 0.05, np.log10(l0+1), '{} V/km'.format(l0), labelpos='E',\n transform=pdata['dataprojection'], color=lab0magcol, coordinates='figure')\n ax.quiverkey(qp, 0.43, 0.05, np.log10(l1+1), '{} V/km'.format(l1), labelpos='E',\n transform=pdata['dataprojection'], color=lab1magcol, coordinates='figure')\n ax.quiverkey(qp, 0.27, 0.05, np.log10(l2+1), '{} V/km'.format(l2), labelpos='E',\n transform=pdata['dataprojection'], color=lab2magcol, coordinates='figure')\n ax.quiverkey(qp, 0.12, 0.05, np.log10(l3+1), '{} V/km'.format(l3), labelpos='E',\n transform=pdata['dataprojection'], color=lab2magcol, coordinates='figure')\n plt.colorbar(qp, label='|E$_H$| [V/km]', extend='both')\n else:\n if sstyle is None:\n sstyle = dict()\n if 'arrowsize' not in sstyle: sstyle['arrowsize'] = 0.75\n if 'color' not in sstyle: sstyle['color'] = 'black'\n if 'linewidth' not in sstyle:\n mag = np.sqrt(vec_e**2+vec_n**2)\n lw = ((2.5*mag)+0.5)/(2.5*maxVec)\n lw[lw>=maxVec] = (2.5*maxVec)+0.5\n sstyle['linewidth'] = lw\n ax.streamplot(lons, lats, vec_e, vec_n, transform=pdata['dataprojection'], zorder=33, **sstyle)\n return ax\n\n\ndef makeMap(figure=None, axes=None, maptime=dt.datetime.now(), figsize=(10,4), projection=ccrs.PlateCarree(),\n extent=[-165.0, 145.0, 30.0, 80.0], nightshade=True):\n #PlateCarree is an equirectangular projection where lines of equal longitude\n #are vertical and lines of equal latitude are horizontal. Spacing between lats\n #and longs are also equal.\n if figure is None:\n fig = plt.figure(figsize=figsize)\n else:\n fig = figure\n if axes is None:\n ax = plt.axes(projection=projection)\n else:\n ax = axes\n ax.coastlines(color='darkgrey')\n ax.add_feature(cfea.BORDERS, linestyle=':', edgecolor='darkgrey')\n if nightshade:\n ax.add_feature(night.Nightshade(maptime, alpha=0.3))\n lon_formatter = LongitudeFormatter(number_format='.1f',\n degree_symbol='',\n dateline_direction_label=True)\n lat_formatter = LatitudeFormatter(number_format='.1f',\n degree_symbol='')\n ax.xaxis.set_major_formatter(lon_formatter)\n ax.yaxis.set_major_formatter(lat_formatter)\n ax.set_extent(extent, crs=ccrs.PlateCarree())\n\n return fig, ax\n\n\ndef forwardDiff(a, b, c, dt):\n return (-c + 4*b - 3*a)/(2*dt)\n\ndef backwardsDiff(x, y, z, dt):\n return (3*z - 4*y + x)/(2*dt)\n\ndef centralDiff(a, c, dt):\n return (c-a)/(2*dt)\n\n\nclass ElecData(dm.SpaceData):\n def addTimes(self, filenames):\n toAdd = [readEcsv(fn) for fn in filenames]\n if 'times' not in self.attrs:\n self.attrs['times'] = [self.attrs['time']]\n for ta in toAdd:\n self.attrs['times'].append(ta.attrs['time'])\n for key in self:\n if 'Lat' in key or 'Lon' in key: continue\n if '_raw' in key:\n self[key] = np.stack([self[key], *[ta[key] for ta in toAdd]])\n self[key] = self[key].T\n else:\n self[key] = np.dstack([self[key], *[ta[key] for ta in toAdd]])\n\n\ndef readEcsv(fname):\n try:\n import pandas as pd\n has_pandas = True\n except (ImportError, ModuleNotFoundError):\n has_pandas = False\n\n if has_pandas:\n dframe = pd.read_csv(fname, sep=',')\n rawdata = dframe.values # get underlying numpy array\n else:\n rawdata = np.loadtxt(fname, delimiter=',', skiprows=1)\n\n edata = ElecData()\n #fileidx = int(re.search('\\d{4}', fname).group())\n #offset = fileidx*5\n tstr = re.search('\\d{8}-(\\d{6})', fname).group()\n edata.attrs['time'] = dt.datetime(int(tstr[:4]), int(tstr[4:6]), int(tstr[6:8]), int(tstr[9:11]), int(tstr[11:13]), int(tstr[13:15]))\n edata['Lat_raw'] = rawdata[:, 0]\n edata['Lon_raw'] = rawdata[:, 1]\n edata['Ee_raw'] = rawdata[:, 2]\n edata['En_raw'] = rawdata[:, 3]\n nlat = len(set(edata['Lat_raw']))\n nlon = len(set(edata['Lon_raw']))\n edata['Lat'] = np.reshape(rawdata[:, 0], [nlat, nlon])[:,0]\n edata['Lon'] = np.reshape(rawdata[:, 1], [nlat, nlon])[0,:]\n edata['Ee'] = np.reshape(rawdata[:, 2], [nlat, nlon])\n edata['En'] = np.reshape(rawdata[:, 3], [nlat, nlon])\n edata['Emag'] = np.sqrt(edata['Ee']**2.0 + edata['En']**2.0)\n\n return edata\n\n\ndef makeSymlinks(dirname, kind='dbdt'):\n #make symlinks to images with numeric naming so it can be easily passed to ffmpeg\n pngfns = sorted(glob.glob(os.path.join(dirname,'{0}*png'.format(kind))))\n for idx, fn in enumerate(pngfns):\n os.symlink(os.path.abspath(fn), \n os.path.abspath(os.path.join(dirname,\n 'img{0:04d}.png'.format(idx))))\n\n\ndef northAmerica(fname, emin=1e-2, emax=5, conus=False, quiver=False):\n import matplotlib.ticker as mticker\n from matplotlib import gridspec\n from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER\n import cartopy.io.shapereader as shpreader\n #read\n data = readEcsv(fname)\n #setup\n myproj = ccrs.Mercator()\n pdata = {}\n pdata['plotprojection'] = myproj\n pdata['plotvar'] = 'Emag'\n pdata['dataprojection'] = ccrs.PlateCarree()\n pdata['maxplotcol'] = emax\n pdata['plotvec'] = 'E'\n #plot\n extent = [-130, -60, 25, 50] if conus else [-140, -35, 25, 65]\n labels = list(range(extent[0], extent[1], 20))\n fig = plt.figure(figsize=(10, 7))\n gs = fig.add_gridspec(3, 3)\n ax = fig.add_subplot(gs[:, :], projection=myproj)\n ax2 = fig.add_subplot(gs[2, :])\n fig, ax = makeMap(figure=fig, axes=ax, figsize=(10,4), maptime=data.attrs['time'],\n projection=myproj, extent=extent, nightshade=False)\n states = list(shpreader.Reader('/home/smorley/shape/cb_2018_us_state_500k.shp').geometries())\n ax.add_geometries(states, pdata['dataprojection'], edgecolor='silver', facecolor='none')\n #plotFilledContours(data,pdata,addTo=ax)\n if not quiver:\n from scipy.interpolate import interp2d\n from matplotlib.colors import LogNorm\n extentin0360 = (np.asarray(extent) + 360) % 360\n ifun = interp2d(data['Lon'], data['Lat'], data['Emag'], kind='cubic')\n lons = np.arange(extentin0360[0], extentin0360[1], 0.1)\n lats = np.arange(extentin0360[2], extentin0360[3], 0.1)\n emag = ifun(lons, lats)\n emin = emin if emin else 1e-3\n emag[emag < emin] = emin\n cm = ax.pcolormesh(lons, lats, emag,\n #vmin=0, vmax=emax,\n norm=LogNorm(vmin=emin, vmax=emax),\n shading='nearest',\n transform=ccrs.PlateCarree(),\n cmap='inferno')\n fig.colorbar(cm, ax=ax, extend='both', label='|E$_{H}$| [V/km]')\n plotVectors(data, pdata, addTo=ax, quiver=quiver)\n gl = ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, linewidth=1, color='gray', alpha=0.6, linestyle='--')\n gl.xlocator = mticker.FixedLocator(labels)\n gl.xformatter = LONGITUDE_FORMATTER\n gl.yformatter = LATITUDE_FORMATTER\n gl.top_labels = False\n gl.right_labels = False\n ax.set_title(data.attrs['time'].isoformat())\n\n\ndef world(fname, emax=5):\n import matplotlib.ticker as mticker\n from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER\n #read\n data = readEcsv(fname)\n #setup\n myproj = ccrs.Mercator()\n pdata = {}\n pdata['plotprojection'] = myproj\n pdata['plotvar'] = 'Emag'\n pdata['dataprojection'] = ccrs.PlateCarree()\n pdata['maxplotcol'] = emax\n pdata['plotvec'] = 'E'\n #plot\n fig, ax = makeMap(maptime=data.attrs['time'], projection=myproj, extent=[-175,175,-73,73])\n plotFilledContours(data, pdata, addTo=ax)\n plotVectors(data, pdata, addTo=ax)\n gl = ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, linewidth=1, color='gray', alpha=0.6, linestyle='--')\n gl.xlocator = mticker.FixedLocator(list(range(-160, 180, 40)))\n gl.xformatter = LONGITUDE_FORMATTER\n gl.yformatter = LATITUDE_FORMATTER\n gl.top_labels = False\n gl.right_labels = False\n ax.set_title(data.attrs['time'].isoformat())\n #plt.show()\n\n\nif __name__ == '__main__':\n import glob\n import os\n runname = 'scaledA2_3d' # '20041108_3d' # 'scaledA2_3d'\n hdir = os.path.expanduser('~')\n fnames = sorted(glob.glob(hdir + '/tmp/*0435*.csv'))\n\n def fmtTime(estr, timeonly=True):\n yr = int(estr[1:5])\n mn = int(estr[5:7])\n dy = int(estr[7:9])\n hr = int(estr[10:12])\n mi = int(estr[12:14])\n sc = int(estr[14:])\n if timeonly:\n tmstr = ''\n else:\n tmstr = '{}-{:02d}-{:02d}T'.format(yr, mn, dy)\n tmstr += '{:02d}:{:02d}:{:02d}'.format(hr, mi, sc)\n return tmstr\n\n print('Processing {} input files'.format(len(fnames)))\n for fname in fnames:\n indir, infname = os.path.split(fname)\n outdir = os.path.split(indir)[1]\n outfn1 = infname.split('_')[-1].split('.')[0]\n outfname_q = os.path.join(outdir, outfn1+'_quiv_IEEE.png')\n #outfname_m = os.path.join(outdir, outfn1+'_mesh.png')\n if not os.path.isdir(outdir):\n os.makedirs(outdir)\n #northAmerica(fname, emax=5, conus=True)\n #plt.title('{}; {}'.format(runname, fmtTime(outfn1)))\n #plt.savefig(outfname_m)\n #plt.close('all')\n northAmerica(fname, emax=5, conus=True, quiver=True)\n\n #plt.title('{}; {}'.format(runname, fmtTime(outfn1)))\n plt.title('Scenario A2; {}'.format(runname, fmtTime(outfn1)))\n plt.show()\n #plt.savefig(outfname_q)\n #plt.close('all')\n"
},
{
"alpha_fraction": 0.5312777161598206,
"alphanum_fraction": 0.5562555193901062,
"avg_line_length": 49.20044708251953,
"blob_id": "72962d372bca84051f5cc81c023a5b880d32e391",
"content_id": "b010707856f67975211ae519ed84286af7d77562",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22540,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 449,
"path": "/dBdt/plotMagGrid.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import glob\nimport re\nimport os\nimport datetime as dt\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport cartopy.crs as ccrs\nimport cartopy.io.shapereader as shapereader\nimport spacepy.datamodel as dm\nfrom spacepy.pybats import bats\n\nimport gmdtools\n\n\ndef ensembleThresh(searchpatt='mag_grid_e20100405-083[12][0-5]0.out', outdir='dBdt_images'):\n useProject = ccrs.PlateCarree #Projection to use for plotting, e.g., ccrs.AlbersEqualArea\n plotprojection = useProject(central_longitude=-90.0)\n\n pdata = {'thresh': 2.0, #nT/s\n 'plotvar': 'dBdth',\n 'dataprojection': ccrs.PlateCarree(),\n 'plotprojection': plotprojection,\n }\n\n #add transmission lines from ArcGIS shapefile\n fname = 'txlines/Transmission_lines.shp'\n txshapes = list(shapereader.Reader(fname).geometries())\n albers = ccrs.AlbersEqualArea(central_longitude=-96.0,\n central_latitude=23.0,\n standard_parallels=(29.5,45.5))\n txinpc = [plotprojection.project_geometry(ii, albers) for ii in txshapes]\n pdata['shapes'] = txinpc\n\n members = {'run_fullmag_001': [],\n 'run_fullmag_002': [],\n 'run_fullmag_030': [],\n 'run_fullmag_042': [],\n #'run_fullmag_043': [],\n 'run_fullmag_044': [],\n }\n colors = {'run_fullmag_001': 'firebrick',\n 'run_fullmag_002': 'goldenrod',\n 'run_fullmag_030': 'olive',\n 'run_fullmag_042': 'skyblue',\n #'run_fullmag_043': 'slateblue',\n 'run_fullmag_044': 'brown',\n }\n for key in members.keys():\n rundir = key[4:]\n globterm = os.path.join(key, 'RESULTS', rundir, 'GM', searchpatt)\n members[key] = sorted(glob.glob(globterm))\n tstep=10 #diff between subsequent files in seconds\n allruns = list(members.keys())\n #following code assumes that same files are found by glob for each ensemble\n #member, so we'll check that here to avoid mixing timesteps\n tmplist = [os.path.basename(fn) for fn in members[allruns[0]]]\n for memb in allruns[1:]:\n complist = [os.path.basename(fn) for fn in members[memb]]\n try:\n assert tmplist==complist\n except AssertionError:\n print(memb)\n raise AssertionError\n\n #startpoint, forward diff.\n baseline = allruns.pop()\n infiles = members[baseline]\n pdata['ccolor'] = colors[baseline]\n\n mdata = bats.MagGridFile(infiles[0])\n plusone = bats.MagGridFile(infiles[1])\n plustwo = bats.MagGridFile(infiles[2])\n mdata['dBdtn'] = dm.dmarray(forwardDiff(mdata['dBn'], plusone['dBn'],\n plustwo['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(forwardDiff(mdata['dBe'], plusone['dBe'],\n plustwo['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotContour(mdata, pdata, addTo=None)\n\n for memb in allruns:\n mfiles = members[memb]\n pdata['ccolor'] = colors[memb]\n mdata = bats.MagGridFile(mfiles[0])\n plusone = bats.MagGridFile(mfiles[1])\n plustwo = bats.MagGridFile(mfiles[2])\n mdata['dBdtn'] = dm.dmarray(forwardDiff(mdata['dBn'], plusone['dBn'],\n plustwo['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(forwardDiff(mdata['dBe'], plusone['dBe'],\n plustwo['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotContour(mdata, pdata, addTo=ax)\n #windows can't handle colons in filenames...\n isotime = mdata.attrs['time'].isoformat()\n plt.savefig(os.path.join(outdir, r'{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''))), dpi=300)\n plt.close()\n\n #all except endpoints, central diff\n for idx, fname in enumerate(infiles[1:-1], start=1):\n pdata['ccolor'] = colors[baseline]\n minusone = bats.MagGridFile(infiles[idx-1])\n mdata = bats.MagGridFile(fname)\n plusone = bats.MagGridFile(infiles[idx+1])\n mdata['dBdtn'] = dm.dmarray(centralDiff(minusone['dBn'],\n plusone['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(centralDiff(minusone['dBe'],\n plusone['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = plotContour(mdata, pdata, addTo=None)\n for memb in allruns:\n mfiles = members[memb]\n pdata['ccolor'] = colors[memb]\n minusone = bats.MagGridFile(mfiles[idx-1])\n mdata = bats.MagGridFile(mfiles[idx])\n plusone = bats.MagGridFile(mfiles[idx+1])\n mdata['dBdtn'] = dm.dmarray(centralDiff(minusone['dBn'],\n plusone['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(centralDiff(minusone['dBe'],\n plusone['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotContour(mdata, pdata, addTo=ax)\n #windows can't handle colons in filenames...\n isotime = mdata.attrs['time'].isoformat()\n plt.savefig(os.path.join(outdir, r'{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''))), dpi=300)\n plt.close()\n\n #final point, backwards diff.\n pdata['ccolor'] = colors[baseline]\n minustwo = bats.MagGridFile(infiles[-3])\n minusone = bats.MagGridFile(infiles[-2])\n mdata = bats.MagGridFile(infiles[-1])\n mdata['dBdtn'] = dm.dmarray(backwardsDiff(minustwo['dBn'], minusone['dBn'],\n mdata['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(backwardsDiff(minustwo['dBn'], minusone['dBe'],\n mdata['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 + mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotContour(mdata, pdata, addTo=None)\n for memb in allruns:\n mfiles = members[memb]\n pdata['ccolor'] = colors[memb]\n minustwo = bats.MagGridFile(mfiles[-3])\n minusone = bats.MagGridFile(mfiles[-2])\n mdata = bats.MagGridFile(mfiles[-1])\n mdata['dBdtn'] = dm.dmarray(backwardsDiff(minustwo['dBn'],\n minusone['dBn'],\n mdata['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(backwardsDiff(minustwo['dBe'],\n minusone['dBe'],\n mdata['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotContour(mdata, pdata, addTo=ax)\n #windows can't handle colons in filenames...\n isotime = mdata.attrs['time'].isoformat()\n plt.savefig(os.path.join(outdir, r'{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''))), dpi=300)\n plt.close()\n\n #make symlinks to images with numeric naming so it can be easily passed to ffmpeg\n gmdtools.makeSymlinks(outdir, kind='dBdt')\n\n\ndef singleRundBdt(runname, searchpatt='mag_grid_e20100405-0[89][0-5][0-9][03]0.out',\n outdir = 'dBdt_maps', links=True):\n useProject = ccrs.PlateCarree #Projection to use for plotting, e.g., ccrs.AlbersEqualArea\n plotprojection = useProject(central_longitude=-90.0)\n\n pdata = {'plotvar': 'dBdth',\n 'dataprojection': ccrs.PlateCarree(),\n 'plotprojection': plotprojection,\n }\n\n #add transmission lines from ArcGIS shapefile\n #fname = 'txlines/Transmission_lines.shp'\n #txshapes = list(shapereader.Reader(fname).geometries())\n #albers = ccrs.AlbersEqualArea(central_longitude=-96.0,\n # central_latitude=23.0,\n # standard_parallels=(29.5,45.5))\n #txinpc = [plotprojection.project_geometry(ii, albers) for ii in txshapes]\n pdata['shapes'] = None#txinpc\n\n rundir = runname[4:]\n globterm = os.path.join(runname, 'RESULTS', rundir, 'GM', searchpatt)\n globterm = os.path.join(runname, searchpatt)\n tstep=60#30 #diff between subsequent files in seconds\n allfiles = sorted(glob.glob(globterm))\n\n #startpoint, forward diff.\n infiles = allfiles\n\n #all except endpoints, central diff\n for idx, fname in enumerate(infiles[1:-1], start=1):\n minusone = bats.MagGridFile(infiles[idx-1])#, format='ascii')\n mdata = bats.MagGridFile(fname)#, format='ascii')\n plusone = bats.MagGridFile(infiles[idx+1])#, format='ascii')\n mdata['dBdtn'] = dm.dmarray(gmdtools.centralDiff(minusone['dBn'],\n plusone['dBn'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdte'] = dm.dmarray(gmdtools.centralDiff(minusone['dBe'],\n plusone['dBe'], tstep),\n attrs={'units': 'nT/s'})\n mdata['dBdth'] = dm.dmarray(np.sqrt(mdata['dBdtn']**2 +\n mdata['dBdte']**2),\n attrs={'units': 'nT/s'})\n ax = gmdtools.plotFilledContours(mdata, pdata, addTo=None)\n #windows can't handle colons in filenames...\n isotime = mdata.attrs['time'].isoformat()\n plt.savefig(os.path.join(outdir, r'{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''))), dpi=300)\n plt.close()\n if links:\n gmdtools.makeSymlinks(outdir, kind='dBdt')\n\n\ndef singleRunE(runname, searchpatt='1_geoe_*.csv', outdir = 'E_maps', vecs=True, links=True):\n useProject = ccrs.PlateCarree #Projection to use for plotting, e.g., ccrs.AlbersEqualArea\n plotprojection = useProject(central_longitude=-90.0)\n\n pdata = {'plotvar': 'Emag',\n 'plotvec': 'E',\n 'dataprojection': ccrs.PlateCarree(),\n 'plotprojection': plotprojection,\n }\n\n #add transmission lines from ArcGIS shapefile\n #fname = 'txlines/Transmission_lines.shp'\n #txshapes = list(shapereader.Reader(fname).geometries())\n #albers = ccrs.AlbersEqualArea(central_longitude=-96.0,\n # central_latitude=23.0,\n # standard_parallels=(29.5,45.5))\n #txinpc = [plotprojection.project_geometry(ii, albers) for ii in txshapes]\n pdata['shapes'] = None#txinpc\n\n rundir = runname[4:]\n globterm = os.path.join(runname, searchpatt)\n allfiles = sorted(glob.glob(globterm))\n infiles = allfiles\n #downselect files to use\n #TODO: remove hardcoded downselect of timerange\n #allfiles = [fn for fn in allfiles if (int(re.search('\\d{8}-(\\d{6})', fn).groups()[0]) >= 80000) and (int(re.search('\\d{8}-(\\d{6})', fn).groups()[0]) <= 90000)]\n #infiles = [fn for fn in allfiles if re.search('\\d{8}-(\\d{6})', fn).groups()[0][-2:] in ['00', '15', '30', '45']]\n\n #loop over files and plot map of |E|\n for fname in infiles:\n edata = gmdtools.readEcsv(fname)\n ax = gmdtools.plotFilledContours(edata, pdata, addTo=None)\n runnum = int(rundir[-3:])\n if vecs:\n ax = gmdtools.plotVectors(edata, pdata, addTo=ax, quiver=False, maxVec=2.75)\n anchor = (-9.195, 38.744) #Lisbon #(-7.9304, 37.0194) #Faro, Port.\n ax.text(anchor[0], anchor[1], 'Member #{0}'.format(runnum), verticalalignment='top', weight='semibold',\n bbox=dict(facecolor='white', alpha=0.3, edgecolor='None'), transform=ccrs.PlateCarree())\n #windows can't handle colons in filenames...\n isotime = edata.attrs['time'].isoformat()\n if 'QBC' in rundir: runnum = 'QBC{0}'.format(runnum)\n plt.savefig(os.path.join(outdir, r'{2}_{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''), runnum)), dpi=300)\n plt.close()\n if links:\n gmdtools.makeSymlinks(outdir, kind='E')\n\n\ndef singleRunEwithEnsemble(runname, ensname, searchpatt='1_geoe_*.csv', outdir='E_maps', eVar='Estd'):\n '''\n Optional Parameters\n ------------------\n\n eVar : string\n Estd or Emag\n '''\n import cartopy.feature as cfea\n import cartopy.feature.nightshade as night\n from cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter\n useProject = ccrs.PlateCarree #Projection to use for plotting, e.g., ccrs.AlbersEqualArea\n plotprojection = useProject(central_longitude=-90.0)\n\n pdata = {'plotvar': 'Emag',\n 'plotvec': 'E',\n 'dataprojection': ccrs.PlateCarree(),\n 'plotprojection': plotprojection,\n }\n doQuiver = False #may want to change this in future, so I'm leaving the code in\n #add features from ArcGIS shapefile?\n pdata['shapes'] = None\n\n rundir = runname[4:]\n globterm = os.path.join(runname, searchpatt)\n allfiles = sorted(glob.glob(globterm))\n\n #downselect files to use\n #TODO: remove hardcoded downselect of timerange\n allfiles = [fn for fn in allfiles if (int(re.search('\\d{8}-(\\d{6})', fn).groups()[0]) >= 81500) and (int(re.search('\\d{8}-(\\d{6})', fn).groups()[0]) <= 84500)]\n infiles = [fn for fn in allfiles if re.search('\\d{8}-(\\d{6})', fn).groups()[0][-2:] in ['00', '15', '30', '45']]\n\n #get ensemble member directories\n members = [en for en in glob.glob(ensname) if en!=runname]\n print('Using {0} ensemble members'.format(len(members)))\n for mm in members:\n print('{0}'.format(mm))\n\n #loop over files and plot map of |E|\n for fname in infiles:\n edata = gmdtools.readEcsv(fname)\n #find matching file for each ens. member\n filepart = os.path.split(fname)[-1]\n collect = [edata]\n for mdir in members:\n fname = os.path.join(mdir, filepart)\n try:\n collect.append(gmdtools.readEcsv(fname))\n except:\n print('Hit an issue with {0}'.format(fname))\n continue\n #collect Emag and calculate stadard deviation across ensemble members at each gridpoint\n combinedMag = np.dstack(cc['Emag'] for cc in collect)\n combinedEast = np.dstack(cc['Ee'] for cc in collect)\n combinedNorth = np.dstack(cc['En'] for cc in collect)\n ensmean = dm.dmcopy(edata)\n ensmean['Ee_raw'] = np.stack(cc['Ee_raw'] for cc in collect).mean(axis=0)\n ensmean['En_raw'] = np.stack(cc['En_raw'] for cc in collect).mean(axis=0)\n ensmean['Estd'] = combinedMag.std(axis=-1)\n ensmean['Ee_ensMean'] = combinedEast.mean(axis=-1)\n ensmean['En_ensMean'] = combinedNorth.mean(axis=-1)\n ensmean['Emag'] = np.sqrt(ensmean['Ee_ensMean']**2 + ensmean['En_ensMean']**2)\n #\n print('Working on timestep {0}. # members = {1}'.format(edata.attrs['time'], len(collect)))\n #\n fig = plt.figure(figsize=(10,5.5))\n #set up first map panel (reference run)\n pdata['plotvar'] = 'Emag'\n sstyle = {'color': 'black'}\n qstyle = {'color': 'darkgrey', 'pivot': 'mid', 'alpha': 0.6, 'scale': 1, 'scale_units': 'xy'}\n ax = plt.subplot(2, 1, 1, projection=pdata['plotprojection'])\n ax.coastlines(color='darkgrey')\n ax.add_feature(cfea.BORDERS, linestyle=':', edgecolor='darkgrey')\n ax.add_feature(night.Nightshade(edata.attrs['time'], alpha=0.3))\n lon_formatter = LongitudeFormatter(number_format='.1f',\n degree_symbol='',\n dateline_direction_label=True)\n lat_formatter = LatitudeFormatter(number_format='.1f',\n degree_symbol='')\n ax.xaxis.set_major_formatter(lon_formatter)\n ax.yaxis.set_major_formatter(lat_formatter)\n ax.set_extent([-165.0, 45.0, 30.0, 80.0], crs=ccrs.PlateCarree())\n ax = gmdtools.plotFilledContours(edata, pdata, addTo=ax)\n ax = gmdtools.plotVectors(edata, pdata, addTo=ax, maxVec=2.75, sstyle=sstyle)\n ax.set_title('{0}'.format(edata.attrs['time'].isoformat()))\n #set up second map panel (use requested (Emag_ens or Estd)\n ax2 = plt.subplot(2, 1, 2, projection=pdata['plotprojection'])\n ax2.coastlines(color='darkgrey')\n ax2.add_feature(cfea.BORDERS, linestyle=':', edgecolor='darkgrey')\n ax2.add_feature(night.Nightshade(edata.attrs['time'], alpha=0.3))\n ax2.xaxis.set_major_formatter(lon_formatter)\n ax2.yaxis.set_major_formatter(lat_formatter)\n ax2.set_extent([-165.0, 45.0, 30.0, 80.0], crs=ccrs.PlateCarree())\n pdata['plotvar'] = eVar\n ax2 = gmdtools.plotFilledContours(ensmean, pdata, addTo=ax2)\n #plot all ensemble members as light grey quivers\n if doQuiver:\n for ense in collect:\n ax2 = gmdtools.plotVectors(ense, pdata, addTo=ax2, quiver=True, qstyle=qstyle)\n qstyle['alpha'] = 1\n qstyle['color'] = 'black'\n #then plot ensemble mean with streamlines...\n sstyle['color'] = 'darkblue'\n #collect Emag and calculate [mean/standard deviation] across ensemble members at each gridpoint\n ax2 = gmdtools.plotVectors(ensmean, pdata, addTo=ax2, quiver=False, maxVec=2.75,\n qstyle=qstyle, sstyle=sstyle)\n for aa in [ax, ax2]:\n aa.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n aa.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n\n #now annotate panels with \"Reference\" and \"Ensemble\" (put text at Lisbon, Portugal)\n anchor = (-9.195, 38.744) #Lisbon #(-7.9304, 37.0194) #Faro, Port.\n #ensText = 'Ensemble Mean + $\\sigma(|E|)$' if eVar=='Estd' else 'Ensemble Mean'\n ensText = 'Ensemble Mean'\n ax.text(anchor[0], anchor[1], 'Unperturbed', verticalalignment='top', weight='semibold',\n bbox=dict(facecolor='white', alpha=0.3, edgecolor='None'), transform=ccrs.PlateCarree())\n ax2.text(anchor[0], anchor[1], ensText+'\\n(N={0})'.format(len(collect)), \n verticalalignment='top', weight='semibold', color='darkblue',\n bbox=dict(facecolor='white', alpha=0.3, edgecolor='None'), transform=ccrs.PlateCarree())\n\n #windows can't handle colons in filenames...\n isotime = edata.attrs['time'].isoformat()\n plt.tight_layout()\n plt.savefig(os.path.join(outdir, r'{0}_{1}.png'.format(pdata['plotvar'],\n isotime.replace(':',''))), dpi=300)\n plt.close()\n gmdtools.makeSymlinks(outdir, kind='E')\n\n\n #TODO: Make \"hazard map\" with dB/dt per pixel, per 20 minute averaging interval.\n # Can use naive probabilistic classifier by taking 50th percentile from ensemble\n # Can use peak or 95th percentile.\n # Note that estimating the PDF using KDEs is similar in concept to\n # Bayesian Model Averaging, but without bias-correction of the ensemble\n # members.\n\n #TODO: Find dB/dt for each time, for each pixel, and display thresholded map of\n # mean (median?)\n\n #TODO: Probably should use an equal-area projection for publishing results...\n # Lambert Cylindrical?\n\nif __name__=='__main__':\n #saveloc = 'E_maps_ens_mean'#'dBdt_indivMaps'\n saveloc = 'dBdt_indivMaps'\n saveloc = 'dBdt_AMR'\n if not os.path.isdir(saveloc):\n os.mkdir(saveloc)\n #singleRundBdt('20100405_MagG030', searchpatt='mag_*0833*[05]*', outdir=saveloc, links=False)\n singleRundBdt('AMRsouth', searchpatt='mag_*', outdir=saveloc, links=False)\n #singleRunE('20100405_QBC4_030', searchpatt='*083[01]*csv', outdir=saveloc, vecs=False, links=False)\n #singleRunE('20100405_Ensemble030', searchpatt='*083[01]*csv', outdir=saveloc, vecs=False, links=False)\n #singleRunEwithEnsemble('20100405_EnsembleOrig', '20100405_Ensemble*', searchpatt='geoe_*.csv', outdir=saveloc, eVar='Emag')\n #saveloc = 'E_maps_ens_std'#'dBdt_indivMaps'\n #if not os.path.isdir(saveloc):\n # os.mkdir(saveloc)\n #singleRunEwithEnsemble('20100405_EnsembleOrig', '20100405_Ensemble*', searchpatt='geoe_*.csv', outdir=saveloc, eVar='Estd')\n #saveloc = 'E_maps_indiv'#'dBdt_indivMaps'\n #if not os.path.isdir(saveloc):\n # os.mkdir(saveloc)\n #singleRunE('20100405_Ensemble001', searchpatt='geoe_*083245*.csv', outdir=saveloc, links=False)\n #singleRunE('20100405_Ensemble002', searchpatt='geoe_*083245*.csv', outdir=saveloc, links=False)\n #singleRunE('20100405_Ensemble042', searchpatt='geoe_*083245*.csv', outdir=saveloc, links=False)\n"
},
{
"alpha_fraction": 0.5529865026473999,
"alphanum_fraction": 0.5751026272773743,
"avg_line_length": 39.46440505981445,
"blob_id": "4fc21be4327257ed9edfbbcd042893abcbac7c80",
"content_id": "064dd17269d32fb349a1ea4a2d53490b8ad918b1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11937,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 295,
"path": "/dBdt/gmdtools.py",
"repo_name": "drsteve/SWMFtools",
"src_encoding": "UTF-8",
"text": "import glob\nimport re\nimport os\nimport itertools\nimport datetime as dt\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.colors as mplc\nimport cartopy.crs as ccrs\nimport cartopy.feature as cfea\nimport cartopy.feature.nightshade as night\nimport cartopy.util as cuti\nfrom cartopy.mpl.ticker import LongitudeFormatter, LatitudeFormatter\nimport spacepy.datamodel as dm\n\n\ndef discrete_cmap(N, base_cmap=None):\n \"\"\"Create an N-bin discrete colormap from the specified input map\"\"\"\n\n # Note that if base_cmap is a string or None, you can simply do\n # return plt.cm.get_cmap(base_cmap, N)\n # The following works for string, None, or a colormap instance:\n\n base = plt.cm.get_cmap(base_cmap)\n color_list = base(np.linspace(0, 1, N))\n cmap_name = base.name + str(N)\n return base.from_list(cmap_name, color_list, N)\n\n\ndef plotFilledContours(mdata, pdata, addTo=None):\n plotvar = pdata['plotvar']\n try:\n data, lons = cuti.add_cyclic_point(np.transpose(mdata[plotvar]), \n mdata['Lon'])\n except ValueError:\n try:\n data, lons = cuti.add_cyclic_point(mdata[plotvar], mdata['Lon'])\n except:\n data = mdata[plotvar]\n lons = mdata['Lon']\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'])\n\n if pdata['shapes'] is not None:\n ax.add_geometries(pdata['shapes'], pdata['plotprojection'], \n edgecolor='black', facecolor='none')\n #ax.gridlines()\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0}'.format(mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n norm = mplc.Normalize()\n clipdata = np.array(data)\n minplotcol = 0.0\n skipPlot = False\n if 'Emag' in plotvar:\n maxplotcol = 2.5 if 'maxplotcol' not in pdata else pdata['maxplotcol']\n colmap = 'magma_r'\n clabel = '|E| [V/km]'\n elif 'jr' in plotvar:\n minplotcol = -1.\n maxplotcol = 1.\n colmap = 'seismic'\n clabel = 'j$_{R}$ [mA/m$^{2}$]'\n #cmg = ax.contourf(lons, mdata['Lat'], clipdata, np.linspace(-2,2,50),\n # transform=pdata['dataprojection'], cmap=colmap,#'YlOrRd',\n # vmin=minplotcol, vmax=maxplotcol, norm=norm,\n # alpha=0.5)#, extend='max')\n cmg = ax.pcolormesh(lons, mdata['Lat'], clipdata, transform=pdata['dataprojection'], cmap='seismic')\n skipPlot = True\n elif 'Estd' in plotvar:\n minplotcol = 2e-1\n maxplotcol = 3\n colmap = discrete_cmap(7, 'YlOrBr')\n clabel = '$\\sigma$(|E|) [V/km]'\n clipdata = clipdata + 1e-6\n norm = mplc.LogNorm(vmin=3e-3, vmax=3)\n else:\n maxplotcol = 25\n colmap = 'magma_r'\n clabel = '(dB/dt)$_{H}$ [nT/s]'\n #cmg = ax.contourf(lons, mdata['Lat'], np.array(data), np.linspace(0,20,150),\n # transform=pdata['dataprojection'], cmap='magma_r',#'YlOrRd',\n # vmin=0, vmax=maxplotcol,\n # alpha=0.5, extend='max')\n if not skipPlot: \n clipdata[clipdata>maxplotcol] = maxplotcol\n cmg = ax.contourf(lons, mdata['Lat'], clipdata, np.linspace(0,25,50),\n transform=pdata['dataprojection'], cmap=colmap,#'YlOrRd',\n vmin=minplotcol, vmax=maxplotcol, norm=norm,\n alpha=0.5)#, extend='max')\n cmg.cmap.set_over('k')\n cmg.set_clim(minplotcol, maxplotcol)\n #cmg.cmap.set_under(cmg.cmap(0))\n map_dummy = plt.cm.ScalarMappable(cmap=colmap, norm=norm)\n map_dummy.set_array(np.array(data))\n map_dummy.set_clim(minplotcol, maxplotcol)\n cax = plt.colorbar(map_dummy, ax=ax, extend='max', shrink=0.4, pad=0.04, drawedges=False)\n cax.set_label(clabel)\n return ax\n\n\ndef plotContour(mdata, pdata, addTo=None):\n plotvar = pdata['plotvar']\n data, lons = cuti.add_cyclic_point(np.transpose(mdata[plotvar]), \n mdata['Lon'])\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'])\n\n if pdata['shapes'] is not None:\n ax.add_geometries(pdata['shapes'], pdata['plotprojection'], \n edgecolor='black', facecolor='none')\n #ax.gridlines()\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0}[{1}]\\n{2}'.format(plotvar, \n mdata[plotvar].attrs['units'], \n mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n cax = ax.contourf(lons, mdata['Lat'], np.array(data), [pdata['thresh'], data.max()], \n transform=pdata['dataprojection'], colors=pdata['ccolor'],\n alpha=0.75)\n return ax\n\n\ndef plotVectors(mdata, pdata, addTo=None, quiver=False, maxVec=2.5, qstyle=None, sstyle=None):\n '''\n\n Optional arguments\n ------------------\n addTo : Axes or None\n If None (default), then a new figure is created. Otherwise the supplied\n Axes are used to plot the vectors on. The axes are assumed to support\n projections (e.g. cartopy)\n quiver : boolean\n If True makes a quiver plot. If False (default) draws streamlines scaled\n in width by the vector magnitude.\n maxVec : float\n Limit for the linewidth of streamlines.\n qstyle : dict or None\n Dictionary containing plot style kwargs for quiver plots\n '''\n plotvar = pdata['plotvec']\n if 'Lat_raw' in mdata:\n if quiver:\n lons = mdata['Lon_raw'][::2]\n lats = mdata['Lat_raw'][::2]\n vec_e = mdata['{0}e_raw'.format(plotvar)][::2]\n vec_n = mdata['{0}n_raw'.format(plotvar)][::2]\n else:\n lons = mdata['Lon_raw']\n lats = mdata['Lat_raw']\n vec_e = mdata['{0}e_raw'.format(plotvar)]\n vec_n = mdata['{0}n_raw'.format(plotvar)]\n else:\n latlon = list(itertools.product(mdata['Lon'], mdata['Lat']))\n lons = np.array(latlon)[:,0]\n lats = np.array(latlon)[:,1]\n vec_e = np.ravel(mdata['{0}e'.format(plotvar)])\n vec_n = np.ravel(mdata['{0}n'.format(plotvar)])\n if addTo is None:\n fig, ax = makeMap(maptime=mdata.attrs['time'], projection=pdata['plotprojection'])\n ax.set_xticks([-150, -120, -90, -60, -30, 0, 30], crs=ccrs.PlateCarree())\n ax.set_yticks([35, 45, 55, 65, 75], crs=ccrs.PlateCarree())\n ax.set_title('{0}[{1}]\\n{2}'.format(plotvar, \n mdata[plotvar].attrs['units'], \n mdata.attrs['time'].isoformat()))\n else:\n ax = addTo\n if quiver:\n if qstyle is None:\n qstyle = dict()\n ax.quiver(lons, lats, vec_e, vec_n, transform=pdata['dataprojection'], zorder=33, **qstyle)\n else:\n if sstyle is None:\n sstyle = dict()\n if 'arrowsize' not in sstyle: sstyle['arrowsize'] = 0.75\n if 'color' not in sstyle: sstyle['color'] = 'black'\n if 'linewidth' not in sstyle:\n mag = np.sqrt(vec_e**2+vec_n**2)\n lw = ((2.5*mag)+0.5)/(2.5*maxVec)\n lw[lw>=maxVec] = (2.5*maxVec)+0.5\n sstyle['linewidth'] = lw\n ax.streamplot(lons, lats, vec_e, vec_n, transform=pdata['dataprojection'], zorder=33, **sstyle)\n return ax\n\n\ndef makeMap(maptime=dt.datetime.now(), figsize=(10,4), projection=ccrs.PlateCarree(),\n extent=[-165.0, 145.0, 30.0, 80.0], nightshade=True):\n #PlateCarree is an equirectangular projection where lines of equal longitude\n #are vertical and lines of equal latitude are horizontal. Spacing between lats\n #and longs are also equal.\n fig = plt.figure(figsize=figsize)\n ax = plt.axes(projection=projection)\n ax.coastlines(color='darkgrey')\n ax.add_feature(cfea.BORDERS, linestyle=':', edgecolor='darkgrey')\n if nightshade:\n ax.add_feature(night.Nightshade(maptime, alpha=0.3))\n lon_formatter = LongitudeFormatter(number_format='.1f',\n degree_symbol='',\n dateline_direction_label=True)\n lat_formatter = LatitudeFormatter(number_format='.1f',\n degree_symbol='')\n ax.xaxis.set_major_formatter(lon_formatter)\n ax.yaxis.set_major_formatter(lat_formatter)\n ax.set_extent(extent, crs=ccrs.PlateCarree())\n\n return fig, ax\n\n\ndef forwardDiff(a, b, c, dt):\n return (-c + 4*b - 3*a)/(2*dt)\n\ndef backwardsDiff(x, y, z, dt):\n return (3*z - 4*y + x)/(2*dt)\n\ndef centralDiff(a, c, dt):\n return (c-a)/(2*dt)\n\n\nclass ElecData(dm.SpaceData):\n def addTimes(self, filenames):\n toAdd = [readEcsv(fn) for fn in filenames]\n if 'times' not in self.attrs:\n self.attrs['times'] = [self.attrs['time']]\n for ta in toAdd:\n self.attrs['times'].append(ta.attrs['time'])\n for key in self:\n if 'Lat' in key or 'Lon' in key: continue\n if '_raw' in key:\n self[key] = np.stack([self[key], *[ta[key] for ta in toAdd]])\n self[key] = self[key].T\n else:\n self[key] = np.dstack([self[key], *[ta[key] for ta in toAdd]])\n\n\ndef readEcsv(fname):\n rawdata = np.loadtxt(fname, delimiter=',', skiprows=1)\n edata = ElecData()\n #fileidx = int(re.search('\\d{4}', fname).group())\n #offset = fileidx*5\n tstr = re.search('\\d{8}-(\\d{6})', fname).group()\n edata.attrs['time'] = dt.datetime(int(tstr[:4]), int(tstr[4:6]), int(tstr[6:8]), int(tstr[9:11]), int(tstr[11:13]), int(tstr[13:15]))\n edata['Lat_raw'] = rawdata[:, 0]\n edata['Lon_raw'] = rawdata[:, 1]\n edata['Ee_raw'] = rawdata[:, 2]\n edata['En_raw'] = rawdata[:, 3]\n nlat = len(set(edata['Lat_raw']))\n nlon = len(set(edata['Lon_raw']))\n edata['Lat'] = np.reshape(rawdata[:, 0], [nlat, nlon])[:,0]\n edata['Lon'] = np.reshape(rawdata[:, 1], [nlat, nlon])[0,:]\n edata['Ee'] = np.reshape(rawdata[:, 2], [nlat, nlon])\n edata['En'] = np.reshape(rawdata[:, 3], [nlat, nlon])\n edata['Emag'] = np.sqrt(edata['Ee']**2.0 + edata['En']**2.0)\n\n return edata\n\n\ndef makeSymlinks(dirname, kind='dbdt'):\n #make symlinks to images with numeric naming so it can be easily passed to ffmpeg\n pngfns = sorted(glob.glob(os.path.join(dirname,'{0}*png'.format(kind))))\n for idx, fn in enumerate(pngfns):\n os.symlink(os.path.abspath(fn), \n os.path.abspath(os.path.join(dirname,\n 'img{0:04d}.png'.format(idx))))\n\n\ndef northAmerica(fname):\n import matplotlib.ticker as mticker\n from cartopy.mpl.gridliner import LONGITUDE_FORMATTER, LATITUDE_FORMATTER\n #read\n data = readEcsv(fname)\n #setup\n myproj = ccrs.Mercator()\n pdata = {}\n pdata['plotprojection']=myproj\n pdata['plotvar']='Emag'\n pdata['dataprojection']=ccrs.PlateCarree()\n pdata['maxplotcol']=5\n pdata['plotvec']='E'\n #plot\n fig, ax = makeMap(maptime=data.attrs['time'], projection=myproj, extent=[-140,-35,25,70])\n plotFilledContours(data,pdata,addTo=ax)\n plotVectors(data,pdata,addTo=ax)\n gl = ax.gridlines(crs=ccrs.PlateCarree(), draw_labels=True, linewidth=1, color='gray', alpha=0.6, linestyle='--')\n gl.xlocator = mticker.FixedLocator([-140, -120, -100, -80, -60, -40, -20, 0])\n gl.xformatter = LONGITUDE_FORMATTER\n gl.yformatter = LATITUDE_FORMATTER\n gl.xlabels_top = False\n gl.ylabels_right = False\n ax.set_title(data.attrs['time'].isoformat())\n #plt.show()\n"
}
] | 24 |
neonbadger/calculator-2
|
https://github.com/neonbadger/calculator-2
|
a7a3dd385704579c0c078e010a76e7d50907eeee
|
115300339fd20fbade89325a922e263f7dcad7dd
|
105173816778483acead99caa8b4679ad66bb0f0
|
refs/heads/master
| 2021-01-10T07:05:14.015812 | 2016-01-07T21:00:56 | 2016-01-07T21:00:56 | 49,230,542 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49581748247146606,
"alphanum_fraction": 0.5201520919799805,
"avg_line_length": 24.19230842590332,
"blob_id": "ff5e6a72c2903325464c0b9c78a3e5a9c6447438",
"content_id": "0ffddc63273ec5e9bc7de537bd63a01c706301a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 52,
"path": "/calculator.py",
"repo_name": "neonbadger/calculator-2",
"src_encoding": "UTF-8",
"text": "\"\"\"\ncalculator.py\n\nUsing our arithmetic.py file from Exercise02, create the\ncalculator program yourself in this file.\n\"\"\"\n\nfrom arithmetic import *\n\nwhile True:\n input = raw_input()\n\n token = input.split(\" \")\n\n if \"q\" in token:\n print \"Had enough? Okay.\"\n break\n elif len(token) <= 2:\n print \"Sorry, you need more than one number to do that.\"\n continue \n elif len(token) >= 3:\n \n if len(token) > 3:\n print \"we will perform operation on the first 2 numbers from your input.\"\n \n try:\n num1 = float(token[1])\n num2 = float(token[2])\n except ValueError:\n print \"Please put in valid numbers to perform calculations.\"\n continue\n\n if token[0] == \"+\":\n print add(num1, num2)\n elif token[0] == \"-\":\n print subtract(num1, num2)\n elif token[0] == \"*\":\n print multiply(num1, num2)\n elif token[0] == \"/\":\n print divide(num1, num2)\n elif token[0] == \"square\":\n print square(num1)\n elif token[0] == \"cube\":\n print cube(num1)\n elif token[0] == \"pow\":\n print power(num1, num2)\n elif token[0] == \"mod\":\n print mod(num1, num2)\n\n\n\n# Your code goes here\n\n "
}
] | 1 |
juliechoo-iad/VcsProject
|
https://github.com/juliechoo-iad/VcsProject
|
51b5b66d9522c8844dbecb5205036b048daf9d26
|
ad6dfce56f0540e806450398f4822cbba5fba5a6
|
d97c2eba7bb2c7e003a5b8c7371082c586756bcc
|
refs/heads/master
| 2023-06-24T11:30:26.592916 | 2021-07-24T00:40:15 | 2021-07-24T00:40:15 | 387,812,671 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 16.5,
"blob_id": "0a403a1c10c697e003b1e26dcf56ada4bffdc71e",
"content_id": "5216213c55990feb11661c5ba2817837afe4bf7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 4,
"path": "/main.py",
"repo_name": "juliechoo-iad/VcsProject",
"src_encoding": "UTF-8",
"text": "print(\"Hello, VCS\")\nprint(3+4)\nprint('Vcs is easy to use')\nprint(4%2)"
},
{
"alpha_fraction": 0.5282555222511292,
"alphanum_fraction": 0.6314496397972107,
"avg_line_length": 28.071428298950195,
"blob_id": "bd538f3243dba0711453fd3993ec583fed7de17d",
"content_id": "5d10443ee4331dbdd027d42a8350cb70ec265334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 14,
"path": "/demoVcs.py",
"repo_name": "juliechoo-iad/VcsProject",
"src_encoding": "UTF-8",
"text": "class Calculator:\n def add(num1, num2):\n print(\"Sum is \",(num1+num2))\n def minus(num1, num2):\n print(\"Difference is \",(num1 - num2))\n def multiply(num1, num2):\n print(\"Product is \",(num1 * num2))\n def divide(num1, num2):\n print(\"Quotient is \",(num1 / num2))\n\nCalculator.add(5000,1000)\nCalculator.minus(500,400)\nCalculator.multiply(50,40)\nCalculator.divide(1000,2000)\n"
}
] | 2 |
magicknight/Xi-cam.gui
|
https://github.com/magicknight/Xi-cam.gui
|
b79192b57ded551f7541565381256ff3623a4985
|
41bb8a0a3351d9c432c1a44bb7748bb268f3541d
|
3e73f97a3815ff0a3eff3bf349c701f69ba1c4b6
|
refs/heads/master
| 2020-11-27T22:53:08.103351 | 2019-12-21T00:00:52 | 2019-12-21T00:00:52 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5977147221565247,
"alphanum_fraction": 0.6008011698722839,
"avg_line_length": 34.00689697265625,
"blob_id": "787d58a6d13be3d8dfe07717915757e1d5d1b8d5",
"content_id": "86c1a5c9cdbfd6fa13ecbe760949bf3943ff24e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15228,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 435,
"path": "/xicam/gui/bluesky/search.py",
"repo_name": "magicknight/Xi-cam.gui",
"src_encoding": "UTF-8",
"text": "\"\"\"\nExperimental Qt-based data browser for bluesky\n\"\"\"\nimport ast\nfrom datetime import datetime\nimport event_model\nimport functools\nimport itertools\nimport jsonschema\nimport logging\nimport queue\nimport threading\nimport time\n\nfrom qtpy.QtCore import Qt, Signal, QThread\nfrom qtpy.QtGui import QStandardItemModel, QStandardItem\nfrom qtpy.QtWidgets import (\n QAbstractItemView,\n QPushButton,\n QComboBox,\n QDateTimeEdit,\n QHeaderView,\n QHBoxLayout,\n QMessageBox,\n QLabel,\n QLineEdit,\n QVBoxLayout,\n QWidget,\n QTableView,\n )\nfrom .utils import ConfigurableQObject\nfrom .top_utils import load_config, Callable\n\n\nMAX_SEARCH_RESULTS = 100 # TODO Use fetchMore instead of a hard limit.\nlog = logging.getLogger('bluesky_browser')\nBAD_TEXT_INPUT = \"\"\"\nQLineEdit {\n background-color: rgb(255, 100, 100);\n}\n\"\"\"\nGOOD_TEXT_INPUT = \"\"\"\nQLineEdit {\n background-color: rgb(255, 255, 255);\n}\n\"\"\"\nRELOAD_INTERVAL = 11\n_validate = functools.partial(jsonschema.validate, types={'array': (list, tuple)})\n\n\ndef default_search_result_row(entry):\n metadata = entry.describe()['metadata']\n start = metadata['start']\n stop = metadata['stop']\n start_time = datetime.fromtimestamp(start['time'])\n if stop is None:\n str_duration = '-'\n else:\n duration = datetime.fromtimestamp(stop['time']) - start_time\n str_duration = str(duration)\n str_duration = str_duration[:str_duration.index('.')]\n return {'Unique ID': start['uid'][:8],\n 'Transient Scan ID': (start.get('scan_id', '-')),\n 'Plan Name': start.get('plan_name', '-'),\n 'Start Time': start_time.strftime('%Y-%m-%d %H:%M:%S'),\n 'Duration': str_duration,\n 'Exit Status': '-' if stop is None else stop['exit_status']}\n\n\nclass SearchState(ConfigurableQObject):\n \"\"\"\n Encapsulates CatalogSelectionModel and SearchResultsModel. Executes search.\n \"\"\"\n new_results_catalog = Signal([])\n new_results_catalog = Signal([])\n search_result_row = Callable(default_search_result_row, config=True)\n\n def __init__(self, catalog):\n self.update_config(load_config())\n self.catalog = catalog\n self.enabled = False # to block searches during initial configuration\n self.catalog_selection_model = CatalogSelectionModel()\n self.search_results_model = SearchResultsModel(self)\n self._subcatalogs = [] # to support lookup by item's positional index\n self._results = [] # to support lookup by item's positional index\n self._results_catalog = None\n self._new_entries = queue.Queue(maxsize=MAX_SEARCH_RESULTS)\n self.list_subcatalogs()\n self.set_selected_catalog(0)\n self.query_queue = queue.Queue()\n self.show_results_event = threading.Event()\n self.reload_event = threading.Event()\n\n search_state = self\n\n super().__init__()\n\n self.new_results_catalog.connect(self.show_results)\n\n class ReloadThread(QThread):\n def run(self):\n while True:\n t0 = time.monotonic()\n # Never reload until the last reload finished being\n # displayed.\n search_state.show_results_event.wait()\n # Wait for RELOAD_INTERVAL to pass or until we are poked,\n # whichever happens first.\n search_state.reload_event.wait(\n max(0, RELOAD_INTERVAL - (time.monotonic() - t0)))\n search_state.reload_event.clear()\n # Reload the catalog to show any new results.\n search_state.reload()\n\n self.reload_thread = ReloadThread()\n self.reload_thread.start()\n\n class ProcessQueriesThread(QThread):\n def run(self):\n while True:\n try:\n search_state.process_queries()\n except Exception as e:\n log.error(e)\n \n\n self.process_queries_thread = ProcessQueriesThread()\n self.process_queries_thread.start()\n\n def request_reload(self):\n self._results_catalog.force_reload()\n self.reload_event.set()\n\n def apply_search_result_row(self, entry):\n try:\n return self.search_result_row(entry)\n except Exception as exc:\n # Either the documents in entry are not valid or the definition of\n # search_result_row (which will be user-configurable) has failed to\n # account for some possiblity. Figure out which situation this is.\n try:\n _validate(entry.metadata['start'],\n event_model.schemas[event_model.DocumentNames.start])\n except jsonschema.ValidationError:\n log.exception(\"Invalid RunStart Document: %r\",\n entry.metadata['start'])\n raise SkipRow(\"invalid document\") from exc\n try:\n _validate(entry.metadata['stop'],\n event_model.schemas[event_model.DocumentNames.stop])\n except jsonschema.ValidationError:\n if entry.metadata['stop'] is None:\n log.debug(\"Run %r has no RunStop document.\",\n entry.metadata['start']['uid'])\n else:\n log.exception(\"Invalid RunStop Document: %r\",\n entry.metadata['stop'])\n raise SkipRow(\"invalid document\")\n log.exception(\"Run with uid %s raised error with search_result_row.\",\n entry.metadata['start']['uid'])\n raise SkipRow(\"error in search_result_row\") from exc\n\n def __del__(self):\n if hasattr(self.reload_thread):\n self.reload_thread.terminate()\n\n def list_subcatalogs(self):\n self._subcatalogs.clear()\n self.catalog_selection_model.clear()\n for name in self.catalog:\n self._subcatalogs.append(name)\n self.catalog_selection_model.appendRow(QStandardItem(str(name)))\n\n def set_selected_catalog(self, item):\n name = self._subcatalogs[item]\n self.selected_catalog = self.catalog[name]()\n self.search()\n\n def check_for_new_entries(self):\n # check for any new results and add them to the queue for later processing\n for uid, entry in itertools.islice(self._results_catalog.items(), MAX_SEARCH_RESULTS):\n if uid in self._results:\n continue\n self._results.append(uid)\n self._new_entries.put(entry)\n\n def process_queries(self):\n # If there is a backlog, process only the newer query.\n block = True\n while True:\n try:\n query = self.query_queue.get_nowait()\n block = False\n except queue.Empty:\n if block:\n query = self.query_queue.get()\n break\n print(query)\n log.debug('Submitting query %r', query)\n t0 = time.monotonic()\n self._results_catalog = self.selected_catalog.search(query)\n self.check_for_new_entries()\n duration = time.monotonic() - t0\n log.debug('Query yielded %r results (%.3f s).',\n len(self._results_catalog), duration)\n self.new_results_catalog.emit()\n\n def search(self):\n self.search_results_model.clear()\n self.search_results_model.selected_rows.clear()\n self._results.clear()\n if not self.enabled:\n return\n query = {'time': {}}\n if self.search_results_model.since is not None:\n query['time']['$gte'] = self.search_results_model.since\n if self.search_results_model.until is not None:\n query['time']['$lt'] = self.search_results_model.until\n query.update(**self.search_results_model.custom_query)\n self.query_queue.put(query)\n\n def show_results(self):\n header_labels_set = False\n self.show_results_event.clear()\n t0 = time.monotonic()\n counter = 0\n\n while not self._new_entries.empty():\n counter += 1\n entry = self._new_entries.get()\n row = []\n try:\n row_data = self.apply_search_result_row(entry)\n except SkipRow:\n continue\n if not header_labels_set:\n # Set header labels just once.\n self.search_results_model.setHorizontalHeaderLabels(list(row_data))\n header_labels_set = True\n for value in row_data.values():\n item = QStandardItem()\n item.setData(value, Qt.DisplayRole)\n row.append(item)\n self.search_results_model.appendRow(row)\n if counter:\n duration = time.monotonic() - t0\n log.debug(\"Displayed %d new results (%.3f s).\", counter, duration)\n self.show_results_event.set()\n\n def reload(self):\n t0 = time.monotonic()\n if self._results_catalog is not None:\n self._results_catalog.reload()\n self.check_for_new_entries()\n duration = time.monotonic() - t0\n log.debug(\"Reloaded search results (%.3f s).\", duration)\n self.new_results_catalog.emit()\n\n\nclass CatalogSelectionModel(QStandardItemModel):\n \"\"\"\n List the subcatalogs in the root Catalog.\n \"\"\"\n ...\n\n\nclass SearchResultsModel(QStandardItemModel):\n \"\"\"\n Perform searches on a Catalog and model the results.\n \"\"\"\n selected_result = Signal([list])\n open_entries = Signal([str, list])\n valid_custom_query = Signal([bool])\n\n def __init__(self, search_state, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.custom_query = {}\n self.search_state = search_state\n self.since = None\n self.until = None\n self.selected_rows = set()\n\n def emit_selected_result(self, selected, deselected):\n self.selected_rows |= set(index.row() for index in selected.indexes())\n self.selected_rows -= set(index.row() for index in deselected.indexes())\n entries = []\n for row in sorted(self.selected_rows):\n uid = self.search_state._results[row]\n entry = self.search_state._results_catalog[uid]\n entries.append(entry)\n self.selected_result.emit(entries)\n\n def emit_open_entries(self, target, indexes):\n rows = set(index.row() for index in indexes)\n entries = []\n for row in rows:\n uid = self.search_state._results[row]\n entry = self.search_state._results_catalog[uid]\n entries.append(entry)\n self.open_entries.emit(target, entries)\n\n def on_search_text_changed(self, text):\n try:\n self.custom_query = dict(ast.literal_eval(text)) if text else {}\n except Exception:\n self.valid_custom_query.emit(False)\n else:\n self.valid_custom_query.emit(True)\n self.search_state.search()\n\n def on_since_time_changed(self, datetime):\n self.since = datetime.toSecsSinceEpoch()\n self.search_state.search()\n\n def on_until_time_changed(self, datetime):\n self.until = datetime.toSecsSinceEpoch()\n self.search_state.search()\n\n\nclass SearchInputWidget(QWidget):\n \"\"\"\n Input fields for specifying searches on SearchResultsModel\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.search_bar = QLineEdit()\n search_bar_layout = QHBoxLayout()\n search_bar_layout.addWidget(QLabel('Custom Query:'))\n search_bar_layout.addWidget(self.search_bar)\n mongo_query_help_button = QPushButton()\n mongo_query_help_button.setText('?')\n search_bar_layout.addWidget(mongo_query_help_button)\n mongo_query_help_button.clicked.connect(self.show_mongo_query_help)\n\n self.since_widget = QDateTimeEdit()\n self.since_widget.setCalendarPopup(True)\n self.since_widget.setDisplayFormat('yyyy-MM-dd HH:mm')\n since_layout = QHBoxLayout()\n since_layout.addWidget(QLabel('Since:'))\n since_layout.addWidget(self.since_widget)\n\n self.until_widget = QDateTimeEdit()\n self.until_widget.setCalendarPopup(True)\n self.until_widget.setDisplayFormat('yyyy-MM-dd HH:mm')\n until_layout = QHBoxLayout()\n until_layout.addWidget(QLabel('Until:'))\n until_layout.addWidget(self.until_widget)\n\n layout = QVBoxLayout()\n layout.addLayout(since_layout)\n layout.addLayout(until_layout)\n layout.addLayout(search_bar_layout)\n self.setLayout(layout)\n\n def mark_custom_query(self, valid):\n \"Indicate whether the current text is a parsable query.\"\n if valid:\n stylesheet = GOOD_TEXT_INPUT\n else:\n stylesheet = BAD_TEXT_INPUT\n self.search_bar.setStyleSheet(stylesheet)\n\n def show_mongo_query_help(self):\n \"Launch a Message Box with instructions for custom queries.\"\n msg = QMessageBox()\n msg.setIcon(QMessageBox.Information)\n msg.setText(\"For advanced search capability, enter a valid Mongo query.\")\n msg.setInformativeText(\"\"\"\nExamples:\n\n{'plan_name': 'scan'}\n{'proposal': 1234},\n{'$and': ['proposal': 1234, 'sample_name': 'Ni']}\n\"\"\")\n msg.setWindowTitle(\"Custom Mongo Query\")\n msg.setStandardButtons(QMessageBox.Ok)\n msg.exec_()\n\n\nclass CatalogList(QComboBox):\n \"\"\"\n List of subcatalogs\n \"\"\"\n ...\n\n\nclass CatalogSelectionWidget(QWidget):\n \"\"\"\n Input widget for selecting a subcatalog\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.catalog_list = CatalogList()\n layout = QHBoxLayout()\n layout.addWidget(QLabel(\"Catalog:\"))\n layout.addWidget(self.catalog_list)\n self.setLayout(layout)\n\n\nclass SearchResultsWidget(QTableView):\n \"\"\"\n Table of search results\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n self.setEditTriggers(QAbstractItemView.NoEditTriggers)\n self.setSortingEnabled(True)\n self.setSelectionBehavior(QTableView.SelectRows)\n self.setShowGrid(False)\n self.verticalHeader().setVisible(False)\n self.horizontalHeader().setDefaultAlignment(Qt.AlignHCenter)\n self.horizontalHeader().setSectionResizeMode(QHeaderView.ResizeToContents)\n self.setAlternatingRowColors(True)\n\n\nclass SearchWidget(QWidget):\n \"\"\"\n Search input and results list\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n self.catalog_selection_widget = CatalogSelectionWidget()\n self.search_input_widget = SearchInputWidget()\n self.search_results_widget = SearchResultsWidget()\n\n layout = QVBoxLayout()\n layout.addWidget(self.catalog_selection_widget)\n layout.addWidget(self.search_input_widget)\n layout.addWidget(self.search_results_widget)\n self.setLayout(layout)\n\n\nclass SkipRow(Exception):\n ...\n"
},
{
"alpha_fraction": 0.5539714694023132,
"alphanum_fraction": 0.5658519864082336,
"avg_line_length": 33.25581359863281,
"blob_id": "b49757cfb625efe552eb6d400d0c82b246b9ada4",
"content_id": "e40112693f594126d44cf0fc099df4a7a7b5fd41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2946,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 86,
"path": "/xicam/gui/widgets/plotwidgetmixins.py",
"repo_name": "magicknight/Xi-cam.gui",
"src_encoding": "UTF-8",
"text": "from qtpy.QtWidgets import QApplication\nimport pyqtgraph as pg\nimport numpy as np\n\n\nclass HoverHighlight(pg.PlotWidget):\n \"\"\"\n Highlights any scatter spots moused-over, giving a feel that they can be clicked on for more info\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super(HoverHighlight, self).__init__(*args, **kwargs)\n self._last_highlighted = None\n self._last_pen = None\n\n def mouseMoveEvent(self, ev):\n if self._last_highlighted:\n self._last_highlighted.setPen(self._last_pen)\n self._last_highlighted = None\n\n super(HoverHighlight, self).mouseMoveEvent(ev)\n\n if self.plotItem.boundingRect().contains(ev.pos()):\n mousePoint = self.plotItem.mapToView(pg.Point(ev.pos()))\n\n for item in self.scene().items():\n if isinstance(item, pg.PlotDataItem):\n if item.curve.mouseShape().contains(mousePoint):\n scatter = item.scatter # type: pg.ScatterPlotItem\n points = scatter.pointsAt(mousePoint)\n if points:\n self._last_pen = points[0].pen()\n self._last_highlighted = points[0]\n points[0].setPen(pg.mkPen(\"w\", width=2))\n break\n\n\nclass CurveLabels(HoverHighlight):\n def __init__(self, *args, **kwargs):\n super(CurveLabels, self).__init__(*args, **kwargs)\n\n self._arrow = None\n self._text = None\n self._curvepoint = None\n\n def plot(self, *args, **kwargs):\n if \"symbolSize\" not in kwargs:\n kwargs[\"symbolSize\"] = 10\n if \"symbol\" not in kwargs:\n kwargs[\"symbol\"] = \"o\"\n if \"symbolPen\" not in kwargs:\n kwargs[\"symbolPen\"] = pg.mkPen((0, 0, 0, 0))\n if \"symbolBrush\" not in kwargs:\n kwargs[\"symbolBrush\"] = pg.mkBrush((0, 0, 0, 0))\n\n item = self.plotItem.plot(*args, **kwargs)\n\n item.sigPointsClicked.connect(self.showLabel)\n\n def showLabel(self, item, points):\n if self._curvepoint:\n self.scene().removeItem(self._arrow)\n self.scene().removeItem(self._text)\n\n point = points[0]\n self._curvepoint = pg.CurvePoint(item.curve)\n self.addItem(self._curvepoint)\n self._arrow = pg.ArrowItem(angle=90)\n self._arrow.setParentItem(self._curvepoint)\n self._arrow.setZValue(10000)\n self._text = pg.TextItem(item.name(), anchor=(0.5, -1.0), border=pg.mkPen(\"w\"), fill=pg.mkBrush(\"k\"))\n self._text.setParentItem(self._curvepoint)\n\n self._curvepoint.setIndex(list(item.scatter.points()).index(point))\n\n\nif __name__ == \"__main__\":\n qapp = QApplication([])\n w = CurveLabels()\n for i in range(10):\n pen = pg.mkColor((i, 10))\n w.plot(np.random.random((100,)) + i * 0.5, name=str(i), pen=pen)\n\n w.show()\n\n qapp.exec_()\n"
}
] | 2 |
pinturam/PyCodeChallenges
|
https://github.com/pinturam/PyCodeChallenges
|
6a1508f4cc76aaf6c9ce08570ae04f7bd8674a39
|
23c1920cd597c1598df4d20cc79537a3ff7fcc44
|
a71b544f3de9e0bfb40b5f322d5714261b93e5b5
|
refs/heads/master
| 2022-12-19T07:29:56.152743 | 2020-09-28T18:27:03 | 2020-09-28T18:27:03 | 296,605,567 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4440559446811676,
"alphanum_fraction": 0.4720279574394226,
"avg_line_length": 21.83333396911621,
"blob_id": "4c7bde3fef4649192686b31c174e2a28ea111fcb",
"content_id": "f7a77a0cf5038af4251ba0d5a86a56c38af522d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/ArmstrongNumbersBetween.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "lower = int(input('enter lower range: '))\r\nupper = int(input('enter upper range: '))\r\n\r\nfor num in range(lower, upper+1):\r\n s = 0\r\n temp = num\r\n while temp > 0:\r\n digit = temp % 10\r\n s += digit**3\r\n temp //= 10\r\n if num == s:\r\n print(s)\r\n"
},
{
"alpha_fraction": 0.6736596822738647,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 28.64285659790039,
"blob_id": "0ec0c1e6ff112d4c0dc649edfef13f2fc94dc37a",
"content_id": "12a37c454fdb4f73b860f4c8e783af15d6410399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 429,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 14,
"path": "/ArithmeticOperations.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# python program to perform arithmetic operations like additions, subtraction, multiplication and division\r\n\r\nnum1 = input(\"Enter first number: \")\r\nnum2 = input(\"Enter second number: \")\r\n\r\nadd = float(num1) + float(num2)\r\nsub = float(num1) - float(num2)\r\nmul = float(num1) * float(num2)\r\ndiv = float(num1) / float(num2)\r\n\r\nprint('addition', add)\r\nprint('subtraction', sub)\r\nprint('multiplication', mul)\r\nprint('division ', div)\r\n"
},
{
"alpha_fraction": 0.6593406796455383,
"alphanum_fraction": 0.6593406796455383,
"avg_line_length": 28.33333396911621,
"blob_id": "3f41584f2288fc69a3805aeddea95b1450f8dc5f",
"content_id": "aed88f353b41504ccc5b553c710c54b8425c1aed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 91,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 3,
"path": "/DecimalToOctal.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "decimal = int(input('enter a decimal number: '))\r\n\r\nprint(\"Octal Number: \", oct(decimal))\r\n"
},
{
"alpha_fraction": 0.4681274890899658,
"alphanum_fraction": 0.49203187227249146,
"avg_line_length": 18.91666603088379,
"blob_id": "8f713b64f49442dcf6cb9c0f05282c0f49b458bb",
"content_id": "5a4d704ab74df612e4bf0deec4318d82fb4c6947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 24,
"path": "/InsertionSort.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# Insertion Sort:\r\ndef insertion_sort(lst):\r\n for i in range(1, len(lst)):\r\n key = lst[i]\r\n j = i -1\r\n while j >= 0 and key < lst[j]:\r\n lst[j+1] = lst[j]\r\n j -= 1\r\n lst[j+1] = key\r\n\r\n\r\n# main\r\nlst1 = []\r\nn = int(input('Enter size of list: '))\r\nprint('Enter elements of list: ')\r\nfor i in range(0, n):\r\n e = int(input())\r\n lst1.append(e)\r\n\r\n\r\ninsertion_sort(lst1)\r\nprint('Sorted list is: ')\r\nfor i in range(len(lst1)):\r\n print(lst1[i])\r\n"
},
{
"alpha_fraction": 0.6943396329879761,
"alphanum_fraction": 0.6943396329879761,
"avg_line_length": 22.090909957885742,
"blob_id": "1835435ff6a7529c21c84b414c1090fd9bc2b10c",
"content_id": "b21ad124b7f73ceb854b4d879188aa1fcac6d66b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 11,
"path": "/AlphabetOrder.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# program to sort words in alphabetic order\r\n\r\n# taking a string\r\nstring = input('enter a string :')\r\n# splitting the string into list of words\r\nwords = string.split()\r\n# sort the list\r\nwords.sort()\r\n# display the sorted words\r\nfor word in words:\r\n print(word)\r\n"
},
{
"alpha_fraction": 0.5045045018196106,
"alphanum_fraction": 0.5360360145568848,
"avg_line_length": 16.66666603088379,
"blob_id": "5258df9077792eef24801a5d427af4c9c97493f8",
"content_id": "be8289784b98233e40ed5efd8cd09dcf0e0fd3f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 12,
"path": "/ArmstrongNumber.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "num = int(input('enter a number: '))\r\ns = 0\r\ntemp = num\r\nwhile temp > 0:\r\n digit = temp % 10\r\n s += digit ** 3\r\n temp //= 10\r\n\r\nif num == s:\r\n print('Armstrong Number')\r\nelse:\r\n print('Not Armstrong Number')"
},
{
"alpha_fraction": 0.6777777671813965,
"alphanum_fraction": 0.6777777671813965,
"avg_line_length": 28.66666603088379,
"blob_id": "5c0a60079ff534ac1b74b29c7970f877abaf643d",
"content_id": "887192ae2739c0f01c9fbe8db3e75e6ab98fa11c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 3,
"path": "/DecimalToBinary.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "decimal = int(input('enter a decimal number: '))\r\n\r\nprint(\"binary number: \", bin(decimal))"
},
{
"alpha_fraction": 0.4438202381134033,
"alphanum_fraction": 0.466292142868042,
"avg_line_length": 15.800000190734863,
"blob_id": "2243e13b7b10f86b4b2cda65dd2806f66e2b8253",
"content_id": "3f5a5264dfe9557587baa80ff4fc54a9209a2575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/SumOfNaturalNumbers.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "num = int(input('enter a number: '))\r\n\r\nif num < 0:\r\n print('enter a positive number')\r\nelse:\r\n s = 0\r\n while num > 0:\r\n s += num\r\n num -=1\r\n print(s)\r\n"
},
{
"alpha_fraction": 0.511904776096344,
"alphanum_fraction": 0.5436508059501648,
"avg_line_length": 20.909090042114258,
"blob_id": "bf014bd770a8f9072e8073ac3dc0a995555d7252",
"content_id": "d23c060dc63fcfa92dcbb30cabe7ca2092b7ab58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 22,
"path": "/FibonacciSeries.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# program to print fibonacci series\r\n# ...\r\n\r\n# taking terms\r\nterms = int(input('enter terms :'))\r\n# initialize first two terms\r\nn1 = 0\r\nn2 = 1\r\ncount = 2\r\n# check if terms is valid or not\r\nif terms <= 0:\r\n print('please, enter a positive interger')\r\nelif terms == 1:\r\n print('Fibonacci series: ', n1)\r\nelse:\r\n print('Fibonacci series: ', n1, \",\", n2, end=\",\")\r\n while count < terms:\r\n nth = n1 + n2\r\n print(nth, end=',')\r\n n1 = n2\r\n n2 = nth\r\n count += 1\r\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 26,
"blob_id": "f24e38a79180d5e283e55e8e0e1dbfaff1c2b2aa",
"content_id": "f8bfde88324019d06205d3589239757ea30dbe8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 3,
"path": "/ASCIIvalue.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "character = input('enter a character: ')\r\n\r\nprint('ASCII value :', ord(character))\r\n"
},
{
"alpha_fraction": 0.6486486196517944,
"alphanum_fraction": 0.6486486196517944,
"avg_line_length": 26.928571701049805,
"blob_id": "7e208e31ea9afa9e4fdbfc32b9417742f8eb9c9f",
"content_id": "2d52ce035aa278cca6ff39e2c46a8b46f694fb81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 14,
"path": "/RemovePunctuation.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# program to remove punctuation form a string\r\n# define punctuation\r\npunctuation = '''!()-[];:'\"\\,<>./?@#$%^&*_~'''\r\n# take input as string from user\r\nstring = input('enter a string :')\r\n# remove punctuation form string\r\nno_punctuation = \" \"\r\nfor char in string:\r\n if char not in punctuation:\r\n no_punctuation = no_punctuation + char\r\n\r\n\r\n# display the unpunctual string\r\nprint(no_punctuation)\r\n\r\n"
},
{
"alpha_fraction": 0.5891891717910767,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 18.55555534362793,
"blob_id": "4b81e72956e8ed85fde5a1a9de21e7c9277aae13",
"content_id": "2f65c1c2684df96617996774554c47e286915988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 9,
"path": "/CheckInteger.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# taking input form user\r\nnum = float(input('enter a number :'))\r\n\r\nif num > 0:\r\n print('positive integer')\r\nelif num < 0:\r\n print('negative integer')\r\nelse:\r\n print('Zero')\r\n"
},
{
"alpha_fraction": 0.5950413346290588,
"alphanum_fraction": 0.5950413346290588,
"avg_line_length": 30.653846740722656,
"blob_id": "29714172031ce81e030075745d46e75d6942c9d1",
"content_id": "d72edf237d04a56904034a23f54c5eae6d202a8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 847,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 26,
"path": "/ReverseCircularLinkedList.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# Program to create a Circular Linked List of n nodes and display it in reverse order\r\n\r\n# Creat a node of list\r\nclass Node:\r\n def __init__(self, data):\r\n self.data = data\r\n self.next = None\r\n\r\n# Create Circular Linked list\r\nclass CircularLinkedList:\r\n # Declaring head and tail pointer as null\r\n def __init__(self):\r\n self.head = Node(None)\r\n self.tail = Node(None)\r\n self.head.next = self.tail\r\n self.tail.next = self.head\r\n\r\n # Creating function for adding new node at the end of the list\r\n def add(self, data):\r\n newNode = Node(data)\r\n # Check whether list is empty\r\n if self.head.data is None:\r\n # If list is empty, both head and tail will point to new node\r\n self.head = newNode\r\n self.tail = newNode\r\n newNode.next = s"
},
{
"alpha_fraction": 0.7050691246986389,
"alphanum_fraction": 0.7235022783279419,
"avg_line_length": 29,
"blob_id": "69be68b90a920112465832371227f340ab343183",
"content_id": "c7366720a1b410d207d4db64a02501a813c77f24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 7,
"path": "/CelsiusToFahrenheit.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# collect input from user\r\ncelsius = float(input('enter temperature in celsius: '))\r\n\r\n# calculating temperature in fahrenheit\r\nfahrenheit = (celsius*1.8) + 32\r\n\r\nprint('temperature in fahrenheit is : ', fahrenheit)\r\n"
},
{
"alpha_fraction": 0.5463258624076843,
"alphanum_fraction": 0.5623003244400024,
"avg_line_length": 19,
"blob_id": "639c5ba6c346a9ec0db96c48fabade278004e648",
"content_id": "704fc3572039251914bacbd9d58621c55d0b6d20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 15,
"path": "/FactorialRecursion.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "def factorial(n):\r\n if n == 1:\r\n return n\r\n else:\r\n return n*factorial(n-1)\r\n\r\n\r\nnum = int(input('enter a number: '))\r\n\r\nif num <= 0:\r\n print('sorry, factorial does not exist for negative number')\r\nelif num == 0:\r\n print('factorial = 0')\r\nelse:\r\n print('factorial = ', factorial(num))"
},
{
"alpha_fraction": 0.6804123520851135,
"alphanum_fraction": 0.6804123520851135,
"avg_line_length": 30.33333396911621,
"blob_id": "ef8ead80db76b02c77f4e7720c8536098bb85589",
"content_id": "67ce8ea08e41dc8dc913f0cbffeabe5480166af6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 3,
"path": "/DecimalToHexadecimal.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "decimal = int(input('enter a decimal number: '))\r\n\r\nprint(\"Hexadecimal Number: \", hex(decimal))\r\n"
},
{
"alpha_fraction": 0.6366119980812073,
"alphanum_fraction": 0.6448087692260742,
"avg_line_length": 26.153846740722656,
"blob_id": "8b41971f0e995ccd538c0ce63f4a52f5ca301876",
"content_id": "a0d371876e1fc3a8f5ae673967baff790498851b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 13,
"path": "/AreaOfTriangle.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# taking input three sides of triangle\r\na = float(input(\"enter first side of triangle :\"))\r\nb = float(input(\"enter second side of triangle :\"))\r\nc = float(input(\"enter third side of triangle :\"))\r\n\r\n# calculate of semi perimeter\r\ns = (a+b+c)/2\r\n\r\n# calculate area of triangle\r\narea = (s*(s-a)*(s-b)*(s-c))**0.5\r\n\r\n# print area\r\nprint(\"area of triangle is :\", area)\r\n"
},
{
"alpha_fraction": 0.4808080792427063,
"alphanum_fraction": 0.5272727012634277,
"avg_line_length": 21.571428298950195,
"blob_id": "6a5fd5e44ddfa815c480c0b07a6f243354c2493f",
"content_id": "e5a04c10045089286f37ae237f78bdc4c9f40df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/BubbleSort.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# Implementing Bubble Sort\r\n\r\ndef bubble_sort(lst):\r\n for i in range(len(lst)):\r\n for j in range(0,len(lst) - i - 1):\r\n if lst[j] > lst[j+1]:\r\n lst[j], lst[j+1] = lst[j+1], lst[j]\r\n\r\n\r\n# main:\r\nlst1 = []\r\nn = int(input('Enter size of list: '))\r\nprint('Enter elements: ')\r\nfor i in range(0, n):\r\n e = int(input())\r\n lst1.append(e)\r\n# lst = [12,23,24,235,124]\r\nbubble_sort(lst1)\r\nprint('Sorted list is: ')\r\nfor i in range(len(lst1)):\r\n print(lst1[i])\r\n"
},
{
"alpha_fraction": 0.5492957830429077,
"alphanum_fraction": 0.6338028311729431,
"avg_line_length": 22,
"blob_id": "fc0c6a376395019480055be390a87e6a6dbd335d",
"content_id": "b00d9f0d189616f9ee949abc589d99ae37b3f89a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 6,
"path": "/KmToMiles.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# take input in km\r\nkm = float(input('enter km :'))\r\n\r\n# conversion (formula: miles = km*0.62137)\r\nmiles = km*0.62137\r\nprint(\"miles :\", miles)"
},
{
"alpha_fraction": 0.6060606241226196,
"alphanum_fraction": 0.6242424249649048,
"avg_line_length": 25.66666603088379,
"blob_id": "e7f36451def6e1721e757594de8e330e47a47741",
"content_id": "f0b992cf10f64125f4a9a345f6a93531326aa4e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 330,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 12,
"path": "/Factorial.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# program to find factorial of a number\r\nnum = int(input('enter a number: '))\r\n\r\nfactorial = 1\r\nif num < 0:\r\n print('sorry, factorial does not exist for negative number')\r\nelif num == 0:\r\n print('factorial = 1')\r\nelse:\r\n for i in range(1, num+1):\r\n factorial = factorial*i\r\n print('the factorial = ', factorial)"
},
{
"alpha_fraction": 0.6818181872367859,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 21,
"blob_id": "9922e66e3d2c21e22ea6e0710ae097ce783ff9c3",
"content_id": "832e4f7941d95ce98fc343ac84f68c8199b398a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/RandomNumbers.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "import random\r\nprint(random.randint(12, 21))"
},
{
"alpha_fraction": 0.5414012670516968,
"alphanum_fraction": 0.5541401505470276,
"avg_line_length": 18.933332443237305,
"blob_id": "ac0a15e2b96969b8a4088e3b9bb9074ef2f6e5be",
"content_id": "4a0531fe87ca814e2d61af4fe40d5e83721a6eaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 15,
"path": "/FibonacciRecursion.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "def fibonacci(n):\r\n if n <= 1:\r\n return n\r\n else:\r\n return fibonacci(n-1) + fibonacci(n-2)\r\n\r\n\r\nterms = int(input('enter terms: '))\r\n\r\nif terms <= 0:\r\n print('please enter a positive integer')\r\nelse:\r\n print('fibonacci series: ')\r\n for i in range(terms):\r\n print(fibonacci(i))\r\n"
},
{
"alpha_fraction": 0.4427083432674408,
"alphanum_fraction": 0.4921875,
"avg_line_length": 18.210525512695312,
"blob_id": "6573a4300ca4f66272e67c3e5235298c8bc0c5f9",
"content_id": "c413b8454a683c914379d39910dfd4d4237f9362",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 19,
"path": "/TransposeMatrix.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# taking first matrix\r\nX = [[1, 2, 3],\r\n [4, 5, 6],\r\n [7, 8, 9]]\r\n\r\n# taking a blank result matrix\r\nresult = [[0, 0, 0],\r\n [0, 0, 0],\r\n [0, 0, 0]]\r\n# iterating through rows\r\nfor i in range(len(X)):\r\n # iterating through columns\r\n for j in range(len(X[0])):\r\n result[j][i] = X[i][j]\r\n\r\n\r\n# printing result matrix\r\nfor r in result:\r\n print(r)\r\n"
},
{
"alpha_fraction": 0.6988636255264282,
"alphanum_fraction": 0.6988636255264282,
"avg_line_length": 23.14285659790039,
"blob_id": "a6b896708f600a14c31da26f954e5364b72452d7",
"content_id": "46273421c1277733616122c99c0d5e0184e27a74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 176,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 7,
"path": "/DispalyCalender.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "# importing calender module\r\nimport calendar\r\nyear = int(input('enter year: '))\r\nmonth = int(input('enter month: '))\r\n\r\n# display calender\r\nprint(calendar.month(year, month))\r\n"
},
{
"alpha_fraction": 0.6141079068183899,
"alphanum_fraction": 0.6141079068183899,
"avg_line_length": 19.909090042114258,
"blob_id": "4574f8538102d8aab95cc3bb305cbb3740052b16",
"content_id": "aa6f29ef85f838488a0899f9e1ce286d4784f616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 11,
"path": "/SwapTwoVariables.py",
"repo_name": "pinturam/PyCodeChallenges",
"src_encoding": "UTF-8",
"text": "x = input(\"enter value of x :\")\r\ny = input(\"enter value of y: \")\r\n\r\n# create a temporary variable and swap the values\r\ntemp = x\r\nx = y\r\nx = y\r\ny = temp\r\n\r\nprint(\"after swapping x is {}\".format(x))\r\nprint(\"after swapping y is {}\".format(y))\r\n"
}
] | 25 |
odootests/openacademy
|
https://github.com/odootests/openacademy
|
2bf23fac2312356aca2e4a95b770d6faf400bce4
|
61b6f104883922d3f185485b7940de05df14e014
|
24b71fb536af08344af14e7363e42ca33fc522a1
|
refs/heads/master
| 2021-05-05T17:01:18.940906 | 2018-01-15T15:46:25 | 2018-01-15T15:46:25 | 117,338,579 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7818930149078369,
"avg_line_length": 47.79999923706055,
"blob_id": "d1bae6f16844101527214d7dc8b440b86cb62e6f",
"content_id": "4e06023aca1b53ee34e6d0bd123b687dfb0d5f6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 5,
"path": "/partner.py",
"repo_name": "odootests/openacademy",
"src_encoding": "UTF-8",
"text": "from odoo import fields, models\nclass Partner(models.Model):\n\t_inherit='res.partner'\n\tis_instructor = fields.Boolean(\"instructor\", default=False)\n\tsession_ids = fields.Many2many('openacademy.session', string='Attended Sessions', readonly=True)"
},
{
"alpha_fraction": 0.6808578968048096,
"alphanum_fraction": 0.6866196990013123,
"avg_line_length": 31.55208396911621,
"blob_id": "32587b9e72106b2f15cf8c3bc80d0e47c8a594b6",
"content_id": "c3c95ed0307d9252b4c246f5e65b7e19c9619338",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3124,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 96,
"path": "/models/session.py",
"repo_name": "odootests/openacademy",
"src_encoding": "UTF-8",
"text": "from odoo import models, fields, api, exceptions\nfrom datetime import timedelta\n\nclass Session(models.Model):\n\t_name='openacademy.session'\n\tsession_name= fields.Char(required=True)\n\tstart_date = fields.Date()\n\tduration = fields.Float(digits=(6,2), help=\"Duration in days\")\n\tseats = fields.Integer(string=\"Number of seats\")\n\tactive = fields.Boolean(default=True)\n\tcolor = fields.Integer()\n\tinstructor_id = fields.Many2one('res.partner', string='Course Instructor', domain=['|', ('is_instructor', '=', True), ('category_id.name', 'ilike', \"Teacher\")])\n\tcourse_id = fields.Many2one('openacademy.course', ondelete='cascade', string='Course', required=True)\n\tattendee_ids = fields.Many2many('res.partner', string=\"Attendees\")\n\tseats_taken = fields.Float(string=\"Seats Taken\", compute='calc_seats_taken')\n\tend_date = fields.Date(string=\"End Date\", store=True, compute='get_end_date', inverse='set_end_date')\n\n\thours = fields.Float(string=\"Duration in hours\", compute='calc_hours', inverse='set_hours')\n\t\n\tattendees_count = fields.Integer(string='Attendees Count', compute='calc_attendees', store=True)\n\tstate = fields.Selection([('draft', 'Draft'), ('confirmed', 'Confirmed'), ('done','Done')])\n\n\[email protected]\n\tdef action_draft(self):\n\t\tself.state='draft'\n\n\[email protected]\n\tdef action_confirm(self):\n\t\tself.state = 'confirmed'\n\n\[email protected]\n\tdef action_done(self):\n\t\tself.state = 'done'\n\n\[email protected]('attendee_ids')\n\tdef calc_attendees(self):\n\t\tfor rec in self:\n\t\t\trec.attendees_count = len(rec.attendee_ids)\n\n\[email protected]('start_date', 'duration')\n\tdef get_end_date(self):\n\t\tfor rec in self:\n\t\t\tif not(rec.start_date and rec.duration):\n\t\t\t\trec.end_date = rec.start_date\n\t\t\t\tcontinue\n\t\t\tstart = fields.Datetime.from_string(rec.start_date)\n\t\t\tduration = timedelta(days=rec.duration, seconds=-1)\n\t\t\trec.end_date = start + duration\n\n\tdef set_end_date(self):\n\t\tfor rec in self:\n\t\t\tif not (rec.start_date and rec.end_date):\n\t\t\t\tcontinue\n\t\t\tstart_date = fields.Datetime.from_string(rec.start_date)\n\t\t\tend_date = fields.Datetime.from_string(rec.end_date)\n\t\t\trec.duration = (end_date - start_date).days +1\n\n\[email protected]('seats', 'attendee_ids')\n\tdef calc_seats_taken(self):\n\t\tfor rec in self:\n\t\t\tif not rec.seats:\n\t\t\t\trec.seats_taken = 0.0\n\t\t\telse:\n\t\t\t\trec.seats_taken = 100.0 * len(rec.attendee_ids) / rec.seats\n\n\[email protected]('seats', 'attendee_ids')\n\tdef verify_valid_seats(self):\n\t\tif self.seats <0:\n\t\t\treturn {\n\t\t\t\t'warning': { \n\t\t\t\t\t'title': \"Incorrect amount for seats\",\n\t\t\t\t\t'message': \"No. of seats can't be negative\"\n\t\t\t\t},\n\t\t\t}\n\t\tif self.seats < len(self.attendee_ids):\n\t\t\treturn {\n\t\t\t\t'warning': {\n\t\t\t\t\t'title': \"Too many Attendees\",\n\t\t\t\t\t'message': \"More Attendees than seats\"\n\t\t\t\t}\n\t\t\t}\n\t\t\t\n\[email protected]('instructor_id', 'attendee_ids')\n\tdef check_instructor_not_in_attendees(self):\n\t\tfor rec in self:\n\t\t\tif rec.instructor_id and rec.instructor_id in rec.attendee_ids:\n\t\t\t\traise exceptions.ValidationError(\"The Instructor cannot be an attendee\")\n\n\[email protected]('duration')\n\tdef calc_hours(self):\n\t\tfor rec in self:\n\t\t\trec.hours = rec.duration * 24\n\n\tdef set_hours(self):\n\t\tfor rec in self:\n\t\t\trec.duration = rec.hours / 24"
},
{
"alpha_fraction": 0.5573294758796692,
"alphanum_fraction": 0.5616835951805115,
"avg_line_length": 27.75,
"blob_id": "6a510b5a09a2b63875f02c7d03c3fcfb3d6e1bae",
"content_id": "a735f02529a12d755be7514ea35a2608d95844f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/__manifest__.py",
"repo_name": "odootests/openacademy",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n{\n 'name': \"OpenAcademy\",\n 'summary': \"Summary\",\n 'description': \"Description\",\n 'author': \"Haha\",\n 'website': \"http://www.the_name_of_your_website.com\",\n 'category': 'Module Development',\n 'version': '0.1',\n 'depends': ['base', 'report', 'board'],\n 'data': [\n 'security/ir.model.access.csv',\n 'views/views.xml',\n 'views/templates.xml',\n 'views/openacademy_course.xml',\n 'views/openacademy_session.xml',\n 'views/partner.xml',\n 'views/openacademy_session_workflow.xml',\n 'views/reports.xml',\n 'views/session_board.xml'\n ],\n 'installable': True,\n 'application': True\n}"
},
{
"alpha_fraction": 0.6369637250900269,
"alphanum_fraction": 0.6429042816162109,
"avg_line_length": 29.31999969482422,
"blob_id": "cc58cc2b919f78a56e2afc86b8290055b77c3c04",
"content_id": "a9dae58ec75d8afe83b496720fb70b770493b57f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 50,
"path": "/models/course.py",
"repo_name": "odootests/openacademy",
"src_encoding": "UTF-8",
"text": "# -9*- coding: utf-8 -*-\n\nfrom odoo import models, fields, api, exceptions\n\nclass Course(models.Model):\n\t_name='openacademy.course'\n\tcourse_name = fields.Char(string=\"Title\", required=True)\n\tdescription = fields.Text()\n\tresponsible_id = fields.Many2one('res.users', ondelete='set null', string=\"Course Taker\", index=True)\n\tsession_ids = fields.One2many('openacademy.session', 'course_id', string='Sessions')\n\t\n\tdef __str__(self):\n\t\treturn self.course_name\n\t\t\n\[email protected]\n\tdef copy(self, default=None):\n\t\tdefault = dict(default or {})\n\t\tcopy_count = self.search_count([('course_name', '=ilike', u\"Copy of {}\".format(self.course_name))])\n\t\tif not copy_count:\n\t\t\tnew_course_name = u\"Copy of {}\".format(self.course_name)\n\t\telse: \n\t\t\tnew_course_name = u\"Copy of {} {}\".format(self.course_name, copy_count)\n\n\t\tdefault['course_name'] = new_course_name\n\t\treturn super(Course, self).copy(default)\n\n\n\t_sql_constraints = [\n \t(\n \t\t'name_description_check', \n \t\t'CHECK(course_name != description)',\n \t\t'The Course Title and description must be different'\n \t),\n \t(\n \t\t'check_name_unique', \n \t\t'UNIQUE(course_name)' , \n \t\t\"The Course title must be unique\"\n \t),\n ]\n# class openacademy(models.Model):\n# _name = 'openacademy.openacademy'\n\n# name = fields.Char()\n# value = fields.Integer()\n# value2 = fields.Float(compute=\"_value_pc\", store=True)\n# description = fields.Text()\n#\n# @api.depends('value')\n# def _value_pc(self):\n# self.value2 = float(self.value) / 100"
}
] | 4 |
virajnilakh/SentimentAnalysis
|
https://github.com/virajnilakh/SentimentAnalysis
|
e29b6779acd01efcd854449976ed47a15954a62b
|
96f2c43f0ecfa64f90c08fc03e765373e2c087cb
|
feac188f98cf6239754609eef558e4907780cc98
|
refs/heads/master
| 2021-01-23T05:09:17.816296 | 2017-04-03T21:28:53 | 2017-04-03T21:28:53 | 86,279,418 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4559706449508667,
"alphanum_fraction": 0.47398266196250916,
"avg_line_length": 20.72101402282715,
"blob_id": "fa7c92cf211a925f47b6101d1fb02ebe03da11be",
"content_id": "2aef4cbd8f687dfcbacf02d9e8150686fd50da90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5996,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 276,
"path": "/indexjoin.py",
"repo_name": "virajnilakh/SentimentAnalysis",
"src_encoding": "UTF-8",
"text": "import re\nimport math\nimport operator\n\nfrom autocorrect import spell\nfrom stemming.porter2 import stem\nfrom nltk.corpus import stopwords\nstop_words = set(stopwords.words('english'))\n\ndef getWords(text):\n return re.compile('\\w+').findall(text)\ndef normalize(d):\n norm = 0\n for k, v in d.iteritems():\n norm = norm + v ** 2\n norm = math.sqrt(norm)\n for k, v in d.iteritems():\n d[k] = d[k] / norm\n return d\nwith open('./train.dat', 'r') as fh:\n lines = fh.readlines()\npos = []\nneg = []\npindex = -1\nnindex = -1\nflag = 1\nfor l in lines:\n if (l[0:2] != \"-1\"):\n if (l[0:2] == \"+1\" or flag):\n pos.append(\"\")\n pindex += 1\n if (l[0:2] == \"+1\"):\n pos[pindex] = l[2:]\n else:\n pos[pindex] = pos[pindex] + l\n flag = 1\n else:\n\n neg[nindex] = neg[nindex] + l\n flag = 0\n else:\n if (l[0:2] == \"-1\"):\n neg.append(\"\")\n nindex += 1\n neg[nindex] = l[2:]\n flag = 0\n'''print \"relearning\"\n#relearning\nwith open('./test.dat', 'r') as fh:\n lines = fh.readlines()\n\ntest=[\"\"]\nind=0\nfor l in lines:\n test[ind]=test[ind]+l\n if \"\\n\" in l:\n ind+=1\n test.append(\"\")\ntest=test[:-1]\nwith open('./ans26.dat', 'r') as fh:\n lines = fh.readlines()\nrind=0\nfor l in test:\n if lines[rind]==\"+1\\n\":\n pos.append(l)\n else:\n neg.append(l)\n rind+=1'''\npindex=0\nnindex=0\n#pos=pos[:50]\n#neg=neg[:50]\nprint \"creating document of words\"\n#creates documents of words\nfor l in pos:\n pos[pindex]=getWords(l)\n pindex+=1\nfor l in neg:\n neg[nindex]=getWords(l)\n nindex+=1\nprint \"indexing\"\n#indexing\nindex={}\nc=0\nfor l in pos+neg:\n for w in l:\n w = w.lower()\n #w = stem(w)\n if w in stop_words:\n continue\n if w not in index:\n index[w]=c\n c+=1\n'''pos_str=\"\"\nneg_str=''\nfor l in pos:\n for w in l:\n pos_str+=(w+\" \")\nfor l in neg:\n for w in l:\n neg_str+=(w+\" \")\n'''\nprint \"word-freq format\"\nprint \"pos word freq\"\n#converts document in word-freq format\npos_dict=[]\nfor d in pos:\n p={}\n pd={}\n for w in d:\n\n w = w.lower()\n #w=stem(w)\n if w in stop_words:\n continue\n if index[w] not in p:\n pd[w]=1\n p[index[w]] = 1\n else:\n pd[w]+=1\n p[index[w]] += 1\n pos_dict.append(p)\n #print pd\n\nneg_dict=[]\nfor d in neg:\n n={}\n nd={}\n for w in d:\n w = w.lower()\n #w = stem(w)\n if w in stop_words:\n continue\n if index[w] not in n:\n n[index[w]] = 1\n nd[w]=1\n else:\n n[index[w]] += 1\n nd[w]+=1\n neg_dict.append(n)\n #print nd\nprint \"normalizing\"\nfor l in pos_dict+neg_dict:\n l=normalize(l)\n\n\n'''print \"tf-idf\"\n#tfidf\nfor w in index:\n c1=0\n c2=0\n for l in pos_dict:\n if index[w] in l:\n c1+=1\n for l in neg_dict:\n if index[w] in l:\n c2+=1\n for l in pos_dict:\n if index[w] in l:\n l[index[w]]*=len(neg_dict)/c1\n for l in neg_dict:\n if index[w] in l:\n l[index[w]]*=len(pos_dict)/c2'''\nprint \"contructinng feature matrix\"\n#contructinng feature matrix\nindex = sorted(index.items(), key=operator.itemgetter(1))\nprint \"sorting done\"\nfeature=[]\nfor v in index:\n f={}\n for j in range(len(pos_dict)):\n if v[1] in pos_dict[j]:\n f[j]=pos_dict[j][v[1]]\n for j in range(len(neg_dict)):\n if v[1] in neg_dict[j]:\n f[-j]=neg_dict[j][v[1]]\n feature.append(f)\nother={}\nfor v in index:\n other[v[0]]=v[1]\nindex=other\n\nprint \"test input\"\n#test\nwith open('./test.dat', 'r') as fh:\n lines = fh.readlines()\n\ntest=[\"\"]\nind=0\nfor l in lines:\n test[ind]=test[ind]+l\n if \"\\n\" in l:\n ind+=1\n test.append(\"\")\ntest=test[:-1]\n\nind=0\nans_a=[]\nf = open(\"ans25.dat\", \"w+\")\nfor t in test:\n ans=0\n pos_ans = {}\n neg_ans = {}\n pindex = 0\n nindex = 0\n test_dict = {}\n t=getWords(t)\n for w in t:\n w = w.lower()\n #w = stem(w)\n if w in stop_words:\n continue\n if w not in test_dict:\n test_dict[w] = 1\n else:\n test_dict[w] = test_dict[w] + 1\n\n\n test_dict=normalize(test_dict)\n for k,v in test_dict.iteritems():\n if k in index:\n for j,u in feature[index[k]].iteritems():\n if j>0:\n if j in pos_ans:\n pos_ans[j]+=v*u\n else:\n pos_ans[j]=0\n else:\n if j in neg_ans:\n neg_ans[j]+=v*u\n else:\n neg_ans[j]=0\n pos_ans = sorted(pos_ans.items(), key=operator.itemgetter(1))\n pos_ans = pos_ans[-25:]\n neg_ans = sorted(neg_ans.items(), key=operator.itemgetter(1))\n neg_ans = neg_ans[-25:]\n for v in pos_ans:\n ans += v[1]\n for v in neg_ans:\n ans -= v[1]\n if ans >= 0:\n ans_a.append(\"+1\")\n f.write(\"+1\\n\")\n else:\n ans_a.append(\"-1\")\n f.write(\"-1\\n\")\n\n '''for p in pos_dict:\n pos_ans.append(0)\n for k,v in test_dict.iteritems():\n #print k,v\n if k not in index:\n continue\n if index[k] in p:\n pos_ans[pindex]+=p[index[k]]*v\n pindex+=1\n for n in neg_dict:\n neg_ans.append(0)\n for k,v in test_dict.iteritems():\n if k not in index:\n continue\n if index[k] in n:\n neg_ans[nindex]+=n[index[k]]*v\n nindex+=1\n pos_ans.sort(reverse=True)\n neg_ans.sort(reverse=True)\n for v in pos_ans[:10]:\n ans+=v\n for v in neg_ans[:10]:\n ans-=v\n if v>0:\n ans_a.append(\"+1\")\n f.write(\"+1\\n\")\n else:\n ans_a.append(\"-1\")\n f.write(\"-1\\n\")'''\n\n"
}
] | 1 |
jordan52/grpcCppPythonBoilerplate
|
https://github.com/jordan52/grpcCppPythonBoilerplate
|
e29f4ecf2b4926c0509155dc39497416d43d5215
|
c368272776bac4eb3d6ca29e5152e3459c61f278
|
43719d20175bcac95f26a92f80eeccd303e819f6
|
refs/heads/main
| 2023-08-20T09:01:34.378140 | 2021-10-18T19:58:08 | 2021-10-18T19:58:08 | 413,209,200 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7859078645706177,
"alphanum_fraction": 0.7994579672813416,
"avg_line_length": 22.125,
"blob_id": "e23fd36c8f9b097db597b96ecfbde5bd59a93736",
"content_id": "b04873c1f3da3802ed7063bb03557e5345c36cf6",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 369,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 16,
"path": "/CMakeLists.txt",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.16)\nproject(grpcCppPythonBoilerplate)\n\nset(CMAKE_MODULE_PATH \"${CMAKE_SOURCE_DIR}/cmake\")\nset(CMAKE_CXX_STANDARD 14)\n\nadd_subdirectory(protobuf)\nadd_subdirectory(cppserver)\nadd_subdirectory(cppclient)\n\n#add_executable(grpcCppPythonBoilerplate main.cpp)\n\n\n# To run this you will run\n# cmake -DCMAKE_FIND_PACKAGE_PREFER_CONFIG=TRUE\n# make"
},
{
"alpha_fraction": 0.6801736354827881,
"alphanum_fraction": 0.6931982636451721,
"avg_line_length": 25.615385055541992,
"blob_id": "cf7f3a81fea869b1253348656f453e310ce924e7",
"content_id": "b5a750df1de1ac91325df59f6c1fa8cb970b90a8",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 691,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 26,
"path": "/pythonclient/main.py",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "import grpc\nimport sys\nimport os\n\n# I don't like this, but it is the simplest way to grab the proto files.\nsys.path.append(os.path.join(os.path.dirname(os.path.dirname(__file__)),'protobuf'))\n\nfrom proto import status_pb2\nfrom proto import statusservice_pb2_grpc\n\n\ndef getstatus(stub):\n statreq = status_pb2.StatusRequest(name = \"python client\")\n statres = stub.GetStatus(statreq)\n print(statres)\n print(f\"manual member get for name is {statres.name}\")\n\ndef run():\n with grpc.insecure_channel('localhost:50051') as channel:\n\n stub = statusservice_pb2_grpc.StatusServiceStub(channel)\n print(\"running\")\n getstatus(stub)\n\nif __name__ == '__main__':\n run()"
},
{
"alpha_fraction": 0.6310110688209534,
"alphanum_fraction": 0.6344019770622253,
"avg_line_length": 29.31775665283203,
"blob_id": "bb84fa911dfe219e8338e902212ee134c2daef7b",
"content_id": "46b57f9ae0920f13b3329798292284916577ff61",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3244,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 107,
"path": "/cppserver/src/main.cpp",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "#include <proto/status.pb.h>\n#include <proto/statusservice.grpc.pb.h>\n\n#include <grpc/grpc.h>\n#include <grpcpp/server_builder.h>\n\n#include <iostream>\n\n#include \"spdlog/spdlog.h\"\n#include \"spdlog/fmt/ostr.h\"\n#include \"spdlog/sinks/stdout_color_sinks.h\"\n#include \"spdlog/sinks/basic_file_sink.h\"\n\n#include <boost/program_options.hpp>\n\nnamespace po = boost::program_options;\n\nclass StatusService final : public protoboilerplate::StatusService::Service {\nprivate:\n std::shared_ptr<spdlog::logger> _logger;\npublic:\n StatusService(){\n _logger = spdlog::get(\"server_logger\");\n }\n virtual ::grpc::Status GetStatus(::grpc::ServerContext* context, const ::protoboilerplate::StatusRequest* request, ::protoboilerplate::StatusResponse* response)\n {\n _logger->warn(\"Server: GetStatus for \\\"{}\\\".\", request->name());\n response->set_name(\"OK\");\n return grpc::Status::OK;\n }\n};\n\nvoid initlogging(){\n\n try\n {\n auto console_sink = std::make_shared<spdlog::sinks::stdout_color_sink_mt>();\n console_sink->set_level(spdlog::level::warn);\n console_sink->set_pattern(\"[multi_sink_example] [%^%l%$] %v\");\n\n auto file_sink = std::make_shared<spdlog::sinks::basic_file_sink_mt>(\"logs/multisink.txt\", true);\n file_sink->set_level(spdlog::level::trace);\n\n\n spdlog::sinks_init_list sink_list = { file_sink, console_sink };\n\n spdlog::logger logger(\"server_logger\", sink_list.begin(), sink_list.end());\n\n logger.set_level(spdlog::level::debug);\n logger.warn(\"this should appear in both console and file\");\n logger.info(\"this message should not appear in the console, only in the file\");\n logger.flush(); //todo:\n\n // or you can even set multi_sink logger as default logger\n spdlog::set_default_logger(std::make_shared<spdlog::logger>(\"server_logger\", spdlog::sinks_init_list({console_sink, file_sink})));\n\n }\n catch (const spdlog::spdlog_ex& ex)\n {\n std::cout << \"Log initialization failed: \" << ex.what() << std::endl;\n }\n}\n\nint main(int argc, char* argv[])\n{\n std::string address_port = \"0.0.0.0:50051\";\n\n // parse command line and config\n po::options_description desc(\"Allowed options\");\n desc.add_options()\n (\"help\", \"produce help message\")\n (\"port\", po::value(&address_port), \"set listening address:port\")\n ;\n po::variables_map vm;\n po::store(po::parse_command_line(argc, argv, desc), vm);\n po::notify(vm);\n if (vm.count(\"help\")) {\n std::cout << desc << \"\\n\";\n return 0;\n }\n if (vm.count(\"port\")) {\n address_port = vm[\"port\"].as<std::string>();\n }\n\n // set up the logger\n\n initlogging();\n\n auto logger = spdlog::get(\"server_logger\");\n\n logger->warn(\"Server Starting\");\n\n grpc::ServerBuilder builder;\n builder.AddListeningPort(address_port, grpc::InsecureServerCredentials());\n\n StatusService my_statusservice;\n builder.RegisterService(&my_statusservice);\n\n logger->warn(\"Server getting ready to listen on {}!\", address_port);\n logger->warn(\"yikes\");\n logger->error(\"double yikes\");\n\n std::unique_ptr<grpc::Server> server(builder.BuildAndStart());\n server->Wait();\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6986899375915527,
"alphanum_fraction": 0.710698664188385,
"avg_line_length": 26.787878036499023,
"blob_id": "72b87867039ba24925a2975cd58246b269e82b28",
"content_id": "294d62febddfa2a9227615ffefa883d6a18bb38b",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 916,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 33,
"path": "/pythonserver/main.py",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "import grpc\nimport sys\nimport os\nfrom concurrent import futures\n# I don't like this, but it is the simplest way to grab the proto files.\nsys.path.append(os.path.join(os.path.dirname(os.path.dirname(__file__)),'protobuf'))\n\nfrom proto import status_pb2\nfrom proto import statusservice_pb2_grpc\n\n\n\n\nclass StatusSerivceServicer(statusservice_pb2_grpc.StatusServiceServicer):\n \"\"\"Provides methods that implement functionality of route guide server.\"\"\"\n\n def __init__(self):\n print(\"initializing status service\")\n\n def GetStatus(self, request, context):\n print(\"Got a status!\")\n\ndef run():\n\n server = grpc.server(futures.ThreadPoolExecutor(max_workers=10))\n statusservice_pb2_grpc.add_StatusServiceServicer_to_server(\n StatusSerivceServicer(), server)\n server.add_insecure_port('[::]:50051')\n server.start()\n server.wait_for_termination()\n\nif __name__ == '__main__':\n run()"
},
{
"alpha_fraction": 0.6930232644081116,
"alphanum_fraction": 0.6930232644081116,
"avg_line_length": 15.538461685180664,
"blob_id": "4b28027294c2d6f627c6b1889932cc44743a5cec",
"content_id": "8c2e4c473edbbbbc92ad285f8fedb605fb97cbec",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 215,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 13,
"path": "/cppclient/CMakeLists.txt",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "find_package(Threads)\n\nset(SOURCES\n src/main.cpp\n )\n\nsource_group(TREE ${CMAKE_CURRENT_SOURCE_DIR} FILES ${SOURCES})\n\nadd_executable(client ${SOURCES})\ntarget_link_libraries(client\n PRIVATE\n proto\n )\n"
},
{
"alpha_fraction": 0.7560659646987915,
"alphanum_fraction": 0.758288562297821,
"avg_line_length": 69.10389709472656,
"blob_id": "e78f3a3e2efdecdb1589fef519627dab93a72734",
"content_id": "5b76bf666818a10b0d79abb33cc7226838da261e",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5399,
"license_type": "permissive",
"max_line_length": 768,
"num_lines": 77,
"path": "/README.md",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "\n# grpcCppPythonBoilerplate\n\n## purpose\n\nWhat is my purpose? You don't want to know, but the purpose of this repo is to illustrate one way of using gRPC and protobuf to build a client and server in c++. It also has a python client that can hit that server just like the c++ client does. A few weeks ago I was like, \"I really need to learn me some modern c++\" and when I got started I tried to think of something to build. I couldn't think of anything good so I just started raw dogging some sockets. That got old real quick so I did some crap with [asio](https://think-async.com/Asio/) which was better but not awesome. While digging for answers I kept coming across people praising [protobuf](https://developers.google.com/protocol-buffers) and [gRPC](https://grpc.io/) so I figued I should give them a shot.\n\nWhile doing all this, I found myself fighting a lot with [cmake](https://cmake.org/) because I really have no idea what it is. In fact, only yesterday I learned that cmake just makes the makefiles and you still have to use make (I was using an IDE which did all the making out on my behalf. (Not going to lie, it is way better doing it manually yourself. Give it a shot, you can thank me later.)) The point here is that, hopefully, this project represents one way you can use cmake to generate your protobuf source files (or whatever they're called) and the gRPC service and also build some projects that use those. Of course, I learned how to do this yesterday so, you know, it probably ain't right.\n\nTo wrap this mess up, I think this is a decent boilerplate project that you could copy, add your own probobuf and gRPC specs, use them in a client/server demo, and build without too much trouble. Hopefully I will think of something useful to build using this and, you know, build it with some of that post modern c++ style.\n\n## building and getting started\n\nI have no idea if you will have any luck bulding and running this project. I can say that I'm doing this on a clapped out thinkpad running ubuntu with who knows what installed on it. I also know that I had to install a few extra things to get this project off the ground. I also know that over the past few weeks I have installed a ton of crap. So, I'm not 100% sure what you'll need.\n\n> **if I am missing something, please update this readme and do a PR. someone somewhere would really appreciate it.**\n\nThis project uses cmake to build the protobuf definitions for c++ and python and also to build the c++ client and server. I think I got that working by doing the things here (https://cmake.org/install/)\n\nOh, and hey, listen:\n\n> **Part of the cmake file in the protobuf directory (At this time) has a hard-coded path to the grpc_python_plugin executable on my machine. You, of course, are going to have to change that to get it to work on your machine. Unless your name is jordan and you installed grpc in ~/.local. If you did... sup twinsie!??!**\n\none note on that, i just read on some blog post `One small wrinkle I ran into is that you also have to make install the protobuf library (pulled in as a Git submodule by the gRPC checkout process). Even though gRPC's Makefile compiles it, it doesn't install it.` so maybe if I installed the protobuf lib that came with gRCP things would be easier? you should try it and do a PR.\n\ninstall gRPC locally, i have it at ~/.local/ because I followed these instructions exactly (https://grpc.io/docs/languages/cpp/quickstart/)\n\nI already had python3 on my machine so I did this\n\n`pip3 install --upgrade protobuf`\n\n`pip3 install grpcio-tools`\n\n`pip3 install googleapis-common-protos`\n\n\nAnd THEN, I decided I wanted to be able to pass arguments to the apps and have config files. I decided to use boost::program_options. To get that to work (and make it so you can compile this mess) you have to install boost. On my machine, i downloaded the tar file from boost, unziped (i know) it to ~/.local and had all kinds of trouble getting cmake to see it. WELP... you have to build it. so, I did that by doing bootstrap.sh and then ./b2 - after that was done it just worked.\n\nAnd THEN, I decided I wanted logging. So, I did this in my ~/.local directory:\n$ git clone https://github.com/gabime/spdlog.git\n$ cd spdlog && mkdir build && cd build\n$ cmake .. && make -j\nand then updated the cmake file to use it.\nbut that didn't work because when you make spdlog it doesn't install it. Since I didn't specify a build prefix when I did the initial cmake, it wanted to install it to /user/local... which, i was like... this is fine so I ran\nsudo make install\nand that installed it to /usr/local/include and /usr/local/lib\n\nHopefully you can just make the project by doing this:\n\nto make the project\n`cmake -DCMAKE_FIND_PACKAGE_PREFER_CONFIG=TRUE`\n\n`make`\n\nDid it build? Of course! let's run these things. You'll need a few terminals. Not to humblebrag, but I use a few tmux panes.\n\n`cd cppserver`\n\n`./server`\n\nnew terminal:\n`cd cppclient`\n\n`./client`\n\nnew terminal:\n`cd pythonclient`\n\n`python3 main.py`\n\nThe output for those programs is nothing exciting, but it is proof that you can get processes to talk to each other by sending protobuf message to each other via gRCP. yay.\n\n# notes about the python client\nThe python client is a crappy example, I think. I'm not 100% happy about the protobuf import situation. Seems real janky.\n\n\n# Thanks\nInspired by https://github.com/faaxm/exmpl-cmake-grpc\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 20.350000381469727,
"blob_id": "913da882b5af99728d117ab878d0fdd6b587334f",
"content_id": "c8534d36df5c80bfd05970929b9c19aeb2fce39b",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 427,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 20,
"path": "/cppserver/CMakeLists.txt",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "find_package(Threads)\n\n\nfind_package(Boost COMPONENTS program_options REQUIRED)\nfind_package(spdlog REQUIRED)\n\nset(SOURCES\n src/main.cpp\n )\n\nsource_group(TREE ${CMAKE_CURRENT_SOURCE_DIR} FILES ${SOURCES})\n\nadd_executable(server ${SOURCES})\n#target_include_directories( server PRIVATE ${Boost_INCLUDE_DIR})\ntarget_link_libraries(server\n PRIVATE\n Boost::program_options\n spdlog::spdlog\n proto\n )\n"
},
{
"alpha_fraction": 0.760378360748291,
"alphanum_fraction": 0.7666841745376587,
"avg_line_length": 41.28888702392578,
"blob_id": "e5327b8f8880f50588c43a1a8e65d75e8cf07e67",
"content_id": "3fcc3af27df24b41720b97c8a9c8d112f05d2905",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 1903,
"license_type": "permissive",
"max_line_length": 155,
"num_lines": 45,
"path": "/protobuf/CMakeLists.txt",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "find_package(protobuf CONFIG REQUIRED)\nfind_package(gRPC CONFIG REQUIRED)\nfind_package(Threads)\n\nset(PROTO_FILES\n proto/status.proto\n proto/statusservice.proto\n )\n\nadd_library(proto ${PROTO_FILES})\ntarget_link_libraries(proto\n PUBLIC\n protobuf::libprotobuf\n gRPC::grpc\n gRPC::grpc++\n )\ntarget_include_directories(proto PUBLIC ${CMAKE_CURRENT_BINARY_DIR})\n\nget_target_property(grpc_cpp_plugin_location gRPC::grpc_cpp_plugin LOCATION)\nprotobuf_generate(TARGET proto LANGUAGE cpp)\nprotobuf_generate(TARGET proto LANGUAGE grpc GENERATE_EXTENSIONS .grpc.pb.h .grpc.pb.cc PLUGIN \"protoc-gen-grpc=${grpc_cpp_plugin_location}\")\nprotobuf_generate(TARGET proto LANGUAGE python)\n# if you have errors here, look at https://stackoverflow.com/questions/34713861/python-grpc-protobuf-stubs-generation-issue-grpc-out-protoc-gen-grpc-plugin\n# obviously, you're going to have to change the following line to get this to work on your system\nprotobuf_generate(TARGET proto LANGUAGE grpc GENERATE_EXTENSIONS .py PLUGIN \"protoc-gen-grpc=/home/jordan/.local/bin/grpc_python_plugin\")\n\n# I can't figure out how to use protobuf_generate for grpc python files\n\n# For that python command, i think you can reidrect the python files somehwere else using something like this example but I'm not sure I want to\n# set(PROTO_SOURCE_DIR ${CMAKE_CURRENT_SOURCE_DIR}/definitions)\n#set(PROTOC_OUTPUT_DIR ${CMAKE_CURRENT_BINARY_DIR})\n#\n#protobuf_generate(LANGUAGE python\n# PROTOS ${PROTO_SOURCE_DIR}/TemperatureTagGroup.proto\n# ${THINGAPI_INCLUDE_DIR}/adlinktech/datariver/descriptor.proto\n# OUT_VAR PB_FILES\n# PROTOC_OUT_DIR ${PROTOC_OUTPUT_DIR}\n#)\n\n\n# if that above doesn't generate the python you may have to\n# sudo apt install python3-pip\n# pip3 install --upgrade protobuf\n# pip3 install grpcio-tools\n# python3 -m grpc_tools.protoc -I. --python_out=. --grpc_python_out=. ./proto/statusservice.proto\n"
},
{
"alpha_fraction": 0.7084308862686157,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 30.66666603088379,
"blob_id": "e499f2e979ba82cc886e1f69c5b5c52ed3dbf321",
"content_id": "d0a6f2adf9cd7a8f97885d1e0e918c76f12d83c3",
"detected_licenses": [
"MIT-0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 854,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 27,
"path": "/cppclient/src/main.cpp",
"repo_name": "jordan52/grpcCppPythonBoilerplate",
"src_encoding": "UTF-8",
"text": "#include <proto/status.pb.h>\n#include <proto/statusservice.grpc.pb.h>\n\n#include <grpc/grpc.h>\n#include <grpcpp/create_channel.h>\n\n#include <iostream>\n\n\nint main(int argc, char* argv[]) {\n\n\n protoboilerplate::StatusRequest statusRequest;\n protoboilerplate::StatusResponse statusResponse;\n\n statusRequest.set_name(\"cppclient\");\n\n auto channel = grpc::CreateChannel(\"localhost:50051\", grpc::InsecureChannelCredentials());\n std::unique_ptr<protoboilerplate::StatusService::Stub> stub = protoboilerplate::StatusService::NewStub(channel);\n grpc::ClientContext context; // need a new context per call... sort of.\n grpc::Status status = stub->GetStatus(&context, statusRequest, &statusResponse);\n\n std::cout << \"GRCP Status Service Show Me What You Got:\" << std::endl;\n std::cout << \"Name: \" << statusResponse.name() << std::endl;\n\n\n}"
}
] | 9 |
alinasuarez1/123prrrrrEACH
|
https://github.com/alinasuarez1/123prrrrrEACH
|
2de161cff24e36fc5eaaaf32bb1a23a5e6a13916
|
7eaa94052d473c46bf34d66e34256511e77880bb
|
978b13d78a4327f3f847a576c896e27d3e4e9ab7
|
refs/heads/master
| 2020-06-24T20:31:46.826532 | 2019-08-02T03:36:57 | 2019-08-02T03:36:57 | 199,079,190 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6684027910232544,
"alphanum_fraction": 0.6697916388511658,
"avg_line_length": 35.93589782714844,
"blob_id": "daf815d2c54218afb84160fe6d2d08237c6d36a0",
"content_id": "3f7b523c67cbe85682c20cca3f8ca4a3c21d9e6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2880,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 78,
"path": "/socialdata.py",
"repo_name": "alinasuarez1/123prrrrrEACH",
"src_encoding": "UTF-8",
"text": "from socialmodels import UserProfile\nfrom socialmodels import Video\n\ndef save_profile(email, firstname, lastname, age, description, nationality, location, language, nickname, profilepic):\n p = get_user_profile(email)\n if p:\n p.firstname = firstname\n p.lastname = lastname\n p.age = age\n p.description = description\n p.nationality = nationality\n p.location = location\n p.language = language\n p.nickname = nickname\n p.profilepic = profilepic\n else:\n p = UserProfile(email = email, firstname= firstname, lastname=lastname, description=description, nationality=nationality, location=location, language=language, nickname=nickname ,profilepic=profilepic)\n p.put() #saves it in the database\n\ndef get_user_profile(email):\n q = UserProfile.query(UserProfile.email == email)\n results = q.fetch(1)\n for profile in results:\n return profile\n return None\n\ndef get_profile_by_name(firstname):\n q = UserProfile.query(UserProfile.firstname == firstname)\n results = q.fetch(1)\n for profile in results:\n return profile\n return None\n\ndef get_recent_profiles(): #Can use on the feed, to return profiles/videos of recent users\n q = UserProfile.query().order(-UserProfile.last_update)\n return q.fetch(50)\n\ndef get_videos(var):\n v = Video.query().order(-Video.last_update)\n return v.fetch(var)\n\ndef upload_video(email ,url, description, language, title):\n profile = get_user_profile(email)\n \n v = Video(email = email, title= title, description=description, language=language, url=url)\n var = v.put()\n profile.videos.append(var)\n profile.put()\n\ndef follow_user(emailfollower, emailfollowing):\n if emailfollower != emailfollowing:\n ufollower = get_user_profile(emailfollower) #grabs profile of whoever followed\n ufollowing = get_user_profile(emailfollowing) #grabs profile of whoever is being followed\n print(\"follow_user before if\")\n print(ufollower)\n print (ufollowing)\n if ufollower and ufollowing:\n print(\"profiles exist on followuser\")\n if not(ufollowing.key.urlsafe()in ufollower.following):\n print(\"it is still going, somehow...\")\n ufollower.following.append(ufollowing.key.urlsafe())\n ufollowing.followers.append(ufollower.key.urlsafe())\n ufollower.put()\n ufollowing.put()\n else:\n print(\"you can't follow yourself dummy\")\n\ndef get_recent_followed_profiles(email):\n user_profile = get_user_profile(email)\n followed_ids = set()\n for followed in user_profile.following:\n followed_ids.add(followed)\n profiles = get_recent_profiles()\n result = []\n for profile in profiles:\n if profile.key.urlsafe() in followed_ids:\n result.append(profile)\n return result"
},
{
"alpha_fraction": 0.6972111463546753,
"alphanum_fraction": 0.6972111463546753,
"avg_line_length": 30.375,
"blob_id": "206ac39c1cc28e1596f37e85130e7c8e37a4b2ff",
"content_id": "7e1c88b8f2f7e716579a4c3ba629422fd7fd2a7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1004,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 32,
"path": "/socialmodels.py",
"repo_name": "alinasuarez1/123prrrrrEACH",
"src_encoding": "UTF-8",
"text": "from google.appengine.ext import ndb\n\n\n\nclass Video(ndb.Model):\n url = ndb.StringProperty()\n title = ndb.StringProperty()\n description = ndb.StringProperty()\n language = ndb.StringProperty()\n last_update = ndb.DateTimeProperty(auto_now=True)\n email = ndb.StringProperty()\n\n\nclass UserProfile(ndb.Model):\n followers = ndb.StringProperty(repeated=True)\n following = ndb.StringProperty(repeated=True)\n firstname = ndb.StringProperty()\n lastname = ndb.StringProperty()\n videos = ndb.KeyProperty(Video, repeated=True)\n age = ndb.StringProperty()\n nickname = ndb.StringProperty()\n email = ndb.StringProperty()\n description = ndb.TextProperty()\n location = ndb.StringProperty()\n language = ndb.StringProperty()\n nationality = ndb.StringProperty()\n profilepic = ndb.BlobKeyProperty()\n last_update = ndb.DateTimeProperty(auto_now=True) #Sets property to the time it is updated\n # \"Age\"\n # \"loaction\"\n # \"language\"\n # \"speaker = False/True\"\n"
},
{
"alpha_fraction": 0.8684210777282715,
"alphanum_fraction": 0.8684210777282715,
"avg_line_length": 36,
"blob_id": "c5fce9dd9301ac436bbcff75bbccb41bbf5482ca",
"content_id": "313bc9d170d347c427f5c69737087c40baa9a306",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 38,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 1,
"path": "/text/profileFeed.py",
"repo_name": "alinasuarez1/123prrrrrEACH",
"src_encoding": "UTF-8",
"text": "from socialmodels import UserProfile\n\n"
},
{
"alpha_fraction": 0.4000000059604645,
"alphanum_fraction": 0.4124223589897156,
"avg_line_length": 28.851852416992188,
"blob_id": "08ba7f2ee6897cb09afdfabba7864ad88b653588",
"content_id": "816e83e674b6e2a3c0e5807f6df8c7fbba0ca305",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 805,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 27,
"path": "/templates/feed.html",
"repo_name": "alinasuarez1/123prrrrrEACH",
"src_encoding": "UTF-8",
"text": "<html>\n <head>\n <link rel=\"stylesheet\" href=\"/static/homepage.css\">\n </head>\n <body>\n <br>\n <h1>Feed</h1>\n {% for video in videos %}\n <div class=\"main_video_div\">\n \n <div id=\"vid_iframe\">\n <iframe width=\"420\" height=\"250\"\n src=\"{{video.url}}\" allowfullscreen=\"true\">\n </iframe> \n </div>\n\n <div id=\"vid_info\">\n <h2>{{video.title}}</h2>\n <a href=\"/profileview/{{video.email}}\" id=\"profile-links\">By user:{{video.firstname}} {{video.lastname}}</a>\n <p id=\"vid_description\">{{video.description}}</p>\n </div>\n </div>\n <br>\n {% endfor %}\n \n </body>\n</body>"
},
{
"alpha_fraction": 0.7027027010917664,
"alphanum_fraction": 0.7837837934494019,
"avg_line_length": 17.5,
"blob_id": "0148026b25d0390b711b4a97c814e2fed9467bf0",
"content_id": "647f67a0d5cb44880bb0d54d3a9f6cbcde472782",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 37,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 2,
"path": "/text/README.md",
"repo_name": "alinasuarez1/123prrrrrEACH",
"src_encoding": "UTF-8",
"text": "# 123prrrrrEACH\nLet's get preaching!\n"
}
] | 5 |
zerju/route_optimization_ga
|
https://github.com/zerju/route_optimization_ga
|
46f7e3810557661bea945b50e647cc8cd1785861
|
d114e9c39928ecd107540a3e07c7e3461df040ec
|
06d11bebff0081df728ced1801aeffc5ebba0399
|
refs/heads/master
| 2020-12-28T03:24:48.783098 | 2020-02-04T09:27:56 | 2020-02-04T09:27:56 | 238,164,604 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6701260209083557,
"alphanum_fraction": 0.7590808272361755,
"avg_line_length": 63.28571319580078,
"blob_id": "a6ff343d0e4a04972e66db3660feab7e956dfd50",
"content_id": "963e57534985c38feac8a3102537f570616d4371",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 21,
"path": "/README.md",
"repo_name": "zerju/route_optimization_ga",
"src_encoding": "UTF-8",
"text": "# Route Optimizing with Genetic Algoritms\n\nOptimizing the route from one end of the map to the other end using Python as the programming language. Below you can see images of the optimizations happening:\n\n### Current iteration is 0 and the best steps so far are 26 with distance of 13.583345\n\n\n### Current iteration is 1 and the best steps so far are 14 with distance of 6.611847\n\n\n### Current iteration is 2 and the best steps so far are 4 with distance of 2.107514\n\n\n### Current iteration is 3 and the best steps so far are 4 with distance of 1.881516\n\n\n### Current iteration is 6 and the best steps so far are 3 with distance of 1.168557\n\n\n### Current iteration is 7 and the best steps so far are 3 with distance of 0.168198\n"
},
{
"alpha_fraction": 0.5568885207176208,
"alphanum_fraction": 0.5756579041481018,
"avg_line_length": 26.63101577758789,
"blob_id": "573e52e8fe41643cef844234ce07825b45ebf776",
"content_id": "8d2c0babcb499ff0e4b330bbc75dff2bb4b91199",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5168,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 187,
"path": "/route_optimization.py",
"repo_name": "zerju/route_optimization_ga",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport random\nimport copy\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n\ndef map_init(chance_of_zeros, size):\n our_map = np.zeros((size, size))\n for i in range(0, size):\n for j in range(0, i):\n if random.random() > chance_of_zeros:\n our_map[i][j] = random.random()\n our_map[j][i] = our_map[i][j]\n\n return our_map\n\n\ndef generate_starting_paths(size, our_map):\n paths = []\n for i in range(0, size):\n paths.append(generate_new_path(our_map))\n\n return paths\n\n\ndef fitnes(path, our_map):\n the_score = 0\n for i in range(1, len(path)):\n if (our_map[path[i - 1]][path[i]] == 0) and i != len(our_map) - 1:\n print(\"Something went wrong with our path\")\n the_score = the_score + our_map[path[i - 1]][path[i]]\n\n return the_score\n\n\ndef crossing(a, b):\n elements_in_common = set(a) & set(b)\n if len(elements_in_common) == 2:\n return a, b\n else:\n elements_in_common.remove(0)\n elements_in_common.remove(max(a))\n value = random.sample(elements_in_common, 1)\n\n cut_a = np.random.choice(np.where(np.isin(a, value))[0])\n cut_b = np.random.choice(np.where(np.isin(b, value))[0])\n\n new_a1 = copy.deepcopy(a[0:cut_a])\n new_a2 = copy.deepcopy(b[cut_b:])\n\n new_b1 = copy.deepcopy(b[0:cut_b])\n new_b2 = copy.deepcopy(a[cut_a:])\n\n new_a = np.append(new_a1, new_a2)\n new_b = np.append(new_b1, new_b2)\n\n return new_a, new_b\n\n\ndef mutate(path, probability, our_map):\n new_path = copy.deepcopy(path)\n for i in range(1, len(new_path)):\n if random.random() < probability:\n should_go = True\n while should_go:\n\n possible_values = np.nonzero(our_map[new_path[i - 1]])\n selected_values = random.randint(0, len(possible_values[0]) - 1)\n np.append(new_path, possible_values[0][selected_values])\n\n if new_path[i] == len(our_map) - 1:\n should_go = False\n else:\n i += 1\n\n return new_path\n\n\ndef generate_new_path(our_map):\n size_of_map = len(our_map)\n path = np.zeros(1, dtype=int)\n should_go = True\n i = 1\n\n while should_go:\n\n possible_values = np.nonzero(our_map[path[i - 1]])\n selected_values = random.randint(0, len(possible_values[0]) - 1)\n path = np.append(path, possible_values[0][selected_values])\n\n if path[i] == size_of_map - 1:\n should_go = False\n else:\n i += 1\n\n return path\n\n\ndef get_population_score(paths, our_map):\n scores = []\n for i in range(0, len(paths)):\n scores += [fitnes(paths[i], our_map)]\n\n return scores\n\n\ndef choose_paths_for_crossing(scores):\n array = np.array(scores)\n temp = array.argsort()\n ranks = np.empty_like(temp)\n ranks[temp] = np.arange(len(array))\n\n fitnes = [len(ranks) - x for x in ranks]\n\n aggregate_scores = copy.deepcopy(fitnes)\n\n for i in range(1, len(aggregate_scores)):\n aggregate_scores[i] = fitnes[i] + aggregate_scores[i - 1]\n\n probability = [x / aggregate_scores[-1] for x in aggregate_scores]\n\n rand = random.random()\n\n for i in range(0, len(probability)):\n if rand < probability[i]:\n return i\n\n\ndef main():\n num_of_zeroes = 0.7\n size_of_map = 200\n size_of_population = 30\n num_of_iterations = 100\n num_of_pairs = 9\n num_of_winners_to_keep = 2\n\n our_map = map_init(num_of_zeroes, size_of_map)\n\n paths = generate_starting_paths(size_of_population, our_map)\n\n final_distance = 1000000\n\n for i in range(0, num_of_iterations):\n new_paths = []\n\n scores = get_population_score(paths, our_map)\n\n best = paths[np.argmin(scores)]\n num_of_moves = len(best)\n distance = fitnes(best, our_map)\n\n if distance != final_distance:\n print('Current iteration is %i and the best steps so far are %i with distance of %f' % (i, num_of_moves, distance))\n draw(our_map, best, i)\n\n for j in range(0, num_of_pairs):\n new_1, new_2 = crossing(paths[choose_paths_for_crossing(scores)], paths[choose_paths_for_crossing(scores)])\n new_paths = new_paths + [new_1, new_2]\n\n for j in range(0, len(new_paths)):\n new_paths[j] = np.copy(mutate(new_paths[j], 0.05, our_map))\n\n new_paths += [paths[np.argmin(scores)]]\n for j in range(1, num_of_winners_to_keep):\n keep = choose_paths_for_crossing(scores)\n new_paths += [paths[keep]]\n\n while len(new_paths) < size_of_population:\n new_paths += [generate_new_path(our_map)]\n\n paths = copy.deepcopy(new_paths)\n\n final_distance = distance\n\n\ndef draw(our_map, path, num_of_iteration):\n sns.heatmap(our_map)\n\n x = [0.5] + [x + 0.5 for x in path[0:len(path) - 1]] + [len(our_map) - 0.5]\n y = [0.5] + [x + 0.5 for x in path[1:len(path)]] + [len(our_map) - 0.5]\n\n plt.plot(x, y, marker='o', linewidth=4, markersize=12, linestyle=\"-\", color='white')\n plt.savefig('images/plot_%i.png' % (num_of_iteration), dpi=300)\n plt.show()\n\nmain()\n\n"
}
] | 2 |
marcusvinysilva/jokenpo
|
https://github.com/marcusvinysilva/jokenpo
|
cfbb0d3bd7f948770610831e0c971833b2f9a523
|
ce6b06166c07e918e77ff9bb2a1d530e01a78b56
|
a6b5f418f206f7ebb9b0d59150a62b84c0ffb44d
|
refs/heads/main
| 2023-07-18T09:05:31.845132 | 2021-09-03T15:02:40 | 2021-09-03T15:02:40 | 387,938,155 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7869918942451477,
"alphanum_fraction": 0.7869918942451477,
"avg_line_length": 60.5,
"blob_id": "f3b89f13af3b6c080a565e1b0fe8edd106ee82db",
"content_id": "1e788250a4763415ec0a904d6bb61749160d591c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 10,
"path": "/README.md",
"repo_name": "marcusvinysilva/jokenpo",
"src_encoding": "UTF-8",
"text": "# Jokenpô\n\nUtilizando os conceitos aprendidos até estruturas de repetição, crie um programa que jogue pedra, papel e tesoura (Jokenpô) com você. O programa tem que:\n\n- Permitir que eu decida quantas rodadas iremos fazer;\n- Ler a minha escolha (Pedra, papel ou tesoura);\n- Decidir de forma aleatória a decisão do computador;\n- Mostrar quantas rodadas cada jogador ganhou;\n- Determinar quem foi o grande campeão de acordo com a quantidade de vitórias de cada um (computador e jogador);\n- Perguntar se o Jogador quer jogar novamente, se sim inicie volte a escolha de quantidade de rodadas, se não finalize o programa.\n"
},
{
"alpha_fraction": 0.5173364877700806,
"alphanum_fraction": 0.5303388237953186,
"avg_line_length": 37.07692337036133,
"blob_id": "59b9c96178af6cd6751595d99d41e22fdb659c56",
"content_id": "a61b19e533adcdda2798e2e6c0a3b59111fa4b51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2554,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 65,
"path": "/jokenpo.py",
"repo_name": "marcusvinysilva/jokenpo",
"src_encoding": "UTF-8",
"text": "from random import randint\r\n\r\njokenpo = ['PEDRA', 'PAPEL', 'TESOURA']\r\n\r\nwhile True:\r\n print('='*29)\r\n print('-'*10, 'JOKENPÔ', '-'*10)\r\n print('='*29)\r\n vitorias_jogador = 0\r\n vitorias_computador = 0\r\n qtd_rodadas = int(input('Quantas rodadas iremos jogar? '))\r\n for i in range(qtd_rodadas):\r\n print()\r\n escolha_jogador = int(input('[0] PEDRA\\n[1] PAPEL\\n[2] TESOURA\\nQual é a sua escolha? '))\r\n escolha_computador = randint(0,2)\r\n print()\r\n print(f'O computador escolheu {jokenpo[escolha_computador]}')\r\n print(f'Você escolheu {jokenpo[escolha_jogador]}')\r\n print()\r\n if escolha_computador == 0:\r\n if escolha_jogador == 0:\r\n print('EMPATOU')\r\n elif escolha_jogador == 1:\r\n print('VOCÊ VENCEU')\r\n vitorias_jogador += 1\r\n elif escolha_jogador == 2:\r\n print('COMPUTADOR VENCEU')\r\n vitorias_computador += 1\r\n else:\r\n print('ESCOLHA INVÁLIDA')\r\n elif escolha_computador == 1:\r\n if escolha_jogador == 0:\r\n print('COMPUTADOR VENCEU')\r\n vitorias_computador += 1 \r\n elif escolha_jogador == 1:\r\n print('EMPATOU')\r\n elif escolha_jogador == 2:\r\n print('VOCÊ VENCEU')\r\n vitorias_jogador += 1\r\n else:\r\n print('ESCOLHA INVÁLIDA')\r\n elif escolha_computador == 2:\r\n if escolha_jogador == 0:\r\n print('VOCÊ VENCEU')\r\n vitorias_jogador += 1 \r\n elif escolha_jogador == 1:\r\n print('COMPUTADOR VENCEU')\r\n vitorias_computador += 1\r\n elif escolha_jogador == 2:\r\n print('EMPATOU')\r\n else:\r\n print('ESCOLHA INVÁLIDA')\r\n print()\r\n print(f'O computador venceu {vitorias_computador} rodadas.')\r\n print(f'Você venceu {vitorias_jogador} rodadas.')\r\n if vitorias_jogador > vitorias_computador:\r\n print('\\nO grande campeão dessa partida foi VOCÊ')\r\n elif vitorias_computador > vitorias_jogador:\r\n print('\\nO grande campeão dessa partida foi o COMPUTADOR')\r\n elif vitorias_jogador == vitorias_computador:\r\n print('\\nNão tivemos um campeão nessa rodada. Jogue Novamente!')\r\n continuar = input('\\nVamos jogar novamente? [S/N]: ').upper()\r\n if continuar == 'N':\r\n break\r\nprint('\\nVocê finalizou o programa.')"
}
] | 2 |
alijkhalil/video_processing_networks
|
https://github.com/alijkhalil/video_processing_networks
|
13666840e1104b92cf83733182d870eadb2c4b9c
|
5801b223d81e086c1e0225fad2a66a47177b869a
|
7099fe0930f1605c19b4e6374d84aa7bb103892e
|
refs/heads/master
| 2021-04-30T10:42:33.930305 | 2019-03-28T09:17:49 | 2019-03-31T20:29:28 | 121,340,333 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7997903823852539,
"alphanum_fraction": 0.7997903823852539,
"avg_line_length": 51.94444274902344,
"blob_id": "c2e1a82d298dee7d1f68c27a4be961c1f466e086",
"content_id": "6cf0bf702fdb9349268eced5d0c824e521ed2440",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 954,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 18,
"path": "/README.md",
"repo_name": "alijkhalil/video_processing_networks",
"src_encoding": "UTF-8",
"text": "This repo contains only one of a several custom video processing \nneural nets. The one available here is a custom version of \nthe Productive Corrective Network (PCN). (It's model based on \ndifferential image processing and Kalman filters.) Other video \nprocessing networks may be released at a later point.\n\nAlthough this repo does not contain any working examples with \nthis particular PCN model, you can find an example using my NBA \nplay-by-play dataset and Horovod (for distributed training) in \nthe 'distrib_training_scripts' repository under the 'sample_train_scripts'\ndirectory.\n\nFinally, it should be noted that every video processing network \nfound in this repo is deliberately designed to consume a lot \nof GPU memory and therefore may only work on super end-high GPUs with \ntheir default parameters. However, every model can also be customized \n(using their respective constructors) to consume a much smaller memory \nfootprint if needed. "
},
{
"alpha_fraction": 0.519198477268219,
"alphanum_fraction": 0.5251783728599548,
"avg_line_length": 42.8757209777832,
"blob_id": "2bd4131bdfc98dc4b0e4eb41f8c199e5f06bb72a",
"content_id": "83b6c9795d8132664333c5fbbc0b92befc7aaed8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 38128,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 869,
"path": "/pcn/pcn.py",
"repo_name": "alijkhalil/video_processing_networks",
"src_encoding": "UTF-8",
"text": "# Import statements\nimport sys, os\nimport numpy as np\nimport tensorflow as tf\n\nfrom keras import backend as K\n\nfrom keras import activations\nfrom keras import constraints\nfrom keras import initializers\nfrom keras import regularizers\n\nfrom keras.models import Model, Sequential\nfrom keras.engine.topology import InputSpec, Layer\nfrom keras.layers import Input, Dense, Lambda, Add, Flatten\nfrom keras.layers.convolutional import Conv2D, SeparableConv2D\nfrom keras.layers import AveragePooling2D, GlobalAveragePooling2D\nfrom keras.layers import Recurrent, LSTM, GRU\nfrom keras.layers.normalization import BatchNormalization\nfrom keras.regularizers import l2\nfrom keras.legacy import interfaces\nfrom keras.layers.core import Activation\n\ndir_path = os.path.dirname(os.path.realpath(__file__))\nsys.path.append(dir_path + \"/../../\") # Assumes 'dl_utilities' is two directories up from this file\n\nfrom dl_utilities.layers import general as dl_layers # Requires 'sys.path.append' call above\nfrom dl_utilities.layers import pcn as pcn_layers # Requires 'sys.path.append' call above\n\n \n \n# Global variables\nGLOBAL_AVG_POOL_STR='global'\nDEFAULT_WEIGHT_DECAY=1E-4\n \nMODEL_STEM_INDEX = 0\nMODEL_NUM_STEM_CONV = 3\nMODEL_STATES_P_BLOCK = 2\n\nMIN_STEM_LAYER_CHAN=32\nMIN_NUM_BLOCKS=2\nMIN_FINAL_DENSE_LAYERS = 2\n\n\n\n# Simple helper to get current state index based on block index\ndef get_starting_state_index(block_index, time_steps_p_block):\n num_states = int(np.sum(time_steps_p_block[:block_index]))\n return num_states * MODEL_STATES_P_BLOCK\n \n# Function to get the new downsized logit dimension after a pooling operation \ndef get_downsized_dim(cur_dim, pool_dim_size):\n return int((cur_dim + pool_dim_size - 1) // pool_dim_size)\n \n \n# Function to get state shapes\ndef get_state_shapes(pcn_cell, input_shape): \n batch_size = input_shape[0]\n init_shape = (batch_size, ) + input_shape[2:]\n \n state_shapes = [ ]\n for i, num_channels in enumerate(pcn_cell.stem_plus_block_filters[:-1]):\n start_index = get_starting_state_index(i, pcn_cell.time_steps_p_block)\n end_index = get_starting_state_index(i+1, pcn_cell.time_steps_p_block)\n \n num_iters = end_index - start_index\n for j in range(num_iters):\n state_shapes.append(init_shape[:-1] + (num_channels, ))\n \n for pcn_block_i in pcn_cell.downsize_block_indices:\n cur_i = get_starting_state_index(pcn_block_i, pcn_cell.time_steps_p_block)\n \n if cur_i < pcn_cell.total_states:\n orig_shape = state_shapes[cur_i]\n h_val = get_downsized_dim(orig_shape[1], pcn_cell.downsize_values[pcn_block_i][0])\n w_val = get_downsized_dim(orig_shape[2], pcn_cell.downsize_values[pcn_block_i][1])\n \n for i in range(cur_i, pcn_cell.total_states):\n num_channels = state_shapes[i][-1]\n state_shapes[i] = (batch_size, h_val, w_val, num_channels)\n \n return state_shapes\n \n \n# Function for getting total logits in state space to understand memory imprint of model\ndef get_total_internal_state_logits(pcn_cell, input_shape): \n total_logits = 0\n \n state_shapes = get_state_shapes(pcn_cell, input_shape)\n for cur_shape in state_shapes: \n additional_logits = 1\n for i in range(len(cur_shape)):\n if cur_shape[i] is not None:\n additional_logits *= cur_shape[i]\n \n total_logits += additional_logits\n\n return total_logits\n\n \n \n# Predictive Corrective Network definition\nclass PCN_Cell(Recurrent):\n \"\"\"\n The PCN cell represents the core logic for the Predictive Corrective Network \n model. At a high level, the model can be expressed as an RNN with a receptive \n field across N time steps. It is based on the underlying theory of linear \n dynamic systems for modeling time series involved in Kalman Filters. \n Ultimately, the model aims to predict actions in a sequence of individual frames \n in a video. However, the model can be refactored to either provide a video-level \n label or provide a video-level embedding by fine-tuning the PCN parameters. \n \n # Issues:\n -Instability of training RNN's on Keras\n -particularly with high dropout rate\n -size of model and inability to train larger batches/time-series\n -requires extensive computing powers (e.g. many high-end GPUs)\n -may require 3D average pooling to video before passing to the PCN cell\n \n # Arguments\n output_units: Positive integer\n -dimensionality of the output state space\n stem_plus_block_filters: List of greater than MIN_NUM_BLOCKS integers\n -output filters for the last upscaling convolution in each PCN \"block\" (plus the initial stem)\n -first value must be at least 32\n time_steps_p_block: List of at least MIN_NUM_BLOCKS non-negative integers\n -how many time steps back should skip connections be for each block\n -skips that are too many time steps back, esp in early blocks, will use lots of memory\n downsize_block_indices: List of increasing, non-negative integers\n -represents indices of PCN \"blocks\" requiring an preliminary 2x2 resolution downsize\n -values should be less than the number of PCN blocks (since the last block is handled uniquely)\n downsize_values: List of tuples for downsizing each PCN block in the 'downsize_block_indices' list\n -the list should be the exact same length as the 'downsize_block_indices' list\n -will apply downsizing tuples in order (from lowest to highest index in 'downsize_block_indices' list)\n final_downsize_approach: One of the following downsizing approaches for post-processing the last PCN block\n -None: no downsizing after the last PCN block\n -'global': apply a global pool to reduce spatial dimensions to 1x1\n -tuple: an average pooling with that pool size (and the same stride size)\n num_conv_p_kalman_filter: Positive integer\n -number of separable convolution operations for each Kalman Filter function\n num_res_connect_p_block: Positive integer\n -number of residual blocks for post-processing after each \"block\" in model\n num_final_dense_layers: Positive integer\n -number of dense layers to conclude the model\n frame_level_output: a Boolean value\n -flag to return each frame's output or only final output embedding at last time step\n \n # References\n - [PCN] (https://arxiv.org/pdf/1704.03615.pdf)\n \"\"\"\n \n @interfaces.legacy_recurrent_support\n def __init__(self, \n output_units, \n stem_plus_block_filters=[128, 256, 512, 1024],\n time_steps_p_block=[0, 1, 3],\n downsize_block_indices=[0, 1, 2],\n downsize_values=[(8,8), (5,5), (2,2)],\n final_downsize_approach=GLOBAL_AVG_POOL_STR, \n num_conv_p_kalman_filter=2,\n num_res_connect_p_block=4,\n num_final_dense_layers=3,\n final_dropout=0.1,\n frame_level_output=False,\n **kwargs):\n \n super(PCN_Cell, self).__init__(**kwargs)\n \n # Perform checks on inputs\n if output_units is None or output_units < 0:\n raise ValueError(\"The 'output_units' variable must be a positive integer.\")\n \n if type(stem_plus_block_filters) is not list: \n raise ValueError(\"The 'stem_plus_block_filters' variable must be a list.\") \n \n if MIN_NUM_BLOCKS >= len(stem_plus_block_filters):\n raise ValueError(\"The 'stem_plus_block_filters' list should contain greater than %d items.\" % MIN_NUM_BLOCKS)\n \n if len(stem_plus_block_filters) != (len(time_steps_p_block) + 1):\n raise ValueError(\"The 'time_steps_p_block' list should have one fewer element than the 'stem_plus_block_filters' list.\")\n \n prev_el = MIN_STEM_LAYER_CHAN\n for el in stem_plus_block_filters:\n if prev_el <= el:\n prev_el = el\n else: \n raise ValueError(\"The 'stem_plus_block_filters' element values must never \"\n \"decrease and start at a minimum of %d.\" % MIN_STEM_LAYER_CHAN) \n \n if type(downsize_block_indices) is not list: \n raise ValueError(\"The 'downsize_blocks' variable must be a list.\")\n \n prev_el = -1\n for el in downsize_block_indices:\n if prev_el < el:\n prev_el = el\n else:\n raise ValueError(\"The 'downsize_block_indices' list values must be increasing.\") \n \n if len(np.unique(downsize_block_indices)) != len(downsize_block_indices):\n raise ValueError(\"The 'downsize_blocks' list should not have duplicate values.\")\n \n if type(downsize_values) is not list: \n raise ValueError(\"The 'downsize_values' variable must be a list.\")\n \n if len((downsize_values)) != len(downsize_block_indices):\n raise ValueError(\"The 'downsize_values' list should be the same size as the 'downsize_block_indices' list.\")\n \n if num_final_dense_layers < MIN_FINAL_DENSE_LAYERS:\n raise ValueError(\"The 'num_final_dense_layers' value should be at least %d.\" % MIN_FINAL_DENSE_LAYERS)\n \n for el in downsize_block_indices:\n if el >= len(time_steps_p_block) or el < 0:\n raise ValueError(\"The 'downsize_blocks' indicies should be a maximum value of %d.\" % \n len(time_steps_p_block))\n \n if (final_downsize_approach is not None and \n final_downsize_approach != GLOBAL_AVG_POOL_STR and \n final_downsize_approach is not tuple):\n raise ValueError(\"The 'final_downsize_approach' variable must be either be \"\n \"None, a tuple, or %s.\" % GLOBAL_AVG_POOL_STR) \n \n \n # Assign member variables\n self.internal_layers = {}\n self.input_spec[0].ndim = 5\n \n self.output_units = output_units\n self.stem_plus_block_filters = stem_plus_block_filters\n self.model_num_blocks = len(time_steps_p_block)\n \n self.time_steps_p_block = np.array(time_steps_p_block)\n self.total_states = int(np.sum(self.time_steps_p_block) * MODEL_STATES_P_BLOCK)\n \n self.downsize_block_indices = downsize_block_indices\n self.final_downsize_approach = final_downsize_approach \n self.downsize_values = [ None ] * self.model_num_blocks\n for downsize_i, pcn_block_i in enumerate(downsize_block_indices):\n self.downsize_values[pcn_block_i] = downsize_values[downsize_i]\n \n self.num_conv_p_kalman_filter = num_conv_p_kalman_filter\n self.num_res_connect_p_block = num_res_connect_p_block\n self.num_final_dense_layers = num_final_dense_layers\n \n self.dropout = min(0.9, max(0., final_dropout))\n self.return_sequences = frame_level_output\n \n\n # Override to ensure that implementation does rely on Keras to have 'return_state' support\n def call(self, inputs, mask=None, initial_state=None, training=None):\n if initial_state is not None:\n if not isinstance(initial_state, (list, tuple)):\n initial_states = [initial_state]\n else:\n initial_states = list(initial_state)\n \n if isinstance(inputs, list):\n initial_states = inputs[1:]\n inputs = inputs[0]\n elif self.stateful:\n initial_states = self.states\n else:\n initial_states = self.get_initial_state(inputs)\n\n if len(initial_states) != len(self.states):\n raise ValueError('Layer has ' + str(len(self.states)) +\n ' states but was passed ' +\n str(len(initial_states)) +\n ' initial states.')\n \n input_shape = K.int_shape(inputs)\n if self.unroll and input_shape[1] is None:\n raise ValueError('Cannot unroll a RNN if the '\n 'time dimension is undefined. \\n'\n '- If using a Sequential model, '\n 'specify the time dimension by passing '\n 'an `input_shape` or `batch_input_shape` '\n 'argument to your first layer. If your '\n 'first layer is an Embedding, you can '\n 'also use the `input_length` argument.\\n'\n '- If using the functional API, specify '\n 'the time dimension by passing a `shape` '\n 'or `batch_shape` argument to your Input layer.')\n \n constants = self.get_constants(inputs, training=None)\n preprocessed_input = self.preprocess_input(inputs, training=None)\n last_output, outputs, states = K.rnn(self.step,\n preprocessed_input,\n initial_states,\n go_backwards=self.go_backwards,\n mask=mask,\n constants=constants,\n unroll=self.unroll,\n input_length=input_shape[1])\n \n if self.stateful:\n updates = []\n for i in range(len(states)):\n updates.append((self.states[i], states[i]))\n self.add_update(updates, inputs)\n\n if self.return_sequences:\n output = outputs\n else:\n output = last_output\n\n # Properly set learning phase\n if getattr(last_output, '_uses_learning_phase', False):\n output._uses_learning_phase = True\n\n if not isinstance(states, (list, tuple)):\n states = [states]\n else:\n states = list(states)\n \n # Return output and states combined (in a list) \n return [output] + states\n\n \n # No suppport for \"add_weight\" - instead use higher-level Layers and \"add_layer\" function\n def add_weight(self, shape, initializer,\n name=None,\n trainable=True,\n regularizer=None,\n constraint=None):\n \n raise ValueError(\"The 'add_weight' function is not allowed for this \" \\\n \"particular RNN layer. Use 'add_layer' function instead.\") \n \n \n # Layer functions\n def add_layer(self, layer, name, input_shape):\n self.internal_layers[name] = layer\n self.internal_layers[name].build(input_shape)\n \n \n def get_layer(self, name):\n return self.internal_layers[name]\n \n \n # Weight override function \n @property\n def trainable_weights(self):\n tmp_weights = []\n \n for i_layer in self.internal_layers.values():\n tmp_weights.extend(i_layer.trainable_weights)\n \n return tmp_weights\n\n @property\n def non_trainable_weights(self):\n tmp_weights = []\n \n for i_layer in self.internal_layers.values():\n tmp_weights.extend(i_layer.non_trainable_weights)\n \n return tmp_weights\n \n \n # Override generic RNN functions because states are unique for this cell\n def compute_output_shape(self, input_shape):\n if isinstance(input_shape, list):\n input_shape = input_shape[0]\n \n # Output shape\n batch_size = input_shape[0] \n if self.return_sequences:\n output_shape = (batch_size, input_shape[1], self.output_units)\n else:\n output_shape = (batch_size, self.output_units)\n\n # State shapes \n state_shape = [ ]\n for i_spec in self.state_spec:\n cur_dim = i_spec.shape\n state_shape.append((batch_size, ) + cur_dim[1:])\n \n # Return concatenation of the two shapes \n return [output_shape] + state_shape\n \n \n def get_initial_state(self, inputs):\n # Build an all-zero tensor of shape (samples, 1) \n initial_state = K.zeros_like(inputs) # (samples, timesteps, ) + img_dims\n initial_state = K.sum(initial_state, axis=(1, 2, 3, 4), keepdims=True) # (samples, 1, 1, 1, 1)\n initial_state = K.squeeze(initial_state, axis=-1) # (samples, 1, 1, 1)\n \n # Build zero-ed intermediate states by getting dimension of each state\n initial_states = []\n for i_spec in self.state_spec:\n cur_dim = i_spec.shape\n tile_shape = list((1, ) + cur_dim[1:])\n \n tmp_state = K.tile(initial_state, tile_shape) # (samples, ) + state_dim\n initial_states.append(tmp_state)\n \n # Return them\n return initial_states\n \n \n def reset_states(self, states_value=None):\n if not self.stateful:\n raise AttributeError('PCN_Cell must be stateful.')\n \n if not self.input_spec:\n raise RuntimeError('PCN_Cell has never been called '\n 'and thus has no states.')\n \n batch_size = self.input_spec.shape[0]\n if not batch_size:\n raise ValueError('If a RNN is stateful, it needs to know '\n 'its batch size. Specify the batch size '\n 'of your input tensors: \\n'\n '- If using a Sequential model, '\n 'specify the batch size by passing '\n 'a `batch_input_shape` '\n 'argument to your first layer.\\n'\n '- If using the functional API, specify '\n 'the time dimension by passing a '\n '`batch_shape` argument to your Input layer.')\n \n if states_value is not None:\n if not isinstance(states_value, (list, tuple)):\n states_value = [states_value]\n \n if len(states_value) != len(self.states):\n raise ValueError('The layer has ' + str(len(self.states)) +\n ' states, but the `states_value` '\n 'argument passed '\n 'only has ' + str(len(states_value)) +\n ' entries')\n \n if self.states[0] is None:\n self.states = []\n for i_spec in self.state_spec:\n cur_dim = i_spec.shape\n self.states.append(K.zeros((batch_size, ) + cur_dim[1:]))\n \n if not states_value:\n return\n \n for i, state_tuple in enumerate(zip(self.states, self.state_spec)):\n state, tmp_state_spec = state_tuple\n cur_dim = tmp_state_spec.shape\n \n tmp_state_shape = (batch_size, ) + cur_dim[1:]\n if states_value:\n value = states_value[i]\n\n if value.shape != tmp_state_shape:\n raise ValueError(\n 'Expected state #' + str(i) +\n ' to have shape ' + str(tmp_state_shape) +\n ' but got array with shape ' + str(value.shape))\n else:\n value = np.zeros(tmp_state_shape)\n \n K.set_value(state, value)\n \n \n # Should contain all layers with weights associated with them\n def build(self, input_shape):\n # Get relavent dimension values\n if isinstance(input_shape, list):\n input_shape = input_shape[0]\n \n batch_size = input_shape[0] if self.stateful else None\n orig_img_dim = input_shape[2:]\n \n \n # Set state shapes\n new_input_shape = (batch_size, ) + input_shape[1:]\n init_shape = (batch_size, ) + orig_img_dim\n state_shapes = get_state_shapes(self, new_input_shape)\n \n # Set input and state spec values \n self.input_spec = InputSpec(shape=((batch_size, None) + orig_img_dim)) \n self.state_spec = [ InputSpec(shape=cur_shape) for cur_shape in state_shapes ] # states\n\n \n # Initialize states to None\n self.states = [ None ] * self.total_states\n if self.stateful:\n self.reset_states()\n\n \n # Define stem layers (e.g. simple 2D conv)\n updated_shape = init_shape[:-1] + (self.stem_plus_block_filters[MODEL_STEM_INDEX], )\n num_channels = updated_shape[-1]\n \n for i in range(MODEL_NUM_STEM_CONV):\n # Add conv layers here\n weight_name = ('stem_conv_kernel_%d' % i) \n layer_id = ('stem_conv_layer_%d' % i)\n \n tmp_layer = Conv2D(num_channels, (3, 3), kernel_initializer='he_uniform', \n padding='same', use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n \n if i == 0:\n self.add_layer(tmp_layer, layer_id, init_shape)\n else:\n self.add_layer(tmp_layer, layer_id, updated_shape)\n \n # Add Batch Norm layer here\n weight_name = ('stem_bn_kernel_%d' % i) \n layer_id = ('stem_bn_layer_%d' % i)\n \n tmp_layer = BatchNormalization(name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, updated_shape)\n \n \n # Add layers for remaining blocks \n cur_shape = updated_shape\n \n for i in range(self.model_num_blocks):\n # Get number of channels for the block\n num_channels = self.stem_plus_block_filters[i]\n if i in self.downsize_block_indices:\n h = get_downsized_dim(cur_shape[1], self.downsize_values[i][0])\n w = get_downsized_dim(cur_shape[2], self.downsize_values[i][1])\n \n cur_shape = (cur_shape[0], h, w, num_channels) \n next_channels = self.stem_plus_block_filters[i+1]\n \n \n # Tanh layer function used to modulate activations between time steps\n if self.time_steps_p_block[i]:\n weight_name = ('tanh_weights_%d' % i) \n layer_id = ('tanh_layer_%d' % i) \n\n tmp_layer = pcn_layers.GetTanhValue(name=weight_name)\n self.add_layer(tmp_layer, layer_id, cur_shape) \n \n \n # Conv weights operating on the difference between time steps\n for j in range(self.num_conv_p_kalman_filter):\n # Define conv layers here\n weight_name = ('kalman_conv_kernel_%d_%d' % (i, j)) \n layer_id = ('kalman_conv_layer_%d_%d' % (i, j))\n \n tmp_layer = SeparableConv2D(num_channels, (3, 3), kernel_initializer='he_uniform', \n padding='same', use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, cur_shape)\n \n # Define Batch Norm layers\n weight_name = ('kalman_bn_kernel_%d_%d' % (i, j))\n layer_id = ('kalman_bn_layer_%d_%d' % (i, j))\n \n tmp_layer = BatchNormalization(name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, cur_shape)\n\n \n # Post processing residual connections (after addition)\n for j in range(self.num_res_connect_p_block):\n downsize_channels = int(num_channels // 2)\n downsize_shape = cur_shape[:-1] + (downsize_channels, )\n \n # Add residual convolutions here\n weight_name = ('res_conv_kernel_%d_%d_1' % (i, j)) \n layer_id = ('res_conv_layer_%d_%d_1' % (i, j))\n \n tmp_layer = SeparableConv2D(downsize_channels, (3, 3), kernel_initializer='he_uniform', \n padding='same', use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, cur_shape)\n \n weight_name = ('res_conv_kernel_%d_%d_2' % (i, j)) \n layer_id = ('res_conv_layer_%d_%d_2' % (i, j))\n \n tmp_layer = SeparableConv2D(num_channels, (3, 3), kernel_initializer='he_uniform', \n padding='same', use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, downsize_shape)\n \n # Add residual Batch Norm here\n weight_name = ('res_bn_kernel_%d_%d_1' % (i, j)) \n layer_id = ('res_bn_layer_%d_%d_1' % (i, j))\n \n tmp_layer = BatchNormalization(name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, downsize_shape) \n\n weight_name = ('res_bn_kernel_%d_%d_2' % (i, j)) \n layer_id = ('res_bn_layer_%d_%d_2' % (i, j))\n \n tmp_layer = BatchNormalization(name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, cur_shape)\n\n \n # Final convolution to upscale number of filters if needed\n weight_name = ('final_conv_kernel_%d' % i) \n layer_id = ('final_conv_layer_%d' % i)\n \n tmp_layer = SeparableConv2D(next_channels, (3, 3), kernel_initializer='he_uniform', \n padding='same', use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, cur_shape)\n \n \n # Add final 'num_final_dense_layers' Dense layers\n final_shape = cur_shape[:-1] + (next_channels, )\n \n if self.final_downsize_approach is not None:\n if self.final_downsize_approach != GLOBAL_AVG_POOL_STR:\n h_val = get_downsized_dim(final_shape[1], self.final_downsize_approach[0])\n w_val = get_downsized_dim(final_shape[2], self.final_downsize_approach[1])\n \n final_shape = (h_val, w_val, final_shape[-1])\n else:\n final_shape = (1, 1, final_shape[-1])\n\n final_channels = 1\n for dim in final_shape:\n final_channels *= dim\n \n diff = int((self.output_units - final_channels) // 2)\n intermediate_channels = final_channels + diff\n self.intermediate_shape = (batch_size, intermediate_channels)\n \n for i in range(self.num_final_dense_layers - 1):\n weight_name = ('final_dense_kernel_%d' % i)\n layer_id = ('final_dense_layer_%d' % i)\n \n tmp_layer = Dense(intermediate_channels, use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY), \n name=weight_name)\n if i == 0: \n self.add_layer(tmp_layer, layer_id, (batch_size, final_channels))\n else:\n self.add_layer(tmp_layer, layer_id, self.intermediate_shape)\n \n weight_name = ('final_dense_kernel_%d' % (self.num_final_dense_layers - 1)) \n layer_id = ('final_dense_layer_%d' % (self.num_final_dense_layers - 1))\n \n tmp_layer = Dense(self.output_units, use_bias=False, \n kernel_regularizer=l2(DEFAULT_WEIGHT_DECAY),\n name=weight_name)\n \n self.add_layer(tmp_layer, layer_id, self.intermediate_shape)\n \n \n # Set built flag\n self.built = True\n \n\n # Called immediately before RNN step as part of set-up process\n # Passed as \"state\" element (after output and intermediary states) as result of RNN iteration\n # Normally used to pass dropout masks\n def get_constants(self, inputs, training=None):\n constants = []\n tile_shape = list((1, ) + self.intermediate_shape[1:])\n \n # Set ones tensor with shape of hidden layer\n ones = K.ones_like(K.reshape(inputs[:, 0, 0, 0, 0], (-1, 1))) # (samples, 1)\n for _ in range(2, len(tile_shape)): # (samples, 1, ...., 1)\n ones = K.expand_dims(ones)\n \n ones = K.tile(ones, tile_shape) # Now it is the same shape as the second to last layer\n \n # Get input and recurrent dropout masks\n if 0.0 < self.dropout < 1.0: \n dp_mask = K.in_train_phase(K.dropout(ones, self.dropout),\n ones,\n training=training) \n \n else:\n dp_mask = ones\n \n constants.append(dp_mask)\n \n \n # Return them \n return constants\n\n \n def step(self, inputs, states):\n # Break down previous output/states\n core_states = states[:-1]\n dp_mask = states[-1]\t\t# from \"get_constants\"\n\n \n # Pass images through stem (with optional downsize)\n new_states = []\n \n stem = inputs\n for i in range(MODEL_NUM_STEM_CONV):\n conv_layer_id = ('stem_conv_layer_%d' % i)\n bn_layer_id = ('stem_bn_layer_%d' % i)\n \n stem = self.get_layer(conv_layer_id)(stem)\n stem = self.get_layer(bn_layer_id)(stem)\n \n if (i+1) == MODEL_NUM_STEM_CONV:\n if MODEL_STEM_INDEX in self.downsize_block_indices:\n stem = AveragePooling2D(pool_size=self.downsize_values[MODEL_STEM_INDEX], \n padding='same')(stem)\n else:\n stem = Activation('relu')(stem) # JADO - consider changing to swish activation\n \n \n # Pass through PCN \"blocks\" \n x = stem\n for i in range(self.model_num_blocks):\n # Get subtraction value \n if self.time_steps_p_block[i]:\n start_index = get_starting_state_index(i, self.time_steps_p_block)\n\n norm_stem = pcn_layers.NormalizePerChannel()(x) \n x = dl_layers.Subtract()([norm_stem, core_states[start_index]])\n \n # Get tanh-based scalar value (for each example in batch)\n tanh_layer_id = ('tanh_layer_%d' % i) \n tahn_output = self.get_layer(tanh_layer_id)(x)\n \n new_states.append(norm_stem)\n else:\n x = Activation('relu')(x)\n \n # Pass substract layer through the Kalman filter MLP\n for j in range(self.num_conv_p_kalman_filter):\n conv_layer_id = ('kalman_conv_layer_%d_%d' % (i, j))\n bn_layer_id = ('kalman_bn_layer_%d_%d' % (i, j))\n \n x = self.get_layer(conv_layer_id)(x)\n x = self.get_layer(bn_layer_id)(x)\n if (j+1) != self.num_conv_p_kalman_filter: \n x = Activation('relu')(x)\n \n \n # Get addition combinition of two time steps (based on tanh value)\n if self.time_steps_p_block[i]:\n x = pcn_layers.GetTanhCombination()([tahn_output, x, core_states[start_index+1]])\n new_states.append(x)\n\n \n # Post processing residual connections (after addition)\n for j in range(self.num_res_connect_p_block): \n conv_layer_id_1 = ('res_conv_layer_%d_%d_1' % (i, j))\n conv_layer_id_2 = ('res_conv_layer_%d_%d_2' % (i, j))\n bn_layer_id_1 = ('res_bn_layer_%d_%d_1' % (i, j))\n bn_layer_id_2 = ('res_bn_layer_%d_%d_2' % (i, j))\n \n res_term = Activation('relu')(x)\n res_term = self.get_layer(conv_layer_id_1)(res_term)\n res_term = self.get_layer(bn_layer_id_1)(res_term)\n\n res_term = Activation('relu')(res_term)\n res_term = self.get_layer(conv_layer_id_2)(res_term)\n res_term = self.get_layer(bn_layer_id_2)(res_term)\n \n x = Add()([x, res_term])\n \n \n # Final convolution to upscale number of filters if needed\n conv_layer_id = ('final_conv_layer_%d' % i)\n \n x = Activation('relu')(x)\n x = self.get_layer(conv_layer_id)(x)\n \n if (i+1) in self.downsize_block_indices:\n x = AveragePooling2D(pool_size=self.downsize_values[i+1], padding='same')(x)\n \n \n # Downsize final convolution layer if needed\n if self.final_downsize_approach is not None:\n if self.final_downsize_approach != GLOBAL_AVG_POOL_STR:\n x = AveragePooling2D(pool_size=self.final_downsize_approach, \n padding='same')(x)\n else:\n x = GlobalAveragePooling2D()(x)\n \n \n # Apply final fully connected layers \n if len(K.int_shape(x)) > 2:\n x = Flatten()(x)\n \n for i in range(self.num_final_dense_layers):\n final_layer_id = ('final_dense_layer_%d' % i)\n final_output = self.get_layer(final_layer_id)(x)\n \n if (i+1) != self.num_final_dense_layers:\n x = Activation('relu')(final_output)\n \n if 0.0 < self.dropout:\n x = x * dp_mask\n \n \n # Re-organize old states and add new ones\n for i in range(self.model_num_blocks):\n start_i = get_starting_state_index(i, self.time_steps_p_block)\n next_i = get_starting_state_index(i+1, self.time_steps_p_block)\n \n cur_time_end_i = next_i - MODEL_STATES_P_BLOCK\n prev_time_start_i = start_i + MODEL_STATES_P_BLOCK\n \n for count, new_i in enumerate(range(start_i, cur_time_end_i)):\n new_states.insert(new_i, states[prev_time_start_i + count])\n \n \n # Set learning phase flag\n if 0.0 < self.dropout:\n final_output._uses_learning_phase = True\n \n \n # Return output and updated states\n return final_output, new_states\n\n \n def get_config(self): \n config = {'output_units': self.output_units,\n 'stem_plus_block_filters': self.stem_plus_block_filters,\n 'downsize_block_indices': self.downsize_block_indices,\n 'final_downsize_approach': self.final_downsize_approach,\n 'num_conv_p_kalman_filter': self.num_conv_p_kalman_filter,\n 'num_res_connect_p_block': self.num_res_connect_p_block,\n 'num_final_dense_layers': self.num_final_dense_layers,\n 'dropout': self.dropout}\n \n base_config = super(PCN_Cell, self).get_config()\n \n return dict(list(base_config.items()) + list(config.items())) \n \n \n \n \n \n \n################ MAIN ################\n'''\n#https://github.com/achalddave/predictive-corrective\n#https://github.com/achalddave/predictive-corrective/blob/master/download.sh\n#https://github.com/achalddave/thumos-scripts/blob/master/parse_temporal_annotations_to_hdf5.py\n#http://www.thumos.info/download.html\n\nif __name__ == '__main__':\n\n time_steps = 20\n img_dimensions = (32, 32, 3)\n num_labels = 100\n \n input = Input((time_steps, ) + img_dimensions)\n\n pcn_cell = PCN_Cell(num_labels)\n out_layers = pcn_cell(input)\n\n final_layer = out_layers[0]\n final_preds = Activation('softmax')(final_layer)\n\n model = Model(input, final_preds)\n model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])\n\n model.summary() \n print(\"Done.\")\n'''\n"
}
] | 2 |
darkon5/Inquisicion
|
https://github.com/darkon5/Inquisicion
|
5262788f09f1a920571636388f04764119ab20db
|
73731fac62b80a0388d9eba072658b84af0c9505
|
44840fa5ccd241f520cab0af1cfa27b9cb92d340
|
refs/heads/master
| 2020-03-28T09:43:34.922708 | 2018-09-09T18:50:41 | 2018-09-09T18:50:41 | 148,055,292 | 0 | 0 |
MIT
| 2018-09-09T18:46:06 | 2018-09-09T17:54:09 | 2018-09-09T17:54:08 | null |
[
{
"alpha_fraction": 0.58302241563797,
"alphanum_fraction": 0.5867537260055542,
"avg_line_length": 27.210525512695312,
"blob_id": "b5a4211d01a6c40f547c6cc7f4e2234a5f2469fa",
"content_id": "0ec390b4631a2dc7cd663883458a17cf656943c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1072,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 38,
"path": "/inquisicion/util/nsfw.py",
"repo_name": "darkon5/Inquisicion",
"src_encoding": "UTF-8",
"text": "from logging import getLogger\nfrom os import write, close, remove\nfrom tempfile import mkstemp\nfrom nsfw import classify\nfrom PIL import Image\n\nlogger = getLogger(__name__)\n\n\nclass NSFW(object):\n \"\"\"\n Manage the Yahoo NSFW Neural Network\n \"\"\"\n\n def is_nsfw(self):\n \"\"\"\n Analyze the given image and return a boolean depending on the results\n of the neural network\n \"\"\"\n try:\n logger.debug('Start analyzing the image')\n img = Image.open(self.file_path)\n img.convert('RGB')\n _, nsfw = classify(img)\n return nsfw > 0.7 # Consider NSFW if ratio is higher than 0.7\n except IOError as e:\n logger.error(\"Exception with PIL Image: {}\".format(e.message))\n return False\n finally:\n remove(self.file_path)\n\n def __init__(self, image):\n \"\"\"\n Constructor must be supplied with an image being a byte-array.\n \"\"\"\n self.file, self.file_path = mkstemp()\n write(self.file, image)\n close(self.file)\n"
}
] | 1 |
johnerrol/OOP
|
https://github.com/johnerrol/OOP
|
8a466b08cb649b22286a2f56c49afe7308f3d847
|
52fd30a53879f4f85ea58135f2d0d4f452e383a0
|
4cc98b6a5140350580204466db5050814e9cf812
|
refs/heads/master
| 2021-01-23T11:50:17.965034 | 2012-09-12T03:14:51 | 2012-09-12T03:14:51 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6315789222717285,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 8.5,
"blob_id": "b113b4a674936714a95d4d4276fcceb97fe6a06e",
"content_id": "64e4c020062b4159af829b37494b07c55264aefe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 19,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 2,
"path": "/README.txt",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "John Errol Rivera\nProf.Sony Valdez"
},
{
"alpha_fraction": 0.5874999761581421,
"alphanum_fraction": 0.6150000095367432,
"avg_line_length": 20.77777862548828,
"blob_id": "9ad5b3102cdabcfe5ff39de57ed9b7dbdc1f0cf9",
"content_id": "ea421cdf598d9bedcd27ad3ee15d5d2b441f97f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 18,
"path": "/app_size 2.py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "import tkinter\n\n\nclass Application(tkinter.Frame):\n def __init__(self,master):\n tkinter.Frame.__init__(self,master)\n self.config(width=1000)\n self.config(height=200)\n self.config(bg=\"#FF0000\")\n self.pack()\n self.CreateWidget()\n def CreateWidget(self):\n pass\n\nroot=tkinter.Tk()\napp=Application(master=root)\napp.mainloop()\nroot.destroy() \n"
},
{
"alpha_fraction": 0.710941731929779,
"alphanum_fraction": 0.7177463173866272,
"avg_line_length": 32.26363754272461,
"blob_id": "053b176b9f3e17c62e96c93fac63a2a44a6a087e",
"content_id": "ccb09829797c1e67bb121556581f9bcabff71d30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3674,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 110,
"path": "/perlim exam_riverajohnerrol .py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "class BasketballPlayer:\n def SetInfo(self,name,age,PointsLastSeason,Personal Fouls,Injuries,Blood Type,Time Playing,Team,Sex):\n self.Name=name\n self.Age=age\n self.Points Last Season=points last season\n self.Personal Fouls=personal fouls\n self.Injuries=injuries\n self.Blood Type=blood type\n self.Time Playing=time playing\n self.Team=team\n self.Sex=sex\n def show(self):\n print(\"Name:%s\" %(self.Name))\n print(\"Name:%i\" %(self.Age))\n print(\"Points Last Season: %s\" % (self.Points Last Season))\n print(\"Personal Fouls: %s\" %(self.Personal Fouls))\n print(\"Injuries: %i\" %(self.Injuries))\n print(\"Blood Type: %s\" %(self.Blood Type))\n print(\"Time Playing: %i\" %(self.Time Playing))\n print(\"Team: %s\" %(self.Team))\n print(\"Sex: %i\" %(self.Sex))\n\nclass BasketballPlayerInfo(Information):\n def SetInfo(self,name,age,pointslastseason,personal fouls,injuries,blood type,time playing,time,sex):\n self.Name=name\n self.Age=age\n self.PointsLastSeason=\"\"\n self.Personal Fouls=6\n sef.Injuries=injuries\n self.Blood Type=blood type\n self.Time Playing=time playing\n self.Team=\"L.A. Lakers\"\n self.Sex=Sex\n\nclass BasketballPlayerInfo(Information):\n def SetInfo(self,name,age,pointslastseason,personal fouls,injuries,blool type,time playing,team,sex):\n self.Name=name\n self.Age=age\n self.PointsLastSeason=\"\"\n self.Personal Fouls=6\n sef.Injuries=injuries\n self.Blood Type=blood type\n self.Time Playing=time playing\n self.Team=\"L.A. Lakers\"\n self.Sex=Sex\n\nclass BasketballPlayerInfo(Information):\n def SetInfo(self,name,age,pointslastseason,personal fouls,injuries,blood type,time playing,team,sex):\n self.Name=name\n self.Age=age\n self.PointsLastSeason=\"\" \n self.Personal Fouls=6\n sef.Injuries=injuries\n self.Blood Type=blood type\n self.Time Playing=time playing\n self.Team=\"L.A. Lakers\"\n self.Sex=Sex\n\n\nListOfBasketball Player=[]\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Jane\",17,)\nListOfBasketball Players.append(basketball player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Errol\",19,)\nListOfBasketball players.append(basketball player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Elvira\",22)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Joy\",19)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbaketball player.SetInfo(\"BJ\",19)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball.SetInfo(\"Jamaica\",18)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Lorna\",27)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Ate Ruth\",18)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Geraldine\",16)\nListOfBasketball Players.append(Basketball Player)\n\nbasketball player=BasketballPlayerInfo()\nbasketball player.SetInfo(\"Maureen\",20)\nListOfBasketball Players.append(Basketball Player)\n\nstudent=BasketballPlayerInfo()\nstudent.SetInfo(\"Jamie\",16)\nListOfStudents.append(Basketball Player)\n\n\n\nfor basketball player in ListOfBasketball Players:\n basketball player.show()\n Show Name()\n Show Team()\n \n\n \n"
},
{
"alpha_fraction": 0.6169995069503784,
"alphanum_fraction": 0.6221198439598083,
"avg_line_length": 33.26315689086914,
"blob_id": "df8fbc9360d529cc515f4c2fcf8344af4a563a18",
"content_id": "145a3c415f199175d4afa399d9044e95bd2d3633",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1953,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 57,
"path": "/class tkinter 4.py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "import tkinter\nclass Application(tkinter.Frame):\n def __init__(self,master):\n tkinter.Frame.__init__(self,master)\n self.pack()\n self.points=0\n self.Morningbutton=tkinter.Button()\n self.Morningbutton[\"text\"]= \"clickhere\"\n self.Morningbutton[\"command\"]=self.morning\n self.Morningbutton.pack()\n\n self.AfternoonButton=tkinter.Button()\n self.AfternoonButton[\"text\"]= \"clickme\"\n self.AfternoonButton[\"command\"]=self.afternoon\n self.AfternoonButton.pack()\n\n self.GwapoakoButton=tkinter.Button()\n self.GwapoakoButton[\"text\"]=\"click\"\n self.GwapoakoButton[\"command\"]=self.gwapoako\n self.GwapoakoButton.pack()\n \n self.pointsbutton=tkinter.Button()\n self.pointsbutton[\"text\"]= \"points\"\n self.pointsbutton[\"command\"]=self.Displaypoints\n self.pointsbutton.pack()\n\n self.quitbutton=tkinter.Button()\n self.quitbutton[\"text\"]= \"quit\"\n self.quitbutton[\"command\"]=self.exit\n self.quitbutton.pack()\n\n\n def morning(self):\n response=tkinter.messagebox.showinfo(\"Question #1 Is Yellow Sun Yellow?\")\n if(response==True):\n self.points+=1\n def afternoon(self):\n response=tkinter.messagebox.showinfo(\"Question#2 Is Wood Edible?\")\n if(response==False):\n self.points+=1\n tkinter.messagebox.showinfo(\"Results\",\"Total Points is %i\" %(points))\n def gwapoako(self):\n response=tkinter.messagebox.showinfo(\"Question #3 Is Fried Chickren Madc Of Pigs?\")\n if(response==True):\n self.points+=1\n def exit(self):\n response=tkinter.messagebox.askyesno(\"Your Total Points Is 2?\")\n if(response==True):\n self.points+=1\n def displaypoints(self):\n if(response==True):\n self.points+=1\n \nroot=tkinter.Tk()\napp=Application(master=root)\napp.mainloop()\nroot.destroy()\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5,
"avg_line_length": 16.799999237060547,
"blob_id": "032721611050ab857ab13ed1c8440135e07fef2e",
"content_id": "d11c79b348d19d3abee5c50ea2007bfa6cc6a375",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 5,
"path": "/cloth .py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "class Cloth:\n def__init__(self):\n self.Brand=\"\"\n self.Color=\"\"\n self.Size=\"\"\n \n"
},
{
"alpha_fraction": 0.4905821979045868,
"alphanum_fraction": 0.5256849527359009,
"avg_line_length": 42.25925827026367,
"blob_id": "a5a66633ea6183bda011bf7096f792b03dea92ce",
"content_id": "acb46ff1e6a635c6dac45b5b4e84600e1c4934a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1168,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 27,
"path": "/mygame.py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "Python 3.2.3 (default, Apr 11 2012, 07:15:24) [MSC v.1500 32 bit (Intel)] on win32\nType \"copyright\", \"credits\" or \"license()\" for more information.\n>>> ================================ RESTART ================================\n>>> \nTraceback (most recent call last):\n File \"C:/Python32/pygame.py\", line 1, in <module>\n import pygame\n File \"C:/Python32\\pygame.py\", line 2, in <module>\n pygame.init()\nAttributeError: 'module' object has no attribute 'init'\n>>> ================================ RESTART ================================\n>>> \nTraceback (most recent call last):\n File \"C:/Python32/pygame.py\", line 1, in <module>\n import pygame\n File \"C:/Python32\\pygame.py\", line 2, in <module>\n pygame.init()\nAttributeError: 'module' object has no attribute 'init'\n>>> ================================ RESTART ================================\n>>> \nTraceback (most recent call last):\n File \"C:/Python32/pygame.py\", line 1, in <module>\n import pygame\n File \"C:/Python32\\pygame.py\", line 2, in <module>\n pygame.init()\nAttributeError: 'module' object has no attribute 'init'\n>>> ================================ RESTART ================================\n"
},
{
"alpha_fraction": 0.7986111044883728,
"alphanum_fraction": 0.7986111044883728,
"avg_line_length": 27.799999237060547,
"blob_id": "de6a039a82e2fd8ff4416c31a0172dd415b05ec3",
"content_id": "9e7645c61de26ed117eca6926a99919f0f3f3207",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 5,
"path": "/class tkinter 5.py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "import tkinter\nroot=tkinter.Tk()\ntkinter.messagebox.showinfo(\"title\",\"message\",icon=tkinter.messagebox.QUESTION)\nroot.mainloop()\nroot.destroy()\n"
},
{
"alpha_fraction": 0.5577797889709473,
"alphanum_fraction": 0.5777980089187622,
"avg_line_length": 23.244443893432617,
"blob_id": "25814afedf49c34805458cdf236df5ec91960ca4",
"content_id": "f62be6e1b315cb77ed76c46ea69451a362aa31f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1099,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 45,
"path": "/base_app 4.py",
"repo_name": "johnerrol/OOP",
"src_encoding": "UTF-8",
"text": "import tkinter\n\n\nclass Application(tkinter.Frame):\n def __init__(self,master):\n tkinter.Frame.__init__(self,master)\n self.pack()\n self.CreateWidget()\n def CreateWidget(self):\n self.textbox1=tkinter.Text()\n self.textbox1.pack()\n self.button1=tkinter.Button()\n self.button1[\"command\"]=self.button1_click\n self.button1[\"text\"]=\"click\"\n self.button1.pack()\n \n \n self.button2=tkinter.Button()\n self.button2[\"command\"]=self.button2_save\n self.button2[\"text\"]=\"save\"\n self.button2.pack()\n\n \n self.button3=tkinter.Button()\n self.button3[\"command\"]=self.button3_load\n self.button3[\"text\"]=\"load\"\n self.button3.pack()\n\n \n def button1_click(self):\n text=self.textbox.get(0.0,tkinter.END)\n print(text.upper())\n print(text.lower())\n print(text.title())\n\n def button2_save(self):\n pass\n def button3_load(self):\n pass\n \n\nroot=tkinter.Tk()\napp=Application(master=root)\napp.mainloop()\nroot.destroy() \n"
}
] | 8 |
Apaillard/GLPO
|
https://github.com/Apaillard/GLPO
|
cfb94305b616f512d4933afc5f7cb9bd5d7ffdb3
|
a7f23d5e1ccef2a6eb989408b68ef49735b34a32
|
7c1eb0a39ab2261c4900cbdcb74ae9293d94701e
|
refs/heads/master
| 2022-11-14T18:29:07.199657 | 2020-06-21T15:56:59 | 2020-06-21T15:56:59 | 273,531,595 | 0 | 0 |
MIT
| 2020-06-19T15:50:14 | 2020-06-19T15:52:43 | 2020-06-21T15:56:59 |
Python
|
[
{
"alpha_fraction": 0.6366559267044067,
"alphanum_fraction": 0.6366559267044067,
"avg_line_length": 27.272727966308594,
"blob_id": "93db56ca82e1b92c2b4b7cd815b46fef40677f48",
"content_id": "6879732b50baabe69bbf8ef4965a103c9c830f6b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1244,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 44,
"path": "/model/dao/sport_dao.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from model.mapping.sport import Sport\nfrom model.dao.dao import DAO\nfrom model.dao.dao_error_handler import dao_error_handler\n\n\nclass SportDAO(DAO):\n \"\"\"\n Sport Mapping DAO\n \"\"\"\n\n @dao_error_handler\n def get(self, id):\n return self._database_session.query(Sport).filter_by(id=id).one()\n\n @dao_error_handler\n def get_all(self):\n return self._database_session.query(Sport).order_by(Sport.name).all()\n\n @dao_error_handler\n def get_by_name(self, name: str):\n return self._database_session.query(Sport).filter_by(name=name).one()\n\n @dao_error_handler\n def create(self, data: dict):\n sport = Sport(name=data.get('name'), description=data.get('description'))\n self._database_session.add(sport)\n self._database_session.flush()\n return sport\n\n @dao_error_handler\n def update(self, sport: Sport, data: dict):\n if 'name' in data:\n sport.name = data['name']\n if 'description' in data:\n sport.description = data['description']\n\n self._database_session.merge(sport)\n self._database_session.flush()\n\n return sport\n\n @dao_error_handler\n def delete(self, entity):\n self._database_session.delete(entity)\n"
},
{
"alpha_fraction": 0.6236842274665833,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 39,
"blob_id": "e8760ac19a3a515d5f11a6daa4e5ffb2cba78754",
"content_id": "72dd1e20c352af726b0e3e1e805a375f5b25a723",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 19,
"path": "/vue/menu_connexion_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import Label, Button\nfrom vue.base_frame import BaseFrame\n\n\nclass MenuConnexionFrame(BaseFrame):\n def __init__(self, root_frame):\n super().__init__(root_frame)\n self.create_widgets()\n\n def create_widgets(self):\n self.title = Label(self, text=\"Welcome in BDS App\")\n self.subscribe = Button(self, text=\"Subscribe\", width=30, command=self._root_frame.new_member)\n self.connexion = Button(self, text=\"Connexion\", width=30, command=self._root_frame.show_connexion)\n self.quit = Button(self, text=\"QUIT\", fg=\"red\", width=30,\n command=self.quit)\n self.title.pack(side=\"top\")\n self.subscribe.pack()\n self.connexion.pack()\n self.quit.pack(side=\"bottom\")\n"
},
{
"alpha_fraction": 0.616119384765625,
"alphanum_fraction": 0.616119384765625,
"avg_line_length": 23.617647171020508,
"blob_id": "53cb1c53f477689325fdced1af01a6f77d343fc1",
"content_id": "fcee01166ec33b538ecdebccd3dd710d70b56f61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1675,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 68,
"path": "/model/database.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom sqlalchemy import create_engine\nfrom sqlalchemy.orm import sessionmaker\n\nfrom model.mapping import Base\n\n\nclass DatabaseEngine:\n \"\"\"\n Database Engine\n Handle Database connections and sessions\n \"\"\"\n\n def __init__(self, url='sqlite:///:memory:', verbose=False):\n self._engine = create_engine(url, echo=verbose)\n self._Session = sessionmaker(bind=self._engine, autoflush=False)\n\n def new_session(self):\n sqlalchemy_session = self._Session()\n return Session(sqlalchemy_session)\n\n def create_database(self):\n Base.metadata.create_all(self._engine)\n\n def remove_database(self):\n Base.metadata.drop_all(self._engine)\n\n\nclass Session:\n\n def __init__(self, sql_alchemy_session, autocommit=True):\n self._session = sql_alchemy_session\n self._autocommit = autocommit\n\n def __enter__(self):\n return self\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n if self._autocommit:\n if exc_type is not None:\n self._session.rollback()\n else:\n self._session.commit()\n self._session.close()\n return False\n\n def add(self, entity):\n self._session.add(entity)\n\n def query(self, *entity_class):\n return self._session.query(*entity_class)\n\n def merge(self, entity):\n return self._session.merge(entity)\n\n def delete(self, entity):\n self._session.delete(entity)\n\n def flush(self):\n self._session.flush()\n\n def commit(self):\n self._session.commit()\n\n def close(self):\n self._session.close()\n\n def refresh(self, entity):\n self._session.refresh(entity)\n"
},
{
"alpha_fraction": 0.6020602583885193,
"alphanum_fraction": 0.6089279055595398,
"avg_line_length": 38.10447692871094,
"blob_id": "ba079173d0f00b92ca5000b39ee557a2fd0fc7b7",
"content_id": "9c38fe1cf4f27fe4b6d8b67a1b7fc266fa48dfb1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2621,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 67,
"path": "/vue/member_frames/list_members_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom tkinter import *\n\nfrom vue.base_frame import BaseFrame\nfrom controller.person_controller import PersonController\n\n\nclass ListMembersFrame(BaseFrame):\n\n def __init__(self, person_controller: PersonController, root_frame: Frame, person_type: str = None):\n super().__init__(root_frame)\n self._person_controller = person_controller\n\n self._members = None\n if person_type is None:\n self._person_type = 'person'\n else:\n self._person_type = person_type\n self._create_widgets()\n\n def _create_widgets(self):\n\n self.title = Label(self, text=\"List %s:\" % self._person_type.capitalize())\n self.title.grid(row=0, column=0)\n\n # grille\n yDefil = Scrollbar(self, orient='vertical')\n self.listbox = Listbox(self, yscrollcommand=yDefil.set, width=30, selectmode='single')\n yDefil['command'] = self.listbox.yview\n self.listbox.bind('<<ListboxSelect>>', self.on_select)\n yDefil.grid(row=1, column=2, sticky='ns')\n self.listbox.grid(row=1, column=0, columnspan=2, sticky='nsew')\n\n # Return bouton\n self.new_person_button = Button(self, text=\"New %s\" % self._person_type, command=self.new_person)\n self.show_profile_button = Button(self, text=\"Show profile\", command=self.show_profile)\n self.menu = Button(self, text=\"Return\", fg=\"red\",\n command=self.show_menu)\n self.new_person_button.grid(row=3, sticky=\"nsew\")\n self.menu.grid(row=4, column=0, sticky=\"w\")\n\n def on_select(self, event):\n if len(self.listbox.curselection()) == 0:\n self.show_profile_button.grid_forget()\n else:\n self.show_profile_button.grid(row=3, column=1, sticky=\"nsew\")\n\n def new_person(self):\n if self._person_type == 'member':\n self._root_frame.new_member()\n elif self._person_type == 'coach':\n self._root_frame.new_coach()\n\n def show_profile(self):\n if len(self.listbox.curselection()) == 0:\n self.show_profile_button.grid_forget()\n else:\n index = int(self.listbox.curselection()[0])\n member = self._members[index]\n self._root_frame.show_profile(member['id'])\n\n def show(self):\n self._members = self._person_controller.list_people(person_type=self._person_type)\n self.listbox.delete(0, END)\n for index, member in enumerate(self._members):\n text = member['firstname'].capitalize() + ' ' + member['lastname'].capitalize()\n self.listbox.insert(index, text)\n super().show()\n"
},
{
"alpha_fraction": 0.603569746017456,
"alphanum_fraction": 0.6120244264602661,
"avg_line_length": 36.33333206176758,
"blob_id": "fdc271d5b9b5b6df483fa66ef675447181c1603c",
"content_id": "2b9bac88ffe309d84bb7430f49ec9a464997b21b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2129,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 57,
"path": "/vue/sport_frames/list_sports_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom tkinter import *\n\nfrom vue.base_frame import BaseFrame\nfrom controller.sport_controller import SportController\n\n\nclass ListSportsFrame(BaseFrame):\n\n def __init__(self, sport_controller: SportController, root_frame: Frame):\n super().__init__(root_frame)\n self._sport_controller = sport_controller\n\n self._sports = None\n self._create_widgets()\n\n def _create_widgets(self):\n\n self.title = Label(self, text=\"List sports:\")\n self.title.grid(row=0, column=0)\n\n # grille\n yDefil = Scrollbar(self, orient='vertical')\n self.listbox = Listbox(self, yscrollcommand=yDefil.set, width=30, selectmode='single')\n yDefil['command'] = self.listbox.yview\n self.listbox.bind('<<ListboxSelect>>', self.on_select)\n yDefil.grid(row=1, column=2, sticky='ns')\n self.listbox.grid(row=1, column=0, columnspan=2, sticky='nsew')\n\n # Return bouton\n self.new_sport_button = Button(self, text=\"New Sport\", command=self._root_frame.new_sport)\n self.show_sport_button = Button(self, text=\"Show profile\", command=self.show_sport)\n self.menu = Button(self, text=\"Return\", fg=\"red\",\n command=self.show_menu)\n self.new_sport_button.grid(row=3, sticky=\"nsew\")\n self.menu.grid(row=4, column=0, sticky=\"w\")\n\n def on_select(self, event):\n if len(self.listbox.curselection()) == 0:\n self.show_sport_button.grid_forget()\n else:\n self.show_sport_button.grid(row=3, column=1, sticky=\"nsew\")\n\n def show_sport(self):\n if len(self.listbox.curselection()) == 0:\n self.show_sport_button.grid_forget()\n else:\n index = int(self.listbox.curselection()[0])\n sport = self._sports[index]\n self._root_frame.show_sport(sport['id'])\n\n def show(self):\n self._sports = self._sport_controller.list_sports()\n self.listbox.delete(0, END)\n for index, sport in enumerate(self._sports):\n text = sport['name'].capitalize()\n self.listbox.insert(index, text)\n super().show()\n"
},
{
"alpha_fraction": 0.6477794647216797,
"alphanum_fraction": 0.6600306034088135,
"avg_line_length": 30.85365867614746,
"blob_id": "9f28a756fc49a6e72cb734731f62684a7827b590",
"content_id": "db213ecfea6179ec775103d32371becc43d2fbed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1306,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 41,
"path": "/model/mapping/sport.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from model.mapping import Base\nimport uuid\n\nfrom sqlalchemy import Column, String, UniqueConstraint, ForeignKey\nfrom sqlalchemy.orm import relationship\n\n\nclass Sport(Base):\n __tablename__ = 'sports'\n\n id = Column(String(36), default=str(uuid.uuid4()), primary_key=True)\n\n # Sport is unique in database\n name = Column(String(50), nullable=False, unique=True)\n description = Column(String(512), nullable=True)\n people = relationship(\"SportAssociation\", back_populates=\"sport\")\n\n def __repr__(self):\n return \"<Sport %s>\" % self.name\n\n def to_dict(self):\n return {\n \"id\": self.id,\n \"name\": self.name,\n \"description\": self.description\n }\n\n\nclass SportAssociation(Base):\n \"\"\"\n Association class between person and sport\n help relationship: https://docs.sqlalchemy.org/en/13/orm/basic_relationships.html\n \"\"\"\n __tablename__ = 'sport_associations'\n __table_args__ = (UniqueConstraint('person_id', 'sport_id'),)\n\n person_id = Column(String(36), ForeignKey('people.id'), primary_key=True)\n sport_id = Column(String(36), ForeignKey('sports.id'), primary_key=True)\n level = Column(String(50))\n person = relationship(\"Person\", back_populates=\"sports\")\n sport = relationship(\"Sport\", back_populates=\"people\")\n"
},
{
"alpha_fraction": 0.6114432215690613,
"alphanum_fraction": 0.6122971773147583,
"avg_line_length": 31.52777862548828,
"blob_id": "d9658f00a7cbd108ab62273407df9dabd658ffa4",
"content_id": "ba666a1e10ba54a31451cd3d12bb0dc0f9393b3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1171,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 36,
"path": "/vue/member_frames/new_member_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom exceptions import Error\nfrom vue.member_frames.new_person_frame import NewPersonFrame\n\n\nclass NewMemberFrame(NewPersonFrame):\n\n def __init__(self, person_controller, master=None):\n super().__init__(person_controller, master)\n\n def create_widgets(self):\n super().create_widgets()\n self.medical_certificate = BooleanVar()\n self.medical_certificate.set(False)\n\n self.medical_certificate_ckeck = Checkbutton(self, text=\"Medical certificate\",\n variable=self.medical_certificate)\n self.medical_certificate_ckeck.grid(row=4)\n\n def valid(self):\n\n data = super().get_data()\n data['medical_certificate'] = bool(self.medical_certificate.get())\n\n try:\n member_data = self._person_controller.create_member(data)\n messagebox.showinfo(\"Success\",\n \"Member %s %s created !\" % (member_data['firstname'], member_data['lastname']))\n\n except Error as e:\n messagebox.showerror(\"Error\", str(e))\n return\n\n self.show_menu()\n"
},
{
"alpha_fraction": 0.5745391845703125,
"alphanum_fraction": 0.5823374390602112,
"avg_line_length": 45.79146957397461,
"blob_id": "0a80343a65a75b524a453f572f95153ea1557fd9",
"content_id": "dc8b01c3edcb74485131f501e5ebfd6a34e3e361",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9874,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 211,
"path": "/vue/member_frames/profile_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom tkinter import *\nfrom tkinter import ttk\nfrom tkinter import messagebox\nfrom vue.base_frame import BaseFrame\nfrom functools import partial\n\n\nclass ProfileFrame(BaseFrame):\n\n def __init__(self, person_controller, sport_controller, person, master=None):\n super().__init__(master)\n self._person = person\n print(self._person)\n self._person_controller = person_controller\n self._sport_controller = sport_controller\n self._sports = []\n self._name_pattern = re.compile(\"^[\\S-]{2,50}$\")\n self._email_pattern = re.compile(\"^([a-zA-Z0-9_\\-\\.]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]{2,5})$\")\n self._create_widgets()\n\n def _create_widgets(self):\n\n self.title = Label(self, text=\"%s profile: \" % self._person.get('type', '').capitalize(), font='bold')\n self.title.grid(row=0, column=0, sticky=W)\n\n self.firstname_entry = self.create_entry(\"Firstname: \", row=1, validate_callback=self.validate_name,\n columnspan=3)\n self.lastname_entry = self.create_entry(\"Lastname: \", row=2, validate_callback=self.validate_name,\n columnspan=3)\n self.email_entry = self.create_entry(\"Email: \", row=3, validate_callback=self.validate_email,\n columnspan=4)\n if self._person['type'] == 'person':\n self.medical_certificate = BooleanVar()\n self.medical_certificate.set(self._person['medical_certificate'])\n self.medical_certificate_ckeck = Checkbutton(self, text=\"Medical certificate\",\n variable=self.medical_certificate)\n self.medical_certificate_ckeck.grid(row=4)\n elif self._person['type'] == 'coach':\n self.contract_entry = self.create_entry(\"contract: \", row=4, columnspan=4)\n self.degree_entry = self.create_entry(\"degree: \", row=5, columnspan=4)\n\n Label(self, text=\"Address:\", font='bold').grid(row=10, sticky='w')\n self.street_entry = self.create_entry(\"Street: \", row=11, columnspan=4)\n self.postal_code_entry = self.create_entry(\"Postal Code: \", row=12, validate_callback=self.validate_postal_code,\n columnspan=2)\n self.city_entry = self.create_entry(\"City: \", row=13, columnspan=3)\n self.country_entry = self.create_entry(\"Country: \", row=14, columnspan=3)\n\n # Buttons\n self.edit_button = Button(self, text=\"Edit\",\n command=self.edit)\n self.cancel_button = Button(self, text=\"Cancel\", command=self.refresh)\n self.update_button = Button(self, text=\"Update\", command=self.update)\n self.remove_button = Button(self, text=\"Remove\", command=self.remove)\n self.return_button = Button(self, text=\"Return\", fg=\"red\",\n command=self.back)\n\n self.return_button.grid(row=20, column=0)\n self.edit_button.grid(row=20, column=1, sticky=\"nsew\")\n self.remove_button.grid(row=20, column=2, sticky=\"nsew\")\n\n # Sport Frame\n self.sports_frame = Frame(self)\n self.sports_frame.grid(row=0, column=6, rowspan=20, sticky=\"n\", padx=10)\n self.list_sports_frame = None\n\n def validate_name(self, event, entry=None):\n if not self._name_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def validate_email(self, event, entry=None):\n if not self._email_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def validate_postal_code(self, event, entry=None):\n if not re.match(\"[\\d]+\", entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def edit(self):\n self.edit_button.grid_forget()\n self.remove_button.grid_forget()\n entries = [self.firstname_entry, self.lastname_entry, self.email_entry, self.street_entry,\n self.postal_code_entry, self.city_entry, self.country_entry]\n if self._person['type'] == 'coach':\n entries += [self.contract_entry, self.degree_entry]\n for entry in entries:\n entry.config(state=NORMAL)\n self.cancel_button.grid(row=20, column=2, sticky=\"nsew\")\n self.update_button.grid(row=20, column=1, sticky=\"nsew\")\n\n def _refresh_entry(self, entry, value=\"\"):\n entry.delete(0, END)\n if value != \"\":\n entry.insert(0, value)\n entry.config(state=DISABLED)\n\n def refresh(self):\n # Restore window with person value and cancel edition\n self.cancel_button.grid_forget()\n self.update_button.grid_forget()\n self._refresh_entry(self.firstname_entry, self._person['firstname'])\n self._refresh_entry(self.lastname_entry, self._person['lastname'])\n self._refresh_entry(self.email_entry, self._person['email'])\n address = self._person.get('address', {})\n self._refresh_entry(self.street_entry, address.get('street', ''))\n self._refresh_entry(self.postal_code_entry, str(address.get('postal_code', '')))\n self._refresh_entry(self.city_entry, address.get('city', ''))\n self._refresh_entry(self.country_entry, address.get('country', ''))\n if self._person['type'] == 'person':\n self.medical_certificate.set(self._person['medical_certificate'])\n elif self._person['type'] == 'coach':\n self._refresh_entry(self.degree_entry, self._person['degree'])\n self._refresh_entry(self.contract_entry, self._person['contract'])\n self.edit_button.grid(row=20, column=1, sticky=\"nsew\")\n self.remove_button.grid(row=20, column=2, sticky=\"nsew\")\n self.refresh_sports()\n\n def refresh_sports(self):\n\n if self.list_sports_frame is not None:\n self.list_sports_frame.destroy()\n self.list_sports_frame = Frame(master=self.sports_frame)\n self.list_sports_frame.grid(row=1, columnspan=3, sticky=\"w\")\n\n Label(self.list_sports_frame, text=\"Sports: \", font='bold').grid(row=0, sticky=\"w\")\n i = 1\n if \"sports\" in self._person:\n for sport in self._person['sports']:\n self.list_sports_frame.columnconfigure(i, weight=1)\n Label(self.list_sports_frame, text=sport['name']).grid(row=i, column=0, sticky=\"w\")\n Label(self.list_sports_frame, text=sport['level']).grid(row=i, column=1, sticky=\"w\")\n del_button = Button(self.list_sports_frame, text=\"-\", command=partial(self.delete_sport, sport['id']))\n del_button.grid(row=i, column=2, sticky=\"w\")\n i += 1\n\n # Add sport\n self.choose_sport_box = ttk.Combobox(self.list_sports_frame, values=[sport['name'] for sport in self._sports])\n self.level_box = ttk.Combobox(self.list_sports_frame, values=[\"beginner\", \"high\", \"professional\"])\n self.add_sport_button = Button(self.list_sports_frame, text=\"+\", command=self.add_sport)\n\n self.choose_sport_box.grid(row=i, column=0, stick=\"nsew\")\n self.level_box.grid(row=i, column=1, stick=\"nsew\")\n self.add_sport_button.grid(row=i, column=2, stick=\"w\")\n\n def update(self):\n\n data = dict(firstname=self.firstname_entry.get(),\n lastname=self.lastname_entry.get(),\n email=self.email_entry.get())\n\n if self.street_entry.get() != \"\" and self.city_entry.get() != \"\" and \\\n re.match(\"[\\d]+\", self.postal_code_entry.get()):\n address = dict(street=self.street_entry.get(),\n postal_code=int(self.postal_code_entry.get()),\n city=self.city_entry.get())\n if self.country_entry.get() != \"\":\n address['country'] = self.country_entry.get()\n data['address'] = address\n\n if self._person['type'] == 'person':\n data['medical_certificate'] = bool(self.medical_certificate.get())\n person = self._person_controller.update_person(self._person['id'], data)\n elif self._person['type'] == 'coach':\n data['contract'] = self.contract_entry.get()\n data['degree'] = self.degree_entry.get()\n person = self._person_controller.update_coach(self._person['id'], data)\n else:\n person = self._person_controller.update_person(self._person['id'], data)\n self._person = person\n self.refresh()\n\n def remove(self):\n person_id = self._person['id']\n self._person_controller.delete_person(person_id)\n # show confirmation\n messagebox.showinfo(\"Success\",\n \"person %s %s deleted !\" % (self._person['firstname'], self._person['lastname']))\n self.back()\n\n def get_sport_id(self, name):\n for sport in self._sports:\n if sport['name'] == name:\n return sport['id']\n return None\n\n def add_sport(self):\n sport_name = self.choose_sport_box.get()\n level = self.level_box.get()\n if sport_name != \"\" and level != \"\":\n sport_id = self.get_sport_id(sport_name)\n if sport_id is not None:\n self._person = self._person_controller.add_sport_person(self._person['id'], sport_id, level)\n else:\n messagebox.showerror(\"Sport %s not found\" % sport_name)\n self.refresh_sports()\n\n def delete_sport(self, sport_id):\n\n self._person = self._person_controller.delete_sport_person(self._person['id'], sport_id)\n self.refresh_sports()\n\n def show(self):\n self._sports = self._sport_controller.list_sports()\n self.refresh()\n super().show()\n"
},
{
"alpha_fraction": 0.6145925521850586,
"alphanum_fraction": 0.6184172034263611,
"avg_line_length": 34.041236877441406,
"blob_id": "6d8619936293f7d1ce61b69a59b540fcf61e91a6",
"content_id": "f25c715c5cd81eda191347c8a5ce6233352f7359",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3399,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 97,
"path": "/tests/test_membre.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "import unittest\nimport uuid\nfrom exceptions import InvalidData, Error, ResourceNotFound\nfrom controller.person_controller import PersonController\nfrom model.database import DatabaseEngine\nfrom model.mapping.person import Person\nfrom model.mapping.address import Address\n\n\nclass TestPersonController(unittest.TestCase):\n \"\"\"\n Unit Tests sport controller\n https://docs.python.org/fr/3/library/unittest.html\n \"\"\"\n\n @classmethod\n def setUpClass(cls) -> None:\n cls._database_engine = DatabaseEngine()\n cls._database_engine.create_database()\n with cls._database_engine.new_session() as session:\n\n\n\n steeve = Person(id=str(uuid.uuid4()),\n firstname=\"steeve\",\n lastname=\"gates\",\n email=\"[email protected]\")\n steeve.address = Address(street=\"21 rue docteur guerin\",\n city=\"Laval\",\n postal_code=53000)\n cls.steeve_id = steeve.id\n session.add(steeve)\n session.flush()\n\n def setUp(self) -> None:\n \"\"\"\n Function called before each test\n \"\"\"\n self.person_controller = PersonController(self._database_engine)\n\n def test_list_Persones(self):\n Persones = self.person_controller.list_people(person_type=\"Person\")\n self.assertGreaterEqual(len(Persones), 1)\n\n def test_get_Person(self):\n\n Person = self.person_controller.get_person(self.steeve_id, person_type=\"Person\")\n self.assertEqual(Person['firstname'], \"steeve\")\n self.assertEqual(Person['lastname'], \"gates\")\n self.assertEqual(Person['id'], self.steeve_id)\n self.assertIn(\"address\", Person)\n self.assertEqual(Person[\"address\"][\"city\"], \"Laval\")\n\n def test_get_Person_not_exists(self):\n with self.assertRaises(ResourceNotFound):\n self.person_controller.get_person(str(uuid.uuid4()))\n\n\n def test_create_Person_missing_data(self):\n data = {}\n with self.assertRaises(InvalidData):\n self.person_controller.create_person(data, person_type=\"Person\")\n\n\n def test_update_Person(self):\n Person_data = self.person_controller.update_person(\n self.steeve_id, {\"email\": \"[email protected]\"})\n self.assertEqual(Person_data['email'], \"[email protected]\")\n\n def test_update_Person_invalid_data(self):\n with self.assertRaises(InvalidData):\n self.person_controller.update_person(self.steeve_id, {\"email\": \"test\"})\n\n def test_update_Person_not_exists(self):\n with self.assertRaises(ResourceNotFound):\n self.person_controller.update_member(\"test\", {\"description\": \"test foot\"})\n\n def test_delete_Person(self):\n with self._database_engine.new_session() as session:\n rob = Person(id=str(uuid.uuid4()), firstname=\"rob\", lastname=\"stark\",\n email=\"[email protected]\")\n session.add(rob)\n session.flush()\n rob_id = rob.id\n\n self.person_controller.delete_person(rob_id)\n with self.assertRaises(ResourceNotFound):\n self.person_controller.delete_person(rob_id)\n\n def test_delete_Person_not_exists(self):\n with self.assertRaises(ResourceNotFound):\n self.person_controller.delete_person(str(uuid.uuid4()))\n\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.6169772148132324,
"alphanum_fraction": 0.6169772148132324,
"avg_line_length": 20.909090042114258,
"blob_id": "2e9cd8b989ca094a22e6d28582bf9e2dc61eb0bd",
"content_id": "b029b727f568fd3896cdd9eb79a437e36ef3d1e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 483,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 22,
"path": "/model/dao/dao.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nclass DAO:\n \"\"\"\n DAO Interface Object\n \"\"\"\n\n def __init__(self, database_session):\n self._database_session = database_session\n\n def get(self, id):\n raise NotImplementedError()\n\n def get_all(self):\n raise NotImplementedError()\n\n def create(self, data: dict):\n raise NotImplementedError()\n\n def update(self, entity, data: dict):\n raise NotImplementedError()\n\n def delete(self, entity):\n raise NotImplementedError()\n"
},
{
"alpha_fraction": 0.5976116061210632,
"alphanum_fraction": 0.6053997874259949,
"avg_line_length": 38.32653045654297,
"blob_id": "4b4f8a36bb22996eb04f03ba693d187ee1af6337",
"content_id": "9d00d6ad470f194995b76172bca38767e110e1e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1927,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 49,
"path": "/vue/member_frames/connexion_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom vue.base_frame import BaseFrame\nfrom exceptions import Error\n\nclass ConnexionFrame(BaseFrame):\n def __init__(self, person_controller, master=None):\n super().__init__(master)\n self._person_controller = person_controller\n self.create_widgets()\n self.name_pattern = re.compile(\"^[\\S-]{2,50}$\")\n self.email_pattern = re.compile(\"^([a-zA-Z0-9_\\-\\.]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]{2,5})$\")\n\n def create_widgets(self):\n\n self.firstname_entry = self.create_entry(\"Firstname\", row=0, validate_callback=self.validate_name)\n self.lastname_entry = self.create_entry(\"Lastname\", row=1, validate_callback=self.validate_name)\n\n self.valid = Button(self, text=\"valid\", fg=\"red\", command=self.valid)\n self.cancel = Button(self, text=\"cancel\", fg=\"red\", command=self.show_menu_connexion)\n\n self.valid.grid(row=4, column=1, sticky=E)\n self.cancel.grid(row=4, column=2, sticky=W)\n\n def validate_name(self, event, entry=None):\n if not self.name_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def validate_email(self, event, entry=None):\n if not self.email_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def valid(self):\n if self.firstname_entry.get() == 'Admin':\n self.show_menu()\n else:\n try:\n member_data = self._person_controller.search_person(firstname=self.firstname_entry.get(), lastname=self.lastname_entry.get())\n messagebox.showinfo(\"Success\", \"Member %s %s connecté !\" % (member_data['firstname'], member_data['lastname']))\n self.show_menu_membre()\n\n except Error as e:\n messagebox.showerror(\"Error\", str(e))\n return"
},
{
"alpha_fraction": 0.568355917930603,
"alphanum_fraction": 0.5769004225730896,
"avg_line_length": 39.89156723022461,
"blob_id": "f5c3fddb5fa1241500c55a6d41f40e9c07c1af6e",
"content_id": "817b55e97923e7f84d6b027e9237037215764882",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3394,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 83,
"path": "/vue/member_frames/new_person_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom vue.base_frame import BaseFrame\nfrom exceptions import Error\n\n\nclass NewPersonFrame(BaseFrame):\n\n def __init__(self, person_controller, master=None):\n super().__init__(master)\n self._person_controller = person_controller\n self.create_widgets()\n self.name_pattern = re.compile(\"^[a-zA-Z-]{2,50}$\")\n self.email_pattern = re.compile(\"^([a-zA-Z0-9_\\-\\.]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]{2,5})$\")\n\n def create_widgets(self):\n\n Label(self, text=\"Data informations:\", font='bold').grid(row=0, sticky='w')\n self.firstname_entry = self.create_entry(\"Firstname\", row=1, validate_callback=self.validate_name)\n self.lastname_entry = self.create_entry(\"Lastname\", row=2, validate_callback=self.validate_name)\n self.email_entry = self.create_entry(\"Email\", row=3, validate_callback=self.validate_email)\n self.medical_certificate = BooleanVar()\n self.medical_certificate.set(False)\n\n Label(self, text=\"Address:\", font='bold').grid(row=10, sticky='w')\n self.street_entry = self.create_entry(\"Street\", row=11)\n self.postal_code_entry = self.create_entry(\"Postal Code\", row=12, validate_callback=self.validate_postal_code)\n self.city_entry = self.create_entry(\"City\", row=13)\n self.country_entry = self.create_entry(\"Country\", row=14)\n\n self.valid = Button(self, text=\"valid\", fg=\"red\",\n command=self.valid)\n self.cancel = Button(self, text=\"cancel\", fg=\"red\",\n command=self.show_menu_connexion)\n self.valid.grid(row=20, column=1, sticky=E)\n self.cancel.grid(row=20, column=2, sticky=W)\n\n def validate_name(self, event, entry=None):\n if not self.name_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def validate_postal_code(self, event, entry=None):\n if not re.match(\"[\\d]+\", entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def validate_email(self, event, entry=None):\n if not self.email_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def get_data(self):\n data = dict(firstname=self.firstname_entry.get(),\n lastname=self.lastname_entry.get(),\n email=self.email_entry.get())\n\n if self.street_entry.get() != \"\" and self.city_entry.get() != \"\" and \\\n re.match(\"[\\d]+\", self.postal_code_entry.get()):\n address = dict(street=self.street_entry.get(),\n postal_code=int(self.postal_code_entry.get()),\n city=self.city_entry.get())\n if self.country_entry.get() != \"\":\n address['country'] = self.country_entry.get()\n data['address'] = address\n return data\n\n def valid(self):\n data = self.get_data()\n try:\n member_data = self._person_controller.create_person(data)\n messagebox.showinfo(\"Success\",\n \"Member %s %s created !\" % (member_data['firstname'], member_data['lastname']))\n\n except Error as e:\n messagebox.showerror(\"Error\", str(e))\n return\n\n self.back()\n"
},
{
"alpha_fraction": 0.6488222479820251,
"alphanum_fraction": 0.6488222479820251,
"avg_line_length": 26.47058868408203,
"blob_id": "b1330ec17c33ea81996e53dd7238618f1e2f5efe",
"content_id": "044d67614a34d2fa7435533d29bb302a0830d107",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 467,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 17,
"path": "/model/dao/person_dao_fabric.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom model.dao.person_dao import PersonDAO\nfrom model.dao.member_dao import MemberDAO\n\n\nclass PersonDAOFabric:\n\n def __init__(self, database_session):\n self._database_session = database_session\n\n def get_dao(self, type=None):\n if type is None:\n return PersonDAO(self._database_session)\n\n if type == 'member':\n return MemberDAO(self._database_session)\n else:\n return PersonDAO(self._database_session)"
},
{
"alpha_fraction": 0.6477997303009033,
"alphanum_fraction": 0.6484375,
"avg_line_length": 33.273223876953125,
"blob_id": "f458165de7c790506015f0377e44ed63085ee69e",
"content_id": "741fb19c6a90f2ccd271744dc0f9dfd6ceff45e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6272,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 183,
"path": "/vue/root_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\n\nfrom vue.menu_frame import MenuFrame\nfrom vue.menu_membre_frame import MenuMembreFrame\nfrom vue.menu_connexion_frame import MenuConnexionFrame\nfrom vue.member_frames.new_member_frame import NewMemberFrame\nfrom vue.member_frames.new_coach_frame import NewCoachFrame\nfrom vue.member_frames.list_members_frame import ListMembersFrame\nfrom vue.member_frames.list_membres_membre_frame import ListMembersMembresFrame\nfrom vue.member_frames.profile_frame import ProfileFrame\nfrom vue.member_frames.profile_membre_frame import ProfileMembreFrame\nfrom vue.sport_frames.list_sports_frame import ListSportsFrame\nfrom vue.sport_frames.list_sports_member_frame import ListSportsMemberFrame\nfrom vue.sport_frames.new_sport_frame import NewSportFrame\nfrom vue.sport_frames.sport_profile_frame import SportProfileFrame\nfrom vue.sport_frames.sport_profile_member_frame import SportProfileMemberFrame\nfrom vue.member_frames.connexion_frame import ConnexionFrame\n\n\n\nclass RootFrame(Frame):\n \"\"\"\n Member actions\n help: http://www.xavierdupre.fr/app/teachpyx/helpsphinx/c_gui/tkinter.html\n \"\"\"\n\n def __init__(self, person_controller, sport_controller, master=None):\n super().__init__(master)\n self._person_controller = person_controller\n self._sport_controller = sport_controller\n self._menu_frame = MenuFrame(self)\n self._menu_membre_frame = MenuMembreFrame(self)\n self._menu_connexion_frame = MenuConnexionFrame(self)\n self._frames = []\n\n def new_member(self):\n self.hide_menu()\n self.hide_frames()\n # Show formular subscribe\n subscribe_frame = NewMemberFrame(self._person_controller, self)\n subscribe_frame.show()\n self._frames.append(subscribe_frame)\n\n def new_coach(self):\n self.hide_menu()\n self.hide_frames()\n subscribe_frame = NewCoachFrame(self._person_controller, self)\n subscribe_frame.show()\n self._frames.append(subscribe_frame)\n\n def new_sport(self):\n self.hide_menu()\n self.hide_frames()\n new_sport_frame = NewSportFrame(self._sport_controller, self)\n new_sport_frame.show()\n self._frames.append(new_sport_frame)\n\n def show_members(self):\n # show members\n self.hide_menu()\n list_frame = ListMembersFrame(self._person_controller, self, person_type='member')\n self._frames.append(list_frame)\n list_frame.show()\n\n def show_members_membre(self):\n # show members\n self.hide_menu()\n list_frame = ListMembersMembresFrame(self._person_controller, self, person_type='member')\n self._frames.append(list_frame)\n list_frame.show()\n \n def show_coaches(self):\n # show members\n self.hide_menu()\n list_frame = ListMembersFrame(self._person_controller, self, person_type='coach')\n self._frames.append(list_frame)\n list_frame.show()\n\n def show_coaches_membre(self):\n # show members\n self.hide_menu()\n list_frame = ListMembersMembresFrame(self._person_controller, self, person_type='coach')\n self._frames.append(list_frame)\n list_frame.show()\n\n def show_profile(self, member_id):\n self.hide_menu()\n member_data = self._person_controller.get_person(member_id)\n self.hide_frames()\n profile_frame = ProfileFrame(self._person_controller, self._sport_controller, member_data, self)\n self._frames.append(profile_frame)\n profile_frame.show()\n\n def show_profile_membre(self, member_id):\n self.hide_menu()\n member_data = self._person_controller.get_person(member_id)\n self.hide_frames()\n profile_frame = ProfileMembreFrame(self._person_controller, self._sport_controller, member_data, self)\n self._frames.append(profile_frame)\n profile_frame.show()\n\n def show_sports(self):\n self.hide_menu()\n list_frame = ListSportsFrame(self._sport_controller, self)\n self._frames.append(list_frame)\n list_frame.show()\n\n def show_sports_member(self):\n self.hide_menu()\n list_frame = ListSportsMemberFrame(self._sport_controller, self)\n self._frames.append(list_frame)\n list_frame.show()\n\n def show_sport(self, sport_id):\n self.hide_menu()\n sport_data = self._sport_controller.get_sport(sport_id)\n self.hide_frames()\n profile_frame = SportProfileFrame(self._sport_controller, sport_data, self)\n self._frames.append(profile_frame)\n profile_frame.show()\n\n def show_sport_member(self, sport_id):\n self.hide_menu()\n sport_data = self._sport_controller.get_sport(sport_id)\n self.hide_frames()\n profile_frame = SportProfileMemberFrame(self._sport_controller, sport_data, self)\n self._frames.append(profile_frame)\n profile_frame.show()\n\n def show_connexion(self):\n self.hide_menu()\n # Show fennetre de connexion\n connexion_frame = ConnexionFrame(self._person_controller, self)\n connexion_frame.show()\n self._frames.append(connexion_frame)\n\n def hide_frames(self):\n for frame in self._frames:\n frame.hide()\n\n def show_menu(self):\n self.hide_menu()\n for frame in self._frames:\n frame.destroy()\n self._frames = []\n self._menu_frame.show()\n\n def show_menu_membre(self):\n self.hide_menu()\n for frame in self._frames:\n frame.destroy()\n self._frames = []\n self._menu_membre_frame.show()\n\n def show_menu_connexion(self):\n self.hide_menu()\n for frame in self._frames:\n frame.destroy()\n self._frames = []\n self._menu_connexion_frame.show()\n\n\n def hide_menu(self):\n self._menu_frame.hide()\n self._menu_connexion_frame.hide()\n self._menu_membre_frame.hide()\n\n\n def back(self):\n if len(self._frames) <= 1:\n self.show_menu()\n return\n last_frame = self._frames[-1]\n last_frame.destroy()\n del(self._frames[-1])\n last_frame = self._frames[-1]\n last_frame.show()\n\n def cancel(self):\n self.show_menu()\n\n def quit(self):\n self.master.destroy()\n"
},
{
"alpha_fraction": 0.7114337682723999,
"alphanum_fraction": 0.7114337682723999,
"avg_line_length": 24.627906799316406,
"blob_id": "9bc2a75103fb9e576e14268e8a4cb4ab03085f88",
"content_id": "ce3033fa5794ac2871d1bb76165653cba63e17c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1102,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 43,
"path": "/main.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "import logging\nimport sys\nfrom model.database import DatabaseEngine\nfrom controller.person_controller import PersonController\nfrom controller.sport_controller import SportController\n\nfrom vue.root_frame import RootFrame\n\n\ndef main():\n\n # configure logging\n root = logging.getLogger()\n root.setLevel(logging.DEBUG)\n\n handler = logging.StreamHandler(sys.stdout)\n handler.setLevel(logging.DEBUG)\n formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n logging.info(\"Start BDS App\")\n\n # Init db\n logging.info(\"Init database\")\n database_engine = DatabaseEngine(url='sqlite:///bds.db')\n database_engine.create_database()\n\n # controller\n person_controller = PersonController(database_engine)\n sport_controller = SportController(database_engine)\n\n # init vue\n root = RootFrame(person_controller, sport_controller)\n root.master.title(\"bds subscription app\")\n root.show_menu_connexion()\n\n # start\n root.mainloop()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6111645698547363,
"alphanum_fraction": 0.6150144338607788,
"avg_line_length": 30.484848022460938,
"blob_id": "aac20d2f46b01a41a924982682af29e025b4104f",
"content_id": "e12ad4fa52af425dcbd0fb3143071be9167ef837",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1039,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 33,
"path": "/vue/member_frames/new_coach_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom vue.member_frames.new_person_frame import NewPersonFrame\nfrom exceptions import Error\n\n\nclass NewCoachFrame(NewPersonFrame):\n\n def __init__(self, person_controller, master=None):\n super().__init__(person_controller, master)\n\n def create_widgets(self):\n super().create_widgets()\n self.contract_entry = self.create_entry(\"contract: \", row=4, columnspan=4)\n self.degree_entry = self.create_entry(\"degree: \", row=5, columnspan=4)\n\n def valid(self):\n\n data = super().get_data()\n data['contract'] = self.contract_entry.get()\n data['degree'] = self.degree_entry.get()\n\n try:\n member_data = self._person_controller.create_coach(data)\n messagebox.showinfo(\"Success\",\n \"Member %s %s created !\" % (member_data['firstname'], member_data['lastname']))\n\n except Error as e:\n messagebox.showerror(\"Error\", str(e))\n return\n\n self.show_menu()\n"
},
{
"alpha_fraction": 0.6320907473564148,
"alphanum_fraction": 0.6353322267532349,
"avg_line_length": 28.33333396911621,
"blob_id": "419807ef67b3355155b7adc28774025187724036",
"content_id": "e1d1b20ffcfcc05bfefffb20295c812c36943eef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 617,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 21,
"path": "/model/mapping/member.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nfrom sqlalchemy import Column, Boolean, String, ForeignKey\nfrom model.mapping.person import Person\n\n\nclass Member(Person):\n __tablename__ = 'members'\n\n id = Column(String(36), ForeignKey('people.id'), primary_key=True)\n medical_certificate = Column(Boolean(), nullable=False, default=False)\n\n __mapper_args__ = {\n 'polymorphic_identity': 'member',\n }\n\n def __repr__(self):\n return \"<Member(%s %s)>\" % (self.firstname, self.lastname.upper())\n\n def to_dict(self):\n _dict = super().to_dict()\n _dict['medical_certificate'] = self.medical_certificate\n return _dict\n"
},
{
"alpha_fraction": 0.5962671637535095,
"alphanum_fraction": 0.6070727109909058,
"avg_line_length": 32.93333435058594,
"blob_id": "15016226aed441c44f1532778a513e0857f088c7",
"content_id": "b65751a4c5af03cd95ab99a5ca55b5cc24407f80",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1018,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 30,
"path": "/vue/sport_frames/sport_formular_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\n\nfrom vue.base_frame import BaseFrame\n\n\nclass SportFormularFrame(BaseFrame):\n\n def __init__(self, master=None):\n super().__init__(master)\n self.create_widgets()\n self.name_pattern = re.compile(\"^[a-zA-Z-]{2,50}$\")\n\n def create_widgets(self):\n\n Label(self, text=\"Data informations:\", font='bold').grid(row=0, sticky='w')\n self.name_entry = self.create_entry(\"Name: \", row=1, validate_callback=self.validate_name)\n Label(self, text=\"Descripton: \").grid(row=2, sticky=\"w\")\n self.description_entry = Text(self, fg='black')\n self.description_entry.grid(row=3, column=0, columnspan=3)\n\n def validate_name(self, event, entry=None):\n if not self.name_pattern.match(entry.get()):\n entry.config(fg='red')\n else:\n entry.config(fg='black')\n\n def get_data(self):\n data = dict(name=self.name_entry.get(),\n description=self.description_entry.get(\"0.0\", \"end\"))\n return data\n"
},
{
"alpha_fraction": 0.6097378134727478,
"alphanum_fraction": 0.6097378134727478,
"avg_line_length": 33.230770111083984,
"blob_id": "08e5fbce2828f5068735be9c12a730b736592c45",
"content_id": "4bd6e2397760bfdde80e064c965e69955a784264",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 39,
"path": "/model/dao/member_dao.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from model.mapping.member import Member\nfrom model.dao.person_dao import PersonDAO\nfrom model.dao.dao_error_handler import dao_error_handler\n\n\nclass MemberDAO(PersonDAO):\n \"\"\"\n Member Mapping DAO\n \"\"\"\n\n def __init__(self, database_session):\n super().__init__(database_session, person_type=Member)\n\n @dao_error_handler\n def create(self, data: dict):\n member = Member(firstname=data.get('firstname').lower(), lastname=data.get('lastname').lower(),\n email=data.get('email'),\n medical_certificate=data.get('medical_certificate', False))\n if 'address' in data.keys():\n address = data['address']\n member.set_address(address['street'], address['postal_code'], address['city'],\n address.get('country', 'FRANCE'))\n self._database_session.add(member)\n self._database_session.flush()\n return member\n\n @dao_error_handler\n def update(self, member: Member, data: dict):\n # Update Person data\n super().update(member, data)\n\n # Update Member data\n if 'medical_certificate' in data:\n member.medical_certificate = data['medical_certificate']\n\n self._database_session.merge(member)\n self._database_session.flush()\n\n return member\n"
},
{
"alpha_fraction": 0.6438356041908264,
"alphanum_fraction": 0.6849315166473389,
"avg_line_length": 11.166666984558105,
"blob_id": "915d0ba419e1f9acbca42f13ab6599d5aa32d4f0",
"content_id": "35d71cb57253a93a22ddb512105c1c90878514f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 146,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 12,
"path": "/README.md",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "# TD cours de genie logiciel 2020\n\n## Start application\n\n```\npython3 main.py\n```\n\n## import dependencies\n```\npip3 install -r requirements.txt\n```\n"
},
{
"alpha_fraction": 0.7823129296302795,
"alphanum_fraction": 0.7823129296302795,
"avg_line_length": 35.75,
"blob_id": "82a09ad71aea65853136f79c39eecb577cf828ae",
"content_id": "353bb0d27d95ea056106a59cbdf37eee9eb49505",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 4,
"path": "/model/mapping/__init__.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from sqlalchemy.ext.declarative import declarative_base\n\n\"\"\" base class from which all mapped classes should inherit \"\"\"\nBase = declarative_base()\n"
},
{
"alpha_fraction": 0.7918033003807068,
"alphanum_fraction": 0.7926229238510132,
"avg_line_length": 86.14286041259766,
"blob_id": "bcf6ea90bd095c7d53a845833aeeb3f1524ca56c",
"content_id": "c930306b0551162985a2f6b0791f3c51d7c76185",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3714,
"license_type": "permissive",
"max_line_length": 515,
"num_lines": 42,
"path": "/CONTRIBUTING.md",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "# Contributing Guide\n\n## Code practices\n\n- The code must be compliant with PEP8\n- Strings must be surrounded by double quotes\n- Avoid @staticmethod and @classmethod as much as possible\n\n\n## GIT practices\n\n### Commit Related Changes\n\nA commit should be a wrapper for related changes. For example, fixing two different bugs should produce two separate commits. Small commits make it easier for other team members to understand the changes and roll them back if something went wrong. With tools like the staging area and the ability to stage only parts of a file, Git makes it easy to create very granular commits.\n\n### Commit Often\n\nCommitting often keeps your commits small and, again, helps you commit only related changes. Moreover, it allows you to share your code more frequently with others. That way it’s easier for everyone to integrate changes regularly and avoid having merge conflicts. Having few large commits and sharing them rarely, in contrast, makes it hard both to solve conflicts and to comprehend what happened.\n\n### Don’t Commit Half-Done Work\n\nYou should only commit code when it’s completed. This doesn’t mean you have to complete a whole, large feature before committing. Quite the contrary: split the feature’s implementation into logical chunks and remember to commit early and often. But don’t commit just to have something in the repository before leaving the office at the end of the day. If you’re tempted to commit just because you need a clean working copy (to check out a branch, pull in changes, etc.) consider using Git’s “Stash” feature instead.\n\n### Test Before You Commit\n\nResist the temptation to commit something that you “think” is completed. Test it thoroughly to make sure it really is completed and has no side effects (as far as one can tell). While committing half-baked things in your local repository only requires you to forgive yourself, having your code tested is even more important when it comes to pushing / sharing your code with others.\n\n### Write Good Commit Messages\n\nBegin your message with a short summary of your changes (up to 50 characters as a guideline). Separate it from the following body by including a blank line. The body of your message should provide detailed answers to the following questions: What was the motivation for the change? How does it differ from the previous implementation? Use the imperative, present tense („change“, not „changed“ or „changes“) to be consistent with generated messages from commands like git merge.\n\n### Version Control is not a Backup System\n\nHaving your files backed up on a remote server is a nice side effect of having a version control system. But you should not use your VCS like it was a backup system. When doing version control, you should pay attention to committing semantically (see “related changes”) – you shouldn’t just cram in files.\n\n### Use Branches\n\nBranching is one of Git’s most powerful features – and this is not by accident: quick and easy branching was a central requirement from day one. Branches are the perfect tool to help you avoid mixing up different lines of development. You should use branches extensively in your development workflows: for new features, bug fixes, experiments, ideas…\n\n### Agree on a Workflow\n\nGit lets you pick from a lot of different workflows: long-running branches, topic branches, merge or rebase, git-flow… Which one you choose depends on a couple of factors: your project, your overall development and deployment workflows and (maybe most importantly) on your and your teammates’ personal preferences. However you choose to work, just make sure to agree on a common workflow that everyone follows.\n"
},
{
"alpha_fraction": 0.620771050453186,
"alphanum_fraction": 0.6317859888076782,
"avg_line_length": 46.074073791503906,
"blob_id": "4cb7392cd7617bbfca26d6d8256eb7a0792e2852",
"content_id": "fa670dce75c6a139fd50305850ac0a8ce788ed6b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1271,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 27,
"path": "/vue/menu_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import Label, Button\nfrom vue.base_frame import BaseFrame\n\n\nclass MenuFrame(BaseFrame):\n def __init__(self, root_frame):\n super().__init__(root_frame)\n self.create_widgets()\n\n def create_widgets(self):\n self.title = Label(self, text=\"Welcome in BDS App\")\n #self.subscribe = Button(self, text=\"Subscribe\", width=30, command=self._root_frame.show_subscribe)\n #self.new_coach = Button(self, text=\"New coach\", width=30, command=self._root_frame.new_coach)\n #self.new_sport = Button(self, text=\"New sport\", width=30, command=self._root_frame.new_sport)\n self.members = Button(self, text=\"Members\", width=30, command=self._root_frame.show_members)\n self.coaches = Button(self, text=\"Coaches\", width=30, command=self._root_frame.show_coaches)\n self.sports = Button(self, text=\"Sports\", width=30, command=self._root_frame.show_sports)\n self.quit = Button(self, text=\"QUIT\", fg=\"red\", width=30,\n command=self.quit)\n self.title.pack(side=\"top\")\n #self.subscribe.pack()\n #self.new_coach.pack()\n #self.new_sport.pack()\n self.members.pack()\n self.coaches.pack()\n self.sports.pack()\n self.quit.pack(side=\"bottom\")\n"
},
{
"alpha_fraction": 0.6502463221549988,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 31.479999542236328,
"blob_id": "21384f33316b53238923d691ce956d55f7b51576",
"content_id": "505d4350f2b11867ae97450041bbbedc0b9c64fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 812,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 25,
"path": "/model/dao/dao_error_handler.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom exceptions import ResourceNotFound, Error\nfrom sqlalchemy.orm.exc import NoResultFound\nfrom sqlalchemy.exc import IntegrityError, SQLAlchemyError\n\n\ndef dao_error_handler(func):\n \"\"\"\n Decorator pattern\n https://www.python.org/dev/peps/pep-0318/\n \"\"\"\n def handler(*args, **kwargs):\n try:\n return func(*args, **kwargs)\n except NoResultFound:\n logging.error(\"NoResultFound caught from SQLAlchemy\")\n raise ResourceNotFound(\"Resource not found\")\n except IntegrityError as e:\n logging.debug(\"Integrity error caught from SQLAlchemy (%s)\" % str(e))\n raise Error(\"Error data may be malformed\")\n except SQLAlchemyError as e:\n raise Error(\"An error occurred (%s)\" % str(e))\n\n return handler\n"
},
{
"alpha_fraction": 0.5906801223754883,
"alphanum_fraction": 0.6032745838165283,
"avg_line_length": 28.407407760620117,
"blob_id": "c2c213f9360d760fed758a5d0944b45d2c6d6354",
"content_id": "7a699eaf2b87091fe847a881472a4d49037b485d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 794,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 27,
"path": "/model/mapping/address.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from model.mapping import Base\nimport uuid\n\nfrom sqlalchemy import Column, String, Integer\n\n\nclass Address(Base):\n __tablename__ = 'addresses'\n\n id = Column(String(36), default=str(uuid.uuid4()), primary_key=True)\n\n street = Column(String(256), nullable=False)\n city = Column(String(50), nullable=False)\n postal_code = Column(Integer(), nullable=False)\n country = Column(String(50), nullable=False, default=\"FRANCE\")\n\n def __repr__(self):\n return \"<Address(%s, %d, %s %s)>\" % (self.street, self.postal_code, self.city, self.country.upper())\n\n def to_dict(self):\n return {\n \"id\": self.id,\n \"street\": self.street,\n \"city\": self.city,\n \"postal_code\": self.postal_code,\n \"country\": self.country\n }\n"
},
{
"alpha_fraction": 0.678787887096405,
"alphanum_fraction": 0.678787887096405,
"avg_line_length": 13.909090995788574,
"blob_id": "34e41af5de81a6a28440f7f7faecfa166cb10372",
"content_id": "ab3d9c7923dfda72e734b1fa45eee67880798baf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 11,
"path": "/exceptions.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "\nclass Error(Exception):\n \"\"\"Base class for exceptions in this module.\"\"\"\n pass\n\n\nclass ResourceNotFound(Error):\n pass\n\n\nclass InvalidData(Error):\n pass\n"
},
{
"alpha_fraction": 0.6091572642326355,
"alphanum_fraction": 0.6144658327102661,
"avg_line_length": 36.209877014160156,
"blob_id": "1bc6f517aa68de89d2ca571b7e9a528add2a2e9f",
"content_id": "ed11c44cada6bd4b5e24de8976c0a62cd15d8ff3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3014,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 81,
"path": "/model/mapping/person.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from model.mapping import Base\nimport uuid\n\nfrom sqlalchemy import Column, String, UniqueConstraint, ForeignKey\nfrom sqlalchemy.orm import relationship\nfrom model.mapping.address import Address\nfrom model.mapping.sport import SportAssociation\nfrom model.dao.dao_error_handler import dao_error_handler\nfrom exceptions import ResourceNotFound\n\n\nclass Person(Base):\n __tablename__ = 'people'\n\n id = Column(String(36), default=str(uuid.uuid4()), primary_key=True)\n\n firstname = Column(String(50), nullable=False)\n lastname = Column(String(50), nullable=False)\n email = Column(String(256), nullable=False)\n person_type = Column(String(50), nullable=False)\n address_id = Column(String(36), ForeignKey(\"addresses.id\"), nullable=True)\n\n address = relationship(\"Address\", cascade=\"all,delete-orphan\", single_parent=True)\n sports = relationship(\"SportAssociation\", back_populates=\"person\")\n\n __table_args__ = (UniqueConstraint('firstname', 'lastname'),)\n # https://docs.sqlalchemy.org/en/13/orm/inheritance.html\n __mapper_args__ = {\n 'polymorphic_identity': 'person',\n 'polymorphic_on': person_type\n }\n\n def __repr__(self):\n return \"<Person(%s %s)>\" % (self.firstname, self.lastname.upper())\n\n def to_dict(self):\n _data = {\n \"id\": self.id,\n \"firstname\": self.firstname,\n \"lastname\": self.lastname,\n \"email\": self.email,\n \"type\": self.person_type,\n \"sports\": []\n }\n for sport_association in self.sports:\n _data['sports'].append({\"level\": sport_association.level,\n \"id\": sport_association.sport.id,\n \"name\": sport_association.sport.name})\n\n if self.address is not None:\n _data['address'] = {\n \"street\": self.address.street,\n \"postal_code\": self.address.postal_code,\n \"city\": self.address.city,\n \"country\": self.address.country\n }\n return _data\n\n def set_address(self, street: str, postal_code: str, city: int, country: str = 'FRANCE'):\n self.address = Address(street=street, city=city, postal_code=postal_code, country=country)\n\n @dao_error_handler\n def add_sport(self, sport, level, session):\n asoociation = SportAssociation(level=level)\n asoociation.sport = sport\n self.sports.append(asoociation)\n session.flush()\n\n @dao_error_handler\n def delete_sport(self, sport, session):\n sport_association = None\n for association in self.sports:\n if association.sport == sport:\n sport_association = association\n break\n if sport_association is not None:\n self.sports.remove(sport_association)\n session.delete(sport_association)\n session.flush()\n else:\n raise ResourceNotFound(\"Sport %s not assigned to user %s\" % (sport.name, self.firstname))\n"
},
{
"alpha_fraction": 0.5856466889381409,
"alphanum_fraction": 0.5870662331581116,
"avg_line_length": 39.132911682128906,
"blob_id": "740aec9735d4bfed1ce09be870137fd40310c95a",
"content_id": "ba4df42f3fba17cf5f0d406eb55aa89c0c73b214",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6340,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 158,
"path": "/controller/person_controller.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "import re\nimport logging\n\nfrom model.dao.person_dao_fabric import PersonDAOFabric\nfrom model.dao.sport_dao import SportDAO\n\nfrom exceptions import Error, InvalidData\n\n\nclass PersonController:\n \"\"\"\n Member actions\n \"\"\"\n\n def __init__(self, database_engine):\n self._database_engine = database_engine\n\n def list_people(self, person_type=None):\n logging.info(\"Get people\")\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n members = dao.get_all()\n members_data = [member.to_dict() for member in members]\n return members_data\n\n def get_person(self, person_id, person_type=None):\n logging.info(\"Get person %s\" % person_id)\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n member = dao.get(person_id)\n member_data = member.to_dict()\n return member_data\n\n def get_member(self, member_id):\n return self.get_person(member_id, person_type='member')\n\n def create_person(self, data, person_type=None):\n logging.info(\"Create member with data %s\" % str(data))\n self._check_person_data(data)\n try:\n with self._database_engine.new_session() as session:\n # Save member in database\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n member = dao.create(data)\n member_data = member.to_dict()\n return member_data\n except Error as e:\n # log error\n logging.error(\"An Error occured (%s)\" % str(e))\n raise e\n\n def create_member(self, data):\n return self.create_person(data, 'member')\n\n def create_coach(self, data):\n return self.create_person(data, 'coach')\n\n def _update_person(self, member_id, member_data, person_type=None):\n logging.info(\"Update %s with data: %s\" % (member_id, str(member_data)))\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n person = dao.get(member_id)\n\n person = dao.update(person, member_data)\n return person.to_dict()\n\n def update_person(self, member_id, member_data):\n self._check_person_data(member_data, update=True)\n return self._update_person(member_id, member_data, person_type='person')\n\n def update_member(self, member_id, data):\n self._check_member_data(data, update=True)\n return self._update_person(member_id, data, person_type='member')\n\n def update_coach(self, member_id, data):\n self._check_coach_data(data, update=True)\n return self._update_person(member_id, data, person_type='coach')\n\n def add_sport_person(self, person_id, sport_id, level):\n logging.info(\"Add sport %s to person %s\" % (sport_id, person_id))\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao()\n person = dao.get(person_id)\n sport = SportDAO(session).get(sport_id)\n person.add_sport(sport, level, session)\n return person.to_dict()\n\n def delete_sport_person(self, person_id, sport_id):\n logging.info(\"Delete sport %s from user %s\" % (person_id, sport_id))\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao()\n person = dao.get(person_id)\n sport = SportDAO(session).get(sport_id)\n person.delete_sport(sport, session)\n return person.to_dict()\n\n def delete_person(self, member_id, person_type=None):\n logging.info(\"Delete person %s\" % member_id)\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n member = dao.get(member_id)\n dao.delete(member)\n\n def search_person(self, firstname, lastname, person_type=None):\n logging.info(\"Search person %s %s\" % (firstname, lastname))\n # Query database\n with self._database_engine.new_session() as session:\n dao = PersonDAOFabric(session).get_dao(type=person_type)\n member = dao.get_by_name(firstname, lastname)\n return member.to_dict()\n\n def _check_member_data(self, data, update=False):\n self._check_person_data(data, update=update)\n specs = {\n 'medical_certificate': {\"type\": bool},\n }\n self._check_data(data, specs, update=update)\n\n def _check_coach_data(self, data, update=False):\n self._check_person_data(data, update=update)\n specs = {\n 'degree': {\"type\": str},\n 'certificate': {\"type\": str}\n }\n self._check_data(data, specs, update=update)\n\n def _check_person_data(self, data, update=False):\n name_pattern = re.compile(\"^[\\S-]{2,50}$\")\n email_pattern = re.compile(\"^([a-zA-Z0-9_\\-\\.]+)@([a-zA-Z0-9_\\-\\.]+)\\.([a-zA-Z]{2,5})$\")\n specs = {\n 'firstname': {\"type\": str, \"regex\": name_pattern},\n 'lastname': {\"type\": str, \"regex\": name_pattern},\n 'email': {\"type\": str, \"regex\": email_pattern}\n }\n self._check_data(data, specs, update=update)\n\n if 'address' in data:\n address = data['address']\n specs = {\n 'street': {\"type\": str},\n 'postal_code': {\"type\": int},\n 'city': {\"type\": str}\n }\n self._check_data(address, specs, update=update)\n\n def _check_data(self, data, specs, update=False):\n for mandatory, specs in specs.items():\n if not update:\n if mandatory not in data or data[mandatory] is None:\n raise InvalidData(\"Missing value %s\" % mandatory)\n else:\n if mandatory not in data:\n continue\n value = data[mandatory]\n if \"type\" in specs and not isinstance(value, specs[\"type\"]):\n raise InvalidData(\"Invalid type %s\" % mandatory)\n if \"regex\" in specs and isinstance(value, str) and not re.match(specs[\"regex\"], value):\n raise InvalidData(\"Invalid value %s\" % mandatory)"
},
{
"alpha_fraction": 0.6013590097427368,
"alphanum_fraction": 0.6115515232086182,
"avg_line_length": 36.30986022949219,
"blob_id": "f28b3c55171f8220a1cb7387cbc8c9939785e7e0",
"content_id": "cf7ced72eb447f9fd63330064bfbf3a93d4b3f47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2649,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 71,
"path": "/vue/sport_frames/sport_profile_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom vue.sport_frames.sport_formular_frame import SportFormularFrame\nfrom exceptions import Error\n\n\nclass SportProfileFrame(SportFormularFrame):\n\n def __init__(self, sport_controller, sport, master=None):\n super().__init__(master)\n self._sport_controller = sport_controller\n self._sport = sport\n self.refresh()\n\n def create_widgets(self):\n super().create_widgets()\n\n # Buttons\n self.edit_button = Button(self, text=\"Edit\",\n command=self.edit)\n self.cancel_button = Button(self, text=\"Cancel\", command=self.refresh)\n self.update_button = Button(self, text=\"Update\", command=self.update)\n self.remove_button = Button(self, text=\"Remove\", command=self.remove)\n self.return_button = Button(self, text=\"Return\", fg=\"red\",\n command=self.back)\n\n self.return_button.grid(row=20, column=0)\n self.edit_button.grid(row=20, column=1, sticky=\"nsew\")\n self.remove_button.grid(row=20, column=2, sticky=\"nsew\")\n\n def edit(self):\n self.edit_button.grid_forget()\n self.remove_button.grid_forget()\n entries = [self.name_entry, self.description_entry]\n for entry in entries:\n entry.config(state=NORMAL)\n self.cancel_button.grid(row=20, column=2, sticky=\"nsew\")\n self.update_button.grid(row=20, column=1, sticky=\"nsew\")\n\n def _refresh_entry(self, entry, value=\"\"):\n entry.delete(0, END)\n if value != \"\":\n entry.insert(0, value)\n entry.config(state=DISABLED)\n\n def refresh(self):\n # Restore window with member value and cancel edition\n self.cancel_button.grid_forget()\n self.update_button.grid_forget()\n self._refresh_entry(self.name_entry, self._sport['name'])\n self.description_entry.delete(\"0.0\", END)\n self.description_entry.insert(\"0.0\", self._sport['description'])\n self.description_entry.config(state=DISABLED)\n self.edit_button.grid(row=20, column=1, sticky=\"nsew\")\n self.remove_button.grid(row=20, column=2, sticky=\"nsew\")\n\n def update(self):\n\n data = self.get_data()\n sport = self._sport_controller.update_sport(self._sport['id'], data)\n self._sport = sport\n self.refresh()\n\n def remove(self):\n sport_id = self._sport['id']\n self._sport_controller.delete_sport(sport_id)\n # show confirmation\n messagebox.showinfo(\"Success\",\n \"Sport %s deleted !\" % self._sport['name'])\n self.back()\n"
},
{
"alpha_fraction": 0.6240179538726807,
"alphanum_fraction": 0.6329966187477112,
"avg_line_length": 41.42856979370117,
"blob_id": "5313ce862a91b1725bdeb52a1155920db5c27efd",
"content_id": "2412d69bccc6efe88d33de0fb30c6d8f96b4bf92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 891,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 21,
"path": "/vue/menu_membre_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import Label, Button\nfrom vue.base_frame import BaseFrame\n\n\nclass MenuMembreFrame(BaseFrame):\n def __init__(self, root_frame):\n super().__init__(root_frame)\n self.create_widgets()\n\n def create_widgets(self):\n self.title = Label(self, text=\"Welcome in BDS App\")\n self.members = Button(self, text=\"Members\", width=30, command=self._root_frame.show_members_membre)\n self.coaches = Button(self, text=\"Coaches\", width=30, command=self._root_frame.show_coaches_membre)\n self.sports = Button(self, text=\"Sports\", width=30, command=self._root_frame.show_sports_member)\n self.quit = Button(self, text=\"QUIT\", fg=\"red\", width=30,\n command=self.quit)\n self.title.pack(side=\"top\")\n self.members.pack()\n self.coaches.pack()\n self.sports.pack()\n self.quit.pack(side=\"bottom\")\n"
},
{
"alpha_fraction": 0.5676918625831604,
"alphanum_fraction": 0.568554162979126,
"avg_line_length": 35.25,
"blob_id": "e1910a0c532ea33a1e3c4c9744fde37e3a795ad4",
"content_id": "fedc3e2bcc832c6e779bef9cae5046b4f7dc394d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3479,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 96,
"path": "/controller/sport_controller.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "import re\nimport logging\n\nfrom model.dao.sport_dao import SportDAO\n\nfrom exceptions import Error, InvalidData, ResourceNotFound\n\n\nclass SportController:\n \"\"\"\n Sport actions\n \"\"\"\n\n def __init__(self, database_engine):\n self._database_engine = database_engine\n\n def list_sports(self):\n logging.info(\"List sports\")\n with self._database_engine.new_session() as session:\n sports = SportDAO(session).get_all()\n sports_data = [sport.to_dict() for sport in sports]\n return sports_data\n\n def get_sport(self, sport_id):\n logging.info(\"Get sport %s\" % sport_id)\n with self._database_engine.new_session() as session:\n sport = SportDAO(session).get(sport_id)\n sport_data = sport.to_dict()\n return sport_data\n\n def create_sport(self, data):\n logging.info(\"Create sport with data %s\" % str(data))\n\n self._check_sport_data(data)\n sport_name = data['name']\n sports = self.list_sports()\n if sport_name in [sport['name'] for sport in sports]:\n raise Error(\"Sport '%s' already exist\" % sport_name)\n\n try:\n with self._database_engine.new_session() as session:\n # Save member in database\n dao = SportDAO(session)\n sport = dao.create(data)\n sport_data = sport.to_dict()\n return sport_data\n except Error as e:\n # log error\n logging.error(\"An Error occured (%s)\" % str(e))\n raise e\n\n def update_sport(self, sport_id, sport_data):\n logging.info(\"Update sport %s with data: %s\" % (sport_id, str(sport_data)))\n self._check_sport_data(sport_data, update=True)\n with self._database_engine.new_session() as session:\n dao = SportDAO(session)\n sport = dao.get(sport_id)\n sport = dao.update(sport, sport_data)\n return sport.to_dict()\n\n def delete_sport(self, sport_id):\n logging.info(\"Delete person %s\" % sport_id)\n with self._database_engine.new_session() as session:\n dao = SportDAO(session)\n sport = dao.get(sport_id)\n dao.delete(sport)\n\n def search_sport(self, name):\n logging.info(\"Search sport %s\" % name)\n # Query database\n with self._database_engine.new_session() as session:\n dao = SportDAO(session)\n sport = dao.get_by_name(name)\n return sport.to_dict()\n\n def _check_sport_data(self, data, update=False):\n name_pattern = re.compile(\"^[\\S-]{2,50}$\")\n specs = {\n \"name\": {\"type\": str, \"regex\": name_pattern},\n \"description\": {\"type\": str}\n }\n self._check_data(data, specs, update=update)\n\n def _check_data(self, data, specs, update=False):\n for mandatory, specs in specs.items():\n if not update:\n if mandatory not in data or data[mandatory] is None:\n raise InvalidData(\"Missing value %s\" % mandatory)\n else:\n if mandatory not in data:\n continue\n value = data[mandatory]\n if \"type\" in specs and not isinstance(value, specs[\"type\"]):\n raise InvalidData(\"Invalid type %s\" % mandatory)\n if \"regex\" in specs and isinstance(value, str) and not re.match(specs[\"regex\"], value):\n raise InvalidData(\"Invalid value %s\" % mandatory)"
},
{
"alpha_fraction": 0.5764272809028625,
"alphanum_fraction": 0.5819520950317383,
"avg_line_length": 30.941177368164062,
"blob_id": "9d9c38c914441760f3d30a892997a2aef090b003",
"content_id": "73ec3004ea2b40df43125bbbc7963c445f3fb848",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1086,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 34,
"path": "/vue/sport_frames/new_sport_frame.py",
"repo_name": "Apaillard/GLPO",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom tkinter import messagebox\n\nfrom vue.sport_frames.sport_formular_frame import SportFormularFrame\nfrom exceptions import Error\n\n\nclass NewSportFrame(SportFormularFrame):\n\n def __init__(self, sport_controller, master=None):\n super().__init__(master)\n self._sport_controller = sport_controller\n\n def create_widgets(self):\n super().create_widgets()\n self.valid = Button(self, text=\"valid\", fg=\"red\",\n command=self.valid)\n self.cancel = Button(self, text=\"cancel\", fg=\"red\",\n command=self.back)\n self.valid.grid(row=20, column=1, sticky=E)\n self.cancel.grid(row=20, column=2, sticky=W)\n\n def valid(self):\n data = self.get_data()\n try:\n sport_data = self._sport_controller.create_sport(data)\n messagebox.showinfo(\"Success\",\n \"Sport %s created !\" % sport_data['name'])\n\n except Error as e:\n messagebox.showerror(\"Error\", str(e))\n return\n\n self.back()\n"
}
] | 32 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.