
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
jovianjaison/Car-Service-Webapp
|
https://github.com/jovianjaison/Car-Service-Webapp
|
fb25b47e30e71cd1671fcf086bd0417b09a8a8b3
|
2c620058bca4ca899f7611f5ad4000e3e5c72bfb
|
48ede43940ab9a8b5d9bef6baa330dc76c01997a
|
refs/heads/master
| 2020-03-28T00:14:49.627815 | 2018-10-04T12:35:11 | 2018-10-04T12:35:11 | 147,388,317 | 4 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.732119619846344,
"alphanum_fraction": 0.7490246891975403,
"avg_line_length": 23.0625,
"blob_id": "c0f346b05335b10cc81af0378ff420409aff0847",
"content_id": "aad7d30d321c9d739236293d9246c8e33a1e74ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 32,
"path": "/first/models.py",
"repo_name": "jovianjaison/Car-Service-Webapp",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\nclass Company(models.Model):\n\tname = models.CharField(max_length=20)\n\n\tdef __str__(self):\n\t\treturn self.name\n\nclass Cars(models.Model):\n\tname = models.CharField(max_length=20)\n\tcompany=models.ForeignKey(Company,on_delete=models.CASCADE)\n\n\tdef __str__(self):\n\t\treturn self.name\n\nclass Garage(models.Model):\n\tname = models.CharField(max_length=20)\n\taddress=models.CharField(max_length=50)\n\tphone=models.IntegerField(max_length=10)\n\t\n\n\tdef __str__(self):\n\t\treturn self.name\n\nclass Parts(models.Model):\n\tname = models.CharField(max_length=20)\n\tprice=models.IntegerField(max_length=7)\n\tmodel=models.ForeignKey(Cars,on_delete=models.CASCADE)\n\tgarage_name=models.ForeignKey(Garage,on_delete=models.CASCADE)\n\n\tdef __str__(self):\n\t\treturn self.name"
},
{
"alpha_fraction": 0.7355072498321533,
"alphanum_fraction": 0.737922728061676,
"avg_line_length": 35.043479919433594,
"blob_id": "8059c2640b6943164b8bf2c09e42b8f62854213a",
"content_id": "b96169d9081855a8173a1608a6962949dc226916",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 828,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 23,
"path": "/first/forms.py",
"repo_name": "jovianjaison/Car-Service-Webapp",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Company\nfrom .models import Cars\n\nMY_CHOICES = []\npost_company=Company.objects.all()\nfor i in post_company:\n\tMY_CHOICES.append([i.id,i.name])\nprint(MY_CHOICES)\nclass TheForm(forms.Form):\n\t#post_car=Cars.objects.all()\n\tname = forms.ChoiceField(label='Select your car company:',choices=MY_CHOICES,widget=forms.Select(attrs={'class':'custom-select mr-sm-2'}))\n\t'''car_model=forms.ChoiceField(label='Select car model:'),\n\twidget=forms.Select(choices=post_car)'''\n\nMY_CHOICES_RE = []\npost_car=Cars.objects.all()\nfor j in post_car:\n\tMY_CHOICES_RE.append([j.id,j.name])\nprint(MY_CHOICES_RE)\nclass TheFormRe(forms.Form):\n\t#post_car=Cars.objects.all()\n\tname = forms.ChoiceField(label='Select your car model:',choices=MY_CHOICES_RE,widget=forms.Select(attrs={'class':'custom-select mr-sm-2'}))"
},
{
"alpha_fraction": 0.5642594695091248,
"alphanum_fraction": 0.5911872982978821,
"avg_line_length": 33.04166793823242,
"blob_id": "47e0161aa15e69c6b3d4234a4a461d06673ede9e",
"content_id": "8882e2b0a779c61c37b1fe080d479b1c78abfe62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 24,
"path": "/first/migrations/0004_parts.py",
"repo_name": "jovianjaison/Car-Service-Webapp",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.1.1 on 2018-10-02 04:47\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('first', '0003_garage'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Parts',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=20)),\n ('price', models.IntegerField(max_length=7)),\n ('garage_name', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='first.Garage')),\n ('model', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='first.Cars')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7752808928489685,
"alphanum_fraction": 0.7752808928489685,
"avg_line_length": 21.5,
"blob_id": "b5816d7c9655e47a0a31e612f6259732107dba71",
"content_id": "e68f66a91492953d47130fd36408e551bd85f4fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 4,
"path": "/cars/view.py",
"repo_name": "jovianjaison/Car-Service-Webapp",
"src_encoding": "UTF-8",
"text": "from .models import Comment\n\ndef index(request):\n\treturn render(request,'first/Car.html')"
},
{
"alpha_fraction": 0.6878306865692139,
"alphanum_fraction": 0.6913580298423767,
"avg_line_length": 28.34482765197754,
"blob_id": "ea05598b32068de6499872406c1f51adf6ff69d5",
"content_id": "81ff59f4b108e0500ec4a97598dc367550e2cb78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1701,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 58,
"path": "/first/views.py",
"repo_name": "jovianjaison/Car-Service-Webapp",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,redirect\nfrom .models import Company\nfrom .models import Cars\nfrom .models import Parts\nfrom .forms import TheForm\nfrom .forms import TheFormRe\nfrom django.views.decorators.http import require_POST\n\ndef index(request):\n\t#post_company=Company.objects.all()\n\t#post_car=Cars.objects.filter()\n\tform = TheForm()\n\tformr= TheFormRe()\n\t'''a=request.GET.get('id1')\n\tcname=request.POST.get('company')\n\n\t i in \tprint('Here !!! '+a)'''\n\treturn render(request,'first/front.html',{'form':form,'formr':formr})\n\n@require_POST\ndef getData(request):\n\tform = TheForm(request.POST)\n\tcname=request.POST['name']\n\tprint(cname)\n\t#post_car=Cars.objects.filter(company__exact='id1')\n\treturn redirect('index')\n\n@require_POST\ndef getDataRe(request):\n\tform = TheFormRe(request.POST)\n\tcname=request.POST['name']\n\tprint(cname)\n\tpost_car=Cars.objects.all()\n\tpost_parts=Parts.objects.all()\n\tans=\"temp\"\n\tfor i in post_car:\n\t\tif i.id==int(cname):\n\t\t\tans=i.name\n\tMY_CHOICES_RT = []\n\tfor j in post_parts:\n\t\tif ans==str(j.model):\n\t\t\tMY_CHOICES_RT.append([j.name,j.price,j.garage_name,j.model])\t\t\n\n\tresult_string = \"\"\"<HTML><head><style>{body{background-color:yellow;}}</style></head><body><h1>Dealer list</h1><table border=1>\n\t<tr><b> <td>Parts</td> <td>Price</td><td>Garage Name</td><td>Model</td></b></tr>\\n\"\"\"\n\n\tfor k in MY_CHOICES_RT:\n\t\tresult_string += \"<tr>\\n\"\n\t\tfor l in k:\n\t\t\tresult_string += \"<td>%s</td>\"%l \n\t\tresult_string += \"\\n</tr>\\n\" \n\tresult_string += \"\"\"</table></body></HTML>\"\"\"\n\tdisplay = open(\"first/templates/first/Onsubmit.html\", 'w')\n\tdisplay.write(result_string)\n\tdisplay.close()\n\n\t#post_car=Cars.objects.filter(company__exact='id1')\n\treturn render(request,'first/Onsubmit.html')"
}
] | 5 |
Jeremias-V/MIPS-To-Binary
|
https://github.com/Jeremias-V/MIPS-To-Binary
|
748c6c18f9a53bbadf8616e31c3a326e4f8f0894
|
f25a326de9be9b57bfa1984dfa71e59851323718
|
be21867c0a29beb538887d48789555d243fa79b6
|
refs/heads/main
| 2023-05-05T20:51:50.640879 | 2021-05-30T20:09:40 | 2021-05-30T20:09:40 | 342,639,270 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49147120118141174,
"alphanum_fraction": 0.5561478137969971,
"avg_line_length": 34.54545593261719,
"blob_id": "bef009433d1fd544fe61bdcaac4cc9e6a1887b24",
"content_id": "f1a5a86e941d1bf8e70321a8c63887c4111dd798",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2814,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 77,
"path": "/src/HexTranslator/InstructionTranslations/RTranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom HexTranslator.InstructionTranslations.HexToBin import HexToBin, HexToInt\r\nfrom HexTranslator.InstructionSet import Registers, RType, Functions\r\n\r\nregisters = Registers.getRegisters()\r\nfunctions = Functions.getFunctions()\r\nzeros = ['$0', '$zero']\r\ninvalid = ['$k0', '$k1']\r\njra = ['001000']\r\nrtype_rd_rs_rt = ['100000', '100001', '100100', '100111', '100101', '101010', '101011', '100010', '100011']\r\nrtype_rd_rt_sh = ['000000', '000010', '000011']\r\nrtype_move_rd = ['010000', '010010']\r\nrtype_rs_rt = ['011010', '011011', '011000', '011001']\r\nrtype = RType.getOpcodes()\r\n\r\n\r\ndef translateR(line, line1, line2):\r\n arregloSalida = [[],[],[]]\r\n if(line in jra):\r\n salida = \"jr $ra\"\r\n return salida\r\n if(line in rtype_rd_rs_rt):\r\n rs = line1\r\n auxrs = rs[0:5]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[1].append(rsSalida)\r\n rt = line1\r\n auxrt = rt[5:10]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[2].append(rtSalida)\r\n rd = line1\r\n auxrd = rd[10:15]\r\n if(auxrd in registers):\r\n rdSalida = registers[auxrd]\r\n arregloSalida[0].append(rdSalida)\r\n salida = functions[line] + \" \" + arregloSalida[0][0] + \", \" + arregloSalida[1][0] + \", \" + arregloSalida[2][0]\r\n return salida\r\n if(line in rtype_rd_rt_sh):\r\n rs = line2\r\n auxrs =rs[5:10]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[1].append(rsSalida)\r\n rt = line2\r\n auxrt = rt[10:15]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[2].append(rtSalida)\r\n num = line2\r\n auxnum = num[15:20]\r\n bintodec = int(auxnum,2)\r\n salida = functions[line] + \" \" + arregloSalida[2][0] + \", \" + arregloSalida[1][0] + \", \" + str(bintodec)\r\n return salida\r\n if(line in rtype_move_rd):\r\n r = line1\r\n auxr = r[10:15]\r\n if(auxr in registers):\r\n rSalida = registers[auxr]\r\n arregloSalida[0].append(rSalida)\r\n salida = functions[line] + \" \" + arregloSalida[0][0]\r\n return salida\r\n if(line in rtype_rs_rt):\r\n first = line1\r\n auxfirst = first[0:5]\r\n if(auxfirst in registers):\r\n fSalida = registers[auxfirst]\r\n arregloSalida[0].append(fSalida)\r\n second = line1\r\n auxSecond = second[5:10]\r\n if(auxSecond in registers):\r\n sSalida = registers[auxSecond]\r\n arregloSalida[1].append(sSalida)\r\n salida = functions[line] + \" \" + arregloSalida[0][0] + \", \" + arregloSalida[1][0]\r\n return salida\r\n return \"Codigo invalido\"\r\n"
},
{
"alpha_fraction": 0.4753747284412384,
"alphanum_fraction": 0.5010706782341003,
"avg_line_length": 29.129032135009766,
"blob_id": "3e67344230c2916fc041a349b9a5f369c5f882f2",
"content_id": "bdbdebe2ba1e20ba4f4b432a0207795372b6c3b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 31,
"path": "/src/Translator/Parser/clean.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nsys.path.append(\"..\")\n\ndef cleanCode(lines):\n k = 1\n tagAddress = {}\n lineAddress = {}\n pos = int(0x00400000)\n final = list()\n cur_path = os.path.dirname(__file__)\n path = cur_path + '/instructions.txt'\n lines = lines.split('\\n')\n with open(path, 'r') as f:\n instructions = f.read().split()\n for line in lines:\n originalLine = list(line.split('\\n'))\n line = list(line.split())\n if(line and len(line[0]) > 1 and line[0][-1] == ':'):\n tag = line[0][:-1]\n tagAddress[tag] = pos\n if not line or line[0] == '#' or line[0][0] == '.' or (line[0] not in instructions):\n pass\n else:\n tmp = ' '.join(originalLine)\n ans = tmp.split(\"#\", 1)\n final.append(ans[0].split())\n lineAddress[k] = pos\n k+= 1\n pos += 4\n return [final, tagAddress, lineAddress]\n"
},
{
"alpha_fraction": 0.48422712087631226,
"alphanum_fraction": 0.5173501372337341,
"avg_line_length": 18.8125,
"blob_id": "528c1e7062d24ff5cfd28aec0c68025e5f470ad9",
"content_id": "81e482d12581d8e4819dd98a84dd5ae5eefafe05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 634,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/src/Translator/InstructionTranslations/Complements.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"..\")\n\ndef twosComplement(bits, n):\n if n < 0:\n n = ( 1<<bits ) + n\n ans = '{:0%ib}' % bits\n return ans.format(n)\n\ndef IntToBin(f, n):\n return \"{:0>{}b}\".format(n,f)\n\ndef IntToHex(f, n):\n return \"{0:#0{1}x}\".format(n,f+2)\n\ndef HexToInt(h):\n return int(h)\n\ndef HexToBin(f, n):\n return IntToBin(int(f), HexToInt(n))\n\ndef isHex(s):\n if(len(s) > 1 and s[0] == '0' and s[1] == 'x'):\n return True\n else:\n return False\n\ndef isTag(s):\n for c in s:\n if (ord(c) < 97 or ord(c) > 122) and (ord(c) < 65 or ord(c) > 90):\n return False\n return True\n"
},
{
"alpha_fraction": 0.44039127230644226,
"alphanum_fraction": 0.4903199374675751,
"avg_line_length": 36.054264068603516,
"blob_id": "1ee498c63f9ae4d27eadfadc71796d4e4ee96f7d",
"content_id": "34d6ff3b8b624c50f5b8b7cb64fae6ca83be851e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4907,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 129,
"path": "/src/HexTranslator/InstructionTranslations/ITranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom HexTranslator.InstructionTranslations.HexToBin import HexToBin, HexToInt\r\nfrom HexTranslator.InstructionSet import Registers, IType\r\nsys.path.append(\"..\")\r\nregisters = Registers.getRegisters()\r\nzeros = ['$0', '$zero']\r\ninvalid = ['$k0', '$k1']\r\nitype_rt_rs = ['001000', '001001', '001100', '001111', '001101', '001010', '001011']\r\nitype_load = ['100011', '100101', '100100', '110000']\r\nitype_store = ['101011', '101001', '101000', '111000']\r\nitype_rs_rt = ['000100', '000101']\r\nitype = IType.getOpcodes()\r\n\r\ndef twos_comp(val, bits):\r\n if (val & (1 << (bits - 1))) != 0:\r\n val = val - (1 << bits) \r\n return val \r\n\r\ndef translateI(line, line1):\r\n arregloSalida = [[],[],[]]\r\n if(line in itype_rs_rt):\r\n rs = line1\r\n auxrs = rs[0:5]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[0].append(rsSalida)\r\n rt = line1\r\n auxrt = rt[5:10]\r\n bintohex =line1\r\n auxbin = bintohex[10:26]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[1].append(rtSalida)\r\n esComple = bintohex[10:11]\r\n if(esComple != '1'):\r\n bintohex = int(auxbin,2)\r\n res = hex((bintohex))\r\n arregloSalida[2].append(res)\r\n else:\r\n out = twos_comp(int(auxbin, 2), len(auxbin))\r\n out = str(out)\r\n arregloSalida[2].append(out)\r\n salida = itype[line] + \" \" +arregloSalida[0][0] + \", \" + arregloSalida[1][0] + \", \" + arregloSalida[2][0]\r\n return salida\r\n if(line in itype_store):\r\n rs = line1\r\n auxrs =rs[0:5]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[2].append(rsSalida)\r\n rt = line1\r\n auxrt = rt[5:10]\r\n bintohex = line1\r\n auxbin = bintohex[10:26]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[0].append(rtSalida)\r\n esComple = bintohex[10:11]\r\n if(esComple != '1'):\r\n bintohex = int(auxbin,2)\r\n res = hex(bintohex)\r\n arregloSalida[1].append(res)\r\n else:\r\n out = twos_comp(int(auxbin, 2), len(auxbin))\r\n out = str(out)\r\n arregloSalida[1].append(out)\r\n salida = itype[line] + \" \" +arregloSalida[0][0] + \", \" + arregloSalida[1][0] + \"(\" + arregloSalida[2][0] + \")\"\r\n return salida\r\n if(line in itype_load):\r\n rs = line1\r\n auxrs =rs[0:5]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[2].append(rsSalida)\r\n rt = line1\r\n auxrt = rt[5:10]\r\n bintohex = line1\r\n auxbin = bintohex[10:26]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[0].append(rtSalida)\r\n esComple = bintohex[10:11]\r\n if(esComple != '1'):\r\n bintohex = int(auxbin,2)\r\n res = hex(bintohex)\r\n arregloSalida[1].append(res)\r\n else:\r\n out = twos_comp(int(auxbin, 2), len(auxbin))\r\n out = str(out)\r\n arregloSalida[1].append(out)\r\n salida = itype[line] + \" \" +arregloSalida[0][0] + \", \" + arregloSalida[1][0] + \"(\" + arregloSalida[2][0] + \")\"\r\n return salida\r\n if(line in itype_rt_rs):\r\n if(line == \"001111\"):\r\n rs = line1\r\n auxrs = rs[5:10]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[1].append(rsSalida)\r\n num = line1\r\n auxbin = num[10:26]\r\n num = int(auxbin,2)\r\n res = str(num)\r\n salida = itype[line] + \" \" + arregloSalida[1][0] + \", \" + res\r\n return salida\r\n rs = line1\r\n auxrs =rs[0:5]\r\n if(auxrs in registers):\r\n rsSalida = registers[auxrs]\r\n arregloSalida[1].append(rsSalida)\r\n rt = line1\r\n auxrt = rt[5:10]\r\n bintohex = line1\r\n auxbin = bintohex[10:26]\r\n if(auxrt in registers):\r\n rtSalida = registers[auxrt]\r\n arregloSalida[0].append(rtSalida)\r\n esComple = auxbin[10:11]\r\n if(esComple != '1'):\r\n bintohex = int(auxbin,2)\r\n res = str(bintohex)\r\n arregloSalida[2].append(res)\r\n else:\r\n out = twos_comp(int(auxbin, 2), len(auxbin))\r\n out = str(out)\r\n arregloSalida[2].append(out)\r\n salida = itype[line] + \" \" +arregloSalida[0][0] + \", \" + arregloSalida[1][0] + \", \" + arregloSalida[2][0] \r\n return salida\r\n return \"Codigo invalido\""
},
{
"alpha_fraction": 0.5917159914970398,
"alphanum_fraction": 0.5976331233978271,
"avg_line_length": 27.16666603088379,
"blob_id": "408cad22422a7db89f6d44fdac0076e061c84109",
"content_id": "52745cfc01a23414beecc2703761931b0adc0e0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 12,
"path": "/src/HexTranslator/InstructionSet/IType.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import os\n\ndef getOpcodes():\n opcodes = dict()\n cur_path = os.path.dirname(__file__)\n path = cur_path + '/Instructions/IType.txt'\n with open(path, 'r') as f:\n instructions = f.read().split('\\n')\n for i in instructions:\n currentIns = i.split()\n opcodes[currentIns[1]] = currentIns[0]\n return opcodes\n"
},
{
"alpha_fraction": 0.6057142615318298,
"alphanum_fraction": 0.6114285588264465,
"avg_line_length": 28.16666603088379,
"blob_id": "8ee1b13ef626f93839457f14f0a6b5d7f2fbd7d7",
"content_id": "8f17307015fd26db4e92d21cb89a1fe3e7989271",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 12,
"path": "/src/HexTranslator/InstructionSet/Functions.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import os\n\ndef getFunctions():\n functions = dict()\n cur_path = os.path.dirname(__file__)\n path = cur_path + '/Instructions/Functions.txt'\n with open(path, 'r') as f:\n instructions = f.read().split('\\n')\n for i in instructions:\n currentIns = i.split()\n functions[currentIns[1]] = currentIns[0]\n return functions\n"
},
{
"alpha_fraction": 0.4890212118625641,
"alphanum_fraction": 0.5068849921226501,
"avg_line_length": 27.892473220825195,
"blob_id": "6921c766f003d2c0f4a019fd4c003ede483b94a6",
"content_id": "a71d28818f40b16762c83a5fd8b1de8a1ae9eced",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2687,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 93,
"path": "/src/Translator/InstructionTranslations/ITranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "from Translator.InstructionTranslations.Complements import IntToBin, HexToBin, isHex, twosComplement\nfrom Translator.InstructionSet import Registers, IType\nimport sys\nsys.path.append(\"..\")\n\nregisters = Registers.getRegisters()\nitype = IType.getOpcodes()\nzeros = ['$0', '$zero', '$gp']\ninvalid = ['$k0', '$k1']\nitype_rt_rs = ['addi', 'addiu', 'andi', 'ori', 'slti', 'sltiu']\nitype_load = ['lw', 'lhu', 'lbu', 'll']\nitype_store = ['sw', 'sh', 'sb', 'sc']\nitype_rs_rt = ['beq', 'bne']\n\ndef getITypeParams(s):\n inmediate = \"\"\n register = \"\"\n i = 0\n while(i < len(s) and s[i] != \"(\"):\n inmediate += s[i]\n i += 1\n if(s[i] == \"(\"):\n i += 1\n while(i < len(s) and s[i] != \")\"):\n register += s[i]\n i += 1\n if(s[i] == \")\"):\n return [inmediate, register]\n else:\n return []\n else:\n return []\n\ndef translateI(line):\n ans = \"\"\n opcode = line[0]\n if(opcode == 'lui'):\n rs = '$0'\n rt = line[1][:-1]\n if(rt in zeros):\n return ans\n inmediate = line[2]\n elif(opcode in itype_rt_rs):\n rs = line[2][:-1]\n rt = line[1][:-1]\n if(rt in zeros):\n return ans\n inmediate = line[3]\n elif(opcode in itype_rs_rt):\n rs = line[1][:-1]\n if(rs in zeros):\n return ans\n rt = line[2][:-1]\n inmediate = line[3]\n elif(opcode in itype_load or opcode in itype_store):\n params = getITypeParams(line[2])\n inmediate = params[0]\n rs = params[1]\n rt = line[1][:-1]\n if(rt in zeros):\n return ans\n else:\n return ans\n if(rs in registers and rt in registers and rs not in invalid and rt not in invalid):\n # check if is a valid register missing to check $0\n rs = registers[rs]\n rt = registers[rt]\n else:\n return ans\n if(isHex(inmediate)):\n tmp = HexToBin(16, int(inmediate, 16))\n if(int(tmp,2).bit_length() <= 16):\n # Inmediate is <= to 16 bits and rs_rt type\n ans = itype[opcode] + rs + rt + tmp\n else:\n return ans\n elif(inmediate[0] != '-'):\n # Address is positive decimal\n tmp = IntToBin(16, int(inmediate))\n if(int(tmp,2).bit_length() <= 16):\n ans = itype[opcode] + rs + rt + tmp\n else:\n return ans\n elif(inmediate[0] == '-'):\n # Address is negative decimal\n number = int(inmediate)\n if(number.bit_length() > 16):\n return ans\n tmp = twosComplement(16, number)\n ans = itype[opcode] + rs + rt + tmp\n else:\n return ans\n return ans\n"
},
{
"alpha_fraction": 0.5427631735801697,
"alphanum_fraction": 0.5635964870452881,
"avg_line_length": 25.823530197143555,
"blob_id": "cb69cc5cf2a68698abe2bc6adef01f227c4a88bd",
"content_id": "813e6f1ecc1d9920709db9d7821213b15cf3be49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 912,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 34,
"path": "/src/Translator/InstructionTranslations/JTranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\nfrom Translator.InstructionTranslations.Complements import HexToBin, IntToBin, isHex\nfrom Translator.InstructionSet import Registers, JType\nsys.path.append(\"..\")\n\njtype = JType.getOpcodes()\n\ndef translateJ(line):\n \"\"\"\n Check for valid address (26 bits) and translate\n to binary no matter if its decimal or hex.\n \"\"\"\n ans = \"\"\n opcode = line[0]\n address = line[1]\n ans += jtype[opcode]\n if(isHex(address)):\n # Address is hex\n tmp = HexToBin(26, int(address, 16))\n if(int(tmp,2).bit_length() <= 26):\n # Address is <= to 26 bits\n ans += tmp\n else:\n return \"\"\n elif(address[0] != '-'):\n # Address is non negative decimal\n tmp = IntToBin(26, int(address))\n if(int(tmp,2).bit_length() <= 26):\n ans += tmp\n else:\n return \"\"\n else:\n return \"\"\n return ans\n"
},
{
"alpha_fraction": 0.4986020624637604,
"alphanum_fraction": 0.5163094401359558,
"avg_line_length": 28.80555534362793,
"blob_id": "4e3b5fe5e5d5490fb3730111598c39e5adeabedf",
"content_id": "e23dd2bab611d5aec42ed656b19f78974a9f4d20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2146,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 72,
"path": "/src/Translator/InstructionTranslations/RTranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "from Translator.InstructionTranslations.Complements import IntToBin, HexToBin, isHex, twosComplement\nimport sys\nsys.path.append(\"..\")\nfrom Translator.InstructionSet import Registers, RType, Functions\n\nregisters = Registers.getRegisters()\nfunctions = Functions.getFunctions()\nrtype = RType.getOpcodes()\nzeros = ['$0', '$zero', '$gp']\ninvalid = ['$k0', '$k1']\nrtype_rd_rs_rt = ['add', 'addu', 'and', 'nor', 'or', 'slt', 'sltu', 'sub', 'subu']\nrtype_rd_rt_sh = ['sll', 'srl', 'sra']\nrtype_move_rd = ['mfhi', 'mflo']\nrtype_rs_rt = ['div', 'divu', 'mult', 'multu']\n\ndef translateR(line):\n ans = \"\"\n opcode = line[0]\n funct = opcode\n shamt = \"0\"\n if(opcode == \"jr\"):\n rs = line[1]\n rt = \"$0\"\n rd = \"$0\"\n elif(opcode in rtype_rd_rs_rt):\n rs = line[2][:-1]\n rt = line[3]\n rd = line[1][:-1]\n if(rd in zeros):\n return ans\n elif(opcode in rtype_rd_rt_sh):\n rs = '$0'\n rt = line[2][:-1]\n rd = line[1][:-1]\n shamt = line[3]\n if(rd in zeros):\n return ans\n elif(opcode in rtype_move_rd):\n # mfhi mflo? rd\n rs = '$0'\n rt = '$0'\n rd = line[1]\n if(rd in zeros):\n return ans\n elif(opcode in rtype_rs_rt):\n rs = line[1][:-1]\n if(rs in zeros):\n return ans\n rt = line[2]\n rd = '$0'\n else:\n return ans\n if(rs in registers and rt in registers and rd in registers and\n rs not in invalid and rt not in invalid and rd not in invalid):\n # check for $0\n rs = registers[rs]\n rt = registers[rt]\n rd = registers[rd]\n else:\n return ans\n if(isHex(shamt)):\n tmp = HexToBin(5, int(shamt, 16))\n if(int(tmp,2).bit_length() <= 5):\n # shamt is <= to 5 bits\n ans = rtype[opcode] + rs + rt + rd + tmp + functions[funct]\n elif(shamt[0] != '-'):\n # can't be negative\n tmp = IntToBin(5, int(shamt))\n if(int(tmp,2).bit_length() <= 5):\n # shamt is <= to 5 bits\n ans = rtype[opcode] + rs + rt + rd + tmp + functions[funct]\n return ans\n"
},
{
"alpha_fraction": 0.492916464805603,
"alphanum_fraction": 0.5017098188400269,
"avg_line_length": 38.36538314819336,
"blob_id": "666a5d19fb95235afbb2ccd91f01251ac3036eff",
"content_id": "2299bbeb128d74e6be743b50cea3591c8e61b82b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2047,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 52,
"path": "/src/Translator/Translate.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\nfrom sys import stdin\n\nfrom Translator.Parser import clean\nfrom Translator.InstructionSet import RType, IType, JType\nfrom Translator.InstructionTranslations import RTranslation, ITranslation, JTranslation\nfrom Translator.InstructionTranslations.Complements import isTag\n\nitype = IType.getOpcodes()\njtype = JType.getOpcodes()\nrtype = RType.getOpcodes()\n\ndef translateMIPS(lines):\n tmp = clean.cleanCode(lines)\n lines = tmp[0]\n tags = tmp[1]\n address = tmp[2]\n ans = \"\"\n k = 0\n try:\n for l in lines:\n k += 1\n if len(l) == 0:\n return \"\"\n opcode = l[0]\n if(opcode in itype):\n if(len(l) == 4 and isTag(l[3])):\n l[3] = str(int((tags[l[3]] - (address[k] + 4))/4))\n translation = ITranslation.translateI(l)\n if translation != \"\":\n ans += translation + '\\n'\n else:\n return ' '.join(l) + \" is not a valid instruction.\" + '\\nIn line ' + str(k) + ' (ignoring tags).'\n elif(opcode in jtype and len(l) == 2):\n if(isTag(l[1])):\n l[1] = str(int(tags[l[1]]/4))\n translation = JTranslation.translateJ(l)\n if translation != \"\":\n ans += translation + '\\n'\n else:\n return ' '.join(l) + \" is not a valid instruction.\" + '\\nIn line ' + str(k) + ' (ignoring tags).'\n elif(opcode in rtype):\n translation = RTranslation.translateR(l)\n if translation != \"\":\n ans += translation + '\\n'\n else:\n return ' '.join(l) + \" is not a valid instruction.\" + '\\nIn line ' + str(k) + ' (ignoring tags).'\n else:\n return \"Invalid instruction \" + ' '.join(l) + '\\nIn line ' + str(k) + ' (ignoring tags).'\n except Exception as e:\n return \"ERROR: \" + str(e) + '\\nIn line ' + str(k) + ' (ignoring tags).'\n return ans\n"
},
{
"alpha_fraction": 0.7876983880996704,
"alphanum_fraction": 0.795634925365448,
"avg_line_length": 71,
"blob_id": "bd767ad50259a5da73c2ac03e04925847c6ae9e0",
"content_id": "ba90244e071b298262bd61205691c99d5e885c17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "# MIPS Code to Binary encoding\n[Translate MIPS](https://github.com/Jeremias-V/MIPS-To-Binary/tree/main/src/Translator) instructions to Binary encoding.\nNo Pseudo Instructions nor floating-point instructions allowed.\n\n# HEX Encoding to MIPS\n[Translate Hexadecimal](https://github.com/Jeremias-V/MIPS-To-Binary/tree/main/src/HexTranslator) encoded instructions (i.e. the same as binary encoding but the binary to hex equivalent).\nThis feature was added/coded by [@7Ragnaro7](https://github.com/7Ragnaro7).\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 11.333333015441895,
"blob_id": "dca9064d11c795516e1783140b56c2954d81eb06",
"content_id": "a42e79fcbdb61f7dce29e7a1e8952effc5a35887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 9,
"path": "/src/main.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "from sys import stdin\nimport sys\nfrom GUI import gui\nsys.path.append(\"..\")\n\n\ndef main():\n gui.show()\nmain()\n"
},
{
"alpha_fraction": 0.5755813717842102,
"alphanum_fraction": 0.5813953280448914,
"avg_line_length": 15.399999618530273,
"blob_id": "85503a4936e4ca0a61dd0d1eecec64c209c907fd",
"content_id": "10b31b8aea58bb2fbe52bbf87cf897b63d52c30c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 10,
"path": "/src/HexTranslator/InstructionTranslations/HexToBin.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\r\n\r\ndef IntToBin(f, n):\r\n return \"{:0>{}b}\".format(n,f)\r\n\r\ndef HexToInt(h):\r\n return int(h)\r\n\r\ndef HexToBin(f, n):\r\n return IntToBin(int(f), HexToInt(n))"
},
{
"alpha_fraction": 0.6005966067314148,
"alphanum_fraction": 0.6247928142547607,
"avg_line_length": 34.494117736816406,
"blob_id": "fcc6bcc644fb726f955c23ff74cf195ae925bde6",
"content_id": "7c4da5154c9ead2ee46259e12cfcd1df7b6374a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3017,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 85,
"path": "/src/GUI/gui.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nsys.path.append(\"..\")\n\nfrom src.Translator.Parser.clean import cleanCode\nfrom src.Translator.Translate import translateMIPS\nfrom src.HexTranslator.Translate import translateHexToMips\nimport tkinter as tk\nfrom tkinter import filedialog\n\ndef show():\n\n root = tk.Tk()\n root.geometry(\"1480x940\")\n root.title(\"MIPS Translator\")\n\n width = 65\n height = 40\n \n window = tk.Frame(root)\n # Input\n inputLabel = tk.Label(window, text=\"MIPS / HEX\", font=\"consoles 12\") \n inputLabel.grid(row=0, column=0)\n inputCode = tk.Text(window, font = \"consoles 10\", width = width+15, height = height)\n inputCode.grid(row=1, column=0)\n\n # Output\n outputLabel = tk.Label(window, text=\"Translation\", font=\"consoles 12\") \n outputLabel.grid(row=0, column=1)\n outputCode = tk.Text(window, font = \"consoles 10\", width = width-15, height = height)\n outputCode.grid(row=1, column=1)\n\n buttons = tk.Frame(root)\n\n def cleanButton():\n ## function to clean the code\n lines = inputCode.get(1.0, tk.END)\n inputCode.delete(1.0, tk.END)\n cleanerCode = cleanCode(lines)[0]\n ans = \"\"\n for l in cleanerCode:\n ans += ' '.join(l) + '\\n'\n inputCode.insert(tk.INSERT, ans)\n\n def translateMIPSButton():\n lines = inputCode.get(1.0, tk.END)\n outputCode.delete(1.0, tk.END)\n ans = translateMIPS(lines)\n outputCode.insert(tk.INSERT, ans)\n\n def translateHEXButton():\n lines = inputCode.get(1.0, tk.END).split('\\n')\n outputCode.delete(1.0, tk.END)\n ans = translateHexToMips(lines)\n outputCode.insert(tk.INSERT, ans)\n pass\n\n\n def clear():\n inputCode.delete(1.0, tk.END)\n outputCode.delete(1.0, tk.END)\n\n def openFileButton():\n root.filename = filedialog.askopenfilename(initialdir=\"../../\", title=\"Select A File\", filetypes=((\"MIPS File\", \"*.s\"),(\"Text File\", \"*.txt\"),(\"All files\", \"*.*\")))\n path = root.filename\n if path != \"\":\n clear()\n with open(path, 'r') as f:\n fileInfo = f.read()\n inputCode.insert(tk.INSERT, fileInfo) \n\n\n clearButton = tk.Button(buttons, text=\"Clear\", command = clear, bd = 5)\n clearButton.grid(row = 0, column = 0, pady = 5, padx=5)\n cleanButton = tk.Button(buttons, text=\"Clean Code\", command = cleanButton, bd = 5)\n cleanButton.grid(row = 0, column = 1, pady = 5, padx=5)\n translateMIPSButton = tk.Button(buttons, text=\"Translate MIPS\", command = translateMIPSButton, bd = 5)\n translateMIPSButton.grid(row = 1, column = 0, pady = 2, padx=5)\n translateHEXButton = tk.Button(buttons, text=\"Translate HEX\", command = translateHEXButton, bd = 5)\n translateHEXButton.grid(row = 1, column = 1, pady = 2, padx=5)\n openFileButton = tk.Button(buttons, text=\"Open File\", command = openFileButton, bd = 5)\n openFileButton.grid(row=0, column=2, pady=2, padx = 5)\n window.pack()\n buttons.pack()\n root.mainloop()\n"
},
{
"alpha_fraction": 0.4993773400783539,
"alphanum_fraction": 0.5180572867393494,
"avg_line_length": 37.17073059082031,
"blob_id": "f9e54abea1dd11bc4d53b119e234890862ad0101",
"content_id": "7ee2832ca92c4bb7c9e31f09144fabaafccd81c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1606,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 41,
"path": "/src/HexTranslator/Translate.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom sys import stdin\r\nfrom HexTranslator.InstructionSet import JType, IType, RType\r\nfrom HexTranslator.InstructionTranslations.HexToBin import HexToBin\r\nfrom HexTranslator.InstructionTranslations import JTranslation, ITranslation, RTranslation\r\n\r\njtype = JType.getOpcodes()\r\nitype = IType.getOpcodes()\r\nrtype = RType.getOpcodes()\r\n\r\ndef translateHexToMips(lines):\r\n ans = \"\"\r\n finalAns = \"\"\r\n k = 0\r\n try:\r\n for l in lines:\r\n if l != '':\r\n k += 1\r\n l = int(l, 16)\r\n opcode = HexToBin(32,l)\r\n opcodeBin = opcode[0:6]\r\n if(opcodeBin in jtype):\r\n opcodeBin2 = opcode[6:32]\r\n translation = JTranslation.translateJ(opcodeBin2)\r\n ans = jtype[opcodeBin] + \" \" + translation\r\n finalAns += ans + '\\n'\r\n elif(opcodeBin in itype):\r\n opcodeBin2 = opcode[6:32]\r\n ans = ITranslation.translateI(opcodeBin,opcodeBin2)\r\n finalAns += ans + '\\n'\r\n elif(opcodeBin in rtype):\r\n opcodeTotal = opcode[6:32]\r\n opcodefinal = opcode[26:32]\r\n opcodeBin2 = opcode[6:21]\r\n ans = RTranslation.translateR(opcodefinal,opcodeBin2, opcodeTotal)\r\n finalAns += ans + '\\n'\r\n else:\r\n return \"Invalid\" + '\\nIn line ' + str(k)\r\n except Exception as e:\r\n return \"Error: \" + str(e) + '\\nIn line ' + str(k)\r\n return finalAns\r\n"
},
{
"alpha_fraction": 0.6725888252258301,
"alphanum_fraction": 0.682741105556488,
"avg_line_length": 26.285715103149414,
"blob_id": "3c66574aa4931fdd8f42a922c399ee709fe427a7",
"content_id": "b7f3eb25fcf68a59fa1815222e6c72c81fa9f464",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 14,
"path": "/src/HexTranslator/InstructionTranslations/JTranslation.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom HexTranslator.InstructionTranslations.HexToBin import HexToBin, HexToInt\r\nfrom HexTranslator.InstructionSet import Registers, JType\r\nsys.path.append(\"..\")\r\nregisters = Registers.getRegisters()\r\nzeros = ['$0', '$zero']\r\ninvalid = ['$k0', '$k1']\r\njtype = JType.getOpcodes()\r\n\r\ndef translateJ(line):\r\n aux = int(line,2)\r\n res = hex((aux))\r\n res = str(res)\r\n return res"
},
{
"alpha_fraction": 0.6057142615318298,
"alphanum_fraction": 0.6114285588264465,
"avg_line_length": 28.16666603088379,
"blob_id": "90eda99670fc00482e1a9625f5b255e518199a3f",
"content_id": "601bb24264a291f3e0fa9faded3cfbf07cae8191",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 12,
"path": "/src/HexTranslator/InstructionSet/Registers.py",
"repo_name": "Jeremias-V/MIPS-To-Binary",
"src_encoding": "UTF-8",
"text": "import os\n\ndef getRegisters():\n registers = dict()\n cur_path = os.path.dirname(__file__)\n path = cur_path + '/Instructions/Registers.txt'\n with open(path, 'r') as f:\n instructions = f.read().split('\\n')\n for i in instructions:\n currentIns = i.split()\n registers[currentIns[1]] = currentIns[0]\n return registers\n"
}
] | 17 |
vigneshr97/Lane-Detection
|
https://github.com/vigneshr97/Lane-Detection
|
7d89ae040878996d867ed21e77fb38bada12ca20
|
c057bd4003d006b73c59489916f93c27503d17cb
|
c3e7aee8a119fd939b4d436a5c3e169eaf543344
|
refs/heads/master
| 2020-04-02T12:38:38.918166 | 2019-03-10T19:06:19 | 2019-03-10T19:06:19 | 154,443,727 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6539546251296997,
"alphanum_fraction": 0.6920907497406006,
"avg_line_length": 43.66666793823242,
"blob_id": "0dfd4fd024d8145899e1dec4ad53134c27c1e7d3",
"content_id": "6001f68fb12f00ea974aba2c25affd1524c7dd45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17018,
"license_type": "no_license",
"max_line_length": 213,
"num_lines": 381,
"path": "/lane_detection.py",
"repo_name": "vigneshr97/Lane-Detection",
"src_encoding": "UTF-8",
"text": "#Advanced Lane Finding Project\n#The goals / steps of this project are the following:\n#Compute the camera calibration matrix and distortion coefficients given a set of chessboard images.\n#Apply a distortion correction to raw images.\n#Use color transforms, gradients, etc., to create a thresholded binary image.\n#Apply a perspective transform to rectify binary image (\"birds-eye view\").\n#Detect lane pixels and fit to find the lane boundary.\n#Determine the curvature of the lane and vehicle position with respect to center.\n#Warp the detected lane boundaries back onto the original image.\n#Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.\n\nimport numpy as np \nimport pickle\nimport cv2\nimport matplotlib as mpl\nmpl.use('TkAgg')\nimport matplotlib.pyplot as plt \nimport matplotlib.image as mpimg\nimport glob\nimport os\n\ncal_images = glob.glob('camera_cal/calibration*.jpg')\n\ndef calibrate():\n\tobjp = np.zeros((6*9,3), np.float32)\n\tobjp[:,:2] = np.mgrid[0:9, 0:6].T.reshape(-1,2)\n\tobjpoints = []\n\timgpoints = []\n\tfor idx, fname in enumerate(cal_images):\n\t\timage = cv2.imread(fname)\n\t\tgray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\t\tret, corners = cv2.findChessboardCorners(gray, (9,6), None)\n\t\tprint(fname+' '+str(ret))\n\t\tif ret == True:\n\t\t\tobjpoints.append(objp)\n\t\t\timgpoints.append(corners)\n\t\t\t#cv2.drawChessboardCorners(img, (8,6), corners, ret)\n\treturn objpoints, imgpoints\n\ndef undistort(img, objpoints, imgpoints):\n\tret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, (img.shape[1], img.shape[0]), None, None)\n\tundist = cv2.undistort(img, mtx, dist, None, mtx)\n\treturn undist\n\ndef hls_pipeline(img, s_thresh = (180, 255), sxthresh = (10, 100)):\n\thls = cv2.cvtColor(img, cv2.COLOR_RGB2HLS)\n\tl_channel = hls[:,:,1]\n\ts_channel = hls[:,:,2]\n\tsobelx = cv2.Sobel(l_channel, cv2.CV_64F, 1, 0, ksize = 3)\n\tsobely = cv2.Sobel(s_channel, cv2.CV_64F, 0, 1, ksize = 3) \n\tabs_sobelx = np.absolute(sobelx)\n\tscaled_sobel = np.uint8(255*abs_sobelx/np.max(abs_sobelx))\n\t#abs_sobel_dir = np.arctan2(np.absolute(sobely),np.absolute(sobelx))\n\n #sdirbinary = np.zeros_like(scaled_sobel)\n #sdirbinary[((abs_sobel_dir>=dir_thresh[0])&(abs_sobel_dir<=dir_thresh[1]))] = 1\n\n\tsxbinary = np.zeros_like(scaled_sobel)\n\tsxbinary[(scaled_sobel >= sxthresh[0]) & (scaled_sobel <= sxthresh[1])] = 1\n\n\ts_binary = np.zeros_like(s_channel)\n\ts_binary[(s_channel >= s_thresh[0]) & (s_channel <= s_thresh[1])] = 1\n\n\t#both combined\n\tcombo = np.zeros_like(scaled_sobel)\n\tcombo[(sxbinary==1)|(s_binary==1)] = 1\n\tcombo *= 255\n\t# Stack each channel\n\t#color_binary = np.dstack((combo,combo,combo))*255\n\t#color_binary = np.dstack((sxbinary,s_binary), np.dot(sxbinary,s_binary), np.dot(sxbinary,s_binary))) * 255\n\tcolor_binary = np.dstack((np.zeros_like(sxbinary), sxbinary, s_binary)) * 255\n\t#cv2.imwrite('combo.jpg',combo)\n\t#cv2.imwrite('color.jpg',color_binary)\n\treturn combo\n\ndef unwarp_image(img):\n\timg_size = (img.shape[1],img.shape[0])\n\t#src = np.float32([[img.shape[1]/2-55,img.shape[0]/2+100],[img.shape[1]/2+55,img.shape[0]/2+100],[(img.shape[1]*5/6)+60,img.shape[0]],[img.shape[1]/6-10,img.shape[0]]])\n\tsrc = np.float32([[img.shape[1]/2-60,img.shape[0]/2+90],[img.shape[1]/2+60,img.shape[0]/2+90],[(img.shape[1]*3/4)+140,img.shape[0]-20],[img.shape[1]/4-110,img.shape[0]-20]])\n\tdst = np.float32([[img.shape[1]/4,0],[img.shape[1]*3/4,0],[img.shape[1]*3/4,img.shape[0]],[img.shape[1]/4,img.shape[0]]])\n\tM = cv2.getPerspectiveTransform(src, dst)\n\tMinv = cv2.getPerspectiveTransform(dst, src)\n\twarped = cv2.warpPerspective(img, M, (img.shape[1],img.shape[0]), flags=cv2.INTER_LINEAR)\n\t#warped_color = cv2.warpPerspective(undist, M, (img.shape[1],img.shape[0]), flags=cv2.INTER_LINEAR)\n\t#cv2.imwrite('warped.jpg',warped)\n\t#cv2.imwrite('warped_color.jpg',warped_color)\n\t#cv2.imwrite('original.jpg',img)\n\treturn warped, M, Minv\n\ndef find_lane_pixels(img):\n\thistogram = np.sum(img[img.shape[0]//2:,:], axis=0)\n\tout_img = np.dstack((img, img, img))\n\tmidpoint = np.int(histogram.shape[0]//2)\n\tleftx_base = np.argmax(histogram[:midpoint])\n\trightx_base = np.argmax(histogram[midpoint:]) + midpoint\n\tnwindows = 9\n\tmargin = 100\n\tminpix = 50\n\twindow_height = np.int(img.shape[0]//nwindows)\n\tnonzero = img.nonzero()\n\tnonzeroy = np.array(nonzero[0])\n\tnonzerox = np.array(nonzero[1])\n\tleftx_current = leftx_base\n\trightx_current = rightx_base\n\tleft_lane_inds = []\n\tright_lane_inds = []\n\n\tfor window in range(nwindows):\n\t\twin_y_low = img.shape[0] - (window+1)*window_height\n\t\twin_y_high = img.shape[0] - window*window_height\n\t\twin_xleft_low = leftx_current - margin\n\t\twin_xleft_high = leftx_current + margin\n\t\twin_xright_low = rightx_current - margin\n\t\twin_xright_high = rightx_current + margin\n\n\t\t#cv2.rectangle(out_img,(win_xleft_low,win_y_low),(win_xleft_high,win_y_high),(0,255,0), 2) \n\t\t#cv2.rectangle(out_img,(win_xright_low,win_y_low),(win_xright_high,win_y_high),(0,255,0), 2) \n\n\t\tgood_left_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) & (nonzerox >= win_xleft_low) & (nonzerox < win_xleft_high)).nonzero()[0]\n\t\tgood_right_inds = ((nonzeroy >= win_y_low) & (nonzeroy < win_y_high) & (nonzerox >= win_xright_low) & (nonzerox < win_xright_high)).nonzero()[0]\n\n\t\tleft_lane_inds.append(good_left_inds)\n\t\tright_lane_inds.append(good_right_inds)\n\n\t\tif len(good_left_inds) > minpix:\n\t\t\tleftx_current = np.int(np.mean(nonzerox[good_left_inds]))\n\t\tif len(good_right_inds) > minpix: \n\t\t\trightx_current = np.int(np.mean(nonzerox[good_right_inds])) \n\n\ttry:\n\t\tleft_lane_inds = np.concatenate(left_lane_inds)\n\t\tright_lane_inds = np.concatenate(right_lane_inds)\n\texcept ValueError:\n\t\tpass\n\n\t# Extract left and right line pixel positions\n\tleftx = nonzerox[left_lane_inds]\n\tlefty = nonzeroy[left_lane_inds] \n\trightx = nonzerox[right_lane_inds]\n\trighty = nonzeroy[right_lane_inds]\n\n\treturn leftx, lefty, rightx, righty, out_img\n\ndef fit_polynomial(img):\n\tleftx, lefty, rightx, righty, out_img = find_lane_pixels(img)\n\tleft_fit = np.polyfit(lefty, leftx, 2)\n\tright_fit = np.polyfit(righty, rightx, 2)\n\n\tploty = np.linspace(0, img.shape[0]-1, img.shape[0] )\n\ttry:\n\t\tleft_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n\t\tright_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n\texcept TypeError:\n\t\t# Avoids an error if `left` and `right_fit` are still none or incorrect\n\t\tprint('The function failed to fit a line!')\n\t\tleft_fitx = 1*ploty**2 + 1*ploty\n\t\tright_fitx = 1*ploty**2 + 1*ploty\n\n\t#storing all the points in the curve\n\tleftfitpt = []\n\trightfitpt = []\n\tfor i in range(len(ploty)):\n\t\tleftfitpt.append([left_fitx[i],ploty[i]])\n\t\trightfitpt.append([right_fitx[i],ploty[i]])\n\t\n\t## Visualization ##\n\t# Colors in the left and right lane regions\n\tout_img[lefty, leftx] = [255, 0, 0]\n\tout_img[righty, rightx] = [0, 0, 255]\n\n\t# Plots the left and right polynomials on the lane lines\n\t#plt.plot(left_fitx, ploty, color='yellow')\n\t#plt.plot(right_fitx, ploty, color='yellow')\n\tleftfitpt = np.array([leftfitpt],np.int32)\n\trightfitpt = np.array([rightfitpt],np.int32)\n\tleftfitpt.reshape((-1,1,2))\n\trightfitpt.reshape((-1,1,2))\n\tout_img = cv2.polylines(out_img,[leftfitpt],False,(0,255,255),2)\n\tout_img = cv2.polylines(out_img,[rightfitpt],False,(0,255,255),2)\n\treturn out_img, left_fit, right_fit\n\ndef search_around_poly(img, left_fit, right_fit):\n\tmargin = 10\n\tnonzero = img.nonzero()\n\tnonzeroy = np.array(nonzero[0])\n\tnonzerox = np.array(nonzero[1])\n\n\tleft_lane_inds = ((nonzerox > (left_fit[0]*(nonzeroy**2) + left_fit[1]*nonzeroy + left_fit[2] - margin)) & (nonzerox < (left_fit[0]*(nonzeroy**2) + left_fit[1]*nonzeroy + left_fit[2] + margin)))\n\tright_lane_inds = ((nonzerox > (right_fit[0]*(nonzeroy**2) + right_fit[1]*nonzeroy + right_fit[2] - margin)) & (nonzerox < (right_fit[0]*(nonzeroy**2) + right_fit[1]*nonzeroy + right_fit[2] + margin)))\n\n # Again, extract left and right line pixel positions\n\tleftx = nonzerox[left_lane_inds]\n\tlefty = nonzeroy[left_lane_inds] \n\trightx = nonzerox[right_lane_inds]\n\trighty = nonzeroy[right_lane_inds]\n\n\tleft_fit = np.polyfit(lefty, leftx, 2)\n\tright_fit = np.polyfit(righty, rightx, 2)\n\t# Fit new polynomials\n\tploty = np.linspace(0, img.shape[0]-1, img.shape[0])\n\tleft_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n\tright_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n\n\t## Visualization ##\n\t# Create an image to draw on and an image to show the selection window\n\tout_img = np.dstack((img, img, img))*255\n\twindow_img = np.zeros_like(out_img)\n\t# Color in left and right line pixels\n\tout_img[nonzeroy[left_lane_inds], nonzerox[left_lane_inds]] = [255, 0, 0]\n\tout_img[nonzeroy[right_lane_inds], nonzerox[right_lane_inds]] = [0, 0, 255]\n\n\t# Generate a polygon to illustrate the search window area\n\t# And recast the x and y points into usable format for cv2.fillPoly()\n\tleft_line_window1 = np.array([np.transpose(np.vstack([left_fitx-margin, ploty]))])\n\tleft_line_window2 = np.array([np.flipud(np.transpose(np.vstack([left_fitx+margin,ploty])))])\n\tleft_line_pts = np.hstack((left_line_window1, left_line_window2))\n\tright_line_window1 = np.array([np.transpose(np.vstack([right_fitx-margin, ploty]))])\n\tright_line_window2 = np.array([np.flipud(np.transpose(np.vstack([right_fitx+margin,ploty])))])\n\tright_line_pts = np.hstack((right_line_window1, right_line_window2))\n\n\t# Draw the lane onto the warped blank image\n\tcv2.fillPoly(window_img, np.int_([left_line_pts]), (0,255, 0))\n\tcv2.fillPoly(window_img, np.int_([right_line_pts]), (0,255, 0))\n\tresult = cv2.addWeighted(out_img, 1, window_img, 0.3, 0)\n\n\t# Plot the polynomial lines onto the image\n\tleftfitpt = []\n\trightfitpt = []\n\tfor i in range(len(ploty)):\n\t\tleftfitpt.append([left_fitx[i],ploty[i]])\n\t\trightfitpt.append([right_fitx[i],ploty[i]])\n\t\n\t#plt.plot(left_fitx, ploty, color='yellow')\n\t#plt.plot(right_fitx, ploty, color='yellow')\n\tleftfitpt = np.array([leftfitpt],np.int32)\n\trightfitpt = np.array([rightfitpt],np.int32)\n\tleftfitpt.reshape((-1,1,2))\n\trightfitpt.reshape((-1,1,2))\n\tresult = cv2.polylines(result,[leftfitpt],False,(0,255,255),2)\n\tresult = cv2.polylines(result,[rightfitpt],False,(0,255,255),2)\n\t## End visualization steps ##\n\treturn result, left_fit, right_fit\n\ndef convolution(img):\n\twindow_width = 50 \n\twindow_height = 80 # Break image into 9 vertical layers since image height is 720\n\tmargin = 100 # How much to slide left and right for searching\n\twindow_centroids = [] # Store the (left,right) window centroid positions per level\n\twindow = np.ones(window_width) # Create our window template that we will use for convolutions\n\tl_sum = np.sum(img[int(3*img.shape[0]/4):,:int(img.shape[1]/2)], axis=0)\n\tl_center = np.argmax(np.convolve(window,l_sum))-window_width/2\n\tr_sum = np.sum(img[int(3*img.shape[0]/4):,int(img.shape[1]/2):], axis=0)\n\tr_center = np.argmax(np.convolve(window,r_sum))-window_width/2+int(img.shape[1]/2)\n\n\twindow_centroids.append((l_center,r_center))\n\n\tfor level in range(1,(int)(img.shape[0]/window_height)):\n\t\timage_layer = np.sum(img[int(img.shape[0]-(level+1)*window_height):int(img.shape[0]-level*window_height),:], axis=0)\n\t\tconv_signal = np.convolve(window, image_layer)\n\t\toffset = window_width/2\n\t\tl_min_index = int(max(l_center+offset-margin,0))\n\t\tl_max_index = int(min(l_center+offset+margin,img.shape[1]))\n\t\tl_center = np.argmax(conv_signal[l_min_index:l_max_index])+l_min_index-offset\n\t\tr_min_index = int(max(r_center+offset-margin,0))\n\t\tr_max_index = int(min(r_center+offset+margin,img.shape[1]))\n\t\tr_center = np.argmax(conv_signal[r_min_index:r_max_index])+r_min_index-offset\n\t\twindow_centroids.append((l_center,r_center))\n\n\tif len(window_centroids) > 0:\n\t\tl_points = np.zeros_like(img)\n\t\tr_points = np.zeros_like(img)\n\t\t\n\t\tfor level in range(0,len(window_centroids)):\n\t\t\t# Window_mask is a function to draw window areas\n\t\t\tl_mask = np.zeros_like(img)\n\t\t\tr_mask = np.zeros_like(img)\n\t\t\tl_mask[int(img.shape[0]-(level+1)*window_height):int(img.shape[0]-level*window_height),max(0,int(window_centroids[level][0]-window_width/2)):min(int(window_centroids[level][0]+window_width/2),img.shape[1])] = 1\n\t\t\tr_mask[int(img.shape[0]-(level+1)*window_height):int(img.shape[0]-level*window_height),max(0,int(window_centroids[level][1]-window_width/2)):min(int(window_centroids[level][1]+window_width/2),img.shape[1])] = 1\n\t\t\t# Add graphic points from window mask here to total pixels found \n\t\t\tl_points[(l_points == 255) | ((l_mask == 1) ) ] = 255\n\t\t\tr_points[(r_points == 255) | ((r_mask == 1) ) ] = 255\n\n\t\t# Draw the results\n\t\ttemplate = np.array(r_points+l_points,np.uint8) # add both left and right window pixels together\n\t\tzero_channel = np.zeros_like(template) # create a zero color channel\n\t\ttemplate = np.array(cv2.merge((zero_channel,template,zero_channel)),np.uint8) # make window pixels green\n\t\twarpage= np.dstack((img, img, img))*255 # making the original road pixels 3 color channels\n\t\toutput = cv2.addWeighted(warpage, 1, template, 0.5, 0.0) # overlay the orignal road image with window results\n \t\t# If no window centers found, just display orginal road image\n\telse:\n\t\toutput = np.array(cv2.merge((img,img,img)),np.uint8)\n\treturn output\n\ndef measure_curvature_pixels(img, left_fit, right_fit):\n\tploty = np.linspace(0, img.shape[0]-1, img.shape[0] )\n\ty_eval = np.max(ploty)\n\tleft_curverad = ((1 + (2*left_fit[0]*y_eval + left_fit[1])**2)**1.5) / np.absolute(2*left_fit[0])\n\tright_curverad = ((1 + (2*right_fit[0]*y_eval + right_fit[1])**2)**1.5) / np.absolute(2*right_fit[0])\n\n\treturn left_curverad, right_curverad\n\ndef measure_curvature_real(img, left_fit, right_fit):\n\tym_per_pix = 30/720\n\txm_per_pix = 3.7/(img.shape[1]/2+250)\n\tploty = np.linspace(0,img.shape[0]-1, img.shape[0])\n\tleft_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n\tright_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n\tleft_fit_cr = np.polyfit(ploty*ym_per_pix, left_fitx*xm_per_pix, 2)\n\tright_fit_cr = np.polyfit(ploty*ym_per_pix, right_fitx*xm_per_pix, 2)\n\ty_eval = np.max(ploty)\n\tleft_curverad = ((1 + (2*left_fit_cr[0]*y_eval*ym_per_pix + left_fit_cr[1])**2)**1.5) / np.absolute(2*left_fit_cr[0])\n\tright_curverad = ((1 + (2*right_fit_cr[0]*y_eval*ym_per_pix + right_fit_cr[1])**2)**1.5) / np.absolute(2*right_fit_cr[0])\n\treturn left_curverad, right_curverad\n\ndef normal_view_transform(img, undist, warped, left_fit, right_fit, Minv):\n\twarp_zero = np.zeros_like(warped).astype(np.uint8)\n\tcolor_warp = np.dstack((warp_zero, warp_zero, warp_zero))\n\n\tploty = np.linspace(0,img.shape[0]-1, img.shape[0])\n\tleft_fitx = left_fit[0]*ploty**2 + left_fit[1]*ploty + left_fit[2]\n\tright_fitx = right_fit[0]*ploty**2 + right_fit[1]*ploty + right_fit[2]\n\n\tpts_left = np.array([np.transpose(np.vstack([left_fitx, ploty]))])\n\tpts_right = np.array([np.flipud(np.transpose(np.vstack([right_fitx, ploty])))])\n\n\tpts = np.hstack((pts_left, pts_right))\n\tcv2.fillPoly(color_warp, np.int_([pts]), (0,255, 0))\n\tnewwarp = cv2.warpPerspective(color_warp, Minv, (img.shape[1], img.shape[0])) \n\tresult = cv2.addWeighted(undist, 1, newwarp, 0.3, 0)\n\treturn result\n\nobjpoints, imgpoints = calibrate()\ni = 0\ndef pipeline(image):\n\tglobal i\n\tglobal left_fit\n\tglobal right_fit\n\tundist = undistort(image, objpoints, imgpoints)\n\thls = hls_pipeline(undist)\n\tunwarped, perspective_M, Minv = unwarp_image(hls)\n\tif i == 0:\n\t\tout_img, left_fit, right_fit = fit_polynomial(unwarped)\n\telse:\n\t\tresult, left_fit, right_fit = search_around_poly(unwarped, left_fit, right_fit)\n\ti+=1\n\tleft_curverad, right_curverad = measure_curvature_real(image, left_fit, right_fit)\n\tfinal_output = normal_view_transform(image, undist, unwarped, left_fit, right_fit, Minv)\n\tleft_fitx = left_fit[0]*(image.shape[0]-1)**2 + left_fit[1]*(image.shape[0]-1) + left_fit[2]\n\tright_fitx = right_fit[0]*(image.shape[0]-1)**2 + right_fit[1]*(image.shape[0]-1) + right_fit[2]\n\tdistance = (image.shape[1]/2 - (left_fitx+right_fitx)/2)*3.7/(image.shape[1]/2+250)\n\tprint(distance)\n\tif distance > 0:\n\t\tleftorright = 'right'\n\telse:\n\t\tleftorright = 'left'\n\tdistance *= -1\n\tfont = cv2.FONT_HERSHEY_SIMPLEX\n\tcv2.putText(final_output, 'Radius of Curvature: '+str(round((left_curverad+right_curverad)/2, 2))+'m', (230, 50), font, 0.8, (0, 255, 0), 2, cv2.LINE_AA)\n\tcv2.putText(final_output, 'Position of the car: '+str(round(distance, 2))+'m '+leftorright+' from the centre', (230,100), font, 0.8, (0, 255, 0), 2, cv2.LINE_AA)\n\treturn final_output\n\n# test_cap = cv2.VideoCapture('project_video.mp4')\n# ret, frame = test_cap.read()\n# test_cap.release()\ncap = cv2.VideoCapture('project_video.mp4')\nfourcc = cv2.VideoWriter_fourcc(*'mp4v')\nout = cv2.VideoWriter('output.mp4',fourcc, 30.0, (720,1280))\nobjpoints, imgpoints = calibrate()\ncv2.imwrite('output_images/calibrated_chess_board.jpg', undistort(cv2.imread('camera_cal/calibration2.jpg'), objpoints, imgpoints))\n\nwhile cap.isOpened():\n\tret, frame = cap.read()\n\tif ret == False:\n\t\tbreak\n\tfinal_output = pipeline(frame)\n\tcv2.imshow('frame', final_output)\n\tcv2.imwrite('output/final'+str(i)+'.jpg',final_output)\n\tout.write(final_output)\ncap.release()\nout.release()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.7322351336479187,
"alphanum_fraction": 0.7566214203834534,
"avg_line_length": 60.29703140258789,
"blob_id": "d740337df71636e51ab1bc9599b4009a0bb9eda1",
"content_id": "7d9bc234f12b19d2f5678516523057b7a7563afe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6192,
"license_type": "no_license",
"max_line_length": 882,
"num_lines": 101,
"path": "/README.md",
"repo_name": "vigneshr97/Lane-Detection",
"src_encoding": "UTF-8",
"text": "## Lane Finding Project\n[](http://www.udacity.com/drive)\n\n\nIn this project, the goal was to write a software pipeline to identify the lane boundaries in a video.\n\nThe Project\n---\n\nThe steps of this project involved the following:\n\n* Compute the camera calibration matrix and distortion coefficients given a set of chessboard images.\n* Apply a distortion correction to raw images.\n* Use color transforms, gradients, etc., to create a thresholded binary image.\n* Apply a perspective transform to rectify binary image (\"birds-eye view\").\n* Detect lane pixels and fit to find the lane boundary.\n* Determine the curvature of the lane and vehicle position with respect to center.\n* Warp the detected lane boundaries back onto the original image.\n* Output visual display of the lane boundaries and numerical estimation of lane curvature and vehicle position.\n\nThe images for camera calibration are stored in the folder called `camera_cal`. \n\n[//]: # (Image References)\n\n## [Rubric](https://review.udacity.com/#!/rubrics/571/view) Points\n\n### Here I will consider the rubric points individually and describe how I addressed each point in my implementation. \n\n---\n\n### Writeup / README\n\n\nThe code begins with all the libraries being imported. Then all the required functions are declared and at the end, the functions are called to obtain the results.\n\n### Camera Calibration\n\n#### 1. Briefly state how you computed the camera matrix and distortion coefficients. Provide an example of a distortion corrected calibration image.\n \nThe code for this step is contained in lines 24-38 of proj2.py\n\nI start by preparing \"object points\", which will be the (x, y, z) coordinates of the chessboard corners in the world. Here I am assuming the chessboard is fixed on the (x, y) plane at z=0, such that the object points are the same for each calibration image. Thus, `objp` is just a replicated array of coordinates, and `objpoints` will be appended with a copy of it every time I successfully detect all chessboard corners in a test image. `imgpoints` will be appended with the (x, y) pixel position of each of the corners in the image plane with each successful chessboard detection. The given chessboard images were 9x6 chess boards. 17 out of the 20 calibration images used from the folder camera_cal had their corners detected and the respective imagepoints were found. The remaining 3 images didn't have some corners within the image range and hence failed in corner detection.\n\nI then used the output `objpoints` and `imgpoints` to compute the camera calibration and distortion coefficients using the `cv2.calibrateCamera()` function. I applied this distortion correction to the test image using the `cv2.undistort()` function and obtained this result: \n\n\n\n### Pipeline (single images)\n\nThe distortion matrix obtained was used to unwarp one of the test images as below\n\n\n\nThen, I used a combination of color and gradient thresholds to generate a binary image (thresholding steps at lines #45 through #74 in `proj2.py`). Here's an example of my output for this step.\n\n\n\nThe code for my perspective transform includes a function called `unwarp_image()`, which appears in lines 76 through 88 in the code. The `warper()` function takes as inputs an image (`img`), as well as source (`src`) and destination (`dst`) points. I chose to hardcode the source and destination points in the following manner:\n\n```python\nsrc = np.float32([[img.shape[1]/2-60,img.shape[0]/2+90],[img.shape[1]/2+60,img.shape[0]/2+90],[(img.shape[1]*3/4)+140,img.shape[0]-20],[img.shape[1]/4-110,img.shape[0]-20]])\ndst = np.float32([[img.shape[1]/4,0],[img.shape[1]*3/4,0],[img.shape[1]*3/4,img.shape[0]],[img.shape[1]/4,img.shape[0]]])\n\n```\n\nThis resulted in the following source and destination points:\n\n| Source | Destination | \n|:-------------:|:-------------:| \n| 580, 450 | 320, 0 | \n| 700, 450 | 960, 0 |\n| 1100, 700 | 960, 720 |\n| 210, 700 | 320, 720 |\n\nI verified that my perspective transform was working as expected by drawing the `src` and `dst` points onto a test image and its warped counterpart to verify that the lines appear parallel in the warped image.\n\n\n\n\nWindow search was performed to obtain the lane pixels. Then polyfit function helped in obtaining the second order equation of the the two curves like the following image. The functions are found from lines 90 through 180. The window search is restricted near the initially found curve after the first frame is processed and the function search_around_poly found from lines 180 through 242 performs this\n\n\nThe radii of curvature of the two curves are calculated using the given formula and they are converted from pixels to metres by approximate measurements. The average of the two radii is assumed as the radius of the curve. The midpoint of the bottom of the two edges is obtained and the distance of it from the midpoint of the frame is the distance of the car from the centre of the lane. lines 302-313\n\nThe inverse perspective transform is performed and the image is brought back to the normal view. The corresponding function is found in the lines 315 to 330\n\n\n\n---\n\n### Pipeline (video)\n\n#### 1. Provide a link to your final video output. Your pipeline should perform reasonably well on the entire project video (wobbly lines are ok but no catastrophic failures that would cause the car to drive off the road!).\n\nHere's a [link to my video result](./project_video.mp4)\n\n---\n\n### Discussion\n\nThough the project is more robust than the previous one, it fails under a few conditions. When the brightness increases, the detected region wobbles around. The presence of a thick crack on the lane might result in wrong predictions as seen in a challenge video. The presence of bikes and sharp curves lead to further wrong predictions.\n\n"
}
] | 2 |
michaelciere/neural-dots
|
https://github.com/michaelciere/neural-dots
|
b95ea95180d34670ba46c2c49481dae9c0f0ccdd
|
ea92cd469ca10f277f1784ad28c9670deb20b73a
|
e48585e43bc36ac71343cd71231488e60b256baf
|
refs/heads/master
| 2022-12-12T05:30:02.848265 | 2018-11-29T16:33:26 | 2018-11-29T16:33:26 | 156,424,666 | 1 | 0 | null | 2018-11-06T17:52:55 | 2019-02-26T11:55:43 | 2022-11-21T22:16:24 |
Python
|
[
{
"alpha_fraction": 0.5071770548820496,
"alphanum_fraction": 0.5246069431304932,
"avg_line_length": 27.58823585510254,
"blob_id": "32495422b14b95e337fc8004fa3e16e5e20ce89f",
"content_id": "38ed5856540650c5bcd99b31fb8f641e7b35d099",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2926,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 102,
"path": "/download_littlegolem.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport urllib2\nfrom bs4 import BeautifulSoup\n\n# compile list of all playerids who have played in championship league 1\n\ndef extract_player_ids(txt):\n players = set()\n player_names = set()\n for line in txt.splitlines():\n if line[:9] == '[YellowId' \\\n or line[:6] == '[RedId':\n plid = int(line.split('\"')[1])\n players.add(plid)\n elif line[:7] == '[Yellow' \\\n or line[:4] == '[Red':\n plname = line.split('\"')[1]\n player_names.add(plname)\n return players, player_names\n\ndef get_championship_players():\n\n base_url = 'https://www.littlegolem.net/jsp/tournament/tournament.jsp?trnid=dots.ch.'\n\n players = set()\n player_names = set()\n for i in range(1,51,1):\n print 'processing championship %d.1.1' % i\n url = base_url + str(i) + '.1.1'\n \n response = urllib2.urlopen(url)\n html = response.read()\n soup = BeautifulSoup(html, 'lxml')\n \n for link in soup.findAll('a', href=True, text='PGN/SGF'):\n SGF_link = link['href']\n \n response = urllib2.urlopen('https://www.littlegolem.net' + SGF_link)\n txt = response.read()\n \n plids, plnames = extract_player_ids(txt)\n player_names.update(plnames)\n players.update(plids)\n\n return list(players), list(player_names)\n\n \n \n # if line[:6] == '[Event' :\n # # new game, reset flag\n # take_game = False\n # elif line[:5] == '[Size':\n # take_game = True\n # elif line[:2] == ';b[':\n # game_strings.append(lines\n \n # print line\n\n\n\nif __name__ == '__main__':\n\n # get list of top players\n top_plids, top_plnames = get_championship_players()\n print \"Top %d Players:\" % len(top_plids)\n print top_plnames \n\n\n # extract all games played by top players\n \n with open('data/player_game_list_txt.txt', 'r') as f:\n all_games_txt = f.read()\n lines = all_games_txt.splitlines()\n n_games = (len(lines)-5) / 11\n\n print '%d games in database' % n_games\n\n games = [lines[4 + 11*i: 14 + 11*i] for i in range(n_games)]\n\n top_p0_games = []\n top_p1_games = []\n for game in games:\n if game[1].split('\"')[1] != '5':\n # wrong size\n continue\n p0_id = int(game[4].split('\"')[1])\n p1_id = int(game[6].split('\"')[1])\n if p0_id in top_plids:\n top_p0_games.append(game)\n if p1_id in top_plids:\n top_p1_games.append(game)\n\n # save to new file\n with open('data/p0_expert_games.txt', 'w') as f:\n for game in top_p0_games:\n f.write('\\n'.join(game))\n f.write('\\n\\n')\n with open('data/p1_expert_games.txt', 'w') as f:\n for game in top_p1_games:\n f.write('\\n'.join(game))\n f.write('\\n\\n')\n \n\n"
},
{
"alpha_fraction": 0.5033556818962097,
"alphanum_fraction": 0.7046979665756226,
"avg_line_length": 16.383333206176758,
"blob_id": "e24347dc8ef0a45cdf3ed2c6e5afcba9fe58cb68",
"content_id": "3c096ada14136db459540ed5510c0ada25d4bbda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1043,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 60,
"path": "/requirements.txt",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "absl-py==0.6.1\nastor==0.7.1\nawsebcli==3.14.6\nbackports.ssl-match-hostname==3.5.0.1\nbackports.weakref==1.0.post1\nbleach==1.5.0\nblessed==1.15.0\nbotocore==1.12.33\ncached-property==1.5.1\ncement==2.8.2\ncertifi==2018.10.15\nchardet==3.0.4\nClick==7.0\ncolorama==0.3.9\ndocker==3.5.1\ndocker-compose==1.21.2\ndocker-pycreds==0.3.0\ndockerpty==0.4.1\ndocopt==0.6.2\ndocutils==0.14\nenum34==1.1.6\nFlask==1.0.2\nfuncsigs==1.0.2\nfunctools32==3.2.3.post2\nfutures==3.2.0\ngast==0.2.0\ngrpcio==1.16.0\nh5py==2.8.0\nhtml5lib==0.9999999\nidna==2.6\nipaddress==1.0.22\nitsdangerous==1.1.0\nJinja2==2.10\njmespath==0.9.3\njsonschema==2.6.0\nKeras==2.2.4\nKeras-Applications==1.0.6\nKeras-Preprocessing==1.0.5\nMarkdown==3.0.1\nMarkupSafe==1.0\nmock==2.0.0\nnumpy==1.15.3\npathspec==0.5.5\npbr==5.1.0\nprotobuf==3.6.1\npython-dateutil==2.7.5\nPyYAML==3.13\nrequests>=2.20.0\nscipy==1.1.0\nsemantic-version==2.5.0\nsix==1.11.0\ntensorboard==1.11.0\ntensorflow==1.5.0\ntensorflow-tensorboard==1.5.1\ntermcolor==1.1.0\ntexttable==0.9.1\nurllib3==1.22\nwcwidth==0.1.7\nwebsocket-client==0.53.0\nWerkzeug==0.14.1\n"
},
{
"alpha_fraction": 0.5016769766807556,
"alphanum_fraction": 0.5205108523368835,
"avg_line_length": 33.27433776855469,
"blob_id": "3756e64755ea9e30406d1004b24e7d47116d8519",
"content_id": "f513f9922d89235bd39314601f44545680cb02d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7752,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 226,
"path": "/board.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nImplements a dots-and boxes board.\n\"\"\"\n\nimport types\n\nclass DotsBoard:\n def __init__(self, width=5, height=5):\n \"\"\"\n Initializes a rectangular gameboard.\n width and height are interpreted as number of boxes, not dots\n \"\"\"\n self.width, self.height = width, height\n assert 2 <= self.width and 2 <= self.height,\\\n \"Game can't be played on this board's dimension.\"\n self.lines = set() # moves that have been played (by either player)\n self.squares = {} # captured squares\n self.scores = {0: 0, 1: 0}\n self.player = 0 # whose turn it is\n\n def createPosition(self, lines, player, score0, score1):\n self.player = player\n for move in lines:\n self.lines.add(move)\n self.scores[0] = score0\n self.scores[1] = score1\n \n def isGameOver(self):\n \"\"\"Returns true if no more moves can be made.\n The maximum number of lines drawn is\n w * (h+1) + h * (w+1) = 2*w*h + w + h\n \"\"\"\n w, h = self.width, self.height\n return len(self.lines) == 2*w*h + h + w\n\n def validMove(self, move):\n if (self._isGoodCoord(move[0]) \\\n and self._isGoodCoord(move[1])):\n return True\n return False\n\n def validSquare(self, square):\n x1, y1 = square\n if x1 + 1 <= self.width and y1 + 1 <= self.height:\n return True\n else:\n return False\n \n def square2lines(self, square):\n \"\"\"\n returns the four lines that make up a square.\n A square is represented by the coordinates of\n its lower left corner\n \"\"\"\n x1, y1 = square\n lines = [((x1,y1),(x1+1,y1)),\n ((x1,y1),(x1,y1+1)),\n ((x1+1,y1),(x1+1,y1+1)),\n ((x1,y1+1),(x1+1,y1+1))]\n\n return lines\n \n def capturedSquares(self, move):\n \"\"\"\n Returns a list of the the lower left\n corners of the squares captured by a move. (at most two)\n \"\"\"\n assert self.validMove(move)\n (x1, y1), (x2, y2) = move\n if x1 > x2:\n x1, x2 = x2, x1\n if y1 > y2:\n y1, y2 = y1, y2\n \n captured_squares = []\n if self._isHorizontal(move):\n # check squares above and below line\n square_below = (x1, y1 - 1)\n square_above = (x1, y1)\n if (self.validSquare(square_below) \\\n and all(line in self.lines\n for line in self.square2lines(square_below))):\n captured_squares.append(square_below)\n if (self.validSquare(square_above) \\\n and all(line in self.lines\n for line in self.square2lines(square_above))):\n captured_squares.append(square_above)\n else:\n # check squares to the left and to the right of line\n square_left = (x1 - 1, y1)\n square_right = (x1, y1)\n if (self.validSquare(square_left) \\\n and all(line in self.lines\n for line in self.square2lines(square_left))):\n captured_squares.append(square_left)\n if (self.validSquare(square_right) \\\n and all(line in self.lines\n for line in self.square2lines(square_right))):\n captured_squares.append(square_right)\n\n return captured_squares\n\n def _isHorizontal(self, move):\n \"Return true if the move is in horizontal orientation.\"\n return abs(move[0][0] - move[1][0]) == 1\n\n def _isVertical(self, move):\n \"Return true if the move is in vertical orientation.\"\n return not self.isHorizontal(self, move)\n \n def play(self, move):\n \"\"\"Place a particular move on the board. If any wackiness\n occurs, raise an AssertionError. Returns a list of\n bottom-left corners of squares captured after a move.\"\"\"\n assert (self._isGoodCoord(move[0]) and\n self._isGoodCoord(move[1])),\\\n \"Bad coordinates, out of bounds of the board.\"\n move = self._makeMove(move[0], move[1])\n assert(not move in self.lines),\\\n \"Bad move, line already occupied.\"\n self.lines.add(move)\n ## Check if a square is completed.\n square_corners = self.capturedSquares(move)\n if len(square_corners) > 0:\n for corner in square_corners:\n self.squares[corner] = self.player\n self.scores[self.player] += 1\n else:\n self._switchPlayer()\n return square_corners\n\n def _makeMove(self, move0, move1):\n assert self.validMove((move0, move1))\n if move0[0] > move1[0] or move0[1] > move1[1]:\n return (move1, move0)\n else:\n return (move0, move1)\n \n def _switchPlayer(self):\n self.player = (self.player + 1) % 2\n\n def __str__(self):\n \"\"\"Return a nice string representation of the board.\"\"\"\n buffer = []\n \n ## do the top line\n for i in range(self.width):\n line = ((i, self.height), (i+1, self.height))\n if line in self.lines:\n buffer.append(\"+--\")\n else: buffer.append(\"+ \")\n buffer.append(\"+\\n\")\n\n ## and now do alternating vertical/horizontal passes\n for j in range(self.height-1, -1, -1):\n ## vertical:\n for i in range(self.width+1):\n line = ((i, j), (i, j+1))\n if line in self.lines:\n buffer.append(\"|\")\n else:\n buffer.append(\" \")\n if (i,j) in self.squares:\n buffer.append(\"%s \" % self.squares[(i,j)])\n else:\n buffer.append(\" \")\n buffer.append(\"\\n\")\n\n ## horizontal\n for i in range(self.width):\n line = ((i, j), (i+1, j))\n if line in self.lines:\n buffer.append(\"+--\")\n else: buffer.append(\"+ \")\n buffer.append(\"+\\n\")\n\n return ''.join(buffer)\n\n def _isGoodCoord(self, coord):\n \"\"\"Returns true if the given coordinate is good.\n A coordinate is \"good\" if it's within the boundaries of the\n game board, and if the coordinates are integers.\"\"\"\n return (0 <= coord[0] <= self.width+1\n and 0 <= coord[1] <= self.height+1\n and type(coord[0]) is int\n and type(coord[1]) is int)\n \n\ndef _test(width, height):\n \"\"\"A small driver to make sure that the board works. It's not\n safe to use this test function in production, because it uses\n input().\"\"\"\n board = DotsBoard(width, height)\n turn = 1\n scores = [0, 0]\n while not board.isGameOver():\n print \"Turn %d (Player %s)\" % (turn, board.player)\n print board\n move = input(\"Move? \")\n squares_completed = board.play(move)\n if squares_completed:\n print \"Square completed.\"\n scores[self.player] += len(squares_completed)\n turn = turn + 1\n print \"\\n\"\n print \"Game over!\"\n print \"Final board position:\"\n print board\n print\n print \"Final score:\\n\\tPlayer 0: %s\\n\\tPlayer 1: %s\" % \\\n (scores[0], scores[1])\n\n\n\nif __name__ == \"__main__\":\n \"\"\"If we're provided arguments, try using them as the\n width/height of the game board.\"\"\"\n import sys\n if len(sys.argv[1:]) == 2:\n _test(int(sys.argv[1]), int(sys.argv[2]))\n elif len(sys.argv[1:]) == 1:\n _test(int(sys.argv[1]), int(sys.argv[1]))\n else:\n _test(5, 5)\n\n \n"
},
{
"alpha_fraction": 0.7665598392486572,
"alphanum_fraction": 0.7825854420661926,
"avg_line_length": 77,
"blob_id": "d4f15a0c7e03fc71298a11b3d147ff1f14d61748",
"content_id": "33409fb3c483afe93d45637bdab3a4fe2ff1d785",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1872,
"license_type": "no_license",
"max_line_length": 466,
"num_lines": 24,
"path": "/README.md",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "# Neural Dots - A neural network that plays dots and boxes\n\nThis repository contains all the scripts that were used to create the dots-and-boxes web app [available here](http://dots-and-boxes.eu-central-1.elasticbeanstalk.com/).\n\nIf this is no longer online by the time you are reading this, you can run the app locally by running\n```\nexport FLASK_APP=application.py\nflask run\n```\nand then pointing your web browser at 127.0.0.1:5000\n\n\n# How it works\n\nA convolutional neural net was trained to predict the moves played by experts in 5x5 dots-and-boxes games played on [www.littlegolem.net](www.littlegolem.net), where 'expert' is defined as 'anyone who ever played in the first league of the championship'. There are roughly 800,000 positions in the database.\n\nUnlike chess or Go, the moves (i.e. the lines between dots) are not arranged in a normal grid, but in a diagonal grid. Since a convolutional neural net needs a rectangular grid of inputs, the diagonal move grids were transformed by first rotating 45 degrees and then padding the corners with zeros. Possibly there is a better way that requires less zero-padding, but this works well enough, at least for 5x5 games.\n\nThe result is a neural net that takes a position as input and then outputs a probability distribution over all legal moves. During the first 25 moves of a game, the bot simply draws a move from this distribution. After move 25, it uses a short phase of Monte Carlo Tree Search. The exact MCTS algorithm is the same one that was used for AlphaGo, described on page 7 of [the Nature paper](https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf).\n\n\n# I keep losing. How do I beat this thing?\n\nIt is pretty easy to beat if you know some basic dots and boxes strategy, like the [double-cross and the chain rule](http://gcrhoads.byethost4.com/DotsBoxes/dots_strategy.html?i=1).\n"
},
{
"alpha_fraction": 0.4508169889450073,
"alphanum_fraction": 0.4663398563861847,
"avg_line_length": 26.1733341217041,
"blob_id": "6745fbe7d5bd8ba8fed275e15df9bcd42c5436cf",
"content_id": "741b92f22d057eea8e4291c5ca0587857a3a08e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6120,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 225,
"path": "/application.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom math import *\nimport re\n\n\nfrom state import State\nfrom play import Engine\n\nfrom keras.models import Model\nfrom keras.models import model_from_json\n\nimport os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\nfrom flask import Flask, request, render_template, url_for, redirect\napp = application = Flask(__name__)\n\ndef render_board(state, state_str, player):\n # render board as html\n\n # if len(state.board.lines) > 0:\n # state_str = 'l'.join(['%s%s%s%s' % (line[0][0], line[0][1],\n # line[1][0], line[1][1])\n # for line in state.board.lines])\n # else:\n # state_str = None\n\n player_to_move = 'r' if state.board.player == 0 else 'b'\n\n if player_to_move == player:\n to_move = True\n else:\n to_move = False\n \n if state_str is not None:\n move_strings = re.split('r|b', state_str)\n last_move = move_strings[-1]\n else:\n move_strings = set()\n last_move = ''\n\n \n def dot(x,y):\n dot = '<rect x=\"%d\", y=\"%d\", width=\"8\", height=\"8\", style=fill:gray></rect>' \\\n % (x, y)\n return dot\n\n \n def hline(x,y, id_str, played=False, last=False):\n if state_str is None:\n state_str_new = player_to_move + id_str\n else:\n state_str_new = state_str + player_to_move + id_str\n\n \n if to_move and (not played):\n line_str = '<a href= \"?g=%s\">' % state_str_new\n else:\n line_str = ''\n\n if (not played):\n colour = 'lightblue'\n else:\n if last:\n colour = 'red'\n else:\n colour = 'black'\n \n line_str += '<rect class=\"line\", x=\"%d\", y=\"%d\", width=\"65\", height=\"8\", style=\"fill:%s\"></rect>' % (x, y, colour)\n\n if (not played) and to_move:\n line_str += '</a>'\n \n return line_str\n\n \n def vline(x,y, id_str, played=False, last=False):\n if state_str is None:\n state_str_new = player_to_move + id_str\n else:\n state_str_new = state_str + player_to_move + id_str\n\n if to_move and (not played):\n line_str = '<a href= \"?g=%s\">' % state_str_new\n else:\n line_str = ''\n\n if (not played):\n colour = 'lightblue'\n else:\n if last:\n colour = 'red'\n else:\n colour = 'black'\n\n line_str += '<rect class=\"line\", x=\"%d\", y=\"%d\", width=\"8\", height=\"65\", style=\"fill:%s\"></rect>' % (x, y, colour)\n\n if (not played) and to_move:\n line_str += '</a>'\n\n return line_str\n \n \n height, width = 5, 5\n \n buffer = []\n\n # horizontal lines and dots\n for j in range(height+1):\n for i in range(width):\n x = (8+65)*i\n y = (8+65)*(height - j)\n buffer.append(dot(x,y))\n id_str = '%d%d%d%d' % (i, j, i+1, j)\n last = False\n if id_str in move_strings:\n played = True\n if id_str == last_move:\n last = True\n else:\n played = False\n buffer.append(hline(x+8,y, id_str, played, last))\n buffer.append(dot(x+65+8,y))\n\n # vertical lines\n for j in range(height):\n for i in range(width+1):\n line = ((i, j), (i, j+1))\n\n x = (65+8)*i\n y = 8 + (8+65)* (height - j - 1)\n id_str = '%d%d%d%d' % (i, j, i, j+1)\n last = False\n if id_str in move_strings:\n played = True\n if id_str == last_move:\n last = True\n else:\n played = False\n buffer.append(vline(x, y, id_str, played, last))\n\n # boxes\n for box, plyr in state.board.squares.iteritems():\n if plyr == 0:\n colour = 'red'\n elif plyr == 1:\n colour = 'blue'\n\n x = 8 + int(box[0]) * (65+8)\n y = 8 + (4 - int(box[1])) * (65+8)\n \n square = '<rect x = \"%s\", y = \"%s\", height=\"65\", width=\"65\", style=\"fill:%s; opacity:0.5\"></rect>' % (x,y,colour)\n\n buffer.append(square)\n \n \n svg = '<div><svg class = \"board\", width = \"374\", height = \"374\">' + '\\n'.join(buffer) + '</svg></div>'\n return svg\n\n\nengine = Engine()\n\[email protected]('/')\ndef start():\n return render_template('start.html')\n\[email protected]('/play/<player>')\ndef play(player):\n\n state_str = request.args.get('g')\n \n state = State()\n if state_str is not None:\n for m in re.split('r|b', state_str)[1:]:\n move = ((int(m[0]), int(m[1])),\n (int(m[2]), int(m[3])))\n state.board.play(move)\n \n board_html = render_board(state, state_str, player)\n\n p_to_move = 'Red' if state.board.player == 0 else 'Blue'\n return render_template(\"play.html\", board=board_html,\n player_to_move = p_to_move,\n score = '%d-%d' % (state.board.scores[0],\n state.board.scores[1]))\n\[email protected]('/play/<player>', methods=['POST'])\ndef move(player):\n state_str = request.args.get('g')\n state = State()\n if state_str is not None:\n for m in re.split('r|b', state_str)[1:]:\n move = ((int(m[0]), int(m[1])),\n (int(m[2]), int(m[3])))\n state.board.play(move)\n\n if state.board.isGameOver():\n return 'finished'\n \n\n if len(state.board.lines) < 27:\n comp_move = engine.make_move(state)\n else:\n comp_move, _ = engine.treesearch(state, seconds=4)\n \n player_to_move = 'r' if state.board.player == 0 else 'b'\n \n state.board.play(comp_move)\n \n \n move_str = '%s%d%d%d%d' % \\\n (player_to_move,\n comp_move[0][0], comp_move[0][1],\n comp_move[1][0], comp_move[1][1])\n\n return move_str\n\n\n\n\n\nif __name__ == '__main__':\n\n application.debug = True\n application.run()\n\n \n"
},
{
"alpha_fraction": 0.48166900873184204,
"alphanum_fraction": 0.5059357285499573,
"avg_line_length": 32.80473327636719,
"blob_id": "4016f44a2bdfa6444661910b50fa6bfba37886b5",
"content_id": "ef3792bc0d8bb0b880a1f450c0c5b27e43c95c54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5728,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 169,
"path": "/train.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport numpy as np\nfrom math import *\n\nfrom board import DotsBoard\n\nfrom sklearn.model_selection import train_test_split\n\nfrom keras.layers import Input, Dense, Conv2D, Flatten, Activation, \\\n Multiply, Lambda, Reshape, Concatenate\nfrom keras.models import Model\nfrom keras.models import model_from_json\nfrom keras import regularizers\nimport keras.backend as K\n\nimport os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\nclass PolicyNet:\n\n def __init__(self, n=10000):\n self.create_model()\n\n def create_model(self):\n # Define input shape\n inputs = Input(shape=(10,10,3))\n \n # Add layers\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(inputs)\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(x)\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(x)\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(x)\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(x)\n x = Conv2D(64, (3, 3), padding='same', activation='relu',\n data_format = 'channels_last')(x)\n\n # Policy head\n #turn_plane = Lambda(lambda z: z[:,:,:,2])(inputs)\n #turn_plane = Reshape((10,10,1))(turn_plane)\n #x = Concatenate(axis=-1)([x, turn_plane])\n \n x = Conv2D(1, (1,1), activation=None)(x)\n x = Flatten()(x)\n \n #x = Dense(100, use_bias=True, activation=None,\n # kernel_regularizer=regularizers.l2(0.001),\n # bias_regularizer = None)(x)\n # Filter out impossible moves\n mask = Lambda(lambda z: z[:,:,:,1])(inputs)\n mask = Flatten()(mask)\n x = Multiply()([mask, x])\n \n predictions = Activation('softmax')(x)\n \n # Compile the model\n self.model = Model(inputs=inputs, outputs=predictions)\n self.model.compile(optimizer='adam', loss='categorical_crossentropy',\n metrics=['categorical_accuracy'])\n\n \n def train(self, n_epochs = 3):\n X_train, X_test, Y_train, Y_test = train_test_split(self.X, self.Y,\n test_size=0.10)\n\n \n self.model.fit(X_train, Y_train,\n validation_data=(X_test, Y_test),\n epochs=n_epochs, batch_size=32)\n\n \n def load_data(self, n=None, augmented=True):\n move_action_pairs = []\n if augmented:\n filename = 'data/expert_moves_augmented.dat'\n else:\n filename = 'data/expert_moves.dat'\n\n num_lines = sum(1 for line in open(filename))\n print 'loading %d position/move pairs' % num_lines\n \n \n if n is None:\n \n X = np.zeros((num_lines, 10, 10, 3), dtype=np.uint8)\n Y = np.zeros((num_lines, 10, 10, 1), dtype=np.uint8)\n i = 0\n with open(filename, 'r') as f:\n line = f.readline()\n while line:\n position, move0, move1 = line.split(' ')\n position = np.array(list(position),\n dtype = np.uint8).reshape((10,10,3))\n X[i, ...] = position\n Y[i, int(move0), int(move1), 0] = 1\n \n i += 1\n if i % 25000 == 0:\n print i\n line = f.readline()\n\n self.X = X\n self.Y = Y.reshape(self.X.shape[0], -1)\n \n\n #print 'splitlines succesful'\n\n\n else:\n with open(filename, 'r') as f:\n lines = f.read().splitlines()\n if n is None or n>len(lines):\n n = len(lines)\n idxs = np.random.randint(len(lines), size = n)\n \n for idx in idxs:\n position, move0, move1 = lines[idx].split(' ')\n position = np.array(list(position), dtype = np.uint8).reshape((10,10,3))\n move = (int(move0), int(move1))\n move_action_pairs.append((position, move))\n\n positions, moves = zip(*move_action_pairs)\n \n self.X = np.concatenate([aux[np.newaxis, ...]\n for aux in positions], axis=0)\n self.Y = np.zeros((self.X.shape[0], 10, 10, 1))\n\n for i, move in enumerate(moves):\n self.Y[i, move[0], move[1], 0] = 1\n self.Y = self.Y.reshape(self.X.shape[0], -1)\n \n\n \n def save_to_disk(self):\n # serialize model to JSON\n model_json = self.model.to_json()\n with open(\"model.json\", \"w\") as json_file:\n json_file.write(model_json)\n # serialize weights to HDF5\n self.model.save_weights(\"model.h5\")\n print(\"Saved model to disk\")\n\n def load_from_disk(self):\n # load json and create model\n json_file = open('model.json', 'r')\n loaded_model_json = json_file.read()\n json_file.close()\n loaded_model = model_from_json(loaded_model_json)\n # load weights into new model\n loaded_model.load_weights(\"model.h5\")\n print(\"Loaded model from disk\")\n self.model = loaded_model\n \n\n \nif __name__ == '__main__':\n\n\n model = PolicyNet()\n \n print 'loading data...' \n model.load_data(n = 10000000, augmented=False)\n model.train(n_epochs = 10)\n\n model.save_to_disk()\n \n \n \n"
},
{
"alpha_fraction": 0.4807108938694,
"alphanum_fraction": 0.4989163279533386,
"avg_line_length": 31.378948211669922,
"blob_id": "d1763c532f82d52f2d67a26df2fc8e87e604f713",
"content_id": "3ef950843e207f14e10f49461a2ed52d9b824ff5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9228,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 285,
"path": "/play.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport numpy as np\nfrom math import *\n\nfrom state import State\n\nfrom keras.layers import Input, Dense, Conv2D, Flatten, Activation\nfrom keras.models import Model\nfrom keras.models import model_from_json\n\nimport time\n\nimport copy\n\nimport os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\n\ndef load_from_file(n=10000000):\n move_action_pairs = []\n with open('data/expert_moves.dat', 'r') as f:\n for row in f.read().splitlines()[:n]:\n position, move0, move1 = row.split(' ')\n position = np.array(list(position), dtype = np.uint8).reshape((10,10,3))\n move = (int(move0), int(move1))\n move_action_pairs.append((position, move))\n return move_action_pairs\n\ndef save_model(model):\n # serialize model to JSON\n model_json = model.to_json()\n with open(\"model.json\", \"w\") as json_file:\n json_file.write(model_json)\n # serialize weights to HDF5\n model.save_weights(\"model.h5\")\n print(\"Saved model to disk\")\n\ndef load_model():\n # load json and create model\n json_file = open('model.json', 'r')\n loaded_model_json = json_file.read()\n json_file.close()\n loaded_model = model_from_json(loaded_model_json)\n \n loaded_model._make_predict_function()\n \n # load weights into new model\n loaded_model.load_weights(\"model.h5\")\n print(\"Loaded model from disk\")\n\n return loaded_model\n\n\n\n\nclass Engine:\n\n def __init__(self):\n self.model = load_model()\n\n def make_move(self, state):\n ser = state.serialize()\n move_probs = self.model.predict(ser[np.newaxis,...]).ravel()\n\n while 1:\n move = np.random.choice(100, p = move_probs)\n# move = np.argmax(move_probs)\n move = (move/10, move%10) # check if this is correct\n move = state.unrotate_move(move)\n if state.board.validMove(move) \\\n and not move in state.board.lines:\n break \n\n return move\n \n def rollout(self, starting_state):\n \n state_ = copy.deepcopy(starting_state)\n\n while not state_.board.isGameOver():\n move = self.make_move(state_)\n state_.board.play(move)\n\n # who won?\n if state_.board.scores[0] > state_.board.scores[1]:\n result = 0\n else:\n result = 1\n\n return result\n\n def edges(self, ser):\n # get edges (moves) from curent node (position)\n idxs = np.where(ser[:,:,1].ravel() == 1)\n return idxs[0]\n\n \n def treesearch(self, starting_state, seconds=10):\n\n\n if seconds == 0:\n return self.make_move(starting_state), 0.0\n \n # do a Monte Carlo Tree Search\n ser = starting_state.serialize()\n root = {'player': starting_state.board.player,\n 'visit_count': 0, 'action_value': 0.5, 'path': tuple(),\n 'children': {}}\n\n max_depth = 1000\n num_rollouts = 1\n def traverse(node, state_, depth=0):\n if node['visit_count'] == 0:\n # first visit, set player\n node['player'] = state_.board.player\n \n node['visit_count'] += 1\n \n ser = state_.serialize()\n edges = self.edges(ser)\n # check if game is over\n if len(edges) == 0:\n scores = state_.board.scores\n if scores[0] > scores[1]:\n value = 0.0\n elif scores[0] == scores[1]:\n value = 0.5\n else:\n value = 1.0\n\n node['action_value'] = value\n\n elif len(node['children']) == 0:\n if depth < max_depth \\\n and (node['visit_count'] > 3 or len(node['path'])==0):\n # expand leaf\n move_probs = self.model.predict(ser[np.newaxis,...]).ravel()\n node['prior'] = {edge: move_probs[edge]\n for edge in edges}\n \n for edge in edges:\n node['children'][edge] = {'player': None,\n 'visit_count': 0,\n 'action_value': 0.5,\n 'path': node['path'] + (edge,),\n 'children': {}}\n \n # evaluate leaf\n value = float(self.rollout(state_))\n\n action_value = (node['visit_count'] - 1.) \\\n * node['action_value'] \\\n + value\n action_value *= 1. / node['visit_count']\n node['action_value'] = action_value\n \n # update values of parents\n # or maybe just return the value\n else:\n # not a leaf node, traverse further\n c_puct = 1.0 # exploration constant\n u_multiplier = sqrt(log(node['visit_count'])) * c_puct\n u = {i: u_multiplier * node['prior'][i] \\\n / sqrt(0.1 + child['visit_count'])\n for i, child in node['children'].iteritems()}\n\n child_values = {i: child['action_value']\n if node['player'] == 1\n else (1. - child['action_value'])\n for i, child in node['children'].iteritems()}\n \n probs = {i: u[i] + child_values[i]\n for i, child in node['children'].iteritems()}\n\n move = max(probs, key=probs.get)\n move_ = state_.unrotate_move((move/10, move%10))\n state_.board.play(move_)\n\n value = traverse(node['children'][move],\n state_, depth+1)\n \n action_value = (node['visit_count'] - 1.) \\\n * node['action_value'] \\\n + value\n action_value *= 1. / node['visit_count']\n node['action_value'] = action_value\n\n return value\n\n start = time.clock()\n while (time.clock() - start) < seconds:\n state_ = copy.deepcopy(starting_state)\n traverse(root, state_)\n \n def transform_move(move):\n return starting_state.unrotate_move((move/10, move%10))\n \n # print {transform_move(child_k): child_v['visit_count']\n # for child_k, child_v in root['children'].iteritems()\n # if child_v['visit_count'] > 0}\n \n # print root['prior']\n \n visit_counts = {k: child['visit_count']\n for k, child in root['children'].iteritems()}\n return transform_move(max(visit_counts,\n key = visit_counts.get)), root['action_value']\n \n \n #i, child in root['children'].iteritems():\n# print child['visit_count'], child['action_value']\n \ndef load_from_file(n=None):\n move_action_pairs = []\n with open('data/expert_moves.dat', 'r') as f:\n lines = f.read().splitlines()\n if n is None or n>len(lines):\n n = len(lines)\n idxs = np.random.randint(len(lines), size = n)\n for idx in idxs:\n position, move0, move1 = lines[idx].split(' ')\n position = np.array(list(position), dtype = np.uint8).reshape((10,10,3))\n move = (int(move0), int(move1))\n move_action_pairs.append((position, move))\n return move_action_pairs\n \n\nif __name__ == '__main__':\n\n state = State()\n \n engine = Engine()\n\n # state = State()\n # print state, '\\n'\n # while not state.board.isGameOver():\n # move, value = engine.treesearch(state, seconds=60)\n # state.board.play(move)\n # print state, '\\n'\n # print value\n # print 'Player %d to play' % state.board.player\n # print state.board.scores\n\n \n # position, _ = load_from_file(n=1)[0]\n import urllib2\n url = 'https://www.littlegolem.net/servlet/sgf/1488860/game1488860.txt'\n url2 = 'https://www.littlegolem.net/servlet/sgf/1488860/game1488860.txt'\n url3 = 'https://www.littlegolem.net/servlet/sgf/1495378/game1495378.txt'\n response = urllib2.urlopen(url3)\n txt = response.read()\n \n game_str = txt\n print txt\n\n from load_expert_moves import ExpertGames\n games = ExpertGames()\n position = games.extract(game_str)[25][0]\n \n state = State()\n state.deserialize(position)\n\n# move = ((5,0), (5,1))\n# state.board.play(move)\n \n print state\n print 'player %d to move' % state.board.player\n\n def test_mcts():\n move, value = engine.treesearch(state, 30)\n print move, value\n\n \n \n\n \n # start = time.clock()\n # for _ in range(100):\n # state.deserialize(position)\n # result = engine.rollout(state)\n # results.append(result)\n\n # print sum(results) / float(len(results))\n\n # print 'seconds per rollout: %.2f' % ((time.clock() - start) / 100.)\n"
},
{
"alpha_fraction": 0.41954708099365234,
"alphanum_fraction": 0.43793630599975586,
"avg_line_length": 24.741228103637695,
"blob_id": "7fd439a2f059b0591d97b24da92d5f0b658201fe",
"content_id": "33de470cb607622fef0600f461ff9c6e9284732c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5873,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 228,
"path": "/static/app.js",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "var finished = false\n\n\n$(document).ready(function() {\n\n url = $(location).attr('href');\n state_str = url.split('=').slice(-1)[0]\n player = url.split('/').slice(-1)[0][0];\n\n if ((state_str.length) / 5 == 60) {\n\tfinished = true\n }\n\n colour = player_to_move\n\n if (!(finished)) {\n\tif ((colour==\"Red\" && player=='b') || (colour==\"Blue\" && player=='r')) {\n\t getCompMove();\n\t}\n }\n\t \n});\n\nfunction getCompMove() {\n\n $.post(this.href).done(function(move) {\n\t \n\tif (move == 'finished') {\n\t finished = true;\t \n\t \n\t} else {\n\t if (url.slice(-1) == 'b') {\n\t\tnew_url = $(location).attr('href') + '?g=' + move\n\t } else {\n\t\tnew_url = $(location).attr('href') + move\n\t }\n\t document.location.href = new_url\n\t}\n\n\t//alert(new_state_str);\n//\tdocument.location.href = new_url;\n });\n\n \n \n}\n\n// function compTimePlus(){\n// comp_seconds++;\n// document.getElementById(\"count\").value = comp_seconds;\n// }\n\n// function compTimeMinus(){\n// if (comp_seconds > 0) {\n// \tcomp_seconds--;\n// \tdocument.getElementById(\"count\").value = comp_seconds;\n// }\n// }\n\n// function startGame() {\n// if (player == 1 && comp == true) {\n// \tplayCompMove();\n// }\n// };\n\n// function squareLines(x,y) {\n// lines = [[x, y, x+1, y],\n// [x, y, x, y+1],\n// [x, y+1, x+1, y+1],\n// [x+1, y, x+1, y+1]];\n// lines2 = ['','','','']\n// $.each(lines, function(i, arr) {\n// lines2[i] = arr.join('') });\n// return(lines2)\n// }\n\n// function capturedSquares(move) {\n// coords = move.split(\"\")\n// coords = $.each(coords, function(i,val) {\n// coords[i] = parseInt(val)});\n// x1 = coords[0]\n// y1 = coords[1]\n// x2 = coords[2]\n// y2 = coords[3]\n\n// if (y1 == y2) {\n// // horizontal move\n// box1 = squareLines(x1,y1);\n// box2 = squareLines(x1, y1-1);\n// box1_captured = true\n// box2_captured = true\n// $.each(box1, function(i, line) {\n// if (!(moves_played.has(line))) {\n// box1_captured = false\n// }\n// });\n// $.each(box2, function(i, line) {\n// if (!(moves_played.has(line))) {\n// box2_captured = false\n// }\n// });\n// boxes = [];\n// if (box1_captured) {\n// str = \"\" + x1 + \"\" + y1;\n// boxes.push(str);\n// }\n// if (box2_captured) {\n// str = \"\" + x1 + \"\" + (y2-1);\n// boxes.push(str)\n// }\n// return(boxes)\n// } else {\n// // vertical move\n// box1 = squareLines(x1,y1);\n// box2 = squareLines(x1-1, y1);\n// box1_captured = true\n// box2_captured = true\n// $.each(box1, function(i, line) {\n// if (!(moves_played.has(line))) {\n// box1_captured = false\n// }\n// });\n// $.each(box2, function(i, line) {\n// if (!(moves_played.has(line))) {\n// box2_captured = false\n// }\n// });\n// boxes = [];\n// if (box1_captured) {\n// str = \"\" + x1 + \"\" + y1;\n// boxes.push(str);\n// }\n// if (box2_captured) {\n// str = \"\" + (x1-1) + \"\" + y1;\n// boxes.push(str)\n// }\n// return(boxes)\n// }\n// };\n\n// function colorBox(box, plyr) {\n// if (plyr == 0) {\n// colour = \"red; opacity:0.5\";\n// } else {\n// colour = \"blue; opacity:0.5\";\n// }\n// x_ = 8 + parseInt(box[0]) * (65+8);\n// y_ = 8 + (4 - parseInt(box[1])) * (65+8);\n// var elem = '<rect x = \"' + x_ + '\", y = \"' + y_ + '\", height=\"65\", width=\"65\", style=\"fill:' + colour + '\"></rect>';\n// $('.board').append(elem);\n// $(\"#cont\").html($(\"#cont\").html());\n// };\n\n// function playMove(move) {\n// moves_played.add(move);\n// $.post(\"/\", {'move': move});\n \n// $(('#'+last_move)).attr('style', 'fill:black');\n// $(('#'+move)).attr('style', 'fill:red');\n// last_move = move;\n\n// var squares = capturedSquares(move);\n// $.each(squares, function(i,sq) {\n// colorBox(sq, player_to_move);\n// });\n \n// if (squares.length > 0) {\n// scores[player_to_move] = scores[player_to_move] + squares.length\n// \t$('p#score').text(scores[0] + \"-\" + scores[1]);\n// };\n \n// if (scores[0] + scores[1] == 25) {\n// if (scores[player] > 12.5) {\n// $('p#tomove').text(\"You won!\")\n// } else {\n// $('p#tomove').text(\"You lost.\")\n// }\n// } else {\n// \tif (squares.length == 0) {\n// \t switchPlayer();\n// \t if (player_to_move != player) {\n// \t\tplayCompMove();\n// \t } // else: player to move, wait\n// \t} else {\n// \t if (player_to_move != player) {\n// \t\t// still comp's turn, get another move\n// \t\tplayCompMove();\n// \t } // else: still player's turn, wait for next move\n// \t}\n// }\n\n\n// };\n\n// function playCompMove(){\n// var sec = 0;\n// if (moves_played.size > 25) {\n// \tsec = 4;\n// }\n// comp_move = $.post(\"/\", {'move': (\"c\" + sec)}, function( data ) {\n// \tcomp_move = data;\n// \tplayMove(comp_move);\n// });\n// };\n\n// function lineClick(){\n \n// //alert(\"Move: \" + $(this).attr(\"id\"));\n// var move = $(this).attr(\"id\");\n\n// if (moves_played.has(move) || (!(started)) || (player_to_move!=player)) {\n// //alert('Invalid move!'); \n// } else {\n// \tplayMove(move);\n// }\n\n// length}\n\n// function switchPlayer() {\n// player_to_move = 1-player_to_move;\n// $('p#tomove').text(\"Player \" + player_to_move + \" to move\")\n// if (player_to_move != player && comp == true) {\n// $('svg.board').find('> rect.line').css(\"cursor\", \"auto\")\n// } else {\n// $('svg.board').find('> rect.line').css(\"cursor\", \"pointer\")\n// }\n \n// }\n\n\n\n\n"
},
{
"alpha_fraction": 0.45316001772880554,
"alphanum_fraction": 0.48050200939178467,
"avg_line_length": 29.148649215698242,
"blob_id": "0a3b3e75cb252a3ce19bb4a8408e98ab0e4bfae5",
"content_id": "4e153ac2c739a38b4acd81819af38b2bd9996ca7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4462,
"license_type": "no_license",
"max_line_length": 345,
"num_lines": 148,
"path": "/state.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport numpy as np\nfrom math import *\n\nfrom board import DotsBoard\n\n\nclass State(object):\n\n def __init__(self, width=5, height=5):\n # width / height in boxes, not dots\n assert width==5 and height==5\n self.w = width\n self.h = height\n self.board = DotsBoard(width, height)\n\n self.possible_moves_mask = np.zeros((10,10))\n for i in range(5):\n for j in range(6):\n horiz_move = ((i,j),(i+1,j))\n assert self.board.validMove(horiz_move)\n x,y = self.rotate_move(horiz_move)\n self.possible_moves_mask[x,y] = 1\n vert_move = ((j,i),(j,i+1))\n assert self.board.validMove(vert_move)\n x2,y2 = self.rotate_move(vert_move)\n self.possible_moves_mask[x2,y2] = 1\n\n \n def __str__(self):\n return self.board.__str__()\n\n def convert_lg_turn(self, move_str):\n if move_str[0] == 'b':\n player = 0\n elif move_str[0] == 'r':\n player = 1\n else:\n raise ValueError('invalid move')\n \n char2hcoord = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4, 'f': 5}\n char2vcoord = {'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1, 'f': 0}\n \n moves = [] \n offset = 2\n while 1:\n if move_str[offset] == 'h':\n point = (char2hcoord[move_str[offset + 2]],\n char2vcoord[move_str[offset + 1]])\n move = (point, (point[0]+1, point[1]))\n moves.append(move)\n offset += 3\n elif move_str[offset] == 'v':\n point = (char2hcoord[move_str[offset + 2]],\n char2vcoord[move_str[offset + 1]])\n move = ((point[0], point[1]-1), point)\n moves.append(move)\n offset += 3\n else:\n break\n \n return moves\n \n def play_lg_turn(self, turn_str):\n\n moves = self.convert_lg_turn(turn_str)\n for move in moves:\n self.board.play(move)\n\n def rotate_move(self, move):\n x, y = ((move[0][0] + move[1][0]) / 2.0 - 2.5,\n (move[0][1] + move[1][1]) / 2.0 - 2.5)\n x2, y2 = int(x - y + 4.5), int(x + y + 4.5)\n return x2, y2\n\n def unrotate_move(self, rot_move):\n\n x, y = rot_move\n x, y = x - 4.5, y - 4.5\n x, y = (x + y) / 2.0 + 2.5, (y - x) / 2.0 + 2.5\n \n move = ((int(floor(x)), int(floor(y))),\n (int(ceil(x)), int(ceil(y))))\n\n assert(self.rotate_move(move) == rot_move)\n return move\n \n def serialize(self):\n \"\"\"\n represent a dots board as a binary tensor\n \"\"\"\n gstate = np.zeros((10,10, 3), dtype=np.uint8)\n\n gstate[:,:,1] = self.possible_moves_mask\n for move in self.board.lines:\n x, y = self.rotate_move(move)\n gstate[x,y,0] = 1\n gstate[x,y,1] = 0\n if self.board.player == 1:\n gstate[:,:,2] = 1\n\n return gstate\n\n def deserialize(self, gstate):\n\n player = gstate[0,0,2]\n\n rotated_moves = zip(*np.where(gstate[:,:,0] == 1))\n\n moves = [self.unrotate_move(rot_move)\n for rot_move in rotated_moves]\n\n self.board = DotsBoard(5,5)\n self.board.createPosition(moves, player, 0,0)\n \n \n\nif __name__ == \"__main__\":\n \n game_str = ';b[hdb];r[vce];b[hec];r[hbc];b[vdd];r[vac];b[hcd];r[vbb];b[hcc];r[hca];b[hcb];r[veb];b[vdb];r[ved];b[hda];r[hbe];b[hed];r[hce];b[vae];r[hee];b[vab];r[hfa];b[vdf];r[hfe];b[had];r[haa];b[hfb];r[vaf];b[haevbe];r[vbfhfd];b[veevefhea];r[vdaveavaa];b[hbavbavcb];r[vcavccvad];b[hbdvbdvbchachab];r[hbbhdd];b[vdevcdhdevcfhdcvdchebvechfc]'\n\n turns = game_str.split(';')[1:]\n \n state = State()\n for turn in turns[:5]:\n print state, '\\n'\n state.play_lg_turn(turn)\n print state\n\n print 'score: %d-%d' % (state.board.scores[0], state.board.scores[1])\n\n ser = state.serialize()\n print ser[:,:,1]\n\n print '\\n'\n\n state.deserialize(ser)\n print state\n\n # state = State()\n # for turn in turns:\n # state.play_lg_turn(turn)\n # all_moves = state.board.lines\n # mask = np.zeros((10,10), dtype=bool)\n # for move in all_moves:\n # x, y = state.rotate_move(move)\n # mask[x,y] = True\n"
},
{
"alpha_fraction": 0.4888549745082855,
"alphanum_fraction": 0.5148091316223145,
"avg_line_length": 29.59813117980957,
"blob_id": "bd6779de6cecd82100a95fee54c33fac8da7e7ca",
"content_id": "c22562fcfa870118464d00603bed6a190e449a23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3275,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 107,
"path": "/load_expert_moves.py",
"repo_name": "michaelciere/neural-dots",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport numpy as np\nimport urllib2\n\nfrom state import State\n\nclass ExpertGames:\n\n def __init__(self):\n\n pass\n\n\n def extract(self, game_str, p0=True, p1=True):\n lines = game_str.splitlines()\n assert lines[1][6:9] == '\"5\"'\n p0name = lines[3].split('\"')[1]\n p1name = lines[5].split('\"')[1]\n #print p0name, 'vs.', p1name\n\n try:\n game_str = lines[9]\n except IndexError:\n # game over before any moves were played\n return None\n turns = game_str.split(';')[1:]\n\n move_action_pairs = []\n \n state = State()\n for turn in turns:\n moves = state.convert_lg_turn(turn)\n for move in moves:\n if (state.board.player == 0 and p0 is True) \\\n or (state.board.player == 1 and p1 is True):\n position = state.serialize()\n move_ = state.rotate_move(move)\n move_action_pairs.append((position, move_))\n \n state.board.play(move)\n \n return move_action_pairs\n\n def save_to_file(self, move_action_pairs):\n \n with open('data/expert_moves.dat', 'w') as f: \n for position, move in move_action_pairs:\n f.write(''.join(map(str, position.flatten())))\n f.write(' %d %d\\n' % (move[0], move[1]))\n\n def load_from_file(self):\n move_action_pairs = []\n with open('data/expert_moves.dat', 'r') as f:\n for row in f.read().splitlines():\n position, move0, move1 = row.split(' ')\n position = np.array(list(position), dtype = np.uint8).reshape((10,10,3))\n move = (int(move0), int(move1))\n move_action_pairs.append((position, move))\n return move_action_pairs\n\n def get_game_strings(self, txt, n=10000000000):\n lines = txt.splitlines()\n i = 0\n while i*11 < len(lines) and i < n:\n if i+10 > len(lines):\n break\n yield '\\n'.join(lines[i*11:i*11+10])\n i += 1\n\n\nif __name__ == \"__main__\":\n \n games = ExpertGames()\n\n move_action_pairs = []\n n_moves = 0\n \n with open('data/p0_expert_games.txt', 'r') as f:\n txt = f.read()\n for i, game_str in enumerate(games.get_game_strings(txt)):\n ma_pairs = games.extract(game_str, p0=True, p1=False)\n if ma_pairs is not None:\n move_action_pairs.extend(ma_pairs)\n n_moves += len(ma_pairs)\n\n if i % 100 == 0:\n print n_moves, '\\t moves'\n\n with open('data/p1_expert_games.txt', 'r') as f:\n txt2 = f.read()\n for i, game_str in enumerate(games.get_game_strings(txt2)):\n ma_pairs = games.extract(game_str, p0=False, p1=True)\n if ma_pairs is not None:\n move_action_pairs.extend(ma_pairs)\n n_moves += len(ma_pairs)\n\n if i % 100 == 0:\n print n_moves, '\\t moves'\n \n \n games.save_to_file(move_action_pairs)\n move_action_pairs2 = games.load_from_file()\n \n for ma1, ma2 in zip(move_action_pairs, move_action_pairs2):\n assert np.array_equal(ma1[0], ma2[0])\n assert ma1[1] == ma2[1]\n\n"
}
] | 10 |
chaelin0722/GraduationProject_CV24
|
https://github.com/chaelin0722/GraduationProject_CV24
|
657da98929c444a6f156363634cbf6d430a9f02d
|
bb37d65f5dd8ec9db2bfc433c3a569c99ee0b32c
|
bf206a6aa49cefd0d0ac088390946d0504a54f67
|
refs/heads/master
| 2023-06-16T00:52:55.235058 | 2021-06-10T07:42:53 | 2021-06-10T07:42:53 | 314,842,737 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6066945791244507,
"alphanum_fraction": 0.7364016771316528,
"avg_line_length": 27.117647171020508,
"blob_id": "aafd576f383cf776235c103fc8bf7190e1706eb1",
"content_id": "3f67efe07380ff7d0289b145ceec362a9732263b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 17,
"path": "/README.md",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "## Integration of Object Detection and depth information using kinect \n<center>-- Sookmyung women's University 2021 Graduation Project --</center>\n\n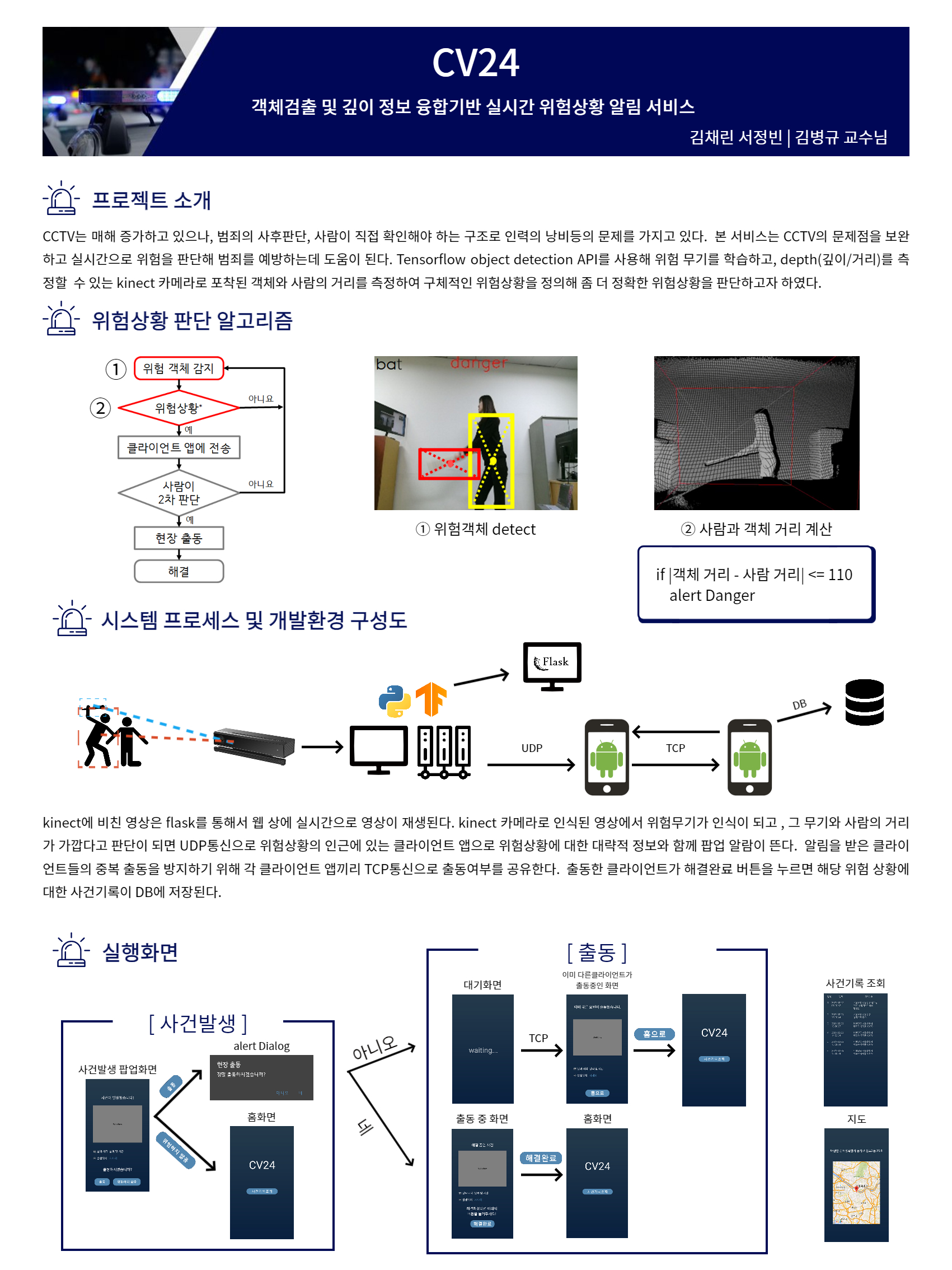\n\n### - ver. we use\n- xboxone v2\n- Windows 10\n- Kinect SDK2.0\n- CUDA v11.1\n- CuDNN v8.0.4\n- Tensorflow 2.4.0\n- Tensorflow Objection Detection API\n- PYTHON 3.7.0\n\n\n#### the final result is in `/FINAL` directory.\n"
},
{
"alpha_fraction": 0.698952853679657,
"alphanum_fraction": 0.7015706896781921,
"avg_line_length": 19.105262756347656,
"blob_id": "7a9ee6b0fedfab4703640454b18b5bcc80757f1f",
"content_id": "100dc675e0d55e834688ac943c2c6b23f8309592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 19,
"path": "/kinect_py_code/kinect_ver/location.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport requests\nfrom dotenv import load_dotenv\n\nload_dotenv(verbose=True)\n\nLOCATION_API_KEY = os.getenv('LOCATION_API_KEY')\n\nurl = f'https://www.googleapis.com/geolocation/v1/geolocate?key=AIzaSyBBI9hvhxn9BSa3Zb4dl3OMlBWmivQyNsU'\ndata = {\n 'considerIp': True,\n}\n\nresult = requests.post(url, data)\ndata = result.json()\nprint(\"data : \",data)\n\nprint(data['location']['lat'])\nprint(data['location']['lng'])"
},
{
"alpha_fraction": 0.5503876209259033,
"alphanum_fraction": 0.5968992114067078,
"avg_line_length": 9.833333015441895,
"blob_id": "f034019de036828581dccaefe4dbf6a01cb953a2",
"content_id": "59aab4a38151be2caaa374f61d8b84c2921c57ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 129,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 12,
"path": "/kinect_py_code/local_models/gloabl_test.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "global count\ncount = 1\n\ndef test():\n global count\n count = 100\n a = 10\n\n return a + count\n\nprint(test())\nprint(count)"
},
{
"alpha_fraction": 0.5247747898101807,
"alphanum_fraction": 0.5923423171043396,
"avg_line_length": 18.34782600402832,
"blob_id": "ef01224f74dce31d764eec30a25fcd6a03fc5818",
"content_id": "ddf549467902102c17c3bcfa6bba3d612b922eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 23,
"path": "/kinect_py_code/client_video.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import socket\nimport cv2\n\nUDP_IP = '127.0.0.1'\nUDP_PORT = 9505\n\nsock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n\ncap = cv2.VideoCapture(0)\n\nwhile True:\n ret, frame = cap.read()\n d = frame.flatten()\n s = d.tostring()\n\n for i in range(20):\n sock.sendto(bytes([i]) + s[i * 46080:(i + 1) * 46080], (UDP_IP, UDP_PORT))\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\ncap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.5737021565437317,
"alphanum_fraction": 0.5881015658378601,
"avg_line_length": 40.904762268066406,
"blob_id": "742f535094465a56b322a7cd53319c2f32db8402",
"content_id": "e0c98d9f3d12eeacf2c7f4a5128c2e1d0aff8846",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2647,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 63,
"path": "/kinect_py_code/get_depth.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "from wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame\nimport cv2\nimport numpy as np\nfrom pykinect2 import PyKinectV2\nimport pygame\nkinect = AcquisitionKinect()\nframe= Frame()\n#################\nSKELETON_COLORS = [pygame.color.THECOLORS[\"red\"],\n pygame.color.THECOLORS[\"blue\"],\n pygame.color.THECOLORS[\"green\"],\n pygame.color.THECOLORS[\"orange\"],\n pygame.color.THECOLORS[\"purple\"],\n pygame.color.THECOLORS[\"yellow\"],\n pygame.color.THECOLORS[\"violet\"]]\narray_x =[]\narray_y =[]\narray_z =[]\nwhile True:\n kinect.get_frame(frame)\n kinect.get_color_frame()\n image_np = kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np, (kinect._kinect.color_frame_desc.Height, kinect._kinect.color_frame_desc.Width,4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n### testing..\n #tt = Kinect._mapper.MapCameraPointToDepthSpace(joints[PyKinectV2.JointType_Head].position)\n ''' \n if kinect._kinect.has_new_depth_frame():\n kinect._depth = kinect._kinect.get_last_depth_frame()\n if body_frame is not None:\n for i in range(0, kinect.max_body_count):\n body = body_frame.bodies[i]\n if body.is_tracked:\n ###\n '''\n if kinect._bodies is not None:\n if kinect._kinect.has_new_depth_frame:\n for i in range(0, kinect._kinect.max_body_count):\n body = kinect._bodies.bodies[i]\n if not body.is_tracked:\n continue\n joints = body.joints\n # convert joint coordinates to color space\n joint_points = kinect._kinect.body_joints_to_color_space(joints)\n kinect.draw_body(joints, joint_points, SKELETON_COLORS[i])\n # get the skeleton joint x y z\n depth_points = kinect._kinect.body_joints_to_depth_space(joints)\n x = int(depth_points[PyKinectV2.JointType_SpineMid].x)\n y = int(depth_points[PyKinectV2.JointType_SpineMid].y)\n _depth = kinect._kinect.get_last_depth_frame()\n z = int(_depth[y * 512 + x])\n array_x.append(x)\n array_y.append(y)\n array_z.append(z) # array의 필요성..?\n print(\"depth spine : \", x)\n\n #print(\"elbow_left_depth : \", array_z)\n cv2.imshow(\"w\",cv2.resize(image_np,(800,580)))\n # cv2.imshow(\"skeleton\",cv2.resize(image_np,(800,580)))\n if cv2.waitKey(25) & 0xFF==ord('q'):\n cv2.destroyAllWindows()\n break"
},
{
"alpha_fraction": 0.7348790168762207,
"alphanum_fraction": 0.7520161271095276,
"avg_line_length": 54.11111068725586,
"blob_id": "65a0508990b453132f6a55a0bcb3b00fde57788a",
"content_id": "e755ea4e835f092875c0b21ee88f58ba710338a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 992,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 18,
"path": "/kinect_py_code/load_model_path.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "\ndef load_model(model_name):\n model_dir = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/'+model_name\n #model_dir = 'C:/Users/IVPL-D14/FineTunedModels/'\n model_dir = pathlib.Path(model_dir)/\"saved_model\"\n print('[INFO] Loading the model from '+ str(model_dir))\n model = tf.saved_model.load(str(model_dir))\n return model\n\n\nPATH_TO_LABELS = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/knife_label_map.pbtxt'\n#PATH_TO_LABELS = 'C:/Users/IVPL-D14/models/research/object_detection/training/labelmap.pbtxt'\ncategory_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS)#, use_display_name=True)\nmodel_name = 'trained_model_large_original_15000'\n#model_name = '511_batch8_finetuned_model'\nprint('[INFO] Downloading model and loading to network : '+ model_name)\ndetection_model = load_model(model_name)\ndetection_model.signatures['serving_default'].output_dtypes\ndetection_model.signatures['serving_default'].output_shapes"
},
{
"alpha_fraction": 0.6487300992012024,
"alphanum_fraction": 0.6797245144844055,
"avg_line_length": 29.578947067260742,
"blob_id": "bcd39566ae1cd15914204a94af6b6ec2b26092bb",
"content_id": "154927a9e71f3a475457dc3dbd09f7df1cf67762",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2337,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 76,
"path": "/kinect_py_code/kinect_ver/classifier_Test.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nfrom tensorflow.keras.models import load_model\nfrom tensorflow.keras.applications.resnet50 import preprocess_input\nfrom tensorflow.keras.preprocessing.image import img_to_array\nfrom PIL import ImageFont, ImageDraw, Image\n\nimport time\n\nimport numpy as np\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\n\nfrom keras.preprocessing import image\nKinect = AcquisitionKinect()\nframe = Frame()\n\n#%%\nmodel = load_model('C:/Users/IVPL-D14/models/research/object_detection/knife_bat_fcl.h5')\nmodel.summary()\n\nimg_width, img_height = 224, 224 # Default input size for VGG16\n# Instantiate convolutional base\nfrom keras.applications import VGG16\n\nconv_base = VGG16(weights='imagenet',\n include_top=False,\n input_shape=(img_width, img_height, 3))\nwhile True:\n global count\n count = 0\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n\n #img = cv2.resize(image_np, (224, 224), interpolation=cv2.INTER_AREA)\n img = cv2.resize(image_np, (224, 224), interpolation=cv2.INTER_AREA)\n\n #x = img_to_array(img)\n #x = np.expand_dims(x, axis=0)\n #x = preprocess_input(x)\n #prediction = model.predict(x)\n #predicted_class = np.argmax(prediction[0]) # 예측된 클래스 0, 1, 2\n\n #print(prediction[0])\n #print(predicted_class)\n ##\n img_tensor = image.img_to_array(img) # Image data encoded as integers in the 0–255 range\n img_tensor /= 255. # Normalize to [0,1] for plt.imshow application\n\n # Extract features\n features = conv_base.predict(img_tensor.reshape(1, img_width, img_height, 3))\n\n # Make prediction\n try:\n prediction = model.predict(features)\n except:\n prediction = model.predict(features.reshape(1, 7 * 7 * 512))\n\n # Write prediction\n if prediction < 0.5:\n print('bat')\n else:\n print('knife')\n\n cv2.imshow('classifier', image_np)\n\n # press \"Q\" to stop\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n# release resources\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.5675817131996155,
"alphanum_fraction": 0.607320249080658,
"avg_line_length": 24.164474487304688,
"blob_id": "2f42bc58984f5e6d82dfecf3076ce6abfba8ea00",
"content_id": "6b6d441a6c08ebcb58cda94301281f180c997f05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3961,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 152,
"path": "/kinect_py_code/kinect_ver/total_info_client.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import socket\nfrom socket import *\nimport cv2\nimport numpy as np\n#from wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\n#from wrapperPyKinect2.frame import Frame as Frame\nimport json\nimport os\nimport requests\nimport time\nfrom dotenv import load_dotenv\nload_dotenv(verbose=True)\n\n#Kinect = AcquisitionKinect()\n#frame = Frame()\n\nLOCATION_API_KEY = os.getenv('LOCATION_API_KEY')\nurl = f'https://www.googleapis.com/geolocation/v1/geolocate?key=AIzaSyBBI9hvhxn9BSa3Zb4dl3OMlBWmivQyNsU'\ndata = {\n 'considerIp': True,\n}\n### date time ###\nimport datetime\n#########socket\n\n'''\n## date, time, situation_description, videostream, loaction\ncount = 0\n\nresult = requests.post(url, data)\ndata = result.json()\nlat = data['location']['lat']\nlong = data['location']['lng']\nnow = datetime.datetime.now()\nnowDatetime = now.strftime('%Y-%m-%d %H:%M:%S')\n# print(nowDatetime) # 2015-04-19 12:11:32,\n\nwhile count < 1:\n count += 1\n total_info = {\n \"addr\": {\n \"lat\": lat,\n \"long\": long\n },\n \"DateTime\": nowDatetime,\n }\n\n UDP_IP2 = \"192.168.0.59\"\n\n UDP_PORT2 = 9090\n addr2 = UDP_IP2, UDP_PORT2\n s2 = socket(AF_INET, SOCK_DGRAM)\n\n s2.sendto(json.dumps(total_info).encode(), addr2)\n data2, fromaddr2 = s2.recvfrom(1024)\n print('client received %r from %r' % (data2, fromaddr2))\n\n print(\"sleep 5secs\")\n time.sleep(5)\n print(\"done sleepling\")\n\nwhile True:\n ###############\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n image_np = cv2.resize(image_np, (640,480))\n d = image_np.flatten()\n str = d.tostring()\n\n UDP_IP = \"192.168.0.43\"\n UDP_PORT = 9091\n s = socket(AF_INET, SOCK_DGRAM)\n addr = UDP_IP, UDP_PORT\n\n for i in range(30):\n s.sendto(bytes([i]) + str[i * 61440:(i + 1) * 61440], addr)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\n '''\n\n\n\n\n#### test python client, emulate server\nimport sys\nfrom socket import *\nimport datetime\nimport os\nimport requests\nfrom dotenv import load_dotenv\nimport json\nload_dotenv(verbose=True)\nLOCATION_API_KEY = os.getenv('LOCATION_API_KEY')\nurl = f'https://www.googleapis.com/geolocation/v1/geolocate?key=AIzaSyBBI9hvhxn9BSa3Zb4dl3OMlBWmivQyNsU'\ndata = {\n 'considerIp': True,\n}\nBUFSIZE = 1024\nport = 9090\n#host2 = []\naddr = []\nhost_temp = ['192.168.0.59','192.168.0.75', '192.168.0.44']\n#for i in range(10):\n# host2.append(host + str(i))\n#addr = (host,port)\ns = socket(AF_INET, SOCK_DGRAM)\ns.bind(('', 0))\n# 준비 완료 화면에 출력\nprint('udp echo client ready, reading stdin')\ncount = 0\nwhile count < 1:\n # 터미널 차(입력창)에서 타이핑을하고 ENTER키를 누를때 까지\n #line = sys.stdin.readline()\n # 변수에 값이 없다면\n #if not line:\n # break\n s = socket(AF_INET, SOCK_DGRAM)\n ## date, time, situation_description, videostream, loaction\n result = requests.post(url, data)\n data = result.json()\n lat = data['location']['lat']\n long = data['location']['lng']\n # print(\"data : \", data)\n # print(data['location']['lat'])\n # print(data['location']['lng'])\n now = datetime.datetime.now()\n nowDatetime = now.strftime('%Y-%m-%d %H:%M:%S')\n print(nowDatetime) # 2015-04-19 12:11:32\n total_info = {\n \"addr\": {\n \"lat\": lat,\n \"long\": long\n },\n \"DateTime\" : nowDatetime\n }\n for i in range(3):\n addr = (host_temp[i], port)\n print('####',addr)\n # 입력받은 텍스트를 서버로 발송\n s.sendto(json.dumps(total_info).encode(), addr)\n # 리턴 대기\n data, fromaddr = s.recvfrom(BUFSIZE)\n # 서버로부터 받은 메시지 출력\n print('client received %r from %r' % (data, fromaddr))\n count = count+1\n"
},
{
"alpha_fraction": 0.6513240933418274,
"alphanum_fraction": 0.6639344096183777,
"avg_line_length": 31.155405044555664,
"blob_id": "4711f58166c62071d36f9ea4121f73548510e51d",
"content_id": "da0514594701f761bd35e79acc86fe8a8b3d4685",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4832,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 148,
"path": "/kinect_py_code/webcam_socket.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\n\n#import warnings\n#warnings.filterwarnings('ignore',category=FutureWarning)\n\nimport numpy as np\nimport six.moves.urllib as urllib\nimport sys\nimport tarfile\nimport tensorflow as tf\nimport zipfile\n\nfrom collections import defaultdict\nfrom io import StringIO\nfrom matplotlib import pyplot as plt\nfrom PIL import Image\nfrom IPython.display import display\nimport pathlib\n\nfrom object_detection.utils import ops as utils_ops\nfrom object_detection.utils import label_map_util\nfrom object_detection.utils import visualization_utils as vis_util\n\nimport numpy as np\nimport cv2\nimport ctypes\nimport _ctypes\nimport sys\n#import face_recognition\nimport os\nfrom scipy import io\nimport math\nfrom gtts import gTTS\n\n### 소켓 통신 부분\n\nimport sys\nfrom socket import *\n##\nBUFSIZE = 1024\nhost = '127.0.0.1'\nport = 1111\naddr = host, port\ncap = cv2.VideoCapture(0)\nglobal count\ncount = 1\n\n# patch tf1 into `utils.ops`\nutils_ops.tf = tf.compat.v1\n# Patch the location of gfile\ntf.gfile = tf.io.gfile\n\nprint(\"[INFO] TF verion = \",tf.__version__)\n\ndef load_model(model_name):\n model_dir = './local_models/'+model_name\n model_dir = pathlib.Path(model_dir)/\"saved_model\"\n print('[INFO] Loading the model from '+ str(model_dir))\n model = tf.saved_model.load(str(model_dir))\n return model\n\nPATH_TO_LABELS = './data/knife_label_map.pbtxt'\ncategory_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS)#, use_display_name=True)\nmodel_name = 'trained_model_large_original_15000'\nprint('[INFO] Downloading model and loading to network : '+ model_name)\ndetection_model = load_model(model_name)\ndetection_model.signatures['serving_default'].output_dtypes\ndetection_model.signatures['serving_default'].output_shapes\n\n\ndef run_inference_for_single_image(model, image):\n image = np.asarray(image)\n # The input needs to be a tensor, convert it using `tf.convert_to_tensor`.\n input_tensor = tf.convert_to_tensor(image)\n # The model expects a batch of images, so add an axis with `tf.newaxis`.\n input_tensor = input_tensor[tf.newaxis, ...]\n\n # Run inference\n model_fn = model.signatures['serving_default']\n output_dict = model_fn(input_tensor)\n\n # All outputs are batches tensors.\n # Convert to numpy arrays, and take index [0] to remove the batch dimension.\n # We're only interested in the first num_detections.\n num_detections = int(output_dict.pop('num_detections'))\n output_dict = {key: value[0, :num_detections].numpy()\n for key, value in output_dict.items()}\n output_dict['num_detections'] = num_detections\n\n # detection_classes should be ints.\n output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)\n\n # Handle models with masks:\n if 'detection_masks' in output_dict:\n # Reframe the the bbox mask to the image size.\n detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(\n output_dict['detection_masks'], output_dict['detection_boxes'],\n image.shape[0], image.shape[1])\n detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,\n tf.uint8)\n output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()\n\n return output_dict\n\ndef run_inference(model, cap):\n fn = 0\n\n while cap.isOpened():\n ret, image_np = cap.read()\n # Actual detection.\n print(\"[INFO]\" + str(fn) + \"-th frame -- Running the inference and showing the result....!!!\")\n output_dict = run_inference_for_single_image(model, image_np)\n # Visualization of the results of a detection.\n vis_util.visualize_boxes_and_labels_on_image_array(\n image_np,\n output_dict['detection_boxes'],\n output_dict['detection_classes'],\n output_dict['detection_scores'],\n category_index,\n instance_masks=output_dict.get('detection_masks_reframed', None),\n use_normalized_coordinates=True,\n line_thickness=8)\n\n cv2.imshow('object_detection', cv2.resize(image_np, (800, 580)))\n##################3\n\n\n global count\n if output_dict['detection_scores'][0] >= 0.8 and count == 1:\n s = socket(AF_INET, SOCK_DGRAM)\n line = \"emergency occured!\"\n s.sendto(line.encode(), addr)\n data, fromaddr = s.recvfrom(BUFSIZE)\n print('client received %r from %r' % (data, fromaddr))\n count += 1\n\n# 다시 clinet로부터 ok 데이터 받으면 count를 1로 되돌려 놓고 다시 신호를 줄 준비를 하자\n############33\n fn = fn + 1\n\n if cv2.waitKey(25) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n break\n\n\n## 실행!\nrun_inference(detection_model, cap)"
},
{
"alpha_fraction": 0.5542347431182861,
"alphanum_fraction": 0.6173848509788513,
"avg_line_length": 21.450000762939453,
"blob_id": "afb4588f5d13150b68ac540cce8e71e96ec3b38e",
"content_id": "8612610baa21308d4e0e4cef60e02ab1a240c3a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1414,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 60,
"path": "/kinect_py_code/kinect_ver/total_info_server.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import socket\nimport numpy\nimport cv2\nfrom socket import *\n##\ns = [b'\\xff' * 61440 for x in range(30)]\n\nfourcc = cv2.VideoWriter_fourcc(*'DIVX')\nout = cv2.VideoWriter('output.avi', fourcc, 25.0, (640, 480))\n\n###\nUDP_IP = \"192.168.0.42\"\n\n\nUDP_PORT2 = 9090\naddr2 = UDP_IP, UDP_PORT2\nsock2 = socket(AF_INET, SOCK_DGRAM)\nsock2.bind(('', UDP_PORT2))\n# sock2.bind((UDP_IP2, UDP_PORT2))\n\ntest, addr2 = sock2.recvfrom(1024)\n# 받은 메시지와 클라이언트 주소 화면에 출력\nprint('server received %r from %r' % (test, addr2))\n\n# 받은 메시지를 클라이언트로 다시 전송\nsock2.sendto(test, addr2)\n\n'''\nwhile True:\n UDP_PORT = 9091\n addr = UDP_IP, UDP_PORT\n sock = socket(AF_INET, SOCK_DGRAM)\n sock.bind((UDP_IP, UDP_PORT))\n\n picture = b''\n\n data, addr = sock.recvfrom(61441)\n s[data[0]] = data[1:61441]\n\n if data[0] == 29:\n for i in range(30):\n picture += s[i]\n frame = numpy.fromstring(picture, dtype=numpy.uint8)\n frame = frame.reshape(480, 640, 3)\n cv2.imshow(\"frame\", frame)\n out.write(frame)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n \n break\n'''\n''' \nERROR!\n DeprecationWarning: The binary mode of fromstring is deprecated, as it behaves surprisingly on unicode inputs. Use frombuffer instead\n frame = numpy.fromstring(picture, dtype=numpy.uint8)\n \n \n \n'''"
},
{
"alpha_fraction": 0.5950292348861694,
"alphanum_fraction": 0.6217105388641357,
"avg_line_length": 26.918367385864258,
"blob_id": "8630a251a7a228e0d14b582d9e26ccc57de0af0e",
"content_id": "eecc2220c606fbc2787526a2db1455d1a4d725d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2748,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 98,
"path": "/kinect_py_code/kinect_ver/real_time_stream_toWeb.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "'''\nimport cv2\nimport time\n\nimport numpy as np\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\nKinect = AcquisitionKinect()\nframe = Frame()\n\nfourcc = cv2.VideoWriter_fourcc(*'DIVX')\nout = cv2.VideoWriter('saved.avi', fourcc, 25.0, (640, 480))\nt_end = time.time() + 60 / 6\ncnt = False;\nglobal count\n\nwhile True:\n global count\n count = 0\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n image_np = cv2.resize(image_np, (640,480))\n\n cv2.imshow('video_Save', image_np) # 컬러 화면 출력\n if count == 0:\n video_frame = cv2.flip(image_np, 1)\n out.write(video_frame)\n if time.time() >= t_end:\n break\n\n # print('count: ',count)\n\n if cv2.waitKey(1) == ord('q'):\n break\n\n\nout.release()\ncv2.destroyAllWindows()\n'''\n\n\nimport numpy as np\nimport camera\n#from wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\n#from wrapperPyKinect2.frame import Frame as Frame\n#Kinect = AcquisitionKinect()\n#frame = Frame()\nimport cv2\nfrom flask import Flask, render_template, Response\nimport time\napp = Flask(__name__)\n\n\[email protected]('/')\ndef index():\n \"\"\"Video streaming home page.\"\"\"\n #return render_template('index.php')\n return render_template('/index.html')\n\n\ndef gen():\n '''\n while True:\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n\n img = cv2.resize(image_np, (0, 0), fx=0.5, fy=0.5)\n frames = cv2.imencode('.jpg', img)[1].tobytes()\n yield (b'--frame\\r\\n'b'Content-Type: image/jpeg\\r\\n\\r\\n' + frames + b'\\r\\n')\n time.sleep(0.1)\n'''\n cap = cv2.VideoCapture(0)\n\n while True:\n ret, frame = cap.read()\n img = cv2.resize(frame, (0, 0), fx=0.5, fy=0.5)\n frames = cv2.imencode('.jpg', img)[1].tobytes()\n yield (b'--frame\\r\\n'b'Content-Type: image/jpeg\\r\\n\\r\\n' + frames + b'\\r\\n')\n time.sleep(0.1)\n\[email protected]('/video_feed')\ndef video_feed():\n \"\"\"Video streaming route. Put this in the src attribute of an img tag.\"\"\"\n return Response(gen(),\n mimetype='multipart/x-mixed-replace; boundary=frame')\n\nif __name__ == '__main__':\n app.run(host='127.0.0.1', debug=True)\n"
},
{
"alpha_fraction": 0.5667365193367004,
"alphanum_fraction": 0.6457023024559021,
"avg_line_length": 25.518518447875977,
"blob_id": "83751e83246ff5ddc733bee4b3ee90aa6052a348",
"content_id": "774ffb34a140414eedf6256f33f22f0bfaf9a5a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1769,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 54,
"path": "/kinect_py_code/kinect_ver/video_client.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "from socket import *\nimport cv2\nimport numpy as np\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\nKinect = AcquisitionKinect()\nframe = Frame()\n\n#UDP_IP = '192.168.44.31'\nUDP_IP = '127.0.0.1' # 본인주소\n\nUDP_PORT = 9090\n\ns= socket(AF_INET, SOCK_DGRAM)\n\n\n\nwhile True:\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n image_np = cv2.resize(image_np, (640,480))\n\n d = image_np.flatten()\n str = d.tostring()\n\n #for i in range(20):\n # s.sendto(bytes([i]) + str[i * 46080:(i + 1) * 46080], (UDP_IP, UDP_PORT))\n for i in range(30):\n s.sendto(bytes([i]) + str[i * 61440:(i + 1) * 61440], (UDP_IP, UDP_PORT))\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\ncv2.destroyAllWindows()\n\n'''\nClient의 Webcam에서 생성하는 각 프레임은 640x480 RGB 픽셀을 가지는데 이것의 실제 데이터 크기는 640 x 480 x 3 = 921,600 Byte이다. 이 때 3은 RGB 즉, 빨강, 초록, 파랑을 나타내기 위해 사용하는 것이다.\n\n \n\n그런데 UDP는 한번에 데이터를 65,535 Byte 까지 보낼 수 있어 위의 921,600 Byte를 한 번에 보낼 수 없다. 그래서 데이터를 나눠서 보내야하는데 해당 코드에서는 921,600 Byte를 20으로 나눈 46,080 Byte를 보내주고 있다. \n\n \n\n그래서 46080이 코드에서 계속 나오는 것이다. \n\n \n\n그래서 만약 OpenCV에서 생성하는 프레임이 다르다면 그에 맞게 고쳐주면 된다.'''"
},
{
"alpha_fraction": 0.43433770537376404,
"alphanum_fraction": 0.4349061846733093,
"avg_line_length": 22.46666717529297,
"blob_id": "5e728defe45d967c4796edf0a9b94f86fcd74539",
"content_id": "661f1d824a2a7ce7e1a4782a0907329f2244745e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1945,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 75,
"path": "/FINAL/backend_final/insert.php",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "<?php\n\n error_reporting(E_ALL);\n ini_set('display_errors',1);\n\n include('dbcon.php');\n\n\n $android = strpos($_SERVER['HTTP_USER_AGENT'], \"Android\");\n\n\n if( (($_SERVER['REQUEST_METHOD'] == 'POST') && isset($_POST['submit'])) || $android )\n {\n\n // 안드로이드 코드의 postParameters 변수에 적어준 이름을 가지고 값을 전달 받습니다.\n\n $time = $_POST['time'];\n $address = $_POST['address'];\n if(empty($time)){\n $errMSG = \"YYYY-MM-DD HH:MM:SS 순서대로 입력하세요.\";\n }\n\n\n if(!isset($errMSG)) // 이름과 나라 모두 입력이 되었다면\n {\n try{\n // SQL문을 실행하여 데이터를 MySQL 서버의 person 테이블에 저장합니다.\n $stmt = $con->prepare('INSERT INTO test(time, address)\n VALUES(:time, :address)');\n $stmt->bindParam(':time', $time);\n $stmt->bindParam(':address', $address);\n\n if($stmt->execute())\n {\n $successMSG = \"새로운 사용자를 추가했습니다.\";\n }\n else\n {\n $errMSG = \"사용자 추가 에러\";\n }\n\n } catch(PDOException $e) {\n die(\"Database error: \" . $e->getMessage());\n }\n }\n }\n\n?>\n\n\n<?php\n if (isset($errMSG)) echo $errMSG;\n if (isset($successMSG)) echo $successMSG;\n\n\t$android = strpos($_SERVER['HTTP_USER_AGENT'], \"Android\");\n\n if( !$android )\n {\n?>\n <html>\n <body>\n\n <form action=\"<?php $_PHP_SELF ?>\" method=\"POST\">\n datetime: <input type = \"text\" name = \"time\" />\n address: <input type = \"text\" name = \"address\" />\n <input type = \"submit\" name = \"submit\" />\n\n </form>\n\n </body>\n </html>\n\n<?php\n }\n?>"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5733333230018616,
"avg_line_length": 21.925926208496094,
"blob_id": "b563b4f6b40ddc562e84f46ab40bc72d1e479bf5",
"content_id": "8e43b4cf77e308193a4e52ce6b9a3712713c0fdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2761,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 108,
"path": "/kinect_py_code/kinect_ver/test.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "# Usage: udpecho -s [port] (to start a server)\n# or: udpecho -c host [port] <file (client)\n\nimport socket\n'''\nimport cv2\nimport numpy as np\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\nKinect = AcquisitionKinect()\nframe = Frame()\n\n\nwhile True:\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n #image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n #image_np = cv2.resize(image_np, (800, 580))\n\n cv2.imshow('object_detection', image_np)\n\n\n if cv2.waitKey(25) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n break\n\ncv2.destroyAllWindows()\n\n'''\nimport sys\nfrom socket import *\nECHO_PORT = 9090\nBUFSIZE = 1024\n\ndef main():\n if len(sys.argv) < 2:\n usage()\n if sys.argv[1] == '-s':\n server()\n elif sys.argv[1] == '-c':\n client()\n else:\n usage()\n\ndef usage():\n sys.stdout = sys.stderr\n print('Usage: udpecho -s [port] (server)')\n print('or: udpecho -c host [port] <file (client)')\n sys.exit(2)\n\ndef server():\n # 매개변수가 2개 초과이면 두번째 매개변수를 포트로 지정한다.\n if len(sys.argv) > 2:\n port = eval(sys.argv[2])\n # 매개변수가 2개이면 기본포트로 설정한다.\n else:\n port = ECHO_PORT\n\n #소켓 생성\n s = socket(AF_INET, SOCK_DGRAM)\n #포트 설정\n s.bind(('', port))\n print('udp echo server ready')\n\n # 무한루프\n while 1:\n #클라이언트로 메세지 도착하면 다음줄로 넘어가고, 그렇지 않다면 대기\n data, addr = s.recvfrom(BUFSIZE)\n #받은 메세지와 클라이언트 주소 출력\n print('server received %r from %r' % (data, addr))\n # 받은 메세지를 클라이언트로 다시 전송\n s.sendto(data, addr)\n\ndef client():\n if len(sys.argv) < 3:\n usage()\n\n # 두번째 매개변수를 서버 IP로 설정\n host = sys.argv[2]\n\n if len(sys.argv) > 3:\n port = eval(sys.argv[3])\n else:\n port = ECHO_PORT\n addr = host, port\n\n s = socket(AF_INET, SOCK_DGRAM)\n s.bind(('', 0))\n\n print('udp echo client ready, reading stdin')\n\n while 1:\n line = sys.stdin.readline()\n if not line:\n break\n\n # 입력받은 텍스트 서버로 발송\n s.sendto(line.encode(), addr)\n #s.sendto(line, addr)\n # 리턴 대기\n data, fromaddr = s.recvfrom(BUFSIZE)\n print('client received %r from %r' % (data, fromaddr))\n\nmain()"
},
{
"alpha_fraction": 0.5362403988838196,
"alphanum_fraction": 0.5648202896118164,
"avg_line_length": 20.896774291992188,
"blob_id": "b83075c29fd1a6b65ed2b5e5f35cf8c9a35a9c8c",
"content_id": "05935bfe37a930a8c092ee804ee62802a6a7a8c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3830,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 155,
"path": "/kinect_py_code/test_client.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "# Usage: udpecho -s [port] (to start a server)\n# or: udpecho -c host [port] <file (client)\n\n#### test python client, emulate server\n\nimport sys\nfrom socket import *\nimport datetime\nimport os\nimport requests\nfrom dotenv import load_dotenv\nimport json\nload_dotenv(verbose=True)\n\nLOCATION_API_KEY = os.getenv('LOCATION_API_KEY')\n\nurl = f'https://www.googleapis.com/geolocation/v1/geolocate?key=AIzaSyBBI9hvhxn9BSa3Zb4dl3OMlBWmivQyNsU'\ndata = {\n 'considerIp': True,\n}\nBUFSIZE = 1024\n#host = '127.0.0.1'\n#host = '192.168.18.161' # 정빈\n\nhost = '192.168.0.7'\n#host='203.153.146.18'\n#공기계 IP주소\n#host = '192.168.11.159'\n\nport = 9090\naddr = host, port\n\ns = socket(AF_INET, SOCK_DGRAM)\ns.bind(('', 0))\n\n# 준비 완료 화면에 출력\nprint('udp echo client ready, reading stdin')\ncount = 0\nwhile count < 2:\n # 터미널 차(입력창)에서 타이핑을하고 ENTER키를 누를때 까지\n #line = sys.stdin.readline()\n # 변수에 값이 없다면\n #if not line:\n # break\n\n s = socket(AF_INET, SOCK_DGRAM)\n ## date, time, situation_description, videostream, loaction\n\n result = requests.post(url, data)\n data = result.json()\n lat = data['location']['lat']\n long = data['location']['lng']\n # print(\"data : \", data)\n # print(data['location']['lat'])\n # print(data['location']['lng'])\n\n now = datetime.datetime.now()\n nowDatetime = now.strftime('%Y-%m-%d %H:%M:%S')\n print(nowDatetime) # 2015-04-19 12:11:32\n\n total_info = {\n \"addr\": {\n \"lat\": lat,\n \"long\": long\n },\n \"situation\": \"emergency occured\",\n \"DateTime\" : nowDatetime\n }\n\n # 입력받은 텍스트를 서버로 발송\n s.sendto(json.dumps(total_info).encode(), addr)\n # 리턴 대기\n data, fromaddr = s.recvfrom(BUFSIZE)\n # 서버로부터 받은 메시지 출력\n print('client received %r from %r' % (data, fromaddr))\n count = count+1\n'''\nimport sys\nfrom socket import *\n\nECHO_PORT = 50000 + 7\nBUFSIZE = 1024\n\ndef main():\n if len(sys.argv) < 2:\n usage()\n if sys.argv[1] == '-s':\n server()\n elif sys.argv[1] == '-c':\n client()\n else:\n usage()\n\ndef usage():\n sys.stdout = sys.stderr\n print('Usage: udpecho -s [port] (server)')\n print('or: udpecho -c host [port] <file (client)')\n sys.exit(2)\n\ndef server():\n # 매개변수가 2개 초과이면 두번째 매개변수를 포트로 지정한다.\n if len(sys.argv) > 2:\n port = eval(sys.argv[2])\n # 매개변수가 2개이면 기본포트로 설정한다.\n else:\n port = ECHO_PORT\n\n #소켓 생성\n s = socket(AF_INET, SOCK_DGRAM)\n #포트 설정\n s.bind(('', port))\n print('udp echo server ready')\n\n # 무한루프\n while 1:\n #클라이언트로 메세지 도착하면 다음줄로 넘어가고, 그렇지 않다면 대기\n data, addr = s.recvfrom(BUFSIZE)\n #받은 메세지와 클라이언트 주소 출력\n print('server received %r from %r' % (data, addr))\n # 받은 메세지를 클라이언트로 다시 전송\n s.sendto(data, addr)\n\ndef client():\n if len(sys.argv) < 3:\n usage()\n\n # 두번째 매개변수를 서버 IP로 설정\n host = sys.argv[2]\n\n if len(sys.argv) > 3:\n port = eval(sys.argv[3])\n else:\n port = ECHO_PORT\n addr = host, port\n\n s = socket(AF_INET, SOCK_DGRAM)\n s.bind(('', 0))\n\n print('udp echo client ready, reading stdin')\n\n while 1:\n line = sys.stdin.readline()\n if not line:\n break\n\n # 입력받은 텍스트 서버로 발송\n s.sendto(line.encode(), addr)\n #s.sendto(line, addr)\n # 리턴 대기\n data, fromaddr = s.recvfrom(BUFSIZE)\n print('client received %r from %r' % (data, fromaddr))\n\nmain()\n\n'''\n"
},
{
"alpha_fraction": 0.5590277910232544,
"alphanum_fraction": 0.5879629850387573,
"avg_line_length": 22.37837791442871,
"blob_id": "400baf35df0f5447f2e125541a1476bbfe941717",
"content_id": "e765e6d0e281979feb7c5cb68c3489937fb1d041",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 926,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 37,
"path": "/kinect_py_code/save_video.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "#save webcam video and capture last frame\n\nimport cv2\nimport time\nimport timeit\ncap = cv2.VideoCapture(0)\n\nfourcc = cv2.VideoWriter_fourcc(*'DIVX')\nout = cv2.VideoWriter('save.avi', fourcc, 25.0, (640, 480))\ncnt = False;\n\ntime_end = time.time() + 10\nwhile True:\n ret, frame = cap.read() # Read 결과와 frame\n\n if not ret:\n print(\"no video available\")\n break\n cv2.imshow('video_Save', frame) # 컬러 화면 출력\n\n if cnt is False:\n frame = cv2.flip(frame, 1)\n # 프레임 저장\n out.write(frame)\n if time.time() > time_end:\n out.release()\n cnt = True\n # q (화면종료) 한 순간의 frame이 캡쳐되어 저장된다.\n #capture last frame\n #cv2.imwrite('video_Save.png', frame, params=[cv2.IMWRITE_PNG_COMPRESSION,0])\n\n\n if cv2.waitKey(1) == ord('q'):\n break\n\ncap.release()\ncv2.destroyAllWindows()"
},
{
"alpha_fraction": 0.7242268323898315,
"alphanum_fraction": 0.7242268323898315,
"avg_line_length": 21.852941513061523,
"blob_id": "856fb0c93640306a7f0f297a312daf9453ce67b5",
"content_id": "ec0a37d4472f6fe39ff6d3915add9a3128f5ecdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 34,
"path": "/UDP_POPUP/app/src/main/java/com/example/server/PopUp.java",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "//simple test 부분\n\npackage com.example.server;\n\nimport androidx.appcompat.app.AppCompatActivity;\n\nimport android.content.Intent;\nimport android.os.Bundle;\nimport android.os.Handler;\nimport android.util.DisplayMetrics;\nimport android.view.Gravity;\nimport android.view.WindowManager;\nimport android.widget.TextView;\n\npublic class PopUp extends AppCompatActivity {\n\n TextView txtText;\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.activity_pop_up);\n\n //ui\n txtText = (TextView)findViewById(R.id.txtText);\n\n Intent intent = getIntent();\n String data = intent.getStringExtra(\"message\");\n txtText.setText(data); //이부분을 json parsing\n\n\n\n\n }\n}"
},
{
"alpha_fraction": 0.570740282535553,
"alphanum_fraction": 0.5871915221214294,
"avg_line_length": 41.343284606933594,
"blob_id": "a43220b85a69b4629a0cd7dbdf9c160387008a50",
"content_id": "5e401860d7fac1fc3ca588cb99af6efdf133d021",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8592,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 201,
"path": "/kinect_py_code/0113_knife_depth.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\nimport numpy as np\nimport tensorflow as tf\nimport pathlib\nfrom object_detection.utils import ops as utils_ops\nfrom object_detection.utils import label_map_util\nfrom object_detection.utils import visualization_utils as vis_util\nimport numpy as np\nimport cv2\nimport ctypes\nimport _ctypes\nimport sys\n#import face_recognition\nimport os\nfrom scipy import io\nimport math\nfrom gtts import gTTS\nfrom pykinect2 import PyKinectV2\nfrom pykinect2.PyKinectV2 import *\nfrom pykinect2 import PyKinectRuntime\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\nKinect = AcquisitionKinect()\nframe = Frame()\n### 소켓 통신 부분\nimport sys\nfrom socket import *\nBUFSIZE = 1024\nhost = '127.0.0.1'\nport = 1111\naddr = host, port\nglobal count\ncount = 1\n# patch tf1 into `utils.ops`\nutils_ops.tf = tf.compat.v1\n# Patch the location of gfile\ntf.gfile = tf.io.gfile\nprint(\"[INFO] TF verion = \",tf.__version__)\n###############\n## DEPTH ##\n## define\nglobal xCenter\nglobal yCenter\nxCenter = 0\nyCenter = 0\nimport pygame\nSKELETON_COLORS = [pygame.color.THECOLORS[\"red\"],\n pygame.color.THECOLORS[\"blue\"],\n pygame.color.THECOLORS[\"green\"],\n pygame.color.THECOLORS[\"orange\"],\n pygame.color.THECOLORS[\"purple\"],\n pygame.color.THECOLORS[\"yellow\"],\n pygame.color.THECOLORS[\"violet\"]]\narray_x =[]\narray_y =[]\narray_z =[]\n##########\ndef load_model(model_name):\n model_dir = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/'+model_name\n model_dir = pathlib.Path(model_dir)/\"saved_model\"\n print('[INFO] Loading the model from '+ str(model_dir))\n model = tf.saved_model.load(str(model_dir))\n return model\nPATH_TO_LABELS = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/knife_label_map.pbtxt'\ncategory_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS)#, use_display_name=True)\nmodel_name = 'trained_model_large_original_15000'\nprint('[INFO] Downloading model and loading to network : '+ model_name)\ndetection_model = load_model(model_name)\ndetection_model.signatures['serving_default'].output_dtypes\ndetection_model.signatures['serving_default'].output_shapes\ndef run_inference_for_single_image(model, image):\n image = np.asarray(image)\n # The input needs to be a tensor, convert it using `tf.convert_to_tensor`.\n input_tensor = tf.convert_to_tensor(image)\n # The model expects a batch of images, so add an axis with `tf.newaxis`.\n input_tensor = input_tensor[tf.newaxis, ...]\n # Run inference\n model_fn = model.signatures['serving_default']\n output_dict = model_fn(input_tensor)\n # All outputs are batches tensors.\n # Convert to numpy arrays, and take index [0] to remove the batch dimension.\n # We're only interested in the first num_detections.\n num_detections = int(output_dict.pop('num_detections'))\n output_dict = {key: value[0, :num_detections].numpy()\n for key, value in output_dict.items()}\n output_dict['num_detections'] = num_detections\n # detection_classes should be ints.\n output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)\n # Handle models with masks:\n if 'detection_masks' in output_dict:\n # Reframe the the bbox mask to the image size.\n detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(\n output_dict['detection_masks'], output_dict['detection_boxes'],\n image.shape[0], image.shape[1])\n detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,\n tf.uint8)\n output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()\n return output_dict\n\ndef run_inference(model):\n fn = 0\n while True:\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n image_np = Kinect._kinect.get_last_color_frame()\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n image_np = cv2.resize(image_np, (800, 580))\n print(\"[INFO]\" + str(fn) + \"-th frame -- Running the inference and showing the result....!!!\")\n output_dict = run_inference_for_single_image(model, image_np)\n # Visualization of the results of a detection.\n vis_util.visualize_boxes_and_labels_on_image_array(\n image_np,\n output_dict['detection_boxes'],\n output_dict['detection_classes'],\n output_dict['detection_scores'],\n category_index,\n instance_masks=output_dict.get('detection_masks_reframed', None),\n use_normalized_coordinates=True,\n line_thickness=8)\n ## get bounding box depth\n boxes = np.squeeze(output_dict['detection_boxes'])\n scores = np.squeeze(output_dict['detection_scores'])\n # set a min thresh score, say 0.8\n min_score_thresh = 0.5\n bboxes = boxes[scores > min_score_thresh]\n # get image size\n im_width = 800\n im_height = 580\n final_box = []\n for box in bboxes:\n ymin, xmin, ymax, xmax = box\n final_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n print('box: ',final_box)\n\n if final_box is not None:\n for i in range(len(final_box)):\n xCenter = (final_box[i][1] + final_box[i][0]) / 2\n yCenter = (final_box[i][3] + final_box[i][2]) / 2\n #### depth of bounding box\n x = int(xCenter)\n y = int(yCenter)\n print('x, y = ',x,y)\n if x < 300 and y < 300:\n _depth = Kinect._kinect.get_last_depth_frame()\n z = int(_depth[y * 512 + x])\n ## check and compare with body depth\n print(\"bounding box depth : \", z)\n cv2.circle(image_np, (x,y), 10, (255, 0, 0), -1)\n ## draw for just check!!\n #cv2.line(image_np, (int(final_box[i][0]), int(final_box[i][3])),\n # (int(final_box[i][1]), int(final_box[i][3])), (255, 0, 0), 5, 4)\n #cv2.line(image_np, (int(final_box[i][0]), int(final_box[i][2])),\n # (int(final_box[i][1]), int(final_box[i][2])), (255, 0, 0), 5, 4)\n\n if Kinect._bodies is not None:\n if Kinect._kinect.has_new_depth_frame:\n for i in range(0, Kinect._kinect.max_body_count):\n body = Kinect._bodies.bodies[i]\n if not body.is_tracked:\n continue\n joints = body.joints\n # convert joint coordinates to color space\n joint_points = Kinect._kinect.body_joints_to_color_space(joints)\n Kinect.draw_body(joints, joint_points, SKELETON_COLORS[i])\n # get the skeleton joint x y z\n depth_points = Kinect._kinect.body_joints_to_depth_space(joints)\n x = int(depth_points[PyKinectV2.JointType_SpineMid].x)\n y = int(depth_points[PyKinectV2.JointType_SpineMid].y)\n _depth = Kinect._kinect.get_last_depth_frame()\n z = int(_depth[y * 512 + x])\n array_x.append(x)\n array_y.append(y)\n array_z.append(z) # array의 필요성..?\n #print(\"depth spine : \", x)\n print('x, y :', x,y)\n print(\"depth spine : \", z)\n cv2.imshow('object_detection', image_np)\n\n##################3\n '''\n global count\n #if output_dict['detection_scores'][0] >= 0.8 and count == 1:\n if z == 180 :\n ## test\n s = socket(AF_INET, SOCK_DGRAM)\n line = \"emergency occured!\"\n s.sendto(line.encode(), addr)\n data, fromaddr = s.recvfrom(BUFSIZE)\n print('client received %r from %r' % (data, fromaddr))\n count += 1\n # 다시 clinet로부터 ok 데이터 받으면 count를 1로 되돌려 놓고 다시 신호를 줄 준비를 하자\n '''\n fn = fn + 1\n if cv2.waitKey(25) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n break\n## 실행!\nrun_inference(detection_model)"
},
{
"alpha_fraction": 0.7182320356369019,
"alphanum_fraction": 0.7384898662567139,
"avg_line_length": 35.20000076293945,
"blob_id": "d55f6716c47c9323f04ab97b2a2ad0a61bba42c4",
"content_id": "f5b15c63911ca08034558a3c18c01d6207288eb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1604,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 30,
"path": "/training 순서와 주의할 점!.md",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "### training 순서와 주의할 점!\n\n** 파일명에 공백, 괄호와 같은 기호 (_은 제외) 는 없어야 한다. 안그러면 python 인코딩문제가 발생\n\n0.사진이 너무 크면 안됩니다. 200KB보다 적어야 하며, 720x1280 크기보다는 작아야 한다.\n 이미지가 너 무크면 학습 시간이 길어집니다. repository에 있는 resizer.py를 사용하면 크기를 재조정할 수 있습니다.\n\n1. sizeChecker.py를 실행해서 박스를친 부분이 학습에 사용될 데이터로 적절한지 체크\n\nC:\\tensorflow1\\models\\research\\object_detection> python sizeChecker.py --move \n\n2. 먼저, 모든 train과 test 폴더에 있는 이미지들이 포함된 xml 데이터를 csv 파일로 바꾼다.\n \\object_detection 폴더에서, anaconda 명령창에서 밑의 명령어를 실행하세요 :\n\n C:\\tensorflow1\\models\\research\\object_detection> python xml_to_csv.py \n\n (\\object_detection\\images 폴더에 train_labels.csv 과 test_labels.csv 가 생성될 것)\n\n3. generate_tfrecord.py 수정\n그 후에, generate_tfrecord.py를 텍스트 편집기로 열어봅니다. \n31번째 줄에 각 사물에 맞는 ID 번호가 적혀진 라벨 맵을 바꿔야 합니다. \n단계 5b에 있는 labelmap.pbtxt 파일과 같은 갯수여야 합니다.\n\n4. labelmap.pbtxt 수정\n\n5. python generate_tfrecord.py --csv_input=images\\train_labels.csv --image_dir=images\\train --output_path=train.record\n=> train.record 생성\n\n5. python generate_tfrecord.py --csv_input=images\\test_labels.csv --image_dir=images\\test --output_path=test.record \n=> test.record 생성 "
},
{
"alpha_fraction": 0.5951953530311584,
"alphanum_fraction": 0.6130444407463074,
"avg_line_length": 38.77231979370117,
"blob_id": "1189d46b2be2fa0425b98fe9ac41043867d9ad8e",
"content_id": "a1ef33a4cfbda968691cf09aea7444cc76b75aea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8990,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 224,
"path": "/kinect_py_code/kinect_ver/detection_with_humanDepth.py",
"repo_name": "chaelin0722/GraduationProject_CV24",
"src_encoding": "UTF-8",
"text": "import os\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\n#import warnings\n#warnings.filterwarnings('ignore',category=FutureWarning)\nimport numpy as np\nimport six.moves.urllib as urllib\nimport sys\nimport tarfile\nimport tensorflow as tf\nimport zipfile\nfrom collections import defaultdict\nfrom io import StringIO\nfrom matplotlib import pyplot as plt\nfrom PIL import Image\nfrom IPython.display import display\nimport pathlib\nfrom object_detection.utils import ops as utils_ops\nfrom object_detection.utils import label_map_util\nfrom object_detection.utils import visualization_utils as vis_util\nimport numpy as np\nimport cv2\nimport ctypes\nimport _ctypes\nimport sys\n#import face_recognition\nimport os\nfrom scipy import io\nimport math\nfrom gtts import gTTS\nfrom pykinect2 import PyKinectV2\nfrom pykinect2.PyKinectV2 import *\nfrom pykinect2 import PyKinectRuntime\nfrom wrapperPyKinect2.acquisitionKinect import AcquisitionKinect\nfrom wrapperPyKinect2.frame import Frame as Frame\nKinect = AcquisitionKinect()\nframe = Frame()\n### 소켓 통신 부분\nimport sys\nfrom socket import *\n##\nBUFSIZE = 1024\nhost = '127.0.0.1'\nport = 1111\naddr = host, port\nglobal count\ncount = 1\n# patch tf1 into `utils.ops`\nutils_ops.tf = tf.compat.v1\n# Patch the location of gfile\ntf.gfile = tf.io.gfile\nprint(\"[INFO] TF verion = \",tf.__version__)\n###############\n## DEPTH ##\nimport pygame\nSKELETON_COLORS = [pygame.color.THECOLORS[\"red\"],\n pygame.color.THECOLORS[\"blue\"],\n pygame.color.THECOLORS[\"green\"],\n pygame.color.THECOLORS[\"orange\"],\n pygame.color.THECOLORS[\"purple\"],\n pygame.color.THECOLORS[\"yellow\"],\n pygame.color.THECOLORS[\"violet\"]]\narray_x =[]\narray_y =[]\narray_z =[]\n##########\n\ndef load_model(model_name):\n #model_dir = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/'+model_name\n model_dir = 'C:/Users/IVPL-D14/fine_tuned_model/' + model_name\n\n #model_dir = pathlib.Path(model_dir)/\"saved_model\"\n\n\n print('[INFO] Loading the model from '+ str(model_dir))\n model = tf.saved_model.load(str(model_dir))\n return model\n\n\n# PATH_TO_LABELS = 'C:/Users/IVPL-D14/models/research/object_detection/local_models/knife_label_map.pbtxt'\nPATH_TO_LABELS = 'C:/Users/IVPL-D14/models/research/object_detection/training/labelmap.pbtxt'\n\ncategory_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS)#, use_display_name=True)\n#model_name = 'trained_model_large_original_15000'\nmodel_name = 'saved_model'\n\nprint('[INFO] Downloading model and loading to network : '+ model_name)\ndetection_model = load_model(model_name)\ndetection_model.signatures['serving_default'].output_dtypes\ndetection_model.signatures['serving_default'].output_shapes\n\n\ndef run_inference_for_single_image(model, image):\n image = np.asarray(image)\n # The input needs to be a tensor, convert it using `tf.convert_to_tensor`.\n input_tensor = tf.convert_to_tensor(image)\n # The model expects a batch of images, so add an axis with `tf.newaxis`.\n input_tensor = input_tensor[tf.newaxis, ...]\n # Run inference\n model_fn = model.signatures['serving_default']\n output_dict = model_fn(input_tensor)\n # All outputs are batches tensors.\n # Convert to numpy arrays, and take index [0] to remove the batch dimension.\n # We're only interested in the first num_detections.\n num_detections = int(output_dict.pop('num_detections'))\n output_dict = {key: value[0, :num_detections].numpy()\n for key, value in output_dict.items()}\n output_dict['num_detections'] = num_detections\n # detection_classes should be ints.\n output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)\n # Handle models with masks:\n if 'detection_masks' in output_dict:\n # Reframe the the bbox mask to the image size.\n detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(\n output_dict['detection_masks'], output_dict['detection_boxes'],\n image.shape[0], image.shape[1])\n detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,\n tf.uint8)\n output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()\n return output_dict\n\n\ndef run_inference(model):\n fn = 0\n while True:\n Kinect.get_frame(frame)\n Kinect.get_color_frame()\n image_np = Kinect._kinect.get_last_color_frame()\n # image_np = Kinect._frameRGB\n image_depth = Kinect._frameDepthQuantized\n Skeleton_img = Kinect._frameSkeleton\n image_np = np.reshape(image_np,\n (Kinect._kinect.color_frame_desc.Height, Kinect._kinect.color_frame_desc.Width, 4))\n image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n show_img = image_np\n # show_img = image_np[ 200:1020, 350:1780]\n show_img = cv2.resize(show_img, (512, 424))\n # image_np = cv2.cvtColor(image_np, cv2.COLOR_RGBA2RGB)\n # image_np = image_np[ 200:1020, 350:1780]\n # image_np = cv2.resize(image_np, (512,424))\n rgb_small_frame = cv2.resize(image_np, (0, 0), fx=0.25, fy=0.25)\n # Actual detection.\n print(\"[INFO]\" + str(fn) + \"-th frame -- Running the inference and showing the result....!!!\")\n output_dict = run_inference_for_single_image(model, image_np)\n # Visualization of the results of a detection.\n vis_util.visualize_boxes_and_labels_on_image_array(\n image_np,\n output_dict['detection_boxes'],\n output_dict['detection_classes'],\n output_dict['detection_scores'],\n category_index,\n instance_masks=output_dict.get('detection_masks_reframed', None),\n use_normalized_coordinates=True,\n line_thickness=8)\n ## using coordinates to get centroid of bounding box\n coordinates = vis_util.return_coordinates(\n image_np,\n output_dict['detection_boxes'],\n output_dict['detection_classes'],\n output_dict['detection_scores'],\n category_index,\n use_normalized_coordinates=True,\n line_thickness=8,\n min_score_thresh=0.5)\n\n if coordinates is not None:\n for i in range(len(coordinates)):\n for j in range(4):\n print(\"each coords : \", coordinates[i][j])\n\n if coordinates is not None:\n for i in range(len(coordinates)):\n xCenter = (coordinates[i][0] + coordinates[i][2]) / 2\n yCenter = (coordinates[i][1] + coordinates[i][3]) / 2\n #### depth of bounding box\n x = int(xCenter)\n y = int(yCenter)\n _depth = Kinect._kinect.get_last_depth_frame()\n z = int(_depth[y * 512 + x])\n ## check and compare with body depth\n print(\"bounding box depth : \", z)\n\n #cv2.circle(image_np, (int(xCenter), int(yCenter)), 10, (255, 0, 0), -1)\n\n if Kinect._bodies is not None:\n if Kinect._kinect.has_new_depth_frame:\n for i in range(0, Kinect._kinect.max_body_count):\n body = Kinect._bodies.bodies[i]\n if not body.is_tracked:\n continue\n joints = body.joints\n # convert joint coordinates to color space\n joint_points = Kinect._kinect.body_joints_to_color_space(joints)\n Kinect.draw_body(joints, joint_points, SKELETON_COLORS[i])\n # get the skeleton joint x y z\n depth_points = Kinect._kinect.body_joints_to_depth_space(joints)\n x = int(depth_points[PyKinectV2.JointType_SpineMid].x)\n y = int(depth_points[PyKinectV2.JointType_SpineMid].y)\n _depth = Kinect._kinect.get_last_depth_frame()\n z = int(_depth[y * 512 + x])\n array_x.append(x)\n array_y.append(y)\n array_z.append(z) # array의 필요성..?\n print(\"depth spine : \", x)\n\n cv2.imshow('object_detection', cv2.resize(image_np, (800, 580)))\n##################3\n '''\n global count\n if output_dict['detection_scores'][0] >= 0.8 and count == 1:\n s = socket(AF_INET, SOCK_DGRAM)\n line = \"emergency occured!\"\n s.sendto(line.encode(), addr)\n data, fromaddr = s.recvfrom(BUFSIZE)\n print('client received %r from %r' % (data, fromaddr))\n count += 1\n # 다시 clinet로부터 ok 데이터 받으면 count를 1로 되돌려 놓고 다시 신호를 줄 준비를 하자\n '''\n############33\n fn = fn + 1\n if cv2.waitKey(25) & 0xFF == ord('q'):\n cv2.destroyAllWindows()\n break\n## 실행!\nrun_inference(detection_model)"
}
] | 20 |
dtanalytic/stat
|
https://github.com/dtanalytic/stat
|
3848e0e9d7310dd49cfcb8ce8089af257e728aa9
|
30ac5ee1fc262d359eb172706e5bc0fdf6f50fe2
|
4fe9cbae580de78de4e53a6826301900f632826d
|
refs/heads/master
| 2022-12-25T04:05:49.306065 | 2020-08-23T09:28:41 | 2020-08-23T09:28:41 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5740922689437866,
"alphanum_fraction": 0.6074582934379578,
"avg_line_length": 33,
"blob_id": "6c39db6a9d7bf005869f1fbc949b6b9cb3cca650",
"content_id": "f6c5eeca3b98175c4e6758ac4f5807d83f26d29f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 30,
"path": "/stat.py",
"repo_name": "dtanalytic/stat",
"src_encoding": "UTF-8",
"text": "import scipy.stats as stats\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nif __name__=='__main__':\n \n SMALL_SIZE = 10\n MEDIUM_SIZE = 14\n BIGGER_SIZE = 18\n \n plt.rc('font', size=BIGGER_SIZE) # controls default text sizes\n plt.rc('axes', titlesize=SMALL_SIZE) # fontsize of the axes title\n plt.rc('axes', labelsize=MEDIUM_SIZE) # fontsize of the x and y labels\n plt.rc('xtick', labelsize=BIGGER_SIZE) # fontsize of the tick labels\n plt.rc('ytick', labelsize=BIGGER_SIZE) # fontsize of the tick labels\n plt.rc('legend', fontsize=SMALL_SIZE) # legend fontsize\n plt.rc('figure', titlesize=BIGGER_SIZE) # fontsize of the figure title\n \n \n x = np.linspace(0,1,100)\n betas = [(1,1),(3,1),(10,10), (1,2)]\n fig, ax = plt.subplots(1,len(betas),sharey=True)\n \n for i,(a,b) in enumerate(betas):\n ax[i].plot(x, stats.beta(a,b).pdf(x))\n \n fig.text(0.5,0.05,'X')\n fig.text(0.05,0.5,'p(X)',rotation=90)\n # stat = stats.beta"
}
] | 1 |
AparnApu/Balancing-Chemical-Equations
|
https://github.com/AparnApu/Balancing-Chemical-Equations
|
de53248da66fd66d0e491aad39ed4ea8b7e046d0
|
94d43468198c5d842f246755407c105487574c89
|
2f6bf1c21b5cbb489b5b8f105a39ce127877dc47
|
refs/heads/master
| 2022-06-29T23:51:46.662363 | 2020-05-11T07:10:45 | 2020-05-11T07:10:45 | 262,940,561 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3767918050289154,
"alphanum_fraction": 0.39590445160865784,
"avg_line_length": 22.26984214782715,
"blob_id": "d9f543aa83b63ba96403b0ed576a51a93c0f7e35",
"content_id": "39048737f73ed744dc5678ea225a64c331d44bbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1465,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 63,
"path": "/RxnBalance_wrapper.py",
"repo_name": "AparnApu/Balancing-Chemical-Equations",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Apr 24 15:50:29 2020\n\n@author: apuap\n\"\"\"\n###########################################\n# error check\n # invalid compound \n # atom on left and right must match\n\n# enhancements\n # bracket compounds\n # ionic compounds\n # multiple rxn support\n # doc strings multiline\n###########################################\n\nfrom RxnBalance_ClassModule import RxnBalance\n\n###########################################\n# user input\n###########################################\n\n#ob = RxnBalance(unbal_str = 'SeCl6 + O2 -> SeO2 + Cl2') #1113\nob = RxnBalance(unbal_str = 'NH3 + O2 -> NO + H2O') #4546\n\n###########################################\n# strip input of whitespaces\n###########################################\n\nob.strip_space()\n\n###########################################\n# to separate input into reactants & products\n###########################################\n\nob.input_split()\n\n###########################################\n# to split elements in reactants & products\n###########################################\n\nob.r_p_split()\n\n###########################################\n# to form matrix A\n###########################################\n\nob.create_ListOfDict()\nob.input_check()\nob.fill_emptyKeys()\nob.matrix_formation()\n\n###########################################\n# to solve system of homogenous equations\n###########################################\n\nfinAns = ob.main()\n\nAnsStr = ob.display(finAns)\n\nprint(AnsStr)"
},
{
"alpha_fraction": 0.6787564754486084,
"alphanum_fraction": 0.6994818449020386,
"avg_line_length": 39.19444274902344,
"blob_id": "64a0ce80a34f067a2573010d6b0e2f8d58019dd8",
"content_id": "2f7d38da4bd95af7f1b866d536b1095fde926e91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2897,
"license_type": "no_license",
"max_line_length": 363,
"num_lines": 72,
"path": "/README.md",
"repo_name": "AparnApu/Balancing-Chemical-Equations",
"src_encoding": "UTF-8",
"text": "# Balancing-Chemical-Equations\n\n## Table of Contents\n\n- [Introduction](#Introduction)\n- [Motivation](#Motivation)\n- [Working](#Working)\n- [Contributions](#Contributions)\n- [Acknowledgement](#Acknowledgement)\n\n<!-- toc -->\n\n\n## Introduction\nThis program balances your chemical reaction. It uses an optimizer based on Diophantine's equation solving.\n\n## Motivation\nI've always liked chemistry and coding, so this program was a fun project to undertake! But this program stretched my brain and coding skills quite a bit - from parsing the equation and its atoms to solving the system of homegenous linear equations using an optimizer. All in all, I thoroughly enjoyed the challenge because I learnt quite a lot from this project!\n\n## Working\nThe basic principle is that I need to cast the equation into this form: Ax = 0 (homogenous linear system of equations that has an integer solution). \n \nDimensions of A are: \nNumber of rows = number of atoms \nNumber of columns = total number of compounds (ie, number of reactants + number of products) \nTo get the equation to that point, the code splits the compounds into the reactant side and product side. I then create a list of dictionaries for the multiplicity of the atoms in each compound. If atoms does not exist, the multiplicity is zero. \nFor example, \n \nUnbalanced Reaction: NH<sub>3</sub> + O<sub>2</sub> -> NO + H<sub>2</sub>O \nList of dictionaries (on reactant side): [{'N': 1, 'H': 3, 'O': 0}, {'O': 2, 'N': 0, 'H': 0}] \nList of dictionaries (on product side): [{'N': 1, 'O': 1, 'H': 0}, {'H': 2, 'O': 1, 'N': 0}]\n\nOnce this is done, I form two matrices (reactant side and product side) like this: \n(Reactant side): \nH: [3, 0] \nN: [1, 0] \nO: [0, 2] \n \n(Product side): \nH: [0, 2] \nN: [1, 0] \nO: [1, 1] \n\nI then stack them side by side, with the product side matrix being negated.\nSo, I get my matrix A: \n[ 3, 0, 0, -2] \n[ 1, 0, -1, 0] \n[ 0, 2, -1, -1] \n\nI used **Differential Evolution** to get a solution x which satisfies the Ax = 0. \nThe problem there is that the solution x isn't an integer. So, I find a value α for which α * x is an integer.\n\n\nTo run the code: \nFork the repo (link: (https://github.com/AparnApu/Balancing-Chemical-Equations/fork) or download/ clone it. Run the file 'RxnBalance_wrapper.py'.\nI have already included two test cases (lines 25 - 26), which you can modify. There are no packages to install.\n \n### Code snippet to modify:\n\n```\n#ob = RxnBalance(unbal_str = 'SeCl6 + O2 -> SeO2 + Cl2') #1113\nob = RxnBalance(unbal_str = 'NH3 + O2 -> NO + H2O') #4546\n```\n\n\n## Contributions\nOpen to contributions!\nA possible enhancement I am yet to add are compounds that involve brackets. \nFork the repo, edit it and commit your change.\n\n## Acknowledgement\nA huge thankyou to my dad who came up with the idea for this project and helped me navigate my way through this complicated code!\n\n"
},
{
"alpha_fraction": 0.4280005991458893,
"alphanum_fraction": 0.43347638845443726,
"avg_line_length": 24.988462448120117,
"blob_id": "bf3afe8e25219d46eef42b1d6cfb680ebd1ca296",
"content_id": "9271920f71da169792fa28ea941333c18c2c1883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6757,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 260,
"path": "/RxnBalance_ClassModule.py",
"repo_name": "AparnApu/Balancing-Chemical-Equations",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Apr 24 16:05:44 2020\n\n@author: apuap\n\"\"\"\n\nimport sys\nimport numpy as np\nfrom scipy.optimize import differential_evolution\n\n\nclass RxnBalance:\n \n \n def __init__(self, unbal_str):\n \n self.unbal_str = unbal_str\n \n return\n \n \n def strip_space(self):\n \n self.unbal_str = \"\".join(self.unbal_str.split())\n \n \n def input_split(self):\n \n temp = self.unbal_str.split('->')\n \n self.reac = temp[0]\n self.prod = temp[1]\n \n \n def r_p_split(self):\n \n self.comp_reac = self.reac.split('+')\n self.comp_prod = self.prod.split('+')\n self.Nr = len(self.comp_reac)\n self.Np = len(self.comp_prod)\n \n \n def dict_AtomMultiplicity(self, compound):\n \n string = compound\n\n p = len(string)\n \n Atoms = {} # Dictionary to store atom as key, and multiplicity as value\n num_string = 0\n currentAtom = \"\"\n \n for i in range(0, p): # parsing the string char by char\n \n if(string[i].isdigit()):\n \n num_string = string[i]\n \n for j in range(i+1, p):\n \n if(string[j].isdigit()):\n \n num_string += string[j] \n \n else:\n \n break\n \n if not ( currentAtom in Atoms.keys() ): \n Atoms[currentAtom] = int(num_string) ## key - value allocation ##\n else:\n Atoms[currentAtom] = int(num_string) + Atoms[currentAtom] \n \n currentAtom = \"\"\n \n elif(string[i].islower()):\n \n currentAtom = currentAtom + string[i]\n \n elif(string[i].isupper()):\n \n if not ( currentAtom in Atoms.keys() ): \n Atoms[currentAtom] = 1 # end of the existing key with value=1 (value explicitly give would go to digit tree) ## key - value allocation ##\n else:\n Atoms[currentAtom] = int(num_string) + Atoms[currentAtom] \n \n currentAtom = string[i] # start of a new key\n \n if (currentAtom != \"\"):\n Atoms[currentAtom] = 1\n \n del Atoms[\"\"]\n \n return Atoms\n \n \n def create_ListOfDict(self):\n \n self.ListofDict_R = []\n self.ListofDict_P = []\n temp_dict_R = {}\n temp_dict_P = {}\n \n for i in range(self.Nr):\n \n temp_dict_R = self.dict_AtomMultiplicity(self.comp_reac[i])\n self.ListofDict_R.append(temp_dict_R)\n \n for i in range(self.Np):\n \n temp_dict_P = self.dict_AtomMultiplicity(self.comp_prod[i])\n self.ListofDict_P.append(temp_dict_P)\n \n \n def create_allKeys(self, LoD):\n \n allK = {}\n tempSet ={}\n p = len(LoD)\n \n for i in range(p):\n \n tempSet = set(LoD[i].keys())\n allK = tempSet.union(allK)\n \n return allK\n \n \n def input_check(self):\n \n self.allKeys_P = {}\n self.allKeys_R = {}\n \n self.allKeys_R = self.create_allKeys(self.ListofDict_R)\n self.allKeys_P = self.create_allKeys(self.ListofDict_P)\n \n if not (self.allKeys_R == self.allKeys_P):\n \n print(\"Input entered is incorrect. Please re-enter data.\\nProgram will exit now.\")\n sys(exit)\n \n else:\n \n print(\"Input entered has been parsed, loading your input now.\")\n \n def fill_emptyKeys(self):\n \n for i in range(len(self.ListofDict_R)):\n \n diffR = self.allKeys_R.difference(self.ListofDict_R[i])\n \n for x in diffR:\n self.ListofDict_R[i][x] = 0\n \n for i in range(len(self.ListofDict_P)):\n \n diffP = self.allKeys_R.difference(self.ListofDict_P[i])\n \n for x in diffP:\n self.ListofDict_P[i][x] = 0\n \n \n self.Na = len(self.allKeys_R)\n\n \n def matrix_formation(self):\n \n self.allKeys_R = list(self.allKeys_R)\n self.allKeys_R.sort()\n \n self.arr_R = np.zeros((self.Na,self.Nr), int)\n self.arr_P = np.zeros((self.Na,self.Np), int)\n\n for i in range(self.Na):\n \n for j in range(self.Nr):\n \n self.arr_R[i][j] = self.ListofDict_R[j][self.allKeys_R[i]]\n \n for i in range(self.Na):\n \n for j in range(self.Np):\n \n self.arr_P[i][j] = self.ListofDict_P[j][self.allKeys_R[i]]\n \n \n self.A = np.hstack((self.arr_R, self.arr_P*-1))\n \n \n def myobj(self, x, *refz):\n \n resd = np.dot(refz[0], x) - refz[1]\n \n err = np.linalg.norm(resd)\n \n return err\n \n def dec_to_int(self, arr):\n \n min_val = np.amin(arr)\n \n arr = arr / min_val\n \n x = 1\n \n while True:\n \n temp = arr * x\n \n delta = temp - np.round(temp)\n \n err= np.linalg.norm(delta)\n \n if (err<0.05):\n break\n else:\n x = x + 0.01\n \n res = np.round(temp).astype('int')\n \n return res\n \n def main(self):\n \n b = np.zeros(self.Na, int)\n\n bounds = [(1, 10)] * (self.Nr + self.Np)\n \n args = (self.A, b)\n \n self.result = differential_evolution(self.myobj, bounds, args=args)\n \n fin_result = self.dec_to_int(self.result.x)\n \n return(fin_result)\n \n \n def display(self, ans):\n \n self.coef_R = list(ans[0:self.Nr])\n self.coef_P = list(ans[self.Nr:len(ans)])\n \n finR = []\n finP = []\n \n for i in range(len(self.coef_R)):\n \n finR.append(str(self.coef_R[i]) + self.comp_reac[i])\n \n for i in range(len(self.coef_P)):\n \n finP.append(str(self.coef_P[i]) + self.comp_prod[i])\n \n finR = ' + '.join(finR)\n finP = ' + '.join(finP)\n \n self.finStr = finR + ' -> ' + finP\n \n return self.finStr\n"
}
] | 3 |
sudarshansaikia1999/nlp_hack2
|
https://github.com/sudarshansaikia1999/nlp_hack2
|
c097321219b236dbec683df83ade2534317e983a
|
cee29bb3400467257810661b2f1abf8510b736d6
|
f97c14cd0809b420a832627cbe3f52634587e3ed
|
refs/heads/main
| 2022-12-28T09:45:21.729891 | 2020-10-08T17:33:10 | 2020-10-08T17:33:10 | 302,415,096 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6398618817329407,
"alphanum_fraction": 0.6625555157661438,
"avg_line_length": 27.405797958374023,
"blob_id": "5bec098afed502ce9d4fa722095dbe032365cc12",
"content_id": "58c36ba6dec71766dc8503394a676e8f6f0af8dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2027,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 69,
"path": "/gmap.py",
"repo_name": "sudarshansaikia1999/nlp_hack2",
"src_encoding": "UTF-8",
"text": "'''\r\nA Web application that shows Google Maps around schools, using\r\nthe Flask framework, and the Google Maps API.\r\n'''\r\n\r\nfrom flask import Flask, render_template, abort,url_for,request\r\nimport pandas as pd\r\nimport pickle\r\nimport numpy as np\r\napp = Flask(__name__)\r\n\r\n\r\n\r\nmodel=pickle.load(open('model.pkl','rb'))\r\n\r\n\r\n\r\[email protected](\"/\")\r\ndef index():\r\n return render_template('index.html')\r\n\r\n###data set doesn't contain my country details. so taking an arbitary location for demo\r\[email protected](\"/visualization\")\r\ndef vis():\r\n data= pd.read_csv(\"1_county_level_confirmed_cases.csv\")\r\n\r\n\r\n loc=(data[data['lat']==34.69847452].index.values)\r\n population=data['total_population'][loc[0]]\r\n confirmed=data['confirmed'][loc[0]]\r\n deaths=data['deaths'][loc[0]]\r\n if (confirmed>=1000):\r\n text='Your symptoms are sevre! Consult doctors as early as possible '\r\n return render_template('visual.html',population=population,confirmed=confirmed,deaths=deaths,text=text)\r\n else:\r\n text= 'Low covid sensitive area!'\r\n return render_template('visual.html',pupulation=population,confirmed=confirmed,deaths=deaths,text=text)\r\n\r\n\r\[email protected](\"/health-check\")\r\ndef check():\r\n return render_template('check.html')\r\n\r\n\r\[email protected]('/health-check-up',methods=['GET','POST'])\r\ndef Disease():\r\n int_features = [int(x) for x in request.form.values()]\r\n final_features = [np.array(int_features)]\r\n prediction = model.predict(final_features)\r\n\r\n output = round(prediction[0], 2)\r\n if output==0:\r\n prediction_text='Congratulations! You are completely fit'\r\n elif output==1:\r\n prediction_text='Severe Chance of covid19. consult doctor'\r\n return render_template('<h1>{{ prediction_text }}</h1>', prediction_text=prediction_text)\r\n\r\n\r\n\r\n#for testing\r\n'''\r\[email protected]('/health-check-results')\r\ndef Pred():\r\n c=model.predict([[1,1,1,1,1,0,1,1,1,1,0,1,0,0,0,0,0,1,0]])\r\n d=c[0]\r\n return render_template('results.html')\r\n\r\n'''\r\napp.run(host='localhost', debug=True)"
}
] | 1 |
deepakdeedar/CoffeeMachine
|
https://github.com/deepakdeedar/CoffeeMachine
|
fbd6d10293127d88d072857ed682a37274d74683
|
240794ae412b6f21cb62176760db4d1e417c21d8
|
afae949b646f95f47be8c01e3225ae612d2ea0e8
|
refs/heads/master
| 2023-01-28T17:29:46.445315 | 2020-12-07T05:17:11 | 2020-12-07T05:17:11 | 319,211,915 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49562257528305054,
"alphanum_fraction": 0.5179961323738098,
"avg_line_length": 24.712499618530273,
"blob_id": "04ee737fbb5666dce40d46f1b9d5ed510ebe0a6d",
"content_id": "3274c50831ecdbb590769b85424fed8fbfa1da27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2070,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 80,
"path": "/main.py",
"repo_name": "deepakdeedar/CoffeeMachine",
"src_encoding": "UTF-8",
"text": "MENU = {\n \"espresso\": {\n \"ingredients\": {\n \"water\": 50,\n \"coffee\": 18,\n },\n \"cost\": 15,\n },\n \"latte\": {\n \"ingredients\": {\n \"water\": 200,\n \"milk\": 150,\n \"coffee\": 24,\n },\n \"cost\": 25,\n },\n \"cappuccino\": {\n \"ingredients\": {\n \"water\": 250,\n \"milk\": 100,\n \"coffee\": 24,\n },\n \"cost\": 30\n }\n}\nprofit = 0\nresources = {\n \"water\": 300,\n \"milk\": 200,\n \"coffee\": 100,\n}\n\ndef sufficient(order_ingredients):\n for item in order_ingredients:\n if resources[item] < order_ingredients[item]:\n print(f\"Sorry not enough {item}\")\n return False\n return True\n\ndef coin():\n print(\"Please insert coins\")\n total = int(input(\"How many ₹1 coin: \")) * 1\n total += int(input(\"How many ₹2 coin: \")) * 2\n total += int(input(\"How many ₹5 coin: \")) * 5\n total += int(input(\"How many ₹10 coin: \")) * 10\n return total\n\ndef successfull(payment, drink_cost):\n if payment >= drink_cost:\n change = payment - drink_cost\n print(f\"Here is {change} in change.\")\n global profit\n profit += payment\n return True\n else:\n print(\"Sorry that's not enough money. Money refunded.\")\n return False\n\ndef make_coffee(choice, ingredients):\n for item in ingredients:\n resources[item] -= ingredients[item]\n print(f\"Here is your {choice} ☕️. Enjoy!\")\n\non = True\n\nwhile on:\n choice = input(\"What would you like? (espresso/latte/cappuccino): \")\n if choice == \"off\":\n on = False\n elif choice == \"report\":\n print(f\"Water: {resources['water']}ml\")\n print(f\"Milk: {resources['milk']}ml\")\n print(f\"Coffee: {resources['coffee']}g\")\n print(f\"Money: ₹{profit}\")\n else:\n drink = MENU[choice]\n if sufficient(drink['ingredients']):\n payment = coin()\n if successfull(payment, drink['cost']):\n make_coffee(choice, drink['ingredients'])"
}
] | 1 |
marcoceppi/Silph-Weather
|
https://github.com/marcoceppi/Silph-Weather
|
8bc221bd04c445c7b50bff785008120475b07247
|
f158c0e1ebeb1f77c4d2996bf38fbfe3b102a262
|
3707d4cb7e3ab45143b2c3b3161e11d10412341f
|
refs/heads/master
| 2021-05-06T03:35:57.935525 | 2017-12-20T15:56:38 | 2017-12-20T15:56:38 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6761006116867065,
"alphanum_fraction": 0.7295597195625305,
"avg_line_length": 21.714284896850586,
"blob_id": "6f34193f0fa53fa83fb7cf25aaf516e87276348e",
"content_id": "ea37bd6ca475c359d5be9ed2bf832d44cd2620ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 318,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 14,
"path": "/weather.py",
"repo_name": "marcoceppi/Silph-Weather",
"src_encoding": "UTF-8",
"text": "import pyowm\n\nowm = pyowm.OWM('d6c1adeac7d7008ab74147f5a68f20be') \nobservation = owm.weather_at_place(\"waco, us\") \nw = observation.get_weather() \nwind = w.get_wind() \ntemperature = w.get_temperature('fahrenheit')\ntomorrow = pyowm.timeutils.tomorrow() \n\n\nprint(w) \nprint(wind) \nprint(temperature)\nprint(tomorrow)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 15,
"blob_id": "7cbe5c77a5bb94fe09d04e5f32addacd90c5d3c6",
"content_id": "e0e7110afb1ed9f1eb0e5ea75c925316caf15ca4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "permissive",
"max_line_length": 15,
"num_lines": 1,
"path": "/README.md",
"repo_name": "marcoceppi/Silph-Weather",
"src_encoding": "UTF-8",
"text": "# Silph-Weather\n"
},
{
"alpha_fraction": 0.5556991696357727,
"alphanum_fraction": 0.5580253005027771,
"avg_line_length": 30.97520637512207,
"blob_id": "c5fb00e190001ff1433a4ec01b212c269aa2cafa",
"content_id": "d4a26146732aa49312e34e8971882b8195c411e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3869,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 121,
"path": "/weatherbot.py",
"repo_name": "marcoceppi/Silph-Weather",
"src_encoding": "UTF-8",
"text": "import discord\nfrom discord.ext import commands\nfrom discord.ext.commands import bot\nimport asyncio\n\n\nbot = commands.Bot(command_prefix='!')\n\n\[email protected]\nasync def on_ready():\n print('Logged in as')\n print(bot.user.name)\n print(bot.user.id)\n print('-----RUNNING-----')\n\n\necho \"# Silph-Weather\" >> README.md\ngit init\ngit add README.md\ngit commit -m \"first commit\"\ngit remote add origin https://github.com/adeafblindman/Silph-Weather.git\ngit push -u origin master\n\n\n\n\[email protected](pass_context=True)\nasync def ping(ctx):\n\tawait bot.say(\"im alive!\")\n\[email protected](pass_context=True)\nasync def w(ctx, *input_string: tuple):\n location = ''\n weather_msg = ''\n notifications = []\n forecast.channel = ctx.message.channel\n forecast.is_metric = False\n forecast.is_pm = False\n forecast.invalid_flag = False\n forecast.is_saving = False\n forecast.flag_string = ''\n\n def save():\n if not forecast.is_saving:\n forecast.flag_string += 's'\n forecast.is_saving = True\n\n def metric():\n if not forecast.is_metric:\n forecast.flag_string += 'm'\n forecast.is_metric = True\n\n def private_message():\n if not forecast.is_pm:\n forecast.flag_string += 'p'\n forecast.is_pm = True\n\n def invalid_flag():\n if not forecast.invalid_flag:\n forecast.flag_string += 'i'\n forecast.invalid_flag = True\n\n flags = {\n '-save': save,\n '-metric': metric,\n '-pm': private_message\n }\n\n for i in input_string:\n word = ''.join(i)\n try:\n flags[word]()\n except KeyError:\n if word[0] == '-':\n invalid_flag()\n else:\n location += '{} '.format(word)\n\n location = location.rstrip()\n\n is_from_server = not isinstance(ctx.message.server,type(None))\n logger_text = '{}'+' - User: {0} User ID: {1} Server Name: {2} ' \\\n 'Server ID: {3} Location: {4} Flags: {5}'.format(ctx.message.author.name,\n ctx.message.author.id,\n ctx.message.server.name if is_from_server else 'N/A',\n ctx.message.server.id if is_from_server else 'N/A',\n location if location != '' else 'N/A',\n forecast.flag_string if not forecast.flag_string == '' else 'N/A')\n\n logger.info(logger_text.format('Forecast Request'))\n\n await bot.send_typing(forecast.channel)\n try:\n weather_msg += get_forecast(location, forecast.is_metric)\n logger.info(logger_text.format('Forecast Retrieved'))\n\n if forecast.is_pm:\n if is_from_server:\n forecast.channel = ctx.message.author\n await bot.say('Hey {}, weather information is being sent to your PMs.'.format(ctx.message.author.mention))\n\n if forecast.is_saving: # only saves if no WeatherException caught, preventing useless saves\n notifications.append(':warning:'+make_shortcut(ctx.message.author, ctx.message.server, location, forecast.is_metric))\n\n if forecast.invalid_flag:\n notifications.append(':warning:Flag(s) identified but not resolved. for all flags view github.com/lluisrojass/discord-weather-bot')\n\n for m in notifications:\n weather_msg += m + '\\n'\n\n except WeatherException:\n weather_msg += ':warning: {}'.format(sys.exc_info()[1])\n logger.info(logger_text.format('Error Retrieving Weather ({})'.format(sys.exc_info()[1])))\n\n await bot.send_message(forecast.channel, weather_msg)\n\n\n\n\nbot.run('Mzg4OTMxNzE5NDE3NDMwMDE2.DRuLgQ.sTPf1VyMR4JqmJf2bUtNH7of_ko')\n"
}
] | 3 |
maxrudolph1/vsepr_hero
|
https://github.com/maxrudolph1/vsepr_hero
|
94391eb0d03cc130602e5f6191293c99bd7d9994
|
15ed7100e323af7e5f1d79738363729e65e7b1b4
|
c227490351aea69ebc1a641bf4b1bd92d9a53916
|
refs/heads/master
| 2020-04-02T03:35:20.622570 | 2018-10-21T13:38:15 | 2018-10-21T13:38:15 | 153,974,018 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6007497906684875,
"alphanum_fraction": 0.6419869065284729,
"avg_line_length": 28.66666603088379,
"blob_id": "79767e48b0cfdf090134c17444a5a35d447c30c2",
"content_id": "aea5b537be1be02a1159ff10cf296a66320ede25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1067,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 36,
"path": "/main.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import sys\nimport cv2\nimport copy\nimport numpy as np\nimport matplotlib.pyplot as plt\n\ndef main():\n sys.argv.pop(0)\n for image_filename in sys.argv:\n analyzeImage(image_filename)\n\n\ndef analyzeImage(image_filename):\n\n image = cv2.imread(image_filename)\n image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)\n lower_black = np.array([0,0,0], dtype = \"uint16\")\n upper_black = np.array([70, 70, 70], dtype = \"uint16\")\n black_image = cv2.inRange(image, lower_black, upper_black)\n \n ret, contours, hierarchy = cv2.findContours(black_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n # image = cv2.drawContours(image, contours, -1, (0,255,0), 1)\n for contour in contours:\n peri = cv2.arcLength(contour, True)\n approx = cv2.approxPolyDP(contour, 0.02 * peri, True)\n x, y, w, h = cv2.boundingRect(approx)\n rect_image = cv2.rectangle(image, (x, y), (x + w, y + h), (255,0,0), 2)\n displayImage(rect_image)\n\n\ndef displayImage(image):\n plt.imshow(image)\n plt.show()\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.53998202085495,
"alphanum_fraction": 0.570530116558075,
"avg_line_length": 23.66666603088379,
"blob_id": "59d4bb8935b8d8dddd993fce1302b07a27cb37ba",
"content_id": "5dd7acc35e79918fdc5c4cf04427a39f2b858cae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 45,
"path": "/image_train.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nimport pytesseract\nimport text_detection as td\nimport sys\nimport copy\nimport matplotlib.pyplot as plt\n\n\n\ndef main():\n sys.argv.pop(0)\n for image_filename in sys.argv:\n analyzeImage(image_filename)\n\n\ndef analyzeImage(file_name):\n\n img = cv2.imread(file_name)\n mser = cv2.MSER_create()\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #Converting to GrayScale\n gray_img = img.copy()\n\n msers, bbox = mser.detectRegions(gray) # bbox is xmin, ymin, xrange, yrange\n\n portions = []\n blocks = []\n count = 0\n for n in range(0, len(bbox)):\n portions.append(gray[bbox[n][1]:(bbox[n][1] + bbox[n][3]), bbox[n][0]:(bbox[n][0] + bbox[n][2])])\n #cv2.rectangle(img, (bbox[n][0], bbox[n][1]) , (bbox[n][0] + bbox[n][2], bbox[n][1] + bbox[n][3]), (0,255,255), 2 )\n cv2.imshow('Image', portions[n])\n\n inp = input('character:')\n inp = 'tsta'\n sttr = inp + '_' +str(count+n) + '.bmp'\n\n cv2.imwrite(sttr, portions[n])\n cv2.waitKey(0)\n if inp = 'i':\n \n\n\nif __name__ == \"__main__\":\n main()\n\n\n\n"
},
{
"alpha_fraction": 0.5313531160354614,
"alphanum_fraction": 0.566006600856781,
"avg_line_length": 30.905263900756836,
"blob_id": "6c73aedb5e98f48b645b5bf792c92afd29e5d620",
"content_id": "d6072d18cef41a0d28612f8146a296c97f71b790",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3030,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 95,
"path": "/main-2.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import sys\nimport cv2\nimport copy\nimport itertools\nimport numpy as np\nimport scipy.stats\nimport matplotlib.pyplot as plt\n\ndef main():\n sys.argv.pop(0)\n for image_filename in sys.argv:\n analyzeImage(image_filename)\n\ndef analyzeImage(image_filename):\n image = cv2.imread(image_filename)\n\n lower_black = np.array([0,0,0], dtype = \"uint16\")\n upper_black = np.array([70, 70, 70], dtype = \"uint16\")\n black_image = cv2.inRange(image, lower_black, upper_black)\n \n ret, contours, hierarchy = cv2.findContours(black_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)\n # image = cv2.drawContours(image, contours, -1, (0,255,0), 1)\n bounding_boxes = []\n for contour in contours:\n peri = cv2.arcLength(contour, True)\n approx = cv2.approxPolyDP(contour, 0.02 * peri, True)\n x, y, w, h = cv2.boundingRect(approx)\n if w > 20 and h > 20:\n bounding_boxes.append((x, y, w, h))\n # rect_image = cv2.rectangle(image, (x, y), (x + w, y + h), (255,0,0), 2)\n # displayImage(rect_image)\n\n bonds = findBonds(image, bounding_boxes)\n\n\n\n\n\ndef findBonds(image, bounding_boxes):\n box_centers = [(x[0] + x[2]/2, x[1] + x[3]/2) for x in bounding_boxes]\n combos = list(itertools.combinations(box_centers, 3))\n bonds = []\n for combo in combos:\n x_coors = [x[0] for x in combo]\n y_coors = [x[1] for x in combo]\n slope, intercept, r_value, p_value, std_err = scipy.stats.linregress(x_coors, y_coors)\n if abs(r_value) > .97:\n bonds = [bonds, combo]\n drawRelation(image, combo, slope, intercept, r_value, p_value, std_err)\n \n return bonds\n\ndef imageEquality(image1, image2):\n\n\n if len(image1.shape) == 3:\n cv2.cvtColor(image1, cv2.COLOR_BGR2GRAY)\n\n if len(image2.shape) == 3:\n cv2.cvtColor(image2, cv2.COLOR_BGR2GRAY)\n \n r = len(image1)\n c = len(image1[0])\n\n image2 = cv2.resize(image2, r,c)\n count = 0\n for i in range(0, r):\n for k in range(0,c):\n count = count + abs(image1[i,k] - image2[i][k]) \n \n if count / (r * c) > .1:\n return False\n else:\n return True\n\n \n \n\ndef drawRelation(image, combo, slope, intercept, r_value, p_value, std_err):\n point_image = copy.deepcopy(image)\n for point in combo:\n point_image = cv2.circle(point_image, (int(round(point[0])), int(round(point[1]))), 20, (255, 0, 0), 20)\n\n top_x = int(round((point_image.shape[0] - intercept) / slope))\n bottom_x = int(round((0 - intercept) / slope))\n point_image = cv2.line(point_image, (bottom_x, 0), (top_x, point_image.shape[0]), (255,0,0), 5)\n print(f\"r_value: {r_value}, p_value: {p_value}, std_err: {std_err}\")\n displayImage(point_image)\n\ndef displayImage(image):\n plt.imshow(image)\n plt.show()\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.43928036093711853,
"alphanum_fraction": 0.5029984712600708,
"avg_line_length": 21.627119064331055,
"blob_id": "d77c6f479e3a340dce4f9d95f99143ff56445f87",
"content_id": "b135d935c1318e1c44713c920d76433d317377d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1334,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 59,
"path": "/image_edit.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\ndef pad_white(img):\n\n\n\n if len(img.shape) == 3:\n img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n pad = .25\n\n r = len(img)\n c = len(img[0])\n newImg = np.zeros((round((1+pad*2)*r),round((1+pad*2)*c)), np.uint8) + 255\n top = round(pad * r)\n left = round(pad * c) \n\n for i in range(round(top), top + r-1):\n for k in range(round(left), left + c-1):\n newImg[i, k] = img[i - top, k - left]\n\n return newImg\n\ndef image_overlap(img, box1, box2, thresh):\n if len(img.shape) == 3:\n cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n\n newImg = np.zeros(r,c, np.uint8)\n for i in range(box1[1], box1[1] + box1[3]):\n for k in range(box1[0], box1[0] + box1[2]):\n newImg[i][k] = 100\n count = 0\n for i in range(box2[1], box2[1] + box2[3]):\n for k in range(box2[0], box2[0] + box2[2]):\n if newImg[i][k] == 100:\n count = count + 1\n\n A1 = box1[2]*box1[3]\n A2 = box2[2]* box2[3]\n overlap = 0\n if A1 >= A2:\n overlap = A2/count\n else:\n overlap = A1/count\n\n if overlap > thresh:\n if A1 >= A2:\n return box1\n else:\n return box2\n else:\n return 0\n\n\n\n\n\n \n\n newImg = np.zeros((round((1+pad*2)*r),round((1+pad*2)*c)), np.uint8) + 255"
},
{
"alpha_fraction": 0.5423514246940613,
"alphanum_fraction": 0.5726928114891052,
"avg_line_length": 24.516128540039062,
"blob_id": "90ae3f75840c36ebfc74c010be241b2b8e6be8ca",
"content_id": "6c9727f7d96abba1dd22cd4bf4c6e141590101b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 791,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 31,
"path": "/text_detection.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nimport pytesseract\nimport image_edit as ie\n\ndef getString(img):\n if len(img.shape) == 3:\n cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)\n kernel = np.ones((1,1), np.uint8)\n img = cv2.dilate(img, kernel, iterations = 1)\n img = cv2.erode(img, kernel, iterations = 1)\n\n #img = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2)\n\n \n padded = ie.pad_white(img)\n pad = np.append(padded, padded, axis=1)\n\n std = pytesseract.image_to_string(pad)\n\n if len(std) == 0:\n return ''\n else:\n if std.isalnum:\n if std.startswith('I') | std.startswith('l'):\n return ''\n else:\n return std[0]\n else:\n return ''\n return std\n"
},
{
"alpha_fraction": 0.5814176201820374,
"alphanum_fraction": 0.6159003973007202,
"avg_line_length": 25.64102554321289,
"blob_id": "77358a20041848c5234cf94ec7a618edbff67177",
"content_id": "ced097c1972a15d2da7bba4c54615ea623bfed41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1044,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 39,
"path": "/mserDetection.py",
"repo_name": "maxrudolph1/vsepr_hero",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nimport pytesseract\nimport text_detection as td\nclass Block:\n def __init__(self, bound, img):\n self.bound = bound\n self.ch = ''\n self.img = img\n \n def getString():\n td.getString(self.img)\n\n\n#from tesseract import image_to_string\n\nimg = cv2.imread('../../../Desktop/ch3.jpg')\nmser = cv2.MSER_create()\ngray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #Converting to GrayScale\ngray_img = img.copy()\n\nmsers, bbox = mser.detectRegions(gray) # bbox is xmin, ymin, xrange, yrange\nprint(len(bbox))\nportions = []\nblocks = []\n\nfor n in range(0, len(bbox)):\n portions.append(gray[bbox[n][1]:(bbox[n][1] + bbox[n][3]), bbox[n][0]:(bbox[n][0] + bbox[n][2])])\n cv2.rectangle(img, (bbox[n][0], bbox[n][1]) , (bbox[n][0] + bbox[n][2], bbox[n][1] + bbox[n][3]), (0,255,255), 2 )\n blocks.append(Block(bbox[n,:], portions[n]))\n\n\n\ncv2.imshow('Blocked Image', img)\ncv2.waitKey(0)\n \nfor n in range(0, len(blocks)):\n cv2.imshow(blocks[n].getString(), blocks[n].img)\n cv2.waitKey(0)\n\n\n\n\n\n"
}
] | 6 |
aopem/ee459-final-project
|
https://github.com/aopem/ee459-final-project
|
91120db71b41a20ecc24157a1fd240edb6ddb195
|
ffccd0e4da702c2131096f5f508d4e1f9521810d
|
718f326554334a70cfd0d6ffd037405f4e2dfdc2
|
refs/heads/master
| 2021-01-06T01:19:28.001569 | 2020-05-07T03:33:40 | 2020-05-07T03:33:40 | 241,187,527 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5414634346961975,
"alphanum_fraction": 0.6243902444839478,
"avg_line_length": 24.75,
"blob_id": "56bc559a3be1e65f8f5020a2afa939fb9faad2a2",
"content_id": "07da98e6ac3367a6086717707106bef2db9692e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/main/lib/i2c.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef I2C_H\n#define I2C_H\n\nvoid i2c_init(uint8_t bdiv);\nuint8_t i2c_io(uint8_t device_addr, uint8_t *ap, uint16_t an, \n uint8_t *wp, uint16_t wn, uint8_t *rp, uint16_t rn);\n\n#endif // I2C_H"
},
{
"alpha_fraction": 0.5478699207305908,
"alphanum_fraction": 0.5877233147621155,
"avg_line_length": 22.728260040283203,
"blob_id": "8df66904c0ac8255b7ab34e364a194ea6ab2edb0",
"content_id": "1dd3f89f4ff28c0a446a32e4100fdda24917026b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4366,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 184,
"path": "/main/lib/rfid.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "// https://github.com/asif-mahmud/MIFARE-RFID-with-AVR/blob/master/lib/avr-rfid-library/lib/mfrc522.c\n// RFID component used: MFRC522\n#include <rfid.h>\n#include <spi.h>\n\nvoid rfid_init() {\n uint8_t byte;\n rfid_reset();\n \n rfid_write(TModeReg, 0x8D);\n rfid_write(TPrescalerReg, 0x3E);\n rfid_write(TReloadReg_1, 30); \n rfid_write(TReloadReg_2, 0); \n rfid_write(TxASKReg, 0x40); \n rfid_write(ModeReg, 0x3D);\n \n byte = rfid_read(TxControlReg);\n if(!(byte&0x03))\n {\n rfid_write(TxControlReg,byte|0x03);\n }\n\n byte = mfrc522_read(ComIEnReg);\n mfrc522_write(ComIEnReg,byte|0x20);\n byte = mfrc522_read(DivIEnReg);\n mfrc522_write(DivIEnReg,byte|0x80);\n}\n\nvoid rfid_write(uint8_t reg, uint8_t data) {\n ENABLE_CHIP();\n spi_transmit((reg<<1)&0x7E);\n spi_transmit(data);\n DISABLE_CHIP();\n}\n\nuint8_t rfid_read(uint8_t reg) {\n uint8_t data; \n ENABLE_CHIP();\n spi_transmit(((reg<<1)&0x7E)|0x80);\n data = spi_transmit(0x00);\n DISABLE_CHIP();\n return data;\n}\n\nvoid rfid_reset() {\n rfid_write(CommandReg,SoftReset_CMD);\n}\n\nuint8_t rfid_request(uint8_t req_mode, uint8_t * tag_type) {\n uint8_t status; \n uint32_t backBits; //The received data bits\n\n rfid_write(BitFramingReg, 0x07); //TxLastBists = BitFramingReg[2..0] ???\n \n tag_type[0] = req_mode;\n status = rfid_to_card(Transceive_CMD, tag_type, 1, tag_type, &backBits);\n\n if ((status != CARD_FOUND) || (backBits != 0x10)) { \n status = ERROR;\n }\n \n return status;\n}\n\nuint8_t rfid_to_card(uint8_t cmd, uint8_t *send_data, uint8_t send_data_len, \n uint8_t *back_data, uint32_t *back_data_len) {\n uint8_t status = ERROR;\n uint8_t irqEn = 0x00;\n uint8_t waitIRq = 0x00;\n uint8_t lastBits;\n uint8_t n;\n uint8_t tmp;\n uint32_t i;\n\n switch (cmd) {\n case MFAuthent_CMD: //Certification cards close\n irqEn = 0x12;\n waitIRq = 0x10;\n break;\n\n case Transceive_CMD: //Transmit FIFO data\n irqEn = 0x77;\n waitIRq = 0x30;\n break;\n\n default:\n break;\n }\n \n n=rfid_read(ComIrqReg);\n rfid_write(ComIrqReg,n&(~0x80)); //clear all interrupt bits\n n=rfid_read(FIFOLevelReg);\n rfid_write(FIFOLevelReg,n|0x80); //flush FIFO data\n \n rfid_write(CommandReg, Idle_CMD); //NO action; Cancel the current cmd???\n\n //Writing data to the FIFO\n for (i=0; i<send_data_len; i++) { \n rfid_write(FIFODataReg, send_data[i]); \n }\n\n //Execute the cmd\n rfid_write(CommandReg, cmd);\n if (cmd == Transceive_CMD) { \n n=rfid_read(BitFramingReg);\n rfid_write(BitFramingReg,n|0x80); \n } \n \n //Waiting to receive data to complete\n i = 2000; //i according to the clock frequency adjustment, the operator M1 card maximum waiting time 25ms???\n do {\n //CommIrqReg[7..0]\n //Set1 TxIRq RxIRq IdleIRq HiAlerIRq LoAlertIRq ErrIRq TimerIRq\n n = rfid_read(ComIrqReg);\n i--;\n } while ((i!=0) && !(n&0x01) && !(n&waitIRq));\n\n tmp=rfid_read(BitFramingReg);\n rfid_write(BitFramingReg,tmp&(~0x80));\n \n if (i != 0) { \n if (!(rfid_read(ErrorReg) & 0x1B)) { //BufferOvfl Collerr CRCErr ProtecolErr\n status = CARD_FOUND;\n \n if (n & irqEn & 0x01) { \n status = CARD_NOT_FOUND; //?? \n }\n\n if (cmd == Transceive_CMD) {\n n = rfid_read(FIFOLevelReg);\n lastBits = rfid_read(ControlReg) & 0x07;\n\n if (lastBits) { \n *back_data_len = (n-1)*8 + lastBits; \n } else { \n *back_data_len = n*8; \n }\n\n if (n == 0) \n n = 1; \n \n if (n > MAX_LEN) \n n = MAX_LEN; \n \n //Reading the received data in FIFO\n for (i=0; i<n; i++) { \n back_data[i] = rfid_read(FIFODataReg); \n }\n }\n\n } else { \n status = ERROR; \n } \n }\n\n return status;\n}\n\n\nuint8_t rfid_get_card_serial(uint8_t * serial_out) {\n uint8_t status;\n uint8_t i;\n uint8_t serNumCheck=0;\n uint32_t unLen;\n \n rfid_write(BitFramingReg, 0x00); //TxLastBists = BitFramingReg[2..0]\n \n serial_out[0] = PICC_ANTICOLL;\n serial_out[1] = 0x20;\n status = rfid_to_card(Transceive_CMD, serial_out, 2, serial_out, &unLen);\n\n if (status == CARD_FOUND) {\n //Check card serial number\n for (i=0; i<4; i++) { \n serNumCheck ^= serial_out[i];\n }\n\n if (serNumCheck != serial_out[i]) { \n status = ERROR; \n }\n }\n \n return status;\n}\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6832579374313354,
"avg_line_length": 14.857142448425293,
"blob_id": "9546b43cd29af6c616ab792bb56b3cbf39d31112",
"content_id": "edb580362ed8b5807f10b6f17cc629a50dcc04e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 14,
"path": "/main/lib/headers.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef HEADERS_H\n#define HEADERS_H\n\n#include <cc3000.h>\n#include <const.h>\n#include <hx711.h>\n#include <i2c.h>\n#include <lcd.h>\n#include <misc.h>\n#include <rfid.h>\n#include <servo.h>\n#include <spi.h>\n\n#endif // HEADERS_H"
},
{
"alpha_fraction": 0.5687185525894165,
"alphanum_fraction": 0.6655052304267883,
"avg_line_length": 27.711111068725586,
"blob_id": "7c856526cec56417f1a331f5b06dcd71eab3bfaf",
"content_id": "f40719c001f9a6ccab2003ecc24d296eb5b025e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2583,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 90,
"path": "/main/lib/rfid_const.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef MFRC522_CONST_H\n#define MFRC522_CONST_H\n\n/*** COMMANDS ***/\n#define Idle_CMD 0x00\n#define Mem_CMD 0x01\n#define GenerateRandomId_CMD 0x02\n#define CalcCRC_CMD 0x03\n#define Transmit_CMD 0x04\n#define NoCmdChange_CMD 0x07\n#define Receive_CMD 0x08\n#define Transceive_CMD 0x0C\n#define Reserved_CMD 0x0D\n#define MFAuthent_CMD 0x0E\n#define SoftReset_CMD 0x0F\n\n/*** REGISTERS ***/\n//Page 0 ==> Command and Status\n#define Page0_Reserved_1 0x00\n#define CommandReg 0x01\n#define ComIEnReg 0x02\n#define DivIEnReg 0x03\n#define ComIrqReg 0x04\n#define DivIrqReg 0x05\n#define ErrorReg 0x06\n#define Status1Reg 0x07\n#define Status2Reg 0x08\n#define FIFODataReg 0x09\n#define FIFOLevelReg 0x0A\n#define WaterLevelReg 0x0B\n#define ControlReg 0x0C\n#define BitFramingReg 0x0D\n#define CollReg 0x0E\n#define Page0_Reserved_2 0x0F\n\n//Page 1 ==> Command\n#define Page1_Reserved_1 0x10\n#define ModeReg 0x11\n#define TxModeReg 0x12\n#define RxModeReg 0x13\n#define TxControlReg 0x14\n#define TxASKReg 0x15\n#define TxSelReg 0x16\n#define RxSelReg 0x17\n#define RxThresholdReg 0x18\n#define DemodReg 0x19\n#define Page1_Reserved_2 0x1A\n#define Page1_Reserved_3 0x1B\n#define MfTxReg 0x1C\n#define MfRxReg 0x1D\n#define Page1_Reserved_4 0x1E\n#define SerialSpeedReg 0x1F\n\n//Page 2 ==> CFG\n#define Page2_Reserved_1 0x20\n#define CRCResultReg_1 0x21\n#define CRCResultReg_2 0x22\n#define Page2_Reserved_2 0x23\n#define ModWidthReg 0x24\n#define Page2_Reserved_3 0x25\n#define RFCfgReg 0x26\n#define GsNReg 0x27\n#define CWGsPReg 0x28\n#define ModGsPReg 0x29\n#define TModeReg 0x2A\n#define TPrescalerReg 0x2B\n#define TReloadReg_1 0x2C\n#define TReloadReg_2 0x2D\n#define TCounterValReg_1 0x2E\n#define TCounterValReg_2 0x2F\n\n//Page 3 ==> TestRegister\n#define Page3_Reserved_1 0x30\n#define TestSel1Reg 0x31\n#define TestSel2Reg 0x32\n#define TestPinEnReg 0x33\n#define TestPinValueReg 0x34\n#define TestBusReg 0x35\n#define AutoTestReg 0x36\n#define VersionReg 0x37\n#define AnalogTestReg 0x38\n#define TestDAC1Reg 0x39\n#define TestDAC2Reg 0x3A\n#define TestADCReg 0x3B\n#define Page3_Reserved_2 0x3C\n#define Page3_Reserved_3 0x3D\n#define Page3_Reserved_4 0x3E\n#define Page3_Reserved_5 0x3F\n\n#endif // MFRC522_CONST_H"
},
{
"alpha_fraction": 0.6483253836631775,
"alphanum_fraction": 0.6674641370773315,
"avg_line_length": 19.950000762939453,
"blob_id": "385471f8364c5c35245a13e2cf3ae3a18ac99eb5",
"content_id": "61e6dd1e63cb1425e2a58f697207fcaa40e72b4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 20,
"path": "/main/lib/spi.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef SPI_H\n#define SPI_H\n\n#include <avr/io.h>\n\n#define SPI_DDR DDRB\n#define SPI_PORT PORTB\n#define SPI_PIN PINB\n#define SPI_MOSI PB3\n#define SPI_MISO PB4\n#define SPI_SS PB2 // not necessary, we are always master\n#define SPI_SCK PB5\n\n#define ENABLE_CHIP() (SPI_PORT &= (~(1<<SPI_SS)))\n#define DISABLE_CHIP() (SPI_PORT |= (1<<SPI_SS))\n\nvoid spi_init();\nuint8_t spi_transmit(uint8_t data);\n\n#endif // SPI_H"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.7169811129570007,
"avg_line_length": 14.285714149475098,
"blob_id": "7295f048801f4ee00870cecccbf13e39d8845697",
"content_id": "f85472bf9095768a09409163e17d49f3519dd177",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 7,
"path": "/main/lib/servo.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef SERVO_H\n#define SERVO_H\n\nvoid servo_init(void);\nint servo_rotate_to(int angle);\n\n#endif // SERVO_H"
},
{
"alpha_fraction": 0.730721116065979,
"alphanum_fraction": 0.7528136968612671,
"avg_line_length": 38.983333587646484,
"blob_id": "9b4e9df1b9e2de42e4b85f16adcb473d723fa4ce",
"content_id": "58eb957128005c2313b45ff8554f808fbe4b3c41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2399,
"license_type": "no_license",
"max_line_length": 294,
"num_lines": 60,
"path": "/README.md",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "# USC EE 459 Final Project - Spring 2020\n\n#### Title: Google Parcel\n\n#### Due Date: 05/07/20\n\n#### Members: Andrew Opem, David Karapetyan, Natan Benchimol\n\n\n### Project Outline\n\nFor our final project we designed the electrical hardware and software of a smart mailbox. \nThe hardware consists of sensors, controllers, and microelectronics likes resistors, capacitors, etc. \nThis repository contains the software that is intended to drive the hardware. \nIt utilizes the interrupt pins and a main while loop to detect when certain sensors are triggered.\n\n\n\n### Program Microcontroller\n1. Change `OBJECTS` line in `Makefile` to correct `.o` file.\n * ex. `tests/lab3_test.o`\n2. `make flash`\n\n\n\n### Adapted Modules:\n\nFor each module in our program that adapted code snippets from online sources, the links for each source are listed below.\nThe full disclaimers for each snippet is at the top of each `.c` or `.cpp` file.\n\n* [I2C](http://ee-classes.usc.edu/ee459/library/plaintext.php?file=samples/AVR/at328-7.c)\n\n* [SPI](https://github.com/asif-mahmud/MIFARE-RFID-with-AVR/blob/master/lib/avr-rfid-library/lib/spi.c)\n\n* [LCD](http://ee-classes.usc.edu/ee459/library/plaintext.php?file=samples/AVR/at328-7.c)\n\n* [HX711](https://github.com/getsiddd/HX711)\n\n* [CC3000](https://github.com/asif-mahmud/MIFARE-RFID-with-AVR/blob/master/lib/avr-rfid-library/lib/mfrc522.c)\n\n* [RFID](https://github.com/asif-mahmud/MIFARE-RFID-with-AVR/blob/master/lib/avr-rfid-library/lib/mfrc522.c)\n\n* [SERVO](https://www.electronicwings.com/avr-atmega/servo-motor-interfacing-with-atmega16)\n\n\n### Additional Notes:\n\n* General:\n\n\tSince we did not have access to the hardware in our design, we were unable to test our code on any of the hardware components.\n\n* CC3000 WiFi Module:\n\n\tThe code for this module was adapted from an arduino library and has some snippets in C++.\n\tWe did not convert all of the code to C, so the final project will not compile properly. \n\tWe mentioned this to professor Weber and he said that he understands that given enough time we would be able to convert the code to C so he is not too worried about that. \n\n* RFID Module:\n\n\tWhen checking for an RFID match, we chose generic test values to compare with. In reality, each module that is shipped to a customer will have to have its own unique RFID associated with the hardware. We did not generate an algorithm or function to distribute these as this is just a protoype. "
},
{
"alpha_fraction": 0.5351449251174927,
"alphanum_fraction": 0.6050724387168884,
"avg_line_length": 15.835366249084473,
"blob_id": "2e26c48fd495e535fc8590d2ce44089fce7b4431",
"content_id": "8a1142b8b2c61ac7dbfbf635eb109868206add1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2760,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 164,
"path": "/main/lib/hx711.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "// code from: https://github.com/getsiddd/HX711\n#define __USE_C99_MATH\n\n#include <stdbool.h>\n#include <stdint.h>\n#include <avr/io.h>\n#include <util/delay.h>\n#include <hx711.h>\n/*\nvoid HX711_init(uint8_t gain);\nint HX711_is_ready();\nvoid HX711_set_gain(uint8_t gain);\nint32_t HX711_read();\nint32_t HX711_read_average(uint8_t times);\ndouble HX711_get_value(uint8_t times);\nfloat HX711_get_units(uint8_t times);\nvoid HX711_tare(uint8_t times);\nvoid HX711_set_scale(float scale);\nfloat HX711_get_scale();\nvoid HX711_set_offset(int32_t offset);\nint32_t HX711_get_offset();\nvoid HX711_power_down();\nvoid HX711_power_up();\nuint8_t shiftIn(void);\n*/\nvoid HX711_init(uint8_t gain)\n{\n PD_SCK_SET_OUTPUT;\n DOUT_SET_INPUT;\n\n HX711_set_gain(gain);\n}\n\nint HX711_is_ready(void)\n{\n return (DOUT_INPUT & (1 << DOUT_PIN)) == 0;\n}\n\nvoid HX711_set_gain(uint8_t gain)\n{\n switch (gain)\n {\n case 128: // channel A, gain factor 128\n GAIN = 1;\n break;\n case 64: // channel A, gain factor 64\n GAIN = 3;\n break;\n case 32: // channel B, gain factor 32\n GAIN = 2;\n break;\n }\n\n PD_SCK_SET_LOW;\n HX711_read();\n}\n\nuint32_t HX711_read(void)\n{\n // wait for the chip to become ready\n while (!HX711_is_ready());\n\n unsigned long count; \n unsigned char i;\n \n DOUT_SET_HIGH;\n \n _delay_us(1);\n \n PD_SCK_SET_LOW;\n _delay_us(1);\n \n count=0; \n while(DOUT_READ); \n for(i=0;i<24;i++)\n { \n PD_SCK_SET_HIGH; \n _delay_us(1);\n count=count<<1; \n PD_SCK_SET_LOW; \n _delay_us(1);\n if(DOUT_READ)\n count++; \n } \n count = count>>6;\n PD_SCK_SET_HIGH; \n _delay_us(1);\n PD_SCK_SET_LOW; \n _delay_us(1);\n count ^= 0x800000;\n return(count);\n}\n\nuint32_t HX711_read_average(uint8_t times)\n{\n uint32_t sum = 0;\n for (uint8_t i = 0; i < times; i++)\n {\n sum += HX711_read();\n // TODO: See if yield will work | yield();\n }\n return sum / times;\n}\n\ndouble HX711_get_value(uint8_t times)\n{\n return HX711_read_average(times) - OFFSET;\n}\n\nfloat HX711_get_units(uint8_t times)\n{\n return HX711_get_value(times) / SCALE;\n}\n\nvoid HX711_tare(uint8_t times)\n{\n double sum = HX711_read_average(times);\n HX711_set_offset(sum);\n}\n\nvoid HX711_set_scale(float scale)\n{\n SCALE = scale;\n}\n\nfloat HX711_get_scale(void)\n{\n return SCALE;\n}\n\nvoid HX711_set_offset(double offset)\n{\n OFFSET = offset;\n}\n\ndouble HX711_get_offset(void)\n{\n return OFFSET;\n}\n\nvoid HX711_power_down(void)\n{\n PD_SCK_SET_LOW;\n PD_SCK_SET_HIGH;\n _delay_us(70);\n}\n\nvoid HX711_power_up(void)\n{\n PD_SCK_SET_LOW;\n}\n\nuint8_t shiftIn(void)\n{\n uint8_t value = 0;\n\n for (uint8_t i = 0; i < 8; ++i)\n {\n PD_SCK_SET_HIGH;\n value |= DOUT_READ << (7 - i);\n PD_SCK_SET_LOW;\n }\n return value;\n}"
},
{
"alpha_fraction": 0.564837634563446,
"alphanum_fraction": 0.5917133092880249,
"avg_line_length": 21.432161331176758,
"blob_id": "633b2d19b8459e9c5faeafd9c7951103d22735cf",
"content_id": "2513513ddb999325b9c86a71a559062da0f578d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4465,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 199,
"path": "/main/atmega_main.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#include <avr/io.h>\n#include <util/delay.h>\n#include <lib/headers.h>\n\nvolatile int motion_sensor_flag = 0;\t// flag for checking if RFID is triggered\nvolatile int rfid_flag = 0;\t\t\t\t\t\t// flag for checking if the motion sensor is triggered\nvolatile int wifi_flag = 1;\n\n#define USER_RFID 0xAA\n#define POST_RFID 0xBB\n\nvoid init(void);\n\nint main(){\n\tint ms_count = 0;\t\t// motion sensor count\n\tint door_count = 0;\t// door count\n\tint ts_flag = 0;\t\t// telescopic flag\n\n\tuint8_t str[16];\t\t// for storing RFID data\n\tuint8_t tag_id = 0; // for reading RFID tag data\n\n\tinit();\t\t\t\t\t\t\t// initialize all modules\n\tsei();\t\t\t\t\t\t\t// global interrupt enable\n\n\t// this is a c++ library!! (for wifi module)\n\tAdafruit_CC3000_Client client(); \t/* C++ CODE */\n\tclient.connect();\t\t\t\t\t\t\t\t\t/* C++ CODE */\n\n\tint package_inside = 0 // use to see if there is a package inside\n\n\t// used with weight sensor\n\tdouble tare_point_128 = HX711_get_offset();\n\tdouble current_weight_128 = HX711_read_average(10) - tare_point_128;\n\n\twhile(1) {\t\t\t\t\t// main loop\n\n\t\tif (motion_sensor_flag) {\n\t\t\tmotion_sensor_flag = 0;\n\n\t\t\t// send signal to pi to turn on camera\n\t\t\trpi_camera(1);\n\n\t\t\t// set count back to zero\n\t\t\tms_count = 0;\n\n\t\t\t// prepare user notification\n\t\t\tclient.write(\"Motion detected at mailbox\"); /* C++ CODE */\n\t\t}\n\n\t\tif (ms_count > 1000 && !motion_sensor_flag) {\n\n\t\t\t// turn off camera\n\t\t\trpi_camera(0);\n\t\t\tms_count = 0;\n\t\t}\n\n\t\tif (rfid_flag) {\n\t\t\trfid_flag = 0;\n\n\t\t\t// read rfid tag\n\t\t\ttag_id = rfid_request(PICC_REQALL, str);\n\n\t\t\tif (tag_id == CARD_FOUND) {\n\t\t\t\n\t\t\t\t// check rfid\n\t\t\t\tif (tag_id == USER_RFID) { \t\t\t// user\n\n\t\t\t\t\t// unlocks\n\t\t\t\t\tlock_unlock(1);\n\n\t\t\t\t\t// wait 30 secs\t\n\t\t\t\t\t_delay_ms(30000);\t\t\t\n\t\t\t\t}\n\t\t\t\telse if (tag_id == POST_RFID) {\t// postman\n\n\t\t\t\t\t// unlocks\n\t\t\t\t\tlock_unlock(1);\n\t\t\t\t\tlcd_clear_screen();\n\t\t\t\t\tlcd_moveto(0,0);\n\t\t\t\t\tlcd_stringout(\"Successful Delivery?\");\n\n\t\t\t\t\t// wait for a button press\n\t\t\t\t\twhile ( !(button_pressed(SUCCESSFUL_BUTTON) || button_pressed(UNSUCCESSFUL_BUTTON)) ) {}\n\n\t\t\t\t\tif (button_pressed(SUCCESSFUL_BUTTON)) {\n\t\t\t\t\t\tlcd_clear_screen();\n\t\t\t\t\t\tlcd_moveto(0,0);\n\t\t\t\t\t\tlcd_stringout(\"Thank you!\");\n\t\t\t\t\t\t_delay_ms(2000);\n\t\t\t\t\t\tlcd_clear_screen();\n\n\t\t\t\t\t\t// prepare user notification\n\t\t\t\t\t\tclient.write(\"Package delivered successfully\"); /* C++ CODE */\n\t\t\t\t\t}\n\t\t\t\t\telse if (button_pressed(UNSUCCESSFUL_BUTTON)) {\n\n\t\t\t\t\t\t// check if already expanded or not\n\t\t\t\t\t\tif (!ts_flag) {\n\t\t\t\t\t\t\tlcd_clear_screen();\n\t\t\t\t\t\t\tlcd_moveto(0,0);\n\t\t\t\t\t\t\tlcd_stringout(\"Creating Space\");\n\t\t\t\t\t\t\tservo_rotate_to(90);\n\t\t\t\t\t\t\tts_flag = 1;\n\n\t\t\t\t\t\t\t// prepare user notification\n\t\t\t\t\t\t\tclient.write(\"Package delivered successfully\"); /* C++ CODE */\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse {\n\t\t\t\t\t\t\tlcd_clear_screen();\n\t\t\t\t\t\t\tlcd_moveto(0,0);\n\t\t\t\t\t\t\tlcd_stringout(\"No Extra Space\");\n\n\t\t\t\t\t\t\t// prepare user notification\n\t\t\t\t\t\t\tclient.write(\"Package delivery unsuccessful\"); /* C++ CODE */\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\n\t\t\t\t\t// wait 30 secs\t\n\t\t\t\t\t_delay_ms(30000);\t\t\t\t\t\n\t\t\t\t\t}\n\t\t\t\t\telse {\t// thief\n\t\t\t\t\t\t// prepare user notification\n\t\t\t\t\t\tclient.write(\"SECURITY ALERT: Unauthorized attempt to unlock\"); /* C++ CODE */\n\n\t\t\t\t\t\tbuzzer_on();\n\t\t\t\t\t\trpi_camera(1);\n\t\t\t\t\t\t_delay_ms(1000);\n\t\t\t\t\t\tbuzzer_off();\n\t\t\t\t\t\trpi_camera(0);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t\telse {\t// no RFID tag found or error\n\t\t\t\t\tlcd_clear_screen();\n\t\t\t\t\tlcd_moveto(0,0);\n\t\t\t\t\tlcd_stringout(\"No Card Found\");\n\t\t\t\t}\n\n\t\t\t// check if door is left open\n\t\t\tif (!lock_locked()) {\n\t\t\t\tbuzzer_on();\n\t\t\t}\n\t\t\telse {\n\t\t\t\tbuzzer_off();\n\t\t\t}\n\t\t} // rfid flag if statement\n\n\t\tif (door_count > 5000 && !lock_locked()) {\t// if 5 mins has passed\n\t\t\t\n\t\t\t// alert user \n\t\t\tclient.write(\"SECURITY ALERT: Door left open for at least 5 minutes\"); /* C++ CODE */\n\t\t}\n\t\telse {\n\t\t\tbuzzer_off();\n\t\t}\n\n\t\t// check if current weight shows there is a package present\n\t\tif (current_weight_128 > 1)\n\t\t\tpackage_inside = 1;\n\t\telse\n\t\t\tpackage_inside = 0\n\n\t\t// update weight sensor, counts\n\t\tcurrent_weight_128 = HX711_read_average(10) - tare_point_128;\n\n\t\tms_count++;\n\t\tdoor_count++;\n\n\t}\t// end main while\n\n\treturn 0;\n}\n\n\nvoid init() {\n\ti2c_init(BDIV);\n\tspi_init();\n\tbutton_init(SUCCESSFUL_BUTTON);\n\tbutton_init(UNSUCCESSFUL_BUTTON);\n\tmotion_sensor_init();\n\tbuzzer_init();\n\tlock_init();\n\trpi_init();\n\tlcd_init();\n\tservo_init();\n\trfid_init();\n\tHX711_init(128);\n}\n\n\nISR(PCINT2_vect) {\n // check which module\n\tif (motion_detected()) {\t\t// motion sensor interrupt is triggered\n\t\tmotion_sensor_flag = 1;\n\t}\n\n\tif (PIND & RFID == 1) {\t\t\t// RFID interrupt is triggered\n\t\trfid_flag = 1;\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.5863377451896667,
"alphanum_fraction": 0.5977229475975037,
"avg_line_length": 26.038461685180664,
"blob_id": "f0268d3ce36a19a2fbee987f227ed6ef39531aef",
"content_id": "e8681b2238ac0b216470685ad677a82b02e05de9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2108,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 78,
"path": "/main/lib/misc.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#include <avr/io.h>\n#include <util/delay.h>\n#include <const.h>\n\nvoid button_init(int pin) {\n DDRB &= ~(1 << pin); // set pin as input (both buttons on DDRB)\n PORTB |= (1 << pin); // turn on internal pull-up resistor\n}\n\nint button_pressed(int pin) {\n return !(PINB & pin); // return opposite of PINB value since button\n} // not pressed when input high and pressed when\n // input is low\n\n// do not need function for green LED since\n// it is connected to solenoid lock pin\nvoid led_red_init(void) {\n DDRC |= (1 << RED_LED); // configure as output\n}\n\nvoid led_red(int on) {\n if (on)\n PORTC |= (1 << RED_LED);\n else \n PORTC &= ~(1 << RED_LED);\n}\n\nvoid motion_sensor_init(void) {\n DDRD &= ~(1 << MOTION_SENSOR); // configure as input\n}\n\nint motion_detected(void) {\n return (PIND & MOTION_SENSOR);\n}\n\nvoid lock_init(void) {\n DDRC |= (1 << GREEN_LED_AND_LOCK); // configure output to MOSFET\n DDRC &= ~(1 << REED_SWITCH); // configure reed switch input\n}\n\nvoid lock_unlock(int on) {\n if (on)\n PORTC |= (1 << GREEN_LED_AND_LOCK); // unlocks\n else \n PORTC &= ~(1 << GREEN_LED_AND_LOCK); // locks\n}\n\nint lock_locked(void) {\n return !(PINC & REED_SWITCH); // reed switch is high when no connection\n} // then gets pulled to GND on connect\n\n// buzzer code modified from\n// https://www.robomart.com/blog/buzzer-io-interfacing-atmega32-microcontroller/\nvoid buzzer_on(void) {\n unsigned char port_restore = 0;\n port_restore = PINC;\n port_restore |= 0x08;\n PORTC = port_restore;\n}\n \nvoid buzzer_off(void) {\n unsigned char port_restore = 0;\n port_restore = PINC;\n port_restore &= 0xF7;\n PORTC = port_restore;\n}\n\n/* functions for communicating with Raspberry Pi */\nvoid rpi_init(void) {\n DDRC |= (1 << RPI); // set pin as output\n}\n\nvoid rpi_camera(int on) {\n if (on)\n PORTC |= (1 << RPI); // RPI will check every 3 sec. to see if\n else // the pin is still high, then continue to \n PORTC &= ~(1 << RPI); // record for additional 3 sec. if pin high\n}"
},
{
"alpha_fraction": 0.5140306353569031,
"alphanum_fraction": 0.5765306353569031,
"avg_line_length": 31.70833396911621,
"blob_id": "01eec655567dd34cfd6c08c72e57abaffcad949d",
"content_id": "08b598706bd98575e5f4c1ee6d6a5839add5976b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 784,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 24,
"path": "/main/lib/const.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef CONST_H\n#define CONST_H\n\n// misc. constants for use in header files\n#define FOSC 7372800 // Clock frequency\n#define BAUD 9600 // Baud rate\n#define MYUBRR FOSC/16/BAUD-1 // Value for UBRR0 register\n#define BDIV (FOSC / 100000 - 16) / 2 + 1 // Puts I2C rate just below 100kHz (for i2c_init)\n\n// pin connections\n#define SUCCESSFUL_BUTTON PB0\n#define UNSUCCESSFUL_BUTTON PB1\n#define BUZZER PB2\n#define RPI PC0\n#define RED_LED PC1\n#define REED_SWITCH PC2\n#define GREEN_LED_AND_LOCK PC3\n#define CC3000 PD2\n#define HX711 PD4\n#define RFID PD5\n#define SERVO PD6\n#define MOTION_SENSOR PD7\n\n#endif // CONST_H"
},
{
"alpha_fraction": 0.538863480091095,
"alphanum_fraction": 0.5682560205459595,
"avg_line_length": 18.615385055541992,
"blob_id": "c75bae9ad4cc39f04af6e2a2f5f07db84db4d15d",
"content_id": "2b5c9706defa57f945d31058019686f020041ce8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1531,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 78,
"path": "/tests/lab4_serial_test.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#include <avr/io.h>\n#include <stdio.h>\n\nvoid serial_init(unsigned short);\nvoid serial_out(char);\nvoid serial_outs(char*);\nchar serial_in(void);\n\n#define FOSC 7372800 // Clock frequency\n#define BAUD 9600 // Baud rate\n#define MYUBRR FOSC/16/BAUD-1 // Value for UBRR0 register\n\nchar output[30];\n\nint main(void) {\n\n // voltage level test\n serial_init(MYUBRR);\n\n char in_byte;\n\n while (1) {\n\n // loopback test\n in_byte = serial_in();\n\n // string test\n if (in_byte >= '0' && in_byte <= '9') {\n sprintf(output, \"you put in a number: %c\\r\\n\", in_byte);\n serial_outs(output);\n }\n else {\n sprintf(output, \"you sinned this way: %c\\r\\n\", in_byte);\n serial_outs(output);\n }\n }\n\n return 0;\n}\n\n// Serial Communication Functions\n/*\n * serial_init - Initialize the USART port\n */\nvoid serial_init(unsigned short ubrr) {\n UBRR0 = ubrr; // Set baud rate\n UCSR0B |= (1 << TXEN0); // Turn on transmitter\n UCSR0B |= (1 << RXEN0); // Turn on receiver\n UCSR0C = (3 << UCSZ00); // Set for async. operation, no parity,\n // one stop bit, 8 data bits\n}\n\n\nvoid serial_outs(char *s)\n{\n char ch;\n\n while ((ch = *s++) != '\\0')\n serial_out(ch);\n}\n\n/*\n * serial_out - Output a byte to the USART0 port\n */\nvoid serial_out(char ch)\n{\n while ((UCSR0A & (1 << UDRE0)) == 0);\n UDR0 = ch;\n}\n\n/*\n * serial_in - Read a byte from the USART0 and return it\n */\nchar serial_in()\n{\n while (!(UCSR0A & (1 << RXC0)));\n return UDR0;\n}\n\n"
},
{
"alpha_fraction": 0.5499700903892517,
"alphanum_fraction": 0.6014362573623657,
"avg_line_length": 38.80952453613281,
"blob_id": "1b4ebac42548687a120123ed7216c0ccc1fde1dc",
"content_id": "5ee691f3be1e904d36ed958f2aac124768f0a759",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1671,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 42,
"path": "/main/lib/rfid.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef RFID_H\n#define RFID_H\n\n#include <rfid_const.h>\n\n#define CARD_FOUND 1\n#define CARD_NOT_FOUND 2\n#define ERROR 3\n\n#define MAX_LEN 16\n\n//Card types\n#define Mifare_UltraLight 0x4400\n#define Mifare_One_S50 0x0400\n#define Mifare_One_S70 0x0200\n#define Mifare_Pro_X 0x0800\n#define Mifare_DESFire 0x4403\n\n// Mifare_One card command word\n#define PICC_REQIDL 0x26 // find the antenna area does not enter hibernation\n#define PICC_REQALL 0x52 // find all the cards antenna area\n#define PICC_ANTICOLL 0x93 // anti-collision\n#define PICC_SElECTTAG 0x93 // election card\n#define PICC_AUTHENT1A 0x60 // authentication key A\n#define PICC_AUTHENT1B 0x61 // authentication key B\n#define PICC_READ 0x30 // Read Block\n#define PICC_WRITE 0xA0 // write block\n#define PICC_DECREMENT 0xC0 // debit\n#define PICC_INCREMENT 0xC1 // recharge\n#define PICC_RESTORE 0xC2 // transfer block data to the buffer\n#define PICC_TRANSFER 0xB0 // save the data in the buffer\n#define PICC_HALT 0x50 // Sleep\n\nvoid rfid_init();\nvoid rfid_reset();\nvoid rfid_write(uint8_t reg, uint8_t data);\nuint8_t rfid_read(uint8_t reg);\nuint8_t rfid_request(uint8_t req_mode, uint8_t * tag_type);\nuint8_t rfid_to_card(uint8_t cmd, uint8_t *send_data, uint8_t send_data_len, uint8_t *back_data, uint32_t *back_data_len);\nuint8_t rfid_get_card_serial(uint8_t * serial_out);\n\n#endif // RFID_H"
},
{
"alpha_fraction": 0.6184971332550049,
"alphanum_fraction": 0.6387283205986023,
"avg_line_length": 24.66666603088379,
"blob_id": "32306720cb840f67aea63c1150da42152460553d",
"content_id": "00fa15fec5f7ca3683f79989c9824d48b5f4a4c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 27,
"path": "/main/rpi_main.py",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "from picamera import PiCamera\nimport Rpi.GPIO as GPIO\nimport time\n\ndef main():\n atmega_signal = 4\n\n # set pin on RPI to wait for ATmega328P signal\n GPIO.setmode(GPIO.BOARD)\n GPIO.setup(atmega_signal, GPIO.IN)\n\n # initialize camera\n camera = PiCamera()\n resolution = (1024, 768)\n\n # set resolution for camera\n camera.resolution = resolution\n\n while True:\n if GPIO.input(atmega_signal) == 1: # check if atmega has sent a signal\n camera.start_recording(\"./videos\") # if high, record for 3 seconds\n time.sleep(3) \n else:\n camera.stop_recording() # else do not record at all/stop recording\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.29801324009895325,
"alphanum_fraction": 0.3874172270298004,
"avg_line_length": 22.609375,
"blob_id": "9ca12e72cd2bbb2e68e6bcc6d967c6d402d7ffc6",
"content_id": "bbee21ab58f77793e7fea7e307627731225f7499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1510,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 64,
"path": "/tests/lab3_test.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#include <avr/io.h>\n#include <util/delay.h>\n\nint main(void) {\n // set all I/O pins to zeros\n PORTB = 0x00;\n PORTC = 0x00;\n PORTD = 0x00;\n\n // set all I/O pins to outputs\n DDRB |= 0xFF;\n DDRC |= 0xFF;\n DDRD |= 0xFF;\n\n // loop through pins\n while (1) {\n PORTB |= (1 << PB1); // 15, trigger pin\n PORTB &= ~(1 << PB1); \n PORTB |= (1 << PB2); // 16\n PORTB &= ~(1 << PB2);\n PORTB |= (1 << PB3); // 17\n PORTB &= ~(1 << PB3); \n PORTB |= (1 << PB4); // 18\n PORTB &= ~(1 << PB4);\n PORTB |= (1 << PB5); // 19\n PORTB &= ~(1 << PB5);\n PORTB |= (1 << PB7); // 10 \n PORTB &= ~(1 << PB7);\n PORTB |= (1 << PB0); // 14\n PORTB &= ~(1 << PB0);\n\n PORTC |= (1 << PC0); // 23\n PORTC &= ~(1 << PC0);\n PORTC |= (1 << PC1); // 24\n PORTC &= ~(1 << PC1);\n PORTC |= (1 << PC2); // 25\n PORTC &= ~(1 << PC2);\n PORTC |= (1 << PC3); // 26\n PORTC &= ~(1 << PC3);\n PORTC |= (1 << PC4); // 27\n PORTC &= ~(1 << PC4);\n PORTC |= (1 << PC5); // 28\n PORTC &= ~(1 << PC5);\n\n PORTD |= (1 << PD0); // 2\n PORTD &= ~(1 << PD0);\n PORTD |= (1 << PD1); // 3\n PORTD &= ~(1 << PD1);\n PORTD |= (1 << PD2); // 4\n PORTD &= ~(1 << PD2);\n PORTD |= (1 << PD3); // 5\n PORTD &= ~(1 << PD3);\n PORTD |= (1 << PD4); // 6\n PORTD &= ~(1 << PD4);\n PORTD |= (1 << PD5); // 11\n PORTD &= ~(1 << PD5);\n PORTD |= (1 << PD6); // 12\n PORTD &= ~(1 << PD6);\n PORTD |= (1 << PD7); // 13\n PORTD &= ~(1 << PD7);\n }\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5012460947036743,
"alphanum_fraction": 0.5523364543914795,
"avg_line_length": 25.09756088256836,
"blob_id": "62fee992c4598af409faa5b6bff8086a1b31df6e",
"content_id": "5c33fe1c184a9709b440534bfc15686ab785310e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3210,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 123,
"path": "/examples/at328-6.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "/*************************************************************\n* at328-6.c - Demonstrate interface to a serial LCD display\n*\n* This program will print a message on an LCD display\n* using a serial interface. It is designed to work with a\n* Matrix Orbital LK204-25 using an RS-232 interface.\n*\n* Revision History\n* Date Author Description\n* 11/07/07 A. Weber First Release\n* 02/26/08 A. Weber Code cleanups\n* 03/03/08 A. Weber More code cleanups\n* 04/22/08 A. Weber Added \"one\" variable to make warning go away\n* 04/11/11 A. Weber Adapted for ATmega168\n* 11/18/13 A. Weber Renamed for ATmega328P\n*************************************************************/\n\n#include <avr/io.h>\n#include <util/delay.h>\n\nvoid lcd_init(void);\nvoid lcd_moveto(unsigned char, unsigned char);\nvoid lcd_stringout(char *);\n\nvoid sci_init(void);\nvoid sci_out(char);\nvoid sci_outs(char *);\n\nchar str1[] = \"12345678901234567890\";\nchar str2[] = \">> USC EE459L <<\";\nchar str3[] = \">> at328-6.c <<<\";\nchar str4[] = \"-- April 11, 2011 --\";\n\n#define FOSC 9830400\t\t// Clock frequency\n#define BAUD 19200 // Baud rate used by the LCD\n#define MYUBRR FOSC/16/BAUD-1 // Value for UBRR0 register\n\nint main(void) {\n\n sci_init(); // Initialize the SCI port\n \n lcd_init(); // Initialize the LCD\n\n lcd_moveto(0, 0);\n lcd_stringout(str1); // Print string on line 1\n lcd_moveto(1, 2);\n lcd_stringout(str2); // Print string on line 2\n lcd_moveto(2, 2);\n lcd_stringout(str3); // Print string on line 3\n lcd_moveto(3, 0);\n lcd_stringout(str4); // Print string on line 4\n\n while (1) { // Loop forever\n }\n\n return 0; /* never reached */\n}\n\n/*\n lcd_init - Initialize the LCD\n*/\nvoid lcd_init()\n{\n _delay_ms(250); // Wait 500msec for the LCD to start up\n _delay_ms(250);\n sci_out(0xfe); // Clear the screen\n sci_out(0x58);\n}\n\n/*\n moveto - Move the cursor to the row and column given by the arguments.\n Row is 0 or 1, column is 0 - 15.\n*/\nvoid lcd_moveto(unsigned char row, unsigned char col)\n{\n sci_out(0xfe); // Set the cursor position\n sci_out(0x47);\n sci_out(col + 1);\n sci_out(row + 1);\n}\n\n\n/*\n lcd_stringout - Print the contents of the character string \"str\"\n at the current cursor position.\n*/\nvoid lcd_stringout(char *str)\n{\n sci_outs(str); // Output the string\n}\n\n/* ----------------------------------------------------------------------- */\n\n/*\n sci_init - Initialize the SCI port\n*/\nvoid sci_init(void) {\n UBRR0 = MYUBRR; // Set baud rate\n UCSR0B |= (1 << TXEN0); // Turn on transmitter\n UCSR0C = (3 << UCSZ00); // Set for asynchronous operation, no parity, \n // one stop bit, 8 data bits\n}\n\n/*\n sci_out - Output a byte to SCI port\n*/\nvoid sci_out(char ch)\n{\n while ( (UCSR0A & (1<<UDRE0)) == 0);\n UDR0 = ch;\n}\n\n/*\n sci_outs - Print the contents of the character string \"s\" out the SCI\n port. The string must be terminated by a zero byte.\n*/\nvoid sci_outs(char *s)\n{\n char ch;\n\n while ((ch = *s++) != '\\0')\n sci_out(ch);\n}\n"
},
{
"alpha_fraction": 0.6288184523582458,
"alphanum_fraction": 0.6576368808746338,
"avg_line_length": 41.32926940917969,
"blob_id": "ee7c950b82cdbbc3c58a16bfafba058af8bd3790",
"content_id": "1e087057cff963a58d751b66573d1c72e029cafd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3470,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 82,
"path": "/main/lib/hx711.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef HX711_H\n#define HX711_H\n\n#define PD_SCK_PORT PORTB // Power Down and Serial Clock Input Port\n#define PD_SCK_DDR DDRB // Power Down and Serial Clock DDR\n#define PD_SCK_PIN PB5 // Power Down and Serial Clock Pin\n\n#define PD_SCK_SET_OUTPUT PD_SCK_DDR |= (1<<PD_SCK_PIN)\n\n#define PD_SCK_SET_HIGH PD_SCK_PORT |= (1<<PD_SCK_PIN)\n#define PD_SCK_SET_LOW PD_SCK_PORT &= ~(1<<PD_SCK_PIN)\n\n#define DOUT_PORT PORTD // Serial Data Output Port\n#define DOUT_DDR DDRD // Serial Data Output DDR\n#define DOUT_INPUT PIND // Serial Data Output Input\n#define DOUT_PIN PD4 // Serial Data Output Pin\n#define DOUT_READ (DOUT_INPUT & (1<<DOUT_PIN)) // Serial Data Output Read Pin\n\n#define DOUT_SET_HIGH DOUT_PORT |= (1<<DOUT_PIN)\n#define DOUT_SET_LOW DOUT_PORT &= ~(1<<DOUT_PIN)\n#define DOUT_SET_INPUT DOUT_DDR &= ~(1<<DOUT_PIN); DOUT_SET_HIGH\n#define DOUT_SET_OUTPUT DOUT_DDR |= (1<<DOUT_PIN); DOUT_SET_LOW\n\nuint8_t GAIN; // amplification factor\ndouble OFFSET; // used for tare weight\nfloat SCALE; // used to return weight in grams, kg, ounces, whatever\n\n// define clock and data pin, channel, and gain factor\n// channel selection is made by passing the appropriate gain: 128 or 64 for channel A, 32 for channel B\n// gain: 128 or 64 for channel A; channel B works with 32 gain factor only\nvoid HX711_init(uint8_t gain);\n\n// check if HX711 is ready\n// from the datasheet: When output data is not ready for retrieval, digital output pin DOUT is high. Serial clock\n// input PD_SCK should be low. When DOUT goes to low, it indicates data is ready for retrieval.\nint HX711_is_ready(void);\n\n// set the gain factor; takes effect only after a call to read()\n// channel A can be set for a 128 or 64 gain; channel B has a fixed 32 gain\n// depending on the parameter, the channel is also set to either A or B\nvoid HX711_set_gain(uint8_t gain);\n\n// waits for the chip to be ready and returns a reading\nuint32_t HX711_read(void);\n\n// returns an average reading; times = how many times to read\nuint32_t HX711_read_average(uint8_t times);\n\n// returns (read_average() - OFFSET), that is the current value without the tare weight; times = how many readings to do\ndouble HX711_get_value(uint8_t times);\n\n// returns get_value() divided by SCALE, that is the raw value divided by a value obtained via calibration\n// times = how many readings to do\nfloat HX711_get_units(uint8_t times);\n\n// set the OFFSET value for tare weight; times = how many times to read the tare value\nvoid HX711_tare(uint8_t times);\n\n// set the SCALE value; this value is used to convert the raw data to \"human readable\" data (measure units)\nvoid HX711_set_scale(float scale);\n\n// get the current SCALE\nfloat HX711_get_scale(void);\n\n// set OFFSET, the value that's subtracted from the actual reading (tare weight)\nvoid HX711_set_offset(double offset);\n\n// get the current OFFSET\ndouble HX711_get_offset(void);\n\n// puts the chip into power down mode\nvoid HX711_power_down(void);\n\n// wakes up the chip after power down mode\nvoid HX711_power_up(void);\n\n// Sends/receives data. Modified from Arduino source\nuint8_t shiftIn(void);\n\nunsigned long HX711_Read(void);\n\n#endif // HX711_H"
},
{
"alpha_fraction": 0.512665867805481,
"alphanum_fraction": 0.5556895732879639,
"avg_line_length": 30.871795654296875,
"blob_id": "83d4549a8d9164731886749f8c598549e5260d62",
"content_id": "dd55040c85866085a56a11bdfc1687e773a737ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2487,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 78,
"path": "/main/lib/lcd.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#include <lcd.h>\n#include <i2c.h>\n#include <avr/io.h>\n#include <util/delay.h>\n#include <const.h>\n\n#define LCDAddressI2C 0x50\n#define Prefix 0xFE\n#define ClearScreen 0x51\n#define MoveCursor 0x47 // follow this with 2 hex digits for row then col pos\n#define DisplayOn 0x41\n\n/*\n lcd_init - Initialize the LCD\n*/\nvoid lcd_init() {\n i2c_init(BDIV);\n\n _delay_ms(250); // Wait 500msec for the LCD to start up\n _delay_ms(250);\n\n uint8_t cmd[6]; // 6 bytes to hold 2 byte prefix (0xFE) \n // last 4 bytes for actual commands \n\n cmd[0] = Prefix >> 8; // Separate into 2 bytes, where MSB first\n cmd[1] = Prefix & 0xFF; // and LSB second \n cmd[2] = ClearScreen >> 8; // repeat for clear screen command\n cmd[3] = ClearScreen & 0xFF;\n cmd[4] = DisplayOn >> 8; // repeat for display on command\n cmd[5] = DisplayOn & 0xFF;\n\n i2c_io(LCDAddressI2C, NULL, 0, cmd, 6, NULL, 0); \n}\n\n/*\n moveto - Move the cursor to the row and column given by the arguments.\n Row is 0 or 1, column is 0 - 15.\n*/\nvoid lcd_moveto(unsigned char row, unsigned char col) {\n uint8_t cmd[6]; // 6 bytes to hold 2 byte prefix (0xFE) \n // 2 bytes to hold command\n // 2 bytes to hold row, col\n\n cmd[0] = Prefix >> 8; // Separate into 2 bytes, where MSB first\n cmd[1] = Prefix & 0xFF; // and LSB second \n cmd[2] = MoveCursor >> 8; // repeat for move cursor command\n cmd[3] = MoveCursor & 0xFF;\n cmd[4] = row + 1 & 0xFF; // repeat for row, col \n cmd[5] = col + 1 & 0xFF;\n\n i2c_io(LCDAddressI2C, NULL, 0, cmd, 6, NULL, 0);\n}\n\n\n/*\n lcd_stringout - Print the contents of the character string \"str\"\n at the current cursor position.\n*/\nvoid lcd_stringout(char* str, unsigned char len) {\n int i = 0;\n\n while (i < len) {\n i2c_io(LCDAddressI2C, NULL, 0, str[i], len, NULL, 0);\n i++;\n }\n}\n\nvoid lcd_clear_screen(void) {\n uint8_t cmd[4]; // 4 bytes to hold 2 byte prefix (0xFE) \n // last 2 bytes for actual command \n\n cmd[0] = Prefix >> 8; // Separate into 2 bytes, where MSB first\n cmd[1] = Prefix & 0xFF; // and LSB second \n cmd[2] = ClearScreen >> 8; // repeat for clear screen command\n cmd[3] = ClearScreen & 0xFF;\n\n i2c_io(LCDAddressI2C, NULL, 0, cmd, 4, NULL, 0); \n}\n\n"
},
{
"alpha_fraction": 0.7292817831039429,
"alphanum_fraction": 0.7292817831039429,
"avg_line_length": 19.22222137451172,
"blob_id": "c037065bd7b092834d7872094edbef782bf33df7",
"content_id": "67b7285f6c6016f27c06a603dcfd5c21bbe40c94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 9,
"path": "/main/lib/lcd.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef LCD_H\n#define LCD_H\n\nvoid lcd_init(void);\nvoid lcd_moveto(unsigned char row, unsigned char col);\nvoid lcd_stringout(char* str);\nvoid lcd_clear_screen(void);\n\n#endif // LCD_H"
},
{
"alpha_fraction": 0.5498046875,
"alphanum_fraction": 0.62890625,
"avg_line_length": 34.344825744628906,
"blob_id": "205d5771b5851add04ac56a3f1dcd1aeda9ec4fb",
"content_id": "29f16111c16e0447cf6286331113c670acc977c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1024,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 29,
"path": "/main/lib/servo.c",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "// code modified from: https://www.electronicwings.com/avr-atmega/servo-motor-interfacing-with-atmega16\n#include <avr/io.h>\n#include <util/delay.h>\n#include <servo.h>\n\nvoid servo_init(unsigned char servo_pin) {\n DDRD |= (1 << SERVO); // Make OC1A pin as output \n TCNT1 = 0; // Set timer1 count zero\n ICR1 = 2499; // Set TOP count for timer1 in ICR1 register\n\n // Set Fast PWM, TOP in ICR1, Clear OC1A on compare match, clk/64\n TCCR1A = (1<<WGM11)|(1<<COM1A1);\n TCCR1B = (1<<WGM12)|(1<<WGM13)|(1<<CS10)|(1<<CS11);\n}\n\n/* servo_rotate_to - rotates servo to angle between -90 to +90 degrees\n * OC1RA register values correspond to servo angle between -90 to +90 degrees\n * OC1RA = 65 -> -90 degrees\n * OC1RA = 175 -> 0 degrees\n * OC1RA = 300 -> +90 degrees\n */\nint servo_rotate_to(int angle) {\n if (angle >= -90 && angle <= 90) {\n OC1RA = angle + 175; // add 175 offset to angle to get OC1RA value\n _delay_ms(1500); // give servo time to rotate\n return 1;\n }\n return 0;\n}"
},
{
"alpha_fraction": 0.714640200138092,
"alphanum_fraction": 0.714640200138092,
"avg_line_length": 15.833333015441895,
"blob_id": "0688eee65f67738e671e1cd5cc5157552a1acb12",
"content_id": "8fc058eec52e4a06d37309d4e1bf6be436d190a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 24,
"path": "/main/lib/misc.h",
"repo_name": "aopem/ee459-final-project",
"src_encoding": "UTF-8",
"text": "#ifndef MISC_H\n#define MISC_H\n\nvoid button_init(int pin);\nint button_pressed(int pin);\n\nvoid led_red_init(void);\nvoid led_red(int on);\n\nvoid motion_sensor_init(void);\nint motion_detected(void);\n\nvoid lock_init(void);\nvoid lock_unlock(int on);\nint lock_locked(void);\n\nvoid buzzer_init(void);\nvoid buzzer_on(void);\nvoid buzzer_off(void);\n\nvoid rpi_init(void);\nvoid rpi_camera(int on);\n\n#endif // MISC_H"
}
] | 21 |
xiangshen-dk/stackdriver-metrics-export
|
https://github.com/xiangshen-dk/stackdriver-metrics-export
|
d1aed801e396d60eb16f47954fa3404c1fa799dc
|
5d47ee8b6baab6c1642dc3c253bcae6c72af3587
|
224aa3f4b8c69a593e24d84dcf2f41da3e0e9648
|
refs/heads/master
| 2022-11-21T12:30:09.648020 | 2020-07-27T02:35:42 | 2020-07-27T02:35:42 | 279,750,508 | 0 | 0 |
Apache-2.0
| 2020-07-15T03:15:16 | 2020-06-24T04:09:02 | 2020-06-24T04:09:00 | null |
[
{
"alpha_fraction": 0.5940883755683899,
"alphanum_fraction": 0.5987708568572998,
"avg_line_length": 36.5494499206543,
"blob_id": "8b18598a1805a60c72b8e4521ef85bc2777b5285",
"content_id": "ce15f2200d6a8005b2c73f3b64aa9e99e0848192",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3417,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 91,
"path": "/list_metrics/start.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport webapp2\nimport config\nimport os\nimport json\nimport logging\nfrom datetime import datetime \nimport cloudstorage as gcs\nfrom cloudstorage import NotFoundError\nfrom google.appengine.api import app_identity\n\nclass ReceiveStart(webapp2.RequestHandler):\n def set_last_end_time(self, bucket_name):\n \"\"\" Write the end_time as a string value in a JSON object in GCS. \n This file is used to remember the last end_time in case one isn't provided\n \"\"\"\n project_id = app_identity.get_application_id()\n end_time = datetime.now()\n end_time_str = end_time.strftime('%Y-%m-%dT%H:%M:%S.%fZ')\n\n end_time_str_json = {\n \"end_time\": end_time_str\n }\n write_retry_params = gcs.RetryParams(backoff_factor=1.1)\n gcs_file = gcs.open('/{}/{}'.format(\n bucket_name, '{}.{}'.format(\n project_id,\n config.LAST_END_TIME_FILENAME)),\n 'w',\n content_type='text/plain',\n retry_params=write_retry_params)\n gcs_file.write(json.dumps(end_time_str_json))\n gcs_file.close()\n\n def get(self):\n last_end_time_str = \"\"\n try:\n # get the App Engine default bucket name to store a GCS file with last end_time\n project_id = app_identity.get_application_id()\n bucket_name = os.environ.get('BUCKET_NAME',\n app_identity.get_default_gcs_bucket_name()\n )\n\n gcs_file = gcs.open('/{}/{}'.format(\n bucket_name, '{}.{}'.format(\n project_id,\n config.LAST_END_TIME_FILENAME)))\n contents = gcs_file.read()\n logging.debug(\"GCS FILE CONTENTS: {}\".format(contents))\n json_contents = json.loads(contents) \n last_end_time_str = json_contents[\"end_time\"]\n gcs_file.close()\n except NotFoundError as nfe:\n logging.error(\"Missing file when reading from GCS: {}\".format(nfe))\n last_end_time_str = None\n except Exception as e:\n logging.error(\"Received error when reading from GCS: {}\".format(e))\n last_end_time_str = None\n\n try:\n if not last_end_time_str:\n self.set_last_end_time(bucket_name)\n except NotFoundError as nfe:\n logging.error(\"Missing file when writing to GCS: {}\".format(nfe))\n last_end_time_str = None\n except Exception as e:\n logging.error(\"Received error when writing to GCS: {}\".format(e))\n last_end_time_str = None\n \n self.response.headers['Content-Type'] = 'text/plain'\n self.response.status = 200\n\n\napp = webapp2.WSGIApplication([\n ('/_ah/start', ReceiveStart)\n], debug=True)\n"
},
{
"alpha_fraction": 0.931034505367279,
"alphanum_fraction": 0.931034505367279,
"avg_line_length": 28.5,
"blob_id": "16e06919e08ea89fd169f6cc66f7a56a1cafdf61",
"content_id": "05e52da46960ca1f07b404c7814e932d3a153cf3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 2,
"path": "/list_metrics/requirements.txt",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "google-api-python-client\nGoogleAppEngineCloudStorageClient"
},
{
"alpha_fraction": 0.37217944860458374,
"alphanum_fraction": 0.40751248598098755,
"avg_line_length": 34.498802185058594,
"blob_id": "f53320a47af693611d126164051e2985275b7deb",
"content_id": "73e5534d829e372c477d25068ffa706dcb56a9df",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14802,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 417,
"path": "/write_metrics/main_test.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport webtest\nimport unittest\nimport main\nimport config\nimport base64\nimport json\nfrom google.appengine.ext import testbed\n\nclass AppTest(unittest.TestCase):\n \n def setUp(self):\n \"\"\" Set-up the webtest app\n \"\"\"\n self.app = webtest.TestApp(main.app) \n self.batch_id = \"R1HIA55JB5DOQZM8R53OKMCWZ5BEQKUJ\"\n\n def test_post_empty_data(self):\n \"\"\" Test sending an empty message\n \"\"\"\n response = self.app.post('/_ah/push-handlers/receive_message')\n self.assertEqual(response.status_int, 200)\n self.assertEqual(response.body, \"No request body received\")\n self.assertRaises(ValueError)\n\n def test_incorrect_token_post(self):\n \"\"\" Test sending an incorrect token\n \"\"\" \n request = self.build_request(token=\"incorrect_token\")\n response = self.app.post('/_ah/push-handlers/receive_message',json.dumps(request).encode('utf-8'),content_type=\"application/json\")\n self.assertEqual(response.status_int, 200)\n self.assertRaises(ValueError)\n\n def test_correct_labels(self):\n \"\"\" Test whether the correct labels are extracted from the metric API responses\n \"\"\"\n timeseries = self.build_timeseries()\n\n metric_labels_list = main.get_labels(timeseries[\"metric\"],\"labels\") \n expected_metric_labels_list = self.build_metric_labels()\n self.assertEqual(sorted(metric_labels_list), sorted(expected_metric_labels_list))\n\n resource_labels_list = main.get_labels(timeseries[\"resource\"],\"labels\")\n expected_resource_labels_list = self.build_resource_labels()\n self.assertEqual(sorted(resource_labels_list), sorted(expected_resource_labels_list))\n\n user_labels_list = main.get_labels(self.build_user_labels_request(),\"userLabels\")\n expected_user_labels_list = self.build_expected_user_labels_response()\n self.assertEqual(sorted(user_labels_list), sorted(expected_user_labels_list))\n\n system_labels_list = main.get_system_labels(self.build_user_labels_request(),\"systemLabels\")\n expected_system_labels_list = self.build_expected_system_labels_response()\n self.assertEqual(sorted(system_labels_list), sorted(expected_system_labels_list)) \n\n def test_correct_build_distribution_values(self):\n \"\"\" Test whether the correct distribution values are built given a timeseries input\n \"\"\"\n timeseries_with_distribution_values = self.build_distribution_value()\n\n distribution_value = main.build_distribution_value(timeseries_with_distribution_values[\"points\"][0][\"value\"][\"distributionValue\"])\n expected_distribution_value = self.build_expected_distribution_value()\n self.assertEqual(distribution_value,expected_distribution_value)\n\n def test_correct_build_row(self):\n \"\"\" Test whether the correct JSON object is created for insert into BigQuery given a timeseries input\n \"\"\"\n timeseries = self.build_timeseries()\n bq_body = main.build_rows(timeseries,self.batch_id)\n \n bq_expected_response = self.build_expected_bq_response()\n self.assertEqual(bq_body, bq_expected_response)\n\n def build_timeseries(self):\n \"\"\" Build a timeseries object to use as input\n \"\"\"\n timeseries = {\n \"metricKind\": \"DELTA\", \n \"metric\": {\n \"labels\": {\n \"response_code\": \"0\"}, \n \"type\": \"agent.googleapis.com/agent/request_count\"\n }, \n \"points\": [\n {\n \"interval\": {\n \"endTime\": \"2019-02-18T22:09:53.939194Z\", \n \"startTime\": \"2019-02-18T21:09:53.939194Z\"\n }, \n \"value\": {\n \"int64Value\": \"62\"\n }\n }, \n {\n \"interval\": {\n \"endTime\": \"2019-02-18T21:09:53.939194Z\", \n \"startTime\": \"2019-02-18T20:09:53.939194Z\"\n }, \n \"value\": {\n \"int64Value\": \"61\"\n }\n }\n ], \n \"resource\": {\n \"labels\": {\n \"instance_id\": \"9113659852587170607\", \n \"project_id\": \"YOUR_PROJECT_ID\", \n \"zone\": \"us-east4-a\"\n }, \n \"type\": \"gce_instance\"\n }, \n \"valueType\": \"INT64\"\n }\n\n return timeseries\n\n def build_expected_bq_response(self):\n \"\"\" Build the expected BigQuery insert JSON object \n \"\"\"\n response = [\n { \n \"json\": {\n \"batch_id\": self.batch_id, \n \"metric\": {\n \"labels\": [\n {\n \"key\": \"response_code\", \n \"value\": \"0\"\n }\n ], \n \"type\": \"agent.googleapis.com/agent/request_count\"\n }, \n \"metric_kind\": \"DELTA\", \n \"point\": {\n \"interval\": {\n \"end_time\": \"2019-02-18T22:09:53.939194Z\", \n \"start_time\": \"2019-02-18T21:09:53.939194Z\"\n }, \n \"value\": {\n \"int64_value\": \"62\"\n }\n }, \n \"resource\": {\n \"labels\": [\n {\n \"key\": \"instance_id\", \n \"value\": \"9113659852587170607\"\n }, \n {\n \"key\": \"project_id\", \n \"value\": \"YOUR_PROJECT_ID\"\n }, \n {\n \"key\": \"zone\", \n \"value\": \"us-east4-a\"\n }\n ], \n \"type\": \"gce_instance\"\n }, \n \"value_type\": \"INT64\"\n }\n }, \n {\n \"json\": {\n \"batch_id\": self.batch_id, \n \"metric\": {\n \"labels\": [\n {\n \"key\": \"response_code\", \n \"value\": \"0\"\n }\n ], \n \"type\": \"agent.googleapis.com/agent/request_count\"\n }, \n \"metric_kind\": \"DELTA\", \n \"point\": {\n \"interval\": {\n \"end_time\": \"2019-02-18T21:09:53.939194Z\", \n \"start_time\": \"2019-02-18T20:09:53.939194Z\"\n }, \n \"value\": {\n \"int64_value\": \"61\"\n }\n }, \n \"resource\": {\n \"labels\": [\n {\n \"key\": \"instance_id\", \n \"value\": \"9113659852587170607\"\n }, \n {\n \"key\": \"project_id\", \n \"value\": \"YOUR_PROJECT_ID\"\n }, \n {\n \"key\": \"zone\", \n \"value\": \"us-east4-a\"\n }\n ], \n \"type\": \"gce_instance\"\n }, \n \"value_type\": \"INT64\"\n }\n }\n ]\n return response\n\n def build_metric_labels(self):\n \"\"\" Build the expected metric labels list\n \"\"\"\n response = [ \n {\n \"key\": \"response_code\", \n \"value\": \"0\"\n }\n ]\n return response\n\n def build_resource_labels(self):\n \"\"\" Build the expected resource labels list\n \"\"\"\n response = [ \n {\n \"key\": \"instance_id\", \n \"value\": \"9113659852587170607\"\n }, \n {\n \"key\": \"project_id\", \n \"value\": \"YOUR_PROJECT_ID\"\n }, \n {\n \"key\": \"zone\", \n \"value\": \"us-east4-a\"\n }\n ]\n return response\n \n def build_request(self,token=config.PUBSUB_VERIFICATION_TOKEN):\n \"\"\" Build a Pub/Sub message as input\n \"\"\"\n payload = {\n \"metricKind\": \"DELTA\", \n \"metric\": {\n \"labels\": {\n \"response_code\": \"0\"\n }, \n \"type\": \"agent.googleapis.com/agent/request_count\"\n }, \n \"points\": [\n {\n \"interval\": {\"endTime\": \"2019-02-18T22:09:53.939194Z\", \"startTime\": \"2019-02-18T21:09:53.939194Z\"}, \n \"value\": {\"int64Value\": \"62\"}\n }, \n {\n \"interval\": {\"endTime\": \"2019-02-18T21:09:53.939194Z\", \"startTime\": \"2019-02-18T20:09:53.939194Z\"}, \n \"value\": {\"int64Value\": \"61\"}\n }\n ], \n \"resource\": {\n \"labels\": {\n \"instance_id\": \"9113659852587170607\", \n \"project_id\": \"YOUR_PROJECT_ID\", \n \"zone\": \"us-east4-a\"\n }, \n \"type\": \"gce_instance\"\n }, \n \"valueType\": \"INT64\"\n }\n request = {\n \"message\": \n {\n \"attributes\": {\n \"batch_id\": self.batch_id,\n \"token\": token\n },\n \"data\": base64.b64encode(json.dumps(payload))\n }\n \n }\n return request\n\n def build_user_labels_request(self):\n \"\"\" Build the JSON input for the userLabels and systemLabels \n \"\"\"\n request = {\n \"systemLabels\": {\n \"name\": \"appName\",\n \"list_name\": [ \"a\",\"b\",\"c\"],\n \"boolean_value\": False\n },\n \"userLabels\": {\n \"key1\": \"value1\",\n \"key2\": \"value2\"\n }\n }\n return request\n\n def build_expected_system_labels_response(self):\n \"\"\" Build the expected system labels list\n \"\"\"\n labels = [\n {\n \"key\": \"name\",\n \"value\": \"appName\"\n },\n {\n \"key\": \"boolean_value\",\n \"value\": \"False\"\n },\n {\n \"key\": \"list_name\",\n \"value\": \"a\"\n },\n {\n \"key\": \"list_name\",\n \"value\": \"b\"\n },\n {\n \"key\": \"list_name\",\n \"value\": \"c\"\n }\n ]\n return labels\n \n def build_expected_user_labels_response(self):\n \"\"\" Build the expected user labels list\n \"\"\"\n labels = [\n {\n \"key\": \"key1\",\n \"value\": \"value1\"\n },\n {\n \"key\": \"key2\",\n \"value\": \"value2\"\n }\n ]\n return labels\n \n def build_distribution_value(self):\n \"\"\" Build the expected JSON object input for the distribution values test\n \"\"\"\n timeseries = {\n \"metricKind\": \"DELTA\", \n \"metric\": {\n \"type\": \"serviceruntime.googleapis.com/api/response_sizes\"\n }, \n \"points\": [\n {\n \"interval\": {\n \"endTime\": \"2019-02-19T04:00:00.841487Z\", \n \"startTime\": \"2019-02-19T03:00:00.841487Z\"\n }, \n \"value\": {\n \"distributionValue\": {\n \"count\": \"56\", \n \"mean\": 17,\n \"sumOfSquaredDeviation\": 1.296382457204002e-25,\n \"bucketCounts\": [\"56\"], \n \"bucketOptions\": {\n \"exponentialBuckets\": {\n \"scale\": 1, \n \"growthFactor\": 10, \n \"numFiniteBuckets\": 8\n }\n }\n }\n }\n }\n ], \n \"resource\": {\n \"labels\": {\n \"service\": \"monitoring.googleapis.com\", \n \"credential_id\": \"serviceaccount:106579349769273816070\", \n \"version\": \"v3\", \n \"location\": \"us-central1\", \n \"project_id\": \"ms-demo-app01\", \n \"method\": \"google.monitoring.v3.MetricService.ListMetricDescriptors\"\n }, \n \"type\": \"consumed_api\"\n }, \n \"valueType\": \"DISTRIBUTION\"}\n return timeseries\n \n def build_expected_distribution_value(self):\n \"\"\" Build the expected JSON object for the distribution values test\n \"\"\"\n distribution_value = {\n \"count\": 56,\n \"mean\": 17.0,\n \"sumOfSquaredDeviation\": 0.0,\n \"bucketOptions\": {\n \"exponentialBuckets\": {\n \"numFiniteBuckets\": 8,\n \"growthFactor\": 10.0,\n \"scale\": 1\n }\n },\n \"bucketCounts\": {\n \"value\": [56]\n }\n }\n return distribution_value"
},
{
"alpha_fraction": 0.62042236328125,
"alphanum_fraction": 0.6423416137695312,
"avg_line_length": 36.79798126220703,
"blob_id": "ec1c72c0bdd4109807d3a1048d12ca5e000a9966",
"content_id": "2d99ad7709e8972d374ff932803090ff24a38a92",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3741,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 99,
"path": "/get_timeseries/main_test.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport webtest\nimport unittest\nimport main\nimport config\nimport base64\nimport json\nfrom google.appengine.ext import testbed\n\nclass AppTest(unittest.TestCase):\n def setUp(self):\n \"\"\" Set-up the webtest app\n \"\"\"\n self.app = webtest.TestApp(main.app) \n \n def test_aligner_reducer_values(self):\n \"\"\" Test the get_aligner_reducer() function logic\n \"\"\"\n crossSeriesReducer, perSeriesAligner = main.get_aligner_reducer(config.GAUGE,config.BOOL)\n self.assertEqual(crossSeriesReducer, config.REDUCE_MEAN)\n self.assertEqual(perSeriesAligner, config.ALIGN_FRACTION_TRUE)\n\n crossSeriesReducer, perSeriesAligner = main.get_aligner_reducer(config.GAUGE,config.INT64)\n self.assertEqual(crossSeriesReducer, config.REDUCE_SUM)\n self.assertEqual(perSeriesAligner, config.ALIGN_SUM)\n\n crossSeriesReducer, perSeriesAligner = main.get_aligner_reducer(config.DELTA,config.INT64)\n self.assertEqual(crossSeriesReducer, config.REDUCE_SUM)\n self.assertEqual(perSeriesAligner, config.ALIGN_SUM)\n\n crossSeriesReducer, perSeriesAligner = main.get_aligner_reducer(config.CUMULATIVE,config.INT64)\n self.assertEqual(crossSeriesReducer, config.REDUCE_SUM)\n self.assertEqual(perSeriesAligner, config.ALIGN_DELTA)\n\n def test_post_empty_data(self): \n \"\"\" Test sending an empty message\n \"\"\"\n response = self.app.post('/_ah/push-handlers/receive_message')\n self.assertEqual(response.status_int, 200)\n self.assertEqual(response.body, \"No request body received\")\n self.assertRaises(ValueError)\n\n def test_incorrect_token_post(self):\n \"\"\" Test sending an incorrect token\n \"\"\"\n request = self.build_request(token=\"incorrect_token\")\n response = self.app.post('/_ah/push-handlers/receive_message',json.dumps(request).encode('utf-8'),content_type=\"application/json\")\n self.assertEqual(response.status_int, 200)\n self.assertRaises(ValueError)\n\n def build_request(self,\n token=config.PUBSUB_VERIFICATION_TOKEN,\n batch_id=\"12h3eldjhwuidjwk222dwd09db5zlaqs\",\n metric_type=\"bigquery.googleapis.com/query/count\",\n metric_kind=config.GAUGE,\n value_type=config.INT64,\n start_time=\"2019-02-18T13:00:00.311635Z\",\n end_time=\"2019-02-18T14:00:00.311635Z\",\n aggregation_alignment_period=\"3600s\"):\n \"\"\" Build a request to submit \n \"\"\"\n\n payload = {\n \"metric\": {\n \"type\": metric_type,\n \"metricKind\": metric_kind,\n \"valueType\": value_type\n },\n \"start_time\": start_time,\n \"end_time\": end_time,\n \"aggregation_alignment_period\": aggregation_alignment_period\n }\n request = {\n \"message\": \n {\n \"attributes\": {\n \"batch_id\": batch_id,\n \"token\": token\n },\n \"data\": base64.b64encode(json.dumps(payload))\n }\n \n }\n return request"
},
{
"alpha_fraction": 0.6835334300994873,
"alphanum_fraction": 0.6946826577186584,
"avg_line_length": 29.6842098236084,
"blob_id": "b1d5726ac71a11744f29305611b78a3d14f4a391",
"content_id": "0fca4a19785bdb9da706f8d8b16ee26e81dcbd21",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1166,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 38,
"path": "/get_service_limits/config.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nSERVICE_INCLUSIONS = {\n \"include_all_enabled_service\": \"\",\n \"include_services\":[\n \"dialogflow.googleapis.com\",\n # \"monitoring.googleapis.com\",\n # \"compute.googleapis.com\",\n ],\n}\n\n# https://cloud.google.com/resource-manager/reference/rest/v1/projects/list\nPROJECT_INCLUSIONS = {\n \"include_all_projects\": \"\",\n \"filter\": \"name:*\",\n \"include_projects\": [\n \"your-project-id\",\n # \"bank-app-3a968\",\n ],\n}\n\nBIGQUERY_DATASET='metric_export'\nBIGQUERY_STATS_TABLE='service_limits'\nPUBSUB_VERIFICATION_TOKEN = '16b2ecfb-7734-48b9-817d-4ac8bd623c87'\n"
},
{
"alpha_fraction": 0.6383838653564453,
"alphanum_fraction": 0.6463384032249451,
"avg_line_length": 39.922481536865234,
"blob_id": "f082b58e57e45e6f01bb368eb29a42ac328e1125",
"content_id": "d4d39bf7f29e51436b6cff575cd772688ca25d5e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15840,
"license_type": "permissive",
"max_line_length": 190,
"num_lines": 387,
"path": "/test/end_to_end_test.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport argparse\nimport json\nfrom googleapiclient.discovery import build\nimport config\n\n\n\n# Compare the # from the metricDescriptors.list API and timeSeries.list\nmetric_results_api = {}\nmetric_descriptors = {}\n\n# Compare the # from the timeSeries.list and what is available in BQ\ntimeseries_results_api = {}\ntimeseries_results_bq = {}\n\ndef build_timeseries_api_args(project_name=\"\",\n batch_id=\"\",\n filter_str=\"\",\n end_time_str=\"\",\n start_time_str=\"\",\n aggregation_alignment_period=\"\",\n group_by=config.GROUP_BY_STRING,\n perSeriesAligner=config.ALIGN_SUM,\n nextPageToken=\"\"\n ):\n # build a dict with the API parameters\n api_args={}\n api_args[\"project_name\"] = project_name\n api_args[\"metric_filter\"] = filter_str\n api_args[\"end_time_str\"] = end_time_str\n api_args[\"start_time_str\"] = start_time_str\n api_args[\"aggregation_alignment_period\"] = aggregation_alignment_period\n api_args[\"group_by\"] = group_by\n api_args[\"perSeriesAligner\"]=perSeriesAligner\n api_args[\"nextPageToken\"]=nextPageToken\n\n return api_args\n\ndef get_timeseries_list(api_args):\n timeseries_resp_list = []\n while True:\n timeseries = get_timeseries(api_args)\n\n if timeseries:\n\n # retryable error codes based on https://developers.google.com/maps-booking/reference/grpc-api/status_codes\n if \"executionErrors\" in timeseries:\n if timeseries[\"executionErrors\"][\"code\"] != 0:\n print \"Received an error getting the timeseries with code: {} and msg: {}\".format(timeseries[\"executionErrors\"][\"code\"],timeseries[\"executionErrors\"][\"message\"])\n logging.error(\"Received an error getting the timeseries with code: {} and msg: {}\".format(timeseries[\"executionErrors\"][\"code\"],timeseries[\"executionErrors\"][\"message\"]))\n break\n else:\n timeseries_resp_list.append(timeseries)\n if \"nextPageToken\" in timeseries:\n api_args[\"nextPageToken\"] = timeseries[\"nextPageToken\"]\n else:\n break\n\n else:\n logging.debug(\"No timeseries returned, no reason to write anything\")\n print \"No timeseries returned, no reason to write anything\"\n msgs_without_timeseries=1\n break\n print \"metric: {}\".format(json.dumps(timeseries_resp_list,indent=4, sort_keys=True))\n return timeseries_resp_list\n\ndef get_bigquery_records(batch_id, metric_type):\n query =\"SELECT \" \\\n \"batch_id,metric.type,metric_kind,value_type,point.interval.start_time,point.interval.end_time,point.value.int64_value \" \\\n \"FROM \" \\\n \"`sage-facet-201016.metric_export.sd_metrics_export_fin` \" \\\n \"WHERE \" \\\n \"batch_id=\\\"{}\\\" AND metric.type=\\\"{}\\\"\".format(batch_id,metric_type)\n\n\n response = query_bigquery(query)\n job_ref = response[\"jobReference\"]\n results = get_query_results_bigquery(job_ref)\n return results\n\ndef query_bigquery(query):\n\n bigquery = build('bigquery', 'v2',cache_discovery=True)\n\n body = {\n \"query\": query,\n \"useLegacySql\": \"false\"\n }\n logging.debug('body: {}'.format(json.dumps(body,sort_keys=True, indent=4)))\n print 'body: {}'.format(json.dumps(body,sort_keys=True, indent=4))\n response = bigquery.jobs().query(\n projectId=\"sage-facet-201016\",\n body=body\n ).execute()\n \n logging.debug(\"BigQuery said... = {}\".format(response))\n print \"BigQuery said... = {}\".format(response)\n\n return response\n\ndef get_query_results_bigquery(job_ref):\n bigquery = build('bigquery', 'v2',cache_discovery=True)\n\n response = bigquery.jobs().getQueryResults(\n projectId=\"sage-facet-201016\",\n jobId=job_ref[\"jobId\"]\n ).execute()\n \n logging.debug(\"BigQuery said... = {}\".format(response))\n print \"BigQuery said... = {}\".format(json.dumps(response,sort_keys=True, indent=4))\n\n return response\n\ndef get_metrics(next_page_token,filter_str=\"\"):\n \n service = build('monitoring', 'v3',cache_discovery=True)\n project_name = 'projects/{project_id}'.format(\n project_id=\"sage-facet-201016\"\n )\n \n metrics = service.projects().metricDescriptors().list(\n name=project_name,\n pageToken=next_page_token,\n filter=filter_str\n ).execute()\n\n logging.debug(\"response is {}\".format(json.dumps(metrics, sort_keys=True, indent=4)))\n return metrics\n\ndef check_exclusions(metric):\n exclusions = config.EXCLUSIONS\n for exclusion in exclusions['metricKinds']:\n logging.debug(\"exclusion check: {},{}\".format(metric['metricKind'],exclusion['metricKind']))\n if ((metric['metricKind'] == exclusion['metricKind']) and \n (metric['valueType'] == exclusion['valueType'])):\n logging.debug(\"excluding based on metricKind {},{} AND {},{}\".format(metric['metricKind'],exclusion['metricKind'],metric['valueType'],exclusion['valueType']))\n return False\n\n for exclusion in exclusions['metricTypes']:\n logging.debug(\"exclusion metricTypes check: {},{}\".format(metric['type'],exclusion['metricType']))\n if metric['type'].find(exclusion['metricType']) != -1:\n logging.debug(\"excluding based on metricType {},{}\".format(metric['type'],exclusion['metricType']))\n return False \n \n for exclusion in exclusions['metricTypeGroups']:\n logging.debug(\"exclusion metricTypeGroups check: {},{}\".format(metric['type'],exclusion['metricTypeGroup']))\n if metric['type'].find(exclusion['metricTypeGroup']) != -1:\n logging.debug(\"excluding based on metricTypeGroup {},{}\".format(metric['type'],exclusion['metricTypeGroup']))\n return False \n return True\n\ndef build_metric_descriptors_list():\n stats = {}\n msgs_published=0\n msgs_excluded=0\n metrics_count_from_api=0\n \n metrics_list ={}\n next_page_token=\"\"\n while True:\n metric_list = get_metrics(next_page_token)\n\n metrics_count_from_api+=len(metric_list['metricDescriptors'])\n for metric in metric_list['metricDescriptors']:\n logging.debug(\"Processing metric {}\".format(metric))\n if check_exclusions(metric):\n metric_type = metric[\"type\"]\n metric_results_api[metric_type]=1\n metric_descriptors[metric_type]=metric\n msgs_published+=1\n else:\n logging.debug(\"Excluded the metric: {}\".format(metric['name']))\n msgs_excluded+=1\n if \"nextPageToken\" in metric_list:\n next_page_token=metric_list[\"nextPageToken\"]\n else:\n break\n stats[\"msgs_published\"] = msgs_published\n stats[\"msgs_excluded\"] = msgs_excluded\n stats[\"metrics_count_from_api\"]=metrics_count_from_api\n return stats\n \ndef get_aligner_reducer(metric_kind, metric_val_type):\n if metric_kind==config.GAUGE:\n if metric_val_type==config.BOOL:\n crossSeriesReducer=config.REDUCE_MEAN\n perSeriesAligner=config.ALIGN_FRACTION_TRUE\n elif metric_val_type in [config.INT64,config.DOUBLE,config.DISTRIBUTION]:\n crossSeriesReducer=config.REDUCE_SUM\n perSeriesAligner=config.ALIGN_SUM\n elif metric_val_type==config.STRING:\n crossSeriesReducer=config.REDUCE_COUNT\n perSeriesAligner=config.ALIGN_NONE\n else:\n logging.debug(\"No match for GAUGE {},{}\".format(metric_kind, metric_val_type))\n elif metric_kind==config.DELTA:\n if metric_val_type in [config.INT64,config.DOUBLE,config.DISTRIBUTION]:\n crossSeriesReducer=config.REDUCE_SUM\n perSeriesAligner=config.ALIGN_SUM\n else:\n logging.debug(\"No match for DELTA {},{}\".format(metric_kind, metric_val_type))\n elif metric_kind==config.CUMULATIVE:\n if metric_val_type in [config.INT64, config.DOUBLE,config.DISTRIBUTION]:\n crossSeriesReducer=config.REDUCE_SUM\n perSeriesAligner=config.ALIGN_DELTA\n else:\n logging.debug(\"No match for CUMULATIVE {},{}\".format(metric_kind, metric_val_type))\n else:\n logging.debug(\"No match for {},{}\".format(metric_kind, metric_val_type))\n\n return crossSeriesReducer, perSeriesAligner\n\n\ndef get_and_count_timeseries(data):\n \n metric_type = data[\"metric\"]['type']\n metric_kind = data[\"metric\"]['metricKind']\n metric_val_type = data[\"metric\"]['valueType']\n end_time_str = data[\"end_time\"]\n start_time_str = data[\"start_time\"]\n aggregation_alignment_period = data[\"aggregation_alignment_period\"]\n\n logging.debug('get_timeseries for metric: {},{},{},{},{}'.format(metric_type,metric_kind, metric_val_type, start_time_str, end_time_str))\n \n project_name = 'projects/{project_id}'.format(\n project_id=\"sage-facet-201016\"\n )\n \n # Capture the stats \n stats = {}\n msgs_published=0\n msgs_without_timeseries=0\n metrics_count_from_api=0\n\n # get the appropriate aligner based on the metric_kind and value_type\n crossSeriesReducer, perSeriesAligner = get_aligner_reducer(metric_kind,metric_val_type)\n\n # build a dict with the API parameters\n api_args={}\n api_args[\"project_name\"] = project_name\n api_args[\"metric_filter\"] = \"metric.type=\\\"{}\\\" \".format(metric_type)\n api_args[\"end_time_str\"] = data[\"end_time\"]\n api_args[\"start_time_str\"] = data[\"start_time\"]\n api_args[\"aggregation_alignment_period\"] = data[\"aggregation_alignment_period\"]\n api_args[\"group_by\"] = config.GROUP_BY_STRING\n api_args[\"crossSeriesReducer\"]=crossSeriesReducer\n api_args[\"perSeriesAligner\"]=perSeriesAligner\n api_args[\"nextPageToken\"]=\"\"\n\n # Call the projects.timeseries.list API\n timeseries ={}\n while True:\n timeseries = get_timeseries(api_args)\n\n if timeseries:\n\n # retryable error codes based on https://developers.google.com/maps-booking/reference/grpc-api/status_codes\n if \"executionErrors\" in timeseries:\n if timeseries[\"executionErrors\"][\"code\"] != 0:\n logging.error(\"Received an error getting the timeseries with code: {} and msg: {}\".format(timeseries[\"executionErrors\"][\"code\"],timeseries[\"executionErrors\"][\"message\"]))\n break\n else:\n # write the first timeseries\n if metric_type in timeseries_results_api: \n timeseries_results_api[metric_type] = len(timeseries[\"timeSeries\"])\n else:\n timeseries_results_api[metric_type] += len(timeseries[\"timeSeries\"])\n metrics_count_from_api+=len(timeseries[\"timeSeries\"])\n if \"nextPageToken\" in timeseries:\n api_args[\"nextPageToken\"] = timeseries[\"nextPageToken\"]\n else:\n break\n\n else:\n logging.debug(\"No timeseries returned, no reason to write anything\")\n timeseries_results_api[metric_type]=0\n msgs_without_timeseries=1\n break\n\n stats[\"msgs_published\"] = msgs_published\n stats[\"msgs_without_timeseries\"] = msgs_without_timeseries\n stats[\"metrics_count_from_api\"] = metrics_count_from_api\n logging.debug(\"Stats are {}\".format(json.dumps(stats)))\n\n return response_code\n\ndef get_timeseries(api_args):\n service = build('monitoring', 'v3',cache_discovery=True)\n timeseries = service.projects().timeSeries().list(\n name=api_args[\"project_name\"],\n filter=api_args[\"metric_filter\"],\n aggregation_alignmentPeriod=api_args[\"aggregation_alignment_period\"],\n #aggregation_crossSeriesReducer=api_args[\"crossSeriesReducer\"],\n aggregation_perSeriesAligner=api_args[\"perSeriesAligner\"],\n aggregation_groupByFields=api_args[\"group_by\"],\n interval_endTime=api_args[\"end_time_str\"],\n interval_startTime=api_args[\"start_time_str\"],\n pageToken=api_args[\"nextPageToken\"]\n ).execute()\n logging.debug('response: {}'.format(json.dumps(timeseries,sort_keys=True, indent=4)))\n return timeseries\n\nif __name__ == '__main__':\n \n parser = argparse.ArgumentParser(\n description=__doc__,\n formatter_class=argparse.RawDescriptionHelpFormatter)\n parser.add_argument(\n 'batch_id',\n help='The batch_id to use in the test.')\n\n args = parser.parse_args()\n logging.debug(\"Running with batch_id: {}\".format(args.batch_id))\n logging.basicConfig(filename='/home/cbaer/stackdriver-metrics-export/test/test.log',filemode='w',level=logging.DEBUG)\n logging.getLogger('googleapiclient.discovery_cache').setLevel(logging.ERROR)\n \"\"\"\n stats = {}\n stats = build_metric_descriptors_list()\n print \"stats: {}\".format(json.dumps(stats, sort_keys=True, indent=4))\n\n for metric in metric_descriptors:\n get_and_count_timeseries(metric)\n \"\"\"\n\n # test 1. the number of items in metric_descriptors should match the number of keys in timeseries_results_api\n\n # test 2. the count of each item in timeseries_results_api should match the count of each item in timeseries_results_bq\n\n \"\"\" Test the values match across metricDescriptors.list, timeseries.list and BigQuery table.\n You should pick a metric_type, start_time, end_time and batch_id from the Stackdriver Logs\n \"\"\" \n project_id=\"sage-facet-201016\"\n project_name=\"projects/{}\".format(project_id)\n batch_id = args.batch_id\n start_time_str = \"2019-02-20T15:26:19.025680Z\" \n end_time_str = \"2019-02-20T16:00:01.131179Z\" \n aggregation_alignment_period = \"3600s\"\n \n metric_type_list = [\n \"monitoring.googleapis.com/stats/num_time_series\",\n \"pubsub.googleapis.com/subscription/push_request_count\",\n \"monitoring.googleapis.com/billing/bytes_ingested\",\n \"logging.googleapis.com/byte_count\",\n \"kubernetes.io/container/memory/request_utilization\",\n # \"compute.googleapis.com/instance/integrity/late_boot_validation_status\",\n \"serviceruntime.googleapis.com/api/request_count\"\n ]\n\n for metric_type in metric_type_list:\n filter_str = 'metric.type = \"{}\"'.format(metric_type)\n api_args=build_timeseries_api_args(\n project_name,batch_id,filter_str,end_time_str,start_time_str,\n aggregation_alignment_period,config.GROUP_BY_STRING,config.ALIGN_SUM,\"\")\n\n timeseries_resp_list = get_timeseries_list(api_args)\n number_of_api_timeseries = 0\n for timeseries in timeseries_resp_list:\n \n for timeseries_rec in timeseries[\"timeSeries\"]:\n point_cnt=len(timeseries_rec[\"points\"])\n print \"ALERT: {} point_cnt {}\".format(metric_type,point_cnt)\n number_of_api_timeseries+= point_cnt \n print \"ALERT: {} - {}\".format(metric_type,number_of_api_timeseries)\n \n results = get_bigquery_records(batch_id, metric_type)\n\n number_of_bq_timeseries = int(results[\"totalRows\"])\n assert number_of_api_timeseries==number_of_bq_timeseries, \"Count doesnt match for {} - API:{}, BQ:{}\".format(\n metric_type,number_of_api_timeseries,number_of_bq_timeseries\n )\n\n\n\n"
},
{
"alpha_fraction": 0.7212598323822021,
"alphanum_fraction": 0.7314960360527039,
"avg_line_length": 30.75,
"blob_id": "677ca60f956086853cdfa96d89cab2108f51ef32",
"content_id": "724563903e73e2f5c50c86be73e6c4f5d2d46e36",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1270,
"license_type": "permissive",
"max_line_length": 219,
"num_lines": 40,
"path": "/get_service_limits/README.md",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "\n# Deployment Instructions\n\n1. Create the BigQuery tables. Assuming the datasets has already been created.\n```\nbq mk --table metric_export.service_limits ../bigquery_schemas/bigquery_schema_service_limits_table.json\n```\n\n\n2. Set your PROJECT_ID variable, by replacing [YOUR_PROJECT_ID] with your GCP project id\n```\nexport PROJECT_ID=[YOUR_PROJECT_ID]\n```\n\n3. Replace the token in the config.py files\n```\nTOKEN=$(python -c \"import uuid; msg = uuid.uuid4(); print msg\")\nsed -i s/16b2ecfb-7734-48b9-817d-4ac8bd623c87/$TOKEN/g config.json\n```\n\n4. Deploy the App Engine apps\n```\npip install -t lib -r requirements.txt\necho \"y\" | gcloud app deploy\n```\n\n5. Create the Pub/Sub topics and subscriptions after setting YOUR_PROJECT_ID\n```\nexport GET_SERVICE_LIMITS_URL=https://get-service-limits-dot-$PROJECT_ID.appspot.com\n\ngcloud pubsub topics create get_service_limits_start\ngcloud pubsub subscriptions create get_service_limits_start --topic get_service_limits_start --ack-deadline=60 --message-retention-duration=10m --push-endpoint=\"$GET_SERVICE_LIMITS_URL/_ah/push-handlers/receive_message\"\n```\n\n6. Deploy the Cloud Scheduler job\n```\ngcloud scheduler jobs create pubsub get_service_limits \\\n--schedule \"1 1 * * *\" \\\n--topic get_service_limits_start \\\n--message-body \"{ \\\"token\\\":\\\"$(echo $TOKEN)\\\"}\"\n```"
},
{
"alpha_fraction": 0.6432507038116455,
"alphanum_fraction": 0.663085401058197,
"avg_line_length": 38.04301071166992,
"blob_id": "fe329f7fda3f65b81f19664db92391b632e5bfb5",
"content_id": "6da10f58d5a319cc3ebddf0865d8659811d0f18b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3630,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 93,
"path": "/list_metrics/main_test.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2019 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport webtest\nimport unittest\nimport main\nimport config\nimport base64\nimport json\n\n\nclass AppTest(unittest.TestCase):\n def setUp(self):\n \"\"\" Set-up the webtest app\n \"\"\"\n self.app = webtest.TestApp(main.app)\n \n def test_check_date_format(self):\n \"\"\" Test the check_date_format function\n \"\"\"\n results = main.check_date_format(\"23232\")\n self.assertIsNone(results)\n results = main.check_date_format(\"2019-02-08T14:00:00.311635Z\")\n self.assertIsNotNone(results)\n\n def test_post_empty_data(self):\n \"\"\" Test sending an empty message\n \"\"\"\n response = self.app.post('/_ah/push-handlers/receive_message')\n self.assertEqual(response.status_int, 200)\n self.assertEqual(response.body, \"No request body received\")\n\n def test_incorrect_aggregation_alignment_period_post(self): \n \"\"\" Test sending incorrect aggregation_alignment_period as input\n \"\"\"\n request = self.build_request(aggregation_alignment_period = \"12\")\n response = self.app.post('/_ah/push-handlers/receive_message',json.dumps(request).encode('utf-8'),content_type=\"application/json\")\n self.assertEqual(response.status_int, 200)\n self.assertRaises(ValueError)\n self.assertEqual(response.body, \"aggregation_alignment_period needs to be digits followed by an 's' such as 3600s, received: 12\")\n\n request = self.build_request(aggregation_alignment_period = \"12s\")\n response = self.app.post('/_ah/push-handlers/receive_message',json.dumps(request).encode('utf-8'),content_type=\"application/json\")\n self.assertEqual(response.status_int, 200)\n self.assertRaises(ValueError)\n self.assertEqual(response.body, \"aggregation_alignment_period needs to be more than 60s, received: 12s\")\n\n\n def test_exclusions_check(self):\n \"\"\" Test the exclusion logic\n \"\"\"\n assert main.check_exclusions(\"aws.googleapis.com/flex/cpu/utilization\") == False, \"This should be excluded\"\n assert main.check_exclusions(\"appengine.googleapis.com/flex/cpu/utilization\") == True, \"This should not be excluded\"\n\n\n\n def test_incorrect_token_post(self): \n \"\"\" Test sending an incorrect token\n \"\"\"\n request = self.build_request(token=\"incorrect_token\")\n response = self.app.post('/_ah/push-handlers/receive_message',json.dumps(request).encode('utf-8'),content_type=\"application/json\")\n self.assertEqual(response.status_int, 200)\n self.assertRaises(ValueError)\n \n def build_request(self,token=config.PUBSUB_VERIFICATION_TOKEN,aggregation_alignment_period=\"3600s\"):\n \"\"\" Build a Pub/Sub message as input\n \"\"\"\n\n payload = {\n \"token\": token,\n \"aggregation_alignment_period\": aggregation_alignment_period\n }\n request = {\n \"message\": \n {\n \"data\": base64.b64encode(json.dumps(payload))\n }\n \n }\n return request"
},
{
"alpha_fraction": 0.6112917065620422,
"alphanum_fraction": 0.6147826910018921,
"avg_line_length": 39.32524108886719,
"blob_id": "dd073d857f616da2302f4d697c596f525beaad88",
"content_id": "de4309fe93144ecf348c95f38013c718427e51ec",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8307,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 206,
"path": "/get_service_limits/main.py",
"repo_name": "xiangshen-dk/stackdriver-metrics-export",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# Copyright 2020 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport webapp2\nimport json\nimport base64\nimport config\nfrom datetime import datetime\nfrom googleapiclient import discovery\nfrom googleapiclient.discovery import build\nfrom googleapiclient.discovery import HttpError\nfrom google.appengine.api import app_identity\n\ndef build_bigquery_data(proj_id, svc_name, limit_data):\n fields = []\n for k, v in limit_data.get(\"values\").items():\n fields.append({\"key\": k, \"value\": v})\n update_time = datetime.now().isoformat()\n # Build the data structure to for BigQuery\n bq_msg = {\n \"project_id\": proj_id,\n \"service\": svc_name,\n \"name\": limit_data.get(\"name\"),\n \"description\": limit_data.get(\"description\"),\n \"defaultLimit\": limit_data.get(\"defaultLimit\"),\n \"maxLimit\": limit_data.get(\"maxLimit\"),\n \"freeTier\": limit_data.get(\"freeTier\"),\n \"duration\": limit_data.get(\"duration\"),\n \"metric\": limit_data.get(\"metric\"),\n \"unit\": limit_data.get(\"unit\"),\n \"displayName\": limit_data.get(\"displayName\"),\n \"update_time\": update_time,\n \"values\": fields,\n }\n json_msg = {\n \"json\": bq_msg\n }\n logging.debug(\"json_msg {}\".format(json.dumps(json_msg, sort_keys=True, indent=4)))\n return json_msg\n\ndef write_to_bigquery(json_row_list):\n \"\"\" Write rows to the BigQuery stats table using the googleapiclient and the streaming insertAll method\n https://cloud.google.com/bigquery/docs/reference/rest/v2/tabledata/insertAll\n \"\"\"\n logging.debug(\"write_to_bigquery\")\n bigquery = build('bigquery', 'v2', cache_discovery=True)\n body = {\n \"kind\": \"bigquery#tableDataInsertAllRequest\",\n \"skipInvalidRows\": \"true\",\n \"ignoreUnknownValues\": \"true\",\n \"rows\": json_row_list\n }\n logging.debug('body: {}'.format(json.dumps(body, sort_keys=True, indent=4)))\n response = bigquery.tabledata().insertAll(\n projectId=app_identity.get_application_id(),\n datasetId=config.BIGQUERY_DATASET,\n tableId=config.BIGQUERY_STATS_TABLE,\n body=body\n ).execute()\n logging.debug(\"BigQuery said... = {}\".format(response))\n bq_msgs_with_errors = 0\n if \"insertErrors\" in response:\n if len(response[\"insertErrors\"]) > 0:\n logging.error(\"Error: {}\".format(response))\n bq_msgs_with_errors = len(response[\"insertErrors\"])\n logging.debug(\"bq_msgs_with_errors: {}\".format(bq_msgs_with_errors))\n else:\n logging.debug(\"Completed writing limits data, there are no errors, response = {}\".format(response))\n return response\n\ndef get_projects():\n # Get projects\n all_projects = []\n crm = discovery.build(\"cloudresourcemanager\", \"v1\", cache_discovery=True)\n if config.PROJECT_INCLUSIONS[\"include_all_projects\"]:\n proj_filter = config.PROJECT_INCLUSIONS.get(\"filter\", \"name:s*\")\n result = crm.projects().list(filter=proj_filter).execute()\n all_projects.extend(result[\"projects\"])\n while result.get(\"nextPageToken\", \"\"):\n result = crm.projects().list(filter=proj_filter, pageToken=result[\"nextPageToken\"]).execute()\n all_projects.extend(result[\"projects\"])\n else:\n for proj in config.PROJECT_INCLUSIONS.get(\"include_projects\"):\n result = crm.projects().get(projectId=proj).execute()\n all_projects.append(result)\n \n return all_projects\n\ndef get_json_rows(all_projects):\n # Get service limits\n all_limits = {}\n service = discovery.build('serviceusage', 'v1', cache_discovery=True)\n for proj_data in all_projects:\n project_id = proj_data[\"projectId\"]\n all_limits[project_id] = {}\n if config.SERVICE_INCLUSIONS[\"include_all_enabled_service\"]:\n response = service.services().list(parent=\"projects/{}\".format(project_id)).execute()\n services = response.get('services')\n for s in services:\n if s['state'] == \"ENABLED\":\n svc_name = s[\"config\"][\"name\"]\n all_limits[project_id][svc_name] = {}\n while response.get(\"nextPageToken\", \"\"):\n response = service.services().list(parent=\"projects/{}\".format(project_id), pageToken=response[\"nextPageToken\"]).execute()\n services = response.get('services')\n for s in services:\n if s['state'] == \"ENABLED\":\n svc_name = s[\"config\"][\"name\"]\n all_limits[project_id][svc_name] = {}\n else:\n for svc in config.SERVICE_INCLUSIONS.get(\"include_services\"):\n all_limits[project_id][svc] = {}\n\n for k_svc in all_limits[project_id].keys(): \n proj_svc = \"projects/{}/services/{}\".format(proj_data[\"projectNumber\"], k_svc)\n response = service.services().get(name=proj_svc).execute()\n state = response['state']\n if state == \"ENABLED\":\n all_limits[project_id][k_svc] = response[\"config\"].get(\"quota\")\n \n all_json_rows = []\n\n for proj_id in all_limits.keys():\n for svc_name in all_limits[proj_id].keys():\n for limit in all_limits[proj_id][svc_name][\"limits\"]:\n all_json_rows.append(build_bigquery_data(proj_id, svc_name, limit))\n return(all_json_rows)\n\ndef save_svc_limits():\n all_projects = get_projects()\n all_json_rows = get_json_rows(all_projects)\n write_to_bigquery(all_json_rows)\n\nclass ReceiveMessage(webapp2.RequestHandler):\n\n def post(self):\n \"\"\" Receive the Pub/Sub message via POST\n Validate the input and then process the message\n \"\"\"\n\n logging.debug(\"received message\")\n\n response_code = 200\n try:\n if not self.request.body:\n raise ValueError(\"No request body received\")\n envelope = json.loads(self.request.body.decode('utf-8'))\n logging.debug(\"Raw pub/sub message: {}\".format(envelope))\n\n if \"message\" not in envelope:\n raise ValueError(\"No message in envelope\")\n\n if \"messageId\" in envelope[\"message\"]:\n logging.debug(\"messageId: {}\".format(envelope[\"message\"][\"messageId\"]))\n message_id = envelope[\"message\"][\"messageId\"]\n\n if \"data\" not in envelope[\"message\"]:\n raise ValueError(\"No data in message\")\n payload = base64.b64decode(envelope[\"message\"][\"data\"])\n logging.debug('payload: {} '.format(payload))\n\n data = json.loads(payload)\n logging.debug('data: {} '.format(data))\n\n # Check the input parameters\n if not data:\n raise ValueError(\"No data in Pub/Sub Message\")\n \n # if the pubsub PUBSUB_VERIFICATION_TOKEN isn't included or doesn't match, don't continue\n if \"token\" not in data:\n raise ValueError(\"token missing from request\")\n if not data[\"token\"] == config.PUBSUB_VERIFICATION_TOKEN:\n raise ValueError(\"token from request doesn't match, received: {}\".format(data[\"token\"]))\n\n save_svc_limits()\n\n except ValueError as ve:\n logging.error(\"Missing inputs from Pub/Sub: {}\".format(ve))\n self.response.write(ve)\n except KeyError as ke:\n logging.error(\"Key Error: {}\".format(ke))\n self.response.write(ke)\n except HttpError as he:\n logging.error(\"Encountered exception calling APIs: {}\".format(he))\n self.response.write(he)\n\n self.response.status = response_code\n\n\napp = webapp2.WSGIApplication([\n ('/_ah/push-handlers/receive_message', ReceiveMessage)\n], debug=True)\n"
}
] | 9 |
Snakemake-Profiles/surfsara-grid
|
https://github.com/Snakemake-Profiles/surfsara-grid
|
040d8c016acbb98198bb0207f425c423655ed93e
|
056bf3e69b13ef9dcd687bc7c90a1f1fff9d6869
|
e608d3acd3e1085d7b5281e2209edbf0a5233a8f
|
refs/heads/master
| 2021-09-14T05:45:27.780038 | 2018-05-08T19:59:32 | 2018-05-08T19:59:32 | 104,745,106 | 5 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7198275923728943,
"alphanum_fraction": 0.7284482717514038,
"avg_line_length": 12.647058486938477,
"blob_id": "ef6dbddfff65ee8867421e3850e2a5c4342c232a",
"content_id": "836c1e6e555577d39629e830c627da65a4c81a84",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 232,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 17,
"path": "/{{cookiecutter.profile_name}}/grid-jobscript.sh",
"repo_name": "Snakemake-Profiles/surfsara-grid",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# properties = {properties}\n\nset -e\n\nuser=$2\n\nexport PATH=/cvmfs/softdrive.nl/$user/Miniconda2/bin:$PATH\necho \"hostname:\"\nhostname -f\nwhich activate\nsource activate snakemake\n\ntar -xf grid-source.tar\n\n{exec_job}\necho $?\n"
},
{
"alpha_fraction": 0.7309034466743469,
"alphanum_fraction": 0.7464133501052856,
"avg_line_length": 34.81944274902344,
"blob_id": "7f66d49d766e5c730fbf3aedb8362de25c1e95bc",
"content_id": "dd94f8d5f61ab6ccc658035ea2b53c4c8c36da6a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2579,
"license_type": "permissive",
"max_line_length": 202,
"num_lines": 72,
"path": "/README.md",
"repo_name": "Snakemake-Profiles/surfsara-grid",
"src_encoding": "UTF-8",
"text": "# surfsara-grid\n\nThis profile configures Snakemake to run on the [SURFsara Grid](https://www.surf.nl/en/services-and-products/grid/index.html).\n\n## Setup\n\n### Prerequisites\n\n#### Step 1: Login to softdrive\n\n ssh [email protected]\n\n#### Step 2: Setup bioconda\n\nThen, install Miniconda 2 (in order to not interfere with python 2 grid tools).\n\n wget https://repo.continuum.io/miniconda/Miniconda2-latest-Linux-x86_64.sh\n chmod +x Miniconda2-latest-Linux-x86_64.sh\n ./Miniconda2-latest-Linux-x86_64.sh -b -p /cvmfs/softdrive.nl/$USER/Miniconda2\n\nAnd add the installation to the PATH (put the following into your .bashrc):\n\n export PATH=/cvmfs/softdrive.nl/$USER/Miniconda2/bin:$PATH\n\nFinally, setup the channel order for bioconda:\n\n conda config --add channels defaults\n conda config --add channels conda-forge\n conda config --add channels bioconda\n\n#### Step 3: Create a Snakemake environment\n\n conda create -n snakemake snakemake python=3.6 pandas cookiecutter\n\nThe name (given to `-n`) is mandatory here, because the submission scripts of this profile assume this environment to exist.\n\n#### Step 4: Publish softdrive\n\nFinally, softdrive has to be published with\n\n publish-my-softdrive\n\nIt will take some time (up to half an hour) until other nodes will have access to the update.\n\n### Deploy profile\n\nTo deploy this profile, login to your grid UI and run\n\n mkdir -p ~/.config/snakemake\n cd ~/.config/snakemake\n cookiecutter https://github.com/snakemake-profiles/surfsara-grid.git\n\nWhen asked for the storage path, insert whatever shall be the place where your data analysis results shall be stored. It has to be a subdirectory of `gridftp.grid.sara.nl:2811/pnfs/grid.sara.nl/data/`. \nThen, you can run Snakemake with\n\n snakemake --profile surfsara-grid ...\n\nso that jobs are submitted to the grid. \nIf a job fails, you will find the \"external jobid\" in the Snakemake error message.\nYou can investigate the job via this ID as shown [here](http://docs.surfsaralabs.nl/projects/grid/en/latest/Pages/Basics/first_grid_job.html?highlight=glite#track-the-job-status).\nIf Snakemake is killed and restarted afterwards, it will automatically resume still running jobs.\n\n### Proxy certificates\n\nNote that Snakemake needs valid proxy certificates throughout its runtime.\nIt is advisable to use maximum lifetimes for those, i.e., generate them with\n\n voms-proxy-init --voms <voms> --valid 168:00\n myproxy-init -d -n -c 744 -t 744\n glite-wms-job-delegate-proxy -d $USER\n\nwhile replacing `<voms>` with your value (e.g. `lsgrid:/lsgrid/Project_MinE`).\n"
},
{
"alpha_fraction": 0.5991531610488892,
"alphanum_fraction": 0.6040931344032288,
"avg_line_length": 31.5747127532959,
"blob_id": "2fd7a2634ce255ea51be9468b05e8f9d593b13ff",
"content_id": "bf2d380a431c6e45567b6bc1904488823659cf7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2834,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 87,
"path": "/{{cookiecutter.profile_name}}/grid-submit.py",
"repo_name": "Snakemake-Profiles/surfsara-grid",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport tempfile\nimport textwrap\nimport sys\nimport subprocess\nimport os\nimport getpass\nimport json\nimport shutil\nimport glob\n\nfrom snakemake.utils import read_job_properties\n\n\ndef wait_for_proxy():\n stdout = sys.stdout\n sys.stdout = sys.stderr\n input(\"UI proxy expired. Please create a new proxy (see README) and press ENTER to continue.\")\n sys.stdout = stdout\n\n\njobscript = sys.argv[1]\njob_properties = read_job_properties(jobscript)\n\ncommit = subprocess.run([\"git\", \"rev-parse\", \"HEAD\"], stdout=subprocess.PIPE, check=True).stdout.decode().strip()\nsource = \".grid-source-{}.tar\".format(commit)\n\nif not os.path.exists(source):\n for f in glob.glob(\".grid-source-*.tar\"):\n os.remove(f)\n subprocess.run([\"git\", \"archive\", \"--format\", \"tar\", \"-o\", source, \"HEAD\"], check=True)\n\n\nwith tempfile.TemporaryDirectory() as jobdir:\n jdlpath = os.path.join(jobdir, \"job.jdl\")\n {% raw %}\n with open(jdlpath, \"w\") as jdl:\n jdl.write(textwrap.dedent(\"\"\"\n Type = \"Job\";\n JobType = \"Normal\";\n Executable = \"/bin/bash\";\n Arguments = \"jobscript.sh {commit} {user}\";\n PerusalFileEnable = true;\n PerusalTimeInterval = 120;\n StdOutput = \"stdout.txt\";\n StdError = \"stderr.txt\";\n SmpGranularity = {threads};\n CPUNumber = {threads};\n RetryCount = 0;\n ShallowRetryCount = 0;\n Requirements = other.GlueCEPolicyMaxWallClockTime >= {minutes} &&\n other.GlueHostArchitectureSMPSize >= {cores} && \n RegExp(\"gina\", other.GlueCEUniqueID);\n InputSandbox = {{\"jobscript.sh\", \"grid-source.tar\"}};\n OutputSandbox = {{\"stdout.txt\",\"stderr.txt\"}};\n \"\"\").format(commit=commit,\n user=getpass.getuser(),\n threads=job_properties[\"threads\"],\n cores=job_properties[\"threads\"] + 2,\n minutes=job_properties[\"resources\"].get(\"minutes\", 240)))\n {% endraw %}\n\n shutil.copyfile(jdlpath, \"last-job.jdl\")\n shutil.copyfile(jobscript, \"last-jobscript.sh\")\n shutil.copyfile(jobscript, os.path.join(jobdir, \"jobscript.sh\"))\n shutil.copyfile(source, os.path.join(jobdir, \"grid-source.tar\"))\n\n workdir = os.getcwd()\n os.chdir(jobdir)\n cmd = [\"glite-wms-job-submit\", \"--json\", \"-d\", getpass.getuser(), jdl.name]\n for i in range(10):\n try:\n res = subprocess.run(cmd, check=True, stdout=subprocess.PIPE)\n break\n except subprocess.CalledProcessError as e:\n if \"UI_PROXY_EXPIRED\" in e.stdout.decode():\n wait_for_proxy()\n continue\n if i >= 9:\n raise e\n\n res = json.loads(res.stdout.decode())\n os.chdir(workdir)\n\n# print jobid for use in Snakemake\nprint(res[\"jobid\"])\n"
},
{
"alpha_fraction": 0.5993485450744629,
"alphanum_fraction": 0.6052117347717285,
"avg_line_length": 26.410715103149414,
"blob_id": "20455515124c85d1358f4b1ea13eaf229eed1244",
"content_id": "066b8f0c5084541f30877aa26882b457671b5530",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1535,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 56,
"path": "/{{cookiecutter.profile_name}}/grid-status.py",
"repo_name": "Snakemake-Profiles/surfsara-grid",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport json\nimport subprocess\nimport sys\nimport time\n\n\ndef wait_for_proxy():\n stdout = sys.stdout\n sys.stdout = sys.stderr\n input(\"UI proxy expired. Please create a new proxy (see README) and press ENTER to continue.\")\n sys.stdout = stdout\n\n\nSTATUS_ATTEMPTS = 20\n\njobid = sys.argv[1]\n\n# try to get status 10 times\nfor i in range(STATUS_ATTEMPTS):\n try:\n cmd = \"glite-wms-job-status --json {}\".format(jobid)\n res = subprocess.run(cmd, check=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT, shell=True)\n res = json.loads(res.stdout.decode())\n break\n except subprocess.CalledProcessError as e:\n if \"UI_PROXY_EXPIRED\" in e.stdout.decode():\n wait_for_proxy()\n continue\n if i >= STATUS_ATTEMPTS - 1:\n if \"already purged\" in e.stdout.decode():\n # we know nothing about this job, so it is safer to consider\n # it failed and rerun\n print(\"failed\")\n exit(0)\n print(\"glite-wms-job-status error: \", e.stdout, file=sys.stderr)\n raise e\n else:\n time.sleep(5)\n\nstatus = res[jobid][\"Current Status\"]\nif status == \"Done(Success)\":\n print(\"success\")\nelif status == \"Done(Exit Code !=0)\":\n print(\"failed\")\nelif status.startswith(\"Done\"):\n print(\"failed\")\nelif status == \"Cancelled\":\n print(\"failed\")\nelif status == \"Aborted\":\n print(\"failed\")\nelif status == \"Cleared\":\n print(\"failed\")\nelse:\n print(\"running\")\n"
}
] | 4 |
efprentice/votsch-thermal
|
https://github.com/efprentice/votsch-thermal
|
9ea3728d0ff7459c51b717b1932fc4014b12f3ab
|
613c966d8200dfe88c9ea5bee5cef2dbd272c780
|
83f66dc979ef3f241d844669634378d5bcd2677c
|
refs/heads/main
| 2023-06-17T08:01:43.703999 | 2021-07-14T11:58:56 | 2021-07-14T11:58:56 | 385,920,832 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8299999833106995,
"alphanum_fraction": 0.8299999833106995,
"avg_line_length": 49,
"blob_id": "a7e6e7976c32d7aff3cabfeb4a071b48159d7f55",
"content_id": "ac1a4aac3f93311dca88bb52dacdeac718902a56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 2,
"path": "/README.md",
"repo_name": "efprentice/votsch-thermal",
"src_encoding": "UTF-8",
"text": "# votsch-thermal\nTest scripts and plotting for all procedures related to the Votsch thermal chamber\n"
},
{
"alpha_fraction": 0.6430678367614746,
"alphanum_fraction": 0.6558505296707153,
"avg_line_length": 17.83333396911621,
"blob_id": "4060584f84d585dff8cf635e5422820dbf688631",
"content_id": "8b27113bbe49a57dda73a8616cdbd92db9d02fce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1017,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 54,
"path": "/arduino_readtemp-press-humid.py",
"repo_name": "efprentice/votsch-thermal",
"src_encoding": "UTF-8",
"text": "import os\nimport serial\nimport time\nimport io\nimport sys\n\nimport csv\n\nfrom datetime import datetime\n\n\nserial_port_name = '/dev/ttyACM0'\nbaudrate = 9600\ntime_delay = 2 # seconds\n\ndef main():\n\tser = serial.Serial(serial_port_name, baudrate, timeout=1)\n\tif ser.isOpen():\n \t\tprint(ser.name + ' is open')\n\n\tfname = raw_input('Give a name to the csv file (eg YYYYMMDD_model-description): ')\n\tfname = fname+'.csv'\n\n\tfields=['Date','Time','Pressure[mb]','Humidity[%]','Temp[C]']\n\n\twith open(fname, 'w') as f:\n \t\twriter = csv.writer(f)\n \t\twriter.writerow(fields)\n\n\tprint(fields)\n\n\twhile True:\n\n\t\treadout = ser.read(100)\n\t\treadout_list = readout.split()\n\n\t\tpress = readout_list[0]\n\t\thumid = readout_list[2]\n\t\ttempc = readout_list[4]\n\n\t\tnow = datetime.now()\n\t\tcurrent_time = now.strftime('%H:%M:%S')\n\t\tdate = now.strftime('%D')\n\n\t\tfields=[date,current_time,press,humid,tempc]\n\t\tprint(fields)\n\n\t\twith open(fname, 'a') as f:\n \t\t\twriter = csv.writer(f)\n \t\t\twriter.writerow(fields)\n\n\t\ttime.sleep(time_delay)\n\nmain()\n"
},
{
"alpha_fraction": 0.6253164410591125,
"alphanum_fraction": 0.6464135050773621,
"avg_line_length": 18.42622947692871,
"blob_id": "cc984498c461acb6673731d8ad684c208a805048",
"content_id": "4de2a90871ce668c825b780156ef08fd08b3e1a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1185,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 61,
"path": "/votsch_readtemp.py",
"repo_name": "efprentice/votsch-thermal",
"src_encoding": "UTF-8",
"text": "import os\nimport serial\nimport time\nimport io\nimport sys\n\nimport csv\n\nfrom datetime import datetime\n\n\nserial_port_name = \"/dev/ttyUSB0\"\nbaudrate = 9600\ntime_delay = 60 # seconds\n\ndef main():\n\tser = serial.Serial(serial_port_name, baudrate, timeout=1)\n\tif ser.isOpen():\n \t\tprint(ser.name + ' is open')\n\n\tfname = raw_input(\"Give a name to the csv file: \")\n\tfname = fname+\".csv\"\n\n\tfields=['Date','Time','Temp_1']\n\n\twith open(fname, 'w') as f:\n \t\twriter = csv.writer(f)\n \t\twriter.writerow(fields)\n\n\tprint(fields)\n\n\twhile True:\n\n\t\tcommand = '$12|<CR>'\n\t\tprint(command.encode())\t\t\n\t\tser.write(command.encode())\n\t\ttemp_1 = ser.read(100)\n\t\tprint(temp_1)\n\n\t\t#ser.write(\"IN_PV_00\\r\\n\".encode())\n\t\t#temp_1 = ser.print(bmp.readTemperature())\n\t\t#outflow_temp_str = outflow_temp_str.split()\n\n\t\t#ser.write(\"IN_PV_03\\r\\n\".encode())\n\t\t#external_temp_str = ser.read(100)\n\t\t#external_temp_str = external_temp_str.split()\n\n\t\tnow = datetime.now()\n\t\tcurrent_time = now.strftime(\"%H:%M:%S\")\n\t\tdate = now.strftime('%D')\n\n\t\tfields=[date,current_time,temp_1]\n\t\tprint(fields)\n\n\t\twith open(fname, 'a') as f:\n \t\t\twriter = csv.writer(f)\n \t\t\twriter.writerow(fields)\n\n\t\ttime.sleep(time_delay)\n\nmain()\n"
}
] | 3 |
FalkoHof/rsem-rna-seq-pipeline
|
https://github.com/FalkoHof/rsem-rna-seq-pipeline
|
843f75c9d457730088a315f4bf94859d0bb0fbdc
|
62936eb7d49a3583c29e0004002b04139c3deb53
|
872f8597f472eb6825219c96271a80ee9f2dc5a8
|
refs/heads/master
| 2020-08-30T09:25:07.175479 | 2017-01-25T13:03:21 | 2017-01-25T13:03:21 | 218,332,779 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.680084764957428,
"alphanum_fraction": 0.723870038986206,
"avg_line_length": 31.18181800842285,
"blob_id": "8f9f3a93c43a58e7b61978698986e37440369cc7",
"content_id": "0b1d430df3fb228758d0a2afd2046b1f348dd72d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1416,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 44,
"path": "/rsem_make_reference.sh",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#PBS -P rnaseq_nod\n#PBS -N make_rsem_reference\n#PBS -j oe\n#PBS -q workq\n#PBS -o /lustre/scratch/users/falko.hofmann/log/rsem/ref/araport11_160706.log\n#PBS -l walltime=00:30:00\n#PBS -l select=1:ncpus=8:mem=64gb\n\n# === begin ENVIRONMENT SETUP ===\n##### specify folders and variables #####\naligner=\"star\"\nannotation_file=/lustre/scratch/users/$USER/Ath_annotations/araport11/Araport11_genes_transposons_fixed_201606.gtf\nfasta_file=/lustre/scratch/users/$USER/indices/fasta/Col_mS.fa\nout_dir=/lustre/scratch/users/$USER/indices/rsem/$aligner/araport11\nprefix=`basename $out_dir`\n\n##### load required modules #####\nmodule load RSEM/1.2.30-foss-2016a\n# conditional loading of modules based on aligner to be used by RSEM\nif [ $aligner == \"bowtie\" ]; then\n module load Bowtie/1.1.2-foss-2015b\nfi\nif [ $aligner == \"bowtie2\" ]; then\n module load Bowtie2/2.2.7-foss-2015b\nfi\nif [ $aligner == \"star\" ]; then\n module load rna-star/2.5.2a-foss-2016a\nfi\n\n# === end ENVIRONMENT SETUP ===\n\necho 'Building rsem reference...'\necho 'Annotation file: ' $annotation_file\necho 'Fasta file: ' $fasta_file\necho 'Output directory: ' $out_dir\necho 'Aligner to be used: ' $aligner\n\nmkdir -p $out_dir\n#TODO: change implementation, so that file extention is automatically recognized\nrsem-prepare-reference --num-threads 8 --gtf $annotation_file --$aligner \\\n $fasta_file $out_dir/$prefix\n\necho 'Building rsem reference... - Done'\n"
},
{
"alpha_fraction": 0.6690565943717957,
"alphanum_fraction": 0.700377345085144,
"avg_line_length": 32.54430389404297,
"blob_id": "60057f5696b3aa636792eb90e3347b5054d0b79e",
"content_id": "e4cc18ef958d7aca58d7b179f91cfcf222aac73b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2650,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 79,
"path": "/utils/library_complexity_pipe.sh",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#PBS -P rnaseq_nod\n#PBS -N lib_complexity_pipe\n#PBS -J 1-22\n#PBS -j oe\n#PBS -q workq\n#PBS -o /lustre/scratch/users/falko.hofmann/log/160202-lib_complexity\n#PBS -l walltime=48:00:00\n#PBS -l select=1:ncpus=8:mem=34gb\n\n#set variables\n\n##### specify folders and variables #####\n#set script dir\npipe_dir=/lustre/scratch/users/$USER/pipelines/rsem-rna-seq-pipeline\n#set ouput base dir\nbase_dir=/lustre/scratch/users/$USER/rna_seq\n#location of the mapping file for the array job\npbs_mapping_file=$pipe_dir/pbs_mapping_file.txt\n#super folder of the temp dir, script will create subfolders with $sample_name\ntemp_dir=$base_dir/temp/lib_complexity\n#some output folders\npicard_bin=lustre/scratch/users/$USER/software/picard/dist\n\npreseq_ouput=$base_dir/preseq\npicard_ouput=$base_dir/picard\n\n## build array index\n##### Obtain Parameters from mapping file using $PBS_ARRAY_INDEX as line number\ninput_mapper=`sed -n \"${PBS_ARRAY_INDEX} p\" $pbs_mapping_file` #read mapping file\nnames_mapped=($input_mapper)\nsample_dir=${names_mapped[1]} # get the sample dir\nsample_name=`basename $sample_dir` #get the base name of the dir as sample name\n\ntemp_dir_s=$temp_dir/$sample_name\nbam_file=$sample_dir/rsem/$sample_name.genome.bam\nbam_file_concordant=$temp_dir_s/$sample_name.concordant.bam\nbed_file=$temp_dir_s/$sample_name.bed\nbed_file_sorted=$temp_dir_s/$sample_name.sorted.bed\n\n#load modules\nmodule load SAMtools/1.3-goolf-1.4.10\nmodule load BamTools/2.2.3-goolf-1.4.10\nmodule load BEDTools/v2.17.0-goolf-1.4.10\nmodule load preseq/2.0.2-goolf-1.4.10\nmodule load Java/1.8.0_66\n\n#print some output for logging\necho '#########################################################################'\necho 'Estimating libary complexity for: '$sample_name\necho 'Sample directory: ' $sample_dir\necho '#########################################################################'\n\n#create some directories\nmkdir -p $preseq_ouput\nmkdir -p $picard_ouput\nmkdir -p $temp_dir_s\n\nsamtools view -b -f 0x2 $bam_file > $bam_file_concordant\nsamtools sort -m 4G -@ 8 -o $bam_file_concordant\n\n#bedtools bamtobed -i $bam_file_concordant > $bed_file\n#sort -k 1,1 -k 2,2n -k 3,3n -k 6,6 $bed_file > $bed_file_sorted\n\n#run preseq\npreseq c_curve -P -s 100000 -o $preseq_ouput/$sample_name'_preseq_c_curve.txt' \\\n $bed_file_sorted\npreseq lc_extrap -P -s 100000 -n 1000 -o $preseq_ouput/$sample_name'_lc_extrap.txt' \\\n $bed_file_sorted\n\ncd $picard_bin\njava -Xmx15G -jar picard.jar EstimateLibraryComplexity\\\n INPUT=$bam_file_concordant \\\n OUTPUT=$picard_ouput/$sample_name'_picard_complexity.txt'\n\n#clean up\nrm -rf $temp_dir_s\n\necho 'Finished libary complexity pipeline for: '$sample_name\n"
},
{
"alpha_fraction": 0.6200926303863525,
"alphanum_fraction": 0.6376268267631531,
"avg_line_length": 31.974544525146484,
"blob_id": "8843f15edb5903aedf6a1fb7b8e652b88d46e657",
"content_id": "9497e73e05ae071c27aca439c62e6ab1fc7c2622",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 9068,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 275,
"path": "/rsem_pipe.sh",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#PBS -P rnaseq_nod\n#PBS -N rsem-pipe\n#PBS -J 1-2\n#PBS -j oe\n#PBS -q workq\n#PBS -o /lustre/scratch/users/falko.hofmann/log/160705_rsem/rsem-rna_^array_index^_mapping.log\n#PBS -l walltime=24:00:00\n#PBS -l select=1:ncpus=8:mem=48gb\n\n\n#TODO: update README & make the make_pbs_mapping file.\n# === begin ENVIRONMENT SETUP ===\n####set to 0 (false) or 1 (true) to let the repsective code block run\n#1. run rsem\n#TODO: add conditional adaptor trimming\n#1. trim adaptors\n#trim_adaptors=1\n#2. run rsem\nrun_rsem=1\n#3. make plots or not\nmake_plots=1\n#4. delete unecessary files from temp_dir\nclean=0\n##### specify RSEM parameters\naligner=star\nthreads=8 #set this to the number of available cores\n##### specify folders and variables #####\n#set script dir\npipe_dir=/lustre/scratch/users/$USER/pipelines/rsem-rna-seq-pipeline\n#set ouput base dir\nbase_dir=/lustre/scratch/users/$USER/rna_seq\n#folder for rsem reference\nrsem_ref_dir=/lustre/scratch/users/$USER/indices/rsem/$aligner/nod_v01\n#add folder basename as prefix (follows convention from rsem_make_reference)\nrsem_ref=$rsem_ref_dir/$(basename \"$rsem_ref_dir\")\n#location of the mapping file for the array job\npbs_mapping_file=$pipe_dir/pbs_mapping_file.txt\n#super folder of the temp dir, script will create subfolders with $sample_name\ntemp_dir=$base_dir/temp\n\n\nif [ $make_plots -eq 1 ]; then\n module load R/3.2.3-foss-2016a\nfi\n##### Obtain Parameters from mapping file using $PBS_ARRAY_INDEX as line number\ninput_mapper=`sed -n \"${PBS_ARRAY_INDEX} p\" $pbs_mapping_file` #read mapping file\nnames_mapped=($input_mapper)\n\nsample_dir=${names_mapped[1]} # get the sample dir\nfile_type=${names_mapped[2]} # get the file type\nseq_type=${names_mapped[3]} # get the seq type\nadaptor_type=${names_mapped[4]} # get the adaptor type\n\nsample_name=`basename $sample_dir` #get the base name of the dir as sample name\n\n#print some output for logging\necho '#########################################################################'\necho 'Starting RSEM RNA-seq pipeline for: ' $sample_name\necho 'Sample directory: ' $sample_dir\necho 'Rsem reference: ' $rsem_ref\necho 'Aligner to be used: ' $aligner\necho 'Mapping file: ' $pbs_mapping_file\necho 'Specified file type: ' $file_type\necho 'Specified sequencing mode: ' $seq_type\necho 'Specified adaptor type: ' $adaptor_type\necho '#########################################################################'\n\n#some error handling function\nfunction error_exit\n{\n echo \"$1\" 1>&2\n exit 1\n}\n\n#make output folder\ncd $sample_dir\n\n#folders for temp files\ntemp_dir_s=$temp_dir/$sample_name\nmkdir -p $temp_dir_s\n\nsamples_trimmed=$sample_dir/trimmed\nmkdir -p $samples_trimmed\n\nif [ $run_rsem -eq 1 ]; then\n #1. check file typ and convert to fastq\n case $file_type in\n \"bam\")\n echo \"File type bam. Converting to fastq...\"\n f=($(ls $sample_dir | grep -e \".bam\")) # get all bam files in folder\n #throw error if more or less than 1 file is present\n if [[ \"${#f[@]}\" -ne \"1\" ]]; then\n error_exit \"Error: wrong number of bam files in folder. Files present: ${#f[@]}\"\n fi\n #load modules\n module load BEDTools/v2.17.0-goolf-1.4.10\n module load SAMtools/1.3-foss-2015b\n\n samtools sort -n -m 4G -@ $threads -o $sample_dir/${f%.*}.sorted.bam \\\n $sample_dir/$f\n bedtools_params=\"bedtools bamtofastq -i $sample_dir/${f%.*}.sorted.bam \"\n case $seq_type in\n \"PE\") #modify bedtools params for PE conversion\n bedtools_params=$bedtools_params\" -fq $sample_dir/${f%.*}.1.fq\"\\\n \" -fq2 $sample_dir/${f%.*}.2.fq\"\n ;;\n \"SE\") #modify bedtools params for SE conversion\n bedtools_params=$bedtools_params\" -fq $sample_dir/${f%.*}.fq\"\n ;;\n *) #exit when unexpected input is encountered\n error_exit \"Error: wrong paramter for seq type selected! Select PE or SE.\"\n ;;\n esac\n #print the command to be exectuted\n echo \"Command exectuted for converting bam to fastq:\\n $bedtools_params\"\n eval $bedtools_params #run the command\n echo \"Converting to fastq... Done\"\n ;;\n \"fq\")\n echo \"File type fastq. No conversion necessary...\"\n # do nothing...\n ;;\n *) #exit when unexpected input is encountered\n error_exit \"Error: wrong paramter for file type selected! Select bam or fq.\"\n ;;\n esac\n\n #2. do adaptor trimming according to seq_type and adaptor_type\n #get the zipped files\n f=($(ls $sample_dir | grep -e \".fq.gz\\|.fastq.gz\"))\n #check if more than 0 zipped files are present, if so unzip\n if [[ \"${#f[@]}\" -gt \"0\" ]]; then\n gunzip \"${f[@]}\"\n fi\n\n f=($(ls $sample_dir| grep -e \".fq\\|.fastq\"))\n trim_params=\"trim_galore --dont_gzip --stringency 4 -o $samples_trimmed\"\n case $adaptor_type in\n \"nextera\")\n trimming=$trimming\" --nextera\"\n ;;\n \"illumina\")\n trimming=$trimming\" --illumina\"\n ;;\n \"unknown\") #run trim galore with autodetect\n #do nothing == autodetect\n ;;\n \"none\")\n #FIXME this will cause the pipeline to crash atm.\n trim_params=\"No trimming selected...\" #Don't trimm\n ;;\n ^[NCAGTncagt]+$) #check if alphabet corresponds to the genetic alphabet\n if [[ $seq_type == \"SE\" ]]; then\n trimming=$trimming\" -a $adaptor_type\"\n else\n error_exit \"Error: Wrong paramter for adaptor or seq type selected! \\\n See documentation for valid types\"\n fi\n ;;\n ^[NCAGTncagt\\/]+$) #check if alphabet corresponds to the genetic alphabet\n if [[ $seq_type == \"PE\" ]]; then\n seqs=(${adaptor_type//\\// })\n trimming=$trimming\" -a ${seqs[0]} -a2 ${seqs[1]}\"\n else\n error_exit \"Error: Wrong paramter for adaptor or seq type selected! \\\n See documentation for valid types\"\n fi\n ;;\n *) #exit when unexpected input is encountered\n error_exit \"Error: Wrong paramter for adaptor type selected! \\\n See documentation for valid types\"\n ;;\n esac\n\n fq1=\"\"\n fq2=\"\"\n fq=\"\"\n case $seq_type in\n \"PE\")\n trim_params=$trim_params\" --paired $sample_dir/${f[0]} $sample_dir/${f[1]}\"\n #fq1=$sample_dir/$samples_trimmed/${f[0]%.*}1_val_1.fq\n #fq2=$sample_dir/$samples_trimmed/${f[1]%.*}2_val_2.fq\n fq1=$samples_trimmed/${f[0]%.*}_val_1.fq\n fq2=$samples_trimmed/${f[1]%.*}_val_2.fq\n ;;\n \"SE\")\n trim_params=$trim_params\" $sample_dir/$f\"\n #TODO: check if the file name is correct like this.\n #fq=$sample_dir/$samples_trimmed/${f%.*}_trimmed.fq\n fq=$samples_trimmed/${f%.*}_trimmed.fq\n ;;\n *) #exit when unexpected input is encountered\n error_exit \"Error: Wrong paramter for seq type selected! \\\n See documentation for valid types\"\n ;;\n esac\n #load module\n module load Trim_Galore/0.4.1-foss-2015a\n #print the command to be exectuted\n echo \"Command exectuted for adaptor trimming:\" \\n \"$trim_params\"\n if [[ $adaptor_type != \"none\" ]]; then\n eval \"$trim_params\" #run the command\n fi\n\n rsem_opts=\"\"\n case $seq_type in\n \"PE\")\n rsem_opts=$rsem_opts\"--paired-end $fq1 $fq2\"\n ;;\n \"SE\")\n rsem_opts=$rsem_opts\"$fq\"\n ;;\n *) #exit when unexpected input is encountered\n error_exit \"Error: Wrong paramter for seq type selected!\" \\\n \"See documentation for valid types\"\n ;;\n esac\n\n # run rsem to calculate the expression levels\n # --estimate-rspd: estimate read start position to check if the data has bias\n # --output-genome-bam: output bam file as genomic, not transcript coordinates\n # --seed 12345 set seed for reproducibility of rng\n # --calc-ci calcutates 95% confidence interval of the expression values\n # --ci-memory 30000 set memory\n rsem_params=\"--$aligner \\\n --num-threads $threads \\\n --temporary-folder $temp_dir_s \\\n --append-names \\\n --estimate-rspd \\\n --output-genome-bam \\\n --sort-bam-by-coordinate \\\n --seed 12345 \\\n --calc-ci \\\n --ci-memory 40000\"\n\n rsem_params+=\" \"$rsem_opts\n rsem_params+=\" \"$rsem_ref\n rsem_params+=\" \"$sample_name\n\n #sem_cmds=$rsem_params $rsem_opts $rsem_ref $sample_name\n\n cd $sample_dir/rsem/\n mkdir -p $sample_dir/rsem/\n # conditional loading of modules based on aligner to be used by RSEM\n if [ \"$aligner\" == \"bowtie\" ]; then\n module load Bowtie/1.1.2-foss-2015b\n fi\n if [ \"$aligner\" == \"bowtie2\" ]; then\n module load Bowtie2/2.2.7-foss-2015b\n fi\n if [ \"$aligner\" == \"star\" ]; then\n module load rna-star/2.5.2a-foss-2016a\n fi\n module load RSEM/1.2.30-foss-2016a\n #rsem command that should be run\n echo \"rsem-calculate-expression $rsem_params >& $sample_name.log\"\n eval \"rsem-calculate-expression $rsem_params >& $sample_name.log\"\nfi\n\n#run the rsem plot function\nif [ $make_plots -eq 1 ]; then\n rsem-plot-model $sample_dir/rsem/$sample_name $sample_dir/rsem/$sample_name.pdf\nfi\n\n#delete the temp files\nif [ $clean -eq 1 ]; then\n gzip $sample_dir/*.fq $sample_dir/*.fastq\n rm $sample_dir/${f%.*}.sorted.bam\n rm $sample_dir/rsem/*.transcript.bam\n rm -rf $temp_dir_s\n rm -rf $samples_trimmed\nfi\n\necho 'Finished RSEM RNA-seq pipeline for: '$sample_name\n"
},
{
"alpha_fraction": 0.7383928298950195,
"alphanum_fraction": 0.7433035969734192,
"avg_line_length": 51.093021392822266,
"blob_id": "96aa59d633999b17d09883f7c6e23b7ec1340721",
"content_id": "3737828de56792a91cc8dde107743a8bc7c80006",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6720,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 129,
"path": "/README.md",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "# Nodine lab RSEM RNA-seq pipeline\nThis repository contains a collections of scripts to map RNA-seq data via your\naligner of choice and quantify the mapped reads via\n[RSEM](https://github.com/deweylab/RSEM).\n\nTo get the scripts run in your folder of choice:\n```shell\ngit clone https://gitlab.com/nodine-lab/rsem-rna-seq-pipeline.git\n```\nThis pipeline contains a collection of three scripts that should be run in the\nfollowing order:\n1. rsem_make_reference.sh - a script to build an rsem index\n2. make_pbs_mapping_table.sh - a script for creating a mapping table to tell\n rsem_pipe.sh which files/folders should be processed\n3. rsem_pipe.sh - the pipeline script to align and quantify rna seq data.\n\nThe most recent updates are contained in the development branch. To make use of most recent version run after you have cloned the repository:\n```shell\ngit fetch origin develop \ngit checkout develop\n```\nThis will make git fetch the contents of the development branch and switch to it. \n\nIf you are lab member and want to hack around on the pipeline and create your\nown customized pipelines either\n[fork](https://help.github.com/articles/fork-a-repo/)\nthe repository (prefered for customization) or create a seperate [branch](https://git-scm.com/book/en/v2/Git-Branching-Branches-in-a-Nutshell)\n(prefered for hacking on bug fixes etc.).\n```shell\n$ git branch some_fix\n$ git checkout some_fix\n```\n\n## 1. rsem_make_reference.sh\n- A bash script to create an RSEM reference for a certain aligner with a certain\n annotation and fasta file. Edit according to need and preferences (e.g.\n preferred aligner, annotation file format, fasta file location). This script\n should be submitted as pbs job via ```qsub rsem_make_reference.sh```.\n [STAR](https://github.com/alexdobin/STAR) is the recommended (and default)\n aligner.\n- Variables that need personalization:\n - #PBS -o: This path needs to be changed. Add here a path to where the log\n file of the run should be stored.\n - aligner: specify the aligner that should be used.\n accepted input is: bowtie, bowtie2, star.\n You need to pick the same aligner later for the rsem_pipe.sh script\n - annotation_file: specify here the path to the annotation file that should be\n used. The pipeline is currently designed to work with gtf files (--gtf flag)\n . However, other file formats are also possible. See the [STAR documentation]\n (http://deweylab.biostat.wisc.edu/rsem/rsem-prepare-reference.html) on that\n and change the script otherwise according to your needs. For the nod_v01\n annotation use the files in '/projects/rnaseq_nod/nod_v01_annotation'.\n - fasta_file: specify here the path to the fasta file (genome) that should be\n used to build the rsem reference. For Col-0 with mRNA spike ins, use the\n Col_mS.fa file located '/projects/rnaseq_nod/fasta/'\n - out_dir: specify here the folder where the rsem reference should be stored\n at. Defaults to: '/lustre/scratch/users/$USER/indices/rsem/$aligner/nod_v01'\n\n## 2. make_pbs_mapping_table.sh\n- Bash script to create a mapping file for pbs array jobs. Should be run via the\n standard shell environment (e.g. submit a small interactive job and run it\n there). Needs an folder as command line argument.\n The script will list the subfolders and output a mapping of\n <line number> <dir> <file_type> <seq_mode> <adaptor> to stdout. The default\n for adaptor is 'unknown', which will trigger trim_galore to run in auto\n detect adaptor type mode. If you want to explicitly specify an adapter you\n need to do so by hand. You can also type in DNA sequences in this field and\n use the / delimiter as in <adaptor1>/<adaptor2> to specifiy fw and rv adaptors\n in PE mode (see also example below).\n- Pipe the output to a file and specify that file in the rsem_pipe.sh script.\n The idea here is that you don't manually need to type in sample names when you\n want to submit a batch job. Just input the super folder of all your samples\n as command line argument.\n\n ```\n example: ./make_pbs_mapping_table.sh /Some/Super/Folders/ > pbs_mapping_file.txt\n\n or if you have not set the excutable bit...\n\n example: sh make_pbs_mapping_table.sh /Some/Super/Folders/ > pbs_mapping_file.txt\n\n ```\n- Afterwards I would recommend to briefly check if the paths in the\n 'pbs_mapping_file.txt' are correct. I would also recommend to create this file\n in the same folder as all the pipeline scripts are created (this is the assumed\n default for rsem_pipe.sh).\n Warning: only works on systems with gnu readlink installed.\n (Cluster & linux is fine, for the Mac you need to install readlink e.g.\n via Homebrew, no idea where Cygwin stands on that)\n- Alternatively the file can also be generated manually as e.g. shown below:\n\n ```shell\n 1 /Some/Folder/RNA-seq/sample_a/ fq SE illumina\n 2 /Some/Folder/RNA-seq/sample_b/ bam PE nextera\n 3 /Some/Folder/RNA-seq/sample_c/ fq SE unknown\n 4 /Some/Folder/RNA-seq/sample_d/ fq SE ACGTTGG\n 5 /Some/Folder/RNA-seq/sample_e/ fq PE ACGTTGG/TAGGCCT\n\n ...\n ```\n\n## 3. rsem_pipe.sh\n#TODO: Needs to be updated\n- Bash script that runs RSEM with your aligner of choice (can be specified\n in the script). Requires you to run rsem_make_reference.sh and\n make_pbs_mapping_table.sh before. Should be submitted as pbs job via\n ```qsub rsem_pipe.sh```.\n- Variables that need personalization:\n - #PBS -o: This path needs to be changed. Add here a path to where the log\n file of the run should be stored. Use ^array_index^ if you are running a batch\n job and want get the number of the batch job array for the file name.\n - flow control: set these variables to either 0 or 1. 1 means run this part of\n the script 0 means don't run it.\n 1. run_rsem: run rsem-calculate-expression to quantify the input (Default: 1).\n 2. make_plot: run rsem-plot-model to ouput diagnostic pdf (Default: 1).\n 3. clean: delete all temporary files (Default: 0).\n - aligner: specify the aligner that should be used.\n accepted input is: bowtie, bowtie2, star.\n Pick the same one you used to build your rsem reference via the\n rsem_make_reference.sh script.\n - rsem_ref_dir: specify the path of the rsem reference that was build via\n the rsem_make_reference.sh script.\n - pipe_dir: specify here the folder in which the pipeline scripts are located\n - base_dir: specify here a super folder in which the folders log_files and\n temp_dir will be created\n - log_files: folder where rsem stdout will be written to for logging purposes\n - pbs_mapping_file: specify here the location of the mapping file generated\n via make_pbs_mapping_table.sh (Default: $pipe_dir/pbs_mapping_file.txt)\n - temp_dir: temp folder path (Default: $base_dir/temp/)\n"
},
{
"alpha_fraction": 0.6177266836166382,
"alphanum_fraction": 0.6248308420181274,
"avg_line_length": 28.858585357666016,
"blob_id": "342bdd7815ef73a757876a2a82f5694dfb8c7a1a",
"content_id": "0fcd6a1a7e303f17d82be8c6f478b384c27ad3f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2956,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 99,
"path": "/utils/summary_statistics.py",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "import glob\nimport argparse\nfrom argparse import RawTextHelpFormatter\nfrom os.path import basename\n\n#for help see message displayed\ndesc = ('Generates a summary table from RSEM alignment statistics. Use nix style'\n 'paths that can be globbed and point towards the from .cnt files as '\n 'input.')\n\nparser = argparse.ArgumentParser(description=desc,formatter_class=RawTextHelpFormatter)\nparser.add_argument('-i', '--input', dest = 'input', metavar = 'i', type = str,\\\n help = 'name of the input path, supports globbing. \\\n Requires quotes around the value)', \\\n required = True)\n\nparser.add_argument('-o', '--output', dest = 'output', metavar = 'o', \\\n type = str, help = 'name of the output file', \\\n required = True)\n\nargs = parser.parse_args()\ninputPath = args.input\noutputFile = args.output\n\nprint(\"Input path: \" + str(inputPath))\nprint(\"Output file: \" + str(outputFile))\n\ndef getFileNames(directory):\n \"\"\"Function that returns the full paths of files that match a globbing\n pattern.\n \"\"\"\n filenames = glob.glob(directory)\n return filenames\n\ndef readFile(f):\n \"\"\"Function that all lines in the supplied file.\n \"\"\"\n print(\"Parsing file: \" + str(f))\n fin = open(f,'r')\n lines = fin.readlines()\n fin.close()\n return lines\n\ndef getStatsFromCntFile(lines):\n \"\"\"Function processes the lines from a RSEM cnt file and returns\n #total reads, #aligned reads, #unique matching reads & #multi mapping reads\n \"\"\"\n # wanted stats:\n #first two lines contain the wanted\n # total reads (Ntot) (0,3)\n # aligned reads (N1) (0,1)\n # unique matching reads (nUnique) (1,0)\n # multi mapping reads (n) (1,1)\n\n mat = [l.strip('\\n').split(' ') for l in lines[:2]]\n n_tot = mat[0][3]\n n_1 = mat[0][1]\n n_uni = mat[1][0]\n n_multi = mat[1][1]\n\n stats = [n_tot,n_1,n_uni,n_multi]\n return '\\t'.join(stats)\n\ndef getSampleId(f):\n \"\"\"Returns the sample name of .cnt file\n \"\"\"\n return basename(f).split('.cnt')[0]\n\ndef processCntFile(f,d):\n \"\"\"Function that reads and processes the the lines from a RSEM cnt file and\n returns #total reads, #aligned reads, #unique matching reads and #multi\n mapping reads\n \"\"\"\n sample_id = getSampleId(f)\n lines = readFile(f)\n stats = getStatsFromCntFile(lines)\n if sample_id in d:\n print \"Warning: \" + sample_id + \" occours more than once!\"\n d[sample_id]=stats\n return d\n\ndef writeToFile(f,d):\n \"\"\"Function that writes count statistics to a file.\n \"\"\"\n fout = open(f,'w')\n h=\"sample\\ttotal_reads\\taligned_reads\\tunique_mapping\\tmulti_mapping\\n\"\n fout.write(h)\n for key in sorted(d):\n v = d[key]\n line = key +'\\t'+ v + '\\n'\n fout.write(line)\n fout.close()\n\nd = dict()\nfiles = getFileNames(inputPath)\nfor f in files:\n d = processCntFile(f, d)\n\nwriteToFile(outputFile, d)\n"
},
{
"alpha_fraction": 0.6001979112625122,
"alphanum_fraction": 0.6115784049034119,
"avg_line_length": 33.25423812866211,
"blob_id": "86331a1028341214296c09aff03e782194e8c616",
"content_id": "c3ddde06f4e6ee3ed3d2e3a184c88231ff25149b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2021,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 59,
"path": "/make_pbs_mapping_table.sh",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#load samtools module and redirect out put to null to give a clean ouput\nml SAMtools/1.3.1-foss-2016a &> /dev/null\n\ninput_dir=$1 #uses folder supplied by command line args\nx=1 #counter later used for pbs array index number\n\n#TODO implement some system that autodetects the adaptor_type\nadaptor_type=\"unknown\" #default adaptor_type\n #loop over subfolders and identify the seq file types in the subfolders\nfor d in $(readlink -m $input_dir/*/) ;\ndo\n #initilize some variables\n file_type=\"\"\n seq_type=\"\"\n check_for_bam=\"no\"\n\n fq=($(ls $d | grep -e \".fq.gz\\|.fastq.gz\\|.fq\\|.fastq\")) #grep all fq files\n #some sanity checking...\n if [[ \"${#fq[@]}\" -gt \"2\" ]]; then\n echo \"Warning! More than 2 fq files found! Skipping... Check path $d\" >&2\n #when 2 fq files are found mode is PE and fq\n elif [[ \"${#fq[@]}\" -eq \"2\" ]]; then\n seq_type=\"PE\"\n file_type=\"fq\"\n #when 1 fq file is found mode is SE and fq\n elif [[ \"${#fq[@]}\" -eq \"1\" ]]; then\n seq_type=\"SE\"\n file_type=\"fq\"\n #when no fq files are found check for bam files\n else\n check_for_bam=\"yes\"\n fi\n\n if [[ \"$check_for_bam\" == \"yes\" ]]; then\n bam=($(ls $d | grep -e \".bam\")) #grep all bam files\n #some sanity checking...\n if [[ \"${#bam[@]}\" -gt \"1\" ]]; then\n echo \"Warning! More than 1 bam file found! Skipping... Check path $d\" >&2\n #when a bam file is found set the mode to bam end test the seq_type\n elif [[ \"${#bam[@]}\" -eq \"1\" ]]; then\n file_type=\"bam\"\n #check with samtools flag how many paired reads are present\n pe_reads=$(samtools view -c -f 1 $d/$bam)\n #when paired reads are present set mode to PE, otherwise set it to SE\n if [[ $pe_reads -gt \"0\" ]]; then\n seq_type=\"PE\"\n else\n seq_type=\"SE\"\n fi\n else\n #print some error when neither fq nor bam files are found\n echo \"Warning! Neither fq nor bam files found! Skipping... Check path $d\" >&2\n fi\n fi\n\n printf \"%d %s %s %s %s\\n\" $x $d $file_type $seq_type $adaptor_type\n ((x++))\ndone\n"
},
{
"alpha_fraction": 0.6318042874336243,
"alphanum_fraction": 0.6338430047035217,
"avg_line_length": 32.367347717285156,
"blob_id": "2a73f49f78fa1c586468b160ab89a885e98cbec3",
"content_id": "7773746dfbcea2fc2c0d81164fc57b04781e81bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4905,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 147,
"path": "/utils/make_master_table.py",
"repo_name": "FalkoHof/rsem-rna-seq-pipeline",
"src_encoding": "UTF-8",
"text": "# script that can concatenate the values from a specific colum in different\n# files to one master file. The script will make sure only the same rows are\n# paired. Supply files names as globbing pattern.\nimport glob\nimport os\nimport argparse\nfrom collections import defaultdict\nfrom collections import Set\nfrom argparse import RawTextHelpFormatter\n\n\n#for help see message displayed\ndesc = 'Concatenate a couple of tab delimted files based on the colum index \\\n(0 based) to one master table file.\\nUse c 1 for htseq-count, c 4 for \\\nkallisto and c 5 RSEM TPM. See the respective files if you want to \\\nconcatenate other data. The file input name needs do be sourrounded by \"\"\\\nquotation marks.'\n\nparser = argparse.ArgumentParser(description=desc,formatter_class=RawTextHelpFormatter)\nparser.add_argument('-s', '--sort', default = True, \\\n help = 'sort the output file', action = 'store_true')\nparser.add_argument('-n', '--no-sort', default = False, dest = 'sort', \\\n help = 'sort the output file', action = 'store_false') \\\n #TODO: implement conditional sorting\nparser.add_argument('-c', '--columns', dest = 'columns', metavar = 'c', \\\n type = int, help = 'Index of colum to be parsed (0 based)',\\\n required = True)\nparser.add_argument('-i', '--input', dest = 'input', metavar = 'i', type = str,\\\n help = 'name of the input file, supports globbing. \\\n Requires quotes around the value)', \\\n required = True)\nparser.add_argument('-o', '--output', dest = 'output', metavar = 'o', \\\n type = str, help = 'name of the output file', \\\n required = True)\nargs = parser.parse_args()\n\nd = defaultdict(list)\n\ndef processFiles(d, directory):\n \"\"\"Function that processes RNA-seq quantification files and returns a\n dictionary with <sample_name>, <data> as key value pair.\n \"\"\"\n header=[]\n header.append('id')\n filenames = getFileNames(directory)\n\n for name in filenames:\n print(\"Processing: \" + name)\n if isFileEmpty(name):\n print('Warning file is empty: ' + name)\n continue\n sampleName = generateColHeader(name)\n d = processFile(name, d)\n header.append(sampleName)\n return header, d\n\ndef isFileEmpty(file):\n \"\"\"Function that checks a file contains data.\n \"\"\"\n return (os.stat(file).st_size == 0)\n\ndef getFileNames(directory):\n \"\"\"Function that returns the full paths of files that match a globbing\n pattern.\n \"\"\"\n filenames = glob.glob(directory)\n return filenames\n\ndef generateColHeader(filename):\n \"\"\"Function that processes kallisto, htseq count and rsem files and returns\n the sample name.\n \"\"\"\n kallisto_str = '_abundance.tsv'\n htseq_count = '.htseq-count'\n rsem_str = '.genes.results'\n f = filename.split('/')[-1]\n\n if kallisto_str in f:\n name = file[:-len(kallisto_str)]\n elif htseq_count in f:\n name = file[:-len(htseq_count)]\n elif rsem_str in f:\n name = file[:-len(rsem_str)]\n else:\n name = file.split('.')[0]\n return name\n\ndef processFile(filename, d):\n \"\"\"Function that processes a file and returns a dictionary containing\n <sample_name>, <data> as key, value pair.\n \"\"\"\n fin = open(filename,'r')\n entrys =[]\n for line in fin:\n cols = processLine(line)\n entrys.append(cols)\n fin.close()\n d = addToDict(entrys, d)\n return d\n\ndef processLine(line):\n \"\"\"Function that processes a line of tab seperated text and returns a tuple\n of strings. The function takes the column number specified in the command\n line arguments, returns its value and the value of the 1st column (gene name).\n \"\"\"\n line = line.strip('\\n')\n cols = line.split('\\t')\n\n id_col = 0\n indices = [id_col, value_col]\n values = [cols[i] for i in indices]\n #__ denotes not genes but meta info from the mapping in htseq count\n #(ambigious, unmapped etc). if a line contains this delimter add a xx in\n #front, so that when the file gets sorted it comes out last.\n if '__' in values[id_col]:\n values[id_col] = 'xx' + values[id_col]\n return tuple(values)\n\ndef addToDict(entries,d):\n for k, v in entries:\n d[k].append(v)\n return d\n\ndef writeToFile(filename, header, d):\n \"\"\"Function that writes supplied data to a file, including the supplied\n header.\n \"\"\"\n fout = open(filename,'w')\n h = '\\t'.join(header) + '\\n'\n fout.write(h)\n\n for key in sorted(d):\n values = d[key]\n line = key +'\\t'+ '\\t'.join(values) + '\\n'\n fout.write(line)\n fout.close()\n\nglobal sort\nglobal value_col\n\nvalue_col = args.columns\nsort = args.sort\ninputPattern = args.input\noutputFile = args.output\n\nheader, d = processFiles(d, inputPattern)\nwriteToFile(outputFile,header,d)\n"
}
] | 7 |
bgffgb/strategy_backtester
|
https://github.com/bgffgb/strategy_backtester
|
8b64e83199a4e7dd38d0a01638c67acdd7a5cf8b
|
c704363924a95a21b6dde3ed02774734fb184bd4
|
ad04d53ca452f3f70cba790a006e2425ee2d2d3a
|
refs/heads/main
| 2023-06-27T02:10:02.214452 | 2021-07-31T16:52:04 | 2021-07-31T16:52:04 | 381,609,176 | 0 | 0 | null | 2021-06-30T07:10:43 | 2021-07-27T06:40:02 | 2021-07-31T16:52:04 |
Python
|
[
{
"alpha_fraction": 0.5054615139961243,
"alphanum_fraction": 0.5324690937995911,
"avg_line_length": 30.67680549621582,
"blob_id": "29968782f7a339662bcb8d85a993731542c44fa7",
"content_id": "3bd4a554ed937c17e57705edce99d1fa331869a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8331,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 263,
"path": "/indicators/rnd.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom core.optionchain import OptionChain\nfrom core.option import Option\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.optimize import *\nfrom scipy.special import betainc, beta\n\nlogger = logging.getLogger(__name__)\n\nPROB_TH = 0.01\n\n\ndef scatter(x, y, textx=None, texty=None, title=None, x2=None, y2=None):\n fig, ax = plt.subplots()\n plt.scatter(x, y)\n if textx:\n ax.set_xlabel(textx)\n if texty:\n ax.set_ylabel(texty)\n if title:\n ax.set_title(title)\n if x2:\n plt.scatter(x2, y2, marker='.')\n plt.draw()\n plt.waitforbuttonpress(0)\n plt.close()\n\n\ndef curve_fit_optim(x, scale, d1, d2):\n bx = d1 * (x / scale) / (d1 * (x / scale) + d2)\n ba = d1 / 2\n bb = d2 / 2\n return betainc(ba, bb, bx)\n\n\ndef add_call_bull_spreads(sorted_calls, strikes, probs, D=2):\n N = len(sorted_calls)\n for i in range(1, N):\n strike1, op1 = sorted_calls[i]\n if op1.midprice() <= 1:\n # Premium is less than 0.01\n continue\n for j in range(max(0, i - D), i):\n strike0, op0 = sorted_calls[j]\n if op0.midprice() <= 1:\n # Premium is less than 0.01\n continue\n mid_strike = (strike0 + strike1) / 2\n\n bullspread_premium = (-op0.midprice() + op1.midprice()) / 100\n implied_prob = (bullspread_premium / (strike1 - strike0)) + 1\n\n if implied_prob < 0:\n implied_prob = 0\n if implied_prob > 1:\n implied_prob = 1\n # print(mid_strike, implied_prob, bullspread_premium)\n strikes.append(mid_strike)\n probs.append(implied_prob)\n return strikes, probs\n\n\ndef add_put_bull_spreads(sorted_puts, strikes, probs, D=2):\n N = len(sorted_puts)\n for i in range(0, N - 1):\n strike1, op1 = sorted_puts[i]\n if op1.midprice() <= 1:\n # Premium is less than 0.01\n continue\n for j in range(i + 1, min(N, i + D + 1)):\n strike0, op0 = sorted_puts[j]\n if op0.midprice() <= 1:\n # Premium is less than 0.01\n continue\n mid_strike = (strike0 + strike1) / 2\n\n bullspread_premium = (op0.midprice() - op1.midprice()) / 100\n implied_prob = - bullspread_premium / (strike1 - strike0)\n\n if implied_prob < 0:\n implied_prob = 0\n if implied_prob > 1:\n implied_prob = 1\n # print(mid_strike, implied_prob, bullspread_premium)\n strikes.append(mid_strike)\n probs.append(implied_prob)\n return strikes, probs\n\n\ndef get_RND_distribution(options: OptionChain):\n sorted_calls = options.get_sorted_calls()\n sorted_puts = options.get_sorted_puts()\n\n # New plan..\n strikes = []\n probs = []\n D = 2\n strikes, probs = add_call_bull_spreads(sorted_calls, strikes, probs, D=D)\n strikes, probs = add_put_bull_spreads(sorted_puts, strikes, probs, D=D)\n\n popt, _ = curve_fit(curve_fit_optim, strikes, probs)\n\n \"\"\"\n For debugging purposes\n # Plot fitted cumulative curve\n fitted = [curve_fit_optim(s, *popt) for s in strikes]\n scatter(strikes, probs, x2=strikes, y2=fitted)\n print('COST F', sqdiffsum(fitted, probs))\n \"\"\"\n\n return Distribution('F', popt)\n\n\ndef curve_fit_optim(x, scale, d1, d2):\n bx = d1 * (x / scale) / (d1 * (x / scale) + d2)\n ba = d1 / 2\n bb = d2 / 2\n return betainc(ba, bb, bx)\n\n\ndef sqdiffsum(v1, v2):\n tot = 0\n for a, b, in zip(v1, v2):\n tot += (a - b) ** 2\n return tot * 100\n\n\nclass Distribution:\n def __init__(self, type, params):\n self.type = type\n self.params = [float(p) for p in params]\n self.mean_reference = self.get_mean()\n self.steps = 400\n self.min_strike = 0\n self.max_strike = 100000\n self.mean_shift = 0\n self.var_level = 1\n self.adjust_min_strike()\n self.adjust_max_strike()\n self.mean_shift_reference = (self.max_strike - self.min_strike)\n self.lut = {}\n self.problut = {}\n\n def solve_lower_bound(self, th):\n lower = 0\n upper = 10000\n while lower <= upper:\n mid = (lower + upper) / 2\n prob = self.get_cumulative(mid)\n if prob < th:\n lower = mid + 0.01\n else:\n upper = mid - 0.01\n return mid\n\n def solve_upper_bound(self, th):\n lower = 0\n upper = 10000\n while lower <= upper:\n mid = (lower + upper) / 2\n prob = self.get_cumulative(mid)\n if prob < 1 - th:\n lower = mid + 0.01\n else:\n upper = mid - 0.01\n return mid\n\n def adjust_min_strike(self):\n self.lut = {}\n self.problut = {}\n self.min_strike = self.solve_lower_bound(PROB_TH)\n\n def adjust_max_strike(self):\n self.lut = {}\n self.problut = {}\n self.max_strike = self.solve_upper_bound(PROB_TH)\n\n def set_mean_shift_level(self, level):\n self.lut = {}\n self.problut = {}\n amount = level * 0.02 * self.mean_shift_reference\n self.mean_shift = amount\n\n def set_var_shift_level(self, level):\n self.lut = {}\n self.problut = {}\n scale = 0.9 ** level\n self.var_level = scale\n\n def get_mean(self):\n if self.type == 'F':\n return (self.params[2] / (self.params[2] - 2)) * self.params[0]\n if self.type == 'FF':\n m1 = (self.params[2] / (self.params[2] - 2)) * self.params[0]\n m2 = (self.params[5] / (self.params[5] - 2)) * self.params[3]\n r = self.params[6]\n return r * m1 + (1 - r) * m2\n\n def get_cumulative(self, x):\n if x in self.lut:\n return self.lut[x]\n x = (x - self.mean_reference) * self.var_level + self.mean_reference + self.mean_shift\n if self.type == 'F':\n scale, d1, d2 = self.params\n bx = d1 * (x / scale) / (d1 * (x / scale) + d2)\n ba = d1 / 2\n bb = d2 / 2\n self.lut[x] = betainc(ba, bb, bx)\n return self.lut[x]\n if self.type == 'FF':\n scale, d1, d2, scaleB, d1B, d2B, r = self.params\n bx = d1 * (x / scale) / (d1 * (x / scale) + d2)\n ba = d1 / 2\n bb = d2 / 2\n bx2 = d1B * (x / scaleB) / (d1B * (x / scaleB) + d2B)\n ba2 = d1B / 2\n bb2 = d2B / 2\n self.lut[x] = r * betainc(ba, bb, bx) + (1 - r) * betainc(ba2, bb2, bx2)\n return self.lut[x]\n\n def get_probability(self, x, strike_lower=0, strike_higher=10000):\n x_min = (strike_lower + x) / 2\n x_max = (strike_higher + x) / 2\n if self.type == 'F':\n prob = self.get_cumulative(x_max) - self.get_cumulative(x_min)\n return prob\n if self.type == 'FF':\n prob = self.get_cumulative(x_max) - self.get_cumulative(x_min)\n return prob\n\n def get_prob_arrays(self, steps=500, th_lower=0.01, th_upper=0.01, strike_min=None, strike_max=None):\n if strike_min is None:\n strike_min = self.solve_lower_bound(th_lower)\n if strike_max is None:\n strike_max = self.solve_upper_bound(th_upper)\n\n lut_key = (steps, strike_min, strike_max)\n if lut_key in self.problut:\n return self.problut[lut_key]\n\n strikes = np.arange(strike_min, strike_max, (strike_max - strike_min) / steps)\n prob_array, cum_array = [0], []\n for i in range(1, len(strikes) - 1):\n prob = self.get_probability(strikes[i], strikes[i - 1], strikes[i + 1])\n prob_array.append(prob)\n cum = self.get_cumulative(strikes[i]) - self.get_cumulative(strikes[i - 1])\n cum_array.append(cum)\n prob_array.append(0)\n\n # Save to look-up table\n self.problut[lut_key] = (strikes, prob_array, cum_array)\n return strikes, prob_array, cum_array\n\n def get_option_expected_return(self, o: Option):\n strikes, prob_array, cum_array = self.get_prob_arrays()\n\n expected_return = 0\n for st, pr in zip(strikes, prob_array):\n expected_return += pr * o.get_profit(st)\n\n return expected_return\n"
},
{
"alpha_fraction": 0.6369290351867676,
"alphanum_fraction": 0.6448638439178467,
"avg_line_length": 45.63999938964844,
"blob_id": "a2e4f92285e88ec08a42fdfd1c0a1733c8cdcb34",
"content_id": "cbf83afd47a6d59383303e1ae25bec2da5d26907",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4663,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 100,
"path": "/core/event.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from core.optionchainset import OptionChainSet\nfrom utils.tools import nr_days_between_dates\n\nclass Event:\n \"\"\"\n A wrapper class to represent a point in time, with all the raw data associated with it.\n\n To keep things simple, an Event is assumed to stand for a daily price update.\n Otherwise, it gets tricky with different UNIX timestamps for different options.\n We can figure out a way later to extend it to other time granularities (ie: 15 mins. 1h, etc)\n\n \"\"\"\n def __init__(self, ticker, quotedate, price, option_chains: OptionChainSet):\n \"\"\"\n :param ticker: ticker string of the underlying (\"SPY\", \"QQQ\", ...)\n :param quotedate: date string (YYYY-MM-DD) when the quote was taken, as used in the DB\n :param price: price of the underlying at the time the data was fetched\n :param option_chains: a set of all option chains\n \"\"\"\n self.ticker = ticker\n self.quotedate = quotedate\n self.price = price\n self.option_chains = option_chains\n\n def find_expiry(self, preferred_dte=2, allow0dte=False):\n \"\"\"\n Return option chain with DTE closest to preferred_dte\n :param preferred_dte: preferred number of days to expiry\n :param allow0dte: allow or not 0 DTE options\n :return: the option chain closest to the required DTE, or None if none found\n \"\"\"\n # Find an expiration with preferred DTE\n best_expiry = None\n closest_dte = None\n for expiration in self.get_option_expiries():\n expiration_dte = nr_days_between_dates(self.quotedate, expiration)\n if expiration_dte == 0 and not allow0dte:\n continue\n if best_expiry is None or abs(expiration_dte - preferred_dte) < abs(closest_dte - preferred_dte):\n best_expiry, closest_dte = expiration, expiration_dte\n return best_expiry\n\n def find_option_by_min_credit(self, type, preferred_credit, preferred_dte=2, allow0dte=False):\n \"\"\"\n Find a call with DTE and Delta as close as possible to specs\n :param type: \"CALL\" or \"PUT\"\n :param preferred_credit: preferred amount of credit we would like to receive\n :param preferred_dte: preferred number of days to expiry\n :param allow0dte: allow or not 0 DTE options\n :return: the call option closest to the required values, or None if none found\n \"\"\"\n # Find an expiration with preferred DTE\n best_expiry = self.find_expiry(preferred_dte=preferred_dte, allow0dte=allow0dte)\n\n # Find an option with closest matching credit\n opchain = self.option_chains.get_option_chain_by_expiry(best_expiry)\n best_option = None\n closest_credit = None\n for option in opchain.options:\n if option.type == type:\n if best_option is None or abs(option.midprice() - preferred_credit) < abs(closest_credit - preferred_credit):\n best_option, closest_credit = option, option.midprice()\n return best_option\n\n def find_option_by_delta(self, type, preferred_dte=2, preferred_delta=0.5, allow0dte=False):\n \"\"\"\n Find a call with DTE and Delta as close as possible to specs\n :param type: \"CALL\" or \"PUT\"\n :param preferred_dte: preferred number of days to expiry\n :param preferred_delta: preferred delta of the call (between 0 and 1)\n :param allow0dte: allow or not 0 DTE options\n :return: the call option closest to the required values, or None if none found\n \"\"\"\n # Find an expiration with preferred DTE\n best_expiry = self.find_expiry(preferred_dte=preferred_dte, allow0dte=allow0dte)\n\n # Find an option with closest matching delta\n opchain = self.option_chains.get_option_chain_by_expiry(best_expiry)\n best_option = None\n closest_delta = None\n for option in opchain.options:\n if option.type == type and option.delta != 0:\n if best_option is None or abs(option.delta - preferred_delta) < abs(\n closest_delta - preferred_delta):\n best_option, closest_delta = option, option.delta\n\n return best_option\n\n def get_option_by_symbol(self, symbol):\n \"\"\"\n :param symbol: an option symbol (structure: \"SPY:2021:07:02:CALL:425\")\n :return: the option from the option_chains, or None if cannot be found\n \"\"\"\n return self.option_chains.get_option_by_symbol(symbol)\n\n def get_option_expiries(self):\n \"\"\"\n :return: list of option expirations\n \"\"\"\n return self.option_chains.get_expiries()"
},
{
"alpha_fraction": 0.6674073934555054,
"alphanum_fraction": 0.6688888669013977,
"avg_line_length": 26.020000457763672,
"blob_id": "31723a0b99de2e1a10d2d43f4239445bd3101e13",
"content_id": "9f63307e6251d7854ee9c478d67362fbb712dffe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1350,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 50,
"path": "/backtest.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import json\nimport logging\nimport sys\n\nfrom core.backtest_engine import BackTestEngine\nfrom utils.analysis import analyze\n\nlogger = logging.getLogger(__name__)\n\n\ndef main():\n \"\"\"\n Usage: backtest.py <backtest_config_filename>\n Example: backtest.py sample.json\n\n Where the file is a JSON file with strategy parameters to be back-tested\n Check sample.json as an example (used as default file if none provided)\n Check README.md for a more detailed explanation.\n \"\"\"\n\n # Default strategy to backtest if no JSON file is provided\n filename = \"sample.json\"\n if len(sys.argv) > 1:\n filename = sys.argv[1]\n\n # Set up logging for the session.\n logging.basicConfig(filename='session.log', level=logging.INFO)\n\n test_params = None\n try:\n with open(filename) as f:\n test_params = json.load(f)\n except Exception as e:\n print(\"Sorry mate, something is wrong with your input file {}. {}\".format(filename, e))\n logger.info(\"Sorry mate, something is wrong with your input file {}. {}\".format(filename, e))\n return\n\n # Create a session and configure the session.\n engine = BackTestEngine(test_params)\n\n # Run the session.\n ticker_summary = engine.run()\n\n # Run statistical analysis\n analyze(test_params, ticker_summary)\n\n\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.5262869596481323,
"alphanum_fraction": 0.5262869596481323,
"avg_line_length": 38.673912048339844,
"blob_id": "293ca46679f3e5339f51d05f8d6cdfffd8c0c3d5",
"content_id": "cfa30af9454b7e0798954d805169cc32ced1a697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1826,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 46,
"path": "/utils/analysis.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import logging\n\nlogger = logging.getLogger(__name__)\n\n\ndef mean(arr):\n return sum(arr) / len(arr)\n\n\ndef analyze(test_params, ticker_summary):\n \"\"\"\n Run some quick statistical analysis based on configuraiton file\n :param test_params: contains parameters to evaluate\n :param ticker_summary: result of a BacktestEngine test-run based on the same test_params configuration\n \"\"\"\n\n if \"analyze\" in test_params:\n for detail in test_params[\"analyze\"]:\n stratname = detail[\"strategy\"]\n params = detail[\"params\"]\n\n logger.info(\"Statistics strategy {}\".format(stratname))\n\n for p in params:\n buckets_perf = {}\n buckets_drawdown = {}\n param_val_list = []\n\n # Do bucketing of summary results based on param list\n for ticker, summary in ticker_summary.items():\n for perf, drawdown, netval, id, strat in summary:\n if strat.params[\"strategy\"] == stratname:\n param_val = strat.params[p]\n if param_val not in buckets_perf:\n buckets_perf[param_val] = []\n buckets_drawdown[param_val] = []\n param_val_list.append(param_val)\n buckets_perf[param_val].append(perf)\n buckets_drawdown[param_val].append(drawdown)\n\n # Print stats\n param_val_list.sort()\n for pv in param_val_list:\n avg_perf = mean(buckets_perf[pv])\n avg_drawdown = mean(buckets_drawdown[pv])\n logger.info(\"{} val {} avg_performance {} avg_maxdrawdown {}\".format(p, pv, avg_perf, avg_drawdown))\n\n"
},
{
"alpha_fraction": 0.6051063537597656,
"alphanum_fraction": 0.6110638380050659,
"avg_line_length": 45.09803771972656,
"blob_id": "95af712737b3572e5c09d88ad4951a3c881e435c",
"content_id": "6f02a4f538d6b3b476c845fd15795ba45e938b10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2350,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 51,
"path": "/strategy/wheel.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from math import floor\n\nfrom core.event import Event\nfrom core.order import Order\nfrom strategy.strategy import Strategy\nfrom utils.tools import symbol_to_params\n\n\nclass Wheel(Strategy):\n \"\"\"\n Wheel strategy\n Given a starting amount of cash, this strategy first writes cash secured puts (CSP), and if taking assignment of\n the shares, switches to writing covered calls (CC). If the shares are called away, it switches back to writing CSP.\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n self.preferred_call_dte = params.get(\"calldte\", 5)\n self.preferred_call_delta = params.get(\"calldelta\", 0.3)\n self.preferred_put_dte = params.get(\"putdte\", 5)\n self.preferred_put_delta = params.get(\"putdelta\", -0.3)\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n orders = []\n if len(open_positions) == 0:\n # When no open positions, sell cash covered puts\n best_option = event.find_option_by_delta(type=\"PUT\", preferred_dte=self.preferred_put_dte,\n preferred_delta=self.preferred_put_delta)\n\n # Check how many contracts we can afford max, once premium is added\n self.buy_qty = floor(totalcash / (best_option.strike - best_option.midprice() / 100)) // 100\n\n order = Order(-self.buy_qty, best_option.symbol)\n orders.append(order)\n elif len(open_positions) == 1:\n for (symbol, qty) in open_positions:\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n if option_expiry is None:\n # Open stock position, sell covered calls\n best_option = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.preferred_call_dte,\n preferred_delta=self.preferred_call_delta)\n order = Order(-self.buy_qty, best_option.symbol)\n orders.append(order)\n\n return orders\n\n def take_assignment(self):\n return True\n\n def get_unique_id(self):\n return \"Wheel(CallDelta:{};CallDTE:{};PutDelta:{};PutDTE:{})\".\\\n format(self.preferred_call_delta, self.preferred_call_dte, self.preferred_put_delta, self.preferred_put_dte)"
},
{
"alpha_fraction": 0.5555424690246582,
"alphanum_fraction": 0.5595391988754272,
"avg_line_length": 43.99470901489258,
"blob_id": "403d3c9b0ecceb0f9155a9f60d8742a7b4e92bf9",
"content_id": "3df9c38c58e1330bf997b12db88a9e330f6c51e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8507,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 189,
"path": "/core/portfolio.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom core.event import Event\nfrom strategy.strategy import Strategy\nfrom utils.tools import symbol_to_params\n\nlogger = logging.getLogger(__name__)\n\n\nclass Portfolio:\n \"\"\"\n Portfolio manager that handles:\n - buying/selling of positions\n - closing out options contracts that expired and updating the portfolio accordingly\n - storing the historical net asset value of the account over time\n - .. calculating returns, max drawdown, etc\n\n Positions held are identified by their symbol, which is either a ticker (like \"SPY\") or an option symbol (like\n \"SPY:2021:07:02:CALL:425\")\n\n The structure of the portfolio class:\n - holdings_qty: maps symbols to quantity held\n - holdings_quote_date: maps symbols to the latest price quote date on record\n - holdings_last_price_info: maps symbols to the latest known price\n - net_value_history: list of (date, netvalue) pairs in chronological order (historical portfolio net asset values)\n \"\"\"\n def __init__(self, starting_cash, strategy: Strategy):\n self.cash = starting_cash\n self.strategy = strategy\n self.holdings_qty = {}\n self.holdings_quote_date = {}\n self.holdings_last_price_info = {}\n\n # Add a sole datapoint to mark the beginning of the portfolio (and it's net value at the start)\n self.net_value_history = [(\"start\", self.cash)]\n\n def __str__(self):\n \"\"\"\n :return: easily readable string of the portfolio status\n \"\"\"\n msg = \"Portfolio holdings:\\n Cash: {}\\n\".format(self.cash)\n for symbol in self.holdings_qty.keys():\n qty = self.holdings_qty[symbol]\n val = qty * self.holdings_last_price_info[symbol]\n msg += \"Pos: {} Symbol: {} Value: {}\\n\".format(qty, symbol, val)\n return msg\n\n def get_open_positions(self):\n \"\"\"\n :return: a list of (symbol, quantity) pairs, representing current portfolio holdings\n \"\"\"\n return self.holdings_qty.items()\n\n def get_performance(self):\n \"\"\"\n :return: percentage up or down of the portfolio\n \"\"\"\n initial_net_value = self.net_value_history[0][1]\n current_net_value = self.get_net_value()\n percentage_change = (current_net_value - initial_net_value) / initial_net_value\n return percentage_change * 100\n\n def get_max_drawdown(self):\n \"\"\"\n :return: calculate max drawdown throughout the history of the portfolio\n \"\"\"\n mdd = 0\n maxnetval = self.net_value_history[0][1]\n for (date, netval) in self.net_value_history:\n maxnetval = max(maxnetval, netval)\n if maxnetval != 0:\n mdd = min(mdd, (netval - maxnetval) * 1.0 / maxnetval)\n return mdd * 100\n\n def get_net_value(self):\n \"\"\"\n :return: net liquidation value of the portfolio\n \"\"\"\n net_value = self.cash\n for symbol in self.holdings_qty.keys():\n net_value += self.holdings_qty[symbol] * self.holdings_last_price_info[symbol]\n return net_value\n\n def adjust_holdings(self, symbol, qty, price):\n \"\"\"\n Add/Update quantity owned of different products by qty number specified\n :param symbol: symbol of the product (option symbol or ticker for underlying)\n :param qty: amount to adjust qty owned by; positive values to go long, negative ones to go short\n :param price: price to be paid for the product\n \"\"\"\n\n cash_cost = qty * price\n self.cash -= cash_cost\n\n if symbol not in self.holdings_qty:\n # Add new entry about this holding\n self.holdings_qty[symbol] = 0\n self.holdings_qty[symbol] += qty\n\n if self.holdings_qty[symbol] == 0:\n # Remove this position\n self.holdings_qty.pop(symbol, None)\n self.holdings_quote_date.pop(symbol, None)\n self.holdings_last_price_info.pop(symbol, None)\n\n def update_data(self, event: Event):\n for symbol in self.holdings_qty.keys():\n if symbol == event.ticker:\n self.holdings_last_price_info[symbol] = event.price\n self.holdings_quote_date[symbol] = event.quotedate\n else:\n option = event.get_option_by_symbol(symbol)\n if option:\n self.holdings_last_price_info[symbol] = option.midprice()\n self.holdings_quote_date[symbol] = option.quotedate\n # Make sure to also update ticker price\n self.holdings_last_price_info[event.ticker] = event.price\n\n def update_portfolio(self, order_list, event: Event):\n \"\"\"\n With each new event, the portfolio class:\n - updates holdings based on new incoming orders\n - update info on prices on record for all portfolio holdings\n - handles expired option contracts/assignments\n\n :param order_list: list of new orders to be executed\n :param event: an Event class with price data\n \"\"\"\n # Update holdings\n for order in order_list:\n if order.symbol == event.ticker:\n # It's an order for the underlying\n self.adjust_holdings(symbol=order.symbol, qty=order.qty, price=event.price)\n else:\n # It's an option contract\n option = event.get_option_by_symbol(order.symbol)\n if option:\n # Only execute if not None\n self.adjust_holdings(symbol=order.symbol, qty=order.qty, price=option.midprice())\n else:\n logger.info(\"Could not execute order, cannot find option with symbol {}\".format(order.symbol))\n\n # Update product quote dates/last prices\n self.update_data(event)\n\n # Handle expired options\n symbols = list(self.holdings_qty.keys())\n for symbol in symbols:\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n if option_expiry is not None:\n if event.quotedate >= option_expiry and event.ticker == ticker:\n # Option expired/expires end of day\n if self.strategy.take_assignment():\n # Strategy takes assignment\n if option_type == \"CALL\":\n if strike < event.price:\n # Call is in the money\n # Add shares\n logger.debug(\"Call option {} took assignment (EOD stock price {})\".\n format(symbol, event.price))\n self.adjust_holdings(event.ticker, 100 * self.holdings_qty[symbol], strike)\n else:\n # Call expires worthless\n logger.debug(\"Call option {} expires worthless (EOD stock price {})\".\n format(symbol, event.price))\n pass\n else:\n if strike > event.price:\n # Put is in the money\n # Add shares\n logger.debug(\"Put option {} took assignment (EOD stock price {})\".\n format(symbol, event.price))\n self.adjust_holdings(event.ticker, -100 * self.holdings_qty[symbol], strike)\n else:\n # Put expires worthless\n logger.debug(\"Put option {} expires worthless (EOD stock price {})\".\n format(symbol, event.price))\n pass\n\n # Remove options from holdings\n self.adjust_holdings(symbol, -self.holdings_qty[symbol], 0)\n else:\n # Strategy closes positions before expiry\n logger.debug(\"Option {} closed out at price of {} (EOD stock price {})\".\n format(symbol, self.holdings_last_price_info[symbol], event.price))\n self.adjust_holdings(symbol, -self.holdings_qty[symbol], self.holdings_last_price_info[symbol])\n\n # Update historical net value\n self.net_value_history.append((event.quotedate, self.get_net_value()))\n\n\n\n"
},
{
"alpha_fraction": 0.5462666153907776,
"alphanum_fraction": 0.5493005514144897,
"avg_line_length": 45.3515625,
"blob_id": "fc0be4279aafbe2d3862bface342edd2d57d0698",
"content_id": "3134f8c01826b5ec9f87b3dee932df006f95627a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5933,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 128,
"path": "/strategy/delta_neutral.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from math import floor\n\nfrom core.event import Event\nfrom core.order import Order\nfrom strategy.strategy import Strategy\nfrom utils.tools import symbol_to_params\n\n\nclass DeltaNeutral(Strategy):\n \"\"\"\n A semi-delta neutral strategy using a four legged strategy:\n - long deep ITM Put + Call legs\n - short OTM Put + Call legs of shorter expiry\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n self.long_dte = params.get(\"longdte\", 30)\n self.long_delta = params.get(\"longdelta\", 0.9)\n self.short_dte = params.get(\"shortdte\", 3)\n self.short_delta = params.get(\"shortdelta\", 0.3)\n self.closeonprofit = params.get(\"closeonprofit\", 1)\n self.creditroll = params.get(\"creditroll\", 0)\n self.short_put_value = 0\n self.short_call_value = 0\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n orders = []\n long_position_present = False\n short_put_present = False\n short_call_present = False\n call_min_roll_price = None\n put_min_roll_price = None\n\n for (symbol, qty) in open_positions:\n if qty > 0:\n # We have a long position present\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n if event.quotedate >= option_expiry:\n # Close current long position\n close_order = Order(-qty, symbol)\n orders.append(close_order)\n else:\n long_position_present = True\n\n for (symbol, qty) in open_positions:\n if qty < 0:\n # We have a short position present\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n close_short_position = False\n\n if event.quotedate >= option_expiry or not long_position_present:\n close_short_position = True\n\n curr_option = event.get_option_by_symbol(symbol)\n if curr_option:\n current_short_pos_value = event.get_option_by_symbol(symbol).midprice() * qty\n if \"CALL\" in symbol:\n refval = self.short_call_value\n if \"PUT\" in symbol:\n refval = self.short_put_value\n if refval != 0 and current_short_pos_value / refval <= 1 - self.closeonprofit:\n close_short_position = True\n\n # Check if we need to roll for credit\n if curr_option and close_short_position and self.creditroll == 1:\n if \"CALL\" in symbol:\n call_min_roll_price = curr_option.midprice()\n if \"PUT\" in symbol:\n put_min_roll_price = curr_option.midprice()\n\n if close_short_position:\n # Close current short position\n close_order = Order(-qty, symbol)\n orders.append(close_order)\n else:\n if \"CALL\" in symbol:\n short_call_present = True\n if \"PUT\" in symbol:\n short_put_present = True\n\n if not long_position_present:\n # Buy as many long contracts as we can afford\n best_call = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.long_dte,\n preferred_delta=self.long_delta)\n best_put = event.find_option_by_delta(type=\"PUT\", preferred_dte=self.long_dte,\n preferred_delta=-self.long_delta)\n\n self.buy_qty = floor(totalvalue / (best_call.midprice() + best_put.midprice()))\n\n order = Order(self.buy_qty, best_call.symbol)\n orders.append(order)\n order = Order(self.buy_qty, best_put.symbol)\n orders.append(order)\n\n if not short_call_present:\n # Write covered options against long positions\n best_call = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.short_dte,\n preferred_delta=self.short_delta)\n if self.creditroll == 1 and call_min_roll_price and best_call.midprice() < call_min_roll_price:\n # Find an option that satisfies credit requirement\n best_call = event.find_option_by_min_credit(type=\"CALL\", preferred_dte=self.short_dte,\n preferred_credit=call_min_roll_price)\n\n self.short_call_value = -self.buy_qty * best_call.midprice()\n order = Order(-self.buy_qty, best_call.symbol)\n orders.append(order)\n\n if not short_put_present:\n # Write covered options against long positions\n best_put = event.find_option_by_delta(type=\"PUT\", preferred_dte=self.short_dte,\n preferred_delta=-self.short_delta)\n if self.creditroll == 1 and put_min_roll_price and best_put.midprice() < put_min_roll_price:\n # Find an option that satisfies credit requirement\n best_put = event.find_option_by_min_credit(type=\"PUT\", preferred_dte=self.short_dte,\n preferred_credit=put_min_roll_price)\n\n self.short_put_value = -self.buy_qty * best_put.midprice()\n order = Order(-self.buy_qty, best_put.symbol)\n orders.append(order)\n\n return orders\n\n def take_assignment(self):\n return False\n\n def get_unique_id(self):\n return \"DeltaNeutral(LongDelta:{};LongDTE:{};ShortDelta:{};ShortDTE:{};CloseProfit:{};CreditRoll:{})\". \\\n format(self.long_delta, self.long_dte, self.short_delta, self.short_dte, self.closeonprofit, self.creditroll)\n"
},
{
"alpha_fraction": 0.639211118221283,
"alphanum_fraction": 0.639211118221283,
"avg_line_length": 31.547170639038086,
"blob_id": "b3abf8a399ab76aed1cab165a770e601cd7a89c5",
"content_id": "7c6bbd4287b3f8bb93207f040307e357f3d44c55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1724,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 53,
"path": "/strategy/strategy.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nfrom core.event import Event\n\n\nclass Strategy:\n \"\"\"\n Abstract interface class for all strategies to implement\n\n __init___: initialization is done with a dictionary of strategy specific parameters\n handle_event: gets a a new Event (with quotedate later than any previous event) and returns stock/option buy/sell\n orders\n \"\"\"\n\n def __init__(self, params):\n \"\"\"\n :param params: a json of strategy specific parameters, mapping strings to their values\n \"\"\"\n self.params = params\n self.unique_id = \"\"\n\n @abstractmethod\n def take_assignment(self):\n \"\"\"\n Should the strategy take assignment of shares/let shares be called away when options expire\n :return: True or False\n \"\"\"\n pass\n\n @abstractmethod\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n \"\"\"\n :param open_positions: a list of (symbol, quantity) pairs, representing current portfolio holdings\n :param totalcash: current available cash on hand (can be negative)\n :param totalvalue: total current liquidation value of the portfolio\n :param event: a new event with option chain data to react to\n :return:a list of Order classes\n \"\"\"\n pass\n\n @abstractmethod\n def get_unique_id(self):\n \"\"\"\n :return: the unique id string for this strategy\n \"\"\"\n return self.unique_id\n\n @abstractmethod\n def set_unique_id(self, uid):\n \"\"\"\n :param uid: a string to uniquely identify a strategy; handy when backtesting different combinations of parameters\n \"\"\"\n self.unique_id = uid"
},
{
"alpha_fraction": 0.5630027055740356,
"alphanum_fraction": 0.5996425151824951,
"avg_line_length": 30.08333396911621,
"blob_id": "a26aa38f927f96fd43b2b3521b9c5516182b3856",
"content_id": "4e32fe6b9de21d89a8a4fee6c9a85a822781c965",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 36,
"path": "/utils/tools.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from datetime import date\n\n\ndef nr_days_between_dates(date1, date2):\n \"\"\"\n :param date1: a date string in the form of \"YYYY-MM-DD\"\n :param date2: a date string in the form of \"YYYY-MM-DD\"\n :return: number of days between two dates\n \"\"\"\n year1, month1, day1 = date1.split(\"-\")\n year2, month2, day2 = date2.split(\"-\")\n d1 = date(int(year1), int(month1), int(day1))\n d2 = date(int(year2), int(month2), int(day2))\n delta = d2 - d1\n return abs(delta.days)\n\n\ndef symbol_to_params(symbol):\n \"\"\"\n Dirty function to turn symbol into option info\n If symbol formatting is not correct, returns symbol and 3x Nones\n :param symbol: str in the format of \"SPY:2021:07:02:CALL:425\"\n :return:\n ticker (ie: \"SPY\")\n expiry (str, \"YYYY-MM-DD\" format)\n option type (\"CALL\" or \"PUT\")\n strike (float)\n \"\"\"\n arr = symbol.split(\":\")\n if len(arr) < 6:\n return symbol, None, None, None\n ticker = arr[0]\n expiry = arr[1] + \"-\" + arr[2] + \"-\" + arr[3]\n option_type = arr[4]\n strike = float(arr[5])\n return ticker, expiry, option_type, strike\n"
},
{
"alpha_fraction": 0.5766391754150391,
"alphanum_fraction": 0.5798957943916321,
"avg_line_length": 44.60396194458008,
"blob_id": "9a9ccdaaa002dfe34d3fb9614b6101b19326e771",
"content_id": "6269529311dc7fe7c6b39c83394f9840f57fc261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4606,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 101,
"path": "/strategy/leveraged_covered_call.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import logging\nfrom math import floor\n\nfrom core.event import Event\nfrom core.order import Order\nfrom strategy.strategy import Strategy\nfrom utils.tools import symbol_to_params\n\nlogger = logging.getLogger(__name__)\n\nclass LeveragedCoveredCall(Strategy):\n \"\"\"\n A Covered Call strategy using deep ITM options as the long leg instead of owning stocks\n It imitates a poor man's covered call (PMCC): deep ITM call options for the long leg,\n shorter expiry covered calls for the short leg.\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n self.long_dte = params.get(\"longdte\", 30)\n self.long_delta = params.get(\"longdelta\", 0.9)\n self.short_dte = params.get(\"shortdte\", 3)\n self.short_delta = params.get(\"shortdelta\", 0.3)\n self.closeonprofit = params.get(\"closeonprofit\", 1)\n self.creditroll = params.get(\"creditroll\", 0)\n self.short_pos_value = 0\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n orders = []\n\n long_position_present = False\n short_position_present = False\n min_roll_price = None\n \n for (symbol, qty) in open_positions:\n if qty > 0:\n # We have a long position present\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n if event.quotedate >= option_expiry:\n # Close current long position\n close_order = Order(-qty, symbol)\n orders.append(close_order)\n else:\n long_position_present = True\n else:\n # We have a short position present\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n close_short_position = False\n\n # Close short position if we don't have a long leg or it is expiring\n if event.quotedate >= option_expiry or not long_position_present:\n close_short_position = True\n\n # Close short position if profit target reached\n\n curr_option = event.get_option_by_symbol(symbol)\n if curr_option:\n current_short_pos_value = event.get_option_by_symbol(symbol).midprice() * qty\n if self.short_pos_value != 0 and current_short_pos_value / self.short_pos_value <= 1 - self.closeonprofit:\n close_short_position = True\n\n # Check if we need to roll for credit\n if curr_option and close_short_position and self.creditroll == 1:\n min_roll_price = curr_option.midprice()\n\n if close_short_position:\n # Close current short position\n close_order = Order(-qty, symbol)\n orders.append(close_order)\n else:\n short_position_present = True\n\n if not long_position_present:\n # Buy as many long contracts as we can afford\n best_option = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.long_dte,\n preferred_delta=self.long_delta)\n self.buy_qty = floor(totalvalue / best_option.midprice())\n\n order = Order(self.buy_qty, best_option.symbol)\n orders.append(order)\n\n if not short_position_present:\n # Write covered calls against long position\n best_option = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.short_dte,\n preferred_delta=self.short_delta)\n if self.creditroll == 1 and min_roll_price and best_option.midprice() < min_roll_price:\n logger.debug(\"Credit roll triggered\")\n # Find an option that satisfies credit requirement\n best_option = event.find_option_by_min_credit(type=\"CALL\", preferred_dte=self.short_dte,\n preferred_credit=min_roll_price)\n self.short_pos_value = -self.buy_qty * best_option.midprice()\n order = Order(-self.buy_qty, best_option.symbol)\n orders.append(order)\n\n return orders\n\n def take_assignment(self):\n return False\n\n def get_unique_id(self):\n return \"LeveragedCoveredCall(LongDelta:{};LongDTE:{};ShortDelta:{};ShortDTE:{};CloseProfit:{};CreditRoll:{})\". \\\n format(self.long_delta, self.long_dte, self.short_delta, self.short_dte, self.closeonprofit, self.creditroll)\n"
},
{
"alpha_fraction": 0.6167374849319458,
"alphanum_fraction": 0.6206326484680176,
"avg_line_length": 41.787879943847656,
"blob_id": "b311525bb3abe2a5b25e02dfa6548221e5ac772e",
"content_id": "2d526d97f84286de493b1dbe2ed2fbe88f5d9b43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8472,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 198,
"path": "/core/backtest_engine.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "import copy\nimport logging\n\nfrom core.portfolio import Portfolio\nfrom utils.data_loader import events_generator\nfrom strategy.buyandhold import BuyAndHold\nfrom strategy.covered_call import CoveredCall\nfrom strategy.delta_neutral import DeltaNeutral\nfrom strategy.leveraged_covered_call import LeveragedCoveredCall\nfrom strategy.rnd_strategy import RndStrategy\nfrom strategy.wheel import Wheel\n\nlogger = logging.getLogger(__name__)\n\n\ndef strategy_from_params(params):\n \"\"\"\n Add initializaiton of new strategies here; map a string to their class;\n :param params: parameters unique to the strategy\n :return: an initialized strategy\n \"\"\"\n if params[\"strategy\"].lower() == \"buyandhold\":\n return BuyAndHold(params)\n if params[\"strategy\"].lower() == \"coveredcall\":\n return CoveredCall(params)\n if params[\"strategy\"].lower() == \"wheel\":\n return Wheel(params)\n if params[\"strategy\"].lower() == \"leveragedcoveredcall\":\n return LeveragedCoveredCall(params)\n if params[\"strategy\"].lower() == \"deltaneutral\":\n return DeltaNeutral(params)\n if params[\"strategy\"].lower() == \"rndstrategy\":\n return RndStrategy(params)\n\n\ndef get_all_permutations(original_params, params_to_generate, index, pos, permutation_list):\n N = len(index)\n if pos == len(index):\n # Create a deep copy of the original parameters\n param_cpy = copy.deepcopy(original_params)\n # Rewrite params according to current permutation\n for i in range(N):\n key, value = params_to_generate[i]\n param_cpy[key] = value[index[i]]\n permutation_list.append(param_cpy)\n else:\n # Generate all possible permutations\n L = len(params_to_generate[pos][1])\n for i in range(L):\n index[pos] = i\n get_all_permutations(original_params, params_to_generate, index, pos + 1, permutation_list)\n\n\ndef generate_permutations(params):\n params_to_generate = []\n for key, value in params.items():\n if type(value) == list:\n params_to_generate.append((key, value))\n\n N = len(params_to_generate)\n permutation_list = []\n get_all_permutations(params, params_to_generate, [0 for _ in range(N)], 0, permutation_list)\n return permutation_list\n\n\ndef spawn_strategies(params):\n \"\"\"\n Spawn initialized strategies according to param specs\n :param params: dictionary of parameters (see Readme)\n :return: list of initialized strategies\n \"\"\"\n strategy_list = []\n if \"strategy\" in params:\n # A single strategy is specified\n perm_list = generate_permutations(params)\n for param_version in perm_list:\n strategy_list.append(strategy_from_params(param_version))\n elif \"strategies\" in params:\n # Add multiple strategies for testing\n for strat_params in params[\"strategies\"]:\n # Generate all permutations of array-style parameters\n perm_list = generate_permutations(strat_params)\n for param_version in perm_list:\n strategy_list.append(strategy_from_params(param_version))\n return strategy_list\n\n\nclass BackTestEngine:\n \"\"\"\n The whole big backbone for backtesting.\n Given the test parameters, it will:\n - initialize the different strategies to be tested (and compared against each other)\n - initialize a portfolio for each of these strategies\n - load the options data from the DB\n - generate a series of chronological events\n - get the orders made by the strategies reacting to the events & update their portfolios\n - close down expired option positions on expiry (take assignment)\n - generate a final report in the end for each strategies performance\n \"\"\"\n\n def __init__(self, test_params):\n \"\"\"\n Do a whole lot of default initializations and sanity checking\n :param test_params: a json dictionary of test parameters; check sample.json for an example\n \"\"\"\n # Start date\n logger.info(\"Setting up new Backtest run.\")\n self.start_date = test_params.get(\"fromDate\", None)\n if self.start_date is None:\n self.start_date = \"2021-06-01\"\n logger.info(\n \"No 'fromDate' (start date) specified. Using default value of {} (inclusive)\".format(self.start_date))\n else:\n logger.info(\"Start date set to {} (inclusive)\".format(self.start_date))\n\n # End date\n self.end_date = test_params.get(\"toDate\", None)\n if self.end_date is None:\n self.end_date = \"2021-06-21\"\n logger.info(\"No 'toDate' (end date) specified. Using default value of {} (exclusive)\".format(self.end_date))\n else:\n logger.info(\"End date set to {} (exclusive)\".format(self.end_date))\n\n # Ticker\n self.ticker = test_params.get(\"ticker\", None)\n if self.ticker is None:\n self.ticker = [\"SPY\"]\n logger.info(\"No 'ticker' sp\"\n \"ecified. Using default value of {}\".format(self.ticker))\n\n # Make sure ticker is a list\n if type(self.ticker) != list:\n self.ticker = [self.ticker]\n\n # Set a starting cash amount, consistent across all strategies\n self.startcash = test_params.get(\"startcash\", 1000000)\n\n # Save out test-params for strategy re-initialization\n self.test_params = test_params\n\n def run(self):\n \"\"\"\n Run portfolio simulation over historical data for all the strategies\n :return: final summary result dictionary of {ticker : (performance, maxdrawdown, netvalue, strategy_id)} entries,\n sorted by performance\n \"\"\"\n\n summary_by_ticker = {}\n\n # Run a full backtest for every ticker listed\n for next_ticker in self.ticker:\n logger.info(\"Testing ticker {}\".format(next_ticker))\n\n # Get strategies initialized\n strategy_list = spawn_strategies(self.test_params)\n\n # Initialize a portfolio for each of these strategies\n portfolio_list = [Portfolio(starting_cash=self.startcash, strategy=strat) for strat in strategy_list]\n\n # Simulate events\n if len(strategy_list) == 0:\n logger.info(\"No strategies specified; nothing to test.\")\n else:\n logger.info(\"Testing strategies: {}\".format(\",\".join([s.get_unique_id() for s in strategy_list])))\n\n for event in events_generator(ticker=next_ticker, fromdate=self.start_date, todate=self.end_date):\n logger.info(\"New event for {}, date {}, price {}\".format(event.ticker, event.quotedate, event.price))\n\n for strategy, portfolio in zip(strategy_list, portfolio_list):\n # Take order decisions from strategy\n orders = strategy.handle_event(open_positions=portfolio.get_open_positions(),\n totalcash=portfolio.cash,\n totalvalue=portfolio.get_net_value(), event=event)\n if len(orders) > 0:\n logger.debug(\"{} placed orders: {}\".format(strategy.get_unique_id(), [str(o) for o in orders]))\n # Update portfolio holdings\n portfolio.update_portfolio(orders, event)\n logger.debug(\"Strategy {} Portfolio Value {} Performance {:.2f}% MaxDrawdown {:.2f}%\".\n format(strategy.get_unique_id(), portfolio.get_net_value(),\n portfolio.get_performance(), portfolio.get_max_drawdown()))\n\n # Sort strategies by results and risk\n summary = []\n for strategy, portfolio in zip(strategy_list, portfolio_list):\n summary.append((portfolio.get_performance(), portfolio.get_max_drawdown(),\n portfolio.get_net_value(), strategy.get_unique_id(), strategy))\n summary.sort(reverse=True)\n\n # Print final portfolio stats\n logger.info(\"Out of events! Final results\")\n for perf, drawdown, netval, id, _ in summary:\n logger.info(\"Strategy {} Portfolio Value {} Performance {:.2f}% MaxDrawdown {:.2f}%\".\n format(id, netval, perf, drawdown))\n\n # Save out summary for this ticker\n summary_by_ticker[next_ticker] = summary\n\n return summary_by_ticker\n"
},
{
"alpha_fraction": 0.5535982251167297,
"alphanum_fraction": 0.5610944628715515,
"avg_line_length": 42.73770523071289,
"blob_id": "1e98b68f952ce1d289ceb2479848227f02d384d2",
"content_id": "54fd0421d5da2f2f488987f4d5937d1dd64b9a21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2668,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 61,
"path": "/strategy/covered_call.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from math import floor\n\nfrom core.event import Event\nfrom core.order import Order\nfrom strategy.strategy import Strategy\nfrom utils.tools import symbol_to_params\n\nclass CoveredCall(Strategy):\n \"\"\"\n Simple Covered Call strategy\n Opens a position for as many shares (multiple of 100x) as it can afford and sells covered calls against it\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n self.preferred_dte = params.get(\"dte\", 5)\n self.preferred_delta = params.get(\"delta\", 0.3)\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n orders = []\n if len(open_positions) == 0:\n # When starting up, buy as many of the underlying ticker as possible\n self.buy_qty = floor(totalcash / event.price)\n # Make the order a multiple of 100\n self.buy_qty = (self.buy_qty // 100) * 100\n order = Order(self.buy_qty, event.ticker)\n orders.append(order)\n\n # Sell covered calls against position\n if len(open_positions) <= 1:\n # No open option positions currently, sell covered calls\n best_option = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.preferred_dte,\n preferred_delta=self.preferred_delta)\n if best_option:\n order = Order(-self.buy_qty / 100, best_option.symbol)\n orders.append(order)\n\n else:\n for (symbol, qty) in open_positions:\n ticker, option_expiry, option_type, strike = symbol_to_params(symbol)\n # Check if we need to roll covered calls further out\n if option_type == \"CALL\" and event.quotedate >= option_expiry:\n # Only roll out if call is in the money\n if strike <= event.price:\n # Close current position\n close_order = Order(-qty, symbol)\n orders.append(close_order)\n\n # Open new one further out\n best_option = event.find_option_by_delta(type=\"CALL\", preferred_dte=self.preferred_dte,\n preferred_delta=self.preferred_delta)\n if best_option:\n open_order = Order(qty, best_option.symbol)\n orders.append(open_order)\n\n return orders\n\n def take_assignment(self):\n return True\n\n def get_unique_id(self):\n return \"CoveredCall(Delta:\"+str(self.preferred_delta)+\";DTE:\"+str(self.preferred_dte)+\")\"\n"
},
{
"alpha_fraction": 0.7705176472663879,
"alphanum_fraction": 0.7790403962135315,
"avg_line_length": 42.41095733642578,
"blob_id": "438efaa34a8b6f168020b73ddb0342ca98067f25",
"content_id": "d23eb6278787872dc1afc0e1fb12caac6a63bc31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3168,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 73,
"path": "/README.md",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "# Installation & requirements\nPython 3.5+, along with some additional requirements in the requrements.txt file.\nInstall it via `pip install -r requirements.txt`.\n\n# Usage\n\nFrom the main folder, simply do a `python backtest.py <backtestfile.json>`.\n\nCheck `sample.json` for a reference on how to set up a backtest file, or have a look at the strategy \nspecific sample files in the `sample_jsons` folder. \n\nLogging is done to the local file `session.log`, also used for debugging purposes.\n\n# Implemented strategies\n\nThis list should grow as new things are implemented :)\nFor each implemented strategy, there is a sample .json file with configurations in the `sample_jsons` folder.\n\nThe backtest allows for spawning multiple parallel strategies to be tested against each other, by specifying an \narray of strategies via the `strategies` keyword. For testing a single strategy, use the `strategy` keyword instead.\n\n## BuyAndHold\n\nGiven a starting amount of cash, this strategy spends it all buying shares of the underlying (no options) \nand stays idle after that.\n\n## CoveredCall\n\nGiven a starting amount of cash, this strategy spends it all buying shares of the underlying (no options),\nand then keeps selling covered calls against it. On expiration, the options are rolled further out if they are ITM \n(rolling) or are allowed to expire worthless otherwise.\n\n## LeveragedCoveredCall\n\nA Covered Call strategy using deep ITM options as the long leg instead of owning stocks.\nIt imitates a poor man's covered call (PMCC): deep ITM call options for the long leg,\nshorter expiry covered calls for the short leg.\n\nParams:\n1. longdte: DTE for the long option leg\n1. longdelta: delta for the long option leg\n1. shortdte: DTE for the short option leg\n1. shortdelta: delta for the short option leg\n1. closeonprofit: roll short leg given fraction of profit reached (0.7 -> close short leg when 70% profit reached)\n1. creditroll: 1 to force rolling positions for credit, ignoring delta; 0 otherwise\n\n## Wheel\n\nGiven a starting amount of cash, this strategy first writes cash secured puts (CSP), and if taking assignment of\nthe shares, switches to writing covered calls (CC). If the shares are called away, it switches back to writing CSP.\n\n## RndStrategy\n\nPick an option chain of preferred DTE and run Risk Neutral Distribution (RND) calculation over it.\nBased on the RND, place 5 orders with the highest profit percentage options.\nOptions are close out on expiry.\n\n## DeltaNeutral\n\nA semi-delta neutral strategy using a four legged strategy:\n- long (large delta and DTE) Put + Call legs\n- short (shorted delta and DTE) Put + Call legs\n\nBasically, calendar spreads where the long leg is delta neutral, while the short leg attempts to capture theta decay/ \nprofits from short-term price fluctuations.\n \nParams:\n1. longdte: DTE for the long option leg\n1. longdelta: delta for the long option leg\n1. shortdte: DTE for the short option leg\n1. shortdelta: delta for the short option leg\n1. closeonprofit: roll short leg given fraction of profit reached (0.7 -> close short leg when 70% profit reached)\n1. creditroll: 1 to force rolling positions for credit, ignoring delta; 0 otherwise"
},
{
"alpha_fraction": 0.5843828916549683,
"alphanum_fraction": 0.5843828916549683,
"avg_line_length": 32.16666793823242,
"blob_id": "3861a2e6688e0684c85e50d6efc93d9d2f8d50e5",
"content_id": "e06289d3a9247173c7a3ec601e4d16d744b8ca0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 12,
"path": "/core/order.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "class Order:\n def __init__(self, qty, symbol):\n \"\"\"\n Wrapper class for structured orders\n :param qty: positive amounts: buy/long; negative amounts: sell/short\n :param symbol: ticker for underlying; option symbol for options\n \"\"\"\n self.qty = qty\n self.symbol = symbol\n\n def __str__(self):\n return \"({},{})\".format(self.symbol, self.qty)"
},
{
"alpha_fraction": 0.6292797923088074,
"alphanum_fraction": 0.6304604411125183,
"avg_line_length": 27.266666412353516,
"blob_id": "be3273ba167f8280700e2e06a4075536246bf062",
"content_id": "734d2fc026676107b71cc694a5beaa5eb78c3411",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 847,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 30,
"path": "/strategy/buyandhold.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from math import floor\n\nfrom core.event import Event\nfrom core.order import Order\nfrom strategy.strategy import Strategy\n\n\nclass BuyAndHold(Strategy):\n \"\"\"\n Simple Buy and Hold strategy.\n Opens a position for as many shares as it can afford and never seels :)\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n if len(open_positions) == 0:\n # When starting up, buy as many of the underlying ticker as possible\n buy_qty = floor(totalcash / event.price)\n order = Order(buy_qty, event.ticker)\n return [order]\n\n # Just wait and hold, nothing to do...\n return []\n\n def take_assignment(self):\n return False\n\n def get_unique_id(self):\n return \"BuyAndHold\""
},
{
"alpha_fraction": 0.6568701267242432,
"alphanum_fraction": 0.6593820452690125,
"avg_line_length": 39.632652282714844,
"blob_id": "240fac07e8307c48d5721771291d338c4ef72f14",
"content_id": "3ede8bbfb4ad1984c1e904cfdf4bcb135bd26fb7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3981,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 98,
"path": "/utils/data_loader.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "\"\"\"\nUtility functions to handle getting data out of the DB in a structured way\n\"\"\"\nimport logging\nimport records\nimport time\n\nfrom core.option import Option\nfrom core.optionchainset import OptionChainSet\nfrom core.event import Event\n\nlogger = logging.getLogger(__name__)\n\n# DB instance initialization\nwith open(\"credentials.txt\") as f:\n username, password = f.readlines()\n username = username.strip()\n password = password.strip()\nrecdb = records.Database('mysql://'+username+':'+password+'@localhost/rtoptionsdb')\n\n\ndef events_generator(ticker, fromdate=\"2021-06-01\", todate=None):\n \"\"\"\n Loads in option data from the Database and yield Events in a a chronological order.\n Yield is used (instead of return) to reduce memory requirements & speed things up a bit.\n\n If no todate is provided, everything is queried from starting point\n\n :param ticker: string of the ticker (\"SPY\", \"QQQ\", ...)\n :param fromdate: date string (YYYY-MM-DD) from when events should be read form the DB (fromdate included)\n :param todate: date string (YYYY-MM-DD) until when events should be read form the DB (todate NOT included)\n :return: yields an Event as long as there are Events left\n \"\"\"\n\n # Build up the query gradually\n query_str = \"SELECT * FROM bt_OptionDataTable WHERE Ticker='\" + ticker + \"'\"\n\n # TODO: Validate if fromdate, fromtime, todate, totime have correct syntax (YYYY-MM-DD and YYYY-MM-DDThh:mm:ss)\n if fromdate:\n query_str += \" AND QuoteDate >= '\" + fromdate + \"'\"\n else:\n logger.error(\"No fromdate is specified.\")\n return\n\n if todate:\n query_str += \" AND QuoteDate < '\" + todate + \"'\"\n\n # Sort chronologically\n query_str += \" ORDER BY QuoteDate;\"\n logger.info(\"Running query: {}\".format(query_str))\n\n # Run query - this can take a while\n tic = time.time()\n rows = recdb.query(query_str)\n toc = time.time()\n logger.info(\"Query took {} seconds\".format(toc - tic))\n data = rows.export('df')\n logger.info(\"Processing {} total returned option records\".format(len(data)))\n\n \"\"\"\n Create events out of the options table rows.\n Option rows are sorted by UNIX timestamp in chronological order\n Group all option entries with the same QuoteDate into one big option chain\n containing everything/providing fast structured access. \n \"\"\"\n prevdate = None\n prevprice = None\n current_chains = None\n for j in range(len(data)):\n # Verify if option has all the fields we need\n if data.OptBid[j] == 0 and data.OptAsk[j] == 0:\n # Consider it invalid only when Bid/Ask prices all zero - very suspicious\n continue\n\n # Turn DB entry into an Option class instance\n o = Option(ticker=data.Ticker[j], expiry=data.OptExpDate[j], symbol=data.OptionSymbol[j],\n strike=data.OptStrike[j], type=data.OptType[j], bid=data.OptBid[j], ask=data.OptAsk[j],\n oi=data.OptOpenInterest[j], vol=data.OptVolume[j], quotedate=data.QuoteDate[j],\n underlying=data.StockPrice[j], daytoexp=data.DaysToExp[j], iv=data.GreekIV[j],\n delta=data.GreekDelta[j], gamma=data.GreekGamma[j], theta=data.GreekTheta[j], vega=data.GreekVega[j])\n\n if prevdate != o.quotedate:\n if prevdate:\n # Create new event based on data gathered so far\n # NOTE: deriving the price of the underlying from the option is a bit iffy;\n new_event = Event(ticker=ticker, price=prevprice, quotedate=prevdate, option_chains=current_chains)\n yield new_event\n\n prevdate = o.quotedate\n prevprice = o.underlying\n current_chains = OptionChainSet(ticker)\n else:\n # Add option to current option chain\n current_chains.add_option(o)\n\n # Last event\n new_event = Event(ticker=ticker, price=prevprice, quotedate=prevdate, option_chains=current_chains)\n yield new_event"
},
{
"alpha_fraction": 0.6234309673309326,
"alphanum_fraction": 0.6304044723510742,
"avg_line_length": 42.45454406738281,
"blob_id": "93106c66560f1f3f0ffb4430a1e224fb96e75104",
"content_id": "3a215415f8a8c43730e69727fc881b23aacab3cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2868,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 66,
"path": "/strategy/rnd_strategy.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from math import floor\n\nfrom core.event import Event\nfrom core.optionchain import OptionChain\nfrom core.order import Order\nfrom indicators.rnd import get_RND_distribution, Distribution\nfrom strategy.strategy import Strategy\n\nclass RndStrategy(Strategy):\n \"\"\"\n A strategy that buys/sells option spreads with high expected returns based on RND distribution\n Positions are closed out at expiry\n \"\"\"\n def __init__(self, params):\n super().__init__(params)\n self.dte = params.get(\"dte\", 5)\n self.possize = params.get(\"possize\", 10)\n self.min_call_delta = params.get(\"mincalldelta\", 0.3)\n self.max_call_delta = params.get(\"maxcalldelta\", 0.7)\n self.min_put_delta = params.get(\"minputdelta\", -0.7)\n self.max_put_delta = params.get(\"maxputdelta\", -0.3)\n\n # Safety check, negative numbers can be confusing\n if self.min_put_delta > self.max_put_delta:\n self.min_put_delta, self.max_put_delta = self.max_put_delta, self.min_put_delta\n\n def get_option_profits(self, chain: OptionChain, distribution: Distribution):\n # Evaluate all option probabilities matching delta criterias\n option_returns = []\n for strike, op in chain.get_sorted_calls():\n if self.min_call_delta <= op.delta <= self.max_call_delta:\n ret = distribution.get_option_expected_return(op)\n perc = ret / op.midprice() * 100\n option_returns.append((abs(perc), perc, op))\n\n for strike, op in chain.get_sorted_puts():\n if self.min_put_delta <= op.delta <= self.max_put_delta:\n ret = distribution.get_option_expected_return(op)\n perc = ret / op.midprice() * 100\n option_returns.append((abs(perc), perc, op))\n option_returns.sort(reverse=True)\n return option_returns\n\n def handle_event(self, open_positions, totalcash, totalvalue, event: Event):\n orders = []\n best_expiry = event.find_expiry(preferred_dte=self.dte, allow0dte=False)\n chain = event.option_chains.get_option_chain_by_expiry(best_expiry)\n distribution = get_RND_distribution(chain)\n\n options_by_rnd_profit = self.get_option_profits(chain=chain, distribution=distribution)\n for i in range(min(5, len(options_by_rnd_profit))):\n _, perc, op = options_by_rnd_profit[i]\n possize = self.possize\n if perc < 0:\n possize = -self.possize\n orders.append(Order(qty=possize, symbol=op.symbol))\n\n return orders\n\n def take_assignment(self):\n return False\n\n def get_unique_id(self):\n return \"RNDStrategy(DTE:{};Pos:{};CallDelta:{}-{};PutDelta:{}-{})\".\\\n format(self.dte, self.possize, self.min_call_delta, self.max_call_delta,\n self.min_put_delta, self.max_put_delta)\n"
},
{
"alpha_fraction": 0.568532407283783,
"alphanum_fraction": 0.5782282948493958,
"avg_line_length": 35.6129035949707,
"blob_id": "0f14755b8c3b53d2d66bc282a69cac86d1a85a73",
"content_id": "d1d8cac3d8c380693b157c3538d5f4beb361ea19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2269,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 62,
"path": "/core/option.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "class Option:\n \"\"\"\n A wrapper class to represent a single option\n \"\"\"\n\n def __init__(self, ticker, expiry, symbol, strike, type, bid, ask, oi, vol, quotedate,\n underlying=None, daytoexp=None, iv=None, delta=None, gamma=None, theta=None, vega=None):\n \"\"\"\n :param ticker: ticker string of the underlying (\"SPY\", \"QQQ\", ...)\n :param symbol: uniqye string to identify an option contract (structure: SPY:2021:07:02:CALL:425)\n :param expiry: date string (YYYY-MM-DD) of option expiry\n :param strike: float of the strike price\n :param type: \"PUT\" or \"CALL\" (str)\n :param bid: bid price (float)\n :param ask: ask price (float)\n :param oi: open interest (int)\n :param vol: volume (int)\n :param quotedate: date string (YYYY-MM-DD) when the quote was taken, as used in the DB\n :param underlying: price of the underlying (float)\n :param daytoexp: days to expiry (int)\n :param iv: implied volatility (float)\n :param delta: greeks delta (float)\n :param gamma: greeks gamma (float)\n :param theta: greeks theta (float)\n :param vega: greeks vega (float)\n \"\"\"\n self.ticker = ticker\n self.expiry = expiry\n self.symbol = symbol\n self.strike = strike\n self.type = type\n self.bid = bid\n self.ask = ask\n self.oi = oi\n self.vol = vol\n self.quotedate = quotedate\n self.underlying = underlying\n self.daytoexp = daytoexp\n self.iv = iv\n self.delta = delta\n self.gamma = gamma\n self.theta = theta\n self.vega = vega\n\n def __str__(self):\n return \"{} quote time: {}\".format(self.symbol, self.quotedate)\n\n def midprice(self):\n return 100 * (self.bid + self.ask) / 2\n\n def get_profit(self, stock_price):\n '''\n Returns profit fot this option, assuming it is held LONG (quantity = -1)\n '''\n profit = self.midprice() / 100\n\n if self.type == 'CALL' and stock_price > self.strike:\n profit += (self.strike - stock_price)\n if self.type == 'PUT' and stock_price < self.strike:\n profit += (stock_price - self.strike)\n\n return -100 * profit"
},
{
"alpha_fraction": 0.5973089933395386,
"alphanum_fraction": 0.6035559773445129,
"avg_line_length": 35.52631759643555,
"blob_id": "d321dedb8175c1e91d9909d700b3845829fc284b",
"content_id": "872f73048317fb51ea40deacd04098ba9ec5efa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2081,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 57,
"path": "/core/optionchainset.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "from .optionchain import OptionChain\n\n\nclass OptionChainSet:\n \"\"\"\n A set of all option chains, built from DB data\n \"\"\"\n def __init__(self, ticker, option_list=None):\n \"\"\"\n Construct the set of structured option chains form a list of queried options\n\n :param ticker: ticker string of the underlying (\"SPY\", \"QQQ\", ...)\n :param option_list: a list of Option classes to be added to the option chains (optional)\n \"\"\"\n\n # Store options in a dictionary, using the expiry as a key\n self.ticker = ticker\n self.tot_options = 0\n self.option_chains_by_expiry = {}\n self.symbol_to_option = {}\n\n if option_list:\n for o in option_list:\n self.add_option(o)\n\n def add_option(self, o):\n # Just make sure option ticker matches the option chain we are building\n if o.ticker == self.ticker:\n expiry = o.expiry\n if expiry not in self.option_chains_by_expiry:\n # Create a new option chain for this expiry\n self.option_chains_by_expiry[expiry] = OptionChain(ticker=self.ticker, quotedate=o.quotedate)\n self.option_chains_by_expiry[expiry].add_option(o)\n self.tot_options += 1\n\n # For quick lookups, store option symbol -> option mapping\n self.symbol_to_option[o.symbol] = o\n\n def get_expiries(self):\n \"\"\"\n :return: a list of expiry dates\n \"\"\"\n return self.option_chains_by_expiry.keys()\n\n def get_option_chain_by_expiry(self, expiry):\n \"\"\"\n :param expiry: string in the form of \"YYYY-MM-DD\"\n :return: return an option chain with the given expiry, or None if expiry is not valid\n \"\"\"\n return self.option_chains_by_expiry.get(expiry, None)\n\n def get_option_by_symbol(self, symbol):\n \"\"\"\n :param symbol: an option symbol (structure: \"SPY:2021:07:02:CALL:425\")\n :return: the option if present, or None if cannot be found\n \"\"\"\n return self.symbol_to_option.get(symbol, None)"
},
{
"alpha_fraction": 0.5459940433502197,
"alphanum_fraction": 0.5474777221679688,
"avg_line_length": 27.10416603088379,
"blob_id": "f61591eec2cb2b8aa12d5b14040591e6b04bf0b2",
"content_id": "de03f0471b4c068edec8f6162360bc8c15c3519c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1348,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 48,
"path": "/core/optionchain.py",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "class OptionChain:\n \"\"\"\n A wrapper class to represent an option chain for a given point in time\n \"\"\"\n def __init__(self, ticker, quotedate, option_list=None):\n \"\"\"\n\n :param ticker: ticker string of the underlying (\"SPY\", \"QQQ\", ...)\n :param quotedate: date string (YYYY-MM-DD) when the quote was taken, as used in the DB\n :param option_list: a list of Option classes to initialize the chain (optional)\n \"\"\"\n\n self.ticker = ticker\n self.quotedate = quotedate\n self.tot_options = 0\n self.options = []\n self.calls = []\n self.puts = []\n self.sorted = False\n\n if option_list:\n for o in option_list:\n self.add_option(o)\n\n def add_option(self, o):\n self.tot_options += 1\n self.options.append(o)\n self.sorted = False\n\n if o.type == 'CALL':\n self.calls.append((o.strike, o))\n if o.type == 'PUT':\n self.puts.append((o.strike, o))\n\n def make_sorted(self):\n self.calls.sort()\n self.puts.sort()\n self.sorted = True\n\n def get_sorted_calls(self):\n if not self.sorted:\n self.make_sorted()\n return self.calls\n\n def get_sorted_puts(self):\n if not self.sorted:\n self.make_sorted()\n return self.puts"
},
{
"alpha_fraction": 0.4948025047779083,
"alphanum_fraction": 0.6943867206573486,
"avg_line_length": 16.178571701049805,
"blob_id": "2bd5677a423f993982f98709ee3ef76bc677e621",
"content_id": "aa49ed48e9cf1e88bfc322aaf78ffec8b1a95420",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 28,
"path": "/requirements.txt",
"repo_name": "bgffgb/strategy_backtester",
"src_encoding": "UTF-8",
"text": "click==8.0.1\ncolorama==0.4.4\ncycler==0.10.0\ndocopt==0.6.2\net-xmlfile==1.1.0\nfreeze-requirements==0.5.3\nimportlib-metadata==4.6.1\njdcal==1.4.1\nkiwisolver==1.3.1\nmatplotlib==3.3.3\nmysql-connector-python==8.0.25\nmysqlclient==2.0.3\nnumpy==1.21.0\nopenpyxl==2.4.11\npandas==1.3.0\nPillow==8.3.1\nprotobuf==3.17.3\npyparsing==2.4.7\npython-dateutil==2.8.1\npytz==2021.1\nrecords==0.5.3\nscipy==1.5.4\nsh==1.14.2\nsix==1.16.0\nSQLAlchemy==1.3.24\ntablib==3.0.0\ntyping-extensions==3.10.0.0\nzipp==3.5.0\n"
}
] | 21 |
krishnakumar85/Eikam
|
https://github.com/krishnakumar85/Eikam
|
fb2e48df1289efa638d8c0f39b397ac6551f00b4
|
72050621580dd86ddb0895e104ff9995e63dd88c
|
1d7d8150674936995d19805358d0972ce2d6d72b
|
refs/heads/master
| 2020-12-24T15:13:52.265404 | 2012-02-23T18:20:17 | 2012-02-23T18:20:17 | 3,549,743 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5691986083984375,
"alphanum_fraction": 0.5748310089111328,
"avg_line_length": 39.85135269165039,
"blob_id": "2b3088996a70fea122d9fb6e99525ab64456b7c4",
"content_id": "c89e6ce3cb9474838750a70c2bb413fcb9d9a7fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6214,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 148,
"path": "/src/DataStore.py",
"repo_name": "krishnakumar85/Eikam",
"src_encoding": "UTF-8",
"text": "# To implement data store object to hide data store policy\r\n# TODO: Refactor code into multiple files\r\n\r\nimport sys\r\nimport sqlite3\r\nimport os\r\nimport string\r\n\r\nclass DataStore(dict):\r\n pass\r\n\r\nclass InternalDataStore:\r\n \"\"\"\r\n 1) Stores information on headers, their aliases, type of data\r\n \"\"\"\r\n def __init__(self):\r\n #check if header info is available in any of the types\r\n # 1) get tables\r\n # 2) get actual header names\r\n # 3) compare with existing headers\r\n # 4) determine alias names of headers to store in sqlite\r\n self.header = None\r\n self.header_mapping = None\r\n self.mapped_header = None\r\n \r\n def get_header_mapping(self, header):\r\n self.header = header\r\n \r\n #TODO: db file from configuration\r\n db = sqlite3.connect(\"internal.db\")\r\n cur = db.cursor()\r\n try:\r\n cur.execute(\"SELECT field,mapping from internal_header_mapping\")\r\n mappings = cur.fetchall()\r\n except sqlite3.OperationalError, e:\r\n print \"Error:\",e\r\n cur.execute('CREATE TABLE internal_header_mapping(id INTEGER PRIMARY KEY, field CHAR, mapping CHAR)')\r\n db.commit()\r\n cur.execute(\"SELECT field,mapping from internal_header_mapping\")\r\n mappings = cur.fetchall()\r\n# print mappings\r\n \r\n new_mappings = {}\r\n for thismapping in mappings:\r\n new_mappings[thismapping[0]] = thismapping[1]\r\n# print new_mapping\r\n ret_header_mapping = {}\r\n self.mapped_header = [] #required to maintain order of the mapped header list\r\n for header_field in self.header:\r\n if not new_mappings.has_key(header_field):\r\n # insert new mapping in table \r\n while True:\r\n new_mapping = raw_input(\"Enter mapping for \"+header_field+\":\")\r\n #TODO: use regex to complete the sql field naming rules\r\n if not new_mapping.__contains__(\" \"):\r\n break\r\n \r\n cur.execute(\"INSERT INTO internal_header_mapping VALUES (NULL, ?, ?)\", (header_field, new_mapping))\r\n db.commit()\r\n \r\n ret_header_mapping[header_field] = new_mapping\r\n self.mapped_header.append(new_mapping)\r\n else:\r\n ret_header_mapping[header_field] = new_mappings[header_field]\r\n self.mapped_header.append(new_mappings[header_field])\r\n #print \"MAPPED HEADER\",self.mapped_header\r\n cur.close()\r\n db.close()\r\n \r\n self.header_mapping = ret_header_mapping\r\n return ret_header_mapping\r\n \r\n \r\nclass ToolDataStore:\r\n \"\"\"\r\n 1) Stores information about files, their md5sum, time stamps.\r\n Intended to be temporary.\r\n \"\"\"\r\n def __init__(self, parser_obj):\r\n self.parser_obj = parser_obj\r\n self.filename = None\r\n# print self.filename\r\n #TODO: time consuming, check based on configuration\r\n #FIXME: read() may not return till EOF\r\n self.md5sum = 0\r\n self.mtime = None\r\n # print self.mtime\r\n #clean_filename is the table name for storing parsed records\r\n replace_space_uscore = string.maketrans(' ', '_')\r\n self.clean_filename = os.path.basename(self.parser_obj.filename).rsplit('.')[0].lower().translate(replace_space_uscore)\r\n \r\n # 1) get database entry for this file.\r\n # 2) Compare the entry with new entries.\r\n # 3) if equal, skip parsing\r\n # 4) if not, parse and commit to self.db\r\n self.db = sqlite3.connect(\"internal.db\") #TODO: self.db file from configuration \r\n cur = self.db.cursor()\r\n input_info = [None, None, None]\r\n try:\r\n cur.execute(\"SELECT filename, md5sum, mtime from tool_input_info WHERE filename=?\",(self.parser_obj.filename,))\r\n input_info = cur.fetchall()\r\n except sqlite3.OperationalError, e:\r\n print \"Error:\",e\r\n \r\n #FIXME: try-except block for database stmnt execution\r\n cur.execute('CREATE TABLE tool_input_info(id INTEGER PRIMARY KEY, filename CHAR, md5sum CHAR, mtime INTEGER)')\r\n self.db.commit()\r\n cur.execute('INSERT INTO tool_input_info(id, filename, md5sum, mtime) VALUES(NULL, ?,?,?)',(self.parser_obj.filename, self.md5sum, self.mtime))\r\n self.db.commit()\r\n cur.execute(\"SELECT filename, md5sum, mtime from tool_input_info WHERE filename=?\",(self.parser_obj.filename,))\r\n input_info = cur.fetchall()\r\n \r\n #print input_info\r\n self.filename = input_info[0][0]\r\n self.mtime = input_info[0][2]\r\n self.md5sum = input_info[0][1]\r\n \r\n def reinit(self):\r\n #drop table, create table\r\n #print \"REINIT\"\r\n cur = self.db.cursor()\r\n cur.execute(\"DROP TABLE IF EXISTS \"+self.clean_filename)\r\n self.db.commit()\r\n \r\n mapped_header = self.parser_obj.internalstore.mapped_header\r\n print type(mapped_header)\r\n table_fields = string.join(mapped_header,\",\")\r\n \r\n #print \"table_fieds\",table_fields\r\n cur.execute(\"CREATE TABLE \"+self.clean_filename+\"(\"+table_fields+\")\")\r\n self.db.commit()\r\n \r\n def insert_parsed_record(self,record_data):\r\n cur = self.db.cursor()\r\n\r\n mapped_header = self.parser_obj.internalstore.mapped_header\r\n #print mapped_header\r\n table_fields = string.join(mapped_header,\",\")\r\n #print record_data\r\n \r\n q_val = string.join((\"? \"*len(record_data)).split(),\",\")\r\n cur.execute(\"INSERT INTO \"+self.clean_filename+\"(\"+table_fields+\") \"+\" VALUES (\"+q_val+\")\", (record_data))\r\n self.db.commit()\r\n \r\n #FIXME: update must be present only after the parsed content is stored in the db.\r\n cur.execute(\"UPDATE tool_input_info SET md5sum=?, mtime=? WHERE filename=?\",(self.parser_obj.md5sum, self.parser_obj.mtime, self.parser_obj.filename))\r\n self.db.commit()\r\n #print \"Data comitted\"\r\n\r\n \r\n \r\n \r\n"
},
{
"alpha_fraction": 0.5527984499931335,
"alphanum_fraction": 0.5602426528930664,
"avg_line_length": 30.990909576416016,
"blob_id": "0c7e30e1ab581bb6791171ea2170a082d8f733a0",
"content_id": "3b4489f6cc58ead9fa16054a958cf4dfebb676cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3627,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 110,
"path": "/src/Parser.py",
"repo_name": "krishnakumar85/Eikam",
"src_encoding": "UTF-8",
"text": "import os\r\nimport csv\r\nimport md5\r\nfrom DataStore import *\r\n\r\nclass ParserException(Exception):\r\n pass\r\n\r\nclass Parser:\r\n @staticmethod\r\n def register_extension():\r\n raise ParserException(\"Need to register an extension! override 'register_extension' static method\")\r\n pass\r\n\r\nclass CSVParser(Parser):\r\n def __init__(self, filename, hasHeader=True):\r\n self.filename = filename\r\n self.hasHeader = hasHeader\r\n self.header = None\r\n self.mtime = os.stat(self.filename).st_mtime\r\n self.__md5 = 0 #use md5sum instead of md5\r\n self.mystore = ToolDataStore(self)\r\n self.internalstore = InternalDataStore()\r\n # initialise ToolDatabase object for this file\r\n \r\n @staticmethod\r\n def register_extension():\r\n return 'csv'\r\n \r\n def get_header(self):\r\n \r\n if self.header != None:\r\n return self.header\r\n \r\n self.fd = open(self.filename)\r\n self.dialect = csv.Sniffer().sniff(self.fd.readline())\r\n self.fd.seek(0); #reset position to start from beginning of file\r\n \r\n #detect header line\r\n #count non null fields(len1)\r\n #count non null fields of next line (len2). if len2 < len1, then first one is header\r\n headerIndex = 0\r\n index = 0\r\n for line in csv.reader(self.fd, self.dialect):\r\n nfields = len(line)\r\n countfields = 0\r\n index += 1\r\n for field in line:\r\n if(len(field) != 0):\r\n countfields += 1\r\n if nfields == countfields:\r\n headerIndex = index\r\n retheader = line\r\n break\r\n #self.fd.close() # For continuing the flow while parsing, this fd must remain uncommented.\r\n \r\n self.header = retheader\r\n return retheader\r\n \r\n def parse(self):\r\n self.get_header() #automatically sets self.header\r\n self.internalstore.get_header_mapping(self.header)\r\n \r\n if (self.mystore.filename == self.filename and self.mystore.mtime == self.mtime):\r\n if self.mystore.md5sum == self.md5sum:\r\n # parse into self.db\r\n return\r\n \r\n self.get_header()\r\n self.mystore.reinit()\r\n for line in csv.reader(self.fd, self.dialect):\r\n #print line\r\n self.mystore.insert_parsed_record(line)\r\n self.fd.close()\r\n \r\n def __getattr__(self, name):\r\n # print \"here in getattr\"\r\n if name == \"md5sum\":\r\n if self.__md5 == 0: #not computed before\r\n# print \"compute md5sum\"\r\n self.__md5 = md5.new(open(self.filename).read()).hexdigest()\r\n return self.__md5\r\n\r\nclass XLSParser(Parser):\r\n def __init__(self,filename):\r\n self.filename = filename\r\n \r\n @staticmethod\r\n def register_extension():\r\n return 'xls'\r\n \r\n__Parsers__ = [CSVParser, XLSParser]\r\n\r\ndef parse(filename, type=None):\r\n \"\"\"\r\n @summary: Wrapper function to choose a proper Parser class.\r\n @return: Parser instance\r\n @param filename: The file that needs to be parsed.\r\n @param type: to identify the type of parser to be chosen (Future use)\r\n \"\"\"\r\n xtn = os.path.basename(filename).rsplit('.', 1)[1]\r\n for thisparser in __Parsers__:\r\n #TODO: check parameter 'type' for extension\r\n if thisparser.register_extension() == xtn:\r\n #FIXME: use args and kwargs\r\n return thisparser(filename) \r\n\r\n\r\nif __name__ == \"__main__\":\r\n parse(\"..\\crdc.csv\", \"csv\")"
},
{
"alpha_fraction": 0.5813953280448914,
"alphanum_fraction": 0.5813953280448914,
"avg_line_length": 17.727272033691406,
"blob_id": "6b966474a327d665844bebb763d950df75dc89b4",
"content_id": "ba970211188d8ba95fcee4db4c1bff828493b4bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 11,
"path": "/unittest/Test_DataStore.py",
"repo_name": "krishnakumar85/Eikam",
"src_encoding": "UTF-8",
"text": "import unittest\r\n\r\nclass TestDataStore(unittest.TestCase):\r\n def setUp(self):\r\n pass\r\n def teardown(self):\r\n pass\r\n def testimple(self):\r\n pass\r\n def testcomplex(self):\r\n pass"
},
{
"alpha_fraction": 0.5461254715919495,
"alphanum_fraction": 0.5461254715919495,
"avg_line_length": 17.5,
"blob_id": "db3d8cd0ebf13a92db41234578367f06140912a2",
"content_id": "bfd01b9d0f29b32a81b1b5490be7cba38f925d7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 14,
"path": "/unittest/Test_Parser.py",
"repo_name": "krishnakumar85/Eikam",
"src_encoding": "UTF-8",
"text": "import unittest\r\n\r\nclass TestGetHeader(unittest.TestCase):\r\n def setUp(self):\r\n pass\r\n def tearDown(self):\r\n pass\r\n def testsimple(self):\r\n pass\r\n def testcomplex(self):\r\n pass\r\n \r\nif __name__ == \"__main__\":\r\n unittest.main()"
},
{
"alpha_fraction": 0.5180723071098328,
"alphanum_fraction": 0.5180723071098328,
"avg_line_length": 19.25,
"blob_id": "2a534ab32a968c22812b183e2c7ffead6c003f76",
"content_id": "ff3707fdb149ea6ccece23c778f252d4193327da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 4,
"path": "/src/main.py",
"repo_name": "krishnakumar85/Eikam",
"src_encoding": "UTF-8",
"text": "import Parser\r\n\r\nif __name__ == \"__main__\":\r\n Parser.parse(\"..\\crdc.csv\", \"csv\")"
}
] | 5 |
turp/xmas
|
https://github.com/turp/xmas
|
b9a165a7f4172b44041cf4978edc2e27f9ece6c8
|
4de53965b02bc049a7e25660e67e9e9d18be7c0f
|
9dc510d04e3fc35b3d1f5da59402f384b2e53bf0
|
refs/heads/master
| 2020-01-23T11:44:44.123825 | 2016-02-06T23:24:18 | 2016-02-06T23:24:18 | 48,017,364 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7397647500038147,
"alphanum_fraction": 0.7597141861915588,
"avg_line_length": 43.47682189941406,
"blob_id": "65eea692d933f3fd499d845565467790aabe1015",
"content_id": "ea49973b8a096c532e894296159dadb24ea883b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6719,
"license_type": "permissive",
"max_line_length": 786,
"num_lines": 151,
"path": "/README.md",
"repo_name": "turp/xmas",
"src_encoding": "UTF-8",
"text": "# xmas\nRaspberry Pi Christmas Light Experiment\n\n## Acknowledgements\n\nI couldn't have done any of this without the help of a lot of people on the internet. Special thanks to [Osprey22](http://www.instructables.com/member/Osprey22/) for a great [Instructables article](http://www.instructables.com/id/Raspberry-Pi-Christmas-Tree-Light-Show/?ALLSTEPS) showing how to wire up the Raspberry Pi to relay switch and tree. Also want to thank [SkiWithPete](https://www.youtube.com/user/skiwithpete) for [this great video](https://www.youtube.com/watch?v=oaf_zQcrg7g) made it really clear about how to connect the Rasberry Pi to the SainSmart relay module. He talks about an issue he had with the Raspberry Pi 2 Model B, but I never experienced it. Some of the source code found here is based on his scripts found at [Github](https://github.com/skiwithpete/relaypi)\n\n## Progress So Far\n\nI finally caught the bug. After seeing a neighbor choreograph his entire outdoor light display with music, I set about trying to figure out how to do something similar. I'm starting small, just trying to automate 6-8 different sets of lights on a tree, but you never know where this will end.\n\nAfter a quick google search, I stumbled upon this article on by [Osprey22](http://www.instructables.com/member/Osprey22/) on Instructables [Raspberry Pi Christmas Tree Light Show](http://www.instructables.com/id/Raspberry-Pi-Christmas-Tree-Light-Show/?ALLSTEPS)\n\nI bought some gear to get started:\n\n\n\n[SainSmart 8-Channel Relay Module](http://www.amazon.com/gp/product/B0057OC5WK) - this is used to turn power on and off to the individual power outlets\n\n\n\n[Jumper Wire Cables](http://www.amazon.com/gp/product/B00M5WLZDW)\n\n[CanaKit Raspberry Pi 2 Complete Starter Kit with WiFi](http://www.amazon.com/gp/product/B008XVAVAW) - to get me started easily \n\nI hooked them up to a wireless keyboard/mouse and a monitor (using a HDMI cable), popped the SD card into the Raspberry Pi (RaPi) and installed Raspian operating system using the NOOBS installer. This already cam installed on the SD card, but you can also visit the [Raspberry Pi NOOBS Setup](https://www.raspberrypi.org/help/noobs-setup/) page to learn how to do this yourself\n\nNext I started following the instructions in the Instructables article\n\n### Static IP Address\n\nI setup a static IP address by right-clicking on my wifi connection and selecting WiFi Networks (dhcpcdui) Settings. Select interface and wlan0 and set the IP address and Router number\n\n\n\n### Install Telnet\n\nNext, I [installed telnet](http://www.ronnutter.com/raspberry-pi-enabling-telnet/):\n\n sudo apt-get install telnetd\n sudo /etc/init.d/openbsd-inetd restart \n\nVerify the telnet by opening a command prompt:\n\n netstat -a | grep telnet\n\nYou should only see something like this:\n\n tcp 0 0 *:telnet *:* LISTEN\n\nbut once you connect to it from another machine using telnet, you'll see something like:\n\n tcp 0 0 *:telnet *:* LISTEN\n tcp 0 0 raspberrypi.loca:telnet 192.168.15.161:49610 ESTABLISHED\n\nFinally, if you want to restrict who can login:\n\n sudo nano /etc/hosts.allow\n\nand add lines similar to these at the bottom of the file:\n\n in.telnetd : 192.168.1.161 : allow\n in.telnetd : 192.168.15. : deny\n\nSave and restart the service:\n\n sudo /etc/init.d/openbsd-inetd restart \n\n### FTP Services\n\nNext, I installed an [FTP Server](https://mike632t.wordpress.com/2015/11/29/setting-up-a-secure-ftp-server/)\n\n sudo apt-get update\n\tsudo apt-get upgrade\n\tsudo apt-get install vsftpd\n\nLet's see if it's installed\n\t\n netstat -npl|grep vsftpd\n tcp6 0 0 :::21 :::* LISTEN 1984/vsftpd \n\nThat's it. If you want to configure the service (like add security features) check out the article linked above.\n\n### Install PyGame\n\nTo write scripts to play audio, install [pygame for Python 3](https://www.raspberrypi.org/forums/viewtopic.php?f=32&t=33157&p=332140&hilit=croston%2bpygame#p284266). I also referenced this [article](http://www.philjeffes.co.uk/wordpress/?p=259)\n\n sudo apt-get install mercurial \n hg clone https://bitbucket.org/pygame/pygame\n cd pygame\n\n sudo apt-get install libsdl-dev libsdl-image1.2-dev libsdl-mixer1.2-dev libsdl-ttf2.0-dev \n sudo apt-get install libsmpeg-dev libportmidi-dev libavformat-dev libswscale-dev\n sudo apt-get install python3-dev python3-numpy\n\n python3 setup.py build \n sudo python3 setup.py install\n\n### Wiring up Relay Module\n\n[This great video](https://www.youtube.com/watch?v=oaf_zQcrg7g) made it really clear about how to connect the Rasberry Pi to the SainSmart relay module. He talks about an issue he had with the Raspberry Pi 2 Model B, but I never experienced it.\n\nWired the board up using GPIO.Board configuration. Plugged it in and ran the basic.py test script:\n\n\tpython ./basic.py\n\nand everything worked\n\n### Automatic Lightshow\n\nI found an [article](https://chivalrytimberz.wordpress.com/2012/12/03/pi-lights/) by Chivalry Timbers (it could be his real name) about running a light show directly from a MIDI file. About three paragraphs in, he referenced a project called [Lightshow Pi](http://lightshowpi.org/download-and-install/) that will allow you to use a MP3 instead.\n\n### Download Lightshow Pi\n\t\n\t# Install git (if you don't already have it)\n\tsudo apt-get install git-core\n\t\n\t# Clone the repository to /home/pi/lightshowpi\n\tcd ~\n\tgit clone https://[email protected]/togiles/lightshowpi.git\n\t\n\t# Grab the stable branch\n\tcd lightshowpi\n\tgit fetch && git checkout stable\n\n### Install LightShow Pi\n\n\tcd /home/pi/lightshowpi\n\tsudo ./install.sh\n\nThe install process can take several minutes. You should reboot after the install completes:\n\n\tsudo reboot\n\n### Wire up the relay (differently)\n\nThere are a couple different wiring schemes out there. Lightshow uses a different one than I used for the first setup. This is the best numbering diagram I could find:\n\n\n\n### Verifying Your Hardware Configuration\n\nYou can verify your hardware setup and configuration are setup properly by blinking each channel one at a time using the following command from the main LightShow Pi directory (/home/pi/lightshowpi if you’ve followed the default install steps):\n\n\tsudo python py/hardware_controller.py --state=flash\n\t\nYou can also fade each channel in and out using software PWM using the following command:\n\n\tsudo python py/hardware_controller.py --state=fade\n\nPress <CTRL>-C in the same terminal window to stop the blinking / fading lights test.\n\n"
},
{
"alpha_fraction": 0.6429587602615356,
"alphanum_fraction": 0.6642958521842957,
"avg_line_length": 17.0256404876709,
"blob_id": "c62520ea9a880f383189a1aaf2c840ec8c74c3fb",
"content_id": "7d545a31f0b3a3e1a666d21bad629590eb6d7762",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 39,
"path": "/basic.py",
"repo_name": "turp/xmas",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport RPi.GPIO as GPIO\nimport time\n\nGPIO.setmode(GPIO.BOARD)\n\n# init list with pin numbers\n\npinList = [3, 5, 7, 11, 13, 15, 19, 21]\n\n# loop through pins and set mode and state to 'low'\n\nfor i in pinList: \n GPIO.setup(i, GPIO.OUT) \n GPIO.output(i, GPIO.HIGH)\n\n# time to sleep between operations in the main loop\n\nSleepTimeL = 2\n\ntry:\n for i in pinList:\n GPIO.output(i, GPIO.LOW)\n print i\n time.sleep(SleepTimeL);\n \n GPIO.cleanup()\n print \"Good bye!\"\n\n# End program cleanly with keyboard\nexcept KeyboardInterrupt:\n print \" Quit\"\n\n # Reset GPIO settings\n GPIO.cleanup()\n\n\n# find more information on this script at\n# http://youtu.be/oaf_zQcrg7g\n"
}
] | 2 |
blmsl/scrumboard
|
https://github.com/blmsl/scrumboard
|
81156df1db9a7a6480b35d3830da51f79ba88513
|
ae05e9fd5592563a9d08a1639d0c034a1828ee18
|
2383a089173326b07180b1e6d760a1ea2dc5f040
|
refs/heads/master
| 2020-04-27T10:03:25.637049 | 2019-03-02T17:25:01 | 2019-03-02T17:25:01 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5782880783081055,
"alphanum_fraction": 0.5782880783081055,
"avg_line_length": 24.210525512695312,
"blob_id": "dd4411526581c2f3adcf9ca4a99dd5054ead3052",
"content_id": "88e9806aa7243b854d2c87852f55f0ad76ac8bff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 19,
"path": "/angular/src/app/extra/EntryInterface.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as firebase from 'firebase/app';\nimport 'firebase/firestore';\nexport interface EntryInterface {\n txt: string;\n state?: 'todo' | 'inProgress' | 'done';\n priority?: '!' | '!!' | '!!!';\n time: firebase.firestore.FieldValue;\n imgUrl?: string;\n commentsCount?: number;\n developer?: string;\n id?: string;\n assigned?: string;\n link?: {\n url: string,\n imageUrl?: string;\n title?: string;\n description?: string;\n };\n}\n"
},
{
"alpha_fraction": 0.6220800280570984,
"alphanum_fraction": 0.6230400204658508,
"avg_line_length": 29.930692672729492,
"blob_id": "3fb1182121cd11d12100e2bebc00acb779b6deda",
"content_id": "e912ffc8799ef02390577d2efe653eeaeb44a379",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 3125,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 101,
"path": "/angular/src/app/modules/add-scrum-entry/add-scrum-entry.component.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import { Component, OnInit, Inject } from '@angular/core';\nimport { MAT_DIALOG_DATA, MatDialogRef } from '@angular/material/dialog';\nimport { AngularFirestoreCollection, AngularFirestore } from 'angularfire2/firestore';\nimport { EntryInterface } from '../../extra/EntryInterface';\nimport { Validators, FormBuilder } from '@angular/forms';\nimport { firestore } from 'firebase/app';\nimport { MapToIterablePipe } from '../../extra/map-to-iterable.pipe';\nimport { TeamsInterface } from '../../extra/TeamsInterface';\nimport { Observable } from 'rxjs';\n\n@Component({\n selector: 'app-add-scrum-entry',\n templateUrl: './add-scrum-entry.component.html',\n styleUrls: ['./add-scrum-entry.component.css']\n})\nexport class AddScrumEntryComponent implements OnInit {\n\n priority: '!' | '!!' | '!!!' = '!';\n\n linkPreview = false;\n image = false;\n subtasks = false;\n assignDeveloper = false;\n\n subtaskList: { txt: string, finished: boolean }[] = [{ txt: 'test', finished: true }];\n\n teamMembers$: Observable<any>;\n\n form = this.formBuilder.group({\n txt: ['', Validators.required],\n assignedDeveloper: [''],\n linkInp: [''],\n });\n\n constructor(private afs: AngularFirestore, public dialogRef: MatDialogRef<AddScrumEntryComponent>, private formBuilder: FormBuilder,\n @Inject(MAT_DIALOG_DATA) public data: {\n entryCollection: AngularFirestoreCollection<EntryInterface>, entry?: EntryInterface, teamId: string\n }) {\n console.log(data.entry);\n if (data.entry) {\n this.priority = data.entry.priority;\n if (data.entry.assigned) {\n this.assignDeveloper = true;\n this.form.patchValue({ assignedDeveloper: data.entry.assigned });\n }\n if (data.entry.link) {\n this.linkPreview = true;\n this.form.patchValue({ linkInp: data.entry.link });\n }\n this.form.patchValue({ txt: data.entry.txt });\n }\n this.teamMembers$ = this.afs.doc<TeamsInterface>('teams/' + this.data.teamId).valueChanges().take(1).shareReplay(1).map(team => {\n const users = new MapToIterablePipe().transform(team.members);\n const teamMembers = [];\n for (const user of users) {\n teamMembers.push(\n { value: user.key, viewValue: user.val.name }\n );\n }\n console.log(teamMembers);\n return teamMembers;\n });\n }\n\n ngOnInit() {\n }\n\n add() {\n if (this.form.valid) {\n let assigned = null;\n let link = null;\n if (this.assignDeveloper) {\n assigned = this.form.value.assignedDeveloper;\n }\n if (this.linkPreview) {\n link = this.form.value.linkInp;\n }\n if (this.data.entry) {\n this.data.entryCollection.doc(this.data.entry.id).update({\n txt: this.form.value.txt,\n priority: this.priority,\n assigned,\n link\n });\n } else {\n this.data.entryCollection.add({\n txt: this.form.value.txt,\n state: 'todo', priority: this.priority,\n time: firestore.FieldValue.serverTimestamp(),\n assigned,\n link\n });\n }\n this.close();\n }\n }\n\n close() {\n this.dialogRef.close();\n }\n}\n\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 18.200000762939453,
"blob_id": "a522d9c9b2c8da4f29cd4d894e1b0f16aee20ffd",
"content_id": "cfe74936f8b2a85725af19e5591f7485a75164cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 5,
"path": "/angular/src/app/extra/NotificationInterface.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "export interface NotificationInterface {\n title: string;\n txt: string;\n id?: string;\n}\n"
},
{
"alpha_fraction": 0.5636850595474243,
"alphanum_fraction": 0.5681637525558472,
"avg_line_length": 30.10677146911621,
"blob_id": "43531dd9b38793bcebd4871ac84e97aca95e185d",
"content_id": "ac5d15bc36a5ed65bc2adc93e37f371cc5eac74a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 23891,
"license_type": "no_license",
"max_line_length": 166,
"num_lines": 768,
"path": "/angular/src/app/ui/scrum/scrum.component.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import { AddScrumEntryComponent } from './../../modules/add-scrum-entry/add-scrum-entry.component';\nimport { EntryInterface } from './../../extra/EntryInterface';\nimport { TeamsService } from './../../services/teams.service';\nimport { Board } from './../../extra/BoardInterface';\nimport { NavbarService } from './../../services/navbar.service';\nimport { Component, OnInit, OnDestroy, AfterViewInit, ViewChild } from '@angular/core';\nimport { ActivatedRoute } from '@angular/router';\nimport { AngularFirestoreCollection, DocumentChangeAction, AngularFirestore, AngularFirestoreDocument } from 'angularfire2/firestore';\nimport { Observable, BehaviorSubject, Subscription, combineLatest, forkJoin } from 'rxjs';\nimport { AuthServiceService } from '../../services/auth-service.service';\nimport 'rxjs/add/operator/switchMap';\nimport swal from 'sweetalert2';\nimport { firestore } from 'firebase/app';\nimport { MatSnackBar } from '@angular/material/snack-bar';\nimport { trigger, transition, style, animate } from '@angular/animations';\nimport { MatDialog } from '@angular/material/dialog';\nimport { ThreadComponent } from '../../modules/thread/thread.component';\nimport { TeamsInterface } from '../../extra/TeamsInterface';\nimport { MapToIterablePipe } from '../../extra/map-to-iterable.pipe';\nimport { HotkeysService, Hotkey } from 'angular2-hotkeys';\nimport { SwalComponent } from '@toverux/ngx-sweetalert2';\nimport { merge } from 'rxjs/operators';\n\n@Component({\n selector: 'app-scrum',\n templateUrl: './scrum.component.html',\n styleUrls: ['./scrum.component.css'],\n animations: [\n\n trigger('entriesAnim', [\n\n transition('void => in', [\n style({ transform: 'scale(0.5)', opacity: 0 }), // initial\n animate('1s cubic-bezier(.8, -0.6, 0.2, 1.5)',\n style({ transform: 'scale(1)', opacity: 1 })) // final\n ]),\n\n transition(':leave', [\n style({ transform: 'scale(1)', opacity: 1, height: '*' }),\n animate('1s cubic-bezier(.8, -0.6, 0.2, 1.5)',\n style({\n transform: 'scale(0.5)', opacity: 0,\n height: '0px', margin: '0px'\n }))\n ])\n\n ]),\n ]\n\n})\n\n\nexport class ScrumComponent implements OnInit, OnDestroy, AfterViewInit {\n\n id: string;\n teamId: string;\n\n boardDoc: AngularFirestoreDocument<Board>;\n\n isPublic = false; // used for the make public link swal popup\n isSignedIn = false;\n shareableLink: string;\n\n swalVar;\n\n entryCollection: AngularFirestoreCollection<EntryInterface>;\n\n $todo: Observable<EntryInterface[]>;\n $inProgress: Observable<EntryInterface[]>;\n $done: Observable<EntryInterface[]>;\n\n bugCollection: AngularFirestoreCollection<EntryInterface>;\n $bugs: Observable<EntryInterface[]>;\n\n ideaCollection: AngularFirestoreCollection<EntryInterface>;\n $ideas: Observable<EntryInterface[]>;\n\n noteCollection: AngularFirestoreCollection<EntryInterface>;\n $notes: Observable<EntryInterface[]>;\n\n client_bugs_collection: AngularFirestoreCollection<EntryInterface>;\n $client_bugs: Observable<EntryInterface[]>;\n\n client_feature_collection: AngularFirestoreCollection<EntryInterface>;\n $c_features: Observable<EntryInterface[]>;\n\n client_notes_collection: AngularFirestoreCollection<EntryInterface>;\n $c_notes: Observable<EntryInterface[]>;\n\n sortBy = '{\"field\": \"priority\", \"direction\": \"desc\"}';\n $orderBy: BehaviorSubject<string>;\n\n sub: Subscription;\n navTab = 'todo';\n loading = true;\n loadingSub: Subscription;\n\n disableAnimations: boolean;\n\n @ViewChild('linkShareSwal') private linkShareSwal: SwalComponent;\n\n ngAfterViewInit(): void {\n this.disableAnimations = true;\n }\n\n constructor(public route: ActivatedRoute,\n public teamsService: TeamsService,\n public auth: AuthServiceService,\n public snackBar: MatSnackBar,\n public navbarService: NavbarService,\n public dialog: MatDialog,\n public afs: AngularFirestore,\n private hotkeysService: HotkeysService) {\n this.id = this.route.snapshot.paramMap.get('id');\n this.teamId = this.route.snapshot.paramMap.get('teamId');\n this.shareableLink = 'https://scrum.magson.no/scrum/' + this.teamId + '/' + this.id;\n\n this.boardDoc = afs.doc<Board>('teams/' + this.teamId + '/boards/' + this.id);\n this.sub = this.boardDoc.valueChanges().subscribe(board => {\n this.isPublic = board.isPublic;\n navbarService.title = board.name;\n });\n\n\n // set the orderBy to last used\n if (localStorage.orderBy) {\n this.sortBy = localStorage.orderBy;\n }\n this.$orderBy = new BehaviorSubject<string>(this.sortBy);\n\n this.entryCollection = this.boardDoc\n .collection<EntryInterface>('entries');\n\n const $entries = this.$orderBy.switchMap(sortBy => {\n const config = JSON.parse(sortBy);\n return this.toMap(this.boardDoc\n .collection<EntryInterface>('entries', ref => ref.orderBy(config.field, config.direction)).snapshotChanges());\n });\n\n this.$todo = $entries.map(entrier => entrier.filter(entry => entry.state === 'todo'));\n this.$inProgress = $entries.map(entrier => entrier.filter(entry => entry.state === 'inProgress'));\n this.$done = $entries.map(entrier => entrier.filter(entry => entry.state === 'done'));\n\n this.bugCollection = this.boardDoc.collection<EntryInterface>('bugs');\n this.$bugs = this.toMap(this.bugCollection.snapshotChanges());\n\n this.ideaCollection = this.boardDoc.collection<EntryInterface>('ideas');\n this.$ideas = this.toMap(this.ideaCollection.snapshotChanges());\n\n this.noteCollection = this.boardDoc.collection<EntryInterface>('notes');\n this.$notes = this.toMap(this.noteCollection.snapshotChanges());\n\n this.client_bugs_collection = this.boardDoc.collection<EntryInterface>('client_bugs');\n this.$client_bugs = this.toMap(this.client_bugs_collection.snapshotChanges());\n\n this.client_feature_collection = this.boardDoc.collection<EntryInterface>('client_feature_request');\n this.$c_features = this.toMap(this.client_feature_collection.snapshotChanges());\n\n this.client_notes_collection = this.boardDoc.collection<EntryInterface>('client_notes');\n this.$c_notes = this.toMap(this.client_notes_collection.snapshotChanges());\n\n\n\n this.loadingSub = combineLatest(this.$todo, this.$inProgress, this.$done)\n .subscribe(([_1, _2, _3]) => this.loading = false);\n\n this.auth.user$.take(1).subscribe((user) => {\n if (user) {\n this.isSignedIn = true;\n }\n });\n this.hotkeysService.add(new Hotkey('n', (event: KeyboardEvent): boolean => {\n\n switch (this.navTab) {\n case 'todo':\n console.log('todo');\n this.add();\n break;\n case 'bugs':\n console.log('bugs');\n this.addBug();\n break;\n case 'ideas':\n console.log('ideas');\n this.addIdea();\n break;\n case 'notes':\n console.log('notes');\n this.addNote();\n break;\n case 'beta':\n console.log('beta');\n this.add_feedback();\n break;\n default:\n break;\n }\n\n return false;\n }));\n this.hotkeysService.add(new Hotkey('1', (event: KeyboardEvent): boolean => {\n this.navTab = 'todo';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('2', (event: KeyboardEvent): boolean => {\n this.navTab = 'bugs';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('3', (event: KeyboardEvent): boolean => {\n this.navTab = 'ideas';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('4', (event: KeyboardEvent): boolean => {\n this.navTab = 'notes';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('5', (event: KeyboardEvent): boolean => {\n this.navTab = 'beta';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('6', (event: KeyboardEvent): boolean => {\n this.navTab = 'info';\n return false;\n }));\n this.hotkeysService.add(new Hotkey('ctrl+s', (event: KeyboardEvent): boolean => {\n this.linkShareSwal.show();\n return false;\n }));\n }\n\n delete(entry: EntryInterface) {\n swal({\n title: 'Are you sure?',\n text: 'This will delete this task permanently!',\n type: 'warning',\n showCancelButton: true,\n confirmButtonText: 'Delete',\n confirmButtonColor: '#e95d4f',\n cancelButtonText: 'Cancel',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Delete method here\n this.entryCollection.doc(entry.id).delete().then(() => {\n const snack = this.snackBar.open('Entry was deleted', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n this.entryCollection.add(entry);\n });\n\n // Google analytics event\n (<any>window).ga('send', 'event', {\n eventCategory: 'Scrumboard interaction',\n eventAction: 'Delete task',\n });\n });\n }\n });\n }\n\n updateEntryState(entry: EntryInterface, state: 'todo' | 'inProgress' | 'done') {\n if (state === 'inProgress') {\n this.auth.user$.take(1).subscribe((user) => {\n // tslint:disable-next-line:max-line-length\n this.entryCollection.doc(entry.id).update({ state: state, imgUrl: user.photoURL, developer: user.displayName, time: firestore.FieldValue.serverTimestamp() });\n });\n } else {\n this.entryCollection.doc(entry.id).update({ state: state, time: firestore.FieldValue.serverTimestamp() });\n }\n\n }\n\n edit(entry: EntryInterface) {\n this.dialog.open(AddScrumEntryComponent, {\n data: { entryCollection: this.entryCollection, entry, teamId: this.teamId },\n // position: {\n // bottom: '0px'\n // }\n });\n }\n\n ngOnInit() {\n this.navbarService.backBtn = true;\n if (this.route.snapshot.queryParamMap.get('e')) {\n this.$todo.pipe(merge(this.$inProgress), merge(this.$done)).subscribe(entries => {\n entries.forEach(entry => {\n if (entry.id === this.route.snapshot.queryParamMap.get('e')) {\n this.openThread(entry);\n }\n });\n });\n }\n }\n\n sortChanged() {\n this.$orderBy.next(this.sortBy);\n localStorage.orderBy = this.sortBy;\n }\n\n ngOnDestroy() {\n this.navbarService.backBtn = false;\n\n this.sub.unsubscribe();\n this.loadingSub.unsubscribe();\n }\n\n\n uploadBoardVisibility(val) {\n console.log(this.isPublic, val);\n this.boardDoc.update({\n isPublic: val.checked\n });\n }\n\n toMap(observable: Observable<DocumentChangeAction<EntryInterface>[]>): Observable<EntryInterface[]> {\n return observable.map(actions => {\n return actions.map(a => {\n const data = a.payload.doc.data() as EntryInterface;\n data.id = a.payload.doc.id;\n return data;\n });\n });\n }\n\n async add() {\n this.dialog.open(AddScrumEntryComponent, {\n data: { entryCollection: this.entryCollection, teamId: this.teamId },\n // position: {\n // bottom: '0px'\n // }\n });\n }\n\n identify(idx, item: EntryInterface) {\n return item.id;\n }\n\n copyLinkTxt() {\n const copyText = <HTMLInputElement>document.getElementById('shareableLinkInp');\n copyText.select();\n document.execCommand('copy');\n }\n\n checkIfChecked(priority: string, x: string) {\n if (priority === x) { return 'checked'; }\n return null;\n }\n\n sendEvent = (filter: String) => {\n (<any>window).ga('send', 'event', {\n eventCategory: 'User settings',\n eventLabel: filter,\n eventAction: 'Change filter',\n eventValue: 10\n });\n }\n\n /* ---------------------------------------------------------------------------------------------------- */\n /* BUGS METHODS */\n\n async addBug() {\n const { value: post } = await swal({\n title: 'Report bug',\n input: 'text',\n reverseButtons: true,\n showCancelButton: true,\n });\n if (post) {\n // add to firebase\n this.auth.user$.take(1).subscribe((user) => {\n this.bugCollection.add({\n txt: post, developer: user.displayName, time: firestore.FieldValue.serverTimestamp(),\n imgUrl: user.photoURL\n });\n });\n // Google analytics event\n (<any>window).ga('send', 'event', {\n eventCategory: 'Scrumboard interaction',\n eventAction: 'New bug reported',\n });\n }\n }\n\n async editBug(bug: EntryInterface) {\n const { value: post } = await swal({\n title: 'Edit bug',\n input: 'text',\n inputValue: bug.txt,\n reverseButtons: true,\n showCancelButton: true,\n onOpen: function () {\n const input = (<HTMLInputElement>swal.getInput());\n input.setSelectionRange(0, input.value.length);\n },\n inputValidator: (value) => {\n return !value && 'You need to write something!';\n }\n });\n if (post) {\n this.bugCollection.doc(bug.id).update({\n txt: post\n });\n }\n }\n\n move_to_inprogress(entry: EntryInterface, collection: AngularFirestoreCollection<EntryInterface>) {\n swal({\n title: 'Move to in progress?',\n type: 'question',\n showCancelButton: true,\n confirmButtonText: 'Yes!',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n if (!entry.priority) {\n entry.priority = '!!!';\n }\n // Add to inProgress\n this.auth.user$.take(1).subscribe((user) => {\n this.entryCollection.add({\n txt: entry.txt, priority: entry.priority, developer: user.displayName, time: firestore.FieldValue.serverTimestamp(),\n imgUrl: user.photoURL, state: 'inProgress'\n });\n\n });\n // Delete from collection\n collection.doc(entry.id).delete().then(() => {\n const snack = this.snackBar.open('Moved to in progress', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n collection.add(entry);\n });\n });\n }\n });\n }\n\n deleteBug(bug: EntryInterface, collection: AngularFirestoreCollection<EntryInterface>) {\n swal({\n title: 'Are you sure?',\n text: 'This will delete this bug permanently!',\n type: 'warning',\n showCancelButton: true,\n confirmButtonText: 'Delete',\n confirmButtonColor: '#e95d4f',\n cancelButtonText: 'Cancel',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Delete method here\n collection.doc(bug.id).delete().then(() => {\n const snack = this.snackBar.open('Bug was deleted', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n collection.add(bug);\n });\n\n // Google analytics event\n });\n }\n });\n }\n\n /* BUGS METHODS END*/\n /* ---------------------------------------------------------------------------------------------------- */\n\n /* ---------------------------------------------------------------------------------------------------- */\n /* IDEAS METHODS */\n async addIdea() {\n const { value: post } = await swal({\n title: 'What is your wonderful idea?',\n input: 'text',\n reverseButtons: true,\n showCancelButton: true,\n });\n if (post) {\n // add to firebase\n this.auth.user$.take(1).subscribe((user) => {\n this.ideaCollection.add({\n txt: post, developer: user.displayName, time: firestore.FieldValue.serverTimestamp(),\n imgUrl: user.photoURL\n });\n });\n\n // Google analytics event\n (<any>window).ga('send', 'event', {\n eventCategory: 'Scrumboard interaction',\n eventAction: 'New idea created',\n });\n }\n }\n\n async editIdea(idea: EntryInterface) {\n const { value: post } = await swal({\n title: 'Edit idea',\n input: 'text',\n inputValue: idea.txt,\n reverseButtons: true,\n showCancelButton: true,\n onOpen: function () {\n const input = (<HTMLInputElement>swal.getInput());\n input.setSelectionRange(0, input.value.length);\n },\n inputValidator: (value) => {\n return !value && 'You need to write something!';\n }\n });\n if (post) {\n this.ideaCollection.doc(idea.id).update({\n txt: post\n });\n }\n }\n\n deleteIdea(idea: EntryInterface) {\n swal({\n title: 'Are you sure?',\n text: 'This will delete your idea permanently!',\n type: 'warning',\n showCancelButton: true,\n confirmButtonText: 'Delete',\n confirmButtonColor: '#e95d4f',\n cancelButtonText: 'Cancel',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Delete method here\n this.ideaCollection.doc(idea.id).delete().then(() => {\n const snack = this.snackBar.open('Your idea is now history', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n this.ideaCollection.add(idea);\n });\n // Google analytics event\n\n });\n }\n });\n }\n\n /* IDEAS METHODS END */\n /* ---------------------------------------------------------------------------------------------------- */\n\n /* ---------------------------------------------------------------------------------------------------- */\n /* NOTES METHODS */\n\n async addNote() {\n const { value: post } = await swal({\n title: 'Add a something to remember',\n input: 'text',\n reverseButtons: true,\n showCancelButton: true,\n });\n if (post) {\n // add to firebase\n this.auth.user$.take(1).subscribe((user) => {\n this.noteCollection.add({\n txt: post, developer: user.displayName, time: firestore.FieldValue.serverTimestamp(),\n imgUrl: user.photoURL\n });\n });\n\n // Google analytics event\n (<any>window).ga('send', 'event', {\n eventCategory: 'Scrumboard interaction',\n eventAction: 'New note created',\n });\n }\n }\n\n async editNote(note: EntryInterface, collection: AngularFirestoreCollection<EntryInterface>) {\n const { value: post } = await swal({\n title: 'Edit note',\n input: 'text',\n inputValue: note.txt,\n reverseButtons: true,\n showCancelButton: true,\n onOpen: function () {\n const input = (<HTMLInputElement>swal.getInput());\n input.setSelectionRange(0, input.value.length);\n },\n inputValidator: (value) => {\n return !value && 'You need to write something!';\n }\n });\n if (post) {\n collection.doc(note.id).update({\n txt: post\n });\n }\n }\n\n deleteNote(note: EntryInterface, collection: AngularFirestoreCollection<EntryInterface>) {\n swal({\n title: 'Are you sure?',\n text: 'This will delete your note permanently!',\n type: 'warning',\n showCancelButton: true,\n confirmButtonText: 'Delete',\n confirmButtonColor: '#e95d4f',\n cancelButtonText: 'Cancel',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Delete method here\n collection.doc(note.id).delete().then(() => {\n const snack = this.snackBar.open('Your note is now history', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n collection.add(note);\n });\n // Google analytics event\n\n });\n }\n });\n }\n\n /* NOTES METHODS END */\n /* ---------------------------------------------------------------------------------------------------- */\n\n /* ---------------------------------------------------------------------------------------------------- */\n /* FEEDBACK METHODS */\n\n moveToBugs(bug: EntryInterface) {\n swal({\n title: 'Move to collection of bugs?',\n type: 'question',\n showCancelButton: true,\n confirmButtonText: 'Yes!',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Add to todo\n this.bugCollection.add({\n txt: bug.txt, priority: bug.priority, time: firestore.FieldValue.serverTimestamp()\n });\n // Delete from bug collection\n this.client_bugs_collection.doc(bug.id).delete().then(() => {\n this.client_bugs_collection.doc(bug.id).delete().then(() => {\n const snack = this.snackBar.open('Moved to tasks', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n this.client_bugs_collection.add(bug);\n });\n });\n });\n }\n });\n }\n\n async edit_feature_request(entry: EntryInterface) {\n const { value: post } = await swal({\n title: 'Edit',\n input: 'text',\n inputValue: entry.txt,\n reverseButtons: true,\n showCancelButton: true,\n onOpen: function () {\n const input = (<HTMLInputElement>swal.getInput());\n input.setSelectionRange(0, input.value.length);\n },\n inputValidator: (value) => {\n return !value && 'You need to write something!';\n }\n });\n if (post) {\n this.client_feature_collection.doc(entry.id).update({\n txt: post\n });\n }\n }\n\n delete_feature_request(entry: EntryInterface) {\n swal({\n title: 'Are you sure?',\n text: 'This will delete it permanently!',\n type: 'warning',\n showCancelButton: true,\n confirmButtonText: 'Delete',\n confirmButtonColor: '#e95d4f',\n cancelButtonText: 'Cancel',\n reverseButtons: true\n }).then((result) => {\n if (result.value) {\n // Delete method here\n this.client_feature_collection.doc(entry.id).delete().then(() => {\n const snack = this.snackBar.open('Your feature request is now history', 'Undo', {\n duration: 2500\n });\n snack.onAction().subscribe(() => {\n // Add to database again\n this.client_feature_collection.add(entry);\n });\n // Google analytics event\n\n });\n }\n });\n }\n\n async add_feedback() {\n const { value: post } = await swal({\n title: 'Send feedback',\n html: `\n <select id=\"feedbackSelect\" class=\"swal2-select\" style=\"outline:0;\">\n <option value=\"client_bugs\">Bug</option>\n <option value=\"client_feature_request\">Feature request</option>\n <option value=\"client_note\">Note</option>\n </select>\n <textarea id=\"feedbackTxt\" class=\"swal2-textarea\"></textarea>`,\n showCancelButton: true,\n reverseButtons: true,\n preConfirm: () => {\n return [\n (<HTMLInputElement>document.getElementById('feedbackSelect')).value,\n (<HTMLInputElement>document.getElementById('feedbackTxt')).value,\n ];\n }\n });\n if (post[1] !== '') {\n this.auth.user$.take(1).subscribe(user => {\n this.afs.collection(post[0]).add({\n txt: post[1],\n date: firestore.FieldValue.serverTimestamp(),\n });\n });\n } else if (post[1] === '') {\n swal({\n title: 'Invalid.',\n type: 'error',\n text: 'Please fill in something!'\n });\n }\n }\n\n /* FEEDBACK METHODS END */\n /* ---------------------------------------------------------------------------------------------------- */\n\n /* ---------------------------------------------------------------------------------------------------- */\n /* COMMENTS METHODS */\n\n\n openThread(entry: EntryInterface) {\n const dialogRef = this.dialog.open(ThreadComponent, {\n data: { entry, teamId: this.teamId, boardId: this.id },\n // position: {\n // bottom: '0px'\n // }\n });\n }\n\n\n /* COMMENTS METHODS END */\n /* ---------------------------------------------------------------------------------------------------- */\n}\n\n"
},
{
"alpha_fraction": 0.6072834730148315,
"alphanum_fraction": 0.6151574850082397,
"avg_line_length": 36.62963104248047,
"blob_id": "ba35715c8ca35f07bc2a39b94ea3c5efa2bb2deb",
"content_id": "af6efd0ab394ba9f0720579df375ee306acfd7a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1016,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 27,
"path": "/functions/src/sendNotification.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as functions from 'firebase-functions';\nimport * as admin from 'firebase-admin';\n\nexport const sendNotification = functions.firestore\n .document('users/{uid}/notifications/{notificationId}')\n .onCreate(async (snap, context) => {\n const messaging = admin.messaging();\n const firestore = admin.firestore();\n const userId = context.params.uid;\n const notifiation = snap.data();\n const payload = {\n notification: {\n title: notifiation.title,\n body: notifiation.txt,\n click_action: notifiation.link,\n icon: \"https://scrumboard.io/assets/[email protected]\"\n }\n };\n const user = (await firestore.doc('users/' + userId).get()).data();\n console.log({ userId, message: notifiation, user })\n const tokens = user.fcmTokens;\n const promises = [];\n tokens.forEach(token => {\n promises.push(messaging.sendToDevice(token, payload)); \n });\n return Promise.all(promises);\n });\n"
},
{
"alpha_fraction": 0.6610950827598572,
"alphanum_fraction": 0.6616714596748352,
"avg_line_length": 34.408164978027344,
"blob_id": "e1ea596775389e34267348e3410495e0a2e455d5",
"content_id": "321ace5864863e91bab6bbb2813d730ace70b43f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1735,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 49,
"path": "/angular/src/app/services/messaging.service.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import { NotificationInterface } from './../extra/NotificationInterface';\nimport { Injectable } from '@angular/core';\nimport { AngularFireMessaging } from '@angular/fire/messaging';\nimport { mergeMapTo } from 'rxjs/operators';\nimport { AuthServiceService } from './auth-service.service';\nimport { AngularFirestore, DocumentChangeAction } from 'angularfire2/firestore';\nimport { firestore } from 'firebase/app';\nimport { Observable } from 'rxjs';\n\n@Injectable({\n providedIn: 'root'\n})\nexport class MessagingService {\n\n notifications$: Observable<NotificationInterface[]>;\n\n constructor(private afMessaging: AngularFireMessaging, private auth: AuthServiceService, private afs: AngularFirestore) {\n this.notifications$ = this.auth.user$.switchMap(user => {\n return this.toMap(this.afs.collection<NotificationInterface>('users/' + user.uid + '/notifications').snapshotChanges());\n });\n\n this.afMessaging.requestPermission\n .pipe(mergeMapTo(this.afMessaging.tokenChanges))\n .subscribe(\n (token) => {\n console.log(token);\n // Upload token to server\n this.auth.user$.filter(user => user != null).subscribe(user => {\n this.afs.doc<any>('users/' + user.uid).update({\n fcmTokens: firestore.FieldValue.arrayUnion(token)\n });\n });\n },\n (error) => { console.error(error); },\n );\n }\n\n toMap(observable: Observable<DocumentChangeAction<NotificationInterface>[]>): Observable<NotificationInterface[]> {\n return observable.map(actions => {\n return actions.map(a => {\n const data = a.payload.doc.data() as NotificationInterface;\n data.id = a.payload.doc.id;\n return data;\n });\n });\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.7740350961685181,
"alphanum_fraction": 0.7740350961685181,
"avg_line_length": 43.5625,
"blob_id": "147a77da42a6aa578f1f4088893ddd9ba21e024c",
"content_id": "5c2ac8922b3e99dee6b11cc01d9aeb0f2a9ef397",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 1425,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 32,
"path": "/functions/src/index.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as admin from 'firebase-admin';\n\nadmin.initializeApp({\n storageBucket: 'magson-developer.appspot.com',\n});\n\nconst firestore = admin.firestore();\nconst settings = { timestampsInSnapshots: true };\nfirestore.settings(settings);\n\nimport { addNonExistentUsers } from './addNonExistentUsers';\nimport { sendInviteToNonExistentUsers } from './sendInviteToNonExistentUsers';\nimport { sendWelcomeEmail } from './sendWelcomeEmail';\nimport { newRequest } from './newRequest';\nimport { listAllUsers } from './listAllUsers';\nimport { getUserByMail } from './getUserByMail';\nimport { deleteEmptyTeams } from './deleteEmptyTeams';\nimport { createAdmin } from './createAdmin';\nimport { addMember } from './addMember';\nimport { accountcleanup } from './accountcleanup';\nimport { teamImageResizer } from './teamImageResizer';\nimport { deleteScrum } from './deleteScrum';\nimport { onEntryCreated, onEntryDeleted, onEntryUpdated } from './scrumAggregation';\nimport { sendNotification } from './sendNotification';\nimport { onNewScrumComments, onDeletedScrumComments } from './onNewScrumComment';\n\n\nexport { accountcleanup, addMember, createAdmin, deleteEmptyTeams, \n getUserByMail, listAllUsers, newRequest, deleteScrum, \n sendWelcomeEmail, sendInviteToNonExistentUsers, addNonExistentUsers, \n teamImageResizer, onEntryCreated, onEntryDeleted, onEntryUpdated,\n sendNotification, onNewScrumComments, onDeletedScrumComments }"
},
{
"alpha_fraction": 0.7094017267227173,
"alphanum_fraction": 0.7150996923446655,
"avg_line_length": 27.1200008392334,
"blob_id": "fde8eaf5d8cff88fdd7e0cd844aab81a0eb352c6",
"content_id": "94d6514aedcfc5c7f3e59738edff28041554a367",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 25,
"path": "/databaseUpdater.py",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import firebase_admin\nfrom firebase_admin import credentials\nfrom firebase_admin import firestore\n\ncred = credentials.Certificate(\"serviceAccountKey.json\")\nfirebase_admin.initialize_app(cred)\nfs = firestore.client()\n\nteamId = 'imtaPFFgbkn5PrLzwzis'\nboardId = 'L6tuzaNSOp1aeUHGp2hZ'\n\nboardDoc = fs.document(u'teams/' + teamId + '/boards/' + boardId)\n\nentryCollection = boardDoc.collection('entries')\n\ncollections = ['todo', 'inProgress', 'done']\n\nfor collection in collections:\n todos = boardDoc.collection(collection).get()\n for data in todos:\n id = data.id\n todo = data.to_dict()\n todo['state'] = collection\n print(todo)\n entryCollection.document(id).set(todo)"
},
{
"alpha_fraction": 0.4793087840080261,
"alphanum_fraction": 0.4979536235332489,
"avg_line_length": 39.72222137451172,
"blob_id": "92ba23c7c54b4359bc7d8640a3e82e3de1b24eae",
"content_id": "7ee3f3754874cc707e58903335c75283b1fc12ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2199,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 54,
"path": "/functions/src/extra/linkPreview.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as puppeteer from 'puppeteer';\n\nexport function linkPreview(url: string): Promise<{\n title: string,\n desc: string,\n img: string\n}> {\n return new Promise(async (resolve, reject) => {\n try {\n const browser = await puppeteer.launch({\n headless: true,\n args: ['--no-sandbox', '--disable-setuid-sandbox']\n });\n const page = await browser.newPage();\n await page.setUserAgent('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3419.0 Safari/537.36');\n await page.setRequestInterception(true);\n page.on('request', (request) => {\n if (['image', 'stylesheet', 'font', 'script'].indexOf(request.resourceType()) !== -1) {\n request.abort();\n } else {\n request.continue();\n }\n });\n await page.goto(url, { waitUntil: 'networkidle0' });\n const title = await page.title();\n console.log('Scraping website: ', title);\n const desc = await page.evaluate(() => {\n try {\n try { return (<any>document.querySelectorAll(\"head > meta[property='og:description']\")[0]).content; }\n catch { return (<any>document.querySelectorAll(\"head > meta[name='description']\")[0]).content; }\n } catch {\n return null;\n }\n });\n const img = await page.evaluate(() => {\n try {\n try { return (<any>document.querySelectorAll(\"head > meta[property='og:image']\")[0]).content }\n catch { return (<any>document.querySelectorAll(\"img\")[0]).src }\n } catch {\n return null\n }\n });\n console.log({ desc, title, img });\n\n await browser.close();\n resolve({ title, desc, img })\n } catch (err) {\n console.error(err);\n reject(err);\n }\n });\n}\n\n// linkPreview('https://stackoverflow.com/questions/47328830/get-title-from-newly-opened-page-puppeteer');\n"
},
{
"alpha_fraction": 0.6517302393913269,
"alphanum_fraction": 0.6535049080848694,
"avg_line_length": 37.20338821411133,
"blob_id": "c99fa291d783d804557187d26e470b137776cb2f",
"content_id": "3f9f8a21028eb0affd7f0a7fdbd74287cb40d860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2254,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 59,
"path": "/functions/src/scrumAggregation.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as functions from 'firebase-functions';\nimport * as admin from 'firebase-admin';\nimport { linkPreview } from './extra/linkPreview';\n\nconst fs = admin.firestore();\n\nexport const onEntryCreated = functions.runWith({ memory: '1GB' }).firestore\n .document('teams/{teamId}/boards/{boardId}/entries/{entryId}')\n .onCreate(async (snap, context) => {\n return Promise.all([\n update(context.params.teamId, context.params.boardId, { add: snap.data().state, delete: false }),\n createLinkPreview(snap.data().link, snap.ref)\n ]);\n });\n\nexport const onEntryDeleted = functions.firestore\n .document('teams/{teamId}/boards/{boardId}/entries/{entryId}')\n .onDelete(async (snap, context) =>\n update(context.params.teamId, context.params.boardId, { add: false, delete: snap.data().state }));\n\nexport const onEntryUpdated = functions.firestore\n .document('teams/{teamId}/boards/{boardId}/entries/{entryId}')\n .onUpdate(async (change, context) => {\n const before = change.before.data()\n const after = change.after.data();\n\n if (before.state === after.state) return false;\n\n return update(context.params.teamId, context.params.boardId,\n { delete: before.state, add: after.state });\n });\n\nasync function update(teamId: string, boardId: string, stateChange?: stateChangeInterface) {\n const boardDoc = (await fs.doc('teams/' + teamId + '/boards/' + boardId).get()).data();\n let aggregatedData = boardDoc.aggregatedData;\n if (!aggregatedData) {\n aggregatedData = { todo: 0, inProgress: 0, done: 0 };\n }\n if (stateChange.add) {\n aggregatedData[stateChange.add]++;\n }\n if (stateChange.delete) {\n aggregatedData[stateChange.delete]--;\n }\n return fs.doc('teams/' + teamId + '/boards/' + boardId).update({ aggregatedData });\n}\n\nasync function createLinkPreview(link: string, ref: FirebaseFirestore.DocumentReference): Promise<any> {\n if (link) {\n const preview = await linkPreview(link);\n return ref.update({ link: preview })\n }\n else return Promise.resolve();\n}\n\ninterface stateChangeInterface {\n add: 'todo' | 'inProgress' | 'done' | false;\n delete: 'todo' | 'inProgress' | 'done' | false;\n}\n"
},
{
"alpha_fraction": 0.6897150874137878,
"alphanum_fraction": 0.6904100179672241,
"avg_line_length": 31.704545974731445,
"blob_id": "d5ec35d9c4de75506c4e5ad2c83c32b598520487",
"content_id": "84c1907b6679a49abb56d43574690c182b018d79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2878,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 88,
"path": "/angular/src/app/modules/thread/thread.component.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import { CommentInterface } from './../../extra/CommentInterface';\nimport { Component, OnInit, Inject } from '@angular/core';\nimport { MatDialogRef, MAT_DIALOG_DATA } from '@angular/material/dialog';\nimport { EntryInterface } from '../../extra/EntryInterface';\nimport { FormControl, FormGroup, Validators } from '@angular/forms';\nimport { AngularFirestore, AngularFirestoreCollection, AngularFirestoreDocument, DocumentChangeAction } from 'angularfire2/firestore';\nimport { Observable } from 'rxjs/Observable';\nimport { AuthServiceService } from '../../services/auth-service.service';\nimport * as firebase from 'firebase/app';\nimport 'firebase/firestore';\n\n@Component({\n selector: 'app-thread',\n templateUrl: './thread.component.html',\n styleUrls: ['./thread.component.css']\n})\nexport class ThreadComponent implements OnInit {\n\n entryDoc: AngularFirestoreDocument;\n entry$: Observable<EntryInterface>;\n commentsCollection: AngularFirestoreCollection<CommentInterface>;\n comments$: Observable<CommentInterface[]>;\n\n commentFormControl = new FormControl('', [\n Validators.required,\n ]);\n\n commentForm = new FormGroup({\n comment: this.commentFormControl\n });\n\n constructor(public dialogRef: MatDialogRef<ThreadComponent>,\n @Inject(MAT_DIALOG_DATA) public data: {entry: EntryInterface, teamId: string, boardId: string},\n public auth: AuthServiceService,\n public afs: AngularFirestore) {\n this.entryDoc = this.afs.doc<EntryInterface>('teams/' + data.teamId + '/boards/' + data.boardId + '/entries/' + data.entry.id);\n this.commentsCollection = this.entryDoc.collection('comments', ref => ref.orderBy('time', 'desc'));\n\n this.comments$ = this.toMap(this.commentsCollection.snapshotChanges());\n }\n\n ngOnInit() {\n }\n\n editComment(comment) {\n const newTxt = prompt('New txt', comment.txt);\n if (newTxt) {\n this.commentsCollection.doc(comment.doc.id).update({\n txt: newTxt\n });\n }\n }\n\n deleteComment(comment: CommentInterface) {\n console.log(comment);\n this.commentsCollection.doc(comment.id).delete();\n }\n\n onFormSubmit() { // Creating new comment\n const input = this.commentForm.value.comment;\n if (this.commentFormControl.valid) {\n this.auth.user$.take(1).subscribe(user => {\n this.commentsCollection.add({\n username: user.displayName,\n uid: user.uid,\n txt: input,\n imgUrl: user.photoURL,\n time: firebase.firestore.FieldValue.serverTimestamp()\n } as CommentInterface);\n });\n }\n }\n\n close() {\n this.dialogRef.close();\n }\n\n toMap(observable: Observable<DocumentChangeAction<CommentInterface>[]>): Observable<CommentInterface[]> {\n return observable.map(actions => {\n return actions.map(a => {\n const data = a.payload.doc.data() as CommentInterface;\n data.id = a.payload.doc.id;\n return data;\n });\n });\n }\n\n}\n"
},
{
"alpha_fraction": 0.5482476949691772,
"alphanum_fraction": 0.549687922000885,
"avg_line_length": 41.51020431518555,
"blob_id": "9c93d247558751912c6889651af8fe14ff16f507",
"content_id": "bed0c390a6900b50e2a6597a075752b8e0ae11aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TypeScript",
"length_bytes": 2083,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 49,
"path": "/functions/src/onNewScrumComment.ts",
"repo_name": "blmsl/scrumboard",
"src_encoding": "UTF-8",
"text": "import * as functions from 'firebase-functions';\nimport * as admin from 'firebase-admin';\n\nexport const onNewScrumComments = functions.firestore\n .document('teams/{teamId}/boards/{boardId}/entries/{entryId}/comments/{commentId}')\n .onCreate((snap, context) => {\n const firestore = admin.firestore();\n const comment = snap.data();\n const promises = [];\n // Update commentsCount aggregated value\n const scrumRef = snap.ref.parent.parent;\n scrumRef.get().then(scrumSnap => {\n const data = scrumSnap.data();\n if (data.commentsCount) {\n promises.push(scrumRef.update({\n commentsCount: data.commentsCount + 1\n }));\n } else {\n promises.push(scrumRef.update({\n commentsCount: 1\n }));\n }\n });\n // Send notifcation to all users except sending comment\n firestore.doc('teams/' + context.params.teamId).get().then(teamSnap => {\n const team = teamSnap.data();\n Object.keys(team.members).forEach(uid => {\n if (comment.uid !== uid) {\n promises.push(firestore.collection('users/' + uid + '/notifications').add({\n title: 'New comment!',\n txt: comment.username + \": \" + comment.txt,\n link: 'https://scrumboard.io/scrum/' + context.params.teamId + '/' + context.params.boardId + '?e=' + context.params.entryId\n }));\n }\n });\n })\n return Promise.all(promises);\n });\n\nexport const onDeletedScrumComments = functions.firestore\n .document('teams/{teamId}/boards/{boardId}/entries/{entryId}/comments/{commentId}')\n .onDelete(async (snap, context) => {\n // Update commentsCount aggregated value\n const scrumRef = snap.ref.parent.parent;\n const data = (await scrumRef.get()).data();\n return scrumRef.update({\n commentsCount: data.commentsCount - 1\n });\n });\n"
}
] | 12 |
pluto0x0/pinganjing
|
https://github.com/pluto0x0/pinganjing
|
e6adf4bc82752f843c23fd876db8ab7681cbc90f
|
98b8462b5096476580fdcceebcfb4d1968290df2
|
2de543818e71f611f29ecf66087a6a72396a9ace
|
refs/heads/master
| 2022-11-29T06:17:30.125561 | 2020-08-11T11:29:54 | 2020-08-11T11:29:54 | 283,720,947 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7310924530029297,
"alphanum_fraction": 0.7394958138465881,
"avg_line_length": 13.875,
"blob_id": "ce2e4b20ba6f5f0a945eacceb59f77a7d3b74975",
"content_id": "3e0220e9c6741a116c13e5665fac40a9074b0326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 8,
"path": "/README.md",
"repo_name": "pluto0x0/pinganjing",
"src_encoding": "UTF-8",
"text": "# pinganjing\n平安经生成器(年龄、食物、动物、历史名人…)\n\n# reference\n\nhttps://gumble.pw/python-num2chinese.html\n\nhttp://thuocl.thunlp.org/\n"
},
{
"alpha_fraction": 0.48730286955833435,
"alphanum_fraction": 0.5052124857902527,
"avg_line_length": 32.41071319580078,
"blob_id": "71d3a4e33d142077aa93caaee715a591fc4600e2",
"content_id": "b314943b83cff97a20cfc5e1f92844e2da1835c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3989,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 112,
"path": "/平安经.py",
"repo_name": "pluto0x0/pinganjing",
"src_encoding": "UTF-8",
"text": "import itertools\nimport sys\n\n\ndef num2chinese(num, big=False, simp=True, o=False, twoalt=False):\n \"\"\"\n Converts numbers to Chinese representations.\n\n `big` : use financial characters.\n `simp` : use simplified characters instead of traditional characters.\n `o` : use 〇 for zero.\n `twoalt`: use 两/兩 for two when appropriate.\n\n Note that `o` and `twoalt` is ignored when `big` is used,\n and `twoalt` is ignored when `o` is used for formal representations.\n \"\"\"\n # check num first\n nd = str(num)\n if abs(float(nd)) >= 1e48:\n raise ValueError('number out of range')\n elif 'e' in nd:\n raise ValueError('scientific notation is not supported')\n c_symbol = '正负点' if simp else '正負點'\n if o: # formal\n twoalt = False\n if big:\n c_basic = '零壹贰叁肆伍陆柒捌玖' if simp else '零壹貳參肆伍陸柒捌玖'\n c_unit1 = '拾佰仟'\n c_twoalt = '贰' if simp else '貳'\n else:\n c_basic = '〇一二三四五六七八九' if o else '零一二三四五六七八九'\n c_unit1 = '十百千'\n if twoalt:\n c_twoalt = '两' if simp else '兩'\n else:\n c_twoalt = '二'\n c_unit2 = '万亿兆京垓秭穰沟涧正载' if simp else '萬億兆京垓秭穰溝澗正載'\n revuniq = lambda l: ''.join(k for k, g in itertools.groupby(reversed(l)))\n nd = str(num)\n result = []\n if nd[0] == '+':\n result.append(c_symbol[0])\n elif nd[0] == '-':\n result.append(c_symbol[1])\n if '.' in nd:\n integer, remainder = nd.lstrip('+-').split('.')\n else:\n integer, remainder = nd.lstrip('+-'), None\n if int(integer):\n splitted = [\n integer[max(i - 4, 0):i] for i in range(len(integer), 0, -4)\n ]\n intresult = []\n for nu, unit in enumerate(splitted):\n # special cases\n if int(unit) == 0: # 0000\n intresult.append(c_basic[0])\n continue\n elif nu > 0 and int(unit) == 2: # 0002\n intresult.append(c_twoalt + c_unit2[nu - 1])\n continue\n ulist = []\n unit = unit.zfill(4)\n for nc, ch in enumerate(reversed(unit)):\n if ch == '0':\n if ulist: # ???0\n ulist.append(c_basic[0])\n elif nc == 0:\n ulist.append(c_basic[int(ch)])\n elif nc == 1 and ch == '1' and unit[1] == '0':\n # special case for tens\n # edit the 'elif' if you don't like\n # 十四, 三千零十四, 三千三百一十四\n ulist.append(c_unit1[0])\n elif nc > 1 and ch == '2':\n ulist.append(c_twoalt + c_unit1[nc - 1])\n else:\n ulist.append(c_basic[int(ch)] + c_unit1[nc - 1])\n ustr = revuniq(ulist)\n if nu == 0:\n intresult.append(ustr)\n else:\n intresult.append(ustr + c_unit2[nu - 1])\n result.append(revuniq(intresult).strip(c_basic[0]))\n else:\n result.append(c_basic[0])\n if remainder:\n result.append(c_symbol[2])\n result.append(''.join(c_basic[int(ch)] for ch in remainder))\n return ''.join(result)\n\n\nout = open('平安经.txt', 'w',encoding='utf-8')\n\nsys.stdout = out\n\nprint('各年龄平安\\n')\n\nfor i in range(1, 101):\n print(num2chinese(i) + '岁平安' + (',' if i < 100 else '\\n'), end='')\n\ndata = {'animal': '动物', 'diming': '地名', 'food': '食物', 'lishimingren': '历史名人'}\n\nfor name in data:\n print('\\n各{0}平安\\n'.format(data[name]))\n with open('source/{0}.txt'.format(name), 'r', encoding='utf-8') as f:\n line = f.readline()\n while line:\n print(line[:-1] + '平安', end='')\n line = f.readline()\n print(',' if line else '\\n', end='')\nout.close()"
}
] | 2 |
ravishdesai/FASAI_API
|
https://github.com/ravishdesai/FASAI_API
|
c2f1f05a70e1bcbf92784b6c6b2e305a4b4b780f
|
0cce9ca580c641e280393cf526571ad60aa8a944
|
63f2362a0c6dae0dfc7b7f09485fb20806095f96
|
refs/heads/main
| 2023-08-14T22:44:33.726326 | 2021-09-23T15:05:39 | 2021-09-23T15:05:39 | 409,638,419 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5439062118530273,
"alphanum_fraction": 0.5662431716918945,
"avg_line_length": 47.41379165649414,
"blob_id": "f960452aea47f01133e5897cf6cb9c15e47f8ad9",
"content_id": "0b9048844a0accede9298633c08e957b69a65ed4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7163,
"license_type": "no_license",
"max_line_length": 275,
"num_lines": 145,
"path": "/fassai_api.py",
"repo_name": "ravishdesai/FASAI_API",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\r\nimport time\r\nimport cv2 \r\nimport pytesseract\r\nimport base64\r\nfrom PIL import Image\r\nfrom io import BytesIO\r\nfrom selenium.webdriver.firefox.options import Options\r\n\r\nfrom flask import Flask,make_response\r\nfrom flask_restful import Api,Resource,reqparse,abort\r\nimport json\r\n\r\napp = Flask(__name__)\r\napi = Api(app)\r\n\r\nclass WebScrapping:\r\n\r\n # opt = webdriver.ChromeOptions()\r\n # opt.add_argument('-headless')\r\n web = webdriver.Firefox()\r\n web.get('https://foscos.fssai.gov.in/')\r\n First_Click = web.find_element_by_xpath('/html/body/app-root/div[2]/div/div[2]/input').click()\r\n Second_Click = web.find_element_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/ul/li[3]/a').click()\r\n\r\n time.sleep(2)\r\n\r\n # Function For Getting Captcha Value\r\n def Captcha(self):\r\n images = self.web.find_elements_by_tag_name('img')\r\n for image in images:\r\n if(image.get_attribute('alt')==\"Captcha\"):\r\n c = image.get_attribute('src')\r\n Get_Base64_Value = c[23:]\r\n break\r\n\r\n Get_Image = Image.open(BytesIO(base64.b64decode(Get_Base64_Value)))\r\n\r\n pytesseract.pytesseract.tesseract_cmd=r\"C:/Users/Divy/AppData/Local/Tesseract-OCR/tesseract.exe\"\r\n custom_config = r'--oem 3 --psm 6 outputbase digits'\r\n Get_Captcha = pytesseract.image_to_string(Get_Image)\r\n\r\n return Get_Captcha\r\n\r\n # Function For Getting Detail After Autofill form\r\n def Get_Detail_form(self):\r\n dataInJson = {}\r\n all_detail = []\r\n Get_detail = self.web.find_elements_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[2]/div/form/div/div/div/div[1]/table/tbody/tr/td')\r\n for item in Get_detail:\r\n company_detail = item.text\r\n all_detail.append(company_detail)\r\n if(company_detail == \"View Products\"):\r\n try:\r\n get_list_product_len = len(self.web.find_elements_by_xpath('//*[@id=\"governmentAgenciesDiv1\"]/div[1]/div/div/div[2]/app-product-details/div/div/form/div'))\r\n if(get_list_product_len<=1):\r\n path3 = '/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[2]/div[2]/table/tbody/tr/td[2]'\r\n get_product_data = self.web.find_elements_by_xpath(path3)\r\n a = []\r\n for data in get_product_data:\r\n all_product_data = data.text\r\n a.append(all_product_data)\r\n dataInJson['uncategorised'] = a\r\n all_detail.append(dataInJson) \r\n \r\n return all_detail\r\n \r\n else:\r\n category_count=0\r\n product_count = 0\r\n for i in range(2,get_list_product_len+1):\r\n path1 = '/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[2]/app-product-details/div/div/form/div['+str(i)+']/h5'\r\n path2 = '/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[2]/app-product-details/div/div/form/div['+str(i)+']/div/table/tbody/tr/td[2]'\r\n get_list_category1 = self.web.find_elements_by_xpath(path1)\r\n get_data_product = self.web.find_elements_by_xpath(path2)\r\n for data in get_list_category1:\r\n categories_data = data.text\r\n category_count = category_count+1\r\n product_count=0\r\n all_detail.append(categories_data)\r\n a = []\r\n for data in get_data_product:\r\n categories_product_data = data.text\r\n product_count = product_count+1\r\n a.append(categories_product_data)\r\n dataInJson[categories_data] = a\r\n all_detail.append(dataInJson)\r\n dataInJson = {}\r\n\r\n \r\n except:\r\n print('Error in product data')\r\n\r\n return all_detail\r\n\r\n # Function For Automatic fill form\r\n def Autofillform(self,Get_License_Number):\r\n # Get_License_Number = \"20717030000293\"\r\n Send_License_Number = self.web.find_element_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[1]/form/div/div/div[3]/div/input').clear()\r\n Send_License_Number = self.web.find_element_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[1]/form/div/div/div[3]/div/input').send_keys(Get_License_Number)\r\n Get_From_Captcha = self.Captcha()\r\n Send_Captcha = self.web.find_element_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div[1]/form/div/div/div[4]/div/input').send_keys(Get_From_Captcha)\r\n Submit_button = self.web.find_element_by_xpath('/html/body/app-root/app-index/main-layout/div/div[2]/div/div[1]/div/div[1]/div[1]/div/div/div[1]/div/div/div[2]/div[1]/div/div[4]/div[1]/div/div/div/form/div/div/div[4]/button').click()\r\n\r\n time.sleep(5)\r\n\r\n fassai_detail = self.Get_Detail_form()\r\n return fassai_detail\r\n\r\n time.sleep(2)\r\n\r\n# def abort_if_license_no_doesnt_exist(license_Id):\r\n# if (license_Id is None):\r\n# abort(404, message=\"Please pass License No\")\r\n\r\nclass GetFssaiDetail(Resource,WebScrapping):\r\n\r\n def inJsonFormat(self,rawData):\r\n\r\n dataInJson = {}\r\n dataInJson['licenseId'] = rawData[3]\r\n dataInJson['companyName'] = rawData[1]\r\n dataInJson['premisesAddress'] = rawData[2]\r\n dataInJson['licenseType'] = rawData[4]\r\n dataInJson['valid'] = rawData[5]\r\n dataInJson['products'] = rawData[-1]\r\n\r\n return dataInJson\r\n\r\n def get(self,license_Id):\r\n # abort_if_license_no_doesnt_exist(license_Id)\r\n # print(type(license_Id))\r\n\r\n rawData = self.Autofillform(license_Id)\r\n data = self.inJsonFormat(rawData)\r\n resp = make_response(json.dumps(data),200)\r\n return resp\r\n \r\n # return license_Id\r\n\r\n\r\napi.add_resource(GetFssaiDetail,'/getFSSAIDetails/<int:license_Id>')\r\n\r\nif __name__ == \"__main__\":\r\n app.run(debug=True)"
},
{
"alpha_fraction": 0.8091953992843628,
"alphanum_fraction": 0.8137931227684021,
"avg_line_length": 216.5,
"blob_id": "e6f85e8f72af2d3c5c6605ed8eaffd02e004228b",
"content_id": "5ec87e902bf7caa9453bd47ea28e8fec48ee46b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 422,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ravishdesai/FASAI_API",
"src_encoding": "UTF-8",
"text": "# FASAI_API\n“Web Scraping with Python” initiates the scraping of the captcha image src and uses base64 to convert src into image. After that we use OCR to extract the digit from the captcha image. We have used the selenium library for scraping and after decoding captcha from images we autofill the application number and captcha through API and all the result such as product detail are scraped and return the detail into JSON format\n"
}
] | 2 |
Uthinley/RMADIA
|
https://github.com/Uthinley/RMADIA
|
00b04c3c0b54787917174fb175e372b12712ee9b
|
5b9a0fd3d7ef661e211f73c555a130f48d97af5c
|
2a39ad47dae7f92632e081d9881d91140bb03004
|
refs/heads/master
| 2022-10-27T06:12:29.593929 | 2020-05-20T05:43:35 | 2020-05-20T05:43:35 | 265,460,896 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.712592601776123,
"alphanum_fraction": 0.712592601776123,
"avg_line_length": 34.578948974609375,
"blob_id": "dc290b99f9cd566ce1d86a68ac524ba00fe24cb6",
"content_id": "deccf34157f6c972073e538bdd3676778748939f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 19,
"path": "/WhistleBlower/urls.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.urls import path\nfrom . import views\nfrom django.conf import settings\nfrom django.conf.urls.static import static\n\n\nurlpatterns = [\n path('', views.index, name=\"index_page\"),\n path('submit/', views.submit, name=\"submit_page\"),\n path('login', views.login, name=\"login_page\"),\n path('loginsubmit', views.loginsubmit, name=\"login_submit_page\"),\n path('logout', views.logout, name=\"logout_page\"),\n path('verify/<int:id>', views.verify, name=\"verify_page\"),\n path('verify_drop/', views.verify_drop, name=\"verify_drop\"),\n]\n\nif settings.DEBUG:\n urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)"
},
{
"alpha_fraction": 0.5086848735809326,
"alphanum_fraction": 0.5905707478523254,
"avg_line_length": 21.38888931274414,
"blob_id": "66745a7ee504665086c8e853cf7c238eed140085",
"content_id": "32dd7a47728149788e7c1d2e3b84a58b3775da51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 18,
"path": "/WhistleBlower/migrations/0003_report_status.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.3 on 2020-03-03 05:14\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('WhistleBlower', '0002_auto_20200302_1524'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='report',\n name='status',\n field=models.CharField(default='S', max_length=10),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6758720874786377,
"alphanum_fraction": 0.6918604373931885,
"avg_line_length": 27.58333396911621,
"blob_id": "abc3e65ebfe009f6d2f34e74a6abe2fb6ab37ca9",
"content_id": "3f9e4092bb1068bf915c51298adbbfd3951e4b96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 688,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/WhistleBlower/models.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\nclass report(models.Model):\n Employee_Id = models.IntegerField()\n Employee_email = models.CharField(max_length= 50)\n\n S_name = models.CharField(max_length=30)\n s_job_pos = models.CharField(max_length=30)\n s_phone = models.IntegerField()\n s_address = models.CharField(max_length=100)\n\n what_wrong = models.TextField()\n who_wrong = models.TextField()\n where_wrong = models.TextField()\n enabled_wrong = models.TextField()\n solution = models.TextField()\n\n incident_date = models.DateField()\n\n documents = models.FileField(default=\"\")\n\n status = models.CharField(max_length=10, default=\"S\")\n\n\n"
},
{
"alpha_fraction": 0.7821782231330872,
"alphanum_fraction": 0.7821782231330872,
"avg_line_length": 19.200000762939453,
"blob_id": "63d068206b6df92ed6b6a1943605242eac3b85c9",
"content_id": "d69eb15686deff715b554ce5df06d507159282b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 5,
"path": "/WhistleBlower/apps.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass WhistleblowerConfig(AppConfig):\n name = 'WhistleBlower'\n"
},
{
"alpha_fraction": 0.508370041847229,
"alphanum_fraction": 0.5330396294593811,
"avg_line_length": 34.46875,
"blob_id": "9e2ca2c9633885619d3e2e4439a39f0b297b6ccc",
"content_id": "44e3e1db9f9847a0cda6bb2062ea5cf19ff90901",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1135,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 32,
"path": "/WhistleBlower/migrations/0001_initial.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.3 on 2020-02-13 05:52\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='report',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('Employee_Id', models.IntegerField(max_length=30)),\n ('Employee_email', models.CharField(max_length=50)),\n ('S_name', models.CharField(max_length=30)),\n ('s_job_pos', models.CharField(max_length=30)),\n ('s_phone', models.IntegerField(max_length=20)),\n ('s_address', models.CharField(max_length=100)),\n ('what_wrong', models.TextField()),\n ('who_wrong', models.TextField()),\n ('where_wrong', models.TextField()),\n ('enabled_wrong', models.TextField()),\n ('solution', models.TextField()),\n ('incident_date', models.DateField()),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5094890594482422,
"alphanum_fraction": 0.5372262597084045,
"avg_line_length": 23.464284896850586,
"blob_id": "f497359db1f02e35b9f0e1555be747b8121fc85e",
"content_id": "9e325bc1269cdf05d724008743c23a596b372093",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 28,
"path": "/WhistleBlower/migrations/0002_auto_20200302_1524.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.3 on 2020-03-02 09:24\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('WhistleBlower', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='report',\n name='documents',\n field=models.FileField(default='', upload_to=''),\n ),\n migrations.AlterField(\n model_name='report',\n name='Employee_Id',\n field=models.IntegerField(),\n ),\n migrations.AlterField(\n model_name='report',\n name='s_phone',\n field=models.IntegerField(),\n ),\n ]\n"
},
{
"alpha_fraction": 0.601730465888977,
"alphanum_fraction": 0.601730465888977,
"avg_line_length": 32.66371536254883,
"blob_id": "8b219c17fb729062b01bb18b08bbee8556c1db8a",
"content_id": "eb8899322daeaa43ff244b9651df9893ee499397",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3814,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 113,
"path": "/WhistleBlower/views.py",
"repo_name": "Uthinley/RMADIA",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom .models import report\nfrom django.contrib.auth.models import User, auth\nfrom django.contrib import messages\nfrom django.conf import settings\nfrom django.core.files.storage import FileSystemStorage\n\n# Create your views here.\ndef index(request):\n return render(request, \"index.html\")\n\n\ndef login(request):\n return render(request, \"login.html\")\n\n\ndef verify(request, id):\n if id:\n details = report.objects.get(id=id)\n \n return render(request, \"details.html\", {'details':details})\n\n\ndef verify_drop(request):\n if 'drop' in request.POST:\n id = request.POST['id']\n t = report.objects.get(id=id)\n t.status = \"D\"\n t.save()\n \n return redirect('login_submit_page')\n\n elif 'verify'in request.POST:\n id = request.POST['id']\n v = report.objects.get(id=id)\n v.status=\"V\"\n v.save()\n\n return redirect('login_submit_page')\n\n\ndef loginsubmit(request):\n if request.session.has_key('user'):\n context = report.objects.all()\n total = report.objects.all().count()\n print(\"session is there.********************************\")\n \n return render(request, \"admindashboard.html\", {'context':context, 'total':total})\n \n else:\n if request.method == 'POST':\n username = request.POST['login_user']\n password = request.POST['passwd']\n\n user = auth.authenticate(username=username, password=password)\n \n if user is not None:\n auth.login(request, user)\n context = report.objects.all()\n total = report.objects.all().count()\n request.session['user'] = username\n print(\"sesssion just stated &&&&&&&\")\n return render(request, \"admindashboard.html\", {'context':context, 'total':total})\n else:\n messages.info(request, \"Invalid Credentials\")\n print('here in invalid')\n return render(request,'login.html')\n else:\n pass\n # return render(request, \"login.html\")\n\ndef logout(request):\n if request.session.has_key('user'):\n auth.logout(request)\n request.session.flush()\n return redirect(\"login_page\")\n\n\ndef submit(request):\n if request.method == 'POST':\n Eid = request.POST['Eid']\n email = request.POST['email']\n sname = request.POST['sname']\n sjob = request.POST['sjob']\n sphone = request.POST['sphone']\n saddress = request.POST['saddress']\n whatwrong = request.POST['whatwrong']\n whowrong = request.POST['whowrong']\n wherewrong = request.POST['wherewrong']\n whoenabled = request.POST['whoenabled']\n # location = request.POST['location']\n incident_date = request.POST['incident_date']\n solution = request.POST['solution']\n\n #file upload\n uploaded_file = request.FILES['a_file']\n fs = FileSystemStorage()\n filename = fs.save(uploaded_file.name, uploaded_file)\n uploaded_file_url = fs.url(filename)\n \n report_info = report(Employee_Id=Eid, Employee_email=email, S_name=sname, s_job_pos=sjob, s_phone= sphone, \n s_address= saddress, what_wrong= whatwrong, who_wrong= whowrong, where_wrong= wherewrong, enabled_wrong= whoenabled, solution= solution,\n incident_date= incident_date, documents=uploaded_file_url)\n\n report_info.save()\n\n print(report_info.save())\n messages.info(request, \"Information has been submitted successfully!!\")\n\n\n return redirect('index_page')\n else:\n messages.info(request, \"There was problem submitting the information. please contact the system administrator.\")\n \n\n"
}
] | 7 |
nazarlonevskyi/telegram_bot
|
https://github.com/nazarlonevskyi/telegram_bot
|
ef1ba4e71f66f384526e95f25330d9d117697424
|
16693c05f773acd10066b1df9d790d911836f191
|
956f6b851e25b5e539a7b40906c487173095fa60
|
refs/heads/main
| 2023-05-31T11:10:56.004363 | 2021-06-09T14:18:02 | 2021-06-09T14:18:02 | 368,519,947 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7395577430725098,
"alphanum_fraction": 0.7407862544059753,
"avg_line_length": 26.931034088134766,
"blob_id": "a6eaab3f451a02e39ae5f641c084dc3cecfcb489",
"content_id": "0135ec1964680453134595b1b83f87939e3a13b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 814,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 29,
"path": "/README.md",
"repo_name": "nazarlonevskyi/telegram_bot",
"src_encoding": "UTF-8",
"text": "# course_work_telegram_bot\n\nThis repository contains a test bot for the telegram.\nThe bot is written in python using the [Telegram Bot API](https://core.telegram.org/api) \nand wrapper library over api [pyTelegramBotAPI](https://github.com/eternnoir/pyTelegramBotAPI/). \nTo make the bot work, you need to substitute your tokens in [config.py](https://github.com/nazarlonevskyi/telegram_bot/blob/main/conf.py).\n***\nAPI\n--\nThe following APIs are also used for the bot:\n* [RandomDog](https://random.dog/woof.json)\n* [StatsDog](https://thedogapi.com/)\n* [DogeCoin](https://yobit.net/api)\n***\nPrepare\n--\nTo use bot you need install next packages by pip:\n* pytelegrambotapi\n* telebot\n* vedis\n* requests\n***\nStart\n--\nTo start telegram bot you need use next command\n\n`python3 testbot.py`\n***\ncreated by @nazr.lonevskyi\n\n\n\n\n"
},
{
"alpha_fraction": 0.5769764184951782,
"alphanum_fraction": 0.5811372995376587,
"avg_line_length": 25.703702926635742,
"blob_id": "bbd3d78910f89826fc61a9a18dd18d03027bfe6b",
"content_id": "d1f20dcb525ec6cd13b1d29e5c8654eca66b1a09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 892,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 27,
"path": "/baza.py",
"repo_name": "nazarlonevskyi/telegram_bot",
"src_encoding": "UTF-8",
"text": "from vedis import Vedis\nimport conf as config\n\n\ndef set_data(key, value):\n \"\"\"*--\n Запис нових даних в базу.\n \"\"\"\n with Vedis(config.db_file) as db:\n try:\n db[key] = value\n return True\n except:\n # тут бажано обробити ситуацію\n return False\n\n\ndef get_data(key):\n \"\"\"\n Отримання даних з бази.\n \"\"\"\n with Vedis(config.db_file) as db:\n try:\n return db[key].decode() # Якщо використовуєтьcя Vedis версії нижче, ніж 0.7.1, то .decode() НЕ ПОТРІБЕН\n except KeyError: # Якщо такого ключа не виявилось\n #return config.States.S_START.value # значення по замовчуванню - початок діалогу\n return False\n"
},
{
"alpha_fraction": 0.5642538666725159,
"alphanum_fraction": 0.5663519501686096,
"avg_line_length": 43.86470413208008,
"blob_id": "a2f1baeb6e677a985d7fdb08c39bac555d7f6269",
"content_id": "998703a8668203c390f63cb03b899dc65b31e77e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8563,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 170,
"path": "/testbot.py",
"repo_name": "nazarlonevskyi/telegram_bot",
"src_encoding": "UTF-8",
"text": "import telebot\nimport re\nimport requests\nimport baza\nimport conf as config\nfrom conf import offensive_messages, love_messages\nfrom datetime import datetime\n\nbot = telebot.TeleBot(config.token)\n\n\n# При введенні команди '/start' привітаємося з користувачем.\[email protected]_handler(commands=['start'])\ndef handle_start_help(message):\n if (baza.get_data(str(message.chat.id) + 'name')):\n bot.send_message(message.chat.id, f\" Привіт, {baza.get_data(str(message.chat.id) + 'name')},\"\n f\"\\nЯкщо ти не знаєш що далі, пиши /help!\")\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUO9gphfpZQlB3jFnUPHwirSSQz-0JwACHwADnP4yMCBW8jz3ttrRHwQ')\n else:\n bot.send_message(message.chat.id, \" Привіт!\"\n \"\\nЯ, бот, який любить собак🤫, класно правда?\"\n \"\\nЯ можу багато чого, тож,\"\n \"\\nЯк я можу до тебе звертатись? \")\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUO9gphfpZQlB3jFnUPHwirSSQz-0JwACHwADnP4yMCBW8jz3ttrRHwQ')\n baza.set_data(message.chat.id, config.States.S_ENTER_NAME.value)\n\n\n# При введенні команди '/set_name' змінимо ім'я користувача.\[email protected]_handler(commands=['set_name'])\ndef set_name(message):\n bot.send_message(message.chat.id, \"Тож, як тебе звати?\")\n baza.set_data(message.chat.id, config.States.S_ENTER_NAME.value)\n\n\n# Записуємо ім'я користувача\[email protected]_handler(func=lambda message: baza.get_data(message.chat.id) == config.States.S_ENTER_NAME.value)\ndef user_entering_name(message):\n # В випадку з іменем не будемо нічого перевіряти\n bot.send_message(message.chat.id, \"Чудове ім'я, запам'ятаю!\")\n bot.send_message(message.chat.id, f\"Що ж далі? Пиши: /help\")\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUPVgphgbJwqWZHpnNSbooLkUw-Uq0QACEgADnP4yMOA1S0Oue2vUHwQ')\n baza.set_data(str(message.chat.id) + 'name', message.text)\n baza.set_data(message.chat.id, config.States.S_START.value)\n\n\n# При введенні команди '/help' виведемо команди для роботи з ботом.\[email protected]_handler(commands=['help'])\ndef handle_start_help(message):\n bot.send_message(message.chat.id, 'Command list: ⤵️ '\n '\\n/start -start, '\n '\\n/price - check crypto Doge'\n '\\n/set_name - u can change your name, '\n '\\n/random_dog i send .jpg or .gif random dog'\n '\\n/random_stats_dog - i send a random info about dog')\n\n\n# При введенні користувачем образливих слів саме до бота з масиву 'offensive_messages' з 'config'\n# будемо відповідати до нього\[email protected]_handler(func=lambda message: message.text \\\n and re.sub(r'\\s+', ' ', message.text.lower()) \\\n in map(lambda x: x, offensive_messages))\ndef offensive_message(message):\n words = re.sub(r'\\s+', ' ', message.text.lower()).split()\n bot.reply_to(message, f\"Сам {words[0]}\")\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUPtgphnA3-a9qSU6w7FqpUXVtx00cAACGwADnP4yMByL0TjtFNWIHwQ')\n\n\n# При введенні користувачем приэмних слів саме до бота з масиву 'love_messages' з 'config'\n# будемо відповідати до нього\[email protected]_handler(func=lambda message: message.text \\\n and re.sub(r'\\s+', ' ', message.text.lower()) \\\n in map(lambda x: x, love_messages))\ndef love_message(message):\n words = re.sub(r'\\s+', ' ', message.text.lower()).split()\n bot.send_message(message.chat.id, 'WOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOW ')\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUQpgphth27f3rL6LkuwQmdhF6CtDDAACGQADnP4yMGtnBiuSyxWjHwQ')\n\n\n# При введенні команди '/random_dog' виведемо випадкове фото чи відео собаки.\[email protected]_handler(commands=['random_dog'])\ndef random_dog(message):\n try:\n r = requests.get(url=config.random_dog_api)\n response = r.json()\n except:\n bot.send_message(message.chat.id, 'Нажаль не вдалось отримати відповідь 😔')\n return\n\n extension = response[\"url\"].split('.')[-1]\n # Якщо відео\n if ('mp4' in extension):\n bot.send_video(message.chat.id, response[\"url\"])\n # gif\n elif ('gif' in extension):\n bot.send_video_note(message.chat.id, response[\"url\"])\n # Фото\n else:\n bot.send_photo(message.chat.id, response[\"url\"])\n\n\n# При введенні команди '/random_stats_dog' виведемо випадкове фото чи відео собаки.\[email protected]_handler(commands=['random_stats_dog'])\ndef random_stats_dog_help(message):\n bot.send_message(message.chat.id, '🤗 Це моя основна можливість'\n '\\n🤫 Я знаю все про собак'\n '\\n❔ Хочеш перевірити? '\n '\\n✔ Ти можеш сказати \"name\", і я тобі назву рандомне ім`я '\n '\\n✔ Я скажу породу та вік собаки, його можливості,пиши\"breed\"'\n '\\n✔ Темперамент і походження - пиши \"temp\"')\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUPhgphiW3lLddusR1Qn2oRCodDHELQACEAADnP4yMIzJFdBdAnGcHwQ')\n\n# При введенні команди '/price'.\[email protected]_handler(commands=['price'])\ndef random_stats_dog_help(message):\n bot.send_message(message.chat.id, '🤗 Ти знав, що в честь собаки назвали криптовалюту?'\n '\\n🤫 Я знаю про неї все'\n '\\n❔ Хочеш перевірити? '\n '\\n✔ Напиши \"show me a doge crupto price\" ')\n bot.send_sticker(message.chat.id, 'CAACAgIAAxkBAAEBUVZgpnrGmreMkOzg1hSL37ot8hNZUgACIwADnP4yMGLSFbgqnabRHwQ')\n\n\[email protected]_handler(content_types=[\"text\"])\ndef random_stats(message):\n if message.text.lower() == \"show me a doge crupto price\":\n req = requests.get(url=config.dogecoin_stats_api)\n response = req.json()\n high_price = response[\"ticker\"][\"high\"]\n sell_price = response[\"ticker\"][\"sell\"]\n buy_price = response[\"ticker\"][\"buy\"]\n bot.send_message( message.chat.id,f\"⏺ Now: {datetime.now().strftime('%d.%m.%Y %H:%M')}\"\n f\"\\n\\n\\n⬆️ High DOGE price: {high_price,}\"\n f\"\\n\\n➡️ Sell DOGE price: {sell_price},\"\n f\"\\n\\n⬅️ Buy DOGE price: {buy_price}\"\n )\n\n if message.text.lower() == \"name\":\n response = requests.get(url=config.random_stats_api)\n response.headers.get(\"Content-Type\")\n 'application/json; charset=utf-8'\n category_name = response.json()['name']\n bot.send_message(message.chat.id,\n f\"Name: {category_name}\"\n )\n\n if message.text.lower() == \"breed\":\n req = requests.get(url=config.random_stats_api_1)\n req.headers.get(\"Content-Type\")\n 'application/json; charset=utf-8'\n breedgroup = req.json()[\"breed_group\"]\n life = req.json()[\"life_span\"]\n bred = req.json()['bred_for']\n bot.send_message(message.chat.id, f\"Breed: {breedgroup},\"\n f\"\\nLife span: {life},\"\n f\"\\nBred for: {bred}\"\n )\n\n if message.text.lower() == \"temp\":\n requ = requests.get(url=config.random_stats_api)\n requ.headers.get(\"Content-Type\")\n 'application/json; charset=utf-8'\n temperament = requ.json()['temperament']\n origin = requ.json()['origin']\n bot.send_message(message.chat.id, f\"Temperament: {temperament}\"\n f\"\\nOrigin: {origin}\"\n )\n\nbot.polling()\n\nif __name__ == '__testbot__':\n bot.polling()"
},
{
"alpha_fraction": 0.6805869340896606,
"alphanum_fraction": 0.6918736100196838,
"avg_line_length": 37.5217399597168,
"blob_id": "1515fbf1c83eada138ffec7af69265f76c7568ba",
"content_id": "fd628298e404d19aaa3daa008178375f6d8ff838",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 23,
"path": "/conf.py",
"repo_name": "nazarlonevskyi/telegram_bot",
"src_encoding": "UTF-8",
"text": "from enum import Enum\n\n\ntoken = 'YOUR TOKEN'\ndb_file = 'database.vdb'\nrandom_dog_api = 'https://random.dog/woof.json'\nrandom_stats_api = 'https://api.thedogapi.com/v1/breeds/4'\nrandom_stats_api_1 = 'https://api.thedogapi.com/v1/breeds/5'\ndogecoin_stats_api = 'https://yobit.net/api/2/doge_usd/ticker'\n\n# Образливі повідомлення\noffensive_messages = [\"поганий\", \"тупий\", \"нефункціональний\", \"дурний\", \"кончений\",]\n# Приємні повідомення\nlove_messages = [\"крутий\", \"ти мені подобаєшся\", \"i love you\", \"дякую\"]\nclass States(Enum):\n \"\"\"\n Використовується БД Vedis, в якій всі збережені значеня,\n тому і тут будуть використовуватися також рядки (str)\n \"\"\"\n S_START = \"0\" # Початок нового діалогу\n S_ENTER_NAME = \"1\" # Введення імені користувача\n S_SEND_PIC_FOR_AGE = \"2\" # Введення фото для визначення віку\n S_ENTER_QUESTION = \"3\" # Введення питання для \"так чи ні\"\n"
}
] | 4 |
Navneeta7/BankNote-Authentication
|
https://github.com/Navneeta7/BankNote-Authentication
|
4ed16632449ae3676d8eea4215e75e3fd435e6a1
|
e26dd7d06567e57f079cbae0dac194dd225dfb83
|
9bc895d13108069aca8fccb01d94b9f9f805af85
|
refs/heads/main
| 2023-08-22T02:16:34.830447 | 2021-10-15T07:35:21 | 2021-10-15T07:35:21 | 412,225,152 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6283422708511353,
"alphanum_fraction": 0.6684492230415344,
"avg_line_length": 22.799999237060547,
"blob_id": "eb24a75a2eb014bfcc24500114a49747231c4734",
"content_id": "66bc6392d727b16dee76763f5fab3ecd8ab17daa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 15,
"path": "/Testfile.py",
"repo_name": "Navneeta7/BankNote-Authentication",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Sep 26 19:31:04 2021\r\n\r\n@author: hp\r\n\"\"\"\r\nimport requests\r\nimport pandas as pd\r\n\r\nurl= \"https://raw.githubusercontent.com/krishnaik06/Dockers/master/TestFile.csv\"\r\nres = requests.get(url, allow_redirects= True)\r\nwith open(\"TestFile.csv\", \"wb\")as file:\r\n \r\n file.write(res.content)\r\nTestFile= pd.read_csv('TestFile.csv') "
},
{
"alpha_fraction": 0.8402777910232544,
"alphanum_fraction": 0.8402777910232544,
"avg_line_length": 71,
"blob_id": "51a979e3a0fcc4139092b25bbc2d0c3b77cb8075",
"content_id": "ddb7918c3c4d43bdb89d0606a85573b0e7f69472",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 4,
"path": "/README.md",
"repo_name": "Navneeta7/BankNote-Authentication",
"src_encoding": "UTF-8",
"text": "# Bank-Note Authentication & Deployment\nBank Note Authentication UCI data| Kaggle\nBank Note Authentication using decision tree rules and machine learning techinques\nBuilt a authentication system which predicts whether the given note is genuine or not and deployed the model with flasgger\n"
}
] | 2 |
PabloCastellano/refine-python
|
https://github.com/PabloCastellano/refine-python
|
335e9bb12c78e230a2277f869abb5c97b078faae
|
9c76cde216c35a846d1a4755ec4066db8f4cf033
|
90dd6a36cedbbf1a972afd4fea186e59ca1e0c0f
|
refs/heads/master
| 2021-01-11T13:55:07.863226 | 2017-06-20T13:53:06 | 2017-06-20T13:56:26 | 94,892,057 | 0 | 0 | null | 2017-06-20T13:05:26 | 2017-04-20T09:06:01 | 2011-01-09T20:49:39 | null |
[
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 20,
"blob_id": "9c376bb63787ed711d87fe36ed6b13312a2240ac",
"content_id": "1abddd273e6c0082bdb9334f08c7eecd458d9734",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 8,
"path": "/tests/test.py",
"repo_name": "PabloCastellano/refine-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport refine\n\nr = refine.Refine()\np = r.new_project(\"dates.csv\")\np.apply_operations(\"operations.json\")\nprint(p.export_rows())\np.delete_project()\n"
},
{
"alpha_fraction": 0.633147120475769,
"alphanum_fraction": 0.6356300711631775,
"avg_line_length": 33.27659606933594,
"blob_id": "6cc2c289d9361baf5c20d4b7798d75e575c9a299",
"content_id": "8a84ebb5f6f59fa842af076110b24f281158beaf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1611,
"license_type": "permissive",
"max_line_length": 191,
"num_lines": 47,
"path": "/setup.py",
"repo_name": "PabloCastellano/refine-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import setup\n\nlong_description = \"\"\"\nThis allows you to script Refine by creating projects from data files, applying extracted JSON operation histories against the data and then exporting the transformed data back out of Refine.\n\"\"\"\n\ndef get_install_requires():\n \"\"\"\n parse requirements.txt, ignore links, exclude comments\n \"\"\"\n requirements = []\n for line in open('requirements.txt').readlines():\n line = line.rstrip()\n # skip to next iteration if comment or empty line\n if any([line.startswith('#'), line == '', line.startswith('http'), line.startswith('git'), line == '-r base.txt']):\n continue\n # add line to requirements\n requirements.append(line)\n return requirements\n\nsetup(\n name='refine',\n version='0.1',\n packages=['refine'],\n entry_points={\n 'console_scripts': ['refine-cli = refine:main']},\n install_requires=get_install_requires(),\n # metadata for upload to PyPI\n author=\"David Huynh\",\n author_email=\"\",\n description=(\"Python client library for Google Refine\"),\n license='MIT',\n keywords=['OpenRefine', 'CSV', 'data'],\n url='https://github.com/PabloCastellano/refine-python',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Topic :: Text Processing'\n ],\n long_description=long_description\n)\n"
},
{
"alpha_fraction": 0.575654149055481,
"alphanum_fraction": 0.5813424587249756,
"avg_line_length": 32.1698112487793,
"blob_id": "ce2798074fcdb3610691cec469ef5e77242cda94",
"content_id": "bfbca7228b2a0e590815e349e1914603e8799a1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3516,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 106,
"path": "/refine/__init__.py",
"repo_name": "PabloCastellano/refine-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#\n# Authors:\n# David Huynh (@dfhuynh)\n# Pablo Castellano (@PabloCastellano)\n\nimport argparse\nimport os.path\nimport time\nimport requests\n\n\nclass Refine:\n def __init__(self, server='http://127.0.0.1:3333'):\n self.server = server[0, -1] if server.endswith('/') else server\n\n def new_project(self, file_path, options=None):\n file_name = os.path.split(file_path)[-1]\n project_name = options['project_name'] if options != None and 'project_name' in options else file_name\n\n files = {'file': (file_name, open(file_path, 'rb'), 'application/vnd.ms-excel', {'Expires': '0'})}\n\n r = requests.post(self.server + '/command/core/create-project-from-upload', files=files)\n if '?project=' in r.request.path_url:\n _id = r.request.path_url.split('?project=')[1]\n return RefineProject(self.server, _id, project_name)\n\n # TODO: better error reporting\n return None\n\n\nclass RefineProject:\n def __init__(self, server, id, project_name):\n self.server = server\n self.id = id\n self.project_name = project_name\n\n def wait_until_idle(self, polling_delay=0.5):\n while True:\n r = requests.get(self.server + '/command/core/get-processes?project=' + self.id)\n response_json = r.json()\n if 'processes' in response_json and len(response_json['processes']) > 0:\n time.sleep(polling_delay)\n else:\n return\n\n def apply_operations(self, file_path, wait=True):\n fd = open(file_path)\n operations_json = fd.read()\n\n data = {\n 'operations': operations_json\n }\n r = requests.post(self.server + '/command/core/apply-operations?project=' + self.id, data)\n response_json = r.json()\n if response_json['code'] == 'error':\n raise Exception(response_json['message'])\n elif response_json['code'] == 'pending':\n if wait:\n self.wait_until_idle()\n return 'ok'\n\n return response_json['code'] # can be 'ok' or 'pending'\n\n def export_rows(self, format='tsv', printColumnHeader=True):\n data = {\n 'engine': '{\"facets\":[],\"mode\":\"row-based\"}',\n 'project': self.id,\n 'format' : format,\n 'printColumnHeader': printColumnHeader\n }\n r = requests.post(self.server + '/command/core/export-rows/' + self.project_name + '.' + format, data)\n return r.content.decode(\"utf-8\")\n\n def export_project(self, format='openrefine.tar.gz'):\n data = {\n 'project' : self.id,\n 'format' : format\n }\n response = urllib2.urlopen(self.server + '/command/core/export-project/' + self.project_name + '.' + format, data)\n return response.read()\n\n def delete_project(self):\n data = {\n 'project': self.id\n }\n r = requests.post(self.server + '/command/core/delete-project', data)\n response_json = r.json()\n return response_json.get('code', '') == 'ok'\n\n\ndef main():\n parser = argparse.ArgumentParser(description='Apply operations to a CSV file by using the OpenRefine API')\n parser.add_argument(\"input\", help=\"Input CSV\")\n parser.add_argument(\"operations\", help=\"Operations CSV\")\n args = parser.parse_args()\n\n r = Refine()\n p = r.new_project(args.input)\n p.apply_operations(args.operations)\n print(p.export_rows())\n p.delete_project()\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 3 |
godesady/cnn-webshell-detect
|
https://github.com/godesady/cnn-webshell-detect
|
d62fa0fd44fc95cb85ea1299ea39e23980bcb808
|
5a9267e93c7a858cc3078d9ea3c38ae8fb7607cb
|
ba332227d69f950712c0a0940e2d7688db886023
|
refs/heads/master
| 2020-04-27T11:26:12.315165 | 2018-10-30T17:23:00 | 2018-10-30T17:23:00 | 174,295,291 | 1 | 0 |
Apache-2.0
| 2019-03-07T07:38:08 | 2018-12-26T07:48:25 | 2018-10-30T17:23:01 | null |
[
{
"alpha_fraction": 0.5918117165565491,
"alphanum_fraction": 0.597695529460907,
"avg_line_length": 27.725351333618164,
"blob_id": "1de439c45bccb27c329cde7aeb17abb6214f5cf9",
"content_id": "251e6f1d3fe973abfb400c2c5e27a9ee7c02bc12",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4079,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 142,
"path": "/server.py",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport atexit\nimport hashlib\nimport logging\nimport os\nimport time\nfrom configparser import ConfigParser\n\nimport tflearn\nfrom flask import *\nfrom numpy import argmax\n\nimport training\nfrom lib import Database\n\n\nconfig = ConfigParser()\nconfig.read('config.ini')\n\napp = Flask(__name__)\napp.config['UPLOAD_FOLDER'] = config['api']['upload_path']\napp.config['MAX_CONTENT_LENGTH'] = int(config['api']['upload_max_length'])\n\nlogging.basicConfig(level=logging.DEBUG, filename='server.log', filemode='w',\n format='%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s')\n\n\nclass TempFile():\n\n def __init__(self, path, name):\n self.filepath = os.path.abspath(path)\n self.filename = name\n\n def get_filename(self):\n return self.filename\n\n def get_filepath(self):\n return os.path.realpath(os.path.join(self.filepath, self.filename))\n\n def __del__(self):\n # file = os.join(self.filepath, self.filename)\n # if os.path.isfile(file):\n # os.remove(self.file)\n pass\n\n\ndef check_with_model(file_id):\n global model\n\n file = TempFile(os.path.join(app.config['UPLOAD_FOLDER']), file_id)\n file_opcodes = [training.get_file_opcode(file.get_filepath())]\n training.serialize_codes(file_opcodes)\n file_opcodes = tflearn.data_utils.pad_sequences(file_opcodes, maxlen=seq_length, value=0.)\n\n res_raw = model.predict(file_opcodes)\n res = {\n # revert from categorical\n 'judge': True if argmax(res_raw, axis=1)[0] else False,\n 'chance': float(res_raw[0][argmax(res_raw, axis=1)[0]])\n }\n return res\n\n\ndef vaild_file(filename):\n ALLOWED_EXTENSIONS = ['php']\n return '.' in filename and filename.rsplit('.', 1)[1] in ALLOWED_EXTENSIONS\n\n\[email protected]('/check/result/<file_id>')\ndef check_webshell(file_id):\n if os.path.isfile(os.path.join(app.config['UPLOAD_FOLDER'], file_id)):\n db = Database()\n fetch = db.check_result(file_id)\n if fetch:\n logging.info('got previous record: {0}'.format(file_id))\n malicious_judge = (fetch[0] == 1)\n malicious_chance = fetch[1]\n res = {\n 'file_id': file_id,\n 'malicious_judge': malicious_judge,\n 'malicious_chance': malicious_chance\n }\n else:\n logging.info('checking file: {0}'.format(file_id))\n res_check = check_with_model(file_id)\n res = {\n 'file_id': file_id,\n 'malicious_judge': res_check['judge'],\n 'malicious_chance': res_check['chance']\n }\n db.create_result(file_id, res_check['judge'], res_check['chance'])\n logging.info('record created: {0}'.format(file_id))\n else:\n res = {\n 'file_id': file_id,\n 'malicious_judge': None,\n 'malicious_chance': None\n }\n return jsonify(res)\n\n\[email protected]('/check/upload', methods=['GET', 'POST'])\ndef receive_file():\n if request.method == 'POST':\n file = request.files['file']\n if file and vaild_file(file.filename):\n file_id = hashlib.md5((file.filename+str(time.time())).encode('utf-8')).hexdigest()\n file.save(os.path.join(app.config['UPLOAD_FOLDER'], file_id))\n return redirect(url_for('check_webshell', file_id=file_id))\n else:\n return abort(400)\n\n elif request.method == 'GET':\n return render_template('upload.html')\n\n\[email protected]('/')\ndef index():\n return redirect(url_for('receive_file'))\n\n\[email protected]\ndef atexit():\n logging.info('server stop')\n\n\nif __name__ == '__main__':\n global model, seq_length\n\n host = config['server']['host']\n port = int(config['server']['port'])\n\n model_record = config['training']['model_record']\n seq_length = json.load(open(model_record, 'r'))['seq_length']\n\n model = training.get_model()\n logging.info('model loaded')\n\n logging.info('server started')\n app.run(host='0.0.0.0', debug=True)\n"
},
{
"alpha_fraction": 0.6520960330963135,
"alphanum_fraction": 0.6621282696723938,
"avg_line_length": 30.670454025268555,
"blob_id": "59cd058ef593090cbb66bb8ff15fb556ddd81d91",
"content_id": "f265895a45d8e14085efe0480f1783fce58fe608",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2791,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 88,
"path": "/test_model_metric_new.py",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport json\nfrom functools import reduce\nfrom configparser import ConfigParser\n\nimport tflearn\nfrom numpy import argmax\nfrom sklearn import model_selection, metrics\n\nimport training\n\n\nconfig = ConfigParser()\nconfig.read('config.ini')\nblack_files = config['training']['black_files']\nwhite_files = config['training']['white_files']\nmodel_record = config['training']['model_record']\n\n\ndef test_model(x1_code, y1_label, x2_code, y2_label):\n global model_record\n\n x1_code.extend(x2_code)\n y1_label.extend(y2_label)\n\n print('serializing opcode from data set')\n training.serialize_codes(x1_code)\n\n x_train, x_test, y_train, y_test = model_selection.train_test_split(x1_code, y1_label, shuffle=True)\n print('train: {0}, test: {1}'.format(len(x_train), len(x_test)))\n\n record = json.load(open(model_record, 'r'))\n seq_length = len(reduce(lambda x, y: x if len(x) > len(y) else y, x1_code))\n optimizer = record['optimizer']\n learning_rate = record['learning_rate']\n loss = record['loss']\n n_epoch = record['n_epoch']\n batch_size = record['batch_size']\n\n x_train = tflearn.data_utils.pad_sequences(x_train, maxlen=seq_length, value=0.)\n x_test = tflearn.data_utils.pad_sequences(x_test, maxlen=seq_length, value=0.)\n\n y_train = tflearn.data_utils.to_categorical(y_train, nb_classes=2)\n\n network = training.create_network(\n seq_length,\n optimizer=optimizer,\n learning_rate=learning_rate,\n loss=loss)\n model = tflearn.DNN(network, tensorboard_verbose=0)\n model.fit(\n x_train, y_train,\n n_epoch=n_epoch,\n shuffle=True,\n validation_set=0.1,\n show_metric=True,\n batch_size=batch_size,\n run_id='webshell')\n\n y_pred = model.predict(x_test)\n y_pred = argmax(y_pred, axis=1)\n\n print('metrics.accuracy_score:')\n print(metrics.accuracy_score(y_test, y_pred))\n print('metrics.confusion_matrix:')\n print(metrics.confusion_matrix(y_test, y_pred))\n print('metrics.precision_score:')\n print(metrics.precision_score(y_test, y_pred))\n print('metrics.recall_score:')\n print(metrics.recall_score(y_test, y_pred))\n print('metrics.f1_score:')\n print(metrics.f1_score(y_test, y_pred))\n\n\nif __name__ == '__main__':\n print('loading black files...')\n black_code_list = training.get_all_opcode(black_files)\n black_label = [1] * len(black_code_list)\n print('{0} black files loaded'.format(len(black_code_list)))\n\n print('loading white files...')\n white_code_list = training.get_all_opcode(white_files)\n white_label = [0] * len(white_code_list)\n print('{0} white files loaded'.format(len(white_code_list)))\n\n test_model(black_code_list, black_label, white_code_list, white_label)\n "
},
{
"alpha_fraction": 0.6776859760284424,
"alphanum_fraction": 0.7355371713638306,
"avg_line_length": 15.5,
"blob_id": "2b2ec6f70f34205826a223e7b0ca4f53119e9b76",
"content_id": "24658ad2018bd9d86ba574a280aabecc180eb8f0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 363,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 22,
"path": "/config.ini",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "[server]\nhost = 0.0.0.0\nport = 8080\n\n[api]\nupload_path = uploads\nupload_max_length = 10485760\n\n[training]\nblack_files = dataset/black/\nwhite_files = dataset/white/\nopcode_file = opcode.txt\nmodel_path = persistence/model.tfl\nmodel_record = persistence/record.json\nepoch = 10\nbatch = 100\n\n[database]\nhost = localhost\nusername = \npassword = \ndatabase = eagleeye_cnn\n"
},
{
"alpha_fraction": 0.751937985420227,
"alphanum_fraction": 0.7635658979415894,
"avg_line_length": 22.454545974731445,
"blob_id": "9db389a395fde822fe9fee28a2ea05919648266a",
"content_id": "f81c37ebdab495dde43be35f2c30df18ea3f523c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 258,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 11,
"path": "/init.sql",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "CREATE DATABASE IF NOT EXISTS eagleeye_cnn CHARACTER SET utf8;\n\nUSE eagleeye_cnn;\n\nCREATE TABLE IF NOT EXISTS detect_result\n(\n file_id VARCHAR(32) PRIMARY KEY,\n malicious_judge BOOLEAN NOT NULL,\n malicious_chance FLOAT,\n created_at DATETIME NOT NULL,\n);\n"
},
{
"alpha_fraction": 0.828125,
"alphanum_fraction": 0.84375,
"avg_line_length": 7,
"blob_id": "e07b4bc1d67ff04d2d2fad21c65271462a27dd7b",
"content_id": "b0d37d6588e555416d11e51a3646227ae3804588",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 64,
"license_type": "permissive",
"max_line_length": 12,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "pymysql\nflask\nh5py\nnumpy\nscipy\nscikit-learn\n#tensorflow\ntflearn\n"
},
{
"alpha_fraction": 0.546174168586731,
"alphanum_fraction": 0.5527704358100891,
"avg_line_length": 23.852458953857422,
"blob_id": "9f2ae14915bd257e5bd9ff6172b1059b11ce7568",
"content_id": "e7589295344308a05ddcdc32475d35a59fffa46d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1516,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 61,
"path": "/lib.py",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport logging\nimport time\nfrom configparser import ConfigParser\n\nimport pymysql\nfrom flask import abort\n\n\nconfig = ConfigParser()\nconfig.read('config.ini')\ndb_config = {\n 'host': config['database']['host'],\n 'user': config['database']['username'],\n 'password': config['database']['password'],\n 'database': config['database']['database']\n}\n\n\nclass Database():\n\n def __init__(self):\n global db_config\n\n self.conn = pymysql.connect(**db_config)\n self.curs = self.conn.cursor()\n\n\n def __del__(self):\n self.curs.close()\n self.conn.close()\n\n\n def create_result(self, fid, judge, chance):\n sql = 'INSERT INTO result(fid, judge, chance, ctime) VALUES (%s, %s, %s, %s);'\n parm = (fid, judge, chance, time.strftime(\"%Y-%m-%d %H:%M:%S\"))\n try:\n self.curs.execute(sql, parm)\n except Exception:\n self.conn.rollback()\n logging.exception('SQL: {0}'.format(sql))\n abort(500)\n else:\n self.conn.commit()\n\n\n def check_result(self, fid):\n sql = 'SELECT judge, chance, ctime FROM result WHERE fid = %s;'\n parm = (fid,)\n try:\n self.curs.execute(sql, parm)\n except Exception:\n logging.exception('SQL: {0}'.format(sql))\n abort(500)\n else:\n if self.curs.rowcount == 0:\n return None\n result = self.curs.fetchone()\n return result\n"
},
{
"alpha_fraction": 0.6110466718673706,
"alphanum_fraction": 0.623803973197937,
"avg_line_length": 30.935184478759766,
"blob_id": "05a92c754efe9bde9666cec72b7c7a20fb827673",
"content_id": "61abf70d55f99476ef7a0f71fe2669caa14fc783",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7000,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 216,
"path": "/training.py",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport json\nimport os\nimport re\nimport subprocess\nfrom configparser import ConfigParser\nfrom functools import reduce\n\nimport tensorflow as tf\nimport tflearn\nfrom sklearn.utils import shuffle\n\n\nconfig = ConfigParser()\nconfig.read('config.ini')\nblack_files = config['training']['black_files']\nwhite_files = config['training']['white_files']\nopcode_file = config['training']['opcode_file']\nmodel_path = config['training']['model_path']\nmodel_record = config['training']['model_record']\ntrain_epoch = int(config['training']['epoch'])\ntrain_batch = int(config['training']['batch'])\n\n\ndef get_php_file(base_dir):\n file_list = []\n for path, dirs, files in os.walk(base_dir):\n for file in files:\n if file.endswith('.php'):\n filename = os.path.realpath(os.path.join(path, file))\n file_list.append(filename)\n return file_list\n\n\ndef get_all_opcode(base_dir):\n file_list = get_php_file(base_dir)\n opcode_list = []\n for file in file_list:\n opcode = get_file_opcode(file)\n if opcode:\n opcode_list.append(opcode)\n return opcode_list\n\n\ndef get_file_opcode(filename):\n php_path = '/usr/bin/php'\n cmd = ('{0} -dvld.active=1 -dvld.execute=0'.format(php_path)).split()\n cmd.append(filename)\n p = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)\n\n opcodes = []\n pattern = r'([A-Z_]{2,})\\s+'\n for line in p.stdout.readlines()[8:-3]:\n try:\n match = re.search(pattern, str(line, encoding='utf-8'))\n except UnicodeDecodeError:\n match = re.search(pattern, str(line))\n if match:\n opcodes.append(match.group(1))\n p.terminate()\n return opcodes\n\n\ndef serialize_decorator(func):\n global opcode_file\n\n with open(opcode_file, 'r') as f:\n code_record = list(map(lambda x: x.strip(), f.readlines()))\n\n def wrapped(*args, **kwargs):\n return func(*args, _code_record=code_record, **kwargs)\n return wrapped\n\n\n@serialize_decorator\ndef serialize_codes(code_list, _code_record):\n for file_code in code_list:\n for index, code in enumerate(file_code):\n if _code_record.count(code):\n file_code[index] = _code_record.index(code) + 1\n else:\n file_code[index] = 0\n\n\ndef create_network(seq_length, optimizer, learning_rate, loss):\n # 输入参数的最大长度为序列的最大长度\n network = tflearn.input_data(shape=[None, seq_length], name='input')\n\n # CNN 模型, 使用 3 个数量为 128, 长度分别为 3, 4, 5 的一维卷积函数处理数据\n network = tflearn.embedding(network, input_dim=100000, output_dim=128)\n branch1 = tflearn.layers.conv.conv_1d(network, 128, 3, padding='valid', activation='relu', regularizer='L2')\n branch2 = tflearn.layers.conv.conv_1d(network, 128, 4, padding='valid', activation='relu', regularizer=\"L2\")\n branch3 = tflearn.layers.conv.conv_1d(network, 128, 5, padding='valid', activation='relu', regularizer=\"L2\")\n tflearn.layers.merge_ops.merge([branch1, branch2, branch3], mode='concat', axis=1)\n\n network = tf.expand_dims(network, 2)\n network = tflearn.layers.conv.global_max_pool(network)\n network = tflearn.layers.core.dropout(network, 0.8)\n network = tflearn.fully_connected(network, 2, activation='softmax')\n network = tflearn.layers.estimator.regression(\n network,\n optimizer=optimizer,\n learning_rate=learning_rate,\n loss=loss,\n name='target')\n return network\n\n\ndef train_model(x1_code, y1_label, x2_code, y2_label):\n global model_path, model_record\n\n train_optimizer = 'adam'\n train_learning_rate = 0.001\n train_loss = 'categorical_crossentropy'\n\n x1_code.extend(x2_code)\n y1_label.extend(y2_label)\n\n # Shuffle the ordinary of dataset\n x_train, y_train = shuffle(x1_code, y1_label)\n\n # Serialize the opcodes into numbers\n print('[*] serializing opcode from persistence set')\n serialize_codes(x_train)\n\n # Find the max length of sequence\n train_seq_length = len(reduce(lambda x, y: x if len(x) > len(y) else y, x1_code))\n print('[+] max length of persistence set: {0}'.format(train_seq_length))\n\n # Padding all sequence to max length\n x_train = tflearn.data_utils.pad_sequences(x_train,\n maxlen=train_seq_length,\n value=0.)\n\n # Categorical label\n y_train = tflearn.data_utils.to_categorical(y_train, nb_classes=2)\n\n # tflearn.config.init_graph(gpu_memory_fraction=0.9, soft_placement=True)\n\n network = create_network(\n train_seq_length,\n optimizer=train_optimizer,\n learning_rate=train_learning_rate,\n loss=train_loss)\n\n # 实例化 CNN 对象并训练数据\n print('[*] traning started')\n print('[+] epoch: {0}, batch_size: {1}'.format(train_epoch, train_batch))\n model = tflearn.DNN(network, tensorboard_verbose=0)\n model.fit(\n x_train, y_train,\n n_epoch=train_epoch,\n shuffle=True,\n validation_set=0.1,\n show_metric=True,\n batch_size=train_batch,\n run_id='webshell')\n\n record = {\n 'seq_length': train_seq_length,\n 'optimizer': train_optimizer,\n 'learning_rate': train_learning_rate,\n 'loss': train_loss,\n 'n_epoch': train_epoch,\n 'batch_size': train_batch\n }\n json.dump(record, open(model_record, 'w'))\n model.save(model_path)\n print('[+] model saved in {0}'.format(model_path))\n\n return model\n\n\ndef get_model():\n global model_path, model_record, black_files, white_files\n\n if os.path.isfile(os.path.join(os.path.dirname(model_path), 'checkpoint')):\n print('[*] loading model...')\n\n record = json.load(open(model_record, 'r'))\n seq_length = record['seq_length']\n optimizer = record['optimizer']\n learning_rate = record['learning_rate']\n loss = record['loss']\n\n network = create_network(\n seq_length,\n optimizer=optimizer,\n learning_rate=learning_rate,\n loss=loss)\n model = tflearn.DNN(network, tensorboard_verbose=1)\n model.load(model_path)\n print('[+] {0} loaded'.format(model_path))\n return model\n\n print('[*] loading black files...')\n black_code_list = get_all_opcode(black_files)\n black_label = [1] * len(black_code_list)\n print('[+] {0} black files loaded'.format(len(black_code_list)))\n\n print('[*] loading white files...')\n white_code_list = get_all_opcode(white_files)\n white_label = [0] * len(white_code_list)\n print('[+] {0} white files loaded'.format(len(white_code_list)))\n\n print('[*] training model...')\n model = train_model(black_code_list, black_label,\n white_code_list, white_label)\n print('[+] training complete')\n return model\n\n\nif __name__ == '__main__':\n get_model()\n"
},
{
"alpha_fraction": 0.676831841468811,
"alphanum_fraction": 0.6861499547958374,
"avg_line_length": 30.905405044555664,
"blob_id": "399b9b512c9e1cb22a53e0c77ed76f5f7fc7cdc1",
"content_id": "da02d387f719a407f23be4f170f8d0719e6d1368",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2361,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 74,
"path": "/test_model_metric_exist.py",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport json\nfrom configparser import ConfigParser\n\nimport tflearn\nfrom numpy import argmax\nfrom sklearn import metrics\nfrom sklearn.utils import shuffle\n\nimport training\n\n\nconfig = ConfigParser()\nconfig.read('config.ini')\nblack_files = config['training']['black_files']\nwhite_files = config['training']['white_files']\nmodel_path = config['training']['model_path']\nmodel_record = config['training']['model_record']\n\n\ndef test_model(x1_code, y1_label, x2_code, y2_label):\n global model_path, model_record\n\n x1_code.extend(x2_code)\n y1_label.extend(y2_label)\n\n x_test, y_test = shuffle(x1_code, y1_label)\n print('size of testing set: {0}'.format(len(x_test)))\n\n print('serializing opcode from testing set')\n training.serialize_codes(x_test)\n\n record = json.load(open(model_record, 'r'))\n seq_length = record['seq_length']\n optimizer = record['optimizer']\n learning_rate = record['learning_rate']\n loss = record['loss']\n\n x_test = tflearn.data_utils.pad_sequences(x_test, maxlen=seq_length, value=0.)\n y_test = tflearn.data_utils.to_categorical(y_test, nb_classes=2)\n\n network = training.create_network(seq_length, optimizer=optimizer, learning_rate=learning_rate, loss=loss)\n model = tflearn.DNN(network, tensorboard_verbose=0)\n model.load(model_path)\n\n y_pred = model.predict(x_test)\n y_pred = argmax(y_pred, axis=1)\n\n print('metrics.accuracy_score:')\n print(metrics.accuracy_score(y_test, y_pred))\n print('metrics.confusion_matrix:')\n print(metrics.confusion_matrix(y_test, y_pred))\n print('metrics.precision_score:')\n print(metrics.precision_score(y_test, y_pred))\n print('metrics.recall_score:')\n print(metrics.recall_score(y_test, y_pred))\n print('metrics.f1_score:')\n print(metrics.f1_score(y_test, y_pred))\n\n\nif __name__ == '__main__':\n print('loading black files...')\n black_code_list = training.get_all_opcode(black_files)\n black_label = [1] * len(black_code_list)\n print('{0} black files loaded'.format(len(black_code_list)))\n\n print('loading white files...')\n white_code_list = training.get_all_opcode(white_files)\n white_label = [0] * len(white_code_list)\n print('{0} white files loaded'.format(len(white_code_list)))\n\n test_model(black_code_list, black_label, white_code_list, white_label)\n"
},
{
"alpha_fraction": 0.5652173757553101,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 6.340425491333008,
"blob_id": "4f1f62ba4caa8a5d519c8a90140c5cba57b44fa3",
"content_id": "c00309ebda5753099b9418b32b7c0eafb54c507c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 447,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 47,
"path": "/README.md",
"repo_name": "godesady/cnn-webshell-detect",
"src_encoding": "UTF-8",
"text": "# CNN Webshell 检测\n\n## 安装\n\n第三方库:\n\n```\npip install -r requirements\n```\n\n初始化数据库:\n\n```\nmysql -u<username> -p<password> < init.sql\n```\n\n## 使用\n\n模型训练:\n\n```\n./training.py\n```\n\n测试已有模型:\n\n```\n./test_model_metric_exist.py\n```\n\n训练新模型并测试:\n\n```\n./test_model_metric_new.py\n```\n\n测试 RNN 模型:\n\n```\n./test_model_metric_rnn.py\n```\n\n运行检测 Demo 页面:\n\n```\n./server.py\n```\n"
}
] | 9 |
abir101-prog/githubFinder
|
https://github.com/abir101-prog/githubFinder
|
de79346112f33cc40f5b6dd1143a9b9e4e71195b
|
735951fdc2025f7e71839644a1f1cb79fcc1a772
|
f6859173f3f4c998788695bc04e46bfd307f19df
|
refs/heads/master
| 2022-12-07T17:41:33.499615 | 2020-08-22T22:36:11 | 2020-08-22T22:36:11 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7097039222717285,
"alphanum_fraction": 0.7129934430122375,
"avg_line_length": 30.179487228393555,
"blob_id": "e14d3a16b28f5115262ce82b60db847b52f91baf",
"content_id": "6b0b4ea80befa3ea3ad568cfc2d850106a20078d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1216,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 39,
"path": "/fetch_data.py",
"repo_name": "abir101-prog/githubFinder",
"src_encoding": "UTF-8",
"text": "import requests\nimport json\nfrom os import environ\n\n# client id and secret key\nclient_id = environ.get(\"ghclient_id\")\nclient_secret = environ.get(\"ghclient_secret\")\n\n\ndef get_user(user):\n\tcontent = requests.get(f'https://api.github.com/users/{user}?client_id={client_id}&client_secret={client_secret}').content\n\tcontent_dict = json.loads(content)\n\n\tif content_dict.get('message'):\n\t\treturn -1\n\n\t# data that will be displayed\n\tfiltered_keys = ['avatar_url', 'name', 'public_repos', 'followers', 'following', 'created_at']\n\tcleaned_data = {key: content_dict[key] if content_dict[key] != None else 'Not given' for key in filtered_keys}\n\t# fixing date\n\tcleaned_data['created_at'] = cleaned_data['created_at'][:10]\n\treturn cleaned_data\n\n\n\ndef get_image(url):\n\treturn requests.get(url, stream=True).raw\n\t\n\ndef get_repos(user):\n\tcontent = requests.get(f'https://api.github.com/users/{user}/repos?per_page=5&client_id={client_id}&client_secret={client_secret}').content\n\tcontent_dict = json.loads(content)\n\tfiltered_keys = ['name', 'watchers', 'forks']\n\tdata_list = [] # list of repos\n\tfor repo in content_dict:\n\t\tcleaned_data = {key: repo[key] for key in filtered_keys}\n\t\tdata_list.append(cleaned_data)\n\n\treturn data_list\n"
},
{
"alpha_fraction": 0.6504424810409546,
"alphanum_fraction": 0.6504424810409546,
"avg_line_length": 14.133333206176758,
"blob_id": "a71403317707c4b64faca3939aa22b8d3b3e944c",
"content_id": "c2a5f5a7f8fb3c93356507994c91b0d1154e1fe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 15,
"path": "/main.py",
"repo_name": "abir101-prog/githubFinder",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom gui import Home\n\ndef main():\n\troot = Tk()\n\troot.title('GitHub Finder')\n\troot.iconphoto(False, PhotoImage(file=\"github.png\"))\n\n\tview = Home(root)\n\n\n\troot.mainloop()\n\nif __name__ == '__main__':\n\tmain()"
},
{
"alpha_fraction": 0.631911039352417,
"alphanum_fraction": 0.663161039352417,
"avg_line_length": 35.988887786865234,
"blob_id": "f80cc24498b81628a6f93ca42e638b826b4cddbc",
"content_id": "2b542c2cda74687768b827559cc5750ea09b2b4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3328,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 90,
"path": "/gui.py",
"repo_name": "abir101-prog/githubFinder",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom fetch_data import get_user, get_image, get_repos\nfrom PIL import ImageTk, Image\nfrom io import BytesIO\n\nclass Home:\n\tdef __init__(self, root):\n\t\tself.root = root\n\t\t\n\t\tself.parent = Frame(root)\n\t\tself.parent.grid(row=0, column=0) # parent will contain everything\t\t\n\t\t\n\t\tself.form = LabelFrame(self.parent, padx=20, pady=5)\n\t\tself.form.grid(row=0, column=0, pady=10., padx=10) # first child of parent\n\t\tself.create_form_children()\n\t\t\n\t\tself.user = LabelFrame(self.parent, padx=20, pady=5) # second child of parent, will be seen after user is requested\n\t\tself.repos = LabelFrame(self.parent, padx=20, pady=5) #third child of parent, will be seen after...\n\t\t\n\n\tdef create_form_children(self):\n\t\tself.title = Label(self.form, text='GitHub User Finder!')\n\t\tself.title.grid(row=0, column=0, columnspan=3)\n\t\tself.user_label = Label(self.form, text='Enter username')\n\t\tself.user_label.grid(row=1, column=0)\n\t\tself.user_entry = Entry(self.form, width=50, borderwidth=3)\n\t\tself.user_entry.grid(row=1, column=1, columnspan=2, padx=10, pady=10, ipady=5)\n\t\tself.search_btn = Button(self.form, text='Search', width=30, padx=20, \n\t\t\tpady=5, fg='#ffffff', bg='#5ca9d6', command=self.display_user)\n\t\tself.search_btn.grid(row=2, column=1, columnspan=2, pady=5)\n\n\n\tdef display_user(self):\n\t\t# get the username\n\t\tusername = self.user_entry.get()\n\t\tdata = get_user(username) # fetch data through api\n\t\tif data != -1: # if data is returned\n\t\t\tchildren_u = self.user.grid_slaves() \n\t\t\tfor child in children_u:\n\t\t\t\tchild.destroy() # removing everything from user LabelFrame\n\t\t\ti = 0\n\t\t\tfor (key, value) in data.items():\n\t\t\t\tif key == 'avatar_url':\n\t\t\t\t\timage = get_image(value)\n\t\t\t\t\timage = Image.open(image)\n\t\t\t\t\timage = image.resize((150, 150))\n\n\t\t\t\t\timg = ImageTk.PhotoImage(image)\n\t\t\t\t\tpanel = Label(self.user, image=img)\n\t\t\t\t\tpanel.image = img\n\t\t\t\t\tpanel.grid(row=i, column=0)\n\t\t\t\telse:\n\t\t\t\t\t# formatting string:\n\t\t\t\t\tkey_2_label = key.split('_')\n\t\t\t\t\tkey_2_label = [word.capitalize() for word in key_2_label]\n\t\t\t\t\tkey_2_label = ' '.join(key_2_label)\n\n\t\t\t\t\tLabel(self.user, text=key_2_label).grid(row=i, column=0)\n\t\t\t\t\tl = Label(self.user, text=value, width=30)\n\t\t\t\t\tl.grid(row=i, column=1)\n\t\t\t\ti += 1\n\t\t\tself.user.grid(row=1, column=0, pady=10)\n\t\t\tButton(self.user, text='Show Repositories', width=30, padx=20, pady=10,\n\t\t\t fg='#ffffff', bg='#5ca9d6', command=lambda: self.show_repo(username)).grid(row=i, column=0, columnspan=2)\n\t\t\t\n\t\t\tchildren_r = self.repos.grid_slaves()\n\t\t\tfor child in children_r:\n\t\t\t\tchild.destroy() # removing everything from repo LabelFrame\n\t\t\tself.repos.grid_forget()\n\n\n\tdef show_repo(self, user):\n\n\t\trepos = get_repos(user)\n\t\tj = 0\n\t\tif len(repos) == 0:\n\t\t\tLabel(self.repos, text='No Repository found', bg='#f54049', fg='#ffffff', width=30).grid(row=0, column=0, columnspan=3)\n\t\telse:\n\t\t\t# table heading:\n\t\t\tLabel(self.repos, text='Name').grid(row=j, column=0)\n\t\t\tLabel(self.repos, text='Watchers').grid(row=j, column=1)\n\t\t\tLabel(self.repos, text='Forks').grid(row=j, column=2)\n\t\tj += 1\n\t\t# repo data\n\t\tfor repo in repos:\n\t\t\tLabel(self.repos, text=repo.get(\"name\")).grid(row=j, column=0)\n\t\t\tLabel(self.repos, text=repo.get(\"watchers\")).grid(row=j, column=1)\n\t\t\tLabel(self.repos, text=repo.get(\"forks\")).grid(row=j, column=2)\n\t\t\tj += 1\n\t\tself.repos.grid(row=2, column=0, pady=10)"
},
{
"alpha_fraction": 0.8105726838111877,
"alphanum_fraction": 0.8105726838111877,
"avg_line_length": 112.5,
"blob_id": "ff7fcfdf735525b800fe6cf4d362cea838773a7a",
"content_id": "b367db1bb888dc9295c848849f41f90311035e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 2,
"path": "/README.md",
"repo_name": "abir101-prog/githubFinder",
"src_encoding": "UTF-8",
"text": "# githubFinder\npython app for finding user in github using tkinter, request and github api. To use this program Register an OAuth application to get client ID and client secret(without these keys, api requests will be limited)\n"
}
] | 4 |
sanchita0319/EDD-Green-Team-Interns
|
https://github.com/sanchita0319/EDD-Green-Team-Interns
|
30ca5b12725e9e31d139dbcd62babdecfe7f05ed
|
0cb66a79eceef328a07bdd3ca5d9d7ece31753af
|
46c1c395e8a4e39306fa83831d15133aa5c391b7
|
refs/heads/master
| 2021-04-29T19:55:25.182425 | 2018-04-04T00:34:14 | 2018-04-04T00:34:14 | 121,587,027 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5566750764846802,
"alphanum_fraction": 0.5755667686462402,
"avg_line_length": 20.600000381469727,
"blob_id": "de2d81effe01ee0c6c68c54d435a098756cb91e7",
"content_id": "adb304775969bd2b935336ee51c98f53a14f80f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 794,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 35,
"path": "/bridge.py",
"repo_name": "sanchita0319/EDD-Green-Team-Interns",
"src_encoding": "UTF-8",
"text": "import math\r\n# d = distance between center of bridge and robot\r\n# t = seconds at which measurement is being taken after initation\r\n# m = mass of groundbot\r\n#b_intertia = inertia of the bridge\r\n#theta = angle in rad\r\ndistance = []\r\nmass = []\r\ndef distance_mass(distance, mass):\r\n total = 0\r\n for i in distance:\r\n total += i\r\n print (total)\r\n global d \r\n d = total\r\n sum = 0\r\n for i in mass:\r\n sum += i\r\n total1 = sum / len(mass)\r\n print (total1)\r\n global m\r\n m = total1\r\n \r\ntheta = 0\r\n\r\ndef next_theta(d,m,theta,b_inertia,t):\r\n w =0\r\n torque = 9.8 * m * math.cos(theta) * d\r\n t_inertia = b_inertia + m * d ** 2\r\n acc = t_inertia / torque\r\n w = w + acc * t\r\n theta = theta + 1/2 * acc * t**2 + w*t\r\n print (theta)\r\n global theta1\r\n theta1 = theta\r\n \r\n"
},
{
"alpha_fraction": 0.7916666865348816,
"alphanum_fraction": 0.7916666865348816,
"avg_line_length": 24,
"blob_id": "af6ee756082e889a4a441c8ce1ea20cba6d01943",
"content_id": "a2d5e8d587be82179235e92f1a95effc13c021fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/README.md",
"repo_name": "sanchita0319/EDD-Green-Team-Interns",
"src_encoding": "UTF-8",
"text": "# EDD-Green-Team-Interns"
}
] | 2 |
mwatson6/TCP-UDP-Port-Scanner
|
https://github.com/mwatson6/TCP-UDP-Port-Scanner
|
e380b70a90a707506f63c15db3463559fa57b541
|
b3aaf1c045328d9ab4a868f6ab0a6b0290ddcc69
|
e3e0948ea68a94dde2013ab28b05ece9b4ee1428
|
refs/heads/master
| 2019-07-16T12:12:21.225906 | 2017-03-04T18:17:36 | 2017-03-04T18:17:36 | 83,913,545 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5744540095329285,
"alphanum_fraction": 0.5814030170440674,
"avg_line_length": 24.964284896850586,
"blob_id": "f11c12ac29fa4ff51d454fab405bb4b228e6a61b",
"content_id": "6a9e8cc90799d1c1e35f24890c8ef501e36f0dc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3022,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 112,
"path": "/PortScanner.txt",
"repo_name": "mwatson6/TCP-UDP-Port-Scanner",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom socket import *\r\nimport subprocess\r\nimport sys, time\r\nfrom datetime import datetime\r\nfrom reportlab.pdfgen import canvas\r\n\r\n#initializing arbitrary values\r\nhost = ''\r\nmax_port = 100\r\nmin_port = 1\r\n\r\ndef scan_host_tcp(host, port, r_code =1):\r\n try:\r\n s = socket(AF_INET, SOCK_STREAM) #SOCK_STREAM is TCP\r\n\r\n code = s.connect_ex((host, port))\r\n\r\n if code == 0:\r\n r_code = code #success code to say it's open\r\n s.close()\r\n except Exception as e:\r\n pass\r\n\r\n return r_code\r\n\r\ndef scan_host_udp(host, port, r_code = 1):\r\n try:\r\n s = socket(AF_INET, SOCK_DGRAM) #SOCK_DGRAM is UDP\r\n s.settimeout(0.1) #time in between packets\r\n s.sendto(\"--TEST LINE--\", (host, port))\r\n recv, svr = s.recvfrom(255)\r\n\r\n except Exception as e:\r\n try:\r\n errno, errtxt = e\r\n except ValueError:\r\n print (\"%s udp open\" % (port)) #success code to say it's open\r\n Openports.append(port)\r\n else:\r\n if verbose: print(\"%d/udp \\tclosed\" % (port))\r\n\r\n s.close()\r\n\r\n\r\n#User Inputs\r\ntry:\r\n host = input(\"[*] Enter Target Host Address: \")\r\n max_port_tcp = int(input(\"[*]What port do you want to scan to with tcp? \")) + 1\r\n min_port_tcp = int(input(\"[*]What port do you want to start from? \"))\r\n max_port_udp = int(input(\"[*]What port do you want to scan to with udp? \")) + 1\r\n min_port_udp = int(input(\"[*]What port do you want to start from? \"))\r\nexcept KeyboardInterrupt:\r\n print(\"\\n\\n[*] User Requested an Interrupt.\")\r\n print(\"\\[*] Application Shutting Down.\")\r\n sys.exit(1)\r\n\r\n\r\n#Generating data usable for functions\r\nhostip = gethostbyname(host)\r\nprint(\"\\n[*] Host: %s IP: %s\" % (host, hostip))\r\nprint(\"[*] Scanning Started At %s...\\n\" % (time.strftime(\"%H:%M:%S\")))\r\nstart_time = datetime.now()\r\n\r\n#Creating a list of open ports\r\nOpenPorts = list()\r\n\r\n#TCP SCAN\r\nfor port in range(min_port_tcp, max_port_tcp):\r\n try:\r\n response_tcp = scan_host_tcp(host, port)\r\n\r\n if response_tcp == 0:\r\n print(\"[*] Port %d: Open.\" % (port))\r\n OpenPorts.append(port)\r\n except Exception as e:\r\n pass\r\n print(\"Port \" + str(port) + \" Scanned with TCP.\")\r\n\r\n#UDP Scan\r\nfor port in range(min_port_udp, max_port_udp):\r\n try:\r\n response_udp = scan_host_udp(host, port)\r\n except Exception as e:\r\n pass\r\n print(\"Port \" + str(port) + \" Scanned with UDP.\")\r\n\r\n\r\nstop_time = datetime.now()\r\ntotal_time_duration = stop_time - start_time\r\n\r\n#For readability\r\nprint(\"\\n\")\r\n\r\nfor x in OpenPorts:\r\n print(\"Port \" + str(x) + \" is open.\\n\")\r\n\r\nprint(\"\\n[*] Scanning Finished at %s ... \" % (time.strftime(\"%H:%M:%S\")))\r\nprint(\"[*] Scanning Duration: %s ...\" % (total_time_duration))\r\n\r\n#Writing to a PDF\r\ndef writeString(c): #Writing to PDF\r\n c.drawString(25, 750, str(OpenPorts))\r\n\r\nc=canvas.Canvas(\"Scan.pdf\")\r\nwriteString(c)\r\n\r\nc.showPage()\r\nc.save()\r\n\r\n#Well wishes\r\nprint(\"[*] Good day mate!\")\r\n\r\n"
},
{
"alpha_fraction": 0.7677100300788879,
"alphanum_fraction": 0.7710049152374268,
"avg_line_length": 45.69230651855469,
"blob_id": "5184043789ef155bb1778605de015f36fd5ca307",
"content_id": "66d8a323568fdedbb08a189445e28c5011f97252",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 227,
"num_lines": 13,
"path": "/README.md",
"repo_name": "mwatson6/TCP-UDP-Port-Scanner",
"src_encoding": "UTF-8",
"text": "# TCP-UDP-Port-Scanner\nA scanner that will take whichever ports you want to scan on a host using TCP and UDP protocols\n\n\nYou will need:\n Python 3.6\n ReportLab Library\n \nTo install ReportLab Library, follow https://bitbucket.org/rptlab/reportlab.\n\nThe .whl file can be found at https://www.reportlab.com/pypi/packages/. You will need to register for an account but it's free.\n\nThe PDF that is generated will be in the current working directory as 'Scan.pdf'. It's a bit ugly, so if you want to make it prettier, try to understand this documentation: https://www.reportlab.com/docs/reportlab-userguide.pdf\n"
}
] | 2 |
mortalius/tagreplicator
|
https://github.com/mortalius/tagreplicator
|
f62ba16780fa0db053bb81c322c963f666d62619
|
45e61dc4205f94727ead3509383f571a19c12f97
|
2de514f67f55fe944745c886b06e2d21492513ad
|
refs/heads/master
| 2023-07-22T12:58:55.587827 | 2017-12-07T11:30:47 | 2017-12-07T11:30:47 | 105,139,015 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6261292695999146,
"alphanum_fraction": 0.6421125531196594,
"avg_line_length": 40.14285659790039,
"blob_id": "b523639063835d447387ffbbcab3fa7a83f6073f",
"content_id": "67a2d80663c3ceb591cb4f9519724554d6835132",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1439,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 35,
"path": "/lambda_upload.sh",
"repo_name": "mortalius/tagreplicator",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlambda_archive=\"lambda_bundle.zip\"\nzip_targets=\"tagreplicator.py requirements.txt\"\n\nprofile=\"profileX\"\nhandler=\"tagreplicator.lambda_handler\"\nrole=\"arn:aws:iam::205685244378:role/service-role/LAMBDA_ROLE\"\nfunction_name=\"tag replicator\"\ndescription=\"Propagates tags to snapshots and volumes based on tags from associated volumes/instances/amis\"\n``environment=\"Variables={REGION=us-east-1,DRYRUN=True,AMI_LOOKUP=False,TAGS=cost}\"\n\n# workaround for possible impossibility to set file world-readable\ncp $zip_targets /tmp/\ncd /tmp\nchmod a+r $zip_targets\nrm -f $lambda_archive\nzip $lambda_archive $zip_targets\n\n\nif [ \"$1\" == \"update\" ]; then\n echo \"Updating $function_name\"\n aws --profile $profile lambda update-function-code --function $function_name --zip-file fileb://$lambda_archive\nelif [ \"$1\" == \"delete\" ]; then\n echo \"Deleting $function_name\"\n aws --profile $profile lambda delete-function --function $function_name\nelse\n echo \"Creating $function_name\"\n aws --profile $profile lambda create-function --function $function_name --runtime python2.7 \\\n --role \"$role\" \\\n --handler \"$handler\" \\\n --zip-file fileb://$lambda_archive \\\n --timeout 300 --memory-size 512 \\\n --description \"$description\" \\\n --environment \"$environment\"\nfi"
},
{
"alpha_fraction": 0.5578833222389221,
"alphanum_fraction": 0.5641964077949524,
"avg_line_length": 43.33155059814453,
"blob_id": "0205f6fa19cad9c86269e28c9e170274ed6e7a65",
"content_id": "637b931c8e8376d169a6777ccf6134898253b433",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24869,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 561,
"path": "/tagreplicator.py",
"repo_name": "mortalius/tagreplicator",
"src_encoding": "UTF-8",
"text": "# Replicates tags to snapshot and volume using tags from volume/instance and ami(from snapshot description)\n# Dmitry Aliev (c)\n\n# TODO\n# README.md\n# Add info on where tag came from\n# use more convinient arg parser\n\n\nfrom __future__ import print_function\nimport boto3\nfrom botocore.exceptions import ClientError\nfrom collections import Counter\nimport re\nimport os\nimport csv\nimport sys\nimport argparse\nimport pprint\nfrom datetime import datetime\n\n\ndef parse_arguments():\n REGION = 'us-east-1'\n PROFILE = None\n parser = argparse.ArgumentParser(description=\"\"\"\nTag replicator. Scans for untagged resources (AMIs or Snapshots) and tags them with tags from associated resources.\n\"\"\")\n subparsers = parser.add_subparsers(help='Tagging Mode')\n\n parser.add_argument(\"--profile\", required=False, default=PROFILE, type=str,\n help=\"awscli profile to use\")\n parser.add_argument(\"--region\", required=False, default=REGION, type=str,\n help=\"AWS region (us-east-1 by default)\")\n\n # Snapshots tagging mode\n snapshot_parser = subparsers.add_parser('snapshot_mode', help='Find untagged Snapshots and propogate tags to them from associated volumes and instances')\n snapshot_parser.set_defaults(mode='snapshot_mode')\n snapshot_parser.add_argument(\"--tags\", action='store', type=str, required=True,\n help=\"List of tags to replicate, separated by comma, e.g Owner,cost (case sensitive)\")\n snapshot_parser.add_argument(\"--tag-untagged-with\", action='store', type=str, required=False, metavar='TAG:VALUE',\n help=\"Tag snapshots and volumes with <tag:value> where <tag> hadn't been found.\")\n snapshot_parser.add_argument(\"--ami-lookup\", action=\"store_true\", default=False,\n help=\"Lookup for tags from AMI. False by default\")\n snapshot_parser.add_argument(\"--stats-only\", action=\"store_true\", default=False,\n help=\"Print stats on snapshots total vs <tags> untagged snapshots and exit\")\n snapshot_parser.add_argument(\"--report\", action=\"store_true\", default=False,\n help=\"Generate csv report\")\n snapshot_parser.add_argument(\"--dry-run\", action=\"store_true\", default=False,\n help=\"No actual tagging. Could be used with --report\")\n\n # AMI tagging mode\n ami_parser = subparsers.add_parser('ami_mode', help='Find untagged AMIs and propagate tags to them from associated snapshots')\n ami_parser.set_defaults(mode='ami_mode')\n ami_parser.add_argument(\"--tags\", action='store', type=str, required=True,\n help=\"List of tags to replicate, separated by comma, e.g Owner,cost (case sensitive)\")\n ami_parser.add_argument(\"--tag-untagged-with\", action='store', type=str, required=False, metavar='TAG:VALUE',\n help=\"Tag AMIs with <tag:value> where <tag> hadn't been found.\")\n ami_parser.add_argument(\"--stats-only\", action=\"store_true\", default=False,\n help=\"Print stats on AMIs total vs <tags> untagged AMIs and exit\")\n ami_parser.add_argument(\"--report\", action=\"store_true\", default=False,\n help=\"Generate csv report\")\n ami_parser.add_argument(\"--dry-run\", action=\"store_true\", default=False,\n help=\"No actual tagging. Could be used with --report\")\n\n args = parser.parse_args()\n\n profile = args.profile\n region = args.region\n tag_mode = args.mode\n\n tags_list = args.tags.split(',')\n tag_untagged = args.tag_untagged_with\n stats_only = args.stats_only\n dryrun = args.dry_run\n report = args.report\n\n generic_params = (profile, region)\n if tag_mode == \"ami_mode\":\n mode_params = (tags_list, tag_untagged, stats_only, dryrun, report)\n elif tag_mode == \"snapshot_mode\":\n ami_lookup = args.ami_lookup\n mode_params = (tags_list, tag_untagged, ami_lookup, stats_only, dryrun, report)\n\n return (tag_mode, generic_params, mode_params)\n\n\nclass TagReplicator:\n\n def __init__(self):\n self.ec2 = None\n self.ec2client = None\n\n self.profile = None\n self.region = 'us-east-1'\n # self.stats_only = False\n # self.dryrun = False\n # self.report = False\n\n self.owner_account_id = ''\n self.count_tagged_resources = Counter()\n self.count_propagated_tags = Counter()\n\n self.start_time = None\n\n def get_untagged_snapshots(self, account_id, tags):\n self.print(\"Getting untagged snapshots..\")\n all_owned_snapshots_filter = [\n {\n 'Name': 'owner-id',\n 'Values': [account_id]\n }\n ]\n snaps_all = self.ec2.snapshots.filter(Filters=all_owned_snapshots_filter)\n snaps_all_ids = [s.snapshot_id for s in snaps_all]\n\n tags_filter = [\n {\n 'Name': 'owner-id',\n 'Values': [account_id]\n }\n ]\n for tag in tags:\n tags_filter.append(\n {\n 'Name': 'tag-key',\n 'Values': [tag]\n }\n )\n snaps_tagged = self.ec2.snapshots.filter(Filters=tags_filter)\n snaps_tagged_ids = [s.snapshot_id for s in snaps_tagged]\n return set(snaps_all_ids) - set(snaps_tagged_ids)\n\n def get_untagged_amis(self, account_id, tags):\n self.print(\"Getting untagged AMIs..\")\n all_owned_amis_filter = [\n {\n 'Name': 'owner-id',\n 'Values': [account_id]\n }\n ]\n tags_filter = [\n {\n 'Name': 'owner-id',\n 'Values': [account_id]\n }\n ]\n for tag in tags:\n tags_filter.append(\n {\n 'Name': 'tag-key',\n 'Values': [tag]\n }\n )\n amis_all = self.ec2client.describe_images(Filters=all_owned_amis_filter)['Images']\n amis_all_ids = [s['ImageId'] for s in amis_all]\n amis_tagged = self.ec2client.describe_images(Filters=tags_filter)['Images']\n amis_tagged_ids = [s['ImageId'] for s in amis_tagged]\n return set(amis_all_ids) - set(amis_tagged_ids)\n\n\n def volume_exists(self, id):\n try:\n self.ec2.Volume(id).size\n except ClientError as e:\n if e.response['Error']['Code'] == 'InvalidVolume.NotFound':\n return False\n else:\n raise e\n return True\n\n def tag_resource_with_tags(self, resource, tags, dryrun, index=0):\n prefix = resource.id.split('-')[0]\n self.count_propagated_tags[prefix] += len(tags)\n tags_to_create = []\n for key, value in tags.iteritems():\n tags_to_create.append(\n {\n 'Key': key,\n 'Value': value\n }\n )\n self.print(\"{idx} Tagging {dst:22} with tag:{key}={value} {note}\".format(\n idx=index if index else '',\n dst=resource.id,\n key=key,\n value=value,\n note='(dry run)' if dryrun else ''))\n if dryrun:\n return\n resource.create_tags(Tags=tags_to_create)\n\n def extract_untagged(self, src_details, dst_details, tags):\n missing_tags = {}\n for dtag in tags:\n if src_details['tags'].get(dtag):\n if not dst_details['tags'].get(dtag):\n missing_tags[dtag] = src_details['tags'].get(dtag)\n return missing_tags\n\n def get_ami_details(self, ami):\n# {'ami_id': 'ami-04994d7e',\n# 'snapshots': ['snap-0f029f88f550fdc1f'],\n# 'tags': {'Business Owner': 'Elaine Wilson',\n# 'Component': 'APP',\n# 'Description': 'CUS-PROD-APP-backend',\n# 'Environment': 'PROD',\n# 'JiraTicket': 'NFR-661',\n# 'Name': 'HMHVPC01-CUSPRODAPP02',\n# 'Project': 'CUS',\n# 'Technical Owner': 'John Hurley',\n# 'Tier': 'APP',\n# 'cost': 'common_userstore',\n# 'cpm_policy_name': 'CNA_Dublin_Prod_Weekly',\n# 'cpm_server_id': '3122ead2-8b45-41c9-95b3-14050dbb6350'}}\n try:\n _tags = ami.tags\n ami_tags = {s['Key']: s['Value'] for s in _tags} if _tags else {}\n ami_snapshots = [mapping.get('Ebs').get('SnapshotId') for mapping in ami.block_device_mappings if mapping.get('Ebs')]\n except ClientError as e:\n if e.response['Error']['Code'] == 'InvalidAMIID.NotFound':\n return {}\n else:\n return {'image_id': ami.image_id,\n 'tags': ami_tags,\n 'snapshots': ami_snapshots\n }\n\n\n def get_ami_details_by_id(self, ami_id):\n try:\n # response = self.ec2client.describe_images(ImageIds=[ami_id])\n response = self.ec2.Images(ami_id)\n except ClientError as e:\n if e.response['Error']['Code'] == 'InvalidAMIID.NotFound':\n return {}\n\n _tags = response['Images'][0].get('Tags')\n ami_tags = {s['Key']: s['Value'] for s in _tags} if _tags else {}\n\n _BlockDeviceMappings = response['Images'][0].get('BlockDeviceMappings')\n snapshots = [mapping.get('Ebs').get('SnapshotId') for mapping in _BlockDeviceMappings]\n return {'ami_id': ami_id,\n 'tags': ami_tags,\n 'snapshots': snapshots\n }\n\n def get_snapshot_details(self, snap):\n # TODO: Check if snapshot exists ??\n snap_tags = {s['Key']: s['Value'] for s in snap.tags} if snap.tags else {}\n description = snap.description\n snap_details = {'id': snap.id,\n 'volume_id': snap.volume_id,\n 'description': description,\n 'volume_size': snap.volume_size,\n 'start_date': snap.start_time.strftime(\"%d/%m/%Y\"),\n 'tags': snap_tags}\n\n d_ami = re.search(r'ami-[\\w\\d]+', description)\n snap_details['description_ami'] = d_ami.group(0) if d_ami else ''\n\n d_vol = re.search(r'ami-[\\w\\d]+', description)\n snap_details['description_vol'] = d_vol.group(0) if d_vol else ''\n\n d_inst = re.search(r'ami-[\\w\\d]+', description)\n snap_details['description_instance'] = d_inst.group(0) if d_vol else ''\n\n return snap_details\n\n def get_volume_details(self, vol):\n try:\n vol_tags = {s['Key']: s['Value'] for s in vol.tags} if vol.tags else {}\n except ClientError as e:\n if e.response['Error']['Code'] == 'InvalidVolume.NotFound':\n return {}\n return {'id': vol.id,\n 'tags': vol_tags}\n\n def get_instance_details(self, instance):\n # TODO: Check if instance exists\n instance_tags = {s['Key']: s['Value'] for s in instance.tags} if instance.tags else {}\n return {'id': instance.id,\n 'state': instance.state['Name'],\n 'tags': instance_tags}\n\n def print(self, msg):\n d = datetime.now() - self.start_time\n print(\"%3s %s %s\" % (d.seconds, 'sec |', msg))\n\n def connect(self, profile, region):\n self.start_time = datetime.now()\n # TODO: Exception handling, Return tuple (true/false, error message)\n session = boto3.Session(profile_name=profile, region_name=region)\n self.ec2 = session.resource('ec2')\n self.ec2client = session.client('ec2')\n\n try:\n self.owner_account_id = session.client('sts').get_caller_identity()['Account']\n except ClientError as e:\n raise e\n return True\n\n def do_snapshot_tagging(self, desired_tags, dryrun, stats_only, ami_lookup, do_report, do_tag_untagged):\n untagged_snapshots = self.get_untagged_snapshots(self.owner_account_id, desired_tags)\n\n self.print(\"%-35s %s\" % (\"Account Id:\", self.owner_account_id))\n self.print(\"%-35s %s\" % (\"Region:\", self.region))\n self.print(\"%-35s %s\" % (\"Tags to replicate:\", ', '.join(desired_tags)))\n self.print(\"%-35s %s\" % (\"Snapshots to process (untagged):\", len(untagged_snapshots)))\n\n if stats_only:\n return True\n\n if do_report:\n csv_filename = \"{0}_{1}_{2}\".format(self.owner_account_id, self.region, \"untagged_snapshots.csv\")\n csv_file = open(csv_filename, 'w')\n csv_out = csv.writer(csv_file)\n\n header_row = ['SnapshotId']\n header_row += ['SnapTag: ' + tag for tag in desired_tags]\n header_row += ['SnapshotDescription', 'StartDate', 'VolumeId', 'VolumeSize']\n header_row += ['VolTag: ' + tag for tag in desired_tags]\n header_row += ['InstanceId', 'InstanceState']\n header_row += ['InstanceTag: ' + tag for tag in desired_tags]\n header_row += ['comment1', 'comment2', 'comment3']\n\n csv_out.writerow(header_row)\n\n for idx, snapshot_id in enumerate(untagged_snapshots):\n snap = self.ec2.Snapshot(snapshot_id)\n snap_details = self.get_snapshot_details(snap)\n volume = self.ec2.Volume(snap_details['volume_id'])\n volume_details = self.get_volume_details(volume)\n instance = None\n instance_details = {}\n\n extracted_tags = {}\n tags_for_volume = {}\n tags_for_snapshot = {}\n\n\n # print('{idx}'.format(idx=str(idx)), end=\"\\r\")\n comment1 = comment2 = comment3 = ''\n\n # Gather tags to replicate for each entity vol snap\n # Snap <- Vol\n # if instance attached:\n # Vol <- Instance\n # Snap <-------- Instance\n # if ami_lookup and ami found in description\n # Snap <-------- AMI\n # Vol <- AMI\n\n is_volume_exists = self.volume_exists(snap_details['volume_id'])\n if is_volume_exists:\n extracted_tags = self.extract_untagged(volume_details, snap_details, desired_tags)\n tags_for_snapshot = dict(extracted_tags.items() + tags_for_snapshot.items())\n\n # If volume have instance attached\n # if volume.attachments and set(volume_details['tags'].keys()) != set(desired_tags):\n if volume.attachments:\n # And volume has some desired tags omitted So try to complete with instance tags.\n if (set(desired_tags) - set(volume_details['tags'])):\n instance = self.ec2.Instance(volume.attachments[0]['InstanceId'])\n instance_details = self.get_instance_details(instance)\n # complete tags_for_snapshot with instance tags\n extracted_tags = self.extract_untagged(instance_details, snap_details, desired_tags)\n tags_for_snapshot = dict(extracted_tags.items() + tags_for_snapshot.items())\n\n # complete tags_for_volume with instance tags\n extracted_tags = self.extract_untagged(instance_details, volume_details, desired_tags)\n tags_for_volume = dict(extracted_tags.items() + tags_for_volume.items())\n else:\n comment3 = \"No tagging needed for volume\"\n else:\n comment1 = \"Volume NOT exists\"\n\n # AMI lookup if requested\n if ami_lookup and snap_details['description_ami']:\n ami_details = self.get_ami_details_by_id(snap_details['description_ami'])\n if ami_details:\n # Snapshot <- AMI gathering\n extracted_tags = self.extract_untagged(ami_details, snap_details, desired_tags)\n # snap_tags_before_ami = tags_for_snapshot\n # tags_from_ami_only = {k:extracted_tags[k] for k in set(extracted_tags) - set(tags_for_snapshot)}\n tags_for_snapshot = dict(extracted_tags.items() + tags_for_snapshot.items())\n\n # if ami_details['tags']:\n # print('AMI tags: ', ami_details['tags'])\n # print('Snap tags before: ', snap_tags_before_ami)\n # print('AMI tags not it Snap: ', tags_from_ami_only)\n\n # Volume <- AMI gathering\n if self.volume_exists(snap_details['volume_id']):\n extracted_tags = self.extract_untagged(ami_details, volume_details, desired_tags)\n tags_for_volume = dict(extracted_tags.items() + tags_for_volume.items())\n\n # Add default tag to snap/volume\n default_tag, default_value = do_tag_untagged.split(':')\n\n ### TODO REVIEW\n volume_needs_default_tagging = True if (not tags_for_volume and is_volume_exists and not volume_details.get('tags').get(default_tag)) else False\n\n # if requested AND no desired tag was found previously\n if do_tag_untagged and not tags_for_snapshot.get(default_tag):\n tags_for_snapshot[default_tag] = default_value\n # if requested AND no desired tag was found previously AND volume had no tag !!!!!!! TODO Rework condition to Set\n # if do_tag_untagged and not tags_for_volume.get(default_tag) :\n if do_tag_untagged and volume_needs_default_tagging:\n tags_for_volume[default_tag] = default_value\n\n # Tagging with gathered tags\n if tags_for_snapshot:\n comment2 = \"Tagged with: %s\" % (', '.join([k + \":\" + v for k, v in tags_for_snapshot.iteritems()]))\n self.count_tagged_resources['snap'] += 1\n self.tag_resource_with_tags(snap, tags_for_snapshot, dryrun, idx)\n else:\n comment2 = 'No any tags found for snapshot'\n\n if is_volume_exists:\n if tags_for_volume:\n comment3 = \"Tagged with: %s\" % (', '.join([k + \":\" + v for k, v in tags_for_volume.iteritems()]))\n self.count_tagged_resources['vol'] += 1\n self.tag_resource_with_tags(volume, tags_for_volume, dryrun, idx)\n else:\n comment3 = 'No any tags found for volume' if not comment3 else comment3\n\n # Assemble row for csv\n if do_report:\n data_row = [snap_details['id']]\n data_row += [snap_details.get('tags', {}).get(tag, '') for tag in desired_tags]\n data_row += [snap_details['description'],\n snap_details['start_date'],\n volume_details.get('id'),\n snap_details.get('volume_size')\n ]\n data_row += [volume_details.get('tags', {}).get(tag, '') for tag in desired_tags]\n data_row += [instance_details.get('id'),\n instance_details.get('state')\n ]\n data_row += [instance_details.get('tags', {}).get(tag, '') for tag in desired_tags]\n data_row += [comment1, comment2, comment3]\n\n csv_out.writerow(data_row)\n\n if do_report:\n csv_file.close()\n\n note = \"(forecast)\" if dryrun else ''\n print(\"\\n==== Summary {0}====\".format(note))\n print(\"%-35s %s\" % (\"Snapshot tags replicated:\", self.count_propagated_tags['snap']))\n print(\"%-35s %s\" % (\"Volume tags replicated:\", self.count_propagated_tags['vol']))\n print(\"%-35s %s\" % (\"Snapshots tagged:\", self.count_tagged_resources['snap']))\n print(\"%-35s %s\" % (\"Volumes tagged:\", self.count_tagged_resources['vol']))\n print(\"See %s for detailed report. \" % (csv_filename) if do_report else '')\n\n def do_ami_tagging(self, desired_tags, do_tag_untagged, stats_only, dryrun, do_report):\n untagged_amis = list(self.get_untagged_amis(self.owner_account_id, desired_tags))\n\n self.print(\"%-35s %s\" % (\"Account Id:\", self.owner_account_id))\n self.print(\"%-35s %s\" % (\"Region:\", self.region))\n self.print(\"%-35s %s\" % (\"Tags to replicate:\", ', '.join(desired_tags)))\n self.print(\"%-35s %s\" % (\"AMIs to process (untagged):\", len(untagged_amis)))\n\n if stats_only:\n return True\n\n if do_report:\n # TODODODODODOD\n pass\n\n for idx, ami_id in enumerate(untagged_amis):\n print(\"idx - %d || ami-id - %s\" % (idx, ami_id))\n ami = self.ec2.Image(ami_id)\n ami_details = self.get_ami_details(ami)\n\n extracted_tags = {}\n tags_for_ami = {}\n\n # Enumerating snapshots with an intent to find desired tags\n for snapshot_id in ami_details['snapshots']:\n snap = self.ec2.Snapshot(snapshot_id)\n snap_details = self.get_snapshot_details(snap)\n extracted_tags = self.extract_untagged(snap_details, ami_details, desired_tags)\n tags_for_ami = dict(extracted_tags.items() + tags_for_ami.items())\n if tags_for_ami.keys() == desired_tags:\n break\n\n if tags_for_ami:\n if tags_for_ami.keys() == desired_tags:\n # We found all tags\n print('All tags for ami - %s were found: %s' % (ami.image_id, tags_for_ami))\n else:\n print('Some tags for ami - %s were found: %s' % (ami.image_id, tags_for_ami))\n else:\n print('No desired tags was found in associated snapshots')\n\n\ndef main():\n mode, generic_params, mode_params = parse_arguments()\n profile, region = generic_params\n\n tagging = TagReplicator()\n tagging.connect(profile, region)\n\n if mode == \"snapshot_mode\":\n tags_list, do_tag_untagged, ami_lookup, stats_only, dryrun, report = mode_params\n print(\"mode - %s, mode_params - %s\" % (mode, mode_params))\n tagging.do_snapshot_tagging(tags_list, dryrun, stats_only, ami_lookup, report, do_tag_untagged)\n elif mode == \"ami_mode\":\n tags_list, do_tag_untagged, stats_only, dryrun, report = mode_params\n print(\"mode - %s, mode_params - %s\" % (mode, mode_params))\n tagging.do_ami_tagging(tags_list, do_tag_untagged, stats_only, dryrun, report)\n\n\ndef lambda_handler(event, context):\n # TOODOODODO FIX FOR AMI_MODE\n env_region = os.environ.get('REGION', 'us-east-1')\n env_dryrun = False if os.environ.get('DRYRUN', False) in ['False', False, 'No'] else True\n env_ami_lookup = False if os.environ.get('AMI_LOOKUP', False) in ['False', False, 'No'] else True\n env_tags = os.environ['TAGS'].split(',')\n\n if not env_tags:\n print('No tags specified')\n return\n\n tagging = TagReplicator()\n tagging.connect(profile=None, region=env_region)\n tagging.do_snapshot_tagging(desired_tags=env_tags, dryrun=env_dryrun, stats_only=False,\n ami_lookup=env_ami_lookup, do_report=False, do_tag_untagged='')\n\n\nif __name__ == '__main__':\n try:\n main()\n except KeyboardInterrupt:\n print('User break. Finishing..')\n sys.exit(1)\n # except Exception as e:\n # print(e)\n\n\n# An error occurred (RequestLimitExceeded) when calling the DescribeSnapshots operation (reached max retries: 4): Request limit exceeded.: ClientError\n# Traceback (most recent call last):\n# File \"/var/task/tagreplicator.py\", line 382, in lambda_handler\n# tagging.do_snapshot_tagging(desired_tags=env_tags, dryrun=env_dryrun, stats_only=False, ami_lookup=env_ami_lookup, do_report=False)\n# File \"/var/task/tagreplicator.py\", line 270, in do_snapshot_tagging\n# snap_details = self.get_snapshot_details(snap)\n# File \"/var/task/tagreplicator.py\", line 200, in get_snapshot_details\n# snap_tags = {s['Key']: s['Value'] for s in snap.tags} if snap.tags else {}\n# File \"/var/runtime/boto3/resources/factory.py\", line 339, in property_loader\n# self.load()\n# File \"/var/runtime/boto3/resources/factory.py\", line 505, in do_action\n# response = action(self, *args, **kwargs)\n# File \"/var/runtime/boto3/resources/action.py\", line 83, in __call__\n# response = getattr(parent.meta.client, operation_name)(**params)\n# File \"/var/runtime/botocore/client.py\", line 312, in _api_call\n# return self._make_api_call(operation_name, kwargs)\n# File \"/var/runtime/botocore/client.py\", line 601, in _make_api_call\n# raise error_class(parsed_response, operation_name)\n# ClientError: An error occurred (RequestLimitExceeded) when calling the DescribeSnapshots operation (reached max retries: 4): Request limit exceeded."
},
{
"alpha_fraction": 0.6785904765129089,
"alphanum_fraction": 0.680192232131958,
"avg_line_length": 39.71739196777344,
"blob_id": "92b8e1e09fa53292a84445e12448c44ea5ad2448",
"content_id": "47597165eafa80b4dc59e40ab0578a0958449078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1873,
"license_type": "no_license",
"max_line_length": 297,
"num_lines": 46,
"path": "/README.md",
"repo_name": "mortalius/tagreplicator",
"src_encoding": "UTF-8",
"text": "# Tag replicator\n\nScans for snapshots that do not have required tags, tries to gather tags from volume/instance and/or AMI, and then assigns tags to:\n* snapshots with tags from volume/instance/ami\n* volumes with tags from instance/ami\n\n### Usage\n```\nusage: tagreplicator.py [-h] [--profile PROFILE] [--region REGION] --tags TAGS\n [--ami-lookup] [--stats-only] [--report] [--dry-run]\n\nTag replicator. Scans for <tags> untagged snapshots and tags snapshot\nwith volume/instance/ami tag.\n\noptional arguments:\n -h, --help show this help message and exit\n --profile PROFILE awscli profile to use\n --region REGION AWS region (us-east-1 by default)\n --tags TAGS List of tags to replicate, separated by comma, e.g\n Owner,cost (case sensitive\n --ami-lookup Lookup for tags from AMI. False by default\n --stats-only Print stats on snapshots total vs <tags> untagged snapshots and exit\n --report Generate csv report\n --dry-run No actual tagging. Could be used with --report\n```\n\n\n### Examples\n\nIn this example script looks for all snapshots owned by your account in `us-east-1` region that do not have one or more of the tags `cost/Project/Technical owner`. Then searches for volumes/instances and AMI tags as ami-lookup option is used, and then tags snapshots and volumes with missing tags.\n```\ntagreplicator.py --profile myprofile --region us-east-1 --tags \"cost,Project,Technical Owner\" --ami-lookup\n```\n\n### Lambda usage\n\nScript can be easily run as lambda job by specifying lambda handler as `lambda_handler`. \n\nWhen running as lambda job, script looks for next environment variables:\n\n| Variable | Description |\n|--- |--- |\n| REGION | Region |\n| TAGS | List of tags |\n| AMI_LOOKUP| Look for AMI tags. Set to `True` |\n| DRYRUN | Dry run |\n"
}
] | 3 |
the-c0d3r/folderlocker
|
https://github.com/the-c0d3r/folderlocker
|
ad85ed9f96e95edfad3bf1340f61e732e2c02b6a
|
722699d79c8157636dbe510df42e8241172902e6
|
6c5a110e830fdd47ae8565cfcd08fbdfcb98285a
|
refs/heads/master
| 2021-01-19T13:53:11.450304 | 2014-09-26T10:25:57 | 2014-09-26T10:25:57 | 18,025,927 | 3 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6528925895690918,
"alphanum_fraction": 0.6652892827987671,
"avg_line_length": 25.925926208496094,
"blob_id": "97ea9a2b16d9de9e530d698a4b0e3da49c3ca56c",
"content_id": "0465fe53268eb45f6f8f4f4d31ad18299e1c9a73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 726,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 27,
"path": "/README.md",
"repo_name": "the-c0d3r/folderlocker",
"src_encoding": "UTF-8",
"text": "**Folderlocker**\n============\n\nA GUI Version of the famous batch script **`folderlocker.bat`** translated into `python`. \n\n- **`Username`** and **`Password`** Feature. \n- One Click *`Lock`* & *`Unlock`*\n\n----------\n\n\nUsage\n-----\n\n1. Go to Online Md5 Generator Website, Example : [md5HashGenerator.com](http://www.md5hashgenerator.com/)\n2. Create Your own md5 hash sum of your preferable Username and Password\n3. Replace the user hash with your username hash sum \n ```python \n user = 'f8f87915dce091a5571941436df26619' # Replace in between the Single Quote\n ```\n\n4. Replace the pwd hash with your password hash sum\n ```python\n pwd = '0192023a7bbd73250516f069df18b500' # Replace in between the Single Quote\n ```\n\n5. Place this in Drive's root directory."
},
{
"alpha_fraction": 0.5636170506477356,
"alphanum_fraction": 0.5790418386459351,
"avg_line_length": 45.412879943847656,
"blob_id": "f878a95138c07e7aa7004977be91839024d3adf5",
"content_id": "923a2b43f52fc2a17e35a9f163517ba58ec48db0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12253,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 264,
"path": "/folderlocker.pyw",
"repo_name": "the-c0d3r/folderlocker",
"src_encoding": "UTF-8",
"text": "import os\nfrom Tkinter import *\nimport tkMessageBox\n\nclass Locker(Frame):\n \n def __init__(self,parent):\n Frame.__init__(self,parent, background=\"white\")\n \n self.parent = parent\n self.initvariable()\n self.initUI()\n\n def initvariable(self):\n global user,pwd,locker#, fake_user, fake_pwd\n user = 'f8f87915dce091a5571941436df26619' # My private Username\n pwd = '0192023a7bbd73250516f069df18b500' # And this is my private Password\n locker = '9e96fc70cb53a94092a5d720647a5447' # This is the folder name, when it is locked!\n\n def makehash(self,data): # Just a simple method to get md5 hash\n from hashlib import md5\n tmp = md5()\n tmp.update(data)\n return tmp.hexdigest() # to return the md5 hash sum\n \n def msg(self,title,message): # to show error message conveniently \n tkMessageBox.showerror(title,message)\n \n def about(self):\n tkMessageBox.showinfo('About',\n 'This script is written by Anubis from MSF forum\\n\\\n Folder locker will hide the folder named \"locker\" out of view.\\n\\\n I can\\'t find a way to view the hidden folder under windows environment. This script is for windows ONLY!\\n\\n\\t\\t\\tAnubis [MSF Moderator]') \n\n def update_status(self):\n st = self.search_locker()\n\n lbl_new = Label(winloggedin,text=\"Status : [%s]\" % st)\n lbl_new.pack()\n \n def create_locker(self): # To create locker folder, if hidden or revealed folder is not detected\n import os\n drive = os.path.abspath('')[0:3]\n os.mkdir('%slocker' % drive) # Create locker folder\n tkMessageBox.showinfo('Created',('Locker has been created successfully at %s' % drive))\n tkMessageBox.showinfo('Info','You should put everything you want to hide into locker folder,\\n\\tWhen you\\'re done, click lock')\n \n def search_locker(self): # Used to search if the folder called Locker exist\n import os\n drive = os.path.abspath('')[0:3]\n #current_dir = os.path.abspath(\"\") # Tells computer that we'll be working on local directory\n for i in os.listdir(drive): # Iterate through all file names\n if self.makehash(i) == locker: # Make hash of the file and if has the same value as locker variable\n return 'locked' # It will return locked. Meaning there is the hidden control panel folder\n break # And will break free from for loop, meaning there is no need to continue through the rest files.\n \n if i == 'locker': # Or, we need to check if the folder called [locker] is present in the directory\n return 'unlocked' # If yes, it means, it is unlocked!\n break # And yes, break free of the loop.\n # I don't use elif because, I need to check for both of them. Not single one of them.\n self.create_locker()\n \n def unlock(self): # As you may have guessed, this is the part of the code, doing all those revel work\n from os import system\n import os\n status = self.search_locker() # To see if the locker has been locked or not\n drive = os.path.abspath('')[0:3] # Just to get the current drive letter\n if status == 'locked': # When the locker is confirmed to be locked!, unlock it.\n system('attrib \"%sControl Panel.{21EC2020-3AEA-1069-A2DD-08002B30309D}\" -s -h' % drive)\n system('ren \"%sControl Panel.{21EC2020-3AEA-1069-A2DD-08002B30309D}\" locker' % drive)\n tkMessageBox.showinfo('Command Completed','Locker has been Unlocked successfully') # And shows that this has been unlocked!\n system(('explorer %s' % str(drive+'locker')))\n winloggedin.destroy() # Deletes the current GUI and \n self.loggedin() # Shows the logged in GUI again\n \n elif status == 'unlocked': # When locker is unlocked but the user commands to unlock, show that it is unlocked!\n tkMessageBox.showinfo('Information','Locker seem to be unlocked')\n\n elif not status: # Hmm.. This means that locker is not existent \n tkMessageBox.showinfo('Errrr..','Locker hasn\\'t been created!')\n\n def lock(self):\n from os import system\n import os\n global drive\n status = self.search_locker()\n drive = os.path.abspath('')[0:3]\n if status == 'unlocked': # If locker is unlocked, lock it.\n system('ren %slocker \"Control Panel.{21EC2020-3AEA-1069-A2DD-08002B30309D}\"' % drive)\n system('attrib \"%sControl Panel.{21EC2020-3AEA-1069-A2DD-08002B30309D}\" +s +h' % drive)\n now_status = self.search_locker() # To check the result\n \n if now_status == 'unlocked': # If the locker is still unlocked, it means that command is not successful.\n tkMessageBox.showinfo('Sorry, can\\'t close it right now','Please close any opening files and folders from LOCKER and try again.')\n elif now_status == 'locked':\n tkMessageBox.showinfo('Command Completed','Locker has been locked successfully')\n winloggedin.destroy() # we needed another window because, status has changed.\n self.loggedin()\n \n elif status == 'unlocked':\n tkMessageBox.showinfo('Information','Locker seem to be unlocked!')\n \n elif not status: # Hmm.. This means that locker is not existent \n tkMessageBox.showinfo('Errrr..','Locker hasn\\'t been created!')\n \n def initUI(self):\n self.notloggedin()\n\n def notloggedin(self):\n # UI Before Logging in\n # 300,200\n self.centerWindow(self.parent)\n self.parent.focus_force()\n self.parent.title('Please Login!')\n\n #$LOGIN LABELS\n global lbl_user,lbl_pass\n #=======================\n lbl_user = Label(self.parent,text=\"User : \") \n lbl_user.place(x=10,y=13)\n lbl_pass = Label(self.parent,text=\"Pass : \")\n lbl_pass.place(x=10,y=40)\n\n #$LOGIN TEXT BOX\n global txt_user,txt_pass\n #=======================\n txt_user = Entry(self.parent,width='30') # Username Entry box\n txt_user.place(x=48,y=15)\n txt_pass = Entry(self.parent,width='30',show='*') # Password Entry box, show='*' used to cover the password\n txt_pass.place(x=48,y=43)\n Entry.focus_set(txt_user)\n\n #$LOGIN BUTTONS\n global btn_quit,btn_login\n #========================\n btn_login = Button(self.parent,text=\"Login\",command=self.get,width='7')\n btn_login.place(x=145,y=70)\n btn_quit = Button(self.parent,text=\"Quit\",command=self.bye,width='7')\n btn_quit.place(x=204,y=70)\n\n \n self.parent.mainloop()\n\n def get(self):\n #============================================\n # check if usr and pwd are empty\n user = txt_user.get() # Get username\n passwd = txt_pass.get() # Get password\n if user != '' and passwd != '': # If both username and passwords are not empty, proceed to check the login\n self.login()\n elif user == '': # If username is empty, shows error message, that username is missing.\n self.msg('Error','Plese Provide Username')\n Entry.focus_set(txt_user) # Set focus on username field\n \n elif user != '' and passwd == '': # or else, if username is there but, password is not filled in, show message\n self.msg('Error','Please Provide Password')\n Entry.focus_set(txt_pass)\n \n def login(self):\n # This method will take user input and test if the login names and passwords are correct\n global username,password # I need to use it in other places, so making them global is essential\n\n #=============================================\n username = txt_user.get().strip() # To remove un-necessary white spaces\n password = txt_pass.get().strip()\n user_hash = self.makehash(username) # convert user to hash\n password_hash = self.makehash(password) # convert password to hash\n \n if user_hash != user: # when username is not equal to the hash stored in user variable, show error message\n self.msg('Error!','Username and password do not match')\n txt_user.delete(0,len(str(txt_user.get()))) # delete the filled in text, \n txt_pass.delete(0,len(str(txt_pass.get()))) # if not, user will have to select them and delete them\n Entry.focus_set(txt_user)\n \n elif user_hash == user and password_hash != pwd or user_hash != user and password_hash == pwd: # when username is correct but the password is wrong, show error message\n self.msg('Error!','Username and password do not match')\n txt_user.delete(0,len(str(txt_user.get())))\n txt_pass.delete(0,len(str(txt_pass.get())))\n Entry.focus_set(txt_user)\n \n elif user_hash == user and password_hash == pwd: # Check if we got successful login attempt\n tkMessageBox.showinfo('Welcome','Welcome back [%s]' % username) # Greet the user\n self.parent.destroy() # User login window is no longer need because, user has logged in\n self.loggedin() # So move on to logged in window\n \n\n def loggedin(self):\n #$CONFIGURATIONS\n global winloggedin,lbl_status\n winloggedin = Tk()\n winloggedin.focus_force()\n winloggedin.title('Welcome Back [%s]' % username)\n self.centerWindow(winloggedin)\n winloggedin.minsize(300,120)\n winloggedin.maxsize(350,150)\n \n self.update_status()\n\n #$LABELS\n lbl_frame = Label(winloggedin,text='+==========================+')\n lbl_frame.pack()\n btn_label = LabelFrame(winloggedin)\n btn_label.pack()\n\n #$BUTTONS\n btn_open_locker = Button(btn_label,text=\"Unlock\",command=self.unlock,width='10')#,state=DISABLED)\n btn_open_locker.pack(side=RIGHT)\n btn_close_locker = Button(btn_label,text=\"Lock\",command=self.lock,width='10')\n btn_close_locker.pack(side=LEFT)\n btn_quit = Button(winloggedin,text=\"QUIT!\",command=self.bye,width='10')\n btn_quit.pack()\n\n menubar = Menu(winloggedin) # Creates the menu bar\n help_menu = Menu(winloggedin,tearoff=0)\n help_menu.add_command(label=\"About\",command=self.about)\n menubar.add_cascade(label=\"Help\",menu=help_menu)\n winloggedin.config(menu=menubar)\n\n winloggedin.mainloop()\n\n def centerWindow(self,frame):\n # For making the window appear magically at the center of the screen\n\n if frame == self.parent: w=300;h=150;\n elif frame == winloggedin: w=270;h=150;\n #self.parent.maxsize(350,230)\n #self.parent.minsize(350,230)\n\n sw = frame.winfo_screenwidth()\n # sw is equal to screen width\n sh = frame.winfo_screenheight()\n # sh equal to screen height\n\n x = (sw-w)/2\n y = (sh-h)/2\n frame.geometry('%dx%d+%d+%d' % (w,h,x,y))\n # Set the geometry\n\n\n def bye(self): # In py2exe compiled exe file, command=exit is causing trouble, so I created this to do the same trick\n import sys,tkMessageBox\n status = self.search_locker()\n if status == 'unlocked':\n resp = tkMessageBox.askyesno('Are you Sure?','Are you sure to exit?\\nLocker is still opened, want to lock it?')\n if resp == True:\n self.lock()\n \n elif resp == False:\n tkMessageBox.showinfo('','Ok then, but please make sure to lock it once you\\'re done with it.')\n sys.exit()\n \n elif status == 'locked':\n sys.exit()\n else:\n sys.exit()\n\n\ndef main():\n root = Tk()\n app = Locker(root)\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 2 |
AlisonLuo/HTN
|
https://github.com/AlisonLuo/HTN
|
d9c2881e19e9f244d9977f65fc733d99dbf85378
|
78bebfb3d95a7d240a34cc7919168fc3333fbe39
|
ab70c6082fda8d7a73b4a3047d0db3d5a319e077
|
refs/heads/master
| 2020-07-26T06:38:40.480356 | 2019-09-15T09:15:08 | 2019-09-15T09:15:08 | 208,566,472 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6341040730476379,
"alphanum_fraction": 0.6358381509780884,
"avg_line_length": 53.6129035949707,
"blob_id": "72ccb4f9bb4beb85095b6f15ec356f6d5853d1be",
"content_id": "8d2af4b214c5ad3a0f4ae0a1fbd067470f929e02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1730,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 31,
"path": "/app.py",
"repo_name": "AlisonLuo/HTN",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request\r\nimport json\r\nimport requests\r\n\r\n\r\[email protected]('/home', methods=[\"GET\", \"POST\"])\r\ndef form_example():\r\n if request.method == 'POST': #this block is only entered when the form is submitted\r\n start_date = request.form.get('start_date')\r\n end_date = request.form.get('end_date')\r\n duration = request.form.get('duration')\r\n destination = request.form['destination']\r\n season = request.form['season']\r\n origin = request.form['origin']\r\n num_travellers = request.form['num']\r\n flight_required = request.form['flight_required']\r\n username = request.form.get('username')\r\n #do some matching\r\n response = requests.get(f\"http://accentour-final-bronze.uedpnpkwfs.us-east-2.elasticbeanstalk.com/get_tours_by_university_season_city/{destination}/fall/waterloo\")\r\n\r\n uni_tours = response.json()\r\n\r\n for i in range(len(response.json())):\r\n date_tour = response.json()[i]['Date']\r\n if date_tour >= start_date and date_tour <= end_date and response.json()[i]['AvailableSpots']>num_travellers:\r\n tour_id = response.json()[i]['ID']\r\n requests.post(f\"http://accentour-final-bronze.uedpnpkwfs.us-east-2.elasticbeanstalk.com/create_user?username={username}\")\r\n requests.post(f\"http://accentour-final-bronze.uedpnpkwfs.us-east-2.elasticbeanstalk.com/book_tour?tour_id={tour_id}&spots_required={num_travellers}&username={username}\")\r\n return f\"Success! You have been booked for tour ID # {tour_id}!\"\r\n #print(response.json()[i]['Date'])\r\n return \"Sorry, we could not find an available tour for your selected dates.\"\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5236181020736694,
"alphanum_fraction": 0.5346733927726746,
"avg_line_length": 32.20000076293945,
"blob_id": "c9f024fcc2d65f488bb1367979ed50d7ffbdbeff",
"content_id": "77315c1119b6c6a04f9c1d3eb801e71e038bb4bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 995,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/Home.js",
"repo_name": "AlisonLuo/HTN",
"src_encoding": "UTF-8",
"text": "import React, { Component } from \"react\";\nimport \"./index.css\";\n \nclass Home extends Component {\n render() {\n return (\n <div>\n <h1>Tell us about yourself</h1>\n <p>\n <a>I am a </a>\n <button type=\"button\" className=\"button\">Student</button>\n <button type=\"button\" className=\"button\">Broker</button>\n </p>\n <h2>Plan Your Trip</h2>\n <h3>Where are you going?</h3>\n <input type=\"text\" placeholder=\"From\"></input>\n <input type=\"text\" placeholder=\"To\"></input>\n <h3>What dates?</h3>\n <input type=\"date\" placeholder=\"Start Date\"></input>\n <input type=\"date\" placeholder=\"End Date\"></input>\n <h3>How many people are travelling?</h3> \n <input type=\"number\" placeholder=\"#\" min=\"1\"></input> \n <br/> <br/> <br/> <br/> \n <button type=\"button\" className=\"button\">Find my Tour!</button> \n </div>\n );\n }\n}\n \nexport default Home;"
},
{
"alpha_fraction": 0.5286968350410461,
"alphanum_fraction": 0.5313977003097534,
"avg_line_length": 31.217391967773438,
"blob_id": "504fcd909487c5a09c93131e7eb61a76b43e93bf",
"content_id": "5a8c3282b9558dc898ce59f5d7866b57755a534e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1481,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 46,
"path": "/Main.js",
"repo_name": "AlisonLuo/HTN",
"src_encoding": "UTF-8",
"text": "import React, { Component } from \"react\";\nimport {\n Route,\n NavLink,\n HashRouter\n} from \"react-router-dom\";\nimport Home from \"./Home\";\nimport Stuff from \"./Stuff\";\nimport Contact from \"./Contact\";\nimport \"./index.css\";\n \nclass Main extends Component {\n render() {\n return (\n <HashRouter>\n <div>\n <div className=\"App\">\n <header className=\"App-header\">\n <div className=\"title\">\n <h1 className=\"accentours_title\">accentours </h1>\n <p className=\"logo\"><img src={\"logo.png\"} className=\"App-logo\" alt=\"logo\" /></p>\n </div>\n </header>\n <div className=\"cover\">\n {/* <h2 className=\"connecting\">connecting university students across Canada everyday</h2> */}\n {/* <button type=\"button\" className=\"button\" id=\"bookbtn\">Book a Tour Today!</button> */}\n </div>\n </div>\n <ul className=\"header\">\n <li><NavLink exact to=\"/\">Start Bookings</NavLink></li>\n <li><NavLink to=\"/stuff\">Matches</NavLink></li>\n <li><NavLink to=\"/contact\">Contact</NavLink></li>\n </ul>\n <hr></hr>\n <div className=\"content\">\n <Route exact path=\"/\" component={Home}/>\n <Route path=\"/stuff\" component={Stuff}/>\n <Route path=\"/contact\" component={Contact}/>\n </div>\n </div>\n </HashRouter>\n );\n }\n}\n \nexport default Main;"
}
] | 3 |
saty2146/coreview
|
https://github.com/saty2146/coreview
|
6766fa8fa30f0bdef86effc7bfff2e9322c873b1
|
07c2af3b38cbe2cf13830e03f2536c009e0de5b5
|
94fe81655c1cbabd99c595fd675b187a1a48b6d2
|
refs/heads/master
| 2022-12-24T07:15:08.671994 | 2019-11-14T15:00:19 | 2019-11-14T15:00:19 | 110,098,572 | 3 | 1 | null | 2017-11-09T10:04:59 | 2021-02-09T07:44:59 | 2022-12-08T00:41:27 |
HTML
|
[
{
"alpha_fraction": 0.5107851624488831,
"alphanum_fraction": 0.5168248414993286,
"avg_line_length": 25.953489303588867,
"blob_id": "19d6607264d46d5c20f7777ae8c87f23e565c1d5",
"content_id": "3b52a30380c74e47ed76d138fec9306d9c38a323",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 43,
"path": "/app/templates/vlan.html",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n\n{% block content %}\n\n<script src=\"//ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script> \n<script src=\"{{ url_for('static', filename='js/datatable.js') }}\"></script>\n\n<div class=\"form-group row\">\n <div class=\"col-md-6\" style=\"font-size:25px\">\n VLANS\n </div>\n <div class=\"col-md-6\" \"pull-right\">\n {{ created }}\n </div>\n</div>\n <table id=mytable class=\"table table-hover table-bordered table-responsive table-condensed\">\n <thead>\n <tr>\n <th>id</th>\n {% for attr in box_attr %}\n <th>{{ attr }}</th>\n {% endfor %}\n </tr>\n </thead>\n <tbody class=\"searchable\">\n {% for item in vlan %}\n {% set data = vlan[item] %}\n <p>\n <td> {{ item }} </td>\n {% for attr in box_attr %}\n {% if data[attr] == 'Error' %}\n <td><span class=\"glyphicon glyphicon-remove-circle\" style=\"color:red\" aria-hidden=\"true\" title=\"Error\"></span><small> not found</small></td>\n {% else %}\n\n <td>{{ data[attr] }}</td>\n {% endif %}\n {% endfor %}\n </tr>\n {% endfor %}\n </tbody>\n </table>\n\n{% endblock %}\n"
},
{
"alpha_fraction": 0.5612327456474304,
"alphanum_fraction": 0.5633955001831055,
"avg_line_length": 26.604476928710938,
"blob_id": "b3b3e5c20bc8a13d4acd2f57a215d5975638de8b",
"content_id": "194bb419fb92bc419302c31925142965f7140c13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3699,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 134,
"path": "/app/librouteros/api.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\nfrom posixpath import join as pjoin\n\nfrom librouteros.exceptions import TrapError, MultiTrapError\n\n\nclass Parser:\n\n api_mapping = {'yes': True, 'true': True, 'no': False, 'false': False}\n\n @staticmethod\n def apiCast(value):\n \"\"\"\n Cast value from API to python.\n\n :returns: Python equivalent.\n \"\"\"\n try:\n casted = int(value)\n except ValueError:\n casted = Parser.api_mapping.get(value, value)\n return casted\n\n @staticmethod\n def parseWord(word):\n \"\"\"\n Split given attribute word to key, value pair.\n\n Values are casted to python equivalents.\n\n :param word: API word.\n :returns: Key, value pair.\n \"\"\"\n _, key, value = word.split('=', 2)\n value = Parser.apiCast(value)\n return (key, value)\n\n\nclass Composer:\n\n python_mapping = {True: 'yes', False: 'no'}\n\n @staticmethod\n def pythonCast(value):\n \"\"\"\n Cast value from python to API.\n\n :returns: Casted to API equivalent.\n \"\"\"\n # this is necesary because 1 == True, 0 == False\n if type(value) == int:\n return str(value)\n else:\n return Composer.python_mapping.get(value, str(value))\n\n @staticmethod\n def composeWord(key, value):\n \"\"\"\n Create a attribute word from key, value pair.\n Values are casted to api equivalents.\n \"\"\"\n return '={}={}'.format(key, Composer.pythonCast(value))\n\n\nclass Api(Composer, Parser):\n\n def __init__(self, protocol):\n self.protocol = protocol\n\n def __call__(self, cmd, **kwargs):\n \"\"\"\n Call Api with given command.\n\n :param cmd: Command word. eg. /ip/address/print\n :param kwargs: Dictionary with optional arguments.\n \"\"\"\n words = tuple(self.composeWord(key, value) for key, value in kwargs.items())\n self.protocol.writeSentence(cmd, *words)\n return self._readResponse()\n\n def _readSentence(self):\n \"\"\"\n Read one sentence and parse words.\n\n :returns: Reply word, dict with attribute words.\n \"\"\"\n reply_word, words = self.protocol.readSentence()\n words = dict(self.parseWord(word) for word in words)\n return reply_word, words\n\n def _readResponse(self):\n \"\"\"\n Read untill !done is received.\n\n :throws TrapError: If one !trap is received.\n :throws MultiTrapError: If > 1 !trap is received.\n :returns: Full response\n \"\"\"\n response = []\n reply_word = None\n while reply_word != '!done':\n reply_word, words = self._readSentence()\n response.append((reply_word, words))\n\n self._trapCheck(response)\n # Remove empty sentences\n return tuple(words for reply_word, words in response if words)\n\n def close(self):\n self.protocol.close()\n\n @staticmethod\n def _trapCheck(response):\n traps = tuple(words for reply_word, words in response if reply_word == '!trap')\n if len(traps) > 1:\n traps = tuple(\n TrapError(message=trap['message'], category=trap.get('category'))\n for trap in traps\n )\n raise MultiTrapError(*traps)\n elif len(traps) == 1:\n trap = traps[0]\n raise TrapError(message=trap['message'], category=trap.get('category'))\n\n @staticmethod\n def joinPath(*path):\n \"\"\"\n Join two or more paths forming a command word.\n\n >>> api.joinPath('/ip', 'address', 'print')\n >>> '/ip/address/print'\n \"\"\"\n return pjoin('/', *path).rstrip('/')\n"
},
{
"alpha_fraction": 0.4669603407382965,
"alphanum_fraction": 0.6872246861457825,
"avg_line_length": 14.477272987365723,
"blob_id": "fb5a9f2c548a36e02aa32c265cf5003c32a5d5b6",
"content_id": "7992e8685bff0d49f55d34a09d8d86d24e3c5978",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 44,
"path": "/requirements.txt",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "bcrypt==3.1.7\nbitsets==0.7.12\ncertifi==2017.7.27.1\ncffi==1.13.1\nchainmap==1.0.2\nchardet==3.0.4\nclick==6.7\nconcepts==0.7.12\ncryptography==2.8\ndominate==2.3.1\nelasticsearch==6.2.0\nenum34==1.1.6\nfeatures==0.5.8\nfileconfig==0.5.6\nFlask==0.12.2\nFlask-Bootstrap==3.3.7.1\nFlask-WTF==0.14.2\nfuture==0.18.1\ngraphviz==0.8.2\nidna==2.6\nipaddress==1.0.18\nitsdangerous==0.24\nJinja2==2.9.6\nlibrouteros==2.2.0\nlxml==4.4.1\nMarkupSafe==1.0\nnetaddr==0.7.19\nnetmiko==2.4.2\nparamiko==2.6.0\npyaml==17.12.1\npycparser==2.19\npyIOSXR==0.53\nPyNaCl==1.3.0\npyserial==3.4\nPyYAML==3.13\nrequests==2.18.4\nscp==0.13.2\nsix==1.12.0\ntextfsm==1.1.0\nurllib3==1.22\nvisitor==0.1.3\nWerkzeug==0.12.2\nWTForms==2.1\nyml==0.0.1\n"
},
{
"alpha_fraction": 0.5018225908279419,
"alphanum_fraction": 0.5048602819442749,
"avg_line_length": 39.14634323120117,
"blob_id": "8eb84a3b198c7e71665b348b22a8cae249e23ee1",
"content_id": "1a09d768df221e254992d0dbd933e8c2acc20f9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1646,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 41,
"path": "/app/templates/vlanid.html",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% block content %}\n\n<h3>VLAN</h3>\n<form action=\"\" method=\"post\" name=\"vlanid\">\n <div class=\"form-group row\">\n <div class=\"col-sm-5\">\n {{ form.hidden_tag() }}\n <label>show vlan id</label>\n {% for error in form.vlanid.errors %}\n <span style=\"color: red;\">[{{ error }}]</span>\n {% endfor %}\n {{ form.vlanid(class_=\"form-control form-group\", placeholder=\"vlanid\") }}\n <button type=\"submit\" name=\"search\" class=\"btn btn-primary\">Search</button>\n </div>\n</form>\n<div class=\"col-sm-1\"></div>\n<div class=\"col-sm-4\">\n {%- if not first_request %}\n <label>Result from {{ host }}</label>\n <ul class=\"list-group\">\n {% if result %}\n {% set data = result['TABLE_vlanbriefid']['ROW_vlanbriefid'] %}\n {% set basic_data = result['TABLE_mtuinfoid']['ROW_mtuinfoid'] %}\n <li class=\"list-group-item\"><small>Vlan: </small>{{ basic_data['vlanshowinfo-vlanid'] }}</li>\n <li class=\"list-group-item\"><small>vlan-mode: </small>{{ basic_data['vlanshowinfo-vlanmode'] }}</li>\n <li class=\"list-group-item\"><small>vlan-type: </small>{{ basic_data['vlanshowinfo-media-type'] }}</li>\n {% for value in data %}\n <li class=\"list-group-item\"><small>{{value}}: </small>{{ data[value] }}</li>\n {% endfor %}\n {% else %}\n <li class=\"list-group-item\"><small>Vlan: </small>Not Found</li>\n\n\n {% endif %}\n {% else %}\n {% endif %}\n </ul>\n</div>\n\n{% endblock %}\n"
},
{
"alpha_fraction": 0.32258063554763794,
"alphanum_fraction": 0.40645161271095276,
"avg_line_length": 30,
"blob_id": "e2beeb52e409d44742a189afc593d9790ce7901b",
"content_id": "a89bc46ebc846b006c9bea379f43f29555c2c88f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 155,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 5,
"path": "/app/static/js/datatable.js",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "$(document).ready(function() {\n $('#mytable').DataTable( {\n \"lengthMenu\": [[15, 25, 50, -1], [15, 25, 50, \"All\"]]\n } );\n} );\n"
},
{
"alpha_fraction": 0.46666666865348816,
"alphanum_fraction": 0.46666666865348816,
"avg_line_length": 30.704545974731445,
"blob_id": "963d2aa62305398dc45487276b1aad975ed37cd6",
"content_id": "1e48f1d5648f473adb04235d473f26dbc149f72d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1395,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 44,
"path": "/app/static/js/modals.js",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "// Open modal in AJAX callback\n\n$('#mytable').on('click','.openPopup', function(event){\n// console.log(\"trigger show open modal\");\n event.preventDefault();\n jQuery.noConflict();\n var dataURL = $(this).attr('data-href');\n var iface = $(this).attr('data-iface');\n var mtittle = $(this).attr('data-mtittle');\n var html = ''\n $.ajax({\n url: dataURL,\n method: \"GET\",\n dataType: \"json\",\n async: true,\n success: function (data) {\n if($.isArray(data)) {\n // alert(\"a is an array!\");\n $.each(data, function (i) {\n// $.each(data[i], function (index, value) {\n// html+=\"<ul><li>\" + index + \": \" + value + \"</li></ul>\"\n html+=\"<ul><li>\" + data[i]['disp_mac_addr'] + \"</li></ul>\"\n //});\n });\n } else{\n// alert(\"a is not an array!\");\n $.each(data, function (index, value) {\n html+=\"<ul><li>\" + index + \": \" + value + \"</li></ul>\"\n });\n\n }\n $(\".modal-body\").html(html);\n $(\".modal-title\").html(mtittle + ' ' + iface);\n $(\"#error-modal\").modal('show');\n //return false;\n },\n });\n /* hidden.bs.modal event */\n $('#error-modal').on('hidden.bs.modal', function () {\n// window.alert('hidden event fired!');\n $(\".modal-body\").html(\"\");\n $(\".modal-title\").html(\"Loading...\");\n});\n});\n"
},
{
"alpha_fraction": 0.5534964799880981,
"alphanum_fraction": 0.5736513733863831,
"avg_line_length": 34.43362808227539,
"blob_id": "eb79654bf57404d911432d227b2699fd3e62be04",
"content_id": "e574262ddf42a41c328e2d4406ee8a6ad655fdfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40040,
"license_type": "no_license",
"max_line_length": 308,
"num_lines": 1130,
"path": "/app/views.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request, flash, redirect, url_for, jsonify\nfrom app import app\nfrom forms import PortchannelForm, PeeringForm, RtbhForm, ScrubbingForm, PppoeForm, VxlanForm, DateForm, DslForm, L2circuitForm, L2vpnForm, RouteForm, VlanForm, FPVlanForm\nfrom mycreds import *\nfrom nxapi_light import *\nimport json, requests, re, threading, socket, sys, ssl, time, os.path, yaml\nfrom collections import OrderedDict\nfrom librouteros import login\nfrom librouteros import TrapError, FatalError, ConnectionError, MultiTrapError\nlogger.setLevel(logging.INFO)\nimport datetime, glob\nfrom elasticsearch import Elasticsearch\nimport copy, netaddr, StringIO\n\nrequests.packages.urllib3.disable_warnings()\n\nip_whitelist = ['81.89.63.129',\n '81.89.63.130',\n '81.89.63.131',\n '81.89.63.132',\n '81.89.63.133',\n '81.89.63.134',\n '81.89.63.135',\n '81.89.63.136',\n '81.89.63.137',\n '81.89.63.138',\n '81.89.63.139',\n '81.89.63.140',\n '81.89.63.141',\n '81.89.63.142',\n '81.89.63.143',\n '81.89.63.144',\n '81.89.63.145',\n '81.89.63.146',\n '81.89.63.147',\n '81.89.63.148',\n '81.89.63.149',\n '81.89.63.150',\n '127.0.0.1'\n ]\n\n\ndef load_config():\n with open('app/config.yml', 'r') as f:\n conf = yaml.safe_load(f)\n boxes = conf['boxes']\n pairs = conf['pairs']\n pppoe_gws = conf['pppoe_gws']\n\n return(conf, boxes, pairs, pppoe_gws)\n\nconf, boxes, pairs, pppoe_gws = load_config()\n\ndef load_iff_errs():\n resource_path = os.path.join(app.root_path)\n os.chdir(resource_path)\n\n with open('ifaces_core_errs.yml', 'r') as f:\n ifaces = yaml.safe_load(f)\n\n return ifaces\n\nconf, boxes, pairs, pppoe_gws = load_config()\n\ndef valid_ip():\n client = request.remote_addr\n if client in ip_whitelist:\n return True\n else:\n return False\n\ndef get_ifaces_pos(host):\n\n ifaces = []\n ip_box = boxes[host]['ip']\n \n if host == 'n31':\n start = 301\n end = 400\n else:\n start = 401\n end = 500\n\n box = NXAPIClient(hostname=ip_box, username = USERNAME, password = PASSWORD)\n po_list = box.get_po_list(box.nxapi_call([\"show port-channel summary\"]))\n po_list = map(int, po_list)\n po_list = sorted(x for x in po_list if x >= start and x <= end)\n po_list = set(range(start,end)) - set(po_list)\n po_list = sorted(list(po_list))\n print \"before request running\"\n\n iface_status = box.get_iface_status(box.nxapi_call([\"show interface status\"]))\n\n for item in iface_status:\n key = item['interface']\n value = item['state']\n \n if value == 'connected':\n value = 'Up'\n else:\n value = 'Down'\n\n key_value = key + ' ' + value\n iface_regex = re.compile(r\".*({}).*\".format('Ethernet'))\n mo_iface = iface_regex.search(key)\n if mo_iface:\n ifaces.append(key_value)\n else:\n pass\n\n po_number = po_list[0]\n\n return (ifaces, po_number)\n\ndef create_twin_dict(output1, output2):\n\n iface_status = OrderedDict() \n\n for i in range(len(output1)):\n iface_dict1 = output1[i]\n iface_name = iface_dict1['interface']\n for key in iface_dict1.keys():\n newkey = key + \"1\"\n iface_dict1[newkey] = iface_dict1.pop(key)\n iface_status[iface_name] = iface_dict1\n \n for i in range(len(output2)):\n iface_dict2 = output2[i]\n iface_name = iface_dict2['interface']\n iface_status.setdefault(iface_name, {'speed':'100'})\n\n for key in iface_dict2.keys():\n newkey = key + \"2\"\n iface_dict2[newkey] = iface_dict2.pop(key)\n iface_status[iface_name].update(iface_dict2)\n \n return iface_status\n\ndef convert_mac(raw_list, mac_key):\n\n for arp in raw_list:\n if mac_key in arp:\n mac = str(arp[mac_key])\n mac = mac.translate(None, \".\")\n mac = ':'.join(s.encode('hex') for s in mac.decode('hex'))\n arp[mac_key] = mac\n\n return raw_list\n\ndef peering_status():\n data = {'command':'show neighbor summary'}\n r = requests.post('http://192.168.8.3:5001/show_neighbor_summary', data=data)\n status = json.loads(r.text)\n return status\n\ndef route_advertisement():\n data = {'command':'show adj-rib-out'}\n r = requests.post('http://192.168.8.3:5001/show_adj_rib_out', data=data)\n advertisement = json.loads(r.text)\n return advertisement\n\ndef last_log():\n data = {'command':''}\n r = requests.post('http://192.168.8.3:5001/show_full_log', data=data)\n log = json.loads(r.text)\n return log\n\ndef conf_cleaner(raw_conf):\n clean_conf = raw_conf.replace('\\r', '') # delete '\\r'\n clean_conf = clean_conf.split('\\n') # split\n clean_conf = list(map(str, clean_conf)) # delete whitespaces items\n clean_conf = list(map(str.strip, clean_conf)) # stripping\n clean_conf = list(filter(str.strip, clean_conf))\n clean_conf = [elem for elem in clean_conf if elem != '!' and elem != 'end' and elem != 'configure terminal']\n return clean_conf\n\[email protected]('/',methods=['POST','GET'])\[email protected]('/index', methods=['POST','GET'])\ndef index():\n\n if valid_ip():\n return render_template('index.html', title='Home', conf=conf)\n else:\n return render_template('404.html', title = 'Not Found')\n\[email protected]('/',methods=['POST','GET'])\[email protected]('/contact', methods=['POST','GET'])\ndef contact():\n\n if valid_ip():\n return render_template('contact.html', title='Contact', conf=conf)\n else:\n return render_template('404.html', title = 'Not Found')\n\[email protected]('/port_status_tn3', methods=['POST','GET'])\ndef port_status_tn3():\n\n return render_template('port_status_tn3.html', title='Port Status SHC3', conf=conf)\n\[email protected]('/port/<twins>', methods=['POST','GET'])\ndef port(twins):\n return render_template('port.html', twins = twins, conf=conf)\n\[email protected]('/port/ajax_<twins>', methods=['POST','GET'])\ndef ajax_port(twins):\n \n hosts = pairs[twins]['members']\n ip_box1 = boxes[hosts[0]]['ip']\n ip_box2 = boxes[hosts[1]]['ip']\n location = boxes[hosts[0]]['location']\n title = str(location) + \" \" + str(hosts[0]) + str(hosts[1])\n box1 = NXAPIClient(hostname = ip_box1, username = USERNAME, password = PASSWORD)\n iface_box1 = box1.get_iface_status(box1.nxapi_call([\"show interface status\"]))\n box2 = NXAPIClient(hostname=ip_box2, username = USERNAME, password = PASSWORD)\n iface_box2 = box2.get_iface_status(box2.nxapi_call([\"show interface status\"]))\n \n iface_status = create_twin_dict(iface_box1, iface_box2)\n\n return render_template('ajax_port.html', title=title, iface_status = iface_status, hosts = hosts, twins = twins, location = location)\n\[email protected]('/port_host/<host>', methods=['POST','GET'])\ndef port_host(host):\n return render_template('port_host.html', host=host, conf=conf)\n\[email protected]('/port_host/ajax_port_<host>', methods=['POST','GET'])\ndef ajax_port_host(host):\n \n ip_box = boxes[host]['ip']\n location = boxes[host]['location']\n title = str(location) + \" \" + str(host)\n box = NXAPIClient(hostname = ip_box, username = USERNAME, password = PASSWORD)\n iface_status = box.get_iface_status(box.nxapi_call([\"show interface status\"]))\n \n return render_template('ajax_port_host.html', title=title, iface_status = iface_status, host = host, location = location)\n\ndef merge_sfp_iface(l1, l2, key):\n merged = {}\n for item in l1+l2:\n if item[key] in merged:\n merged[item[key]].update(item)\n else:\n merged[item[key]] = item\n return [val for (_, val) in merged.items()]\n\[email protected]('/sfp/<host>', methods=['POST','GET'])\ndef sfp(host):\n return render_template('sfp.html', host=host, conf=conf)\n\[email protected]('/sfp/ajax_sfp_<host>', methods=['POST','GET'])\ndef ajax_sfp_host(host):\n \n ip_box = boxes[host]['ip']\n location = boxes[host]['location']\n title = str(location) + \" \" + str(host)\n box = NXAPIClient(hostname = ip_box, username = USERNAME, password = PASSWORD)\n sfp_details = box.get_all_transceiver_details(box.nxapi_call([\"show interface transceiver details\"]))\n sfp_desc = box.get_iface_description(box.nxapi_call([\"show interface description\"]))\n sfp_status = merge_sfp_iface(sfp_desc, sfp_details, 'interface')\n\n return render_template('ajax_sfp.html', title=title, sfp_status = sfp_status, host = host, location = location, conf=conf)\n\[email protected]('/arp/<host>', methods=['POST','GET'])\ndef arp(host):\n return render_template('arp.html', host=host, conf=conf)\n\[email protected]('/arp/ajax_<host>', methods=['POST','GET'])\ndef ajax_arp(host):\n\n location = boxes[host]['location']\n title = str(location) + \" \" + str(boxes[host])\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n arp_list = box.get_arp_list(box.nxapi_call([\"show ip arp\"]))\n arp_list = convert_mac(arp_list, 'mac')\n \n return render_template('ajax_arp.html', title=title, arp_list = arp_list, location = location, host = host)\n\[email protected]('/mac/<host>', methods=['POST','GET'])\ndef mac(host):\n\n return render_template('mac.html', host=host, conf=conf)\n\[email protected]('/mac/ajax_<host>', methods=['POST','GET'])\ndef ajax_mac(host):\n\n location = boxes[host]['location']\n title = str(location) + \" \" + str(boxes[host])\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n mac_list = box.get_mac_list(box.nxapi_call([\"show mac address dynamic\"]))\n mac_list = convert_mac(mac_list, 'disp_mac_addr')\n \n return render_template('ajax_mac.html', title=title, mac_list = mac_list, location = location, host = host)\n\[email protected]('/rtbh', methods=['POST','GET'])\ndef rtbh():\n form = RtbhForm()\n \n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n ipv4 = form.ipv4.data\n action = form.action.data\n \n try:\n if action:\n payload = \"neighbor 109.74.150.18 announce route \" + ipv4 + \"/32 next-hop 192.0.2.1 community [29405:666]\"\n else: \n payload = \"neighbor 109.74.150.18 withdraw route \" + ipv4 + \"/32 next-hop 192.0.2.1 community [29405:666]\"\n\n data = {'command':payload}\n r = requests.post('http://192.168.8.3:5001/announce', data=data)\n response = json.loads(r.text)\n status = peering_status()\n advertisement = route_advertisement()\n log = last_log()\n\n except:\n response = \"Could not connect to API\"\n\n return render_template('rtbh.html', title='RTBH', form=form, status=status, advertisement=advertisement, log=log, conf=conf)\n else:\n\n advertisement = route_advertisement()\n status = peering_status()\n log = last_log()\n\n return render_template('rtbh.html', title='RTBH', form=form, status=status, advertisement=advertisement, log=log, conf=conf)\n\[email protected]('/scrubbing', methods=['POST','GET'])\ndef scrubbing():\n form = ScrubbingForm()\n \n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n action = form.action.data\n network_id = form.network.data\n network = [f[1] for f in form.network.choices if f[0] == network_id]\n network = network[0]\n\n if action:\n payload = \"neighbor 109.74.147.190 announce route \" + network + \" next-hop 192.0.2.1 community [29405:778]\"\n else: \n payload = \"neighbor 109.74.147.190 withdraw route \" + network + \" next-hop 192.0.2.1 community [29405:778]\"\n\n try:\n data = {'command':payload}\n r = requests.post('http://192.168.8.3:5001/announce', data=data)\n response = json.loads(r.text)\n status = peering_status()\n advertisement = route_advertisement()\n log = last_log()\n\n except:\n response = \"Could not connect to API\"\n\n return render_template('scrubbing.html', title='Scrubbing', form=form, status=status, advertisement=advertisement, log=log, conf=conf)\n else:\n\n advertisement = route_advertisement()\n status = peering_status()\n log = last_log()\n\n return render_template('scrubbing.html', title='Scrubbing', form=form, status=status, advertisement=advertisement,log=log, conf=conf)\n\ndef pppoe_status(pppoe):\n \n status = {}\n gw_status = {}\n for k,v in pppoe_gws.iteritems():\n gw = k\n ip = v\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n server_address = (ip, 8728)\n sock.settimeout(5.0)\n\n try:\n sock.connect(server_address)\n api = login(username='api', password='apina', sock=sock)\n #params = {'.proplist':('type,.id,name,mac-address')}\n #result = api(cmd='/interface/print', **params)\n #result = api(cmd='/interface/pppoe-server/print')\n except socket.error, exc:\n print \"Socket error: %s\" % exc\n gw_status[gw] = 'Socket error'\n continue\n\n except (ConnectionError, TrapError, FatalError, MultiTrapError), exc:\n print exc\n gw_status[gw] = exc\n continue\n\n try:\n params = {'.proplist':('.id,name,address,caller-id,uptime,service')}\n result = api(cmd='/ppp/active/print', **params)\n # result = api(cmd='/ip/firewall/service-port/print')\n\n except (ConnectionError, TrapError, FatalError, MultiTrapError), exc:\n print exc\n gw_status[gw] = exc\n continue\n\n gw_status[gw] = 'OK'\n\n for acc in result: \n if acc['name'] == pppoe:\n status = acc\n params = {'.proplist':('target,max-limit')}\n queues = api(cmd='/queue/simple/print', **params)\n for queue in queues:\n target = '<pppoe-' + pppoe + '>'\n if queue['target'] == target:\n shape_up_down = queue['max-limit'].split(\"/\")\n shape = str(int(shape_up_down[0])/1000000) + 'M' + ' / ' + str(int(shape_up_down[1])/1000000) + 'M'\n status['shape'] = shape\n break\n else:\n time.sleep(0.2)\n sock.close()\n continue\n break\n\n sock.close()\n\n return (status, gw, gw_status, ip)\n\ndef terminate_pppoe(gw, id_rule):\n result = False\n for k, v in pppoe_gws.iteritems():\n if k == gw:\n ip = v\n sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n server_address = (ip, 8728)\n sock.settimeout(5.0)\n\n try:\n sock.connect(server_address)\n api = login(username='api', password='apina', sock=sock)\n\n except socket.error, exc:\n print \"Socket error: %s\" % exc\n\n try:\n if api is not None:\n params = {'.id': id_rule}\n result = api(cmd='/ppp/active/remove', **params)\n print result\n except:\n print \"API error\"\n\n return result\n\ndef pppoe_get_vendor(mac):\n MAC_URL = 'http://macvendors.co/api/%s'\n r = requests.get(MAC_URL % mac)\n r = r.json()\n r = r['result']\n\n if 'error' not in r:\n mac = r['company'] \n else:\n mac = None\n return mac\n\ndef create_query_log(id_pppoe):\n\n query = {\n \"query\": {\n \"bool\": {\n \"must\": [\n {\n \"match\": {\n \"sysloghost\": \"radiusint1*\"\n }\n },\n {\n \"match_phrase\": {\n \"message\": id_pppoe\n }\n },\n {\n \"range\": {\n \"@timestamp\": {\n \"time_zone\": \"+02:00\",\n \"gte\": \"now-14d\",\n \"lt\": \"now\"\n }\n }\n }\n ]\n }\n },\n \"sort\": {\n \"@timestamp\": \"desc\"\n }\n }\n\n return query\n\ndef pppoe_get_log(pppoe, query):\n\n es = Elasticsearch([{'host': '192.168.35.225', 'port': 9200}])\n try:\n query = es.search(body=query, request_timeout=30, size=50 )\n log = [doc for doc in query['hits']['hits']]\n except Exception:\n log = [{'_source': { 'message': 'ConnectionTimeout. Try again'}}]\n\n return log\n\[email protected]('/ftth', methods=['POST','GET'])\ndef ftth():\n form = PppoeForm()\n first_request = True\n mac_address = None\n vendor = None\n log = None\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n if request.form['action'] == 'search':\n print \"Search\"\n print request\n pppoe = form.pppoe.data\n id_pppoe, realm = pppoe.split(\"@\")\n status, gw, gw_status,gw_ip = pppoe_status(pppoe)\n\n if status:\n mac_address = status['caller-id']\n vendor = pppoe_get_vendor(mac_address)\n query_log = create_query_log(pppoe)\n log = pppoe_get_log(pppoe, query_log)\n else:\n # get log even if account is not found (aka auth failure:)\n query_log = create_query_log(pppoe)\n log = pppoe_get_log(pppoe, query_log)\n\n return render_template('ftth.html', title='Ftth', form=form, status=status, gw=gw, gw_ip=gw_ip, gw_status = gw_status, vendor=vendor, log = log, first_request = first_request,conf=conf)\n else:\n print \"Terminating ...\"\n id_rule = request.form['id']\n gw = request.form['gw']\n pppoe = request.form['pppoe']\n result = terminate_pppoe(gw, id_rule)\n #if result_box1 and result_box2:\n flash(pppoe + ' has been terminated')\n return redirect(url_for('ftth'))\n\n\n return render_template('ftth.html', title='Ftth', form=form, first_request = first_request, conf=conf)\n\[email protected]('/dsl', methods=['POST','GET'])\ndef dsl():\n form = DslForm()\n first_request = True\n log = None\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n dsl = form.dsl.data\n id_dsl, realm = dsl.split(\"@\")\n\n query_log = create_query_log(dsl)\n log = pppoe_get_log(dsl, query_log)\n\n return render_template('dsl.html', title='Dsl', form=form, log = log, first_request = first_request, conf=conf)\n\n return render_template('dsl.html', title='Dsl', form=form, first_request = first_request, conf=conf)\n\[email protected]('/route', methods=['POST','GET'])\ndef route():\n form = RouteForm()\n first_request = True\n host = 'n931'\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n route = form.route.data\n ip_box = boxes[host]['ip']\n box = NXAPIClient(hostname=ip_box, username=USERNAME, password=PASSWORD)\n if netaddr.valid_ipv4(route) is True:\n result = box.get_ip_route(box.nxapi_call([\"show ip route \" + route]))\n else:\n result = box.get_ip_route(box.nxapi_call([\"show ipv6 route \" + route]))\n\n print result\n\n return render_template('route.html', title='Route', form=form, result=result, host=host, first_request = first_request, conf=conf)\n\n return render_template('route.html', title='Route', form=form, first_request = first_request, conf=conf)\n\[email protected]('/vlanid', methods=['POST','GET'])\ndef vlanid():\n form = VlanForm()\n first_request = True\n host = 'n31'\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n vlanid = form.vlanid.data\n ip_box = boxes[host]['ip']\n box = NXAPIClient(hostname=ip_box, username=USERNAME, password=PASSWORD)\n result = box.get_vlan_id(box.nxapi_call([\"show vlan id \" + str(vlanid)]))\n print result\n\n return render_template('vlanid.html', title='Vlan', form=form, result=result, host=host, first_request = first_request, conf=conf)\n\n return render_template('vlanid.html', title='Vlan', form=form, first_request = first_request, conf=conf)\n\[email protected]('/fpvlan', methods=['POST','GET'])\ndef fpvlan():\n form = FPVlanForm()\n first_request = True\n hosts = ['n31','n32','n41','n42']\n check_hosts = ['n31','n32']\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n\n if request.form['action'] == 'Generate':\n print \"Generate\"\n vlanid = form.vlanid.data\n vlanname = form.vlanname.data\n for host in check_hosts:\n ip_box = boxes[host]['ip']\n box = NXAPIClient(hostname=ip_box, username=USERNAME, password=PASSWORD)\n result = box.get_vlan_id(box.nxapi_call([\"show vlan id \" + str(vlanid)]))\n if result:\n flash('Vlan already exists')\n break\n print result\n\n return render_template('fpvlan.html', title='FPVlan', form=form, result=result, vlanid=vlanid, vlanname=vlanname, host=host, first_request = first_request, conf=conf)\n\n else:\n print \"Deploy\"\n fp_conf = request.form['configuration.data']\n # data cleaner, config list creation\n fp_conf = conf_cleaner(request.form['configuration.data'])\n print fp_conf\n for host in hosts:\n ip_box = boxes[host]['ip']\n box = NXAPIClient(hostname=ip_box, username=USERNAME, password=PASSWORD)\n result = box.set_cmd(box.nxapi_call(fp_conf))\n if result:\n flash_ok = True\n\n if flash_ok:\n flash('Deployment has been successfull')\n else:\n flash('Something is wrong')\n\n return redirect(url_for('fpvlan'))\n\n return render_template('fpvlan.html', title='FPVlan', form=form, first_request = first_request, conf=conf)\n\[email protected]('/pppoejq', methods=['POST','GET'])\ndef pppoejq():\n form = PppoeForm()\n return render_template('jquery.html')\n\[email protected]('/peering', methods=['POST','GET'])\ndef peering():\n form = PeeringForm()\n first_request = True\n peers = {1:['six','ipv6-six'],2:['nix.cz','ipv6-nix.cz'],3:['nix.sk','ipv6-nix.sk'],4:['AMS-IX-IPV4','AMS-IX-IPV6']}\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n peering = form.peering.data\n peergroup = [peers[f] for f in peers if f == peering]\n print peergroup\n return render_template('peering.html', title='Peering', form=form, peergroup=peergroup, first_request = first_request, conf=conf)\n\n return render_template('peering.html', title='Peering', form=form, first_request = first_request, conf=conf)\n\ndef load_asr_ifaces(asr):\n\n filename = os.path.join(app.root_path, asr + '_ifaces.yml')\n\n with open(filename, 'r') as f:\n asr = yaml.safe_load(f)\n ifaces = asr['ifaces']\n\n ids = [i for i in range(len(ifaces))]\n id_ifaces = list(zip(ids, ifaces))\n\n return id_ifaces\n\ndef update_asr_ifaces(asr):\n host = asr + '-asr'\n ip = boxes[host]['ip']\n ifaces = {'ifaces':[]}\n\n from pyIOSXR import IOSXR\n box = IOSXR(hostname=ip, username=IOSXRUSERNAME, password=IOSXRPASSWORD, port=22, timeout=120)\n box.open()\n output = box.show_interfaces_brief()\n buf = StringIO.StringIO(output)\n box.close()\n\n lines = buf.read().split(\"\\n\")\n arpa_regex = re.compile(r\".*({}).*\".format('ARPA'))\n\n for line in lines[3:]:\n mo_arpa = arpa_regex.search(line)\n if mo_arpa:\n row = mo_arpa.group().split()\n ifaces['ifaces'].append(row[0])\n\n filename = os.path.join(app.root_path, asr + '_ifaces.yml')\n\n with open(filename, 'w') as f:\n yaml.dump(ifaces, f, default_flow_style=False)\n\[email protected]('/l2circuit_<from_to>', methods=['POST','GET'])\[email protected]('/l2circuit_<from_to>/<int:update>', methods=['POST','GET'])\ndef l2circuit(from_to, update=0):\n\n print from_to, update\n\n asr = from_to.split('_')[0]\n\n if update == 1:\n update_asr_ifaces(asr)\n\n form = L2circuitForm()\n form.iface.choices = load_asr_ifaces(asr)\n\n first_request = True\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n if request.form['action'] == 'Generate':\n print \"Generate\"\n iface_id = form.iface.data\n vlan = form.vlan.data\n clientid = form.clientid.data\n company = form.company.data\n circuit_type = form.circuit_type.data\n description = str(clientid) + \"-\" + company\n iface = [f[1] for f in form.iface.choices if f[0] == iface_id]\n iface = iface[0]\n if asr == 'six':\n neighbor_ip = '185.176.72.127'\n else:\n neighbor_ip = '185.176.72.126'\n\n return render_template('l2circuit.html', title='L2circuit', form=form, asr=asr, from_to=from_to, neighbor_ip=neighbor_ip, circuit_type=circuit_type, iface=iface, vlan=vlan, description=description, first_request = first_request, conf=conf)\n\n return render_template('l2circuit.html', title='L2circuit', form=form, asr=asr, from_to=from_to, first_request = first_request, conf=conf)\n\[email protected]('/l2vpn_<from_to>', methods=['POST','GET'])\ndef l2vpn(from_to):\n\n asr1,asr2 = from_to.split('_')\n form = L2vpnForm()\n form.iface1.choices = load_asr_ifaces(asr1)\n form.iface2.choices = load_asr_ifaces(asr2)\n\n first_request = True\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n iface1_id = form.iface1.data\n iface2_id = form.iface2.data\n vlan = form.vlan.data\n clientid = form.clientid.data\n company = form.company.data\n circuit1_type = form.circuit1_type.data\n circuit2_type = form.circuit2_type.data\n description = str(clientid) + \"-\" + company\n iface1 = [f[1] for f in form.iface1.choices if f[0] == iface1_id]\n iface1 = iface1[0]\n iface2 = [f[1] for f in form.iface2.choices if f[0] == iface2_id]\n iface2 = iface2[0]\n neighbors = {'six': '185.176.72.127', 'sit': '185.176.72.126'}\n asr1_ip, asr2_ip = neighbors[asr1], neighbors[asr2]\n\n return render_template('l2vpn.html', title='L2vpn', form=form, asr1=asr1, asr2=asr2, from_to=from_to, asr1_ip=asr1_ip, asr2_ip=asr2_ip, circuit1_type=circuit1_type, iface1=iface1,circuit2_type=circuit2_type, iface2=iface2, vlan=vlan, description=description, first_request = first_request, conf=conf)\n\n return render_template('l2vpn.html', title='L2vpn', form=form, asr1=asr1, asr2=asr2, from_to=from_to, first_request = first_request, conf=conf)\n\ndef get_vxlan_data(vlanid):\n vlanidhex = bin(vlanid)[2:].zfill(16)\n octet1 = int(vlanidhex[:8], 2)\n octet2 = int(vlanidhex[8:], 2)\n return (octet1, octet2)\n\n\[email protected]('/po_summary/<host>', methods=['POST','GET'])\ndef po_summary(host):\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n po_summary = box.get_po_summary(box.nxapi_call([\"show port-channel summary\"]))\n print po_summary\n\n return render_template('po_summary.html', title='Po_summary', po_summary=po_summary, host=host, conf=conf)\n\[email protected]('/vxlan', methods=['POST','GET'])\ndef vxlan():\n form = VxlanForm()\n first_request = True\n vxlan_data = {}\n\n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n vlanid = form.vlanid.data\n vni = 10000 + int(vlanid )\n octet1, octet2 = get_vxlan_data(vlanid)\n vxlan_data['octet1'] = octet1\n vxlan_data['octet2'] = octet2\n vxlan_data['vni'] = vni\n\n return render_template('vxlan.html', title='Vxlan', form=form, vxlan_data = vxlan_data, first_request = first_request,conf=conf)\n\n return render_template('vxlan.html', title='Vxlan', form=form, first_request = first_request, conf=conf)\n\[email protected]('/po/<twins>', methods=['POST','GET'])\ndef po(twins):\n \n if twins == 'tn3':\n ifaces, po_number = get_ifaces_pos(\"n31\")\n ifaces = ifaces[48:] #remove parent ports from list (Ethernet1/1-48)\n location = 'SHC3'\n else: \n ifaces, po_number = get_ifaces_pos(\"n41\")\n ifaces = ifaces[64:] #remove parent ports from list (Ethernet1/1-48, Ethernet3/1-16,)\n location = 'DC4'\n\n first_request = True\n twins = twins\n form = PortchannelForm()\n ids = [i for i in range(len(ifaces))]\n form.iface1.choices = form.iface2.choices = list(zip(ids, ifaces))\n portchannel = form.portchannel.data\n\n porttype = form.porttype.data\n iface1_id = form.iface1.data\n \n if form.validate_on_submit():\n print \"validated\"\n first_request = False\n #print portchannel, porttype, location, iface1_id\n #dummy_conf = [\"interface Eth131/1/1\", \"non shutdown\", \"interface Eth131/1/2\", \"shutdown\"]\n\n if request.form['action'] == 'Generate':\n print \"Generate\"\n portchannel = form.portchannel.data\n porttype = form.porttype.data\n iface1_id = form.iface1.data\n iface2_id = form.iface2.data\n clientid = form.clientid.data\n company = form.company.data\n vlans = form.vlans.data\n\n iface1 = [f[1] for f in form.iface1.choices if f[0] == iface1_id]\n iface2 = [f[1] for f in form.iface2.choices if f[0] == iface2_id]\n iface1 = iface1[0]\n iface2 = iface2[0]\n\n description = str(clientid) + \"-\" + company\n\n form.clientid.data = clientid\n\n return render_template('portchannel.html', title='Portchannel', form=form, po_number=po_number, description=description, location=location, portchannel=portchannel, iface1=iface1, iface2 = iface2, trunk = porttype, vlans=vlans, twins = twins, first_request = first_request, conf=conf)\n else:\n print \"Deploy\"\n # data cleaner, config list creation\n po_conf = request.form['configuration.data']\n po_conf = po_conf.replace('\\r', '') #delete '\\r'\n po_conf = po_conf.split('\\n') #split\n po_conf = list(map(str, po_conf)) #delete whitespaces items\n po_conf = list(map(str.strip, po_conf)) #stripping\n po_conf = list(filter(str.strip, po_conf))\n po_conf = [ elem for elem in po_conf if elem != '!' and elem != 'end' and elem != 'configure terminal']\n\n hosts = pairs[twins]['members']\n ip_box1 = boxes[hosts[0]]['ip']\n ip_box2 = boxes[hosts[1]]['ip']\n box1 = NXAPIClient(hostname = ip_box1, username = USERNAME, password = PASSWORD)\n result_box1 = box1.set_cmd(box1.nxapi_call(po_conf))\n box2 = NXAPIClient(hostname=ip_box2, username = USERNAME, password = PASSWORD)\n result_box2 = box2.set_cmd(box2.nxapi_call(po_conf))\n\n if result_box1 and result_box2:\n flash('Deployment has been successfull')\n else:\n flash('Something is wrong')\n\n return redirect(url_for('po', twins = twins))\n\n else:\n clientid = 0\n print form.errors\n\n return render_template('portchannel.html', title='Portchannel', form=form, twins = twins, location = location, first_request=first_request, conf=conf)\n\[email protected]('/ifsw/<host>/<path:iface>', methods=['POST','GET'])\ndef ifsw(host, iface):\n\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n ifsw = box.get_iface_switchport(box.nxapi_call([\"show interface \" + iface + \" switchport\"]))\n ifsw = json.dumps(ifsw)\n\n return ifsw\n \n\n #return render_template('iface_switchport.html', title='Interface switchport configuration', iface=iface, host=host, ifsw=ifsw, conf=conf)\n\[email protected]('/iferr/<host>/<path:iface>', methods=['POST','GET'])\ndef iferr(host, iface):\n\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n iferr = box.get_iface_errors(box.nxapi_call([\"show interface \" + iface + \" counters errors\"]))\n iferr = json.dumps(iferr)\n\n return iferr\n #return render_template('iface_errors.html', title='Interface errors', iface=iface, host=host, iferr=iferr, conf=conf)\n\[email protected]('/maclist/<host>/<path:iface>', methods=['POST','GET'])\ndef maclist(host, iface):\n\n ip = boxes[host]['ip']\n box = NXAPIClient(hostname=ip, username = USERNAME, password = PASSWORD)\n maclist = box.get_mac_list(box.nxapi_call([\"show mac address-table interface \" + iface]))\n maclist = json.dumps(maclist)\n\n print maclist\n return maclist\n\[email protected]('/logs', methods=['POST','GET'])\ndef logs():\n form = DateForm()\n ids = [i for i in range(len(boxes))]\n form.box.choices = list(zip(ids, boxes))\n\n if form.validate_on_submit():\n print(\"validated\")\n dt = str(form.dt.data)\n date = dt.replace('-','')\n box_id = form.box.data\n box = [f[1] for f in form.box.choices if f[0] == box_id]\n severity_id = form.severity.data\n severity = [f[1] for f in form.severity.choices if f[0] == severity_id]\n payload = { 'date':date, 'severity':severity, 'box':box }\n r = requests.get('http://217.73.28.16:5002/syslog', params=payload)\n print(r.url)\n logs = json.loads(r.text)\n\n return render_template('logs.html', logs=logs, form=form, conf=conf) \n \n else:\n date = datetime.datetime.now().strftime (\"%Y%m%d\")\n # Uncomment if you want to allow default view\n #severity = all\n #box = six\n #payload = { 'date':date, 'severity':severity, 'box':box }\n #r = requests.get('http://217.73.28.16:5002/syslog', params=payload)\n #logs = json.loads(r.text)\n\n logs = {}\n return render_template('logs.html', logs=logs, form=form, conf=conf)\n\ndef get_vlan(nxhosts):\n '''\n Walk through json vlan-db files located in vlan-db directory (created by cronjob) and create dictionary in format:\n\n vlan = {vlanid1: { box1_name: name,\n box1_state: state,\n box1_mode: mode,\n box2name: name,\n box2_state: state,\n box2_mode: mode,\n ...\n }\n vlanid2: { box1_name: name,\n box1_state: state,\n box1_mode: mode,\n box2name: name,\n box2_state: state,\n box2_mode: mode,\n ...\n }\n }\n :return:(vlan, key_attributes, file_created)\n '''\n\n vlan = {}\n boxes = []\n vlan_attr = ['N', 'S', 'M']\n\n resource_path = os.path.join(app.root_path, 'vlan-db' + '/' + nxhosts)\n\n if nxhosts == 'n5k':\n created = time.ctime(os.path.getctime(resource_path + '/n31-vlan-db.json'))\n elif nxhosts == 'n9k':\n created = time.ctime(os.path.getctime(resource_path + '/n911-vlan-db.json'))\n else:\n pass\n\n for filename in glob.glob(resource_path + '/*.json'):\n box = os.path.basename(filename).split(\"-\")\n box = box[0]\n boxes.append(box)\n\n box_attr = [str(_box) + '_' + str(_attr) for _attr in vlan_attr for _box in boxes]\n\n for filename in glob.glob(resource_path + '/*.json'):\n box = os.path.basename(filename).split(\"-\")\n box = box[0]\n with open(filename) as file:\n data = json.load(file)\n vlan_brief = data['TABLE_vlanbrief']['ROW_vlanbrief']\n vlan_mode = data['TABLE_mtuinfo']['ROW_mtuinfo']\n\n for item in vlan_brief:\n vlanid = item['vlanshowbr-vlanid']\n vlanname = item['vlanshowbr-vlanname']\n vlanstate = item['vlanshowbr-vlanstate']\n\n vlanname_key = str(box) + '_' + 'N'\n vlanstate_key = str(box) + '_' + 'S'\n\n vlan.setdefault(vlanid,{str(_box) + '_' + str(_attr):'Error' for _attr in vlan_attr if _attr == 'N' for _box in boxes})\n\n vlan[vlanid][vlanname_key] = vlanname\n vlan[vlanid][vlanstate_key] = vlanstate\n for item in vlan_mode:\n vlanid = item['vlanshowinfo-vlanid']\n _vlanmode = item['vlanshowinfo-vlanmode']\n if _vlanmode == 'fabricpath-vlan':\n vlanmode = 'FP'\n elif _vlanmode == 'ce-vlan':\n vlanmode = 'CE'\n else:\n pass\n\n vlanmode_key = str(box) + '_' + 'M'\n vlan[vlanid][vlanmode_key] = vlanmode\n\n return (vlan, box_attr, created)\n\[email protected]('/vlan/<nxhosts>', methods=['POST','GET'])\ndef vlan(nxhosts):\n\n\n vlan, box_attr, created = get_vlan(nxhosts)\n\n return render_template('vlan.html', vlan=vlan, box_attr = box_attr, created = created, nxhosts = nxhosts, conf=conf )\n\ndef create_iff_errs_diff(ifaces_new, ifaces_cur):\n\n ifaces = copy.deepcopy(ifaces_new)\n\n for k, v in ifaces_new.iteritems():\n for in_k, in_v in v.iteritems():\n if in_k != 'interface' and in_k != 'type' and in_k != 'speed' and in_k != 'desc':\n k_diff = str(in_k) + '_diff'\n v_diff = int(ifaces_new[k][in_k]) - int(ifaces_cur[k][in_k])\n ifaces[k][k_diff] = v_diff\n\n return ifaces\n\[email protected]('/iferrs', methods=['POST','GET'])\ndef iferrs():\n ifaces_all = load_iff_errs()\n ifaces_new = {}\n ifaces_cur = {}\n result = {}\n\n resource_path = os.path.join(app.root_path, 'iface-err')\n iface_desc_path = os.path.join(app.root_path, 'iface-desc')\n\n for box in ifaces_all:\n\n if (os.path.isdir(resource_path)):\n os.chdir(resource_path)\n\n file_new = box + '-iface-err-new.json'\n file_cur = box + '-iface-err-cur.json'\n file_desc = box + '-iface-desc.json'\n \n if (os.path.exists(file_new)) and (os.path.exists(file_cur)):\n created_new = time.ctime(os.path.getmtime(file_new))\n created_cur = time.ctime(os.path.getmtime(file_cur))\n\n with open(file_new) as file_n:\n data_n = json.load(file_n)\n data_n = data_n['TABLE_interface']['ROW_interface']\n data_n = [item for item in data_n if 'eth_fcs_err' in item]\n\n with open(iface_desc_path + '/' + file_desc) as file_d:\n data_d = json.load(file_d)\n data_d = data_d['TABLE_interface']['ROW_interface']\n\n data = merge_sfp_iface(data_n, data_d, 'interface')\n\n for item in data:\n if item['interface'] in ifaces_all[box] and 'eth_fcs_err' in item:\n iface_key = item['interface']\n ifaces_new[iface_key] = item\n\n with open(file_cur) as file:\n data_cur = json.load(file)\n data_cur = data_cur['TABLE_interface']['ROW_interface']\n\n for item_cur in data_cur:\n if item_cur['interface'] in ifaces_all[box] and 'eth_fcs_err' in item_cur:\n iface_key = item_cur['interface']\n ifaces_cur[iface_key] = item_cur\n\n result[box] = create_iff_errs_diff(ifaces_new, ifaces_cur)\n\n ifaces_new.clear()\n ifaces_cur.clear()\n\n return render_template('iface_core_errs.html', ifaces=result, created_new = created_new, created_cur = created_cur, conf=conf )\n"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7758620977401733,
"avg_line_length": 28,
"blob_id": "8c7b574dee66574a7e3a0661e38e47560394d7c3",
"content_id": "886d5d277e168add14c284461d6be45684915b61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/config.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "WTF_CSRF_ENABLED = True\nSECRET_KEY = 'ciammewHyHomgasEf6'\n"
},
{
"alpha_fraction": 0.577464759349823,
"alphanum_fraction": 0.577464759349823,
"avg_line_length": 22.66666603088379,
"blob_id": "0f25f65634dd091363c577797cecdb9c7ae60e91",
"content_id": "9536e3bf23bad5780d5219ff9c4fdda349e445d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 71,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 3,
"path": "/app/static/js/clipboard.js",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "$(document).ready(function () {\n new Clipboard('.copy-text');\n});\n"
},
{
"alpha_fraction": 0.5794884562492371,
"alphanum_fraction": 0.5859748125076294,
"avg_line_length": 32.080970764160156,
"blob_id": "4cdcce4619147d43307984bd8c2b88745ce13244",
"content_id": "28fde1e67e5f41246a8ecfa96dfb55ca1c5d95a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8171,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 247,
"path": "/app/nxapi_light.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport logging\nimport requests\nimport os, json, pickle\nimport mycreds\nfrom collections import OrderedDict\nrequests.packages.urllib3.disable_warnings()\nlogger = logging.getLogger(\"\")\n#logger.setLevel(logging.DEBUG)\nfrom string import Template\n#overwrite requests logger to warning only\n#logging.getLogger(\"requests\").setLevel(logging.WARNING)\n\n\nclass NXAPIClient(object):\n\n def __init__(self, **kwargs):\n\n self.headers = {'content-type': 'application/json-rpc'}\n self.hostname = kwargs.get(\"hostname\", None)\n self.username = kwargs.get(\"username\", \"username\")\n self.password = kwargs.get(\"password\", \"password\")\n self.port = kwargs.get(\"port\", \"8181\")\n self.verify = kwargs.get(\"verify\", False)\n self._http = \"https://\"\n self._session = None # current session\n self._cookie = None # active cookiejar\n self.cookie = kwargs.get(\"cookie\", \"cookie/%s_nxapi.cookie\" % self.hostname)\n self.url = \"%s%s:%s%s\" % (self._http, self.hostname, self.port, '/ins')\n self.headers = {'content-type': 'application/json-rpc'}\n \n if self.hostname is None or len(self.hostname)<=0:\n raise Exception(\"missing or invalid argument 'hostname'\")\n if self.username is None or len(self.username)<=0:\n raise Exception(\"missing or invalid argument 'username'\")\n if self.password is None or len(self.password)<=0:\n raise Exception(\"missing or invalid argument 'password'\")\n\n if os.path.isfile(self.cookie):\n try:\n with open(self.cookie) as f:\n self._cookie = requests.utils.cookiejar_from_dict(pickle.load(f))\n self._session = requests.Session()\n \n if self.is_authenticated():\n logging.debug(\"successfully restored session\")\n return\n else:\n logging.debug(\"failed to restore previous session (unauthenticated)\")\n except:\n logging.warn(\"failed to restore session from %s\" % self.cookie)\n \n self.authenticate()\n\n def authenticate(self):\n logging.debug(\"creating new session for user %s to %s\" % (self.username, self.url))\n self._session = requests.Session()\n \n try:\n payload = self.nxapi_payload()\n response = self._session.post(self.url, data=json.dumps(payload), auth=(self.username,self.password), headers=self.headers, verify=self.verify)\n except:\n logging.error(\"connection error occurred\")\n return False\n \n logging.debug(\"session successfully created\")\n self._cookie = requests.utils.dict_from_cookiejar(response.cookies)\n \n try:\n with open(self.cookie, 'w') as f:\n pickle.dump(self._cookie, f)\n \n except: logging.warn(\"failed to save cookie to file: %s\" % self.cookie)\n \n self._session = requests.Session()\n return True\n\n def is_authenticated(self):\n \"\"\"\n dummy request to check if the current session is valid. If 200 code is\n received then returns True else return False\n \"\"\"\n\n if self._session is None or self._cookie is None:\n return False\n logging.debug(\"checking for valid authentication with request to %s\" % self.url)\n try:\n payload = self.nxapi_payload()\n response = self._session.post(self.url, data=json.dumps(payload), headers=self.headers, cookies=self._cookie, verify=self.verify)\n except:\n logging.error(\"connection error occurred\")\n return False\n \n return (response.status_code == 200)\n \n def payload_template(self,cmd,id):\n template = {\"jsonrpc\": \"2.0\",\n \"method\": \"cli\",\n \"params\": {\"cmd\": cmd, \n \"version\": 1}, \"id\": id}\n\n return template\n\n def nxapi_payload(self,cmd=[\"show ver\"]):\n \"\"\"\n prepare payload message with specific command for nxapi_call \n \"\"\"\n payload = []\n \n for i in range(len(cmd)):\n payload.append(self.payload_template(cmd[i],i+1))\n\n return payload\n\n def nxapi_call(self, cmd=[\"show hostname\"]):\n \"\"\"\n common NX-API call\n \"\"\"\n print cmd\n payload = self.nxapi_payload(cmd)\n response = self._session.post(self.url, data=json.dumps(payload), headers=self.headers, cookies=self._cookie, verify=self.verify)\n\n if response.status_code != 200:\n logging.error(\"failed to create session\")\n #print response.json()\n\n return response.json()\n\n def get_iface_status(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface']\n\n return output\n\n def get_iface_description(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface']\n \n return output\n\n def get_iface_switchport(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface']\n \n return output\n\n def get_module_errors(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface']\n \n return output\n\n def get_iface_errors(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface'][0]\n \n return output\n\n def get_transceiver_details(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface'][0]\n \n return output\n\n def get_all_transceiver_details(self, response):\n\n output = response['result']['body']['TABLE_interface']['ROW_interface']\n \n return output\n\n def get_arp_list(self, response):\n\n output = response['result']['body']['TABLE_vrf']['ROW_vrf']['TABLE_adj']['ROW_adj']\n \n return output\n\n def get_mac_list(self, response):\n\n if response['result'] and not 'error' in response and 'TABLE_mac_address' in response['result']['body']:\n\n\n output = response['result']['body']['TABLE_mac_address']['ROW_mac_address']\n\n return output\n else:\n output = {'disp_mac_addr': 'empty'}\n return output\n\n def get_ip_route(self, response):\n\n output = response['result']['body']['TABLE_vrf']['ROW_vrf']['TABLE_addrf']['ROW_addrf']['TABLE_prefix']['ROW_prefix']\n\n return output\n\n def get_vlan_id(self, response):\n\n if response['result']:\n\n output = response['result']['body']\n\n return output\n else:\n output = {}\n return output\n\n def get_po_list(self, response):\n \n po_list = []\n\n output = response['result']['body']['TABLE_channel']['ROW_channel']\n for item in output:\n po_list.append(item['group'])\n \n po_list.sort()\n \n return po_list\n\n def get_po_summary(self, response):\n\n output = response['result']['body']['TABLE_channel']['ROW_channel']\n\n return output\n\n def set_cmd(self, response):\n \n output = response\n for item in response:\n if 'error' in item:\n return False\n break\n return output\n\nif __name__ == \"__main__\":\n # SETUP logging at debug level to stdout (default)\n logger = logging.getLogger(\"\")\n logger.setLevel(logging.DEBUG)\n # overwrite requests logger to warning only\n logging.getLogger(\"requests\").setLevel(logging.WARNING)\n\n#Testing\n nxapi = NXAPIClient(hostname=\"192.168.35.40\", username=mycreds.USERNAME, password=mycreds.PASSWORD)\n #dummy_conf = [\"interface Eth131/1/1\", \"non shutdown\", \"interface Eth131/1/2\", \"shutdown\"]\n #test = nxapi.get_all_transceiver_details(nxapi.nxapi_call([\"show interface transceiver details\"]))\n #test = nxapi.get_ip_route(nxapi.nxapi_call([\"show ip route 192.168.8.120\"]))\n #test = nxapi.get_po_summary(nxapi.nxapi_call([\"sh port-channel summary\"]))\n #print test\n"
},
{
"alpha_fraction": 0.4589272141456604,
"alphanum_fraction": 0.46689656376838684,
"avg_line_length": 52.703704833984375,
"blob_id": "00df75cfb3d407de773ff3404bab5090ec0cfe1d",
"content_id": "1768dc38cb65a76e0473860821a95c4519347284",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 13050,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 243,
"path": "/app/templates/base.html",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "{% extends \"bootstrap/base.html\" %}\n{% block scripts %}\n{{ super() }}\n<!--Import jQuery before export.js-->\n<script type=\"text/javascript\" src=\"https://code.jquery.com/jquery-2.1.1.min.js\"></script>\n\n<!--Data Table-->\n<script type=\"text/javascript\" src=\" https://cdn.datatables.net/1.10.13/js/jquery.dataTables.min.js\"></script>\n<script type=\"text/javascript\" src=\" https://cdn.datatables.net/buttons/1.2.4/js/dataTables.buttons.min.js\"></script>\n\n<!--Export table buttons-->\n<script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/jszip/2.5.0/jszip.min.js\"></script>\n<script type=\"text/javascript\" src=\"https://cdn.rawgit.com/bpampuch/pdfmake/0.1.24/build/pdfmake.min.js\" ></script>\n<script type=\"text/javascript\" src=\"https://cdn.rawgit.com/bpampuch/pdfmake/0.1.24/build/vfs_fonts.js\"></script>\n<script type=\"text/javascript\" src=\"https://cdn.datatables.net/buttons/1.2.4/js/buttons.html5.min.js\"></script>\n<script type=\"text/javascript\" src=\"https://cdn.datatables.net/buttons/1.2.1/js/buttons.print.min.js\"></script>\n\n<!--Export table button CSS-->\n<link rel=\"stylesheet\" href=\"https://cdn.datatables.net/1.10.13/css/jquery.dataTables.min.css\">\n<link rel=\"stylesheet\" href=\"https://cdn.datatables.net/buttons/1.2.4/css/buttons.dataTables.min.css\">\n<link rel=\"stylesheet\" href=\"https://cdn.datatables.net/1.10.16/css/dataTables.bootstrap.min.css\">\n\n<!--favicon.ico-->\n<link rel=\"shortcut icon\" href=\"{{ url_for('static', filename='pictures/favicon.ico') }}\">\n\n<!--Custom CSS-->\n<link rel= \"stylesheet\" type= \"text/css\" href= \"{{ url_for('static',filename='css/custom.css') }}\">\n\n<!--Export Datetimepicker-->\n<link rel=\"stylesheet\" href=\"https://cdnjs.cloudflare.com/ajax/libs/bootstrap-datetimepicker/4.17.37/css/bootstrap-datetimepicker.min.css\" />\n<script src=\"https://cdnjs.cloudflare.com/ajax/libs/moment.js/2.10.6/moment.min.js\"></script> \n<script src=\"https://cdnjs.cloudflare.com/ajax/libs/bootstrap-datetimepicker/4.17.37/js/bootstrap-datetimepicker.min.js\"></script>\n\n{% endblock %}\n\n{% block navbar %}\n <div class=\"container-fluid\">\n <!-- Static navbar -->\n <nav class=\"navbar navbar-inverse bg-primary\">\n <div class=\"container-fluid\">\n <div class=\"navbar-header\">\n <button type=\"button\" class=\"navbar-toggle collapsed\" data-toggle=\"collapse\" data-target=\"#navbar\" aria-expanded=\"false\" aria-controls=\"navbar\">\n <span class=\"sr-only\">Toggle navigation</span>\n <span class=\"icon-bar\"></span>\n <span class=\"icon-bar\"></span>\n <span class=\"icon-bar\"></span>\n </button>\n <a class=\"navbar-brand\" href=\"/index\">VNET</a>\n </div>\n <div id=\"navbar\" class=\"navbar-collapse collapse\">\n <ul class=\"nav navbar-nav\">\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">IFACE <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li class=\"dropdown-header\">DATACENTER N5K twins</li>\n {% set twins = conf['pairs'] %}\n {% for twin in twins %}\n {% set location = twins[twin]['location'] %}\n {% set group = twins[twin]['group'] %}\n {% if group == 'n5k' %}\n <li><a href=\"/port/{{ twin }}\">{{ location | upper }}_{{ group }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">CORE N9K twins</li>\n {% for twin in twins %}\n {% set location = twins[twin]['location'] %}\n {% set group = twins[twin]['group'] %}\n {% if group == 'n9k' %}\n <li><a href=\"/port/{{ twin }}\">{{ location | upper }}_{{ group }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">POP N3K</li>\n {% set boxes = conf['boxes'] %}\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n3k' %}\n <li><a href=\"/port_host/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">SFP <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li class=\"dropdown-header\">DATACENTER N5K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n5k' %}\n <li><a href=\"/sfp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">CORE N9K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n9k' %}\n <li><a href=\"/sfp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">POP N3K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n3k' %}\n <li><a href=\"/sfp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">ARP <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li class=\"dropdown-header\">DATACENTER N5K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n5k' %}\n <li><a href=\"/arp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">CORE N9K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n9k' %}\n <li><a href=\"/arp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">POP N3K</li>\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n3k' %}\n <li><a href=\"/arp/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">MAC <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li class=\"dropdown-header\">DATACENTER N5K</li>\n {% set boxes = conf['boxes'] %}\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n5k' %}\n <li><a href=\"/mac/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">CORE N9K</li>\n {% set boxes = conf['boxes'] %}\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n9k' %}\n <li><a href=\"/mac/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n <li role=\"separator\" class=\"divider\"></li>\n <li class=\"dropdown-header\">POP N3K</li>\n {% set boxes = conf['boxes'] %}\n {% for box in boxes %}\n {% set location = boxes[box]['location'] %}\n {% set group = boxes[box]['group'] %}\n {% if group == 'n3k' %}\n <li><a href=\"/mac/{{ box }}\">{{ location | upper }}_{{ box }}</a></li>\n {% endif %}\n {% endfor %}\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">VLAN <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/vlan/n5k\">DATACENTER N5K</a></li>\n <li><a href=\"/vlan/n9k\">CORE N9K</a></li>\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">PORTCHANNELS <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/po_summary/n31\">SHC3</a></li>\n <li><a href=\"/po_summary/n41\">DC4</a></li>\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">ConfGen <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/peering\">Peering</a></li>\n <li><a href=\"/fpvlan\">FP Vlan</a></li>\n <li><a href=\"/po/tn3\">Port-Channel SHC3</a></li>\n <li><a href=\"/po/tn4\">Port-Channel DC4</a></li>\n <li><a href=\"/l2circuit_six_dc4\">L2 Circuit SIX-DC4</a></li>\n <li><a href=\"/l2circuit_sit_dc4\">L2 Circuit SIT-DC4</a></li>\n <li><a href=\"/l2vpn_six_sit\">L2 Circuit SIX-SIT</a></li>\n </ul>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">Search <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/route\">Route</a></li>\n <li><a href=\"/vlanid\">Vlan</a></li>\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">DDoS <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/rtbh\">RTBH</a></li>\n <li><a href=\"/scrubbing\">SCRUBBING</a></li>\n </ul>\n </li>\n <li class=\"dropdown\">\n <a href=\"#\" class=\"dropdown-toggle\" data-toggle=\"dropdown\" role=\"button\" aria-haspopup=\"true\" aria-expanded=\"false\">PPPoE <span class=\"caret\"></span></a>\n <ul class=\"dropdown-menu\">\n <li><a href=\"/ftth\">FTTH</a></li>\n <li><a href=\"/dsl\">DSL</a></li>\n </ul>\n </li>\n <ul class=\"nav navbar-nav\">\n <li><a href=\"/iferrs\">IF_ERRs</a></li>\n </ul>\n <ul class=\"nav navbar-nav\">\n <li><a href=\"/logs\">LOGs</a></li>\n </ul>\n <ul class=\"nav navbar-nav navbar-right\">\n <li><a href=\"/contact\">Contact</a></li>\n </ul>\n </div><!--/.nav-collapse -->\n </div><!--/.container-fluid -->\n </nav>\n{% endblock %}\n\n {% block content %}{% endblock %}\n </body>\n </html>\n"
},
{
"alpha_fraction": 0.66557377576828,
"alphanum_fraction": 0.6699453592300415,
"avg_line_length": 28.047618865966797,
"blob_id": "fb898bcd57033dc176fc69461ff70b624c2f8fc5",
"content_id": "d8243c7177580793584f641bf90ee8f180387e50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1830,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 63,
"path": "/app/librouteros/__init__.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\nfrom binascii import unhexlify, hexlify\nfrom hashlib import md5\ntry:\n from collections import ChainMap\nexcept ImportError:\n from chainmap import ChainMap\n\nfrom librouteros.exceptions import TrapError, FatalError, ConnectionError, MultiTrapError\nfrom librouteros.connections import ApiProtocol, SocketTransport\nfrom librouteros.api import Api\n\n\ndefaults = {\n 'subclass': Api,\n 'encoding': 'ASCII',\n }\n\n\ndef login(username, password, sock, **kwargs):\n \"\"\"\n Login to routeros device.\n\n Upon success return a Connection class.\n\n :param username: Username to login with.\n :param password: Password to login with. Only ASCII characters allowed.\n :param sock: Connected socket. May be SSL/TLS or plain TCP.\n :param subclass: Subclass of Api class. Defaults to Api class from library.\n \"\"\"\n arguments = ChainMap(kwargs, defaults)\n transport = SocketTransport(sock=sock)\n protocol = ApiProtocol(transport=transport, encoding=arguments['encoding'])\n api = arguments['subclass'](protocol=protocol)\n\n try:\n sentence = api('/login')\n token = sentence[0]['ret']\n encoded = encode_password(token, password)\n api('/login', name=username, response=encoded)\n except:\n pass\n try:\n sentence = api('/login')\n api('/login', name=username, password=password)\n\n except (ConnectionError, TrapError, FatalError, MultiTrapError):\n transport.close()\n raise\n\n return api\n\n\ndef encode_password(token, password):\n\n token = token.encode('ascii', 'strict')\n token = unhexlify(token)\n password = password.encode('ascii', 'strict')\n md = md5()\n md.update(b'\\x00' + password + token)\n password = hexlify(md.digest())\n return '00' + password.decode('ascii', 'strict')\n"
},
{
"alpha_fraction": 0.6518869400024414,
"alphanum_fraction": 0.6919952630996704,
"avg_line_length": 55.27619171142578,
"blob_id": "8e279941c6ba87731531718c101319cbe701ae8b",
"content_id": "8e60bc85c61926ca2a8064a75443c37db047d04d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5909,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 105,
"path": "/app/forms.py",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, BooleanField, SubmitField, SelectField, RadioField\nfrom wtforms import TextAreaField, TextField, IntegerField, ValidationError, DateField, validators\nfrom wtforms.validators import DataRequired, IPAddress, NumberRange, Optional\nimport ipaddress\n\n#def load_six_asr():\n#\n# with open('app/six_asr.yml', 'r') as f:\n# six_asr = yaml.safe_load(f)\n# ifaces = six_asr['ifaces']\n#\n# ids = [i for i in range(len(ifaces))]\n# id_ifaces = list(zip(ids, ifaces))\n##\n# return id_ifaces\n\ndef vnet_ipv4(form, field):\n if (\n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'46.229.224.0/20') and \n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'81.89.48.0/20') and \n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'93.184.64.0/20') and\n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'109.74.144.0/20') and\n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'217.73.16.0/20') and\n ipaddress.ip_address(field.data) not in ipaddress.ip_network(u'185.176.72.0/22')\n ):\n raise ValidationError('This is not VNET IP address')\n\ndef ipv4_ipv6_validator(form, field):\n if not ipaddress.ip_address(field.data):\n raise ValidationError('This is not IP address')\n\n\nclass PortchannelForm(FlaskForm):\n portchannel = SelectField('portchannel', coerce=int, choices=[(1,'Yes'),(0,'No')])\n porttype = SelectField('porttype', coerce=int, choices = [(0, 'Access'), (1, 'Trunk')])\n clientid = IntegerField('clientid', validators=[Optional()])\n company = StringField('company', validators=[DataRequired()])\n iface1 = SelectField('iface1', coerce=int)\n iface2 = SelectField('iface2', coerce=int)\n vlans = StringField('vlans', validators=[DataRequired()])\n configuration = TextAreaField('configuration', default=\"Empty\")\n\nclass PeeringForm(FlaskForm):\n peering = SelectField('peering', coerce=int, choices=[(1,'SIX'),(2,'NIX.CZ'),(3,'NIX.SK'),(4,'AMS-IX')])\n description = StringField('description', validators=[DataRequired()])\n asn = IntegerField('asn', validators=[Optional()])\n ipv4 = StringField('ipv4', validators=[DataRequired(),IPAddress(ipv4=True, ipv6=False, message=None)])\n ipv6 = StringField('ipv6', validators=[DataRequired(), IPAddress(ipv4=False, ipv6=True, message=None)])\n prefixlimipv4 = IntegerField('prefixlimipv4', validators=[DataRequired(), NumberRange(min=1, max=None, message=None)])\n prefixlimipv6 = IntegerField('prefixlimipv6', validators=[DataRequired(),NumberRange(min=1, max=None, message=None)])\n\nclass L2circuitForm(FlaskForm):\n circuit_type = SelectField('circuit_type', coerce=int, choices = [(0, 'Port based - QinQ delivered on port without S-tag'), (1, 'Vlan based - QinQ delivered on NNI with S-tag')])\n iface = SelectField('iface', coerce=int)\n clientid = IntegerField('clientid', validators=[Optional()])\n company = StringField('company', validators=[DataRequired()])\n vlan = IntegerField('vlan', validators=[DataRequired()])\n six_asr_conf = TextAreaField('six_asr_conf', default=\"Empty\")\n asr41_asr42_conf = TextAreaField('asr41_asr42_conf', default=\"Empty\")\n n41_n42_conf = TextAreaField('n41_n42_conf', default=\"Empty\")\n\nclass L2vpnForm(FlaskForm):\n circuit1_type = SelectField('circuit1_type', coerce=int, choices = [(0, 'Port based - QinQ delivered on port without S-tag'), (1, 'Vlan based - QinQ delivered on NNI with S-tag')])\n iface1 = SelectField('iface1', coerce=int)\n circuit2_type = SelectField('circuit2_type', coerce=int, choices = [(0, 'Port based - QinQ delivered on port without S-tag'), (1, 'Vlan based - QinQ delivered on NNI with S-tag')])\n iface2 = SelectField('iface2', coerce=int)\n clientid = IntegerField('clientid', validators=[Optional()])\n company = StringField('company', validators=[DataRequired()])\n vlan = IntegerField('vlan', validators=[DataRequired()])\n six_asr_conf = TextAreaField('six_asr_conf', default=\"Empty\")\n sit_asr_conf = TextAreaField('sit_asr_conf', default=\"Empty\")\n\nclass VxlanForm(FlaskForm):\n vlanid = IntegerField('vlan', validators=[DataRequired(), NumberRange(min=1, max=9999, message='1-9999')])\n vlanname = StringField('vlanname', validators=[DataRequired()])\n\nclass PppoeForm(FlaskForm):\n pppoe = StringField('pppoe account', [validators.DataRequired(), validators.Regexp('\\[email protected]', message=\"Invalid format\")])\n\nclass DslForm(FlaskForm):\n dsl = StringField('dsl account', [validators.DataRequired(), validators.Regexp('\\S+@\\S+', message=\"Invalid format\")])\n\nclass RouteForm(FlaskForm):\n route = StringField('route', validators=[DataRequired(), ipv4_ipv6_validator])\n\nclass VlanForm(FlaskForm):\n vlanid = IntegerField('vlanid', validators=[DataRequired(), NumberRange(min=1, max=3967, message='1-3967')])\n\nclass FPVlanForm(FlaskForm):\n vlanid = IntegerField('vlanid', validators=[DataRequired(), NumberRange(min=1, max=3967, message='1-3967')])\n vlanname = StringField('vlanname', validators=[DataRequired()])\n\nclass RtbhForm(FlaskForm):\n ipv4 = StringField('ipv4', validators=[DataRequired(),IPAddress(ipv4=True, ipv6=False, message=None),vnet_ipv4])\n action = SelectField('action', coerce=int, choices=[(1,'announce'),(0,'withdraw')])\n\nclass ScrubbingForm(FlaskForm):\n action = SelectField('action', coerce=int, choices=[(1,'announce'),(0,'withdraw')])\n network = SelectField('network', coerce=int, choices=[(0,''),(1,'86.110.233.0/24'),(2,'46.229.237.0/24'),(3,'81.89.54.0/24'),(4,'93.184.75.0/24'),(5,'185.176.75.0/24')])\n\nclass DateForm(FlaskForm):\n dt = DateField('dt', format=\"%d/%m/%Y\")\n box = SelectField('box', coerce=int)\n severity = SelectField('severity', coerce=int, choices=[(1, 'all'),(2, 'err'),(3, 'warning'),(4, 'notice')])\n"
},
{
"alpha_fraction": 0.4082140624523163,
"alphanum_fraction": 0.41148102283477783,
"avg_line_length": 37.49101638793945,
"blob_id": "1b80d91e1969a84029c8667f5a6498a614c22413",
"content_id": "bb30fcb09194c05174c9210ade5f520b70d37b05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 6428,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 167,
"path": "/app/templates/ajax_sfp.html",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "{% block content %}\n\n<script src=\"//ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script>\n<script src=\"{{ url_for('static', filename='js/datatable.js') }}\"></script>\n\n<div class=\"form-group row\">\n <div class=\"col-md-11\" style=\"font-size:25px\">\n {{ location }}: SFP Status {{ host }}\n {% set group = conf['boxes'][host]['group'] %}\n </div>\n <div class=\"col-md-1\"><div class=\"pull-right\">\n <a href=\"{{ url_for('sfp', host=host) }}\"><button class=\"btn btn-primary\" align=\"left\"><span class=\"glyphicon glyphicon-refresh \"aria-hidden=\"true\"></span></button></a>\n </div>\n</div>\n</div>\n <table id=mytable class=\"table table-hover table-bordered table-responsive\">\n <thead>\n <tr>\n <th>Interface</th>\n <th>Description</th>\n <th>Type</th>\n <th>Name</th>\n <th>Partnum</th>\n <th>Temperature</th>\n <th>TX_pwr</th>\n <th>RX_pwr</th>\n <th>Warnings</th>\n </tr>\n </thead>\n <tbody class=\"searchable\">\n \n {% for value in sfp_status %}\n \n {% set sfp = value['sfp'] %}\n \n {% if sfp == 'present' %}\n {% set iface = value['interface'] %}\n {% set desc = value['desc'] %}\n {% set type = value['type'] %}\n {% set name = value['name'] %}\n {% set partnum = value['partnum'] %}\n\n {% if group != 'n5k' and 'TABLE_lane' in value %}\n {% set path = value['TABLE_lane']['ROW_lane'] %}\n {% else %}\n {% set path = value %}\n {% endif %}\n \n {% if type == 'QSFP-40GE-LR4' or type == 'QSFP-40G-SR4' or type == 'QSFP-40G-ER4' %}\n {% set qsfp = True %}\n {% endif %}\n \n {% if qsfp %}\n {% set temperature = path[0]['temperature'] | float %}\n {% set tx_pwr = [] %}\n {% set rx_pwr = [] %}\n {% for n in range(4) %}\n {% do tx_pwr.append(path[n]['tx_pwr']) %}\n {% do rx_pwr.append(path[n]['rx_pwr']) %}\n {% set rx_pwr_cur = path[n]['rx_pwr'] | float %}\n {% set rx_pwr_warn_lo = path[n]['rx_pwr_warn_lo'] | float %}\n {% set rx_pwr_warn_hi = path[n]['rx_pwr_warn_hi'] | float %}\n {% set tx_pwr_cur = path[n]['tx_pwr'] | float %}\n {% set tx_pwr_warn_lo = path[n]['tx_pwr_warn_lo'] | float %}\n {% set tx_pwr_warn_hi = path[n]['tx_pwr_warn_hi'] | float %}\n\n {% if rx_pwr_cur > rx_pwr_warn_lo and rx_pwr_cur< rx_pwr_warn_hi %}\n {% set rx_pwr_warn = False %}\n {% else %}\n {% set rx_pwr_warn = True %}\n {% endif %}\n {% if tx_pwr_cur > tx_pwr_warn_lo and tx_pwr_cur< tx_pwr_warn_hi %}\n {% set tx_pwr_warn = False %}\n {% else %}\n {% set tx_pwr_warn = True %}\n {% endif %}\n\n {% endfor %}\n {% else %}\n {% if 'tx_pwr' in path %}\n {% set tx_pwr = path['tx_pwr'] | float %}\n {% set tx_pwr_warn_lo = path['tx_pwr_warn_lo'] | float %}\n {% set tx_pwr_warn_hi = path['tx_pwr_warn_hi'] | float %}\n {% if tx_pwr > tx_pwr_warn_lo and tx_pwr < tx_pwr_warn_hi %}\n {% set tx_pwr_warn = False %}\n {% else %}\n {% set tx_pwr_warn = True %}\n {% endif %}\n {% endif %}\n\n {% if 'rx_pwr' in path %}\n {% set rx_pwr = path['rx_pwr'] | float %}\n {% set rx_pwr_warn_lo = path['rx_pwr_warn_lo'] | float %}\n {% set rx_pwr_warn_hi = path['rx_pwr_warn_hi'] | float %}\n\n {% if 'temperature' in path %}\n {% set temperature = path['temperature'] | float %}\n {% set temp_warn_lo = path['temp_warn_lo'] | float %}\n {% set temp_warn_hi = path['temp_warn_hi'] | float %}\n \n {% if rx_pwr > rx_pwr_warn_lo and rx_pwr < rx_pwr_warn_hi %}\n {% set rx_pwr_warn = False %}\n {% else %}\n {% set rx_pwr_warn = True %}\n {% endif %}\n {% else %}\n {% set temperature = 0 %}\n {% endif %}\n\n {% if temperature > temp_warn_lo and temperature < temp_warn_hi %}\n {% set temp_warn = False %}\n {% else %}\n {% set temp_warn = True %}\n {% endif %}\n {% endif %}\n {% endif %}\n\n <tr>\n <td> {{ iface }} </td>\n <td> {{ desc }} </td>\n <td> {{ type }} </td>\n <td> {{ name }} </td>\n <td> {{ partnum }} </td>\n {% if temp_warn %}\n <td><span style=\"color:red\">{{ temperature }}</span></td>\n {% else %}\n <td> {{ temperature }} </td>\n {% endif %}\n {% if tx_pwr_warn %}\n {% if tx_pwr_warn is iterable %}\n <td><span style=\"color:red\">{{ tx_pwr|join(', ') }}</span></td>\n {% else %}\n <td><span style=\"color:red\">{{ tx_pwr }}</span></td>\n {% endif %}\n {% else %}\n {% if tx_pwr_warn is iterable %}\n <td> {{ tx_pwr|join(', ') }} </td>\n {% else %}\n <td> {{ tx_pwr }} </td>\n {% endif %}\n {% endif %}\n {% if rx_pwr_warn %}\n {% if rx_pwr_warn is iterable %}\n <td><span style=\"color:red\">{{ rx_pwr|join(', ') }}</span></td>\n {% else %}\n <td><span style=\"color:red\">{{ rx_pwr }}</span></td>\n {% endif %}\n {% else %}\n {% if rx_pwr_warn is iterable %}\n <td> {{ rx_pwr|join(', ') }} </td>\n {% else %}\n <td> {{ rx_pwr }} </td>\n {% endif %}\n {% endif %}\n\n {% if tx_pwr_warn or rx_pwr_warn or temp_warn %}\n <td><span class=\"glyphicon glyphicon-remove-circle\" style=\"color:red\" aria-hidden=\"true\" title=\"down\"></span> Warning</td>\n {% else %}\n <td><span class=\"glyphicon glyphicon-ok-circle\" style=\"color:green\" aria-hidden=\"true\" title=\"connected\"></span> Ok</td>\n {% endif %}\n {% endif %}\n {% endfor %}\n </tbody>\n </table>\n</div>\n\n{% endblock %}\n"
},
{
"alpha_fraction": 0.5821917653083801,
"alphanum_fraction": 0.5890411138534546,
"avg_line_length": 19.85714340209961,
"blob_id": "8cb043bd65078b4900bd2a0395883d564ba862ab",
"content_id": "0cfb86e2cf5213b47adfc7d9da1de3cc4b6665bb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 146,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 7,
"path": "/app/static/js/datepicker.js",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "$(function () {\n var dateNow = new Date();\n $('#datetimepicker1').datetimepicker({\n defaultDate:dateNow,\n format: 'DD/MM/YYYY',\n });\n});\n"
},
{
"alpha_fraction": 0.4985673427581787,
"alphanum_fraction": 0.5031518340110779,
"avg_line_length": 30.160715103149414,
"blob_id": "05c477ce8f03895a1b2b75583aa6a087d97062c1",
"content_id": "d228b571386e5200b899dbd9931ea04fe8ff20c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 1745,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 56,
"path": "/app/templates/po_summary.html",
"repo_name": "saty2146/coreview",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n\n{% block content %}\n\n<script src=\"//ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js\"></script> \n<script src=\"{{ url_for('static', filename='js/datatable.js') }}\"></script>\n\n<div class=\"form-group row\">\n <div class=\"col-md-6\" style=\"font-size:25px\">\n PORT-CHANNELS {{ host }}\n </div>\n <div class=\"col-md-6\" \"pull-right\">\n {{ created }}\n </div>\n</div>\n <table id=mytable class=\"table table-hover table-bordered table-responsive table-condensed\">\n <thead>\n <tr>\n <th>Port-channel</th>\n <th>Protocol</th>\n <th>Group</th>\n <th>Status</th>\n <th>Member ports</th>\n </tr>\n </thead>\n <tbody class=\"searchable\">\n {% for item in po_summary %}\n {% set portchannel = item['port-channel'] %}\n {% set type = item['prtcl'] %}\n {% set group = item['group'] %}\n {% set status = item['status'] %}\n {% if item['TABLE_member'] %}\n {% set members = item['TABLE_member']['ROW_member'] %}\n {% if members|length == 1 %}\n {{ members|join(', ') }}\n {% else %}\n {% endif %}\n {% else %}\n {% set members = None %}\n {% endif %}\n <tr>\n <td> {{ portchannel }} </td>\n <td> {{ type }} </td>\n <td> {{ group }} </td>\n <td> {{ members }} </td>\n {% if status == 'U' %}\n <td><span class=\"glyphicon glyphicon-ok-circle\" style=\"color:green\" aria-hidden=\"true\" title=\"up\"></span> Up</td>\n {% else %}\n <td><span class=\"glyphicon glyphicon-remove-circle\" style=\"color:red\" aria-hidden=\"true\" title=\"down\"></span> Down</td>\n {% endif %}\n </tr>\n {% endfor %}\n </tbody>\n </table>\n\n{% endblock %}\n"
}
] | 16 |
michaeljoy255/personal-projects
|
https://github.com/michaeljoy255/personal-projects
|
b93aa69ae053752f94d1de8682e1aed20e5065e8
|
1589c7e347bdf88eb7b4040df3fa27ea3f8f4099
|
d4df7812e943835beafbf6949c1825706c799aff
|
refs/heads/master
| 2021-01-24T00:33:25.099175 | 2018-02-24T19:23:43 | 2018-02-24T19:23:43 | 122,771,270 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7911392450332642,
"alphanum_fraction": 0.8069620132446289,
"avg_line_length": 62.20000076293945,
"blob_id": "f0d3ca10cb634f0b10186e1e5225434357fda133",
"content_id": "5313622f81af6b55b2730e59d361c09660f5a7c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 5,
"path": "/python/CRC-PiCameraApp/README.md",
"repo_name": "michaeljoy255/personal-projects",
"src_encoding": "UTF-8",
"text": "# Raspberry Pi 2 Camera Controller\nThis is a simple GUI program written in Python that gives you access to many of\nthe options available on the Raspberry Pi's Camera in a easy to use and\nunderstand interface. It was done as a demonstration program for the students\nof the Notre Dame Summer Scholars program in 2015.\n"
},
{
"alpha_fraction": 0.5441462397575378,
"alphanum_fraction": 0.5636588335037231,
"avg_line_length": 38.190311431884766,
"blob_id": "044ccfc7db570ecc1af80fdfaa07c84f9c2d72f1",
"content_id": "515bdbaf4e87eb615c1878b5ca0c29f581796311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11326,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 289,
"path": "/python/CRC-PiCameraApp/PiCamera.py",
"repo_name": "michaeljoy255/personal-projects",
"src_encoding": "UTF-8",
"text": "#######################################\n# #\n# University of Notre Dame #\n# Center for Research Computing #\n# #\n# Summer Scholars 2015 #\n# Example PiCamera Program #\n# #\n#######################################\n\nimport os\nimport time\nimport datetime\nimport picamera\nfrom Tkinter import *\nfrom ttk import Style, Label, Combobox\n\n# DEBUG OPTION - Adds a DEBUG button to the UI\n_debug = True\n\n# Container class for widgets\nclass PiCamInterface(Frame):\n # Initializations\n def __init__(self, parent):\n Frame.__init__(self, parent)\n self.parent = parent # Tk root window\n \n # Program Variables\n self._resolution = IntVar()\n self._hflip = IntVar()\n self._vflip = IntVar()\n self._brightness = IntVar()\n self._contrast = IntVar()\n self._previewTime = DoubleVar()\n self._recordTime = DoubleVar()\n self._expoOpt = StringVar()\n self._imageOpt = StringVar()\n\n self.InitializeUI()\n \n\n #----------Setup Interface\n def InitializeUI(self): \n self.parent.title(\"PiCamera Interface\")\n self.style = Style()\n self.style.theme_use(\"clam\") # default, clam, alt, classic\n self.pack(fill=BOTH, expand=1)\n\n # Layout\n frameResolution = Frame(self, relief=RAISED, borderwidth=1)\n frameOptions = Frame(self, relief=RAISED, borderwidth=1)\n frameOptions1 = Frame(frameOptions, relief=RAISED, borderwidth=1)\n frameOptions2 = Frame(frameOptions, relief=RAISED, borderwidth=1)\n frameOptions3 = Frame(frameOptions, relief=RAISED, borderwidth=1)\n frameScales = Frame(self, relief=RAISED, borderwidth=1)\n frameButtons = Frame(self, relief=RAISED, borderwidth=1)\n\n #\n # CAMERA OPTIONS\n #\n # Left Frame []--\n labelOptions1 = Label(frameOptions1, text=\"Exposure Modes\")\n comboExpoOpt = Combobox(frameOptions1, state='readonly', textvariable=self._expoOpt,\n width=12)\n comboExpoOpt['values'] = ('off', 'auto', 'night', 'nightpreview', 'backlight',\n 'spotlight', 'sports', 'snow', 'beach', 'verylong',\n 'fixedfps', 'antishake', 'fireworks')\n # Center Frame -[]-\n labelOptions2 = Label(frameOptions2, text=\"Image Effects\")\n comboImageOpt = Combobox(frameOptions2, state='readonly',textvariable=self._imageOpt,\n width=12)\n comboImageOpt['values'] = ('none', 'negative', 'solarize', 'sketch', 'denoise',\n 'emboss', 'oilpaint', 'hatch', 'gpen', 'pastel',\n 'watercolor', 'film', 'blur', 'saturation', 'colorswap',\n 'washedout', 'posterise', 'colorpoint', 'colorbalance',\n 'cartoon', 'deinterlace1', 'deinterlace2')\n # Right Frame --[]\n labelOptions3 = Label(frameOptions3, text=\"Misc. Options\")\n check1 = Checkbutton(frameOptions3, text=\"Flip Horizontally\", variable=self._hflip,\n onvalue=True, offvalue=False, padx=4, pady=4)\n check2 = Checkbutton(frameOptions3, text=\"Flip Vertically\", variable=self._vflip,\n onvalue=True, offvalue=False, padx=4, pady=4)\n \n # Pack frameOptions\n frameOptions.pack(fill=BOTH, side=TOP)\n frameOptions1.pack(fill=BOTH, side=LEFT, expand=True)\n frameOptions2.pack(fill=BOTH, side=LEFT, expand=True)\n frameOptions3.pack(fill=BOTH, side=LEFT, expand=True)\n labelOptions1.pack(side=TOP)\n labelOptions2.pack(side=TOP)\n labelOptions3.pack(side=TOP)\n comboExpoOpt.pack(side=TOP) \n comboImageOpt.pack(side=TOP)\n check1.pack(side=TOP)\n check2.pack(side=TOP)\n\n #\n # PICTURE RESOLUTION\n #\n labelResolution = Label(frameResolution, text=\"Picture Resolution\") \n R1 = Radiobutton(frameResolution, text=\"640 x 480\", variable=self._resolution,\n value=1, padx=8, pady=8)\n R2 = Radiobutton(frameResolution, text=\"1280 x 720\", variable=self._resolution,\n value=2, padx=8, pady=8)\n R3 = Radiobutton(frameResolution, text=\"1920 x 1080\", variable=self._resolution,\n value=3, padx=8, pady=8)\n R4 = Radiobutton(frameResolution, text=\"2592 x 1944\", variable=self._resolution,\n value=4, padx=8, pady=8)\n\n # Pack frameResolution\n frameResolution.pack(fill=BOTH, side=TOP)\n labelResolution.pack(fill=BOTH, side=TOP)\n R1.pack(side=LEFT)\n R2.pack(side=LEFT)\n R3.pack(side=LEFT)\n R4.pack(side=LEFT)\n\n #\n # SCALABLE SETTINGS (sliders)\n #\n labelScales = Label(frameScales, text=\"Scalable Settings\")\n scaleRecord = Scale(frameScales, label=\"Recording Time (sec)\", variable=self._recordTime,\n resolution=0.5, from_=5, to=30, orient=HORIZONTAL, length=400)\n scalePreview = Scale(frameScales, label=\"Preview Time (sec)\", variable=self._previewTime,\n resolution=0.1, from_=1, to=10, orient=HORIZONTAL, length=400)\n scaleBright = Scale(frameScales, label=\"Brightness\", variable=self._brightness,\n resolution=1, from_=0, to=100, orient=HORIZONTAL, length=400)\n scaleContrast = Scale(frameScales, label=\"Contrast\", variable=self._contrast,\n resolution=1, from_=-100, to=100, orient=HORIZONTAL, length=400)\n\n # Pack frameScales\n frameScales.pack(fill=BOTH, side=TOP)\n labelScales.pack(fill=BOTH, side=TOP)\n scaleRecord.pack(side=TOP)\n scalePreview.pack(side=TOP)\n scaleBright.pack(side=TOP)\n scaleContrast.pack(side=TOP)\n\n #\n # BUTTONS\n #\n labelSpacer = Label(frameButtons)\n quitButton = Button(frameButtons, text=\"Quit\", command=quit)\n button1 = Button(frameButtons, text=\"Take Picture\", command=self.Picture)\n button2 = Button(frameButtons, text=\"Take Video\", command=self.Video)\n button3 = Button(frameButtons, text=\"Defaults\", command=self.Defaults)\n if _debug == True:\n buttonDebug = Button(frameButtons, text=\"DEBUG\", command=self.Debug)\n\n # Pack frameButtons\n frameButtons.pack(fill=BOTH, side=TOP, expand=True)\n labelSpacer.pack()\n button1.pack(side=LEFT, anchor=NW)\n button2.pack(side=LEFT, anchor=NW)\n button3.pack(side=LEFT, anchor=NW)\n quitButton.pack(side=RIGHT, anchor=NE)\n if _debug == True:\n buttonDebug.pack(side=RIGHT, anchor=NE)\n\n # Start with default settings\n self.Defaults()\n\n \n #----------Single image capture function\n def Picture(self):\n print \"-----Preparing Camera (Picture)-----\"\n # Activating the PiCamera\n self.camera = picamera.PiCamera()\n\n # Update settings before taking picture\n self.Settings()\n\n # Use time to make a unique filename \n now = datetime.datetime.now()\n _picname = \"pipicture\" + str(now.microsecond) + \".jpg\"\n \n self.camera.start_preview()\n time.sleep( self._previewTime.get() )\n self.camera.stop_preview()\n self.camera.capture( _picname )\n print \"Capturing picture: \" + _picname \n\n # Close camera to perserve CPU cycles and battery life\n self.camera.close()\n\n # Open image with gpicview\n print \"Opening preview of image: \" + _picname\n os.system(\"gpicview \" + _picname)\n\n\n #----------Video capture function\n def Video(self):\n print \"-----Preparing Camera (Video)-----\"\n # Activating the PiCamera\n self.camera = picamera.PiCamera()\n\n # Update settings before taking video\n self.Settings()\n \n # Use time to make a unique filename \n now = datetime.datetime.now()\n _vidname = \"pivideo\" + str(now.microsecond) + \".h264\"\n\n self.camera.start_preview() \n self.camera.start_recording( _vidname )\n self.camera.wait_recording( self._recordTime.get() )\n self.camera.stop_recording()\n self.camera.stop_preview()\n print \"Capturing video: \" + _vidname \n \n # Close camera to perserve CPU cycles and battery life\n self.camera.close()\n\n # Open image with gpicview\n print \"Playing preview of video: \" + _vidname\n os.system(\"omxplayer --win '0 0 320 240' \" + _vidname)\n \n\n #----------Restore default settings\n def Defaults(self):\n self._resolution.set(1)\n self._hflip.set(0)\n self._vflip.set(0)\n self._brightness.set(50)\n self._contrast.set(0)\n self._recordTime.set(5.0)\n self._previewTime.set(1.0)\n self._expoOpt.set('auto')\n self._imageOpt.set('none')\n print \"Default settings restored\"\n \n\n #----------Only usable if _debug = True\n def Debug(self):\n print \"------VARIABLE INFORMATION------\"\n print \" Exposure Mode: \" + self._expoOpt.get()\n print \" Image Effect: \" + self._imageOpt.get()\n print \"Horizontal Flip: \" + str(self._hflip.get())\n print \" Radio Button: \" + str(self._resolution.get())\n print \" Recording Time: \" + str(self._recordTime.get())\n print \" Preview Time: \" + str(self._previewTime.get())\n print \" Brightness: \" + str(self._brightness.get())\n print \" Contrast: \" + str(self._contrast.get())\n\n\n #----------Loads all appropriate settings for the camera\n def Settings(self):\n if self._resolution.get() == 1:\n self.camera.resolution = (640, 480)\n print \"Camera resolution set to 640 x 480\"\n if self._resolution.get() == 2:\n self.camera.resolution = (1280, 720)\n print \"Camera resolution set to 1280 x 720\"\n if self._resolution.get() == 3:\n self.camera.resolution = (1920, 1080)\n print \"Camera resolution set to 1920 x 1080\"\n if self._resolution.get() == 4:\n self.camera.resolution = (2592, 1944)\n print \"Camera resolution set to 2592 x 1944\"\n \n if self._hflip.get() == True:\n self.camera.hflip = True\n else:\n self.camera.hflip = False\n \n if self._vflip.get() == True:\n self.camera.vflip = True\n else:\n self.camera.vflip = False\n\n self.camera.brightness = self._brightness.get()\n self.camera.contrast = self._contrast.get()\n self.camera.exposure_mode = self._expoOpt.get()\n self.camera.image_effect = self._imageOpt.get()\n print \"Camera settings updated\"\n \n\n########## MAIN ##########\ndef main():\n root = Tk()\n root.geometry(\"+40+40\") # Initial window position\n app = PiCamInterface(root)\n root.mainloop()\n \n\nif __name__ == '__main__':\n main()\n \n# END OF FILE\n"
},
{
"alpha_fraction": 0.8101851940155029,
"alphanum_fraction": 0.8101851940155029,
"avg_line_length": 53,
"blob_id": "85945854a581eb0a398837d7abe5d241ec159e34",
"content_id": "b76ff97005132c0edfdd1e76be77f93e161dcc25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 4,
"path": "/README.md",
"repo_name": "michaeljoy255/personal-projects",
"src_encoding": "UTF-8",
"text": "# Personal projects\nThis repository is for small personal projects, experiments, and book related\nprojects that I do in my free time. The projects will be contained in a folder\nnamed after the primary language used.\n"
}
] | 3 |
bam8r4/pymail
|
https://github.com/bam8r4/pymail
|
13d445c509a3234cbb308fdf87df2dd0f269c40b
|
177c72bd8bf2740975fed24316fb07b86720d515
|
346a654bb1b89f6b4833afd7d673a431f44c29e8
|
refs/heads/master
| 2023-01-31T16:58:53.919047 | 2020-12-17T05:05:00 | 2020-12-17T05:05:00 | 322,160,169 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6412213444709778,
"alphanum_fraction": 0.6990185379981995,
"avg_line_length": 19.377777099609375,
"blob_id": "a6ed052440d13b53ec8540e00a857f3aa146f517",
"content_id": "ecddd8a7fed15dc063bbcdd0850db1c646a8951c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 917,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 45,
"path": "/tbomb.py",
"repo_name": "bam8r4/pymail",
"src_encoding": "UTF-8",
"text": "import smtplib\n\nsender1 = '[email protected]'\nsender2 = '[email protected]'\nsender3 = '[email protected]'\nsender4 = '[email protected]'\nsender5 = '[email protected]'\n\npassword = 'yourEmailPassword'\n\nrec = 'theirnumber@provider'\n\n#Message you want to send.\nmessage = \"\"\"Ham bone chicken wing\"\"\"\n\ns1 = smtplib.SMTP(\"smtp.gmail.com\", 587)\ns1.starttls()\ns1.login(sender1,password)\n\ns2 = smtplib.SMTP(\"smtp.gmail.com\", 587)\ns2.starttls()\ns2.login(sender2,password)\n\ns3 = smtplib.SMTP(\"smtp.gmail.com\", 587)\ns3.starttls()\ns3.login(sender3,password)\n\ns4 = smtplib.SMTP(\"smtp.gmail.com\", 587)\ns4.starttls()\ns4.login(sender4,password)\n\ns5 = smtplib.SMTP(\"smtp.gmail.com\", 587)\ns5.starttls()\ns5.login(sender5,password)\n\nnumberMessagesToSend = 15\n\nfor x in range(0,numberMessagesToSend):\n s1.sendmail(sender1, rec, message)\n s2.sendmail(sender2, rec, message)\n s3.sendmail(sender3, rec, message)\n s4.sendmail(sender4, rec, message)\n s5.sendmail(sender5, rec, message)\n\ns.quit()\n"
}
] | 1 |
alkaChoudhary/RobotUtils
|
https://github.com/alkaChoudhary/RobotUtils
|
9759fb81736dcdcc50af50e62690bde95c3085b8
|
2703a4ae8d571089fd9b40e75794727b123be5df
|
0584a0094dec96999f34b139fb975a4f4869fd0c
|
refs/heads/master
| 2021-04-27T00:04:56.414539 | 2018-03-04T00:47:32 | 2018-03-04T00:47:32 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5465648770332336,
"alphanum_fraction": 0.6213740706443787,
"avg_line_length": 19.870967864990234,
"blob_id": "fe4cda33056bfdf768eede0091c06c02c2a0c60a",
"content_id": "7b95359ecb8b000b4bf0be96703218236a3d0692",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 655,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 31,
"path": "/robot.py",
"repo_name": "alkaChoudhary/RobotUtils",
"src_encoding": "UTF-8",
"text": "import math as m\nfrom ik import IK\n\nclass robot:\n\tdef __init__(self,name='irb120'):\n\t\tif name is None:\n\t\t\tself.dh=[]\n\t\t\tself.rho=[]\n\t\telif name=='irb120':\n\t\t\tIRB120()\n\n\tdef BuildKineModules(self):\n\t\tassert (len(dh)>0,'No dh params found')\n\t\tassert( len(rho)==len(dh),'Specify all joint descriptions')\n\t\tself.IK=IK(self)\n\n\tdef AddLink(alpha,d,a,theta,ro):\n\t\tself.dh+=[alpha,a,d,theta]\n\t\tself.rho+=ro\n\n\tdef IRB120(self):\n\t\tAddLink(m.pi/2,0.29,0,0)\n\t\tAddLink(0,0,0.27,m.pi/2)\n\t\tAddLink(m.pi/2,0,0.07,0)\n\t\tAddLink(-m.pi/2,0.302,0)\n\t\tAddLink(m.pi/2,0,0,0)\n\t\tAddLink(0,0.072,0,0)\n\n\tdef calcDH(self,q):\n\t\tfor qi in range(len(q)):\n\t\t\tself.dh[qs][3]=q[qi]\n\n\t\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.47230613231658936,
"alphanum_fraction": 0.5498489141464233,
"avg_line_length": 25.864864349365234,
"blob_id": "54ec606fd0d005708078e7faf768b0b2d1ff89be",
"content_id": "47c765f773325a65ef7358122add6dfde4b33844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 37,
"path": "/jacob.py",
"repo_name": "alkaChoudhary/RobotUtils",
"src_encoding": "UTF-8",
"text": "import numpt as np\nimport math as m\n\ndef Jacobian(dh):\n\n\tT=__ConstructTransform__(dh,rho)\n\n\th=T[0:3,3]\n\tt=__ExtractOrients__(T[0:3,0:3])\n\n\tzs=[np.dot(t,np.array([0,0,1,1]))[0:3] for t in T]\n\tOn=np.dot(T[-1],np.array([0,0,0,1]))\n\tOs=[On-np.dot(T[i],np.array([0,0,0,1])) for i in range(len(T))]\n\tj=[]\n\tfor l in range(len(zs)):\n\t\tj+=[np.concatenate(np.cross(zs[l],Os[l]),zs[l],axis=0) if rho[l]==1 else np.concatenate(zs[l],np.zeros([3,1]),axis=0)]\n\n\treturn np.matrix(j)\n\n\ndef __ConstructTransform__(dh):\n\tT=[np.identity(4)]\n\tfor l in dh:\n\t\tT+=np.dot( np.matrix(T[-1]),np.matrix([[m.cos(l[3]),-m.sin(l[3])*m.cos(l[0]),m.sin(l[3])*m.sin(l[0]), l[1]*m.cos(l[3])],\\\n\t\t\t\t\t\t[m.sin(l[3]), m.cos(l[3])*m.cos(l[0]), -m.cos(l[3])*m.sin(l[0]), l[1]*m.sin(l[3])],\\\n\t\t\t\t\t\t[0, m.sin(l[0]),m.cos(l[0]),l[2]],\\\n\t\t\t\t\t\t[0,0,0,1]]))\n\tT.pop(0)\n\treturn T\n\n\n\ndef __ExtractOrients__(R):\n\tt1=m.atan2(R[2,1],R[2,2])\n\tt2=m.atan2(-R[2,0],m.sqrt(R[2,1]**2+R[2,2]**2))\n\tt3=m.atan2(R[1,0],R[0,0])\n\treturn np.array([t1,t2,t3])"
},
{
"alpha_fraction": 0.6284403800964355,
"alphanum_fraction": 0.6399082541465759,
"avg_line_length": 18,
"blob_id": "3f61ace729c333f8f30355a334b95981f4731269",
"content_id": "3886441adae98347addba4f1b2f44085fa1fccde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 23,
"path": "/ik.py",
"repo_name": "alkaChoudhary/RobotUtils",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom jacob import Jacobian\n\n class IK:\n \tdef __init__(self,robot):\n \t\tself.robot=robot\n\n \tdef IterJInv(self,xf,qi):\n \t\tif qi is None:\n \t\t\tqi=np.zeros(self.J.shape[1])\n \t\t\n \t\tJinv=np.transpose(self.J)\n\n \t\twhile np.abs(np.dot(Jinv,qi)-xf)>0.001:\n \t\t\trobot.calcDH(qi)\n \t\t\tJ=Jacobian(robot.dh,robot.rho)\n \t\t\tJinv=np.dot(np.transpose(J),np.dot(J,np.transpose(J)))\n \t\t\tqi+=Jinv\n\n \t\treturn qi\n\n \tdef CCD(self,xf,qi):\n \t\tpass"
}
] | 3 |
lckaslmd/pyp-w1-gw-language-detector
|
https://github.com/lckaslmd/pyp-w1-gw-language-detector
|
5dbcbeb2595761073d40fb2c139cb9428b690b06
|
377ea76202e94011935a421d0e3ade993025efa6
|
81da5e092df8195002cf8e51547247a3fae94b86
|
refs/heads/master
| 2021-01-11T21:36:50.184216 | 2017-01-13T10:01:42 | 2017-01-13T10:01:42 | 78,817,660 | 0 | 0 | null | 2017-01-13T05:16:33 | 2017-01-12T23:09:17 | 2017-01-13T04:25:17 | null |
[
{
"alpha_fraction": 0.7171717286109924,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 18.799999237060547,
"blob_id": "0a2fb723ff53a937cdc13cc610918df692f5016b",
"content_id": "05f6f431fd1385edda30fb98c92d62fac013b76e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 5,
"path": "/tox.ini",
"repo_name": "lckaslmd/pyp-w1-gw-language-detector",
"src_encoding": "UTF-8",
"text": "[tox]\nenvlist = py27,py34,py35\n[testenv]\ndeps=-rdev-requirements.txt\ncommands=python setup.py test\n"
},
{
"alpha_fraction": 0.5769230723381042,
"alphanum_fraction": 0.5788461565971375,
"avg_line_length": 33.66666793823242,
"blob_id": "ff21d148b7868189d99b5f968baf54faf4f4f1f2",
"content_id": "501126fbf81694bd36b17a29ebe9360abaac46c5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 15,
"path": "/language_detector/main.py",
"repo_name": "lckaslmd/pyp-w1-gw-language-detector",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"This is the entry point of the program.\"\"\"\n\ndef detect_language(text, languages):\n \"\"\"Returns the detected language of given text.\"\"\"\n\n character_list = [ c for c in text if c.isalpha() or c.isdigit() or c is ' ' ]\n word_list = \"\".join(character_list).lower().split()\n\n results = { lang['name']:len([ word for word in word_list\n if word in lang['common_words'] ])\n for lang in languages }\n\n return max(results, key=results.get)\n"
}
] | 2 |
khaidzir/seq2seq
|
https://github.com/khaidzir/seq2seq
|
371b0a943331df04ee2b6000dc501495268ec64c
|
f8f94b7c79f8f3f9c7d4bcd8da2c868439ea2088
|
97867ebae63c094f8aeda6204ae2e4c129650125
|
refs/heads/master
| 2020-03-22T04:35:28.795524 | 2018-07-27T03:48:53 | 2018-07-27T03:48:53 | 139,508,154 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6299927234649658,
"alphanum_fraction": 0.6466957330703735,
"avg_line_length": 37.25,
"blob_id": "e75c88706e6634169125bb0d9ab5558f01d0554d",
"content_id": "12e78df604c2b78063f49b0d8fa1dd7ab7306625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5508,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 144,
"path": "/metric.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "from util import normalize_no_punc\n\ndef print_conf_matrix(writer, matrix) :\n for i in range(len(matrix)) :\n for j in range(len(matrix[i])) :\n writer.write(\"%d\\t\"%(matrix[i][j]))\n writer.write(\"\\n\")\n\ndef print_prec_rec(writer, vector) :\n for i in range(len(vector)) :\n writer.write(\"%d : %.4f\\n\"%(i,vector[i]))\n\ndef get_stats(conf_mat) :\n # Get n data\n n_data = sum([sum(row) for row in conf_mat])\n n_class = len(conf_mat)\n\n # Calculate accuracy\n acc = 0\n for i in range(n_class) : \n acc += conf_mat[i][i]\n if n_data == 0 :\n acc = 0\n else :\n acc /= n_data\n\n # Calculate precision\n prec = [0 for _ in range(n_class)]\n for i in range(n_class) :\n div_prec = 0\n for j in range(n_class) :\n div_prec += conf_mat[i][j]\n if div_prec == 0 :\n prec[i] = 0\n else :\n prec[i] = conf_mat[i][i]/div_prec\n\n # Calculate recall\n rec = [0 for _ in range(n_class)]\n for i in range(n_class) :\n div_rec = 0\n for j in range(n_class) :\n div_rec += conf_mat[j][i]\n if div_rec == 0 :\n rec[i] = 0\n else :\n rec[i] = conf_mat[i][i]/div_rec\n\n return acc,prec,rec\n\ndef equal_sentence(sent1, sent2) :\n if len(sent1) != len(sent2) :\n return False\n for i in range(len(sent1)) :\n if sent1[i] != sent2[i] :\n return False\n return True\n\nidx2class = {\n 0: 'Mohon maaf jika aku ada salah. Bantu aku perbaiki kesalahanku ya.',\n 1: 'Senang bisa membantu kamu. Silakan jangan ragu untuk tanya aku lagi jika kamu ingin mencari berita.',\n 2: 'Selamat siang',\n 3: 'Terima kasih feedbacknya, kami Beritagar berkomitmen untuk selalu meningkatkan kualitas berita kami',\n 4: 'Informasi lebih lanjut dapat dilihat di tombol paling kanan atas atau kontak [email protected]',\n 5: 'Hi, bot beritagar disini siap membantu kamu mencari berita-berita yang paling oke hanya dengan cukup tanyakan topik berita yang ingin kamu lihat.',\n 6: 'Selamat malam',\n 7: 'ga bisa, semoga kelak di masa depan aku bisa ya',\n 8: 'Maaf aku tidak tahu. Bot Beritagar hanya melayani pencarian berita',\n 9: 'Silakan',\n 10: 'Baik, bot beritagar siap membantu kamu mencari berita',\n 11: 'Maaf aku tidak bisa. Bot Beritagar hanya melayani pencarian berita',\n 12: 'Aku tidak mengerti yang kamu ucapkan. Coba lagi ya.',\n 13: 'Selamat sore',\n 14: 'Selamat pagi',\n 15: 'Baca berita aja. Bot beritagar disini siap membantu kamu mencari berita-berita yang paling oke hanya dengan cukup tanyakan topik berita yang ingin kamu lihat',\n 16: 'Terima kasih',\n 17: 'Ada, silakan ketik kata kunci dari berita yang diinginkan',\n 18: 'Maaf aku tidak mengerti. Bot Beritagar hanya melayani pencarian berita'\n}\n\nclass2idx = {\n 'Mohon maaf jika aku ada salah. Bantu aku perbaiki kesalahanku ya.' : 0,\n 'Senang bisa membantu kamu. Silakan jangan ragu untuk tanya aku lagi jika kamu ingin mencari berita.' : 1,\n 'Selamat siang' : 2,\n 'Terima kasih feedbacknya, kami Beritagar berkomitmen untuk selalu meningkatkan kualitas berita kami' : 3,\n 'Informasi lebih lanjut dapat dilihat di tombol paling kanan atas atau kontak [email protected]' : 4,\n 'Hi, bot beritagar disini siap membantu kamu mencari berita-berita yang paling oke hanya dengan cukup tanyakan topik berita yang ingin kamu lihat.' : 5,\n 'Selamat malam' : 6,\n 'ga bisa, semoga kelak di masa depan aku bisa ya' : 7,\n 'Maaf aku tidak tahu. Bot Beritagar hanya melayani pencarian berita' : 8,\n 'Silakan' : 9,\n 'Baik, bot beritagar siap membantu kamu mencari berita' : 10,\n 'Maaf aku tidak bisa. Bot Beritagar hanya melayani pencarian berita' : 11,\n 'Aku tidak mengerti yang kamu ucapkan. Coba lagi ya.' : 12,\n 'Selamat sore' : 13,\n 'Selamat pagi' : 14,\n 'Baca berita aja. Bot beritagar disini siap membantu kamu mencari berita-berita yang paling oke hanya dengan cukup tanyakan topik berita yang ingin kamu lihat' : 15,\n 'Terima kasih' : 16,\n 'Ada, silakan ketik kata kunci dari berita yang diinginkan' : 17,\n 'Maaf aku tidak mengerti. Bot Beritagar hanya melayani pencarian berita' : 18\n}\n\nconf_matrix = [ [0 for _ in range(len(idx2class))] for c in range(len(idx2class)) ]\n\nhyp_file = 'test/chatbot_new/word2vec/skipgram/combined_sgram/nontask_charembed'\nref_file = '/home/prosa/Works/Text/korpus/chatbot_dataset/plain/preprocessed/split/test-nontask.csv'\nfout = 'test/chatbot_new/word2vec/skipgram/combined_sgram/nontask_charembed_confmat'\n\nrefs = []\nhyps = []\nwith open(ref_file) as f :\n for line in f :\n line = line.strip()\n split = line.split('\\t')\n refs.append(normalize_no_punc(split[2]).split())\n\nwith open(hyp_file) as f :\n for line in f :\n line = line.strip()\n hyps.append(normalize_no_punc(line).split())\nhyps = hyps[:-1]\n\nassert(len(refs) == len(hyps))\n\n# for i in range(len(hyps)) :\n# conf_matrix[class2idx[hyps[i]]][class2idx[refs[i]]] += 1\n\n# acc,prec,recall = get_stats(conf_matrix)\n# fout = open(fout, 'w')\n# fout.write(str(idx2class))\n# fout.write(\"\\n\\nAccuracy : %.4f\"%(acc))\n# fout.write(\"\\n\\nPrecision :\\n\")\n# print_prec_rec(fout, prec)\n# fout.write(\"\\n\\nRecall :\\n\")\n# print_prec_rec(fout, recall)\n# fout.write(\"\\n\\nConfusion matrix :\\n\")\n# print_conf_matrix(fout, conf_matrix)\n# fout.close()\n\nhit = 0\nfor i in range(len(refs)) :\n if equal_sentence(refs[i], hyps[i]) :\n hit += 1\nprint(\"Akurasi : %.4f\\n\"%(hit/len(refs)))\n"
},
{
"alpha_fraction": 0.7216196656227112,
"alphanum_fraction": 0.7284888029098511,
"avg_line_length": 34.93506622314453,
"blob_id": "89cc3d3f1125a2d5021cc822c42708680cd84e9a",
"content_id": "73d95253d496f66187b8dce20beb949a587bef61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2766,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 77,
"path": "/inference_wordembed.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom train_bidirectional import Trainer\nfrom model2 import PreTrainedEmbeddingEncoderRNN, AttnDecoderRNN\nfrom preprocess import prepareData, unicodeToAscii, normalizeString\nfrom gensim.models import KeyedVectors\nfrom lang import Lang\nimport params\nfrom gensim.models import KeyedVectors\n\ndef preprocessSentence(sentence, max_len) :\n sentence = normalizeString(unicodeToAscii(sentence))\n split = sentence.split()\n if len(split) >= max_len :\n split = split[:max_len-1]\n return ' '.join(split)\n\n# Config variables\nencoder_file = 'model/chatbot/augmented_data/word2vec/skipgram/twitter_sgram/encoder-d100-e5.pt'\ndecoder_file = 'model/chatbot/augmented_data/word2vec/skipgram/twitter_sgram/decoder-d100-e5.pt'\nencoder_attr_dict = torch.load(encoder_file)\ndecoder_attr_dict = torch.load(decoder_file)\n\n# Dataset (for build dictionary)\n# src_lang, tgt_lang, pairs = prepareData('dataset/input-output.txt', reverse=False)\n\n# Lang\ndecoder_lang = Lang()\ndecoder_lang.load_dict(decoder_attr_dict['lang'])\n\n# Word vector\n# word_vector = KeyedVectors.load_word2vec_format(\"word_vector/koran.vec\", binary=True)\nword_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n\n# Params\nuse_cuda = params.USE_CUDA\nhidden_size = word_vectors.vector_size\n\n# Encoder & Decoder\n# encoder = EncoderEmbeddingRNN(src_lang.n_words, hidden_size, word_vector)\n# attn_decoder = AttnDecoderRNN(hidden_size, tgt_lang.n_words, dropout_p=0.1, max_length=max_len)\n# encoder.loadState(ENCODER_MODEL)\n# attn_decoder.loadState(DECODER_MODEL)\nencoder = PreTrainedEmbeddingEncoderRNN(word_vectors, encoder_attr_dict['max_length'])\nencoder.loadAttributes(encoder_attr_dict)\nattn_decoder = AttnDecoderRNN(decoder_attr_dict['hidden_size'], decoder_lang, max_length=decoder_attr_dict['max_length'])\nencoder.loadAttributes(encoder_attr_dict)\nattn_decoder.loadAttributes(decoder_attr_dict)\n\nif use_cuda:\n encoder = encoder.cuda()\n attn_decoder = attn_decoder.cuda()\n\ntrainer = Trainer([], encoder, attn_decoder)\n\nsentence = input(\"Input : \")\nwhile (sentence != \"<end>\") :\n sentence = preprocessSentence(sentence, attn_decoder.max_length)\n output_words, attentions = trainer.evaluate(sentence)\n output = ' '.join(output_words[:-1])\n print(output)\n sentence = input(\"Input : \")\n\n# file_test = \"test/test.txt\"\n# results = []\n# with open(file_test, \"r\", encoding=\"utf-8\") as f :\n# for line in f :\n# line = line.strip()\n# output_words, attentions = trainer.evaluate(encoder, attn_decoder, line, max_len=max_len)\n# output = ' '.join(output_words[:-1])\n# results.append(output)\n\n# file_out = \"test/result.txt\"\n# fout = open(file_out, \"w\", encoding=\"utf-8\")\n# for result in results :\n# fout.write(\"%s\\n\"%(result))\n# fout.close()"
},
{
"alpha_fraction": 0.5850875973701477,
"alphanum_fraction": 0.5941711068153381,
"avg_line_length": 38.30287551879883,
"blob_id": "ea81808157018742baf970b7b418da94d601f9f3",
"content_id": "3a5850c244c8fae1973b56fda9958ed7dfb019bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23229,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 591,
"path": "/model_bidirectional_v1_lstm.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport numpy as np\nfrom torch.autograd import Variable\nfrom gensim.models import KeyedVectors\nfrom lang import Lang\nimport params\nimport random\nimport time\n\ndef build_char_lang() :\n lang = Lang()\n lang.word2index = dict()\n lang.index2word = dict()\n lang.n_words = 0\n chars = \"!\\\"$%&'()*+,-./0123456789:;<>?[]abcdefghijklmnopqrstuvwxyz\"\n for c in chars :\n lang.addWord(c)\n return lang\n\n# Model for word feature extraction based on character embedding using CNN\nclass CNNWordFeature(nn.Module) :\n def __init__(self, embedding_size, feature_size, max_length, seeder=int(time.time()) ) :\n super(CNNWordFeature, self).__init__()\n random.seed(seeder)\n torch.manual_seed(seeder)\n if params.USE_CUDA :\n torch.cuda.manual_seed_all(seeder)\n self.embedding_size = embedding_size\n self.feature_size = feature_size\n self.max_length = max_length\n self.lang = build_char_lang()\n self.vocab_size = self.lang.n_words\n\n # embedding layer\n self.embedding = nn.Embedding(self.vocab_size, self.embedding_size)\n\n # convolutional layers for 2,3,4 window\n self.conv2 = nn.Conv2d(1, (self.feature_size//3)+(self.feature_size%3), (2,self.embedding_size))\n self.conv3 = nn.Conv2d(1, self.feature_size//3, (3,self.feature_size))\n self.conv4 = nn.Conv2d(1, self.feature_size//3, (4,self.feature_size))\n\n # maxpool layers\n self.maxpool2 = nn.MaxPool2d(kernel_size=(self.max_length-1,1))\n self.maxpool3 = nn.MaxPool2d(kernel_size=(self.max_length-2,1))\n self.maxpool4 = nn.MaxPool2d(kernel_size=(self.max_length-3,1))\n\n # linear layer\n # self.linear = nn.Linear(2*(feature_size//2), feature_size)\n\n if params.USE_CUDA :\n self.cuda()\n\n # char_idxs is a list of char index (list of torch.autograd.Variable)\n def forward(self, char_idxs) :\n # Get embedding for every chars\n embeddings = Variable(torch.zeros(self.max_length, self.feature_size))\n if params.USE_CUDA :\n embeddings = embeddings.cuda()\n for i in range(len(char_idxs)) :\n c_embed = self.embedding(char_idxs[i])\n embeddings[i] = c_embed.view(1,1,-1)\n embeddings = embeddings.view(1, 1, self.max_length, -1)\n\n # Pass to cnn\n relu2 = F.relu(self.conv2(embeddings))\n relu3 = F.relu(self.conv3(embeddings))\n relu4 = F.relu(self.conv4(embeddings))\n\n # Max pooling\n pool2 = self.maxpool2(relu2).view(-1)\n pool3 = self.maxpool3(relu3).view(-1)\n pool4 = self.maxpool4(relu4).view(-1)\n \n # Concat\n concat = torch.cat((pool2,pool3,pool4))\n # concat = pool2.view(1,-1)\n # concat = torch.cat((pool2,pool3)).view(1,-1)\n\n # Pass to linear layer\n # output = self.linear(concat).view(-1)\n # output = pool2.view(-1)\n output = concat\n\n return output\n\n\n# Encoder base class, only contains hidden_size, lstm layer, and empty vector\nclass BaseEncoderBiRNN(nn.Module):\n def __init__(self, input_size, hidden_size, max_length, dropout_p=0.0, seeder=int(time.time()) ):\n super(BaseEncoderBiRNN, self).__init__()\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.max_length = max_length\n self.model_type = 'base'\n self.dropout_p = dropout_p\n random.seed(seeder)\n torch.manual_seed(seeder)\n if params.USE_CUDA :\n torch.cuda.manual_seed_all(seeder)\n\n # Dropout layer\n self.dropout = nn.Dropout(p=self.dropout_p)\n\n # Forward and backward RNN\n self.fwd_lstm = nn.LSTM(input_size, hidden_size)\n self.rev_lstm = nn.LSTM(input_size, hidden_size)\n\n # define empty word vector (oov)\n # self.empty_vector = np.array([0. for _ in range(hidden_size)])\n self.empty_vector = np.array([0. for _ in range(input_size)])\n\n # define initial cell and hidden vector\n self.h0 = Variable(torch.zeros(1, 1, self.hidden_size))\n self.c0 = Variable(torch.zeros(1, 1, self.hidden_size))\n\n if params.USE_CUDA :\n self.cuda()\n self.h0 = self.h0.cuda()\n self.c0 = self.c0.cuda()\n\n # Input is list of embedding\n def forward(self, input):\n embedding_inputs = input\n\n # Forward to fwd_lstm unit\n # (fwd_hidden, fwd_cell) = self.initHidden()\n fwd_hidden, fwd_cell = self.h0, self.c0\n fwd_outputs = Variable(torch.zeros(self.max_length, self.hidden_size))\n if params.USE_CUDA :\n fwd_outputs = fwd_outputs.cuda()\n for k,embed in enumerate(embedding_inputs) :\n embed = self.dropout(embed)\n fwd_output,(fwd_hidden, fwd_cell) = self.fwd_lstm(embed, (fwd_hidden, fwd_cell))\n fwd_outputs[k] = fwd_output[0][0]\n\n # Forward to rev_lstm unit\n (rev_hidden, rev_cell) = self.initHidden()\n rev_outputs = Variable(torch.zeros(self.max_length, self.hidden_size))\n if params.USE_CUDA :\n rev_outputs = rev_outputs.cuda()\n n = len(embedding_inputs)-1\n for i in range(n,-1,-1) :\n rev_output,(rev_hidden, rev_cell) = self.rev_lstm(embedding_inputs[i], (rev_hidden, rev_cell))\n rev_outputs[i] = rev_output[0][0]\n \n # Concatenate fwd_output and rev_output\n outputs = torch.cat( (fwd_outputs, rev_outputs), 1 )\n hidden = torch.cat( (fwd_hidden, rev_hidden), 2 )\n cell = torch.cat( (fwd_cell, rev_cell), 2 )\n \n if params.USE_CUDA :\n # return outputs.cuda(), hidden.cuda()\n outputs = outputs.cuda()\n hidden = hidden.cuda()\n\n # projected_output = self.projection(hidden)\n projected_output = (hidden, cell)\n\n return outputs, (hidden, cell), projected_output\n\n def initHidden(self):\n h0 = Variable(torch.zeros(1, 1, self.hidden_size))\n c0 = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return (h0.cuda(), c0.cuda())\n else:\n return (h0, c0)\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if params.USE_CUDA :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return None\n\n def loadAttributes(self, attr_dict):\n self.input_size = attr_dict['input_size']\n self.hidden_size = attr_dict['hidden_size']\n self.max_length = attr_dict['max_length']\n self.model_type = attr_dict['model_type']\n self.dropout_p = attr_dict['dropout_p']\n\n# Encoder ...\nclass WordCharEncoderBiRNN(BaseEncoderBiRNN) :\n def __init__(self, input_size, hidden_size, max_length, char_feature='cnn', dropout_p=0.0, seeder=int(time.time())) :\n super(WordCharEncoderBiRNN, self).__init__(input_size*2, hidden_size, max_length, dropout_p=dropout_p, seeder=seeder)\n assert (char_feature == 'rnn' or char_feature == 'cnn' or char_feature == 'cnn_rnn')\n if char_feature == 'rnn' :\n self.charbased_model = self.build_rnn(seeder)\n elif char_feature == 'cnn' :\n self.charbased_model = self.build_cnn(seeder)\n elif char_feature == 'cnn_rnn' :\n self.charbased_rnn = self.build_rnn(seeder)\n self.charbased_cnn = self.build_cnn(seeder)\n self.char_feature = char_feature\n self.model_type = ''\n\n def build_cnn(self, seeder=int(time.time()) ) :\n return CNNWordFeature(self.input_size//2, self.input_size//2, params.CHAR_LENGTH, seeder=seeder)\n\n def build_rnn(self, seeder=int(time.time()) ) :\n lang = build_char_lang()\n return WordEncoderBiRNN(self.input_size//4, self.input_size//4, params.CHAR_LENGTH, lang, seeder=seeder)\n\n # Word_embeddings is word_vector of sentence, words is list of word\n def forward(self, word_embeddings, words) :\n assert(len(word_embeddings) == len(words))\n\n # Get word embeddings extracted from its character\n char_embeddings = []\n for word in words :\n # Get character indexes\n if self.char_feature == 'cnn_rnn' :\n inputs = [self.charbased_cnn.lang.word2index[c] for c in word]\n else :\n inputs = [self.charbased_model.lang.word2index[c] for c in word]\n inputs = Variable(torch.LongTensor(inputs))\n if params.USE_CUDA :\n inputs = inputs.cuda()\n \n # Get vector rep of word (pass to charbased_model)\n if self.char_feature == 'cnn' :\n vec = self.charbased_model(inputs)\n elif self.char_feature == 'rnn' :\n _, _, (vec, cell) = self.charbased_model(inputs)\n elif self.char_feature == 'cnn_rnn' :\n cnn_vec = self.charbased_cnn(inputs)\n _, _, (rnn_vec, cell) = self.charbased_rnn(inputs)\n # Addition\n # vec = cnn_vec + rnn_vec\n # Average\n # vec = (cnn_vec + rnn_vec) / 2\n # Hadamard product\n vec = cnn_vec * rnn_vec\n\n # Add to list of word embeddings based on char\n char_embeddings.append(vec.view(1,1,-1))\n\n # concat word_embeddings with char_embeddings\n embeddings = []\n for i in range(len(word_embeddings)) :\n embeddings.append(torch.cat((word_embeddings[i],char_embeddings[i]),2) )\n\n # print('word embedding :')\n # print(word_embeddings)\n # print('word-char embedding :')\n # print(char_embeddings)\n # print('embedding :')\n # print(embeddings)\n\n # Forward to rnn\n return super(WordCharEncoderBiRNN, self).forward(embeddings)\n\n def loadAttributes(self, attr_dict) :\n super(WordCharEncoderBiRNN, self).loadAttributes(attr_dict)\n self.load_state_dict(attr_dict['state_dict'])\n\n def getAttrDict(self) :\n return {\n 'model_type' : self.model_type,\n 'char_feature' : self.char_feature,\n 'input_size' : self.input_size,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'dropout_p' : self.dropout_p,\n 'state_dict' : self.getCpuStateDict(),\n }\n\nclass PreTrainedEmbeddingWordCharEncoderBiRNN(WordCharEncoderBiRNN) :\n def __init__(self, word_vectors, hidden_size, max_length, char_feature='cnn', dropout_p=0.0, seeder=int(time.time())) :\n super(PreTrainedEmbeddingWordCharEncoderBiRNN, self).__init__(word_vectors.vector_size, hidden_size, max_length, char_feature, dropout_p=dropout_p, seeder=seeder)\n empty_vector = np.array([0. for _ in range(word_vectors.vector_size)])\n self.empty_vector = Variable(torch.Tensor(empty_vector).view(1, 1, -1))\n self.cache_dict = dict()\n self.word_vectors = word_vectors\n self.model_type = 'pre_trained_embedding_wordchar'\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n\n def get_word_vector(self, word_input) :\n if word_input in self.cache_dict :\n return self.cache_dict[word_input]\n else :\n if word_input in self.word_vectors :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vectors[word_input]\n word_vector = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n word_vector = word_vector.cuda()\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vector\n word_vector = self.empty_vector\n self.cache_dict[word_input] = word_vector\n return word_vector\n\n # Feed forward method, input is list of word\n def forward(self, input) :\n word_embeddings = [self.get_word_vector(word) for word in input]\n return super(PreTrainedEmbeddingWordCharEncoderBiRNN, self).forward(word_embeddings, input)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'char_feature' : self.char_feature,\n 'input_size' : self.input_size,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'dropout_p' : self.dropout_p,\n 'state_dict' : self.getCpuStateDict(),\n }\n\n def loadAttributes(self, attr_dict) :\n super(PreTrainedEmbeddingWordCharEncoderBiRNN, self).loadAttributes(attr_dict)\n\n# Encoder word based\nclass WordEncoderBiRNN(BaseEncoderBiRNN):\n def __init__(self, input_size, hidden_size, max_length, lang, dropout_p=0.0, seeder=int(time.time())):\n super(WordEncoderBiRNN, self).__init__(input_size, hidden_size, max_length, dropout_p=dropout_p, seeder=seeder)\n self.model_type = 'word_based'\n\n # define parameters\n self.lang = lang\n self.vocab_size = lang.n_words\n\n # define layers\n self.embedding = nn.Embedding(self.vocab_size, self.input_size)\n\n # empty vector for oov\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n\n def loadAttributes(self, attr_dict) :\n super(WordEncoderBiRNN, self).loadAttributes(attr_dict)\n self.lang.load_dict(attr_dict['lang'])\n self.vocab_size = self.lang.n_words\n self.load_state_dict(attr_dict['state_dict'])\n if params.USE_CUDA :\n self.cuda()\n\n # Feed forward method, input is a list of word index (list of torch.autograd.Variable)\n def forward(self, input):\n # Get embedding vector\n embedding_inputs = []\n for idx in input :\n if idx.data.item() != params.OOV_INDEX :\n embed = self.embedding(idx).view(1,1,-1)\n else :\n embed = self.empty_vector\n embedding_inputs.append(embed)\n \n return super(WordEncoderBiRNN, self).forward(embedding_inputs)\n\n # Get word index of every word in sentence\n def get_indexes(self, sentence, reverse_direction=False) :\n if not reverse_direction :\n arr = [self.lang.word2index[word] if word in self.lang.word2index else -1 for word in sentence]\n else :\n arr = [self.lang.word2index[sentence[i]] if sentence[i] in self.lang.word2index else -1 for i in range(len(sentence)-1,-1,-1)]\n retval = Variable(torch.LongTensor(arr))\n if params.USE_CUDA :\n return retval.cuda()\n return retval\n\n # Get dict representation of attributes\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'input_size' : self.input_size,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n\n# Encoder using pre trained word embedding\nclass PreTrainedEmbeddingEncoderBiRNN(BaseEncoderBiRNN) :\n def __init__(self, word_vectors, hidden_size, max_length, dropout_p=0.0, char_embed=False, seeder=int(time.time())):\n super(PreTrainedEmbeddingEncoderBiRNN, self).__init__(word_vectors.vector_size, hidden_size, max_length, dropout_p=dropout_p, seeder=seeder)\n self.model_type = 'pre_trained_embedding'\n\n # define word vector embedding\n self.word_vectors = word_vectors\n\n # empty vector for oov\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n\n # char embed\n self.char_embed = char_embed\n if self.char_embed :\n lang = build_char_lang()\n self.charbased_model = WordEncoderBiRNN(self.hidden_size//2, params.CHAR_LENGTH, lang, seeder=seeder)\n\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n\n self.cache_dict = dict()\n\n def get_word_vector(self, word_input) :\n if word_input in self.cache_dict :\n return self.cache_dict[word_input]\n else :\n if word_input in self.word_vectors :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vectors[word_input]\n word_vector = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n word_vector = word_vector.cuda()\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_vector = self.empty_vector\n self.cache_dict[word_input] = word_vector\n return word_vector\n\n # Feed forward method, input is list of word\n def forward(self, input):\n embedding_inputs = []\n for word in input :\n if (word not in self.word_vectors) and (self.char_embed) :\n inputs = [self.charbased_model.lang.word2index[c] for c in word]\n inputs = Variable(torch.LongTensor(inputs))\n if params.USE_CUDA :\n inputs = inputs.cuda()\n _, _, (c_hidden, c_cell) = self.charbased_model(inputs)\n embedding_inputs.append(c_hidden)\n else :\n embedding_inputs.append(self.get_word_vector(word))\n return super(PreTrainedEmbeddingEncoderBiRNN, self).forward(embedding_inputs)\n\n def loadAttributes(self, attr_dict) :\n super(PreTrainedEmbeddingEncoderBiRNN, self).loadAttributes(attr_dict)\n self.load_state_dict(attr_dict['state_dict'])\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'input_size' : self.input_size,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'char_embed' : self.char_embed,\n 'dropout_p' : self.dropout_p,\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n# Encoder using word embedding vector as input\nclass EmbeddingEncoderInputBiRNN(nn.Module):\n def __init__(self, hidden_size, word_vector):\n super(EmbeddingEncoderInputBiRNN, self).__init__(hidden_size)\n self.model_type = 'word_vector_based'\n\n # define word vector embedding\n self.word_vector = word_vector\n\n # define layers\n self.linear = nn.Linear(self.word_vector.vector_size, hidden_size)\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(self.word_vector.vector_size)])\n\n def loadAttributes(self, attr_dict) :\n super(EmbeddingEncoderInputBiRNN, self).loadAttributes(attr_dict)\n self.max_length = attr_dict['max_length']\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n input = input.cuda()\n\n # Feed forward to linear unit\n input = self.linear(input)\n\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n# Decoder\nclass AttnDecoderRNN(nn.Module):\n def __init__( self, input_size, hidden_size, max_length, lang, dropout_p=0.5, seeder=int(time.time()) ):\n super(AttnDecoderRNN, self).__init__()\n random.seed(seeder)\n torch.manual_seed(seeder)\n if params.USE_CUDA :\n torch.cuda.manual_seed_all(seeder)\n\n # define parameters\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.output_size = lang.n_words\n self.dropout_p = dropout_p\n self.max_length = max_length\n self.lang = lang\n\n # define layers\n self.embedding = nn.Embedding(self.output_size, self.input_size)\n self.attn = nn.Linear(self.input_size+self.hidden_size, self.max_length)\n self.attn_combine = nn.Linear(self.input_size+self.hidden_size, self.input_size)\n self.dropout = nn.Dropout(self.dropout_p)\n self.lstm = nn.LSTM(self.input_size, self.hidden_size)\n self.out = nn.Linear(self.hidden_size, self.output_size)\n\n if params.USE_CUDA :\n self.cuda()\n\n def loadAttributes(self, attr_dict) :\n self.input_size = attr_dict['input_size']\n self.hidden_size = attr_dict['hidden_size']\n self.dropout_p = attr_dict['dropout_p']\n self.max_length = attr_dict['max_length']\n self.lang.load_dict(attr_dict['lang'])\n self.output_size = self.lang.n_words\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is index of word (Variable)\n def forward(self, input, hidden, encoder_outputs):\n hidden,cell = hidden\n\n embedded = self.embedding(input).view(1, 1, -1)\n embedded = self.dropout(embedded)\n\n attn_input = torch.cat((embedded[0], hidden[0]), 1)\n attn_weights = F.softmax(self.attn(attn_input), dim=1)\n attn_applied = torch.bmm(\n attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))\n\n output = torch.cat((embedded[0], attn_applied[0]), 1)\n output = self.attn_combine(output).unsqueeze(0)\n output = F.relu(output)\n output, (hidden,cell) = self.lstm(output, (hidden,cell) )\n output = F.log_softmax(self.out(output[0]), dim=1)\n\n return output, (hidden,cell), attn_weights\n\n def initHidden(self):\n h0 = Variable(torch.zeros(1, 1, self.hidden_size))\n c0 = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return (h0.cuda(), c0.cuda())\n else:\n return (h0, c0)\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if params.USE_CUDA :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return {\n 'input_size' : self.input_size,\n 'hidden_size' : self.hidden_size,\n 'dropout_p' : self.dropout_p,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n\n"
},
{
"alpha_fraction": 0.5621890425682068,
"alphanum_fraction": 0.5759662985801697,
"avg_line_length": 29.395349502563477,
"blob_id": "216b949f8fa1ea307cf7a278f77a93712e0f21f9",
"content_id": "a2daa5bf190cb3b3283bb892b5149a585369b8cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2613,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 86,
"path": "/util.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom torch.autograd import Variable\nimport numpy as np\nimport params\nimport unicodedata\nimport re\nfrom io import open\nfrom simple_wordvector import SimpleWordVector\n\nnumbers = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']\nnumbers_ext = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ',', '.']\nNUM_TOKEN = \"<NUM>\"\n\n# --- NORMALIZATION: TO CLEAN UNICODE CHARACTERS ----\ndef unicodeToAscii(sentence):\n return ''.join(\n c for c in unicodedata.normalize('NFD', sentence)\n if unicodedata.category(c) != 'Mn'\n )\ndef normalizeString(sentence):\n sentence = unicodeToAscii(sentence.lower().strip())\n sentence = re.sub(r\"([,.;?!'\\\"\\-()<>[\\]/\\\\&$%*@~+=])\", r\" \\1 \", sentence)\n sentence = re.sub(r\"[^a-zA-Z0-9,.;?!'\\\"\\-()<>[\\]/\\\\&$%*@~+=]+\", r\" \", sentence)\n return sentence\n\ndef is_numeric(word) :\n if word[0] not in numbers :\n return False\n for c in word :\n if c not in numbers_ext :\n return False\n return True\n\ndef filter_numeric(words) :\n sentence = ''\n for word in words :\n if is_numeric(word) :\n sentence += NUM_TOKEN\n else :\n sentence += word\n sentence += ' '\n return sentence[:-1]\n\ndef normalize_no_punc(sentence) :\n sentence = unicodeToAscii(sentence.lower().strip())\n sentence = re.sub(r\"([;?!'\\\"\\-()<>[\\]/\\\\&$%*@~+=])\", r\" \", sentence)\n sentence = filter_numeric(sentence.split())\n sentence = re.sub(r\"[^a-z<>A-Z0-9]+\", r\" \", sentence)\n return sentence\n\n# Get list of word indexes representation from sentence (list of words)\ndef get_sequence_index(sentence, word2index) :\n arr = [word2index[word] if word in word2index else params.OOV_INDEX for word in sentence]\n retval = Variable(torch.LongTensor(arr))\n if params.USE_CUDA :\n return retval.cuda()\n return retval\n\n# Get wordvector from text file\ndef load_wordvector_text(word_vector_file):\n \n model = SimpleWordVector()\n with open(word_vector_file,'r') as f :\n setsize = False\n for line in f :\n split = line.split()\n word = split[0]\n wv = np.array( [float(val) for val in split[1:]] )\n model[word] = wv\n if not setsize :\n model.vector_size = len(wv)\n setsize = True\n return model\n\n'''\nglovefile = '/home/prosa/Downloads/glove.6B/glove.6B.50d.txt'\nmodel = load_wordvector_text(glovefile)\nword = input('kata : ')\nwhile word != '<end>' :\n if word in model :\n print(model[word])\n else :\n print('euweuh!')\n word = input('kata : ')\n'''"
},
{
"alpha_fraction": 0.6256880760192871,
"alphanum_fraction": 0.6348623633384705,
"avg_line_length": 27.63157844543457,
"blob_id": "e50830f2b55185c34bcf2b97a40a51f71feaec25",
"content_id": "8f320f03333bfef8ea7ec95519e1a5a4fc5cc818",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 19,
"path": "/oovcheck_wordvector.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import params\nfrom gensim.models import KeyedVectors\n\nfiletrain = \"/home/prosa/Works/Text/korpus/chatbot_dataset/plain/preprocessed/split-augmented/perfile/train-nontask.aug\"\nword_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n\ncount = 0\nn_oov = 0\n\nwith open(filetrain) as f :\n for line in f :\n line = line.strip().split('\\t')\n for word in line[0].split() :\n count += 1\n if word not in word_vectors :\n n_oov += 1\n\nprint(\"Total oov : %d\\n\"%(n_oov))\nprint(\"Total kata : %d\\n\"%(count))\n\n"
},
{
"alpha_fraction": 0.5921052694320679,
"alphanum_fraction": 0.5970394611358643,
"avg_line_length": 26.68181800842285,
"blob_id": "0d4dafb1ca2599dbfceadd216c85b416c3e928e1",
"content_id": "c98ecc5ef9a27b3c414bcd0052b007ff9ea3fed1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 22,
"path": "/utility/plothelper.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "'''\n-------------------- PLOT RELATED HELPER FUNCTION --------------------\n\nhelper function for plot related operation\nmainly used for plotting change in loss value for each iterations\n\n----------------------------------------------------------------------\n'''\n\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as ticker\nimport numpy as np\n\n# showing simple 2d plot\ndef showPlot(points):\n plt.figure()\n fig, ax = plt.subplots()\n # this locator puts ticks at regular intervals\n loc = ticker.MultipleLocator(base=0.2)\n ax.yaxis.set_major_locator(loc)\n plt.plot(points)\n #plt.show()"
},
{
"alpha_fraction": 0.5091513991355896,
"alphanum_fraction": 0.5158069729804993,
"avg_line_length": 24.08333396911621,
"blob_id": "667932c2d62153e17c5ba2b315d20c2b42c6e189",
"content_id": "fa0c56938b8ae8e783b5f606362bb100dd968069",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 24,
"path": "/utility/timehelper.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "'''\n-------------------- TIME RELATED HELPER FUNCTION --------------------\n\nhelper function for time related operation (mainly used for logging)\n\n----------------------------------------------------------------------\n'''\n\nimport time\nimport math\n\n# converting second to minute\ndef asMinutes(s):\n m = math.floor(s / 60)\n s -= m * 60\n return '%dm %ds' % (m, s)\n\n# getting current time and estimating current training progress\ndef timeSince(since, percent):\n now = time.time()\n s = now - since\n es = s / (percent)\n rs = es - s\n return ('%s (- %s)' % (asMinutes(s), asMinutes(rs)))"
},
{
"alpha_fraction": 0.7328358292579651,
"alphanum_fraction": 0.7597014904022217,
"avg_line_length": 45.2068977355957,
"blob_id": "69e9912f1a9d28e3b29b787735507db40a6c6ec6",
"content_id": "e3da0e9683648ad198012b5649a58880461e199b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1340,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 29,
"path": "/params.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nOOV_INDEX = -1\nUSE_CUDA = torch.cuda.is_available()\nSOS_TOKEN = '<SOS>'\nEOS_TOKEN = '<EOS>'\nSEEDER = 39862021\nCHAR_LENGTH = 50\n# WORD_VECTORS_FILE = 'word_vector/prosa-w2v/prosa.vec'\n\n# FASTTEXT CBOW\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/tools/fastText-0.1.0/data/preprocessed_codot_article.bin'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/tools/fastText-0.1.0/data/preprocessed_twitter_cbow.bin'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/tools/fastText-0.1.0/data/codot_twitter_cbow.bin'\n\n# WORD2VEC CBOW\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/cbow/codot_combine_twitter_cbow.vec'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/cbow/codot_cbow.vec'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/cbow/twitter_cbow.vec'\n\n# WORD2VEC SKIPGRAM\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/skipgram/codot_combine_twitter_sgram.vec'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/skipgram/codot_sgram.vec'\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/word2vec/skipgram/twitter_sgram.vec'\n\n# WORD_VECTORS_FILE = '/home/prosa/Works/Text/word_embedding/en/GoogleNews-vectors-negative300.bin'\n\n# GLOVE ENGLISH\nWORD_VECTORS_FILE = '/home/prosa/Downloads/glove.6B/glove.6B.50d.txt'\n"
},
{
"alpha_fraction": 0.566766083240509,
"alphanum_fraction": 0.5742213129997253,
"avg_line_length": 39.68988800048828,
"blob_id": "53c991e837c0892016862e672b185d039d48b2db",
"content_id": "3cc95960fa2d7b52f8347b3888b2fc40f3fd6fd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18108,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 445,
"path": "/train_bidirectional.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import time\nimport random\n\nimport torch\nimport torch.nn as nn\nfrom torch.autograd import Variable\nfrom torch import optim\nfrom utility.timehelper import timeSince\nimport params\nimport util\n\nclass Trainer:\n def __init__(self, pairs, encoder, decoder, teacher_forcing_r=0.5):\n assert encoder.max_length == decoder.max_length\n self.pairs = pairs\n self.teacher_forcing_r = teacher_forcing_r\n self.processed_pairs = None\n self.encoder = encoder\n self.decoder = decoder\n\n # Process input sentence so can be processed by encoder's forward\n def process_input(self, sentence) :\n input = sentence.split()\n if self.encoder.model_type == 'word_based' :\n return util.get_sequence_index(input, self.encoder.lang.word2index)\n elif self.encoder.model_type == 'pre_trained_embedding' :\n return input\n elif self.encoder.model_type == 'pre_trained_embedding_wordchar' :\n return input\n\n # Process pair so can be processed by encoder's forward\n def process_pair(self, pair) :\n if self.encoder.model_type == 'word_based' :\n return self.process_word_based_pair(pair)\n elif self.encoder.model_type == 'pre_trained_embedding' :\n return self.process_pre_trained_embedding_pair(pair)\n elif self.encoder.model_type == 'pre_trained_embedding_wordchar' :\n return self.process_pre_trained_embedding_pair(pair)\n\n # Process pairs to index of words\n def process_word_based_pair(self, pair) :\n source = pair[0].split()\n target = pair[1].split()\n target.append(params.EOS_TOKEN)\n return [util.get_sequence_index(source, self.encoder.lang.word2index), util.get_sequence_index(target, self.decoder.lang.word2index)]\n\n def process_pre_trained_embedding_pair(self, pair) :\n source = pair[0].split()\n target = pair[1].split()\n target.append(params.EOS_TOKEN)\n target = util.get_sequence_index(target, self.decoder.lang.word2index)\n return [source, target]\n\n # Function to train data in general\n def trainOneStep(self, source_var, target_var, encoder_optimizer, decoder_optimizer, criterion):\n\n # encoder training side\n encoder_optimizer.zero_grad()\n decoder_optimizer.zero_grad()\n\n source_len = len(source_var)\n target_len = len(target_var)\n\n encoder_outputs,encoder_hidden,projected_hidden = self.encoder(source_var)\n\n loss = 0\n\n # decoder training side\n decoder_input = Variable(torch.LongTensor([self.decoder.lang.word2index[params.SOS_TOKEN]]))\n if params.USE_CUDA :\n decoder_input = decoder_input.cuda()\n decoder_hidden = projected_hidden\n\n # probabilistic step, set teacher forcing ration to 0 to disable\n if random.random() < self.teacher_forcing_r:\n # use teacher forcing, feed target from corpus as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = self.decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n target = torch.tensor([target_var[de_idx]])\n if params.USE_CUDA :\n target = target.cuda()\n loss += criterion(decoder_output, target)\n decoder_input = target_var[de_idx]\n else:\n # without forcing, use its own prediction as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = self.decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n topv, topi = decoder_output.data.topk(1)\n ni = topi[0][0]\n\n decoder_input = Variable(topi)\n if de_idx >= len(target_var) :\n print( str(len(target_var)) + ' - ' + str(de_idx) )\n target = torch.tensor([target_var[de_idx]])\n if params.USE_CUDA :\n target = target.cuda()\n loss += criterion(decoder_output, target)\n if ni == self.decoder.lang.word2index[params.EOS_TOKEN]:\n break\n\n # back propagation, optimization\n loss.backward()\n encoder_optimizer.step()\n decoder_optimizer.step()\n\n # return loss.data[0] / target_len\n return loss.item() / target_len\n\n # main function, iterating the training process\n def train(self, n_iter, learning_rate=0.01, print_every=1000, epoch=1):\n\n start = time.time()\n print_loss_total = 0\n\n encoder_optimizer = optim.SGD(self.encoder.parameters(), lr=learning_rate)\n decoder_optimizer = optim.SGD(self.decoder.parameters(), lr=learning_rate)\n criterion = nn.NLLLoss()\n\n self.processed_pairs = []\n for pair in self.pairs :\n self.processed_pairs.append(self.process_pair(pair))\n training_pairs = self.processed_pairs\n assert len(training_pairs) == n_iter\n # training_pairs = []\n # for i in range(n_iter):\n # training_pairs.append(random.choice(self.processed_pairs))\n\n for ep in range(epoch) :\n for iter in range(1, n_iter+1):\n training_pair = training_pairs[iter-1]\n source_var = training_pair[0]\n target_var = training_pair[1]\n\n loss = self.trainOneStep(source_var, target_var,\n encoder_optimizer, decoder_optimizer,\n criterion)\n print_loss_total += loss\n\n if iter % print_every == 0:\n print_loss_avg = print_loss_total / print_every\n print_loss_total = 0\n print('{0} ({1} {2}%) {3:0.4f}'.format(\n timeSince(start, iter/n_iter), iter, iter/n_iter*100,\n print_loss_avg))\n\n # Function to train data in general\n def trainOneStepV2(self, source_var, target_var, criterion):\n\n # encoder training side\n source_len = len(source_var)\n target_len = len(target_var)\n\n encoder_outputs,encoder_hidden,projected_hidden = self.encoder(source_var)\n\n loss = 0\n\n # decoder training side\n decoder_input = Variable(torch.LongTensor([self.decoder.lang.word2index[params.SOS_TOKEN]]))\n if params.USE_CUDA :\n decoder_input = decoder_input.cuda()\n decoder_hidden = projected_hidden\n\n # probabilistic step, set teacher forcing ration to 0 to disable\n if random.random() < self.teacher_forcing_r:\n # use teacher forcing, feed target from corpus as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = self.decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n target = torch.tensor([target_var[de_idx]])\n if params.USE_CUDA :\n target = target.cuda()\n loss += criterion(decoder_output, target)\n decoder_input = target_var[de_idx]\n else:\n # without forcing, use its own prediction as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = self.decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n topv, topi = decoder_output.data.topk(1)\n ni = topi[0][0]\n\n decoder_input = Variable(topi)\n if de_idx >= len(target_var) :\n print( str(len(target_var)) + ' - ' + str(de_idx) )\n target = torch.tensor([target_var[de_idx]])\n if params.USE_CUDA :\n target = target.cuda()\n loss += criterion(decoder_output, target)\n if ni == self.decoder.lang.word2index[params.EOS_TOKEN]:\n break\n\n # return loss.data[0] / target_len\n # return loss.item() / target_len\n return loss\n\n # main function, iterating the training process\n def train_batch(self, learning_rate=0.01, print_every=1000, epoch=1, batch_size=1, save_every=0, folder_model=None):\n\n assert ( (save_every > 0 and folder_model is not None) or save_every <= 0 )\n\n if folder_model is not None and folder_model[-1] != '/' :\n folder_model += '/'\n\n start = time.time()\n print_loss_total = 0\n\n # encoder_optimizer = optim.SGD(self.encoder.parameters(), lr=learning_rate)\n # decoder_optimizer = optim.SGD(self.decoder.parameters(), lr=learning_rate)\n\n encoder_optimizer = optim.RMSprop(self.encoder.parameters(), lr=learning_rate)\n decoder_optimizer = optim.RMSprop(self.decoder.parameters(), lr=learning_rate)\n\n criterion = nn.NLLLoss()\n\n self.processed_pairs = []\n for pair in self.pairs :\n self.processed_pairs.append(self.process_pair(pair))\n training_pairs = self.processed_pairs\n\n n_training = len(training_pairs)\n n_total = n_training * epoch\n progress = 0\n # Epoch loop\n for ep in range(epoch) :\n print(\"Epoch - %d/%d\"%(ep+1, epoch))\n permutation = torch.randperm(n_training)\n\n # Train set loop\n for i in range(0, n_training, batch_size):\n\n # Batch data\n endidx = i+batch_size if i+batch_size<n_training else n_training\n indices = permutation[i:endidx]\n\n # Zero gradient\n encoder_optimizer.zero_grad()\n decoder_optimizer.zero_grad()\n loss = 0\n\n # Batch loop\n for iter in range(0, len(indices)) :\n training_pair = training_pairs[indices[iter]]\n source_var = training_pair[0]\n target_var = training_pair[1]\n\n curr_loss = self.trainOneStepV2(source_var, target_var,\n criterion)\n print_loss_total = curr_loss.item() / len(target_var)\n loss += curr_loss\n progress += 1\n\n if progress % print_every == 0:\n print_loss_avg = print_loss_total / print_every\n print_loss_total = 0\n print('{0} ({1} {2}%) {3:0.4f}'.format(\n timeSince(start, progress/n_total), progress, progress/n_total*100,\n print_loss_avg))\n \n # back propagation, optimization\n loss.backward()\n\n # for param in self.encoder.parameters():\n # print(param.grad.data.sum())\n # start debugger\n # print( list(self.encoder.parameters())[0].grad )\n # import pdb; pdb.set_trace()\n\n encoder_optimizer.step()\n decoder_optimizer.step()\n\n if save_every > 0 and (ep+1)%save_every == 0 :\n torch.save(self.encoder.getAttrDict(), folder_model + 'encoder-e' + str(ep+1) + '.pt')\n torch.save(self.decoder.getAttrDict(), folder_model + 'decoder-e' + str(ep+1) + '.pt')\n\n # evaluation section\n def evaluate(self, sentence):\n assert self.encoder.max_length == self.decoder.max_length\n\n # Convert sentence (words) to list of word index\n source_var = self.process_input(sentence)\n source_len = len(source_var)\n\n # Set training mode to false\n self.encoder.train(False)\n self.decoder.train(False)\n\n # Forward to encoder\n encoder_outputs,encoder_hidden, projected_hidden = self.encoder(source_var)\n\n # SOS_TOKEN as first input word to decoder\n decoder_input = Variable(torch.LongTensor([self.decoder.lang.word2index[params.SOS_TOKEN]]))\n if params.USE_CUDA :\n decoder_input = decoder_input.cuda()\n \n # Encoder projected hidden state as initial decoder hidden state\n decoder_hidden = projected_hidden\n\n decoded_words = []\n decoder_attentions = torch.zeros(self.decoder.max_length, self.decoder.max_length)\n\n # Decoding iteration, stop until found EOS_TOKEN or max_length is reached\n for de_idx in range(self.decoder.max_length):\n decoder_output, decoder_hidden, decoder_attention = self.decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n decoder_attentions[de_idx] = decoder_attention.data\n topv, topi = decoder_output.data.topk(1)\n ni = topi[0][0].item()\n\n if ni == self.decoder.lang.word2index[params.EOS_TOKEN]:\n decoded_words.append(params.EOS_TOKEN)\n break\n else:\n decoded_words.append(self.decoder.lang.index2word[ni])\n\n decoder_input = Variable(topi)\n\n # Set back training mode\n self.encoder.train(True)\n self.decoder.train(True)\n\n return decoded_words, decoder_attentions[:de_idx+1]\n\n def evaluate_beam_search(self, sentence, beam_width):\n assert self.encoder.max_length == self.decoder.max_length\n\n # Convert sentence (list of words) to list of word index\n source_var = self.process_input(sentence)\n source_len = len(source_var)\n\n # Set training mode to false\n self.encoder.train(False)\n self.decoder.train(False)\n\n # Forward to encoder\n encoder_outputs, encoder_hidden, projected_hidden = self.encoder(source_var)\n\n # SOS_TOKEN as first input word to decoder\n first_input = [self.decoder.lang.word2index[params.SOS_TOKEN]]\n \n # Encoder hidden state as initial decoder hidden state\n decoder_hidden = projected_hidden\n\n global_list = []\n current_beam_width = beam_width\n maintained_list = [ (decoder_hidden, first_input, 0) ]\n while(current_beam_width > 0) :\n temp_list = []\n for item in maintained_list :\n temp_list += self.beam_search_one_step(encoder_outputs, item[0], item[1], item[2], current_beam_width)\n\n temp_list.sort(key=lambda tup: tup[2], reverse=True)\n temp_list = temp_list[:current_beam_width]\n\n maintained_list = []\n for item in temp_list :\n if item[1][-1] == self.decoder.lang.word2index[params.EOS_TOKEN] or len(item[1]) == self.decoder.max_length :\n global_list.append(item)\n current_beam_width -= 1\n else :\n maintained_list.append(item)\n\n # Set back training mode\n self.encoder.train(True)\n self.decoder.train(True)\n\n global_list.sort(key=lambda tup: tup[2], reverse=True)\n return [ self.to_seq_words(item[1]) for item in global_list[:beam_width] ]\n\n # Beam search for one step\n # Return value is array of tuples (decoder_hidden_state, seq_word_idx, score)\n def beam_search_one_step(self, encoder_outputs, hidden_state, seq_word_idx, score, beam_width) :\n decoder_input = Variable(torch.LongTensor( [seq_word_idx[-1]] ))\n if params.USE_CUDA :\n decoder_input = decoder_input.cuda()\n decoder_output, decoder_hidden, decoder_attention = self.decoder(decoder_input, hidden_state, encoder_outputs)\n topv, topi = decoder_output.data.topk(beam_width)\n retval = []\n for i in range(beam_width) :\n new_seq_word_idx = seq_word_idx + [topi[0][i].item()]\n retval.append( (decoder_hidden, new_seq_word_idx, score+topv[0][i].item()) )\n return retval\n\n # Convert sequence of word index to sequence of words\n def to_seq_words(self, seq_word_idx) :\n return [ self.decoder.lang.index2word[idx] for idx in seq_word_idx ]\n \n def evaluateRandomly(self, n=10):\n for i in range(n):\n pair = random.choice(self.pairs)\n print('> {}'.format(pair[0]))\n print('= {}'.format(pair[1]))\n output_words, attentions = self.evaluate(pair[0])\n output_sentence = ' '.join(output_words)\n print('< {}'.format(output_sentence))\n print('')\n\n def evaluateTrainSet(self) :\n for pair in self.pairs :\n print('> {}'.format(pair[0]))\n print('= {}'.format(pair[1]))\n output_words, attentions = self.evaluate(pair[0])\n output_sentence = ' '.join(output_words)\n print('< {}'.format(output_sentence))\n print('')\n\n def evaluateAll(self):\n references = []\n outputs = []\n for i in range(10):\n pair = random.choice(self.pairs)\n references.append(pair[1])\n output_words, attentions = self.evaluate(encoder, decoder, pair[0])\n output_sentence = ' '.join(output_words)\n outputs.append(output_sentence)\n\n with open('result/reference.txt', 'w', encoding='utf-8') as f:\n for reference in references:\n f.write('{}\\n'.format(reference))\n f.close()\n\n with open('result/output.txt', 'w', encoding='utf-8') as f:\n for output in outputs:\n f.write('{}\\n'.format(output))\n f.close()\n\n def evaluateFromTest(self, test_pairs):\n references = []\n outputs = []\n for pair in test_pairs:\n references.append(pair[1])\n output_words, attentions = self.evaluate(encoder, decoder, pair[0])\n output_sentence = ' '.join(output_words)\n outputs.append(output_sentence)\n\n with open('result/reference.txt', 'w', encoding='utf-8') as f:\n for reference in references:\n f.write('{}\\n'.format(reference))\n f.close()\n\n with open('result/output.txt', 'w', encoding='utf-8') as f:\n for output in outputs:\n f.write('{}\\n'.format(output))\n f.close()\n\n"
},
{
"alpha_fraction": 0.6969563364982605,
"alphanum_fraction": 0.7026907801628113,
"avg_line_length": 31.855072021484375,
"blob_id": "4dc0bb24b2891446624447b2e544671787fcf0d3",
"content_id": "1b6666e06bad1d0be7433cc090d11e2851c3a9e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2267,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 69,
"path": "/inference_wordembed2.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom train_wordembed import Trainer\nfrom model import EncoderRNN, EncoderEmbeddingInputRNN, AttnDecoderRNN\nfrom preprocess import prepareData, unicodeToAscii, normalizeString\nfrom gensim.models import KeyedVectors\nimport configparser\n\ndef preprocessSentence(sentence, max_len) :\n sentence = normalizeString(unicodeToAscii(sentence))\n split = sentence.split()\n if len(split) >= max_len :\n split = split[:max_len-1]\n return ' '.join(split)\n\n# Config variables\nconfig = configparser.ConfigParser()\nconfig.read('config.ini')\nDATASET = config['DATA']['Dataset']\nENCODER_MODEL = config['MODELS']['EncoderModel']\nDECODER_MODEL = config['MODELS']['DecoderModel']\nWORD_VECTOR = config['MODELS']['WordVector']\nMAX_LEN = int(config['PARAMS']['MaxLength'])\n\n# Dataset (for build dictionary)\nsrc_lang, tgt_lang, pairs = prepareData('dataset/input-output.txt', reverse=False)\n\n# Word vector\nword_vector = KeyedVectors.load_word2vec_format(\"word_vector/koran.vec\", binary=True)\n\n# Params\nuse_cuda = torch.cuda.is_available()\nhidden_size = 64\nmax_len = MAX_LEN\n\n# Encoder & Decoder\nencoder = EncoderEmbeddingInputRNN(src_lang.n_words, hidden_size, word_vector)\nattn_decoder = AttnDecoderRNN(hidden_size, tgt_lang.n_words, dropout_p=0.1, max_length=max_len)\nencoder.loadState(ENCODER_MODEL)\nattn_decoder.loadState(DECODER_MODEL)\n\nif use_cuda:\n encoder = encoder.cuda()\n attn_decoder = attn_decoder.cuda()\n\ntrainer = Trainer(src_lang, tgt_lang, pairs)\n\nsentence = input(\"Input : \")\nwhile (sentence != \"<end>\") :\n sentence = preprocessSentence(sentence, max_len)\n output_words, attentions = trainer.evaluate(encoder, attn_decoder, sentence, max_len=max_len)\n output = ' '.join(output_words[:-1])\n print(output)\n sentence = input(\"Input : \")\n\n# file_test = \"test/test.txt\"\n# results = []\n# with open(file_test, \"r\", encoding=\"utf-8\") as f :\n# for line in f :\n# line = line.strip()\n# output_words, attentions = trainer.evaluate(encoder, attn_decoder, line, max_len=max_len)\n# output = ' '.join(output_words[:-1])\n# results.append(output)\n\n# file_out = \"test/resultv2-h64.txt\"\n# fout = open(file_out, \"w\", encoding=\"utf-8\")\n# for result in results :\n# fout.write(\"%s\\n\"%(result))\n# fout.close()\n"
},
{
"alpha_fraction": 0.7265822887420654,
"alphanum_fraction": 0.7362025380134583,
"avg_line_length": 39.306121826171875,
"blob_id": "f3e3d7d763941941fb980ee9c1ab928cdd5802c6",
"content_id": "c9f05f29f268471c3e0038b514a3063caf36c6ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1975,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 49,
"path": "/main_wordembed.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom model2 import PreTrainedEmbeddingEncoderRNN, AttnDecoderRNN\nfrom preprocess import prepareData\nfrom train_bidirectional import Trainer\nfrom preprocess import buildPairs\nfrom gensim.models import KeyedVectors\nimport params\n\nuse_cuda = torch.cuda.is_available()\n\ntrainfile = '/home/prosa/Works/Text/mt/dataset/filter-en-id/lenlim80/sorted/train.dummy'\nsrc_lang, tgt_lang, pairs = prepareData(trainfile, reverse=False)\n\n# Word vector\nword_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n\nhidden_size = word_vectors.vector_size\nmax_len = 8\nencoder = PreTrainedEmbeddingEncoderRNN(word_vectors, max_len)\nattn_decoder = AttnDecoderRNN(hidden_size, tgt_lang, dropout_p=0.1, max_length=max_len)\n\nif use_cuda:\n encoder = encoder.cuda()\n attn_decoder = attn_decoder.cuda()\n\nepoch = 100\nnum_iter = len(pairs)\ntrainer = Trainer(pairs, encoder, attn_decoder)\n# trainer.train(encoder, attn_decoder, num_iter, print_every=num_iter//10, max_len=max_len, epoch=epoch)\ntrainer.train(num_iter, print_every=num_iter//10, epoch=epoch)\ntrainer.evaluateRandomly()\n# trainer.evaluateAll(encoder, attn_decoder)\n\n# str_iter = str(num_iter//1000) + 'k'\n# torch.save(encoder.getAttrDict(), 'model/chatbot/encoder-uni-d' + str(hidden_size) + '-i' + str_iter + '.pt')\n# torch.save(attn_decoder.getAttrDict(), 'model/chatbot/decoder-uni-d' + str(hidden_size) + '-i' + str_iter + '.pt')\n\ntorch.save(encoder.getAttrDict(), 'model/mt/dummy/encoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\ntorch.save(attn_decoder.getAttrDict(), 'model/mt/dummy/decoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n\n# Open testfile as test and build pairs from it\n# test_pairs = buildPairs(\"corpus/test-ind-eng.txt\")\n\n# Test using test data\n# trainer.evaluateFromTest(test_pairs, encoder, attn_decoder, max_len=max_len)\n\n# encoder.saveState('checkpoint/encoder-ind-eng-' + str(num_iter*2) + '.pt')\n# attn_decoder.saveState('checkpoint/decoder-ind-eng-' + str(num_iter*2) + '.pt')\n"
},
{
"alpha_fraction": 0.5856590270996094,
"alphanum_fraction": 0.5919637084007263,
"avg_line_length": 34.828311920166016,
"blob_id": "7cb47f447608e90a65274d16c8ad051f11edaf15",
"content_id": "6121720e3d60d748a0238c34b72ba3d93db4a6e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11896,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 332,
"path": "/model2.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport numpy as np\nfrom torch.autograd import Variable\nfrom gensim.models import KeyedVectors\nimport params\n\nOOV_INDEX = -1 # Word index to represent oov word\n\n# Encoder base class, only contains hidden_size, gru layer, and empty vector\nclass BaseEncoderRNN(nn.Module):\n def __init__(self, hidden_size, max_length):\n super(BaseEncoderRNN, self).__init__()\n self.hidden_size = hidden_size\n self.max_length = max_length\n\n self.gru = nn.GRU(hidden_size, hidden_size)\n\n self.model_type = 'base'\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(hidden_size)])\n\n # Feed forward method, input is word\n def forward(self, input):\n embedding_inputs = input\n\n # Forward to fwd_gru unit\n hidden = self.initHidden()\n outputs = Variable(torch.zeros(self.max_length, self.hidden_size))\n if params.USE_CUDA :\n outputs = outputs.cuda()\n for k,embed in enumerate(embedding_inputs) :\n output,hidden = self.gru(embed, hidden)\n outputs[k] = output[0][0]\n\n return outputs, hidden, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if torch.cuda.is_available() :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return None\n\n def loadAttributes(self, attrDict):\n return None\n\n'''\n# Encoder word based\nclass WordEncoderRNN(BaseEncoderRNN):\n def __init__(self, hidden_size, lang):\n super(WordEncoderRNN, self).__init__(hidden_size)\n self.model_type = 'word_based'\n\n # define parameters\n self.lang = lang\n self.input_size = lang.n_words\n\n # define layers\n self.embedding = nn.Embedding(self.input_size, hidden_size)\n\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n if torch.cuda.is_available() :\n self.empty_vector = self.empty_vector.cuda()\n\n def loadAttributes(self, attr_dict) :\n self.hidden_size = attr_dict['hidden_size']\n self.lang.load_dict(attr_dict['lang'])\n self.input_size = lang.n_words\n self.max_length = attr_dict['max_length']\n self.embedding = nn.Embedding(self.input_size, self.hidden_size)\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n if torch.cuda.is_available() :\n self.empty_vector = self.empty_vector.cuda()\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is word\n def forward(self, input, hidden):\n # If word is not oov, take embedding vector of it\n if input in lang.word2index :\n embedded = self.embedding(lang.word2index[input]).view(1,1,-1)\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n embedded = self.empty_vector\n output = embedded\n # Forward to GRU unit\n output, hidden = self.gru(output, hidden)\n return output, hidden\n\n def getAttrDict(self):\n state_dict= self.state_dict()\n if torch.cuda.is_available() :\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n\n# Encoder using pre trained word embedding\nclass PreTrainedEmbeddingEncoderRNN(BaseEncoderRNN) :\n def __init__(self, word_vector, max_length, char_embed=False):\n super(PreTrainedEmbeddingEncoderRNN, self).__init__(word_vector.vector_size, max_length)\n self.model_type = 'pre_trained_embedding'\n self.max_length = max_length\n\n # define word vector embedding\n self.word_vectors = word_vector\n\n # empty vector for oov\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n\n # char embed\n self.char_embed = char_embed\n\n # word vector for start of string\n sos = torch.ones(self.hidden_size)\n self.sos_vector = Variable(sos).view(1, 1, -1)\n\n # word vector for end of string\n eos = torch.ones(self.hidden_size) * -1\n self.eos_vector = Variable(eos).view(1, 1, -1)\n\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n self.sos_vector = self.sos_vector.cuda()\n self.eos_vector = self.eos_vector.cuda()\n\n self.cache_dict = dict()\n self.cache_dict[params.SOS_TOKEN] = self.sos_vector\n self.cache_dict[params.EOS_TOKEN] = self.eos_vector\n\n def loadAttributes(self, attr_dict) :\n self.max_length = attr_dict['max_length']\n self.hidden_size = attr_dict['hidden_size']\n self.load_state_dict(attr_dict['state_dict'])\n\n def get_word_vector(self, word_input) :\n if word_input in self.cache_dict :\n return self.cache_dict[word_input]\n else :\n if word_input in self.word_vectors :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vectors[word_input]\n word_vector = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n word_vector = word_vector.cuda()\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_vector = self.empty_vector\n self.cache_dict[word_input] = word_vector\n return word_vector\n\n '''\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if torch.cuda.is_available():\n input = input.cuda()\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n '''\n\n # Feed forward method, input is list of word\n def forward(self, input):\n embedding_inputs = []\n for word in input :\n if (word not in self.word_vectors) and (self.char_embed) :\n inputs = [self.charbased_model.lang.word2index[c] for c in word]\n inputs = Variable(torch.LongTensor(inputs))\n if params.USE_CUDA :\n inputs = inputs.cuda()\n _, char_vector = self.charbased_model(inputs)\n embedding_inputs.append(char_vector)\n else :\n embedding_inputs.append(self.get_word_vector(word))\n return super(PreTrainedEmbeddingEncoderRNN, self).forward(embedding_inputs)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'state_dict' : self.getCpuStateDict(),\n }\n\n'''\n# Encoder using word embedding vector as input\nclass EmbeddingEncoderInputRNN(nn.Module):\n def __init__(self, hidden_size, word_vector):\n super(EmbeddingEncoderInputRNN, self).__init__(hidden_size)\n self.model_type = 'word_vector_based'\n\n # define word vector embedding\n self.word_vector = word_vector\n\n # define layers\n self.linear = nn.Linear(self.word_vector.vector_size, hidden_size)\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(self.word_vector.vector_size)])\n\n def loadAttributes(self, attr_dict) :\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if torch.cuda.is_available():\n input = input.cuda()\n\n # Feed forward to linear unit\n input = self.linear(input)\n\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n\n# Decoder\nclass AttnDecoderRNN(nn.Module):\n def __init__(self, hidden_size, lang, dropout_p=0.1, max_length=10):\n super(AttnDecoderRNN, self).__init__()\n\n # define parameters\n self.hidden_size = hidden_size\n self.output_size = lang.n_words\n self.dropout_p = dropout_p\n self.max_length = max_length\n self.lang = lang\n\n # define layers\n self.embedding = nn.Embedding(self.output_size, self.hidden_size)\n self.attn = nn.Linear(self.hidden_size * 2, self.max_length)\n self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)\n self.dropout = nn.Dropout(self.dropout_p)\n self.gru = nn.GRU(self.hidden_size, self.hidden_size)\n self.out = nn.Linear(self.hidden_size, self.output_size)\n\n def loadAttributes(self, attr_dict) :\n self.hidden_size = attr_dict['hidden_size']\n self.dropout_p = attr_dict['dropout_p']\n self.max_length = attr_dict['max_length']\n self.lang.load_dict(attr_dict['lang'])\n self.output_size = self.lang.n_words\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method\n def forward(self, input, hidden, encoder_outputs):\n embedded = self.embedding(input).view(1, 1, -1)\n embedded = self.dropout(embedded)\n\n attn_weights = F.softmax(\n self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)\n attn_applied = torch.bmm(\n attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))\n\n output = torch.cat((embedded[0], attn_applied[0]), 1)\n output = self.attn_combine(output).unsqueeze(0)\n output = F.relu(output)\n output, hidden = self.gru(output, hidden)\n output = F.log_softmax(self.out(output[0]), dim=1)\n\n return output, hidden, attn_weights\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if torch.cuda.is_available() :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return {\n 'hidden_size' : self.hidden_size,\n 'dropout_p' : self.dropout_p,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n\n"
},
{
"alpha_fraction": 0.7544209361076355,
"alphanum_fraction": 0.7641344666481018,
"avg_line_length": 46.7976188659668,
"blob_id": "72b538f20af4c1d4205c36c6a0b3b231167bdb93",
"content_id": "b6a2ffe75298eaeaa5fb86be9b6b7c2fce88ef26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4015,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 84,
"path": "/main_bidirectional.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom model_bidirectional_v1_lstm import WordEncoderBiRNN, PreTrainedEmbeddingEncoderBiRNN, PreTrainedEmbeddingWordCharEncoderBiRNN, AttnDecoderRNN\nfrom preprocess import prepareData\nfrom train_bidirectional import Trainer\nfrom preprocess import buildPairs\nfrom gensim.models import KeyedVectors\nimport params\nfrom util import load_wordvector_text\nfrom lang import Lang\n\n# train_file = '/home/prosa/Works/Text/korpus/chatbot_dataset/plain/preprocessed/split-augmented/combine/nontask/train-nontask.aug.shuffle.pre'\n# train_file = '/home/prosa/Works/Text/korpus/chatbot_dataset/plain/preprocessed/split-augmented/combine/nontask/train.test'\n# src_lang, tgt_lang, pairs = prepareData('dataset/chatbot/input-output.txt', reverse=False)\n\n# train_file = '/home/prosa/Works/Text/mt/dataset/filter-en-id/lenlim80/sorted/train.dummy'\n# train_file = '/home/prosa/Works/Text/mt/dataset/filter-en-id/lenlim80/sorted/limit-en-id.sorted.01.txt'\n# train_file = '/home/prosa/Works/Text/korpus/asr_dataset/dataset_pruned/word/dummy'\n# train_file = '/home/prosa/Works/Text/korpus/dialogue/dataset_filtered/gabung.shuffle'\n# train_file = '/home/prosa/Works/Text/korpus/dialogue/misc.txt'\n\ntrain_file = '/home/prosa/Works/Text/seq2seq/dataset/en-id-10k-v2.txt'\n\nsrc_lang, tgt_lang, pairs = prepareData(train_file, reverse=False)\n\n# Word vector\n# word_vectors = KeyedVectors.load_word2vec_format(params.WORD_VECTORS_FILE, binary=True)\n# word_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\nword_vectors = load_wordvector_text(params.WORD_VECTORS_FILE)\n\n\n############\n# folder_model = 'model/dialogue/fix/oovchar_rnn/'\n\n# folder_model = 'model/dialogue/dummy/wordchar_cnn/'\n# folder_model = 'model/dialogue/dummy/oovchar_rnn/'\nfolder_model = 'model/dialogue/dummy/wordchar_rnn/'\n# folder_model = 'model/dialogue/dummy/word/'\n\n# folder_model = 'model/dialogue/fix/oovchar_rnn/'\n# folder_model = 'model/mt/tesis/oovchar_rnn/'\n\n'''\n# Load and continue train\nencoder_file = folder_model + 'encoder-e50.pt'\ndecoder_file = folder_model + 'decoder-e50.pt'\nencoder_dict = torch.load(encoder_file)\ndecoder_dict = torch.load(decoder_file)\ndecoder_lang = Lang()\ndecoder_lang.load_dict(decoder_dict['lang'])\nencoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, encoder_dict['hidden_size'], encoder_dict['max_length'], char_embed=encoder_dict['char_embed'], seeder=params.SEEDER)\n# encoder = PreTrainedEmbeddingWordCharEncoderBiRNN(word_vectors, encoder_dict['input_size'], encoder_dict['max_length'], char_feature='cnn', seeder=params.SEEDER)\nattn_decoder = AttnDecoderRNN(decoder_dict['input_size'], decoder_dict['hidden_size'], decoder_dict['max_length'], decoder_lang, seeder=params.SEEDER)\nencoder.loadAttributes(encoder_dict)\nattn_decoder.loadAttributes(decoder_dict)\n\n'''\n\n# New model\ninput_size = word_vectors.vector_size\nhidden_size = 256\nmax_length = 50\ndropout_p = 0.0\nchar_feature = 'rnn'\n# encoder = WordEncoderBiRNN(hidden_size, max_length, src_lang, seeder=params.SEEDER)\nencoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, hidden_size, max_length, char_embed=False, dropout_p=dropout_p, seeder=params.SEEDER)\n# encoder = PreTrainedEmbeddingWordCharEncoderBiRNN(word_vectors, hidden_size, max_length, char_feature=char_feature, dropout_p=dropout_p, seeder=params.SEEDER)\nattn_decoder = AttnDecoderRNN(input_size, hidden_size*2, max_length, tgt_lang, dropout_p=dropout_p, seeder=params.SEEDER)\n\n\nfolder_model_2 = folder_model\nnum_iter = len(pairs)\nepoch = 50\nlr = 0.001\nbatch_size = 4\nsave_every = 5\ntrainer = Trainer(pairs, encoder, attn_decoder)\ntrainer.train_batch(learning_rate=lr, print_every=17, epoch=epoch, batch_size=batch_size, save_every=save_every, folder_model=folder_model_2)\ntrainer.evaluateRandomly(n=100)\n# trainer.evaluateTrainSet()\n\n# torch.save(encoder.getAttrDict(), folder_model + 'encoder-final-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n# torch.save(attn_decoder.getAttrDict(), folder_model + 'decoder-final-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n#################\n"
},
{
"alpha_fraction": 0.7409836053848267,
"alphanum_fraction": 0.757377028465271,
"avg_line_length": 36.19512176513672,
"blob_id": "da7523d6130e3371d3818f77f9dbc96244eeef05",
"content_id": "254411e88b744c757516d11bd00e34eeba01495f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1525,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 41,
"path": "/main_wordembed2.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom model import EncoderRNN, EncoderEmbeddingInputRNN, AttnDecoderRNN\nfrom preprocess import prepareData\nfrom train_wordembed2 import Trainer\nfrom preprocess import buildPairs\nfrom gensim.models import KeyedVectors\n\nuse_cuda = torch.cuda.is_available()\n\nsrc_lang, tgt_lang, pairs = prepareData('dataset/input-output.txt', reverse=False)\n\n# Word vector\nword_vector = KeyedVectors.load_word2vec_format(\"word_vector/koran.vec\", binary=True)\n\nhidden_size = 64\nmax_len = 50\nencoder = EncoderEmbeddingInputRNN(src_lang.n_words, hidden_size, word_vector)\nattn_decoder = AttnDecoderRNN(hidden_size, tgt_lang.n_words, dropout_p=0.1, max_length=max_len)\n\nif use_cuda:\n encoder = encoder.cuda()\n attn_decoder = attn_decoder.cuda()\n\nnum_iter = 100000\ntrainer = Trainer(src_lang, tgt_lang, pairs)\ntrainer.train(encoder, attn_decoder, num_iter, print_every=num_iter//100, max_len=max_len)\ntrainer.evaluateRandomly(encoder, attn_decoder, max_len=max_len)\n# trainer.evaluateAll(encoder, attn_decoder)\n\nencoder.saveState('model/encoder-embedding2-h64' + str(num_iter) + '.pt')\nattn_decoder.saveState('model/decoder-embedding2-h64' + str(num_iter) + '.pt')\n\n# Open testfile as test and build pairs from it\n# test_pairs = buildPairs(\"corpus/test-ind-eng.txt\")\n\n# Test using test data\n# trainer.evaluateFromTest(test_pairs, encoder, attn_decoder, max_len=max_len)\n\n# encoder.saveState('checkpoint/encoder-ind-eng-' + str(num_iter*2) + '.pt')\n# attn_decoder.saveState('checkpoint/decoder-ind-eng-' + str(num_iter*2) + '.pt')\n"
},
{
"alpha_fraction": 0.6286153793334961,
"alphanum_fraction": 0.6353846192359924,
"avg_line_length": 30.563106536865234,
"blob_id": "e2d9637e515dec5e027301e30c7110461829b4d1",
"content_id": "a87171a36dea36f24ee85f78e4c5ecf26ab4a38e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3250,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 103,
"path": "/preprocess.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals, print_function, division\nfrom io import open\nimport unicodedata\nimport re\nimport os\n\nfrom lang import Lang\n\nimport util\n\n# --- NORMALIZATION: TO CLEAN UNICODE CHARACTERS ----\n\nMAX_LEN = 80\n\ndef unicodeToAscii(sentence):\n return ''.join(\n c for c in unicodedata.normalize('NFD', sentence)\n if unicodedata.category(c) != 'Mn'\n )\n\ndef normalizeString(sentence):\n # sentence = unicodeToAscii(sentence.lower().strip())\n # sentence = re.sub(r\"([,.;?!'\\\"\\-()<>[\\]/\\\\&$%*@~+=])\", r\" \\1 \", sentence)\n # sentence = re.sub(r\"[^a-zA-Z0-9,.;?!'\\\"\\-()<>[\\]/\\\\&$%*@~+=]+\", r\" \", sentence)\n return sentence\n\ndef filterPair(pair):\n return True\n # return len(pair[0].split()) < MAX_LEN and len(pair[1].split()) < MAX_LEN\n\ndef filterPairs(pairs):\n return [pair for pair in pairs if filterPair(pair)]\n\n# main function, readLang + prepareData\ndef readLang(filepath, reverse=False):\n print(\"reading lines...\")\n\n # read the file and split into lines\n lines = open(filepath, encoding='utf-8').read().strip().split('\\n')\n\n # getting the language names from filename\n # filename = os.path.splitext(os.path.basename(filepath))[0]\n # lang = filename.split('-')\n\n # split every line into pairs and normalize\n # pairs = [[normalizeString(s) for s in l.split('\\t')] for l in lines]\n\n # For chatbot, normalize only input side\n pairs = []\n for l in lines :\n split = l.split('\\t')\n pairs.append([split[0], split[1]])\n # pairs.append( [util.normalize_no_punc(split[0]), split[1]] )\n # pairs.append( [util.normalize_no_punc(split[0]), split[2]] )\n\n # reverse pairs if needed, make lang instances\n if reverse:\n pairs = [list(reversed(p)) for p in pairs]\n source_lang = Lang()\n target_lang = Lang()\n else:\n source_lang = Lang()\n target_lang = Lang()\n\n return source_lang, target_lang, pairs\n\n\ndef prepareData(filepath, reverse=False):\n\n # reading input file, obtaib lang names, initiate lang instances\n source_lang, target_lang, pairs = readLang(filepath, reverse)\n print('read {} sentence pairs.'.format(len(pairs)))\n\n # dummy filtering process, fastening the dev check\n # pairs = filterPairs(pairs)\n # print('reduced to {} sentence pairs.'.format(len(pairs)))\n\n # mapping vocabs/words in each languages into indexes\n print('counting words...')\n for pair in pairs:\n source_lang.addSentence(pair[0])\n target_lang.addSentence(pair[1])\n\n # for checking / logging purpose\n print('counted words:')\n print('> {0}: {1}'.format('source', source_lang.n_words))\n print('> {0}: {1}'.format('target', target_lang.n_words))\n\n return source_lang, target_lang, pairs\n\ndef buildPairs(filepath) :\n # read the file and split into lines\n lines = open(filepath, encoding='utf-8').read().strip().split('\\n')\n\n # split every line into pairs and normalize\n pairs = [[normalizeString(s) for s in l.split('\\t')] for l in lines]\n print('read {} sentence pairs.'.format(len(pairs)))\n\n # dummy filtering process, fastening the dev check\n pairs = filterPairs(pairs)\n print('reduced to {} sentence pairs.'.format(len(pairs)))\n\n return pairs"
},
{
"alpha_fraction": 0.6741889715194702,
"alphanum_fraction": 0.6826516389846802,
"avg_line_length": 38.831459045410156,
"blob_id": "9afa3d64ea1bd4bcfaa73d3758092ab1403d3610",
"content_id": "cbae187e12230d32a46901f67d4626182d7ff0a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3545,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 89,
"path": "/cross_calidation.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\n\nfrom gensim.models import FastText\nfrom gensim.models import KeyedVectors\nfrom preprocess import prepareData\nfrom model_bidirectional import WordEncoderBiRNN, PreTrainedEmbeddingEncoderBiRNN, AttnDecoderRNN\nfrom train_bidirectional import Trainer\nimport params\n\nroot_folder = '/home/prosa/Works/Text/'\ndataset_folder = root_folder + 'korpus/chatbot_dataset/'\n\nsrc_lang, tgt_lang, pairs = prepareData(dataset_folder + 'input-response.shuffle', reverse=False)\nword_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n# word_vectors = FastText.load_fasttext_format(params.WORD_VECTORS_FILE)\n\nhidden_size = word_vectors.vector_size\nmax_length = 50\nk_validation = 10\nn_data = len(pairs)\nlast_idx = 0\nepoch = 5\n\ntests = []\noutputs = []\nrefs = []\n\nfor k in range(k_validation) :\n # Prepare dataset for kth-fold\n ntest = n_data//k_validation\n if k < n_data%k_validation :\n ntest += 1\n test_set = pairs[last_idx:last_idx+ntest]\n train_set = pairs[:last_idx] + pairs[last_idx+ntest:]\n last_idx += ntest\n\n # Train\n num_iter = len(train_set)\n encoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, max_length)\n decoder = AttnDecoderRNN(2*hidden_size, max_length, tgt_lang)\n trainer = Trainer(train_set, encoder, decoder)\n print(\"Training fold-%d (%d data)...\"%(k+1, len(train_set)))\n trainer.train(num_iter, print_every=num_iter//100, epoch=epoch)\n\n # Validation\n print(\"Validation fold-%d (%d data)...\"%(k+1, len(test_set)))\n for pair in test_set :\n tests.append(pair[0])\n refs.append(pair[1])\n decoded_words, _ = trainer.evaluate(pair[0])\n if decoded_words[-1] == '<EOS>' :\n decoded_words = decoded_words[:-1]\n outputs.append(' '.join(decoded_words))\n\n# Write results to file\n# test_file = 'test/chatbot/fasttext/combined_cbow/test-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\n# output_file = 'test/chatbot/fasttext/combined_cbow/output-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\n# ref_file = 'test/chatbot/fasttext/combined_cbow/ref-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\n\n# Word2vec\ntest_file = 'test/chatbot/word2vec/codot_cbow/test-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\noutput_file = 'test/chatbot/word2vec/codot_cbow/output-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\nref_file = 'test/chatbot/word2vec/codot_cbow/ref-d' + str(hidden_size) + '-e' + str(epoch) + '.txt'\n\nfileouts = [test_file, output_file, ref_file]\ndataouts = [tests, outputs, refs]\n\nfor i in range(len(dataouts)) :\n fout = open(fileouts[i], 'w', encoding='utf-8')\n for sent in dataouts[i] :\n fout.write(\"%s\\n\"%(sent))\n fout.close()\n\n# Build final model\nprint('\\nBuild final model...')\nnum_iter = len(pairs)\nencoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, max_length)\ndecoder = AttnDecoderRNN(2*hidden_size, max_length, tgt_lang)\ntrainer = Trainer(pairs, encoder, decoder)\ntrainer.train(num_iter, print_every=num_iter//100, epoch=epoch)\n\n# Save model\n# FastText\n# torch.save(encoder.getAttrDict(), 'model/chatbot/fasttext/combined_cbow/encoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n# torch.save(decoder.getAttrDict(), 'model/chatbot/fasttext/combined_cbow/decoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n\n# Word2vec\ntorch.save(encoder.getAttrDict(), 'model/chatbot/word2vec/codot_cbow/encoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\ntorch.save(decoder.getAttrDict(), 'model/chatbot/word2vec/codot_cbow/decoder-d' + str(hidden_size) + '-e' + str(epoch) + '.pt')\n"
},
{
"alpha_fraction": 0.590260922908783,
"alphanum_fraction": 0.5966776013374329,
"avg_line_length": 36.10317611694336,
"blob_id": "93d92b00513cd12a9b4684ebc5d929f787cc89a0",
"content_id": "c1c8e4c21ce74fd39dd445223c771663d2f6375a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14026,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 378,
"path": "/model_bidirectional_v1.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport numpy as np\nfrom torch.autograd import Variable\nfrom gensim.models import KeyedVectors\nfrom lang import Lang\nimport params\nimport random\nimport time\n\n# Encoder base class, only contains hidden_size, gru layer, and empty vector\nclass BaseEncoderBiRNN(nn.Module):\n def __init__(self, hidden_size, max_length, seeder=int(time.time()) ):\n super(BaseEncoderBiRNN, self).__init__()\n self.hidden_size = hidden_size\n self.max_length = max_length\n self.model_type = 'base'\n random.seed(seeder)\n torch.manual_seed(seeder)\n if params.USE_CUDA :\n torch.cuda.manual_seed_all(seeder)\n\n # Forward and backward RNN\n self.fwd_gru = nn.GRU(hidden_size, hidden_size)\n self.rev_gru = nn.GRU(hidden_size, hidden_size)\n\n # Linear nn\n # self.projection = nn.Linear(hidden_size*2, hidden_size)\n\n if params.USE_CUDA :\n self.cuda()\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(hidden_size)])\n\n # Input is list of embedding\n def forward(self, input):\n embedding_inputs = input\n\n # Forward to fwd_gru unit\n fwd_hidden = self.initHidden()\n fwd_outputs = Variable(torch.zeros(self.max_length, self.hidden_size))\n if params.USE_CUDA :\n fwd_outputs = fwd_outputs.cuda()\n for k,embed in enumerate(embedding_inputs) :\n fwd_output,fwd_hidden = self.fwd_gru(embed, fwd_hidden)\n fwd_outputs[k] = fwd_output[0][0]\n\n # Forward to rev_gru unit\n rev_hidden = self.initHidden()\n rev_outputs = Variable(torch.zeros(self.max_length, self.hidden_size))\n if params.USE_CUDA :\n rev_outputs = rev_outputs.cuda()\n n = len(embedding_inputs)-1\n for i in range(n,-1,-1) :\n rev_output,rev_hidden = self.rev_gru(embedding_inputs[i], rev_hidden)\n rev_outputs[i] = rev_output[0][0]\n \n # Concatenate fwd_output and rev_output\n outputs = torch.cat( (fwd_outputs, rev_outputs), 1 )\n hidden = torch.cat( (fwd_hidden, rev_hidden), 2 )\n \n if params.USE_CUDA :\n # return outputs.cuda(), hidden.cuda()\n outputs = outputs.cuda()\n hidden = hidden.cuda()\n\n # projected_output = self.projection(hidden)\n projected_output = hidden\n\n return outputs, hidden, projected_output\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return result.cuda()\n else:\n return result\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if params.USE_CUDA :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return None\n\n def loadAttributes(self, attr_dict):\n self.hidden_size = attr_dict['hidden_size']\n self.max_length = attr_dict['max_length']\n self.model_type = attr_dict['model_type']\n\n# Encoder word based\nclass WordEncoderBiRNN(BaseEncoderBiRNN):\n def __init__(self, hidden_size, max_length, lang, seeder=int(time.time())):\n super(WordEncoderBiRNN, self).__init__(hidden_size, max_length, seeder=seeder)\n self.model_type = 'word_based'\n\n # define parameters\n self.lang = lang\n self.input_size = lang.n_words\n\n # define layers\n self.embedding = nn.Embedding(self.input_size, hidden_size)\n\n # empty vector for oov\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n\n def loadAttributes(self, attr_dict) :\n super(WordEncoderBiRNN, self).loadAttributes(attr_dict)\n self.lang.load_dict(attr_dict['lang'])\n self.input_size = self.lang.n_words\n self.load_state_dict(attr_dict['state_dict'])\n if params.USE_CUDA :\n self.cuda()\n\n # Feed forward method, input is a list of index word (list of torch.autograd.Variable)\n def forward(self, input):\n # Get embedding vector\n embedding_inputs = []\n for idx in input :\n if idx.data.item() != params.OOV_INDEX :\n embed = self.embedding(idx).view(1,1,-1)\n else :\n embed = self.empty_vector\n embedding_inputs.append(embed)\n\n return super(WordEncoderBiRNN, self).forward(embedding_inputs)\n\n # Get word index of every word in sentence\n def get_indexes(self, sentence, reverse_direction=False) :\n if not reverse_direction :\n arr = [self.lang.word2index[word] if word in self.lang.word2index else -1 for word in sentence]\n else :\n arr = [self.lang.word2index[sentence[i]] if sentence[i] in self.lang.word2index else -1 for i in range(len(sentence)-1,-1,-1)]\n retval = Variable(torch.LongTensor(arr))\n if params.USE_CUDA :\n return retval.cuda()\n return retval\n\n # Get dict representation of attributes\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n\n# Encoder using pre trained word embedding\nclass PreTrainedEmbeddingEncoderBiRNN(BaseEncoderBiRNN) :\n def __init__(self, word_vectors, max_length, char_embed=False, seeder=int(time.time())):\n super(PreTrainedEmbeddingEncoderBiRNN, self).__init__(word_vectors.vector_size, max_length, seeder=seeder)\n self.model_type = 'pre_trained_embedding'\n\n # define word vector embedding\n self.word_vectors = word_vectors\n\n # empty vector for oov\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n\n # char embed\n self.char_embed = char_embed\n if self.char_embed :\n lang = Lang()\n lang.word2index = dict()\n lang.index2word = dict()\n lang.n_words = 0\n chars = 'abcdefghijklmnopqrstuvwxyz0123456789'\n for c in chars :\n lang.addWord(c)\n self.charbased_model = WordEncoderBiRNN(self.hidden_size//2, params.CHAR_LENGTH, lang, seeder=seeder)\n\n # word vector for start of string\n sos = torch.ones(self.hidden_size)\n self.sos_vector = Variable(sos).view(1, 1, -1)\n\n # word vector for end of string\n eos = torch.ones(self.hidden_size) * -1\n self.eos_vector = Variable(eos).view(1, 1, -1)\n\n if params.USE_CUDA :\n self.cuda()\n self.empty_vector = self.empty_vector.cuda()\n self.sos_vector = self.sos_vector.cuda()\n self.eos_vector = self.eos_vector.cuda()\n\n self.cache_dict = dict()\n self.cache_dict[params.SOS_TOKEN] = self.sos_vector\n self.cache_dict[params.EOS_TOKEN] = self.eos_vector\n\n def loadAttributes(self, attr_dict) :\n super(PreTrainedEmbeddingEncoderBiRNN, self).loadAttributes(attr_dict)\n self.hidden_size = attr_dict['hidden_size']\n self.max_length = attr_dict['max_length']\n self.load_state_dict(attr_dict['state_dict'])\n\n def get_word_vector(self, word_input) :\n if word_input in self.cache_dict :\n return self.cache_dict[word_input]\n else :\n if word_input in self.word_vectors :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vectors[word_input]\n word_vector = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n word_vector = word_vector.cuda()\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_vector = self.empty_vector\n self.cache_dict[word_input] = word_vector\n return word_vector\n\n # Feed forward method, input is list of word\n def forward(self, input):\n embedding_inputs = []\n for word in input :\n if (word not in self.word_vectors) and (self.char_embed) :\n inputs = [self.charbased_model.lang.word2index[c] for c in word]\n inputs = Variable(torch.LongTensor(inputs))\n if params.USE_CUDA :\n inputs = inputs.cuda()\n _, _, char_vector = self.charbased_model(inputs)\n embedding_inputs.append(char_vector)\n else :\n embedding_inputs.append(self.get_word_vector(word))\n return super(PreTrainedEmbeddingEncoderBiRNN, self).forward(embedding_inputs)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'char_embed' : self.char_embed,\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n# Encoder using word embedding vector as input\nclass EmbeddingEncoderInputBiRNN(nn.Module):\n def __init__(self, hidden_size, word_vector):\n super(EmbeddingEncoderInputBiRNN, self).__init__(hidden_size)\n self.model_type = 'word_vector_based'\n\n # define word vector embedding\n self.word_vector = word_vector\n\n # define layers\n self.linear = nn.Linear(self.word_vector.vector_size, hidden_size)\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(self.word_vector.vector_size)])\n\n def loadAttributes(self, attr_dict) :\n super(EmbeddingEncoderInputBiRNN, self).loadAttributes(attr_dict)\n self.max_length = attr_dict['max_length']\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if params.USE_CUDA:\n input = input.cuda()\n\n # Feed forward to linear unit\n input = self.linear(input)\n\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def getAttrDict(self):\n return {\n 'model_type' : self.model_type,\n 'hidden_size' : self.hidden_size,\n 'max_length' : self.max_length,\n 'state_dict' : self.getCpuStateDict(),\n }\n'''\n# Decoder\nclass AttnDecoderRNN(nn.Module):\n def __init__(self, hidden_size, max_length, lang, dropout_p=0.1, seeder=int(time.time()) ):\n super(AttnDecoderRNN, self).__init__()\n random.seed(seeder)\n torch.manual_seed(seeder)\n if params.USE_CUDA :\n torch.cuda.manual_seed_all(seeder)\n\n # define parameters\n self.hidden_size = hidden_size\n self.output_size = lang.n_words\n self.dropout_p = dropout_p\n self.max_length = max_length\n self.lang = lang\n\n # define layers\n self.embedding = nn.Embedding(self.output_size, self.hidden_size)\n self.attn = nn.Linear(self.hidden_size * 2, self.max_length)\n # self.attn_combine = nn.Linear(self.hidden_size * 3, self.hidden_size)\n self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)\n self.dropout = nn.Dropout(self.dropout_p)\n self.gru = nn.GRU(self.hidden_size, self.hidden_size)\n self.out = nn.Linear(self.hidden_size, self.output_size)\n\n if params.USE_CUDA :\n self.cuda()\n\n def loadAttributes(self, attr_dict) :\n self.hidden_size = attr_dict['hidden_size']\n self.dropout_p = attr_dict['dropout_p']\n self.max_length = attr_dict['max_length']\n self.lang.load_dict(attr_dict['lang'])\n self.output_size = self.lang.n_words\n self.load_state_dict(attr_dict['state_dict'])\n\n # Feed forward method, input is index of word (Variable)\n def forward(self, input, hidden, encoder_outputs):\n embedded = self.embedding(input).view(1, 1, -1)\n embedded = self.dropout(embedded)\n\n attn_input = torch.cat((embedded[0], hidden[0]), 1)\n attn_weights = F.softmax(self.attn(attn_input), dim=1)\n attn_applied = torch.bmm(\n attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))\n\n output = torch.cat((embedded[0], attn_applied[0]), 1)\n output = self.attn_combine(output).unsqueeze(0)\n output = F.relu(output)\n output, hidden = self.gru(output, hidden)\n output = F.log_softmax(self.out(output[0]), dim=1)\n\n return output, hidden, attn_weights\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if params.USE_CUDA:\n return result.cuda()\n else:\n return result\n\n def getCpuStateDict(self) :\n state_dict = self.state_dict()\n if params.USE_CUDA :\n for key in state_dict :\n state_dict[key] = state_dict[key].cpu()\n return state_dict\n\n def getAttrDict(self):\n return {\n 'hidden_size' : self.hidden_size,\n 'dropout_p' : self.dropout_p,\n 'max_length' : self.max_length,\n 'lang' : self.lang.getAttrDict(),\n 'state_dict' : self.getCpuStateDict(),\n }\n\n"
},
{
"alpha_fraction": 0.7093785405158997,
"alphanum_fraction": 0.733466386795044,
"avg_line_length": 48.751773834228516,
"blob_id": "e3efa65c0d716974996221225a2a656f4a24be4a",
"content_id": "9f723f832163beeceaf06b5511ebd60ec2a4f156",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7016,
"license_type": "no_license",
"max_line_length": 242,
"num_lines": 141,
"path": "/inference_bidirectional.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nfrom train_bidirectional import Trainer\n# from model_bidirectional import WordEncoderBiRNN, PreTrainedEmbeddingEncoderBiRNN, AttnDecoderRNN\nfrom model_bidirectional_v1_lstm import WordEncoderBiRNN, PreTrainedEmbeddingEncoderBiRNN, PreTrainedEmbeddingWordCharEncoderBiRNN, AttnDecoderRNN\nfrom preprocess import prepareData, unicodeToAscii, normalizeString\nimport util\nfrom lang import Lang\nimport params\nfrom gensim.models import KeyedVectors\nfrom gensim.models import FastText\n\ndef preprocessSentence(sentence, max_len) :\n # sentence = normalizeString(unicodeToAscii(sentence))\n # sentence = util.normalizeString(sentence)\n # sentence = util.normalize_no_punc(sentence)\n split = sentence.split()\n if len(split) >= max_len :\n split = split[:max_len-1]\n return ' '.join(split)\n\n# Model files\n# encoder_file = 'model/mt/encoder-word-en-id-d256-i20k.pt'\n# decoder_file = 'model/mt/decoder-word-en-id-d256-i20k.pt'\n# encoder_file = 'model/chatbot/fasttext/twitter_cbow/encoder-d100-e5.pt'\n# decoder_file = 'model/chatbot/fasttext/twitter_cbow/decoder-d100-e5.pt'\n# encoder_file = 'model/chatbot/augmented_data/word2vec/cbow/combined_cbow/charembed_encoder-d100-e3-v2.pt'\n# decoder_file = 'model/chatbot/augmented_data/word2vec/cbow/combined_cbow/charembed_decoder-d100-e3-v2.pt'\n# encoder_file = 'model/dialogue/encoder-charembed-d50-e100.pt'\n# decoder_file = 'model/dialogue/decoder-charembed-d50-e100.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/fix/word/encoder-e15.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/fix/word/decoder-e15.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/word/lr10-3/encoder-e50.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/word/lr10-3/decoder-e50.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_rnn/encoder-e50.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_rnn/decoder-e50.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn/encoder-e25.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn/decoder-e25.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/word/encoder-e50.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/word/decoder-e50.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/oovchar_rnn/encoder-e100.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/oovchar_rnn/decoder-e100.pt'\n\nencoder_file = 'model/mt/tesis/wordchar_rnn/do_0_5/encoder-e100.pt'\ndecoder_file = 'model/mt/tesis/wordchar_rnn/do_0_5/decoder-e100.pt'\n\n# encoder_file = 'model/mt/tesis/wordchar_cnn/do_0_5/encoder-e100.pt' \n# decoder_file = 'model/mt/tesis/wordchar_cnn/do_0_5/decoder-e100.pt' \n\n# encoder_file = 'model/mt/tesis/word/do_0_5/encoder-e100.pt'\n# decoder_file = 'model/mt/tesis/word/do_0_5/decoder-e100.pt'\n\n# encoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn_rnn/avg/encoder-e50.pt'\n# decoder_file = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn_rnn/avg/decoder-e50.pt'\n\nencoder_attr_dict = torch.load(encoder_file)\ndecoder_attr_dict = torch.load(decoder_file)\n\n# Lang\n# encoder_lang = Lang()\ndecoder_lang = Lang()\n# encoder_lang.load_dict(encoder_attr_dict['lang'])\ndecoder_lang.load_dict(decoder_attr_dict['lang'])\n\n# Word vectors\n# word_vectors = KeyedVectors.load_word2vec_format(params.WORD_VECTORS_FILE, binary=True)\n# word_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n# word_vectors = FastText.load_fasttext_format(params.WORD_VECTORS_FILE)\nword_vectors = util.load_wordvector_text(params.WORD_VECTORS_FILE)\n\n# encoder_attr_dict['dropout_p'] = 0.0\n\n# Encoder & Decoder\n# encoder = WordEncoderBiRNN(encoder_attr_dict['hidden_size'], encoder_attr_dict['max_length'], encoder_lang)\n# encoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, encoder_attr_dict['hidden_size'] , encoder_attr_dict['max_length'], dropout_p=encoder_attr_dict['dropout_p'], char_embed=encoder_attr_dict['char_embed'])\nencoder = PreTrainedEmbeddingWordCharEncoderBiRNN(word_vectors, encoder_attr_dict['hidden_size'], encoder_attr_dict['max_length'], char_feature=encoder_attr_dict['char_feature'], dropout_p=encoder_attr_dict['dropout_p'], seeder=params.SEEDER)\nencoder.loadAttributes(encoder_attr_dict)\nattn_decoder = AttnDecoderRNN(decoder_attr_dict['input_size'], decoder_attr_dict['hidden_size'], decoder_attr_dict['max_length'], decoder_lang, dropout_p=decoder_attr_dict['dropout_p'])\nencoder.loadAttributes(encoder_attr_dict)\nattn_decoder.loadAttributes(decoder_attr_dict)\n\n# Trainer\ntrainer = Trainer([], encoder, attn_decoder)\n\n'''\nsentence = input(\"Input : \")\nwhile (sentence != \"<end>\") :\n sentence = preprocessSentence(sentence, attn_decoder.max_length)\n output_words, attentions = trainer.evaluate(sentence)\n output = ' '.join(output_words[:-1])\n print(output)\n # output = trainer.evaluate_beam_search(sentence, 5)\n # output = [ sent[1:-1] for sent in output ]\n # output = [ ' '.join(item) for item in output ]\n # print(output)\n sentence = input(\"Input : \")\n\n'''\n\n# file_test = \"/home/prosa/Works/Text/korpus/dialogue/dataset/testset/testset1k.txt\"\n# file_test = '/home/prosa/Works/Text/korpus/dialogue/misc.txt'\n# file_test = '/home/prosa/Works/Text/seq2seq/dataset/en-id-10k-v2.txt'\nfile_test = '/home/prosa/Works/Text/seq2seq/test/mt/test-en-id-1k.v2.txt'\nresults = []\nhit = 0\nn_test = 1\nbeam_search = True\nbeam_width = 5\nwith open(file_test, \"r\", encoding=\"utf-8\") as f :\n for line in f :\n line = line.strip()\n split = line.split('\\t')\n if (beam_search) :\n outputs = trainer.evaluate_beam_search(split[0], beam_width)\n output = outputs[0][1:-1]\n output = ' '.join(output)\n else :\n output_words, attentions = trainer.evaluate(split[0])\n output = ' '.join(output_words[:-1])\n results.append(output)\n\n\n# file_out = \"/home/prosa/Works/Text/seq2seq/test/dialogue/fix/word/output1k.txt\"\n# file_out = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/word/hyp.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_rnn/hyp-beam-3.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn/hyp.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/dialogue/dummy/wordchar_cnn_rnn/avg/hyp.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/oovchar_rnn/hyp.txt'\nfile_out = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/wordchar_rnn/do_0_5/hyp-beam-5.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/word/do_0_5/hyp-beam-5.txt'\n# file_out = '/home/prosa/Works/Text/seq2seq/model/mt/tesis/wordchar_cnn/do_0_5/hyp-beam-3.txt'\nfout = open(file_out, \"w\", encoding=\"utf-8\")\nfor result in results :\n fout.write(\"%s\\n\"%(result))\n# fout.write(\"Akurasi : %.4f\"%(hit/n_test))\nfout.close()\n\n"
},
{
"alpha_fraction": 0.6135677099227905,
"alphanum_fraction": 0.6211205720901489,
"avg_line_length": 35.22885513305664,
"blob_id": "c14ccb669a92a568d3c4e1d5423155572dadd99d",
"content_id": "b66b676c359b0b602fc49e9db3c2c50a17354acb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7282,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 201,
"path": "/model.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport numpy as np\nfrom torch.autograd import Variable\nfrom gensim.models import KeyedVectors\n\nOOV_INDEX = -1 # Word index to represent oov word\n\n# Encoder word based\nclass EncoderRNN(nn.Module):\n def __init__(self, input_size, hidden_size):\n super(EncoderRNN, self).__init__()\n\n # define parameters\n self.hidden_size = hidden_size # Dimension of embedding word vector\n\n # define layers\n self.embedding = nn.Embedding(input_size, hidden_size)\n self.gru = nn.GRU(hidden_size, hidden_size)\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(hidden_size)])\n self.empty_vector = Variable(torch.Tensor(self.empty_vector)).view(1, 1, -1)\n if torch.cuda.is_available() :\n self.empty_vector = self.empty_vector.cuda()\n\n # Feed forward method, input is index of word\n def forward(self, input, hidden):\n # If word is not oov, take embedding vector of it\n if input.data[0] != OOV_INDEX :\n embedded = self.embedding(input).view(1, 1, -1)\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n embedded = self.empty_vector\n output = embedded\n # Forward to GRU unit\n output, hidden = self.gru(output, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def loadState(self, filepath):\n self.load_state_dict(torch.load(filepath, map_location=lambda storage, loc: storage))\n # self.load_state_dict(torch.load(filepath))\n\n# Encoder using pre trained word embedding\nclass EncoderEmbeddingRNN(nn.Module):\n def __init__(self, input_size, hidden_size, word_vector):\n super(EncoderEmbeddingRNN, self).__init__()\n\n # define parameters\n self.hidden_size = hidden_size # Dimension of embedding word vector\n\n # define layers\n self.gru = nn.GRU(hidden_size, hidden_size)\n\n # define word vector embedding\n self.word_vector = word_vector\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(hidden_size)])\n\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if torch.cuda.is_available():\n input = input.cuda()\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def loadState(self, filepath):\n self.load_state_dict(torch.load(filepath, map_location=lambda storage, loc: storage))\n # self.load_state_dict(torch.load(filepath))\n\n# Encoder using pre-trained embedding as input\nclass EncoderEmbeddingInputRNN(nn.Module):\n def __init__(self, input_size, hidden_size, word_vector):\n super(EncoderEmbeddingInputRNN, self).__init__()\n\n # define parameters\n self.hidden_size = hidden_size # Dimension of embedding word vector\n\n # define word vector embedding\n self.word_vector = word_vector\n\n # define layers\n self.linear = nn.Linear(self.word_vector.vector_size, hidden_size)\n self.gru = nn.GRU(hidden_size, hidden_size)\n\n # define empty word vector (oov)\n self.empty_vector = np.array([0. for _ in range(self.word_vector.vector_size)])\n\n # Feed forward method, input is a word\n def forward(self, input, hidden):\n if input in self.word_vector :\n # If word is not oov, take embedding vector of it\n word_embed = self.word_vector[input]\n else :\n # Word is oov, take [0, 0, 0, ...] as embedding vectors\n word_embed = self.empty_vector\n input = Variable(torch.Tensor(word_embed)).view(1, 1, -1)\n if torch.cuda.is_available():\n input = input.cuda()\n\n # Feed forward to linear unit\n input = self.linear(input)\n\n # Feed forward to gru unit\n output, hidden = self.gru(input, hidden)\n return output, hidden\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def loadState(self, filepath):\n self.load_state_dict(torch.load(filepath, map_location=lambda storage, loc: storage))\n # self.load_state_dict(torch.load(filepath))\n\n# Decoder\nclass AttnDecoderRNN(nn.Module):\n def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=10):\n super(AttnDecoderRNN, self).__init__()\n\n # define parameters\n self.hidden_size = hidden_size\n self.output_size = output_size\n self.dropout_p = dropout_p\n self.max_length = max_length\n\n # define layers\n self.embedding = nn.Embedding(self.output_size, self.hidden_size)\n self.attn = nn.Linear(self.hidden_size * 2, self.max_length)\n self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)\n self.dropout = nn.Dropout(self.dropout_p)\n self.gru = nn.GRU(self.hidden_size, self.hidden_size)\n self.out = nn.Linear(self.hidden_size, self.output_size)\n\n # Feed forward method\n def forward(self, input, hidden, encoder_outputs):\n embedded = self.embedding(input).view(1, 1, -1)\n embedded = self.dropout(embedded)\n\n attn_weights = F.softmax(\n self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)\n attn_applied = torch.bmm(\n attn_weights.unsqueeze(0), encoder_outputs.unsqueeze(0))\n\n output = torch.cat((embedded[0], attn_applied[0]), 1)\n output = self.attn_combine(output).unsqueeze(0)\n output = F.relu(output)\n output, hidden = self.gru(output, hidden)\n output = F.log_softmax(self.out(output[0]), dim=1)\n\n return output, hidden, attn_weights\n\n def initHidden(self):\n result = Variable(torch.zeros(1, 1, self.hidden_size))\n if torch.cuda.is_available():\n return result.cuda()\n else:\n return result\n\n def saveState(self, filepath):\n torch.save(self.state_dict(), filepath)\n\n def loadState(self, filepath):\n self.load_state_dict(torch.load(filepath, map_location=lambda storage, loc: storage))\n # self.load_state_dict(torch.load(filepath))\n"
},
{
"alpha_fraction": 0.5185528993606567,
"alphanum_fraction": 0.5445268750190735,
"avg_line_length": 31.696969985961914,
"blob_id": "471ead3fe995b1148e3012f23704e03cf453e4fa",
"content_id": "829a601124b473fdc0d84d4ee8858a101aa44786",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 33,
"path": "/lang.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "class Lang:\n def __init__(self):\n self.word2index = {'<SOS>': 0, '<EOS>': 1}\n self.word2count = {}\n self.index2word = {0: '<SOS>', 1: '<EOS>'}\n self.n_words = 2 # for indexing purpose? is it needed?\n\n def load_dict(self, attrDict) :\n self.word2index = attrDict['word2index']\n self.word2count = attrDict['word2count']\n self.index2word = attrDict['index2word']\n self.n_words = attrDict['n_words']\n\n def addSentence(self, sentence):\n for word in sentence.split():\n self.addWord(word)\n\n def addWord(self, word):\n if word not in self.word2index:\n self.word2index[word] = self.n_words\n self.word2count[word] = 1\n self.index2word[self.n_words] = word\n self.n_words += 1\n else:\n self.word2count[word] += 1\n\n def getAttrDict(self) :\n return {\n 'word2index' : self.word2index,\n 'word2count' : self.word2count,\n 'index2word' : self.index2word,\n 'n_words' : self.n_words\n }"
},
{
"alpha_fraction": 0.5640548467636108,
"alphanum_fraction": 0.572890043258667,
"avg_line_length": 36.2337646484375,
"blob_id": "d93e4568d809e0de1d03485d17d54dcd49218acd",
"content_id": "bb2699bf7ce8640b9e4b5f8a3de3aa5d5784b82f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8602,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 231,
"path": "/train_wordembed2.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import time\nimport random\n\nimport torch\nimport torch.nn as nn\nfrom torch.autograd import Variable\nfrom torch import optim\n\nfrom utility.timehelper import timeSince\n\nSOS_token = 0\nEOS_token = 1\n\nuse_cuda = torch.cuda.is_available()\n\n\nclass Trainer:\n def __init__(self, source_lang, target_lang, pairs, teacher_forcing_r=0.5):\n self.source_lang = source_lang\n self.target_lang = target_lang\n self.pairs = pairs\n self.teacher_forcing_r = teacher_forcing_r\n\n # Function for transforming sentence to sequence of indexes (based on dict)\n def indexesFromSentence(self, lang, sentence):\n return [lang.word2index[word] for word in sentence.split(' ')]\n\n def variableFromSentence(self, lang, sentence):\n indexes = self.indexesFromSentence(lang, sentence)\n indexes.append(EOS_token)\n var = Variable(torch.LongTensor(indexes).view(-1, 1))\n if use_cuda:\n return var.cuda()\n else:\n return var\n\n def variablesFromPair(self, pair):\n source_var = pair[0].split()\n target_var = self.variableFromSentence(self.target_lang, pair[1])\n return source_var, target_var\n\n # Function to train data in general\n def trainOneStep(self, source_var, target_var, encoder, decoder,\n encoder_optimizer, decoder_optimizer, criterion,\n max_len=10):\n\n # encoder training side\n encoder_hidden = encoder.initHidden()\n\n encoder_optimizer.zero_grad()\n decoder_optimizer.zero_grad()\n\n source_len = len(source_var)\n target_len = target_var.size()[0]\n\n encoder_outputs = Variable(torch.zeros(max_len, encoder.hidden_size))\n if use_cuda:\n encoder_outputs = encoder_outputs.cuda()\n\n loss = 0\n\n for en_idx in range(source_len):\n encoder_output, encoder_hidden = encoder(source_var[en_idx],\n encoder_hidden)\n encoder_outputs[en_idx] = encoder_output[0][0]\n\n # decoder training side\n decoder_input = Variable(torch.LongTensor([[SOS_token]]))\n decoder_input = decoder_input.cuda() if use_cuda else decoder_input\n decoder_hidden = encoder_hidden\n\n # probabilistic step, set teacher forcing ration to 0 to disable\n if random.random() < self.teacher_forcing_r:\n # use teacher forcing, feed target from corpus as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n loss += criterion(decoder_output, target_var[de_idx])\n decoder_input = target_var[de_idx]\n else:\n # without forcing, use its own prediction as the next input\n for de_idx in range(target_len):\n decoder_output, decoder_hidden, decoder_attention = decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n topv, topi = decoder_output.data.topk(1)\n ni = topi[0][0]\n\n decoder_input = Variable(torch.LongTensor([[ni]]))\n if use_cuda:\n decoder_input = decoder_input.cuda()\n\n loss += criterion(decoder_output, target_var[de_idx])\n if ni == EOS_token:\n break\n\n # back propagation, optimization\n loss.backward()\n encoder_optimizer.step()\n decoder_optimizer.step()\n\n return loss.data[0] / target_len\n\n # main function, iterating the training process\n def train(self, encoder, decoder, n_iter, learning_rate=0.01,\n print_every=1000, max_len=10):\n\n start = time.time()\n print_loss_total = 0\n\n encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)\n decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)\n criterion = nn.NLLLoss()\n\n training_pairs = []\n for i in range(n_iter):\n training_pairs.append(\n self.variablesFromPair(random.choice(self.pairs)))\n\n for iter in range(1, n_iter+1):\n training_pair = training_pairs[iter-1]\n source_var = training_pair[0]\n target_var = training_pair[1]\n\n loss = self.trainOneStep(source_var, target_var, encoder, decoder,\n encoder_optimizer, decoder_optimizer,\n criterion, max_len=max_len)\n print_loss_total += loss\n\n if iter % print_every == 0:\n print_loss_avg = print_loss_total / print_every\n print_loss_total = 0\n print('{0} ({1} {2}%%) {3:0.4f}'.format(\n timeSince(start, iter/n_iter), iter, iter/n_iter*100,\n print_loss_avg))\n\n # evaluation section\n def evaluate(self, encoder, decoder, sentence, max_len=10):\n source_var = sentence.split()\n source_len = len(source_var)\n encoder_hidden = encoder.initHidden()\n\n encoder.train(False)\n decoder.train(False)\n\n encoder_outputs = Variable(torch.zeros(max_len, encoder.hidden_size))\n if use_cuda:\n encoder_outputs = encoder_outputs.cuda()\n\n for en_idx in range(source_len):\n encoder_output, encoder_hidden = encoder(source_var[en_idx],\n encoder_hidden)\n encoder_outputs[en_idx] = \\\n encoder_outputs[en_idx] + encoder_output[0][0]\n\n decoder_input = Variable(torch.LongTensor([[SOS_token]]))\n decoder_input = decoder_input.cuda() if use_cuda else decoder_input\n decoder_hidden = encoder_hidden\n\n decoded_words = []\n decoder_attentions = torch.zeros(max_len, max_len)\n\n for de_idx in range(max_len):\n decoder_output, decoder_hidden, decoder_attention = decoder(\n decoder_input, decoder_hidden, encoder_outputs)\n decoder_attentions[de_idx] = decoder_attention.data\n topv, topi = decoder_output.data.topk(1)\n ni = topi[0][0]\n\n if ni == EOS_token:\n decoded_words.append('<EOS>')\n break\n else:\n decoded_words.append(self.target_lang.index2word[ni])\n\n decoder_input = Variable(torch.LongTensor([[ni]]))\n if use_cuda:\n decoder_input = decoder_input.cuda()\n\n encoder.train(True)\n decoder.train(True)\n\n return decoded_words, decoder_attentions[:de_idx+1]\n\n def evaluateRandomly(self, encoder, decoder, n=10, max_len=10):\n for i in range(n):\n pair = random.choice(self.pairs)\n print('> {}'.format(pair[0]))\n print('= {}'.format(pair[1]))\n output_words, attentions = self.evaluate(encoder, decoder, pair[0], max_len=max_len)\n output_sentence = ' '.join(output_words)\n print('< {}'.format(output_sentence))\n print('')\n\n def evaluateAll(self, encoder, decoder, max_len=10):\n references = []\n outputs = []\n for i in range(10):\n pair = random.choice(self.pairs)\n references.append(pair[1])\n output_words, attentions = self.evaluate(encoder, decoder, pair[0], max_len=max_len)\n output_sentence = ' '.join(output_words)\n outputs.append(output_sentence)\n\n with open('result/reference.txt', 'w', encoding='utf-8') as f:\n for reference in references:\n f.write('{}\\n'.format(reference))\n f.close()\n\n with open('result/output.txt', 'w', encoding='utf-8') as f:\n for output in outputs:\n f.write('{}\\n'.format(output))\n f.close()\n\n def evaluateFromTest(self, test_pairs, encoder, decoder, max_len=10):\n references = []\n outputs = []\n for pair in test_pairs:\n references.append(pair[1])\n output_words, attentions = self.evaluate(encoder, decoder, pair[0], max_len=max_len)\n output_sentence = ' '.join(output_words)\n outputs.append(output_sentence)\n\n with open('result/reference.txt', 'w', encoding='utf-8') as f:\n for reference in references:\n f.write('{}\\n'.format(reference))\n f.close()\n\n with open('result/output.txt', 'w', encoding='utf-8') as f:\n for output in outputs:\n f.write('{}\\n'.format(output))\n f.close()\n\n"
},
{
"alpha_fraction": 0.7020440101623535,
"alphanum_fraction": 0.7028301954269409,
"avg_line_length": 37.54545593261719,
"blob_id": "b7f495e0e96ead73009b2bc781b03d466add8ef6",
"content_id": "582b54e4b04f20d9fc3d1bb24cbf4720fe3338d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 33,
"path": "/model_file.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nfrom model2 import WordEncoderRNN, PreTrainedEmbeddingEncoderRNN, EmbeddingEncoderInputRNN, AttnDecoderRNN\nfrom lang import Lang\nfrom gensim.models import KeyedVectors\n\ndef model_save(model, filepath) :\n attr_dict = model.getAttrDict()\n torch.save(attr_dict, filepath)\n\ndef encoder_load(file_path, word_vector=None) :\n attr_dict = torch.load(file_path)\n encoder_type = attr_dict['model_type']\n encoder = None\n if encoder_type == \"word_based\" :\n encoder = WordEncoderRNN(attr_dict['hidden_size'], Lang(attr_dict['lang']))\n encoder.loadAttributes(attr_dict)\n elif encoder_type == \"pre_trained_embedding\" :\n encoder = WordEncoderRNN(word_vector)\n encoder.loadAttributes(attr_dict)\n elif encoder_type == \"word_vector_based\" :\n encoder = EmbeddingEncoderInputRNN(attr_dict['hidden_size'])\n encoder.loadAttributes(attr_dict)\n return encoder\n\ndef decoder_load(file_path) :\n attr_dict = torch.load(file_path)\n hidden_size = attr_dict['hidden_size']\n lang = Lang(attr_dict['lang'])\n dropout_p = attr_dict['dropout_p']\n max_length = attr_dict['max_length']\n decoder = AttnDecoderRNN(hidden_size, lang, dropout_p, max_length)\n decoder.loadAttributes(attr_dict)\n return decoder\n"
},
{
"alpha_fraction": 0.7525614500045776,
"alphanum_fraction": 0.7612704634666443,
"avg_line_length": 33.24561309814453,
"blob_id": "c113c1cb50080605192853fd1c3aac64af0b7ece",
"content_id": "d35bfab37e07d640cd82e53e3429b4f3644d7045",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1952,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 57,
"path": "/dummy.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nfrom preprocess import prepareData\nfrom torch.autograd import Variable\nfrom train_bidirectional import Trainer\nimport numpy as np\nfrom lang import Lang\nfrom model_bidirectional import WordEncoderBiRNN,PreTrainedEmbeddingEncoderBiRNN,AttnDecoderRNN\nfrom gensim.models import KeyedVectors\nimport params\n\n# train_file = '/home/prosa/Works/Text/korpus/chatbot_dataset/plain/preprocessed/split-augmented/combine/nontask/train.test'\n# src_lang, tgt_lang, pairs = prepareData(train_file, reverse=False)\n\n# Word vector\n# word_vector = KeyedVectors.load_word2vec_format(\"word_vector/koran.vec\", binary=True)\nword_vectors = KeyedVectors.load(params.WORD_VECTORS_FILE)\n\nencoder_file = 'encoder_dummy.pt'\ndecoder_file = 'decoder_dummy.pt'\nencoder_dict = torch.load(encoder_file)\ndecoder_dict = torch.load(decoder_file)\n\ndecoder_lang = Lang()\ndecoder_lang.load_dict(decoder_dict['lang'])\n\nhidden_size = word_vectors.vector_size\nmax_length = 32\n# encoder = WordEncoderBiRNN(hidden_size, max_length, src_lang)\nencoder = PreTrainedEmbeddingEncoderBiRNN(word_vectors, max_length, char_embed=True, seeder=params.SEEDER)\nattn_decoder = AttnDecoderRNN(2*hidden_size, max_length, decoder_lang, seeder=params.SEEDER)\n\n# Load and continue train\nencoder.loadAttributes(encoder_dict)\nattn_decoder.loadAttributes(decoder_dict)\n\ntrainer = Trainer([], encoder, attn_decoder)\nsentences = [\n 'saya muahdg makan',\n 'halloooooo buooott awkwkwk',\n 'zehahahaha nuasf bisa geloooo'\n]\ni = 1\nfor sent in sentences :\n decoded_words,_ = trainer.evaluate(sent)\n print(str(i) + ' : ' + ' '.join(decoded_words))\n i += 1\n\n# num_iter = 9769\n# num_iter = 10\n# epoch=5\n# trainer = Trainer(pairs, encoder, attn_decoder)\n# trainer.train(num_iter, print_every=num_iter//100, epoch=epoch)\n# trainer.train(num_iter, 1, epoch=epoch)\n\n# torch.save(encoder.getAttrDict(), 'encoder_dummy.pt')\n# torch.save(attn_decoder.getAttrDict(), 'decoder_dummy.pt')\n"
},
{
"alpha_fraction": 0.5419161915779114,
"alphanum_fraction": 0.544910192489624,
"avg_line_length": 22.571428298950195,
"blob_id": "18fffdd1ed9e8e6a9e6a2d798a14444301b06fe5",
"content_id": "7b91ae6a816b5e8748e77d847498395485788a5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 14,
"path": "/simple_wordvector.py",
"repo_name": "khaidzir/seq2seq",
"src_encoding": "UTF-8",
"text": "class SimpleWordVector() :\n\n def __init__(self) :\n self.word_dict = {}\n self.vector_size = 0\n\n def __getitem__(self, key) :\n return self.word_dict[key]\n\n def __setitem__(self, key, value) :\n self.word_dict[key] = value\n\n def __contains__(self, item) :\n return item in self.word_dict\n "
}
] | 24 |
Asante218/pythonProject
|
https://github.com/Asante218/pythonProject
|
dd1f91be6109e4a96f81eadee10b335686fd4138
|
76c9ecfc316e4a4df88db13757d5d073887c84eb
|
adbaf7a874747a4d7b310903b200b4b6a522488b
|
refs/heads/main
| 2023-06-21T09:25:42.804138 | 2021-07-23T08:01:33 | 2021-07-23T08:01:33 | 378,123,174 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5799999833106995,
"alphanum_fraction": 0.5799999833106995,
"avg_line_length": 48,
"blob_id": "27178741119a1c8c98d4a0c1d8fb5ecfd742b441",
"content_id": "3419082595905c0710fee18d73e390f97f7b1a7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 1,
"path": "/data types",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "\n\nveicheles = [\"car\", \"bus\", \"truck\", \"motorbike\"]"
},
{
"alpha_fraction": 0.6736486554145813,
"alphanum_fraction": 0.6898648738861084,
"avg_line_length": 20.735294342041016,
"blob_id": "1ba5a087f271889eabbf95cffd2a25dbd520fb2e",
"content_id": "f80f0020c6612f51cc0e8b8ea05413b61db5f67b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1480,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 68,
"path": "/functionsPractice.py",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "\n#Write a function calculation() such that it can accept two variables \n#and calculate the addition and subtraction of them. And also it must return both \n#addition and subtraction in a single return call\n\n\n\nnumber1 = int(input(\"insert the first number : \"))\n\n\nnumber2 = int(input(\"insert the second number : \"))\n\n\n\n\ndef calculation( x , y ):\n\treturn x + y , x - y\n\t\n\t\n\ntotal = calculation( number1, number2 )\n\nprint(total)\n\n\n#Write a function called lastElement. This function takes one parameter (a list)\n# and returns the last value in the list. It should return None if the list is empty.\n\n\ndef lastElement(list):\n\treturn list[-1]\n\n\nlist1 = [ 1 , 2 , 3 , 4 , 5 ]\nprint((lastElement(list1)))\n\n\n\n\n# Wrtie a function called singleLetterCount. This function takes in two parametrs (two strings).\n# The first parameter should be a word and second should be a letter. The function returns\n# the number of times that letter appears in the word. The function should be case insensitive (does not\n# matter if the input is lowercase or uppercase). If the letter is not found in the word, the function\n# should return 0.\n\nletter = input(\"insert a letter : \")\nword = input(\"insert a word : \")\n\ndef singleLetterCount(g , good):\n\tif g in good:\n\t\treturn \"Yes!\" , good.count(g)\n\n\n\telse:\n\t\treturn \"none\" , 0\n\n\n\t\n\nprint(singleLetterCount(letter , word))\n\ndef f(a, b = 1, c = 2):\n print('a is: ',a, 'b is: ', b, 'c is: ', c)\n\n\n\nprint(\"this is for function f\")\nf(2, c = 2)\nf(c = 100, a = 110)\n\n"
},
{
"alpha_fraction": 0.6219512224197388,
"alphanum_fraction": 0.6529933214187622,
"avg_line_length": 17.77083396911621,
"blob_id": "32a11811fd0b9c7c5640c9bcfff559ed4c2d7c42",
"content_id": "896751d6337a62286756dace88b0e9688ddc8eeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 902,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 48,
"path": "/calculator.py",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "#author : Asante\n#calculator program\n#date 19/06/2021\n\n\nprint(\"Welcome to Asante's personal calculator.\")\nnumber1 = int (input(\"Please pick the first number you want to calculate:\"))\nprint(number1)\n\n\noperation = int (input(\" Choose 1 to add, 2 to subtract, 3 to multiply, 4 to divide:\"))\nprint(operation)\n\n\nnumber2 = int (input(\"Please pick a second number to multiply, divide, subtract, or add by:\"))\n\ndef multiply(x , y):\n\treturn x * y\n\ndef divide(a , b):\n\treturn a / b\n\ndef add(s , l):\n\treturn s + l\n\ndef subract(h , p):\n\treturn h - p\n\ntotal = 0\n\n\nif operation == 1:\n\ttotal = add(number1, number2) \n\tprint (total)\nelif operation == 2:\n\ttotal = subract(number1, number2)\n\tprint (total)\n\nelif operation == 3:\n\ttotal = multiply(number1, number2)\n\tprint (total)\n\nelif operation == 4:\n\ttotal = divide(number1, number2)\n\tprint (total) \n\nelse:\n\tprint(\"Invalid input.\")\n\n"
},
{
"alpha_fraction": 0.5204678177833557,
"alphanum_fraction": 0.5789473652839661,
"avg_line_length": 10.466666221618652,
"blob_id": "1f74786b1c062538fb82356b905ce888f9220759",
"content_id": "98d37f22f47a579cd93c03550a1e94b5c98bb24f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 171,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/programOne.py",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "#author: asante\nnumbers = [1, 2, 3, 4]\n\n\nadding = 0\nadding = numbers[0] / numbers[1] / numbers[2] / numbers[3] \nprint(adding)\n\n\n\n\n#for x in a:\n #print(x)\n \n #print(a[3])"
},
{
"alpha_fraction": 0.5320910811424255,
"alphanum_fraction": 0.5817805528640747,
"avg_line_length": 12.814285278320312,
"blob_id": "279d02957be019664007223b208fc437d0955592",
"content_id": "41c0df86f79ebf983904db732e68eb0ad066d948",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 966,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 70,
"path": "/dataTypes.py",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "#Authuor: Asante\n#date : 25/06/2021\n\ndef add(s , l):\n\treturn s + l\n\n\n\n#strings \nname = \"Asante\"\nlastName = \"Mwesigwa\"\n\n\n\n\n# integer\nage = 9\nyearBorn = 2011\n\n\n# float\ndecimal = 1.5\n\ndecimal = add(decimal, 10)\n\nprint(\"My name is \" , name ,\",I am \" , age , \"years old and I was born in\" , yearBorn , \"I can,t wait til i am \" , decimal , \"years old .\")\n\n\n\n\n\n#list\nnumberList = [ 1 , 2 , 3 , 4 , 5]\n\ndecimaList = [ 0.5 , 1.5 , 2.5 , 3.5 , 4.5 , 5.5]\n\nstringList = [\"happy\" , \"sad\" , \" angry \" ]\n\nmixedList = [ 1 , 1.5 , \"happy\"]\n\n\nfor x in mixedList:\n print( x , end= ' ')\n\n#, end = '')\n\n# dictionary\n\nthisdict = {\n\t\"good\":\"bad\",\n\t\"heroic\":\"evil\"\n}\nprint(thisdict)\n\nperson = {\n\t\"name\":\"Asante\",\n\t\"eyeColor\":\"brown\",\n\t\"hairColor\":\"black\",\n\t\"age\":9,\n\t\"height\":14,\n\t\"weight\":30\n}\n\n\nall_pairs = list(person.items())\nprint('First Key value pair: ', all_pairs[0])\n\nprint(person.get('name'))\nprint(person['name'])\n#My name is Asante, I am 9 years old and I wans born in 2011"
},
{
"alpha_fraction": 0.6870229244232178,
"alphanum_fraction": 0.6895674467086792,
"avg_line_length": 18.649999618530273,
"blob_id": "1070891658b1d8cf6f6d2b7587447814789b8e07",
"content_id": "ff66b70b413e3a6090f82aa46374205b8cf340be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 20,
"path": "/classes.py",
"repo_name": "Asante218/pythonProject",
"src_encoding": "UTF-8",
"text": "\n#Write a Python program to create a class and print your name as \n# a variable in the class and print your age using a function in the class\n\nclass PersonInfo:\n personName = \"Asante\"\n\n def age(self):\n return 9 \n\npeople = PersonInfo()\nprint(people.personName)\nprint(people.age())\n\nclass A:\n def __init__(self,b):\n self.b=b\n def display(self):\n print(self.b)\nobj=A(\"Hello\")\ndel obj"
}
] | 6 |
JunYang-tes/node-keybinder
|
https://github.com/JunYang-tes/node-keybinder
|
c6bd89288d6878f1c53d33822f1968a3a5bd6d64
|
f5ed789f301c0913b70864a5d3ab0300dc63e76b
|
374af4db688c44b0ab5158234820b5d87950effe
|
refs/heads/master
| 2021-06-16T23:52:24.162832 | 2017-04-30T16:38:54 | 2017-04-30T16:38:54 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6027777791023254,
"alphanum_fraction": 0.6027777791023254,
"avg_line_length": 21.5625,
"blob_id": "6f69cf9f5afa9b0d8cda03d2674feecb06344f03",
"content_id": "69b86dcc2060579307939b146c8257fb8f11da69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/test/test.js",
"repo_name": "JunYang-tes/node-keybinder",
"src_encoding": "UTF-8",
"text": "const keybinder = require(\"../build/Release/keybinder.node\");\n\nkeybinder.on(\"<Ctrl>B\", () => {\n console.log(\"Ctrl+B\")\n})\nkeybinder.on(\"<Ctrl>D\", () => {\n console.log(\"Ctrl+D\")\n})\nkeybinder.on(\"<Ctrl><Alt>A\",()=>{\n console.log(\"Ctrl+Alt+A\")\n})\nkeybinder.start();\nkeybinder.on(\"<Alt>B\",()=>{\n console.log(\"Alt+B\")\n})\nconsole.log(\"try Ctrl+B Ctrl+D or Alt+B\")"
},
{
"alpha_fraction": 0.3417266309261322,
"alphanum_fraction": 0.35611510276794434,
"avg_line_length": 20.384614944458008,
"blob_id": "d67a4145ab0ed243255854f08f4bde77447a674d",
"content_id": "6162fd4915f4b66a93582171cef0fb3e310383d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 26,
"path": "/binding.gyp",
"repo_name": "JunYang-tes/node-keybinder",
"src_encoding": "UTF-8",
"text": "{\n \"targets\": [\n {\n \"target_name\": \"keybinder\",\n \"sources\": [\n \"src/binder.cc\"\n ],\n \"conditions\":[\n ['OS==\"linux\"',{\n 'cflags':[\n '<!@(pkg-config --cflags keybinder-3.0)'\n ],\n 'cflags_cc': ['-fexceptions'],\n 'cflags_cc!': [ '-fno-rtti' ],\n 'ldflags':[\n '<!@(pkg-config --libs keybinder-3.0)'\n ]\n }\n ]\n ],\n \"libraries\":[\n '<!@(pkg-config --libs gtkmm-3.0 keybinder-3.0)'\n ],\n }\n ]\n}\n"
},
{
"alpha_fraction": 0.6529563069343567,
"alphanum_fraction": 0.6683804392814636,
"avg_line_length": 14.600000381469727,
"blob_id": "ea0651b44a9c279b24f645038caa01d62e3621ce",
"content_id": "eff183d957a372bbee75bda9df5e88dc4a829765",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 25,
"path": "/README.md",
"repo_name": "JunYang-tes/node-keybinder",
"src_encoding": "UTF-8",
"text": "# Dependencies\n+ node-gyp\n+ GTK+ 3.0 (keybinder-3.0)\n+ gobject-introspection\n+ libkeybinder-3.0\n\n# Usage\nUsing npm or yarn to install\n```\nyarn add node-keybinder\n```\nor\n```\nnpm install node-keybinder\n```\n\n```\nconst keybinder = require(\"keybinder\");\n\nkeybinder.on(\"<Ctrl>B\", () => {\n console.log(\"Ctrl+B\")\n})\n//If you have a another GTK event loop,do not call start.\nkeybinder.start()\n```"
},
{
"alpha_fraction": 0.6699961423873901,
"alphanum_fraction": 0.6730695366859436,
"avg_line_length": 24.52941131591797,
"blob_id": "f313f253ef41c03a179a6824dd6a5f13ac85f5e3",
"content_id": "f89a1f1674b7fa6eccae91c89443f14060faf456",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2603,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 102,
"path": "/src/binder.cc",
"repo_name": "JunYang-tes/node-keybinder",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <iostream>\n#include <gtk/gtk.h>\n#include <keybinder.h>\n#include <node.h>\n#include <string>\n#include <thread>\n#include <uv.h>\n#include <map>\n#include <mutex>\n#include <condition_variable>\n#include <deque>\n\nusing namespace v8;\nusing namespace node;\nusing namespace std;\n\ntemplate <typename T>\nclass queue\n{\nprivate:\n std::mutex d_mutex;\n std::condition_variable d_condition;\n std::deque<T> d_queue;\npublic:\n void push(T const& value) {\n {\n std::unique_lock<std::mutex> lock(this->d_mutex);\n d_queue.push_front(value);\n }\n this->d_condition.notify_one();\n }\n T pop() {\n std::unique_lock<std::mutex> lock(this->d_mutex);\n this->d_condition.wait(lock, [=]{ return !this->d_queue.empty(); });\n T rc(std::move(this->d_queue.back()));\n this->d_queue.pop_back();\n return rc;\n }\n};\nstruct Baton\n{\n uv_work_t request;\n string key;\n};\n\nthread *listen_th=NULL;\nqueue<string> keys;\nmap<string,Persistent<Function>*> callbacks;\n\n\nvoid handler (const char *keystring, void *user_data) {\n keys.push(string(keystring));\n}\nvoid listener(){\n gtk_main();\n}\n\n\nvoid on(const FunctionCallbackInfo<Value>& args){\n Isolate* isolate = Isolate::GetCurrent();\n HandleScope scope(isolate);\n auto key =string(*String::Utf8Value(args[0].As<String>()));\n keybinder_bind(key.c_str(),handler,NULL);\n Local<Function> callback = args[1].As<Function>();\n Persistent<Function> *p=new Persistent<Function>();\n p->Reset(isolate,callback);\n callbacks[key]= p;//Persistent<Function>(isolate,callback)\n}\nvoid wait_key (uv_work_t* req){\n Baton* baton = static_cast<Baton*>(req->data);\n baton->key = keys.pop();\n}\nvoid call(uv_work_t* req,int){\n Baton* baton = static_cast<Baton*>(req->data);\n Isolate* isolate = Isolate::GetCurrent();\n HandleScope handleScope(isolate);\n callbacks[baton->key]->Get(isolate)->Call(isolate->GetCurrentContext()->Global(),0,NULL);\n uv_queue_work(uv_default_loop(), &baton->request, wait_key, call); \n}\n\nvoid start(const FunctionCallbackInfo<Value>& args){\n if(!listen_th){\n listen_th=new thread(listener);\n }\n}\n\nvoid init(Handle<Object> exports) \n{\n gtk_init(0,NULL);\n keybinder_init();\n Isolate* isolate = Isolate::GetCurrent();\n exports->Set(String::NewFromUtf8(isolate, \"on\"),\n FunctionTemplate::New(isolate, on)->GetFunction());\n \n exports->Set(String::NewFromUtf8(isolate, \"start\"),\n FunctionTemplate::New(isolate, start)->GetFunction()); \n Baton* baton = new Baton();\n baton->request.data = baton;\n uv_queue_work(uv_default_loop(), &baton->request, wait_key, call);\n}\nNODE_MODULE(gui, init)"
}
] | 4 |
HackerSchoolCZ/hackathon_team_2
|
https://github.com/HackerSchoolCZ/hackathon_team_2
|
ec6f9c570f52951d51f4a20b26217212cc680ac6
|
a31b909aea9dac9c808a0eb9a2d86d26fba82276
|
7bc591d34231dd06dcc6db05b335066c58273d37
|
refs/heads/master
| 2020-04-08T02:03:39.990605 | 2018-11-24T16:44:59 | 2018-11-24T16:44:59 | 158,921,131 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.520729660987854,
"alphanum_fraction": 0.5431177616119385,
"avg_line_length": 27.950000762939453,
"blob_id": "d332b3d2dcfff55065ad9ed6423798d72969df02",
"content_id": "41f8bdbe2e797dd7a5808b89563577896d017eab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 40,
"path": "/Libraries/library.py",
"repo_name": "HackerSchoolCZ/hackathon_team_2",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport numpy as np\r\nfrom robot.api import logger\r\nfrom robot.errors import ExecutionFailed\r\n\r\nclass library(object):\r\n \r\n \"\"\"\r\n Library for template matching\r\n \"\"\"\r\n \r\n ROBOT_LIBRARY_VERSION = 1.0\r\n \r\n def Find_Image(self, screen_img, template_img, output_img):\r\n \r\n \"\"\"\r\n Keyword accepts three parameters\r\n \r\n Example:\r\n | Find_Image | screenshot_path | template_path | output_path |\r\n \"\"\"\r\n \r\n img_rgb = cv2.imread(screen_img)\r\n img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)\r\n template = cv2.imread(template_img, 0)\r\n w, h = template.shape[::-1]\r\n\r\n res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)\r\n threshold = 0.8\r\n loc = np.where( res >= threshold)\r\n for pt in zip(*loc[::-1]):\r\n cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (0,0,255), 2)\r\n\r\n cv2.imwrite(output_img, img_rgb)\r\n\r\n if loc[0].any() and loc[1].any():\r\n logger.info(\"Template found\", also_console=True)\r\n else:\r\n logger.error(\"Template not found\")\r\n raise ExecutionFailed(\"FAILED\")\r\n "
}
] | 1 |
WintrumWang/AdaBoost.C2MIL
|
https://github.com/WintrumWang/AdaBoost.C2MIL
|
39cf65d9a25ade7558257f744f7c772d49a2d9d8
|
03790a40b860422cb6884810a9d7f8890351a569
|
d7e8d403ae9c554263d043465e0e79396a15c927
|
refs/heads/master
| 2020-06-01T08:16:30.394187 | 2019-06-07T09:09:26 | 2019-06-07T09:09:26 | 172,991,221 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6056658029556274,
"alphanum_fraction": 0.6202486157417297,
"avg_line_length": 42.031578063964844,
"blob_id": "0922327bc38594bc8f25c86ec4622fe8c0aa4df2",
"content_id": "233865ec65cc886870ed4f22adaaf0747bc632d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8366,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 190,
"path": "/AdaBoost_C2MIL.py",
"repo_name": "WintrumWang/AdaBoost.C2MIL",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nimport numpy as np\r\nimport pandas as pd\r\nimport random\r\nfrom sklearn import metrics\r\nimport sys\r\n\r\nMIN_SAMPLE = sys.argv[1]\r\nEPSILON = sys.argv[2]\r\nNUM_ITER = sys.argv[3]\r\nNUM_CANDIDATE = sys.argv[4]\r\nDATA_FILE = sys.argv[5]\r\n\r\nraw_data = pd.read_csv(DATA_FILE, header=None)\r\nraw_data = np.array(raw_data)\r\nsam_label = raw_data[:,[0,2]]\r\nraw_data = np.delete(raw_data,0,axis=1)\r\ntest_group_num = int(len(np.unique(raw_data[:,1]))/5)\r\ntest_group = random.sample(list(np.unique(raw_data[:,1])),test_group_num)\r\nraw_data_test = raw_data[np.where(np.isin(raw_data[:,1],test_group))]\r\nsam_label_test = sam_label[np.where(np.isin(sam_label[:,1],test_group))]\r\nraw_data_train = raw_data[np.where(np.isin(raw_data[:,1],test_group) == False)]\r\nsample_num = raw_data_train.shape[0]\r\nsmall_num = 1/sample_num\r\n\r\ndef calSumWP(dataSet):\r\n return np.sum(dataSet[np.where(dataSet[:, -2] == 1), -1])\r\n\r\ndef calSumWN(dataSet):\r\n return np.sum(dataSet[np.where(dataSet[:, -2] != 1), -1])\r\n\r\ndef calImpurity(dataSet):\r\n w_p = calSumWP(dataSet)\r\n w_n = calSumWN(dataSet)\r\n return (w_p * w_n) ** 0.5\r\n\r\ndef calHypo(dataSet):\r\n w_p = calSumWP(dataSet)\r\n w_n = calSumWN(dataSet)\r\n return 0.5 * np.log((w_p + small_num) / (w_n + small_num))\r\n\r\ndef splitDataset(dataSet, feat, value):\r\n dataSet1 = dataSet[dataSet[:, feat] <= value]\r\n dataSet2 = dataSet[dataSet[:, feat] > value]\r\n return dataSet1, dataSet2\r\n\r\ndef chooseCriterion(dataSet, min_sample=MIN_SAMPLE, epsilon=EPSILON):\r\n feat_num = dataSet.shape[1] - 2\r\n sImpurity = calImpurity(dataSet)\r\n bestColumn = 0\r\n bestValue = 0\r\n minImpurity = np.inf\r\n if len(np.unique(dataSet[:, -2])) == 1:\r\n return None, calHypo(dataSet)\r\n for feat in range(feat_num):\r\n if len(np.unique(dataSet[:,feat])) <= NUM_CANDIDATE:\r\n for row in range(dataSet.shape[0]):\r\n dataSet1, dataSet2 = splitDataset(dataSet, feat, dataSet[row, feat])\r\n if len(dataSet1) < min_sample or len(dataSet2) < min_sample:\r\n continue\r\n nowImpurity = calImpurity(dataSet1) + calImpurity(dataSet2)\r\n if nowImpurity < minImpurity:\r\n minImpurity = nowImpurity\r\n bestColumn = feat\r\n bestValue = dataSet[row, feat]\r\n else:\r\n candidate = np.linspace(np.min(dataSet[:,feat]),np.max(dataSet[:,feat]),NUM_CANDIDATE)\r\n for candi in candidate:\r\n dataSet1, dataSet2 = splitDataset(dataSet, feat, candi)\r\n if len(dataSet1) < min_sample or len(dataSet2) < min_sample:\r\n continue\r\n nowImpurity = calImpurity(dataSet1) + calImpurity(dataSet2)\r\n if nowImpurity < minImpurity:\r\n minImpurity = nowImpurity\r\n bestColumn = feat\r\n bestValue = candi\r\n if (sImpurity - minImpurity) < epsilon:\r\n return None, calHypo(dataSet)\r\n dataSet1, dataSet2 = splitDataset(dataSet, bestColumn, bestValue)\r\n if len(dataSet1) < min_sample or len(dataSet2) < min_sample:\r\n return None, calHypo(dataSet)\r\n return bestColumn, bestValue\r\n\r\ndef buildTree(dataSet):\r\n bestColumn, bestValue = chooseCriterion(dataSet)\r\n if bestColumn is None:\r\n return bestValue\r\n tree = {}\r\n tree['spCol'] = bestColumn\r\n tree['spVal'] = bestValue\r\n lSet, rSet = splitDataset(dataSet, bestColumn, bestValue)\r\n tree['left'] = calHypo(lSet)\r\n tree['right'] = calHypo(rSet)\r\n return tree\r\n\r\ndef predictHypo(dataSet, tree):\r\n if type(tree) is not dict:\r\n return tree\r\n if dataSet[tree['spCol']] <= tree['spVal']:\r\n return tree['left']\r\n else:\r\n return tree['right']\r\n\r\ndef outputHypo(dataSet, each_tree):\r\n data_num = dataSet.shape[0]\r\n hypo = np.zeros((data_num,), dtype=np.float32)\r\n for i in range(data_num):\r\n hypo[i] = predictHypo(dataSet[i], each_tree)\r\n return hypo\r\n\r\ndef sigmoid(x):\r\n return 1/(1+np.exp(-x))\r\n\r\ndef integrate(df):\r\n return np.sum(np.multiply(np.sign(df['sample_hypo']), sigmoid(df['sample_hypo'])))/np.sum(sigmoid(df['sample_hypo']))\r\n\r\ndef adaboostTrainer(raw_data, num_iter):\r\n positive_index = np.where(raw_data[:, 0] == 1)[0]\r\n negative_index = np.where(raw_data[:, 0] != 1)[0]\r\n raw_data[negative_index, 1] = np.linspace(np.max(raw_data[:, 1]), np.max(raw_data[:, 1])+negative_index.shape[0], negative_index.shape[0], dtype=np.int64)\r\n data = raw_data[:, 2:]\r\n label = raw_data[:, 0]\r\n group = raw_data[:, 1]\r\n base_learnerArray = []\r\n m, n = np.shape(data)\r\n group_num = np.unique(group).shape[0]\r\n group_joint_label = pd.DataFrame({'group': group, 'label': label})\r\n group_label = np.array(group_joint_label.groupby(['group']).max()).reshape(group_num,)\r\n group_weight = np.hstack((np.unique(group).reshape(group_num, 1), np.array(np.ones((group_num, 1)), dtype=np.float32)/group_num))\r\n sample_predictionArray = np.zeros((m,), dtype=np.float32)\r\n group_predictionArray = np.zeros((group_num,), dtype=np.float32)\r\n while num_iter:\r\n sample_weight = np.zeros((m, 1), dtype=np.float32)\r\n for row in range(m):\r\n sample_weight[row, 0] = group_weight[np.where(group_weight[:, 0] == group[row])[0][0], 1] / np.sum(group == group[row])\r\n tran_data = np.hstack((data, label.reshape(m, 1), sample_weight))\r\n base_tree = buildTree(tran_data)\r\n sample_hypo = outputHypo(tran_data, base_tree)\r\n df = pd.DataFrame({'group': group, 'sample_hypo': sample_hypo})\r\n group_hypo = np.array(df.groupby(['group']).apply(lambda df: integrate(df)))\r\n loss = np.multiply(np.sign(group_hypo), group_label)\r\n error = np.sum(group_weight[np.where(loss == -1), 1])\r\n alpha = np.log((1 - error) / error) / 2\r\n base_learnerArray.append({'tree': base_tree, 'alpha': alpha})\r\n sample_predictionArray += sample_hypo*alpha\r\n group_predictionArray += group_hypo*alpha\r\n print(num_iter)\r\n print(base_tree)\r\n num_iter -= 1\r\n expon = np.multiply(-alpha*np.sign(group_hypo), group_label)\r\n group_weight[:, 1] = np.multiply(group_weight[:, 1], np.exp(expon))\r\n group_weight[:, 1] = group_weight[:, 1] / np.sum(group_weight[:, 1])\r\n sample_finalPrediction = np.sign(sample_predictionArray)\r\n group_finalPrediction = np.sign(group_predictionArray)\r\n return base_learnerArray\r\n\r\ndef adaboostPredictor(data_predict, base_learnerArray):\r\n group_predict = data_predict[:, -1]\r\n pre_sample_num = data_predict.shape[0]\r\n pre_group_num = np.unique(group_predict).shape[0]\r\n sample_hypoPredict = np.zeros((pre_sample_num,), dtype=np.float32)\r\n group_hypoPredict = np.zeros((pre_group_num,), dtype=np.float32)\r\n alpha_sum = 0\r\n for base_learner in base_learnerArray:\r\n sample_hypoBase = outputHypo(data_predict, base_learner['tree'])\r\n df = pd.DataFrame({'group': group_predict, 'sample_hypo': sample_hypoBase})\r\n group_hypoBase = np.array(df.groupby(['group']).apply(lambda df: integrate(df)))\r\n sample_hypoPredict += base_learner[\"alpha\"] * sample_hypoBase\r\n group_hypoPredict += base_learner[\"alpha\"] * group_hypoBase\r\n alpha_sum += base_learner[\"alpha\"]\r\n sample_finalPredict = np.sign(sample_hypoPredict)\r\n group_finalPredict = np.sign(group_hypoPredict)\r\n sample_hypoProb = sigmoid(sample_hypoPredict / alpha_sum)\r\n group_hypoProb = sigmoid(group_hypoPredict / alpha_sum)\r\n return sample_finalPredict, group_finalPredict, sample_hypoProb, group_hypoProb\r\n\r\ndef main():\r\n tree = adaboostTrainer(raw_data_train, num_iter=NUM_ITER)\r\n data_predict = np.hstack((raw_data_test[:,2:], raw_data_test[:,1].reshape(raw_data_test.shape[0],1)))\r\n sam, gro, samprob, groprob = adaboostPredictor(data_predict, tree)\r\n sam_truth = sam_label_test[:, 0]\r\n gro_truth = np.array(pd.DataFrame(raw_data_test[:, 0:2]).groupby([1]).mean()).T[0]\r\n sam_acc = np.sum(sam_truth == sam)/raw_data_test.shape[0]\r\n gro_acc = np.sum(gro_truth == gro)/test_group_num\r\n sam_auc = metrics.roc_auc_score(sam_truth, samprob)\r\n gro_auc = metrics.roc_auc_score(gro_truth, groprob)\r\n print(sam_acc, gro_acc, sam_auc, gro_auc)\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
},
{
"alpha_fraction": 0.7784090638160706,
"alphanum_fraction": 0.7878788113594055,
"avg_line_length": 65,
"blob_id": "9545079467fea55fd0d9003f27f2a834dc0bf704",
"content_id": "c7a5682f6795605fe0ab1d6982716eb3dab0b8a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 208,
"num_lines": 8,
"path": "/README.md",
"repo_name": "WintrumWang/AdaBoost.C2MIL",
"src_encoding": "UTF-8",
"text": "# AdaBoost.C2MIL\n\nA new method combining adaboost and multiple instance learning. This method was designed for solving protein function prediction problems without residue labels. And it can be used for other similar purposes.\n\nThe file AdaBoost.C2MIL.py is the implementation of AdaBoost.C2MIL, and its input data file needs the instance labels, bag labels and bag identities as the first three columns with other features following.\n\nData format:\n Instance label | Bag label | Bag identity | Feature 1 | Feature 2 | ......\n"
}
] | 2 |
lmodenbach/python-challenge
|
https://github.com/lmodenbach/python-challenge
|
42d2fe3eff514643483badb6d0e948d2eab37bf0
|
05ab4156f67d19896402f6da4fe89b14c5c7cd61
|
3da6a663b36000a98ee1564f08b7c77d4d4332b4
|
refs/heads/main
| 2023-08-01T03:23:00.132293 | 2021-09-13T06:54:17 | 2021-09-13T06:54:17 | 352,439,122 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6157112717628479,
"alphanum_fraction": 0.6388534903526306,
"avg_line_length": 42.61111068725586,
"blob_id": "e79c06acb851af02371f951d527cc2bf38172c36",
"content_id": "1a7d5338481832ddeb40c9c2f93dc6d90e4ceca8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4710,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 108,
"path": "/PyPoll/main.py",
"repo_name": "lmodenbach/python-challenge",
"src_encoding": "UTF-8",
"text": "import os\nimport csv\n\n#create input variable and store path to source csv\nelection_data_csv = os.path.join(\"..\", \"Resources\", \"PyPoll\", \"election_data.csv\")\n\n #create output variable and store path to .txt file\nwriting_path = os.path.join(\"..\", \"Analysis\", \"PyPoll_analysis.txt\")\n\n#define function to output data, takes 3 lists of results with desired data in corresponding indices\ndef election_analysis(candidate_data, percent_data, totals_data):\n outputString = (\n f\"-----------------------------------------------------------------------------\\n\"\n f\"Election Results\\n\"\n f\"-------------------------------\\n\"\n f\"Total Votes: {totals_data[0]}\\n\"\n f\"-------------------------------\\n\"\n f\"{candidate_data[0]}: {percent_data[0]:.3f}% ({totals_data[1]})\\n\"\n f\"{candidate_data[1]}: {percent_data[1]:.3f}% ({totals_data[2]})\\n\"\n f\"{candidate_data[2]}: {percent_data[2]:.3f}% ({totals_data[3]})\\n\"\n f\"{candidate_data[3]}: {percent_data[3]:.3f}% ({totals_data[4]})\\n\"\n f\"-------------------------------\\n\"\n f\"Winner: {candidate_data[4]}\\n\"\n f\"-----------------------------------------------------------------------------\\n\"\n )\n return outputString\n\n\n#pass in path variable and open up csv file for reading\nwith open(election_data_csv, 'r') as csvFile:\n\n#specify a csv reader using commas as delimiter\n csvReader = csv.reader(csvFile, delimiter=',')\n\n#declare lists and variables, initialize if needed\n candidate_results = []\n percent_results = [] \n totals_results = []\n vote_count = -1\n totals_candidate_0 = 0\n totals_candidate_1 = 0\n totals_candidate_2 = 0\n totals_candidate_3 = 0\n\n#for loop to iterate through rows in csv file\n for row in csvReader:\n\n#increment vote_count with each row, initialized to -1 so header doesn't add a vote\n vote_count += 1\n\n#if on first row of data, grab first candidate and record the vote\n if (vote_count == 1):\n candidate_results.append(row[2])\n totals_candidate_0 += 1\n\n#otherwise... \n elif (vote_count > 1 ):\n\n#check if candidate is in candidate list and append if not \n if (row[2] not in candidate_results):\n candidate_results.append(row[2])\n\n#augment the vote for the appropriate candidate \n if (row[2] == candidate_results[0]):\n totals_candidate_0 += 1\n elif (row[2] == candidate_results[1]):\n totals_candidate_1 += 1 \n elif (row[2] == candidate_results[2]):\n totals_candidate_2 += 1\n elif (row[2] == candidate_results[3]):\n totals_candidate_3 += 1\n\n#add vote_count and candidate totals to results\n totals_results.append(vote_count)\n totals_results.append(totals_candidate_0)\n totals_results.append(totals_candidate_1)\n totals_results.append(totals_candidate_2)\n totals_results.append(totals_candidate_3)\n\n#calculate and record percents, round decimal before converting to int to do math so we don't lose data\n percent_candidate_0 = int(round((totals_candidate_0/vote_count)*100))\n percent_results.append(percent_candidate_0)\n percent_candidate_1 = int(round((totals_candidate_1/vote_count)*100))\n percent_results.append(percent_candidate_1)\n percent_candidate_2 = int(round((totals_candidate_2/vote_count)*100))\n percent_results.append(percent_candidate_2) \n percent_candidate_3 = int(round((totals_candidate_3/vote_count)*100))\n percent_results.append(percent_candidate_3)\n\n#figure out who the winner is through comparisons then record\n if (percent_candidate_0 > percent_candidate_1 & percent_candidate_0 > percent_candidate_2 & percent_candidate_0 > percent_candidate_3):\n candidate_results.append(candidate_results[0])\n elif (percent_candidate_1 > percent_candidate_0 & percent_candidate_1 > percent_candidate_2 & percent_candidate_1 > percent_candidate_3): \n candidate_results.append(candidate_results[1])\n elif (percent_candidate_2 > percent_candidate_0 & percent_candidate_2 > percent_candidate_1 & percent_candidate_2 > percent_candidate_3):\n candidate_results.append(candidate_results[2])\n elif (percent_candidate_3 > percent_candidate_0 & percent_candidate_3 > percent_candidate_1 & percent_candidate_3 > percent_candidate_2):\n candidate_results.append(candidate_results[3])\n else: \n candidate_results.append(\"No clear winner\")\n\n\n#print formatted output\nprint(election_analysis(candidate_results, percent_results, totals_results))\n\n#write output to a new text file\nwith open(writing_path, \"w\") as textFile:\n textFile.write(election_analysis(candidate_results, percent_results, totals_results))\n"
},
{
"alpha_fraction": 0.6099748015403748,
"alphanum_fraction": 0.6169795393943787,
"avg_line_length": 36.125,
"blob_id": "e3695b0970c46941e32d7b376ec1c77f755551c4",
"content_id": "c4c2958ac08f989c669103f5aa91fbeb68935255",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3569,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 96,
"path": "/PyBank/main.py",
"repo_name": "lmodenbach/python-challenge",
"src_encoding": "UTF-8",
"text": "import os\nimport csv\n\n#create input variable and store path to source csv\nbudget_data_csv_path = os.path.join(\"..\", \"Resources\", \"PyBank\", \"budget_data.csv\")\n\n#create output variable and store path to .txt file\nwriting_path = os.path.join(\"..\", \"Analysis\", \"PyBank_analysis.txt\")\n\n#define function to output data, takes a list of results with desired data in different indices and \n#create/return a formatted string\ndef budget_analysis(budget_data_list):\n output_string = (\n f\"-----------------------------------------------------------------------------\\n\"\n f\"Financial Analysis\\n\"\n f\"-------------------------------\\n\"\n f\"Total Months: {budget_data_list[0]}\\n\"\n f\"Total: ${budget_data_list[1]}\\n\"\n f\"Average Change: ${budget_data_list[2]:.2f}\\n\"\n f\"Greatest Increase in profits: {budget_data_list[3]} (${budget_data_list[4]})\\n\"\n f\"Greatest Decrease in profits: {budget_data_list[5]} (${budget_data_list[6]})\\n\"\n f\"-----------------------------------------------------------------------------\\n\"\n )\n return output_string\n \n#pass in path variable and open up csv file for reading\nwith open(budget_data_csv_path, 'r') as csvFile:\n\n#specify a csv reader using commas as delimiter\n csvReader = csv.reader(csvFile, delimiter=',')\n\n#declare lists and variables and initialize if needed\n data_results = []\n list_of_changes = []\n total_profits_losses = 0\n rowControl = 0\n prev_row_PorL = 0\n min_change = 0\n max_change = 0\n max_month_year = \"\"\n min_month_year = \"\"\n \n#for loop to iterate through rows in csv file\n for row in csvReader:\n\n#chop off header\n if (rowControl == 0):\n rowControl += 1\n\n#pick up first profit/loss and store both as first previous profit/loss and first of the total profits/losses \n elif (rowControl == 1):\n prev_row_PorL = int(row[1])\n total_profits_losses += int(row[1])\n rowControl += 1\n\n#calculate change and append to list, reset previous profit/loss, accumulate total profits/losses \n else: \n current_PorL = int(row[1])\n current_change = current_PorL - prev_row_PorL\n list_of_changes.append(current_change)\n prev_row_PorL = int(row[1]) \n total_profits_losses += int(row[1])\n \n#keep track of max and min change, and the associated month/year - if no change in max/min do nothing\n if (current_change > max_change):\n max_change = current_change\n max_month_year = row[0]\n elif (current_change < min_change):\n min_change = current_change\n min_month_year = row[0] \n\n#get row count (one more than number of differences) and store it\n total_months = len(list_of_changes) + 1\n data_results.append(total_months)\n\n#store sum of profits/losses\n data_results.append(total_profits_losses) \n\n#find average of change in profits/losses and store\n profit_loss_avg_change = sum(list_of_changes) / len(list_of_changes)\n data_results.append(profit_loss_avg_change)\n\n#store max_change and associated month/year\n data_results.append(max_month_year)\n data_results.append(max_change)\n \n#store min change and associated month/year \n data_results.append(min_month_year)\n data_results.append(min_change) \n \n#pass results list to string function and print\n print(budget_analysis(data_results))\n \n#write string to a new text file\nwith open(writing_path, \"w\") as textFile:\n textFile.write(budget_analysis(data_results))\n\n "
},
{
"alpha_fraction": 0.7344497442245483,
"alphanum_fraction": 0.8133971095085144,
"avg_line_length": 82.5999984741211,
"blob_id": "9b30a3b7a605b68f856a5c387fac582d4fb73686",
"content_id": "244baf8f3f2f191d839f422077032af5727bcb8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 5,
"path": "/README.md",
"repo_name": "lmodenbach/python-challenge",
"src_encoding": "UTF-8",
"text": "# python-challenge\n Repository contains two main.py programs, one for PyBank bank data display objectives and one for PyPoll polling data display objectives, \n as well as a resource folder containing images and and source data csvs. Contains output from both main.py programs piped into text files\n \n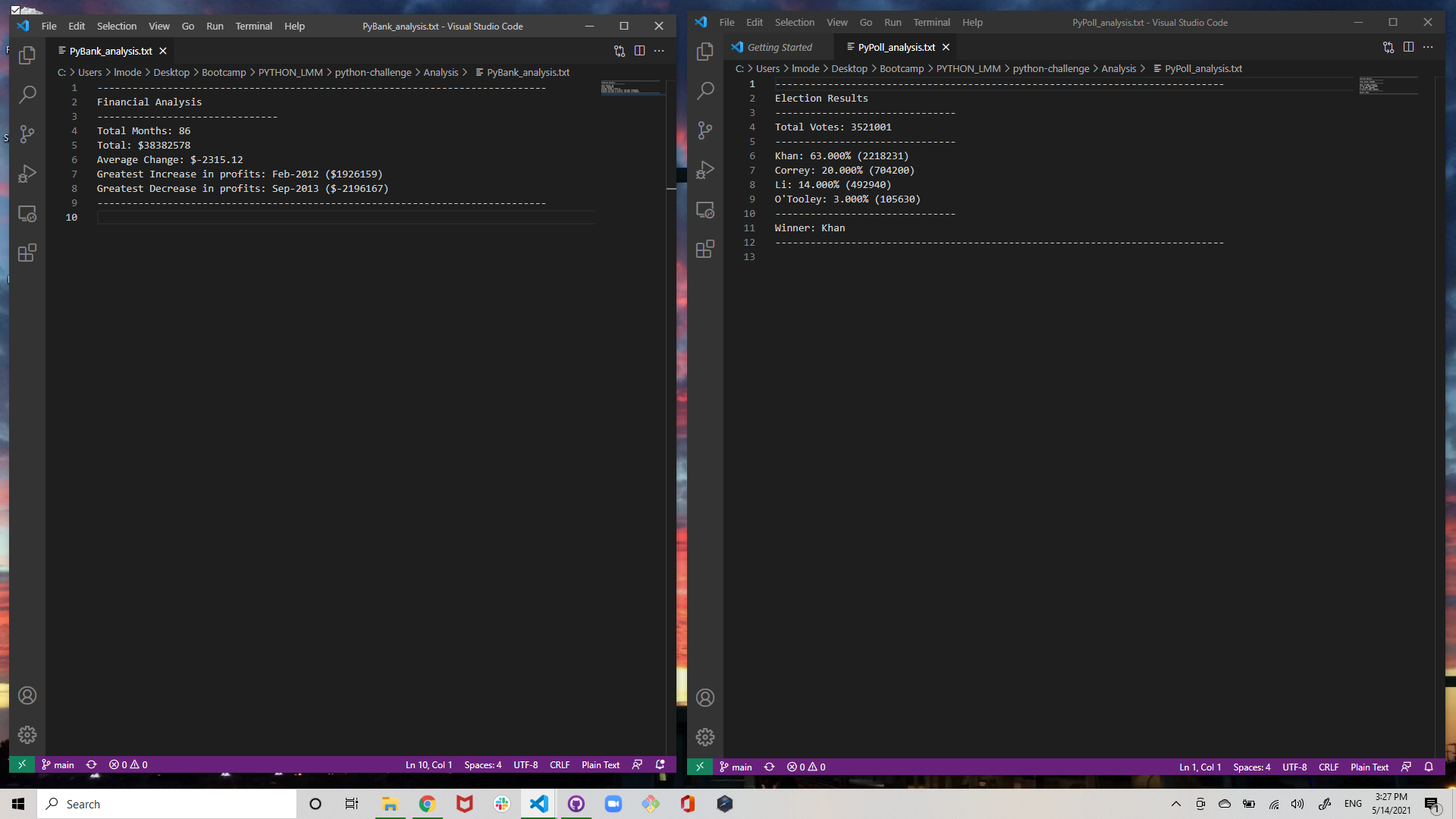\n"
}
] | 3 |
ivoreroman/api-boilerplate
|
https://github.com/ivoreroman/api-boilerplate
|
776d6b2f77466a7a959db75b24d43858a0ae69af
|
32c269ed7bdcd1404aa1b2ba23ef63e681c720eb
|
45d29ac1f5e699ab637ed4d224033779136ee049
|
refs/heads/master
| 2021-07-17T09:04:34.834444 | 2017-10-22T05:21:16 | 2017-10-22T05:21:16 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6396396160125732,
"alphanum_fraction": 0.6718146800994873,
"avg_line_length": 16.659090042114258,
"blob_id": "1c1a1cede99d38320ecf772f4b8bd166f643b74d",
"content_id": "4b284986765ff9c502f7c7cf942e3b1dcacdb6ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 777,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 44,
"path": "/tox.ini",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "[tox]\nenvlist = py36,linters\nskip_missing_interpreters = true\nskipsdist = true\n\n[testenv]\ndeps =\n -r{toxinidir}/requirements/dev.txt\ncommands =\n py.test {posargs: tests}\n\n[testenv:linters]\nbasepython = python3.6\ndeps =\n {[testenv:flake8]deps}\n {[testenv:pylint]deps}\ncommands =\n {[testenv:flake8]commands}\n {[testenv:pylint]commands}\n\n[testenv:flake8]\ndeps =\n flake8==3.4.1\n flake8-import-order==0.13\ncommands =\n flake8 {posargs: tests api}\n\n[testenv:pylint]\ndeps =\n -r{toxinidir}/requirements/dev.txt\n pylint==1.7.4\ncommands =\n pylint --disable=C,R {posargs: tests api}\n\n[flake8]\nexclude =\n .tox,\n .cache,\n __pycache__,\n *.pyc\nmax-complexity = 10\nmax-line-length = 120\nimport-order-style = google\napplication-import-names = api\n"
},
{
"alpha_fraction": 0.7288135886192322,
"alphanum_fraction": 0.7389830350875854,
"avg_line_length": 18.66666603088379,
"blob_id": "2e9145e2159857ad5b2e76ac368a5e063ef44a16",
"content_id": "02a28205b6853b77c3b354ae0c5988ab908aaafe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 295,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 15,
"path": "/tests/test_app.py",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "import falcon\nfrom falcon import testing\n\nimport pytest\nfrom api.app import api\n\n\[email protected](name=\"client\")\ndef fixture_client():\n return testing.TestClient(api)\n\n\ndef test_healt_check(client):\n response = client.simulate_get('/_health')\n assert response.status == falcon.HTTP_200\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 15.428571701049805,
"blob_id": "2f993a8e488ffc07f59f504423f7fd68861e61fe",
"content_id": "b33d1077611ea22c46d032b3ff70477235f2de36",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 7,
"path": "/api/app.py",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "import falcon\n\nfrom api.resources import HealthCheck\n\n\napi = falcon.API()\napi.add_route('/_health', HealthCheck())\n"
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 15.5,
"blob_id": "87e9788bfbcad185de4fcd1b9500899c7203b44a",
"content_id": "b730b3818478e70469374f5abf30c0c8022de9da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 66,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 4,
"path": "/api/resources/__init__.py",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "from .health_check import HealthCheck\n\n\n__all__ = ['HealthCheck']\n"
},
{
"alpha_fraction": 0.5978260636329651,
"alphanum_fraction": 0.614130437374115,
"avg_line_length": 19.44444465637207,
"blob_id": "d032e6a782c7f2508f16c7794a04a9ad5ea64754",
"content_id": "3cdfd297b38705560c01fb868758c859e4e0d05b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 9,
"path": "/api/resources/health_check.py",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "import falcon\n\n\nclass HealthCheck(object):\n\n def on_get(self, _, resp):\n resp.body = 'OK'\n resp.content_type = falcon.MEDIA_TEXT\n resp.status = falcon.HTTP_200\n"
},
{
"alpha_fraction": 0.7359412908554077,
"alphanum_fraction": 0.7408313155174255,
"avg_line_length": 14.730769157409668,
"blob_id": "1d8daca72216bdd4141079994b2a1f7bc2eca44a",
"content_id": "30f24a14b6161e4742e3c3c6db699478c0d7818e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 409,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 26,
"path": "/Makefile",
"repo_name": "ivoreroman/api-boilerplate",
"src_encoding": "UTF-8",
"text": "run:\n\tgunicorn --reload api.app:api\n\ninstall: install-deps install-githooks\n\ninstall-deps:\n\tpip install --upgrade pip\n\tpip install -r requirements/dev.txt\n\ninstall-githooks:\n\tcp git-hooks/pre-commit .git/hooks/pre-commit\n\tchmod +x .git/hooks/pre-commit\n\ntest-all:\n\ttox\n\ntest:\n\ttox -e py35\n\nlint:\n\ttox -e linters\n\nclean:\n\trm -rf .tox\n\n.PHONY: run install install-deps install-githooks test-all test lint clean\n"
}
] | 6 |
hidirb/Baccarat
|
https://github.com/hidirb/Baccarat
|
2cffb2dedfb6bccf45718ab8e15c680048e32924
|
870954f0f688c79417e794e974f503c994d5fc12
|
87a118a62bef6a23397759c9af1ce00108bca01a
|
refs/heads/main
| 2023-02-02T06:11:53.262402 | 2020-12-17T15:37:43 | 2020-12-17T15:37:43 | 322,337,499 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48415595293045044,
"alphanum_fraction": 0.5073938965797424,
"avg_line_length": 23.677724838256836,
"blob_id": "02cc51606b9cf92ed18a4d6d174a58b98f75c306",
"content_id": "d19de5d328cc04af4345fb734ba126dd59ec081c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5207,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 211,
"path": "/pickAcard.py",
"repo_name": "hidirb/Baccarat",
"src_encoding": "UTF-8",
"text": "import random\nimport os\ndef createDeck():\n Deck = []\n\n faceValues = [\"A\",\"J\",\"Q\",\"K\"]\n for i in range(4):\n for card in range(2,11):\n Deck.append(str(card))\n\n for card in faceValues:\n Deck.append(card)\n random.shuffle(Deck)\n return Deck\n\n\n\n\nclass Player:\n\n def __init__(self,hand = [],money = 1000):\n self.hand = hand\n self.score = self.setScore()\n self.money = money\n self.bet = 0\n\n def __str__(self):\n currentHand = \"\"\n for card in self.hand:\n currentHand += str(card) + \" \"\n finalStatus = \"Player's Hand: \" + currentHand + \"Score \" + str(self.score)\n\n return finalStatus\n\n\n def setScore(self):\n self.score = 0\n faceCardsDict = {\"A\":1,\"J\":0,\"Q\":0,\"K\":0,\n \"2\":2,\"3\":3,\"4\":4,\"5\":5,\"6\":6,\n \"7\":7,\"8\":8,\"9\":9,\"10\":0}\n\n for card in self.hand:\n self.score += faceCardsDict[card]\n if self.score > 9:\n self.score -= 10\n return self.score\n\n def play(self,newHand):\n self.hand =newHand\n self.score = self.setScore()\n\n def playerBet(self,amount):\n self.money -= amount\n self.bet += amount\n\n def win(self,result):\n if result == True:\n self.money += 2*self.bet\n self.bet = 0\n else:\n self.bet = 0\n\n def baccarat(self):\n if self.score == 9:\n return True\n else:\n return False\n\n def tie(self):\n if chooseBet == 1 or chooseBet == 2: \n self.money += self.bet\n self.bet = 0\n else:\n if chooseBet == 3 or chooseBet == 4:\n self.money += 2*self.bet\n self.bet = 0\n\n def playerWin(self):\n if player1.score > House.score:\n player1.win(True)\n\n\nclass Bank:\n def __init__(self,hand = [], money = 1000):\n self.hand = hand\n self.score = self.setScore()\n self.money = money\n self.bet = 0\n\n def __str__(self):\n currentHand = \"\"\n for card in self.hand:\n currentHand += str(card) + \" \"\n finalStatus = \"Banker's Hand: \" + currentHand + \"Score \" + str(self.score)\n\n return finalStatus\n \n def setScore(self):\n self.score = 0\n faceCardsDict = {\"A\":1,\"J\":0,\"Q\":0,\"K\":0,\n \"2\":2,\"3\":3,\"4\":4,\"5\":5,\"6\":6,\n \"7\":7,\"8\":8,\"9\":9,\"10\":0}\n\n for card in self.hand:\n self.score += faceCardsDict[card]\n if self.score > 9:\n self.score -= 10\n return self.score\n\n def play(self,newHand):\n self.hand =newHand\n self.score = self.setScore()\n\n # def win(self,result):\n # if result == True:\n # self.money += 2*self.bet\n # self.bet = 0\n # else:\n # self.bet = 0\n\n # def playerBet(self,amount):\n # self.money -= amount\n # self.bet += amount\n\n # def bankWin(self):\n # if player1.score < House.score:\n # House.win(True)\n\ndef clear():\n helpTab = input(\"Type help for help \") \n if helpTab == (\"help\"):\n os.system(\"help.txt\")\n\n\ncardDeck = createDeck()\nfirstHand = [cardDeck.pop(),cardDeck.pop()]\nsecondHand = [cardDeck.pop(),cardDeck.pop()]\nplayer1 = Player(firstHand)\nHouse = Bank(secondHand)\ncardDeck = createDeck()\n\nname = input(\"Please enter your name: \")\nprint(\"Welcome to baccarat \",name)\nwhile(True):\n if len(cardDeck) < 49:\n cardDeck = createDeck()\n firstHand = [cardDeck.pop(),cardDeck.pop()]\n secondHand = [cardDeck.pop(),cardDeck.pop()]\n player1.play(firstHand)\n House.play(secondHand)\n print(\"Your total playable cash is \", player1.money)\n placeBet = int(input(\"Please enter your bet amount: \"))\n print(\"\\nHere are your bet choices: \\n1) Player \\n2) Bank \\n3) Player/Tie \\n4) Bank/Tie \\n5 Help\")\n chooseBet = input(\"Choose your bet: \")\n\n player1.playerBet(placeBet)\n print(player1)\n print(House)\n \n if chooseBet == 1:\n if player1.score > House.score:\n player1.win(True)\n print(name,\"Wins\")\n\n elif player1.score == House.score:\n player1.tie()\n\n else:\n player1.win(False)\n print(name,\"Loses\")\n\n elif chooseBet == 2:\n if player1.score < House.score:\n player1.win(True)\n print(name,\"Wins\")\n\n elif player1.score == House.score:\n player1.tie()\n\n else:\n player1.win(False)\n print(name,\"Loses\")\n\n elif chooseBet == 3:\n if player1.score > House.score:\n player1.win(True)\n print(name,\"Wins\")\n\n elif player1.score == House.score:\n player1.tie()\n\n else:\n player1.win(False)\n print(name,\"Loses\")\n\n\n elif chooseBet == 4:\n if player1.score < House.score:\n player1.win(True)\n print(name,\"Wins\")\n\n elif player1.score == House.score:\n player1.tie()\n\n else:\n player1.win(False)\n print(name,\"Loses\")\n\n\n else:\n clear()\n"
}
] | 1 |
devpark0714/react-django-clone
|
https://github.com/devpark0714/react-django-clone
|
67666478fb091aa7bf6bf52dac79e7e22e6b4c56
|
fe835e0784df2a76fda9d8ac427cddabc15a2223
|
14b960b9951926154433fdc145f61e2fb91d433b
|
refs/heads/master
| 2023-02-17T06:27:38.140263 | 2021-01-05T18:31:48 | 2021-01-05T18:31:48 | 325,769,195 | 1 | 0 | null | 2020-12-31T09:53:48 | 2021-01-05T09:08:32 | 2021-01-05T18:31:49 |
Python
|
[
{
"alpha_fraction": 0.7752808928489685,
"alphanum_fraction": 0.7752808928489685,
"avg_line_length": 29,
"blob_id": "e76d5624c7e14fd8ba65eba13ec76f47a0dc84ea",
"content_id": "06168d2b0884c6a4501062a30fc126fc9390888e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 3,
"path": "/server/docker_compose/db/Dockerfile",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "FROM postgres:latest\n\n# COPY ./docker_compose/db/create.sql /docker-entrypoint-initdb.d/"
},
{
"alpha_fraction": 0.7876923084259033,
"alphanum_fraction": 0.7907692193984985,
"avg_line_length": 35.22222137451172,
"blob_id": "36f9c0a82c8bb78370243ab261b0ac1ca86bb2cb",
"content_id": "c92504c27ab548ea49cfab1df986ea256f7331f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 9,
"path": "/server/docker_compose/db/create.sql",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "CREATE USER suwee WITH PASSWORD '1234';\nALTER ROLE suwee SET client_encoding TO 'utf8';\nALTER ROLE suwee SET default_transaction_isolation TO 'read committed';\nALTER ROLE suwee SET TIMEZONE TO 'Asia/Seoul';\n\nALTER ROLE suwee WITH SUPERUSER;\n\nCREATE DATABASE suwee_db;\nGRANT ALL PRIVILEGES ON DATABASE suwee_db TO suwee;"
},
{
"alpha_fraction": 0.6485981345176697,
"alphanum_fraction": 0.6542056202888489,
"avg_line_length": 17.44827651977539,
"blob_id": "c02f189b416fe804813d377e8c01e4072be2529e",
"content_id": "6d5a3893ab3b1b4bec5ceb9b4d7c1c34fe5af55c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 29,
"path": "/server/docker_compose/django/Dockerfile",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "FROM python:3.8.1\nMAINTAINER JiChan Lee [email protected]\n\n\nWORKDIR /home/server/\n\n\nRUN apt-get update\n\n\n# python packages\nRUN pip install --upgrade pip\nCOPY ./requirements.txt/ /home/server/\nRUN pip install -r requirements.txt\n\n\n# server source\nCOPY ./manage.py /home/server/\nCOPY ./book/ /home/server/book/\nCOPY ./library/ /home/server/library/\nCOPY ./suwee/ /home/server/suwee/\nCOPY ./user/ /home/server/user/\n\n\n# client source\n\n\n# service run scripts\nCOPY ./docker_entrypoint.sh /home/server/\n"
},
{
"alpha_fraction": 0.5857534408569336,
"alphanum_fraction": 0.5961644053459167,
"avg_line_length": 33.433963775634766,
"blob_id": "42bc90229c2005a2c977406efe9f12a112597746",
"content_id": "c1ef5bbaf10e01858bd59ccb71c7aa0c823f1fc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1825,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 53,
"path": "/server/book/migrations/0002_auto_20210105_0105.py",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.3 on 2021-01-04 16:05\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('book', '0001_initial'),\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.AddField(\n model_name='review',\n name='likes',\n field=models.ManyToManyField(related_name='review_likes', through='book.Like', to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='review',\n name='user',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='like',\n name='review',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='book.review'),\n ),\n migrations.AddField(\n model_name='like',\n name='user',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to=settings.AUTH_USER_MODEL),\n ),\n migrations.AddField(\n model_name='book',\n name='category',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='book.category'),\n ),\n migrations.AddField(\n model_name='book',\n name='keyword',\n field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.SET_NULL, to='book.keyword'),\n ),\n migrations.AddField(\n model_name='book',\n name='reviews',\n field=models.ManyToManyField(through='book.Review', to=settings.AUTH_USER_MODEL),\n ),\n ]\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 20,
"blob_id": "10548334527ae8500ba645805c3a1300fc91c99e",
"content_id": "94511eeeaeb2e324d0e02b6ecbf92ef5989e5e5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/README.md",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "# react-django-clone"
},
{
"alpha_fraction": 0.5517241358757019,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 11.55555534362793,
"blob_id": "3351785c1cb3b9607e7f7300892078f08cb7fb44",
"content_id": "425c0685fa0841305be979d70aae1b133d3b435a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 9,
"path": "/server/README.md",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "# Django Clone Coding\n\n사용기술:\n- Python 3.8.1\n- Django 3.1.3\n- MariaDB 10.4.12\n- Docker\n- Docker-Compose\n- AWS-EC2\n\n\n\n"
},
{
"alpha_fraction": 0.6124600768089294,
"alphanum_fraction": 0.6345047950744629,
"avg_line_length": 31.257732391357422,
"blob_id": "95cd7ee0ba804c9d73206e37b8a96c0d3f9317c6",
"content_id": "fc2331ea1737b5ccef2718fa1a463703136919c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3176,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 97,
"path": "/server/user/models.py",
"repo_name": "devpark0714/react-django-clone",
"src_encoding": "UTF-8",
"text": "import time\nimport hmac\nimport base64\nimport hashlib\nimport requests\nimport json\nimport datetime\nfrom random import randint\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractUser\nfrom django.db import models\nfrom django.utils import timezone\n\nfrom model_utils.models import TimeStampedModel\n\n\nclass User(AbstractUser):\n image_url = models.URLField(max_length=200, null=True)\n phone_number = models.CharField(max_length=11, null=True)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n kakao_id = models.CharField(max_length=45, null=True)\n books = models.ManyToManyField('book.Book', through='UserBook')\n\n class Meta:\n db_table = 'users'\n\n\nclass UserBook(models.Model):\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n book = models.ForeignKey('book.Book', on_delete=models.CASCADE)\n page = models.IntegerField()\n time = models.IntegerField()\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n class Meta:\n db_table = 'user_books'\n\n\nclass SMSAuthRequest(TimeStampedModel):\n phone_number = models.CharField(verbose_name='휴대폰 번호', primary_key=True, max_length=50)\n auth_number = models.IntegerField(verbose_name='인증 번호')\n\n class Meta:\n db_table = 'sms_auth_requests'\n\n def save(self, *args, **kwargs):\n self.auth_number = randint(100000, 1000000)\n super().save(*args, **kwargs)\n self.send_sms()\n\n def send_sms(self):\n url = 'https://sens.apigw.ntruss.com'\n uri = '/sms/v2/services/ncp:sms:kr:261818325710:python/messages'\n api_url = url + uri\n\n body = {\n \"type\": \"SMS\",\n \"contentType\": \"COMM\",\n \"from\": \"01027287069\",\n \"content\": \"[테스트] 인증 번호 [{}]를 입력해주세요.\".format(self.auth_number),\n \"messages\": [{\"to\": self.phone_number}]\n }\n\n timeStamp = str(int(time.time() * 1000))\n access_key = \"IOtPwtO8ScDz19bkE6va\"\n string_to_sign = \"POST \" + uri + \"\\n\" + timeStamp + \"\\n\" + access_key\n signature = self.make_signature(string_to_sign)\n\n headers = {\n \"Content-Type\": \"application/json; charset=UTF-8\",\n \"x-ncp-apigw-timestamp\": timeStamp,\n \"x-ncp-iam-access-key\": access_key,\n \"x-ncp-apigw-signature-v2\": signature\n }\n\n requests.post(api_url, data=json.dumps(body), headers=headers)\n\n def make_signature(self, string):\n secret_key = bytes(settings.SECRET_KEY['sms'], 'UTF-8')\n string = bytes(string, 'UTF-8')\n string_hmac = hmac.new(secret_key, string, digestmod=hashlib.sha256).digest()\n string_base64 = base64.b64encode(string_hmac).decode('UTF-8')\n\n return string_base64\n\n @classmethod\n def check_auth_number(cls, p_num, c_num):\n time_limit = timezone.now() - datetime.timedelta(minutes=5)\n result = cls.objects.filter(\n phone_number=p_num,\n auth_number=c_num,\n modified__gte=time_limit\n )\n return result.exists()\n\n"
}
] | 7 |
denivy/HackerRankPython
|
https://github.com/denivy/HackerRankPython
|
f86ab96a86f24e39a2961fe22a2ee62eae5bfaec
|
7662c8f3f14983610c6058b0f407cb8fe57521d7
|
dfe1a3dc6cd744c74ba43680b733fb542ced2358
|
refs/heads/master
| 2021-01-19T17:44:30.793050 | 2014-05-14T14:08:13 | 2014-05-14T14:08:13 | 19,781,537 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5738422870635986,
"alphanum_fraction": 0.5982478260993958,
"avg_line_length": 27.03508758544922,
"blob_id": "c9d659eee512a2a314f116b0891e55afd3136bd4",
"content_id": "df27c104a77f717f173545bf3f0248afa7417c6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1598,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 57,
"path": "/HackerRank/Algorithms/sorting/countingSort3.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "size=int(input())\nnumbers=[]\nassert 1 <= size <= 1000000\nfor i in range(0,size):#for each line of input\n nums, strs = input().split()\n numbers.append(int(nums))\ncounters={}\nfor x in range(0,100):\n counters[x] = 0\nfor e in numbers:\n counters[e] += 1\ncounts=\"\"\ntotal=0\nfor z in counters: #for each element of counters...\n total += counters[z]\n counts += str(total) + ' '\nprint(counts.strip() )\n\n\n###import random\n###import sys\n##size=int(input())\n###size=random.randint(1,1000000)\n##numbers=[]\n###strings=[]\n###with open('inputData.txt', 'r') as f:\n### size=int(f.readline())\n### for line in f:\n### #print('line=',line,'line.split()=',line.split() )\n### nums,strs=line.split()\n### #print (\"nums=\",nums, \"strs=\",strs)\n### numbers.append(int(nums))\n### strings.append(strs)\n##assert 1 <= size <= 1000000\n##for i in size:#for each line of input\n## nums, strs = input().split()\n## numbers.append(int(nums))\n## #strings.append(strs)\n###print('size=',size)\n###print('numbers=',numbers)\n###print('strings=',strings)\n##counters={}\n##for x in range(0,100):\n## counters[x] = 0\n##for e in numbers:\n## counters[e] += 1\n##counts=\"\"\n##total=0\n##for z in counters: #for each element of counters...\n## total += counters[z]\n## counts += str(total) + ' '\n###print (\"counters=\",counters)\n###counts=\"\" #to be printed to screen\n###for y in counters: #for each counter...\n### counts += (str(y) + ' ') * counters[y] #print the number of occurences, + sum of the number of occurances of all preceding elements....\n\n##print(counts.strip() )\n"
},
{
"alpha_fraction": 0.512873649597168,
"alphanum_fraction": 0.5395087599754333,
"avg_line_length": 29.44144058227539,
"blob_id": "4a66c702416fce925a5b7877a505e5ee29622339",
"content_id": "b6b65d9ae2c0729b9526a13a4c8c86c4f2c140a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3379,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 111,
"path": "/HackerRank/Algorithms/sorting/MarksToys.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#this is a total hack because their problem set was bunk...but hey i did manage it.\nimport random\nfor _ in range(0,1000):\n numItems = random.randint(1,10**5)\n cash = random.randint(1,10**9)\n prices = random.sample(range(1,10**9),numItems)\n #numItems, cash=[int(x) for x in input().split()]\n #prices = [int(x) for x in input().split()]\n #print(\"sorting...\")\n def quickSort(array):\n if len(array) == 1:\n return array\n else:\n p=array.pop(0)\n head=[]\n tail=[]\n for i in array:\n if p < i:\n tail.append(i) \n if p > i:\n head.append(i)\n if len(head) != 0:\n head=quickSort(head)\n if len(tail) != 0:\n tail=quickSort(tail)\n return head + [p] + tail\n #print(\"sorting...\")\n #prices=quickSort(prices)\n prices.sort()\n #toys=[]\n total=0\n i=0\n #numToys=0\n #print(\"slicing\")\n while total <= cash:\n if i > 0 :\n total += prices[i]\n #toys.append(prices[i])\n #numToys+=1\n i += 1 \n #print( \"i-1=\",i-1)\n #print(\"sum(prices[:i] =\", sum(prices[:i]))\n #print(\"sum(prices[:i-1]) =\", sum(prices[:i-1]))\n #print(\"total =\", total)\n #print(\"cash =\", str(cash))\n currentBest = sum(prices[:i-1])\n count=i+1\n for x in range(0, numItems - i): #look at all remaining possibilites\n sumz = sum(prices[x:x+i-1]) #if a better one exists,\n if sumz > currentBest and sumz <= cash:\n #currentBest = sumz\n count+=1\n break\n #print(\"Whoa Nelly!\")\n print(count)\n\n#import random\n##import sys\n##numItems = random.randint(1,10**5)\n##cash = random.randint(1,10**9)\n##prices = random.sample(range(1,10**9),numItems)\n\n##numItems, cash=[int(x) for x in input().split()]\n##prices = [int(x) for x in input().split()]\n\n#numItems = 7\n#cash = 50\n#prices = [1, 12, 5, 111, 200, 1000, 10]\n\n#print (\"numItems=\",numItems,\"cash=\",cash,\"prices=\",prices)\n\n#toys=[]\n##choose a set of items toys such that value of sum(toys) <= cash and len(toys) is as large as possible.\n##for e in prices:\n\n\n###size=random.randint(1,1000000)\n##numbers=[]\n###strings=[]\n###with open('inputData.txt', 'r') as f:\n### size=int(f.readline())\n### for line in f:\n### #print('line=',line,'line.split()=',line.split() )\n### nums,strs=line.split()\n### #print (\"nums=\",nums, \"strs=\",strs)\n### numbers.append(int(nums))\n### strings.append(strs)\n##assert 1 <= size <= 1000000\n##for i in size:#for each line of input\n## nums, strs = input().split()\n## numbers.append(int(nums))\n## #strings.append(strs)\n###print('size=',size)\n###print('numbers=',numbers)\n###print('strings=',strings)\n##counters={}\n##for x in range(0,100):\n## counters[x] = 0\n##for e in numbers:\n## counters[e] += 1\n##counts=\"\"\n##total=0\n##for z in counters: #for each element of counters...\n## total += counters[z]\n## counts += str(total) + ' '\n###print (\"counters=\",counters)\n###counts=\"\" #to be printed to screen\n###for y in counters: #for each counter...\n### counts += (str(y) + ' ') * counters[y] #print the number of occurences, + sum of the number of occurances of all preceding elements....\n\n##print(counts.strip() )\n"
},
{
"alpha_fraction": 0.5322906374931335,
"alphanum_fraction": 0.5597881078720093,
"avg_line_length": 34.088497161865234,
"blob_id": "fe0379117cb48a329853a81813ed7bcb798ebd13",
"content_id": "f11a8086c1e96aa1d284ec5b4a365a32e0675c1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3964,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 113,
"path": "/HackerRank/Algorithms/warmup/AngryChildren.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "numPackets = int(input())\nkids = int(input())\nassert 1 < numPackets < 10**5\nassert 1 < kids < numPackets\npackets=[]\nfor i in range(0,numPackets): #for every packet\n packets.append(int(input()))\npackets.sort()\nanswer=10**15\nfor x in range(0, numPackets - kids + 1):\n diff=packets[x + kids -1] - packets[x]\n if diff < answer:\n answer=diff\nprint(answer)\n\n\n\n##import random\n#import bisect\n\n####################################\n##numPackets = int(input())\n##kids = int(input())\n####################################\n##numPackets = 7\n##kids = 3\n##input_array = [10,100,300,200,1000,20,30]\n#########################################\n########################################\n#numPackets = random.randint(1,10**5)\n#kids = random.randint(1,numPackets)\n#assert 1 < numPackets < 10**5\n#assert 1 < kids < numPackets\n\n#packets=[]\n##maxValue=0\n##maxKey=0\n##minkey=0\n##minValue=10**9\n\n#for i in range(0,numPackets): #for every packet\n# ################################\n# #numCandies = int(input())\n# #numCandies = input_array[i]\n# numCandies = random.randint(0, 10**9) #generate a random number of candies\n# ################################\n# #print (\"numCandies=\",numCandies)\n# assert 0 <= numCandies <= 10**9\n \n# if len(packets) < kids: #first just fill it with the appropriate number of items. \n# bisect.insort(packets, numCandies)\n\n# else:\n\n# highest = packets[-1] \n# lowest = packets[0]\n# diff = highest - lowest\n\n# if numCandies > lowest and numCandies - lowest < diff:\n# packets.pop()\n# bisect.insort(packets,numCandies) \n# elif numCandies < highest and highest - numCandies < diff:\n# packets.pop(0)\n# bisect.insort(packets,numCandies)\n \n#print(max(packets) - min(packets))\n\n\n##import random\n##for _ in range (20):\n## #numPackets = int(input())\n## #numPackets = 7\n## numPackets = random.randint(1,10**5)\n## assert 1 < numPackets < 10**5\n## #kids = int(input())\n## #kids = 3\n## kids = random.randint(1,numPackets)\n## assert 1 < kids < numPackets\n## packets_chosen={}\n## #input_array = [10,100,300,200,1000,20,30]\n## maxValue=maxKey=minkey=0\n## minValue=10**9\n## for i in range(0,numPackets): \n## #numCandies = int(input())\n## #numCandies = input_array[i]\n## numCandies = random.randint(0, 10**9)\n## #print (\"numCandies=\",numCandies,\"currentMax=\",currentMax)\n## assert 0 <= numCandies <= 10**9\n## #build a list of items with length equal to the number of kids. keep track of the index and the value of the current highest values and lowest values\n## if len(packets_chosen) < kids:\n## packets_chosen[i]=numCandies\n## #is it the biggest?\n## if numCandies > maxValue:\n## maxValue = numCandies\n## maxKey = i\n## #is it the smallest\n## elif numCandies < minValue:\n## minValue = numCandies\n## minKey = i\n## else:\n## #once the list is built, the only time we update it is if we find a value that is smaller than one we already have\n## if numCandies-minValue < numCandies-maxValue: #if its smaller than our current max...\n## packets_chosen[maxKey]=numCandies\n## maxValue = numCandies\n## elif maxValue-numCandies < maxValue-minValue:\n## packets_chosen[minKey]=numCandies\n## minValue = numCandies\n## #maxKey = packets_chosen[-1]\n## #elif numCandies > currentMin:\n## # currentMin,minIndex = numCandies,i\n## #print(\"packets_chosen=\",packets_chosen,\"maxIndex=\",maxIndex,\"currentMax=\",currentMax,\"minIndex=\", minIndex, \"currentMin=\",currentMin)\n## #print(\"packets_chosen=\",packets_chosen,\"currentMax=\",currentMax)\n## print(max(packets_chosen) - min(packets_chosen))"
},
{
"alpha_fraction": 0.6132075190544128,
"alphanum_fraction": 0.6226415038108826,
"avg_line_length": 32.66666793823242,
"blob_id": "b4b0f9eea85ccdc41a235562189a5c013eb6eb3c",
"content_id": "e7776ffaf852e479fee96f6516546b8352f5135e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 3,
"path": "/HackerRank/Algorithms/searching/FindTheMedian.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "numItems=int(input())\narray=[int(x) for x in input().split(' ')]\nprint(sorted(array)[len(array)//2])\n\n "
},
{
"alpha_fraction": 0.5348837375640869,
"alphanum_fraction": 0.5745553970336914,
"avg_line_length": 20.52941131591797,
"blob_id": "f8902c4798c383101187eefab9ec3ecaa7f7512b",
"content_id": "54ea6e21599b5da82808b02037ca808a4f598f0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 34,
"path": "/HackerRank/Algorithms/sorting/quicksort2.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "numItems=int(input())\nassert 1 <= numItems <= 1000\narray=[int(x) for x in input().split(' ')]\np=array[0]\narray.pop(0)\nhead=[]\ntail=[]\nfor i in array:\n if p < i:\n tail.append(i)\n if p > i:\n head.append(i)\nsortz = head + [p] + tail\nprint(\" \".join(str(x) for x in sortz))\n\n#import random\n\n##numItems=int(input())\n#numItems=random.randint(1,1000)\n#assert 1 <= numItems <= 1000\n##array=[int(x) for x in input().split(' ')]\n#array= random.sample(range(-1000,1000), numItems + 1) #add one for p...\n#p=array[0]\n#array.pop(0)\n##input()\n#head=[]\n#tail=[]\n#for i in range(0,p):\n# if p < i:\n# head.append(i)\n# if p > i:\n# tail.append(i)\n#sortz = head + [p] + tail\n#print(\" \".join(str(x) for x in sortz))"
},
{
"alpha_fraction": 0.4629155993461609,
"alphanum_fraction": 0.4961636960506439,
"avg_line_length": 26.964284896850586,
"blob_id": "e1e69a8a28a88b4179a2c599f58774f7772f59ab",
"content_id": "e7b8bf51bee0be6d6b60219a20c1ad1dfaab34b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 782,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 28,
"path": "/HackerRank/Algorithms/sorting/quickSortFinal.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "import random\nnumItems = random.randint(1,10**5)\n#numItems=int(input())\n#numItems = 7\nassert 1 <= numItems <= 10**5\n#array=[int(x) for x in input().split(' ')]\n#array=[5, 8, 1, 3, 7, 9, 2]\narray = random.sample(range(-10**5,10**5), numItems)\nprint(\"starting sort...\")\ndef quickSort(array):\n if len(array) == 1:\n return array\n else:\n p=array.pop(0)\n head=[]\n tail=[]\n for i in array:\n if p < i:\n tail.append(i) \n if p > i:\n head.append(i)\n if len(head) != 0:\n head=quickSort(head)\n if len(tail) != 0:\n tail=quickSort(tail)\n #print(\" \".join(str(x) for x in head + [p] + tail))\n return head + [p] + tail\nprint(quickSort(array))"
},
{
"alpha_fraction": 0.4133574068546295,
"alphanum_fraction": 0.7265343070030212,
"avg_line_length": 33.65625,
"blob_id": "9fab71f8ab0295d8350326978c26daed07ee9d6b",
"content_id": "5705cc42d757710ad8628b99e90e3ac7734c3561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "no_license",
"max_line_length": 378,
"num_lines": 32,
"path": "/HackerRank/Algorithms/searching/Flowers.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#import random\n\n#numFlowers= random.randint(1,1000000)\n#numPeople = random.randint(1,100)\n#prices = random.sample(range(1,1000000), numFlowers)\n\n#numFlowers=3\n#numPeople=3\n#prices = [2,5,6]\n#expected output = 13\n\n#numFlowers=50\n#numPeople=3\n#prices=[int(x) for x in \"390225 426456 688267 800389 990107 439248 240638 15991 874479 568754 729927 980985 132244 488186 5037 721765 251885 28458 23710 281490 30935 897665 768945 337228 533277 959855 927447 941485 24242 684459 312855 716170 512600 608266 779912 950103 211756 665028 642996 262173 789020 932421 390745 433434 350262 463568 668809 305781 815771 550800\".split()]\n#expected output = 163578911\n\nnumFlowers, numPeople = [int(x) for x in input().split()]\nprices = [int(x) for x in input().split()]\n\nassert 1 <= numFlowers\nassert numPeople <= 1000000\nassert len(prices) == numFlowers\n\ncost=0\nroundz=0\nprices.sort(reverse=True)\n\nfor x in range(numFlowers):\n #print(\"round=\", roundz, \"x=\", x, \"prices[x]=\", prices[x], \"costThisRound=\", prices[x] * (roundz + 1))\n cost += prices[x] * (roundz + 1)\n if (x + 1) % numPeople == 0: roundz += 1\nprint(cost)"
},
{
"alpha_fraction": 0.47101449966430664,
"alphanum_fraction": 0.5163043737411499,
"avg_line_length": 33.5625,
"blob_id": "70bfc306715235103b1b490c540bda32124248bf",
"content_id": "448c6f23ca7df58380de966d9084ce601e6a28bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 552,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 16,
"path": "/HackerRank/Algorithms/sorting/insertionSort3.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#numItems=int(input())\nnumItems = 9\nassert 1 <= numItems <= 1000\n#array=[int(x) for x in input().split(' ')]\narray=[9, 8, 6, 7, 3, 5, 4, 1, 2]\nfor i in range(1,len(array)):\n j=i\n #print(\"--\")\n #print(\"array=\",array,\"i=\",i,\"j=\",j,\"array[i]=\",array[i],\"array[i-1]=\",array[i-1])\n while array[j] < array[j-1] and j > 0:\n value=array[j]\n array[j] = array[j-1]\n array[j-1]=value\n j-=1\n #print(\"array=\",array,\"i=\",i,\"j=\",j,\"array[j]=\",array[j],\"array[j-1]=\",array[j-1])\n print(\" \".join(str(x) for x in array))"
},
{
"alpha_fraction": 0.4277673661708832,
"alphanum_fraction": 0.4596622884273529,
"avg_line_length": 23.813953399658203,
"blob_id": "307cc8b674bcc5413e7d27b026f9e3deb6b6dd0e",
"content_id": "c24d1cd99e3eaa70f1dedcb1b9eca072ab1458ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1066,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 43,
"path": "/HackerRank/Algorithms/sorting/runningTimeQuickSort.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "####################################################\nclass Swaps:\n def __init__(self):\n self.counter=0\n def inc(self):\n self.counter += 1\n def getCount(self):\n return self.counter\n####################################################\ndef quickSort(array2):\n if len(array2) <= 1:\n return\n pivot=array2[-1]\n part=0\n for i in range(0,len(array2)):\n if array2[i] <= pivot:\n temp=array2[i]\n array2[i]=array2[part]\n array2[part]=temp\n swaps.inc() \n part+=1\n quickSort(array2[:part-1]) \n quickSort(array2[part:])\n################################################## \nnumItems=int(input())\narray=[int(x) for x in input().split(' ')]\nassert 1 <= numItems <= 1000\narray2 = array.copy()\nshifts=0\nswaps=Swaps()\n\nfor i in range(1,len(array)):\n j=i\n\n while array[j] < array[j-1] and j > 0:\n value=array[j]\n array[j] = array[j-1]\n array[j-1]=value\n j-=1\n shifts+=1\n\nquickSort(array2)\nprint(shifts-(swaps.getCount()))"
},
{
"alpha_fraction": 0.555059552192688,
"alphanum_fraction": 0.5892857313156128,
"avg_line_length": 23,
"blob_id": "942e6348d78df14198b78155b49923e6ef6bea9d",
"content_id": "2f47e0a9f0cc27e4cea555376655d2af38303168",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 28,
"path": "/HackerRank/Algorithms/warmup/isFibonacci.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "import random\n\n##random generated\n#numTests = random.randint(1,10**5)\n#numbers = random.sample(range(1,10**10),numTests)\n#Samples\n#numTests = 3\n#numbers=[5,7,8]\n#user Entry\nnumbers=[]\nnumTests = int(input())\nfor i in range(0,numTests):\n numbers.append(int(input()))\n\nfor x in numbers: #for each number in the list...\n #print (x) \n a,b=0,1\n #print (\"fib sequence of x=\")\n fib = [0,1]\n while a < x: #generate a fibonacci sequence.\n fib[0]=fib[1] #only track the last two numbers in a fib sequence\n fib[1] = a\n a,b = b, a+b\n #print (fib)\n if fib[-1] + fib[-2] == x:\n print(\"IsFibo\")\n else:\n print(\"IsNotFibo\")\n"
},
{
"alpha_fraction": 0.5102639198303223,
"alphanum_fraction": 0.5483871102333069,
"avg_line_length": 25.230770111083984,
"blob_id": "11649edaaa20de76c7ab387517d7dec034f49727",
"content_id": "c0641a24a7c6bbbf60e1ca1232c6110e37e9dd39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 13,
"path": "/HackerRank/Algorithms/sorting/quickSort1.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "\ns=int(input())\nassert 1 <= s <= 1000\narray=[int(x) for x in input().split(' ')]\nsortz=array[:1]\nfor i in range(1,len(array)):\n sortz.append(array[i])\n j=len(sortz)-1\n while sortz[j] < sortz[j-1] and j > 0:\n temp=sortz[j]\n sortz[j]=sortz[j-1]\n sortz[j-1]=temp\n j-=1\nprint(\" \".join(str(x) for x in sortz))"
},
{
"alpha_fraction": 0.48439961671829224,
"alphanum_fraction": 0.5367160439491272,
"avg_line_length": 25.889829635620117,
"blob_id": "22f952a98b70cec67a03f531f89f21bfc5d556b1",
"content_id": "e863954eb141c65f4594104eea4d29fb7242143b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3173,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 118,
"path": "/HackerRank/Algorithms/sorting/2Arrays.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "numTests = int(input())\nassert 1 <= numTests <= 10\nfor _ in range(numTests):\n howMany, maxValue = [int(x) for x in (input().split())]\n A=[int(x) for x in (input().split())]\n B=[int(x) for x in (input().split())]\n assert 1 <= howMany <= 1000\n assert 1 <= maxValue <= 10**9\n assert len(A) == howMany and len(B) == howMany\n A.sort()\n B.sort(reverse=True)\n conditionMet=\"YES\"\n for e in range(len(A)): #for each element in a\n if A[e] + B[e] < maxValue:\n conditionMet=\"NO\"\n print(conditionMet)\n\n\n\n\n##import random\n##numTests = random.randint(1,10)\n##numTests = 2\n##howManyMaxVals=[(3,10),(4,5)]\n##Avals=[ [2,1,3], [1,2,2,1] ]\n##Bvals=[ [7,8,9], [3,3,3,4] ]\n#numTests = int(input())\n#assert 1 <= numTests <= 10\n#for _ in range(numTests):\n# #howMany = random.randint(1,1000)\n# #maxValue = random.randint(1,10**9)\n# #A = random.sample(range(0,10**9),howMany)\n# #B = random.sample(range(0,10**9),howMany)\n# #howMany,maxValue = howManyMaxVals[_]\n# #A = Avals[_]\n# #B = Bvals[_]\n# howMany, maxValue = int(input())\n# A=int(input())\n# B=int(input())\n# assert 1 <= howMany <= 1000\n# assert 1 <= maxValue <= 10**9\n# assert len(A) == howMany and len(B) == howMany\n# A.sort()\n# B.sort(reverse=True)\n# conditionMet=\"YES\"\n# for e in range(len(A)): #for each element in a\n# if A[e] + B[e] < maxValue:\n# conditionMet=\"NO\"\n# print(conditionMet)\n\n\n\n\n\n\n\n\n\n\n\n##import random\n###numTests = int(input())\n##numTests = random.randint(1,5)\n##assert 1 <= numTests <= 5\n##for _ in range(0,numTests):\n## #numItems=int(input())\n## #numItems = 9\n## numItems = random.randint(1,100000)\n## assert 1 <= numItems <= 100000\n## #array=[int(x) for x in input().split(' ')]\n## #array=[9, 8, 6, 7, 3, 5, 4, 1, 2]\n## array = random.sample(range(1,1000000),numItems)\n## array2 = sorted(array)\n## count=0\n## for i in array:\n## count += abs(i - array2.index(i))\n## #j=i\n## ##print(\"--\")\n## ##print(\"array=\",array,\"i=\",i,\"j=\",j,\"array[i]=\",array[i],\"array[i-1]=\",array[i-1])\n## #while array[j] < array[j-1] and j > 0:\n## # value=array[j]\n## # array[j] = array[j-1]\n## # array[j-1]=value\n## # j-=1\n## # count+=1\n## # #print(\"array=\",array,\"i=\",i,\"j=\",j,\"array[j]=\",array[j],\"array[j-1]=\",array[j-1])\n## #print(\" \".join(str(x) for x in array))\n## print(count)\n\n\n\n\n##import random\n###numTests = int(input())\n###numTests = random.randint(1,10)\n##numTests = 2\n##assert 1 <= numTests <= 10\n##howMany=[(3,10),(4,5)]\n##Avals=[ [2,1,3], [1,2,2,1] ]\n##Bvals=[ [7,8,9], [3,3,3,4] ]\n##for _ in numTests:\n## #howMany, maxValue = int(input())\n## #A=int(input())\n## #B=int(input())\n## #howMany = random.randint(1,1000)\n## #maxValue = random.randint(1,10**9)\n## #A = random.sample(range(0,10**9),howMany)\n## #B = random.sample(range(0,10**9),howMany)\n## howMany,maxValue = howMany[_]\n## A = Avals[_]\n## B = Bvals[_]\n## assert 1 <= howMany <= 1000\n## assert 1 <= maxValue <= 10**9\n## assert len(A) == howMany and len(B) == howMany\n## print(\"A=\",A,\"B=\",B)\n\n## A.sort()\n## B.sort()\n"
},
{
"alpha_fraction": 0.6100917458534241,
"alphanum_fraction": 0.6574923396110535,
"avg_line_length": 17.16666603088379,
"blob_id": "9364b71a2934a5e902d4a4199f1ba4c001cce0de",
"content_id": "fc283b5f452a3b5c067d4c7e6206cff582bd123e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 36,
"path": "/HackerRank/Algorithms/searching/LonelyInteger.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#import random\n\n#numIntegers = random.randrange(1,100,2)\n#intArray = random.sample(range(0,100),numIntegers)\n#numIntegers=1\n#intArray=[1]\n#output 1\n\n#numIntegers=3\n#intArray=[1, 1, 2]\n##output 2\n\n#numIntegers=5\n#intArray=[0, 0, 1, 2, 1]\n\n#should be linear? depends on what append and remove do...\n\n\n\nnumIntegers = int(input())\nintArray = [ int(x) for x in input().split() ]\n\nassert 1 <= numIntegers <= 100\nassert numIntegers % 2 == 1 #numIntegers needs to be odd\nassert len(intArray) == numIntegers\n\nonce=[]\ntwice=[]\n\nfor x in intArray: #0n\n if x in once:\n twice.append(x)\n once.remove(x)\n else:\n once.append(x)\nprint(once[0])\n"
},
{
"alpha_fraction": 0.6551312804222107,
"alphanum_fraction": 0.6587111949920654,
"avg_line_length": 26.032258987426758,
"blob_id": "f8230f7f995ab6cbfda81dc4c7b277e6d15e7cfd",
"content_id": "04905894e3e19c39174e895e5b3154ff54c4e7cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 838,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 31,
"path": "/HackerRank/Algorithms/searching/Encryption.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#message = \"ifmanwasmeanttostayonthegroundgodwouldhavegivenusroots\"\n#message = \"haveaniceday\"\n#message = \"feedthedog\"\n#message = \"chillout\"\nimport math\nmessage=input()\nlength = len(message)\nassert 1 <= length <= 81\n\nfloorz = int(math.sqrt(length))\nceilz = int(math.ceil(math.sqrt(length)))\n\nif floorz is not ceilz:\n if floorz < ceilz and floorz * ceilz >= length:\n rows,cols = floorz,ceilz\n else:\n rows,cols = ceilz,ceilz\nelse: rows,cols = floorz,floorz\n\nencode=[]\nanswer= dict.fromkeys(range(cols),\"\")\n\nfor x in range(rows):\n encode = (message[(x*cols):((x*cols) + cols)])\n for y in range(len(encode)):\n answer[y] += encode[y]\nprint (\" \".join(answer.values()))\n#print(\"y=\",y,\"encode[y]=\",encode[y])\n#print (\"encode=\",encode)\n#print (\"answer=\",answer)\n#print(\"length=\",length,\"rows=\",rows, \"cols=\",cols)\n"
},
{
"alpha_fraction": 0.33280274271965027,
"alphanum_fraction": 0.33644115924835205,
"avg_line_length": 77.53571319580078,
"blob_id": "5c7cd1e8e485b0ae346d7ea8583b2f2f2d7a4a17",
"content_id": "2a8fcf374cba507d07e5853b874d99efd71fc803",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8795,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 112,
"path": "/HackerRank/graph.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "##############################################################################################################################\n## Dennis Tracy Ivy, Jr.\n## 04/4/2014\n## self study of MIT 6.00\n## ps11 - optimization, dynamic programming, graphs, etc\n##############################################################################################################################\n\n###############################################################################################################################\n# Customized class definitions for use in the ps11 problem set\n##############################################################################################################################\n\nclass Node(object): #creates a node\n def __init__(self, name): #initializer\n self.name = str(name)\n def getName(self): #name getter\n return self.name\n def __str__(self): #string version\n return self.name\n def __repr__(self): #required for type\n return self.name\n def __eq__(self, other): #used for comparison\n return self.name == other.name \n def __ne__(self, other):\n return not self.__eq__(other) #explicit comparison\n#############################################################################################################################\nclass Edge(object): #creates an edge\n def __init__(self, src, dest): #initializer\n self.src = src\n self.dest = dest\n def getSource(self): #source getter\n return self.src\n def getDestination(self): #destination getter\n return self.dest\n def __str__(self): #pretty string\n return str(self.src) + '->' + str(self.dest)\n#############################################################################################################################\nclass WEdge(Edge): #create a weighted edge object (extends Edge)\n def __init__(self, src, dest, distance, outdoor):\n \n self.src = src #initialize instance variables\n self.dest = dest\n self.distance = int(distance)\n self.outdoor = int(outdoor)\n\n def getSource(self): #source getter\n return self.src\n def getDestination(self): #destination getter\n return self.dest \n def getDistance(self): #total distance getter\n return int(self.distance)\n def getOutdoorDistance(self): #outdoor distance getter\n return int(self.outdoor)\n def __str__(self): #create a pretty string to return\n return str(self.src.getName().rjust(2) ) + '->' + \\\n str(self.dest.getName().ljust(2) ) + \\\n ' distance=' + str(self.distance).rjust(3) + \\\n ' outdoor=' + str(self.outdoor).rjust(3)\n#############################################################################################################################\nclass Digraph(object):\n\n def __init__(self): #initialize the graph\n self.nodes = []\n self.edges = {}\n def addNode(self, node): #add a node to the graph\n \n if node in self.nodes: #if it already exists.\n #print(\"Duplicate Node!\")\n raise ValueError('Duplicate node') #raise an error\n else:\n if type(node) != Node: #if its not the right type\n raise TypeError #raise an error\n self.nodes.append(node) #add it to the graph\n self.edges[str(node)] = [] #create an empty list container to hold the nodes future edges\n\n def addEdge(self, edge): #add an edge to the graph\n src = edge.getSource() #find the source\n dest = edge.getDestination() #and the destination of the supplied edge\n if not(src in self.nodes and dest in self.nodes): #check to make sure they exist\n #print (\"Node not in graph!\") #and if not throw an exception\n raise ValueError('Node not in graph') \n self.edges[str(src)].append(edge) #if they do exist, add them to the graph\n\n def childrenOf(self, node): #returns a list of children\n return self.edges[ str(node) ] #for the current node (returns a list of WEdge objects)\n\n def hasNode(self, node): #if this node exists in the graph\n if node in self.nodes: #find it\n return True #and return either true\n else: return False #or false accordingly\n\n def calcPathLength(self, path, toPrint=False): #calculates a numeric value of a path in format ['1','3','5']\n distances=[] #locals\n outdoors=[]\n for i in range (0,len(path)-1): #for each leg of the journey\n d,o = self.distanceFromParentToChild(Node(path[i]),Node(path[i+1])) #get the distance between each node\n distances.append(d) #and put them in an array\n outdoors.append(o)\n if toPrint==True: #if i want to display some debug info\n print (str(sum(distances)).rjust(3), \"/\", str(sum(outdoors)).ljust(3))\n return ( sum(distances), sum(outdoors) ) #return the sums in tuple format i.e. (120,75)\n\n def distanceFromParentToChild(self, src, dest): #get the distance from one node to another node\n for i in self.edges[str(src)]: #check all possible pathways initiating from the source node\n if i.getDestination() == dest: #if it exists\n return (i.getDistance(), i.getOutdoorDistance()) #return a tuple containing the total and outdoor distances\n \n def __str__(self): #convert this graph to a useful string\n res = '' #empty str t return\n for k in sorted(self.edges): #for all the nodes\n for d in self.edges[k]: #for each edge\n res = res + str(d) + '\\n' #create a pretty string :P\n return res[:-1] #slice off the last newline and return"
},
{
"alpha_fraction": 0.4262114465236664,
"alphanum_fraction": 0.6024228930473328,
"avg_line_length": 29.299999237060547,
"blob_id": "dfb596a26e4e73947a4a3765761ccd0a4d067c55",
"content_id": "ec802669ed716f0f8237473153f33956b66ae45f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 908,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 30,
"path": "/HackerRank/Algorithms/searching/ClosestNumbers.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#import random\n#numItems = random.randint(10, 200000)\n#array = random.sample(range(-10**7,10**7),numItems)\n\n#numItems = 10\n#array = [ -20, -3916237, -357920, -3620601, 7374819, -7330761, 30, 6246457, -6461594, 266854 ]\n\n#numItems = 12\n#array = [ -20, -3916237, -357920, -3620601, 7374819, -7330761, 30, 6246457, -6461594, 266854, -520, -470 ]\n\n#numItems = 4\n#array = [ 5, 4, 3, 2, ]\n\nnumItems = int(input())\narray = [ int(x) for x in input().split() ]\nans=''\nassert 10 <= numItems <= 200000\nassert len(array) == numItems\narray.sort()\nminDiff = abs(array[0] - array[1])\nfor i in range(len(array)-1):\n diff = abs(array[i] - array[i + 1])\n #print(\"minDiff=\",minDiff, \"i=\",i, \"diff=\",diff)\n if diff < minDiff:\n minDiff = diff\nfor i in range(len(array)-1):\n diff= abs(array[i] - array[i + 1])\n if diff == minDiff:\n ans += str(array[i]) + ' ' + str(array[i+1]) + ' '\nprint(ans.strip())"
},
{
"alpha_fraction": 0.45168447494506836,
"alphanum_fraction": 0.4627784788608551,
"avg_line_length": 70.23870849609375,
"blob_id": "bfb79b771e153a2af1cd69c718f1e81593b170e8",
"content_id": "47f6391a86942dcdf4f87c770f756429ddddeeba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22084,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 310,
"path": "/HackerRank/MIT_OCW_6_PS11.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "##############################################################################################################################\n## Dennis Tracy Ivy, Jr.\n## 04/2/2014\n## self study of MIT 6.00\n## ps11 - optimization, dynamic programming, graphs, etc\n##############################################################################################################################\nimport string #import libraries\nfrom graph import * #import custom classes\n##############################################################################################################################\n# this function takes a file name and using the data contained there in, builds and returns a digraph\n##############################################################################################################################\ndef load_map(mapFilename): #read from a file and create the graph\n\n print (\"Loading map from file...\")\n g=Digraph() #create a graph object\n if type(mapFilename) != str: #test to ensure file exists\n raise FileNotFoundError(\"Trouble opening\" + mapFilename) #if not throw an exception\n with open(mapFilename, 'r') as f: #open the file safely\n for line in f: #read it a line at a time\n try: #attempt to read from the file\n src,dest,dist,outdoor = line.split() #split it up into variables\n except: #if couldn't read from the file\n raise Exception(\"Trouble reading from file\" + mapFilename) #throw an exception\n src_node = Node(src) #create some nodes\n dest_node = Node(dest) \n\n if not g.hasNode(src_node) : g.addNode(src_node) #if the nodes don't already exist\n if not g.hasNode(dest_node) : g.addNode(dest_node) #add them to the graph\n\n edge=WEdge(src_node,dest_node,dist,outdoor) #create an edge\n g.addEdge(edge) #and add it to the graph as well\n \n #with open(\"graph.txt\", 'w') as out: #for debugging purposes\n # out.write(str(g)) #uncomment to write the graph to a file\n #print(g) #or print it to the screen\n return g #return the graph\n##############################################################################################################################\n#recursive function to find the shortest path thru the graph using brute force exhaustive depth first search\n#inputs:\n# digraph = a digraph representing the relationship between buildings on the campus of MIT and their connections\n# start = a string representing the number of the building to start from\n# end = a string representing the number of the building to travel to\n# maxTotalDist = the maximum distance you're willing to walk to get from start to end\n# maxDistOutdoors = the maximum distance you're willing to travel outdoors to get from start to end\n# visited = a list of nodes you've already visited, defaults to None\n# counter = a counter allowing you to know when you've failed to find a valid path\n#outputs:\n# returns a list of buildings describing the path you should take. buildings are represented as strings.\n# ex: ['1','2','3','4','5']\n#exceptions:raises an exception if the path is not found or the start/end nodes are not contained in the graph\n##############################################################################################################################\ndef bruteForceSearch(digraph, start, end, maxTotalDist, maxDistOutdoors, visited=None, counter=0): \n\n if visited == None : visited = [] #initialize visited on our first trip thru\n try:\n start = Node(start) #create nodes for the given values\n end = Node(end)\n except:\n raise ChildProcessError('Unable to create nodes')\n if not ( digraph.hasNode(start) and digraph.hasNode(end) ): #and confirm that these nodes exist int the graph\n raise ValueError(\"Start or End does not exist\")\n path = [str(start)] #this is only EVER 1 node long???\n if start == end : return path #if we found it, start backtracking\n shortest = None #initialize the shortest path\n bestPath = None #initialize the best path value\n \n for node in digraph.childrenOf(start): #for each child of the current node\n destination = node.getDestination() #find out the destination\n\n if ( str(destination) not in visited ): #check to see if we've been there before\n visited = visited + [str(destination)] #if not, we plan to visit it now, so update the list\n newPath = bruteForceSearch(digraph, #call the function with the same \n destination, #using the current child node\n end, #the same end\n maxTotalDist, #same maxtotaldist\n maxDistOutdoors, #and same maxDistOutdoors\n visited,\n counter=counter+1) #and the recently updated copy of the visited list\n if newPath == None : #when we cant find a way thru, newPath will be none so...\n continue #try the next child by breaking out of the loop\n \n currentPath,outdoor=digraph.calcPathLength(path + newPath) #if we did find a way thru \n if outdoor > maxDistOutdoors or currentPath > maxTotalDist: #check to see if its too long\n visited.remove(str(destination)) #necessary to avoid skipping over previously checked paths...\n continue #and if so, break out of the loop and try the next child\n\n currentPath, outdoor=digraph.calcPathLength(newPath) #if we made it thru AND it wasn't too big\n if bestPath == None or (currentPath < bestPath): #check to see if its our first time to get this far on this level, \n shortest = newPath #OR if our currentPath is shorter than the best path found so far \n bestPath,outdoor = digraph.calcPathLength(shortest) #and if so, update things accordingly\n \n if shortest != None: #check to make sure we found something\n return path + shortest #and if so return it\n else : #if we didn't find a way thru for this level,\n if counter==0: raise ValueError #if we never found a solution, raise an error\n return None #return none\n##############################################################################################################################\n#recursive function to find the shortest path thru the graph using directed depth first search w/memoization/dynamic programming\n#inputs:\n# digraph = a digraph representing the relationship between buildings on the campus of MIT and their connections\n# start = a string representing the number of the building to start from\n# end = a string representing the number of the building to travel to\n# maxTotalDist = the maximum distance you're willing to walk to get from start to end\n# maxDistOutdoors = the maximum distance you're willing to travel outdoors to get from start to end\n# visited = a list of nodes you've already visited, defaults to None\n# memo = a dictionary of key value pairs describing how to get from node to node \n# counter = a counter allowing you to know when you've failed to find a valid path\n#outputs:\n# returns a list of buildings describing the path you should take. buildings are represented as strings.\n# ex: ['1','2','3','4','5']\n#exceptions:raises an exception if the path is not found or the start/end nodes are not contained in the graph\n##############################################################################################################################\ndef directedDFS(digraph, start, end, maxTotalDist, maxDistOutdoors,visited = None, memo = None, counter=0):\n\n if visited == None : visited = [] #initialize visited on our first trip thru\n if memo == None : memo = {} #initialize the memo\n start = Node(start) #create nodes for the given values\n end = Node(end)\n if not (digraph.hasNode(start) and digraph.hasNode(end)): #and confirm that these nodes exist int he graph\n raise ValueError(\"Start or End does not exist\")\n path = [str(start)] #this is only EVER 1 node long???\n if start == end : return path #if we found it, start backtracking\n shortest = None #initialize the shortest path\n bestPath = None #initialize the best path value\n \n for node in digraph.childrenOf(start): #for each child of the current node\n destination = node.getDestination() #find out the destination\n if ( str(destination) not in visited ): #check to see if we've been there before\n visited = visited + [str(destination)] #if not, we plan to visit it now, so update the list\n try:\n newPath = memo[str(destination),str(end)]\n except:\n newPath = directedDFS (digraph, #call the function with the same \n destination, #using the current child node\n end, #the same end\n maxTotalDist, #same maxtotaldist\n maxDistOutdoors, #and same maxDistOutdoors\n visited, #and the recently updated copy of the visited list\n memo, #and the potentially new memo.\n counter=counter+1) #and increment the counter\n\n if newPath == None : #when we cant find a way thru, newPath will be none so...\n continue #try the next child by breaking out of the loop\n \n currentPath,outdoor=digraph.calcPathLength(path + newPath) #if we did find a way thru \n if outdoor > maxDistOutdoors or currentPath > maxTotalDist: #check to see if its too long\n visited.remove(str(destination)) #so we have to backtrack a little\n try: #and remove any references to this node\n del(memo[str(destination),str(end)]) #in our visited and memo collections\n except: #we use a try in case the item doesn't actually exist in memo\n pass #if it doesn't exist, just do nothing\n continue #break out of the loop and try the next child\n\n currentPath, outdoor=digraph.calcPathLength(newPath) #if we made it thru AND it wasn't too big\n if bestPath == None or (currentPath < bestPath): #check to see if its our first time to get this far on this level, \n shortest = newPath #OR if our currentPath is shorter than the best path found so far \n bestPath,outdoor = digraph.calcPathLength(shortest) #and if so, update things accordingly\n memo[str(destination), str(end)] = newPath \n \n if shortest != None: #when we've made it thru all the children,check to make sure we found something\n return path + shortest #and if so, add the current node and return it\n else : #if we didn't find a way thru for this level,\n if counter==0: raise ValueError #check to see if we never found a solution...if not, raise an error\n return None #return none\n############################################################################################################################## \n#### The following unit tests are part of this assignment, though i extended them somewhat for my own debugging purposes\n#### Uncomment below when ready to test\n##############################################################################################################################\nif __name__ == '__main__':\n## # Test cases\n LARGE_DIST = 1000000\n digraph = load_map(\"mit_map.txt\")\n#### # Test case 1\n print (\"---------------\")\n print (\"Test case 1:\")\n print (\"Find the shortest-path from Building 32 to 56\")\n expectedPath1 = ['32', '56']\n print (\"Expected: \", expectedPath1)\n brutePath1 = bruteForceSearch(digraph, '32', '56', LARGE_DIST, LARGE_DIST)\n print (\"Brute-force: \", brutePath1)\n dfsPath1 = directedDFS(digraph, '32', '56', LARGE_DIST, LARGE_DIST)\n print (\"DFS: \", dfsPath1)\n #try:\n # digraph.calcPathLength(expectedPath1, toPrint=True)\n # digraph.calcPathLength(brutePath1, toPrint=True)\n # digraph.calcPathLength(dfsPath1, toPrint=True)\n #except:\n # print(\"Uh oh...problem somewhere!\")\n #input()\n # Test case 2\n print (\"---------------\")\n print (\"Test case 2:\")\n print (\"Find the shortest-path from Building 32 to 56 without going outdoors\")\n expectedPath2 = ['32', '36', '26', '16', '56']\n print (\"Expected: \", expectedPath2)\n brutePath2 = bruteForceSearch(digraph, '32', '56', LARGE_DIST, 0)\n print (\"Brute-force: \", brutePath2)\n dfsPath2 = directedDFS(digraph, '32', '56', LARGE_DIST, 0)\n print (\"DFS: \", dfsPath2)\n #try:\n # digraph.calcPathLength(expectedPath2, toPrint=True)\n # digraph.calcPathLength(brutePath2, toPrint=True)\n # digraph.calcPathLength(dfsPath2, toPrint=True)\n #except:\n # print(\"trouble right here in river city.\")\n##\n## # Test case 3\n print (\"---------------\")\n print (\"Test case 3:\")\n print (\"Find the shortest-path from Building 2 to 9\")\n expectedPath3 = ['2', '3', '7', '9']\n print (\"Expected: \", expectedPath3)\n brutePath3 = bruteForceSearch(digraph, '2', '9', LARGE_DIST, LARGE_DIST)\n print (\"Brute-force: \", brutePath3)\n dfsPath3 = directedDFS(digraph, '2', '9', LARGE_DIST, LARGE_DIST)\n print (\"DFS: \", dfsPath3)\n\n #digraph.calcPathLength(expectedPath3, toPrint=True)\n #digraph.calcPathLength(brutePath3, toPrint=True)\n #digraph.calcPathLength(dfsPath3, toPrint=True)\n#\n# # Test case 4\n print (\"---------------\")\n print (\"Test case 4:\")\n print (\"Find the shortest-path from Building 2 to 9 without going outdoors\")\n expectedPath4 = ['2', '4', '10', '13', '9']\n print (\"Expected: \", expectedPath4)\n brutePath4 = bruteForceSearch(digraph, '2', '9', LARGE_DIST, 0)\n print (\"Brute-force: \", brutePath4)\n dfsPath4 = directedDFS(digraph, '2', '9', LARGE_DIST, 0)\n print (\"DFS: \", dfsPath4)\n\n #digraph.calcPathLength(expectedPath4, toPrint=True)\n #digraph.calcPathLength(brutePath4, toPrint=True)\n #digraph.calcPathLength(dfsPath4, toPrint=True)\n#\n# # Test case 5\n print (\"---------------\")\n print (\"Test case 5:\")\n print (\"Find the shortest-path from Building 1 to 32\")\n expectedPath5 = ['1', '4', '12', '32']\n print (\"Expected: \", expectedPath5)\n brutePath5 = bruteForceSearch(digraph, '1', '32', LARGE_DIST, LARGE_DIST)\n print (\"Brute-force: \", brutePath5)\n dfsPath5 = directedDFS(digraph, '1', '32', LARGE_DIST, LARGE_DIST)\n print (\"DFS: \", dfsPath5)\n #digraph.calcPathLength(expectedPath5, toPrint=True)\n #digraph.calcPathLength(brutePath5, toPrint=True)\n #digraph.calcPathLength(dfsPath5, toPrint=True)\n##\n## # Test case 6\n print (\"---------------\")\n print (\"Test case 6:\")\n print (\"Find the shortest-path from Building 1 to 32 without going outdoors\")\n expectedPath6 = ['1', '3', '10', '4', '12', '24', '34', '36', '32']\n print (\"Expected: \", expectedPath6)\n brutePath6 = bruteForceSearch(digraph, '1', '32', LARGE_DIST, 0)\n print (\"Brute-force: \", brutePath6)\n dfsPath6 = directedDFS(digraph, '1', '32', LARGE_DIST, 0)\n print (\"DFS: \", dfsPath6)\n #try:\n # digraph.calcPathLength(expectedPath6, toPrint=True)\n # digraph.calcPathLength(brutePath6, toPrint=True)\n # digraph.calcPathLength(dfsPath6, toPrint=True)\n #except:\n # print(\"error\")\n#\n # Test case 7\n print (\"---------------\")\n print (\"Test case 7:\")\n print (\"Find the shortest-path from Building 8 to 50 without going outdoors\")\n bruteRaisedErr = 'No'\n dfsRaisedErr = 'No'\n try:\n #print(\"trying brute force...\")\n bruteForceSearch(digraph, '8', '50', LARGE_DIST, 0)\n except ValueError:\n bruteRaisedErr = 'Yes'\n \n try:\n #print(\"trying directedDFS...\")\n directedDFS(digraph, '8', '50', LARGE_DIST, 0)\n except ValueError:\n dfsRaisedErr = 'Yes'\n \n print (\"Expected: No such path! Should throw a value error.\")\n print (\"Did brute force search raise an error?\", bruteRaisedErr)\n print (\"Did DFS search raise an error?\", dfsRaisedErr)\n\n # Test case 8\n print (\"---------------\")\n print (\"Test case 8:\")\n print (\"Find the shortest-path from Building 10 to 32 without walking\")\n print (\"more than 100 meters in total\")\n bruteRaisedErr = 'No'\n dfsRaisedErr = 'No'\n try:\n # #print(\"trying brute force...\")\n x=bruteForceSearch(digraph, '10', '32', 100, LARGE_DIST) #assgning to a value just to see what happens\n except ValueError:\n bruteRaisedErr = 'Yes' \n try:\n #print(\"trying directedDFS...\")\n y=directedDFS(digraph, '10', '32', 100, LARGE_DIST) #exception should be raised and handled and no value should be assigned?\n except ValueError:\n dfsRaisedErr = 'Yes'\n \n print (\"Expected: No such path! Should throw a value error.\")\n print (\"Did brute force search raise an error?\", bruteRaisedErr)\n print (\"Did DFS search raise an error?\", dfsRaisedErr)\n"
},
{
"alpha_fraction": 0.45824095606803894,
"alphanum_fraction": 0.5920177102088928,
"avg_line_length": 25.54901885986328,
"blob_id": "902f53108462e4c3093e69f942a28208a7b66e72",
"content_id": "2346dc6ddba1d5217db70c073a88f2034cdf8ab7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1353,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 51,
"path": "/HackerRank/Algorithms/searching/missingNumbers.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#import random\n#numItems = random.randint(10, 200000)\n#array = random.sample(range(-10**7,10**7),numItems)\n\n\n#numA = int(input())\n#arrayA = [ int(x) for x in input().split() ]\n#numB = int(input())\n#arrayB = [ int(x) for x in input().split() ]\n\n#numA = 10\n#arrayA = [203, 204, 205, 206, 207, 208, 203, 204, 205, 206]\n#numB = 13\n#arrayB = [203, 204, 204, 205, 206, 207, 205, 208, 203, 206, 205, 206, 204]\n#expected output = 204 205 206\n\nwith open('test3.txt', 'r') as f:\n numA = int(f.readline())\n arrayA = [int(x) for x in f.readline().split()]\n numB = int(f.readline())\n arrayB = [int(x) for x in f.readline().split()]\n\n#expected output = 2437 2438 2442 2444 2447 2451 2457 2458 2466 2473 2479 2483 2488 2489 2510 2515 2517 2518\n\nans=''\ndiff=[]\ndictA = {}\ndictB = {}\n\nfor i in arrayA:\n if i not in dictA:\n dictA[i] = 1\n else:\n dictA[i] += 1\n#print (\"dictA=\",dictA)\nfor i in arrayB:\n if i not in dictB:\n dictB[i] = 1\n else:\n dictB[i] += 1\n#print(\"dictB=\",dictB)\nfor i in dictB:\n if i not in dictA and i not in diff:\n print(\"appending\",i,\"due to nonexistence\")\n diff.append(i)\n elif dictB[i] != dictA[i] and i not in diff:\n print(\"appending\",i,\"due to inequality\")\n diff.append(i)\nprint (\" \".join([str(x) for x in diff]).strip() )\n\nprint(dictA[2419], \"?=\", dictB[2419])"
},
{
"alpha_fraction": 0.3772031366825104,
"alphanum_fraction": 0.38582271337509155,
"avg_line_length": 41.480873107910156,
"blob_id": "88e7a3f8c908a63b235c63d88530e277050f0545",
"content_id": "3a9ba133dc23a5a6ce44eda74bf7937ee0e54c25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7773,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 183,
"path": "/HackerRank/Algorithms/searching/CoinOnTheTable.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "#############################################################################################################################\ndef findStar(cols):\n for c in range(len(cols)):\n for x in range(len(cols[c])):\n square = cols[c][x]\n if square == '*':\n return (c,x)\n#############################################################################################################################\ndef moveCoin(coin,cols,getDirection=False):\n for c in range(len(cols)):\n for x in range(len(cols[c])):\n square = cols[c][x]\n if coin == (c,x):\n if getDirection == True: return square\n if square == '*':\n return (c,x)\n if square == 'U':\n if c > 1:\n return (c-1,x)\n else: return None\n elif square == 'L':\n if x > 0:\n return (c,x-1)\n else: return None\n elif square == 'D':\n if c < len(cols):\n return (c+1,x)\n else: return None\n elif square == 'R':\n if x < len(cols[c]):\n return (c,x+1)\n#############################################################################################################################\ndef calcNumMoves(coin,star,cols,returnTuple=False):\n x = abs( coin[0] - star[0] )\n y = abs( coin[1] - star[1] )\n if returnTuple:\n return (x,y)\n else: return x + y\n#############################################################################################################################\ndef tryThisBoard(coin,cols):\n loc = cols[ coin[0] ][ coin[1] ]\n for step in range(time):\n coin = moveCoin(coin,cols)\n if coin != None:\n newloc = cols[ coin[0] ][ coin[1] ]\n else: newloc = None\n #print(\"newloc=\",newloc)\n if newloc == '*':\n return True\n else:\n return False\n#############################################################################################################################\ndef find_path(g, start, end):\n distances={}\n order={}\n for i in g.keys():\n if i == start: distances[i] = 0\n else: distances[i] = float(\"inf\")\n from copy import copy\n drop1 = copy(distances)\n while len(drop1) > 0:\n minNode = min(drop1, key = drop1.get)\n for i in g[minNode]:\n keyz = list(i)[0]\n dist = i[keyz]\n if distances[keyz] > (distances[minNode] + dist):\n distances[keyz] = distances[minNode] + dist\n drop1[keyz] = distances[minNode] + dist\n order[keyz] = minNode\n del drop1[minNode]\n temp = copy(end)\n rpath = []\n path = []\n while 1:\n rpath.append(temp)\n if temp in order: temp = order[temp]\n else: return -1\n if temp == start:\n rpath.append(temp)\n break\n for j in range(len(rpath)-1,-1,-1):\n path.append(rpath[j])\n return path\n#############################################################################################################################\ndef buildGraph(cols,i):\n g={}\n for r in range(len(cols)): #for each row\n for c in range( len(cols[r] )) : #for each column\n square=cols[r][c] #\n name = (r,c)\n g[name] = None\n if square == '*':\n g[name] = []\n pass\n else:\n if r > 0: #if theres a path upward\n if square == 'U':\n distance = 1\n else: distance = i\n dest = (r-1,c)\n edge = { dest:distance }\n if g[name] == None:\n g[name] = [edge]\n else: g[name] += [edge] #else if it does already exist, concat the new dest.\n \n if c < len(cols[r])-1: #if there's a path to the right\n if square == 'R':\n distance = 1\n else: distance = i\n dest=(r,c+1)\n edge = { dest:distance }\n if g[name] == None:\n g[name] = [edge]\n else: g[name] += [edge] #else if it does already exist, concat the new dest.\n \n if r < len(cols)-1: #if theres a path down\n if square == 'D':\n distance = 1\n else : distance = i\n dest=(r+1,c)\n edge = { dest:distance }\n if g[name] == None:\n g[name] = [edge]\n else: g[name] += [edge] #else if it does already exist, concat the new dest.\n \n if c > 0: #if theres a path to the left\n if square == 'L':\n distance = 1\n else: distance = i\n dest = (r, c-1)\n edge = { dest:distance }\n if g[name] == None:\n g[name] = [edge]\n else: g[name] += [edge] #else if it does already exist, concat the new dest.\n return g\n\n\ncols = []\nnumRows, numCols, time = [int(x) for x in input().split()]\n\nfor i in range(numRows):\n cols.append(input())\n\ncoin = (0,0)\nstar = findStar(cols)\nminMoves = calcNumMoves(coin,star,cols)\nanswer=[]\n\nif minMoves <= time: #if it can be done...\n if tryThisBoard(coin,cols) == False: #can it be done with the current board?\n # if not, build the graph\n\n for i in [2,10,100]:\n g=buildGraph(cols,i)\n ans=0\n path=find_path(g,coin,star) \t#get the optimal path\n\n if len(path) <= time+1: #assuming its not too long...\n for node in range(len(path)-1): #for each step in our optimal path\n x,y = path[node] #get the movement made\n nextx,nexty = path[node+1] #and the expected movement\n movementCalledFor = cols[x][y]\n deltax = x - nextx\n deltay = y - nexty\n if deltax == 0 and deltay < 0: #if change in x is zero, and change in y is negative, we moved right (50%?)\n movementMade = 'R'\n elif deltay == 0 and deltax < 0: #if change in y is zero, and change in x is negative, we moved down (50%)\n movementMade = 'D'\n elif deltax == 0 and deltay > 0: #if change in x is zero, and change in y is positive, we moved left \n movementMade = 'L'\n elif deltay == 0 and deltax > 0: #if chagne in y is zero, and change in x is positive, we moved up\n movementMade = 'U'\n \n else:raise Exception #otherwise, something funky happened, so exit with an error\n \n if movementMade != movementCalledFor: #and compare them...if there's been a change...\n ans += 1\n #print (ans)\n answer.append(ans)\n print(min(answer))\n else: #if tryThisBoard() is TRUE\n print(\"0\") #nothing needs to be done\nelse: print (\"-1\") #if its impossible to solve this puzzle in the given time..."
},
{
"alpha_fraction": 0.4844169318675995,
"alphanum_fraction": 0.5001031756401062,
"avg_line_length": 25.626373291015625,
"blob_id": "c5a3fe4b262d7bcabfe27cb41d55ba4a3957369e",
"content_id": "71f37b1ce3cffe6a85d7869061e629144419a194",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4845,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 182,
"path": "/HackerRank/Algorithms/searching/QueensOnBoard.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "import sys\nfrom test import test_generators as tg\nnumRowsArray = []\nnumColsArray = []\nrow=[]\nboards=[]\ncount=0\nwith open(\"queensOnBoard.txt\") as f:\n numTests = int( f.readline() )\n assert 1 <= numTests <= 100\n for i in range(0,numTests):\n numRows, numCols = [ int(x) for x in f.readline().split() ]\n #print(\"numRows=\",numRows,\"numCols=\",numCols)\n assert 1 <= numRows <=50\n assert 1 <= numCols <=5\n numRowsArray.append(numRows)\n numColsArray.append(numCols)\n board=[]\n for r in range(0,numRows): #for designated number of rows... \n row = str(f.readline()).strip()\n row = list(row)\n #print (\"row=\",row)\n assert 1 <= len(row) <= numCols\n board.append(row)\n #print(\"board=\",board)\n boards.append(board)\n#print (\"numTests=\",numTests,\"numRowsArray=\",numRowsArray, \"numColsArray=\",numColsArray)\n#print (\"boards=\", boards)\n\n#numTests=int(input())\n#assert 1 <= numTests <= 100\nfor _ in range(0,numTests):\n #########################################################\n ###Get input from user....\n ##numRows,numCols = [int(x) for x in input().split()]\n ##assert 1 <= numRows <=50\n ##assert 1 <= numCols <=5\n ##board=[]\n ##for r in range(0,numRows):\n ## row=input().strip()\n ## assert 1 <= len(row) <= numCols\n ## row=list(row)\n ## board.append(row)\n #########################################################\n ###Get input from file\n numRows=numRowsArray[_]\n numCols=numColsArray[_]\n board=boards[_]\n #print (\"numRows=\",numRows,\"numCols=\",numCols)\n #print (\"board=\")\n columns=[]\n diagonal=[]\n for row in board:\n print (row)\n BOARD_SIZE = numRows\n\nclass BailOut(Exception):\n print(\"bailed out!\")\n pass\n\ndef validate(queens):\n left = right = col = queens[-1]\n for r in reversed(queens[:-1]):\n left, right = left-1, right+1\n if r in (left, col, right):\n raise BailOut\n\ndef add_queen(queens):\n for i in range(BOARD_SIZE):\n test_queens = queens + [i]\n try:\n validate(test_queens)\n if len(test_queens) == BOARD_SIZE:\n return test_queens\n else:\n return add_queen(test_queens)\n except BailOut:\n pass\n #raise BailOut\n\nqueens = add_queen([3])\nprint (queens)\nprint (\"\\n\".join(\". \"*q + \"Q \" + \". \"*((BOARD_SIZE - q) - 1) for q in queens))\nprint(\"count=\",count)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n#BOARD_SIZE = 8\n#count=0\n#def under_attack(col, queens):\n# left = right = col\n\n# for r, c in reversed(queens):\n# left, right = left - 1, right + 1\n\n# if c in (left, col, right):\n# return True\n# return False\n\n#def solve(n):\n# if n == 0:\n# return [[]]\n\n# smaller_solutions = solve(n - 1)\n\n# return [solution+[(n,i+1)]\n# for i in range(BOARD_SIZE)\n# for solution in smaller_solutions\n# if not under_attack(i+1, solution)]\n#for answer in solve(BOARD_SIZE):\n# count += 1\n #print (answer)\n\n #n = tg.Queens(3)\n #n.printsolution()\n #s= n.solve()\n ##print (next(s))\n #for i in s:\n # print (i) #for row in board:\n # for col in range(len(board)):\n # columns=[ board[x][col] for x in range(0, len(board))] #\n # #print (\"columns=\")\n # #for i in columns: print (i)\n #for r in range(len(board)):\n # for c in range( len(board[r]) ): \n # print(\"r=\",r, \"c=\",c, \"board[r]=\",board[r],\"board[r][c]=\",board[r][c])\n # #if r+1 <= len(board) and c+1 <= r:\n # # diagonal += board[r+1][c+1]\n # ##diagonal = board[r][c] + board[r+1][c+1]\n # print (\"diagonal=\",diagonal)\n ##for i in enumerate(board): print(i)\n\n \n\n\n #LONG diagonals\n #diagonal1 = [ board[x][x] for x in range(0,len(board)) ]\n #diagonal2 = [ board[x][len(board) - x- 1] for x in range(0,len(board)) ]\n\n\n ##print(\"board=\",board)\n ##build diagonal\n #if i == '.': #if the space is empty\n # #are there any other queens on this row?\n # if 'Q' not in row:\n # #are there any other queens in this column?\n # if 'Q' not in columns:\n # if 'Q' not in diagonal:\n # count+=1\n #got all the solos?\n\n #########################################################\n #Process Data\n #for the maximum number of queens possible (at worst, n*m) \n #place a queen in all possible positions...\n #\n #for r in board:\n # for c in board[r]:\n # print(\"c=\",c,\"r=\",r)\n #answer=count\n\n #print(answer % 100000000)\n #print(answer % 1000000007)\n #print(answer % 10**7)"
},
{
"alpha_fraction": 0.5476190447807312,
"alphanum_fraction": 0.5696778893470764,
"avg_line_length": 42.287879943847656,
"blob_id": "4238dcbd825d8a23d5bf18ddc820fd62ffb39b7e",
"content_id": "3e341ff61bbaac491fc32da549ec2f963280a597",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2856,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 66,
"path": "/HackerRank/Algorithms/warmup/service-lane.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "import random\nimport bisect\n###################################\n#numPackets = int(input())\n#numPackets = 7\nnumPackets = random.randint(1,10**5)\n###################################\nassert 1 < numPackets < 10**5\n#######################################\n#kids = int(input())\n#kids = 3\nkids = random.randint(1,numPackets)\n########################################\nassert 1 < kids < numPackets\npackets_chosen=[]\ninput_array = [10,100,300,200,1000,20,30]\nmaxValue=maxKey=minkey=0\nminValue=10**9\nfor i in range(0,numPackets): \n ################################3\n #numCandies = int(input())\n #numCandies = input_array[i]\n numCandies = random.randint(0, 10**9)\n #####################################\n #print (\"numCandies=\",numCandies,\"currentMax=\",currentMax)\n assert 0 <= numCandies <= 10**9\n #build a list of items with length equal to the number of kids. keep track of the index and the value of the current highest values and lowest values\n if len(packets_chosen) < kids:\n bisect.insort(packets_chosen,numCandies)\n #packets_chosen[i]=numCandies\n #is it the biggest?\n \n else:\n #once the list is built, the only time we update it is if we find a value that is smaller than one we already have\n diff = packets_chosen[-1] - packets_chosen[0]\n \n if numCandies - packets_chosen[0] < diff: #if the difference is smaller than our current max...\n #print(\"HERE\")\n packets_chosen.pop()#pop one off\n packets_chosen.append(numCandies)#add one on\n i=len(packets_chosen)-1 #find the length, and subtract one\n while packets_chosen[i] < packets_chosen[i-1]: #shift it into place\n swap = packets_chosen[i]\n packets_chosen[i] = packets_chosen[i-1]\n packets_chosen[i-1] = swap\n i-=1\n elif packets_chosen[-1] > numCandies > packets_chosen[0]: #or bigger than our current min...\n #print(\"THERE\")\n packets_chosen.pop(0) #pop the first element.\n packets_chosen.insert(0,numCandies) #insert a new one\n i=0\n while packets_chosen[i] > packets_chosen[i+1]:\n swap = packets_chosen[i]\n packets_chosen[i] = packets_chosen[i+1]\n packets_chosen[i+1] = swap\n i+=1\n \n #print(\"numCandies=\",numCandies)\n #print(\"minVal=\",minValue,\"maxVal=\",maxValue)\n #print(\"minKey=\",minKey,\"maxKey=\",maxKey)\n #maxKey = packets_chosen[-1]\n #elif numCandies > currentMin:\n # currentMin,minIndex = numCandies,i\n #print(\"packets_chosen=\",packets_chosen,\"maxIndex=\",maxIndex,\"currentMax=\",currentMax,\"minIndex=\", minIndex, \"currentMin=\",currentMin)\n #print(\"packets_chosen=\",packets_chosen)\nprint(max(packets_chosen) - min(packets_chosen))"
},
{
"alpha_fraction": 0.5876623392105103,
"alphanum_fraction": 0.6233766078948975,
"avg_line_length": 27.090909957885742,
"blob_id": "d39dec2182d211265ae2e9c346fff4418f373dfa",
"content_id": "6c850be92bb9f7dd896e5cf75e5762685395770b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 11,
"path": "/HackerRank/Algorithms/sorting/insertionSort2.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "numItems=int(input())\nassert 1 <= numItems <= 1000\narray=[int(x) for x in input().split(' ')]\ninsertThis = array[-1]\ni=len(array)-2\nwhile insertThis < array[i] and i >= 0:\n array[i+1]=array[i]\n i-=1\n print(\" \".join(str(x) for x in array))\narray[i+1]=insertThis\nprint(\" \".join(str(x) for x in array))"
},
{
"alpha_fraction": 0.5827205777168274,
"alphanum_fraction": 0.6084558963775635,
"avg_line_length": 26.149999618530273,
"blob_id": "c09f4e0ffaf9678b549012f5e9493a327a409cf0",
"content_id": "66572dc4fd9e4116c6a793e30b7ef13155deca97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 20,
"path": "/HackerRank/Algorithms/sorting/countingSort4.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "size=int(input())\ndict=[]\nassert 1 <= size <= 1000000\nfor i in range(0,size):#for each line of input\n nums, strs = input().split()\n dict.append([ int(nums), strs ])\nfor x in range(0,len(dict)//2):\n dict[x][1]='-'\nanswer=\"\" \nfor x in sorted(dict, key=lambda x: x[0]):\n answer += x[1] + ' '\nprint (answer.strip())\n \n#size=int(input())\n#print(\"size=\",size)\n#print(\"len(numbers)=\",len(numbers),\"len(strings)=\",len(strings),'len(dict)=',len(dict))\n#print(\"numbers=\",numbers)\n#print(\"strings=\",strings)\n#print(\"dict=\",dict)\n#input\n\n"
},
{
"alpha_fraction": 0.5641025900840759,
"alphanum_fraction": 0.622710645198822,
"avg_line_length": 21.83333396911621,
"blob_id": "ffc787990bd10a5351f8e8af21c32282a41776c8",
"content_id": "5c98854ca945b6357aef954e3c5b884be18445d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/HackerRank/Algorithms/sorting/countingSort2.py",
"repo_name": "denivy/HackerRankPython",
"src_encoding": "UTF-8",
"text": "size=int(input())\nassert 100 <= size <= 1000000\nnumbers=[int(x) for x in input().split()]\ncounters={}\ncounts=\"\"\nfor x in range(0,100):\n counters[x] = 0\nfor e in numbers:\n counters[e] += 1\nfor y in counters:\n counts += (str(y)+' ')*counters[y]\nprint(counts.strip())"
}
] | 24 |
ArtellaPipe/artellapipe-tools-modelchecker
|
https://github.com/ArtellaPipe/artellapipe-tools-modelchecker
|
b7328048325339a7759acdbc3e889e7b55032868
|
2940d4dc25b39122447051d9c7d730c0646916bc
|
8e36434f1b16491e20492c22d8395038e10045f1
|
refs/heads/master
| 2020-09-16T05:04:09.834540 | 2020-08-21T21:36:03 | 2020-08-21T21:36:03 | 223,661,742 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6934046149253845,
"alphanum_fraction": 0.6951871514320374,
"avg_line_length": 24.5,
"blob_id": "dc41678db0e0597e38f317c4128ae20e5cffe376",
"content_id": "18f988793eb66abb89af0c435f6648deea192178",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 561,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 22,
"path": "/artellapipe/tools/modelchecker/widgets/modelchecker.py",
"repo_name": "ArtellaPipe/artellapipe-tools-modelchecker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nModule that contains model checker implementation for Artella\n\"\"\"\n\nfrom __future__ import print_function, division, absolute_import\n\n__author__ = \"Tomas Poveda\"\n__license__ = \"MIT\"\n__maintainer__ = \"Tomas Poveda\"\n__email__ = \"[email protected]\"\n\nfrom artellapipe.libs.pyblish.core import tool\n\n\nclass ArtellaModelChecker(tool.ArtellaPyblishTool, object):\n\n def __init__(self, project, config, settings, parent):\n\n super(ArtellaModelChecker, self).__init__(project=project, config=config, settings=settings, parent=parent)\n"
},
{
"alpha_fraction": 0.7312014102935791,
"alphanum_fraction": 0.7381157875061035,
"avg_line_length": 51.6363639831543,
"blob_id": "81076012e60513e32f9497ed420129dc0d60897f",
"content_id": "14606eb5161f45af25883e096f15262614205e72",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1157,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 22,
"path": "/README.rst",
"repo_name": "ArtellaPipe/artellapipe-tools-modelchecker",
"src_encoding": "UTF-8",
"text": "artellapipe-tools-modelchecker\n============================================================\n\nTool to execute modeling checks for geometry\n\n.. image:: https://travis-ci.com/ArtellaPipe/artellapipe-tools-modelchecker.svg?branch=master&kill_cache=1\n :target: https://travis-ci.com/ArtellaPipe/artellapipe-tools-modelchecker\n\n.. image:: https://coveralls.io/repos/github/ArtellaPipe/artellapipe-tools-modelchecker/badge.svg?branch=master&kill_cache=1\n :target: https://coveralls.io/github/ArtellaPipe/artellapipe-tools-modelchecker?branch=master\n\n.. image:: https://img.shields.io/badge/docs-sphinx-orange\n :target: https://artellapipe.github.io/artellapipe-tools-modelchecker/\n\n.. image:: https://img.shields.io/github/license/ArtellaPipe/artellapipe-tools-modelchecker\n :target: https://github.com/ArtellaPipe/artellapipe-tools-modelchecker/blob/master/LICENSE\n\n.. image:: https://img.shields.io/pypi/v/artellapipe-tools-modelchecker?branch=master&kill_cache=1\n :target: https://pypi.org/project/artellapipe-tools-modelchecker/\n\n.. image:: https://img.shields.io/badge/code_style-pep8-blue\n :target: https://www.python.org/dev/peps/pep-0008/"
}
] | 2 |
Adityank003/machine-learning-iris-data-set-prediction
|
https://github.com/Adityank003/machine-learning-iris-data-set-prediction
|
0e0a276429c887dd75eddbea5b670f66b8d175e8
|
16b0c6bb7cd20ad1bd7da0a28cb63b75e487349a
|
d1455570f169140a1a4062314555402199f6ba9b
|
refs/heads/master
| 2021-01-01T07:40:38.690686 | 2017-07-18T07:28:05 | 2017-07-18T07:28:05 | 97,566,359 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6461538672447205,
"alphanum_fraction": 0.6958041787147522,
"avg_line_length": 24.03636360168457,
"blob_id": "9f9ebbb3b8114a7a554e01efab142ecfd79240f6",
"content_id": "a85a280b421e0ab6b7c64c43be36593f0e32eea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1430,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 55,
"path": "/mliris.py",
"repo_name": "Adityank003/machine-learning-iris-data-set-prediction",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon Jul 17 11:12:55 2017\r\n\r\n@author: adityan\r\n\"\"\"\r\n\r\nimport pandas as pd\r\nimport sklearn\r\n\r\n#Read the data from the csv file\r\nf = open(\"iris.txt\")\r\nf.readline() # skip the header\r\ndata = pd.read_csv(f)\r\n\r\n\r\n#Divide to training and testing data sets\r\n\r\n#Getting features except the last column i.e the label\r\nx_features = data.iloc[25:125, :-1]\r\n#Getting label for the exracted features i.e only last column\r\nx_label = data.iloc[25:125, -1]\r\n\r\n#Testing data\r\n#Splitting it in weird way into 3 dataframes\r\nx1_test_features = data.iloc[100:125, :-1]\r\nx1_test_label = data.iloc[100:125, -1]\r\n\r\n#you can decide how to split data\r\nx2_test_features = data.iloc[0:-1, :-1]\r\nx2_test_label = data.iloc[0:-1, -1]\r\n\r\n\r\nx3_test_features = data.iloc[50:75, :-1]\r\nx3_test_label = data.iloc[50:75, -1]\r\n\r\n\r\n#Conactenating the split data to test\r\nx_test_features = [x1_test_features,x2_test_features,x3_test_features]\r\nx_test_f = pd.concat(x_test_features)\r\n\r\nx_test_label = [x1_test_label,x2_test_label,x3_test_label]\r\nx_test_l = pd.concat(x_test_label)\r\n\r\n\r\n#decision tree classifier\r\n#you can use any other classifier as Randomforest,Knn etc\r\nclf = tree.DecisionTreeClassifier()\r\nclf= clf.fit(x_features, x_label)\r\npredictions = clf.predict(x_test_f)\r\nprint(predictions)\r\n\r\n#accuracy definition\r\nfrom sklearn.metrics import accuracy_score\r\nprint(\"Accuracy:\",accuracy_score(x_test_l, predictions) * 100)"
}
] | 1 |
Jairamjavv/kivy---what-i-did
|
https://github.com/Jairamjavv/kivy---what-i-did
|
9b023039638d6067db6dc7154b548bfc3563b009
|
8695e878f4b882decc10b12f83da2841f59298c3
|
830e7ca993d6fbef61cad799d40806c37345864c
|
refs/heads/master
| 2021-01-22T00:52:19.503605 | 2018-01-08T18:26:11 | 2018-01-08T18:26:11 | 102,196,429 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.7232767343521118,
"avg_line_length": 57.882354736328125,
"blob_id": "3222f90c114aa056d20cf8bdc25e81d2671d6e01",
"content_id": "453a986874d3e106c28172fed3c995454af8b29c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 298,
"num_lines": 17,
"path": "/README.md",
"repo_name": "Jairamjavv/kivy---what-i-did",
"src_encoding": "UTF-8",
"text": "# kivy---what-i-did\nThis page is about what i learned about in kivy.\n\nTo continue with the kivy app development go to www.kivy.org\n<br>\nLets dig a bit deeper on what KIVY is about.\n <li> 1. Kivy is GUI development framewook. </li>\n <li> 2. It supports Cross-Platform support. </li>\n <li> 3. Based on OpenGL (Open Graphics Library) wrapper for python. </li>\n <li> 4. Builtin modules and functions for easy use. </li>\n <li> 5. Support variety of option to play with GUI development. </li>\n \n<br>\n In the step0_1 I imported the kivy using import. Later I called the App().run()<br>The whole program gonna use class syntax. Object Oriented concepts are required a lot here.<br>\n\n<br>\n In the step0_2 I Createds a class called MyApp. It inherits the App class in kivy. Later on tutorials the inherited class can be styles using the kv language. There lies a function inside the MyApp class which should be named build. Why we name it as build? We will see it in later tutorials.<br>\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 13.666666984558105,
"blob_id": "bc6841ccedfe9f9f66eefc4d9a179b07c5769ec6",
"content_id": "55e152b9ec1400067eaa23a9214f66177f1f452e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 3,
"path": "/step0_3.py",
"repo_name": "Jairamjavv/kivy---what-i-did",
"src_encoding": "UTF-8",
"text": "from kivy.app import App\n\nclass MyApp(App):\n \n"
},
{
"alpha_fraction": 0.7431192398071289,
"alphanum_fraction": 0.7431192398071289,
"avg_line_length": 71.66666412353516,
"blob_id": "a38bd58e3cc750c7b77384171b58bcd881436972",
"content_id": "305ed0be30e56554e4303d3cc6fee57433e9f878",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 3,
"path": "/Learn_KV_Language.md",
"repo_name": "Jairamjavv/kivy---what-i-did",
"src_encoding": "UTF-8",
"text": "#Lets get into the KV language for styling the apps.\n<li>Create a file (Your file should always have the same name as your app class) with .kv as the extension. </li>\n<li>The file should be in the same directory.</li>\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 17,
"blob_id": "9b57228e07c109ac7ae6f131987d2ca65353ef9f",
"content_id": "72dac51cca4d5787d6c1320333e5f574aa17babc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 7,
"path": "/step0_1.py",
"repo_name": "Jairamjavv/kivy---what-i-did",
"src_encoding": "UTF-8",
"text": "#To import the kivy module and running the app.\nimport kivy\nkivy.require(<version no>)\n\nfrom kivy.app import App\n\nApp().run()\n"
}
] | 4 |
ChortJulio/AntTracker
|
https://github.com/ChortJulio/AntTracker
|
e821340ea447eae706ebe4def25285dd9a7d888a
|
a89fb7fedbb7a8f7d12b024387f6330180fa010f
|
4d525d05a367438283e1df8236864b6dd74fa6bf
|
refs/heads/main
| 2023-05-26T05:19:58.607539 | 2021-06-03T17:28:21 | 2021-06-03T17:28:21 | 368,252,009 | 0 | 0 |
MIT
| 2021-05-17T16:26:00 | 2021-05-17T16:26:01 | 2021-05-17T18:04:25 | null |
[
{
"alpha_fraction": 0.7627118825912476,
"alphanum_fraction": 0.7669491767883301,
"avg_line_length": 32.71428680419922,
"blob_id": "f0f876f02aa478ae3d344dd38d6573ba8d5f39e6",
"content_id": "578e2227422004373e8d6781b7011cfa28517c08",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 7,
"path": "/ant_tracker/labeler/trackLabeledTagfile.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from classes import AntCollection\n\nfilename = \"dia\"\ntagfile = f\"{filename}.tag\"\ntrackerJson = AntCollection.deserialize(filename=tagfile).serializeAsTracker()\nwith open(\"./dia-labeled2.rtg\",\"w\") as target:\n target.write(trackerJson)\n"
},
{
"alpha_fraction": 0.5813953280448914,
"alphanum_fraction": 0.5864509344100952,
"avg_line_length": 43.95454406738281,
"blob_id": "9f87642c8d7aec0547c979c7082566033d95840a",
"content_id": "765b6abc0131321f3f59091837c76a76e6c89b5e",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 990,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 22,
"path": "/check_env.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from typing import Literal\n\ndef check_env(module: Literal['tracker', 'labeler']):\n import sys\n frozen = getattr(sys, 'frozen', False) and hasattr(sys, '_MEIPASS')\n if not frozen:\n from pathlib import Path\n for file in (Path(\"../.env_info\"), Path(\".env_info\")):\n env_info_file = file\n if env_info_file.exists():\n break\n else:\n raise ValueError(\"Debe generar un conda env con create-env.ps1\")\n needed_env = [line.split(':')[1] for line in env_info_file.read_text().split(\"\\n\") if line.startswith(module)]\n if not needed_env:\n raise ValueError(\"Debe generar un conda env con create-env.ps1\")\n needed_env = needed_env[0]\n import os\n current_env = os.environ['CONDA_DEFAULT_ENV']\n if needed_env != current_env:\n raise ValueError(f\"Sólo ejecutar este archivo en el conda-env \"\n f\"generado por create-env.ps1 ({needed_env})\")\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 14.428571701049805,
"blob_id": "6f89a89f685e5e0e83b12c0dc82ec7ff88787f32",
"content_id": "f46368f1665b13f5313d8e424cb3568b9f24cb63",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 7,
"path": "/ant_tracker/tracker_gui/pyinstall.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PyInstaller.__main__\n\nPyInstaller.__main__.run([\n 'AntTracker.spec',\n '--onedir',\n '-y',\n])\n"
},
{
"alpha_fraction": 0.6789201498031616,
"alphanum_fraction": 0.6829408407211304,
"avg_line_length": 29.017240524291992,
"blob_id": "feb1a623ab2df0e3dd6c2b1ae7a74b40a16af4f7",
"content_id": "36f0e32ffa06bfc88d4f5c5826e29516dfcef1f9",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1741,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 58,
"path": "/ant_tracker/tracker/tag2track.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import argparse\nimport json\nimport numpy as np\nfrom packaging.version import Version\nfrom pathlib import Path\n\nfrom .blob import Blob\nfrom .info import TracksInfo\nfrom .parameters import SegmenterParameters, TrackerParameters\nfrom .track import Track\n\nparser = argparse.ArgumentParser(description=\"Convert .tag file to .trk file format\")\nparser.add_argument('file')\nparser.add_argument('--output', '-o', type=str, default=None,\n help=\"Archivo de salida\")\nargs = parser.parse_args()\nfile: str = args.file\noutput = args.output\n\nif not file.endswith('.tag'):\n raise ValueError('Must be a .tag file!')\nprint(f\"Converting {file}\")\nfilename = file[:-4]\nif output is None:\n output = Path(f'{filename}-gt.trk' if output is None else output)\nprint(f\"Output will be {output}\")\nvideo_filename = f\"{filename}.mp4\"\n\nwith open(f'{filename}.tag', 'r') as f:\n manual_track = json.load(f)\n\nants = manual_track[\"ants\"]\nshape = manual_track[\"videoShape\"]\nclosed_tracks = []\nfor ant in ants:\n i = ant[\"id\"]\n blobs = dict()\n areas = ant[\"areasByFrame\"]\n for area_by_frame in areas:\n frame, area = area_by_frame[\"frame\"], area_by_frame[\"area\"]\n mask = np.zeros(shape, dtype='uint8')\n mask[tuple(area)] = 1\n blob = Blob(mask=mask)\n blobs[frame] = blob\n closed_tracks.append(Track(i - 1, dict(sorted(blobs.items())), force_load_to=ant[\"loaded\"]))\n\ninfo = TracksInfo(\n video_path=video_filename,\n tracks=sorted(closed_tracks, key=lambda t: t.id),\n segmenter_version=Version(\"0\"),\n segmenter_parameters=SegmenterParameters.mock(),\n tracker_version=Version(\"0\"),\n tracker_parameters=TrackerParameters.mock(),\n)\n\nprint(\"Done\")\ninfo.save(output)\nprint(f\"Saved to {output}\")\n"
},
{
"alpha_fraction": 0.6151770949363708,
"alphanum_fraction": 0.6215106844902039,
"avg_line_length": 34.08641815185547,
"blob_id": "89aa99ab865c8dcd8ab2a5337e9ab261c31dd624",
"content_id": "8f5d8c9fa1b1814e75150af0493925a9ebad75c7",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8526,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 243,
"path": "/ant_tracker/tracker/track.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nfrom enum import auto\n\nimport numpy as np\nfrom memoized_property import memoized_property\nfrom typing import Dict, List, NewType, Optional, Tuple, Type, TypeVar, TypedDict\n\nfrom .blob import Blob\nfrom .common import Color, ColorImage, FrameNumber, SerializableEnum, Side\nfrom .kellycolors import KellyColors\n\nTrackId = NewType('TrackId', int)\n\nclass Loaded(SerializableEnum):\n Yes = auto()\n No = auto()\n Undefined = auto()\n\n @staticmethod\n def parse(b: Optional[bool]): return Loaded.Undefined if b is None else Loaded.Yes if b else Loaded.No\n\n def to_bool(self): return None if self == Loaded.Undefined else True if self == Loaded.Yes else False\n\n@dataclass\nclass Track:\n id: TrackId\n # Should be invariantly sorted, as frames are inserted sequentially and without gaps\n blobs: Dict[FrameNumber, Blob]\n\n # noinspection PyShadowingBuiltins\n def __init__(self, id: TrackId, blobs: Dict[FrameNumber, Blob], *, force_load_to: Optional[bool] = None):\n \"\"\"\n Build a track from a set of `blobs`, with `id`. Currently encompasses labeled ants as well,\n using `force_load_to` to set the load state.\n\n TODO: split labeled ants and tracks into different classes.\n \"\"\"\n self.id = id\n self.blobs = blobs\n self.__load_probability = None\n if force_load_to is not None:\n self.__load_probability = 1 * force_load_to\n self.__loaded = Loaded.parse(force_load_to)\n\n def __repr__(self):\n return f\"Track(T{self.id}, \" + (\n f\"loaded={self.loaded})\" if self.loaded != Loaded.Undefined else f\"load_prob={self.load_probability}\")\n\n @property\n def loaded(self) -> Loaded:\n \"\"\"Returns either ``Loaded.Yes`` or ``Loaded.No`` if `self` is a labeled ant,\n or ``Loaded.Undefined`` if it's a track.\"\"\"\n return self.__loaded\n\n def set_load_probability(self, prob):\n \"\"\"Use a ``LeafDetector`` instance to get `prob`\"\"\"\n self.__load_probability = prob\n\n @property\n def load_probability(self):\n \"\"\"Returns probability of track being loaded. If `self` is a labeled ant, use ``loaded`` instead.\"\"\"\n return self.__load_probability\n\n @property\n def load_detected(self):\n return self.__load_probability is not None\n\n @property\n def load_prediction(self):\n \"\"\"Returns a prediction based on load probability.\"\"\"\n return self.__load_probability > 0.5\n\n @property\n def load_certainty(self):\n \"\"\"Returns certainty of prediction given by `load_prediction`\"\"\"\n return abs(self.load_probability - 0.5) + 0.5\n\n @property\n def color(self):\n return KellyColors.get(self.id)\n\n def at(self, frame: FrameNumber):\n return self.blobs.get(frame, None)\n\n def path(self) -> np.ndarray:\n \"\"\"Returns an array of shape (3, n_blobs), where dim0 is (x, y, frame_number)\"\"\"\n return np.array([[blob.center_xy.x, blob.center_xy.y, frame] for frame, blob in self.blobs.items()])\n\n def direction_of_travel(self, imshape: Tuple[int, int], percentage=0.1) -> Tuple[Side, Side]:\n first, last = self.first_blob().center_xy, self.last_blob().center_xy\n return Side.from_point(first, imshape, percentage), Side.from_point(last, imshape, percentage)\n\n @memoized_property\n def velocity_mean(self):\n if len(self.blobs) < 2:\n return np.array([0, 0])\n return (self.last_blob().center - self.first_blob().center) / (self.last_frame() - self.first_frame())\n\n @memoized_property\n def speed_mean(self):\n return self.speed_lowpass.mean()\n\n @memoized_property\n def speed_max(self):\n return self.speed_lowpass.max(initial=0)\n\n @property\n def speed_lowpass(self):\n from scipy.ndimage import uniform_filter1d\n return uniform_filter1d(np.linalg.norm(self.velocities, axis=1), size=40)\n\n @memoized_property\n def direction_mean(self):\n \"\"\"En grados de la horizontal, [0, 360)\"\"\"\n v = self.velocity_mean\n d = np.rad2deg(np.arctan2(v[1], v[0]))\n return (d + 360) % 360\n\n @property\n def velocities(self):\n if len(self.blobs) < 2:\n return np.array([[0, 0]])\n return np.array(np.diff(self.path()[:, 0:2], axis=0))\n\n @property\n def areas(self):\n return np.array([blob.area for frame, blob in self.blobs.items()])\n\n @memoized_property\n def area_mean(self):\n return np.mean(self.areas)\n\n @memoized_property\n def area_median(self):\n return np.median(self.areas)\n\n @memoized_property\n def width_mean(self):\n return np.mean([blob.width for frame, blob in self.blobs.items()])\n\n @memoized_property\n def length_mean(self):\n return np.mean([blob.length for frame, blob in self.blobs.items()])\n\n @memoized_property\n def width_median(self):\n return np.median([blob.width for frame, blob in self.blobs.items()])\n\n @memoized_property\n def length_median(self):\n return np.median([blob.length for frame, blob in self.blobs.items()])\n\n def first_frame(self) -> Optional[FrameNumber]:\n if len(self.blobs) == 0: return None\n return min(self.blobs.keys())\n\n def last_frame(self) -> Optional[FrameNumber]:\n if len(self.blobs) == 0: return None\n return max(self.blobs.keys())\n\n def first_blob(self) -> Blob:\n return self.at(self.first_frame())\n\n def last_blob(self) -> Blob:\n return self.at(self.last_frame())\n\n def cut(self, last: FrameNumber, first: FrameNumber = 0) -> 'Track':\n return Track(self.id, {frame: blob for frame, blob in self.blobs.items() if first < frame < last})\n\n def get_safe_blobs(self, percentage) -> Dict[FrameNumber, Blob]:\n \"\"\"Get blobs that are at least ``percentage`` of the imshape into the frame\"\"\"\n return {frame: blob for frame, blob in self.blobs.items() if blob.is_fully_visible(percentage)}\n\n def as_closed(self) -> 'Track':\n return self\n\n # region Drawing\n\n def draw_track_line(self, frame: FrameNumber, image: ColorImage, last_n_frames=10) -> ColorImage:\n from .common import draw_line\n copy = image.copy()\n frames_involved = self.blobs.keys()\n first_frame = max(frame - last_n_frames, min(frames_involved))\n last_frame = min(frame, max(frames_involved))\n frames_to_draw = range(first_frame + 1, last_frame + 1)\n for f in frames_to_draw:\n center1 = self.at(f - 1).center_xy\n center2 = self.at(f).center_xy\n copy = draw_line(copy, center1, center2, color=self.color, width=3)\n return copy\n\n def draw_blob(self, frame: FrameNumber, image: ColorImage, label_color: Color = None) -> ColorImage:\n from .common import Colors\n blob = self.at(frame)\n if blob is None:\n return image\n label_color = label_color or Colors.BLACK\n return blob.draw_contour(image, text=f'T{self.id}', color=self.color, text_color=label_color)\n\n T = TypeVar('T', bound='Track')\n\n @classmethod\n def draw_tracks(cls, tracks: List[T], image: ColorImage, frame: FrameNumber) -> ColorImage:\n \"\"\"Returns a copy of ``image`` with all blobs in ``frame`` of ``tracks`` drawn onto it\"\"\"\n copy = image.copy()\n for track in tracks:\n copy = cls.draw_blob(track, frame, copy)\n return copy\n\n # endregion\n\n @classmethod\n def get(cls: Type[T], tracks: List[T], track_id: TrackId) -> T:\n return [track for track in tracks if track.id == track_id][0]\n\n # region Serialization\n\n class Serial(TypedDict):\n id: int\n loaded: Optional[bool]\n load_probability: Optional[float]\n blobs: Dict[str, Blob.Serial]\n\n def encode(self) -> 'Track.Serial':\n return {\n \"id\": self.id,\n \"loaded\": self.loaded.to_bool(),\n \"load_probability\": self.load_probability,\n \"blobs\": {str(i): blob.encode() for i, blob in self.blobs.items()}\n }\n\n @classmethod\n def decode(cls, serial: 'Track.Serial', imshape: Tuple[int, int]):\n self = cls(\n TrackId(serial[\"id\"]),\n {int(i): Blob.decode(blob, imshape) for i, blob in serial[\"blobs\"].items()},\n force_load_to=serial.get('loaded', None)\n )\n if 'load_probability' in serial:\n self.set_load_probability(serial['load_probability'])\n return self\n\n # endregion\n"
},
{
"alpha_fraction": 0.5458356142044067,
"alphanum_fraction": 0.5628347396850586,
"avg_line_length": 42.231544494628906,
"blob_id": "863ffe7a586b081b500777c700927b23b0b8d92d",
"content_id": "c4b193f3126e2dd7eebeadab8d139064136c6dc9",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12908,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 298,
"path": "/ant_tracker/labeler/PreLabeler.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import sys # for progress bar\nimport cv2 as cv\nimport numpy as np\n\nfrom .classes import *\n\ndef fill_holes(img, kernel):\n Im = img // 255\n Ic = 1 - Im\n\n F = np.zeros_like(Im)\n F[:, 0] = Ic[:, 0]\n F[:, -1] = Ic[:, -1]\n F[0, :] = Ic[0, :]\n F[-1, :] = Ic[-1, :]\n\n dif = np.zeros_like(img).astype(bool)\n while np.any(~dif):\n Fnew = cv.dilate(F, kernel) * Ic\n dif = F == Fnew\n F = Fnew\n return (1 - F) * 255\n\ndef minimum_ant_area(min_radius):\n return np.pi * min_radius ** 2\n\n# noinspection PyShadowingNames,DuplicatedCode\ndef labelVideo(file, metodo=\"mog2\", roi=None, historia=50, ant_thresh=50, sheet_thresh=150, discard_percentage=.8,\n minimum_ant_radius=4, start_frame=0) -> np.ndarray:\n lastmask = None\n video = cv.VideoCapture(file)\n length = int(video.get(cv.CAP_PROP_FRAME_COUNT))\n\n i = 0\n\n toolbar_width = 40\n # setup toolbar\n progressMsg = \"Procesando 0/%d\" % length\n sys.stdout.write(progressMsg + \"[%s]\" % (\" \" * toolbar_width))\n sys.stdout.flush()\n sys.stdout.write(\"\\b\" * (len(progressMsg) + toolbar_width + 2)) # return to start of line, after '['\n\n if metodo == \"mediana\":\n last_frames = []\n while video.isOpened():\n ret, frame = video.read()\n if ret == 0:\n break\n if roi is not None:\n frame = frame[roi]\n if i < historia:\n last_frames.append(frame)\n else:\n last_frames[:-1] = last_frames[1:]\n last_frames[-1] = frame\n i += 1\n\n if len(last_frames) != 1:\n fondo = np.median(last_frames, axis=0).astype('uint8')\n else:\n fondo = frame\n\n frame_sin_fondo = cv.absdiff(cv.cvtColor(frame, cv.COLOR_BGR2GRAY), cv.cvtColor(fondo, cv.COLOR_BGR2GRAY))\n\n _, mask = cv.threshold(frame_sin_fondo, ant_thresh, 255, cv.THRESH_BINARY)\n\n # Eliminar la parte de la máscara correspondiente a la lámina\n objects = frame.copy()\n objects[mask == 0, ...] = (0, 0, 0)\n objects = cv.cvtColor(objects, cv.COLOR_BGR2GRAY)\n _, lamina = cv.threshold(objects, sheet_thresh, 255, cv.THRESH_BINARY)\n # thresh = np.mean(cv.cvtColor(frame,cv.COLOR_BGR2GRAY))*background_ratio\n # _,lamina = cv.threshold(objects,thresh,255,cv.THRESH_BINARY)\n mask = cv.subtract(mask, lamina)\n\n mask = cv.morphologyEx(mask, cv.MORPH_OPEN, cv.getStructuringElement(cv.MORPH_CROSS, (3, 3)))\n mask = cv.morphologyEx(mask, cv.MORPH_CLOSE, cv.getStructuringElement(cv.MORPH_ELLIPSE, (7, 7))).astype(\n 'int16')\n\n # Descartar la máscara si está llena de movimiento (se movió la cámara!)\n if np.count_nonzero(mask) > np.size(mask) * discard_percentage:\n yield np.zeros(mask.shape, dtype='int') if lastmask is None else lastmask\n continue\n\n mask[mask != 0] = 1\n\n progress = toolbar_width * i // length + 1\n progressMsg = \"Procesando %d/%d \" % (i + 1, length)\n sys.stdout.write(progressMsg)\n sys.stdout.write(\"[%s%s]\" % (\"-\" * progress, \" \" * (toolbar_width - progress)))\n sys.stdout.flush()\n sys.stdout.write(\"\\b\" * (len(progressMsg) + toolbar_width + 2)) # return to start of line, after '['\n\n lastmask = cv.morphologyEx(mask.copy(), cv.MORPH_OPEN, cv.getStructuringElement(cv.MORPH_CROSS, (5, 5)))\n yield mask\n elif metodo in [\"mog2\", \"gsoc\"]:\n if metodo == \"mog2\":\n subt = cv.createBackgroundSubtractorMOG2(detectShadows=False, history=historia)\n if metodo == \"gsoc\":\n try:\n subt = cv.bgsegm.createBackgroundSubtractorGSOC(replaceRate=0.0002 * historia)\n except Exception as e:\n print(\"Desinstalar opencv-python-headless e instalar opencv-contrib-python-headless\")\n raise e\n while video.isOpened():\n ret, frame = video.read()\n if ret == 0:\n break\n\n i += 1\n if i - 1 < max(start_frame - 50, 0):\n continue\n\n if roi is not None:\n frame = frame[roi]\n\n # noinspection PyUnboundLocalVariable\n mask = subt.apply(frame, 0)\n\n if i - 1 < start_frame:\n continue\n\n # Eliminar la parte de la máscara correspondiente a la lámina\n objects = frame.copy()\n objects[mask == 0, ...] = (0, 0, 0)\n objects = cv.cvtColor(objects, cv.COLOR_BGR2GRAY)\n _, lamina = cv.threshold(objects, sheet_thresh, 255, cv.THRESH_BINARY)\n\n mask = cv.subtract(mask, lamina)\n\n r = minimum_ant_radius\n mask = cv.morphologyEx(mask, cv.MORPH_CLOSE, cv.getStructuringElement(cv.MORPH_ELLIPSE, (int(r), int(r))))\n mask = cv.morphologyEx(mask, cv.MORPH_OPEN,\n cv.getStructuringElement(cv.MORPH_ELLIPSE, (int(r * .8), int(r * .8))))\n # mask = cv.morphologyEx(mask,cv.MORPH_DILATE,\n # cv.getStructuringElement(cv.MORPH_ELLIPSE,(int(r*.8),int(r*.8))))\n # Rellenar huecos para mejor detección\n mask = fill_holes(mask, cv.getStructuringElement(cv.MORPH_CROSS, (int(r), int(r))))\n\n # Descartar la máscara si está llena de movimiento (se movió la cámara!)\n if np.count_nonzero(mask) > np.size(mask) * discard_percentage:\n yield np.zeros(mask.shape, dtype='int') if lastmask is None else lastmask\n continue\n\n contours, _ = cv.findContours(mask.astype('uint8'), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_TC89_L1)\n\n mask = np.zeros_like(mask)\n min_area = minimum_ant_area(minimum_ant_radius)\n contours = [cv.approxPolyDP(cont, 0.01, True) for cont in contours if cv.contourArea(cont) > min_area]\n mask = cv.fillPoly(mask, contours, 1)\n\n progress = toolbar_width * i // length + 1\n progressMsg = \"Procesando %d/%d \" % (i + 1, length)\n sys.stdout.write(progressMsg)\n sys.stdout.write(\"[%s%s]\" % (\"-\" * progress, \" \" * (toolbar_width - progress)))\n sys.stdout.flush()\n sys.stdout.write(\"\\b\" * (len(progressMsg) + toolbar_width + 2)) # return to start of line, after '['\n\n lastmask = cv.morphologyEx(mask.copy(), cv.MORPH_OPEN, cv.getStructuringElement(cv.MORPH_CROSS, (5, 5)))\n # print(f\"frame {i-1}\")\n yield mask\n # elif metodo == \"log\":\n # def toTuple(point: Vector) -> Tuple[int,int]:\n # return tuple(point.astype(int))\n # while(video.isOpened()):\n # ret, frame = video.read()\n # if ret == 0:\n # break\n # if roi != None:\n # frame = frame[roi]\n # i += 1\n #\n # frame = cv.cvtColor(frame,cv.COLOR_BGR2GRAY)\n #\n # gaussian = cv.GaussianBlur(frame,(7,7),500)\n #\n # log = cv.Laplacian(gaussian,cv.CV_32F,None,7)\n # log_norm = cv.normalize(log,None,0,255,cv.NORM_MINMAX, cv.CV_8U)\n #\n # # _,thresholded = cv.threshold(log_norm, 160, 255, cv.THRESH_TOZERO)\n # thresholded = log.copy()\n # thresholded[log<i*.1] = 0\n # thresholded_norm = cv.normalize(thresholded,None,0,255,cv.NORM_MINMAX, cv.CV_8U)\n #\n # maxim = local_minima((255-thresholded_norm),1)\n # cv.imshow('threshinv', (255-thresholded_norm))\n # print(len(maxim))\n # # print(maxim)\n #\n # # if cv.waitKey(0) & 0xff == 27:\n # # raise RuntimeError\n # # cv.imshow('maxim', np.array((maxim*255)).astype('uint8'))\n # # maxima_pos = np.argwhere(maxim)\n #\n # located_maxima = cv.cvtColor(thresholded_norm.copy(),cv.COLOR_GRAY2BGR)\n # for m in maxim:\n # # print(m)\n # located_maxima = cv.circle(located_maxima,m,4,(255,0,0),-1)\n #\n # mask = thresholded.copy().astype('uint8')\n # mask[mask!=0] = 1\n #\n # # cv.imshow('frame',frame)\n # # cv.imshow('gaussian',gaussian)\n # # # cv.imshow('log',log)\n # # cv.imshow('log_norm',log_norm)\n # # cv.imshow('thresholded_norm',thresholded_norm)\n # cv.imshow('located_maxima',located_maxima)\n #\n # if cv.waitKey(0) & 0xff == 27:\n # raise RuntimeError\n #\n # progress = toolbar_width*i//length+1\n # progressMsg = \"Procesando %d/%d \" % (i+1,length)\n # sys.stdout.write(progressMsg)\n # sys.stdout.write(\"[%s%s]\" % (\"-\" * progress,\" \" * (toolbar_width-progress)))\n # sys.stdout.flush()\n # sys.stdout.write(\"\\b\" * (len(progressMsg)+toolbar_width+2)) # return to start of line, after '['\n #\n # yield mask\n\n sys.stdout.write(\"\\n\") # this ends the progress bar\n video.release()\n return\n\nif __name__ == '__main__':\n from pathlib import Path\n import os\n\n def valid_roi(string):\n lst = [int(i) for i in string.split(\",\")]\n if len(lst) != 4 or any(i < 0 for i in lst) or lst[2] == 0 or lst[3] == 0:\n raise argparse.ArgumentTypeError(\"%r no es un rectángulo (x,y,w,h)\" % string)\n return slice(lst[1], lst[1] + lst[3]), slice(lst[0], lst[0] + lst[2])\n def ensure_dir(file_path):\n directory = os.path.dirname(file_path)\n if not os.path.exists(directory):\n os.makedirs(directory)\n\n import argparse\n\n parser = argparse.ArgumentParser(description=\"Segmentar hormigas con un algoritmo menos que óptimo\")\n parser.add_argument('filename', help=\"Path al video\")\n parser.add_argument('--output', '-o', type=str, default=None, metavar=\"O\", help=\"Nombre del archivo de salida\")\n parser.add_argument('--method', '-m', type=str, default='mog2', metavar=\"M\",\n help=\"Método de segmentación [mediana,mog2,gsoc,log]. Def: mog2\")\n parser.add_argument('--hist', '-g', type=int, default=50, metavar=\"H\", help=\"Número de frames de historia. Def: 50\")\n parser.add_argument('--antThresh', '-a', type=int, default=50, metavar=\"A\",\n help=\"Umbral para segmentar hormigas (sólo mediana y log). Def: 50\")\n parser.add_argument('--sheetThresh', '-s', type=int, default=150, metavar=\"S\",\n help=\"Umbral para remover lámina de fondo (mientras mayor el número, más sensible). Def: 150\")\n parser.add_argument('--roi', '-r', type=valid_roi, default=None, metavar=\"rect\",\n help=\"Zona de interés, rectángulo \\\"x,y,w,h\\\". (default: todo el video)\")\n parser.add_argument('--discard', '-d', type=float, default=0.8, metavar=\"D\",\n help=\"Porcentaje de la imagen por sobre la cual si se encuentra movimiento, \"\n \"es descartada la máscara (default: 0.8)\")\n\n args = parser.parse_args()\n\n if args.output is None:\n outfile = args.filename[:-3] + \"tag\" # hacky\n else:\n outfile = args.output\n print(\"outfile: \", outfile)\n # ensure_dir(\"./tmp/\")\n # import shutil\n # shutil.rmtree(\"./tmp/\")\n # ensure_dir(\"./tmp/\")\n antCollection = AntCollection(info=LabelingInfo(video_path=Path(args.filename), ants=[], unlabeled_frames=[]))\n # antCollection_dict = {\"ants\": [], \"unlabeledFrames\": [], \"videoSize\": 0, \"videoShape\": (0,0)}\n # unlabeledFrames = antCollection_dict[\"unlabeledFrames\"]\n print(\"OpenCV: \", cv.__version__)\n import time\n\n start_time = time.process_time()\n for frame, mask in enumerate(\n labelVideo(args.filename, metodo=args.method, roi=args.roi, historia=args.hist, ant_thresh=args.antThresh,\n sheet_thresh=args.sheetThresh, discard_percentage=args.discard)):\n antCollection.addUnlabeledFrame(frame, mask)\n print(\"File: %s - Method: %s\" % (args.filename, args.method))\n print(\"Number of frames: %d\" % (frame + 1)) # noqa\n print(\"Time elapsed: %02f seconds\" % (time.process_time() - start_time))\n # print(\"\\n%d\" % frame)\n print(\"mask.shape\", str(mask.shape)) # noqa\n print(\"mask.size\", str(mask.size))\n antCollection.videoSize = mask.size # noqa\n antCollection.videoShape = mask.shape\n antCollection.videoLength = frame + 1\n\n jsonstring = antCollection.serialize()\n antCollection2 = AntCollection.deserialize(video_path=Path(args.filename), jsonstring=jsonstring)\n if jsonstring == antCollection2.serialize():\n print(\"Serialization consistent\")\n else:\n raise ValueError(\"Serialization failed\")\n\n with open(outfile, \"w\") as file:\n file.write(jsonstring)\n"
},
{
"alpha_fraction": 0.5485047698020935,
"alphanum_fraction": 0.559549868106842,
"avg_line_length": 36.93280792236328,
"blob_id": "910f8b2390838ffef62593d5dad77f95ae0e7851",
"content_id": "33730db233373299a3aa8fee0dd2acce7670d380",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9597,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 253,
"path": "/ant_tracker/tracker/ongoing_track.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass, field\n\nimport numpy as np\nfrom filterpy.kalman import KalmanFilter\nfrom filterpy.common import Q_discrete_white_noise\nfrom typing import Optional, Tuple, List, Dict, TypedDict, Union\n\nfrom .blob import Blob\nfrom .common import ColorImage, FrameNumber, Vector, to_tuple_flip, Side\nfrom .track import Track\n\nSAMPLE_RATE = 1 # seconds/frame\n\ndef kalman_filter_init(sample_rate=1):\n kf = KalmanFilter(dim_z=2, dim_x=4)\n dt = sample_rate\n # Measurement noise (pretty low, b/c segmentation is fairly high fidelity)\n kf.R = np.array([[1, 0],\n [0, 1]])\n # Process noise\n kf.Q = Q_discrete_white_noise(2,dt,20,block_size=2,order_by_dim=False)\n # Initial estimate variance\n kf.P *= 100\n # State update/transition matrix\n kf.F = np.array([[1, 0, dt, 0], # x = x_0 + dt*v_x\n [0, 1, 0, dt], # y = y_0 + dt*v_y\n [0, 0, 1, 0], # v_x = v_x0\n [0, 0, 0, 1]]) # v_y = v_y0\n # Control matrix (acceleration)\n kf.B = np.array([[dt ** 2 / 2, 0], # + dt^2*a_x/2\n [0, dt ** 2 / 2], # + dt^2*a_y/2\n [dt, 0], # + dt*a_x\n [0, dt]]) # + dt*a_y\n # Measurement matrix (measure only x & y)\n kf.H = np.array([[1, 0, 0, 0],\n [0, 1, 0, 0]])\n\n return kf\n\n@dataclass\nclass OngoingTrack(Track):\n kf: KalmanFilter = field(init=False, default_factory=lambda: kalman_filter_init(sample_rate=SAMPLE_RATE),\n repr=False)\n a_sigma: float = field(repr=False)\n frames_lost: int = field(init=False, default=0)\n closed: bool = field(init=False, default=False)\n\n imshape: Tuple[int, int] = field(repr=False)\n frames_until_close: int = field(repr=False)\n can_predict: bool = field(init=False, default=True)\n random_state: np.random.RandomState\n\n def __post_init__(self):\n blob = self.blobs[min(self.blobs.keys())]\n self.kf.x = np.reshape(np.hstack((blob.center, [0, 0])), (4, 1))\n\n def __repr__(self):\n s = f\"OTrack(T{self.id}, x={self.x}\"\n if self.closed:\n s += \", closed\"\n if self.is_currently_lost:\n s += f\", frames_lost: {self.frames_lost}/{self.frames_until_close}\"\n s += \")\"\n return s\n\n @property\n def x(self):\n return self.kf.x.flatten()\n\n @property\n def is_currently_lost(self):\n return self.frames_lost > 0\n\n @property\n def is_exiting(self):\n if Side.from_point(self.last_blob().center_xy, self.imshape, percentage=0.05) is Side.Center:\n return False\n return True\n\n def as_closed(self) -> Track:\n return Track(self.id, self.blobs)\n\n def predict(self, u: Optional[Vector] = None):\n if not self.can_predict:\n raise ValueError(f'Cannot predict on {self}. update() first')\n if self.closed:\n raise ValueError(f'Cannot predict on {self}. Track closed')\n self.kf.predict()\n self.can_predict = False\n return self.x\n\n def update(self, frame: FrameNumber, blob: Optional[Blob] = None):\n \"\"\"\n If track wasn't found in a frame, ``blob`` should be ``None``, to update using last prediction.\n\n Closes the track and does nothing if ``frames_until_close`` was reached\n \"\"\"\n if self.closed:\n raise ValueError(f'Cannot update {self} because it\\'s closed.'\n ' Call as_closed() and replace the track,'\n ' or filter by (not closed)')\n if blob is None:\n if self.frames_lost > self.frames_until_close or self.is_exiting:\n self.close()\n return\n # lower velocity estimate, probably a collision\n self.kf.x[2:4] = self.kf.x[2:4] * self.a_sigma\n self.kf.update((self.kf.x[0:2] + self.kf.x[2:4]).T)\n newblob = self.at(frame - 1).new_moved_to(self.kf.x[0:2, :], self.imshape)\n self.__add_blob(frame, newblob)\n self.frames_lost += 1\n else:\n self.frames_lost = 0\n self.kf.update(blob.center)\n self.__add_blob(frame, blob)\n self.can_predict = True\n\n def close(self):\n for frame in range(self.last_frame() - self.frames_lost + 1, self.last_frame() + 1):\n self.blobs.pop(frame)\n self.closed = True\n self.can_predict = False\n\n def __add_blob(self, frame: FrameNumber, blob: Blob):\n last_frame = max(self.blobs.keys())\n if frame != last_frame + 1:\n raise ValueError(f'Tried to add {blob} to frame {frame}, where frame should\\'ve been {last_frame + 1}. \\n'\n f'Frames: {list(self.blobs.keys())}')\n self.blobs[frame] = blob\n\n def draw_blob(self, frame: FrameNumber, image: ColorImage, unused_param=None) -> ColorImage:\n from .common import draw_line, blend, Colors\n import skimage.draw as skdraw\n copy = Track.draw_blob(self, frame, image, Colors.GRAY if self.is_currently_lost else None)\n center = self.at(frame).center_xy\n predicted_next_pos = to_tuple_flip(self.x[2:4] + self.at(frame).center)\n copy = draw_line(copy, center, predicted_next_pos)\n rr, cc = skdraw.circle_perimeter(predicted_next_pos.y, predicted_next_pos.x, 2, shape=image.shape)\n copy[rr, cc] = blend(copy[rr, cc], Colors.BLACK, 0.8)\n if self.is_currently_lost and not self.closed:\n copy = self.draw_x(frame, copy)\n return self.last_blob().draw_label(copy, text=f'since: {self.frames_lost}', size=10, separation=7)\n else:\n return copy\n\n def draw_x(self, frame: FrameNumber, image: ColorImage) -> ColorImage:\n from .common import Colors\n\n def cross(x, y, shape, size=2):\n import skimage.draw as skdraw\n lf = x - size if x - size >= 0 else 0\n rg = x + size if x + size < shape[1] else shape[1] - 1\n tp = y - size if y - size >= 0 else 0\n bt = y + size if y + size < shape[0] else shape[0] - 1\n rr1, cc1 = skdraw.line(tp, lf, bt, rg)\n rr2, cc2 = skdraw.line(bt, lf, tp, rg)\n return np.hstack((rr1, rr2)), np.hstack((cc1, cc2))\n\n center = self.at(frame).center_xy\n rr, cc = cross(center.x, center.y, image.shape)\n copy = image.copy()\n copy[rr, cc] = Colors.RED\n return copy\n\n # region Invalid overrides\n\n @property\n def loaded(self):\n \"\"\"Do not use, get a :class:`Track` instance first with :method:`as_closed`\"\"\"\n raise AttributeError\n\n # endregion\n # region Serialization\n\n class Serial(TypedDict):\n id: int\n blobs: Dict[str, Blob.Serial]\n kf: Dict[str, Union[str, int]]\n frames_lost: int\n\n def encode(self) -> 'OngoingTrack.Serial':\n return {\n 'id': self.id,\n 'blobs': {str(i): blob.encode() for i, blob in self.blobs.items()},\n 'kf': encode_kalman(self.kf),\n 'frames_lost': self.frames_lost,\n }\n\n # noinspection PyMethodOverriding\n @classmethod\n def decode(cls, track_serial: 'OngoingTrack.Serial',\n a_sigma: float, imshape: Tuple[int, int], frames_until_close: int,\n random_state=np.random.RandomState) -> 'OngoingTrack':\n\n self = cls(id=track_serial['id'],\n blobs={int(i): Blob.decode(blob, imshape) for i, blob in track_serial[\"blobs\"].items()},\n a_sigma=a_sigma, imshape=imshape, frames_until_close=frames_until_close, random_state=random_state)\n self.kf = decode_kalman(track_serial['kf'])\n self.frames_lost = track_serial['frames_lost']\n return self\n\n # endregion\n\ndef encode_numpy(array: np.ndarray):\n return array.tolist()\n\ndef decode_numpy(list_: List) -> np.ndarray:\n return np.array(list_)\n\ndef encode_kalman(kf: KalmanFilter):\n return {\n 'dim_x': kf.dim_x,\n 'dim_z': kf.dim_z,\n 'dim_u': kf.dim_u,\n 'x': encode_numpy(kf.x),\n 'P': encode_numpy(kf.P),\n 'x_prior': encode_numpy(kf.x_prior),\n 'P_prior': encode_numpy(kf.P_prior),\n 'x_post': encode_numpy(kf.x_post),\n 'P_post': encode_numpy(kf.P_post),\n 'F': encode_numpy(kf.F),\n 'Q': encode_numpy(kf.Q),\n 'R': encode_numpy(kf.R),\n 'H': encode_numpy(kf.H),\n 'K': encode_numpy(kf.K),\n 'y': encode_numpy(kf.y),\n 'S': encode_numpy(kf.S),\n 'SI': encode_numpy(kf.SI),\n 'M': encode_numpy(kf.M),\n 'B': encode_numpy(kf.B),\n 'alpha': kf.alpha,\n }\n\ndef decode_kalman(serial) -> KalmanFilter:\n kf = KalmanFilter(dim_x=serial['dim_x'], dim_z=serial['dim_z'], dim_u=serial['dim_u'])\n kf.x = decode_numpy(serial['x'])\n kf.P = decode_numpy(serial['P'])\n kf.x_prior = decode_numpy(serial['x_prior'])\n kf.P_prior = decode_numpy(serial['P_prior'])\n kf.x_post = decode_numpy(serial['x_post'])\n kf.P_post = decode_numpy(serial['P_post'])\n kf.F = decode_numpy(serial['F'])\n kf.Q = decode_numpy(serial['Q'])\n kf.R = decode_numpy(serial['R'])\n kf.H = decode_numpy(serial['H'])\n kf.K = decode_numpy(serial['K'])\n kf.y = decode_numpy(serial['y'])\n kf.S = decode_numpy(serial['S'])\n kf.SI = decode_numpy(serial['SI'])\n kf.M = decode_numpy(serial['M'])\n kf.B = decode_numpy(serial['B'])\n kf.alpha = serial['alpha']\n return kf\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 14.428571701049805,
"blob_id": "6224faa94b85dcfbc9456c81e0bb5701f3f68079",
"content_id": "670391f44e6a2963a386bc2cbeab18f7bd711058",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 7,
"path": "/ant_tracker/labeler/pyinstall.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PyInstaller.__main__\n\nPyInstaller.__main__.run([\n 'AntLabeler.spec',\n '--onedir',\n '-y',\n])\n"
},
{
"alpha_fraction": 0.5784009695053101,
"alphanum_fraction": 0.5786706209182739,
"avg_line_length": 42.8875732421875,
"blob_id": "b0f700dc6cde4c91583cc7c48ae166f25380aff6",
"content_id": "4ad2620a3b583e06968d97e15c4547ee6dca603a",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7419,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 169,
"path": "/ant_tracker/tracker_gui/session.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import field, dataclass\nfrom enum import auto\n\nimport datetime\nimport json\nfrom pathlib import Path\nfrom typing import Union, List, Dict, Optional\n\nfrom .extracted_parameters import ExtractedParameters, SelectionStep\nfrom ..tracker.common import ensure_path, to_json, SerializableEnum, crop_from_rect, filehash\nfrom ..tracker.track import TrackId, Track\nfrom ..tracker.tracking import Tracker\n\n@dataclass\nclass SessionInfo:\n class State(SerializableEnum):\n New = auto()\n GotParameters = auto()\n Tracking = auto()\n DetectingLeaves = auto()\n Finished = auto()\n\n @staticmethod\n def __indexes() -> List['SessionInfo.State']:\n S = SessionInfo.State\n return [S.New, S.GotParameters, S.Tracking, S.DetectingLeaves, S.Finished]\n\n def __gt__(self, other: 'SessionInfo.State'):\n S = SessionInfo.State\n s = S.__indexes().index(self)\n o = S.__indexes().index(other)\n return s > o\n\n def __lt__(self, other: 'SessionInfo.State'):\n S = SessionInfo.State\n s = S.__indexes().index(self)\n o = S.__indexes().index(other)\n return s < o\n\n def __le__(self, other: 'SessionInfo.State'):\n return not (self > other)\n\n def __ge__(self, other: 'SessionInfo.State'):\n return not (self < other)\n\n videofiles: List[Path]\n first_start_time: datetime.datetime\n lengths: Dict[Path, Optional[int]]\n states: Dict[Path, State]\n parameters: Dict[Path, Optional[ExtractedParameters]]\n unfinished_trackers: Dict[Path, Optional[Tracker]]\n detection_probs: Dict[Path, Dict[TrackId, float]]\n __is_first_run: bool = field(init=False, default=False)\n\n @staticmethod\n def __sort(files: List[Path]):\n from natsort import natsorted\n return natsorted(files, key=lambda f: str(f))\n\n @classmethod\n def first_run(cls, files: List[Path], first_start_time: datetime.datetime):\n self = cls(\n videofiles=cls.__sort(files),\n first_start_time=first_start_time,\n lengths={f: None for f in files},\n states={f: SessionInfo.State.New for f in files},\n parameters={f: None for f in files},\n unfinished_trackers={f: None for f in files},\n detection_probs={f: {} for f in files},\n )\n self.__is_first_run = True\n return self\n\n @property\n def is_first_run(self):\n return self.__is_first_run\n\n @staticmethod\n def get_trkfile(videofile: Union[Path, str]):\n videofile = ensure_path(videofile)\n return videofile.parent / (videofile.stem + '.trk')\n\n def add_new_files(self, files: List[Path]):\n self.videofiles += files\n self.videofiles = self.__sort(self.videofiles)\n self.lengths = {**self.lengths, **{f: None for f in files}}\n self.states = {**self.states, **{f: SessionInfo.State.New for f in files}}\n self.parameters = {**self.parameters, **{f: None for f in files}}\n self.unfinished_trackers = {**self.unfinished_trackers, **{f: None for f in files}}\n self.detection_probs = {**self.detection_probs, **{f: {} for f in files}}\n\n def remove_deleted_files(self, files: List[Path]):\n for file in files:\n self.videofiles.remove(file)\n del self.lengths[file]\n del self.states[file]\n del self.parameters[file]\n del self.unfinished_trackers[file]\n del self.detection_probs[file]\n self.videofiles = self.__sort(self.videofiles)\n\n def record_tracker_state(self, file: Union[Path, str], tracker: Tracker):\n file = ensure_path(file)\n if file not in self.videofiles: raise ValueError(f\"El archivo {file} no pertenece a esta sesión\")\n if filehash(Path(tracker.video_path)) != filehash(file):\n raise ValueError(f\"El archivo {file} no corresponde a este Tracker ({tracker.video_path})\")\n if self.states[file] != SessionInfo.State.Tracking:\n raise ValueError(f\"El archivo {file} no está actualmente en tracking (estado: {self.states[file]})\")\n self.unfinished_trackers[file] = tracker\n\n def record_detection(self, file: Union[Path, str], track: Track, prob: float):\n file = ensure_path(file)\n self.detection_probs[file][track.id] = prob\n\n def save(self, path: Union[Path, str]):\n path = ensure_path(path)\n for file in self.videofiles:\n if self.states[file] != SessionInfo.State.Tracking and self.unfinished_trackers[file]:\n self.unfinished_trackers[file] = None\n if self.states[file] != SessionInfo.State.DetectingLeaves and self.detection_probs[file]:\n self.detection_probs[file] = {}\n path.write_text(\n to_json({\n 'videofiles': [str(p.name) for p in self.videofiles],\n 'first_start_time': self.first_start_time.isoformat(),\n 'lengths': {str(p.name): l for p, l in self.lengths.items()},\n 'states': {str(p.name): s.name for p, s in self.states.items()},\n 'parameters': {str(p.name): (s.encode() if s is not None else None) for p, s in\n self.parameters.items()},\n 'unfinished_trackers': {str(p.name): (t.encode_unfinished() if t is not None else None) for p, t in\n self.unfinished_trackers.items()},\n 'detection_probs': {str(p.name): {str(i): prob for i, prob in probs.items()} for p, probs in\n self.detection_probs.items()}\n })\n )\n\n @classmethod\n def load(cls, path: Union[Path, str], with_trackers=False):\n path = ensure_path(path)\n d = json.loads(path.read_text())\n\n trackers = {(path.parent / p): None for p, t in d['unfinished_trackers'].items()}\n if with_trackers:\n for p, t in d['unfinished_trackers'].items():\n if t is not None:\n file = (path.parent / p)\n crop_rect = ExtractedParameters.decode(d['parameters'][p]).rect_data[SelectionStep.TrackingArea]\n import pims\n from pims.process import crop\n video = pims.PyAVReaderIndexed(file)\n video = crop(video, crop_from_rect(video.frame_shape[0:2], crop_rect))\n trackers[file] = Tracker.decode_unfinished(t, video, file)\n if 'detection_probs' in d:\n detection_probs = {(path.parent / p): {int(i): prob for i, prob in probs.items()} for p, probs in\n d['detection_probs'].items()}\n else:\n detection_probs = {(path.parent / p): {} for p in d['videofiles']}\n\n self = cls(\n [(path.parent / p) for p in d['videofiles']],\n datetime.datetime.fromisoformat(d['first_start_time']),\n {(path.parent / p): l for p, l in d['lengths'].items()},\n {(path.parent / p): SessionInfo.State[s] for p, s in d['states'].items()},\n {(path.parent / p): (ExtractedParameters.decode(s) if s is not None else None) for p, s in\n d['parameters'].items()},\n trackers,\n detection_probs,\n )\n return self\n"
},
{
"alpha_fraction": 0.6812748908996582,
"alphanum_fraction": 0.7131474018096924,
"avg_line_length": 34.85714340209961,
"blob_id": "3657c5766f17433f14fbbc9469869dc20ed37a7b",
"content_id": "ec69f711a6b20f68e3372fc298d690f0d18c2305",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 251,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 7,
"path": "/ant_tracker/labeler/printprofile.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import pstats\n\np = pstats.Stats('profile')\np.sort_stats('cumtime').print_stats(\"encoder\",10)\np.sort_stats('cumtime').print_stats(\"classes\",10)\n# p.strip_dirs().sort_stats('cumulative').print_stats(10)\np.strip_dirs().sort_stats('time').print_stats(10)\n"
},
{
"alpha_fraction": 0.6014705896377563,
"alphanum_fraction": 0.6188725233078003,
"avg_line_length": 38.61165237426758,
"blob_id": "166c94e70a16a56847f3eaddc4971eeb5877a9da",
"content_id": "2630fccf8384bd20942541512e434ef94b4b8669",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4086,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 103,
"path": "/ant_tracker/tracker/leafdetect.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom abc import ABC, abstractmethod\nfrom pathlib import Path\nfrom typing import Optional, Union, Tuple\n\nfrom .blob import Blob\nfrom .common import Video, ColorImage\nfrom .track import Track\n\ndef _get_blob_rect(blob: Blob, imshape: Tuple[int, int], extra_pixels: int, square: bool):\n x0, x1, y0, y1 = blob.bbox.xxyy\n if y1 - y0 <= 1 or x1 - x0 <= 1: return None\n rect = blob.bbox\n if square:\n rect = (\n blob.bbox\n .scale(imshape, extra_pixels=extra_pixels)\n .square(imshape)\n )\n return rect\n\ndef _get_frame_slice(video: Video, blob: Blob, frame_n: int, extra_pixels: int, square=False) -> Optional[ColorImage]:\n image = video[frame_n]\n x0, x1, y0, y1 = _get_blob_rect(blob, image.shape, extra_pixels, square).xxyy\n return image[y0:y1, x0:x1, :]\n\nclass LeafDetector(ABC):\n def __init__(self, video: Video, extra_pixels=15, img_size=64, n_frames=75):\n \"\"\"\n Args:\n extra_pixels: número de píxeles alrededor del Blob que se toman para el slice de video\n img_size: tamaño del input al detector (img_size,img_size,3)\n n_frames: número de frames usado por el detector, los tracks se samplearán según sea necesario\n \"\"\"\n self.video = video\n self.img_size = img_size\n self.n_frames = n_frames\n self.extra_pixels = extra_pixels\n\n def probability(self, track: Track) -> float:\n _input = self._track2input(track)\n if _input is None:\n return 0\n return self.call_model(_input)\n\n @abstractmethod\n def call_model(self, model_input):\n pass\n\n def _track2input(self, track: Track):\n from skimage.transform import resize\n blobs = track.get_safe_blobs(percentage=0.05)\n if len(blobs) == 0:\n blobs = track.get_safe_blobs(percentage=0.025)\n if len(blobs) == 0:\n return None\n slices = []\n for frame_n, blob in sorted(blobs.items()):\n slice_with_ant = _get_frame_slice(\n self.video,\n blob,\n frame_n,\n extra_pixels=self.extra_pixels,\n square=True\n )\n if slice_with_ant is None:\n continue\n slices.append(slice_with_ant)\n if len(slices) == 0: return None\n slices = np.array(slices)\n images = []\n indexes = np.round(np.linspace(0, len(slices) - 1, self.n_frames)).astype(int)\n for s in slices[indexes]:\n images.append(resize(s, (64, 64), preserve_range=True))\n images = np.stack(images, axis=0) / 255.0\n images = np.expand_dims(images, axis=0)\n return images\n\n# noinspection PyUnresolvedReferences\nclass TFLeafDetector(LeafDetector):\n def __init__(self, model_folder: Union[Path, str], video: Video, extra_pixels=15, img_size=64, n_frames=75):\n import tensorflow as tf\n from .tf_model_reqs import F1Score\n self.model = tf.keras.models.load_model(model_folder, custom_objects={'F1Score': F1Score})\n super(TFLeafDetector, self).__init__(video, extra_pixels, img_size, n_frames)\n\n def call_model(self, model_input):\n return self.model(model_input).numpy()[0, 0]\n\n# noinspection PyUnresolvedReferences\nclass TFLiteLeafDetector(LeafDetector):\n def __init__(self, tfl_model: Union[Path, str], video: Video, extra_pixels=15, img_size=64, n_frames=75):\n import tflite_runtime.interpreter as tflite\n self.interpreter = tflite.Interpreter(tfl_model)\n self.interpreter.allocate_tensors()\n self.in_index = self.interpreter.get_input_details()[0]['index']\n self.out_index = self.interpreter.get_output_details()[0]['index']\n super(TFLiteLeafDetector, self).__init__(video, extra_pixels, img_size, n_frames)\n\n def call_model(self, model_input):\n self.interpreter.set_tensor(self.in_index, model_input.astype(np.float32))\n self.interpreter.invoke()\n return self.interpreter.get_tensor(self.out_index).item()\n"
},
{
"alpha_fraction": 0.5359387397766113,
"alphanum_fraction": 0.5397000312805176,
"avg_line_length": 42.86519241333008,
"blob_id": "809b122b6f1d0d9cfc36b658beafbdb6bc7c924e",
"content_id": "c9694271b20ed8543e9417ddff2aabb7ff153302",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21801,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 497,
"path": "/ant_tracker/tracker/tracking.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom packaging.version import Version\nfrom pathlib import Path\nfrom scipy.spatial.distance import cdist\nfrom typing import List, NewType, Optional, Tuple, Union, TypedDict, Dict\n\nfrom .blob import Blob\nfrom .common import FrameNumber, Video, ensure_path, to_json, encode_np_randomstate, decode_np_randomstate\nfrom .info import TracksInfo\nfrom .ongoing_track import OngoingTrack\nfrom .parameters import TrackerParameters, SegmenterParameters\nfrom .segmenter import Blobs, Segmenter, LogWSegmenter\nfrom .track import Track, TrackId\n\nTrackerVersion = Version('2.0.2dev1')\n\nBlobIndex = NewType('BlobIndex', int)\nAssignment = Tuple[TrackId, BlobIndex]\n\nclass Tracker:\n # region Init\n def __init__(self, video_path: Union[Path, str], segmenter: Segmenter = None, *,\n params: TrackerParameters = TrackerParameters(use_defaults=True)):\n self.video_path = video_path\n self.version = TrackerVersion\n self.__tracks: Optional[List[Track]] = None\n self.params = params\n if segmenter is None: # from deserialization\n return\n self.segmenter = segmenter\n self.video_length = segmenter.video_length\n self.video_shape = segmenter.video_shape\n self.last_id: TrackId = TrackId(0)\n self.__inprogress_tracks: List[Track] = []\n self.__last_tracked_frame: FrameNumber = -1\n self.__random_state = np.random.RandomState()\n\n # endregion\n\n # region Tracking\n\n @property\n def last_tracked_frame(self):\n return self.__last_tracked_frame\n\n def next_id(self) -> TrackId:\n i = self.last_id\n self.last_id += 1\n return i\n\n @staticmethod\n def kalman_get_measurement(blobs: List[Blob]) -> List[Tuple[float, float]]:\n return [(blob.center[0], blob.center[1]) for blob in blobs]\n\n @property\n def is_finished(self):\n return self.__tracks is not None\n\n @property\n def tracks(self) -> List[Track]:\n if not self.is_finished:\n list(self.track_progressive())\n return self.__tracks\n\n def track_progressive_continue(self):\n last_frame = self.__last_tracked_frame\n if last_frame == -1: # first time, from track_progressive()\n prev_blobs = []\n else:\n prev_blobs = [track.at(last_frame) for track in self.__inprogress_tracks if\n track.at(last_frame) is not None]\n frames_with_blobs = self.segmenter.segment_rolling_from(last_frame + 1, prev_blobs)\n tracks = self.__inprogress_tracks\n for frame, blobs in frames_with_blobs:\n if frame == 0:\n for blob in blobs:\n track_id = self.next_id()\n track = OngoingTrack(\n id=track_id, blobs={0: blob},\n frames_until_close=self.params.frames_until_close,\n imshape=self.video_shape,\n a_sigma=self.params.a_sigma,\n random_state=self.__random_state,\n )\n tracks.append(track)\n continue\n\n ongoing_tracks = Tracker.ongoing(tracks)\n\n # region Get detections and estimates\n detections = Tracker.kalman_get_measurement(blobs)\n number_of_detections = len(detections)\n estimates_and_ids = [(track.predict(), track.id) for track in ongoing_tracks]\n estimates = [estimate for estimate, track_id in estimates_and_ids]\n number_of_estimates = len(estimates)\n # endregion\n\n id_assignments = []\n new_blob_idxs = []\n lost_ids = []\n if number_of_estimates == 0:\n if number_of_detections != 0:\n new_blob_idxs = list(range(len(blobs)))\n elif number_of_detections == 0:\n if number_of_estimates != 0:\n lost_ids = [track_id for estimate, track_id in estimates_and_ids]\n else:\n # region Calculate the distance matrix and apply Munkres algorithm\n estimates_nd = np.array(estimates)[:, 0:2] # get only position, not velocity\n detections_nd = np.array(detections)\n\n estimate_areas = np.array(\n [[Track.get(ongoing_tracks, track_id).at(frame - 1).area] for _, track_id in\n estimates_and_ids])\n estimates_y_x_area = np.hstack((estimates_nd, estimate_areas))\n\n detection_areas = np.array([[b.area] for b in blobs])\n detections_y_x_area = np.hstack((detections_nd, detection_areas))\n\n dist: np.ndarray = cdist(estimates_y_x_area, detections_y_x_area).T\n from scipy.optimize import linear_sum_assignment\n det, est = linear_sum_assignment(dist)\n indexes = [(estim, detect) for estim, detect in zip(est, det)]\n\n # endregion\n\n # region Find lost assignments and new tracks\n id_assignments: List[Assignment] = []\n lost_ids: List[TrackId] = []\n for estim, detect in indexes:\n track_id = estimates_and_ids[estim][1]\n detect_index_in_frame: BlobIndex = detect\n track_yx = Track.get(ongoing_tracks, track_id).at(frame - 1).center\n detect_yx = blobs[detect_index_in_frame].center\n distance = np.linalg.norm(track_yx - detect_yx)\n if distance < self.params.max_distance_between_assignments:\n id_assignments.append((track_id, detect_index_in_frame))\n else:\n # Far away assignments are tracks that were lost\n lost_ids.append(track_id)\n pass\n prev_ids = [track_id for estimate, track_id in estimates_and_ids]\n # Tracks that weren't assigned are lost\n lost_ids.extend([track_id\n for track_id in prev_ids\n if\n track_id not in [prev_id for prev_id, next_id in id_assignments]\n and track_id not in lost_ids\n ])\n # Detections that weren't assigned are new tracks\n new_blob_idxs = [blob_index\n for blob_index in range(len(blobs))\n if blob_index not in [blob_idx for track_id, blob_idx in id_assignments]\n ]\n\n # endregion\n\n # region Update filters for each track\n for prev_track, blob_index in id_assignments:\n track = OngoingTrack.get(tracks, prev_track)\n next_blob = blobs[blob_index]\n track.update(frame, next_blob)\n for track_id in lost_ids:\n track = OngoingTrack.get(tracks, track_id)\n track.update(frame)\n # endregion\n\n # region Close tracks that were lost for too many frames\n tracks = [(track.as_closed() if track.closed else track)\n if isinstance(track, OngoingTrack) else track\n for track in tracks]\n # endregion\n\n # region Create new tracks\n for blob_index in new_blob_idxs:\n blob = blobs[blob_index]\n new_track = OngoingTrack(\n id=self.next_id(),\n blobs={frame: blob},\n frames_until_close=self.params.frames_until_close,\n imshape=self.video_shape,\n a_sigma=self.params.a_sigma,\n random_state=self.__random_state,\n )\n tracks.append(new_track)\n # endregion\n\n self.__inprogress_tracks = tracks\n self.__last_tracked_frame = frame\n\n yield frame\n\n self.__tracks = [track.as_closed() for track in tracks]\n\n def track_progressive(self):\n yield from self.track_progressive_continue()\n\n def track_viz(self, video: Optional[Video] = None, *, step_by_step=False, fps=10):\n # region Drawing\n if video is not None:\n from matplotlib import pyplot as plt\n from .plotcommon import Animate\n fig, ax = plt.subplots(1, 2)\n axli = ax.flatten()\n fig_track, ax_track = plt.subplots(1, 1)\n if step_by_step:\n process_next_frame = False\n if video:\n def on_key_press(event):\n nonlocal process_next_frame\n if event.key == ' ':\n process_next_frame = True\n elif event.key == 'escape':\n import sys\n sys.exit()\n\n plt.gcf().canvas.mpl_connect('key_press_event', on_key_press)\n # endregion\n\n tracks: List[Track] = []\n frame: FrameNumber\n for frame, blobs in self.segmenter.frames_with_blobs:\n if frame == 0:\n for blob in blobs:\n track_id = self.next_id()\n track = OngoingTrack(\n id=track_id, blobs={0: blob},\n frames_until_close=self.params.frames_until_close,\n imshape=self.video_shape,\n a_sigma=self.params.a_sigma,\n random_state=self.__random_state,\n )\n tracks.append(track)\n continue\n\n print(f\"Tracking at {frame=}\")\n ongoing_tracks = Tracker.ongoing(tracks)\n\n # region Drawing\n if video is not None:\n axli[0].clear()\n axli[1].clear()\n axli[0].set_title(f'Frame {frame - 1}')\n axli[1].set_title(f'Frame {frame}')\n prev_image = OngoingTrack.draw_tracks(ongoing_tracks, video[frame - 1], frame - 1)\n Animate.draw(axli[0], prev_image, override_hash=True)\n image = Blob.draw_blobs(blobs, video[frame])\n Animate.draw(axli[1], image, override_hash=True)\n track_img = OngoingTrack.draw_tracks(\n sorted(ongoing_tracks, key=lambda t: -1 if t.is_currently_lost else 0), video[frame - 1],\n frame - 1)\n for track in tracks:\n track_img = track.draw_track_line(frame, track_img)\n Animate.draw(ax_track, track_img)\n\n # endregion\n\n # region Get detections and estimates\n detections = Tracker.kalman_get_measurement(blobs)\n number_of_detections = len(detections)\n # number_of_detections = len(blobs)\n estimates_and_ids = [(track.predict(), track.id) for track in ongoing_tracks]\n estimates = [estimate for estimate, track_id in estimates_and_ids]\n number_of_estimates = len(estimates)\n # endregion\n\n id_assignments = []\n new_blob_idxs = []\n lost_ids = []\n if number_of_estimates == 0:\n if number_of_detections != 0:\n new_blob_idxs = list(range(len(blobs)))\n elif number_of_detections == 0:\n if number_of_estimates != 0:\n lost_ids = [track_id for estimate, track_id in estimates_and_ids]\n else:\n # region Calculate the distance matrix and apply Munkres algorithm\n estimates_nd = np.array(estimates)[:, 0:2] # get only position, not velocity\n detections_nd = np.array(detections)\n\n estimate_areas = np.array(\n [[Track.get(ongoing_tracks, track_id).at(frame - 1).area] for _, track_id in\n estimates_and_ids])\n estimates_y_x_area = np.hstack((estimates_nd, estimate_areas))\n\n detection_areas = np.array([[b.area] for b in blobs])\n detections_y_x_area = np.hstack((detections_nd, detection_areas))\n\n dist: np.ndarray = cdist(estimates_y_x_area, detections_y_x_area).T\n # distance_btwn_estimate_n_detections = dist.copy()\n from scipy.optimize import linear_sum_assignment\n det, est = linear_sum_assignment(dist)\n indexes = [(estim, detect) for estim, detect in zip(est, det)]\n\n # endregion\n\n # region Find lost assignments and new tracks\n id_assignments: List[Assignment] = []\n lost_ids: List[TrackId] = []\n for estim, detect in indexes:\n track_id = estimates_and_ids[estim][1]\n detect_index_in_frame: BlobIndex = detect\n track_yx = Track.get(ongoing_tracks, track_id).at(frame - 1).center\n detect_yx = blobs[detect_index_in_frame].center\n distance = np.linalg.norm(track_yx - detect_yx)\n # print(f'(Track:{track_id}->Detect:{detect_index_in_frame}): {distance=}')\n if distance < self.params.max_distance_between_assignments:\n id_assignments.append((track_id, detect_index_in_frame))\n else:\n # Far away assignments are tracks that were lost\n lost_ids.append(track_id)\n pass\n prev_ids = [track_id for estimate, track_id in estimates_and_ids]\n # Tracks that weren't assigned are lost\n lost_ids.extend([track_id\n for track_id in prev_ids\n if\n track_id not in [prev_id for prev_id, next_id in id_assignments]\n and track_id not in lost_ids\n ])\n # next_ids: Sequence[BlobIndex] = range(len(blobs))\n # Detections that weren't assigned are new tracks\n new_blob_idxs = [blob_index\n for blob_index in range(len(blobs))\n if blob_index not in [blob_idx for track_id, blob_idx in id_assignments]\n ]\n\n # endregion\n\n # region Update filters for each track\n for prev_track, blob_index in id_assignments:\n track = OngoingTrack.get(tracks, prev_track)\n next_blob = blobs[blob_index]\n track.update(frame, next_blob)\n for track_id in lost_ids:\n track = OngoingTrack.get(tracks, track_id)\n track.update(frame)\n # endregion\n\n # region Close tracks that were lost for too many frames\n tracks = [(track.as_closed() if track.closed else track)\n if isinstance(track, OngoingTrack) else track\n for track in tracks]\n # endregion\n\n # region Create new tracks\n for blob_index in new_blob_idxs:\n blob = blobs[blob_index]\n new_track = OngoingTrack(\n id=self.next_id(),\n blobs={frame: blob},\n frames_until_close=self.params.frames_until_close,\n imshape=self.video_shape,\n a_sigma=self.params.a_sigma,\n random_state=self.__random_state,\n )\n tracks.append(new_track)\n # endregion\n\n self.__inprogress_tracks = tracks\n self.__last_tracked_frame = frame\n\n # region Drawing\n blob_correlation = Tracker.correlate_blobs(frame, ongoing_tracks, blobs, id_assignments)\n\n if video is not None:\n for prev_blob, next_blob in blob_correlation:\n from matplotlib.patches import ConnectionPatch\n con = ConnectionPatch(xyA=prev_blob.center_xy, xyB=next_blob.center_xy,\n coordsA=\"data\", coordsB=\"data\",\n axesA=axli[0], axesB=axli[1], color=(1, 0, 0, 0.2), lw=1)\n axli[1].add_artist(con)\n for lost_id in lost_ids:\n lost_track = OngoingTrack.get(ongoing_tracks, lost_id)\n if (lost_blob := lost_track.at(frame)) is not None:\n # because it could've been closed in this frame, thus not having a blob\n prev_image = lost_blob.draw_label(prev_image, 'LOST', size=10)\n Animate.draw(axli[0], prev_image, override_hash=True)\n # axli[0].text(lost_blob.center_xy[0], lost_blob.center_xy[1] - 10, 'LOST')\n for blob_index in new_blob_idxs:\n new_blob = blobs[blob_index]\n image = new_blob.draw_label(image, 'NEW', size=10)\n Animate.draw(axli[1], image, override_hash=True)\n # axli[1].text(new_blob.center_xy[0], new_blob.center_xy[1] - 10, 'NEW')\n\n plt.draw()\n if step_by_step:\n while not process_next_frame:\n plt.pause(0.05)\n process_next_frame = False\n\n if video is not None:\n plt.pause(1 / fps)\n\n # endregion\n\n self.__tracks = [track.as_closed() for track in tracks]\n\n @staticmethod\n def correlate_blobs(\n frame: FrameNumber,\n tracks: List['OngoingTrack'],\n blobs: Blobs,\n id_assignments: List[Assignment]) -> List[Tuple[Blob, Blob]]:\n correlation = []\n for prev_id, next_id in id_assignments:\n track = OngoingTrack.get(tracks, prev_id)\n prev_blob = track.at(frame)\n next_blob = blobs[next_id]\n correlation.append((prev_blob, next_blob))\n return correlation\n\n @staticmethod\n def ongoing(tracks: List[Track]) -> List[OngoingTrack]:\n return [track for track in tracks if isinstance(track, OngoingTrack)]\n\n @staticmethod\n def closed(tracks: List[Track]) -> List[Track]:\n return [track for track in tracks if isinstance(track, Track) and not isinstance(track, OngoingTrack)]\n\n # endregion\n\n # region Serialization\n def save_unfinished(self, file: Union[Path, str]):\n if self.is_finished: raise ValueError(\"El tracking ya fue finalizado, use info()\")\n file = ensure_path(file)\n with file.open('w') as f:\n f.write(to_json(self.encode_unfinished()))\n\n @classmethod\n def load_unfinished(cls, file: Union[Path, str], video: Video, video_path: Union[Path, str]):\n file = ensure_path(file)\n with file.open('r') as f:\n import json\n self = cls.decode_unfinished(json.load(f), video, video_path)\n return self\n\n class UnfinishedSerial(TypedDict):\n __closed_tracks: List[Track.Serial]\n __ongoing_tracks: List[OngoingTrack.Serial]\n __last_tracked_frame: int\n __np_randomstate: Tuple\n segmenter_parameters: Dict\n tracker_parameters: Dict\n video_length: int\n video_shape: Tuple[int, int]\n\n def encode_unfinished(self) -> 'Tracker.UnfinishedSerial':\n return {\n '__closed_tracks': [Track.encode(track) for track in Tracker.closed(self.__inprogress_tracks)],\n '__ongoing_tracks': [OngoingTrack.encode(track) for track in Tracker.ongoing(self.__inprogress_tracks)],\n '__last_tracked_frame': self.__last_tracked_frame,\n '__np_randomstate': encode_np_randomstate(self.__random_state.get_state()),\n 'segmenter_parameters': self.segmenter.params.encode(),\n 'tracker_parameters': self.params.encode(),\n 'video_length': self.video_length,\n 'video_shape': self.video_shape,\n }\n\n @classmethod\n def decode_unfinished(cls, serial: 'Tracker.UnfinishedSerial', video: Video, video_path: Path):\n video_shape = serial['video_shape']\n self = cls(video_path, params=TrackerParameters.decode(serial['tracker_parameters']))\n self.segmenter = LogWSegmenter(video, SegmenterParameters.decode(serial['segmenter_parameters']))\n self.video_path = video_path\n self.video_length = serial['video_length']\n self.video_shape = video_shape\n self.__last_tracked_frame = serial['__last_tracked_frame']\n\n self.__random_state = np.random.RandomState()\n self.__random_state.set_state(decode_np_randomstate(serial['__np_randomstate']))\n\n closed_tracks = [Track.decode(track, video_shape) for track in serial['__closed_tracks']]\n ongoing_tracks = [OngoingTrack.decode(\n track,\n self.params.a_sigma,\n video_shape,\n self.params.frames_until_close,\n self.__random_state\n ) for track in serial['__ongoing_tracks']]\n\n self.__inprogress_tracks = closed_tracks + ongoing_tracks\n self.last_id = TrackId(max([track.id for track in self.__inprogress_tracks]) + 1)\n\n return self\n\n def info(self):\n if not self.is_finished: raise ValueError('track() first!')\n return TracksInfo(\n video_path=self.video_path,\n segmenter_version=self.segmenter.version,\n segmenter_parameters=self.segmenter.params,\n tracker_version=self.version,\n tracker_parameters=self.params,\n tracks=self.tracks,\n )\n # endregion\n"
},
{
"alpha_fraction": 0.5942834615707397,
"alphanum_fraction": 0.5992586016654968,
"avg_line_length": 35.3510627746582,
"blob_id": "552c962ffefbff9ac21425f34fc1f049ba80779f",
"content_id": "ed8991920a39577d4d69b132a2115aa13b3eb6f7",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10252,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 282,
"path": "/ant_tracker/labeler/gui_classes.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import pyforms_gui.utils.tools as tools\nfrom AnyQt import QtCore, _api, uic # noqa\nfrom AnyQt.QtGui import QIcon, QPixmap, QFont, QColor\nfrom AnyQt.QtWidgets import (QAbstractItemView, QComboBox, QDialogButtonBox, QGridLayout, QLabel,\n QTableWidgetItem,\n QWidget, QDialog, QFileDialog)\nfrom confapp import conf\nfrom pyforms.controls import ControlBase, ControlList, ControlPlayer, ControlFile, ControlLabel\n\nfrom .classes import *\nfrom confapp import conf\n\nclass ColorIcon:\n def __init__(self, r=None, g=None, b=None):\n icon = QPixmap(15, 15) # 15px\n if r is None:\n icon.fill(QColor(*getNextColor())) # * = tuple expansion\n else:\n icon.fill(QColor(r, g, b))\n self.icon = QIcon(icon)\n for size in self.icon.availableSizes():\n self.icon.addPixmap(self.icon.pixmap(size, QIcon.Normal, QIcon.Off), QIcon.Selected, QIcon.Off)\n self.icon.addPixmap(self.icon.pixmap(size, QIcon.Normal, QIcon.On), QIcon.Selected, QIcon.On)\n\nclass ControlListAnts(ControlList):\n def set_value(self, column, row, value):\n if isinstance(value, QWidget):\n self.tableWidget.setCellWidget(row, column, value)\n value.show()\n self.tableWidget.setRowHeight(row, value.height())\n elif isinstance(value, ControlBase):\n self.tableWidget.setCellWidget(row, column, value.form)\n value.show()\n self.tableWidget.setRowHeight(row, value.form.height())\n elif isinstance(value, ColorIcon):\n item = QTableWidgetItem()\n item.setIcon(value.icon)\n # item.setData(QtCore.Qt.EditRole, *args)\n self.tableWidget.setItem(row, column, item)\n else:\n args = [value]\n item = QTableWidgetItem()\n item.setData(QtCore.Qt.EditRole, *args)\n self.tableWidget.setItem(row, column, item)\n\n @property\n def single_select(self):\n return self.tableWidget.selectionBehavior()\n\n @single_select.setter\n def single_select(self, value):\n if value:\n self.tableWidget.setSelectionMode(QAbstractItemView.SingleSelection)\n else:\n pass\n # self.tableWidget.setSelectionMode(QAbstractItemView.DragSelectingState)\n\nclass ControlPlayerAnts(ControlPlayer):\n def __init__(self, *args, **kwargs):\n super(ControlPlayerAnts, self).__init__(args, kwargs)\n self.frame_cache_len = 10\n self.frame_cache = {}\n self._current_frame_index = 0\n\n @property\n def video_index(self):\n return self._current_frame_index\n\n @video_index.setter\n def video_index(self, value):\n if value < 0: value = -1\n if value >= self.max: value = self.max - 1\n self._current_frame_index = value\n\n def reload_queue(self, index, display_index):\n # print(f\"VC index: {int(self._value.get(1))}, index: {index}, display index: {display_index}\")\n n_frames_to_load = self.frame_cache_len\n if not int(self._value.get(1)) == display_index:\n self._value.set(1, index)\n n_frames_to_load *= 2\n\n self.frame_cache.clear()\n for i in range(n_frames_to_load):\n success, frame = self._value.read()\n if not success:\n break\n self.frame_cache[index + i] = frame\n\n def get_frame(self, index, get_previous=False):\n # print(f\"{list(self.frame_cache.keys())}\")\n f = self.frame_cache.get(index, None)\n if f is not None:\n return f\n else:\n first_frame_to_get = max(0, index - self.frame_cache_len // 2 + 1) if get_previous else index\n self.reload_queue(first_frame_to_get, index)\n return self.frame_cache.get(index, None)\n\n def call_next_frame(self, update_slider=True, update_number=True, increment_frame=True, get_previous=False):\n # move the player to the next frame\n self.before_frame_change()\n self.form.setUpdatesEnabled(False)\n self._current_frame_index = self.video_index\n\n # if the player is not visible, stop\n if not self.visible:\n self.stop()\n self.form.setUpdatesEnabled(True)\n return\n\n # if no video is selected\n if self.value is None:\n self._current_frame = None\n self._current_frame_index = None\n return\n\n if len(self.frame_cache) == 0: # first time drawing\n self._current_frame_index = 0\n else:\n self._current_frame_index += 1\n frame = self.get_frame(self._current_frame_index, get_previous=get_previous)\n\n # # no frame available. leave the function\n if frame is None:\n self.stop()\n self.form.setUpdatesEnabled(True)\n return\n self._current_frame = frame\n frame = self.process_frame_event(\n self._current_frame.copy()\n )\n\n # draw the frame\n if isinstance(frame, list) or isinstance(frame, tuple):\n self._video_widget.paint(frame)\n else:\n self._video_widget.paint([frame])\n\n if not self.videoProgress.isSliderDown():\n\n if update_slider and self._update_video_slider:\n self._update_video_slider = False\n self.videoProgress.setValue(self._current_frame_index)\n self._update_video_slider = True\n\n if update_number:\n self._update_video_frame = False\n self.videoFrames.setValue(self._current_frame_index)\n self._update_video_frame = True\n\n self.form.setUpdatesEnabled(True)\n self.after_frame_change()\n\n def videoPlay_clicked(self):\n \"\"\"Slot for Play/Pause functionality.\"\"\"\n # self.before_frame_change()\n if self.is_playing:\n self.stop()\n else:\n self.play()\n self.when_play_clicked()\n # self.after_frame_change()\n\n def videoProgress_sliderReleased(self):\n # self.before_frame_change()\n if self._update_video_slider:\n new_index = self.videoProgress.value()\n self.video_index = new_index\n # self._value.set(1, new_index)\n self.call_next_frame(update_slider=False, increment_frame=False, get_previous=True)\n # self.after_frame_change()\n\n def video_frames_value_changed(self, pos):\n # self.before_frame_change()\n if self._update_video_frame:\n self.video_index = pos - 1\n # self._value.set(1, pos) # set the video position\n self.call_next_frame(update_number=False, increment_frame=False, get_previous=True)\n # self.after_frame_change()\n\n def back_one_frame(self):\n \"\"\"\n Back one frame.\n :return:\n \"\"\"\n self.video_index -= 2\n self.call_next_frame(get_previous=True)\n\n def before_frame_change(self):\n pass\n\n def after_frame_change(self):\n pass\n\n def when_play_clicked(self):\n pass\n\n @property\n def move_event(self):\n return self._video_widget.onMove\n\n @move_event.setter\n def move_event(self, value):\n self._video_widget.onMove = value\n\nclass ControlFileAnts(ControlFile):\n def __init__(self, *args, **kwargs):\n self.__exec_changed_event = True\n super(ControlFile, self).__init__(*args, **kwargs)\n self.use_save_dialog = kwargs.get('use_save_dialog', False)\n self.filter = kwargs.get('filter', None)\n\n def click(self):\n if self.use_save_dialog:\n value, _ = QFileDialog.getSaveFileName(self.parent, self._label, self.value) # noqa\n else:\n if conf.PYFORMS_DIALOGS_OPTIONS:\n value = QFileDialog.getOpenFileName(self.parent, self._label, self.value,\n filter=self.filter,\n options=conf.PYFORMS_DIALOGS_OPTIONS)\n else:\n value = QFileDialog.getOpenFileName(self.parent, self._label, self.value,\n filter=self.filter) # noqa\n\n if _api.USED_API == _api.QT_API_PYQT5:\n value = value[0]\n elif _api.USED_API == _api.QT_API_PYQT4:\n value = str(value)\n\n if value and len(value) > 0: self.value = value\n\nclass ControlLabelFont(ControlLabel):\n def __init__(self, *args, **kwargs):\n self._font = kwargs.get('font', QFont())\n super(ControlLabel, self).__init__(*args, **kwargs)\n\n def init_form(self):\n import inspect\n path = inspect.getfile(ControlLabel)\n\n control_path = tools.getFileInSameDirectory(path, \"label.ui\")\n self._form = uic.loadUi(control_path)\n self._form.label.setText(self._label)\n self._form.label.setFont(self._font)\n self._selectable = False # noqa\n super(ControlLabel, self).init_form()\n\n# from pyforms_gui.controls.control_player.AbstractGLWidget import AbstractGLWidget, MouseEvent\n\n# def mouseReleaseEvent(self, event):\n# super(AbstractGLWidget, self).mousePressEvent(event)\n# self.setFocus(QtCore.Qt.MouseFocusReason)\n\n# self._mouse_pressed = True\n# self._mouseX = event.x()\n# self._mouseY = event.y()\n# self._mouse_clicked_event = MouseEvent(event)\n\n# self.repaint()\n\n# AbstractGLWidget.mouseReleaseEvent = mouseReleaseEvent\n\nclass ResolutionDialog(QDialog):\n def __init__(self, window_title, parent=None):\n super(ResolutionDialog, self).__init__(parent) # noqa\n self.setWindowTitle(window_title)\n label = QLabel(\"Resolución del video?\")\n self.combo = QComboBox()\n self.combo.addItems([\"Baja (640x480)\", \"Media (720x510)\", \"Alta (1080x720)\"])\n box = QDialogButtonBox(QDialogButtonBox.Ok | QDialogButtonBox.Cancel)\n box.accepted.connect(self.accept)\n box.rejected.connect(self.reject)\n\n lay = QGridLayout(self)\n lay.addWidget(label)\n lay.addWidget(self.combo)\n lay.addWidget(box)\n\n self.setMinimumWidth(len(window_title) * 10)\n\n def get_selection(self):\n return ['low', 'med', 'high'][self.combo.currentIndex()]\n"
},
{
"alpha_fraction": 0.6776315569877625,
"alphanum_fraction": 0.6776315569877625,
"avg_line_length": 37,
"blob_id": "47df9dba0b97116da5b496848504b343eb371cf7",
"content_id": "906b44310949ec09f230299c10484eb7567807dc",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 4,
"path": "/ant_tracker/tracker/__init__.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import os\nfrom pathlib import Path\n\nos.environ['PATH'] = str((Path(__file__).parent.parent.parent / \"lib\").resolve()) + os.pathsep + os.environ['PATH']\n"
},
{
"alpha_fraction": 0.6659707427024841,
"alphanum_fraction": 0.6659707427024841,
"avg_line_length": 35.846153259277344,
"blob_id": "4466dd2720e3d141481de963e346bbd8cb408a8c",
"content_id": "227ab0c1d638bc168d275460cd02802202d80713",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 13,
"path": "/copy_labeler_files.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import shutil\nfrom pathlib import Path\n\nantlabeler_files = set([p.name for p in Path(\"dist/AntLabeler/\").glob(\"*\")])\nanttracker_files = set([p.name for p in Path(\"dist/AntTracker/\").glob(\"*\")])\n\nfor file in antlabeler_files - anttracker_files:\n from_file = Path(f\"dist/AntLabeler/{file}\")\n to_file = Path(f\"dist/AntTracker/{file}\")\n if from_file.is_file():\n shutil.copy(from_file, to_file)\n elif from_file.is_dir():\n shutil.copytree(from_file, to_file)\n"
},
{
"alpha_fraction": 0.5608314871788025,
"alphanum_fraction": 0.5735229849815369,
"avg_line_length": 38.39655303955078,
"blob_id": "c0e6f5393d31709f5d4795fa17b1d49a0a7e2ea7",
"content_id": "4303407e1a496f3c7d66eed972c7ba9687fbdc13",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4570,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 116,
"path": "/ant_tracker/tracker/plotcommon.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import matplotlib\nimport matplotlib.colors as colors\nimport mpl_toolkits.axes_grid1\nimport numpy as np\nfrom matplotlib.image import AxesImage\nfrom matplotlib.patches import Rectangle\nfrom matplotlib.pyplot import Axes\nfrom matplotlib.widgets import Button\nfrom typing import Dict, Optional, Union\n\nfrom .common import BinaryMask, Image_T\n\nclass Animate:\n __hash: Dict[Axes, AxesImage] = dict()\n\n @classmethod\n def draw(cls, axis: Axes, img: Union[Image_T, BinaryMask], autoscale=False, override_hash=False, cmap='viridis'):\n def get_clim():\n if img.dtype in [bool, float, 'float32', 'float64']:\n _vmin, _vmax = 0, 1\n else:\n _vmin, _vmax = 0, 255\n if autoscale:\n _vmin, _vmax = None, None\n return _vmin, _vmax\n\n vmin, vmax = get_clim()\n axes_image: Optional[AxesImage] = cls.__hash.get(axis, None)\n if axes_image is None or override_hash:\n axis.set_yticks([])\n axis.set_xticks([])\n axes_image = axis.imshow(img, vmin=vmin, vmax=vmax, cmap=cmap)\n cls.__hash[axis] = axes_image\n else:\n if autoscale:\n axes_image.set_norm(None)\n else:\n vmin, vmax = get_clim()\n axes_image.set_clim(vmin, vmax)\n axes_image.set_data(img)\n axes_image.set_cmap(cmap)\n\n# Visto en https://stackoverflow.com/a/41152160\nclass PageSlider(matplotlib.widgets.Slider):\n def __init__(self, ax, label, numpages=10, valinit=0, valfmt='%1d',\n closedmin=True, closedmax=True,\n dragging=True, **kwargs):\n\n self.facecolor = kwargs.get('facecolor', \"w\")\n self.activecolor = kwargs.pop('activecolor', \"b\")\n self.fontsize = kwargs.pop('fontsize', 10)\n self.numpages = numpages\n\n super(PageSlider, self).__init__(ax, label, 0, numpages,\n valinit=valinit, valfmt=valfmt, **kwargs)\n\n self.poly.set_visible(False)\n self.vline.set_visible(False)\n self.pageRects = []\n for i in range(numpages):\n facecolor = self.activecolor if i == valinit else self.facecolor\n r = matplotlib.patches.Rectangle((float(i) / numpages, 0), 1. / numpages, 1,\n transform=ax.transAxes, facecolor=facecolor)\n ax.add_artist(r)\n self.pageRects.append(r)\n ax.text(float(i) / numpages + 0.5 / numpages, 0.5, str(i + 1),\n ha=\"center\", va=\"center\", transform=ax.transAxes,\n fontsize=self.fontsize)\n self.valtext.set_visible(False)\n\n divider = mpl_toolkits.axes_grid1.make_axes_locatable(ax)\n bax = divider.append_axes(\"right\", size=\"5%\", pad=0.05)\n fax = divider.append_axes(\"right\", size=\"5%\", pad=0.05)\n self.button_back = matplotlib.widgets.Button(bax, label=u'$\\u25C0$',\n color=self.facecolor, hovercolor=self.activecolor)\n self.button_forward = matplotlib.widgets.Button(fax, label=u'$\\u25B6$',\n color=self.facecolor, hovercolor=self.activecolor)\n self.button_back.label.set_fontsize(self.fontsize)\n self.button_forward.label.set_fontsize(self.fontsize)\n self.button_back.on_clicked(self.backward)\n self.button_forward.on_clicked(self.forward)\n\n def _update(self, event):\n super(PageSlider, self)._update(event)\n i = int(self.val)\n if i >= self.valmax:\n return\n self._colorize(i)\n\n def _colorize(self, i):\n for j in range(self.numpages):\n self.pageRects[j].set_facecolor(self.facecolor)\n self.pageRects[i].set_facecolor(self.activecolor)\n\n def forward(self, event):\n current_i = int(self.val)\n i = current_i + 1\n if (i < self.valmin) or (i >= self.valmax):\n return\n self.set_val(i)\n self._colorize(i)\n\n def backward(self, event):\n current_i = int(self.val)\n i = current_i - 1\n if (i < self.valmin) or (i >= self.valmax):\n return\n self.set_val(i)\n self._colorize(i)\n\nclass Log1pInvNormalize(colors.Normalize):\n def __init__(self, vmin=None, vmax=None, clip=False):\n colors.Normalize.__init__(self, vmin, vmax, clip)\n\n def __call__(self, value, clip=None):\n return np.ma.masked_array((1 - (np.log1p(value) / np.log1p(self.vmax))) ** 0.85)\n"
},
{
"alpha_fraction": 0.5583460330963135,
"alphanum_fraction": 0.5635809302330017,
"avg_line_length": 47.52411651611328,
"blob_id": "9173515b5a311aec06943e7596bdb58c70406e28",
"content_id": "5b1239b0df93f439a50dcfd83d56ead445bf7895",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15106,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 311,
"path": "/ant_tracker/tracker_gui/results_overview.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nimport os\nimport pims\nimport threading\nfrom pathlib import Path\nfrom pims.process import crop\n\nfrom . import constants as C\nfrom .export import Exporter\nfrom .extracted_parameters import SelectionStep\nfrom .guicommon import align, change_bar_color, write_event_value_closure\nfrom .parameter_extraction import extract_pixel_size\nfrom .session import SessionInfo\nfrom ..tracker.common import Rect, crop_from_rect\nfrom ..tracker.info import TracksCompleteInfo, Direction\nfrom ..tracker.leafdetect import TFLiteLeafDetector\nfrom ..tracker.segmenter import LogWSegmenter\nfrom ..tracker.track import Track\nfrom ..tracker.tracking import Tracker\n\nPB_DEEP_BLUE = \"#082567\"\nPB_GREEN = \"#01826B\"\nPB_GRAY = '#D0D0D0'\n\nclass K:\n Scroll = '-SCROLL-'\n Cancel = '-CANCEL-'\n Export = '-EXPORT-'\n OpenExport = '-OPEN_EXPORT-'\n Report = '-REPORT-'\n ThreadFinished = '-THREAD_DONE-'\n\nPBAR_HEIGHT = 10\nPBAR_HEIGHT_PAD = 11\n\ndef short_fn(path):\n return \"/\".join(path.parts[-2:])\ndef filelabel(path: Path):\n return f'-FLABEL!!{short_fn(path)}-'\ndef progbar(path: Path):\n return f'-BAR!!{short_fn(path)}-'\ndef is_progbar(key: str):\n return key.startswith('-BAR!!')\ndef finished(path: Path):\n return f'-FINISHED!!{short_fn(path)}-'\ndef is_finished(key: str):\n return key.startswith('-FINISHED!!')\ndef get_finished_btn(key: str):\n return '-LABEL!!' + key.split('!!')[1]\ndef antlabel(path: Path):\n return f'-LABEL!!{short_fn(path)}-'\ndef is_antlabel(key: str):\n return key.startswith('-LABEL!!')\n\ndef open_labeler(trkfile):\n exp_layout = [\n [sg.Text(\"AntLabeler aún no permite revisar tracks.\")],\n [sg.Text(\n \"Sin embargo, existe un visor experimental para ver el resultado del tracking sobre el video.\")],\n [sg.Text(\"Desea utilizarlo?\")],\n [sg.Ok(\"Sí\"), sg.Cancel(\"No\")],\n ]\n resp = sg.Window(\"No disponible\", exp_layout,\n icon=C.LOGO_AT_ICO, modal=True, keep_on_top=True).read(close=True)[0]\n if resp == 'Sí':\n from .trkviz import trkviz_subprocess\n trkviz_subprocess(trkfile)\n\ndef filter_func(info: TracksCompleteInfo):\n f = info.filter_func(**C.TRACKFILTER)\n return lambda t: info.track_direction(t) != Direction.UN and f(t)\n\nclass TrackTask:\n def __init__(self, save_every_n_frames=1000, save_every_n_leaf_detects=100):\n self._running = True\n self.exc = None\n self.save_every_n_frames = save_every_n_frames\n self.save_every_n_leaf_detects = save_every_n_leaf_detects\n\n def terminate(self):\n self._running = False\n\n def run(self, window: sg.Window, sesspath: Path, with_leaves: bool):\n try:\n self.inner_run(window, sesspath, with_leaves)\n except: # noqa\n import sys\n self.exc = sys.exc_info()\n\n def inner_run(self, window: sg.Window, sesspath: Path, with_leaves: bool):\n send = write_event_value_closure(window)\n session = SessionInfo.load(sesspath, with_trackers=True)\n start_time = session.first_start_time\n for path in session.videofiles:\n p = session.parameters[path]\n crop_rect: Rect = p.rect_data[SelectionStep.TrackingArea]\n marker: Rect = p.rect_data[SelectionStep.SizeMarker]\n pixel_size_in_mm = extract_pixel_size(marker)\n trkfile = session.get_trkfile(path)\n\n progress_key = progbar(path)\n S = SessionInfo.State\n\n if session.states[path] == S.GotParameters:\n send(K.Report, f\"{short_fn(path)}, comenzando tracking...\")\n if session.states[path] == S.Tracking:\n send(K.Report, f\"{short_fn(path)}, recuperando tracking...\")\n if session.states[path] == S.DetectingLeaves:\n send(K.Report, f\"{short_fn(path)}, comenzando detección de hojas...\")\n video = None\n info = None\n if with_leaves and session.states[path] == S.Finished:\n send(K.Report, f\"{short_fn(path)}, cargando información previa...\")\n info = TracksCompleteInfo.load(trkfile)\n load_relevant = filter_func(info)\n leafstate = [track.load_detected for track in info.tracks if load_relevant(track)]\n if not all(leafstate):\n session.states[path] = S.DetectingLeaves\n send(K.Report, f\"{short_fn(path)}, retomando detección de hojas...\")\n\n if session.states[path] < S.Finished:\n send(K.Report, f\"{short_fn(path)}, cargando video...\")\n video = pims.PyAVReaderIndexed(path)\n video = crop(video, crop_from_rect(video.frame_shape[0:2], crop_rect))\n if not info and S.DetectingLeaves <= session.states[path] <= S.Finished:\n send(K.Report, f\"{short_fn(path)}, cargando información previa...\")\n info = TracksCompleteInfo.load(trkfile)\n\n if session.states[path] in (S.GotParameters, S.Tracking):\n if session.states[path] == S.GotParameters:\n tracker = Tracker(path, LogWSegmenter(video, p.segmenter_parameters), params=p.tracker_parameters)\n track_generator = tracker.track_progressive()\n else: # if session.states[path] == S.Tracking:\n tracker = session.unfinished_trackers[path]\n send(progress_key, {'p': tracker.last_tracked_frame})\n send(K.Report, f\"{short_fn(path)}, recuperando tracking desde: \"\n f\"{tracker.last_tracked_frame}/{tracker.video_length}\")\n track_generator = tracker.track_progressive_continue()\n\n for frame in track_generator:\n send(K.Report, f\"{short_fn(path)}, tracking: {frame}/{tracker.video_length}\")\n send(progress_key, {'p': frame})\n if frame > 0 and frame % self.save_every_n_frames == 0:\n session.states[path] = S.Tracking\n send(K.Report, f\"{short_fn(path)}, guardando tracking hasta frame {frame}...\")\n session.record_tracker_state(path, tracker)\n session.save(sesspath)\n if not self._running:\n return\n send(K.Report, f\"{short_fn(path)}, guardando tracking...\")\n info = TracksCompleteInfo(tracker.info(), pixel_size_in_mm, crop_rect, p.nest_side,\n start_time=start_time)\n info.save(trkfile)\n session.states[path] = S.DetectingLeaves\n session.save(sesspath)\n send(progress_key, {'color': PB_GREEN, 'background': PB_DEEP_BLUE})\n if session.states[path] == S.DetectingLeaves:\n if with_leaves:\n send(K.Report, f\"{short_fn(path)}, comenzando detección de hojas...\")\n # only detect leaves for tracks that will be aggregated into export pages 1 and 2\n load_relevant = filter_func(info)\n tracks = [track for track in info.tracks if load_relevant(track)]\n send(progress_key, {'p': 1, 'max': len(tracks) + 1})\n detected_ids = session.detection_probs[path].keys()\n send(progress_key, {'p': len(detected_ids) + 1, 'max': len(tracks) + 1})\n to_detect = {track.id for track in tracks} - detected_ids\n detector = TFLiteLeafDetector(C.TFLITE_MODEL, video)\n send(K.Report, f\"{short_fn(path)}, retomando detección de hojas... \")\n for i_trk, track in enumerate(tracks):\n if track.id in to_detect:\n send(K.Report, f\"{short_fn(path)}, detectando hojas: {i_trk}/{len(tracks)}\")\n session.record_detection(path, track, detector.probability(track))\n if i_trk > 0 and i_trk % self.save_every_n_leaf_detects == 0:\n send(K.Report, f\"{short_fn(path)}, guardando detecciones hasta hormiga {i_trk}...\")\n session.save(sesspath)\n send(progress_key, {'p': i_trk + 1})\n if not self._running:\n return\n send(K.Report, f\"{short_fn(path)}, guardando detecciones de hoja...\")\n for track_id, prob in session.detection_probs[path].items():\n Track.get(info.tracks, track_id).set_load_probability(prob)\n info = TracksCompleteInfo(info, pixel_size_in_mm, crop_rect, p.nest_side, start_time=start_time)\n info.save(trkfile)\n session.states[path] = S.Finished\n session.save(sesspath)\n if session.states[path] == S.Finished:\n send(K.Report, f\"{short_fn(path)}, finalizado.\")\n send(progress_key, {'p': 1, 'max': 1, 'visible': False})\n send(finished(path), {'trkfile': trkfile})\n start_time = info.end_time\n send(K.ThreadFinished, None)\n\ndef results_overview(sesspath: Path, with_leaves=True):\n from .loading_window import LoadingWindow\n with LoadingWindow(\"Configurando...\"):\n session = SessionInfo.load(sesspath)\n exportpath = sesspath.parent / \"export.xlsx\"\n paths = session.videofiles\n bars_column_height = 250\n win_height = bars_column_height + 100\n win_width = 600\n fn_width = int(max([len(short_fn(p)) for p in paths]) * 0.9)\n inner_width = win_width - 80\n\n layout = [\n [sg.Column([\n [sg.ProgressBar(10, 'h', (0, 0), pad=(0, 0), k='-SPACER_BAR-')],\n *[[sg.T(short_fn(path).rjust(fn_width), size=(fn_width, 1), justification='right',\n k=filelabel(path)),\n sg.ProgressBar(session.lengths[path], 'h', (0, PBAR_HEIGHT),\n bar_color=(PB_DEEP_BLUE, PB_GRAY),\n pad=(0, PBAR_HEIGHT_PAD), k=progbar(path)),\n sg.Button(\"Revisar etiquetado\", visible=False, k=antlabel(path))] for path in paths]],\n\n scrollable=True, vertical_scroll_only=True, expand_x=True, size=(win_width, bars_column_height),\n k=K.Scroll,\n )],\n [sg.HorizontalSeparator()],\n [sg.InputText(\"Recuperando datos...\", k=K.Report, disabled=True, visible=True)],\n [align([sg.vbottom([\n sg.pin(sg.Button(\"Abrir archivo\", k=K.OpenExport, visible=False)),\n sg.pin(sg.Button(\"Exportar resultados\", k=K.Export, visible=False)),\n sg.Button(\"Detener\", k=K.Cancel)]\n )], 'right')],\n ]\n window = sg.Window(\"AntTracker - Procesando...\", layout, icon=C.LOGO_AT_ICO,\n size=(win_width, win_height), disable_close=True, finalize=True)\n for path in paths:\n lw, _ = window[filelabel(path)].get_size()\n window[progbar(path)].Widget.configure(length=inner_width - lw)\n window['-SPACER_BAR-'].Widget.configure(length=inner_width)\n window[K.Report].expand(expand_x=True)\n x, y = window.CurrentLocation()\n window.move(x, y - 100)\n\n task = TrackTask()\n t = threading.Thread(target=task.run, args=(window, sesspath, with_leaves), daemon=True)\n t.start()\n\n while True:\n event, values = window.read(1000)\n if not t.is_alive() and task.exc: # errored out\n raise task.exc[0](f\"TaskThread threw an exception: {task.exc[1]}\").with_traceback(task.exc[2])\n if event == sg.TIMEOUT_EVENT:\n pass\n elif event == sg.WIN_CLOSED or event == K.Cancel:\n msg = (\"¿Está seguro de que desea detener el procesamiento? \"\n \"Los videos ya procesados mantendrán sus resultados.\\n\"\n \"El progreso en el video actual es guardado períodicamente y se restaurará cuando continue.\")\n if ((not t.is_alive()) or\n sg.popup(msg, modal=True, custom_text=(C.RESP_SI, C.RESP_NO)) == C.RESP_SI):\n task.terminate()\n window.close()\n del window\n return None\n elif is_progbar(event):\n val = values[event]\n pbar: sg.ProgressBar = window[event] # noqa\n if 'color' in val:\n change_bar_color(pbar, val['color'], val.get('background', None))\n if 'p' in val:\n pbar.update(val['p'], max=val.get('max', None), visible=val.get('visible', None))\n elif event == K.Report:\n window[event].update(values[event])\n elif is_finished(event):\n btn_key = get_finished_btn(event)\n window[btn_key].update(visible=True)\n window[btn_key].expand(expand_x=True)\n window[btn_key].metadata = values[event]\n elif event == K.ThreadFinished:\n window[K.Cancel].update(\"Cerrar\")\n window[K.Export].update(visible=True)\n window.set_title(\"AntTracker - Resultados\")\n elif is_antlabel(event):\n trkfile = window[event].metadata['trkfile']\n open_labeler(trkfile)\n elif event == K.OpenExport:\n with LoadingWindow():\n os.startfile(exportpath)\n window[K.OpenExport].update(\"Abriendo...\", disabled=True)\n\n def wait_n_update():\n from time import sleep\n sleep(10)\n window[K.OpenExport].update(\"Abrir archivo\", disabled=False)\n\n threading.Thread(target=wait_n_update, daemon=True).start()\n elif event == K.Export:\n session = SessionInfo.load(sesspath)\n trkfiles = [session.get_trkfile(f) for f in session.videofiles]\n infos = []\n title = \"Exportando...\"\n sg.OneLineProgressMeter(title, 0, len(trkfiles), 'XP', \"Cargando tracks...\")\n for i_f, f in enumerate(trkfiles, 1):\n infos.append(TracksCompleteInfo.load(f))\n sg.OneLineProgressMeter(title, i_f, len(trkfiles), 'XP', \"Cargando tracks...\")\n ex = Exporter()\n for msg, progress, progmax in ex.export_progress(infos):\n sg.OneLineProgressMeter(title, progress, progmax, 'XP', msg)\n while True:\n try:\n ex.save(exportpath)\n break\n except PermissionError:\n sg.popup_ok(f\"El siguiente archivo está abierto o protegido:\",\n exportpath,\n f\"Presione Ok para probar nuevamente.\", title=\"Error\", line_width=len(str(exportpath)))\n window[K.Report].update(f\"Exportado a: {exportpath}\")\n window[K.OpenExport].update(visible=True)\n else:\n print(event)\n"
},
{
"alpha_fraction": 0.5918072462081909,
"alphanum_fraction": 0.5944578051567078,
"avg_line_length": 37.425926208496094,
"blob_id": "d5e6820b5f5822629fb5076f8a085184edc6bce6",
"content_id": "0ca550920d5962fec2a1ccb4633e73f44ddef9d9",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4152,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 108,
"path": "/ant_tracker/tracker_gui/guicommon.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nfrom typing import Union, Literal, List, Dict\n\ndef write_event_value_closure(window):\n def send(event, value):\n try:\n window.write_event_value(event, value)\n except RuntimeError as e:\n # este error ocurre intermitentemente, y la única manera de reproducirlo más o menos consistentemente es\n # abrir un popup en el main thread mientras se hacen llamadas a write_event_value.\n # hay un juego de threads que PySimpleGUI no supo resolver y que causa el error, pero generalmente no\n # suele haber problema si ignoramos el error y hacemos la llamada de vuelta\n print(\"Ignorado: \", repr(e))\n print(\"Intentando nuevamente...\")\n send(event, value)\n\n return send\n\nclass ClickableText(sg.Text):\n _to_bind: Dict[str, 'ClickableText'] = {}\n\n def __init__(self, s, k, font=(\"Helvetica\", 8), **kwargs):\n super(ClickableText, self).__init__(s, justification='center', pad=(0, 0), font=font, text_color=\"blue\", k=k,\n **kwargs)\n ClickableText._to_bind[self.Key] = self\n self.action = lambda e: print(f\"No action set for: {self}\")\n self.bound = False\n\n @classmethod\n def bind_all(cls):\n for key, elem in cls._to_bind.items():\n if not elem.bound:\n elem.bind_self()\n elem.bound = True\n\n def bind_self(self):\n def _underline(elem, set_to: bool):\n original_font = elem.TKText['font']\n\n def underline(_):\n if set_to:\n elem.TKText.configure(font=original_font + ' underline')\n else:\n elem.TKText.configure(font=original_font)\n\n return underline\n\n self.Widget.bind('<Button-1>', self.action)\n self.Widget.bind('<Enter>', _underline(self, True))\n self.Widget.bind('<Leave>', _underline(self, False))\n self.set_cursor(\"hand2\")\n\nclass Link(ClickableText):\n \"\"\"Clickable link. Must call ``ClickableText.bind_all`` after finalizing the containing Window\"\"\"\n\n def __init__(self, link, font=(\"Helvetica\", 8), linktext=None, **kwargs):\n if linktext is None:\n linktext = link\n key = None\n if 'k' in kwargs:\n key = kwargs['k']\n del kwargs['k']\n if 'key' in kwargs:\n key = kwargs['key']\n del kwargs['key']\n if key is None: key = f\"__ANTTRACKER__!LINK_{linktext}\"\n super(Link, self).__init__(linktext, font=font, k=key, **kwargs)\n\n def _goto(_link):\n def goto(_):\n import webbrowser\n webbrowser.open(_link)\n\n return goto\n\n self.action = _goto(link)\n\nclass Email(Link):\n \"\"\"Clickable e-mail link. Must call ``ClickableText.bind_all`` after finalizing the containing Window\"\"\"\n\n def __init__(self, email, font=(\"Helvetica\", 8), **kwargs):\n super(Email, self).__init__(f\"mailto:{email}\", linktext=email, font=font, k=f\"__ANTTRACKER__!EMAIL_{email}\",\n **kwargs)\n\ndef transparent_multiline(text, width, height, **kwargs):\n return sg.Multiline(text, size=(width, height), disabled=True, write_only=True, background_color=\"#f2f2f2\",\n border_width=0, auto_size_text=False, **kwargs)\n\ndef align(layout_or_elem: Union[List[List[sg.Element]], sg.Element], justification: Literal['left', 'right', 'center']):\n if not isinstance(layout_or_elem, list):\n layout_or_elem = [[layout_or_elem]]\n return sg.Column(layout_or_elem, element_justification=justification, expand_x=True)\n\ndef parse_number(s):\n try:\n return int(s)\n except ValueError:\n return float(s)\n\ndef release(key): return key + \"+UP\"\n\ndef change_bar_color(progbar: sg.ProgressBar, color: str, background: str = None):\n from tkinter import ttk\n s = ttk.Style()\n if background:\n s.configure(progbar.TKProgressBar.style_name, background=color, troughcolor=background)\n else:\n s.configure(progbar.TKProgressBar.style_name, background=color)\n"
},
{
"alpha_fraction": 0.5493130683898926,
"alphanum_fraction": 0.5526639223098755,
"avg_line_length": 43.10344696044922,
"blob_id": "d2d9560da4ec9c5a681305e4b9cc758ef7207cae",
"content_id": "25c58a506d25693d4c5aae74d54dcfd2bc56fa0e",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8993,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 203,
"path": "/ant_tracker/tracker/parameters.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass, asdict\nfrom typing import ClassVar, Dict\n\n@dataclass\nclass SegmenterParameters:\n gaussian_sigma: float\n minimum_ant_radius: int\n movement_detection_history: int\n discard_percentage: float\n movement_detection_threshold: int\n approx_tolerance: float\n\n doh_min_sigma: float\n doh_max_sigma: float\n doh_num_sigma: int\n\n name_map: ClassVar = {\n 'gaussian_sigma': \"Sigma de gaussiana\",\n 'minimum_ant_radius': \"Radio mínimo detectable\",\n 'movement_detection_history': \"Historia detección de fondo\",\n 'discard_percentage': \"Porcentaje para descarte\",\n 'movement_detection_threshold': \"Umbral de detec. de movimiento\",\n 'approx_tolerance': \"Tolerancia en aproximación\",\n 'doh_min_sigma': \"Mínimo sigma DOH\",\n 'doh_max_sigma': \"Máximo sigma DOH\",\n 'doh_num_sigma': \"Número de valores de sigma\",\n }\n description_map: ClassVar = {\n 'gaussian_sigma': \"Nivel de borroneado de imagen para detección de objetos. A mayor valor, \"\n \"más grandes y circulares las detecciones, pero menos detecciones espurias.\",\n 'minimum_ant_radius': \"En píxeles, el radio mínimo que ocupa una hormiga. Hormigas \"\n \"más chicas no serán detectadas. Mismos efectos que el parámetro anterior.\",\n 'movement_detection_history': \"Número de cuadros almacenados para detección de fondo. A mayor cantidad, \"\n \"aumenta la capacidad de distinguir el fondo de las hormigas, pero aumenta \"\n \"el tiempo de procesamiento.\",\n 'discard_percentage': \"Sensibilidad a movimientos de cámara. Si se detecta que más de X% del cuadro \"\n \"es distinto al anterior, las detecciones se descartan.\",\n 'movement_detection_threshold': \"Valor por sobre el cual se determina que un píxel está en movimiento. \"\n \"A mayor valor, más sensible al movimiento.\",\n 'approx_tolerance': \"Tolerancia al simplificar las formas detectadas. A menor valor, mayor \"\n \"precisión en la forma (aunque casi insignificante), \"\n \"pero mucho mayor tamaño de archivos generados \"\n \"y mayor tiempo de procesamiento.\",\n 'doh_min_sigma': \"Mínimo valor de sigma para el algoritmo DOH. Mientras menor sea, \"\n \"mayor probabilidad de encontrar hormigas pequeñas.\",\n 'doh_max_sigma': \"Máximo valor de sigma para el algoritmo DOH. Mientras mayor sea, \"\n \"mayor probabilidad de detectar objetos grandes como una sola hormiga.\",\n 'doh_num_sigma': \"Cantidad de valores intermedios entre mínimo y máximo que se consideran \"\n \"en DOH. Mientras más valores, mejor precisión, \"\n \"pero mayor tiempo de procesamiento.\",\n }\n\n def __init__(self, params: Dict = None, **kwargs):\n if params is None:\n params = {}\n\n def kwarg_or_dict(key):\n d = params.get(key, None)\n if d is not None:\n return d\n d = kwargs.get(key, None)\n return d\n\n self.gaussian_sigma = kwarg_or_dict('gaussian_sigma')\n self.minimum_ant_radius = kwarg_or_dict('minimum_ant_radius')\n self.movement_detection_history = kwarg_or_dict('movement_detection_history')\n self.discard_percentage = kwarg_or_dict('discard_percentage')\n self.movement_detection_threshold = kwarg_or_dict('movement_detection_threshold')\n self.approx_tolerance = kwarg_or_dict('approx_tolerance')\n self.doh_min_sigma = kwarg_or_dict('doh_min_sigma')\n self.doh_max_sigma = kwarg_or_dict('doh_max_sigma')\n self.doh_num_sigma = kwarg_or_dict('doh_num_sigma')\n\n def values(self):\n return [v for k, v in self.items()]\n\n def keys(self):\n return [k for k, v in self.items()]\n\n def items(self):\n return [(k, v) for k, v in asdict(self).items() if v is not None]\n\n def names(self):\n return [v for k, v in self.name_map.items() if asdict(self)[k] is not None]\n\n def descriptions(self):\n return [v for k, v in self.description_map.items() if asdict(self)[k] is not None]\n\n def encode(self):\n return dict(self.items())\n\n @classmethod\n def decode(cls, serial):\n return cls(serial)\n\n @classmethod\n def mock(cls):\n return SegmenterParameters()\n\n# noinspection PyPep8Naming\ndef LogWSegmenterParameters(params=None):\n if params is None:\n params = {}\n return SegmenterParameters({\n **{\n \"gaussian_sigma\": 8,\n \"minimum_ant_radius\": 10,\n \"movement_detection_history\": 50,\n \"discard_percentage\": .3,\n \"movement_detection_threshold\": 25,\n \"approx_tolerance\": 1,\n }, **params\n })\n\n# noinspection PyPep8Naming\ndef DohSegmenterParameters(params=None):\n if params is None:\n params = {}\n return SegmenterParameters({\n **{\n \"gaussian_sigma\": 8,\n \"minimum_ant_radius\": 10,\n \"movement_detection_history\": 50,\n \"discard_percentage\": .3,\n \"movement_detection_threshold\": 25,\n \"approx_tolerance\": 1,\n \"doh_min_sigma\": 6,\n \"doh_max_sigma\": 30,\n \"doh_num_sigma\": 4,\n }, **params\n })\n\n@dataclass\nclass TrackerParameters:\n max_distance_between_assignments: int\n frames_until_close: int\n a_sigma: float\n defaults: ClassVar = {\n \"max_distance_between_assignments\": 30,\n \"frames_until_close\": 8,\n \"a_sigma\": 0.05,\n }\n name_map: ClassVar = {\n 'max_distance_between_assignments': \"Distancia entre asignaciones\",\n 'frames_until_close': \"N° de cuadros para cerrar trayecto\",\n 'a_sigma': \"Peso del componente de aceleración\",\n }\n description_map: ClassVar = {\n 'max_distance_between_assignments': \"Distancia máxima (en píxeles) a la que se puede asignar \"\n \"una detección en un cuadro a otra en el cuadro siguiente. \"\n \"A mayor número, mayores chances de recuperarse ante detecciones \"\n \"fallidas, pero aumentan las posibilidades de error en tracking.\",\n 'frames_until_close': \"Número de cuadros, desde que se pierde el seguimiento de un trayecto, \"\n \"hasta que efectivamente se da por perdido.\",\n 'a_sigma': \"Peso del componente de aceleración, en cualquier dirección, \"\n \"en el modelo de tracking. A mayor valor, el algoritmo asume cada vez \"\n \"más errático el movimiento de las hormigas.\",\n }\n\n def __init__(self, params: Dict = None, use_defaults=False, **kwargs):\n if params is None:\n params = {}\n\n def kwarg_or_dict_or_default(key):\n d = params.get(key, None)\n if d is not None: return d\n d = kwargs.get(key, None)\n if d is not None: return d\n if use_defaults: return self.defaults[key]\n return None\n\n self.max_distance_between_assignments = kwarg_or_dict_or_default('max_distance_between_assignments')\n self.frames_until_close = kwarg_or_dict_or_default('frames_until_close')\n self.a_sigma = kwarg_or_dict_or_default('a_sigma')\n\n def values(self):\n return [v for k, v in self.items()]\n\n def keys(self):\n return [k for k, v in self.items()]\n\n def items(self):\n return [(k, v) for k, v in asdict(self).items() if v is not None]\n\n def names(self):\n return [v for k, v in self.name_map.items() if asdict(self)[k] is not None]\n\n def descriptions(self):\n return [v for k, v in self.description_map.items() if asdict(self)[k] is not None]\n\n def name_desc_values(self):\n return list(zip(self.names(), self.descriptions(), self.values()))\n\n def encode(self):\n return dict(self.items())\n\n @classmethod\n def decode(cls, serial):\n return cls(serial)\n\n @classmethod\n def mock(cls):\n return TrackerParameters()\n"
},
{
"alpha_fraction": 0.5895478129386902,
"alphanum_fraction": 0.5925096869468689,
"avg_line_length": 38.56510543823242,
"blob_id": "c4a09587501b7b67ae33f2c95befe922b3fd8479",
"content_id": "4149ea11b395d71bc7c9059b7793aa9ec318bbf0",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15194,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 384,
"path": "/ant_tracker/tracker/info.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import dataclasses\nfrom dataclasses import InitVar, dataclass, field\n\nimport datetime\nimport numpy as np\nimport ujson\nfrom packaging.version import Version\nfrom pathlib import Path\nfrom typing import Any, ClassVar, Dict, List, Optional, Tuple, TypedDict, Union, Callable\n\nfrom .common import FrameNumber, to_json, Side, Rect, filehash, ensure_path, SerializableEnum\nfrom .parameters import SegmenterParameters, TrackerParameters\nfrom .track import Track\n\nclass Direction(SerializableEnum):\n EN = \"EN\"\n \"Entrando al nido\"\n SN = \"SN\"\n \"Saliendo del nido\"\n UN = \"??\"\n \"Desconocido/Irrelevante\"\n\n@dataclass\nclass TracksInfo:\n tracks: List[Track] = field(repr=False)\n\n segmenter_version: Version\n segmenter_parameters: SegmenterParameters\n tracker_version: Version\n tracker_parameters: TrackerParameters\n\n video_name: str = field(init=False)\n video_hash: str = field(init=False)\n video_shape: Tuple[int, int] = field(init=False)\n video_length: int = field(init=False)\n video_fps_average: float = field(init=False)\n video_path: InitVar[Optional[Union[Path, str]]] = None\n\n file_extension: ClassVar = '.trk'\n\n def __post_init__(self, video_path: Optional[Union[Path, str]] = None):\n if video_path is not None:\n if not isinstance(video_path, Path):\n video_path = Path(video_path)\n self.video_name = video_path.name\n try:\n import av\n container = av.open(str(video_path)) # noqa\n self.video_length = container.streams.video[0].frames\n self.video_shape = (container.streams.video[0].codec_context.height,\n container.streams.video[0].codec_context.width)\n self.video_fps_average = float(container.streams.video[0].average_rate)\n\n except ImportError:\n try:\n import cv2 as cv\n video = cv.VideoCapture(str(video_path), cv.CAP_FFMPEG)\n self.video_shape = (int(video.get(cv.CAP_PROP_FRAME_HEIGHT)),\n int(video.get(cv.CAP_PROP_FRAME_WIDTH)))\n self.video_length = int(video.get(cv.CAP_PROP_FRAME_COUNT))\n self.video_fps_average = video.get(cv.CAP_PROP_FPS)\n except ImportError:\n raise ImportError(\"No se encontraron las librerías cv2 ni av\")\n self.video_hash = filehash(video_path)\n\n @property\n def video_duration(self) -> datetime.timedelta:\n return datetime.timedelta(seconds=float(self.video_length / self.video_fps_average))\n\n def filter_tracks(self, *,\n last_frame: FrameNumber = None,\n length_of_tracks=6,\n filter_center_center=True\n ) -> List[Track]:\n \"\"\"Returns a filtered ``self.tracks``. If a track has blobs beyond ``last_frame`` it is cut short.\n\n Parameters:\n last_frame: Last frame to consider.\n length_of_tracks: Minimum number of blobs in a track.\n filter_center_center: Remove tracks that started and ended in the center.\n Returns:\n The filtered list of Tracks.\n \"\"\"\n _filter = self.filter_func(last_frame=last_frame,\n length_of_tracks=length_of_tracks,\n filter_center_center=filter_center_center)\n return [\n track if last_frame is None else track.cut(last_frame)\n for track in self.tracks if _filter(track)\n ]\n\n def filter_func(self, *,\n last_frame: FrameNumber = None,\n length_of_tracks=6,\n filter_center_center=True) -> Callable[[Track], bool]:\n \"\"\"\n Parameters:\n last_frame: Last frame to consider.\n length_of_tracks: Minimum number of blobs in a track.\n filter_center_center: Remove tracks that started and ended in the center.\n Returns:\n A filtering function for Tracks\n \"\"\"\n\n def _filter(track: Track):\n if len(track.blobs) < length_of_tracks: return False\n if filter_center_center:\n if track.direction_of_travel(self.video_shape) == (Side.Center, Side.Center):\n return False\n if last_frame is not None:\n if track.last_frame() > last_frame: return False\n return True\n\n return _filter\n\n def last_tracked_frame(self) -> FrameNumber:\n return max([track.last_frame() for track in self.tracks])\n\n def get_blobs_in_frame(self, frame: FrameNumber):\n blobs = []\n for track in self.tracks:\n blob = track.at(frame)\n if blob is None: continue\n blobs.append(blob)\n return blobs\n\n def track_direction(self, track: Track, nest_side: Side):\n _from, to = track.direction_of_travel(self.video_shape)\n if _from != nest_side and to == nest_side:\n return Direction.EN\n elif _from == nest_side and to != nest_side:\n return Direction.SN\n else:\n return Direction.UN\n\n def is_from_video(self, path: Union[Path, str]):\n path = ensure_path(path)\n return self.video_hash == filehash(path)\n\n # region Serialization\n\n class Serial(TypedDict):\n tracks: List[Track.Serial]\n\n tracker_version: str\n tracker_parameters: Dict[str, Any]\n segmenter_version: str\n segmenter_parameters: Dict[str, Any]\n video_name: str\n video_hash: str\n video_length: int\n video_shape: Tuple[int, int]\n video_fps_average: float\n\n def encode(self) -> 'TracksInfo.Serial':\n return {\n \"tracks\": [track.encode() for track in self.tracks],\n \"tracker_version\": str(self.tracker_version),\n \"tracker_parameters\": dataclasses.asdict(self.tracker_parameters),\n \"segmenter_version\": str(self.tracker_version),\n \"segmenter_parameters\": dataclasses.asdict(self.segmenter_parameters),\n \"video_name\": self.video_name,\n \"video_hash\": self.video_hash,\n \"video_length\": self.video_length,\n \"video_shape\": self.video_shape,\n \"video_fps_average\": self.video_fps_average,\n }\n\n @classmethod\n def decode(cls, serial: 'TracksInfo.Serial'):\n shape = tuple(serial[\"video_shape\"])\n self = TracksInfo(\n tracks=[Track.decode(track, shape) for track in serial[\"tracks\"]],\n segmenter_version=Version(serial[\"segmenter_version\"]),\n segmenter_parameters=SegmenterParameters(serial[\"segmenter_parameters\"]),\n tracker_version=Version(serial[\"tracker_version\"]),\n tracker_parameters=TrackerParameters(serial[\"tracker_parameters\"]),\n )\n self.video_name = serial[\"video_name\"]\n self.video_hash = serial[\"video_hash\"]\n self.video_shape = shape\n self.video_length = serial[\"video_length\"]\n if \"video_fps_average\" in serial:\n self.video_fps_average = serial[\"video_fps_average\"]\n else:\n # safeguard for AntLabeler version <=1.6\n self.video_fps_average = None\n self.__class__ = cls\n return self\n\n def serialize(self) -> str:\n return to_json(self.encode())\n\n @classmethod\n def deserialize(cls, *, filename=None, jsonstring=None):\n if filename is not None:\n with open(filename, 'r') as file:\n d = ujson.load(file)\n elif jsonstring is not None:\n d = ujson.loads(jsonstring)\n else:\n raise TypeError(\"Provide either JSON string or filename.\")\n return cls.decode(d)\n\n @classmethod\n def _is_extension_valid(cls, file: Path):\n return file.suffix == cls.file_extension\n\n def save(self, file: Union[Path, str]):\n file = ensure_path(file)\n if not self._is_extension_valid(file):\n raise ValueError(f'Wrong extension ({file.suffix}). Only {self.file_extension} files are valid.')\n with file.open('w') as f:\n f.write(self.serialize())\n\n @classmethod\n def load(cls, file: Union[Path, str]):\n file = ensure_path(file)\n if not cls._is_extension_valid(file):\n raise ValueError(f'Wrong extension ({file.suffix}). Only {cls.file_extension} files are valid.')\n return cls.deserialize(filename=file)\n\n # endregion\n\ndef reposition_into_crop(info: TracksInfo, crop_rect: Rect):\n from .blob import Blob\n from .track import TrackId\n\n def _clip_contour(contour, imshape):\n def consecutive_not_equal(array):\n return np.append(np.where(np.diff(array) != 0), len(array) - 1)\n\n # if the contour is completely outside of imshape\n if np.all(contour[:, 0] < 0) or np.all(contour[:, 0] > imshape[0] - 1) or \\\n np.all(contour[:, 1] < 0) or np.all(contour[:, 1] > imshape[1] - 1):\n return None\n contour[:, 0] = np.clip(contour[:, 0], 0, imshape[0] - 1)\n contour[:, 1] = np.clip(contour[:, 1], 0, imshape[1] - 1)\n relevant_y_idx = consecutive_not_equal(contour[:, 0])\n relevant_x_idx = consecutive_not_equal(contour[:, 1])\n relevant_idx = np.intersect1d(relevant_x_idx, relevant_y_idx)\n contour = contour[relevant_idx, :]\n\n return contour\n\n offx, offy = crop_rect.topleft.x, crop_rect.topleft.y\n new_shape = crop_rect.height, crop_rect.width\n new_tracks = []\n new_track_id = 0\n for track in info.tracks:\n # a single track may look like multiple tracks if it crosses the crop border\n new_tracks_from_single_track = []\n blobs = {}\n for frame, blob in track.blobs.items():\n new_contour = blob.contour.copy()\n new_contour[:, 0] = blob.contour[:, 0] - offy\n new_contour[:, 1] = blob.contour[:, 1] - offx\n new_contour = _clip_contour(new_contour, new_shape)\n if new_contour is None:\n if blobs:\n new_tracks_from_single_track.append(\n Track(TrackId(new_track_id), blobs, force_load_to=track.loaded.to_bool())\n )\n new_track_id += 1\n blobs = {}\n else:\n blobs[frame] = Blob(imshape=new_shape, contour=new_contour)\n if blobs:\n new_tracks_from_single_track.append(\n Track(TrackId(new_track_id), blobs, force_load_to=track.loaded.to_bool())\n )\n new_track_id += 1\n new_tracks.extend(new_tracks_from_single_track)\n info.tracks = new_tracks\n info.video_shape = new_shape\n return info\n\nclass TracksCompleteInfo(TracksInfo):\n mm_per_pixel: float = field(init=False)\n crop_rect: Rect = field(init=False)\n nest_side: Side = field(init=False)\n start_time: datetime.datetime = field(init=False)\n end_time: datetime.datetime = field(init=False)\n\n def __init__(self, info: TracksInfo, mm_per_pixel: float, crop_rect: Rect, nest_side: Side,\n start_time: datetime.datetime):\n self.tracks = info.tracks\n\n self.segmenter_version = info.segmenter_version\n self.segmenter_parameters = info.segmenter_parameters\n self.tracker_version = info.tracker_version\n self.tracker_parameters = info.tracker_parameters\n\n self.video_name = info.video_name\n self.video_hash = info.video_hash\n self.video_length = info.video_length\n self.video_fps_average = info.video_fps_average\n\n self.mm_per_pixel = mm_per_pixel\n self.crop_rect = crop_rect\n self.nest_side = nest_side\n\n self.start_time = start_time\n self.end_time = start_time + info.video_duration\n\n self.video_shape = crop_rect.height, crop_rect.width\n\n def time_at(self, frame: FrameNumber) -> datetime.datetime:\n if frame < 0: raise ValueError(f\"frame < 0\")\n if frame >= self.video_length: raise ValueError(f\"frame >= length\")\n return self.start_time + datetime.timedelta(seconds=frame / self.video_fps_average)\n\n class __NonFrame(SerializableEnum):\n \"\"\"For use by ``frame_at`` and ``tracks_in_time``\"\"\"\n Before = \"Before this video\"\n After = \"After this video\"\n\n def __frame_at(self, time: datetime.datetime) -> Union[FrameNumber, __NonFrame]:\n \"\"\"Approximates the frame in the video corresponding to the `time` given.\n If no such frame exists, returns a ``__NonFrame``.\"\"\"\n if time < self.start_time: return self.__NonFrame.Before\n if time > self.end_time: return self.__NonFrame.After\n delta = time - self.start_time\n return int(delta.seconds * self.video_fps_average)\n\n def frame_at(self, time: datetime.datetime) -> Optional[FrameNumber]:\n at = self.__frame_at(time)\n if at in self.__NonFrame: return None\n return at\n\n def tracks_in_time(self, start: datetime.datetime, end: datetime.datetime):\n sf = self.__frame_at(start)\n ef = self.__frame_at(end)\n\n NF = self.__NonFrame\n if sf == NF.Before:\n sf = 0\n if ef == NF.After:\n sf = self.video_length\n\n if sf == NF.After or ef == NF.Before:\n return []\n\n return [track for track in self.tracks if sf <= track.first_frame() <= ef or sf <= track.last_frame() <= ef]\n\n def tracks_at(self, time: datetime.datetime) -> List[Track]:\n frame = self.frame_at(time)\n if frame is None: return []\n return [track for track in self.tracks if track.at(frame) is not None]\n\n def track_direction(self, track: Track, nest_side=None):\n \"\"\"Uses ``self.nest_side``. If nest_side is passed, it is ignored.\"\"\"\n return super(TracksCompleteInfo, self).track_direction(track, self.nest_side)\n\n # region Serialization\n\n class Serial(TracksInfo.Serial):\n mm_per_pixel: float\n crop_rect: Rect\n nest_side: str\n start_time: str\n end_time: str\n\n def encode(self) -> 'TracksCompleteInfo.Serial':\n d: 'TracksCompleteInfo.Serial' = super(TracksCompleteInfo, self).encode() # noqa\n return {**d, # noqa\n 'mm_per_pixel': self.mm_per_pixel,\n 'crop_rect': self.crop_rect,\n 'nest_side': self.nest_side.name,\n 'start_time': self.start_time.isoformat(),\n 'end_time': self.end_time.isoformat(),\n }\n\n @classmethod\n def decode(cls, serial: 'TracksCompleteInfo.Serial'):\n self: 'TracksCompleteInfo' = super(TracksCompleteInfo, cls).decode(serial) # noqa\n self.mm_per_pixel = serial['mm_per_pixel']\n self.crop_rect = Rect(*serial['crop_rect'])\n self.nest_side = Side[serial['nest_side']]\n self.start_time = datetime.datetime.fromisoformat(serial['start_time'])\n self.end_time = datetime.datetime.fromisoformat(serial['end_time'])\n return self\n\n # endregion\n"
},
{
"alpha_fraction": 0.5657503008842468,
"alphanum_fraction": 0.5794359445571899,
"avg_line_length": 37.54587173461914,
"blob_id": "53bf152e4b98436f0f32c38f123be41c804eb981",
"content_id": "9cefdc66aaf2eae84960ddeac3554bf83317c2a3",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8403,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 218,
"path": "/ant_tracker/tracker/blob.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom memoized_property import memoized_property\nfrom typing import List, Optional, Tuple, TypedDict\n\nfrom .common import BinaryMask, Color, ColorImage, Contour, Image_T, NpPosition, Position, Rect, Side, to_array, \\\n to_tuple, to_tuple_flip, Colors, GrayscaleImage\nfrom .kellycolors import KellyColors\n\nclass Blob:\n def __init__(self, *, imshape: Tuple[int, int], mask: BinaryMask = None, contour: Contour = None,\n approx_tolerance=1):\n if (mask is None) == (contour is None):\n raise ValueError(\"Only mask or contour, not both\")\n if mask is not None:\n from skimage.measure import approximate_polygon, find_contours\n self.contour = approximate_polygon(np.array(find_contours(mask, 0)[0]), approx_tolerance)\n elif contour is not None:\n self.contour = contour\n self.contour = _clip_contour(self.contour, imshape)\n self.center = self.contour.mean(axis=0)\n self.shape = imshape\n\n def __repr__(self):\n return f\"Blob(at={self.center_xy})\"\n\n @property\n def bbox(self) -> Rect:\n ymin = np.min(self.contour[:, 0])\n ymax = np.max(self.contour[:, 0])\n xmin = np.min(self.contour[:, 1])\n xmax = np.max(self.contour[:, 1])\n return Rect.from_points((xmin, ymin), (xmax, ymax))\n\n @property\n def center_xy(self):\n return to_tuple_flip(self.center)\n\n @memoized_property\n def area(self):\n return self.central_moments[0, 0]\n\n @property\n def central_moments(self):\n from skimage.measure import moments_coords_central\n return moments_coords_central(self.full_contour)\n\n def is_fully_visible(self, percentage):\n center_rect = Side.center_rect(self.shape, percentage)\n return (self.bbox.topleft in center_rect) and (self.bbox.bottomright in center_rect)\n\n @memoized_property\n def is_touching_border(self):\n for pixel in np.array(self.full_contour).T:\n if (\n pixel[0] == self.shape[0] - 1 or\n pixel[1] == self.shape[1] - 1 or\n pixel[0] == 0 or\n pixel[1] == 0\n ): return True\n return False\n\n @property\n def full_contour(self) -> Tuple[np.ndarray, np.ndarray]:\n from skimage.draw import line, polygon_perimeter\n if len(self.contour[:, 0]) == 1:\n # moments_coords_central needs at least 2 points\n return (\n np.array([self.contour[0, 0], self.contour[0, 0]]),\n np.array([self.contour[0, 1], self.contour[0, 1]])\n )\n if len(self.contour[:, 0]) == 2:\n return line(self.contour[0, 0], self.contour[0, 1], self.contour[1, 0], self.contour[1, 1])\n try:\n return polygon_perimeter(self.contour[:, 0], self.contour[:, 1], shape=self.shape, clip=True)\n except IndexError:\n # sometimes, when near the border, polygon_perimeter fails. I tried to make it always work, but no dice\n # so just take the original contour and get out\n return self.contour[:, 0], self.contour[:, 1]\n\n @memoized_property\n def radius(self):\n return np.linalg.norm(self.contour - self.center, axis=1).max(initial=0)\n\n def props(self):\n from skimage.measure import regionprops\n mask = self.get_mask()\n r = regionprops(mask.astype(np.uint8))\n if len(r) == 0: # flat or near-flat blob\n return None\n return r[0]\n\n @memoized_property\n def length(self):\n p = self.props()\n if not p: return 1\n return p.major_axis_length\n\n @memoized_property\n def width(self):\n p = self.props()\n if not p: return 1\n return p.minor_axis_length\n\n def get_mask(self):\n from skimage.draw import polygon\n fc = self.full_contour\n rr, cc = polygon(fc[0], fc[1], self.shape)\n ret = np.zeros(self.shape, dtype=bool)\n ret[rr, cc] = True\n return ret\n\n # region Creation\n\n def new_moved_to(self, to: NpPosition, imshape: Tuple[int, int]):\n contour = _clip_contour(np.round(self.contour + (to.flatten() - self.center)), imshape)\n\n # check for flat blobs: most likely moved too far out\n ymax = contour[:, 0].max()\n ymin = contour[:, 0].min()\n xmax = contour[:, 1].max()\n xmin = contour[:, 1].min()\n\n if ymax == ymin: # all y are equal\n if ymax == self.shape[0] - 1: # and equal to the max possible\n contour[-1, 0] = ymax - 1 # make a single one different so the blob isn't flat\n else: # also takes care of cases that aren't on the border\n contour[:-1, 0] = ymin + 1\n if xmax == xmin:\n if xmax == self.shape[1] - 1:\n contour[:-1, 1] = xmax - 1\n else:\n contour[:-1, 1] = xmin + 1\n return Blob(contour=contour, imshape=imshape)\n\n # endregion\n # region Drawing\n\n # noinspection PyTypeChecker\n def draw_contour(self, img: ColorImage, *, frame_id: int = None,\n color: Optional[Color] = None, alpha=0.5,\n filled: bool = True,\n text: str = None, text_color: Color = Colors.BLACK) -> ColorImage:\n import skimage.draw as skdraw\n from .common import blend\n \"\"\"Returns a copy of `img` with `self.contour` drawn\"\"\"\n if frame_id is not None:\n color = KellyColors.get(frame_id)\n text = str(frame_id)\n else:\n color = color if color is not None else KellyColors.next()\n\n copy: ColorImage = img.copy()\n fc = self.full_contour\n if np.any(fc):\n copy[fc[0], fc[1]] = blend(copy[fc[0], fc[1]], color, 1)\n if filled:\n rr, cc = skdraw.polygon(fc[0], fc[1], shape=self.shape)\n copy[rr, cc] = blend(copy[rr, cc], color, alpha)\n if text is not None:\n copy = self.draw_label(copy, text=text, color=text_color)\n return copy\n\n def draw_label(self, image: Image_T, text: str, *, color: Color = Colors.BLACK, size=20, separation=9):\n from .common import draw_text\n import skimage.draw as skdraw\n copy = image.copy()\n vector_to_center_of_img = np.array(copy.shape[0:2]) / 2 - self.center\n norm = np.linalg.norm(vector_to_center_of_img)\n magnitude = np.log1p(norm) * separation\n vector_to_center_of_img = vector_to_center_of_img * magnitude / norm\n\n pos = to_tuple_flip(self.center + vector_to_center_of_img)\n\n rr, cc = skdraw.line(self.center_xy.y, self.center_xy.x, pos.y, pos.x)\n rr, cc = np.clip(rr, 0, self.shape[0]), np.clip(cc, 0, self.shape[1])\n copy[rr, cc] = (20, 20, 20)\n copy = draw_text(copy, text=text, size=size, pos=pos, color=color)\n return copy\n\n @classmethod\n def draw_blobs(cls, blobs: List['Blob'], image: ColorImage) -> ColorImage:\n \"\"\"Returns a copy of `image` with all `blobs` drawn onto it, with its index as a label\"\"\"\n copy: ColorImage = image.copy()\n for i, blob in enumerate(blobs):\n copy = blob.draw_contour(copy, frame_id=i)\n return copy\n\n @classmethod\n def make_label_image(cls, blobs: List['Blob'], imshape: Tuple[int, int]) -> GrayscaleImage:\n import skimage.draw as skdraw\n img = np.zeros(imshape, dtype='int')\n for color, blob in enumerate(blobs, start=1):\n fc = blob.full_contour\n if np.any(fc):\n rr, cc = skdraw.polygon(fc[0], fc[1], shape=imshape)\n img[rr, cc] = color\n return img\n\n # endregion\n # region Serialization\n\n class Serial(TypedDict):\n contour: List[Position]\n\n def encode(self) -> 'Blob.Serial':\n return {'contour': [to_tuple(point) for point in self.contour]}\n\n @classmethod\n def decode(cls, ant_as_dict: 'Blob.Serial', imshape: Tuple[int, int]) -> 'Blob':\n contour = _clip_contour(np.array([to_array(point) for point in ant_as_dict[\"contour\"]]), imshape)\n return cls(contour=contour, imshape=imshape)\n\n # endregion\n\ndef _clip_contour(contour, imshape):\n contour[:, 0] = np.clip(contour[:, 0], 0, imshape[0] - 1)\n contour[:, 1] = np.clip(contour[:, 1], 0, imshape[1] - 1)\n return contour.astype('int32')\n"
},
{
"alpha_fraction": 0.7041950225830078,
"alphanum_fraction": 0.7092147469520569,
"avg_line_length": 37.73611068725586,
"blob_id": "09ace5d5c59364281e4317db9a86b84cbc57c446",
"content_id": "ecf7751999a8e68d78ac49f8f7a825812e24569d",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2806,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 72,
"path": "/ant_tracker/tracker_gui/constants.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "\"\"\"Constants\"\"\"\nimport sys\n\nFROZEN = getattr(sys, 'frozen', False) and hasattr(sys, '_MEIPASS')\n\nTFLITE_MODEL = \"model.tflite\"\nSPINNER = \"images/spinner.gif\"\nSMALLSPINNER = \"images/small spinner.gif\"\nLOGO_FICH = \"images/logo_fich.png\"\nLOGO_SINC = \"images/logo_sinc.png\"\nLOGO_UNER = \"images/logo_uner.png\"\nLOGO_AGRO = \"images/logo_agro.png\"\nLOGO_AT = \"images/icon.png\"\nLOGO_AT_ICO = \"images/icon.ico\"\nif not FROZEN:\n from pathlib import Path\n\n this_dir = Path(__file__).parent\n TFLITE_MODEL = str(this_dir / TFLITE_MODEL)\n SPINNER = str(this_dir / SPINNER)\n SMALLSPINNER = str(this_dir / SMALLSPINNER)\n LOGO_FICH = str(this_dir / LOGO_FICH)\n LOGO_SINC = str(this_dir / LOGO_SINC)\n LOGO_UNER = str(this_dir / LOGO_UNER)\n LOGO_AGRO = str(this_dir / LOGO_AGRO)\n LOGO_AT = str(this_dir / LOGO_AT)\n LOGO_AT_ICO = str(this_dir / LOGO_AT_ICO)\n\nTHEME = 'Default1'\n\nRESP_SI = \" Sí \"\nRESP_NO = \" No \"\n\nANTLABELER_UNAVAILABLE = \"AntLabeler no pudo ser encontrado.\"\n\nTRACKFILTER = {'filter_center_center': True, 'length_of_tracks': 5}\n\ndef format_triple_quote(s):\n if s[0] == \"\\n\": s = s[1:]\n return s.replace(\"\\n\\n\\n\", \"-SPACE-\") \\\n .replace(\"\\n\\n\", \"-NL-\") \\\n .replace(\"\\n\", \" \") \\\n .replace(\" \", \" \") \\\n .replace(\"-NL-\", \"\\n\") \\\n .replace(\"-SPACE-\", \"\\n\\n\") \\\n .replace(\"\\n \", \"\\n\")\n\n# Usar dos saltos de línea para separar en párrafos. Para dejar un espacio entre párrafos, usar tres saltos de línea.\nABOUT_INFO = format_triple_quote(\"\"\"\nDesarrollado durante 2019-2020 por Francisco Daniel Sturniolo,\nen el marco de su Proyecto Final de Carrera para el título de Ingeniero en Informática\nde la Facultad de Ingeniería y Ciencias Hídricas de la Universidad Nacional del Litoral,\nbajo la dirección de Leandro Bugnon y la co-dirección de Julián Sabattini, \ntitulado \"Desarrollo de una herramienta para identificación automática del ritmo de forrajeo\nde hormigas cortadoras de hojas a partir de registros de video\".\n\n\nEl mismo pretende analizar el comportamiento de forrajeo de las HCH a partir de videos tomados de la salida de un\nhormiguero (tales como los obtenidos a partir del dispositivo AntVRecord), detectando las trayectorias tomadas por las\nhormigas y su posible carga de hojas, para luego extraer estadísticas temporales de su comportamiento\ny volumen vegetal recolectado.\n\n\nTambién incluido con este programa se encuentra AntLabeler, una utilidad de etiquetado para videos de la misma índole, \nque fue utilizada para validar los resultados obtenidos por AntTracker sobre videos de prueba. El uso de esta\nherramienta actualmente se encuentra supercedido por AntTracker, pero se provee como una forma de revisar con precisión\nlas trayectorias y cargas detectadas.\n\n\n\nThis software uses libraries from the FFmpeg project under the LGPLv2.1.\n\"\"\")\n"
},
{
"alpha_fraction": 0.5060325860977173,
"alphanum_fraction": 0.514927327632904,
"avg_line_length": 40.74632263183594,
"blob_id": "bebacbacf90946b270aa13faded63ba51570f0af",
"content_id": "dbc5195415f2e66e1bd041ff31b6d1a20716ceff",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11364,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 272,
"path": "/ant_tracker/tracker_gui/trkviz.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from enum import Enum, auto\nfrom multiprocessing import freeze_support\n\nimport PySimpleGUI as sg\nimport math\nimport matplotlib # matplotlib is imported by pims by default\nimport numpy as np\nfrom pathlib import Path\nfrom typing import Union, List\n\nmatplotlib.use('agg') # we set agg to avoid it using tk and risk multithreading issues\nimport pims\nfrom pims.process import crop\n\nfrom . import constants as C\nfrom .loading_window import LoadingWindow\nfrom .parameter_extraction import MyGraph\nfrom ..tracker.ant_labeler_info import LabelingInfo\nfrom ..tracker.common import Colors, crop_from_rect, Side, blend\nfrom ..tracker.info import TracksCompleteInfo, TracksInfo\nfrom ..tracker.track import Track, Loaded\n\nclass K(Enum):\n Graph = auto()\n FrameSlider = auto()\n FrameBack = auto()\n FrameForw = auto()\n Graph2 = auto()\n FrameSlider2 = auto()\n FrameBack2 = auto()\n FrameForw2 = auto()\n TrackList = auto()\n Tabs = auto()\n Tab1 = auto()\n Tab2 = auto()\n Filter = auto()\n HideMask = auto()\n\ndef load_video(path: Union[Path, str]):\n with LoadingWindow(\"Cargando video...\"):\n return pims.PyAVReaderIndexed(path)\n\ndef listbox_items(tracks: List[Track], info: TracksInfo):\n return [f\"T{t.id} \" +\n (f\"P:{round(t.load_probability, 2) if t.load_probability else '??'}, \" if t.loaded == Loaded.Undefined else\n f\"Carga: {'Si' if t.loaded == Loaded.Yes else 'No'}\") +\n (f\"Dir: {info.track_direction(t)}\" if isinstance(info, TracksCompleteInfo) else \"\")\n for t in tracks]\n\ndef pull_track_id(string: str):\n return int(string.split(\" \")[0].split(\"T\")[1])\n\ndef trkviz_subprocess(trk_or_tag: Union[Path, str] = None):\n import multiprocessing\n p = multiprocessing.Process(target=trkviz, args=(trk_or_tag,))\n p.start()\n\ndef trkviz(trk_or_tag: Union[Path, str] = None):\n try:\n sg.theme(C.THEME)\n if trk_or_tag is None:\n trkfile = sg.popup_get_file(\"Seleccionar archivo\", file_types=((\"trk/tag\", \"*.trk *.tag\"),),\n no_window=True)\n if not trkfile: return\n else:\n trkfile = trk_or_tag\n trkfile = Path(trkfile)\n\n complete = False\n label = False\n will_filter = True\n try:\n info = LabelingInfo.load(trkfile)\n label = True\n except: # noqa\n try:\n info = TracksCompleteInfo.load(trkfile)\n complete = True\n except: # noqa\n info = TracksInfo.load(trkfile)\n try_this_file = trkfile.parent / info.video_name\n if try_this_file.exists():\n video = load_video(try_this_file)\n else:\n vidfile: str = sg.popup_get_file(\"Seleccionar video (cancelar para no usar video)\",\n file_types=((\"video\", \"*.mp4 *.h264 *.avi\"),),\n no_window=True)\n if vidfile:\n video = load_video(vidfile)\n else:\n video = None\n if video and complete:\n video = crop(video, crop_from_rect(video.frame_shape[0:2], info.crop_rect))\n if label:\n will_filter = False\n\n with LoadingWindow(\"Cargando tracks\"):\n filtered_tracks = info.filter_tracks(**C.TRACKFILTER)\n if will_filter:\n tracks = filtered_tracks\n else:\n tracks = info.tracks\n\n singleantlayout = [\n [\n sg.Column([\n [sg.Listbox(listbox_items(tracks, info),\n size=(20, 15), k=K.TrackList, enable_events=True,\n select_mode=sg.LISTBOX_SELECT_MODE_BROWSE)]\n ]),\n sg.Column([\n [MyGraph(info.video_shape, k=K.Graph2)],\n [\n sg.B(\"◀\", k=K.FrameBack2),\n sg.Slider(orientation='h', enable_events=True, k=K.FrameSlider2),\n sg.B(\"▶\", k=K.FrameForw2)\n ],\n ])\n ]\n\n ]\n allvideolayout = [\n [sg.Column([\n [MyGraph(info.video_shape, k=K.Graph)],\n [\n sg.B(\"◀\", k=K.FrameBack),\n sg.Slider(orientation='h', enable_events=True, k=K.FrameSlider),\n sg.B(\"▶\", k=K.FrameForw)\n ],\n ], expand_x=True,\n )]\n ]\n layout = [\n [sg.Checkbox(\"Filtrar\", will_filter, enable_events=True, k=K.Filter),\n sg.Checkbox(\"Esconder máscara\", enable_events=True, k=K.HideMask)],\n [sg.TabGroup(\n [[sg.Tab(\"Video completo\", allvideolayout, k=K.Tab1),\n sg.Tab(\"Por hormiga\", singleantlayout, k=K.Tab2)]], k=K.Tabs,\n enable_events=True)]\n ]\n window = sg.Window(f\"trkviz - {info.video_name}\", layout, return_keyboard_events=True, finalize=True)\n g: MyGraph = window[K.Graph] # noqa\n g2: MyGraph = window[K.Graph2] # noqa\n window[K.FrameSlider].update(range=(0, info.video_length - 1))\n window[K.FrameSlider].update(value=0)\n window[K.FrameSlider].expand(expand_x=True)\n\n def empty_frame():\n return np.ones(info.video_shape + (3,), dtype='uint8') * 255\n\n def update_current_frame(curr_frame):\n image = video[curr_frame] if video else empty_frame()\n if not window[K.HideMask].get():\n image = Track.draw_tracks(info.tracks, image, curr_frame)\n g.draw_frame(image)\n\n def update_ant_pic(curr_frame):\n if selected_ant and selected_ant.at(curr_frame):\n image = video[curr_frame] if video else empty_frame()\n if not window[K.HideMask].get():\n blob = selected_ant.at(curr_frame)\n image = selected_ant.draw_blob(curr_frame, image).copy()\n from skimage.draw import rectangle_perimeter, line\n\n # draw bounding box\n rect = blob.bbox\n rr, cc = rectangle_perimeter(rect.topleft.yx, rect.bottomright.yx, shape=image.shape)\n image[rr, cc] = Colors.GREEN\n\n # draw leafdetector box\n if blob.is_fully_visible(0.05):\n from ..tracker.leafdetect import _get_blob_rect\n rect = _get_blob_rect(\n blob,\n image.shape,\n extra_pixels=15,\n square=True\n )\n rr, cc = rectangle_perimeter(rect.topleft.yx, rect.bottomright.yx, shape=image.shape)\n image[rr, cc] = Colors.RED\n # image = draw_text(image, round(displayed_prob,2), rect.center).copy()\n\n # draw center area\n rect = Side.center_rect(image.shape, 0.05)\n rr, cc = rectangle_perimeter(rect.topleft.yx, rect.bottomright.yx)\n image[rr, cc] = Colors.BLUE\n\n # draw length & width\n props = blob.props()\n if props:\n y0, x0 = int(props.centroid[0]), int(props.centroid[1])\n orientation = props.orientation\n x1 = int(x0 + math.cos(orientation) * 0.5 * props.minor_axis_length)\n y1 = int(y0 - math.sin(orientation) * 0.5 * props.minor_axis_length)\n x2 = int(x0 - math.sin(orientation) * 0.5 * props.major_axis_length)\n y2 = int(y0 - math.cos(orientation) * 0.5 * props.major_axis_length)\n rr, cc = line(y0, x0, y1, x1)\n image[rr, cc] = blend(image[rr, cc], Colors.RED, 0.5)\n rr, cc = line(y0, x0, y2, x2)\n image[rr, cc] = blend(image[rr, cc], Colors.BLUE, 0.5)\n\n g2.draw_frame(image)\n\n selected_ant = None\n minframe = 0\n maxframe = info.video_length\n update = update_current_frame\n slider = K.FrameSlider\n update_current_frame(0)\n # from ..tracker.leafdetect import TFLiteLeafDetector\n # detector = TFLiteLeafDetector(c.TFLITE_MODEL, video)\n # displayed_prob = 0\n while True:\n event, values = window.read()\n if event == sg.WIN_CLOSED or event == 'q':\n break\n if event == K.HideMask:\n update(int(values[slider]))\n if event == K.Filter:\n with LoadingWindow(spinner=C.SMALLSPINNER):\n if window[K.Filter].get():\n tracks = filtered_tracks\n else:\n tracks = info.tracks\n window[K.TrackList].update(listbox_items(tracks, info), set_to_index=0)\n elif event == K.Tabs:\n window[K.Tab1].set_focus(False)\n window[K.Tab2].set_focus(False)\n if values[event] == K.Tab1:\n minframe = 0\n maxframe = info.video_length\n slider = K.FrameSlider\n update = update_current_frame\n window[slider].update(value=minframe, range=(minframe, maxframe))\n update(0)\n else:\n window[K.TrackList].update(set_to_index=0)\n selected_ant = info.tracks[0]\n minframe = selected_ant.first_frame()\n maxframe = selected_ant.last_frame()\n # displayed_prob = detector.probability(selected_ant)\n slider = K.FrameSlider2\n window[slider].update(value=minframe, range=(minframe, maxframe))\n update = update_ant_pic\n update(minframe)\n elif event in (K.FrameSlider, K.FrameSlider2):\n update(int(values[event]))\n elif event in (K.FrameBack, K.FrameBack2, 'Left:37', 'MouseWheel:Up'):\n current_frame = int(values[slider])\n if current_frame > minframe:\n window[slider].update(value=current_frame - 1)\n update(current_frame - 1)\n elif event in (K.FrameForw, K.FrameForw2, 'Right:39', 'MouseWheel:Down'):\n current_frame = int(values[slider])\n if current_frame < maxframe:\n window[slider].update(value=current_frame + 1)\n update(current_frame + 1)\n elif event == K.TrackList:\n i = pull_track_id(values[event][0])\n track = Track.get(info.tracks, i)\n selected_ant = track\n minframe = selected_ant.first_frame()\n maxframe = selected_ant.last_frame()\n window[slider].update(value=minframe, range=(minframe, maxframe))\n # displayed_prob = detector.probability(selected_ant)\n update_ant_pic(minframe)\n finally:\n LoadingWindow.close_all()\n\nif __name__ == '__main__':\n freeze_support()\n trkviz()\n"
},
{
"alpha_fraction": 0.770588219165802,
"alphanum_fraction": 0.778151273727417,
"avg_line_length": 29.512821197509766,
"blob_id": "081cca31bcd0da782196a557013beabf2c456ed1",
"content_id": "1032a8d8fe8b636a1739765eebf174326621d5bb",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1190,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 39,
"path": "/ant_tracker/labeler/pyforms_patch/pyforms_gui/settings.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\n\nPYFORMS_MAIN_WINDOW_ICON_PATH = None\n\nPYFORMS_MAINWINDOW_MARGIN = 7\n\nPYFORMS_CONTROL_CODE_EDITOR_DEFAULT_FONT_SIZE = '12'\nPYFORMS_CONTROL_EVENTS_GRAPH_DEFAULT_SCALE = 1\n\nPYFORMS_QUALITY_TESTS_PATH = None\n\nPYFORMS_STYLESHEET = None\nPYFORMS_STYLESHEET_DARWIN = None\nPYFORMS_STYLESHEET_LINUX = None\nPYFORMS_STYLESHEET_WINDOWS = None\n\nPYFORMS_CONTROLPLAYER_FONT = 9\n\n# In a normal loading, there may be errors that show up which are not important.\n# This happens because plugins_finder will search for classes on plugins which are not present because they are not needed.\n# However, if plugin is not loaded at all, this will show all related errors.\n# See pyforms_gui.utils.plugins_finder.find_class()\nPYFORMS_SILENT_PLUGINS_FINDER = True\n\nPYFORMS_GL_ENABLED \t\t\t= True\n\nPYFORMS_DIALOGS_OPTIONS = None\nPYFORMS_COLORDIALOGS_OPTIONS = None\n\n#from AnyQt.QtWidgets import QColorDialog, QFileDialog\n#PYFORMS_DIALOGS_OPTIONS = QFileDialog.DontUseNativeDialog\n#PYFORMS_COLORDIALOGS_OPTIONS = QColorDialog.DontUseNativeDialog\n\nimport logging\nPYFORMS_LOG_HANDLER_LEVEL = logging.INFO\nPYFORMS_LOG_FORMAT = '[%(levelname)-7s] %(name)-60s %(message)s'\n"
},
{
"alpha_fraction": 0.4444444477558136,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 17,
"blob_id": "e41e7abeae5194374f0992edfe6b24d8df57035f",
"content_id": "5a6b31479c5822ddaa122f28e692f71aca0644c9",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 1,
"path": "/ant_tracker/tracker_gui/version.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "version = \"0.99f\"\n"
},
{
"alpha_fraction": 0.637005627155304,
"alphanum_fraction": 0.6473634839057922,
"avg_line_length": 38.33333206176758,
"blob_id": "9cdd95b6064888919bfbceeb0a295b21331c98de",
"content_id": "e906d8bf9919c0d3a562580e4c360c1815e3b283",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2126,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 54,
"path": "/ant_tracker/tracker/main.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import argparse\nimport pathlib\nimport pims\n\nfrom .parameters import DohSegmenterParameters, LogWSegmenterParameters, TrackerParameters\nfrom .segmenter import DohSegmenter, LogWSegmenter, Segmenter\nfrom .tracking import Tracker\n\ndef main(file: pathlib.Path, resolution, segmentver, play, outdir=\"./data\"):\n seg_params = {\n 1: LogWSegmenterParameters, 2: DohSegmenterParameters\n }[segmentver](dict(\n approx_tolerance=0.25 if resolution == \"low\" else 1,\n gaussian_sigma={\"low\": 8, \"med\": 14, \"high\": 16}[resolution],\n minimum_ant_radius={\"low\": 4, \"med\": 8, \"high\": 10}[resolution],\n ))\n video = pims.PyAVReaderIndexed(file)\n\n segmenter: Segmenter = {\n 1: LogWSegmenter(video, params=seg_params),\n 2: DohSegmenter(video, params=seg_params)\n }[segmentver]\n\n # segmenter.segment()\n # with open('dia.prl', 'w') as f:\n # f.write(segmenter.serialize())\n\n track_params = TrackerParameters(\n use_defaults=True,\n max_distance_between_assignments=seg_params.minimum_ant_radius * 8,\n )\n tracker = Tracker(file, segmenter, params=track_params)\n if play:\n tracker.track_viz(video, step_by_step=False, fps=60)\n else:\n tracker.track_viz()\n\n outfile = pathlib.Path(outdir, f\"{file.stem}-{tracker.version}.trk\")\n\n tracker.info().save(outfile)\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description=\"Generar .trk a partir de un video\")\n parser.add_argument('file')\n parser.add_argument('--resolution', '-r', type=str, choices=['low', 'med', 'high'], help=\"Resolución del video\",\n required=True)\n parser.add_argument('--segmentver', '-s', type=int, choices=[1, 2], help=\"Versión del segmentador\",\n required=True)\n parser.add_argument('--play', '-p', type=bool, default=False)\n parser.add_argument('--outputDir', '-o', type=str, default='./data',\n help=\"Directorio de salida\")\n args = parser.parse_args()\n\n main(pathlib.Path(args.file), args.resolution, args.segmentver, args.play, pathlib.Path(args.outputDir))\n"
},
{
"alpha_fraction": 0.6313278079032898,
"alphanum_fraction": 0.6504149436950684,
"avg_line_length": 33.18439865112305,
"blob_id": "d001a5ad507db2789ea8dc150c95141e9c9b1d59",
"content_id": "aaa44e7b20c75bf983d73f9a0e995d15c8fe41cb",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4821,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 141,
"path": "/ant_tracker/tracker/validate_segmenter.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import glob\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pims\nimport skimage.metrics\nfrom matplotlib.axes import Axes\nfrom matplotlib.figure import Figure\nfrom matplotlib.ticker import MaxNLocator\nfrom matplotlib.widgets import Slider\nfrom skimage.color import label2rgb\nfrom typing import Tuple, List\n\nfrom .ant_labeler_info import LabelingInfo\nfrom .blob import Blob\nfrom .common import Video\nfrom .segmenter import DohSegmenter, LogWSegmenter, Blobs\n\nfile = \"HD2\"\nver = \"2.0.2.dev1\"\nsegClass = {\"2.0.2.dev1\": LogWSegmenter, \"2.0.2.dev2\": DohSegmenter}[ver]\n\nsegmenter = segClass.deserialize(filename=glob.glob(f\"./testdata/segmenter/{file}*{ver}*\")[0])\n\nfblobs = list(segmenter.frames_with_blobs)\n\ntruth = LabelingInfo.load(glob.glob(f\"vid_tags/**/{file}.tag\")[0])\n\ndef blobs_scores(blobs_true: Blobs, blobs_pred: Blobs, imshape: Tuple[int, int]):\n if len(blobs_true) == 0 and len(blobs_pred) == 0: return 0, 1, 1\n im_true = Blob.make_label_image(blobs_true, imshape)\n im_pred = Blob.make_label_image(blobs_pred, imshape)\n _, precision, recall = skimage.metrics.adapted_rand_error(im_true, im_pred)\n recall_weighted_rand_error = 1 - (5 * precision * recall / (4 * precision + recall))\n\n return recall_weighted_rand_error, precision, recall\n\ndef draw_segmentation(video: Video, all_blobs_true: List[Blobs], all_blobs_pred: List[Blobs]):\n fig_comp: Figure = plt.figure(constrained_layout=False)\n fig_comp.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1)\n\n gs = fig_comp.add_gridspec(2, 2, height_ratios=[1, 0.5], wspace=0.0, hspace=0.1)\n ax_true: Axes = fig_comp.add_subplot(gs[0, 0])\n ax_pred: Axes = fig_comp.add_subplot(gs[0, 1])\n # ax_distances: Axes = fig.add_subplot(gs[1, :])\n\n ax_true.set_title('Ground Truth')\n ax_pred.set_title('Segment')\n\n ax_frame_slider = fig_comp.add_axes([0.1, 0.05, 0.8, 0.04])\n frame_slider = Slider(ax_frame_slider, 'Frame', 0, len(video), 0, valfmt=\"%d\", valstep=1)\n\n def __frame_update_fn(val):\n nonlocal frame_n\n frame_n = int(val)\n draw_figure()\n\n frame_slider.on_changed(__frame_update_fn)\n\n def on_key_press(event):\n nonlocal play, frame_slider\n if event.key == 'a':\n frame_slider.set_val((frame_slider.val - 1) % len(video))\n elif event.key == 'd':\n frame_slider.set_val((frame_slider.val + 1) % len(video))\n elif event.key == 'p':\n play = not play\n elif event.key == 'escape' or event.key == 'q':\n import sys\n sys.exit()\n\n fig_comp.canvas.mpl_connect('key_press_event', on_key_press)\n\n def draw_figure():\n from .plotcommon import Animate\n nonlocal frame_slider\n frame_slider.val = frame_n\n frame = video[frame_n]\n\n label_true = Blob.make_label_image(all_blobs_true[frame_n], frame.shape[:2])\n label_pred = Blob.make_label_image(all_blobs_pred[frame_n], frame.shape[:2])\n\n frame_true = label2rgb(label_true, frame, bg_label=0)\n frame_pred = label2rgb(label_pred, frame, bg_label=0)\n\n Animate.draw(ax_true, frame_true)\n Animate.draw(ax_pred, frame_pred)\n\n fig_comp.canvas.draw_idle()\n\n frame_n = 0\n exit_flag = False\n play = False\n last_drawn_frame_n = -1\n while not exit_flag and frame_n < len(video):\n if last_drawn_frame_n != frame_n or play:\n draw_figure()\n last_drawn_frame_n = frame_n\n if play:\n frame_n += 1\n plt.pause(0.001)\n\nrand_errors = []\nps = []\nrs = []\nfor frame in range(truth.video_length):\n blobs_true = truth.get_blobs_in_frame(frame)\n blobs_pred = fblobs[frame]\n rand_error, p, r = blobs_scores(blobs_true, blobs_pred, segmenter.video_shape)\n rand_errors.append(rand_error)\n ps.append(p)\n rs.append(r)\n\nplt.style.use('seaborn-deep')\n\nplt.figure()\nplt.title(file)\nplt.plot(rand_errors, c='r', label=\"1-F2\")\nplt.axhline(np.nanmean(rand_errors), ls='dashed', c='r')\nplt.ylim(0, 1)\nplt.ylabel(\"Adapted Rand F2 Error\")\nplt.xlabel(\"Frame\")\n\nax2 = plt.gca().twinx()\nax2.plot(rs, c='g', label=\"Recall\")\nax2.plot(ps, c='b', label=\"Precision\")\nax2.axhline(np.nanmean(rs), ls='dashed', c='g')\nax2.axhline(np.nanmean(ps), ls='dashed', c='b')\n\nnumber_of_blobs_per_frame = [len(truth.get_blobs_in_frame(frame)) for frame in range(truth.video_length)]\nax3 = plt.gca().twinx()\nax3.bar(list(range(truth.video_length)), number_of_blobs_per_frame, alpha=0.3)\nax3.set_ylabel('N° hormigas presentes')\nax3.yaxis.set_major_locator(MaxNLocator(integer=True))\n\nresults = {\n 'segmenter': segmenter.serialize()\n}\ndraw_segmentation(pims.PyAVReaderIndexed(glob.glob(f\"vid_tags/**/{file}.mp4\")[0]),\n [truth.get_blobs_in_frame(frame) for frame in range(truth.video_length)],\n fblobs)\n"
},
{
"alpha_fraction": 0.6748911738395691,
"alphanum_fraction": 0.7010159492492676,
"avg_line_length": 21.225807189941406,
"blob_id": "3c6263551806bb50066ee358754d62687c5ffcc4",
"content_id": "cdd75070e55ffc4d94da37b52f14f9c584833d1e",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 689,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 31,
"path": "/ant_tracker/tracker/test_segmenter_continue.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import pims\n\nfrom .segmenter import LogWSegmenter\n\ntestjson = \"test_segmenter.json\"\nvideofile = \"vid_tags/720x510/HD720_1.mp4\"\n\nvideo = pims.PyAVReaderIndexed(videofile)\nseg = LogWSegmenter(video)\n\nfor frame_n, blobs in seg.frames_with_blobs:\n if frame_n == 3:\n break\nwith open(testjson, 'w') as f:\n f.write(seg.serialize())\n\nseg2 = LogWSegmenter.deserialize(filename=testjson)\nseg2.set_video(video)\n\nfor frame_n, blobs in seg2.segment_rolling_continue():\n if frame_n == 6:\n break\nfor frame_n, blobs in seg.segment_rolling_continue():\n if frame_n == 6:\n break\n\nassert seg.serialize() == seg2.serialize()\nprint(\"Test passed\")\nimport os\n\nos.remove(testjson)\n"
},
{
"alpha_fraction": 0.6745341420173645,
"alphanum_fraction": 0.6906832456588745,
"avg_line_length": 32.54166793823242,
"blob_id": "24b9814c43947c9f769c23623b4de0608d9cd4b9",
"content_id": "1e518f3b278b0d812e3874a33d9f12fc5a19eab8",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 807,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 24,
"path": "/ant_tracker/labeler/test.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import sys\nimport cv2 as cv\nimport numpy as np\nimport json\n\ncv.namedWindow(\"Máscaras\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\nwith open(\"./Video16cr.tag\",'r') as file:\n antCollection = json.load(file)\n videoShape = antCollection[\"videoShape\"]\n videoSize = antCollection[\"videoSize\"]\n for unlabeledFrame in antCollection[\"unlabeledFrames\"]:\n packed_mask = unlabeledFrame[\"packed_mask\"]\n packed_mask_ndarray = np.array(packed_mask,dtype='uint8')\n # print(packed_mask_ndarray)\n mask = np.unpackbits(packed_mask_ndarray, axis=None)[:videoSize].reshape(videoShape).astype('uint8')*255\n # print(mask)\n cv.imshow(\"Máscaras\",mask)\n cv.waitKey(1)\n\n# cap = cv.VideoCapture(\"../Video16c.mp4\")\n\n\ncv.waitKey(0)\ncv.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.6534835696220398,
"alphanum_fraction": 0.6596918702125549,
"avg_line_length": 35.54621887207031,
"blob_id": "411acdcf57616aeffe6ba1abe0c3c6adaff2bc42",
"content_id": "e8f6f7ac48d637fbbba2a2a3097b2e970e8a30cf",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4357,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 119,
"path": "/ant_tracker/tracker/ant_labeler_info.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "\"\"\"Este archivo es un workaround por la estructura de módulos de AntLabeler y AntTracker.\n\nAntLabeler debería usar labeler.classes.LabelingInfo, que tiene la\ncapacidad de guardar a partir de la estructura de clases de AntLabeler.\n\nCualquier otro uso que involucre leer los datos contenidos en un .tag\ndebería usar tracker.ant_labeler_info.LabelingInfo.\n\nCuidado, ambos archivos deben modificarse en conjunto para evitar incompatibilidades.\n\nTODO: generar una solución que atienda a ambos casos, independientemente de cv2/pyav\n\"\"\"\nfrom dataclasses import dataclass, field\n\nimport itertools\nimport numpy as np\nimport ujson\nfrom packaging.version import Version\nfrom pathlib import Path\nfrom typing import ClassVar, List, Union, TypedDict\n\nfrom .common import Position, to_json, to_tuple\nfrom .info import TracksInfo\nfrom .track import Track\n\ndef groupSequence(lst: List[int]):\n # Visto en https://stackoverflow.com/a/2154437\n from operator import itemgetter\n ranges = []\n lst.sort()\n for k, g in itertools.groupby(enumerate(lst), lambda x: x[0] - x[1]):\n group = (map(itemgetter(1), g))\n group = list(map(int, group))\n ranges.append((group[0], group[-1]))\n return ranges\n\nclass UnlabeledFrame:\n def __init__(self, frame: int, contours):\n self.contours = [np.array(c) for c in contours]\n self.frame = frame\n\n def __repr__(self):\n return f\"Frame: {self.frame}, {len(self.contours)} unlabeled contours\"\n\n class Serial(TypedDict):\n frame: int\n contours: List[List[Position]]\n\n def encode(self) -> 'UnlabeledFrame.Serial':\n d = {\n \"frame\": self.frame,\n \"contours\": [[\n to_tuple(point) for point in contour\n ] for contour in self.contours],\n }\n return d\n\n @staticmethod\n def decode(unlabeled_as_dict: 'UnlabeledFrame.Serial') -> 'UnlabeledFrame':\n return UnlabeledFrame(frame=unlabeled_as_dict['frame'], contours=unlabeled_as_dict['contours'])\n\n# noinspection DuplicatedCode\n@dataclass\nclass LabelingInfo(TracksInfo):\n unlabeledFrames: List[UnlabeledFrame] = field(init=False)\n labeler_version: Version = field(init=False)\n file_extension: ClassVar = '.tag'\n\n def __init__(self):\n raise AttributeError\n\n class Serial(TracksInfo.Serial):\n unlabeled_frames: List[UnlabeledFrame.Serial]\n labeler_version: str\n\n def encode(self) -> 'LabelingInfo.Serial':\n return {\n **super(LabelingInfo, self).encode(),\n 'unlabeled_frames': [uf.encode() for uf in self.unlabeledFrames],\n 'labeler_version': str(self.labeler_version),\n }\n\n @classmethod\n def decode(cls, info: 'LabelingInfo.Serial'):\n labeler_version = Version(info.get('labeler_version', \"1.0\"))\n if labeler_version < Version(\"2.0\"):\n raise ValueError(_version_error_msg(labeler_version))\n if labeler_version < Version(\"2.1\"):\n info['tracks'] = _flip_contours_before_2_1(info['tracks'])\n\n self = super(LabelingInfo, cls).decode(info)\n self.labeler_version = labeler_version\n ufs = [UnlabeledFrame.decode(uf) for uf in info['unlabeled_frames']]\n self.unlabeledFrames = [uf for uf in ufs if uf.contours]\n return self\n\n def serialize(self, pretty=False) -> str:\n if pretty: return to_json(self.encode())\n return ujson.dumps(self.encode())\n\n def save(self, file: Union[Path, str], pretty=False):\n if not isinstance(file, Path):\n file = Path(file)\n if not self._is_extension_valid(file):\n raise ValueError(f'Wrong extension ({file.suffix}). Only {self.file_extension} files are valid.')\n with file.open('w') as f:\n f.write(self.serialize(pretty=pretty))\n\ndef _version_error_msg(current_version):\n return (f\"Esta clase soporta sólo versión >=2.0 del protocolo. \"\n f\"Abra este archivo con una versión nueva de AntLabeler para actualizar. \"\n f\"Versión actual: {current_version}\")\n\ndef _flip_contours_before_2_1(tracks: List[Track.Serial]):\n # had to do this to flip all x/y cause I did it wrong in AntLabeler\n for track in tracks:\n for blob in track['blobs'].values():\n blob['contour'] = [Position(p[1], p[0]) for p in blob['contour']]\n return tracks\n"
},
{
"alpha_fraction": 0.5648462772369385,
"alphanum_fraction": 0.5960532426834106,
"avg_line_length": 33.91987228393555,
"blob_id": "93ea61ab5463fbf1f71916a0e37cc39007d912d4",
"content_id": "642e87dc7022027be1b839c17d3b59fae98a75f0",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10895,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 312,
"path": "/ant_tracker/tracker/common.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from enum import Enum, auto\n\nimport numpy as np\nimport sys\nfrom functools import partial\nfrom pathlib import Path\nfrom typing import Dict, List, NamedTuple, NewType, Sequence, Tuple, TypeVar, Union, cast, Any, Generator, Iterable\n\nfrom .prettyjson import prettyjson\n\nColor = Union[Tuple[int, int, int], Tuple[float, float, float]]\nBinaryMask = np.ndarray\nColorImage = NewType('ColorImage', np.ndarray)\nGrayscaleImage = NewType('GrayscaleImage', np.ndarray)\nImage_T = Union[ColorImage, GrayscaleImage]\ntry:\n # noinspection PyUnresolvedReferences\n from pims import FramesSequence\n # noinspection PyUnresolvedReferences\n from slicerator import Pipeline\n\n Video = Union[FramesSequence, Sequence[ColorImage], Pipeline]\nexcept ImportError:\n Video = Sequence[ColorImage]\nNpPosition = np.ndarray\nVector = np.ndarray\nContour = np.ndarray\nFrameNumber = int\nPixel = np.ndarray\n\nclass Position(NamedTuple):\n x: int\n y: int\n\n @property\n def yx(self):\n return self.y, self.x\n\n def distance_to(self, other):\n from math import sqrt\n return sqrt((self.x - other.x) ** 2 + (self.y - other.y) ** 2)\n\n def __repr__(self):\n return f\"(x={self.x}, y={self.y})\"\n\nclass Rect(NamedTuple):\n \"\"\"A rectangle in a coordinate system with (0,0) at top-left and (xmax, ymax) at bottom-right.\"\"\"\n x0: int\n x1: int\n y0: int\n y1: int\n\n @classmethod\n def from_points(cls, one: Tuple[int, int], other: Tuple[int, int]):\n \"\"\"Creates an instance from two 2ples. The resulting `Rect` has the coordinates ordered so that\n `(x0,y0)` is top-left and `(x1,y1)` is bottom-right.\"\"\"\n fx, fy = one\n lx, ly = other\n x0 = min(fx, lx)\n x1 = max(fx, lx)\n y0 = min(fy, ly)\n y1 = max(fy, ly)\n return cls(x0=x0, x1=x1, y0=y0, y1=y1)\n\n @property\n def xxyy(self):\n return self.x0, self.x1, self.y0, self.y1\n\n @property\n def height(self):\n return self.y1 - self.y0\n\n @property\n def width(self):\n return self.x1 - self.x0\n\n @property\n def diagonal_length(self):\n from math import sqrt\n return sqrt(self.height ** 2 + self.width ** 2)\n\n @property\n def center(self):\n return Position(x=self.x0 + (self.x1 - self.x0) // 2, y=self.y0 + (self.y1 - self.y0) // 2)\n\n @property\n def topleft(self):\n return Position(x=self.x0, y=self.y0)\n\n @property\n def bottomright(self):\n return Position(x=self.x1, y=self.y1)\n\n def __contains__(self, point: Union[Tuple[int, int], Position]):\n \"\"\"`point` in `self`\"\"\"\n if isinstance(point, Position):\n x = point.x\n y = point.y\n else:\n x = point[0]\n y = point[1]\n return (self.topleft.x < x < self.bottomright.x) and (self.topleft.y < y < self.bottomright.y)\n\n def scale(self, imshape: Tuple[int, int], *, factor: float = None, extra_pixels: int = None):\n \"\"\"Scale the rect by `factor` or add `extra_pixels` to each side\"\"\"\n if (factor is None) == (extra_pixels is None):\n raise ValueError(\"Only factor or extra_pixels, not both\")\n elif factor is not None:\n w = self.width * factor\n h = self.height * factor\n return Rect(\n x0=int(self.center.x - w / 2),\n x1=int(self.center.x + w / 2 + 1),\n y0=int(self.center.y - h / 2),\n y1=int(self.center.y + h / 2 + 1),\n ).__bring_back_in(imshape).clip(imshape)\n elif extra_pixels is not None:\n return Rect(\n x0=int(self.x0 - extra_pixels),\n x1=int(self.x1 + extra_pixels),\n y0=int(self.y0 - extra_pixels),\n y1=int(self.y1 + extra_pixels),\n ).__bring_back_in(imshape).clip(imshape)\n\n def square(self, imshape: Tuple[int, int]):\n s = max(self.height, self.width)\n return Rect(\n x0=self.center.x - s // 2,\n x1=self.center.x + s // 2 + s % 2,\n y0=self.center.y - s // 2,\n y1=self.center.y + s // 2 + s % 2,\n ).__bring_back_in(imshape)\n\n def __bring_back_in(self, imshape: Tuple[int, int]):\n height, width = imshape[0], imshape[1]\n x0, x1, y0, y1 = self.x0, self.x1, self.y0, self.y1\n if x0 < 0:\n x1 += -x0\n x0 = 0\n elif x1 >= width:\n x0 -= ((x1 - width) + 1)\n x1 = width - 1\n if y0 < 0:\n y1 += -y0\n y0 = 0\n elif y1 >= height:\n y0 -= ((y1 - height) + 1)\n y1 = height - 1\n return Rect(x0=x0, x1=x1, y0=y0, y1=y1)\n\n def clip(self, imshape: Tuple[int, int]):\n height, width = imshape[0], imshape[1]\n return Rect(\n x0=0 if self.x0 < 0 else self.x0,\n y0=0 if self.y0 < 0 else self.y0,\n x1=width - 1 if self.x1 >= width else self.x1,\n y1=height - 1 if self.y1 >= height else self.y1,\n )\n\ndef crop_from_rect(imshape: Tuple[int, int], crop_rect: Rect):\n whole_rect = Rect.from_points((0, 0), (imshape[1] - 1, imshape[0] - 1))\n xleft = crop_rect.topleft.x - whole_rect.topleft.x\n xright = whole_rect.bottomright.x - crop_rect.bottomright.x\n ytop = crop_rect.topleft.y - whole_rect.topleft.y\n ybot = whole_rect.bottomright.y - crop_rect.bottomright.y\n return (ytop, ybot), (xleft, xright), (0, 0)\n\ndef to_tuple(point: NpPosition, cast_to_int=True) -> Position:\n p = point.astype(int) if cast_to_int else point\n return Position(x=p[0].item(), y=p[1].item())\n\ndef to_tuple_flip(point: NpPosition, cast_to_int=True):\n p = to_tuple(point, cast_to_int)\n fp = flip_pair(p)\n return Position(x=fp[0], y=fp[1])\n\nT = TypeVar('T')\nU = TypeVar('U')\n\ndef flip_pair(t: Tuple[T, U]) -> Tuple[U, T]:\n \"\"\"Flips a 2-ple\"\"\"\n return t[1], t[0]\n\ndef to_array(point: Position) -> NpPosition:\n return cast(NpPosition, np.array(point))\n\ndef to_json(thing: Union[Dict, List]) -> str:\n return prettyjson(thing, maxlinelength=120)\n\ndef unzip(it):\n return map(list, zip(*it))\n\ndef eq_gen_it(gen_or_it_1: Union[Iterable, Generator], gen_or_it2: Union[Iterable, Generator]):\n # https://stackoverflow.com/a/9983596\n from itertools import zip_longest\n return all(a == b for a, b in zip_longest(gen_or_it_1, gen_or_it2, fillvalue=object()))\n\ndef rgb2gray(image: ColorImage) -> GrayscaleImage:\n from skimage.color import rgb2gray\n return (255 * rgb2gray(image)).astype('uint8')\n\nclass ProgressBar:\n def __init__(self, length, width=40):\n self.toolbar_width = width\n self.length = length\n self.progress_idx = 0\n # setup toolbar\n self.progressMsg = \"Procesando 0/%d\" % self.length\n sys.stdout.write(self.progressMsg + \"[%s]\" % (\" \" * self.toolbar_width))\n sys.stdout.flush()\n sys.stdout.write(\"\\b\" * (len(self.progressMsg) + self.toolbar_width + 2)) # return to start of line, after '['\n\n def next(self):\n self.progress_idx += 1\n progress = self.toolbar_width * self.progress_idx // self.length + 1\n progress_msg = \"Procesando %d/%d \" % (self.progress_idx, self.length)\n sys.stdout.write(progress_msg)\n sys.stdout.write(\"[%s%s]\" % (\"-\" * progress, \" \" * (self.toolbar_width - progress)))\n sys.stdout.flush()\n sys.stdout.write(\"\\b\" * (len(progress_msg) + self.toolbar_width + 2)) # return to start of line, after '['\n\ndef ensure_path(path: Union[Path, str]):\n if isinstance(path, str): path = Path(path)\n return path\n\ndef filehash(path: Union[Path, str]):\n import hashlib\n path = ensure_path(path)\n with path.open('rb') as f:\n h = hashlib.sha256(f.read()).hexdigest()\n return h\n\nclass SerializableEnum(str, Enum):\n def _generate_next_value_(self, start, count, last_values):\n return self\n\nclass Colors(NamedTuple):\n BLACK = 0, 0, 0\n WHITE = 255, 255, 255\n GRAY = 185, 185, 185\n RED = 255, 0, 0\n GREEN = 0, 255, 0\n BLUE = 0, 0, 255\n\ndef draw_line(image: Image_T, start: Position, end: Position, color: Color = Colors.BLACK, width=1):\n from PIL import Image, ImageDraw\n pilimage = Image.fromarray(image.copy())\n draw = ImageDraw.ImageDraw(pilimage)\n draw.line([start, end], width=width, fill=color)\n return np.array(pilimage)\n\ndef draw_text(image: Image_T, text: Any, pos: Position, size=20, color: Color = Colors.BLACK):\n \"\"\"\"Returns a copy of `image` with `text` drawn on `pos`, with optional `size`\"\"\"\n from PIL import Image, ImageDraw, ImageFont\n text = str(text)\n font = ImageFont.truetype(\"arial.ttf\", size=size)\n pilimage = Image.fromarray(image.copy())\n draw = ImageDraw.ImageDraw(pilimage)\n draw.text((pos.x - size // 2, pos.y - size // 2), text, font=font, fill=color)\n return np.asarray(pilimage)\n\nPixelOrPixels = TypeVar('PixelOrPixels', Pixel, Sequence[Pixel])\n\ndef blend(base: PixelOrPixels, top: Union[Color, Pixel], alpha) -> PixelOrPixels:\n if isinstance(top, tuple):\n top = np.array(top)\n return (base * (1 - alpha) + top * alpha).astype(int)\n\nclass Side(SerializableEnum):\n Bottom = auto()\n Top = auto()\n Left = auto()\n Right = auto()\n Center = auto()\n\n @staticmethod\n def center_rect(imshape: Tuple[int, int], percentage: float):\n smaller_dim = min(imshape[0], imshape[1])\n top = int(smaller_dim * percentage)\n bottom = int(imshape[0] - top)\n left = int(smaller_dim * percentage)\n right = int(imshape[1] - left)\n return Rect.from_points((left, top), (right, bottom))\n\n @staticmethod\n def from_point(point: Position, imshape: Tuple[int, int], percentage: float):\n smaller_dim = min(imshape[0], imshape[1])\n top = smaller_dim * percentage\n bottom = imshape[0] - top\n left = smaller_dim * percentage\n right = imshape[1] - left\n if point.y < top: return Side.Top\n if point.y > bottom: return Side.Bottom\n if point.x < left: return Side.Left\n if point.x > right: return Side.Right\n return Side.Center\n\nsquare_rect_test = partial(Rect.square, imshape=(20, 20))\n\n# assert (square_rect_test(Rect(0, 10, 0, 10)) == Rect(0, 10, 0, 10))\n# assert (square_rect_test(Rect(0, 10, 5, 15)) == Rect(0, 10, 5, 15))\n# assert (square_rect_test(Rect(0, 10, 0, 15)) == Rect(0, 15, 0, 15))\n# assert (square_rect_test(Rect(0, 10, 10, 15)) == Rect(0, 10, 7, 17))\n# assert (square_rect_test(Rect(0, 10, 16, 21)) == Rect(0, 10, 9, 19))\n# assert (square_rect_test(Rect(0, 10, 16, 21)) == Rect(0, 10, 9, 19))\n# assert (square_rect_test(Rect(-10, 5, 18, 22)) == Rect(0, 15, 4, 19))\n\ndef encode_np_randomstate(state):\n return state[0], state[1].tolist(), state[2], state[3], state[4]\n\ndef decode_np_randomstate(state):\n return state[0], np.array(state[1], dtype='uint32'), state[2], state[3], state[4]\n"
},
{
"alpha_fraction": 0.41063347458839417,
"alphanum_fraction": 0.46436652541160583,
"avg_line_length": 22.731544494628906,
"blob_id": "95bfba257ec4d437e187e095eedc2174074f568d",
"content_id": "a335b0bf0f3269068097fca52af69ce6757eebec",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3536,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 149,
"path": "/ant_tracker/labeler/classes_test.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from classes import *\nimport numpy as np\nimport numpy.testing as npt\n\nimport unittest\n\nclass TestClasses(unittest.TestCase):\n def setUp(self):\n pass\n def testSizeShape(self):\n a = np.array([[0,1,0],\n [0,1,0],\n [0,1,0]])\n b = np.array([[0,0,0],\n [0,1,1],\n [0,0,0]],dtype=\"uint8\")\n\n ants = AntCollection(a)\n\n self.assertEqual(ants.videoSize,b.size)\n self.assertEqual(ants.videoShape,b.shape)\n def testEncodeDecode(self):\n a = np.array([[0,1,0],\n [0,1,0],\n [0,1,0]])\n b = np.array([[0,0,0],\n [0,1,1],\n [0,0,0]])\n c = np.array([[0,0,1],\n [0,0,1],\n [1,0,0]])\n\n ants = AntCollection(a)\n\n for _ in range(4):\n ants.newAnt()\n\n ants.addUnlabeledFrame(1,a)\n ants.addUnlabeledFrame(2,b)\n ants.addUnlabeledFrame(3,c)\n\n a = np.array([[0,1,0],\n [0,3,0],\n [2,2,0]])\n b = np.array([[0,1,1],\n [0,3,3],\n [2,0,0]])\n c = np.array([[4,0,1],\n [2,0,3],\n [2,0,0]])\n\n ants.updateAreas(1,a)\n ants.updateAreas(2,b)\n ants.updateAreas(3,c)\n\n jsonstring = ants.serialize()\n print(jsonstring)\n ants2 = ants.deserialize(jsonstring=jsonstring)\n\n self.assertEqual(jsonstring,ants2.serialize())\n def testFillNextFrames(self):\n a = np.array([[0,1,0],\n [0,1,0],\n [0,0,0]])\n b = np.array([[0,0,0],\n [0,1,1],\n [0,0,0]])\n c = np.array([[0,0,1],\n [0,0,1],\n [1,0,0]])\n empty = np.array(\n [[0,0,0],\n [0,0,0],\n [0,0,0]])\n first = np.array(\n [[0,3,0],\n [0,3,0],\n [0,0,0]])\n\n ants = AntCollection(a)\n\n for _ in range(4):\n ants.newAnt()\n\n ants.updateAreas(1,first)\n ants.updateAreas(2,empty.copy())\n ants.updateAreas(3,empty.copy())\n\n # ants.addUnlabeledFrame(1,a)\n ants.addUnlabeledFrame(2,b)\n ants.addUnlabeledFrame(3,c)\n\n ants.labelFollowingFrames(1,3,conflict_radius=0)\n\n c_mask = ants.getMask(3)\n expected = np.array([\n [0,0,3],\n [0,0,3],\n [-1,0,0]])\n npt.assert_array_equal(c_mask,expected)\n\n\n# abyframe = AreasByFrame()\n# abyframe.updateArea(1,a)\n# abyframe.updateArea(2,b)\n# abyframe.updateArea(3,c)\n# print(abyframe.encode())\n\n# ant1 = Ant()\n# ant1.updateArea(1,a)\n# ant1.updateArea(2,b)\n# ant1.updateArea(3,c)\n\n# print(ant1.encode())\n\n# ant2 = Ant()\n# ant2.updateArea(1,a)\n# ant2.updateArea(2,b)\n# ant2.updateArea(3,c)\n\n# ant3 = Ant()\n# ant3.updateArea(1,a)\n# ant3.updateArea(2,b)\n# ant3.updateArea(3,c)\n\n\n# ants = [ant1,ant2,ant3]\n\n# with open(\"test.txt\",\"w\") as fd:\n# print(json.dump({\"ants\": ants},fd,cls=AntsEncoder,indent=2))\n\n# frame = 1\n# mask = np.zeros(ants2.videoShape,dtype='int16')\n# for (id, area) in ((ant.id,ant.getArea(frame)) for ant in ants2.ants if ant.getArea(frame) != None):\n# antMask = area.getMask()\n# print(\"id: %d\" % id)\n# print(antMask)\n# mask = mask + antMask*id\n\n# print(mask)\n\n\n\n\n# colored_mask = np.array([\n# [0,1,2],\n# [3,0,0],\n# [0,0,0],\n# ])\n"
},
{
"alpha_fraction": 0.5995623469352722,
"alphanum_fraction": 0.6083648204803467,
"avg_line_length": 44.90867614746094,
"blob_id": "d11b8a66d1a63b6d46fae7991840a8d0a44f2630",
"content_id": "51a61d25966a4d3b15561fad6b1caf6b2408bb35",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20125,
"license_type": "permissive",
"max_line_length": 199,
"num_lines": 438,
"path": "/ant_tracker/tracker/validate.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass, field\n\nimport argparse\nimport numpy as np\nimport pims\nimport skimage.draw as skdraw\nfrom matplotlib import pyplot as plt\nfrom matplotlib.axes import Axes\nfrom matplotlib.figure import Figure\nfrom matplotlib.widgets import Slider\nfrom pathlib import Path\nfrom pims.process import crop\nfrom scipy.optimize import linear_sum_assignment\nfrom scipy.spatial.distance import directed_hausdorff\nfrom typing import List, Optional, overload, Dict, Tuple\n\nfrom .ant_labeler_info import LabelingInfo\nfrom .common import Video, to_json, Side, blend, crop_from_rect\nfrom .info import TracksInfo, TracksCompleteInfo, reposition_into_crop, Direction\nfrom .plotcommon import Animate, Log1pInvNormalize\nfrom .track import Track\n\nframe_grace_margin = 10\n\ndef get_distances(tracks_truth: List[Track], tracks_tracked: List[Track], distances_filename=None) -> np.ndarray:\n def hausdorff(u: np.ndarray, v: np.ndarray):\n return max(directed_hausdorff(u, v)[0], directed_hausdorff(v, u)[0])\n\n import os.path\n if distances_filename and os.path.isfile(distances_filename):\n return np.load(distances_filename)\n\n distances = np.ndarray((len(tracks_truth), len(tracks_tracked)), dtype=float)\n\n for i, t1 in enumerate(tracks_truth):\n p1 = t1.path()\n for j, t2 in enumerate(tracks_tracked):\n p2 = t2.path()\n distances[i, j] = hausdorff(p1, p2)\n if distances_filename:\n np.save(distances_filename, distances)\n return distances\n\ndef draw_results(video: Video, tracks_truth: List[Track], tracks_tracked: List[Track], distances: np.ndarray,\n idx_truth: np.ndarray,\n idx_tracked: np.ndarray):\n fig_comp: Figure = plt.figure(constrained_layout=False)\n fig_comp.subplots_adjust(left=0.1, right=0.9, top=0.9, bottom=0.1)\n\n gs = fig_comp.add_gridspec(2, 2, height_ratios=[1, 0.5], wspace=0.0, hspace=0.1)\n ax_truth: Axes = fig_comp.add_subplot(gs[0, 0])\n ax_track: Axes = fig_comp.add_subplot(gs[0, 1])\n # ax_distances: Axes = fig.add_subplot(gs[1, :])\n plt.figure()\n ax_distances: Axes = plt.gca()\n ax_distances.set_ylabel(\"ID's etiquetadas\")\n ax_distances.set_xlabel(\"ID's trackeadas\")\n\n ax_truth.set_title('Ground Truth')\n ax_track.set_title('Tracking')\n\n normalize = Log1pInvNormalize(vmin=distances.min(), vmax=distances.max())\n colormap = plt.get_cmap('viridis')\n\n ax_distances.imshow(distances, norm=Log1pInvNormalize())\n for i, j in zip(idx_truth, idx_tracked):\n # if distances[i, j] > percentile_50:\n # continue\n ax_distances.annotate('!', (j, i), color=(0.8, 0, 0))\n\n ax_frame_slider = fig_comp.add_axes([0.1, 0.05, 0.8, 0.04])\n frame_slider = Slider(ax_frame_slider, 'Frame', 0, len(video), 0, valfmt=\"%d\", valstep=1)\n\n def __frame_update_fn(val):\n nonlocal frame_n\n frame_n = int(val)\n draw_figure()\n\n frame_slider.on_changed(__frame_update_fn)\n\n def on_key_press(event):\n nonlocal play, frame_slider\n if event.key == 'a':\n frame_slider.set_val((frame_slider.val - 1) % len(video))\n elif event.key == 'd':\n frame_slider.set_val((frame_slider.val + 1) % len(video))\n elif event.key == 'p':\n play = not play\n elif event.key == 'escape' or event.key == 'q':\n import sys\n sys.exit()\n\n fig_comp.canvas.mpl_connect('key_press_event', on_key_press)\n\n def draw_figure():\n nonlocal frame_slider, artists, annotations\n frame_slider.val = frame_n\n frame = video[frame_n]\n for a in artists:\n ax_track.artists.remove(a)\n for ann in annotations:\n ann.remove()\n annotations = []\n artists = []\n fig_comp.suptitle(f\"{frame_n=}\")\n frame_truth = Track.draw_tracks(tracks_truth, frame, frame_n).copy()\n frame_tracked = Track.draw_tracks(tracks_tracked, frame, frame_n).copy()\n\n for track in tracks_tracked:\n if (blob := track.at(frame_n)) is not None:\n bbox = (blob\n .bbox\n .scale(frame.shape, extra_pixels=8)\n .square(frame.shape)\n )\n rr, cc = skdraw.rectangle((bbox.y0, bbox.x0), (bbox.y1, bbox.x1))\n color = (20, 230, 20) if blob.is_fully_visible(0.05) else (230, 20, 20)\n frame_tracked[rr, cc] = blend(frame_tracked[rr, cc], color, 0.3)\n\n for track in tracks_truth:\n if (blob := track.at(frame_n)) is not None:\n bbox = (blob\n .bbox\n .scale(frame.shape, extra_pixels=8)\n .square(frame.shape)\n )\n rr, cc = skdraw.rectangle((bbox.y0, bbox.x0), (bbox.y1, bbox.x1))\n\n color = (20, 230, 20) if blob.is_fully_visible(0.05) else (230, 20, 20)\n frame_truth[rr, cc] = blend(frame_truth[rr, cc], color, 0.3)\n\n Animate.draw(ax_truth, frame_truth)\n Animate.draw(ax_track, frame_tracked)\n\n for i, j in zip(idx_truth, idx_tracked):\n # if distances[i, j] > percentile_50:\n # # print(f\"Truth {i} -> Track {j}: distance too high: {distances[i, j]}\")\n # continue\n from matplotlib.patches import ConnectionPatch\n\n blob_truth = tracks_truth[i].at(frame_n)\n blob_tracked = tracks_tracked[j].at(frame_n)\n if blob_truth is None or blob_tracked is None:\n continue\n\n norm_distance = normalize(distances[i, j])\n\n annotations.extend([\n ax_truth.annotate(f\"{distances[i, j]:.2f}\", blob_truth.center_xy),\n ])\n con = ConnectionPatch(xyA=blob_truth.center_xy, xyB=blob_tracked.center_xy,\n coordsA=\"data\", coordsB=\"data\",\n axesA=ax_truth, axesB=ax_track,\n color=colormap(norm_distance),\n lw=(norm_distance * 3).astype(int) + 1)\n a = ax_track.add_artist(con)\n artists.append(a)\n fig_comp.canvas.draw_idle()\n\n artists = []\n annotations = []\n frame_n = 0\n exit_flag = False\n play = False\n last_drawn_frame_n = -1\n while not exit_flag and frame_n < len(video):\n if last_drawn_frame_n != frame_n or play:\n draw_figure()\n last_drawn_frame_n = frame_n\n if play:\n frame_n += 1\n plt.pause(0.001)\n@dataclass\nclass ExportLikeMeasures:\n total_EN: int = field(default=0)\n total_SN: int = field(default=0)\n speed_mean: float = field(default=0)\n area_median: float = field(default=0)\n length_median: float = field(default=0)\n width_median: float = field(default=0)\n@dataclass\nclass Measures:\n label: ExportLikeMeasures = field(default=ExportLikeMeasures())\n track: ExportLikeMeasures = field(default=ExportLikeMeasures())\n\ndef export_like_measures(label: LabelingInfo, tracked: TracksCompleteInfo, trackfilter: Dict = None):\n measures = Measures()\n tracks_label = label.filter_tracks(**trackfilter) if trackfilter else label.filter_tracks()\n tracks_tracked = (tracked.filter_tracks(last_frame=label.last_tracked_frame(), **trackfilter) if trackfilter else\n tracked.filter_tracks(last_frame=label.last_tracked_frame()))\n for m, info, tracks in zip([measures.label, measures.track], [label, tracked], [tracks_label, tracks_tracked]):\n total_ants = 0\n for track in tracks:\n direction = info.track_direction(track, tracked.nest_side)\n if direction in (Direction.EN, Direction.SN):\n m.total_EN += 1 if direction == Direction.EN else 0\n m.total_SN += 1 if direction == Direction.SN else 0\n m.speed_mean += track.speed_mean\n m.area_median += track.area_median\n m.length_median += track.length_median\n m.width_median += track.width_median\n total_ants += 1\n m.speed_mean /= total_ants\n m.area_median /= total_ants\n m.length_median /= total_ants\n m.width_median /= total_ants\n return measures\n\n@overload\ndef measure_all_data(truth: LabelingInfo, tracked: TracksInfo, *, trackfilter: Dict = ...) -> Dict: ...\n@overload\ndef measure_all_data(truth: LabelingInfo, tracked: TracksInfo, *, trackfilter: Dict = ...,\n cachedir: Path, file_truth: Path, file_tracked: Path) -> Dict: ...\n@overload\ndef measure_all_data(truth: LabelingInfo, tracked: TracksInfo, *, trackfilter: Dict = ...,\n cachedir: Path, file_truth: Path, file_tracked: Path, return_for_plots=True) -> Tuple: ...\ndef measure_all_data(truth: LabelingInfo, tracked: TracksInfo, *, trackfilter: Dict = None,\n cachedir: Path = None, file_truth: Path = None, file_tracked: Path = None,\n return_for_plots=False):\n \"\"\"Obtiene un conjunto de datos validando ``tracked`` contra ``truth``. Estos datos están divididos en 3 subgrupos,\n y cada uno continene las siguientes medidas de error:\n\n - \"mean_direction\": error en la dirección media (en grados desde la horizontal)\n - \"mean_speed\": error en la velocidad media\n - \"max_speed\": error en la velocidad máxima\n - \"median_area\": error en el área mediana ocupada\n - \"max_area\": error en el área máxima ocupada\n\n Los tres subgrupos antes mencionados son:\n\n - `measures_dev` contiene medidas de error track-por-track promediadas. También cantidades:\n\n - \"discarded_by_video_cutoff\": Cantidad de tracks descartados de la comparación porque comenzaron en el centro (los primeros en cuadro al comenzar la grabación)\n - \"discarded_by_direction\": Cantidad de tracks descartados de ``tracked`` porque no seguían la misma dirección que su correspondiente en ``truth``\n - \"discarded_by_ontological_inertia\": Cantidad de tracks descartados de ``tracked`` porque desaparecieron en el centro\n - \"total_real\": Cantidad total de tracks en ``truth``\n - \"total_tracked\": Cantidad total de tracks en ``tracked``\n - \"total_assigned\": Cantidad de tracks en ``tracked`` que se asignaron a tracks en ``truth``\n - \"total_tracked_non_discarded\": Cantidad en ``tracked`` que no fueron descartados por las razones anteriores\n - \"total_real_interesting\": Cantidad en ``truth`` que no comenzaron en el centro\n\n - `measures_test` contiene medidas de error calculadas globalmente, y los números \"total_real_interesting\" y \"total_tracked_non_discarded\" que son iguales a sus correspondientes en `measures_dev`\n\n - `per_ant_comparisons` tiene medidas de error track-por-track (que promediadas resultan en las que se encuen en `measures_dev`. Además, contiene:\n\n - \"assignment\": tupla (i,j) que indica que el track ``i`` en ``truth`` se corresponde con el track ``j`` en ``tracked``\n - \"distance\": distancia de Hausdorff entre los dos tracks\n - \"first_blob_distance\": distancia en píxeles entre los primeros blobs de cada track\n - \"direction_of_travel\": tupla ((SideIn_i,SideOut_i)),(SideIn_j,SideOut_j)) que indica desde dónde entró y salió cada track\n \"\"\"\n if trackfilter:\n tracks_truth = truth.filter_tracks(**trackfilter)\n tracks_tracked = tracked.filter_tracks(last_frame=truth.last_tracked_frame(), **trackfilter)\n else:\n tracks_truth = truth.filter_tracks()\n tracks_tracked = tracked.filter_tracks(last_frame=truth.last_tracked_frame())\n if cachedir is not None:\n distances_filename = Path(f'{cachedir}/distances__{file_truth.stem}__{file_tracked.stem}.npy')\n else:\n distances_filename = \"\"\n distances = get_distances(tracks_truth, tracks_tracked, distances_filename)\n idx_truth, idx_tracked = linear_sum_assignment(distances)\n assigned_distances = distances[idx_truth, idx_tracked]\n percentile_25 = np.percentile(assigned_distances, 25)\n percentile_50 = np.percentile(assigned_distances, 50)\n percentile_75 = np.percentile(assigned_distances, 75)\n interquartile_range = percentile_75 - percentile_25\n\n per_ant_measures = [\n \"mean_direction\",\n \"mean_speed\",\n \"max_speed\",\n \"median_area\",\n \"max_area\"\n ]\n comparisons = []\n i: int\n j: int\n for i, j in zip(idx_truth, idx_tracked):\n # if distances[i, j] > percentile_50:\n # # only ants that we're confident in\n # continue\n\n track_truth = tracks_truth[i]\n track_tracked = tracks_tracked[j]\n\n comparisons.append({\n \"assignment\": (i, j),\n \"distance\": distances[i, j],\n \"first_blob_distance\": np.linalg.norm(track_truth.first_blob().center - track_tracked.first_blob().center),\n \"direction_of_travel\": (\n track_truth.direction_of_travel(truth.video_shape),\n track_tracked.direction_of_travel(tracked.video_shape)\n ),\n \"errors\": {\n \"mean_direction\": track_truth.direction_mean - track_tracked.direction_mean,\n \"mean_speed\": track_truth.speed_mean - track_tracked.speed_mean,\n \"max_speed\": track_truth.speed_max - track_tracked.speed_max,\n \"median_area\": track_truth.area_median - track_tracked.area_median,\n \"max_area\": track_truth.areas.max() - track_tracked.areas.max(),\n }\n })\n\n measures_dev = {\n \"errors\": {measure: 0 for measure in per_ant_measures},\n # \"discarded_by_hausdorff\": 0,\n \"discarded_by_video_cutoff\": 0,\n \"discarded_by_direction\": 0,\n \"discarded_by_ontological_inertia\": 0,\n \"total_real\": len(tracks_truth),\n \"total_tracked\": len(tracks_tracked),\n \"total_assigned\": len(idx_tracked),\n \"total_tracked_non_discarded\": 0,\n \"total_real_interesting\": 0,\n }\n n = 0\n for comp in comparisons:\n # if comp[\"distance\"] > percentile_50:\n # global_measures[\"discarded_by_hausdorff\"] += 1\n # # in dev, don't consider bad assignments\n # continue\n if Side.Center in comp[\"direction_of_travel\"][0]:\n measures_dev[\"discarded_by_video_cutoff\"] += 1\n # we only check ants that started on an edge, so as to get rid of bad tracks by ontological inertia\n continue\n if comp[\"direction_of_travel\"][0] != comp[\"direction_of_travel\"][1]:\n measures_dev[\"discarded_by_direction\"] += 1\n # if traveling in the wrong direction\n continue\n if Side.Center in comp[\"direction_of_travel\"][1]:\n measures_dev[\"discarded_by_ontological_inertia\"] += 1\n # if ant appears/disappears in center\n continue\n n += 1\n for measure in per_ant_measures:\n measures_dev[\"errors\"][measure] += comp[\"errors\"][measure] ** 2\n if n != 0:\n for measure in per_ant_measures:\n measures_dev[\"errors\"][measure] /= n\n measures_dev[\"total_tracked_non_discarded\"] = n\n measures_dev[\"total_real_interesting\"] = measures_dev[\"total_real\"] - measures_dev[\n \"discarded_by_video_cutoff\"]\n\n interesting_truth_tracks = [track for track in tracks_truth if\n Side.Center not in track.direction_of_travel(truth.video_shape)]\n non_discarded_tracks = [track for track in tracks_tracked if\n Side.Center not in track.direction_of_travel(tracked.video_shape)]\n\n measures_test = {\n \"errors\": {measure: 0 for measure in per_ant_measures},\n \"total_real_interesting\": len(interesting_truth_tracks),\n \"total_tracked_non_discarded\": len(non_discarded_tracks),\n }\n\n global_truth_measures = {measure: 0 for measure in per_ant_measures}\n for track in interesting_truth_tracks:\n global_truth_measures[\"mean_direction\"] += track.direction_mean\n global_truth_measures[\"mean_speed\"] += track.speed_mean\n global_truth_measures[\"max_speed\"] += track.speed_max\n global_truth_measures[\"median_area\"] += track.area_median\n global_truth_measures[\"max_area\"] += track.areas.max()\n if len(interesting_truth_tracks) != 0:\n global_truth_measures = {measure: value / len(interesting_truth_tracks) for measure, value in\n global_truth_measures.items()}\n global_track_measures = {measure: 0 for measure in per_ant_measures}\n for track in non_discarded_tracks:\n global_track_measures[\"mean_direction\"] += track.direction_mean\n global_track_measures[\"mean_speed\"] += track.speed_mean\n global_track_measures[\"max_speed\"] += track.speed_max\n global_track_measures[\"median_area\"] += track.area_median\n global_track_measures[\"max_area\"] += track.areas.max()\n if len(non_discarded_tracks) != 0:\n global_track_measures = {measure: value / len(non_discarded_tracks) for measure, value in\n global_track_measures.items()}\n\n measures_test[\"errors\"] = {\n measure: abs(global_truth_measures[measure] - global_track_measures[measure]) /\n global_truth_measures[measure] for measure in per_ant_measures\n }\n\n measures = {'measures_dev': measures_dev, 'measures_test': measures_test, 'per_ant_comparisons': comparisons}\n if return_for_plots:\n return measures, distances, idx_truth, idx_tracked\n return measures\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Comparar dos archivos .trk\")\n\n parser.add_argument('truth')\n parser.add_argument('tracked')\n parser.add_argument('--video', '-v', type=str, default=None,\n help=\"Video del que fueron generados, para graficar ambos\")\n parser.add_argument('--output', '-o', type=str, default=\"data\", help=\"Directorio de salida\")\n parser.add_argument('--cache', type=bool, default=False, help=\"Cachear distancias entre tracks de .trk y .tag\")\n\n import pathlib\n args = parser.parse_args()\n file_tracked = pathlib.Path(args.tracked)\n file_truth = pathlib.Path(args.truth)\n\n complete = False\n try:\n tracked = TracksCompleteInfo.load(file_tracked)\n complete = True\n except:\n tracked = TracksInfo.load(file_tracked)\n truth = LabelingInfo.load(file_truth)\n if complete:\n truth = reposition_into_crop(truth, tracked.crop_rect)\n\n video: Optional[Video] = None\n if args.video is not None:\n video = pims.PyAVReaderIndexed(args.video)[:]\n if complete:\n video = crop(video, crop_from_rect(video.frame_shape[0:2], tracked.crop_rect))\n\n if args.cache:\n measures, distances, idx_truth, idx_tracked = measure_all_data(truth, tracked,\n cachedir=Path(\".cachedata\"),\n file_truth=file_truth, file_tracked=file_tracked,\n return_for_plots=True)\n else:\n measures, distances, idx_truth, idx_tracked = measure_all_data(truth, tracked, return_for_plots=True)\n\n results_filename = pathlib.Path(args.output) / 'validation__{file_truth.stem}__{file_tracked.stem}.json'\n with open(results_filename, 'w') as f:\n f.write(to_json(measures))\n\n if video is not None:\n draw_results(video=video,\n tracks_truth=truth.filter_tracks(),\n tracks_tracked=tracked.filter_tracks(last_frame=truth.last_tracked_frame()),\n distances=distances,\n idx_truth=idx_truth,\n idx_tracked=idx_tracked)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5740267634391785,
"alphanum_fraction": 0.580368161201477,
"avg_line_length": 41.68421173095703,
"blob_id": "40cd1f6e24eca613c868b7e0694c1743ad550a37",
"content_id": "19d9127e015fc13b870c0d53e07c3b917d4c9a53",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22727,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 532,
"path": "/ant_tracker/tracker/segmenter.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pims\nimport skimage.draw as skdraw\nimport skimage.feature as skfeature\nimport skimage.filters as skfilters\nimport skimage.measure as skmeasure\nimport skimage.morphology as skmorph\nimport skimage.segmentation as skseg\nimport ujson\nfrom packaging.version import Version\nfrom scipy.spatial import cKDTree\nfrom typing import Any, Dict, Generator, List, Tuple, TypedDict, Sequence\n\nfrom .blob import Blob\nfrom .common import BinaryMask, ColorImage, GrayscaleImage, ProgressBar, Video, rgb2gray, to_json, FrameNumber, \\\n eq_gen_it\nfrom .parameters import SegmenterParameters, LogWSegmenterParameters, DohSegmenterParameters\n\nSegmenterVersion = Version(\"2.0.2dev1\")\n\nBlobs = List[Blob]\n\ndef _get_mask_with_steps(frame: GrayscaleImage, last_frames: List[GrayscaleImage], *, params: SegmenterParameters):\n if len(last_frames) == 0:\n background = GrayscaleImage(np.zeros_like(frame))\n else:\n background = GrayscaleImage(np.median(last_frames, axis=0))\n\n movement: GrayscaleImage = np.abs(frame - background)\n\n mask: BinaryMask = movement > params.movement_detection_threshold\n\n # Descartar la máscara si está llena de movimiento (se movió la cámara!)\n if np.count_nonzero(mask) > np.size(mask) * params.discard_percentage:\n zeros = np.zeros(mask.shape, dtype='bool')\n return zeros, zeros, zeros, zeros, background, movement\n\n radius = params.minimum_ant_radius\n closed_mask = skmorph.binary_closing(mask, skmorph.disk(round(radius)))\n opened_mask = skmorph.binary_opening(closed_mask, skmorph.disk(round(radius * 0.8)))\n dilated_mask = skmorph.binary_dilation(opened_mask, skmorph.disk(round(radius)))\n\n return dilated_mask, mask, closed_mask, opened_mask, background, movement\n\ndef _get_mask(frame: GrayscaleImage, last_frames: List[GrayscaleImage], *, params: SegmenterParameters):\n return _get_mask_with_steps(frame, last_frames, params=params)[0]\n\ndef _get_blobs_in_frame_with_steps_logw(frame: GrayscaleImage, movement_mask: BinaryMask, params: SegmenterParameters,\n prev_blobs: List[Blob]):\n def empty():\n return [], np.zeros_like(frame, dtype=float), \\\n np.zeros_like(frame, dtype=float), \\\n np.zeros_like(frame, dtype=float), \\\n np.zeros_like(frame, dtype=bool), \\\n np.zeros_like(frame, dtype='uint8')\n\n if not movement_mask.any():\n return empty()\n gauss = skfilters.gaussian(frame, sigma=params.gaussian_sigma)\n log = skfilters.laplace(gauss, mask=movement_mask)\n\n if not log.any():\n return empty()\n\n try:\n t = skfilters.threshold_isodata(log)\n except IndexError:\n print(\"Umbralizado fallido (no había bordes significativos en las regiones en movimiento). Salteando frame\")\n return empty()\n threshed_log = log.copy()\n threshed_log[threshed_log > t] = 0\n\n intensity_mask = threshed_log.copy()\n intensity_mask[intensity_mask != 0] = True\n intensity_mask[intensity_mask == 0] = False\n\n blobs: Blobs = []\n # region Watershed if there were blobs too close to eachother in last frame\n intersection_zone = np.zeros_like(frame, dtype='bool')\n close_markers_labels = np.zeros_like(frame, dtype='uint8')\n if len(prev_blobs) > 1:\n points = np.array([[blob.center_xy.y, blob.center_xy.x] for blob in prev_blobs])\n kdt = cKDTree(points)\n idx = []\n # every blob (kdt) against every other blob (points[i])\n for i, blob in enumerate(prev_blobs[:-1]):\n new = list(kdt.query_ball_point(points[i], maximum_clear_radius(blob.radius)))\n if len(new) == 1:\n new.remove(i)\n idx.extend(new)\n close_idx = np.unique(idx)\n if len(close_idx) > 0:\n close_markers_mask = np.zeros_like(frame, dtype='uint8')\n for idx in close_idx:\n rr, cc = skdraw.disk((points[idx][0], points[idx][1]),\n int(maximum_clear_radius(prev_blobs[idx].radius)),\n shape=intersection_zone.shape)\n intersection_zone[rr, cc] = True\n rr, cc = skdraw.disk((points[idx][0], points[idx][1]), int(params.minimum_ant_radius * 1.5),\n shape=intersection_zone.shape)\n close_markers_mask[rr, cc] = idx + 1\n close_markers_labels = skseg.watershed(np.zeros_like(frame), markers=close_markers_mask,\n mask=intensity_mask * intersection_zone)\n props = skmeasure.regionprops(close_markers_labels)\n for p in props:\n if p.area < minimum_ant_area(params.minimum_ant_radius):\n continue\n label: bool = p.label\n blobs.append(Blob(imshape=frame.shape, mask=(close_markers_labels == label),\n approx_tolerance=params.approx_tolerance))\n # endregion\n\n mask_not_intersecting = intensity_mask * (~intersection_zone)\n labels, nlabels = skmeasure.label(mask_not_intersecting, return_num=True)\n props = skmeasure.regionprops(labels)\n\n for p in props:\n if p.area < minimum_ant_area(params.minimum_ant_radius):\n continue\n label: bool = p.label\n blobs.append(Blob(imshape=frame.shape, mask=(labels == label), approx_tolerance=params.approx_tolerance))\n\n return blobs, gauss, log, threshed_log, intersection_zone, (close_markers_labels + labels)\n\ndef _get_blobs_in_frame_with_steps_doh(frame: GrayscaleImage, movement_mask: BinaryMask, params: SegmenterParameters):\n if not movement_mask.any():\n return [], np.zeros_like(frame, dtype=float), \\\n np.zeros_like(frame, dtype=float), \\\n np.zeros_like(frame, dtype='uint8'), \\\n np.zeros_like(frame, dtype='uint8'),\n masked_frame = frame.copy()\n masked_frame[~movement_mask] = 255\n yxs: np.ndarray = skfeature.blob_doh(masked_frame, min_sigma=params.doh_min_sigma, max_sigma=params.doh_max_sigma,\n num_sigma=params.doh_num_sigma)\n markers = yxs[:, 0:2].astype(int).tolist()\n\n marker_mask = np.zeros_like(frame, dtype='uint8')\n for _id, marker in enumerate(markers, 1):\n if not movement_mask[marker[0], marker[1]]:\n continue\n marker_mask[marker[0], marker[1]] = _id\n # rr, cc = skdraw.circle_perimeter(marker[0], marker[1], 10, shape=masked_frame.shape)\n # masked_frame[rr, cc] = 0\n\n gauss = skfilters.gaussian(frame, sigma=params.gaussian_sigma)\n log = skfilters.laplace(gauss, mask=movement_mask)\n\n t = skfilters.threshold_isodata(log)\n labels = skseg.watershed(log, markers=marker_mask, mask=(log < t))\n props = skmeasure.regionprops(labels)\n\n blobs: Blobs = []\n for p in props:\n if p.area < minimum_ant_area(params.minimum_ant_radius):\n continue\n label: bool = p.label\n blobs.append(Blob(imshape=frame.shape, mask=(labels == label), approx_tolerance=params.approx_tolerance))\n\n return blobs, gauss, log, labels, masked_frame\n\ndef _get_blobs_logw(frame: GrayscaleImage, movement_mask: BinaryMask, params: SegmenterParameters,\n prev_blobs: List[Blob]):\n return _get_blobs_in_frame_with_steps_logw(frame, movement_mask, params, prev_blobs)[0]\n\ndef _get_blobs_doh(frame: GrayscaleImage, movement_mask: BinaryMask, params: SegmenterParameters):\n return _get_blobs_in_frame_with_steps_doh(frame, movement_mask, params)[0]\n\ndef minimum_ant_area(min_radius):\n return np.pi * min_radius ** 2\n\ndef maximum_clear_radius(radius):\n return radius * 3\n\nclass Segmenter:\n def __init__(self, video: Video = None, params: SegmenterParameters = None):\n if video is None:\n return\n self.__frames_with_blobs: Dict[FrameNumber, Blobs] = {}\n self.__last_frames = []\n self.__video = video\n self.__prev_blobs: Tuple[FrameNumber, Blobs] = (-1, [])\n self.params = params\n self.video_length = len(video)\n self.video_shape = tuple(video[0].shape[0:2])\n\n @property\n def is_finished(self):\n if not self.__frames_with_blobs: return False\n segmented_all_frames = eq_gen_it(self.__frames_with_blobs.keys(), range(self.video_length))\n return segmented_all_frames\n\n @property\n def reached_last_frame(self):\n return bool(self.__frames_with_blobs) and max(self.__frames_with_blobs) == self.video_length - 1\n\n @classmethod\n def segment_single(cls, params: SegmenterParameters, frame: np.ndarray, previous_frames: Sequence[ColorImage]):\n gray_frame = rgb2gray(frame)\n pvf = [rgb2gray(p) for p in previous_frames]\n mask = _get_mask(gray_frame, pvf, params=params)\n mock = cls()\n mock.params = params\n return cls._get_blobs(mock, gray_frame, mask, [])\n\n def _get_mask(self, frame):\n return _get_mask(frame, self.__last_frames, params=self.params)\n\n def _get_blobs(self, gray_frame, mask, prev_blobs) -> Blobs:\n raise NotImplementedError\n\n def __cycle_last_frames(self, frame: GrayscaleImage):\n if len(self.__last_frames) < self.params.movement_detection_history:\n self.__last_frames.append(frame)\n else:\n self.__last_frames[:-1] = self.__last_frames[1:]\n self.__last_frames[-1] = frame\n\n def segment_rolling_continue(self):\n \"\"\"Continuar segmentando desde el último frame segmentado.\"\"\"\n yield from self.segment_rolling_from(max(self.__frames_with_blobs) + 1)\n\n def segment_rolling_from(self, from_frame_n: FrameNumber, prev_blobs: Blobs = None):\n \"\"\"Segmentar desde un frame en particular. Bajo operación normal, ``prev_blobs`` debe ser None.\n Pueden ocurrir estas situaciones:\n\n - Se comienza desde el frame 0: no hay blobs previos.\n - Se comienza desde un frame segmentado o el siguiente al último: Usa los blobs en ``__frames_with_blobs``.\n Ver también: ``segment_rolling_continue()``\n - Se comienza desde algún otro frame en particular: se deberá proporcionar la lista de blobs previos,\n probablemente de una instancia de ``tracking.Tracker``. De no tener este dato, puede pasarse una lista vacía,\n a riesgo de perder reproducibilidad.\n \"\"\"\n if self.__video is None:\n raise ValueError(\"Este segmentador no tiene un video cargado. Use set_video()\")\n if from_frame_n < 0 or from_frame_n >= self.video_length:\n raise ValueError(f\"Frame {from_frame_n} inexistente\")\n if from_frame_n == 0:\n prev_blobs = []\n elif self.__frames_with_blobs and (from_frame_n - 1) in self.__frames_with_blobs:\n prev_blobs = self.__frames_with_blobs[from_frame_n - 1]\n elif prev_blobs is None:\n raise ValueError(f\"Debe proporcionar los blobs del frame anterior ({from_frame_n - 1}): \"\n \"puede obtenerlos a partir del Tracker \"\n \"si se dispone de él, o bien proporcionar una lista vacía \"\n \"(corriendo el riesgo de perder reproducibilidad)\")\n n = min(self.params.movement_detection_history, from_frame_n)\n self.__last_frames = [rgb2gray(f) for f in self.__video[from_frame_n - n:from_frame_n]] if from_frame_n != 0 else []\n for frame_n, frame in enumerate(self.__video[from_frame_n:], from_frame_n):\n if frame_n in self.__frames_with_blobs:\n yield frame_n, self.__frames_with_blobs[frame_n]\n else:\n gray_frame = rgb2gray(frame)\n mask = self._get_mask(gray_frame)\n blobs = self._get_blobs(gray_frame, mask, prev_blobs)\n self.__cycle_last_frames(gray_frame)\n self.__frames_with_blobs[frame_n] = blobs\n self.__prev_blobs = (frame_n, blobs)\n prev_blobs = blobs\n yield frame_n, blobs\n\n @property\n def frames_with_blobs(self) -> Generator[Tuple[FrameNumber, Blobs], None, None]:\n if self.is_finished:\n yield from self.__frames_with_blobs.items()\n return\n yield from self.segment_rolling_from(0)\n\n def blobs_at(self, frame_n: FrameNumber):\n if frame_n in self.__frames_with_blobs:\n return self.__frames_with_blobs[frame_n]\n else:\n raise KeyError(\"Ese cuadro no fue segmentado aún\")\n\n def set_video(self, video: Video):\n \"\"\"Usar luego de cargar un segmentador serializado.\"\"\"\n self.__video = video\n\n @property\n def version(self):\n raise NotImplementedError\n\n class Serial(TypedDict):\n frames_with_blobs: Dict[FrameNumber, List[Blob.Serial]]\n parameters: Dict[str, Any]\n video_length: int\n video_shape: Tuple[int, int]\n version: str\n\n def encode(self):\n return {\n 'frames_with_blobs': {str(frame): [blob.encode() for blob in blobs] for frame, blobs in\n self.__frames_with_blobs.items()},\n 'parameters': dict(self.params.items()),\n 'video_length': self.video_length,\n 'video_shape': self.video_shape,\n 'version': str(self.version)\n }\n\n @classmethod\n def decode(cls, d: 'Segmenter.Serial'):\n segmenter = cls()\n shape = d['video_shape']\n segmenter.__frames_with_blobs = {\n FrameNumber(frame): [Blob.decode(blob, shape) for blob in blobs]\n for frame, blobs in d['frames_with_blobs'].items()\n }\n segmenter.params = SegmenterParameters(d['parameters'])\n segmenter.video_length = d['video_length']\n segmenter.video_shape = shape\n return segmenter\n\n def serialize(self) -> str:\n return to_json(self.encode())\n\n @classmethod\n def deserialize(cls, *, filename=None, jsonstring=None):\n if filename is not None:\n with open(filename, 'r') as file:\n segmenter_dict = ujson.load(file)\n elif jsonstring is not None:\n segmenter_dict = ujson.loads(jsonstring)\n else:\n raise TypeError(\"Provide either JSON string or filename.\")\n return cls.decode(segmenter_dict)\n\nclass LogWSegmenter(Segmenter):\n def __init__(self, video: Video = None, params: SegmenterParameters = None):\n if params is None: params = LogWSegmenterParameters()\n super(LogWSegmenter, self).__init__(video, params)\n\n @property\n def version(self):\n return Version('2.0.2dev1')\n\n def _get_blobs(self, gray_frame, mask, prev_blobs):\n return _get_blobs_logw(gray_frame, mask, self.params, prev_blobs)\n\nclass DohSegmenter(Segmenter):\n def __init__(self, video: Video = None, params: SegmenterParameters = None):\n if params is None: params = DohSegmenterParameters()\n super(DohSegmenter, self).__init__(video, params)\n\n @property\n def version(self):\n return Version('2.0.2dev2')\n\n def _get_blobs(self, gray_frame, mask, prev_blobs):\n return _get_blobs_doh(gray_frame, mask, self.params)\n\n# noinspection PyUnboundLocalVariable\ndef main():\n from matplotlib import pyplot as plt\n from matplotlib.figure import Figure\n from matplotlib.widgets import Slider\n from mpl_toolkits.axes_grid1 import ImageGrid\n\n from .plotcommon import Animate, PageSlider\n from .common import Colors\n import argparse\n parser = argparse.ArgumentParser(description=\"Visualize segmentation of a video\")\n parser.add_argument('file')\n parser.add_argument('--firstFrame', '-f', type=int, default=None, metavar=\"F\",\n help=\"Primer frame a procesar\")\n parser.add_argument('--lastFrame', '-l', type=int, default=None, metavar=\"L\",\n help=\"Último frame a procesar\")\n parser.add_argument('--draw', '-d', type=bool, default=False, metavar=\"D\",\n help=\"Mostrar la segmentación en imágenes\")\n parser.add_argument('--play', '-p', type=bool, default=False, metavar=\"P\",\n help=\"Avanzar frames automáticamente (con --draw)\")\n\n args = parser.parse_args()\n file: str = args.file\n draw = args.draw\n play = args.play\n\n video = pims.PyAVReaderIndexed(f\"{file}\")\n p = SegmenterParameters(gaussian_sigma=5)\n\n frame_n = 0 if args.firstFrame is None else args.firstFrame\n last_frame_to_process = len(video) if args.lastFrame is None else args.lastFrame\n print(f\"Processing from frames {frame_n} to {last_frame_to_process}\")\n last_drawn_frame_n = -1\n exit_flag = False\n update = False\n update_page = False\n page = 0\n total_pages = 13\n if draw:\n def on_key_press(event):\n nonlocal frame_n, exit_flag, play, page, page_slider, update, update_page\n if event.key == 'a':\n frame_n -= 1\n elif event.key == 'd':\n frame_n += 1\n elif event.key == 'p':\n play = not play\n update = True\n elif event.key == 'k':\n page = (page + 1) % total_pages\n page_slider.set_val(page)\n update_page = True\n elif event.key == 'j':\n page = (page - 1) % total_pages\n page_slider.set_val(page)\n update_page = True\n elif event.key == 't':\n nonlocal log\n try:\n log\n except UnboundLocalError:\n print(\"log undefined\")\n return\n skfilters.try_all_threshold(log)\n elif event.key == 'escape':\n exit_flag = True\n\n fig: Figure = plt.figure()\n grid = ImageGrid(fig, (0.1, 0.1, 0.8, 0.8),\n nrows_ncols=(1, 2),\n share_all=True,\n axes_pad=0.05,\n label_mode=\"1\",\n )\n fig.suptitle(f\"{frame_n=}\")\n fig.canvas.mpl_connect('key_press_event', on_key_press)\n\n def __sigma_update_fn(val):\n nonlocal p, update\n p.gaussian_sigma = val\n update = True\n\n # noinspection PyPep8Naming\n sigmaS = Slider(fig.add_axes([0.1, 0.1, 0.8, 0.04]), 'sigma', 1., 20, valinit=p.gaussian_sigma, valstep=0.2)\n sigmaS.on_changed(__sigma_update_fn)\n\n ax_page_slider = fig.add_axes([0.1, 0.05, 0.8, 0.04])\n page_slider = PageSlider(ax_page_slider, 'Page', total_pages, activecolor=\"orange\")\n\n def __page_update_fn(val):\n nonlocal page, update_page\n i = int(val)\n page = i\n update_page = True\n\n page_slider.on_changed(__page_update_fn)\n else:\n progress_bar = ProgressBar(last_frame_to_process)\n\n print(f\"{exit_flag=}\")\n print(f\"{frame_n=}\")\n print(f\"{len(video)=}\")\n last_frames = []\n\n def draw_step(ax_, step):\n Animate.draw(ax_, step['im'], autoscale=step.get('autoscale', False))\n ax_.set_title(step['title'])\n\n prev_blobs = []\n while not exit_flag and frame_n < last_frame_to_process:\n if last_drawn_frame_n != frame_n or update:\n print(f\"{frame_n=}\")\n frame: ColorImage = video[frame_n]\n\n grayframe = rgb2gray(frame)\n\n if last_drawn_frame_n != frame_n:\n movement_mask, first_mask, closed_mask, opened_mask, background, movement = _get_mask_with_steps(\n grayframe, last_frames, params=p)\n if len(last_frames) < p.movement_detection_history:\n last_frames.append(grayframe)\n else:\n last_frames[:-1] = last_frames[1:]\n last_frames[-1] = grayframe\n\n _out = _get_blobs_in_frame_with_steps_logw(grayframe,\n movement_mask,\n params=p,\n prev_blobs=prev_blobs)\n blobs, gauss, log, threshed_log, intersection_zone, labels = _out\n\n prev_blobs = blobs\n frame_with_blobs = Blob.draw_blobs(blobs, frame).copy()\n\n if draw:\n for blob in blobs:\n # only do watershed where previous frame blobs had intersecting circles\n rr, cc = skdraw.circle_perimeter(blob.center_xy[1], blob.center_xy[0],\n int(p.minimum_ant_radius),\n shape=frame_with_blobs.shape)\n frame_with_blobs[rr, cc] = Colors.RED\n rr, cc = skdraw.circle_perimeter(blob.center_xy[1], blob.center_xy[0],\n int(maximum_clear_radius(blob.radius)),\n shape=frame_with_blobs.shape)\n frame_with_blobs[rr, cc] = Colors.BLUE\n\n fig.suptitle(f\"{frame_n=}\")\n last_drawn_frame_n = frame_n\n if play:\n frame_n += 1\n update_page = True\n update = False\n else:\n frame_n += 1\n progress_bar.next()\n if draw:\n if update_page:\n steps = [\n {'im': frame, 'title': \"frame\"},\n {'im': movement, 'title': \"movement\", 'autoscale': True},\n {'im': first_mask, 'title': \"first_mask\"},\n {'im': closed_mask, 'title': \"closed_mask\"},\n {'im': opened_mask, 'title': \"opened_mask\"},\n {'im': movement_mask, 'title': \"dilated_mask\"},\n {'im': frame, 'title': \"frame\"},\n {'im': gauss, 'title': \"gauss\", 'autoscale': True},\n {'im': log, 'title': \"log\", 'autoscale': True},\n {'im': threshed_log, 'title': \"threshed_log\", 'autoscale': True},\n {'im': intersection_zone, 'title': \"intersection_zone\"},\n {'im': labels, 'title': \"labels\", 'autoscale': True},\n {'im': frame_with_blobs, 'title': \"blobs\"},\n ]\n\n draw_step(grid[0], steps[page])\n draw_step(grid[1], steps[(page + 1) % total_pages])\n\n plt.draw()\n update_page = False\n plt.pause(0.05)\n plt.close()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.536074161529541,
"alphanum_fraction": 0.5429262518882751,
"avg_line_length": 37.765625,
"blob_id": "2d60cc60d1473bafed5e35f8682478aa0408e60b",
"content_id": "44932be593160ea2ffaf12281e0c841d9981f897",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2483,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 64,
"path": "/ant_tracker/tracker_gui/excepthook.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import traceback\n\nimport PySimpleGUI as sg\nimport datetime\nimport re\nimport sys\nfrom pathlib import Path\n\nfrom . import constants as C\nfrom .guicommon import align\nfrom .loading_window import LoadingWindow\n\ndef make_excepthook(path: Path, in_routine=False):\n def excepthook(exc_type, exc_value, exc_tb):\n LoadingWindow.close_all()\n lines = traceback.format_exception(exc_type, exc_value, exc_tb)\n\n def shorten(match):\n _path = Path(match.group(1))\n relevant_parts = []\n for p in _path.parts[::-1]:\n relevant_parts.append(p)\n if p in (\"envs\", \"Miniconda3\", \"Lib\", \"site-packages\", \"ant_tracker\"):\n break\n return f'File \"{Path(*relevant_parts[::-1])}\"'\n\n # if PyInstaller-frozen, shorten paths for privacy\n if C.FROZEN:\n lines = [re.sub(r'File \"([^\"]+)\"', shorten, line) for line in lines]\n\n tb = \"\".join(lines)\n print(tb)\n filename = str(path / (\"error-\" + datetime.datetime.now(tz=None).strftime('%Y-%m-%dT%H_%M_%S') + \".log\"))\n with open(filename, \"w\") as f:\n f.write(tb)\n import textwrap\n mlwidth = 100\n mlheight = 15\n w = sg.Window(\"Error\", [\n [sg.Text(f\"Se produjo un error. El siguiente archivo contiene los detalles:\")],\n [sg.InputText(filename, disabled=True, k='-FILE-')],\n [sg.Text(textwrap.fill(\n \"Por favor envíe el mismo \" + (\n \"y, en lo posible, los archivos \"\n \".anttrackersession y .trk en la misma carpeta \" if in_routine else \"\") +\n \"a la persona que le proporcionó este programa.\", 100))],\n [sg.Multiline(tb, size=(mlwidth, mlheight), disabled=True, k='-D-', visible=False)],\n [align(sg.Button(\"Ver detalle\", k='-DB-'), 'left'), align(sg.CloseButton(\"Cerrar\"), 'right')],\n ], finalize=True)\n w['-FILE-'].expand(expand_x=True)\n detail_visible = False\n while True:\n event, values = w.read()\n if event == sg.WIN_CLOSED:\n break\n elif event == '-DB-':\n x, y = w.CurrentLocation()\n w.move(x - int(mlwidth * 1.5), y - mlheight * 10)\n detail_visible = not detail_visible\n w['-D-'].update(visible=detail_visible)\n w['-DB-'].update(visible=False)\n sys.exit(0)\n\n return excepthook\n"
},
{
"alpha_fraction": 0.49276202917099,
"alphanum_fraction": 0.49565720558166504,
"avg_line_length": 24.02898597717285,
"blob_id": "706944ec82c8ba0fb48a5da78bd9623f99eacef8",
"content_id": "01e4ba6e9b0edb38db8889071c48bdef17113edd",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1727,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 69,
"path": "/AntTracker.spec",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "# -*- mode: python ; coding: utf-8 -*-\n\nimport os\n\nconsole = True\nupx = False\nupx_exclude = ['ucrtbase.dll', 'VCRUNTIME140.dll']\n\ndatas = [\n ('ant_tracker/tracker_gui/model.tflite', '.'),\n ('ant_tracker/tracker_gui/images', 'images'),\n]\n\nbinaries = []\n\nblock_cipher = None\na = Analysis(['tracker_main.py'],\n pathex=[],\n binaries=binaries,\n datas=datas,\n hiddenimports=['pkg_resources.py2_warn'],\n hookspath=[],\n runtime_hooks=[],\n excludes=[],\n win_no_prefer_redirects=False,\n win_private_assemblies=False,\n cipher=block_cipher,\n noarchive=True)\n\npyz = PYZ(a.pure, a.zipped_data,\n cipher=block_cipher)\n\n# # one-file mode\n# exe = EXE(pyz,\n# a.scripts,\n# a.binaries,\n# a.zipfiles,\n# a.datas,\n# # [],\n# name='AntTracker',\n# debug=False,\n# bootloader_ignore_signals=False,\n# strip=False,\n# upx=upx,\n# upx_exclude=upx_exclude,\n# runtime_tmpdir=None,\n# console=console)\n\n# folder mode\nexe = EXE(pyz,\n a.scripts,\n # [('v', None, 'OPTION')], # Verbose output\n exclude_binaries=True,\n name='AntTracker',\n debug=False,\n bootloader_ignore_signals=False,\n strip=False,\n upx=upx,\n console=console,\n icon=\"ant_tracker/tracker_gui/images/icon.ico\")\n\ncoll = COLLECT(exe,\n a.binaries,\n a.zipfiles,\n a.datas,\n strip=False,\n upx=upx,\n upx_exclude=upx_exclude,\n name='AntTracker')\n"
},
{
"alpha_fraction": 0.5416133403778076,
"alphanum_fraction": 0.7285531163215637,
"avg_line_length": 19.0256404876709,
"blob_id": "0c2f26eab481cc0d72bde932e305bbd8ad97d1f5",
"content_id": "252ef2dcca93a362079c987452d265263853741c",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 781,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 39,
"path": "/requirements-tracker.txt",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "altgraph==0.17\nav==8.0.3\ncertifi==2020.6.20\ncycler==0.10.0\ndecorator==4.4.2\net-xmlfile==1.0.1\nfilterpy==1.4.5\nfuture==0.18.2\nimageio==2.9.0\njdcal==1.4.1\nkiwisolver==1.3.1\nmatplotlib==3.2.2\nmemoized-property==1.0.3\nnatsort==7.0.1\nnetworkx==2.5\nnumpy==1.18.5\nopenpyxl==3.0.5\npackaging==20.4\npefile==2019.4.18\nPillow==8.0.1\nPIMS==0.5\npyinstaller==4.0\npyinstaller-hooks-contrib==2020.10\npyparsing==2.4.7\npypiwin32==223\nPySimpleGUI==4.32.1\npython-dateutil==2.8.1\nPyWavelets==1.1.1\npywin32==300\npywin32-ctypes==0.2.0\nscikit-image==0.17.2\nscipy==1.5.4\nscreeninfo==0.6.6\nsix==1.15.0\nslicerator==1.0.0\ntflite-runtime @ https://github.com/google-coral/pycoral/releases/download/release-frogfish/tflite_runtime-2.5.0-cp38-cp38-win_amd64.whl\ntifffile==2020.10.1\nujson==4.0.1\nwincertstore==0.2\n"
},
{
"alpha_fraction": 0.6574548482894897,
"alphanum_fraction": 0.6759527325630188,
"avg_line_length": 33.77519226074219,
"blob_id": "c3404de091a598b92c8d001e9bd037a19783fc7b",
"content_id": "6700c71a969854b3c3e9cadc809360ebf1fbfb3a",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4488,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 129,
"path": "/ant_tracker/labeler/AntStats.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from classes import *\nimport cv2 as cv\nimport numpy as np\nimport argparse\nimport datetime\nfrom itertools import chain\n\nparser = argparse.ArgumentParser()\nparser.add_argument('filename',type=str,help=\"[Nombre de archivo]{.mp4,.tag,.rtg}\")\nparser.add_argument('--draw','-d',action=\"store_const\",const=True,default=False,help=\"Dibujar trayectorias\")\nparser.add_argument('--save','-s',action=\"store_const\",const=True,default=False,help=\"Guardar trayectorias como imágenes\")\n\nargs = parser.parse_args()\n\nnp.set_printoptions(formatter={'float': '{: 0.3f}'.format})\ndef drawTrajectory(trajectory: List[Rect], img, antId):\n color = getNextColor.forId(antId)\n points = [rect.center() for rect in trajectory]\n\n points = np.int0(points)\n return cv.polylines(img, [points], False, color, 1)\ndef toTuple(point: Vector) -> Tuple[int,int]:\n return tuple(point.astype(int))\n\nfilename = args.filename\ndraw = args.draw\nsaveFrames = args.save\n\nstatsDict = dict({\n \"filename\": filename,\n \"ants\": [],\n \"goingUpAvgVel\": 0,\n \"goingDnAvgVel\": 0,\n \"goingUpN\": 0,\n \"goingDnN\": 0\n })\n\ntracker = Tracker.deserialize(filename=f\"./{filename}-tracked.rtg\")\n# tracker = Tracker.deserialize(filename=f\"./{filename}-labeled.rtg\")\n\nif draw or saveFrames:\n video = cv.VideoCapture(f\"./{filename}.mp4\")\n _,originalFrame = video.read()\nif saveFrames:\n framesToSave = []\n\ncrossingAnts = chain(tracker.getAntsThatCrossed(CrossDirection.GoingDown),tracker.getAntsThatCrossed(CrossDirection.GoingUp))\n\ngoingUpAvgVel = np.ndarray(2)\ngoingUpN = 0\ngoingDnAvgVel = np.ndarray(2)\ngoingDnN = 0\n\nant: TrackedAnt\nfor ant in crossingAnts:\n frameAndVels, averageVel, averageSpeed = ant.getVelocity()\n maxSpeed = max([np.linalg.norm(vel) for vel in frameAndVels[1]])\n direction = tracker.getCrossDirection(ant)\n trajectory = ant.getTrajectory()\n rect: Rect\n rectSizes = [rect.size() for rect in trajectory]\n avgSize = np.mean(rectSizes)\n medianSize = np.median(rectSizes)\n stdShape = np.std([rect.ratio() for rect in trajectory])\n stdSize = np.std(rectSizes)\n leafHolding = ant.isHoldingLeaf() == HoldsLeaf.Yes\n\n if direction == CrossDirection.GoingUp:\n goingUpAvgVel += averageVel\n goingUpN += 1\n if direction == CrossDirection.GoingDown:\n goingDnAvgVel += averageVel\n goingDnN += 1\n\n print(f\"{'[LEAF]' if leafHolding else '[NOLF]'} ID: {ant.id}. Avg. Vel: {averageVel}. Avg. Spd: {averageSpeed}.\")\n statsDict[\"ants\"].append(dict({\n \"id\":ant.id,\n \"avgVel\":averageVel.tolist(),\n \"avgSpd\":averageSpeed,\n \"maxSpd\":maxSpeed,\n \"avgSize\":avgSize,\n \"medianSize\":medianSize,\n \"stdSize\":stdSize,\n \"stdShape\":stdShape,\n \"direction\":direction,\n \"leafHolding\":leafHolding\n }))\n\n if draw or saveFrames:\n firstFrame = originalFrame.copy()\n firstFrame = cv.putText(firstFrame,'[LEAF]' if leafHolding else '[NOLF]',(20,20),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n firstFrame = cv.putText(firstFrame,f\"Av.Vel: {averageVel}\",(20,40),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n firstFrame = cv.putText(firstFrame,f\"Av.Spd: {averageSpeed}\",(20,60),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n cv.arrowedLine(firstFrame, (20,80), toTuple((20,80) + averageVel*5), (0,0,0), 1, tipLength=.3)\n\n for frame,vel in frameAndVels:\n rect1 = ant.getRectAtFrame(frame)\n pt1 = toTuple(rect1.center())\n pt2 = toTuple(rect1.center() + vel)\n cv.arrowedLine(firstFrame, pt1, pt2, (0,0,0), 1, tipLength=1)\n firstFrame = drawTrajectory(ant.getTrajectory(),firstFrame,ant.id)\n # firstFrame = cv.putText(firstFrame,str(ant.id),(50,50),cv.FONT_HERSHEY_SIMPLEX,1,255)\n if draw:\n cv.imshow(str(ant.id),firstFrame)\n if saveFrames:\n framesToSave.append((ant.id,firstFrame))\n\nif draw: k = cv.waitKey(00) & 0xff\n\ngoingUpAvgVel /= goingUpN\ngoingDnAvgVel /= goingDnN\n\nstatsDict[\"goingUpAvgVel\"] = goingUpAvgVel\nstatsDict[\"goingDnAvgVel\"] = goingDnAvgVel\nstatsDict[\"goingUpN\"] = goingUpN\nstatsDict[\"goingDnN\"] = goingDnN\n\n\nstatsJson = ujson.dumps(statsDict,indent=2)\n\ntstamp = int(datetime.datetime.now(tz=None).timestamp())\nfolder = f\"./tracked-{filename}-{tstamp}\"\nfrom os import mkdir\nmkdir(folder)\nwith open(f\"{folder}/data.log\", \"w\") as datafile:\n datafile.write(statsJson)\nif saveFrames:\n for antId,frame in framesToSave:\n cv.imwrite(f\"{folder}/{antId}.jpg\",frame)\n\n"
},
{
"alpha_fraction": 0.5654362440109253,
"alphanum_fraction": 0.568791925907135,
"avg_line_length": 42.774009704589844,
"blob_id": "652104093a00f661e66e7734642716c21ffa936d",
"content_id": "b78faa06aa300676e19e22d3d57ae0fb8f769d9c",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7770,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 177,
"path": "/ant_tracker/tracker_gui/ant_tracker_routine.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nimport av\nimport datetime\nimport pims\nfrom itertools import chain\nfrom pathlib import Path\nfrom typing import Union, List\n\nfrom . import constants as C\nfrom .loading_window import LoadingWindow\nfrom .parameter_extraction import extract_parameters_from_video\nfrom .results_overview import results_overview\nfrom .session import SessionInfo\n\ndef get_datetime():\n sg.theme('BlueMono')\n win = sg.Window(\"Ingrese fecha y hora del primer video\",\n [[sg.T(\"Fecha:\"), sg.In(\"\", disabled=True, enable_events=True, k='-DATE_INP-'),\n sg.CalendarButton(\"Abrir calendario\", target='-DATE_INP-', title=\"Elegir fecha\",\n format=\"%Y-%m-%d\",\n enable_events=True, k='-DATE-')],\n [sg.T(\"Hora:\"), sg.In(\"HH:MM:SS\", disabled=True, k='-TIME_INP-')],\n [sg.B('OK', disabled=True), sg.B('Cancelar')]], finalize=True, return_keyboard_events=True)\n while True:\n event, values = win.read()\n if event in (sg.WIN_CLOSED, 'Cancelar'):\n win.close()\n sg.theme('Default1')\n return None\n elif event == 'OK':\n win.close()\n sg.theme('Default1')\n return dtime # noqa\n date = win['-DATE_INP-'].get()\n win['-TIME_INP-'].update(disabled=(date == \"\"))\n time = win['-TIME_INP-'].get()\n try:\n dtime = datetime.datetime.strptime(f\"{date} {time}\", \"%Y-%m-%d %H:%M:%S\")\n win['OK'].update(disabled=False)\n except ValueError:\n win['OK'].update(disabled=True)\n\ndef load_video(path: Union[Path, str], message=\"Cargando video...\"):\n with LoadingWindow(message, C.SMALLSPINNER):\n v = pims.PyAVReaderIndexed(path)\n return v\ndef get_video_len(path: Union[Path, str], message=\"Cargando video...\"):\n with LoadingWindow(message, C.SMALLSPINNER):\n vlen = av.open(str(path)).streams.video[0].frames # noqa\n return vlen\n\ndef ant_tracker_routine():\n folder = sg.popup_get_folder(\"Seleccione la carpeta con los videos a procesar\", no_window=True)\n if not folder: return\n folder = Path(folder)\n\n from .excepthook import make_excepthook\n import sys\n sys.excepthook = make_excepthook(Path(folder), True)\n\n session: SessionInfo\n sesspath = Path(folder) / \".anttrackersession\"\n\n files = list(chain(folder.glob(\"*.mp4\"), folder.glob(\"*.avi\"), folder.glob(\"*.h264\")))\n\n def check_frame_info(_files):\n with LoadingWindow(\"Validando videos...\"):\n import av\n valid_files: List[Path] = []\n invalid_files: List[Path] = []\n for f in _files:\n container = av.open(str(f)) # noqa\n if container.streams.video[0].frames != 0:\n valid_files.append(f)\n else:\n invalid_files.append(f)\n\n if invalid_files:\n invmsg = \\\n [\n \"Se encontraron archivos de video con información faltante dentro de la carpeta. \"\n \"Normalmente esto ocurre con videos con extensión .h264 obtenidos en bruto de AntVRecord. \"\n \"Deberá obtener los videos procesados luego de finalizada la grabación \"\n \"(generalmente con extensión .mp4).\",\n \"Los videos inválidos son:\",\n \"\",\n ] + [\"/\".join(f.parts[-2:]) for f in invalid_files] + [\n \"\",\n \"Los mismos serán ignorados al procesar.\"\n ]\n sg.PopupOK(\"\\n\".join(invmsg), title=\"Información faltante\", modal=True, icon=C.LOGO_AT_ICO)\n return valid_files\n\n if sesspath.exists():\n msg = (\"Parece ser que el proceso de tracking en esta carpeta ya fue comenzado.\\n\"\n \"¿Desea continuar desde el último punto?\\n\\n\"\n \"⚠ ¡Cuidado! Si elije \\\"No\\\", se perderá todo el\"\n \" progreso previo y el procesamiento comenzará de cero.\")\n response = sg.Popup(msg, title=\"Sesión previa detectada\", custom_text=(C.RESP_SI, C.RESP_NO),\n modal=True, icon=C.LOGO_AT_ICO)\n if response == C.RESP_SI:\n with LoadingWindow(\"Cargando sesión previa...\"):\n session = SessionInfo.load(sesspath)\n newfiles = [f for f in files if f not in session.videofiles]\n deletedfiles = [f for f in session.videofiles if f not in files]\n newfiles = check_frame_info(newfiles)\n if newfiles or deletedfiles:\n with LoadingWindow(\"Cargando sesión previa...\"):\n session.add_new_files(newfiles)\n session.remove_deleted_files(deletedfiles)\n session.save(sesspath)\n elif response == C.RESP_NO:\n start_date = get_datetime()\n if start_date is None: return\n files = check_frame_info(files)\n session = SessionInfo.first_run(files, start_date)\n else:\n return\n else:\n start_date = get_datetime()\n if start_date is None: return\n files = check_frame_info(files)\n session = SessionInfo.first_run(files, start_date)\n\n # noinspection PyUnboundLocalVariable\n files = session.videofiles\n\n if len(files) == 0:\n sg.PopupOK(\"No se encontraron videos válidos en esta carpeta.\", title=\"No hay videos\", icon=C.LOGO_AT_ICO)\n return\n\n if session.is_first_run:\n video = load_video(files[0])[:]\n\n p = extract_parameters_from_video(video, files[0])\n if p is None: return\n session.parameters[files[0]] = p\n session.states[files[0]] = SessionInfo.State.GotParameters\n session.lengths[files[0]] = len(video)\n\n single_video = (len(files) == 1) or (\n sg.Popup(\"¿Desea usar los parámetros determinados en este video para el resto\"\n \" de los videos del lote?\\nSi decide no hacerlo, deberá realizar\"\n \" este proceso para cada uno de los videos.\",\n title=\"Continuar\", custom_text=(C.RESP_SI, C.RESP_NO),\n modal=True) == C.RESP_SI)\n\n if single_video:\n session.parameters = {f: p for f in files}\n session.states = {f: SessionInfo.State.GotParameters for f in files}\n for i_file, file in enumerate(files[1:], 2):\n session.lengths[file] = get_video_len(file, f\"Cargando video {i_file} de {len(files)}\")\n session.save(sesspath)\n else:\n # noinspection DuplicatedCode\n for i_file, file in enumerate(files[1:], 2):\n video = load_video(file, f\"Cargando video {i_file} de {len(files)}\")[:]\n p = extract_parameters_from_video(video, file)\n if p is None: return\n session.parameters[file] = p\n session.states[file] = SessionInfo.State.GotParameters\n session.lengths[file] = len(video)\n session.save(sesspath)\n\n else: # not the first run\n new_files = [p for p, s in session.states.items() if s == SessionInfo.State.New]\n # noinspection DuplicatedCode\n for i_file, file in enumerate(new_files, 1):\n video = load_video(file, f\"Cargando video {i_file} de {len(new_files)}\")[:]\n p = extract_parameters_from_video(video, file)\n if p is None: return\n session.parameters[file] = p\n session.states[file] = SessionInfo.State.GotParameters\n session.lengths[file] = len(video)\n session.save(sesspath)\n\n results_overview(sesspath)\n"
},
{
"alpha_fraction": 0.2704918086528778,
"alphanum_fraction": 0.403460830450058,
"avg_line_length": 22.869565963745117,
"blob_id": "a162dc5e578d12857a20954b623d41c58d05d9f5",
"content_id": "faa408666b648651337ea9ac5a8b5d4acf63eb54",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 46,
"path": "/ant_tracker/tracker/kellycolors.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from typing import List\n\nfrom .common import Color\n\nclass KellyColors:\n index = 0\n\n def __init__(self):\n super().__init__()\n\n @classmethod\n def next(cls) -> Color:\n ret = cls.all()[cls.index]\n cls.index = (cls.index + 1) % len(cls.all())\n return ret\n\n @classmethod\n def get(cls, index: int) -> Color:\n \"\"\"Gets a modulo-indexed color\"\"\"\n return cls.all()[index % len(cls.all())]\n\n @classmethod\n def all(cls) -> List[Color]:\n \"\"\"Returns all kelly colors\"\"\"\n return [\n (255, 179, 0),\n (128, 62, 117),\n (255, 104, 0),\n (166, 189, 215),\n (193, 0, 32),\n (206, 162, 98),\n (129, 112, 102),\n (0, 125, 52),\n (246, 118, 142),\n (0, 83, 138),\n (255, 122, 92),\n (83, 55, 122),\n (255, 142, 0),\n (179, 40, 81),\n (244, 200, 0),\n (127, 24, 13),\n (147, 170, 0),\n (89, 51, 21),\n (241, 58, 19),\n (35, 44, 22)\n ]\n"
},
{
"alpha_fraction": 0.4984275698661804,
"alphanum_fraction": 0.5073729753494263,
"avg_line_length": 39.650569915771484,
"blob_id": "9bb86dedb4f47606680259cb3973be82ce05d85c",
"content_id": "78f5669b715813cc3d338e3977da6d235c17a3a5",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14334,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 352,
"path": "/ant_tracker/tracker_gui/export.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import datetime\nimport numpy as np\nfrom functools import partial\nfrom openpyxl import Workbook\nfrom openpyxl.styles import Alignment\nfrom openpyxl.worksheet.worksheet import Worksheet\nfrom pathlib import Path\nfrom typing import List, Iterable\n\nfrom . import constants as C\nfrom .session import SessionInfo\nfrom ..tracker.info import TracksCompleteInfo, Direction\nfrom ..tracker.track import Track\n\ndef EN(track: Track, info: TracksCompleteInfo):\n return info.track_direction(track) == Direction.EN\n\ndef SN(track: Track, info: TracksCompleteInfo):\n return info.track_direction(track) == Direction.SN\n\ndef loaded(tracks: Iterable[Track]):\n yield from (track for track in tracks if track.load_detected and track.load_prediction)\n\ndef unloaded(tracks: Iterable[Track]):\n yield from (track for track in tracks if track.load_detected and not track.load_prediction)\n\ndef onedim_conversion(length_or_speed: float, mm_per_pixel: float):\n \"\"\"\n :param length_or_speed: in [px] or [px/s]\n :param mm_per_pixel: in [mm/px]\n :return: length i [mm] or speed in [mm/s]\n \"\"\"\n return length_or_speed * mm_per_pixel\n\ndef area_conversion(area: float, mm_per_pixel: float):\n \"\"\"\n :param area: in [px^2]\n :param mm_per_pixel: in [mm/px]\n :return: area in [mm^2]\n \"\"\"\n return area * (mm_per_pixel ** 2)\n\ndef length(cell):\n if not cell.value: return 0\n if isinstance(cell.value, float):\n lc = len(str(round(cell.value, 2))) + 1\n elif isinstance(cell.value, datetime.datetime):\n lc = 19\n else:\n lc = len(str(cell.value)) + 1\n return lc\n\ndef adjust_column_widths(ws: Worksheet):\n dims = {}\n for row in ws.rows:\n for cell in row:\n if cell.row == 1: continue\n if cell.value:\n dims[cell.column_letter] = max(dims.get(cell.column_letter, 13), length(cell))\n for col, value in dims.items():\n ws.column_dimensions[col].width = value\n\n from openpyxl.utils import get_column_letter\n for rng in ws.merged_cells.ranges:\n cols = {}\n for cell in rng.cells:\n col = get_column_letter(cell[1])\n cols[col] = max(ws.column_dimensions[col].width, length(ws.cell(cell[1], cell[0])))\n total_length = sum(cols.values())\n for col in cols:\n ws.column_dimensions[col].width = total_length / len(cols)\n\ndef center_headers(ws: Worksheet, rows=1):\n for row in ws.iter_rows(1, rows):\n for cell in row:\n cell.alignment = Alignment(horizontal='center', vertical='center', wrap_text=True)\n ws.row_dimensions[1].height = 30\n\ndef adjust_decimal_places(ws: Worksheet, decimal_places=2):\n for row in ws.rows:\n for cell in row:\n if isinstance(cell.value, float):\n cell.number_format = '0' + ('.' + '0' * decimal_places) if decimal_places else ''\n\nclass Exporter:\n def __init__(self):\n self.__wb = None\n\n @property\n def workbook(self) -> Workbook:\n if self.__wb is None:\n raise AttributeError(\"Primero debe llamar a export(_progress)\")\n return self.__wb\n\n def save(self, path: Path):\n self.workbook.save(path)\n\n def export(self, infos: List[TracksCompleteInfo], time_delta=datetime.timedelta(minutes=1)):\n list(self.export_progress(infos, time_delta))\n return self.__wb\n\n def export_progress(self, infos: List[TracksCompleteInfo], time_delta=datetime.timedelta(minutes=1)):\n yield \"Inicializando...\", 0, 1\n wb = Workbook()\n ws = wb.active\n\n # region Por hormiga\n ws.title = \"Por hormiga\"\n ws.append([\n \"Video\",\n \"ID\",\n \"Dirección\",\n \"Carga\",\n \"Certeza en carga\",\n \"Velocidad prom. [mm/s]\",\n \"Área mediana [mm²]\",\n \"Largo mediana [mm]\",\n \"Ancho mediana [mm]\",\n \"Tiempo entrada\",\n \"Tiempo salida\",\n \"Frame inicio\",\n \"Frame final\",\n ])\n\n progress_i = 0\n progress_max = sum([len(info.filter_tracks(**C.TRACKFILTER)) for info in infos])\n yield \"Inicializando...\", 1, 1\n yield \"Generando análisis por hormiga\", progress_i, progress_max\n for info in infos:\n od = partial(onedim_conversion, mm_per_pixel=info.mm_per_pixel)\n area = partial(area_conversion, mm_per_pixel=info.mm_per_pixel)\n for track in info.filter_tracks(**C.TRACKFILTER):\n ws.append([\n info.video_name,\n track.id,\n \"EN\" if EN(track, info) else \"SN\" if SN(track, info) else \"??\",\n (\"Si\" if track.load_prediction else \"No\") if track.load_detected else \"??\",\n track.load_certainty if track.load_detected else 0,\n od(track.speed_mean),\n area(track.area_median),\n od(track.length_median),\n od(track.width_median),\n info.time_at(track.first_frame()),\n info.time_at(track.last_frame()),\n track.first_frame(),\n track.last_frame(),\n ])\n progress_i += 1\n yield \"Generando análisis por hormiga\", progress_i, progress_max\n\n # endregion\n\n # region Por video\n ws = wb.create_sheet(\"Por video\")\n progress_i = 0\n progress_max = len(infos) * 16\n yield \"Generando análisis por video\", progress_i, progress_max\n\n ws.append([\"Video\",\n \"Hora Inicio\",\n \"Hora Fin\",\n \"Total hormigas entrando al nido (EN)\", \"\",\n \"Total hormigas saliendo del nido (SN)\", \"\",\n \"Velocidad promedio EN [mm/s]\", \"\",\n \"Velocidad promedio SN [mm/s]\", \"\",\n \"Área mediana EN [mm²]\", \"\",\n \"Área mediana SN [mm²]\", \"\",\n \"Largo mediana EN [mm]\", \"\",\n \"Largo mediana SN [mm]\", \"\",\n \"Ancho mediana EN [mm]\", \"\",\n \"Ancho mediana SN [mm]\", \"\",\n ])\n ws.append([\"\", \"\", \"\"] + [\"Cargadas\", \"Sin carga\"] * 10)\n merge = ['A1:A2', 'B1:B2', 'C1:C2', 'D1:E1', 'F1:G1', 'H1:I1', 'J1:K1', 'L1:M1', 'N1:O1', 'P1:Q1', 'R1:S1',\n 'T1:U1', 'V1:W1']\n for m in merge: ws.merge_cells(m)\n props = ('speed_mean', 'area_median', 'length_median', 'width_median')\n\n for info in infos:\n filtered = info.filter_tracks(**C.TRACKFILTER)\n EN_tracks = [track for track in filtered if EN(track, info)]\n SN_tracks = [track for track in filtered if SN(track, info)]\n del filtered # to save on memory\n\n od = partial(onedim_conversion, mm_per_pixel=info.mm_per_pixel)\n area = partial(area_conversion, mm_per_pixel=info.mm_per_pixel)\n\n data = {'EN': {'l': {}, 'u': {}}, 'SN': {'l': {}, 'u': {}}}\n for k1, tracks in zip(('EN', 'SN'), (EN_tracks, SN_tracks)):\n for k2, load in zip(('l', 'u'), (loaded, unloaded)):\n for prop, conv in zip(props, (od, area, od, od)):\n data[k1][k2][prop] = conv(np.mean([\n getattr(track, prop) for track in load(tracks)\n ]))\n progress_i += 1\n yield \"Generando análisis por video\", progress_i, progress_max\n\n ws.append([\n info.video_name,\n info.start_time,\n info.end_time,\n len(list(loaded(EN_tracks))),\n len(list(unloaded(EN_tracks))),\n len(list(loaded(SN_tracks))),\n len(list(unloaded(SN_tracks))),\n data['EN']['l']['speed_mean'],\n data['EN']['u']['speed_mean'],\n data['SN']['l']['speed_mean'],\n data['SN']['u']['speed_mean'],\n data['EN']['l']['area_median'],\n data['EN']['u']['area_median'],\n data['SN']['l']['area_median'],\n data['SN']['u']['area_median'],\n data['EN']['l']['length_median'],\n data['EN']['u']['length_median'],\n data['SN']['l']['length_median'],\n data['SN']['u']['length_median'],\n data['EN']['l']['width_median'],\n data['EN']['u']['width_median'],\n data['SN']['l']['width_median'],\n data['SN']['u']['width_median'],\n ])\n\n lastrow = len(infos) + 2\n ws.append([\"Total\", f\"=MIN(B3:B{lastrow})\", f\"=MAX(C3:C{lastrow})\"] +\n [f\"=SUM({c}3:{c}{lastrow})\" for c in \"DEFG\"] +\n [f\"=AVERAGE({c}3:{c}{lastrow})\" for c in \"HIJKLMNOPQRSTUVW\"])\n ws.cell(lastrow + 1, 2).number_format = 'yyyy-mm-dd h:mm:ss'\n ws.cell(lastrow + 1, 3).number_format = 'yyyy-mm-dd h:mm:ss'\n\n # endregion\n\n # region En el tiempo\n ws = wb.create_sheet(\"En el tiempo\")\n ws.append([\n \"Hora Inicio\",\n \"Hora Fin\",\n \"Total hormigas entrando al nido (EN)\", \"\",\n \"Total hormigas saliendo del nido (SN)\", \"\",\n \"Velocidad promedio EN [mm/s]\", \"\",\n \"Velocidad promedio SN [mm/s]\", \"\",\n \"Área mediana EN [mm²]\", \"\",\n \"Área mediana SN [mm²]\", \"\",\n \"Largo mediana EN [mm]\", \"\",\n \"Largo mediana SN [mm]\", \"\",\n \"Ancho mediana EN [mm]\", \"\",\n \"Ancho mediana SN [mm]\", \"\",\n ])\n ws.append([\"\", \"\"] + [\"Cargadas\", \"Sin carga\"] * 10)\n merge = ['A1:A2', 'B1:B2', 'C1:D1', 'E1:F1', 'G1:H1', 'I1:J1', 'K1:L1', 'M1:N1', 'O1:P1', 'Q1:R1', 'S1:T1',\n 'U1:V1']\n for m in merge: ws.merge_cells(m)\n\n start_time = min([info.start_time for info in infos])\n end_time = max([info.end_time for info in infos])\n\n progress_i = 0\n progress_max = (end_time - start_time) // time_delta + 1\n yield \"Generando análisis en el tiempo\", progress_i, progress_max\n time = start_time\n while time < end_time:\n totals = {'en-load': 0, 'en-ntld': 0, 'sn-load': 0, 'sn-ntld': 0}\n speeds = {'en-load': [], 'en-ntld': [], 'sn-load': [], 'sn-ntld': []}\n areas = {'en-load': [], 'en-ntld': [], 'sn-load': [], 'sn-ntld': []}\n lengths = {'en-load': [], 'en-ntld': [], 'sn-load': [], 'sn-ntld': []}\n widths = {'en-load': [], 'en-ntld': [], 'sn-load': [], 'sn-ntld': []}\n for info in infos:\n _filter = info.filter_func(**C.TRACKFILTER)\n tracks = [track for track in info.tracks_in_time(time, time + time_delta)\n if track.load_detected and _filter(track)]\n if tracks:\n od = partial(onedim_conversion, mm_per_pixel=info.mm_per_pixel)\n area = partial(area_conversion, mm_per_pixel=info.mm_per_pixel)\n\n for track in tracks:\n if track.load_prediction and EN(track, info):\n key = 'en-load'\n elif not track.load_prediction and EN(track, info):\n key = 'en-ntld'\n elif track.load_prediction and SN(track, info):\n key = 'sn-load'\n elif not track.load_prediction and SN(track, info):\n key = 'sn-ntld'\n else:\n continue\n\n totals[key] += 1\n speeds[key].append(od(track.speed_mean))\n areas[key].append(area(track.area_median))\n lengths[key].append(od(track.length_median))\n widths[key].append(od(track.width_median))\n\n ws.append([\n time,\n time + time_delta,\n totals['en-load'],\n totals['en-ntld'],\n totals['sn-load'],\n totals['sn-ntld'],\n np.mean(speeds['en-load']),\n np.mean(speeds['en-ntld']),\n np.mean(speeds['sn-load']),\n np.mean(speeds['sn-ntld']),\n np.mean(areas['en-load']),\n np.mean(areas['en-ntld']),\n np.mean(areas['sn-load']),\n np.mean(areas['sn-ntld']),\n np.mean(lengths['en-load']),\n np.mean(lengths['en-ntld']),\n np.mean(lengths['sn-load']),\n np.mean(lengths['sn-ntld']),\n np.mean(widths['en-load']),\n np.mean(widths['en-ntld']),\n np.mean(widths['sn-load']),\n np.mean(widths['sn-ntld']),\n ])\n time += time_delta\n progress_i += 1\n yield \"Generando análisis en el tiempo\", progress_i, progress_max\n # endregion\n\n for i_ws, ws in enumerate(wb.worksheets):\n adjust_column_widths(ws)\n adjust_decimal_places(ws)\n if i_ws in (0, 2):\n center_headers(ws, 2)\n else:\n center_headers(ws)\n\n # Los datos se calculan en órden: hormiga-video-tiempo, porque 'hormiga' indica\n # progreso más rápido que las demás y da a entender más rápidamente que hay trabajo\n # en proceso. Sin embargo, el órden de hojas tiene que ser: video-hormiga-tiempo\n wb.move_sheet(\"Por video\", -1)\n\n self.__wb = wb\n yield \"Finalizado\", 1, 1\n\nif __name__ == '__main__':\n sesspath = Path(\"../tracker/vid_tags/Prueba 1 AntTracker 4-Dic-2020/.anttrackersession\")\n session = SessionInfo.load(sesspath)\n trkfiles = [session.get_trkfile(f) for f in session.videofiles]\n e = Exporter()\n for t, i, mx in e.export_progress([TracksCompleteInfo.load(f) for f in trkfiles]):\n print(t, f\"{i}/{mx}\")\n\n file = sesspath.parent / \"export.xlsx\"\n while True:\n try:\n e.save(file)\n break\n except PermissionError:\n input(f\"El archivo {file} está abierto o protegido. Presione Enter para probar nuevamente\")\n"
},
{
"alpha_fraction": 0.5614289045333862,
"alphanum_fraction": 0.570402979850769,
"avg_line_length": 45.55525588989258,
"blob_id": "28ff1e23ac9fbd26ebc6ad5b442cc9038649647d",
"content_id": "46b40a3c6ac9cc28ea37784dfb4bfcc07730b101",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17298,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 371,
"path": "/ant_tracker/tracker_gui/parameter_extraction.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nimport numpy as np\nfrom itertools import chain\nfrom pathlib import Path\nfrom typing import Dict, List, Union, Optional\n\nfrom . import constants as C\nfrom .extracted_parameters import SelectionStep, ExtractedParameters\nfrom .guicommon import parse_number, release\nfrom ..tracker.blob import Blob\nfrom ..tracker.common import Side, Rect, Video, ensure_path\nfrom ..tracker.parameters import SegmenterParameters, TrackerParameters, LogWSegmenterParameters\nfrom ..tracker.segmenter import LogWSegmenter\n\nclass MyGraph(sg.Graph):\n def __init__(self, imshape, *args, **kwargs):\n import screeninfo\n\n screen_height = max([monitor.height for monitor in screeninfo.get_monitors()])\n\n self.video_scale = (screen_height - 250) / imshape[0]\n self.default_line_width = np.ceil(1 / self.video_scale)\n graph_shape = int(imshape[1] * self.video_scale), int(imshape[0] * self.video_scale)\n self.frame_id = None\n\n super(MyGraph, self).__init__(graph_shape, (0, imshape[0] - 1), (imshape[1] - 1, 0), *args, **kwargs)\n\n def draw_frame(self, frame: np.ndarray):\n from PIL import Image\n import io\n\n if self.frame_id is not None:\n self.delete_figure(self.frame_id)\n buf = io.BytesIO()\n Image.fromarray(frame).resize(self.CanvasSize).save(buf, format='PNG')\n self.frame_id = self.draw_image(data=buf.getvalue(), location=(0, 0))\n self.TKCanvas.tag_lower(self.frame_id)\n\n def DrawRectangle(self, rect: Rect,\n fill_color: str = None, line_color: str = None, line_width: int = None, **kwargs\n ) -> Union[int, None]:\n \"\"\"\n Draw a rectangle given a `Rect`. Can control the line and fill colors,\n and also pass kwargs to underlying tk call.\n :param rect: the rectangle to draw\n :param fill_color: color of the interior\n :param line_color: color of outline\n :param line_width: width of the line in pixels\n :return: id returned from tkinter that you'll need if you want to manipulate the rectangle\n \"\"\"\n\n converted_top_left = self._convert_xy_to_canvas_xy(rect.topleft.x, rect.topleft.y)\n converted_bottom_right = self._convert_xy_to_canvas_xy(rect.bottomright.x, rect.bottomright.y)\n if self._TKCanvas2 is None:\n print('*** WARNING - The Graph element has not been finalized and cannot be drawn upon ***')\n print('Call Window.Finalize() prior to this operation')\n return None\n if line_width is None:\n line_width = self.default_line_width\n try: # in case closed with X\n _id = self._TKCanvas2.create_rectangle(converted_top_left[0], converted_top_left[1],\n converted_bottom_right[0],\n converted_bottom_right[1], fill=fill_color, outline=line_color,\n width=line_width, **kwargs)\n except: # noqa\n _id = None\n return _id\n\n draw_rectangle = DrawRectangle\n\nclass K:\n Graph = '-GRAPH-'\n FrameSlider = '-FRAME_SLIDER-'\n FrameBack = '-FRAME_BACK-'\n FrameForw = '-FRAME_FORWARD-'\n SelectInstructions = '-SELECT_INSTRUCTIONS-'\n BackButton = '-BACK_BUTTON-'\n ContinueButton = '-START_TRACK_BUTTON-'\n ShowDetailsButton = '-SHOW_PARAM_DETS-'\n ParameterDetails = '-PARAM_DETS-'\n PreviewButton = '-PREVIEW_BUTTON-'\n RefreshButton = '-REFRESH_BUTTON-'\n\ndef extract_parameters_from_video(video: Video, filepath: Union[Path, str]):\n filepath = ensure_path(filepath)\n imshape = video[0].shape[0:2]\n\n _segmenterParameters = LogWSegmenterParameters()\n _trackerParameters = TrackerParameters(use_defaults=True)\n parameters_gotten = False\n\n def wrap(s):\n import textwrap\n return \"\\n\".join(textwrap.wrap(s, 70))\n\n details_list = sg.Column(\n [\n *[[sg.Text(n, size=(28, 1), pad=(0, 0), tooltip=wrap(d)),\n sg.Text(\"❔\", font=(\"Arial\", 8), size=(2, 1), tooltip=wrap(d), pad=(0, 0)),\n sg.InputText(v, size=(7, 1), pad=(0, 0), k=k)] for k, n, d, v in\n chain(\n zip(_segmenterParameters.keys(),\n _segmenterParameters.names(),\n _segmenterParameters.descriptions(),\n _segmenterParameters.values()),\n zip(_trackerParameters.keys(),\n _trackerParameters.names(),\n _trackerParameters.descriptions(),\n _trackerParameters.values())\n )\n ],\n [sg.B(\"Actualizar\", k=K.RefreshButton)]],\n element_justification='right', visible=False, k=K.ParameterDetails)\n\n def update_params(win, segParams: SegmenterParameters, trackerParams: TrackerParameters):\n [win[k](v) for k, v in chain(segParams.items(), trackerParams.items())]\n\n def get_params(win):\n return (SegmenterParameters({k: parse_number(win[k].get()) for k, _ in _segmenterParameters.items()}),\n TrackerParameters({k: parse_number(win[k].get()) for k, _ in _trackerParameters.items()}))\n\n layout = [\n [\n sg.Column(\n [\n [sg.Text(\"1. Encierre en un rectángulo la posición del marcador de 10mm.\", k=K.SelectInstructions)],\n [\n sg.pin(sg.B(\"Retroceder\", visible=False, k=K.BackButton)),\n sg.pin(sg.B(\"Mostrar parámetros\", visible=False, k=K.ShowDetailsButton)),\n sg.pin(sg.B(\"Previsualizar\", visible=False, k=K.PreviewButton)),\n sg.pin(sg.B(\"Continuar\", visible=False, k=K.ContinueButton)),\n ],\n [details_list]\n ],\n vertical_alignment='top', expand_y=True, expand_x=True\n ),\n sg.Column(\n [[MyGraph(imshape, k=K.Graph, enable_events=True, drag_submits=True)],\n [\n sg.B(\"◀\", k=K.FrameBack),\n sg.Slider(orientation='h', enable_events=True, k=K.FrameSlider),\n sg.B(\"▶\", k=K.FrameForw)],\n ], expand_x=True,\n )\n ],\n [sg.Button('Go', visible=False), sg.Button('Nothing', visible=False), sg.Button('Exit', visible=False)]\n ]\n\n window = sg.Window(f\"AntTracker - {filepath}\", layout, icon=C.LOGO_AT_ICO, modal=True, finalize=True)\n window[K.SelectInstructions].expand(expand_y=True, expand_x=True)\n g: MyGraph = window[K.Graph] # noqa\n\n g.draw_frame(video[0])\n previewing_segmentation = False\n\n window[K.FrameSlider].update(range=(0, len(video) - 1))\n window[K.FrameSlider].update(value=0)\n window[K.FrameSlider].expand(expand_x=True)\n\n rect_start = (0, 0)\n\n dragging = False\n\n rect: Rect = None # noqa\n selection_id = None\n rect_colors = {SelectionStep.SizeMarker: \"tomato\", SelectionStep.TrackingArea: \"SlateBlue1\",\n SelectionStep.AntFrame1: \"DodgerBlue2\", SelectionStep.AntFrame2: \"DodgerBlue4\"}\n rect_names = {SelectionStep.SizeMarker: \"Marcador\", SelectionStep.TrackingArea: \"Área de tracking\",\n SelectionStep.AntFrame1: \"H1\", SelectionStep.AntFrame2: \"H2\"}\n rect_ids: Dict[SelectionStep, List[int]] = {step: [] for step in rect_names.keys()}\n rect_data: Dict[SelectionStep, Optional[Rect]] = {step: None for step in rect_names.keys()}\n\n def calc_parameters(r_data: Dict[SelectionStep, Rect]):\n _sp = LogWSegmenterParameters()\n _tp = TrackerParameters(use_defaults=True)\n\n antrect1 = r_data[SelectionStep.AntFrame1]\n antrect2 = r_data[SelectionStep.AntFrame2]\n average_ant_diagonal = (antrect1.diagonal_length + antrect2.diagonal_length) / 2\n\n _sp.approx_tolerance = round(0.015 * average_ant_diagonal - 0.35, 2)\n _sp.gaussian_sigma = round(0.08 * average_ant_diagonal + 5, 2)\n _sp.minimum_ant_radius = round(0.1 * average_ant_diagonal)\n\n _tp.max_distance_between_assignments = round(antrect1.center.distance_to(antrect2.center) * 2, 2)\n\n return _sp, _tp\n\n def _w(x):\n return int(x * .08)\n\n def _w_1(x):\n return int(x * (1 - .08))\n\n nest_sides: Dict[Side, Rect] = {\n Side.Top: Rect.from_points((0, 0), (imshape[1] - 1, _w(imshape[0]))),\n Side.Left: Rect.from_points((0, 0), (_w(imshape[1]), imshape[0] - 1)),\n Side.Right: Rect.from_points((_w_1(imshape[1]), 0), (imshape[1] - 1, imshape[0] - 1)),\n Side.Bottom: Rect.from_points((0, _w_1(imshape[0])), (imshape[1] - 1, imshape[0] - 1)),\n }\n nest_side_ids = {}\n side_rect = None\n hover_rect = None\n chosen_side = None\n current_step = SelectionStep.First\n\n def set_selection_instructions(win, step):\n def selection_instructions(_step):\n ret = \"1. Encierre en un rectángulo la posición del marcador de 10mm.\"\n if _step == SelectionStep.SizeMarker: return ret\n ret += \"\\n2. Encierre el área donde se realizará el tracking. Considere que mientras mayor sea el área, \" \\\n \"mayor es el tiempo de procesamiento necesario, pero más precisas serán las medidas obtenidas \" \\\n \"a lo largo del tiempo.\"\n if _step == SelectionStep.TrackingArea: return ret\n ret += \"\\n3. Encierre la totalidad del tamaño de una hormiga promedio en movimiento. En lo posible, \" \\\n \"busque una que se mueva en línea recta.\"\n if _step == SelectionStep.AntFrame1: return ret\n ret += \"\\n4. Avance 5 cuadros, y encierre la nueva posición de la misma hormiga.\"\n if _step == SelectionStep.AntFrame2: return ret\n ret += \"\\n5. Haga click en el lado que corresponde a la ubicación del nido.\"\n if _step == SelectionStep.NestSide: return ret\n ret += \"\\n6. Puede revisar los parámetros en el menú que se encuentra debajo,\" \\\n \"y previsualizar la segmentación con el botón correspondiente. \" \\\n \"Si está de acuerdo, presione Continuar.\"\n return ret\n\n win[K.SelectInstructions].update(value=selection_instructions(step))\n\n def update_current_frame(frame):\n image = video[frame]\n if previewing_segmentation and frame > 0:\n progbar = sg.ProgressBar(2, orientation='h', size=(20, 20))\n progwin = sg.Window('Previsualizando', [[progbar]], modal=True, disable_close=True).finalize()\n params = get_params(window)[0]\n n = min(params.movement_detection_history, frame)\n progbar.update_bar(0)\n blobs = LogWSegmenter.segment_single(params, image, video[frame - n:frame])\n progbar.update_bar(1)\n image = Blob.draw_blobs(blobs, image)\n progbar.update_bar(2)\n progwin.close()\n g.draw_frame(image)\n\n while True:\n event, values = window.read()\n if event == sg.WIN_CLOSED:\n window.close()\n return None\n elif event == K.FrameSlider:\n update_current_frame(int(values[K.FrameSlider]))\n elif event == K.FrameBack:\n current_frame = int(values[K.FrameSlider])\n if current_frame > 0:\n window[K.FrameSlider].update(value=current_frame - 1)\n update_current_frame(current_frame - 1)\n elif event == K.FrameForw:\n current_frame = int(values[K.FrameSlider])\n if current_frame < len(video):\n window[K.FrameSlider].update(value=current_frame + 1)\n update_current_frame(current_frame + 1)\n elif event == K.Graph:\n if current_step != SelectionStep.Done:\n if current_step == SelectionStep.NestSide:\n for side, rect in nest_sides.items():\n if side_rect is None and values[K.Graph] in rect:\n chosen_side = side\n side_rect = g.draw_rectangle(rect, line_width=0, line_color=\"green\", fill_color=\"green\",\n stipple=\"gray50\")\n current_step = current_step.next()\n break\n elif not dragging:\n dragging = True\n rect_start = values[K.Graph]\n elif dragging:\n if selection_id is not None:\n g.delete_figure(selection_id)\n rect = Rect.from_points(rect_start, values[K.Graph]).clip(imshape)\n selection_id = g.draw_rectangle(rect, line_color=rect_colors[current_step])\n elif event == release(K.Graph) and dragging:\n if current_step != SelectionStep.Done:\n rect_ids[current_step].append(\n g.draw_rectangle(rect, line_color=rect_colors[current_step])\n )\n rect_ids[current_step].append(\n g.draw_text(rect_names[current_step], rect.topleft, rect_colors[current_step],\n text_location=sg.TEXT_LOCATION_BOTTOM_LEFT)\n )\n rect_data[current_step] = rect\n if current_step == SelectionStep.AntFrame2:\n start = rect_data[SelectionStep.AntFrame1]\n end = rect_data[SelectionStep.AntFrame2]\n rect_ids[current_step].append(\n g.draw_line(start.center, end.center, color=rect_colors[current_step])\n )\n\n current_step = current_step.next()\n if selection_id is not None:\n g.delete_figure(selection_id)\n dragging = False\n elif event == K.BackButton:\n window[K.ParameterDetails].Visible = False\n previewing_segmentation = False\n current_step = current_step.back()\n if current_step in rect_ids:\n [g.delete_figure(i) for i in rect_ids[current_step]]\n rect_ids[current_step] = []\n rect_data[current_step] = None\n elif event == K.ShowDetailsButton:\n window[K.ParameterDetails].Visible = not window[K.ParameterDetails].Visible\n elif event == K.PreviewButton:\n previewing_segmentation = not previewing_segmentation\n update_current_frame(int(values[K.FrameSlider]))\n elif event == K.RefreshButton:\n update_current_frame(int(values[K.FrameSlider]))\n elif event == K.ContinueButton:\n sp, tp = get_params(window)\n window.close()\n return ExtractedParameters(sp, tp, rect_data, chosen_side)\n else:\n print(event, values)\n\n if current_step == SelectionStep.NestSide:\n if not nest_side_ids:\n def draw_hover_rect(r: Rect):\n def _(_):\n nonlocal hover_rect\n hover_rect = g.draw_rectangle(r, line_color=\"green\", fill_color=\"green\",\n stipple=\"gray50\",\n line_width=0)\n g.TKCanvas.tag_bind(hover_rect, '<Leave>', delete_hover_rect)\n\n return _\n\n def delete_hover_rect(_):\n nonlocal hover_rect\n if hover_rect is not None:\n g.delete_figure(hover_rect) # noqa\n hover_rect = None\n\n nest_side_ids = {\n side: g.draw_rectangle(r, line_color=\"green\", fill_color=\"green\", stipple=\"gray12\",\n line_width=0)\n for side, r in\n nest_sides.items()}\n for side, i in nest_side_ids.items():\n g.TKCanvas.tag_bind(i, '<Enter>', draw_hover_rect(nest_sides[side]))\n elif nest_side_ids:\n [g.delete_figure(i) for i in nest_side_ids.values()]\n nest_side_ids = {}\n if current_step <= SelectionStep.NestSide:\n if side_rect is not None: g.delete_figure(side_rect)\n side_rect = None\n if current_step == SelectionStep.Done:\n if not parameters_gotten:\n sp, tp = calc_parameters(rect_data)\n update_params(window, sp, tp)\n parameters_gotten = True\n else:\n parameters_gotten = False\n\n set_selection_instructions(window, current_step)\n window[K.BackButton].update(visible=current_step != SelectionStep.First)\n window[K.ShowDetailsButton].update(visible=current_step == SelectionStep.Done)\n window[K.PreviewButton].update(visible=current_step == SelectionStep.Done)\n window[K.ContinueButton].update(visible=current_step == SelectionStep.Done)\n window[K.ParameterDetails].update(visible=window[K.ParameterDetails].Visible)\n\ndef extract_pixel_size(marker: Rect):\n diameter_px = (marker.height + marker.width) / 2\n pixel_size_in_mm = 10 / diameter_px\n return pixel_size_in_mm\n"
},
{
"alpha_fraction": 0.5965890288352966,
"alphanum_fraction": 0.5992128849029541,
"avg_line_length": 39.6533317565918,
"blob_id": "b7b6785477cf3d4a16c6b3913a875369d7480228",
"content_id": "29c22b0ec5efe2c7d3472332a40e10e9cb417582",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3049,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 75,
"path": "/ant_tracker/tracker/tf_model_reqs.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom tensorflow import math as tfmath\nfrom tensorflow.keras.metrics import Metric\nfrom tensorflow.python.keras import backend as K\nfrom tensorflow.python.keras.utils import metrics_utils\nfrom tensorflow.python.keras.utils.generic_utils import to_list\nfrom tensorflow.python.ops import init_ops\nfrom tensorflow.python.ops import math_ops\n\nclass F1Score(Metric):\n def __init__(self,\n thresholds=None,\n top_k=None,\n class_id=None,\n name=None,\n dtype=None):\n super(F1Score, self).__init__(name=name, dtype=dtype)\n self.init_thresholds = thresholds\n self.top_k = top_k\n self.class_id = class_id\n\n default_threshold = 0.5 if top_k is None else metrics_utils.NEG_INF\n self.thresholds = metrics_utils.parse_init_thresholds(\n thresholds, default_threshold=default_threshold)\n self.true_positives = self.add_weight(\n 'true_positives',\n shape=(len(self.thresholds),),\n initializer=init_ops.zeros_initializer)\n self.false_negatives = self.add_weight(\n 'false_negatives',\n shape=(len(self.thresholds),),\n initializer=init_ops.zeros_initializer)\n self.false_positives = self.add_weight(\n 'false_positives',\n shape=(len(self.thresholds),),\n initializer=init_ops.zeros_initializer)\n\n def update_state(self, y_true, y_pred, sample_weight=None):\n return metrics_utils.update_confusion_matrix_variables(\n {\n metrics_utils.ConfusionMatrix.TRUE_POSITIVES: self.true_positives,\n metrics_utils.ConfusionMatrix.FALSE_NEGATIVES: self.false_negatives,\n metrics_utils.ConfusionMatrix.FALSE_POSITIVES: self.false_positives\n },\n y_true,\n y_pred,\n thresholds=self.thresholds,\n top_k=self.top_k,\n class_id=self.class_id,\n sample_weight=sample_weight)\n\n def result(self):\n recall = math_ops.div_no_nan(self.true_positives,\n self.true_positives + self.false_negatives)\n precision = math_ops.div_no_nan(self.true_positives,\n self.true_positives + self.false_positives)\n\n n = math_ops.multiply_no_nan(recall, precision)\n d = tfmath.add(recall, precision)\n result = 2 * math_ops.div_no_nan(n, d)\n return result[0] if len(self.thresholds) == 1 else result\n\n def reset_states(self):\n num_thresholds = len(to_list(self.thresholds))\n K.batch_set_value(\n [(v, np.zeros((num_thresholds,))) for v in self.variables])\n\n def get_config(self):\n config = {\n 'thresholds': self.init_thresholds,\n 'top_k': self.top_k,\n 'class_id': self.class_id\n }\n base_config = super(F1Score, self).get_config()\n return dict(list(base_config.items()) + list(config.items()))\n"
},
{
"alpha_fraction": 0.5624434351921082,
"alphanum_fraction": 0.569566011428833,
"avg_line_length": 29.0108699798584,
"blob_id": "077b1fc4b6eeeb599334338458e1a131f96f876f",
"content_id": "ff4fc73636c08ee85229d95b81fd50bb2ff718ad",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16567,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 552,
"path": "/ant_tracker/labeler/pyforms_patch/pyforms_gui/controls/control_player/control_player.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n\"\"\" pyforms_gui.controls.ControlPlayer.ControlPlayer\n\n\"\"\"\n__author__ = \"Ricardo Ribeiro\"\n__credits__ = [\"Ricardo Ribeiro\"]\n__license__ = \"MIT\"\n__version__ = \"0.0\"\n__maintainer__ = \"Ricardo Ribeiro\"\n__email__ = \"[email protected]\"\n__status__ = \"Development\"\n\nimport logging, os, math\nfrom AnyQt.QtWidgets import QStyle\n\ntry:\n import cv2\nexcept:\n raise Exception('OpenCV is not available. ControlPlayer will not be working')\n\n\nfrom confapp \t import conf\nfrom AnyQt \t\t\t import uic, _api\nfrom AnyQt \t\t\t import QtCore\nfrom AnyQt.QtWidgets import QFrame\nfrom AnyQt.QtWidgets import QApplication\nfrom AnyQt.QtWidgets import QMainWindow\nfrom AnyQt.QtWidgets import QMessageBox\n\nfrom pyforms_gui.controls.control_base import ControlBase\n\nif _api.USED_API == _api.QT_API_PYQT5:\n import platform\n if platform.system() == 'Darwin':\n from pyforms_gui.controls.control_player.VideoQt5GLWidget import VideoQt5GLWidget as VideoGLWidget\n else:\n from pyforms_gui.controls.control_player.VideoGLWidget \t import VideoGLWidget\n\nelif _api.USED_API == _api.QT_API_PYQT4:\n from pyforms_gui.controls.control_player.VideoGLWidget \t\t import VideoGLWidget\n\n\nlogger = logging.getLogger(__name__)\n\nclass ControlPlayer(ControlBase, QFrame):\n\n def __init__(self, *args, **kwargs):\n self._video_widget = None # GL widget\n\n QFrame.__init__(self)\n ControlBase.__init__(self, *args, **kwargs)\n\n # self._multiple_files = kwargs.get('multiple_files', False)\n\n self._current_frame = None # current frame image\n self._current_frame_index = None # current frame index\n\n self.process_frame_event = kwargs.get('process_frame_event', self.process_frame_event)\n\n self._speed = 1\n self.logger = logging.getLogger('pyforms')\n\n self._update_video_frame = True # if true update the spinbox with the current frame\n self._update_video_slider = True # if true update the slider with the current frame\n #\n # self._scroll_frames_action = self.add_popup_menu_option('Use scroll to move between frames', lambda x: x)\n # self._scroll_frames_action.setCheckable(True)\n\n def __scroll_move_between_frames_evt(self):\n pass\n #self._scroll_frames_action.setIcon(QStyle.SP_DesktopIcon)\n\n def init_form(self):\n # Get the current path of the file\n rootPath = os.path.dirname(__file__)\n\n # Load the UI for the self instance\n uic.loadUi(os.path.join(rootPath, \"video.ui\"), self)\n\n\n # Define the icon for the Play button\n self.videoPlay.setIcon(conf.PYFORMS_ICON_VIDEOPLAYER_PAUSE_PLAY)\n self.detach_btn.setIcon(conf.PYFORMS_ICON_VIDEOPLAYER_DETACH)\n\n self.detach_btn.clicked.connect(self.__detach_player_evt)\n\n self._video_widget = VideoGLWidget()\n self._video_widget._control = self\n self.videoLayout.addWidget(self._video_widget)\n self.videoPlay.clicked.connect(self.videoPlay_clicked)\n self.videoFrames.valueChanged.connect(self.video_frames_value_changed)\n self.videoProgress.valueChanged.connect(self.videoProgress_valueChanged)\n self.videoProgress.sliderReleased.connect(self.videoProgress_sliderReleased)\n self._timer = QtCore.QTimer(self)\n self._timer.timeout.connect(self.call_next_frame)\n\n self.form.horizontalSlider.valueChanged.connect(self.__rotateZ)\n self.form.verticalSlider.valueChanged.connect(self.__rotateX)\n\n self._current_frame = None\n\n self.view_in_3D = False\n\n\n\n ##########################################################################\n ############ FUNCTIONS ###################################################\n ##########################################################################\n\n def save_form(self, data, path=None):\n return data\n\n def load_form(self, data, path=None):\n pass\n\n def hide(self):\n QFrame.hide(self)\n\n def show(self):\n QFrame.show(self)\n\n def play(self):\n \"\"\"\n Play the video.\n :return:\n \"\"\"\n try:\n self.videoPlay.setChecked(True)\n self._timer.start( 1000.0/float(self.fps+1) )\n except Exception as e:\n self.videoPlay.setChecked(False)\n logger.error(e, exc_info=True)\n\n def stop(self):\n \"\"\"\n Stop the video\n :return:\n \"\"\"\n self.videoPlay.setChecked(False)\n self._timer.stop()\n\n def toggle_playing(self):\n \"\"\"\n Play or pause the video.\n :return:\n \"\"\"\n if self.is_playing:\n self.stop()\n else:\n self.play()\n\n def refresh(self):\n \"\"\"\n Refresh the frame in the player.\n :return:\n \"\"\"\n if self._current_frame is not None:\n frame = self.process_frame_event(self._current_frame.copy())\n if isinstance(frame, list) or isinstance(frame, tuple):\n self._video_widget.paint(frame)\n else:\n self._video_widget.paint([frame])\n else:\n self._video_widget.paint(None)\n\n def jump_forward(self):\n \"\"\"\n Jump 20 seconds forward.\n :return:\n \"\"\"\n self.video_index += 20 * self.fps\n self.call_next_frame()\n\n def jump_backward(self):\n \"\"\"\n Jump 20 seconds backward.\n :return:\n \"\"\"\n self.video_index -= 20 * self.fps\n self.call_next_frame()\n\n def back_one_frame(self):\n \"\"\"\n Back one frame.\n :return:\n \"\"\"\n self.video_index -= 2\n self.call_next_frame()\n\n def forward_one_frame(self):\n \"\"\"\n Forward one frame.\n :return:\n \"\"\"\n self.call_next_frame()\n\n\n def set_speed_1x(self):\n \"\"\"\n Set video playing speed 1x.\n :return:\n \"\"\"\n self.next_frame_step = 1\n self.video_widget.show_tmp_msg('Speed: 1x')\n\n def set_speed_2x(self):\n \"\"\"\n Set video playing speed 2x.\n :return:\n \"\"\"\n self.next_frame_step = 2\n self.video_widget.show_tmp_msg('Speed: 2x')\n\n def set_speed_3x(self):\n \"\"\"\n Set video playing speed 3x.\n :return:\n \"\"\"\n self.next_frame_step = 3\n self.video_widget.show_tmp_msg('Speed: 3x')\n\n def set_speed_4x(self):\n \"\"\"\n Set video playing speed 4x.\n :return:\n \"\"\"\n self.next_frame_step = 4\n self.video_widget.show_tmp_msg('Speed: 4x')\n\n def set_speed_5x(self):\n \"\"\"\n Set video playing speed 5x.\n :return:\n \"\"\"\n self.next_frame_step = 5\n self.video_widget.show_tmp_msg('Speed: 5x')\n\n def set_speed_6x(self):\n \"\"\"\n Set video playing speed 6x.\n :return:\n \"\"\"\n self.next_frame_step = 6\n self.video_widget.show_tmp_msg('Speed: 6x')\n\n def set_speed_7x(self):\n \"\"\"\n Set video playing speed 7x.\n :return:\n \"\"\"\n self.next_frame_step = 7\n self.video_widget.show_tmp_msg('Speed: 7x')\n\n def set_speed_8x(self):\n \"\"\"\n Set video playing speed 8x.\n :return:\n \"\"\"\n self.next_frame_step = 8\n self.video_widget.show_tmp_msg('Speed: 8x')\n\n def set_speed_9x(self):\n \"\"\"\n Set video playing speed 9x.\n :return:\n \"\"\"\n self.next_frame_step = 9\n self.video_widget.show_tmp_msg('Speed: 9x')\n\n ##########################################################################\n ############ EVENTS ######################################################\n ##########################################################################\n\n def process_frame_event(self, frame): return frame\n\n @property\n def double_click_event(self): return self._video_widget.onDoubleClick\n @double_click_event.setter\n def double_click_event(self, value): self._video_widget.onDoubleClick = value\n\n @property\n def click_event(self): return self._video_widget.onClick\n @click_event.setter\n def click_event(self, value): self._video_widget.onClick = value\n\n @property\n def drag_event(self): return self._video_widget.onDrag\n @drag_event.setter\n def drag_event(self, value): self._video_widget.onDrag = value\n\n @property\n def end_drag_event(self): return self._video_widget.onEndDrag\n @end_drag_event.setter\n def end_drag_event(self, value): self._video_widget.onEndDrag = value\n\n @property\n def key_press_event(self):\n return self._video_widget.on_key_press\n @key_press_event.setter\n def key_press_event(self, value):\n self._video_widget.on_key_press = value\n\n @property\n def key_release_event(self): return self._video_widget.on_key_release\n @key_release_event.setter\n def key_release_event(self, value): self._video_widget.on_key_release = value\n\n ##########################################################################\n ############ PROPERTIES ##################################################\n ##########################################################################\n\n @property\n def video_widget(self): return self._video_widget\n\n @property\n def next_frame_step(self): return self._speed\n @next_frame_step.setter\n def next_frame_step(self, value): self._speed = value\n\n @property\n def view_in_3D(self): return self._video_widget.onEndDrag\n @view_in_3D.setter\n def view_in_3D(self, value):\n self.form.horizontalSlider.setVisible(value)\n self.form.verticalSlider.setVisible(value)\n\n @property\n def video_index(self): return int(self._value.get(1)) if self._value else None\n\n @video_index.setter\n def video_index(self, value):\n if value<0: value = 0\n if value>=self.max: value = self.max-1\n self._value.set(1, value)\n\n @property\n def max(self):\n if self._value is None or self._value=='':\n return 0\n return int(self._value.get(7))\n\n @property\n def frame(self): return self._current_frame\n\n @frame.setter\n def frame(self, value):\n if isinstance(value, list) or isinstance(value, tuple):\n self._video_widget.paint(value)\n elif value is not None:\n self._video_widget.paint([value])\n else:\n self._video_widget.paint(None)\n QApplication.processEvents()\n\n @property\n def fps(self):\n \"\"\"\n Return the video frames per second\n \"\"\"\n return self._value.get(5)\n\n @property\n def scroll_frames(self):\n return self._scroll_frames_action.isChecked()\n\n @property\n def help_text(self): return self._video_widget._helpText\n\n @help_text.setter\n def help_text(self, value): self._video_widget._helpText = value\n\n @property\n def form(self): return self\n\n @property\n def frame_width(self): return self._value.get(3)\n\n @property\n def frame_height(self): return self._value.get(4)\n\n @property\n def is_playing(self): return self._timer.isActive()\n\n @property\n def value(self): return ControlBase.value.fget(self)\n\n\n @value.setter\n def value(self, value):\n self.form.setUpdatesEnabled(False)\n if value is None:\n self.stop()\n self.videoControl.setEnabled(False)\n self.refresh()\n self._video_widget.reset()\n\n if value == 0:\n self._value = cv2.VideoCapture(0)\n elif isinstance(value, str) and value:\n self._value = cv2.VideoCapture(value,cv2.CAP_FFMPEG)\n else:\n self._value = value\n\n if self._value and value != 0:\n self.videoProgress.setMinimum(0)\n self.videoProgress.setValue(0)\n self.videoProgress.setMaximum(\n self._value.get(7))\n self.videoFrames.setMinimum(0)\n self.videoFrames.setValue(0)\n self.videoFrames.setMaximum(\n self._value.get(7))\n\n if self._value:\n self.videoControl.setEnabled(True)\n\n self.refresh()\n self.form.setUpdatesEnabled(True)\n\n\n ##########################################################################\n ############ PRIVATE FUNCTIONS ###########################################\n ##########################################################################\n\n def __rotateX(self):\n self._video_widget.rotateX = self.form.verticalSlider.value()\n self.refresh()\n\n def __rotateZ(self):\n self._video_widget.rotateZ = self.form.horizontalSlider.value()\n self.refresh()\n\n\n\n\n\n def call_next_frame(self, update_slider=True, update_number=True, increment_frame=True):\n # move the player to the next frame\n self.form.setUpdatesEnabled(False)\n\n self._current_frame_index = self.video_index\n\n # if the player is not visible, stop\n if not self.visible:\n self.stop()\n self.form.setUpdatesEnabled(True)\n return\n\n # if no video is selected\n if self.value is None:\n self._current_frame = None\n self._current_frame_index = None\n return\n\n # read next frame\n (success, self._current_frame) = self.value.read()\n\n # increment frame index if the step is bigger than 1\n if increment_frame and self.next_frame_step > 1:\n self.video_index += self.next_frame_step\n\n # no frame available. leave the function\n if not success:\n self.stop()\n self.form.setUpdatesEnabled(True)\n return\n\n frame = self.process_frame_event(\n self._current_frame.copy()\n )\n\n # draw the frame\n if isinstance(frame, list) or isinstance(frame, tuple):\n self._video_widget.paint(frame)\n else:\n self._video_widget.paint([frame])\n\n if not self.videoProgress.isSliderDown():\n\n if update_slider and self._update_video_slider:\n self._update_video_slider = False\n self.videoProgress.setValue(self._current_frame_index)\n self._update_video_slider = True\n\n if update_number:\n self._update_video_frame = False\n self.videoFrames.setValue(self._current_frame_index)\n self._update_video_frame = True\n\n self.form.setUpdatesEnabled(True)\n\n\n def __detach_player_evt(self):\n \"\"\"\n Called by the detach button\n \"\"\"\n self._old_layout = self.parentWidget().layout()\n self._old_layout_index = self._old_layout.indexOf(self)\n self._detach_win = QMainWindow(parent=self.parent)\n self._detach_win.setWindowTitle('Player')\n self._detach_win.setCentralWidget(self)\n self.detach_btn.hide()\n self._detach_win.closeEvent = self.__detach_win_closed_evt\n self._detach_win.show()\n\n def __detach_win_closed_evt(self, event):\n \"\"\"\n Called when the detached window is closed\n \"\"\"\n self._old_layout.insertWidget(self._old_layout_index, self)\n self.detach_btn.show()\n self._detach_win.close()\n del self._detach_win\n\n def videoPlay_clicked(self):\n \"\"\"Slot for Play/Pause functionality.\"\"\"\n if self.is_playing:\n self.stop()\n else:\n self.play()\n\n def convertFrameToTime(self, totalMilliseconds):\n # totalMilliseconds = totalMilliseconds*(1000.0/self._value.get(5))\n if math.isnan(totalMilliseconds): return 0, 0, 0\n totalseconds = int(totalMilliseconds / 1000)\n minutes = int(totalseconds / 60)\n seconds = totalseconds - (minutes * 60)\n milliseconds = totalMilliseconds - (totalseconds * 1000)\n return (minutes, seconds, milliseconds)\n\n def videoProgress_valueChanged(self):\n milli = self._value.get(0)\n (minutes, seconds, milliseconds) = self.convertFrameToTime(milli)\n self.videoTime.setText(\n \"%02d:%02d:%03d\" % (minutes, seconds, milliseconds))\n\n\n\n def videoProgress_sliderReleased(self):\n\n if not self.is_playing and self._update_video_slider:\n new_index = self.videoProgress.value()\n self._value.set(1, new_index)\n self.call_next_frame(update_slider=False, increment_frame=False)\n\n def video_frames_value_changed(self, pos):\n\n if not self.is_playing and self._update_video_frame:\n self._value.set(1, pos) # set the video position\n self.call_next_frame(update_number=False, increment_frame=False)\n\n"
},
{
"alpha_fraction": 0.5012345910072327,
"alphanum_fraction": 0.7185184955596924,
"avg_line_length": 17.409090042114258,
"blob_id": "2eabc5b571aff2e6485c94e10b1ffde653b3f0f6",
"content_id": "78fd113324c9264a22d71dac033c3410cb7c0522",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 405,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 22,
"path": "/requirements-labeler.txt",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "altgraph==0.17\nAnyQt==0.0.10\ncertifi==2020.6.20\nconfapp==1.1.11\nfuture==0.18.2\nmemoized-property==1.0.3\nnatsort==7.0.1\nnumpy==1.18.5\nopencv-python-headless==4.5.1.48\npackaging==20.4\npefile==2019.4.18\npyinstaller==4.0\npyinstaller-hooks-contrib==2020.10\nPyOpenGL==3.1.5\npyparsing==2.4.7\nPyQt5==5.13.0\nPyQt5-sip==12.8.0\npython-dateutil==2.8.1\npywin32-ctypes==0.2.0\nsix==1.15.0\nujson==4.0.1\nwincertstore==0.2\n"
},
{
"alpha_fraction": 0.6524781584739685,
"alphanum_fraction": 0.666472315788269,
"avg_line_length": 37.977272033691406,
"blob_id": "77d17f96a2832160323546334dc911455c687992",
"content_id": "cd4014df009144a73f896684dd42ddb6898e7003",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1715,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 44,
"path": "/ant_tracker/labeler/idMatching.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from classes import Tracker, TrackedAnt, TrackingState, getNextColor, first\nimport cv2 as cv\nfrom typing import List\nimport logging\n\n# logging.basicConfig(filename=\"idMatch.log\",format=\"[%(asctime)s]: %(message)s\",filemode=\"w\",level=logging.DEBUG)\n\n# def draw_ants(img, ants: List[TrackedAnt], frame: int):\n# for ant in ants:\n# color = getNextColor.kelly_colors[ant.id%len(getNextColor.kelly_colors)]\n# rect: Rect = first(ant.rects, lambda r: r.frame == frame)\n# if rect is not None:\n# x,y,w,h = rect.unpack()\n# img = cv.rectangle(img, (x,y), (x+w,y+h), color, 2)\n# img = cv.putText(img,str(ant.id),(x,y),cv.FONT_HERSHEY_SIMPLEX,1,255)\n# img = cv.putText(img,TrackingState.toString(ant.state,True),(x-10,y-3),cv.FONT_HERSHEY_SIMPLEX,1,255)\n# return img\n\n# cv.namedWindow(\"tracked\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n# cv.namedWindow(\"labeled\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n\n# labeled = Tracker.deserialize(filename=\"dia-labeled.rtg\")\ntracked = Tracker.deserialize(filename=\"dia-tracked.rtg\")\n\nfor ant in tracked.getAntsThatDidntCross():\n print(ant.getVelocity())\n print(ant.getVelocityAtFrame(14))\n break\n\n# tracked.modifyOwnIdsToMatch(labeled)\n\n# video = cv.VideoCapture(\"dia.mp4\")\n# for frame in range(0,500):\n# _,originalFrame = video.read()\n# img = originalFrame.copy()\n# img = draw_ants(img,tracked.trackedAnts,frame)\n# cv.imshow(\"tracked\",img)\n\n# imgColl = originalFrame.copy()\n# imgColl = draw_ants(imgColl,labeled.trackedAnts,frame)\n# cv.imshow(\"labeled\",imgColl)\n# k = cv.waitKey(0) & 0xff\n# if k == 27:\n# break\n"
},
{
"alpha_fraction": 0.5909326076507568,
"alphanum_fraction": 0.6302361488342285,
"avg_line_length": 33.322486877441406,
"blob_id": "dd260a6629441db31614bc61f4d28a8d4d3632f8",
"content_id": "cc9374873223f9f2cfe2aa1e86e29aa017c5f369",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11602,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 338,
"path": "/ant_tracker/labeler/pdi_mine.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom matplotlib import pyplot as plt\nimport cv2 as cv\nfrom scipy.signal import unit_impulse\n\ndef b2r(img):\n \"\"\"Returns BGR `img` in RGB.\"\"\"\n return cv.cvtColor(img,cv.COLOR_BGR2RGB)\ndef r2h(img):\n \"\"\"Returns RGB `img` in HSV.\"\"\"\n return cv.cvtColor(img,cv.COLOR_RGB2HSV)\ndef h2r(img):\n \"\"\"Returns HSV `img` in RGB.\"\"\"\n return cv.cvtColor(img,cv.COLOR_HSV2RGB)\ndef rect(x,w,y,h,center=None):\n if center:\n return (slice(y-h//2,y+h-h//2),slice(x-w//2,x+w-w//2))\n return (slice(y,y+h),slice(x,x+w))\ndef circle(shape, radius=None, center=None):\n img_w = shape[0]; img_h = shape[1]\n if center is None: # use the middle of the image\n center = [int(img_w/2), int(img_h/2)]\n if radius is None: # use the smallest distance between the center and image walls\n radius = min(center[0], center[1], img_w-center[0], img_h-center[1])\n Y, X = np.ogrid[:img_h, :img_w]\n dist_from_center = np.sqrt((X - center[0])**2 + (Y-center[1])**2)\n mask = dist_from_center <= radius\n return mask\ndef merge_masks(shape,*args):\n img_w = shape[0]; img_h = shape[1]\n ret = np.zeros((img_h,img_w),dtype=bool)\n for mask in args:\n ret[mask] = 1\n return ret\ndef kernelLaplace():\n return np.array([[0,1,0],[1,4,1],[0,1,0]])\ndef kernelProm(size):\n return np.array((1/(size**2))*np.ones((size,size)))\ndef kernelGauss(size,sigma=None):\n if (sigma == None or sigma<=0):\n sigma = 0.3*((size-1)*0.5 - 1) + 0.8\n x = y = np.arange(size) - int(np.floor(size/2))\n ret = np.zeros((size,size),dtype=float)\n for i in range(size):\n for j in range(size):\n ret[i,j] = np.exp(-(x[i]**2 + y[j]**2)/(2*sigma**2))\n ret /= np.sum(ret)\n return ret\ndef normalize(img,max_=255.0):\n \"\"\"Normalizes `img` between 0 and `max_` (default 255).\"\"\"\n img -= img.min()\n img = (img*max_/img.max()).astype('uint8')\n return img\ndef lut(array):\n array = normalize(array)\n array = np.clip(array, 0, 255).astype('uint8')\n return array\ndef expandlut(min,max):\n array = np.array([\n (255*x/(max-min) - 255*min/(max-min)) if (x>min and x<max)\n else 0 if x<=min\n else 255\n for x in range(256)])\n array = normalize(array)\n array = np.clip(array, 0, 255).astype('uint8')\n return array\ndef loglut():\n log = np.log(1+np.arange(0,256))\n log = normalize(log)\n # log = np.clip(log, 0, 255).astype('uint8')\n return log\ndef powlut(gamma):\n ppow = np.arange(0,256)**gamma\n ppow = normalize(ppow)\n # ppow = np.clip(ppow, 0, 255).astype('uint8')\n return ppow\ndef prom(*args):\n if type(args[0]) is list:\n ret = np.zeros_like(args[0][0],dtype='float64')\n for arg in args[0]:\n ret += arg\n return (ret/len(args[0])).astype(args[0][0].dtype)\n else:\n ret = np.zeros_like(args[0],dtype='float64')\n for arg in args:\n ret += arg\n return (ret/len(args)).astype(args[0].dtype)\ndef mult(img,mask):\n return img*mask\ndef highboost(img,A,ksize=3,hue=False):\n kernelHB = A*unit_impulse((ksize,ksize),'mid') - kernelGauss(ksize,-1)\n if hue: return (cv.filter2D(img,cv.CV_16S,kernelHB)).astype('uint8')\n return normalize(cv.filter2D(img,cv.CV_16S,kernelHB),255.).astype('uint8')\ndef equalize(img):\n \"\"\"Returns an equalized version of single channel `img`.\"\"\"\n hist = cv.calcHist([img],[0],None,[256],[0,256])\n H = hist.cumsum()\n H = H * hist.max()/ H.max()\n lin = H*255/max(H)\n lut = np.clip(lin, 0, 255)\n lut = lut.astype('uint8')\n return lut[img]\ndef equalizergb(img):\n \"\"\"Returns a RGB-channels equalized version of `img`.\"\"\"\n r,g,b = cv.split(img)\n r=equalize(r)\n g=equalize(g)\n b=equalize(b)\n return cv.merge([r,g,b])\ndef equalizev(img):\n \"\"\"Returns a v-channel equalized version of `img`.\"\"\"\n h,s,v = cv.split(cv.cvtColor(img,cv.COLOR_RGB2HSV))\n v=equalize(v)\n return cv.cvtColor(cv.merge([h,s,v]),cv.COLOR_HSV2RGB)\ndef mse(A,B,axis=None):\n return np.square(np.subtract(A, B)).mean(axis=axis)\ndef fft(img,log=False,magnitude=False):\n IMG = np.fft.fftshift(np.fft.fft2(img.astype('float32')))\n if not magnitude: return IMG\n mg = cv.magnitude(IMG.real,IMG.imag)\n if not log:\n return cv.magnitude(IMG.real,IMG.imag)\n else:\n mg = np.log(mg+1)\n return cv.normalize(mg,mg,0,1,cv.NORM_MINMAX)\ndef ifft(IMG):\n return normalize(np.real(np.fft.ifft2(np.fft.ifftshift(IMG)))).astype('uint8')\ndef rotate(img, angle):\n \"\"\"Rotates `img` by `angle` degrees around the center\"\"\"\n r = cv.getRotationMatrix2D((img.shape[0] / 2, img.shape[1] / 2), angle, 1.0)\n return cv.warpAffine(img, r, img.shape)\ndef noised_gauss(img,std):\n \"\"\"Returns a pair `[image,noise]`\n where `image` is `img` with added gaussian noise\n with `std` standard deviation\n and `noise` is the pattern added by that noise.\"\"\"\n noise = np.random.normal(0,std,img.shape)\n img_noise = np.clip(img.astype(float)+noise,0,255).astype('uint8')\n return img_noise,noise\ndef noised_unif(img,min_,max_):\n \"\"\"Returns a pair `[image,noise]`\n where `image` is `img` with added uniform noise\n with `min_` and `max_` values\n and `noise` is the pattern added by that noise.\"\"\"\n noise = np.random.uniform(min_,max_,img.shape)\n img_noise = np.clip(img.astype(float)+noise,0,255).astype('uint8')\n return img_noise,noise\ndef noised_snp(img,pad):\n \"\"\"Returns a pair `[image,noise]`\n where `image` is `img` with added salt-and-pepper noise\n and `pad` being a measure of its noisiness\n and `noise` is the pattern added by that noise.\"\"\"\n noise = np.random.randint(0,255,img.shape)\n img_noise = img.copy()\n img_noise[noise < pad] = 0\n img_noise[noise > 255-pad] = 255\n noise[noise < pad] = 0\n noise[noise > 255-pad] = 255\n noise[(noise != 0) & (noise != 255)] = 127\n return img_noise,noise\ndef fill_holes(img,kernel):\n I = img//255\n Ic = 1-I\n\n F = np.zeros_like(I)\n F[:,0] = Ic[:,0]\n F[:,-1] = Ic[:,-1]\n F[0,:] = Ic[0,:]\n F[-1,:] = Ic[-1,:]\n\n # cv.namedWindow(\"F\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n # cv.namedWindow(\"dif\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n\n dif = np.zeros_like(img).astype(bool)\n while np.any(~dif):\n # print(\"loop\")\n Fnew = cv.dilate(F,kernel)*Ic\n dif = F == Fnew\n # cv.imshow(\"F\",F)\n # cv.imshow(\"dif\",dif.astype('uint8'))\n # print(dif)\n # cv.waitKey(1)\n F = Fnew\n return (1-F)*255\n\n\n### Drawing functions\n\ndef hist(img,ax=None,ref_ax=None,cdf=False,real=False,dpi=None):\n \"\"\"Draw histogram of `img` in `ax`,\n with aspect ratio given by `ref_ax`\n (which should be the axes the image was drawn in).\n Set `cdf` to True to plot cumulative distribution function\n on top.\"\"\"\n f = None\n if ax==None:\n f = plt.figure(dpi=dpi)\n ax = plt.gca()\n im = img.ravel()\n if not real:\n ax.hist(im,256,[0,256])\n ax.set_xlim((-10,265))\n ax.set_xticks([0,25,50,75,100,125,150,175,200,225,255])\n else:\n ax.hist(im,512)\n ax.tick_params(labelsize=5,pad=.01,width=.25,labelrotation=30)\n if ref_ax:\n asp = np.diff(ax.get_xlim())[0] / np.diff(ax.get_ylim())[0]\n asp /= np.abs(np.diff(ref_ax.get_xlim())[0] / np.diff(ref_ax.get_ylim())[0])\n ax.set_aspect(asp)\n return f\n if cdf:\n ax2 = ax.twinx()\n hist,_ = np.histogram(im,256,[0,256])\n ax2.plot(np.cumsum(hist),'r--',alpha=0.7)\n ax2.tick_params(right=False,labelright=False,bottom=False,labelbottom=False)\n if ref_ax:\n ax2.set_aspect(asp)\n return f\ndef colhist(img,type:\"None|joined|split\"=None,dpi=None):\n \"\"\"Draw `img` and all three channels' histograms in\n subplots. `type` can be:\n 'joined': all three histograms in a single axes, default\n 'split': three separate histograms\"\"\"\n r,g,b = (cv.split(img)); r = r.ravel(); g = g.ravel(); b = b.ravel()\n rc = (1,0,0,.5); gc = (0,1,0,.5); bc = (0,0,1,.5)\n f,a = plt.subplots(1,4 if type=='split' else 2,dpi=dpi)\n a[0].imshow(img); a[0].set_xticks([]); a[0].set_yticks([])\n\n if type == None or type == 'joined':\n # f.subplots_adjust(wspace=0.1,right=3,bottom=-.5)\n a[1].hist([r,g,b],256,[0,256],color=[rc,gc,bc],histtype='stepfilled')\n asp = np.diff(a[1].get_xlim())[0] / np.diff(a[1].get_ylim())[0]\n asp /= np.abs(np.diff(a[0].get_xlim())[0] / np.diff(a[0].get_ylim())[0])\n a[1].set_aspect(asp)\n elif type == 'split':\n # f.subplots_adjust(wspace=0.2,right=4)\n a[1].hist(r,256,[0,256],color='r')\n a[2].hist(g,256,[0,256],color='g')\n a[3].hist(b,256,[0,256],color='b')\n asp = np.diff(a[1].get_xlim())[0] / np.diff(a[1].get_ylim())[0]\n asp /= np.abs(np.diff(a[0].get_xlim())[0] / np.diff(a[0].get_ylim())[0])\n a[1].set_aspect(asp)\n a[2].set_aspect(asp)\n a[3].set_aspect(asp)\n return f\ndef lutshow(img,lut):\n \"\"\"Draw `img` and a `lut` transformation,\n and the result of applying it to `img`\"\"\"\n f,ax = plt.subplots(1,3,dpi=150)\n imshow(img,ax[0])\n ax[1].plot(lut)\n ax[1].plot(np.arange(0,256),'--')\n ax[1].set_aspect('equal', 'box')\n ax[1].tick_params(left=False,bottom=False,labelleft=False,labelbottom=False)\n imshow(lut[img],ax[2])\n return f\ndef imshow(img,ax=None,title=None,tsize=None,dpi=None,vmin=None,vmax=None,interactive=False):\n \"\"\"Draw `img` in `ax` with `title` caption on top,\n of size `tsize`.\n\n For single channel images,\n `vmin` and `vmax` are set automatically,\n but you may set custom values to specify\n the range between which grays will be drawn\n (values outside of the range\n will be either black or white).\n \"\"\"\n if not (img<=1).all() and (img>=0).all() and (img<=255).all():\n if vmin==None: vmin = 0\n if vmax==None: vmax = 255\n f = None\n if ax==None:\n f = plt.figure(dpi=dpi)\n ax = plt.gca()\n axImage = ax.imshow(img,vmin=vmin,vmax=vmax,cmap='gray',interpolation='none')\n ax.set_xticks([])\n ax.set_yticks([])\n if title:\n ax.set_title(title,dict(size=tsize))\n if interactive: return f, axImage\n else: return f\ndef channelplot(img,model:\"rgb|hsv\"=\"rgb\",title=\"img\",dpi=None):\n if model==\"rgb\":\n [t0,t1,t2] = \"rgb\"\n [c0,c1,c2] = cv.split(img)\n elif model==\"hsv\":\n [t0,t1,t2] = \"hsv\"\n [c0,c1,c2] = cv.split(cv.cvtColor(img,cv.COLOR_RGB2HSV))\n\n f,a = plt.subplots(1,4,dpi=dpi)\n\n imshow(img,a[0]); a[0].set_title(title)\n imshow(c0,a[1]); a[1].set_title(t0)\n imshow(c1,a[2]); a[2].set_title(t1)\n imshow(c2,a[3]); a[3].set_title(t2)\n return f\ndef fftshow(img,dpi=150,alpha=0.9,log=False,threed=False,interactive=False):\n \"\"\"Plots `img` and its DFT magnitude in log scale\n in both 2D and 3D views.\n \"\"\"\n if threed:\n f,a = plt.subplots(1,3,dpi=dpi)\n f.subplots_adjust(right=0.01,left=-0.4)\n IMG = fft(img,log=log,magnitude=True)\n imshow(img,a[0])\n a[0].axis('off')\n imshow(IMG,a[1])\n a[1].axis('off')\n a[2].remove()\n ax = f.add_subplot(1, 3, 3, projection='3d')\n ax.set_xticks([]), ax.set_yticks([]), ax.set_zticks([])\n x = np.linspace(0,img.shape[1]-1,img.shape[1])\n y = np.linspace(0,img.shape[0]-1,img.shape[0])\n X, Y = np.meshgrid(x, y)\n ax.plot_surface(X,Y,IMG,cmap='gray',alpha=alpha, shade=False, lw=.5)\n ax.set_aspect('equal', 'box')\n return f\n else:\n f,a = plt.subplots(1,2,dpi=dpi)\n IMG = fft(img,log=log,magnitude=True)\n _,axImage1 = imshow(img,a[0],interactive=True)\n a[0].axis('off')\n _,axImage2 = imshow(IMG,a[1],interactive=True)\n a[1].axis('off')\n if interactive:\n return f, (axImage1,axImage2)\n else:\n return f\ndef save(f,path_or_page,dpi=None):\n \"\"\"Saves figure `f` to `path`.\n\n Modifies `f`'s background alpha in place.\"\"\"\n f.patch.set_alpha(0)\n if type(path_or_page) is str:\n f.savefig(path_or_page,dpi=dpi,bbox_inches=\"tight\",transparent=True,interpolation='none',pad_inches=0,tight=True)\n else:\n path_or_page.savefig(f,dpi=dpi,bbox_inches=\"tight\",transparent=True,interpolation='none')\n\n"
},
{
"alpha_fraction": 0.6255424618721008,
"alphanum_fraction": 0.644761323928833,
"avg_line_length": 26.3389835357666,
"blob_id": "8c568303e696bc8f8be81d76f40f9fb742a6219a",
"content_id": "51a22354a6361d326edb2707e3b798c937e5c49d",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1613,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 59,
"path": "/ant_tracker/tracker/test_tracker_continue.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import pims\n\nfrom .common import to_json\nfrom .segmenter import LogWSegmenter\nfrom .tracking import Tracker\n\ntestjson = \"test_tracker.json\"\nvideofile = \"vid_tags/720x510/HD720_1.mp4\"\n\nvideo = pims.PyAVReaderIndexed(videofile)[:30]\ntracker = Tracker(videofile, LogWSegmenter(video))\nfor frame_n in tracker.track_progressive():\n if frame_n == 6:\n break\ntracker.save_unfinished(testjson)\n\ntracker2 = Tracker.load_unfinished(testjson)\nfor frame_n in tracker2.track_progressive_continue():\n if frame_n == 9:\n break\n\nfor frame_n in tracker.track_progressive_continue():\n if frame_n == 9:\n break\n\nt1e = tracker.encode_unfinished()\nt2e = tracker2.encode_unfinished()\n\nassert to_json(t1e) == to_json(t2e)\nprint(\"Test passed\")\nimport os\n\nos.remove(testjson)\n\n# class Timer:\n# def __init__(self, title: str = \"\"):\n# self.title = title\n#\n# def __enter__(self):\n# import timeit\n# print(\"-\" * 6 + self.title + \"-\" * 6)\n# self.start = timeit.default_timer()\n#\n# def __exit__(self, exc_type, exc_val, exc_tb):\n# import timeit\n# print(\"-\" * 6 + f\"{self.title} end. Time: \", timeit.default_timer() - self.start)\n#\n# tracker = Tracker(videofile, LogWSegmenter(video))\n# with Timer(\"Running all at once\"):\n# for frame_n in tracker.track_progressive():\n# pass\n#\n# tracker2 = Tracker(videofile, LogWSegmenter(video))\n# with Timer(\"Stopping then continuing\"):\n# for frame_n in tracker2.track_progressive():\n# if frame_n == 10:\n# break\n# for frame_n in tracker2.track_progressive_continue():\n# pass\n"
},
{
"alpha_fraction": 0.580986499786377,
"alphanum_fraction": 0.5874437689781189,
"avg_line_length": 40.48527526855469,
"blob_id": "5ec993123bffdb30ebd5a821b367547c5042848f",
"content_id": "528340496580768a90831780d7fcf4d19adb5354",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29605,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 713,
"path": "/ant_tracker/labeler/classes.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass, field\nfrom enum import Enum\n\nimport cv2 as cv\nimport itertools\nimport numpy as np\nimport ujson\nfrom packaging.version import Version\nfrom pathlib import Path\nfrom typing import ClassVar, List, NoReturn, Tuple, Dict, Union, Optional, NewType, TypedDict\n\nfrom ..tracker.ant_labeler_info import groupSequence\nfrom ..tracker.blob import Blob\nfrom ..tracker.common import Position, to_json, to_tuple\nfrom ..tracker.info import TracksInfo\nfrom ..tracker.kellycolors import KellyColors\nfrom ..tracker.parameters import SegmenterParameters, TrackerParameters\nfrom ..tracker.track import Loaded, Track, TrackId\n\nCollectionVersion = Version(\"2.1\")\n\nColor = Tuple[int, int, int]\nBinaryMask = NewType(\"BinaryMask\", np.ndarray)\nColoredMask = NewType(\"ColoredMask\", np.ndarray)\nColoredMaskWithUnlabel = NewType(\"ColoredMaskWithUnlabel\", np.ndarray)\nVector = np.ndarray\nFrameAndVelocity = Tuple[int, Vector]\n\nclass AreaInFrame:\n def __init__(self, frame: int, mask: BinaryMask):\n self.frame = frame\n self.area = (np.nonzero(mask))\n self.area = (self.area[0].tolist(), self.area[1].tolist())\n self.shape = mask.shape\n\n def encode(self) -> Dict:\n return {\"frame\": self.frame, \"area\": self.area}\n\n def getMask(self) -> BinaryMask:\n mask = np.zeros(self.shape, dtype='uint8')\n mask[self.area] = 1\n return BinaryMask(mask)\n\n @staticmethod\n def decode(area: Dict, shape) -> \"AreaInFrame\":\n areaInFrame = AreaInFrame(-1, BinaryMask(np.ndarray((0, 0))))\n areaInFrame.frame = area[\"frame\"]\n areaInFrame.area = area[\"area\"]\n areaInFrame.shape = shape\n return areaInFrame\n\nclass AreasByFrame:\n def __init__(self):\n self.areas_per_frame: List[AreaInFrame] = []\n\n def getArea(self, frame) -> Union[Tuple[int, AreaInFrame], Tuple[None, None]]:\n which = [(index, areaInFrame) for index, areaInFrame\n in enumerate(self.areas_per_frame)\n if areaInFrame.frame == frame]\n if len(which) == 1:\n return which[0][0], which[0][1]\n elif len(which) == 0:\n return None, None\n else:\n raise ValueError(\"More than one area in frame %d\" % frame)\n\n def updateArea(self, frame: int, mask: BinaryMask):\n index, areaInFrame = self.getArea(frame)\n if not np.any(mask):\n if index is not None:\n self.areas_per_frame.pop(index)\n elif index is not None:\n self.areas_per_frame[index] = AreaInFrame(frame, mask)\n else:\n self.areas_per_frame.append(AreaInFrame(frame, mask))\n\n def encode(self):\n return [areaInFrame.encode() for areaInFrame in self.areas_per_frame]\n\n @staticmethod\n def decode(areas_as_list, shape) -> \"AreasByFrame\":\n areasByFrame = AreasByFrame()\n for area_as_dict in areas_as_list:\n areasByFrame.areas_per_frame.append(\n AreaInFrame.decode(area_as_dict, shape)\n )\n return areasByFrame\n\ndef epsilon(shape):\n size = shape[0] * shape[1]\n if size < 350000:\n return 0.01\n if size < 650000:\n return 0.03\n else:\n return 0.08\n\ndef get_contour(mask: BinaryMask):\n c, _ = cv.findContours(mask.astype('uint8'), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_TC89_L1)\n if not c: return []\n a = [cv.contourArea(cnt) for cnt in c]\n maxidx = a.index(max(a))\n contour = np.array(cv.approxPolyDP(c[maxidx], epsilon(mask.shape), True))\n contour = np.flip(contour.reshape((contour.shape[0], 2)), axis=1)\n return contour\n\ndef get_mask(contour, shape):\n mask = np.zeros(shape)\n if not np.any(contour): return mask\n pts = np.flip(contour, axis=1).reshape((-1, 1, 2))\n return cv.fillPoly(mask, [pts], 255).astype(bool)\n\nclass Ant:\n def __init__(self, _id: int):\n self.id = _id\n self.color = KellyColors.get(_id)\n # self.icon = ColorIcon(*self.color)\n self.loaded = False\n self.areasByFrame = AreasByFrame()\n\n def __repr__(self):\n ret = \"Ant - Id: \" + str(self.id) + \"; Color: \" + str(self.color)\n if self.loaded:\n ret += \"; IsLoaded\"\n return ret\n\n def updateArea(self, frame, mask):\n self.areasByFrame.updateArea(frame, mask)\n\n def getArea(self, frame):\n return self.areasByFrame.getArea(frame)[1]\n\n def isInFrame(self, frame):\n return self.areasByFrame.getArea(frame) != (None, None)\n\n def getMasksToUnlabel(self):\n areaInFrame: AreaInFrame\n frames_and_masks = [(areaInFrame.frame, areaInFrame.getMask())\n for areaInFrame in self.areasByFrame.areas_per_frame]\n # print(str(frames_and_masks))\n return frames_and_masks\n\n def getMask(self, frame) -> Optional[BinaryMask]:\n areaInFrame: AreaInFrame\n _, areaInFrame = self.areasByFrame.getArea(frame)\n if not areaInFrame:\n return None\n else:\n return areaInFrame.getMask()\n\n def getInvolvedFrames(self) -> List[int]:\n areaInFrame: AreaInFrame\n return [areaInFrame.frame for areaInFrame in self.areasByFrame.areas_per_frame]\n\n def getLastFrame(self):\n return max(self.getInvolvedFrames(), default=0)\n\n def getGroupsOfFrames(self) -> List[Tuple[int, int]]:\n return groupSequence(self.getInvolvedFrames())\n\n def as_track(self):\n i = self.id\n blobs = dict()\n areas = self.areasByFrame.areas_per_frame\n for area_in_frame in areas:\n frame, mask = area_in_frame.frame, area_in_frame.getMask()\n blob = Blob(imshape=mask.shape, contour=get_contour(mask))\n blobs[frame] = blob\n # noinspection PyTypeChecker\n blobs = dict(sorted(blobs.items()))\n return Track(TrackId(i - 1), blobs, force_load_to=self.loaded)\n\n @staticmethod\n def from_track(track: Track, shape: Tuple[int, int]):\n self = Ant(track.id + 1)\n self.loaded = Loaded.to_bool(track.loaded)\n self.areasByFrame = AreasByFrame()\n for frame, blob in track.blobs.items():\n mask = get_mask(blob.contour, shape)\n self.areasByFrame.updateArea(frame, mask)\n return self\n\n def encode(self):\n return dict({\n \"id\": self.id,\n \"loaded\": self.loaded,\n \"areasByFrame\": self.areasByFrame.encode()\n })\n\n @staticmethod\n def decode(ant_as_dict, shape) -> \"Ant\":\n ant = Ant(-1)\n ant.id = ant_as_dict[\"id\"]\n ant.loaded = ant_as_dict[\"loaded\"]\n ant.areasByFrame = AreasByFrame.decode(ant_as_dict[\"areasByFrame\"], shape)\n return ant\n\nclass UnlabeledFrame:\n def __init__(self, frame: Optional[int] = None, mask=None, _l=None, _i=None, _v=None, _f=None, contours=None):\n if frame is None:\n if _l is not None:\n self.frame = _f\n self.length = _l\n self.indices = _i\n self.values = _v\n return\n else:\n raise TypeError(\"Frame & Mask || Frame & contours || setters\")\n elif mask is not None:\n contours, _ = cv.findContours(mask.astype('uint8'), cv.RETR_EXTERNAL, cv.CHAIN_APPROX_TC89_L1)\n contours = [cv.approxPolyDP(c, epsilon(mask.shape), True) for c in contours]\n contours = [c.reshape(c.shape[0], 2) for c in contours]\n self.contours = contours\n elif contours is not None:\n self.contours = [np.array(c) for c in contours]\n else:\n raise TypeError(\"Frame & Mask || Frame & contours || setters\")\n self.frame = frame\n #\n # packed_mask = np.packbits(mask,axis=None)\n # self.length = len(packed_mask)\n # self.indices = np.nonzero(packed_mask)\n # self.indices = (self.indices[0].tolist())\n # self.values = packed_mask[self.indices].tolist()\n\n def __repr__(self):\n return f\"Frame: {self.frame}, {len(self.contours)} unlabeled contours\"\n\n def getMask(self, shape):\n mask = cv.fillPoly(np.zeros(shape), self.contours, 255)\n return BinaryMask(mask.astype(bool))\n\n class Serial(TypedDict):\n frame: int\n contours: List[List[Position]]\n\n class OldSerial(TypedDict):\n frame: int\n length: int\n indices: List[int]\n values: List[int]\n\n def encode(self) -> 'UnlabeledFrame.Serial':\n d = {\n \"frame\": self.frame,\n \"contours\": [[\n to_tuple(point) for point in contour\n ] for contour in self.contours],\n }\n return d\n\n @staticmethod\n def decode(unlabeled_as_dict: Union['UnlabeledFrame.OldSerial', 'UnlabeledFrame.Serial'], shape=None,\n size=None) -> \"UnlabeledFrame\":\n if 'values' in unlabeled_as_dict:\n # OldSerial\n def old_getMask(uf, _shape, _size) -> BinaryMask:\n \"\"\"Get a binary mask with ones on segmented pixels\"\"\"\n packed_mask = np.zeros(uf.length, dtype='uint8')\n packed_mask[uf.indices] = uf.values\n mask = np.unpackbits(packed_mask, axis=None)[:_size].reshape(_shape)\n return BinaryMask(mask)\n\n u = UnlabeledFrame(\n _l=unlabeled_as_dict[\"length\"],\n _i=unlabeled_as_dict[\"indices\"],\n _v=unlabeled_as_dict[\"values\"],\n _f=unlabeled_as_dict[\"frame\"],\n )\n contours, _ = cv.findContours(old_getMask(u, shape, size).astype('uint8'), cv.RETR_EXTERNAL,\n cv.CHAIN_APPROX_TC89_L1)\n contours = [cv.approxPolyDP(c, epsilon(shape), True) for c in contours]\n contours = [c.reshape(c.shape[0], 2) for c in contours]\n u.contours = contours\n else:\n u = UnlabeledFrame(frame=unlabeled_as_dict['frame'], contours=unlabeled_as_dict['contours'])\n return u\n\ndef get_track(tracks: List[Track], ant_id):\n return [track for track in tracks if track.id == ant_id - 1][0]\n\nclass AntCollection:\n def __init__(self, anymask: Optional[np.ndarray] = None, video_length=None, info=None):\n self.ants: List[Ant] = []\n self.id_iter = itertools.count(start=1)\n self.videoSize = anymask.size if anymask is not None else 0\n self.videoShape = anymask.astype('uint8').shape if anymask is not None else (0, 0)\n if video_length is not None:\n self.videoLength = video_length\n self.getUnlabeledMask = self.__getUnlabeledMaskClosure(self.videoShape)\n self.info: LabelingInfo = info\n self.version = CollectionVersion\n\n @staticmethod\n def __getUnlabeledMaskClosure(shape):\n def getMask(unl: UnlabeledFrame) -> BinaryMask:\n return unl.getMask(shape)\n\n return getMask\n\n def newAnt(self) -> Ant:\n _id = next(self.id_iter)\n ant = Ant(_id)\n self.ants.append(ant)\n track = Track(TrackId(_id - 1), {})\n self.info.tracks.append(track)\n return ant\n\n def getAnt(self, ant_id) -> Optional[Ant]:\n which = [ant for ant in self.ants if ant.id == ant_id]\n if len(which) == 1:\n return which[0]\n elif len(which) == 0:\n return None\n else:\n raise ValueError(\"More than one ant with id %d\" % ant_id)\n\n def deleteAnt(self, ant_id):\n # Desetiquetar todas las áreas\n dead_ant = self.getAnt(ant_id)\n print(\"deleteAnt: dead_ant:\", str(dead_ant))\n if dead_ant is None:\n raise ValueError(\"Trying to delete a nonexistent ant with id %d\" % ant_id)\n else:\n for frame, mask in dead_ant.getMasksToUnlabel():\n print(\"deleteAnt: frame:\", str(frame))\n self.updateUnlabeledFrame(frame, mask)\n self.ants.remove(dead_ant)\n dead_track = get_track(self.info.tracks, ant_id)\n self.info.tracks.remove(dead_track)\n\n def update_load(self, ant_id, loaded: bool):\n self.getAnt(ant_id).loaded = loaded\n get_track(self.info.tracks, ant_id)._Track__loaded = Loaded.parse(loaded)\n\n def getUnlabeledFrameGroups(self):\n unl = []\n for frame in self.info.unlabeledFrames:\n if len(frame.contours) > 0:\n unl.append(frame.frame)\n return groupSequence(unl), len(unl)\n\n def serialize(self) -> NoReturn:\n raise DeprecationWarning(\"Do not serialize as collection! Create a LabelingInfo instance instead\")\n # return to_json({\n # \"ants\": [ant.encode() for ant in self.ants],\n # \"unlabeledFrames\": [uF.encode() for uF in self.unlabeledFrames],\n # \"videoSize\": self.videoSize,\n # \"videoShape\": self.videoShape,\n # \"version\": str(CollectionVersion)\n # })\n\n @staticmethod\n def deserialize(video_path, jsonstring=None, filename=None) -> \"AntCollection\":\n if filename is not None:\n with open(filename, 'r') as file:\n antDict = ujson.load(file)\n elif jsonstring is not None:\n antDict = ujson.loads(jsonstring)\n else:\n raise TypeError(\"Provide either JSON string or filename.\")\n if 'labeler_version' in antDict and Version(antDict['labeler_version']) >= Version(\"2\"):\n info = LabelingInfo.deserialize(jsonstring=jsonstring, filename=filename)\n antCollection = AntCollection.from_info(info)\n else:\n antCollection = AntCollection(np.zeros(antDict[\"videoShape\"], dtype=\"uint8\"))\n\n for ant in antDict[\"ants\"]:\n antCollection.ants.append(Ant.decode(ant, antCollection.videoShape))\n antCollection.id_iter = itertools.count(start=antCollection.getLastId() + 1)\n\n antCollection.getUnlabeledMask = \\\n antCollection.__getUnlabeledMaskClosure(antCollection.videoShape)\n if \"version\" in antDict:\n antCollection.version = Version(antDict[\"version\"])\n else:\n antCollection.version = Version(\"1\")\n\n antCollection.info = LabelingInfo(\n video_path=video_path,\n ants=antCollection.ants,\n unlabeled_frames=[\n UnlabeledFrame.decode(uF, antCollection.videoShape, antCollection.videoSize)\n for uF in antDict[\"unlabeledFrames\"]\n ],\n )\n return antCollection\n\n def updateAreas(self, frame: int, colored_mask: ColoredMaskWithUnlabel):\n for ant in self.ants:\n contour = get_contour(colored_mask == ant.id)\n mask = get_mask(contour, self.videoShape)\n ant.updateArea(frame, mask)\n\n has_blob_in_frame = np.any(mask)\n track = get_track(self.info.tracks, ant.id)\n if has_blob_in_frame:\n track.blobs[frame] = Blob(imshape=mask.shape, contour=contour)\n elif track.at(frame) is not None:\n track.blobs.pop(frame)\n\n # Marcar áreas como etiquetadas\n index, unlabeled = self.getUnlabeled(frame)\n if index is not None:\n unlabeled_mask = self.getUnlabeledMask(unlabeled)\n\n # Quedan sólo las que no tienen etiqueta y que falten etiquetar\n unlabeled_mask = np.logical_and(colored_mask == -1, unlabeled_mask)\n\n if np.any(unlabeled_mask):\n self.overwriteUnlabeledFrame(frame, unlabeled_mask)\n else:\n self.deleteUnlabeledFrame(frame)\n\n def addUnlabeledFrame(self, frame: int, mask: BinaryMask):\n if np.any(mask):\n uf = UnlabeledFrame(frame, mask)\n self.info.unlabeledFrames.append(uf)\n\n def deleteUnlabeledFrame(self, frame: int):\n index, unlabeled = self.getUnlabeled(frame)\n if index is not None:\n self.info.unlabeledFrames.remove(unlabeled)\n\n def overwriteUnlabeledFrame(self, frame: int, mask: BinaryMask):\n index, unlabeled = self.getUnlabeled(frame)\n if index is not None:\n self.deleteUnlabeledFrame(frame)\n self.addUnlabeledFrame(frame, mask)\n\n def updateUnlabeledFrame(self, frame: int, new_mask: BinaryMask):\n index, unlabeled_packed = self.getUnlabeled(frame)\n if index is None:\n self.addUnlabeledFrame(frame, new_mask)\n else:\n unlabeled_mask = self.getUnlabeledMask(unlabeled_packed)\n unlabeled_mask = np.logical_or(unlabeled_mask, new_mask).astype('uint8')\n self.overwriteUnlabeledFrame(frame, unlabeled_mask)\n\n def getUnlabeled(self, frame) -> Union[Tuple[int, UnlabeledFrame], Tuple[None, None]]:\n \"\"\"Returns the `frame`th packed frame of unlabeled regions and its index in the list\"\"\"\n which = [(index, unlabeledFrame) for index, unlabeledFrame\n in enumerate(self.info.unlabeledFrames)\n if unlabeledFrame.frame == frame]\n if len(which) == 1:\n return which[0][0], which[0][1]\n elif len(which) == 0:\n return None, None\n else:\n raise ValueError(\"More than one packed mask in frame %d\" % frame)\n\n def getMask(self, frame) -> ColoredMaskWithUnlabel:\n mask = np.zeros(self.videoShape).astype('int16')\n area: AreaInFrame\n ant: Ant\n for (ant_id, area) in ((ant.id, ant.getArea(frame)) for ant in self.ants if ant.isInFrame(frame)):\n antmask = area.getMask().astype(bool)\n mask[antmask] = (antmask.astype('int16') * ant_id)[antmask]\n\n _, unlabeledFrame = self.getUnlabeled(frame)\n if unlabeledFrame is not None:\n ulmask = unlabeledFrame.getMask(self.videoShape)\n mask[ulmask] = (unlabeledFrame.getMask(self.videoShape).astype('int16') * (-1))[ulmask]\n\n return ColoredMaskWithUnlabel(mask)\n\n def cleanUnlabeledAndAntOverlaps(self, frame: int):\n index, unlabeledFrame = self.getUnlabeled(frame)\n if index is not None:\n unlmask = unlabeledFrame.getMask(self.videoShape).astype('bool')\n for ant in self.ants:\n if ant.isInFrame(frame):\n antmask = ant.getMask(frame).astype('bool')\n unlmask: BinaryMask = np.logical_and(unlmask, ~antmask)\n self.overwriteUnlabeledFrame(frame, unlmask)\n\n def cleanErrorsInFrame(self, frame, for_specific_ant: Ant = None):\n _, unlabeledFrame = self.getUnlabeled(frame)\n if unlabeledFrame is None:\n mask = np.zeros(self.videoShape).astype('int16')\n else:\n mask = unlabeledFrame.getMask(self.videoShape).astype('int16') * (-1)\n # print(\"cleaning frame \", frame)\n if for_specific_ant is not None:\n for ant in self.ants:\n if ant.isInFrame(frame):\n mask = mask + ant.getMask(frame).astype('int16') * ant.id\n alreadyPainted: BinaryMask = mask != 0\n aboutToPaint = for_specific_ant.getMask(frame)\n overlap: BinaryMask = np.logical_and(alreadyPainted, aboutToPaint)\n if np.any(overlap):\n for_specific_ant.updateArea(frame, np.zeros(self.videoShape))\n else:\n for ant in self.ants:\n if ant.isInFrame(frame):\n # print(\"- cleaning ant \", ant.id)\n alreadyPainted = mask != 0\n aboutToPaint = ant.getMask(frame)\n overlap: BinaryMask = np.logical_and(alreadyPainted, aboutToPaint)\n if np.any(overlap):\n ant.updateArea(frame, np.zeros(self.videoShape))\n else:\n mask = mask + ant.getMask(frame).astype('int16') * ant.id\n\n def cleanErrors(self, number_of_frames, for_specific_ant: Ant = None, from_this_frame=0):\n for frame in range(from_this_frame, number_of_frames):\n self.cleanErrorsInFrame(frame, for_specific_ant)\n\n def labelFollowingFrames(self, current_frame, ant_id, tracking_radius=160, conflict_radius=60):\n def centroids_no_background(mask):\n _, _, _, cents = cv.connectedComponentsWithStats(mask.astype('uint8'))\n return cents[1:]\n\n def closest_two_nodes(node, nodes):\n nodes = np.asarray(nodes)\n dist_2 = np.sum((nodes - node) ** 2, axis=1)\n index = dist_2.argsort()\n return nodes[index[:2]], dist_2[index[:2]]\n\n # Ordenar todos los frames que quedan después del actual\n # Por las dudas, en teoría ya deberían estar ordenados\n unlabeledFutureFrames = sorted(\n [uframe for uframe in self.info.unlabeledFrames\n if uframe.frame > current_frame],\n key=lambda uframe: uframe.frame)\n # Estamos en el último frame/no quedan más frames sin etiquetar hacia adelante:\n if not unlabeledFutureFrames:\n return\n ant = self.getAnt(ant_id)\n # track = get_track(self.info.tracks, ant_id)\n # TODO: maybe make it so you can retag tagged regions (not that essential)\n last_frame = unlabeledFutureFrames[0].frame - 1\n last_mask = ant.getMask(current_frame)\n if last_mask is None:\n raise ValueError(\"El frame del que se quiere rellenar no tiene una hormiga ya etiquetada\")\n # last_mask = np.zeros_like(self.getUnlabeledMask(unlabeledFutureFrames[0]),dtype='uint8')\n for uFrame in unlabeledFutureFrames:\n unlabel_mask = self.getUnlabeledMask(uFrame)\n frame = uFrame.frame\n print(\"Frame: \", frame)\n if frame != last_frame + 1:\n print(\"Hubo un salto, no hay chances de ver overlap\")\n break\n colored_mask = self.getMask(frame)\n if np.any(colored_mask == ant_id):\n print(\"En este frame ya hay una hormiga etiquetada con ese id\")\n break\n\n last_centroid = centroids_no_background(last_mask)\n if len(last_centroid) != 1:\n # FIXME: En realidad esto sí puede suceder,\n # si el usuario trata de rellenar en un frame donde ya pintó con ese id\n # Probablemente lo mejor sea largar QDialog de error avisando que\n # está intentando hacer algo indebido\n raise ValueError(\"En la máscara anterior debería haber un solo centroide\")\n last_centroid = last_centroid[0]\n\n centroids = centroids_no_background(unlabel_mask)\n if len(centroids) == 0:\n print(\"Nos quedamos sin hormigas\")\n break\n elif len(centroids) == 1:\n print(\"Hay una sola hormiga, es probablemente la que buscamos...\")\n dist = np.sum((centroids[0] - last_centroid) ** 2, axis=0)\n if dist > tracking_radius:\n print(\"Está muy lejos, probablemente sea una que recién aparece en otro lado\")\n print(\"(o bien la hormiga es muy rápida...)\")\n break\n else:\n x, y = np.int(centroids[0][0]), np.int(centroids[0][1]) # noqa\n if colored_mask[y, x] == -1:\n print(\"Floodfill(centroids[0])\")\n upcasted_mask = colored_mask.astype('int32')\n cv.floodFill(image=upcasted_mask,\n mask=None,\n seedPoint=(x, y),\n newVal=ant_id,\n loDiff=0,\n upDiff=0)\n colored_mask = upcasted_mask.astype('int16').copy()\n self.updateAreas(frame, colored_mask)\n else:\n print(\"El centroide del área anterior no cae en un área etiquetable\")\n break\n else:\n print(\"Más de una hormiga, busquemos las más cercanas\")\n closest, dist = closest_two_nodes(last_centroid, centroids)\n if dist[1] < conflict_radius:\n print(\"Dos hormigas muy cerca de la anterior, cortemos\")\n break\n elif dist[0] > tracking_radius:\n print(\"Está muy lejos, probablemente la hormiga que seguíamos se fue de cámara\")\n break\n else:\n x, y = np.int(closest[0][0]), np.int(closest[0][1]) # noqa\n if colored_mask[y, x] == -1:\n print(\"Floodfill(centroids[0])\")\n upcasted_mask = colored_mask.astype('int32')\n cv.floodFill(image=upcasted_mask,\n mask=None,\n seedPoint=(x, y),\n newVal=ant_id,\n loDiff=0,\n upDiff=0)\n colored_mask = upcasted_mask.astype('int16').copy()\n self.updateAreas(frame, colored_mask)\n else:\n print(\"El centroide del área anterior no cae en un área etiquetable\")\n break\n\n # Unos en la parte recién filleada\n last_mask = (colored_mask == ant_id).astype('uint8')\n last_frame = frame\n # self.cleanErrorsInFrame(frame,ant)\n return\n\n def getLastLabeledFrame(self):\n return max((ant.getLastFrame() for ant in self.ants), default=0)\n\n def getLastFrame(self):\n lastAntFrame = self.getLastLabeledFrame()\n lastUnlabeledFrame = max((unlabeledFrame.frame for unlabeledFrame in self.info.unlabeledFrames), default=0)\n return max(lastAntFrame, lastUnlabeledFrame)\n\n def getLastId(self):\n if len(self.ants) == 0:\n return 0\n else:\n return max([ant.id for ant in self.ants])\n\n def ants_as_tracks(self):\n return [ant.as_track() for ant in self.ants]\n\n @staticmethod\n def from_info(info: 'LabelingInfo'):\n self = AntCollection(np.zeros(info.video_shape, dtype=\"uint8\"), video_length=info.video_length, info=info)\n self.ants = [Ant.from_track(track, info.video_shape) for track in info.tracks]\n self.id_iter = itertools.count(start=self.getLastId() + 1)\n self.getUnlabeledMask = self.__getUnlabeledMaskClosure(self.videoShape)\n self.version = info.labeler_version\n return self\n\nclass SerializableEnum(str, Enum):\n def _generate_next_value_(self, start, count, last_values):\n return self\n\ndef first(iterable, condition=lambda x: True):\n \"\"\"\n Returns the first element that satisfies `condition`. \\n\n Returns `None` if not found.\n \"\"\"\n return next((x for x in iterable if condition(x)), None)\n\n# noinspection DuplicatedCode\n@dataclass\nclass LabelingInfo(TracksInfo):\n unlabeledFrames: List[UnlabeledFrame] = field(init=False)\n labeler_version: Version = field(init=False)\n file_extension: ClassVar = '.tag'\n\n def __init__(self, video_path, ants: List[Ant], unlabeled_frames: List[UnlabeledFrame]):\n\n super(LabelingInfo, self).__init__(\n video_path=video_path,\n tracks=sorted([ant.as_track() for ant in ants], key=lambda t: t.id),\n segmenter_version=Version(\"0\"),\n segmenter_parameters=SegmenterParameters.mock(),\n tracker_version=Version(\"0\"),\n tracker_parameters=TrackerParameters.mock(),\n )\n self.unlabeledFrames: List[UnlabeledFrame] = [uf for uf in unlabeled_frames if uf.contours]\n self.labeler_version = CollectionVersion\n\n class Serial(TracksInfo.Serial):\n unlabeled_frames: List[UnlabeledFrame.Serial]\n labeler_version: str\n\n def encode(self) -> 'LabelingInfo.Serial':\n return { # noqa\n **super(LabelingInfo, self).encode(),\n 'unlabeled_frames': [uf.encode() for uf in self.unlabeledFrames],\n 'labeler_version': str(self.labeler_version),\n }\n\n @classmethod\n def decode(cls, info: 'LabelingInfo.Serial'):\n labeler_version = Version(info.get('labeler_version', \"1.0\"))\n if labeler_version < Version(\"2.1\"):\n info['tracks'] = _flip_contours_before_2_1(info['tracks'])\n self = super(LabelingInfo, cls).decode(info)\n self.labeler_version = labeler_version\n size = self.video_shape[0] * self.video_shape[1]\n ufs = [UnlabeledFrame.decode(uf, self.video_shape, size) for uf in info['unlabeled_frames']]\n self.unlabeledFrames = [uf for uf in ufs if uf.contours]\n return self\n\n def serialize(self, pretty=False) -> str:\n if pretty: return to_json(self.encode())\n return ujson.dumps(self.encode())\n\n def save(self, file: Union[Path, str], pretty=False):\n if not isinstance(file, Path): # noqa\n file = Path(file)\n if not self._is_extension_valid(file):\n raise ValueError(f'Wrong extension ({file.suffix}). Only {self.file_extension} files are valid.')\n with file.open('w') as f:\n f.write(self.serialize(pretty=pretty))\n\ndef _flip_contours_before_2_1(tracks: List[Track.Serial]):\n for track in tracks:\n for blob in track['blobs'].values():\n blob['contour'] = [Position(p[1], p[0]) for p in blob['contour']]\n return tracks\n"
},
{
"alpha_fraction": 0.7902837991714478,
"alphanum_fraction": 0.7902837991714478,
"avg_line_length": 62.96923065185547,
"blob_id": "196536a4027fd263703dac35df12512593df1b90",
"content_id": "8b33c1db8a82bfff7fc5ee632c1614466a761872",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4214,
"license_type": "permissive",
"max_line_length": 463,
"num_lines": 65,
"path": "/ant_tracker/labeler/readme.md",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "# AntLabeler\n\nAntLabeler es un programa que permite etiquetar manualmente videos de hormigas en movimiento, guardando progresivamente el etiquetado en un archivo .json. Cuenta con la posibilidad de continuar el etiquetado de un mismo video a lo largo de múltiples sesiones.\n\n## Uso\n\n### Inicio\n\nAl ejecutar el programa se abren dos selectores de archivos en secuencia. El primero permite seleccionar el video a etiquetar. El segundo permite seleccionar un archivo de etiquetas existente. Si no se selecciona ninguno, el archivo se generará automáticamente usando el mismo nombre de archivo que el video, con una extensión `.tag`. El proceso de generación puede tardar unos minutos.\n\n### Reproductor\n\nEl componente principal es un reproductor de video, donde se visualiza el video a etiquetar, y superpuesto sobre él, el etiquetado vigente. En un inicio, las regiones que el proceso de generación reconoció como hormigas se encuentran marcadas en color rojo y un marcador cian. Estas áreas son las _regiones **inetiquetadas**_. El usuario deberá buscar regiones inetiquetadas y asignarles una etiqueta, manteniendo correspondencia temporal cuadro a cuadro.\n\nEl video puede reproducirse normalmente con el botón _play_, o avanzar cuadro por cuadro con las teclas `A/D` o `⬅/➡`. Además, se puede hacer _zoom_ en el video con la rueda del mouse, y mover la imagen manteniendo apretado el botón de la rueda.\n\n### Listado de objetos y selección\n\nDel lado derecho se encuentra una lista de objetos con botones `+` y `-` para agregar y eliminar hormigas. Una vez agregadas, se podrá seleccionar una para proceder a etiquetarla. Cualquier acción de etiquetado que se realice con una hormiga seleccionada aplicará su identificador.\n\nAdemás de su número y color identificador, en la lista aparece el intervalo de cuadros en el cual la hormiga se encuentra involucrada. Es esperable que haya sólo un intervalo, ya que la hormiga se mantiene en cámara desde que ingresa hasta que se retira, y no vuelve a aparecer; pero si así fuese etiquetada, aquí aparecerían más intervalos.\n\nEn esta lista se puede asignar el estado de cargada/no cargada a la hormiga. Este se mantiene durante toda la vida de la hormiga, siguiendo los supuestos del punto anterior.\n\nCuando se elimina una hormiga, todas las regiones en las que estaba etiquetada se convierten en inetiquetadas.\n\n### Acciones de etiquetado\n\nHay tres modos de etiquetado, nombrados por su equivalente en un programa de dibujo: _Dibujar_, _Borrar_ y _Rellenar_.\n\nEn el modo Dibujar, hacer click sobre el cuadro etiqueta un círculo con el identificador de la hormiga seleccionada. El radio del círculo está dado por el selector que se encuentra al tope de la pantalla. El modo Borrar elimina cualquier etiqueta que se encuentre debajo de un círculo del mismo radio. Estos dos modos son útiles para refinar la segmentación producida a la creación del archivo de etiquetas, o bien para corregir errores.\n\nEl modo Rellenar detecta una región debajo del mouse y la etiqueta con el identificador seleccionado. Esta región puede ser inetiquetada o bien ya haberse etiquetado con otro identificador.\n\nCualquier acción de etiquetado con estos modos puede deshacerse presionando (y posiblemente manteniendo pulsado) `Ctrl+Z`.\n\n#### Rellenado a futuro\n\nLa opción rellenado a futuro simplifica el etiquetado de una sola hormiga, al hacer una predicción de cuales regiones en los cuadros siguientes son probables a corresponder a la hormiga que acaba de etiquetarse. Al etiquetar en el modo Rellenar, se etiquetará esa misma hormiga en tantos cuadros como AntLabeler tenga seguridad de que no se producirán errores. Sin embargo, cualquier etiquetado que se produzca en cuadros futuros no podrá deshacerse con `Ctrl+Z`.\n\n### Atajos de teclado\n\n`(A/D)` o `(⬅/➡)`\n~ Retroceder/avanzar un cuadro\n\n`(W/S)` o `(⬆/⬇)`\n~ Mover la selección de hormiga\n\n`R`, `T`, `Y`\n~ Dibujar, Borrar, Rellenar\n\n`Ctrl+Z`\n~ Deshacer último cambio (en este cuadro)\n\nTecla más/menos (`+`/`-`)\n~ Aumentar/disminuir radio de dibujo\n\n`Espacio`\n~ Reproduce/detiene el video\n\n`U`\n~ Activar/desactivar rellenado a futuro\n\n`M`\n~ Mostrar/Ocultar máscara de etiquetado\n"
},
{
"alpha_fraction": 0.5484502911567688,
"alphanum_fraction": 0.5513003468513489,
"avg_line_length": 45.78333282470703,
"blob_id": "4134669e41211886d2600e4610484b52d1e37967",
"content_id": "76b9911e7b20a31e1e92c78eb29e009d5712bd7f",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5624,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 120,
"path": "/ant_tracker/tracker_gui/validator.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nfrom pathlib import Path\n\nfrom . import constants as C\nfrom .guicommon import align\nfrom .loading_window import LoadingWindow\nfrom ..tracker.validate import Measures\n\nXLSX = '.xlsx'\n\ndef validate_routine():\n def file_open(description, file_types, k, default=\"\", save=False, **browse_kwargs):\n browse_cls = sg.FileBrowse if not save else sg.FileSaveAs\n return sg.Column([\n [sg.Text(description, pad=(0, 0))],\n [sg.Input(default_text=default, pad=(3, 0), k=k),\n browse_cls(\"Examinar\", file_types=file_types, pad=(3, 0), **browse_kwargs)]\n ])\n\n layout = [\n [file_open(\"Archivo de tracking:\", file_types=((\"Tracking\", \"*.trk\"),), k='-TRK-')],\n [file_open(\"Archivo de etiquetas:\", file_types=((\"Etiquetas\", \"*.tag\"),), k='-TAG-')],\n [align(sg.Ok(\"Validar\"), 'right')],\n ]\n window = sg.Window(\"Seleccionar archivos\", layout, modal=True, icon=C.LOGO_AT_ICO, finalize=True)\n\n while True:\n event, values = window.read()\n if event == sg.WIN_CLOSED:\n break\n if event == 'Validar':\n try:\n trk, tag = Path(values['-TRK-']), Path(values['-TAG-'])\n except:\n sg.popup_error(\"Hubo un error al leer los archivos. \"\n \"Asegúrese de haber proporcionado las rutas correctas.\")\n continue\n if trk.suffix != '.trk' or tag.suffix != '.tag':\n sg.popup_error(\"Debe cargar todos los archivos y asegurarse de que sus extensiones sean correctas.\")\n continue\n else:\n from functools import partial\n Load = partial(LoadingWindow, spinner=C.SMALLSPINNER)\n with Load(\"Cargando tracking...\"):\n from ..tracker.info import TracksCompleteInfo, reposition_into_crop\n tracked = TracksCompleteInfo.load(trk)\n with Load(\"Cargando etiquetas...\"):\n from ..tracker.ant_labeler_info import LabelingInfo\n truth = reposition_into_crop(LabelingInfo.load(tag), tracked.crop_rect)\n if tracked.video_hash != truth.video_hash:\n sg.popup_error(\"Los archivos corresponden a videos distintos.\")\n continue\n with Load(\"Validando...\"):\n from ..tracker.validate import export_like_measures\n measures = export_like_measures(truth, tracked, trackfilter=C.TRACKFILTER)\n wb = make_xl(measures)\n\n while True:\n try:\n exportpath = (tag.parent / 'valid').with_suffix(XLSX)\n\n def get_exportpath(prev_path):\n return Path(sg.Window(\n \"Validación - Archivo de salida\", [\n [file_open(\"Archivo de salida\", ((\"Excel\", '*.xlsx'),), '-', str(prev_path), True,\n initial_folder=tag.parent, default_extension=XLSX)],\n [align(sg.Ok(), 'right')]\n ], icon=C.LOGO_AT_ICO, disable_close=True, modal=True).read(close=True)[1]['-'])\n\n exportpath = get_exportpath(exportpath).with_suffix(XLSX)\n while not exportpath.parent.exists() and not exportpath.is_absolute():\n sg.popup_error(\"Debe asegurarse de que la ruta de salida sea válida.\")\n exportpath = get_exportpath(exportpath).with_suffix(XLSX)\n\n wb.save(exportpath)\n break\n except PermissionError:\n sg.popup_error(\"El archivo está abierto o protegido de alguna manera.\\n\"\n \"Intente cerrar el programa que mantiene el archivo abierto o \"\n \"guardarlo con otro nombre.\")\n\n window.close()\n break\n\ndef make_xl(measures: Measures):\n from openpyxl import Workbook\n wb = Workbook()\n ws = wb.active\n import dataclasses\n labeldict = dataclasses.asdict(measures.label)\n trackdict = dataclasses.asdict(measures.track)\n descriptions = {\n 'total_EN': \"Total EN\",\n 'total_SN': \"Total SN\",\n 'speed_mean': \"Velocidad prom. [px/s]\",\n 'area_median': \"Área mediana [px²]\",\n 'length_median': \"Largo mediana [px]\",\n 'width_median': \"Ancho mediana [px]\",\n }\n\n ws.append([\"Medidas\", \"Etiquetas\", \"Tracks\", \"Error relativo\"])\n for k in labeldict.keys():\n error = abs(labeldict[k] - trackdict[k]) / labeldict[k] if labeldict[k] != 0 else 'N/A'\n ws.append([descriptions[k], labeldict[k], trackdict[k], error])\n from .export import adjust_column_widths, adjust_decimal_places\n adjust_column_widths(ws)\n adjust_decimal_places(ws, 3)\n for rows in ws['D2:D7']:\n for cell in rows:\n cell.number_format = '0.00%'\n ws.append([])\n ws.append([\"Aclaración: cada una de las medidas es un promedio a lo largo de todas las hormigas.\"])\n ws.append([\"eg: Velocidad prom. es el promedio de las velocidades promedio de todas las hormigas.\"])\n ws.append([\"Además para valores de la columna 'Etiquetas' iguales a 0, no se calcula el error.\"])\n ws.append([\"En este caso, asegúrese de etiquetar más hormigas para obtener muestras representativas.\"])\n\n return wb\n\nif __name__ == '__main__':\n validate_routine()\n"
},
{
"alpha_fraction": 0.5416523814201355,
"alphanum_fraction": 0.5536510348320007,
"avg_line_length": 28.170000076293945,
"blob_id": "8900d49870637eddd5882856c1ef858976693d54",
"content_id": "ee9971e9472fcafc9cfde257637dc86c1009c0da",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2917,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 100,
"path": "/ant_tracker/tracker/plot_tracks.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import glob\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom functools import partial\nfrom matplotlib.cm import get_cmap\nfrom matplotlib.collections import PatchCollection\nfrom matplotlib.patches import Rectangle\n\nfrom .ant_labeler_info import LabelingInfo\nfrom .common import unzip\nfrom .info import TracksInfo\nfrom .track import Loaded\n\nplt.close('all')\n\ndef get_color(x, y, shape, xcolor='Spectral', ycolor='gray'):\n xcolormap = get_cmap(xcolor)\n ycolormap = get_cmap(ycolor)\n\n if np.isscalar(x) and np.isscalar(y):\n if type(x) == int: x = x / shape[1]\n if type(y) == int: y = y / shape[0]\n xc = np.array(xcolormap(x))\n yc = np.array(ycolormap(y))\n else:\n if x.dtype == int: x = x / shape[1]\n if x.dtype == int: y = y / shape[0]\n xc = xcolormap(x)\n yc = ycolormap(y)\n r = (xc + yc) / 2\n return r\n\ndef plot_tracks(info: TracksInfo):\n fig = plt.figure()\n is_labeled = isinstance(info, LabelingInfo)\n ax = plt.gca()\n rects = []\n leaves = []\n leaf_probs = []\n rect_h = 0.9\n rect_w = 1\n for itrack, track in enumerate(info.tracks):\n path = track.path()\n for x, y, frame in path:\n rects.append(\n Rectangle((frame, itrack - 0.5), rect_w, rect_h, color=get_color(int(x), int(y), info.video_shape),\n )\n )\n if is_labeled:\n if track.loaded == Loaded.Yes:\n leaves.append((\n (track.last_frame() + track.first_frame()) / 2,\n itrack,\n ))\n else:\n leaf_probs.append((\n (track.last_frame() + track.first_frame()) / 2,\n itrack,\n track.load_probability,\n ))\n pc = PatchCollection(rects, match_original=True)\n ax.add_collection(pc)\n if is_labeled:\n if len(leaves) > 0:\n lx, ly = unzip(leaves)\n ax.scatter(lx, ly, marker=\"*\", ec='k', s=60)\n else:\n for lx, ly, prob in leaf_probs:\n ax.text(lx, ly, f\"{int(prob * 100)}%\")\n ax.scatter(lx, ly, marker=\"*\", ec='k', s=60, alpha=prob)\n ax.set_ylim(-0.5, len(info.tracks))\n ax.set_xlim(0, info.video_length)\n ax.set_ylabel(\"Track\")\n ax.set_xlabel(\"Frame\")\n ax.set_title(info.video_name + (\" - GT\" if is_labeled else \"\"))\n plt.show()\n\ndef __main():\n video = \"HD1\"\n version = \"dev1\"\n\n filename = f\"data/{video}-2.0.2.{version}.trk\"\n\n info = TracksInfo.load(filename)\n info_gt = LabelingInfo.load(glob.glob(f\"vid_tags/**/{video}.tag\")[0])\n\n shape = info.video_shape\n get_colors = partial(get_color, shape=shape)\n X, Y = np.meshgrid(np.linspace(0, 1, shape[1]), np.linspace(0, 1, shape[0]))\n Z = get_colors(X, Y)\n\n plt.figure()\n plt.imshow(Z)\n\n plot_tracks(info)\n plot_tracks(info_gt)\n\nif __name__ == '__main__':\n __main()\n"
},
{
"alpha_fraction": 0.5080728530883789,
"alphanum_fraction": 0.5106492638587952,
"avg_line_length": 32.26856994628906,
"blob_id": "73a0eb7d47aca561b4c6cb25dbd1e461fdbd4a52",
"content_id": "7158de427ce0d0a0b53057467f55e332571bb14e",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5826,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 175,
"path": "/ant_tracker/tracker_gui/main_window.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\nimport sys\nfrom pathlib import Path\n\nfrom . import constants as C\nfrom .about import about\nfrom .excepthook import make_excepthook\nfrom .guicommon import align, Email, ClickableText, write_event_value_closure\nfrom .version import version\n\ndef title(s):\n return sg.Text(s, font=(\"Helvetica\", 16), justification='center')\ndef center_text(s, **kwargs):\n return sg.Text(s, justification='center', **kwargs)\n\ndef small_credits():\n def text(s, **kwargs):\n return sg.Text(s, font=(\"Helvetica\", 8), pad=(0, 0), **kwargs)\n\n def bold(s, **kwargs):\n return sg.Text(s, font=(\"Helvetica Bold\", 8), pad=(0, 0), **kwargs)\n\n return [\n sg.Column([\n [bold(\"Francisco Daniel Sturniolo\")],\n [text(\"Desarrollador\")],\n [Email(\"[email protected]\")]\n ]),\n sg.VerticalSeparator(),\n sg.Column([\n [bold(\"Dr. Leandro Bugnon\")],\n [text(\"Director\")],\n [Email(\"[email protected]\")]\n ]),\n sg.VerticalSeparator(),\n sg.Column([\n [bold(\"Dr. Julián Alberto Sabattini\")],\n [text(\"Co-Director\")],\n [Email(\"[email protected]\")]\n ]),\n ]\n\ndef find_antlabeler() -> Path:\n labeler = Path(\"AntLabeler.exe\")\n if not labeler.exists():\n raise FileNotFoundError\n return labeler\n\ndef main():\n from .loading_window import LoadingWindow\n\n sg.theme(C.THEME)\n with LoadingWindow():\n sys.excepthook = make_excepthook(Path.cwd())\n\n # import a few modules:\n # 1. to import as much as we can while a loading window is up;\n # 2. to fix the exe hanging while importing certain modules\n import matplotlib # matplotlib is imported by pims by default\n\n matplotlib.use('agg') # we set agg to avoid it using tk and risk multithreading issues\n print(\"loaded: \", matplotlib)\n import pims\n\n print(\"loaded: \", pims)\n from scipy import stats\n\n print(\"loaded: \", stats)\n from filterpy.stats import stats\n\n print(\"loaded: \", stats)\n from ..tracker import tracking\n\n print(\"loaded: \", tracking)\n from ..tracker import leafdetect\n\n det = leafdetect.TFLiteLeafDetector(C.TFLITE_MODEL, [])\n print(\"loaded: \", leafdetect)\n\n layout = [\n [align([\n [sg.Image(C.LOGO_AT)],\n [title(f\"AntTracker v{version}\")],\n\n [sg.HorizontalSeparator()],\n\n [center_text(\"Realizado en el marco del Proyecto Final de Carrera: \\n\"\n \"Desarrollo de una herramienta para identificación automática del ritmo de forrajeo\\n\"\n \" de hormigas cortadoras de hojas a partir de registros de video.\")],\n [sg.HorizontalSeparator()],\n\n small_credits(),\n\n [sg.HorizontalSeparator()],\n\n [sg.Image(C.LOGO_FICH)],\n [sg.Image(C.LOGO_SINC),\n sg.Column([[sg.Image(C.LOGO_UNER)], [sg.Image(C.LOGO_AGRO)]],\n element_justification='center')],\n ], 'center')],\n\n [align([[\n sg.Button(\"Avanzado\", k='-ADVANCED-'),\n sg.Button(\"Más información\", k='-MORE_INFO-'),\n sg.Button(\"Abrir carpeta de videos\", k='-OPEN_FOLDER-', focus=True)]], 'right')]\n ]\n win = sg.Window(\"AntTracker\", layout, icon=C.LOGO_AT_ICO, finalize=True)\n ClickableText.bind_all()\n while True:\n event, values = win.read()\n if event == sg.WIN_CLOSED:\n break\n if event == '-OPEN_FOLDER-':\n from .ant_tracker_routine import ant_tracker_routine\n\n win.disable()\n ant_tracker_routine()\n win.enable()\n if event == '-MORE_INFO-':\n about()\n if event == '-ADVANCED-':\n buttons = {\n '-ANTLABELER-': \"AntLabeler\",\n '-VALIDATOR-': \"Validador trk/tag\",\n '-TRKVIZ-': \"Visualizador de trk/tag\\n(experimental)\",\n }\n adv_layout = [[align([\n *[[sg.Button(text, size=(20, 2), k=k)] for k, text in buttons.items()],\n [sg.HorizontalSeparator()],\n [sg.Button(\"Regresar\", k='-BACK-')],\n ], 'center')]]\n adv_win = sg.Window(\"Avanzado\", adv_layout, icon=C.LOGO_AT_ICO, modal=True)\n\n def wait_n_send(k):\n send = write_event_value_closure(adv_win)\n\n def _w():\n from time import sleep\n sleep(5)\n send('!!' + k, '-OPEN_DONE-')\n\n import threading\n threading.Thread(target=_w, daemon=True).start()\n\n while True:\n event, values = adv_win.read()\n if event == sg.WIN_CLOSED or event == '-BACK-':\n adv_win.close()\n break\n if event.startswith('!!'):\n key = event.split('!!')[1]\n adv_win[key].update(buttons[key], disabled=False)\n if event == '-ANTLABELER-':\n try:\n p = find_antlabeler()\n except FileNotFoundError:\n sg.popup(C.ANTLABELER_UNAVAILABLE)\n continue\n adv_win[event].update(\"Abriendo...\", disabled=True)\n import os\n\n os.startfile(p)\n wait_n_send(event)\n if event == '-TRKVIZ-':\n adv_win[event].update(\"Abriendo...\", disabled=True)\n from .trkviz import trkviz_subprocess\n\n trkviz_subprocess()\n wait_n_send(event)\n if event == '-VALIDATOR-':\n from .validator import validate_routine\n\n validate_routine()\n\n win.close()\n"
},
{
"alpha_fraction": 0.6726457476615906,
"alphanum_fraction": 0.6726457476615906,
"avg_line_length": 21.299999237060547,
"blob_id": "bfd030b0b0d3e0aef6d141f3d38ed8d5ff2b6af4",
"content_id": "67e80489a241ffb1d8e4238d7c4feca7e137e6ac",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 10,
"path": "/tracker_main.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from multiprocessing import freeze_support\n\nif __name__ == '__main__':\n freeze_support()\n from check_env import check_env\n\n check_env(\"tracker\")\n from ant_tracker.tracker_gui.main_window import main\n\n main()\n"
},
{
"alpha_fraction": 0.8348110318183899,
"alphanum_fraction": 0.8348110318183899,
"avg_line_length": 46.57777786254883,
"blob_id": "151e89d5f55dd8cf0e35027e18212922c1b7edbf",
"content_id": "f22b748a2b64b7cdc00e374d160cdd18d44925ed",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2143,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 45,
"path": "/ant_tracker/labeler/pyforms_patch/pyforms_gui/allcontrols.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "\n\nimport logging; logger = logging.getLogger(__name__)\n\n\n\nfrom .controls.control_base import ControlBase\nfrom .controls.control_boundingslider import ControlBoundingSlider\nfrom .controls.control_button import ControlButton\nfrom .controls.control_checkbox import ControlCheckBox\nfrom .controls.control_checkboxlist import ControlCheckBoxList\nfrom .controls.control_combo import ControlCombo\nfrom .controls.control_dir import ControlDir\nfrom .controls.control_dockwidget import ControlDockWidget\nfrom .controls.control_emptywidget import ControlEmptyWidget\nfrom .controls.control_file import ControlFile\nfrom .controls.control_filestree import ControlFilesTree\ntry:\n from .controls.control_image import ControlImage\nexcept Exception as e:\n logger.warning('ControlImage will not work. Please check OpenCV is installed.')\n logger.debug('ControlImage will not work', exc_info=True)\nfrom .controls.control_label import ControlLabel\nfrom .controls.control_list import ControlList\nfrom .controls.control_mdiarea import ControlMdiArea\nfrom .controls.control_number import ControlNumber\ntry:\n from .controls.control_opengl import ControlOpenGL\nexcept Exception as e:\n logger.warning('ControlOpenGL will not work. Please check PyOpenGL is installed.')\n logger.debug('ControlOpenGL will not work', exc_info=True)\nfrom .controls.control_progress import ControlProgress\nfrom .controls.control_slider import ControlSlider\nfrom .controls.control_tableview import ControlTableView\nfrom .controls.control_text import ControlText\nfrom .controls.control_password import ControlPassword\nfrom .controls.control_textarea import ControlTextArea\nfrom .controls.control_toolbox import ControlToolBox\nfrom .controls.control_toolbutton import ControlToolButton\nfrom .controls.control_tree import ControlTree\nfrom .controls.control_treeview import ControlTreeView\nfrom .controls.control_event_timeline.control_eventtimeline import ControlEventTimeline\nfrom .controls.control_events_graph.control_eventsgraph import ControlEventsGraph\ntry:\n from .controls.control_player.control_player import ControlPlayer\nexcept Exception as e:\n logger.error( e )\n"
},
{
"alpha_fraction": 0.5672245025634766,
"alphanum_fraction": 0.5886399149894714,
"avg_line_length": 36.40583419799805,
"blob_id": "dda93e04b1b968a0f819e20efbfc1992c89f2253",
"content_id": "97cd2f84507a7ec413cf3a24c2e9312494e25bfa",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14104,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 377,
"path": "/ant_tracker/labeler/AntTracker.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from classes import *\nfrom PreLabeler import labelVideo\nfrom os.path import splitext, exists # for file management\nfrom typing import Dict\nfrom enum import Enum, auto\nimport itertools\nimport cv2 as cv\n\nclass Method(Enum):\n MEANSHIFT=auto(),\n CAMSHIFT=auto(),\n KALMAN=auto(),\n PYRLK=auto(),\n\nfilename = \"dia\"\nreset_tags = False\nmethod = Method.KALMAN\nshowInProgressTracking = True\nlastFrameToTrack = 200 ## `None` o un número\nold = True\n\nfile = f\"{filename}.mp4\"\nvideo = cv.VideoCapture(file)\nvshape = (int(video.get(cv.CAP_PROP_FRAME_HEIGHT)),int(video.get(cv.CAP_PROP_FRAME_WIDTH)))\nvlen = int(video.get(cv.CAP_PROP_FRAME_COUNT))\n\n# Nombre default de archivo de etiquetas: nombre_video.tag\ntagfile = f\"{filename}-untagged.tag\"\n\ndef new_tags(file: str, tagfile: str) -> AntCollection:\n antCollection = AntCollection(np.empty(vshape))\n for frame,mask in enumerate(labelVideo(file)):\n antCollection.addUnlabeledFrame(frame,mask)\n antCollection.videoSize = mask.size\n antCollection.videoShape = tuple(mask.shape)\n jsonstring = antCollection.serialize()\n\n with open(tagfile,\"w\") as file:\n file.write(jsonstring)\n return antCollection\n\nif reset_tags:\n antCollection = new_tags(file,tagfile)\nelse:\n try:\n antCollection = AntCollection.deserialize(filename=tagfile)\n except:\n antCollection = new_tags(file,tagfile)\n\n# cv.namedWindow(\"regions\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n# cv.namedWindow(\"mask\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\nif showInProgressTracking:\n cv.namedWindow(\"img\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n# cv.namedWindow(\"original\",cv.WINDOW_NORMAL | cv.WINDOW_KEEPRATIO | cv.WINDOW_GUI_NORMAL)\n\nbox_stays_threshold = 0.05\nheight_ratio = 0.1\nwidth_ratio = 0.1\n # left, top, width, height\nimage_rect = Rect(0, 0, vshape[1], vshape[0])\nzone_up = Rect(\n 0,\n 0,\n vshape[1],\n int(vshape[0]*height_ratio)\n)\nzone_down = Rect(\n 0,\n int(vshape[0]*(1-height_ratio)),\n vshape[1],\n int(vshape[0]*height_ratio)\n)\nzone_left = Rect(\n 0,\n int(vshape[0]*height_ratio),\n int(vshape[1]*width_ratio),\n int(vshape[0]*(1-2*height_ratio))\n)\nzone_right = Rect(\n int(vshape[1]*(1-width_ratio)),\n int(vshape[0]*height_ratio),\n int(vshape[1]*width_ratio),\n int(vshape[0]*(1-2*height_ratio))\n)\nzone_middle = Rect(\n int(vshape[1]*width_ratio),\n int(vshape[0]*height_ratio),\n int(vshape[1]*(1-2*width_ratio)),\n int(vshape[0]*(1-2*height_ratio))\n)\n\nidList = []\ndef first_available(l: List[int]) -> int:\n c = 1\n while c in l:\n c += 1\n return c\nterm_crit = ( cv.TERM_CRITERIA_EPS | cv.TERM_CRITERIA_COUNT, 10, 1 )\n\ndef get_new_boxes(unlabeleds: ColoredMaskWithUnlabel, exclude: Rect, frame: int) -> List[Dict]:\n # remove ants in exclude\n x,y,w,h = exclude.unpack()\n zone_regions = unlabeleds.copy()\n # zone_regions = cv.rectangle(zone_regions, (x,y), (x+w,y+h), 0,-1)\n # cv.imshow(\"regions\",zone_regions*255)\n\n nlabels, labels, stats, centroids = cv.connectedComponentsWithStats(zone_regions)\n nlabels, stats, centroids = nlabels-1, stats[1:], centroids[1:]\n\n boxes = []\n\n for label in range(nlabels):\n # rect = Rect(\n # stats[label][cv.CC_STAT_LEFT]-3 if stats[label][cv.CC_STAT_LEFT]-3>=0 else 0,\n # stats[label][cv.CC_STAT_TOP]-3 if stats[label][cv.CC_STAT_TOP]-3>=0 else 0,\n # stats[label][cv.CC_STAT_WIDTH]+6,\n # stats[label][cv.CC_STAT_HEIGHT]+6)\n rect = Rect(\n stats[label][cv.CC_STAT_LEFT],\n stats[label][cv.CC_STAT_TOP],\n stats[label][cv.CC_STAT_WIDTH],\n stats[label][cv.CC_STAT_HEIGHT],\n frame)\n # if rect.is_in_boundary_of(image_rect): continue\n\n x,y,w,h = rect.unpack()\n roi = originalFrame[y:y+h, x:x+w]\n hsv_roi = cv.cvtColor(roi,cv.COLOR_BGR2HSV)\n\n mask = labels[y:y+h, x:x+w]\n mask[mask==0] = 0\n mask[mask!=0] = 255\n mask = mask.astype('uint8')\n\n hist = cv.calcHist([hsv_roi],[2],mask,[255],[0,255])\n cv.normalize(hist,hist,0,255,cv.NORM_MINMAX)\n antId = 1\n # if idList == []:\n # antId = 1\n # else:\n # antId = first_available(idList)\n boxes.append(dict(id=antId,rect=rect,hist=hist))\n idList.append(antId)\n return boxes\n\ndef draw_boxes(frame,name,boxes):\n img = frame.copy()\n for box in boxes:\n x,y,w,h = box[\"rect\"].unpack()\n label = box[\"id\"]\n img = cv.rectangle(img, (x,y), (x+w,y+h), getNextColor.kelly_colors[label%len(getNextColor.kelly_colors)],2)\n img = cv.putText(img,str(label),(x,y),cv.FONT_HERSHEY_SIMPLEX,1,255)\n # cv.imshow(name,img)\n pass\n\n_,originalFrame = video.read()\nfirstFrame = originalFrame.copy()\n_,unlabeledFrame = antCollection.getUnlabeled(0)\nlastFrame = antCollection.getLastFrame() if lastFrameToTrack is None else lastFrameToTrack\nunlabeleds = antCollection.getUnlabeledMask(unlabeledFrame)\nboxes = get_new_boxes(unlabeleds,zone_middle,0)\n\ntracker = Tracker(vlen,vshape,minDistanceBetween=10)\n\ntracker.add_new_ants([box[\"rect\"] for box in boxes],zone_middle,image_rect)\n\n\nif method == Method.KALMAN:\n kalman = cv.KalmanFilter(4,2)\n kalman.measurementMatrix = np.array([[1,0,0,0],\n [0,1,0,0]],np.float32)\n\n kalman.transitionMatrix = np.array([[1,0,1,0],\n [0,1,0,1],\n [0,0,1,0],\n [0,0,0,1]],np.float32)\n\n kalman.processNoiseCov = np.array([[1,0,0,0],\n [0,1,0,0],\n [0,0,1,0],\n [0,0,0,1]],np.float32) * 0.03\n\n measurement = np.array((2,1), np.float32)\n prediction = np.zeros((2,1), np.float32)\n\ndef draw_ants(img, ants: List[TrackedAnt], frame: int):\n for ant in ants:\n color = getNextColor.kelly_colors[ant.id%len(getNextColor.kelly_colors)]\n rect: Rect = first(ant.rects, lambda r: r.frame == frame)\n if rect is not None:\n x,y,w,h = rect.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), color, 2 if rect.overlaps(zone_middle) else 1)\n img = cv.putText(img,str(ant.id),(x,y),cv.FONT_HERSHEY_SIMPLEX,1,255)\n img = cv.putText(img,TrackingState.toString(ant.state,True),(x-10,y-3),cv.FONT_HERSHEY_SIMPLEX,1,255)\n return img\n\nfor frame in range(1,lastFrame):\n _,originalFrame = video.read()\n _,unlabeledFrame = antCollection.getUnlabeled(frame)\n unlabeleds = antCollection.getUnlabeledMask(unlabeledFrame)\n new_possib_boxes = get_new_boxes(unlabeleds, zone_middle, frame)\n\n if not old:\n draw_boxes(originalFrame,'boxes',new_possib_boxes)\n tracker.add_new_ants([box[\"rect\"] for box in new_possib_boxes],zone_middle,image_rect)\n # print(tracker)\n\n img = originalFrame.copy()\n x,y,w,h = zone_up.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_down.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_left.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_right.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_middle.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 127,2)\n img = draw_ants(img,tracker.trackedAnts,frame)\n\n if showInProgressTracking:\n cv.imshow('trackedAnts',img)\n\n stillboxes = []\n # print(idList)\n\n\n if old:\n\n ## Se descartan las cajas que tengan color de fondo\n for box in boxes:\n x,y,w,h = box[\"rect\"].unpack()\n roi = unlabeleds[y:y+h, x:x+w]\n\n if np.mean(roi) > box_stays_threshold:\n # if np.median(roi) > 0.5:\n stillboxes.append(box)\n else:\n idList.remove(box[\"id\"])\n boxes = stillboxes\n\n # draw_boxes(originalFrame,'new possib boxes',new_possib_boxes)\n ## Agregamos las cajas nuevas (que no se superpongan con las viejas)\n new_boxes = boxes.copy()\n for newbox in new_possib_boxes:\n # if is_on_zone_boundary(bx,by,bw,bh): continue\n if not any((box[\"rect\"].overlaps(newbox[\"rect\"]) for box in boxes)):\n new_boxes.append(newbox)\n else:\n idList.remove(newbox[\"id\"])\n # overlap = False\n # for box in boxes:\n # overlap = box[\"rect\"].overlaps(newbox[\"rect\"])\n # if overlap:\n # print(\"overlap: \", box[\"id\"], newbox[\"id\"])\n # break\n # if not overlap: new_boxes.append(newbox)\n boxes = new_boxes\n\n # draw_boxes(originalFrame,'boxes before update',boxes)\n\n\n img = originalFrame.copy()\n x,y,w,h = zone_up.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_down.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_left.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_right.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 0,2)\n x,y,w,h = zone_middle.unpack()\n img = cv.rectangle(img, (x,y), (x+w,y+h), 127,2)\n\n # _,unlabeledFrame = antCollection.getUnlabeled(frame)\n # mask = antCollection.getUnlabeledMask(unlabeledFrame)\n for box in boxes:\n hist,label = box[\"hist\"],box[\"id\"]\n color = getNextColor.kelly_colors[label%len(getNextColor.kelly_colors)]\n hsv = cv.cvtColor(originalFrame,cv.COLOR_BGR2HSV)\n dst = cv.calcBackProject([hsv],[2],hist,[0,255],1)\n\n # print(\"before: \", bounding_rect)\n rect: Rect\n rect = box[\"rect\"]\n boxtuple = rect.unpack()\n\n if method == Method.CAMSHIFT:\n track_box, boxtuple = cv.CamShift(dst, boxtuple, term_crit)\n pts = cv.boxPoints(track_box)\n pts = np.int0(pts)\n img = cv.polylines(img,[pts], True, color, 2)\n x,y,w,h = boxtuple\n box[\"rect\"] = Rect(x,y,w,h)\n elif method == Method.MEANSHIFT:\n track_box, boxtuple = cv.meanShift(dst, boxtuple, term_crit)\n x,y,w,h = boxtuple\n box[\"rect\"] = Rect(x,y,w,h)\n img = cv.rectangle(img, (x,y), (x+w,y+h), color, 2 if box[\"rect\"].overlaps(zone_middle) else 1)\n elif method == Method.KALMAN:\n center = rect.center().astype(np.float32)\n kalman.correct(center)\n prediction = kalman.predict()\n x = np.int(prediction[0]-(0.5*w))\n y = np.int(prediction[1]-(0.5*h))\n \n # w = np.int(prediction[0]+(0.5*w))\n # h = np.int(prediction[1]+(0.5*h))\n box[\"rect\"] = Rect(x,y,w,h)\n img = cv.rectangle(img, (x,y), (x+w,y+h), color,2)\n\n img = cv.putText(img,str(label),(x,y),cv.FONT_HERSHEY_SIMPLEX,1,255)\n # cv.imshow('mask',unlabeleds*255)\n # cv.imshow('original',originalFrame)\n if (showInProgressTracking):\n cv.imshow('img',img)\n k = cv.waitKey(0) & 0xff\n if k == 27:\n break\n\n# with open(f\"./{filename}-tracked.rtg\",\"w\") as target:\n# target.write(tracker.serialize())\n\ndef toTuple(point: Vector) -> Tuple[int,int]:\n return tuple(point.astype(int))\ndef drawTrajectory(trajectory: List[Rect], img, antId):\n color = getNextColor.forId(antId)\n points = [rect.center() for rect in trajectory]\n\n points = np.int0(points)\n return cv.polylines(img, [points], False, color, 1)\nfrom itertools import chain\n\n## Hay tres casos:\n## una hormiga se queda quieta en el medio (state = Ant)\n## una hormiga va al medio y vuelve (state = Left)\n## una hormiga queda muchos frames sin reconocer en el medio (state = Ant) y después se reconoce (state = any)\nif not old:\n ants = list(tracker.getAntsThatDidntCross())\n print(len(ants))\n\n video = cv.VideoCapture(f\"./{filename}.mp4\")\n _,originalFrame = video.read()\n\n for ant in ants:\n frameAndVels, averageVel, averageSpeed = ant.getVelocity()\n if frameAndVels == []: continue\n maxSpeed = max([np.linalg.norm(vel) for frame,vel in frameAndVels])\n direction = tracker.getCrossDirection(ant)\n trajectory = ant.getTrajectory()\n rect: Rect\n rectSizes = [rect.size() for rect in trajectory]\n avgSize = np.mean(rectSizes)\n medianSize = np.median(rectSizes)\n stdShape = np.std([rect.ratio() for rect in trajectory])\n stdSize = np.std(rectSizes)\n leafHolding = ant.isHoldingLeaf() == HoldsLeaf.Yes\n\n firstFrame = originalFrame.copy()\n firstFrame = cv.putText(firstFrame,'[LEAF]' if leafHolding else '[NOLF]',(20,20),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n firstFrame = cv.putText(firstFrame,f\"Av.Vel: {averageVel}\",(20,40),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n firstFrame = cv.putText(firstFrame,f\"Av.Spd: {averageSpeed}\",(20,60),cv.FONT_HERSHEY_SIMPLEX,0.3,255)\n cv.arrowedLine(firstFrame, (20,80), toTuple((20,80) + averageVel*5), (0,0,0), 1, tipLength=.3)\n\n for frame,vel in frameAndVels:\n rect1 = ant.getRectAtFrame(frame)\n pt1 = toTuple(rect1.center())\n pt2 = toTuple(rect1.center() + vel)\n cv.arrowedLine(firstFrame, pt1, pt2, (0,0,0), 1, tipLength=1)\n firstFrame = drawTrajectory(ant.getTrajectory(),firstFrame,ant.id)\n # firstFrame = cv.putText(firstFrame,str(ant.id),(50,50),cv.FONT_HERSHEY_SIMPLEX,1,255)\n cv.imshow(str(ant.id),firstFrame)\n k = cv.waitKey(0) & 0xff\n\n # trackerJson = AntCollection.deserialize(filename=\"dia.tag\").serializeAsTracker()\n # with open(\"./dia-labeled.rtg\",\"w\") as target:\n # target.write(trackerJson)\n"
},
{
"alpha_fraction": 0.6276660561561584,
"alphanum_fraction": 0.6307129859924316,
"avg_line_length": 30.55769157409668,
"blob_id": "dceaf987f36252c0e3a231ee53f70cfb7c3482d7",
"content_id": "92ce1f53409e096f7206f14a5409ca02e32c210f",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1641,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 52,
"path": "/ant_tracker/tracker_gui/extracted_parameters.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nfrom enum import Enum\nfrom typing import Dict\n\nfrom ..tracker.common import Side, Rect\nfrom ..tracker.parameters import SegmenterParameters, TrackerParameters\n\nclass SelectionStep(Enum):\n SizeMarker, TrackingArea, AntFrame1, AntFrame2, NestSide, Done = range(6)\n First = SizeMarker\n\n def __lt__(self, other):\n return self.value < other.value\n\n def __le__(self, other):\n return self.value <= other.value\n\n def __gt__(self, other):\n return not (self <= other)\n\n def __ge__(self, other):\n return not (self < other)\n\n def next(self):\n if self != SelectionStep.Done: return SelectionStep(self.value + 1)\n\n def back(self):\n if self != SelectionStep.First: return SelectionStep(self.value - 1)\n\n@dataclass\nclass ExtractedParameters:\n segmenter_parameters: SegmenterParameters\n tracker_parameters: TrackerParameters\n rect_data: Dict[SelectionStep, Rect]\n nest_side: Side\n\n def encode(self):\n return {\n 'segmenter_parameters': dict(self.segmenter_parameters.items()),\n 'tracker_parameters': dict(self.tracker_parameters.items()),\n 'rect_data': {step.name: rect for step, rect in self.rect_data.items()},\n 'nest_side': self.nest_side.name,\n }\n\n @classmethod\n def decode(cls, d):\n return cls(\n SegmenterParameters(d['segmenter_parameters']),\n TrackerParameters(d['tracker_parameters']),\n {SelectionStep[step]: Rect(*rect) for step, rect in d['rect_data'].items()},\n Side[d['nest_side']],\n )\n"
},
{
"alpha_fraction": 0.74210524559021,
"alphanum_fraction": 0.74210524559021,
"avg_line_length": 46.5,
"blob_id": "80c0903c2498bb7f09f2a1642ebe3381f1fb4b4e",
"content_id": "f9d327117924587ccf7fbf9e4c83b4d25836075d",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 8,
"path": "/pyinstaller-hooks/hook-pyforms.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from PyInstaller.utils.hooks import collect_data_files\n\nhiddenimports = [\"pyforms.settings\", \"pyforms_gui\", \"pyforms_gui.settings\", \"pyforms.controls\", \"pyforms_gui.resources_settings\", \"pyforms.resources_settings\"]\n\ndatas = collect_data_files('pyforms',include_py_files=True)\ndatas = collect_data_files('pyforms_gui',include_py_files=True)\n\nprint(\"------ Hooked pyforms ------\")\n"
},
{
"alpha_fraction": 0.5560062527656555,
"alphanum_fraction": 0.5634609460830688,
"avg_line_length": 42.80192184448242,
"blob_id": "cf58ad0cbe33b966eb230c21e60ce9a2741281fa",
"content_id": "e4171b4c82ae97e47e963ebe1255dce45273c658",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36567,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 833,
"path": "/ant_tracker/labeler/AntLabeler.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from collections import deque # for edit history\nfrom os.path import splitext, exists\nfrom pathlib import Path\nfrom typing import List, Tuple\n\nfrom PyQt5.QtGui import QMouseEvent\nfrom packaging.version import Version\n\nimport numpy as np\nfrom AnyQt import QtCore, QtGui\nfrom AnyQt.QtWidgets import QToolTip, QTreeWidgetItem, QMessageBox, QProgressDialog, QCheckBox, QApplication\n\n# import pyforms_gui.allcontrols\nfrom pyforms.basewidget import BaseWidget\nfrom pyforms.controls import (ControlButton, ControlCheckBox,\n ControlLabel, ControlList,\n ControlSlider, ControlText)\n\nimport cv2 as cv\nfrom .classes import *\nfrom .gui_classes import *\nfrom .PreLabeler import labelVideo\n\ndef clip(x, y, shape):\n if y >= shape[0]: y = shape[0] - 1\n if x >= shape[1]: x = shape[1] - 1\n if y < 0: y = 0\n if x < 0: x = 0\n return int(x), int(y)\n\nMAX_EDIT_HIST = 1000\nDEBUG = False\nSEL_UP = 1\nSEL_DOWN = -1\nVID_FORWARD = 1\nVID_BACKWARD = -1\nANT_ID_COLUMN = 0\nICON_COLUMN = 1\nLOADED_COLUMN = 2\nINVOLVED_FRAMES_COLUMN = 3\nSPACER_LABEL = \"=========================================\"\nEDITING_LABEL = \"🚫 Edición deshabilitada\"\nWARNING_UNLABEL = \"⚠️ Hay regiones sin etiquetar en este cuadro!\"\nWARNING_UNLABELS = \"⚠️ Hay regiones sin etiquetar en los siguientes cuadros: \"\nWARNING_REPEATED = \"❌ Hay hormigas con más de una región.\\nSólo se guardará la región más grande.\"\nAUTOFILL_QUESTION = \"Desea activar el rellenado a futuro?\\n\\n\"\nAUTOFILL_HELP = \"Cuando se rellena un área sin etiquetar, \" + \\\n \"las áreas en los cuadros siguientes intentan etiquetarse \" + \\\n \"automáticamente. \\n\\n️️️️️⚠️ ¡Cuidado! Luego de rellenar, \" + \\\n \"los cambios en frames siguientes no pueden deshacerse.\"\nAUTOFILL_WARNING = \"¡Ya hay una hormiga etiquetada en este cuadro!\\n\\n\" + \\\n \"Normalmente solo debería ser necesario rellenar una \" + \\\n \"vez por hormiga, por cuadro. Si necesita rellenar más de \" + \\\n \"una vez, desactive Rellenado a futuro.\"\nLEAF_IMAGE = cv.imread(\"./leaf.png\", cv.IMREAD_UNCHANGED)\n\nclass AntLabeler(BaseWidget):\n def __init__(self):\n super().__init__('AntLabeler')\n\n self._videofile = ControlFileAnts('Video a etiquetar', filter=\"Video (*.mp4 *.avi *.wmv *.webm *.h264)\")\n self._tagfile = ControlFileAnts('Archivo de etiquetas (si no hay uno disponible, cancelar)',\n filter=\"Archivo de etiqueta (*.tag)\")\n self._player = ControlPlayerAnts('Player')\n self._radslider = ControlSlider('Radio (+,-)', default=5, minimum=1, maximum=25)\n self._drawbutton = ControlButton('Dibujar (R)')\n self._erasebutton = ControlButton('Borrar (T)')\n self._fillbutton = ControlButton('Rellenar (Y)')\n self._unlerasebutton = ControlButton('Borrar etiquetas del frame actual')\n self._totalerasebutton = ControlButton('Borrar etiquetas de todo el video')\n self._autofillcheck = ControlCheckBox('Rellenado a futuro (U)', helptext=AUTOFILL_HELP,\n default=True if DEBUG else False)\n self._labelscheck = ControlCheckBox('Esconder n°s y hojas (N)', default=True)\n self._maskcheck = ControlCheckBox('Esconder máscara (M)', default=False)\n self._editinglabel = ControlLabelFont(EDITING_LABEL, font=QtGui.QFont(\"Times\", 12))\n self._unlabelwarn = ControlLabelFont(WARNING_UNLABEL, font=QtGui.QFont(\"Times\", 11))\n self._unlabelswarn = ControlLabelFont(WARNING_UNLABEL, font=QtGui.QFont(\"Times\", 9))\n self._repeatedwarn = ControlLabelFont(WARNING_REPEATED, font=QtGui.QFont(\"Times\", 12))\n self._spacerlabel = ControlLabelFont(SPACER_LABEL, font=QtGui.QFont(\"Times\", 10))\n\n headers = [\"\"] * 4\n headers[ANT_ID_COLUMN] = \"ID\"\n headers[ICON_COLUMN] = \"Color\"\n headers[LOADED_COLUMN] = \"Cargada\"\n headers[INVOLVED_FRAMES_COLUMN] = \"Cuadros\"\n self._objectlist = ControlListAnts('Hormigas',\n add_function=self.__add_new_ant,\n remove_function=self.__remove_selected_ant,\n horizontal_headers=headers,\n select_entire_row=True,\n resizecolumns=True,\n item_selection_changed_event=self.__select_ant)\n self._objectlist.readonly = True\n self._objectlist.single_select = True\n\n self._formset = [\n (\n '_player',\n '||', '|',\n [\n '_radslider',\n ('_drawbutton', '_erasebutton', '_fillbutton',),\n ('_unlerasebutton', '_totalerasebutton'),\n '_autofillcheck',\n ('_maskcheck', '_labelscheck'),\n '_objectlist',\n '=',\n '_spacerlabel',\n '_unlabelwarn',\n '_unlabelswarn',\n '_repeatedwarn',\n '_editinglabel',\n ],\n )\n ]\n\n # self.antCollection = AntCollection()\n if DEBUG:\n self._videofile.value = \"C:/f/pfc/ants/labeled1/labeler/HD13.mp4\"\n self._player.value = self._videofile.value\n self._tagfile.value = \"C:/f/pfc/ants/labeled1/labeler/HD13.tag\"\n self.antCollection = AntCollection.deserialize(video_path=self._videofile.value,\n filename=self._tagfile.value)\n else:\n self.__openFiles()\n\n self.colored_mask = self.antCollection.getMask(0)\n self.hist = deque(maxlen=MAX_EDIT_HIST)\n\n # Define the event that will be called when the run button is processed\n self._drawbutton.value = self.__drawEvent\n self._erasebutton.value = self.__eraseEvent\n self._fillbutton.value = self.__fillEvent\n self._unlerasebutton.value = self.__eraseUnlabeled\n self._totalerasebutton.value = self.__totalEraseEvent\n self._radslider.changed_event = self.__radiusChange\n self._player.process_frame_event = self.__process_frame\n self._player.before_frame_change = self.__before_frame_change\n self._player.after_frame_change = self.__after_frame_change\n\n self._player.drag_event = self.__drag\n self._player.click_event = self.__click\n self._player.move_event = self.__mouse_move\n self._player.key_release_event = self.__keyhandler\n self._objectlist.key_release_event = self.__keyhandler\n\n self._player.when_play_clicked = self.__play_clicked\n self._autofillcheck.changed_event = self.__toggle_autofill\n self._maskcheck.changed_event = self.__toggle_mask\n self._labelscheck.changed_event = self.__toggle_labels\n\n self.currentFrame = 0\n self.mouse_x = 0\n self.mouse_y = 0\n self.draw_radius = 5\n self.clickAction = \"draw\"\n self.autofillEnabled = True if DEBUG else False\n self.__first_fill = True\n self.should_save = False\n self._drawbutton.enabled = False\n self._erasebutton.enabled = True\n self._fillbutton.enabled = True\n\n self.selected_ant_id: Optional[int] = None\n self.showMask = not self._maskcheck.value\n self.showLabels = not self._labelscheck.value\n self.unlabeledframes = \"\"\n self.__update_warning()\n self.__updateEditing()\n self.__fill_list()\n\n # Sino no se ven los bordes del video\n self.video_widget = self._player._video_widget # noqa\n self.video_widget.zoom = 0.2\n self.video_widget.update()\n\n self.unlabeledframes = self.__get_unlabeled_frames()\n self._objectlist.setFocus()\n self._player.call_next_frame()\n\n def __openFiles(self):\n # Abre un diálogo de elección de archivo\n self._videofile.click()\n\n __vid = cv.VideoCapture(self._videofile.value, cv.CAP_FFMPEG)\n if __vid.isOpened():\n print(__vid.getBackendName())\n vshape = (int(__vid.get(cv.CAP_PROP_FRAME_HEIGHT)), int(__vid.get(cv.CAP_PROP_FRAME_WIDTH)))\n vlen = int(__vid.get(cv.CAP_PROP_FRAME_COUNT))\n fps = __vid.get(cv.CAP_PROP_FPS)\n __vid.release()\n else:\n raise CancelingException(\"%s no es un video válido\" % self._videofile.value)\n\n # Asignar video al reproductor\n self._player.value = self._videofile.value\n\n # Nombre default de archivo de etiquetas: nombre_video.tag\n default_tagfile = splitext(self._videofile.value)[0] + \".tag\"\n # self._tagfile.value = default_tagfile\n self._tagfile.click()\n bkp = self._tagfile.value[:-4] + \"-backup.tag\"\n try:\n self.antCollection = AntCollection.deserialize(video_path=self._videofile.value,\n filename=self._tagfile.value)\n if self.antCollection.version < Version(\"2.0\"):\n from shutil import copy2\n copy2(self._tagfile.value, bkp)\n except: # noqa\n print(\"%s no es un archivo de etiquetas válido, generando uno\" % self._tagfile.value)\n questionDialog = ResolutionDialog(\"Pre-etiquetado\")\n if not questionDialog.exec_(): raise CancelingException(\"Creación de archivo de etiquetas cancelada.\")\n print(questionDialog.get_selection())\n minimum_ant_radius = {\"low\": 4, \"med\": 8, \"high\": 10}[questionDialog.get_selection()]\n info = LabelingInfo(video_path=Path(self._videofile.value), ants=[], unlabeled_frames=[])\n self.antCollection = AntCollection(np.empty(vshape), info=info)\n progress = QProgressDialog(\"Creando un archivo de etiquetas...\", \"Cancelar\", 0, vlen, self)\n progress.setWindowTitle(\"AntLabeler\")\n progress.setMinimumWidth(400)\n progress.setWindowModality(QtCore.Qt.ApplicationModal)\n progress.setValue(0)\n for frame, mask in enumerate(labelVideo(self._videofile.value, minimum_ant_radius=minimum_ant_radius)):\n self.antCollection.addUnlabeledFrame(frame, mask)\n progress.setValue(frame)\n if progress.wasCanceled():\n raise CancelingException(\"Creación de archivo de etiquetas cancelada.\")\n self.antCollection.videoSize = mask.size # noqa\n self.antCollection.videoShape = tuple(mask.shape)\n self.antCollection.videoLength = frame + 1 # noqa\n\n if exists(default_tagfile):\n file_i = 2\n tagfile = splitext(self._videofile.value)[0] + str(file_i) + \".tag\"\n while exists(tagfile):\n file_i += 1\n tagfile = splitext(self._videofile.value)[0] + str(file_i) + \".tag\"\n else:\n tagfile = default_tagfile\n self.antCollection.info.save(tagfile, pretty=True)\n self._tagfile.value = tagfile\n progress.setValue(vlen)\n\n if not (self.antCollection.videoShape == vshape):\n raise ValueError(\"Video %s con tamaño %s no coincide con archivo de etiquetas %s con tamaño %s\"\n % (self._videofile.value, str(vshape), self._tagfile.value,\n str(self.antCollection.videoShape)))\n self.number_of_frames = vlen\n if self.antCollection.version < Version(\"1.1\"):\n print(\"Cleaning v1 errors\")\n self.antCollection.cleanErrors(self.number_of_frames)\n if self.antCollection.version < Version(\"2.0\"):\n self.antCollection.videoLength = vlen\n last_frame_w_ant = self.antCollection.getLastLabeledFrame()\n if last_frame_w_ant < self.antCollection.videoLength - 1:\n questionDialog = ResolutionDialog(f\"Reprocesar frames faltantes (desde el {last_frame_w_ant})\")\n if questionDialog.exec_():\n minimum_ant_radius = {\"low\": 4, \"med\": 6, \"high\": 8}[questionDialog.get_selection()]\n\n def msg(f):\n return f\"Reprocesando frame {f}/{vlen - 1}...\\n\" \\\n f\"Un backup del archivo original se encuentra en\\n\" \\\n f\"{bkp}\"\n\n progress = QProgressDialog(msg(last_frame_w_ant + 1), \"Cancelar\", 0, vlen - last_frame_w_ant + 1,\n self)\n progress.setWindowTitle(\"AntLabeler\")\n progress.setMinimumWidth(400)\n progress.setWindowModality(QtCore.Qt.ApplicationModal)\n progress.setValue(0)\n for frame, mask in enumerate(\n labelVideo(self._videofile.value, minimum_ant_radius=minimum_ant_radius,\n start_frame=last_frame_w_ant + 1), start=last_frame_w_ant + 1\n ):\n self.antCollection.overwriteUnlabeledFrame(frame, mask)\n progress.setValue(frame - last_frame_w_ant + 1)\n progress.setLabelText(msg(frame))\n if progress.wasCanceled():\n raise CancelingException(\"Actualización de archivo de etiquetas cancelada.\")\n progress.setValue(vlen - last_frame_w_ant + 1)\n if self.antCollection.version < Version(\"2.1\"):\n self.antCollection.info.video_fps_average = fps\n self.antCollection.version = CollectionVersion\n self.antCollection.info.labeler_version = CollectionVersion\n\n def closeEvent(self, event):\n print(\"saving...\")\n if self.antCollection.version < Version(\"1.1\"):\n print(\"Cleaning v1 errors\")\n self.antCollection.cleanErrors(self.number_of_frames)\n self.should_save = True\n self.__saveFrame(self.currentFrame, pretty=True)\n\n print(\"closing...\")\n event.accept()\n\n def resizeEvent(self, event):\n # print(\"wWidth: \",str(self.geometry().width()))\n if len(self._splitters) < 2:\n raise ValueError(\"Tiene que haber dos splitters!\")\n windowWidth = self.geometry().width()\n windowHeight = self.geometry().height()\n # tools to warnings\n pRatio = 0.75\n self._splitters[0].setSizes([windowHeight * pRatio, windowHeight * (1 - pRatio)])\n # window to tools\n pRatio = 0.80\n self._splitters[1].setSizes([windowWidth * pRatio, windowWidth * (1 - pRatio)])\n self._player.setFocus()\n # return super().resizeEvent(event)\n\n def __mouse_move(self, x_, y_):\n x, y = clip(x_, y_, self.colored_mask.shape)\n self.mouse_x = x\n self.mouse_y = y\n tooltip = \"\"\n if not self.showLabels:\n ant_id = self.colored_mask[y, x]\n if ant_id not in [0, -1]:\n tooltip = f'<span style=\"color: white\">ID: {ant_id}</span>'\n if self.antCollection.getAnt(ant_id).loaded:\n tooltip += '<span style=\"color: white\"> - Cargada</span>'\n self.video_widget.setToolTip(tooltip)\n\n def __click(self, e: QMouseEvent, x_, y_):\n x, y = clip(x_, y_, self.colored_mask.shape)\n if e.button == QtCore.Qt.RightButton:\n ant_id = self.colored_mask[y, x]\n if ant_id not in [0, -1]:\n self.__set_selected_ant(ant_id)\n if self.clickAction == \"fill\" and self.editingEnabled and self.selected_ant_id is not None:\n # print(\"About to fill\")\n print(str((x, y)))\n print(self.colored_mask[y, x])\n if self.colored_mask[y, x] == 0:\n # print(\"Background, no fill\")\n # NO rellenar fondo\n return e # findClosestRegion()?\n doAutofill = self.autofillEnabled and self.colored_mask[y, x] == -1\n\n if self.__first_fill and not self.autofillEnabled and self.colored_mask[y, x] == -1 and not DEBUG:\n self.__first_fill = False\n if QMessageBox().question(self, 'Rellenado a futuro',\n AUTOFILL_QUESTION + AUTOFILL_HELP,\n QMessageBox.Yes, QMessageBox.No) == QMessageBox.Yes:\n self._autofillcheck.value = True\n if doAutofill and np.any(self.colored_mask == self.selected_ant_id):\n # No hagamos autofill si esa hormiga ya está etiquetada en este frame\n QMessageBox().critical(self, 'Error', AUTOFILL_WARNING) # noqa\n return e\n self.hist.append(self.colored_mask.copy())\n upcasted_mask = self.colored_mask.astype('int32')\n cv.floodFill(image=upcasted_mask,\n mask=None,\n seedPoint=(x, y),\n newVal=self.selected_ant_id,\n loDiff=0,\n upDiff=0)\n self.colored_mask = upcasted_mask.astype('int16').copy()\n if doAutofill:\n # print(\"autofilling\")\n self.antCollection.updateAreas(self.currentFrame, self.colored_mask)\n self.antCollection.labelFollowingFrames(self.currentFrame, self.selected_ant_id)\n self.__update_list(True)\n self._player.refresh()\n self.should_save = True\n return e\n\n def __drag(self, _, end):\n def inbounds(_x, _y):\n ix, iy = (_x, _y)\n my, mx = self.antCollection.videoShape\n if _x < 0:\n ix = 0\n elif _x >= mx:\n ix = mx - 1\n if _y < 0:\n iy = 0\n elif _y >= my:\n iy = my - 1\n return ix, iy\n\n # Si estamos moviendo la pantalla\n if self.video_widget._move_img: return # noqa\n # Le corresponde a __click()\n if self.clickAction == \"fill\": return\n\n if self.editingEnabled:\n (x, y) = inbounds(np.int(end[0]), np.int(end[1]))\n if self.clickAction == \"draw\" and self.selected_ant_id is not None:\n self.hist.append(self.colored_mask.copy())\n cv.circle(self.colored_mask, (x, y), self.draw_radius, self.selected_ant_id, -1)\n elif self.clickAction == \"erase\":\n self.hist.append(self.colored_mask.copy())\n cv.circle(self.colored_mask, (x, y), self.draw_radius, 0, -1)\n self._player.refresh()\n self.should_save = True\n\n def __color_frame(self, frame) -> (np.ndarray, List[int]):\n \"\"\"Retorna el frame coloreado con las áreas etiquetadas y no etiquetadas,\n junto con una lista de ids y su cantidad de componentes conectadas\n \"\"\"\n\n # De https://stackoverflow.com/a/52742571\n def put4ChannelImageOn3ChannelImage(back, fore, x, y):\n back4 = cv.cvtColor(back, cv.COLOR_BGR2BGRA)\n rows, cols, channels = fore.shape\n trans_indices = fore[..., 3] != 0 # Where not transparent\n overlay_copy = back4[y:y + rows, x:x + cols]\n overlay_copy[trans_indices] = fore[trans_indices]\n back4[y:y + rows, x:x + cols] = overlay_copy\n back = cv.cvtColor(back4, cv.COLOR_BGRA2BGR)\n return back\n\n (height, width) = self.antCollection.videoShape\n middle = (width // 2, height // 2)\n ids_and_colors = {}\n for ant_id in np.unique(self.colored_mask):\n if ant_id == 0: # Fondo\n continue\n elif ant_id == -1: # Regiones sin etiquetas\n coloring = np.zeros_like(self.colored_mask, dtype='uint8')\n coloring[self.colored_mask == -1] = 255\n _, _, _, centroids = cv.connectedComponentsWithStats(coloring)\n coloring = cv.cvtColor(coloring, cv.COLOR_GRAY2BGR)\n coloring[:, :, 0:2] = 0\n frame = cv.addWeighted(coloring, 0.5, frame, 1, 0, dtype=cv.CV_8U)\n for c in centroids[1:]:\n size = max(self.antCollection.videoShape) // 100\n cv.drawMarker(frame, tuple(c.astype(int)), (255, 255, 0), cv.MARKER_DIAMOND, -1, size)\n else: # Región con hormiga\n ant = self.antCollection.getAnt(ant_id)\n if ant is None:\n print(\"None ant: \", ant_id)\n color = (255, 255, 0)\n else:\n color = ant.color[::-1] # gets bgr instead of rgb\n ids_and_colors[ant_id] = color\n coloring = np.zeros_like(frame, dtype='uint8')\n for ant_id, color in ids_and_colors.items():\n coloring[self.colored_mask == ant_id] = color\n frame = cv.addWeighted(coloring, 0.8, frame, 1, 0, dtype=cv.CV_8U)\n dups = []\n if self.showLabels:\n coloring = np.zeros_like(self.colored_mask, dtype='uint8')\n coloring[self.colored_mask != -1] = self.colored_mask[self.colored_mask != -1]\n nlabels, labels, _, centroids = cv.connectedComponentsWithStats(coloring.astype('uint8'))\n found = []\n for label in np.unique(labels):\n if label == 0: continue\n c = centroids[label]\n w = np.argwhere(labels == label)[0, :]\n ant_id = self.colored_mask[w[0], w[1]]\n vector_to_middle = np.array(middle) - c\n vector_to_middle = vector_to_middle / np.linalg.norm(vector_to_middle)\n pos = tuple((c + vector_to_middle * 2).astype(int))\n ant = self.antCollection.getAnt(ant_id)\n found.append(ant.id)\n if ant is not None and ant.loaded: # Dibujar la hojita\n try:\n frame = put4ChannelImageOn3ChannelImage(frame, LEAF_IMAGE, pos[0], pos[1] + 10)\n except: # noqa\n pass\n cv.putText(frame, str(ant.id), pos, cv.FONT_HERSHEY_DUPLEX, 0.5, (0, 0, 0), 1)\n u, c = np.unique(found, return_counts=True)\n dups = u[c > 1]\n return frame, dups\n\n def __process_frame(self, frame):\n \"\"\"\n Do some processing to the frame and return the result frame\n \"\"\"\n dups = []\n if self.showMask:\n frame, dups = self.__color_frame(frame)\n self.__update_warning(dups)\n return frame\n\n def __drawEvent(self):\n self.clickAction = \"draw\"\n self._drawbutton.enabled = False\n self._erasebutton.enabled = True\n self._fillbutton.enabled = True\n\n def __eraseEvent(self):\n self.clickAction = \"erase\"\n self._drawbutton.enabled = True\n self._erasebutton.enabled = False\n self._fillbutton.enabled = True\n\n def __fillEvent(self):\n self.clickAction = \"fill\"\n self._drawbutton.enabled = True\n self._erasebutton.enabled = True\n self._fillbutton.enabled = False\n\n def __eraseUnlabeled(self):\n if QMessageBox().question(self,\n \"Borrar regiones sin etiquetar\",\n \"¿Está seguro de que quiere borrar las regiones \"\n f\"sin etiquetar del cuadro {self.currentFrame}?\",\n QMessageBox.Yes, QMessageBox.No) == QMessageBox.Yes:\n self.antCollection.deleteUnlabeledFrame(self.currentFrame)\n self.colored_mask[self.colored_mask == -1] = 0\n self.should_save = True\n self._player.refresh()\n\n def __totalEraseEvent(self):\n if QMessageBox().question(self,\n \"Borrar regiones sin etiquetar\",\n \"¿Está seguro de que quiere borrar todas las \"\n f\"regiones sin etiquetar del video?\",\n QMessageBox.Yes, QMessageBox.No) == QMessageBox.Yes:\n #Hacer iteracion desde frame 1 a frame max\n for i in range(self._player.max):\n self.antCollection.deleteUnlabeledFrame(i)\n self.colored_mask[self.colored_mask == -1] = 0\n self.should_save = True\n self._player.refresh()\n\n def __radiusChange(self):\n self.draw_radius = self._radslider.value\n\n def __update_loaded(self):\n for row in range(self._objectlist.tableWidget.rowCount()):\n ant_id = int(self._objectlist.value[row][ANT_ID_COLUMN])\n loaded = self._objectlist.value[row][LOADED_COLUMN].isChecked()\n self.antCollection.update_load(ant_id, loaded)\n\n def __saveFrame(self, frame=None, pretty=False):\n \"\"\"\n Si frame==None, sólo se guarda el estado de carga de las hormigas\n \"\"\"\n if self.editingEnabled:\n if frame is not None and self.should_save:\n print(\"saving frame %d\" % self.currentFrame)\n self.antCollection.updateAreas(frame, self.colored_mask)\n self.unlabeledframes = self.__get_unlabeled_frames()\n self.__update_loaded()\n if self.should_save:\n self.antCollection.info.save(f\"{self._tagfile.value[:-4]}.tag\", pretty=pretty)\n\n self.should_save = False\n\n def __before_frame_change(self):\n self.__saveFrame(self.currentFrame)\n pass\n\n def __after_frame_change(self):\n self.currentFrame = self._player.video_index\n self.colored_mask = self.antCollection.getMask(self.currentFrame)\n self.__update_list(dry=True)\n self._player.refresh()\n\n def __update_warning(self, dups=None):\n repeated = dups and len(dups) > 0\n unlabeled = self.colored_mask.min() == -1\n unlabeleds = self.unlabeledframes != \"\"\n if unlabeled:\n self._unlabelwarn.value = WARNING_UNLABEL\n else:\n self._unlabelwarn.value = \" \"\n if repeated:\n self._repeatedwarn.value = WARNING_REPEATED\n else:\n self._repeatedwarn.value = \" \"\n if unlabeleds:\n self._unlabelswarn.value = WARNING_UNLABELS + '\\n' + self.unlabeledframes\n else:\n self._unlabelswarn.value = \" \"\n\n def __moveByFrame(self, direction):\n if direction == VID_FORWARD:\n if self.currentFrame != self._player.max:\n self.hist.clear()\n self._player.forward_one_frame()\n elif direction == VID_BACKWARD:\n if self.currentFrame != 0:\n self.hist.clear()\n self._player.back_one_frame()\n\n def __add_new_ant(self):\n new_ant = self.antCollection.newAnt()\n self._objectlist + self.__get_list_item(new_ant)\n return\n\n def __on_loaded_check(self, _):\n self.should_save = True\n self.__saveFrame()\n self._player.refresh()\n\n def __get_unlabeled_frames(self) -> str:\n def formatter(groups):\n strings = [[]]\n for n, group in enumerate(groups):\n if group[0] == group[1]:\n strings[-1].append(f\"{group[0]}\")\n else:\n strings[-1].append(f\"({group[0]}→{group[1]})\")\n if (n + 1) % 5 == 0:\n strings.append([])\n return \"\\n\".join([\", \".join(s) for s in strings])\n\n grps, nframes = self.antCollection.getUnlabeledFrameGroups()\n if nframes < 20:\n return formatter(grps)\n else:\n return \"\"\n\n @staticmethod\n def __get_involved_frames(ant: Ant) -> str:\n def formatter(groups):\n strings = []\n for group in groups:\n strings.append(\"(%d→%d)\" % (group[0], group[1]))\n return \" ∪ \".join(strings)\n\n return formatter(ant.getGroupsOfFrames())\n\n def __get_list_item(self, ant: Ant):\n list_item: List[Any] = [\"\"] * 4\n list_item[ANT_ID_COLUMN] = ant.id\n list_item[ICON_COLUMN] = ColorIcon(*ant.color)\n list_item[LOADED_COLUMN] = QCheckBox(\"\", self)\n list_item[INVOLVED_FRAMES_COLUMN] = self.__get_involved_frames(ant)\n\n if ant.loaded: list_item[LOADED_COLUMN].toggle()\n list_item[LOADED_COLUMN].stateChanged.connect(self.__on_loaded_check)\n return list_item\n\n def __fill_list(self):\n ant: Ant\n for ant in self.antCollection.ants:\n self._objectlist + self.__get_list_item(ant)\n\n def __update_list(self, dry=False):\n \"\"\"Un update dry solamente actualiza la lista de cuadros de cada hormiga\"\"\"\n if dry:\n for row in range(self._objectlist.tableWidget.rowCount()):\n _id = int(self._objectlist.value[row][ANT_ID_COLUMN])\n newIF = self.__get_involved_frames(self.antCollection.getAnt(_id))\n self._objectlist.tableWidget.item(row, INVOLVED_FRAMES_COLUMN).setText(newIF)\n else:\n row = self._objectlist.tableWidget.currentRow()\n self._objectlist.value = []\n self.__fill_list()\n self.__set_selection(row)\n\n def __remove_selected_ant(self):\n # Mucho de esto es innecesario, probablemente. TODO: Revisar qué es necesario realmente\n if QMessageBox().question(self,\n f\"Eliminar hormiga {self.selected_ant_id}\",\n f\"¿Está seguro de que desea eliminar la hormiga con ID: {self.selected_ant_id}? \\n\"\n \"Esta acción no puede revertirse.\",\n QMessageBox.Yes, QMessageBox.No) == QMessageBox.No:\n return\n print(\"id of removed ant:\", str(self.selected_ant_id))\n self.antCollection.updateAreas(self.currentFrame, self.colored_mask)\n # afterUpdate = self.antCollection.getMask(self.currentFrame)\n\n self.antCollection.deleteAnt(self.selected_ant_id)\n self.colored_mask = self.antCollection.getMask(self.currentFrame)\n\n self.antCollection.updateAreas(self.currentFrame, self.colored_mask)\n self.colored_mask = self.antCollection.getMask(self.currentFrame)\n\n self._objectlist - (-1) # Remove current row\n self.__select_ant()\n self.hist.clear()\n self._player.refresh()\n\n def __select_ant(self):\n try:\n _id = int(self._objectlist.get_currentrow_value()[ANT_ID_COLUMN])\n self.selected_ant_id = _id\n except: # noqa\n self.selected_ant_id = None\n\n def __get_selected_ant(self) -> Ant:\n ant = list(filter(lambda a: a.id == self.selected_ant_id, self.antCollection.ants))[0]\n return ant\n\n def __undo(self):\n if self.editingEnabled and (len(self.hist) != 0):\n self.colored_mask = self.hist.pop()\n self._player.refresh()\n\n def __play_clicked(self):\n # print(\"playclicked\")\n if self._player.is_playing:\n self.__updateEditing()\n else:\n self.__updateEditing()\n\n def __setEditing(self, true_or_false):\n if true_or_false:\n self._editinglabel.value = \" \"\n self.colored_mask = self.antCollection.getMask(self.currentFrame)\n self._player.refresh()\n else:\n self._editinglabel.value = EDITING_LABEL\n self.editingEnabled = true_or_false\n\n def __updateEditing(self):\n if self.showMask and not self._player.is_playing:\n self.__setEditing(True)\n else:\n self.__setEditing(False)\n\n def __change_radius(self, amt):\n v = self._radslider.value + amt\n if v > self._radslider.max:\n v = self._radslider.max\n elif v < 1:\n v = 1\n self._radslider.value = v\n\n def __set_selected_ant(self, ant_id):\n for row_idx in range(self._objectlist.tableWidget.rowCount()):\n i = self._objectlist.get_value(column=ANT_ID_COLUMN, row=row_idx)\n if i == str(ant_id):\n self.__set_selection(row_idx)\n break\n\n def __set_selection(self, row):\n col = 1\n if row >= self._objectlist.tableWidget.rowCount():\n row = self._objectlist.tableWidget.rowCount() - 1\n elif row < 0:\n row = 0\n self._objectlist.tableWidget.setCurrentCell(row, col)\n self.__select_ant()\n\n def __change_selection(self, direction):\n if self.selected_ant_id is None:\n row = 0 if direction == SEL_DOWN else self._objectlist.tableWidget.rowCount() - 1\n col = 0\n else:\n row = self._objectlist.tableWidget.currentRow()\n col = self._objectlist.tableWidget.currentColumn()\n if direction == SEL_UP:\n row = (row - 1) % self._objectlist.tableWidget.rowCount()\n elif direction == SEL_DOWN:\n row = (row + 1) % self._objectlist.tableWidget.rowCount()\n self._objectlist.tableWidget.setCurrentCell(row, col)\n self.__select_ant()\n\n def __toggle_autofill(self):\n self.autofillEnabled = self._autofillcheck.value\n\n def __toggle_mask(self):\n self.showMask = not self._maskcheck.value\n self._labelscheck.enabled = self.showMask\n self.__updateEditing()\n self._player.refresh()\n\n def __toggle_labels(self):\n self.showLabels = not self._labelscheck.value\n self._player.refresh()\n\n def __keyhandler(self, event):\n key = event.key()\n modifiers = event.modifiers()\n\n if key == QtCore.Qt.Key_Plus:\n self.__change_radius(1)\n if key == QtCore.Qt.Key_Minus:\n self.__change_radius(-1)\n if key == QtCore.Qt.Key_Space:\n self._player.videoPlay_clicked()\n if key == QtCore.Qt.Key_R:\n self.__drawEvent()\n if key == QtCore.Qt.Key_T:\n self.__eraseEvent()\n if key == QtCore.Qt.Key_Y:\n self.__fillEvent()\n if key == QtCore.Qt.Key_B:\n self.__totalEraseEvent()\n if key == QtCore.Qt.Key_U:\n self._autofillcheck.value = not self._autofillcheck.value\n if key == QtCore.Qt.Key_M:\n self._maskcheck.value = not self._maskcheck.value\n if key == QtCore.Qt.Key_N:\n self._labelscheck.value = not self._labelscheck.value\n elif key in (QtCore.Qt.Key_A, QtCore.Qt.Key_Left):\n self.__moveByFrame(VID_BACKWARD)\n elif key in (QtCore.Qt.Key_D, QtCore.Qt.Key_Right):\n self.__moveByFrame(VID_FORWARD)\n elif key in (QtCore.Qt.Key_S, QtCore.Qt.Key_Down):\n self.__change_selection(SEL_DOWN)\n elif key in (QtCore.Qt.Key_W, QtCore.Qt.Key_Up):\n self.__change_selection(SEL_UP)\n elif (modifiers & QtCore.Qt.ControlModifier) != 0 and key == QtCore.Qt.Key_Z:\n self.__undo()\n elif (modifiers & QtCore.Qt.ControlModifier) != 0 and key == QtCore.Qt.Key_Delete:\n raise Exception(\"Force crash\")\n\nclass CancelingException(Exception):\n pass\n\ndef excepthook(exc_type, exc_value, exc_tb):\n import traceback\n import datetime\n\n if exc_type is not CancelingException:\n tb = \"\".join(traceback.format_exception(exc_type, exc_value, exc_tb))\n print(tb)\n filename = f\"error-{datetime.datetime.now(tz=None).strftime('%Y-%m-%dT%H_%M_%S')}.log\"\n with open(filename, \"w\") as f:\n f.write(tb)\n QMessageBox.critical(None, 'Error',\n f\"Se produjo un error. El archivo {filename} contiene los detalles.\\n\" +\n \"Por favor envíe el mismo y el archivo .tag con el que estaba trabajando \"\n \"a la persona de quien recibió este programa.\") # noqa\n QApplication.exit() # noqa\n\ndef main():\n from pyforms import start_app\n import sys\n\n # from shutil import copy\n # try:\n # import cProfile\n # cProfile.run('start_app(AntLabeler)','profile')\n sys.excepthook = excepthook\n app = start_app(AntLabeler)\n sys.exit(0)\n # except:\n # copy(\"Video16cr.tag_original\",\"Video16cr.tag\")\n # raise Exception()\n # copy(\"Video16cr.tag_original\",\"Video16cr.tag\")\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5325393676757812,
"alphanum_fraction": 0.5397703051567078,
"avg_line_length": 37.540985107421875,
"blob_id": "5d96b3c83afa8eb7252920ab198856872e2fc850",
"content_id": "dec43c8f6e39d94f30c26ac8555397ce6c28a959",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2355,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 61,
"path": "/ant_tracker/tracker_gui/about.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "import PySimpleGUI as sg\n\nfrom . import constants as C\nfrom .guicommon import transparent_multiline, Email, Link, ClickableText\n\ndef about(width=90, height=20):\n def text(s, **kwargs):\n return sg.Text(s, font=(\"Helvetica\", 8), pad=(0, 0), **kwargs)\n\n def bold(s, **kwargs):\n return sg.Text(s, font=(\"Helvetica Bold\", 8), justification='center', pad=(0, 0), **kwargs)\n\n creds = [\n sg.Column([\n [bold(\"Francisco Daniel Sturniolo\")],\n [text(\"Desarrollador\")],\n [text(\"Facultad de Ingeniería y Ciencias Hídricas\")],\n [text(\"Universidad Nacional del Litoral\")],\n [text(\"Santa Fe, Santa Fe, Argentina\")],\n [Email(\"[email protected]\")],\n ]),\n sg.VerticalSeparator(),\n sg.Column([\n [bold(\"Dr. Leandro Bugnon\")],\n [text(\"Director\")],\n [text(\"Research Institute for Signals, Systems and\\nComputational Intelligence, sinc(i)\")],\n [text(\"(FICH-UNL/CONICET)\")],\n [text(\"Ciudad Universitaria\")],\n [text(\"Santa Fe, Santa Fe, Argentina\")],\n [Email(\"[email protected]\")],\n [Link(\"www.sinc.unl.edu.ar\", linktext=\"sinc(i)\")],\n ]),\n sg.VerticalSeparator(),\n sg.Column([\n [bold(\"Dr. Julián Alberto Sabattini\")],\n [text(\"Co-Director\")],\n [text(\"Ecology Agricultural Systems\")],\n [text(\"Faculty of Agricultural Sciences\")],\n [text(\"National University of Entre Rios\")],\n [text(\"Route No. 11 km 10.5\")],\n [text(\"Oro Verde, Entre Ríos (Argentina)\")],\n [Email(\"[email protected]\")],\n [Link(\"https://www.researchgate.net/profile/Julian_Sabattini\", linktext=\"ResearchGate\")],\n [text(\"Skype: juliansabattini\")],\n ]),\n ]\n layout = [\n creds,\n [sg.HorizontalSeparator()],\n [transparent_multiline(C.ABOUT_INFO, width, height)],\n [sg.Text(\"AntTracker es código abierto (licencia MIT) y puede encontrarse en:\"),\n Link(\"http://github.com/fd-sturniolo/anttracker\", font=(\"Helvetica\", 10))],\n ]\n win = sg.Window(\"Sobre AntTracker\", layout, icon=C.LOGO_AT_ICO,\n disable_minimize=True, modal=True, finalize=True)\n ClickableText.bind_all()\n while True:\n e, _ = win.read()\n if e == sg.WIN_CLOSED:\n win.close()\n break\n"
},
{
"alpha_fraction": 0.6274510025978088,
"alphanum_fraction": 0.6274510025978088,
"avg_line_length": 20.85714340209961,
"blob_id": "6f87124a90be8b171f8d8b2bcce5ef465e6647fd",
"content_id": "08607854ef7d9e6ecf9670e3a595ebb06ea71424",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 153,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 7,
"path": "/labeler_main.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "if __name__ == '__main__':\n from check_env import check_env\n\n check_env(\"labeler\")\n from ant_tracker.labeler.AntLabeler import main\n\n main()\n"
},
{
"alpha_fraction": 0.5891968607902527,
"alphanum_fraction": 0.5920398235321045,
"avg_line_length": 24.125,
"blob_id": "6027cb15761b483e327266832f03be4422eae859",
"content_id": "30ec4035049073ba53d809d9100d5e8da2668b1b",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1407,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 56,
"path": "/ant_tracker/tracker_gui/loading_window.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "from typing import List\n\nfrom . import constants as C\n\nclass FakeLoadTask:\n def __init__(self, message, spinner):\n self.message = message\n self.spinner = spinner\n self._running = True\n\n def finish(self):\n self._running = False\n\n def run(self):\n import PySimpleGUI as sg\n sg.theme('Default1')\n while self._running:\n sg.popup_animated(self.spinner, self.message, time_between_frames=100)\n sg.popup_animated(None)\n return\n\ndef fake_loader(message, spinner):\n from multiprocessing import Process\n task = FakeLoadTask(message, spinner)\n p = Process(target=task.run, daemon=True)\n\n class FakeLoader:\n @staticmethod\n def finish():\n nonlocal task, p\n task.finish()\n p.kill()\n\n p.start()\n return FakeLoader()\n\nclass LoadingWindow:\n __windows: List['LoadingWindow'] = []\n\n def __init__(self, message=\"Cargando...\", spinner=C.SPINNER):\n self.message = message\n self.spinner = spinner\n LoadingWindow.__windows.append(self)\n\n def __enter__(self):\n self.fl = fake_loader(self.message, self.spinner)\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n self.fl.finish()\n\n @classmethod\n def close_all(cls):\n for window in cls.__windows:\n window.fl.finish()\n del window\n cls.__windows = []\n"
},
{
"alpha_fraction": 0.7730989456176758,
"alphanum_fraction": 0.779640257358551,
"avg_line_length": 36.630767822265625,
"blob_id": "d2bd024c72ef53fc52a02d2259a31f1b81c6c192",
"content_id": "762f7479ba2580d69c90b25916d86624b49a3975",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2471,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 65,
"path": "/README.md",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "# AntTracker\n\n## Instrucciones\n\nEl proyecto hace uso de dos environments de `conda` con algunas librerías en común,\ny se compone de un módulo `ant_tracker` con tres submódulos:\n\n| Módulo | Environment|\n|--------|------------|\n|`labeler` |`NOMBRE_ENV_LABELER`|\n|`tracker` |`NOMBRE_ENV_TRACKER`|\n|`tracker_gui`|`NOMBRE_ENV_TRACKER`|\n\nEl script `create-env.ps1` le ayudará a crear los environments.\n\n#### Requerimientos\n- `git`\n- `conda` (Miniconda o Anaconda)\n\n#### Setup & Compilación\n```powershell\ngit clone \"https://github.com/fd-sturniolo/AntTracker.git\"\ncd AntTracker\n.\\create-env NOMBRE_ENV_TRACKER NOMBRE_ENV_LABELER\n.\\build -All\n```\n\nLos `.exe` generados se encuentran luego en la carpeta `dist`.\n\n#### Distribución\n\nActualmente la carpeta generada `dist/AntTracker` se empaqueta en un instalador con\n[InstallSimple](http://installsimple.com/). El ejecutable requiere instalar el\n[paquete Visual C++ Redistributable](https://www.microsoft.com/es-es/download/details.aspx?id=48145).\n\n## TODO\n\n- Implementar distribución mediante [NSIS](https://nsis.sourceforge.io/Main_Page) con instalación automática del Redist.\n- Mejorar versionado de módulos\n\n## Información\n\nDesarrollado durante 2019-2020 por Francisco Daniel Sturniolo,\nen el marco de su Proyecto Final de Carrera para el título de Ingeniero en Informática\nde la Facultad de Ingeniería y Ciencias Hídricas de la Universidad Nacional del Litoral,\nbajo la dirección de Leandro Bugnon y la co-dirección de Julián Sabattini,\ntitulado \"Desarrollo de una herramienta para identificación automática del ritmo de forrajeo\nde hormigas cortadoras de hojas a partir de registros de video\".\n\n\nEl mismo pretende analizar el comportamiento de forrajeo de las HCH a partir de videos tomados de la salida de un\nhormiguero (tales como los obtenidos a partir del dispositivo AntVRecord), detectando las trayectorias tomadas por las\nhormigas y su posible carga de hojas, para luego extraer estadísticas temporales de su comportamiento\ny volumen vegetal recolectado.\n\n\nTambién incluido con este programa se encuentra AntLabeler, una utilidad de etiquetado para videos de la misma índole,\nque fue utilizada para validar los resultados obtenidos por AntTracker sobre videos de prueba. El uso de esta\nherramienta actualmente se encuentra supercedido por AntTracker, pero se provee como una forma de revisar con precisión\nlas trayectorias y cargas detectadas.\n\n\n## Legales\n\nThis software uses libraries from the FFmpeg project under the LGPLv2.1.\n"
},
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7636363506317139,
"avg_line_length": 22.571428298950195,
"blob_id": "600bb5202bf63af0aec8cec146e2218c087f1562",
"content_id": "2ec450f2bcf41802650f0ef79da96f8b47930e65",
"detected_licenses": [
"LGPL-2.1-only",
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 7,
"path": "/ant_tracker/labeler/local_settings.py",
"repo_name": "ChortJulio/AntTracker",
"src_encoding": "UTF-8",
"text": "SETTINGS_PRIORITY = 1\n\nPYFORMS_STYLESHEET = 'style.css'\nPYFORMS_STYLESHEET_LINUX = 'style.css'\nPYFORMS_STYLESHEET_WINDOWS = 'style.css'\n\nPYFORMS_WEB_ENABLED = False\n"
}
] | 64 |
parthgoyal123/Python3-BootCamp
|
https://github.com/parthgoyal123/Python3-BootCamp
|
a9b0c03a1d2bd487fff7bf84c64785c399a15281
|
bf69d4584266221e24a8bf2677de2513beab3693
|
507f7bd042efae2d7d733aa1f6653bb22415eb02
|
refs/heads/master
| 2020-04-28T04:10:45.006840 | 2019-03-11T09:40:30 | 2019-03-11T09:40:30 | 174,967,452 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.627470850944519,
"alphanum_fraction": 0.6305119395256042,
"avg_line_length": 39.26530456542969,
"blob_id": "938d29b5a76451c76cdfcbc640e39206d5715128",
"content_id": "b111d9e081df6654d970029b3ee4453b561c117b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1973,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 49,
"path": "/File_IO_Python.py",
"repo_name": "parthgoyal123/Python3-BootCamp",
"src_encoding": "UTF-8",
"text": "\n#* ============== Basic File Input Output ============= *#\n\n# myfile = open('whoops_wrong.txt')\t\t\t\t\t\t\t\t\t\t\t\t\t# will not open, as there is no file whoops_wrond\nmyfile = open('myfile.txt')\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# open the file\n\nprint(myfile.read())\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# read all the contents of the file\nprint(myfile.read())\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# we observe that nothing is printed, since the cursor has reached the end\nmyfile.seek(0)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# get the file pointer reader to start again\n\ncontent = myfile.read()\nmyfile.seek(0)\nlines = myfile.readlines()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# get all the lines separately in a list\nprint(lines)\t\nmyfile.close()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# important to close the file after use\n\nmyfile = open('/media/parthgoyal123/Data/Python3 BootCamp/myfile.txt')\t\t\t\t# write the absolute path if file in other location\nprint(myfile.read())\n\n# grabbing the contents of the file without worrying about closing the file\nwith open('myfile.txt') as my_new_file:\n\tcontents = my_new_file.read()\n\nprint('')\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# printing new line\nprint(contents + '\\tHello World')\n\n''' \nDifferent modes while accessing a file\n\nmode = 'r' read only\nmode = 'w' write only (overwrite or create new!)\nmode = 'a' append only\nmode = 'r+' reading and writing\nmode = 'w+' writing and reading (overwrites existing files or creates a new file!)\n'''\n\nwith open(file = 'newfile.txt', mode = 'r') as f:\t\t\t\t\t\t\t\t\t# reading from a file using mode = 'r'\n\tprint(f.read())\n\nwith open(file = 'newfile.txt', mode = 'a') as f:\t\t\t\t\t\t\t\t\t# appending to a file using mode = 'a'\n\tf.write('\\nFour on Four')\n\nwith open(file = 'newfile.txt', mode = 'r') as f:\t\t\t\t\t\t\t\t\t# reading from a file using mode = 'r' and observing the change\n\tprint(f.read())\n\nwith open(file = 'new_file_write.txt', mode = 'w') as f:\t\t\t\t\t\t\t# creating a new file and writing into the file\n\tf.write('I created this file!!')\n\nwith open(file = 'new_file_write.txt', mode = 'r') as f:\t\t\t\t\t\t\t# reading from a new_file using mode = 'r'\n\tprint(f.read())"
},
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8403361439704895,
"avg_line_length": 58.5,
"blob_id": "1704874cbb12b3ffb996d671d370c2d6392fe223",
"content_id": "6ac856bf778af8c2bfa786c0508a37c8f64886f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 2,
"path": "/README.md",
"repo_name": "parthgoyal123/Python3-BootCamp",
"src_encoding": "UTF-8",
"text": "# Python3-BootCamp\nThis repository has python3 notebooks and my solutions to questions in the python jupyter notebooks\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.3333333432674408,
"avg_line_length": 58,
"blob_id": "cd3853e27ceb3a3c83e61e07fdcc323c9ee2e06c",
"content_id": "160065795c827ca805274d11f324647e1246e46b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 1,
"path": "/IO_Python.py",
"repo_name": "parthgoyal123/Python3-BootCamp",
"src_encoding": "UTF-8",
"text": "\n#* ============== Basic File Input Output ============= *#\n"
},
{
"alpha_fraction": 0.5523191094398499,
"alphanum_fraction": 0.5808905363082886,
"avg_line_length": 38.34306716918945,
"blob_id": "6d2f2787b4cbb1221a4405f30d0e4dbe39bb475f",
"content_id": "c46909e1a96e9edea8b38088d2f9b84f385d360a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5390,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 137,
"path": "/Basic_Python.py",
"repo_name": "parthgoyal123/Python3-BootCamp",
"src_encoding": "UTF-8",
"text": "\n#* ============== Basic Data Types ============= *#\n\ninteger = 3\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t#int - whole numbers\nfloating_point = 2.3\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t#float - Numbers with a decimal point\nstring = 'Hello'\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t#str - ordered sequence of characters\nlists = [10, 'hello', '2000']\t\t\t\t\t\t\t\t\t\t\t\t\t\t#list - ordered sequence of objects\ndictionaries = {'hello': '100', 'goodbye': '200000'}\t\t\t\t\t\t\t\t#dict - unordered key:value pairs\ntuples = (10, 'hello', 200.3)\t\t\t\t\t\t\t\t\t\t\t\t\t\t#tup - ordered immutable sequence of objects\nsets = {'a', 'b'}\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t#set - unordered collection of unique objects\nbooleans = True\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t#bool - logical value indication True or False\n\n#! Python uses dynamic typing\n\n# type() may help in determining the type of variable\nprint(type(integer))\nprint(type(sets))\n\n#* ----------- Numbers ------------ *#\n\n2+1\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# addition\n2-1\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# subtraction\n2*4\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# multiply\n7/4\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# division\n2**4\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# power to 4\n4%3\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# modulo\n7//4\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# floor division (returns int)\n\n#* ----------- Strings ------------ *#\n\n# '' or \"\" both work\n# Indexing starts from 0 (In octave, it starts from 1)\n\nprint(string)\nlength_string = len(string)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# returns the length of the string\nprint(length_string)\n\n# Since strings are ordered sequence it means we can use indexing [] and slicing [start:stop:step] to grab sub-sections of the string.\nmystring = 'Hello World'\nindexing1 = mystring[0]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# grabbing a single character\n# Python has reverse indexing i.e let string = 'hello', then string[0] = 'h', string[-4] = string[1] = 'e', etc..\nindexing2 = mystring[-1]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# grabbing the last character using reverse indexing\n\n# In splicing, start index is included, but not stops (i.e. stop index is excluded)\nslicing1 = mystring[2:]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# from index 2 to last\nslicing2 = mystring[:3]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# upto index 3 but not including 3\nslicing3 = mystring[3:6]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# grabbing a sub-section\nslicing4 = mystring[::2]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# from start to end with step size 2\nslicing5 = mystring[::-1]\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# reversing a string\n\n#! Strings are immutable i.e if mystring = 'hello', then we cannot do mystring[2] = 'h'... (assign it to a new string instead)\n\nprint(mystring + ' Hello' + ' World')\t\t\t\t\t\t\t\t\t\t\t\t# concatenation\t\nletter = 'zy'\nprint(letter * 10)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# multiplying string repeats all the characters n times\n\nprint(mystring.upper())\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# upper FUNCTION #! do not forget (), since it is a method\nprint(mystring.lower())\nmystring = 'My name is Parth'\nprint(mystring.split())\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# split whenever encounter whitespace\nprint(mystring.split('i'))\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# split whenever encounter 'i'\n\n# .format() method for string formatting\nprint('This is a string {}'.format('Inserted'))\nprint('The {f} {b} {q}'.format(f = 'fox', b = 'brown', q = 'quick'))\t\t\t\t# we can use indexing numbers too, but the indicated method is best\n\n# float formatting '{value:width.precision f}'\nresult = 100/777\nprint('The result was {r:10.5f}'.format(r = result))\t\t\t\t\t\t\t\t# upto 5 floating point precision, but by using 10- we are adding whitespace\n\n# f string method for string formatting\nprint(f'Hello there, how are you?\\n{mystring}')\t\t\t\t\t\t\t\t\t\t# variable name within the braces {}\n\n#* ----------- Lists ------------ *#\n\nmylist = [1,2,3]\nmylist = ['String', 10, 100.0]\t\t\t\t\t\t\t\t\t\t\t\t\t\t# can be reassigned\nprint (len(mylist))\n# indexing and slicing same as in Strings\n# list concatenation is also possible\n# lists are mutable\nmylist.append(6)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# appending the list at last (check into other methods)\nmylist.pop()\npopped_item = mylist.pop(1)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# by default .pop(-1) acts\nmylist = [45, -89, 56, 100, -78]\nmylist.sort()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# sorting the list\nprint(mylist)\n\nmylist.reverse()\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# reverse the list\nprint(mylist)\n\n#* ----------- Dictionaries ------------ *#\n\n#! unordered and cannot be sorted, indexed or sliced\n\nmydict = {'apple': 2.99, 'oranges': 1.99, 'milk': 5.80}\nprint(mydict['apple'])\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# returns the value of key 'apple'\nprint(mydict.values())\nprint(mydict.keys())\nprint(mydict.items())\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# get all the items stored in the dictionary\n\nmydict = {'k1': [0,1,2], 'k2': ['hello', 'apple', 'world']}\nprint(mydict['k2'][2].upper())\t\t\t\t\t\t\t\t\t\t\t\t\t\t# get the value of k2, then string at index 2 and return upper of it\n\n#* ----------- Tuples ------------ *#\n\n# Similar to lists (indexing, splicing etc) but immutable\nmytuple = (1, 2, 3)\nmylist = [1, 2, 3]\nmytuple = ('a', 'a', 'b')\nprint(mytuple.count('a'))\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# number of times 'a' in the tuple\nprint(mytuple.index('b'))\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# first index of 'b'\n\n#! mytuple[0] = 'hello' will not work, immutable\n\n#* ----------- Sets ------------ *#\n\n# keeps distinct elements in sorted order\nmyset = [1,1,1,2,2,6,5,3,5,6,5,6,2,3,3,4]\nmyset = set(myset)\nprint(myset)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# only distinct items kept in set\nmyset.add(4)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# adding a previously added object won't have any impact\nmyset.add(7)\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# this will be added\nprint(myset)\n\n#* ----------- Booleans ------------ *#\n\nprint(1 > 2)\nprint(1 == 2)\nprint(1 <= 2)\nprint(1 != 2)\n\nmybool = 1 != 2\nprint(type(mybool))\nprint(mybool)\n\nmybool = None\nprint(type(mybool))\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t# NoneType variable"
},
{
"alpha_fraction": 0.5401069521903992,
"alphanum_fraction": 0.5695187449455261,
"avg_line_length": 37.72413635253906,
"blob_id": "9be760a5d31feb35ef11dd3e2c79ed6268c35219",
"content_id": "b7fae0c028bed8037b028fd2dbd96e22a195c83e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1122,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 29,
"path": "/guessing_game.py",
"repo_name": "parthgoyal123/Python3-BootCamp",
"src_encoding": "UTF-8",
"text": "from random import randint\nrandom_integer = randint(1,101)\nprint('----------- About the Game -----------')\nprint('1. Make a guess b/w 1 and 100')\nprint('2. If your guess within 10, we tell you that your guess WARM; else if further than 10, then COLD')\nprint('3. Closer to the previous guess WARMER')\nprint('4. Farther from the previous guess COLDER')\nprint('5. If matched, I will tell you the number of guesses it took you')\nguesses = [0]\nprint(random_integer)\nwhile True:\n guess = int(input('Make a valid guess b/w 1 and 100: '))\n if(guess >=1 and guess<= 100):\n guesses.append(guess)\n if(guesses[-1] == random_integer):\n print(f'CONGRATS!! you got the correct guess in {len(guesses) - 1}')\n break\n if(guesses[-2] == 0):\n if(abs(guess - random_integer) <= 10):\n print('Warm')\n else:\n print('Cold')\n else:\n if(abs(guess - random_integer) <= abs(guesses[-2] - random_integer)):\n print('Warmer')\n else:\n print('Colder')\n else:\n print('Not a valid guess')"
}
] | 5 |
LuisFilipeMLoureiro/ComunicacaoSerial
|
https://github.com/LuisFilipeMLoureiro/ComunicacaoSerial
|
81473e8ef1b747c641b9287a49e87b23b1f04242
|
639a3c0aba1cf272f42be5228ef3b43dbd5c11cc
|
96da0ffb7ef241d8ad8b8302319a912f7ccf43b1
|
refs/heads/master
| 2022-12-12T21:02:25.267368 | 2020-09-18T23:56:52 | 2020-09-18T23:56:52 | 296,752,634 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4711496829986572,
"alphanum_fraction": 0.48286333680152893,
"avg_line_length": 38.401710510253906,
"blob_id": "4d490a1abfee5ed6fc00e21730ca3a36f08824b5",
"content_id": "aa456eb28b308d50c9339742b793218c4b6b47b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9284,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 234,
"path": "/Clientaplicacao.py",
"repo_name": "LuisFilipeMLoureiro/ComunicacaoSerial",
"src_encoding": "UTF-8",
"text": "#####################################################\n# Camada Física da Computação\n#Carareto\n#11/08/2020\n#SERVER\n####################################################\n\n\n#esta é a camada superior, de aplicação do seu software de comunicação serial UART.\n#para acompanhar a execução e identificar erros, construa prints ao longo do código! \n\nimport sys\nfrom enlace import *\nimport time\nfrom dicionario import printador_dic, header_maker, eap_maker\n\n\n\nprint(\"CLIENT\")\n# voce deverá descomentar e configurar a porta com através da qual ira fazer comunicaçao\n# para saber a sua porta, execute no terminal :\n# python -m serial.tools.list_ports\n# se estiver usando windows, o gerenciador de dispositivos informa a porta\n\n#use uma das 3 opcoes para atribuir à variável a porta usada\n#serialName = \"/dev/ttyACM0\" # Ubuntu (variacao de)\n#serialName = \"/dev/tty.usbmodem1463201\" # Mac (variacao de)\nserialName = \"COM9\" # Windows(variacao de)\n\n\ndef main():\n try:\n #declaramos um objeto do tipo enlace com o nome \"com\". Essa é a camada inferior à aplicação. Observe que um parametro\n #para declarar esse objeto é o nome da porta.\n com = enlace(serialName)\n \n # Ativa comunicacao. Inicia os threads e a comunicação seiral \n com.enable()\n printador_dic()\n \n #Se chegamos até aqui, a comunicação foi aberta com sucesso. Faça um print para informar.\n \n #aqui você deverá gerar os dados a serem transmitidos. \n #seus dados a serem transmitidos são uma lista de bytes a serem transmitidos. Gere esta lista com o \n #nome de txBuffer. Esla sempre irá armazenar os dados a serem enviados.\n \n #txBuffer = imagem em bytes!\n\n\n \n\n\n\n contador = 0\n play = True\n ESTADO = \"INICIO\"\n \n\n while play:\n if ESTADO == \"INICIO\":\n header = header_maker(1,0,0,0)\n eap = eap_maker()\n pacote = header + eap \n com.rx.clearBuffer()\n com.sendData(pacote)\n print(pacote)\n print(\"Envio do Handshake\")\n ESTADO = \"HANDSHAKE\"\n \n \n if ESTADO == \"HANDSHAKE\":\n \n start = time.time()\n controle = True\n while controle:\n lenBuffer = com.rx.getBufferLen() # o problema é que nao temos certeza de que seria o tx que receberia o len de do bytes que tem no buffer\n if lenBuffer == 14:\n ESTADO = \"VIVO\"\n controle = False\n print(\"CLIENT RECONHECE SERVER COMO VIVO\")\n \n end = time.time()\n delta_t = end - start\n print(\"delta_t: \", delta_t)\n if delta_t > 5:\n controle = False\n continuidade = input(\"Servidor inativo. Tentar novamente? S/N \")\n if continuidade == \"S\":\n controle = True\n header = header_maker(1,0,0,0)\n eap = eap_maker()\n pacote = header + eap \n com.sendData(pacote)\n print(pacote)\n print(\"Envio do Handshake\")\n ESTADO = \"HANDSHAKE\" \n start = time.time()\n else:\n print(\"Servidor Inativo. Encerrando\")\n break\n\n if ESTADO == \"VIVO\":\n rxBuffer, nRx = com.getData(10)\n eop, eop2 = com.getData(4)\n tipo_msg = rxBuffer[1]\n if tipo_msg == 3:\n print(\"Aplicação respondeu\")\n imageW = \"./imageB.png\"\n txBuffer = open(imageW, 'rb').read()\n tamanho_arquivo = len(txBuffer)\n lenBuffer = len(txBuffer)\n razao = tamanho_arquivo//114 if tamanho_arquivo % 114 == 0 else tamanho_arquivo//114 + 1\n contador = 0\n pacote_correspondete = 1\n\n print(\"tamanho arquivo: {}\".format(tamanho_arquivo))\n\n while tamanho_arquivo > 0:\n if tamanho_arquivo >=114:\n header = header_maker(0,razao,pacote_correspondete,114)\n payload = txBuffer[contador:contador+114]\n print(\"LEN PAYLOAD: {}\".format(len(payload)))\n eop = eap_maker()\n pacote = header + payload + eop\n com.sendData(pacote)\n\n pacote_correspondete +=2\n contador += 114\n tamanho_arquivo -= 1106\n\n time.sleep(0.01)\n rxBuffer, nRx = com.getData(14)\n if rxBuffer[1]==4:\n print(\"Confirmação de pacote recebido foi lida. Próximo pacote será mandado.\")\n elif rxBuffer[1]==2:\n pacote_correspondete -=1\n contador -= 114\n tamanho_arquivo += 114\n elif rxBuffer[1]==5:\n pacote_correspondete -=2\n contador -= 114*2\n tamanho_arquivo += 114*2\n print(\"CONTADOR: {}\".format(contador))\n print(\"Tamanho restante do arquivo: {}\".format(tamanho_arquivo))\n print(\"PACOTE ATUAL: {}\".format(pacote_correspondete))\n print(\"RAZAO (NUMERO DE PACOTES): {}\".format(razao))\n\n\n \n else:\n \n header = header_maker(0,razao,pacote_correspondete,tamanho_arquivo)\n print(\"TAMANHO_ARQUIVO: {}\".format(tamanho_arquivo))\n payload = txBuffer[contador:lenBuffer]\n print(\"LEN PAYLOAD: {}\".format(len(payload)))\n eop = eap_maker()\n pacote = header + payload + eop\n com.sendData(pacote)\n print(\"ÚLTIMO PACOTE FOI MANDADO\")\n \n\n pacote_correspondete +=1\n contador += 114\n tamanho_arquivo -= 114\n play= False\n \n\n \n\n \n \n\n\n\n\n\n\n \n\n \n\n \n #tamanho_arquivo_restante -= 114\n # Proximos passos: faxer o content do arquivo como o conteudo do arquivo e fazer o recebimento de arquivos\n \n #faça aqui uma conferência do tamanho do seu txBuffer, ou seja, quantos bytes serão enviados.\n \n \n \n\n #prox passos: fazer um vetor de bytes de 10 e fazer os ifs, primeiro enviando o handshake e depois o de dado com o input\n #finalmente vamos transmitir os tados. Para isso usamos a funçao sendData que é um método da camada enlace.\n #faça um print para avisar que a transmissão vai começar.\n #tente entender como o método send funciona!\n \n\n # A camada enlace possui uma camada inferior, TX possui um método para conhecermos o status da transmissão\n # Tente entender como esse método funciona e o que ele retorna\n #txSize = com.tx.getStatus()\n \n #Agora vamos iniciar a recepção dos dados. Se algo chegou ao RX, deve estar automaticamente guardado\n #Observe o que faz a rotina dentro do thread RX\n #print um aviso de que a recepção vai começar.\n \n #Será que todos os bytes enviados estão realmente guardadas? Será que conseguimos verificar?\n #Veja o que faz a funcao do enlaceRX getBufferLen\n \n #acesso aos bytes recebidos\n #rxBuffer, nRx = com.getData(txLen)\n \n \n #print (rxBuffer)\n \n \n \n # Encerra comunicação\n print(\"-------------------------\")\n print(\"Comunicação encerrada\")\n print(\"-------------------------\")\n com.disable()\n except Exception as e:\n exception_type, exception_object, exception_traceback = sys.exc_info()\n filename = exception_traceback.tb_frame.f_code.co_filename\n line_number = exception_traceback.tb_lineno\n print(\"ERRO: {}\".format(e))\n print(\"Exception type: \", exception_type)\n print(\"File name: \", filename)\n print(\"Line number: \", line_number)\n \n com.disable()\n\n #so roda o main quando for executado do terminal ... se for chamado dentro de outro modulo nao roda\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.471102774143219,
"alphanum_fraction": 0.5092158913612366,
"avg_line_length": 39.012821197509766,
"blob_id": "5af8ecb8a8cc81a37e70c5917ccecd94394db601",
"content_id": "592d17772bd647d3bc29707b3b2e2a39c3ebddcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3206,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 78,
"path": "/dicionario.py",
"repo_name": "LuisFilipeMLoureiro/ComunicacaoSerial",
"src_encoding": "UTF-8",
"text": "#####################################################\r\n# Camada Física da Computação \r\n# DICIONARIO\r\nimageW = \"imageB.png\"\r\ntxBuffer = open(imageW, 'rb').read()\r\ntamanho_arquivo = len(txBuffer)\r\nrazao = round(tamanho_arquivo/114)\r\n\r\ndef printador_dic():\r\n \r\n print(\"########################################\")\r\n print(\"DICIONARIO INICIO\")\r\n print()\r\n print(\"########################################\")\r\n print()\r\n print( \"HEADER\" )\r\n print(\"########################################\")\r\n print()\r\n print(\"BYTE 0 - Inicio de um Header\")\r\n print()\r\n print((255).to_bytes(2, byteorder='big'), \"Inicio de HEADER\")\r\n print(\"########################################\")\r\n print()\r\n print(\"BYTE 1 - Tipo de Mensagem\")\r\n print((0).to_bytes(1, byteorder='big'), \"Dados\")\r\n print((1).to_bytes(1, byteorder='big'), \"HandShake\")\r\n print((2).to_bytes(1, byteorder='big'), \"Erro\")\r\n print((3).to_bytes(1, byteorder='big'), \"Estou Vivo!\")\r\n print((4).to_bytes(1, byteorder='big'), \"Pacote recebido, pode mandar o próximo!\")\r\n print((5).to_bytes(1, byteorder='big'), \"Mandou o pacote errado!\")\r\n print(\"########################################\")\r\n print()\r\n print(\"BYTE 2 - Número de Pacotes a ser enviados para a mensagem\")\r\n print(\"########################################\")\r\n print()\r\n print(\"BYTE 3 - Pacote correspondente dessa mensagem\")\r\n print(\"########################################\")\r\n print()\r\n print(\"BYTE 4 - Tamanho do Payload\")\r\n print(\"########################################\")\r\n print(\"DICIONARIO FIM\")\r\n print()\r\n print(\"########################################\")\r\n print()\r\n\r\n'''def header_maker1(arg1,arg3,arg4):\r\n un0 = (255).to_bytes(1,byteorder=\"big\") #Anuciar Header (FF)\r\n un1 = (arg1).to_bytes(1,byteorder=\"big\") # Tipo de mensagem\r\n un2 = (razao).to_bytes(1,byteorder=\"big\") # Razao\r\n un3 = (arg3).to_bytes(1,byteorder=\"big\") # pacote correspondente do pacote\r\n un4 = (arg4).to_bytes(1,byteorder=\"big\") # tamanho do pacote\r\n un5 = (0).to_bytes(1,byteorder=\"big\")\r\n un6 = (0).to_bytes(1,byteorder=\"big\")\r\n un7 = (0).to_bytes(1,byteorder=\"big\")\r\n un8 = (0).to_bytes(1,byteorder=\"big\")\r\n un9 = (0).to_bytes(1,byteorder=\"big\")\r\n un10 = (0).to_bytes(1,byteorder=\"big\")\r\n\r\n header= un0 + un1 + un2 + un3 + un4 + un5 + un6 + un7 + un8 + un10\r\n return header\r\n '''\r\ndef header_maker(arg1,arg2,arg3,arg4):\r\n un0 = (255).to_bytes(1,byteorder=\"big\") #Anuciar Header (FF)\r\n un1 = (arg1).to_bytes(1,byteorder=\"big\") # Tipo de mensagem\r\n un2 = (arg2).to_bytes(1,byteorder=\"big\") # Razao (numero total de pacotes)\r\n un3 = (arg3).to_bytes(1,byteorder=\"big\") # pacote correspondente do pacote\r\n un4 = (arg4).to_bytes(1,byteorder=\"big\") # tamanho do pacote\r\n un5 = (0).to_bytes(1,byteorder=\"big\")\r\n un6 = (0).to_bytes(1,byteorder=\"big\")\r\n un7 = (0).to_bytes(1,byteorder=\"big\")\r\n un8 = (0).to_bytes(1,byteorder=\"big\")\r\n un9 = (0).to_bytes(1,byteorder=\"big\")\r\n \r\n\r\n header = un0 + un1 + un2 + un3 + un4 + un5 + un6 + un7 + un8 + un9\r\n return header\r\ndef eap_maker():\r\n return (0).to_bytes(4,byteorder=\"big\")\r\n\r\n"
},
{
"alpha_fraction": 0.5192860960960388,
"alphanum_fraction": 0.5286413431167603,
"avg_line_length": 33.914573669433594,
"blob_id": "7e85da1b496c9016ce5ae786187e083842a53872",
"content_id": "55e3a29d35e1c27acb3e9039f209572c9a033eb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7005,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 199,
"path": "/Serveraplicacao.py",
"repo_name": "LuisFilipeMLoureiro/ComunicacaoSerial",
"src_encoding": "UTF-8",
"text": "#####################################################\n# Camada Física da Computação\n#Carareto\n#11/08/2020\n#CLIENT\n####################################################\n\n\n#esta é a camada superior, de aplicação do seu software de comunicação serial UART.\n#para acompanhar a execução e identificar erros, construa prints ao longo do código! \n\nimport sys\nfrom enlace import *\nimport time\nfrom dicionario import printador_dic, header_maker, eap_maker\n\nprint(\"SERVER\")\n# voce deverá descomentar e configurar a porta com através da qual ira fazer comunicaçao\n# para saber a sua porta, execute no terminal :\n# python -m serial.tools.list_ports\n# se estiver usando windows, o gerenciador de dispositivos informa a porta\n\n#use uma das 3 opcoes para atribuir à variável a porta usada\n#serialName = \"/dev/ttyACM0\" # Ubuntu (variacao de)\n#serialName = \"/dev/tty.usbmodem1463101\" # Mac (variacao de)\nserialName = \"COM10\" # Windows(variacao de)\n\n\ndef main():\n try:\n #declaramos um objeto do tipo enlace com o nome \"com\". Essa é a camada inferior à aplicação. Observe que um parametro\n #para declarar esse objeto é o nome da porta.\n com = enlace(serialName)\n \n # Ativa comunicacao. Inicia os threads e a comunicação seiral \n com.enable()\n \n #Se chegamos até aqui, a comunicação foi aberta com sucesso. Faça um print para informar.\n \n #aqui você deverá gerar os dados a serem transmitidos. \n #seus dados a serem transmitidos são uma lista de bytes a serem transmitidos. Gere esta lista com o \n #nome de txBuffer. Esla sempre irá armazenar os dados a serem enviados.\n \n #txBuffer = imagem em bytes!\n\n\n \n\n print(\"Aguardando Pacote\")\n #faça aqui uma conferência do tamanho do seu txBuffer, ou seja, quantos bytes serão enviados.\n \n \n \n #finalmente vamos transmitir os tados. Para isso usamos a funçao sendData que é um método da camada enlace.\n #faça um print para avisar que a transmissão vai começar.\n #tente entender como o método send funciona!\n #com.sendData(txBuffer)\n\n # A camada enlace possui uma camada inferior, TX possui um método para conhecermos o status da transmissão\n # Tente entender como esse método funciona e o que ele retorna\n #txSize = com.tx.getStatus()\n \n #Agora vamos iniciar a recepção dos dados. Se algo chegou ao RX, deve estar automaticamente guardado\n #Observe o que faz a rotina dentro do thread RX\n #print um aviso de que a recepção vai começar.\n \n #Será que todos os bytes enviados estão realmente guardadas? Será que conseguimos verificar?\n #Veja o que faz a funcao do enlaceRX getBufferLen\n rodando=True\n ESTADO = \"INCIO\"\n foto=bytes(0)\n pacote_passado=0\n\n #acesso aos bytes recebidos\n while rodando:\n print(\"mensagem do tipo: \", ESTADO)\n rxBuffer, nRx = com.getData(10)\n \n inicio_header = rxBuffer[0]\n tipo_header = rxBuffer[1]\n print(\"INICIO HEADER: {}\".format(inicio_header))\n if inicio_header == 255:\n ESTADO = \"HEADER\"\n else:\n ESTADO = \"ERRO\"\n header=header_maker(2,0,0,0)\n eop=eap_maker()\n pacote=header+eop\n com.sendData(pacote)\n\n if ESTADO == \"HEADER\":\n if tipo_header == 1:\n ESTADO = \"HANDSHAKE\"\n elif tipo_header == 0:\n ESTADO = \"DADOS\"\n if ESTADO == \"HANDSHAKE\":\n eop, sz = com.getData(4)\n\n\n header = header_maker(3,0,0,0)\n eop = eap_maker()\n pacote = header + eop\n com.sendData(pacote)\n\n elif ESTADO == \"DADOS\":\n total_pacotes=rxBuffer[2]\n pacote_atual=rxBuffer[3]\n tamanho_pacote=rxBuffer[4]\n dif_pacotes=pacote_atual-pacote_passado\n print(\"PACOTE PASSADO: {}\".format(pacote_passado))\n pacote_passado+=1\n rxBuffer,nRx=com.getData(tamanho_pacote) \n print(\"TAMANHO PACOTE:{}\".format(tamanho_pacote))\n foto_parte=rxBuffer\n \n eop, eop2 = com.getData(4)\n print(eop)\n print(\"PACOTE ATUAL: {}\".format(pacote_atual))\n \n if int.from_bytes(eop, byteorder='big')!=0 or dif_pacotes!=1:\n if dif_pacotes!=1:\n print(\"PACOTE NAO ERA UM MAIOR QUE O PASSADO\")\n header=header_maker(5,0,0,0)\n else:\n print(\"PAYLOAD COM TAMANHO DIFERENTE DO HEADER, PEDINDO PRA MANDAR PACOTE DE NOVO.\")\n header=header_maker(2,0,0,0)\n ESTADO = \"ERRO\"\n #MANDAR MENSAGEM FALANDO PRA MANDAR DE NOVO\n \n eop=eap_maker()\n pacote=header+eop\n com.sendData(pacote)\n pacote_passado-=1\n \n elif pacote_atual>=total_pacotes:\n print(\"Recebido último pacote\")\n foto+=foto_parte\n \n header=header_maker(4,0,0,0)\n eop=eap_maker()\n pacote=header+eop\n com.sendData(pacote)\n\n f=open(\"./imagem_gerada.png\", 'wb')\n print(\"imagem recebida pelo server\")\n f.write(foto)\n f.close()\n print(\"imagem escrita pelo server\")\n\n rodando=False\n ESTADO=\"FIM\"\n \n \n else:\n foto+=foto_parte\n print(\"Pacote recebido!\")\n header=header_maker(4,0,0,0)\n eop=eap_maker()\n pacote=header+eop\n com.sendData(pacote)\n \n\n\n\n\n \n\n\n\n\n\n\n\n\n\n\n \n \n \n \n # Encerra comunicação\n print(\"-------------------------\")\n print(\"Comunicação encerrada\")\n print(\"-------------------------\")\n com.disable()\n except Exception as e:\n exception_type, exception_object, exception_traceback = sys.exc_info()\n filename = exception_traceback.tb_frame.f_code.co_filename\n line_number = exception_traceback.tb_lineno\n\n print(\"Exception type: \", exception_type)\n print(\"File name: \", filename)\n print(\"Line number: \", line_number)\n \n com.disable()\n\n #so roda o main quando for executado do terminal ... se for chamado dentro de outro modulo nao roda\nif __name__ == \"__main__\":\n main()\n"
}
] | 3 |
FrcsCza/MyProject
|
https://github.com/FrcsCza/MyProject
|
0371a5de4f4bd39c56e317a5a116cfaf6f538ad7
|
8c9f1508839154decab4645902243e8a3c3bd6f8
|
ae337779a803605e43ef2510d0ba5d022e4bcc6a
|
refs/heads/master
| 2020-02-22T13:30:59.059741 | 2017-03-21T10:04:09 | 2017-03-21T10:04:09 | 62,472,757 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5162702798843384,
"alphanum_fraction": 0.5209925174713135,
"avg_line_length": 35.79545593261719,
"blob_id": "e34fca5fc67edc3fac82cf25d6ceaf6f9574fe9f",
"content_id": "80aa4b07b993fb3617fc01850edc7e95ab5698b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11710,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 308,
"path": "/keyrus_func.py",
"repo_name": "FrcsCza/MyProject",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/python\r\n# -*- coding: utf-8 -*-\r\n\r\n\"\"\"\r\nÉditer de Spyder\r\n\r\nModule regroupant les fonctions Keyrus : \r\nworkOrNot\r\nimport_transfoDF\r\ndiff_ut\r\nemprunt_velo\r\nretour_velo (à modifier)\r\ndist_event\r\nstations_around\r\nDF_maker\r\n\"\"\"\r\n\r\nimport pandas as pd\r\nimport numpy as np\r\nfrom geopy.distance import great_circle\r\nfrom json import load\r\nimport io, glob\r\nimport exceptions\r\nimport datetime\r\n\r\n# Pour plus tard lors de la creation en lib : limitera l'improt des fonctions contenus pour eviter d'importer aussi toutes les\r\n# fonctions contenues dans les librairies de dependances. \r\n__all__ = ['workOrNot', 'import_transfoDF', 'diff_ut', 'diff_delta', 'emprunt_velo', 'retour_velo', 'dist_event', 'stations_around', \r\n\t 'DF_maker']\r\n\r\ndef workOrNot(wdate):\r\n\r\n \"\"\"\r\n Input : date au format datetime64 ou timestamp pandas de la forme '2016-06-13 21:55:42'\r\n\r\n Description : \r\n Prend une date et renvoie si c'est un jour de la semaine ou du weekend\r\n\r\n Output : boolean\r\n \"\"\"\r\n\r\n if wdate.weekday() <= 4: \r\n wdate = 1\r\n else : \r\n wdate = 0\r\n\r\n return wdate\r\n\r\n\r\n##############################################################################################################\r\n##############################################################################################################\r\n\r\n\r\ndef import_transfoDF(path, modif_epoch = 1) :\r\n\r\n \"\"\"\r\n Input : - file directory\r\n\t - 1 par défaut (change le timestamp), garde le Epoch sinon\r\n \r\n Description:\r\n Import du fichier provenant de directory, transformation de la date de epoch vers un timestamp lisible si on ne précise rien le fait\r\n par défaut, si toute autre valeur est donnée, le format Epoch est concervé.\r\n création des colonnes latitudes et longitudes.\r\n \r\n Output : Dataframe pandas\r\n \"\"\"\r\n\r\n data = pd.read_csv(path, index_col=[0])\r\n\r\n if (modif_epoch == 1) : \r\n # reformatage du format Epoch en format de date lisible : \r\n data.last_update = pd.to_datetime(data.last_update/1000, unit = 's')\r\n \r\n\r\n # passage du timestamp en index : \r\n data = data.set_index('last_update')\r\n\r\n #création des colonnes latitudes et longitudes : \r\n np_position = data.position.map(lambda x: eval(x)).values\r\n # latitude\r\n data['latitude'] = [i['lat'] for i in np_position]\r\n # longitude : \r\n data['longitude'] = [i['lng'] for i in np_position]\r\n \r\n return data\r\n\r\n##############################################################################################################\r\n##############################################################################################################\r\n\r\n\r\ndef diff_ut(liste):\r\n \r\n \"\"\"\r\n Input : list of float or int\r\n \r\n Description : \r\n Somme les différences consécutives calculées sur la liste avec la fonction numpy.diff a[i+1] - a[i] = diff[i]\r\n \r\n Output : float\r\n \"\"\"\r\n\r\n res = np.diff(liste)\r\n \r\n for i in xrange(len(res)):\r\n if (res[i] > 0):\r\n res[i] = 0\r\n else :\r\n res[i] = res[i]\r\n \r\n return -np.sum(res)\r\n\r\n##############################################################################################################\r\n############################################################################################################## \r\n\r\n\r\ndef diff_delta(liste):\r\n \r\n \"\"\"\r\n Input : list of float or int\r\n \r\n Description : \r\n Somme les différences consécutives calculées sur la liste avec la fonction numpy.diff a[i+1] - a[i] = diff[i]\r\n \r\n Output : float\r\n \"\"\"\r\n res = np.zeros(len(liste))\r\n \r\n for i in xrange(len(res)):\r\n if (liste[i] < 0):\r\n res[i] = liste[i]\r\n \r\n return res\r\n \r\n##############################################################################################################\r\n############################################################################################################## \r\n\r\n \r\ndef emprunt_velo(num_id, DF_jcd, timinterval = '15t'):\r\n \r\n \"\"\"\r\n Input: float, DataFrame, string ('yt' toutes les y min , 'h' toutes les heures, 'xh' toutes les x heures)\r\n \r\n Description : \r\n Prend un numéro de station vélib et le DataFrame JCDecaux et calcule l'utilisation sur la journée de cette station, renvoie une\r\n Serie pandas indexée par le temps avec des intervalles de temps dépendant de ce qui a été préciser par la chaine de caractère\r\n \r\n Output: pd.Series\r\n \"\"\"\r\n\r\n tab = DF_jcd[DF_jcd.number == num_id].available_bikes.reset_index()\r\n\r\n maliste = list(np.diff(tab.available_bikes))\r\n maliste.insert(0,0)\r\n maliste = diff_delta(maliste)\r\n\r\n tab['delta_bike'] = maliste\r\n tab = tab.set_index('last_update')\r\n\r\n return tab.delta_bike.resample(timinterval, closed = 'left', label='right').agg(np.sum)\r\n \r\n##############################################################################################################\r\n##############################################################################################################\r\n\r\n\r\ndef retour_velo(num_id, DF_jcd, timinterval = '15t'):\r\n \r\n \"\"\"\r\n Input: float, DataFrame, string ('yt' toutes les y min , 'h' toutes les heures, 'xh' toutes les x heures)\r\n \r\n Description : \r\n Prend un numéro de station vélib et le DataFrame JCDecaux et calcule le nombre de retour de vélo sur la journée de cette station, renvoie une\r\n Serie pandas indexée par le temps avec des intervalles de temps dépendant de ce qui a été préciser par la chaine de caractère en timinterval\r\n \r\n Output: pd.Series\r\n \"\"\"\r\n res = 0\r\n \r\n res = DF_jcd[DF_jcd.number == num_id]['available_bike_stands'].resample(timinterval, closed = 'left', label = 'right').agg(diff_ut)\r\n \r\n return res\r\n\r\n##############################################################################################################\r\n##############################################################################################################\r\n\r\n\r\n# direction du fichier contenant une seule mesure:\r\npoz = 'C:/Users/Francois.Czarny.KEYRUSCORP/Documents/Bike_Sharing_Demand_Kaggle/jcdecaux_api/jcdecaux_api_ 31-05-2016_22_/05.json'\r\n\r\n# lecture du fichier, et mise du contenu dans la variable content:\r\nwith open(poz) as f :\r\n content = load(f)\r\n\r\n# passage de content (liste de dict) en dataframe pandas:\r\nsimpljson = pd.DataFrame(content)\r\n\r\n# creation de la liste vide destinée à contenir tout mes points geolocalisés:\r\npositions = []\r\n# remplissage de la liste vide par la geolocalisation des stations vélib:\r\nfor i in xrange(len(simpljson.position)):\r\n positions.append([simpljson.position.ix[i]['lat'], simpljson.position.ix[i]['lng']])\r\n# convert positions to a numpy object\r\npositions = np.array(positions)\r\n\r\n\r\ntableID_velib = pd.DataFrame([simpljson.address, simpljson.number, simpljson.position]).T\r\n\r\n# Creation des colonnes latitude et longitude : \r\ntableID_velib['latitude'] =[tableID_velib.position[i].pop('lat') for i in xrange(len(tableID_velib))]\r\ntableID_velib['longitude'] =[tableID_velib.position[i].pop('lng') for i in xrange(len(tableID_velib))]\r\n\r\n# suppression de la colonne position : \r\ntableID_velib = tableID_velib.drop('position', axis=1)\r\n\r\n\r\n# suppression des variables de construction : \r\ndel poz, simpljson, content\r\n\r\n\r\n################################################################################################################\r\n \r\n\r\n# définition de la fonction calculant la distance d'un evenement par rapport à l'ensemble des stations vélib: \r\ndef dist_event(geolocEvent, list_velib = positions): \r\n \"\"\"\r\n Input : list, listes des coordonnées GPS d'un point \r\n \r\n Description :\r\n Calcule la distance du point geolocEvent par rapport à toutes les stations Velib de Paris\r\n \r\n Output : np.array, vecteur de toutes les distances \r\n \"\"\"\r\n \r\n dist = []\r\n [dist.append(great_circle(geolocEvent, list_velib[i]).km) for i in xrange(len(list_velib))]\r\n \r\n return np.array(dist).round(3)\r\n \r\n \r\n##############################################################################################################\r\n##############################################################################################################\r\n \r\n \r\ndef stations_around(centreGeoloc, rayon):\r\n \"\"\"\r\n Input : - list, liste des corrdonnées du centre\r\n - float, rayon dans lequel se situe les stations\r\n \r\n Calcule les coordonnées des stations vélib autour du point \"centre\" et situées dans le rayon\r\n \r\n Output : dict avec : \r\n - 'number' : les numéros (id) des stations situées dans le rayon donné\r\n - 'latlon' : les coordonnées des stations vélib situées dans le rayon indiqué autour du centre\r\n \"\"\"\r\n\r\n list_dist = dist_event(centreGeoloc)\r\n \r\n return {'number' : np.array(tableID_velib.number, np.int)[(list_dist < rayon).nonzero()],\r\n 'latlon' : np.array(positions)[(dist_event(centreGeoloc) < rayon).nonzero()] }\r\n \r\n # Pour pouvoir revenir à un format de liste au cas ou cela s'avérerait fastidieux de se servir d'un dictionnaire :\r\n # return [np.array(tableID_velib.number, np.int)[(list_dist < rayon).nonzero()],\r\n # np.array(positions)[(dist_event(centreGeoloc) < rayon).nonzero()] ]\r\n \r\n \r\n##############################################################################################################\r\n############################################################################################################## \r\n \r\n\r\n# prend un fichier JSON et retourne un Dataframe pandas :\r\nimport glob\r\nimport exceptions\r\n\r\ndef DF_maker(path, df_concat = pd.DataFrame()): \r\n \r\n \"\"\"\r\n Input : a folder's directory [and eventually the DataFrame you want to concatenate\r\n \r\n Search every .json in subfiles and sub-subfiles of the path and create a DataFrame containing this json\r\n compt_file compute how many files are in this DataFrame\r\n \r\n Output : This function return a list with : \r\n a DataFrame, \r\n an integer corresponding to the number of iteration \r\n a list with the directories of corrupted files \r\n \"\"\"\r\n # Partie recherche des .json : \r\n json_f = glob.glob(path + '*/*.json') + glob.glob(path + '*/*/*.json')\r\n json_f = [json_f[i].replace('\\\\','/') for i in range(len(json_f))]\r\n corrupted_files = []\r\n \r\n for json_iter in json_f: \r\n # Gestion des exceptions si l'import s'est mal passé et n'a pas concatené\r\n try:\r\n with open(json_iter, 'r') as filename : \r\n # On recupere la date de l'import du fichier json contenu dans le nom du fichier :\r\n date_import = (json_iter.replace('/home/ubuntu/testDF_maker/jcdecaux_api_ ','').replace('.json','').replace('_', ' '))\r\n obj = json.load(filename)\r\n df_concat = df_concat.append(pd.DataFrame(obj, np.repeat(date_import, pd.DataFrame(obj).shape[0])))\r\n \r\n except SyntaxError:\r\n print('Une erreur est apparue à l\\'itération ' + str(compt_file) + ' dans le fichier : ' + json_iter)\r\n corrupted_files.append(json_iter)\r\n \r\n # On renomme la colonne qui s'était appelé index pour eviter les problèmes : \r\n df_concat = df_concat.reset_index()\r\n df_concat.rename(columns={'index':'date_import'}, inplace=True) \r\n \r\n return [df_concat, len(json_f), corrupted_files]\r\n \r\n"
}
] | 1 |
LuaaGnc/Menu
|
https://github.com/LuaaGnc/Menu
|
55c4144e8c247115f83bde27abf148adffe6ba60
|
c91b68ffc139ea54fc42d996e9b9acf1da731828
|
6c913502bf495e0e13718043c7b5e22b9b3e5687
|
refs/heads/main
| 2023-02-27T08:58:23.173450 | 2021-02-07T14:58:14 | 2021-02-07T14:58:14 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.45938628911972046,
"alphanum_fraction": 0.4996991455554962,
"avg_line_length": 26.700000762939453,
"blob_id": "13298304b4e5bcb6d757e186fd97bf9540ec0cdc",
"content_id": "6ce3bbd7a60683183f01207ff7dcd02cccb83191",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3343,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 120,
"path": "/menu/__init__.py",
"repo_name": "LuaaGnc/Menu",
"src_encoding": "UTF-8",
"text": "import os.path\nfrom time import sleep\n\n# Definição de Cores a utilizar\ncores = ('\\033[m', # 0 - Sem cores\n '\\033[0;30;31m', # 1 - vermelho\n '\\033[0;30;32m', # 2 - Verde\n '\\033[0;30;33m', # 3 - Amarelo\n '\\033[0;30;34m', # 4 - Azul\n '\\033[0;30;35m', # 5 - Roxo\n '\\033[7;30m', # 6 - Branco\n '\\033[0m') # 7 - Final\n\nopcoes = {\n 'zero': 'MENU PRINCIPAL',\n \n 'um': 'Ver pessoas cadastradas',\n \n 'dois': 'Cadastrar nova pessoa',\n \n 'tres': 'Sair do Programa',\n 'tres_opt': 'ATÉ LOGO - - - - SAINDO DO SISTEMA - - - - ATÉ LOGO'\n }\n \n\ndef introd_menu(numero='0'):\n\n print('-' * 30)\n print(cores[5] + f'{opcoes[\"zero\"].center(30)}' + cores[7])\n print('-' * 30)\n print('1 - ', cores[4] + opcoes['um'] + cores[7])\n print('2 - ', cores[4] + opcoes['dois'] + cores[7])\n print('3 - ', cores[4] + opcoes['tres'] + cores[7])\n print('-' * 30)\n \n num = input(cores[3] + 'Sua opção >> ' + cores[7])\n print('\\n\\n')\n \n if num == '3':\n saida()\n else:\n valido_menu(num)\n \n\n# Valida se o número é ou não válido\ndef valido_menu(numero):\n \"\"\"\n :param numero: Valor qualquer\n :return: int(numero)\n\n --> Verifica se o valor corresponde a um número correspondente aos demonstrados no menu!\n --> Números disponíveis: [1, 2, 3]\n \"\"\"\n \n if numero == '1' or numero == '2':\n # Leva para LISTA ou CADASTRO\n print('-' * 60)\n print(f' Opção {numero}'.center(60))\n print('-' * 60, end='\\n\\n')\n sleep(0.3)\n \n if numero == '1':\n opt1()\n else:\n opt2()\n \n sleep(2)\n introd_menu()\n\n else:\n # Significa que cometeram um erro\n if numero.isnumeric():\n print(cores[1] + 'ERRO!! -> Digite um valor válido!\\n\\n' + cores[7])\n sleep(1.5)\n introd_menu()\n else:\n print(cores[1] + 'ERRO!! -> Digite um número inteiro válido\\n\\n' + cores[7])\n sleep(1.5)\n introd_menu()\n\n\n# Ver pessoas cadastradas\ndef opt1():\n # Local de armazenamento do arquivo\n path = 'C:\\\\Users\\\\luisg\\\\OneDrive\\\\Documentos\\\\GitHub\\\\Menu\\\\db\\\\db.txt'\n \n # Se o arquivo não for encontrado, ele cria um arquivo\n try:\n # Abre para leitura\n arquivo = open(path, 'r+')\n except FileNotFoundError:\n # Cria o arquivo\n arquivo = open(path, 'w+')\n \n for i in arquivo.readlines():\n print(f' --> {i}')\n print()\n\n\n# Cadastrar uma pessoa\ndef opt2():\n \n # Abre o arquivo no PATH determinado e no APPEND mode\n file = open('C:\\\\Users\\\\luisg\\\\OneDrive\\\\Documentos\\\\GitHub\\\\Menu\\\\db\\\\db.txt', 'a+')\n \n nome = input(cores[5] + 'Digite o nome da pessoa: ' + cores[7])\n idade = int(input(cores[5] + 'Digite a idade da pessoa: ' + cores[7]))\n \n # Escreve no arquivo\n file.write(f'nome: {nome} + idd: {idade}\\n')\n file.close()\n \n print('-' * 30)\n print(cores[2] + 'CADASTRADO COM SUCESSO'.center(30) + cores[7])\n print('-' * 30)\n \ndef saida():\n print('-' * 100)\n print(cores[2] + opcoes['tres_opt'].center(100) + cores[7])\n print('-' * 100, end='\\n\\n\\n')\n"
},
{
"alpha_fraction": 0.7400000095367432,
"alphanum_fraction": 0.7400000095367432,
"avg_line_length": 11.5,
"blob_id": "a613199054dd09ba7b036ccef7aa656e819f8645",
"content_id": "9e19ccbe13dcc8ca0ca358546e32192147559b54",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 4,
"path": "/__init__.py",
"repo_name": "LuaaGnc/Menu",
"src_encoding": "UTF-8",
"text": "from menu import introd_menu\n\n# Run\nintrod_menu()\n"
},
{
"alpha_fraction": 0.7746478915214539,
"alphanum_fraction": 0.7746478915214539,
"avg_line_length": 34.5,
"blob_id": "2b1577c7763c7d65efad1cc2afa9574fdb35b489",
"content_id": "bf4ae3eee704851ca5fe8979b821f60b56d26492",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 71,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 2,
"path": "/README.md",
"repo_name": "LuaaGnc/Menu",
"src_encoding": "UTF-8",
"text": "# Menu\n Creates a menu and manipulates a file that stores name and age\n"
}
] | 3 |
FurryMemes/DHHack
|
https://github.com/FurryMemes/DHHack
|
bf38b9731c67536574daebbb2d9fe52a8f1a2f07
|
2c1075b037ac5837b2fb9985b739a6b2a80d0137
|
42044ddd9e0f67b11f9c2c962829253d479b4363
|
refs/heads/master
| 2022-01-12T14:05:41.038964 | 2022-01-02T09:56:33 | 2022-01-02T09:56:33 | 223,551,028 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5609756112098694,
"alphanum_fraction": 0.7804877758026123,
"avg_line_length": 40,
"blob_id": "be82a23df6011a0ee12b00aebe0558a01bc58d13",
"content_id": "2eab0ae9b5a5cd3ce8d3ed2cecebdfd720805bb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/map/furrymemes/runserver.sh",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "python3 manage.py runserver 0.0.0.0:7647\n"
},
{
"alpha_fraction": 0.70652174949646,
"alphanum_fraction": 0.70652174949646,
"avg_line_length": 16.399999618530273,
"blob_id": "365741d9dbc77eb31115c6d97f409b48db8014b1",
"content_id": "89fe4dc0e8cdbefa83c5b79c9bb39e52b06179e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/map/furrymemes/maping/apps.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\r\n\r\n\r\nclass MapingConfig(AppConfig):\r\n name = 'maping'\r\n"
},
{
"alpha_fraction": 0.4067796468734741,
"alphanum_fraction": 0.44915252923965454,
"avg_line_length": 34.75757598876953,
"blob_id": "91dd981af8f263314420ce228c362d05a612df12",
"content_id": "139156e7a482f46699e64979154841198f2da6d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1180,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 33,
"path": "/f9.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "import random\n\ndef get_map_data(x, y, x2, y2, w, h, w2, h2, mass_data):\n answer = [[0 for i in range(abs(x - x2))] for _ in range(abs(y - y2))]\n colors = [[[] for i in range(abs(x - x2))] for _ in range(abs(y - y2))]\n w_to_x = abs(w - w2) / abs(x - x2)\n h_to_y = abs(h - h2) / abs(y - y2)\n max_c = 0\n min_c = 0\n for i in range(len(mass_data)):\n if min(w, w2) <= mass_data[i][0] and max(w, w2) >= mass_data[i][0]:\n if min(h, h2) <= mass_data[i][1] and max(h, h2) >= mass_data[i][1]:\n x = int(w_to_x * mass_data[i][0])\n y = int(h_to_y * mass_data[i][1])\n answer[x][y] += 1\n max_c = max(max_c, answer[x][y])\n min_c = min(min_c, answer[x][y])\n\n kof = (max_c - min_c) / min(100, len(mass_data) // 40)\n while kof > 10 and max_c * kof > 200:\n kof -= 10\n\n if kof == 0:\n kof = 1\n\n for x in range(len(answer)):\n for y in range(len(answer[0])):\n if answer[x][y] == 0:\n colors[x][y] = [0, 0, 0]\n else:\n colors[x][y] = [0, 0, 255 - int(answer[x][y] * kof)]\n #print(colors)\n return colors\n"
},
{
"alpha_fraction": 0.604651153087616,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 27.66666603088379,
"blob_id": "0bfeb99ab1458a158346f5da7b990822475a48aa",
"content_id": "97326f5a97367a7c67451ac08b4ddec6305326cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 605,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 21,
"path": "/get_graph.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "from igramscraper.instagram import Instagram\nimport datetime\nimport matplotlib.pyplot as plt\n\ndef get_graph(tag):\n instagram = Instagram()\n instagram.with_credentials('dimafedkk75', '030693Fsa')\n instagram.login()\n \n medias = instagram.get_medias_by_tag(tag, count= 500)\n a = []\n for i in range(24):\n a.append(0)\n for posts in medias:\n a[int(str(datetime.datetime.fromtimestamp(posts.created_time))[11:13])] += 1\n for i in range(24):\n plt.scatter(i, a[i], marker='o', cmap=\"blue\")\n plt.plot([i for i in range(24)], a)\n plt.show()\n\nget_graph('еда')\n"
},
{
"alpha_fraction": 0.7016128897666931,
"alphanum_fraction": 0.7177419066429138,
"avg_line_length": 22.799999237060547,
"blob_id": "622ec3a7162e55e75e1552386d33c6fcde7772f9",
"content_id": "d54ff2c5770bb5a7601c379073b37c8c00b2fd11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 5,
"path": "/map/furrymemes/maping/models.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "from django.db import models\r\n\r\n\r\nclass Group(models.Model):\r\n group_name = models.TextField(max_length=20, blank=True)\r\n"
},
{
"alpha_fraction": 0.6729857921600342,
"alphanum_fraction": 0.6824644804000854,
"avg_line_length": 31.461538314819336,
"blob_id": "a0e7834044862146e4ffa35ca345bda8419af275",
"content_id": "a1799338ddce6d56bfe549a7a14fc09761af26d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 13,
"path": "/LICENSE.md",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "# THE MUFFIN-WARE LICENSE\n\n[@pavTiger](http://t.me/pavtiger), [@dikiray](https://vk.com/dimafedkk), [@uliana2006eskova](https://vk.com/ulyanaeskova) have made this. As long as you retain this notice\nyou can do whatever you want with this stuff. If we meet some day, and you think\nthis stuff is worth it, you can buy us a muffin in return.\n\n> Artushkov Pavel, <[email protected]>\n\n> Fedorenko Dmitriy, <[email protected]>\n\n> Eskova Uliana, <[email protected]>\n\n> Marenkov Alexey <[email protected]>\n"
},
{
"alpha_fraction": 0.5478423833847046,
"alphanum_fraction": 0.6829268336296082,
"avg_line_length": 37.07143020629883,
"blob_id": "052a5ec9aa6965f5f0c91769f1a1b52c3cac1be3",
"content_id": "3059e1a07fb0385dc56eb61481100ed28d6636b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 533,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 14,
"path": "/get_id_users.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "# https://vk.com/dev/groups\nimport vk_api\n\ndef get_id_users(group):\n idd = '9f79d9a11e43730af251d10434201eefb9a665c637eba51e27466f6c4d7557c399484a80ca5aa29adb765'\n vk_session = vk_api.VkApi(token=idd)\n #print(vk_session.method('groups.getMembers', {'group_id': group}))\n try:\n return vk_session.method('groups.getMembers', {'group_id': group})['items']\n except:\n return vk_session.method('groups.getMembers', {'group_id': 80799846})['items']\n\nif __name__ == '__main__':\n print(get_id_users(80799846))\n"
},
{
"alpha_fraction": 0.5038268566131592,
"alphanum_fraction": 0.5415676832199097,
"avg_line_length": 37.06185531616211,
"blob_id": "9a57e1fe97ef59f6a33a3ecfb0075f68c7238f85",
"content_id": "71a62eff7e6bb1e619fc76e8146d8192f927c69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3789,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 97,
"path": "/map/furrymemes/maping/views.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\nfrom .models import Group\r\nfrom .forms import GroupForm\r\nimport vk_api\r\nimport json\r\n\r\ndef get_id_users(group):\r\n idd = '9f79d9a11e43730af251d10434201eefb9a665c637eba51e27466f6c4d7557c399484a80ca5aa29adb765'\r\n vk_session = vk_api.VkApi(token=idd)\r\n #print(vk_session.method('groups.getMembers', {'group_id': group}))\r\n try:\r\n return vk_session.method('groups.getMembers', {'group_id': group})['items']\r\n except:\r\n return vk_session.method('groups.getMembers', {'group_id': 80799846})['items']\r\n\r\ndef get_posts_data(group_id):\r\n users_id = get_id_users(group_id)\r\n vk_session = vk_api.VkApi(token='9f79d9a11e43730af251d10434201eefb9a665c637eba51e27466f6c4d7557c399484a80ca5aa29adb765')\r\n points = []\r\n\r\n for i in range(min(1000, 100)):\r\n posts = {}\r\n tr = False\r\n try:\r\n posts = vk_session.method('wall.get', {'owner_id': users_id[i], 'count': 25})\r\n tr = True\r\n # print('not_bad_error')\r\n except:\r\n # print('bad_error')\r\n pass\r\n if tr and 'items' in posts.keys():\r\n z = 0\r\n for post in range(len(posts['items'])):\r\n if 'geo' in posts['items'][post].keys():\r\n z += 1\r\n geo = posts['items'][post]['geo']\r\n points.append([geo['coordinates'].split()[0], geo['coordinates'].split()[1]])\r\n # print(points)\r\n\r\n if z != 0:\r\n try:\r\n posts = vk_session.method('wall.get', {'owner_id': id, 'count': 200, 'offset': 25})\r\n # print('not_bad_error')\r\n except:\r\n # print('bad_error')\r\n pass\r\n for post in range(len(posts['items'])):\r\n if 'geo' in posts['items'][post].keys():\r\n geo = posts['items'][post]['geo']\r\n points.append([geo['coordinates'].split()[0], geo['coordinates'].split()[1]])\r\n # print(points)\r\n return points\r\n\r\n\r\n\r\ndef arr_to_geojson(arr):\r\n d = {}\r\n for i in range(len(arr)):\r\n d[i] = {'latitude': arr[i][0], 'longitude': arr[i][1]}\r\n dump = json.dumps(d)\r\n return dump\r\n\r\n\"\"\"def default_map(request):\r\n # TODO: move this token to Django settings from an environment variable\r\n # found in the Mapbox account settings and getting started instructions\r\n # see https://www.mapbox.com/account/ under the \"Access tokens\" section\r\n if request.method == \"POST\":\r\n form = GroupForm(request.POST)\r\n if form.is_valid():\r\n points = arr_to_geojson(get_posts_data(request.POST.get('group_name')))\r\n else:\r\n form = GroupForm()\r\n points = {}\r\n mapbox_access_token = 'pk.my_mapbox_access_token'\r\n return render(request, 'default.html',\r\n { 'mapbox_access_token': 'pk.eyJ1IjoibWFzaGF0cmV0MjAwNiIsImEiOiJjazNia2c1amYwajNwM2NsZGpheHB1Y29mIn0.QegkEY39EJLAuB1Y_ba47A',\r\n 'form': form,\r\n 'points': points,\r\n })\"\"\"\r\n\r\ndef default_map(request):\r\n # TODO: move this token to Django settings from an environment variable\r\n # found in the Mapbox account settings and getting started instructions\r\n # see https://www.mapbox.com/account/ under the \"Access tokens\" section\r\n if request.method == \"POST\":\r\n form = GroupForm(request.POST)\r\n if form.is_valid():\r\n points = arr_to_geojson(get_posts_data(int(request.POST.get('group_name'))))\r\n else:\r\n form = GroupForm()\r\n points = {}\r\n mapbox_access_token = 'pk.my_mapbox_access_token'\r\n return render(request, 'default.html',\r\n { 'mapbox_access_token': 'pk.eyJ1IjoibWFzaGF0cmV0MjAwNiIsImEiOiJjazNia2c1amYwajNwM2NsZGpheHB1Y29mIn0.QegkEY39EJLAuB1Y_ba47A',\r\n 'form': form,\r\n 'points': points\r\n })\r\n"
},
{
"alpha_fraction": 0.43703243136405945,
"alphanum_fraction": 0.49127182364463806,
"avg_line_length": 36.30232620239258,
"blob_id": "226d3da247fb4aacc39e50a3408bd8345ded0d8b",
"content_id": "98231686ea36cfa2d4970fb2f42df219519bc607",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1604,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 43,
"path": "/get_post_data.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "import vk_api\nfrom get_id_users import get_id_users\n\ndef get_posts_data(group_id):\n users_id = get_id_users(group_id)\n vk_session = vk_api.VkApi(token='1c62622a5c606fe72b7aa7f54af6101552df0a725ab4a53ed1422be0d0f4571674709f47d84fbd45d5dbb')\n points = []\n\n for i in range(min(1000, len(users_id))):\n posts = {}\n tr = False\n try:\n posts = vk_session.method('wall.get', {'owner_id': users_id[i], 'count': 25})\n tr = True\n # print('not_bad_error')\n except:\n # print('bad_error')\n pass\n if tr and 'items' in posts.keys():\n z = 0\n for post in range(len(posts['items'])):\n if 'geo' in posts['items'][post].keys():\n z += 1\n geo = posts['items'][post]['geo']\n points.append([geo['coordinates'].split()[0], geo['coordinates'].split()[1]])\n\n if z != 0:\n try:\n posts = vk_session.method('wall.get', {'owner_id': id, 'count': 200, 'offset': 25})\n # print('not_bad_error')\n except:\n # print('bad_error')\n pass\n for post in range(len(posts['items'])):\n if 'geo' in posts['items'][post].keys():\n geo = posts['items'][post]['geo']\n points.append([geo['coordinates'].split()[0], geo['coordinates'].split()[1]])\n print(len(points))\n return points\n\nget_posts_data(80799846)\nif __name__ == \"main\":\n get_posts_data(80799846)\n"
},
{
"alpha_fraction": 0.6645962595939636,
"alphanum_fraction": 0.6645962595939636,
"avg_line_length": 21,
"blob_id": "ae3ce19e9e844b5d6c6adcad32307cfe203992f3",
"content_id": "5d92463e17b5774da1d9b882c1f09e8a3ff47fe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 7,
"path": "/map/furrymemes/maping/urls.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\r\nfrom django.urls import path\r\nfrom . import views\r\n\r\nurlpatterns = [\r\n url( r'', views.default_map, name= \"default\"),\r\n]\r\n"
},
{
"alpha_fraction": 0.7980769276618958,
"alphanum_fraction": 0.8125,
"avg_line_length": 82,
"blob_id": "3d6368f6cc4f25c0d7a5552aeafb64c3335d1b09",
"content_id": "bb3adc19ec47a01778ad5f24deda9b610b725b64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 286,
"num_lines": 5,
"path": "/README.md",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "# DHHack\n\n[presentation](https://docs.google.com/presentation/d/1ZxeEoEKrTgoRRZouj5IZHrpII_guOQswC69XJ29VGac/edit?usp=sharing)\n\nThe idea of this thing was brought to us at a recent hackathon DHHack where we needed to think of creating digital solutions in various fields of humanitarian knowledge. Our idea was to analyze the post of a certain group in a social network and show all geotags (locations) from posts. \n"
},
{
"alpha_fraction": 0.4789271950721741,
"alphanum_fraction": 0.501915693283081,
"avg_line_length": 20.83333396911621,
"blob_id": "afb826f3eccc78c531684bcb301caae2c8fca6d3",
"content_id": "0a30a4652152daa1e9c2ebc1cf5f360c0b483619",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 12,
"path": "/matrix_to_geojson.py",
"repo_name": "FurryMemes/DHHack",
"src_encoding": "UTF-8",
"text": "import json\n\ndef arr_to_geojson(arr):\n d = {}\n for i in range(len(arr)):\n d[i] = {'latitude': arr[i][0], 'longitude': arr[i][1]}\n dump = json.dumps(d)\n return dump\n\nif __name__ == '__main__':\n arr = [[1, 2], [3, 4]]\n arr_to_geojson(arr)"
}
] | 12 |
onlyskin/yondeoku
|
https://github.com/onlyskin/yondeoku
|
f8e834bddf5a9ae5c2246fcf94493bd8ddfc75ea
|
63bce3d8787aec413709b537d6fab875556b8975
|
f8d34a8828c42e8c7a63e139204a556bb2dec840
|
refs/heads/master
| 2021-01-19T17:10:34.406929 | 2017-05-27T23:46:53 | 2017-05-27T23:46:53 | 83,733,671 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6597077250480652,
"alphanum_fraction": 0.6638830900192261,
"avg_line_length": 35.769229888916016,
"blob_id": "4bc4bbb8d8a59d68da3f32d28ec37cdea1dddc74",
"content_id": "0e7abc04e93adcc32a819f829bc521a899eab9d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 13,
"path": "/yondeoku/_get_lemmas_above_threshold.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "def _get_lemmas_above_threshold(lemmas, threshold):\n occurrences = _build_occurrences_dict(lemmas)\n above_threshold = [o for o in occurrences.keys() if occurrences[o] >= threshold]\n return set(above_threshold)\n\ndef _build_occurrences_dict(strings):\n occurrences = {}\n for string in strings:\n if string in occurrences.keys():\n occurrences[string] = occurrences[string] + 1\n else:\n occurrences[string] = 1\n return occurrences\n\n"
},
{
"alpha_fraction": 0.6631393432617188,
"alphanum_fraction": 0.6701940298080444,
"avg_line_length": 36.79999923706055,
"blob_id": "ec6de0c6339dbbc8780f5c3368fc92f97a090c76",
"content_id": "cabc3b4e584248cf793e5718645e98e90cafd8e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 15,
"path": "/tests/test_plLemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\nimport pytest\n\nfrom yondeoku.Section import Section\nfrom yondeoku.Lemma import Lemma\nfrom yondeoku.polish.plLemmatizer import testing_plLemmatizer\nfrom yondeoku.polish.Lemmatizer import Lemmatizer\n\ndef test_it_has_lang():\n\tassert testing_plLemmatizer().language == 'pl'\n\ndef test_lemmatize_():\n\ttest_section = Section(0, 15, u'stali psom')\n\tassert testing_plLemmatizer().lemmatize(test_section) == {Lemma(u'pies'), Lemma(u'stać'), Lemma(u'stal'), Lemma(u'stały')}\n"
},
{
"alpha_fraction": 0.6010830402374268,
"alphanum_fraction": 0.6245487332344055,
"avg_line_length": 29.72222137451172,
"blob_id": "4fd13d37bb54019134186f659068a94080345f34",
"content_id": "34db68e109361cd33cd5ff516d53aabb086f437f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 554,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 18,
"path": "/tests/test_yondeokuApp.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom mock import Mock\n\nfrom yondeokuApp import _get_all_read_sections, _get_lemmas_from_sections\n\ndef test_it_returns_sections():\n double = [\n Mock(sections=[Mock(read=True), Mock(read=False), Mock(read=False)]),\n Mock(sections=[Mock(read=True), Mock(read=True), Mock(read=False)])\n ]\n assert len(_get_all_read_sections(double)) == 3\n\ndef test_it_returns_lemmas():\n double = [\n Mock(lemmas=[1, 2, 3]),\n Mock(lemmas=[4, 5, 6])\n ]\n assert _get_lemmas_from_sections(double) == [1, 2, 3, 4, 5, 6]\n\n"
},
{
"alpha_fraction": 0.6660109162330627,
"alphanum_fraction": 0.6708196997642517,
"avg_line_length": 27.416149139404297,
"blob_id": "50c10c72a9041bf36311cf4ba7414c9f9bac3b59",
"content_id": "f5a1e7b80aa56bb8b53d58f428619390bdd79c84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4583,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 161,
"path": "/tests/test_database_user.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\nimport pytest\nimport os\nimport json\n\nfrom sqlalchemy.exc import IntegrityError\n\nfrom yondeokuApp import app as realApp\nfrom yondeokuApp import db as _db\nfrom yondeokuApp import User, Block, Word, ModelEncoder\n\nTESTDB_PATH = 'sqlite:////tmp/test.db'\n\nrealApp.config['SQLALCHEMY_DATABASE_URI'] = TESTDB_PATH\nrealApp.config['TESTING'] = True\n\[email protected](scope='session')\ndef app(request):\n ctx = realApp.app_context()\n ctx.push()\n\n def teardown():\n ctx.pop()\n\n request.addfinalizer(teardown)\n return realApp\n\[email protected](scope='function')\ndef db(app, request):\n \"\"\"Session-wide test database.\"\"\"\n\n if os.path.exists(TESTDB_PATH):\n os.unlink(TESTDB_PATH)\n _db.init_app(app)\n\n _db.create_all()\n\n def teardown():\n _db.drop_all()\n # os.unlink(TESTDB_PATH)\n\n request.addfinalizer(teardown)\n return _db\n\[email protected](scope='function')\ndef session(db, request):\n \"\"\"Creates a new database session for a test.\"\"\"\n connection = db.engine.connect()\n transaction = connection.begin()\n\n options = dict(bind=connection, binds={})\n session = db.create_scoped_session(options=options)\n\n db.session = session\n\n def teardown():\n transaction.rollback()\n connection.close()\n session.remove()\n\n request.addfinalizer(teardown)\n return session\n\ndef test_model_can_handle_unicode(session):\n hanako = User(username=u'花子', password='password')\n session.add(hanako)\n session.commit()\n assert hanako.username == u'花子'\n\ndef test_user_has_id_username_and_password(session):\n\tsam = User(username='sam', password='password')\n\tsession.add(sam)\n\tsession.commit()\n\tassert sam.id and sam.username == 'sam' and sam.password == 'password'\n\ndef test_user_username_must_be_unique(session):\n sam1 = User(username='sam')\n sam2 = User(username='sam')\n session.add(sam1)\n session.add(sam2)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_username_cannot_be_null(session):\n x = User(password='password')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_password_cannot_be_null(session):\n x = User(username='test')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_username_cannot_be_empty_string(session):\n x = User(username='', password='password')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_password_cannot_be_empty_string(session):\n x = User(username='test', password='')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_has_threshold(session):\n x = User(username='test', password='password', threshold=10)\n session.add(x)\n session.commit()\n assert x.threshold == 10\n\ndef test_threshold_defaults_to_8(session):\n x = User(username='test', password='password')\n session.add(x)\n session.commit()\n assert x.threshold == 8\n\ndef test_threshold_cannot_be_negative(session):\n x = User(username='test', password='password', threshold=-4)\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_threshold_cannot_be_0(session):\n x = User(username='test', password='password', threshold=0)\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_User_json_has_id_username_threshold(session):\n x = User(username='test', password='password')\n x.gBlocks = []\n session.add(x)\n session.commit()\n reconstituted_json = json.loads(json.dumps(x, cls=ModelEncoder))\n assert (reconstituted_json['id'] is not None\n and reconstituted_json['username'] is not None\n and reconstituted_json['threshold'] is not None)\n\ndef test_User_json_has_correct_len_known(session):\n x = User(username='test', password='password')\n x.gBlocks = []\n kw1 = Word(language='pl', word='kot')\n kw2 = Word(language='pl', word='pies')\n x.known.append(kw1)\n x.known.append(kw2)\n session.add(x)\n session.commit()\n reconstituted_json = json.loads(json.dumps(x, cls=ModelEncoder))\n assert len(reconstituted_json['known']) == 2\n\ndef test_Word_json_has_language_and_word(session):\n kw1 = Word(language='pl', word='kot')\n session.add(kw1)\n session.commit()\n reconstituted_json = json.loads(json.dumps(kw1, cls=ModelEncoder))\n assert (reconstituted_json['language'] is not None\n and reconstituted_json['word'] is not None)\n"
},
{
"alpha_fraction": 0.6890380382537842,
"alphanum_fraction": 0.6901565790176392,
"avg_line_length": 48.72222137451172,
"blob_id": "ce44d1cec9c55fc9a823e845edf3221737e0e344",
"content_id": "2adfd1cd6cfbc012a6d7ebef75923f3de86cf58a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 902,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/yondeoku/polish/settings.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\n\n#Notes on the lemmaDict.json file\n#This was generated from the 'lemmatization-pl.txt' file\n#which was downloaded from http://www.lexiconista.com/datasets/lemmatization/\n#I generated a json dict mapping from {inflected: [base, ...]}\n#The problem is the original file didn't contain the base forms of words among\n#the inflected forms, which means that in the case that you input a base\n#form of a word which is also an inflected form of another word, you will\n#get back a list with the base form of the other word, but not the base form of this word\n#hopefully this shouldn't cause too many issues in general as it should be a fairly\n#rare occurence\n\nDICT_PATH = u'lemmaDict.json'\nDATA_PATH = u'data/'\nLEKTOREK_CACHE_PATH = u'lektorek_cache.json'\nPUNCTUATION_STRING = u'!?,.:;()[]{}/„”‚’-\"\\''"
},
{
"alpha_fraction": 0.733668327331543,
"alphanum_fraction": 0.7353433966636658,
"avg_line_length": 41.71428680419922,
"blob_id": "0a6cbc8baf78bccb15c6064822746dab29c03c3f",
"content_id": "d57a1c9ba7841adc606b4a1d45f6978c0084804c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 14,
"path": "/yondeoku/Section.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class Section(object):\n\t'''Language independent Section class. Objects of this type\n\tare to be found in the 'sections' Array on gBlock instances.\n\t{Sections}'s lemma property is initialised as an empty [].\n\tThe appropriate language's lemmatizer is then mapped over a\n\t{gBlock}'s 'sections' Array to fill in the lemma Arrays.\n\tThe Section's blockRef property is a simple 2 element Array\n\trepresenting the index in and out of the block's text property\n\tthat corresponds to this section.'''\n\n\tdef __init__(self, _in, _out, text):\n\t\tself.blockRef = [_in, _out]\n\t\tself.text = text\n\t\tself.lemmas = set()"
},
{
"alpha_fraction": 0.7670753002166748,
"alphanum_fraction": 0.7688266038894653,
"avg_line_length": 34.6875,
"blob_id": "42482ec79e1caabbbfcba26e3ace82a66a7bdae4",
"content_id": "0459605e71305eb356d299439bce337799c68633",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 571,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 16,
"path": "/tests/test_make_definition_list_from_lemma_list.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.define import makeDefinitionListFromLemmaList\nfrom yondeoku.Lemma import Lemma\n\ndef test_returns_empty_list_when_empty_list_passed():\n\tresult = makeDefinitionListFromLemmaList('pl', [])\n\tassert result == []\n\ndef test_raises_value_error_when_language_not_implemented():\n\twith pytest.raises(ValueError):\n\t\tmakeDefinitionListFromLemmaList('zz', [])\n\ndef test_returns_length_three_object_when_passed_in_three_lemmas():\n\tresult = makeDefinitionListFromLemmaList('pl', [Lemma('ochrona'), Lemma('pomidor'), Lemma('klucz')])\n\tassert len(result) == 3\n"
},
{
"alpha_fraction": 0.7363013625144958,
"alphanum_fraction": 0.7363013625144958,
"avg_line_length": 28.25,
"blob_id": "e12ee2b804697ca3ddcc8c06183390332237d9ae",
"content_id": "a313e9f32aabfcfd00a120fcb6b8df54d6aa77ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 20,
"path": "/yondeoku/japanese/jaLemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "from jNlp.jTokenize import jTokenize\n\nfrom yondeoku.AbstractLemmatizer import AbstractLemmatizer\nfrom yondeoku.Lemma import Lemma\n\nclass jaLemmatizer(AbstractLemmatizer):\n\t'''Concrete Japanese Lemmatizer class.'''\n\n\tdef __init__(self):\n\t\tprint 'Initializing jaLemmatizer'\n\t\tsuper(jaLemmatizer, self).__init__('ja')\n\n\tdef lemmatize(self, Section):\n\t\t'''Takes a {Section} object, returns a list\n\t\t[{Definition}...] objects based on the Section's\n\t\ttext property.'''\n\t\ttext = Section.text.strip()\n\t\ttokens = jTokenize(text)\n\t\tlemmas = map(lambda x: Lemma(x), tokens)\n\t\treturn set(lemmas)"
},
{
"alpha_fraction": 0.567258894443512,
"alphanum_fraction": 0.5723350048065186,
"avg_line_length": 16.53333282470703,
"blob_id": "f20a4ec5b4ada2d1fedc49f1a741edc939fd9006",
"content_id": "03714e1e080230f8febe202433eedf25b101154b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 45,
"path": "/static/User.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class User {\n constructor(userdata) {\n this._userdata = userdata;\n }\n\n get userdata() {\n return this._userdata;\n }\n\n get known() {\n return this.userdata.known;\n }\n\n get username() {\n return this.userdata.username;\n }\n\n get threshold() {\n return this.userdata.threshold;\n }\n\n get blocks() {\n return this.userdata.blocks;\n }\n\n get_known(language) {\n var known = this.known;\n var filtered = known.filter(function (w) {\n return w.language === language;\n });\n filtered.sort(function(a, b) {\n if (a.word < b.word)\n return -1;\n if (a.word > b.word)\n return 1;\n return 0;\n });\n return filtered;\n }\n\n get_block(id) {\n var block = this.blocks.filter(function(b) {return b.id == id;})[0]\n return block;\n }\n}"
},
{
"alpha_fraction": 0.738780677318573,
"alphanum_fraction": 0.740897536277771,
"avg_line_length": 29.662338256835938,
"blob_id": "e6586a7e6efe107d1390c1a134f6ab644fc034e8",
"content_id": "4e5f82fd42db12d1c66dd97a91b9d07c5a4e341c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2362,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 77,
"path": "/yondeoku/gBlock.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import json\n\nfrom yondeoku.languageAPI import languageAPI, supported_languages\nfrom yondeoku.overlap import normalizeRanges\n\nclass gBlock(object):\n\t'''Language independent Block class. Objects of this type\n\tare to be found in the 'gBlocks' Array on User instances.\n\tWe initialize these gBlock objects from the Block model as\n\ta wrapper.'''\n\n\tdef __init__(self, Block):\n\t\t'''We now initialize gBlocks from the db.Model\n\t\tobjects returned by flask sqlalchemy.'''\n\t\tlanguage = Block.language\n\t\ttext = Block.text\n\t\treadRanges = json.loads(Block.read_ranges)\n\n\t\ttry:\n\t\t\tassert language in supported_languages\n\t\texcept:\n\t\t\traise ValueError\n\n\t\ttry:\n\t\t\tfor i in readRanges:\n\t\t\t\tassert len(i) == 2\n\t\texcept:\n\t\t\traise ValueError\n\n\t\ttools = languageAPI[language]()\n\t\tsectionizer = tools.sectionizer\n\t\tlemmatizer = tools.lemmatizer\n\n\t\t#core properties which save to database\n\t\tself.id = Block.id\n\t\tself.language = language\n\t\tself.text = text\n\t\t#normalizes\n\t\tself.readRanges = normalizeRanges(readRanges)\n\n\t\t#implementation dependent properties, not stored\n\t\tself.sections = sectionizer.sectionize(text)\n\t\tdef addLemmas(Section):\n\t\t\tSection.lemmas = lemmatizer.lemmatize(Section)\n\t\tmap(lambda x: addLemmas(x), self.sections)\n\t\tself.readSections = self.computeReadSections()\n\n\tdef update_readRanges(self, new_range):\n\t\t'''Updates the core readRanges array to include a new\n\t\trange. Normalises the ranges. Currently need to call\n\t\tcomputeReadSections again separately.'''\n\t\tself.readRanges.append(new_range)\n\t\tself.readRanges = normalizeRanges(self.readRanges)\n\n\tdef computeReadSections(self):\n\t\t'''Computes a boolean array corresponding to the\n\t\tsections array based on the Block's core 'readRanges'\n\t\tproperty. This function is only to be called during\n\t\tBlock initialisation.'''\n\t\treadSections = [False] * len(self.sections)\n\t\tfor i, Section in enumerate(self.sections):\n\t\t\tSection.read = False\n\t\t\tsectionStart = Section.blockRef[0]\n\t\t\tsectionEnd = Section.blockRef[1]\n\t\t\tfor r in self.readRanges:\n\t\t\t\trangeStart = r[0]\n\t\t\t\trangeEnd = r[1]\n\t\t\t\tif sectionStart >= rangeStart and sectionEnd <= rangeEnd:\n\t\t\t\t\treadSections[i] = True\n\t\t\t\t\tSection.read = True\n\t\treturn readSections\n\n\tdef makeReadRangeString(self):\n\t\t'''gBlock method which returns a jsonified\n\t\tstring of the read_ranges [[]...] which updates\n\t\tthe original Block Model.'''\n\t\treturn json.dumps(self.readRanges)\n\n"
},
{
"alpha_fraction": 0.5509433746337891,
"alphanum_fraction": 0.5584905743598938,
"avg_line_length": 35.517242431640625,
"blob_id": "a5098702d01c0f574e89dec4b8a6dd25b07c1966",
"content_id": "88dae666e06a73cdd9d49775419fa56dd6eab9a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1060,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 29,
"path": "/tests/test_get_lemmas_above_threshold.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom mock import Mock\n\nfrom yondeoku._get_lemmas_above_threshold import (_get_lemmas_above_threshold,\n _build_occurrences_dict)\n\ndef test_it_returns_dict():\n lemmas = ['a', 'a', 'a', 'b', 'b', 'c', 'd']\n assert _build_occurrences_dict(lemmas) == {'a': 3, 'b': 2, 'c': 1, 'd': 1}\n\ndef test_above_threshold_returns_a():\n lemmas = ['a', 'a', 'a', 'b', 'b', 'c', 'd']\n threshold = 3\n assert _get_lemmas_above_threshold(lemmas, threshold) == set(['a'])\n\ndef test_above_threshold_returns_b():\n lemmas = ['a', 'a', 'b', 'b', 'b', 'c', 'd']\n threshold = 3\n assert _get_lemmas_above_threshold(lemmas, threshold) == set(['b'])\n\ndef test_above_threshold_returns_b():\n lemmas = ['a', 'a', 'b', 'b', 'b', 'c', 'd']\n threshold = 3\n assert _get_lemmas_above_threshold(lemmas, threshold) == set(['b'])\n\ndef test_above_threshold_returns_b_and_c():\n lemmas = ['c', 'c', 'b', 'b', 'b', 'c', 'd']\n threshold = 3\n assert _get_lemmas_above_threshold(lemmas, threshold) == set(['b', 'c'])\n\n"
},
{
"alpha_fraction": 0.7110694050788879,
"alphanum_fraction": 0.7129455804824829,
"avg_line_length": 27.052631378173828,
"blob_id": "b6c08138226ece70c313045a1cad8191d4b8720f",
"content_id": "7fc172b3af5f4bbb0dcb4566a47a4d5cb83b003a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 19,
"path": "/yondeoku/japanese/jaSectionizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\nimport re\n\nfrom yondeoku.AbstractSectionizer import AbstractSectionizer\nfrom yondeoku.Section import Section\nfrom yondeoku.makeSections import makeSections\n\nclass jaSectionizer(AbstractSectionizer):\n\t'''Concrete Japanese Sectionizer class.'''\n\n\tdef __init__(self):\n\t\tsuper(jaSectionizer, self).__init__('ja')\n\n\tdef sectionize(self, text):\n\t\t'''Returns a list of {Section} objects given a\n\t\t{gBlock} object.'''\n\t\tsections = makeSections(text, [u'。', u'!', u'?'], u'」')\n\t\treturn sections\n"
},
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.5661882162094116,
"avg_line_length": 28.85714340209961,
"blob_id": "7b59cda6dec88329aa573454083afc46dd76b7e9",
"content_id": "29dea01cee2028fbc9980ee89b6e283139aa8f7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/static/utilities.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "// returns string percent of 'true' values in an array\nfunction get_percent(array) {\n\tif (array.length == 0)\n\t\treturn '100%';\n var true_values = 0;\n for (var i = 0; i < array.length; i++) {\n if (array[i] === true)\n true_values = true_values + 1;\n }\n return String(Math.round(true_values / array.length * 100)) + '%';\n}\n\n//returns string ratio of 'true' values in an array\nfunction get_ratio(array) {\n var true_values = 0;\n for (var i = 0; i < array.length; i++) {\n if (array[i] === true)\n true_values = true_values + 1;\n }\n return true_values + '/' + array.length;\n}\n"
},
{
"alpha_fraction": 0.715859055519104,
"alphanum_fraction": 0.7180616855621338,
"avg_line_length": 22.894737243652344,
"blob_id": "a18f23e424d27d2852f9b261af4d586100b40f4e",
"content_id": "71a0942d554609911c9e5c67aa2c317dbe7dbcf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 19,
"path": "/yondeoku/polish/Lemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import ujson as json\nimport codecs\n\nfrom yondeoku.polish.settings import DICT_PATH\n\nclass Lemmatizer(object):\n\n\tdef __init__(self, dictPath=DICT_PATH):\n\t\tf = codecs.open(dictPath, mode='r', encoding='utf-8')\n\t\tself.lemmaDict = json.load(f)\n\n\tdef lookupLemma(self, word):\n\t\t'''Bound method which returns a list of lemmas\n\t\tfound in the internal dictionary for the given\n\t\tword.'''\n\t\ttry:\n\t\t\treturn self.lemmaDict[word]\n\t\texcept KeyError:\n\t\t\treturn [word]\n"
},
{
"alpha_fraction": 0.6389830708503723,
"alphanum_fraction": 0.6406779885292053,
"avg_line_length": 30.052631378173828,
"blob_id": "52c47d8a9283c1b85bdfcdd5f65431d80a844c79",
"content_id": "f109a476075e6c840c85af95e7fca9f2f7425074",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 19,
"path": "/yondeoku/polish/plSectionizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\nimport re\n\nfrom yondeoku.AbstractSectionizer import AbstractSectionizer\nfrom yondeoku.Section import Section\nfrom yondeoku.makeSections import makeSections\n\nclass plSectionizer(AbstractSectionizer):\n\t'''Concrete Polish Sectionizer class.'''\n\n\tdef __init__(self):\n\t\tsuper(plSectionizer, self).__init__('pl')\n\t\n\tdef sectionize(self, text):\n\t\t'''Returns a list of {Section} objects given a\n\t\t{gBlock} object.'''\n\t\tsections = makeSections(text, [u'\\.', u'!', u'\\?'], u'”')\n\t\treturn sections\n"
},
{
"alpha_fraction": 0.36592039465904236,
"alphanum_fraction": 0.37114426493644714,
"avg_line_length": 18.331729888916016,
"blob_id": "11d10f553b6252c5d624ed4bfb0c1911b43af429",
"content_id": "a151f1e9dd8e60b4cbe334c2512b8b453764c0ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4093,
"license_type": "no_license",
"max_line_length": 422,
"num_lines": 208,
"path": "/static/tests/mock_block.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "var mock_block_data = {\n \"id\": 1,\n \"language\": \"pl\",\n \"readSections\": [\n false,\n false,\n false,\n false\n ],\n \"read_ranges\": [],\n \"sections\": [\n {\n \"blockRef\": [\n 0,\n 13\n ],\n \"lemmas\": [\n {\n \"word\": \"treść\"\n },\n {\n \"word\": \"zarys\"\n }\n ],\n \"text\": \"Zarys treści.\"\n },\n {\n \"blockRef\": [\n 13,\n 184\n ],\n \"lemmas\": [\n {\n \"word\": \"\"\n },\n {\n \"word\": \"opis\"\n },\n {\n \"word\": \"podstawowy\"\n },\n {\n \"word\": \"wyraz\"\n },\n {\n \"word\": \"oraz\"\n },\n {\n \"word\": \"eksplikacja\"\n },\n {\n \"word\": \"wiek\"\n },\n {\n \"word\": \"propozycja\"\n },\n {\n \"word\": \"artykuł\"\n },\n {\n \"word\": \"semantyczny\"\n },\n {\n \"word\": \"zdanie\"\n },\n {\n \"word\": \"własność\"\n },\n {\n \"word\": \"przedstawić\"\n },\n {\n \"word\": \"syntaktyczny\"\n },\n {\n \"word\": \"być\"\n },\n {\n \"word\": \"zawierać\"\n },\n {\n \"word\": \"zdać\"\n },\n {\n \"word\": \"przecież\"\n }\n ],\n \"text\": \" W artykule przedstawiona jest propozycja opisu podstawowych własności syntaktycznych wyrazu przecież oraz propozycja eksplikacji semantycznej zdań zawierających przecież.\"\n },\n {\n \"blockRef\": [\n 184,\n 286\n ],\n \"lemmas\": [\n {\n \"word\": \"\"\n },\n {\n \"word\": \"pierwszy\"\n },\n {\n \"word\": \"wszystko\"\n },\n {\n \"word\": \"teza\"\n },\n {\n \"word\": \"partykuła\"\n },\n {\n \"word\": \"wszystek\"\n },\n {\n \"word\": \"że\"\n },\n {\n \"word\": \"artykuł\"\n },\n {\n \"word\": \"próba\"\n },\n {\n \"word\": \"przed\"\n },\n {\n \"word\": \"część\"\n },\n {\n \"word\": \"uzasadnić\"\n },\n {\n \"word\": \"uzasadnienie\"\n },\n {\n \"word\": \"być\"\n },\n {\n \"word\": \"zawierać\"\n },\n {\n \"word\": \"przecież\"\n }\n ],\n \"text\": \" Pierwsza część artykułu zawiera przede wszystkim próbę uzasadnienia tezy, że przecież jest partykułą.\"\n },\n {\n \"blockRef\": [\n 286,\n 410\n ],\n \"lemmas\": [\n {\n \"word\": \"\"\n },\n {\n \"word\": \"wnioskowanie\"\n },\n {\n \"word\": \"jaka\"\n },\n {\n \"word\": \"tekst\"\n },\n {\n \"word\": \"entymematyczny\"\n },\n {\n \"word\": \"wiek\"\n },\n {\n \"word\": \"propozycja\"\n },\n {\n \"word\": \"wnioskować\"\n },\n {\n \"word\": \"drugi\"\n },\n {\n \"word\": \"część\"\n },\n {\n \"word\": \"przedstawić\"\n },\n {\n \"word\": \"interpretacja\"\n },\n {\n \"word\": \"częsty\"\n },\n {\n \"word\": \"być\"\n },\n {\n \"word\": \"wykładnik\"\n },\n {\n \"word\": \"przecież\"\n }\n ],\n \"text\": \" W drugiej części tekstu przedstawiona jest propozycja interpretacji przecież jako wykładnika wnioskowania entymematycznego.\"\n }\n ],\n \"text\": \"Zarys treści. W artykule przedstawiona jest propozycja opisu podstawowych własności syntaktycznych wyrazu przecież oraz propozycja eksplikacji semantycznej zdań zawierających przecież. Pierwsza część artykułu zawiera przede wszystkim próbę uzasadnienia tezy, że przecież jest partykułą. W drugiej części tekstu przedstawiona jest propozycja interpretacji przecież jako wykładnika wnioskowania entymematycznego.\"\n}\n\nvar mock_block = new Block(mock_block_data);"
},
{
"alpha_fraction": 0.7547488212585449,
"alphanum_fraction": 0.7560151815414429,
"avg_line_length": 34.37313461303711,
"blob_id": "052768f31dc75c6bb066e5ea8943441103af3ae0",
"content_id": "a466d39ac9b0751bac4ec537144cb6ba86edfb10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2369,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 67,
"path": "/yondeoku/polish/plLemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import re\n\nfrom yondeoku.AbstractLemmatizer import AbstractLemmatizer\nfrom yondeoku.Lemma import Lemma\nfrom yondeoku.polish.Lemmatizer import Lemmatizer\nfrom yondeoku.polish.settings import DICT_PATH, PUNCTUATION_STRING\n\ndef plLemmatizer():\n\t'''Initializes a plLemmatizer with the full dictionary.'''\n\treturn generic_plLemmatizer(DICT_PATH)\n\ndef testing_plLemmatizer():\n\t'''Initializes a plLemmatizer with a reduced dictionary.'''\n\treturn generic_plLemmatizer('mock/testDict.json')\n\nclass generic_plLemmatizer(AbstractLemmatizer):\n\t'''Concrete Polish Lemmatizer class. Must be passed a string\n\tspecifying the dictionary file to initialise. with. The above\n\tplLemmatizer and testing_plLemmatizer provide a consistent\n\tAPI as the dictionary file is to be specified within the\n\tplLemmatizer backend. It has only been extracted for testing.'''\n\n\tdef __init__(self, dictionary_path):\n\t\tprint 'Initializing plLemmatizer'\n\t\tsuper(generic_plLemmatizer, self).__init__('pl')\n\t\tself.myLemmatizer = Lemmatizer(dictionary_path)\n\n\tdef lemmatize(self, Section):\n\t\t'''Takes a {Section} object, returns a list\n\t\t[{Definition}...] objects based on the Section's\n\t\ttext property.'''\n\t\ttext = Section.text\n\t\twordList = self.splitAndStrip(text)\n\t\tlemmaSet = set()\n\t\tfor word in wordList:\n\t\t\tlemmaList = self.myLemmatizer.lookupLemma(word)\n\t\t\tfor lemma in lemmaList:\n\t\t\t\tlemmaSet.add(Lemma(lemma))\n\t\treturn lemmaSet\n\n\tdef splitAndStrip(self, text):\n\t\t'''This method breaks a text into tokens on whitespace\n\t\tand strips any punctuation away. Returns a list of strings.'''\n\t\tpattern = re.compile(r'\\s+')\n\t\tstartIndex = 0\n\t\ttokens = []\n\t\tmatch = pattern.search(text)\n\t\t#catch the case where there is no whitespace\n\t\tif match == None:\n\t\t\treturn [text.strip(PUNCTUATION_STRING).lower()]\n\t\t#get the token preceding each piece of whitespace\n\t\twhile match:\n\t\t\twhitespaceSpan = match.span()\n\t\t\t#set token to slice from end of previous whitespace\n\t\t\t#to start of current whitespace\n\t\t\ttokenText = text[startIndex:whitespaceSpan[0]]\n\t\t\ttokens.append(tokenText)\n\n\t\t\t#update new startIndex and search again\n\t\t\tstartIndex = whitespaceSpan[1]\n\t\t\tmatch = pattern.search(text, startIndex)\n\n\t\t#catch the token remaining after no more whitespace is found\n\t\tfinalTokenText = text[startIndex:]\n\t\ttokens.append(finalTokenText)\n\t\ttokens = map(lambda x: x.strip(PUNCTUATION_STRING).lower(), tokens)\n\t\treturn tokens"
},
{
"alpha_fraction": 0.7527527809143066,
"alphanum_fraction": 0.7527527809143066,
"avg_line_length": 27.826923370361328,
"blob_id": "680cc6ef7e22bb7660a45c41255770f23efed186",
"content_id": "4c9f1a4a95ef13907c0ba6ab8a1b42c5b5525e06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2997,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 104,
"path": "/API.md",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "Decided:\n- all APIs should interact with the database model\n- we have our own user/block abstractions, this is because:\n\t- there is derived information which it is not sensible to store in the database, either because:\n\t\t- the exact implementations may change causing slight changes to the derived information\n\t\t- the information is quite large and in more abstracted forms\n- separate vocab list generators etc which consume our user/block abstractions\n\n\n\n\nQuestions:\n- should we have a gUser class as well as a gBlock class or is it unnecessary?\n- should we do the processing to work out what words are new in a given section on the server side or on the client side (currently client)\n\t- the language absolutely known list would have to be passed down to the server\n\t- all known words would have to be passed down to the server\n- how should the abs known grammar words go down?\n\t- should really be initialised at the start of the website opening\n\t- eventually for efficiency's sake would need to be specific to the users block's language, but for now not necessary\n\n\nGUSER OBJECTS\n- id property\n- unique 'username' property ''\n- threshold property\n- gBlocks property [{gBlock}]\n- known property {'ja': [], 'pl': []}\n\nGBLOCK OBJECTS\n- 'language' property as ''\n- 'text' property as ''\n- 'sections' property as [{Section}...]\n- 'readRanges' property as [[]...]\n\nBLOCK MODEL\n- 'id' column INTEGER\n- 'language' column STRING\n- 'text' column STRING\n- 'read_ranges' column STRING\n- 'user_id' column as FOREIGN KEY INTEGER\n- 'user' column as backref to USER MODEL OBJ\n\nDEFINERS\nAll definers have:\n- 'language' property as ''\n- define method\n\t- takes a single lemma\n\t- returns [{Definition}...]\n\nDEFINITION OBJECTS\n- found as ''\n- definition []\n- pronunciation ''\n\n\nSECTIONIZERS\nAll sectionizers have:\n- 'language' property as ''\n- sectionize method\n\t- takes a text ''\n\t- returns [{Section}]\n\nSECTION OBJECTS\nAll {Section} objects should be found in the 'sections' array\nstored on a {gBlock} object\n- blockRef [_in, _out]\n- text ''\n- lemmas set()\n\n\nLEMMATIZERS\nAll lemmatizers have:\nArray property to a [{Lemma}...]\n- 'language' property as ''\n- lemmatize method\n- takes a Section object\n- returns a set({Lemma}...)\n\nLEMMA OBJECTS\nAll lemmas objects should be found in the 'lemmas' array\nstored on a {Section} object\n- lemma\n- optional index in and out??\n\nGRAMMARWORDS\n- a python list variable defined in a file\n- contains a list of all the basic grammatical words for the given language\n\nlanguageAPI - a dictionary mapping language strings to their LangTools class object (see below)\n\nLangTools Class - an object with properties for the language specific functions, etc. that must be defined for each language, where functions, the properties are generally references to constructor functions\n- sectionizer\n- lemmatizer\n- definer\n- grammarwords\n\n\n\n\n\nROUTE SPECIFIC FUNCTIONS\nyondeoku.define.makeDefinitionListFromLemmaList\n- takes a list of Lemma objects\n- returns a list of lists of Definition objects"
},
{
"alpha_fraction": 0.6241610646247864,
"alphanum_fraction": 0.6308724880218506,
"avg_line_length": 30.928571701049805,
"blob_id": "01a9c1d5ea5a0180a2714ac4d920a1eb9954ce54",
"content_id": "72b54ed148ce65d74d8880b3600afc7b0ac29002",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 455,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 14,
"path": "/tests/test_jaLemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\nimport pytest\n\nfrom yondeoku.Section import Section\nfrom yondeoku.Lemma import Lemma\nfrom yondeoku.japanese.jaLemmatizer import jaLemmatizer\n\ndef test_it_has_lang():\n\tassert jaLemmatizer().language == 'ja'\n\ndef test_lemmatize_():\n\ttest_section = Section(0, 2, u'私が')\n\tassert jaLemmatizer().lemmatize(test_section) == {Lemma(u'私'), Lemma(u'が')}\n"
},
{
"alpha_fraction": 0.5518672466278076,
"alphanum_fraction": 0.5560166239738464,
"avg_line_length": 29.25,
"blob_id": "efbcaae2f6b1d480ffd4a4d517c951f191ca3e31",
"content_id": "339590c565343efe53026a028f8838b2bdefcac3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 8,
"path": "/tests/test_plSectionizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\nimport pytest\n\nfrom yondeoku.japanese.jaSectionizer import jaSectionizer\n\ndef test_it_has_lang():\n\tassert jaSectionizer().language == 'ja'"
},
{
"alpha_fraction": 0.7445054650306702,
"alphanum_fraction": 0.7445054650306702,
"avg_line_length": 27.076923370361328,
"blob_id": "e88c0b043aa6296a150fa85dcde2c98ef3713962",
"content_id": "0c9fd5ef8354dfc5195a73588b08dacb52ab1be9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 13,
"path": "/yondeoku/polish/plDefiner.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "from yondeoku.AbstractDefiner import AbstractDefiner\nfrom yondeoku.polish.getLektorekDef import getDefObjList\n\nclass plDefiner(AbstractDefiner):\n\t'''Concrete Polish Definer class.'''\n\n\tdef __init__(self):\n\t\tsuper(plDefiner, self).__init__('pl')\n\n\tdef define(self, word):\n\t\t'''Return a list of {Definition} objects.'''\n\t\tresult = getDefObjList(word)\n\t\treturn result"
},
{
"alpha_fraction": 0.47181010246276855,
"alphanum_fraction": 0.47181010246276855,
"avg_line_length": 29.636363983154297,
"blob_id": "219bcbf2f0205d3c507f5475dd10a69793542232",
"content_id": "4a404959da846917de97b4f2b0982919d2217852",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1015,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 33,
"path": "/static/views/Review.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "var Review = {\n\tview: function() {\n\t\treturn m('#study',\n\t\t\tm('#study-container', [\n\t\t\t\tm('a', {href: \"/select\", oncreate: m.route.link}, 'Back to user page...'),\n\t\t\t\t(currentBlock == null ?\n\t\t\t\t\tm('Please choose a text to study from your user page...') :\n\t\t\t\t\tm('table', {id: 'vocabItems'}, [\n\t\t\t\t\t\tm('thead',\n\t\t\t\t\t\t\tm('tr', [\n\t\t\t\t\t\t\t\tm('th'),\n\t\t\t\t\t\t\t\tm('th', 'Word'),\n\t\t\t\t\t\t\t\tm('th', 'Definitions'),\n\t\t\t\t\t\t\t\tm('th')\n\t\t\t\t\t\t\t])\n\t\t\t\t\t\t),\n\t\t\t\t\t\tm('tbody', newWords.map((w) => {\n\t\t\t\t\t\t\treturn m('tr', {class: 'lemma'}, [\n\t\t\t\t\t\t\t\tm('td', {class: 'add no-top',\n\t\t\t\t\t\t\t\t\t\tonclick: function(e) {console.log('add known lemma')}}, '◎'),\n\t\t\t\t\t\t\t\tm('td', {class: 'lemma'}, w.lemma),\n\t\t\t\t\t\t\t\tm('td', {class: 'definition'}, w.definition),\n\t\t\t\t\t\t\t\tm('td', {class: (w.studied ? 'confirm no-top studied' : 'confirm no-top'),\n\t\t\t\t\t\t\t\t\tonclick: function(e) {w.studied = true;}}, '◉')\n\t\t\t\t\t\t\t\t])\n\t\t\t\t\t\t}))\n\t\t\t\t\t])\n\t\t\t\t),\n\t\t\t\tm('a', {href: \"/read\", oncreate: m.route.link}, 'Done studying, let me read the section!')\n\t\t\t])\n\t\t)\n\t}\n}\n"
},
{
"alpha_fraction": 0.7643504738807678,
"alphanum_fraction": 0.7643504738807678,
"avg_line_length": 32.099998474121094,
"blob_id": "30d32575344044b642ea05b33f9ab2f71e428148",
"content_id": "ac20ba9771282687e5b9814e75539664047f7832",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 10,
"path": "/yondeoku/AbstractDefiner.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class AbstractDefiner(object):\n\t'''Abstract Definer class. Subclass for a given language,\n\timplement init to set self.language to appropriate language\n\tstring, implement the define method.'''\n\n\tdef __init__(self, language):\n\t\tself.language = language\n\n\tdef define(self):\n\t\traise NotImplementedError(\"Should have implemented this\")\n"
},
{
"alpha_fraction": 0.6832669377326965,
"alphanum_fraction": 0.687915027141571,
"avg_line_length": 34.880950927734375,
"blob_id": "4c08f47bed32475107ba00d47309d9838607feda",
"content_id": "663fa82a50d1f0170354a3e5ee7d63f13d52445b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1506,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 42,
"path": "/yondeoku/makeSections.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import re\nfrom yondeoku.Section import Section\n\ndef makeSections(text, sentence_breakers, end_quote):\n\t'''Returns the text as a [{Section}...], the sentence_breakers\n\tis a list of strings denoting sentence boundaries - e.g. '.!?'\n\tThe end_quote is a single char representing a closing quote in\n\ta given language.'''\n\n\tsections = []\n\n\t# returns a regex which will capture any of the sentence breakers, or any of the\n\t# sentence breakers plus an end quote\n\tregexString = '(' + u'|'.join(\n \t[c + end_quote + '\\n+' for c in sentence_breakers] +\n \t[c + '\\n+' for c in sentence_breakers] +\n \t[c + end_quote for c in sentence_breakers] +\n [c for c in sentence_breakers]\n\t) + ')'\n\tpattern = re.compile(regexString)\n\tseparators = re.finditer(pattern, text)\n\tseparatorsList = list(separators)\n\tif len(separatorsList) == 0:\n\t\treturn [Section(0, len(text), text)]\n\tfor i, m in enumerate(separatorsList):\n\t\t#if it's the first separator, the start index is 0\n\t\tif i == 0:\n\t\t\t_in = 0\n\t\t#otherwise the start index is the end of the last separator\n\t\telse:\n\t\t\t_in = separatorsList[i-1].end()\n\t\t_out = m.end()\n\t\tsubtext = text[_in:_out]\n\t\tsection = Section(_in, _out, subtext)\n\t\tsections.append(section)\n\t#if the final separator ends before the end of the text\n\tlastFoundSepEnd = separatorsList[-1].end()\n\tif lastFoundSepEnd < len(text):\n\t\tfinalSubText = text[lastFoundSepEnd:]\n\t\tfinalSection = Section(lastFoundSepEnd, len(text), finalSubText)\n\t\tsections.append(finalSection)\n\treturn sections"
},
{
"alpha_fraction": 0.7637795209884644,
"alphanum_fraction": 0.7637795209884644,
"avg_line_length": 20.16666603088379,
"blob_id": "02e509cd7406d9c4199311b6b599435d77f584cc",
"content_id": "be6dd46a7954e738486bd0f1161087ac1dd74312",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 127,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 6,
"path": "/tests/test_jaDefiner.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.japanese.jaDefiner import jaDefiner\n\ndef test_it_has_lang():\n\tassert jaDefiner().language == 'ja'\n"
},
{
"alpha_fraction": 0.5303102731704712,
"alphanum_fraction": 0.5322195887565613,
"avg_line_length": 40.91999816894531,
"blob_id": "f4a7642182562994efbbe9c62deb92f4dfd1a2c4",
"content_id": "b209a87389a802154c8e10a90f8b005767b0b867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2095,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 50,
"path": "/static/views/Select.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "function KnownWordsView(model, language) {\n var words = model.user.get_known(language);\n return m('.known-display', [\n m('.known-words-title', model.language_map[language] + ' known words: (' + words.length + ')'),\n m('.known-words', words.map((o) => m('', o.word)))\n ])\n}\n\nfunction UserInfoView(model) {\n return m('#user-info', [\n m('h3', 'Username: ' + model.user.username),\n m('', {title: 'These are the words that you have marked as definitely known while reading texts.'},\n model.languages.map(function(l) {return KnownWordsView(model, l);})),\n m('', {title: 'After this numer of encounters of a given word, it will no longer appear in your vocab lists.'}, 'Threshold: ' + model.user.threshold)\n ])\n}\n\nfunction BlockInfoView(model, viewmodel) {\n return m('#block-info', [\n m('', [\n 'The current texts you have are: ',\n m('span.note', '(click to expand, read sections marked in red)')\n ]),\n m('a#addBlock', {href: '/add', oncreate: m.route.link}, 'Add a new text.'),\n model.user.blocks.map((b) => m('.block', [\n m('.percent', [m('p', get_percent(b.readSections)), m('p', get_ratio(b.readSections) + ' sections')]),\n m('', {\n class: (viewmodel.is_expanded(b.id) ? ['expanded block-text'] : 'header-text'),\n onclick: function(e) {viewmodel.toggle(b.id);}\n }, (viewmodel.is_expanded(b.id) ? b.text : b.text.slice(0, 50) + '...')\n ),\n m('a', {href: \"/study\",\n oncreate: m.route.link,\n onclick: function(e) {model.current_block_id = b.id;}\n }, 'Read This Text'),\n m('a', {href: \"/select\",\n oncreate: m.route.link,\n onclick: function(e) {ctrl.safe_delete_block_request(b.id)}}, 'Delete This Text')\n ]))\n ])\n}\n\nvar Select = {\n view: function() {\n return m(\"#select\", [\n UserInfoView(model),\n BlockInfoView(model, block_info_view_model)\n ]);\n }\n}"
},
{
"alpha_fraction": 0.7752161622047424,
"alphanum_fraction": 0.7752161622047424,
"avg_line_length": 33.70000076293945,
"blob_id": "5a1911e057dcfbbacba7f15b470e95bfb24878f3",
"content_id": "9b826e16c0cfabaf6bc7a71ee0a330632a5fc4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 10,
"path": "/yondeoku/AbstractSectionizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class AbstractSectionizer(object):\n\t'''Abstract Sectionizer class. Subclass for a given language,\n\timplement init to set self.language to appropriate language\n\tstring, implement the sectionize method.'''\n\n\tdef __init__(self, language):\n\t\tself.language = language\n\n\tdef sectionize(self):\n\t\traise NotImplementedError(\"Should have implemented this\")\n"
},
{
"alpha_fraction": 0.597278892993927,
"alphanum_fraction": 0.6144217848777771,
"avg_line_length": 36.87628936767578,
"blob_id": "851c418828cad3f3ac3ca8dd3f93f950b43de350",
"content_id": "c50f532f01ae127defe0281d771995d864ed6806",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3675,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 97,
"path": "/tests/test_get_next_words.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom mock import Mock\n\nfrom yondeoku._get_next_words import (_filter_lemmas_by_new,\n _get_next_n_words_and_section_indices, _enumerate_unread_sections)\n\ndef test_it_filters_lemmas():\n lemmas = ['c', 'c', 'b', 'b', 'e', 'b', 'c', 'd']\n exclude_set = set(['c', 'd'])\n assert _filter_lemmas_by_new(lemmas, exclude_set) == ['b', 'b', 'e', 'b']\n\ndef test_enumerate_unread_sections():\n section1 = Mock(read=True)\n section2 = Mock(read=False)\n section3 = Mock(read=False)\n double = Mock(sections=[section1, section2, section3])\n result = _enumerate_unread_sections(double)\n assert result == [(1, section2), (2, section3)]\n\ndef test_get_next_n_words_and_section_indices_first_over_n():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=['a', 'b', 'c', 'd', 'e', 'f'])\n section3 = Mock(read=False, lemmas=['a', 'b', 'c'])\n double = Mock(sections=[section1, section2, section3])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1]\n assert result['lemmas'] == ['a', 'b', 'c', 'd', 'e', 'f']\n\ndef test_get_next_n_words_and_section_indices_second_pushes_over_n():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=['a', 'b', 'c', 'd'])\n section3 = Mock(read=False, lemmas=['a', 'b', 'c'])\n double = Mock(sections=[section1, section2, section3])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1]\n assert result['lemmas'] == ['a', 'b', 'c', 'd']\n\ndef test_get_next_n_words_and_section_indices_first_exactly_n():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=['a', 'b', 'c', 'd', 'e'])\n section3 = Mock(read=False, lemmas=['a', 'b', 'c'])\n double = Mock(sections=[section1, section2, section3])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1]\n assert result['lemmas'] == ['a', 'b', 'c', 'd', 'e']\n\ndef test_get_next_n_words_and_section_indices_first_plus_second_n():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=['a', 'b', 'c'])\n section3 = Mock(read=False, lemmas=['d', 'e'])\n section4 = Mock(read=False, lemmas=['d', 'e'])\n double = Mock(sections=[section1, section2, section3, section4])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1, 2]\n assert result['lemmas'] == ['a', 'b', 'c', 'd', 'e']\n\ndef test_get_next_n_words_and_section_indices_less_than_n_total_left():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=['a', 'b', 'c'])\n section3 = Mock(read=False, lemmas=['d'])\n double = Mock(sections=[section1, section2, section3])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1, 2]\n assert result['lemmas'] == ['a', 'b', 'c', 'd']\n\ndef test_get_next_n_words_and_section_indices_less_than_n_total_left():\n exclude_set = set([])\n\n section1 = Mock(read=True, lemmas=['read', 'section'])\n section2 = Mock(read=False, lemmas=[])\n section3 = Mock(read=False, lemmas=['d'])\n double = Mock(sections=[section1, section2, section3])\n\n result = _get_next_n_words_and_section_indices(double, exclude_set, 5)\n\n assert result['indices'] == [1, 2]\n assert result['lemmas'] == ['d']\n\n"
},
{
"alpha_fraction": 0.6873239278793335,
"alphanum_fraction": 0.6918309926986694,
"avg_line_length": 25.863636016845703,
"blob_id": "b5191ff970b74dadc7c7d86f05fefd4021018b89",
"content_id": "105d22dd4c7eabb3b782e3a85110a26c39529d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1775,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 66,
"path": "/tests/test_get_routes.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\nimport pytest\nimport json\nimport os\n\nfrom yondeokuApp import app as realApp, db as _db, User\nfrom flask import url_for\n\nfrom yondeoku.japanese.grammarWords import jaGrammarWords\n\nTESTDB_PATH = 'sqlite:////tmp/fake.db'\nrealApp.config['SQLALCHEMY_DATABASE_URI'] = TESTDB_PATH\nrealApp.config['TESTING'] = True\n\[email protected](scope='session')\ndef app(request):\n ctx = realApp.app_context()\n ctx.push()\n\n def teardown():\n ctx.pop()\n\n request.addfinalizer(teardown)\n return realApp\n\[email protected](scope='function')\ndef db(app, request):\n \"\"\"Session-wide test database.\"\"\"\n\n if os.path.exists(TESTDB_PATH):\n os.unlink(TESTDB_PATH)\n _db.init_app(app)\n\n _db.create_all()\n\n fakeUser = User(username='fakeUser', password='password')\n _db.session.add(fakeUser)\n _db.session.commit()\n\n def teardown():\n _db.drop_all()\n # os.unlink(TESTDB_PATH)\n\n request.addfinalizer(teardown)\n return _db\n\ndef test_get_grammatical_words_route_returns_200(client):\n\tassert client.get(url_for('getGrammaticalWords', language='pl')).status_code == 200\n\ndef test_get_grammatical_words_route_returns_correct_length_json(client):\n\treturnedJSON = client.get(url_for('getGrammaticalWords', language='ja')).json\n\tassert len(returnedJSON) == len(jaGrammarWords)\n\ndef test_index_route_returns_html(app):\n\tclient = realApp.test_client()\n\tresponse = client.get('/').response\n\tassert 'html' in list(response)[0]\n\ndef test_user_data_route(app, db):\n\tclient = realApp.test_client()\n\tresponse = client.get(url_for('user', username='fakeUser'))\n\tdata = response.data\n\tdata_keys = json.loads(data).keys()\n\tdata_keys.sort()\n\tassert data_keys == ['blocks', 'id', 'known', 'threshold', 'username']\n\n\n"
},
{
"alpha_fraction": 0.6733333468437195,
"alphanum_fraction": 0.6739682555198669,
"avg_line_length": 25.25,
"blob_id": "23d0eb3553f0b9cacefa0677156665606322f5ae",
"content_id": "89f1e1ee9593424a285ca23d8cbb9e283c6e7b7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3150,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 120,
"path": "/tests/test_database_block.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\nimport pytest\nimport os\n\nfrom sqlalchemy.exc import IntegrityError\n\nfrom yondeokuApp import app as realApp\nfrom yondeokuApp import db as _db\nfrom yondeokuApp import User, Block, Word\n\nTESTDB_PATH = 'sqlite:////tmp/test.db'\n\nrealApp.config['SQLALCHEMY_DATABASE_URI'] = TESTDB_PATH\nrealApp.config['TESTING'] = True\n\[email protected](scope='session')\ndef app(request):\n ctx = realApp.app_context()\n ctx.push()\n\n def teardown():\n ctx.pop()\n\n request.addfinalizer(teardown)\n return realApp\n\[email protected](scope='function')\ndef db(app, request):\n \"\"\"Session-wide test database.\"\"\"\n\n if os.path.exists(TESTDB_PATH):\n os.unlink(TESTDB_PATH)\n _db.init_app(app)\n\n _db.create_all()\n\n def teardown():\n _db.drop_all()\n # os.unlink(TESTDB_PATH)\n\n request.addfinalizer(teardown)\n return _db\n\[email protected](scope='function')\ndef session(db, request):\n \"\"\"Creates a new database session for a test.\"\"\"\n connection = db.engine.connect()\n transaction = connection.begin()\n\n options = dict(bind=connection, binds={})\n session = db.create_scoped_session(options=options)\n\n db.session = session\n\n def teardown():\n transaction.rollback()\n connection.close()\n session.remove()\n\n request.addfinalizer(teardown)\n return session\n\ndef test_block_created(session):\n\ttest_block = Block(language='pl', text='test')\n\tsession.add(test_block)\n\tsession.commit()\n\tassert test_block.id\n\ndef test_block_has_language_and_text(session):\n\ttest_block = Block(language='pl', text='test')\n\tsession.add(test_block)\n\tsession.commit()\n\tassert test_block.language == 'pl' and test_block.text == 'test'\n\ndef test_block_has_correct_user_id_attr(session):\n\tsam = User(username='sam', password='password')\n\ttest_block = Block(language='pl', text='test')\n\tsam.blocks.append(test_block)\n\tsession.add(sam)\n\tsession.commit()\n\tassert test_block.user == sam\n\ndef test_block_appended_to_user(session):\n sam = User(username='sam', password='password')\n test_block = Block(language='pl', text='test')\n sam.blocks.append(test_block)\n session.add(sam)\n session.commit()\n assert len(session.query(User).first().blocks) == 1\n\ndef test_block_language_cannot_be_null(session):\n x = Block(text='testing')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_block_text_cannot_be_null(session):\n x = Block(language='pl')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_block_read_ranges_defaults_to_empty_list_string(session):\n x = Block(language='pl', text='testing')\n session.add(x)\n session.commit()\n assert x.read_ranges == '[]'\n\ndef test_block_text_cannot_be_empty_string(session):\n x = Block(language='pl', text='', read_ranges='[]')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_block_language_cannot_be_empty_string(session):\n x = Block(language='', text='testing', read_ranges='[]')\n session.add(x)\n with pytest.raises(IntegrityError):\n session.commit()\n"
},
{
"alpha_fraction": 0.7927125692367554,
"alphanum_fraction": 0.7927125692367554,
"avg_line_length": 28.404762268066406,
"blob_id": "05b5639e1127dd87f9cf49374aa0ddec75f1a01b",
"content_id": "8cc0240c9526aa625ba5aecd856b0b39384c7851",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1235,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 42,
"path": "/yondeoku/languageAPI.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "from yondeoku.japanese.jaDefiner import jaDefiner\nfrom yondeoku.japanese.jaSectionizer import jaSectionizer\nfrom yondeoku.japanese.jaLemmatizer import jaLemmatizer\nfrom yondeoku.japanese.grammarWords import jaGrammarWords\nfrom yondeoku.polish.plDefiner import plDefiner\nfrom yondeoku.polish.plSectionizer import plSectionizer\nfrom yondeoku.polish.plLemmatizer import plLemmatizer\nfrom yondeoku.polish.grammarWords import plGrammarWords\n\nclass LangTools(object):\n\t'''Object wrapper for the core tools which need to be\n\tdefined for any new language.'''\n\n\tdef __init__(self, sectionizer, lemmatizer, definer, grammarWords):\n\t\tself.sectionizer = sectionizer()\n\t\tself.lemmatizer = lemmatizer()\n\t\tself.definer = definer()\n\t\tself.grammarWords = set(grammarWords)\n\nplTools = None\njaTools = None\n\ndef getPlTools():\n\tglobal plTools\n\tif plTools == None:\n\t\tplTools = LangTools(plSectionizer, plLemmatizer, plDefiner, plGrammarWords)\n\t\treturn plTools\n\telse:\n\t\treturn plTools\n\ndef getJaTools():\n\tglobal jaTools\n\tif jaTools == None:\n\t\tjaTools = LangTools(jaSectionizer, jaLemmatizer, jaDefiner, jaGrammarWords)\n\t\treturn jaTools\n\telse:\n\t\treturn jaTools\n\nlanguageAPI = {'pl': getPlTools,\n\t\t\t\t'ja': getJaTools}\n\nsupported_languages = languageAPI.keys()\n"
},
{
"alpha_fraction": 0.6720430254936218,
"alphanum_fraction": 0.698924720287323,
"avg_line_length": 19.77777862548828,
"blob_id": "bf83c9039ddfe0d051fbad6996e457c7cc30ee29",
"content_id": "5d4c083222c5dbc05ceb6cd30037443637625a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 9,
"path": "/tests/test_Lemma.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.Lemma import Lemma\n\ndef test_it_hashes_the_same():\n\tlemma1 = Lemma(u'test')\n\tlemma2 = Lemma (u'test')\n\ttest_set = {lemma1, lemma2}\n\tassert len(test_set) == 1"
},
{
"alpha_fraction": 0.6716417670249939,
"alphanum_fraction": 0.6880596876144409,
"avg_line_length": 30.952381134033203,
"blob_id": "b64e94a7ef418ec3f5040d6cb7b133e88ede7160",
"content_id": "223b2750aa0907d94a65b442c6b07b5251f48c86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 670,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 21,
"path": "/yondeoku/normalizeRanges.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "def normalizeRanges(rangeList):\n\t'''Takes a list of [_in, _out] range Arrays and\n\treturns a normalized list of [_in, _out] range\n\tArrays with no overlaps.'''\n\tif len(rangeList) <= 1:\n\t\treturn rangeList\n\tstack = []\n\tsorted_rangeList = sorted(rangeList, key=lambda x: x[0])\n\tstack.append(sorted_rangeList.pop(0))\n\twhile sorted_rangeList:\n\t\tstack_top = stack[-1]\n\t\tnext_range = sorted_rangeList.pop(0)\n\t\tprint 'stack top:', stack_top\n\t\tprint 'next range:', next_range\n\t\tif stack_top[1] < next_range[0]:\n\t\t\tprint 'next range appended'\n\t\t\tstack.append(next_range)\n\t\telif stack_top[1] < next_range[1]:\n\t\t\tprint 'stack top updated'\n\t\t\tstack_top[1] = next_range[1]\n\treturn stack"
},
{
"alpha_fraction": 0.3285714387893677,
"alphanum_fraction": 0.33571428060531616,
"avg_line_length": 9.84615421295166,
"blob_id": "fc47c2d6a6e44c62f666e94f84110387fb296443",
"content_id": "fed3189e1721fe54d4b05ca7526d541175711362",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 13,
"path": "/yondeoku/japanese/grammarWords.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\n\njaGrammarWords = [\n \"を\",\n \"に\",\n \"で\",\n \"は\",\n \"と\",\n \"の\",\n \"た\",\n \"て\",\n]"
},
{
"alpha_fraction": 0.7877551317214966,
"alphanum_fraction": 0.795918345451355,
"avg_line_length": 60.25,
"blob_id": "4ed6c4880ec6564f20868a8bf7508c173a82a74f",
"content_id": "5be7f6343bbc6c9b8147d17c4daac42d061678a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 4,
"path": "/backup/README.md",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "If the testing database gets corrupted or deleted, make sure /private/tmp/fake.db is not anything important, then reinstantiate the db from yondeoku_3.0 top level directory by running:\n```\nPYTHONPATH=. python backup/createDbForTestUserMe.py\n```\n"
},
{
"alpha_fraction": 0.731586217880249,
"alphanum_fraction": 0.7343448400497437,
"avg_line_length": 30.241378784179688,
"blob_id": "90c1797accdb97255fb812e15d9c58ee18ce9f65",
"content_id": "a3799d0b07e427e382a86083e967af5573da94ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3625,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 116,
"path": "/yondeoku/polish/getLektorekDef.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport requests\nimport json\nimport re\nimport codecs\nimport time\nfrom pprint import pprint\n\nfrom yondeoku.polish.settings import LEKTOREK_CACHE_PATH\nfrom yondeoku.Definition import Definition\n\n#word -> boolean\ndef checkLektorekCache(word, LEKTOREK_CACHE_PATH):\n\tf = codecs.open(LEKTOREK_CACHE_PATH, 'r', 'utf-8')\n\tJSON = json.loads(f.read())\n\tf.close()\n\tif word in JSON:\n\t\treturn True\n\telse:\n\t\treturn False\n\n#str word -> JSON\ndef getJSONfromURL(word):\n\t'''Makes an http request to lektorek and returns {} if it fails\n\tand a dict loaded from the entire returned json if it passes.'''\n\tprint word\n\turl = api_url = \"http://lektorek.org/dapi/v1/index.php/search/chomper/polish/\" + word + \"?diacritics=false&pos=all\"\n\tr = requests.get(url)\n\tif r.status_code != 200:\n\t\treturn {}\n\telse:\n\t\trequestJSON = json.loads(r.text)\n\t\treturn requestJSON\n\n#JSON -> [str] HTML\ndef getCorrectDef(JSON):\n\t'''Takes the raw JSON string (either cached or requested)\n\tand returns a list of definitions deemed to be correct by\n\tthe function. This can be modified later, because we have\n\tsaved the entire JSON in the cache.'''\n\tif JSON == {}:\n\t\treturn []\n\tresults = JSON[u'results']\n\tdefinitions = []\n\tfor result in results:\n\t\tif result[u'polish_word'] == JSON[u'found_as']:\n\t\t\tdefinitions.append(result[u'embedded_definition'])\n\treturn definitions\n\ndef cacheLektorekResult(word, JSON, LEKTOREK_CACHE_PATH):\n\t'''Caches the entire JSON from the getJSONfromURL call.'''\n\tf = codecs.open(LEKTOREK_CACHE_PATH, 'r', 'utf-8')\n\tcachedJSON = json.loads(f.read())\n\tf.close()\n\tcachedJSON[word] = JSON\n\tf = codecs.open(LEKTOREK_CACHE_PATH, 'w', 'utf-8')\n\tf.write(json.dumps(cachedJSON, sort_keys=True, indent=4, separators=(',', ': ')))\n\tf.close()\n\ndef getLektorekJSONFromCache(word, LEKTOREK_CACHE_PATH):\n\tf = codecs.open(LEKTOREK_CACHE_PATH, 'r', 'utf-8')\n\tJSON = json.loads(f.read())\n\tf.close()\n\treturn JSON[word]\n\n#Returns a [str] for the word\n#Takes a base form, only returns words\n#from the Lektorek JSON if they\n#exactly equal the input string\n###FOR USE WITH LEMMAS\ndef getLektorekDef(word, LEKTOREK_CACHE_PATH):\n\tif not checkLektorekCache(word, LEKTOREK_CACHE_PATH):\n\t\tJSON = getJSONfromURL(word)\n\t\tcacheLektorekResult(word, JSON, LEKTOREK_CACHE_PATH)\n\t\tresult = getCorrectDef(JSON)\n\t\treturn result\n\telse:\n\t\tJSON = getLektorekJSONFromCache(word, LEKTOREK_CACHE_PATH)\n\t\tresult = getCorrectDef(JSON)\n\t\treturn result\n\ndef getCorrectDefAsDefinitions(JSON):\n\t'''Variant of getCorrectDef, which returns actual Definition\n\tobjects, preserving the found_as property from the JSON.'''\n\tif JSON == {}:\n\t\treturn []\n\tresults = JSON[u'results']\n\tdefinitions = []\n\tfor result in results:\n\t\tif result[u'polish_word'] == JSON[u'found_as']:\n\t\t\tmeaning = result[u'embedded_definition']\n\t\t\tfound_as = JSON[u'found_as']\n\t\t\tobj = Definition(meaning, None, found_as)\n\t\t\tdefinitions.append(obj)\n\treturn definitions\n\n\ndef getLektorekDefAsDefinitions(word, LEKTOREK_CACHE_PATH):\n\t'''Variant of getLektorekDef, which returns actual Definition\n\tobjects, preserving the found_as property form the JSON.'''\n\tif not checkLektorekCache(word, LEKTOREK_CACHE_PATH):\n\t\tJSON = getJSONfromURL(word)\n\t\tcacheLektorekResult(word, JSON, LEKTOREK_CACHE_PATH)\n\t\tresult = getCorrectDefAsDefinitions(JSON)\n\t\treturn result\n\telse:\n\t\tJSON = getLektorekJSONFromCache(word, LEKTOREK_CACHE_PATH)\n\t\tresult = getCorrectDefAsDefinitions(JSON)\n\t\treturn result\n\ndef getDefObjList(word):\n\t'''Returns a list of Definition objects. To be used by the\n\tplDefiner class.'''\n\tdefinitionList = getLektorekDefAsDefinitions(word, LEKTOREK_CACHE_PATH)\n\treturn definitionList\n\n"
},
{
"alpha_fraction": 0.626101553440094,
"alphanum_fraction": 0.6277800798416138,
"avg_line_length": 22.534652709960938,
"blob_id": "6f4d4dbbc52724eb7ff42dbcede0314e94904d52",
"content_id": "f82eb69e2ee79f5430157747c8a61ea448b818bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2383,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 101,
"path": "/static/main.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "var model = {\n\tlanguages: ['pl', 'ja'],\n\tlanguage_map: {pl: 'Polish', ja: 'Japanese'},\n\tusername: 'Sam',\n\tuser: new User({threshold: 'loading...', username: 'loading...', known: [], blocks: []}),\n\tcurrent_block_id: 1,\n}\n\nvar study_state_manager = {\n\tcurrent_section_indices: [],\n\tnew_lemmas: [],\n\treset: function() {\n\t\tthis.current_section_indices = [];\n\t\tthis.new_lemmas = [];\n\t}\n}\n\nvar block_info_view_model = {\n\texpanded: [],\n\tis_expanded: function(block_id) {\n\t\treturn this.expanded.indexOf(block_id) != -1;\n\t},\n\texpand: function(block_id) {\n\t\tif (this.expanded.indexOf(block_id) == -1) {\n\t\t\tthis.expanded.push(block_id);\n\t\t}\n\t},\n\tcontract: function(block_id) {\n\t\tthis.expanded.splice(this.expanded.indexOf(block_id), 1);\n\t},\n\ttoggle: function(block_id) {\n\t\tif (this.is_expanded(block_id)) {\n\t\t\tthis.contract(block_id);\n\t\t} else {\n\t\t\tthis.expand(block_id);\n\t\t}\n\t}\n};\n\nvar ctrl = {\n\tinitialized: false,\n\tinitialize: function(model) {\n\t\tif (!this.initialized) {\n\t\t\tlet self = this;\n\t\t\tm.request({\n\t\t\t\tmethod: 'GET',\n\t\t\t\turl: 'user/' + model.username\n\t\t\t})\n\t\t\t.then(function(result) {\n\t\t\t\tself.set_user_data(model, result);\n\t\t\t\tself.update_study_state_manager(study_state_manager);\n\t\t\t\tself.initialized = true;\n\t\t\t});\n\t\t}\n\t},\n\tset_user_data: function(model, userdata) {\n\t\tmodel.user = new User(userdata);\n\t},\n\tadd_block_request: function(text, language) {\n\t\tlet self = this;\n\t\tm.request({\n\t\t\tmethod: 'POST',\n\t\t\turl: 'add_block/' + model.username,\n\t\t\tdata: {text: text, language: language}\n\t\t})\n\t\t.then(function(result) {\n\t\t\tself.set_user_data(model, result);\n\t\t});\n\t},\n\tsafe_delete_block_request: function(block_id) {\n\t\tvar confirmation = confirm('Are you sure you want to delete this text?')\n\t\tif (confirmation) {\n\t\t\tthis._delete_block_request(block_id);\n\t\t}\n\t},\n\t_delete_block_request: function(block_id) {\n\t\tlet self = this;\n\t\tm.request({\n\t\t\tmethod: 'POST',\n\t\t\turl: 'delete_block/' + model.username,\n\t\t\tdata: {id: block_id}\n\t\t})\n\t\t.then(function(result) {\n\t\t\tself.set_user_data(model, result);\n\t\t});\n\t},\n\tget_current_block: function(model) {\n\t\treturn model.user.get_block(model.current_block_id);\n\t},\n\tupdate_study_state_manager: function(model, study_state_manager) {\n\t\tm.request({\n\t\t\tmethod: 'POST',\n\t\t\turl: 'get_study_words',\n\t\t\tdata: {user_id: model.user.id,\n\t\t\t\t block_id: get_current_block(model)}\n\t\t})\n\t\t.then(function(result) {\n\t\t\tconsole.log(result);\n\t\t});\n\t}\n}\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7361111044883728,
"alphanum_fraction": 0.7361111044883728,
"avg_line_length": 30,
"blob_id": "f5a48cdd0eaf71fa0879f5550741804c629a59ad",
"content_id": "6105d44575a3db21697ccde7e565d8a3be4848e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 7,
"path": "/yondeoku/Definition.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class Definition(object):\n\t'''Language independent definition class.'''\n\n\tdef __init__(self, meaning, pronunciation, found_as):\n\t\tself.meaning = meaning\n\t\tself.pronunciation = pronunciation\n\t\tself.found_as = found_as"
},
{
"alpha_fraction": 0.6716762781143188,
"alphanum_fraction": 0.6745664477348328,
"avg_line_length": 35.02083206176758,
"blob_id": "f720eb2b710d5a91fc5d17deb6554ca401fca803",
"content_id": "9eef5b2be5693813213033ff55a1fd99ee9b71f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1730,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 48,
"path": "/tests/test_get_lektorek_def.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import json\nimport codecs\n\nimport pytest\n\nfrom yondeoku.polish.getLektorekDef import (getCorrectDef, checkLektorekCache,\n cacheLektorekResult, getLektorekJSONFromCache)\n\nmock_cache_path = 'mock/mockLektorekCache.json'\nemptyJSON = {}\n\ndef setup_module(module):\n with codecs.open('mock/testJSONLektorek.json', 'r', 'utf-8') as f:\n global testJSON\n testJSON = json.loads(f.read())\n with codecs.open(mock_cache_path, 'r', 'utf-8') as f:\n global mock_cache_original_state\n mock_cache_original_state = json.loads(f.read())\n\ndef teardown_module(module):\n with codecs.open(mock_cache_path, 'w', 'utf-8') as f:\n f.write(json.dumps(mock_cache_original_state, sort_keys=True, indent=4,\n separators=(',', ': ')))\n\ndef test_it_gets_correct_polish_word():\n assert testJSON['results'][0]['polish_word'] == 'chmura'\n\ndef test_it_gets_correct_def():\n assert getCorrectDef(testJSON) == [u\"<span class=\\\"bold\\\">chmura </span>\" \\\n \"<span class=\\\"italics\\\">f </span>cloud\"]\n\ndef test_it_gets_correct_from_empty_json():\n assert getCorrectDef(emptyJSON) == []\n\ndef test_check_lektorek_cache_true_for_pyszny():\n assert checkLektorekCache(u'pyszny', mock_cache_path)\n\ndef test_check_lektorek_cache_false_for_wiarygodny():\n assert not checkLektorekCache(u'wiarygodny', mock_cache_path)\n\ndef test_get_lektorek_json_from_cache():\n assert getLektorekJSONFromCache('pyszny', mock_cache_path) == {'tested': 'yes'}\n\ndef test_cache_lektorek_result():\n cacheLektorekResult('testing', {'testing a result': 'tested'},\n mock_cache_path)\n assert (getLektorekJSONFromCache('testing', mock_cache_path) ==\n {\"testing a result\": \"tested\"})\n\n"
},
{
"alpha_fraction": 0.6390423774719238,
"alphanum_fraction": 0.6408839821815491,
"avg_line_length": 29.11111068725586,
"blob_id": "26f799a71126f24c9baba8848469092c8ac29b40",
"content_id": "aac0f3bd0cae39f1ed13de624fdb6d91f6e51546",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 18,
"path": "/tests/test_yondeoku_polish_Lemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\n\nimport pytest\n\nfrom yondeoku.polish.Lemmatizer import Lemmatizer\n\ntest_Lemmatizer = Lemmatizer('mock/testDict.json')\n\ndef test_it_has_lemma_dict():\n assert test_Lemmatizer.lemmaDict[u'psom'] == [u'pies']\n\ndef test_word_yields_inflections():\n assert test_Lemmatizer.lookupLemma(u'lekarkami') == [u'lekarka']\n\n\ndef test_word_not_in_dict_returns_self_in_list():\n assert test_Lemmatizer.lookupLemma(u'awerioawer') == [u'awerioawer']\n\n"
},
{
"alpha_fraction": 0.6878452897071838,
"alphanum_fraction": 0.6878452897071838,
"avg_line_length": 24.85714340209961,
"blob_id": "bd70822ea533ad1b7087a4a3b3cd2c20a2aa4564",
"content_id": "4f489545d5f903463df1e9e60224ef7fdda3e61f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 14,
"path": "/yondeoku/Lemma.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class Lemma(object):\n\t'''Language independent Lemma class. Objects of this type\n\tare to be found in the 'lemma' Array on Section instances.\n\tLemm's currently are implemented as a container on the word\n\tproperty only.'''\n\n\tdef __init__(self, lemma):\n\t\tself.word = lemma\n\n\tdef __hash__(self):\n\t\treturn hash(self.word)\n\n\tdef __eq__(a, b):\n\t\treturn a.word == b.word\n"
},
{
"alpha_fraction": 0.7599999904632568,
"alphanum_fraction": 0.7599999904632568,
"avg_line_length": 19.83333396911621,
"blob_id": "0220bd757c54630bbd2e06894be1080260b6260d",
"content_id": "6167a1017756b9ec898f16697ea6d7765ea61de2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 6,
"path": "/tests/test_plDefiner.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.polish.plDefiner import plDefiner\n\ndef test_it_has_lang():\n\tassert plDefiner().language == 'pl'\n"
},
{
"alpha_fraction": 0.663112998008728,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 27.1200008392334,
"blob_id": "353e44d239a792b5f683be2090dca476278b3db2",
"content_id": "0ffb25a26cac5052e9c1584306e2845315a75a39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1407,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 50,
"path": "/backup/createDbForTestUserMe.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import codecs\n\nfrom yondeokuApp import db, app, User, Block, Word\n\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/fake.db'\n\nctx = app.app_context()\nctx.push()\n\ndb.create_all()\n\nme = User(username='Sam', password='password')\n\ndef get_blocks_from_files():\n\tdef block_from_filename(filename, language):\n\t\twith codecs.open('backup/' + filename, 'r', 'utf-8') as f:\n\t\t\treturn Block(language=language, text=f.read())\n\n\tpl_files = ['block' + str(x) for x in range(4)]\n\tpl_blocks = map(lambda x: block_from_filename(x, 'pl'), pl_files)\n\tja_files = ['block' + str(x) for x in range(4, 5)]\n\tja_blocks = map(lambda x: block_from_filename(x, 'ja'), ja_files)\n\tall_blocks = pl_blocks + ja_blocks\n\treturn all_blocks\n\ndef get_words_from_file():\n\tdef get_words(filename, language):\n\t\twith codecs.open('backup/' + filename, 'r', 'utf-8') as f:\n\t\t\tdef word_from_string(string):\n\t\t\t\tif string != '':\n\t\t\t\t\treturn Word(language=language, word=string)\n\n\t\t\twords = f.read().split('\\n')\n\t\t\tWords = map(lambda x: word_from_string(x), words)\n\t\t\tWords = filter(lambda x: x != None, Words)\n\t\t\treturn Words\n\tpl_words = get_words('pl_known', 'pl')\n\tja_words = get_words('ja_known', 'ja')\n\treturn pl_words + ja_words\n\nall_blocks = get_blocks_from_files()\nfor block in all_blocks:\n\tme.blocks.append(block)\n\nall_words = get_words_from_file()\nfor word in all_words:\n\tme.known.append(word)\n\ndb.session.add(me)\ndb.session.commit()\n\n"
},
{
"alpha_fraction": 0.5724020600318909,
"alphanum_fraction": 0.5724020600318909,
"avg_line_length": 26.952381134033203,
"blob_id": "84a6db0e52bef1c2bb590a53acf2f81f30ea63c0",
"content_id": "22168ae6781f2d4975294af2f82ca4fc6e699955",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 42,
"path": "/static/views/Add.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "var add_view_model = {\n\tlanguages: ['pl', 'ja'],\n\tnew_block_text: '',\n\tnew_block_language: 'pl',\n\tupdate_new_block_text: function(text) {\n\t\tadd_view_model.new_block_text = text;\n\t},\n\tupdate_new_block_language: function(language) {\n\t\tadd_view_model.new_block_language = language;\n\t}\n};\n\n\nvar Add = {\n\tview: function() {\n\t\treturn m('#add',\n\t\t\tm('#add-block-container', [\n\t\t\t\tm('p', 'Paste your new text into the box below:'),\n\t\t\t\tm('#controls', [\n\t\t\t\t\tm('#input-container',\n\t\t\t\t\t\tm('select', {oninput: m.withAttr('value', add_view_model.update_new_block_language)},\n\t\t\t\t\t\t\tadd_view_model.languages.map(function(l) {\n\t\t\t\t\t\t\t\treturn m('option', {label: l, value: l}, l)\n\t\t\t\t\t\t\t}))\n\t\t\t\t\t),\n\t\t\t\t\tm('#button-container', [\n\t\t\t\t\t\tm('a', {href: \"/select\",\n\t\t\t\t\t\t\t\toncreate: m.route.link,\n\t\t\t\t\t\t\t\tonclick: function(e) {\n\t\t\t\t\t\t\t\t\tctrl.add_block_request(add_view_model.new_block_text, add_view_model.new_block_language)\n\t\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\t\t}, 'Add Text'),\n\t\t\t\t\t\tm('a', {href: \"/select\",\n\t\t\t\t\t\t\t\toncreate: m.route.link}, 'Back to User Page')\n\t\t\t\t\t])\n\t\t\t\t]),\n\t\t\t\tm('textarea', {id: 'new_block_text',\n\t\t\t\t\toninput: m.withAttr('value', add_view_model.update_new_block_text)})\n\t\t\t])\n\t\t);\n\t}\n};\n"
},
{
"alpha_fraction": 0.7580246925354004,
"alphanum_fraction": 0.7580246925354004,
"avg_line_length": 35.818180084228516,
"blob_id": "6adbce7f8efdab8c26adf1ba17128b1a37b516f8",
"content_id": "0fcf37759c4c014c47454b86a45aee18ad76f6f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 11,
"path": "/yondeoku/AbstractLemmatizer.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class AbstractLemmatizer(object):\n\t'''Abstract Lemmatizer class. Subclass for a given language,\n\timplement init to set self.language to appropriate language\n\tstring, implement the lemmatize method, which must take a\n\t{Section} object and return a [{Lemma}...]'''\n\n\tdef __init__(self, language):\n\t\tself.language = language\n\n\tdef lemmatize(self):\n\t\traise NotImplementedError(\"Should have implemented this\")\n"
},
{
"alpha_fraction": 0.6387525200843811,
"alphanum_fraction": 0.6456829309463501,
"avg_line_length": 26.484127044677734,
"blob_id": "89b177449e0bd60c7b6e8788f6baed0893b69550",
"content_id": "330e1f306a3221e125f31c17423f4c8dc1915202",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3463,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 126,
"path": "/tests/test_database_word.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\nimport pytest\nimport os\n\nfrom sqlalchemy.exc import IntegrityError\n\nfrom yondeokuApp import app as realApp\nfrom yondeokuApp import db as _db\nfrom yondeokuApp import User, Block, Word\n\nTESTDB_PATH = 'sqlite:////tmp/test.db'\n\nrealApp.config['SQLALCHEMY_DATABASE_URI'] = TESTDB_PATH\nrealApp.config['TESTING'] = True\n\[email protected](scope='session')\ndef app(request):\n ctx = realApp.app_context()\n ctx.push()\n\n def teardown():\n ctx.pop()\n\n request.addfinalizer(teardown)\n return realApp\n\[email protected](scope='function')\ndef db(app, request):\n \"\"\"Session-wide test database.\"\"\"\n\n if os.path.exists(TESTDB_PATH):\n os.unlink(TESTDB_PATH)\n _db.init_app(app)\n\n _db.create_all()\n\n def teardown():\n _db.drop_all()\n # os.unlink(TESTDB_PATH)\n\n request.addfinalizer(teardown)\n return _db\n\[email protected](scope='function')\ndef session(db, request):\n \"\"\"Creates a new database session for a test.\"\"\"\n connection = db.engine.connect()\n transaction = connection.begin()\n\n options = dict(bind=connection, binds={})\n session = db.create_scoped_session(options=options)\n\n db.session = session\n\n def teardown():\n transaction.rollback()\n connection.close()\n session.remove()\n\n request.addfinalizer(teardown)\n return session\n\ndef test_word_created(session):\n kw = Word(language='pl', word='kot')\n user = User(username='sam', password='password')\n session.add(user)\n session.add(kw)\n session.commit()\n assert kw.id > 0 and kw.language == 'pl' and kw.word == 'kot'\n\ndef test_same_word_same_lang_raises_error(session):\n kw1 = Word(language='pl', word='kot')\n kw2 = Word(language='pl', word='kot')\n session.add(kw1)\n session.add(kw2)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_same_word_diff_lang_is_okay(session):\n kw1 = Word(language='pl', word='kot')\n kw2 = Word(language='jp', word='kot')\n session.add(kw1)\n session.add(kw2)\n session.commit()\n\ndef test_diff_word_same_lang_is_okay(session):\n kw1 = Word(language='pl', word='kot')\n kw2 = Word(language='pl', word='pies')\n session.add(kw1)\n session.add(kw2)\n session.commit()\n\ndef test_word_language_cannot_be_empty_string(session):\n kw = Word(language='', word='kot')\n session.add(kw)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_word_word_cannot_be_empty_string(session):\n kw = Word(language='pl', word='')\n session.add(kw)\n with pytest.raises(IntegrityError):\n session.commit()\n\ndef test_user_has_two_known_words(session):\n sam = User(username='sam', password='password')\n kw1 = Word(language='pl', word='kot')\n kw2 = Word(language='pl', word='pies')\n sam.known.append(kw1)\n sam.known.append(kw2)\n session.add(sam)\n session.commit()\n sam_known = list(session.query(User).first().known)\n assert kw1 in sam_known and kw2 in sam_known\n\ndef test_known_word_has_two_users(session):\n sam = User(username='sam', password='password')\n hector = User(username='hector', password='password')\n kw1 = Word(language='pl', word='pies')\n sam.known.append(kw1)\n hector.known.append(kw1)\n session.add(kw1)\n session.commit()\n pies_users = list(session.query(Word).first().users)\n assert sam in pies_users and hector in pies_users\n"
},
{
"alpha_fraction": 0.8191304206848145,
"alphanum_fraction": 0.8191304206848145,
"avg_line_length": 51.272727966308594,
"blob_id": "d6c3dbf88ab25412a737720be9aa7eae3cbc6814",
"content_id": "6a3393c3738fecab688103ed08cc5e955c2c5b2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 575,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 11,
"path": "/README.md",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "# yondeoku\nYondeoku is a webapp for advanced language learners. It generates custom vocab\nstudy lists for arbitrary texts.\n\nYondeoku takes into account the texts you've already read and the words you've\nexplicitly marked as known to work out which words are new in any given text.\nThe webapp in development currently supports reading texts in Polish and Japanese.\n\nYondeoku is currently still in its development phase and is not deployed online.\nThe backend is written in Python using the Flask web development framework.\nThe frontend is written in JavaScript using Angular.\n"
},
{
"alpha_fraction": 0.545176088809967,
"alphanum_fraction": 0.6186829805374146,
"avg_line_length": 30.047618865966797,
"blob_id": "d2d3385f523776ad51d987616c9f028235b2efd1",
"content_id": "a343d60ddd56456b609081c95ffd70fef86fb9b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 653,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 21,
"path": "/tests/test_normalizeRanges.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.overlap import normalizeRanges\n\ndef test_normalizes_empty_range():\n\tassert normalizeRanges([]) == []\n\ndef test_normalizes_single_item_range():\n\tassert normalizeRanges([[1, 3]]) == [[1, 3]]\n\ndef test_normalizes_contained_overlap():\n\tassert normalizeRanges([[0, 5], [2, 3], [8, 10]]) == [[0, 5], [8, 10]]\n\ndef test_normalizes_part_overlap():\n\tassert normalizeRanges([[0, 5], [4, 7], [9, 11]]) == [[0, 7], [9, 11]]\n\ndef test_normalizes_touching_overlap():\n\tassert normalizeRanges([[0, 5], [5, 7], [9, 11]]) == [[0, 7], [9, 11]]\n\ndef test_keeps_non_overlap_same():\n\tassert normalizeRanges([[0, 5], [6, 7]]) == [[0, 5], [6, 7]]\n\n"
},
{
"alpha_fraction": 0.7465940117835999,
"alphanum_fraction": 0.7465940117835999,
"avg_line_length": 27.30769157409668,
"blob_id": "f86b98b95ee88bbc2d7931fbbc5974f39fd04b59",
"content_id": "35b6a14d15db5464111f6b883d7ee50263e3386a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 13,
"path": "/yondeoku/japanese/jaDefiner.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "from yondeoku.AbstractDefiner import AbstractDefiner\nfrom yondeoku.japanese.getDefinition import getDefObjList\n\nclass jaDefiner(AbstractDefiner):\n\t'''Concrete Japanese Definer class.'''\n\n\tdef __init__(self):\n\t\tsuper(jaDefiner, self).__init__('ja')\n\n\tdef define(self, word):\n\t\t'''Return a list of {Definition} objects.'''\n\t\tresult = getDefObjList(word)\n\t\treturn result"
},
{
"alpha_fraction": 0.6214689016342163,
"alphanum_fraction": 0.6305084824562073,
"avg_line_length": 30.64285659790039,
"blob_id": "b47ebd58f56052f257b3604fae8023ad57c6d98e",
"content_id": "304a3daa3a761ae56c7371b7661604f9f5a5a48f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 28,
"path": "/static/tests/test_block.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "describe('Block', function() {\n\n\tit('gets index 2', function() {\n\t\tb = {blockdata: {readSections: [true, true, false]}};\n\t\tresult = Block.prototype.get_next_unread_section_index.apply(b);\n\t\tassert.strictEqual(result, 2);\n\t})\n\n\tit('gets index 1', function() {\n\t\tb = {blockdata: {readSections: [true, false, true, true, false]}};\n\t\tresult = Block.prototype.get_next_unread_section_index.apply(b, [0]);\n\t\tassert.strictEqual(result, 1);\n\t})\n\n\tit('gets index 4', function() {\n\t\tb = {blockdata: {readSections: [true, false, true, true, false]}};\n\t\tresult = Block.prototype.get_next_unread_section_index.apply(b, [2]);\n\t\tassert.strictEqual(result, 4);\n\t})\n\n\tit('gets a, b, c', function() {\n\t\tb = new Block({readSections: [true, false], sections: [{lemmas: []}, {lemmas: ['a', 'b', 'c']}]});\n\t\tresult = b.get_next_unread_section_lemmas();\n\t\tassert.deepEqual(result, ['a', 'b', 'c']);\n\t})\n\n\n});"
},
{
"alpha_fraction": 0.6765799522399902,
"alphanum_fraction": 0.678438663482666,
"avg_line_length": 18.962963104248047,
"blob_id": "e0a084b620686ae0429000c4731e62f183d7298f",
"content_id": "92869811964f2bae61a6343c02af62192f3f8a10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 27,
"path": "/static/Block.js",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "class Block {\n constructor(block) {\n this._blockdata = block;\n }\n\n get blockdata() {\n return this._blockdata;\n }\n\n get sections() {\n return this.blockdata.sections;\n }\n\n get_next_unread_section_index(startIndex) {\n return this.blockdata.readSections.indexOf(false, startIndex);\n }\n\n get_section_lemmas(index) {\n return this.blockdata.sections[index].lemmas;\n }\n\n get_next_unread_section_lemmas(startIndex) {\n var index = this.get_next_unread_section_index(0);\n return this.get_section_lemmas(index);\n }\n\n}"
},
{
"alpha_fraction": 0.6737884283065796,
"alphanum_fraction": 0.6831682920455933,
"avg_line_length": 30.983333587646484,
"blob_id": "d57eec2306db8293d78afe1ae2a3f2a4b18b3e01",
"content_id": "0c3560792f36f6ecb1fb35b80d2d8c6b32dbba22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2117,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 60,
"path": "/tests/test_makeSections.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# -*- coding: utf-8 -*-\nimport pytest\n\nfrom yondeoku.makeSections import makeSections\n\nja_sentence_breakers = [u'。', u'!', u'?']\nja_end_quote = u'」'\n\npl_sentence_breakers = [u'\\.', u'!', u'\\?']\npl_end_quote = u'”'\n\ndef test_make_sections_returns_one_section():\n\ttext = u'思う。'\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert len(result) == 1\n\ndef test_make_sections_returns_two_sections():\n\ttext = u'''でも、どんない。\\n思う。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert len(result) == 2\n\ndef test_make_sections_returns_three_sections():\n\ttext = u'''とは、すった。\\n\\nしかし! そうしてた。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert len(result) == 3\n\ndef test_Section_blockRef():\n\ttext = u'''でも、どんない。\\n思う。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert result[1].blockRef == [9, 12]\n\ndef test_Section_blockRef():\n\ttext = u'''でも、どんない。\\n思う。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert result[0].blockRef == [0, 9]\n\ndef test_Section_blockref_with_trailing_section():\n\ttext = u'''でもない。思う'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert result[1].blockRef == [5, 7] and result[1].text == u'思う'\n\ndef test_Section_text():\n\ttext = u'''でも、どんない。\\n思う。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert result[1].text == u'思う。'\n\ndef test_make_sections_returns_three_sections():\n\ttext = u'''Czarne, zżarte. Ich. „Z chłop!”'''\n\tresult = makeSections(text, pl_sentence_breakers, pl_end_quote)\n\tassert len(result) == 3\n\ndef it_returns_one_section():\n\ttext = u'testing'\n\tassert makeSections(text, pl_sentence_breakers, pl_end_quote).text == u'testing'\n\ndef test_it_groups_two_new_lines_with_first_section():\n\ttext = u'''でも、どんない。\\n\\n思う。'''\n\tresult = makeSections(text, ja_sentence_breakers, ja_end_quote)\n\tassert result[1].text == u'思う。'\n"
},
{
"alpha_fraction": 0.5817184448242188,
"alphanum_fraction": 0.5836684703826904,
"avg_line_length": 35.3053092956543,
"blob_id": "4a26cb694ef9f35e0487edd51d99b60e7d3c96db",
"content_id": "28755c64c6ed0750867cfe53ac17b1dbcb742762",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8205,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 226,
"path": "/yondeokuApp.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import json\n\nfrom flask import Flask, render_template, request\nfrom flask_sqlalchemy import SQLAlchemy\n\nfrom yondeoku.languageAPI import languageAPI\nfrom yondeoku.gBlock import gBlock\nfrom yondeoku.Section import Section\nfrom yondeoku.Lemma import Lemma\n# from yondeoku.make_study_list import make_study_list\n\napp = Flask(__name__)\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:////tmp/real.db'\ndb = SQLAlchemy()\ndb.init_app(app)\n\nDEBUG = True\nPORT = 3000\nHOST = '0.0.0.0'\n\n# .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-\n# / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\\n#`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-'\n\nmap_table = db.Table('user_word_map_table',\n db.Column('user_id', db.Integer, db.ForeignKey('user.id')),\n db.Column('word_id', db.Integer, db.ForeignKey('word.id')),\n )\n\nclass User(db.Model):\n\tid = db.Column(db.Integer, db.Sequence('user_id_seq'), primary_key=True)\n\tusername = db.Column(db.String, unique=True, nullable=False)\n\tpassword = db.Column(db.String, nullable=False)\n\tknown = db.relationship('Word', secondary=map_table, backref='users')\n\tthreshold = db.Column(db.Integer, nullable=False, default=8)\n\tblocks = db.relationship('Block', backref=\"user\")\n\t__table_args__ = (\n\t\tdb.CheckConstraint(username != '', name='check_username_not_empty_string'),\n\t\tdb.CheckConstraint(password != '', name='check_password_not_empty_string'),\n\t\tdb.CheckConstraint(threshold > 0, name='check_threshold_greather_than_0'),\n\t\t)\n\nclass Block(db.Model):\n\tid = db.Column(db.Integer, db.Sequence('block_id_seq'), primary_key=True)\n\tlanguage = db.Column(db.String, nullable=False)\n\ttext = db.Column(db.String, nullable=False)\n\t# readRanges are stored as a jsonified list of lists\n\tread_ranges = db.Column(db.String, nullable=False, default='[]')\n\tuser_id = db.Column(db.ForeignKey('user.id'))\n\t__table_args__ = (\n\t\tdb.CheckConstraint(language != '', name='check_language_not_empty_string'),\n\t\tdb.CheckConstraint(text != '', name='check_text_not_empty_string'),\n\t\t)\n\nclass Word(db.Model):\n\tid = db.Column(db.Integer, db.Sequence('word_id_seq'), primary_key=True)\n\tlanguage = db.Column(db.String, nullable=False)\n\tword = db.Column(db.String, nullable=False)\n\t__table_args__ = (\n\t\tdb.UniqueConstraint('language', 'word'),\n\t\tdb.CheckConstraint(language != '', name='check_language_not_empty_string'),\n\t\tdb.CheckConstraint(word != '', name='check_word_not_empty_string'),\n\t\t)\n\n# .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-\n# / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\\n#`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-'\n\ndef _get_all_read_sections(gBlocks):\n all_sections = reduce(lambda a, b: a + b, [x.sections for x in gBlocks])\n read_sections = [s for s in all_sections if s.read]\n return read_sections\n\ndef _get_user_read_sections(user_id, language):\n gBlocks = _get_user_gBlocks(user_id, language)\n return _get_all_read_sections(gBlocks)\n\ndef _get_user_known_words(user_id, language):\n user = User.query.filter_by(id=user_id).first()\n return [w.word for w in user.known if w.language == language]\n\ndef _get_grammatical_words(block_id):\n language = _get_block_language(block_id)\n return languageAPI[language]().grammarWords\n\ndef _get_block_language(block_id):\n block = Block.query.filter_by(id=block_id).first()\n return block.language\n\ndef _get_user_gBlocks(user_id, language):\n user = User.query.filter_by(id=user_id).first()\n return [gBlock(x) for x in user.blocks if x.language == language]\n\nfrom yondeoku._get_lemmas_above_threshold import _get_lemmas_above_threshold\n\ndef _get_lemmas_from_sections(sections):\n return reduce(lambda a, b: a + b, [x.lemmas for x in sections], [])\n\ndef _get_user_lemmas_above_threshold(user_id, language):\n gBlocks = _get_user_gBlocks(user_id, language)\n lemmas = _get_lemmas_from_sections(_get_all_read_sections(gBlocks))\n return _get_lemmas_above_threshold(lemmas, 8)\n\n# .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-\n# / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\\n#`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-'\n\nclass ModelEncoder(json.JSONEncoder):\n def default(self, obj):\n \t# this will only work once the user's blocks have been\n \t# converted to gBlocks\n if isinstance(obj, User):\n return {\n \"id\": obj.id,\n \"username\": obj.username,\n \"threshold\": obj.threshold,\n \"known\": obj.known,\n \"blocks\": obj.gBlocks\n }\n if isinstance(obj, gBlock):\n return {\n \"id\": obj.id,\n \"language\": obj.language,\n \"text\": obj.text,\n \"read_ranges\": obj.readRanges,\n \"sections\": obj.sections,\n \"readSections\": obj.readSections\n }\n if isinstance(obj, Word):\n return {\n \"language\": obj.language,\n \"word\": obj.word\n }\n if isinstance(obj, Section):\n \treturn {\n \t\t\"text\": obj.text,\n \t\t\"lemmas\": obj.lemmas,\n \t\t\"blockRef\": obj.blockRef,\n \"read\": obj.read\n \t}\n if isinstance(obj, Lemma):\n \treturn {\n \t\t\"word\": obj.word\n \t}\n if isinstance(obj, set):\n \treturn list(obj)\n return super(ModelEncoder, self).default(obj)\n\ndef get_user_data_json(username):\n activeUser = User.query.filter_by(username=username).first()\n activeUser.gBlocks = map(lambda x: gBlock(x), activeUser.blocks)\n return json.dumps(activeUser, cls=ModelEncoder, sort_keys=True, indent=4,\n separators=(',', ': '))\n\n# .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-\n# / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\\n#`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-'\n\[email protected]('/')\ndef index():\n\treturn render_template('index.html')\n\[email protected]('/tests')\ndef tests():\n return render_template('runner.html')\n\[email protected]('/user/<username>', methods=['GET'])\ndef user(username):\n\t'''This retrieves the user data for user with specific\n\tusername and returns it as json to the webpage.'''\n\treturn get_user_data_json(username)\n\[email protected]('/add_block/<username>', methods=['POST'])\ndef add_block(username):\n block_text = request.get_json()['text']\n block_language = request.get_json()['language']\n\n user = User.query.filter_by(username=username).first()\n b = Block(language=block_language, text=block_text)\n user.blocks.append(b)\n print user.blocks[-1].text\n db.session.add(user)\n db.session.commit()\n return get_user_data_json(username)\n\[email protected]('/delete_block/<username>', methods=['POST'])\ndef delete_block(username):\n block_id = request.get_json()['id']\n\n block = Block.query.filter_by(id=block_id).first()\n\n db.session.delete(block)\n db.session.commit()\n\n return get_user_data_json(username)\n\nfrom yondeoku._get_next_words import _get_next_n_words_and_section_indices\n\ndef make_study_list(user_id, block_id):\n current_block = Block.query.filter_by(id=block_id).first()\n current_gBlock = gBlock(current_block)\n\n above_threshold_word_set = _get_user_lemmas_above_threshold(user_id, current_block.language)\n grammatical_word_set = _get_grammatical_words(block_id)\n known_word_set = _get_user_known_words(user_id, current_block.language)\n exclude_set = above_threshold_word_set.union(grammatical_word_set).union(known_word_set)\n\n return _get_next_n_words_and_section_indices(current_gBlock, exclude_set, 10)\n\[email protected]('/get_study_words', methods=['POST'])\ndef get_next_words():\n print 'get study words received post'\n print request.get_json()\n\n user_id = request.get_json()['user_id']\n block_id = request.get_json()['block_id']\n study_list = make_study_list(user_id, block_id)\n\n return json.dumps(study_list, cls=ModelEncoder)\n\n# .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-. .-.-\n# / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\ \\ / / \\\n#`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-' `-`-'\n\nif __name__ == '__main__':\n\tapp.run(debug=DEBUG, host=HOST, port=PORT)\n"
},
{
"alpha_fraction": 0.6996699571609497,
"alphanum_fraction": 0.7089108824729919,
"avg_line_length": 33.40909194946289,
"blob_id": "36efd8a5a297f676012f491eebb8912c4d3ec9da",
"content_id": "7b40dc8e6d37efec86847a2cc73f9e7d096ecb71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1515,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 44,
"path": "/tests/test_gBlock.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom yondeoku.gBlock import gBlock\nfrom yondeokuApp import Block\n\ntest_model_block = Block(language='pl', text=u'przyjaciela brzmi. herbaty, stali! psom, lekarkami.', read_ranges='[[0, 3]]')\ntest_gblock = gBlock(test_model_block)\nempty_block = Block(language='pl', text='testing', read_ranges='[]')\n\nblock_with_unsupported = Block(language='it', text='testing', read_ranges='[]')\nblock_with_bad_range = Block(language='pl', text='testing', read_ranges='[[0, 1, 2]]')\n\ndef test_gBlock_created_and_has_lang_and_text():\n\tassert test_gblock.language == 'pl' and test_gblock.text == u'przyjaciela brzmi. herbaty, stali! psom, lekarkami.'\n\ndef test_unsupported_lang_raises_error():\n\twith pytest.raises(ValueError):\n\t\tgBlock(block_with_unsupported)\n\ndef test_unsupported_range_len_raises_error():\n\twith pytest.raises(ValueError):\n\t\tgBlock(block_with_bad_range)\n\ndef test_it_has_empty_read_ranges():\n\tassert gBlock(empty_block).readRanges == []\n\ndef test_it_has_sections():\n\tassert len(test_gblock.sections) == 3\n\ndef test_it_has_read_sections():\n\tassert len(test_gblock.readSections) == 3\n\ndef test_it_has_read_ranges():\n\tassert test_gblock.readRanges == [[0, 3]]\n\ndef test_section_marked_as_read():\n\tmb = Block(language='pl', text=u'testing. this', read_ranges='[[0, 8]]')\n\tgb = gBlock(mb)\n\tassert gb.readSections == [True, False]\n\ndef test_section_not_marked_as_read():\n\tmb = Block(language='pl', text=u'testing. this', read_ranges='[[3, 10]]')\n\tgb = gBlock(mb)\n\tassert gb.readSections == [False, False]\n\n"
},
{
"alpha_fraction": 0.6103183031082153,
"alphanum_fraction": 0.6125137209892273,
"avg_line_length": 32.703704833984375,
"blob_id": "b56f788ee08b98e29ba1c27a856cd294d6e1288b",
"content_id": "aeb8c9fad61e1a80c5df577c29f7482f28512421",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 27,
"path": "/yondeoku/_get_next_words.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "def _filter_lemmas_by_new(lemmas, exclude_set):\n return [l for l in lemmas if l not in exclude_set]\n\ndef _enumerate_unread_sections(gBlock):\n output = []\n for i, s in enumerate(gBlock.sections):\n if not s.read:\n output.append((i, s))\n return output\n\ndef _get_next_n_words_and_section_indices(gBlock, exclude_set, n):\n indices = []\n new_lemmas = []\n unread_sections = _enumerate_unread_sections(gBlock)\n\n while len(indices) <= n and unread_sections:\n index, section = unread_sections.pop(0)\n next_lemmas = section.lemmas\n next_new_lemmas = _filter_lemmas_by_new(next_lemmas, exclude_set)\n if len(new_lemmas) == 0 or len(new_lemmas) + len(next_new_lemmas) <= n:\n indices.append(index)\n new_lemmas.extend(next_new_lemmas)\n else:\n break\n\n return {'indices': indices,\n 'lemmas': new_lemmas}\n\n"
},
{
"alpha_fraction": 0.7345090508460999,
"alphanum_fraction": 0.7361773252487183,
"avg_line_length": 36.81081008911133,
"blob_id": "8b350751d7e953af1e83dab3913370bc1db07932",
"content_id": "0a6bcf7c165b60f3e021d70ca2e1688a54aa54ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4196,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 111,
"path": "/yondeoku/japanese/getDefinition.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8\n\nimport re\nfrom pprint import pprint\nimport itertools\nfrom yondeoku.japanese.monash_edict_search import *\nfrom yondeoku.Definition import Definition\n\nedict_path = 'yondeoku/japanese/edict2'\n\nclass fakeEdictEntry(object):\n \n def __init__(self, japanese=None, furigana=None, glosses=[], tags=set(), unparsed=[]):\n # Japanese - note, if only a kana reading is present, it's\n # stored as \"japanese\", and furigana is left as None.\n self.japanese = japanese\n self.furigana = furigana\n # Native language glosses\n self.glosses = glosses\n # Info fields should be inserted here as \"tags\".\n self.tags = tags\n # Currently unhandled stuff goes here...\n self.unparsed = unparsed\n\n#str -> [edictEntry object]\n#edictEntry - {glosses[], unparsed[], furigana'', japanese'', tags[set]}\ndef searchEdict(query):\n\tkp = Parser(edict_path)\n\tresults = []\n\tsearch = kp.search(query)\n\tfor result in search:\n\t\t#removes any strings in brackets from the japanese definition\n\t\tresult.japanese = re.sub('\\(.*?\\)', '', result.japanese)\n\t\t#adds multiple EdictEntry objects if any japanese definitions contain\n\t\t#multiple definitions, so that they can be compared for closeness\n\t\t#separately\n\t\tif ';' in result.japanese:\n\t\t\tparts = result.japanese.split(';')\n\t\t\tfor part in parts:\n\t\t\t\tresults.append(fakeEdictEntry(japanese=part, furigana=result.furigana,\n\t\t\t\t\t\tglosses=result.glosses, tags=result.tags, unparsed=result.unparsed))\n\t\telse:\n\t\t\tresults.append(result)\n\treturn results\n\n#str, [obj] -> filtered[obj]\n#filters the list of edictEntry objects returned by searchEdict\n#to return a list of those edictEntry's whose Japanese is closest\n#in length to the original search term\ndef getClosestEntries(word, candidateEntries):\n\t#first filter any results where the searched word is not actually in the Japanese\n\tcandidateEntries = filter(lambda x: word in x.japanese, candidateEntries)\n\t#if there are no results left (or none to start with), just return a faked object\n\tif candidateEntries == []:\n\t\treturn []\n\twordLength = len(word)\n\tcandidateWords = map(lambda x: x.japanese, candidateEntries)\n\t#prints the word and the current candidates to the console\n\t#this is so that we can continue to improve the way we select\n\t#the closest entries, as we need to see them before they're filtered\n\t#over time for different entries that come up\n\tdeveloperInspection(word, candidateWords)\n\tcandidateWordLengths = map(len, candidateWords)\n\tcandidateWordDistances = map(lambda x: abs(wordLength - x), candidateWordLengths)\n\t#filter to return all entries with the minimum distance\t\n\tminDistance = min(candidateWordDistances)\n\tselectors = [x == minDistance for x in candidateWordDistances]\n\tclosestEntries = list(itertools.compress(candidateEntries, selectors))\n\treturn closestEntries\n\n#str => [{japanese: '', glosses: []}]\n#returns all items from the edict which had the closest length to the\n#original search term. I recommend checking to see if any add only extra\n#kana when the final definition is presented to the user, as this should\n#be the best match\ndef getDefinition(token):\n\tresult = []\n\tshortened = 0\n\tmax = 2\n\twhile not result:\n\t\tif shortened > 0:\n\t\t\ttoken = token[:-shortened]\n\t\tEdictEntries = searchEdict(token)\n\t\tfilteredEdictEntries = getClosestEntries(token, EdictEntries)\n\t\tfor entry in filteredEdictEntries:\n\t\t\tjapanese = entry.japanese\n\t\t\tglosses = entry.glosses[:3]\n\t\t\tfurigana = entry.furigana\n\t\t\toutput = {'japanese': japanese, 'glosses': glosses, 'furigana': furigana}\n\t\t\tresult.append(output)\n\t\tif shortened <= max:\n\t\t\tshortened = shortened + 1\n\t\telse:\n\t\t\tbreak\n\treturn result\n\ndef getDefObjList(token):\n\t'''Returns a list of Definition objects. To be used by the\n\tjaDefiner class. This is partly a wrapper on getDefinition\n\tfor temporary backwards compatibility.'''\n\tdef objToDefinition(obj):\n\t\treturn Definition(obj.glosses, obj.furigana, obj.japanese)\n\n\tdefinitionList = getDefinition(token)\n\tresult = map(objToDefinition, definitionList)\n\treturn result\n\ndef developerInspection(word, candidateWords):\n\tprint 'search token: ' + word + ':\\n'\n\tprint 'search results:\\n' + '\\n'.join(candidateWords) + '\\n'"
},
{
"alpha_fraction": 0.4352501630783081,
"alphanum_fraction": 0.43536338210105896,
"avg_line_length": 13.296116828918457,
"blob_id": "5641edb0bfa874b3b4811923e3d66d56d1ec9e33",
"content_id": "9b0f154480954f96e1d5e2e3aa7e841b453d989d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9072,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 618,
"path": "/yondeoku/polish/grammarWords.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python \n# -*- coding: utf-8 -*-\n\nplGrammarWords = [\n \"a\",\n \"aby\",\n \"albo\",\n \"ale\",\n \"ani\",\n \"aż\",\n \"bez\",\n \"beze\",\n \"blisko\",\n \"bo\",\n \"ci\",\n \"ciebie\",\n \"cię\",\n \"co\",\n \"cokolwiek\",\n \"coś\",\n \"czasami\",\n \"czego\",\n \"czemu\",\n \"czterdziestoma\",\n \"czterdziestu\",\n \"czterdzieści\",\n \"czterech\",\n \"czterej\",\n \"czterem\",\n \"czterema\",\n \"czternastoma\",\n \"czternastu\",\n \"czternaście\",\n \"cztery\",\n \"czterysta\",\n \"czterystoma\",\n \"czterystu\",\n \"czworga\",\n \"czworgiem\",\n \"czworgu\",\n \"czworo\",\n \"czy\",\n \"czyi\",\n \"czyich\",\n \"czyim\",\n \"czyimi\",\n \"czyj\",\n \"czyja\",\n \"czyje\",\n \"czyjego\",\n \"czyjej\",\n \"czyjemu\",\n \"czyjkolwiek\",\n \"czyją\",\n \"czyjś\",\n \"czym\",\n \"często\",\n \"dla\",\n \"dlaczego\",\n \"dlaczegokolwiek\",\n \"dlaczegoś\",\n \"dlatego\",\n \"do\",\n \"dokąd\",\n \"dokądkolwiek\",\n \"dokąds\",\n \"dotąd\",\n \"dość\",\n \"dwa\",\n \"dwadzieścia\",\n \"dwaj\",\n \"dwanaście\",\n \"dwie\",\n \"dwiema\",\n \"dwieście\",\n \"dwoje\",\n \"dwojga\",\n \"dwojgiem\",\n \"dwojgu\",\n \"dwom\",\n \"dwoma\",\n \"dwu\",\n \"dwudziestoma\",\n \"dwudziestu\",\n \"dwunastoma\",\n \"dwunastu\",\n \"dwustoma\",\n \"dwustu\",\n \"dwóch\",\n \"dwóm\",\n \"dziesięcioma\",\n \"dziesięciu\",\n \"dziesięć\",\n \"dziewięcioro\",\n \"dziewięciuset\",\n \"dziewiętnastoma\",\n \"dziewiętnastu\",\n \"dziewiętnaście\",\n \"dziewięć\",\n \"dziewięćset\",\n \"dzisiaj\",\n \"dziwięcioma\",\n \"dziwięciorga\",\n \"dziwięciorgiem\",\n \"dziwięciorgu\",\n \"dziwięciu\",\n \"dziwięćdziesiąt\",\n \"dziwięćdziesięcioma\",\n \"dziwięćdziesięciu\",\n \"dzięki\",\n \"dziś\",\n \"gdy\",\n \"gdzie\",\n \"gdziekolwiek\",\n \"gdzieś\",\n \"go\",\n \"i\",\n \"ich\",\n \"ile\",\n \"iloma\",\n \"ilu\",\n \"im\",\n \"inna\",\n \"inne\",\n \"innego\",\n \"innej\",\n \"innemu\",\n \"inni\",\n \"inny\",\n \"innych\",\n \"innym\",\n \"innymi\",\n \"inną\",\n \"ja\",\n \"jacy\",\n \"jak\",\n \"jaka\",\n \"jaki\",\n \"jakich\",\n \"jakie\",\n \"jakiego\",\n \"jakiej\",\n \"jakiemu\",\n \"jakikolwiek\",\n \"jakim\",\n \"jakimi\",\n \"jakiś\",\n \"jakkolwiek\",\n \"jakoś\",\n \"jaką\",\n \"je\",\n \"jeden\",\n \"jedenastoma\",\n \"jedenastu\",\n \"jedenaście\",\n \"jedna\",\n \"jedne\",\n \"jednego\",\n \"jednej\",\n \"jednemu\",\n \"jedni\",\n \"jedno\",\n \"jednych\",\n \"jednym\",\n \"jednymi\",\n \"jedną\",\n \"jego\",\n \"jej\",\n \"jemu\",\n \"jeszcze\",\n \"jeśli\",\n \"jutro\",\n \"już\",\n \"ją\",\n \"każda\",\n \"każde\",\n \"każdego\",\n \"każdej\",\n \"każdemu\",\n \"każdy\",\n \"każdym\",\n \"każdą\",\n \"kiedy\",\n \"kiedykolwiek\",\n \"kiedyś\",\n \"kilka\",\n \"kilkoma\",\n \"kilku\",\n \"kim\",\n \"kogo\",\n \"komu\",\n \"koło\",\n \"kto\",\n \"ktokolwiek\",\n \"ktoś\",\n \"która\",\n \"które\",\n \"którego\",\n \"której\",\n \"któremu\",\n \"który\",\n \"których\",\n \"którykolwiek\",\n \"którym\",\n \"którymi\",\n \"któryś\",\n \"którzy\",\n \"którą\",\n \"którędy\",\n \"ku\",\n \"mi\",\n \"milion\",\n \"miliona\",\n \"milionach\",\n \"milionami\",\n \"milionem\",\n \"milionie\",\n \"milionom\",\n \"milionowi\",\n \"miliony\",\n \"milionów\",\n \"mimo\",\n \"mię\",\n \"między\",\n \"mnie\",\n \"mną\",\n \"moi\",\n \"moich\",\n \"moim\",\n \"moimi\",\n \"moja\",\n \"moje\",\n \"mojego\",\n \"mojej\",\n \"mojemu\",\n \"moją\",\n \"mu\",\n \"my\",\n \"mój\",\n \"na\",\n \"nad\",\n \"nade\",\n \"nam\",\n \"nami\",\n \"naokoło\",\n \"naprzeciw\",\n \"narpzeciwko\",\n \"nas\",\n \"nasi\",\n \"nasz\",\n \"nasza\",\n \"nasze\",\n \"naszego\",\n \"naszej\",\n \"naszemu\",\n \"naszych\",\n \"naszym\",\n \"naszymi\",\n \"naszą\",\n \"nic\",\n \"nich\",\n \"niczego\",\n \"niczemu\",\n \"niczym\",\n \"nie\",\n \"niego\",\n \"niej\",\n \"niektóre\",\n \"niektórych\",\n \"niektórym\",\n \"niektórymi\",\n \"niektórzy\",\n \"niemu\",\n \"nigdy\",\n \"nigdzie\",\n \"nijak\",\n \"nikim\",\n \"nikogo\",\n \"nikomu\",\n \"nikt\",\n \"nim\",\n \"nimi\",\n \"nią\",\n \"niż\",\n \"o\",\n \"oba\",\n \"obaj\",\n \"obie\",\n \"obiema\",\n \"oboje\",\n \"obojga\",\n \"obojgiem\",\n \"obojgu\",\n \"obok\",\n \"oboma\",\n \"obu\",\n \"obydwoje\",\n \"obydwojga\",\n \"obydwojgiem\",\n \"obydwojgu\",\n \"od\",\n \"ode\",\n \"odtąd\",\n \"około\",\n \"on\",\n \"ona\",\n \"one\",\n \"oni\",\n \"ono\",\n \"oprócz\",\n \"osiem\",\n \"osiemdziesiąt\",\n \"osiemdziesięcioma\",\n \"osiemdziesięciu\",\n \"osiemnastoma\",\n \"osiemnastu\",\n \"osiemnaście\",\n \"osiemset\",\n \"owa\",\n \"owe\",\n \"owego\",\n \"owej\",\n \"owemu\",\n \"owi\",\n \"owo\",\n \"owych\",\n \"owym\",\n \"owymi\",\n \"ową\",\n \"ośmioma\",\n \"ośmiorga\",\n \"ośmiorgiem\",\n \"ośmiorgu\",\n \"ośmioro\",\n \"ośmiu\",\n \"ośmiuset\",\n \"pan\",\n \"pana\",\n \"panach\",\n \"panami\",\n \"panem\",\n \"pani\",\n \"paniach\",\n \"paniami\",\n \"panie\",\n \"paniom\",\n \"panią\",\n \"panom\",\n \"panowie\",\n \"panu\",\n \"panów\",\n \"paroma\",\n \"paru\",\n \"parę\",\n \"pań\",\n \"państwa\",\n \"państwem\",\n \"państwo\",\n \"państwu\",\n \"pewien\",\n \"pewna\",\n \"pewne\",\n \"pewnego\",\n \"pewnej\",\n \"pewnemu\",\n \"pewni\",\n \"pewnych\",\n \"pewnym\",\n \"pewnymi\",\n \"pewną\",\n \"pięcioma\",\n \"pięciorga\",\n \"pięciorgiem\",\n \"pięciorgu\",\n \"pięcioro\",\n \"pięciu\",\n \"pięciuset\",\n \"pięcset\",\n \"piętnastoma\",\n \"piętnastu\",\n \"piętnaście\",\n \"pięć\",\n \"pięćdziesiąt\",\n \"pięćdziesięcioma\",\n \"pięćdziesięciu\",\n \"po\",\n \"pod\",\n \"podczas\",\n \"pode\",\n \"podług\",\n \"ponieważ\",\n \"potem\",\n \"poza\",\n \"pośród\",\n \"przeciw\",\n \"przeciwko\",\n \"przed\",\n \"przede\",\n \"przedtem\",\n \"przez\",\n \"przeze\",\n \"przy\",\n \"prócz\",\n \"raz\",\n \"rzadko\",\n \"sam\",\n \"sama\",\n \"same\",\n \"samego\",\n \"samej\",\n \"samemu\",\n \"sami\",\n \"samo\",\n \"samych\",\n \"samym\",\n \"samymi\",\n \"samą\",\n \"siebie\",\n \"siedem\",\n \"siedemdziesiąt\",\n \"siedemdziesięcioma\",\n \"siedemdziesięciu\",\n \"siedemnastoma\",\n \"siedemnastu\",\n \"siedemnaście\",\n \"siedemset\",\n \"siedmiorga\",\n \"siedmiorgiem\",\n \"siedmiorgu\",\n \"siedmioro\",\n \"siedmiu\",\n \"siedmiuset\",\n \"siedzmioma\",\n \"się\",\n \"skąd\",\n \"skądkolwiek\",\n \"skądś\",\n \"sobie\",\n \"sobą\",\n \"spośród\",\n \"sto\",\n \"stoma\",\n \"stu\",\n \"stąd\",\n \"swoi\",\n \"swoich\",\n \"swoim\",\n \"swoimi\",\n \"swoja\",\n \"swoje\",\n \"swojego\",\n \"swojej\",\n \"swojemu\",\n \"swoją\",\n \"swój\",\n \"szesnastoma\",\n \"szesnastu\",\n \"szesnaście\",\n \"sześcioma\",\n \"sześciorga\",\n \"sześciorgiem\",\n \"sześciorgu\",\n \"sześcioro\",\n \"sześciu\",\n \"sześciuset\",\n \"sześć\",\n \"sześćdziesiąt\",\n \"sześćdziesięcioma\",\n \"sześćdziesięciu\",\n \"sześćset\",\n \"ta\",\n \"tacy\",\n \"tak\",\n \"taka\",\n \"taki\",\n \"takich\",\n \"takie\",\n \"takiego\",\n \"takiej\",\n \"takiemu\",\n \"takim\",\n \"takimi\",\n \"taką\",\n \"tam\",\n \"tamtędy\",\n \"tcyh\",\n \"te\",\n \"tego\",\n \"tej\",\n \"temu\",\n \"ten\",\n \"teraz\",\n \"to\",\n \"tobie\",\n \"tobą\",\n \"troje\",\n \"trojga\",\n \"trojgiem\",\n \"trojgu\",\n \"trzech\",\n \"trzej\",\n \"trzem\",\n \"trzema\",\n \"trzy\",\n \"trzydziestoma\",\n \"trzydziestu\",\n \"trzydzieści\",\n \"trzynastoma\",\n \"trzynastu\",\n \"trzynaście\",\n \"trzysta\",\n \"trzystoma\",\n \"trzystu\",\n \"tu\",\n \"tutaj\",\n \"twa\",\n \"twe\",\n \"twego\",\n \"twej\",\n \"twemu\",\n \"twoi\",\n \"twoich\",\n \"twoim\",\n \"twoimi\",\n \"twoja\",\n \"twoje\",\n \"twojego\",\n \"twojej\",\n \"twojemu\",\n \"twoją\",\n \"twych\",\n \"twym\",\n \"twymi\",\n \"twój\",\n \"twą\",\n \"ty\",\n \"tyle\",\n \"tyloma\",\n \"tylu\",\n \"tym\",\n \"tymi\",\n \"tysiąc\",\n \"tysiąca\",\n \"tysiącach\",\n \"tysiącami\",\n \"tysiące\",\n \"tysiącem\",\n \"tysiącom\",\n \"tysiącowi\",\n \"tysiącu\",\n \"tysięcy\",\n \"tą\",\n \"tę\",\n \"tędy\",\n \"u\",\n \"w\",\n \"wam\",\n \"wami\",\n \"was\",\n \"wasi\",\n \"wasz\",\n \"wasza\",\n \"wasze\",\n \"waszego\",\n \"waszej\",\n \"waszemu\",\n \"waszych\",\n \"waszym\",\n \"waszymi\",\n \"waszą\",\n \"wczoraj\",\n \"we\",\n \"według\",\n \"wiele\",\n \"wieloma\",\n \"wielu\",\n \"wokoło\",\n \"wokół\",\n \"wszyscy\",\n \"wszystek\",\n \"wszystka\",\n \"wszystkich\",\n \"wszystkie\",\n \"wszystkiego\",\n \"wszystkiej\",\n \"wszystkiemu\",\n \"wszystkim\",\n \"wszystkimi\",\n \"wszystko\",\n \"wszystką\",\n \"wszędzie\",\n \"wtedy\",\n \"wy\",\n \"wśród\",\n \"z\",\n \"za\",\n \"zamiast\",\n \"zanim\",\n \"zaraz\",\n \"zawsze\",\n \"zbyt\",\n \"ze\",\n \"zwykle\",\n \"ów\",\n \"żaden\",\n \"żadna\",\n \"żadne\",\n \"żadnego\",\n \"żadnej\",\n \"żadnemu\",\n \"żadni\",\n \"żadnych\",\n \"żadnym\",\n \"żadnymi\",\n \"żadną\",\n \"że\",\n \"żeby\"\n]"
},
{
"alpha_fraction": 0.7213982939720154,
"alphanum_fraction": 0.7213982939720154,
"avg_line_length": 26,
"blob_id": "b6a314caf77ae7be2122b206928e533d9342e531",
"content_id": "6135f642d6427b7447e00c25838e041d9179fc5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 944,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 35,
"path": "/yondeoku/define.py",
"repo_name": "onlyskin/yondeoku",
"src_encoding": "UTF-8",
"text": "from yondeoku.languageAPI import languageAPI\n\n# [{Lemma}...] -> [ [{Definition}...] ... ]\ndef makeDefinitionListFromLemmaList(language, lemmaList):\n\t'''A method to which returns a list of lists of {Definition}\n\tobjects. The input must take the form of a list of {Lemma}\n\tobjects. All Lemma objects must be from the same language,\n\twhich is to be specified when calling the function so that\n\tthe correct definer will be instantiated.'''\n\ttry:\n\t\tassert language in languageAPI.keys()\n\texcept:\n\t\traise ValueError\n\n\tif lemmaList == []:\n\t\treturn []\n\n\t#{Lemma} -> [{Definition}...]\n\tdef makeDefinitionList(language, Lemma, definer):\n\n\t\ttry:\n\t\t\tassert language in languageAPI.keys()\n\t\texcept:\n\t\t\traise ValueError\n\n\t\tif Lemma.word == '':\n\t\t\treturn []\n\n\t\treturn definer.define(Lemma.word)\n\n\tdefiner = languageAPI[language]().definer\n\tdefinitionListList = map(\n\t\tlambda x: makeDefinitionList(language, x, definer),\n\t\tlemmaList)\n\treturn definitionListList"
}
] | 58 |
EM180303/Projeto-Python
|
https://github.com/EM180303/Projeto-Python
|
161c43552436f63ca1e9a0a16e738cf9b8a7dfa7
|
4194f5ee561e1c8ec1c0128ca713e1f627cb4429
|
d8220c69d9168314f568423195df7ac5326e00d5
|
refs/heads/master
| 2023-02-02T09:26:14.458396 | 2020-12-19T01:10:01 | 2020-12-19T01:10:01 | 313,179,446 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5448889136314392,
"alphanum_fraction": 0.5799999833106995,
"avg_line_length": 26.765432357788086,
"blob_id": "1424cac25cb341a1b012d0f5ea1d878a735bb78e",
"content_id": "a7e35ff85f141557d8cec9348d06ed721ea9a994",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2252,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 81,
"path": "/Eduardo_Marques_Jokenpo.py",
"repo_name": "EM180303/Projeto-Python",
"src_encoding": "UTF-8",
"text": "import os\nimport time\nfrom typing import Container\nnome = []\njokenpo = []\njokenpo.append('x')\njokenpo.append('Pedra')\njokenpo.append('Papel')\njokenpo.append('Tesoura')\nescolha = []\nescolha.append('x')\nrodada = []\nrodada.append(0)\nrodada.append(0)\nrodada.append(0)\nvencedor = False\n\nprint('***Bem vindos!***')\nprint('Preparados para o Jokenpo? Sim?')\n# para que o nome do jogador 1 fique na lista com o indice 1 e o nome do jogador 2 no 2\nnome.append('x')\nnome.append(str(input('Então informe o nome do jogador 1: ')))\nnome.append(str(input('Agora o nome do jogador 2: ')))\n\nprint('\\n Quem vencer 2 rodadas primeiro ganha')\n\ntime.sleep(2)\nos.system(\"cls\")\n\nwhile (vencedor == False):\n for cont in [1, 2]:\n print('Somente ', nome[cont], ' pode ver apartir de agora \\n')\n for i in [1, 2, 3]:\n print('Digite ',i,' para escolher ',jokenpo[i])\n escolha.insert(cont, int(input()))\n print('Você escolheu ',jokenpo[escolha[cont]])\n\n time.sleep(2)\n os.system(\"cls\")\n\n for i in [1, 2]: \n print(nome[i],' escolheu: ',jokenpo[i])\n \n time.sleep(2)\n os.system(\"cls\")\n\n if (escolha[1] == escolha[2]):\n print('Empate')\n time.sleep(2)\n os.system(\"cls\")\n rodada[0]+= 1\n elif (((escolha[1] == 1) and (escolha[2] == 3)) or ((escolha[1] == 2) and (escolha[2] == 1)) or ((escolha[1] == 3) and (escolha[2] == 2))): \n print(nome[1],' ganhou essa rodada')\n time.sleep(2)\n os.system(\"cls\")\n rodada[1] += 1\n rodada[0]+= 1\n elif (((escolha[2] == 1) and (escolha[1] == 3)) or ((escolha[2] == 2) and (escolha[1] == 1)) or ((escolha[2] == 3) and (escolha[1] == 2))): \n print(nome[2],' ganhou essa rodada')\n time.sleep(2)\n os.system(\"cls\")\n rodada[2] += 1\n rodada[0] += 1\n\n if ((rodada[1] == 2) or (rodada[2] == 2)):\n vencedor = True\n else:\n vencedor = False\n\nos.system(\"cls\")\n\nif(rodada[1] > rodada[2]):\n print('O vencedor foi ',nome[1])\n print('Placar: ')\n print(nome[1],': ',rodada[1],' X ',nome[2],' : ',rodada[2])\n print('Quantidade de rodadas: ',rodada[0])\nelse:\n print('O vencedor foi ',nome[2])\n print('Placar: ')\n print(nome[1],': ',rodada[1],' X ',nome[2],' : ',rodada[2])\n print('Quantidade de rodadas: ',rodada[0])\n\n"
},
{
"alpha_fraction": 0.5631533265113831,
"alphanum_fraction": 0.6040940880775452,
"avg_line_length": 39.046512603759766,
"blob_id": "05363990d7b0f9830ef76005754d36b9fe5134d1",
"content_id": "35c4de8daa6cd32dd84657d6891de6576d45f7ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6983,
"license_type": "no_license",
"max_line_length": 520,
"num_lines": 172,
"path": "/Feria_Organica_Eduardo_Marques.py",
"repo_name": "EM180303/Projeto-Python",
"src_encoding": "UTF-8",
"text": "import os\nimport time\n\nfolhas = ('Alface americano', 'Alface crespa', 'Alho poró', 'Capim santo', 'Cebola', 'Cebolinha', 'Coentro', 'Couve folha', 'Chinguezay (acelga chinesa)', 'Espinafre', 'Hortelã', 'Salsinha', 'Rúcula')\npreçoFolhas = (2.50, 2.50, 2.00, 2.50, 3.00, 2.50, 2.50, 2.50, 3.00, 3.00, 2.50, 2.50, 2.50)\n\nfrutas = ('Banana pacovan', 'Cana (Saquinho)', 'Laranja comum', 'Laranja mimo', 'Maracujá (1 Kg)')\npreçoFrutas = (0.25, 2.00, 0.50, 0.50, 7.00)\n\nraizes = ('Batata doce (1 Kg)', 'Cará (1 Kg)', 'Cenoura', 'Jerimum (1 Kg)', 'Macaxeira (1 Kg)', 'Rabanete', 'Quiabo')\npreçoRaizes = (4.00, 5.00, 3.00, 5.00, 4.00, 2.50, 0.13)\n\noutros = ('Fava seca (1 Kg)', 'Mel italiana (250 g)', 'Mel italiana (5 g)', 'Mel no favo (450 gramas)', 'Ovos de capoeira', 'Polpa de cajá (400 g)', 'Própolis (20 ml)', 'Pão com trigo (Pequeno)', 'Bolo (S / Trigo)', 'Bolinho de bacia (c / trigo)', 'Mini pizza', 'Pizza brotinho', 'Bolacha C / Trigo (Saquinho)', 'Sucos S / Açúcar (200 ml)', 'Sucos C / Açúcar (200 ml)', 'Sucos (1 litro)', 'Refeições congeladas (500 g)', 'Refeições congeladas (750 g)', 'Hambúrguer de ora-pro-nóbis', 'Molhos prontos', 'Massa artesanal')\npreçoOutros = (12.00, 20.00, 35.00, 25.00, 1.00, 6.00, 16.00, 7.00, 10.00, 2.00, 3.00, 5.00, 5.00, 3.00, 3.00, 10.00, 12.00, 15.00, 2.00, 10.00, 12.00) \n\npastinhas = ('Pepita de girassol', 'Homus de grão de bico com páprica', 'Bisnaga maionese de pepita girassol (250 ml)', 'Pimentas ao mel de engenho', 'Confit de tomatinho, Pimenta, Pimentão ou Berinjela', 'Geleia de tomate C / Pimenta, Abacaxi ou Manga', 'Caponata Siciliana')\npreçoPastinhas = (5.00, 10.00, 10.00, 15.00, 15.00, 13.00, 13.00)\n\nlanchesST = ('Quiche de macaxeira C / Alho poró', 'Quiche de macaxeira C / Tomate seco', 'Sanduiche S / Glúten de ricota', 'Sanduíche S / Glúten de caponata Siciliana', 'Sanduíche S / Glúten de ragu')\npreçoLanchesST = (5.00, 5.00, 6.00, 6.00, 6.00)\n\nlanchesCT = ('Empada de falso camarão', 'Empada de antepasto de berinjela', 'Empada de Tofu C / Cebola caramelizada', 'Pãozinhos de inhame recheados')\npreçoLanchesCT = (5.00, 5.00, 5.00, 5.00)\n\nformasPagamento = ('Dinheiro', 'Cartão de crédito', 'Cartão de débito')\n\ncarrinhoV = []\nquantidade = 0\ncarrinhoP = []\ncontinuar = True\ncarrinhoQ = []\ntotal = 0\nverificador = False\n\ndef exibir(x, y, z):\n print('-=' * 35)\n print('CÓDIGO PRODUTO VAlOR')\n print('*' * 70)\n for i in range(x):\n print(f'{i} - {y[i]} - R$ {z[i]}')\n print('*' * 70)\n print()\n time.sleep(1)\n\nwhile continuar == True: \n verificador = False\n while verificador == False:\n\n print('\\tFOLHAS E HORTALIÇAS / O MOLHO(Nº0)') \n exibir(len(folhas), folhas, preçoFolhas)\n\n print('\\tFRUTAS(Nº1)')\n exibir(len(frutas), frutas, preçoFrutas)\n\n print('\\tRAÍZES, TUBÉRCULOS, LEGUMES E AFINS(Nº2)')\n exibir(len(raizes), raizes, preçoRaizes)\n\n print('\\tOUTROS(Nº3)')\n exibir(len(outros), outros, preçoOutros)\n\n print('\\tPASTINHAS, ANTEPASTOS E GELEIAS(Nº4)')\n exibir(len(pastinhas), pastinhas, preçoPastinhas)\n\n print('\\tLANCHES (sem trigo)(Nº5)')\n exibir(len(lanchesST), lanchesST, preçoLanchesST)\n\n print('\\tLANCHES (com trigo)(Nº6)')\n exibir(len(lanchesCT), lanchesCT, preçoLanchesCT)\n\n nLista = int(input('Digite o número da lista em que o produto que você deseja se encontra: '))\n\n time.sleep(1)\n os.system(\"cls\")\n\n def escolhaP (x,y):\n produto = int(input('Qual o código do produto que você deseja? '))\n quantidade = int(input(f'Quantos(a) {x[produto]} você deseja? '))\n valor = (quantidade * y[produto])\n print(f'Vai ficar R$ {valor}')\n carrinhoQ.append(quantidade)\n carrinhoV.append(valor)\n carrinhoP.append(x[produto])\n carrinhoAtual = sum(carrinhoV)\n print(f'Seu carrinho = {carrinhoAtual}')\n\n if nLista == 0:\n print('\\tFOLHAS E HORTALIÇAS / O MOLHO(Nº0)') \n exibir(len(folhas), folhas, preçoFolhas)\n escolhaP(folhas, preçoFolhas)\n verificador = True\n elif nLista == 1:\n print('\\tFRUTAS(Nº1)')\n exibir(len(frutas), frutas, preçoFrutas)\n escolhaP(frutas, preçoFrutas)\n verificador = True\n elif nLista == 2:\n print('\\tRAÍZES, TUBÉRCULOS, LEGUMES E AFINS(Nº2)')\n exibir(len(raizes), raizes, preçoRaizes)\n escolhaP(raizes, preçoRaizes)\n verificador = True\n elif nLista == 3:\n print('\\tOUTROS(Nº3)')\n exibir(len(outros), outros, preçoOutros)\n escolhaP(outros, preçoOutros)\n verificador = True\n elif nLista == 4:\n print('\\tPASTINHAS, ANTEPASTOS E GELEIAS(Nº4)')\n exibir(len(pastinhas), pastinhas, preçoPastinhas)\n escolhaP(pastinhas, preçoPastinhas)\n verificador = True\n elif nLista == 5:\n print('\\tLANCHES (sem trigo)(Nº5)')\n exibir(len(lanchesST), lanchesST, preçoLanchesST)\n escolhaP(lanchesST, preçoLanchesST)\n verificador = True\n elif nLista == 6:\n print('\\tLANCHES (com trigo)(Nº6)')\n exibir(len(lanchesCT), lanchesCT, preçoLanchesCT)\n escolhaP(lanchesCT, preçoLanchesCT)\n verificador = True\n else:\n print('Lista não encontrada')\n time.sleep(2)\n os.system(\"cls\")\n verificador = False\n\n time.sleep(2)\n os.system(\"cls\")\n \n pergunta = str(input('Deseja continuar comprando? {S para sim / N para não} '))\n pergunta = pergunta.upper()\n\n if pergunta == 'S':\n continuar = True\n elif pergunta == 'N':\n continuar = False\n print('Compra encerrada')\n\n time.sleep(2)\n os.system(\"cls\")\n\nnome = str(input('Qual o seu nome? '))\nendereço = str(input('Qual seu endereço? '))\nfor i in range(3):\n print(f'{i} - Se for pagar em {formasPagamento[i]}')\n\npagamento = int(input('Qual forma de pagamento? {0/1/2} '))\n\nprint('Obrigado pela preferência, volte sempre!')\n\ntotal = sum(carrinhoV)\n\nwith open('Comprovante.txt', 'x', encoding = 'utf8') as arquivo:\n arquivo.write('\\t\\tCUPOM FISCAL\\n')\n arquivo.write(50 * '-=')\n arquivo.write('\\n')\n arquivo.write(f'Nome: {nome}\\n')\n arquivo.write(f'Endereço: {endereço}\\n')\n arquivo.write(f'Forma de pagamento: {formasPagamento[pagamento]}\\n')\n arquivo.write('\\n')\n arquivo.write('Nº - PRODUTO - QUANTIDADE - VALOR\\n')\n arquivo.write(50 * '-=')\n arquivo.write('\\n')\n for i in range(len(carrinhoP)):\n arquivo.write(f'{i+1} - {carrinhoP[i]} - {carrinhoQ[i]} - R$ {carrinhoV[i]}\\n')\n arquivo.write('\\n')\n arquivo.write(f'Total: R$ {total}')\n\nos.system(\"cls\")\n\narquivo = open('Comprovante.txt', encoding='utf8')\nprint(arquivo.read())\n"
}
] | 2 |
NexusRJ/Market
|
https://github.com/NexusRJ/Market
|
74d7cf9046183c86f4ee35aa2c74e0de31e1ec12
|
f247817301df84a459fec90c60aff08def55f7f1
|
e8294631698488db64e6b73c7eb05bad2f0a323a
|
refs/heads/master
| 2016-07-30T22:21:46.327137 | 2015-05-30T06:47:32 | 2015-05-30T06:47:32 | 34,556,706 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6757936477661133,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 32.171051025390625,
"blob_id": "66291a04fd6d84df4d8a7d57fe989a8fe1c940ba",
"content_id": "63a0b0bb1e642cf19b2b642c600e4f9a1b3f78c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2520,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 76,
"path": "/Marketapp/models.py",
"repo_name": "NexusRJ/Market",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib import admin\n\n\nclass User(models.Model):\n\n ''' no primary key so django will make a default primary key called 'id' '''\n username = models.CharField(max_length=30)\n password = models.CharField(max_length=30)\n employee_name = models.CharField(max_length=30)\n sex = models.CharField(max_length=10)\n department = models.CharField(max_length=20)\n tel = models.CharField(max_length=15)\n email = models.EmailField(max_length=100)\n\n class Meta:\n ordering = ('id',)\n\n\nclass Goods(models.Model):\n good_name = models.CharField(max_length=30)\n good_type = models.CharField(max_length=20)\n good_num = models.IntegerField(max_length=10)\n class Meta:\n ordering = ('id',)\n\n\nclass Account(models.Model):\n account_type = models.IntegerField(max_length=2)\n good_name = models.CharField(max_length=20)\n amount = models.FloatField(max_length=20)\n date = models.DateTimeField(auto_now_add=True)\n\n class Meta:\n ordering = ('-date',)\n\n\nclass Sellrecords(models.Model):\n date = models.DateTimeField(auto_now_add=True)\n good_name = models.CharField(max_length=20)\n good_type = models.CharField(max_length=20)\n good_num = models.IntegerField(max_length=20)\n sell_price = models.FloatField(max_length=20)\n username = models.CharField(max_length=30)\n account = models.ForeignKey(Account, related_name=\"sellAccount\")\n\n class Meta:\n ordering = ('-date',)\n\n\nclass Purchrecords(models.Model):\n date = models.DateTimeField(auto_now_add=True)\n inORout = models.CharField(max_length=5)\n good_name = models.CharField(max_length=20)\n good_type = models.CharField(max_length=20)\n good_num = models.CharField(max_length=20)\n pur_price = models.FloatField(max_length=20)\n username = models.CharField(max_length=30)\n account = models.ForeignKey(Account, related_name=\"purchAccount\")\n\n class Meta:\n ordering = ('-date',)\n\n\nclass UserAdmin(admin.ModelAdmin):\n list_display = ('id', 'username', 'employee_name', 'sex', 'email', 'department', 'tel')\n\nclass PurchrecordsAdmin(admin.ModelAdmin):\n list_display = ('id', 'good_name', 'good_type', 'good_num', 'pur_price', 'username', 'date')\n\nclass SellrecordsAdmin(admin.ModelAdmin):\n list_display = ('id', 'good_name', 'good_type', 'good_num', 'sell_price', 'username', 'date')\n\nadmin.site.register(User, UserAdmin)\nadmin.site.register(Purchrecords, PurchrecordsAdmin)\nadmin.site.register(Sellrecords, SellrecordsAdmin)"
},
{
"alpha_fraction": 0.6171334981918335,
"alphanum_fraction": 0.6217715740203857,
"avg_line_length": 40.655303955078125,
"blob_id": "f1ec6a8a67aac77dd1d0952b80418259c6487879",
"content_id": "210f7a130bad9985cfa4ab9132253a9bda036edf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10996,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 264,
"path": "/Marketapp/views.py",
"repo_name": "NexusRJ/Market",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponseRedirect, HttpResponse, HttpResponseForbidden, HttpResponseServerError\nfrom django.shortcuts import render\nfrom .models import User, Goods, Sellrecords, Purchrecords, Account\nfrom django.contrib.sessions import *\nonepage = 4\n\ndef login(request):\n if request.REQUEST.get(\"username\") and request.REQUEST.get(\"passwd\"):\n username = request.REQUEST.get(\"username\")\n passwd = request.REQUEST.get(\"passwd\")\n try:\n u = User.objects.get(username=username)\n if passwd == u.password:\n request.session[\"username\"] = username\n return HttpResponseRedirect('/')\n except:\n return render(request, \"cues/PasswdWrong.html\", {})\n\n else:\n return render(request, \"login.html\", {})\n\n\ndef index(request):\n if \"username\" in request.session:\n try:\n username = request.session.get(\"username\")\n u = User.objects.get(username=username)\n return render(request, \"index.html\", {\"truename\": u.employee_name})\n except Exception:\n del request.session[\"username\"]\n return HttpResponseRedirect(\"/login\")\n else:\n return HttpResponseRedirect(\"/login\")\n\n\ndef register(request):\n if request.REQUEST.get(\"username\"):\n username = request.REQUEST.get(\"username\")\n try:\n u = User.objects.get(username=username)\n return render(request, \"cues/Wrong.html\", {\"truename\": \"Guest\", \"failinfo\": 3, \"link\": \"/\"})\n except:\n pass\n passwd = request.REQUEST.get(\"passwd\")\n truename = request.REQUEST.get(\"truename\")\n sex = request.REQUEST.get(\"sex\")\n department = request.REQUEST.get(\"department\")\n phonenum = request.REQUEST.get(\"phonenum\")\n email = request.REQUEST.get(\"email\")\n try:\n p = User.objects.create(username=username, password=passwd, employee_name=truename, sex=sex, department=department, tel=phonenum, email=email)\n request.session[\"username\"] = username\n return render(request, \"cues/SignSuccess.html\", {})\n except:\n return render(request, \"cues/Wrong.html\", {\"truename\": \"Guest\", \"failinfo\": 4, \"link\": \"/\"})\n else:\n return render(request, \"cues/Wrong.html\", {\"truename\": \"Guest\", \"failinfo\": 4, \"link\": \"/\"})\n\n\ndef logout(request):\n del request.session[\"username\"]\n return HttpResponseRedirect('/')\n\n\ndef userinfo(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n return render(request, \"userinfo.html\", {\"username\": u.username, \"truename\": u.employee_name, \"sex\": u.sex, \"department\": u.department, \"phonenum\": u.tel, \"email\": u.email,})\n\n\ndef purchin(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n return render(request, \"purchin.html\", {\"truename\": u.employee_name})\n\n\ndef purchout(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n return render(request, \"purchout.html\", {\"truename\": u.employee_name})\n\n\ndef purch(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n if request.REQUEST.get(\"type\"):\n type = request.REQUEST.get(\"type\")\n good_name = request.REQUEST.get(\"goodname\")\n good_type = request.REQUEST.get(\"goodtype\")\n good_num = int(request.REQUEST.get(\"goodnum\"))\n pur_price = float(request.REQUEST.get(\"purchprice\"))\n if type == \"in\":\n try:\n g = Goods.objects.get(good_name=good_name)\n g.good_num += good_num\n g.save()\n except:\n g = Goods.objects.create(good_name=good_name, good_type=good_type, good_num=good_num)\n a = Account.objects.create(account_type=-1, good_name=good_name, amount=good_num*pur_price)\n p = Purchrecords.objects.create(inORout=type, good_name=good_name, good_type=good_type, good_num=good_num, pur_price=pur_price, username=username, account=a)\n elif type == \"out\":\n try:\n g = Goods.objects.get(good_name=good_name)\n except:\n return render(request, \"cues/Wrong.html\", {\"truename\": u.employee_name, \"failinfo\": 1, \"link\": \"/purchout\"})\n if g.good_num < good_num:\n return render(request, \"cues/Wrong.html\", {\"truename\": u.employee_name, \"failinfo\": 2, \"link\": \"/purchout\"})\n g.good_num -= good_num\n a = Account.objects.create(account_type=1, good_name=good_name, amount=good_num*pur_price)\n p = Purchrecords.objects.create(inORout=type, good_name=good_name, good_type=good_type, good_num=good_num, pur_price=pur_price, username=username, account=a)\n if g.good_num==0:\n g.delete()\n else:\n g.save()\n return HttpResponseRedirect('/')\n else:\n return render(request, \"purchin.html\", {\"truename\": u.employee_name, })\n\ndef sale(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n if request.REQUEST.get(\"sellprice\"):\n good_name = request.REQUEST.get(\"goodname\")\n good_num = int(request.REQUEST.get(\"goodnum\"))\n sell_price = float(request.REQUEST.get(\"sellprice\"))\n try:\n g = Goods.objects.get(good_name=good_name)\n except:\n return render(request, \"cues/Wrong.html\", {\"truename\": u.employee_name, \"failinfo\": 1, \"link\": \"/sale\"})\n if g.good_num < good_num:\n return render(request, \"cues/Wrong.html\", {\"truename\": u.employee_name, \"failinfo\": 2, \"link\": \"/sale\"})\n g.good_num -= good_num\n\n a = Account.objects.create(account_type=1, good_name=good_name, amount=good_num*sell_price)\n p = Sellrecords.objects.create(good_name=good_name, good_type=g.good_type, good_num=good_num, sell_price=sell_price, username=username, account=a)\n if g.good_num == 0:\n g.delete()\n else:\n g.save()\n return HttpResponseRedirect(\"/\")\n else:\n return render(request, \"sale.html\", {\"truename\": u.employee_name, })\n\ndef goods(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n try:\n curpage = int(request.GET.get('curPage', 1))\n allpage = int(request.GET.get('allPage', 1))\n pagetype = str(request.GET.get('pageType', ''))\n except ValueError:\n curpage = 1\n allpage = 1\n pagetype = ''\n #just calculate once when first connect db\n if curpage == 1 and allpage == 1:\n allpagecounts = Goods.objects.count()\n allpage = allpagecounts/onepage\n remainpages = allpagecounts % onepage\n if remainpages > 0:\n allpage += 1\n if pagetype == 'pageUp':\n curpage -= 1\n elif pagetype == 'pageDown':\n curpage += 1\n startpage = (curpage-1) * onepage\n endpage = startpage + onepage\n goods = Goods.objects.all()[startpage:endpage]\n return render(request, \"goods.html\", {\"goods\": goods, \"truename\": u.employee_name, 'curPage': curpage, 'allPage': allpage })\n\n\ndef salerec(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n try:\n curpage = int(request.GET.get('curPage', 1))\n allpage = int(request.GET.get('allPage', 1))\n pagetype = str(request.GET.get('pageType', ''))\n except ValueError:\n curpage = 1\n allpage = 1\n pagetype = ''\n #just calculate once when first connect db\n if curpage == 1 and allpage == 1:\n allpagecounts = Sellrecords.objects.count()\n allpage = allpagecounts/onepage\n remainpages = allpagecounts % onepage\n if remainpages > 0:\n allpage += 1\n if pagetype == 'pageUp':\n curpage -= 1\n elif pagetype == 'pageDown':\n curpage += 1\n startpage = (curpage-1) * onepage\n endpage = startpage + onepage\n recs = Sellrecords.objects.all()[startpage:endpage]\n return render(request, \"saleRecs.html\", {\"recs\": recs, \"truename\": u.employee_name, 'curPage': curpage, 'allPage': allpage})\n\ndef purchrec(request):\n username = request.session[\"username\"]\n u = User.objects.get(username=username)\n try:\n curpage = int(request.GET.get('curPage', 1))\n allpage = int(request.GET.get('allPage', 1))\n pagetype = str(request.GET.get('pageType', ''))\n except ValueError:\n curpage = 1\n allpage = 1\n pagetype = ''\n #just calculate once when first connect db\n if curpage == 1 and allpage == 1:\n allpagecounts = Purchrecords.objects.count()\n allpage = allpagecounts/onepage\n remainpages = allpagecounts % onepage\n if remainpages > 0:\n allpage += 1\n if pagetype == 'pageUp':\n curpage -= 1\n elif pagetype == 'pageDown':\n curpage += 1\n startpage = (curpage-1) * onepage\n endpage = startpage + onepage\n recs = Purchrecords.objects.all()[startpage:endpage]\n return render(request, \"purRecs.html\", {\"recs\": recs, \"truename\": u.employee_name, 'curPage': curpage, 'allPage': allpage})\n\n\ndef changePasswd(request):\n username = request.session['username']\n u = User.objects.get(username=username)\n if not request.REQUEST.get(\"oldpassword\"):\n return render(request, \"changePasswd.html\", {\"username\": username, \"truename\": u.employee_name})\n else:\n oldpassword = request.REQUEST.get(\"oldpassword\")\n newpassword = request.REQUEST.get(\"newpassword2\")\n if u.password == oldpassword:\n try:\n u.password = newpassword\n u.save()\n return render(request, \"cues/ChangeSuccess.html\", {\"truename\": u.employee_name})\n except:\n return render(request, \"cues/ChangeFailed.html\", {\"truename\": u.employee_name, \"failinfo\": 1})\n else:\n return render(request, \"cues/ChangeFailed.html\", {\"truename\": u.employee_name, \"failinfo\": 2})\n #return render(request, \"cues/ChangeFailed.html\", {\"truename\": u.employee_name})\n\n\ndef statistics(request):\n username = request.session['username']\n u = User.objects.get(username=username)\n inamount = Purchrecords.objects.filter(inORout='in')\n outamount = Purchrecords.objects.filter(inORout='out')\n sellamount = Sellrecords.objects.all()\n inValue = outValue = sellValue = 0.0\n for each in inamount:\n inValue += float(each.pur_price)*int(each.good_num)\n for each in outamount:\n outValue += float(each.pur_price)*int(each.good_num)\n for each in sellamount:\n sellValue += float(each.sell_price)*int(each.good_num)\n cashFlow = sellValue - inValue + outValue\n return render(request, \"statistics.html\", {\"truename\": u.employee_name, \"inValue\": inValue, \"outValue\": outValue, \"sellValue\": sellValue, \"cashFlow\": cashFlow})\n\ndef SomethingWrong(request, trouble):\n pass"
},
{
"alpha_fraction": 0.40935006737709045,
"alphanum_fraction": 0.40935006737709045,
"avg_line_length": 40.761905670166016,
"blob_id": "e428792a91d8167e4d13bb9edeaeca35de18d5f8",
"content_id": "fc6fd714d015cd3f81917a93a4951a0e7b2ec744",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 877,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 21,
"path": "/Marketapp/urls.py",
"repo_name": "NexusRJ/Market",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import patterns, include, url\nfrom django.http import request\nfrom Marketapp.views import *\n\nurlpatterns = patterns('',\n url(r'^$', index),\n url(r'^login$', login),\n url(r'^register$', register),\n url(r'^logout$', logout),\n url(r'^userinfo$', userinfo),\n url(r'^purch$', purch),\n url(r'^purchin$', purchin),\n url(r'^purchout$', purchout),\n url(r'^sale$', sale),\n url(r'^goods$', goods),\n url(r'^salerec$', salerec),\n url(r'^purchrec$', purchrec),\n url(r'^changePasswd$', changePasswd),\n url(r'^statistics$', statistics),\n\n )\n"
}
] | 3 |
KeivanR/Hanoi
|
https://github.com/KeivanR/Hanoi
|
1a1a69af2950bafc8ba4d785eaf54d47b4d5447a
|
c343b8a1ac74f7a5c876cf76bdc3423ceacf58b2
|
bc2ee472c3016553fd4d36776fddd287b3610a4f
|
refs/heads/master
| 2022-11-06T01:10:36.480489 | 2020-06-24T09:29:02 | 2020-06-24T09:29:02 | 274,472,128 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5088967680931091,
"alphanum_fraction": 0.5516014099121094,
"avg_line_length": 16.5625,
"blob_id": "0ed86a48d4313db8546e736fdbb69efe10e36ffc",
"content_id": "9553bd3af73106eb3865752a57920abc0d439485",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 843,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 48,
"path": "/hanoi.py",
"repo_name": "KeivanR/Hanoi",
"src_encoding": "UTF-8",
"text": "import time\nn = 12\nfirst_pile = []\nfor i in range(n,0,-1):\n\tfirst_pile.append(i)\ntab = [first_pile,[],[]]\ndisk = []\nnothing = ''\nfor i in range(0,1+4*(n-1)):\n\tnothing+=' '\nfor i in range(1,n+1):\n\tstr = ''\n\tfor j in range(0,2*(n-i)):\n\t\tstr+=' '\n\tfor j in range(0,1+4*(i-1)):\n\t\tstr+='_'\n\tfor j in range(0,2*(n-i)):\n\t\tstr+=' '\n\tdisk.append(str)\nprint(disk)\ndef strpiece(tab_col,j):\n\tif j>=len(tab_col):\n\t\treturn nothing\n\telse:\n\t\treturn disk[tab_col[j]-1]\ndef disp(tab):\n\tfor j in range(n-1,-1,-1):\n\t\tfor i in range(0,len(tab)):\n\t\t\tprint('|'+strpiece(tab[i],j),end='')\n\t\tprint('|')\n\tprint('')\n\ndef move(tab,n,i,j):\n\tif (n==1):\n\t\ttab[j].append(tab[i][-1])\n\t\tdel tab[i][-1]\n\t\tdisp(tab)\n\t\t#time.sleep(.1)\n\telse:\n\t\to = [0,1,2]\n\t\to.remove(i)\n\t\to.remove(j)\n\t\tk = o[0]\n\t\tmove(tab,n-1,i,k)\n\t\tmove(tab,1,i,j)\n\t\tmove(tab,n-1,k,j)\nprint(tab)\nmove(tab,n,0,2)\n"
}
] | 1 |
artintal/goa2
|
https://github.com/artintal/goa2
|
45121ee66d119112c33214a60b4ccc73ed14d3f5
|
792ab21640934fd20b179af0b573502fa5a98e94
|
9d6053d0654297b4f3789cbab77b7a36c707604a
|
refs/heads/master
| 2021-01-17T23:07:52.823876 | 2015-11-13T16:22:15 | 2015-11-13T16:22:15 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.5657407641410828,
"avg_line_length": 17.947368621826172,
"blob_id": "892ab708668d9eff9ec541b9ce79f9020c902e07",
"content_id": "62557a0ebd64d9358cd55defa079c982468f3a34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1080,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 57,
"path": "/benchmarks/blackscholes/test.sh",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Usage: test.sh __EXE_NAME__ size __FITNESS_FILE__\n\n#echo $0 \"$@\" >> testlog\n\nexe=$1\nsize=$2\nfitnessfile=$3\n\nroot=`dirname \"$0\"`\nroot=`cd \"$root\" ; pwd`\nroot=`dirname \"$root\"`\nroot=`dirname \"$root\"`\n\ncase \"$exe\" in\n */*) : ;;\n *) exe=./$exe ;;\nesac\n\ncase $size in\n test) input=\"inputs/in_4.txt\" ;;\n tiny) input=\"inputs/in_16.txt\" ;;\n small) input=\"inputs/in_4K.txt\" ;;\n medium) input=\"inputs/in_16K.txt\" ;;\n large) input=\"inputs/in_64K.txt\" ;;\n huge) input=\"inputs/in_10M.txt\" ;;\nesac\ngolden=`echo $input | sed -e 's/in/out/g'`\n\noutfile=`mktemp`\ntmpfit=`mktemp`\n\ncleanup() {\n test -f \"$outfile\" && rm -f \"$outfile\"\n test -f \"$tmpfit\" && rm -f \"$tmpfit\"\n}\n\ncheck_status() {\n if [ $1 -ne 0 ] ; then\n cleanup\n echo 0 > \"$fitnessfile\"\n exit $1\n fi\n}\n\n\"$root\"/bin/est-energy.py -o \"$tmpfit\" -- \"$exe\" 1 $input $outfile\ncheck_status $?\n\ndiff $outfile $golden > /dev/null 2>&1\ncheck_status $?\n\nawk '{print 1/$1}' < \"$tmpfit\" > \"$fitnessfile\"\ncleanup\n\n# exit 1 so that genprog doesn't find a \"repair\"\nexit 1\n"
},
{
"alpha_fraction": 0.46028512716293335,
"alphanum_fraction": 0.48268839716911316,
"avg_line_length": 31.719999313354492,
"blob_id": "32985daacaaa9cea10a31e1bda17b1e6ddcddbc2",
"content_id": "a200409f9f25997bf4eb01f508639b47c61b5569",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 2455,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 75,
"path": "/bin/plot_fitness.R",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/Rscript --vanilla\n\nargs <- commandArgs( TRUE )\nif ( length( args ) < 4 || length( args ) %% 2 != 0 )\n stop( \"Usage: plot_fitness.R pdffile title {legend csvfile}...\" )\n \noriginal <- NA\n\nxlim <- c( 0, 0 )\nylim <- c( 0, 0 )\nfig <- list()\nfor ( i in 2:( length(args) / 2 ) ) {\n name <- args[ i*2 - 1 ]\n csvfile <- args[ i*2 ]\n csv <- read.csv( csvfile )\n if ( \"model\" %in% names( csv ) ) {\n fig[[ name ]] <- data.frame(\n x = csv$variant, y1 = 1 / csv$model, y2 = NA\n )\n } else if ( \"generation\" %in% names( csv ) ) {\n\ttmp <- data.frame(\n x = rep( NA, max( csv$generation ) + 1 ),\n y1 = rep( NA, max( csv$generation ) + 1 ),\n y2 = rep( NA, max( csv$generation ) + 1 )\n )\n for ( j in unique( csv$generation ) ) {\n tmp$x[ j + 1 ] <- max( which( csv$generation == j ) )\n tmp$y1[ j + 1 ] <- max( csv$fitness[ csv$generation == j ] )\n tmp$y2[ j + 1 ] <- mean( csv$fitness[ csv$generation == j ] )\n }\n original <- csv$fitness[ csv$variant == \"original\" ]\n fig[[ name ]] <- tmp\n } else if ( \"best\" %in% names( csv ) ) {\n fig[[ name ]] <- data.frame(\n x = (1:nrow(csv)) * 2, y1 = csv$best, y2 = csv$average\n )\n } else {\n stop( paste( \"do not know how to process\", csvfile ) )\n }\n xlim <- range( xlim, fig[[ name ]]$x )\n ylim <- range( ylim, fig[[ name ]]$y1 )\n}\n\ncol <- rainbow( length( fig ), start = 0.55, end = 0.1 )\n\npdf( args[ 1 ] )\nplot( NA,\n xlim = xlim,\n ylim = if ( is.na( original ) ) ylim else ylim / original,\n xlab = \"fitness evaluations\",\n ylab = if ( is.na( original ) ) \"fitness\" else \"improvement\",\n main = args[ 2 ]\n)\nfor ( i in 1:length( fig ) ) {\n name <- names( fig )[ i ]\n if ( is.na( original ) )\n lines( fig[[ name ]]$x, fig[[ name ]]$y1, col = col[ i ], lwd = 2 )\n else\n lines( fig[[ name ]]$x, fig[[ name ]]$y1 / original, col = col[ i ], lwd = 2 )\n}\nif ( ! is.na( original ) ) {\n points( 0, 1, cex = 1.5 )\n col <- c( \"black\", col )\n legend <- c( \"original\", names( fig ) )\n lty <- c( 0, rep( 1, length( fig ) ) )\n lwd <- c( 1, rep( 2, length( fig ) ) )\n pch <- c( 1, rep( NA, length( fig ) ) )\n} else {\n legend <- names( fig )\n lty <- 1\n lwd <- 2\n pch <- NA\n}\nlegend( \"bottomright\", legend = legend, col = col, lwd = lwd, lty = lty, pch = pch, pt.cex = 1.5 )\ndev.off()\n\n"
},
{
"alpha_fraction": 0.515709638595581,
"alphanum_fraction": 0.539544939994812,
"avg_line_length": 31.564706802368164,
"blob_id": "7e476f93d2155c243b782cbe7606b885e7e385d1",
"content_id": "202f5bc101d53c55173255769d53ee6841a2ee7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2769,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 85,
"path": "/bin/est-energy.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\n\nfrom contextlib import contextmanager\nfrom numpy.distutils import cpuinfo\nfrom optparse import OptionParser\nimport os\nfrom subprocess import call, check_call, Popen\nimport sys\nfrom tempfile import NamedTemporaryFile\n\nparser = OptionParser(\n usage = \"%prog [options] -- command [args...]\"\n)\nparser.add_option(\n \"-o\", metavar = \"file\", help = \"write estimated Joules to the named file\"\n)\nparser.add_option(\n \"--max-simultaneous-counters\", metavar = \"N\", type = int, default = 5,\n help = \"maximum number of counters that can be collected simultaneously\"\n)\noptions, args = parser.parse_args()\n\n@contextmanager\ndef mktemp( suffix = '' ):\n try:\n tmp = NamedTemporaryFile( suffix = suffix, delete = False )\n tmp.close()\n yield tmp.name\n finally:\n if os.path.exists( tmp.name ):\n os.remove( tmp.name )\n\ndef collect_counters( counters, cmd, stdout = sys.stdout, stderr = sys.stderr):\n result = dict()\n n = options.max_simultaneous_counters\n if len( counters ) > n:\n with open( \"/dev/null\", 'w' ) as devnull:\n for group in [ counters[i:i+n] for i in range( 0, len( counters ), n ) ]:\n result.update( collect_counters( group, cmd, stdout, stderr ) )\n stdout = devnull\n stderr = devnull\n else:\n with mktemp() as datfile:\n cmd = [\n \"perf\", \"stat\", \"-o\", datfile, \"-e\", \",\".join( counters ), \"--\"\n ] + cmd\n try:\n check_call( cmd, stdout = stdout, stderr = stderr )\n except KeyboardInterrupt:\n exit( 127 )\n counters += [ \"seconds\" ]\n with open( datfile ) as fh:\n for line in fh:\n line = line.split()\n if len( line ) >= 2 and \\\n line[ 0 ][ 0 ].isdigit() and \\\n line[ 1 ] in counters:\n result[ line[ 1 ] ] = float( line[ 0 ].replace( \",\", \"\" ) )\n return result\n\ndef intel_sandybridge_power_model( d ):\n return d[ \"seconds\" ] * (\n 31.530 +\n 20.490 * ( d[ \"instructions\" ] / d[ \"cycles\" ] ) +\n 9.838 * ( ( d[ \"r532010\" ] + d[ \"r538010\" ] ) / d[ \"cycles\" ] ) +\n -4.102 * ( d[ \"cache-references\" ] / d[ \"cycles\" ] ) +\n 2962.678 * ( d[ \"cache-misses\" ] / d[ \"cycles\" ] )\n )\n\ncounters = [\n \"cycles\",\n \"instructions\",\n \"cache-references\",\n \"cache-misses\",\n]\nif cpuinfo.cpuinfo().is_AMD():\n counters += [ \"r533f00\" ]\nelse:\n counters += [ \"r532010\", \"r538010\" ]\n\nif options.o is None:\n fh = sys.stdout\nelse:\n fh = open( options.o, 'w' )\nprint >>fh, intel_sandybridge_power_model( collect_counters( counters, args ) )\n\n"
},
{
"alpha_fraction": 0.5014164447784424,
"alphanum_fraction": 0.5325779318809509,
"avg_line_length": 17.102563858032227,
"blob_id": "b91a1d870b8774f98faa94f45114948294f1a2ad",
"content_id": "ab0a144f2fa945fdeb73583d28b79471b08f3025",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1412,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 78,
"path": "/benchmarks/ferret/test.sh",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Usage: test.sh __EXE_NAME__ size __FITNESS_FILE__\n\nif [ $# -lt 3 ] ; then\n echo \"Usage: $0 __EXE_NAME__ size __FITNESS_FILE__\"\n exit 2\nfi\n\nexe=$1\nsize=$2\nfitnessfile=$3\n\nroot=`dirname \"$0\"`\nroot=`cd \"$root\" ; pwd`\nroot=`dirname \"$root\"`\nroot=`dirname \"$root\"`\n\ncase \"$exe\" in\n */*) : ;;\n *) exe=./$exe ;;\nesac\n\ncase \"$size\" in\n tiny) size=dev ;;\nesac\n\nset x $exe \"inputs/input_$size/corel\" lsh \"inputs/input_$size/queries\"\nshift\ncase $size in\n test) set x \"$@\" 5 5 1 ;;\n dev) set x \"$@\" 5 5 1 ;;\n small) set x \"$@\" 10 20 1 ;;\n medium) set x \"$@\" 10 20 1 ;;\n large) set x \"$@\" 10 20 1 ;;\n huge) set x \"$@\" 50 20 1 ;;\nesac\nshift\n\ntmpfit=`mktemp`\noutput=`mktemp`\ngolden=`dirname \"$2\" | sed -e 's/in/out/g'`\n\nrun_test() {\n set x \"$root\"/bin/est-energy.py -o \"$tmpfit\" -- \"$@\" ; shift\n set x setarch `uname -m` -R \"$@\" ; shift\n \"$@\"\n}\n\ncleanup() {\n test -f \"$output\" && rm -f \"$output\"\n test -f \"$tmpfit\" && rm -f \"$tmpfit\"\n}\n\ncheck_status() {\n if [ $1 -ne 0 ] ; then\n cleanup\n echo 0 > \"$fitnessfile\"\n exit $1\n fi\n}\n\nrun_test \"$@\" \"$output\" > /dev/null 2>&1\ncheck_status $?\n\nif [ ! -r \"$golden\" ] ; then\n mkdir -p `dirname \"$golden\"`\n cp \"$output\" \"$golden\"\nfi\n\ndiff $output $golden\ncheck_status $?\n\nawk '{print 1/$1}' < \"$tmpfit\" > \"$fitnessfile\"\ncleanup\n\n# exit 1 so that genprog doesn't find a \"repair\"\nexit 1\n"
},
{
"alpha_fraction": 0.5666897296905518,
"alphanum_fraction": 0.5713890790939331,
"avg_line_length": 30.867841720581055,
"blob_id": "0cc8fb4bec0f316de3930a87256b41803ad5266d",
"content_id": "ea8f8671789627fa0e286b49a132c2d946d48679",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7235,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 227,
"path": "/bin/minimize.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\n\nfrom contextlib import closing, contextmanager\nfrom difflib import SequenceMatcher\nimport numpy\nfrom optparse import OptionParser\nimport os\nimport re\nimport shelve\nfrom scipy.stats import mannwhitneyu\nimport shutil\nfrom subprocess import call, CalledProcessError\nimport sys\nimport tempfile\n\nroot = os.path.dirname( os.path.dirname( os.path.abspath( sys.argv[ 0 ] ) ) )\nsys.path.append( os.path.join( root, \"lib\" ) )\nfrom DD import DD\nfrom genprogutil import GenProgEnv\nfrom testutil import reduce_error\nfrom util import infomsg, mktemp\n\n# Casting minimization of energy as a delta-debugging problem. The original\n# assembly code is taken as \"yesterday's code\" and hte output from the GA is\n# taken as \"today's code.\" A subset of deltas \"passes\" if the modeled energy\n# usage is substantially different from the energy used by the GA output, and\n# fails if it is substantially the same. Thus, the minimal failing deltas\n# constitute the minimal set of deltas that have substantially the same energy\n# as the optimized variant.\n\nparser = OptionParser( usage = \"%prog [options] genprog configuration\" )\nparser.add_option(\n \"--genome\", metavar = \"genome\", help = \"minimize set of edits in genome\"\n)\nparser.add_option(\n \"--genome-file\", metavar = \"file\",\n help = \"minimize set of edits in the named file\"\n)\nparser.add_option(\n \"--sources\", metavar = \"prefix\",\n help = \"minimize line-by-line deltas from original to sources in prefix\"\n)\nparser.add_option(\n \"--search\", metavar = \"alg\",\n choices = ( \"delta\", \"brute\" ), default = \"delta\",\n help = \"algorithm for minimizing the deltas\"\n)\nparser.add_option(\n \"--alpha\", metavar = \"a\", type = float, default = 0.05,\n help = \"alpha value for statistically differentiating energy distributions\"\n)\nparser.add_option(\n \"--cache\", metavar = \"file\", help = \"cache fitness results to named file\"\n)\nparser.add_option(\n \"--compound-edits\", action = \"store_true\",\n help = \"do not convert swaps and replaces into appends and deletes\"\n)\nparser.add_option(\n \"--low-error\", metavar = \"p\", type = float, default = 0.01,\n help = \"repeat measurements until (standard error / mean) < (1+p)\"\n)\noptions, args = parser.parse_args()\n\nif len( args ) < 2:\n parser.print_help()\n exit()\n\ndeltas = None\nif options.genome is not None:\n deltas = options.genome.split()\nelif options.genome_file is not None:\n with open( options.genome_file ) as fh:\n deltas = \" \".join( fh.readlines() ).split()\nelif options.sources is not None:\n print >>sys.stderr, \"file-based differences not implemented yet\"\n exit( 2 )\nif deltas is None:\n print >>sys.stderr, \"ERROR: either --genome, --genome-file or --sources is required\"\n parser.print_help()\n exit( 1 )\n\ngenprog = args[ 0 ]\nconfigfile = args[ 1 ]\n\n########\n# \n########\n\ndef first( sequence ):\n return list( map( lambda (_,y): y, sequence ) )\n\nclass GenomeBuilder:\n def __init__( self, genprog ):\n self.genprog = genprog\n\n def build( self, genome ):\n if len( genome ) == 0:\n infomsg( \"INFO: genome: original\" )\n else:\n infomsg( \"INFO: genome:\", *first( genome ) )\n return self.genprog.build_variant( first( genome ) )\n\n def key( self, genome ):\n return \" \".join( first( genome ) )\n\nclass DDGenome( DD ):\n def __init__( self, genprog, builder, deltas ):\n DD.__init__( self )\n self.builder = builder\n self.genprog = genprog\n\n infomsg( \"INFO: computing optimized energy usage\" )\n self.optimized = self.get_fitness( deltas )\n self.mean = numpy.mean( self.optimized )\n\n def get_fitness( self, deltas ):\n global cache\n key = self.builder.key( deltas )\n if key in cache:\n return cache[ key ]\n with self.builder.build( deltas ) as exe:\n if exe is None:\n cache[ key ] = list()\n return list()\n def tester():\n fitness = self.genprog.run_test( exe )\n infomsg( \" \", fitness )\n return fitness\n fitness = list( reduce_error( tester, options.low_error, 20 ) )\n cache[ key ] = fitness\n return fitness\n\n def _test( self, deltas ):\n # \"Passing\" behavior is more like the original (slower, more energy).\n # \"Failing\" behavior is more optimized (faster, less energy).\n\n try:\n fitness = self.get_fitness( deltas )\n if len( fitness ) == 0:\n return self.UNRESOLVED\n if any( map( lambda f: f == 0, fitness ) ):\n return self.UNRESOLVED\n pval = mannwhitneyu( self.optimized, fitness )[ 1 ]\n if pval < options.alpha and numpy.mean( fitness ) < self.mean:\n return self.PASS\n else:\n return self.FAIL\n except CalledProcessError:\n return self.UNRESOLVED\n\n########\n# \n########\n\ndef brute_force( dd, deltas ):\n def powerset( deltas ):\n if len( deltas ) == 0:\n yield list()\n else:\n for grp in powerset( deltas[ 1: ] ):\n yield grp\n yield [ deltas[ 0 ] ] + grp\n best = deltas\n for grp in powerset( deltas ):\n if len( grp ) >= len( best ):\n continue\n if dd._test( grp ) == dd.FAIL:\n best = grp\n return best\n\ndef get_builder( deltas ):\n if options.sources is None:\n if not options.compound_edits:\n fieldpat = re.compile( r'[a-z]\\((\\d+),(\\d+)\\)' )\n pending = list( reversed( deltas ) )\n deltas = list()\n while len( pending ) > 0:\n gene = pending.pop()\n if gene[ 0 ] == 'a':\n deltas.append( gene )\n elif gene[ 0 ] == 'd':\n deltas.append( gene )\n elif gene[ 0 ] == 'r':\n m = fieldpat.match( gene )\n dst, src = m.group( 1, 2 )\n pending += [ 'd(%s)' % dst, 'a(%s,%s)' % ( dst, src ) ]\n elif gene[ 0 ] == 's':\n m = fieldpat.match( gene )\n dst, src = m.group( 1, 2 )\n pending += [\n 'r(%s,%s)' % ( dst, src ),\n 'r(%s,%s)' % ( src, dst )\n ]\n else:\n infomsg( \"ERROR: unrecognized gene:\", gene )\n exit( 1 )\n deltas = list( enumerate( deltas ) )\n builder = GenomeBuilder( genprog )\n else:\n print >>sys.stderr, \"file-based differences not implemented yet\"\n exit( 2 )\n return deltas, builder\n\n@contextmanager\ndef memcache():\n yield dict()\n\n########\n#\n########\n\ngenprog = GenProgEnv( genprog, configfile )\n\nif options.cache is not None:\n get_cache = lambda: closing( shelve.open( options.cache ) )\nelse:\n get_cache = memcache\n\nwith get_cache() as cache:\n deltas, builder = get_builder( deltas )\n dd = DDGenome( genprog, builder, deltas )\n if options.search == \"delta\":\n deltas = dd.ddmin( deltas )\n else:\n deltas = brute_force( dd, deltas )\n infomsg( \"simplified genome:\\n \", *first( deltas ) )\n\n"
},
{
"alpha_fraction": 0.5368026494979858,
"alphanum_fraction": 0.5428973436355591,
"avg_line_length": 28.20547866821289,
"blob_id": "b85a69332ea4323a47d7ea653aaec94b2940678f",
"content_id": "7d43ee0538946bf01149e94ebb5be1a3b27b989d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2133,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 73,
"path": "/bin/parse-genprog-log.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python2\n\nimport csv\nfrom optparse import OptionParser\nimport re\n\nparser = OptionParser( usage = \"%prog [options] logfile\" )\nparser.add_option(\n \"--csv\", metavar = \"file\", help = \"write generations to csv file\"\n)\nparser.add_option(\n \"--filter\", metavar = \"alg\", choices = ( \"steps\", ),\n help = \"only include a subset of variants\"\n)\noptions, args = parser.parse_args()\n\nif len( args ) < 1:\n parser.print_help()\n exit()\n\ndef mymax( a, b ):\n if a is None:\n return b\n if b is None:\n return a\n return max( a, b )\n\nvariant_pat = re.compile( r\"^\\t\\s*(\\d+(\\.\\d+)?)\\s+(.*)\" )\ngeneration_pat = re.compile( r\"generation (\\d+) \" )\n\noriginal = None\nbest = None\n\ngen = 0\ntable = list()\nwith open( args[ 0 ] ) as fh:\n for line in fh:\n m = variant_pat.search( line )\n if m is not None:\n fitness = float( m.group( 1 ) )\n variant = m.group( 3 )\n table.append( ( gen, fitness, variant ) )\n if variant == \"original\":\n original = fitness\n best = mymax( best, fitness )\n continue\n m = generation_pat.search( line )\n if m is not None:\n gen = int( m.group( 1 ) )\n continue\n\nif options.csv is None:\n if original is not None:\n print \"original:\", original\n print \"best: \", best\n if original is not None:\n print \"improvement: %2.4g%%\" % ( ( 1 - ( original / best ) ) * 100 )\n print \"variants considered:\", len( table )\nelse:\n if options.filter is not None:\n if options.filter == \"steps\":\n new_table = list()\n current = None\n for gen, fitness, variant in table:\n if current is None or current < fitness:\n new_table.append( ( gen, fitness, variant ) )\n current = fitness\n table = new_table\n with open( options.csv, 'w' ) as fh:\n writer = csv.writer( fh )\n writer.writerow( [ \"generation\", \"fitness\", \"variant\" ] )\n for gen, fitness, variant in table:\n writer.writerow( map( str, [ gen, fitness, variant ] ) )\n\n"
},
{
"alpha_fraction": 0.5084033608436584,
"alphanum_fraction": 0.5222688913345337,
"avg_line_length": 29.113924026489258,
"blob_id": "303a5dfc4be27b2d8e81e031d9983fbd357caea1",
"content_id": "8d057ef804040af83562e75db09332612798d0d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2380,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 79,
"path": "/lib/testutil.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "from math import factorial, pi, sqrt\nimport os\nfrom subprocess import check_call\nimport sys\nfrom util import infomsg, mktemp\n\ndebug_file = None\n\ndef get_fitness(\n root, run_cmd, validate_cmd = None,\n stdout = sys.stdout, stderr = sys.stderr ):\n with mktemp() as tmpfit:\n cmd = [\n os.path.join( root, \"bin\", \"limit\" ),\n os.path.join( root, \"bin\", \"est-energy.py\" ), \"-o\", tmpfit,\n \"--\",\n ] + run_cmd\n\n if debug_file is not None:\n infomsg( \"DEBUG:\", *cmd, fh = debug_file )\n check_call( cmd, stdout = stdout, stderr = stderr )\n\n if validate_cmd is not None:\n if debug_file is not None:\n infomsg( \"DEBUG:\", *validate_cmd, fh = debug_file )\n check_call( validate_cmd, stdout = stdout, stderr = stderr )\n\n with open( tmpfit ) as fh:\n line = fh.next().strip()\n if debug_file is not None:\n infomsg( \"DEBUG: raw fitness:\", line, fh = debug_file )\n return 1.0 / float( line )\n\ndef reduce_error( f, alpha, probes = 5 ):\n global debug_file\n\n # variance computation adapted from:\n # https://en.wikipedia.org/wiki/Algorithms_for_calculating_variance\n # correction computation adapted from:\n # https://en.wikipedia.org/wiki/Unbiased_estimation_of_standard_deviation\n\n # The correction below is for odd numbers of probes. Rather than coding\n # up both corrections, we just force the number of probes to be odd.\n\n if probes % 2 == 0:\n probes += 1\n\n log = debug_file\n debug_file = None\n\n n = 0\n mean = 0.0\n M2 = 0.0\n errp = 1.0\n\n while alpha < errp:\n for i in range( probes ):\n x = f()\n if log is not None:\n infomsg( x, fh = log )\n yield x\n n = n + 1\n delta = x - mean\n mean = mean + delta / n\n M2 = M2 + delta * ( x - mean )\n var = M2 / ( n - 1 )\n if var == 0:\n break\n errp = sqrt( var / n ) / mean\n if n < 100:\n k = n // 2\n c4 = sqrt( pi / k ) * factorial ( 2*k-1 ) / ( 2 ** ( 2*k-1 ) * factorial( k - 1 ) ** 2 )\n errp = errp / c4\n\n probes += probes\n\n if log is not None:\n infomsg( n, \"probes: relative standard error =\", errp, fh = log )\n debug_file = log\n\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.5594315528869629,
"avg_line_length": 24.766666412353516,
"blob_id": "dc6ee46b6a5588ddfd0db4595a9b6abd5a18a48e",
"content_id": "8421e482d858eacab6d25e3bb3a6a15bcb5263a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 774,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 30,
"path": "/lib/util.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "from contextlib import contextmanager\nimport os\nimport sys\nimport tempfile\n\ndef infomsg( arg1, *args, **kwargs ):\n fh = kwargs.get( \"fh\", sys.stdout )\n extra = set( kwargs.keys() ) - { \"fh\" }\n if len( extra ) > 0:\n raise TypeError(\n \"infomsg() got an unexpected keyword argument '%s'\" %\n next( iter( extra ) )\n )\n\n args = \" \".join( map( str, [ arg1 ] + list( args ) ) )\n print >>fh, args\n fh.flush()\n try:\n os.fsync( fh.fileno() )\n except OSError: pass\n\n@contextmanager\ndef mktemp( suffix = '' ):\n tmp = tempfile.NamedTemporaryFile( suffix = suffix, delete = False )\n try:\n tmp.close()\n yield tmp.name\n finally:\n if os.path.exists( tmp.name ):\n os.remove( tmp.name )\n\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5873016119003296,
"avg_line_length": 16.85714340209961,
"blob_id": "505dc00ebec05f8c51b41624d2f455800b16ae21",
"content_id": "d190079ff1936288ebf2ae560bff52d115d67443",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 7,
"path": "/benchmarks/blackscholes/compile.sh",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Usage: compile.sh __SOURCE_NAME__ __EXE_NAME__\n\nsrc=`dirname \"$1\"`/blackscholes.s\n\ng++ -lpthread \"$src\" -o \"$2\"\n\n"
},
{
"alpha_fraction": 0.567627489566803,
"alphanum_fraction": 0.5997782945632935,
"avg_line_length": 21,
"blob_id": "f4207252dd4202010746e8f5cac164105139a4a5",
"content_id": "5408804cb2a72dea508a09d6372ad9a8f91e0e88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1804,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 82,
"path": "/benchmarks/swaptions/test.sh",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Usage: test.sh __EXE_NAME__ size __FITNESS_FILE__\n\n#echo $0 \"$@\" >> testlog\n\nexe=$1\nsize=$2\nfitnessfile=$3\n\nroot=`dirname \"$0\"`\nroot=`cd \"$root\" ; pwd`\nroot=`dirname \"$root\"`\nroot=`dirname \"$root\"`\n\ncase \"$exe\" in\n */*) : ;;\n *) exe=./$exe ;;\nesac\n\ncase $size in\n test) args=\"-ns 1 -sm 5 -nt 1\" ;;\n tiny) args=\"-ns 3 -sm 50 -nt 1\" ;;\n small) args=\"-ns 16 -sm 10000 -nt 1\" ;;\n medium) args=\"-ns 32 -sm 20000 -nt 1\" ;;\n large) args=\"-ns 64 -sm 40000 -nt 1\" ;;\n huge) args=\"-ns 128 -sm 1000000 -nt 1\" ;;\nesac\ngolden=\"outputs/$size.txt\"\n\noutfile=`mktemp`\ntmpfit=`mktemp`\n\ncleanup() {\n test -f \"$outfile\" && rm -f \"$outfile\"\n test -f \"$tmpfit\" && rm -f \"$tmpfit\"\n}\n\ncheck_status() {\n if [ $1 -ne 0 ] ; then\n cleanup\n echo 0 > \"$fitnessfile\"\n exit $1\n fi\n}\n\n# We want to call the binary using several different wrappers. Possible reasons\n# for these wrappers include:\n# - estimate energy usage\n# - measure actual energy usage\n# - disable address space randomization\n# - force the process onto a particular CPU\n# We will accumulate the prefixes in $@. We must pay attention to the order\n# here, since, for example, we only want to estimate the energy of the binary,\n# not of the other tools...\n\n# estimate energy usage\n\nset x \"$root\"/bin/est-energy.py -o \"$tmpfit\" -- ; shift\n\n# disable address space randomization\n\nset x setarch `uname -m` -R \"$@\" ; shift\n\n########\n# run the command with the accumulated tools\n\n\"$@\" \"$exe\" $args 2> \"$outfile\" > /dev/null\ncheck_status $?\n\nif [ ! -r $golden ] ; then\n cp $outfile $golden\nfi\n\ndiff $outfile $golden > /dev/null 2>&1\ncheck_status $?\n\nawk '{print 1/$1}' < \"$tmpfit\" > \"$fitnessfile\"\ncleanup\n\n# exit 1 so that genprog doesn't find a \"repair\"\nexit 1\n"
},
{
"alpha_fraction": 0.4563106894493103,
"alphanum_fraction": 0.47192907333374023,
"avg_line_length": 31.88888931274414,
"blob_id": "4666c0b5bd53f55fc9ac1a3c34175335e036ddc8",
"content_id": "71807b617e330f96f31b47ce65b7f69e839e9bd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2369,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 72,
"path": "/lib/genprogutil.py",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "from contextlib import contextmanager\nimport os\nfrom subprocess import call, check_call\nimport tempfile\n\nfrom util import mktemp\n\nclass Config( dict ):\n def load( self, fname ):\n with open( fname ) as fh:\n for line in fh:\n terms = line.strip().split( None, 1 )\n if len( terms ) == 1:\n self[ terms[ 0 ] ] = None\n else:\n self[ terms[ 0 ] ] = terms[ 1 ]\n\nclass GenProgEnv:\n def __init__( self, genprog, configfile ):\n self.genprog = genprog\n self.configfile = configfile\n self.config = Config()\n\n self.config.load( configfile )\n\n @contextmanager\n def build_variant( self, genome ):\n if len( genome ) == 0:\n genome = [ \"original\" ]\n\n seed = self.config.get( \"--config\", \"0\" )\n\n cmd = [\n self.genprog, self.configfile,\n \"--seed\", seed,\n \"--keep-source\",\n \"--no-test-cache\",\n \"--search\", \"oracle\",\n \"--oracle-genome\", \" \".join( genome ),\n \"--test-command\", \"true\",\n ]\n\n keepfiles = [ \"000000\", \"repair.debug.\" + seed ]\n\n tmpdir = tempfile.mkdtemp( dir = \".\" )\n try:\n for fname in keepfiles:\n if os.path.exists( fname ):\n os.rename( fname, os.path.join( tmpdir, fname ) )\n with open( \"/dev/null\", 'w' ) as fh:\n check_call( cmd, stdout = fh, stderr = fh )\n\n if os.path.exists( \"000000/000000\" ):\n yield \"000000/000000\"\n else:\n yield None\n finally:\n for fname in keepfiles:\n if os.path.exists( fname ):\n check_call( [ \"rm\", \"-rf\", fname ] )\n if os.path.exists( os.path.join( tmpdir, fname ) ):\n os.rename( os.path.join( tmpdir, fname ), fname )\n check_call( [ \"rm\", \"-rf\", tmpdir ] )\n\n def run_test( self, exe ):\n cmd = self.config[ \"--test-command\" ]\n cmd = cmd.replace( \"__EXE_NAME__\", exe )\n with mktemp() as fitnessfile:\n tmp = cmd.replace( \"__FITNESS_FILE__\", fitnessfile )\n call( [ \"sh\", \"-c\", tmp ] )\n with open( fitnessfile ) as fh:\n return float( fh.next().strip() )\n\n"
},
{
"alpha_fraction": 0.4996817409992218,
"alphanum_fraction": 0.5493316650390625,
"avg_line_length": 19.946666717529297,
"blob_id": "3664075cca32cfdc8930f7fdc2c01ad540c5463a",
"content_id": "b4ebdf806232e8ed6b51d164cf8f704adc5d0ef0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1571,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 75,
"path": "/benchmarks/bodytrack/test.sh",
"repo_name": "artintal/goa2",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Usage: test.sh __EXE_NAME__ size __FITNESS_FILE__\n\nif [ $# -lt 3 ] ; then\n echo \"Usage: $0 __EXE_NAME__ size __FITNESS_FILE__\"\n exit 2\nfi\n\nexe=$1\nsize=$2\nfitnessfile=$3\n\nroot=`dirname \"$0\"`\nroot=`cd \"$root\" ; pwd`\nroot=`dirname \"$root\"`\nroot=`dirname \"$root\"`\n\ncase \"$exe\" in\n */*) : ;;\n *) exe=./$exe ;;\nesac\n\ncase $size in\n test) set x $exe inputs/sequenceB_1 4 1 5 1 0 1 ;;\n tiny) set x $exe inputs/sequenceB_1 4 1 100 3 0 1 ;;\n small) set x $exe inputs/sequenceB_1 4 1 1000 5 0 1 ;;\n medium) set x $exe inputs/sequenceB_2 4 2 2000 5 0 1 ;;\n large) set x $exe inputs/sequenceB_4 4 4 4000 5 0 1 ;;\n huge) set x $exe inputs/sequenceB_261 4 261 4000 5 0 1 ;;\nesac\nshift\ninput=$2\ngolden=\"outputs/$size\"\n\nbackup=`mktemp --suffix .tgz`\ntmpfit=`mktemp`\ntar cfz \"$backup\" \"$input\"\n\nrun_test() {\n set x \"$root\"/bin/est-energy.py -o \"$tmpfit\" -- \"$@\" ; shift\n set x setarch `uname -m` -R \"$@\" ; shift\n \"$@\"\n}\n\ncleanup() {\n rm -rf \"$input\"\n test -f \"$backup\" && tar xzf \"$backup\" && rm -f \"$backup\"\n test -f \"$tmpfit\" && rm -f \"$tmpfit\"\n}\n\ncheck_status() {\n if [ $1 -ne 0 ] ; then\n cleanup\n echo 0 > \"$fitnessfile\"\n exit $1\n fi\n}\n\nrun_test \"$@\" > /dev/null\ncheck_status $?\n\nif [ ! -d \"$golden\" ] ; then\n mkdir -p \"$golden\"\n ( cd \"$input\" ; tar cf - . ) | ( cd \"$golden\" ; tar xf - )\nfi\n\ndiff -r $input $golden > /dev/null 2>&1\ncheck_status $?\n\nawk '{print 1/$1}' < \"$tmpfit\" > \"$fitnessfile\"\ncleanup\n\n# exit 1 so that genprog doesn't find a \"repair\"\nexit 1\n"
}
] | 12 |
jeremylcarter/pyrtition
|
https://github.com/jeremylcarter/pyrtition
|
5c97a9167ee28d0b2a5bb234ce111098139172c2
|
7d1f40995a09bb71154ad040e33058e7d8f7de0e
|
9f3d7ef029e0ee5dd78c9ab4cc7fa1cce4a711e8
|
refs/heads/master
| 2021-07-13T11:33:53.554132 | 2021-01-21T01:46:57 | 2021-01-21T01:46:57 | 228,796,870 | 1 | 1 |
MIT
| 2019-12-18T08:47:08 | 2020-03-10T02:51:37 | 2020-03-10T03:45:47 |
Python
|
[
{
"alpha_fraction": 0.7650273442268372,
"alphanum_fraction": 0.7650273442268372,
"avg_line_length": 17.299999237060547,
"blob_id": "ed647252dc5bcc75737d52404155417a58fb8e87",
"content_id": "fcddf3fd0176ad8c27ff2a14e71504218d0e91f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 10,
"path": "/pyrtition/topic/topic_message.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\nfrom datetime import datetime\nfrom typing import Any\n\n\n@dataclass()\nclass TopicMessage:\n producer_name: str\n timestamp: datetime\n data: Any\n"
},
{
"alpha_fraction": 0.6267123222351074,
"alphanum_fraction": 0.6438356041908264,
"avg_line_length": 21.538461685180664,
"blob_id": "2023964cb966cdba0f3d78787281478a53b64a96",
"content_id": "635c38bbd050d7f43a12e2a41ffac6f08afe41ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 13,
"path": "/setup.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\n\nsetup(\n name=\"pyrtition\",\n version=\"1.0.5\",\n packages=find_packages(exclude=\"tests\"),\n license='MIT',\n author='Jeremy Carter',\n author_email='[email protected]',\n python_requires='>=3.6',\n url=\"https://github.com/jeremylcarter/pyrtition\"\n)"
},
{
"alpha_fraction": 0.7767857313156128,
"alphanum_fraction": 0.7767857313156128,
"avg_line_length": 15,
"blob_id": "d8756123ba889797937c69fd5249fdf05936f9bd",
"content_id": "26d7a03fab04b34e326d31a18ce19c0ce2d55fad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 7,
"path": "/pyrtition/topic/topic_partition_capacity.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from dataclasses import dataclass\n\n\n@dataclass\nclass TopicPartitionCapacity:\n number: int\n producers: int\n"
},
{
"alpha_fraction": 0.6820566654205322,
"alphanum_fraction": 0.6820566654205322,
"avg_line_length": 30.766666412353516,
"blob_id": "454cb34db79a368af67eb924eb57ab47f6652fcb",
"content_id": "09b035e21be0a86a46ecf7b052ef1c63dcb77f9b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 953,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 30,
"path": "/pyrtition/consumer/threaded_topic_consumer.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from typing import Dict, Callable\n\nfrom pyrtition.consumer.topic_partition_consumer_thread import TopicPartitionConsumerThread\nfrom pyrtition.topic.topic_coordinator import TopicCoordinator\nfrom pyrtition.topic.topic_message import TopicMessage\n\n\nclass ThreadedTopicConsumer:\n _topic: TopicCoordinator\n _threads: Dict[int, TopicPartitionConsumerThread]\n\n on_message: Callable[[TopicMessage, int, int], None]\n\n def __init__(self, topic: TopicCoordinator):\n self._topic = topic\n self._threads = dict()\n\n def start(self):\n for partition in self._topic.partitions.values():\n thread = TopicPartitionConsumerThread(partition, self.on_message)\n self._threads[partition.number] = thread\n\n for thread in self._threads.values():\n thread.start()\n\n def stop(self):\n for thread in self._threads.values():\n thread.stop()\n thread.join()\n del thread\n"
},
{
"alpha_fraction": 0.6863753199577332,
"alphanum_fraction": 0.6940873861312866,
"avg_line_length": 30.1200008392334,
"blob_id": "ee185bdd43a11a61d1c4658a0acab9e36d391cc0",
"content_id": "f05256f54396501fa1bc91d5d6a1b4aa53de3b51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 25,
"path": "/tests/test_threaded_topic_consumer.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "import time\nfrom unittest import TestCase\n\nfrom pyrtition.topic.topic_coordinator import TopicCoordinator\nfrom pyrtition.topic.topic_message import TopicMessage\n\n\nclass TestThreadedTopicConsumer(TestCase):\n def test_start(self):\n topic_coordinator = TopicCoordinator(\"test\", 4)\n topic_coordinator.start_consuming(on_message, False)\n\n producers = 10\n for i in range(0, producers):\n topic_coordinator.publish(f\"producer-{i}\", i)\n for i in range(0, producers):\n topic_coordinator.publish(f\"producer-{i}\", i)\n time.sleep(1)\n topic_coordinator.stop_consuming()\n\n\ndef on_message(message: TopicMessage, partition_number: int, thread_id: int):\n print(message)\n print(partition_number)\n print(thread_id)\n"
},
{
"alpha_fraction": 0.6671428680419922,
"alphanum_fraction": 0.6700000166893005,
"avg_line_length": 29.434782028198242,
"blob_id": "bde4490d71c5105a662a2093cb9caa25895d4e98",
"content_id": "4bc8eed902e85b27879225c7b3c8771117c0707c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 700,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 23,
"path": "/tests/test_coordinator.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom pyrtition.coordinator import Coordinator\n\n\nclass TestCoordinator(TestCase):\n def test_get_or_create_topic(self):\n coordinator = Coordinator()\n coordinator.get_or_create_topic(\"topic\")\n\n is_in_topics = \"topic\" in coordinator.topics\n self.assertTrue(is_in_topics)\n\n def test_publish(self):\n coordinator = Coordinator()\n coordinator.get_or_create_topic(\"topic\")\n\n is_in_topics = \"topic\" in coordinator.topics\n self.assertTrue(is_in_topics)\n\n coordinator.publish(\"topic\", \"test\", 1)\n assigned = coordinator.topics[\"topic\"].get_producer_partition(\"test\")\n self.assertTrue(assigned > 0)\n"
},
{
"alpha_fraction": 0.5587392449378967,
"alphanum_fraction": 0.5587392449378967,
"avg_line_length": 32.22618865966797,
"blob_id": "8d8413a46ee57f464ed0024cfc2d3b68542c191f",
"content_id": "0d65cdd0725425a42d22156de66f1d5b8353d705",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2792,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 84,
"path": "/pyrtition/consumer/topic_partition_consumer_thread.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "import threading\nimport logging\nfrom queue import Queue\nfrom typing import Callable, Optional\n\nfrom pyrtition.topic.topic_message import TopicMessage\nfrom pyrtition.topic.topic_partition import TopicPartition\n\n\nclass TopicPartitionConsumerThread(threading.Thread):\n number: int\n running: bool = False\n\n _stop_event: threading.Event\n _signal = threading.Condition\n _topic_partition: TopicPartition\n _queue: Queue\n _on_message: Callable[[TopicMessage, int, int], None] = None\n _thread_id: int\n _use_signals: bool = False\n\n def __init__(self, topic_partition: TopicPartition,\n on_message: Optional[Callable[[TopicMessage, int, int], None]] = None,\n use_signals: bool = False):\n super(TopicPartitionConsumerThread, self).__init__()\n self.setDaemon(True)\n self.setName(f\"{topic_partition.topic_name}-{topic_partition.number}\")\n self._use_signals = use_signals\n self._signal = threading.Condition()\n self._topic_partition = topic_partition\n self._queue = topic_partition.get_queue()\n self.number = topic_partition.number\n self.running = False\n if on_message:\n self._on_message = on_message\n\n def notify(self):\n if self._use_signals:\n try:\n with self._signal:\n self._signal.notify()\n except RuntimeError as ex:\n # We have tried to notify the signal when it is being re-acquired\n pass\n\n def run(self) -> None:\n self.thread_id = threading.get_ident()\n self.running = True\n\n if self._use_signals:\n self.with_with_signals()\n else:\n self.run_without_signals()\n\n def run_without_signals(self):\n while self.running:\n message = self._queue.get()\n if message and self._on_message:\n try:\n self._on_message(message, self.number, self.thread_id)\n except Exception as ex:\n logging.exception(ex)\n pass\n self._queue.task_done()\n\n def with_with_signals(self):\n while self.running:\n self._signal.acquire()\n try:\n while self._queue.empty():\n self._signal.wait()\n message = self._queue.get()\n if message and self._on_message:\n try:\n self._on_message(message, self.number, self.thread_id)\n except Exception as ex:\n logging.exception(ex)\n pass\n finally:\n self._queue.task_done()\n self._signal.release()\n\n def stop(self):\n self.running = False\n\n"
},
{
"alpha_fraction": 0.6309947371482849,
"alphanum_fraction": 0.6337172985076904,
"avg_line_length": 38.13934326171875,
"blob_id": "330b00d3b8ac3c25e427e9f2e215b2424dd60782",
"content_id": "5c23d9a1cc5427b598d45dc3778e991047414160",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4775,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 122,
"path": "/pyrtition/topic/topic_coordinator.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "import random\nimport logging\nfrom queue import Queue\nfrom threading import RLock\nfrom typing import Dict, List, Any, Optional, Callable\n\nfrom pyrtition.topic.topic_message import TopicMessage\nfrom pyrtition.topic.topic_partition import TopicPartition\nfrom pyrtition.topic.topic_partition_capacity import TopicPartitionCapacity\n\n\nclass TopicCoordinator:\n name: str\n max_partition_count: int\n\n partitions: Dict[int, TopicPartition]\n _producer_cache: Dict[str, int]\n _lock: RLock\n\n def __init__(self, name=\"default\", max_partition_count: int = 4):\n self.name = name\n self.max_partition_count = max_partition_count\n self._lock = RLock()\n self.__partition()\n\n def __partition(self):\n self.partitions = dict()\n self.producer_cache = dict()\n for i in range(self.max_partition_count):\n self.__create_partition(i + 1)\n\n def __create_partition(self, number: int) -> bool:\n partition = TopicPartition(self.name, number)\n self.partitions[number] = partition\n return True\n\n def __assign_new_producer_to_partition(self, producer_name: str) -> int:\n self._lock.acquire()\n try:\n next_available_partition = self.__get_next_available_partition()\n if next_available_partition is not None:\n partition = self.partitions[next_available_partition]\n partition.assign_producer(producer_name)\n self.producer_cache[producer_name] = partition.number\n return partition.number\n finally:\n self._lock.release()\n\n def __get_next_available_partition(self):\n capacities = self.get_capacity()\n try:\n # Sort them in descending order\n capacities.sort(key=lambda c: c.producers)\n\n # If there is only 1 available then just return it\n if len(capacities) == 1:\n return capacities[0].number\n\n # Pick the next available zero capacity partition\n next_available_zero_capacity = next((c for c in capacities if c.producers == 0), None)\n if next_available_zero_capacity is not None:\n return next_available_zero_capacity.number\n\n # Either pick the lowest available partition or a random one\n pick_lowest = random.getrandbits(1)\n if pick_lowest:\n return capacities[0].number\n else:\n # Pick a random partition\n random_index = random.randint(0, (len(capacities) - 1))\n if random_index < len(capacities):\n return capacities[random_index].number\n\n # As a last resort just return the first partition\n return capacities[0].number\n except Exception as ex:\n logging.exception(ex)\n # As a last resort just return the first partition\n return capacities[0].number\n\n def get_producer_partition(self, producer_name: str) -> int:\n if producer_name in self.producer_cache:\n return self.producer_cache[producer_name]\n raise Exception(f\"Producer {producer_name} is not in topic {self.name}\")\n\n def get_or_add_producer_partition(self, producer_name: str) -> int:\n if producer_name in self.producer_cache:\n return self.producer_cache[producer_name]\n else:\n return self.__assign_new_producer_to_partition(producer_name)\n\n def publish(self, producer_name: str, data: Optional[Any]) -> bool:\n assigned_to = self.get_or_add_producer_partition(producer_name)\n\n if data is not None and assigned_to > 0:\n self.partitions[assigned_to].put_value(producer_name, data)\n return True\n return False\n\n def is_queue_empty(self, partition: int) -> bool:\n if self.partitions[partition]:\n return self.partitions[partition].is_queue_empty()\n\n def dequeue(self, partition: int) -> Any:\n if self.partitions[partition]:\n return self.partitions[partition].dequeue()\n\n def get_queue(self, partition: int) -> Queue:\n if self.partitions[partition]:\n return self.partitions[partition].get_queue()\n\n def get_capacity(self) -> List[TopicPartitionCapacity]:\n return list([TopicPartitionCapacity(partition.number, partition.producer_count)\n for partition in self.partitions.values()])\n\n def start_consuming(self, on_message: Callable[[TopicMessage, int, int], None] = None, use_signals: bool = False):\n for partition in self.partitions.values():\n partition.start_consuming(on_message, use_signals)\n\n def stop_consuming(self):\n for partition in self.partitions.values():\n partition.stop_consuming()\n"
},
{
"alpha_fraction": 0.8199999928474426,
"alphanum_fraction": 0.8399999737739563,
"avg_line_length": 49,
"blob_id": "adacc6a8eedc0fd003ef832f2427efc4fec1389a",
"content_id": "639464b6cbdbd6a15bd3ef6606e0b3d86bbf7af3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 4,
"path": "/README.md",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "# pyrtition\nA simple multithreaded and partitioned Producer/Consumer implementation\n\n\n"
},
{
"alpha_fraction": 0.6396476030349731,
"alphanum_fraction": 0.6400880813598633,
"avg_line_length": 30.985916137695312,
"blob_id": "d8e7c2f4c938a43044b727449be043aad8d5c83a",
"content_id": "9b94bd6a3435a5092dea39893111f7149620bc80",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2270,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 71,
"path": "/pyrtition/topic/topic_partition.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom queue import Queue\nfrom threading import RLock\nfrom typing import Set, Any, Optional, Callable\n\nfrom pyrtition.topic.topic_message import TopicMessage\n\n\nclass TopicPartition:\n topic_name: str\n number: int\n producer_count: int\n producers: Set[str]\n _queue: Queue\n _lock: RLock\n _consumer_thread: Any = None\n\n def __init__(self, name: str, number: int):\n self.topic_name = name\n self.number = number\n self.producer_count = 0\n self.producers = set()\n self._queue = Queue()\n self._lock = RLock()\n\n def dequeue(self) -> Optional[TopicMessage]:\n if not self._queue.empty():\n return self._queue.get()\n\n def is_queue_empty(self) -> bool:\n return self._queue.empty()\n\n def get_queue(self) -> Queue:\n return self._queue\n\n def has_producer(self, producer_name):\n return producer_name in self.producers\n\n def assign_producer(self, producer_name) -> int:\n self._lock.acquire()\n try:\n self.producers.add(producer_name)\n self.producer_count = len(self.producers)\n return self.producer_count\n finally:\n self._lock.release()\n\n def put_value(self, producer_name: str, data: Any):\n if not self.has_producer(producer_name):\n raise Exception(f\"Producer {producer_name} is not a member of this partition\")\n\n message = TopicMessage(producer_name=producer_name, timestamp=datetime.utcnow(), data=data)\n self._queue.put(message)\n\n # Notify any consumers\n if self._consumer_thread:\n self._consumer_thread.notify()\n\n def start_consuming(self, on_message: Callable[[TopicMessage, int, int], None] = None, use_signals: bool = False):\n # We can only consume if we have an on_message callable\n if not on_message:\n return\n\n from pyrtition.consumer.topic_partition_consumer_thread import TopicPartitionConsumerThread\n consumer_thread = TopicPartitionConsumerThread(self, on_message, use_signals)\n consumer_thread.start()\n self._consumer_thread = consumer_thread\n\n def stop_consuming(self):\n if self._consumer_thread:\n self._consumer_thread.stop()"
},
{
"alpha_fraction": 0.6535031795501709,
"alphanum_fraction": 0.662420392036438,
"avg_line_length": 29.19230842590332,
"blob_id": "385b42fd2bc3ce041eb0dc2d8a1ce1a8a3f3387d",
"content_id": "c4fd5a393d7949e78f272830fa6a57dd56292bcc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 26,
"path": "/tests/test_topic_coordinator.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom pyrtition.topic.topic_coordinator import TopicCoordinator\n\n\nclass TestTopicCoordinator(TestCase):\n\n def test_get_or_add_producer(self):\n topic_coordinator = TopicCoordinator()\n\n producers = 1000\n\n for i in range(0, producers):\n topic_coordinator.publish(f\"producer-{i}\", i)\n\n capacities = topic_coordinator.get_capacity()\n total_producers = sum(capacity.producers for capacity in capacities)\n\n dequeued = 0\n for partition in topic_coordinator.partitions.values():\n while not partition.is_queue_empty():\n partition.dequeue()\n dequeued += 1\n\n self.assertEqual(producers, total_producers)\n self.assertEqual(dequeued, total_producers)\n"
},
{
"alpha_fraction": 0.6280393004417419,
"alphanum_fraction": 0.629073977470398,
"avg_line_length": 34.796295166015625,
"blob_id": "e3235b809706866f4bb9eee8a317663574f09699",
"content_id": "a63033f7cce899a23090640d9281f71eccae6ba0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1933,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 54,
"path": "/pyrtition/coordinator.py",
"repo_name": "jeremylcarter/pyrtition",
"src_encoding": "UTF-8",
"text": "from queue import Queue\nfrom threading import RLock\nfrom typing import Dict, Callable, Optional\n\nfrom pyrtition.topic.topic_coordinator import TopicCoordinator\nfrom pyrtition.topic.topic_message import TopicMessage\n\n\nclass Coordinator:\n topics: Dict[str, TopicCoordinator]\n\n _lock: RLock\n\n def __init__(self):\n self.topics = dict()\n self._lock = RLock()\n\n def get_topic(self, topic_name: str) -> Optional[TopicCoordinator]:\n if topic_name in self.topics:\n return self.topics[topic_name]\n return None\n\n def get_or_create_topic(self, topic_name: str, max_partition_count: int = 4) -> TopicCoordinator:\n if topic_name in self.topics:\n return self.topics[topic_name]\n new_topic: TopicCoordinator\n try:\n self._lock.acquire()\n new_topic = TopicCoordinator(topic_name, max_partition_count)\n self.topics[topic_name] = new_topic\n finally:\n self._lock.release()\n return new_topic\n\n def publish(self, topic_name, producer_name, value: any, create_if_not_exists: bool = False) -> bool:\n if create_if_not_exists:\n topic = self.get_or_create_topic(topic_name)\n else:\n topic = self.get_topic(topic_name)\n if topic:\n return topic.publish(producer_name, value)\n else:\n return False\n\n def get_topic_partition_queue(self, topic_name: str, partition: int) -> Queue:\n topic = self.get_or_create_topic(topic_name)\n return topic.get_queue(partition)\n\n def create_and_start_consuming(self, topic_name: str, max_partition_count: int = 4,\n on_message: Callable[[TopicMessage, int, int], None] = None) -> TopicCoordinator:\n topic = self.get_or_create_topic(topic_name, max_partition_count)\n if on_message:\n topic.start_consuming(on_message)\n return topic\n"
}
] | 12 |
msharp9/DogBreedIdentificationKaggle
|
https://github.com/msharp9/DogBreedIdentificationKaggle
|
bd5d55c3c9018550acaaf8e474375dc522404ddd
|
8d916da7efd0254a191ac6c25da09d36dde31ae5
|
f80c7f3a2f577d82e4105fc042f011583b6d58e5
|
refs/heads/master
| 2021-05-08T20:52:49.984847 | 2018-02-13T02:14:23 | 2018-02-13T02:14:23 | 119,622,868 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6834532618522644,
"alphanum_fraction": 0.7218225598335266,
"avg_line_length": 23.52941131591797,
"blob_id": "c906a58bc5b6bb64db7c61e2ee276eda7618ea9e",
"content_id": "f51f5b8d154817f2d2dac1623e10e2707f7cd0d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 17,
"path": "/config/config.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# define the paths to the images directory\nIMAGES_PATH = \"train\"\nTEST_IMAGES_PATH = \"test\"\nOUTPUT_PATH = \"output\"\nNUM_CLASSES = 120\nINPUT_SIZE = 299\n\n# define the path to the HDF5 files\nTRAIN_HDF5 = \"hdf5/train.hdf5\"\nVAL_HDF5 = \"hdf5/val.hdf5\"\nTEST_HDF5 = \"hdf5/test.hdf5\"\n\n# path to the output model file\nMODEL_PATH = \"output/dogs.model\"\n\n# define the path to the dataset mean\nDATASET_MEAN = \"output/dogs_mean.json\"\n"
},
{
"alpha_fraction": 0.7742261290550232,
"alphanum_fraction": 0.7920592427253723,
"avg_line_length": 34.380950927734375,
"blob_id": "2503c2e0d2cd82748b1ae4b1ff02d6e345da00c1",
"content_id": "555ad9d3d058b05924990916bf734fa5a0f7296a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2972,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 84,
"path": "/train_model.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python train_model.py\n\nimport matplotlib\nmatplotlib.use(\"Agg\")\n\n# import the necessary packages\nfrom config import config\nfrom pyimagesearch.callbacks import TrainingMonitor\nfrom pyimagesearch.io import HDF5DatasetGenerator\nfrom pyimagesearch.preprocessing import ImageToArrayPreprocessor\nfrom pyimagesearch.preprocessing import SimplePreprocessor\nfrom pyimagesearch.nn.conv import FCHeadNet\nfrom keras.applications import xception\nfrom keras.applications import imagenet_utils\nfrom keras.models import Model\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom keras.optimizers import Adam\nfrom keras.optimizers import RMSprop\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.metrics import classification_report\nfrom sklearn.metrics import accuracy_score\nimport numpy as np\nimport pickle\nimport h5py\nimport os\n\n\n# construct the training image generator for data augmentation\naug = ImageDataGenerator(preprocessing_function=xception.preprocess_input,\n\trotation_range=30, zoom_range=0.2,\n\twidth_shift_range=0.2, height_shift_range=0.2, shear_range=0.1,\n\thorizontal_flip=True, fill_mode=\"nearest\")\naug2 = ImageDataGenerator(preprocessing_function=xception.preprocess_input)\n\n# # open the HDF5 database for reading then determine the index of\n# # the training and testing split, provided that this data was\n# # already shuffled *prior* to writing it to disk\n# db = h5py.File(config.TRAIN_HDF5, \"r\")\n# print(db[\"label_names\"], len(db[\"label_names\"]))\n\nsp = SimplePreprocessor(299, 299)\niap = ImageToArrayPreprocessor()\n# initialize the training and validation dataset generators\ntrainGen = HDF5DatasetGenerator(config.TRAIN_HDF5, 32, aug=aug,\n\tpreprocessors=[sp, iap], classes=config.NUM_CLASSES, set=\"train\")\nvalGen = HDF5DatasetGenerator(config.TRAIN_HDF5, 32, aug=aug2,\n\tpreprocessors=[sp, iap], classes=config.NUM_CLASSES, set=\"val\")\n\n# construct the set of callbacks\npath = os.path.sep.join([config.OUTPUT_PATH, \"{}.png\".format(\n\tos.getpid())])\ncallbacks = [TrainingMonitor(path)]\n\n# build model\nxception_model = xception.Xception(input_shape=(299,299,3), weights='imagenet', include_top=False)#, pooling='avg')\nheadModel = FCHeadNet.build(xception_model, config.NUM_CLASSES, 1024)\nmodel = Model(inputs=xception_model.input, outputs=headModel)\n# freeze the xception model layers\nfor layer in xception_model.layers:\n\tlayer.trainable = False\n\n# compile model\nopt = RMSprop(lr=0.001)\nmodel.compile(loss=\"categorical_crossentropy\", optimizer=opt,\n\tmetrics=[\"accuracy\"])\n\n# train the network\nmodel.fit_generator(\n\ttrainGen.generator(),\n\tsteps_per_epoch=trainGen.numImages // 32,\n\tvalidation_data=valGen.generator(),\n\tvalidation_steps=(valGen.numImages-valGen.startImages) // 32,\n\tepochs=1,\n\tcallbacks=callbacks, verbose=1)\n\n# save the model to file\nprint(\"[INFO] serializing model...\")\nmodel.save(config.MODEL_PATH, overwrite=True)\n\n# close the HDF5 datasets\ntrainGen.close()\nvalGen.close()\n"
},
{
"alpha_fraction": 0.7483537197113037,
"alphanum_fraction": 0.7530573606491089,
"avg_line_length": 31.212121963500977,
"blob_id": "2ac23f151001034fa7184a8662e11e51e24d9d64",
"content_id": "8e33df97e042a72962ed42389336b0a1b8446f02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2126,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 66,
"path": "/build_hdf52.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python build_hdf52.py\n\n# import the necessary packages\nfrom config import config\nfrom keras.preprocessing.image import img_to_array\nfrom keras.preprocessing.image import load_img\nfrom sklearn.preprocessing import LabelEncoder\nfrom pyimagesearch.io import HDF5DatasetWriter\nfrom imutils import paths\nimport numpy as np\nimport pandas as pd\nimport progressbar\nimport random\nimport os\n\n# Grab Label Data and build dictionary/grab class names\ndata = pd.read_csv('labels.csv')\nids_data = data['id']\nlabels_data = data['breed']\ndict_data = data.set_index('id')['breed'].to_dict()\nclassNames = [str(x) for x in np.unique(labels_data)]\n\n# grab the list of images that we'll be describing then randomly\n# shuffle them to allow for easy training and testing splits via\n# array slicing during training time\nprint(\"[INFO] loading images...\")\nimagePaths = list(paths.list_images(config.IMAGES_PATH))\nrandom.shuffle(imagePaths) # pre-shuffled, nothing wrong with shuffling again\nids = [os.path.splitext(os.path.basename(path))[0] for path in imagePaths]\nlabels = [dict_data[i] for i in ids]\n\n# encode the labels\nle = LabelEncoder()\nlabels = le.fit_transform(labels)\n\n# initialize the HDF5 dataset writer, then store the class label names in the dataset\ndataset = HDF5DatasetWriter((len(imagePaths), config.INPUT_SIZE, config.INPUT_SIZE, 3),\n\tconfig.TRAIN_HDF5)\ndataset.storeClassLabels(le.classes_)\n\n# initialize the progress bar\nwidgets = [\"Saving Images: \", progressbar.Percentage(), \" \",\n\tprogressbar.Bar(), \" \", progressbar.ETA()]\npbar = progressbar.ProgressBar(maxval=len(imagePaths),\n\twidgets=widgets).start()\n\n# loop over the images in batches\nfor i in np.arange(0, len(imagePaths)):\n # Grab values\n\timagePath = imagePaths[i]\n\tlabel = labels[i]\n\t_id = ids[i]\n\n\t# load the input image using the Keras helper utility\n\t# while ensuring the image is resized\n\timage = load_img(imagePath, target_size=(config.INPUT_SIZE, config.INPUT_SIZE))\n\timage = img_to_array(image)\n\n\t# add the features and labels to our HDF5 dataset\n\tdataset.add([image], [label], [_id])\n\tpbar.update(i)\n\n# close the dataset\ndataset.close()\npbar.finish()\n"
},
{
"alpha_fraction": 0.7234969735145569,
"alphanum_fraction": 0.7298867106437683,
"avg_line_length": 33.089107513427734,
"blob_id": "3257d259402e7557c7335674574ef47dd8938e78",
"content_id": "f15a7b6a0e9fc150d61f2bea36af4aa5c2f53674",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3443,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 101,
"path": "/build_hdf5.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python build_hdf5.py\n\n# import the necessary packages\nfrom config import config\nfrom sklearn.preprocessing import LabelEncoder\nfrom sklearn.model_selection import train_test_split\nfrom pyimagesearch.preprocessing import AspectAwarePreprocessor\nfrom pyimagesearch.io import HDF5DatasetWriter\nfrom imutils import paths\nimport numpy as np\nimport pandas as pd\nimport progressbar\nimport json\nimport cv2\nimport os\n\n# Grab Label Data and build dictionary/grab class names\ndata = pd.read_csv('labels.csv')\nids_data = data['id']\nlabels_data = data['breed']\ndict_data = data.set_index('id')['breed'].to_dict()\nclassNames = [str(x) for x in np.unique(labels_data)]\n\n# grab the paths to the images\nimagePaths = list(paths.list_images(config.IMAGES_PATH))\nids = [os.path.splitext(os.path.basename(path))[0] for path in imagePaths]\nlabels = [dict_data[i] for i in ids]\n\n# Kaggle is nice enough to prepare data for you (it's also already randomized)\n# print(ids_data == ids) # True\n# print(labels_data == labels) # True\n\n# Encode Labels\nle = LabelEncoder()\nlabels = le.fit_transform(labels)\n\n# perform stratified sampling from the training set\nsplit = train_test_split(images, labels, ids,\n\ttest_size=round(len(images)*0.15), stratify=labels)\n(trainPaths, testPaths, trainLabels, testLabels, trainIds, testIds) = split\n\n# perform another stratified sampling, this time to build the validation data\nsplit = train_test_split(trainPaths, trainLabels, trainIds,\n\ttest_size=round(len(imagePaths)*0.15), stratify=trainLabels)\n(trainPaths, valPaths, trainLabels, valLabels, trainIds, valIds) = split\n\n# construct a list pairing the training, validation, and testing\n# image paths along with their corresponding labels and output HDF5 files\ndatasets = [\n\t(\"train\", trainPaths, trainLabels, trainIds, config.TRAIN_HDF5),\n\t(\"val\", valPaths, valLabels, valIds, config.VAL_HDF5),\n\t(\"test\", testPaths, testLabels, testIds, config.TEST_HDF5)]\n\n# initialize the image pre-processor and the lists of RGB channel averages\naap = AspectAwarePreprocessor(config.INPUT_SIZE, config.INPUT_SIZE)\n(R, G, B) = ([], [], [])\n\n# loop over the dataset tuples\nfor (dType, paths, labels, ids, outputPath) in datasets:\n\t# create HDF5 writer\n\tprint(\"[INFO] building {}...\".format(outputPath))\n\twriter = HDF5DatasetWriter((len(paths), config.INPUT_SIZE, config.INPUT_SIZE, 3),\n\t\toutputPath)\n\twriter.storeClassLabels(le.classes_)\n\n\t# initialize the progress bar\n\twidgets = [\"Building Dataset: \", progressbar.Percentage(), \" \",\n\t\tprogressbar.Bar(), \" \", progressbar.ETA()]\n\tpbar = progressbar.ProgressBar(maxval=len(paths),\n\t\twidgets=widgets).start()\n\n\t# loop over the image paths\n\tfor (i, (path, label, _id)) in enumerate(zip(paths, labels, ids)):\n\t\t# load the image and process it\n\t\timage = cv2.imread(path)\n\t\timage = aap.preprocess(image)\n\n\t\t# if we are building the training dataset, then compute the\n\t\t# mean of each channel in the image, then update the respective lists\n\t\tif dType == \"train\":\n\t\t\t(b, g, r) = cv2.mean(image)[:3]\n\t\t\tR.append(r)\n\t\t\tG.append(g)\n\t\t\tB.append(b)\n\n\t\t# add the image and label # to the HDF5 dataset\n\t\twriter.add([image], [label], [_id])\n\t\tpbar.update(i)\n\n\t# close the HDF5 writer\n\tpbar.finish()\n\twriter.close()\n\n# construct a dictionary of averages, then serialize the means to a JSON file\nprint(\"[INFO] serializing means...\")\nD = {\"R\": np.mean(R), \"G\": np.mean(G), \"B\": np.mean(B)}\n\nf = open(config.DATASET_MEAN, \"w\")\nf.write(json.dumps(D))\nf.close()\n"
},
{
"alpha_fraction": 0.7746759653091431,
"alphanum_fraction": 0.7846460342407227,
"avg_line_length": 32.43333435058594,
"blob_id": "c000e2d74c10c213bf67ea7d5b3432c0169c423f",
"content_id": "81b7f13613d3ea3fbc7fb58b26e28d6063ee84d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2006,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 60,
"path": "/submission.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python submission.py\n\n# import the necessary packages\nfrom config import config\nfrom pyimagesearch.preprocessing import ImageToArrayPreprocessor\nfrom pyimagesearch.preprocessing import SimplePreprocessor\nfrom pyimagesearch.preprocessing import MeanPreprocessor\nfrom pyimagesearch.preprocessing import CropPreprocessor\nfrom pyimagesearch.io import HDF5DatasetGenerator\nfrom pyimagesearch.utils.ranked import rank5_accuracy\nfrom keras.applications import xception\nfrom keras.models import load_model\nfrom keras.preprocessing.image import ImageDataGenerator\nimport numpy as np\nimport pandas as pd\nimport progressbar\nimport json\nimport h5py\n\n# initialize the image preprocessors\nsp = SimplePreprocessor(299, 299)\niap = ImageToArrayPreprocessor()\naug = ImageDataGenerator(preprocessing_function=xception.preprocess_input)\n\n# # preprocess images\n# procImages = []\n# # loop over the images\n# for image in images:\n# \timage = sp.preprocess(image)\n# \timage = iap.preprocess(image)\n# \timage = xception.preprocess_input(image)\n# \tprocImages.append(image)\n#\n# # update the images array to be the processed images\n# images = np.array(procImages)\n\n# load the pretrained network\nprint(\"[INFO] loading model...\")\nmodel = load_model(config.MODEL_PATH)\n\n# initialize the testing dataset generator, then make predictions on\n# the testing data\nprint(\"[INFO] predicting on test data...\")\ntestGen = HDF5DatasetGenerator(config.TEST_HDF5, 64, aug=aug,\n\tpreprocessors=[sp, iap], classes=config.NUM_CLASSES)\n# print(testGen.numImages, testGen.numImages//64)\npredictions = model.predict_generator(testGen.generator(),\n\tsteps=162)\ntestGen.close()\n\n# Create Pandas dataframe and save to csv\ndb = h5py.File(config.TEST_HDF5)\ncols = np.append('id', db[\"label_names\"][:])\nids = np.asarray(db[\"ids\"])\nprint(db[\"ids\"].shape, db[\"images\"].shape)\nprint(ids.shape, predictions.shape)\nresults = np.hstack((ids[:, np.newaxis], predictions))\ndf = pd.DataFrame(data=results, columns=cols)\ndf.to_csv('output/submission.csv', index=False)\n"
},
{
"alpha_fraction": 0.7806666493415833,
"alphanum_fraction": 0.8013333082199097,
"avg_line_length": 34.71428680419922,
"blob_id": "72131545cc0d2d01ea2aae77dd7daaba830a53c4",
"content_id": "37be7e7853df1c883ed14254459eb64c2aba9f05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1500,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 42,
"path": "/predictions.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python predictions.py\n\n# import the necessary packages\nfrom config import config\nfrom pyimagesearch.preprocessing import ImageToArrayPreprocessor\nfrom pyimagesearch.preprocessing import SimplePreprocessor\nfrom pyimagesearch.preprocessing import MeanPreprocessor\nfrom pyimagesearch.preprocessing import CropPreprocessor\nfrom pyimagesearch.io import HDF5DatasetGenerator\nfrom pyimagesearch.utils.ranked import rank5_accuracy\nfrom keras.applications import xception\nfrom keras.models import load_model\nfrom keras.preprocessing.image import ImageDataGenerator\nimport numpy as np\nimport progressbar\nimport json\n\n\n# initialize the image preprocessors\nsp = SimplePreprocessor(299, 299)\niap = ImageToArrayPreprocessor()\naug = ImageDataGenerator(preprocessing_function=xception.preprocess_input)\n\n# load the pretrained network\nprint(\"[INFO] loading model...\")\nmodel = load_model(config.MODEL_PATH)\n\n# initialize the testing dataset generator, then make predictions on\n# the testing data\nprint(\"[INFO] predicting on test data (no crops)...\")\ntestGen = HDF5DatasetGenerator(config.TRAIN_HDF5, 64, aug=aug,\n\tpreprocessors=[sp, iap], classes=config.NUM_CLASSES)\npredictions = model.predict_generator(testGen.generator(),\n\tsteps=testGen.numImages // 64)\n\n# compute the rank-1 and rank-5 accuracies\n(rank1, rank5) = rank5_accuracy(predictions, testGen.db[\"labels\"])\nprint(predictions)\nprint(\"[INFO] rank-1: {:.2f}%\".format(rank1 * 100))\nprint(\"[INFO] rank-5: {:.2f}%\".format(rank5 * 100))\ntestGen.close()\n"
},
{
"alpha_fraction": 0.7345254421234131,
"alphanum_fraction": 0.763411283493042,
"avg_line_length": 33.619049072265625,
"blob_id": "16fd51ab8aa181fc05106781850e5c620bb847bf",
"content_id": "4af3d301c7193e053a02f16e27d16281987812a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 727,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 21,
"path": "/inspect_model.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# import the necessary packages\nfrom keras.applications import VGG16\nfrom keras.applications import ResNet50\nfrom keras.applications import xception\nfrom keras.applications import inception_v3\nimport argparse\n\n# load the VGG16 network\nprint(\"[INFO] loading network...\")\n# modelVGG16 = VGG16(weights=\"imagenet\")\n# modelResNet50 = ResNet50(weights=\"imagenet\")\nmodelx = xception.Xception(weights=\"imagenet\")\n# modeli = inception_v3.InceptionV3(weights=\"imagenet\")\nprint(\"[INFO] showing layers...\")\n\nmodels = [modelVGG16, modelResNet50, modelx, modeli]\n\n# loop over the layers in the network and display them to the console\nfor model in models:\n\tfor (i, layer) in enumerate(model.layers):\n\t\tprint(\"[INFO] {}\\t{}\".format(i, layer))\n"
},
{
"alpha_fraction": 0.745947003364563,
"alphanum_fraction": 0.7600610256195068,
"avg_line_length": 37.8370361328125,
"blob_id": "19728f5dec34ef7b9700af05ad32072ff64dd713",
"content_id": "180446691f0f94408d021f1f131b0a644bfd3687",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5243,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 135,
"path": "/DogBreedTrainer.py",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "# USAGE\n# python finetune_flowers17.py --dataset ../datasets/flowers17/images \\\n# \t--model flowers17.model\n\n# import the necessary packages\nfrom config import config\nfrom sklearn.preprocessing import LabelBinarizer\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report\nfrom pyimagesearch.preprocessing import ImageToArrayPreprocessor\nfrom pyimagesearch.preprocessing import AspectAwarePreprocessor\nfrom pyimagesearch.datasets import SimpleDatasetLoader\nfrom pyimagesearch.nn.conv import FCHeadNet\nfrom keras.preprocessing.image import ImageDataGenerator\nfrom keras.optimizers import RMSprop\nfrom keras.optimizers import SGD\nfrom keras.applications import VGG16\nfrom keras.applications import xception\nfrom keras.layers import Input\nfrom keras.models import Model\nfrom imutils import paths\nimport numpy as np\nimport pandas as pd\nimport argparse\nimport os\n\n# construct the image generator for data augmentation\naug = ImageDataGenerator(rotation_range=30, width_shift_range=0.1,\n\theight_shift_range=0.1, shear_range=0.1, zoom_range=0.2,\n\thorizontal_flip=True, fill_mode=\"nearest\")\n\n# grab the list of images that we'll be describing, then extract\n# the class label names from the image paths\nprint(\"[INFO] loading images...\")\nimagePaths = list(paths.list_images(config.IMAGES_PATH))\ndata = pd.read_csv('labels.csv')\n# ids = data['id']\nclassNames = data['breed']\nclassNames = [str(x) for x in np.unique(classNames)]\ndata_dict = data.set_index('id')['breed'].to_dict()\n\n# le = LabelEncoder()\n# labels = le.fit_transform(labels)\n# labels_inv = le.inverse_transform(labels)\n# classNames = [pt.split(os.path.sep)[-2] for pt in imagePaths]\n# classNames = [str(x) for x in np.unique(classNames)]\n\n# initialize the image preprocessors\naap = AspectAwarePreprocessor(config.INPUT_SIZE, config.INPUT_SIZE)\niap = ImageToArrayPreprocessor()\n\n# load the dataset from disk then scale the raw pixel intensities to\n# the range [0, 1]\nsdl = SimpleDatasetLoader(preprocessors=[aap, iap])\n(data, ids) = sdl.load(imagePaths, verbose=500)\nlabels = [data_dict[i] for i in ids]\ndata = data.astype(\"float\") / 255.0\n\n# partition the data into training and testing splits using 75% of\n# the data for training and the remaining 25% for testing\n(trainX, testX, trainY, testY) = train_test_split(data, labels,\n\ttest_size=0.25, stratify=labels)\n\n# convert the labels to vectors\ntrainY = LabelBinarizer().fit_transform(trainY)\ntestY = LabelBinarizer().fit_transform(testY)\n\n# load the VGG16 network, ensuring the head FC layer sets are left\n# off\nbaseModel = xception.Xception(weights=\"imagenet\", include_top=False,\n\tinput_tensor=Input(shape=(config.INPUT_SIZE, config.INPUT_SIZE, 3)))\n\n# initialize the new head of the network, a set of FC layers\n# followed by a softmax classifier\nheadModel = FCHeadNet.build(baseModel, config.NUM_CLASSES, 256)\n\n# place the head FC model on top of the base model -- this will\n# become the actual model we will train\nmodel = Model(inputs=baseModel.input, outputs=headModel)\n\n# loop over all layers in the base model and freeze them so they\n# will *not* be updated during the training process\nfor layer in baseModel.layers:\n\tlayer.trainable = False\n\n# compile our model (this needs to be done after our setting our\n# layers to being non-trainable\nprint(\"[INFO] compiling model...\")\nopt = RMSprop(lr=0.001)\nmodel.compile(loss=\"categorical_crossentropy\", optimizer=opt,\n\tmetrics=[\"accuracy\"])\n\n# train the head of the network for a few epochs (all other\n# layers are frozen) -- this will allow the new FC layers to\n# start to become initialized with actual \"learned\" values\n# versus pure random\nprint(\"[INFO] training head...\")\nmodel.fit_generator(aug.flow(trainX, trainY, batch_size=16),\n\tvalidation_data=(testX, testY), epochs=25,\n\tsteps_per_epoch=len(trainX) // 16, verbose=1)\n\n# evaluate the network after initialization\nprint(\"[INFO] evaluating after initialization...\")\npredictions = model.predict(testX, batch_size=16)\nprint(classification_report(testY.argmax(axis=1),\n\tpredictions.argmax(axis=1), target_names=classNames))\n\n# # now that the head FC layers have been trained/initialized, lets\n# # unfreeze the final set of CONV layers and make them trainable\n# for layer in baseModel.layers[15:]:\n# \tlayer.trainable = True\n#\n# # for the changes to the model to take affect we need to recompile\n# # the model, this time using SGD with a *very* small learning rate\n# print(\"[INFO] re-compiling model...\")\n# opt = SGD(lr=0.001)\n# model.compile(loss=\"categorical_crossentropy\", optimizer=opt,\n# \tmetrics=[\"accuracy\"])\n#\n# # train the model again, this time fine-tuning *both* the final set\n# # of CONV layers along with our set of FC layers\n# print(\"[INFO] fine-tuning model...\")\n# model.fit_generator(aug.flow(trainX, trainY, batch_size=32),\n# \tvalidation_data=(testX, testY), epochs=100,\n# \tsteps_per_epoch=len(trainX) // 32, verbose=1)\n#\n# # evaluate the network on the fine-tuned model\n# print(\"[INFO] evaluating after fine-tuning...\")\n# predictions = model.predict(testX, batch_size=32)\n# print(classification_report(testY.argmax(axis=1),\n# \tpredictions.argmax(axis=1), target_names=classNames))\n\n# save the model to disk\nprint(\"[INFO] serializing model...\")\nmodel.save(config.MODEL_PATH)\n"
},
{
"alpha_fraction": 0.7735010981559753,
"alphanum_fraction": 0.784604012966156,
"avg_line_length": 83.4375,
"blob_id": "31f285001dfb87f49c8fdc695a1c2a2f373e3af9",
"content_id": "7eff62588130824deb0efe1646b0cd106bd5bdc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1351,
"license_type": "no_license",
"max_line_length": 339,
"num_lines": 16,
"path": "/README.md",
"repo_name": "msharp9/DogBreedIdentificationKaggle",
"src_encoding": "UTF-8",
"text": "Kaggle Challenge for Dog Breed Identification. This is a currently a playground competition. 120 different breeds and ~10K images. \nIt's about 60-90 images a dog breed, which is a low training set, going to have to use some type of augmentation.\nGoing to focus on using Xception/InceptionV3 models as they proven to be most effect on a sample in the top voted kernal.\n\n\nFirst attempted just training it straight but loading 10K images is too much to do in memory for my RAM, will need to take advantage of hdf5. Also, since I'm joining this challenge late I won't dive deep into fine tuning the models, but do simple top level transfer learning. This should help w/ time, especially since I don't have a GPU.\n\nTrained a very simple model using xception + a simple head on top. Just want to see where it gets me. Probably don't have time to mess around with it more though.\n\nIt was a low score but surprisingly not last. Since it's only a playground challenge and it ends soon won't fully train model. (You know, more than 1 epoch :D)\n\nDogBreedTrainer.py was just a first pass and a good place to start if you have a beefy computer.\nbuild_hdf5.py scripts to build the different databases\ntrain_model.py to create the model\npredictions.py to evaluate the model\nsubmission.py to prepare the csv file in the correct format for the Kaggle submission\n"
}
] | 9 |
sujcho/python-practice
|
https://github.com/sujcho/python-practice
|
ae2025e81852c73812fc7ef1ff8a85d0db94b3cf
|
ce09afa075f0fa0ea993c739f4bb95501ab9c5ab
|
f53c395a40656ebaf5160ff00f866bf4b7dacecb
|
refs/heads/master
| 2021-01-11T17:57:23.495209 | 2017-09-06T23:45:41 | 2017-09-06T23:45:41 | 79,877,355 | 0 | 0 | null | 2017-01-24T04:10:51 | 2017-01-24T04:10:55 | 2017-03-01T19:48:58 |
Python
|
[
{
"alpha_fraction": 0.6629213690757751,
"alphanum_fraction": 0.7303370833396912,
"avg_line_length": 24.428571701049805,
"blob_id": "0bb01423a4c40b11856ae8a743075e35e8a4262c",
"content_id": "46558c52c8e34c23ab2b3120f78dee0db1429984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 7,
"path": "/python/hw07/hw07_2.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "\"\"\"import hw07_1 and use hw07_1.IsValidIdentifier() to test the user using raw_input\"\"\"\n\nimport hw07_1\n\ninput = raw_input(\"Type a word: \")\n\nprint hw07_1.IsValidIdentifier(input)\n"
},
{
"alpha_fraction": 0.612500011920929,
"alphanum_fraction": 0.612500011920929,
"avg_line_length": 39.5,
"blob_id": "b64410f4bf4b45097175466b32e6293904a5b2b2",
"content_id": "0aca7023391cfd427453db2d36b065fe8d636266",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/Meanstack/test/test.js",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "var test = require('simple_npm');\nconsole.log(test(\"tom\",[\"cat\",\"dog\", \"tom\"]));"
},
{
"alpha_fraction": 0.5718799233436584,
"alphanum_fraction": 0.6050552725791931,
"avg_line_length": 20.100000381469727,
"blob_id": "f7f7bf62f009f0a673be6bbe29d775a9bf284217",
"content_id": "0f91505d14f937f1c2763ebb9bd85f612c3d01e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 30,
"path": "/python/lab01/conditions.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"concions.py demeonstrates if/elif/els and while/else.\"\"\"\n\nnumber = 4\n\n# if/elit/else\n\nif number < 10:\n print number, 'is small.'\nelif number >= 1000:\n print number, 'is big.'\nelse: print number, 'is medium'\n\n#Alternate syntax for 2.5 -- all one line but less readable.\n\nprint number, \"is\",\n\nprint \"small.\" if number < 10 \\\n else \"big.\" if number >= 1000\\\n else \"medium.\"\n\n# else occurs in a loop too\n\nwhile number < 6:\n if number % 3 == 0:\n print number, 'is divisible by 3.'\n break\n number += 1\nelse:\n print 'Nothing in the loop was divisible by 3.'\n"
},
{
"alpha_fraction": 0.5795601606369019,
"alphanum_fraction": 0.5847347974777222,
"avg_line_length": 23.935483932495117,
"blob_id": "f704996c1331c561b776ca73cde7b260f9788c11",
"content_id": "c3e62cf5bf8dd8b59b3427f7b934e8cbbb8c8082",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1546,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 62,
"path": "/python/assignment3/application/driver/hw11_3.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nThis module will ask for a starting directory name and will look for and report any words that are palindromes throughout the directory structure.\n\"\"\"\nimport os\nimport sys\n\n\ndef GetText(file_name):\n \"\"\"Opens a file and returns content\"\"\"\n try:\n #if there is a file, read the content\n open_file = open(file_name)\n try:\n text = open_file.read()\n finally:\n open_file.close()\n\n except IOError, msg:\n print file_name, msg\n\n return text\n\ndef FindPalindromes(anything, dirname, fnames):\n \"\"\"\n Find plaindromes in a path tree\n \"\"\"\n #import hw11_2 as a moudle\n sys.path.insert(0,\"..\")\n import utils.hw11_2 as pal\n\n for file_name in fnames:\n full_path = os.path.join(dirname,file_name)\n\n #if it is not a file, skip\n if not os.path.isfile(full_path):\n continue\n #if it is a file, get content of it\n content = GetText(full_path)\n content = content.split()\n\n for word in content:\n #check palindromes\n result = pal.Palindromize(word)\n if not result == None:\n print result\n\ndef main():\n while True:\n print \"Enter starting directory\"\n starting_dir = raw_input()\n\n if os.path.exists(starting_dir):\n break\n else:\n print \"Path does not exists. Please check again\"\n\n os.path.walk(starting_dir, FindPalindromes, \"Walking:\")\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6304985284805298,
"alphanum_fraction": 0.6319648027420044,
"avg_line_length": 31.4761905670166,
"blob_id": "05140db22a029e6f07f9111e467200b2a512f91d",
"content_id": "e517a5704b6ea5f504f1cbb64efe727825855d14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 682,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 21,
"path": "/python/lab02/lab_2-7.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr.bin/env python\n\"\"\"Write a program that reads in two integers and determines wheter the first is a multiple of the seconds.\"\"\"\n\nwhile True: # True/False are keywords.\n try:\n first = int(raw_input(\"Enter the first number: \"))\n break\n except ValueError: #built in exception\n print \"Please try again.\"\n\nwhile True: # True/False are keywords.\n try:\n second = int(raw_input(\"Enter the second number: \"))\n break\n except ValueError: #built in exception\n print \"Please try again.\"\n\nif first % second == 0:\n print '%d is a multiple of %d' % (first, second)\nelse:\n print '%d is a not multiple of %d' % (first, second)\n"
},
{
"alpha_fraction": 0.6029850840568542,
"alphanum_fraction": 0.611940324306488,
"avg_line_length": 18.705883026123047,
"blob_id": "bc9a97ca4fd5014a865f5ae8257235138f67aa29",
"content_id": "4c72237a47494b8268a6f1e7b35c4697f45fc164",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 17,
"path": "/python/lab04/flipCoins.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"Write a funciton called \"Coin\" that emulates the flip of a coin, returning 'heads' or 'tails/ \"\"\"\n\n\nimport random\n\n#Flipping a Coin\ndef Coin():\n #Going to flip the Coin\n coin = random.randrange(0,2)\n if coin == 0:\n flip = \"heads\"\n else:\n flip =\"tails\"\n return flip;\n\nprint Coin()\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.4285714328289032,
"avg_line_length": 11.25,
"blob_id": "e52fe90e5a973035b4ca3429aebe1d6348f54de7",
"content_id": "abf111899a1875baa1925337ebbf21e6c34ae5a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 4,
"path": "/python/test2.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "class A:\n class B:\n print 'Hi'\na = A()\n"
},
{
"alpha_fraction": 0.5974981784820557,
"alphanum_fraction": 0.6019131541252136,
"avg_line_length": 33.846153259277344,
"blob_id": "17c91cd1810f64431ba0e2d84e32955e137ab0eb",
"content_id": "c1712328489dbd2bce3c2b1c398af2736bf06938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 39,
"path": "/python/hw07/hw07_1.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nPython identifiers that tests a string.\n\"\"\"\nimport keyword\n\ndef IsValidIdentifier(my_str):\n \"\"\"\n IsValidIdentifier ( ) receives a string and returns a tuple (Boolean, reason string).\n Returns True, if:\n (a) The first character must be a letter or underscore.\n (b) Letters beyond the first can be alphanumeric or underscore.\n (c) Identifiers can not be keywords.\n Else returns False with a reason string.\n \"\"\"\n\n #Test the string for if it is a keyword\n if keyword.iskeyword(my_str):\n return (False, \"%s: %s\" % (\"Invalid\", \"this is a keyword!\"))\n\n #Test if the first character is a letter or underscore\n if not my_str[0].isalpha() and my_str[0] != '_':\n return (False, \"%s: %s\" % (\"Invalid\", \"first symbol must be alphabetic or underscore.\"))\n\n #For each character in the string,\n for ch in my_str[1:]:\n #if not, the string is invalid\n if not ch.isalnum() and ch != '_':\n return (False, \"%s: '%s' %s\" % (\"Invalid\", ch, \"is not allowed.\"))\n\n return (True, \"Valid!\")\n\n#Show results only when it is executed from the command line.\nif __name__ == '__main__':\n DATA = ('x', '_x', '2x', 'x,y ', 'yield', 'is_this_good')\n for case in DATA:\n result = IsValidIdentifier(case)\n print \"%s -> %s\" % (case, result[1])\n"
},
{
"alpha_fraction": 0.49463191628456116,
"alphanum_fraction": 0.504217803478241,
"avg_line_length": 23.13888931274414,
"blob_id": "deb53f6b010007cfd5d3550c321961dc2a37f5a9",
"content_id": "8ba35c072cfb531c8bc0c845ceacd95e4af58138",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2608,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 108,
"path": "/linux/using_driver.c",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <fcntl.h>\t\t/* open */\n#include <unistd.h>\t\t/* exit */\n#include <errno.h>\n#include <string.h>\n#include <sys/ioctl.h>\n\n#define MAJOR_NUM 60\n#define IOC_MAGIC MAJOR_NUM\n#define IOCTL_READ_SIZE _IO(IOC_MAGIC,0)\n#define IOCTL_INIT_BUFFER _IO(IOC_MAGIC,1) // defines our ioctl call\n\n\nvoid printError(int num){\n printf (\"Error no is : %d\\n\", num);\n char * msg = strerror(num);\n printf(\"Error description is : %s\\n\", msg);\n};\n\nint main(){\n\n int file_desc;\n int result;\n char *ptr;\n ptr = (char*)malloc(sizeof(char) * 1024);\n\n //open device driver\n printf(\"/dev/mymodule: open!!\\n\");\n file_desc = open(\"/dev/mymodule\", O_RDWR);\n if (file_desc < 0)\n {\n printError(errno);\n }\n printf(\"****************************\\n\");\n\n printf(\"/dev/mymodule: ioctl!!\\n\");\n result = ioctl(file_desc,IOCTL_READ_SIZE);\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"Size of default string: %d \\n\", result);\n printf(\"****************************\\n\");\n\n printf(\"/dev/mymodule: read!!\\n\");\n result = read(file_desc, ptr, 1024);\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"Content of string: %s \\n\", ptr);\n printf(\"****************************\\n\");\n\n\n printf(\"/dev/mymodule: write!!\\n\");\n char* newString = \"String updated\";\n result = write(file_desc, newString, strlen(newString));\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"****************************\\n\");\n\n\n printf(\"/dev/mymodule: read!!\\n\");\n result = read(file_desc, ptr, strlen(newString));\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"Content of string: %s \\n\", ptr);\n printf(\"****************************\\n\");\n\n\n printf(\"/dev/mymodule: ioctl!!, read the size of string\\n\");\n result = ioctl(file_desc,IOCTL_READ_SIZE);\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"Size of string: %d \\n\", result);\n printf(\"****************************\\n\");\n\n\n printf(\"/dev/mymodule: ioctl!!, init buffer\\n\");\n result = ioctl(file_desc, IOCTL_INIT_BUFFER);\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"****************************\\n\");\n\n printf(\"/dev/mymodule: read!!\\n\");\n result = read(file_desc, ptr, 1024);\n if(result < 0)\n {\n printError(errno);\n }\n printf(\"Content of string: %s \\n\", ptr);\n printf(\"****************************\\n\");\n\n printf(\"/dev/mymodule: close!!\\n\");\n close(file_desc);\n printf(\"****************************\\n\");\n\n return 0;\n }\n\n"
},
{
"alpha_fraction": 0.7147058844566345,
"alphanum_fraction": 0.7235293984413147,
"avg_line_length": 23.285715103149414,
"blob_id": "90d8a9968f17b29754208a0fd4246c895da974b8",
"content_id": "e8649ba160b19d2a99f1be73eb0e1a433fe9ca83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 14,
"path": "/python/lab01/output.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Python\n\"\"\"output.py Demonstrates 3 ways to delimit strings. \"\"\"\n\nprint 'Hello world'\nprint\nprint 'She said \"Hello world\"'\nprint\nprint \"She said 'Hello Word'\"\nprint\nprint \"\"\"Little dark woman of my suffering,\nwith eyes of flying paper,\nyou say \"Yes\" to everyone,\nbut you never say when.\n\"\"\" # end of string started on line 10\n"
},
{
"alpha_fraction": 0.550000011920929,
"alphanum_fraction": 0.5684210658073425,
"avg_line_length": 20.11111068725586,
"blob_id": "5fa2c5b14bdfb005044ceb41bfa2753c58da46f9",
"content_id": "b18f1a26dc8e216cca0eb7738740aa04d4a1b510",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 18,
"path": "/python/lab03/lab_3_5.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"Print the decimal equivalent of a binary string that is given by the user:\"\"\"\n\n\n\ninput = raw_input(\"Enter a binary number: \")\nsum = 0\nmult = 0\nfor digit in input:\n if digit != '0' and digit != '1':\n print \"Not a binary number\"\n break;\n else:\n sum += int(digit) * pow(2,mult)\n mult += 1\n\nif sum != 0:\n print \"%d\" % sum\n"
},
{
"alpha_fraction": 0.40672269463539124,
"alphanum_fraction": 0.451260507106781,
"avg_line_length": 15.746479034423828,
"blob_id": "096f8862132bac0ada9d5cbdac8ce68be2d2c71b",
"content_id": "eb379a83981c83f7f58a764a5494f394777e370f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1220,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 71,
"path": "/python/binary_search.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "\nfrom __future__ import print_function\n\n\"\"\"1 2 3, 4 5 6, 7 8 9 : median = 5\"\"\"\n\n\"\"\" 1 2 3 4 5 6 7 8 9 에서 7보다 작은 엘리먼트 인덱스 찾기 \"\"\"\n\n\nimport math\n\ndef findMedianInRow(row, x):\n\n\n start = 0;\n end = len(row)-1\n\n print(\"x\",x)\n while(start <= end):\n mid = math.floor((start + end)/2)\n print(\"row[mid]\",row[mid], mid)\n if row[mid] == x:\n return mid + 1\n\n if row[mid] > x:\n end = mid - 1\n else:\n start = mid + 1\n\n if x > row[end]:\n return end + 1\n else:\n return 0\n\ndef findMedian(A):\n\n n = len(A[0])\n m = len(A)\n med_idx = math.floor(n*m/2)\n\n mid = 0\n start = 0\n end = 1000000\n\n while start <= end :\n mid = int(math.floor((start + end)/2))\n count = 0\n\n for i in range(0,m,1):\n count += findMedianInRow(A[i],mid)\n print(\"count\", count)\n\n count = count -1\n\n if count == med_idx :\n return mid\n\n if count < med_idx :\n start = mid + 1\n\n else :\n end = mid - 1\n\n return mid\n\n\ndef main():\n A = [[1,1,1,1,3,3,3]]\n\n print(findMedian(A))\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6185566782951355,
"alphanum_fraction": 0.6328310966491699,
"avg_line_length": 30.524999618530273,
"blob_id": "5e55d6d44238248680258dd7404e4d3634590793",
"content_id": "dd3e9ea382dfef57536321e15510dda807857a0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1261,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 40,
"path": "/python/assignment3/application/utils/hw11_2.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*\n\"\"\"Palindromize (phrase) that returns the lowercase version of the phrase\"\"\"\nimport string\n\ndef Palindromize (phrase):\n \"\"\"Palindromize (phrase) returns the lowercase version of the phrase with whitespace and punctuation removed if the phrase is a palindrome. If not, it returns None. \"\"\"\n\n #remove punctuation\n phrase = phrase.strip(string.punctuation)\n #remove whitespace\n phrase = \"\".join(phrase.split(\" \"))\n\n length = len(phrase)\n\n #If only one character, it's not palindrome\n if length == 1 or not phrase :\n return None\n\n #get first half of the phrase\n first_half = phrase[:length/2].lower()\n #get second half of the phrase\n\n if length % 2 == 1:\n second_half = phrase[(length/2)+1:].lower()\n else:\n second_half = phrase[length/2:].lower()\n\n #Is this Plaindrom?\n #reverse the second half and compare with first half\n if first_half == second_half[::-1]:\n return phrase\n else:\n return None\n\n\nif __name__ == \"__main__\":\n DATA = ('Murder for a jar of red rum', '12321', 'nope', 'abcbA', '3443', 'what','Never odd or even', 'Rats live on no evil star')\n for data in DATA:\n print \"%s: %s\" % (data, Palindromize(data))\n"
},
{
"alpha_fraction": 0.48747390508651733,
"alphanum_fraction": 0.49791231751441956,
"avg_line_length": 26.371429443359375,
"blob_id": "6a8adff0e2d94a0e550feeaa6aad00fa7bbefdfb",
"content_id": "b391539850101196dbcf7162b1847b859d78ad72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 958,
"license_type": "no_license",
"max_line_length": 213,
"num_lines": 35,
"path": "/python/lab07/07_1.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "\"\"\"Write a function that, when passed a string of alphanumeric characters, returns a string of digits, Each character that is in the input string is converted to the digit that corresponds to it on a phone keypad:\n\"\"\"\n\ndef convertToDigit(str):\n number = \"\"\n for ch in str:\n ch = ch.lower()\n if ch in \"abc\":\n number += '2'\n elif ch in \"def\":\n number += '3'\n elif ch in \"ghi\":\n number += '4'\n elif ch in \"jkl\":\n number += '5'\n elif ch in \"mno\":\n number += '6'\n elif ch in \"pqrs\":\n number += '7'\n elif ch in \"tuv\":\n number += '8'\n elif ch in \"wxyz\":\n number += '9'\n else:\n number += ch\n return number\n\ndef main():\n DATA = (\"peanut\", \"salt\", \"lemonade\", \"good time\", \":10\", \"Zilch\");\n\n for item in DATA:\n print convertToDigit(item)\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6355797648429871,
"alphanum_fraction": 0.642160177230835,
"avg_line_length": 26.543750762939453,
"blob_id": "b2d33e802e8b5b3a5c6e3405a8dd535f822a3b24",
"content_id": "7a318424334f7f5c8519c5019add33d8fc900874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4407,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 160,
"path": "/linux/mymodule.c",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "/*\n * hello-1.c - The simplest kernel module.\n */\n#include <linux/slab.h>\n#include <linux/module.h>\t/* Needed by all modules */\n#include <linux/kernel.h>\t/* Needed for KERN_INFO */\n#include <linux/fs.h>\n#include <linux/types.h> /* size_t */\n#include <linux/uaccess.h>\n#include <linux/string.h>\n#include <linux/ioctl.h>\n\n#define MAJOR_NUM 60\n#define DRIVER_AUTHOR \"SU JIN CHO\"\n#define DRIVER_DESC \"A simple driver\"\n\n/*iocil command*/\n#define IOC_MAGIC MAJOR_NUM\n#define IOCTL_READ_SIZE _IO(IOC_MAGIC,0)\n#define IOCTL_INIT_BUFFER _IO(IOC_MAGIC,1)\n\n/*function declaration */\nint my_open(struct inode *inode, struct file *filp);\nint my_close(struct inode *inode, struct file *filp);\nssize_t my_read(struct file *filp, char *buf, size_t count, loff_t *f_pos);\nssize_t my_write(struct file *filp, const char *buf, size_t count, loff_t *f_pos);\nlong my_ioctl(struct file *f, unsigned int cmd, unsigned long arg);\nvoid my_exit(void);\nint my_init(void);\n\n/*access functions */\nstatic struct file_operations fops = {\n .read = my_read,\n .write = my_write,\n .open = my_open,\n .release = my_close,\n .unlocked_ioctl = my_ioctl\n};\n\n/* Declaration of the init and exit functions */\nmodule_init(my_init);\nmodule_exit(my_exit);\n\n/*module information */\nMODULE_AUTHOR(DRIVER_AUTHOR);\nMODULE_DESCRIPTION(DRIVER_DESC);\nMODULE_LICENSE(\"GPL\");\n\nint major = 60; /*Major number assign to my device driver */\nchar* buffer;\n\nint my_init(void)\n{\n int result;\n\n //register module\n printk(KERN_INFO \"mymodule: register start\\n\");\n result = register_chrdev(MAJOR_NUM, \"mymodule\", &fops);\n if(result < 0){\n printk(KERN_ERR \"ERROR: Cannot register the module!\\n\");\n return result;\n }\n\n\t//allocate buffer\n\tbuffer = (char*)kmalloc(sizeof(char)*1024, GFP_KERNEL);\n\tif(!buffer){\n\t printk(KERN_ERR \"mymodule: (ERROR) Cannot allocate the buffer!\\n\");\n\t return -1;\n\t}\n\n printk(KERN_INFO \"mymodule: (SUCCESS) register end\\n\");\n\treturn 0;\n}\n\nint my_open(struct inode *inode, struct file *filp){\n\n printk(KERN_INFO \"mymodule: open start\\n\");\n //initialize the buffer to a known text\n buffer = \"Welcome to UCSC Second Assignment\";\n printk(KERN_INFO \"mymodule: (SUCCESS) open end\\n\");\n return 0;\n}\n\nint my_close(struct inode *inode, struct file *filp){\n\n printk(KERN_INFO \"mymodule: close start\\n\");\n buffer = \"\";\n printk(KERN_INFO \"mymodule: (SUCCESS) close end\\n\");\n return 0;\n}\n\nssize_t my_read(struct file *filp, char *userBuf, size_t count, loff_t *f_pos){\n\n long result;\n printk(KERN_INFO \"mymodule: read start\\n\");\n\n //copy_to_user( to, from, n );\n result = copy_to_user(userBuf, buffer, 1024);\n if(result != 0){\n printk(KERN_ERR \"mymodule: (ERROR) cannot from the kernel space buffer\\n\");\n }\n printk(KERN_INFO \"mymodule: read end(SUCCESS)\\n\");\n return 0;\n}\n\nssize_t my_write( struct file *filp, const char *userBuf, size_t count, loff_t *f_pos) {\n\n int err;\n printk(KERN_INFO \"mymodule: write start\\n\");\n\n //copy_from_user( to, from, n );\n buffer = kmalloc(count, GFP_KERNEL);\n err = copy_from_user(buffer, userBuf, count);\n if(err < 0){\n printk(KERN_ERR \"mymodule: (ERROR) cannot write to the kernel space buffer\\n\");\n kfree(buffer);\n return err;\n }\n\n printk(KERN_INFO \"mymodule: write end (SUCCESS)\\n\");\n return 0;\n}\n\nlong my_ioctl(struct file *f, unsigned int ioctl_cmd, unsigned long arg){\n\n int result;\n printk(KERN_INFO \"mymodule: ioctl start\\n\");\n switch(ioctl_cmd){\n case IOCTL_READ_SIZE:\n printk(KERN_INFO \"mymodule: ioctl, read the size of string\\n\");\n result = strlen(buffer);\n break;\n case IOCTL_INIT_BUFFER:\n printk(KERN_INFO \"mymodule: ioctl, init buffer\\n\");\n buffer = kmalloc(1024, GFP_KERNEL);\n buffer = \"Welcome to UCSC Second Assignment\";\n result = strlen(buffer);\n break;\n default:\n printk(KERN_ERR \"mymodule: (ERROR) Wrong ioctl command\\n\");\n return -1;\n }\n\n printk(KERN_INFO \"mymodule: ioctl end (SUCCESS)\\n\");\n return result;\n}\n\nvoid my_exit(void)\n{\n\t/* Freeing the major number */\n\tprintk(KERN_INFO \"mymodule: unregister start\\n\");\n unregister_chrdev(MAJOR_NUM, \"mymodule\");\n\n /* Freeing buffer memory */\n if (buffer) {\n kfree(buffer);\n }\n\n printk(KERN_INFO \"mymodule: unregister (SUCCESS) end\\n\");\n}\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6378205418586731,
"avg_line_length": 30.200000762939453,
"blob_id": "705820ec8cb088a80f7af12447c051a082b52771",
"content_id": "bd5d97ee3c5e96f8e01c5ad77ad3b4b33e7a041a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 624,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 20,
"path": "/python/lab04/randrange.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\" randrange.py Rolls dice, demonstrating random.randrage(,\n and a tuple with accessing a particular element with an index\"\"\"\n\nimport random\ndoubles = (\"Can't happen\", \"Snake eyes!\", \"Little Joe!\", \"Hard six!\", \"Hard eight!\",\"Fever!\",\"Box cars!\")\n\n#Rolling Two Dices\ndef Rollem():\n #Going to random module and find a randrage function\n dice = random.randrange(1,7), random.randrange(1,7);\n print \"%d and %d\" % dice\n if dice[0] == dice[1]:\n print doubles[dice[0]]\n\nwhile True:\n response = raw_input(\"Ready to roll?!\");\n if response[0] in \"Qq\":\n break\n Rollem()\n"
},
{
"alpha_fraction": 0.4449152648448944,
"alphanum_fraction": 0.4689265489578247,
"avg_line_length": 18.16216278076172,
"blob_id": "2ce9f8a5c9ae22a41b010f09dd8606fe6b6f9636",
"content_id": "ee5546cc6dd2d37c077a059ccb7f3433d56925d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 37,
"path": "/css/week3/drop-down.html",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <title>Drop Down Menu -1</title>\n <meta></meta>\n</head>\n<body>\n<div id=\"nav\">\n<li>Home</li>\n<li>About\n <ul>\n <li>Company</li>\n <li>The Team</li>\n </ul>\n</li\n<li>\n <ul>\n <li><a href=\"1.html\">Service 1</a></li>\n <li><a href=\"2.html\">Service 2</a></li>\n <li><a href=\"3.html\">Service 3</a></li>\n <li><a href=\"4.html\">Service 4</a></li>\n <li><a href=\"5.html\">Service 5</a></li>\n </ul>\n</li>\n<li>\n <ul>\n <li>Service 1</li>\n <li>Service 2</li>\n <li>Service 3</li>\n <li>Service 4</li>\n <li>Service 5</li>\n </ul>\n</li>\n</div>\n</body>\n</html>"
},
{
"alpha_fraction": 0.6049149632453918,
"alphanum_fraction": 0.6200377941131592,
"avg_line_length": 28.38888931274414,
"blob_id": "165e1a915e6b769bcdae8e6a0ac5d0ec0625151a",
"content_id": "0479f96589fadf5decf087c0604c76f71f64a34d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 18,
"path": "/python/lab01/primes.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"primes/py -- Produces a list of prime numbers.\nHere, we are only cheching the \"look\" of the Python code.\n\"\"\"\nMAX = 100 #Here is a comment.\n\nprint 'primes are :' # A new line is added by default.\nnumber = 3\nwhile number < MAX:\n div = 2\n while div * div <= number:\n if number % div == 0:\n break\n div += 1\n else: #Overloaded 'else', loop didn't break'.\n print number, #Trailing Comma suppresses the new line.\n number += 2\nprint #This only produces the new line.\n"
},
{
"alpha_fraction": 0.5766870975494385,
"alphanum_fraction": 0.5950919985771179,
"avg_line_length": 22.285715103149414,
"blob_id": "8857b97508ce77cb1110c36895803239b45071bd",
"content_id": "4de40aed1ddfd26d735e2ed6afd91003191f8052",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 7,
"path": "/python/example2.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "class PoliteList(list):\n def __str__(self):\n return \"\"\"Here are your data:\n%s\nThank you for asking.\"\"\" % (list.__str__(self))\n\nprint PoliteList([1,2,3])\n"
},
{
"alpha_fraction": 0.4025973975658417,
"alphanum_fraction": 0.41558441519737244,
"avg_line_length": 14.399999618530273,
"blob_id": "8e6d465c9f2bd265900bc0aea379b92819381806",
"content_id": "60b50a7d09c302cff39c1901d63989daa54838a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 20,
"path": "/python/quiz.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "def DoThis():\n def Report():\n print(\"test\")\n print (amount)\n amount = 3\n Report()\n\ndef DoThis_2():\n def Report():\n print (amount)\n Report()\n amount = 3\n\ndef main():\n DoThis()\n DoThis_2()\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5468208193778992,
"alphanum_fraction": 0.589595377445221,
"avg_line_length": 28.827587127685547,
"blob_id": "3d7f164dd7d82df92b43c0f299fe55795cc53b37",
"content_id": "236e5d0c14533ec4a444e82aa6e5806a0535266a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 865,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 29,
"path": "/python/assignment3/hw11_1.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nGiveAsciiChart returns ascii chart as a string\n\"\"\"\n\ndef GiveAsciiChart1():\n \"\"\"\n GiveAsciiChart1() is a version that take the readibility as the first prioriority.\n GiveAsciiChart1() returns ascii chart (only from value 32 to 126) as a string\n \"\"\"\n chart = \"\"\n for num in range(32, 126):\n ascii_value = chr(num)\n chart += \"%4s\" % str(num)+\":\"+ ascii_value\n if (num+1)%4 == 0:\n chart += \"\\n\"\n return chart\n\ndef GiveAsciiChart2():\n \"\"\"\n GiveAsciiChart2() is a version with .\n GiveAsciiChart1() returns ascii chart (only from value 32 to 126) as a string\n \"\"\"\n return \"\\n\".join([\" \".join([\"%4s\" % (str(num+i)+\":\"+ chr(num+i)) for i in range(0,4)]) for num in range (32,126,4)])\n\nif __name__ == '__main__':\n GiveAsciiChart1()\n GiveAsciiChart2()\n"
},
{
"alpha_fraction": 0.5607287287712097,
"alphanum_fraction": 0.5890688300132751,
"avg_line_length": 18,
"blob_id": "3c5d6ce6db237085587b8842d6c16933cfa72b59",
"content_id": "66327cbb19f86fcf5c2a40c22edad581a6e99428",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 26,
"path": "/Java/Algorithm/src/greedy/SelectActivity.java",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "package greedy;\n\npublic class SelectActivity {\n\n\tpublic static void findMaxActivity(int start[], int finish[]){\n\t\tint i = 0;\n\t\t\n\t\tSystem.out.println(i);\n\t\t\n\t\tfor (int j = 1; j< start.length; j++){\n\t\t\tif(start[j] >= finish[i]){\n\t\t\t\tSystem.out.println(j);\n\t\t\t\ti = j;\n\t\t\t}\n\t\t}\n\t}\n\t\n\tpublic static void main(String[] args) {\n\t\t// TODO Auto-generated method stub\n\n\t\tint start_time[] = {1, 3, 0, 5, 8, 5};\n\t\tint finish_time[] = {2, 4, 6, 7, 9, 9};\n\t\n\t\tfindMaxActivity(start_time, finish_time);\t\n\t}\n}\n"
},
{
"alpha_fraction": 0.6647058725357056,
"alphanum_fraction": 0.6838235259056091,
"avg_line_length": 41.5,
"blob_id": "f7556babba09e0cff8ef8a5986dfdba23f11ba13",
"content_id": "b77f296f9876954491a6095b66ed3eaf169d6266",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 680,
"license_type": "no_license",
"max_line_length": 215,
"num_lines": 16,
"path": "/python/lab05/5-1.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python\n\n\"\"\"Write a funciton that returns a total cost from the sales price and sales tax rate. Both price and tax_rate shoudl be in the argument list. Provide a defualt value for the tax rate = 8.25%. Test your function.\"\"\"\n\ndef Cost(sales, tax_rate=\"8.25\"):\n print sales * (1 + (float(tax_rate) * 0.01))\n\nCost(100)\n\n\"\"\"Write a breakfast function that takes five arguments: meat, eggs, potatoes, toast, beverage\"\"\"\n\ndef Breakfast(meat=\"bacon\", eggs=\"over easy\", potatoes=\"hash brown\", toast=\"white\", beverage=\"coffee\"):\n print 'Here is your', meat, 'and', eggs ,'with' , potatoes , 'and' , toast\n print 'Can I bring you more' , beverage ,'?'\n\nBreakfast();\n"
},
{
"alpha_fraction": 0.46628132462501526,
"alphanum_fraction": 0.489402711391449,
"avg_line_length": 15.741935729980469,
"blob_id": "79e23b55b2e2fd822599dec6a624361d38a38ea6",
"content_id": "74f0abd29a41a99b2072b51bcf499981eba88bc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 519,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 31,
"path": "/python/lab01/draw_tree.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\" Write a script that uses nested while loops to produce this pattern:\n\n *\n * * *\n * * * * *\n* * * * * * *\n\"\"\"\n\nnumber = 4\nnum_of_stars = 1;\nwhile number > 0:\n stars = 0;\n space = 0;\n while space < number:\n print \" \",\n space += 1\n while stars < num_of_stars:\n print \"*\",\n stars += 1\n print\n num_of_stars += 2\n number -= 1\n\n#simple way\n\n\nwhile number > 0:\n print number * ' ' + num_of_stars * '*'\n num_of_stars += 2\n number -= 1\n"
},
{
"alpha_fraction": 0.6438356041908264,
"alphanum_fraction": 0.6712328791618347,
"avg_line_length": 15.222222328186035,
"blob_id": "1644e1c92d73bdfc189db1e01746406a07cb5d4f",
"content_id": "31400bf579f9e9bd06c1b5d5971fd0d120a36923",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 9,
"path": "/python/lab04/doubler.py",
"repo_name": "sujcho/python-practice",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python\n\"\"\"Function with one argument.\"\"\"\n\ndef Doubler(x):\n return 2 * x\n\nprint Doubler(2)\nprint Doubler(\"Hi\")\nprint Doubler(2.2)\n"
}
] | 25 |
gokul2908/Cantera-and-Python
|
https://github.com/gokul2908/Cantera-and-Python
|
f09b3fdfaba8bd40c00b521e9010d380d2950728
|
9e7d63d42c0a56a58b8ccdd20433e0a5de14035d
|
cb44a1c4e33920d6370fc098ac984e7892b47b25
|
refs/heads/main
| 2023-03-25T07:43:12.530183 | 2021-03-23T13:14:48 | 2021-03-23T13:14:48 | 350,208,575 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 20,
"blob_id": "76dfc9e6fde6017abd53c740bb0103784692486e",
"content_id": "81337abb99eaf809255be910840c28829e35c306",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/README.md",
"repo_name": "gokul2908/Cantera-and-Python",
"src_encoding": "UTF-8",
"text": "# Cantera-and-Python"
},
{
"alpha_fraction": 0.45191556215286255,
"alphanum_fraction": 0.6624967455863953,
"avg_line_length": 35.894229888916016,
"blob_id": "eee17fd5721a16a493eb10969fa90a7c4c31d821",
"content_id": "7c53f275eaedb40167cdccf8cf16bbfca2b38817",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3840,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 104,
"path": "/adiabatic_flame_temp_equivalence_ratio.py",
"repo_name": "gokul2908/Cantera-and-Python",
"src_encoding": "UTF-8",
"text": "'''\nAdiabatic flame temperature for methane\nCH4 + 2(O2 + 3.76N2) = 0.8CO2 + 1.6H20 + 7.52N2 + O2\nfor lean mixture\nCH4 + 2/ER(O2+3.76N2) -> CO2 + 2H2O + (7.52/ER)N2 + (2/Φ- 2)O2\nfor rich mixture\nCH4 + 2/ER(O2+3.76N2) -> ( 4/ER–3)CO2 + 2H2O + (7.52/ER)N2 + (4- 4/ER)CO\n'''\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport cantera as ct\n\n\ndef h(T, coeff): # fuction to determine the enthalpy\n\tR = 8.314 # jol/mol-k\n\ta1 = coeff[0]\n\ta2 = coeff[1]\n\ta3 = coeff[2]\n\ta4 = coeff[3]\n\ta5 = coeff[4]\n\ta6 = coeff[5]\n\ta7 = coeff[6]\n\n\treturn (a1 + a2*T/2 + a3*pow(T,2)/3 + a4*pow(T,3)/4 + a5*pow(T,4)/5 + a6/T)*R*T\n\ndef f(T,ER): # fuction to determine total enthalpy of product & reactant\n\n\t#enthalpy of reactants\n\tt_sat = 298.15\n\th_CH4_r = h(t_sat,CH4_coefficient_l)\n\th_O2_r = h(t_sat,O2_coefficient_l)\n\th_N2_r = h(t_sat,N2_coefficient_l)\n\n\tH_reactants = h_CH4_r + (2/ER)*(h_O2_r + 3.76*h_N2_r)\t\n\n\t#enthalpy of produce\n\th_CO2_p = h(T,CO2_coefficient_h)\n\th_N2_p = h(T,N2_coefficient_h)\n\th_H2O_p = h(T,H2O_coefficient_h)\n\t#h_CH4_p = h(T,CH4_coefficient_h)\n\th_O2_p = h(T,O2_coefficient_h)\n\th_CO_p = h(T,CO_coefficient_h)\n\n\tif ER==1: #Stoichiometric \n\t\tH_product = h_CO2_p + 7.52*h_N2_p + 2*h_H2O_p + 0.4*h_O2_p\n\telse:\n\t \tif ER>1: #rich mixture\n\t \t\tH_product = ((4/ER)-3)*h_CO2_p + (7.52/ER)*h_N2_p + 2*h_H2O_p + (4-(4/ER))*h_CO_p\n\t \telse: \t #lean mixture\n\t \t\tH_product = h_CO2_p + (7.52/ER)*h_N2_p + 2*h_H2O_p + ((2/ER)-2)*h_O2_p\n\n\treturn H_product-H_reactants\n\ndef fprime(T,ER): #Numerical differntiation\n\treturn (f(T+1e-6,ER)-f(T,ER))/1e-6\n\n#Methane Coefficient from Nasa polynomials data\nCH4_coefficient_l = [ 5.14987613E+00, -1.36709788E-02, 4.91800599E-05, -4.84743026E-08, 1.66693956E-11, -1.02466476E+04, -4.64130376E+00]\n#Oxygen \nO2_coefficient_l = [ 3.78245636E+00, -2.99673416E-03, 9.84730201E-06, -9.68129509E-09, 3.24372837E-12, -1.06394356E+03, 3.65767573E+00]\nO2_coefficient_h = [ 3.28253784E+00, 1.48308754E-03, -7.57966669E-07, 2.09470555E-10, -2.16717794E-14, -1.08845772E+03, 5.45323129E+00]\n#Nitrogen\nN2_coefficient_h = [ 0.02926640E+02, 0.14879768E-02, -0.05684760E-05, 0.10097038E-09, -0.06753351E-13, -0.09227977E+04, 0.05980528E+02]\nN2_coefficient_l = [ 0.03298677E+02, 0.14082404E-02, -0.03963222E-04, 0.05641515E-07, -0.02444854E-10, -0.10208999E+04, 0.03950372E+02]\n#Carbon-di-oxide\nCO2_coefficient_h = [ 3.85746029E+00, 4.41437026E-03, -2.21481404E-06, 5.23490188E-10, -4.72084164E-14, -4.87591660E+04, 2.27163806E+00]\n#Carbon-mono-oxide\nCO_coefficient_h = [ 2.71518561E+00, 2.06252743E-03, -9.98825771E-07, 2.30053008E-10, -2.03647716E-14, -1.41518724E+04, 7.81868772E+00]\n#Water vapor\nH2O_coefficient_h = [ 3.03399249E+00, 2.17691804E-03, -1.64072518E-07, -9.70419870E-11, 1.68200992E-14, -3.00042971E+04, 4.96677010E+00]\n\nER_x = np.linspace(0.1,2,100) #Equivalence ratio \nT_guess = 2000\ntol = 1e-5\nalpha = 1\ntemp = [] # empty array for newton rhapson technique\ntemp_cantera = [] # empty array for cantera\ngas = ct.Solution('gri30.xml') # centera\n\nfor ER in ER_x:\n\twhile (abs(f(T_guess,ER))>tol ):\n\t\tT_guess = T_guess - alpha*(f(T_guess,ER)/fprime(T_guess,ER)) # newton rhapson technique\n\t\n\tgas.TPX = 298.15,101325,{\"CH4\":1,\"O2\":2/ER,\"N2\":(2*3.76/ER)}\n\tgas.equilibrate(\"HP\",\"auto\")\t\n\tprint(\"Adiabatic Flame temperature From newton rhapson technique is \",+ T_guess)\n\tprint(\"Adiabatic Flame temperature From Cantera is \",+ gas.T)\n\ttemp.append(T_guess)\n\ttemp_cantera.append(gas.T)\n\t\t\n\nplt.plot(ER_x,temp,color=\"red\")\nplt.plot(ER_x,temp_cantera,color=\"blue\")\nplt.xlabel(\"Equivalence ratio\")\nplt.ylabel(\"Adiabatic flame temperature\")\nplt.grid(\"on\")\nplt.title(\"Adiabatic flame temperature\")\nplt.legend([\"Newton rhapson technique\",\"cantera\"])\nplt.show()\n\nprint(temp_cantera.index(max(temp_cantera)))\naa = temp_cantera.index(max(temp_cantera))\nER = ER_x[aa]\nprint(ER)\n"
},
{
"alpha_fraction": 0.5880597233772278,
"alphanum_fraction": 0.6447761058807373,
"avg_line_length": 14.904762268066406,
"blob_id": "3d978f63e14379a3a04e2c6edf4a7b9784e41a6b",
"content_id": "bdb34232d631b3b74edab0c993662deeac94d0d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 21,
"path": "/newton_rhapson_technique.py",
"repo_name": "gokul2908/Cantera-and-Python",
"src_encoding": "UTF-8",
"text": "# newton rhapson technique\n\n\ndef f(x):\n\treturn pow(x,3) + 4*pow(x,2) + 2*x -5\n\ndef fprime(x):\n\treturn 3*pow(x,2) + 8*x + 2\n\n\nx_guess = 10\ntolerance = 1e-22\nalpha = 1.29\niterations = 0\n\nwhile (f(x_guess)>tolerance):\n\tx_guess = x_guess - alpha*(f(x_guess)/fprime(x_guess))\n\titerations = iterations + 1\n\nprint(iterations)\nprint(x_guess)\n\n"
}
] | 3 |
trevorassaf/delphi
|
https://github.com/trevorassaf/delphi
|
370638c1375c4cf1e036e942ffca6e5e279c6230
|
562feb12771ced3cf763b85c75b489039d09f829
|
735f331dce082fcda3858837d40ee072f3d57049
|
refs/heads/master
| 2016-09-06T00:18:22.206096 | 2014-11-10T01:41:05 | 2014-11-10T01:41:05 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6234010457992554,
"alphanum_fraction": 0.6241534948348999,
"avg_line_length": 19.596899032592773,
"blob_id": "064270b8a9f9ab0b7ccbd0e5cc9bd3050eae2b21",
"content_id": "9cd3add9a2ffbf17e1b129675cfc63d5d4a69666",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2658,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 129,
"path": "/src/php/api/fantasy_football_api/TeamsApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class TeamsResultMode {\n const INVALID_RESP = 0;\n const SUCCESSFUL_RESP = 1;\n}\n\nfinal class TeamsResult {\n\n const CITY = \"City\";\n const CONFERENCE = \"Conference\";\n const DIVISION = \"Division\";\n const FULL_NAME = \"FullName\";\n const KEY = \"Key\";\n const NAME = \"Name\";\n\n private\n $city,\n $conference,\n $division,\n $fullName,\n $key,\n $name;\n\n public static function createFromJsonString($json_str) {\n $result_array = json_decode($json_str, true);\n if ($result_array == null) {\n throw new Exception(\"invalid scores-by-week-result\");\n }\n\n $result_struct_array = array();\n foreach ($result_array as $result) {\n $result_struct_array[] = self::createFromArray($result); \n }\n\n return $result_struct_array;\n }\n\n public static function createFromArray($result_array) {\n return new self(\n $result_array[self::CITY],\n $result_array[self::CONFERENCE],\n $result_array[self::DIVISION],\n $result_array[self::FULL_NAME],\n $result_array[self::KEY],\n $result_array[self::NAME]\n );\n }\n\n private function __construct(\n $city,\n $conference,\n $division,\n $fullName,\n $key,\n $name) {\n $this->city = $city;\n $this->conference = $conference;\n $this->division = $division;\n $this->fullName = $fullName;\n $this->key = $key;\n $this->name = $name;\n }\n\n public function getCity() {\n return $this->city;\n }\n\n public function getConference() {\n return $this->conference;\n }\n\n public function getDivision() {\n return $this->division;\n }\n\n public function getFullName() {\n return $this->fullName;\n }\n\n public function getKey() {\n return $this->key;\n }\n\n public function getName() {\n return $this->name;\n }\n}\n\nclass TeamsApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"Teams\";\n\n private\n $seasonKey,\n $resultArray;\n\n public function __construct($seasonKey) {\n $this->seasonKey = $seasonKey; \n parent::__construct();\n }\n\n protected function validateAndCacheResponse($response) {\n try {\n $this->resultArray = TeamsResult::createFromJsonString($response);\n } catch (Exception $e) {\n $this->resultMode = TeamsResultMode::INVALID_RESP;\n return false;\n } \n\n $this->resultMode = TeamsResultMode::SUCCESSFUL_RESP;\n return true;\n }\n\n protected function genUrlSuffix() {\n return self::METHOD_NAME . \"/\" . $this->seasonKey;\n }\n\n public function getResultArray() {\n return $this->resultArray;\n }\n\n public function getSeasonKey() {\n return $this->seasonKey;\n }\n}\n\n"
},
{
"alpha_fraction": 0.5355191230773926,
"alphanum_fraction": 0.5464481115341187,
"avg_line_length": 12.071428298950195,
"blob_id": "cf103e956a82a2021cf5076ec7d06d21e310a4f7",
"content_id": "f1fa534f9bfa674c58b7a79ef4bd789474c4066b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/src/php/access_layer/sandbox/team_test.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../Team.php\");\n\n$team = Team::create(\n \"49\\'ers\",\n \"San Franciso\",\n \"SF\",\n \"California\"\n);\n\nvar_dump($team);\n$team->delete();\n"
},
{
"alpha_fraction": 0.6873747706413269,
"alphanum_fraction": 0.6873747706413269,
"avg_line_length": 21.68181800842285,
"blob_id": "f85f424fb8cab6a36e52df3cd358de0c7fc3b7af",
"content_id": "4ffb21cc90e40607db4c5b07104699ca743edc9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 22,
"path": "/src/php/api/OutgoingApiReq.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/ApiRequest.php\");\n\nabstract class OutgoingApiReq extends ApiRequest {\n\n private $request;\n\n public function __construct($request) {\n parent::__construct();\n $this->request = $request;\n }\n\n public function process() {\n // Perform request and process response\n $response = $this->request->execute(); \n $this->validateAndCacheResponse($response);\n }\n\n protected abstract function validateAndCacheResponse($response);\n}\n"
},
{
"alpha_fraction": 0.6566757559776306,
"alphanum_fraction": 0.6566757559776306,
"avg_line_length": 14.956521987915039,
"blob_id": "25c6c580116963fd238057c256adcd428df77fe8",
"content_id": "c31ce4dff74e9a1c26b8c0965c663f89d3cd9636",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 23,
"path": "/src/php/api/ApiRequest.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nabstract class ApiRequest {\n\n protected\n $isValidResult,\n $resultMode;\n\n public function __construct() {\n $this->isValidResult = false;\n $this->resultMode = null;\n }\n\n abstract function process();\n\n public function isValidResult() {\n return $this->isValidResult;\n }\n\n public function getResultMode() {\n return $this->resultMode;\n }\n}\n"
},
{
"alpha_fraction": 0.6154419779777527,
"alphanum_fraction": 0.6161879897117615,
"avg_line_length": 24.5238094329834,
"blob_id": "c7dff8185f165bb1f2208bdaba18c69ac1a7ee70",
"content_id": "119d44e25abb5367d973ee6e82100b7a65fffe44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2681,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 105,
"path": "/src/php/scripts/admin_client.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../access_layer/User.php\");\n\n// -- CONSTANTS\ndefined(\"OPERATION_KEY\") ? null : define(\"OPERATION_KEY\", \"op\");\ndefined(\"TABLE_KEY\") ? null : define(\"TABLE_KEY\", \"table\");\ndefined(\"PARAMS_KEY\") ? null : define(\"PARAMS_KEY\", \"json_params\");\ndefined(\"ENDPOINT_URL\") \n ? null \n : define(\"ENDPOINT_URL\", \"http://organicdump.com/delphi/src/php/endpoints/admin_endpoints.php\");\n\n// Table fields\n$USER_FIELDS = array(\n User::ID_DB_KEY,\n User::FBID_DB_KEY,\n User::USERNAM_DB_KEY,\n User::FIRSTNAME_DB_KEY,\n User::LASTNAME_DB_KEY,\n User::BIRTHDATE_DB_KEY,\n User::SEX_DB_KEY,\n User::BALANCE_DB_KEY,\n User::ISADMIN_DB_KEY);\n\n// -- FUNCTIONS\nfunction userSelectTable() {\n echo \"-- Select table to modify: \\n\";\n echo \"\\t - Options: Users, Teams, Seasons, Games, Bets, UserBets, Friends\\n\";\n echo \"\\t - Table: \";\n $table_name = readline();\n echo \"\\n\";\n return $table_name;\n}\n\nfunction userSelectParams($table_name, $col_names) {\n $params = array();\n foreach ($col_names as $col_name) {\n echo \"\\t - \" . $col_name . \": \";\n $value = readline();\n if ($value !== '') {\n $params[$col_name] = urlencode($value);\n }\n }\n}\n\nfunction tableCreate($table_name) {\n echo \"-- Create new record in table: \" . $table_name . \"\\n\";\n $params = null; \n switch ($table_name) {\n case \"Users\":\n global $USER_FIELDS;\n $params = userSelectParams($table_name, $USER_FIELDS); \n break;\n default:\n die(\"ERROR: bad table specified: \" . $table_name);\n break; \n }\n return $params;\n}\n\nfunction userSelectOperationType() {\n echo \"-- Select operation to perform: \\n\";\n echo \"\\t - Options: create, read, update, delete\\n\";\n echo \"\\t - Operation: \";\n $operation_type = readline();\n echo \"\\n\";\n return $operation_type;\n}\n\nfunction sendRequest($table_name, $operation, $params) {\n $json_params = json_encode($params);\n $fields_string = \n TABLE_KEY . \"=\" . $table_name \n . \"&\" . OPERATION_KEY . \"=\" . $operation_type \n . \"&\" . PARAMS_KEY . \"=\" . $json_params;\n\n $ch = curl_init();\n curl_setopt($ch, CURLOPT_URL, ENDPOINT_URL);\n curl_setopt($ch, CURLOPT_POST, 3);\n curl_setopt($ch, CURLOPT_POSTFIELDS, $fields_string);\n $result = curl_exec($ch);\n curl_close($ch);\n}\n\nwhile (1) {\n // Table name\n $table_name = userSelectTable();\n\n // Operation type\n $operation_type = userSelectOperationType();\n\n $params = null;\n switch ($operation_type) {\n case \"create\":\n $params = tableCreate($table_name);\n break;\n default:\n die(\"ERROR: invalid operaiton-type: \" . $operation_type);\n break; \n }\n\n // Send Request\n $result = sendRequest($table_name, $operation, $params);\n}\n\n"
},
{
"alpha_fraction": 0.7163265347480774,
"alphanum_fraction": 0.7163265347480774,
"avg_line_length": 26.16666603088379,
"blob_id": "4ab164ff54f2648fe059a439219f5c0d5a3fca8d",
"content_id": "44ce371729e06fdac4c8b281fae492962dbd6bcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 490,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 18,
"path": "/src/php/access_layer/exceptions/DuplicateFriendRequestException.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nclass DuplicateFriendRequestException extends Exception {\n\n private \n $requestingUserId,\n $approvingUserId;\n\n public function __construct($requestingUserId, $approvingUserId) {\n $this->requestingUserId = $requestingUserId;\n $this->approvingUserId = $approvingUserId; \n }\n\n public function __toString() {\n return \"ERROR: <DuplicateFriendRequestException> requestingUserId: \" \n . $this->requestingUserId . \", approvingUserId: \" . $this->approvingUserId;\n }\n}\n\n"
},
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6122105121612549,
"avg_line_length": 24.537633895874023,
"blob_id": "6af7d6e1cc65eebc86261db467bd90396e0888ac",
"content_id": "5582a9b200dd97abb6d0bc27f1f144d9a891bb4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2375,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 93,
"path": "/src/php/access_layer/Season.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject\");\n\nclass Season extends DelphiObject {\n// -- CLASS CONSTANTS\n const SEASON_TABLE_NAME = \"Seasons\";\n const TEAMID_DB_KEY = \"teamId\";\n const WINS_DB_KEY = \"wins\";\n const LOSSES_DB_KEY = \"losses\";\n const TIES_DB_KEY = \"ties\";\n const GAMESPLAYED_DB_KEY = \"gamesPlayed\";\n\n // Default valus\n const WINS_DEFAULT_VALUE = 0;\n const LOSSES_DEFAULT_VALUE = 0;\n const TIES_DEFAULT_VALUE = 0;\n const GAMES_PLAYED_DEFAULT_VALUE = 0;\n\n // -- CLASS VARS\n protected static $tableName = self::SEASON_TABLE_NAME;\n\n// -- INSTANCE VARS\t\n private\n $teamId,\n $wins,\n $losses,\n $ties,\n $gamesPlayed,\n\n public static function createDefault($teamId) {\n return static::createObject(\n self::TEAMID_DB_KEY => $teamId,\n self::WINS_DB_KEY => self::WINS_DEFAULT_VALUE,\n self::LOSSES_DB_KEY => self::LOSSES_DEFAULT_VALUE,\n self::TIES_DB_KEY => self::TIES_DEFAULT_VALUE,\n self::GAMESPLAYED_DB_KEY => self::GAMES_PLAYED_DEFAULT_VALUE,\n ); \n } \n\n public static function create(\n $teamId,\n $wins,\n $losses,\n $ties,\n $gamesPlayed) {\n return static::createObject(\n array(\n self::TEAMID_DB_KEY => $teamId,\n self::WINS_DB_KEY => $wins,\n self::LOSSES_DB_KEY => $losses,\n self::TIES_DB_KEY => $ties,\n self::GAMESPLAYED_DB_KEY => $gamesPlayed,\n )\n );\n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->teamId = $params[self::TEAMID_DB_KEY];\t\n $this->wins = $params[self::WINS_DB_KEY];\t\n $this->losses = $params[self::LOSSES_DB_KEY];\t\n $this->ties = $params[self::TIES_DB_KEY];\t\n $this->gamesPlayed = $params[self::GAMESPLAYED_DB_KEY];\t\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::TEAMID_DB_KEY => $this->teamId,\n self::WINS_DB_KEY => $this->wins,\n self::LOSSES_DB_KEY => $this->losses,\n self::TIES_DB_KEY => $this->ties,\n self::GAMESPLAYED_DB_KEY => $this->gamesPlayed,\n );\n } \n\n // -- Getters\n public function getTeamId() { \n\t\treturn $this->teamId;\n\t}\n public function getWins() { \n\t\treturn $this->wins;\n\t}\n public function getLosses() { \n\t\treturn $this->losses;\n\t}\n public function getTies() { \n\t\treturn $this->ties;\n\t}\n public function getGamesPlayed() { \n\t\treturn $this->gamesPlayed;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6590330600738525,
"alphanum_fraction": 0.6590330600738525,
"avg_line_length": 14.720000267028809,
"blob_id": "87c0b11ab1344daf165cfd107b154c99b9b9e40f",
"content_id": "3534a9545165d53f8ffafdff4f3043c430815fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 25,
"path": "/src/php/api/Api.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\n\nabstract class ApiRequest {\n\n protected\n $isValidResult,\n $resultMode;\n\n public function __construct() {\n $this->isValidResponse = false;\n $this->resultMode = null;\n }\n\n abstract function process();\n\n public function isValidResponse() {\n return $this->isValidResponse;\n }\n\n public function getResultMode() {\n return $this->resultMode;\n }\n}\n"
},
{
"alpha_fraction": 0.6984732747077942,
"alphanum_fraction": 0.7010177969932556,
"avg_line_length": 20.83333396911621,
"blob_id": "d59162e15630662c9b01c768e417d23127b67df1",
"content_id": "15365a64de2f5d15c872bdc773d8527119a0e383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 36,
"path": "/src/php/api/fantasy_football_api/CurrentSeasonYearApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class CurrentSeasonYearResultModeApi {\n\n const INVALID_RESPONSE = 0;\n const VALID_RESPONSE = 1;\n}\n\nclass CurrentSeasonYearApi extends FantasyFootballApi {\n \n const METHOD_NAME = \"CurrentSeason\";\n\n private $year;\n\n protected function validateAndCacheResponse($response) {\n if (!is_numeric($response)) {\n $this->resultMode = CurrentSeasonYearResultModeApi::INVALID_RESPONSE;\n return false; \n }\n\n $this->year = (int)$response;\n $this->resultMode = CurrentSeasonYearResultModeApi::VALID_RESPONSE;\n return true;\n }\n\n protected function genUrlSuffix() {\n return self::METHOD_NAME;\n }\n\n public function getCurrentSeasonYear() {\n return $this->year;\n }\n}\n"
},
{
"alpha_fraction": 0.6919475793838501,
"alphanum_fraction": 0.6938202381134033,
"avg_line_length": 21.25,
"blob_id": "4f326890ab1fe14b0368afdcaa8f364231d638cd",
"content_id": "bcf567b4af174fe2555cabe8459e37964648bed2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1068,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 48,
"path": "/src/php/api/fantasy_football_api/CheckGamesInProgressApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class ResponseType {\n\n const TRUE = \"true\";\n const FALSE = \"false\";\n}\n\nabstract class CheckIfGameIsInProgressResultMode {\n\n const INVALID_RESPONSE = 0;\n const VALID_RESPONSE = 1;\n}\n\nclass CheckIfGameIsInProgressApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"AreAnyGamesInProgress\";\n\n private $areGamesInProgress;\n\n protected function validateAndCacheResponse($response) {\n switch ($response) {\n case ResponseType::TRUE:\n $this->areGamesInProgress = true;\n break;\n case ResponseType::FALSE:\n $this->areGamesInProgress = false; \n break;\n default:\n $this->resultMode = CheckIfGameIsInProgressResultMode::INVALID_RESPONSE;\n return false;\n }\n\n $this->resultMode = checkIfGamesIsInProgressResultMode::VALID_RESPONSE;\n return true;\n }\n\n protected function genUrlSuffix() {\n return self::METHOD_NAME;\n }\n\n public function areGamesInProgress() {\n return $this->areGamesInProgress;\n }\n}\n"
},
{
"alpha_fraction": 0.6663598418235779,
"alphanum_fraction": 0.6672802567481995,
"avg_line_length": 25.5,
"blob_id": "607b9bb03da1c1ae488f5755707eb9a997569e4f",
"content_id": "a37a926f43c690f4364232771cf06df41256a583",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2173,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 82,
"path": "/src/php/access_layer/SeasonAdminInfo.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nclass SeasonAdminInfo extends DelphiObject {\n\n // -- CLASS CONSTANTS\n const SEASON_ADMIN_INFO_TABLE_NAME = \"SeasonAdminInfo\";\n const CURRENT_WEEK_KEY = \"current_week\";\n const CURRENT_YEAR_KEY = \"current_year\";\n const SEASONKEY_KEY = \"season_key\";\n\n protected static $tableName = self::SEASON_ADMIN_INFO_TABLE_NAME;\n\n // -- INSTANCE VARS\n private\n $currentWeek,\n $currentYear,\n $seasonKey;\n\n public static function create(\n $currentWeek,\n $currentYear) {\n $fund_vars = parent::createFundamentalVars();\n $fund_vars[self::CURRENT_WEEK_KEY] = $currentWeek;\n $fund_vars[self::CURRENT_YEAR_KEY] = $currentYear;\n $fund_vars[self::SEASONKEY_KEY] = \n FantasyFootballApi::genSeasonKey($currentWeek, $currentYear);\n return static::createObject($fund_vars);\n }\n\n public static function fetchMostRecentSeasonInfo() {\n $query = self::genFetchMostRecentSeasonInfoQuery();\n $result_array = static::$database->fetchArraysFromQuery($query);\n if (empty($result_array)) {\n return null;\n }\n\n return new static($result_array[0]);\n }\n\n private static function genFetchMostRecentSeasonInfoQuery() {\n return \"\n SELECT * \n FROM SeasonAdminInfo\n WHERE current_year =\n (SELECT MAX(current_year) FROM SeasonAdminInfo)\n ORDER BY current_week DESC\n LIMIT 1;\";\n }\n\n private static function genSeasonKey($year, $week) {\n \n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->currentWeek = $params[self::CURRENT_WEEK_KEY];\n $this->currentYear = $params[self::CURRENT_YEAR_KEY];\n $this->seasonKey = $params[self::SEASONKEY_KEY];\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::CURRENT_WEEK_KEY => $this->currentWeek,\n self::CURRENT_YEAR_KEY => $this->currentYear,\n self::SEASONKEY_KEY => $this->seasonKey,\n );\n }\n\n public function getCurrentWeek() {\n return $this->currentWeek;\n }\n\n public function getCurrentYear() {\n return $this->currentYear;\n }\n\n public function getSeasonKey() {\n return $this->seasonKey;\n }\n}\n"
},
{
"alpha_fraction": 0.7512690424919128,
"alphanum_fraction": 0.7512690424919128,
"avg_line_length": 11.3125,
"blob_id": "4d69415539719a886b5f3cf0db32a40f5ee9225a",
"content_id": "d5011e15338278b02ed012052a64ae5041a3398a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 16,
"path": "/src/sql/drop_tables.sql",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "-- Drop tables in 'Delphi' db\nDROP TABLE SeasonAdminInfo;\n\nDROP TABLE Friends;\n\nDROP TABLE UserBets;\n\nDROP TABLE Bets;\n\nDROP TABLE Users;\n\nDROP TABLE Games;\n\nDROP TABLE Seasons;\n\nDROP TABLE Teams;\n"
},
{
"alpha_fraction": 0.6649214625358582,
"alphanum_fraction": 0.6719022393226624,
"avg_line_length": 22.387754440307617,
"blob_id": "2b922f056b8bc2e18f881fec5cee9b8ede900c93",
"content_id": "5aab534f12fa0478087f407fe8497f724212e33c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1146,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 49,
"path": "/src/php/api/fantasy_football_api/CurrentWeekApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class CurrentWeekResultMode {\n\n const INVALID_RESPONSE = 0;\n const WEEK_NUMBER_OUT_OF_RANGE = 1;\n const VALID_RESPONSE = 2;\n}\n\nclass CurrentWeekApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"CurrentWeek\";\n\n const MIN_WEEK_NUM = 1;\n const MAX_REGULAR_SEASON_WEEK_NUM = 17;\n const MAX_WEEK_NUM = 21;\n\n private \n $weekNum,\n $isRegularSeason;\n\n protected function validateAndCacheResponse($response) {\n if (!is_numeric($response)) {\n $this->resultMode = CurrentWeekResultModeApi::INVALID_RESPONSE;\n return false; \n }\n\n $this->weekNum = (int)$response;\n\n if (self::MIN_WEEK_NUM > $this->weekNum || self::MAX_WEEK_NUM < $this->weekNum) {\n $this->resultMode = CurrentWeekResultMode::WEEK_NUMBER_OUT_OF_RANGE;\n return false;\n }\n\n $this->resultMode = VALID_RESPONSE;\n $this->isRegularSeason = $this->weekNum > self::MAX_REGULAR_SEASON_WEEK_NUM;\n }\n\n protected function genUrlSuffix() {\n return self::METHOD_NAME;\n }\n\n public function getCurrentWeek() {\n return $this->weekNum;\n }\n}\n"
},
{
"alpha_fraction": 0.6905537247657776,
"alphanum_fraction": 0.6905537247657776,
"avg_line_length": 22.615385055541992,
"blob_id": "926eb02297078e854514124d087bd4c03d1a9e9f",
"content_id": "9bc8278c7152a37e8623905c889622aac789c8dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 307,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/src/php/discus/http/PostRequest.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/HttpRequest.php\");\n\nclass PostRequestBuilder extends HttpRequestBuilder {\n\n public function build() {\n $this->method = HttpRequestMethod::POST;\n $params = $this->genParamsWithContent();\n return new HttpRequest($this->url, $params);\n }\n}\n"
},
{
"alpha_fraction": 0.6087419986724854,
"alphanum_fraction": 0.6556503176689148,
"avg_line_length": 23.05128288269043,
"blob_id": "a999fad01ae33eef72c06178aea11274ace8f7c4",
"content_id": "2e180e05b51fb68cf6cc0ed243a459bd090e5130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 938,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 39,
"path": "/examples/delphi.py",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "import urllib2\nimport json\n\napi_key = \"94134631-49C0-4079-A011-EC727A676638\"\n\ndef print_greeting():\n\tprint(\"=== TASTE THE NFL ===\")\n\ndef get_week():\n\twhile True:\n\t\tweek = raw_input(\"What 2014 week (1-17)? \").strip()\n\t\tif is_valid_week(week):\n\t\t\treturn week\n\t\tprint(\"Bad.\")\n\ndef is_valid_week(str):\n try:\n \tweek = int(str)\n \treturn week > 0 and week < 18\n except ValueError:\n \treturn False\n\ndef get_week_results():\n\turl = \"http://api.nfldata.apiphany.com/trial/JSON/ScoresByWeek/2014REG/%s?key=%s\" % (week, api_key)\n\tresponse = urllib2.urlopen(url)\n\treturn response.read()\n\nprint_greeting()\nweek = get_week()\nraw_json = get_week_results()\nweek_object = json.loads(raw_json);\n\nfor i in range(0, len(week_object)):\n\twk = week_object[i];\n\thome_team = wk['HomeTeam']\n\thome_score = wk['HomeScore']\n\taway_team = wk['AwayTeam']\n\taway_score = wk['AwayScore']\n\tprint(\"%s %s @ %s %s\" % (home_team, home_score, away_team, away_score))\n"
},
{
"alpha_fraction": 0.6163498163223267,
"alphanum_fraction": 0.6163498163223267,
"avg_line_length": 23.811321258544922,
"blob_id": "47ae6af2c8fb3115040d127f144093adc747d804",
"content_id": "5b72a85ed7053d5573d1d5bf153b157b671afbcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2630,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 106,
"path": "/src/php/access_layer/Team.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nclass Team extends DelphiObject {\n// -- CLASS CONSTANTS\n const TEAM_TABLE_NAME = \"Teams\";\n const NAME_DB_KEY = \"name\";\n const FULL_NAME_DB_KEY = \"full_name\";\n const CITY_DB_KEY = \"city\";\n const KEY_DB_KEY = \"team_key\";\n const DIVISION_DB_KEY = \"division\";\n const CONFERENCE_DB_KEY = \"conference\";\n const SEASON_DB_KEY = \"season_key\";\n\n // -- CLASS VARS\n protected static $tableName = self::TEAM_TABLE_NAME;\n\n protected static $uniqueKeys = array(\n DelphiObject::ID_KEY,\n self::NAME_DB_KEY,\n self::FULL_NAME_DB_KEY,\n self::KEY_DB_KEY,\n );\n\n// -- INSTANCE VARS\t\n private\n $name,\n $fullName,\n $city,\n $key,\n $division,\n $conference,\n $season;\n\n public static function create(\n $name,\n $fullName,\n $city,\n $key,\n $division,\n $conference,\n $season) {\n $create_vars = static::createFundamentalVars(); \n $create_vars[self::NAME_DB_KEY] = $name;\n $create_vars[self::FULL_NAME_DB_KEY] = $fullName;\n $create_vars[self::CITY_DB_KEY] = $city;\n $create_vars[self::KEY_DB_KEY] = $key;\n $create_vars[self::DIVISION_DB_KEY] = $division;\n $create_vars[self::CONFERENCE_DB_KEY] = $conference;\n $create_vars[self::SEASON_DB_KEY] = $season;\n return static::createObject($create_vars); \n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->name = $params[self::NAME_DB_KEY];\t\n $this->fullName = $params[self::FULL_NAME_DB_KEY];\n $this->city = $params[self::CITY_DB_KEY];\t\n $this->key = $params[self::KEY_DB_KEY];\n $this->division = $params[self::DIVISION_DB_KEY];\n $this->conference = $params[self::CONFERENCE_DB_KEY];\n $this->season = $params[self::SEASON_DB_KEY];\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::NAME_DB_KEY => $this->name,\n self::FULL_NAME_DB_KEY => $this->fullName,\n self::CITY_DB_KEY => $this->city,\n self::KEY_DB_KEY => $this->key,\n self::DIVISION_DB_KEY => $this->division,\n self::CONFERENCE_DB_KEY => $this->conference,\n self::SEASON_DB_KEY => $this->season,\n );\n } \n\n // -- Getters\n public function getName() { \n\t\treturn $this->name;\n\t}\n\n public function getFullName() {\n return $this->fullName;\n }\n\n public function getCity() { \n\t\treturn $this->city;\n\t}\n\n public function getTeamKey() {\n return $this->key;\n }\n\n public function getDivision() {\n return $this->division;\n }\n\n public function getConference() {\n return $this->conference;\n }\n\n public function getSeasonKey() {\n return $this->season;\n }\n}\n"
},
{
"alpha_fraction": 0.6196318864822388,
"alphanum_fraction": 0.650306761264801,
"avg_line_length": 22.285715103149414,
"blob_id": "659785651f8dd1c7bbbbe2d85a9fa27fdc76c09f",
"content_id": "ca693c85bf7a3986d2c26222177c8290213b948f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 7,
"path": "/src/php/api/fantasy_football_api/sandbox/scores_by_week_api.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nrequire_once(dirname(__FILE__).\"/../ScoresByWeekApi.php\");\n\n$api = new ScoresByWeekApi(1, 2012, \"REG\"); \n$api->process();\nvar_dump($api->getResultArray());\n"
},
{
"alpha_fraction": 0.6030534505844116,
"alphanum_fraction": 0.6412213444709778,
"avg_line_length": 20.83333396911621,
"blob_id": "dd9f82d835aaf3ff0fcb6a5c3732b0398af2043f",
"content_id": "6f9286631c2078c97f29da80a5be3db52be3e185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 6,
"path": "/src/php/api/fantasy_football_api/sandbox/team_game_stats_test.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nrequire_once(dirname(__FILE__).\"/../TeamGameStatsApi.php\");\n\n$api = new TeamGameStatsApi(1, 2012, \"REG\"); \n$api->process();\n"
},
{
"alpha_fraction": 0.6053921580314636,
"alphanum_fraction": 0.6838235259056091,
"avg_line_length": 26.200000762939453,
"blob_id": "f4d9b6939b449a3e909cc00b3c42913447c06310",
"content_id": "ba003c4abea1d99511380912c2f0ea5477da767a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 15,
"path": "/src/php/discus/sandbox/test_http_req.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nrequire_once(dirname(__FILE__).\"/../http/GetRequest.php\");\n\n$api_key = \"94134631-49C0-4079-A011-EC727A676638\";\n$week = 1;\n\n$builder = new GetRequestBuilder();\n$url = sprintf(\"http://api.nfldata.apiphany.com/trial/JSON/ScoresByWeek/2014REG/%s\", $week);\n\n$builder->setUrl($url);\n$builder->setContentParam(\"key\", $api_key);\n$request = $builder->build();\n$result = $request->execute();\nvar_dump($result);\n"
},
{
"alpha_fraction": 0.6480206251144409,
"alphanum_fraction": 0.6480206251144409,
"avg_line_length": 27.809917449951172,
"blob_id": "1824998f1f70e2520ecb985c2aeccd8e683fee8b",
"content_id": "5b92ff36fe65305fc2726d05d5d2945c40719f0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3486,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 121,
"path": "/src/php/access_layer/Game.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nabstract class GameStatus {\n\n const SCHEDULED = \"scheduled\"; \n const COMPLETED = \"completed\";\n const IN_PROGRESS = \"in_progress\";\n const CANCELLED = \"cancelled\";\n const RESCHEDULED = \"rescheduled\";\n}\n\nclass Game extends DelphiObject {\n// -- CLASS CONSTANTS\n const GAME_TABLE_NAME = \"Games\";\n const DATE_DB_KEY = \"date\";\n const HOMETEAMID_DB_KEY = \"homeTeamKey\";\n const AWAYTEAMID_DB_KEY = \"awayTeamKey\";\n const HOMETEAMSCORE_DB_KEY = \"homeTeamScore\";\n const AWAYTEAMSCORE_DB_KEY = \"awayTeamScore\";\n const PERIOD_DB_KEY = \"period\";\n const STATUS_DB_KEY = \"status\";\n const GAMETIM_DB_KEY = \"gameTime\";\n const SEASONID_DB_KEY = \"seasonKey\";\n\n // -- CLASS VARS\n protected static $tableName = self::GAME_TABLE_NAME;\n\n// -- INSTANCE VARS\t\n private\n $date,\n $homeTeamId,\n $awayTeamId,\n $homeTeamScore,\n $awayTeamScore,\n $period,\n $status,\n $gameTime,\n $seasonId;\n\n public static function create(\n $date,\n $homeTeamId,\n $awayTeamId,\n $homeTeamScore,\n $awayTeamScore,\n $period,\n $status,\n $gameTime,\n $seasonId) {\n $create_vars = parent::createFundamentalVars();\n $create_vars[self::DATE_DB_KEY] = $date;\n $create_vars[self::HOMETEAMID_DB_KEY] = $homeTeamId;\n $create_vars[self::AWAYTEAMID_DB_KEY] = $awayTeamId;\n $create_vars[self::HOMETEAMSCORE_DB_KEY] = $homeTeamScore;\n $create_vars[self::AWAYTEAMSCORE_DB_KEY] = $awayTeamScore;\n $create_vars[self::PERIOD_DB_KEY] = $period;\n $create_vars[self::STATUS_DB_KEY] = $status;\n $create_vars[self::GAMETIM_DB_KEY] = $gameTime;\n $create_vars[self::SEASONID_DB_KEY] = $seasonId;\n\n return static::createObject($create_vars);\n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->date = $params[self::DATE_DB_KEY];\t\n $this->homeTeamId = $params[self::HOMETEAMID_DB_KEY];\t\n $this->awayTeamId = $params[self::AWAYTEAMID_DB_KEY];\t\n $this->homeTeamScore = $params[self::HOMETEAMSCORE_DB_KEY];\t\n $this->awayTeamScore = $params[self::AWAYTEAMSCORE_DB_KEY];\t\n $this->period = $params[self::PERIOD_DB_KEY];\t\n $this->status = $params[self::STATUS_DB_KEY];\t\n $this->gameTime = $params[self::GAMETIM_DB_KEY];\t\n $this->seasonId = $params[self::SEASONID_DB_KEY];\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::DATE_DB_KEY => $this->date,\n self::HOMETEAMID_DB_KEY => $this->homeTeamId,\n self::AWAYTEAMID_DB_KEY => $this->awayTeamId,\n self::HOMETEAMSCORE_DB_KEY => $this->homeTeamScore,\n self::AWAYTEAMSCORE_DB_KEY => $this->awayTeamScore,\n self::PERIOD_DB_KEY => $this->period,\n self::STATUS_DB_KEY => $this->status,\n self::GAMETIM_DB_KEY => $this->gameTime,\n self::SEASONID_DB_KEY => $this->seasonId,\n );\n } \n\n // -- Getters\n public function getDate() { \n\t\treturn $this->date;\n\t}\n public function getHomeTeamKey() { \n\t\treturn $this->homeTeamId;\n\t}\n public function getAwayTeamKey() { \n\t\treturn $this->awayTeamId;\n\t}\n public function getHomeTeamScore() { \n\t\treturn $this->homeTeamScore;\n\t}\n public function getAwayTeamScore() { \n\t\treturn $this->awayTeamScore;\n\t}\n public function getPeriod() { \n\t\treturn $this->period;\n\t}\n public function getStatus() { \n\t\treturn $this->status;\n\t}\n public function getGameTim() { \n\t\treturn $this->gameTime;\n }\n public function getSeasonKey() {\n return $this->seasonId;\n }\n}\n"
},
{
"alpha_fraction": 0.6209150552749634,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 20.85714340209961,
"blob_id": "ef6fd89e1af7e175bd3066dd9eccc3c4abd455f2",
"content_id": "28a84cf102f1a8fc14b25432c9976096186e0f8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 153,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 7,
"path": "/src/php/api/fantasy_football_api/sandbox/schedules_test.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nrequire_once(dirname(__FILE__).\"/../SchedulesApi.php\");\n\n$api = new SchedulesApi(2012, \"REG\");\n$api->process();\nvar_dump($api->getResultArray());\n"
},
{
"alpha_fraction": 0.6183035969734192,
"alphanum_fraction": 0.6183035969734192,
"avg_line_length": 21.399999618530273,
"blob_id": "d1af16535e0ccf587d3de112143a3542becbde08",
"content_id": "8a920c334a7a574a5db0785eed23f1920e6207fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 20,
"path": "/src/php/discus/http/GetRequest.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/HttpRequest.php\");\n\nclass GetRequestBuilder extends HttpRequestBuilder {\n\n public function build() {\n $this->method = HttpRequestMethod::GET;\n $params = $this->genParams();\n\n $url = $this->url;\n if (isset($this->content)) {\n $content_string = http_build_query($this->content);\n $url .= \"?\" . $content_string; \n }\n\n return new HttpRequest($url, $params);\n }\n}\n"
},
{
"alpha_fraction": 0.7379679083824158,
"alphanum_fraction": 0.7433155179023743,
"avg_line_length": 25.571428298950195,
"blob_id": "96fa5bd580bae8c1ce1b2f4bfbccca929ec6d929",
"content_id": "b4bded97432bf1ef281693d88ac8abe01642bb2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 7,
"path": "/src/sql/useful_queries.sql",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "-- Select most recent SeasonAdminInfo\nSELECT * \n FROM SeasonAdminInfo\n WHERE current_year =\n (SELECT MAX(current_year) FROM SeasonAdminInfo)\n ORDER BY current_week DESC\n LIMIT 1;\n\n"
},
{
"alpha_fraction": 0.7177206873893738,
"alphanum_fraction": 0.7269433736801147,
"avg_line_length": 26.351350784301758,
"blob_id": "e8ee264ff5a48750dafbf9472b7575d01ec3b11a",
"content_id": "cee1e643e21f91a059189f26ecf2a92c7731cea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 3036,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 111,
"path": "/src/sql/create_tables.sql",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "-- TODO\n -- shouldn't avatar be fb pic?\n -- should be separating betting from user table\n \n-- Users Table\nCREATE TABLE Users (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n fbId INT NOT NULL UNIQUE,\n username VARCHAR(20) NOT NULL UNIQUE,\n firstName VARCHAR(20) NOT NULL,\n lastName VARCHAR(20) NOT NULL,\n birthdate DATE NOT NULL,\n sex ENUM('male', 'gender', 'unspecified') NOT NULL,\n balance INT NOT NULL,\n isAdmin TINYINT(1) NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Friends Table\nCREATE TABLE Friends (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n requestingUserId INT NOT NULL,\n approvingUserId INT NOT NULL,\n requestStatus ENUM(\"pending\", \"approved\") NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Teams Table\nCREATE TABLE Teams (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n name VARCHAR(20) NOT NULL UNIQUE, -- unique for football, only. Must change for other sports\n full_name VARCHAR(40) NOT NULL UNIQUE,\n city VARCHAR(20) NOT NULL,\n team_key VARCHAR(3) NOT NULL UNIQUE,\n division VARCHAR(20) NOT NULL,\n conference VARCHAR(20) NOT NULL,\n season_key VARCHAR(20) NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Season Table\nCREATE TABLE Seasons (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n teamId INT NOT NULL,\n wins INT NOT NULL,\n losses INT NOT NULL,\n ties INT NOT NULL,\n gamesPlayed INT NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Score Table\nCREATE TABLE Games (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n date DATETIME NOT NULL,\n homeTeamKey VARCHAR(3) NOT NULL,\n awayTeamKey VARCHAR(3) NOT NULL,\n homeTeamScore INT NOT NULL,\n awayTeamScore INT NOT NULL,\n period INT NOT NULL,\n status ENUM(\"scheduled\", \"completed\", \"in_progress\", \"cancelled\", \"rescheduled\") NOT NULL,\n gameTime VARCHAR(20) NOT NULL,\n seasonKey VARCHAR(10) NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Bets Table\nCREATE TABLE Bets (\n id INT NOT NULL UNIQUE AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n gameId INT NOT NULL,\n teamId INT NOT NULL,\n bettingUserId INT NOT NULL,\n bettingUserHandicap FLOAT NOT NULL, \n wager INT NOT NULL,\n cancellationPenalty INT NOT NULL,\n status ENUM(\"pending\", \"approved\", \"completed\", \"cancelled\") NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- User Bets\nCREATE TABLE UserBets (\n id INT NOT NULL AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n userId INT NOT NULL,\n betId INT NOT NULL,\n PRIMARY KEY(id)\n);\n\n-- Administrative Information about Seasons\nCREATE TABLE SeasonAdminInfo (\n id INT NOT NULL AUTO_INCREMENT,\n created_time DATETIME NOT NULL,\n last_updated_time DATETIME NOT NULL,\n PRIMARY KEY(id),\n current_week INT NOT NULL,\n current_year INT NOT NULL,\n season_key VARCHAR(10) NOT NULL\n);\n"
},
{
"alpha_fraction": 0.633511483669281,
"alphanum_fraction": 0.6339762806892395,
"avg_line_length": 22.259458541870117,
"blob_id": "30463118d87ac431a6344e7949db546be7cf18ce",
"content_id": "68607c34f402856f4cb06bbd4b75ec6fd076a9b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 4303,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 185,
"path": "/src/php/api/fantasy_football_api/ScoresByWeekApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class ScoresByWeekResultMode {\n\n const SUCCESSFUL_RESP = 0;\n const INVALID_RESP = 1;\n}\n\nfinal class ScoresByWeekResult {\n\n const AWAY_SCORE = \"AwayScore\";\n const AWAY_TEAM = \"AwayTeam\";\n const HOME_SCORE = \"HomeScore\";\n const HOME_TEAM = \"HomeTeam\";\n const GAME_KEY = \"GameKey\";\n const HAS_STARTED = \"HasStarted\";\n const IS_IN_PROGRESS = \"IsInProgress\";\n const IS_OVERTIME = \"IsOvertime\";\n const IS_OVER = \"IsOver\";\n const TIME_REMAINING = \"TimeRemaining\";\n const WEEK = \"Week\";\n\n private\n $awayScore,\n $awayTeam,\n $homeScore,\n $homeTeam,\n $gameKey,\n $hasStarted,\n $isInProgress,\n $isOvertime,\n $isOver,\n $timeRemaining,\n $week;\n\n public static function createFromJsonString($json_str) {\n $result_array = json_decode($json_str, true);\n if ($result_array == null) {\n throw new Exception(\"invalid scores-by-week-result\");\n }\n\n $result_struct_array = array();\n foreach ($result_array as $result) {\n $result_struct_array[] = self::createFromArray($result); \n }\n\n return $result_struct_array;\n }\n\n public static function createFromArray($result_array) {\n return new self(\n $result_array[self::AWAY_SCORE],\n $result_array[self::AWAY_TEAM],\n $result_array[self::HOME_SCORE],\n $result_array[self::HOME_TEAM],\n $result_array[self::GAME_KEY],\n $result_array[self::HAS_STARTED],\n $result_array[self::IS_IN_PROGRESS],\n $result_array[self::IS_OVERTIME],\n $result_array[self::IS_OVER],\n $result_array[self::TIME_REMAINING],\n $result_array[self::WEEK]\n ); \n }\n\n public function __construct(\n $away_score,\n $away_team,\n $home_score,\n $home_team,\n $game_key,\n $has_started,\n $is_in_progress,\n $is_overtime,\n $is_over,\n $time_remaining,\n $week) {\n $this->awayScore = $away_score;\n $this->awayTeam = $away_team;\n $this->homeScore = $home_score;\n $this->homeTeam = $home_team;\n $this->gameKey = $game_key;\n $this->hasStarted = $has_started;\n $this->isInProgress = $is_in_progress;\n $this->isOvertime = $is_overtime;\n $this->isOver = $is_over;\n $this->timeRemaining = $time_remaining;\n $this->week = $week;\n }\n\n public function getAwayScore() {\n return $this->awayScore;\n }\n\n public function getAwayTeam() {\n return $this->awayTeam;\n }\n\n public function getHomeScore() {\n return $this->homeScore;\n }\n\n public function getHomeTeam() {\n return $this->homeTeam;\n }\n\n public function getGameKey() {\n return $this->gameKey;\n }\n\n public function getHasStarted() {\n return $this->hasStarted;\n }\n\n public function isInProgress() {\n return $this->isInProgress;\n }\n\n public function isOver() {\n return $this->isOver;\n }\n\n public function isOvertime() {\n return $this->isOvertime;\n }\n\n public function getWeek() {\n return $this->week;\n }\n\n public function getTimeRemaining() {\n return $this->timeRemaining;\n }\n}\n\nclass ScoresByWeekApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"ScoresByWeek\";\n\n\n private\n $weekNum,\n $yearNum,\n $seasonSuffix,\n $resultArray;\n\n public function __construct($week_num, $year_num, $season_suffix) {\n // Check valid week num\n if (!FantasyFootballApi::isValidWeekNum($week_num, $season_suffix)) {\n throw new Exception(\"invalid week-num/season-suffix combination\");\n }\n\n $this->weekNum = $week_num;\n $this->yearNum = $year_num;\n $this->seasonSuffix = $season_suffix; \n parent::__construct();\n }\n\n protected function validateAndCacheResponse($response) {\n try {\n $this->resultArray = ScoresByWeekResult::createFromJsonString($response); \n } catch (Exception $e) {\n $this->resultMode = ScoresByWeekResultMode::INVALID_RESP;\n return false;\n }\n\n $this->resultMode = ScoresByWeekResultMode::SUCCESSFUL_RESP;\n return true;\n }\n\n protected function genUrlSuffix() {\n $year_season_str = \n FantasyFootballApi::genSeasonQueryString(\n $this->yearNum, $this->seasonSuffix);\n return self::METHOD_NAME . \"/\" . $year_season_str . \"/\" . $this->weekNum;\n }\n\n public function getResultArray() {\n return $this->resultArray;\n }\n\n}\n"
},
{
"alpha_fraction": 0.6295292973518372,
"alphanum_fraction": 0.6302065849304199,
"avg_line_length": 20.244604110717773,
"blob_id": "eb1762839d097af5432a88161ddb7415d98f23f1",
"content_id": "25aedd53087d4a91e552725f41f2a1a4a12f2932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2953,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 139,
"path": "/src/php/api/fantasy_football_api/SchedulesApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class SchedulesResultMode {\n\n const INVALID_RESP = 0;\n const SUCCESSFUL_RESP = 1;\n}\n\nfinal class SchedulesResult {\n\n const AWAY_TEAM = \"AwayTeam\";\n const DATE = \"Date\";\n const HOME_TEAM = \"HomeTeam\";\n const SEASON = \"Season\";\n const WEEK = \"Week\";\n const POINT_SPREAD = \"PointSpread\";\n const OVER_UNDER = \"OverUnder\";\n\n private\n $awayTeam,\n $date,\n $homeTeam,\n $season,\n $week,\n $pointSpread,\n $overUnder;\n\n public static function createFromJsonString($json_str) {\n $result_array = json_decode($json_str, true);\n if ($result_array == null) {\n throw new Exception(\"invalid scores-by-week-result\");\n }\n\n $result_struct_array = array();\n foreach ($result_array as $result) {\n $result_struct_array[] = self::createFromArray($result); \n }\n\n return $result_struct_array;\n }\n\n public static function createFromArray($result_array) {\n return new self(\n $result_array[self::AWAY_TEAM],\n $result_array[self::DATE],\n $result_array[self::HOME_TEAM],\n $result_array[self::SEASON],\n $result_array[self::WEEK],\n $result_array[self::POINT_SPREAD],\n $result_array[self::OVER_UNDER]\n );\n } \n\n private function __construct(\n $away_team,\n $date,\n $home_team,\n $season,\n $week,\n $point_spread,\n $over_under) {\n $this->awayTeam = $away_team;\n $this->date = $date;\n $this->homeTeam = $home_team;\n $this->season = $season;\n $this->week = $week;\n $this->pointSpread = $point_spread;\n $this->overUnder = $over_under;\n }\n\n public function getAwayTeamKey() {\n return $this->awayTeam;\n }\n\n public function getDate() {\n return $this->date;\n } \n\n public function getHomeTeamKey() {\n return $this->homeTeam;\n }\n\n public function getSeason() {\n return $this->season;\n }\n\n public function getWeek() {\n return $this->week;\n }\n\n public function getPointSpread() {\n return $this->pointSpread;\n }\n\n public function getOverUnder() {\n return $this->overUnder;\n }\n}\n\nclass SchedulesApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"Schedules\";\n\n private\n $seasonKey,\n $resultArray;\n\n public function __construct($season_key) {\n $this->seasonKey = $season_key;\n parent::__construct();\n }\n\n protected function validateAndCacheResponse($response) {\n try {\n $this->resultArray = SchedulesResult::createFromJsonString($response);\n } catch (Exception $e) {\n $this->resultMode = SchedulesResultMode::INVALID_RESP;\n return false;\n }\n\n $this->resultMode = SchedulesResultMode::SUCCESSFUL_RESP;\n return true;\n }\n\n protected function genUrlSuffix() {\n return self::METHOD_NAME . \"/\" . $this->seasonKey;\n }\n\n public function getResultArray() {\n return $this->resultArray;\n }\n\n public function getSeasonKey() {\n return $this->seasonKey;\n }\n}\n"
},
{
"alpha_fraction": 0.6087751388549805,
"alphanum_fraction": 0.6160877346992493,
"avg_line_length": 21.79166603088379,
"blob_id": "cc44e08b025f5a6097012abb12c6f61e633a50f5",
"content_id": "16e1325778cf9540a087e3de1841e838b50b2416",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 24,
"path": "/src/php/daemons/update_teams.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../api/fantasy_football_api/TeamsApi.php\");\nrequire_once(dirname(__FILE__).\"/../access_layer/Team.php\");\n\n$api = new TeamsApi(2013, \"REG\");\n$api->process();\n\n$result_array = $api->getResultArray();\n$teams = array();\nforeach ($result_array as $result) {\n $teams[] = Team::create(\n $result->getName(),\n $result->getFullName(),\n $result->getCity(),\n $result->getKey(),\n $result->getDivision(),\n $result->getConference(),\n $api->getSeasonKey()\n );\n}\n\nvar_dump($teams);\n"
},
{
"alpha_fraction": 0.6438502669334412,
"alphanum_fraction": 0.6463457942008972,
"avg_line_length": 28.526315689086914,
"blob_id": "9a3a7063f71d8114bb310b29144840ba53a39d5e",
"content_id": "c0c46e7584bb6f1c4f6b66fed72c5297e36beebd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2805,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 95,
"path": "/src/php/daemons/update_season_info.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../api/fantasy_football_api/CurrentWeekApi.php\");\nrequire_once(dirname(__FILE__).\"/../api/fantasy_football_api/CurrentSeasonYearApi.php\");\nrequire_once(dirname(__FILE__).\"/../api/fantasy_football_api/TeamsApi.php\");\nrequire_once(dirname(__FILE__).\"/../api/fantasy_football_api/SchedulesApi.php\");\nrequire_once(dirname(__FILE__).\"/../access_layer/SeasonAdminInfo.php\");\nrequire_once(dirname(__FILE__).\"/../access_layer/Team.php\");\nrequire_once(dirname(__FILE__).\"/../access_layer/Game.php\");\n\n// -- FUNCTIONS\nfunction updateSeasonConfiguration($current_week, $current_year) {\n $season_info = SeasonAdminInfo::fetchMostRecentSeasonInfo(); \n \n // Insert new record\n if ($season_info == null || $season_info->getCurrentWeek() != $current_week || \n $season_info->getCurrentYear() != $current_year) {\n $season_info = SeasonAdminInfo::create($current_week, $current_year);\n updateTeams($season_info->getSeasonKey());\n updateGameSchedule($season_info->getSeasonKey());\n return;\n }\n\n // Update timestamp for existing season-admin-info\n $season_info->save();\n}\n\nfunction updateGameSchedule($seasonKey) {\n $api = new SchedulesApi($seasonKey);\n $api->process();\n $result_array = $api->getResultArray();\n $games = array();\n $timestamp = explode(\"-\", $result_array[0]->getDate()); \n $timestamp = $timestamp[0];\n var_dump($timestamp);\n $date_format = date('Y-m-d G:i:s', (int)$timestamp);\n var_dump($date_format);\n foreach ($result_array as $result) {\n $timestamp = explode(\"-\", $result->getDate());\n $date_format = date('Y-m-d G:i:s', (int)($timestamp[0]));\n $games[] = Game::create(\n $date_format,\n $result->getHomeTeamKey(),\n $result->getAwayTeamKey(),\n 0,\n 0,\n 0,\n GameStatus::SCHEDULED,\n 0,\n $seasonKey\n );\n }\n \n var_dump($games);\n}\n\nfunction updateTeams($season_key) {\n $api = new TeamsApi($season_key); \n $api->process();\n $result_array = $api->getResultArray();\n $teams = array();\n foreach ($result_array as $result) {\n $teams[] = Team::create(\n $result->getName(),\n $result->getFullName(),\n $result->getCity(),\n $result->getKey(),\n $result->getDivision(),\n $result->getConference(),\n $api->getSeasonKey()\n );\n }\n\n // var_dump($teams);\n}\n\nfunction fetchInfoAndUpdateSeasonConfiguration() {\n $current_week_api = new CurrentWeekApi();\n $current_week_api->process();\n $current_week = $current_week_api->getCurrentWeek();\n\n $current_year_api = new CurrentSeasonYearApi();\n $current_year_api->process();\n $current_year = $current_year_api->getCurrentSeasonYear();\n\n updateSeasonConfiguration($current_week, $current_year);\n}\n\nfunction main() {\n fetchInfoAndUpdateSeasonConfiguration();\n}\n\n// -- MAIN\nmain();\n"
},
{
"alpha_fraction": 0.6252934336662292,
"alphanum_fraction": 0.6258803009986877,
"avg_line_length": 24.244443893432617,
"blob_id": "b8cc6916dbe1c4f3537874d4646703cbcb7771bf",
"content_id": "5a8b0ef11e8ef05fb15b301fb32f89a62b301a4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3408,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 135,
"path": "/src/php/access_layer/Album.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/P1DbObject.php\");\n\n// -- CONSTANTS\n// Db table name\ndefined(\"ALBUM_TABLE_NAME\") ? null : define(\"ALBUM_TABLE_NAME\", \"Album\");\n// Db keys\ndefined(\"ALBUM_ID_DB_KEY\") ? null : define(\"ALBUM_ID_DB_KEY\", \"albumid\");\ndefined(\"ALBUM_TITLE_DB_KEY\") ? null : define(\"ALBUM_TITLE_DB_KEY\", \"title\");\ndefined(\"ALBUM_CREATED_DB_KEY\") ? null : define(\"ALBUM_CREATED_DB_KEY\", \"created\");\ndefined(\"ALBUM_LAST_UPDATED_DB_KEY\") ? null : define(\"ALBUM_LAST_UPDATED_DB_KEY\", \"lastupdated\");\ndefined(\"ALBUM_USERNAME_DB_KEY\") ? null : define(\"ALBUM_USERNAME_DB_KEY\", \"username\");\n\nclass Album extends P1DbObject {\n // -- CLASS VARS\n protected static $tableName = ALBUM_TABLE_NAME;\n\n protected static $primaryKeys = array(ALBUM_ID_DB_KEY);\n\n // -- CONSTANTS\n const ID_KEY = ALBUM_ID_DB_KEY;\n const TITLE_KEY = ALBUM_TITLE_DB_KEY;\n const CREATED_KEY = ALBUM_CREATED_DB_KEY;\n const LAST_UPDATED_KEY = ALBUM_LAST_UPDATED_DB_KEY;\n const USERNAME_KEY = ALBUM_USERNAME_DB_KEY;\n\n // -- INSTANCE VARS\n private\n $albumId,\n $title,\n $created,\n $lastUpdated,\n $userName;\n\n public static function create(\n $title,\n $created,\n $lastUpdated,\n $userName) {\n return static::createObject(\n array(\n self::TITLE_KEY => $title,\n self::CREATED_KEY => $created,\n self::LAST_UPDATED_KEY => $lastUpdated,\n self::USERNAME_KEY => $userName,\n )\n ); \n }\n\n /**\n * Fetch all albums owned by user specified by $username.\n *\n * @param username : username of user\n * @return array:Album\n */\n public static function fetchByUsername($username) {\n return static::getObjectsByParams(\n array(\n self::USERNAME_KEY => $username,\n )\n ); \n }\n\n public static function fetchByAlbumId($album_id) {\n return static::getObjectByPrimaryKey(\n array(\n self::ID_KEY => $album_id,\n )\n );\n }\n\n // -- PROTECTED FUNCTIONS\n protected function initInstanceVars($params) {\n $this->albumId = $params[self::ID_KEY];\n $this->title = $params[self::TITLE_KEY];\n $this->created = $params[self::CREATED_KEY];\n $this->lastUpdated = $params[self::LAST_UPDATED_KEY];\n $this->userName = $params[self::USERNAME_KEY];\n }\n\n protected function getDbFields() {\n return array(\n self::ID_KEY => $this->albumId,\n self::TITLE_KEY => $this->title,\n self::CREATED_KEY => $this->created,\n self::LAST_UPDATED_KEY => $this->lastUpdated,\n self::USERNAME_KEY => $this->userName,\n );\n }\n\n protected function getPrimaryKeys() {\n return array(\n self::ID_KEY => $this->albumId,\n );\n }\n\n protected function createObjectCallback($init_params) {\n $album_id = mysql_insert_id();\n $init_params = $init_params[self::ID_KEY] = $album_id;\n return $init_params;\n }\n\n // -- PUBLIC FUNCTIONS\n // Getters\n public function getAlbumId() {\n return $this->albumId;\n }\n\n public function getTitle() {\n return $this->title;\n }\n\n public function getCreated() {\n return $this->created;\n }\n\n public function getLastUpdated() {\n return $this->lastUpdated;\n }\n\n public function getUserName() {\n return $this->userName;\n }\n\n // Setters\n /**\n * Set lastUpdated time to new time.\n *\n * @param time : string formatted in sql's datetime style\n */\n public function setLastUpdated($time) {\n $this->lastUpdated = $time;\n }\n}\n"
},
{
"alpha_fraction": 0.6589861512184143,
"alphanum_fraction": 0.6658986210823059,
"avg_line_length": 21.44827651977539,
"blob_id": "2c5a92439d75400d6843e8e9b766ae0073ff2759",
"content_id": "32233ad23d074c3292587a8d701b9bad2c17de00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1302,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 58,
"path": "/src/php/api/fantasy_football_api/TeamGameStatsApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/FantasyFootballApi.php\");\n\nabstract class TeamGameStatsResultMode {\n\n const SUCCESSFUL_RESP = 0;\n const INVALID_RESP = 1;\n}\n\nclass TeamGameStatsResultStruct {\n\n private\n\n}\n\nclass ScoresByWeekApi extends FantasyFootballApi {\n\n const METHOD_NAME = \"ScoresByWeek\";\n\n const PRESEASON_WEEK_MIN = 0;\n const PRESEASON_WEEK_MAX = 4;\n const REGULAR_SEASON_WEEK_MIN = 1;\n const REGULAR_SEASON_WEEK_MAX = 17;\n const POST_SEASON_WEEK_MIN = 1;\n const POST_SEASON_WEEK_MAX = 4;\n\n\n private\n $weekNum,\n $yearNum,\n $seasonSuffix;\n\n public function __construct($week_num, $year_num, $season_suffix) {\n // Check valid week num\n if (!FantasyFootballAp::isValidWeekNum($week_num, $season_suffix)) {\n throw new Exception(\"invalid week-num/season-suffix combination\");\n }\n\n $this->weekNum = $week_num;\n $this->yearNum = $year_num;\n $this->seasonSuffix = $season_suffix; \n parent::__construct();\n }\n\n protected function validateAndCacheResponse($response) {\n \n }\n\n protected function genUrlSuffix() {\n $year_season_str = \n FantasyFootballApi::genSeasonQueryString(\n $this->yearNum, $this->seasonSuffix);\n return self::METHOD_NAME . \"/\" . $year_season_str . \"/\" . $this->weekNum;\n }\n\n}\n"
},
{
"alpha_fraction": 0.7284768223762512,
"alphanum_fraction": 0.7284768223762512,
"avg_line_length": 15.777777671813965,
"blob_id": "01b0c0305d04a79b74e602ea5f24e86c93811d00",
"content_id": "b7b833f3ddb8c352addfc24a6100d19dd2a7fcf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 9,
"path": "/src/php/api/fantasy_football_api/CheckIfGameIsInProgressApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../OutgoingApiReq.php\");\n\nclass CheckIfGameIsInProgressApi extends FantasyFootballApi {\n\n\n}\n"
},
{
"alpha_fraction": 0.7162162065505981,
"alphanum_fraction": 0.7162162065505981,
"avg_line_length": 22.125,
"blob_id": "d539aa2ea83fc5d3e8930148c1896f946e653355",
"content_id": "c2481e56acb15f63e759b97f701898d50da95ecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 370,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 16,
"path": "/src/php/api/IncommingApiReq.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/ApiRequest.php\");\n\nabstract class IncommingApiReq extends ApiRequest {\n\n public function process() {\n $this->isValidResult = $this->validateRequest(); \n $this->cacheRequestParameters();\n }\n\n protected abstract function validateRequest();\n\n protected abstract function cacheRequestParameters();\n}\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 22.75,
"blob_id": "8b60c22794d1e27f9ac66a14dd40699de8f9d5f3",
"content_id": "d9d01df14f7797740df675e281fc2bc46a913190",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 8,
"path": "/src/php/api/fantasy_football_api/sandbox/test_fantasy.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../CheckGamesInProgressApi.php\");\n\n$api = new CheckIfGameIsInProgressApi();\n$api->process();\nvar_dump($api->areGamesInProgress());\n"
},
{
"alpha_fraction": 0.6128396987915039,
"alphanum_fraction": 0.6128396987915039,
"avg_line_length": 28.523256301879883,
"blob_id": "88392c6fb4f5ab510ecb584ada468bee05e866d0",
"content_id": "fe9bcebbe1814f7f777ce991e293e998b7d6b625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2539,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 86,
"path": "/src/php/endpoints/admin_endpoint.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/OperationType.php\");\n// Access layer\nrequire_once(dirname(__FILE__).\"/../../access_layer/User.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/Friend.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/Team.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/Season.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/Game.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/Bet.php\");\nrequire_once(dirname(__FILE__).\"/../../access_layer/UserBet.php\");\n\n// -- CONSTANTS\ndefined(\"TABLE_KEY\") ? null : define(\"TABLE_KEY\", \"table\");\ndefined(\"OPERATION_KEY\") ? null : define(\"OPERATION_KEY\", \"op\");\ndefined(\"PARAMS_JSON_KEY\") ? null : define(\"PARAMS_JSON_KEY\", \"json_params\");\n\n// -- FUNCTIONS\n\nfunction tableCreate($table_name, $params) {\n $record = null;\n switch($table_name) {\n case User::$tableName:\n $record = User::createObject($params);\n break;\n case Team::$tableName:\n $record = Team::createObject($params);\n break;\n case Season::$tableName:\n $record = Season::createObject($params);\n break;\n case Game::$tableName:\n $record = Game::createObject($params);\n break;\n case Bet::$tableName:\n $record = Bet::createObject($params);\n break;\n case UserBet::$tableName:\n $record = UserBet::createObject($params);\n break;\n default:\n die(\"ERROR: bad table name in func:tableCreate()\");\n break;\n } \n\n var_dump($record);\n}\n\nfunction processRequestWithPostParams() {\n // Validate POST params\n if (!isset($_POST[TABLE_KEY])) {\n die(\"ERROR: set '\" . TABLE_KEY . \"' table key\");\n } else if (!isset($_POST[OPERATION_KEY])) {\n die(\"ERROR: set '\" . OPERATION_KEY . \"' operation key\"); \n } else if (!isset($_POST[PARAMS_JSON_KEY])) {\n die(\"ERROR: set '\" . PARAMS_JSON_KEY . \"' params key\");\n }\n\n // Capture vars\n $table_name = $_POST[TABLE_KEY];\n $operation_type = $_POST[OPERATION_KEY];\n $params = json_decode($_POST[PARAMS_JSON_KEY]); \n\n switch ($op_type) {\n case OperationType::CREATE:\n tableCreate($table_name, $params);\n break;\n case OperationType::READ:\n tableRead($table_name, $params);\n break;\n case OperationType::UPDATE:\n tableUpdate($table_name, $params);\n break;\n case OperationType::DELETE:\n tableDelete($table_name, $params);\n break; \n default:\n die(\"ERROR: bad op-type specified: \" . $op_type);\n break;\n }\n}\n\nfunction main() {\n processRequestWithPostParams();\n}\n"
},
{
"alpha_fraction": 0.6463459134101868,
"alphanum_fraction": 0.6463459134101868,
"avg_line_length": 27.36458396911621,
"blob_id": "10ecf4c3c1301e78c74d716cb05c1beeca9df806",
"content_id": "89e24873c7d784411414b02fe3bebd94cfb99c5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2723,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 96,
"path": "/src/php/access_layer/Bet.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nclass Bet extends DelphiObject {\n \n // -- CLASS CONSTANTS\n const BET_TABLE_NAME = \"Bets\";\n const GAMEID_DB_KEY = \"gameId\";\n const TEAMID_DB_KEY = \"teamId\";\n const BETTINGUSERID_DB_KEY = \"bettingUserId\";\n const BETTINGUSERHANDICAP_DB_KEY = \"bettingUserHandicap\";\n const WAGER_DB_KEY = \"wager\";\n const CANCELLATIONPENALTY_DB_KEY = \"cancellationPenalty\";\n const STATUS_DB_KEY = \"status\";\n\n // -- CLASS VARS\n protected static $tableName = self::BET_TABLE_NAME;\n\n// -- INSTANCE VARS\t\n private\n $gameId,\n $teamId,\n $bettingUserId,\n $bettingUserHandicap,\n $wager,\n $cancellationPenalty,\n $status;\n\n public static function create(\n $gameId,\n $teamId,\n $bettingUserId,\n $bettingUserHandicap,\n $wager,\n $cancellationPenalty,\n $status) {\n return static::createObject(\n array(\n self::GAMEID_DB_KEY => $gameId,\n self::TEAMID_DB_KEY => $teamId,\n self::BETTINGUSERID_DB_KEY => $bettingUserId,\n self::BETTINGUSERHANDICAP_DB_KEY => $getBettingUserHandicap,\n self::wager => $wager,\n self::CANCELLATIONPENALTY_DB_KEY => $cancellationPenalty,\n self::STATUS_DB_KEY => $status,\n )\n ); \n }\n\n protected function initInstanceVars($params) {\n $this->gameId = $params[self::GAMEID_DB_KEY];\t\n $this->teamId = $params[self::TEAMID_DB_KEY];\t\n $this->bettingUserId = $params[self::BETTINGUSERID_DB_KEY];\t\n $this->bettingUserHandicap = $params[self::BETTINGUSERHANDICAP_DB_KEY];\t\n $this->wager = $params[self::WAGER_DB_KEY];\t\n $this->cancellationPenalty = $params[self::CANCELLATIONPENALTY_DB_KEY];\t\n $this->status = $params[self::STATUS_DB_KEY];\t\n }\n\n protected function getDbFields() {\n return array(\n self::GAMEID_DB_KEY => $this->gameId,\n self::TEAMID_DB_KEY => $this->teamId,\n self::BETTINGUSERID_DB_KEY => $this->bettingUserId,\n self::BETTINGUSERHANDICAP_DB_KEY => $this->bettingUserHandicap,\n self::WAGER_DB_KEY => $this->wager,\n self::CANCELLATIONPENALTY_DB_KEY => $this->cancellationPenalty,\n self::STATUS_DB_KEY => $this->status,\n );\n } \n\n // -- Getters\n public public function getGameId() { \n\t\treturn $this->gameId;\n\t}\n public function getTeamId() { \n\t\treturn $this->teamId;\n\t}\n public function getBettingUserId() { \n\t\treturn $this->bettingUserId;\n\t}\n public function getBettingUserHandicap() { \n\t\treturn $this->bettingUserHandicap;\n\t}\n public function getWager() { \n\t\treturn $this->wager;\n\t}\n public function getCancellationPenalty() { \n\t\treturn $this->cancellationPenalty;\n\t}\n public function getStatus() { \n\t\treturn $this->status;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6649797558784485,
"alphanum_fraction": 0.6649797558784485,
"avg_line_length": 23.395061492919922,
"blob_id": "f4d606ca8fec80cf4287f5d356dff005ac5d9edf",
"content_id": "051e5ddaec4962e4104c3439a4f620706220f34a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1976,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 81,
"path": "/src/php/access_layer/DelphiObject.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/warehouse/DatabaseObject.php\");\n\nabstract class DelphiObject extends DatabaseObject {\n\n // Db keys\n const ID_KEY = \"id\";\n const CREATED_TIME = \"created_time\";\n const LAST_UPDATED_TIME = \"last_updated_time\";\n\n protected static $uniqueKeys = array(self::ID_KEY);\n\n private\n $id,\n $createdTime,\n $lastUpdatedTime;\n\n protected static function createFundamentalVars() {\n $datetime = self::genDateTime();\n return array(\n self::CREATED_TIME => $datetime,\n self::LAST_UPDATED_TIME => $datetime,\n );\n }\n\n public static function fetchById($id) {\n return static::getObjectByUniqueKey(self::ID_KEY, $id);\n }\n\n public static function genDateTime() {\n return date(\"Y-m-d H:i:s\");\n }\n\n protected abstract function initAuxillaryInstanceVars($params);\n protected abstract function getAuxillaryDbFields();\n\n protected function createObjectCallback($init_params) {\n $id = mysql_insert_id();\n $init_params[self::ID_KEY] = $id;\n return $init_params;\n }\n\n protected function getPrimaryKeys() {\n return array(self::ID_KEY => $this->id);\n }\n\n protected function initInstanceVars($params) {\n $this->id = $params[self::ID_KEY];\n $this->createdTime = $params[self::CREATED_TIME];\n $this->lastUpdatedTime = $params[self::LAST_UPDATED_TIME];\n\n $this->initAuxillaryInstanceVars($params);\n }\n\n protected function getDbFields() {\n $fields = $this->getAuxillaryDbFields();\n $fields[self::ID_KEY] = $this->id;\n $fields[self::CREATED_TIME] = $this->createdTime;\n $fields[self::LAST_UPDATED_TIME] = $this->lastUpdatedTime;\n return $fields;\n }\n\n public function save() {\n $this->lastUpdatedTime = self::genDateTime();\n parent::save();\n }\n \n public function getId() {\n return $this->id;\n }\n\n public function getCreatedTime() {\n return $this->createdTime;\n }\n\n public function getLastUpdatedTime() {\n return $this->lastUpdatedTime;\n }\n}\n"
},
{
"alpha_fraction": 0.4940239191055298,
"alphanum_fraction": 0.5378485918045044,
"avg_line_length": 11.550000190734863,
"blob_id": "e9630c45569bb3be0c0a8f6a0febde5d49adffdd",
"content_id": "711953dadab6c20ac84c221a3d610accf22b61b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 251,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/src/php/access_layer/sandbox/user_test.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- Dependencies\nrequire_once(dirname(__FILE__).\"/../User.php\");\n\n// -- MAIN\n$user = User::create(\n 111113,\n \"PrinceOfDenmarkBitch\",\n \"Hamlet\",\n \"Son of Hamlet\",\n date(\"Y-m-d\"), \n \"male\",\n 1000, \n 1\n);\n\nvar_dump($user);\n\n$user->delete();\n"
},
{
"alpha_fraction": 0.6615336537361145,
"alphanum_fraction": 0.6618478894233704,
"avg_line_length": 31.46938705444336,
"blob_id": "68532dbfb96ee68e40de201b904594e8204d5de9",
"content_id": "ea8bdeb37eb1a01250694892393a9e18ca9f34d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3182,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 98,
"path": "/src/php/access_layer/Friend.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\nrequire_once(dirname(__FILE__).\"/exceptions/DuplicateFriendRequestException.php\");\n\nclass Friend extends DelphiObject {\n// -- CLASS CONSTANTS\n const FRIEND_TABLE_NAME = \"Friends\";\n const REQUESTINGUSERID_DB_KEY = \"requestingUserId\";\n const APPROVINGUSERID_DB_KEY = \"approvingUserId\";\n\n // -- CLASS VARS\n protected static $tableName = FRIEND_TABLE_NAME;\n\n// -- INSTANCE VARS\t\n private\n $requestingUserId,\n $approvingUserId;\n\n public static function create($requestingUserId, $approvingUserId) {\n // Ensure Friend record does not already exist.\n $query = self::genCheckExistingFriendRecordQuery($requestingUserId, $approvingUserId);\n if (0 != static::$database->fetchArraysFromQuery($query)) {\n throw new DuplicateFriendRequestException($requestingUserId, $approvingUserId);\n }\n\n return static::createObject(\n array(\n self::REQUESTINGUSERID_DB_KEY => $requestingUserId,\n self::APPROVINGUSERID_DB_KEY => $approvingUserId,\n )\n );\n }\n \n private static function genCheckExistingFriendRecordQuery($requestingUserId, $approvingUserId) {\n return \n \"SELECT COUNT(*) FROM \" . self::$tableName\n . \" WHERE (\" . self::REQUESTINGUSERID_DB_KEY . \"=\" . $this->requestingUserId \n . \" AND \" . self::APPROVINGUSERID_DB_KEY . \"=\" . $this->approvingUserId\n . \") OR \" . self::REQUESTINGUSERID_DB_KEY . \"=\" . $this->approvingUserId\n . \" AND \" . self::APPROVINGUSERID_DB_KEY . \"=\" . $this->requestingUserId;\n }\n\n\n public static function fetchFriends($userId) {\n // Fetch Friends from db\n $query = genFetchFriendsQuery($userId); \n $friend_records = static::$database->fetchArraysFromQuery($query);\n\n // Deserialize Friend assocs\n $friends = array();\n foreach ($friend_records as $rec) {\n $friends[] = new static($rec);\n }\n return $friends;\n }\n\n private static function genFetchFriendsQuery($userId) {\n return\n \"SELECT * FROM \" . self::$tableName\n . \" WHERE (\" . self::REQUESTINGUSERID_DB_KEY . \"=\" . $userId . \") OR (\"\n . self::APPROVINGUSERID_DB_KEY . \"=\" . $userId . \")\";\n }\n\n public static function deleteFriends($userId) {\n // Delete Friends from db\n $query = genDeleteFriendsQuery($userId); \n static::$database->query($query);\n }\n\n private static function genDeleteFriendsQuery($userId) {\n return \n \"DELETE * FROM \" . self::$tableName\n . \" WHERE \" . self::REQUESTINGUSERID_DB_KEY . \"=\" . $userId \n . \" OR \" . self::APPROVINGUSERID_DB_KEY . \"=\" . $userId;\n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->requestingUserId = $params[self::REQUESTINGUSERID_DB_KEY];\t\n $this->approvingUserId = $params[self::APPROVINGUSERID_DB_KEY];\t\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::REQUESTINGUSERID_DB_KEY => $this->requestingUserId,\n self::APPROVINGUSERID_DB_KEY => $this->approvingUserId,\n );\n } \n\n // -- Getters\n public function getRequestingUserId() { \n\t\treturn $this->requestingUserId;\n\t}\n public function getApprovingUserId() { \n\t\treturn $this->approvingUserId;\n }\n}\n"
},
{
"alpha_fraction": 0.6109725832939148,
"alphanum_fraction": 0.6109725832939148,
"avg_line_length": 20.48214340209961,
"blob_id": "b61f7ff9508bfe95dfde11ee31cd576292cf15cf",
"content_id": "b309a0abdb65d611878356d140926038cad4dcec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1203,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 56,
"path": "/src/php/access_layer/UserBet.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nclass UserBet extends DelphiObject {\n// -- CLASS CONSTANTS\n const USERBET_TABLE_NAME = \"UserBets\";\n const USERID_DB_KEY = \"userId\";\n const BETID_DB_KEY = \"betId\";\n\n // -- CLASS VARS\n protected static $tableName = self::USERBET_TABLE_NAME;\n\n// -- INSTANCE VARS\t\n private\n $userId,\n $betId;\n\n public static function create($userId, $betId) {\n return static::createObject(\n array(\n self::USERID_DB_KEY => $userId,\n self::BETID_DB_KEY => $betId,\n )\n );\n }\n \n public static function fetchByBetId($betId) {\n return static::getObjectsByParams(\n array(\n self::BETID_DB_KEY => $betId,\n )\n );\n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->userId = $params[self::USERID_DB_KEY];\t\n $this->betId = $params[self::BETID_DB_KEY];\t\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::USERID_DB_KEY => $this->userId,\n self::BETID_DB_KEY => $this->betId,\n );\n } \n\n // -- Getters\n public function getUserId() { \n\t\treturn $this->userId;\n\t}\n public function getBetId() { \n\t\treturn $this->betId;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6052631735801697,
"alphanum_fraction": 0.6052631735801697,
"avg_line_length": 8.25,
"blob_id": "07efa685f6cb1b971857aac0b22033c21b4e5e0e",
"content_id": "d526ab0312fb9d0f2f690f34f8d802edc9c9e372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/README.md",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "delphi\n======\n\nWe shan't defy augury \n"
},
{
"alpha_fraction": 0.5869346857070923,
"alphanum_fraction": 0.5869346857070923,
"avg_line_length": 15.86440658569336,
"blob_id": "4b2187f70d0540b4c2e2ab2ce5b4ff794811bbfa",
"content_id": "8267c58935656244457fae3540839e09bc36118b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 995,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 59,
"path": "/src/php/discus/Request.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\nabstract class RequestType {\n\n const HTTP = \"http\";\n const HTTPS = \"https\";\n}\n\nclass Request {\n \n private\n $type,\n $url,\n $params;\n\n public function __construct($type, $url, $params) {\n $this->type = $type;\n $this->url = $url;\n $this->params = $params;\n }\n\n /**\n * Execute request and return result.\n *\n * @return string : request result\n */\n public function execute() {\n $context_options = array(\n $this->type => $this->params, \n );\n $request_context = stream_context_create($context_options);\n var_dump($this->url);\n return file_get_contents($this->url, null, $request_context);\n }\n}\n\nclass RequestBuilder {\n\n protected\n $type,\n $url,\n $params;\n\n public function build() {\n return new Request($type, $url, $params);\n }\n\n public function setType($type) {\n $this->type = $type;\n }\n\n public function setUrl($url) {\n $this->url = $url;\n }\n\n public function setParams($params) {\n $this->params = $params;\n }\n}\n"
},
{
"alpha_fraction": 0.6185925006866455,
"alphanum_fraction": 0.6185925006866455,
"avg_line_length": 24.962406158447266,
"blob_id": "56b7e40521d6ff90c6059036e5b2a9a81a02746e",
"content_id": "a09be045fd36e0fe512a11e1b4bd43565a199fb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 3453,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 133,
"path": "/src/php/access_layer/User.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/DelphiObject.php\");\n\nclass User extends DelphiObject {\n// -- CLASS CONSTANTS\n const USER_TABLE_NAME = \"Users\";\n const FBID_DB_KEY = \"fbId\";\n const USERNAM_DB_KEY = \"username\";\n const FIRSTNAME_DB_KEY = \"firstName\";\n const LASTNAME_DB_KEY = \"lastName\";\n const BIRTHDATE_DB_KEY = \"birthdate\";\n const SEX_DB_KEY = \"sex\";\n const BALANCE_DB_KEY = \"balance\";\n const ISADMIN_DB_KEY = \"isAdmin\";\n\n // -- CLASS VARS\n protected static $tableName = self::USER_TABLE_NAME;\n\n protected static $uniqueKeys = array(\n DelphiObject::ID_KEY,\n self::FBID_DB_KEY,\n self::USERNAM_DB_KEY);\n\n // -- INSTANCE VARS\t\n private\n $fbId,\n $username,\n $firstName,\n $lastName,\n $birthdate,\n $sex,\n $balance,\n $isAdmin;\n\n public static function create(\n $fbId,\n $username,\n $firstName,\n $lastName,\n $birthdate,\n $sex,\n $balance,\n $isAdmin) {\n return static::createObject(\n array(\n self::FBID_DB_KEY => $fbId,\n self::USERNAM_DB_KEY => $username,\n self::FIRSTNAME_DB_KEY => $firstName,\n self::LASTNAME_DB_KEY => $lastName,\n self::BIRTHDATE_DB_KEY => $birthdate,\n self::SEX_DB_KEY => $sex,\n self::BALANCE_DB_KEY => $balance,\n self::ISADMIN_DB_KEY => $isAdmin,\n )\n );\n }\n\n public static function fetchByUsername($username) {\n return static::getObjectByUniqueKey(self::USERNAME_DB_KEY, $username);\n }\n\n public static function fetchByFbId($fbId) {\n return static::getObjectByUniqueKey(self::FBID_DB_KEY, $fbId);\n }\n\n protected function getUniqueKeys() {\n $unique_keys = parent::getUniqueKeys();\n $unique_keys[self::USERNAM_DB_KEY] = $this->username;\n $unique_keys[self::FBID_DB_KEY] = $this->fbId;\n return $unique_keys;\n }\n\n protected function initAuxillaryInstanceVars($params) {\n $this->fbId = $params[self::FBID_DB_KEY];\t\n $this->username = $params[self::USERNAM_DB_KEY];\t\n $this->firstName = $params[self::FIRSTNAME_DB_KEY];\t\n $this->lastName = $params[self::LASTNAME_DB_KEY];\t\n $this->birthdate = $params[self::BIRTHDATE_DB_KEY];\t\n $this->sex = $params[self::SEX_DB_KEY];\t\n $this->balance = $params[self::BALANCE_DB_KEY];\t\n $this->isAdmin = $params[self::ISADMIN_DB_KEY];\t\n }\n\n protected function getAuxillaryDbFields() {\n return array(\n self::FBID_DB_KEY => $this->fbId,\n self::USERNAM_DB_KEY => $this->username,\n self::FIRSTNAME_DB_KEY => $this->firstName,\n self::LASTNAME_DB_KEY => $this->lastName,\n self::BIRTHDATE_DB_KEY => $this->birthdate,\n self::SEX_DB_KEY => $this->sex,\n self::BALANCE_DB_KEY => $this->balance,\n self::ISADMIN_DB_KEY => $this->isAdmin,\n );\n } \n\n // -- Getters\n public function getFbId() { \n\t\treturn $this->fbId;\n\t}\n public function getUsername() { \n\t\treturn $this->username;\n\t}\n public function getFirstName() { \n\t\treturn $this->firstName;\n\t}\n public function getLastName() { \n\t\treturn $this->lastName;\n\t}\n public function getBirthdate() { \n\t\treturn $this->birthdate;\n\t}\n public function getSex() { \n\t\treturn $this->sex;\n\t}\n public function getBalance() { \n\t\treturn $this->balance;\n\t}\n public function getIsAdmin() { \n\t\treturn $this->isAdmin;\n }\n\n // -- Setters\n public function enableAdminPriviliges() {\n $this->isAdmin = true;\n }\n\n public function revokeAdminPriviliges() {\n $this->isAdmin = false;\n }\n}\n"
},
{
"alpha_fraction": 0.6162657737731934,
"alphanum_fraction": 0.6162657737731934,
"avg_line_length": 21.045454025268555,
"blob_id": "8d894e573ceb0af7b25f548a02a96d36ed2aabb2",
"content_id": "83aff280437e6af46e0bdf862357009dda39fe07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 4365,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 198,
"path": "/src/php/discus/http/HttpRequest.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../Request.php\");\n\nabstract class HttpRequestMethod {\n const GET = \"GET\";\n const POST = \"POST\";\n}\n\nclass HttpRequest extends Request {\n\n public function __construct($url, $params) {\n parent::__construct(RequestType::HTTP, $url, $params);\n }\n}\n\nclass HttpRequestBuilder {\n\n const CONTENT = \"content\";\n const METHOD = \"method\";\n const HEADER = \"heder\";\n const USER_AGENT = \"user_agent\";\n const PROXY = \"proxy\";\n const REQUEST_FULLURI = \"request_fulluri\";\n const FOLLOW_LOCATION = \"follow_location\";\n const MAX_REDIRECTS = \"max_redirects\";\n const PROTOCOL_VERSION = \"protocol_version\";\n const TIMEOUT = \"timeout\";\n const IGNORE_ERRORS = \"ignore_errors\";\n\n protected\n $method,\n $header,\n $userAgent,\n $content,\n $proxy,\n $requestFulluri,\n $followLocation,\n $maxRedirects,\n $protocolVersion,\n $timeout,\n $ignoreErrors,\n $url;\n\n public function build() {\n $params = $this->genParams();\n return new HttpRequest($this->url, $params);\n }\n\n protected function genParamsWithContent() {\n $params = $this->genParams();\n if (isset($this->content)) {\n $params[self::CONTENT] = http_build_query($this->content);\n }\n return $params;\n }\n\n protected function genParams() {\n // Configure http params\n $params = array();\n if (isset($this->method)) {\n $params[self::METHOD] = $this->method;\n }\n\n if (isset($this->header)) {\n $params[self::HEADER] = $this->header;\n }\n\n if (isset($this->userAgent)) {\n $params[self::USER_AGENT] = $this->agent;\n }\n\n if (isset($this->userAgent)) {\n $params[self::PROXY] = $this->proxy;\n }\n\n if (isset($this->requestFulluri)) {\n $params[self::REQUEST_FULLURI] = $this->requestFulluri;\n }\n\n if (isset($this->followLocation)) {\n $params[self::FOLLOW_LOCATION] = $this->followLocation;\n }\n\n if (isset($this->maxRedirects)) {\n $params[self::MAX_REDIRECTS] = $this->maxRedirects;\n }\n\n if (isset($this->protocolVersion)) {\n $params[self::PROTOCOL_VERSION] = $this->protocolVersion;\n }\n\n if (isset($this->timeout)) {\n $params[self::TIMEOUT] = $this->timeout;\n }\n\n if (isset($this->ignoreErrors)) {\n $params[self::IGNORE_ERRORS] = $this->ignoreErrors;\n }\n \n return $params; \n }\n\n // -- PUBLIC FUNCTIONS\n public function setMethod($method) {\n $this->method = $method;\n return $this;\n }\n\n public function setHeader($header) {\n $this->header = $header;\n return $this;\n }\n\n public function userAgent($user_agent) {\n $this->userAgent = $user_agent;\n return $this;\n }\n\n public function setProxy($proxy) {\n $this->proxy = $proxy;\n return $this;\n }\n\n public function setContent($content) {\n $this->content = $content;\n return $this;\n }\n\n public function setContentParam($key, $value) {\n if (!isset($this->content)) {\n $this->content = array();\n }\n\n $this->content[$key] = $value;\n return $this;\n }\n\n public function isContentParamSet($key) {\n if (!isset($this->content)) {\n $this->content = array();\n }\n\n return isset($this->content[$key]);\n }\n\n public function getContentParam($key) {\n if (!$this->isContentParamSet($key)) {\n throw new Exception(\"content param is not set: key: {$key}\");\n }\n\n return $this->content[$key];\n }\n\n public function deleteContentParam($key) {\n if (!$this->isContentParamSet($key)) {\n throw new Exception(\"content param is not set: key: {$key}\");\n }\n \n unset($this->content[$key]); \n }\n\n public function setRequestFulluri($requestFulluri) {\n $this->requestFulluri = $requestFulluri;\n return $this;\n }\n\n public function setFollowLocation($follow_location) {\n $this->followLocation = $follow_location;\n return $this;\n }\n\n public function setMaxRedirects($max_redirects) {\n $this->maxRedirects = $max_redirects;\n return $this;\n }\n\n public function setProtocolVersion($protocolVersion) {\n $this->protocolVersion = $protocolVersion;\n return $this;\n }\n\n public function setTimeout($timeout) {\n $this->timeout = $timeout;\n return $this;\n }\n\n public function setIgnoreErrors($ignoreErrors) {\n $this->ignoreErrors = $ignoreErrors;\n return $this;\n }\n\n public function setUrl($url) {\n $this->url = $url;\n return $this;\n }\n}\n"
},
{
"alpha_fraction": 0.6646403074264526,
"alphanum_fraction": 0.676798403263092,
"avg_line_length": 33.83529281616211,
"blob_id": "a44e341846b87677fd3d1643d2e4f99eb05b4f2b",
"content_id": "449d9a175b7b003174101f8de6c7d98c9d12a8b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2961,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 85,
"path": "/src/php/api/fantasy_football_api/FantasyFootballApi.php",
"repo_name": "trevorassaf/delphi",
"src_encoding": "UTF-8",
"text": "<?php\n\n// -- DEPENDENCIES\nrequire_once(dirname(__FILE__).\"/../OutgoingApiReq.php\");\nrequire_once(dirname(__FILE__).\"/../../discus/http/GetRequest.php\");\n\nabstract class ResponseFormat {\n const XML = \"XML\";\n const JSON = \"JSON\";\n}\n\nabstract class FantasyFootballApi extends OutgoingApiReq {\n\n // -- CLASS CONSTANTS\n const APIKEY_VALUE = \"94134631-49C0-4079-A011-EC727A676638\";\n const APIKEY_KEY = \"key\";\n const FANTASY_API_URL = \"http://api.nfldata.apiphany.com/trial/\";\n\n const PRE_SEASON_QUERY_SUFFIX = \"PRE\";\n const REGULAR_SEASON_QUERY_SUFFIX = \"REG\";\n const POST_SEASON_QUERY_SUFFIX = \"POST\";\n\n const PRESEASON_WEEK_MIN = 0;\n const PRESEASON_WEEK_MAX = 4;\n const REGULAR_SEASON_WEEK_MIN = 1;\n const REGULAR_SEASON_WEEK_MAX = 17;\n const POST_SEASON_WEEK_MIN = 18;\n const POST_SEASON_WEEK_MAX = 21;\n\n /**\n * Format of response.\n */\n private static $FORMAT = ResponseFormat::JSON;\n\n public static function genRegularSeasonQueryString($year_num) {\n return self::genSeasonQueryString($year_num, self::REGULAR_SEASON_QUERY_SUFFIX);\n }\n\n public static function genPreSeasonQueryString($year_num) {\n return self::genSeasonQueryString($year_num, self::PRE_SEASON_QUERY_SUFFIX);\n }\n\n public static function genPostSeasonQueryString($year_num) {\n return self::genSeasonQueryString($year_num, self::POST_SEASON_QUERY_SUFFIX);\n }\n\n public static function genSeasonQueryString($year_num, $season_str) {\n return \"{$year_num}$season_str\";\n }\n\n public function isValidWeekNum($week_num, $season_suffix) {\n switch ($season_suffix) {\n case FantasyFootballApi::PRE_SEASON_QUERY_SUFFIX:\n return $week_num >= self::PRESEASON_WEEK_MIN && $week_num <= self::PRESEASON_WEEK_MAX;\n case FantasyFootballApi::REGULAR_SEASON_QUERY_SUFFIX:\n return $week_num >= self::REGULAR_SEASON_WEEK_MIN && $week_num <= self::REGULAR_SEASON_WEEK_MAX;\n case FantasyFootballApi::POST_SEASON_QUERY_SUFFIX:\n return $week_num >= self::POST_SEASON_WEEK_MIN && $week_num <= self::POST_SEASON_WEEK_MAX;\n default:\n return false; \n }\n }\n\n public static function genSeasonKey($week, $year) {\n if ($week >= self::REGULAR_SEASON_WEEK_MIN && $week <= self::REGULAR_SEASON_WEEK_MAX) {\n $suffix = self::REGULAR_SEASON_QUERY_SUFFIX;\n } else if ($week >= self::POST_SEASON_WEEK_MIN && $week <= self::POST_SEASON_WEEK_MAX) {\n $suffix = self::POST_SEASON_QUERY_SUFFIX;\n } else {\n throw new Exception(\"bad week num: {$week}\");\n }\n return self::genSeasonQueryString($year, $suffix);\n }\n\n public function __construct() {\n $url = self::FANTASY_API_URL . self::$FORMAT . \"/\" . $this->genUrlSuffix();\n $request_builder = new GetRequestBuilder();\n $request_builder->setUrl($url);\n $request_builder->setContentParam(self::APIKEY_KEY, self::APIKEY_VALUE);\n $request = $request_builder->build();\n parent::__construct($request);\n }\n\n protected abstract function genUrlSuffix(); \n}\n"
}
] | 44 |
cdeil/gammatools
|
https://github.com/cdeil/gammatools
|
cc1d1b70fa27b34256be4aa43d8dd24b78ed27c2
|
a9c04138439304b7977c2f4ee142b4df50032004
|
90119853224a11fac4f9d2b0d68057d20ab7c855
|
refs/heads/master
| 2021-01-15T18:59:07.854474 | 2015-01-30T17:05:24 | 2015-01-30T17:05:24 | 30,082,942 | 0 | 1 | null | 2015-01-30T17:28:40 | 2015-01-30T17:05:28 | 2015-01-30T17:05:28 | null |
[
{
"alpha_fraction": 0.49875402450561523,
"alphanum_fraction": 0.5270448327064514,
"avg_line_length": 22.6875,
"blob_id": "a50e16f7145ae227ee2c829b557cd1df3a508acf",
"content_id": "b20908dff1026a5457217db583c93f303571c9a5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13644,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 576,
"path": "/gammatools/fermi/psf_likelihood.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport copy\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport numpy as np\n\nfrom gammatools.core.histogram import Histogram\n\nfrom gammatools.core.model_fn import PDF, ParamFnBase\n\nfrom gammatools.core.util import convolve2d_gauss\nimport scipy.special as spfn\n\n\nclass ConvolvedGaussFn(PDF):\n def __init__(self,pset,psf_model): \n PDF.__init__(self,pset)\n self._psf_model = copy.deepcopy(psf_model)\n# self._pid = [pnorm.pid(),psigma.pid()]\n\n x = np.linspace(-4,4,800)\n self._ive = UnivariateSpline(x,spfn.ive(0,10**x),s=0,k=2)\n\n @staticmethod\n def create(norm,sigma,psf_model,pset=None,prefix=''):\n\n if pset is None: pset = ParameterSet()\n# \n p0 = pset.createParameter(norm,prefix + 'norm')\n p1 = pset.createParameter(sigma,prefix + 'sigma')\n pset.addSet(psf_model.param()) \n\n return ConvolvedGaussFn(pset,psf_model)\n\n def _eval(self,dtheta,pset):\n\n a = pset.array()\n\n print 'a ', a\n\n# norm = pset[self._pid[0]]\n# sig = pset[self._pid[1]]\n\n# self._psf_model.setParam(pset)\n v = self._psf_model.eval(dtheta,pset)\n\n return a[0]*self.convolve(lambda x: self._psf_model.eval(x),\n dtheta,a[1],3.0,nstep=200)\n\n def _integrate(self,xlo,xhi,pset):\n\n xlo = np.array(xlo,ndmin=1,copy=True)\n xhi = np.array(xhi,ndmin=1,copy=True)\n\n xlo.shape += (1,)\n xhi.shape += (1,)\n\n nbin = 3\n\n xedge = np.linspace(0,1,nbin+1)\n x = 0.5*(xedge[1:]+xedge[:-1])\n x.shape = (1,) + x.shape\n\n xp = np.zeros(shape=xlo.shape + (nbin,))\n\n xp = xlo + x*(xhi-xlo)\n dx = (xhi-xlo)/float(nbin)\n dx.shape = (1,) + dx.shape\n\n v = self.eval(xp.flat,pset)\n v = v.reshape((v.shape[0],) + xp.shape)\n v *= 2*dx*xp*np.pi\n\n return np.sum(v,axis=2)\n\n def convolve(self,fn,r,sig,rmax,nstep=200):\n r = np.array(r,ndmin=1,copy=True)\n sig = np.array(sig,ndmin=1,copy=True)\n\n rp = np.ones(shape=(1,1,nstep))\n rp *= np.linspace(0,rmax,nstep)\n \n r = r.reshape((1,r.shape[0],1))\n sig = sig.reshape(sig.shape + (1,))\n \n dr = rmax/float(nstep)\n\n sig2 = sig*sig\n x = r*rp/(sig2)\n\n x[x==0] = 1E-4\n je = self._ive(np.log10(x.flat))\n je = je.reshape(x.shape)\n\n# je2 = spfn.ive(0,x)\n# plt.hist(((je-je2)/je2).flat)\n# plt.show()\n\n fnrp = fn(rp.flat)\n fnrp = fnrp.reshape((sig.shape[0],) + (1,) + (rp.shape[2],))\n s = np.sum(rp*fnrp/(sig2)*\n np.exp(np.log(je)+x-(r*r+rp*rp)/(2*sig2)),axis=2)*dr\n\n return s\n\n \n\nclass KingFn(PDF):\n def __init__(self,psigma,pgamma,pnorm=None):\n\n pset = ParameterSet([psigma,pgamma])\n self._pid = [psigma.pid(),pgamma.pid()]\n if not pnorm is None: \n pset.addParameter(pnorm)\n self._pid += [pnorm.pid()]\n PDF.__init__(self,pset,cname='dtheta') \n\n @staticmethod\n def create(sigma,gamma,norm=1.0,offset=0):\n\n return KingFn(Parameter(offset+0,sigma,'sigma'),\n Parameter(offset+1,gamma,'gamma'),\n Parameter(offset+2,norm,'norm'))\n\n# def setSigma(self,sigma):\n# self._param.getParByID(self._pid[1]).set(sigma)\n\n# def setNorm(self,norm):\n# self._param.getParByID(self._pid[0]).set(norm)\n\n def norm(self):\n return self._param.getParByID(self._pid[2])\n\n def _eval(self,x,pset):\n\n sig = pset[self._pid[0]]\n g = pset[self._pid[1]] \n if len(self._pid) == 3: norm = pset[self._pid[2]]\n else: norm = 1.0\n\n# if len(norm) > 1:\n# norm = norm.reshape(norm.shape + (1,)*dtheta.ndim)\n# sig = sig.reshape(sig.shape + (1,)*dtheta.ndim)\n# g = g.reshape(g.shape + (1,)*dtheta.ndim)\n\n g[g<=1.1] = 1.1\n\n n = 2*np.pi*sig*sig \n u = np.power(x,2)/(2*sig*sig)\n \n return norm*(1-1/g)*np.power(1+u/g,-g)/n\n \n def integrate(self,dlo,dhi,pset):\n\n sig = pset[self._pid[0]]\n g = pset[self._pid[1]] \n if len(self._pid) == 3: norm = pset[self._pid[2]]\n else: norm = 1.0\n\n g[g<=1.1] = 1.1\n\n um = dlo*dlo/(2.*sig*sig)\n ua = dhi*dhi/(2.*sig*sig)\n f0 = (1+um/g)**(-g+1)\n f1 = (1+ua/g)**(-g+1)\n return norm*(f0-f1)\n\n def cdf(self,dtheta,p=None):\n \n return self.integrate(0,dtheta,p)\n\nclass PulsarOnFn(PDF):\n\n def __init__(self,non,noff,alpha,psf_model):\n self._non = copy.copy(non)\n self._noff = copy.copy(noff)\n self._alpha = alpha\n self._model = model\n self._xedge = xedge\n self._mub0 = (self._non+self._noff)/(1+alpha)\n \n\n def eval(dtheta,p=None):\n\n alpha = self._alpha\n\n mus = self._psf_model.integrate(xlo,xhi,p)\n\n mub = ((self._mub0/2. - mus/(2.*alpha) + \n np.sqrt(noff*mus/(alpha*(1+alpha)) + \n (self._mub0/2.-mus/(2.*alpha))**2)))\n\nclass BinnedPLFluxModel(PDF):\n\n def __init__(self,spectral_model,spatial_model,ebin_edges,exp):\n pset = ParameterSet()\n pset.addSet(spectral_model.param())\n pset.addSet(spatial_model.param())\n PDF.__init__(self,pset) \n self._ebin_edges = ebin_edges\n self._exp = exp\n self.spatial_model = spatial_model\n self.spectral_model = spectral_model\n\n def _eval(self,x,p):\n\n v0 = self.spatial_model._eval(x,p)\n v1 = self.spectral_model._eval(self._ebin_edges[0],\n self._ebin_edges[1],p)\n return v0*v1*self._exp\n\n def _integrate(self,xlo,xhi,p):\n\n v0 = self.spatial_model._integrate(xlo,xhi,p)\n v1 = self.spectral_model._integrate(self._ebin_edges[0],\n self._ebin_edges[1],p)\n return v0*v1*self._exp\n\nclass PowerlawFn(PDF):\n\n def __init__(self,pnorm,pgamma):\n pset = ParameterSet([pnorm,pgamma])\n self._pid = [pnorm.pid(),pgamma.pid()]\n self._enorm = 3.0\n PDF.__init__(self,pset,cname='energy') \n\n def _eval(self,x,p):\n\n norm = p[self._pid[0]]\n gamma = p[self._pid[1]] \n\n return norm*10**(-gamma*(x-self._enorm))\n\n def _integrate(self,xlo,xhi,p):\n\n x = 0.5*(xhi+xlo)\n dx = xhi-xlo\n\n norm = p[self._pid[0]]\n gamma = p[self._pid[1]] \n\n g1 = -gamma+1\n return norm/g1*10**(gamma*self._enorm)*(10**(xhi*g1) - 10**(xlo*g1))\n\nclass BinnedLnL(ParamFnBase):\n\n def __init__(self,non,xedge,model):\n ParamFnBase.__init__(self,model.param())\n self._non = non\n self._model = model\n self._xedge = xedge \n\n @staticmethod\n def createFromHist(hon,model):\n return BinnedLnL(hon.counts(),hon.edges(),model)\n\n def eval(self,p):\n\n pset = self._model.param(True).update(p)\n\n nbin = len(self._xedge)-1\n xlo = self._xedge[:-1]\n xhi = self._xedge[1:]\n\n\n non = (np.ones(shape=(pset.size(),nbin))*self._non)\n\n mus = self._model.integrate(xlo,xhi,pset)\n msk_on = non > 0\n\n lnl = (-mus)\n lnl[msk_on] += non[msk_on]*np.log(mus[msk_on])\n\n if pset.size() > 1: return -np.sum(lnl,axis=1)\n else: return -np.sum(lnl)\n\nclass Binned2DLnL(ParamFnBase):\n\n def __init__(self,non,xedge,yedge,model):\n ParamFnBase.__init__(self,model.param())\n self._non = non.flat\n self._model = model\n self._xedge = xedge \n self._yedge = yedge \n\n xlo, ylo = np.meshgrid(self._xedge[:-1],self._yedge[:-1])\n xhi, yhi = np.meshgrid(self._xedge[1:],self._yedge[1:])\n\n self._xlo = xlo.T.flat\n self._ylo = ylo.T.flat\n\n self._xhi = xhi.T.flat\n self._yhi = yhi.T.flat\n\n @staticmethod\n def createFromHist(hon,model):\n return Binned2DLnL(hon.counts(),hon.xedges(),hon.yedges(),model)\n\n def eval(self,p):\n\n pset = self._model.param(True).update(p)\n\n nbinx = len(self._xedge)-1\n nbiny = len(self._yedge)-1\n\n non = (np.ones(shape=(pset.size(),nbinx*nbiny))*self._non)\n\n clo = { 'energy' : self._xlo, 'dtheta' : self._ylo }\n chi = { 'energy' : self._xhi, 'dtheta' : self._yhi }\n\n mus = self._model.integrate(clo,chi,pset)\n msk_on = non > 0\n\n lnl = (-mus)\n lnl[msk_on] += non[msk_on]*np.log(mus[msk_on])\n\n print lnl.shape\n\n if pset.size() > 1: return -np.sum(lnl,axis=1)\n else: return -np.sum(lnl)\n\nclass OnOffBinnedLnL(ParamFnBase):\n\n def __init__(self,non,noff,xedge,alpha,model):\n ParamFnBase.__init__(self,model.param())\n self._non = copy.copy(non)\n self._noff = copy.copy(noff)\n self._alpha = alpha\n self._model = model\n self._xedge = xedge\n self._mub0 = (self._non+self._noff)/(1+alpha)\n\n @staticmethod\n def createFromHist(hon,hoff,alpha,model):\n return OnOffBinnedLnL(hon.counts(),hoff.counts(),hon.edges(),\n alpha,model)\n\n def eval(self,p):\n\n pset = self._model.param(True)\n pset.update(p)\n\n alpha = self._alpha\n\n nbin = len(self._xedge)-1\n\n xlo = self._xedge[:-1]\n xhi = self._xedge[1:]\n\n# non = copy.deepcopy(self._non)\n# noff = copy.deepcopy(self._noff)\n\n# non.shape = (1,) + non.shape\n# noff.shape = (1,) + noff.shape\n\n# if pset.size() > 1:\n non = (np.ones(shape=(pset.size(),nbin))*self._non)\n noff = (np.ones(shape=(pset.size(),nbin))*self._noff)\n# else: \n# non = self._non\n# noff = self._noff\n\n mus = self._model.integrate(xlo,xhi,pset)\n\n mub = ((self._mub0/2. - mus/(2.*alpha) + \n np.sqrt(noff*mus/(alpha*(1+alpha)) + \n (self._mub0/2.-mus/(2.*alpha))**2)))\n\n\n\n msk_on = non > 0\n msk_off = noff > 0\n \n lnl = (-self._alpha*mub - mus - mub)\n lnl[msk_on] += non[msk_on]*np.log(self._alpha*mub[msk_on]+\n mus[msk_on])\n\n if np.any(msk_off):\n lnl[msk_off] += noff[msk_off]*np.log(mub[msk_off])\n\n if pset.size() > 1:\n return -np.sum(lnl,axis=1)\n else:\n return -np.sum(lnl)\n\n\n\n \n\n\nif __name__ == '__main__':\n\n gfn = ConvolvedGaussFn.create(3.0,0.1,KingFn.create(0.1,3.0),4)\n\n pset = gfn.param()\n\n pset = pset.makeParameterArray(0,np.linspace(0.5,1,8))\n\n print pset\n\n xlo = np.array([0])\n xhi = np.array([0.5])\n\n print gfn.integrate(xlo,xhi,pset)\n\n sys.exit(0)\n\n fn = PolarPolyFn.create(2,[0.1,1.0])\n\n p0 = Parameter(2,3.7,'p0')\n\n cm = CompositeModel()\n\n# cm.addModel(fn,[p0],'(1-p0)**2+a1**3')\n cm.addModel(fn)\n\n\n pset = copy.deepcopy(cm.param())\n\n print 'pset ', pset\n\n p = pset.array()\n rnd = np.random.uniform(0.0,1.0,(len(p),10,1))\n\n prnd = p - 0.5*p + rnd*(2.0*p - (p - 0.5*p))\n\n print 'p ', p.shape\n print 'prnd ', prnd.shape\n\n\n pset.setParam(prnd)\n\n x = np.linspace(0,1,5)\n print 'x: ', x\n\n\n print 'cm.eval(1.0) ---------------'\n print cm.eval(1.0)\n print 'cm.eval(x) -----------------'\n print cm.eval(x)\n print 'cm.eval(x,p) ---------------'\n print cm.eval(x,p)\n print cm.eval(x,prnd)\n print cm.eval(x,pset)\n\n\n\n kfn = KingFn.create(0.2,5.0,0.5)\n\n kfn_pset = copy.deepcopy(kfn.param())\n\n kfn_pset = kfn_pset.makeParameterArray(1,np.linspace(0.5,1,8))\n\n print kfn_pset\n\n print 'kfn.eval(x)'\n print kfn.eval(x)\n print 'kfn.integrate(x[:-1],x[1:])'\n print kfn.integrate(x[:-1],x[1:])\n print 'kfn.integrate(x[:-1],x[1:])'\n v = kfn.integrate(x[:-1],x[1:],kfn_pset)\n print v.shape\n print v\n\n gfn = ConvolvedGaussFn.create(1.0,1.0,kfn,3)\n\n pset = copy.deepcopy(gfn.param())\n\n pset.getParByID(1).set(0.01)\n\n print pset\n\n\n print 'gfn.eval(x)'\n print gfn.eval(x)\n\n print gfn.eval(x,pset)\n\n print 'gfn.integrate(x[:-1],x[1:])'\n print gfn.param()\n print gfn.integrate(x[:-1],x[1:])\n\n pset = pset.makeParameterArray(1,np.linspace(0.5,1,8))\n\n\n\n print 'gfn.integrate(x[:-1],x[1:])'\n print pset\n print gfn.integrate(x[:-1],x[1:],pset)\n\n sys.exit(0)\n\n sys.exit(0)\n \n gfn = ConvolvedGaussFn.create(0.01,1.0,kfn,3)\n\n x = np.linspace(0,3,100)\n\n# plt.plot(x,gfn.eval(x))\n\n pset = gfn.param()\n\n print pset\n\n pset[4] = 0.15\n\n plt.plot(x,gfn.eval(x,pset))\n\n pset[4] = 0.05\n\n p = pset.makeParameterArray(4,np.linspace(0.1,0.2,3))\n\n plt.plot(x,gfn.eval(x,p)[0])\n plt.plot(x,gfn.eval(x,p)[1])\n plt.plot(x,gfn.eval(x,p)[2])\n\n\n plt.show()\n\n sys.exit(0)\n\n nevent = 10000\n\n cm = CompositeModel()\n# cm.addModel(KingFn.create(1.0,3.0,0.5*nevent))\n\n cm.addModel(PolyFn.create(3,[0,1,2]))\n# cm.addModel(KingFn.create(0.2,3.0,0.5*nevent,3))\n\n print cm.param()\n\n nbin = 80\n\n h0 = Histogram([0,5.0],nbin)\n h1 = Histogram([0,5.0],nbin)\n\n\n\n h0.fill(cm.rnd(nevent,10.0))\n\n lnlfn = OnOffBinnedLnL(h0._counts,h1._counts,h0._xedges,1.0,cm)\n\n plt.figure()\n\n sig = np.linspace(0.9,1.1,100)\n\n \n\n\n p = cm.param().makeParameterArray(1,sig)\n\n\n#print lnlfn.eval(p)\n#print lnlfn.eval(p[0])\n\n\n plt.plot(sig,lnlfn.eval(p))\n\n lnlfn.fit()\n\n\n\n#plt.plot(sig,lnlfn.eval())\n\n plt.figure()\n\n\n x = np.linspace(0,3,100)\n\n h0.plot()\n \n plt.plot(h0._x,cm.integrate(h0._xedges[:-1],h0._xedges[1:]))\n\n plt.show()\n"
},
{
"alpha_fraction": 0.6056337952613831,
"alphanum_fraction": 0.615934431552887,
"avg_line_length": 25.422222137451172,
"blob_id": "249cbb1dd64a80a46a7ba000ad46c78b6863eb97",
"content_id": "77c6c4119efd95e4971005b58ece540c3e872a4b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4757,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 180,
"path": "/scripts/gtselect.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport logging\nimport pprint\n#from LogFile import LogFile\nimport shutil\nimport pyfits\nfrom GtApp import GtApp\n#from pySimbad import pySimbad\nimport numpy as np\nimport argparse\n\nfrom gammatools.fermi.task import SelectorTask\n\nusage = \"usage: %(prog)s [options] [ft1file]\"\ndescription = \"Run both gtmktime and gtselect on an FT1 file.\"\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\n#parser.add_argument('--ra', default = None, type=float,\n# help = 'Source RA')\n\n#parser.add_argument('--dec', default = None, type=float,\n# help = 'Source Dec')\n\n#parser.add_argument('--rad', default = 180, type=float,\n# help = 'Radius of ROI')\n\n#parser.add_argument('--evclass', default = None, type=int,\n# help = 'Event class.')\n\n#parser.add_argument('--evtype', default = None, type=int,\n# help = 'Event class.')\n\n#parser.add_argument('--emin', default = 1.5, type=float,\n# help = 'Minimum event energy in log10(E/MeV)')\n\n#parser.add_argument('--emax', default = 5.5, type=float,\n# help = 'Maximum event energy in log10(E/MeV)')\n\n#parser.add_argument('--zmax', default = 100, type=float,\n# help = 'Maximum zenith angle')\n\n#parser.add_argument('--source', default = None, \n# help = 'Source name')\n\nparser.add_argument('--output', default = None, \n help = 'Output file')\n\n#parser.add_argument('--scfile', default = None, \n# help = 'Spacecraft file.')\n\n#parser.add_argument('--overwrite', default = False, action='store_true', \n# help = 'Overwrite output file if it exists.') \n\n#parser.add_argument('--filter', default = 'default', \n# help = 'Set the mktime filter.')\n\nSelectorTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\nif len(args.files) < 1:\n parser.error(\"Incorrect number of arguments.\")\n\nif len(args.files) > 1 and args.output:\n print 'Output argument only valid with 1 file argument.'\n sys.exit(1)\n \nfor f in args.files:\n\n if args.output is None:\n m = re.search('(.+)\\.fits?',f)\n if m: outfile = m.group(1) + '_sel.fits'\n else: outfile = os.path.splitext(f)[0] + '_sel.fits'\n else:\n outfile = args.output\n\n \n \n gt_task = SelectorTask(f,outfile,opts=args)\n gt_task.run()\n\n\n \nsys.exit(0)\n \n#output_prefix = 'gtselect'\n#logfile = 'gtselect.log'\n#m = re.search(\"(.+)_(ft1|ls1).fits\",os.path.basename(args[1]))\n#if m is not None:\n# outfile = m.group(1) + '_sel_' + m.group(2) + '.fits'\n# logfile = output_prefix + '.log'\n\n\n \n# Redirect stdout and stderr\n#sys.stdout = LogFile('stdout',logfile,quiet=False)\n#sys.stderr = LogFile('stderr',logfile,quiet=False)\n\n#source_ra = opts.ra\n#source_dec = opts.dec\n#if opts.source is not None:\n# pysim = pySimbad()\n# pysim.findSource(opts.source)\n# source_ra = pysim.ra\n# source_dec = pysim.dec\n#elif source_ra is None or source_dec is None:\n# # Find RA/DEC from FITS file\n# hdulist = pyfits.open(args[1])\n# print hdulist[1].header['DSVAL2']\n# m = re.search(\"circle\\(([0-9\\.]+),([0-9\\.]+)\",hdulist[1].header['DSVAL2'])\n# if m is not None:\n# source_ra = float(m.group(1))\n# source_dec = float(m.group(2))\n# else:\n# source_ra = 'INDEF'\n# source_dec = 'INDEF' \n#print 'RA: %s'%(source_ra)\n#print 'DEC: %s'%(source_dec)\n\n\nfiles = []\nfor i in range(1,len(args)):\n files.append(os.path.abspath(args[i]))\n\n \ncwd = os.getcwd()\ntmpdir = tempfile.mkdtemp(prefix=os.environ['USER'] + '.', dir='/scratch')\n\nos.chdir(tmpdir)\n\n\nfd, file_list = tempfile.mkstemp(dir=tmpdir)\nfor file in files:\n os.write(fd,file + '\\n')\n\npresel_outfile = 'presel.fits'\nsel_outfile = outfile\n\nfilter = GtApp('gtselect', 'dataSubselector')\nmaketime = GtApp('gtmktime', 'dataSubselector')\n\nfilter['ra'] = source_ra\nfilter['dec'] = source_dec\nfilter['rad'] = opts.rad\n\nif opts.emin is not None:\n filter['emin'] = np.power(10,opts.emin)\n\nif opts.emax is not None:\n filter['emax'] = np.power(10,opts.emax)\n\n\nif opts.zmax is not None:\n filter['zmax'] = opts.zmax\n\nfilter['outfile'] = presel_outfile\nfilter['infile'] = '@' + file_list\n\nmaketime['scfile'] = scfile\nmaketime['evfile'] = presel_outfile\nmaketime['filter'] = 'IN_SAA!=T&&DATA_QUAL==1&&LAT_CONFIG==1&&ABS(ROCK_ANGLE)<52'\nmaketime['outfile'] = sel_outfile\nmaketime['roicut'] = 'no'\n\ntry:\n filter.run()\n maketime.run()\nexcept:\n print logging.getLogger('stderr').exception(sys.exc_info()[0])\n\nos.system('mv ' + sel_outfile + ' ' + cwd)\n\n\nshutil.rmtree(tmpdir)\n\n"
},
{
"alpha_fraction": 0.437010258436203,
"alphanum_fraction": 0.5030138492584229,
"avg_line_length": 28.283185958862305,
"blob_id": "bcc4d8c9cddc505bbb6882ac1b741028178694e4",
"content_id": "711f5d0974a3b10c550ebefab5fdc05734c27621",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3318,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 113,
"path": "/gammatools/core/tests/test_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nimport copy\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.util import *\nfrom gammatools.core.config import *\nfrom gammatools.core.histogram import Axis\n\nclass TestUtil(unittest.TestCase):\n\n def test_convolve2d_king(self):\n \n gfn = lambda r, s: np.power(2*np.pi*s**2,-1)*np.exp(-r**2/(2*s**2))\n kfn = lambda r, s, g: np.power(2*np.pi*s**2,-1)*(1.-1./g)* \\\n np.power(1+0.5/g*(r/s)**2,-g)\n\n kfn0 = lambda x, y, mux, muy, s, g: kfn(np.sqrt((x-mux)**2+(y-muy)**2),s,g)\n\n xaxis = Axis.create(-3,3,501)\n yaxis = Axis.create(-3,3,501)\n\n x, y = np.meshgrid(xaxis.center,yaxis.center)\n xbin, ybin = np.meshgrid(xaxis.width,yaxis.width)\n\n r = np.sqrt(x**2+y**2)\n\n # Scalar Input\n\n mux = 0.5\n muy = -0.2\n mur = (mux**2+muy**2)**0.5\n\n gsig = 0.1\n ksig = 0.2\n kgam = 4.0\n\n fval0 = np.sum(kfn0(x,y,mux,muy,ksig,kgam)*gfn(r,gsig)*xbin*ybin)\n fval1 = convolve2d_king(lambda t: gfn(t,gsig),mur,ksig,kgam,3.0,\n nstep=10000)\n# fval2 = convolve2d_gauss(lambda t: kfn(t,ksig,kgam),mur,gsig,3.0,\n# nstep=1000)\n# print fval0, fval1, fval2, fval1/fval0\n\n assert_almost_equal(fval0,fval1,4)\n\n def test_convolve2d_gauss(self):\n\n gfn0 = lambda x, y, mux, muy, s: np.power(2*np.pi*s**2,-1)* \\\n np.exp(-((x-mux)**2+(y-muy)**2)/(2*s**2))\n\n gfn1 = lambda r, s: np.power(2*np.pi*s**2,-1)*np.exp(-r**2/(2*s**2))\n \n \n\n xaxis = Axis.create(-3,3,501)\n yaxis = Axis.create(-3,3,501)\n\n x, y = np.meshgrid(xaxis.center,yaxis.center)\n xbin, ybin = np.meshgrid(xaxis.width,yaxis.width)\n\n # Scalar Input\n\n sigma0 = 0.1\n sigma1 = 0.2\n\n mux = 0.5\n muy = -0.2\n mur = (mux**2+muy**2)**0.5\n\n fval0 = np.sum(gfn0(x,y,mux,muy,sigma1)*gfn0(x,y,0,0,sigma0)*xbin*ybin)\n fval1 = convolve2d_gauss(lambda t: gfn1(t,sigma0),mur,sigma1,3.0,\n nstep=1000)\n\n assert_almost_equal(fval0,fval1,4)\n\n # Vector Input for Gaussian Width\n\n sigma0 = 0.1\n sigma1 = np.array([0.1,0.15,0.2])\n\n mux = 0.5\n muy = -0.2\n mur = (mux**2+muy**2)**0.5\n\n fval0 = []\n for i in range(len(sigma1)):\n fval0.append(np.sum(gfn0(x,y,mux,muy,sigma1[i])*\n gfn0(x,y,0,0,sigma0)*xbin*ybin))\n \n fval1 = convolve2d_gauss(lambda t: gfn1(t,sigma0),mur,sigma1,3.0,\n nstep=1000)\n\n assert_almost_equal(np.ravel(fval0),np.ravel(fval1),4)\n\n # Vector Input\n\n sigma0 = 0.1\n sigma1 = 0.2\n\n mux = np.array([0.3,0.4,0.5])\n muy = np.array([-0.2,-0.2,0.2])\n mur = (mux**2+muy**2)**0.5\n\n fval0 = []\n for i in range(len(mux)):\n fval0.append(np.sum(gfn0(x,y,mux[i],muy[i],sigma1)*\n gfn0(x,y,0,0,sigma0)*\n xbin*ybin))\n\n fval1 = convolve2d_gauss(lambda t: gfn1(t,sigma0),mur,sigma1,3.0,\n nstep=1000)\n\n assert_almost_equal(fval0,fval1,4)\n \n"
},
{
"alpha_fraction": 0.521124005317688,
"alphanum_fraction": 0.5403395891189575,
"avg_line_length": 32.106754302978516,
"blob_id": "838fa3949ed8531c1d1cfc9b7c1107f88d9dea03",
"content_id": "7e6fbb15797f9161ef69cf1e50961879803e7e38",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30392,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 918,
"path": "/gammatools/core/fits_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@file fits_util.py\n\n@brief Various utility classes for manipulating FITS data.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood\"\n__date__ = \"01/01/2014\"\n\n\n\nimport re\nimport copy\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport pywcsgrid2\nimport pywcsgrid2.allsky_axes\nfrom pywcsgrid2.allsky_axes import make_allsky_axes_from_header\n#import astropy.wcs as pywcs\nfrom astropy_helper import pywcs\nfrom astropy_helper import pyfits\n#from astropy.io.fits.header import Header\nimport numpy as np\nimport healpy as hp\nfrom gammatools.core.algebra import Vector3D\nfrom gammatools.fermi.catalog import *\nfrom gammatools.core.util import *\nfrom gammatools.core.histogram import *\n\ndef stack_images(files,output_file,hdu_index=0):\n\n hdulist0 = None\n for i, f in enumerate(files):\n hdulist = pyfits.open(f)\n if i == 0: hdulist0 = hdulist\n else:\n hdulist0[hdu_index].data += hdulist[hdu_index].data\n hdulist0.writeto(output_file,clobber=True)\n\ndef load_ds9_cmap():\n # http://tdc-www.harvard.edu/software/saoimage/saoimage.color.html\n ds9_b = {\n 'red' : [[0.0 , 0.0 , 0.0], \n [0.25, 0.0 , 0.0], \n [0.50, 1.0 , 1.0], \n [0.75, 1.0 , 1.0], \n [1.0 , 1.0 , 1.0]],\n 'green' : [[0.0 , 0.0 , 0.0], \n [0.25, 0.0 , 0.0], \n [0.50, 0.0 , 0.0], \n [0.75, 1.0 , 1.0], \n [1.0 , 1.0 , 1.0]],\n 'blue' : [[0.0 , 0.0 , 0.0], \n [0.25, 1.0 , 1.0], \n [0.50, 0.0 , 0.0], \n [0.75, 0.0 , 0.0], \n [1.0 , 1.0 , 1.0]]\n }\n \n plt.register_cmap(name='ds9_b', data=ds9_b) \n plt.cm.ds9_b = plt.cm.get_cmap('ds9_b')\n return plt.cm.ds9_b\n\ndef get_circle(ra,dec,rad_deg,n=100):\n th = np.linspace(np.radians(rad_deg),\n np.radians(rad_deg),n)\n phi = np.linspace(0,2*np.pi,n)\n\n v = Vector3D.createThetaPhi(th,phi)\n\n v.rotatey(np.pi/2.-np.radians(dec))\n v.rotatez(np.radians(ra))\n\n return np.degrees(v.lon()), np.degrees(v.lat())\n\nclass FITSAxis(Axis):\n\n def __init__(self,ctype,crpix,crval,cdelt,naxis,logaxis=False,offset=0.0):\n\n self._type = ctype\n self._crpix = crpix\n self._crval = crval\n self._delta = cdelt\n self._naxis = naxis\n self._coordsys = None\n self._sky_coord = False\n if logaxis:\n self._delta = np.log10((self._crval+self._delta)/self._crval)\n self._crval = np.log10(self._crval)\n \n if np.fmod(crpix,1.0):\n edges = np.linspace(0.0,self._naxis,self._naxis+1) - 0.5\n else:\n edges = np.linspace(0.0,self._naxis,self._naxis+1) \n\n if re.search('GLON',self._type) or re.search('GLAT',self._type):\n self._coordsys = 'gal'\n self._sky_coord = True\n elif re.search('RA',self._type) or re.search('DEC',self._type):\n self._coordsys = 'cel'\n self._sky_coord = True\n\n super(FITSAxis, self).__init__(edges,label=ctype)\n \n @property\n def naxis(self):\n return self._naxis\n \n @property\n def type(self):\n return self._type\n\n def to_axis(self,apply_crval=True):\n return Axis(self.pix_to_coord(self.edges,apply_crval))\n \n def pix_to_coord(self,p,apply_crval=True):\n \"\"\"Convert from FITS pixel coordinates to projected sky\n coordinates.\"\"\"\n if apply_crval:\n return self._crval + (p-self._crpix)*self._delta\n else:\n return (p-self._crpix)*self._delta\n\n def coord_to_pix(self,x,apply_crval=True):\n\n if apply_crval:\n return self._crpix + (x-self._crval)/self._delta \n else:\n return self._crpix + x/self._delta \n\n def coord_to_index(self,x):\n pix = self.coord_to_pix(x)\n index = np.round(pix)\n return index\n\n @staticmethod\n def create_from_axis(ctype,axis):\n return FITSAxis(ctype,0,axis.lo_edge(),axis.width[0],axis.nbins)\n \n @staticmethod\n def create_from_header(header,iaxis,logaxis=False,offset=0.0):\n return FITSAxis(header.get('CTYPE'+str(iaxis+1)),\n header.get('CRPIX'+str(iaxis+1))-1,\n header.get('CRVAL'+str(iaxis+1)),\n header.get('CDELT'+str(iaxis+1)),\n header.get('NAXIS'+str(iaxis+1)),\n logaxis,offset)\n \n @staticmethod\n def create_axes(header):\n\n if 'NAXIS' in header: naxis = header.get('NAXIS')\n elif 'WCSAXES' in header: naxis = header.get('WCSAXES')\n \n axes = []\n for i in range(naxis):\n \n ctype = header.get('CTYPE'+str(i+1))\n if ctype == 'Energy' or ctype == 'photon energy':\n axis = FITSAxis.create_from_header(header,i,logaxis=True)\n else:\n axis = FITSAxis.create_from_header(header,i)\n\n axes.append(axis)\n\n return axes\n\n\nclass HealpixImage(HistogramND):\n\n def __init__(self,axes,hp_axis_index=0,counts=None,var=None):\n super(HealpixImage, self).__init__(axes,counts=counts,var=var)\n\n self._hp_axis = self.axes()[hp_axis_index]\n self._nside = hp.npix2nside(self._hp_axis.nbins)\n self._nest=False\n\n @property\n def nside(self):\n return self._nside\n\n @property\n def nest(self):\n return self._nest\n \n def createFromHist(self,h):\n \"\"\"Take an input HistogramND object and cast it into a\n HealpixSkyImage if appropriate.\"\"\"\n \n if h.ndim() == 2:\n return HealpixSkyCube(h.axes(),h.counts)\n else:\n return HealpixSkyImage(h.axes(),h.counts)\n\n def slice(self,sdims,dim_index):\n\n h = HistogramND.slice(self,sdims,dim_index)\n if h.ndim() == 2:\n return HealpixSkyCube(h.axes(),h.counts)\n elif h.ndim() == 1: \n return HealpixSkyImage(h.axes(),h.counts)\n else:\n h._axes[0] = Axis(h.axis().pix_to_coord(h.axis().edges()))\n return h\n\n def project(self,pdims,bin_range=None):\n \n h = HistogramND.project(self,pdims,bin_range)\n return self.createFromHist(h)\n \n def marginalize(self,mdims,bin_range=None):\n\n mdims = np.array(mdims,ndmin=1,copy=True)\n pdims = np.setdiff1d(self._dims,mdims) \n return self.project(pdims,bin_range)\n \nclass HealpixSkyImage(HealpixImage):\n\n def __init__(self,axes,counts=None,var=None):\n super(HealpixSkyImage, self).__init__(axes,counts=counts,var=var)\n \n def fill(self,lon,lat,w=1.0):\n ipix = hp.ang2pix(self.nside,lat,lon,nest=self.nest)\n super(HealpixSkyImage,self).fill(ipix,w)\n\n def interpolate(self,lon,lat):\n \n pixcrd = self._wcs.wcs_world2pix(lon, lat, 0)\n return interpolate2d(self._xedge,self._yedge,self._counts,\n *pixcrd)\n\n def center(self):\n \"\"\"Returns lon,lat.\"\"\"\n\n pixcrd = np.array(self.axes()[0].edges[:-1],dtype=int)\n pixang0, pixang1 = hp.pixelfunc.pix2ang(self.nside,pixcrd)\n \n pixang0 = np.ravel(pixang0)\n pixang1 = np.ravel(pixang1)\n pixang0 = np.pi/2. - pixang0\n \n return np.vstack((np.degrees(pixang1),np.degrees(pixang0)))\n \n\n def mask(self,lonrange=None,latrange=None):\n \n c = self.center()\n msk = np.empty(self.axis(0).nbins,dtype='bool'); msk.fill(True)\n msk &= (c[1] > latrange[0])&(c[1] < latrange[1])\n self._counts[msk]=np.nan\n \n def integrate(self,lonrange=None,latrange=None):\n\n c = self.center()\n msk = np.empty(self.axis(0).nbins,dtype='bool'); msk.fill(True)\n msk &= (c[1] > latrange[0])&(c[1] < latrange[1])\n return np.sum(self._counts[msk]) \n \n def smooth(self,sigma):\n\n im = HealpixSkyImage(copy.deepcopy(self.axes()),\n counts=copy.deepcopy(self._counts),\n var=copy.deepcopy(self._var))\n \n sc = hp.sphtfunc.smoothing(im.counts,sigma=np.radians(sigma))\n\n im._counts = sc\n im._var = copy.deepcopy(sc)\n\n return im\n \n def plot(self,**kwargs):\n\n kwargs_imshow = { 'norm' : None,\n 'vmin' : None, 'vmax' : None }\n\n zscale_power = kwargs.get('zscale_power',2.0)\n zscale = kwargs.get('zscale',None)\n cbar = kwargs.get('cbar',True)\n cbar_label = kwargs.get('cbar_label','')\n title = kwargs.get('title','')\n levels = kwargs.get('levels',None)\n\n kwargs_imshow['vmin'] = kwargs.get('vmin',None)\n kwargs_imshow['vmax'] = kwargs.get('vmax',None)\n\n cmap = mpl.cm.get_cmap(kwargs.get('cmap','jet'))\n cmap.set_under('white')\n kwargs_imshow['cmap'] = cmap\n\n if zscale == 'pow':\n vmed = np.median(self.counts)\n vmax = max(self.counts)\n vmin = min(1.1*self.counts[self.counts>0])\n# vmin = max(vmed*(vmed/vmax),min(self.counts[self.counts>0]))\n\n kwargs_imshow['norm'] = PowerNorm(gamma=1./zscale_power,\n clip=True)\n elif zscale == 'log': kwargs_imshow['norm'] = LogNorm()\n else: kwargs_imshow['norm'] = Normalize(clip=True)\n \n from healpy import projaxes as PA\n \n fig = plt.gcf()\n\n extent = (0.02,0.05,0.96,0.9)\n ax=PA.HpxMollweideAxes(fig,extent,coord=None,rot=None,\n format='%g',flipconv='astro')\n\n ax.set_title(title)\n fig.add_axes(ax)\n\n img0 = ax.projmap(self.counts,nest=self.nest,xsize=1600,coord='C',\n **kwargs_imshow)\n\n if levels:\n cs = ax.contour(img0,extent=ax.proj.get_extent(),\n levels=levels,colors=['k'],\n interpolation='nearest')\n\n hp.visufunc.graticule(verbose=False,lw=0.5,color='k')\n\n if cbar:\n\n im = ax.get_images()[0]\n cb = fig.colorbar(im, orientation='horizontal', \n shrink=.8, pad=0.05,format='%.3g')\n #, ticks=[min, max])\n cb.ax.xaxis.set_label_text(cbar_label)\n\n if zscale=='pow':\n gamma = 1./zscale_power\n\n print vmin, vmed, vmax\n\n ticks = np.linspace(vmin**gamma,\n vmax**gamma,6)**(1./gamma)\n\n print ticks\n\n cb.set_ticks(ticks)\n\n# cb.ax.xaxis.labelpad = -8\n # workaround for issue with viewers, see colorbar docstring\n cb.solids.set_edgecolor(\"face\")\n\n \nclass HealpixSkyCube(HealpixImage):\n\n def __init__(self,axes,hp_axis_index=0,counts=None):\n super(HealpixSkyCube, self).__init__(axes,hp_axis_index,counts)\n\n def center(self):\n pixcrd = np.array(self.axes()[1].edges[:-1],dtype=int)\n pixang0, pixang1 = hp.pixelfunc.pix2ang(self.nside,pixcrd)\n\n pixloge = self.axes()[0].center\n\n# print pixloge \n# x,y = np.meshgrid(pixloge,pixang0,indexing='ij')\n \n pixloge = np.repeat(pixloge[:,np.newaxis],len(pixang0),axis=1)\n pixang0 = np.repeat(pixang0[np.newaxis,:],len(pixloge),axis=0)\n pixang1 = np.repeat(pixang1[np.newaxis,:],len(pixloge),axis=0)\n\n pixloge = np.ravel(pixloge)\n pixang0 = np.ravel(pixang0)\n pixang1 = np.ravel(pixang1)\n pixang0 = np.pi/2. - pixang0\n\n \n return np.vstack((pixloge,np.degrees(pixang1),np.degrees(pixang0)))\n \n print pixloge.shape\n print pixang0.shape\n\n print x.shape\n print y.shape\n print self.counts.shape\n\n\n print x[:,1000]\n print pixloge[:,1000]\n\n print y[10,:]\n print pixang0[10,:]\n \n return pixang\n \n @staticmethod\n def create(energy_axis,nside):\n\n npix = hp.pixelfunc.nside2npix(nside)\n hp_axis = Axis.create(0,npix,npix) \n return HealpixSkyCube([energy_axis,hp_axis],1)\n \n @staticmethod\n def createFromFITS(fitsfile,image_hdu='SKYMAP'):\n \"\"\" \"\"\"\n\n hdulist = pyfits.open(fitsfile) \n header = hdulist[image_hdu].header\n ebounds = hdulist['EBOUNDS'].data\n\n v = hdulist[image_hdu].data\n\n dtype = v.dtype[0]\n image_data = copy.deepcopy(v.view((dtype, len(v.dtype.names))))\n #np.array(hdulist[image_hdu].data).astype(float)\n \n nbin = len(ebounds) \n emin = ebounds[0][1]/1E3\n emax = ebounds[-1][2]/1E3\n delta = np.log10(emax/emin)/nbin\n\n energy_axis = Axis.create(np.log10(emin),np.log10(emax),nbin)\n hp_axis = Axis.create(0,image_data.shape[0],image_data.shape[0])\n \n return HealpixSkyCube([energy_axis,hp_axis],1,image_data.T)\n\n \nclass FITSImage(HistogramND):\n \"\"\"Base class for SkyImage and SkyCube classes. Handles common\n functionality for performing sky to pixel coordinate conversions.\"\"\"\n \n def __init__(self,wcs,axes,counts=None,roi_radius_deg=180.,roi_msk=None):\n super(FITSImage, self).__init__(axes,counts=counts,\n var=copy.deepcopy(counts))\n \n self._wcs = wcs\n self._roi_radius_deg = roi_radius_deg\n self._header = self._wcs.to_header(True)\n \n self._lon = self._header['CRVAL1']\n self._lat = self._header['CRVAL2']\n \n self._roi_msk = np.empty(shape=self._counts.shape[:2],dtype=bool)\n self._roi_msk.fill(False)\n \n if not roi_msk is None: self._roi_msk |= roi_msk\n \n xpix, ypix = np.meshgrid(self.axis(0).center,self.axis(1).center)\n xpix = np.ravel(xpix)\n ypix = np.ravel(ypix)\n \n# self._pix_lon, self._pix_lat = self._wcs.wcs_pix2sky(xpix,ypix, 0)\n self._pix_lon, self._pix_lat = self._wcs.wcs_pix2world(xpix,ypix, 0)\n\n self.add_roi_msk(self._lon,self._lat,roi_radius_deg,True,\n self.axis(1)._coordsys)\n\n def __getnewargs__(self):\n\n self._wcs = pywcs.WCS(self._header)\n return ()\n# return (self._wcs,self._counts,self._ra,self._dec,self._roi_radius)\n \n def add_roi_msk(self,lon,lat,rad,invert=False,coordsys='cel'):\n \n v0 = Vector3D.createLatLon(np.radians(self._pix_lat),\n np.radians(self._pix_lon))\n \n if self._axes[0]._coordsys == 'gal' and coordsys=='cel':\n lon,lat = eq2gal(lon,lat)\n elif self._axes[0]._coordsys == 'cel' and coordsys=='gal':\n lon,lat = gal2eq(lon,lat)\n \n v1 = Vector3D.createLatLon(np.radians(lat),np.radians(lon))\n\n dist = np.degrees(v0.separation(v1))\n dist = dist.reshape(self._counts.shape[:2])\n \n if not invert: self._roi_msk[dist<rad] = True\n else: self._roi_msk[dist>rad] = True\n\n def slice(self,sdims,dim_index):\n\n h = HistogramND.slice(self,sdims,dim_index)\n if h.ndim() == 3:\n return SkyCube(self._wcs,h.axes(),h.counts,\n self._roi_radius_deg,self._roi_msk)\n elif h.ndim() == 2: \n return SkyImage(self._wcs,h.axes(),h.counts,\n self._roi_radius_deg,self._roi_msk)\n else:\n h._axes[0] = Axis(h.axis().pix_to_coord(h.axis().edges()))\n return h\n\n def project(self,pdims,bin_range=None,offset_coord=False):\n\n h = HistogramND.project(self,pdims,bin_range)\n return self.createFromHist(h,offset_coord=offset_coord)\n \n def marginalize(self,mdims,bin_range=None,offset_coord=False):\n\n mdims = np.array(mdims,ndmin=1,copy=True)\n pdims = np.setdiff1d(self._dims,mdims)\n return self.project(pdims,bin_range,offset_coord=offset_coord)\n\n @property\n def lat(self):\n return self._lat\n\n @property\n def lon(self):\n return self._lon\n\n @property\n def roi_radius(self):\n return self._roi_radius_deg\n\n @property\n def wcs(self):\n return self._wcs\n \n def createFromHist(self,h,offset_coord=False):\n \"\"\"Take an input HistogramND object and cast it into a\n SkyImage if appropriate.\"\"\"\n \n if h.ndim() == 2:\n\n if h.axis(0)._sky_coord and h.axis(1)._sky_coord:\n return SkyImage(self._wcs,h.axes(),h.counts,\n self._roi_radius_deg,self._roi_msk)\n else:\n axis0 = Axis(h.axis(0).pix_to_coord(h.axis(0).edges,not offset_coord))\n axis1 = Axis(h.axis(1).pix_to_coord(h.axis(1).edges,not offset_coord))\n \n h._axes[0] = axis0\n h._axes[1] = axis1\n return h\n else:\n h._axes[0] = Axis(h.axis().pix_to_coord(h.axis().edges, not offset_coord))\n return h\n\n @staticmethod\n def createFromHDU(hdu):\n \"\"\"Create an SkyCube or SkyImage object from a FITS HDU.\"\"\"\n header = hdu.header\n\n if header['NAXIS'] == 3: return SkyCube.createFromHDU(hdu)\n elif header['NAXIS'] == 2: return SkyImage.createFromHDU(hdu)\n else:\n print 'Wrong number of axes.'\n sys.exit(1)\n \n @staticmethod\n def createFromFITS(fitsfile,ihdu=0):\n \"\"\" \"\"\"\n hdulist = pyfits.open(fitsfile)\n return FITSImage.createFromHDU(hdulist[ihdu])\n \nclass SkyCube(FITSImage):\n \"\"\"Container class for a FITS counts cube with two space\n dimensions and one energy dimension.\"\"\"\n \n def __init__(self,wcs,axes,counts=None,roi_radius_deg=180.,roi_msk=None):\n super(SkyCube, self).__init__(wcs,axes,counts,roi_radius_deg,roi_msk)\n \n def get_spectrum(self,lon,lat):\n\n xy = self._wcs.wcs_world2pix(lon,lat, 0)\n ilon = np.round(xy[0][0])\n ilat = np.round(xy[1][0])\n\n ilon = min(max(0,ilon),self._axes[0]._naxis-1)\n ilat = min(max(0,ilat),self._axes[1]._naxis-1)\n\n c = self._counts.T[ilon,ilat,:]\n edges = self._axes[2].edges\n return Histogram.createFromArray(edges,c)\n\n def plot_energy_slices(self,rebin=4,logz=False):\n\n frame_per_fig = 1\n nx = 1\n ny = 1\n\n plt.figure()\n \n images = self.get_energy_slices(rebin)\n for i, im in enumerate(images):\n subplot = '%i%i%i'%(nx,ny,i%frame_per_fig+1)\n im.plot(subplot=subplot,logz=logz)\n \n def energy_slice(self,ibin):\n\n counts = np.sum(self._counts[ibin:ibin+1],axis=0)\n return SkyImage(self._wcs,self._axes[:2],counts)\n \n def get_integrated_map(self,emin,emax):\n \n ebins = self._axes[2].edges\n\n loge = 0.5*(ebins[1:] + ebins[:-1])\n dloge = ebins[1:] - ebins[:-1]\n\n imin = np.argmin(np.abs(emin-ebins))\n imax = np.argmin(np.abs(emax-ebins))\n edloge = 10**loge[imin:imax+1]*dloge[imin:imax+1]\n\n counts = np.sum(self._counts[imin:imax+1].T*edloge*np.log(10.),\n axis=2)\n\n return SkyImage(self._wcs,self._axes[:2],counts)\n\n def fill(self,lon,lat,loge):\n\n pixcrd = self._wcs.wcs_world2pix(lon,lat, 0)\n ecrd = self._axes[2].coord_to_pix(loge)\n super(SkyCube,self).fill(np.vstack((pixcrd[0],pixcrd[1],ecrd)))\n\n def interpolate(self,lon,lat,loge):\n pixcrd = self._wcs.wcs_world2pix(lon,lat, 0)\n ecrd = np.array(self._axes[2].coord_to_pix(loge),ndmin=1)\n return super(SkyCube,self).interpolate(pixcrd[0],pixcrd[1],ecrd)\n \n @staticmethod\n def createFromHDU(hdu):\n \n header = pyfits.Header.fromstring(hdu.header.tostring())\n# header = hdu.header\n\n wcs = pywcs.WCS(header,naxis=[1,2])#,relax=True)\n# wcs1 = pywcs.WCS(header,naxis=[3])\n axes = copy.deepcopy(FITSAxis.create_axes(header))\n return SkyCube(wcs,axes,copy.deepcopy(hdu.data.astype(float).T))\n \n @staticmethod\n def createFromFITS(fitsfile,ihdu=0):\n \n hdulist = pyfits.open(fitsfile) \n header = hdulist[ihdu].header\n wcs = pywcs.WCS(header,naxis=[1,2],relax=True)\n\n print hdulist.info()\n\n if hdulist[1].name == 'ENERGIES':\n v = hdulist[1].data\n v = copy.deepcopy(v.view((v.dtype[0], len(v.dtype.names))))\n v = np.log10(v)\n energy_axis = Axis.createFromArray(v)\n axes = copy.deepcopy(FITSAxis.create_axes(header))\n axes[2]._crval = energy_axis.edges[0]\n axes[2]._delta = energy_axis.width[0]\n axes[2]._crpix = 0.0\n else: \n axes = copy.deepcopy(FITSAxis.create_axes(header))\n return SkyCube(wcs,axes,\n copy.deepcopy(hdulist[ihdu].data.astype(float).T))\n\n @staticmethod\n def createFromTree(tree,lon,lat,lon_var,lat_var,egy_var,roi_radius_deg,\n energy_axis,cut='',bin_size_deg=0.2,coordsys='cel'):\n\n im = SkyCube.createROI(lon,lat,roi_radius_deg,energy_axis,\n bin_size_deg,coordsys) \n im.fill(get_vector(tree,lon_var,cut=cut),\n get_vector(tree,lat_var,cut=cut),\n get_vector(tree,egy_var,cut=cut))\n return im\n \n @staticmethod\n def createROI(ra,dec,roi_radius_deg,energy_axis,\n bin_size_deg=0.2,coordsys='cel'):\n\n nbin = np.ceil(2.0*roi_radius_deg/bin_size_deg)\n \n wcs = SkyImage.createWCS(ra,dec,roi_radius_deg,bin_size_deg,coordsys)\n header = wcs.to_header(True)\n header['NAXIS1'] = nbin\n header['NAXIS2'] = nbin\n axes = FITSAxis.create_axes(header)\n axes.append(FITSAxis.create_from_axis('Energy',energy_axis))\n return SkyCube(wcs,axes,roi_radius_deg=roi_radius_deg)\n \nclass SkyImage(FITSImage):\n\n def __init__(self,wcs,axes,counts,roi_radius_deg=180.,roi_msk=None):\n super(SkyImage, self).__init__(wcs,axes,counts,roi_radius_deg,roi_msk)\n\n self._ax = None\n \n @staticmethod\n def createFromTree(tree,lon,lat,lon_var,lat_var,roi_radius_deg,cut='',\n bin_size_deg=0.2,coordsys='cel'):\n\n im = SkyImage.createROI(lon,lat,roi_radius_deg,bin_size_deg,coordsys) \n im.fill(get_vector(tree,lon_var,cut=cut),\n get_vector(tree,lat_var,cut=cut))\n return im\n\n @staticmethod\n def createFromHDU(hdu):\n \n header = hdu.header\n wcs = pywcs.WCS(header,relax=True)\n axes = copy.deepcopy(FITSAxis.create_axes(header))\n \n return SkyImage(wcs,axes,copy.deepcopy(hdu.data.astype(float).T))\n \n @staticmethod\n def createFromFITS(fitsfile,ihdu=0):\n \n hdulist = pyfits.open(fitsfile)\n return SkyImage.createFromFITS(hdulist[ihdu])\n\n @staticmethod\n def createWCS(ra,dec,roi_radius_deg,bin_size_deg=0.2,coordsys='cel'):\n nbin = np.ceil(2.0*roi_radius_deg/bin_size_deg)\n deg_to_pix = bin_size_deg\n wcs = pywcs.WCS(naxis=2)\n\n wcs.wcs.crpix = [nbin/2.+0.5, nbin/2.+0.5]\n wcs.wcs.cdelt = np.array([-deg_to_pix,deg_to_pix])\n wcs.wcs.crval = [ra, dec]\n \n if coordsys == 'cel': wcs.wcs.ctype = [\"RA---AIT\", \"DEC--AIT\"]\n else: wcs.wcs.ctype = [\"GLON-AIT\", \"GLAT-AIT\"] \n wcs.wcs.equinox = 2000.0\n return wcs\n \n @staticmethod\n def createROI(ra,dec,roi_radius_deg,bin_size_deg=0.2,coordsys='cel'):\n nbin = np.ceil(2.0*roi_radius_deg/bin_size_deg)\n wcs = SkyImage.createWCS(ra,dec,roi_radius_deg,bin_size_deg,coordsys)\n\n header = wcs.to_header(True)\n header['NAXIS1'] = nbin\n header['NAXIS2'] = nbin\n \n axes = FITSAxis.create_axes(header)\n im = SkyImage(wcs,axes,np.zeros(shape=(nbin,nbin)),roi_radius_deg)\n return im\n\n# lon, lat = get_circle(ra,dec,roi_radius_deg)\n# xy = wcs.wcs_world2pix(lon, lat, 0)\n\n# xmin = np.min(xy[0])\n# xmax = np.max(xy[0])\n\n# if roi_radius_deg >= 90.:\n# xypole0 = wcs.wcs_world2pix(0.0, -90.0, 0)\n# xypole1 = wcs.wcs_world2pix(0.0, 90.0, 0)\n# ymin = xypole0[1]\n# ymax = xypole1[1]\n# else:\n# ymin = np.min(xy[1])\n# ymax = np.max(xy[1])\n\n \n def ax(self):\n return self._ax\n \n def fill(self,lon,lat,w=1.0):\n\n pixcrd = self._wcs.wcs_world2pix(lon,lat, 0)\n super(SkyImage,self).fill(np.vstack((pixcrd[0],pixcrd[1])),w)\n\n def interpolate(self,lon,lat):\n \n pixcrd = self._wcs.wcs_world2pix(lon, lat, 0)\n return interpolate2d(self._xedge,self._yedge,self._counts,\n *pixcrd)\n\n def center(self):\n pixcrd = super(SkyImage,self).center()\n skycrd = self._wcs.wcs_pix2sky(pixcrd[0], pixcrd[1], 0)\n\n return np.vstack((skycrd[0],skycrd[1]))\n\n def smooth(self,sigma,compute_var=False,summed=False):\n\n sigma /= 1.5095921854516636 \n sigma /= np.abs(self._axes[0]._delta)\n \n from scipy import ndimage\n im = SkyImage(copy.deepcopy(self.wcs),\n copy.deepcopy(self.axes()),\n copy.deepcopy(self._counts),\n self.roi_radius,\n copy.deepcopy(self._roi_msk))\n\n # Construct a kernel\n nk =41\n fn = lambda t, s: 1./(2*np.pi*s**2)*np.exp(-t**2/(s**2*2.0))\n b = np.abs(np.linspace(0,nk-1,nk) - (nk-1)/2.)\n k = np.zeros((nk,nk)) + np.sqrt(b[np.newaxis,:]**2 +\n b[:,np.newaxis]**2)\n k = fn(k,sigma)\n k /= np.sum(k)\n\n im._counts = ndimage.convolve(self._counts,k,mode='nearest')\n \n# im._counts = ndimage.gaussian_filter(self._counts, sigma=sigma,\n# mode='nearest')\n\n if compute_var:\n var = ndimage.convolve(self._counts, k**2, mode='wrap')\n im._var = var\n else:\n im._var = np.zeros(im._counts.shape)\n \n if summed: im /= np.sum(k**2)\n \n return im\n\n def plot_marker(self,lonlat=None,**kwargs):\n\n if lonlat is None: lon, lat = (self._lon,self._lat)\n xy = self._wcs.wcs_world2pix(lon,lat, 0)\n self._ax.plot(xy[0],xy[1],**kwargs)\n\n plt.gca().set_xlim(self.axis(0).lo_edge(),self.axis(0).hi_edge())\n plt.gca().set_ylim(self.axis(1).lo_edge(),self.axis(1).hi_edge()) \n \n def plot_circle(self,rad_deg,radec=None,**kwargs):\n\n if radec is None: radec = (self._lon,self._lat)\n\n lon,lat = get_circle(radec[0],radec[1],rad_deg)\n xy = self._wcs.wcs_world2pix(lon,lat, 0)\n self._ax.plot(xy[0],xy[1],**kwargs)\n\n self._ax.set_xlim(self.axis(0).lo_edge(),self.axis(0).hi_edge())\n self._ax.set_ylim(self.axis(1).lo_edge(),self.axis(1).hi_edge()) \n\n \n def plot(self,subplot=111,logz=False,catalog=None,cmap='jet',**kwargs):\n\n from matplotlib.colors import NoNorm, LogNorm, Normalize\n\n kwargs_contour = { 'levels' : None, 'colors' : ['k'],\n 'linewidths' : None,\n 'origin' : 'lower' }\n \n kwargs_imshow = { 'interpolation' : 'nearest',\n 'origin' : 'lower','norm' : None,\n 'vmin' : None, 'vmax' : None }\n\n zscale = kwargs.get('zscale',None)\n zscale_power = kwargs.get('zscale_power',2.0)\n beam_size = kwargs.get('beam_size',None)\n \n if zscale == 'pow':\n kwargs_imshow['norm'] = PowerNormalize(power=zscale_power)\n elif logz: kwargs_imshow['norm'] = LogNorm()\n else: kwargs_imshow['norm'] = Normalize()\n\n ax = pywcsgrid2.subplot(subplot, header=self._wcs.to_header())\n# ax = pywcsgrid2.axes(header=self._wcs.to_header())\n\n load_ds9_cmap()\n colormap = mpl.cm.get_cmap(cmap)\n colormap.set_under('white')\n\n counts = copy.copy(self._counts)\n \n if np.any(self._roi_msk): \n kwargs_imshow['vmin'] = 0.8*np.min(self._counts[~self._roi_msk.T])\n counts[self._roi_msk.T] = -np.inf\n \n# vmax = np.max(self._counts[~self._roi_msk])\n# c = self._counts[~self._roi_msk] \n# if logz: vmin = np.min(c[c>0])\n\n update_dict(kwargs_imshow,kwargs)\n update_dict(kwargs_contour,kwargs)\n \n im = ax.imshow(counts.T,**kwargs_imshow)\n im.set_cmap(colormap)\n\n if kwargs_contour['levels']: \n cs = ax.contour(counts.T,**kwargs_contour)\n # plt.clabel(cs, fontsize=5, inline=0)\n \n# im.set_clim(vmin=np.min(self._counts[~self._roi_msk]),\n# vmax=np.max(self._counts[~self._roi_msk]))\n \n ax.set_ticklabel_type(\"d\", \"d\")\n\n if self._axes[0]._coordsys == 'gal':\n ax.set_xlabel('GLON')\n ax.set_ylabel('GLAT')\n else: \n ax.set_xlabel('RA')\n ax.set_ylabel('DEC')\n\n# plt.colorbar(im,orientation='horizontal',shrink=0.7,pad=0.15,\n# fraction=0.05)\n ax.grid()\n\n if catalog:\n cat = Catalog.get(catalog)\n\n kwargs_cat = {'src_color' : 'k' }\n if cmap == 'ds9_b': kwargs_cat['src_color'] = 'w'\n\n cat.plot(self,ax=ax,**kwargs_cat)\n \n# ax.add_compass(loc=1)\n# ax.set_display_coord_system(\"gal\") \n # ax.locator_params(axis=\"x\", nbins=12)\n\n ax.add_size_bar(1./self._axes[0]._delta, # 30' in in pixel\n r\"$1^{\\circ}$\",loc=3,color='w')\n \n if beam_size is not None:\n ax.add_beam_size(2.0*beam_size[0]/self._axes[0]._delta,\n 2.0*beam_size[1]/self._axes[1]._delta,\n beam_size[2],beam_size[3],\n patch_props={'fc' : \"none\", 'ec' : \"w\"})\n \n self._ax = ax\n \n return im\n"
},
{
"alpha_fraction": 0.5426923036575317,
"alphanum_fraction": 0.5550000071525574,
"avg_line_length": 27.886110305786133,
"blob_id": "50b646a22092b38f2681bec868423dfa922b4a89",
"content_id": "148fa6a47c396ee034ccf1bad3cc98b4b820a225",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10400,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 360,
"path": "/gammatools/core/quantile.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@author Matthew Wood <[email protected]>\n\"\"\"\n\nimport numpy as np\nimport copy\nfrom scipy.interpolate import UnivariateSpline\nimport scipy.optimize as opt\nimport matplotlib.pyplot as plt\nfrom gammatools.core.histogram import Histogram\nfrom scipy.stats import norm\n\nclass HistBootstrap(object):\n def __init__(self,hist,fn):\n\n self._fn = fn\n self._hist = hist\n self._x = np.array(hist.edges,copy=True)\n self._ncounts = copy.copy(hist.counts)\n\n def bootstrap(self,niter=1000,**kwargs):\n\n nbin = len(self._ncounts)\n ncounts_tmp = np.zeros((nbin,niter))\n\n for i in range(nbin):\n\n if self._ncounts[i] > 0:\n ncounts_tmp[i,:] += np.random.poisson(self._ncounts[i],niter)\n\n fval = []\n for i in range(niter):\n self._hist.counts = ncounts_tmp[:,i]\n #fn = self._fn(self._hist) \n fval.append(self._fn(self._hist,**kwargs))\n\n \n fval_mean = np.mean(np.array(fval))\n fval_rms = np.std(np.array(fval))\n \n return fval_mean, fval_rms\n\n\nclass HistQuantileBkgFn(object):\n \"\"\"\n HistQuantileBkgFn(hcounts,bkg_fn)\n\n Class that computes quantiles of a histogram using a user-provided\n background function which is normalized by a Poisson-distributed\n random variate.\n\n Parameters\n ----------\n hcounts : histogram\n\n Histogram object containg the counts data for which the\n quantile will be estimated.\n\n bkg_fn : function\n\n Function that returns the cumulative background.\n \n \"\"\"\n def __init__(self,hcounts,bkg_fn,nbkg):\n\n self._xedge = np.array(hcounts.axis().edges)\n self._ncounts = copy.copy(hcounts.counts)\n self._ncounts = np.concatenate(([0],self._ncounts))\n self._bkg_fn = bkg_fn\n self._nbkg = nbkg\n\n def quantile(self,fraction=0.68):\n return self._quantile(self._nbkg,self._xedge,self._ncounts,fraction)\n \n def _quantile(self,nbkg=None,xedge=None,ncounts=None,fraction=0.68):\n\n if nbkg is None: nbkg = self._nbkg \n if ncounts is None: ncounts = self._ncounts\n if xedge is None: xedge = self._xedge\n \n ncounts_cum = np.cumsum(ncounts)\n nbkg_cum = self._bkg_fn(xedge)*nbkg\n\n nex_cum = copy.copy(ncounts_cum)\n nex_cum -= nbkg_cum\n nex_tot = nex_cum[-1]\n\n fn_nexcdf = UnivariateSpline(xedge,nex_cum,s=0,k=1)\n \n # Find the first instance of crossing 1\n\n r = (nex_cum-nex_tot) \n idx = np.where(r>=0)[0][0]\n xmax = xedge[idx]\n \n q = opt.brentq(lambda t: fn_nexcdf(t)-nex_tot*fraction,xedge[0],xmax)\n\n return q\n \n \n def bootstrap(self,fraction=0.68,niter=100,xmax=None):\n\n nedge = len(self._ncounts[self._xedge<=xmax])\n xedge = self._xedge[:nedge]\n \n h = Histogram.createHistModel(xedge,self._ncounts[1:nedge])\n nbkg = np.random.poisson(self._nbkg,niter)\n ncounts = np.random.poisson(np.concatenate(([0],h.counts)),\n (niter,nedge))\n \n xq = []\n\n for i in range(niter):\n xq.append(self._quantile(nbkg[i],self._xedge[:nedge],\n ncounts[i],fraction))\n\n xq_mean = np.mean(np.array(xq))\n xq_rms = np.std(np.array(xq))\n \n return xq_mean, xq_rms\n\n\nclass HistGOF(object):\n\n def __init__(self,h,hmodel):\n\n self._h = h\n self._hmodel = hmodel\n\n self.chi2 = 0\n\n# for b in self._h.iterbins():\n# self.chi2 += np.power(\n \n def chi2(self):\n return self.chi2\n \n\nclass HistQuantileOnOff(object):\n \"\"\"\n HistQuantileOnOff(hon,hoff,alpha)\n\n Class that computes quantiles for the distribution of the excess\n signal in histogram given histograms for signal+backround (hon)\n and background only (hoff). \n\n Parameters\n ----------\n hon : histogram\n\n Histogram with distribution of signal and background.\n\n hoff : histogram\n\n Histogram with background.\n\n alpha : float\n\n Scaling factor between background in on and off distributions.\n \n \"\"\"\n def __init__(self,hon,hoff,alpha):\n\n self._axis = hon.axis()\n self._alpha = alpha\n self._non = np.concatenate(([0],hon.counts))\n self._noff = np.concatenate(([0],hoff.counts))\n\n\n def eval(self,fraction):\n\n return self.binomial(self._non,self._noff,fraction)\n\n\n def bootstrap(self,fraction=0.68,niter=1000,xmax=None):\n\n nedge = len(self._non)\n hon = Histogram.createHistModel(self._axis.edges,self._non[1:])\n hoff = Histogram.createHistModel(self._axis.edges,self._noff[1:])\n\n non = np.random.poisson(np.concatenate(([0],hon.counts)),\n (niter,nedge))\n noff = np.random.poisson(np.concatenate(([0],hoff.counts)),\n (niter,nedge))\n\n xq = []\n\n for i in range(niter):\n\n xq.append(self._quantile(non[i],noff[i],fraction))\n\n \n\n xq_mean = np.mean(np.array(xq))\n xq_rms = np.std(np.array(xq))\n\n return xq_mean, xq_rms\n\n def quantile(self,fraction=0.68):\n return self._quantile(self._non,self._noff,fraction)\n\n def _quantile(self,non=None,noff=None,fraction=0.68):\n\n if non is None: non = self._non \n if noff is None: noff = self._noff\n \n non_cum = np.cumsum(non)\n noff_cum = np.cumsum(noff)\n nex_cum = copy.copy(non_cum)\n nex_cum -= self._alpha*noff_cum\n \n non_tot = non_cum[-1]\n noff_tot = noff_cum[-1]\n nex_tot = non_tot-self._alpha*noff_tot\n \n fn_nexcdf = UnivariateSpline(self._axis.edges,nex_cum,s=0,k=1)\n\n return opt.brentq(lambda t: fn_nexcdf(t)-nex_tot*fraction,\n self._axis.edges[0],self._axis.edges[-1])\n\n def binomial(self,non,noff,fraction=0.68):\n\n non_cum = np.cumsum(non)\n noff_cum = np.cumsum(noff)\n nex_cum = copy.copy(non_cum)\n nex_cum -= self._alpha*noff_cum\n \n non_tot = non_cum[-1]\n noff_tot = noff_cum[-1]\n nex_tot = non_tot-self._alpha*noff_tot\n\n fn_noncdf = UnivariateSpline(self._axis.edges,non_cum,s=0)\n fn_noffcdf = UnivariateSpline(self._axis.edges,noff_cum,s=0,k=1)\n fn_nexcdf = UnivariateSpline(self._axis.edges,nex_cum,s=0)\n\n xq = opt.brentq(lambda t: fn_nexcdf(t)-nex_tot*fraction,\n self._axis.edges[0],self._axis.edges[-1])\n\n eff_on = fn_noncdf(xq)/non_tot\n eff_off = fn_noffcdf(xq)/noff_tot\n\n nerr_on = np.sqrt(non_tot*eff_on*(1-eff_on))\n nerr_off = np.sqrt(noff_tot*eff_off*(1-eff_off))\n\n nerr = np.sqrt(nerr_on**2 + nerr_off**2)\n\n nerr_hi = nex_tot*fraction+nerr\n nerr_lo = nex_tot*fraction-nerr\n\n xq_hi = self._axis.edges[-1]\n xq_lo = self._axis.edges[0]\n\n if nerr_hi < nex_tot:\n xq_hi = opt.brentq(lambda t: fn_nexcdf(t)-nerr_hi,\n self._axis.edges[0],self._axis.edges[-1])\n\n if nerr_lo > 0:\n xq_lo = opt.brentq(lambda t: fn_nexcdf(t)-nerr_lo,\n self._axis.edges[0],self._axis.edges[-1])\n\n xq_err = 0.5*(xq_hi-xq_lo)\n \n return xq, xq_err\n\n\nclass HistQuantile(object):\n\n def __init__(self,hist):\n\n self._h = copy.deepcopy(hist)\n self._x = np.array(hist.edges,copy=True)\n self._ncounts = copy.copy(hist.counts)\n self._ncounts = np.concatenate(([0],self._ncounts))\n\n\n def eval(self,fraction,method='binomial',**kwargs):\n\n if method == 'binomial':\n return self.binomial(self._ncounts,fraction,**kwargs)\n elif method == 'mc':\n return self.bootstrap(fraction,**kwargs)\n elif method is None:\n return [HistQuantile.quantile(self._h,fraction),0]\n else:\n print 'Unknown method ', method\n sys.exit(1)\n\n\n def bootstrap(self,fraction=0.68,niter=1000):\n\n nbin = len(self._ncounts)\n ncounts_tmp = np.random.poisson(self._ncounts,(niter,nbin))\n \n xq = []\n for i in range(niter):\n xq.append(HistQuantile.array_quantile(self._x,\n ncounts_tmp[i],fraction))\n\n xq_mean = np.mean(np.array(xq))\n xq_rms = np.std(np.array(xq))\n\n return xq_mean, xq_rms\n\n @staticmethod\n def quantile(h,fraction=0.68):\n counts = np.concatenate(([0],h.counts))\n return HistQuantile.array_quantile(h.axis().edges,counts,fraction)\n \n @staticmethod\n def array_quantile(edges,ncounts,fraction=0.68):\n \"\"\"Find the value of X which contains the given fraction of counts\n in the histogram.\"\"\"\n ncounts_cum = np.cumsum(ncounts)\n ncounts_tot = ncounts_cum[-1]\n\n fn_ncdf = UnivariateSpline(edges,ncounts_cum,s=0,k=1)\n\n return opt.brentq(lambda t: fn_ncdf(t)-ncounts_tot*fraction,\n edges[0],edges[-1])\n\n @staticmethod\n def cumulative(h,x):\n\n if x <= h._xedges[0]: return 0\n elif x >= h._xedges[-1]: return h.sum()\n \n counts = np.concatenate(([0],h.counts))\n counts_cum = np.cumsum(counts)\n fn_ncdf = UnivariateSpline(h.axis().edges,counts_cum,s=0,k=1)\n return fn_ncdf(x)\n \n def binomial(self,ncounts,fraction=0.68):\n\n ncounts_cum = np.cumsum(ncounts)\n ncounts_tot = ncounts_cum[-1]\n\n fn_ncdf = UnivariateSpline(self._x,ncounts_cum,s=0,k=1) \n xq = opt.brentq(lambda t: fn_ncdf(t)-ncounts_tot*fraction,\n self._x[0],self._x[-1])\n\n eff = fn_ncdf(xq)/ncounts_tot\n nerr = np.sqrt(ncounts_tot*eff*(1-eff))\n\n nerr_hi = ncounts_tot*fraction+nerr\n nerr_lo = ncounts_tot*fraction-nerr\n\n xq_hi = self._x[-1]\n xq_lo = self._x[0]\n\n if nerr_hi < ncounts_tot:\n xq_hi = opt.brentq(lambda t: fn_ncdf(t)-nerr_hi,\n self._x[0],self._x[-1])\n\n if nerr_lo > 0:\n xq_lo = opt.brentq(lambda t: fn_ncdf(t)-nerr_lo,\n self._x[0],self._x[-1])\n\n xq_err = 0.5*(xq_hi-xq_lo)\n \n return xq, xq_err\n\n"
},
{
"alpha_fraction": 0.5989066362380981,
"alphanum_fraction": 0.6021421551704407,
"avg_line_length": 34.85200119018555,
"blob_id": "b2db6b548e1eb941277e9a7bd65132b876dfdc13",
"content_id": "5396c7a02dab8abc8615e8b8e207ca4a7d1ed4c5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8963,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 250,
"path": "/gammatools/fermi/pylike_tools.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom gammatools.fermi import units\nfrom gammatools.core.util import tolist\n\nfrom FluxDensity import FluxDensity\nfrom SummedLikelihood import SummedLikelihood\n\nfrom pyLikelihood import ParameterVector, SpatialMap_cast, PointSource_cast\nimport pyLikelihood\n\ndef GetCountsMap(binnedAnalysis):\n \"\"\" Get the shape of the observed counts map\n from a BinnedAnalysis object\n\n binnedAnalysis: The BinnedAnalysis object \n\n returns np.ndarray( (nEBins, nPixX, nPixY), 'd' )\n \"\"\"\n ll = binnedAnalysis.logLike \n shape = GetCountsMapShape(ll.countsMap())\n a = np.ndarray( (shape[2],shape[1],shape[0]), 'f' )\n a.flat = binnedAnalysis.logLike.countsMap().data()\n return a\n\n\ndef GetCountsMapShape(countsMap):\n \"\"\" Get the shape of the observed counts map\n from a CountsMap object\n\n countsMap: The CountsMap object \n\n returns tuple ( nEBins, nPixX, nPixY )\n \"\"\"\n n0 = countsMap.imageDimension(0)\n n1 = countsMap.imageDimension(1)\n try:\n n2 = countsMap.imageDimension(2)\n except:\n return (n0,n1)\n return (n0,n1,n2)\n\ndef get_gtlike_source(like,name):\n\n if isinstance(like,SummedLikelihood):\n return like.components[0].logLike.getSource(name)\n else:\n return like.logLike.getSource(name)\n\ndef name_to_spectral_dict(like, name, errors=False, minos_errors=False, covariance_matrix=False):\n\n print name\n\n source = get_gtlike_source(like,name)\n spectrum = source.spectrum()\n d=gtlike_spectrum_to_dict(spectrum, errors)\n if minos_errors:\n parameters=ParameterVector()\n spectrum.getParams(parameters)\n for p in parameters: \n pname = p.getName()\n if p.isFree():\n lower,upper=like.minosError(name, pname)\n try:\n d['%s_lower_err' % pname] = -1*lower*p.getScale()\n d['%s_upper_err' % pname] = upper*p.getScale()\n except Exception, ex:\n print 'ERROR computing Minos errors on parameter %s for source %s:' % (pname,name), ex\n traceback.print_exc(file=sys.stdout)\n d['%s_lower_err' % pname] = np.nan\n d['%s_upper_err' % pname] = np.nan\n else:\n d['%s_lower_err' % pname] = np.nan\n d['%s_upper_err' % pname] = np.nan\n if covariance_matrix:\n d['covariance_matrix'] = get_covariance_matrix(like, name)\n return d\n\ndef get_full_energy_range(like):\n return like.energies[[0,-1]]\n\ndef gtlike_flux_dict(like,name, emin=None,emax=None,flux_units='erg', energy_units='MeV',\n errors=True, include_prefactor=False, prefactor_energy=None):\n \"\"\" Note, emin, emax, and prefactor_energy must be in MeV \"\"\"\n\n if emin is None and emax is None: \n emin, emax = get_full_energy_range(like)\n\n cef=lambda e: units.convert(e,'MeV',flux_units)\n ce=lambda e: units.convert(e,'MeV',energy_units)\n f=dict(flux=like.flux(name,emin=emin,emax=emax),\n flux_units='ph/cm^2/s',\n eflux=cef(like.energyFlux(name,emin=emin,emax=emax)),\n eflux_units='%s/cm^2/s' % flux_units,\n emin=ce(emin),\n emax=ce(emax),\n energy_units=energy_units)\n\n if errors:\n try:\n # incase the errors were not calculated\n f['flux_err']=like.fluxError(name,emin=emin,emax=emax)\n f['eflux_err']=cef(like.energyFluxError(name,emin=emin,emax=emax))\n except Exception, ex:\n print 'ERROR calculating flux error: ', ex\n traceback.print_exc(file=sys.stdout)\n f['flux_err']=-1\n f['eflux_err']=-1\n\n if include_prefactor:\n assert prefactor_energy is not None\n source = get_gtlike_source(like,name)\n# source = like.logLike.getSource(name)\n spectrum = source.spectrum()\n cp = lambda e: units.convert(e,'1/MeV','1/%s' % flux_units)\n f['prefactor'] = cp(SpectrumPlotter.get_dnde_mev(spectrum,prefactor_energy))\n f['prefactor_units'] = 'ph/cm^2/s/%s' % flux_units\n f['prefactor_energy'] = ce(prefactor_energy)\n return tolist(f)\n\ndef energy_dict(emin, emax, energy_units='MeV'):\n ce=lambda e: units.convert(e,'MeV',energy_units)\n return dict(emin=ce(emin),\n emax=ce(emax),\n emiddle=ce(np.sqrt(emin*emax)),\n energy_units=energy_units)\n\ndef gtlike_ts_dict(like, name, verbosity=True):\n return dict(\n reoptimize=like.Ts(name,reoptimize=True, verbosity=verbosity),\n noreoptimize=like.Ts(name,reoptimize=False, verbosity=verbosity)\n )\n\ndef gtlike_spectrum_to_dict(spectrum, errors=False):\n \"\"\" Convert a pyLikelihood object to a python \n dictionary which can be easily saved to a file. \"\"\"\n parameters=ParameterVector()\n spectrum.getParams(parameters)\n d = dict(name = spectrum.genericName(), method='gtlike')\n for p in parameters: \n d[p.getName()]= p.getTrueValue()\n if errors: \n d['%s_err' % p.getName()]= p.error()*p.getScale() if p.isFree() else np.nan\n if d['name'] == 'FileFunction': \n ff=pyLikelihood.FileFunction_cast(spectrum)\n d['file']=ff.filename()\n return d\n\ndef gtlike_name_to_spectral_dict(like, name, errors=False, minos_errors=False, covariance_matrix=False):\n# source = like.logLike.getSource(name)\n source = get_gtlike_source(like,name)\n spectrum = source.spectrum()\n d=gtlike_spectrum_to_dict(spectrum, errors)\n if minos_errors:\n parameters=ParameterVector()\n spectrum.getParams(parameters)\n for p in parameters: \n pname = p.getName()\n if p.isFree():\n lower,upper=like.minosError(name, pname)\n try:\n d['%s_lower_err' % pname] = -1*lower*p.getScale()\n d['%s_upper_err' % pname] = upper*p.getScale()\n except Exception, ex:\n print 'ERROR computing Minos errors on parameter %s for source %s:' % (pname,name), ex\n traceback.print_exc(file=sys.stdout)\n d['%s_lower_err' % pname] = np.nan\n d['%s_upper_err' % pname] = np.nan\n else:\n d['%s_lower_err' % pname] = np.nan\n d['%s_upper_err' % pname] = np.nan\n if covariance_matrix:\n d['covariance_matrix'] = get_covariance_matrix(like, name)\n return d\n\ndef gtlike_source_dict(like, name, emin=None, emax=None, \n flux_units='erg', energy_units='MeV', \n errors=True, minos_errors=False, covariance_matrix=True,\n save_TS=True, add_diffuse_dict=True,\n verbosity=True):\n\n if emin is None and emax is None:\n emin, emax = get_full_energy_range(like)\n\n d=dict(\n logLikelihood=like.logLike.value(),\n )\n\n d['energy'] = energy_dict(emin=emin, emax=emax, energy_units=energy_units)\n \n d['spectrum']= name_to_spectral_dict(like, name, errors=errors, \n minos_errors=minos_errors, covariance_matrix=covariance_matrix)\n\n if save_TS:\n d['TS']=gtlike_ts_dict(like, name, verbosity=verbosity)\n\n d['flux']=gtlike_flux_dict(like,name,\n emin=emin, emax=emax,\n flux_units=flux_units, energy_units=energy_units, errors=errors)\n\n\n# if add_diffuse_dict:\n# d['diffuse'] = diffuse_dict(like)\n\n return tolist(d)\n\ndef get_covariance_matrix(like, name):\n \"\"\" Get the covarince matrix. \n\n We can mostly get this from FluxDensity, but\n the covariance matrix returned by FluxDensity\n is only for the free paramters. Here, we\n transform it to have the covariance matrix\n for all parameters, and set the covariance to 0\n when the parameter is free.\n \"\"\"\n\n# source = like.logLike.getSource(name)\n source = get_gtlike_source(like,name)\n spectrum = source.spectrum()\n\n parameters=ParameterVector()\n spectrum.getParams(parameters)\n free = np.asarray([p.isFree() for p in parameters])\n scales = np.asarray([p.getScale() for p in parameters])\n scales_transpose = scales.reshape((scales.shape[0],1))\n\n cov_matrix = np.zeros([len(parameters),len(parameters)])\n\n try:\n fd = FluxDensity(like,name)\n cov_matrix[np.ix_(free,free)] = fd.covar\n\n # create absolute covariance matrix:\n cov_matrix = scales_transpose * cov_matrix * scales\n except RuntimeError, ex:\n if ex.message == 'Covariance matrix has not been computed.':\n pass\n else: \n raise ex\n\n return tolist(cov_matrix)\n\ndef diffuse_dict(like):\n \"\"\" Save out all diffuse sources. \"\"\"\n\n f = dict()\n bgs = get_background(like)\n for name in bgs:\n f[name] = name_to_spectral_dict(like, name, errors=True)\n return tolist(f)\n"
},
{
"alpha_fraction": 0.519615888595581,
"alphanum_fraction": 0.5602194666862488,
"avg_line_length": 21.090909957885742,
"blob_id": "9a18804caf56ad1b019a606889e0501b0ed07e5a",
"content_id": "6191c0de5b46a9db6946229b36d58abad89f544c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3645,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 165,
"path": "/gammatools/core/fitting.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy.optimize import curve_fit\n\ndef cov_rho(cov,i,j):\n \"\"\"Return the i,j correlation coefficient of the input covariance\n matrix.\"\"\"\n return cov[i,j]/np.sqrt(cov[i,i]*cov[j,j])\n\ndef cov_angle(cov,i,j):\n \"\"\"Return error ellipse rotation angle for parameters i,j.\"\"\"\n return 0.5*np.arctan((2*cov_rho(cov,i,j)*np.sqrt(cov[i,i]*cov[j,j]))/\n cov[j,j]-cov[i,i])\n \n\ndef fit_svd(x,y,yerr,n=2):\n \"\"\"\n Linear least squares fitting using SVD. Finds the set of\n parameter values that minimize chi-squared by solving the matrix\n equation:\n \n a = (A'*A)^(-1)*A'*y\n \n where A is the m x n design matrix, y is the vector of n data\n points, and yerr is a vector of errors/weights for each data\n point. When the least squares solution is not unique the SVD\n method finds the solution with minimum norm in the fit parameters.\n The solution vector is given by\n \n a = V*W^(-1)*U'*y\n \n where U*W*V' = A is the SVD decomposition of the design matrix.\n The reciprocal of singular and/or small values in W are set to\n 0 in this procedure.\n \"\"\"\n\n x = np.array(x)\n y = np.array(y)\n yerr = np.array(yerr)\n \n A = np.zeros(shape=(len(x),n+1))\n\n for i in range(n+1):\n A[:,i] = np.power(x,i)/yerr\n\n b = y/yerr\n (u,s,v) = np.linalg.svd(A,full_matrices=False)\n ub = np.sum(u.T*b,axis=1)\n a = np.sum(ub*v.T/s,axis=1)\n\n vn = v.T/s\n cov = np.dot(vn,vn.T)\n\n return a, cov\n\n cov2 = np.zeros((2,2))\n\n for i in range(v.shape[0]):\n for j in range(v.shape[1]):\n for k in range(2):\n cov2[i,j] += v[i,k]*v[j,k]/s[k]**2\n\n print 'cov'\n print cov\n\n print 'cov2'\n print cov2\n\n return a, cov2\n\n\nnp.random.seed(1)\n\ndef fn(x,a,b):\n return a + b*x\n\n#x = np.array([-10.0,-5.0,10.0])\nx = np.array([1.0,2.0,3.0,4.0])\ny = fn(x,1.0,-1.0) + 0.2*np.random.normal(size=len(x))\nyerr = 0.2*np.ones(len(x))\n\n\n\ndef chi2_fn(f,x,y,yerr):\n return np.sum((f(x)-y)**2/yerr**2,axis=2)\n\n#print np.polyfit(x,y,1,w=yerr,cov=True)\n\nprint 'Fit 1'\na, cov = curve_fit(fn,x,y,sigma=1./yerr)\nprint a\nprint cov\nprint rho(cov,0,1)\n\nprint 'Fit 2'\na, cov = curve_fit(fn,x,y,sigma=yerr)\nprint a\nprint cov\nprint rho(cov,0,1)\n\nprint 'Fit SVD'\na, cov = fit_svd(x,y,yerr,2)\n#cov[0,1] *= -1\n#cov[1,0] *= -1\n\nnpoint = 1000\n\nax, ay = np.meshgrid(np.linspace(-3.0,3,npoint),np.linspace(-3.0,3.0,npoint),\n indexing='ij')\n\nimport matplotlib.pyplot as plt\n\nchi2 = chi2_fn(lambda t: fn(t,ax.reshape(npoint,npoint,1),\n ay.reshape(npoint,npoint,1)),\n x.reshape(1,1,len(x)),\n y.reshape(1,1,len(x)),\n yerr.reshape(1,1,len(x)))\n\nchi2 = chi2-chi2_fn(lambda t: fn(t,a[0].reshape(1,1,1),\n a[1].reshape(1,1,1)),\n x.reshape(1,1,len(x)),\n y.reshape(1,1,len(x)),\n yerr.reshape(1,1,len(x)))\n\nprint np.min(chi2)\n\n\nplt.figure()\n\nplt.errorbar(x,y,yerr=yerr)\nplt.plot(x,fn(x,*a))\n\nplt.figure()\n\nplt.contour(ax,ay,chi2,levels=[0,1.0,2.3])\n\nplt.errorbar(a[0],a[1],\n xerr=np.sqrt(cov[0,0]),\n yerr=np.sqrt(cov[1,1]),\n marker='o')\n\nplt.gca().grid(True)\n\n\nrho01 = rho(cov,0,1)\n\n\nprint 'rho ', rho01\n\nangle = np.pi - 0.5*np.arctan((2*rho01*np.sqrt(cov[0,0]*cov[1,1]))/\n cov[1,1]-cov[0,0])\n\nprint angle\n\nt = np.linspace(-1,1,100)\n\n#plt.plot(a[0]+t*np.cos(angle),a[1]+t*np.sin(angle))\n\n\nprint a\nprint np.sqrt(cov[0,0]), np.sqrt(cov[1,1])\nprint cov\n\nplt.show()\n\n#print chi2(lambda t: f(t,*a+),\n"
},
{
"alpha_fraction": 0.5947543382644653,
"alphanum_fraction": 0.6032508015632629,
"avg_line_length": 33.24050521850586,
"blob_id": "35305bb27294cc15f008981342b183affc086b3b",
"content_id": "0557db218aff2cc8543b2e0a41f5018c53a6edac",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2707,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 79,
"path": "/scripts/gtmktime.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport logging\nimport shutil\nfrom GtApp import GtApp\nimport numpy as np\nimport argparse\nfrom gammatools.fermi.task import MkTimeTask\nfrom gammatools.core.util import dispatch_jobs\n\nusage = \"%(prog)s [options] [pickle file ...]\"\ndescription = \"\"\"Run gtmktime.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\nparser.add_argument('files', nargs='+')\nparser.add_argument('--scfile', default = None, required=True,\n help = 'Spacecraft file.')\nparser.add_argument('--output', default = None, \n help = 'Set the output filename.')\nparser.add_argument('--outdir', default = None, \n help = 'Set the output directory.')\nparser.add_argument('--queue', default = None, \n help = 'Set queue name.')\nparser.add_argument('--filter', default = 'default_r52', \n help = 'Set the mktime filter.')\n\nargs = parser.parse_args()\n\ngtidir = '/u/gl/mdwood/ki20/mdwood/fermi/data'\n\ngrb_gticut = \"gtifilter('%s/nogrb.gti',START) && gtifilter('%s/nogrb.gti',STOP)\"%(gtidir,gtidir)\nsfr_gticut = \"gtifilter('%s/nosolarflares.gti',(START+STOP)/2)\"%(gtidir)\nsun_gticut = \"ANGSEP(RA_SUN,DEC_SUN,RA_ZENITH,DEC_ZENITH)>115\"\ndefault_gticut = 'IN_SAA!=T&&DATA_QUAL==1&&LAT_CONFIG==1'\n\nfilters = {'default' : default_gticut,\n 'default_r52' : '%s && ABS(ROCK_ANGLE)<52'%default_gticut,\n 'limb' : '%s && ABS(ROCK_ANGLE)>52'%default_gticut,\n 'gticut0' : '%s && %s'%(grb_gticut,sfr_gticut),\n 'gticut1' : '%s && (%s || %s)'%(grb_gticut,sun_gticut,sfr_gticut),\n 'catalog' : '%s && %s && ABS(ROCK_ANGLE)<52 && (%s || %s)'%(default_gticut, grb_gticut,\n sun_gticut, sfr_gticut),\n }\n\nfilter_expr = []\nfor t in args.filter.split(','):\n\n filter_expr.append(filters[t])\n\n#mktime_filter = filters[args.filter]\nmktime_filter = '&&'.join(filter_expr)\n \nif args.outdir is not None:\n args.outdir = os.path.abspath(args.outdir)\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue)\n sys.exit(0)\n\nfor f in args.files:\n\n if args.outdir is not None:\n outfile = os.path.basename(f)\n outfile = os.path.join(args.outdir,outfile)\n elif args.output is None:\n\n m = re.search('(.+)\\.fits?',f)\n if not m is None:\n outfile = m.group(1) + '_sel.fits'\n else:\n outfile = os.path.splitext(f)[0] + '_sel.fits'\n else:\n outfile = args.output\n\n gt_task = MkTimeTask(f,outfile,filter=mktime_filter,scfile=args.scfile)\n gt_task.run()\n\n\n"
},
{
"alpha_fraction": 0.7701342105865479,
"alphanum_fraction": 0.7701342105865479,
"avg_line_length": 19.55172348022461,
"blob_id": "d85a28ac9f9ac3c5190b9b93fdfc394f2950307d",
"content_id": "52e849999b195f7113b9fe332fc2246516c2fabd",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 596,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 29,
"path": "/scripts/gtmodel.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport logging\nimport shutil\nfrom GtApp import GtApp\nimport numpy as np\nimport argparse\nfrom gammatools.fermi.task import SrcModelTask\nfrom gammatools.core.util import dispatch_jobs\n\nusage = \"%(prog)s [options]\"\ndescription = \"\"\"Run gtmodel.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\n#parser.add_argument('files', nargs='+')\n\nparser.add_argument('--output',required=True)\n\nSrcModelTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\ngtmodel = SrcModelTask(args.output,opts=args)\n\n\ngtmodel.run()\n"
},
{
"alpha_fraction": 0.5103984475135803,
"alphanum_fraction": 0.5220602750778198,
"avg_line_length": 25.658031463623047,
"blob_id": "3b2328cf573563c8722dd549616ca302d0082736",
"content_id": "4e25605a45724cf39ad5879f2783caafbaeba870",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5145,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 193,
"path": "/gammatools/core/nonlinear_fitting.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "from parameter_set import *\nfrom util import update_dict\nfrom model_fn import ParamFn\nimport inspect\nfrom gammatools.core.config import Configurable\n#from iminuit import Minuit as Minuit2\n\nclass NLFitter(object):\n \"\"\"Base class for non-linear fitting routines.\"\"\"\n def __init__(self,objfn):\n self._objfn = objfn\n\nclass IMinuitFitter(object):\n\n def __init__(self,objfn,tol=1E-3):\n super(IMinuitFitter,self).__init__(objfn)\n\n def fit(self,pset=None):\n if pset is None: pset = self._objfn.param(True)\n\n# kwargs = {}\n\n# for p in pset:\n# kwargs { p.name() }\n\n m = Minuit2(lambda x: self._objfn.eval(x))\n\n print m.fit()\n\n\nclass MinuitFitter(object):\n \"\"\"Wrapper class for performing function minimization with minuit.\"\"\"\n\n def __init__(self,objfn,tol=1E-3):\n self._objfn = objfn\n self._fval = 0\n self._tol = tol\n self._maxcalls = 1000\n\n def rnd_scan(self,par_index=None,nscan=100,scale=1.3):\n\n pset = copy.copy(self._objfn.param())\n p = pset.array()\n\n if par_index is None: par_index = range(pset.npar())\n\n prnd = np.ones((p.shape[0],nscan,1))\n prnd *= p\n\n for i in par_index:\n rnd = np.random.uniform(0.0,1.0,(nscan,1))\n prnd[i] = p[i] - p[i]/scale + rnd*(scale*p[i] - (p[i] - p[i]/scale))\n\n lnl = self._objfn.eval(prnd)\n\n imin = np.argmin(lnl)\n\n pset.update(prnd[:,imin])\n\n print self._objfn.eval(pset)\n\n return pset\n\n def profile(self,pset,pname,pval,refit=True):\n\n# pset = copy.deepcopy(self._objfn.param())\n pset = copy.deepcopy(pset)\n\n fval = []\n pset.getParByName(pname).fix(True)\n\n if refit is True:\n\n for p in pval: \n \n pset.setParByName(pname,p)\n pset_fit = self.fit(pset)\n fval.append(pset_fit.fval())\n else:\n for p in pval: \n pset.setParByName(pname,p)\n\n v = self._objfn.eval(pset)\n\n# print p, v, pset.getParByName('agn_norm').value()\n\n fval.append(v)\n \n return np.array(fval)\n\n def minimize(self,pset=None):\n\n if pset is None: pset = self._objfn.param(True)\n\n npar = pset.npar()\n\n fixed = pset.fixed\n lo_lims = npar*[None]\n hi_lims = npar*[None]\n lims = []\n \n for i, p in enumerate(pset):\n if not p.lims is None: lims.append(p.lims)\n else: lims.append([0.0,0.0])\n \n print pset.array()\n\n minuit = Minuit(lambda x: self._objfn.eval(x),\n pset.array(),fixed=fixed,limits=lims,\n tolerance=self._tol,strategy=1,\n printMode=-1,\n maxcalls=self._maxcalls)\n (pars,fval) = minuit.minimize()\n\n cov = minuit.errors()\n pset.update(pars)\n \n return FitResults(pset,fval,cov)\n\n def plot_lnl_scan(self,pset):\n print pset\n\n fig = plt.figure(figsize=(12,8))\n for i in range(9):\n\n j = i+4\n \n p = pset.makeParameterArray(j,\n np.linspace((pset[j].flat[0]*0.5),\n (pset[j].flat[0]*2),50))\n y = self._objfn.eval(p)\n ax = fig.add_subplot(3,3,i+1)\n ax.set_title(p.getParByIndex(j).name())\n plt.plot(p[j],y-pset.fval())\n plt.axvline(pset[j])\n\n @staticmethod\n def fit(objfn,**kwargs):\n \"\"\"Convenience method for fitting.\"\"\"\n fitter = Fitter(objfn,**kwargs)\n return fitter.minimize()\n\n\nclass BFGSFitter(Configurable):\n \"\"\"Wrapper class for scipy BFGS function optimization.\"\"\"\n \n default_config = { 'pgtol' : 1E-5, 'factr' : 1E7 }\n\n def __init__(self,objfn,**kwargs):\n super(BFGSFitter,self).__init__(**kwargs) \n self._objfn=objfn\n\n @property\n def objfn(self):\n return self._objfn\n\n @staticmethod\n def fit(fn,p0,**kwargs): \n\n if not isinstance(fn,ParamFn):\n fn = ParamFn.create(fn,p0)\n\n fitter = BFGSFitter(fn,**kwargs)\n return fitter.minimize(**kwargs)\n\n def minimize(self,pset=None,**kwargs):\n\n if pset is None: pset = self._objfn.param(True)\n\n bounds = []\n for p in pset:\n if p.fixed:\n bounds.append([p.value.flat[0],p.value.flat[0]])\n else:\n bounds.append(p.lims)\n\n from scipy.optimize import fmin_l_bfgs_b as fmin_bfgs\n\n bfgs_kwargs = self.config\n#{'pgtol' : 1E-5, bounds=bounds, 'factr' : 1E7 }\n\n bfgs_kwargs['bounds'] = bounds\n update_dict(bfgs_kwargs,kwargs)\n\n res = fmin_bfgs(self._objfn,pset.array(),None,\n approx_grad=1,**bfgs_kwargs)#,factr=1./self._tol)\n\n pset.update(res[0]) \n self._fit_results = FitResults(pset,res[1])\n\n # How to compute errors?\n \n return copy.deepcopy(self._fit_results)\n"
},
{
"alpha_fraction": 0.46777206659317017,
"alphanum_fraction": 0.4891989827156067,
"avg_line_length": 36.31590270996094,
"blob_id": "f0a7375f0889edd5792eab37e3e7e9daf50f06b3",
"content_id": "28c8aed4cca1686d8bd6e4959b7c036e6ac5e87d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 51384,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 1377,
"path": "/gammatools/fermi/validate.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import os\n\nos.environ['CUSTOM_IRF_DIR'] = '/u/gl/mdwood/ki10/analysis/custom_irfs/'\nos.environ['CUSTOM_IRF_NAMES'] = 'P7SOURCE_V6,P7SOURCE_V6MC,P7SOURCE_V9,P7CLEAN_V6,P7CLEAN_V6MC,P7ULTRACLEAN_V6,' \\\n 'P7ULTRACLEAN_V6MC,P6_v11_diff,P7SOURCE_V6MCPSFC,P7CLEAN_V6MCPSFC,P7ULTRACLEAN_V6MCPSFC'\n\nimport sys\nimport copy\nimport re\nimport pickle\nimport argparse\n\nimport math\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom gammatools.core.histogram import Histogram, Histogram2D\nfrom matplotlib import font_manager\n\nfrom gammatools.fermi.psf_model import *\nfrom gammatools.core.quantile import *\nfrom gammatools.fermi.catalog import Catalog\nfrom gammatools.core.plot_util import *\nfrom gammatools.core.config import Configurable\n\nfrom gammatools.core.fits_util import SkyImage\nfrom analysis_util import *\n\n#from psf_lnl import BinnedPulsarLnLFn\n\nfrom data import PhotonData, Data\nfrom irf_util import IRFManager\n\nfrom gammatools.core.mpl_util import SqrtScale, PowerNormalize\nfrom matplotlib import scale as mscale\nmscale.register_scale(SqrtScale)\n\n\n \n\n\nvela_phase_selection = {'on_phase' : '0.0/0.15,0.6/0.7',\n 'off_phase' : '0.2/0.5' }\n\n\n\nclass PSFScalingFunction(object):\n\n def __init__(self,c0,c1,beta):\n self._c0 = c0\n self._c1 = c1\n self._beta = beta\n \n def __call__(self,x):\n\n return np.sqrt((self._c0*np.power(np.power(10,x-2),self._beta))**2 +\n self._c1**2)\n \n\npsf_scaling_fn = { 'front' : PSFScalingFunction(30.0,1.0,-0.8),\n 'back' : PSFScalingFunction(35.0,1.5,-0.8),\n 'p8front' : PSFScalingFunction(9.873*3.0,0.295*3.0,-0.8),\n 'p8back' : PSFScalingFunction(16.556*3.0,0.609*3.0,-0.8),\n 'p8psf0' : PSFScalingFunction(18.487*3.0,0.820*3.0,-0.8),\n 'p8psf1' : PSFScalingFunction(12.637*3.0,0.269*3.0,-0.8),\n 'p8psf2' : PSFScalingFunction(9.191*3.0,0.139*3.0,-0.8),\n 'p8psf3' : PSFScalingFunction(6.185*3.0,0.078*3.0,-0.8) }\n\n\nclass PSFData(Data):\n\n \n def __init__(self,egy_bin_edge,cth_bin_edge,dtype):\n\n egy_bin_edge = np.array(egy_bin_edge,ndmin=1)\n cth_bin_edge = np.array(cth_bin_edge,ndmin=1)\n\n self.dtype = dtype\n self.quantiles = [0.34,0.68,0.90,0.95]\n self.quantile_labels = ['r%2.f'%(q*100) for q in self.quantiles]\n\n self.egy_axis = Axis(egy_bin_edge)\n self.cth_axis = Axis(cth_bin_edge)\n self.egy_nbin = self.egy_axis.nbins\n self.cth_nbin = self.cth_axis.nbins\n\n self.chi2 = Histogram2D(egy_bin_edge,cth_bin_edge)\n self.rchi2 = Histogram2D(egy_bin_edge,cth_bin_edge)\n self.ndf = Histogram2D(egy_bin_edge,cth_bin_edge)\n self.excess = Histogram2D(egy_bin_edge,cth_bin_edge)\n self.bkg = Histogram2D(egy_bin_edge,cth_bin_edge)\n self.bkg_density = Histogram2D(egy_bin_edge,cth_bin_edge)\n\n hist_shape = (self.egy_nbin,self.cth_nbin)\n\n self.sig_density_hist = np.empty(shape=hist_shape, dtype=object)\n self.tot_density_hist = np.empty(shape=hist_shape, dtype=object)\n self.bkg_density_hist = np.empty(shape=hist_shape, dtype=object)\n self.sig_hist = np.empty(shape=hist_shape, dtype=object)\n self.off_hist = np.empty(shape=hist_shape, dtype=object)\n self.tot_hist = np.empty(shape=hist_shape, dtype=object)\n self.bkg_hist = np.empty(shape=hist_shape, dtype=object)\n self.sky_image = np.empty(shape=hist_shape, dtype=object)\n self.sky_image_off = np.empty(shape=hist_shape, dtype=object)\n self.lat_image = np.empty(shape=hist_shape, dtype=object)\n self.lat_image_off = np.empty(shape=hist_shape, dtype=object)\n \n# self.q34 = Histogram2D(egy_bin_edge,cth_bin_edge)\n# self.q68 = Histogram2D(egy_bin_edge,cth_bin_edge)\n# self.q90 = Histogram2D(egy_bin_edge,cth_bin_edge)\n# self.q95 = Histogram2D(egy_bin_edge,cth_bin_edge)\n\n self.qdata = []\n for i in range(len(self.quantiles)):\n self.qdata.append(Histogram2D(egy_bin_edge,cth_bin_edge))\n\n def init_hist(self,fn,theta_max):\n\n for i in range(self.egy_nbin):\n for j in range(self.cth_nbin):\n\n ecenter = self.egy_axis.center[i]\n theta_max = min(theta_max,fn(ecenter))\n theta_edges = np.linspace(0,theta_max,100)\n\n h = Histogram(theta_edges)\n self.sig_density_hist[i,j] = copy.deepcopy(h)\n self.tot_density_hist[i,j] = copy.deepcopy(h)\n self.bkg_density_hist[i,j] = copy.deepcopy(h)\n self.sig_hist[i,j] = copy.deepcopy(h)\n self.tot_hist[i,j] = copy.deepcopy(h)\n self.bkg_hist[i,j] = copy.deepcopy(h)\n self.off_hist[i,j] = copy.deepcopy(h)\n\n\n def print_quantiles(self,prefix):\n\n filename = prefix + '.txt'\n f = open(filename,'w')\n\n for i, ql in enumerate(self.quantile_labels):\n\n q = self.qdata[i]\n\n for icth in range(self.cth_nbin):\n for iegy in range(self.egy_nbin):\n\n line = '%5.3f '%(self.quantiles[i])\n line += '%5.2f %5.2f '%(self.cth_range[icth][0],\n self.cth_range[icth][1])\n line += '%5.2f %5.2f '%(self.egy_range[iegy][0],\n self.egy_range[iegy][1])\n line += '%8.4f %8.4f '%(q.mean[iegy,icth],\n q.err[iegy,icth])\n\n f.write(line + '\\n')\n\n def print_quantiles_tex(self,prefix):\n\n for i, q in enumerate(self.qdata):\n\n filename = prefix + '_' + ql + '.tex'\n f = open(filename,'w')\n\n for icth in range(self.cth_nbin):\n for iegy in range(self.egy_nbin):\n\n line = '%5.2f %5.2f '%(self.cth_range[icth][0],\n self.cth_range[icth][1])\n line += '%5.2f %5.2f '%(self.egy_range[iegy][0],\n self.egy_range[iegy][1])\n line += format_error(q.mean[iegy,icth],\n q.err[iegy,icth],1,True)\n f.write(line + '\\n')\n\n\n\nclass PSFValidate(Configurable):\n\n default_config = { 'egy_bin' : '2.0/4.0/0.25',\n 'egy_bin_edge' : None,\n 'cth_bin' : None,\n 'cth_bin_edge' : None,\n 'event_class_id' : None,\n 'event_type_id' : None,\n 'data_type' : 'agn',\n 'spectrum' : None,\n 'spectrum_pars' : None,\n 'output_prefix' : None,\n 'output_dir' : None,\n 'conversion_type' : None,\n 'phase_selection' : None,\n 'on_phase' : None,\n 'off_phase' : None,\n 'ltfile' : None,\n 'theta_max' : 30.0,\n 'psf_scaling_fn' : None,\n 'irf' : None,\n 'src' : 'iso' }\n \n def __init__(self, config, opts,**kwargs):\n \"\"\"\n @type self: object\n \"\"\"\n super(PSFValidate,self).__init__()\n\n self.update_default_config(IRFManager.defaults)\n \n self.configure(config,opts=opts,**kwargs)\n\n cfg = self.config\n\n self.irf_colors = ['green', 'red', 'magenta', 'gray', 'orange']\n self.on_phases = []\n self.off_phases = []\n self.data = PhotonData()\n\n self._ft = FigTool(opts=opts)\n\n self.font = font_manager.FontProperties(size=10)\n\n if cfg['egy_bin_edge'] is not None:\n self.egy_bin_edge = string_to_array(cfg['egy_bin_edge'])\n elif cfg['egy_bin'] is not None:\n [elo, ehi, ebin] = string_to_array(cfg['egy_bin'],'/')\n self.egy_bin_edge = \\\n np.linspace(elo, ehi, 1 + int((ehi - elo) / ebin))\n elif cfg['data_type'] == 'agn':\n self.egy_bin_edge = np.linspace(3.5, 5, 7)\n else:\n self.egy_bin_edge = np.linspace(1.5, 5.0, 15)\n \n self.cth_bin_edge = string_to_array(cfg['cth_bin_edge'])\n self.output_prefix = cfg['output_prefix']\n if self.output_prefix is None:\n# prefix = os.path.splitext(opts.files[0])[0]\n m = re.search('(.+).P.gz',opts.files[0])\n if m is None: prefix = os.path.splitext(opts.files[0])[0] \n else: prefix = m.group(1) \n \n cth_label = '%03.f%03.f' % (self.cth_bin_edge[0] * 100,\n self.cth_bin_edge[1] * 100)\n\n if not self.config['event_class_id'] is None:\n cth_label += '_c%02i'%(self.config['event_class_id'])\n\n if not self.config['event_type_id'] is None:\n cth_label += '_t%02i'%(self.config['event_type_id'])\n \n self.output_prefix = '%s_' % (prefix)\n\n if not cfg['conversion_type'] is None:\n self.output_prefix += '%s_' % (cfg['conversion_type'])\n \n self.output_prefix += '%s_' % (cth_label)\n\n if cfg['output_dir'] is None:\n self.output_dir = os.getcwd()\n else:\n self.output_dir = cfg['output_dir']\n\n self.show = opts.show\n\n self.models = []\n if self.config['irf'] is not None:\n self.models = self.config['irf'].split(',')\n\n for i in range(len(self.models)):\n if cfg['conversion_type'] == 'front':\n self.models[i] += '::FRONT'\n elif cfg['conversion_type'] == 'back':\n self.models[i] += '::BACK'\n\n if opts.irf_labels is not None:\n self.model_labels = opts.irf_labels.split(',')\n else:\n self.model_labels = self.models\n\n self.mask_srcs = opts.mask_srcs\n\n self.data_type = 'agn'\n if cfg['phase_selection'] == 'vela':\n cfg['on_phase'] = vela_phase_selection['on_phase']\n cfg['off_phase'] = vela_phase_selection['off_phase']\n\n self.conversion_type = cfg['conversion_type']\n self.opts = opts\n\n if not cfg['on_phase'] is None: self.data_type = 'pulsar'\n \n# self.quantiles = [float(t) for t in opts.quantiles.split(',')]\n# self.quantile_labels = ['r%2.f' % (q * 100) for q in self.quantiles]\n\n if self.data_type == 'pulsar':\n self.phases = parse_phases(cfg['on_phase'],cfg['off_phase'])\n self.on_phases = self.phases[0]\n self.off_phases = self.phases[1]\n self.alpha = self.phases[2]\n\n self.psf_data = PSFData(self.egy_bin_edge,\n self.cth_bin_edge,\n 'data')\n\n if cfg['psf_scaling_fn']:\n self.thetamax_fn = psf_scaling_fn[cfg['psf_scaling_fn']]\n elif cfg['conversion_type'] == 'back' or cfg['conversion_type'] is None:\n self.thetamax_fn = psf_scaling_function['back']\n else:\n self.thetamax_fn = psf_scaling_function['front']\n \n self.psf_data.init_hist(self.thetamax_fn, self.config['theta_max'])\n self.build_models()\n\n @staticmethod\n def add_arguments(parser):\n\n IRFManager.add_arguments(parser)\n FigTool.add_arguments(parser)\n\n parser.add_argument('--ltfile', default=None,\n help='Set the livetime cube which will be used '\n 'to generate the exposure-weighted PSF model.')\n\n parser.add_argument('--irf', default=None,\n help='Set the names of one or more IRF models.')\n\n parser.add_argument('--theta_max', default=None, type=float,\n help='Set the names of one or more IRF models.')\n\n parser.add_argument('--irf_labels', default=None,\n help='IRF labels')\n\n parser.add_argument('--output_dir', default=None,\n help='Set the output directory name.')\n\n parser.add_argument('--output_prefix', default=None,\n help='Set the string prefix that will be appended '\n 'to all output files.')\n\n parser.add_argument('--on_phase', default=None,\n help='Type of input data (pulsar/agn).')\n\n parser.add_argument('--off_phase', default=None,\n help='Type of input data (pulsar/agn).')\n\n parser.add_argument('--phase_selection', default=None,\n help='Type of input data (pulsar/agn).')\n \n parser.add_argument('--cth_bin_edge', default='0.2,1.0',\n help='Edges of cos(theta) bins (e.g. 0.2,0.5,1.0).')\n\n parser.add_argument('--egy_bin_edge', default=None,\n help='Edges of energy bins.')\n\n parser.add_argument('--egy_bin', default=None,\n help='Set low/high and energy bin size.')\n\n parser.add_argument('--cuts', default=None,\n help='Set min/max redshift.')\n\n parser.add_argument('--src', default='Vela',\n help='Set the source model.')\n\n\n parser.add_argument('--show', default=False, action='store_true',\n help='Draw plots to screen.')\n\n parser.add_argument('--make_sky_image', default=False,\n action='store_true',\n help='Plot distribution of photons on the sky.')\n\n parser.add_argument('--conversion_type', default=None,\n help='Draw plots.')\n\n parser.add_argument('--event_class', default=None,\n help='Set the event class name.')\n\n parser.add_argument('--event_class_id', default=None, type=int,\n help='Set the event class ID.')\n\n parser.add_argument('--event_type_id', default=None, type=int,\n help='Set the event type ID.')\n\n parser.add_argument('--psf_scaling_fn', default=None, \n help='Set the scaling function to use for '\n 'determining the edge of the ROI at each energy.')\n \n parser.add_argument('--quantiles', default='0.34,0.68,0.90,0.95',\n help='Draw plots.')\n\n parser.add_argument('--mask_srcs', default=None,\n help='Define a list of sources to exclude.')\n\n def build_models(self):\n\n self.psf_models = {}\n\n for imodel, ml in enumerate(self.models):\n \n irfm = IRFManager.create(self.models[imodel], True,\n irf_dir=self.config['irf_dir'])\n\n\n sp = self.config['spectrum']\n sp_pars = string_to_array(self.config['spectrum_pars'])\n \n m = PSFModelLT(irfm,\n src_type=self.config['src'],\n ltfile=self.config['ltfile'],\n spectrum=sp,spectrum_pars=sp_pars)\n # m.set_spectrum('powerlaw_exp',(1.607,3508.6))\n # m.set_spectrum('powerlaw',(2.0))\n \n self.psf_models[ml] = m\n\n self.irf_data = {}\n for ml in self.models:\n self.irf_data[ml] = PSFData(self.egy_bin_edge,\n self.cth_bin_edge,\n 'model')\n\n def load(self, opts):\n\n\n for f in opts.files:\n print 'Loading ', f\n d = load_object(f)\n d.mask(event_class_id=self.config['event_class_id'],\n event_type_id=self.config['event_type_id'],\n conversion_type=self.config['conversion_type'])\n\n self.data.merge(d)\n\n self.data['dtheta'] = np.degrees(self.data['dtheta'])\n\n def fill(self,data):\n\n for iegy in range(self.psf_data.egy_axis.nbins):\n for icth in range(self.psf_data.cth_axis.nbins):\n if self.data_type == 'pulsar':\n self.fill_pulsar(data, iegy, icth)\n else:\n self.fill_agn(data, iegy, icth)\n \n def run(self):\n\n for f in self.opts.files:\n print 'Loading ', f\n d = load_object(f)\n\n\n print self.config['event_class_id']\n \n d.mask(event_class_id=self.config['event_class_id'],\n event_type_id=self.config['event_type_id'],\n conversion_type=self.config['conversion_type'])\n d['dtheta'] = np.degrees(d['dtheta'])\n\n self.fill(d)\n \n for iegy in range(self.psf_data.egy_axis.nbins):\n for icth in range(self.psf_data.cth_axis.nbins):\n self.fill_models(iegy,icth)\n\n for iegy in range(self.psf_data.egy_axis.nbins):\n for icth in range(self.psf_data.cth_axis.nbins):\n if self.data_type == 'pulsar':\n self.fit_pulsar(iegy, icth)\n else:\n self.fit_agn(iegy, icth)\n\n fname = os.path.join(self.output_dir,\n self.output_prefix + 'psfdata')\n\n self.psf_data.save(fname + '.P')\n\n # psf_data.print_quantiles()\n\n # psf_data.print_quantiles_tex(os.path.join(self.output_dir,\n # self.output_prefix))\n\n for ml in self.models:\n fname = self.output_prefix + 'psfdata_' + ml\n self.irf_data[ml].save(fname + '.P')\n\n def plot(self):\n return\n\n def get_counts(self, data, theta_edges, mask):\n\n theta_mask = (data['dtheta'] >= theta_edges[0]) & \\\n (data['dtheta'] <= theta_edges[1])\n\n return len(data['dtheta'][mask & theta_mask])\n\n def plot_theta_residual(self, hsignal, hbkg, hmodel, label):\n\n\n fig = self._ft.create(label,figstyle='residual2',xscale='sqrt',\n norm_interpolation='lin',\n legend_loc='upper right')\n\n hsignal_rebin = hsignal.rebin_mincount(10)\n hbkg_rebin = Histogram(hsignal_rebin.axis().edges)\n hbkg_rebin.fill(hbkg.axis().center,hbkg.counts,\n hbkg.var)\n\n hsignal_rebin = hsignal_rebin.scale_density(lambda x: x**2*np.pi)\n hbkg_rebin = hbkg_rebin.scale_density(lambda x: x**2*np.pi)\n \n for i, h in enumerate(hmodel):\n\n h_rebin = Histogram(hsignal_rebin.axis().edges)\n h_rebin.fill(h.axis().center,h.counts,h.var)\n h_rebin = h_rebin.scale_density(lambda x: x**2*np.pi)\n \n fig[0].add_hist(h_rebin,hist_style='line',linestyle='-',\n label=self.model_labels[i],\n color=self.irf_colors[i],\n linewidth=1.5)\n \n fig[0].add_hist(hsignal_rebin,\n marker='o', linestyle='None',label='signal')\n fig[0].add_hist(hbkg_rebin,hist_style='line',\n linestyle='--',label='bkg',color='k')\n\n \n \n\n fig[0].set_style('ylabel','Counts Density [deg$^{-2}$]')\n\n fig[1].ax().set_ylim(-0.5,0.5)\n \n# fig.plot(norm_index=2,mask_ratio_args=[1])\n fig.plot()\n\n return\n\n # fig = plt.figure()\n fig, axes = plt.subplots(2, sharex=True)\n axes[0].set_xscale('sqrt', exp=2.0)\n axes[1].set_xscale('sqrt', exp=2.0)\n \n pngfile = os.path.join(self.output_dir, label + '.png')\n\n # ax = plt.gca()\n\n # if hsignal.sum() > 0:\n # ax.set_yscale('log')\n\n axes[0].set_ylabel('Counts Density [deg$^{-2}$]')\n axes[0].set_xlabel('$\\\\theta$ [deg]')\n\n # ax.set_title(title)\n\n hsignal_rebin = hsignal.rebin_mincount(10)\n hbkg_rebin = Histogram(hsignal_rebin.axis().edges)\n hbkg_rebin.fill(hbkg.axis().center,hbkg.counts,hbkg.var)\n hsignal_rebin.plot(ax=axes[0], marker='o', linestyle='None',\n label='signal')\n hbkg_rebin.plot(ax=axes[0], marker='o', linestyle='None',\n label='bkg')\n\n for i, h in enumerate(hmodel):\n\n h.plot(hist_style='line', ax=axes[0], fmt='-',\n label=self.model_labels[i],\n color=self.irf_colors[i],\n linewidth=2)\n\n hm = Histogram(hsignal_rebin.axis().edges)\n hm.fill(h.center,h.counts,h.var)\n\n hresid = hsignal_rebin.residual(hm)\n hresid.plot(ax=axes[1],linestyle='None',\n label=self.model_labels[i],\n color=self.irf_colors[i],\n linewidth=2)\n\n\n # ax.set_ylim(1)\n axes[0].grid(True)\n axes[1].grid(True)\n\n axes[0].legend(prop=self.font)\n\n axes[1].set_ylim(-0.5, 0.5)\n\n fig.subplots_adjust(hspace=0)\n\n for i in range(len(axes) - 1):\n plt.setp([axes[i].get_xticklabels()], visible=False)\n\n if self.show is True:\n plt.show()\n\n print 'Printing ', pngfile\n plt.savefig(pngfile)\n\n def plot_psf_cumulative(self, hsignal, hbkg, hmodel, label,title,\n theta_max=None, text=None):\n\n hexcess = hsignal - hbkg\n\n\n fig = self._ft.create(label,figstyle='twopane',xscale='sqrt',\n title=title)\n\n fig[0].add_hist(hsignal,label='Data',linestyle='None')\n fig[0].add_hist(hbkg,hist_style='line',\n label='Bkg',marker='None',linestyle='--',\n color='k')\n\n for i, h in enumerate(hmodel):\n fig[0].add_hist(h,hist_style='line',\n linestyle='-',\n label=self.model_labels[i],\n color=self.irf_colors[i],\n linewidth=1.5)\n\n hexcess_cum = hexcess.normalize()\n hexcess_cum = hexcess_cum.cumulative()\n\n fig[1].add_hist(hexcess_cum,marker='None',linestyle='None',label='Data')\n\n for i, h in enumerate(hmodel):\n t = h - hbkg\n t = t.normalize()\n t = t.cumulative()\n fig[1].add_hist(t,hist_style='line', \n linestyle='-',\n label=self.model_labels[i],\n color=self.irf_colors[i],\n linewidth=1.5)\n\n fig[0].set_style('ylabel','Counts')\n fig[0].set_style('legend_loc','upper right')\n fig[1].set_style('legend_loc','lower right')\n fig[1].set_style('ylabel','Cumulative Fraction')\n\n fig[1].add_hline(1.0, color='k')\n\n# fig[1].axhline(0.34, color='r', linestyle='--', label='34%')\n fig[1].add_hline(0.68, color='b', linestyle='--', label='68%')\n# axes[1].axhline(0.90, color='g', linestyle='--', label='90%')\n fig[1].add_hline(0.95, color='m', linestyle='--', label='95%')\n\n fig[1].set_style('xlabel','$\\\\theta$ [deg]')\n\n fig.plot()\n \n\n# axes[1].legend(prop=self.font, loc='lower right', ncol=2)\n# if theta_max is not None:\n# axes[0].axvline(theta_max, color='k', linestyle='--')\n# axes[1].axvline(theta_max, color='k', linestyle='--')\n\n# if text is not None:\n# axes[0].text(0.3, 0.75, text,\n# transform=axes[0].transAxes, fontsize=10)\n\n\n def fill_agn(self,data,iegy,icth):\n\n qdata = self.psf_data\n\n egy_range = self.psf_data.egy_axis.edges[iegy:iegy+2]\n cth_range = self.psf_data.cth_axis.edges[icth:icth+2]\n ecenter = self.psf_data.egy_axis.center[iegy]\n emin = 10 ** egy_range[0]\n emax = 10 ** egy_range[1]\n theta_edges = self.psf_data.sig_hist[iegy, icth].axis().edges\n\n theta_max=theta_edges[-1]\n\n# theta_max = min(3.0, self.thetamax_fn(ecenter))\n# theta_edges = np.linspace(0, 3.0, int(3.0 / (theta_max / 100.)))\n\n mask = PhotonData.get_mask(data, {'energy': egy_range,\n 'cth': cth_range},\n conversion_type=self.conversion_type,\n event_class=self.opts.event_class,\n cuts=self.opts.cuts)\n\n hcounts = data.hist('dtheta', mask=mask, edges=theta_edges)\n\n domega = (theta_max ** 2) * np.pi\n bkg_edge = [min(2.5, theta_max), 3.5]\n\n bkg_domega = (bkg_edge[1] ** 2 - bkg_edge[0] ** 2) * np.pi\n bkg_counts = self.get_counts(data, bkg_edge, mask)\n bkg_density = bkg_counts / bkg_domega\n\n# print 'BKG ', bkg_counts, bkg_edge\n\n qdata.bkg.fill(self.psf_data.egy_axis.center[iegy],\n self.psf_data.cth_axis.center[icth],\n bkg_counts)\n qdata.bkg_density.set(iegy,icth,\n qdata.bkg.counts[iegy,icth]/bkg_domega,\n qdata.bkg.counts[iegy,icth]/bkg_domega**2)\n\n hbkg = copy.deepcopy(hcounts)\n hbkg.clear()\n for b in hbkg.iterbins():\n bin_area = (b.hi_edge() ** 2 - b.lo_edge() ** 2) * np.pi\n b.set_counts(bin_area * bkg_density)\n\n hexcess = hcounts - hbkg\n \n# htotal_density = hcounts.scale_density(lambda x: x * x * np.pi)\n# hbkg_density = copy.deepcopy(hcounts)\n# hbkg_density._counts[:] = bkg_density\n# hbkg_density._var[:] = 0\n\n # Fill histograms for later plotting\n \n qdata.sig_hist[iegy, icth] += hexcess\n qdata.tot_hist[iegy, icth] += hcounts\n qdata.off_hist[iegy, icth] += hbkg\n qdata.bkg_hist[iegy, icth] += hbkg\n qdata.excess.set(iegy, icth, *qdata.sig_hist[iegy, icth].sum())\n \n qdata.tot_density_hist[iegy, icth] = \\\n qdata.sig_hist[iegy, icth].scale_density(lambda x: x**2*np.pi)\n qdata.bkg_density_hist[iegy, icth]._counts = bkg_density\n\n xedge = np.linspace(-theta_max, theta_max, 301)\n\n if qdata.sky_image[iegy,icth] is None:\n qdata.sky_image[iegy,icth] = Histogram2D(xedge,xedge)\n qdata.lat_image[iegy,icth] = Histogram2D(xedge,xedge)\n\n\n if np.sum(mask):\n qdata.sky_image[iegy,icth].fill(data['delta_ra'][mask],\n data['delta_dec'][mask])\n\n qdata.lat_image[iegy,icth].fill(data['delta_phi'][mask],\n data['delta_theta'][mask])\n\n\n\n\n def fit_agn(self, iegy, icth):\n\n models = self.psf_models\n irf_data = self.irf_data\n psf_data = self.psf_data\n\n egy_range = psf_data.egy_axis.edges[iegy:iegy+2]\n cth_range = psf_data.cth_axis.edges[icth:icth+2]\n ecenter = psf_data.egy_axis.center[iegy]\n emin = 10 ** psf_data.egy_axis.edges[iegy]\n emax = 10 ** psf_data.egy_axis.edges[iegy+1]\n\n theta_max = min(self.config['theta_max'], self.thetamax_fn(ecenter))\n\n bkg_hist = psf_data.bkg_hist[iegy, icth]\n sig_hist = psf_data.sig_hist[iegy, icth]\n on_hist = psf_data.tot_hist[iegy, icth]\n off_hist = psf_data.off_hist[iegy, icth]\n excess_sum = psf_data.excess._counts[iegy, icth]\n\n bkg_density = psf_data.bkg_density._counts[iegy,icth]\n bkg_counts = psf_data.bkg._counts[iegy,icth]\n bkg_domega = bkg_counts/bkg_density\n\n print 'Computing Quantiles'\n bkg_fn = lambda x: x**2 * np.pi * bkg_density\n hq = HistQuantileBkgFn(on_hist, \n lambda x: x**2 * np.pi / bkg_domega,\n bkg_counts)\n \n if excess_sum > 25:\n try:\n self.compute_quantiles(hq, psf_data, iegy, icth, theta_max)\n except Exception, e:\n print e\n \n hmodel_density = []\n hmodel_counts = []\n for i, ml in enumerate(self.model_labels):\n hmodel_density.append(irf_data[ml].tot_density_hist[iegy, icth])\n hmodel_counts.append(irf_data[ml].tot_hist[iegy, icth])\n\n text = 'Bkg Density = %.3f deg$^{-2}$\\n' % (bkg_density)\n text += 'Signal = %.3f\\n' % (excess_sum)\n text += 'Background = %.3f' % (bkg_density * theta_max**2 * np.pi)\n\n fig_label = self.output_prefix + 'theta_density_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n self.plot_theta_residual(psf_data.tot_density_hist[iegy, icth],\n psf_data.bkg_density_hist[iegy, icth],\n hmodel_density, fig_label)\n\n fig_label = self.output_prefix + 'theta_counts_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n fig_title = 'E = [%.3f, %.3f] '%(egy_range[0],egy_range[1])\n fig_title += 'Cos$\\\\theta$ = [%.3f, %.3f]'%(cth_range[0],cth_range[1])\n \n self.plot_psf_cumulative(psf_data.tot_hist[iegy, icth],\n psf_data.bkg_hist[iegy, icth],\n hmodel_counts, fig_label,fig_title,\n None,text)\n# bkg_edge[0], text)\n\n\n r68 = hq.quantile(0.68)\n r95 = hq.quantile(0.95)\n\n\n rs = min(r68 / 4., theta_max / 10.)\n bin_size = 6.0 / 600.\n\n stacked_image = psf_data.sky_image[iegy,icth]\n\n# stacked_image.fill(psf_data['delta_ra'][mask],\n# psf_data['delta_dec'][mask])\n\n plt.figure()\n\n stacked_image = stacked_image.smooth(rs)\n \n\n plt.plot(r68 * np.cos(np.linspace(0, 2 * np.pi, 100)),\n r68 * np.sin(np.linspace(0, 2 * np.pi, 100)), color='k')\n\n plt.plot(r95 * np.cos(np.linspace(0, 2 * np.pi, 100)),\n r95 * np.sin(np.linspace(0, 2 * np.pi, 100)), color='k',\n linestyle='--')\n\n stacked_image.plot()\n plt.gca().set_xlim(-theta_max,theta_max)\n plt.gca().set_ylim(-theta_max,theta_max)\n \n \n# plt.plot(bkg_edge[0] * np.cos(np.linspace(0, 2 * np.pi, 100)),\n# bkg_edge[0] * np.sin(np.linspace(0, 2 * np.pi, 100)),\n# color='k',\n# linestyle='-', linewidth=2)\n\n# plt.plot(bkg_edge[1] * np.cos(np.linspace(0, 2 * np.pi, 100)),\n# bkg_edge[1] * np.sin(np.linspace(0, 2 * np.pi, 100)),\n# color='k',\n# linestyle='-', linewidth=2)\n\n # c68 = plt.Circle((0, 0), radius=r68, color='k',facecolor='None')\n # c95 = plt.Circle((0, 0), radius=r95, color='k',facecolor='None')\n\n # plt.gca().add_patch(c68)\n # plt.gca().add_patch(c95)\n\n fig_label = self.output_prefix + 'stackedimage_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n plt.savefig(fig_label)\n\n return\n \n for i in range(len(data._srcs)):\n\n if not self.opts.make_sky_image: continue\n\n src = data._srcs[i]\n\n srcra = src['RAJ2000']\n srcdec = src['DEJ2000']\n\n print i, srcra, srcdec\n\n im = SkyImage.createROI(srcra, srcdec, 3.0, 3.0 / 600.)\n\n src_mask = mask & (data['src_index'] == i)\n\n im.fill(data['ra'][src_mask], data['dec'][src_mask])\n fig = plt.figure()\n im = im.smooth(rs)\n im.plot()\n\n im.plot_catalog()\n\n im.plot_circle(r68, color='k')\n im.plot_circle(r95, color='k', linestyle='--')\n im.plot_circle(theta_max, color='k', linestyle='-', linewidth=2)\n\n fig_label = self.output_prefix + 'skyimage_src%03i_' % (i)\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n fig.savefig(fig_label + '.png')\n\n\n def fill_pulsar(self, data, iegy, icth):\n\n qdata = self.psf_data\n\n egy_range = qdata.egy_axis.edges[iegy:iegy+2]\n cth_range = qdata.cth_axis.edges[icth:icth+2]\n ecenter = qdata.egy_axis.center[iegy]\n emin = 10 ** egy_range[0]\n emax = 10 ** egy_range[1]\n theta_edges = qdata.sig_hist[iegy, icth].axis().edges\n\n theta_max = theta_edges[-1]\n\n mask = PhotonData.get_mask(data, {'energy': egy_range,\n 'cth': cth_range},\n conversion_type=self.conversion_type,\n event_class=self.opts.event_class,\n cuts=self.opts.cuts)\n\n on_mask = PhotonData.get_mask(data, {'energy': egy_range,\n 'cth': cth_range},\n conversion_type=self.conversion_type,\n event_class=self.opts.event_class,\n cuts=self.opts.cuts,\n phases=self.on_phases)\n\n off_mask = PhotonData.get_mask(data, {'energy': egy_range,\n 'cth': cth_range},\n conversion_type=self.conversion_type,\n event_class=self.opts.event_class,\n cuts=self.opts.cuts,\n phases=self.off_phases)\n\n (hon, hoff, hoffs) = getOnOffHist(data, 'dtheta', phases=self.phases,\n edges=theta_edges, mask=mask)\n\n \n hexcess = copy.deepcopy(hon)\n hexcess -= hoffs\n\n htotal_density = copy.deepcopy(hexcess)\n htotal_density += hoffs\n htotal_density = htotal_density.scale_density(lambda x: x * x * np.pi)\n\n hoffs_density = hoffs.scale_density(lambda x: x * x * np.pi)\n\n excess_sum = np.sum(hexcess._counts)\n on_sum = np.sum(hon._counts)\n off_sum = np.sum(hoff._counts)\n\n # Fill histograms for later plotting\n qdata.tot_density_hist[iegy, icth] += htotal_density\n qdata.bkg_density_hist[iegy, icth] += hoffs_density\n qdata.sig_hist[iegy, icth] += hexcess\n qdata.tot_hist[iegy, icth] += hon\n qdata.off_hist[iegy, icth] += hoff\n qdata.bkg_hist[iegy, icth] += hoffs\n qdata.excess.set(iegy, icth, np.sum(qdata.sig_hist[iegy, icth]._counts))\n\n \n src = data._srcs[0]\n\n xedge = np.linspace(-theta_max, theta_max, 301)\n\n if qdata.sky_image[iegy,icth] is None:\n qdata.sky_image[iegy,icth] = Histogram2D(xedge,xedge)\n qdata.sky_image_off[iegy,icth] = Histogram2D(xedge,xedge)\n\n qdata.lat_image[iegy,icth] = Histogram2D(xedge,xedge)\n qdata.lat_image_off[iegy,icth] = Histogram2D(xedge,xedge)\n \n qdata.sky_image[iegy,icth].fill(data['delta_ra'][on_mask],\n data['delta_dec'][on_mask])\n\n qdata.sky_image_off[iegy,icth].fill(data['delta_ra'][off_mask],\n data['delta_dec'][off_mask])\n\n qdata.lat_image[iegy,icth].fill(data['delta_phi'][on_mask],\n data['delta_theta'][on_mask])\n\n qdata.lat_image_off[iegy,icth].fill(data['delta_phi'][off_mask],\n data['delta_theta'][off_mask])\n\n \n# if not isinstance(qdata.sky_image[iegy,icth],SkyImage): \n# im = SkyImage.createROI(src['RAJ2000'], src['DEJ2000'],\n# theta_max, theta_max / 200.)\n# qdata.sky_image[iegy,icth] = im\n# else:\n# im = qdata.sky_image[iegy,icth]\n\n \n# if len(data['ra'][on_mask]) > 0:\n# im.fill(data['ra'][on_mask], data['dec'][on_mask])\n\n\n def fill_models(self, iegy, icth):\n \"\"\"Fill IRF model distributions.\"\"\"\n\n models = self.psf_models\n irf_data = self.irf_data\n psf_data = self.psf_data\n\n egy_range = psf_data.egy_axis.edges[iegy:iegy+2]\n cth_range = psf_data.cth_axis.edges[icth:icth+2]\n ecenter = psf_data.egy_axis.center[iegy]\n emin = 10 ** psf_data.egy_axis.edges[iegy]\n emax = 10 ** psf_data.egy_axis.edges[iegy+1]\n\n bkg_hist = psf_data.bkg_hist[iegy, icth]\n sig_hist = psf_data.sig_hist[iegy, icth]\n on_hist = psf_data.tot_hist[iegy, icth]\n off_hist = psf_data.off_hist[iegy, icth]\n excess_sum = psf_data.excess._counts[iegy, icth]\n\n for i, ml in enumerate(self.model_labels):\n m = models[ml]\n\n print 'Fitting model ', ml\n hmodel_sig = m.histogram(emin, emax,cth_range[0],cth_range[1],\n on_hist.axis().edges).normalize()\n model_norm = excess_sum\n hmodel_sig *= model_norm\n\n irf_data[ml].excess.set(iegy, icth, sig_hist.sum()[0])\n irf_data[ml].ndf.set(iegy, icth, float(sig_hist.axis().nbins))\n\n hmd = hmodel_sig.scale_density(lambda x: x * x * np.pi)\n hmd += psf_data.bkg_density_hist[iegy, icth]\n\n irf_data[ml].tot_density_hist[iegy, icth] = hmd\n irf_data[ml].bkg_density_hist[iegy, icth] = \\\n copy.deepcopy(psf_data.bkg_density_hist[iegy, icth])\n irf_data[ml].sig_hist[iegy, icth] = hmodel_sig\n irf_data[ml].bkg_hist[iegy, icth] = copy.deepcopy(bkg_hist)\n irf_data[ml].tot_hist[iegy, icth] = hmodel_sig + bkg_hist\n\n for j, q in enumerate(psf_data.quantiles):\n ql = psf_data.quantile_labels[j]\n qm = m.quantile(emin, emax, cth_range[0],cth_range[1], q)\n self.irf_data[ml].qdata[j].set(iegy, icth, qm)\n print ml, ql, qm\n\n# ndf = hexcess.nbins\n\n# qmodel[ml].excess.set(iegy, icth, hexcess.sum()[0])\n# qmodel[ml].ndf.set(iegy, icth, hexcess.nbins)\n# qmodel[ml].chi2.set(iegy,icth,hexcess.chi2(hmodel))\n# qmodel[ml].rchi2.set(iegy,icth,\n# qmodel[ml].chi2[iegy,icth]/hexcess.nbins)\n# print ml, ' chi2/ndf: %f/%d rchi2: %f'%(qmodel[ml].chi2[iegy,icth],\n# ndf,\n# qmodel[ml].rchi2[iegy,icth])\n\n def fit_pulsar(self, iegy, icth):\n \n models = self.psf_models\n irf_data = self.irf_data\n psf_data = self.psf_data\n\n egy_range = psf_data.egy_axis.edges[iegy:iegy+2]\n cth_range = psf_data.cth_axis.edges[icth:icth+2]\n ecenter = psf_data.egy_axis.center[iegy]\n emin = psf_data.egy_axis.edges[iegy]\n emax = psf_data.egy_axis.edges[iegy+1]\n\n print 'Analyzing Bin ', emin, emax\n \n theta_max = min(self.config['theta_max'], self.thetamax_fn(ecenter))\n\n bkg_hist = psf_data.bkg_hist[iegy, icth]\n sig_hist = psf_data.sig_hist[iegy, icth]\n on_hist = psf_data.tot_hist[iegy, icth]\n off_hist = psf_data.off_hist[iegy, icth]\n excess_sum = psf_data.excess.counts[iegy, icth]\n\n bkg_density = bkg_hist.sum() / (theta_max ** 2 * np.pi)\n text = 'Bkg Density = %.3f deg$^{-2}$\\n' % (bkg_density[0])\n text += 'Signal = %.3f\\n' % (psf_data.excess._counts[iegy, icth])\n text += 'Background = %.3f' % (bkg_hist.sum()[0])\n\n print 'Computing Quantiles'\n hq = HistQuantileOnOff(on_hist, off_hist, self.alpha)\n\n\n \n if excess_sum > 25:\n\n try:\n self.compute_quantiles(hq, psf_data, iegy, icth, theta_max)\n except Exception, e:\n print e\n \n hmodel_density = []\n hmodel_counts = []\n\n for i, ml in enumerate(self.model_labels):\n hmodel_density.append(irf_data[ml].tot_density_hist[iegy, icth])\n hmodel_counts.append(irf_data[ml].tot_hist[iegy, icth])\n\n fig_label = self.output_prefix + 'theta_density_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n self.plot_theta_residual(on_hist, bkg_hist, hmodel_counts,\n #psf_data.tot_density_hist[iegy, icth],\n #psf_data.bkg_density_hist[iegy, icth],\n #hmodel_density,\n fig_label)\n\n fig_label = self.output_prefix + 'theta_counts_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n fig_title = 'E = [%.3f, %.3f] '%(egy_range[0],egy_range[1])\n fig_title += 'Cos$\\\\theta$ = [%.3f, %.3f]'%(cth_range[0],cth_range[1])\n \n self.plot_psf_cumulative(on_hist, bkg_hist, hmodel_counts,\n fig_label,fig_title,\n theta_max=None, text=text)\n\n\n\n \n r68 = hq.quantile(0.68)\n r95 = hq.quantile(0.95)\n\n imin = psf_data.sky_image[iegy,icth].axis(0).valToBin(-r68)\n imax = psf_data.sky_image[iegy,icth].axis(0).valToBin(r68)+1\n \n\n model_hists = []\n\n for k,m in models.iteritems():\n\n xy = psf_data.sky_image[iegy,icth].center()\n r = np.sqrt(xy[0]**2 + xy[1]**2)\n psf = m.pdf(10**emin,10**emax,cth_range[0],cth_range[1],r)\n psf = psf.reshape(psf_data.sky_image[iegy,icth].shape())\n \n h = Histogram2D(psf_data.sky_image[iegy,icth].xaxis(),\n psf_data.sky_image[iegy,icth].yaxis(),\n counts=psf)\n\n h = h.normalize()\n h *= excess_sum \n model_hists.append(h)\n \n# im._counts = psf\n\n\n fig_suffix = '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n \n # 2D Sky Image\n self.make_onoff_image(psf_data.sky_image[iegy,icth],\n psf_data.sky_image_off[iegy,icth],\n self.alpha,model_hists,\n 'RA Offset [deg]','DEC Offset [deg]',\n fig_title,r68,r95,\n 'skyimage_' + fig_suffix)\n \n # 2D LAT Image\n self.make_onoff_image(psf_data.lat_image[iegy,icth],\n psf_data.lat_image_off[iegy,icth],\n self.alpha,model_hists,\n 'Phi Offset [deg]','Theta Offset [deg]',\n fig_title,r68,r95,\n 'latimage_' + fig_suffix)\n\n \n return\n\n \n # X Projection\n fig = self._ft.create(self.output_prefix + 'xproj_' + fig_suffix,\n xlabel='Delta RA [deg]')\n\n imx = im.project(0,[[imin,imax]])\n \n fig[0].add_hist(imx,label='Data')\n for i, h in enumerate(model_hists):\n fig[0].add_hist(h.project(0,[[imin,imax]]),hist_style='line',linestyle='-',\n label=self.model_labels[i])\n\n imx2 = imx.slice(0,[[imin,imax]])\n \n mean_err = imx.stddev()/np.sqrt(excess_sum) \n data_stats = 'Mean = %.3f\\nMedian = %.2f'%(imx2.mean(),imx2.quantile(0.5))\n\n fig[0].ax().set_title(fig_title)\n fig[0].ax().text(0.05,0.95,\n '%s'%(data_stats),\n verticalalignment='top',\n transform=fig[0].ax().transAxes,fontsize=10)\n\n\n fig.plot()\n\n # Y Projection\n fig = self._ft.create(self.output_prefix + 'yproj_' + fig_suffix,\n xlabel='Delta DEC [deg]')\n\n imy = im.project(1,[[imin,imax]])\n\n fig[0].add_hist(imy,label='Data')\n for i, h in enumerate(model_hists):\n fig[0].add_hist(h.project(1,[[imin,imax]]),hist_style='line',linestyle='-',\n label=self.model_labels[i])\n\n mean_err = imx.stddev()/np.sqrt(excess_sum) \n data_stats = 'Mean = %.3f\\nRMS = %.2f'%(imx.mean(),imx.stddev())\n \n fig[0].ax().set_title(fig_title)\n fig[0].ax().text(0.05,0.95,\n '%s'%(data_stats),\n verticalalignment='top',\n transform=fig[0].ax().transAxes,fontsize=10)\n \n fig.plot()\n \n \n\n \n return\n \n if excess_sum < 10: return\n\n \n r68 = hq.quantile(0.68)\n r95 = hq.quantile(0.95)\n\n rs = min(r68 / 4., theta_max / 10.)\n\n\n fig = plt.figure()\n im = psf_data.sky_image[iegy,icth].smooth(rs)\n im.plot(logz=True)\n\n im.plot_catalog()\n\n im.plot_circle(r68, color='k')\n im.plot_circle(r95, color='k', linestyle='--')\n im.plot_circle(theta_max, color='k', linestyle='-', linewidth=2)\n\n\n\n fig_label = self.output_prefix + 'skyimage_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f' % (egy_range[0] * 100,\n egy_range[1] * 100,\n cth_range[0] * 100,\n cth_range[1] * 100)\n\n fig.savefig(fig_label + '.png')\n\n def make_onoff_image(self,im,imoff,alpha,model_hists,\n xlabel,ylabel,fig_title,r68,r95,\n fig_suffix):\n\n imin = im.axis(0).valToBin(-r68)\n imax = im.axis(0).valToBin(r68)+1\n \n fig = plt.figure(figsize=(8,8))\n plt.gca().set_title(fig_title)\n \n im = copy.deepcopy(im)\n im -= imoff*alpha\n im.smooth(r68/4.).plot(norm=PowerNormalize(2.))\n \n plt.gca().grid(True)\n plt.gca().set_xlabel(xlabel)\n plt.gca().set_ylabel(ylabel)\n \n plt.plot(r68 * np.cos(np.linspace(0, 2 * np.pi, 100)),\n r68 * np.sin(np.linspace(0, 2 * np.pi, 100)), color='w')\n \n plt.plot(r95 * np.cos(np.linspace(0, 2 * np.pi, 100)),\n r95 * np.sin(np.linspace(0, 2 * np.pi, 100)), color='w',\n linestyle='--')\n \n plt.gca().set_xlim(*im.xaxis().lims())\n plt.gca().set_ylim(*im.yaxis().lims())\n fig_label = self.output_prefix + fig_suffix\n fig.savefig(fig_label + '.png')\n\n # X Projection\n fig = self._ft.create(self.output_prefix + fig_suffix + '_xproj',\n xlabel=xlabel)\n\n imx = im.project(0,[[imin,imax]])\n \n fig[0].add_hist(imx.rebin(2),label='Data',linestyle='None')\n for i, h in enumerate(model_hists):\n fig[0].add_hist(h.project(0,[[imin,imax]]).rebin(2),\n hist_style='line',linestyle='-',\n label=self.model_labels[i])\n\n imx2 = imx.slice(0,[[imin,imax]]).rebin(2)\n med = imx2.quantile(0.5) \n data_stats = 'Mean = %.3f\\nMedian = %.3f $\\pm$ %.3f'%(imx2.mean(),\n med[0],med[1])\n\n fig[0].ax().set_title(fig_title)\n fig[0].ax().text(0.05,0.95,\n '%s'%(data_stats),\n verticalalignment='top',\n transform=fig[0].ax().transAxes,fontsize=10)\n\n\n fig.plot()\n\n # Y Projection\n fig = self._ft.create(self.output_prefix + fig_suffix + '_yproj',\n xlabel=ylabel)\n\n imy = im.project(1,[[imin,imax]])\n \n fig[0].add_hist(imy.rebin(2),label='Data',linestyle='None')\n for i, h in enumerate(model_hists):\n fig[0].add_hist(h.project(0,[[imin,imax]]).rebin(2),\n hist_style='line',linestyle='-',\n label=self.model_labels[i])\n\n imy2 = imy.slice(0,[[imin,imax]])\n med = imy2.quantile(0.5) \n data_stats = 'Mean = %.3f\\nMedian = %.3f $\\pm$ %.3f'%(imy2.mean(),med[0],med[1])\n\n fig[0].ax().set_title(fig_title)\n fig[0].ax().text(0.05,0.95,\n '%s'%(data_stats),\n verticalalignment='top',\n transform=fig[0].ax().transAxes,fontsize=10)\n\n\n fig.plot()\n \n def compute_quantiles(self, hq, qdata, iegy, icth,\n theta_max=None):\n\n emin = 10 ** qdata.egy_axis.edges[iegy]\n emax = 10 ** qdata.egy_axis.edges[iegy+1]\n\n for i, q in enumerate(qdata.quantiles):\n \n ql = qdata.quantile_labels[i]\n qmean = hq.quantile(fraction=q)\n qdist_mean, qdist_err = hq.bootstrap(q, niter=200, xmax=theta_max)\n qdata.qdata[i].set(iegy, icth, qmean, qdist_err ** 2)\n\n print ql, ' %10.4f +/- %10.4f %10.4f' % (qmean, qdist_err, \n qdist_mean)\n\nif __name__ == '__main__':\n usage = \"%(prog)s [options] [pickle file ...]\"\n description = \"\"\"Perform PSF validation analysis on agn or\npulsar data samples.\"\"\"\n parser = argparse.ArgumentParser(usage=usage, description=description)\n\n parser.add_argument('files', nargs='+')\n\n PSFValidate.add_arguments(parser)\n\n args = parser.parse_args()\n\n psfv = PSFValidate(args)\n psfv.run()\n"
},
{
"alpha_fraction": 0.589442789554596,
"alphanum_fraction": 0.6297653913497925,
"avg_line_length": 34.894737243652344,
"blob_id": "6b109166a5d316dc4202353fa39aabb58d24eaba",
"content_id": "f0200df236742862d110577f39780e77feb7c307",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1364,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 38,
"path": "/gammatools/core/tests/test_param_fn.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.parameter_set import *\nfrom gammatools.core.likelihood import *\nfrom gammatools.core.nonlinear_fitting import *\nfrom gammatools.core.model_fn import *\nfrom gammatools.core.histogram import *\n\nclass TestParamFn(unittest.TestCase):\n\n def test_param_fn(self):\n\n def test_fn(x,y):\n return x**2 + 0.2*y**2 - 3.3*y + 4.4*x\n\n x0, y0 = 4.0, -1.7\n x1, y1 = -3.1, 2.3\n x2, y2 = [1.0,2.0,3.0], [-10.3,-1.4,2.2]\n \n pfn = ParamFn.create(test_fn,[x0,y0])\n\n # Test evaluation with internal parameter values\n self.assertEqual(pfn(),test_fn(x0,y0))\n\n # Test evaluation with parameter value scalar arguments\n self.assertEqual(pfn(x1,y1),test_fn(x1,y1))\n\n # Test evaluation with parameter value list arguments\n assert_array_equal(pfn(x2,y2),test_fn(np.array(x2),np.array(y2)))\n\n # Test evaluation with parameter value array arguments\n assert_array_equal(pfn(np.array(x2),np.array(y2)),\n test_fn(np.array(x2),np.array(y2)))\n\n # Test evaluation with parameter value matrix arguments\n assert_array_equal(pfn(np.vstack((np.array(x2),np.array(y2)))),\n test_fn(np.array(x2),np.array(y2)))\n"
},
{
"alpha_fraction": 0.5901698470115662,
"alphanum_fraction": 0.6013733148574829,
"avg_line_length": 25.080188751220703,
"blob_id": "0346cbc50f8b98ffdb61384943bb3f7b29581bd3",
"content_id": "ba0666df298dbb36c2852e73b82ee1a402d85461",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5534,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 212,
"path": "/scripts/skyplot.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\nimport os\nimport sys\nimport copy\nimport argparse\nimport pyfits\n\nimport numpy as np\n\nimport matplotlib\n\n#try: os.environ['DISPLAY']\n#except KeyError: matplotlib.use('Agg')\n\nmatplotlib.interactive(False)\nmatplotlib.use('Agg')\n\nimport matplotlib.pyplot as plt\n\nfrom matplotlib.figure import Figure\nfrom matplotlib.pyplot import gcf, setp\n\n\nfrom matplotlib.widgets import Slider, Button, RadioButtons\nfrom gammatools.core.fits_util import SkyImage, SkyCube, FITSImage\nfrom gammatools.core.fits_viewer import *\nfrom gammatools.core.mpl_util import PowerNormalize\nfrom gammatools.fermi.irf_util import *\nfrom gammatools.fermi.psf_model import *\n\n\n\n\ndef get_irf_version(header):\n\n for k, v in header.iteritems():\n\n m = re.search('DSTYP(\\d)',k) \n if m is None or v != 'IRF_VERSION': continue\n\n return header['DSVAL%s'%(m.group(1))]\n\n return None\n\nusage = \"usage: %(prog)s [options] [FT1 file ...]\"\ndescription = \"\"\"Plot the contents of a FITS image file.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--gui', action='store_true')\n\nparser.add_argument('--rsmooth', default=0.3, type=float)\n\nparser.add_argument('--model_file', default=None)\nparser.add_argument('--prefix', default=None)\n\nparser.add_argument('--hdu', default = 0, type=int,\n help = 'Set the HDU to plot.')\n\n\nargs = parser.parse_args()\n\nhdulist = pyfits.open(args.files[0])\nmodel_hdu = None\nirf_version = None\nim_mdl = None\n\n\nim = FITSImage.createFromHDU(hdulist[args.hdu])\n\n\nif args.model_file:\n model_hdu = pyfits.open(args.model_file)[0]\n irf_version = get_irf_version(model_hdu.header)\n im_mdl = FITSImage.createFromHDU(model_hdu)\n \n\n#fp = FITSPlotter(im,im_mdl,None,args.prefix)\n\n#fp.make_plots_skycube(None,smooth=True,resid_type='fractional',\n# suffix='_data_map_resid_frac')\n\n#fp.make_plots_skycube(4,smooth=True,resid_type='fractional',\n# suffix='_data_map_slice_resid_frac')\n\n#sys.exit(0)\n\n \nirf_dir = '/u/gl/mdwood/ki10/analysis/custom_irfs/'\nif 'CUSTOM_IRF_DIR' in os.environ:\n irf_dir = os.environ['CUSTOM_IRF_DIR']\n\n\nirf = None\nm = None\n\nif irf_version:\n irf = IRFManager.create(irf_version, True,irf_dir=irf_dir)\n ltfile = '/Users/mdwood/fermi/data/p301/ltcube_5years_zmax100.fits'\n m = PSFModelLT(irf,src_type='iso')\n\n\n\n \n#for k, v in hdulist[0].header.iteritems():\n# print k, v\n \n#viewer = FITSImageViewer(im)\n#viewer.plot()\n\n\n\nif args.gui:\n \n app = wx.App()\n\n frame = FITSViewerFrame(args.files,hdu=args.hdu,parent=None,\n title=\"FITS Viewer\",\n size=(2.0*640, 1.5*480))\n\n frame.Show()\n\n\n \n#frame = Frame(im)\n\n\n\n#frame.Show(True)\n\n\n app.MainLoop()\n plt.show()\n\n\n\nelse:\n \n im = FITSImage.createFromHDU(hdulist[args.hdu])\n\n im_mdl = None\n if model_hdu:\n im_mdl = FITSImage.createFromHDU(model_hdu)\n \n\n fp = FITSPlotter(im,im_mdl,m,args.prefix,rsmooth=args.rsmooth)\n \n if isinstance(im,SkyImage):\n fp.make_projection_plots_skyimage(im)\n elif isinstance(im,SkyCube):\n\n # All Energies \n fp.make_energy_residual(suffix='_eresid')\n\n fp.make_plots_skycube(smooth=True,resid_type='significance',\n suffix='_data_map_resid_sigma',plots_per_fig=1)\n\n fp.make_mdl_plots_skycube(suffix='_mdl_map_slice',plots_per_fig=1)\n \n fp.make_plots_skycube(suffix='_data_map',plots_per_fig=1,\n make_projection=True,projection=0.5)\n \n fp.make_plots_skycube(suffix='_data_map_smooth',plots_per_fig=1,\n make_projection=True,projection=0.5,smooth=True)\n \n# fp.make_plots_skycube(smooth=True,\n# suffix='_data_map_smooth',plots_per_fig=1)\n \n# make_plots_skycube(im,4,smooth=True,\n# im_mdl=im_mdl,suffix='_data_map_slice_smooth')\n\n \n \n delta_bin = [2,2,4,10]\n\n\n # Slices\n fp.make_mdl_plots_skycube(suffix='_mdl_map_slice',plots_per_fig=1,delta_bin=delta_bin)\n \n fp.make_mdl_plots_skycube(suffix='_mdl_map_normp3',plots_per_fig=1,\n zscale='pow',zscale_power=4.0,delta_bin=delta_bin)\n\n fp.make_plots_skycube(suffix='_data_map_slice',plots_per_fig=1,delta_bin=delta_bin,\n make_projection=True,projection=0.5)\n \n fp.make_plots_skycube(suffix='_data_map_slice_smooth',plots_per_fig=1,delta_bin=delta_bin,\n make_projection=True,projection=0.5,smooth=True)\n\n fp.make_plots_skycube(smooth=True,resid_type='significance',\n suffix='_data_map_slice_resid_sigma',plots_per_fig=1,\n delta_bin=delta_bin)\n \n sys.exit(0)\n \n fp.make_plots_skycube(smooth=True,resid_type='fractional',\n suffix='_data_map_resid_frac',plots_per_fig=1)\n\n fp.make_plots_skycube(smooth=True,resid_type='fractional',\n suffix='_data_map_slice_resid_frac')\n\n \n \n sys.exit(0)\n \n make_plots_skycube(im,4,residual=True,\n im_mdl=im_mdl,suffix='_data_map_resid2')\n \n make_plots_skycube(im_mdl,4,suffix='_mdl_map')\n \n"
},
{
"alpha_fraction": 0.7579250931739807,
"alphanum_fraction": 0.7579250931739807,
"avg_line_length": 20.030303955078125,
"blob_id": "f4208f90c3aa09baff92f6e243d233016334b81a",
"content_id": "b22ca267d6a37f0294b20d275559781c4809940b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 694,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 33,
"path": "/scripts/gtobssim.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport logging\nimport shutil\nimport yaml\nimport numpy as np\nimport argparse\nfrom gammatools.fermi.task import ObsSimTask\nfrom gammatools.core.util import dispatch_jobs\n\nusage = \"%(prog)s [options]\"\ndescription = \"\"\"Run gtobssim.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\n#parser.add_argument('files', nargs='+')\n#parser.add_argument('--output',required=True)\nparser.add_argument('--config',default=None)\n\nObsSimTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\nconfig = None\n\nif args.config:\n config = yaml.load(open(args.config))\n\ngtobssim = ObsSimTask(config,opts=args)\n\ngtobssim.run()\n"
},
{
"alpha_fraction": 0.454071968793869,
"alphanum_fraction": 0.4695785939693451,
"avg_line_length": 28.879432678222656,
"blob_id": "e5ec18d348937f20f3b1cf3967bdec3a0d90a1a6",
"content_id": "800352de1f5978fcbcb8f52f8bc136b1786b28e2",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8448,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 282,
"path": "/scripts/plot_dsph_results.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport sys\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport argparse\nimport yaml\nimport copy\n\nfrom gammatools.core.plot_util import FigTool\nfrom gammatools.core.util import update_dict, eq2gal\nfrom gammatools.core.histogram import Histogram, Axis\nfrom dsphs.base.results import TargetResults, AnalysisResults\nfrom pywcsgrid2.allsky_axes import *\nfrom matplotlib.offsetbox import AnchoredText\n\ndef merge_targets(results):\n pass\n\ndef make_allsky_scatter(x,y,z,filename):\n\n fig = plt.figure()\n ax = make_allsky_axes(fig,111,\"gal\",\"AIT\",lon_center=0)\n \n p = ax['fk5'].scatter(x,y,c=z,vmin=0,vmax=5,s=10)\n ax.grid(True)\n\n cb = plt.colorbar(p,orientation='horizontal',\n shrink=0.9,pad=0.15,\n fraction=0.05)\n \n plt.savefig(filename)\n\n\ndef make_ts_hists(hists):\n pass\n \n\nif __name__ == \"__main__\":\n\n usage = \"usage: %(prog)s [options] [results file]\"\n description = \"Plot results of dsph analysis.\"\n parser = argparse.ArgumentParser(usage=usage,description=description)\n\n parser.add_argument('files', nargs='+')\n parser.add_argument('--labels', default=None)\n parser.add_argument('--colors', default=None)\n parser.add_argument('--ylim_ratio', default='0.6/1.4')\n parser.add_argument('--prefix', default='')\n\n args = parser.parse_args()\n\n labels = args.labels.split(',')\n\n if args.colors: colors = args.colors.split(',')\n else: colors = ['b','g','r','m','c']\n\n ylim_ratio = [float(t) for t in args.ylim_ratio.split('/')]\n \n hist_set = {'title' : 'test',\n 'ts' : Histogram(Axis.create(0.,16.,160)), \n 'fluxul' : Histogram(Axis.create(-12,-8,100)) }\n \n pwl_hists = []\n dm_hists = []\n\n hists = {}\n \n results = []\n\n\n limits = {}\n \n for f in args.files:\n \n# results = AnalysisResults(f)\n# print results.median('composite') \n# print results.get_results('draco')\n ph = copy.deepcopy(hist_set)\n pwl_hists.append(ph)\n\n dh = []\n \n c = yaml.load(open(f,'r'),Loader=yaml.CLoader)\n\n o = {}\n \n for target_name, target in c.iteritems():\n\n limits.setdefault(target_name,{})\n limits[target_name].setdefault('masses',target['bb']['masses'])\n limits[target_name].setdefault('limits',[])\n\n pulimits = target['bb']['pulimits99']\n \n nancut = ~np.isnan(np.sum(pulimits,axis=1))\n \n limits[target_name]['limits'].append(np.median(pulimits[nancut],axis=0))\n\n if target_name == 'composite':\n print f, target_name, np.median(pulimits[nancut],axis=0)\n \n if target_name != 'composite': \n target['bb']['masses'] = \\\n target['bb']['masses'].reshape((1,) + target['bb']['masses'].shape)\n \n update_dict(o,target,True,True)\n \n\n results.append(o)\n\n\n# plt.figure()\n# plt.plot(c['composite']['bb']['masses'],np.median(c['composite']['bb']['pulimits'],axis=0)) \n# plt.show()\n \n masses = o['bb']['masses'][0]\n for m in masses:\n dh.append(copy.deepcopy(hist_set))\n\n dm_hists.append(dh)\n\n\n if 'pwl' in o:\n ts = o['pwl']['ts']\n ts[ts<0] = 0 \n ph['ts'].fill(np.ravel(ts))\n\n if 'fluxes' in o['pwl']:\n ph['fluxul'].fill(np.log10(np.ravel(o['pwl']['fluxes'])))\n ph['title'] = 'Powerlaw Gamma = 2.0'\n \n hists.setdefault('pwl', [])\n hists['pwl'].append(ph)\n \n for i, (m, h) in enumerate(zip(masses,dh)):\n ts = o['bb']['ts'][:,i]\n ts[ts<0] = 0\n h['ts'].fill(ts)\n if 'fluxes' in o['bb']:\n h['fluxul'].fill(np.log10(np.ravel(o['bb']['fluxes'][:,i])))\n h['title'] = r'$b \\bar b$' + ', M = %.f GeV'%m\n\n key = 'bb' + '_m%05.f'%m\n \n hists.setdefault(key, [])\n hists[key].append(h)\n \n\n ft = FigTool()\n \n for k,v in limits.iteritems():\n\n if k != 'composite': continue\n\n fig = ft.create(args.prefix + '%s_sigmav_ul'%k,\n xscale='log',yscale='log',\n ylim_ratio=ylim_ratio,\n color=colors,\n xlabel='Mass',ylabel='Sigmav',figstyle='ratio2')\n \n for j, f in enumerate(args.files):\n fig[0].add_data(v['masses'],v['limits'][j],label=labels[j])\n \n fig.plot()\n \n \n # Make All-sky hists\n for j, f in enumerate(args.files):\n\n continue\n \n make_allsky_scatter(results[j]['target']['ra'],\n results[j]['target']['dec'],\n np.sqrt(np.ravel(results[j]['pwl']['ts'])),\n 'allsky_pwl.png')\n\n for i, m in enumerate(masses):\n make_allsky_scatter(results[j]['target']['ra'],\n results[j]['target']['dec'],\n np.sqrt(np.ravel(results[j]['bb']['ts'][:,i])),\n 'allsky%02i_bb_%010.2f.png'%(j,m))\n \n# for x, y, z in zip(results[j]['target']['ra'],results[j]['target']['dec'],\n# np.ravel(results[j]['pwl']['ts'])):\n# print x, y, z, eq2gal(x,y)\n \n# print results[j]['target']\n# print results[j]['pwl']['ts'] \n \n \n\n \n \n for k, hist in hists.iteritems():\n\n if k == 'pwl': continue\n \n fig = plt.figure()\n ax = fig.add_subplot(111)\n\n label1 = AnchoredText(hist[0]['title'], loc=2,\n prop={'size':16,'color': 'k'},\n pad=0., borderpad=0.75,\n frameon=False)\n\n ax.add_artist(label1)\n\n\n handles = []\n \n for j, f in enumerate(args.files):\n\n# ax.set_title('M= %.2f GeV'%(m))\n# ax.set_title(hist[j]['title'])\n\n h = hist[j]['ts']\n h = h.normalize().cumulative(False)\n artists = h.plot(hist_style='band',linewidth=1,\n color=colors[j],mask_neg=True,\n label=labels[j])\n handles += [[tuple(artists),labels[j]]]\n\n \n from scipy.special import erfc\n\n label0 = AnchoredText('Preliminary', loc=3,\n prop={'size':18,'color': 'red'},\n pad=0., borderpad=0.75,\n frameon=False)\n ax.add_artist(label0)\n \n x = h.axis().center \n pl, = plt.plot(h.axis().center,0.5*erfc(np.sqrt(x)/np.sqrt(2.)),\n color='k',linestyle='--',label='$\\chi_{1}^2/2$')\n handles += [[pl,'$\\chi_{1}^2/2$']]\n \n ax.grid(True)\n ax.set_yscale('log')\n\n print \n \n ax.legend(zip(*handles)[0],zip(*handles)[1],\n loc='best',prop= {'size' : 10 })\n \n ax.set_ylim(1E-4,1E1)\n ax.set_xlim(0,10)\n ax.set_xlabel('TS')\n ax.set_ylabel('Cumulative Fraction')\n \n plt.savefig(args.prefix + 'ts_%s.png'%(k))\n \n \n fig = plt.figure()\n\n text = ''\n \n for j, f in enumerate(args.files):\n\n ax = fig.add_subplot(111)\n ax.set_title(hist[j]['title'])\n\n h = hist[j]['fluxul'].normalize()\n h.plot(hist_style='step',linewidth=1,\n color=colors[j],\n label=labels[j],marker='o')\n\n text += '%20s = %.3f\\n'%(labels[j] + ' Mean',h.mean())\n \n plt.gca().grid(True)\n\n\n plt.gca().text(0.5,0.95,text,transform=plt.gca().transAxes,\n fontsize=10,verticalalignment='top',\n horizontalalignment='right')\n \n plt.gca().legend(loc='upper right',prop= {'size' : 12 })\n plt.gca().set_ylim(plt.gca().axis()[2],1.25*plt.gca().axis()[3])\n \n plt.gca().set_xlabel('Flux Upper Limit [log$_{10}$(Flux/ph cm$^{-2}$ s$^{-1}$)]')\n \n plt.savefig(args.prefix + 'ul_%s.png'%(k))\n \n \n"
},
{
"alpha_fraction": 0.5141525268554688,
"alphanum_fraction": 0.5167670845985413,
"avg_line_length": 30.873188018798828,
"blob_id": "a708b832f7774350e7b44d33c298a19f1ce804ad",
"content_id": "e52ee728aceb9565d6f41c8a26e8e4412f9f3e05",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8797,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 276,
"path": "/gammatools/core/config.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import inspect\nimport os\nimport copy\nfrom util import update_dict\n\nclass Option(object):\n\n def __init__(self,name,value,docstring='',option_type=str,group=None):\n self._name = name\n self._value = value\n self._docstring = docstring\n self._option_type = option_type\n self._group = group\n\n if option_type == list and len(value):\n self._list_type = type(value[0])\n else:\n self._list_type = str\n \n \n @property\n def name(self):\n return self._name\n \n @property\n def value(self):\n return self._value\n\n @property\n def docstring(self):\n return self._docstring\n\n @property\n def type(self):\n return self._option_type\n\n @property\n def list_type(self):\n return self._list_type\n\n @property\n def group(self):\n return self._group\n\n @property\n def argname(self):\n\n if self._group is not None:\n return self._group + '.' + self._name\n else: return self._name\n \n @staticmethod\n def create(name,x,group=None):\n \"\"\"Create an instance of an option from a tuple or a scalar.\"\"\"\n\n if len(name.split('.')) > 1: \n group, name = name.split('.')\n \n #isinstance(x,list): return Option(x[0],x[1])\n if isinstance(x,Option): return x\n elif isinstance(x,tuple):\n if len(x) == 1:\n value, docstring, option_type = x[0], '', str\n elif len(x) == 2:\n value, docstring, option_type = x[0], x[1], str\n elif len(x) == 3:\n value, docstring, option_type = x[0], x[1], x[2]\n else:\n raise Exception('Wrong size for option tuple.')\n\n if value is not None: option_type = type(value)\n \n return Option(name,value,docstring,option_type,group=group)\n else:\n if x is not None: option_type = type(x)\n else: option_type = str \n return Option(name,x,option_type=option_type,group=group)\n\nclass Configurable(object):\n\n def __init__(self,config=None,register_defaults=True,**kwargs):\n \n self._config = {}\n self._default_config = {}\n if register_defaults: self.register_default_config(self)\n self.configure(config,**kwargs)\n\n @property\n def config(self):\n return self._config\n \n @classmethod\n def register_default_config(cls,c,key='default_config',\n group_key='default_subsection'):\n \"\"\"Register default configuration dictionaries for this class\n and all classes from which it inherits.\"\"\"\n \n for base_class in inspect.getmro(cls):\n\n if key in base_class.__dict__:\n c.update_default_config(base_class.__dict__[key])\n# else:\n# raise Exception('No config dictionary with key %s '%key +\n# 'in %s'%str(cls))\n \n @classmethod\n def get_default_config(cls,key='default_config',group=None):\n \n o = {} \n for base_class in inspect.getmro(cls):\n if key in base_class.__dict__:\n o.update(base_class.__dict__[key])\n \n for k in o.keys():\n o[k] = Option.create(k,o[k],group=group)\n\n return o\n\n @classmethod\n def get_class_config(cls,key='default_config',group=None):\n \n o = copy.deepcopy(cls.__dict__[key])\n for k in o.keys():\n o[k] = Option.create(k,o[k],group=group)\n\n return o\n\n @classmethod\n def add_arguments(cls,parser,config=None,group=None,skip=None):\n \n if config is None:\n config = cls.get_default_config(group=group).values()\n \n groups = {}\n# for k, v in config.iteritems():\n for v in config:\n if v.group is not None and not v.group in groups:\n groups[v.group] = parser.add_argument_group(v.group)\n\n# for k, v in config.iteritems():\n for v in config:\n\n if skip is not None and v.name in skip: continue\n \n if v.group is None: group = parser\n else: group = groups[v.group]\n\n if v.type == bool:\n group.add_argument('--' + v.argname,default=v.value,\n action='store_true',\n help=v.docstring + ' [default: %s]'%v.value)\n else:\n\n if isinstance(v.value,list):\n value=','.join(map(str,v.value))\n opt_type = str\n else:\n value = v.value\n opt_type = v.type\n \n group.add_argument('--' + v.argname,default=value,\n type=opt_type,\n help=v.docstring + ' [default: %s]'%v.value)\n \n \n def update_config(self,config):\n update_dict(self._config,config)\n\n def update_default_config(self,default_dict,group=None):\n \"\"\"Update configuration for the object adding keys for\n elements that are not present. If group is defined then\n this configuration will be nested in a dictionary with that\n key.\"\"\"\n if default_dict is None: return\n\n if not isinstance(default_dict,dict) and \\\n issubclass(default_dict,Configurable):\n default_dict = default_dict.default_config\n elif not isinstance(default_dict,dict):\n raise Exception('Wrong type for default dict.')\n\n if group:\n default_config = self._default_config.setdefault(group,{})\n self._config.setdefault(group,{})\n else:\n default_config = self._default_config\n \n update_dict(default_config,default_dict,True)\n for k in default_dict.keys():\n# if not isinstance(self._default_config[k],Option):\n option = Option.create(k,default_dict[k],group=group) \n default_config[option.name] = option\n\n if option.group:\n self._config.setdefault(option.group,{})\n self._config[option.group][option.name] = option.value\n else:\n self._config[option.name] = self._default_config[k].value\n \n def print_config(self):\n \n print 'CONFIG'\n for k, v in self._default_config.iteritems():\n print '%20s %10s %10s %s'%(k,self._config[k],v.value,\n v.docstring)\n\n @property\n def config(self):\n return self._config\n\n def config_docstring(self,key):\n return self._default_config[key].docstring\n\n def set_config(self,key,value):\n self._config[key] = value\n\n def parse_opts(self,opts):\n\n# import pprint\n# pprint.pprint(self._config)\n \n for k,v in opts.__dict__.iteritems():\n\n if v is None: continue\n\n print 'Parsing ', k, v\n \n argname = k.split('.')\n if len(argname) == 2:\n group = argname[0]\n name = argname[1]\n \n default_config = self._default_config[group][name]\n config = self._config[group]\n else:\n name = argname[0]\n\n if not name in self._default_config: continue\n \n default_config = self._default_config[name]\n config = self._config\n \n \n if isinstance(config,list) and not isinstance(v,list):\n value = v.split(',')\n value = map(default_config.list_type,value)\n# self.set_config(k,value)\n else:\n value = v\n\n config[name] = v\n\n \n def configure(self,config=None,opts=None,group=None,**kwargs):\n \"\"\"Update the configuration of this object with the contents\n of 'config'. When the same option is defined in multiple\n inputs the order of precedence is config -> opts -> kwargs.\"\"\"\n \n if not config is None:\n\n if group and not group in config:\n raise Exception('Exception')\n\n if group:\n update_dict(self._config,config[group])\n else:\n update_dict(self._config,config)\n \n if not opts is None: self.parse_opts(opts)\n \n update_dict(self._config,kwargs)\n \n for k, v in self._config.iteritems():\n\n if v is None or not isinstance(v,str): continue \n if os.path.isfile(v): self._config[k] = os.path.abspath(v)\n"
},
{
"alpha_fraction": 0.6083423495292664,
"alphanum_fraction": 0.6121343374252319,
"avg_line_length": 25.753623962402344,
"blob_id": "3d63608467269f88ac0a3f7e21c7484b1765829e",
"content_id": "45b6e359db79507b5903bfa8b641f1857b1bd81e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1846,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 69,
"path": "/scripts/make_ft1.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport argparse\nimport tempfile\nimport re\nimport shutil\nfrom gammatools.core.util import dispatch_jobs\n\nusage = \"usage: %(prog)s [options] [files]\"\ndescription = \"Run the makeft1 application on a Merit file.\"\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--xml_classifier', default = None,\n required=True,\n help = 'Set the XML cut definition file.')\n\nparser.add_argument('--dict_file', default = None,\n required=True,\n help = 'Set the file that defines the mapping from Merit '\n 'to FT1 variables.')\n\nparser.add_argument('--queue', default = None,\n help='Set the batch queue name.')\n\nargs = parser.parse_args()\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue)\n sys.exit(0)\n\nxml_classifier = os.path.abspath(args.xml_classifier)\ndict_file = os.path.abspath(args.dict_file)\n \ninput_files = []\nfor x in args.files: input_files.append(os.path.abspath(x))\n\ncwd = os.getcwd()\nuser = os.environ['USER']\ntmpdir = tempfile.mkdtemp(prefix=user + '.', dir='/scratch')\n\nprint 'tmpdir ', tmpdir\nos.chdir(tmpdir)\n\nfor x in input_files:\n\n fitsFile = os.path.splitext(x)[0] + '_ft1.fits'\n inFile = os.path.basename(x)\n\n print 'cp %s %s'%(x,inFile)\n os.system('cp %s %s'%(x,inFile))\n \n cmd = 'makeFT1 '\n options = { 'rootFile' : inFile,\n 'xml_classifier' : xml_classifier,\n 'fitsFile' : fitsFile,\n 'dict_file' : dict_file,\n 'TCuts' : '1' }\n\n for k, v in options.iteritems(): cmd += ' %s=%s '%(k,v)\n \n print cmd\n os.system(cmd)\n\nos.chdir(cwd)\nshutil.rmtree(tmpdir)\n"
},
{
"alpha_fraction": 0.5150554776191711,
"alphanum_fraction": 0.5295449495315552,
"avg_line_length": 27.49032211303711,
"blob_id": "68226497aa536a70243bc3134d7099426807fb0c",
"content_id": "8167de82bc4b8282d7828b28f89f5cf426a6420c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4417,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 155,
"path": "/scripts/calc_dmlimit.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport re\n\nimport yaml\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n#import gammatools.dm.jcalc as jcalc\nfrom gammatools.dm.jcalc import *\nfrom gammatools.dm.irf_model import *\nfrom gammatools.dm.dmmodel import *\nfrom scipy.interpolate import UnivariateSpline\nfrom gammatools.dm.halo_model import *\nfrom gammatools.core.stats import limit_pval_to_sigma\n\nimport argparse\n\nif __name__ == \"__main__\":\n\n usage = \"usage: %(prog)s [options]\"\n description = \"\"\"Calculate sensitivity.\"\"\"\n\n parser = argparse.ArgumentParser(usage=usage,description=description)\n \n parser.add_argument('--sthresh', default=None, type=float,\n help = '')\n \n parser.add_argument('--ulthresh', default=None, type=float,\n help = '')\n\n parser.add_argument('--livetime', default=50.0, type=float,\n help = 'Set the exposure in hours.')\n\n parser.add_argument('--rmax', default=None, type=float,\n help = '')\n \n parser.add_argument('--output', default='limits.P', \n help = 'Output file to which limit data will be written.')\n \n parser.add_argument('--source', default=None, \n help = '',required=True)\n\n parser.add_argument('--chan', default='bb', \n help = 'Set the annihilation channel.')\n\n parser.add_argument('--median', default=False, action='store_true',\n help = '')\n\n parser.add_argument('--redge', default=0.0, type=float,\n help = '')\n\n parser.add_argument('--alpha', default=0.2, type=float,\n help = '')\n\n parser.add_argument('--min_fsig', default=0.0, type=float,\n help = '')\n\n parser.add_argument('--plot_lnl', default=False, action='store_true',\n help = '')\n\n parser.add_argument('--irf', default=None, \n help = 'Set the input IRF file.',\n required=True)\n\n parser.add_argument('files', nargs='*')\n\n args = parser.parse_args()\n\n if not args.ulthresh is None:\n sthresh = limit_pval_to_sigma(1.0-args.ulthresh)\n else:\n sthresh = args.sthresh\n\n\n hm = HaloModelFactory.create(args.source)\n irf = IRFModel.createCTAIRF(args.irf)\n chm = ConvolvedHaloModel(hm,irf)\n\n\n src_model = DMFluxModel.createChanModel(chm,1000.0*Units.gev,\n 1E-24*Units.cm3_s,\n args.chan)\n\n dm = DMLimitCalc(irf,args.alpha,args.min_fsig,args.redge)\n\n\n if args.chan == 'ww': mass = np.linspace(2.0,4.0,20)\n elif args.chan == 'zz': mass = np.linspace(2.1,4.0,20)\n else: mass = np.linspace(1.75,4.0,19)\n\n livetime = args.livetime*Units.hr\n\n srcs = []\n\n if len(args.files) == 1:\n d = np.loadtxt(args.files[0],unpack=True)\n\n if args.median:\n rs = np.median(d[1])\n rhos = np.median(d[2])\n d = np.array([[0.],[rs],[rhos]])\n\n s = copy.deepcopy(src) \n s['rhos'] = np.median(d[2])\n s['rs'] = np.median(d[1])\n srcs.append(s)\n else:\n\n for i in range(len(d[0])):\n s = copy.deepcopy(src)\n s['rhos'] = d[2][i]\n s['rs'] = d[1][i]\n if len(d) == 4: s['alpha'] = d[3][i]\n srcs.append(s)\n else:\n srcs.append(hm)\n \n\n o = { 'ul' : np.zeros(shape=(len(srcs),len(mass))), \n 'mass' : mass }\n\n jval = []\n rs = []\n\n for i, s in enumerate(srcs):\n\n dp = s._dp\n\n# jval = dp.jval()/(s['dist']*Units.kpc)**2\n# print dp._rs/Units.kpc, dp._rhos/Units.gev_cm3, jval/Units.gev2_cm5\n# sys.exit(0)\n\n jval.append(dp.jval()/(s.dist*Units.kpc)**2)\n rs.append(dp.rs)\n\n print np.median(np.array(jval))/Units.gev2_cm5\n print np.median(np.array(rs))/Units.kpc\n\n\n for i, s in enumerate(srcs):\n\n src_model._hm = ConvolvedHaloModel(hm,irf)\n o['ul'][i] = dm.limit(src_model,np.power(10,mass)*Units.gev,\n livetime,sthresh)\n\n \n \n# if args.plot_lnl:\n# for j, x in enumerate(mass):\n# dm.plot_lnl(src_model,np.power(10,x)*Units.gev,ul[0][j],tau)\n\n save_object(o,args.output,True)\n\n"
},
{
"alpha_fraction": 0.5316067337989807,
"alphanum_fraction": 0.5467323064804077,
"avg_line_length": 24.713762283325195,
"blob_id": "e6b14df7eb365dcd93996af797370b49abbfd91d",
"content_id": "23b47c268de40ef24844d0e47089d8090d6eb087",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14016,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 545,
"path": "/gammatools/core/model_fn.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@file model_fn.py\n\n@brief Python classes related to fitting/calculation of likelihoods.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood <[email protected]>\"\n\nimport numpy as np\nimport copy\nimport re\nimport abc\nimport inspect\nfrom scipy.interpolate import UnivariateSpline\nfrom histogram import Histogram\nfrom util import expand_aliases, get_parameters\nfrom minuit import Minuit\nfrom parameter_set import Parameter, ParameterSet\nimport matplotlib.pyplot as plt\n\nclass ParamFnBase(object):\n \"\"\"Base class for a parameterized function.\"\"\"\n\n def __init__(self, param = None, name = None):\n\n if param is None: self._param = ParameterSet()\n else: self._param = param\n self._name = name\n\n @staticmethod\n def create(npar):\n\n fn = ParamFn()\n for i in range(npar):\n pass\n\n def setName(self,name):\n \"\"\"Set the name of the function.\"\"\"\n self._name = name\n\n def name(self):\n \"\"\"Return the name of the function.\"\"\"\n return self._name\n\n def npar(self):\n return self._param.npar()\n\n def param(self,make_copy=False):\n \"\"\"Get the parameter set of this function. If the optional input\n argument set is defined then return a copy of the model\n parameter set with values updated from this set.\"\"\"\n\n if make_copy: return copy.deepcopy(self._param)\n else: return self._param\n\n def update(self,pset):\n \"\"\"Update the parameters of this function.\"\"\"\n self._param.update(pset)\n\nclass ParamFn(ParamFnBase):\n\n def __init__(self,fn,pset,name=None):\n ParamFnBase.__init__(self,pset,name)\n self._fn = fn\n\n @staticmethod\n def create(fn,p0):\n\n # Construct a parameter set from inspection of the input function\n npar = len(inspect.getargspec(fn)[0])\n pset = ParameterSet()\n for i in range(npar): pset.createParameter(p0[i])\n return ParamFn(fn,pset)\n\n def __call__(self,*args):\n\n pset = self.param(True)\n pset.update(*args)\n\n return self._fn(*pset.list())\n\nclass PDF(ParamFnBase): \n \"\"\"Abstract base class for a probability distribution function.\n All derived classes must implement an _eval_pdf method which returns\n the function amplitude at a given point in the function phase\n space.\"\"\"\n\n __metaclass__ = abc.ABCMeta\n\n def __init__(self, pset=None, name=None):\n ParamFnBase.__init__(self,pset,name)\n\n def __call__(self,x,p=None):\n return self.eval(x,p)\n\n def eval(self,x,p=None):\n \n pset = self.param(True)\n pset.update(p)\n\n x = np.array(x,ndmin=1)\n\n return self._eval_pdf(x,pset)\n \n @abc.abstractmethod\n def _eval_pdf(self,x,p):\n pass\n\n def set_norm(self,norm,xlo,xhi):\n\n n = self.integrate(xlo,xhi)\n\n for i, p in enumerate(self._param):\n self._param[i].set(self._param[i].value*norm/n)\n\n def integrate(self,xlo,xhi,p=None):\n \n pset = self.param(True)\n pset.update(p)\n\n xlo = np.array(xlo,ndmin=1)\n xhi = np.array(xhi,ndmin=1)\n\n return self._integrate(xlo,xhi,pset)\n\n def _integrate(self,xlo,xhi,p):\n\n w = xhi-xlo\n xc = 0.5*(xhi+xlo)\n return w*self._eval_pdf(xc,p)\n\n def histogram(self,edges,p=None):\n \n pset = self.param(True)\n pset.update(p)\n edges = np.array(edges,ndmin=1)\n\n return self._integrate(edges[:-1],edges[1:],pset)\n\n def create_histogram(self,axis,p=None):\n\n c = self.histogram(axis.edges(),p)\n return Histogram(axis,counts=c,var=0)\n\n def rnd(self,n,xmin,xmax,p=None):\n\n x = np.linspace(xmin,xmax,1000)\n cdf = self.cdf(x,p)\n cdf /= cdf[-1]\n\n fn = UnivariateSpline(cdf,x,s=0,k=1)\n\n pv = np.random.uniform(0.0,1.0,n)\n\n return fn(pv)\n \n def cdf(self,x,p=None): \n return self.integrate(np.zeros(shape=x.shape),x,p)\n\nclass ScaledHistogramModel(PDF):\n\n def __init__(self,h,pset,name=None):\n PDF.__init__(self,pset,name)\n self._h = copy.deepcopy(h)\n \n @staticmethod\n def create(h,norm=1.0,pset=None,name=None,prefix=''):\n\n if pset is None: pset = ParameterSet()\n p0 = pset.createParameter(norm,prefix + 'norm')\n return ScaledHistogramModel(h,ParameterSet([p0]),name) \n\n def var(self,p):\n\n pset = self.param(True)\n pset.update(p)\n \n a = pset.array()\n if a.shape[1] > 1: a = a[...,np.newaxis] \n return a[0]**2*self._h.var\n\n def counts(self,p):\n\n pset = self.param(True)\n pset.update(p)\n \n a = pset.array()\n if a.shape[1] > 1: a = a[...,np.newaxis] \n return a[0]*self._h.counts\n \n def _eval_pdf(self,x,pset):\n \n a = pset.array()\n if a.shape[1] > 1: a = a[...,np.newaxis] \n return a[0]*self._h.interpolate(x)\n\n def _integrate(self,xlo,xhi,pset):\n \n a = pset.array()\n if a.shape[1] > 1: a = a[...,np.newaxis] \n return a[0]*self._h.counts\n \nclass ScaledModel(PDF):\n def __init__(self,model,pset,expr,name=None):\n PDF.__init__(self,name=name)\n\n# pset = model.param()\n par_names = get_parameters(expr)\n for p in par_names: \n self._param.addParameter(pset.getParByName(p))\n self._param.addSet(model.param())\n self._model = model\n\n aliases = {}\n for k, p in self._param._pars.iteritems():\n aliases[p.name()] = 'pset[%i]'%(p.pid())\n expr = expand_aliases(aliases,expr)\n self._expr = expr\n\n def eval(self,x,p=None):\n pset = self.param(True)\n pset.update(p)\n\n if self._expr is None: return self._model.eval(x,pset)\n else: return self._model.eval(x,pset)*eval(self._expr)\n\n def integrate(self,xlo,xhi,p=None): \n pset = self.param(True)\n pset.update(p)\n\n if self._expr is None: return self._model.integrate(xlo,xhi,pset)\n else: return self._model.integrate(xlo,xhi,pset)*eval(self._expr)\n\nclass CompositeSumModel(PDF):\n\n def __init__(self,models=None):\n PDF.__init__(self)\n self._models = []\n\n if not models is None:\n for m in models: self.addModel(m)\n \n def addModel(self,m):\n self._models.append(copy.deepcopy(m))\n self._param.addSet(m.param())\n\n def counts(self,pset=None):\n\n s = None\n for i, m in enumerate(self._models):\n\n v = m.counts(pset)\n \n if i == 0: s = v\n else: s += v\n return s\n\n def var(self,pset=None):\n\n s = None\n for i, m in enumerate(self._models):\n\n v = m.var(pset)\n \n if i == 0: s = v\n else: s += v\n return s\n \n def _eval_pdf(self,x,pset=None):\n\n s = None\n for i, m in enumerate(self._models):\n\n v = m.eval(x,pset)\n \n if i == 0: s = v\n else: s += v\n return s\n \n def _integrate(self,xlo,xhi,pset=None):\n\n s = None\n for i, m in enumerate(self._models):\n\n v = m.integrate(xlo,xhi,pset)\n\n if i == 0: s = v\n else: s += v\n return s\n\n def histogramComponents(self,edges,p=None):\n\n hists = []\n for i, m in enumerate(self._models):\n\n c = m.histogram(edges,p) \n h = Histogram(edges,label=m.name(),counts=c,var=0)\n \n hists.append(h)\n return hists\n\n \ndef polyval(c,x):\n\n c = np.array(c, ndmin=2, copy=True)\n x = np.array(x, ndmin=1, copy=True)\n\n# print 'x ', x.shape, x\n# print 'c ', c.shape, c\n \n x.shape = c.ndim*(1,) + x.shape \n c.shape += (1,)\n\n c0 = c[-1] \n for i in range(2, len(c) + 1) :\n c0 = c[-i] + c0*x\n\n# print 'c0 ', c0.shape, len(x)\n\n if c.shape[1] == 1:\n return c0.reshape(c0.shape[-1])\n else:\n return c0.reshape(c0.shape[1:])\n\nclass GaussFn(PDF):\n\n @staticmethod\n def create(norm,mu,sigma,pset=None):\n \n if pset is None: pset = ParameterSet()\n p0 = pset.createParameter(norm,'norm')\n p1 = pset.createParameter(mu,'mu')\n p2 = pset.createParameter(sigma,'sigma')\n return GaussFn(ParameterSet([p0,p1,p2]))\n\n def _eval_pdf(self,x,pset):\n return self.evals(x,pset.array())\n\n @staticmethod\n def evals(x,a):\n sig2 = a[2]**2 \n return a[0]/np.sqrt(2.*np.pi*sig2)*np.exp(-(x-a[1])**2/(2.0*sig2))\n\nclass Gauss2DProjFn(PDF):\n\n @staticmethod\n def create(norm,sigma,pset=None):\n \n if pset is None: pset = ParameterSet()\n p0 = pset.createParameter(norm,'norm')\n p1 = pset.createParameter(sigma,'sigma')\n return Gauss2DProjFn(ParameterSet([p0,p1]))\n\n def _eval_pdf(self,x,pset):\n return self.evals(x,pset.array())\n\n @staticmethod\n def evals(x,a):\n sig2 = a[1]**2 \n return a[0]/(2.*np.pi*sig2)*np.exp(-x**2/(2.0*sig2))\n\nclass Gauss2DFn(PDF):\n\n @staticmethod\n def create(norm,mux,muy,sigma,pset=None):\n \n if pset is None: pset = ParameterSet()\n p0 = pset.createParameter(norm,'norm')\n p1 = pset.createParameter(mux,'mux')\n p2 = pset.createParameter(muy,'muy')\n p3 = pset.createParameter(sigma,'sigma')\n return Gauss2DFn(ParameterSet([p0,p1,p2,p3]))\n\n def _eval_pdf(self,x,pset):\n return self.evals(x,pset.array())\n\n @staticmethod\n def evals(x,a):\n sig2 = a[3]**2 \n dx = (x[0]-a[1])**2\n dy = (x[1]-a[2])**2\n return a[0]/(2.*np.pi*sig2)*np.exp(-(dx+dy)/(2.0*sig2))\n\n \nclass SpectralModel(PDF):\n\n def flux(self,x,pset):\n return self._eval_pdf(x,pset)\n \n def eflux(self,x,pset):\n return 10**x*self._eval_pdf(x,pset)\n\n def e2flux(self,x,pset):\n return 10**(2*x)*self._eval_pdf(x,pset)\n\nclass LogParabola(PDF):\n\n def __init__(self,pset,name=None):\n PDF.__init__(self,pset,name)\n \n def _eval_pdf(self,x,pset):\n\n a = pset.array()\n es = 10**(x-a[3])\n return 10**a[0]*np.power(es,-(a[1]+a[2]*np.log(es)))\n\n @staticmethod\n def create(norm,alpha,beta,eb):\n\n pset = ParameterSet()\n pset.createParameter(np.log10(norm),'norm')\n pset.createParameter(alpha,'alpha')\n pset.createParameter(beta,'beta')\n pset.createParameter(np.log10(eb),'eb')\n return LogParabola(pset)\n\nclass PowerLawExp(PDF):\n\n def __init__(self,pset,name=None):\n PDF.__init__(self,pset,name)\n \n def _eval_pdf(self,x,pset):\n\n a = pset.array()\n es = 10**(x-a[3])\n return 10**a[0]*np.power(es,-a[1])*np.exp(-10**(x-a[2]))\n\n @staticmethod\n def create(norm,alpha,ecut,eb):\n\n pset = ParameterSet()\n pset.createParameter(np.log10(norm),'norm')\n pset.createParameter(alpha,'alpha')\n pset.createParameter(np.log10(ecut),'ecut')\n pset.createParameter(np.log10(eb),'eb')\n return PowerLawExp(pset)\n\nclass PowerLaw(PDF):\n\n def __init__(self,pset,name=None):\n PDF.__init__(self,pset,name) \n\n def _eval_pdf(self,x,pset):\n\n a = pset.array()\n es = 10**(x-a[2])\n return 10**a[0]*np.power(es,-a[1])\n\n def _integrate(self,xlo,xhi,p):\n\n x = 0.5*(xhi+xlo)\n dx = xhi-xlo\n\n a = pset.array()\n \n norm = 10**a[0]\n gamma = a[1]\n enorm = a[2]\n\n g1 = -gamma+1\n return norm/g1*10**(gamma*enorm)*(10**(xhi*g1) - 10**(xlo*g1))\n\n @staticmethod\n def create(norm,gamma,eb,pset=None,name=None,prefix=''):\n\n if pset is None: pset = ParameterSet()\n p0 = pset.createParameter(np.log10(norm),prefix+'norm')\n p1 = pset.createParameter(gamma,prefix+'gamma')\n p2 = pset.createParameter(np.log10(eb),prefix+'eb')\n return PowerLaw(ParameterSet([p0,p1,p2]),name)\n \nclass PolyFn(PDF):\n def __init__(self,pset,name=None):\n PDF.__init__(self,pset,name)\n self._nc = pset.npar()\n\n @staticmethod\n def create(norder,coeff=None,pset=None,name=None,prefix=''):\n\n if pset is None: pset = ParameterSet()\n if coeff is None: coeff = np.zeros(norder)\n\n pars = []\n for i in range(norder):\n p = pset.createParameter(coeff[i],prefix+'a%i'%i)\n pars.append(p)\n\n return PolyFn(ParameterSet(pars),name)\n\n def _eval_pdf(self,x,pset):\n \n a = pset.array()\n return polyval(a,x)\n\n def _integrate(self,dlo,dhi,pset):\n\n a = pset.array()\n\n if a.ndim == 1:\n aint = np.zeros(self._nc+1)\n aint[1:] = a/np.linspace(1,self._nc,self._nc)\n return polyval(aint,dhi) - polyval(aint,dlo)\n else:\n aint = np.zeros(shape=(self._nc+1,a.shape[1]))\n c = np.linspace(1,self._nc,self._nc)\n c = c.reshape(c.shape + (1,))\n\n aint[1:] = a/c\n v = polyval(aint,dhi) - polyval(aint,dlo)\n return v\n\nclass PolarPolyFn(PolyFn):\n\n @staticmethod\n def create(norder,coeff=None,offset=0):\n\n pset = ParameterSet()\n if coeff is None: coeff = np.zeros(norder)\n for i in range(norder):\n pset.addParameter(Parameter(offset+i,coeff[i],'a%i'%i))\n\n return PolarPolyFn(pset)\n\n \n\n def _integrate(self,dlo,dhi,pset):\n\n a = pset.array()\n\n if a.ndim == 1:\n aint = np.zeros(self._nc+2)\n aint[2:] = a/np.linspace(1,self._nc,self._nc)\n return np.pi*(polyval(aint,dhi) - polyval(aint,dlo))\n else:\n aint = np.zeros(shape=(self._nc+2,) + a.shape[1:])\n c = np.linspace(2,self._nc+1,self._nc)\n c = c.reshape(c.shape + (1,))\n\n# print 'integrate ', aint.shape, c.shape\n\n aint[2:] = a/c\n v = np.pi*(polyval(aint,dhi) - polyval(aint,dlo))\n return v\n\n\n"
},
{
"alpha_fraction": 0.4672962427139282,
"alphanum_fraction": 0.4845105707645416,
"avg_line_length": 29.46390724182129,
"blob_id": "80393e09b7a8845a3057af1b69c3a091376b6a36",
"content_id": "b52e6cb3b5a527a699c426b9674bfa742b7636c5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28697,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 942,
"path": "/gammatools/fermi/halo_analysis.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.optimize import brentq\n\nfrom analysis_util import *\nfrom data import *\nimport stats\nimport yaml\n\nfrom psf_likelihood import *\nfrom exposure import ExposureCalc\n\nfrom optparse import Option\nfrom optparse import OptionParser\n\nclass HaloFit(Data):\n \n def __init__(self,lnl,pset_null=None,pset=None):\n self['lnl'] = lnl\n self['pset_null'] = pset_null\n self['pset'] = pset\n self['ts'] = 0.0\n \n def print_fit(self):\n print 'Null Fit Parameters'\n print self['pset_null']\n\n print 'Signal Fit Parameters'\n print self['pset']\n\n print 'Signal TS: ', self['ts']\n\n def plot(self):\n pass\n\nclass Config(object):\n\n def __init__(self):\n pass\n\n def __getitem__(self,key):\n return self._data[key]\n\n def __setitem__(self,key,val):\n self._data[key] = val\n\n def save(self,outfile):\n\n import cPickle as pickle\n fp = open(outfile,'w')\n pickle.dump(self,fp,protocol = pickle.HIGHEST_PROTOCOL)\n fp.close()\n\nclass BinnedHaloAnalysis(Data,Configurable):\n\n default_config = { 'ebin_edges' : [],\n 'cth_edges' : [],\n 'phases' : [],\n 'halo_sigma' : 0.1,\n 'event_types' : [] }\n \n def __init__(self,exp,pulsar_data,agn_data,config=None):\n super(BinnedHaloAnalysis,self).__init__() \n self.configure(BinnedHaloAnalysis.default_config,config)\n self.cfg = self.config()\n \n self._ha_bin = []\n\n for i in range(len(self.cfg['ebin_edges'][:-1])):\n \n print 'Setting up energy bin ', i, self.cfg['ebin_edges'][i:i+2]\n\n ebin_cfg = copy.deepcopy(cfg)\n ebin_cfg['ebin_edges'] = self.cfg['ebin_edges'][i:i+2]\n\n ha = HaloAnalysis(exp,pulsar_data,agn_data,ebin_cfg)\n self._ha_bin.append(ha)\n\n def __iter__(self):\n return iter(self._ha_bin)\n\n def setup_lnl(self):\n\n for ha in self._ha_bin: ha.setup_lnl()\n\n def fit(self): \n\n for ha in self._ha_bin: ha.fit()\n\n def print_fit(self):\n\n for ha in self._ha_bin: ha.print_fit()\n\n def plot_images(self):\n\n for ha in self._ha_bin: ha.plot_images()\n\n def plot(self):\n \n for ha in self._ha_bin: ha.plot()\n\n def get_ts_halo(self):\n\n ts_halo = []\n for ha in self._ha_bin: ts_halo.append(ha._ts_halo)\n\n return ts_halo\n\n def plot_ul(self,fig=None):\n\n flux = []\n loge = []\n\n# for i in range(len(self.cfg['ebin_edges'][:-1])):\n for i, ha in enumerate(self._ha_bin):\n\n ecenter = 0.5*np.sum(self.cfg['ebin_edges'][i:i+2])\n\n loge.append(ecenter)\n\n fn = copy.deepcopy(ha._halo_model)\n fn.setParamByName('halo_flux',ha._flux_ul_halo)\n\n flux.append((fn.eval(ecenter)*10**(2*ecenter)).flat[0])\n print ecenter, fn.eval(ecenter)*10**(2*ecenter)\n\n# self._flux_ul_halo\n\n if fig is None: fig = plt.figure()\n from plot_util import plot_ul\n\n plot_ul(loge,flux)\n\n# plt.arrow(loge[0],flux[0],0,-flux[0]*0.5,arrowstyle='simple')\n plt.gca().set_yscale('log')\n plt.gca().set_ylim(1E-7,2E-5)\n plt.gca().grid(True)\n\n plt.gca().set_xlabel('Energy [log$_{10}$(E/MeV)]')\n plt.gca().set_ylabel('E$^{2}$dF/dE [MeV cm$^{-2}$ s$^{-1}$]')\n\n# fig.savefig('flux_ul.png')\n \n# plt.show()\n# flux.append()\n\n\nclass HaloAnalysis(Data,Configurable):\n\n default_config = { 'ebin_edges' : [],\n 'theta_edges' : np.linspace(0,3.0,31),\n 'cth_edges' : [],\n 'phases' : [],\n 'halo_sigma' : 0.1,\n 'cuts_file' : None,\n 'event_types' : [] }\n\n def __init__(self,exp,pulsar_data,agn_data,config=None):\n super(HaloAnalysis,self).__init__() \n self.configure(HaloAnalysis.default_config,config) \n self.cfg = self.config()\n\n self._pset = ParameterSet()\n self._pset_null = None\n self._pset_halo = None\n self._ts_halo = None\n self._plnl_halo_flux = None\n self._plnl_halo_dlnl = None\n self._srcs = []\n \n self.load_data(exp,pulsar_data,agn_data)\n\n def set_seed_pset(self,pset):\n\n for p in pset:\n if p.name() in self._pset.names():\n self._pset.getParByName(p.name()).set(p.value())\n\n def fix_param(self,regex):\n self._pset.fixAll(True,regex)\n \n def load_data(self,exp,pulsar_data,agn_data):\n\n nebin = len(self.cfg['ebin_edges'])-1\n ntype = len(self.cfg['event_types'])\n\n self.data = np.empty(shape=(nebin,ntype), dtype=object)\n self._srcs = copy.deepcopy(agn_data._srcs)\n \n for i in range(len(self.data)):\n\n erange = self.cfg['ebin_edges'][i:i+2]\n print erange\n for j, c in enumerate(self.cfg['event_types']):\n self.data[i,j] = self.load_bin_data(c,erange,exp[i],\n pulsar_data,agn_data)\n \n \n\n def load_bin_data(self,c,erange,exp,pulsar_data,agn_data):\n\n data = Data()\n\n \n data['agn_exp'] = exp\n data['energy'] = erange\n data['cth'] = [0.4,1.0]\n data['conversion_type'] = c['conversion_type']\n data['cuts'] = None\n data['par_id'] = []\n if 'cuts' in c: data['cuts'] = c['cuts']\n if 'label' in c: data['label'] = c['label']\n else: data['label'] = c['conversion_type']\n \n ctype = c['conversion_type']\n\n mask = PhotonData.get_mask(pulsar_data,\n {'energy' : erange,\n 'cth' : self.cfg['cth_edges']},\n conversion_type=ctype,\n cuts=data['cuts'],\n cuts_file=self.cfg['cuts_file'])\n\n# data['pulsar_mask'] = mask\n\n (hon,hoff,hoffs) = getOnOffHist(pulsar_data,'dtheta',\n self.cfg['phases'],\n mask=mask,\n edges=self.cfg['theta_edges'])\n\n data['pulsar_theta_hist_on'] = hon\n data['pulsar_theta_hist_off'] = hoff\n data['pulsar_theta_hist_bkg'] = hoffs\n data['pulsar_theta_hist_excess'] = hon - hoffs\n\n hq = stats.HistQuantileBkgHist(hon,hoff,self.cfg['phases'][2])\n\n data['pulsar_q68'] = hq.quantile(0.68)\n\n mask = PhotonData.get_mask(agn_data,\n {'energy' : erange,\n 'cth' : self.cfg['cth_edges']},\n conversion_type=ctype,\n cuts=data['cuts'],\n cuts_file=self.cfg['cuts_file'])\n\n# data['agn_mask'] = mask\n\n data['agn_theta_hist'] = getHist(agn_data,'dtheta',mask=mask,\n edges=self.cfg['theta_edges'])\n\n\n \n \n stacked_image = Histogram2D(np.linspace(-3.0,3.0,301),\n np.linspace(-3.0,3.0,301))\n\n stacked_image.fill(agn_data['delta_ra'][mask],\n agn_data['delta_dec'][mask])\n\n \n src = agn_data._srcs[0]\n\n srcra = src['RAJ2000']\n srcdec = src['DEJ2000']\n\n im = SkyImage.createROI(srcra,srcdec,3.0,3.0/300.)\n im.fill(agn_data['ra'][mask],agn_data['dec'][mask])\n\n data['agn_image'] = im\n# data['agn_image_smoothed'] = im.smooth(data['pulsar_q68']/4.)\n data['agn_stacked_image'] = stacked_image\n# data['agn_stacked_image_smoothed'] = \\\n# stacked_image.smooth(data['pulsar_q68']/4.)\n\n return data\n\n def setup_lnl(self):\n \n self._joint_lnl = JointLnL()\n\n self._pset.clear()\n \n halo_flux = self._pset.createParameter(0.0,'halo_flux',True,\n [0.0,1E-6])\n halo_gamma = self._pset.createParameter(2.0,'halo_gamma',True)\n halo_sigma = self._pset.createParameter(0.3,'halo_sigma',True)\n halo_norm = self._pset.createParameter(1.0,'halo_norm',True)\n\n self._halo_model = PowerlawFn(halo_flux,halo_gamma)\n\n self._pset.setParByName('halo_sigma',self.cfg['halo_sigma'])\n\n for i in range(len(self.data)):\n self.setup_lnl_bin(self.data[i],self._halo_model)\n for j in range(len(self.data[i].flat)):\n self._joint_lnl.add(self.data[i,j]['lnl'])\n\n def setup_lnl_bin(self,data,halo_model):\n \"\"\"Construct the likelihood function for a single\n energy/inclination angle bin.\"\"\"\n\n agn_excess = []\n pulsar_excess = []\n pulsar_fraction = []\n agn_bkg = []\n\n \n \n for d in data:\n\n excess, bkg_density, r68 = analyze_agn(d['agn_theta_hist'],2.5)\n agn_excess.append(excess)\n agn_bkg.append(bkg_density)\n pulsar_excess.append(d['pulsar_theta_hist_excess'].sum())\n\n\n# agn_tot_hist = getHist(agn_data,'dtheta',mask=agn_mask,\n# edges=theta_edges)\n# excess, bkg_density, r68 = analyze_agn(agn_tot_hist,2.5)\n\n agn_excess_tot = np.sum(np.array(agn_excess))\n pulsar_excess_tot = np.sum(np.array(pulsar_excess))\n\n for x in pulsar_excess:\n pulsar_fraction.append(x/pulsar_excess_tot)\n\n pset = self._pset\n\n elabel = 'e%04.f_%04.f'%(data[0]['energy'][0]*100,\n data[0]['energy'][1]*100)\n \n # Total Counts in Vela and AGN\n p0 = pset.createParameter(pulsar_excess_tot,'vela_norm_%s'%(elabel),\n False,[0,max(10,10*pulsar_excess_tot)])\n p1 = pset.createParameter(agn_excess_tot,'agn_norm_%s'%(elabel),\n False,[0,max(10,10*agn_excess_tot)])\n\n pfname = []\n ndata = len(data)\n\n for i in range(1,ndata): \n p = pset.createParameter(pulsar_fraction[i],'acc_f%i_%s'%(i,elabel))\n data[i]['par_id'].append(p.pid())\n pfname.append(p.name())\n\n if ndata > 1:\n expr0 = '(1.0 - (' + '+'.join(pfname) + '))'\n else:\n expr0 = '(1.0)'\n\n for i, d in enumerate(data):\n\n # excess, bkg_density, r68 = analyze_agn(d['agn_hist'],2.5)\n r68 = d['pulsar_q68']\n\n pulsar_model = CompositeModel()\n agn_model = CompositeModel()\n\n p2 = pset.createParameter(0.5*r68,'psf_sigma_%s_%02i'%(elabel,i))\n p3 = pset.createParameter(2.0,'psf_gamma_%s_%02i'%(elabel,i),\n False,[1.1,6.0])\n p4 = pset.createParameter(agn_bkg[i],\n 'agn_iso_%s_%02i'%(elabel,i),False,\n [0.0,10.*agn_bkg[i]])\n\n d['par_id'].append(p2.pid())\n d['par_id'].append(p3.pid())\n d['par_id'].append(p4.pid())\n \n expr = None\n if len(data) > 1 and i == 0: expr = expr0\n elif len(data) > 1: expr = pfname[i-1]\n\n pulsar_src_model = ScaledModel(KingFn(p2,p3,p0),pset,expr,\n name='pulsar')\n agn_src_model = ScaledModel(KingFn(p2,p3,p1),pset,expr,name='agn')\n\n halo_norm = pset.getParByName(\"halo_norm\")\n halo_sigma = pset.getParByName(\"halo_sigma\")\n\n halo_spatial_model = ConvolvedGaussFn(halo_norm,\n halo_sigma,KingFn(p2,p3))\n\n halo_spectral_model = BinnedPLFluxModel(halo_model,\n halo_spatial_model,\n data[i]['energy'],\n data[i]['agn_exp'])\n \n halo_src_model = ScaledModel(halo_spectral_model,\n pset,expr,name='halo')\n\n pulsar_model.addModel(pulsar_src_model)\n agn_model.addModel(agn_src_model)\n agn_model.addModel(halo_src_model)\n\n agn_model.addModel(PolarPolyFn(ParameterSet([p4]),name='iso'))\n\n d['pulsar_model'] = pulsar_model\n d['agn_model'] = agn_model\n\n agn_norm_expr = p1.name()\n if not expr is None: agn_norm_expr += '*' + expr\n\n d['par_agn_norm'] = CompositeParameter(agn_norm_expr,pset)\n d['par_agn_iso'] = p4\n d['par_psf_sigma'] = p2\n d['par_psf_gamma'] = p3\n d['pulsar_lnl'] = \\\n OnOffBinnedLnL.createFromHist(d['pulsar_theta_hist_on'],\n d['pulsar_theta_hist_off'],\n self.cfg['phases'][2],\n pulsar_model)\n\n d['agn_lnl'] = BinnedLnL.createFromHist(d['agn_theta_hist'],\n agn_model)\n\n joint_lnl = JointLnL([d['pulsar_lnl'],d['agn_lnl']])\n d['lnl'] = joint_lnl\n\n def print_fit(self):\n\n print 'Null Fit Parameters'\n print self._pset_null\n\n print 'Signal Fit Parameters'\n print self._pset_halo\n\n print 'Signal TS: ', self._ts_halo\n print 'Halo UL: ', self._flux_ul_halo\n\n def set_halo_prop(self,halo_sigma, halo_gamma=2.0):\n self.cfg['halo_sigma'] = halo_sigma\n self.cfg['halo_gamma'] = halo_gamma\n\n def fit(self):\n \n print 'Fitting'\n\n fixed = self._pset.fixed()\n\n print fixed\n \n self._joint_lnl.setParam(self._pset)\n print self._joint_lnl.param()\n \n fitter = Fitter(self._joint_lnl)\n\n print 'Null fit'\n pset = copy.deepcopy(self._pset)\n \n nbin = len(self.data.flat)\n for i in range(nbin):\n print i, self.data.flat[i]['par_id']\n\n pset.fixAll(True) \n for pid in self.data.flat[i]['par_id']:\n\n if not self._pset.getParByIndex(pid).fixed():\n pset.getParByIndex(pid).fix(False)\n\n print pset \n pset = fitter.fit(pset)\n print pset\n\n for pid in pset.pids():\n pset.getParByIndex(pid).fix(self._pset.getParByIndex(pid).fixed())\n \n pset_null = fitter.fit(pset)\n print pset_null\n\n# fitter.plot_lnl_scan(pset_null)\n# plt.show()\n# sys.exit(0)\n\n self._pset_null = pset_null\n self._pset_halo = None\n self._ts_halo = None\n self._plnl_halo_flux = None\n self._plnl_halo_dlnl = None \n self._flux_ul_halo = 0.0\n\n pset = copy.deepcopy(pset_null)\n\n pset.getParByName('halo_flux').fix(False)\n\n print 'Halo fit'\n pset_halo = fitter.fit(pset)\n print pset_halo\n\n print 'Computing UL' \n self._pset_halo = pset_halo\n self._ts_halo = -2*(pset_halo.fval() - pset_null.fval())\n self.compute_flux_ul()\n\n def compute_flux_ul(self):\n\n delta_lnl = 2.72/2.\n\n print 'Computing Profile Likelihood'\n \n self._plnl_halo_flux, self._plnl_halo_dlnl = \\\n self.compute_flux_plnl()\n\n print 'Flux: ', self._plnl_halo_flux\n print 'lnL: ', self._plnl_halo_dlnl\n \n self._plnl_fn = UnivariateSpline(self._plnl_halo_flux,\n self._plnl_halo_dlnl,s=0,\n k=2)\n \n i = np.argmin(self._plnl_halo_dlnl)\n\n if self._plnl_halo_flux[i] < 0: offset = self._plnl_fn(0)\n else: offset = self._plnl_halo_dlnl[i]\n\n x0 = brentq(lambda t: self._plnl_fn(t) - delta_lnl - offset,\n self._plnl_halo_flux[i],\n self._plnl_halo_flux[-1],xtol=1E-16)\n\n self._flux_ul_halo = x0\n\n return\n\n x = np.linspace(self._plnl_halo_flux[0],self._plnl_halo_flux[-1],100)\n plt.plot(x,fn(x),marker='o')\n plt.gca().grid(True)\n plt.axhline(2.72/2.)\n plt.axvline(x0)\n plt.show()\n\n\n def compute_flux_plnl(self):\n\n pset = self._pset_halo\n\n fitter = Fitter(self._joint_lnl)\n fmin = pset.fval()\n pset = copy.deepcopy(pset)\n\n pset.fixAll()\n pset.fixAll(False,'agn_norm')\n\n halo_flux = np.ravel(pset.getParByName('halo_flux').value())\n\n if halo_flux > 0: xmin = max(-14,np.log10(halo_flux))\n else: xmin = -14\n\n print 'xmin ', xmin\n \n x = np.linspace(xmin,-8,100)\n p = pset.makeParameterArray(0,10**x)\n fv = fitter._objfn.eval(p)\n fn = UnivariateSpline(x,fv,s=0,k=2)\n\n# plt.figure()\n# plt.plot(x,fv-fmin)\n# plt.show()\n\n \n x0 = brentq(lambda t: fn(t) - fmin - 100.,x[0],x[-1],xtol=1E-16)\n \n err = pset.getParError('halo_flux')\n err = max(err,1E-13)\n \n v = np.ravel(pset.getParByName('halo_flux').value())\n\n pmin = v - 5*err\n pmin[pmin<0] = 0\n\n pmax = 10**x0\n pval = np.linspace(v,pmax,20)\n \n fval = fitter.profile(pset,'halo_flux',pval,True)-fmin\n\n return pval,fval\n\n def plot_images(self):\n\n nbin = len(self.data.flat)\n\n bin_per_fig = 4\n\n nfig = int(np.ceil(float(nbin)/float(bin_per_fig)))\n \n nx = 2\n ny = 2\n figsize = (8*1.5,6*1.5) \n\n for i in range(nfig):\n \n fig = plt.figure(figsize=figsize)\n for j in range(i*bin_per_fig,(i+1)*bin_per_fig):\n\n if j >= len(self.data.flat): continue\n\n d = self.data.flat[j]\n\n elabel = 'e%04.f_%04.f'%(d['energy'][0]*100,\n d['energy'][1]*100)\n\n \n subplot = '%i%i%i'%(nx,ny,j%bin_per_fig+1)\n self.plot_images_bin(self.data.flat[j],subplot)\n\n fig.savefig('skyimage_%s_%02i.png'%(elabel,i))\n\n def plot_images_bin(self,data,subplot=111):\n\n im = data['agn_image'].smooth(data['pulsar_q68']/4.)\n\n title = '%s E = [%.3f, %.3f]'%(data['label'],\n data['energy'][0],\n data['energy'][1])\n \n\n ax = im.plot(subplot=subplot)\n ax.set_title(title)\n\n ax.add_beam_size(data['pulsar_q68'],data['pulsar_q68'],0.0,loc=2,\n patch_props={'ec' : 'white', 'fc' : 'None'})\n im.plot_catalog()\n im.plot_circle(3.0,linewidth=2,linestyle='--',color='k')\n \n\n\n def plot(self,pset=None):\n \n pset = [self._pset_null,self._pset_halo]\n pset_labels = ['Null','Halo']\n\n nbin = len(self.data.flat)\n bin_per_fig = 4\n nfig = int(np.ceil(float(nbin)/float(bin_per_fig)))\n \n nx = 2\n ny = 2\n figsize = (8*1.5,6*1.5) \n\n\n for i in range(nfig):\n \n fig0 = plt.figure(figsize=figsize)\n fig1 = plt.figure(figsize=figsize)\n for j in range(i*bin_per_fig,(i+1)*bin_per_fig):\n\n if j >= len(self.data.flat): continue\n\n print i, j\n \n d = self.data.flat[j]\n\n elabel = 'e%04.f_%04.f'%(d['energy'][0]*100,\n d['energy'][1]*100)\n\n\n title = '%s E = [%.3f, %.3f]'%(d['label'],\n d['energy'][0],\n d['energy'][1])\n \n ax1 = fig0.add_subplot(ny,nx,j%bin_per_fig+1)\n ax1.set_title(title)\n \n plt.sca(ax1)\n self.plot_pulsar_bin(self.data.flat[j],ax1,pset,pset_labels)\n ax1.grid(True)\n ax1.legend()\n\n ax2 = fig1.add_subplot(ny,nx,j%bin_per_fig+1)\n ax2.set_title(title)\n \n plt.sca(ax2)\n self.plot_agn_bin(self.data.flat[j],ax2,pset,pset_labels)\n ax2.grid(True)\n ax2.legend()\n\n fig0.savefig('vela_dtheta_%s_%02i.png'%(elabel,i))\n fig1.savefig('src_dtheta_%s_%02i.png'%(elabel,i))\n \n\n def plot_pulsar_bin(self,data,ax,pset,pset_labels):\n edges = data['pulsar_theta_hist_on'].edges()\n\n data['pulsar_theta_hist_on'].plot(ax=ax,label='on')\n data['pulsar_theta_hist_bkg'].plot(ax=ax,label='off')\n\n for i, p in enumerate(pset):\n hm = data['pulsar_model'].histogram(edges,p=p)\n hm += data['pulsar_theta_hist_bkg']\n hm.plot(ax=ax,style='line',label=pset_labels[i])\n \n \n def plot_agn_bin(self,data,ax,pset,pset_labels):\n edges = data['agn_theta_hist'].edges()\n data['agn_theta_hist'].plot(ax=ax,label='Data')\n\n\n psf_sigma_pid = data['par_psf_sigma'].pid()\n psf_gamma_pid = data['par_psf_gamma'].pid()\n\n text = '$\\sigma$ = %6.3f '%(self._pset_null.\n getParByID(psf_sigma_pid).value())\n text += '$\\pm$ %6.3f deg\\n'%(self._pset_null.\n getParError(psf_sigma_pid))\n\n text += '$\\gamma$ = %6.3f '%(self._pset_null.\n getParByID(psf_gamma_pid).value())\n text += '$\\pm$ %6.3f\\n'%(self._pset_null.\n getParError(psf_gamma_pid))\n\n text += '$\\Sigma_{b}$ = %6.3f deg$^{-2}$\\n'%(data['par_agn_iso'].value())\n text += 'N$_{src}$ = %6.3f\\n'%(data['par_agn_norm'].\n eval(self._pset_halo))\n text += 'TS = %6.3f'%(self._ts_halo)\n\n for i, p in enumerate(pset):\n \n hm = data['agn_model'].histogram(edges,p=pset[i])\n hm.plot(ax=ax,style='line',label=pset_labels[i])\n ax.text(0.1,0.7,text,transform=ax.transAxes,fontsize=10)\n\n def plot_bin(self,data,pset=None):\n\n if pset is None:\n pset = [self._pset_null,self._pset_halo]\n\n \n\n\n for i in range(len(data.flat)):\n\n d = self.data.flat[i]\n\n edges = d['pulsar_theta_hist_on'].edges()\n ax0 = fig0.add_subplot(2,2,i+1)\n plt.sca(ax0)\n\n d['pulsar_theta_hist_on'].plot(label='on')\n d['pulsar_theta_hist_bkg'].plot(label='off')\n\n for p in pset:\n hm = d['pulsar_model'].histogram(edges,p=p)\n hm += d['pulsar_theta_hist_bkg']\n hm.plot(style='line')\n\n plt.gca().grid(True)\n\n ax1 = fig1.add_subplot(2,2,i+1)\n plt.sca(ax1)\n\n# plt.figure()\n d['agn_theta_hist'].plot()\n for j in range(len(pset)):\n hm1 = d['agn_model'].histogram(edges,p=pset[j])\n hm1.plot(style='line')\n# hm1c = d['agn_model'].histogramComponents(edges,p=pset)\n# for h in hm1c: h.plot(style='line')\n\n plt.gca().grid(True)\n plt.gca().legend()\n\n# plt.show()\n \n\nclass HaloAnalysisManager(Configurable):\n \"\"\"Halo analysis object. Responsible for parsing configuration\n file and passing data to HaloAnalysisData.\"\"\"\n\n default_config = {'pulsar_data' : None,\n 'agn_data' : None,\n 'on_phase' : '0.0/0.15,0.6/0.7',\n 'off_phase' : '0.2/0.5',\n 'energy_bins' : None,\n 'theta_bins' : '0.0/3.0/60',\n 'halo_sigma' : None,\n 'halo_gamma' : None,\n 'ltfile' : None,\n 'irf' : None,\n 'irf_dir' : None,\n 'cuts_file' : None,\n 'output_file' : None,\n 'event_types' : None }\n\n def __init__(self,config=None):\n super(HaloAnalysisManager,self).__init__() \n self.configure(HaloAnalysisManager.default_config,config)\n\n cfg = self.config()\n \n (bmin,bmax,nbin) = cfg['energy_bins'].split('/')\n self._ebin_edges = np.linspace(float(bmin),float(bmax),int(nbin)+1)\n \n (bmin,bmax,nbin) = cfg['theta_bins'].split('/')\n self._theta_edges = np.linspace(float(bmin),float(bmax),int(nbin)+1)\n\n self._cth_edges = np.linspace(0.4,1.0,2)\n \n\n def load(self):\n\n cfg = self.config()\n \n self._phases = parse_phases(cfg['on_phase'],\n cfg['off_phase'])\n\n self._pulsar_data = PhotonData.load(cfg['pulsar_data']['file'])\n self._agn_data = PhotonData.load(cfg['agn_data']['file'])\n\n self._exp_calc = ExposureCalc.create(cfg['irf'],\n cfg['ltfile'],\n cfg['irf_dir'])\n\n if 'srcs' in cfg['agn_data'] and not \\\n cfg['agn_data']['srcs'] is None:\n self._agn_data.get_srcs(cfg['agn_data']['srcs']) \n\n src_names = []\n for s in self._agn_data._srcs:\n src_names.append(s['Source_Name'])\n \n self._exp = self._exp_calc.getExpByName(src_names, self._ebin_edges)\n # Convert exposure to cm^2 s\n self._exp *= 1E4\n\n self._pulsar_data['dtheta'] = np.degrees(self._pulsar_data['dtheta'])\n self._agn_data['dtheta'] = np.degrees(self._agn_data['dtheta'])\n\n \n mask = PhotonData.get_mask(self._pulsar_data,\n {'energy' : [self._ebin_edges[0],\n self._ebin_edges[-1]] })\n self._pulsar_data.apply_mask(mask)\n\n def run(self):\n \"\"\"Run both the binned and joint halo analysis and write\n analysis objects to an output file.\"\"\"\n\n fit_data = Data()\n\n cfg = copy.deepcopy(self.config())\n\n cfg['ebin_edges'] = self._ebin_edges\n cfg['theta_edges'] = self._theta_edges\n cfg['cth_edges'] = self._cth_edges\n cfg['phases'] = self._phases\n\n # Setup Joint Fit\n ha_binned = BinnedHaloAnalysis(self._exp,self._pulsar_data,\n self._agn_data,cfg) \n ha_binned.setup_lnl()\n ha_binned.fit()\n\n fit_data['binned_fit'] = ha_binned\n\n ha_joint = HaloAnalysis(self._exp,self._pulsar_data,self._agn_data,\n cfg) \n ha_joint.setup_lnl()\n\n for ha in ha_binned:\n ha_joint.set_seed_pset(ha._pset_null)\n\n ha_joint.fix_param('vela')\n ha_joint.fix_param('psf')\n ha_joint.fix_param('acc\\_f')\n ha_joint.fit()\n\n fit_data['joint_fit'] = ha_joint\n\n\n fit_data.save(cfg['output_file'])\n\n\ndef analyze_agn(hon,theta_cut):\n\n i = hon.getBinByValue(theta_cut)\n\n\n xlo = hon._xedges[i]\n xhi = hon._xedges[-1]\n\n\n sig_domega = xlo**2*np.pi\n bkg_domega = (xhi**2-xlo**2)*np.pi\n bkg_counts = np.sum(hon._counts[i:])\n \n bkg_density = bkg_counts/bkg_domega\n\n excess = np.sum(hon._counts[:i]) - bkg_density*sig_domega\n\n if excess <= 0: return 0, bkg_density, 0.0\n \n hq = stats.HistQuantileBkgFn(hon,lambda x: x*x*np.pi/bkg_domega,\n bkg_counts)\n\n return excess, bkg_density, hq.quantile(0.68)\n\n\nif __name__ == '__main__':\n\n gfn = ConvolvedGaussFn.create(3.0,0.1,KingFn.create(0.1,3.0),4)\n\n pset = gfn.param()\n \n p0 = pset.createParameter(1.0,'norm')\n p1 = pset.createParameter(2.0,'gamma')\n\n pfn = PowerlawFn(p0,p1)\n\n cm = CompProdModel()\n cm.addModel(gfn)\n cm.addModel(pfn)\n\n x = np.linspace(1,2,3)\n y = np.linspace(0,1,3)\n\n print pfn.eval(2.0)\n print pfn.eval(3.0)\n print pfn.integrate(2.0,3.0)\n print pfn.eval({'energy' : 3.0 })\n\n print pset\n\n v0 = pfn.eval(x)\n v1 = gfn.eval(y)\n\n print cm.eval(2.0)\n print cm.eval({'energy': x, 'dtheta' : y})\n print v0*v1\n\n\n h = Histogram2D([0,1,2],[0,1,2])\n\n\n print h._xedges\n print h._yedges\n\n h.fill(0.5,0.5,1.0)\n\n lnl = Binned2DLnL.createFromHist(h,cm)\n\n\n print lnl.eval(pset.makeParameterArray(0,np.linspace(0.1,2,3)))\n"
},
{
"alpha_fraction": 0.5142287015914917,
"alphanum_fraction": 0.5308101177215576,
"avg_line_length": 31.254270553588867,
"blob_id": "45e7d70d56722c2a579cb17ca25c684f705e5fae",
"content_id": "1b5244d2ae070f893c463f368ab60d404d40d085",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49091,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 1522,
"path": "/gammatools/core/fits_viewer.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import wx\nimport numpy as np\nimport os\nimport copy\nfrom astropy_helper import pyfits\n\nfrom gammatools.core.plot_util import *\nfrom gammatools.core.stats import poisson_lnl\nfrom gammatools.core.histogram import Histogram, Axis\nfrom gammatools.core.fits_util import SkyImage, SkyCube\nfrom gammatools.fermi.catalog import Catalog\nfrom matplotlib.backends.backend_wxagg import FigureCanvasWxAgg\nfrom matplotlib.backends.backend_wxagg import Toolbar\nimport matplotlib.pyplot as plt\nfrom matplotlib.backends.backend_wx import NavigationToolbar2Wx\nfrom matplotlib.colors import NoNorm, LogNorm, Normalize\n\nfrom itertools import cycle\n\ndef make_projection_plots_skyimage(im):\n\n plt.figure()\n\n im.project(0).plot()\n \n plt.figure()\n\n im.project(1).plot()\n\n\n\n\n \nclass FITSPlotter(object):\n\n fignum = 0\n \n def __init__(self,im,im_mdl,irf=None,prefix=None,outdir='plots',\n rsmooth=0.2):\n\n self._ft = FigTool(fig_dir=outdir)\n self._im = im\n self._im_mdl = im_mdl\n self._irf = irf\n self._prefix = prefix\n self._rsmooth = rsmooth\n if self._prefix is None: self._prefix = 'fig'\n if outdir: self._prefix_path = os.path.join(outdir,self._prefix)\n \n def make_mdl_plots_skycube(self,**kwargs):\n\n self.make_plots_skycube(model=True,**kwargs)\n \n def make_energy_residual(self,suffix=''):\n\n h = self._im.project(2)\n hm = self._im_mdl.project(2)\n\n fig = self._ft.create(self._prefix + suffix,\n figstyle='residual2',\n yscale='log',\n ylabel='Counts',\n xlabel='Energy [log$_{10}$(E/MeV)]')\n\n fig[0].add_hist(hm,hist_style='line',label='Model')\n fig[0].add_hist(h,linestyle='None',label='Data')\n\n fig[1].set_style('ylim',[-0.3,0.3])\n\n\n fig.plot()\n# fig.savefig('%s_%s.png'%(self._prefix,suffix))\n\n def make_plots_skycube(self,delta_bin=None,paxis=None,plots_per_fig=4,\n smooth=False, resid_type=None,make_projection=False,\n suffix='',model=False, projection='psf68',**kwargs):\n\n if model: im = self._im_mdl\n else: im = self._im\n \n nbins = im.axis(2).nbins\n if delta_bin is None:\n bins = np.array([0,nbins])\n nplots = 1\n else:\n# delta_bin = np.array([0,2,4,4,12])\n# nplots = 4\n\n bins = np.cumsum(np.concatenate(([0],delta_bin)))\n nplots = len(bins)-1\n\n nfig = int(np.ceil(float(nplots)/float(plots_per_fig)))\n\n print 'bins ', bins\n print 'nplots ', nplots\n print 'nfig ', nfig\n print 'plots_per_fig ', plots_per_fig\n \n if plots_per_fig > 4 and plots_per_fig <= 8:\n nx, ny = 4, 2\n elif plots_per_fig <= 4 and plots_per_fig > 1:\n nx, ny = 2, 2\n else:\n nx, ny = 1, 1\n\n fig_sx = 5.0*nx\n fig_sy = 5.0*ny\n\n\n figs = []\n for i in range(nfig):\n \n# fig_label = '%0'%(fig_emin*1000,fig_emax*1000)\n fig_label = '%02i'%i\n fig_name = '%s_%s%s.png'%(self._prefix_path,fig_label,suffix)\n fig2_name = '%s_%s%s_zproj.png'%(self._prefix_path,fig_label,suffix)\n fig3_name = '%s_%s%s_xproj.png'%(self._prefix_path,fig_label,suffix)\n fig4_name = '%s_%s%s_yproj.png'%(self._prefix_path,fig_label,suffix)\n \n \n figs.append({'fig' : self.create_figure(figsize=(fig_sx,fig_sy)),\n 'fig2' : self.create_figure(figsize=(fig_sx,fig_sy)),\n 'fig3' : self.create_figure(figsize=(fig_sx,fig_sy)),\n 'fig4' : self.create_figure(figsize=(fig_sx,fig_sy)),\n 'fig_name' : fig_name,\n 'fig2_name' : fig2_name,\n 'fig3_name' : fig3_name,\n 'fig4_name' : fig4_name,\n })\n \n plots = []\n for i in range(nplots):\n \n ifig = i/plots_per_fig\n plots.append({'fig' : figs[ifig]['fig'],\n 'fig2' : figs[ifig]['fig2'],\n 'fig3' : figs[ifig]['fig3'],\n 'fig4' : figs[ifig]['fig4'],\n 'ibin' : [bins[i], bins[i+1]],\n 'subplot' : i%plots_per_fig,\n })\n \n\n print plots\n \n \n# figs = []\n# for i in range(nfig): figs.append(plt.figure(figsize=(fig_sx,fig_sy)))\n \n for i, p in enumerate(plots):\n ##plt.figure(FITSPlotter.fignum,figsize=(fig_sx,fig_sy))\n\n \n ibin0, ibin1 = p['ibin']\n emin = im.axis(2).pix_to_coord(ibin0)\n emax = im.axis(2).pix_to_coord(ibin1)\n\n print 'ibin0, ibin1 ', ibin0, ibin1 \n \n rpsf68 = self._irf.quantile(10**emin,10**emax,0.2,1.0,0.68)\n rpsf95 = self._irf.quantile(10**emin,10**emax,0.2,1.0,0.95)\n\n if smooth:\n delta_proj = 0.0\n elif projection== 'psf68':\n delta_proj = rpsf68\n elif isinstance(projection,float):\n delta_proj = projection\n \n x0 = im.axis(0).coord_to_pix(delta_proj,False)\n x1 = im.axis(0).coord_to_pix(-delta_proj,False)\n y0 = im.axis(1).coord_to_pix(-delta_proj,False)\n y1 = im.axis(1).coord_to_pix(delta_proj,False)\n\n if smooth:\n x1 = x0+1\n y1 = y0+1\n\n title = 'log$_{10}$(E/MeV) = [%.3f, %.3f]'%(emin,emax) \n subplot = '%i%i%i'%(ny,nx,p['subplot']+1)\n \n fig = p['fig']\n fig2 = p['fig2']\n fig3 = p['fig3']\n fig4 = p['fig4']\n\n h = im.marginalize(2,[[ibin0,ibin1]])\n hm = None\n if self._im_mdl:\n hm = self._im_mdl.marginalize(2,[[ibin0,ibin1]])\n\n mc_resid = []\n\n if resid_type:\n for k in range(10):\n mc_resid.append(self.make_residual_map(h,hm,\n smooth,mc=True,\n resid_type=resid_type))\n h = self.make_residual_map(h,hm,smooth,resid_type=resid_type)\n elif smooth:\n h = h.smooth(self._rsmooth,compute_var=True)\n hm = hm.smooth(self._rsmooth,compute_var=True)\n \n# h = self.make_counts_map(im,ibin,ibin+delta_bin,\n# residual,smooth)\n \n\n self.make_image_plot(subplot,h,fig,fig2,\n title,rpsf68,rpsf95,\n smooth=smooth,\n resid_type=resid_type,\n mc_resid=mc_resid,**kwargs)\n\n if make_projection:\n ax = fig3.add_subplot(subplot)\n plt.sca(ax)\n \n hpx = h.project(0,[[x0,x1]],offset_coord=True)\n hpx.plot(ax=ax,linestyle='None',label='Data',**kwargs)\n \n if hm:\n hmpx = hm.project(0,[[x0,x1]],offset_coord=True)\n hmpx.plot(ax=ax,label='Model',hist_style='line',linestyle='-',**kwargs)\n\n ax.grid(True)\n ax.set_xlabel('GLON Offset')\n ax.set_xlim(*hpx.axis().lims())\n ax.legend(loc='upper right')\n ax.set_ylim(0)\n ax.set_title(title)\n \n ax = fig4.add_subplot(subplot)\n plt.sca(ax)\n hpy = h.project(1,[[y0,y1]],offset_coord=True)\n hpy.plot(ax=ax,linestyle='None',label='Data',**kwargs)\n\n if hm:\n hmpy = hm.project(1,[[y0,y1]],offset_coord=True)\n hmpy.plot(ax=ax,label='Model',hist_style='line',linestyle='-',**kwargs)\n \n ax.grid(True)\n ax.set_xlabel('GLAT Offset')\n ax.set_xlim(*hpy.axis().lims())\n ax.legend(loc='upper right') \n ax.set_ylim(0)\n ax.set_title(title)\n\n for f in figs:\n f['fig'].savefig(f['fig_name'])\n\n if not resid_type is None:\n f['fig2'].savefig(f['fig2_name'])\n\n if make_projection:\n f['fig3'].savefig(f['fig3_name'])\n f['fig4'].savefig(f['fig4_name'])\n\n def create_figure(self,**kwargs):\n fig = plt.figure('Figure %i'%FITSPlotter.fignum,**kwargs)\n FITSPlotter.fignum += 1\n return fig\n \n def make_residual_map(self,h,hm,smooth,mc=False,resid_type='fractional'):\n \n if mc:\n h = copy.deepcopy(h)\n h._counts = np.array(np.random.poisson(hm.counts),\n dtype='float')\n \n if smooth:\n hm = hm.smooth(self._rsmooth,compute_var=True,summed=True)\n h = h.smooth(self._rsmooth,compute_var=True,summed=True)\n\n ts = 2.0*(poisson_lnl(h.counts,h.counts) -\n poisson_lnl(h.counts,hm.counts))\n\n s = h.counts - hm.counts\n\n if resid_type == 'fractional':\n h._counts = s/hm.counts\n h._var = np.zeros(s.shape)\n else:\n sigma = np.sqrt(ts)\n sigma[s<0] *= -1\n h._counts = sigma\n h._var = np.zeros(sigma.shape)\n \n# h._counts -= hm._counts\n# h._counts /= np.sqrt(hm._var)\n\n return h\n \n\n def make_image_plot(self,subplot,h,fig,fig2,title,rpsf68,rpsf95,\n smooth=False,\n resid_type=None,mc_resid=None,**kwargs):\n\n plt.figure(fig.get_label())\n\n cb_label='Counts'\n\n if resid_type == 'significance':\n kwargs['vmin'] = -5\n kwargs['vmax'] = 5\n kwargs['levels'] = [-5.0,-3.0,3.0,5.0]\n cb_label = 'Significance [$\\sigma$]'\n elif resid_type == 'fractional':\n kwargs['vmin'] = -1.0\n kwargs['vmax'] = 1.0\n kwargs['levels'] = [-1.0,-0.5,0.5,1.0]\n cb_label = 'Fractional Residual'\n\n if smooth:\n kwargs['beam_size'] = [self._rsmooth,self._rsmooth,0.0,4]\n \n axim = h.plot(subplot=subplot,cmap='ds9_b',**kwargs)\n h.plot_circle(rpsf68,color='w',lw=1.5)\n h.plot_circle(rpsf95,color='w',linestyle='--',lw=1.5)\n h.plot_marker(marker='+',color='w',linestyle='--')\n ax = h.ax()\n ax.set_title(title)\n cb = plt.colorbar(axim,orientation='horizontal',\n shrink=0.9,pad=0.15,\n fraction=0.05)\n\n cb.set_label(cb_label)\n\n cat = Catalog.get('3fgl')\n cat.plot(h,ax=ax,src_color='w',label_threshold=5.0)\n\n if resid_type is None: return\n \n plt.figure(fig2.get_label()) \n ax2 = fig2.add_subplot(subplot)\n\n z = h.counts[10:-10,10:-10]\n\n if resid_type == 'significance':\n zproj_axis = Axis.create(-6,6,120)\n elif resid_type == 'fractional':\n zproj_axis = Axis.create(-1.0,1.0,120)\n else:\n zproj_axis = Axis.create(-10,10,120)\n\n\n hz = Histogram(zproj_axis)\n hz.fill(np.ravel(z))\n\n nbin = np.prod(z.shape)\n \n hz_mc = Histogram(zproj_axis) \n \n if mc_resid:\n for mch in mc_resid:\n z = mch.counts[10:-10,10:-10]\n hz_mc.fill(np.ravel(z))\n\n hz_mc /= float(len(mc_resid))\n\n \n fn = lambda t : 1./np.sqrt(2*np.pi)*np.exp(-t**2/2.)\n \n hz.plot(label='Data',linestyle='None')\n\n if resid_type == 'significance':\n plt.plot(hz.axis().center,\n fn(hz.axis().center)*hz.axis().width*nbin,\n color='k',label='Gaussian ($\\sigma = 1$)')\n \n hz_mc.plot(label='MC',hist_style='line')\n plt.gca().grid(True)\n plt.gca().set_yscale('log')\n plt.gca().set_ylim(0.5)\n\n ax2.legend(loc='upper right',prop= {'size' : 10 })\n\n data_stats = 'Mean = %.2f\\nRMS = %.2f'%(hz.mean(),hz.stddev())\n mc_stats = 'MC Mean = %.2f\\nMC RMS = %.2f'%(hz_mc.mean(),\n hz_mc.stddev())\n \n ax2.set_xlabel(cb_label)\n ax2.set_title(title)\n ax2.text(0.05,0.95,\n '%s\\n%s'%(data_stats,mc_stats),\n verticalalignment='top',\n transform=ax2.transAxes,fontsize=10)\n\n \n \n \n \ndef make_projection_plots_skycube(im,paxis,delta_bin=2):\n\n nbins = im.axis(2).nbins\n nfig = nbins/(8*delta_bin)\n \n for i in range(nfig):\n\n fig, axes = plt.subplots(2,4,figsize=(1.5*10,1.5*5))\n for j in range(8):\n\n ibin = i*nfig*delta_bin + j*delta_bin\n\n if ibin >= nbins: break\n \n print i, j, ibin\n \n h = im.marginalize(2,[ibin,ibin+1])\n emin = im.axis(2).pix_to_coord(ibin)\n emax = im.axis(2).pix_to_coord(ibin+delta_bin)\n\n \n axes.flat[j].set_title('E = [%.3f %.3f]'%(emin,emax))\n\n hp = h.project(paxis)\n hp.plot(ax=axes.flat[j])\n axes.flat[j].set_xlim(*hp.axis().lims())\n axes.flat[j].set_ylim(0)\n \n\nclass Knob:\n \"\"\"\n Knob - simple class with a \"setKnob\" method. \n A Knob instance is attached to a Param instance, e.g., param.attach(knob)\n Base class is for documentation purposes.\n \"\"\"\n def setKnob(self, value):\n pass\n\n\nclass Param(object):\n \"\"\"\n The idea of the \"Param\" class is that some parameter in the GUI may have\n several knobs that both control it and reflect the parameter's state, e.g.\n a slider, text, and dragging can all change the value of the frequency in\n the waveform of this example. \n The class allows a cleaner way to update/\"feedback\" to the other knobs when \n one is being changed. Also, this class handles min/max constraints for all\n the knobs.\n Idea - knob list - in \"set\" method, knob object is passed as well\n - the other knobs in the knob list have a \"set\" method which gets\n called for the others.\n \"\"\"\n def __init__(self, initialValue=None, minimum=0., maximum=1.):\n self.minimum = minimum\n self.maximum = maximum\n if initialValue != self.constrain(initialValue):\n raise ValueError('illegal initial value')\n self.value = initialValue\n self.knobs = []\n \n def attach(self, knob):\n self.knobs += [knob]\n\n def setMax(self, maximum):\n\n self.maximum = maximum\n \n def set(self, value, knob=None):\n self.value = value\n self.value = self.constrain(value)\n for feedbackKnob in self.knobs:\n if feedbackKnob != knob:\n feedbackKnob.setKnob(self.value)\n return self.value\n\n def value(self):\n return self.value\n\n def constrain(self, value):\n if value <= self.minimum:\n value = self.minimum\n if value >= self.maximum:\n value = self.maximum\n return value\n\nclass CtrlGroup(object):\n\n def __init__(self, parent, label, pmin, pmax, fn, pdefault=None):\n self.label = wx.StaticText(parent, label=label)\n \nclass SpinCtrlGroup(CtrlGroup):\n def __init__(self, parent, label, pmin, pmax, fn, pdefault=None):\n CtrlGroup.__init__(self,parent,label,pmin,pmax,fn,pdefault=None)\n \n self.spinCtrl = wx.SpinCtrl(parent,style=wx.SP_ARROW_KEYS)#, pos=(150, 75), size=(60, -1))\n self.spinCtrl.SetRange(pmin,pmax) \n self.spinCtrl.SetValue(pmin)\n# self.spinCtrl.Bind(wx.EVT_SPINCTRL, self.spinCtrlHandler)\n parent.Bind(wx.EVT_SPINCTRL, self.spinCtrlHandler,self.spinCtrl)\n\n self.sizer = wx.GridBagSizer(1,2)#wx.BoxSizer(wx.HORIZONTAL)\n\n self.sizer.Add(self.label, pos=(0,0),\n flag = wx.EXPAND | wx.ALIGN_CENTER,\n border=5)\n\n self.sizer.Add(self.spinCtrl, pos=(0,1),\n flag = wx.EXPAND | wx.ALIGN_CENTER | wx.ALIGN_RIGHT,\n border=5)\n\n# self.sizer.Add(self.label, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n# border=2)\n\n# self.sizer.Add(self.spinCtrl, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n# border=2)\n\n self.fn = fn\n\n def init(self,pmin,pmax,pdefault=None):\n\n print 'spinCtrlGroup init ', pmin, pmax, pdefault\n \n self.spinCtrl.SetRange(pmin,pmax)\n if pdefault is None: self.spinCtrl.SetValue(pmin)\n else: self.spinCtrl.SetValue(pdefault)\n\n def spinCtrlHandler(self, evt):\n v = evt.GetPosition() \n print 'spinCtrlHandler ', v\n self.fn(v)\n\nclass TwinSliderGroup(object):\n def __init__(self, parent, label, pmin, pmax, fnlo, fnhi, pdefault=None):\n \n sizer = wx.BoxSizer(wx.VERTICAL)\n\n self.slider_lo = SliderGroup(parent,label,pmin,pmax,fn=self.loSliderHandler,float_arg=True)\n self.slider_hi = SliderGroup(parent,label,pmin,pmax,fn=self.hiSliderHandler,float_arg=True)\n \n sizer.Add(self.slider_lo.sizer, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n border=2)\n sizer.Add(self.slider_hi.sizer, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n border=2)\n \n self.sizer = sizer\n\n self.fnlo = fnlo\n self.fnhi = fnhi\n\n def init(self,pmin,pmax,pdefault=None):\n\n self.slider_lo.SetMin(pmin)\n self.slider_lo.SetMax(pmax)\n self.slider_hi.SetMin(pmin)\n self.slider_hi.SetMax(pmax)\n# if pdefault is None: self.set(pmin)\n# else: self.set(pdefault)\n \n def loSliderHandler(self, v):\n# self.slider_hi.set(v)\n\n if self.slider_lo.value() > self.slider_hi.value():\n self.slider_hi.set(self.slider_lo.value())\n \n self.fnlo(v)\n \n def hiSliderHandler(self, v):\n\n if self.slider_hi.value() < self.slider_lo.value():\n self.slider_lo.set(self.slider_hi.value())\n \n self.fnhi(v)\n \n\n\n \nclass SliderGroup(object):\n def __init__(self, parent, label, pmin, pmax, fn,\n pdefault=None, float_arg=False):\n self.sliderLabel = wx.StaticText(parent, label=label)\n self.sliderText = wx.TextCtrl(parent, -1, style=wx.TE_PROCESS_ENTER)\n\n# self.spinCtrl = wx.SpinCtrl(parent, value='0')#, pos=(150, 75), size=(60, -1))\n# self.spinCtrl.SetRange(pmin,pax) \n# self.spinCtrl.Bind(wx.EVT_SPINCTRL, self.sliderSpinCtrlHandler)\n\n self.float_arg = float_arg\n \n self.slider_min = 0\n self.slider_max = 1000\n \n self.slider = wx.Slider(parent, -1,style=wx.SL_MIN_MAX_LABELS)#,style=wx.SL_AUTOTICKS | wx.SL_LABELS)\n\n self.init(pmin,pmax,pdefault)\n \n# sizer = wx.GridBagSizer(1,3)\n# sizer.Add(self.sliderLabel, pos=(0,0), \n# border=5,flag = wx.ALIGN_CENTER)#,flag=wx.EXPAND)\n# sizer.Add(self.sliderText, pos=(0,1), \n# border=5,flag = wx.ALIGN_CENTER)#,flag=wx.EXPAND)\n# sizer.Add(self.slider, pos=(0,2),flag=wx.EXPAND | wx.ALIGN_CENTER,border=5)\n\n\n sizer = wx.BoxSizer(wx.HORIZONTAL)\n sizer.Add(self.sliderLabel, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n border=2)\n sizer.Add(self.sliderText, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL,\n border=2)\n sizer.Add(self.slider, 1, wx.EXPAND)\n self.sizer = sizer\n\n self.slider.Bind(wx.EVT_SLIDER, self.sliderHandler)\n self.sliderText.Bind(wx.EVT_TEXT_ENTER, self.sliderTextHandler)\n\n self.fn = fn\n\n def getValue(self):\n\n if self.float_arg: \n return float(self.sliderText.GetValue())\n else:\n return int(self.sliderText.GetValue())\n \n def init(self,pmin,pmax,pdefault=None):\n\n print 'sliderGroup init ', pmin, pmax, pdefault\n \n self.pmin = pmin\n self.pmax = pmax\n \n if not self.float_arg:\n self.slider_min = pmin\n self.slider_max = pmax\n\n self.slider.SetMin(self.slider_min)\n self.slider.SetMax(self.slider_max)\n\n if pdefault is None: self.set(pmin)\n else: self.set(pdefault)\n \n# if pdefault is None: self.set(pmin) \n# self.slider.SetMin(pmin)\n# self.slider.SetMax(pmax)\n# if pdefault is None: self.set(pmin)\n# else: self.set(pdefault)\n \n def disable(self):\n self.slider.Enable(False)\n self.sliderText.Enable(False)\n \n def sliderHandler(self, evt):\n v = evt.GetInt()\n\n if self.float_arg:\n v = self.pmin + float(v)/1000.*(self.pmax-self.pmin)\n \n self.set(v)\n self.fn(v)\n \n def sliderTextHandler(self, evt):\n v = self.sliderText.GetValue()\n self.set(v)\n self.fn(v)\n\n def value(self):\n\n v = self.slider.GetValue()\n if self.float_arg:\n return self.pmin + float(v)/1000.*(self.pmax-self.pmin)\n else: return v\n \n def set(self, value):\n\n print 'sliderGroup value ', value\n \n self.sliderText.SetValue('%s'%value)\n\n if self.float_arg:\n v = 1000*((value-self.pmin)/(self.pmax-self.pmin))\n #v = min(max(v,0),1000)\n\n print 'set ', v, value\n \n self.slider.SetValue(int(v))\n else:\n self.slider.SetValue(int(value))\n\nclass FITSViewerApp(wx.App):\n\n def __init__(self,im):\n\n self._im = im\n wx.App.__init__(self)\n\n\n def OnInit(self):\n\n print 'im: ', self._im\n \n self.frame = FITSViewerFrame(self._im,parent=None,\n title=\"FITS Viewer\",\n size=(1.5*640, 1.5*480))\n \n# self.frame1 = FITSViewerFrame(parent=None,\n# title=\"FITS Viewer\",\n# size=(640, 480))\n self.frame.Show()\n return True\n \nclass FITSViewerFrame(wx.Frame):\n def __init__(self, files, hdu=0,*args, **kwargs):\n wx.Frame.__init__(self, *args,**kwargs)\n\n self.files = files\n self.hdulist = []\n self.show_image = []\n self.image_window = []\n\n for i, f in enumerate(files):\n self.hdulist.append(pyfits.open(f))\n self.show_image.append(True)\n self.image_window.append(ImagePanel(self,i))\n \n self.hdu = hdu\n self.slice = 0\n self.nbin = 1\n self._projx_width = 10.\n self._projx_center = 50.\n self._projy_width = 10.\n self._projy_center = 50.\n\n self.projx_window = PlotPanel(self,12,0,'LAT Projection','','')\n self.projy_window = PlotPanel(self,13,1,'LON Projection','','')\n\n# self.ctrl_slice = SliderGroup(self,'Slice',0,6,fn=self.update_slice)\n \n self.ctrl_slice = SpinCtrlGroup(self,'Slice',0,6,fn=self.update_slice)\n self.ctrl_nbins = SpinCtrlGroup(self,'NBins',0,6,fn=self.update_nbin)\n self.ctrl_hdu = SpinCtrlGroup(self,'HDU',0,6,fn=self.update_hdu)\n\n# self.spinctrl0 = wx.SpinCtrl(self, value='0')#, pos=(150, 75), size=(60, -1))\n# self.spinctrl0.SetRange(0,6)\n \n # self.spinctrl0.Bind(wx.EVT_SPINCTRL, lambda evt: self.update_slice(evt.GetPosition()))\n\n\n \n self.ctrl_projx_center = SliderGroup(self,'X Center',0,100,\n self.update_projx_center,\n float_arg=True)\n\n self.ctrl_projx_width = SliderGroup(self,'X Width',0,100,\n self.update_projx_width,\n float_arg=True)\n\n \n self.ctrl_projy_center = SliderGroup(self,'Y Center',0,100,\n self.update_projy_center,\n float_arg=True)\n\n self.ctrl_projy_width = SliderGroup(self,'Y Width',0,100,\n self.update_projy_width,\n float_arg=True)\n \n self.ctrl_rebin = SpinCtrlGroup(self,'Rebin',1,4,\n fn=self.update_rebin)\n\n self.ctrl_hdu.init(0,len(self.hdulist[0])-1)\n\n sb0 = wx.StaticBox(self, label=\"Optional Attributes\")\n sb0sizer = wx.StaticBoxSizer(sb0, wx.VERTICAL)\n\n sb1 = wx.StaticBox(self, label=\"Projection\")\n sb1sizer = wx.StaticBoxSizer(sb1, wx.VERTICAL)\n\n sb2 = wx.StaticBox(self, label=\"Transform\")\n sb2sizer = wx.StaticBoxSizer(sb2, wx.VERTICAL)\n\n sizer_main = wx.BoxSizer(wx.HORIZONTAL)\n\n sizer_plots = wx.BoxSizer(wx.HORIZONTAL)\n\n sizer_proj = wx.BoxSizer(wx.VERTICAL)\n self.sizer_image = wx.BoxSizer(wx.VERTICAL)\n \n sizer_ctrls = wx.BoxSizer(wx.VERTICAL)\n# sizer.Add(self.window, 1, wx.EXPAND)\n sizer_ctrls.Add(sb0sizer, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n sizer_ctrls.Add(sb1sizer, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n sizer_ctrls.Add(sb2sizer, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n sb0sizer.Add(self.ctrl_slice.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n sb0sizer.Add(self.ctrl_nbins.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n sb0sizer.Add(self.ctrl_hdu.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n fn = []\n\n for i, w in enumerate(self.image_window):\n cb = wx.CheckBox(self, label=\"Image %i\"%i)\n cb.Bind(wx.EVT_CHECKBOX, lambda t,i=i: self.toggle_image(t,i))\n cb.SetValue(True)\n\n sb0sizer.Add(cb, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n # Projection Controls\n\n cb_proj_norm = wx.CheckBox(self, label=\"Normalize\")\n cb_proj_norm.Bind(wx.EVT_CHECKBOX, self.toggle_proj_norm)\n \n sb1sizer.Add(self.ctrl_rebin.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n sb1sizer.Add(self.ctrl_projx_center.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n sb1sizer.Add(self.ctrl_projx_width.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n sb1sizer.Add(self.ctrl_projy_center.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n sb1sizer.Add(self.ctrl_projy_width.sizer, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n \n sb1sizer.Add(cb_proj_norm, 0,\n wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n \n tc0 = wx.TextCtrl(self, -1, style=wx.TE_PROCESS_ENTER)\n\n bt0 = wx.Button(self, label=\"Update\")\n bt0.Bind(wx.EVT_BUTTON, self.update)\n\n sizer_ctrls.Add(bt0, 0, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL, border=5)\n\n cb1 = wx.CheckBox(self, label=\"Log Scale\")\n cb1.Bind(wx.EVT_CHECKBOX, self.toggle_yscale)\n\n cb0 = wx.CheckBox(self, label=\"Smooth\")\n cb0.Bind(wx.EVT_CHECKBOX, self.update_smoothing)\n\n sb2sizer.Add(cb0,flag=wx.LEFT|wx.TOP, border=5)\n sb2sizer.Add(cb1,flag=wx.LEFT|wx.TOP, border=5)\n sb2sizer.Add(bt0,flag=wx.LEFT|wx.TOP, border=5)\n sb2sizer.Add(tc0,flag=wx.LEFT|wx.TOP, border=5)\n\n sizer_main.Add(sizer_ctrls,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n sizer_main.Add(sizer_plots,3, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n\n sizer_plots.Add(self.sizer_image,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n sizer_plots.Add(sizer_proj,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n\n for w in self.image_window:\n self.sizer_image.Add(w,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n\n sizer_proj.Add(self.projx_window,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n sizer_proj.Add(self.projy_window,1, wx.EXPAND | wx.ALIGN_CENTER | wx.ALL)\n\n self.SetSizer(sizer_main)\n\n self.update_hdu(self.hdu)\n self.update_slice(self.slice)\n \n def update_hdu(self,value):\n\n self.hdu = int(value)\n\n for w in self.image_window: w.clear()\n self.projx_window.clear()\n self.projy_window.clear()\n\n for i, hl in enumerate(self.hdulist):\n hdu = hl[self.hdu] \n self.load_hdu(hdu,self.image_window[i])\n\n self.update()\n \n def load_hdu(self,hdu,image_window):\n\n print 'Loading HDU'\n\n style = {}\n\n if 'CREATOR' in hdu.header and hdu.header['CREATOR'] == 'gtsrcmaps':\n style['hist_style'] = 'line'\n style['linestyle'] = '-'\n\n if hdu.header['NAXIS'] == 3:\n im = SkyCube.createFromHDU(hdu)\n\n if image_window: image_window.add(im,style)\n self.projx_window.add(im,style)\n self.projy_window.add(im,style)\n self.ctrl_slice.init(0,im.axis(2).nbins-1)\n self.ctrl_nbins.init(1,im.axis(2).nbins)\n\n self.nbinx = im.axis(0).nbins\n self.nbiny = im.axis(1).nbins\n\n self._projx_center = self.nbinx/2.\n self._projx_width = 10.0\n\n self._projy_center = self.nbiny/2.\n self._projy_width = 10.0\n \n else:\n im = SkyImage.createFromHDU(hdu)\n self.ctrl_slice.init(0,0)\n self.ctrl_slice.disable()\n self.ctrl_nbins.init(0,0)\n self.ctrl_nbins.disable()\n\n self.ctrl_projx_center.init(0,self.nbinx,self._projx_center)\n self.ctrl_projx_width.init(0,self.nbinx,self._projx_width)\n\n self.ctrl_projy_center.init(0,self.nbiny,self._projy_center)\n self.ctrl_projy_width.init(0,self.nbiny,self._projy_width)\n \n def update_slice(self,value):\n\n self.slice = int(value)\n\n for w in self.image_window: w.set_slice(value)\n self.projx_window.set_slice(value)\n self.projy_window.set_slice(value)\n# self.update()\n\n def update_nbin(self,value):\n\n self.nbin = int(value)\n\n for w in self.image_window: w.set_nbin(value)\n self.projx_window.set_nbin(value)\n self.projy_window.set_nbin(value)\n# self.update()\n\n def update_rebin(self,value):\n \n self.projx_window.set_rebin(value)\n self.projy_window.set_rebin(value)\n# self.update()\n\n def update_projx_lo(self,value):\n \n for w in self.image_window: w.set_projx_range_lo(value)\n self.projx_window.set_proj_range_lo(value)\n for w in self.image_window: w.update_lines()\n\n def update_projx_hi(self,value):\n \n for w in self.image_window: w.set_projx_range_hi(value)\n self.projx_window.set_proj_range_hi(value)\n for w in self.image_window: w.update_lines()\n\n def update_projx_center(self,value):\n\n self._projx_center = value\n self.update_projx()\n\n def update_projx_width(self,value):\n\n self._projx_width = value\n self.update_projx()\n\n def update_projx(self):\n\n projx_lo = self._projx_center - self._projx_width*0.5\n projx_hi = self._projx_center + self._projx_width*0.5\n \n for w in self.image_window: w.set_projx_range(projx_lo,projx_hi)\n self.projx_window.set_proj_range(projx_lo,projx_hi)\n for w in self.image_window: w.update_lines()\n self.projx_window.update()\n \n def update_projy_lo(self,value):\n \n for w in self.image_window: w.set_projy_range_lo(value)\n self.projy_window.set_proj_range_lo(value)\n for w in self.image_window: w.update_lines()\n\n def update_projy_hi(self,value):\n \n for w in self.image_window: w.set_projy_range_hi(value)\n self.projy_window.set_proj_range_hi(value)\n for w in self.image_window: w.update_lines()\n\n def update_projy_center(self,value):\n\n self._projy_center = value\n self.update_projy()\n\n def update_projy_width(self,value):\n\n self._projy_width = value\n self.update_projy()\n\n def update_projy(self):\n\n projy_lo = self._projy_center - self._projy_width*0.5\n projy_hi = self._projy_center + self._projy_width*0.5\n \n for w in self.image_window: w.set_projy_range(projy_lo,projy_hi)\n self.projy_window.set_proj_range(projy_lo,projy_hi)\n for w in self.image_window: w.update_lines()\n self.projy_window.update()\n \n def update_smoothing(self, e):\n \n sender = e.GetEventObject()\n isChecked = sender.GetValue()\n\n if isChecked: \n self.image_window[0].smooth = True\n else: \n self.image_window[0].smooth = False\n\n# self.update()\n\n def toggle_image(self, e, i):\n\n w = self.image_window[i]\n\n sender = e.GetEventObject()\n if sender.GetValue(): w.Show()\n else: w.Hide()\n\n self.sizer_image.Layout()\n# self.update()\n\n def toggle_proj_norm(self, e):\n\n sender = e.GetEventObject()\n if sender.GetValue():\n self.projx_window.set_norm(True)\n self.projy_window.set_norm(True)\n else:\n self.projx_window.set_norm(False)\n self.projy_window.set_norm(False)\n self.projx_window.update()\n self.projy_window.update()\n\n def toggle_smoothing(self, e):\n \n sender = e.GetEventObject()\n if sender.GetValue(): \n self.image_window[0].smooth = True\n else: \n self.image_window[0].smooth = False\n\n self.update()\n\n def toggle_yscale(self, evt):\n \n sender = evt.GetEventObject()\n if sender.GetValue():\n for w in self.image_window:\n w.update_style('logz',True)\n else: \n for w in self.image_window:\n w.update_style('logz',False)\n\n self.update()\n\n def update(self,evt=None):\n\n self.update_projx()\n self.update_projy()\n \n for w in self.image_window: w.update()\n self.projx_window.update()\n self.projy_window.update()\n \n# def OnPaint(self, event):\n# print 'OnPaint'\n# self.window.canvas.draw()\n \n\nclass BasePanel(wx.Panel):\n \n def __init__(self, parent,fignum):\n wx.Panel.__init__(self, parent, -1)\n\n self.slice = 0\n self.nbin = 1\n self.rebin = 0\n \n def update_style(self,k,v):\n for i, s in enumerate(self._style):\n self._style[i][k] = v\n\n\n \nclass ImagePanel(BasePanel):\n\n def __init__(self, parent,fignum):\n BasePanel.__init__(self, parent, fignum)\n\n self._fignum = fignum\n self._fig = plt.figure(fignum,figsize=(5,4), dpi=75)\n self.canvas = FigureCanvasWxAgg(self, -1, self._fig)\n self.toolbar = NavigationToolbar2Wx(self._fig.canvas)\n #Toolbar(self.canvas) #matplotlib toolbar\n self.toolbar.Realize()\n\n #self.toolbar.set_active([0,1])\n\n # Now put all into a sizer\n sizer = wx.BoxSizer(wx.VERTICAL)\n # This way of adding to sizer allows resizing\n sizer.Add(self.canvas, 1, wx.LEFT|wx.TOP|wx.GROW)\n # Best to allow the toolbar to resize!\n sizer.Add(self.toolbar, 0, wx.GROW)\n self.SetSizer(sizer)\n self.Fit()\n self._ax = None\n self._projx_lines = [None,None]\n self._projy_lines = [None,None]\n self._im = []\n self._cm = []\n self._style = []\n self._axim = []\n self.smooth = False\n\n self.projx_range = [None, None]\n self.projy_range = [None, None]\n \n# self.toolbar.update() # Not sure why this is needed - ADS\n\n \n def set_projx_range_lo(self,value):\n self.projx_range[0] = value\n\n def set_projx_range_hi(self,value):\n self.projx_range[1] = value\n\n def set_projx_range(self,lovalue,hivalue):\n self.projx_range[0] = lovalue\n self.projx_range[1] = hivalue\n\n def set_projy_range_lo(self,value):\n self.projy_range[0] = value\n\n def set_projy_range_hi(self,value):\n self.projy_range[1] = value\n\n def set_projy_range(self,lovalue,hivalue):\n self.projy_range[0] = lovalue\n self.projy_range[1] = hivalue\n\n def draw(self):\n\n bin_range = [self.slice,self.slice+self.nbin]\n\n if isinstance(self._im,SkyCube):\n im = self._im.marginalize(2,bin_range=bin_range)\n else:\n im = self._im\n\n self.scf()\n self._axim = im.plot()\n\n self.scf()\n self._axim.set_data(im.counts.T)\n self._axim.autoscale()\n self.canvas.draw()\n self._fig.canvas.draw()\n\n def clear(self):\n\n self._im = []\n self._style = []\n self._axim = []\n\n def add(self,im,style):\n\n style.setdefault('logz',False)\n\n self._im.append(im)\n self._style.append(style)\n\n def scf(self):\n plt.figure(self._fignum)\n\n def set_slice(self,value):\n self.slice = int(value)\n\n def set_nbin(self,value):\n self.nbin = int(value)\n\n\n def update(self):\n\n self.update_image()\n self.update_lines()\n \n def update_image(self):\n\n self.scf()\n\n bin_range = [self.slice,self.slice+self.nbin]\n\n self._cm = []\n\n for im in self._im:\n if isinstance(im,SkyCube):\n self._cm.append(im.marginalize(2,bin_range=bin_range))\n else:\n self._cm.append(im)\n\n for i in range(len(self._cm)):\n if self.smooth: self._cm[i] = self._cm[i].smooth(0.1)\n\n if len(self._cm) == 0: return\n\n cm = self._cm\n \n cat = Catalog.get('3fgl')\n \n if len(self._axim) == 0:\n\n axim = cm[0].plot(**self._style[0])\n\n cat.plot(cm[0],src_color='w')\n \n self._axim.append(axim)\n self._ax = plt.gca()\n\n \n \n \n \n plt.colorbar(axim,orientation='horizontal',shrink=0.7,pad=0.15,\n fraction=0.05)\n\n return\n\n self._axim[0].set_data(cm[0].counts.T)\n self._axim[0].autoscale()\n\n if self._style[0]['logz']:\n self._axim[0].set_norm(LogNorm())\n else:\n self._axim[0].set_norm(Normalize())\n\n self.canvas.draw()\n# self._fig.canvas.draw()\n# self.toolbar.update()\n# self._fig.canvas.draw_idle()\n\n def update_lines(self):\n\n if len(self._cm) == 0: return\n \n print 'update lines ', self.projx_range, self.projy_range\n \n cm = self._cm\n\n if self._projx_lines[0]: \n self._ax.lines.remove(self._projx_lines[0])\n\n if self._projx_lines[1]:\n self._ax.lines.remove(self._projx_lines[1])\n\n if self._projy_lines[0]: \n self._ax.lines.remove(self._projy_lines[0])\n\n if self._projy_lines[1]:\n self._ax.lines.remove(self._projy_lines[1])\n \n ixlo = max(0,self.projx_range[0])\n ixhi = max(0,self.projx_range[1])\n\n iylo = max(0,self.projy_range[0])\n iyhi = max(0,self.projy_range[1])\n\n\n self._projx_lines[0] = self._ax.axhline(ixlo,color='w')\n self._projx_lines[1] = self._ax.axhline(ixhi,color='w')\n\n self._projy_lines[0] = self._ax.axvline(iylo,color='w')\n self._projy_lines[1] = self._ax.axvline(iyhi,color='w')\n \n self.canvas.draw()\n \nclass PlotPanel(BasePanel):\n\n def __init__(self, parent,fignum,pindex,title,xlabel,ylabel):\n BasePanel.__init__(self, parent, fignum)\n# wx.Panel.__init__(self, parent, -1)\n\n self._fignum = fignum\n self._pindex = pindex\n self._fig = plt.figure(fignum,figsize=(5,4), dpi=75)\n self.canvas = FigureCanvasWxAgg(self, -1, self._fig)\n self.toolbar = NavigationToolbar2Wx(self.canvas)\n #Toolbar(self.canvas) #matplotlib toolbar\n self.toolbar.Realize()\n\n #self.toolbar.set_active([0,1])\n\n # Now put all into a sizer\n sizer = wx.BoxSizer(wx.VERTICAL)\n # This way of adding to sizer allows resizing\n sizer.Add(self.canvas, 1, wx.LEFT|wx.TOP|wx.GROW)\n # Best to allow the toolbar to resize!\n sizer.Add(self.toolbar, 0, wx.GROW)\n self.SetSizer(sizer)\n self.Fit()\n self._ax = None\n self._im = []\n self._style = []\n self._lines = []\n self._title = title\n self._xlabel = xlabel\n self._ylabel = ylabel\n self._proj_range = None\n self._norm = False\n# self.toolbar.update() # Not sure why this is needed - ADS\n \n def clear(self): \n self._im = []\n self._style = []\n self._lines = []\n\n def add(self,im,style):\n\n style.setdefault('linestyle','None')\n\n if self._proj_range is None:\n self._proj_range = [0,im.axis(self._pindex).nbins]\n \n self._im.append(im)\n self._style.append(style)\n\n def scf(self):\n plt.figure(self._fignum)\n\n def set_slice(self,value):\n self.slice = int(value)\n\n def set_nbin(self,value):\n self.nbin = int(value)\n\n def set_rebin(self,value):\n self.rebin = int(value)\n\n def set_proj_range(self,lo,hi):\n self._proj_range = [lo,hi]\n\n def set_norm(self,v):\n self._norm = v\n \n def update(self):\n\n self.scf()\n\n bin_range = [self.slice,self.slice+self.nbin]\n\n print 'proj_range ', self._proj_range\n\n proj_bin_range = []\n proj_bin_range += [max(0,np.round(self._proj_range[0]))]\n proj_bin_range += [np.round(self._proj_range[1])]\n\n print 'proj_bin_range ', proj_bin_range\n \n# proj_bin_range = [self._im[0].axis(self._pindex).binToVal(self._proj_range[0])[0],\n# self._im[0].axis(self._pindex).binToVal(self._proj_range[1])[0]]\n \n pcm = []\n\n for im in self._im:\n if isinstance(im,SkyCube):\n cm = im.marginalize(2,bin_range=bin_range)\n else:\n cm = im\n\n h = cm.project(self._pindex,\n bin_range=proj_bin_range,\n offset_coord=True).rebin(self.rebin)\n\n if self._norm: h = h.normalize()\n \n pcm.append(h)\n\n if len(self._lines) == 0:\n\n for i, p in enumerate(pcm):\n self._lines.append(p.plot(**self._style[i])[0])\n self._ax = plt.gca()\n self._ax.grid(True)\n self._ax.set_title(self._title)\n return\n\n for i, p in enumerate(pcm):\n p.update_artists(self._lines[i])\n\n self._ax.relim()\n self._ax.autoscale(axis='y')\n\n self.canvas.draw()\n# self._fig.canvas.draw()\n# self.toolbar.update()\n# self._fig.canvas.draw_idle()\n\nclass FourierDemoWindow(wx.Window, Knob):\n def __init__(self, *args, **kwargs):\n wx.Window.__init__(self, *args, **kwargs)\n self.lines = []\n self.figure = plt.Figure()\n self.canvas = FigureCanvasWxAgg(self, -1, self.figure)\n self.canvas.callbacks.connect('button_press_event', self.mouseDown)\n self.canvas.callbacks.connect('motion_notify_event', self.mouseMotion)\n self.canvas.callbacks.connect('button_release_event', self.mouseUp)\n self.state = ''\n self.mouseInfo = (None, None, None, None)\n self.f0 = Param(2., minimum=0., maximum=6.)\n self.A = Param(1., minimum=0.01, maximum=2.)\n\n\n self.sizer = wx.BoxSizer(wx.VERTICAL)\n self.sizer.Add(self.canvas, 1, wx.LEFT | wx.TOP | wx.GROW)\n self.SetSizer(self.sizer)\n\n self.draw()\n \n # Not sure I like having two params attached to the same Knob,\n # but that is what we have here... it works but feels kludgy -\n # although maybe it's not too bad since the knob changes both params\n # at the same time (both f0 and A are affected during a drag)\n self.f0.attach(self)\n self.A.attach(self)\n self.Bind(wx.EVT_SIZE, self.sizeHandler)\n\n self.add_toolbar()\n \n def sizeHandler(self, *args, **kwargs):\n self.canvas.SetSize(self.GetSize())\n \n def mouseDown(self, evt):\n if self.lines[0] in self.figure.hitlist(evt):\n self.state = 'frequency'\n elif self.lines[1] in self.figure.hitlist(evt):\n self.state = 'time'\n else:\n self.state = ''\n self.mouseInfo = (evt.xdata, evt.ydata, max(self.f0.value, .1), self.A.value)\n\n def mouseMotion(self, evt):\n if self.state == '':\n return\n x, y = evt.xdata, evt.ydata\n if x is None: # outside the axes\n return\n x0, y0, f0Init, AInit = self.mouseInfo\n self.A.set(AInit+(AInit*(y-y0)/y0), self)\n if self.state == 'frequency':\n self.f0.set(f0Init+(f0Init*(x-x0)/x0))\n elif self.state == 'time':\n if (x-x0)/x0 != -1.:\n self.f0.set(1./(1./f0Init+(1./f0Init*(x-x0)/x0)))\n \n def mouseUp(self, evt):\n self.state = ''\n\n def draw(self):\n if not hasattr(self, 'subplot1'):\n self.subplot1 = self.figure.add_subplot(211)\n self.subplot2 = self.figure.add_subplot(212)\n x1, y1, x2, y2 = self.compute(self.f0.value, self.A.value)\n color = (1., 0., 0.)\n self.lines += self.subplot1.plot(x1, y1, color=color, linewidth=2)\n self.lines += self.subplot2.plot(x2, y2, color=color, linewidth=2)\n #Set some plot attributes\n self.subplot1.set_title(\"Click and drag waveforms to change frequency and amplitude\", fontsize=12)\n self.subplot1.set_ylabel(\"Frequency Domain Waveform X(f)\", fontsize = 8)\n self.subplot1.set_xlabel(\"frequency f\", fontsize = 8)\n self.subplot2.set_ylabel(\"Time Domain Waveform x(t)\", fontsize = 8)\n self.subplot2.set_xlabel(\"time t\", fontsize = 8)\n self.subplot1.set_xlim([-6, 6])\n self.subplot1.set_ylim([0, 1])\n self.subplot2.set_xlim([-2, 2])\n self.subplot2.set_ylim([-2, 2])\n self.subplot1.text(0.05, .95, r'$X(f) = \\mathcal{F}\\{x(t)\\}$', \\\n verticalalignment='top', transform = self.subplot1.transAxes)\n self.subplot2.text(0.05, .95, r'$x(t) = a \\cdot \\cos(2\\pi f_0 t) e^{-\\pi t^2}$', \\\n verticalalignment='top', transform = self.subplot2.transAxes)\n\n def compute(self, f0, A):\n f = np.arange(-6., 6., 0.02)\n t = np.arange(-2., 2., 0.01)\n x = A*np.cos(2*np.pi*f0*t)*np.exp(-np.pi*t**2)\n X = A/2*(np.exp(-np.pi*(f-f0)**2) + np.exp(-np.pi*(f+f0)**2))\n return f, X, t, x\n\n def repaint(self):\n self.canvas.draw()\n\n def setKnob(self, value):\n # Note, we ignore value arg here and just go by state of the params\n x1, y1, x2, y2 = self.compute(self.f0.value, self.A.value)\n plt.setp(self.lines[0], xdata=x1, ydata=y1)\n plt.setp(self.lines[1], xdata=x2, ydata=y2)\n self.repaint()\n\n def add_toolbar(self):\n self.toolbar = NavigationToolbar2Wx(self.canvas)\n self.toolbar.Realize()\n\n print 'Adding toolbar'\n \n if wx.Platform == '__WXMAC__':\n # Mac platform (OSX 10.3, MacPython) does not seem to cope with\n # having a toolbar in a sizer. This work-around gets the buttons\n # back, but at the expense of having the toolbar at the top\n self.SetToolBar(self.toolbar)\n else:\n # On Windows platform, default window size is incorrect, so set\n # toolbar width to figure width.\n tw, th = self.toolbar.GetSizeTuple()\n fw, fh = self.canvas.GetSizeTuple()\n # By adding toolbar in sizer, we are able to put it at the bottom\n # of the frame - so appearance is closer to GTK version.\n # As noted above, doesn't work for Mac.\n self.toolbar.SetSize(wx.Size(fw, th))\n self.sizer.Add(self.toolbar, 0, wx.LEFT | wx.EXPAND)\n # update the axes menu on the toolbar\n self.toolbar.update()\n"
},
{
"alpha_fraction": 0.47827446460723877,
"alphanum_fraction": 0.4825987219810486,
"avg_line_length": 33.83484649658203,
"blob_id": "269e508d2e98abc75873f5b45a0cd4b97cf7aae2",
"content_id": "c2592f343ead1b2c65fcbf2edec16723b2f8b7f1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19194,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 551,
"path": "/gammatools/fermi/fermi_analysis.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import yaml\nimport os\nimport sys\nimport shutil\nimport copy\nimport glob\nimport numpy as np\nfrom tempfile import mkdtemp\n\nimport xml.etree.cElementTree as ElementTree\n\nfrom gammatools.core.util import prettify_xml\n\nfrom skymaps import SkyDir\nfrom uw.like.pointspec import SpectralAnalysis,DataSpecification\nfrom uw.like.pointspec_helpers import get_default_diffuse, PointSource, FermiCatalog, get_diffuse_source\n\nfrom GtApp import GtApp\nfrom uw.like.roi_catalogs import SourceCatalog, Catalog2FGL, Catalog3Y\n\nfrom BinnedAnalysis import BinnedObs, BinnedAnalysis \nfrom UnbinnedAnalysis import UnbinnedObs, UnbinnedAnalysis\nfrom pyLikelihood import ParameterVector\nimport pyLikelihood\n\nfrom catalog import Catalog, CatalogSource\n\nfrom gammatools.core.config import Configurable\nfrom gammatools.fermi.task import *\nfrom gammatools.fermi.pylike_tools import *\n\nfrom Composite2 import *\nfrom SummedLikelihood import *\n\nclass BinnedGtlike(Configurable):\n\n default_config = {\n 'savedir' : None,\n 'scratchdir' : None,\n 'target' : None,\n 'evfile' : None,\n 'scfile' : None,\n 'ft1file' : (None,'Set the FT1 file.'),\n 'srcmdl' : (None,'Set the ROI model XML file.'),\n 'bexpfile' : (None,'Set the binned exposure map file.'),\n 'srcmapfile' : (None,''),\n 'srcmdlfile' : (None,''),\n 'ccubefile' : (None,''),\n 'ltcube' : None,\n 'galdiff' : None,\n 'isodiff' : None,\n# 'gtbin' : None,\n# 'gtexpcube' : None,\n# 'gtselect' : None,\n# 'gtsrcmap' : None,\n 'catalog' : '2FGL',\n 'optimizer' : 'MINUIT',\n 'irfs' : None }\n \n def __init__(self,src,target_name,config=None,**kwargs):\n super(BinnedGtlike,self).__init__()\n\n self.update_default_config(SelectorTask,group='gtselect')\n self.update_default_config(BinTask,group='gtbin')\n self.update_default_config(SrcMapTask,group='gtsrcmap')\n self.update_default_config(BExpTask,group='gtexpcube')\n \n self.configure(config,**kwargs)\n\n savedir = self.config['savedir']\n if savedir is None: savedir = os.getcwd()\n \n outfile_dict = {\n 'ft1file' : 'ft1.fits',\n 'ccubefile' : 'ccube.fits',\n 'bexpfile' : 'bexp.fits',\n 'srcmdl' : 'srcmdl.xml',\n 'srcmdl_fit' : 'srcmdl_fit.xml',\n 'srcmapfile' : 'srcmap.fits',\n 'srcmdlfile' : 'srcmdl.fits' }\n\n for k, v in outfile_dict.iteritems():\n self.__dict__[k] = os.path.join(savedir,\n \"%s_%s\"%(target_name,v))\n \n if k in self.config and self.config[k]:\n os.system('cp %s %s'%(self.config[k],self.__dict__[k]))\n \n# self.__dict__[k] = os.path.join(savedir,\n# \"%s_%s\"%(target_name,v))\n# else:\n# self.__dict__[k] = self.config[k]\n\n if self.config['isodiff']:\n et = ElementTree.ElementTree(file=self.srcmdl)\n root = et.getroot()\n \n for c in root.findall('source'):\n if not c.attrib['name'] == 'isodiff': continue\n\n c.attrib['name'] = os.path.basename(self.config['isodiff'])\n c.attrib['name'] = os.path.splitext(c.attrib['name'])[0]\n \n sm = c.findall('spectrum')[0]\n sm.attrib['file'] = self.config['isodiff']\n\n output_file = open(self.srcmdl,'w')\n output_file.write(ElementTree.tostring(root))\n \n# self.skydir = SkyDir(src.ra(),src.dec())\n self.src = src\n\n @property\n def like(self):\n return self._like\n\n @property\n def logLike(self):\n return self._like.logLike\n \n def setup_inputs(self):\n \n config = self.config\n \n sel_task = SelectorTask(config['evfile'],self.ft1file,\n ra=self.src.ra,dec=self.src.dec,\n config=config['gtselect'],\n overwrite=False)\n sel_task.run()\n\n bin_task = BinTask(self.ft1file,self.ccubefile,\n config=config['gtbin'],\n xref=self.src.ra,yref=self.src.dec,\n overwrite=False)\n\n bin_task.run()\n\n bexp_task = BExpTask(self.bexpfile,infile=config['ltcube'],\n config=config['gtexpcube'],\n irfs=config['irfs'],\n overwrite=False)\n \n bexp_task.run()\n\n srcmap_task = SrcMapTask(self.srcmapfile,bexpmap=self.bexpfile,\n srcmdl=self.srcmdl,\n cmap=self.ccubefile,\n expcube=config['ltcube'],\n config=config,\n irfs=config['irfs'],\n overwrite=False)\n\n srcmap_task.run()\n\n def setup_gtlike(self):\n \n self._obs = BinnedObs(srcMaps=self.srcmapfile,\n expCube=self.config['ltcube'],\n binnedExpMap=self.bexpfile,\n irfs=self.config['irfs'])\n \n self._like = BinnedAnalysis(binnedData=self._obs,\n srcModel=self.srcmdl,\n optimizer=self.config['optimizer'])\n\n def make_srcmodel(self,srcmdl=None):\n\n if srcmdl is None: srcmdl = self.srcmdl_fit\n \n srcmdl_task = SrcModelTask(self.srcmdlfile,\n srcmaps=self.srcmapfile,\n bexpmap=self.bexpfile,\n srcmdl=srcmdl,\n expcube=self.config['ltcube'],\n config=self.config,\n overwrite=False)\n \n srcmdl_task.run()\n\n def write_model(self):\n self.like.writeXml(self.srcmdl_fit)\n\n def createModelMap(self):\n\n ll = self._like.logLike\n\n fv = pyLikelihood.FloatVector()\n ll.computeModelMap(fv)\n\n shape = GetCountsMapShape(ll.countsMap())\n print shape\n\n v = np.zeros(shape)\n\n \n \n# shape = GetCountsMapShape()\n \n # v = numpy.ndarray((30,100,100),'f')\n v.flat = fv\n\n v = v.reshape(shape[::-1]).T\n\n \n return v\n\n\nclass AnalysisManager(Configurable):\n\n default_config = { 'convtype' : -1,\n 'binsperdec' : 4,\n 'savedir' : None,\n 'scratchdir' : None,\n 'target' : None,\n 'evfile' : None,\n 'scfile' : None,\n 'ltcube' : None,\n 'galdiff' : None,\n 'isodiff' : None,\n 'event_types': None,\n 'gtbin' : None,\n 'catalog' : '2FGL',\n 'optimizer' : 'MINUIT',\n 'joint' : None,\n 'irfs' : None }\n \n def __init__(self,config=None,**kwargs):\n super(AnalysisManager,self).__init__()\n self.update_default_config(SelectorTask,group='select')\n \n self.configure(config,**kwargs)\n\n import pprint\n\n pprint.pprint(self.config)\n\n self._like = SummedLikelihood()\n \n \n @property\n def like(self):\n return self._like\n\n @property\n def logLike(self):\n return self._like.logLike\n \n def setup_roi(self,**kwargs):\n\n target_name = self.config['target']\n \n cat = Catalog.get('2fgl')\n self.src = CatalogSource(cat.get_source_by_name(target_name))\n\n \n if self.config['savedir'] is None:\n self.set_config('savedir',target_name)\n\n if not os.path.exists(self.config['savedir']):\n os.makedirs(self.config['savedir'])\n \n config = self.config\n\n self.savestate = os.path.join(config['savedir'],\n \"%s_savestate.P\"%target_name)\n \n self.ft1file = os.path.join(config['savedir'],\n \"%s_ft1.fits\"%target_name)\n\n \n \n self.binfile = os.path.join(config['savedir'],\n \"%s_binfile.fits\"%target_name)\n self.srcmdl = os.path.join(config['savedir'],\n \"%s_srcmdl.xml\"%target_name)\n \n self.srcmdl_fit = os.path.join(config['savedir'],\n \"%s_srcmdl_fit.xml\"%target_name)\n \n\n if os.path.isfile(config['ltcube']) and \\\n re.search('\\.fits?',config['ltcube']):\n self.ltcube = config['ltcube']\n else:\n ltcube = sorted(glob.glob(config['ltcube']))\n\n \n self.ltcube = os.path.join(config['savedir'],\n \"%s_ltcube.fits\"%target_name)\n\n lt_task = LTSumTask(self.ltcube,infile1=ltcube,\n config=config)\n\n lt_task.run()\n\n \n self.evfile = config['evfile']#sorted(glob.glob(config['evfile']))\n# if len(self.evfile) > 1:\n# evfile_list = os.path.join(self.config('savedir'),'evfile.txt')\n# np.savetxt(evfile_list,self.evfile,fmt='%s')\n# self.evfile = os.path.abspath(evfile_list)\n# else:\n# self.evfile = self.evfile[0]\n \n# if len(self.ltfile) > 1:\n# ltfile_list = os.path.join(self.config('savedir'),'ltfile.txt')\n# np.savetxt(ltfile_list,self.ltfile,fmt='%s')\n# self.ltfile = os.path.abspath(ltfile_list)\n# else:\n# self.ltfile = self.ltfile[0]\n \n# print self.evfile\n# print self.ltfile\n \n self.skydir = SkyDir(self.src.ra,self.src.dec)\n\n sel_task = SelectorTask(self.evfile,self.ft1file,\n ra=self.src.ra,dec=self.src.dec,\n config=config['select'],overwrite=False)\n sel_task.run()\n\n cat.create_roi(self.src.ra,self.src.dec,\n config['isodiff'],\n config['galdiff'], \n self.srcmdl,radius=5.0)\n \n# self.setup_pointlike()\n\n self.components = []\n \n for i, t in enumerate(self.config['joint']):\n\n print 'Setting up binned analysis ', i\n\n# kw = dict(irfs=None,isodiff=None)\n# kw.update(t)\n \n analysis = BinnedGtlike(self.src,\n target_name + '_%02i'%(i),\n config,\n evfile=self.ft1file,\n srcmdl=self.srcmdl,\n gtselect=dict(evclass=t['evclass'],\n evtype=t['evtype']),\n# convtype=t['convtype'],\n irfs=t['irfs'],\n isodiff=t['isodiff'])\n\n analysis.setup_inputs()\n analysis.setup_gtlike()\n \n self.components.append(analysis)\n self._like.addComponent(analysis.like)\n\n# for i, p in self.tied_pars.iteritems():\n# print 'Tying parameters ', i, p \n# self.comp_like.tieParameters(p)\n\n self._like.energies = self.components[0].like.energies\n \n return\n \n for i, p in enumerate(self.components[0].like.params()):\n\n print i, p.srcName, p.getName()\n\n tied_params = [] \n for c in self.components:\n tied_params.append([c.like,p.srcName,p.getName()])\n self.comp_like.tieParameters(tied_params)\n \n# self.tied_pars = {}\n# for x in self.components:\n \n# for s in x.like.sourceNames():\n# p = x.like.normPar(s) \n# pidx = x.like.par_index(s,p.getName())\n\n# if not pidx in self.tied_pars:\n# self.tied_pars[pidx] = []\n\n# self.tied_pars[pidx].append([x.like,s,p.getName()])\n \n# print s, p.getName() \n# self.norm_pars.append([x.like,s,p.getName()])\n# self.norm_pars.append([self.analysis1.like,src,p.getName()])\n\n def fit(self):\n\n saved_state = LikelihoodState(self.like)\n \n print 'Fitting model'\n self.like.fit(verbosity=2, covar=True)\n\n source_dict = gtlike_source_dict(self.like,self.src.name) \n\n import pprint\n pprint.pprint(source_dict)\n\n def write_xml_model(self): \n \n for c in self.components:\n c.write_model()\n# c.make_srcmodel()\n\n def make_source_model(self):\n\n for c in self.components:\n c.make_srcmodel()\n \n# def gtlike_results(self, **kwargs):\n# from lande.fermi.likelihood.save import source_dict\n# return source_dict(self.like, self.name, **kwargs)\n\n# def gtlike_summary(self):\n# from lande.fermi.likelihood.printing import gtlike_summary\n# return gtlike_summary(self.like,maxdist=self.config['radius'])\n \n def free_source(self,name,free=True):\n \"\"\" Free a source in the ROI \n source : string or pointlike source object\n free : boolean to free or fix parameter\n \"\"\"\n freePars = self.like.freePars(name)\n normPar = self.like.normPar(name).getName()\n idx = self.like.par_index(name, normPar)\n if not free:\n self.like.setFreeFlag(name, freePars, False)\n else:\n self.like[idx].setFree(True)\n self.like.syncSrcParams(name)\n \n def save(self):\n from util import save_object\n save_object(self,self.savestate)\n \n def setup_pointlike(self):\n\n if os.path.isfile(self.srcmdl): return\n \n config = self.config\n \n self._ds = DataSpecification(ft1files = self.ft1file,\n ft2files = config['scfile'],\n ltcube = self.ltcube,\n binfile = self.binfile)\n\n \n self._sa = SpectralAnalysis(self._ds,\n binsperdec = config['binsperdec'],\n emin = config['emin'],\n emax = config['emax'],\n irf = config['irfs'],\n roi_dir = self.skydir,\n maxROI = config['radius'],\n minROI = config['radius'],\n zenithcut = config['zmax'],\n event_class= 0,\n conv_type = config['convtype'])\n\n sources = []\n point_sources, diffuse_sources = [],[]\n\n galdiff = config['galdiff'] \n isodiff = config['isodiff']\n\n bkg_sources = self.get_background(galdiff,isodiff)\n sources += filter(None, bkg_sources)\n \n catalog = self.get_catalog(config['catalog'])\n catalogs = filter(None, [catalog])\n\n for source in sources:\n if isinstance(source,PointSource): point_sources.append(source)\n else: diffuse_sources.append(source)\n \n self._roi=self._sa.roi(roi_dir=self.skydir,\n point_sources=point_sources,\n diffuse_sources=diffuse_sources,\n catalogs=catalogs,\n fit_emin=config['emin'], \n fit_emax=config['emax'])\n\n # Create model file\n self._roi.toXML(self.srcmdl,\n convert_extended=True,\n expand_env_vars=True)\n \n @staticmethod\n def get_catalog(catalog=None, **kwargs):\n if catalog is None or isinstance(catalog,SourceCatalog):\n pass\n elif catalog == 'PSC3Y':\n catalog = Catalog3Y('/u/ki/kadrlica/fermi/catalogs/PSC3Y/gll_psc3yearclean_v1_assoc_v6r1p0.fit',\n latextdir='/u/ki/kadrlica/fermi/catalogs/PSC3Y/',\n prune_radius=0,\n **kwargs)\n elif catalog == '2FGL':\n catalog = Catalog2FGL('/u/ki/kadrlica/fermi/catalogs/2FGL/gll_psc_v08.fit',\n latextdir='/u/ki/kadrlica/fermi/catalogs/2FGL/Templates/',\n prune_radius=0,\n **kwargs)\n elif catalog == \"1FGL\":\n catalog = FermiCatalog('/u/ki/kadrlica/fermi/catalogs/gll_psc_v02.fit',\n prune_radius=0,\n **kwargs)\n else:\n raise Exception(\"Unknown catalog: %s\"%catalog)\n\n return catalog\n\n @staticmethod\n def get_background(galdiff=None, isodiff=None, limbdiff=None):\n \"\"\" Diffuse backgrounds\n galdiff: Galactic diffuse counts cube fits file\n isodiff: Isotropic diffuse spectral text file\n limbdiff: Limb diffuse counts map fits file\n \"\"\"\n backgrounds = []\n\n if galdiff is None: gal=None\n else:\n gfile = os.path.basename(galdiff)\n gal = get_diffuse_source('MapCubeFunction',galdiff,\n 'PowerLaw',None,\n os.path.splitext(gfile)[0])\n gal.smodel.set_default_limits()\n gal.smodel.freeze('index')\n backgrounds.append(gal)\n\n if isodiff is None: iso=None\n else:\n ifile = os.path.basename(isodiff)\n iso = get_diffuse_source('ConstantValue',None,'FileFunction'\n ,isodiff,\n os.path.splitext(ifile)[0])\n iso.smodel.set_default_limits()\n backgrounds.append(iso) \n\n if limbdiff is None: limb=None\n else:\n lfile = basename(limbdiff)\n dmodel = SpatialMap(limbdiff)\n smodel = PLSuperExpCutoff(norm=3.16e-6,index=0,\n cutoff=20.34,b=1,e0=200)\n limb = ExtendedSource(name=name,model=smodel,spatial_model=dmodel)\n for i in range(limb.smodel.npar): limb.smodel.freeze(i)\n backgrounds.append(limb)\n backgrounds.append(limb)\n\n return backgrounds\n"
},
{
"alpha_fraction": 0.6326848268508911,
"alphanum_fraction": 0.6687418818473816,
"avg_line_length": 31.125,
"blob_id": "2ea66b856a7494e0c932b8e6d2aec1c9c6e926e1",
"content_id": "8401c0f58f47b5201187c68a9caaf8dc21a30229",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3855,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 120,
"path": "/gammatools/fermi/units.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\" This module is like sympy.physics.units but defines\n new units and physical constants relevant to astrophysics.\n\n This module it defined charge and magnetic field in terms of \n cm, g, and s to be consistent with CGS and typical \n astrophysics text.\n\n This mode also defines some helper functions for dealing\n with quantities that have units.\n \n Author: Joshua Lande <[email protected]>\n\"\"\"\nimport numpy as np\nimport sympy\nimport sympy.physics\nfrom sympy.physics import units\n\nclass UnitsException(Exception): pass\n\n# define new energy units\nunits.keV = 1e3*units.eV\nunits.MeV = 1e6*units.eV\nunits.GeV = 1e9*units.eV\nunits.TeV = 1e12*units.eV\nunits.erg = units.g*units.cm**2/units.s**2\nunits.ph = 1 # photons don't have units =)\n\n\n# More physical constants\none_half = sympy.sympify('1/2')\n\nunits.statcoulomb = units.erg**one_half*units.cm**one_half\nunits.electron_charge = 4.80320425e-10*units.statcoulomb\n\nunits.electron_mass = 9.10938188e-28*units.grams\n\nunits.proton_mass = 1.67262158e-24*units.grams\n\n# 1 Gauss written in terms of cm, g,s is taken from\n# http://en.wikipedia.org/wiki/Gaussian_units\nunits.gauss = units.cm**-one_half*units.g**one_half*units.s**-1\nunits.microgauss = 1e-6*units.gauss\n\nunits.tesla = 1e4*units.gauss\n\nunits.pc = units.parsec = 3.08568025e18*units.cm\nunits.kpc = units.kiloparsec = 1e3*units.parsec\n\n# see http://en.wikipedia.org/wiki/Barn_(unit)\nunits.barn = 1e-24*units.cm**2\nunits.millibarn = 1e-3*units.barn\n\nunits.kiloyear = units.kyr = 1e3*units.year\n\n# classical electron radius\nunits.r0=units.electron_charge**2/(units.electron_mass*units.speed_of_light**2)\n\nunits.alpha = float(units.electron_charge**2/(units.hbar*units.speed_of_light))\n\n# convert from a string to units\nfromstring=lambda string: sympy.sympify(string, sympy.physics.units.__dict__)\n\n# Convert numpy array to sympy array with desired units\ndef tosympy(array, units):\n \"\"\" Convert a numpy array, python array, or python float to a sympy matrix with units.\n\n >>> print tosympy(np.asarray([1]), units.GeV)\n [1.602176487e-10*kg*m**2/s**2]\n >>> print tosympy([1], units.GeV)\n [1.602176487e-10*kg*m**2/s**2]\n >>> print tosympy(1, units.GeV)\n 1.602176487e-10*kg*m**2/s**2\n\n \"\"\"\n try:\n if isinstance(array,list):\n return sympy.Matrix(np.asarray(array))*units\n elif hasattr(array,'shape'):\n return sympy.Matrix(array)*units\n else:\n return array*units\n except:\n raise UnitsException(\"Unable to convert array %s to units %s.\" % (array,units))\n\n# Convert sympy array to numpy array with desired units.\ndef tonumpy(array,units):\n \"\"\" Convert to numpy aa sympy number, a sympy array, or a python array of sympy numbers.\n\n >>> print tonumpy(units.GeV, units.MeV)\n 1000.0\n >>> print tonumpy(tosympy([1],units.GeV),units.MeV)\n [ 1000.]\n >>> print tonumpy([1*units.GeV],units.MeV)\n [ 1000.]\n \"\"\"\n try:\n if isinstance(array,list):\n return np.asarray([float(i/units) for i in array])\n if hasattr(array,'shape'):\n return sympy.list2numpy(array/units).astype(float)\n else:\n return float(array/units)\n except:\n raise UnitsException(\"Unable to convert array %s to units %s.\" % (array,units))\n\n# Convert from one unit to another\ndef convert(x, from_units, to_units):\n try:\n return x*float(fromstring(from_units)/fromstring(to_units))\n except:\n raise UnitsException(\"Unable to convert %s from %s to %s.\" % (x, from_units, to_units))\n\n# Print out a quanitiy with nice units\nrepr=lambda value,unit_string,format='%g': format % float(value/fromstring(unit_string)) + ' ' + unit_string\n\nfrom sympy.physics.units import *\n\nif __name__ == \"__main__\":\n import doctest\n doctest.testmod()\n"
},
{
"alpha_fraction": 0.4785502851009369,
"alphanum_fraction": 0.5078895688056946,
"avg_line_length": 23.581817626953125,
"blob_id": "39585a56dd7137d9e4b32081d3c33de4dbb57f85",
"content_id": "e3de64ff433cf8de13ef4135ef754a80f8cbc134",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4056,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 165,
"path": "/gammatools/core/algebra.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport copy\n\nclass Vector3D(object):\n \n def __init__(self,x):\n x = np.array(x,ndmin=1,copy=True)\n if x.ndim == 1:\n self._x = x.reshape(3,1)\n else:\n self._x = x\n\n def x(self):\n \"\"\"Return cartesian components.\"\"\"\n return self._x\n\n def separation(self,v): \n \"\"\"Return angular separation between this vector and another vector.\"\"\"\n costh = np.sum(self._x*v._x,axis=0) \n\n costh[costh>1.0] = 1.0\n costh[costh<-1.0]=-1.0\n\n return np.arccos(costh)\n \n def norm(self):\n return np.sqrt(np.sum(self._x**2,axis=0))\n\n def theta(self):\n return np.arctan2(np.sqrt(self._x[0]**2 + self._x[1]**2),self._x[2])\n\n def phi(self):\n return np.arctan2(self._x[1],self._x[0]) \n\n def lat(self):\n return np.pi/2.-self.theta()\n\n def lon(self):\n return self.phi()\n \n def normalize(self):\n self._x *= 1./self.norm()\n\n def rotatex(self,angle):\n\n angle = np.array(angle,ndmin=1)\n yaxis = Vector3D(angle[np.newaxis,:]*np.array([1.,0.,0.]).reshape(3,1))\n self.rotate(yaxis)\n\n def rotatey(self,angle):\n\n angle = np.array(angle,ndmin=1)\n yaxis = Vector3D(angle[np.newaxis,:]*np.array([0.,1.,0.]).reshape(3,1))\n self.rotate(yaxis)\n\n def rotatez(self,angle):\n\n angle = np.array(angle,ndmin=1) \n zaxis = Vector3D(angle[np.newaxis,:]*np.array([0.,0.,1.]).reshape(3,1))\n self.rotate(zaxis)\n \n def rotate(self,axis):\n \"\"\"Perform a rotation on this vector with respect to an\n arbitrary axis. The angle of rotation is given by the\n magnitude of the axis vector.\"\"\"\n\n angle = axis.norm()\n tmp = np.zeros(self._x.shape) + axis._x\n eaxis = Vector3D(tmp)\n\n inverse_angle = np.zeros(len(angle))\n inverse_angle[angle>0] = 1./angle[angle>0]\n\n eaxis._x *= inverse_angle\n par = np.sum(self._x*eaxis._x,axis=0)\n \n paxis = Vector3D(copy.copy(self._x))\n paxis._x -= par*eaxis._x\n\n cp = eaxis.cross(paxis)\n \n self._x = par*eaxis._x + np.cos(angle)*paxis._x + np.sin(angle)*cp._x\n \n def dot(self,v):\n\n return np.sum(self._x*v.x(),axis=0)\n\n def cross(self,axis):\n x = np.zeros(self._x.shape)\n \n x[0] = self._x[1]*axis._x[2] - self._x[2]*axis._x[1]\n x[1] = self._x[2]*axis._x[0] - self._x[0]*axis._x[2]\n x[2] = self._x[0]*axis._x[1] - self._x[1]*axis._x[0]\n return Vector3D(x)\n\n def project(self,v):\n \n return self*v\n\n def project2d(self,v):\n \n vp = Vector3D(copy.copy(self._x))\n\n vp.rotatez(-v.phi())\n vp.rotatey(-v.theta())\n \n return vp\n \n @staticmethod\n def createLatLon(lat,lon):\n\n return Vector3D.createThetaPhi(np.pi/2.-lat,lon)\n \n @staticmethod\n def createThetaPhi(theta,phi):\n\n x = np.array([np.sin(theta)*np.cos(phi),\n np.sin(theta)*np.sin(phi),\n np.cos(theta)*(1+0.*phi)])\n\n return Vector3D(x)\n\n def __getitem__(self, i):\n return Vector3D(self._x[:,i])\n\n def __mul__(self,v):\n\n if isinstance(v,Vector3D):\n self._x *= v.x()\n else:\n self._x *= v\n\n return self\n\n def __add__(self,v):\n\n self._x += v.x()\n return self\n\n def __sub__(self,v):\n\n self._x -= v.x()\n return self\n \n def __str__(self):\n return self._x.__str__()\n\nif __name__ == '__main__':\n\n lat = np.array([1.0])#,0.0,-1.0,0.0])\n lon = np.array([0.0])#,1.0, 0.0,-1.0])\n \n v0 = Vector3D.createLatLon(0.0,np.radians(2.0))\n v1 = Vector3D.createLatLon(np.radians(lat),np.radians(lon))\n\n print 'v0: ', v0\n print 'v1: ', v1\n \n v2 = v1.project2d(v0)\n\n y = -np.degrees(v2.theta()*np.cos(v2.phi()))\n x = np.degrees(v2.theta()*np.sin(v2.phi()))\n\n for i in range(4): \n print '%.3f %.3f'%(x[i], y[i])\n"
},
{
"alpha_fraction": 0.57222580909729,
"alphanum_fraction": 0.6007726788520813,
"avg_line_length": 34.5572509765625,
"blob_id": "cfb23394606b69b101f35fcef3a529acfd6644a4",
"content_id": "f688dec947fc7225c3f495b6ef8b3399a034499d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4659,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 131,
"path": "/scripts/get_data.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#! /bin/env python\n\nimport os\nimport sys\nfrom optparse import OptionParser\nimport numpy as np\n#from readTXT import readTXT\n\nevent_samples = { 'pass6' : 'P6_public_v3',\n 'pass7' : 'P7.6_P120_BASE',\n 'pass7r' : 'P7_P202_BASE',\n 'pass8' : 'P8_P301_BASE' }\n\nusage = \"usage: %prog [options] \"\ndescription = \"Download data with astro server tool.\"\nparser = OptionParser(usage=usage,description=description)\nparser.add_option('-s','--source', default = None, type = \"string\", \n dest=\"source\",\n help = 'Source identifier')\nparser.add_option('-o','--output', default = None, type = \"string\", \n help = 'Output file prefix')\n\nparser.add_option('--ra', default = 0, type = float, \n help = 'Minimum energy')\nparser.add_option('--dec', default = 0, type = float, \n help = 'Maximum energy')\n\nparser.add_option('--event_sample', default='pass7r',\n choices=event_samples.keys(),\n help='Event Sample (pass6,pass7,pass7r,pass8)')\n\nparser.add_option('--event_class', default='Source', type = \"string\",\n help='Event Class (Diffuse,Source,Clean)')\n\nparser.add_option('--minEnergy', default = 1.5, type = float, \n help = 'Minimum energy')\nparser.add_option('--maxEnergy', default = 5.5, type = float, \n help = 'Maximum energy')\n\nparser.add_option('--minZenith', default = None, type = float, \n help = 'Minimum energy')\nparser.add_option('--maxZenith', default = None, type = float, \n help = 'Maximum energy')\n\nparser.add_option('--data_type', default = 'ft1',\n choices=['ft1','ls1'],\n help = 'Choose between standard and extended data formats.')\n\nparser.add_option('--years', default = 0.0, type = float, \n help = 'Number of years since mission start time.')\n\nparser.add_option('--days', default = 0.0, type = float, \n help = 'Number of days since mission start time.')\n\nparser.add_option('--minTimestamp', default = None, type = float, \n help = 'Minimum MET timestamp (default: 239557417)')\nparser.add_option('--maxTimestamp', default = None, type = float, \n help = 'Maximum MET timestamp')\nparser.add_option('--radius', default = None, type = float, \n help = 'Angular radius in deg.')\n\nparser.add_option('--max_file_size', default = 0.5, type = float, \n help = 'Maximum file size in GB.')\n\n(opts, arguments) = parser.parse_args()\n\n\nif opts.source is None:\n ra = opts.ra\n dec = opts.dec\n\n\nmin_timestamp = 239557417\nif opts.minTimestamp is not None:\n min_timestamp = opts.minTimestamp\n\n\nmax_timestamp = min_timestamp + opts.years*365*86400 + opts.days*86400\n\nif opts.maxTimestamp is not None:\n max_timestamp = opts.maxTimestamp\n\nft1_suffix = opts.data_type\n \nif opts.output is None:\n output_ft1 = '%9.0f_%9.0f_%s.fits' %(min_timestamp,max_timestamp,ft1_suffix)\n output_ft2 = '%9.0f_%9.0f_ft2-30s.fits' %(min_timestamp,max_timestamp)\nelse:\n output_ft1 = '%s_%9.0f_%9.0f_%s.fits' %(opts.output,\n min_timestamp,max_timestamp,\n ft1_suffix)\n output_ft2 = '%s_%9.0f_%9.0f_ft2-30s.fits' %(opts.output,min_timestamp,max_timestamp)\n\nastroserv = '~glast/astroserver/prod/astro'\n\nif not opts.event_sample in event_samples:\n sys.exit(1)\n\ncommand = astroserv\ncommand += ' --event-sample %s '%(event_samples[opts.event_sample])\ncommand += ' --event-class-name %s '%(opts.event_class)\ncommand += ' --ra %9.5f --dec %9.5f ' %(ra,dec)\n\nif opts.radius is not None:\n command += ' --radius %5.2f' %(opts.radius)\n\nif opts.minZenith is not None:\n command += ' --minZenith %9.3f '%(opts.minZenith)\n\nif opts.maxZenith is not None:\n command += ' --maxZenith %9.3f '%(opts.maxZenith)\n \ncommand += ' --minEnergy %9.2f --maxEnergy %9.2f' %(np.power(10,opts.minEnergy),np.power(10,opts.maxEnergy))\ncommand += ' --output-ft1-max-bytes-per-file %i'%(opts.max_file_size*1E9)\ncommand += ' --output-ls1-max-bytes-per-file %i'%(opts.max_file_size*1E9)\n\ncommand += ' --minTimestamp %.1f' %(min_timestamp)\ncommand += ' --maxTimestamp %.1f' %(max_timestamp)\n\nif opts.data_type == 'ft1':\n command_ft1 = command + ' --output-ft1 ' + output_ft1 + ' store'\nelse:\n command_ft1 = command + ' --output-ls1 ' + output_ft1 + ' store'\n \ncommand_ft2 = command + ' --output-ft2-30s ' + output_ft2 + ' storeft2'\n\nprint command_ft1\nprint command_ft2\n\nos.system(command_ft1)\n#os.system(command_ft2)\n\n"
},
{
"alpha_fraction": 0.5069615244865417,
"alphanum_fraction": 0.5634725689888,
"avg_line_length": 21.61111068725586,
"blob_id": "1eaaa4c20bb57a1fcb73cf029db8c1415fce7226",
"content_id": "3bd48896e76233103c490c760f55335927298e53",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1221,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 54,
"path": "/gammatools/fermi/tests/test_likelihood.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nfrom gammatools.core.model_fn import GaussFn\nfrom gammatools.fermi.psf_likelihood import *\nfrom gammatools.core.histogram import *\n\nclass TestFermiLikelihood(unittest.TestCase):\n\n\n def test_convolved_gauss(self):\n\n return\n\n pset = ParameterSet()\n \n sigma = 0.1\n ksigma = 0.2\n\n gpfn = Gauss2DProjFn.create(1.0,sigma,pset=pset)\n gfn = Gauss2DFn.create(1.0,0.0,0.0,sigma)\n gfn2 = Gauss2DFn.create(1.0,0.0,0.0,ksigma)\n\n print gpfn.param()\n\n cgfn = ConvolvedGaussFn.create(1.0,ksigma,gpfn,pset=pset,prefix='test')\n \n\n\n print cgfn.param()\n\n delta = np.array([0.2,0.1]).reshape((2,1))\n\n xaxis = Axis.create(-1.0,1.0,1000)\n yaxis = Axis.create(-1.0,1.0,1000)\n x, y = np.meshgrid(xaxis.center(),yaxis.center())\n x = np.ravel(x)\n y = np.ravel(y)\n\n print x.shape\n xy = np.vstack((x,y))\n print xy.shape\n\n r = np.sqrt(x**2+y**2)\n\n s = np.sum(gfn.eval(xy+delta)*gfn2(xy))*(2.0/1000.)**2\n\n\n r0 = np.sqrt(delta[0][0]**2+delta[1][0]**2)\n\n x = np.array([0.1,0.2])\n\n print r0\n print cgfn.eval(r0)\n print s\n"
},
{
"alpha_fraction": 0.49568670988082886,
"alphanum_fraction": 0.5141884088516235,
"avg_line_length": 29.379310607910156,
"blob_id": "8022710e74e9efb3b5a64430dd360db7f554375f",
"content_id": "aceb6ba39dd61a4eeee4dc2c40dfb224b3ff445a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17620,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 580,
"path": "/gammatools/core/plot_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import os\nimport matplotlib.gridspec as gridspec\nimport matplotlib.pyplot as plt\nfrom matplotlib.collections import QuadMesh\nfrom scipy.interpolate import UnivariateSpline\nimport itertools\nimport copy\nimport numpy as np\nfrom histogram import *\nfrom series import *\nfrom util import update_dict\nfrom config import Configurable\n\n__author__ = \"Matthew Wood ([email protected])\"\n__abstract__ = \"\"\n\ndef set_font_size(ax,size):\n \"\"\"Update the font size for all elements in a matplotlib axis\n object.\"\"\"\n\n for item in ([ax.title, ax.xaxis.label, ax.yaxis.label] +\n ax.get_xticklabels() + ax.get_yticklabels()):\n item.set_fontsize(size)\n\ndef get_cycle_element(cycle,index):\n\n return cycle[index%len(cycle)]\n\n \nclass FigureSubplot(object):\n \"\"\"Class implementing a single pane in a matplotlib figure. \"\"\"\n\n style = { 'xlabel' : None,\n 'ylabel' : None,\n 'zlabel' : None,\n 'xlim' : None,\n 'ylim' : None,\n 'ylim_ratio' : None,\n 'show_args' : None,\n 'mask_args' : None,\n 'title' : None,\n 'yscale' : 'lin',\n 'xscale' : 'lin',\n 'logz' : False,\n 'marker' : None,\n 'color' : None,\n 'linestyle' : None,\n 'linewidth' : None,\n 'markersize' : None,\n 'hist_style' : None,\n 'hist_xerr' : True,\n 'legend_loc' : 'upper right',\n 'legend_fontsize' : 10,\n 'legend' : True,\n 'norm_style' : 'ratio',\n 'norm_index' : None,\n 'norm_interpolation' : 'log' }\n\n def __init__(self,ax,**kwargs):\n \n self._style = copy.deepcopy(FigureSubplot.style)\n update_dict(self._style,kwargs)\n\n self._ax = ax\n self._cb = None\n self._data = [] \n\n self._style_counter = {\n 'color' : 0,\n 'marker' : 0,\n 'markersize' : 0,\n 'linestyle' : 0,\n 'linewidth' : 0,\n 'hist_style' : 0,\n 'hist_xerr' : 0\n }\n \n self._hline = []\n self._hline_style = []\n self._text = []\n self._text_style = []\n\n def ax(self):\n return self._ax\n\n def set_style(self,k,v):\n self._style[k] = v\n\n def set_title(self,title):\n self.set_style('title',title)\n \n def get_style(self,h,**kwargs):\n \"\"\"Generate style dictionary for a subplot element.\"\"\"\n \n style = copy.deepcopy(h.style()) \n style.update(kwargs)\n \n for k in self._style_counter.keys(): \n\n if not k in style: continue\n if not style[k] is None: continue\n\n if isinstance(self._style[k],list):\n style[k] = get_cycle_element(self._style[k],\n self._style_counter[k])\n self._style_counter[k] += 1\n else:\n style[k] = self._style[k]\n \n return copy.deepcopy(style)\n \n def add_text(self,x,y,s,**kwargs):\n\n style = { 'color' : 'k', 'fontsize' : 10 }\n update_dict(style,kwargs,False)\n\n self._text.append([x,y,s])\n self._text_style.append(style)\n\n def add_data(self,x,y,yerr=None,**kwargs):\n\n s = Series(x,y,yerr) \n style = self.get_style(s,**kwargs)\n s.update_style(style)\n\n self._data.append(s)\n\n def add_series(self,s,**kwargs):\n\n s = copy.deepcopy(s)\n style = self.get_style(s,**kwargs)\n s.update_style(style)\n self._data.append(s)\n\n def add_hist(self,h,**kwargs):\n \n h = copy.deepcopy(h)\n style = self.get_style(h,**kwargs)\n h.update_style(style)\n self._data.append(h)\n\n def add(self,h,**kwargs):\n \n h = copy.deepcopy(h)\n style = self.get_style(h,**kwargs)\n h.update_style(style)\n self._data.append(h)\n\n def add_hline(self,x,**kwargs):\n\n style = { 'color' : None, 'linestyle' : None, 'label' : None }\n\n update_dict(style,kwargs,False)\n\n self._hline.append(x)\n self._hline_style.append(style)\n\n def merge(self,sp):\n\n for d in sp._data: self._data.append(d)\n \n def cumulative(self,**kwargs):\n\n for i, d in enumerate(self._data): \n self._data[i] = self._data[i].normalize()\n self._data[i] = self._data[i].cumulative()\n\n def normalize(self,residual=False,**kwargs):\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n \n norm_index = 0\n if not style['norm_index'] is None:\n norm_index = style['norm_index']\n \n if isinstance(self._data[norm_index],Histogram):\n x = copy.deepcopy(self._data[norm_index].center())\n y = copy.deepcopy(self._data[norm_index].counts)\n elif isinstance(self._data[norm_index],Series):\n x = copy.deepcopy(self._data[norm_index].x())\n y = copy.deepcopy(self._data[norm_index].y())\n\n\n if style['norm_interpolation'] == 'log':\n fn = UnivariateSpline(x,np.log10(y),k=1,s=0)\n else:\n fn = UnivariateSpline(x,y,k=1,s=0)\n \n# msk = y>0\n for i, d in enumerate(self._data):\n\n if isinstance(d,Series):\n msk = (d.x() >= x[0]*0.95) & (d.x() <= x[-1]*1.05)\n if style['norm_interpolation'] == 'log':\n ynorm = 10**fn(d.x())\n else: ynorm = fn(d.x())\n self._data[i]._msk &= msk\n self._data[i] /= ynorm\n\n if style['norm_style'] == 'residual':\n self._data[i] -= 1.0\n \n elif isinstance(d,Histogram): \n if style['norm_interpolation'] == 'log':\n ynorm = 10**fn(d.axis().center)\n else: ynorm = fn(d.axis().center)\n self._data[i] /= ynorm\n if style['norm_style'] == 'residual':\n self._data[i]._counts -= 1.0\n\n def plot(self,**kwargs):\n \n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n\n \n ax = self._ax\n\n yscale = style['yscale']\n if 'yscale' in kwargs: yscale = kwargs.pop('yscale')\n\n xscale = style['xscale']\n if 'xscale' in kwargs: xscale = kwargs.pop('xscale')\n\n logz = style['logz']\n if 'logz' in kwargs: logz = kwargs.pop('logz')\n \n if not style['title'] is None:\n ax.set_title(style['title'])\n\n labels = []\n\n iargs = range(len(self._data))\n if not style['show_args'] is None:\n iargs = style['show_args']\n \n if not style['mask_args'] is None:\n iargs = [x for x in iargs if x not in style['mask_args']]\n\n for i in iargs:\n s = self._data[i]\n labels.append(s.label())\n p = s.plot(ax=ax,logz=logz)\n\n if isinstance(p,QuadMesh):\n self._cb = plt.colorbar(p,ax=ax)\n if not style['zlabel'] is None:\n self._cb.set_label(style['zlabel'])\n \n for i, h in enumerate(self._hline):\n ax.axhline(self._hline[i],**self._hline_style[i])\n\n for i, t in enumerate(self._text):\n ax.text(*t,transform=ax.transAxes, **self._text_style[i])\n\n ax.grid(True)\n if len(labels) > 0 and style['legend']:\n ax.legend(prop={'size' : style['legend_fontsize']},\n loc=style['legend_loc'],ncol=1,numpoints=1)\n\n if not style['ylabel'] is None:\n ax.set_ylabel(style['ylabel'])\n if not style['xlabel'] is None:\n ax.set_xlabel(style['xlabel'])\n\n if not style['xlim'] is None: ax.set_xlim(style['xlim'])\n if not style['ylim'] is None: ax.set_ylim(style['ylim'])\n \n# if ratio: ax.set_ylim(0.0,2.0) \n# if not ylim is None: ax.set_ylim(ylim)\n\n if yscale == 'log': ax.set_yscale('log')\n elif yscale == 'sqrt': ax.set_yscale('sqrt',exp=2.0)\n\n if xscale == 'log': ax.set_xscale('log')\n elif xscale == 'sqrt': ax.set_xscale('sqrt',exp=2.0)\n \n \nclass RatioSubplot(FigureSubplot):\n\n def __init__(self,ax,src_subplot=None,**kwargs):\n super(RatioSubplot,self).__init__(ax,**kwargs)\n self._src_subplot = src_subplot\n\n def plot(self,**kwargs):\n \n if not self._src_subplot is None:\n self._data = copy.deepcopy(self._src_subplot._data)\n self.normalize() \n super(RatioSubplot,self).plot(**kwargs)\n else:\n data = copy.deepcopy(self._data)\n self.normalize()\n super(RatioSubplot,self).plot(**kwargs)\n self._data = data\n \n\nclass Figure(object):\n\n fignum = 100\n \n style = { 'show_ratio_args' : None,\n 'mask_ratio_args' : None,\n 'figstyle' : None,\n 'fontsize' : None,\n 'format' : 'png',\n 'fig_dir' : './',\n 'figscale' : 1.0,\n 'subplot_margins' : {'left' : 0.12, 'bottom' : 0.12,\n 'right' : 0.9, 'top': 0.9 },\n 'figsize' : [8.0,6.0],\n 'panes_per_fig' : 1 }\n\n def __init__(self,figlabel,nsubplot=0,**kwargs):\n \n self._style = copy.deepcopy(Figure.style)\n \n update_dict(self._style,FigureSubplot.style,True)\n update_dict(self._style,kwargs)\n\n figsize = self._style['figsize']\n \n figsize[0] *= self._style['figscale']\n figsize[1] *= self._style['figscale']\n \n self._fig = plt.figure('Figure %i'%Figure.fignum,figsize=figsize)\n Figure.fignum += 1\n \n self._figlabel = figlabel\n self._subplots = [] \n self.add_subplot(nsubplot) \n\n def __getitem__(self,key):\n\n return self._subplots[key]\n\n def add_subplot(self,n=1,**kwargs):\n\n if n == 0: return\n \n if isinstance(n,tuple): nx, ny = n \n elif n == 1: nx, ny = 1,1\n elif n == 2: nx, ny = 2,1\n elif n > 2 and n <= 4: nx, ny = 2,2\n \n for i in range(nx*ny): \n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n ax = self._fig.add_subplot(ny,nx,i+1)\n\n if self._style['figstyle'] == 'ratio':\n self._subplots.append(RatioSubplot(ax,**style))\n else:\n self._subplots.append(FigureSubplot(ax,**style))\n\n def normalize(self,**kwargs):\n\n for s in self._subplots: s.normalize(**kwargs)\n\n def merge(self,fig):\n\n for i, s in enumerate(self._subplots): \n s.merge(fig._subplots[i])\n \n def _plot_twopane_shared_axis(self,sp0,sp1,height_ratio=1.6,**kwargs):\n \"\"\"Generate a figure with two panes the share a common x-axis.\n Tick labels will be suppressed in the x-axis of the upper pane.\"\"\"\n fig = plt.figure()\n\n gs1 = gridspec.GridSpec(2, 1, height_ratios = [height_ratio,1])\n ax0 = fig.add_subplot(gs1[0,0])\n ax1 = fig.add_subplot(gs1[1,0],sharex=ax0)\n\n fig.subplots_adjust(hspace=0.1)\n plt.setp([ax0.get_xticklabels()],visible=False)\n\n sp0.plot(ax0,**kwargs)\n sp1.plot(ax1,**kwargs)\n\n fig.canvas.draw()\n plt.subplots_adjust(left=0.12, bottom=0.12,right=0.95, top=0.95)\n\n return fig\n\n def plot(self,**kwargs):\n\n fig_name = '%s.%s'%(self._figlabel,self._style['format'])\n fig_name = os.path.join(self._style['fig_dir'],fig_name)\n \n for p in self._subplots: p.plot(**kwargs)\n\n if not self._style['fontsize'] is None:\n for p in self._subplots:\n set_font_size(p.ax(),self._style['fontsize'])\n self._fig.subplots_adjust(**self._style['subplot_margins'])\n self._fig.savefig(fig_name)\n \nclass TwoPaneFigure(Figure):\n\n def __init__(self,figlabel,**kwargs):\n\n super(TwoPaneFigure,self).__init__(figlabel,**kwargs)\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n height_ratio=1.6\n\n gs1 = gridspec.GridSpec(2, 1, height_ratios = [height_ratio,1])\n ax0 = self._fig.add_subplot(gs1[0,0])\n ax1 = self._fig.add_subplot(gs1[1,0],sharex=ax0)\n\n style0 = copy.deepcopy(style)\n style1 = copy.deepcopy(style)\n\n style0['xlabel'] = None\n style1['legend'] = False\n style1['title'] = None\n\n fp0 = FigureSubplot(ax0,**style0)\n fp1 = FigureSubplot(ax1,**style1)\n\n self._fig.subplots_adjust(hspace=0.1)\n plt.setp([ax0.get_xticklabels()],visible=False)\n\n self._subplots.append(fp0)\n self._subplots.append(fp1)\n \nclass TwoPaneRatioFigure(Figure):\n\n def __init__(self,figlabel,**kwargs):\n\n super(TwoPaneRatioFigure,self).__init__(figlabel,**kwargs)\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n height_ratio=1.6\n\n gs1 = gridspec.GridSpec(2, 1, height_ratios = [height_ratio,1])\n ax0 = self._fig.add_subplot(gs1[0,0])\n ax1 = self._fig.add_subplot(gs1[1,0],sharex=ax0)\n\n style0 = copy.deepcopy(style)\n style1 = copy.deepcopy(style)\n\n style0['xlabel'] = None\n\n if style['norm_style'] == 'ratio': \n style1['ylabel'] = 'Ratio'\n elif style['norm_style'] == 'residual': \n style1['ylabel'] = 'Fractional Residual'\n \n style1['yscale'] = 'lin'\n style1['ylim'] = style['ylim_ratio']\n style1['legend'] = False\n\n# ratio_subp.set_style('show_args',style['show_ratio_args'])\n# ratio_subp.set_style('mask_args',style['mask_ratio_args'])\n\n fp0 = FigureSubplot(ax0,**style0)\n fp1 = RatioSubplot(ax1,fp0,**style1)\n\n self._fig.subplots_adjust(hspace=0.1)\n plt.setp([ax0.get_xticklabels()],visible=False)\n\n self._subplots.append(fp0)\n self._subplots.append(fp1)\n\n\nclass FigTool(Configurable):\n\n default_config = {\n 'format' :( 'png', 'Set the output image format.' ),\n 'marker' : (['s','o','d','^','v','<','>'],'Set the marker style sequence.'),\n 'color' : ['b','g','r','m','c','grey','brown'],\n 'linestyle' : ['-','--','-.','-','--','-.','-'],\n 'linewidth' : [1.0],\n 'markersize' : [6.0],\n 'figsize' : [8.0,6.0],\n 'norm_index' : None,\n 'legend_loc' : 'best', \n 'fig_dir' :\n ( './', 'Set the output directory.' ),\n 'fig_prefix' :\n ( None, 'Set the common prefix for image files.') }\n\n \n def __init__(self,config=None,opts=None,**kwargs):\n super(FigTool,self).__init__()\n self.configure(config,opts=opts,**kwargs)\n \n def create(self,figlabel,figstyle=None,nax=1,**kwargs):\n\n if self.config['fig_prefix']:\n figlabel = self.config['fig_prefix'] + '_' + figlabel\n\n style = copy.deepcopy(self.config)\n style.update(kwargs)\n \n if figstyle == 'twopane':\n return TwoPaneFigure(figlabel,**style)\n elif figstyle == 'ratio2':\n return TwoPaneRatioFigure(figlabel,**style)\n elif figstyle == 'residual2':\n return TwoPaneRatioFigure(figlabel,\n norm_style='residual',**style)\n elif figstyle == 'ratio':\n return Figure(figlabel,nax,figstyle='ratio',\n **style)\n else:\n return Figure(figlabel,nax,**style)\n\nif __name__ == '__main__':\n\n from optparse import Option\n from optparse import OptionParser\n\n usage = \"usage: %prog [options] <h5file>\"\n description = \"\"\"A description.\"\"\"\n\n parser = OptionParser(usage=usage,description=description)\n FigTool.configure(parser)\n\n (opts, args) = parser.parse_args()\n \n x0 = np.linspace(0,2*np.pi,100.)\n y0 = 2. + np.sin(x0)\n y1 = 2. + 0.5*np.sin(x0+np.pi/4.)\n\n\n ft = FigTool(opts)\n\n fig = ft.create(1,'theta_cut',\n xlabel='X Label [X Unit]',\n ylabel='Y Label [Y Unit]',\n markers=['d','x','+'])\n\n fig[0].add_data(x0,y0,label='label1')\n fig[0].add_data(x0,y1,label='label2')\n\n fig.plot(style='ratio2')\n\n fig1 = ft.create(1,'theta_cut',\n xlabel='Energy [log${10}$(E/GeV)]',\n ylabel='Cut Value [deg]',colors=['r','grey','maroon'])\n\n h0 = Histogram([-3,3],100)\n h1 = Histogram([-3,3],100)\n h2 = Histogram([-4,4],100)\n\n h0.fill(np.random.normal(0,1.0,size=10000))\n h1.fill(np.random.normal(0,0.5,size=10000))\n h2.fill(np.random.normal(0,3.0,size=10000))\n\n fig1[0].add_hist(h0,label='label1',hist_style='filled')\n fig1[0].add_hist(h1,label='label2',hist_style='errorbar')\n fig1[0].add_hist(h2,label='label3',hist_style='step',linestyle='-')\n\n fig1.plot(xlim=[-5,5],legend_loc='upper right')\n\n fig2 = ft.create(1,'theta_cut',\n xlabel='Energy [log${10}$(E/GeV)]',\n ylabel='Cut Value [deg]',colors=['r','grey','maroon'])\n\n h3 = Histogram2D([-3,3],[-3,3],100,100)\n\n x = np.random.normal(0,0.5,size=100000)\n y = np.random.normal(0,1.0,size=100000)\n\n h3.fill(x,y)\n\n fig2[0].add_hist(h3,logz=True)\n\n fig2.plot()\n\n plt.show()\n"
},
{
"alpha_fraction": 0.6199095249176025,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 21.100000381469727,
"blob_id": "033dea20ed46837e2380ef8478ea047c2e57d3a6",
"content_id": "ffbc1dc0f628f4d9bc266ef03630f4271df24964",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 10,
"path": "/gammatools/core/flux_model.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nclass FluxModel(object):\n\n \n def e2flux(self,loge,psi):\n return np.power(10,2*loge)*self.flux(loge,psi)\n\n def eflux(self,loge,psi):\n return np.power(10,loge)*self.flux(loge,psi)\n"
},
{
"alpha_fraction": 0.6284152865409851,
"alphanum_fraction": 0.6338797807693481,
"avg_line_length": 21.36842155456543,
"blob_id": "2576524da0fda23aaf0d3acd6c3c749233e62ddd",
"content_id": "9d98cb96af0b34eb6a0a8243dd721af5057a169f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1281,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 57,
"path": "/scripts/gtltsum.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport shutil\nfrom gammatools.fermi.task import *\nfrom gammatools.core.util import dispatch_jobs\nimport argparse\n\nusage = \"%(prog)s [options] [ft1file ...]\"\ndescription = \"\"\"Create a LT cube.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--output', default = None, \n help = 'Output file')\n\nparser.add_argument('--queue', default = None,\n help='Set the batch queue.')\n\nargs = parser.parse_args()\n\nif len(args.files) < 1:\n parser.error(\"At least one argument required.\")\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue)\n sys.exit(0)\n \n \nif args.output is None:\n\n# m = re.search('(.+)_ft1(.*)\\.fits?',f)\n# if not m is None:\n# outfile = m.group(1) + '_gtltcube.fits'\n# else:\n outfile = os.path.splitext(f)[0] + '_gtltcube.fits'%(args.zmax)\nelse:\n outfile = args.output\n\n\nltlist = 'ltlist.txt'\n\nfh = open(ltlist,'w')\n\nfor f in args.files:\n fh.write('%s\\n'%os.path.abspath(f))\n\nfh.close()\n\nltlist = os.path.abspath(ltlist)\n\ngt_task = LTSumTask(outfile,infile1='@' + ltlist)\n\ngt_task.run()\n \n\n"
},
{
"alpha_fraction": 0.7276119589805603,
"alphanum_fraction": 0.7288557291030884,
"avg_line_length": 24.125,
"blob_id": "2e8bddf711cef726eff007aebddccc5c7ded731e",
"content_id": "d87d9c1ea41b09258fc24bd106e35ead0665955c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 804,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 32,
"path": "/README.rst",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "gammatools\n==========\n\nPython tools for gamma-ray data analysis. This package provides a\nvariety of facilities for analysis and visualization of gamma-ray data.\n\nInstallation\n------------\n\nInstall git and then download the package from the following git repository::\n\n git clone https://github.com/woodmd/gammatools\n\nFrom the package directory you can install the package via setuptools\nin the default location::\n\n python setup.py install\n\nor in a specific location with the prefix option::\n\n python setup.py install --prefix=$HOME/local\n\nProject Status\n--------------\n\n.. image:: https://travis-ci.org/woodmd/gammatools.png\n :target: https://travis-ci.org/woodmd/gammatools\n\nLicense\n-------\ngammatools is licensed under a 3-clause BSD style license - see the\n``licenses/LICENSE.rst`` file.\n"
},
{
"alpha_fraction": 0.4966759979724884,
"alphanum_fraction": 0.5205446481704712,
"avg_line_length": 29.223970413208008,
"blob_id": "d4983fd85a3b1459cab1c31c6004181089b7dc0a",
"content_id": "8a15f7bf932526a3e614aff9479dba346904cd7e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24970,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 826,
"path": "/gammatools/dm/jcalc.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\n@file jcalc.py\n\n@brief Python modules that are used to compute the line-of-sight\nintegral over a spherically symmetric DM distribution.\n\n@author Matthew Wood <[email protected]>\n@author Alex Drlica-Wagner <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood\"\n__date__ = \"12/01/2011\"\n\nimport copy\nimport numpy as np\n\nfrom scipy.integrate import quad\nfrom scipy.interpolate import bisplrep\nfrom scipy.interpolate import bisplev\nfrom scipy.interpolate import interp1d, UnivariateSpline\nimport scipy.special as spfn\nimport scipy.optimize as opt\nfrom gammatools.core.util import *\nfrom gammatools.core.algebra import *\n\nclass LoSFn(object):\n \"\"\"Integrand function for LoS parameter (J). The parameter alpha\n introduces a change of coordinates x' = x^(1/alpha). The change\n of variables means that we need make the substitution:\n\n dx = alpha * (x')^(alpha-1) dx'\n\n A value of alpha > 1 weights the points at which we sample the\n integrand closer to x = 0 (distance of closest approach).\n\n Parameters\n ----------\n d: Distance to halo center.\n xi: Offset angle in radians.\n dp: Density profile.\n alpha: Rescaling exponent for line-of-sight coordinate.\n \"\"\"\n\n def __init__(self,d,xi,dp,alpha=4.0):\n self._d = d\n self._d2 = d*d\n self._xi = xi\n self._sinxi = np.sin(xi)\n self._sinxi2 = np.power(self._sinxi,2)\n self._dp = dp\n self._alpha = alpha\n\n def __call__(self,xp):\n #xp = np.asarray(xp)\n #if xp.ndim == 0: xp = np.array([xp])\n\n x = np.power(xp,self._alpha)\n r = np.sqrt(x*x+self._d2*self._sinxi2)\n rho2 = np.power(self._dp.rho(r),2)\n return rho2*self._alpha*np.power(xp,self._alpha-1.0)\n \nclass LoSFnDecay(LoSFn):\n def __init__(self,d,xi,dp,alpha=1.0):\n super(LoSFnDecay,self).__init__(d,xi,dp,alpha)\n \n def __call__(self,xp):\n #xp = np.asarray(xp)\n #if xp.ndim == 0: xp = np.array([xp])\n\n x = np.power(xp,self._alpha)\n r = np.sqrt(x*x+self._d2*self._sinxi2)\n rho = self._dp.rho(r)\n return rho*self._alpha*np.power(xp,self._alpha-1.0)\n\nclass LoSIntegralFn(object):\n \"\"\"Object that computes integral over DM density squared along a\n line-of-sight offset by an angle psi from the center of the DM\n halo. We introduce a change of coordinates so that the integrand\n is more densely sampled near the distance of closest of approach\n to the halo center.\n\n Parameters\n ----------\n dist: Distance to halo center.\n dp: Density profile.\n alpha: Parameter determining the integration variable: x' = x^(1/alpha)\n rmax: Radius from center of halo at which LoS integral is truncated.\n \"\"\"\n def __init__(self, dp, dist, rmax=None, alpha=3.0,ann=True):\n if rmax is None: rmax = np.inf\n\n self._dp = dp\n self._dist = dist\n self._rmax = rmax\n self._alpha = alpha\n self._ann = ann\n\n @classmethod\n def create(cls,config,method='fast'):\n \n dp = DensityProfile.create(config) \n return LoSIntegralFnFast(dp,config['dist']*Units.kpc,\n config['rmax']*Units.kpc)\n\n\n def __call__(self,psi,dhalo=None):\n \"\"\"Evaluate the LoS integral at the offset angle psi for a halo\n located at the distance dhalo.\n\n Parameters\n ----------\n psi : array_like \n Array of offset angles (in radians)\n\n dhalo : array_like\n Array of halo distances.\n \"\"\"\n\n if dhalo is None: dhalo = np.array(self._dist,ndmin=1)\n else: dhalo = np.array(dhalo,ndmin=1)\n\n psi = np.array(psi,ndmin=1)\n\n if dhalo.shape != psi.shape:\n dhalo = dhalo*np.ones(shape=psi.shape)\n\n v = np.zeros(shape=psi.shape)\n\n for i, t in np.ndenumerate(psi):\n\n s0 = 0\n s1 = 0\n\n if self._ann:\n losfn = LoSFn(dhalo[i],t,self._dp,self._alpha)\n else:\n losfn = LoSFnDecay(dhalo[i],t,self._dp,self._alpha)\n\n # Closest approach to halo center\n rmin = dhalo[i]*np.sin(psi[i])\n\n # If observer inside the halo...\n if self._rmax > dhalo[i]:\n\n if psi[i] < np.pi/2.:\n\n x0 = np.power(dhalo[i]*np.cos(psi[i]),1./self._alpha)\n s0 = 2*quad(losfn,0.0,x0)[0]\n\n x1 = np.power(np.sqrt(self._rmax**2 -\n rmin**2),1./self._alpha)\n \n s1 = quad(losfn,x0,x1)[0]\n else:\n x0 = np.power(np.abs(dhalo[i]*np.cos(psi[i])),\n 1./self._alpha)\n\n x1 = np.power(np.sqrt(self._rmax**2 -\n rmin**2),1./self._alpha)\n s1 = quad(losfn,x0,x1)[0]\n\n # If observer outside the halo...\n elif self._rmax > rmin:\n x0 = np.power(np.sqrt(self._rmax**2 -\n rmin**2),1./self._alpha)\n s0 = 2*quad(losfn,0.0,x0)[0]\n \n v[i] = s0+s1\n\n return v\n\nclass LoSIntegralFnFast(LoSIntegralFn):\n \"\"\"Vectorized version of LoSIntegralFn that performs midpoint\n integration with a fixed number of steps.\n\n Parameters\n ----------\n dist: Distance to halo center.\n dp: Density profile.\n alpha: Parameter determining the integration variable: x' = x^(1/alpha)\n rmax: Radius from center of halo at which LoS integral is truncated.\n nstep: Number of integration steps. Increase this parameter to\n improve the accuracy of the LoS integral.\n \"\"\"\n def __init__(self, dp, dist, rmax=None, alpha=3.0,ann=True,nstep=400):\n super(LoSIntegralFnFast,self).__init__(dp,dist,rmax,alpha,ann)\n\n self._nstep = nstep\n xedge = np.linspace(0,1.0,self._nstep+1)\n self._x = 0.5*(xedge[1:] + xedge[:-1])\n\n def __call__(self,psi,dhalo=None):\n \"\"\"Evaluate the LoS integral at the offset angle psi for a halo\n located at the distance dhalo.\n\n Parameters\n ----------\n psi : array_like \n Array of offset angles (in radians)\n\n dhalo : array_like\n Array of halo distances.\n \"\"\"\n\n if dhalo is None: dhalo = np.array(self._dist,ndmin=1)\n else: dhalo = np.array(dhalo,ndmin=1)\n\n psi = np.array(psi,ndmin=1)\n\n# if dhalo.shape != psi.shape:\n# d = np.zeros(shape=psi.shape)\n# d[:] = dhalo\n# dhalo = d\n# elif dhalo.ndim == 0: dhalo = np.array([dhalo])\n# if psi.ndim == 0: psi = np.array([psi])\n \n v = np.zeros(shape=psi.shape)\n\n if self._ann: losfn = LoSFn(dhalo,psi,self._dp,self._alpha)\n else: losfn = LoSFnDecay(dhalo,psi,self._dp,self._alpha)\n\n # Closest approach to halo center\n rmin = dhalo*np.sin(psi)\n\n msk0 = self._rmax > dhalo\n msk1 = self._rmax > rmin\n\n # Distance between observer and point of closest approach\n xlim0 = np.power(np.abs(dhalo*np.cos(psi)),1./self._alpha)\n\n # Distance from point of closest approach to maximum\n # integration radius\n xlim1 = np.zeros(shape=psi.shape)\n xlim1[msk1] = np.power(np.sqrt(self._rmax**2 - rmin[msk1]**2),\n 1./self._alpha)\n\n # If observer inside the halo...\n if np.any(msk0):\n\n msk01 = msk0 & (psi < np.pi/2.)\n msk02 = msk0 & ~(psi < np.pi/2.)\n\n if np.any(msk01):\n\n dx0 = xlim0/float(self._nstep)\n dx1 = (xlim1-xlim0)/float(self._nstep)\n\n x0 = np.outer(self._x,xlim0)\n x1 = xlim0 + np.outer(self._x,xlim1-xlim0)\n\n s0 = 2*np.sum(losfn(x0)*dx0,axis=0)\n s1 = np.sum(losfn(x1)*dx1,axis=0)\n\n v[msk01] = s0[msk01]+s1[msk01]\n\n if np.any(msk02):\n \n dx1 = (xlim1-xlim0)/float(self._nstep)\n\n x1 = xlim0 + np.outer(self._x,xlim1-xlim0)\n s0 = np.sum(losfn(x1)*dx1,axis=0)\n \n v[msk02] = s0[msk02]\n \n # If observer outside the halo...\n if np.any(~msk0 & msk1):\n \n dx0 = xlim1/float(self._nstep)\n x0 = np.outer(self._x,xlim1)\n\n s0 = 2*np.sum(losfn(x0)*dx0,axis=0)\n\n v[~msk0 & msk1] = s0[~msk0 & msk1]\n\n\n return v\n\nclass LoSIntegralSplineFn(object):\n\n def __init__(self,dp=None,nx=40,ny=20):\n self.dp = copy.copy(dp)\n\n if self.dp is not None:\n nx = 40\n ny = 20\n dhalo, psi = np.mgrid[1:2:ny*1j,0.001:2.0:nx*1j]\n dhalo = np.power(10,dhalo)\n psi = np.radians(psi) \n f = LoSIntegralFn(self.dp)\n self.z = f(dhalo,psi)\n self.init_spline(dhalo,psi,self.z)\n\n def init_spline(self,dhalo,psi,z):\n \"\"\"Compute knots and coefficients of an interpolating spline\n given a grid of points in halo distance (dhalo) and offset\n angle (psi) at which the LoS integral has been computed.\n \"\"\"\n\n kx = 2\n ky = 2\n self._psi_min = psi.min()\n self._tck = bisplrep(dhalo,psi,np.log10(z),s=0.0,kx=kx,ky=ky,\n nxest=int(kx+np.sqrt(len(z.flat))),\n nyest=int(ky+np.sqrt(len(z.flat))))\n\n def __call__(self,dhalo,psi,rho=1,rs=1):\n \"\"\"Compute the LoS integral using a 2D spline table.\n\n Returns\n -------\n\n vals: LoS amplitude per steradian.\n \"\"\"\n\n dhalo = np.asarray(dhalo)\n psi = np.asarray(psi)\n\n if dhalo.ndim == 0: dhalo = np.array([dhalo])\n if psi.ndim == 0: psi = np.array([psi])\n\n if psi.ndim == 2 and dhalo.ndim == 2:\n v = np.power(10,bisplev(dhalo[:,0],psi[0,:],self._tck))\n else:\n v = np.power(10,bisplev(dhalo,psi,self._tck))\n\n v *= rho*rho*rs\n return v\n\n\ndef SolidAngleIntegral(psi,pdf,angle):\n \"\"\" Compute the solid-angle integrated j-value\n within a given radius\n\n Parameters\n ----------\n psi : array_like \n Array of offset angles (in radians)\n\n pdf : array_like\n Array of j-values at angle psi\n \n angle : array_like\n Maximum integration angle (in degrees)\n \"\"\"\n angle = np.asarray(angle)\n if angle.ndim == 0: angle = np.array([angle])\n\n scale=max(pdf)\n norm_pdf = pdf/scale\n\n log_spline = UnivariateSpline(psi,np.log10(norm_pdf),k=1,s=0)\n spline = lambda r: 10**(log_spline(r))\n integrand = lambda r: spline(r)*2*np.pi*np.sin(r)\n\n integral = []\n for a in angle:\n integral.append(quad(integrand, 0, np.radians(a),full_output=True)[0])\n integral = np.asarray(integral)\n\n return integral*scale\n\nclass JProfile(object):\n def __init__(self,losfn):\n\n self._log_psi = np.linspace(np.log10(np.radians(0.001)),\n np.log10(np.radians(90.)),1000)\n self._psi = np.power(10,self._log_psi)\n\n domega = 2*np.pi*(-np.cos(self._psi[1:])+np.cos(self._psi[:-1]))\n x = 0.5*(self._psi[1:]+self._psi[:-1])\n\n self._jpsi = losfn(self._psi)\n self._spline = UnivariateSpline(self._psi,self._jpsi,s=0,k=2)\n self._jcum = np.cumsum(self._spline(x)*domega)\n self._cum_spline = UnivariateSpline(x,self._jcum,s=0,k=2)\n\n @staticmethod\n def create(dp,dist,rmax):\n losfn = LoSIntegralFn(dp,dist,rmax=rmax) \n return JProfile(losfn)\n\n def __call__(self,psi):\n return self._spline(psi)\n\n def integrate(self,psimax):\n\n xedge = np.linspace(0.0,np.radians(psimax),1001)\n x = 0.5*(xedge[1:] + xedge[:-1])\n domega = 2.0*np.pi*(-np.cos(xedge[1:])+np.cos(xedge[:-1]))\n return np.sum(self._spline(x)*domega)\n\n def cumsum(self,psi):\n return self._cum_spline(psi)\n# x = 0.5*(psi[1:]+psi[:-1])\n# dcos = -np.cos(psi[1:])+np.cos(psi[:-1])\n# return np.cumsum(self._spline(x)*dcos)\n\nclass ROIIntegrator(object):\n\n def __init__(self,jspline,lat_cut,lon_cut,source_list=None):\n\n self._jspline = jspline\n self._lat_cut = lat_cut\n self._lon_cut = lon_cut\n\n nbin_thetagc = 720\n thetagc_max = 180.\n\n self._phi_edges = np.linspace(0.,360.,720+1)\n self._theta_edges = np.linspace(0.,thetagc_max,nbin_thetagc+1)\n\n self._sources = None\n\n if not source_list is None:\n source_list = np.loadtxt(opts.source_list,unpack=True,usecols=(1,2))\n self._sources = Vector3D.createLatLon(np.radians(source_list[0]),\n np.radians(source_list[1]))\n\n self.compute()\n\n def compute(self):\n \n yaxis = Vector3D(np.pi/2.*np.array([0.,1.,0.]))\n\n costh_edges = np.cos(np.radians(self._theta_edges))\n costh_width = costh_edges[:-1]-costh_edges[1:]\n \n phi = 0.5*(self._phi_edges[:-1] + self._phi_edges[1:])\n self._theta = 0.5*(self._theta_edges[:-1] + self._theta_edges[1:])\n\n self._jv = []\n self._domega = []\n\n for i0, th in enumerate(self._theta):\n\n jtot = integrate(lambda t: self._jspline(t)*np.sin(t),\n np.radians(self._theta_edges[i0]),\n np.radians(self._theta_edges[i0+1]),100)\n\n# jval = jspline(np.radians(th))*costh_width[i0]\n v = Vector3D.createThetaPhi(np.radians(th),np.radians(phi))\n v.rotate(yaxis)\n\n lat = np.degrees(v.lat())\n lon = np.degrees(v.phi())\n\n src_msk = len(lat)*[True]\n\n if not self._sources is None:\n\n for k in range(len(v.lat())):\n p = Vector3D(v._x[:,k])\n\n sep = np.degrees(p.separation(self._sources))\n imin = np.argmin(sep)\n minsep = sep[imin]\n\n if minsep < 0.62: src_msk[k] = False\n\n msk = ((np.abs(lat)>=self._lat_cut) |\n ((np.abs(lat)<=self._lat_cut)&(np.abs(lon)<self._lon_cut)))\n\n msk &= src_msk\n dphi = 2.*np.pi*float(len(lat[msk]))/float(len(phi))\n\n# hc._counts[i0,msk] = 1\n\n jtot *= dphi\n# jsum += jtot\n# domegasum += costh_width[i0]*dphi\n\n self._jv.append(jtot)\n self._domega.append(costh_width[i0]*dphi)\n \n self._jv = np.array(self._jv)\n self._jv_cum = np.cumsum(self._jv)\n\n self._jv_cum_spline = UnivariateSpline(self._theta_edges[1:],\n self._jv_cum,\n s=0,k=1)\n\n self._domega = np.array(self._domega)\n self._domega_cum = np.cumsum(self._domega)\n \n def eval(self,rgc,decay=False):\n \n if decay:\n units0 = Units.gev_cm2\n units1 = (8.5*Units.kpc*0.4*Units.gev_cm3)\n else:\n units0 = Units.gev2_cm5\n units1 = (8.5*Units.kpc*np.power(0.4*Units.gev_cm3,2))\n\n\n rgc = [float(t) for t in rgc.split('/')]\n\n if len(rgc) == 1:\n jv = self._jv_cum_spline(rgc[0])\n domega = np.cos(np.radians(rgc[0]))*2*np.pi/Units.deg2\n else:\n jv = self._jv_cum_spline(rgc[1]) - self._jv_cum_spline(rgc[0])\n domega = -(np.cos(np.radians(rgc[1])) - np.cos(np.radians(rgc[0])))*2*np.pi/Units.deg2\n\n# i = np.argmin(np.abs(rgc-self._theta))\n\n print '%20.6g %20.6g %20.6g %20.6g'%(jv, \n jv/units0, \n jv/units1,domega)\n\n\n def print_profile(self,decay=False):\n\n if decay:\n units0 = Units.gev_cm2\n units1 = (8.5*Units.kpc*0.4*Units.gev_cm3)\n else:\n units0 = Units.gev2_cm5\n units1 = (8.5*Units.kpc*np.power(0.4*Units.gev_cm3,2))\n\n\n for i, th in enumerate(self._theta_edges[1:]):\n\n jv = self._jv_cum[i]\n\n print '%10.2f %20.6g %20.6g %20.6g %20.6g'%(th, jv, \n jv/units0, \n jv/units1,\n self._domega_cum[i])\n\nclass DensityProfile(object):\n \"\"\" DM density profile that truncates at a maximum DM density.\n \n rho(r) = rho(r) for rho(r) < rhomax AND r > rmin\n = rhomax for rho(r) >= rhomax\n = rho(rmin) for r <= rmin\n \n Parameters\n ----------\n rhos : Density normalization parameter.\n \n rmin : Inner radius interior to which the density will be fixed to\n a constant value. (rhomax = rho(rmin)).\n\n rhomax : Maximum DM density. If rhomax and rmin are both defined\n the maximum DM density will be the lesser of rhomax and rho(rmin).\n \n \"\"\"\n def __init__(self,rhos,rs,rmin=None,rhomax=None):\n self._name = 'profile'\n self._rmin=rmin\n self._rhomax=rhomax\n self._rhos = rhos\n self._rs = rs\n\n def setMassConcentration(self,mvir,c):\n\n rhoc = 9.9E-30*Units.g_cm3\n rvir = np.power(mvir*3.0/(177.7*4*np.pi*rhoc*0.27),1./3.)\n rs = rvir/c\n\n self._rs = rs\n mrvir = self.mass(rvir)\n self._rhos = self._rhos*mvir/mrvir\n\n def rho(self,r):\n\n r = np.array(r,ndmin=1)\n\n if self._rhomax is None and self._rmin is None: \n return self._rho(r)\n elif self._rhomax is None:\n rho = self._rho(r) \n rho[r<self._rmin] = self._rho(self._rmin)\n return rho\n elif self._rmin is None:\n rho = self._rho(r) \n rho[rho>self._rhomax] = self._rhomax\n return rho\n else:\n rho = self._rho(r) \n rhomax = min(self._rho(self._rmin),self._rhomax)\n rho[rho>rhomax] = rhomax\n return rho\n\n# return np.where(rho>self._rhomax,[self._rhomax],rho)\n \n def set_rho(self,rho,r):\n \"\"\"Fix the density normalization at a given radius.\"\"\"\n rhor = self._rho(r)\n self._rhos = rho*self._rhos/rhor\n\n @property\n def name(self):\n return self._name\n\n @property\n def rhos(self):\n return self._rhos\n\n @property\n def rs(self):\n return self._rs\n\n @staticmethod\n def create(opts):\n \"\"\"Method for instantiating a density profile object given the\n profile name and a dictionary.\"\"\"\n\n o = {}\n o.update(opts)\n\n name = opts['type']\n\n def extract(keys,d):\n od = {}\n for k in keys: \n if k in d: od[k] = d[k]\n return od\n\n for k, v in o.iteritems():\n if v is None: continue\n elif isinstance(v,str): o[k] = Units.parse(v)\n elif k == 'dist': o[k] *= Units.kpc\n elif k == 'rs': o[k] *= Units.kpc\n elif k == 'rhos': o[k] *= Units.msun_kpc3\n elif k == 'rhor': o[k] = [o[k][0]*Units.gev_cm3,\n o[k][1]*Units.kpc]\n elif k ==' jval' : o[k] = o[k]*Units.gev2_cm5\n\n if o['rhos'] is None: o['rhos'] = 1.0\n\n if name == 'nfw':\n dp = NFWProfile(**extract(['rhos','rs','rmin'],o))\n elif name == 'gnfw':\n dp = GNFWProfile(**extract(['rhos','rs','rmin','gamma'],o))\n elif name == 'isothermal':\n dp = IsothermalProfile(**extract(['rhos','rs','rmin'],o))\n elif name == 'einasto':\n dp = EinastoProfile(**extract(['rhos','rs','rmin','alpha'],o))\n else:\n print 'No such halo type: ', name\n sys.exit(1)\n\n if 'rhor' in o: dp.set_rho(o['rhor'][0],o['rhor'][1])\n elif 'jval' in o: dp.set_jval(o['jval'],o['rs'],o['dist'])\n\n return dp\n\n\nclass BurkertProfile(DensityProfile):\n \"\"\" Burkert (1995)\n rho(r) = rhos/( (1+r/rs)(1+(r/rs)**2) )\n \"\"\"\n def __init__(self,rhos=1,rs=1,rmin=None,rhomax=None): \n super(BurkertProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'burkert'\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos*np.power(1+x,-1)*np.power(1+x*x,-1)\n\n def _mass(self,r):\n x = r/self._rs \n return 4*np.pi*self._rhos*np.power(self._rs,3)*(log(1+x)-x/(1+x))\n \nclass IsothermalProfile(DensityProfile):\n\n def __init__(self,rhos=1,rs=1,rmin=None,rhomax=None): \n super(IsothermalProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'isothermal'\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos*np.power(1+x,-2)\n\n def _mass(self,r):\n x = r/self._rs \n return 4*np.pi*self._rhos*np.power(self._rs,3)*(log(1+x)-x/(1+x))\n\n \nclass NFWProfile(DensityProfile):\n \"\"\" Navarro, Frenk, and White (1996)\n rho(r) = rhos/( (r/rs)(1+r/rs)**2)\n \"\"\"\n def __init__(self,rhos=1,rs=1,rmin=None,rhomax=None):\n super(NFWProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'nfw'\n\n def set(self,rhos,rs):\n self._rs = rs\n self._rhos = rhos\n\n def set_jval(self,jval,rs,dist):\n rhos = np.sqrt(3./(4.*np.pi)*jval*dist**2/rs**3)\n self._rs = rs\n self._rhos = rhos\n\n def mass(self,r):\n x = r/self._rs\n return 4*np.pi*self._rhos*np.power(self._rs,3)*(np.log(1+x)-x/(1+x))\n\n def jval(self,r=None,rhos=None,rs=None):\n \"\"\"Small angle approximation to halo Jvalue. \"\"\"\n if rhos is None: rhos = self._rhos\n if rs is None: rs = self._rs\n\n if r is not None:\n x = r/rs\n return (4*np.pi/3.)*rhos**2*rs**3*(1.-np.power(1.+x,-3))\n else:\n return (4*np.pi/3.)*rhos**2*rs**3\n\n#(4*M_PI/3.)*std::pow(a(0),2)*std::pow(a(1),3)*(1.-std::pow(1+x,-3));\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos*np.power(x,-1)*np.power(1+x,-2) \n \nclass EinastoProfile(DensityProfile):\n \"\"\" Einasto profile\n rho(r) = rhos*exp(-2*((r/rs)**alpha-1)/alpha)\n \"\"\"\n def __init__(self,rhos=1,rs=1,alpha=0.17,rmin=None,rhomax=None):\n self._alpha = alpha\n super(EinastoProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'einasto'\n\n def set(self,rhos,rs):\n self._rs = rs\n self._rhos = rhos\n\n def mass(self,r):\n\n x = r/self._rs\n gamma = spfn.gamma(3./self._alpha)\n\n return 4*np.pi*self._rhos*np.power(self._rs,3)/self._alpha* \\\n np.exp(2./self._alpha)* \\\n np.power(2./self._alpha,-3./self._alpha)* \\\n gamma*spfn.gammainc(3./self._alpha,\n (2./self._alpha)*np.power(x,self._alpha))\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos*np.exp(-2./self._alpha*(np.power(x,self._alpha)-1))\n\nclass GNFWProfile(DensityProfile):\n \"\"\" Generalized NFW Profile\n rho(r) = rhos/( (r/rs)^g(1+r/rs)**(3-g))\n \"\"\"\n def __init__(self,rhos=1,rs=1,gamma=1.0,rmin=None,rhomax=None):\n self._gamma = gamma\n super(GNFWProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'nfw'\n\n def set(self,rhos,rs):\n self._rs = rs\n self._rhos = rhos\n\n def mass(self,r):\n# x = r/self._rs\n# return 4*np.pi*self._rhos*np.power(self._rs,3)*(np.log(1+x)-x/(1+x))\n return 0\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos*np.power(x,-self._gamma)* \\\n np.power(1+x,-(3-self._gamma)) \n\nclass GeneralNFWProfile(DensityProfile):\n \"\"\" Strigari et al. (2007)\n rho(r) = rhos/( (r/rs)**a (1+(r/rs)**b )**(c-a)/b\n Default: NFW profile\n \"\"\"\n def __init__(self,rhos=1,rs=1,a=1,b=1,c=3,rmin=None,rhomax=None):\n self._rs = rs\n self._a = a\n self._b = b\n self._c = c\n super(GeneralNFWProfile,self).__init__(rhos,rs,rmin,rhomax)\n self._name = 'general_nfw'\n\n def _rho(self,r):\n x = r/self._rs\n return self._rhos/(x**self._a*(1+x**self._b)**((self._c-self._a)/self._b))\n\n\nclass UniformProfile(object):\n \"\"\" Uniform spherical profile\n rho(r) = rhos for r < rs\n rho(r) = 0 otherwise\n \"\"\"\n def __init__(self,rhos=1,rs=1):\n self._name = 'uniform'\n self._rhos = rhos\n self._rs = rs\n\n def _rho(self,r):\n return np.where(r<rs,rhos,0)\n\n\nif __name__ == '__main__':\n print \"Line-of-sight Integral Package...\"\n\n import matplotlib.pyplot as plt\n\n psi = np.linspace(0.01,0.1,500)\n dp = NFWProfile(1,1)\n\n fn0 = LoSIntegralFnFast(dp,100,10)\n fn1 = LoSIntegralFn(dp,100,10)\n\n dhalo = np.linspace(100,100,500)\n v0 = fn0(dhalo,psi)\n\n v1 = fn1(dhalo,psi)\n\n delta = (v1-v0)/v0\n\n print delta\n\n plt.hist(delta,range=[min(delta),max(delta)],bins=100)\n\n plt.show()\n \n"
},
{
"alpha_fraction": 0.46105310320854187,
"alphanum_fraction": 0.4865100085735321,
"avg_line_length": 29.10480308532715,
"blob_id": "fe34ccde0b8211bb6b0a92a79ac81eccac6cfcd0",
"content_id": "bea82d244171034849afcbc6e6c462db8ffefa74",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13788,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 458,
"path": "/scripts/plot_psf_quantiles.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\n\nimport os\nimport sys\nimport copy\nimport numpy as np\nimport pickle\nfrom optparse import Option\nfrom optparse import OptionParser\nimport matplotlib.pyplot as plt\nfrom scipy.interpolate import UnivariateSpline\nfrom gammatools.fermi.data import *\nfrom gammatools.fermi.validate import *\nfrom gammatools.core.plot_util import *\nfrom matplotlib import font_manager\nimport matplotlib as mpl\nimport yaml\n\n#from custom_scales import SqrtScale\n#from matplotlib import scale as mscale\n#mscale.register_scale(SqrtScale)\n\ndef get_next(i,l): return l[i%len(l)]\n\n\ndef plot_cth_quantiles(self):\n\n # ---------------------------------------------------------------------\n # Plot Quantiles as a function of Cos(Theta) \n\n for iegy in range(len(egy_range)):\n\n fig_label = '%04.0f_%04.0f'%(100*egy_range[iegy][0],\n 100*egy_range[iegy][1])\n pngfile = 'cth_' + quantile_label + '_' + fig_label + '_' + \\\n opts.tag + '.png'\n\n fig = plt.figure()\n\n ax = fig.add_subplot(2,1,1)\n ax.grid(True)\n\n title = '%.0f < log$_10$(E/MeV) < %.0f '%(egy_range[iegy][0],\n egy_range[iegy][1])\n\n plt.errorbar(self.cth_center,qmean[iegy],xerr=cth_width/2.,\n yerr=qerr[iegy],fmt='o',label='vela')\n\n for imodel in range(len(models)):\n plt.errorbar(self.cth_center,qmodel[imodel,0,iegy],\n xerr=0.125,yerr=0,fmt='o',\n label=model_labels[imodel],\n color=self.irf_colors[imodel])\n\n\n ax.set_title(title)\n\n ax.set_ylabel('Containment Radius [deg]')\n ax.set_xlabel('Cos$\\\\theta$')\n\n ax.set_xlim(0.25,1)\n ax.legend(prop=font)\n ax = fig.add_subplot(2,1,2)\n\n ax.grid(True)\n ax.set_ylabel('Fractional Residual')\n ax.set_xlabel('Cos$\\\\theta$')\n\n for imodel in range(len(models)):\n\n residual = (qmean[iegy]-qmodel[imodel,iegy])/qmodel[imodel,iegy]\n residual_err = qerr[iegy]/qmodel[imodel,0,iegy]\n\n plt.errorbar(cth,residual,xerr=0.125,\n yerr=residual_err,fmt='o',\n label=model_labels[imodel],\n color=self.irf_colors[imodel])\n\n ax.set_xlim(0.25,1)\n ax.set_ylim(-0.6,0.6)\n ax.legend(prop=font)\n plt.savefig(pngfile)\n\n\ndef plot_egy_quantiles(data,model,config,output=None):\n\n font = font_manager.FontProperties(size=10)\n# mpl.rcParams.update({'font.size': 8})\n \n data_markers = {}\n\n\n # ---------------------------------------------------------------------\n # Plot Quantiles as a function of Energy\n pngfile = 'quantile.png'\n if output is not None: pngfile = output\n \n title = 'PSF Containment ' \n# title += '%.2f < Cos$\\\\theta$ < %.2f'%(cth_lo,cth_hi)\n\n fig, axes = plt.subplots(1+len(config['quantiles']), \n sharex=True,\n figsize=(1.2*8,\n 1.2*8/3.*(1+len(config['quantiles']))))\n for ax in axes: ax.grid(True)\n \n idata = 0\n imodel = 0\n\n for i, q in enumerate(config['quantiles']):\n \n ql = 'r%2.f'%(q*100)\n\n mfn = None\n for md in model:\n if ql not in md.qdata.keys(): continue\n qh = md.qdata[ql].cut(1,0)\n\n mfn = UnivariateSpline(md.egy_center,qh._counts,s=0)\n break\n\n\n for j, d in enumerate(data):\n \n excess_hist = d.excess.cut(1,0)\n mask = excess_hist._counts > 20\n\n qh = d.qdata[ql].cut(1,0)\n \n logx = d.egy_center\n x = np.power(10,logx)\n xlo = (x - np.power(10,d.egy_bin_edge[:-1]))\n xhi = np.power(10,d.egy_bin_edge[1:])-x \n\n mean = qh._counts\n err = np.sqrt(qh._var)\n\n# label = d['label'] + ' %02.f'%(q*100) + '%'\n label = config['data_labels'][j] + ' %02.f'%(q*100) + '%'\n \n x = x[mask]\n xlo = xlo[mask]\n xhi = xhi[mask]\n err = err[mask]\n mean = mean[mask]\n\n if not config['data_markers'] is None:\n marker = get_next(j,config['data_markers'])\n else:\n marker = get_next(i,config['quantile_markers'])\n\n color = get_next(j,config['data_colors'])\n\n axes[0].errorbar(x,mean,xerr=[xlo,xhi],yerr=err,\n marker=marker,\n color=color,\n label=label,linestyle='None')\n\n if mfn is not None:\n residual = -(mfn(logx)-qh._counts)/mfn(logx)\n residual_err = np.sqrt(qh._var)/mfn(logx)\n\n residual = residual[mask]\n residual_err = residual_err[mask]\n\n axes[i+1].errorbar(x,residual,\n xerr=[xlo,xhi],\n yerr=residual_err,\n label=label,\n marker=marker,\n color=color,\n linestyle='None')\n \n\n\n for j, d in enumerate(model):\n \n print 'model ', j\n\n qh = d.qdata[ql].cut(1,0)\n\n# label = d['label'] + ' %02.f'%(q*100) + '%'\n label = config['model_labels'][j] + ' %02.f'%(q*100) + '%'\n x = np.power(10,d.egy_center)\n axes[0].plot(x,qh._counts,label=label,\n color=get_next(j,config['model_colors']))\n# linestyle=config['model_linestyles'][imodel],\n\n logx = d.egy_center\n residual = -(mfn(logx)-qh._counts)/mfn(logx)\n \n axes[i+1].plot(x,residual, label=label,\n color=get_next(j,config['model_colors']))\n\n# if cfg.as_bool('no_title') is not True:\n# ax1.set_title(title)\n\n if not config['title'] is None:\n axes[0].set_title(config['title'])\n \n axes[0].set_yscale('log')\n axes[0].set_xscale('log')\n axes[0].set_xlim(np.power(10,config['xlim'][0]),\n np.power(10,config['xlim'][1]))\n axes[0].set_ylim(0.03,30)\n axes[0].set_ylabel('Containment Radius [deg]',fontsize=12)\n# axes[0].set_xlabel('Energy [MeV]')\n axes[0].legend(prop={'size' : 8},ncol=2,numpoints=1)\n \n for ax in axes[1:]: \n\n if not config['residual_ylim'] is None:\n ax.set_ylim(config['residual_ylim'][0],config['residual_ylim'][1])\n\n lims = ax.axis()\n\n ax.set_ylim(max(-1.0,lims[2]),min(1.0,lims[3]))\n\n ax.set_xscale('log')\n ax.set_xlabel('Energy [MeV]')\n ax.set_ylabel('Fractional Residual',fontsize=12)\n ax.legend(prop={'size' : 8},loc='upper left',ncol=2,numpoints=1)\n\n fig.subplots_adjust(hspace=0)\n\n for i in range(len(axes)-1):\n plt.setp([axes[i].get_xticklabels()], visible=False)\n \n print 'Printing ', pngfile\n plt.savefig(pngfile,bbox_inches='tight')\n\nusage = \"%(prog)s [options] [PSF file ...]\"\ndescription = \"\"\"Plot quantiles of PSF.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\nparser.add_argument('--config', default = None, \n help = '')\n\nparser.add_argument('--show', default = False, action='store_true', \n help = '')\n\n#parser.add_argument('files', nargs='+')\n\nFigTool.add_arguments(parser)\n\nargs = parser.parse_args()\n\nconfig = { 'data_labels' : ['Vela','AGN'], 'model_labels' : ['test'] }\n\nif not args.config is None:\n config.update(yaml.load(open(args.config,'r')))\n\n\n#plt.rc('font', family='serif')\n#plt.rc('font', serif='Times New Roman')\n\nft = FigTool(args,legend_loc='upper right')\n\ndata_colors = ['k','b']\n\nmodel_colors = ['g','m','k','b']\n\ncommon_kwargs = { 'xlabel' : 'Energy [log$_{10}$(E/MeV)]',\n 'ylabel' : 'Containment Radius [deg]',\n 'yscale' : 'log',\n 'figstyle' : 'residual2', 'xlim': [1.5,5.5] }\n\nfor k,v in config['plots'].iteritems():\n\n \n\n data_fig34 = ft.create(k + '_psf_quantile_r34',color=data_colors,\n **common_kwargs)\n\n data_fig68 = ft.create(k + '_psf_quantile_r68',color=data_colors,\n **common_kwargs)\n\n data_fig95 = ft.create(k + '_psf_quantile_r95',color=data_colors,\n **common_kwargs)\n \n mdl_fig34 = ft.create(k + '_psf_quantile_r34',color=model_colors,\n **common_kwargs)\n \n mdl_fig68 = ft.create(k + '_psf_quantile_r68',color=model_colors,\n **common_kwargs)\n\n mdl_fig95 = ft.create(k + '_psf_quantile_r95',color=model_colors,\n **common_kwargs)\n \n norm_index = 1\n\n\n for i, arg in enumerate(v):\n \n\n msk = None\n\n# if 'range' in config:\n# xlim = config['range'][i]\n# x = d.excess.xaxis().center() \n# msk = (x > xlim[0]) & (x < xlim[1])\n\n# j = len(data_fig68[0]._data)\n \n mh34 = None\n mh68 = None\n mh95 = None\n for j, f in enumerate(arg['files']):\n d = PSFData.load(f)\n\n h34 = d.qdata[0].slice(1,0)\n h68 = d.qdata[1].slice(1,0)\n h95 = d.qdata[3].slice(1,0)\n\n if j == 0: \n mh34 = h34\n mh68 = h68\n mh95 = h95\n else:\n mh34 = mh34.merge(h34)\n mh68 = mh68.merge(h68)\n mh95 = mh95.merge(h95)\n\n if arg['type'] == 'model':\n mdl_fig34[0].add_hist(mh34,hist_style='line',\n label=arg['label'])\n mdl_fig68[0].add_hist(mh68,hist_style='line',\n label=arg['label'])\n mdl_fig95[0].add_hist(mh95,hist_style='line',\n label=arg['label'])\n else:\n data_fig34[0].add_hist(mh34,\n linestyle='None',#msk=msk,\n label=arg['label'])\n data_fig68[0].add_hist(mh68,\n linestyle='None',#msk=msk,\n label=arg['label'])\n data_fig95[0].add_hist(mh95,\n linestyle='None',#msk=msk,\n label=arg['label'])\n# label=label)\n\n# norm_index = i\n# j = len(mdl_fig68[0]._data)\n \n# if j >= len(config['model_labels']):\n# label = arg\n# else:\n# label = config['model_labels'][j]\n\n \n# mdl_fig68[0].add_hist(d.qdata[1].slice(1,0),hist_style='line',\n# label=label)\n# mdl_fig95[0].add_hist(d.qdata[3].slice(1,0),hist_style='line',\n# label=label)\n\n\n mdl_fig34.merge(data_fig34)\n mdl_fig68.merge(data_fig68)\n mdl_fig95.merge(data_fig95)\n \n norm_index=0\n\n mdl_fig68.plot()#norm_index=norm_index)\n mdl_fig95.plot()#norm_index=norm_index)\n mdl_fig34.plot()#norm_index=norm_index)\n\nif args.show: plt.show()\n\nsys.exit(0)\n\n\nconfig = { 'quantiles' : [0.68,0.95],\n 'data_labels' : [],\n 'model_labels' : [],\n 'model_colors' : ['r','b','g','c','y'],\n 'data_colors' : ['k','b','k','b'],\n 'data_markers' : ['o','o','s','s'],\n 'title' : None,\n 'quantile_markers' : [], ###None, #['s','d'],\n 'xlim' : [1.5,5.5],\n 'residual_ylim' : None,\n 'args' : []}\n\nif opts.config is not None:\n if os.path.isfile(opts.config):\n config = yaml.load(open(opts.config,'r'))\n else:\n yaml.dump(config,open(opts.config,'w'))\n\nif opts.title is not None:\n config['title'] = opts.title\n \nif opts.data_labels is not None:\n config['data_labels'] = opts.data_labels.split(',')\n\nif opts.model_labels is not None:\n config['model_labels'] = opts.model_labels.split(',')\n\ndata_quantiles = []\nmodel_quantiles = []\n \nargs += config['args']\n\nfor i, arg in enumerate(args):\n\n d = PSFData.load(arg) \n\n if d.dtype == 'data':\n idata = len(data_quantiles)\n data_quantiles.append(d)\n if idata >= len(config['data_labels']): \n config['data_labels'].append(arg)\n else:\n imodel = len(model_quantiles)\n model_quantiles.append(d)\n if imodel >= len(config['model_labels']): \n config['model_labels'].append(arg)\n\n\n \nplot_egy_quantiles(data_quantiles,model_quantiles,config,opts.output)\n\n\nsys.exit(0)\n\nfor i in range(data_quantiles[0].egy_nbin):\n for j in range(data_quantiles[0].cth_nbin):\n\n egy_range = data_quantiles[0].egy_range[i]\n cth_range = data_quantiles[0].cth_range[j]\n\n fig_label = 'theta_counts_'\n fig_label += '%04.0f_%04.0f_%03.f%03.f'%(egy_range[0]*100,\n egy_range[1]*100,\n cth_range[0]*100,\n cth_range[1]*100)\n\n hdata_tot = []\n hbkg = []\n hmodel_sig = []\n hmodel_bkg = []\n\n for d in data_quantiles:\n hdata_tot.append(d.tot_hist[i,j])\n hbkg.append(d.bkg_hist[i,j])\n\n for d in model_quantiles:\n hmodel_sig.append(d.sig_hist[i,j])\n hmodel_bkg.append(d.bkg_hist[i,j])\n\n\n plot_theta_cumulative(hdata_tot,hbkg,hmodel_sig,hmodel_bkg,fig_label)\n\n\n#plt.show()\n"
},
{
"alpha_fraction": 0.5104972124099731,
"alphanum_fraction": 0.5165745615959167,
"avg_line_length": 23.68181800842285,
"blob_id": "a8e3ec37525a425a045df2fc0f38e7ed8a091dd3",
"content_id": "2f8998b62188e2ffb73d6e1f3d619731c4b136c3",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5430,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 220,
"path": "/gammatools/core/series.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\n@file series.py\n\n@brief Python class representing series data (arrays of x/y pairs).\"\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\nimport copy\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom util import *\nfrom gammatools.core.mpl_util import MPLUtil\n\nclass Band(object):\n\n default_style = { 'marker' : None,\n 'facecolor' : None, \n 'linestyle' : None,\n 'linewidth' : None,\n 'alpha' : 0.4,\n 'label' : None }\n\n def __init__(self,x,ylo,yhi,style=None):\n\n self._x = np.array(x,copy=True)\n self._ylo = np.array(ylo,copy=True)\n self._yhi = np.array(yhi,copy=True)\n\n self._style = copy.deepcopy(dict(Series.default_style.items() +\n Series.default_draw_style.items()))\n if not style is None: update_dict(self._style,style)\n\n def plot(self,ax=None,**kwargs):\n\n if ax is None: ax = plt.gca()\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n clear_dict_by_keys(style,Series.default_draw_style.keys(),False)\n clear_dict_by_vals(style,None)\n\n ax.fill_between(self._x,self._ylo,self._yhi,**style)\n\nclass Series(object):\n\n default_style = { 'marker' : None,\n 'color' : None,\n 'markersize' : None,\n 'markerfacecolor' : None,\n 'markeredgecolor' : None,\n 'linestyle' : None,\n 'linewidth' : None,\n 'label' : None,\n 'msk' : None, \n 'draw_style' : 'errorbar' }\n \n\n def __init__(self,x,y,yerr=None,style=None):\n self._x = np.array(x,copy=True)\n self._y = np.array(y,copy=True)\n if not yerr is None: self._yerr = np.array(yerr,copy=True)\n else: self._yerr = yerr\n\n self._msk = np.empty(len(self._x),dtype='bool')\n self._msk.fill(True)\n \n self._style = copy.deepcopy(Series.default_style)\n if not style is None: update_dict(self._style,style)\n\n def x(self):\n return self._x\n\n def y(self):\n return self._y\n\n def yerr(self):\n return self._yerr\n\n def label(self):\n return self._style['label']\n\n def style(self):\n return self._style\n\n def update_style(self,style):\n update_dict(self._style,style)\n\n def plot(self,ax=None,**kwargs):\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n if style['draw_style'] == 'errorbar':\n self._errorbar(ax,**style)\n else:\n self._scatter(ax,**style)\n\n \n def _errorbar(self,ax=None,**kwargs):\n\n if ax is None: ax = plt.gca()\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n if style['msk'] is None: msk = self._msk\n else: msk = style['msk']\n \n kw = extract_dict_by_keys(style,MPLUtil.errorbar_kwargs)\n# clear_dict_by_vals(style,None)\n\n if not self._yerr is None: yerr = self._yerr[msk]\n else: yerr = self._yerr\n\n ax.errorbar(self._x[msk],self._y[msk],yerr,**kw)\n\n def _scatter(self,ax=None,**kwargs):\n\n if ax is None: ax = plt.gca()\n\n style = copy.deepcopy(self._style)\n update_dict(style,kwargs)\n\n if style['msk'] is None: msk = self._msk\n else: msk = style['msk']\n \n kw = extract_dict_by_keys(style,MPLUtil.scatter_kwargs)\n# clear_dict_by_vals(style,None)\n\n if not self._yerr is None: yerr = self._yerr[msk]\n else: yerr = self._yerr\n\n ax.scatter(self._x[msk],self._y[msk],**kw)\n\n\n @staticmethod\n def createPercentileFn(x,y,qfrac=0.5,axis=0):\n \"\"\"Create a series object by evaluating the given percentile\n from a list of 1D functions.\"\"\"\n\n y = np.sort(y,axis=axis)\n n = y.shape[0]\n\n i = n*qfrac\n i = min(n-1,max(0,i))\n\n print i\n\n return Series(x,y[i,:])\n\n\n @staticmethod\n def createFromDict(d):\n\n o = {'x' : None, 'y' : None, 'yerr' : None, 'style' : None }\n o.update(d)\n return Series(**d)\n\n @staticmethod\n def createFromFile(filename):\n\n d = np.loadtxt(filename,unpack=True)\n\n if len(d) == 2: return Series(d[0],d[1])\n elif len(d) == 3: return Series(d[0],d[1],d[2])\n\n def interpolate(self,x):\n return interpolate(self._x,self._y,x)\n\n def mask(self,msk):\n\n o = copy.deepcopy(self)\n o._x = self._x[msk]\n o._y = self._y[msk]\n o._msk = self._msk[msk]\n if not o._yerr is None:\n o._yerr = self._yerr[msk]\n\n return o\n \n def __sub__(self,x):\n\n o = copy.deepcopy(self)\n o._y -= x\n return o\n\n def __div__(self,x):\n\n o = copy.deepcopy(self)\n o._y /= x\n if not o._yerr is None: o._yerr /= x\n return o\n\n def __mul__(self,x):\n\n o = copy.deepcopy(self)\n o._y *= x\n if not o._yerr is None: o._yerr *= x\n return o\n \n\nif __name__ == '__main__':\n\n fig = plt.figure()\n\n\n x0 = np.linspace(0,2*np.pi,100.)\n y0 = 2. + np.sin(x0)\n y1 = 2. + 0.5*np.sin(x0+np.pi/4.)\n\n \n s = Series(x0,y0)\n\n s.plot(marker='o',color='b',markerfacecolor='w',markeredgecolor='b')\n\n plt.show()\n"
},
{
"alpha_fraction": 0.5500446557998657,
"alphanum_fraction": 0.5554066300392151,
"avg_line_length": 29.2297306060791,
"blob_id": "861cb5d7d68437c6f1692e13a4f3c54ce9c45986",
"content_id": "213d0ebe0f0247a71cbf5f35adee4ed9183c2e54",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2238,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 74,
"path": "/scripts/gtexpcube.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport tempfile\nimport re\nfrom GtApp import GtApp\nimport shutil\nimport pyfits\nimport argparse\n\nfrom gammatools.fermi.task import BExpTask\n\n\nusage = \"usage: %(prog)s [options] [ft1file]\"\ndescription = \"Produce a binned counts map.\"\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\n#parser.add_option('--ra', default = None, type='float',\n# help = 'Source RA')\n\n#parser.add_option('--dec', default = None, type='float',\n# help = 'Source Dec')\n\n#parser.add_option('--emin', default = 2, type='float',\n# help = 'Minimum event energy')\n\n#parser.add_option('--emax', default = 5, type='float',\n# help = 'Maximum event energy')\n\n#parser.add_option('--bin_size', default = 0.5, type='float',\n# help = 'Bin size in degrees')\n\n#parser.add_option('--nbin', default = '720/360', type='string',\n# help = 'Number of bins.')\n\n#parser.add_option('--proj', default = 'AIT', type='string',\n# help = 'Projection scheme\\n' \n# 'Aitoff [AIT]\\n'\n# 'Zenithal equal-area [ZEA]\\n'\n# 'Zenithal equidistant [ARC]\\n'\n# 'Plate Carree [CAR]\\n'\n# 'Sanson-Flamsteed [GLS]\\n'\n# 'Mercator [MER]\\n'\n# 'North-Celestial-Pole [NCP]\\n'\n# 'Slant orthographic [SIN]\\n'\n# 'Stereographic [STG]\\n'\n# 'Gnomonic [TAN]\\n')\n\n#parser.add_option('--alg', default = 'CMAP', choices=['CMAP','CCUBE'],\n# help = 'Choose binning algorithm')\n\n#parser.add_option('--coordsys', default = 'CEL', type='string',\n# help = 'Choose coordinate system')\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--output', default = None, \n help = 'Output file')\n\nBExpTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\n\nfor f in args.files:\n\n outfile = args.output \n if outfile is None:\n outfile = os.path.splitext(os.path.basename(f))[0] + '_bexpmap.fits'\n \n \n gtexp = BExpTask(outfile,infile=os.path.abspath(f),opts=args)\n \n gtexp.run()\n\n"
},
{
"alpha_fraction": 0.6750547289848328,
"alphanum_fraction": 0.6925601959228516,
"avg_line_length": 23.675676345825195,
"blob_id": "9f19cd69cb29a676e7f749b5ea44ad5aee7075f4",
"content_id": "2f6c3fb1903fff1820b95d9a3bdbd80fab3251c9",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 914,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 37,
"path": "/scripts/dump_ft1.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\nimport os\nimport sys\nimport copy\nimport argparse\n\nimport pyfits\nimport skymaps\nimport pointlike\nimport numpy as np\nfrom gammatools.core.algebra import Vector3D\nfrom gammatools.fermi.catalog import Catalog\nfrom gammatools.fermi.data import PhotonData\n\nusage = \"usage: %prog [options] [FT1 file ...]\"\ndescription = \"\"\"Inspect the contents of an FT1 file.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--nrow', default = 10, type=int,\n help = 'Set the zenith angle cut.')\n\nargs = parser.parse_args()\n\nhdulist = pyfits.open(args.files[0])\n\nprint hdulist.info()\nprint hdulist[1].columns.names\n\nfor c in hdulist[1].columns.names:\n print '%-25s %-6s %-10s'%(c, hdulist[1].data[c].dtype,\n hdulist[1].data[c].shape),\n print hdulist[1].data[c][:args.nrow]\n\n"
},
{
"alpha_fraction": 0.5109123587608337,
"alphanum_fraction": 0.520183801651001,
"avg_line_length": 32.57575607299805,
"blob_id": "7e5ca5f77d53670b1d66257fb2790b889d47b0fb",
"content_id": "e9d83ee8bd490afdf630f716709b269b63d35f2a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12188,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 363,
"path": "/scripts/load_ft1_data.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\nimport os\nimport sys\nimport copy\nimport argparse\n\nimport pyfits\nimport skymaps\nimport pointlike\nimport numpy as np\nfrom gammatools.core.algebra import Vector3D\nfrom gammatools.fermi.catalog import Catalog\nfrom gammatools.core.util import separation_angle, dispatch_jobs\nfrom gammatools.core.util import bitarray_to_int\nfrom gammatools.core.util import save_object\nfrom gammatools.fermi.data import PhotonData\n\nclass FT1Loader(object):\n\n def __init__(self, zenith_cut, conversion_type,\n event_class_id, event_type_id,\n max_events, max_dist_deg, phase_selection,erange):\n self.zenith_cut = zenith_cut\n self.max_events = max_events\n self.max_dist = np.radians(max_dist_deg)\n self._phist = None\n self.phase_selection = phase_selection\n self.conversion_type = conversion_type\n self.event_class_id = event_class_id\n self.event_type_id = event_type_id\n self.erange = erange\n\n self._photon_data = PhotonData()\n\n\n def setFT2File(self,ft2file):\n\n if ft2file is None:\n return \n elif not os.path.isfile(ft2file):\n print 'Error invalid FT2 file: ', ft2file\n sys.exit(1)\n \n self._phist = pointlike.PointingHistory(ft2file)\n \n def load_photons(self,fname,ft2file=None):\n\n if ft2file is not None: setFT2File(ft2file)\n\n hdulist = pyfits.open(fname)\n# hdulist.info()\n# print hdulist[1].columns.names\n \n if self.max_events is not None:\n table = hdulist[1].data[0:self.max_events]\n else:\n table = hdulist[1].data\n \n msk = table.field('ZENITH_ANGLE')<self.zenith_cut\n\n if not self.event_class_id is None:\n event_class = bitarray_to_int(table.field('EVENT_CLASS'),True)\n msk &= (event_class&((0x1)<<int(self.event_class_id))>0)\n\n if not self.event_type_id is None:\n event_type = bitarray_to_int(table.field('EVENT_TYPE'),True)\n msk &= (event_type&((0x1)<<int(self.event_type_id))>0)\n \n table = table[msk]\n \n if self.erange is not None:\n\n erange = [float(t) for t in self.erange.split('/')]\n \n msk = ((np.log10(table.field('ENERGY')) > erange[0]) &\n (np.log10(table.field('ENERGY')) < erange[1]))\n table = table[msk]\n \n if self.conversion_type is not None:\n\n if self.conversion_type == 'front':\n msk = table.field('CONVERSION_TYPE') == 0\n else:\n msk = table.field('CONVERSION_TYPE') == 1\n\n table = table[msk]\n \n if self.phase_selection is not None:\n msk = table.field('PULSE_PHASE')<0\n phases = self.phase_selection.split(',')\n for p in phases:\n (plo,phi) = p.split('/')\n msk |= ((table.field('PULSE_PHASE')>float(plo)) & \n (table.field('PULSE_PHASE')<float(phi)))\n\n table = table[msk]\n \n \n nevent = len(table)\n \n print 'Loading ', fname, ' nevent: ', nevent\n\n pd = self._photon_data\n \n for isrc, src in enumerate(self.srcs):\n\n vsrc = Vector3D.createLatLon(np.radians(src.dec()),\n np.radians(src.ra()))\n \n# print 'Source ', isrc\n msk = (table.field('DEC')>(src.dec()-np.degrees(self.max_dist))) & \\\n (table.field('DEC')<(src.dec()+np.degrees(self.max_dist)))\n table_src = table[msk]\n\n vra = np.array(table_src.field('RA'),dtype=float)\n vdec = np.array(table_src.field('DEC'),dtype=float)\n \n vptz_ra = np.array(table_src.field('PtRaz'),dtype=float)\n vptz_dec = np.array(table_src.field('PtDecz'),dtype=float)\n \n dth = separation_angle(self.src_radec[isrc][0],\n self.src_radec[isrc][1],\n np.radians(vra),\n np.radians(vdec))\n\n msk = dth < self.max_dist\n table_src = table_src[msk]\n vra = vra[msk]\n vdec = vdec[msk]\n vptz_ra = vptz_ra[msk]\n vptz_dec = vptz_dec[msk]\n \n \n veq = Vector3D.createLatLon(np.radians(vdec),\n np.radians(vra))\n\n eptz = Vector3D.createLatLon(np.radians(vptz_dec),\n np.radians(vptz_ra))\n \n\n vp = veq.project2d(vsrc)\n vx = np.degrees(vp.theta()*np.sin(vp.phi()))\n vy = -np.degrees(vp.theta()*np.cos(vp.phi())) \n\n vptz = eptz.project2d(vsrc)\n\n# print vptz.phi()\n\n vp2 = copy.deepcopy(vp)\n vp2.rotatez(-vptz.phi())\n\n vx2 = np.degrees(vp2.theta()*np.sin(vp2.phi()))\n vy2 = -np.degrees(vp2.theta()*np.cos(vp2.phi())) \n\n# import matplotlib.pyplot as plt\n\n# print vp.theta()[:10]\n# print vp2.theta()[:10]\n \n# print np.sqrt(vx**2+vy**2)[:10]\n# print np.sqrt(vx2**2+vy2**2)[:10]\n \n \n# plt.figure()\n# plt.plot(vx2,vy2,marker='o',linestyle='None')\n\n# plt.gca().set_xlim(-80,80)\n# plt.gca().set_ylim(-80,80)\n \n# plt.figure()\n# plt.plot(vx,vy,marker='o',linestyle='None')\n \n# plt.show()\n\n \n# vx2 = np.degrees(vp.theta()*np.sin(vp.phi()))\n# vy2 = -np.degrees(vp.theta()*np.cos(vp.phi())) \n \n \n src_index = np.zeros(len(table_src),dtype=int)\n src_index[:] = isrc\n\n# src_redshift = np.zeros(len(table_src))\n# src_redshift[:] = self.src_redshifts[isrc]\n# self.redshift += list(src_redshift)\n\n src_phase = np.zeros(len(table_src))\n if 'PULSE_PHASE' in hdulist[1].columns.names:\n src_phase = list(table_src.field('PULSE_PHASE'))\n\n psf_core = np.zeros(len(table_src))\n if 'CTBCORE' in hdulist[1].columns.names:\n psf_core = list(table_src.field('CTBCORE'))\n\n event_type = np.zeros(len(table_src),dtype='int')\n if 'EVENT_TYPE' in hdulist[1].columns.names:\n event_type = bitarray_to_int(table_src.field('EVENT_TYPE'),True)\n \n event_class = bitarray_to_int(table_src.field('EVENT_CLASS'),True)\n \n pd.append('psfcore',psf_core)\n pd.append('time',list(table_src.field('TIME')))\n pd.append('ra',list(table_src.field('RA')))\n pd.append('dec',list(table_src.field('DEC')))\n pd.append('delta_ra',list(vx))\n pd.append('delta_dec',list(vy))\n pd.append('delta_phi',list(vx2))\n pd.append('delta_theta',list(vy2)) \n pd.append('energy',list(np.log10(table_src.field('ENERGY'))))\n pd.append('dtheta',list(dth[msk]))\n pd.append('event_class',list(event_class))\n pd.append('event_type',list(event_type))\n pd.append('conversion_type',\n list(table_src.field('CONVERSION_TYPE').astype('int')))\n pd.append('src_index',list(src_index)) \n pd.append('phase',list(src_phase))\n\n cthv = []\n \n for k in range(len(table_src)):\n\n# event = table_src[k]\n# ra = float(event.field('RA'))\n# dec = float(event.field('DEC'))\n# sd = skymaps.SkyDir(ra,dec) \n# event = table_src[k]\n# theta = float(event.field('THETA'))*deg2rad\n# time = event.field('TIME')\n\n if self._phist is not None: \n pi = self._phist(table_src.field('TIME')[k]) \n cth = np.cos(pi.zAxis().difference(src))\n cthv.append(cth)\n\n pd.append('cth',cthv)\n\n\n# print 'Loaded ', len(self.dtheta), ' events'\n \n hdulist.close()\n\n def loadsrclist(self,fname,srcs):\n self.srcs = []\n self.src_names = []\n self.src_redshifts = []\n self.src_ra_deg = []\n self.src_dec_deg = []\n self.src_radec = []\n\n if not fname is None:\n src_names = np.genfromtxt(fname,unpack=True,dtype=None)\n else:\n src_names = np.array(srcs.split(','))\n \n if src_names.ndim == 0: src_names = src_names.reshape(1)\n\n cat = Catalog.get()\n \n for name in src_names:\n\n src = cat.get_source_by_name(name)\n\n name = src['Source_Name']\n ra = src['RAJ2000']\n dec = src['DEJ2000']\n\n print 'Loading ', name\n \n self._photon_data._srcs.append(src)\n\n sd = skymaps.SkyDir(ra,dec)\n self.srcs.append(sd)\n self.src_names.append(name)\n\n self.src_ra_deg.append(ra)\n self.src_dec_deg.append(dec)\n self.src_radec.append((np.radians(ra),np.radians(dec)))\n \n self.src_redshifts.append(0.)\n \n def save(self,fname):\n save_object(self._photon_data,fname,compress=True)\n # self._photon_data.save(fname)\n\nusage = \"usage: %(prog)s [options] [FT1 file ...]\"\ndescription = \"\"\"Generate a pickle file containing a list of all photons within\nmax_dist_deg of a source defined in src_list. The script accepts as input\na list of FT1 files.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--zenith_cut', default = 105, type=float,\n help = 'Set the zenith angle cut.')\n\nparser.add_argument('--conversion_type', default = None, \n help = 'Set the conversion type.')\n\nparser.add_argument('--event_class_id', default = None, \n help = 'Set the event class bit.')\n\nparser.add_argument('--event_type_id', default = None, \n help = 'Set the event type bit.')\n\nparser.add_argument('--output', default = None, \n help = 'Set the output filename.')\n\nparser.add_argument('--src_list',default = None, \n help = 'Set the list of sources.')\n\nparser.add_argument('--srcs',\n default = None,\n help = 'Set a comma-delimited list of sources.')\n\nparser.add_argument('--sc_file', default = None, \n help = 'Set the spacecraft (FT2) file.')\n\nparser.add_argument('--max_events', default = None, type=int,\n help = 'Set the maximum number of events that will be '\n 'read from each file.')\n\nparser.add_argument('--erange', default = None, \n help = 'Set the energy range in log10(E/MeV).')\n\nparser.add_argument('--max_dist_deg', default = 25.0, type=float,\n help = 'Set the maximum distance.')\n\nparser.add_argument('--phase', default = None, \n help = 'Select the pulsar phase selection (on/off).')\n\nparser.add_argument(\"--queue\",default=None,\n help='Set the batch queue on which to run this job.')\n\nargs = parser.parse_args()\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue)\n sys.exit(0)\n\nif args.output is None:\n args.output = os.path.basename(os.path.splitext(args.files[0])[0] + '.P')\n \nft1_files = args.files\nft2_file = args.sc_file\n\npl = FT1Loader(args.zenith_cut,\n args.conversion_type,\n args.event_class_id,\n args.event_type_id,\n args.max_events,args.max_dist_deg,\n args.phase,args.erange)\n\npl.loadsrclist(args.src_list,args.srcs)\n\npl.setFT2File(args.sc_file)\n\nfor f in ft1_files:\n pl.load_photons(f)\n\npl.save(args.output)\n"
},
{
"alpha_fraction": 0.4862017035484314,
"alphanum_fraction": 0.513583242893219,
"avg_line_length": 30.924484252929688,
"blob_id": "5d4480773547cc793a8bb5119fd5346c76945e80",
"content_id": "f5543a32e1d9a6236d2580b78256793ac2fd9270",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13951,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 437,
"path": "/gammatools/fermi/psf_model.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport re\nimport bisect\nimport pyfits\nimport healpy\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.interpolate import UnivariateSpline\nfrom scipy.integrate import quad\nfrom gammatools.core.histogram import Histogram\nfrom gammatools.fermi.irf_util import *\nfrom gammatools.fermi.catalog import Catalog\n\ndef find_nearest(array,value):\n idx=(np.abs(array-value)).argmin()\n return array[idx]\n\nclass PSFModel(object):\n def __init__(self,psf_file=None,model='powerlaw',sp_param=(2,1000)):\n\n self._dtheta_max_deg = 90.0\n \n if psf_file is not None:\n self.load_file(psf_file)\n\n self.set_spectrum(model=model,sp_param=sp_param)\n\n def set_spectrum(self,model,sp_param):\n self._sp_param = sp_param\n\n if model == 'powerlaw':\n self._wfn = self.powerlaw\n elif model == 'deltafn':\n self._wfn = self.deltafn\n self._deltae = find_nearest(self._energy,self._sp_param[0])\n else:\n self._wfn = self.powerlaw_exp\n\n def load_file(self,file):\n hdulist = pyfits.open(file)\n self._dtheta = np.array(hdulist[2].data.field(0))\n self._energy = np.array(hdulist[1].data.field(0))\n self._exps = np.array(hdulist[1].data.field(1))\n self._psf = np.array(hdulist[1].data.field(2))\n\n def deltafn(self,e):\n\n if np.fabs(e-self._deltae) < 0.01:\n return 1\n else:\n return 0\n\n def powerlaw(self,e):\n\n return e**(-self._sp_param[0])\n\n def powerlaw_exp(self,e):\n\n return e**(-self._sp_param[0])*np.exp(-e/self._sp_param[1]) \n\n def histogram(self,emin,emax,cthmin,cthmax,edges):\n y = self.thetasq(emin,emax,cthmin,cthmax,edges)\n return Histogram(edges,counts=y)\n\n def pdf(self,emin,emax,cthmin,cthmax,theta):\n\n x,y = self.psf(emin,emax,cthmin,cthmax)\n \n f = UnivariateSpline(x,y,s=0)\n return f(theta)\n \n def thetasq(self,emin,emax,cthmin,cthmax,x_theta):\n\n x,y = self.psf(emin,emax,cthmin,cthmax)\n\n f = UnivariateSpline(x,y,s=0)\n\n y_thsq = []\n\n for i in range(len(x_theta)-1):\n\n theta_lo = max(0,x_theta[i])\n theta_hi = x_theta[i+1]\n\n s = quad(lambda t: 2*np.pi*t*f(t),theta_lo,theta_hi)[0]\n s *= (np.pi/180.)**2\n y_thsq.append(s)\n\n\n return np.array(y_thsq)\n\n def quantile(self,emin,emax,cthmin,cthmax,frac=0.68,xmax=None):\n \n radii = np.logspace(-3.0,np.log10(self._dtheta_max_deg),300)\n radii = np.concatenate(([0],radii))\n\n x,y = self.psf(emin,emax,cthmin,cthmax)\n\n f = UnivariateSpline(x,y,s=0)\n\n\n rcenters = 0.5*(radii[:-1]+radii[1:])\n rwidth = np.radians(radii[1:] - radii[:-1])\n \n cdf = 2*np.pi*np.sin(np.radians(rcenters))*f(rcenters)*rwidth\n cdf = np.cumsum(cdf)\n cdf = np.concatenate(([0],cdf))\n stot = cdf[-1]\n\n if not xmax is None:\n fcdf = UnivariateSpline(radii,cdf,s=0) \n stot = fcdf(xmax)\n\n cdf /= stot\n\n indx = bisect.bisect(cdf, frac) - 1\n return ((frac - cdf[indx])/(cdf[indx+1] - cdf[indx])\n *(radii[indx+1] - radii[indx]) + radii[indx])\n\n\n def psf(self,emin,emax,cthmin,cthmax):\n \"\"\"Return energy- and livetime-weighted PSF density vector as\n a function of angular offset for a bin in energy and\n inclination angle.\"\"\"\n \n logemin = np.log10(emin)\n logemax = np.log10(emax)\n\n ilo = np.argwhere(self._energy > emin)[0,0]\n ihi = np.argwhere(self._energy < emax)[-1,0]+1\n \n jlo = np.argwhere(self._ctheta_axis.center > cthmin)[0,0]\n jhi = np.argwhere(self._ctheta_axis.center < cthmax)[-1,0] +1\n \n weights = (self._energy[ilo:ihi,np.newaxis]*\n self._exp[ilo:ihi,jlo:jhi]*\n self._wfn(self._energy[ilo:ihi,np.newaxis]))\n \n wsum = np.sum(weights)\n psf = np.apply_over_axes(np.sum,\n self._psf[:,ilo:ihi,jlo:jhi]*\n weights[np.newaxis,...],\n [1,2])\n psf = np.squeeze(psf) \n psf *= (1./wsum)\n return self._dtheta, psf\n \n def psf2(self,emin,emax):\n \"\"\"Return energy-weighted PSF density vector as a function of\n angular offset for the given energy bin.\"\"\"\n\n idx = ((self._energy - emin) >= 0) & ((self._energy - emax) <= 0)\n weights = \\\n self._energy[idx]*self._exps[idx]*self._wfn(self._energy[idx])\n\n if self._edisp is not None:\n \n idx = ((self._erec_center - np.log10(emin)) >= 0) & \\\n ((self._erec_center - np.log10(emax)) <= 0)\n\n weights = (self._energy*self._exps* \n self._wfn(self._energy)*self._edisp.T).T\n \n # PSF vs. reconstructed energy\n psf = np.zeros(self._dtheta.shape[0])\n wsum = 0\n\n for i in range(len(self._erec_center)):\n if self._erec_center[i] < np.log10(emin): continue\n elif self._erec_center[i] > np.log10(emax): break\n psf += np.sum(self._psf.T*weights[:,i],axis=1) \n wsum += np.sum(weights[:,i])\n \n psf *= 1./wsum\n return self._dtheta, psf\n \n else:\n idx = ((self._energy - emin) >= 0) & ((self._energy - emax) <= 0)\n weights = \\\n self._energy[idx]*self._exps[idx]*self._wfn(self._energy[idx])\n wsum = np.sum(weights)\n psf = np.sum(self._psf[idx].T*weights,axis=1)\n psf *= (1./wsum)\n return self._dtheta, psf\n\nclass PSFModelLT(PSFModel):\n \n def __init__(self,irf,nbin=600,\n ebins_per_decade=16,\n src_type='iso',\n spectrum='powerlaw',\n spectrum_pars=[2.0],\n build_model=True,\n ltfile=None,\n edisp_table=None):\n\n PSFModel.__init__(self,model=spectrum,sp_param=spectrum_pars)\n\n self._src_type = src_type\n self._nbin_dtheta = nbin\n self._irf = irf\n self._edisp_table = edisp_table\n\n self._lonlat = (0, 0)\n if src_type != 'iso' and src_type != 'isodec':\n cat = Catalog.get()\n src = cat.get_source_by_name(src_type)\n self._lonlat = (src['RAJ2000'], src['DEJ2000'])\n \n loge_step = 1./float(ebins_per_decade)\n emin = 1.0+loge_step/2.\n emax = 6.0-loge_step/2.\n nbin = int((emax-emin)/loge_step)+1\n self._loge_axis = Axis.create(emin,emax,nbin)\n \n self._energy = np.power(10,self._loge_axis.center)\n self._exps = np.zeros(self._loge_axis.nbins)\n \n self._psf = np.zeros((self._loge_axis.nbins,self._nbin_dtheta))\n\n self._dtheta = np.array([self._dtheta_max_deg*\n (float(i)/float(self._nbin_dtheta))**2 \n for i in range(self._nbin_dtheta)])\n\n\n self._dtheta_axis = Axis(self._dtheta)\n self._ctheta_axis = Axis.create(0.2,1.0,40)\n self._tau = np.zeros(self._ctheta_axis.nbins)\n \n self.loadLTCube(ltfile)\n self.fillLivetime()\n\n if build_model: self.buildModel()\n\n def buildModel(self):\n \"\"\"Build a model for the exposure-weighted PSF averaged over\n instrument inclination angle.\"\"\"\n\n gx, gy = np.meshgrid(np.log10(self._energy),\n self._ctheta_axis.center) \n\n gx = gx.T\n gy = gy.T\n \n self._psf = np.zeros((self._loge_axis.nbins,self._nbin_dtheta))\n self._edisp = None\n\n shape = (self._loge_axis.nbins, self._ctheta_axis.nbins)\n \n aeff = self._irf.aeff(np.ravel(gx),np.ravel(gy))\n aeff = aeff.reshape(shape)\n aeff[aeff < 0] = 0\n aeff[np.isnan(aeff)] = 0\n\n dtheta = self._dtheta.reshape(self._dtheta.shape + (1,))\n \n self._exp = self._tau*aeff\n self._exps = np.sum(self._exp,axis=1)\n \n psf = self._irf.psf(self._dtheta[...,np.newaxis],\n np.ravel(gx)[np.newaxis,...],\n np.ravel(gy)[np.newaxis,...])\n \n psf[psf<0] = 0\n psf[np.isnan(psf)] = 0\n\n self._psf = psf.reshape((self._nbin_dtheta,) + shape)\n# psf /= self._exps[np.newaxis,:,np.newaxis]\n# psf = np.sum(psf*self._exp,axis=2).T\n# self._psf = psf\n \n if self._edisp_table is not None:\n \n edisp_data = np.load(self._edisp_table)\n log_egy_edges = edisp_data['log_egy_edges']\n self._erec_edges = edisp_data['log_erec_edges']\n log_egy_center = 0.5*(log_egy_edges[:-1]+log_egy_edges[1:])\n self._erec_center = 0.5*(self._erec_edges[:-1]+\n self._erec_edges[1:]) \n costh_edges = edisp_data['costh_edges']\n\n self._edisp = np.zeros((self._log_energy.shape[0],\n self._erec_center.shape[0]))\n self._psf_edisp = np.zeros((self._log_energy.shape[0],\n self._erec_center.shape[0],\n self._nbin_dtheta))\n\n self._edisp = np.sum(edisp_data['edisp'].T*self._tau*aeff,axis=2).T\n self._edisp = (self._edisp.T/self._exps).T\n\n \n self._edisp[np.isnan(self._edisp)] = 0\n self._edisp[np.isinf(self._edisp)] = 0\n \n return\n\n \n def loadLTCube(self,ltcube_file):\n\n if ltcube_file is None: return\n hdulist = pyfits.open(ltcube_file)\n\n self._ltmap = hdulist[1].data.field(0)[:,::-1]\n \n ctheta = np.array(hdulist[3].data.field(0))\n self._ctheta_axis = Axis(np.concatenate(([1],ctheta))[::-1])\n \n# self._ctheta_center = \\\n# np.array([1-(0.5*(np.sqrt(1-self._ctheta[i]) + \n# np.sqrt(1-self._ctheta[i+1])))**2 \n# for i in range(len(self._ctheta)-1)])\n# self._dcostheta = np.array([self._ctheta[i]-self._ctheta[i+1]\n# for i in range(len(self._ctheta)-1)])\n# self._theta_center = np.arccos(self._ctheta_center)*180/np.pi \n \n self._tau = np.zeros(self._ctheta_axis.nbins)\n\n def fillLivetime(self):\n \n for i, cth in enumerate(self._ctheta_axis.center):\n\n dcostheta = self._ctheta_axis.width[i]\n \n if self._src_type == 'iso':\n self._tau[i] = dcostheta\n elif self._src_type == 'isodec':\n sinlat = np.linspace(-1,1,48)\n\n m = self._ltmap[:,i]\n\n self._tau[i] = 0\n for s in sinlat: \n lat = np.arcsin(s)\n th = np.pi/2. - lat \n ipix = healpy.ang2pix(64,th,0,nest=True)\n self._tau[i] += m[ipix]\n \n else:\n th = np.pi/2. - self._lonlat[1]*np.pi/180.\n phi = self._lonlat[0]*np.pi/180.\n m = self._ltmap[:,i]\n ipix = healpy.ang2pix(64,th,phi,nest=True)\n# tau = healpy.get_interp_val(m,th,phi,nest=True)\n self._tau[i] = m[ipix]\n\n\nif __name__ == '__main__':\n\n from optparse import Option\n from optparse import OptionParser\n\n usage = \"usage: %prog [options]\"\n description = \"\"\n parser = OptionParser(usage=usage,description=description)\n\n parser.add_option('--ltfile', default = '', type='string',\n help = 'LT file')\n\n parser.add_option('--irf', default = 'P6_V3_DIFFUSE', type='string',\n help = 'LT file')\n\n (opts, args) = parser.parse_args()\n\n SourceCatalog = { 'vela' : (128.83606354, -45.17643181),\n 'geminga' : (98.475638, 17.770253),\n 'crab' : (83.63313, 22.01447) }\n\n logemin = 3\n logemax = 3.25\n\n emin = np.power(10,logemin)\n emax = np.power(10,logemax)\n\n ctheta_range=(0.4,1.0)\n\n irf = IRFManager('../custom_irfs/psf_P7SOURCE_V6MC_front.fits',\n '../custom_irfs/aeff_P7SOURCE_V6MC_front.fits')\n\n np.seterr(all='raise')\n \n m = PSFModelLT(opts.ltfile, opts.irf,\n nbin=300,\n ctheta_range=ctheta_range,\n src_type='src',\n lonlat=SourceCatalog['vela'])#,irf=irf)\n\n print '34% ', m.quantile(emin,emax,0.34)\n print '68% ', m.quantile(emin,emax,0.68)\n print '85% ', m.quantile(emin,emax,0.85)\n print '95% ', m.quantile(emin,emax,0.95)\n\n\n sys.exit(1)\n\n psf_model1 = PSFModel(sys.argv[1],'powerlaw_exp',1.607,3508.6)\n psf_model2 = PSFModel(sys.argv[2],'powerlaw_exp',1.607,3508.6)\n# psf_model1 = PSFModel(sys.argv[1],'deltafn',60000)\n# psf_model2 = PSFModel(sys.argv[2],'deltafn',60000)\n\n print psf_model1.quantile(emin,emax,0.99)\n\n# psf_model3 = PSFModel(sys.argv[3],'powerlaw',2)\n# psf_model4 = PSFModel(sys.argv[1],'powerlaw_exp',1.607,3508.6)\n\n# x_thsq = np.linspace(0,10,100) \n# fig = plt.figure()\n# y_thsq = psf_model1.thetasq(emin,emax,x_thsq)\n# plt.errorbar(x_thsq,y_thsq,xerr=0.5*(x_thsq[1]-x_thsq[0]))\n\n fig = plt.figure()\n ax = fig.add_subplot(111)\n\n\n x1,y1 = psf_model1.psf(emin,emax)\n plt.plot(x1,y1,color='r')\n\n x2,y2 = psf_model2.psf(emin,emax)\n plt.plot(x2,y2,color='b')\n\n\n ax.set_xlim(0,1.0)\n\n\n\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_xscale('log')\n\n\n\n plt.plot(x1,y1/y2,label='gam=3')\n \n\n ax.legend()\n\n plt.show()\n"
},
{
"alpha_fraction": 0.5723358988761902,
"alphanum_fraction": 0.5932721495628357,
"avg_line_length": 26.06369400024414,
"blob_id": "65e9d4c74df05cbfda0577257fbc1e1186c5f464",
"content_id": "68941136dfdeb9b186017e6bed25728bdbaa0ea9",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4251,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 157,
"path": "/scripts/roi_jcalc.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\nimport sys\nimport pyfits\nimport healpy\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom gammatools.core.histogram import *\nfrom gammatools.core.algebra import Vector3D\nfrom gammatools.core.util import integrate\nfrom gammatools.dm.jcalc import *\nfrom scipy.interpolate import UnivariateSpline\n\n\nusage = \"usage: %prog [options] [FT1 file ...]\"\ndescription = \"\"\"Description.\"\"\"\nparser = OptionParser(usage=usage,description=description)\n\nparser.add_option('--energy_range', default = '4.0/4.5', type='string',\n help = 'Set the energy range in GeV.')\n\nparser.add_option('--profile', default = 'nfw', type='string',\n help = 'Set the profile name.')\n\nparser.add_option('--prefix', default = 'nfw', type='string',\n help = 'Set the output file prefix.')\n\nparser.add_option('--alpha', default = 0.17, type='float',\n help = 'Set the alpha parameter of the DM halo profile.')\n\nparser.add_option('--gamma', default = 1.0, type='float',\n help = 'Set the gamma parameter of the DM halo profile.')\n\nparser.add_option('--lon_cut', default = 6.0, type='float',\n help = 'Set the longitude cut value.')\n\nparser.add_option('--lat_cut', default = 5.0, type='float',\n help = 'Set the latitude cut value.')\n\nparser.add_option('--rgc_cut', default = None, type='float',\n help = 'Set the latitude cut value.')\n\nparser.add_option('--rmin', default = 0.1, type='float',\n help = 'Set the profile name.')\n\nparser.add_option('--decay', default = False, action='store_true',\n help = 'Set the profile name.')\n\nparser.add_option('--source_list', default = None, type='string',\n help = 'Set the profile name.')\n\n(opts, args) = parser.parse_args()\n\n# Density Profiles\n\nprofile_opts = {'rs' : 20*Units.kpc,\n 'rhos' : 0.1*Units.gev_cm3,\n 'rmin' : opts.rmin*Units.pc,\n 'alpha' : opts.alpha,\n 'gamma' : opts.gamma }\n\nif opts.profile == 'isothermal': \n profile_opts['rs'] = 5*Units.kpc\n\ndp = DensityProfile.create(opts.profile,profile_opts)\ndp.set_rho(0.4*Units.gev_cm3,8.5*Units.kpc)\n\n#f = LoSIntegralFnFast(dp,rmax=100*Units.kpc,alpha=2.0,ann=(not opts.decay), \n# nstep=800)\n\nf = LoSIntegralFn(dp,8.5*Units.kpc,\n rmax=100*Units.kpc,alpha=3.0,ann=(not opts.decay))\n\nlog_psi = np.linspace(np.log10(np.radians(0.01)),\n np.log10(np.radians(179.9)),400)\npsi = np.power(10,log_psi)\njpsi = f(psi)\njspline = UnivariateSpline(psi,jpsi,s=0,k=1)\njint = JIntegrator(jspline,opts.lat_cut,opts.lon_cut,opts.source_list)\n#jint.print_profile(opts.decay)\n\nif not opts.rgc_cut is None:\n jint.eval(opts.rgc_cut,opts.decay)\n\njint.compute()\n\nsys.exit(0)\n\n#z = np.ones(shape=(360,360))\n#hc = Histogram2D(theta_edges,phi_edges)\n\nfor i0, th in enumerate(theta):\n\n jtot = integrate(lambda t: jspline(t)*np.sin(t),\n np.radians(theta_edges[i0]),\n np.radians(theta_edges[i0+1]),100)\n\n# jval = jspline(np.radians(th))*costh_width[i0]\n v = Vector3D.createThetaPhi(np.radians(th),np.radians(phi))\n v.rotate(yaxis)\n\n lat = np.degrees(v.lat())\n lon = np.degrees(v.phi())\n\n src_msk = len(lat)*[True]\n\n if not sources is None:\n\n for k in range(len(v.lat())):\n p = Vector3D(v._x[:,k])\n\n sep = np.degrees(p.separation(sources))\n imin = np.argmin(sep)\n minsep = sep[imin]\n\n if minsep < 0.62: src_msk[k] = False\n\n\n\n msk = ((np.abs(lat)>=lat_cut) |\n ((np.abs(lat)<=lat_cut)&(np.abs(lon)<lon_cut)))\n\n dphi2 = 2.*np.pi*float(len(lat[msk]))/float(len(phi))\n\n msk &= src_msk\n dphi = 2.*np.pi*float(len(lat[msk]))/float(len(phi))\n\n hc._counts[i0,msk] = 1\n\n jtot *= dphi\n jsum += jtot\n domegasum += costh_width[i0]*dphi\n\n jv.append(jtot)\n domega.append(costh_width[i0]*dphi)\n\n \n\n\n#plt.imshow(z.T,origin='lower')\n#hc.plot()\n\n#plt.show()\n\n# plt.plot(theta,np.array(jv))\n# plt.gca().set_yscale('log')\n \n#z plt.show()\n\n\n# plt.gca().set_xscale('log')\n\n\n\n# print th, s\n\n# hs.fill(th,jval*s)\n\n\n"
},
{
"alpha_fraction": 0.5647011995315552,
"alphanum_fraction": 0.6001197099685669,
"avg_line_length": 26.46027374267578,
"blob_id": "9ac99069dc1439cc7339baf845fb4a1cf4591693",
"content_id": "244455408e06f36dc3c42cc5d8d137485cfa202a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10023,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 365,
"path": "/scripts/fit_axion_spectrum.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom gammatools.core.histogram import *\nfrom gammatools.core.series import *\nfrom gammatools.core.util import *\nfrom gammatools.core.plot_util import *\nfrom gammatools.core.model_fn import *\nfrom gammatools.core.likelihood import *\nfrom gammatools.dm.irf_model import *\nimport sys\nimport glob\nimport scipy.signal\nimport argparse\n\nclass AxionModel(Model):\n\n def __init__(self,gphist,spfn):\n Model.__init__(self,spfn.param())\n \n self._gphist = gphist\n self._spfn = spfn\n\n def _eval(self,x,p):\n return self._spfn(x,p)*self._gphist.interpolate(x)\n \n\ndef calc_e2flux(dh,mh,fn):\n\n h = dh/mh\n\n x = h.axis().center()\n delta = 10**h.axis().edges()[1:]-10**h.axis().edges()[:-1]\n \n h *= fn(x)*10**(2*x)*Units.mev\n\n return h\n \nusage = \"usage: %(prog)s [options] [detector file]\"\ndescription = \"\"\"A description.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\n#parser.add_argument('--model', default=None, \n# help = '')\n\nparser.add_argument('--irf', default=None, \n help = '')\n\nparser.add_argument('--queue', default=None, \n help = '')\n\nparser.add_argument('--output', default=None, \n help = '')\n\nparser.add_argument('files', nargs='+')\n\nargs = parser.parse_args()\n\nif len(args.files) < 1:\n parser.error(\"At least one argument required.\")\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue,\n skip=['files'])\n sys.exit(0)\n\n\ninput_model = args.files[0]\n \nirf = IRFModel.createCTAIRF(args.irf)\naxion_data = load_object(input_model)\n\nsd = yaml.load(open(args.irf,'r'))\n\n\nfn = LogParabola.create(2.468515027e-11*Units._mev,\n 2.026562251,\n 0.09306285428,\n 1000.92)\n\n\nlivetime = 50*Units.hr\n\no = { 'chi2_sig' : [],\n 'chi2_null' : [],\n 'chi2_null_fit' : [],\n 'dh_null_fit' : [],\n 'dh_axion0' : [],\n 'dh_axion1' : [],\n 'mh_null_fit' : [],\n 'mh_axion0' : [],\n 'mh_axion1' : [],\n 'dh_excess_null_e2flux' : [],\n 'dh_excess_axion1_e2flux' : [],\n 'mh_axion1_e2flux' : [],\n 'mh_axion1_fit_e2flux' : [],\n 'pgg_hist' : [],\n 'flux_ptsrc' : sd['flux_ptsrc'],\n 'g' : axion_data['g'],\n 'src' : axion_data['src'],\n 'm' : axion_data['m'] }\n\n\nnp.random.seed(1)\n\nfor i in range(len(axion_data['Pgg'])):\n#for i in range(2):\n print i\n\n pgg_hist = Histogram(Axis.createFromArray(np.log10(axion_data['EGeV'])+3.0),\n counts=axion_data['Pgg'][i],var=0)\n\n axion_fn = AxionModel(pgg_hist,fn)\n\n cm_bkg = BkgSpectrumModel(irf,livetime) \n cm_ps_null = CountsSpectrumModel(irf,fn,livetime,fold_edisp=True)\n cm_ps_axion0 = CountsSpectrumModel(irf,axion_fn,livetime)\n cm_ps_axion1 = CountsSpectrumModel(irf,axion_fn,livetime,fold_edisp=True)\n\n cm_null = CompositeSumModel([cm_bkg,cm_ps_null])\n cm_axion0 = CompositeSumModel([cm_bkg,cm_ps_axion0])\n cm_axion1 = CompositeSumModel([cm_bkg,cm_ps_axion1])\n \n axis = Axis.create(4.5,7,2.5*64)\n\n mh_bkg = cm_bkg.create_histogram(axis)\n mh_ps_null = cm_ps_null.create_histogram(axis)\n mh_ps_axion0 = cm_ps_axion0.create_histogram(axis)\n mh_ps_axion1 = cm_ps_axion1.create_histogram(axis)\n \n dh_bkg = mh_bkg.random()\n dh_ps_null = mh_ps_null.random()\n dh_ps_axion0 = mh_ps_axion0.random()\n dh_ps_axion1 = mh_ps_axion1.random()\n \n dh_null = dh_bkg + dh_ps_null\n dh_axion0 = dh_bkg + dh_ps_axion0 #cm_axion0.create_histogram(axis).random()\n dh_axion1 = dh_bkg + dh_ps_axion1 #cm_axion1.create_histogram(axis).random()\n\n dh_excess_null = dh_null - mh_bkg\n dh_excess_axion0 = dh_axion0 - mh_bkg\n dh_excess_axion1 = dh_axion1 - mh_bkg\n \n # Fit null hypothesis to axion data\n chi2_fn = BinnedChi2Fn(dh_axion1,cm_null)\n chi2_fn.param().fix(3)\n fitter = BFGSFitter(chi2_fn)\n pset_axion1 = fitter.fit()\n\n dh_null_fit = cm_null.create_histogram(axis,pset_axion1).random()\n\n # Fit null hypothesis to axion data\n chi2_fn = BinnedChi2Fn(dh_null_fit,cm_null)\n chi2_fn.param().fix(3)\n fitter = BFGSFitter(chi2_fn)\n pset_null = fitter.fit(pset_axion1)\n\n mh_null = cm_null.create_histogram(axis)\n mh_null_fit = cm_null.create_histogram(axis,pset_null)\n mh_axion1_fit = cm_null.create_histogram(axis,pset_axion1)\n mh_ps_axion1_fit = cm_ps_null.create_histogram(axis,pset_axion1)\n \n mh_axion0 = cm_axion0.create_histogram(axis)\n mh_axion1 = cm_axion1.create_histogram(axis)\n\n # Chi2 of axion spectrum with null hypothesis\n chi2_sig = dh_axion1.chi2(mh_axion1_fit,5.0)\n\n # Chi2 of input spectrum with null hypothesis\n chi2_null = dh_null.chi2(mh_null,5.0)\n\n # Chi2 of fit spectrum with null hypothesis\n chi2_null_fit = dh_null_fit.chi2(mh_null_fit,5.0)\n\n print chi2_sig\n print chi2_null\n print chi2_null_fit\n\n axis2 = mh_null.rebin(2).rebin_mincount(20).axis()\n \n \n dh_excess_null_e2flux = \\\n calc_e2flux(dh_excess_null.rebin_axis(axis2),\n mh_ps_null.rebin_axis(axis2),fn)\n \n dh_excess_axion1_e2flux = \\\n calc_e2flux(dh_excess_axion1.rebin_axis(axis2),\n mh_ps_null.rebin_axis(axis2),fn)\n\n mh_axion1_fit_e2flux = calc_e2flux(mh_ps_axion1_fit,\n mh_ps_null,fn)\n \n mh_axion1_e2flux = calc_e2flux(mh_ps_axion1,\n mh_ps_null,fn)\n\n\n o['chi2_sig'].append(chi2_sig)\n o['chi2_null'].append(chi2_null)\n o['chi2_null_fit'].append(chi2_null_fit)\n\n if i > 10: continue\n \n o['dh_null_fit'].append(dh_null_fit)\n o['dh_axion0'].append(dh_axion0)\n o['dh_axion1'].append(dh_axion1)\n\n o['mh_null_fit'].append(mh_null_fit)\n o['mh_axion0'].append(mh_axion0)\n o['mh_axion1'].append(mh_axion1)\n\n o['dh_excess_null_e2flux'].append(dh_excess_null_e2flux)\n o['dh_excess_axion1_e2flux'].append(dh_excess_axion1_e2flux)\n \n o['mh_axion1_e2flux'].append(mh_axion1_e2flux)\n o['mh_axion1_fit_e2flux'].append(mh_axion1_fit_e2flux)\n o['pgg_hist'].append(pgg_hist)\n\n\nfit_data = { 'chi2_sig' : o['chi2_sig'],\n 'chi2_null' : o['chi2_null'],\n 'chi2_null_fit' : o['chi2_null_fit'],\n 'g' : o['g'],\n 'm' : o['m'],\n 'src' : o['src'] }\n\nif args.output is None:\n m = re.search('(.+)\\.pickle\\.gz?',input_model)\n if not m is None:\n outfile_fit = m.group(1) + '_fit.pickle'\n outfile_hist = m.group(1) + '_hist.pickle'\nelse:\n outfile_fit = os.path.splitext(args.output)[0] + '_fit.pickle'\n outfile_hist = os.path.splitext(args.output)[0] + '_hist.pickle'\n \nsave_object(o,outfile_hist,True)\nsave_object(fit_data,outfile_fit,True)\n\nsys.exit(0)\n\nft = FigTool()\n\nplt.figure()\nx = np.linspace(4.5,7,800)\nplt.plot(x,axion_fn(x)*10**(2*x)*Units.mev**2/Units.erg)\nplt.plot(x,fn(x)*10**(2*x)*Units.mev**2/Units.erg)\nplt.gca().set_yscale('log')\n\n\nfig = ft.create(1,'axion_model_density',\n ylabel='Counts Density',\n xlabel='Energy [log$_{10}$(E/MeV)]')\n\n\nfig[0].add_data(x,cm_null(x,pset_axion1),marker='None')\nfig[0].add_data(x,cm_axion0(x),marker='None')\nfig[0].add_data(x,cm_axion1(x),marker='None')\nfig.plot(ylim_ratio=[-0.5,0.5],style='residual2')\n\nfig = ft.create(1,'axion_model_counts',\n ylabel='Counts',\n xlabel='Energy [log$_{10}$(E/MeV)]')\n\nfig[0].add_hist(mh_null_fit,hist_style='line')\nfig[0].add_hist(mh_axion0,hist_style='line')\nfig[0].add_hist(mh_axion1,hist_style='line')\n\nfig.plot(ylim_ratio=[-0.5,0.5],style='residual2')\n\nplt.figure()\n\ndh_null.plot()\ndh_axion0.plot()\ndh_axion1.plot()\nmh_axion1_fit.plot(hist_style='line',color='k')\n\n\n\nplt.figure()\n\nh0_e2flux.plot(linestyle='None')\nh1_e2flux.plot(linestyle='None')\nh2_e2flux.plot(linestyle='None')\n\nplt.plot(x,fn(x)*10**(2*x)*Units.mev**2/Units.mev)\nplt.plot(x,fn(x,pset_axion1)*10**(2*x)*Units.mev**2/Units.mev)\n\n\nplt.gca().set_yscale('log')\n\nplt.gca().grid(True)\n\n#plt.gca().set_ylim(1E-14,1E-9)\n\n\nfig = ft.create(1,'axion_counts_residual',\n ylabel='Counts',\n xlabel='Energy [log$_{10}$(E/MeV)]')\n\n\nfig[0].add_hist(mh_axion1_fit,hist_style='line')\nfig[0].add_hist(dh_axion1)\n\nfig.plot(ylim_ratio=[-0.5,0.5],style='residual2')\n\nfig = ft.create(1,'axion_flux_residual',\n yscale='log',\n ylabel='Flux',\n xlabel='Energy [log$_{10}$(E/MeV)]')\n\n\nfig[0].add_data(x,fn(x,pset_axion1)*10**(2*x)*Units.mev**2/Units.mev,\n marker='None')\nfig[0].add_hist(h2_e2flux)\nfig[0].add_hist(mh_axion0_e2flux,hist_style='line',label='ALP')\nfig[0].add_hist(mh_axion1_e2flux,hist_style='line',label='ALP Smoothed')\n\n\nfig.plot(ylim_ratio=[-0.5,0.5],style='residual2')\n\n#fig.plot(style='residual2')\n\nplt.figure()\n\n\ndh_excess_null_e2flux.plot()\ndh_excess_axion1_e2flux.plot()\nx = np.linspace(4.5,7,800)\nplt.plot(x,axion_fn(x)*10**(2*x)*Units.mev**2/Units.mev)\nplt.plot(x,fn(x)*10**(2*x)*Units.mev**2/Units.mev)\n\nplt.gca().set_yscale('log')\n\n\nplt.plot(sd['flux_ptsrc']['x']+3.0,\n sd['flux_ptsrc']['counts']*Units.gev_m2/Units.mev)\n\n\nft = FigTool()\n\nfig = ft.create(1,'axion_model_density',\n ylabel='Counts Density',\n xlabel='Energy [log$_{10}$(E/MeV)]',\n yscale='log',linestyles=['-'])\n\n\n# fig[0].add_data(x,fn(x,pset_axion1)*10**(2*x)*Units.mev**2/Units.mev,\n# marker='None',linestyle='-')\n\nfig[0].add_hist(mh_axion1_fit_e2flux,hist_style='line',linestyle='-',\n label='LogParabola Fit')\n \nfig[0].add_hist(mh_axion1_e2flux,hist_style='line',linestyle='-',\n label='ALP')\n \nfig[0].add_hist(dh_excess_axion1_e2flux,linestyle='None',label='Data',\n color='k')\n\n\nfig.plot(ylim_ratio=[-0.8,0.8],style='residual2')\n \n\n\nplt.show()\n"
},
{
"alpha_fraction": 0.534102737903595,
"alphanum_fraction": 0.5398730635643005,
"avg_line_length": 25.417682647705078,
"blob_id": "4b0d78747ba1d2745f7a157ee89ba8f95f00118d",
"content_id": "fc113a4a7d4a11009f7bb29e1f7869db3147348e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8665,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 328,
"path": "/gammatools/core/parameter_set.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@file parameter_set.py\n\n@brief Python classes that encapsulate model parameters.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n__source__ = \"$Source: /nfs/slac/g/glast/ground/cvs/users/mdwood/python/parameter_set.py,v $\"\n__author__ = \"Matthew Wood <[email protected]>\"\n__date__ = \"$Date: 2013/08/15 20:50:25 $\"\n__revision__ = \"$Revision: 1.2 $, $Author: mdwood $\"\n\nimport numpy as np\nimport copy\nimport re\nfrom scipy.interpolate import UnivariateSpline\nfrom histogram import Histogram\nfrom util import expand_aliases, get_parameters\n\nclass Parameter(object):\n \"\"\"This class encapsulates a single function parameter that can\n take a single value or an array of values. The parameter is\n identified by a unique ID number and a name string.\"\"\"\n\n def __init__(self,pid,value,name,fixed=False,lims=None):\n self._pid = pid\n self._name = name\n self._value = np.array(value,ndmin=1)\n self._err = 0\n\n if lims is None: self._lims = [None,None]\n else: self._lims = lims\n self._fixed = fixed\n\n @property\n def lims(self):\n return self._lims\n \n @property\n def name(self):\n return self._name\n\n @property\n def pid(self):\n return self._pid\n\n @property\n def value(self):\n return self._value\n \n @property\n def error(self):\n return self._err\n\n def fix(self,fix=True):\n self._fixed = fix\n\n @property\n def fixed(self):\n return self._fixed\n\n @property\n def size(self):\n return self._value.shape[0]\n\n def set(self,v):\n self._value = np.array(v,ndmin=1)\n# if isinstance(v,np.array): self._value = v\n# else: self._value[...] = v\n\n def setLoBound(self,v):\n self._lims[0] = v\n\n def setHiBound(self,v):\n self._lims[1] = v\n\n def __str__(self):\n return '%5i %5i %25s %s'%(self._pid,self._fixed,self._name,\n str(self._value.T))\n\nclass ParameterSet(object):\n \"\"\"Class that stores a set of function parameters. Each parameter\n is identified by a unique integer parameter id.\"\"\"\n\n def __init__(self,pars=None):\n\n self._pars_dict = {}\n self._pars = []\n self._par_names = {}\n\n if isinstance(pars,ParameterSet):\n for p in pars: self.addParameter(p)\n elif not pars is None:\n for p in pars: self.addParameter(p)\n\n def __iter__(self):\n return iter(self._pars)\n\n def pids(self):\n return sorted(self._pars_dict.keys())\n \n def names(self):\n \"\"\"Return the names of the parameters in this set.\"\"\"\n return self._par_names.keys()\n\n def pid(self):\n \"\"\"Return the sorted list of parameter IDs in this set.\"\"\"\n return sorted(self._pars_dict.keys())\n\n def fixed(self):\n\n fixed = []\n for i, p in enumerate(self._pars):\n fixed.append(p.fixed())\n return fixed\n\n def array(self):\n \"\"\"Return parameter set contents as NxM numpy array where N is\n the number of parameters and M is the number of parameter\n values.\"\"\"\n\n# if self._pars[pkeys[0]].size() > 1:\n x = np.zeros((len(self._pars),self._pars[0].size))\n for i, p in enumerate(self._pars):\n x[i] = p.value\n\n return x\n\n def list(self):\n \"\"\"Return parameter set contents as list of arrays.\"\"\"\n v = []\n for i, p in enumerate(self._pars):\n v.append(p.value)\n return v\n\n def makeParameterArray(self,ipar,x):\n\n pset = copy.deepcopy(self)\n\n for i, p in enumerate(self._pars):\n if i != ipar: \n pset[i].set(np.ones(len(x))*self._pars[i].value)\n else:\n pset[i].set(x)\n\n return pset\n\n def clear(self):\n\n self._pars.clear()\n self._pars_dict.clear()\n self._par_names.clear()\n\n def fix(self,ipar,fix=True):\n self._pars[ipar].fix(fix)\n\n def fixAll(self,fix=True,regex=None):\n \"\"\"Fix or free all parameters in the set.\"\"\"\n\n keys = []\n\n if not regex is None: \n for k, v in self._par_names.iteritems(): \n if re.search(regex,k): keys.append(v)\n else:\n keys = self._pars_dict.keys()\n\n for k in keys: self._pars_dict[k].fix(fix)\n\n def update(self,*args):\n \"\"\"Update parameter values from an existing parameter set or from\n a numpy array.\"\"\"\n\n if len(args) == 0: return\n elif len(args) == 1:\n\n pset = args[0]\n if pset is None: return\n elif isinstance(pset,ParameterSet):\n for p in pset:\n if p.pid in self._pars_dict:\n self._pars_dict[p.pid].set(p.value)\n else:\n for i, p in enumerate(self._pars):\n self._pars[i].set(np.array(pset[i],ndmin=1))\n else:\n\n if len(args) != len(self._pars):\n raise Exception('Wrong number of arguments for parameter set.')\n\n for i, p in enumerate(args):\n self._pars[i].set(np.array(p,ndmin=1))\n\n\n def createParameter(self,value,name=None,fixed=False,lims=None,pid=None):\n \"\"\"Create a new parameter and add it to the set. Returns a\n reference to the new parameter.\"\"\"\n\n if pid is None:\n\n if len(self._pars_dict.keys()) > 0:\n pid = sorted(self._pars_dict.keys())[-1]+1\n else:\n pid = 0\n\n if name is None: name = 'p%i'%pid\n\n p = Parameter(pid,value,name,fixed,lims)\n self.addParameter(p)\n return p\n\n def addParameter(self,p): \n\n if p.pid in self._pars_dict.keys():\n raise Exception('Parameter with ID %i already exists.'%p.pid)\n elif p.pid in self._pars and p.name != self._pars[p.pid].name:\n raise Exception('Parameter with name %s already exists.'%p.name)\n# print \"Error : Parameter already exists: \", p.pid\n# print \"Error : Mismatch in parameter name: \", p.pid\n# sys.exit(1)\n# if p.name in self._par_names.keys():\n# print \"Error : Parameter with name already exists: \", p.name\n# sys.exit(1)\n\n par = copy.deepcopy(p)\n\n self._pars_dict[p.pid] = par\n# self._pars.append(par)\n self._pars = []\n for k in sorted(self._pars_dict.keys()):\n self._pars.append(self._pars_dict[k])\n\n self._par_names[p.name] = p.pid\n\n def addSet(self,pset): \n\n for p in pset:\n if not p.pid in self._pars_dict.keys():\n self.addParameter(p)\n\n def __getitem__(self,ipar):\n\n if isinstance(ipar,str): \n return self._pars_dict[self._par_names[ipar]]\n else: return self._pars[ipar]\n\n# def __setitem__(self,pid,val):\n# self._pars[pid] = val\n\n def getParByID(self,ipar):\n return self._pars_dict[ipar]\n\n def getParByIndex(self,ipar):\n return self._pars[ipar]\n\n def getParByName(self,name):\n pid = self._par_names[name]\n return self._pars_dict[pid]\n\n def setParByName(self,name,val):\n pid = self._par_names[name]\n self._pars_dict[pid]._value = np.array(val,ndmin=2)\n\n def set(self,*args):\n\n for i, v in enumerate(args):\n self._pars[i].set(v)\n\n def npar(self):\n return len(self._pars)\n\n def size(self):\n\n if len(self._pars) == 0: return 0\n else: return self._pars[0].size()\n\n# def set(self,p):\n# \"\"\"Set the parameter list from an array.\"\"\"\n# for i in range(len(p)):\n# self._pars[i]._value = np.array(p[i])*np.ones(1)\n \n def __str__(self):\n\n os = ''\n for p in self._pars: os += '%s\\n'%(p)\n\n return os\n\nclass FitResults(ParameterSet):\n\n def __init__(self,pset,fval,cov=None):\n ParameterSet.__init__(self,pset)\n\n if cov is None: cov=np.zeros(shape=(pset.npar(),pset.npar()))\n else: self._cov = cov\n \n self._err = np.sqrt(np.diag(cov))\n self._fval = fval\n\n def fval(self):\n return self._fval\n\n def getParError(self,pid):\n\n if isinstance(pid,str):\n pid = self.getParByName(pid).pid\n\n return self._err[pid]\n\n def __str__(self):\n\n os = ''\n for i, p in enumerate(self._pars):\n os += '%s %.6g\\n'%(p,self._err[i])\n\n os += 'fval: %.3f\\n'%(self._fval)\n# os += 'cov:\\n %s'%(str(self._cov))\n\n return os\n\n\nif __name__ == '__main__':\n\n pset = ParameterSet()\n pset.createParameter(0.0,'par0')\n \n for p in pset:\n print p\n"
},
{
"alpha_fraction": 0.5681095719337463,
"alphanum_fraction": 0.5741012692451477,
"avg_line_length": 33.65254211425781,
"blob_id": "8aea76965f300e2eac41940b2eb064f43b9c6dc4",
"content_id": "0e6a33ae79a130fe8d6f5e3e73cf88e9348bcd14",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8178,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 236,
"path": "/gammatools/core/mpl_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "__author__ = 'Matthew Wood <[email protected]>'\n__date__ = '11/14/13'\n\nimport matplotlib\n\nfrom matplotlib import scale as mscale\nfrom matplotlib import transforms as mtransforms\nfrom matplotlib.ticker import FixedLocator, ScalarFormatter, MultipleLocator\nfrom matplotlib.ticker import LogLocator, AutoLocator\nimport numpy as np\nfrom numpy import ma\nimport matplotlib.cbook as cbook\n\nclass MPLUtil(object):\n\n scatter_kwargs = ['marker','color','edgecolor','label'] \n imshow_kwargs = ['interpolation','origin','vmin','vmax']\n pcolormesh_kwargs = ['shading','origin','vmin','vmax']\n contour_kwargs = ['levels','origin','cmap','colors']\n fill_kwargs = ['alpha','where']\n errorbar_kwargs = ['marker','markersize','color','markerfacecolor',\n 'markeredgecolor','linestyle','linewidth','label',\n 'drawstyle']\n hist_kwargs = ['color','alpha','histtype','label']\n\nclass PowerNorm(matplotlib.colors.Normalize):\n \"\"\"\n Normalize a given value to the ``[0, 1]`` interval with a power-law\n scaling. This will clip any negative data points to 0.\n \"\"\"\n def __init__(self, gamma, vmin=None, vmax=None, clip=True):\n matplotlib.colors.Normalize.__init__(self, vmin, vmax, clip)\n self.gamma = gamma\n\n def __call__(self, value, clip=None):\n if clip is None:\n clip = self.clip\n\n result, is_scalar = self.process_value(value)\n\n self.autoscale_None(result)\n gamma = self.gamma\n vmin, vmax = self.vmin, self.vmax\n if vmin > vmax:\n raise ValueError(\"minvalue must be less than or equal to maxvalue\")\n elif vmin == vmax:\n result.fill(0)\n else:\n if clip:\n mask = ma.getmask(result)\n val = ma.array(np.clip(result.filled(vmax), vmin, vmax),\n mask=mask)\n resdat = result.data\n resdat -= vmin\n np.power(resdat, gamma, resdat)\n resdat /= (vmax - vmin) ** gamma\n result = np.ma.array(resdat, mask=result.mask, copy=False)\n result[(value < 0)&~result.mask] = 0\n if is_scalar:\n result = result[0]\n return result\n\n def inverse(self, value):\n if not self.scaled():\n raise ValueError(\"Not invertible until scaled\")\n gamma = self.gamma\n vmin, vmax = self.vmin, self.vmax\n\n if cbook.iterable(value):\n val = ma.asarray(value)\n return ma.power(value, 1. / gamma) * (vmax - vmin) + vmin\n else:\n return pow(value, 1. / gamma) * (vmax - vmin) + vmin\n\n def autoscale(self, A):\n \"\"\"\n Set *vmin*, *vmax* to min, max of *A*.\n \"\"\"\n self.vmin = ma.min(A)\n if self.vmin < 0:\n self.vmin = 0\n warnings.warn(\"Power-law scaling on negative values is \"\n \"ill-defined, clamping to 0.\")\n\n self.vmax = ma.max(A)\n\n def autoscale_None(self, A):\n ' autoscale only None-valued vmin or vmax'\n if self.vmin is None and np.size(A) > 0:\n self.vmin = ma.min(A)\n if self.vmin < 0:\n self.vmin = 0\n warnings.warn(\"Power-law scaling on negative values is \"\n \"ill-defined, clamping to 0.\")\n\n if self.vmax is None and np.size(A) > 0:\n self.vmax = ma.max(A)\n\nclass PowerNormalize(matplotlib.colors.Normalize):\n def __init__(self, vmin=None, vmax=None, power=2., clip=False):\n self.power = power\n matplotlib.colors.Normalize.__init__(self, vmin, vmax, clip)\n\n def __call__(self, value, clip=None):\n\n print 'call ', type(value)\n\n# print 'value ', value\n# print 'clip ', clip\n\n return np.ma.masked_array(np.power((value-self.vmin)/self.vmax,\n 1./self.power))\n\n if isinstance(value,np.ma.masked_array):\n print 'here'\n mask = value.mask\n v = np.ma.masked_array(value,copy=True)\n v[~v.mask] = np.power((v[~v.mask]-self.vmin)/self.vmax,\n 1./self.power)\n\n else:\n print 'here2'\n v = np.ma.masked_array(np.power((value-self.vmin)/self.vmax,\n 1./self.power))\n# import healpy as hp\n# v[v.mask]=10\n\n return v\n\n \nclass SqrtScale(mscale.ScaleBase):\n \"\"\"\n Scales data using the function x^{1/2}.\n \"\"\"\n\n name = 'sqrt'\n\n def __init__(self, axis, **kwargs):\n \"\"\"\n Any keyword arguments passed to ``set_xscale`` and\n ``set_yscale`` will be passed along to the scale's\n constructor.\n\n thresh: The degree above which to crop the data.\n \"\"\"\n\n exp = kwargs.pop('exp', 2.0)\n\n mscale.ScaleBase.__init__(self)\n\n# if thresh >= np.pi / 2.0:\n# raise ValueError(\"thresh must be less than pi/2\")\n self.thresh = 0.0 #thresh\n self.exp = exp\n\n def get_transform(self):\n \"\"\"\n Override this method to return a new instance that does the\n actual transformation of the data.\n \"\"\"\n return self.SqrtTransform(self.thresh,exp=self.exp)\n\n def set_default_locators_and_formatters(self, axis):\n \"\"\"\n Override to set up the locators and formatters to use with the\n scale. This is only required if the scale requires custom\n locators and formatters. Writing custom locators and\n formatters is rather outside the scope of this example, but\n there are many helpful examples in ``ticker.py``.\n \"\"\"\n axis.set_major_locator(AutoLocator())\n axis.set_major_formatter(ScalarFormatter())\n axis.set_minor_formatter(ScalarFormatter())\n return\n\n\n def limit_range_for_scale(self, vmin, vmax, minpos):\n \"\"\"\n Override to limit the bounds of the axis to the domain of the\n transform. In the case of Mercator, the bounds should be\n limited to the threshold that was passed in. Unlike the\n autoscaling provided by the tick locators, this range limiting\n will always be adhered to, whether the axis range is set\n manually, determined automatically or changed through panning\n and zooming.\n \"\"\"\n return max(vmin, self.thresh), max(vmax, self.thresh)\n\n class SqrtTransform(mtransforms.Transform):\n # There are two value members that must be defined.\n # ``input_dims`` and ``output_dims`` specify number of input\n # dimensions and output dimensions to the transformation.\n # These are used by the transformation framework to do some\n # error checking and prevent incompatible transformations from\n # being connected together. When defining transforms for a\n # scale, which are, by definition, separable and have only one\n # dimension, these members should always be set to 1.\n input_dims = 1\n output_dims = 1\n is_separable = True\n has_inverse = True\n\n def __init__(self, thresh, exp):\n mtransforms.Transform.__init__(self)\n self.thresh = thresh\n self.exp = exp\n\n def transform_non_affine(self, a):\n\n masked = np.ma.masked_where(a < self.thresh, a)\n return np.power(masked,1./self.exp)\n\n # if masked.mask.any():\n # return ma.log(np.abs(ma.tan(masked) + 1.0 / ma.cos(masked)))\n # else:\n # return np.log(np.abs(np.tan(a) + 1.0 / np.cos(a)))\n\n def inverted(self):\n return SqrtScale.InvertedSqrtTransform(self.thresh,self.exp)\n\n class InvertedSqrtTransform(mtransforms.Transform):\n input_dims = 1\n output_dims = 1\n is_separable = True\n has_inverse = True\n\n def __init__(self,thresh,exp):\n mtransforms.Transform.__init__(self)\n self.thresh = thresh\n self.exp = exp\n\n def transform_non_affine(self, a):\n return np.power(a,self.exp)\n\n def inverted(self):\n return SqrtScale.SqrtTransform(self.thresh,self.exp)\n"
},
{
"alpha_fraction": 0.6556291580200195,
"alphanum_fraction": 0.6556291580200195,
"avg_line_length": 27.799999237060547,
"blob_id": "a803158e9d6b50670cc8e92b3d3f0d9fea76a9e9",
"content_id": "b5c67cbffb1d3079d0f6d22d75f91848c481d279",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 151,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 5,
"path": "/examples/README.md",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "FITS Image Plotting\n===================\n\nThe SkyImage and SkyCube classes can be used to load and manipulate\nFITS image data. The plot method:\n\n \n"
},
{
"alpha_fraction": 0.6776315569877625,
"alphanum_fraction": 0.6940789222717285,
"avg_line_length": 21.02898597717285,
"blob_id": "36182579f7aa85d05aa4839750556f86f02407cc",
"content_id": "7457d0518e769fcf5bc601668111f20c725f319a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1520,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 69,
"path": "/examples/make_skyplot.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\nFITS Image Plotting \n=================== \n\nThis script demonstrates how to load and plot a FITS file using the\nSkyImage and SkyCube classes.\n\"\"\"\n\n#!/usr/bin/env python\n\nimport os\nimport sys\nimport copy\nimport argparse\nimport numpy as np\nfrom gammatools.core.astropy_helper import pyfits\n\nimport matplotlib.pyplot as plt\n\nfrom gammatools.core.fits_util import FITSImage, SkyCube, SkyImage\nfrom gammatools.fermi.catalog import Catalog\n\nusage = \"usage: %(prog)s [options] [FT1 file ...]\"\ndescription = \"\"\"Plot the contents of a FITS image file.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--hdu', default = 0, type=int,\n help = 'Set the HDU number to plot.')\n \nargs = parser.parse_args()\n\nhdulist = pyfits.open(args.files[0])\n\nim = FITSImage.createFromFITS(args.files[0],args.hdu)\nif isinstance(im,SkyCube):\n\n # Integrate over 3rd (energy) dimension\n im = im.marginalize(2)\n\n\nplt.figure()\n\nim.plot(cmap='ds9_b')\n\nplt.figure()\n\n# Smooth by 0.2 deg\nim.smooth(0.2).plot(cmap='ds9_b')\n\n# Draw an arbitrary contour in Galactic Coordinates\nphi = np.linspace(0,2*np.pi,10000)\nr = np.sqrt(2*np.cos(2*phi))\nx = im.lon + r*np.cos(phi)\ny = im.lat + r*np.sin(phi)\nim.ax()['gal'].plot(x,y,color='w')\n\ncat = Catalog.get('2fgl')\ncat.plot(im,ax=plt.gca(),label_threshold=5,src_color='w')\n\n# Make 1D projection on LON axis\nplt.figure()\npim = im.project(0,offset_coord=True)\npim.plot()\nplt.gca().grid(True)\n\nplt.show()\n"
},
{
"alpha_fraction": 0.3788895606994629,
"alphanum_fraction": 0.40654870867729187,
"avg_line_length": 24.609375,
"blob_id": "19402f0b19a471867e6366d174551b35a112e8a2",
"content_id": "66ca18416caca1d4c06b1ebe4b241fe165f9cc52",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4917,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 192,
"path": "/gammatools/core/bspline.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nclass BSpline(object):\n \"\"\"Class representing a 1-D B-spline.\"\"\"\n \n m2 = np.array([[1.0,-1.0],[0.0,1.0]])\n m3 = 0.5*np.array([[1.0,-2.0,1.0],\n [1.0,2.0,-2.0],\n [0.0,0.0, 1.0]])\n\n m4 = (1./6.)*np.array([[1.0,-3.0, 3.0,-1.0],\n [4.0, 0.0,-6.0, 3.0],\n [1.0, 3.0, 3.0,-3.0],\n [0.0, 0.0, 0.0, 1.0]])\n\n\n def __init__(self,k,w,nd):\n \"\"\"Initialize a 1-D B-spline object.\n\n @param k Knot vector.\n @param w Weights vector.\n @param nd Order of spline (2=linear, 3=quadratic, 4=cubic)\n \"\"\"\n self._k = k\n self._w = w\n self._nd = nd\n\n if nd == 2: self._m = BSpline.m2\n elif nd == 3: self._m = BSpline.m3\n elif nd == 4: self._m = BSpline.m4\n else:\n print 'Spline order ', nd, ' not supported.'\n sys.exit(1)\n\n @staticmethod\n def fit(x,y,yerr,k,nd):\n\n if nd == 2: m = BSpline.m2\n elif nd == 3: m = BSpline.m3\n elif nd == 4: m = BSpline.m4\n else:\n print 'Spline order ', nd, ' not supported.'\n sys.exit(1)\n\n nrow = k.shape[0]\n ndata = x.shape[0]\n \n a = np.zeros(shape=(ndata,nrow))\n\n if yerr is None: yerr = np.ones(ndata) \n b = y/yerr\n \n ix, px = BSpline.poly(x,k,nd)\n# msum = np.sum(m,axis=1)\n\n for i in range(ndata):\n for j in range(nd):\n# a[i,ix[i]:ix[i]+nd] += m[j]*px[j,i]\n a[i,ix[i]+j] += np.sum(m[j]*px[:,i]/yerr[i])\n\n (u,s,v) = np.linalg.svd(a,full_matrices=False)\n ub = np.sum(u.T*b,axis=1)\n w = np.sum(ub*v.T/s,axis=1)\n\n return BSpline(k,w,nd)\n \n\n @staticmethod\n def poly(x,k,nd,ndx=0):\n \"\"\"Evaluate polynomial vector for a set of evaluation points\n (x), knots (k), and spline order (nd).\"\"\"\n\n import scipy.special as spfn\n\n kw = k[1] - k[0]\n\n dx = np.zeros(shape=(k.shape[0],x.shape[0]))\n dx[:] = x\n dx = np.abs(dx.T-k-0.5*kw)\n \n imax = k.shape[0]-nd\n\n ix = np.argmin(dx,axis=1)\n ix[ix>imax] = imax\n\n xp = (x-k[ix])/kw\n\n# px = np.ones(shape=(nd,x.shape[0]))\n# for i in range(1,nd): px[i] = px[i-1]*(xp)\n\n# return ix, px\n\n\n if ndx == 0:\n c = np.ones(nd)\n elif ndx == 1:\n c = np.zeros(nd)\n c[1:] = np.linspace(1,nd-1,nd-1)\n elif ndx > 0:\n for i in range(nd):\n \n j = i-ndx\n\n if i+2+ndx < nd: c[i] = 0.0\n else: c[i] = spfn.gamma(j)\n\n n = np.linspace(0,nd-1-ndx,nd)\n c = spfn.gamma(n)\n\n px = np.zeros(shape=(nd,x.shape[0]))\n for i in range(0,nd): \n\n exp = max(i-ndx,0)\n px[i] = np.power(xp,exp)*c[i] \n\n\n return ix, px*np.power(kw,-ndx)\n\n def __call__(self,x,ndx=0):\n return self.eval(x,ndx)\n\n def get_dict_repr(self):\n\n o = {}\n o['knots'] = self._k\n o['weights'] = self._w\n o['order'] = self._nd\n return o\n\n @staticmethod\n def create_from_dict(o):\n return BSpline(o['knots'], o['weights'], o['order'])\n \n def eval(self,x,ndx=0):\n\n x = np.asarray(x)\n if x.ndim == 0: x = x.reshape((1))\n \n ix, px = BSpline.poly(x,self._k,self._nd,ndx)\n wx = np.ones(shape=(self._nd,x.shape[0]))\n\n for i in range(self._nd): wx[i] = self._w[ix+i]\n\n s = np.zeros(x.shape[0])\n for i in range(self._nd):\n for j in range(self._nd):\n s += wx[i]*self._m[i,j]*px[j]\n\n return s\n\n def get_expr(self,xvar):\n \"\"\"Return symbolic representation in ROOT compatible\n format.\"\"\"\n\n cut = []\n ncut = len(self._k)-(self._nd-1)\n\n kw = self._k[1] - self._k[0]\n\n for i in range(ncut):\n\n if ncut == 1: cond = '1.0'\n elif i == 0:\n cond = '%s <= %f'%(xvar,self._k[i+1])\n elif i == ncut-1:\n cond = '%s > %f'%(xvar,self._k[i])\n else:\n cond = '(%s > %f)*(%s <= %f)'%(xvar,self._k[i],\n xvar,self._k[i+1])\n\n wexp = []\n\n for j in range(self._nd):\n\n ws = 0\n for k in range(self._nd):\n#\n# print i, j, k, ws\n ws += self._w[i+k]*self._m[k,j]\n\n\n if j == 0: px = '(%f)*(1.0)'%(ws)\n else:\n px = '(%f)*(pow((%s-%f)/%f,%i))'%(ws,xvar,\n self._k[i],kw,j)\n\n wexp.append(px)\n \n\n cut.append('(%s)*(%s)'%(cond,'+'.join(wexp)))\n\n return '+'.join(cut)\n"
},
{
"alpha_fraction": 0.6139789819717407,
"alphanum_fraction": 0.6203746199607849,
"avg_line_length": 32.937984466552734,
"blob_id": "3d87aaaa210ad83ba4b29ba20326b606fba649ac",
"content_id": "1a4dfd4653dfef2703314f2ce4b29f4f4da5a22f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4378,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 129,
"path": "/gammatools/core/custom_scales.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "from matplotlib import scale as mscale\nfrom matplotlib import transforms as mtransforms\nfrom matplotlib.ticker import FixedLocator, ScalarFormatter, MultipleLocator\nfrom matplotlib.ticker import LogLocator, AutoLocator\nimport numpy as np\n\nclass SqrtScale(mscale.ScaleBase):\n \"\"\"\n Scales data using the function x^{1/2}.\n \"\"\"\n\n name = 'sqrt'\n\n def __init__(self, axis, **kwargs):\n \"\"\"\n Any keyword arguments passed to ``set_xscale`` and\n ``set_yscale`` will be passed along to the scale's\n constructor.\n\n thresh: The degree above which to crop the data.\n \"\"\"\n\n exp = kwargs.pop('exp', 2.0)\n\n mscale.ScaleBase.__init__(self)\n\n# if thresh >= np.pi / 2.0:\n# raise ValueError(\"thresh must be less than pi/2\")\n self.thresh = 0.0 #thresh\n self.exp = exp\n\n def get_transform(self):\n \"\"\"\n Override this method to return a new instance that does the\n actual transformation of the data.\n \"\"\"\n return self.SqrtTransform(self.thresh,exp=self.exp)\n\n def set_default_locators_and_formatters(self, axis):\n \"\"\"\n Override to set up the locators and formatters to use with the\n scale. This is only required if the scale requires custom\n locators and formatters. Writing custom locators and\n formatters is rather outside the scope of this example, but\n there are many helpful examples in ``ticker.py``.\n \"\"\"\n axis.set_major_locator(AutoLocator())\n axis.set_major_formatter(ScalarFormatter())\n axis.set_minor_formatter(ScalarFormatter())\n return\n\n\n def limit_range_for_scale(self, vmin, vmax, minpos):\n \"\"\"\n Override to limit the bounds of the axis to the domain of the\n transform. In the case of Mercator, the bounds should be\n limited to the threshold that was passed in. Unlike the\n autoscaling provided by the tick locators, this range limiting\n will always be adhered to, whether the axis range is set\n manually, determined automatically or changed through panning\n and zooming.\n \"\"\"\n return max(vmin, self.thresh), max(vmax, self.thresh)\n\n class SqrtTransform(mtransforms.Transform):\n # There are two value members that must be defined.\n # ``input_dims`` and ``output_dims`` specify number of input\n # dimensions and output dimensions to the transformation.\n # These are used by the transformation framework to do some\n # error checking and prevent incompatible transformations from\n # being connected together. When defining transforms for a\n # scale, which are, by definition, separable and have only one\n # dimension, these members should always be set to 1.\n input_dims = 1\n output_dims = 1\n is_separable = True\n has_inverse = True\n\n def __init__(self, thresh, exp):\n mtransforms.Transform.__init__(self)\n self.thresh = thresh\n self.exp = exp\n\n def transform_non_affine(self, a):\n\n masked = np.ma.masked_where(a < self.thresh, a)\n return np.power(masked,1./self.exp)\n\n # if masked.mask.any():\n # return ma.log(np.abs(ma.tan(masked) + 1.0 / ma.cos(masked)))\n # else:\n # return np.log(np.abs(np.tan(a) + 1.0 / np.cos(a)))\n\n def inverted(self):\n return SqrtScale.InvertedSqrtTransform(self.thresh,self.exp)\n\n class InvertedSqrtTransform(mtransforms.Transform):\n input_dims = 1\n output_dims = 1\n is_separable = True\n has_inverse = True\n\n def __init__(self,thresh,exp):\n mtransforms.Transform.__init__(self)\n self.thresh = thresh\n self.exp = exp\n\n def transform_non_affine(self, a):\n return np.power(a,self.exp)\n\n def inverted(self):\n return SqrtScale.SqrtTransform(self.thresh,self.exp)\n\nif __name__ == \"__main__\":\n\n # Now that the Scale class has been defined, it must be registered so\n # that ``matplotlib`` can find it.\n mscale.register_scale(SqrtScale)\n\n import matplotlib.pyplot as plt\n import numpy as np\n x = np.linspace(0,100,100)\n\n\n plt.plot(x, 2*x, '-', lw=2)\n plt.gca().set_xscale('sqrt')\n plt.gca().grid(True)\n\n plt.show()\n"
},
{
"alpha_fraction": 0.6049230694770813,
"alphanum_fraction": 0.6098461747169495,
"avg_line_length": 26.440677642822266,
"blob_id": "dfd1e8876c95c84e247a224ae0e00128ae4e6a67",
"content_id": "6c7189d5465ee874504692bae784c3de79b14b8c",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1625,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 59,
"path": "/scripts/gtltcube.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport re\nimport tempfile\nimport shutil\nfrom gammatools.fermi.task import *\nfrom gammatools.core.util import dispatch_jobs\nimport argparse\n\nusage = \"%(prog)s [options] [ft1file ...]\"\ndescription = \"\"\"Create a LT cube.\"\"\"\nparser = argparse.ArgumentParser(usage=usage, description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--output', default = None, \n help = 'Output file')\n\n#parser.add_argument(\"-l\", \"--logdir\", dest=\"logdir\", default=\".\", \n# help=\"log DIRECTORY (default ./)\")\n\n#parser.add_argument(\"-v\", \"--loglevel\", dest=\"loglevel\", default=\"debug\", \n# help=\"logging level (debug, info, error)\")\n\n#parser.add_argument(\"-q\", \"--quiet\", action=\"store_true\", dest=\"quiet\", \n# help=\"do not log to console\")\n\nparser.add_argument('--queue', default = None,\n help='Set the batch queue.')\n\nLTCubeTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\nif len(args.files) < 1:\n parser.error(\"At least one argument required.\")\n\nif not args.queue is None:\n dispatch_jobs(os.path.abspath(__file__),args.files,args,args.queue)\n sys.exit(0)\n \nfor f in args.files:\n\n f = os.path.abspath(f)\n \n if args.output is None:\n\n# m = re.search('(.+)_ft1(.*)\\.fits?',f)\n# if not m is None:\n# outfile = m.group(1) + '_gtltcube.fits'\n# else:\n outfile = os.path.splitext(f)[0] + '_gtltcube_z%03.f.fits'%(args.zmax)\n else:\n outfile = args.output\n\n gt_task = LTCubeTask(outfile,opts=args,evfile=f)\n\n gt_task.run()\n \n\n"
},
{
"alpha_fraction": 0.513023853302002,
"alphanum_fraction": 0.5455000996589661,
"avg_line_length": 24.960954666137695,
"blob_id": "24f5b152111aadbfdb5eb5ea65b3242f234ad333",
"content_id": "98134913e04b3cdd7ef146aeb926c0777f08014a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11978,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 461,
"path": "/gammatools/core/tests/test_histogram.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.histogram import *\n\n\nclass TestHistogram(unittest.TestCase):\n\n def test_axis_init(self):\n\n edges = np.linspace(0,1,11)\n \n # Initialize from edge array\n\n # Initialize from python dictionary\n\n axis = Axis.createFromDict({'edges' : edges})\n assert_almost_equal(axis.edges,edges)\n\n axis = Axis.createFromDict({'lo' : 0.0, 'hi' : 1.0, 'nbin' : 10})\n assert_almost_equal(axis.edges,edges)\n \n def test_histogram_init(self):\n\n axis = Axis(np.linspace(0,1,6))\n\n # Initialize with constant value\n h = Histogram(axis,counts=1.0,var=2.0)\n assert_almost_equal(h.counts,1.0)\n assert_almost_equal(h.var,2.0)\n \n # Initialize with vector of values\n h = Histogram(axis,counts=axis.center,var=2.0*axis.center)\n assert_almost_equal(h.counts,axis.center)\n assert_almost_equal(h.var,2.0*axis.center)\n\n def test_histogram2d_slice(self):\n\n xaxis = Axis(np.linspace(0,1,6))\n yaxis = Axis(np.linspace(0,2,9))\n\n c = np.outer(np.cos(xaxis.center),np.sin(yaxis.center))\n v = c**2\n\n h = Histogram2D(xaxis,yaxis,counts=c,var=v)\n\n # Slice by Bin Index\n \n hsx = h.slice(0,2)\n\n cx = np.cos(xaxis.center[2])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.slice(1,2)\n\n cy = np.cos(xaxis.center)*np.sin(yaxis.center[2])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n\n hsx = h.slice(0,-2)\n\n cx = np.cos(xaxis.center[-2])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.slice(1,-2)\n\n cy = np.cos(xaxis.center)*np.sin(yaxis.center[-2])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n \n # Slice by bin range\n \n hsx = h.slice(0,[[2,4]])\n\n cx = np.cos(xaxis.center[2:4,np.newaxis])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.slice(1,[[2,4]])\n\n cy = np.cos(xaxis.center[:,np.newaxis])* \\\n np.sin(yaxis.center[np.newaxis,2:4])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n\n hsx = h.slice(0,[[2,None]])\n\n cx = np.cos(xaxis.center[2:,np.newaxis])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.slice(1,[[2,None]])\n\n cy = np.cos(xaxis.center[:,np.newaxis])* \\\n np.sin(yaxis.center[np.newaxis,2:])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n\n hsx = h.slice(0,[[-2,None]])\n\n cx = np.cos(xaxis.center[-2:,np.newaxis])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.slice(1,[[-2,None]])\n\n cy = np.cos(xaxis.center[:,np.newaxis])* \\\n np.sin(yaxis.center[np.newaxis,-2:])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n \n # Slice by Value\n \n hsx = h.sliceByValue(0,0.5)\n\n cx = np.cos(xaxis.center[2])*np.sin(yaxis.center)\n\n assert_almost_equal(hsx.counts,cx)\n assert_almost_equal(hsx.var,cx**2)\n \n hsy = h.sliceByValue(1,0.6)\n\n cy = np.cos(xaxis.center)*np.sin(yaxis.center[2])\n\n assert_almost_equal(hsy.counts,cy)\n assert_almost_equal(hsy.var,cy**2)\n\n def test_histogram2d_marginalize(self):\n\n xaxis = Axis(np.linspace(0,1,6))\n yaxis = Axis(np.linspace(0,2,8))\n\n c = np.outer(np.cos(xaxis.center),np.sin(yaxis.center))\n v = c**2\n\n h = Histogram2D(xaxis,yaxis,counts=c,var=v)\n\n hmx = h.marginalize(0)\n\n assert_almost_equal(hmx.counts,np.sum(c,axis=0))\n assert_almost_equal(hmx.var,np.sum(v,axis=0))\n\n hmy = h.marginalize(1)\n\n assert_almost_equal(hmy.counts,np.sum(c,axis=1))\n assert_almost_equal(hmy.var,np.sum(v,axis=1))\n \n h = Histogram2D(xaxis,yaxis,counts=c,var=v)\n\n hmx = super(Histogram2D,h).marginalize(0,bin_range=[1,3])\n\n assert_almost_equal(hmx.counts,np.sum(c[1:3],axis=0))\n assert_almost_equal(hmx.var,np.sum(v[1:3],axis=0))\n\n hmy = super(Histogram2D,h).marginalize(1,bin_range=[1,3])\n\n assert_almost_equal(hmy.counts,np.sum(c[:,1:3],axis=1))\n assert_almost_equal(hmy.var,np.sum(v[:,1:3],axis=1))\n\n def test_histogram2d_project(self):\n\n xaxis = Axis(np.linspace(0,1,6))\n yaxis = Axis(np.linspace(0,2,8))\n\n c = np.outer(np.cos(xaxis.center),np.sin(yaxis.center))\n v = c**2\n\n h = Histogram2D(xaxis,yaxis,counts=c,var=v)\n\n hmx = h.project(0)\n\n assert_almost_equal(hmx.counts,np.sum(c,axis=1))\n assert_almost_equal(hmx.var,np.sum(v,axis=1))\n\n hmy = h.project(1)\n\n assert_almost_equal(hmy.counts,np.sum(c,axis=0))\n assert_almost_equal(hmy.var,np.sum(v,axis=0))\n\n def test_histogram_fill(self):\n\n h = Histogram(np.linspace(0,1,6))\n\n # Test filling from scalar, list, and array input\n\n xs = 0.1\n xv = h.axis().center\n xl = xv.tolist()\n unitw = np.ones(h.axis().nbins)\n\n # Scalar w/ unit weight\n for x in xv: h.fill(x)\n assert_almost_equal(h.counts,unitw)\n assert_almost_equal(h.var,unitw)\n h.clear() \n\n # List w/ unit weight\n h.fill(xl) \n assert_almost_equal(h.counts,unitw)\n assert_almost_equal(h.var,unitw)\n h.clear()\n\n # Array w/ unit weight\n h.fill(xv) \n assert_almost_equal(h.counts,unitw)\n assert_almost_equal(h.var,unitw)\n h.clear()\n\n # Scalar w/ scalar weight\n wv = np.cos(xv)\n wl = np.cos(xv).tolist()\n for x, w in zip(xv,wv): h.fill(x,w)\n\n assert_almost_equal(h.counts,wv)\n assert_almost_equal(h.var,wv)\n h.clear() \n\n # List w/ list weight\n\n h.fill(xv,wl)\n assert_almost_equal(h.counts,wv)\n assert_almost_equal(h.var,wv)\n h.clear() \n\n # Scalar w/ scalar weight and variance\n wv = np.cos(xv)\n wl = np.cos(xv).tolist()\n vv = wv*np.abs(np.sin(xv))\n\n for x, w,v in zip(xv,wv,vv): h.fill(x,w,v)\n\n assert_almost_equal(h.counts,wv)\n assert_almost_equal(h.var,vv)\n h.clear() \n\n # Test Overflow and Underflow\n\n xv_shift = np.concatenate((xv,xv+0.5,xv-0.5))\n h.fill(xv_shift) \n assert (h.overflow()==np.sum(xv_shift>=1.0))\n assert (h.underflow()==np.sum(xv_shift<0.0))\n\n def test_histogram_rebin(self):\n\n h = Histogram(np.linspace(0,1,6))\n w = [1,2,3,4,5]\n v = [5,4,3,2,1]\n b = h.axis().bins()\n\n h.fill(h.axis().binToVal(b),w,v)\n h = h.rebin(2)\n\n assert_almost_equal(h.counts,[3,7,5])\n assert_almost_equal(h.var,[9,5,1])\n\n h = Histogram(np.linspace(0,1,7))\n w = [1,2,3,4,5,1]\n v = [5,4,3,2,1,1]\n b = h.axis().bins()\n\n h.fill(h.axis().binToVal(b),w,v)\n h = h.rebin_mincount(4)\n\n assert_almost_equal(h.counts,[6,4,5,1])\n assert_almost_equal(h.var,[12,2,1,1])\n\n def test_histogram2d_fill(self):\n\n h = Histogram2D(np.linspace(0,1,6),np.linspace(0,1,6))\n\n unitw = np.ones((h.xaxis().nbins,h.yaxis().nbins))\n\n xv, yv = np.meshgrid(h.xaxis().center, \n h.yaxis().center,indexing='ij')\n xv = np.ravel(xv)\n yv = np.ravel(yv)\n\n # Scalar w/ unit weight\n for x, y in zip(xv,yv): h.fill(x,y)\n\n assert_almost_equal(h.counts,unitw)\n assert_almost_equal(h.var,unitw)\n h.clear()\n\n # Vector w/ unit weight\n h.fill(xv,yv)\n assert_almost_equal(h.counts,unitw)\n assert_almost_equal(h.var,unitw)\n h.clear()\n\n # Scalar w/ scalar weight\n wv = np.cos(xv)*np.sin(yv+0.5*np.pi)\n wl = wv.tolist()\n vv = wv*np.abs(np.sin(xv))\n\n for x, y, w in zip(xv,yv,wv): h.fill(x,y,w)\n assert_almost_equal(h.counts,wv.reshape(5,5))\n assert_almost_equal(h.var,wv.reshape(5,5))\n h.clear()\n\n # Vector w/ vector weight\n h.fill(xv,yv,wv)\n assert_almost_equal(h.counts,wv.reshape(5,5))\n assert_almost_equal(h.var,wv.reshape(5,5))\n h.clear()\n \n # Vector w/ vector weight\n h.fill(xv,yv,wv,vv)\n assert_almost_equal(h.counts,wv.reshape(5,5))\n assert_almost_equal(h.var,vv.reshape(5,5))\n h.clear()\n\n def test_histogram2d_operators(self):\n\n xaxis = Axis(np.linspace(0,1,11))\n yaxis = Axis(np.linspace(0,2,21))\n \n # Addition\n h0 = Histogram2D(xaxis,yaxis)\n h1 = Histogram2D(xaxis,yaxis)\n\n xv, yv = np.meshgrid(h0.xaxis().center, \n h0.yaxis().center,indexing='ij')\n xv = np.ravel(xv)\n yv = np.ravel(yv)\n\n w0 = 1.0+np.cos(xv)**2\n w1 = 1.0+np.sin(yv)**2\n\n h0.fill(xv,yv,w0,np.ones(xaxis.nbins*yaxis.nbins))\n h1.fill(xv,yv,w1,np.ones(xaxis.nbins*yaxis.nbins))\n\n h2 = h0 + h1 + 1.0\n\n assert_almost_equal(np.ravel(h2.counts),w0+w1+1.0)\n assert_almost_equal(h2.var,2.0)\n\n h2.clear()\n\n def test_histogram_operators(self):\n\n axis = Axis(np.linspace(0,1,11))\n xc = axis.center\n\n # Addition\n h0 = Histogram(axis)\n h1 = Histogram(axis)\n\n\n h0.fill(xc,1.0+np.cos(xc)**2,np.ones(axis.nbins))\n h1.fill(xc,1.0+np.sin(xc)**2,np.ones(axis.nbins))\n\n h2 = h0 + h1 + 1.0\n\n assert_almost_equal(h2.counts,4.0)\n assert_almost_equal(h2.var,2.0)\n\n h2.clear()\n\n # Subtraction by Histogram\n\n h2.fill(xc,3.0)\n h2 -= h0\n\n assert_almost_equal(h2.counts,h1.counts)\n assert_almost_equal(h2.var,h2.var)\n\n # Multiplication by Histogram\n\n h2.clear()\n\n h2 += h1\n h2 *= h0\n\n assert_almost_equal(h2.counts,h1.counts*h0.counts)\n\n # Division by Histogram\n\n h2.clear()\n\n h2 += h1\n h2 /= h0\n\n assert_almost_equal(h2.counts,h1.counts/h0.counts)\n\n # Division by Scalar Float\n\n h2.clear()\n h2 += h1\n h2 /= 2.0\n\n assert_almost_equal(h2.counts,h1.counts/2.)\n assert_almost_equal(h2.var,h1.var/4.)\n\n # Division by Vector Float\n\n h2.clear()\n h2 += h1\n h2 /= xc\n\n assert_almost_equal(h2.counts,h1.counts/xc)\n assert_almost_equal(h2.var,h1.var/xc**2)\n\n def test_histogram_quantile(self):\n\n\n h = Histogram(np.linspace(-4,4,1000))\n\n x = h.axis().center\n \n s2 = 0.1**2\n mu = 0.1\n \n h.fill(x,1./np.sqrt(2*np.pi*s2)*np.exp(-(x-mu)**2/(2.*s2)))\n\n q, qerr = h.quantile(fraction=0.5)\n\n assert_almost_equal(q,mu,3)\n\n def test_histogram_quantile_central(self):\n\n\n h = Histogram(np.linspace(-3,3,2000))\n\n x = h.axis().center\n\n sigma = 0.15\n s2 = sigma**2\n mu = x[800]\n\n fn = lambda t: 1./np.sqrt(2*np.pi*s2)*np.exp(-(t-mu)**2/(2.*s2))\n h.fill(x,fn(x))\n\n from gammatools.core.stats import gauss_sigma_to_pval\n\n f0 = gauss_sigma_to_pval(1.0)\n f1 = gauss_sigma_to_pval(2.0)\n \n q, qerr = h.central_quantile(fraction=f0)\n\n# print '%.5f %.5f'%(q, qerr)\n\n assert_almost_equal(q,sigma,3)\n \n q, qerr = h.central_quantile(fraction=f1)\n\n assert_almost_equal(q,2.0*sigma,3)\n \n# print '%.5f %.5f'%(q, qerr)\n\n \n"
},
{
"alpha_fraction": 0.5447704195976257,
"alphanum_fraction": 0.5844481587409973,
"avg_line_length": 28.431766510009766,
"blob_id": "18ca1e906dbd9b95c5d90c5b102bf887c4c662b8",
"content_id": "e63b6c6359e3d21e5a4500e7982dd795b8911b7a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13156,
"license_type": "permissive",
"max_line_length": 180,
"num_lines": 447,
"path": "/scripts/plot_irfs.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\nimport os\n\n#os.environ['CUSTOM_IRF_DIR']='/u/gl/mdwood/ki10/analysis/custom_irfs/'\n#os.environ['CUSTOM_IRF_NAMES']='P6_v11_diff,P7CLEAN_V4,P7CLEAN_V4MIX,P7CLEAN_V4PSF,P7SOURCE_V4,P7SOURCE_V4MIX,P7SOURCE_V4PSF,P7ULTRACLEAN_V4,P7ULTRACLEAN_V4MIX,P7ULTRACLEAN_V4PSF'\n\nimport sys\nimport re\nimport bisect\nimport pyfits\nimport healpy\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom gammatools.core.histogram import *\nfrom gammatools.core.plot_util import *\n\nimport gammatools.fermi.psf_model \nimport argparse\n\nfrom gammatools.fermi.irf_util import *\n \nusage = \"usage: %(prog)s [options]\"\ndescription = \"\"\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--prefix', default = 'prefix_', \n help = 'Set the output file prefix.')\n\nparser.add_argument('--load_from_file', default = False, \n action='store_true',\n help = 'Load IRFs from FITS.')\n\nparser.add_argument('--show', default = False, \n action='store_true',\n help = 'Show plots interactively.')\n\nIRFManager.add_arguments(parser)\n\nargs = parser.parse_args()\n\n\nft = FigTool(marker=['None'],hist_style='line')\n\n\n\n\nlabels = args.files\n\nenergy_label = 'Energy [log$_{10}$(E/MeV)]'\ncosth_label = 'Cos $\\\\theta$'\nacceptance_label = 'Acceptance [m$^2$ sr]'\neffarea_label = 'Effective Area [m$^2$]'\n\npsb_label = '68% PSF Containment [deg]'\npsf68_label = '68% PSF Containment [deg]'\npsf68_ratio_label = '68% PSF Containment Ratio'\npsf95_label = '95% PSF Containment [deg]'\npsf95_ratio_label = '95% PSF Containment Ratio'\n\nirf_models = []\nfor arg in args.files:\n\n m = IRFManager.create(arg,args.load_from_file,args.irf_dir)\n m.dump()\n irf_models.append(m)\n\n \nfor i, irfm in enumerate(irf_models):\n continue\n \n for j, irf in enumerate(irfm._irfs):\n\n irf0 = irf_models[0]._irfs[j]\n \n fig = ft.create('psf_table_%02i'%(i),nax=(3,2),figscale=1.4)\n fig[0].set_title('score')\n fig[0].add_hist(irf._psf._score_hist)\n fig[1].set_title('stail')\n fig[1].add_hist(irf._psf._stail_hist)\n fig[2].set_title('gcore')\n fig[2].add_hist(irf._psf._gcore_hist)\n fig[3].set_title('gtail')\n fig[3].add_hist(irf._psf._gtail_hist)\n fig[4].set_title('fcore')\n fig[4].add_hist(irf._psf._fcore_hist)\n fig.plot()\n\n if i == 0: continue\n \n fig = ft.create('psf_table_ratio_%02i'%(i),nax=(3,2),figscale=1.4)\n fig[0].set_title('score')\n fig[0].add_hist(irf._psf._score_hist/irf0._psf._score_hist)\n fig[1].set_title('stail')\n fig[1].add_hist(irf._psf._stail_hist/irf0._psf._stail_hist)\n fig[2].set_title('gcore')\n fig[2].add_hist(irf._psf._gcore_hist/irf0._psf._gcore_hist)\n fig[3].set_title('gtail')\n fig[3].add_hist(irf._psf._gtail_hist/irf0._psf._gtail_hist)\n fig[4].set_title('fcore')\n fig[4].add_hist(irf._psf._fcore_hist/irf0._psf._fcore_hist)\n fig.plot()\n \n \n\n#x = np.linspace(2.0,3.0,100)\n#y = 0.5*np.ones(100) \n\n#print irf_models[0].psf_quantile(x,y)\n#print irf_models[0]._psf[0].quantile(2.0,0.5)\n\n#sys.exit(0)\n \nacc_hists = []\neffarea_hists = []\npsf68_hists = []\npsf95_hists = []\npsfb_mean_hists = []\npsfb_median_hists = []\npsfb_peak_hists = []\n\n#fig, axes = plt.subplots(2,len(irf_models))\n\n#acc_fig = ft.create('acc')\n#psf_fig = ft.create('psf')\n\nloge_axis = Axis.create(1.00,6.50,44,label=energy_label)\ncth_axis = Axis.create(0.2,1.0,32,label=costh_label)\n\nfor k, irf in enumerate(irf_models):\n hpsf68 = Histogram2D(loge_axis,cth_axis)\n hpsf95 = Histogram2D(loge_axis,cth_axis)\n hpsfb = Histogram2D(loge_axis,cth_axis)\n hacc = Histogram2D(loge_axis,cth_axis)\n heffarea = Histogram2D(loge_axis,cth_axis) \n heffarea._counts = irf.aeff(*heffarea.center()).reshape(heffarea.shape())\n hpsf68._counts = irf.psf_quantile(*hpsf68.center()).reshape(hpsf68.shape())\n hpsf95._counts = irf.psf_quantile(*hpsf95.center(),\n frac=0.95).reshape(hpsf95.shape())\n hpsfb_mean = \\\n HistogramND.createFromFn([loge_axis,cth_axis],\n lambda x, y: irf.fisheye(x,y,ctype='mean'))\n hpsfb_median = \\\n HistogramND.createFromFn([loge_axis,cth_axis],\n lambda x, y: irf.fisheye(x,y,ctype='median'))\n hpsfb_peak = \\\n HistogramND.createFromFn([loge_axis,cth_axis],\n lambda x, y: irf.fisheye(x,y,ctype='peak'))\n\n hpsfb_mean = hpsfb_mean.abs()\n hpsfb_median = hpsfb_median.abs()\n hpsfb_peak = hpsfb_peak.abs()\n \n hacc = heffarea*2.*np.pi*hacc.yaxis().width[np.newaxis,:]\n acc_hists.append(hacc)\n psf68_hists.append(hpsf68)\n psf95_hists.append(hpsf95)\n psfb_mean_hists.append(hpsfb_mean)\n psfb_median_hists.append(hpsfb_median)\n psfb_peak_hists.append(hpsfb_peak)\n effarea_hists.append(heffarea)\n \n fig = ft.create('%s_effarea'%(labels[k]),\n title=labels[k],zlabel=effarea_label,\n xlabel=energy_label,costh_label=costh_label)\n\n fig[0].add_hist(heffarea)\n \n fig.plot()\n\n fig = ft.create('%s_psf68'%(labels[k]),\n title=labels[k],zlabel=psf68_label,\n xlabel=energy_label,costh_label=costh_label,\n logz=True)\n\n fig[0].add_hist(hpsf68)\n \n fig.plot()\n\n fig = ft.create('%s_psf95'%(labels[k]),\n title=labels[k],zlabel=psf95_label,\n xlabel=energy_label,costh_label=costh_label,\n logz=True)\n\n fig[0].add_hist(hpsf95)\n \n fig.plot()\n\n continue\n \n\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(labels[k])\n h = effarea_hists[k]/effarea_hists[0]\n im = h.plot(ax=ax)\n cb = plt.colorbar(im) \n cb.set_label('Effective Area Ratio')\n \n ax.grid(True)\n ax.set_xlabel(energy_label)\n ax.set_ylabel(costh_label)\n \n fig.savefig(opts.prefix + '%s_effarea_ratio.png'%(labels[k]))\n\n \n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(labels[k])\n im = hacc.plot(ax=ax) \n cb = plt.colorbar(im)\n cb.set_label('Acceptance [m$^2$ sr]')\n\n ax.grid(True)\n ax.set_xlabel(energy_label)\n ax.set_ylabel(costh_label)\n \n fig.savefig(opts.prefix + '%s_acceptance.png'%(labels[k]))\n\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(labels[k])\n h = acc_hists[k]/acc_hists[0]\n im = h.plot(ax=ax)\n cb = plt.colorbar(im) \n cb.set_label('Acceptance Ratio')\n \n ax.grid(True)\n ax.set_xlabel(energy_label)\n ax.set_ylabel(costh_label)\n \n fig.savefig(opts.prefix + '%s_acceptance_ratio.png'%(labels[k]))\n \n\n \n fig = plt.figure()\n\n ax = fig.add_subplot(111)\n# ax = psf_fig.add_subplot(2,len(irf_models),k+1+len(irf_models))\n ax.set_title(labels[k])\n h = psf_hists[k]/psf_hists[0]\n im = h.plot(ax=ax)\n plt.colorbar(im)\n \n ax.grid(True)\n ax.set_xlabel(energy_label)\n ax.set_ylabel(costh_label)\n \n fig.savefig(opts.prefix + '%s_psf68_ratio.png'%(labels[k]))\n \n \nfig = ft.create('acc',legend_loc='lower right',figstyle='ratio2',\n xlabel=energy_label,ylabel=acceptance_label,\n hist_xerr=False)\n\nfor i in range(len(acc_hists)):\n hm = acc_hists[i].marginalize(1)\n fig[0].add_hist(hm,label=labels[i],marker='o')\n \n#plt.gca().legend(prop={'size':8},loc='lower right')\n\nfig.plot()\n \ndef make_projection_plots(hists,cut_label,cut_dim,cuts,figname,**kwargs):\n fig = ft.create(figname,nax=4,**kwargs)\n for i in range(len(hists)):\n\n for j in range(len(cuts)):\n# axes.flat[j].set_title('%s = %.2f'%(cut_label,cuts[j]))\n fig[j].set_title('%s = %.2f'%(cut_label,cuts[j]))\n hm = hists[i].sliceByValue(cut_dim,cuts[j])\n fig[j].add_hist(hm,label=labels[i],linestyle='-',\n marker='o')\n\n fig.plot()\n \n# for j, ax in enumerate(axes.flat):\n# ax.set_xlim(hm0[j]._xedges[0],hm0[j]._xedges[-1])\n# ax.legend(prop={'size':8}) \n# if logy: ax.set_yscale('log')\n# fig.savefig(figname,bbox_inches='tight')\n\ncommon_kwargs = { 'hist_xerr': False, 'figscale' : 1.4 }\n\nmake_projection_plots(psfb_mean_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'psfb_mean_egy',\n xlabel=energy_label,\n ylabel='Mean Fisheye Correction [deg]',\n ylim=[1E-3,1E2],\n yscale='log',legend_loc='upper right',**common_kwargs)\n\nmake_projection_plots(psfb_median_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'psfb_median_egy',\n xlabel=energy_label,\n ylabel='Median Fisheye Correction [deg]',\n ylim=[1E-3,1E2],\n yscale='log',legend_loc='upper right',**common_kwargs)\n\nmake_projection_plots(psfb_peak_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'psfb_peak_egy',\n xlabel=energy_label,\n ylabel='Peak Fisheye Correction [deg]',\n ylim=[1E-3,1E2],\n yscale='log',legend_loc='upper right',**common_kwargs)\n\nplt.show()\n\nmake_projection_plots(psf68_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'psf68_egy',\n xlabel=energy_label,ylabel=psf68_label,\n yscale='log',legend_loc='upper right',**common_kwargs)\n\nmake_projection_plots(psf68_hists,'log$_{10}$(E/MeV)',0,[2.0,3.0,4.0,5.0],\n 'psf68_costh',xlabel=costh_label,ylabel=psf68_label,\n legend_loc='upper right',**common_kwargs)\n\nmake_projection_plots(psf95_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'psf95_egy',\n xlabel=energy_label,ylabel=psf95_label,\n yscale='log',legend_loc='upper right',**common_kwargs)\n\nmake_projection_plots(psf95_hists,'log$_{10}$(E/MeV)',0,[2.0,3.0,4.0,5.0],\n 'psf95_costh',xlabel=costh_label,ylabel=psf95_label,\n legend_loc='upper right',**common_kwargs)\n\n#make_projection_plots(psf_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n# 'psf68_ratio_egy',xlabel=energy_label,ylabel=psf_ratio_label)\n#make_projection_plots(psf_hists,'log$_{10}$(E/MeV)',0,[2.0,3.0,4.0,5.0],\n# costh_label,psf_ratio_label,'psf68_ratio_costh')\n\n\nmake_projection_plots(effarea_hists,'Cos $\\\\theta$',1,[1.0,0.8,0.6,0.4],\n 'effarea_egy',xlabel=energy_label,ylabel=effarea_label,\n **common_kwargs)\n\nmake_projection_plots(effarea_hists,'log$_{10}$(E/MeV)',0,[2.0,3.0,4.0,5.0],\n 'effarea_costh',xlabel=costh_label,ylabel=effarea_label,\n **common_kwargs)\n\n\nif args.show: plt.show()\n \nsys.exit(0)\n#irf = IRFManager(args[0],args[1])\n\nh0 = Histogram2D([1.5,5.5],40,[0.4,1.0],24)\nh1 = Histogram2D([1.5,5.5],40,[0.4,1.0],24)\nh2 = Histogram2D([1.5,5.5],40,[0.4,1.0],24)\n\nfor ix, x in enumerate(h0._x):\n for iy, y in enumerate(h0._y):\n h0._counts[ix,iy] = irf._psf.quantile(x,y)\n\nirf._psf._interpolate_density = False\n \nfor ix, x in enumerate(h0._x):\n for iy, y in enumerate(h0._y):\n h1._counts[ix,iy] = irf._psf.quantile(x,y)\n\n\nh2._counts = (h0._counts - h1._counts)/h1._counts\n \nplt.figure()\nh0.plot()\nplt.figure()\nh1.plot()\nplt.figure()\nh2.plot(vmin=-0.1,vmax=0.1)\nplt.colorbar()\n\nplt.figure()\n\nx = np.linspace(1.5,5.5,100)\ny0 = []\ny1 = []\n\n\n\nirf._psf._interpolate_density = True\nfor t in x: y0.append(irf._psf.quantile(t,0.6,0.68))\nirf._psf._interpolate_density = False\nfor t in x: y1.append(irf._psf.quantile(t,0.6,0.68))\n\ny0 = np.array(y0)\ny1 = np.array(y1)\n\n\nplt.plot(x,(y0-y1)/y1)\n\nplt.plot()\n\nplt.show()\n#pyirf = IRFManager.createFromIRF('P7SOURCE_V6MC::FRONT')\n\n\nprint irf._psf.quantile(2.0,0.5)\n\n\n\nprint irf._psf.quantile(2.0,0.5)\n\nsys.exit(1)\n\ndtheta = np.linspace(0,3,100)\n\nplt.figure()\n\nloge = 1.75 \ncth = irf._psf._center[0][4]\n\nplt.plot(dtheta,irf.psf(dtheta,loge,cth),color='b')\nplt.plot(dtheta,irf.psf(dtheta,loge+0.125,cth),color='g')\nplt.plot(dtheta,irf.psf(dtheta,loge+0.25,cth),color='r')\n\nplt.plot(dtheta,np.power(np.pi/180.,2)*pyirf.psf(dtheta,loge,cth),\n linestyle='--',color='b')\nplt.plot(dtheta,np.power(np.pi/180.,2)*pyirf.psf(dtheta,loge+0.125,cth),\n linestyle='--',color='g')\nplt.plot(dtheta,np.power(np.pi/180.,2)*pyirf.psf(dtheta,loge+0.25,cth),\n linestyle='--',color='r')\n\n\n#plt.gca().set_yscale('log')\nplt.gca().set_xscale('log')\nplt.gca().grid(True)\n\nplt.show()\n\nh0 = Histogram([0,4.0],200)\nh1 = Histogram([0,4.0],200)\n\nh0._counts = irf.psf(h0._x,loge,cth)*h0._x*2*np.pi*h0._width\nh1._counts = np.power(np.pi/180.,2)*pyirf.psf(h1._x,loge,cth)*h1._x*2*np.pi*h1._width\n\nplt.figure()\n\nh0.cumulative()\nh1.cumulative()\n\nh0.plot()\nh1.plot()\n\nplt.gca().grid(True)\n\nplt.show()\n"
},
{
"alpha_fraction": 0.4727424681186676,
"alphanum_fraction": 0.49548494815826416,
"avg_line_length": 25.113536834716797,
"blob_id": "93aeb5ec1a0bc017a32fab11e27a8aea8b8be68d",
"content_id": "5f8841e28bba824c912bbaa019a9e08eb8f5c04b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5980,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 229,
"path": "/gammatools/fermi/exposure.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom gammatools.core.histogram import *\nfrom irf_util import IRFManager\nfrom catalog import Catalog\nfrom gammatools.core.util import eq2gal, gal2eq\nimport healpy\n\ndef get_src_mask(src,ra,dec,radius=5.0):\n dist = np.sqrt( ((src[0]-ra)*np.cos(src[1]))**2 + (src[1]-dec)**2)\n msk = dist > np.radians(radius)\n return msk\n\nclass LTCube(object):\n\n def __init__(self,ltfile):\n\n self._ltmap = None\n\n if isinstance(ltfile,list):\n for f in ltfile: self.load_ltfile(f)\n elif not re.search('\\.txt?',ltfile) is None:\n files=np.loadtxt(ltfile,unpack=True,dtype='str')\n for f in files: self.load_ltfile(f)\n else:\n self.load_ltfile(ltfile)\n \n\n def load_ltfile(self,ltfile):\n\n print 'Loading ', ltfile\n \n import healpy\n import pyfits\n \n hdulist = pyfits.open(ltfile)\n \n if self._ltmap is None:\n self._ltmap = hdulist[1].data.field(0)\n self._tstart = hdulist[0].header['TSTART']\n self._tstop = hdulist[0].header['TSTOP']\n else:\n self._ltmap += hdulist[1].data.field(0)\n self._tstart = min(self._tstart,hdulist[0].header['TSTART'])\n self._tstop = max(self._tstop,hdulist[0].header['TSTOP'])\n\n self._cth_edges = np.array(hdulist[3].data.field(0))\n self._cth_edges = np.concatenate(([1],self._cth_edges))\n self._cth_edges = self._cth_edges[::-1]\n self._cth_axis = Axis(self._cth_edges)\n\n self._domega = (self._cth_edges[1:]-self._cth_edges[:-1])*2*np.pi\n \n def get_src_lthist(self,ra,dec):\n \n lthist = Histogram(self._cth_axis)\n ipix = healpy.ang2pix(64,np.pi/2. - np.radians(dec),\n np.radians(ra),nest=True)\n\n lt = self._ltmap[ipix,::-1]\n\n lthist._counts = lt\n\n return lthist\n\n def get_allsky_lthist(self,slat_axis,lon_axis,coordsys='gal'):\n\n h = HistogramND([lon_axis,slat_axis,self._cth_axis])\n\n if coordsys=='gal':\n \n lon, slat = np.meshgrid(h.axis(0).center(),\n h.axis(1).center(),\n indexing='ij')\n \n\n ra, dec = gal2eq(np.degrees(lon),\n np.degrees(np.arcsin(slat)))\n \n ra = np.radians(ra)\n dec = np.radians(dec)\n\n else:\n ra, dec = np.meshgrid(h.axis(0).center(),\n np.arcsin(h.axis(1).center()),\n indexing='ij')\n\n \n ipix = healpy.ang2pix(64,np.ravel(np.pi/2. - dec),\n np.ravel(ra),nest=True)\n\n lt = self._ltmap[ipix,::-1]\n\n print lt.shape\n print h.axes()[0].nbins(), h.axes()[1].nbins(), h.axes()[2].nbins()\n \n lt = lt.reshape((h.axes()[0].nbins(),\n h.axes()[1].nbins(),\n h.axes()[2].nbins()))\n\n h._counts = lt\n\n return h\n \n \n \n def get_hlat_ltcube(self):\n\n \n import healpy\n \n \n\n nbin = 400\n\n ra_edge = np.linspace(0,2*np.pi,nbin+1)\n dec_edge = np.linspace(-1,1,nbin+1)\n\n ra_center = 0.5*(ra_edge[1:] + ra_edge[:-1])\n dec_center = 0.5*(dec_edge[1:] + dec_edge[:-1])\n \n dec, ra = np.meshgrid(np.arcsin(dec_center),ra_center)\n\n lthist = pHist([ra_edge,dec_edge,self._cth_edges])\n \n srcs = np.loadtxt('src.txt',unpack=False)\n ipix = healpy.ang2pix(64,np.ravel(np.pi/2. - dec),\n np.ravel(ra),nest=True)\n\n lt = self._ltmap[ipix,::-1]\n \n (l, b) = eq2gal(np.degrees(ra),np.degrees(dec))\n\n gal_msk = (np.abs(b) > 40.) & (np.abs(b) < 80.)\n eq_msk = (np.abs(np.degrees(dec)) < 79.9)\n\n msk = gal_msk & eq_msk\n for i in range(len(srcs)):\n msk &= get_src_mask(np.radians(srcs[i]),ra,dec,5.0)\n\n lt = lt.reshape((nbin,nbin,40))\n lt[msk==False,:] = 0\n \n \n lthist._counts = lt\n \n self._omega_tot = float(len(msk[msk==True]))/(nbin**2)*4*np.pi\n self._domega_bin = 4*np.pi/(nbin**2)\n \n h0 = lthist.slice([2],[0])\n h1 = lthist.slice([2],[20])\n h2 = lthist.slice([2],[30])\n \n \n plt.figure()\n h0.plot()\n plt.figure()\n h1.plot()\n plt.figure()\n h2.plot()\n \n plt.show()\n\n\n\nclass ExposureCalc(object):\n\n def __init__(self,irfm,ltc):\n self._irfm = irfm\n self._ltc = ltc\n\n def getExpByName(self,src_names,egy_edges):\n\n exp = None\n\n cat = Catalog()\n for s in src_names:\n src = cat.get_source_by_name(s) \n \n if exp is None:\n exp = self.eval(src['RAJ2000'], src['DEJ2000'],egy_edges)\n else:\n exp += self.eval(src['RAJ2000'], src['DEJ2000'],egy_edges)\n\n return exp\n\n def eval(self,ra,dec,egy_edges):\n\n cth = self._ltc._cth_center\n egy = 0.5*(egy_edges[1:] + egy_edges[:-1])\n\n x, y = np.meshgrid(egy,cth)\n\n aeff = self._irfm.aeff(x.T.flat,y.T.flat)\n\n aeff = aeff.reshape((len(egy),len(cth)))\n lthist = self._ltc.get_src_lthist(ra,dec)\n\n exp = np.sum(aeff*lthist._counts,axis=1)\n\n return exp\n \n\n\n @staticmethod\n def create(irf,ltfile,irf_dir=None):\n irfm = IRFManager.create(irf,True,irf_dir)\n ltc = LTCube(ltfile)\n return ExposureCalc(irfm,ltc)\n\n\nif __name__ == '__main__':\n\n import sys\n import matplotlib.pyplot as plt\n\n ltc = LTCube(sys.argv[1])\n\n h = ltc.get_src_lthist(0,0)\n \n h.plot()\n\n egy_edges = np.linspace(1.0,5.0,4.0/0.25)\n\n\n expcalc = ExposureCalc.create('P7SOURCE_V6MC',sys.argv[1])\n\n expcalc.eval(0,0,egy_edges)\n\n plt.show()\n"
},
{
"alpha_fraction": 0.6859375238418579,
"alphanum_fraction": 0.698437511920929,
"avg_line_length": 23.615385055541992,
"blob_id": "60af7d88310a7d7d3d37245022695fd96c16e154",
"content_id": "b7fd4503797917e68776a8fe1752340e68f8dd0b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 640,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 26,
"path": "/gammatools/core/astropy_helper.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "try:\n import astropy\nexcept ImportError:\n has_astropy = False\nelse:\n has_astropy = True\n\nif has_astropy:\n from astropy.io import fits as pyfits\n import astropy.wcs as pywcs\n import warnings\n from astropy.utils.exceptions import AstropyUserWarning\n warnings.filterwarnings('ignore', category=AstropyUserWarning)\n \nelse:\n import pyfits\n import pywcs\n\n def pix2world(self,*args,**kwargs):\n return self.wcs_pix2sky(*args,**kwargs)\n\n def world2pix(self,*args,**kwargs):\n return self.wcs_sky2pix(*args,**kwargs)\n\n pywcs.WCS.wcs_pix2world = pix2world\n pywcs.WCS.wcs_world2pix = world2pix\n"
},
{
"alpha_fraction": 0.5135435461997986,
"alphanum_fraction": 0.5239787101745605,
"avg_line_length": 22.642105102539062,
"blob_id": "9d66b75edcbef093d2606d0b219a677567c06023",
"content_id": "798b1411f27f0c8e9e0262cd72569e785e279130",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4504,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 190,
"path": "/gammatools/core/likelihood.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@file likelihood.py\n\n@brief Python classes related to calculation of likelihoods.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n__source__ = \"$Source: /nfs/slac/g/glast/ground/cvs/users/mdwood/python/likelihood.py,v $\"\n__author__ = \"Matthew Wood <[email protected]>\"\n__date__ = \"$Date: 2013/08/15 20:48:09 $\"\n__revision__ = \"$Revision: 1.8 $, $Author: mdwood $\"\n\nimport numpy as np\nimport copy\nimport re\nfrom scipy.interpolate import UnivariateSpline\nfrom histogram import Histogram\nfrom util import expand_aliases, get_parameters\nfrom minuit import Minuit\nfrom parameter_set import Parameter, ParameterSet\nimport matplotlib.pyplot as plt\nfrom model_fn import ParamFnBase, PDF\n\nclass CompProdModel(PDF):\n\n def __init__(self):\n PDF.__init__(self)\n self._models = []\n\n def addModel(self,m):\n self._models.append(m)\n self._param.addSet(m.param())\n\n def eval(self,x,p=None):\n s = None\n for i, m in enumerate(self._models): \n v = m.eval(x,p)\n if i == 0: s = v\n else: s *= v\n return s\n \n def integrate(self,xlo,xhi,p=None):\n s = None\n for i, m in enumerate(self._models):\n v = m.integrate(xlo,xhi,p)\n if i == 0: s = v\n else: s *= v\n return s\n\nclass CompositeParameter(ParamFnBase):\n\n def __init__(self,expr,pset):\n ParamFnBase.__init__(self,pset)\n\n par_names = get_parameters(expr)\n for p in par_names: \n self.addParameter(pset.getParByName(p))\n\n aliases = {}\n for k, p in self._param._pars.iteritems():\n aliases[p.name()] = 'pset[%i]'%(p.pid())\n expr = expand_aliases(aliases,expr)\n self._expr = expr\n\n def eval(self,x,p=None):\n pset = self.param(True)\n pset.update(p)\n return eval(self._expr)\n\nclass JointLnL(ParamFnBase):\n\n def __init__(self,lnlfn=None):\n ParamFnBase.__init__(self)\n self._lnlfn = []\n if not lnlfn is None: \n for m in lnlfn: self.add(m)\n \n def add(self,lnl):\n self._lnlfn.append(lnl)\n self._param.addSet(lnl.param())\n\n def eval(self,p=None):\n\n pset = self.param(True)\n pset.update(p)\n\n s = None\n for i, m in enumerate(self._lnlfn):\n if i == 0: s = m.eval(pset)\n else: s += m.eval(pset)\n\n return s\n\n\n\ndef chi2(y,var,fy,fvar=None):\n tvar = var \n if not fvar is None: tvar += fvar\n ivar = np.zeros(shape=var.shape)\n ivar[var>0] = 1./tvar[tvar>0]\n \n delta2 = (y-fy)**2\n return delta2*ivar\n\nclass BinnedChi2Fn(ParamFnBase):\n \"\"\"Objective function for binned chi2.\"\"\"\n def __init__(self,h,model):\n ParamFnBase.__init__(self,model.param())\n self._h = h\n self._model = model\n\n def __call__(self,p):\n return self.eval(p)\n \n def eval(self,p):\n\n pset = self._model.param(True)\n pset.update(p)\n\n fv = self._model.histogram(self._h.axis().edges,pset)\n v = chi2(self._h.counts,self._h.var,fv)\n\n if v.ndim == 2:\n s = np.sum(v,axis=1)\n else:\n s = np.sum(v)\n\n return s\n\nclass Chi2Fn(ParamFnBase):\n\n def __init__(self,x,y,yerr,model):\n ParamFnBase.__init__(self,model.param())\n self._x = x\n self._y = y\n self._yerr = yerr\n self._model = model\n\n def __call__(self,p):\n return self.eval(p)\n \n def eval(self,p):\n\n pset = self._model.param(True)\n pset.update(p)\n\n fv = self._model(self._x,pset)\n\n var = self._yerr**2\n delta2 = (self._y-fv)**2\n v = delta2/var\n\n if v.ndim == 2:\n s = np.sum(v,axis=1)\n else:\n s = np.sum(v)\n\n return s\n\n\nclass Chi2HistFn(ParamFnBase):\n\n def __init__(self,h,model):\n ParamFnBase.__init__(self,model.param())\n self._h = h\n self._model = model\n\n def __call__(self,p):\n\n return self.eval(p)\n \n def eval(self,p):\n\n pset = self._model.param(True)\n pset.update(p)\n\n fv = self._model.counts(pset)\n fvar = self._model.var(pset)\n\n var = self._h.var + fvar\n ivar = np.zeros(shape=var.shape)\n ivar[var>0] = 1./var[var>0]\n \n delta2 = (self._h.counts-fv)**2\n v = delta2*ivar\n \n if v.ndim == 2:\n return np.sum(v,axis=1)\n else:\n return np.sum(v)\n\n\n\n \n"
},
{
"alpha_fraction": 0.46725088357925415,
"alphanum_fraction": 0.48736098408699036,
"avg_line_length": 27.80582618713379,
"blob_id": "000a35a2d3135238e3d4f037aba08f7a88299332",
"content_id": "439d69e412da9c9e1626366b1898e16708545e9a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8901,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 309,
"path": "/gammatools/dm/irf_model.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport yaml\nfrom gammatools.core.histogram import *\nfrom gammatools.core.model_fn import *\nfrom gammatools.core.bspline import *\n\nclass IRFModel(object):\n def __init__(self,aeff_ptsrc,aeff,bkg_ptsrc,bkg,psf_r68,edisp_r68):\n\n self._aeff = aeff\n self._aeff_ptsrc = aeff_ptsrc\n self._bkg = bkg\n self._bkg_ptsrc = bkg_ptsrc\n\n self._bkg /= self._bkg.axis().width\n self._bkg_ptsrc /= self._bkg_ptsrc.axis().width\n \n self._psf = psf_r68\n self._edisp = edisp_r68\n\n\n emin = self._aeff_ptsrc.axis().edges[0]\n emax = self._aeff_ptsrc.axis().edges[-1]\n\n msk = ((self._aeff.counts > 0)&\n (self._aeff.axis().center>4.0))\n\n aeff_err = np.log10(1.0 + self._aeff.err[msk]/\n self._aeff.counts[msk])\n\n knots = self._aeff.axis().center[msk][::2]\n self._aeff_fn = BSpline.fit(self._aeff.axis().center[msk],\n np.log10(self._aeff.counts[msk]),\n aeff_err,knots,3)\n\n# plt.figure()\n# x = self._aeff.axis().center\n# plt.plot(x,10**self._aeff_fn(x))\n# self._aeff.plot()\n# plt.gca().set_yscale('log')\n# plt.show()\n\n msk = ((self._aeff_ptsrc.counts > 0)&\n (self._aeff_ptsrc.axis().center>4.0))\n\n\n if np.sum(self._aeff_ptsrc.err[msk]) < 1E-4:\n err = np.ones(np.sum(msk))\n else:\n err = self._aeff_ptsrc.err[msk]\n\n\n self._aeff_ptsrc_fn = BSpline.fit(self._aeff_ptsrc.axis().center[msk],\n self._aeff_ptsrc.counts[msk],err,\n np.linspace(emin,emax,16),4)\n\n \n# plt.figure()\n# x = self._aeff_ptsrc.axis().center\n# plt.plot(x,10**self._aeff_fn(x))\n# plt.plot(x,self._aeff_ptsrc_fn(x))\n# self._aeff.plot()\n# plt.gca().set_yscale('log')\n# plt.show()\n\n\n msk = ((self._bkg_ptsrc.counts > 0)&\n (self._bkg_ptsrc.axis().center>4.0))\n bkg_err = np.log10(1.0 + \n self._bkg_ptsrc.err[msk]/\n self._bkg_ptsrc.counts[msk])\n\n knots = self._bkg_ptsrc.axis().center[msk][::3]\n self._log_bkg_ptsrc_fn = \\\n BSpline.fit(self._bkg_ptsrc.axis().center[msk],\n np.log10(self._bkg_ptsrc.counts[msk]),\n bkg_err,knots,3)\n\n msk = (self._bkg.counts > 0)&(self._bkg.axis().center>4.0)\n bkg_err = np.log10(1.0 + self._bkg.err[msk]/self._bkg.counts[msk])\n\n print knots\n print self._bkg.axis().center[msk]\n print self._bkg.counts[msk]\n print np.log10(self._bkg.counts[msk])\n print bkg_err\n \n knots = self._bkg.axis().center[msk][::3]\n self._log_bkg_fn = BSpline.fit(self._bkg.axis().center[msk],\n np.log10(self._bkg.counts[msk]),\n bkg_err,knots,3)\n\n import pprint\n pprint.pprint(self._log_bkg_fn.__dict__)\n\n \n# plt.figure()\n# self._bkg.plot()\n# x = np.linspace(4,8,100) \n# print 10**self._log_bkg_fn(x)\n# plt.plot(x,10**self._log_bkg_fn(x)) \n# plt.gca().set_yscale('log') \n# plt.show()\n \n self._eaxis = Axis.create(self._aeff_ptsrc.axis().lo_edge(),\n self._aeff_ptsrc.axis().hi_edge(),\n 800)\n\n self._ematrix = Histogram2D(self._eaxis,self._eaxis)\n\n for i in range(self._eaxis.nbins):\n \n ec = self._eaxis.center[i]\n p = [1.0,ec,self._edisp.interpolate(ec)[0]]\n self._ematrix._counts[i] = GaussFn.evals(self._eaxis.center,p)\n\n\n return\n\n self._cols = []\n\n for line in open(f):\n line = line.rstrip()\n m = re.search('#!',line)\n if m is None: continue\n else:\n self._cols = line.split()[1:]\n\n d = np.loadtxt(f,unpack=True)\n\n v = {}\n\n for i in range(len(d)):\n v[self._cols[i]] = d[i]\n\n self.__dict__.update(v)\n\n self.loge_edges = np.linspace(self.emin[0],self.emax[-1],\n len(self.emin)+1)\n\n# self._ebins = np.concatenate((self._emin,self._emax[-1]))\n# print self.__dict__\n\n def smooth_fn(self,x,fn):\n\n axis = self._eaxis\n \n# x0, y0 = np.meshgrid(axis.center,axis.center,ordering='ij')\n \n# m = self._ematrix.interpolate(np.ravel(x0),np.ravel(y0))\n# lobin = axis.valToBinBounded(self._ematrix.axis(0).edges()[0])\n\n# m = m.reshape((axis.nbins,axis.nbins))\n# m[:lobin,:] = 0\n\n m = self._ematrix.counts\n\n cc = fn(axis.center)\n cm = np.dot(m,cc)*axis.width\n return interpolate(axis.center,cm,x)\n\n def aeff(self,x):\n return 10**self._aeff_fn(x)\n\n def aeff_ptsrc(self,x):\n return self._aeff_ptsrc_fn(x)\n\n def bkg(self,x):\n return 10**self._log_bkg_fn(x)\n\n def bkg_ptsrc(self,x):\n return 10**self._log_bkg_ptsrc_fn(x)\n\n def fill_bkg_histogram(self,axis,livetime):\n\n h = Histogram(axis)\n h.fill(axis.center,\n 10**self._log_bkg_fn(axis.center)*axis.width*livetime)\n\n return h\n \n @staticmethod\n def createCTAIRF(f):\n\n d = yaml.load(open(f,'r'))\n\n \n aeff_ptsrc = Histogram(d['aeff_ptsrc_rebin']['xedges']+3.0,\n counts=d['aeff_ptsrc_rebin']['counts'],\n var=d['aeff_ptsrc_rebin']['var'])\n\n aeff_ptsrc *= Units.m2\n\n if not 'aeff_diffuse' in d:\n d['aeff_diffuse'] = d['aeff_erec_ptsrc']\n\n aeff = Histogram(d['aeff_diffuse']['xedges']+3.0,\n counts=d['aeff_diffuse']['counts'],\n var=d['aeff_diffuse']['var'])\n\n aeff *= Units.m2\n\n bkg_ptsrc = Histogram(d['bkg_wcounts_rate']['xedges']+3.0,\n counts=d['bkg_wcounts_rate']['counts'],\n var=d['bkg_wcounts_rate']['var'])\n\n if np.sum(bkg_ptsrc.var) == 0:\n bkg_ptsrc._var = (bkg_ptsrc.counts * 0.1)**2\n\n bkg = Histogram(d['bkg_wcounts_rate_density']['xedges']+3.0,\n counts=d['bkg_wcounts_rate_density']['counts'],\n var=d['bkg_wcounts_rate_density']['var'])\n\n bkg *= Units._deg2\n\n if np.sum(bkg.var) == 0:\n bkg._var = (bkg.counts * 0.1)**2\n\n\n psf = Histogram(d['th68']['xedges']+3.0,\n counts=d['th68']['counts'],\n var=0)\n\n msk = psf.counts == 0\n psf._counts[msk]=0.1\n\n edisp = Histogram(d['edisp68']['xedges']+3.0,\n counts=np.log10(1.0+d['edisp68']['counts']),\n var=0)\n\n return IRFModel(aeff_ptsrc,aeff,bkg_ptsrc,bkg,psf,edisp)\n\n\nclass BkgSpectrumModel(PDF):\n\n def __init__(self,irf,livetime):\n Model.__init__(self)\n self._irf = irf\n self._livetime = livetime\n\n def _eval(self,x,pset):\n\n return 10**self._irf._log_bkg_ptsrc_fn(x)*self._livetime\n \nclass CountsSpectrumModel(PDF):\n\n ncall = 0\n\n def __init__(self,irf,spfn,livetime,fold_edisp=False):\n Model.__init__(self,spfn.param())\n self._irf = irf\n self._spfn = spfn\n self._fold_edisp = fold_edisp\n self._livetime = livetime\n\n def _eval(self,x,pset):\n\n fn = lambda t: self._spfn(t,pset)*self._irf.aeff(t)* \\\n self._livetime*np.log(10.)*10**t*Units.mev\n\n if self._fold_edisp: \n return self._irf.smooth_fn(x,fn)\n else:\n return fn(x)\n\n# return c*exp*np.log(10.)*10**x*Units.mev\n\n def e2flux(self,h):\n\n exp = self._irf.aeff(h.axis().center)*self._livetime\n exp[exp<0] = 0\n\n msk = h.axis().center < 4.5\n\n delta = 10**h.axis().edges()[1:]-10**h.axis().edges()[:-1]\n\n hf = copy.deepcopy(h)\n hf *= 10**(2*h.axis().center)/delta\n hf /= exp\n\n hf._counts[msk] = 0\n hf._var[msk] = 0\n\n return hf\n\n def e2flux2(self,h):\n\n# exp = self._irf.aeff(h.axis().center)*self._livetime\n# exp[exp<0] = 0\n\n exp_fn = lambda t: self._irf.aeff(t)*self._livetime*self._spfn(t)\n \n exp2 = self._irf.smooth_fn(h.axis().center,exp_fn)\n flux = self._spfn(h.axis().center)\n \n msk = h.axis().center < 4.5\n\n delta = 10**h.axis().edges()[1:]-10**h.axis().edges()[:-1]\n\n hf = copy.deepcopy(h)\n hf *= 10**(2*h.axis().center)/delta\n\n hf *= flux\n hf /= exp2\n\n hf._counts[msk] = 0\n hf._var[msk] = 0\n\n return hf\n"
},
{
"alpha_fraction": 0.4650310277938843,
"alphanum_fraction": 0.47264522314071655,
"avg_line_length": 28.610877990722656,
"blob_id": "703fc2826e6af71efb47cb290aa933e10c99ab19",
"content_id": "7e089487c01f4d3fdfa515de71e29e53dfc7e035",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7092,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 239,
"path": "/gammatools/fermi/data.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@file data.py\n\n@brief Python classes for storing and manipulating photon data.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood\"\n__date__ = \"01/01/2013\"\n\nimport numpy as np\nimport re\nimport copy\nimport pyfits\nfrom gammatools.core.algebra import Vector3D\nimport matplotlib.pyplot as plt\nfrom catalog import Catalog, CatalogSource\n\nfrom gammatools.core.histogram import *\nimport yaml\nfrom gammatools.core.util import expand_aliases, eq2gal, interpolate2d\n\n\nclass Data(object):\n\n def __init__(self):\n self._data = {}\n\n def __getitem__(self,key):\n return self._data[key]\n\n def __setitem__(self,key,val):\n self._data[key] = val\n\n def save(self,outfile):\n\n import cPickle as pickle\n fp = open(outfile,'w')\n pickle.dump(self,fp,protocol = pickle.HIGHEST_PROTOCOL)\n fp.close()\n\n @staticmethod\n def load(infile):\n\n import cPickle as pickle\n return pickle.load(open(infile,'rb'))\n\n\n\n\n\nclass PhotonData(object):\n\n def __init__(self):\n self._data = { 'ra' : np.array([]),\n 'dec' : np.array([]),\n 'delta_ra' : np.array([]),\n 'delta_dec' : np.array([]),\n 'delta_phi' : np.array([]),\n 'delta_theta' : np.array([]),\n 'energy' : np.array([]),\n 'time' : np.array([]),\n 'psfcore' : np.array([]),\n 'event_class' : np.array([],dtype='int'),\n 'event_type' : np.array([],dtype='int'),\n 'conversion_type' : np.array([],dtype='int'),\n 'src_index' : np.array([],dtype='int'),\n 'dtheta' : np.array([]),\n 'phase' : np.array([]),\n 'cth' : np.array([]) }\n\n self._srcs = []\n\n def get_srcs(self,names):\n\n src_index = []\n srcs = []\n\n for i, s in enumerate(self._srcs):\n\n src = CatalogSource(s)\n for n in names:\n if src.match_name(n): \n src_index.append(i)\n srcs.append(s)\n\n self._srcs = srcs\n\n mask = PhotonData.get_mask(self,src_index=src_index)\n self.apply_mask(mask)\n \n\n def merge(self,d):\n\n self._srcs = d._srcs\n \n for k, v in self._data.iteritems():\n self._data[k] = np.append(self._data[k],d._data[k])\n \n def append(self,col,d):\n self._data[col] = np.append(self._data[col],d)\n\n def __getitem__(self,col):\n return self._data[col]\n\n def __setitem__(self,col,val):\n self._data[col] = val\n\n def apply_mask(self,mask):\n\n for k in self._data.keys():\n self._data[k] = self._data[k][mask]\n \n def save(self,outfile):\n\n import cPickle as pickle\n fp = open(outfile,'w')\n pickle.dump(self,fp,protocol = pickle.HIGHEST_PROTOCOL)\n fp.close()\n\n def hist(self,var_name,mask=None,edges=None):\n \n h = Histogram(edges) \n if not mask is None: h.fill(self._data[var_name][mask])\n else: h.fill(self._data[var_name])\n return h\n\n def mask(self,selections=None,conversion_type=None,\n event_class=None,\n event_class_id=None,\n event_type_id=None,\n phases=None,cuts=None,\n src_index=None,cuts_file=None):\n\n msk = PhotonData.get_mask(self,selections,conversion_type,event_class,\n event_class_id,event_type_id,phases,\n cuts,src_index,\n cuts_file)\n \n self.apply_mask(msk)\n \n @staticmethod\n def get_mask(data,selections=None,conversion_type=None,\n event_class=None,\n event_class_id=None,\n event_type_id=None,\n phases=None,cuts=None,\n src_index=None,cuts_file=None):\n \n mask = data['energy'] > 0\n\n if not selections is None:\n for k, v in selections.iteritems():\n mask &= (data[k] >= v[0]) & (data[k] <= v[1])\n\n# mask = (data['energy'] >= egy_range[0]) & \\\n# (data['energy'] <= egy_range[1]) & \\\n# (data['cth'] >= cth_range[0]) & (data['cth'] <= cth_range[1]) \\\n \n if not conversion_type is None:\n if conversion_type == 'front':\n mask &= (data['conversion_type'] == 0)\n else:\n mask &= (data['conversion_type'] == 1)\n \n if not cuts is None and not cuts_file is None:\n cut_defs = yaml.load(open(cuts_file,'r'))\n cut_defs['CTBBestLogEnergy'] = 'data[\\'energy\\']'\n cut_defs['CTBCORE'] = 'data[\\'psfcore\\']'\n cut_defs['pow'] = 'np.power'\n\n for c in cuts.split(','):\n \n cv = c.split('/')\n\n if len(cv) == 1:\n cut_expr = expand_aliases(cut_defs,cv[0])\n mask &= eval(cut_expr)\n else:\n clo = float(cv[1])\n chi = float(cv[2])\n\n if len(cv) == 3 and cv[0] in data._data:\n mask &= (data[cv[0]] >= clo)&(data[cv[0]] <= chi)\n\n if not event_class_id is None:\n mask &= (data['event_class'].astype('int')&\n ((0x1)<<event_class_id)>0)\n elif event_class == 'source':\n mask &= (data['event_class'].astype('int')&((0x1)<<2)>0)\n elif event_class == 'clean':\n mask &= (data['event_class'].astype('int')&((0x1)<<3)>0)\n elif event_class == 'ultraclean':\n mask &= (data['event_class'].astype('int')&((0x1)<<4)>0)\n\n if not event_type_id is None:\n\n print np.sum(mask)\n \n mask &= (data['event_type'].astype('int')&\n ((0x1)<<event_type_id)>0)\n\n print np.sum(mask)\n \n if src_index is not None:\n\n src_mask = data['src_index'].astype('int') < 0\n for isrc in src_index: \n src_mask |= (data['src_index'].astype('int') == int(isrc))\n\n mask &= src_mask\n\n if phases is not None:\n \n phase_mask = data['phase'] < 0\n for p in phases: \n phase_mask |= ((data['phase'] > p[0]) & (data['phase'] < p[1]))\n mask &= phase_mask\n\n return mask\n\n @staticmethod\n def load(infile):\n\n import cPickle as pickle\n return pickle.load(open(infile,'rb'))\n \n\nclass QuantileData(object):\n\n def __init__(self,quantile,egy_nbin,cth_nbin):\n\n self.quantile = quantile\n self.label = 'r%2.f'%(quantile*100)\n self.egy_nbin = egy_nbin\n self.cth_nbin = cth_nbin\n self.mean = np.zeros(shape=(egy_nbin,cth_nbin))\n self.err = np.zeros(shape=(egy_nbin,cth_nbin))\n\n \n \n"
},
{
"alpha_fraction": 0.5945147275924683,
"alphanum_fraction": 0.6145508289337158,
"avg_line_length": 27.815166473388672,
"blob_id": "ba63fdb851131ebb96200640bbaa9bf73b7c824c",
"content_id": "0e897ad5f85067de952d06f93e0e5f346d42f2d5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6089,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 211,
"path": "/scripts/run_tempo.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\nfrom optparse import OptionParser\nimport tempfile\nimport re\nimport ROOT\nimport shutil\nfrom gammatools.core.util import dispatch_jobs\n\ndef getEntries(inFile):\n\n FP = ROOT.TFile.Open(inFile)\n tree = FP.Get('MeritTuple')\n return tree.GetEntries()\n\ndef skimMerit(inFile, outfilename, selection,\n nentries, firstentry, enableB = None, disableB = None):\n print 'Preparing merit chunk from %s' % inFile\n\n print 'Opening input file %s' % inFile \n oldFP = ROOT.TFile.Open(inFile)\n oldTree = oldFP.Get('MeritTuple')\n oldTree.SetBranchStatus('*',1)\n oldTree.SetBranchStatus('Pulsar_Phase', 0)\n\n# for branch in enableB:\n# oldTree.SetBranchStatus(branch, 1)\n# for branch in disableB:\n# oldTree.SetBranchStatus(branch, 0)\n \n newFP = ROOT.TFile(outfilename, \"recreate\")\n newTree = oldTree.CopyTree(selection,\"fast\",nentries, firstentry)\n newTree.AutoSave()\n nevents = newTree.GetEntries()\n print 'Skimmed events ', nevents\n newFP.Close()\n print 'Closing output file %s' % outfilename\n oldFP.Close()\n return nevents\n\ndef phase_ft1(ft1File,outFile,logFile,stagedFT2,stagedEphem):\n cmd = '$TEMPO2ROOT/tempo2 '\n cmd += ' -gr fermi -ft1 %s '%(ft1File)\n cmd += ' -ft2 %s '%(stagedFT2)\n cmd += ' -f %s -phase '%(stagedEphem)\n\n print cmd\n os.system(cmd)\n\n print 'mv %s %s'%(ft1File,outFile)\n os.system('mv %s %s'%(ft1File,outFile))\n\ndef phase_merit(meritFile,outFile,logFile,stagedFT2,stagedEphem):\n nevent_chunk = 30000 # number of events to process per chunk\n mergeChain=ROOT.TChain('MeritTuple')\n\n skimmedEvents = getEntries(meritFile)\n \n for firstEvent in range(0, skimmedEvents,nevent_chunk):\n\n filename=os.path.splitext(os.path.basename(meritFile))[0]\n meritChunk=filename + '_%s.root'%firstEvent\n nevts = skimMerit(meritFile, meritChunk, \n '', nevent_chunk, firstEvent)\n\n cmd = '$TEMPO2ROOT/tempo2 -gr root -inFile %s -ft2 %s -f %s -graph 0 -nobs 32000 -npsr 1 -addFriend -phase'%(meritChunk, stagedFT2, stagedEphem)\n\n print cmd\n os.system(cmd + ' >> %s 2>> %s'%(logFile,logFile))\n\n# print tempo\n\n mergeChain.Add(meritChunk)\n\n mergeFile = ROOT.TFile('merged.root', 'RECREATE')\n# Really bad coding\n if mergeChain.GetEntries()>0: mergeChain.CopyTree('')\n\n mergeFile.Write()\n print 'merged events %s' %mergeChain.GetEntries()\n mergeFile.Close()\n\n os.system('mv merged.root %s'%(outFile))\n \n\nusage = \"usage: %prog [options] \"\ndescription = \"Run tempo2 application on one or more FT1 files.\"\nparser = OptionParser(usage=usage,description=description)\n\nparser.add_option('--par_file', default = None, type = \"string\", \n help = 'Par File')\n\nparser.add_option('--ft2_file', default = None, type = \"string\", \n help = 'FT2 file')\n\nparser.add_option(\"--batch\",action=\"store_true\",\n help=\"Split this job into several batch jobs.\")\n\nparser.add_option('--queue', default = None,\n type='string',help='Set the batch queue.')\n\nparser.add_option('--phase_colname', default='J0835_4510_Phase',\n type='string',help='Set the name of the phase column.')\n \n(opts, args) = parser.parse_args()\n\nif opts.par_file is None:\n print 'No par file.'\n sys.exit(1)\n\nif opts.ft2_file is None:\n print 'No FT2 file.'\n sys.exit(1)\n\n\nif not opts.queue is None:\n \n dispatch_jobs(os.path.abspath(__file__),args,opts)\n# for x in args:\n# cmd = 'run_tempo.py %s '%(x)\n \n# for k, v in opts.__dict__.iteritems():\n# if not v is None and k != 'batch': cmd += ' --%s=%s '%(k,v)\n\n# print 'bsub -q %s -R rhel60 %s'%(opts.queue,cmd)\n# os.system('bsub -q %s -R rhel60 %s'%(opts.queue,cmd))\n\n sys.exit(0)\n \npar_file = os.path.abspath(opts.par_file)\nft2_file = os.path.abspath(opts.ft2_file)\n \ninput_files = []\nfor x in args: input_files.append(os.path.abspath(x))\n\n \ncwd = os.getcwd()\nuser = os.environ['USER']\ntmpdir = tempfile.mkdtemp(prefix=user + '.', dir='/scratch')\n\nprint 'tmpdir ', tmpdir\n\nos.chdir(tmpdir)\n\nfor x in input_files:\n\n outFile = x\n inFile = os.path.basename(x)\n logFile=os.path.splitext(x)[0] + '_tempo2.log'\n\n staged_ft2_file = os.path.basename(ft2_file)\n\n print 'cp %s %s'%(ft2_file,staged_ft2_file)\n os.system('cp %s %s'%(ft2_file,staged_ft2_file))\n \n if os.path.isfile(logFile):\n os.system('rm %s'%logFile)\n \n print 'cp %s %s'%(x,inFile)\n os.system('cp %s %s'%(x,inFile))\n \n if not re.search('\\.root?',x) is None:\n phase_merit(inFile,outFile,logFile,staged_ft2_file,par_file)\n elif not re.search('\\.fits?',x) is None:\n phase_ft1(inFile,outFile,logFile,staged_ft2_file,par_file)\n else:\n print 'Unrecognized file extension: ', x\n\n\nos.chdir(cwd)\nshutil.rmtree(tmpdir)\n \nsys.exit(0)\n\nfor x in args:\n\n# x = os.path.abspath(x)\n \n cmd = '$TEMPO2ROOT/tempo2 '\n cmd += ' -gr fermi -ft1 %s '%(x)\n cmd += ' -ft2 %s '%(os.path.abspath(opts.ft2_file))\n cmd += ' -f %s -phase '%(os.path.abspath(opts.par_file))\n\n cwd = os.getcwd()\n\n script_file = tempfile.mktemp('.sh',os.environ['USER'] + '.',cwd)\n ftemp = open(script_file,'w')\n\n ftemp.write('#!/bin/sh\\n')\n ftemp.write('cd %s\\n'%(cwd))\n ftemp.write('TMPDIR=`mktemp -d /scratch/mdwood.XXXXXX` || exit 1\\n')\n ftemp.write('cp %s $TMPDIR\\n'%(x))\n ftemp.write('cd $TMPDIR\\n')\n ftemp.write(cmd + '\\n')\n ftemp.write('cp %s %s\\n'%(x,cwd))\n ftemp.write('cd %s\\n'%(cwd))\n ftemp.write('rm -rf $TMPDIR\\n')\n ftemp.close()\n\n os.system('chmod u+x %s'%(script_file))\n \n# cwd = os.getcwd()\n# tmp_dir = tempfile.mkdtemp(prefix=os.environ['USER'] + '.',\n# dir='/scratch')\n \n# print cmd\n os.system('bsub -q kipac-ibq %s'%(script_file))\n\n#tempo2 -gr fermi -ft1 vela_239557417_302629417_ft1_10.fits -ft2 ../all-sky_239557417_302629417_ft2-30s.fits -f vela.par -phase\n\n\n\n \n\n"
},
{
"alpha_fraction": 0.4739108085632324,
"alphanum_fraction": 0.49939727783203125,
"avg_line_length": 35.29375076293945,
"blob_id": "1ba2c370acc0f86704810a49b8a575a2816e1282",
"content_id": "1203f0040d1b3b00f07152aca2b7d3c95d810ae4",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5807,
"license_type": "permissive",
"max_line_length": 278,
"num_lines": 160,
"path": "/scripts/calc_irf_quantiles.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\n\nimport os\n\nos.environ['CUSTOM_IRF_DIR']='/u/gl/mdwood/ki10/analysis/custom_irfs/'\nos.environ['CUSTOM_IRF_NAMES']='P6_v11_diff,P7CLEAN_V4,P7CLEAN_V4MIX,P7CLEAN_V4PSF,P7SOURCE_V4,P7SOURCE_V4MIX,P7SOURCE_V4PSF,P7ULTRACLEAN_V4,P7ULTRACLEAN_V4MIX,P7ULTRACLEAN_V4PSF,P7SOURCE_V11,P7SOURCE_V6,P7SOURCE_V11A,P7SOURCE_V11B,P7SOURCE_V11C,P7SOURCE_V6MC,P7SOURCE_V6MCPSFC'\n\nimport sys\nimport copy\nimport re\nimport pickle\nimport argparse\n\nimport math\nimport numpy as np\nimport matplotlib.pyplot as plt\n#from skymaps import SkyDir\nfrom gammatools.core.histogram import Histogram, Histogram2D\nfrom matplotlib import font_manager\n\nfrom gammatools.fermi.psf_model import *\nfrom gammatools.fermi.irf_util import *\nfrom gammatools.fermi.validate import PSFData\nfrom gammatools.fermi.catalog import Catalog\n \nclass Main(object):\n\n def __init__(self):\n self.irf_colors = ['green','red','magenta','gray','orange']\n \n def main(self,*argv):\n usage = \"usage: %(prog)s [options]\"\n description = \"\"\"Generates PSF model.\"\"\"\n parser = argparse.ArgumentParser(usage=usage,description=description)\n\n IRFManager.configure(parser)\n\n parser.add_argument('--ltfile', default = None, \n help = 'Set the livetime cube which will be used '\n 'to generate the exposure-weighted PSF model.')\n\n parser.add_argument('--src', default = 'Vela', \n help = '')\n \n parser.add_argument('--irf', default = None, \n help = 'Set the names of one or more IRF models.')\n \n parser.add_argument('--output_dir', default = None, \n help = 'Set the output directory name.')\n \n parser.add_argument('--cth_bin_edge', default = '0.4,1.0', \n help = 'Edges of cos(theta) bins '\n '(e.g. 0.2,0.5,1.0).')\n\n parser.add_argument('--egy_bin_edge', default = None, \n help = 'Edges of energy bins.')\n\n parser.add_argument('--egy_bin', default = '1.25/5.0/0.25', \n help = 'Set min/max energy.')\n \n parser.add_argument('--quantiles', default = '0.34,0.68,0.90,0.95', \n help = 'Define the set of quantiles to compute.')\n \n parser.add_argument('--conversion_type', default = 'front', \n help = 'Draw plots.')\n\n parser.add_argument('--spectrum', default = 'powerlaw/2',\n help = 'Draw plots.')\n\n parser.add_argument('--edisp', default = None,\n help = 'Set the energy dispersion lookup table.')\n \n parser.add_argument('-o', '--output', default = None, \n help = 'Set the output file.')\n \n parser.add_argument('--load_from_file', default = False, \n action='store_true',\n help = 'Load IRFs from FITS.')\n\n opts = parser.parse_args(list(argv))\n\n irfs = opts.irf.split(',')\n\n [elo, ehi, ebin] = [float(t) for t in opts.egy_bin.split('/')]\n egy_bin_edge = np.linspace(elo, ehi, 1 + int((ehi - elo) / ebin))\n cth_bin_edge = [float(t) for t in opts.cth_bin_edge.split(',')]\n quantiles = [float(t) for t in opts.quantiles.split(',')]\n \n for irf in irfs:\n\n if opts.output is None:\n\n output_file = re.sub('\\:\\:',r'_',irf)\n \n output_file += '_%03.f%03.f'%(100*cth_bin_edge[0],\n 100*cth_bin_edge[1]) \n output_file += '_psfdata.P'\n else:\n output_file = opts.output\n\n irfm = IRFManager.create(irf,opts.load_from_file,opts.irf_dir)\n\n lonlat = (0,0)\n if opts.src != 'iso' and opts.src != 'iso2':\n cat = Catalog()\n src = cat.get_source_by_name(opts.src)\n lonlat = (src['RAJ2000'], src['DEJ2000'])\n \n m = PSFModelLT(opts.ltfile, irfm,\n nbin=400,\n cth_range=cth_bin_edge,\n psf_type=opts.src,\n lonlat=lonlat,\n edisp_table=opts.edisp)\n\n spectrum = opts.spectrum.split('/') \n pars = [ float(t) for t in spectrum[1].split(',')] \n m.set_spectrum(spectrum[0],pars)\n# m.set_spectrum('powerlaw_exp',(1.607,3508.6))\n\n psf_data = PSFData(egy_bin_edge,cth_bin_edge,'model')\n\n# f = open(opts.o,'w')\n\n for i in range(len(psf_data.quantiles)):\n\n ql = psf_data.quantile_labels[i]\n q = psf_data.quantiles[i]\n for iegy in range(len(egy_bin_edge)-1):\n\n elo = egy_bin_edge[iegy]\n ehi = egy_bin_edge[iegy+1]\n radius = m.quantile(10**elo,10**ehi,q)\n# print elo, ehi, radius\n psf_data.qdata[i].set(iegy,0,radius)\n\n# line = '%6.3f '%(q)\n# line += '%6.3f %6.3f '%(cth_range[0],cth_range[1])\n# line += '%6.3f %6.3f %8.4f %8.4f'%(elo,ehi,radius,0.0)\n \n# f.write(line + '\\n')\n \n# m.set_spectrum('powerlaw_exp',(1.607,3508.6))\n# m.set_spectrum('powerlaw',(2.0))\n# psf_data.print_quantiles('test')\n psf_data.save(output_file)\n \n # Compute results \n \n \n \n \n\n\nif __name__ == '__main__':\n\n main = Main()\n main.main(*sys.argv[1:])\n"
},
{
"alpha_fraction": 0.5229117274284363,
"alphanum_fraction": 0.5360219478607178,
"avg_line_length": 34.438053131103516,
"blob_id": "1d17ade95d45da6e1120dea1ac9bc161a932ab66",
"content_id": "3ccdafedab053b8d7939f9c3790d777c18b40f1f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8009,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 226,
"path": "/gammatools/core/tests/test_config.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nimport copy\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.util import *\nfrom gammatools.core.config import *\nfrom gammatools.core.histogram import Axis\n\nclass TestConfigurable(unittest.TestCase):\n\n def test_configurable_defaults(self):\n\n class BaseClass(Configurable):\n\n default_config = {'BaseClass_par0' : 0,\n 'BaseClass_par1' : 'x',\n 'BaseClass_par2' : None }\n\n def __init__(self,config=None,**kwargs):\n super(BaseClass,self).__init__(config,**kwargs)\n\n class DerivedClass(BaseClass):\n\n default_config = {'DerivedClass_par0' : 0, \n 'DerivedClass_par1' : 'x', \n 'DerivedClass_par2' : None }\n\n def __init__(self,config=None,**kwargs):\n super(DerivedClass,self).__init__(config,**kwargs)\n\n class DerivedClass2(DerivedClass):\n\n default_config = {'DerivedClass2_par0' : 0, \n 'DerivedClass2_par1' : 'x', \n 'DerivedClass2_par2' : None }\n\n def __init__(self,config=None,**kwargs):\n super(DerivedClass2,self).__init__(config,**kwargs)\n\n config = {'BaseClass_par0' : 1, \n 'BaseClass_par2' : 'y', \n 'DerivedClass_par0' : 'z',\n 'DerivedClass2_par2' : 4 }\n\n kwargs = {'BaseClass_par0' : 2 }\n\n \n base_class1 = BaseClass(config)\n base_class2 = BaseClass(config,**kwargs)\n\n derived_class0 = DerivedClass()\n derived_class1 = DerivedClass(config)\n\n \n derived2_class1 = DerivedClass2(config)\n derived2_class1 = DerivedClass2(config)\n\n # Test no config input\n base_class = BaseClass()\n derived_class = DerivedClass()\n derived2_class = DerivedClass2()\n\n self.assertEqual(base_class.config,\n BaseClass.default_config)\n self.assertEqual(derived_class.config,\n dict(BaseClass.default_config.items()+\n DerivedClass.default_config.items()))\n self.assertEqual(derived2_class.config,\n dict(BaseClass.default_config.items()+\n DerivedClass.default_config.items()+\n DerivedClass2.default_config.items()))\n\n # Test dict input\n base_class = BaseClass(config)\n derived_class = DerivedClass(config)\n derived2_class = DerivedClass2(config)\n\n for k, v in config.iteritems():\n\n if k in base_class.default_config: \n self.assertEqual(base_class.config[k],v)\n\n if k in derived_class.default_config: \n self.assertEqual(derived_class.config[k],v)\n\n if k in derived2_class.default_config: \n self.assertEqual(derived2_class.config[k],v)\n\n self.assertEqual(set(base_class.config.keys()),\n set(BaseClass.default_config.keys()))\n self.assertEqual(set(derived_class.config.keys()),\n set(BaseClass.default_config.keys()+\n DerivedClass.default_config.keys()))\n self.assertEqual(set(derived2_class.config.keys()),\n set(BaseClass.default_config.keys()+\n DerivedClass.default_config.keys()+\n DerivedClass2.default_config.keys()))\n \n # Test dict and kwarg input -- kwargs take precedence over dict\n base_class = BaseClass(config,**kwargs)\n derived_class = DerivedClass(config,**kwargs)\n derived2_class = DerivedClass2(config,**kwargs)\n\n config.update(kwargs)\n\n for k, v in config.iteritems():\n\n if k in base_class.default_config: \n self.assertEqual(base_class.config[k],v)\n\n if k in derived_class.default_config: \n self.assertEqual(derived_class.config[k],v)\n\n if k in derived2_class.default_config: \n self.assertEqual(derived2_class.config[k],v)\n\n self.assertEqual(set(base_class.config.keys()),\n set(BaseClass.default_config.keys()))\n self.assertEqual(set(derived_class.config.keys()),\n set(BaseClass.default_config.keys()+\n DerivedClass.default_config.keys()))\n self.assertEqual(set(derived2_class.config.keys()),\n set(BaseClass.default_config.keys()+\n DerivedClass.default_config.keys()+\n DerivedClass2.default_config.keys()))\n\n return\n # Test update\n base_class = BaseClass()\n derived_class = DerivedClass()\n derived2_class = DerivedClass2()\n\n base_class.update_config(config)\n derived_class.update_config(config)\n derived2_class.update_config(config)\n\n self.assertEqual(base_class.config,base_class1.config)\n self.assertEqual(derived_class.config,derived_class1.config)\n\n def test_configurable_nested_defaults(self):\n\n class BaseClass(Configurable):\n\n default_config = {'BaseClass_par0' : 0,\n 'BaseClass_par1' : 'x',\n 'BaseClass_group0.par0' : 'y',\n 'BaseClass_group0.par1' : 'z',\n }\n\n def __init__(self,config=None,**kwargs):\n super(BaseClass,self).__init__(config,**kwargs)\n \n base_class_defaults = {\n 'BaseClass_par0' : 0,\n 'BaseClass_par1' : 'x',\n 'BaseClass_group0' : {'par0' : 'y', 'par1' : 'z'}\n }\n\n extra_defaults = {\n 'par0' : 'v0',\n 'par1' : 'v1',\n 'group0' : {'par0' : 'y', 'par1' : 'z'}\n }\n\n # Test no config input\n base_class = BaseClass()\n base_class.update_default_config(extra_defaults,'group1')\n\n test_dict = copy.deepcopy(base_class_defaults)\n test_dict['group1'] = extra_defaults\n\n self.assertEqual(base_class.config,test_dict)\n\n # Test dict input\n\n base_class_dict_input = { \n 'BaseClass_par0' : 1,\n 'BaseClass_par1' : 'a',\n 'BaseClass_group0' : {'par0' : 'c', 'par1' : 'd'}\n }\n\n base_class = BaseClass(base_class_dict_input)\n\n self.assertEqual(base_class.config,\n base_class_dict_input)\n\n # Test dict and kwarg input\n\n base_class_dict_input = { \n 'BaseClass_par0' : 1,\n 'BaseClass_par1' : 'a',\n 'BaseClass_group0' : {'par0' : 'c', 'par1' : 'd'}\n }\n\n base_class_kwargs_input = { \n 'BaseClass_par0' : 2,\n 'BaseClass_par1' : 'c',\n 'BaseClass_group0' : {'par0' : 'e' }\n }\n\n test_dict = copy.deepcopy(base_class_defaults)\n update_dict(test_dict,base_class_dict_input)\n update_dict(test_dict,base_class_kwargs_input)\n\n base_class = BaseClass(base_class_dict_input,**base_class_kwargs_input)\n\n self.assertEqual(base_class.config,test_dict)\n\n\n def test_configurable_docstring(self):\n\n class BaseClass(Configurable):\n\n default_config = {'BaseClass_par0' : (0,'Doc for Option a'), \n 'BaseClass_par1' : ('x','Doc for Option b'), \n 'BaseClass_par2' : (None,'Doc for Option c')}\n\n def __init__(self,config=None):\n super(BaseClass,self).__init__()\n self.configure(config,default_config=BaseClass.default_config)\n\n base_class0 = BaseClass()\n\n\n self.assertEqual(base_class0.config_docstring('BaseClass_par0'),\n BaseClass.default_config['BaseClass_par0'][1])\n"
},
{
"alpha_fraction": 0.498301237821579,
"alphanum_fraction": 0.515288770198822,
"avg_line_length": 35.79166793823242,
"blob_id": "d91ec4ba644ce18e46f5c76b3a23baaaf6dce2b0",
"content_id": "c6fe92bcfa9fe6132accdcb8aa47dc6cecbeb8b0",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 883,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#from distutils.core import setup\nfrom setuptools import setup\n\nsetup(name='gammatools',\n version='1.0.0',\n author='Matthew Wood',\n author_email='[email protected]',\n packages=['gammatools',\n 'gammatools.core',\n 'gammatools.fermi',\n 'gammatools.dm'],\n url = \"https://github.com/woodmd/gammatools\",\n download_url = \"https://github.com/woodmd/gammatools/tarball/master\",\n scripts = ['scripts/gtmktime.py','scripts/calc_dmflux.py'],\n data_files=[('gammatools/data',\n ['gammatools/data/dm_halo_models.yaml',\n 'gammatools/data/gammamc_dif.dat'])],\n install_requires=['pywcsgrid2',\n 'numpy >= 1.8.0',\n 'matplotlib >= 1.2.0',\n 'astropy >= 0.3',\n 'scipy >= 0.13'])\n"
},
{
"alpha_fraction": 0.5667189955711365,
"alphanum_fraction": 0.5682888627052307,
"avg_line_length": 21.75,
"blob_id": "3fd2328459e1988bff106e49dabb5cb6c5972775",
"content_id": "47488be0d01d6d1e3821e32adf1464da2ef557cb",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1274,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 56,
"path": "/gammatools/dm/halo_model.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import yaml\n\nimport gammatools\nfrom gammatools.dm.jcalc import *\n\nclass HaloModelFactory(object):\n\n @staticmethod\n def create(src_name,model_file = None,rho_rsun = None, gamma = None):\n\n if model_file is None:\n model_file = os.path.join(gammatools.PACKAGE_ROOT,\n 'data/dm_halo_models.yaml')\n\n halo_model_lib = yaml.load(open(model_file,'r'))\n \n if not src_name in halo_model_lib:\n raise Exception('Could not find profile: ' + src_name)\n\n src = halo_model_lib[src_name]\n\n if rho_rsun is not None:\n src['rhor'] = [rho_rsun,8.5]\n\n if gamma is not None:\n src['gamma'] = gamma\n\n return HaloModel(src)\n\nclass HaloModel(object):\n\n def __init__(self,src):\n self._losfn = LoSIntegralFnFast.create(src)\n self._dp = DensityProfile.create(src)\n self._jp = JProfile(self._losfn)\n self._dist = src['dist']*Units.kpc\n\n @property\n def dist(self):\n return self._dist\n\n @property\n def dp(self):\n return self._dp\n\n @property\n def jp(self):\n return self._jp\n\n @property\n def losfn(self):\n return self._losfn\n\n def jval(self,loge,psi):\n\n return self._jp(psi)\n"
},
{
"alpha_fraction": 0.3999030590057373,
"alphanum_fraction": 0.4270039200782776,
"avg_line_length": 32.323055267333984,
"blob_id": "84c25039914209ff870aebbbd8105c0b12d0e722",
"content_id": "6d2c99ccc63c6ae6f36778a1dc0ea618e504e6a2",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22693,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 681,
"path": "/gammatools/fermi/catalog.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\n@file catalog.py\n\n@brief Python classes for manipulating source catalogs.\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood\"\n__date__ = \"01/01/2013\"\n__date__ = \"$Date: 2013/10/08 01:03:01 $\"\n__revision__ = \"$Revision: 1.13 $, $Author: mdwood $\"\n\nimport numpy as np\nimport sys\nimport os\nimport yaml\nimport copy\nimport re\n\nimport xml.etree.cElementTree as et\n\nfrom gammatools.core.astropy_helper import pyfits\nimport matplotlib.pyplot as plt\n\nimport gammatools\nfrom gammatools.core.util import prettify_xml\nfrom gammatools.core.util import save_object, load_object, gal2eq, eq2gal\nfrom gammatools.core.algebra import Vector3D\n\n\ndef latlon_to_xyz(lat,lon):\n phi = lon\n theta = np.pi/2.-lat\n return np.array([np.sin(theta)*np.cos(phi),\n np.sin(theta)*np.sin(phi),\n np.cos(theta)]).T\n\n\nclass CatalogSource(object):\n\n def __init__(self,data):\n\n self.__dict__.update(data)\n\n self._names_dict = {}\n self._cel_vec = Vector3D.createLatLon(np.radians(self.DEJ2000),\n np.radians(self.RAJ2000))\n\n self._gal_vec = Vector3D.createLatLon(np.radians(self.GLAT),\n np.radians(self.GLON))\n \n #[np.sin(theta)*np.cos(phi),\n # np.sin(theta)*np.sin(phi),\n # np.cos(theta)]\n \n self._names = []\n for k in Catalog.src_name_cols:\n\n if not k in self.__dict__: continue\n\n name = self.__dict__[k].strip()\n if name != '': self._names.append(name)\n\n self._names_dict[k] = name\n \n# name = self.__dict__[k].lower().replace(' ','')\n# if name != '': \n\n\n def names(self):\n return self._names\n\n def get_name(self,key=None):\n\n if key is None:\n return self._names[0]\n else: \n return self._names_dict[key]\n\n @property\n def name(self):\n return self._names[0]\n\n @property\n def ra(self):\n return self.RAJ2000\n\n @property\n def dec(self):\n return self.DEJ2000\n \n def match_name(self,name):\n\n match_string = name.lower().replace(' ','')\n \n if name in self._names: return True\n else: return False\n\n def get_roi_cut(self,radius):\n\n dec = np.radians(self.DEJ2000)\n ra = np.radians(self.RAJ2000)\n\n cut = '(acos(sin(%.8f)*sin(FT1Dec*%.8f)'%(dec,np.pi/180.)\n cut += '+ cos(%.8f)'%(dec)\n cut += '*cos(FT1Dec*%.8f)'%(np.pi/180.)\n cut += '*cos(%.8f-FT1Ra*%.8f))'%(ra,np.pi/180.)\n cut += ' < %.8f)'%(np.radians(radius))\n return cut\n \n def __str__(self):\n\n s = 'Name: %s\\n'%(self._names[0])\n s += 'GLON/GLAT: %f %f\\n'%(self.GLON,self.GLAT)\n s += 'RA/DEC: %f %f'%(self.RAJ2000,self.DEJ2000) \n return s\n \n def __getitem__(self,k):\n\n if not k in self.__dict__: return None\n else: return self.__dict__[k]\n\n\n# for k in Catalog.src_name_cols:\n\n# k = k.lower().replace(' ','')\n# if k == match_string: return True\n\n# return False\n\ndef create_xml_element(root,name,attrib):\n el = et.SubElement(root,name)\n for k, v in attrib.iteritems(): el.set(k,v)\n return el\n\nclass Catalog(object):\n\n cache = {}\n \n catalog_files = { '2fgl' : os.path.join(gammatools.PACKAGE_ROOT,\n 'data/gll_psc_v08.fit'),\n '1fhl' : os.path.join(gammatools.PACKAGE_ROOT,\n 'data/gll_psch_v07.fit'),\n '3fgl' : os.path.join(gammatools.PACKAGE_ROOT,\n 'data/gll_psc_v11.fit'),\n '3fglp' : os.path.join(gammatools.PACKAGE_ROOT,\n 'data/gll_psc4yearsource_v12r3_assoc_v6r6p0_flags.fit'),\n }\n\n src_name_cols = ['Source_Name',\n 'ASSOC1','ASSOC2','ASSOC_GAM','1FHL_Name','2FGL_Name',\n 'ASSOC_GAM1','ASSOC_GAM2','ASSOC_TEV']\n\n def __init__(self):\n\n self._src_data = []\n self._src_index = {}\n self._src_radec = np.zeros(shape=(0,3))\n\n def get_source_by_name(self,name):\n\n if name in self._src_index:\n return self._src_data[self._src_index[name]]\n else:\n return None\n\n def get_source_by_position(self,ra,dec,radius,min_radius=None):\n \n x = latlon_to_xyz(np.radians(dec),np.radians(ra))\n costh = np.sum(x*self._src_radec,axis=1) \n costh[costh>1.0] = 1.0\n\n if min_radius is not None:\n msk = np.where((np.arccos(costh) < np.radians(radius)) &\n (np.arccos(costh) > np.radians(min_radius)))[0]\n else:\n msk = np.where(np.arccos(costh) < np.radians(radius))[0]\n\n srcs = [ self._src_data[i] for i in msk]\n return srcs\n\n def sources(self):\n return self._src_data\n\n def create_roi(self,ra,dec,isodiff,galdiff,xmlfile,radius=180.0):\n\n root = et.Element('source_library')\n root.set('title','source_library')\n\n srcs = self.get_source_by_position(ra,dec,radius)\n\n for s in srcs:\n \n source_element = create_xml_element(root,'source',\n dict(name=s['Source_Name'],\n type='PointSource'))\n\n spec_element = et.SubElement(source_element,'spectrum')\n\n stype = s['SpectrumType'].strip() \n spec_element.set('type',stype)\n\n if stype == 'PowerLaw':\n Catalog.create_powerlaw(s,spec_element)\n elif stype == 'LogParabola':\n Catalog.create_logparabola(s,spec_element)\n elif stype == 'PLSuperExpCutoff':\n Catalog.create_plsuperexpcutoff(s,spec_element)\n \n spat_el = et.SubElement(source_element,'spatialModel')\n spat_el.set('type','SkyDirFunction')\n\n create_xml_element(spat_el,'parameter',\n dict(name = 'RA',\n value = str(s['RAJ2000']),\n free='0',\n min='-360.0',\n max='360.0',\n scale='1.0'))\n\n create_xml_element(spat_el,'parameter',\n dict(name = 'DEC',\n value = str(s['DEJ2000']),\n free='0',\n min='-90.0',\n max='90.0',\n scale='1.0'))\n \n isodiff_el = Catalog.create_isotropic(root,isodiff)\n galdiff_el = Catalog.create_galactic(root,galdiff)\n \n output_file = open(xmlfile,'w')\n output_file.write(prettify_xml(root))\n\n @staticmethod\n def create_isotropic(root,filefunction,name='isodiff'):\n\n el = create_xml_element(root,'source',\n dict(name=name,\n type='DiffuseSource'))\n \n spec_el = create_xml_element(el,'spectrum',\n dict(file=filefunction,\n type='FileFunction',\n ctype='-1'))\n\n create_xml_element(spec_el,'parameter',\n dict(name='Normalization',\n value='1.0',\n free='1',\n max='10000.0',\n min='0.0001',\n scale='1.0'))\n \n spat_el = create_xml_element(el,'spatialModel',\n dict(type='ConstantValue'))\n\n create_xml_element(spat_el,'parameter',\n dict(name='Value',\n value='1.0',\n free='0',\n max='10.0',\n min='0.0',\n scale='1.0'))\n\n return el\n\n @staticmethod\n def create_galactic(root,mapcube,name='galdiff'):\n\n el = create_xml_element(root,'source',\n dict(name=name,\n type='DiffuseSource'))\n\n spec_el = create_xml_element(el,'spectrum',\n dict(type='PowerLaw'))\n \n \n create_xml_element(spec_el,'parameter',\n dict(name='Prefactor',\n value='1.0',\n free='1',\n max='10.0',\n min='0.1',\n scale='1.0'))\n \n create_xml_element(spec_el,'parameter',\n dict(name='Index',\n value='0.0',\n free='0',\n max='1.0',\n min='-1.0',\n scale='-1.0'))\n\n create_xml_element(spec_el,'parameter',\n dict(name='Scale',\n value='1000.0',\n free='0',\n max='1000.0',\n min='1000.0',\n scale='1.0'))\n\n spat_el = create_xml_element(el,'spatialModel',\n dict(type='MapCubeFunction',\n file=mapcube))\n \n create_xml_element(spat_el,'parameter',\n dict(name='Normalization',\n value='1.0',\n free='0',\n max='1E3',\n min='1E-3',\n scale='1.0'))\n\n return el\n \n \n @staticmethod\n def create_powerlaw(src,root):\n\n if src['Flux_Density'] > 0: \n scale = np.round(np.log10(1./src['Flux_Density']))\n else:\n scale = 0.0\n \n value = src['Flux_Density']*10**scale\n \n create_xml_element(root,'parameter',\n dict(name='Prefactor',\n free='0',\n min='0.01',\n max='100.0',\n value=str(value),\n scale=str(10**-scale)))\n\n create_xml_element(root,'parameter',\n dict(name='Index',\n free='0',\n min='-5.0',\n max='5.0',\n value=str(src['Spectral_Index']),\n scale=str(-1.0)))\n \n create_xml_element(root,'parameter',\n dict(name='Scale',\n free='0',\n min=str(src['Pivot_Energy']),\n max=str(src['Pivot_Energy']),\n value=str(src['Pivot_Energy']),\n scale=str(1.0)))\n\n @staticmethod\n def create_logparabola(src,root):\n\n norm_scale = np.round(np.log10(1./src['Flux_Density']))\n norm_value = src['Flux_Density']*10**norm_scale\n\n eb_scale = np.round(np.log10(1./src['Pivot_Energy']))\n eb_value = src['Pivot_Energy']*10**eb_scale\n \n create_xml_element(root,'parameter',\n dict(name='norm',\n free='0',\n min='0.01',\n max='100.0',\n value=str(norm_value),\n scale=str(10**-norm_scale)))\n\n create_xml_element(root,'parameter',\n dict(name='alpha',\n free='0',\n min='-5.0',\n max='5.0',\n value=str(src['Spectral_Index']),\n scale=str(1.0)))\n\n create_xml_element(root,'parameter',\n dict(name='beta',\n free='0',\n min='0.0',\n max='5.0',\n value=str(src['beta']),\n scale=str(1.0)))\n\n \n create_xml_element(root,'parameter',\n dict(name='Eb',\n free='0',\n min='0.01',\n max='100.0',\n value=str(eb_value),\n scale=str(10**-eb_scale)))\n \n @staticmethod\n def create_plsuperexpcutoff(src,root):\n\n norm_scale = np.round(np.log10(1./src['Flux_Density']))\n norm_value = src['Flux_Density']*10**norm_scale\n\n eb_scale = np.round(np.log10(1./src['Pivot_Energy']))\n eb_value = src['Pivot_Energy']*10**eb_scale\n \n create_xml_element(root,'parameter',\n dict(name='norm',\n free='0',\n min='0.01',\n max='100.0',\n value=str(norm_value),\n scale=str(10**-norm_scale)))\n\n create_xml_element(root,'parameter',\n dict(name='alpha',\n free='0',\n min='-5.0',\n max='5.0',\n value=str(src['Spectral_Index']),\n scale=str(1.0)))\n\n create_xml_element(root,'parameter',\n dict(name='beta',\n free='0',\n min='0.0',\n max='5.0',\n value=str(src['beta']),\n scale=str(1.0)))\n\n \n create_xml_element(root,'parameter',\n dict(name='Eb',\n free='0',\n min='0.01',\n max='100.0',\n value=str(eb_value),\n scale=str(10**-eb_scale)))\n \n @staticmethod\n def get(name='2fgl'):\n\n if not name in Catalog.cache:\n\n filename = Catalog.catalog_files[name]\n\n try:\n Catalog.cache[name] = Catalog.create(filename)\n except Exception, message:\n\n print 'Exception ', message\n # Retry loading fits\n m = re.search('(.+)(\\.P|\\.P\\.gz)',filename)\n if m:\n fits_path = m.group(1) + '.fit'\n Catalog.cache[name] = Catalog.create(fits_path)\n\n return Catalog.cache[name]\n \n @staticmethod\n def create(filename):\n\n if re.search('\\.fits$',filename) or re.search('\\.fit$',filename):\n return Catalog.create_from_fits(filename)\n elif re.search('(\\.P|\\.P\\.gz)',filename):\n return load_object(filename)\n else:\n raise Exception(\"Unrecognized suffix in catalog file: %s\"%(filename))\n\n @staticmethod\n def create_from_fits(fitsfile):\n\n cat = Catalog()\n hdulist = pyfits.open(fitsfile)\n table = hdulist[1]\n\n cols = {}\n for icol, col in enumerate(table.columns.names):\n\n col_data = hdulist[1].data[col]\n\n# print icol, col, type(col_data)\n\n if type(col_data[0]) == np.float32: \n cols[col] = np.array(col_data,dtype=float)\n elif type(col_data[0]) == str: \n cols[col] = np.array(col_data,dtype=str)\n elif type(col_data[0]) == np.int16: \n cols[col] = np.array(col_data,dtype=int)\n\n nsrc = len(hdulist[1].data)\n\n cat._src_radec = np.zeros(shape=(nsrc,3))\n\n for i in range(nsrc):\n\n src = {}\n for icol, col in enumerate(cols):\n\n if not col in cols: continue\n\n src[col] = cols[col][i]\n# v = hdulist[1].data[col][i]\n\n# continue\n\n# if type(v) == np.float32: src[col] = float(v)\n# elif type(v) == str: src[col] = v\n# elif type(v) == np.int16: src[col] = int(v)\n src['Source_Name'] = src['Source_Name'].strip()\n \n cat.load_source(CatalogSource(src))\n\n return cat\n \n def load_source(self,src):\n src_name = src['Source_Name']\n src_index = len(self._src_data)\n\n self._src_data.append(src)\n phi = np.radians(src['RAJ2000'])\n theta = np.pi/2.-np.radians(src['DEJ2000'])\n\n self._src_radec[src_index] = [np.sin(theta)*np.cos(phi),\n np.sin(theta)*np.sin(phi),\n np.cos(theta)]\n\n for s in Catalog.src_name_cols:\n if s in src.__dict__ and src[s] != '':\n\n name = src[s].strip()\n self._src_index[name] = src_index\n self._src_index[name.replace(' ','')] = src_index\n self._src_index[name.replace(' ','').lower()] = src_index\n\n def save(self,outfile,format='pickle'):\n\n if format == 'pickle': \n save_object(self,outfile,compress=True)\n elif format == 'yaml': self.save_to_yaml(outfile)\n else:\n print 'Unrecognized output format: ', format\n sys.exit(1)\n\n def save_to_pickle(self,outfile):\n\n import cPickle as pickle\n fp = open(outfile,'w')\n pickle.dump(self,fp,protocol = pickle.HIGHEST_PROTOCOL)\n fp.close()\n\n def plot(self,im,src_color='k',marker_threshold=0,\n label_threshold=20., ax=None,radius_deg=10.0,**kwargs):\n\n if ax is None: ax = plt.gca()\n \n if im.axis(0)._coordsys == 'gal':\n ra, dec = gal2eq(im.lon,im.lat)\n else:\n ra, dec = im.lon, im.lat\n\n #srcs = cat.get_source_by_position(ra,dec,self._roi_radius_deg)\n # Try to determine the search radius from the input file\n srcs = self.get_source_by_position(ra,dec,radius_deg)\n\n src_lon = []\n src_lat = []\n\n labels = []\n signif_avg = []\n \n for s in srcs:\n \n# print s['RAJ2000'], s['DEJ2000'], s['GLON'], s['GLAT']\n src_lon.append(s['RAJ2000'])\n src_lat.append(s['DEJ2000'])\n labels.append(s['Source_Name'])\n signif_avg.append(s['Signif_Avg'])\n \n if im.axis(0)._coordsys == 'gal':\n src_lon, src_lat = eq2gal(src_lon,src_lat)\n \n \n# pixcrd = im.wcs.wcs_sky2pix(src_lon,src_lat, 0)\n pixcrd = im.wcs.wcs_world2pix(src_lon,src_lat, 0)\n\n# ax.autoscale(enable=False, axis='both')\n# ax.set_autoscale_on(False)\n\n for i in range(len(labels)):\n\n if signif_avg[i] > label_threshold: \n ax.text(pixcrd[0][i]+2.0,pixcrd[1][i]+2.0,labels[i],\n color=src_color,size=8,clip_on=True)\n\n if signif_avg[i] > marker_threshold: \n ax.plot(pixcrd[0][i],pixcrd[1][i],\n linestyle='None',marker='+',\n color='g', markerfacecolor = 'None',\n markeredgecolor=src_color,clip_on=True)\n \n plt.gca().set_xlim(im.axis(0).lims())\n plt.gca().set_ylim(im.axis(1).lims())\n \n def save_to_yaml(self,outfile):\n\n print 'Saving catalog ', outfile\n\n yaml.dump({ 'src_data' : self._src_data, \n 'src_name_index' : self._src_index,\n 'src_radec' : self._src_radec },\n file(outfile,'w'))\n\n def load_from_yaml(self,infile):\n\n print 'Loading catalog', infile\n\n d = yaml.load(file(infile,'r'))\n \n self._src_data = d['src_data']\n self._src_index = d['src_name_index']\n self._src_radec = d['src_radec']\n\n \n \n\n\nSourceCatalog = { 'vela' : (128.83606354, -45.17643181),\n 'vela2' : (-45.17643181, 128.83606354),\n 'geminga' : (98.475638, 17.770253),\n 'crab' : (83.63313, 22.01447),\n 'draco' : (260.05163, 57.91536),\n 'slat+100' : (0.0, 90.00),\n 'slat+090' : (0.0, 64.16),\n 'slat+080' : (0.0, 53.13),\n 'slat+060' : (0.0, 36.87),\n 'slat+040' : (0.0, 23.58),\n 'slat+020' : (0.0, 11.54),\n 'slat+000' : (0.0, 0.00),\n 'slat-020' : (0.0,-11.54),\n 'slat-040' : (0.0,-23.58),\n 'slat-060' : (0.0,-36.87),\n 'slat-080' : (0.0,-53.13),\n 'slat-090' : (0.0,-64.16),\n 'slat-100' : (0.0,-90.00) }\n\n\nif __name__ == '__main__':\n\n import argparse\n import re\n\n usage = \"usage: %(prog)s [options] [catalog FITS file]\"\n description = \"Load a FITS catalog and write to an output file.\"\n parser = argparse.ArgumentParser(usage=usage,description=description)\n\n parser.add_argument('files', nargs='+')\n \n parser.add_argument('--output', default = None, \n help = 'Output file')\n \n parser.add_argument('--source', default = None, \n help = 'Output file')\n \n parser.add_argument('--roi_radius', default = 10., type=float,\n help = 'Output file')\n\n args = parser.parse_args()\n\n\n if len(args.files) == 1: \n cat = Catalog.create_from_fits(args.files[0])\n else:\n cat = Catalog()\n\n# if not opts.source is None:\n# src = CatalogSource(cat.get_source_by_name(opts.source))\n\n if not args.output is None:\n \n if re.search('\\.P$',args.output):\n save_object(cat,args.output,compress=True)\n"
},
{
"alpha_fraction": 0.48806703090667725,
"alphanum_fraction": 0.5585716962814331,
"avg_line_length": 26.72222137451172,
"blob_id": "8e7d7f825b9b21a5d8926a9c8cf70430d987d34f",
"content_id": "40c727c85b994b436149bcd3e3f52e105b5e3658",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5489,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 198,
"path": "/gammatools/core/tests/test_likelihood.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.parameter_set import *\nfrom gammatools.core.likelihood import *\nfrom gammatools.core.nonlinear_fitting import *\nfrom gammatools.core.model_fn import *\nfrom gammatools.core.histogram import *\n\n\ndef setup_gauss_test():\n pset = ParameterSet() \n fn = GaussFn.create(100.0,0.0,0.1,pset)\n h = Histogram(Axis.create(-3.0,3.0,100))\n h.fill(h.axis().center,fn.histogram(h.axis().edges))\n\n msk = h.counts < 1.0\n h._counts[msk] = 0.0\n h._var[msk] = 0.0\n\n return h, fn\n\nclass TestLikelihood(unittest.TestCase):\n\n\n def test_parameter_set_init(self):\n\n par0 = Parameter(0,3.0,'par0')\n par1 = Parameter(1,4.0,'par1')\n par4 = Parameter(4,6.0,'par4')\n\n pset = ParameterSet()\n pset.addParameter(par0)\n pset.addParameter(par1)\n pset.addParameter(par4)\n par2 = pset.createParameter(5.0,'par2',pid=2)\n\n pars = [par0,par1,par2,par4]\n\n for i, p in enumerate(pars):\n pname = p.name\n self.assertEqual(pset[i].name,pars[i].name)\n self.assertEqual(pset[i].value,pars[i].value)\n self.assertEqual(pset[pname].name,pars[i].name)\n self.assertEqual(pset[pname].value,pars[i].value)\n\n# assert_array_equal(pset.array(),\n# np.array([3.0,4.0,5.0,6.0],ndmin=2))\n\n def test_parameter_set_access(self):\n\n pset = ParameterSet()\n pset.createParameter(3.0,'p0')\n pset.createParameter(2.0,'p1')\n\n self.assertEqual(pset['p0'].value,3.0)\n self.assertEqual(pset[0].value,3.0)\n\n self.assertEqual(pset['p1'].value,2.0)\n self.assertEqual(pset[1].value,2.0)\n\n\n def test_parameter_set_merge(self):\n\n par0 = Parameter(0,3.0,'par0')\n par1 = Parameter(1,3.0,'par1')\n\n pset0 = ParameterSet()\n\n def test_polyfn_eval(self):\n\n f = PolyFn.create(3,[3.0,-1.0,2.0])\n fn = lambda t, z=2.0: 3.0 - 1.0*t + z*t**2\n\n fni = lambda t, z=2.0: 3.0*t - 1.0*t**2/2. + z*t**3/3.0\n\n x = np.linspace(-2.0,2.0,12)\n a2 = np.linspace(0,10,10)\n pset = f.param()\n pset = pset.makeParameterArray(2,a2)\n\n self.assertEqual(f.eval(2.0),fn(2.0))\n assert_almost_equal(f.eval(x),fn(x))\n assert_almost_equal(f.eval(2.0,pset).flat,fn(2.0,a2))\n\n assert_almost_equal(f.integrate(0.0,2.0),fni(2.0)-fni(0.0))\n assert_almost_equal(f.integrate(0.0,2.0,pset).flat,\n fni(2.0,a2)-fni(0.0,a2))\n\n\n def test_binned_polyfn_fit(self):\n\n np.random.seed(1)\n\n f = PolyFn.create(2,[0,1.0])\n y = f.rnd(1000,0.0,1.0)\n f.set_norm(1000,0.0,1.0)\n pset = f.param()\n\n\n h = Histogram(np.linspace(0,1,10))\n h.fill(y)\n# chi2_fn = Chi2HistFn(h,f)\n chi2_fn = BinnedChi2Fn(h,f)\n# print chi2_fn.eval(pset)\n\n psetv = pset.makeParameterArray(1,pset[1].value*np.linspace(0,2,10))\n chi2_fn.param()[1].set(chi2_fn._param[1].value*1.5)\n\n fitter = MinuitFitter(chi2_fn)\n# print fitter.fit()\n\n def test_hist_model_fit(self):\n\n pset0 = ParameterSet()\n \n fn0 = GaussFn.create(100.0,0.0,0.1,pset0)\n fn1 = GaussFn.create(50.0,1.0,0.1,pset0)\n\n hm0 = Histogram(Axis.create(-3.0,3.0,100))\n hm0.fill(hm0.axis().center,fn0(hm0.axis().center))\n\n hm1 = Histogram(Axis.create(-3.0,3.0,100))\n hm1.fill(hm1.axis().center,fn1(hm1.axis().center))\n \n hm2 = hm0*0.9 + hm1*0.8\n \n pset1 = ParameterSet()\n \n m0 = ScaledHistogramModel.create(hm0,pset=pset1,name='m0')\n m1 = ScaledHistogramModel.create(hm1,pset=pset1,name='m1')\n\n msum = CompositeSumModel([m0,m1])\n chi2_fn = Chi2HistFn(hm2,msum)\n fitter = BFGSFitter(chi2_fn)\n\n pset1[0].set(1.5)\n pset1[1].set(0.5)\n \n f = fitter.minimize(pset1)\n \n assert_almost_equal(f[0].value,0.9,4)\n assert_almost_equal(f[1].value,0.8,4)\n\n def test_binned_chi2_fn(self):\n \n hm0, fn0 = setup_gauss_test()\n pset0 = fn0.param()\n\n chi2_fn = BinnedChi2Fn(hm0,fn0)\n\n pset1 = copy.deepcopy(pset0)\n pset1.set(90.0,0.5,0.2)\n pset1[2].setLoBound(0.001)\n\n fitter = BFGSFitter(chi2_fn)\n\n f = fitter.minimize(pset1)\n\n assert_almost_equal(f[0].value,pset0[0].value,4)\n assert_almost_equal(f[1].value,pset0[1].value,4)\n assert_almost_equal(f[2].value,pset0[2].value,4)\n \n def test_bfgs(self):\n \n hm0, fn0 = setup_gauss_test()\n pset0 = fn0.param()\n \n\n def test_bfgs_fn(self):\n \n x0 = 0.324\n y0 = -1.2\n\n fn = lambda x, y : ((x-x0)**2 + (y-y0)**2)\n fn2 = lambda x, y : -np.exp(-((x-x0)**2+(y-y0)**2))\n\n p0 = BFGSFitter.fit(fn,[1.0,3.0])\n\n assert_almost_equal(p0[0].value,x0,4)\n assert_almost_equal(p0[1].value,y0,4)\n\n p0 = BFGSFitter.fit(fn2,[1.0,3.0],pgtol=1E-8)\n\n assert_almost_equal(p0[0].value,x0,4)\n assert_almost_equal(p0[1].value,y0,4)\n\n fitter = BFGSFitter(ParamFn.create(fn,[1.0,3.0]))\n\n fitter.objfn.param()[0].fix()\n p0 = fitter.minimize()\n\n assert_almost_equal(p0[0].value,1.0,4)\n assert_almost_equal(p0[1].value,y0,4)\n\n# print fn2(*p0.list())\n\n# print fn2(x0,y0)\n"
},
{
"alpha_fraction": 0.5384615659713745,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 15.370369911193848,
"blob_id": "f684ea26e3fb656f0f3a225fbe50ca2cc144eedd",
"content_id": "addf3741b8ba984bf4e0977c445f874e018ddbf6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 27,
"path": "/gammatools/fermi/roi.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "class ROISource(object):\n\n def __init__(self):\n pass\n\n \n\nclass ROI(object):\n\n\n\n def __init__(self):\n\n pass\n\n\n def to_xml(self,xmlfile):\n\n root = et.Element('source_library')\n root.set('title','source_library')\n\n \n# class_event_map = et.SubElement(root,'EventMap')\n# tree._setroot(root)\n \n output_file = open(xmlfile,'w')\n output_file.write(prettify_xml(root))\n"
},
{
"alpha_fraction": 0.5128121376037598,
"alphanum_fraction": 0.5257629156112671,
"avg_line_length": 29.74222755432129,
"blob_id": "e4564f959dd892fc6e4f12c7aea8b9746fd6557e",
"content_id": "6ae579e5830aeeed0b3f10a8ab520d7e2a34e9d5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61309,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 1994,
"path": "/gammatools/core/histogram.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\n@file histogram.py\n\n@brief Python classes for creating, manipulating, and plotting\nhistograms.\"\n\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood <[email protected]>\"\n__date__ = \"$Date: 2013/10/20 23:59:49 $\"\n__revision__ = \"$Revision: 1.30 $, $Author: mdwood $\"\n\nimport sys\nimport numpy as np\nimport copy\nimport matplotlib.pyplot as plt\nfrom scipy.interpolate import UnivariateSpline\nfrom scipy.optimize import brentq\nimport scipy.stats as stats\nfrom gammatools.core.util import *\nfrom gammatools.core.mpl_util import *\nfrom matplotlib.colors import NoNorm, LogNorm, Normalize\n\ndef get_quantile(x,y,f):\n y = np.cumsum(y) \n fn = UnivariateSpline(x,y,s=0,k=1)\n return brentq(lambda t: fn(t)-y[-1]*f,x[0],x[-1])\n\ndef get_quantile_error(x,y,yvar,f):\n y = np.cumsum(y) \n yvar = np.cumsum(yvar) \n\n if y[-1] == 0: return [np.inf,np.inf]\n \n yerr = np.sqrt(yvar)\n \n fn = UnivariateSpline(x,y,s=0,k=1)\n xq = brentq(lambda t: fn(t)-y[-1]*f,x[0],x[-1])\n\n i = np.where(y > y[-1]*f)[0][0]\n\n yhi = y[-1]*f+yerr[i]\n ylo = y[-1]*f-yerr[i]\n\n if yhi < y[-1]: xq_hi = brentq(lambda t: fn(t)-yhi,x[0],x[-1])\n else: xq_hi = x[-1]\n\n if ylo > y[0]: xq_lo = brentq(lambda t: fn(t)-ylo,x[0],x[-1])\n else: xq_lo = x[0]\n \n xq_err = 0.5*(xq_hi-xq_lo)\n xq_var = xq_err**2\n\n# print xq, xq_hi, xq_lo, xq_err\n\n return [xq,xq_var]\n\nclass HistogramND(object):\n \"\"\"\n N-dimensional histogram class. This class serves as the base\n class for lower dimensionality histograms (Histogram and\n Histogram2D) and provides a common functionality for filling the\n counts and error arrays as well as various transformation\n operations (slicing, projecting, marginalizing). Bin occupation\n values and squared errors are stored in two numpy arrays. The\n binning in each dimension is defined by an array of Axis objects\n which are provided to the constructor. \n\n Histograms support most operations that can be applied to numpy\n arrays (addition, multiplication, division, etc.). All arithmetic\n operations will recompute the bin errors using standard error\n propagation rules.\n\n Several transformation methods are provided which can be used to\n project, slice, and marginalize the histogram. All transformation\n methods return a new histogram instance. If the output histogram\n has a lower dimensionality it will be automatically instantiated\n as a 1D or 2D histogram when appropriate.\n\n Note that the recommended method for instantiating a histogram\n object is with the HistogramND.create() method.\n \"\"\"\n\n def __init__(self, axes, counts=None, var=None, \n style=None, label = '__nolabel__'):\n\n self._axes = []\n self._style = {}\n if not style is None: update_dict(self._style,style)\n self._style['label'] = label\n\n for ax in axes:\n if isinstance(ax,Axis): self._axes.append(copy.deepcopy(ax))\n else: self._axes.append(Axis(ax))\n\n shape = []\n for ax in self._axes: shape.append(ax.nbins)\n\n if counts is None: self._counts = np.zeros(shape=shape)\n else: \n self._counts = np.array(counts,copy=True)\n if len(self._counts.shape) == 0: \n self._counts = np.ones(shape=shape)*self._counts\n\n if var is None: self._var = np.zeros(shape=self._counts.shape)\n else: \n self._var = np.array(var,copy=True)\n if len(self._var.shape) == 0: \n self._var = np.ones(shape=shape)*self._var\n\n self._ndim = self._counts.ndim\n\n if self._ndim != len(self._axes):\n raise Exception('Mismatch of data and axis dimensions: %i %i'\n %(len(self._axes),self._ndim))\n \n self._dims = np.array(range(self._ndim),dtype=int)\n\n def shape(self):\n \"\"\"Return the shape of this histogram (length along each dimension).\"\"\"\n return self._counts.shape\n\n def ndim(self):\n return len(self._axes)\n\n def style(self):\n return self._style\n \n def axes(self):\n \"\"\"Return the axes vector.\"\"\"\n return self._axes\n\n def axis(self,idim=0):\n return self._axes[idim]\n\n def center(self):\n \"\"\"Return the center coordinate of each bin in this histogram\n as an NxM array.\"\"\"\n \n if self._ndim == 1:\n return np.array(self._axes[0].center,ndmin=2)\n\n else:\n c = []\n for i in self._dims:\n c.append(self._axes[i].center)\n\n c = np.meshgrid(*c,indexing='ij')\n\n cv = []\n for i in range(len(c)): cv.append(np.ravel(c[i]))\n\n return np.array(cv)\n\n @property\n def counts(self):\n \"\"\"Return the counts array.\"\"\"\n return self._counts\n \n @property\n def var(self):\n return self._var\n\n @property\n def err(self):\n return np.sqrt(self._var)\n\n @staticmethod\n def createFromTH3(hist,label = '__nolabel__'):\n nx = hist.GetNbinsX()\n ny = hist.GetNbinsY()\n nz = hist.GetNbinsZ()\n\n xmin = hist.GetXaxis().GetBinLowEdge(1)\n xmax = hist.GetXaxis().GetBinLowEdge(nx+1)\n\n ymin = hist.GetYaxis().GetBinLowEdge(1)\n ymax = hist.GetYaxis().GetBinLowEdge(ny+1)\n\n zmin = hist.GetZaxis().GetBinLowEdge(1)\n zmax = hist.GetZaxis().GetBinLowEdge(nz+1)\n \n xaxis = Axis.create(xmin,xmax,nx)\n yaxis = Axis.create(ymin,ymax,ny)\n yaxis = Axis.create(zmin,zmax,nz)\n\n counts = np.zeros(shape=(nx,ny,nz))\n var = np.zeros(shape=(nx,ny,nz))\n\n for ix in range(1,nx+1):\n for iy in range(1,ny+1):\n for iz in range(1,nz+1):\n counts[ix-1][iy-1][iz-1] = hist.GetBinContent(ix,iy,iz)\n var[ix-1][iy-1][iz-1] = hist.GetBinError(ix,iy,iz)**2\n\n style = {}\n style['label'] = label\n style['title'] = hist.GetTitle()\n\n h = HistogramND([xaxis,yaxis,zaxis],\n counts=counts,var=var,style=style)\n\n return h\n\n def to_root(self,name,title=None):\n\n if title is None: title=name\n \n import ROOT\n h = ROOT.TH3F(name,title,self.xaxis().nbins,\n self.xaxis().lo_edge(),self.xaxis().hi_edge(),\n self.yaxis().nbins,\n self.yaxis().lo_edge(),self.yaxis().hi_edge(),\n self.zaxis().nbins,\n self.zaxis().lo_edge(),self.zaxis().hi_edge())\n\n for i in range(self.xaxis().nbins):\n for j in range(self.yaxis().nbins):\n for k in range(self.yaxis().nbins):\n h.SetBinContent(i+1,j+1,k+1,self._counts[i,j,k])\n h.SetBinError(i+1,j+1,k+1,np.sqrt(self._var[i,j,k]))\n\n return h\n\n \n def inverse(self):\n c = 1./self._counts\n var = c**2*self._var/self._counts**2\n return HistogramND.create(self._axes,c,var,self._style)\n\n def abs(self):\n c = np.abs(self._counts)\n return HistogramND.create(self._axes,c,self._var,self._style)\n \n def power10(self):\n\n err = np.sqrt(self._var)\n\n msk = (self._counts != np.inf)\n\n c = np.zeros(shape=self._counts.shape)\n clo = np.zeros(shape=self._counts.shape)\n chi = np.zeros(shape=self._counts.shape)\n \n c[msk] = np.power(10,self._counts[msk])\n clo[msk] = np.power(10,self._counts[msk]-err[msk])\n chi[msk] = np.power(10,self._counts[msk]+err[msk])\n\n counts = c \n var = (0.5*(chi-clo))**2\n return HistogramND.create(self._axes,counts,var,self._style)\n\n def fill_from_fn(self,fn):\n \n v = fn(*self.center()).reshape(self.shape())\n self._counts = fn(*self.center()).reshape(self.shape()) \n \n def fill(self,z,w=1.0,v=None):\n \"\"\"\n Fill the histogram from a set of points arranged in an NxM\n matrix where N is the histogram dimension and M is a variable\n number of points.\n\n @param z: Array of NxM points.\n @param w: Array of M bin weights (optional).\n @param v: Array of M bin variances (optional).\n @return:\n \"\"\"\n\n z = np.array(z,ndmin=2)\n w = np.array(w,ndmin=1)\n if v is None: v = w\n else: v = np.array(v,ndmin=1)\n\n if z.shape[0] != self._ndim:\n\n print z.shape, self._ndim\n raise Exception('Coordinate dimension of input array must be '\n 'equal to histogram dimension.')\n\n if w.shape[0] < z.shape[1]: w = np.ones(z.shape[1])*w\n if v.shape[0] < z.shape[1]: v = np.ones(z.shape[1])*v\n\n edges = []\n for i in self._dims: edges.append(self._axes[i].edges)\n\n counts = np.histogramdd(z.T,bins=edges,weights=w)[0]\n var = np.histogramdd(z.T,bins=edges,weights=v)[0]\n\n self._counts += counts\n self._var += var\n\n def random(self,method='poisson',scale=1.0):\n \"\"\"Generate a randomized histogram.\"\"\"\n\n c = np.array(np.random.poisson(scale*self._counts),dtype='float')\n v = copy.copy(c)\n\n return HistogramND.create(self._axes,c,v,self._style)\n\n def project(self,pdims,bin_range=None):\n \"\"\"Project the contents of this histogram into a histogram\n spanning the subspace defined by the list pdims. The optional\n bin_range argument defines the range of bins over which to\n integrate each of the non-projected dimensions. This\n operation is the complement to marginalize.\"\"\"\n\n pdims = np.array(pdims,ndmin=1,copy=True)\n\n mdims = np.setdiff1d(self._dims,pdims)\n axes = []\n new_shape = []\n for i in pdims:\n axes.append(self._axes[i])\n new_shape.append(self._axes[i].nbins)\n \n if not bin_range is None:\n\n bin_range = np.array(bin_range,ndmin=2,copy=True)\n\n if len(bin_range) != len(mdims):\n raise Exception('Length of bin range list must be equal to '\n 'the number of marginalized dimensions.')\n\n slices = len(self._dims)*[None]\n\n for i, idim in enumerate(mdims):\n slices[idim] = slice(bin_range[i][0],bin_range[i][1])\n\n for idim in self._dims:\n if idim in mdims: continue \n slices[idim] = slice(self._axes[idim].nbins)\n \n c = np.apply_over_axes(np.sum,self._counts[slices],\n mdims).reshape(new_shape)\n v = np.apply_over_axes(np.sum,self._var[slices],\n mdims).reshape(new_shape)\n else:\n c = np.apply_over_axes(np.sum,self._counts,mdims).reshape(new_shape)\n v = np.apply_over_axes(np.sum,self._var,mdims).reshape(new_shape)\n \n return HistogramND.create(axes,c,v,self._style)\n\n def quantile(self,dim,fraction=0.5,method='var',niter=100):\n\n sdims = np.setdiff1d(self._dims,[dim])\n \n axes = []\n for i in self._dims:\n\n if i == dim: continue\n else: axes.append(self._axes[i])\n\n h = HistogramND.create(axes,style=self._style)\n\n# h._counts = np.percentile(self._counts,fraction*100.,axis=dim)\n \n for index, x in np.ndenumerate(h._counts):\n\n hs = self.slice(sdims,index)\n \n if method == 'var':\n\n cs = np.concatenate(([0],hs.counts))\n vs = np.concatenate(([0],hs.var))\n \n q, qvar = get_quantile_error(hs.axis().edges,cs,vs,fraction)\n# h._counts[index] = HistQuantile(hs).eval(fraction)\n h._counts[index] = q\n h._var[index] = qvar\n\n elif method == 'bootstrap_poisson':\n\n c = np.random.poisson(np.concatenate(([0],hs.counts)),\n (niter,hs.axis().nbins+1))\n\n xq = []\n \n for i in range(niter):\n xq.append(get_quantile(hs.axis().edges,c[i],fraction))\n\n h._counts[index] = \\\n get_quantile(hs.axis().edges,\n np.concatenate(([0],hs.counts)),fraction)\n h._var[index] = np.std(np.array(xq))**2\n \n return h\n \n \n def normalize(self,dims=None):\n\n if dims is None: dims = self._dims\n else: dims = np.array(dims,ndmin=1,copy=True)\n \n norm = np.apply_over_axes(np.sum,self._counts,dims)\n inorm = np.zeros(norm.shape)\n\n inorm[norm!=0] = 1./norm[norm!=0]\n \n c = self._counts*inorm\n v = self._var*inorm**2\n\n return HistogramND.create(self._axes,c,v,self._style)\n\n def marginalize(self,mdims,bin_range=None):\n mdims = np.array(mdims,ndmin=1,copy=True)\n pdims = np.setdiff1d(self._dims,mdims)\n return self.project(pdims,bin_range)\n\n def cumulative(self,dims=None,reverse=False):\n\n if dims is None: dims = self._dims\n else: dims = np.array(dims,ndmin=1,copy=True)\n\n slices = []\n for i in self._dims:\n if i in dims and reverse: slices.append(slice(None,None,-1))\n else: slices.append(slice(None))\n \n c = np.apply_over_axes(np.cumsum,self._counts[slices],dims)[slices]\n v = np.apply_over_axes(np.cumsum,self._var[slices],dims)[slices]\n\n return HistogramND.create(self._axes,c,v,self._style)\n\n def sum(self):\n\n return np.array([np.sum(self._counts),np.sqrt(np.sum(self._var))])\n \n def slice(self,sdims,dim_index):\n \"\"\"Generate a new histogram from a subspace of this histogram.\n The subspace of the new histogram is defined by providing a\n list of slice dimensions and list of bin indices for the\n dimensions along which the slice will be performed. The size\n of any dimensions not in this list will be preserved in the\n output histogram.\"\"\"\n\n sdims = np.array(sdims,ndmin=1,copy=True)\n dim_index = np.array(dim_index,ndmin=1,copy=True)\n dims = np.setdiff1d(self._dims,sdims)\n\n axes= len(self._dims)*[None]\n new_shape = len(self._dims)*[None]\n slices = len(self._dims)*[None]\n\n for i in dims:\n axes[i] = self._axes[i]\n new_shape[i] = self._axes[i].nbins\n slices[i] = slice(self._axes[i].nbins)\n \n for i, idim in enumerate(sdims):\n\n if dim_index[i] is None:\n index_range = np.array([0,self.axis(idim).nbins])\n else:\n index_range = np.array(dim_index[i],ndmin=1)\n \n if idim >= self._ndim or index_range[0] >= self._axes[idim].nbins:\n raise ValueError('Dimension or Index out of range')\n \n if len(index_range) == 2:\n new_axis = self._axes[idim].slice(index_range[0],\n index_range[1])\n\n axes[idim] = new_axis\n slices[idim] = slice(index_range[0],index_range[1])\n new_shape[idim] = new_axis.nbins \n elif index_range[0] < 0: \n slices[idim] = slice(index_range[0],index_range[0]-1,-1)\n else:\n slices[idim] = slice(index_range[0],index_range[0]+1)\n\n axes = filter(None,axes)\n new_shape = filter(None,new_shape)\n \n c = self._counts[slices].reshape(new_shape)\n v = self._var[slices].reshape(new_shape)\n\n return HistogramND.create(axes,c,v,self._style)\n\n def sliceByValue(self,sdims,dim_coord):\n\n sdims = np.array(sdims,ndmin=1,copy=True)\n dim_coord = np.array(dim_coord,ndmin=1,copy=True)\n\n dim_index = []\n\n for i, idim in enumerate(sdims):\n dim_index.append(self._axes[idim].valToBinBounded(dim_coord[i]))\n\n return self.slice(sdims,dim_index)\n\n def interpolate(self,*x):\n \"\"\"Note: All input arrays must have the same dimension.\"\"\"\n\n center = []\n for i in range(self._ndim): center.append(self._axes[i].center)\n\n if len(x) == 1:\n xv = x[0]\n shape = x[0].shape[1]\n else: \n xv, shape = expand_array(*x)\n\n v = interpolatend(center,self._counts,xv)\n return v.reshape(shape)\n\n def interpolateSlice(self,sdims,dim_coord):\n\n sdims = np.array(sdims,ndmin=1,copy=True)\n dims = np.setdiff1d(self._dims,sdims)\n dim_coord = np.array(dim_coord,ndmin=1,copy=True)\n\n h = self.sliceByValue(sdims,dim_coord)\n\n x = np.zeros(shape=(self._ndim,h._counts.size))\n c = h.center\n\n for i, idim in enumerate(dims): x[idim] = c[i]\n for i, idim in enumerate(sdims): x[idim,:] = dim_coord[i]\n\n center = []\n for i in range(self._ndim): center.append(self._axes[i].center)\n h._counts = interpolatend(center,self._counts,x).reshape(h._counts.shape)\n h._var = interpolatend(center,self._var,x).reshape(h._counts.shape)\n\n return h\n\n def clear(self,fill_value=0.0):\n \"\"\"Clear the contents of this histogram.\"\"\"\n self._counts.fill(fill_value)\n self._var.fill(fill_value)\n \n def __add__(self,x):\n\n o = copy.deepcopy(self)\n\n if x is None:\n return o\n elif isinstance(x, HistogramND):\n o._counts += x._counts\n o._var += x._var\n else:\n o._counts += x\n\n return o\n\n def __sub__(self,x):\n\n o = copy.deepcopy(self)\n\n if isinstance(x, HistogramND):\n o._counts -= x._counts\n o._var += x._var\n else:\n o._counts -= x\n\n return o\n\n def __mul__(self,x):\n\n o = copy.deepcopy(self)\n\n if isinstance(x, HistogramND):\n\n y1 = self._counts\n y2 = x._counts\n y1v = self._var\n y2v = x._var\n\n f0 = np.zeros(self.axis().nbins)\n f1 = np.zeros(self.axis().nbins)\n\n f0[y1 != 0] = y1v/y1**2\n f1[y2 != 0] = y2v/y2**2\n\n o._counts = y1*y2\n o._var = x._counts**2*(f0+f1)\n else:\n o._counts *= x\n o._var *= x*x\n\n return o\n\n def __div__(self,x):\n\n if isinstance(x, HistogramND):\n o = copy.deepcopy(self)\n\n y1 = self._counts\n y2 = x._counts\n y1_var = self._var\n y2_var = x._var\n\n msk = ((y1!=0) & (y2!=0))\n\n o._counts[~msk] = 0.\n o._var[~msk] = 0.\n \n o._counts[msk] = y1[msk] / y2[msk]\n o._var[msk] = (y1[msk] / y2[msk])**2\n o._var[msk] *= (y1_var[msk]/y1[msk]**2 + y2_var[msk]/y2[msk]**2)\n\n return o\n else:\n x = np.array(x,ndmin=1)\n msk = x != 0\n x[msk] = 1./x[msk]\n x[~msk] = 0.0\n return self.__mul__(x)\n\n @staticmethod\n def createFromFn(axes,fn,style=None,label='__nolabel__'):\n\n if not isinstance(axes,list): axes = [axes]\n\n h = HistogramND.create(axes,style=style,label=label)\n h.fill_from_fn(fn)\n return h\n \n @staticmethod\n def create(axes,c=None,v=None,style=None,label='__nolabel__'):\n \"\"\"Factory method for instantiating an empty histogram object.\n Will automatically produce a 1D or 2D histogram if appropriate\n based on the length of the input axes array.\"\"\"\n ndim = len(axes)\n if ndim == 1:\n return Histogram(axes[0],counts=c,var=v,style=style,label=label)\n elif ndim == 2: \n return Histogram2D(axes[0],axes[1],counts=c,var=v,\n style=style,label=label)\n else: return HistogramND(axes,counts=c,var=v,style=style,label=label)\n\n @staticmethod\n def createFromTree(t,vars,axes,cut=None,fraction=1.0,\n label = '__nolabel__'):\n \"\"\"Factory method for instantiating a histogram from a ROOT\n tree.\"\"\"\n nentries=t.GetEntries()\n first_entry = min(int((1.0-fraction)*nentries),nentries)\n nentries = nentries - first_entry\n\n x = []\n for v in vars: x.append(get_vector(t,v,cut,nentries,first_entry))\n z = np.vstack(x)\n\n for i, a in enumerate(axes):\n if isinstance(a,dict):\n vmin = min(z[i])\n vmax = max(z[i])\n\n vmin -= 1E-8*(vmax-vmin)\n vmax += 1E-8*(vmax-vmin)\n\n axis_label = None\n if 'label' in a: axis_label = a['label']\n axes[i] = Axis.create(vmin,vmax,a['nbin'],label=axis_label)\n \n h = HistogramND(axes)\n h.fill(z)\n\n return HistogramND.create(h.axes(),h.counts,h.var,h.style())\n\nclass HistogramIterator(object):\n \"\"\"Iterator class that can be used to loop over the bins of a\n one-dimensional histogram.\"\"\"\n\n def __init__(self,ibin,h):\n self._ibin = ibin\n self._h = h\n\n def set_counts(self,counts):\n self._h._counts[self._ibin] = counts\n\n def bin(self):\n return self._ibin\n\n def counts(self):\n return self._h.counts(self._ibin)\n\n def center(self):\n return self._h.axis().center[self._ibin]\n\n def lo_edge(self):\n return self._h.axis().edges[self._ibin]\n\n def hi_edge(self):\n return self._h.axis().edges[self._ibin+1]\n\n def next(self):\n\n self._ibin += 1\n\n if self._ibin == self._h.nbins:\n raise StopIteration\n else:\n return self\n\n def __iter__(self):\n return self\n\n\nclass Axis(object):\n \"\"\"Axis object representing a sequence of coordinate bins in one\n dimension. Axis objects are used to define the N-dimensional\n space of the histogram class.\"\"\"\n\n def __init__(self,edges,nbins=None,name=None,label=None,units=None):\n \"\"\"Construct an axis object from a sequence of bins edges.\"\"\"\n\n self._name = name\n self._label = label\n self._units = units\n\n edges = np.array(edges,copy=True)\n\n if len(edges) < 2:\n raise ValueError(\"Axis must be initialized with at least two \"\n \"bin edges.\")\n\n if not nbins is None:\n edges = np.linspace(edges[0],edges[-1],nbins+1)\n\n self._edges = edges\n self._nbins = len(edges)-1\n self._xmin = self._edges[0]\n self._xmax = self._edges[-1]\n self._center = 0.5*(self._edges[1:] + self._edges[:-1])\n self._err = 0.5*(self._edges[1:] - self._edges[:-1])\n self._width = 2*self._err\n\n @staticmethod\n def createFromDict(d):\n\n c = copy.deepcopy(d)\n\n if not 'label' in c: c['label'] = None\n \n if 'edges' in c: return Axis(c['edges'],label=c['label'])\n elif 'lo' in c: return Axis.create(c['lo'],c['hi'],c['nbin'],\n label=c['label'])\n\n \n @staticmethod\n def create(lo,hi,nbin,label=None):\n \"\"\"Create an axis object given lower and upper bounds for the\n coordinate and a number of bins.\"\"\"\n return Axis(np.linspace(lo,hi,nbin+1),label=label)\n\n @staticmethod\n def createFromArray(x,label=None):\n if len(x) == 1: delta = 0.5\n else: delta = x[1]-x[0]\n return Axis.create(x[0]-0.5*delta,x[-1]+0.5*delta,len(x),label=label)\n\n def slice(self,lobin,hibin):\n if hibin is None: hibin = self._nbins\n if lobin < 0: lobin -= 1\n \n edges = self._edges[lobin:hibin+1] \n return Axis(edges,label=self._label)\n\n @property\n def nbins(self):\n return self._nbins\n\n @property\n def shape(self):\n return (self._nbins,)\n \n def label(self):\n return self._label\n\n def lims(self):\n return (self._edges[0],self._edges[-1])\n \n def lo_edge(self):\n return self._edges[0]\n\n def hi_edge(self):\n return self._edges[-1]\n\n def bins(self):\n return np.array(range(self._nbins))\n\n @property\n def edges(self):\n \"\"\"Return array of bin edges.\"\"\"\n return self._edges\n\n @property\n def width(self):\n \"\"\"Return array of bin widths.\"\"\"\n return self._width\n\n @property\n def center(self):\n \"\"\"Return array of bin centers.\"\"\"\n return self._center\n\n def binToVal(self,ibin,interpolate=False):\n \"\"\"Convert bin index to axis coordinate.\"\"\"\n\n if not interpolate: return self._center[ibin]\n else: interpolate(np.linspace(0,self._nbins,self.nbins+1),\n self.edges,bin)\n \n def valToBin(self,x):\n \"\"\"Convert axis coordinate to bin index.\"\"\"\n ibin = np.digitize(np.array(x,ndmin=1),self._edges)-1\n return ibin\n \n def valToBinBounded(self,x):\n ibin = self.valToBin(x)\n ibin[ibin < 0] = 0\n ibin[ibin > self.nbins-1] = self.nbins-1\n return ibin\n\n def __str__(self):\n return '%i %s'%(self._nbins,self._edges)\n\nclass Histogram(HistogramND):\n \"\"\"One-dimensional histogram class. Each bin is assigned both a\n content value and an error. Non-equidistant bin edges can be\n defined with an input bin edge array. Supports multiplication,\n addition, and division by a scalar or another histogram object.\"\"\"\n\n default_style = { 'marker' : None,\n 'markersize' : None,\n 'color' : None,\n 'drawstyle' : 'default',\n 'markerfacecolor' : None,\n 'markeredgecolor' : None,\n 'linestyle' : None,\n 'linewidth' : 1,\n 'label' : None,\n 'hist_style' : 'errorbar',\n 'hist_xerr' : None,\n 'hist_yerr' : None,\n 'msk' : None,\n 'max_frac_error' : None }\n\n def __init__(self,axis,counts=None,var=None,\n style=None,label = '__nolabel__'):\n \"\"\"\n Create a 1D histogram object.\n \n @param axis: Axis object or array of bin edges.\n @param label: Label for this histogram.\n @param counts: Vector of bin values. The histogram will be\n initialized with this vector when this argument is defined.\n If this is a scalar its value will be used to initialize all\n bins in the histogram.\n @param var: Vector of bin variances.\n @param style: Style dictionary.\n @return:\n \"\"\"\n\n super(Histogram, self).__init__([axis],counts,var,label=label)\n\n self._underflow = 0\n self._overflow = 0\n\n self._style = copy.deepcopy(Histogram.default_style)\n update_dict(self._style,style)\n self._style['label'] = label\n \n\n def iterbins(self):\n \"\"\"Return an iterator object that steps over the bins in this\n histogram.\"\"\"\n return HistogramIterator(-1,self)\n\n @staticmethod\n def createEfficiencyHistogram(htot,hcut,label = '__nolabel__'):\n \"\"\"Create a histogram of cut efficiency.\"\"\"\n\n h = Histogram(htot.axis(),label=label)\n eff = hcut._counts/htot._counts\n\n h._counts = eff\n h._var = eff*(1-eff)/htot._counts\n\n return h\n\n @staticmethod\n def createFromTree(t,varname,cut,hdef=None,fraction=0.0,\n label = '__nolabel__'):\n\n from ROOT import gDirectory\n\n draw = '%s>>hist'%(varname)\n\n if not hdef is None:\n draw += '(%i,%f,%f)'%(hdef[0],hdef[1],hdef[2])\n\n nevent = t.GetEntries()\n first_entry = int(nevent*fraction)\n\n t.Draw(draw,cut,'goff',nevent,first_entry)\n h = gDirectory.Get('hist')\n h.SetDirectory(0)\n return Histogram.createFromTH1(h,label=label)\n\n @staticmethod\n def createFromTH1(hist,label = '__nolabel__'):\n n = hist.GetNbinsX()\n xmin = hist.GetBinLowEdge(1)\n xmax = hist.GetBinLowEdge(n+1)\n\n h = Histogram(np.linspace(xmin,xmax,n+1),label=label)\n h._counts = np.array([hist.GetBinContent(i) for i in range(1, n + 1)])\n h._var = np.array([hist.GetBinError(i)**2 for i in range(1, n + 1)])\n h._underflow = hist.GetBinContent(0)\n h._overflow = hist.GetBinContent(n+1)\n\n return h\n \n @staticmethod\n def createHistModel(xedge,ncount,min_count=0):\n\n if np.sum(ncount) == 0: return Histogram(xedge)\n\n h = Histogram(xedge)\n h._counts = copy.deepcopy(ncount)\n h._var = copy.deepcopy(ncount)\n h = h.rebin_mincount(min_count)\n\n ncum = np.concatenate(([0],np.cumsum(h._counts)))\n fn = UnivariateSpline(h.axis().edges,ncum,s=0,k=1)\n mu_count = fn(xedge[1:])-fn(xedge[:-1])\n mu_count[mu_count<0] = 0\n\n return Histogram(xedge,counts=mu_count,var=copy.deepcopy(mu_count))\n \n def to_root(self,name,title=None):\n\n if title is None: title=name\n \n import ROOT\n h = ROOT.TH1F(name,title,self.axis().nbins,\n self.axis().lo_edge(),self.axis().hi_edge())\n\n for i in range(self.axis().nbins):\n h.SetBinContent(i+1,self._counts[i])\n h.SetBinError(i+1,np.sqrt(self._var[i]))\n\n return h\n \n def update_artists(self,artists):\n \n artists[0].set_ydata(self.counts)\n artists[0].set_xdata(self.axis().center)\n\n if len(artists[1]) == 0: return\n\n x = self.axis().center\n y = self.counts\n xerr = np.abs(0.5*self.axis().width)\n yerr = self.err\n\n error_positions = (x-xerr,y), (x+xerr,y), (x,y-yerr), (x,y+yerr) \n\n # Update the caplines \n for i,pos in enumerate(error_positions): \n artists[1][i].set_data(pos) \n\n sx = np.array([[x - xerr, y], [x + xerr, y]]).transpose(2,0,1)\n sy = np.array([[x, y-yerr], [x, y+yerr]]).transpose(2,0,1)\n\n artists[2][0].set_segments(sx)\n artists[2][1].set_segments(sy)\n\n def update_style(self,style):\n update_dict(self._style,style)\n\n def label(self):\n return self._style['label']\n\n def _band(self,ax=None,style='step',alpha=0.2,mask_neg=False,**kwargs):\n if ax is None: ax = plt.gca()\n\n kw = extract_dict_by_keys(kwargs,MPLUtil.errorbar_kwargs)\n clear_dict_by_vals(kw,None)\n\n kw_fill = extract_dict_by_keys(kwargs,MPLUtil.fill_kwargs)\n clear_dict_by_vals(kw_fill,None)\n kw_fill['alpha'] = alpha\n\n artists = []\n \n if style=='step':\n xedge = self._axes[0].edges\n x = np.vstack((xedge[:-1],xedge[1:],xedge[1:])).ravel([-1])\n y = np.vstack((self.counts,\n self.counts,\n self.counts)).ravel([-1])\n\n yerr = np.vstack((self.err,\n self.err,\n self.err)).ravel([-1])\n \n ebar = ax.errorbar(x,y,**kw)\n kw_fill['color'] = ebar[0].get_color()\n if mask_neg: kw_fill['where']=y-yerr>0\n ax.fill_between(x,y-yerr,y+yerr,**kw_fill)\n elif style=='center':\n\n ebar = ax.errorbar(self._axes[0].center,self.counts,**kw)\n kw_fill['color'] = ebar[0].get_color()\n if mask_neg: kw_fill['where']=self.counts-self.err>0\n ax.fill_between(self._axes[0].center,\n self.counts+self.err,\n self.counts-self.err,**kw_fill)\n else:\n raise Exception('Unrecognized band style: ', style)\n\n if 'where' in kw_fill: kw_fill.pop('where')\n \n patch, = [ax.add_patch(plt.Rectangle((0,0),0,0,**kw_fill))]\n \n artists += [ebar]\n artists += [patch]\n\n return artists\n\n\n def _errorbar(self, label_rotation=0,\n label_alignment='center', ax=None, \n counts=None, x=None,**kwargs):\n \"\"\"\n Draw this histogram in the 'errorbar' style.\n\n All additional keyword arguments will be passed to\n :func:`matplotlib.pyplot.errorbar`.\n \"\"\"\n style = kwargs\n\n if ax is None: ax = plt.gca()\n if counts is None: counts = self._counts\n if x is None: x = self._axes[0].center\n\n if style['msk'] is None:\n msk = np.empty(len(counts),dtype='bool'); msk.fill(True)\n else:\n msk = style['msk']\n \n xerr = None\n yerr = None\n\n if style['hist_xerr'] or style['hist_xerr'] is None:\n xerr = self._axes[0].width[msk]/2.\n if style['hist_yerr'] or style['hist_yerr'] is None:\n yerr = np.sqrt(self._var[msk])\n if not style.has_key('fmt'): style['fmt'] = '.'\n\n kw = extract_dict_by_keys(style,MPLUtil.errorbar_kwargs)\n clear_dict_by_vals(kw,None)\n\n ebar = ax.errorbar(x[msk], counts[msk],xerr=xerr,yerr=yerr,**kw)\n self._prepare_xaxis(label_rotation, label_alignment)\n return [ebar]\n\n def hist(self,ax=None,counts=None,**kwargs):\n \"\"\"Plot this histogram using the 'hist' matplotlib method.\"\"\"\n if ax is None: ax = plt.gca()\n if counts is None: counts = self._counts\n\n style = kwargs\n \n kw = extract_dict_by_keys(style,MPLUtil.hist_kwargs)\n clear_dict_by_vals(kw,None)\n \n hist = ax.hist(self._axes[0].center, self._axes[0].nbins,\n range=[self._axes[0].lo_edge(),self._axes[0].hi_edge()],\n weights=counts,**kw)\n return [hist]\n\n\n def plot(self,ax=None,overflow=False,**kwargs):\n \"\"\"\n Draw this histogram in the 'plot' style.\n\n All additional keyword arguments will be passed to\n :func:`matplotlib.pyplot.plot`.\n\n Returns an array of matplotlib artists.\n \"\"\"\n\n style = copy.deepcopy(self._style)\n style.update(kwargs)\n\n if ax is None: ax = plt.gca()\n if style['msk'] is None:\n style['msk'] = np.empty(self._axes[0].nbins,dtype='bool')\n style['msk'].fill(True)\n \n if overflow:\n c = copy.deepcopy(self._counts)\n c[0] += self._underflow\n c[-1] += self._overflow\n else:\n c = self._counts\n\n if not style['max_frac_error'] is None:\n frac_err = np.sqrt(self._var)/self._counts\n style['msk'] = frac_err <= style['max_frac_error']\n\n hs = style['hist_style']\n\n if hs == 'errorbar':\n return self._errorbar(ax=ax,counts=c,**style)\n elif hs == 'line':\n\n style['marker'] = 'None'\n style['hist_xerr'] = False\n style['hist_yerr'] = False\n style['fmt'] = '-'\n return self._errorbar(ax=ax,counts=c,**style)\n elif hs == 'stepfilled' or hs == 'bar':\n\n style['histtype'] = hs\n \n# draw_style['linewidth'] = 0\n# del draw_style['linestyle']\n # del draw_style['marker']\n # del draw_style['drawstyle']\n\n return self.hist(ax=ax,counts=c,**style)\n elif hs == 'step':\n \n c = np.concatenate(([0],c,[0]))\n edges = np.concatenate((self._axes[0].edges,\n [self._axes[0].edges[-1]]))\n# msk = np.concatenate((msk,[True]))\n style['hist_xerr'] = False\n style['hist_yerr'] = False\n style['fmt'] = '-'\n style['drawstyle'] = 'steps-pre'\n style['marker'] = 'None'\n return self._errorbar(ax=ax,counts=c,\n x=edges,**style)\n\n elif hs == 'band' or hs == 'band_step' :\n return self._band(style='step',**style) \n elif hs == 'band_center' :\n return self._band(style='center',**style) \n else:\n raise Exception('Unrecognized style: ' + hs)\n\n def scale_density(self,fn):\n\n h = copy.deepcopy(self)\n\n for i in range(self.axis().nbins):\n xhi = fn(self.axis().edges[i+1])\n xlo = fn(self.axis().edges[i])\n\n area = xhi - xlo\n\n h._counts[i] /= area\n h._var[i] /= area**2\n\n return h\n\n def nbins(self):\n \"\"\"Return the number of bins in this histogram.\"\"\"\n return self._axes[0].nbins\n\n def underflow(self):\n return self._underflow\n\n def overflow(self):\n return self._overflow\n\n def stddev(self):\n \"\"\"Comput the standard deviation of this histogram.\"\"\"\n m = self.mean()\n n = np.sum(self.counts)\n dx = self.axis().center - m \n return np.sqrt(np.sum(self.counts*dx**2)/n)\n \n def mean(self):\n x = self.axis().center\n return np.sum(self.counts*x)/np.sum(self.counts)\n \n def sum(self,overflow=False):\n \"\"\"Return the sum of counts in this histogram.\"\"\"\n\n s = 0\n if overflow:\n s = np.sum(self._counts) + self._overflow + self._underflow\n else:\n s = np.sum(self._counts)\n\n return np.array([s,np.sqrt(np.sum(self._var))])\n\n def cumulative(self,lhs=True):\n \"\"\"Convert this histogram to its cumulative distribution.\"\"\"\n\n if lhs:\n counts = np.cumsum(self._counts)\n var = np.cumsum(self._var)\n else:\n counts = np.cumsum(self._counts[::-1])[::-1]\n var = np.cumsum(self._var[::-1])[::-1]\n\n return Histogram(self._axes[0].edges,\n counts=counts,var=var,label=self.label())\n\n def getBinByValue(self,x):\n return np.argmin(np.abs(self._x-x))\n\n def interpolate(self,x,noerror=True):\n \n x = np.array(x,ndmin=1)\n c = interpolate(self._axes[0].center,self._counts,x)\n v = interpolate(self._axes[0].center,self._var,x)\n\n if noerror:\n return c\n else:\n if len(x)==1: return np.array([c[0],np.sqrt(v)[0]])\n else: return np.vstack((c,np.sqrt(v)))\n\n def merge(self,h):\n edges = np.concatenate((h.axis().edges,\n self.axis().edges))\n edges = np.unique(edges)\n o = Histogram(edges)\n o.fill(h.axis().center,h.counts)\n o.fill(self.axis().center,self.counts)\n return o\n\n def normalize(self):\n\n s = np.sum(self._counts)\n\n counts = self._counts/s\n var = self._var/s**2\n\n return Histogram(self._axes[0],\n counts=counts,var=var,label=self.label())\n\n def quantile(self,fraction=0.68,method='var',niter=100,**kwargs):\n\n if method == 'var':\n\n cs = np.concatenate(([0],self.counts))\n vs = np.concatenate(([0],self.var))\n \n return get_quantile_error(self.axis().edges,cs,vs,fraction)\n elif method == 'bootstrap_poisson':\n\n c = np.random.poisson(np.concatenate(([0],self.counts)),\n (niter,self.axis().nbins+1))\n\n xq = [] \n for i in range(niter):\n xq.append(get_quantile(self.axis().edges,c[i],fraction))\n\n q = get_quantile(self.axis().edges,\n np.concatenate(([0],self.counts)),fraction)\n qvar = np.std(np.array(xq))**2\n\n return q, qvar\n \n# import stats\n# return stats.HistQuantile(self).eval(fraction,**kwargs)\n\n def central_quantile(self,fraction=0.68,unbias_method='median',\n method='bootstrap_poisson'):\n\n if unbias_method == 'median': loc = self.quantile(fraction=0.5)[0]\n elif unbias_method == 'mean': loc = self.mean()\n else:\n raise('Exception')\n\n delta_max = max(loc-self.axis().center)\n \n habs = Histogram(Axis.create(0,delta_max,self._axes[0].nbins*2))\n habs.fill(np.abs(self.axis().center-loc),\n self._counts,var=self._var)\n \n return habs.quantile(fraction,method=method,niter=100)\n \n def chi2(self,model,min_counts=None):\n\n msk = (self._var > 0)\n if not min_counts is None:\n msk &= (self._counts>5)\n\n if isinstance(model,Histogram):\n diff = self._counts[msk] - model._counts[msk]\n else:\n diff = self._counts[msk] - model(self._axes[0].center)[msk]\n\n chi2 = np.sum(np.power(diff,2)/self._var[msk])\n ndf = len(msk[msk==True])\n\n pval = 1 - stats.chi2.cdf(chi2, ndf)\n return [chi2,ndf,pval]\n\n def set(self,i,w,var=None):\n self._counts[i] = w\n if not var is None: self._var[i] = var\n \n def fill(self,x,w=1,var=None):\n \"\"\"\n Add counts to the histogram at the coordinates given in the\n array x. By default each point is given unit weight. The\n weight assigned to each element of x can be specified by\n providing a scalar or vector for the w argument.\n \"\"\"\n x = np.array(x,ndmin=1,copy=True)\n w = np.array(w,ndmin=1,copy=True)\n if len(x) == 0: return\n if len(w) < len(x): w = np.ones(len(x))*w\n \n if var is None: var = w\n else:\n var = np.array(var,ndmin=1,copy=True)\n if len(var) < len(w): var = np.ones(len(w))*var\n \n if w.ndim == 1:\n\n if self._axes[0].lo_edge() > self._axes[0].hi_edge(): \n c1 = np.histogram(x,bins=self._axes[0].edges[::-1],\n weights=w)[0][::-1]\n c2 = np.histogram(x,bins=self._axes[0].edges[::-1],\n weights=var)[0][::-1]\n else:\n c1 = np.histogram(x,bins=self._axes[0].edges,weights=w)[0]\n c2 = np.histogram(x,bins=self._axes[0].edges,weights=var)[0]\n \n self._counts += c1\n self._var += c2\n\n if np.any(x>=self._axes[0].hi_edge()):\n self._overflow += np.sum(w[x>=self._axes[0].hi_edge()])\n if np.any(x<self._axes[0].lo_edge()):\n self._underflow += np.sum(w[x<self._axes[0].lo_edge()])\n\n else:\n c = np.histogram(x,bins=self._axes[0].edges)[0]\n\n self._counts += w*c\n self._var += var*c\n\n if np.any(x>=self._axes[0].hi_edge()):\n self._overflow += np.sum(x>=self._axes[0].hi_edge())\n if np.any(x<self._axes[0].lo_edge()):\n self._underflow += np.sum(x<self._axes[0].lo_edge())\n\n\n def rebin_mincount(self,min_count,max_bins=None):\n \"\"\"Return a rebinned copy of this histogram such that all bins\n have an occupation of at least min_count.\n \n Parameters\n ----------\n\n min_count : int\n Minimum occupation of each bin.\n\n max_bins : int\n Maximum number of bins that can be combined.\n \n \"\"\"\n\n bins = [0]\n c = np.concatenate(([0],np.cumsum(self._counts)))\n\n for ibin in range(self._axes[0].nbins+1):\n\n nbin = ibin-bins[-1] \n if not max_bins is None and nbin > max_bins:\n bins.append(ibin)\n elif c[ibin] - c[bins[-1]] >= min_count or \\\n ibin == self._axes[0].nbins:\n bins.append(ibin)\n\n return self.rebin(bins)\n\n def rebin_range(self,n=2,xmin=0,xmax=0):\n\n bins = []\n\n i = 0\n while i < self._axes[0].nbins:\n\n if xmin != xmax and self._axes[0].center[i] >= xmin and \\\n self._axes[0].center[i] <= xmax:\n\n m = n\n if i+n > self._axes[0].nbins:\n m = self._axes[0].nbins-i\n\n i+= m\n bins.append(m)\n else:\n i+= 1\n bins.append(1)\n\n return self.rebin(bins)\n\n\n def rebin(self,bins=2):\n\n if bins <= 1: return copy.deepcopy(self)\n\n bins = np.array(bins)\n\n if bins.ndim == 0:\n bin_index = range(0,self._axes[0].nbins,bins)\n bin_index.append(self._axes[0].nbins)\n bin_index = np.array(bin_index)\n else:\n# if np.sum(bins) != self._axes[0].nbins:\n# raise ValueError(\"Sum of bins is not equal to histogram bins.\")\n bin_index = bins\n\n#np.concatenate((np.array([0],dtype='int'),\n# np.cumsum(bins,dtype='int')))\n\n xedges = self._axes[0].edges[bin_index]\n\n h = Histogram(xedges,label=self.label())\n h.fill(self.axis().center,self._counts,self._var)\n return h\n\n def rebin_axis(self,axis):\n\n h = Histogram(axis,style=self._style)\n h.fill(self.axis().center,self._counts,self._var)\n return h\n\n def residual(self,h):\n \"\"\"\n Generate a residual histogram.\n\n @param h: Input histogram\n @return: Residual histogram\n \"\"\"\n o = copy.deepcopy(self)\n o -= h\n return o/h\n\n def dump(self,outfile=None):\n\n if not outfile is None:\n f = open(outfile,'w')\n else:\n f = sys.stdout\n\n for i in range(len(self._x)):\n s = '%5i %10.5g %10.5g '%(i,self._axes[0].edges[i],\n self._axes[0].edges[i+1])\n s += '%10.5g %10.5g\\n'%(self._counts[i],self._var[i])\n f.write(s)\n\n\n def fit(self,expr,p0):\n\n import ROOT\n import re\n\n g = ROOT.TGraphErrors()\n f1 = ROOT.TF1(\"f1\",expr)\n# f1.SetDirectory(0)\n\n for i in range(len(p0)): f1.SetParameter(i,p0[i])\n\n npar = len(tuple(re.finditer('\\[([\\d]+)\\]',expr)))\n for i in range(self._axes[0].nbins):\n g.SetPoint(i,self._axes[0].center[i],self._counts[i])\n g.SetPointError(i,0.0,self._counts[i]*0.1)\n\n g.Fit(\"f1\",\"Q\")\n\n p = np.zeros(npar)\n for i in range(npar): p[i] = f1.GetParameter(i)\n return p\n\n def find_root(self,y,x0=None,x1=None):\n \"\"\"Solve for the x coordinate at which f(x)-y=0 where f(x) is\n a smooth interpolation of the histogram contents.\"\"\"\n\n fn = UnivariateSpline(self._axes[0].center,self._counts,k=2,s=0)\n\n if x0 is None: x0 = self._axes[0].lo_edge()\n if x1 is None: x1 = self._axes[0].hi_edge()\n\n return brentq(lambda t: fn(t) - y,x0,x1)\n\n def find_max(self,msk=None):\n\n if msk is None:\n msk = np.empty(self._axes[0].nbins,dtype='bool'); msk.fill(True)\n\n return np.argmax(self._counts[msk])\n\n\n def __mul__(self,x):\n\n o = copy.deepcopy(self)\n\n if isinstance(x, Histogram):\n\n y1 = self._counts\n y2 = x._counts\n y1v = self._var\n y2v = x._var\n\n f0 = np.zeros(self.axis().nbins)\n f1 = np.zeros(self.axis().nbins)\n\n f0[y1 != 0] = y1v/y1**2\n f1[y2 != 0] = y2v/y2**2\n\n o._counts = y1*y2\n o._var = x._counts**2*(f0+f1)\n else:\n o._counts *= x\n o._var *= x*x\n\n return o\n\n def __div__(self,x):\n\n if isinstance(x, Histogram):\n o = copy.deepcopy(self)\n\n y1 = self._counts\n y2 = x._counts\n y1_var = self._var\n y2_var = x._var\n\n msk = ((y1!=0) & (y2!=0))\n\n o._counts[~msk] = 0.\n o._var[~msk] = 0.\n \n o._counts[msk] = y1[msk] / y2[msk]\n o._var[msk] = (y1[msk] / y2[msk])**2\n o._var[msk] *= (y1_var[msk]/y1[msk]**2 + y2_var[msk]/y2[msk]**2)\n\n return o\n else:\n x = np.array(x,ndmin=1)\n msk = x != 0\n x[msk] = 1./x[msk]\n x[~msk] = 0.0\n return self.__mul__(x)\n\n def _prepare_xaxis(self, rotation=0, alignment='center'):\n \"\"\"Apply bounds and text labels on x axis.\"\"\"\n# if self.binlabels is not None:\n# plt.xticks(self._x, self.binlabels,\n# rotation=rotation, ha=alignment)\n plt.xlim(self._axes[0].edges[0], self._axes[0].edges[-1])\n\n\n\n\n\nclass Histogram2D(HistogramND):\n\n default_style = { 'keep_aspect' : False, \n 'logz' : False,\n 'levels' : None, \n 'shading' : 'flat',\n 'interpolation' : 'nearest' }\n\n def __init__(self, xaxis, yaxis, \n counts=None, var=None, style=None,\n label = '__nolabel__'):\n\n super(Histogram2D, self).__init__([xaxis,yaxis],counts,var,label=label)\n\n self._xaxis = self._axes[0]\n self._yaxis = self._axes[1]\n\n self._nbins = self._xaxis.nbins*self._yaxis.nbins\n\n self._style = copy.deepcopy(Histogram2D.default_style)\n update_dict(self._style,style)\n self._style['label'] = label\n\n @staticmethod\n def createFromTree(t,vars,axes,cut,fraction=0.0,\n label = '__nolabel__'):\n\n from ROOT import gDirectory\n\n draw = '%s:%s>>hist'%(vars[1],vars[0])\n\n if not axes is None:\n draw += '(%i,%f,%f,%i,%f,%f)'%(axes[0].nbins,\n axes[0].lo_edge(),axes[0].hi_edge(),\n axes[1].nbins,\n axes[1].lo_edge(),axes[1].hi_edge())\n\n nevent = t.GetEntries()\n first_entry = int(nevent*fraction)\n\n ncut = t.Draw(draw,cut,'goff',nevent,first_entry)\n\n h = gDirectory.Get('hist')\n h.SetDirectory(0)\n return Histogram2D.createFromTH2(h)\n\n @staticmethod\n def createFromTH2(hist,label = '__nolabel__'):\n nx = hist.GetNbinsX()\n ny = hist.GetNbinsY()\n\n xmin = hist.GetXaxis().GetBinLowEdge(1)\n xmax = hist.GetXaxis().GetBinLowEdge(nx+1)\n\n ymin = hist.GetYaxis().GetBinLowEdge(1)\n ymax = hist.GetYaxis().GetBinLowEdge(ny+1)\n\n xaxis = Axis.create(xmin,xmax,nx)\n yaxis = Axis.create(ymin,ymax,ny)\n\n counts = np.zeros(shape=(nx,ny))\n var = np.zeros(shape=(nx,ny))\n\n for ix in range(1,nx+1):\n for iy in range(1,ny+1):\n counts[ix-1][iy-1] = hist.GetBinContent(ix,iy)\n var[ix-1][iy-1] = hist.GetBinError(ix,iy)**2\n\n style = {}\n style['label'] = label\n\n h = Histogram2D(xaxis,yaxis,counts=counts,var=var,style=style)\n\n return h\n\n def to_root(self,name,title=None):\n\n if title is None: title=name\n \n import ROOT\n h = ROOT.TH2F(name,title,self.xaxis().nbins,\n self.xaxis().lo_edge(),self.xaxis().hi_edge(),\n self.yaxis().nbins,\n self.yaxis().lo_edge(),self.yaxis().hi_edge())\n\n for i in range(self.xaxis().nbins):\n for j in range(self.yaxis().nbins):\n h.SetBinContent(i+1,j+1,self._counts[i,j])\n h.SetBinError(i+1,j+1,np.sqrt(self._var[i,j]))\n\n return h\n \n def label(self):\n return self._style['label']\n \n def update_style(self,style):\n update_dict(self._style,style)\n\n def nbins(self,idim=None):\n \"\"\"Return the number of bins in this histogram.\"\"\"\n if idim is None: return self._nbins\n elif idim == 0: return self.xaxis().nbins\n elif idim == 1: return self.yaxis().nbins\n else: return 0\n\n def xaxis(self):\n return self._axes[0]\n\n def yaxis(self):\n return self._axes[1]\n\n def lo_edge(self,ix,iy):\n return (self._xaxis.edges[ix],self._yaxis.edges[iy])\n\n def hi_edge(self,ix,iy):\n return (self._xaxis.edges[ix+1],self._yaxis.edges[iy+1])\n\n def maxIndex(self,ix_range=None,iy_range=None):\n \"\"\"Return x,y indices of maximum histogram element.\"\"\"\n\n if ix_range is None: ix_range = [0,self._xaxis.nbins+1]\n elif len(ix_range) == 1: ix_range = [ix_range[0],self._xaxis.nbins+1]\n\n if iy_range is None: iy_range = [0,self._yaxis.nbins+1]\n elif len(iy_range) == 1: iy_range = [iy_range[0],self._yaxis.nbins+1]\n\n a = np.argmax(self._counts[ix_range[0]:ix_range[1],\n iy_range[0]:iy_range[1]])\n\n cv = self._counts[ix_range[0]:ix_range[1],iy_range[0]:iy_range[1]]\n ixy = np.unravel_index(a,cv.shape)\n return (ixy[0]+ix_range[0],ixy[1]+iy_range[0])\n\n def interpolate(self,x,y):\n from util import interpolate2d\n\n x = np.array(x,ndmin=1)\n y = np.array(y,ndmin=1)\n \n xv, shape = expand_array(x,y)\n v = interpolate2d(self._xaxis.center,\n self._yaxis.center,self._counts,xv[0],xv[1])\n\n return v.reshape(shape)\n \n def integrate(self,iaxis=1,bin_range=None):\n if iaxis == 1:\n\n if bin_range is None: bin_range = [0,self._yaxis.nbins]\n\n h = Histogram(self._xaxis.edges)\n for iy in range(bin_range[0],bin_range[1]):\n h._counts[:] += self._counts[:,iy]*self._ywidth[iy]\n h._var[:] += self._var[:,iy]*self._ywidth[iy]**2\n\n return h\n\n\n def marginalize(self,iaxis,bin_range=None):\n \"\"\"Return 1D histogram marginalized over x or y dimension.\n\n @param: iaxis Dimension over which to marginalize.\n \"\"\"\n\n h = Histogram(self._axes[(iaxis+1)%2],style=self._style) \n\n if iaxis == 1:\n\n if bin_range is None: \n h._counts = np.apply_over_axes(np.sum,self._counts,[1]).reshape(h._counts.shape)\n h._var = np.apply_over_axes(np.sum,self._var,[1]).reshape(h._counts.shape)\n else:\n c = self._counts[:,bin_range[0]:bin_range[1]]\n v = self._var[:,bin_range[0]:bin_range[1]]\n\n h._counts = np.apply_over_axes(np.sum,c,[1]).reshape(h._counts.shape)\n h._var = np.apply_over_axes(np.sum,v,[1]).reshape(h._counts.shape)\n else:\n\n if bin_range is None: \n h._counts = np.apply_over_axes(np.sum,self._counts,[0]).reshape(h._counts.shape)\n h._var = np.apply_over_axes(np.sum,self._var,[0]).reshape(h._counts.shape)\n else:\n c = self._counts[bin_range[0]:bin_range[1],:]\n v = self._var[bin_range[0]:bin_range[1],:]\n\n h._counts = np.apply_over_axes(np.sum,c,[0]).reshape(h._counts.shape)\n h._var = np.apply_over_axes(np.sum,v,[0]).reshape(h._counts.shape)\n\n return h\n\n def mean(self,iaxis,**kwargs):\n\n hq = Histogram(self._xaxis.edges)\n\n for i in range(self.nbins(0)):\n h = self.slice(iaxis,i)\n\n x = h.axis().center\n\n mean = np.sum(h.counts*x)/np.sum(h.counts)\n mean_var = mean**2*(np.sum(h.var*x**2)/np.sum(h.counts*x)**2 +\n np.sum(h.var)/np.sum(h.counts)**2)\n\n hq._counts[i] = mean\n hq._var[i] = mean_var\n\n return hq\n\n# def quantile(self,iaxis,fraction=0.68,**kwargs):\n\n# import stats\n\n# iaxis = (iaxis+1)%2\n\n# hq = Histogram(self._axes[iaxis].edges)\n\n# for i in range(self.nbins(iaxis)):\n# h = self.slice(iaxis,i)\n\n# q,qerr = stats.HistQuantile(h).eval(fraction,**kwargs)\n\n# hq._counts[i] = q\n# hq._var[i] = qerr**2\n\n# return hq\n\n def central_quantile(self,fraction=0.68,unbias_method=None):\n hmed = self.quantile(fraction=0.5)\n hmean = self.mean()\n\n lo_index = np.argmin(np.abs(h.yedges()))\n \n habs = Histogram2D(h.xedges(),h.yedges()[lo_index:])\n \n for i in range(h.nbins(0)):\n\n yc = h.yaxis().center\n \n if unbias_method is None: y = np.abs(yc)\n elif unbias_method == 'median': y = np.abs(yc-hmed.counts(i))\n elif unbias_method == 'mean': y = np.abs(yc-hmean.counts(i))\n\n \n habs.fill(np.ones(h.nbins(1))*h.xaxis().center[i],y,h._counts[i],\n var=h._counts[i])\n \n\n return habs.quantile(fraction=0.68,method='mc',niter=100)\n\n def set(self,ix,iy,w,var=None):\n self._counts[ix,iy] = w\n if not var is None: self._var[ix,iy] = var\n\n def fill(self,x,y,w=1,var=None):\n \n x = np.array(x,copy=True,ndmin=1)\n y = np.array(y,copy=True,ndmin=1)\n\n if len(x) < len(y): x = np.ones(len(y))*x[0]\n if len(y) < len(x): y = np.ones(len(x))*y[0]\n\n HistogramND.fill(self,np.vstack((x,y)),w,var)\n\n def fill2(self,x,y,w=1,var=None):\n\n x = np.array(x,ndmin=1)\n y = np.array(y,ndmin=1)\n w = np.array(w,ndmin=0)\n\n if var is None: var = w\n\n bins = [self._xaxis.edges,self._yaxis.edges]\n\n if w.ndim == 1:\n c1 = np.histogram2d(x,y,bins=bins,weights=w)[0]\n c2 = np.histogram2d(x,y,bins=bins,weights=var)[0]\n\n self._counts += c1\n self._var += c2\n else:\n c = np.histogram2d(x,y,bins=bins)[0]\n\n self._counts += w*c\n self._var += var*c\n\n def smooth(self,sigma):\n\n from scipy import ndimage\n\n sigma_bins = sigma/(self._xaxis.edges[1]-self._xaxis.edges[0])\n\n counts = ndimage.gaussian_filter(self._counts, sigma=sigma_bins)\n var = ndimage.gaussian_filter(self._var, sigma=sigma_bins)\n\n return Histogram2D(self._xaxis,self._yaxis,counts=counts,var=var)\n\n def update_axis_labels(self,ax):\n if not self._axes[0].label() is None:\n ax.set_xlabel(self._axes[0].label())\n if not self._axes[1].label() is None:\n ax.set_ylabel(self._axes[1].label())\n\n def plot(self,ax=None,**kwargs):\n return self.pcolor(ax,**kwargs)\n \n def pcolor(self,ax=None,**kwargs):\n \"\"\"Render this histogram with the matplotlib pcolormesh\n method. This method is generally be preferred over the imshow\n method since it allows non-equidistant bins (which is\n permitted by the Histogram2D class.\"\"\"\n\n style = copy.deepcopy(self._style)\n style.update(kwargs)\n\n if ax is None: ax = plt.gca()\n \n if style['logz']: norm = LogNorm()\n else: norm = Normalize()\n\n xedge, yedge = np.meshgrid(self.axis(0).edges,self.axis(1).edges)\n\n kw = extract_dict_by_keys(style,MPLUtil.pcolormesh_kwargs)\n\n p = ax.pcolormesh(xedge,yedge,self._counts.T,norm=norm,\n **kw)\n\n self.update_axis_labels(ax)\n\n return p\n \n \n def contour(self,ax=None,clabel=False,**kwargs):\n \"\"\"Render this histogram with the matplotlib imshow method.\"\"\"\n# levels = [2.,4.,6.,8.,10.]\n\n style = copy.deepcopy(self._style)\n style.update(kwargs)\n\n if ax is None: ax = plt.gca()\n\n if style['logz']: norm = LogNorm()\n else: norm = Normalize()\n\n kw = extract_dict_by_keys(style,MPLUtil.contour_kwargs)\n kw['origin'] = 'lower'\n \n print kw\n\n cs = plt.contour(self._xaxis.center,self._yaxis.center,\n self._counts.T,**kw)\n if clabel: plt.clabel(cs, fontsize=9, inline=1)\n\n self.update_axis_labels(ax)\n\n return cs\n\n def imshow(self,ax=None,**kwargs):\n \"\"\"Render this histogram with the matplotlib imshow method.\"\"\"\n style = copy.deepcopy(self._style)\n style.update(kwargs)\n\n if ax is None: ax = plt.gca()\n\n dx = self._xaxis.hi_edge() - self._xaxis.lo_edge()\n dy = self._yaxis.hi_edge() - self._yaxis.lo_edge()\n\n aspect_ratio = 1\n if not style['keep_aspect']: aspect_ratio=dx/dy\n\n if style['logz']: norm = LogNorm()\n else: norm = Normalize()\n\n kw = extract_dict_by_keys(style,MPLUtil.imshow_kwargs)\n kw['origin'] = 'lower'\n \n im = ax.imshow(self._counts.transpose(),\n aspect=aspect_ratio,norm=norm,\n extent=[self._xaxis.lo_edge(), self._xaxis.hi_edge(),\n self._yaxis.lo_edge(), self._yaxis.hi_edge()],\n **kw)\n\n self.update_axis_labels(ax)\n\n return im\n\ndef get_vector(chain,var,cut=None,nentries=None,first_entry=0):\n\n if cut is None: cut = ''\n \n chain.SetEstimate(chain.GetEntries())\n if nentries is None: nentries = chain.GetEntries()\n ncut = chain.Draw('%s'%(var),cut,'goff',nentries,first_entry)\n return copy.deepcopy(np.frombuffer(chain.GetV1(),\n count=ncut,dtype='double'))\n\n\nif __name__ == '__main__':\n\n fig = plt.figure()\n\n hnd = HistogramND([np.linspace(0,1,10),\n np.linspace(0,1,10)])\n\n\n\n\n h1d = Histogram([0,10],10)\n\n\n h1d.fill(3.5,5)\n h1d.fill(4.5,3)\n h1d.fill(1.5,5)\n h1d.fill(8.5,1)\n h1d.fill(9.5,1)\n\n\n print h1d.axis().edges\n\n for x in h1d.iterbins():\n print x.center, x.counts\n\n\n h1d.rebin([4,4,2])\n\n print h1d.axis().edges\n \n"
},
{
"alpha_fraction": 0.5162005424499512,
"alphanum_fraction": 0.5456790328025818,
"avg_line_length": 25.077529907226562,
"blob_id": "9544bd519f81286d128fc33b88a9f1af460d2f0d",
"content_id": "8413bf8d92ebdb72fb34b7e7dedb278130cf5414",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19845,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 761,
"path": "/gammatools/core/util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import os\nimport errno\nimport numpy as np\nimport scipy.special as spfn\nimport re\nimport cPickle as pickle\nimport gzip\nimport bisect\nimport inspect\nfrom collections import OrderedDict\n\nfrom scipy.interpolate import UnivariateSpline\nfrom scipy.optimize import brentq\n\nclass Units(object):\n\n s = 1.0\n min = 60.*s\n hr = 60.*min\n day = 24.*hr\n week = 7.*day\n year = 365.*day\n \n pc = 3.08568e18 # pc to cm\n kpc = pc*1e3 # kpc to cm\n msun = 1.98892e33 # solar mass to g\n gev = 1.78266e-24 # gev to g \n mev = 1E-3*gev\n tev = 1E3*gev\n ev = 1E-9*gev\n\n log10_mev = np.log10(mev)\n log10_gev = np.log10(gev)\n log10_tev = np.log10(tev)\n\n _mev = 1./mev\n _gev = 1./gev\n _tev = 1./tev\n\n erg = 1./1.602177E-12*ev\n g = 1.0\n\n m = 1E2\n km = 1E3*m\n\n m2 = m**2\n km2 = km**2\n hr = 3600.\n deg = np.pi/180.\n _deg = deg**(-1)\n deg2 = deg**2\n _deg2 = deg2**(-1)\n\n msun_pc3 = msun*np.power(pc,-3) \n msun_kpc3 = msun*np.power(kpc,-3)\n msun2_pc5 = np.power(msun,2)*np.power(pc,-5)\n msun2_kpc5 = np.power(msun,2)*np.power(kpc,-5)\n gev2_cm5 = np.power(gev,2)\n gev_cm3 = np.power(gev,1)\n gev_cm2 = np.power(gev,1)\n gev_m2 = np.power(gev,1)/m2\n erg_cm2 = erg\n g_cm3 = 1.0\n cm3_s = 1.0\n \n \n @classmethod\n def parse(cls,s):\n\n if not isinstance(s,str): return s\n\n m = re.search('([-+]?[0-9]*\\.?[0-9]+([eE][-+]?[0-9]+)?)(\\s+)?(\\w+)?',s)\n\n if m is None: return s\n\n v = float(m.group(1))\n units = m.group(4)\n \n if not m.group(4) is None:\n v *= cls.__dict__[units]\n\n return v\n\n @classmethod\n def convert(cls,x,from_units,to_units):\n\n u0 = from_units.lower()\n u1 = to_units.lower()\n\n u0 = cls.__dict__[u0]\n \n \n\ndef prettify_xml(elem):\n \"\"\"Return a pretty-printed XML string for the Element.\n \"\"\"\n from xml.dom import minidom\n import xml.etree.cElementTree as et\n\n rough_string = et.tostring(elem, 'utf-8')\n reparsed = minidom.parseString(rough_string)\n return reparsed.toprettyxml(indent=\" \") \n \ndef format_error(v, err, nsig=1, latex=False):\n if err > 0:\n logz = math.floor(math.log10(err)) - (nsig - 1)\n z = 10 ** logz\n err = round(err / z) * z\n v = round(v / z) * z\n\n if latex:\n return '$%s \\pm %s$' % (v, err)\n else:\n return '%s +/- %s' % (v, err)\n\ndef common_prefix(strings):\n \"\"\" Find the longest string that is a prefix of all the strings.\n \"\"\"\n if not strings:\n return ''\n prefix = strings[0]\n for s in strings:\n if len(s) < len(prefix):\n prefix = prefix[:len(s)]\n if not prefix:\n return ''\n for i in range(len(prefix)):\n if prefix[i] != s[i]:\n prefix = prefix[:i]\n break\n return prefix\n\ndef string_to_array(x,delimiter=',',dtype=float):\n return np.array([t for t in x.split(delimiter)],dtype=dtype)\n\ndef tolist(x):\n \"\"\"\n convenience function that takes in a \n nested structure of lists and dictionaries\n and converts everything to its base objects.\n This is useful for dupming a file to yaml.\n \n (a) numpy arrays into python lists\n\n >>> type(tolist(np.asarray(123))) == int\n True\n >>> tolist(np.asarray([1,2,3])) == [1,2,3]\n True\n\n (b) numpy strings into python strings.\n\n >>> tolist([np.asarray('cat')])==['cat']\n True\n\n (c) an ordered dict to a dict\n\n >>> ordered=OrderedDict(a=1, b=2)\n >>> type(tolist(ordered)) == dict\n True\n\n (d) converts unicode to regular strings\n\n >>> type(u'a') == str\n False\n >>> type(tolist(u'a')) == str\n True\n\n (e) converts numbers & bools in strings to real represntation,\n (i.e. '123' -> 123)\n\n >>> type(tolist(np.asarray('123'))) == int\n True\n >>> type(tolist('123')) == int\n True\n >>> tolist('False') == False\n True\n \"\"\"\n if isinstance(x,list):\n return map(tolist,x)\n elif isinstance(x,dict):\n return dict((tolist(k),tolist(v)) for k,v in x.items())\n elif isinstance(x,np.ndarray) or \\\n isinstance(x,np.number):\n # note, call tolist again to convert strings of numbers to numbers\n return tolist(x.tolist())\n# elif isinstance(x,PhaseRange):\n# return x.tolist(dense=True)\n elif isinstance(x,OrderedDict):\n return dict(x)\n elif isinstance(x,basestring) or isinstance(x,np.str):\n x=str(x) # convert unicode & numpy strings \n try:\n return int(x)\n except:\n try:\n return float(x)\n except:\n if x == 'True': return True\n elif x == 'False': return False\n else: return x\n else:\n return x\n\n\ndef update_dict(d0,d1,add_new_keys=False,append=False):\n \"\"\"Recursively update the contents of python dictionary d0 with\n the contents of python dictionary d1.\"\"\"\n\n if d0 is None or d1 is None: return\n \n for k, v in d0.iteritems():\n \n if not k in d1: continue\n\n if isinstance(v,dict) and isinstance(d1[k],dict):\n update_dict(d0[k],d1[k],add_new_keys,append)\n elif isinstance(v,np.ndarray) and append:\n d0[k] = np.concatenate((v,d1[k]))\n else: d0[k] = d1[k]\n\n if add_new_keys:\n for k, v in d1.iteritems(): \n if not k in d0: d0[k] = d1[k]\n \ndef clear_dict_by_vals(d,vals):\n\n if not isinstance(vals,list): vals = [vals]\n\n for k in d.keys(): \n if d[k] in vals: del d[k]\n\ndef extract_dict_by_keys(d,keys,exclusive=False):\n \"\"\"Extract a subset of the input dictionary. If exclusive==False\n the output dictionary will contain all elements with keys in the\n input key list. If exclusive==True the output dictionary will\n contain all elements with keys not in the key list.\"\"\"\n\n if exclusive:\n return dict((k, d[k]) for k in d.keys() if not k in keys)\n else:\n return dict((k, d[k]) for k in d.keys() if k in keys)\n\ndef dispatch_jobs(exe,args,opts,queue=None,\n resources='rhel60',skip=None,split_args=True):\n\n skip_keywords = ['queue','resources','batch']\n\n if not skip is None: skip_keywords += skip\n \n if queue is None and 'queue' in opts.__dict__ and \\\n not opts.queue is None:\n queue = opts.queue\n \n cmd_opts = ''\n for k, v in opts.__dict__.iteritems():\n if k in skip_keywords: continue \n if isinstance(v,list): continue\n\n if isinstance(v,bool) and v: cmd_opts += ' --%s '%(k)\n elif isinstance(v,bool): continue\n elif not v is None: cmd_opts += ' --%s=\\\"%s\\\" '%(k,v)\n \n if split_args:\n\n for x in args:\n cmd = '%s %s '%(exe,x)\n batch_cmd = 'bsub -q %s -R %s '%(queue,resources)\n batch_cmd += ' %s %s '%(cmd,cmd_opts) \n print batch_cmd\n os.system(batch_cmd)\n\n else:\n cmd = '%s %s '%(exe,' '.join(args))\n batch_cmd = 'bsub -q %s -R %s '%(queue,resources)\n batch_cmd += ' %s %s '%(cmd,cmd_opts) \n print batch_cmd\n os.system(batch_cmd)\n \n\ndef save_object(obj,outfile,compress=False,protocol=pickle.HIGHEST_PROTOCOL):\n\n if compress:\n fp = gzip.GzipFile(outfile + '.gz', 'wb')\n else:\n fp = open(outfile,'wb')\n pickle.dump(obj,fp,protocol = protocol)\n fp.close()\n\ndef load_object(infile):\n\n if not re.search('\\.gz?',infile) is None:\n fp = gzip.open(infile)\n else:\n fp = open(infile,'rb')\n\n o = pickle.load(fp)\n fp.close()\n return o\n\ndef expand_array(*x):\n \"\"\"Reshape a list of arrays of dimension N such that size of each\n dimension is set to the largest size of any array in the list.\n Every output array has dimension NxM where M = Prod_i =\n max(N_i).\"\"\"\n\n ndim = len(x)\n \n shape = None\n for i in range(len(x)): \n z = np.array(x[i])\n if shape is None: shape = z.shape\n shape = np.maximum(shape,z.shape)\n \n xv = np.zeros((ndim,np.product(shape)))\n for i in range(len(x)):\n xv[i] = np.ravel(np.array(x[i])*np.ones(shape))\n\n return xv, shape\n\ndef bitarray_to_int(x,big_endian=False):\n\n if x.dtype == 'int': return x\n elif x.dtype == 'float': return x.astype('int')\n \n o = np.zeros(x.shape[0],dtype=int)\n\n for i in range(x.shape[1]):\n if big_endian: o += (1<<i)*x[:,::-1][:,i]\n else: o += (1<<i)*x[:,i]\n\n return o\n\n\n\ndef make_dir(d):\n try: os.makedirs(d)\n except os.error, e:\n if e.errno != errno.EEXIST: raise \n\ndef get_parameters(expr):\n m = re.compile('([a-zA-Z])([a-zA-Z0-9\\_\\[\\]]+)')\n pars = []\n\n if expr is None: return pars\n for t in m.finditer(expr):\n pars.append(t.group())\n\n return pars\n\ndef expand_aliases(aliases,expr):\n ignore = ['max','min','sqrt','acos','pow','log','log10']\n m = re.compile('([a-zA-Z])([a-zA-Z0-9\\_\\[\\]]+)')\n\n if expr is None: return expr\n\n has_alias = False\n for t in m.finditer(expr):\n\n var = t.group()\n alias = ''\n if var in aliases: alias = aliases[var]\n \n if var not in ignore and alias != '':\n expr = re.sub(var + '(?![a-zA-Z0-9\\_])',\n '(' + alias + ')',expr)\n has_alias = True\n\n if has_alias: return expand_aliases(aliases,expr)\n else: return expr\n\ndef havsin(theta):\n return np.sin(0.5*theta)**2\n\ndef ahavsin(x):\n return 2.0*np.arcsin(np.sqrt(x))\n\ndef separation_angle_havsin(phiA,lamA,phiB,lamB):\n return ahavsin( havsin(lamA-lamB) + \n np.cos(lamA)*np.cos(lamB)*havsin(phiA-phiB) )\n\ndef separation_angle(ref_ra,ref_dec,ra,dec):\n return np.arccos(np.sin(dec)*np.sin(ref_dec) + \n np.cos(dec)*np.cos(ref_dec)*\n np.cos(ra-ref_ra))\n\n#def dtheta(ref_ra,ref_dec,ra,dec):\n# return np.arccos(np.sin(dec)*np.sin(ref_dec) + \n# np.cos(dec)*np.cos(ref_dec)*\n# np.cos(ra-ref_ra))\n\ndef integrate(fn,lo,hi,npoints):\n edges = np.linspace(lo,hi,npoints+1)\n x = 0.5*(edges[:-1] + edges[1:])\n w = edges[1:] - edges[:-1]\n return np.sum(fn(x)*w)\n\ndef find_root(x,y,y0):\n \"\"\"Solve for the x coordinate at which f(x)-y=0 where f(x) is\n a smooth interpolation of the histogram contents.\"\"\"\n\n fn = UnivariateSpline(x,y-y0,k=2,s=0)\n return brentq(lambda t: fn(t),x[0],x[-1])\n\ndef find_fn_root(fn,x0,x1,y0):\n \"\"\"Solve for the x coordinate at which f(x)-y=0 where f(x) is\n a smooth interpolation of the histogram contents.\"\"\"\n\n return brentq(lambda t: fn(t)-y0,x0,x1)\n\ndef interpolate(x0,z,x):\n \"\"\"Perform linear interpolation in 1 dimension.\n\n Parameters\n ----------\n x0: Array defining coordinate mesh.\n\n z: Array defining the a set of scalar values at the coordinates x0.\n\n x: Point or set of points at which the interpolation should be evaluated.\n\n \"\"\"\n\n x = np.array(x,ndmin=1)\n\n if x0.shape != z.shape:\n raise('Coordinate and value arrays do not have equal dimension.')\n\n wx = x0[1:]-x0[:-1]\n\n ix = np.digitize(x,x0)-1\n ix[ix<0]=0\n ix[ix > x0.shape[0] -2 ] = x0.shape[0] - 2\n xs = (x - x0[:-1][ix])/wx[ix]\n\n return (z[ix]*(1-xs) + z[ix+1]*xs)\n\ndef interpolate2d(x0,y0,z,x,y):\n \"\"\"Perform linear interpolation in 2 dimensions from a 2D mesh.\n\n Parameters\n ----------\n x0: Array defining mesh coordinates in x dimension.\n\n y0: Array defining mesh coordinates in y dimension.\n\n z: Array with the function value evlauted at the set of coordinates\n defined by x0, y0. This must have the dimension N x M where N and M are\n the number of elements in x0 and y0 respectively.\n\n x: X coordinates of point or set of points at which the\n interpolated function should be evaluated. Must have the same dimension\n as y.\n\n y: Y coordinates of point or set of points at which the\n interpolated function should be evaluated. Must have the same dimension\n as x.\n\n \"\"\"\n\n y = np.array(y,ndmin=1)\n x = np.array(x,ndmin=1)\n\n wx = x0[1:]-x0[:-1]\n wy = y0[1:]-y0[:-1]\n\n ix = np.digitize(x,x0)-1\n iy = np.digitize(y,y0)-1\n\n ix[ix<0]=0\n iy[iy<0]=0\n ix[ix > x0.shape[0] -2 ] = x0.shape[0] - 2\n iy[iy > y0.shape[0] -2 ] = y0.shape[0] - 2\n\n xs = (x - x0[:-1][ix])/wx[ix]\n ys = (y - y0[:-1][iy])/wy[iy]\n\n return (z[ix,iy]*(1-xs)*(1-ys) + z[ix+1,iy]*xs*(1-ys) +\n z[ix,iy+1]*(1-xs)*ys + z[ix+1,iy+1]*xs*ys)\n\ndef interpolatend(x0,z,x):\n \"\"\"Perform linear interpolation over an N-dimensional mesh.\n\n Parameters\n ----------\n x0: List of arrays defining mesh coordinates in each of N dimensions.\n\n z: N-dimesional array of scalar values evaluated on the coordinate\n mesh defined by x0. The number of elements along each dimension must\n equal to the corresponding number of mesh points in x0 (N_tot = Prod_i N_i).\n\n x: NxM numpy array specifying the M points in N-dimensional space at\n which the interpolation should be evaluated.\n\n \"\"\"\n\n x = np.array(x,ndmin=2)\n ndim = len(x0)\n\n index = np.zeros(shape=(2**ndim,ndim,len(x[0])),dtype=int)\n psum = np.ones(shape=(2**ndim,len(x[0])))\n\n for i, t in enumerate(x0):\n\n p = np.array(t,ndmin=1)\n w = p[1:]-p[:-1]\n ix = np.digitize(x[i],p)-1\n ix[ix<0]=0\n ix[ix > x0[i].shape[0] -2 ] = len(x0[i]) - 2\n xs = (x[i] - x0[i][:-1][ix])/w[ix]\n\n\n for j in range(len(psum)):\n if j & (1<<i):\n index[j][i] = ix+1\n psum[j] *= xs\n else:\n index[j][i] = ix\n psum[j] *= (1.0-xs)\n\n# print index\n# print index[0].shape\n# print z[np.ix_(index[0])]\n\n for j in range(len(psum)):\n\n idx = []\n for i in range(ndim): idx.append(index[j][i])\n\n# print idx\n\n psum[j] *= z[idx]\n\n return np.sum(psum,axis=0)\n\ndef percentile(x,cdf,frac=0.68):\n \"\"\"Given a cumulative distribution function C(x) find the value\n of x for which C(x) = f.\"\"\"\n indx = bisect.bisect(cdf, frac) - 1\n return ((frac - cdf[indx])/(cdf[indx+1] - cdf[indx])\n *(x[indx+1] - x[indx]) + x[indx])\n\n\ndef edge_to_center(edges):\n return 0.5*(edges[1:]+edges[:-1])\n\ndef edge_to_width(edges):\n return (edges[1:]-edges[:-1])\n\ndef convolve2d_king(fn,r,sig,gam,rmax,nstep=200):\n \"\"\"Evaluate the convolution f'(x,y) = f(x,y) * g(x,y) where f(r) is\n azimuthally symmetric function in two dimensions and g is a\n King function given by:\n\n g(r,sig,gam) = 1/(2*pi*sig^2)*(1-1/gam)*(1+gam/2*(r/sig)**2)**(-gam)\n\n Parameters\n ----------\n\n fn : Input function that takes a single radial coordinate parameter.\n\n r : Array of points at which the convolution is to be evaluated.\n\n sig : Width parameter of the King function.\n\n gam : Gamma parameter of the King function.\n\n \"\"\"\n\n r = np.array(r,ndmin=1,copy=True)\n sig = np.array(sig,ndmin=1,copy=True)\n gam = np.array(gam,ndmin=1,copy=True)\n\n r2p = edge_to_center(np.linspace(0,rmax**2,nstep+1))\n r2w = edge_to_width(np.linspace(0,rmax**2,nstep+1))\n\n if sig.shape[0] > 1: \n r2p = r2p.reshape((1,1,nstep))\n r2w = r2w.reshape((1,1,nstep))\n r = r.reshape((1,r.shape[0],1))\n sig = sig.reshape(sig.shape + (1,1))\n gam = sig.reshape(gam.shape + (1,1))\n saxis = 2\n else:\n r2p = r2p.reshape(1,nstep)\n r2w = r2w.reshape(1,nstep)\n r = r.reshape(r.shape + (1,))\n saxis = 1\n\n u = 0.5*(r/sig)**2\n v = 0.5*r2p*(1./sig)**2\n vw = 0.5*r2w*(1./sig)**2\n\n z = 4*u*v/(gam+u+v)**2\n hgfn = spfn.hyp2f1(gam/2.,(1.+gam)/2.,1.0,z)\n fnrp = fn(np.sqrt(r2p))\n s = np.sum(fnrp*(gam-1.0)/gam*np.power(gam/(gam+u+v),gam)*hgfn*vw,\n axis=saxis)\n\n return s\n\ndef convolve2d_gauss(fn,r,sig,rmax,nstep=200):\n \"\"\"Evaluate the convolution f'(r) = f(r) * g(r) where f(r) is\n azimuthally symmetric function in two dimensions and g is a\n gaussian given by:\n\n g(r) = 1/(2*pi*s^2) Exp[-r^2/(2*s^2)]\n\n Parameters\n ----------\n\n fn : Input function that takes a single radial coordinate parameter.\n\n r : Array of points at which the convolution is to be evaluated.\n\n sig : Width parameter of the gaussian.\n\n \"\"\"\n r = np.array(r,ndmin=1,copy=True)\n sig = np.array(sig,ndmin=1,copy=True)\n\n rp = edge_to_center(np.linspace(0,rmax,nstep+1))\n dr = rmax/float(nstep)\n fnrp = fn(rp)\n\n if sig.shape[0] > 1: \n rp = rp.reshape((1,1,nstep))\n fnrp = fnrp.reshape((1,1,nstep))\n r = r.reshape((1,r.shape[0],1))\n sig = sig.reshape(sig.shape + (1,1))\n saxis = 2\n else:\n rp = rp.reshape(1,nstep)\n fnrp = fnrp.reshape(1,nstep)\n r = r.reshape(r.shape + (1,))\n saxis = 1\n\n sig2 = sig*sig\n x = r*rp/(sig2)\n je = spfn.ive(0,x)\n\n s = np.sum(rp*fnrp/(sig2)*\n np.exp(np.log(je)+x-(r*r+rp*rp)/(2*sig2)),axis=saxis)*dr\n\n return s\n\n# sig2 = sig*sig\n# x = r*rp/(sig2)\n\n# print 'rp: ', rp.shape\n# print 'x: ', x.shape\n\n# je = spfn.ive(0,x)\n# fnrp = fn(rp)\n\n# return np.sum(rp*fnrp/(sig2)*\n# np.exp(np.log(je)+x-(r*r+rp*rp)/(2*sig2)),axis=1)*dr\n\n\ndef convolve1(fn,r,sig,rmax):\n\n r = np.asarray(r)\n\n if r.ndim == 0: r.resize((1))\n\n nr = 200\n rp = np.zeros(shape=(r.shape[0],nr))\n rp[:] = np.linspace(0,rmax,nr)\n\n rp = rp.T\n\n dr = rmax/float(nr)\n\n sig2 = sig*sig\n\n x = r*rp/(sig2)\n\n j = spfn.iv(0,x)\n fnrp = fn(np.ravel(rp))\n fnrp = fnrp.reshape(j.shape)\n\n# plt.figure()\n# plt.plot(np.degrees(rp[:,50]),x[:,50])\n\n# plt.figure()\n# plt.plot(np.degrees(rp[:,50]),\n# rp[:,50]*j[:,50]*fnrp[:,50]*\n# np.exp(-(r[50]**2+rp[:,50]**2)/(2*sig2)))\n# plt.show()\n\n return np.sum(rp*j*fnrp/(sig2)*np.exp(-(r*r+rp*rp)/(2*sig2)),axis=0)*dr\n\nRA_NGP = np.radians(192.859508333333)\nDEC_NGP = np.radians(27.1283361111111)\nL_CP = np.radians(122.932)\nL_0 = L_CP - np.pi / 2.\nRA_0 = RA_NGP + np.pi / 2.\nDEC_0 = np.pi / 2. - DEC_NGP\n\ndef gc2gal(phi,th):\n\n v = Vector3D.createThetaPhi(np.radians(th),np.radians(phi))\n v.rotatey(np.pi/2.)\n\n lat = np.degrees(v.lat())\n lon = np.degrees(v.phi())\n\n return lon, lat\n\ndef gal2eq(l, b):\n\n l = np.array(l,ndmin=1)\n b = np.array(b,ndmin=1)\n \n l = np.radians(l)\n b = np.radians(b)\n\n sind = np.sin(b) * np.sin(DEC_NGP) + np.cos(b) * np.cos(DEC_NGP) * np.sin(l - L_0)\n\n dec = np.arcsin(sind)\n\n cosa = np.cos(l - L_0) * np.cos(b) / np.cos(dec)\n sina = (np.cos(b) * np.sin(DEC_NGP) * np.sin(l - L_0) - np.sin(b) * np.cos(DEC_NGP)) / np.cos(dec)\n\n dec = np.degrees(dec)\n\n ra = np.arccos(cosa)\n ra[np.where(sina < 0.)] = -ra[np.where(sina < 0.)]\n\n ra = np.degrees(ra + RA_0)\n\n ra = np.mod(ra, 360.)\n dec = np.mod(dec + 90., 180.) - 90.\n\n return ra, dec\n\n\ndef eq2gal(ra, dec):\n\n ra = np.array(ra,ndmin=1)\n dec = np.array(dec,ndmin=1)\n \n ra, dec = np.radians(ra), np.radians(dec)\n \n np.sinb = np.sin(dec) * np.cos(DEC_0) - np.cos(dec) * np.sin(ra - RA_0) * np.sin(DEC_0)\n\n b = np.arcsin(np.sinb)\n\n cosl = np.cos(dec) * np.cos(ra - RA_0) / np.cos(b)\n sinl = (np.sin(dec) * np.sin(DEC_0) + np.cos(dec) * np.sin(ra - RA_0) * np.cos(DEC_0)) / np.cos(b)\n\n b = np.degrees(b)\n\n l = np.arccos(cosl)\n l[np.where(sinl < 0.)] = - l[np.where(sinl < 0.)]\n\n l = np.degrees(l + L_0)\n\n l = np.mod(l, 360.)\n b = np.mod(b + 90., 180.) - 90.\n\n return l, b\n"
},
{
"alpha_fraction": 0.5211930871009827,
"alphanum_fraction": 0.5368916988372803,
"avg_line_length": 26.521739959716797,
"blob_id": "a4d729a688b0d75f5e29de78bb2c27d7bbd87474",
"content_id": "bbfa161abeb231a087b46e6b6bed65e3dbce54cf",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 23,
"path": "/gammatools/fermi/plot_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\nimport matplotlib.pyplot as plt\nfrom matplotlib.patches import FancyArrowPatch\n\n\ndef plot_ul(x,y,ax=None,color=None):\n\n if ax is None: ax = plt.gca()\n\n color_cycle = ax._get_lines.color_cycle\n\n color = color_cycle.next()\n\n style = {'linestyle' : 'None', 'linewidth' : 2}\n if not color is None: style['color'] = color\n ax.errorbar(x,y,xerr=0.125,**style)\n\n for i in range(len(x)):\n\n c = FancyArrowPatch((x[i],y[i]), \n (x[i],y[i]*0.6), \n arrowstyle=\"-|>,head_width=4,head_length=8\",\n lw=2,color=color)\n ax.add_patch(c)\n\n\n\n"
},
{
"alpha_fraction": 0.532899022102356,
"alphanum_fraction": 0.6000930666923523,
"avg_line_length": 28.597795486450195,
"blob_id": "d532bf3bac461c7062badaf35b7231e94d1474a8",
"content_id": "5ed1def86cb1dde8ac36d43cfa127e85b7bbb818",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10745,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 363,
"path": "/scripts/make_irf.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\nimport os\nimport sys\nimport copy\nimport glob\nimport yaml\nimport re\nimport ROOT\nimport array\n\nos.environ['PYTHONPATH'] += ':%s'%(os.path.join(os.environ['INST_DIR'],\n 'irfs/handoff_response/python'))\n\n\ndef getGenerateEvents(f):\n\n rf = ROOT.TFile(f)\n if not rf.GetListOfKeys().Contains(\"jobinfo\"): return None\n chain = rf.Get('jobinfo')\n\n \n NGen_sum = 0\n vref = {}\n \n vref['trigger'] = array.array('i',[0])\n vref['generated'] = array.array('i',[0])\n vref['version'] = array.array('f',[0.0])\n vref['revision'] = array.array('f',[0.0])\n vref['patch'] = array.array('f',[0.0])\n chain.SetBranchAddress('trigger',vref['trigger'])\n chain.SetBranchAddress('generated',vref['generated'])\n chain.SetBranchAddress('version',vref['version'])\n\n if chain.GetListOfBranches().Contains('revision'):\n chain.SetBranchAddress('revision',vref['revision'])\n\n if chain.GetListOfBranches().Contains('patch'):\n chain.SetBranchAddress('patch',vref['patch'])\n\n for i in range(chain.GetEntries()):\n chain.GetEntry(i) \n\n ver = int(vref['version'][0])\n rev = int(vref['revision'][0])\n patch = int(vref['patch'][0])\n \n NGen = 0\n\n if ver == 20 and rev == 4: NGen = vref['trigger'][0]\n else: NGen = vref['generated'][0]\n\n if (ver == 20 and rev == 6) or (ver == 20 and rev == 8 and patch < 8):\n NGen *= 0.85055\n\n NGen_sum += NGen\n\n return NGen_sum\n\ndef get_branches(expr):\n ignore = ['max','min','sqrt','acos','pow','log','log10']\n m = re.compile('([a-zA-Z])([a-zA-Z0-9\\_]+)')\n\n branches = []\n for t in m.finditer(expr):\n var = t.group()\n if var not in ignore:\n branches.append(var)\n\n return branches\n\ndef expand_aliases(aliases,expr):\n ignore = ['max','min','sqrt','acos','pow','log','log10']\n m = re.compile('([a-zA-Z])([a-zA-Z0-9\\_]+)')\n\n has_alias = False\n for t in m.finditer(expr):\n\n var = t.group()\n alias = ''\n if var in aliases: alias = aliases[var]\n \n if var not in ignore and alias != '':\n expr = re.sub(var + '(?![a-zA-Z0-9\\_])',\n '(' + alias + ')',expr)\n has_alias = True\n\n if has_alias: return expand_aliases(aliases,expr)\n else: return expr\n\n\n\n \nfrom optparse import OptionParser\nusage = \"Usage: %prog [MC file] [options]\"\ndescription = \"\"\"Generate a set of IRFs from an input merit tuple and\nevent selection.\"\"\"\nparser = OptionParser(usage=usage,description=description)\n\nparser.add_option(\"--selection\",default=None,type='string',\n help=\".\")\n\nparser.add_option(\"--new_edisp\",default=False,action='store_true',\n help=\".\")\n\nparser.add_option(\"--friends\",default=None,type='string',\n help=\".\")\n\nparser.add_option(\"--cuts_file\",default=None,type='string',\n help=\".\")\n\nparser.add_option(\"--class_name\",default=None,type='string',\n help=\"Set the class name.\")\n\nparser.add_option(\"--irf_scaling\",default='pass7',\n help=\"Set the class name.\")\n\nparser.add_option(\"--psf_scaling\",default=None,\n help=\"Set the class name.\")\n\nparser.add_option(\"--psf_overlap\",default='1/1',\n help=\"Set the PSF overlap parameters for energy/angle.\")\n\nparser.add_option(\"--edisp_overlap\",default='1/1',\n help=\"Set the class name.\")\n\nparser.add_option(\"--recon_var\", default='WP8Best',\n help=\"Set the class name.\")\n\nparser.add_option(\"--generated\",default=None,type='float',\n help=\"Set the number of generated events in each file. \"\n \"If this option is not given the number of \"\n \"generated events will be automatically determined from \"\n \"the jobinfo tree if it exists.\")\n\n\n(opts, args) = parser.parse_args()\n\n\n\n\nc = yaml.load(open(args[0],'r'))\n\ninput_file_strings = []\nemin_array = []\nemax_array = []\ngenerated_array = []\n\nfor d in c['datasets']:\n\n o = copy.deepcopy(d)\n o['generated'] = 0\n o['files'] = glob.glob(o['files'])\n\n emin_array.append('%f'%o['emin'])\n emax_array.append('%f'%o['emax'])\n \n for f in o['files']:\n o['generated'] += getGenerateEvents(f)\n input_file_strings.append('\\'%s\\''%f)\n\n generated_array.append('%f'%o['generated'])\n\n#input_file_path = os.path.abspath(args[0])\n#f = ROOT.TFile(input_file_path)\n\n#if not opts.generated is None: generated = opts.generated\n#elif f.GetListOfKeys().Contains(\"jobinfo\"):\n# jobinfo = f.Get('jobinfo')\n# generated = getGenerateEvents(jobinfo)\n#else:\n# print 'Number of generated events not defined.'\n# sys.exit(1)\n \nif opts.class_name is None:\n print 'No class name given.'\n sys.exit(1)\n \nirf_dir = opts.class_name\nirf_output_dir = 'custom_irfs'\n\nif not os.path.isdir(irf_dir):\n os.system('mkdir %s'%(irf_dir))\n \nif not os.path.isdir(irf_output_dir):\n os.system('mkdir %s'%(irf_output_dir))\n\nirf_output_dir = os.path.abspath(irf_output_dir)\n \ncut_defs = {}\nif not opts.cuts_file is None:\n cut_defs = yaml.load(open(opts.cuts_file,'r'))\n\ncut_expr = ''\nif not opts.selection is None:\n cut_expr = expand_aliases(cut_defs,opts.selection)\n\nbranch_names = get_branches(cut_expr)\nbranch_names = list(set(branch_names))\n\nbranch_names += ['%s*'%opts.recon_var]\n\nfriends = ''\nif not opts.friends is None:\n\n friends_list = []\n for s in opts.friends.split(','):\n friend_path = os.path.abspath(s)\n friends_list.append('\\'%s\\''%friend_path) \n \n friends = '\\'%s\\' : [ %s ]'%(input_file_path,','.join(friends_list))\n\nFRONT_SCALE_PARAMS_P8 = [0.0195, 0.1831, -0.2163, -0.4434, 0.0510, 0.6621] \nBACK_SCALE_PARAMS_P8 = [0.0167, 0.1623, -0.1945, -0.4592, 0.0694, 0.5899]\n \n \nif opts.irf_scaling is 'pass7':\n psf_pars_string = '[5.81e-2, 3.77e-4, 9.6e-2, 1.3e-3, -0.8]'\n edisp_front_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n edisp_back_pars_string = '[0.0215, 0.0507, -0.22, -0.243, 0.065, 0.584]'\nelif opts.irf_scaling == 'pass8':\n psf_pars_string = '[5.81e-2, 3.77e-4, 9.6E-2, 1.3E-3, -0.8]'\n edisp_front_pars_string = '[0.0195, 0.1831, -0.2163, -0.4434, 0.0510, 0.6621]'\n edisp_back_pars_string = '[0.0167, 0.1623, -0.1945, -0.4592, 0.0694, 0.5899]' \nelif opts.irf_scaling == 'p8front':\n psf_pars_string = '[5.81e-2, 3.77e-4, 5.81e-2, 3.77e-4, -0.8]'\n edisp_front_pars_string = '[0.0195, 0.1831, -0.2163, -0.4434, 0.0510, 0.6621]'\n edisp_back_pars_string = '[0.0167, 0.1623, -0.1945, -0.4592, 0.0694, 0.5899]'\nelif opts.irf_scaling == 'p8back':\n psf_pars_string = '[9.6e-2, 1.3e-3, 9.6e-2, 1.3e-3, -0.8]'\n edisp_front_pars_string = '[0.0215, 0.0507, -0.22, -0.243, 0.065, 0.584]'\n edisp_back_pars_string = '[0.0215, 0.0507, -0.22, -0.243, 0.065, 0.584]'\nelif opts.irf_scaling == 'psf3':\n psf_pars_string = '[4.97e-02,6.13e-04,4.97e-02,6.13e-04,-0.8]'\n edisp_front_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n edisp_back_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\nelif opts.irf_scaling == 'psf2':\n psf_pars_string = '[7.02e-02,1.07e-03,7.02e-02,1.07e-03,-0.8]'\n edisp_front_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n edisp_back_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\nelif opts.irf_scaling == 'psf1':\n psf_pars_string = '[9.64e-02,1.78e-03,9.64e-02,1.78e-03,-0.8]'\n edisp_front_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n edisp_back_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\nelif opts.irf_scaling == 'psf0':\n psf_pars_string = '[1.53e-01,5.70e-03,1.53e-01,5.70e-03,-0.8]'\n edisp_front_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n edisp_back_pars_string = '[0.0210, 0.058, -0.207, -0.213, 0.042, 0.564]'\n \nif not opts.psf_scaling is None: psf_pars_string = opts.psf_scaling\n \nedisp_energy_overlap, edisp_angle_overlap = opts.edisp_overlap.split('/')\npsf_energy_overlap, psf_angle_overlap = opts.psf_overlap.split('/')\n\n\nx = '''\nfrom gammatools.fermi.IRFdefault import *\n\nclassName=\"%s\"\nselectionName=\"front\"\n\nPrune.fileName = 'skim.root'\nPrune.cuts = '%s'\nPrune.branchNames = \"\"\"\nMcEnergy McLogEnergy McXDir McYDir McZDir\nTkr1FirstLayer\nEvtRun\n%s\n\"\"\".split()\n\nData.files = [%s]\nData.generated = [%s]\nData.logemin = [%s]\nData.logemax = [%s]\n\nBins.set_energy_bins(0.75,6.5)\nEffectiveAreaBins.set_energy_bins(0.75,6.5)\nFisheyeBins.set_energy_bins(0.75,6.5,0.125)\nFisheyeBins.set_angle_bins(0.2,0.05)\n\nData.friends = { %s }\n\nData.var_xdir = '%sXDir'\nData.var_ydir = '%sYDir'\nData.var_zdir = '%sZDir'\nData.var_energy = '%sEnergy'\n\nBins.edisp_energy_overlap = %s\nBins.edisp_angle_overlap = %s\n\nBins.psf_energy_overlap = %s\nBins.psf_angle_overlap = %s\n\nPSF.pars = %s # there must be 5 parameters\n \nEdisp.front_pars = %s # each edisp set must have six parameters\nEdisp.back_pars = %s\n\nparameterFile = 'parameters.root'\n'''%(opts.class_name,cut_expr,' '.join(branch_names),\n ','.join(input_file_strings), ','.join(generated_array),\n ','.join(emin_array), ','.join(emax_array), \n friends,\n opts.recon_var,opts.recon_var,opts.recon_var,opts.recon_var,\n edisp_energy_overlap,edisp_angle_overlap,\n psf_energy_overlap,psf_angle_overlap,\n psf_pars_string,edisp_front_pars_string,edisp_back_pars_string)\n\nf = open(os.path.join(opts.class_name,'setup.py'),'w')\nf.write(x)\nf.close()\n\nos.chdir(irf_dir)\n\nif not os.path.isfile('skim.root'):\n cmd = 'prune setup.py'\n print cmd\n os.system(cmd)\n\n#\n \n#cmd = 'makeirf %s'%irf_dir\nif not os.path.isfile('parameters.root'):\n cmd = 'makeirf setup.py'\n print cmd\n os.system(cmd)\n\n#if not os.path.isfile(os.path.join(irf_dir,'skim.root')):\n# cmd = 'prune %s'%irf_dir\n# print cmd\n# os.system(cmd)\n\n#cmd = 'makeirf %s'%irf_dir\n#print cmd\n#os.system(cmd)\n \n#os.chdir(irf_dir)\n\ncmd = 'makefits new_edisp=%s %s %s'%(opts.new_edisp,'parameters.root',opts.class_name)\nprint cmd\nos.system(cmd)\n\n\nif not re.search('psf',opts.irf_scaling) is None:\n\n os.system('rm *_front.fits')\n os.system('rm *_back.fits')\n\n for s in glob.glob('*%s*fits'%opts.class_name):\n\n print s\n \n sf = os.path.splitext(s)[0] + '_front.fits'\n sb = os.path.splitext(s)[0] + '_back.fits'\n\n os.system('cp %s %s'%(s,sf))\n os.system('cp %s %s'%(s,sb))\n os.system('rm %s'%(s))\n \nos.system('tar cfz %s.tar.gz *%s*fits'%(opts.class_name,opts.class_name))\n\nos.system('cp *%s*fits %s'%(opts.class_name,irf_output_dir))\nos.system('cp %s.tar.gz %s'%(opts.class_name,irf_output_dir))\n\n"
},
{
"alpha_fraction": 0.5176522731781006,
"alphanum_fraction": 0.5710502862930298,
"avg_line_length": 25.541175842285156,
"blob_id": "eb672782166a8002abecaa921df92d19692967b9",
"content_id": "d9fc937eb30c00fde6f3907cd55dbdc3cd6c035b",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2266,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 85,
"path": "/gammatools/core/tests/test_algebra.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import unittest\nimport numpy as np\nimport copy\nfrom numpy.testing import assert_array_equal, assert_almost_equal\nfrom gammatools.core.util import *\nfrom gammatools.core.config import *\nfrom gammatools.core.algebra import *\n\ndef normalize_angle(angle):\n\n return np.fmod(angle+2*np.pi,2*np.pi)\n\nclass TestAlgebra(unittest.TestCase):\n\n def test_vector_norm(self):\n\n v1 = Vector3D.createThetaPhi(np.linspace(0,np.pi,10),\n np.linspace(0,2*np.pi,10))\n\n # Vector Norm \n assert_almost_equal(v1.norm(),np.ones(10))\n\n v2 = v1*2.0\n\n v2.normalize()\n\n assert_almost_equal(v2.norm(),np.ones(10))\n\n\n def test_vector_rotation(self):\n\n v0 = Vector3D.createThetaPhi(np.pi/2.,0.0)\n v1 = Vector3D.createThetaPhi(np.linspace(np.pi/4.,np.pi/2.,10),0.0)\n v2 = Vector3D.createThetaPhi(np.linspace(np.pi/4.,np.pi/2.,10),0.0)\n\n r0 = np.pi/2.\n r1 = np.pi/2.*np.ones(10)\n r2 = np.linspace(np.pi/4.,3.*np.pi/4.,10)\n\n # Apply scalar rotation to scalar\n\n assert_almost_equal(v0.phi(),0.0)\n\n v0.rotatez(0.0*r0)\n assert_almost_equal(v0.phi(),0.0*r0)\n\n v0.rotatez(r0)\n assert_almost_equal(v0.phi(),r0)\n\n v0.rotatez(r0)\n assert_almost_equal(v0.phi(),2.*r0)\n\n v0.rotatez(r0)\n assert_almost_equal(normalize_angle(v0.phi()),3.*r0)\n\n\n # Apply scalar rotation to vector\n\n assert_almost_equal(v1.phi(),0.0*r0)\n\n v1.rotatez(r0)\n assert_almost_equal(v1.phi(),r0)\n\n v1.rotatez(r0)\n assert_almost_equal(v1.phi(),2.0*r0)\n\n v1.rotatez(r0)\n assert_almost_equal(normalize_angle(v1.phi()),3.*r0)\n\n # Apply vector rotation to vector\n\n assert_almost_equal(normalize_angle(v2.phi()),\n normalize_angle(0.0*r2))\n\n v2.rotatez(r2)\n assert_almost_equal(normalize_angle(v2.phi()),\n normalize_angle(1.0*r2))\n\n v2.rotatez(r2)\n assert_almost_equal(normalize_angle(v2.phi()),\n normalize_angle(2.0*r2))\n\n v2.rotatez(r2)\n assert_almost_equal(normalize_angle(v2.phi()),\n normalize_angle(3.0*r2))\n\n \n"
},
{
"alpha_fraction": 0.47934699058532715,
"alphanum_fraction": 0.5105182528495789,
"avg_line_length": 29.604026794433594,
"blob_id": "bcce6388b67d1e4f799712ea0a682cdf17ca49f1",
"content_id": "a72d51986ac94029c8451888a39a531859e3d778",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18254,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 596,
"path": "/gammatools/dm/dmmodel.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport sys\nimport re\nimport yaml\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport gammatools\nimport gammatools.dm.jcalc as jcalc\nfrom gammatools.core.util import Units\nimport scipy.special as spfn\nfrom scipy.optimize import brentq\nfrom scipy.interpolate import UnivariateSpline\nfrom gammatools.core.util import *\nfrom gammatools.core.histogram import *\nfrom gammatools.core.stats import *\n\nclass LimitData(object):\n\n def __init__(self,f,label,color='k',linestyle='-'):\n d = np.load(f)\n self.data = d\n self.mass = d['mass']\n self.ul_med = []\n self.ul68_lo = []\n self.ul68_hi = []\n self.ul95_lo = []\n self.ul95_hi = []\n self.label= label\n self.color=color\n self.linestyle=linestyle\n\n for i in range(len(d['mass'])):\n\n ul = np.sort(d['ul'][:,i])\n ul = ul[ul>0]\n \n n = len(ul)\n \n m = np.median(ul)\n\n self.ul68_lo.append(ul[max(0,n/2.-n*0.34)])\n self.ul68_hi.append(ul[min(n-1,n/2.+n*0.34)])\n self.ul95_lo.append(ul[max(0,n/2.-n*0.95/2.)])\n self.ul95_hi.append(ul[min(n-1,n/2.+n*0.95/2.)])\n self.ul_med.append(np.median(ul))\n\n def plot(self):\n plt.plot(self.mass,self.ul_med,color=self.color,\n linestyle=self.linestyle,\n linewidth=2,label=self.label)\n\n if len(self.data['ul'][:]) > 2:\n plt.gca().fill_between(self.mass, \n self.ul68_lo,self.ul68_hi,\n facecolor=self.color, alpha=0.4)\n\n\n plt.gca().add_patch(plt.Rectangle((0,0),0,0,fc=self.color,alpha=0.4,\n zorder=0,\n label=self.label + \" 68% Containment\"))\n\n if len(self.data['ul'][:]) > 10:\n plt.gca().fill_between(self.mass, \n self.ul95_lo,self.ul95_hi,\n facecolor=self.color, alpha=0.2)\n\n plt.gca().add_patch(plt.Rectangle((0,0),0,0,fc='black',alpha=0.2,\n zorder=0,\n label= self.label + \" 95% Containment\"))\n\n\nclass ModelPMSSM(object):\n\n def __init__(self,model_data,sp):\n\n index = model_data[0]\n model_no = model_data[1]\n model_id = int(1E5*model_data[0]) + int(model_data[1])\n\n self._model_id = int(1E5*index) + int(model_no)\n self._model_no = model_no\n self._model_index = index\n self._spectrum = sp\n self._model_data = model_data\n\nclass ConvolvedHaloModel(object):\n \"\"\"Class that stores the J density profile convolved with an\n energy-dependent PSF.\"\"\"\n def __init__(self,hm,irf):\n\n self._irf = irf\n\n self._loge_axis = self._irf._psf.axis()\n th68 = self._irf._psf.counts\n\n self._psi_axis = Axis(np.linspace(0,np.radians(10.0),401))\n self._psi = self._psi_axis.center\n self._loge = self._loge_axis.center+Units.log10_mev\n\n self._z = np.zeros(shape=(len(self._loge),len(self._psi)))\n\n self._h = Histogram2D(self._loge_axis,self._psi_axis)\n\n for i in range(len(self._loge)):\n self._z[i] = convolve2d_gauss(hm._jp,self._psi,\n np.radians(th68[i]/1.50959),\n self._psi[-1]+np.radians(0.5),\n nstep=1000)\n self._h._counts = self._z\n\n def jval(self,loge,psi):\n\n return interpolate2d(self._loge,self._psi,self._z,\n loge,psi)\n\ndef outer(x,y):\n z = np.ones(shape=(x.shape + y.shape))\n z = (z.T*x.T).T\n z *= y\n return z\n\ndef rebin(x,n):\n\n z = np.zeros(len(x)/n)\n for i in range(len(x)/n):\n z[i] = np.sum(x[i*n:(i+1)*n])\n\n return z\n\nclass DMChanSpectrum(object):\n \"\"\"Class that computes the differential annihilation yield for\n different DM channels. Interpolates a set of tabulated values\n from DarkSUSY.\"\"\"\n def __init__(self,chan,mass = 100*Units.gev, yield_table=None):\n\n if yield_table is None:\n yield_table = os.path.join(gammatools.PACKAGE_ROOT,\n 'data/gammamc_dif.dat')\n\n d = np.loadtxt(yield_table,unpack=True)\n\n xedge = np.linspace(0,1.0,251)\n self._x = 0.5*(xedge[1:]+xedge[:-1])\n\n self._mass = mass\n self._xwidth = self._x[1:]-self._x[:-1]\n\n self._mass_bins = np.array([10.0,25.0,50.0,80.3,91.2,\n 100.0,150.0,176.0,200.0,250.0,\n 350.0,500.0,750.0,\n 1000.0,1500.0,2000.0,3000.0,5000.0])\n\n self._mwidth = self._mass_bins[1:]-self._mass_bins[:-1]\n self._ndec = 10.0\n\n channel = ['cc','bb','tt','tau','ww','zz']\n offset = [0,0,7,0,3,4,0,0]\n\n channel_index = { 'cc' : 0,\n 'bb' : 1,\n 'tt' : 2,\n 'tau' : 3,\n 'ww' : 4,\n 'zz' : 5,\n 'mumu' : 6,\n 'gg' : 7 }\n\n dndx = {}\n\n j = 0\n for i, c in enumerate(channel):\n dndx[c] = np.zeros(shape=(250,18))\n dndx[c][:,offset[i]:18] = d[:,j:j+18-offset[i]]\n# self._dndx[c] = d[:,j:j+18-offset[i]]\n j+= 18-offset[i]\n\n self._dndx = dndx[chan]\n\n# for c, i in channel_index.iteritems():\n# pass\n# print c, i\n\n# self._dndx[c] = d[:,i*18:(i+1)*18]\n\n def e2dnde(self,loge,mass=None):\n \"\"\"\n Evaluate the spectral energy density.\n\n @param m:\n @param loge:\n @return:\n \"\"\"\n e = np.power(10,loge)\n return e**2*self.dnde(loge,mass)\n \n def ednde(self,loge,mass=None): \n e = np.power(10,loge)\n return e*self.dnde(loge,mass)\n\n def dnde(self,loge,mass=None):\n \n loge = np.array(loge,ndmin=1)\n\n if mass is None: m = self._mass\n else: m = mass\n\n e = np.power(10,loge)\n x = (np.log10(e/m)+self._ndec)/self._ndec\n dndx = self.dndx(m,x)\n dndx[e>=m] = 0\n return dndx*0.434/(self._ndec*(e))*250.\n\n def dndx(self,m,x):\n return interpolate2d(self._x,self._mass_bins,self._dndx,x,m/Units.gev)\n\n\nclass DMModelSpectrum(object):\n \"\"\"Class that computes the differential annihilation yield for\n a specific DM model using a pretabulated spectrum. \"\"\"\n def __init__(self,egy,dnde):\n\n self._loge = np.log10(egy) + np.log10(Units.gev)\n self._dnde = 8.*np.pi*dnde*1E-29*np.power(Units.gev,-3)\n\n @staticmethod\n def create(spfile):\n d = np.loadtxt(spfile,unpack=True)\n return DMModelSpectrum(d[0],d[1])\n# self._loge = np.log10(d[0])\n# self._dnde = 8.*np.pi*d[1]*1E-29*np.power(Units.gev,-2)\n\n def e2dnde(self,loge,mass=None): \n e = np.power(10,loge)\n return e**2*self.dnde(loge,mass)\n \n def ednde(self,loge,mass=None): \n e = np.power(10,loge)\n return e*self.dnde(loge,mass)\n\n def dnde(self,loge,mass=None):\n \"\"\"Return the differential gamma-ray rate per annihilation or\n decay.\"\"\"\n\n loge = np.array(loge,ndmin=1)\n dnde = interpolate(self._loge,self._dnde,loge)\n return dnde\n\nclass DMFluxModel(object):\n def __init__(self, sp, hm, mass = 1.0, sigmav = 1.0):\n\n self._mass = mass\n self._sigmav = sigmav\n self._sp = sp\n self._hm = hm\n\n @staticmethod\n def createChanModel(hm,mass,sigmav=3E-26*Units.cm3_s,chan='bb'):\n \"\"\"Create a model with a 100% BR to a single\n annihilation/decay channel.\"\"\"\n sp = DMChanSpectrum(chan)\n return DMFluxModel(sp,hm,mass,sigmav)\n\n @staticmethod\n def createModel(hm,d):\n sp = DMFluxModelSpectrum(d[0],d[1])\n return DMFluxModel(sp,jp,1.0,1.0)\n\n @staticmethod\n def createModelFromFile(hm,spfile):\n sp = DMFluxModelSpectrum.create(spfile)\n return DMFluxModel(sp,hm,1.0,1.0)\n\n def e2flux(self,loge,psi):\n return np.power(10,2*loge)*self.flux(loge,psi)\n\n def eflux(self,loge,psi):\n return np.power(10,loge)*self.flux(loge,psi)\n\n def flux(self,loge,psi):\n djdomega = self._hm.jval(loge,psi)\n flux = 1./(8.*np.pi)*self._sigmav*np.power(self._mass,-2)* \\\n self._sp.dnde(loge,self._mass)\n\n return flux*djdomega\n\nclass DMLimitCalc(object):\n\n def __init__(self,irf,alpha,min_fsig=0.0,redge='0.0/1.0'):\n\n self._irf = irf\n# self._th68 = self._irf._psf.counts \n# self._bkg_rate = (self._det.proton_wcounts_density + \n# self._det.electron_wcounts_density)/(50.0*Units.hr*\n# Units.deg2)\n\n self._loge_axis = Axis.create(np.log10(Units.gev)+1.4,\n np.log10(Units.gev)+3.6,22)\n self._loge = self._loge_axis.center \n self._dloge = self._loge_axis.width\n\n rmin, rmax = [float(t) for t in redge.split('/')]\n\n self._psi_axis = Axis(np.linspace(np.radians(0.0),np.radians(1.0),101))\n self._psi = self._psi_axis.center\n self._domega = np.pi*(np.power(self._psi_axis.edges[1:],2)-\n np.power(self._psi_axis.edges[:-1],2))\n\n self._aeff = self._irf.aeff(self._loge - Units.log10_mev)\n self._bkg_rate = irf.bkg(self._loge - Units.log10_mev)*self._dloge\n\n self._redge = [np.radians(rmin),np.radians(rmax)]\n self._msk = (self._psi > self._redge[0]) & (self._psi < self._redge[1])\n \n\n self._domega_sig = np.sum(self._domega[self._msk])\n self._domega_bkg = self._domega_sig/alpha\n\n\n self._min_fsig = min_fsig\n self._alpha = alpha\n self._alpha_bin = self._domega/self._domega_bkg\n\n# self._iedge = [np.where(self._psi >= self._redge[0])[0][0],\n# np.where(self._psi >= self._redge[1])[0][0]]\n\n\n \n def counts(self,model,tau):\n \"\"\"Compute the signal counts distribution as a function of\n energy and source offset.\"\"\"\n\n x, y = np.meshgrid(self._loge,self._psi,indexing='ij')\n eflux = model.eflux(np.ravel(x),np.ravel(y))\n eflux = eflux.reshape((len(self._loge),len(self._psi)))\n\n exp = (self._dloge*np.log(10.)*self._aeff*tau)\n counts = eflux*exp[:,np.newaxis]*self._domega\n return counts\n\n def bkg_counts(self,tau):\n counts = np.zeros(shape=(len(self._loge),len(self._psi)))\n counts = self._domega[np.newaxis,:]*self._bkg_rate[:,np.newaxis]*tau\n return counts\n \n def plot_lnl(self,dmmodel,mchi,sigmav,tau):\n\n prefix = '%04.f'%(np.log10(mchi/Units.gev)*100)\n \n bc = self.bkg_counts(tau)\n\n dmmodel._mass = mchi\n dmmodel._sigmav = sigmav\n sc = self.counts(dmmodel,tau)\n sc_cum = np.cumsum(sc,axis=1) \n sc_ncum = (sc_cum.T/np.sum(sc,axis=1)).T\n\n\n dlnl = poisson_lnl(sc,bc,0.2)\n dlnl_cum = np.cumsum(dlnl,axis=1)\n\n \n ipeak = np.argmax(np.sum(dlnl,axis=1))\n i68 = np.where(sc_ncum[ipeak] > 0.68)[0][0]\n\n\n fig = plt.figure(figsize=(10,6))\n\n ax = fig.add_subplot(1,2,1)\n\n sc_density = sc/self._domega[self._msk]\n\n def psf(x,s):\n return np.exp(-x**2/(2*s**2))\n\n plt.plot(np.degrees(self._psi),sc_density[ipeak]*(np.pi/180.)**2,\n label='Signal')\n plt.plot(np.degrees(self._psi),\n psf(np.degrees(self._psi),self._th68[ipeak]/1.50959)\n *sc_density[ipeak][0]*(np.pi/180.)**2,label='PSF')\n\n plt.gca().axvline(self._th68[ipeak],color='k',linestyle='--',\n label='PSF 68% Containment Radius')\n\n plt.grid(True)\n\n plt.gca().legend(prop={'size':10})\n\n plt.gca().set_ylabel('Counts Density [deg$^{-2}$]')\n plt.gca().set_xlabel('Offset [deg]')\n plt.gca().set_xlim(0.0,1.0)\n ax = fig.add_subplot(1,2,2)\n\n plt.plot(np.degrees(self._psi),dlnl[ipeak])\n \n plt.grid(True)\n plt.gca().set_xlabel('Offset [deg]')\n plt.gca().set_ylabel('TS')\n\n plt.gca().axvline(self._th68[ipeak],color='k',linestyle='--',\n label='PSF 68% Containment Radius')\n\n plt.gca().axvline(np.degrees(self._psi[i68]),color='r',linestyle='--',\n label='Signal 68% Containment Radius')\n\n plt.gca().set_xlim(0.0,0.5)\n plt.gca().legend(prop={'size':10})\n plt.savefig('%s_density.png'%(prefix))\n\n# dlnl_cum = dlnl_cum.reshape(dlnl.shape)\n\n def make_plot(z,figname):\n plt.figure()\n im = plt.imshow(z.T,interpolation='nearest', origin='lower',\n aspect='auto',\n extent=[self._emin[0],self._emax[-1],\n np.degrees(self._psi_edge[0]),\n np.degrees(self._psi_edge[-1])])\n\n plt.gca().set_xlabel('Energy [log$_{10}$(E/GeV)]')\n plt.gca().set_ylabel('Offset [deg]')\n plt.colorbar(im,ax=plt.gca(),orientation='horizontal',\n fraction=0.05,shrink=0.7,\n pad=0.1)\n\n# figname = '%04.f_lnl.png'%(np.log10(mchi/Units.gev)*100)\n \n plt.gca().grid(True)\n plt.gca().set_ylim(0.0,0.5)\n\n plt.savefig(figname)\n\n make_plot(dlnl,'%s_lnl.png'%(prefix))\n make_plot(dlnl_cum,'%s_lnl_cum.png'%(prefix))\n make_plot(sc,'%s_scounts.png'%(prefix))\n make_plot(sc_ncum,'%s_scounts_cum.png'%(prefix))\n\n# plt.show()\n\n# self._loge),len(self._psi)\n\n\n def significance(self,sc,bc,alpha=None):\n\n if alpha is None: alpha = self._alpha_bin[:,np.newaxis]\n\n dlnl = poisson_median_ts(sc,bc,alpha)[:,self._msk,...]\n if dlnl.ndim == 2:\n return np.sqrt(max(0,np.sum(dlnl)))\n else:\n s0 = np.sum(dlnl,axis=0)\n s1 = np.sum(s0,axis=0)\n s1[s1<=0]=0\n return np.sqrt(s1)\n \n\n def boost(self,model,tau,sthresh=5.0):\n\n b = np.linspace(-4,6,60)\n\n bc = self.bkg_counts(tau)\n sc = self.counts(model,tau)\n\n sc2 = outer(sc,np.power(10,b))\n\n s = self.significance(sc2.T,bc.T)\n# i = np.where(s>sthresh)[0][0]\n\n if s[-1] <= sthresh: return b[-1]\n\n fn = UnivariateSpline(b,s,k=2,s=0)\n b0 = brentq(lambda t: fn(t) - sthresh ,b[0],b[-1])\n return b0\n\n\n def limit(self,dmmodel,mchi,tau,sthresh=5.0):\n\n o = {}\n bc = self.bkg_counts(tau)\n\n dmmodel._mass = mchi\n dmmodel._sigmav = np.power(10.,-28.)\n\n sc = self.counts(dmmodel,tau)\n\n sc_msk = copy.copy(sc); sc_msk[:,~self._msk] = 0\n bc_msk = copy.copy(bc); bc_msk[:,~self._msk] = 0\n\n onoff = OnOffExperiment(np.ravel(sc_msk),\n np.ravel(bc_msk),\n self._alpha)\n\n t0, t0_err = onoff.asimov_mu_ts0(sthresh**2)\n\n sc0 = sc*t0\n ts = onoff.asimov_ts0_signal(t0,sum_lnl=False)\n ts = ts.reshape(sc.shape)\n\n iarg = np.argsort(np.ravel(ts))[::-1]\n ts_sort = ts.flat[iarg]\n\n i0 = int(percentile(np.linspace(0,len(iarg),len(iarg)),\n np.cumsum(ts_sort)/np.sum(ts),0.5))\n\n msk = np.empty(shape=ts_sort.shape,dtype=bool); msk.fill(False)\n msk[iarg[:i0]] = True\n msk = msk.reshape(ts.shape)\n \n scounts = np.sum(sc0[msk])\n bcounts = np.sum(bc[msk])\n sfrac = np.sum(sc0[msk])/np.sum(bc[msk])\n\n if sfrac < self._min_fsig:\n t0 *= self._min_fsig/sfrac\n ts = onoff.asimov_ts0_signal(t0,sum_lnl=False)\n ts = ts.reshape(sc.shape)\n\n print t0, sfrac, self._min_fsig, np.sum(ts[msk])\n\n axis0 = Axis(self._loge_axis.edges-np.log10(Units.gev))\n axis1 = Axis(np.degrees(self._psi_axis.edges))\n\n o['sigmav_ul'] = np.power(10,-28.)*t0\n o['sc_hist'] = Histogram2D(axis0,axis1,counts=sc*t0)\n o['bc_hist'] = Histogram2D(axis0,axis1,counts=bc)\n o['ts_hist'] = Histogram2D(axis0,axis1,counts=ts)\n o['msk_sfrac'] = msk\n o['scounts_msk'] = scounts\n o['bcounts_msk'] = bcounts\n\n return o\n\n axis0 = Axis(self._loge_axis.edges-np.log10(Units.gev))\n axis1 = Axis(np.degrees(self._psi_axis.edges))\n\n dlnl_hist = Histogram2D(axis0,axis1)\n dlnl_hist._counts = copy.copy(dlnl)\n\n dlnl_hist_msk = copy.deepcopy(dlnl_hist)\n \n dlnl_hist_msk._counts[~msk]=0\n\n plt.figure()\n plt.gca().set_title('M = %.2f GeV'%(m/Units.gev))\n im = dlnl_hist.plot()\n\n plt.colorbar(im,label='TS')\n\n plt.gca().set_xlabel('Energy [log$_{10}$(E/GeV)]')\n plt.gca().set_ylabel('Offset [deg]')\n\n plt.figure()\n plt.gca().set_title('M = %.2f GeV'%(m/Units.gev))\n im = dlnl_hist_msk.plot()\n \n plt.colorbar(im,label='TS')\n\n plt.gca().set_xlabel('Energy [log$_{10}$(E/GeV)]')\n plt.gca().set_ylabel('Offset [deg]')\n\n plt.show()\n\n sh2 = Histogram2D(axis,self._psi_axis)\n# sh2._counts[:,self._msk][msk] = 1.0\n sh2._counts[msk] = 1.0\n plt.figure()\n\n sh2.plot()\n\n plt.show()\n\n sh = Histogram2D(axis,self._psi_axis)\n sh._counts[:,self._msk] = sc0\n\n bh = Histogram2D(axis,self._psi_axis)\n bh._counts[:,self._msk] = bc\n\n plt.figure()\n sh.project(0).plot()\n bh.project(0).plot()\n\n plt.gca().set_yscale('log')\n\n shp = sh.project(0)\n bhp = bh.project(0)\n\n plt.figure()\n (shp/bhp).plot()\n \n plt.figure()\n im = (sh/bh).plot(zlabel='test')\n plt.colorbar(im)\n \n plt.show()\n \n\n"
},
{
"alpha_fraction": 0.6804201006889343,
"alphanum_fraction": 0.6991748213768005,
"avg_line_length": 29.295454025268555,
"blob_id": "c144a89ffde968b84fe219e344b7382a25f71e62",
"content_id": "e0536b6586975a9c0d8a527cd4656da8f039d427",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1333,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 44,
"path": "/scripts/validate_psf.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\n\nos.environ['CUSTOM_IRF_DIR'] = '/u/gl/mdwood/ki10/analysis/custom_irfs/'\nos.environ['CUSTOM_IRF_NAMES'] = 'P7SOURCE_V6,P7SOURCE_V6MC,P7SOURCE_V9,P7CLEAN_V6,P7CLEAN_V6MC,P7ULTRACLEAN_V6,' \\\n 'P7ULTRACLEAN_V6MC,P6_v11_diff,P7SOURCE_V6MCPSFC,P7CLEAN_V6MCPSFC,P7ULTRACLEAN_V6MCPSFC'\n\nimport sys\nimport copy\nimport re\nimport argparse\nimport yaml\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib import font_manager\n\nimport gammatools.core.stats as stats\nfrom gammatools.fermi.catalog import Catalog\nfrom gammatools.fermi.validate import *\n\nif __name__ == '__main__':\n usage = \"%(prog)s [options] [pickle file ...]\"\n description = \"\"\"Perform PSF validation analysis on agn or\npulsar data samples.\"\"\"\n parser = argparse.ArgumentParser(usage=usage, description=description)\n\n parser.add_argument('files', nargs='+')\n parser.add_argument('--config', default=None )\n \n PSFValidate.add_arguments(parser)\n \n args = parser.parse_args()\n\n config = {}\n if not args.config is None and os.path.isfile(args.config):\n config = yaml.load(open(args.config,'r'))\n \n psfv = PSFValidate(config,args)\n\n if not args.config is None and not os.path.isfile(args.config):\n yaml.dump(psfv.config(),open(args.config,'w'))\n \n psfv.run()\n"
},
{
"alpha_fraction": 0.5796459913253784,
"alphanum_fraction": 0.5815423727035522,
"avg_line_length": 20.37837791442871,
"blob_id": "a2b9517103754ee0862c8dbffd25e0b480482fac",
"content_id": "757cca8c0a7c9e5a186ef2d94067ce1f97448f23",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1582,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 74,
"path": "/gammatools/fermi/analysis_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import copy\nfrom gammatools.core.histogram import Histogram\nfrom data import PhotonData\n\ndef getHist(data,var_name,mask=None,edges=None):\n \n h = Histogram(edges) \n\n if not mask is None:\n h.fill(data[var_name][mask])\n else:\n h.fill(data[var_name])\n\n return h\n\ndef getOnOffHist(data,var_name,phases,mask=None,edges=None):\n \n (on_phase,off_phase,alpha) = phases\n\n on_mask = PhotonData.get_mask(data,phases=on_phase)\n off_mask = PhotonData.get_mask(data,phases=off_phase)\n\n if not mask is None:\n on_mask &= mask\n off_mask &= mask\n\n hon = Histogram(edges)\n hon.fill(data[var_name][on_mask])\n\n hoff = Histogram(edges)\n hoff.fill(data[var_name][off_mask])\n\n hoffs = copy.deepcopy(hoff)\n hoffs *= alpha\n\n return (hon,hoff,hoffs)\n\ndef parse_phases(on_phase,off_phase):\n \n on_phases = []\n off_phases = []\n alpha = 0\n \n on_phase_range = 0\n phases = on_phase.split(',')\n for p in phases:\n (plo,phi) = p.split('/')\n plo = float(plo)\n phi = float(phi)\n on_phase_range += (phi-plo)\n on_phases.append([plo,phi])\n\n off_phase_range = 0\n phases = off_phase.split(',')\n for p in phases:\n (plo,phi) = p.split('/')\n plo = float(plo)\n phi = float(phi)\n off_phase_range += (phi-plo)\n off_phases.append([plo,phi])\n \n alpha = on_phase_range/off_phase_range\n\n return (on_phases,off_phases,alpha)\n\n\n \nclass ModelBuilder(object):\n\n default_config = { 'xml' : (None) }\n \n def __init__(self):\n\n pass\n"
},
{
"alpha_fraction": 0.4668785035610199,
"alphanum_fraction": 0.4761345684528351,
"avg_line_length": 31.459640502929688,
"blob_id": "ce74d76da68866e0d2439767f46e45bfe6466eaa",
"content_id": "82257025b471283af7bcbee3d33fc394cb29f2cf",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14477,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 446,
"path": "/gammatools/fermi/task.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "import yaml\nimport os\nimport shutil\nimport copy\nfrom tempfile import mkdtemp\nimport re\nimport glob\nfrom GtApp import GtApp\n#from uw.like.roi_catalogs import SourceCatalog, Catalog2FGL, Catalog3Y\n#from BinnedAnalysis import BinnedObs,BinnedAnalysis\n#from UnbinnedAnalysis import UnbinnedObs, UnbinnedAnalysis\n#from pyLikelihood import ParameterVector\n\nfrom gammatools.fermi.catalog import Catalog, CatalogSource\nfrom gammatools.core.config import Configurable\nfrom gammatools.core.util import extract_dict_by_keys\n\nclass TaskDispatcher(Configurable):\n\n default_config = { 'queue' : 'xlong' }\n \n def __init__(self,config=None,**kwargs):\n super(TaskDispatcher,self).__init__(config,**kwargs) \n \nclass Task(Configurable):\n\n default_config = {\n 'scratchdir' : ('/scratch','Set the path under which temporary '\n 'working directories will be created.'),\n 'workdir' : (None,'Set the working directory.'),\n 'verbose' : 1,\n 'overwrite' : (True,'Overwrite the output file if it exists.'),\n 'stage_inputs' : (False,'Copy input files to temporary working directory.') }\n \n def __init__(self,config=None,**kwargs): \n super(Task,self).__init__(config,**kwargs)\n\n self._input_files = []\n self._output_files = []\n \n if self.config['scratchdir'] is None:\n self._scratchdir = os.getcwd()\n else:\n self._scratchdir = self.config['scratchdir']\n\n \n if self.config['workdir'] is None:\n self._savedata=False\n self._workdir=mkdtemp(prefix=os.environ['USER'] + '.',\n dir=self._scratchdir)\n\n if self.config['verbose']:\n print 'Created workdir: ', self._workdir\n \n else:\n self._savedata=False\n self._workdir= self.config['workdir']\n\n if self.config['verbose']:\n print 'Using workdir: ', self._workdir\n \n def register_output_file(self,outfile):\n self._output_files.append(outfile)\n \n def prepare(self):\n\n # stage input files\n self._cwd = os.getcwd()\n os.chdir(self._workdir)\n\n def run(self):\n\n import pprint\n pprint.pprint(self.config)\n \n if len(self._output_files) and \\\n os.path.isfile(self._output_files[0]) and \\\n not self.config['overwrite']:\n print 'Output file exists: ', self._output_files[0]\n return\n \n self.prepare()\n\n self.run_task()\n \n self.cleanup()\n \n def cleanup(self):\n\n self.stage_output_files()\n os.chdir(self._cwd)\n \n if not self._savedata and os.path.exists(self._workdir):\n shutil.rmtree(self._workdir)\n\n def stage_output_files(self):\n for f in self._output_files: \n if self.config['verbose']:\n print 'cp %s %s'%(os.path.basename(f),f) \n os.system('cp %s %s'%(os.path.basename(f),f)) \n \n def __del__(self):\n if not self._savedata and os.path.exists(self._workdir):\n if self.config['verbose']:\n print 'Deleting working directory ', self._workdir\n shutil.rmtree(self._workdir)\n\nclass LTSumTask(Task):\n\n default_config = { 'infile1' : None }\n\n def __init__(self,outfile,config=None,**kwargs):\n super(LTSumTask,self).__init__(config,**kwargs)\n\n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtltsum')\n \n def run_task(self):\n\n outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(outfile=outfile,**self.config)\n \nclass LTCubeTask(Task):\n\n default_config = { 'dcostheta' : 0.025,\n 'binsz' : 1.0,\n 'evfile' : None,\n 'scfile' : (None, 'spacecraft file'),\n 'tmin' : 0.0,\n 'tmax' : 0.0,\n 'zmax' : (100.0,'Set the maximum zenith angle.') }\n\n def __init__(self,outfile,config=None,opts=None,**kwargs):\n super(LTCubeTask,self).__init__(config,opts=opts,**kwargs)\n\n self._config['scfile'] = os.path.abspath(self._config['scfile'])\n \n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtltcube')\n \n def run_task(self):\n\n outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(outfile=outfile,**self.config)\n \n\nclass SrcModelTask(Task):\n\n default_config = {\n 'srcmaps' : None,\n 'srcmdl' : None,\n 'expcube' : None,\n 'bexpmap' : None,\n 'srcmdl' : None,\n 'chatter' : 2,\n 'irfs' : None,\n 'outtype' : 'ccube' }\n\n \n def __init__(self,outfile,config=None,opts=None,**kwargs):\n super(SrcModelTask,self).__init__(config,opts=opts,**kwargs)\n\n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtmodel')\n \n def run_task(self):\n\n outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(outfile=outfile,**self.config)\n \nclass SrcMapTask(Task):\n\n default_config = { 'scfile' : None,\n 'expcube' : None,\n 'bexpmap' : None,\n 'cmap' : None,\n 'srcmdl' : None,\n 'chatter' : 2,\n 'irfs' : None,\n 'resample' : 'yes',\n 'rfactor' : 2,\n 'minbinsz' : 0.1 }\n\n def __init__(self,outfile,config=None,**kwargs):\n super(SrcMapTask,self).__init__()\n self.update_default_config(SrcMapTask)\n self.configure(config,subsection='gtsrcmaps',**kwargs)\n \n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtsrcmaps','Likelihood')\n\n def run_task(self):\n\n config = self.config\n outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(outfile=outfile,emapbnds='no',**config)\n\n\n \nclass BExpTask(Task):\n\n default_config = { 'nxpix' : 360.,\n 'nypix' : 180.,\n 'allsky' : True,\n 'xref' : 0.0,\n 'yref' : 0.0,\n 'emin' : 1000.0,\n 'emax' : 100000.0,\n 'chatter' : 2,\n 'proj' : 'CAR',\n 'enumbins' : 16,\n 'infile' : None,\n 'irfs' : None,\n 'cmap' : 'none',\n 'coordsys' : 'CEL',\n 'ebinalg' : 'LOG',\n 'binsz' : 1.0 }\n \n def __init__(self,outfile,config=None,**kwargs):\n super(BExpTask,self).__init__()\n self.update_default_config(BExpTask)\n self.configure(config,subsection='gtexpcube',**kwargs)\n\n if self.config['allsky']:\n self.set_config('nxpix',360)\n self.set_config('nypix',180)\n self.set_config('xref',0.0)\n self.set_config('yref',0.0)\n self.set_config('binsz',1.0)\n self.set_config('proj','CAR')\n \n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtexpcube2','Likelihood')\n \n\n def run_task(self):\n\n config = copy.deepcopy(self.config)\n del(config['allsky']) \n outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(outfile=outfile,**config)\n\n \n \nclass BinTask(Task):\n\n default_config = { 'nxpix' : 140,\n 'nypix' : None,\n 'xref' : 0.0,\n 'yref' : 0.0,\n 'emin' : 1000.0,\n 'emax' : 100000.0,\n 'scfile' : None,\n 'chatter' : 2,\n 'proj' : 'AIT',\n 'hpx_order' : 3,\n 'enumbins' : 16,\n 'algorithm' : 'ccube',\n 'binsz' : 0.1,\n 'coordsys' : 'CEL'}\n \n def __init__(self,infile,outfile,config=None,opts=None,**kwargs):\n super(BinTask,self).__init__()\n self.configure(config,opts=opts,subsection='gtbin',**kwargs)\n \n self._infile = os.path.abspath(infile)\n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n\n if re.search('^(?!\\@)(.+)(\\.txt|\\.lst)$',self._infile):\n self._infile = '@'+self._infile\n \n self._gtbin=GtApp('gtbin','evtbin')\n \n\n def run_task(self):\n\n config = copy.deepcopy(self.config)\n\n outfile = os.path.basename(self._output_files[0])\n\n if config['nypix'] is None:\n config['nypix'] = config['nxpix']\n \n self._gtbin.run(algorithm=config['algorithm'],\n nxpix=config['nxpix'],\n nypix=config['nypix'],\n binsz=config['binsz'],\n hpx_order=config['hpx_order'],\n evfile=self._infile,\n outfile=outfile,\n scfile=config['scfile'],\n xref=config['xref'],\n yref=config['yref'],\n axisrot=0,\n proj=config['proj'],\n ebinalg='LOG',\n emin=config['emin'],\n emax=config['emax'],\n enumbins=config['enumbins'],\n coordsys=config['coordsys'],\n chatter=config['chatter'])\n\n \nclass SelectorTask(Task):\n\n default_config = { 'ra' : 0.0,\n 'dec' : 0.0,\n 'radius' : 180.0,\n 'tmin' : 0.0,\n 'tmax' : 0.0,\n 'zmax' : 100.,\n 'emin' : 10.,\n 'emax' : 1000000.,\n 'chatter' : 2,\n 'evclsmin' : 'INDEF',\n 'evclass' : 'INDEF',\n 'evtype' : 'INDEF',\n 'convtype' : -1 } \n \n def __init__(self,infile,outfile,config=None,opts=None,**kwargs):\n super(SelectorTask,self).__init__() \n self.configure(config,opts=opts,**kwargs)\n \n self._infile = os.path.abspath(infile)\n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n\n# if re.search('^(?!\\@)(.+)\\.txt$',self._infile):\n if re.search('^(?!\\@)(.+)(\\.txt|\\.lst)$',self._infile):\n self._infile = '@'+self._infile\n \n self._gtselect=GtApp('gtselect','dataSubselector')\n\n\n def run_task(self):\n \n config = self.config\n\n outfile = os.path.basename(self._output_files[0])\n\n\n# print self._infile\n# os.system('cat ' + self._infile[1:])\n \n self._gtselect.run(infile=self._infile,\n outfile=outfile,\n ra=config['ra'], dec=config['dec'], \n rad=config['radius'],\n tmin=config['tmin'], tmax=config['tmax'],\n emin=config['emin'], emax=config['emax'],\n zmax=config['zmax'], chatter=config['chatter'],\n evclass=config['evclass'], # Only for Pass7\n evtype=config['evtype'],\n convtype=config['convtype']) # Only for Pass6\n\n\n\nclass MkTimeTask(Task):\n\n default_config = { 'roicut' : 'no',\n 'filter' : 'IN_SAA!=T&&DATA_QUAL==1&&LAT_CONFIG==1&&ABS(ROCK_ANGLE)<52',\n 'evfile' : None,\n 'scfile' : None } \n \n def __init__(self,infile,outfile,config=None,**kwargs):\n super(MkTimeTask,self).__init__()\n self.update_default_config(MkTimeTask)\n self.configure(config,subsection='gtmktime',**kwargs)\n\n self._infile = os.path.abspath(infile)\n self._outfile = os.path.abspath(outfile)\n self.register_output_file(self._outfile)\n \n self._gtapp=GtApp('gtmktime','dataSubselector')\n\n\n def run_task(self):\n \n config = self.config\n\n outfile = os.path.basename(self._output_files[0])\n \n self._gtapp.run(evfile=self._infile,\n outfile=outfile,\n filter=config['filter'],\n roicut=config['roicut'],\n scfile=config['scfile'])\n\nclass ObsSimTask(Task):\n\n default_config = {\n 'infile' : None, \n 'srclist' : None,\n 'scfile' : None,\n 'ra' : None,\n 'dec' : None,\n 'radius' : None,\n 'emin' : None,\n 'emax' : None,\n 'irfs' : None,\n 'simtime' : None,\n 'evroot' : 'sim',\n 'use_ac' : False,\n 'seed' : 1,\n 'rockangle' : 'INDEF'\n }\n\n \n def __init__(self,config=None,opts=None,**kwargs):\n super(ObsSimTask,self).__init__(config,opts=opts,**kwargs)\n\n# self._outfile = os.path.abspath(outfile)\n# self.register_output_file(self._outfile)\n \n self._gtapp = GtApp('gtobssim')\n \n def run_task(self):\n\n config = extract_dict_by_keys(self.config,\n ObsSimTask.default_config.keys())\n# outfile = os.path.basename(self._output_files[0]) \n self._gtapp.run(**config)\n\n\n def cleanup(self):\n\n # Copy files\n outfiles = glob.glob('sim*fits')\n\n for f in outfiles:\n\n print f\n \n# if os.path.dirname(f) != self._cwd: \n# os.system('cp %s %s'%(f,self._cwd))\n"
},
{
"alpha_fraction": 0.5703079104423523,
"alphanum_fraction": 0.6263973116874695,
"avg_line_length": 30.856250762939453,
"blob_id": "daae67d8152ddb2bf40790eb8a0571909af847bd",
"content_id": "1891bdc3f92278bb67d2d94bf6ee1b8cd019577f",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5099,
"license_type": "permissive",
"max_line_length": 195,
"num_lines": 160,
"path": "/gammatools/fermi/IRFdefault.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "# @file IRFdefault.py\n# @brief define default setup options\n#\n# $Header: /nfs/slac/g/glast/ground/cvs/ScienceTools-scons/irfs/handoff_response/python/IRFdefault.py,v 1.14 2014/06/04 19:34:32 jchiang Exp $\nimport os\np = os.getcwd().split(os.sep)\nprint 'loading setup from %s ' % os.getcwd()\n\n#extract class name from file path\nclassName = p[len(p)-1]\nprint 'eventClass is %s' % className\n\n \nclass Prune(object):\n \"\"\"\n information for the prune step\n \"\"\"\n fileName = 'goodEvent.root' # file to create\n branchNames =\"\"\"\n EvtRun EvtEnergyCorr \n McEnergy McXDir McYDir McZDir \n McXDirErr McYDirErr McZDirErr \n McTkr1DirErr McDirErr \n GltWord OBFGamStatus\n Tkr1FirstLayer VtxAngle \n CTBVTX CTBCORE CTBSummedCTBGAM CTBBest*\n \"\"\".split() # specify branch names to include\n cuts='(GltWord&10)>0 && (GltWord!=35) && (OBFGamStatus>0) && CTBBestEnergyProb>0.1 && CTBCORE>0.1'\n\nclass Data(object):\n files=['../all/'+Prune.fileName] # use pruned file in event class all by default\n # these correspond to the three runs at SLAC and UW\n generate_area = 6.0\n generated=[60e6,150e6, 97e6]\n logemin = [1.25, 1.25, 1.0]\n logemax = [5.75, 4.25, 2.75]\n \n\n# define additional cuts based on event class: these are exclusive, add up to class 'all'\nadditionalCuts = {\n 'all': '',\n 'classA': '&&CTBSummedCTBGAM>=0.5 && CTBCORE>=0.8',\n 'classB': '&&CTBSummedCTBGAM>=0.5 && CTBCORE>=0.5 && CTBCORE<0.8',\n 'classC': '&&CTBSummedCTBGAM>=0.5 && CTBCORE<0.5',\n 'classD': '&&CTBSummedCTBGAM>=0.1 && CTBSummedCTBGAM<0.5',\n 'classF': '&&CTBSummedCTBGAM<0.1',\n 'standard': '&&CTBSummedCTBGAM>0.5'\n }\nif className in additionalCuts.keys():\n Prune.cuts += additionalCuts[className]\nelse:\n pass\n #print 'Event class \"%s\" not recognized: using cuts for class all' %className\n \ntry:\n import numarray as num\nexcept ImportError:\n import numpy as num\n\n#define default binning as attributes of object Bins\nclass Bins(object):\n\n @classmethod\n def set_energy_bins(cls,logemin=None,logemax=None,logedelta=None):\n\n if logemin is None: logemin = cls.logemin\n if logemax is None: logemax = cls.logemax\n if logedelta is None: logedelta = cls.logedelta\n \n cls.energy_bins = int((logemax-logemin)/logedelta)\n cls.energy_bin_edges = (num.arange(cls.energy_bins+1)*logedelta+logemin).tolist()\n\n print 'Energy Bins ', cls.energy_bin_edges\n\n @classmethod\n def set_angle_bins(cls,cthmin=None,cthdelta=None):\n if cthmin is None: cthmin = cls.cthmin\n if cthdelta is None: cthdelta = cls.cthdelta\n\n cls.angle_bins = int((1.0-cthmin)/cthdelta) \n cls.angle_bin_edges = num.arange(cls.angle_bins+1)*cthdelta+cthmin\n \n \n logemin = 1.25\n logemax = 5.75\n logedelta = 0.25 #4 per decade\n\n cthmin = 0.2\n cthdelta = 0.1\n\n # no overlap with adjacent bins for energy dispersion fits\n edisp_energy_overlap = 0 \n edisp_angle_overlap = 0\n\n # no overlap with adjacent bins for psf fits\n psf_energy_overlap = 0 \n psf_angle_overlap = 0\n\nBins.set_energy_bins()\nBins.set_angle_bins()\n\n\nclass FisheyeBins(Bins):\n logemin = Bins.logemin\n logemax = Bins.logemax\n logedelta = 0.25\n\n cthmin = 0.2\n cthdelta = 0.1\n\nFisheyeBins.set_energy_bins()\nFisheyeBins.set_angle_bins()\n \n \nclass EffectiveAreaBins(Bins):\n \"\"\"\n subclass of Bins for finer binning of effective area\n \"\"\"\n logemin = Bins.logemin\n logemax = Bins.logemax\n ebreak = 4.25\n ebinfactor = 4\n ebinhigh = 2\n logedelta = Bins.logedelta \n # generate list with different \n anglebinfactor=4 # bins multiplier\n angle_bin_edges = num.arange(Bins.angle_bins*anglebinfactor+1)*Bins.cthdelta/anglebinfactor+Bins.cthmin\n\n @classmethod\n def set_energy_bins(cls,logemin=None,logemax=None):\n\n if logemin is None: logemin = cls.logemin\n if logemax is None: logemax = cls.logemax\n \n cls.energy_bin_edges = []\n x = logemin\n factor = cls.ebinfactor\n while x<logemax+0.01:\n if x>= cls.ebreak: factor = cls.ebinhigh\n cls.energy_bin_edges.append(x)\n x += cls.logedelta/factor\n\n print 'Energy Bins ', cls.energy_bin_edges\n\nEffectiveAreaBins.set_energy_bins()\n \nclass PSF(object):\n pass\n\nclass Edisp(object):\n Version=2\n #Scale Parameters\n front_pars = [0.0195, 0.1831, -0.2163, -0.4434, 0.0510, 0.6621]\n back_pars = [0.0167, 0.1623, -0.1945, -0.4592, 0.0694, 0.5899]\n #Fit Parameters key=name, value=[pinit,pmin,max]\n# fit_pars = {\"f\":[0.96,0.5,1.],\"s1\":[1.5,0.1,5.], \"k1\":[1.2,0.1,5.], \"bias\":[0.,-3.,3.], \"s2\":[2.5,0.8,8], \"k2\":[.8,.01,8],\"bias2\":[0.,-3.,3.], \"pindex1\":[1.8,0.01,2],\"pindex2\":[1.8,0.01,2]}\n fit_pars = {\"f\":[0.8,0.3,1.0],\"s1\":[1.5,0.1,5.0], \"k1\":[1.0,0.1,3.0], \"bias\":[0.0,-3,3], \"bias2\":[0.0,-3,3], \"s2\":[4.0,1.2,10], \"k2\":[1.0,0.1,3.0],\"pindex1\":[2.0,0.1,5],\"pindex2\":[2.0,0.1,5]}\n \n# the log file - to cout if null\nlogFile = 'log.txt'\n\n\n"
},
{
"alpha_fraction": 0.5471293926239014,
"alphanum_fraction": 0.5695515275001526,
"avg_line_length": 27.69672203063965,
"blob_id": "4b4da8281ae95f2ee8fb71c5e2522b4db1aa13c2",
"content_id": "97db7081bbdb800c57bc5977eb7e27fd41375821",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14004,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 488,
"path": "/gammatools/core/stats.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\"\"\"\n@author Matthew Wood <[email protected]>\n\"\"\"\n\n__author__ = \"Matthew Wood <[email protected]>\"\n__date__ = \"$Date: 2013/10/20 23:53:52 $\"\n\nimport numpy as np\nimport copy\nfrom scipy.interpolate import UnivariateSpline\nimport scipy.optimize as opt\nimport matplotlib.pyplot as plt\nfrom gammatools.core.histogram import Histogram\nfrom scipy.stats import norm\nfrom gammatools.core.util import find_root, find_fn_root\nfrom gammatools.core.nonlinear_fitting import BFGSFitter\n\ndef pval_to_sigma(p):\n \"\"\"Convert the pval of a one-sided confidence interval to sigma.\"\"\"\n return norm().isf(p)\n\ndef sigma_to_pval(s):\n return norm().cdf(s)\n\ndef gauss_pval_to_sigma(p):\n \"\"\"Convert the pval of a two-sided confidence interval to sigma.\"\"\"\n return norm().isf(0.5+p*0.5)\n\ndef gauss_sigma_to_pval(s):\n return 2.0*(norm().cdf(s)-0.5)\n\ndef poisson_lnl(nc,mu):\n \"\"\"Log-likelihood function for a poisson distribution with nc\n observed counts and expectation value mu. Note that this function\n can accept arguments with different lengths along each dimension\n and will apply the standard numpy broadcasting rules during\n evaluation.\"\"\"\n\n nc = np.array(nc,ndmin=1)\n mu = np.array(mu,ndmin=1)\n\n shape = max(nc.shape,mu.shape)\n\n lnl = np.zeros(shape)\n mu = mu*np.ones(shape)\n nc = nc*np.ones(shape)\n\n msk = nc>0\n\n lnl[msk] = nc[msk]*np.log(mu[msk])-mu[msk]\n lnl[~msk] = -mu[~msk]\n return lnl\n\ndef poisson_delta_lnl(nc,mu0,mu1):\n \"\"\"Compute the log-likelihood ratio for a binned counts\n distribution given two models.\"\"\"\n return poisson_lnl(nc,mu0) - poisson_lnl(nc,mu1)\n\n\nclass OnOffExperiment(object):\n \"\"\"Evaluate the sensitivity of an on-off counting experiment. If\n alpha = None then the background will be assumed to be known.\"\"\"\n\n def __init__(self,mus,mub,alpha=None,known_background=False):\n self._mus = np.array(mus,ndmin=1)\n self._mub = np.array(mub,ndmin=1)\n if not alpha is None: self._alpha = np.array(alpha,ndmin=1)\n else: self._alpha = None\n self._data_axes = [0]\n\n def mc_ts(self,mu,ntrial):\n \"\"\"Simulate a set of TS values.\"\"\"\n\n shape = (ntrial,len(self._mus))\n\n ns = np.random.poisson(self._mus*mu,shape).T\n nb = np.random.poisson(self._mub,shape).T\n nc = np.random.poisson(np.sum(self._mub)/self._alpha,(ntrial,1)).T\n\n ns = np.array(ns,dtype='float')\n nb = np.array(nb,dtype='float')\n nc = np.array(nc,dtype='float')\n\n tsv = []\n\n for i in range(ntrial):\n\n # Fit for signal lnl\n fn0 = lambda x,y: -OnOffExperiment.lnl_signal(ns[:,i]+nb[:,i],nc[:,i],\n x*self._mus,y*self._mub,\n self._alpha)\n\n # Fit for signal null lnl\n fn1 = lambda x: -OnOffExperiment.lnl_null(ns[:,i]+nb[:,i],nc[:,i],\n x*self._mub,self._alpha)\n\n p0 = BFGSFitter.fit(fn0,[1.0,1.0],bounds=[[0.01,None],[0.01,None]])\n p1 = BFGSFitter.fit(fn1,[1.0],bounds=[[0.01,None]])\n\n ts = OnOffExperiment.ts(ns[:,i]+nb[:,i],nc[:,i],\n p0[0].value*self._mus,\n p0[1].value*self._mub,\n p1[0].value*self._mub,\n self._alpha)\n \n ts = max(ts,0)\n tsv.append(ts)\n\n return np.array(tsv)\n\n def asimov_mu_ts0(self,ts):\n \"\"\"Return the value of the signal strength parameter for which\n the TS (-2*lnL) for discovery is equal to the given value.\"\"\"\n\n smin = 1E-3\n smax = 1E3\n\n while self.asimov_ts0_signal(smax) < ts: smax *= 10\n while self.asimov_ts0_signal(smin) > ts: smin *= 0.1\n\n mu = find_fn_root(self.asimov_ts0_signal,smin,smax,ts)\n mu_err = np.sqrt(mu**2/ts)\n\n return (mu,mu_err)\n\n def asimov_mu_p0(self,alpha):\n \"\"\"Return the value of the signal strength parameter for which\n the p-value for discovery is equal to the given value.\"\"\"\n \n ts = pval_to_sigma(alpha)**2 \n return self.asimov_mu_ts0(ts)\n\n def asimov_ts0_signal(self,s,sum_lnl=True):\n \"\"\"Compute the median discovery test statistic for a signal\n strength parameter s using the asimov method.\"\"\"\n\n s = np.array(s,ndmin=1)[np.newaxis,...]\n\n mub = self._mub[:,np.newaxis]\n mus = self._mus[:,np.newaxis]\n\n wb = mub/np.apply_over_axes(np.sum,mub,self._data_axes)\n\n # model amplitude for signal counts in signal region under\n # signal hypothesis\n s1 = s*mus\n\n # nb of counts in signal region\n ns = mub + s1\n\n if self._alpha is None: \n\n b0 = wb*np.apply_over_axes(np.sum,ns,self._data_axes)\n lnls1 = poisson_lnl(ns,ns)\n lnls0 = poisson_lnl(ns,b0)\n ts = 2*np.apply_over_axes(np.sum,(lnls1-lnls0),self._data_axes)\n\n return ts\n\n alpha = self._alpha[:,np.newaxis]\n\n # nb of counts in control region\n nc = np.apply_over_axes(np.sum,mub/alpha,self._data_axes)\n\n # model amplitude for background counts in signal region under\n # null hypothesis\n b0 = wb*(nc+np.apply_over_axes(np.sum,ns,\n self._data_axes))*alpha/(1+alpha)\n\n lnl1 = OnOffExperiment.lnl_signal(ns,nc,s1,mub,alpha,\n self._data_axes,sum_lnl)\n lnl0 = OnOffExperiment.lnl_null(ns,nc,b0,alpha,\n self._data_axes,sum_lnl)\n\n return 2*(lnl1-lnl0)\n\n @staticmethod\n def lnl_signal(ns,nc,mus,mub,alpha=None,data_axes=0,sum_lnl=True):\n \"\"\"\n Log-likelihood for signal hypothesis.\n\n Parameters\n ----------\n ns: Vector of observed counts in signal region.\n\n nc: Vector of observed counts in control region(s).\n \"\"\" \n\n lnls = poisson_lnl(ns,mus+mub)\n lnlc = np.zeros(nc.shape)\n\n if alpha: \n # model amplitude for counts in control region\n muc = np.apply_over_axes(np.sum,mub,data_axes)/alpha\n lnlc = poisson_lnl(nc,muc)\n\n if sum_lnl: \n lnls = np.apply_over_axes(np.sum,lnls,data_axes)\n lnls = np.squeeze(lnls,data_axes)\n\n lnlc = np.apply_over_axes(np.sum,lnlc,data_axes)\n lnlc = np.squeeze(lnlc,data_axes)\n\n return lnls+lnlc\n else:\n return lnls\n\n @staticmethod\n def lnl_null(ns,nc,mub,alpha=None,data_axes=0,sum_lnl=True):\n \"\"\"\n Log-likelihood for null hypothesis.\n\n Parameters\n ----------\n ns: Vector of observed counts in signal region.\n\n nc: Vector of observed counts in control region(s).\n \"\"\" \n lnls = poisson_lnl(ns,mub)\n lnlc = np.zeros(nc.shape)\n\n if alpha: \n # model amplitude for counts in control region\n muc = np.apply_over_axes(np.sum,mub,data_axes)/alpha\n lnlc = poisson_lnl(nc,muc)\n\n if sum_lnl: \n lnls = np.apply_over_axes(np.sum,lnls,data_axes)\n lnls = np.squeeze(lnls,data_axes)\n\n lnlc = np.apply_over_axes(np.sum,lnlc,data_axes)\n lnlc = np.squeeze(lnlc,data_axes)\n return lnls+lnlc\n else:\n return lnls\n\n\n @staticmethod\n def ts(ns,nc,mus1,mub1,mub0,alpha,data_axis=0,sum_lnl=True):\n \"\"\"\n Compute the TS (2 x delta log likelihood) between signal and\n null hypotheses given a number of counts and model amplitude\n in the signal/control regions.\n\n Parameters\n ----------\n sc: Observed counts in signal region.\n\n nc: Observed counts in control region.\n \"\"\"\n \n lnl1 = OnOffExperiment.lnl_signal(ns,nc,mus1,mub1,alpha,data_axis,sum_lnl)\n lnl0 = OnOffExperiment.lnl_null(ns,nc,mub0,alpha,data_axis,sum_lnl)\n\n return 2*(lnl1-lnl0)\n\ndef poisson_median_ts(sc,bc,alpha):\n \"\"\"Compute the median TS.\"\"\"\n\n # total counts in each bin\n nc = sc + bc \n\n # number of counts in control region\n cc = bc/alpha\n\n # model for total background counts in null hypothesis\n mub0 = (nc+cc)/(1.0+alpha)*alpha\n\n # model for total background counts in signal hypothesis\n mub1 = bc\n\n # model for signal counts\n mus = sc\n\n lnl0 = nc*np.log(mub0)-mub0 + cc*np.log(mub0/alpha) - mub0/alpha\n lnl1 = nc*np.log(mub1+mus) - mub1 - mus + \\\n cc*np.log(mub1/alpha) - mub1/alpha \n\n return 2*(lnl1-lnl0)\n\ndef poisson_median_ul(sc,bc,alpha):\n \"\"\"Compute the median UL.\"\"\"\n\n # total counts in each bin\n nc = bc \n\n # number of counts in control region\n cc = bc/alpha\n\n # model for total background counts in null hypothesis\n mub0 = (nc+cc)/(1.0+alpha)*alpha\n\n # model for total background counts in signal hypothesis\n mub1 = bc\n\n # model for signal counts\n mus = sc\n\n lnl0 = nc*np.log(mub0)-mub0 + cc*np.log(mub0/alpha) - mub0/alpha\n lnl1 = nc*np.log(mub1+mus) - mub1 - mus + \\\n cc*np.log(mub1/alpha) - mub1/alpha\n \n\n return 2*(lnl1-lnl0)\n\ndef poisson_ts(nc,mus,mub,data_axes=1):\n \"\"\"Test statistic for discovery with known background.\"\"\"\n\n # MLE for signal norm under signal hypothesis\n snorm = np.apply_over_axes(np.sum,nc-mub,data_axes)\n\n lnl0 = nc*np.log(mub) - mub \n lnl1 = nc*np.log(mus*snorm+mub) - (mus*snorm+mub) \n\n dlnl = 2*(lnl1-lnl0)\n \n return dlnl\n\ndef poisson_ul(nc,mus,mub,data_axes=1):\n \"\"\"Test statistic for discovery with known background.\"\"\"\n\n\n # MLE for signal norm under signal hypothesis\n snorm = np.apply_over_axes(np.sum,nc-mub,data_axes)\n snorm[snorm<0] = 0\n\n x = np.linspace(-3,3,50)\n\n mutot = snorm*mus+mub\n\n deltas = 10**x#*np.sum(mub)\n\n smutot = deltas[np.newaxis,np.newaxis,:]*mus[...,np.newaxis] + mutot[...,np.newaxis]\n\n lnl = nc[...,np.newaxis]*np.log(smutot) - smutot\n\n lnl = np.sum(lnl,axis=data_axes)\n\n ul = np.zeros(lnl.shape[0])\n\n for i in range(lnl.shape[0]):\n \n dlnl = -2*(lnl[i]-lnl[i][0])\n\n deltas_root = find_root(deltas,dlnl,2.72)\n\n ul[i] = snorm[i][0] + deltas_root\n\n\n continue\n\n print i, snorm[i][0], deltas_root\n\n z0 = 2*np.sum(poisson_lnl(nc[i],mutot[i]))\n z1 = 2*np.sum(poisson_lnl(nc[i],mutot[i]+deltas_root*mus))\n\n print z0, z1, z1-z0\n\n continue\n\n ul = snorm[i][0] + find_root(deltas,dlnl,2.72)\n\n print '------------'\n\n z0 = 2*np.sum(poisson_lnl(nc[i],mutot[i]))\n z1 = 2*np.sum(poisson_lnl(nc[i],mub+ul*mus))\n\n print z0, z1, z1-z0\n\n print snorm[i][0], ul\n\n# plt.figure()\n# plt.plot(x,dlnl)\n# plt.show()\n return ul\n\n\nif __name__ == '__main__':\n\n from gammatools.core.histogram import *\n\n fn_qmu = lambda n, mu0, mu1: -2*(poisson_lnl(n,mu1) - poisson_lnl(n,mu0))\n np.random.seed(1)\n\n ntrial = 1000\n\n mub = np.array([100.0,50.0]) \n mus = 10.*np.array([3.0,1.0])\n alpha = np.array([1.0])\n\n scalc = OnOffExperiment(mus,mub,alpha)\n\n\n print scalc.asimov_ts0_signal(1.0)\n print scalc.asimov_ts0_signal(np.linspace(0.1,100,10))\n\n\n ts = scalc.mc_ts(1.0,1000)\n\n print np.median(ts)\n\n sys.exit(0)\n\n s = np.linspace(0.1,100,10)\n\n print 'ts0_signal ', scalc.asimov_ts0_signal(s)\n print 'ts0_signal[5] ', s[5], scalc.asimov_ts0_signal(s[5])\n mu, muerr = scalc.asimov_mu_ts0(25.0)\n\n print 'TS(mu): ', scalc.asimov_ts0_signal(mu)\n print 'TS(mu+muerr): ', scalc.asimov_ts0_signal(mu+muerr)\n\n ns = np.random.poisson(mus,(ntrial,len(mus))).T\n nb = np.random.poisson(mub,(ntrial,len(mub))).T\n\n mub = mub[:,np.newaxis]\n mus = mus[:,np.newaxis]\n\n nexcess = ns+nb-mub\n nexcess[nexcess<=0] = 0\n\n ts_mc = -2*(poisson_lnl(ns+nb,mub) - poisson_lnl(ns+nb,ns+nb))\n ts_asimov = fn_qmu(mus+mub,mus+mub,mub)\n \n ul_mc = np.zeros(ntrial)\n\n alpha = 0.05\n dlnl = pval_to_sigma(alpha)**2\n\n for i in range(ntrial):\n\n xroot = find_fn_root(lambda t: fn_qmu((ns+nb)[:,i],\n (mub+nexcess)[:,i],\n (mub+nexcess)[:,i]+t),0,100,dlnl)\n ul_mc[i] = nexcess[i]+xroot\n\n\n sigma_mu_fn = lambda t: np.sqrt(t**2/fn_qmu(mub,mub,mub+t))\n\n ul_asimov_qmu = find_fn_root(lambda t: fn_qmu(mub,mub,mub+t),0,100,dlnl)\n sigma = np.sqrt(ul_asimov_qmu**2/dlnl)\n\n ul_asimov = 1.64*sigma\n ul_asimov_upper = (1.64+1)*sigma\n ul_asimov_lower = (1.64-1)*sigma\n\n\n print 'SIGMA ', sigma\n print 'SIGMA ', sigma_mu_fn(1.0)\n print 'SIGMA ', sigma_mu_fn(10.0)\n print 'Asimov q0 UL ', find_fn_root(lambda t: fn_qmu(mub+t,mub+t,mub),0,100,dlnl)\n print 'Asimov qmu UL ', ul_asimov_qmu, sigma\n print 'Asimov UL ', ul_asimov, ul_asimov_upper-ul_asimov, ul_asimov_lower-ul_asimov\n\n print -2*poisson_delta_lnl(mub,mub,mub+ul_asimov)\n print -2*poisson_delta_lnl(mub,mub,mub+ul_asimov_qmu)\n print fn_qmu(mub,mub,mub+ul_asimov_qmu)\n print dlnl\n\n qmu = -2*poisson_delta_lnl(mub,mub,mub+ul_asimov_qmu)\n\n h = Histogram(Axis.create(0,100,100))\n\n h.fill(ul_mc)\n\n h.normalize().cumulative().plot()\n\n plt.axhline(0.5-0.34,color='g')\n\n plt.axhline(0.5+0.34,color='g')\n\n plt.axvline(ul_asimov_qmu,color='k')\n\n plt.axvline(ul_asimov_qmu+sigma,color='k',linestyle='--')\n plt.axvline(ul_asimov_qmu-sigma,color='k',linestyle='--')\n# plt.axvline(ul_asimov_qmu-sigma/(ul_asimov_qmu+sigma)*ul_asimov_qmu,\n# color='k',linestyle='--')\n\n plt.gca().grid(True)\n\n plt.show()\n\n print 'Median UL ', np.median(ul_mc)\n\n print 'Median TS ', np.median(ts_mc)\n print 'Asimov TS ', ts_asimov\n# print fn_qmu(mus+mub,mus+mub,mub)\n# print fn_qmu(mub,mub,mus+mub)\n"
},
{
"alpha_fraction": 0.5798102021217346,
"alphanum_fraction": 0.5914581418037415,
"avg_line_length": 35.21875,
"blob_id": "9a5a833f37f5ee8e4c08b5b3dfdc96845b22ecb6",
"content_id": "29d5ac7deb15bd4054c6738eb39233858efea4b6",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2318,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 64,
"path": "/gammatools/fermi/merit_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "from gammatools.core.histogram import *\n\ndef createBkgRateHist(dset,var_list,var_axes,cuts=''):\n \n h = HistogramND.createFromTree(dset.chain(),var_list,var_axes,cuts)\n\n livetime = dset.getLivetime() \n ewidth = h.axis(0).width()[[slice(None)] + (len(var_list)-1)*[None]]\n egy = 10**(h.axis(0).center())[[slice(None)] + (len(var_list)-1)*[None]]\n \n h *= egy/(livetime*ewidth*np.log(10.)*4*np.pi*dset.config['fraction'])\n return h\n\ndef createAcceptanceHist(dset,var_list,var_axes,mc_eaxis,mc_cthaxis=None,\n cuts='',mc_evar='McLogEnergy'):\n \n \"\"\"Compute acceptance [m^2 sr] of a MC gamma-ray data set.\n Generates an n-dimensional histogram of acceptance versus log\n of the true gamma-ray energy, cosine of the true inclination angle\n (optional), and one or more reconstruction parameters.\"\"\"\n\n# mc_cthrange['label'] = 'Cos $\\\\theta$'\n# mc_erange['label'] = 'Energy [log$_{10}$(E/MeV)]'\n\n if var_list is None: var_list = []\n if var_axes is None: var_axes = []\n \n egy_bins = mc_eaxis.edges()\n cth_bins = None\n\n slices = len(var_list)*[None]\n \n if not mc_cthaxis is None:\n mc_var_list = [mc_evar,'-McZDir']\n mc_var_axes = [mc_eaxis,mc_cthaxis]\n cth_bins = mc_cthaxis.edges()\n else:\n mc_var_list = [mc_evar]\n mc_var_axes = [mc_eaxis]\n \n var_list = mc_var_list + var_list \n var_axes = mc_var_axes + var_axes\n \n h = HistogramND.createFromTree(dset.chain(),var_list,var_axes,cuts)\n \n thrown_events = dset.getThrownEvents(egy_bins,cth_bins)\n \n if mc_cthaxis:\n\n domega = 2*np.pi*mc_cthaxis.width()[[None,slice(None)] + slices]\n eff = h.counts()/thrown_events[[slice(None),slice(None)] + slices]\n eff_var = eff*(1-eff)/thrown_events[[slice(None),slice(None)] + slices]\n acc = eff*6.0/dset.config['fraction']*domega\n acc_var = eff_var*(6.0/dset.config['fraction']*domega)**2\n else:\n eff = h.counts()/thrown_events[[slice(None)] + slices]\n eff_var = eff*(1-eff)/thrown_events[[slice(None)] + slices]\n acc = eff*6.0*(2*np.pi)/dset.config['fraction']\n acc_var = eff_var*(6.0*(2*np.pi)/dset.config['fraction'])**2\n \n h._counts = acc\n h._var = acc_var\n\n return h\n"
},
{
"alpha_fraction": 0.5366148352622986,
"alphanum_fraction": 0.5756476521492004,
"avg_line_length": 28.840206146240234,
"blob_id": "0ce11a0f422a32d74b266b3640a9d9c4520e4284",
"content_id": "be48cc93fca8a75d1e8fb2317e2f6c3f1fa76ef1",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5790,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 194,
"path": "/scripts/calc_dmflux.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport matplotlib.pyplot as plt\nimport gammatools\nfrom gammatools.dm.dmmodel import *\nfrom gammatools.core.util import *\nfrom gammatools.dm.jcalc import *\nimport sys\nimport yaml\nimport copy\n\nimport argparse\n\ndef make_halo_plots(halo_models,cat):\n\n fig0 = plt.figure()\n ax0 = fig0.add_subplot(111)\n\n fig1 = plt.figure()\n ax1 = fig1.add_subplot(111)\n \n fig2 = plt.figure()\n ax2 = fig2.add_subplot(111)\n\n for h in halo_models:\n dp = DensityProfile.create(cat[h])\n jp = LoSIntegralFn.create(cat[h])\n\n prefix = h + '_'\n\n x = np.linspace(-1.0,2,100)\n\n\n ax0.plot(10**x,dp.rho(10**x*Units.kpc)/Units.gev_cm3,label=h)\n\n psi_edge = np.radians(10**np.linspace(np.log10(0.1),np.log10(45.),100))\n\n psi = 0.5*(psi_edge[1:] + psi_edge[:-1])\n\n jval = jp(psi)\n\n domega = 2*np.pi*(np.cos(psi_edge[1:]) - psi_edge[:-1])\n jcum = np.cumsum(domega*jval)\n\n ax1.plot(np.degrees(psi),jval/Units.gev2_cm5,label=h)\n ax2.plot(np.degrees(psi),jcum/Units.gev2_cm5,label=h)\n\n\n ax0.set_yscale('log')\n ax0.set_xscale('log')\n ax0.axvline(8.5,label='Solar Radius')\n ax0.grid(True)\n ax0.set_xlabel('Distance [kpc]')\n ax0.set_ylabel('DM Density [GeV cm$^{-3}$]')\n\n ax0.legend()\n\n fig0.savefig(prefix + 'density_profile.png')\n\n #psi = np.arctan(10**x*Units.kpc/(8.5*Units.kpc))\n\n ax1.set_yscale('log')\n ax1.set_xscale('log')\n ax1.grid(True)\n ax1.set_xlabel('Angle [deg]')\n ax1.set_ylabel('J Factor [GeV$^{-2}$ cm$^{-5}$ sr$^{-1}$]')\n\n ax1.legend()\n\n fig1.savefig(prefix + 'jval.png')\n\n ax2.set_yscale('log')\n ax2.set_xscale('log')\n ax2.grid(True)\n ax2.set_xlabel('GC Angle [deg]')\n ax2.set_ylabel('Cumulative J Factor [GeV$^{-2}$ cm$^{-5}$]')\n\n ax2.legend()\n\n fig2.savefig(prefix + 'jcum.png')\n\nusage = \"usage: %(prog)s [options]\"\ndescription = \"\"\"Compute the annihilation flux and yield spectrum for a \nDM halo and WIMP model.\"\"\"\n\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('--halo_model', default=None, required=True,\n help = 'Set the name of the halo model. This will be used '\n 'to look up the parameters for this halo from the halo '\n 'model file.')\n\nparser.add_argument('--channel', default=None, required=True,\n help = 'Set the DM annihilation/decay channel.')\n\nparser.add_argument('--sigmav', default=3E-26, \n help = 'Set the annihilation cross section in cm^3 s^{-1}.')\n\nparser.add_argument('--mass', default='1.0/4.0/25', \n help = 'Set the array of WIMP masses at which the DM flux '\n 'will be evaluation.')\n\nargs = parser.parse_args()\n\nhalo_model_lib = yaml.load(open(os.path.join(gammatools.PACKAGE_ROOT,\n 'data/dm_halo_models.yaml'),'r'))\n\nif not args.halo_model in halo_model_lib:\n\n print 'No such model file: ', args.halo_model\n\n for k in sorted(halo_model_lib.keys()): \n print '%20s %s'%(k, halo_model_lib[k])\n sys.exit(1)\n\nhalo_model = halo_model_lib[args.halo_model]\nmassv = [float(t) for t in args.mass.split('/')]\nmassv = np.linspace(massv[0],massv[1],massv[2])\nsigmav = args.sigmav*Units.cm3_s\n\nflux_header = 'Column 0 Energy [Log10(E/MeV)]\\n'\nflux_header += 'Column 1 Halo Offset Angle [radians]\\n'\nflux_header += 'Column 2 E^2 dF/dE [MeV cm^{-2} s^{-1} sr^{-1}]\\n'\nflux_header += 'Column 3 dF/dE [MeV^{-1} cm^{-2} s^{-1} sr^{-1}]\\n'\n\nyield_header = 'Column 0 Energy [Log10(E/MeV)]\\n'\nyield_header += 'Column 1 Annihilation Yield [MeV^{-1}]\\n'\n\ndp = DensityProfile.create(halo_model)\njp = LoSIntegralFn.create(halo_model)\n\npsi_edge = np.radians(10**np.linspace(np.log10(0.01),np.log10(45.),200))\npsi = 0.5*(psi_edge[1:] + psi_edge[:-1])\njval = jp(psi)\n\nfor m in massv:\n\n mass = 10**m*Units.gev\n sp = DMChanSpectrum(args.channel,mass=mass)\n\n loge = np.linspace(-1.0,4.0,16*5+1)\n loge += np.log10(Units.gev)\n\n yld = sp.dnde(loge)\n\n flux = 1./(8.*np.pi)*sigmav*np.power(mass,-2)*sp.dnde(loge)\n flux[flux<=0] = 0\n\n e2flux = flux*10**(2*loge)\n\n e2flux = np.outer(jval,e2flux)\n flux = np.outer(jval,flux)\n\n x,y = np.meshgrid(loge,psi,ordering='ij')\n\n h = copy.copy(flux_header)\n h += 'Mass = %10.5g [GeV]\\n'%10**m\n h += 'Cross Section = %10.5g [cm^{3} s^{-1}]\\n'%(sigmav/Units.cm3_s)\n h += 'Annihilation Channel = %s\\n'%(args.channel)\n\n h += 'Halo rs = %10.5g [kpc]\\n'%(jp._dp._rs/Units.kpc)\n h += 'Halo rhos = %10.5g [GeV cm^{-3}]\\n'%(jp._dp._rhos/Units.gev_cm3)\n h += 'Halo Distance = %10.5g [kpc]\\n'%(jp._dist/Units.kpc)\n h += 'Halo Model = %s'%(dp.__class__.__name__)\n\n np.savetxt('flux_%s_%s_m%06.3f.txt'%(args.halo_model,args.channel,m),\n np.array((np.ravel(x)-np.log10(Units.mev),np.ravel(y),\n np.ravel(e2flux)/Units.mev,\n np.ravel(flux)/(1./Units.mev))).T,\n fmt='%12.5g',\n header=h)\n\n h = copy.copy(yield_header)\n h += 'Mass = %10.5g [GeV]\\n'%10**m\n h += 'Cross Section = %10.5g [cm^{3} s^{-1}]\\n'%(sigmav/Units.cm3_s)\n h += 'Annihilation Channel = %s\\n'%(args.channel)\n\n np.savetxt('yield_%s_m%06.3f.txt'%(args.channel,m),\n np.array((loge-np.log10(Units.mev),yld/Units._mev)).T,\n fmt='%12.5g',header=h)\n\nplt.figure()\n\nplt.plot(loge-np.log10(Units.gev),e2flux[0,:]/Units.erg)\n\n\nplt.gca().set_yscale('log')\n\nplt.figure()\nplt.plot(loge-np.log10(Units.gev),sp.e2dnde(loge)/Units.gev)\n\nplt.gca().set_yscale('log')\n\nplt.gca().grid(True)\n\n"
},
{
"alpha_fraction": 0.49353694915771484,
"alphanum_fraction": 0.514254093170166,
"avg_line_length": 30.682584762573242,
"blob_id": "e3ad3aa2c952bd1058f18e4432479c261b9d1b27",
"content_id": "7b98a35f3ff1b3d4b85c38e217bca58e3593ca3a",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22590,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 712,
"path": "/gammatools/fermi/irf_util.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "\nimport os\nimport copy\nimport re\nfrom gammatools.core.astropy_helper import pyfits\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.interpolate import UnivariateSpline\nimport bisect\nfrom gammatools.core.histogram import *\n\ndef expand_irf(irf):\n \n irf_names = []\n\n if not (re.search('FRONT',irf) or re.search('BACK',irf)):\n irf_names.append(irf + '::FRONT')\n irf_names.append(irf + '::BACK')\n else:\n irf_names.append(irf)\n\n return irf_names\n\n\nclass IRFManager(object):\n\n load_irf = False\n\n defaults = {'irf_dir' : 'custom_irfs',\n 'expand_irf_name' : False,\n 'load_from_file' : True }\n \n def __init__(self,irfs=None):\n\n self._irfs = []\n if not irfs is None: self._irfs = irfs\n\n @staticmethod\n def add_arguments(parser):\n parser.add_argument('--irf_dir', default = None, \n help = 'Set the IRF directory.')\n\n parser.add_argument('--expand_irf_name', default = False,\n action='store_true',\n help = 'Set the IRF directory.')\n \n @staticmethod\n def create(irf_name,load_from_file=False,irf_dir=None):\n \n if load_from_file: return IRFManager.createFromFile(irf_name,irf_dir)\n else: return IRFManager.createFromPyIRF(irf_name)\n\n @staticmethod\n def createFromFile(irf_name,irf_dir=None,expand_irf_name=True):\n\n print 'Create From File ', irf_name\n \n if expand_irf_name: irf_names = expand_irf(irf_name)\n else: irf_names = [irf_name]\n\n print irf_names\n \n irfset = IRFManager()\n \n for name in irf_names: \n irf = IRF.createFromFile(name,irf_dir)\n irfset.add_irf(irf)\n# irf.loadPyIRF(irf_name)\n return irfset\n\n @staticmethod\n def createFromPyIRF(irf_name,expand_irf_name=True):\n\n if expand_irf_name: irf_names = expand_irf(irf_name)\n else: irf_names = [irf_name]\n \n irfset = IRFManager()\n\n for name in irf_names:\n\n print 'Creating ', name\n \n irf = IRF.createFromPyIRF(name)\n irfset.add_irf(irf)\n return irfset\n \n # irf = IRFManager()\n# irf.loadPyIRF(irf_name)\n# return irf\n\n def add_irf(self,irf):\n self._irfs.append(irf)\n\n def fisheye(self,egy,cth,**kwargs):\n \n aeff_tot = self.aeff(egy,cth,**kwargs)\n \n v = None\n for i, irf in enumerate(self._irfs):\n\n aeff = irf.aeff(egy,cth,**kwargs) \n psf = irf.fisheye(egy,cth,**kwargs)*aeff\n if i == 0: v = psf\n else: v += psf\n\n v[aeff_tot>0] = (v/aeff_tot)[aeff_tot>0]\n return v\n \n def psf(self,dtheta,egy,cth,**kwargs):\n \n aeff_tot = self.aeff(egy,cth,**kwargs)\n \n v = None\n for i, irf in enumerate(self._irfs):\n\n aeff = irf.aeff(egy,cth,**kwargs) \n psf = irf.psf(dtheta,egy,cth,**kwargs)*aeff\n if i == 0: v = psf\n else: v += psf\n\n return v/aeff_tot\n\n def psf_quantile(self,egy,cth,frac=0.68):\n x = np.logspace(-3.0,np.log10(90.0),300) \n x = np.concatenate(([0],x))\n xc = 0.5*(x[:-1]+x[1:])\n deltax = np.radians(x[1:] - x[:-1])\n \n xc = xc.reshape((1,300))\n deltax = deltax.reshape((1,300))\n egy = np.ravel(np.array(egy,ndmin=1))\n cth = np.ravel(np.array(cth,ndmin=1))\n egy = egy.reshape((egy.shape[0],) + (1,))\n cth = cth.reshape((cth.shape[0],) + (1,))\n\n y = np.zeros((egy.shape[0],300))\n for i in range(len(self._irfs)):\n y += self._irfs[i].psf(xc,egy,cth).reshape(y.shape)\n\n\n cdf = 2*np.pi*np.sin(np.radians(xc))*y*deltax\n cdf = np.cumsum(cdf,axis=1)\n# cdf = np.concatenate(([0],cdf))\n# cdf = np.vstack((np.zeros(cdf.shape[0]),cdf))\n cdf /= cdf[:,-1][:,np.newaxis]\n\n p = np.zeros(cdf.shape[0])\n for i in range(len(p)): \n p[i] = percentile(x[1:],cdf[i],frac)\n return p\n# return percentile(x,cdf,frac)\n \n def aeff(self,*args,**kwargs):\n\n v = None\n for i in range(len(self._irfs)):\n if i == 0: v = self._irfs[i].aeff(*args,**kwargs)\n else: v += self._irfs[i].aeff(*args,**kwargs)\n\n return v\n\n def edisp(self,*args,**kwargs):\n\n v = None\n for i in range(len(self._irfs)):\n if i == 0: v = self._irfs[i].edisp(*args,**kwargs)\n else: v += self._irfs[i].edisp(*args,**kwargs)\n\n return v\n\n def dump(self):\n for irf in self._irfs: irf.dump()\n \n def save(self,irf_name):\n for irf in self._irfs: irf.save(irf_name)\n\nclass IRF(object):\n\n def __init__(self,psf,aeff,edisp):\n self._psf = psf\n self._aeff = aeff\n self._edisp = edisp\n\n @staticmethod\n def create(irf_name,load_from_file=False,irf_dir=None):\n \n if load_from_file: return IRF.createFromFile(irf_name,irf_dir)\n else: return IRF.createFromIRF(irf_name)\n\n @staticmethod\n def createFromFile(irf_name,irf_dir=None):\n \n if irf_dir is None: irf_dir = 'custom_irfs'\n\n irf_name = irf_name.replace('::FRONT','_front')\n irf_name = irf_name.replace('::BACK','_back')\n\n psf_file = os.path.join(irf_dir,'psf_%s.fits'%(irf_name))\n aeff_file = os.path.join(irf_dir,'aeff_%s.fits'%(irf_name))\n edisp_file = os.path.join(irf_dir,'edisp_%s.fits'%(irf_name))\n\n psf = PSFIRF(psf_file)\n aeff = AeffIRF(aeff_file)\n edisp = EDispIRF(edisp_file)\n \n return IRF(psf,aeff,edisp)\n\n @staticmethod\n def createFromPyIRF(irf_name):\n \"\"\"Create IRF object using pyIrf modules in Science Tools.\"\"\"\n \n import pyIrfLoader\n if not IRFManager.load_irf:\n pyIrfLoader.Loader_go()\n IRFManager.load_irf = True\n\n irf_factory=pyIrfLoader.IrfsFactory.instance()\n irfs = irf_factory.create(irf_name)\n\n psf = PSFPyIRF(irfs.psf())\n aeff = AeffPyIRF(irfs.aeff())\n edisp = EDispPyIRF(irfs.edisp())\n\n return IRF(psf,aeff,edisp)\n \n def aeff(self,*args,**kwargs):\n return self._aeff(*args,**kwargs)\n\n def psf(self,*args,**kwargs):\n return self._psf(*args,**kwargs)\n\n def edisp(self,*args,**kwargs):\n return self._edisp(*args,**kwargs)\n\n def fisheye(self,*args,**kwargs):\n return self._psf.fisheye(*args,**kwargs)\n \n def dump(self):\n\n self._aeff.dump()\n self._psf.dump()\n self._edisp.dump()\n \n def save(self,irf_name):\n\n aeff_file = 'aeff_' + irf_name + '.fits'\n psf_file = 'psf_' + irf_name + '.fits'\n edisp_file = 'edisp_' + irf_name + '.fits'\n\n self._psf.save(psf_file)\n self._aeff.save(aeff_file)\n self._edisp.save(edisp_file)\n \nclass IRFComponent(object):\n\n @staticmethod\n def load_table_axes(data):\n\n elo = np.log10(np.array(data[0][0]))\n ehi = np.log10(np.array(data[0][1]))\n cthlo = np.array(data[0][2])\n cthhi = np.array(data[0][3])\n \n edges = np.concatenate((elo,np.array(ehi[-1],ndmin=1)))\n energy_axis = Axis(edges)\n edges = np.concatenate((cthlo,np.array(cthhi[-1],ndmin=1)))\n cth_axis = Axis(edges)\n \n return energy_axis, cth_axis\n \n def setup_axes(self,data):\n self._energy_axis, self._cth_axis = IRFComponent.load_table_axes(data)\n \nclass AeffIRF(IRFComponent):\n\n def __init__(self,fits_file):\n \n self._hdulist = pyfits.open(fits_file) \n hdulist = self._hdulist\n \n self.setup_axes(hdulist[1].data)\n self._aeff = np.array(hdulist[1].data[0][4])\n\n nx = self._cth_axis.nbins\n ny = self._energy_axis.nbins\n\n self._aeff.resize((nx,ny))\n self._aeff_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=self._aeff,var=0)\n# hdulist.close()\n\n def dump(self):\n self._hdulist.info()\n\n print 'Energy Axis: ', self._energy_axis.edges\n print 'Angle Axis: ', self._cth_axis.edges\n \n for k, v in self._hdulist[0].header.iteritems():\n print '%-30s %s'%(k, v)\n \n \n def __call__(self,egy,cth,**kwargs):\n\n egy = np.array(egy,ndmin=1)\n cth = np.array(cth,ndmin=1)\n aeff = self._aeff_hist.interpolate(cth,egy)\n aeff[aeff<= 0.0] = 0.0\n return aeff\n\n def save(self,filename):\n\n self._hdulist[0].header['FILENAME'] = filename\n \n print 'Writing ', filename\n self._hdulist.writeto(filename,clobber=True)\n \n \nclass AeffPyIRF(IRFComponent):\n\n def __init__(self,irf):\n self._irf = irf\n self._irf.setPhiDependence(False)\n \n def __call__(self,egy,cth):\n\n egy = np.asarray(egy)\n if egy.ndim == 0: egy.resize((1))\n\n cth = np.asarray(cth)\n if cth.ndim == 0: cth.resize((1))\n \n if cth.shape[0] > 1:\n z = np.zeros(shape=cth.shape)\n for j, c in enumerate(cth):\n z[j] = self._irf.value(float(np.power(10,egy)),\n float(np.degrees(np.arccos(c))),0)\n# return z\n else:\n z = self._irf.value(float(np.power(10,egy)),\n float(np.degrees(np.arccos(cth))),0)\n\n z *= 1E-4\n return z\n \nclass EDispIRF(IRFComponent):\n\n def __init__(self,fits_file):\n \n self._hdulist = pyfits.open(fits_file)\n hdulist = self._hdulist\n# hdulist.info()\n \n self._elo = np.log10(np.array(hdulist[1].data[0][0]))\n self._ehi = np.log10(np.array(hdulist[1].data[0][1]))\n self._cthlo = np.array(hdulist[1].data[0][2])\n self._cthhi = np.array(hdulist[1].data[0][3])\n\n edges = np.concatenate((self._elo,np.array(self._ehi[-1],ndmin=1)))\n self._energy_axis = Axis(edges)\n edges = np.concatenate((self._cthlo,np.array(self._cthhi[-1],ndmin=1)))\n self._cth_axis = Axis(edges)\n \n \n self._center = [0.5*(self._cthlo + self._cthhi),\n 0.5*(self._elo + self._ehi)]\n \n self._bin_width = [self._cthhi-self._cthlo,\n self._ehi-self._elo]\n\n def dump(self):\n self._hdulist.info()\n\n print 'Energy Axis: ', self._energy_axis.edges\n print 'Angle Axis: ', self._cth_axis.edges\n \n for k, v in self._hdulist[0].header.iteritems():\n print '%-30s %s'%(k, v)\n \n def save(self,filename):\n\n self._hdulist[0].header['FILENAME'] = filename\n \n print 'Writing ', filename\n self._hdulist.writeto(filename,clobber=True)\n \n\nclass EDispPyIRF(IRFComponent):\n\n def __init__(self,irf):\n self._irf = irf\n \nclass PSFIRF(IRFComponent):\n\n def __init__(self,fits_file,interpolate_density=True):\n\n self._interpolate_density = interpolate_density\n self._hdulist = pyfits.open(fits_file)\n hdulist = self._hdulist\n hdulist.info()\n\n if re.search('front',fits_file.lower()) is not None: self._ct = 'front'\n elif re.search('back',fits_file.lower()) is not None: self._ct = 'back'\n else: self._ct = 'none'\n\n self._cfront = hdulist['PSF_SCALING_PARAMS'].data[0][0][0:2]\n self._cback = hdulist['PSF_SCALING_PARAMS'].data[0][0][2:4]\n self._beta = hdulist['PSF_SCALING_PARAMS'].data[0][0][4]\n \n self.setup_axes(hdulist[1].data)\n nx = self._cth_axis.nbins\n ny = self._energy_axis.nbins\n shape = (nx,ny)\n \n ncore = np.array(hdulist[1].data[0][4]).reshape(shape)\n ntail = np.array(hdulist[1].data[0][5]).reshape(shape)\n score = np.array(hdulist[1].data[0][6]).reshape(shape)\n stail = np.array(hdulist[1].data[0][7]).reshape(shape)\n gcore = np.array(hdulist[1].data[0][8]).reshape(shape)\n gtail = np.array(hdulist[1].data[0][9]).reshape(shape) \n fcore = 1./(1.+ntail*np.power(stail/score,2))\n \n self._ncore_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=ncore,var=0)\n self._ntail_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=ntail,var=0)\n self._score_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=score,var=0)\n self._stail_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=stail,var=0)\n self._gcore_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=gcore,var=0)\n self._gtail_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=gtail,var=0)\n self._fcore_hist = Histogram2D(self._cth_axis,self._energy_axis,\n counts=fcore,var=0)\n\n try:\n \n fisheye_axes = IRFComponent.load_table_axes(hdulist['FISHEYE_CORRECTION'].data)[::-1]\n fisheye_shape = (fisheye_axes[0].nbins,fisheye_axes[1].nbins)\n \n fisheye_mean = np.array(hdulist['FISHEYE_CORRECTION'].\n data[0][4]).reshape(fisheye_shape)\n fisheye_median = np.array(hdulist['FISHEYE_CORRECTION'].\n data[0][5]).reshape(fisheye_shape)\n fisheye_peak = np.array(hdulist['FISHEYE_CORRECTION'].\n data[0][6]).reshape(fisheye_shape)\n except:\n fisheye_axes = (self._cth_axis,self._energy_axis)\n fisheye_mean = np.zeros(shape)\n fisheye_median = np.zeros(shape)\n fisheye_peak = np.zeros(shape)\n\n self._mean_hist = Histogram2D(*fisheye_axes,counts=fisheye_mean,var=0)\n self._median_hist = Histogram2D(*fisheye_axes,counts=fisheye_median,\n var=0)\n self._peak_hist = Histogram2D(*fisheye_axes,counts=fisheye_peak,var=0)\n\n psf_scale = np.degrees(self.psf_scale(self._mean_hist.axis(1).center))\n \n self._mean_hist *= psf_scale\n self._median_hist *= psf_scale\n self._peak_hist *= psf_scale\n \n self._theta_axis = Axis(np.linspace(-3.0,np.log10(90.0),101))\n self._psf_hist = HistogramND([self._cth_axis,\n self._energy_axis,\n self._theta_axis])\n \n th = self._theta_axis.center\n\n for i in range(nx):\n for j in range(ny):\n x = self._cth_axis.center[i]\n y = self._energy_axis.center[j] \n z = self.eval(10**th,y,x)\n self._psf_hist._counts[i,j] = self.eval(10**th,y,x)\n\n\n return\n plt.figure()\n\n egy0 = self._energy_axis.center[10]\n cth0 = self._cth_axis.center[5]\n\n y0 = self.eval2(10**th,egy0,cth0)\n y1 = self.eval(10**th,egy0,cth0)\n\n self._psf_hist.slice([0,1],[5,10]).plot(hist_style='line')\n plt.plot(th,y0)\n plt.plot(th,y1)\n plt.gca().set_yscale('log')\n\n plt.figure()\n self._psf_hist.interpolateSlice([0,1],[cth0,egy0]).plot(hist_style='line')\n self._psf_hist.slice([0,1],[5,10]).plot(hist_style='line')\n plt.gca().set_yscale('log')\n\n plt.figure()\n sh = self._psf_hist.interpolateSlice([0,1],[cth0+0.01,egy0+0.03])\n y0 = self.eval2(10**th,egy0+0.03,cth0+0.01)\n y1 = self.eval(10**th,egy0+0.03,cth0+0.01)\n y2 = sh.counts()\n y3 = self._psf_hist.interpolate(np.vstack(((cth0+0.01)*np.ones(100),\n (egy0+0.03)*np.ones(100),\n th)))\n\n sh.plot(hist_style='line')\n plt.plot(th,y0)\n plt.plot(th,y1)\n plt.plot(th,y3)\n plt.gca().set_yscale('log')\n\n plt.figure()\n plt.plot(th,y0/y2)\n plt.plot(th,y0/y3)\n plt.plot(th,y0/y1)\n# plt.plot(th,y2/y1)\n\n plt.figure()\n self._psf_hist.slice([0],[5]).plot(logz=True)\n\n plt.show()\n\n return\n\n def dump(self):\n self._hdulist.info()\n\n print 'Energy Axis: ', self._energy_axis.edges\n print 'Angle Axis: ', self._cth_axis.edges\n \n for k, v in self._hdulist[0].header.iteritems():\n print '%-30s %s'%(k, v)\n \n def plot(self,ft):\n \n fig = ft.create('psf_table',nax=(3,2),figscale=1.5)\n fig[0].set_title('score')\n fig[0].add_hist(self._score_hist)\n fig[1].set_title('stail')\n fig[1].add_hist(self._stail_hist)\n fig[2].set_title('gcore')\n fig[2].add_hist(self._gcore_hist)\n fig[3].set_title('gtail')\n fig[3].add_hist(self._gtail_hist)\n fig[4].set_title('fcore')\n fig[4].add_hist(self._fcore_hist)\n\n fig.plot()\n \n def __call__(self,dtheta,egy,cth,**kwargs): \n\n if self._interpolate_density:\n return self.eval2(dtheta,egy,cth)\n else:\n return self.eval(dtheta,egy,cth)\n\n def fisheye(self,egy,cth,ctype='mean'):\n\n v = self._mean_hist.interpolate(egy,cth)\n if ctype == 'mean':\n return self._mean_hist.interpolate(cth,egy)\n elif ctype == 'median':\n return self._median_hist.interpolate(cth,egy)\n elif ctype == 'peak':\n return self._peak_hist.interpolate(cth,egy)\n else:\n raise Exception('Invalid fisheye correction.')\n \n def quantile(self,egy,cth,frac=0.68):\n x = np.logspace(-3.0,np.log10(45.0),300)\n x = np.concatenate(([0],x))\n xc = 0.5*(x[:-1]+x[1:])\n y = self(xc,egy,cth)\n\n deltax = np.radians(x[1:] - x[:-1])\n \n cdf = 2*np.pi*np.sin(np.radians(xc))*y*deltax\n cdf = np.cumsum(cdf)\n cdf = np.concatenate(([0],cdf))\n cdf /= cdf[-1]\n\n return percentile(x,cdf,frac)\n\n def psf_scale(self,loge):\n\n if self._ct == 'back': c = self._cback\n else: c = self._cfront\n \n return np.sqrt(np.power(c[0]*np.power(10,-self._beta*(2.0-loge)),2) +\n np.power(c[1],2))\n \n \n def eval(self,dtheta,egy,cth):\n \"\"\"Evaluate PSF by interpolating in PSF parameters.\"\"\"\n \n if self._ct == 'back': c = self._cback\n else: c = self._cfront\n \n spx = np.sqrt(np.power(c[0]*np.power(10,-self._beta*(2.0-egy)),2) +\n np.power(c[1],2))\n\n spx = np.degrees(spx)\n \n x = dtheta/spx\n \n gcore = self._gcore_hist.interpolate(cth,egy)\n score = self._score_hist.interpolate(cth,egy)\n gtail = self._gtail_hist.interpolate(cth,egy)\n stail = self._stail_hist.interpolate(cth,egy)\n fcore = self._fcore_hist.interpolate(cth,egy)\n\n fcore[fcore < 0.0] = 0.0 # = max(0.0,fcore)\n fcore[fcore > 1.0] = 1.0 # min(1.0,fcore)\n\n #gcore = max(1.2,gcore)\n #gtail = max(1.2,gtail)\n \n return (fcore*self.king(x,score,gcore) +\n (1-fcore)*self.king(x,stail,gtail))/(spx*spx)\n\n def eval2(self,dtheta,egy,cth):\n \"\"\"Evaluate PSF by interpolating in PSF density.\"\"\"\n dtheta = np.array(dtheta,ndmin=1)\n egy = np.array(egy,ndmin=1)\n cth = np.array(cth,ndmin=1)\n\n\n dtheta[dtheta <= 10**self._theta_axis.lo_edge()] =\\\n 10**self._theta_axis.lo_edge()\n \n return self._psf_hist.interpolate(cth,egy,np.log10(dtheta))\n\n def king(self,dtheta,sig,g):\n\n if sig.shape[0] > 1:\n\n if dtheta.ndim == 1:\n dtheta2 = np.empty(shape=(dtheta.shape[0],sig.shape[0]))\n dtheta2.T[:] = dtheta\n else:\n dtheta2 = dtheta\n\n sig2 = np.empty(shape=(dtheta.shape[0],sig.shape[0]))\n sig2[:] = sig\n \n g2 = np.empty(shape=(dtheta.shape[0],sig.shape[0]))\n g2[:] = g\n\n n = 1./(2*np.pi*sig2*sig2)\n u = np.power(dtheta2,2)/(2*sig2*sig2)\n \n return n*(1-1/g2)*np.power(1+u/g2,-g2)\n\n else:\n \n n = 1./(2*np.pi*sig*sig)\n u = np.power(dtheta,2)/(2*sig*sig)\n \n return n*(1-1/g)*np.power(1+u/g,-g)\n \n def save(self,filename):\n\n self._hdulist[0].header['FILENAME'] = filename\n \n# print self._hdulist[1].data[0][4].shape, self._ncore.shape\n\n self._hdulist[1].data[0][4] = self._ncore\n self._hdulist[1].data[0][5] = self._ntail\n self._hdulist[1].data[0][6] = self._score\n self._hdulist[1].data[0][7] = self._stail\n self._hdulist[1].data[0][8] = self._gcore\n self._hdulist[1].data[0][9] = self._gtail\n \n self._hdulist[2].data[0][0][0:2] = self._cfront\n self._hdulist[2].data[0][0][2:4] = self._cback\n self._hdulist[2].data[0][0][4] = self._beta\n \n print 'Writing ', filename\n self._hdulist.writeto(filename,clobber=True)\n \nclass PSFPyIRF(PSFIRF):\n\n def __init__(self,irf):\n self._irf = irf\n\n def __call__(self,dtheta,egy,cth):\n\n dtheta = np.asarray(dtheta)\n cth = np.asarray(cth)\n \n if dtheta.ndim == 0:\n return self._irf.value(dtheta,float(np.power(10,egy)),\n float(np.degrees(np.arccos(cth))),0)\n\n if cth.shape[0] > 1: \n z = np.zeros(shape=(dtheta.shape[0],cth.shape[0]))\n\n for i, t in enumerate(dtheta):\n for j, c in enumerate(cth):\n z[i,j] = self._irf.value(t,float(np.power(10,egy)),\n float(np.degrees(np.arccos(c))),0)\n else:\n\n \n \n z = np.zeros(shape=dtheta.shape)\n for i, t in enumerate(dtheta):\n z[i] = self._irf.value(t,float(np.power(10,egy)),\n float(np.degrees(np.arccos(cth))),0)\n\n return z\n \n \n \n"
},
{
"alpha_fraction": 0.6006899476051331,
"alphanum_fraction": 0.6047865748405457,
"avg_line_length": 26.76646614074707,
"blob_id": "eaf59b39eadeeab3004bdac12dea6aec57c92338",
"content_id": "e7e7548d887d2431947318d0674dbf86ba21c83e",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4638,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 167,
"path": "/scripts/gtbin.py",
"repo_name": "cdeil/gammatools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os, sys\nimport copy\nimport tempfile\nimport re\nfrom GtApp import GtApp\nimport shutil\nimport pyfits\nimport argparse\nimport pprint\nfrom gammatools.fermi.task import BinTask, SelectorTask, Task\nfrom gammatools.core.config import *\n\nclass TestObject(Configurable):\n\n default_config = {'testoption' : 'test', 'testoption2' : 'val2'}\n \n def __init__(self,opts,**kwargs):\n super(TestObject,self).__init__(register_defaults=False)\n\n self.update_default_config(TestObject)\n self.update_default_config(BinTask,group='gtbin')\n \n self.configure(opts=opts)\n\n @classmethod\n def add_arguments(cls,parser):\n\n config = TestObject.get_default_config()\n config.update(BinTask.get_class_config(group='gtbin'))\n \n Configurable.add_arguments(parser,config=config)\n \nclass BinSelectTask(Task):\n\n default_config = {'select' : False}#'run_gtselect' : 'test'}\n\n def __init__(self,infile,outfile,opts,**kwargs):\n super(BinSelectTask,self).__init__()\n\n self._infile = infile\n self._outfile = outfile\n \n# self.update_default_config(SelectorTask,group='gtselect')\n self.update_default_config(BinTask)\n self.update_default_config(SelectorTask,group='gtselect')\n\n self.configure(opts=opts)\n\n @classmethod\n def add_arguments(cls,parser):\n\n config = copy.deepcopy(BinSelectTask.get_default_config().values())\n config += BinTask.get_class_config().values()\n config += SelectorTask.get_class_config(group='gtselect').values()\n\n pprint.pprint(config)\n \n Configurable.add_arguments(parser,config=config)\n\n def prepare_file(self,infile):\n\n outfile = os.path.splitext(os.path.basename(self._infile))[0]\n outfile += '_sel.fits'\n outfile = os.path.join(self._workdir,outfile)\n \n print outfile\n print self._workdir\n\n# if re.search('^(?!\\@)(.+)(\\.txt|\\.lst)$',infile):\n# infile = '@'+infile\n \n gtselect = SelectorTask(infile,outfile,\n config=self.config['gtselect'])\n# workdir=self._workdir,savedata=True)\n\n pprint.pprint(gtselect.config) \n gtselect.run()\n\n return outfile\n\n \n def run_task(self):\n\n if self.config['select']: \n infile = self.prepare_file(self._infile)\n else:\n infile = self._infile\n \n gtbin = BinTask(infile,self._outfile,config=self.config)\n print 'gtbin config '\n pprint.pprint(gtbin.config)\n\n gtbin.run()\n \n\nusage = \"usage: %(prog)s [options] [ft1file]\"\ndescription = \"Produce a binned counts map.\"\nparser = argparse.ArgumentParser(usage=usage,description=description)\n\nparser.add_argument('files', nargs='+')\n\nparser.add_argument('--output', default = None, \n help = 'Output file')\n\n#parser.add_argument('--select', default = False, action='store_true',\n# help = 'Run gtselect.')\n\n#keys = SelectorTask.default_config.keys()\n#for k in keys:\n# SelectorTask.default_config['gtselect_' + k] = SelectorTask.default_config[k]\n# del SelectorTask.default_config[k]\n\n#SelectorTask.add_arguments(parser,skip=['verbose']+Task.default_config.keys())\n#BinTask.add_arguments(parser,skip=['verbose'])\n\n#BinSelectTask.add_arguments(parser,dict(BinTask.get_default_config(groupname='gtselect.').items() +\n# BinSelectTask.get_default_config().items()))\n\nBinSelectTask.add_arguments(parser)\n\nargs = parser.parse_args()\n\nfor f in args.files:\n\n outfile = args.output \n if outfile is None:\n outfile = os.path.splitext(os.path.basename(f))[0] + '_binned.fits'\n\n bselect = BinSelectTask(os.path.abspath(f),outfile,args)\n\n pprint.pprint(bselect.config)\n bselect.run()\n\nsys.exit(0)\n\n# First run gtselect\n\n\nfor f in args.files:\n\n# hdulist = pyfits.open(f)\n#hdulist.info()\n\n# ra = 0.0\n# dec = 0.0\n\n # Find RA/DEC from FITS file\n# if args.ra is None or args.dec is None:\n# m = re.search(\"CIRCLE\\(([0-9\\.]+),([0-9\\.]+)\",\n# hdulist[1].header['DSVAL2'])\n# if not m is None:\n# ra = float(m.group(1))\n# dec = float(m.group(2))\n# else:\n# ra = args.ra\n# dec = args.dec\n\n outfile = args.output \n if outfile is None:\n outfile = os.path.splitext(os.path.basename(f))[0] + '_binned.fits'\n \n \n gtbin = BinTask(os.path.abspath(f),outfile,opts=args)\n \n gtbin.run()\n\n"
}
] | 76 |
Radesh-kumar/oppia
|
https://github.com/Radesh-kumar/oppia
|
3f15000e6287d522163a6c6467838eb9b2bfcefb
|
03b463a23c5986065671fead8300ceacf32603dd
|
aeb2ce82922fe4e3e4c5a767a1e5323d9feabb5c
|
refs/heads/develop
| 2022-06-05T00:31:04.262871 | 2022-05-14T09:42:38 | 2022-05-14T09:42:38 | 231,679,482 | 0 | 0 |
Apache-2.0
| 2020-01-03T23:03:35 | 2020-01-03T17:50:31 | 2020-01-03T20:28:19 | null |
[
{
"alpha_fraction": 0.5709483623504639,
"alphanum_fraction": 0.5870348215103149,
"avg_line_length": 35.85840606689453,
"blob_id": "78dd576dec061bcab2477d928425b0bd4a3fde42",
"content_id": "b76b96a2134725ddac2c26b2e82cfbdc029dca77",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4165,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 113,
"path": "/core/python_utils_test.py",
"repo_name": "Radesh-kumar/oppia",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n#\n# Copyright 2019 The Oppia Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS-IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Tests for feature detection utilities for Python 2 and Python 3.\"\"\"\n\nfrom __future__ import annotations\n\nimport ast\nimport builtins\nimport urllib\n\nfrom core import python_utils\nfrom core.tests import test_utils\n\n\nclass PythonUtilsTests(test_utils.GenericTestBase):\n \"\"\"Tests for feature detection utilities that are common for Python 2 and\n Python 3.\n \"\"\"\n\n def test_get_args_of_function_node(self):\n function_txt = b\"\"\"def _mock_function(arg1, arg2):\n pass\"\"\"\n\n ast_node = ast.walk(ast.parse(function_txt))\n function_node = [n for n in ast_node if isinstance(n, ast.FunctionDef)]\n args_list = python_utils.get_args_of_function_node(function_node[0], [])\n self.assertEqual(args_list, ['arg1', 'arg2'])\n\n def test_parse_query_string(self):\n response = urllib.parse.parse_qs(\n 'http://www.google.com?search=oppia')\n self.assertEqual(response, {'http://www.google.com?search': ['oppia']})\n\n def test_recursively_convert_to_str_with_dict(self):\n test_var_1_in_unicode = str('test_var_1')\n test_var_2_in_unicode = str('test_var_2')\n test_var_3_in_bytes = test_var_1_in_unicode.encode(encoding='utf-8')\n test_var_4_in_bytes = test_var_2_in_unicode.encode(encoding='utf-8')\n test_dict = {\n test_var_1_in_unicode: test_var_3_in_bytes,\n test_var_2_in_unicode: test_var_4_in_bytes\n }\n self.assertEqual(\n test_dict,\n {'test_var_1': b'test_var_1', 'test_var_2': b'test_var_2'})\n\n for key, val in test_dict.items():\n self.assertEqual(type(key), str)\n self.assertEqual(type(val), builtins.bytes)\n\n dict_in_str = python_utils._recursively_convert_to_str(test_dict) # pylint: disable=protected-access\n self.assertEqual(\n dict_in_str,\n {'test_var_1': 'test_var_1', 'test_var_2': 'test_var_2'})\n\n for key, val in dict_in_str.items():\n self.assertEqual(type(key), str)\n self.assertEqual(type(val), str)\n\n def test_recursively_convert_to_str_with_nested_structure(self):\n test_var_1_in_unicode = str('test_var_1')\n test_list_1 = [\n test_var_1_in_unicode,\n test_var_1_in_unicode.encode(encoding='utf-8'),\n 'test_var_2',\n b'test_var_3',\n {'test_var_4': b'test_var_5'}\n ]\n test_dict = {test_var_1_in_unicode: test_list_1}\n self.assertEqual(\n test_dict,\n {\n 'test_var_1': [\n 'test_var_1', b'test_var_1', 'test_var_2', b'test_var_3',\n {'test_var_4': b'test_var_5'}]\n }\n )\n\n dict_in_str = python_utils._recursively_convert_to_str(test_dict) # pylint: disable=protected-access\n self.assertEqual(\n dict_in_str,\n {\n 'test_var_1': [\n 'test_var_1', 'test_var_1', 'test_var_2', 'test_var_3',\n {'test_var_4': 'test_var_5'}]\n }\n )\n\n for key, value in dict_in_str.items():\n self.assertNotEqual(type(key), builtins.bytes)\n self.assertTrue(isinstance(key, str))\n\n for item in value:\n self.assertNotEqual(type(item), builtins.bytes)\n self.assertTrue(isinstance(item, (str, bytes, dict)))\n\n for k, v in value[-1].items():\n self.assertEqual(type(k), str)\n self.assertEqual(type(v), str)\n"
}
] | 1 |
MatthewsTomts/Python_Class
|
https://github.com/MatthewsTomts/Python_Class
|
fa2c2b1ff05f4071ee086988edd342fbf1a77e11
|
f326d521d62c45a4fcb429d2a22cf2ab958492cb
|
c221636c8242dbbfcdc5afd171e17f1fc77a673c
|
refs/heads/main
| 2023-06-04T04:54:46.981136 | 2021-06-22T01:37:19 | 2021-06-22T01:37:19 | 320,421,518 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6209876537322998,
"alphanum_fraction": 0.6382716298103333,
"avg_line_length": 37.57143020629883,
"blob_id": "5df5b6de1203a919ae088b95b4a3edad900ac59a",
"content_id": "8f9ef4eeb468b6d025a1770b52f7b56e9769eb88",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 826,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 21,
"path": "/PythonExercicios/ex075.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nums = int(input('Digite o primeiro valor: ')), int(input('Digite o segundo valor: ')),\\\n int(input('Digite o terceiro valor: ')), int(input('Digite o quarto valor: '))\nprint(f'\\nVocê digitou os valores: {nums}')\n\nprint(f'Apareceu {nums.count(9)} vezes o número nove')\n\nif 3 in nums: # try:\n # Mostra a posição do 3 na tupla, caso ele exista na tupla\n print(f'O valor 3 foi digitado na {nums.index(3) + 1}° posição')\nelse: # except ValueError:\n # Informa que não existe um 3 na tupla\n print('O valor 3 não foi digitado em nenhuma posição')\n\npar = 0\nfor num in nums: # Conta a quantidade de números pares\n if num % 2 == 0:\n par += 1\nprint(f'Você digitou {par} números pares que são', end=' ')\nfor n in nums: # Mostra os números pares\n if n % 2 == 0:\n print(n, end=' ')\n"
},
{
"alpha_fraction": 0.6166484355926514,
"alphanum_fraction": 0.6308872103691101,
"avg_line_length": 40.5,
"blob_id": "fadea37c51b8d68bb81eb6b6e6e58b964703681a",
"content_id": "2ef37247daa6f1d322f92949bcab3f1fb348f45e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 918,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 22,
"path": "/PythonExercicios/ex087.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "matriz = [[], [], []]\n# noinspection SpellCheckingInspection\nsomapar = somacol = 0\nfor lin in range(0, 3):\n for col in range(0, 3):\n matriz[lin].append(int(input(f'Digite um número para [{lin}, {col}]: ')))\n if matriz[lin][col] % 2 == 0: # Caso o número inserido for par\n somapar += matriz[lin][col] # ele é adiciona a soma dos pares\n\nprint('-='*30)\nfor lin in matriz:\n # noinspection SpellCheckingInspection\n for icol, col in enumerate(lin):\n print(f'[ {col} ]', end=' ')\n if icol == 2: # Se for a terceira coluna\n somacol += col # o valor é adiciona a soma dos valores da terceira coluna\n print()\n\nprint('-='*30)\nprint(f'A soma de todos os valores pares vale {somapar}')\nprint(f'A soma de todos os valores da terceira coluna vale {somacol}')\nprint(f'O maior valor da segunda linha é {max(matriz[1])}') # Mostra o maior valor da segunda linha\n"
},
{
"alpha_fraction": 0.6084787845611572,
"alphanum_fraction": 0.6533665657043457,
"avg_line_length": 43.55555725097656,
"blob_id": "7c971b95cdb6baea6cd529d7a514fe228cd04c81",
"content_id": "a91218d594f93a66ad873e0d2d3b30f0f8c2e96c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 9,
"path": "/PythonExercicios/ex036.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "val = float(input('Qual o valor da casa? R$ '))\nsal = float(input('Qual o salário do comprador? R$ '))\nano = int(input('Em quantos anos será pago o empréstimo? '))\npres = val / (ano * 12)\nprint(f'Para pagar uma casa de R$ {val:.2f} em {ano} anos, a prestação será de R$ {pres:.2f}')\nif pres > sal * 0.3:\n print('Empréstimo\\033[31;1m não aprovado!')\nelse:\n print('Empréstimo\\033[32;1m aprovado')\n"
},
{
"alpha_fraction": 0.529691219329834,
"alphanum_fraction": 0.6722090244293213,
"avg_line_length": 41.099998474121094,
"blob_id": "2e454133b9ec471fec6c85494ca00fcab6ca9e5a",
"content_id": "5e1f08a60273ff38bc2cae708b7c993bdb2b0e8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 426,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 10,
"path": "/PythonExercicios/ex028.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom time import sleep\nn = randint(0, 5)\nprint('\\033[1;32m=\\033[1;33m-\\033[1;32m=\\033[m' * 20)\nprint('Vou pensar em um número entre 0 e 5. Tente adivinhar...')\nprint('\\033[1;32m-\\033[33;1m=\\033[32;1m-\\033[m' * 20)\nresp = int(input('Em qual número eu pensei? '))\nprint('Processando...')\nsleep(2)\nprint('Parabéns, você acertou!' if n == resp else f'Você errou, eu pensei em \\033[1;36m{n}\\033[m')\n"
},
{
"alpha_fraction": 0.549839198589325,
"alphanum_fraction": 0.5594855546951294,
"avg_line_length": 45.650001525878906,
"blob_id": "d16ffeaddb0c55e00d02e32aa64c11962a5e9a03",
"content_id": "9fe93464ab1408c266f4f03bb2726ccf6e3404f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 942,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 20,
"path": "/PythonExercicios/ex080.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "val = []\nfor c in range(1, 6):\n inserir = int(input(f'Digite o {c}° valor: '))\n if c == 1 or inserir > val[-1]: # Se o valor digitado for o 1° ou maior que o último\n val.append(inserir) # Adiciona o valor digitado ao final da lista\n print('Adicionado ao final da lista...')\n else:\n for i in range(0, len(val)):\n if inserir <= val[i]:\n # Caso o valor digitado seja menor ou igual ao valor analisado ele será adicionado no lugar dele.\n val.insert(i, inserir)\n print(f'Adicionado na posição {i}')\n break\n '''elif inserir > val[len(val)-1]:\n # Caso o valor digitado seja maior que o último valor então ele é adicionado no final\n val.append(inserir)\n print('Adicionado ao final da lista...')\n break'''\nprint('-='*20)\nprint(f'Os valores digitados em ordem: {val}')\n"
},
{
"alpha_fraction": 0.6383838653564453,
"alphanum_fraction": 0.6484848260879517,
"avg_line_length": 32,
"blob_id": "def8b412f7c37c243507c44fbc9a414fde2b925b",
"content_id": "919764216543f8c8a1dc91b2e8bf8c82ff40fdc5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1009,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 30,
"path": "/PythonExercicios/ex083.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "dire = 0\nesq = 0\nexp = input('Digite uma expressão matemática: ')\n# noinspection SpellCheckingInspection\nexps = []\n\n# noinspection SpellCheckingInspection\nfor letra in exp: # Os caracteres da expressão viram elementos na lista exps\n exps.append(letra)\n if letra == '(': # Conta o número de (\n esq += 1\n elif letra == ')': # Conta o número de )\n dire += 1\n\nerro = False\nfor i, char in enumerate(exps): # Caso tenha algum sinal de operação logo depois de (\n if char == '(' and exps[i+1] in '+-*/^)':\n erro = True # A expressão está errado\n if char == ')' and exps[i-1] in '+-*/^' and esq != dire: # Caso tenha alguma sinal de operação logo depois de )\n erro = True # A expressão está errado\n\nexps.pop(1) # Exclui o elemento no index 1\nexps.remove('1') # Excluí o elemento 1\n# noinspection SpellCheckingInspection\ndel exps # Excluí a lista exps\n\nif erro:\n print('Sua expressão está errada!')\nelse:\n print('Sua expressão está certa!')\n"
},
{
"alpha_fraction": 0.5243445634841919,
"alphanum_fraction": 0.5992509126663208,
"avg_line_length": 37.14285659790039,
"blob_id": "b930ec66d7de71492624efbc7b7562980dc10824",
"content_id": "e18f1c0f09c3f1d2bbdffc7c9f420a9e51ba10a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 14,
"path": "/PythonExercicios/ex076.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('-'*50)\nprint(f'{\"LISTAGEM DE PREÇOS\":^50}')\nprint('-'*50)\n\nprodutos = 'Lápis', 1.75, 'Borracha', 2, 'Caderno', 15.9, 'Estojo', 25, 'Transferidor', 4.2, 'Compasso', 9.99,\\\n 'Mochila', 120.32, 'Canetas', 22.3, 'Livro', 34.9\n\nfor pos, pro in enumerate(produtos): # for pos in range(0, len(produtos))\n if pos % 2 == 0: # Caso o index for par então mostra o elemento com essa formatação\n print(f'{pro:.<40}', end='')\n else: # Se for ímpar mostra com essa formatação\n print(f'R${pro:>8.2f}')\n\nprint('-'*50)\n"
},
{
"alpha_fraction": 0.706250011920929,
"alphanum_fraction": 0.737500011920929,
"avg_line_length": 25.66666603088379,
"blob_id": "0ab345c09f1fdd9904f13ca942ec7ff55046ad52",
"content_id": "11e17fc08d58ad98fbf4bb11418a37ee477276a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 6,
"path": "/PythonExercicios/ex021.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "import pygame\npygame.init()\npygame.mixer.music.load('ex021.mp3')\npygame.mixer.music.play()\nwhile pygame.mixer.music.get_busy():\n pygame.time.Clock().tick(1)\n"
},
{
"alpha_fraction": 0.5071770548820496,
"alphanum_fraction": 0.6267942786216736,
"avg_line_length": 33.83333206176758,
"blob_id": "963863e10ce68c0ee32eac6b547a6824eeea430a",
"content_id": "7460d407ed7fda706f57e1dfc7aab62fb743016c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 6,
"path": "/PythonExercicios/ex034.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "sal = float(input('Digite seu salário: R$'))\nif sal <= 1250:\n novo = sal * 1.15\nelse:\n novo = sal * 1.1\nprint(f'Seu antigo salário era \\033[1;37m{sal}\\033[m e o seu novo salário é \\033[36;1m{novo:.2f}')\n"
},
{
"alpha_fraction": 0.5050504803657532,
"alphanum_fraction": 0.6127946376800537,
"avg_line_length": 36.125,
"blob_id": "c32ffd694f41dfdb3dd80ce37681d322ed17d7fb",
"content_id": "579f2e7fb786061f1cec7333d1e98d0909c763e8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 8,
"path": "/PythonExercicios/ex031.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "km = float(input('Qual a distância da viagem? '))\nprint(f'Você está prestes a começar uma viagem de \\033[33;1m{km}Km\\033[m')\n# if km <= 200:\n# preco = km * 0.5\n# else:\n# preco = km * 0.45\npreco = km * 0.5 if km <= 200 else km * 0.45\nprint(f'O valor da passagem é \\033[32;1mR${preco:.2f}')\n"
},
{
"alpha_fraction": 0.5530666708946228,
"alphanum_fraction": 0.5706666707992554,
"avg_line_length": 35.764705657958984,
"blob_id": "62cd8df4658c0a70869199db9013a11b491f7971",
"content_id": "3ecd037148d9819e221d428224d30f6e7ee4cd5d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1879,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 51,
"path": "/PythonExercicios/ex095.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "jogadores = []\nwhile True:\n print('-'*30)\n jogadora = {'Nome': input('Nome do(a) jogador(a): '),\n 'Gols': list(),\n 'Total': 0}\n\n partidas = int(input(f'Quantas partidas {jogadora[\"Nome\"]} jogou? '))\n jogadora['Partidas'] = partidas\n print('Quantos gols ele(a) fez na...')\n for c in range(0, partidas): # Armazena a quantidade de gols em cada partida\n jogadora['Gols'].append(int(input(f'{c + 1}° partida: ')))\n jogadora['Total'] += jogadora['Gols'][c] # E calcula o total\n\n jogadores.append(jogadora.copy()) # Adiciona o dicionário a lista jogadores\n jogadora.clear()\n\n while True:\n resp = input('Deseja continuar? [S/N]: ').strip().upper()[0]\n if resp in 'SN':\n break\n print('ERRO! Responda apenas \"N\" ou \"S\"')\n if resp in 'N':\n break\n\nprint('-='*30)\nprint(f'COD {\"NOME\":<15} {\"GOLS\":<15} {\"TOTAL\":<6}')\nprint('-'*60)\nfor cod, jog in enumerate(jogadores): # Tabela dos(as) Jogadores(as)\n print(f'{cod:>3} {jog[\"Nome\"]:<15} {str(jog[\"Gols\"]):<15} {jog[\"Total\"]:<6}')\n\nwhile True:\n while True:\n print('-' * 60)\n esc = int(input('Mostrar dados de qual jogador(a)? '))\n # Caso a escolha esteja dentro dos códigos das(os) Jogadoras(es) ou seja igual a 999\n if -1 < esc < len(jogadores) or esc == 999:\n break\n print(f'ERRO! O jogador(a) {esc} não foi cadastrado')\n\n if esc == 999:\n break\n\n # Mostra os Dados das(os) Jogadoras(es)\n print(f'LEVANTAMENTO DO JOGADOR(A) {jogadores[esc][\"Nome\"].upper()}:')\n print(f' O(A) jogador(a) {jogadores[esc][\"Nome\"]} jogou {jogadores[esc][\"Partidas\"]} partidas')\n for p, g in enumerate(jogadores[esc]['Gols']):\n print(f' => Na partida {p}, fez {g} gols')\n print(f'Foi um total de {jogadores[esc][\"Total\"]}')\n\nprint('<<< VOLTE SEMPRE >>>')\n"
},
{
"alpha_fraction": 0.5328947305679321,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 42.42856979370117,
"blob_id": "171adcbf473bdffa99fdba9456551dd66300f699",
"content_id": "b8a1dc05937c935e5e33d4256e8cb29a81afcff2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 307,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 7,
"path": "/PythonExercicios/ex032.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from datetime import date\nano = int(input('Digite um ano (Digite 0 para analisar o ano atual): '))\nano = date.today().year if ano == 0 else ano\nif ano % 4 == 0 and ano % 100 != 0 or ano % 400 == 0:\n print(f'\\033[1;37m{ano}\\033[m é Bissexto.')\nelse:\n print(f'\\033[1;37m{ano}\\033[m não é Bissexto.')\n"
},
{
"alpha_fraction": 0.6225165724754333,
"alphanum_fraction": 0.7019867300987244,
"avg_line_length": 74.5,
"blob_id": "c5aaf37a4dc2fbaa20eda5a9404276ed85ec200a",
"content_id": "5688a38e3a994e79fd52ff48e227e60f0bd9f1ed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 2,
"path": "/PythonExercicios/ex013.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "sal = float(input('Digite o salário do funcionário: R$'))\nprint(f'O novo salário desse funcionário, com aumento de 15%, é \\033[32;1mR${sal*1.15:.2f}')\n"
},
{
"alpha_fraction": 0.5852534770965576,
"alphanum_fraction": 0.5929339528083801,
"avg_line_length": 28.590909957885742,
"blob_id": "e86e48f56ed62986103062e5face00d6071e1750",
"content_id": "9d34c1d0ed187c07023f227e9e4a07caf434a603",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 661,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 22,
"path": "/PythonExercicios/ex082.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "val = []\nwhile True:\n val.append(int(input('Digite um número: ')))\n while True: # Caso o usuário não digite S ou N, é feita novamente a pergunta\n resp = input('Deseja continuar? [S/N] ').strip().upper()[0]\n if resp in 'SN':\n break\n if resp in 'N':\n break\n\npar = list()\nimpar = []\nfor v in val:\n if v % 2 == 0: # Caso o valor for par é adicionado a lista par\n par.append(v)\n else: # Mas se for ímpar é adicionado a lista impar\n impar.append(v)\n\nprint('-='*20)\nprint(f'Você digitou os números: {val}')\nprint(f'Entre eles, esses eram os pares: {par}')\nprint(f'E esses os ímpares: {impar}')\n"
},
{
"alpha_fraction": 0.5762144327163696,
"alphanum_fraction": 0.5845896005630493,
"avg_line_length": 20.321428298950195,
"blob_id": "dacddd27e701be76cf4f234af06fc6dd71174f2e",
"content_id": "0f331118d4f55cefe60daefc1d757bcc617fd1f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 606,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 28,
"path": "/PythonTest/Aula22/Uteis/Numeros/__init__.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def fatorial(num):\n \"\"\"\n -> Calcula o fatorial de um número\n :param num: Número que terá o fatorial calculado\n :return: retorna o fatorial de 'num'\n \"\"\"\n f = 1\n for c in range(1, num+1):\n f *= c\n return f\n\n\ndef dobro(num):\n \"\"\"\n -> Calcula o dobro de um número\n :param num: Número que terá seu dobro calculado\n :return: retorna o dobro de 'num'\n \"\"\"\n return num*2\n\n\ndef triplo(num):\n \"\"\"\n -> Calcula o triplo de um número\n :param num: Número que terá seu triplo calculado\n :return: retorna o triplo de 'num'\n \"\"\"\n return num*3\n"
},
{
"alpha_fraction": 0.6311745047569275,
"alphanum_fraction": 0.6575192213058472,
"avg_line_length": 29.366666793823242,
"blob_id": "198b475b551e5b4d0f75b86dd213003c30ef0dd8",
"content_id": "d16b36179666b4a091883b0543318eb982015ebb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 928,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 30,
"path": "/PythonTest/Aula16A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "lanche = 'Hambúrguer', 'Suco', 'Pizza', 'Pudim', 'Batata Frita' # Tuplas são Imutáveis\n# lanche = ('Hambúrguer', 'Suco', 'Pizza', 'Pudim', 'Batata Frita')\n# lanche[1] = 'Água'\nprint(lanche[:3]) # O terceiro elemento é ignorado\nprint(lanche[-3:]) # Do Terceiro (antepenúltimo) elemento, de trás para frente, até o final\nprint(len(lanche), '\\n')\n\nfor cont in range(0, len(lanche)):\n print(f'Eu vou comer {lanche[cont]}!, na posição {cont}')\n\nprint('')\n\nfor pos, comida in enumerate(lanche):\n print(f'Eu vou comer {comida}!, na posição {pos}')\nprint('Comi pra caramba')\n\nprint(f'\\n{sorted(lanche)}')\n\na = 2, 5, 4\nb = 5, 8, 1, 2\nc = b + a\nprint(c)\nprint(c.count(5))\nprint(c.index(5, 1)) # Mostra o index do número 5 apartir da posição 1\n\npessoa = 'Matheus', 18, 'M', 60 # No python, as tuplas aceitam valores de tipos diferentes\n# del(pessoa) # Deleta a tupla pessoa\nprint(pessoa)\n\n# Exercícios 72 - 77\n"
},
{
"alpha_fraction": 0.5594639778137207,
"alphanum_fraction": 0.6515913009643555,
"avg_line_length": 44.92307662963867,
"blob_id": "556e9e3792368a240a28d6d920923ef5c7d6f703",
"content_id": "9e29139c139c78d2cbfc2a2b9b1878e1048a606b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 607,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 13,
"path": "/PythonExercicios/ex042.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "seg1 = float(input('Primeiro segmento: '))\nseg2 = float(input('Segundo segmento: '))\nseg3 = float(input('Terceiro segmento: '))\nif seg3 + seg2 > seg1 and seg3 + seg1 > seg2 and seg2 + seg1 > seg3:\n print('Esses segmentos\\033[32;1m podem\\033[m formar uma reta.')\n if seg3 == seg2 == seg1:\n print('Esse é um triângulo \\033[35;1mEquilátero.')\n elif seg3 != seg2 != seg1 != seg3:\n print('Esse é um triângulo \\033[37;1mEscaleno')\n else:\n print('Esse é um triângulo \\033[36;1mIsósceles')\nelse:\n print('Esses segmentos\\033[31;1m não podem\\033[m formar um triângulo.')\n"
},
{
"alpha_fraction": 0.5677083134651184,
"alphanum_fraction": 0.6640625,
"avg_line_length": 47,
"blob_id": "9b7eae658c073c1ca7f9747fe5bc7d94388bdbe6",
"content_id": "77b16fde93e6e917c87dd1fc5b4977d9e5157688",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 8,
"path": "/PythonExercicios/ex007.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n1 = float(input('Digite a primeira nota: '))\nn2 = float(input('Digite a segunda nota: '))\n# Pede pro usuário digite as duas notas do aluno e armazena nas variáveis\n\nprint(f'A média desse aluno que tirou \\033[32;1m{n1:.1f}\\033[m e '\n f'\\033[32;1m{n2:.1f}\\033[m, foi \\033[32;1m{(n1 + n2) / 2:.1f}')\n# Mostra as notas do aluno e a média\n# notas e média em verde (32) e negrito (1)\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6458333134651184,
"avg_line_length": 27.799999237060547,
"blob_id": "395ec1da73f5f6a359ac9e6e18a30eb0cf5d5952",
"content_id": "1e173ba9f265e27f591b63466b87384fcf0af1f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 148,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 5,
"path": "/PythonTest/Aula08A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from math import sqrt, floor\nn = int(input('Digite um número: '))\nprint(f'A raiz de {n} é igual á {floor(sqrt(n)):.2f}')\n\n# Exercícios: 16 - 21\n"
},
{
"alpha_fraction": 0.624316930770874,
"alphanum_fraction": 0.6325136423110962,
"avg_line_length": 51.28571319580078,
"blob_id": "3e5f55e2163c13cd49ce1f1966fa80065673d9a5",
"content_id": "7aac5f4443eddf6d8fdf36ac7f771e722ad100f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 746,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 14,
"path": "/PythonExercicios/ex092.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from datetime import date\nano = date.today().year\n\npessoa = {'Nome': input('Nome: '),\n 'Idade': ano - int(input('Ano de nascimento: ')), # Recebe o ano de nascimento e calcula a idade\n 'CTPS': int(input('Carteira de Trabalho (0 não tem): '))}\nif pessoa['CTPS'] != 0: # Caso a pessoa tenha carteira de trabalho\n pessoa['Contratação'] = int(input('Ano de Contratação: ')) # O dicionário recebe o ano de contratação\n pessoa['Salário'] = float(input('Salário: R$')) # O salário\n pessoa['Aposentadoria'] = pessoa['Idade'] + (pessoa['Contratação'] - ano + 35) # E a idade de aposentadoria\n\nprint('-='*30)\nfor k, v in pessoa.items(): # Mostra os dados do dicionário\n print(f' - {k} tem o valor {v}')\n"
},
{
"alpha_fraction": 0.5711774826049805,
"alphanum_fraction": 0.5869947075843811,
"avg_line_length": 36.93333435058594,
"blob_id": "b0f8075c0adb34db36d81ed35683dbbd12d6afcf",
"content_id": "9c4c01f50aa6cf1618655d04faf06205d333a968",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 15,
"path": "/PythonExercicios/ex112/UtilidadeCeV/Dado/__init__.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def leia_dinheiro(msg):\n \"\"\"\n -> Recebe um valor digitado pelo usuário e verifica se é um\n valor númerico válido\n :param msg: Mensagem a ser mostrada ao usuário\n :return: Retorno o valor digitado pelo usuário caso seja válido\n \"\"\"\n while True:\n num = input(msg).strip().replace(',', '.') # Substitui as vírgulas por pontos\n if num.replace('.', '').isdigit(): # 'Exluí' os pontos\n num = float(num)\n break\n else:\n print(f'\\033[1;31mERRO! \\\"{num}\\\" não é um preço válido.\\033[m')\n return num\n"
},
{
"alpha_fraction": 0.6637167930603027,
"alphanum_fraction": 0.7256637215614319,
"avg_line_length": 27.25,
"blob_id": "4aca3f33944e8485ddf5b411dce10dde51ab5236",
"content_id": "bb9fc0afcd57d040cbaf20ca21b0134b6aaa5fc5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 4,
"path": "/PythonExercicios/ex112/Teste.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from ex112.UtilidadeCeV import Moeda, Dado\n\np = Dado.leia_dinheiro('Digite o preço: R$')\nMoeda.resumo(p, 80, 35)\n"
},
{
"alpha_fraction": 0.5600000023841858,
"alphanum_fraction": 0.5769230723381042,
"avg_line_length": 31.5,
"blob_id": "b3365441412e485c1f30f6f59ed4188a20d1c484",
"content_id": "88becad7785f992ab350f936756864e053f72ecd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 20,
"path": "/PythonExercicios/ex062.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('Gerador de PA\\n' + '-='*7)\n\na1 = int(input('Primeiro termo: '))\nr = int(input('Razão da PA: '))\nlimite = 10 # Limite inicial dos termos\ncont = 0 # Index dos termos\nmais = 1 # Limite adicionado pelo usuário\n\nwhile mais != 0:\n while cont < limite:\n print(a1, end=' -> ')\n a1 += r\n cont += 1\n '''if cont == n: # Substituí o 'while mais != 0:'\n print('PAUSA')\n n += int(input('Você quer que repita mais quantas vezes? '))'''\n print('PAUSA')\n mais = int(input('Você quer que repita mais quantas vezes? '))\n limite += mais\nprint(f'Progressão finalizada com {cont} termos mostrados')\n"
},
{
"alpha_fraction": 0.6160714030265808,
"alphanum_fraction": 0.6607142686843872,
"avg_line_length": 55,
"blob_id": "4b73823f4a22ced5611eff33390ca601deb3df2e",
"content_id": "2954e5ca5d765bc27ed2e01978bfbc307e29387c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 2,
"path": "/PythonExercicios/ex025.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = input('Digite seu nome completo: ').strip()\nprint(f'Em seu nome tem Silva? \\033[35m{\"silva\" in n.lower()}')\n"
},
{
"alpha_fraction": 0.6125401854515076,
"alphanum_fraction": 0.6318327784538269,
"avg_line_length": 31.736841201782227,
"blob_id": "3a581f8c609e2503364fcd2aa68d524e60a70ff3",
"content_id": "fe0183a337f8ad26306fee0bc45ac3ce93121b29",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 631,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 19,
"path": "/PythonTest/Aula19B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "brasil = []\nestado1 = {'uf': 'São Paulo', 'sigla': 'SP'}\nestado2 = {'uf': 'Paraíba', 'sigla': 'PB'}\nbrasil.append(estado1)\nbrasil.append(estado2)\nprint(brasil[0]['sigla']) # Acessa o 1° dicionário dentro da lista e o item 'sigla'\n\nestado = dict() # Cria um dicionário\npais = list()\nfor c in range(0, 3):\n estado['uf'] = input('Unidade Federativa: ')\n estado['sigla'] = input('Sigla do Estado: ')\n pais.append(estado.copy()) # Cria uma copia, assim os valores da lista 'pais', não ficam vínculados ao dicionário\nfor e in pais:\n for v in e.values():\n print(v, end=' ')\n print()\n\n# Exercício 90 - 95\n"
},
{
"alpha_fraction": 0.5141700506210327,
"alphanum_fraction": 0.6396760940551758,
"avg_line_length": 48.400001525878906,
"blob_id": "96ba3604fe5dcdf8577ceace6107bdd1ab4cd8ff",
"content_id": "b513b99a46ca5a6947cf4754738aea78113a9931",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 5,
"path": "/PythonExercicios/ex046.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from time import sleep\nfor i in range(10, -1, -1): # Faz uma contagem regressiva de 10 até 0\n print(f'\\033[37m{i}') # Mostra o valor de i\n sleep(1) # Pausa o programa por um segundo\nprint('\\033[33;1m🎆🎆🎆🎆🎆\\033[32;1mKaboom\\033[33;1m🎆🎆🎆🎆🎆')\n"
},
{
"alpha_fraction": 0.5936395525932312,
"alphanum_fraction": 0.6731448769569397,
"avg_line_length": 61.88888931274414,
"blob_id": "d4e6916166ffdeaa4074d5ace74b75bfb9cea3d4",
"content_id": "0d4ef089556455b056da03c2dd3d257abf98476b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 9,
"path": "/PythonExercicios/ex006.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = int(input('Digite um número: '))\n# Pede que o usuário digite um número e armazena na variável\n\nprint(f'O dobro desse número é \\033[7;32;1m{n * 2}\\033[m,'\n f'\\nO triplo é \\033[41;1m{n * 3}\\033[m \\nE a raiz quadrada é \\033[1;7;30m{n ** (1/2):.2f}\\033[m')\n# Mostra o dobro, o triplo e a raiz quadrada do número digitado\n# Mostra o dobro em negrito (1), ele teria a fonte verde (32), mas o fundo e a fonte estão invertidas (7)\n# Triplo: negrito (1), fundo vermelho (41)\n# Raiz: negrito (1), a fonte seria branca (30), mas o fundo e a fonte estão invertidos (7)\n"
},
{
"alpha_fraction": 0.5687331557273865,
"alphanum_fraction": 0.6145552396774292,
"avg_line_length": 36.099998474121094,
"blob_id": "96cd71ebf8a4b5d39fa5a4bfe650d139d21f2438",
"content_id": "a0ce76afee94163eac3c9431100122abf59be707",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 750,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 20,
"path": "/PythonExercicios/ex060.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# from math import factorial\nn = int(input('Digite um número para Calcular seu Fatorial: '))\nc = n # Recebe o valor do variável n, essa variável será usada para calcular o fatorial\nfat = 1\n# fatorial = factorial(n) # função que calcular o fatorial de um número\n\nprint(f'O fatorial de \\033[33;1m{n}!\\033[m =', end=' ')\nwhile c != 0:\n print(f'\\033[34;1m{c}\\033[m', end='')\n print(' x ' if c != 1 else ' = ', end='')\n fat *= c # multiplica o valor de fat pelo valor de c e no final temos a fatorial\n c -= 1\nprint(f'\\033[37;1m{fat}\\033[m')\n\n'''cont = n\nfor cont in range(cont, 0, -1): # Igual ao laço acima, mas utilizando for\n print(cont, end='')\n print(' x ' if cont != 1 else ' = ', end='')\n fat *= cont\nprint(fat)'''\n"
},
{
"alpha_fraction": 0.6264821887016296,
"alphanum_fraction": 0.6343873739242554,
"avg_line_length": 35.14285659790039,
"blob_id": "fbf290c5a86a906a5cb2077fffe5129980897c30",
"content_id": "2b49310fcab75b95ad0e4971503f161d0de2fe21",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 525,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 14,
"path": "/PythonExercicios/ex090.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "aluno = dict()\naluno['Nome'] = input('Nome: ') # Adiciona o nome do aluno ao dicionário\naluno['Média'] = float(input(f'Média de {aluno[\"Nome\"]}: ')) # Adiciona a média do aluno\n\nif aluno['Média'] >= 7: # Adiciona a situação do aluno de acordo com a média\n aluno['Situação'] = 'Aprovado'\nelif aluno['Média'] >= 5:\n aluno['Situação'] = 'Recuperação'\nelse:\n aluno['Situação'] = 'Reprovado'\n\nprint('-'*30)\nfor k, v in aluno.items(): # Mostra os dados do dicionário\n print(f'{k} é igual a {v}')\n"
},
{
"alpha_fraction": 0.5792349576950073,
"alphanum_fraction": 0.6065573692321777,
"avg_line_length": 39.66666793823242,
"blob_id": "dd066ccd2732fd75fce98c1adcb3c654d3fe90af",
"content_id": "e748219ec58cfff888d07f13739d1b88a3e463cd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 370,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 9,
"path": "/PythonExercicios/ex067.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "while True:\n n = int(input('Quer ver a tabuada de qual valor? '))\n print('-'*35)\n if n < 0: # Mostra a tabuada enquanto o usuário não digitar um valor negativo\n break\n for i in range(0, 11): # Quando o progressão é de apenas 1, o 1 pode ser omitido\n print(f'{n} X {i} = {n*i}')\n print('-'*35)\nprint('Tabuada Encerrada. Volte Sempre!')\n"
},
{
"alpha_fraction": 0.4975923001766205,
"alphanum_fraction": 0.550561785697937,
"avg_line_length": 28.66666603088379,
"blob_id": "4c5ef3ada8f4619a105e8e78c798ea7dcb735a60",
"content_id": "f115a452f2ef3195a5f5dd29761f93e319ff96fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 632,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 21,
"path": "/PythonExercicios/ex009.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = int(input('Digite um número inteiro: '))\n# Pede para que o usuário digite um número e armazena na variável\n\nprint('\\033[34m-' * 12)\n# Cria um traçado e deixa todos os caracteres a partir do traçado em magenta\n\nprint(f' 0 x {n} = {n * 0}')\nprint(f' 1 x {n} = {n * 1}')\nprint(f' 2 x {n} = {n * 2}')\nprint(f' 3 x {n} = {n * 3}')\nprint(f' 4 x {n} = {n * 4}')\nprint(f' 5 x {n} = {n * 5}')\nprint(f' 6 x {n} = {n * 6}')\nprint(f' 7 x {n} = {n * 7}')\nprint(f' 8 x {n} = {n * 8}')\nprint(f' 9 x {n} = {n * 9}')\nprint(f'10 x {n} = {n * 10}')\n# Mostra a tabuada do número digitado pelo usuário\n\nprint('-' * 12)\n# Cria outro traçado\n"
},
{
"alpha_fraction": 0.5483871102333069,
"alphanum_fraction": 0.5927419066429138,
"avg_line_length": 26.55555534362793,
"blob_id": "9dbca7aa6c55e0f98e783ec8d353340690910fb1",
"content_id": "14bc9d62ebec13507339954615aca23450144614",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 254,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 9,
"path": "/PythonExercicios/ex066.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "soma = cont = 0\n\nwhile True:\n n = int(input('Digite um número [999 para parar]: '))\n if n == 999: # Se o usuário digitar 999 o laço para\n break\n soma += n\n cont += 1\nprint(f'Você digitou {cont} números e a soma deles é {soma}')\n"
},
{
"alpha_fraction": 0.6600000262260437,
"alphanum_fraction": 0.6600000262260437,
"avg_line_length": 54.55555725097656,
"blob_id": "956191c4b8319a7d0390ad377cab54a38409c672",
"content_id": "36450df6703610075569c1b6c419c6926e621da1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 511,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 9,
"path": "/PythonExercicios/ex077.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "palavras = 'aprender', 'programar', 'linguagem', 'python', 'curso', 'grátis', 'estudar', 'praticar', 'trabalhar',\\\n 'mercado', 'programador', 'futuro'\n\nfor palavra in palavras: # Percorre os elementos da tupla\n print(f'\\nNa palavra {palavra.upper()} temos', end=' ')\n for letra in palavra: # Percorre os caracteres de cada elemento da tupla\n # noinspection SpellCheckingInspection\n if letra.lower() in 'aáàãâeêéiíoôõuú': # Mostra as vogais\n print(letra, end=' ')\n"
},
{
"alpha_fraction": 0.5079726576805115,
"alphanum_fraction": 0.5444191098213196,
"avg_line_length": 15.884614944458008,
"blob_id": "f036b7291011a7d4183c69d67d48b04e8a7ccf1c",
"content_id": "ea2d7b24d4d03eea76a0ceb1f3ca5f3b7cdc1a2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 26,
"path": "/PythonTest/Aula13A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "s = 0\nfor c in range(0, 3):\n n = int(input('Digite um valor: '))\n s += n\nprint(f'O somatório de todos os valores {s}')\n\n'''i = int(input('Início: '))\nf = int(input('Fim: '))\np = int(input('Passo: '))\nfor c in range(i, f+1, p):\n print(c)\nprint('FIM')\n\nfor c in range(1, 7):\n print(c)\nprint('Fim')\n\nfor c in range(6, 0, -1):\n print(c)\nprint('Fim')\n\nfor c in range(0, 7, 2):\n print(c)\nprint('Fim')'''\n\n# Exercícios: 46 - 56\n"
},
{
"alpha_fraction": 0.6246649026870728,
"alphanum_fraction": 0.6702412962913513,
"avg_line_length": 36.29999923706055,
"blob_id": "be0d4ba83f126aa6fb63622be78b61ff8e65dd59",
"content_id": "143f153a77c8fa9689bc415da07f9471669d28c2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 382,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 10,
"path": "/PythonExercicios/ex064.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "cont = soma = 0\n\nnum = int(input('Digite um número [999 para parar]: '))\n\nwhile num != 999: # Repete enquanto o usuário não digitar 999\n cont += 1\n soma += num\n num = int(input('Digite um número [999 para parar]: '))\nprint(f'Você digitou {cont} números e a soma deles é {soma}')\n# Mostra o número de números digitados e a soma deles, desconsiderando o flag (999)\n"
},
{
"alpha_fraction": 0.6359773278236389,
"alphanum_fraction": 0.645892322063446,
"avg_line_length": 38.22222137451172,
"blob_id": "36f6432774c24f1801ce009382623e57430cb6d5",
"content_id": "f5f915fa2b769749d218c1714ba6cc4858365d64",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 720,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 18,
"path": "/PythonExercicios/ex078.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "valores = []\nfor c in range(1, 6): # Armazena 5 valores digitados pelo usuário na lista valores\n valores.append(int(input(f'Digite o {c}° valor: ')))\n\nprint('=-'*30)\nprint(f'Você digitou os valores {valores}')\n\nprint(f'O maior valor é {max(valores)} e ele está nas posições', end=' ')\nfor i, v in enumerate(valores):\n if max(valores) == v:\n print(i + 1, end='...')\n # Mostra o maior valor e suas posições, caso tenha aparecido em mais de uma\n\nprint(f'\\nO menor valor foi {min(valores)} e ele está na posição', end=' ')\nfor i, v in enumerate(valores):\n if min(valores) == v:\n print(i + 1, end='...')\n # Mostra o menor valor e suas posições, caso tenha aparecido em mais de uma\n"
},
{
"alpha_fraction": 0.5730769038200378,
"alphanum_fraction": 0.6499999761581421,
"avg_line_length": 64,
"blob_id": "95a818a9e1cba2fd0ee59bcd60a0d19149c8a53d",
"content_id": "8b1bf911a878cac7c29cf505dc70d29f082929db",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 4,
"path": "/PythonExercicios/ex024.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "cid = input('Em que cidade você mora? ') # .strip()\nci = cid.split()\nprint(f'Essa cidade tem Santo no começo do nome? \\033[1;37m{\"SANTO\" in ci[0].upper()}\\033[m')\nprint(f'Essa cidade tem Santo no começo do nome? \\033[0;36m{\"SANTO\" == cid[:5].upper()}\\033[m')\n"
},
{
"alpha_fraction": 0.6583184003829956,
"alphanum_fraction": 0.6762075424194336,
"avg_line_length": 24.409090042114258,
"blob_id": "efffc05b735d704ad298de2c63a3f2bdce2e4d87",
"content_id": "b3868662abceb64d2f8465d90eeda5d865ab79c9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 22,
"path": "/PythonTest/Aula09A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "frase = ' Curso em Vídeo Python '\n# print(frase[::2])\n# print(frase[:13])\n# print(frase.upper().count('O'))\n# print(len(frase.strip()))\n# print(frase.replace('Python', 'Android'))\n# frase[0] = 'J' Imutável: Essa linha resulta em error\n# print(frase) # Imutável\n# print('Curso' in frase)\n# print(frase.find('Curso'))\n# print(frase.find('vídeo'))\n# print(frase.lower().find('vídeo'))\ndividido = frase.split()\nprint(dividido[2][3])\n\n'''print(\"\"\"oifsdçasçfjlsça\naflçjsafjçjasjfçasjf\nasdfçjasljfçjas\nfslçajfsçafk\nsflçsjdkfjçsfj\"\"\")'''\n\n# Exercícios: 22 - 27\n"
},
{
"alpha_fraction": 0.5428773760795593,
"alphanum_fraction": 0.6024096608161926,
"avg_line_length": 38.19444274902344,
"blob_id": "c4ba23ca915d28eef8dbda9743021e11ff312114",
"content_id": "f4b4a7bbc2540eff997180821622bae1a278733f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1446,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 36,
"path": "/PythonExercicios/ex059.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from time import sleep\n\nop = 0 # Variável que representa as opções\nn1 = int(input('Primeiro número: '))\nn2 = int(input('Segundo número: '))\n\nwhile op != 5: # Enquanto op não receber o valor 5\n op = int(input(''' \\033[37;1m[1] Somar\n [2] Multiplicar\n [3] Maior\n [4] Introduzir novos números\n [5] Sair do programa\\033[m\n>>>>> Qual a sua opção? '''))\n # Criar um menu que mostrar as opções que o programa pode executar\n\n if op == 1: # Se op receber 1 então mostra a soma entre os números\n print(f'O resultado da\\033[36;1m soma {n1} + {n2} é {n1 + n2}\\033[m')\n elif op == 2: # Se op recebe 2 então mostra a multiplicação entre os números\n print(f'O resultado da\\033[33;1m multiplicação {n1} X {n2} é {n1 * n2}\\033[m')\n elif op == 3: # Se op recebe 3 então mostra o maior entre os dois número\n if n1 > n2:\n maior = n1\n else:\n maior = n2\n print(f'Entre {n1} e {n2},\\033[30;1m o maior número é {maior}\\033[m')\n elif op == 4: # Se op recebe 4 então o usuário pode inserir novos números\n n1 = int(input('Primeiro número: '))\n n2 = int(input('Segundo número: '))\n elif op == 5: # Se op recebe 5 então o programa é finalizado\n print('Finalizando...')\n else:\n print('\\033[31mOpção inválida.\\033[m')\n print('=-=' * 10)\n\nsleep(2) # Pausa o programa por 2 segundos\nprint('Fim do programa.')\n"
},
{
"alpha_fraction": 0.5446559190750122,
"alphanum_fraction": 0.5622254610061646,
"avg_line_length": 67.30000305175781,
"blob_id": "5dae908f8f0bad766e7138c9364adf5f6f0ccab9",
"content_id": "5778dad02042279e37339334bdaf07713cce6f0f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 689,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 10,
"path": "/PythonExercicios/ex022.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = input('Digite seu nome completo: ').strip()\ncolor = {'l': '\\033[m', 'v': '\\033[1;32m'}\nprint(f'Seu nome em Maiúsculo é {color[\"v\"]}{n.upper()}{color[\"l\"]}')\nprint(f'Seu nome em Minúsculo é {color[\"v\"]}{n.lower()}{color[\"l\"]}')\nprint(f'Seu nome ao todo tem {color[\"v\"]}{len(n.replace(\" \", \"\"))}{color[\"l\"]} letras')\n# print(f'Seu nome ao todo tem {color[\"v\"]}{len(n) - n.count(\" \")}{color[\"l\"]} letras')\nprint(f'Seu primero nome é {color[\"v\"]}{n.split()[0]}{color[\"l\"]}'\n f' e ele tem {color[\"v\"]}{len(n.split()[0])}{color[\"l\"]} letras')\n# print(f'Seu primero nome é {color[\"v\"]}{n.split()[0]}{color[\"l\"]} '\n# f'e ele tem {color[\"v\"]}{n.find(\" \")}{color[\"l\"]} letras')\n"
},
{
"alpha_fraction": 0.5732600688934326,
"alphanum_fraction": 0.5952380895614624,
"avg_line_length": 21.75,
"blob_id": "67aabae01e37dc792347cdb12bb81761b331bbcb",
"content_id": "e89932a6469df698c111826ad428005ead79a4ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 552,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 24,
"path": "/PythonExercicios/ex100.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom time import sleep\n\n\ndef sorteia(lst): # Sorteia 5 números e adiciona a lista do parâmetro\n print(f'Sorteando 5 valores da lista: ', end='')\n for i in range(0, 5):\n lst.append(randint(0, 50))\n print(lst[i], end=' ')\n sleep(0.5)\n print('PRONTO!')\n\n\ndef soma_par(lst): # Soma os número pares da lista(parâmetro)\n soma = 0\n for num in lst:\n if num % 2 == 0:\n soma += num\n print(f'A soma dos números pares é: {soma}')\n\n\nval = list()\nsorteia(val)\nsoma_par(val)\n"
},
{
"alpha_fraction": 0.6761501431465149,
"alphanum_fraction": 0.685230016708374,
"avg_line_length": 55.965518951416016,
"blob_id": "050f654512cd1954e35bfb18121d474dd5900964",
"content_id": "f1b7c1befa155354dd819ed7488c72737ed6e8be",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1692,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 29,
"path": "/PythonExercicios/ex004.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "ent = input('Digite algo: ')\ncolor = {'m': '\\033[34;1m', 'l': '\\033[m', 'v': '\\033[32;1m'}\n# Cria um dicionário chamado color com as chaves 'm' de magenta, 'l' de limpar e 'v' de verde\nprint(type(ent))\n# mostra o tipo da variável\nprint(f'Está tudo em minúsculo? {color[\"m\"]}{ent.islower()}{color[\"l\"]}')\n# mostra se o valor da variável são minúsculas\nprint(f'Está tudo em maiúsculo? {color[\"v\"]}{ent.isupper()}{color[\"l\"]}')\n# mostra se o valor da variável são maiúsculas\nprint(f'É alfanúmerico? {color[\"m\"]}{ent.isalnum()}{color[\"l\"]}')\n# Verifica se o valor da variável é alfanúmerico\nprint(f'É alfabético? {color[\"v\"]}{ent.isalpha()}{color[\"l\"]}')\n# Verifica se o valor tem apenas letras\nprint(f'É númerico? {color[\"m\"]}{ent.isnumeric()}{color[\"l\"]}')\n# Verifica se o valor tem apenas números\nprint(f'É ASCII? {color[\"v\"]}{ent.isascii()}{color[\"l\"]}')\n# Verifica se o valor tem ASCII (símbolos)\nprint(f'É decimal? {color[\"m\"]}{ent.isdecimal()}{color[\"l\"]}')\n# Verifica se o valor é decimal\nprint(f'É um digito? {color[\"v\"]}{ent.isdigit()}{color[\"l\"]}')\n# Verifica se o valor é um digito\nprint(f'É um identificador? {color[\"m\"]}{ent.isidentifier()}{color[\"l\"]}')\n# Verifica se o valor serviria como identificador\nprint(f'É possível mostrar todos os caracteres? {color[\"v\"]}{ent.isprintable()}{color[\"l\"]}')\n# Verifica se todos caracteres são possíveis de mostrar\nprint(f'Todas as palavras estão capitalizadas? {color[\"m\"]}{ent.istitle()}{color[\"l\"]}')\n# Verifica se todos as palavras estão com a primeira letra maiúsculas\nprint(f'Todos os caracteres são espaços? {color[\"v\"]}{ent.isspace()}{color[\"m\"]}')\n# Verifica se a variável tem apenas espaços\n"
},
{
"alpha_fraction": 0.631989598274231,
"alphanum_fraction": 0.6853055953979492,
"avg_line_length": 44.235294342041016,
"blob_id": "2b5547700554e9d24e749e370a6ee98e04152144",
"content_id": "fc44cdf982191718f116570ff8839b3ebbf198aa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 17,
"path": "/PythonExercicios/ex035.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('-_' * 13)\nprint('Analisador de Triângulos')\nprint('_-' * 13)\nreta1 = float(input('Digite o comprimento do primeiro segmento: '))\nreta2 = float(input('Digite o comprimento do segundo segmento: '))\nreta3 = float(input('Digite o comprimento do terceiro segmento: '))\n\nif reta1 + reta2 > reta3 and reta1 + reta3 > reta2 and reta2 + reta3 > reta1:\n print('\\033[32;1mEsses segmentos podem formar um triângulo.\\033[m')\n if reta1 != reta2 and reta1 != reta3 and reta2 != reta3:\n print('Eles formam um triângulo Escaleno')\n elif reta1 == reta2 and reta2 == reta3:\n print('Eles formam um triângulo Equilátero')\n else:\n print('Eles formam um triângulo Isósceles')\nelse:\n print('\\033[31;1mEsses segmentos não podem formar um triângulo.')\n"
},
{
"alpha_fraction": 0.5467153191566467,
"alphanum_fraction": 0.5759124159812927,
"avg_line_length": 36.02702713012695,
"blob_id": "7bd505ead689222e9997cd313bc0b83cec42080d",
"content_id": "a70cb596ace3120e7135b5f77302bbd860471083",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1379,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 37,
"path": "/PythonExercicios/ex089.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "alunos = []\nwhile True:\n aluno = [input('Nome: '), [(float(input('Nota 1: '))), float(input('Nota 2: '))]]\n # Adiciona o nome do aluno e as notas a lista aluno\n alunos.append(aluno[:]) # Adiciona a lista aluno a lista alunos\n aluno.clear() # Limpa a lista aluno\n '''nome = input('Nome: ')\n nota1 = float(input('Nota 1: ')) # Outra maneira de fazer o trecho acima\n nota2 = float(input('Nota 2: '))\n alunos.append([nome, [nota1, nota2]])'''\n \n while True:\n resp = input('Deseja continuar? [S/N] ').strip().upper()[0]\n if resp in 'SN':\n break\n if resp == 'N':\n break\n\nprint('-='*30)\nprint(f'{\"No.\":<4}{\"Nome\":<10}{\"Média\":>8}')\nprint('-'*24)\nfor i, alu in enumerate(alunos): # Mostra o número, o nome e a média dos alunos\n med = (alunos[i][1][0] + alunos[i][1][1])/2\n print(f'{i:<4}{alu[0]:<10}{med:>8}')\nprint('-'*24)\n\nwhile True: # Mostra as notas dos alunos\n esc = int(input('Quer ver as notas de qual aluno? (999 para interromper): '))\n if esc == 999:\n break\n if esc <= len(alunos) - 1: # Caso seja digitado um número correspodente à um aluno\n print(f'Notas da(o) {alunos[esc][0]} são {alunos[esc][1]}')\n else: # Caso não, é mostra essa mensagem\n print('Este aluno não foi cadastrado')\n print('-'*20)\nprint('FINALIZANDO...')\nprint('<<< Volte Sempre >>>')\n"
},
{
"alpha_fraction": 0.6625000238418579,
"alphanum_fraction": 0.6829545497894287,
"avg_line_length": 39,
"blob_id": "32f8abaf0a63e260f75bad5dcae63b3e0627b6ab",
"content_id": "41ce8ae8c06154a0d84308c24b69fc462f62ffc9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 891,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 22,
"path": "/PythonExercicios/ex053.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "frase = input('Digite uma frase: ').lower().strip() # Pede pro usuário digitar uma frase\n\nfrase_cut = frase.split() # Divide essa frase de acordo com os espaços\nfrase_filtro = ''.join(frase_cut) # Junta a frase invertida que foi divida para vira apenas uma palavra\nfrase_inv = frase_filtro[::-1] # Inverte a frase, serve apenas para Python\n\n'''\ninverso = ''\nfor letra in range(len(frase_filtro) - 1, -1, -1):\n inverso += frase_filtro[letra]\n\nfor i in range(0, len(frase_cut_inv)): \n frase_inv_filtro += frase_cut_inv[i]\nfor i in range(0, len(frase_cut)): \n frase_filtro += frase_cut[i]\n'''\n\nprint(f'O inverso de {frase_filtro} é {frase_inv}')\nif frase_inv == frase_filtro: # Verifica se a frase normal e a invertida são iguais, elas estão sem os espaços\n print('Essa frase é \\033[32;1mum palíndromo')\nelse:\n print('Essa frase\\033[31;1m não é um palíndromo')\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5876623392105103,
"avg_line_length": 37.5,
"blob_id": "582a5f3c859a006e7eb6cfddc29d8b470a696773",
"content_id": "50da0222ada2353f139bc39ed5d7f4dffb6724fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 311,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 8,
"path": "/PythonExercicios/ex047.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "for i in range(2, 51, 2): # Conta de dois em dois, mostrando todos os números pares entre 1 e 50\n print(f'\\033[35;1m{i}', end=' ')\nprint('Acabou!')\n\n'''for i in range(1, 51): # Verifica quais números são pares entre 1 e 50\n if i % 2 == 0:\n print(f'\\033[35;1m{i}', end=' ')\nprint('Acabou!')'''\n"
},
{
"alpha_fraction": 0.5384615659713745,
"alphanum_fraction": 0.6730769276618958,
"avg_line_length": 38,
"blob_id": "e9d43b98420ab0ae7da9d06a11c56e9d9e83dc8c",
"content_id": "abad6df4423cdf64d2f5f194fcff966a8a07a99c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 8,
"path": "/PythonExercicios/ex038.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "num1 = int(input('Digite o primeiro número: '))\nnum2 = int(input('Digite o segundo número: '))\nif num1 > num2:\n print('O\\033[37;1m PRIMEIRO\\033[m valor é\\033[36;1m maior')\nelif num2 > num1:\n print('O\\033[37;1m SEGUNDO\\033[m valor é\\033[36;1m maior')\nelse:\n print('Os dois valores são\\033[36;1m iguais')\n"
},
{
"alpha_fraction": 0.5565410256385803,
"alphanum_fraction": 0.5964523553848267,
"avg_line_length": 21.549999237060547,
"blob_id": "c407c372aa5c5e54f61f64de70699820dc46ffe4",
"content_id": "30cb822c13ae5fa5f9ec543fef237e91a450be1d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 20,
"path": "/PythonTest/Aula21B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def fatorial(num=1):\n \"\"\"\n -> Calcula o fatorial de um número\n :param n: número que terá seu fatorial calculado\n :return: retorna o fatorial de n\n \"\"\"\n fat = 1\n for c in range(num, 0, -1):\n fat *= c\n return fat\n\n\nn = int(input('Digite um número: '))\nf1 = fatorial(5)\nf2 = fatorial(4)\nf3 = fatorial()\nprint(f'O fatorial de {n} é igual a {fatorial(n)}')\nprint(f'Os resultados são {f1}, {f2}, {f3}')\n\n# Exercício 101 - 106\n"
},
{
"alpha_fraction": 0.6648745536804199,
"alphanum_fraction": 0.7025089859962463,
"avg_line_length": 36.20000076293945,
"blob_id": "0f3f1f4caf68b8f2c91ad1c14433acee87d5da00",
"content_id": "847f9712675d3d0714cd486dc32e088f03870df3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 568,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 15,
"path": "/PythonTest/Aula17A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "num = [2, 5, 9, 1] # Lista\nnum[2] = 3 # Substituí o elemento na posição dois pelo valor 3\nnum.append(7) # Adicionar o valor 7 no final da lista\nnum.sort(reverse=True) # Organiza os elementos do maior para o menor\nnum.insert(2, 2) # Insere o valor dois na segunda posição deslocando os outros elementos\nif 4 in num:\n num.remove(4) # Remove o elemento 4\nelse:\n print('Não achei o número 4')\nnum.pop(2) # Remove o elemento na posição 2\n\nprint(num)\nprint(f'Essa lista tem {len(num)} elementos') # Mostra o comprimento da lista\n\n# Exercício 78 - 83\n"
},
{
"alpha_fraction": 0.49132493138313293,
"alphanum_fraction": 0.5449526906013489,
"avg_line_length": 23.384614944458008,
"blob_id": "5b6f535a5957618f2a3657d9a2867c9297ccf5a9",
"content_id": "b54fe04fd60ce32a520b57dd79b862181e212252",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1279,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 52,
"path": "/PythonExercicios/ex106.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "c = ('\\033[m', # 0 - Sem cor\n '\\033[30;41;1m', # 1 - Vermelho\n '\\033[30;42;1m', # 2 - Verde\n '\\033[30;43;1m', # 3 - Amarelho\n '\\033[30;44;1m', # 4 - Azul\n '\\033[30;45;1m', # 5 - Magenta\n '\\033[7;30m' # 6 - Branco\n )\n\n\ndef ajuda(func):\n \"\"\"\n -> Função que mostra o help de uma função formatado\n :param func: Nome da função a ser mostrado o help\n :return: sem retorno\n \"\"\"\n from time import sleep\n print(c[6], end='')\n sleep(0.5)\n help(func)\n print(c[0], end='')\n sleep(1)\n\n\ndef titulo(msg, cor=0):\n \"\"\"\n -> Recebe um título e formata ele\n :param msg: Título a ser formatado\n :param cor: cor a se utilizada no fundo\n :return: sem retorno\n \"\"\"\n tam = len(msg) + 10\n print(c[cor] + '~' * tam)\n print(f' {msg} ')\n print('~' * tam)\n print(c[0], end='')\n\n\nwhile True:\n titulo('SISTEMA DE AJUDA PYTHON', 2)\n\n # noinspection SpellCheckingInspection\n funcao = input('Função ou Biblioteca >').strip()\n\n if funcao.upper() == 'FIM':\n titulo('Até Logo!', 1)\n break\n\n titulo(f'Acessando o manual do comando \\'{funcao}\\'', 5)\n # A barra invertida permite que a aspa seja impresssa, sem atrapalhar a string\n\n ajuda(funcao)\n"
},
{
"alpha_fraction": 0.5600600838661194,
"alphanum_fraction": 0.6141141057014465,
"avg_line_length": 26.75,
"blob_id": "7a44971f67cbcba8ca8eb478339cccf4c166fa6b",
"content_id": "77d791dc05370ba30e70844777eaed84166e910d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 679,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 24,
"path": "/PythonExercicios/ex043.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "peso = float(input('Digite o peso da pessoa (Kg): '))\nalt = float(input('Digite a altura da pessoa (m): '))\nimc = peso / alt ** 2\nif imc < 10:\n cat = 'Desnutrição Grau V'\nelif imc < 13:\n cat = 'Desnutrição Grau IV '\nelif imc < 16:\n cat = 'Desnutrição Grau III'\nelif imc < 17:\n cat = 'Desnutrição Grau II'\nelif imc < 18.5:\n cat = 'Desnutrição Grau I'\nelif imc <= 25:\n cat = 'Normal'\nelif imc <= 30:\n cat = 'Pré-Obesidade'\nelif imc < 35:\n cat = 'Obesidade Grau I'\nelif imc <= 40:\n cat = 'Obesidade Grau II'\nelse:\n cat = 'Obesidade Grau III'\nprint(f'O IMC dessa pessoa é \\033[35;1m{imc:.1f}\\033[m e ela está na categoria \\033[36;1m{cat}')\n"
},
{
"alpha_fraction": 0.5024154782295227,
"alphanum_fraction": 0.5531401038169861,
"avg_line_length": 26.600000381469727,
"blob_id": "d10c6bcdac30d2827fa9a20568b8f62ac74de869",
"content_id": "02785478e1b72d5213fe6c137b4946c1b2b30b52",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 15,
"path": "/PythonExercicios/ex052.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = int(input('Digite um número inteiro: '))\np = 0\nfor i in range(1, n + 1): # Verifica se o número que o usuário digitou é primo\n if n % i == 0:\n p += 1\n print(f'\\033[33;1m', end='')\n else:\n print(f'\\033[31;1m', end='')\n print(i, end=' \\033[m')\n\nprint(f'\\nO número {n} foi divisível {p} vezes')\nif p == 2:\n print('Esse número é primo')\nelse:\n print('Esse número não é primo')\n"
},
{
"alpha_fraction": 0.6840659379959106,
"alphanum_fraction": 0.7390109896659851,
"avg_line_length": 51,
"blob_id": "b97b73600c4a39569a1c8d3f24919b2872237b3b",
"content_id": "b5d2f6d8b8b12cfb834c7a484b66c20fa4109924",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 371,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 7,
"path": "/PythonExercicios/ex010.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "din = float(input('Quanto dinheiro você tem na carteira? R$'))\n# Pede que o usuário digite a quantidade de dinheiro que tem na carteira, transforma\n# no tipo float e armazena na variável\n\nprint(f'Você pode comprar \\033[33;40;1mUS${din/5.37:.2f}\\033[m')\n# Fundo branco (40) e fonte amarela (33) e negrito (1)\n# Mostra a quantidade de dólares que é possível comprar\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 14,
"blob_id": "8b2eede1f9a4955238f0efc12c56bc21ad5f157d",
"content_id": "3425aceb5b241cb94c501efa1fc06f9a494f1315",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 17,
"license_type": "permissive",
"max_line_length": 14,
"num_lines": 1,
"path": "/README.md",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# Python_Class\n \n"
},
{
"alpha_fraction": 0.5604395866394043,
"alphanum_fraction": 0.6208791136741638,
"avg_line_length": 25,
"blob_id": "4e2194982dcadd42ea37e8e18fef95abad045c5e",
"content_id": "2892bd6543ec45b499782b9960e54688f4feb576",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 366,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 14,
"path": "/PythonExercicios/ex041.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from datetime import date\nano = int(input('Digite o ano de nascimento do atleta: '))\nida = date.today().year - ano\nif ida <= 9:\n cat = 'Mirim'\nelif ida <= 14:\n cat = 'Infantil'\nelif ida <= 19:\n cat = 'Junior'\nelif ida <= 25:\n cat = 'Sênior'\nelse:\n cat = 'Master'\nprint(f'Esse atleta de \\033[37;1m{ida} anos\\033[m está na\\033[34;1m categoria {cat}')\n"
},
{
"alpha_fraction": 0.6219369769096375,
"alphanum_fraction": 0.68144690990448,
"avg_line_length": 52.5625,
"blob_id": "095e1a0828ec867633c6ab260c77e87043d8d684",
"content_id": "69034b210ac7bd2e6e66f9b180e3a0a99082cbe9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 869,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 16,
"path": "/PythonExercicios/ex058.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\n\npc = randint(0, 10)\n# Escolhe um número entre 0 e 10 para o pc\nplayer = int(input('Tente adivinhar qual número eu escolhi entre 0 e 10: '))\ncont = 0 # variável para contar quantas vezes o player tentou acertar o número\nprint('-'*25)\n\nwhile player != pc: # Enquanto o jogador não acertar o número que o pc 'escolheu'\n if player > pc: # Se o jogador digitar um número maior que o do pc\n player = int(input('\\033[36;1mMenos...\\033[m tente denovo! \\nQual o seu palpite? '))\n elif player < pc: # Se o jogador digite um número menor que o do pc\n player = int(input('\\033[37;1mMais..\\033[m tente denovo! \\nQual o seu palpite? '))\n cont += 1 # Conta o número de tentativas\n print('-' * 25)\nprint(f'\\033[32;1mParabéns\\033[m você acertou! \\nVocê precisou de \\033[35;1m{cont}\\033[m tentativas para acertar!')\n"
},
{
"alpha_fraction": 0.5742765069007874,
"alphanum_fraction": 0.592926025390625,
"avg_line_length": 38.871795654296875,
"blob_id": "8434f656bca1ea4f23937780cf1bf7d31fc9fb21",
"content_id": "c6113d767dec99a6aa6520aaf0b0ccebaf5edc08",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1584,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 39,
"path": "/PythonExercicios/ex068.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\n\nvitorias = 0 # Conta o número de vitórias\n\nprint('-=-' * 10 + f'\\n{\"Vamos Jogar Par ou Ímpar\":^30}')\n\nwhile True:\n player = str(input('-=-' * 10 + '\\nÍmpar ou Par? ')).upper().strip()[0]\n\n if player not in 'IÍP': # Se o Jogador não digitar I, Í ou P, o program vai pedir para que ele digite denovo\n # Não é a melhor solução, seguir exemplo ex070\n print('\\nDigite Ímpar ou Par.\\n')\n continue\n\n pc_num = randint(0, 10) # Escolhe um número pro pc\n player_num = int(input('Digite um número entre 0 e 10: '))\n\n soma = pc_num + player_num\n\n print('-' * 20 + f'\\nVocê jogou {player_num} e o Computador jogou {pc_num}. O Total foi {soma}')\n print('Deu Par' if soma % 2 == 0 else 'Deu Ímpar')\n print('-'*20)\n\n if player == 'P': # Se o jogador escolheu par\n if soma % 2 == 0: # Se a soma for Par, o jogador ganha e o jogo continua\n print('Você ganhou parabéns!')\n vitorias += 1\n else: # Se a soma for Ímpar, o jogador perde e o program encerra\n print('Que pena você perdeu')\n break\n elif player in 'IÍ': # Se o jogador escolher Ímpar\n if soma % 2 != 0: # Se a soma for Ímpar, o jogador ganha e o jogo continua\n print('Você ganhou parabéns!')\n vitorias += 1\n else: # Se a soma for Par, o jogador perde e o program encerra\n print('Que pena você perdeu')\n break\n print('Vamos Jogar Novamente...')\nprint(f'Você teve {vitorias} vitórias consecutivas! Parabéns!')\n"
},
{
"alpha_fraction": 0.5740318894386292,
"alphanum_fraction": 0.587699294090271,
"avg_line_length": 34.5945930480957,
"blob_id": "c1043bc4603cf1d8c4b01b4be7d9a05b318bbcf2",
"content_id": "55dec51e4caf267ca7987c4228fa2d66336988ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1323,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 37,
"path": "/PythonExercicios/ex084.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "dados = []\npessoas = []\nmaior = menor = 0\nwhile True:\n dados.append(input('Nome: '))\n dados.append(float(input('Peso: ')))\n pessoas.append(dados[:])\n\n # cont += 1\n if len(pessoas) == 1: # cont == 1:\n # Caso seja o primeiro valor introduzido na lista pessoas o maior e o menor recebem o mesmo peso\n menor = maior = dados[1]\n else:\n if dados[1] > maior: # Verifica se o peso inserido é maior que o anterior\n maior = dados[1]\n elif dados[1] < menor: # Verifica se o peso inserido é maior que o anterior\n menor = dados[1]\n\n dados.clear() # Excluí os dados da lista para que eles não se repitam na lista pessoas\n while True:\n resp = input('Deseja continuar? [S/N]: ').strip().upper()[0]\n if resp in 'SN': # Verifica se o usuário deseja continuar\n break\n if resp in 'N':\n break\n\nprint('-='*20)\nprint(f'Ao todo, você cadastrou {len(pessoas)} pessoas.')\nprint(f'O maior peso foi {maior:.1f}Kg. Peso de', end=' ')\nfor p in pessoas: # Mostra as pessoas que tem o maior peso\n if p[1] == maior:\n print(f'[{p[0]}]', end=' ')\n\nprint(f'\\nO menor peso foi {menor:.1f}Kg. Peso de', end=' ')\nfor p in pessoas: # Mostra as pessoas que tem o menor peso\n if p[1] == menor:\n print(f'[{p[0]}]', end=' ')\n"
},
{
"alpha_fraction": 0.503113329410553,
"alphanum_fraction": 0.571606457233429,
"avg_line_length": 24.09375,
"blob_id": "0fa9246d1f5e5b82bee4acd49af68ee9af3aaad6",
"content_id": "20066e699955903ed54fae8001c12a86056d2cfb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 809,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 32,
"path": "/PythonExercicios/ex045.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import choice\nfrom time import sleep\nprint('-' * 20)\nprint(f'{\"JOKENPÔ\":^20}')\nprint('-' * 20)\n\npla = int(input('1 - Papel'\n '\\n2 - Pedra'\n '\\n3 - Tesoura'\n '\\nEscolha um número: '))\ncho = ['Papel', 'Pedra', 'Tesoura']\ncom = str(choice(cho))\n\nif 1 > pla or pla > 3:\n exit('Escolha um número válido')\n\nprint('JO')\nsleep(1)\nprint('KEN')\nsleep(1)\nprint('PÔ')\nsleep(1)\n\nif cho[pla - 1] == com:\n res = '\\033[37;1mEmpate'\nelif pla == 1 and com == 'Pedra' or pla == 2 and com == 'Tesoura' or pla == 3 and com == 'Papel':\n res = '\\033[32;1mO Player Venceu'\nelse:\n res = '\\033[31;1mO Computador Venceu'\n\nprint(f'Você escolheu \\033[36;3m{cho[pla - 1]}\\033[m, o computador \\033[35;3m{com}'\n f'\\033[m e o resultado dessa disputa foi {res}')\n"
},
{
"alpha_fraction": 0.5240715146064758,
"alphanum_fraction": 0.5722146034240723,
"avg_line_length": 19.77142906188965,
"blob_id": "3924444508b906f4e439492b03d2535576711a86",
"content_id": "77b3727f90c8b0a9a7bfbe51d32be831ddf1fe5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 734,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 35,
"path": "/PythonTest/Aula20B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def dobra(lst): # Dobra os valores de uma lista\n pos = 0\n while pos < len(lst):\n lst[pos] *= 2\n pos += 1\n\n\ndef contador(*num): # Conta a quantidade de elemento, que foram passados como parâmetro\n tam = len(num)\n '''cont = 0\n for valor in num:\n cont += 1'''\n print(f'Recebi os números {num} que são {tam} ao todo')\n\n\ndef soma(a, b): # Soma dois valores\n print(f'A = {a}, B = {b}')\n print(f'A soma de A + B = {a + b}')\n print('-'*30)\n\n\nsoma(b=4, a=5) # Você não precisa informar os parâmetros na ordem\nsoma(8, 9)\nsoma(2, 1)\nsoma(a=4, b=1)\n\ncontador(2, 1, 7)\ncontador(8, 0)\ncontador(4, 4, 7, 6, 2)\n\nvalores = [7, 2, 5, 0, 4]\ndobra(valores)\nprint(valores)\n\n# Exercícios 96 - 100\n"
},
{
"alpha_fraction": 0.6474359035491943,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 43.57143020629883,
"blob_id": "089fa60879abd23e8ffc76f97c7053bdcdb71821",
"content_id": "358d45ccb7e74fe038e05df7775bd7a7decf7524",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 7,
"path": "/PythonExercicios/ex019.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import choice\nn1 = input('Digite o Nome do primeiro aluno: ')\nn2 = input('Digite o Nome do segundo aluno: ')\nn3 = input('Digite o Nome do terceito aluno: ')\nn4 = input('Digite o Nome do quarto aluno: ')\nalunos = [n1, n2, n3, n4]\nprint(f'O aluno que vai apagar o quadro é \\033[34;1m{choice(alunos)}')\n"
},
{
"alpha_fraction": 0.5438596606254578,
"alphanum_fraction": 0.6578947305679321,
"avg_line_length": 75,
"blob_id": "33820bd2ac73ab5d7bbde7225c0c2519234ab348",
"content_id": "15808112d0562dbf6a57f37fef5d7fd7df9520bd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 3,
"path": "/PythonExercicios/ex-01.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "preco = float(input('Digite o valor do produto: R$'))\nprint(f'O valor desse produto à vista, com 15% de desconto, é \\033[1;37mR${preco * 0.85:.2f}\\033[m')\nprint(f'E a prazo, com aumento de 10%, é \\033[1;36mR${preco * 1.1:.2f}')\n"
},
{
"alpha_fraction": 0.5137614607810974,
"alphanum_fraction": 0.6212319731712341,
"avg_line_length": 41.38888931274414,
"blob_id": "e586a6ab6cc620a8fcb9cb899aaaac8f5febfcc4",
"content_id": "ac29217a73e7c940a4b51a8298dcc1e3d389f0ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 769,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 18,
"path": "/PythonExercicios/ex039.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from datetime import date\nnasc = int(input('Ano de Nascimento: '))\nsex = input('Qual seu sexo? [M/F]: ')\natual = date.today().year\nida = atual - nasc\nalist = nasc + 18\nif sex.upper() == 'M':\n print(f'Quem nasceu em \\033[34;1m{atual}\\033[m tem \\033[34;1m{ida}\\033[m anos em \\033[34;1m{atual}\\033[m')\n if ida == 18:\n print('Está na hora de\\033[36;1m alistar')\n elif ida > 18:\n print(f'Passou(aram-se) \\033[32;1m{ida - 18} ano(s)\\033[m da hora de se alistar')\n print(f'Seu Alistamento foi em \\033[36;1m{alist}')\n else:\n print(f'Falta(m) \\033[31;1m{18 - ida} ano(s)\\033[m até a hora de você se alistar')\n print(f'Seu Alistamento será em \\033[36;1m{alist}')\nelse:\n print('Você\\033[37;1m não precisa\\033[m se alistar')\n"
},
{
"alpha_fraction": 0.6373748779296875,
"alphanum_fraction": 0.6490545272827148,
"avg_line_length": 32.296295166015625,
"blob_id": "f0606a0e45bc1fee193df20583b13d92deeabb26",
"content_id": "4e9a7041ea9bd78a6ba4381ee447adaf04d53dd6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1815,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 54,
"path": "/PythonExercicios/ex109/Moeda.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def aumentar(n=0, porc=0, form=False):\n \"\"\"\n -> Calcula o aumento de um valor, utilizando porcentagem pré-determinada\n :param n: (opcional) Número a ser aumentado\n :param porc: (opcional) Porcentagem a ser utilizada\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna 'n' mais 'porc' porcento, ex: 10 + 20%\n \"\"\"\n num = n * (1 + porc/100)\n return num if not form else moeda(num)\n\n\ndef diminuir(n=0, porc=0, form=False):\n \"\"\"\n -> Retorna um valor com um desconto pré-determinado\n :param n: (opcional) Números a receber o desconto\n :param porc: (opcional) Porcentagem a se descontada\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna o valor 'n' com o desconto\n \"\"\"\n num = n * (1 - porc/100)\n return num if not form else moeda(num)\n\n\ndef dobro(n=0, form=False):\n \"\"\"\n -> Retorna o dobro do valor inserido\n :param n: (opcional) Número a ter seu valor dobrado\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna o dobro de 'n'\n \"\"\"\n num = n * 2\n return num if not form else moeda(num)\n\n\ndef metade(n=0, form=False):\n \"\"\"\n -> Retorna metade do valor inserido\n :param n: (opcional) Número a ser dividido\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna metade de 'n'\n \"\"\"\n num = n / 2\n return num if not form else moeda(num)\n\n\ndef moeda(n, moeda='R$'):\n \"\"\"\n -> Formata os valores monetários\n :param n: (opcional) Valor a ser formatado\n :param moeda: (opcional) Moeda a ser utilizada na formatação\n :return: Valor 'n' formatado\n \"\"\"\n return f'{moeda}{n:.2f}'.replace('.', ',')\n"
},
{
"alpha_fraction": 0.6326671242713928,
"alphanum_fraction": 0.6498966217041016,
"avg_line_length": 42.969696044921875,
"blob_id": "7786fd81a6bf445b99c7f97b8825b85171e2e721",
"content_id": "c87a4c31bbb07f7df08065d02ac52c91ffcd6389",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1459,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 33,
"path": "/PythonExercicios/ex091.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom time import sleep\nfrom operator import itemgetter\n\nprint('Valores sorteados:')\n# Sorteia os 4 dados para os 4 jogadores\njogos = {'Jogador 1': randint(1, 6),\n 'Jogador 2': randint(1, 6),\n 'Jogador 3': randint(1, 6),\n 'Jogador 4': randint(1, 6)}\nfor k, v in jogos.items(): # Mostra os dados de cada jogador\n print(f' O {k} tirou {v}')\n sleep(0.5)\n\nprint('Ranking dos Jogadores:')\n'''jogadores = list() # Lista de controle\nfor i in range(0, 4): # Organiza os jogadores dos que tem o maior dado até o menor\n maior = 0\n kmaior = ''\n for k, v in jogos.items(): # Percorre o dicionário com os jogadores\n if k not in jogadores: # Se o jogador não tiver sido reordenado, estive fora da lista de controle\n if v > maior: # Verifica se o dado dele é o maior\n maior = v\n kmaior = k\n del jogos[kmaior] # Deleta o jogador que foi tiver o maior dado e não estiver na lista de controle\n jogos[kmaior] = maior # Adiciona o jogador, que foi tinha o maior dado nesse loop, no final do dicionário\n jogadores.append(kmaior) # Adiciona a chave do jogador a lista de controle'''\n\njogo = sorted(jogos.items(), key=itemgetter(1), reverse=True) # Organiza o dicionário\n# assim como o trecho comentado acima\nfor i, v in enumerate(jogo): # Mostra os jogadores em ranking\n print(f' {i+1}° lugar: {v[0]} tirou {v[1]}')\n sleep(0.5)\n"
},
{
"alpha_fraction": 0.5561694502830505,
"alphanum_fraction": 0.5948434472084045,
"avg_line_length": 30.941177368164062,
"blob_id": "fca1220cd6dcaf0e8dcdbcc7a2b0f0534cf132ba",
"content_id": "bbd3513c3377eec5c269f5f6871bfa2148ebc78c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 547,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 17,
"path": "/PythonExercicios/ex063.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('-'*30 + '\\nSequência de Fibonacci\\n' + '-'*30)\n\nn1 = index = 0 # Primeiro valor da Sequência e o index dos valores\nn2 = 1 # Segundo valor da Sequência\ntermos = int(input('Quantos termos você quer mostrar? '))\n\nprint('~'*30)\nwhile index < termos:\n index += 1\n if index % 2 != 0:\n print(n1, end=' -> ')\n n1 += n2 # O primeiro valor recebe a soma dele com o segundo valor\n else:\n print(n2, end=' -> ')\n n2 += n1 # O segundo valor recebe a soma dele com o primeiro valor\nprint('Fim!')\nprint('~'*30)\n"
},
{
"alpha_fraction": 0.6288659572601318,
"alphanum_fraction": 0.7044673562049866,
"avg_line_length": 71.75,
"blob_id": "b23fa30be67bea2e71d2da6302f0f94a82435a87",
"content_id": "567dbc07c3380e8fcecc5f460a5f637ccab44a4a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 294,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 4,
"path": "/PythonExercicios/ex011.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "lar = float(input('Qual a largura da parede, em metros? '))\nalt = float(input('Qual a altura da parede, em metros? '))\n# Pede ao usuário que digite as medida da parede\nprint(f'Sua parede tem \\033[31;1m{lar*alt:.1f}m²\\033[m e você precisa de \\033[36;1m{lar*alt/2:.1f}\\033[m Litros de tinta')\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.720588207244873,
"avg_line_length": 16,
"blob_id": "27a82e418e9019eb732009f1c45559461af24654",
"content_id": "1f7a912d8b38dcd3ac961a5891ce8be1bbb0bc89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 69,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 4,
"path": "/PythonTest/Aula08B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "import random\nprint(random.randint(1, 1000))\n\n# Exercícios: 16 - 21\n"
},
{
"alpha_fraction": 0.5156794190406799,
"alphanum_fraction": 0.6376306414604187,
"avg_line_length": 56.400001525878906,
"blob_id": "ac76f9e5fbab0f2058323dcbad3174cdf01f9af8",
"content_id": "201736ecc79fc2707b9babb43fd1b28224fd9e5b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 289,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 5,
"path": "/PythonExercicios/ex029.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "vel = int(input('Qual a velocidade atual do carro em Km/h? '))\nif vel > 80:\n print(f'Você \\033[31;1mexcedeu\\033[m o limite de \\033[32;1m80Km/h\\033[m '\n f'e foi multado, o valor da multa é \\033[1;35mR${(vel - 80) * 7:.2f}\\033[m')\nprint('Tenha um bom dia! Dirija com cuidado')\n"
},
{
"alpha_fraction": 0.4647519588470459,
"alphanum_fraction": 0.5161009430885315,
"avg_line_length": 26.35714340209961,
"blob_id": "26003dcb8710fb2cd71ea1918f6749d884c37b0f",
"content_id": "4a6088dd508df5477d7e80bed2f3942fb82383fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1150,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 42,
"path": "/PythonExercicios/Uteis/__init__.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def linha(tam=20):\n \"\"\"\n -> Cria uma linha\n :param tam: (opcional) Determina o tamanho da linha\n :return: Sem retorno\n \"\"\"\n print('-'*tam)\n\n\ndef mensagem(txt, tam=20):\n \"\"\"\n -> Cria uma mensagem com duas linhas\n :param txt: Mensagem a ser escrita\n :param tam: Tamanho da linha\n :return: Sem retorno\n \"\"\"\n linha(tam)\n print(txt.center(tam))\n linha(tam)\n\n\ndef cores(cor, msg, quebra=False):\n \"\"\"\n -> Cria uma mensagem colorida\n :param cor: Determina a cor da mensagem\n :param msg: Mensagem a ser escrita\n :param quebra: Determina se ela criará uma quebra no final da linha\n :return: Sem retorno\n \"\"\"\n colors = ['\\033[30;1m', # 0 - Branco\n '\\033[31;1m', # 1 - Vermelho\n '\\033[32;1m', # 2 - Verde\n '\\033[33;1m', # 3 - Amarelo\n '\\033[34;1m', # 4 - Azul\n '\\033[35;1m', # 5 - Magenta\n '\\033[36;1m', # 6 - Cinza\n '\\033[m' # 7 - limpar\n ]\n if not quebra:\n print(f'{colors[cor]}{msg}{colors[7]}')\n else:\n print(f'{colors[cor]}{msg}{colors[7]}', end='')\n"
},
{
"alpha_fraction": 0.5091575384140015,
"alphanum_fraction": 0.6410256624221802,
"avg_line_length": 53.599998474121094,
"blob_id": "d87425a5fd0911f79257506367b648eed80cbebf",
"content_id": "292eec752d4f7eae72bffb60fc474398a81e0f93",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 5,
"path": "/PythonExercicios/ex018.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from math import tan, cos, sin, radians\nn = int(input('Digite um ângulo: '))\nrad = radians(n)\nprint(f'O seno de \\033[37;1m{n}\\033[m vale \\033[31;1m{sin(rad):.2f}\\033[m \\nO cosseno vale'\n f' \\033[33;1m{cos(rad):.2f}\\033[m \\nE a tangente vale \\033[32;1m{tan(rad):.2f}')\n"
},
{
"alpha_fraction": 0.5120910406112671,
"alphanum_fraction": 0.5248933434486389,
"avg_line_length": 26.038461685180664,
"blob_id": "251feca2ce41bb499a55ec6050085bf1194aaf13",
"content_id": "d3567e20f40b1364ee4b52f42161bf400d18747a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 709,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 26,
"path": "/PythonExercicios/ex102.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def fatorial(num, show=False):\n \"\"\"\n -> O fatorial calcula o fatorial de um número\n :param num: O número a ser calculado o fatorial\n :param show: (opcional) Mostra ou não a conta\n :return: O valor do Fatorial de um número n\n \"\"\"\n from time import sleep\n fat = 1\n print('-'*30)\n if show:\n print('Os cálculos são: ', end='')\n\n for c in range(num, 0, -1):\n fat *= c # Calcula o fatorial\n if show: # Caso show seja True, mostra o calculo do fatorial\n print(c, end='')\n sleep(0.5)\n if c != 1:\n print(end=' x ')\n else:\n print(end=' = ')\n return fat\n\n\nprint(fatorial(5, True))\n"
},
{
"alpha_fraction": 0.623481810092926,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 40.16666793823242,
"blob_id": "d4ed58962937f5a93ddffa7842fd21992ef2a064",
"content_id": "9c22a3bf26e0719497d641767dbfb801f9a8af0e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 6,
"path": "/PythonExercicios/ex016.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# from math import trunc\n# n = float(input('Digite um número decimal: '))\n# print(f'A parte inteira desse número é \\033[32;1m{trunc(n)}\\033[m')\n\nnum = float(input('Digite um valor: '))\nprint(f'A parte inteira desse número é \\033[32;1m{int(num)}')\n"
},
{
"alpha_fraction": 0.5009191036224365,
"alphanum_fraction": 0.5477941036224365,
"avg_line_length": 40.846153259277344,
"blob_id": "aafac0ee02149e986b2e68f50dfa37282ee8e2fe",
"content_id": "bd18f8f68c0239ed2b14ab915c91e48b87870ca0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1112,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 26,
"path": "/PythonExercicios/ex044.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print(f'{\" Lojas Lojas \":=^40}')\npre = float(input('Digite o valor do produto: R$ '))\ncon = int(input('1 - À vista em Dinheiro/Cheque '\n '\\n2 - À vista no Cartão '\n '\\n3 - em até 2x no Cartão '\n '\\n4 - 3x ou mais no Cartão'\n '\\nSelecione a condição de pagamento: '))\nif con == 1 or con == 2 or con == 3 or con == 4:\n if con == 1:\n pre = pre * 0.9\n forma = 'À vista em Dinheiro/Cheque'\n elif con == 2:\n pre = pre * 0.95\n forma = 'À vista no Cartão'\n elif con == 3:\n print(f'Você irá pagar em 2x de R$ {(pre/2):.2f} SEM JUROS')\n forma = 'em até 2x no Cartão'\n elif con == 4:\n pre = pre * 1.2\n parc = int(input('Quantas parcelas? '))\n print(f'Você irá pagar em {parc}x de R$ {(pre/parc):.2f} COM JUROS')\n forma = '3x ou mais no Cartão'\n # noinspection PyUnboundLocalVariable\n print(f'Você escolheu \\033[35;1m{forma}\\033[m e o total à ser pago é \\033[36;1mR${pre:.2f}')\nelse:\n print('\\033[31;1mOpção inválida de pagamento. Tente Novamente')\n"
},
{
"alpha_fraction": 0.6264367699623108,
"alphanum_fraction": 0.6465517282485962,
"avg_line_length": 52.53845977783203,
"blob_id": "a2fa13f6219f7f7ae678d02bf47afaffe05d5a9f",
"content_id": "fcd218136cb2d6d4fd80214b8dc744fd932e7fad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 702,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 13,
"path": "/PythonExercicios/ex085.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nums = [[], []] # Lista com duas listas internas\nfor i in range(1, 8):\n num = int(input(f'Digite o {i}° número: '))\n if num % 2 == 0: # Caso num for par\n nums[0].append(num) # Adiciona o valor de 'num' dentro da primeira lista de 'nums'\n else: # Caso num for ímpar\n nums[1].append(num) # Adiciona o valor de 'num' dentro da segunda lista de 'nums'\n\nnums[0].sort() # Organiza os valores da lista par\nnums[1].sort() # Organiza os valores da lista ímpar\nprint('-='*30)\nprint(f'Os valores pares digitados foram: {nums[0]}') # Mostra os valores da lista par (nums[0])\nprint(f'Os valores ímpares digitados foram: {nums[1]}') # Mostra os valores da lista ímpar (nums[1])\n"
},
{
"alpha_fraction": 0.5306603908538818,
"alphanum_fraction": 0.6462264060974121,
"avg_line_length": 46.11111068725586,
"blob_id": "ddbf7d4e46f079a44faae92bada5eaee09090d03",
"content_id": "c52c57eea8c2f040322b40a67c2d5da4b6627922",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 426,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 9,
"path": "/PythonExercicios/ex020.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import shuffle\nn1 = input('Digite o Nome do Primeiro aluno: ')\nn2 = input('Digite o Nome do Segundo aluno: ')\nn3 = input('Digite o Nome do Terceiro aluno: ')\nn4 = input('Digite o Nome do Quarto aluno: ')\nal = [n1, n2, n3, n4]\nshuffle(al)\nprint(f'A ordem dos alunos é \\033[7;30;1m {al[0]} \\033[m, \\033[37;1m{al[1]}\\033[m, \\033[1;34m{al[2]}\\033[m, \\033[1;46m {al[3]} \\033[m')\n# print(f'A ordem dos alunos é {al}')\n"
},
{
"alpha_fraction": 0.6957672238349915,
"alphanum_fraction": 0.6957672238349915,
"avg_line_length": 33.3636360168457,
"blob_id": "c1eb8e1d351119e93ecc20a53965fa7425e86e0f",
"content_id": "14df307bb2e7be0208ab6d5418c97b6fb54f7055",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 775,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 22,
"path": "/PythonTest/Aula23B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "try: # Será tentado executar esse bloco de código\n a = int(input('Numerador: '))\n b = int(input('Denominador: '))\n r = a/b\n\n# except Exception as erro: # Caso ocorra um erro será executado esse bloco\n# print(f'Problema encontrado: {erro.__class__}')\n\nexcept (ValueError, TypeError): # Exceção\n print('Tivemos um problema com os tipos de dados que você digitou.')\n\nexcept ZeroDivisionError: # Exceção\n print('Não é possível dividir um número por zero!')\n\nexcept KeyboardInterrupt:\n print('O usuário preferiu não informar os dados!')\n\nelse: # Caso não ocorra um erro será executado esse bloco\n print(f'O resultado é {r}')\n\nfinally: # No final será esse bloco, mesmo que tenha ocorrido um erro ou não\n print('Volte Sempre!!')\n"
},
{
"alpha_fraction": 0.7118644118309021,
"alphanum_fraction": 0.7175140976905823,
"avg_line_length": 31.18181800842285,
"blob_id": "78506485b7e5ed26a7c12c7eb19d538c5978033f",
"content_id": "73bf73aad172a4a4b1a1cf3b2c820a610fbc705f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 11,
"path": "/PythonExercicios/ex114.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from Uteis import cores\nimport urllib.request\n\ntry: # Tenta acessar o site pudim\n site = urllib.request.urlopen('http://pudim.com.br')\n\nexcept (urllib.error.URLError, ValueError): # Caso não consiga mostra essa mensagem\n cores(1, 'Não foi possível acessar o Pudim!')\n\nelse: # Se não mostra essa\n cores(3, 'O Pudim foi acessado com sucesso!')\n"
},
{
"alpha_fraction": 0.459276020526886,
"alphanum_fraction": 0.5723981857299805,
"avg_line_length": 26.625,
"blob_id": "eeb0a115ab009e32a9cd769fe2d7b93fec7e5330",
"content_id": "7bcfbf144e37087295b896224b03c75fc978a812",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 448,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 16,
"path": "/PythonTest/Aula11A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('\\033[1;32mOlá, Mundo!\\033[m')\n\na = 3\nb = 5\nprint(f'Os valores são \\033[32m{a}\\033[m e \\033[31m{b}\\033[m!!!')\n\ncores = {'limpa': '\\033[m',\n 'verde': '\\033[32m',\n 'amarelo': '\\033[34m',\n 'pretoebranco': '\\033[7;30m',\n 'negrito': '\\033[1m'}\n\nnome = 'Oliver'\nprint(f'Olá! Muito prazer em te conhecer, {cores[\"verde\"]}{nome}{cores[\"limpa\"]}!!!')\n\n# Exercícios: Colocar cores em todos os exercícios até agora\n"
},
{
"alpha_fraction": 0.6645161509513855,
"alphanum_fraction": 0.7075268626213074,
"avg_line_length": 65.42857360839844,
"blob_id": "afa9abe2397f38a76a3e5b9aa5d51e423b2d42d2",
"content_id": "1b9d64b855783f6346990ee29cc7b63e44fbeab2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 7,
"path": "/PythonExercicios/ex057.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "sexo = input('Digite o seu sexo [M/F]: ').upper().strip()[0]\n# Pede ao usuário o sexo, remove os espaços no início e no final da frase,\n# torna todas letras maiúsculas e pega a primeira letra\n\nwhile sexo not in 'MF': # Caso o usuário não digite M ou F ele pede para que ele introduza um valor válido.\n sexo = input('\\033[31;1mDados inválidos.\\033[m Por favor, informe seu sexo: ').upper().strip()[0]\nprint(f'Sexo \\033[32;1m{sexo}\\033[m registrado com sucesso')\n"
},
{
"alpha_fraction": 0.5535851716995239,
"alphanum_fraction": 0.5790285468101501,
"avg_line_length": 36.05714416503906,
"blob_id": "fe635abde63b131cc66310aa3cb82a2ddd452b82",
"content_id": "8178112f9944e581b590e1af546fedcbf463f483",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1305,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 35,
"path": "/PythonExercicios/ex069.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "cont_man = cont_maior = cont_woman = idade = 0\n\nwhile True:\n print('-'*30 + f'\\n{\"CADASTRE UM PESSOA\":^30}\\n' + '-'*30)\n\n idade = int(input('Digite a idade da pessoa: '))\n\n sexo = ''\n while sexo == '': # Enquanto sexo = '' repete o loop\n # Não tão eficiente, seguir exemplo do ex070\n sexo = input('Digite o sexo da pessoa: ').upper().strip()[0]\n if sexo not in 'FfMm': # Se sexo não tiver F, f, M ou m\n sexo = ''\n\n print('='*20)\n while True: # Enquanto seguir = '' repete o loop\n # Não tão eficiente, seguir exemplo do ex070\n seguir = input('Continuar? [S/N] ').strip()[0]\n if seguir in 'SsNn': # Se seguir diferente de S e N\n break\n print('='*20)\n\n if idade > 17: # Se a pessoa for de maior\n cont_maior += 1 # cont_maior recebe mais 1\n if sexo == 'M': # Se a pessoa for um homem\n cont_man += 1 # cont_man recebe mais 1\n if sexo == 'F' and idade < 20: # Se a pessoa for uma mulher e tiver menos que 20 anos\n cont_woman += 1 # cont_woman recebe mais 1\n\n if seguir in 'nN': # Se seguir igual n ou N, encerra o laço\n break\n\nprint(f'''{cont_maior} pessoas são maiores de idade.\n{cont_man} homens foram cadastrados.\n{cont_woman} mulheres são menores de 20 anos.''')\n"
},
{
"alpha_fraction": 0.44594594836235046,
"alphanum_fraction": 0.48262548446655273,
"avg_line_length": 17.5,
"blob_id": "73e7d7fe5b878f7270148a442b51123ec1dff861",
"content_id": "07bbd73973743b42d7b8aaf56248579b1931bbfb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 28,
"path": "/PythonTest/Aula14A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = 1\npar = impar = 0\nwhile n != 0:\n n = int(input('Digite um valor: '))\n if n != 0:\n if n % 2 == 0:\n par += 1\n else:\n impar += 1\nprint(f'Você digitou {par} números pares e {impar} números ímpares')\n\n'''r = 'S'\nwhile r == 'S':\n c = int(input('Digite um valor: '))\n r = input('Deseja continuar? [S/N] ').upper()\nprint('Fim')'''\n\n'''c = 0\nwhile c < 10:\n print(c)\n c += 1\nprint('Fim')'''\n\n'''for c in range(1, 10):\n print(c)\nprint('Fim')'''\n\n# Exercícios: 57 - 65\n"
},
{
"alpha_fraction": 0.6285714507102966,
"alphanum_fraction": 0.644444465637207,
"avg_line_length": 31.586206436157227,
"blob_id": "2c1c3609a95cfae2fe4fb30f8a99c975e930bf5c",
"content_id": "74abb34b1886179a0d874c4db8094e7c6c8064e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 970,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 29,
"path": "/PythonTest/Aula21A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def teste(b, ba=0):\n \"\"\"\n Recebe dois valores númericos e mostra seu valores dentro do escopo local,\n mostra como mudar o valor de uma variável global dentro da função, sem\n criar uma variável local\n :param b: Parâmetro númerico\n :param ba: Parâmetro númerico e opcional\n :return: retorna 'soma' que é a soma de todos as variáveis dentro da função\n \"\"\"\n global a # Garante que a variável 'a' abaixo seja a variável 'a' global\n a = 8 # 'a' é uma variável de escopo local, quando a linha acima não é escrita\n b += 4\n c = 2\n soma = a + b + c + ba\n print(f'A dentro vale {a}')\n print(f'B dentro vale {b}')\n print(f'BA dentro vale {ba}') # Parâmetro opcional\n print(f'C dentro vale {c}')\n return soma # Retorna a variável 'soma'\n\n\na = 5 # 'a' é uma variável de escopo global\nr1 = teste(a)\nprint('='*30)\nprint(f'A fora vale {a}')\n\nprint(f'\\nA soma dos valores é {r1}')\n\n# Exercício 101 - 106\n"
},
{
"alpha_fraction": 0.5261121988296509,
"alphanum_fraction": 0.5705996155738831,
"avg_line_length": 31.3125,
"blob_id": "2b3ba4f1038bc921e1a970d73b624e59e478a118",
"content_id": "b457d42c409c33737e2c4fe9a8b7bc849d58d491",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 16,
"path": "/PythonExercicios/ex055.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "maior = 0\nmenor = 0\n\nfor i in range(1, 6): # Verifica qual o peso mais pesada e qual o mais leve, em um grupo de 5 pesos\n peso = float(input(f'Digite o {i}° peso: '))\n if i == 1: # Se for a primeira vez no loop, o menor e o maior recebem o mesmo peso\n menor = peso\n maior = peso\n else:\n if peso > maior:\n maior = peso\n if peso < menor:\n menor = peso\n\nprint(f'O maior peso é \\033[7;1m{maior}kg\\033[m '\n f'\\nE o menor peso é \\033[47;1m{menor}kg\\033[m')\n"
},
{
"alpha_fraction": 0.48159509897232056,
"alphanum_fraction": 0.592024564743042,
"avg_line_length": 39.75,
"blob_id": "77370cbaea0af6dc504400d86d20cd2eb4bedcd4",
"content_id": "422e711ef6da898fc4cb269468a7b8ce7b68a8e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 8,
"path": "/PythonExercicios/ex050.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "s = 0\nc = 0\nfor i in range(1, 7): # Pede para o usuário digitar seis números inteiros e soma aqueles que forem par\n n = int(input(f'Digite o {i}° valor: '))\n if n % 2 == 0:\n s += n\n c += 1\nprint(f'\\n\\033[7;1mVocê digitou \\033[43;1m{c}\\033[m\\033[7;1m números pares e a soma deles é \\033[46;7;1m{s}\\033[m')\n"
},
{
"alpha_fraction": 0.4390243887901306,
"alphanum_fraction": 0.6402438879013062,
"avg_line_length": 81,
"blob_id": "836e5ec516845e318edf8c056f12a9899d03e598",
"content_id": "7d072207c773f35737d723d7e1bbaa979f22a73b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 2,
"path": "/PythonExercicios/ex014.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "c = float(input('Digite a temperatura em Celsius: '))\nprint(f'A temperatura \\033[34;1m{c}°C\\033[m vale \\033[31;1m{c * 1.8 + 32}°F\\033[m e \\033[32;1m{c + 273.15}K')\n"
},
{
"alpha_fraction": 0.49399399757385254,
"alphanum_fraction": 0.5840840935707092,
"avg_line_length": 43.400001525878906,
"blob_id": "399cc86ed5abe0bf332b996eafbd258834d08d87",
"content_id": "ba08f93c9a7b6afef2fb4310b70406fccfc4c971",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 673,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 15,
"path": "/PythonExercicios/ex037.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "num = int(input('Digite um número inteiro: '))\nchoose = int(input('Qual a base de conversão?'\n '\\n[1] para binário'\n '\\n[2] para octal'\n '\\n[3] para hexadecimal '\n '\\nDigite sua opção: '))\nif choose == 1:\n print(f'\\033[37;1m{num}\\033[m convertido para binário vale \\033[31;1m{num:b}')\nelif choose == 2:\n print(f'\\033[37;1m{num}\\033[m convertido para octal vale \\033[32;1m{num:o}')\nelif choose == 3:\n hexa = f'{num:x}'\n print(f'\\033[37;1m{num}\\033[m convertido hexadecimal vale \\033[33;1m{hexa.upper()}')\nelse:\n print('Digite um número\\033[36;1m correspondente\\033[m a uma base')\n"
},
{
"alpha_fraction": 0.5320512652397156,
"alphanum_fraction": 0.6217948794364929,
"avg_line_length": 30.200000762939453,
"blob_id": "0ceaa76f1b2a24c9abfddfadb26943f15a102c59",
"content_id": "df6bfc0a9f875951eda3b06b81b324d66c34bb1d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 5,
"path": "/PythonExercicios/ex030.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "num = int(input('Digite um número inteiro: '))\nif num % 2 == 0:\n print('Esse número é \\033[32;1mPar.')\nelse:\n print('Esse número é \\033[31;1mÍmpar.')\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.6552795171737671,
"avg_line_length": 31.200000762939453,
"blob_id": "52ae7a63b660f770421a25fecbfe50c9adcbd65b",
"content_id": "3a6489be0193d1b3e6af65bab9d46b80c3cfef01",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 324,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 10,
"path": "/PythonExercicios/ex097.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def escreva(msg): # Escreva a frase com uma borda personalizado pelo tamanho da frase\n tam = len(msg) + 4\n print('~'*(tam))\n print(f' {msg}')\n print('~'*(tam))\n\n\nescreva('Matheus Farias') # Chama a função 'escreva' que escreve a frase de uma forma personalizada\nescreva('Curso de Python no Youtube')\nescreva('CEV')\n"
},
{
"alpha_fraction": 0.5554537177085876,
"alphanum_fraction": 0.5875343680381775,
"avg_line_length": 29.30555534362793,
"blob_id": "0e828e32b8698c675a7e341d9d44a03896095900",
"content_id": "90626e09cc78c2e3a0f42c1faad331ab2e5a8aa6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1110,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 36,
"path": "/PythonExercicios/ex098.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from time import sleep\n\n\ndef contador(i, f, p):\n if p == 0: # Caso usuário digite 0 para o passo, ele é substituído por 1\n p = 1\n\n if p > 0 and f < i or p < 0 and f > i:\n # Caso o passo for negativo/[positivo] e o fim maior/[menor] que o começo, o seu sinal é invertido\n p *= -1\n\n print('-=' * 30)\n print(f'Contagem de {i} até {f} de {p} em {p}:')\n sleep(1.5)\n\n if f > i: # Se o fim for maior que o início, ele recebe mais um para que ele possa ser contado\n f += 1\n else: # Se o fim for menor que o início, ele recebe menos um para que ele possa ser contado\n f -= 1\n\n for i in range(i, f, p): # Mostra os números\n print(i, end=' ')\n sleep(0.5)\n print('FIM!')\n\n\ncontador(1, 10, 1) # Chama a função 'contador' que irá contar de 1 até 10 de 1 em 1\n\ncontador(10, 0, 2) # Chama a função 'contador' que irá contar de 10 até 0 de 2 em 2\n\nprint('-='*30)\nprint('Agora é sua vez de personalizar a contagem!')\nini = int(input('Início: '))\nfim = int(input('Fim: '))\npas = int(input('Passo: '))\ncontador(ini, fim, pas)\n"
},
{
"alpha_fraction": 0.6121112704277039,
"alphanum_fraction": 0.6366612315177917,
"avg_line_length": 26.772727966308594,
"blob_id": "ef43be0fc31edaec5595cae00df1722e78ea2489",
"content_id": "23eb6f1396e700b035ae4003904c613d958699b8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 618,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 22,
"path": "/PythonTest/Aula17B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "valores = list() # Cria uma lista vazia\n# valores = [] # Também cria uma lista vazia\nvalores.append(5)\nvalores.append(9)\nvalores.append(4)\n\nfor cont in range(0, 5):\n valores.append(int(input('Digite um número: '))) # Adiciona os valores digitados pelo usuário a lista\n\nfor i, v in enumerate(valores):\n print(f'na posição {i} encontrei o valor {v}...')\nprint('Cheguei ao final da lista')\n\na = [2, 3, 4, 7]\nb = a # Linka a lista 'a' a lista 'b'\nc = a[:] # Cria uma copia da lista 'a', que é a lista 'c'\nb[2] = 8\nprint(f'Lista A: {a}')\nprint(f'Lista B: {b}')\nprint(f'Lista C: {c}')\n\n# Exercício 78 - 83\n"
},
{
"alpha_fraction": 0.5993788838386536,
"alphanum_fraction": 0.6273291707038879,
"avg_line_length": 17.941177368164062,
"blob_id": "6811e99a6ae63a827fb24a530db6158f95ca4d3a",
"content_id": "16094485285c1ceea8806b01dcd2c6b213c9cc19",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 17,
"path": "/PythonTest/Aula20A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def lin(): # Uma função, facilmente discenível pelo início 'def'\n print('-'*30)\n\n\ndef msg(mensagem): # Cria uma mensagem personalizada\n lin() # Chama a função 'lin'\n print(f'{mensagem:^30}')\n lin()\n\n\nmsg('Curso em Vídeo') # Chama a função 'msg'\n\nmsg('Aprenda Python')\n\nmsg('Matheus Farias')\n\n# Exercícios 96 - 100\n"
},
{
"alpha_fraction": 0.6286290287971497,
"alphanum_fraction": 0.6419354677200317,
"avg_line_length": 32.06666564941406,
"blob_id": "22033e5406e3e438543c01f53420f477e137165a",
"content_id": "eb49fde6938c669ded58c4cba8a4ede16247fc96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2504,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 75,
"path": "/PythonExercicios/ex111/UtilidadeCeV/Moeda/__init__.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def aumentar(n=0, porc=0, form=False):\n \"\"\"\n -> Calcula o aumento de um valor, utilizando porcentagem pré-determinada\n :param n: (opcional) Número a ser aumentado\n :param porc: (opcional) Porcentagem a ser utilizada\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna 'n' mais 'porc' porcento, ex: 10 + 20%\n \"\"\"\n num = n * (1 + porc/100)\n return num if not form else moeda(num)\n\n\ndef diminuir(n=0, porc=0, form=False):\n \"\"\"\n -> Retorna um valor com um desconto pré-determinado\n :param n: (opcional) Números a receber o desconto\n :param porc: (opcional) Porcentagem a se descontada\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna o valor 'n' com o desconto\n \"\"\"\n num = n * (1 - porc/100)\n return num if not form else moeda(num)\n\n\ndef dobro(n=0, form=False):\n \"\"\"\n -> Retorna o dobro do valor inserido\n :param n: (opcional) Número a ter seu valor dobrado\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna o dobro de 'n'\n \"\"\"\n num = n*2\n return num if not form else moeda(num)\n\n\ndef metade(n=0, form=False):\n \"\"\"\n -> Retorna metade do valor inserido\n :param n: (opcional) Número a ser dividido\n :param form: (opcional) Caso verdadeiro formata o valor, utilizando a função moeda\n :return: Retorna metade de 'n'\n \"\"\"\n num = n/2\n return num if not form else moeda(num)\n\n\ndef moeda(n, moeda='R$'):\n \"\"\"\n -> Formata os valores monetários\n :param n: Valor a ser formatado\n :param moeda: (opcional) Moeda a ser utilizada na formatação\n :return: Valor 'n' formatado\n \"\"\"\n return f'{moeda}{n:.2f}'\n\n\ndef resumo(n=0, porc_aum=10, porc_des=5):\n \"\"\"\n -> Mostra um resumo do preço inserido\n :param n: (opcional) Preço a ser utilizado\n :param porc_aum: (opcional) Porcentagem do aumento\n :param porc_des: (opcional) Porcentagem do desconto\n :return: Sem retorno\n \"\"\"\n print('-'*30)\n print('RESUMO DO VALOR'.center(30)) # Centraliza o texto\n print('-'*30)\n\n print(f'Preço analisado: \\t{moeda(n)}') # '\\t' Cria uma tabulação\n print(f'Dobro do preço: \\t{dobro(n, True)}')\n print(f'Metade do preço: \\t{metade(n, True)}')\n print(f'{porc_aum}% de aumento: \\t{aumentar(n, porc_aum, True)}')\n print(f'{porc_des}% de desconto: \\t{diminuir(n, porc_des, True)}')\n\n print('-'*30)\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6226415038108826,
"avg_line_length": 28.44444465637207,
"blob_id": "1fe9fb67d05ad84142196bcc376ba263d8a10662",
"content_id": "c35790130885a937645090da605eecfc4b8924ce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 18,
"path": "/PythonTest/Aula10A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# nome = input('Qual seu nome? ')\n# if 'Oliver' in nome:\n# print('Que nome lindo você tem!')\n# else:\n# print('Seu nome é tão normal')\n# print(f'Bom dia, {nome}!')\n\nn1 = float(input('Digite a primeira nota: '))\nn2 = float(input('Digite a segunda nota: '))\nm = (n1 + n2) / 2\nprint(f'Sua média é {m:.1f}')\nprint('Parabéns, você foi Aprovado!' if m >= 6 else 'Você foi Reprovado! Se esforce mais')\n# if m < 6:\n# print('Você reprovou, se esforce mais')\n# else:\n# print('Parabéns, você foi aprovado')\n\n# Exercícios: 28 - 35\n"
},
{
"alpha_fraction": 0.5796178579330444,
"alphanum_fraction": 0.5987260937690735,
"avg_line_length": 26.705883026123047,
"blob_id": "ecb778f6f9ace1a88d2e163765f5c6cf90dbb094",
"content_id": "f485866fccb77a8cac84931030efaba838659d00",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 480,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 17,
"path": "/PythonExercicios/ex104.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def leia_int(txt):\n \"\"\"\n -> Verifica se o valor digitado é numérico\n :param txt: mensagem a ser mostrado para o usuário\n :return: retorna o valor digitado pelo o usuário, caso seja um número\n \"\"\"\n while True:\n num = input(txt)\n if num.isnumeric():\n break\n else:\n print('\\033[31;1mERRO! Digite um número.\\033[m')\n return num\n\n\nn = leia_int('Digite um número: ')\nprint(f'Você acabou de digitar o número {n}')\n"
},
{
"alpha_fraction": 0.6270270347595215,
"alphanum_fraction": 0.6756756901741028,
"avg_line_length": 36,
"blob_id": "51236b4ee5c1636308ee17c20b7b3ba343816ff6",
"content_id": "29bcf764abc8ee6b04a6f85c2bbd8a6261d8c060",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 5,
"path": "/PythonExercicios/ex001.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "msg = '\\033[32;1mOlá, Mundo!'\n# Cria a variável 'msg' com o valor \"Olá, mundo\" do\n# tipo string na cor da fonte verde (32) e em negrito (1)\nprint(msg)\n# Escreva o valor da variável msg na tela\n"
},
{
"alpha_fraction": 0.6677740812301636,
"alphanum_fraction": 0.6976743936538696,
"avg_line_length": 42,
"blob_id": "1736c3b8f75872d1255ed74a80a2fb8ab22ba5e1",
"content_id": "4851b4d8624e38f99217d21c051bebf2e9737e65",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 7,
"path": "/PythonExercicios/ex017.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# from math import sqrt, pow\nfrom math import hypot\nco = float(input('Digite o comprimento do cateto oposto: '))\nca = float(input('Digite o comprimento do cateto adjascente: '))\n# hip = sqrt(pow(co, 2) + pow (ca, 2))\nhip = hypot(co, ca)\nprint(f'A hipotenusa desse triângulo vale \\033[35;1m{hip:.2f}')\n"
},
{
"alpha_fraction": 0.6322931051254272,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 32.5,
"blob_id": "8111dbfc0894e55d64a1a549c3029089d09b7ad9",
"content_id": "b7a1e707dd0039edd150e2717f9f66bdffa3e57e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 749,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 22,
"path": "/PythonExercicios/ex103.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def ficha(nome='<desconhecido>', gols=0):\n \"\"\"\n -> Mostra o nome do(a) jogador(a) e seus gols\n :param nome: nome do(a) jogador(a) (padrão <desconhecido>)\n :param gols: quantidade de gols (padrão 0)\n :return: sem retorno\n \"\"\"\n print(f'O(A) jogador(a) {nome} fez {gols} gol(s) no campeonato.')\n\n\njog = input('Nome do(a) jogador(a): ').strip()\ngol = input('Número de Gols: ')\n\nif gol.isnumeric(): # Caso gol for númerico, é convertido em inteiro\n gol = int(gol)\nelse: # Caso não recebe o valor\n gol = 0\n\nif jog != '': # Caso o nome do jogador tiver sido preenchido, ele é informado na chamada\n ficha(jog, gol)\nelif jog == '': # Caso não ele não é informado e é utilizado o valor padrão\n ficha(gols=gol)\n"
},
{
"alpha_fraction": 0.5888252258300781,
"alphanum_fraction": 0.6160458326339722,
"avg_line_length": 37.77777862548828,
"blob_id": "1547d001dbffeaf5eb645201557c7fc242c6e763",
"content_id": "f633cf7ee0fbbb8539af9683d5b05619dc97be74",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 704,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 18,
"path": "/PythonExercicios/ex074.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\nnums = randint(0, 10), randint(0, 10), randint(0, 10), randint(0, 10), randint(0, 10)\n# tupla com 5 números aleatórios\n\n# maior = menor = 0\nprint(f'Os números sorteador foram:', end=' ')\nfor pos, num in enumerate(nums): # Mostra os 5 elementos da tupla 'nums'\n print(num, end=' ')\n '''if pos == 0:\n maior = menor = num\n else:\n if num > maior:\n maior = num\n elif num < menor:\n menor = num'''\nprint(f'\\nO maior valor foi {max(nums)}') # Mostra o maior elemento dentro da tupla\nprint(f'O menor valor foi {min(nums)}') # Mostra o menor elemento dentro da tupla\n# print(f'\\nO maior número é {maior} e o menor é {menor}')\n"
},
{
"alpha_fraction": 0.5699481964111328,
"alphanum_fraction": 0.6580311059951782,
"avg_line_length": 63.33333206176758,
"blob_id": "5eef8e1fb06f6f904ddc135c7864c81492d5a279",
"content_id": "58c5052a4ecca4b3f3c04137e96bbddb9103af62",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 3,
"path": "/PythonExercicios/ex027.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nome = input('Digite seu nome completo: ').split()\nprint(f'Muito prazer em te conhecer!\\nSeu primeiro nome é \\033[1;32m{nome[0]}\\033[m'\n f'\\nE o último é \\033[1;32m{nome[len(nome) - 1]}')\n"
},
{
"alpha_fraction": 0.5381165742874146,
"alphanum_fraction": 0.591928243637085,
"avg_line_length": 36.16666793823242,
"blob_id": "53aefa86a847f850f5eebf429690305901701871",
"content_id": "f78c17d48e4d7a1da2d0abf0b67312ea3c3397b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 6,
"path": "/PythonTest/Aula06A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n1 = int(input('Digite o primeiro valor: '))\nn2 = int(input('Digite o segundo valor: '))\n# print('A Soma entre', n1, 'e', str(n2) + ', vale', n1 + n2)\nprint(f'A Soma entre {n1} e {n2}, vale {n1 + n2}')\n\n# Exercícios: 3 e 4\n"
},
{
"alpha_fraction": 0.6130653023719788,
"alphanum_fraction": 0.6984924674034119,
"avg_line_length": 65.33333587646484,
"blob_id": "b856573bf6582683cb2c95b03847ce923d6251e2",
"content_id": "129c75dcfa3549f8eebd6507ae1d6a4b1ca4a3f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 205,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 3,
"path": "/PythonExercicios/ex005.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = int(input('Digite um número: '))\nprint(f'O Sucessor desse número é \\033[37;1m{n + 1}\\033[m e o Antecessor é \\033[33;1m{n - 1}')\n# Mostra o sucessor e o antecessor do número digitado pelo usuário\n"
},
{
"alpha_fraction": 0.4892857074737549,
"alphanum_fraction": 0.5428571701049805,
"avg_line_length": 17.66666603088379,
"blob_id": "8a64708a5a1ea64ac82fea6ecad3b855ca54c6e6",
"content_id": "d51ef5b9fbd7c1a873e38561b79118dbaf5e5f4a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 15,
"path": "/PythonTest/Aula15A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "soma = 0\nwhile True:\n n = int(input('Digite um número [999 para parar]: '))\n if n == 999:\n break\n soma += n\nprint(f'A soma desses números é {soma}')\n\n'''cont = 1\nwhile cont <= 10:\n print(cont, end=' -> ')\n cont += 1\nprint('Acabou')'''\n\n# Exercícios: 66 - 71\n"
},
{
"alpha_fraction": 0.48757171630859375,
"alphanum_fraction": 0.6042065024375916,
"avg_line_length": 26.526315689086914,
"blob_id": "8573d90bc39be1279f7553b62aa60bcc20b1c17f",
"content_id": "af81cbb08ae007fce5311e6a0102154cc1ad03f7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 19,
"path": "/PythonExercicios/ex033.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n1 = float(input('Digite o primeiro número: '))\nn2 = float(input('Digite o segundo número: '))\nn3 = float(input('Digite o terceiro número: '))\n# nl = [n1, n2, n3]\n# print(f'O maior número é \\033[1;32m{max(nl)}\\033[m \\nE o menor é \\033[31;1m{min(nl)}\\033[m')\n\nmaior = n2\nif n1 > n2 and n1 > n3:\n maior = n1\nif n3 > n2 and n3 > n1:\n maior = n3\n\nmenor = n1\nif n2 < n1 and n2 < n3:\n menor = n2\nif n3 < n1 and n3 < n2:\n menor = n3\n\nprint(f'O maior número é \\033[32;1m{maior}\\033[m \\nE o menor é \\033[31;1m{menor}')\n"
},
{
"alpha_fraction": 0.5732899308204651,
"alphanum_fraction": 0.5993485450744629,
"avg_line_length": 26.909090042114258,
"blob_id": "235e17062326323116b8a643666cb376c0202e4a",
"content_id": "92e7b33f9179bf5ede5f007676f22b603db04e14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 11,
"path": "/PythonExercicios/ex061.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('Gerador de PA\\n' + '-='*7)\n\na1 = int(input('Primeiro termo: '))\nr = int(input('Razão da PA: '))\ncont = 1 # Index dos termos\n\nwhile cont != 10:\n print(a1, end=' -> ') # Mostra o termo atual\n a1 += r # Adiciona a razão ao termo atual que se torna o próximo termo\n cont += 1\nprint('Acabou')\n"
},
{
"alpha_fraction": 0.5826771855354309,
"alphanum_fraction": 0.6692913174629211,
"avg_line_length": 62.5,
"blob_id": "071ecbed95eb6b306b35e5107d6206ba1bd282d5",
"content_id": "7e65821ac048ab95d4fa9b04d9dbc2b45dae03f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 2,
"path": "/PythonExercicios/ex012.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "des = float(input('Qual o preço do produto? R$'))\nprint(f'O preço do produto com desconto de 5% é \\033[1;37mR${des*0.95:.2f}')\n"
},
{
"alpha_fraction": 0.6135770082473755,
"alphanum_fraction": 0.6788511872291565,
"avg_line_length": 30.91666603088379,
"blob_id": "7488a9a1feee4498dcee305a7ecc24a2649be1d1",
"content_id": "4a02c7d33266f2188ba14f8988c67b98b9ba8fdd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 12,
"path": "/PythonExercicios/ex049.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = int(input('Digite um número inteiro: '))\n# Pede para que o usuário digite um número e armazena na variável\n\nprint('\\033[34;1m-' * 12)\n# Cria um traçado e deixa todos os caracteres a partir do traçado em magenta\n\nfor i in range(0, 11):\n print(f' {i} x {n} = \\033[1;36m{n * i}\\033[34;1m')\n# Mostra a tabuada do número digitado pelo usuário\n\nprint('-' * 12)\n# Cria outro traçado\n"
},
{
"alpha_fraction": 0.6739659309387207,
"alphanum_fraction": 0.7372262477874756,
"avg_line_length": 57.71428680419922,
"blob_id": "4d64dba25b1aa904f54673c83d62e7da7a467741",
"content_id": "c1f00ae8a41ba67650621c05e0e209398b64bdf4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 7,
"path": "/PythonExercicios/ex008.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "mt = float(input('Digite uma distância em Metros: '))\n# Pedi que o usuário digite uma distância em metros e armazena na variável\n\nprint(f'Essa distância convertida vale \\033[36;1m\\n{mt/1000}km \\n{mt/100}hm \\n{mt/10}dam \\n{mt*10}dm '\n f'\\n{mt*100}cm \\n{mt*1000}mm')\n# Mostra essa distância convertida para kilometros, hectometros, decâmetros, decimetros, centímetros e milimetros\n# medidas em turquesa (36)\n"
},
{
"alpha_fraction": 0.57485032081604,
"alphanum_fraction": 0.598802387714386,
"avg_line_length": 29.925926208496094,
"blob_id": "8320a51974e4643171a6f290b5540a04649e1e90",
"content_id": "15ee3a9261d0c4ac5d3c5d18c7050ee3e3cc80d8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 841,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 27,
"path": "/PythonExercicios/ex088.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom time import sleep\n\nprint('-'*40)\nprint(f'{\"Jogue na Mega Sena\":^40}')\nprint('-'*40)\n\n# noinspection SpellCheckingInspection\nquant = int(input('Quantos jogos você quer que eu sorteie? '))\nprint('-='*6 + f' Sorteando {quant} jogos ' + '-='*6)\n\nsorteio = []\njogo = []\nfor index in range (0, quant): # Faz um loop com a quantidade de jogos que o usuário deseja\n for i in range(0, 6): # Faz um loop para gerar 6 números aleatórios que não se repetem\n while True:\n num = randint(0, 60)\n if num not in jogo:\n jogo.append(num)\n break\n jogo.sort() # Organiza os números\n\n sleep(0.5)\n sorteio.append(jogo[:])\n print(f'Jogo {index+1}: {sorteio[index]}') # Mostra os palpites\n jogo.clear()\nprint('-='*7 + ' < Boa sorte! > ' + '-='*7)\n"
},
{
"alpha_fraction": 0.6001608967781067,
"alphanum_fraction": 0.6178600192070007,
"avg_line_length": 26.021739959716797,
"blob_id": "0b5d6f0138a1a4ce434a2ca3ca1b33f363e8536f",
"content_id": "ad57c893baa0dfe052b4973e8f2b89605e2a66ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 46,
"path": "/PythonExercicios/ex108/Moeda.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def aumentar(n=0, porc=0):\n \"\"\"\n -> Calcula o aumento de um valor, utilizando porcentagem pré-determinada\n :param n: (opcional) Número a ser aumentado\n :param porc: (opcional) Porcentagem a ser utilizada\n :return: (opcional) Retorna 'n' mais 'porc' porcento, ex: 10 + 20%\n \"\"\"\n return n * (1 + porc/100)\n\n\ndef diminuir(n=0, porc=0):\n \"\"\"\n -> Retorna um valor com um desconto pré-determinado\n :param n: (opcional) Números a receber o desconto\n :param porc: (opcional) Porcentagem a se descontada\n :return: Retorna o valor 'n' com o desconto\n \"\"\"\n return n * (1 - porc/100)\n\n\ndef dobro(n=0):\n \"\"\"\n -> Retorna o dobro do valor inserido\n :param n: (opcional) Número a ter seu valor dobrado\n :return: Retorna o dobro de 'n'\n \"\"\"\n return n*2\n\n\ndef metade(n=0):\n \"\"\"\n -> Retorna metade do valor inserido\n :param n: (opcional) Número a ser dividido\n :return: Retorna metade de 'n'\n \"\"\"\n return n/2\n\n\ndef moeda(n=0, moeda='R$'):\n \"\"\"\n -> Formata os valores monetários\n :param n: (opcional) Valor a ser formatado\n :param moeda: (opcional) Moeda a ser utilizado na formatação\n :return: Valor 'n' formatado\n \"\"\"\n return f'{moeda}{n:.2f}'.replace('.', ',')\n"
},
{
"alpha_fraction": 0.605597972869873,
"alphanum_fraction": 0.6310432553291321,
"avg_line_length": 31.75,
"blob_id": "92b40d711500f0f62e50c25d54e3261da60581b2",
"content_id": "5a5c815c5aa714161cf2755a6932351d9c31206a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 401,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 12,
"path": "/PythonExercicios/ex096.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def area(la, c): # Função 'area': responsável por calcular a area de objetos baseado em sua largura e comprimento\n a = la * c\n print(f'A área do seu terreno de {la:.1f}m X {c:.1f}m é de {a:.1f}m²')\n\n\nprint('-'*40)\nprint(f'{\"Controle de Terrenos\":^40}')\nprint('-'*40)\n\nlar = float(input('Largura (m): '))\ncomp = float(input('Comprimento (m): '))\narea(lar, comp) # Chama a função 'area'\n"
},
{
"alpha_fraction": 0.7024539709091187,
"alphanum_fraction": 0.745398759841919,
"avg_line_length": 53.33333206176758,
"blob_id": "bca594571592c103b51755d76cfb5f18fa602e4f",
"content_id": "382cbc8464867a1acb985a51fb15e892b34b951e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 6,
"path": "/PythonExercicios/ex002.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nome = input('\\033[30;1mDigite seu nome: ')\n# A variável nome recebe o valor digitado pelo usuário em resposta ao pedido escrito dentro de input \"Digite seu nome\"\n# 0 Branco\nprint(f'É um prazer te conhecer, \\033[36;1m{nome}!')\n# Escreve um texto na tela com a nova sintaxe 'f' para referenciação da variável nome\n# 6 turquesa\n"
},
{
"alpha_fraction": 0.6101694703102112,
"alphanum_fraction": 0.700564980506897,
"avg_line_length": 58,
"blob_id": "7a109a0e0df2d42fe6a99b532771429e6bbc74a6",
"content_id": "a71793f05b73284b583bc9b32fdabcc813fa8742",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 363,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 6,
"path": "/PythonExercicios/ex003.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n1 = int(input('Digite um número: '))\n# pede que o usuário digite um número\nn2 = int(input('Digite outro número: '))\nprint(f'A Soma Entre \\033[31;1m{n1}\\033[m e \\033[32;1m{n2}\\033[m, Vale \\033[36;1m{n1 + n2}')\n# Mostra o resultado da soma dos dois números inseridos pelo usuário\n# utiliza a nova sintaxe com 'f' e {} para refenciação da variável n1 e n2\n"
},
{
"alpha_fraction": 0.5828947424888611,
"alphanum_fraction": 0.5960526466369629,
"avg_line_length": 32.043479919433594,
"blob_id": "c2d836d48dc4dea64f044e5325ca7d738e844813",
"content_id": "f290906452c7ddacd286a6bcf8c5d66141ea7604",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 775,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 23,
"path": "/PythonExercicios/ex081.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# cont = 0\nval = list()\nwhile True:\n val.append(int(input('Digite um número: ')))\n # cont += 1\n while True: # Caso o usuário não digite S ou N, é feita novamente a pergunta\n resp = input('Deseja continuar? [S/N]: ').strip().upper()[0]\n if resp in 'SN':\n break\n if resp == 'N':\n break\n\nprint('-='*20)\nprint(f'Você digitou {len(val)} números')\nif 5 in val: # Caso o 5 tenha sido digitado, mostra as posições\n print('O número 5 foi digitado nas posições:', end=' ')\n for i, v in enumerate(val):\n if v == 5:\n print(i, end='...')\nelse:\n print('O número 5 não foi digitado.')\nval.sort(reverse=True) # Reordena os número em ordem decrescente\nprint(f'\\nOs números em ordem decrescente: {val}')\n"
},
{
"alpha_fraction": 0.5582635402679443,
"alphanum_fraction": 0.5635948181152344,
"avg_line_length": 31.825000762939453,
"blob_id": "89dedd087379f738ed8c113f39d2af6a3e3e9912",
"content_id": "b9ffae20341908312891b661e486a95c4d124222",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1324,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 40,
"path": "/PythonExercicios/ex094.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "pessoas = list()\nsoma = 0\nwhile True:\n pes = {'Nome': input('Nome: ')} # Dicionário com os dados da pessoas\n while True:\n pes['Sexo'] = input('Sexo [F/M]: ').strip().upper()[0]\n if pes['Sexo'] in 'FM':\n break\n print('ERRO! Responda \"F\" ou \"M\"')\n pes['Idade'] = int(input('Idade: '))\n\n soma += pes['Idade'] # Soma da idade que será usada para a média\n pessoas.append(pes.copy()) # lista pessoas recebe uma cópia do dicionário pes\n\n while True:\n resp = input('Deseja continuar? [N/S]: ').strip().upper()[0]\n if resp in 'NS':\n break\n print('ERRO! Responda \"N\" ou \"S\"')\n if resp in 'N':\n break\n\nmedia = soma / len(pessoas)\nprint('-='*30)\nprint(f'- Foram cadastradas {len(pessoas)} pessoas')\nprint(f'- A média das idades é {media:5.2f}')\n\nprint('- As mulheres cadastradas foram: ', end='')\nfor pes in pessoas: # Mostra o nome das mulheres\n if pes['Sexo'] == 'F':\n print(pes['Nome'], end=' ')\n\nprint('\\n- Lista das pessoas que estão acima da média de idade:\\n')\nfor pes in pessoas: # Mostra as pessoa que são mais velhas que a média\n for k, v in pes.items():\n if pes['Idade'] > media:\n print(f'{k} = {v};', end=' ')\n if pes['Idade'] > media:\n print('\\n')\nprint('<<< Encerrado >>>')\n"
},
{
"alpha_fraction": 0.6746987700462341,
"alphanum_fraction": 0.6891566514968872,
"avg_line_length": 82,
"blob_id": "635788f468d571e344950f07f5453b654c7ce1c9",
"content_id": "e8868397f0c817d4334b1cf4429fdf930a7780c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 850,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 10,
"path": "/PythonExercicios/ex073.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "campeonato = 'Bragantino', 'Bahia', 'Ceará', 'Fortaleza', 'Athletico-PR', 'Flamengo', 'Atlético-GO', 'Cuiabá',\\\n 'Sport', 'Juventude', 'Internacional', 'São Paulo', 'Fluminense', 'Grêmio', 'Atlético-MG', 'América-MG',\\\n 'Palmeiras', 'Corinthians', 'Chapecoense', 'Santos'\n\nprint(f'Lista de times: {campeonato}\\n' + '-='*20) # Mostra os elementos da tupla\nprint(f'Os cinco primeiros são {campeonato[:5]}\\n' + '-='*20) # Mostra os cinco primeiros elementos da tupla\nprint(f'Os quatro últimos são {campeonato[-4:]}\\n' + '-='*20) # Mostra os últimos 4 elementos da tupla\nprint(f'Os times em ordem alfabética: {sorted(campeonato)}\\n' + '-='*20) # Mostra os elementos em ordem alfabética\nprint(f'O Chapecoense está na {campeonato.index(\"Chapecoense\") + 1}° posição da tabela do Brasileirão')\n# Mostra a posição da Chapecoense\n"
},
{
"alpha_fraction": 0.5958333611488342,
"alphanum_fraction": 0.6013888716697693,
"avg_line_length": 35,
"blob_id": "e897258b4e8e8607746edc4ea22d6d7c56a518e9",
"content_id": "000c5121572ed0c0cf8e8702e7de6b16d542b91a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 740,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 20,
"path": "/PythonExercicios/ex065.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "resp = 'S'\nnum = soma = cont = menor = maior = 0\n\nwhile resp in 'Ss':\n num = int(input('Digite um valor: '))\n soma += num # Soma todos os números digitados\n cont += 1 # Conta quantos número foram digitados\n\n if cont > 1: # Se não for o primeiro número, então verifica se é o maior ou menor número até agora\n if num > maior:\n maior = num\n elif num < menor:\n menor = num\n else: # Se for o primeiro número, então ele é o maior e o menor número\n maior = menor = num\n\n resp = (input('Deseja continuar? [S/N] ')).strip()[0]\n\nprint(f'Você digitou {cont} números e a média desses números é {soma / cont},'\n f'\\no maior número é {maior} e o menor é {menor}')\n"
},
{
"alpha_fraction": 0.6057047247886658,
"alphanum_fraction": 0.6350671052932739,
"avg_line_length": 34.05882263183594,
"blob_id": "44e5260d05b057285454d9f7adb9cf4e50643856",
"content_id": "b0ac0063e01997b32416d44a83abbd4b4c1d8c51",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1199,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 34,
"path": "/PythonExercicios/ex070.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "produto_barato = '' # Nome do produto mais barato\nvalor_barato = 0 # Valor do produto mais barato\ntotal = 0 # Total da compra\ncont_custo = 0 # Quantos produtos custam mais de 1000\nindex = 0 # index dos produtos\n\nprint('-'*30)\nprint(f'{\"SUPERMERCADO MAIS\":^30}')\nprint('-'*30)\nwhile True:\n nome = input('Qual o nome do produto? ')\n preco = float(input('Qual o valor? R$'))\n\n continuar = ' '\n while continuar not in 'SN': # Enquanto continuar não for S ou N, pede ao usuário que digite novamente\n continuar = input('Deseja continuar? [S/N] ').upper().split()[0]\n print('-'*30)\n\n index += 1\n if index == 1 or preco < valor_barato: # Se o index = 1 ou se o valor é menor que o menor valor anterior\n produto_barato = nome\n valor_barato = preco\n\n if preco > 1000: # Se o valor maior que 1000, cont_custo recebe mais um\n cont_custo += 1\n\n total += preco\n\n if continuar == 'N': # Se continuar = N então encerra o laço\n break\n\nprint(f'Você gastou R${total:.2f}.\\n'\n f'Você comprou {cont_custo} produtos que custavam mais que R$1000.\\n'\n f'E o produto mais barato foi {produto_barato} que custa R${valor_barato:.2f}')\n"
},
{
"alpha_fraction": 0.6234939694404602,
"alphanum_fraction": 0.6280120611190796,
"avg_line_length": 33.94736862182617,
"blob_id": "b7029ee95891d11ce7f9a4b976849be2ab6e3411",
"content_id": "7f131bd42237362975754b1cc0ceeb37e8f64b71",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 19,
"path": "/PythonExercicios/ex079.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "val = list()\nwhile True:\n inserir = int(input('Digite um valor: '))\n if inserir in val: # Caso o valor digitado já tenha sido inserido ele não será inserido novamente\n print('Esse valor já foi inserido.')\n else:\n print('Valor adicionado com sucesso.')\n val.append(inserir)\n\n while True: # Caso o usuário não digite S ou N, será perguntado novamente\n resp = input('Deseja continuar? [S/N] ').strip().upper()[0]\n if resp in 'SN':\n break\n if resp in 'N':\n break\n\nval.sort() # Organiza os elementos em ordem crescente\nprint('-='*20)\nprint(f'Você digitou os valores: {val}') # Mostra os elementos\n"
},
{
"alpha_fraction": 0.6148648858070374,
"alphanum_fraction": 0.625,
"avg_line_length": 37.60869598388672,
"blob_id": "30dd0e947db15118abb13d78e4e36452c21d4ca3",
"content_id": "b904e78ac1f3dd4ef9c8aba3ac25f692d0494e58",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 890,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 23,
"path": "/PythonExercicios/ex093.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "jogador = {'Nome': input('Nome do jogador: '),\n 'Gols': list(),\n 'Total': 0}\npartidas = int(input(f'Quantas partidas o(a) jogador(a) {jogador[\"Nome\"]} jogou? '))\n\nprint('Quantos gols ele fez na...')\nfor c in range(0, partidas): # Recebe a quantidade de gols para cada partida\n jogador['Gols'].append(int(input(f'{c+1}° partida: ')))\n # jogador['Total'] += jogador['Gols'][c]\njogador['Total'] = sum(jogador['Gols']) # Faz a soma de todos os gols do campeonato\n\nprint('-='*30)\nprint(jogador)\nprint('-='*30)\n\nfor k, v in jogador.items(): # Mostra os dados no dicionário\n print(f'O campo {k} tem o valor {v}')\nprint('-='*30)\n\nprint(f'O jogador {jogador[\"Nome\"]} jogou {partidas} partidas')\nfor p, g in enumerate(jogador['Gols']): # Mostra os gols para cada partida\n print(f' => Na partida {p}, fez {g} gols')\nprint(f'Foi um total de {jogador[\"Total\"]}')\n"
},
{
"alpha_fraction": 0.6754385828971863,
"alphanum_fraction": 0.6783625483512878,
"avg_line_length": 25.30769157409668,
"blob_id": "6860e778aca2ad7741ecfe86c851f87af6b2b9f5",
"content_id": "8ca2c3d03955c96f4b94f97900591d85afab3764",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 357,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 13,
"path": "/PythonTest/Aula23A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('oi')\nprint(x) # não existe a variável 'x'\n# Exceção NameError\n\nn = int(input('Número: ')) # Não aceita tipo string\n# Exceção ValueError\nprint(f'Você digitou o número {n}')\n\na = int(input('Numerador: '))\nb = int(input('Denominador: '))\nr = a/b # Não é possível dividir por 0\n# Exceção ZeroDivisionError\nprint(f'O resultado foi {r}')\n"
},
{
"alpha_fraction": 0.5360824465751648,
"alphanum_fraction": 0.5738831758499146,
"avg_line_length": 47.5,
"blob_id": "900baae509134b1004d6e8e5cba9ee35e329026b",
"content_id": "4229b0d7dd99d9e66b251c9e65419e23a352cab7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 12,
"path": "/PythonExercicios/ex086.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "matriz = [[], [], []]\n# matriz = [[0, 0, 0], [0, 0, 0], [0, 0, 0]]\nfor lin in range(0, 3): # Representa as 3 linhas da matriz\n for col in range(0, 3): # Representa as 3 colunas da matriz\n matriz[lin].append(int(input(f'Digite um valor para [{lin}, {col}]: '))) # Adiciona os valor a matriz\n # matriz[lin][col] = int(input(f'Digite...\n\nprint('-='*30)\nfor lin in matriz: # for lin in range(0, 3): # Percorre as linhas da matriz\n for col in lin: # for col in range(0, 3): # Percorre as colunas de cada linha\n print(f'[{col:^5}]', end=' ')\n print()\n"
},
{
"alpha_fraction": 0.5672727227210999,
"alphanum_fraction": 0.6181818246841431,
"avg_line_length": 44.83333206176758,
"blob_id": "4f5b471744bfb36091cb79b5bc13f23e2862f45e",
"content_id": "f608163f9dd07a6194b0c6a197d2dbd713612e92",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 12,
"path": "/PythonTest/Aula07A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nome = input('Qual seu nome? ')\nprint('Prazer em te conhecer, {:20}!'.format(nome))\nprint('Prazer em te conhecer, {:_<20}!'.format(nome))\nprint('Prazer em te conhecer, {:->20}!'.format(nome))\nprint('{:^20}, {:^20}!'.format('Prazer em te conhecer', nome))\n\nn1 = int(input('Digite um número: '))\nn2 = int(input('Digite outro: '))\nprint(f'A soma vale {n1 + n2}, \\nO produto vale {n1 * n2} \\nE a divisão vale {n1 / n2:.3f}, ', end='')\nprint(f'A divisão inteira vale {n1 // n2}, o resto vale {n1 % n2} e a potência vale {n1 ** n2}')\n\n# Exercícios: 5 - 15\n"
},
{
"alpha_fraction": 0.5739514231681824,
"alphanum_fraction": 0.6534216403961182,
"avg_line_length": 44.29999923706055,
"blob_id": "4e2fd02e8801e06af9ca713c96a32389f1d3a516",
"content_id": "13a38b5baac4c6553680b9b42f332c5d363883f3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 10,
"path": "/PythonExercicios/ex054.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from datetime import date\nano_atual = date.today().year # Pega o ano atual do sistema\nmaior = 0\n\nfor i in range(1, 8): # Verifica quem é maior de idade(21 anos) e quem é menor, entre um conjunto de 7 pessoas\n n = int(input(f'Digite o ano de nascimento da {i}° pessoa: '))\n if ano_atual - n > 20:\n maior += 1\nprint(f'\\033[36;1m{maior}\\033[1m são maiores de idade \\033[30;1m'\n f'\\nE \\033[37;1m{7 - maior}\\033[1m são menores de idade')\n"
},
{
"alpha_fraction": 0.5839694738388062,
"alphanum_fraction": 0.6246819496154785,
"avg_line_length": 27.071428298950195,
"blob_id": "e684db28f290d80de9c6e162b47e6e47127b09aa",
"content_id": "eb10c1e56faa83018c15d8d04331071eb6bc524c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 791,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 28,
"path": "/PythonTest/Aula18A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "teste = list()\n\nteste.append('Matheus')\nteste.append(17)\ngalera = [teste[:]] # Cria uma copia de teste dentro de galera\nteste[0] = 'Oliver'\nteste[1] = 22\ngalera.append(teste) # Cria um vínculo entre teste e galera\nprint(galera)\n\npessoas = [['Harvey', 23], ['Madeleine', 19], ['Roger', 250], ['Mark', 20]]\nprint(pessoas[0][0]) # Mostra o primeiro valor da primeira lista desta lista\nfor p in pessoas:\n print(f'{p[0]} tem {p[1]} anos de idade.')\n\ndados = []\npes = []\nfor i in range(0, 3):\n print('-='*10)\n dados.append(input('Nome: '))\n dados.append(int(input('Idade: ')))\n pes.append(dados[:])\n dados.clear() # Excluí os valores dentro de dados\n\nfor p in pes:\n print(f'{p[0]} é maior de idade.' if p[1] > 20 else f'{p[0]} é menor de idade.')\n\n# Exercício 84 -89\n"
},
{
"alpha_fraction": 0.5631918907165527,
"alphanum_fraction": 0.6037822961807251,
"avg_line_length": 39.14814758300781,
"blob_id": "0309eb59818ded43628e2e56762570ddd4f5c1b5",
"content_id": "785ebb6ae2c4f68610a15f52907dac010f6f8d1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2199,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 54,
"path": "/PythonExercicios/ex071.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('='*30)\nprint(f'{\"Caixa Eletrônico\":^30}')\nprint('='*30)\n\nvalor = int(input('Informe o valor a ser sacado: R$'))\n# cin = vinte = dez = um = 0 # Variáveis que representam a quantidade de cada cédula\nced = 50\ntotced = 0\n\nwhile True:\n if valor >= ced: # Se o valor de saque atual for maior que o valor da cédula\n valor -= ced # O valor da cédula vai ser subtraido do valor de saque\n totced += 1 # E o total de cédulas desse valor vai receber mais um\n else: # Se o valor de saque for menor que o valor da cédula\n if totced > 0: # Cada o total de cédulas desse valor for maior que 0\n print(f'Total de {totced} cédulas de {ced}') # Será mostrado o total de cédulas\n\n if ced == 50: # Se o valor da cédula atual for 50\n ced = 20 # Ele vai receber o valor de 20\n elif ced == 20: # Se o valor da cédula atual for 20\n ced = 10 # Ele vai receber o valor de 10\n elif ced == 10: # Se o valor da cédula atual for 10\n ced = 1 # Ele vai receber o valor de 1\n\n totced = 0 # Reinicia a quantidades de cédulas\n if valor == 0: # Se o valor de saque zerar, o programa para\n break\n\n'''while True:\n if valor - 50 >= 0: # Verifica se é possível subtrair 50 do valor atual\n valor -= 50\n cin += 1 # Adicionar mais aos contador de cédulas de 50\n elif valor - 20 >= 0: # Verifica se é possível subtrair 20 do valor atual\n valor -= 20\n vinte += 1 # Adicionar mais aos contador de cédulas de 20\n elif valor - 10 >= 0: # Verifica se é possível subtrair 10 do valor atual\n valor -= 10\n dez += 1 # Adicionar mais aos contador de cédulas de 10\n elif valor - 1 >= 0: # Verifica se é possível subtrair 1 do valor atual\n valor -= 1\n um += 1 # Adicionar mais aos contador de cédulas de 1\n else:\n break\nif cin > 0:\n print(f'Total de {cin} cédulas de R$50.')\nif vinte > 0:\n print(f'Total de {vinte} cédulas de R$20')\nif dez > 0:\n print(f'Total de {dez} cédulas de R$10')\nif um > 0:\n print(f'Total de {um} cédulas de R$1')'''\n\nprint('='*30)\nprint(f'{\"Volte Sempre!\":^30}')\n"
},
{
"alpha_fraction": 0.6605263352394104,
"alphanum_fraction": 0.6894736886024475,
"avg_line_length": 53.28571319580078,
"blob_id": "cfef1595184f146541ed4fec870b6c17ea6dd67b",
"content_id": "24c9e883714a55f0bd73bba41d84d578e798156b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 7,
"path": "/PythonExercicios/ex108/Teste.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from ex108 import Moeda\n\np = float(input('Digite o preço: R$'))\nprint(f'A metade de {Moeda.moeda(p)} é {Moeda.moeda(Moeda.metade(p))}')\nprint(f'O dobro de {Moeda.moeda(p)} é {Moeda.moeda(Moeda.dobro(p))}')\nprint(f'Aumentando 10%, {Moeda.moeda(p)} valerá {Moeda.moeda(Moeda.aumentar(p, 10))}')\nprint(f'Diminuindo 13%, {Moeda.moeda(p)} valerá {Moeda.moeda(Moeda.diminuir(p, 13))}')\n"
},
{
"alpha_fraction": 0.608013927936554,
"alphanum_fraction": 0.6271777153015137,
"avg_line_length": 29.210525512695312,
"blob_id": "e8174ff1d3bf0ba76a46fd6a3718004f1c9c55ca",
"content_id": "f238b160847dfadd6f0891f457aa91e094870634",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 578,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 19,
"path": "/PythonTest/Aula19A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "pessoas = {'nome': 'Matheus',\n 'sexo': 'M',\n 'idade': '17'}\n\nprint(pessoas['sexo'])\nprint(f'O {pessoas[\"nome\"]} tem {pessoas[\"idade\"]} anos.')\nprint(pessoas.keys()) # Mostra as chaves (\"indexes\") do dicionário\nprint(pessoas.values()) # Mostra os valores do dicionário\nprint(pessoas.items()) # Mostra as chaves e os valores do dicionário\n\ndel pessoas['sexo'] # Deleta a chave 'sexo' e o seu valor\npessoas['nome'] = 'Oliver'\npessoas['idade'] = 25\npessoas['peso'] = 70.5\nprint()\nfor k, v in pessoas.items():\n print(f'{k} = {v}')\n\n# Exercício 90 - 95\n"
},
{
"alpha_fraction": 0.5928753018379211,
"alphanum_fraction": 0.6183205842971802,
"avg_line_length": 31.75,
"blob_id": "46ebcc0db54eea82178e65d3696812b46d0b357d",
"content_id": "d0acd6d2cc2b97ec85fb7048f5208a2fa403e32f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 397,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 12,
"path": "/PythonTest/Aula12A.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nome = input('Qual é seu nome? ').upper().strip()\nif nome == 'OLIVER':\n print('Que nome bonito!')\nelif nome == 'MATHEUS' or nome == 'LUCAS' or nome == 'EDUARDA':\n print('Seu nome é bem popular no Brasil')\nelif nome in 'MADELEINE OLIVIA MARY SAM PEARL':\n print('Que belo nome feminino!')\n# else:\n# print('Seu nome é bem normal!')\nprint(f'Tenha um bom dia, \\033[36;1m{nome}!')\n\n# Exercícios: 36 - 45\n"
},
{
"alpha_fraction": 0.5865070819854736,
"alphanum_fraction": 0.6332970857620239,
"avg_line_length": 38.956520080566406,
"blob_id": "2f0e32fce43ff98312d4a5a0959d86e12e95a01b",
"content_id": "37889843618676a1901292fab56e85e2a79110ef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 23,
"path": "/PythonExercicios/ex056.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "idade_older = 0\nnome_older = ''\nidade_F_menos = 0\nidade_soma = 0\n\nfor i in range(1, 5 ):\n # Lê dados de 5 pessoas e mostra a média de idades, o homem mais velho\n # e a quantidade de mulheres que tem menos de 20 anos\n print('-'*7, f'{i}° pessoa', '-'*7)\n nome = input('Nome: ')\n idade = int(input('Idade: '))\n genero = input('Gênero [M/F]: ')\n print('') # Cria um espaço entre cada pessoa\n if genero in 'Mm' and idade > idade_older: # Verifica quem é o homem mais velho\n idade_older = idade\n nome_older = nome\n if genero in 'Ff' and idade < 20: # Verifica quantas mulheres são menores de 20 anos\n idade_F_menos += 1\n idade_soma += idade\n\nprint(f'A média de idade é \\033[7;1m{idade_soma/i}\\033[m')\nprint(f'O homem mais velho é o \\033[37;1m{nome_older}\\033[m e ele tem {idade_older} anos')\nprint(f'Têm \\033[31;1m{idade_F_menos}\\033[m mulheres mais novas que 20 anos')\n"
},
{
"alpha_fraction": 0.5792349576950073,
"alphanum_fraction": 0.6106557250022888,
"avg_line_length": 24.241378784179688,
"blob_id": "bc0f5648d78eeebf6ff1eab7be4f6bb6b38e20f6",
"content_id": "643137f733a721e7319c646801a9ca54547f2cf2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 746,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 29,
"path": "/PythonExercicios/ex115/Sistema.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "import Funções as Func\nfrom Uteis import linha, mensagem, cores\nfrom time import sleep\n\nesc = 0\n\nwhile esc != 3:\n mensagem('Menu Principal', 40)\n menu = ['Ver pessoas cadastradas', 'Cadastrar novas pessoas', 'Sair do Sistema']\n Func.menu(menu)\n linha(40)\n\n # Caso o arquivo 'Dados' não exista, a função open() irá criar um arquivo novo\n\n try:\n esc = Func.leia_int('\\033[33;1mSua opção: \\033[m')\n except TypeError:\n cores(1, 'Erro! Digite um número inteiro válido')\n\n if esc == 1:\n Func.cadastrar()\n elif esc == 2:\n Func.dados()\n elif esc == 3:\n mensagem('Saindo do sistema... Até logo!', 40)\n else:\n cores(1, 'Erro! Digite uma opção válida.')\n\n sleep(1)\n"
},
{
"alpha_fraction": 0.6510066986083984,
"alphanum_fraction": 0.6644295454025269,
"avg_line_length": 17.625,
"blob_id": "036010e1965f7cc343da307792037ed9f79c0138",
"content_id": "d0ca07b46f91ea37f9eaaca275247f23a43df228",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 8,
"path": "/PythonTest/Aula06B.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "n = input('Digite um valor: ')\nprint(n.isnumeric())\nprint(n.isalpha())\nprint(n.isalnum())\nprint(n.isupper())\nprint(n.islower())\n\n# Exercícios: 3 e 4\n"
},
{
"alpha_fraction": 0.31260794401168823,
"alphanum_fraction": 0.5440414547920227,
"avg_line_length": 27.950000762939453,
"blob_id": "576aa35c3afb1f95a8d96bf2fc2bbce77740fb9c",
"content_id": "eb4a844be0ec239a048b033e2ea244c264a2bf8e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 580,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 20,
"path": "/PythonExercicios/ex023.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from math import trunc\nn = int(input('Digite um número entre 0 e 9999: '))\nm1 = trunc(n/1000)\nc2 = trunc(n/100)\nd2 = trunc(n/10)\nc1 = c2 - m1 * 10\nd1 = d2 - m1 * 100 - c1 * 10\nprint(f\"\"\"Unidade: \\033[1;31m{n - m1 * 1000 - c1 * 100 - d1 * 10}\\033[m\nDezena : \\033[32;1m{d1}\\033[m\nCentena: \\033[33;1m{c1}\\033[m\nMilhar : \\033[34;1m{m1}\\033[m\"\"\")\n\n# u = n % 10\n# d = n // 10 % 10\n# c = n // 100 % 10\n# m = n // 1000\n# print(f'Unidade: \\033[32;1m{u}\\033[m\\n'\n# f'Dezena : \\033[33;1m{d}\\033[m\\n'\n# f'Centena: \\033[344;1m{c}\\033[m\\n'\n# f'Milhar : \\033[31;1m{m}\\033[m')\n"
},
{
"alpha_fraction": 0.5408970713615417,
"alphanum_fraction": 0.5540897250175476,
"avg_line_length": 29.31999969482422,
"blob_id": "1b490b402475511c2fbb638cb55651ba4a37a7c8",
"content_id": "36dca2fd7403043b250cd508b9568c1c675331b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 25,
"path": "/PythonExercicios/ex105.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def notas(*num, sit=False):\n \"\"\"\n -> Função para analisar notas e situação de vários alunos\n :param num: uma ou mais notas dos alunos (aceita várias)\n :param sit: (opcional) indica se deve ou não mostrar a situação\n :return: dicionário com dados da turma.\n \"\"\"\n dados = {'Quantidades de notas': len(num),\n 'Maior nota': max(num),\n 'Menor nota': min(num),\n 'Média da Turma': sum(num) / len(num)}\n\n if sit:\n if dados['Média da Turma'] > 7:\n dados['Situação'] = 'Boa'\n elif dados['Média da Turma'] > 5:\n dados['Situação'] = 'Razoável'\n else:\n dados['Situação'] = 'Ruim'\n\n return dados\n\n\nresp = notas(3.5, 2, 6.5, 2, 7, 4, sit=True)\nprint(resp)\n"
},
{
"alpha_fraction": 0.5162094831466675,
"alphanum_fraction": 0.6458852887153625,
"avg_line_length": 43.55555725097656,
"blob_id": "25553f378fe09431c1ac434d2c0c7e2a6ddf6e7c",
"content_id": "071cab832ab8954542e5367eefef336650488577",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 9,
"path": "/PythonExercicios/ex040.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "nt1 = float(input('Digite a primeira nota: '))\nnt2 = float(input('Digite a segunda nota: '))\nm = (nt1 + nt2) / 2\nif m < 5:\n print(f'A média do aluno foi \\033[35;1m{m}\\033[m e ele foi\\033[31;1m Reprovado')\nelif m >= 7:\n print(f'A média do aluno foi \\033[35;1m{m}\\033[m e ele foi\\033[32;1m Aprovado')\nelse:\n print(f'A média do aluno foi \\033[35;1m{m}\\033[m e ele está de\\033[33;1m Recuperção')\n"
},
{
"alpha_fraction": 0.6096000075340271,
"alphanum_fraction": 0.635200023651123,
"avg_line_length": 27.409090042114258,
"blob_id": "6c843aed2a9e9e114566e009f6953a9f0c6aaaaf",
"content_id": "735a8645028d81037db255bf2ce73537aa7818ec",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 635,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 22,
"path": "/PythonExercicios/ex101.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "def votar(ano=2000):\n \"\"\"\n -> Verifica a situação de voto de acordo com o ano de nascimento da pessoa\n :param ano: ano de nascimento da pessoa, (padrão ano 2000)\n :return: Retorna a situação da pessoa\n \"\"\"\n from datetime import date\n\n idade = date.today().year - ano\n print(f'Com {idade} anos, sua situação se voto é ', end='')\n if idade < 16:\n return 'NEGADO!'\n elif 18 > idade or idade > 65:\n return 'OPCIONAL'\n else:\n return 'OBRIGATÓRIO!'\n\n\nprint('-'*30)\n# noinspection SpellCheckingInspection\nano_nasc = int(input('Em que ano você nasceu? '))\nprint(votar(ano_nasc))\n"
},
{
"alpha_fraction": 0.559852659702301,
"alphanum_fraction": 0.5948434472084045,
"avg_line_length": 21.625,
"blob_id": "af36c58cf52430319d905c2e4aba025f7f4a62cd",
"content_id": "1b3e1d7007f3637219b78425dce9c35638b9a901",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 546,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 24,
"path": "/PythonExercicios/ex099.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from time import sleep\n\n\ndef maior(*nums): # Verifica qual o maior valor dentre os valores passado no parâmetro 'nums'\n major = 0\n print('-='*30)\n print('Analisando os valores passados...')\n\n sleep(0.5)\n for num in nums:\n if num > major:\n major = num\n print(num, end=' ')\n sleep(0.5)\n\n print(f'foram informados {len(nums)} valores ao todo.')\n print(f'O maior valor informado foi {major}')\n\n\nmaior(2, 9, 4, 5, 7, 1) # Chama que a função 'maior'\nmaior(4, 7, 0)\nmaior(1, 2)\nmaior(6)\nmaior()\n"
},
{
"alpha_fraction": 0.5690235495567322,
"alphanum_fraction": 0.6632996797561646,
"avg_line_length": 73.25,
"blob_id": "639a2e6ab04841029643d3c6e9142527506aa8b7",
"content_id": "a504059145f14bb75dbe656364d772e88ef12e49",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 4,
"path": "/PythonExercicios/ex026.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "fr = input('Digite uma frase: ').strip().upper()\nprint(f'A letra \"A\" aparece \\033[1;7;33m{fr.count(\"A\")}\\033[m vezes nessa frase')\nprint(f'A primeira posição em que ela aparece é \\033[3m{fr.find(\"A\") + 1}\\033[m')\nprint(f'A última posição em que ela aparece é \\033[3;32m{fr.rfind(\"A\") + 1}\\033[m')\n"
},
{
"alpha_fraction": 0.4481012523174286,
"alphanum_fraction": 0.6050633192062378,
"avg_line_length": 42.88888931274414,
"blob_id": "886ae373cba87846a7c28071ac259127c386391e",
"content_id": "abb34d483fc475c4bf38a6b201d7b07da027876c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 406,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 9,
"path": "/PythonExercicios/ex048.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "s = 0\nc = 0\nfor i in range(1, 500, 2): # Conta de 1 até 500, verifica quais números são ímpares e multiplos de três e soma eles\n if i % 3 == 0:\n s += i\n c += 1\nprint(f'\\033[34;1mA soma dos números ímpares que são multiplos de três'\n f' e estão entre 1 e 500, é\\033[m \\033[41;7;1m{s}\\033[m\\033[34;1m, '\n f'e existem \\033[32;1m{c}\\033[34;1m deles entre 1 e 500\\033[m')\n"
},
{
"alpha_fraction": 0.6318914294242859,
"alphanum_fraction": 0.6352841258049011,
"avg_line_length": 31.75,
"blob_id": "3aea42156e7f9feee45c8a615acbcde2b541d2ae",
"content_id": "93bd0fe28add4e2b24f2f896ff8aef8d9473a8d1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1199,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 36,
"path": "/PythonExercicios/ex113.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from Uteis import cores\n\n\ndef leia_int(msg):\n \"\"\"\n -> Utiliza a função 'input' e verifica se o valor introduzido é Inteiro\n :param msg: Mensagem a ser mostrada ao usuário\n :return: Retorna o valor digitado pelo usuário, caso o valor seja Inteiro\n \"\"\"\n while True:\n try:\n return int(input(msg))\n except KeyboardInterrupt:\n cores(1, 'O usuário preferiu não informar esse número!')\n except ValueError:\n cores(1, 'Erro! por favor, digite um número inteiro válido.')\n\n\ndef leia_float(msg):\n \"\"\"\n -> Utiliza a função 'input' e verifica se o valor introduzido é Real\n :param msg: Mensagem a ser mostrada ao usuário\n :return: Retorna o valor digitado pelo usuário, caso o valor seja Real\n \"\"\"\n while True:\n try:\n return float(input(msg))\n except KeyboardInterrupt:\n cores(1, 'O usuário preferiu não informar esse número!')\n except ValueError:\n cores(1, 'Erro! por favor, digite um número real válido.')\n\n\nnint = leia_int('Digite um Inteiro: ')\nnfloat = leia_float('Digite um Real: ')\nprint(f'O valor inteiro foi {nint} e o real foi {nfloat}')\n"
},
{
"alpha_fraction": 0.5670731663703918,
"alphanum_fraction": 0.6463414430618286,
"avg_line_length": 53.66666793823242,
"blob_id": "bd25f575522622589c84cadb09e65dea6c416764",
"content_id": "2cc1942924c5d269fee13a6469b0cf5d5c2591cd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 3,
"path": "/PythonExercicios/ex015.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "dias = int(input('Quantos dias alugados? '))\nkilo = float(input('Quantos Km rodados? '))\nprint(f'O total a pager é de \\033[1;4;33mR${dias * 60 + kilo * 0.15:.2f}')\n"
},
{
"alpha_fraction": 0.546012282371521,
"alphanum_fraction": 0.6104294657707214,
"avg_line_length": 26.16666603088379,
"blob_id": "f13acf176fe783e02cccc05108322745f751f4be",
"content_id": "e26b638f088678b36d75a72d8f08340401900dd4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 12,
"path": "/PythonExercicios/ex051.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "print('='*30)\nprint(f'{\"10 TERMOS DE UMA PA\":^30}')\nprint('='*30)\n\na1 = int(input('Digite um número: '))\nr = int(input('Digite a razão da Progressão Aritmética: '))\n\n\nfor i in range(a1, a1 + 10 * r, r):\n # Calcula o décimo termo da PA e mostra os 10 primeros termos\n print(f'\\033[1;35m{i}', end=' -> ')\nprint('Acabou!')\n"
},
{
"alpha_fraction": 0.5406896471977234,
"alphanum_fraction": 0.5503448247909546,
"avg_line_length": 27.61842155456543,
"blob_id": "879ba532560a018f17c004cc330ce6a5c6b9a11b",
"content_id": "82d9b4d04277f541f15132840b032a3cf7b11f22",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2191,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 76,
"path": "/PythonExercicios/ex115/Funções.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "from Uteis import mensagem, cores\n\n\ndef cadastrar():\n \"\"\"\n -> Cadastra novas pessoa no 'banco de dados'\n :return: Sem retorno\n \"\"\"\n try:\n inserir = open('Dados.txt', 'a') # Abre o arquivo 'Dados' no modo de escrita\n except FileNotFoundError:\n cores(1, 'Erro ao tentar abrir o arquivo')\n else:\n mensagem('Novo Cadastro', 40)\n\n while True:\n try:\n nome = input('Digite o nome: ').strip()\n except ValueError:\n cores(1, 'Digite um valor válido.')\n else:\n break\n\n while True:\n try:\n idade = leia_int('Digite a idade: ')\n except ValueError:\n cores(1, 'Erro! Digite um valor válido.')\n else:\n break\n\n inserir.write(f'{nome};{idade}\\n')\n print(f'Novo registro de {nome} adicionado.')\n\n\ndef dados():\n \"\"\"\n -> Mostra os dados armazenados no 'banco de dados'\n :return: Sem retorno\n \"\"\"\n try:\n ler = open('Dados.txt', 'r') # Abre o arquivo 'Dados' no modo leitura\n except FileNotFoundError:\n cores(1, 'Erro ao tentar ler o arquivo')\n else:\n mensagem('Pessoas Cadastradas', 40)\n\n for linha in ler:\n valores = linha.split(';')\n valores[1] = valores[1].replace('\\n', '')\n print(f'{valores[0]:<29}{valores[1]:<3} anos')\n\n\ndef menu(lista):\n \"\"\"\n -> Cria um menu com uma lista de opções\n :param lista: Lista de opções\n :return: Sem retorno\n \"\"\"\n for item in range(0, len(lista)):\n cores(3, item+1, True), print(' - ', end=''), cores(4, lista[item])\n\n\ndef leia_int(msg):\n \"\"\"\n -> Utiliza a função 'input' e verifica se o valor introduzido é Inteiro\n :param msg: Mensagem a ser mostrada ao usuário\n :return: Retorna o valor digitado pelo usuário, caso o valor seja Inteiro\n \"\"\"\n while True:\n try:\n return int(input(msg))\n except KeyboardInterrupt:\n cores(1, 'O usuário preferiu não informar esse número!')\n except ValueError:\n cores(1, 'Erro! por favor, digite um número inteiro válido.')\n"
},
{
"alpha_fraction": 0.6927536129951477,
"alphanum_fraction": 0.7159420251846313,
"avg_line_length": 30.363636016845703,
"blob_id": "f211d000aad387f827f67a0b6c2619d4faa10bba",
"content_id": "76b5c856d5b6c48afb87d4cf3dd04c7797a1b39d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 11,
"path": "/PythonTest/Aula22/Numeros.py",
"repo_name": "MatthewsTomts/Python_Class",
"src_encoding": "UTF-8",
"text": "# import Funcoes\nfrom Aula22.Uteis.Numeros.__init__ import fatorial, dobro\n# Não recomendado, pois caso seja importado vários módulos pode haver conflitos com os nomes\n# Pacotes = Bibliotecas\n\nn = int(input('Digite um número: '))\nfat = fatorial(n)\nprint(f'O fatorial de {n} é {fat}')\nprint(f'O dobro de {n} é {dobro(n)}')\n\n# Exercícios 107 -112\n"
}
] | 144 |
kartikeyarai7/Display-Picture-Makers
|
https://github.com/kartikeyarai7/Display-Picture-Makers
|
54cd4e826577a1f80ae1cc1bc0c8e6b477d896a2
|
8f333ab46f7409609bcb6ed49dd1e53ac5bbfd38
|
9e83d873e9ea2743667222fe9474ebdad98eac6d
|
refs/heads/master
| 2022-12-07T03:38:01.207973 | 2020-08-11T12:32:35 | 2020-08-11T12:32:35 | 286,734,013 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 83,
"blob_id": "78b616a9b09ea3a80d0f88586e26916d3c35f104",
"content_id": "d268dd145a7eafd5a4424986d7ff2d696a11bef8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 2,
"path": "/README.md",
"repo_name": "kartikeyarai7/Display-Picture-Makers",
"src_encoding": "UTF-8",
"text": "# Display-Picture-Makers\nUsing Python Imaging Library to create display pictures for Instagram, Facebook and Whatsapp. Black and white filter added for beautification!\n"
},
{
"alpha_fraction": 0.5843247175216675,
"alphanum_fraction": 0.6011196374893188,
"avg_line_length": 38.599998474121094,
"blob_id": "296365f38a6556e35435254271a0840352ee16f0",
"content_id": "94758106eef0dcc2202283f4bc3af4c22d44b277",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1429,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 35,
"path": "/dpmaker.py",
"repo_name": "kartikeyarai7/Display-Picture-Makers",
"src_encoding": "UTF-8",
"text": "from PIL import Image, ImageFilter\r\n\r\nuser = input('Where do you want to use this picture \\n 1. Whatsapp 2.Instagram 3.Facebook \\n Enter the option number: ')\r\n\r\ndef img_converter(user):\r\n if user == \"1\":\r\n img = Image.open(\"./meee.jpg\") #INSERT YOUR IMAGE IN THE SAME DIRECTORY AND SAVE IT AS meee.jpg\r\n img.thumbnail((192,192)) #Thumbnail keeps the aspect ratio\r\n bws_dp = img.convert(\"L\")\r\n # beautified_dp = bws_dp.filter(ImageFilter.SMOOTH) IF YOU WANT TO SMOOTHEN IT, UNCOMMENT THIS\r\n # bws_dp.save(\"Wsdpbw.png\",\"png\") IF YOU WANT TO SAVE UNCOMMENT THIS\r\n # print(beautified_dp)\r\n bws_dp.show()\r\n\r\n\r\n if user == \"2\":\r\n img = Image.open(\"./meee.jpg\")\r\n img.thumbnail((110,110))\r\n bws_dp = img.convert(\"L\")\r\n # beautified_dp = bws_dp.filter(ImageFilter.SMOOTH) IF YOU WANT TO SMOOTHEN IT, UNCOMMENT THIS\r\n # bws_dp.save(\"Wsdpbw.png\",\"png\") IF YOU WANT TO SAVE UNCOMMENT THIS\r\n # print(beautified_dp)\r\n bws_dp.show()\r\n\r\n\r\n if user == \"3\":\r\n img = Image.open(\"./meee.jpg\")\r\n img.thumbnail((170,170))\r\n bws_dp = img.convert(\"L\")\r\n # beautified_dp = bws_dp.filter(ImageFilter.SMOOTH) IF YOU WANT TO SMOOTHEN IT, UNCOMMENT THIS\r\n # bws_dp.save(\"Wsdpbw.png\",\"png\") IF YOU WANT TO SAVE UNCOMMENT THIS\r\n # print(beautified_dp)\r\n bws_dp.show()\r\n\r\nimg_converter(user)\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
SyafiqTermizi/invitations
|
https://github.com/SyafiqTermizi/invitations
|
7d3c3c35d6877ea1664a69ae1f083c3ecd660431
|
a0f2644f80655a148faaaafe4876dbd2de105983
|
1998bf8eeebe9b1d2f78f9467bc8800f65115298
|
refs/heads/master
| 2020-03-28T07:29:01.540824 | 2018-09-08T16:32:01 | 2018-09-08T16:32:01 | 147,904,560 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6878980994224548,
"alphanum_fraction": 0.6878980994224548,
"avg_line_length": 27.636363983154297,
"blob_id": "c911a61aa4f389e7bd7aad16a241303f2e61f035",
"content_id": "647b1a9609dbfd26b9b7da2c75f20eddfb8e2faf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 11,
"path": "/invitations/urls.py",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom . import views\n\n\napp_name = \"invitations\"\nurlpatterns = [\n path('create/', views.InvitationCreateView.as_view(), name='create'),\n path('', views.InvitationListView.as_view(), name='list'),\n path('<int:pk>/delete/', views.InvitationDeleteView.as_view(), name='delete'),\n]"
},
{
"alpha_fraction": 0.8545454740524292,
"alphanum_fraction": 0.8545454740524292,
"avg_line_length": 54,
"blob_id": "529eca5179faad7dbd665437ea5f4fa0610811a0",
"content_id": "297248746ddf30ee1b9cced4f8773e9a669717e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 1,
"path": "/README.md",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "# Scaffolding for Invitations and Basic authentication\n"
},
{
"alpha_fraction": 0.6847826242446899,
"alphanum_fraction": 0.6847826242446899,
"avg_line_length": 19.44444465637207,
"blob_id": "41c5c44ddff1986524a47c338d14b57212df5376",
"content_id": "fcd9d7211d42bfd775dd15e48a998aca54b32103",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 9,
"path": "/invitations/forms.py",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "from django import forms\n\nfrom .models import Invitation\n\nclass InvitationForm(forms.ModelForm):\n\n class Meta:\n model = Invitation\n fields = ('email_address', 'name')\n"
},
{
"alpha_fraction": 0.6386861205101013,
"alphanum_fraction": 0.6441605687141418,
"avg_line_length": 31.235294342041016,
"blob_id": "1f5262cdede524d9c48b0cdf55277a8aa01b9641",
"content_id": "c177fb57f42e88e88807704bd05566ca915cdb3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1096,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 34,
"path": "/users/models.py",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import AbstractUser\nfrom django.contrib.auth.models import UserManager\n\n\nclass UserManager_(UserManager):\n\n def _create_user(self, username, email, password, **extra_fields):\n \"\"\"\n Create and save a user with the given username, email, and password.\n \"\"\"\n if not email:\n raise ValueError('The given email must be set')\n if not username:\n raise ValueError('The given username must be set')\n email = self.normalize_email(email)\n username = self.model.normalize_username(username)\n user = self.model(username=username, email=email, **extra_fields)\n user.set_password(password)\n user.save(using=self._db)\n return user\n\n\nclass User(AbstractUser):\n username = models.CharField(\n unique=True,\n max_length=150,\n help_text='150 characters or fewer. Letters, digits and @/./+/-/_ only.',\n )\n email = models.EmailField(unique=True)\n objects = UserManager_()\n\n def __str__(self):\n return self.username\n"
},
{
"alpha_fraction": 0.7132579684257507,
"alphanum_fraction": 0.7204521894454956,
"avg_line_length": 30.387096405029297,
"blob_id": "39a4ba3f2b81684579be1c0832053cff2b32154a",
"content_id": "11239ac10bddbfa20eb22c56744da888593f0b87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 973,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 31,
"path": "/invitations/models.py",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom django.db import models\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.utils.crypto import get_random_string\n\n\nUser = get_user_model()\n\nclass TimeStampedModel(models.Model):\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n\n class Meta:\n abstract =True\n\n\nclass Invitation(TimeStampedModel):\n email_address = models.EmailField(unique=True)\n name = models.CharField(max_length=250)\n token = models.CharField(max_length=64, unique=True)\n invited_by = models.ForeignKey(User, related_name='invitations', on_delete=models.CASCADE)\n\n def save(self, *args, **kwargs):\n self.token = get_random_string(64)\n return super(Invitation, self).save(*args, **kwargs)\n\n def is_expired(self):\n expiry = self.created_at + datetime.timedelta(days=settings.INVITATION_EXPIRY)\n return self.created_at <= expiry\n"
},
{
"alpha_fraction": 0.6966068148612976,
"alphanum_fraction": 0.6966068148612976,
"avg_line_length": 27.628570556640625,
"blob_id": "770dbbc55b53cbd9f97121e6ae6a837c182876b9",
"content_id": "45f273d3b5b9d4570f9ce0fc2272c588d1be5cd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1002,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 35,
"path": "/invitations/views.py",
"repo_name": "SyafiqTermizi/invitations",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, HttpResponseRedirect, reverse\nfrom django.views.generic import CreateView, ListView, DeleteView\nfrom django.contrib.auth.mixins import LoginRequiredMixin\nfrom django.core.mail import send_mail\n\nfrom .forms import InvitationForm\nfrom .models import Invitation\n\n\nclass InvitationCreateView(LoginRequiredMixin, CreateView):\n model = Invitation\n form_class = InvitationForm\n\n def form_valid(self, form):\n form.instance.invited_by = self.request.user\n f = form.save()\n send_mail(\n 'Subject',\n '{}'.format(f.token),\n '[email protected]',\n [f.email_address],\n fail_silently=False,\n )\n return HttpResponseRedirect(reverse('invitations:list'))\n\n\nclass InvitationListView(LoginRequiredMixin, ListView):\n model = Invitation\n\n\nclass InvitationDeleteView(LoginRequiredMixin, DeleteView):\n model = Invitation\n\n def get_success_url(self):\n return reverse('invitations:list')\n"
}
] | 6 |
MEstlander/RuneBot
|
https://github.com/MEstlander/RuneBot
|
5377f73430369b699a52e4bf2d3c3f11ac331d14
|
14a801b04ea23971d701201a3cd5ed6365061395
|
47e053d4b54ac2ea6bdee25680b41c1e7f0b3632
|
refs/heads/master
| 2020-04-19T02:55:27.651708 | 2019-01-28T07:43:17 | 2019-01-28T07:43:17 | 167,918,763 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48147138953208923,
"alphanum_fraction": 0.5441417098045349,
"avg_line_length": 24.65035057067871,
"blob_id": "fac8ba371ce8f2d9bee8cf94b3147246b83cfa6c",
"content_id": "7ce7d9907cce8740017bfac0f794c0dd9a9c398f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3681,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 143,
"path": "/python-imagesearch-master/Bot.py",
"repo_name": "MEstlander/RuneBot",
"src_encoding": "UTF-8",
"text": "from typing import Any\n\nfrom imagesearch import *\n\n\ntime3=0\ntime2=0\ntime1=0\ni=0\nisx=565\nisy=240\noisx=isx\noisy=isy\n\ndef loop():\n \"\"\"\n Loops through functions\n \"\"\"\n global i,isx,isy,oisx,oisy\n\n while True:\n mining()\n i=i+1\n if i%4==0:\n isx=isx-126\n isy=isy+36\n else:\n isx=isx+42\n if i>=24:\n i=0\n isy=oisy\n isx=oisx\n dropping()\n\ndef dropping():\n \"\"\"\n drops full inventory\n \"\"\"\n global i,isy,isx,oisx,oisy\n while i<24:\n click_image(\"images/iore.png\", (isx-16,isy-16), \"left\", r(0.1,0.1), offset=32)\n i=i+1\n if i%4==0:\n isx=isx-126\n isy=isy+36\n else:\n isx=isx+42\n i=0\n isx=oisx\n isy=oisy\n\n\n\"\"\"\ndef dropone():\n pos = imagesearcharea(\"iore.png\",0,0,963,623)\n while pos[0]==-1:\n pos = imagesearcharea(\"iore.png\",0,0,963,623)\n if pos[0]!=-1:\n click_image(\"iore.png\", pos, \"left\", r(0.1,0.1), offset=15)\n time.sleep(0.5)\n\"\"\"\ndef mineone(ore):\n \"\"\"\n :param ore: path ti en bild som ska hittas\n o sen kollar den också om man får inventory full notification\n o flyttar musen ti ett rändom ställe bort från spele (dunno why ja har de men whatevs)\n \"\"\"\n global time1,i,isx,isy,oisx,oisy\n j=0\n pos=imagesearcharea(ore,0,0,532,400,precision=0.5)\n while pos[0]==-1:\n if j==20:\n print(\"took a long ass time\")\n else:\n pos=imagesearcharea(ore,0,0,532,400,precision=0.5)\n time.sleep(0.3)\n if pos[0]!=-1:\n click_image(ore, pos, \"left\", r(0.1,0.1), offset=40)\n fullinv = imagesearcharea(\"images/fullinvi.png\",0,0,963,623)\n if fullinv[0] != -1:\n dropping()\n pyautogui.moveTo(r(700,500),r(100,500),r(0.5,1))\n time.sleep(r(0,0.5))\n\ndef checkore(isx,isy):\n \"\"\"\n Kollar om det kommer en iron ore till inventoryn\n Image recognitionen gör alla bilder gråa så den kan\n int se skillnad mellan brun(kan mineas) o grå (väntar på respawn)\n \"\"\"\n j=0\n pos=imagesearcharea(\"images/iore.png\",isx,isy,isx+32,isy+32,precision=0.3)\n gempos=imagesearcharea(\"images/gem.png\",isx,isy,isx+32,isy+32,precision=0.2)\n while pos[0]==-1 and gempos[0]==-1:\n gempos=imagesearcharea(\"images/gem.png\",isx,isy,isx+32,isy+32,precision=0.2)\n if j==20:\n print(\"took too long\")\n mining()\n pos=imagesearcharea(\"images/iore.png\",isx,isy,isx+32,isy+32,precision=0.3)\n j+=1\ndef miningtwo():\n \"\"\"\n En annan spot\n \"\"\"\n global i,time1,time2\n print(str(i))\n if i%2==0:\n if (time2-time1) < 5.4:\n time.sleep(min(time2-time1,5.4))\n mineone(\"iore2/rock1.png\")\n checkore(isx,isy)\n time1=time.time()\n else:\n if (time1-time2) < 5.4:\n time.sleep(min(time1-time2,5.4))\n mineone(\"iore2/rock2.png\")\n checkore(isx,isy)\n time2=time.time()\n\ndef mining():\n \"\"\"\n \"Main spotten\"\n \"\"\"\n global i,time1,time2,time3\n print(str(i))\n if i%3==0:\n if (time.time()-time1) < 5.4:\n time.sleep(min(time.time()-time1,5.4))\n mineone(\"iore/rock1.png\")\n checkore(isx,isy)\n time1=time.time()\n elif i%3==1:\n if (time.time()-time2) < 5.4:\n time.sleep(min(time.time()-time2,5.4))\n mineone(\"iore/rock2.png\")\n checkore(isx,isy)\n time2=time.time()\n else:\n if (time.time()-time3) < 5.4:\n time.sleep(min(time.time()-time3,5.4))\n mineone(\"iore/rock3.png\")\n checkore(isx,isy)\n time3=time.time()\n\n\n"
}
] | 1 |
Sameeranjoshi/infra
|
https://github.com/Sameeranjoshi/infra
|
c43dde5d2e41abaa2d8809686fa842fb15bb717d
|
9c6c131faf78654cfdc90bde33d5396f64750952
|
68390ba2f6883aa7edca8f81d4811f684866f2bb
|
refs/heads/master
| 2022-11-14T18:12:02.710852 | 2020-07-07T13:13:58 | 2020-07-07T13:13:58 | 277,759,678 | 0 | 0 |
BSD-2-Clause
| 2020-07-07T08:24:18 | 2020-07-06T16:43:18 | 2020-07-06T17:23:25 | null |
[
{
"alpha_fraction": 0.49525317549705505,
"alphanum_fraction": 0.607594907283783,
"avg_line_length": 21.571428298950195,
"blob_id": "b844f8ef2d7cce35526f804e8beeec1f79c38a24",
"content_id": "d3916bda9a9a7e705c7f6f0da59e2c25b115ed98",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 632,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 28,
"path": "/update_compilers/install_java_compilers.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSCRIPT_DIR=\"$(cd \"$(dirname \"${BASH_SOURCE[0]}\")\" && pwd)\"\n. ${SCRIPT_DIR}/common.inc\n\nget_jdk() {\n local VERSION=$1\n local URL=$2\n local DIR=jdk-${VERSION}\n\n if [[ ! -d ${DIR} ]]; then\n mkdir ${DIR}\n pushd ${DIR}\n fetch ${URL} | tar zxf - --strip-components 1\n popd\n fi\n}\n\nget_jdk1102() {\n get_jdk 11.0.2 https://download.java.net/java/GA/jdk11/9/GPL/openjdk-11.0.2_linux-x64_bin.tar.gz\n}\n\nget_jdk1201() {\n get_jdk 12.0.1 https://download.java.net/java/GA/jdk12.0.1/69cfe15208a647278a19ef0990eea691/12/GPL/openjdk-12.0.1_linux-x64_bin.tar.gz\n}\n\nget_jdk1102\nget_jdk1201\n"
},
{
"alpha_fraction": 0.619178056716919,
"alphanum_fraction": 0.6520547866821289,
"avg_line_length": 18.210525512695312,
"blob_id": "63c34a41901f063821479166045dcf633d6ec28d",
"content_id": "069891bb8877486bb0a5e689219dacb0ce0b5c48",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 365,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 19,
"path": "/init/start-conan.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\nCE_USER=ce\nPATH=$PATH:/home/ubuntu/node/bin\n\ncd /home/ubuntu/ceconan/conanproxy\ngit pull\n\nnpm i -g npm\nnpm i\n\nsudo -u ce -H /home/${CE_USER}/.local/bin/gunicorn -b 0.0.0.0:9300 -w 4 -t 300 conans.server.server_launcher:app &\n\nexec sudo -u ce -H --preserve-env=NODE_ENV -- \\\n /home/ubuntu/node/bin/node \\\n -- index.js \\\n ${EXTRA_ARGS}\n"
},
{
"alpha_fraction": 0.5739471316337585,
"alphanum_fraction": 0.6013712286949158,
"avg_line_length": 19.420000076293945,
"blob_id": "1b0929f739d2004dd76618df25d03631bb99d5cb",
"content_id": "7b537db125711210548b6fe565be427c39bd7d89",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1021,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 50,
"path": "/update_compilers/install_zig_compilers.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSCRIPT_DIR=\"$(cd \"$(dirname \"${BASH_SOURCE[0]}\")\" && pwd)\"\n. ${SCRIPT_DIR}/common.inc\n\ninstall_zig() {\n local VERSION=$1\n local DIR=zig-${VERSION}\n if [[ -d ${DIR} ]]; then\n echo Zig $VERSION already installed, skipping\n return\n fi\n mkdir ${DIR}\n pushd ${DIR}\n\n fetch https://ziglang.org/download/${VERSION}/zig-linux-x86_64-${VERSION}.tar.xz | tar Jxf - --strip-components 1\n rm -f langref.html\n\n popd\n do_strip ${DIR}\n}\n\ninstall_zig_nightly() {\n local VERSION=$1\n local DIR=zig-${VERSION}\n\n if [[ -d ${DIR} ]]; then\n rm -rf ${DIR}\n fi\n\n mkdir ${DIR}\n pushd ${DIR}\n\n local MASTER_URL=$(fetch https://ziglang.org/download/index.json | jq -r '.master.\"x86_64-linux\".tarball')\n fetch $MASTER_URL | tar Jxf - --strip-components 1\n rm -f langref.html\n\n popd\n do_strip ${DIR}\n}\n\ninstall_zig 0.2.0\ninstall_zig 0.3.0\ninstall_zig 0.4.0\ninstall_zig 0.5.0\ninstall_zig 0.6.0\n\nif install_nightly; then\n install_zig_nightly master\nfi\n"
},
{
"alpha_fraction": 0.5943953394889832,
"alphanum_fraction": 0.597113311290741,
"avg_line_length": 39.82780456542969,
"blob_id": "6a970de98e861232f3379874359f2603be443b25",
"content_id": "d6866ff8f1822649559fbfd9d440f24f99beeaa0",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32009,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 784,
"path": "/bin/lib/installation.py",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "from __future__ import annotations\nimport functools\nimport glob\nimport logging\nimport os\nimport re\nimport shutil\nimport subprocess\nimport tempfile\nimport time\nfrom collections import defaultdict, ChainMap\nfrom datetime import datetime\nfrom pathlib import Path\nfrom typing import Optional, Sequence, Collection, List, Union, Dict, Any, IO, Callable\n\nimport requests\nfrom cachecontrol import CacheControl\nfrom cachecontrol.caches import FileCache\n\nfrom lib.amazon import list_compilers\n\nVERSIONED_RE = re.compile(r'^(.*)-([0-9.]+)$')\n\nMAX_ITERS = 5\n\nNO_DEFAULT = \"__no_default__\"\n\nlogger = logging.getLogger(__name__)\n\n\[email protected]_cache(maxsize=1)\ndef s3_available_compilers():\n compilers = defaultdict(lambda: [])\n for compiler in list_compilers():\n match = VERSIONED_RE.match(compiler)\n if match:\n compilers[match.group(1)].append(match.group(2))\n return compilers\n\n\nclass InstallationContext:\n def __init__(self, destination: Path, staging: Path, s3_url: str, dry_run: bool, is_nightly_enabled: bool,\n cache: Optional[Path]):\n self.destination = destination\n self.staging = staging\n self.s3_url = s3_url\n self.dry_run = dry_run\n self.is_nightly_enabled = is_nightly_enabled\n if cache:\n self.info(f\"Using cache {cache}\")\n self.fetcher = CacheControl(requests.session(), cache=FileCache(cache))\n else:\n self.info(\"Making uncached requests\")\n self.fetcher = requests\n\n def debug(self, message: str) -> None:\n logger.debug(message)\n\n def info(self, message: str) -> None:\n logger.info(message)\n\n def warn(self, message: str) -> None:\n logger.warning(message)\n\n def error(self, message: str) -> None:\n logger.error(message)\n\n def clean_staging(self) -> None:\n self.debug(f\"Cleaning staging dir {self.staging}\")\n if self.staging.is_dir():\n subprocess.check_call([\"chmod\", \"-R\", \"u+w\", self.staging])\n shutil.rmtree(self.staging, ignore_errors=True)\n self.debug(f\"Recreating staging dir {self.staging}\")\n self.staging.mkdir(parents=True)\n\n def fetch_to(self, url: str, fd: IO[bytes]) -> None:\n self.debug(f'Fetching {url}')\n request = self.fetcher.get(url, stream=True)\n if not request.ok:\n self.error(f'Failed to fetch {url}: {request}')\n raise RuntimeError(f'Fetch failure for {url}: {request}')\n fetched = 0\n length = int(request.headers.get('content-length', 0))\n self.info(f'Fetching {url} ({length} bytes)')\n report_every_secs = 5\n report_time = time.time() + report_every_secs\n for chunk in request.iter_content(chunk_size=4 * 1024 * 1024):\n fd.write(chunk)\n fetched += len(chunk)\n now = time.time()\n if now >= report_time:\n if length != 0:\n self.info(f'{100.0 * fetched / length:.1f}% of {url}...')\n report_time = now + report_every_secs\n self.info(f'100% of {url}')\n fd.flush()\n\n def fetch_url_and_pipe_to(self, url: str, command: Sequence[str], subdir: str = '.') -> None:\n untar_dir = self.staging / subdir\n untar_dir.mkdir(parents=True, exist_ok=True)\n # We stream to a temporary file first before then piping this to the command\n # as sometimes the command can take so long the URL endpoint closes the door on us\n with tempfile.TemporaryFile() as fd:\n self.fetch_to(url, fd)\n fd.seek(0)\n self.info(f'Piping to {\" \".join(command)}')\n subprocess.check_call(command, stdin=fd, cwd=str(untar_dir))\n\n def stage_command(self, command: Sequence[str]) -> None:\n self.info(f'Staging with {\" \".join(command)}')\n subprocess.check_call(command, cwd=str(self.staging))\n\n def fetch_s3_and_pipe_to(self, s3: str, command: Sequence[str]) -> None:\n return self.fetch_url_and_pipe_to(f'{self.s3_url}/{s3}', command)\n\n def make_subdir(self, subdir: str) -> None:\n (self.destination / subdir).mkdir(parents=True, exist_ok=True)\n\n def read_link(self, link: str) -> str:\n return os.readlink(str(self.destination / link))\n\n def set_link(self, source: Path, dest: str) -> None:\n if self.dry_run:\n self.info(f'Would symlink {source} to {dest}')\n return\n\n full_dest = self.destination / dest\n if full_dest.exists():\n full_dest.unlink()\n self.info(f'Symlinking {dest} to {source}')\n os.symlink(str(source), str(full_dest))\n\n def glob(self, pattern: str) -> Collection[str]:\n return [os.path.relpath(x, str(self.destination)) for x in glob.glob(str(self.destination / pattern))]\n\n def remove_dir(self, directory: str) -> None:\n if self.dry_run:\n self.info(f'Would remove directory {directory} but in dry-run mode')\n else:\n shutil.rmtree(str(self.destination / directory), ignore_errors=True)\n self.info(f'Removing {directory}')\n\n def check_link(self, source: str, link: str) -> bool:\n try:\n link = self.read_link(link)\n self.debug(f'readlink returned {link}')\n return link == source\n except FileNotFoundError:\n self.debug(f'File not found for {link}')\n return False\n\n def move_from_staging(self, source_str: str, dest_str: Optional[str] = None) -> None:\n dest_str = dest_str or source_str\n existing_dir_rename = self.staging / \"temp_orig\"\n source = self.staging / source_str\n dest = self.destination / dest_str\n if self.dry_run:\n self.info(f'Would install {source} to {dest} but in dry-run mode')\n return\n self.info(f'Moving from staging ({source}) to final destination ({dest})')\n if not source.is_dir():\n staging_contents = subprocess.check_output(['ls', '-l', self.staging]).decode('utf-8')\n self.info(f\"Directory listing of staging:\\n{staging_contents}\")\n raise RuntimeError(f\"Missing source '{source}'\")\n # Some tar'd up GCCs are actually marked read-only...\n subprocess.check_call([\"chmod\", \"u+w\", source])\n state = ''\n if dest.is_dir():\n self.info(f'Destination {dest} exists, temporarily moving out of the way (to {existing_dir_rename})')\n dest.replace(existing_dir_rename)\n state = 'old_renamed'\n try:\n source.replace(dest)\n if state == 'old_renamed':\n state = 'old_needs_remove'\n finally:\n if state == 'old_needs_remove':\n self.debug(f'Removing temporarily moved {existing_dir_rename}')\n shutil.rmtree(existing_dir_rename, ignore_errors=True)\n elif state == 'old_renamed':\n self.warn('Moving old destination back')\n existing_dir_rename.replace(dest)\n\n def compare_against_staging(self, source_str: str, dest_str: Optional[str] = None) -> bool:\n dest_str = dest_str or source_str\n source = self.staging / source_str\n dest = self.destination / dest_str\n self.info(f'Comparing {source} vs {dest}...')\n result = subprocess.call(['diff', '-r', source, dest])\n if result == 0:\n self.info('Contents match')\n else:\n self.warn('Contents differ')\n return result == 0\n\n def check_output(self, args: List[str], env: Optional[dict] = None) -> str:\n args = args[:]\n args[0] = str(self.destination / args[0])\n logger.debug('Executing %s in %s', args, self.destination)\n return subprocess.check_output(args, cwd=str(self.destination), env=env).decode('utf-8')\n\n def strip_exes(self, paths: Union[bool, List[str]]) -> None:\n if isinstance(paths, bool):\n if not paths:\n return\n paths = ['.']\n to_strip = []\n for path_part in paths:\n path = self.staging / path_part\n logger.debug(\"Looking for executables to strip in %s\", path)\n if not path.is_dir():\n raise RuntimeError(f\"While looking for files to strip, {path} was not a directory\")\n for dirpath, _, filenames in os.walk(str(path)):\n for filename in filenames:\n full_path = os.path.join(dirpath, filename)\n if os.access(full_path, os.X_OK):\n to_strip.append(full_path)\n\n # Deliberately ignore errors\n subprocess.call(['strip'] + to_strip)\n\n\nclass Installable:\n _check_link: Optional[Callable[[], bool]]\n check_env: Dict\n check_file: Optional[str]\n check_call: List[str]\n\n def __init__(self, install_context: InstallationContext, config: Dict[str, Any]):\n self.install_context = install_context\n self.config = config\n self.target_name = str(self.config.get(\"name\", \"(unnamed)\"))\n self.context = self.config_get(\"context\", [])\n self.name = f'{\"/\".join(self.context)}/{self.target_name}'\n self.depends = self.config.get('depends', [])\n self.install_always = self.config.get('install_always', False)\n self._check_link = None\n self.build_type = self.config_get(\"build_type\", \"\")\n self.build_fixed_arch = self.config_get(\"build_fixed_arch\", \"\")\n self.build_fixed_stdlib = self.config_get(\"build_fixed_stdlib\", \"\")\n self.lib_type = self.config_get(\"lib_type\", \"static\")\n self.url = \"None\"\n self.description = \"\"\n self.prebuildscript = self.config_get(\"prebuildscript\", [])\n self.extra_cmake_arg = self.config_get(\"extra_cmake_arg\", [])\n self.check_env = {}\n self.check_file = None\n self.check_call = []\n\n def _setup_check_exe(self, path_name: str) -> None:\n self.check_env = dict([x.replace('%PATH%', path_name).split('=', 1) for x in self.config_get('check_env', [])])\n\n check_file = self.config_get('check_file', '')\n if check_file:\n self.check_file = os.path.join(path_name, check_file)\n else:\n self.check_call = command_config(self.config_get('check_exe'))\n self.check_call[0] = os.path.join(path_name, self.check_call[0])\n\n def _setup_check_link(self, source: str, link: str) -> None:\n self._check_link = lambda: self.install_context.check_link(source, link)\n\n def link(self, all_installables: Dict[str, Installable]):\n try:\n self.depends = [all_installables[dep] for dep in self.depends]\n except KeyError as ke:\n self.error(f\"Unable to find dependency {ke}\")\n raise\n\n def debug(self, message: str) -> None:\n self.install_context.debug(f'{self.name}: {message}')\n\n def info(self, message: str) -> None:\n self.install_context.info(f'{self.name}: {message}')\n\n def warn(self, message: str) -> None:\n self.install_context.warn(f'{self.name}: {message}')\n\n def error(self, message: str) -> None:\n self.install_context.error(f'{self.name}: {message}')\n\n def verify(self) -> bool:\n return True\n\n def should_install(self) -> bool:\n return self.install_always or not self.is_installed()\n\n def install(self) -> bool:\n self.debug(\"Ensuring dependees are installed\")\n any_missing = False\n for dependee in self.depends:\n if not dependee.is_installed():\n self.warn(\"Required dependee {} not installed\".format(dependee))\n any_missing = True\n if any_missing:\n return False\n self.debug(\"Dependees ok\")\n return True\n\n def is_installed(self) -> bool:\n if self._check_link and not self._check_link():\n self.debug('Check link returned false')\n return False\n\n if self.check_file:\n res = (self.install_context.destination / self.check_file).is_file()\n self.debug(f'Check file for \"{self.check_file}\" returned {res}')\n return res\n\n try:\n res_call = self.install_context.check_output(self.check_call, env=self.check_env)\n self.debug(f'Check call returned {res_call}')\n return True\n except FileNotFoundError:\n self.debug(f'File not found for {self.check_call}')\n return False\n except subprocess.CalledProcessError:\n self.debug(f'Got an error for {self.check_call}')\n return False\n\n def config_get(self, config_key: str, default: Optional[Any] = None) -> Any:\n if config_key not in self.config and default is None:\n raise RuntimeError(f\"Missing required key '{config_key}' in {self.name}\")\n return self.config.get(config_key, default)\n\n def __repr__(self) -> str:\n return f'Installable({self.name})'\n\n @property\n def sort_key(self):\n return self.context, [\n (int(num) if num else 0, non) for num, non in re.findall(r'([0-9]+)|([^0-9]+)', self.target_name)\n ]\n\n\ndef command_config(config: Union[List[str], str]) -> List[str]:\n if isinstance(config, str):\n return config.split(\" \")\n return config\n\n\nclass GitHubInstallable(Installable):\n def __init__(self, install_context, config):\n super().__init__(install_context, config)\n last_context = self.context[-1]\n self.repo = self.config_get(\"repo\", \"\")\n self.domainurl = self.config_get(\"domainurl\", \"https://github.com\")\n self.method = self.config_get(\"method\", \"archive\")\n self.decompress_flag = self.config_get(\"decompress_flag\", \"z\")\n self.strip = False\n self.subdir = os.path.join('libs', self.config_get(\"subdir\", last_context))\n self.target_prefix = self.config_get(\"target_prefix\", \"\")\n self.path_name = self.config_get('path_name', os.path.join(self.subdir, self.target_prefix + self.target_name))\n if self.repo == \"\":\n raise RuntimeError('Requires repo')\n\n splitrepo = self.repo.split('/')\n self.reponame = splitrepo[1]\n default_untar_dir = f'{self.reponame}-{self.target_name}'\n self.untar_dir = self.config_get(\"untar_dir\", default_untar_dir)\n\n check_file = self.config_get(\"check_file\", \"\")\n if check_file == \"\":\n if self.build_type == \"cmake\":\n self.check_file = os.path.join(self.path_name, 'CMakeLists.txt')\n elif self.build_type == \"make\":\n self.check_file = os.path.join(self.path_name, 'Makefile')\n elif self.build_type == \"cake\":\n self.check_file = os.path.join(self.path_name, 'config.cake')\n else:\n raise RuntimeError(f'Requires check_file ({last_context})')\n else:\n self.check_file = f'{self.path_name}/{check_file}'\n\n def clone_branch(self):\n dest = os.path.join(self.install_context.destination, self.path_name)\n if not os.path.exists(dest):\n subprocess.check_call(['git', 'clone', '-q', f'{self.domainurl}/{self.repo}.git', dest],\n cwd=self.install_context.staging)\n else:\n subprocess.check_call(['git', '-C', dest, 'fetch', '-q'], cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'reset', '-q', '--hard', 'origin'],\n cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'checkout', '-q', self.target_name], cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'submodule', 'sync'], cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'submodule', 'update', '--init'], cwd=self.install_context.staging)\n\n def clone_default(self):\n dest = os.path.join(self.install_context.destination, self.path_name)\n if not os.path.exists(dest):\n subprocess.check_call(['git', 'clone', '-q', f'{self.domainurl}/{self.repo}.git', dest],\n cwd=self.install_context.staging)\n else:\n subprocess.check_call(['git', '-C', dest, 'fetch', '-q'], cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'reset', '-q', '--hard', 'origin'],\n cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'submodule', 'sync'], cwd=self.install_context.staging)\n subprocess.check_call(['git', '-C', dest, 'submodule', 'update', '--init'], cwd=self.install_context.staging)\n\n def get_archive_url(self):\n return f'{self.domainurl}/{self.repo}/archive/{self.target_prefix}{self.target_name}.tar.gz'\n\n def get_archive_pipecommand(self):\n return ['tar', f'{self.decompress_flag}xf', '-']\n\n def stage(self):\n self.install_context.clean_staging()\n if self.method == \"archive\":\n self.install_context.fetch_url_and_pipe_to(self.get_archive_url(), self.get_archive_pipecommand())\n elif self.method == \"clone_branch\":\n self.clone_branch()\n elif self.method == \"nightlyclone\":\n self.clone_default()\n else:\n raise RuntimeError(f'Unknown Github method {self.method}')\n\n if self.strip:\n self.install_context.strip_exes(self.strip)\n\n def verify(self):\n if not super().verify():\n return False\n self.stage()\n return self.install_context.compare_against_staging(self.untar_dir, self.path_name)\n\n def install(self):\n if not super().install():\n return False\n self.stage()\n if self.subdir:\n self.install_context.make_subdir(self.subdir)\n if self.method == \"archive\":\n self.install_context.move_from_staging(self.untar_dir, self.path_name)\n return True\n\n def __repr__(self) -> str:\n return f'GitHubInstallable({self.name}, {self.path_name})'\n\n\nclass GitLabInstallable(GitHubInstallable):\n def __init__(self, install_context, config):\n super().__init__(install_context, config)\n self.domainurl = self.config_get(\"domainurl\", \"https://gitlab.com\")\n\n def get_archive_url(self):\n return f'{self.domainurl}/{self.repo}/-/archive/{self.target_name}/{self.reponame}-{self.target_name}.tar.gz'\n\n def __repr__(self) -> str:\n return f'GitLabInstallable({self.name}, {self.path_name})'\n\n\nclass BitbucketInstallable(GitHubInstallable):\n def __init__(self, install_context, config):\n super().__init__(install_context, config)\n self.domainurl = self.config_get(\"domainurl\", \"https://bitbucket.org\")\n\n def get_archive_url(self):\n return f'{self.domainurl}/{self.repo}/downloads/{self.reponame}-{self.target_name}.tar.gz'\n\n def __repr__(self) -> str:\n return f'BitbucketInstallable({self.name}, {self.path_name})'\n\n\nclass S3TarballInstallable(Installable):\n def __init__(self, install_context: InstallationContext, config: Dict[str, Any]):\n super().__init__(install_context, config)\n self.subdir = self.config_get(\"subdir\", \"\")\n last_context = self.context[-1]\n if self.subdir:\n default_s3_path_prefix = f'{self.subdir}-{last_context}-{self.target_name}'\n default_path_name = f'{self.subdir}/{last_context}-{self.target_name}'\n default_untar_dir = f'{last_context}-{self.target_name}'\n else:\n default_s3_path_prefix = f'{last_context}-{self.target_name}'\n default_path_name = f'{last_context}-{self.target_name}'\n default_untar_dir = default_path_name\n s3_path_prefix = self.config_get('s3_path_prefix', default_s3_path_prefix)\n self.path_name = self.config_get('path_name', default_path_name)\n self.untar_dir = self.config_get(\"untar_dir\", default_untar_dir)\n compression = self.config_get('compression', 'xz')\n if compression == 'xz':\n self.s3_path = f'{s3_path_prefix}.tar.xz'\n self.decompress_flag = 'J'\n elif compression == 'gz':\n self.s3_path = f'{s3_path_prefix}.tar.gz'\n self.decompress_flag = 'z'\n elif compression == 'bz2':\n self.s3_path = f'{s3_path_prefix}.tar.bz2'\n self.decompress_flag = 'j'\n else:\n raise RuntimeError(f'Unknown compression {compression}')\n self.strip = self.config_get('strip', False)\n self._setup_check_exe(self.path_name)\n\n def stage(self) -> None:\n self.install_context.clean_staging()\n self.install_context.fetch_s3_and_pipe_to(self.s3_path, ['tar', f'{self.decompress_flag}xf', '-'])\n if self.strip:\n self.install_context.strip_exes(self.strip)\n\n def verify(self) -> bool:\n if not super().verify():\n return False\n self.stage()\n return self.install_context.compare_against_staging(self.untar_dir, self.path_name)\n\n def install(self) -> bool:\n if not super().install():\n return False\n self.stage()\n if self.subdir:\n self.install_context.make_subdir(self.subdir)\n elif self.path_name:\n self.install_context.make_subdir(self.path_name)\n\n self.install_context.move_from_staging(self.untar_dir, self.path_name)\n return True\n\n def __repr__(self) -> str:\n return f'S3TarballInstallable({self.name}, {self.path_name})'\n\n\nclass NightlyInstallable(Installable):\n def __init__(self, install_context: InstallationContext, config: Dict[str, Any]):\n super().__init__(install_context, config)\n self.subdir = self.config_get(\"subdir\", \"\")\n self.strip = self.config_get('strip', False)\n compiler_name = self.config_get('compiler_name', f'{self.context[-1]}-{self.target_name}')\n current = s3_available_compilers()\n if compiler_name not in current:\n raise RuntimeError(f'Unable to find nightlies for {compiler_name}')\n most_recent = max(current[compiler_name])\n self.info(f'Most recent {compiler_name} is {most_recent}')\n self.s3_path = f'{compiler_name}-{most_recent}'\n self.path_name = os.path.join(self.subdir, f'{compiler_name}-{most_recent}')\n self.compiler_pattern = os.path.join(self.subdir, f'{compiler_name}-*')\n self.path_name_symlink = self.config_get('symlink', os.path.join(self.subdir, f'{compiler_name}'))\n self.num_to_keep = self.config_get('num_to_keep', 5)\n self._setup_check_exe(self.path_name)\n self._setup_check_link(self.s3_path, self.path_name_symlink)\n\n def stage(self) -> None:\n self.install_context.clean_staging()\n self.install_context.fetch_s3_and_pipe_to(f'{self.s3_path}.tar.xz', ['tar', 'Jxf', '-'])\n if self.strip:\n self.install_context.strip_exes(self.strip)\n\n def verify(self) -> bool:\n if not super().verify():\n return False\n self.stage()\n return self.install_context.compare_against_staging(self.s3_path, self.path_name)\n\n def should_install(self) -> bool:\n return True\n\n def install(self) -> bool:\n if not super().install():\n return False\n self.stage()\n\n # Do this first, and add one for the file we haven't yet installed... (then dry run works)\n num_to_keep = self.num_to_keep + 1\n all_versions = list(sorted(self.install_context.glob(self.compiler_pattern)))\n for to_remove in all_versions[:-num_to_keep]:\n self.install_context.remove_dir(to_remove)\n\n self.install_context.move_from_staging(self.s3_path, self.path_name)\n self.install_context.set_link(Path(self.s3_path), self.path_name_symlink)\n\n return True\n\n def __repr__(self) -> str:\n return f'NightlyInstallable({self.name}, {self.path_name})'\n\n\nclass TarballInstallable(Installable):\n def __init__(self, install_context: InstallationContext, config: Dict[str, Any]):\n super().__init__(install_context, config)\n self.install_path = self.config_get('dir')\n self.install_path_symlink = self.config_get('symlink', False)\n self.untar_path = self.config_get('untar_dir', self.install_path)\n if self.config_get('create_untar_dir', False):\n self.untar_to = self.untar_path\n else:\n self.untar_to = '.'\n self.url = self.config_get('url')\n if self.config_get('compression') == 'xz':\n decompress_flag = 'J'\n elif self.config_get('compression') == 'gz':\n decompress_flag = 'z'\n elif self.config_get('compression') == 'bz2':\n decompress_flag = 'j'\n else:\n raise RuntimeError(f'Unknown compression {self.config_get(\"compression\")}')\n self.configure_command = command_config(self.config_get('configure_command', []))\n self.tar_cmd = ['tar', f'{decompress_flag}xf', '-']\n strip_components = self.config_get(\"strip_components\", 0)\n if strip_components:\n self.tar_cmd += ['--strip-components', str(strip_components)]\n self.strip = self.config_get('strip', False)\n self._setup_check_exe(self.install_path)\n if self.install_path_symlink:\n self._setup_check_link(self.install_path, self.install_path_symlink)\n\n def stage(self) -> None:\n self.install_context.clean_staging()\n self.install_context.fetch_url_and_pipe_to(f'{self.url}', self.tar_cmd, self.untar_to)\n if self.configure_command:\n self.install_context.stage_command(self.configure_command)\n if self.strip:\n self.install_context.strip_exes(self.strip)\n if not (self.install_context.staging / self.untar_path).is_dir():\n raise RuntimeError(f\"After unpacking, {self.untar_path} was not a directory\")\n\n def verify(self) -> bool:\n if not super().verify():\n return False\n self.stage()\n return self.install_context.compare_against_staging(self.untar_path, self.install_path)\n\n def install(self) -> bool:\n if not super().install():\n return False\n self.stage()\n self.install_context.move_from_staging(self.untar_path, self.install_path)\n if self.install_path_symlink:\n self.install_context.set_link(self.install_path, self.install_path_symlink)\n return True\n\n def __repr__(self) -> str:\n return f'TarballInstallable({self.name}, {self.install_path})'\n\n\nclass ScriptInstallable(Installable):\n def __init__(self, install_context: InstallationContext, config: Dict[str, Any]):\n super().__init__(install_context, config)\n self.install_path = self.config_get('dir')\n self.install_path_symlink = self.config_get('symlink', False)\n self.fetch = self.config_get('fetch')\n self.script = self.config_get('script')\n self.strip = self.config_get('strip', False)\n self._setup_check_exe(self.install_path)\n if self.install_path_symlink:\n self._setup_check_link(self.install_path, self.install_path_symlink)\n\n def stage(self) -> None:\n self.install_context.clean_staging()\n for url in self.fetch:\n url, filename = url.split(' ')\n with (self.install_context.staging / filename).open('wb') as f:\n self.install_context.fetch_to(url, f)\n self.info(f'{url} -> {filename}')\n self.install_context.stage_command(['bash', '-c', self.script])\n if self.strip:\n self.install_context.strip_exes(self.strip)\n\n def verify(self) -> bool:\n if not super().verify():\n return False\n self.stage()\n return self.install_context.compare_against_staging(self.install_path)\n\n def install(self) -> bool:\n if not super().install():\n return False\n self.stage()\n self.install_context.move_from_staging(self.install_path)\n if self.install_path_symlink:\n self.install_context.set_link(self.install_path, self.install_path_symlink)\n return True\n\n def __repr__(self) -> str:\n return f'ScriptInstallable({self.name}, {self.install_path})'\n\n\ndef targets_from(node, enabled, base_config=None):\n if base_config is None:\n base_config = {}\n return _targets_from(node, enabled, [], \"\", base_config)\n\n\ndef is_list_of_strings(value: Any) -> bool:\n return isinstance(value, list) and all(isinstance(x, str) for x in value)\n\n\ndef is_value_type(value: Any) -> bool:\n return isinstance(value, str) \\\n or isinstance(value, bool) \\\n or isinstance(value, float) \\\n or isinstance(value, int) \\\n or is_list_of_strings(value)\n\n\ndef needs_expansion(target):\n for value in target.values():\n if is_list_of_strings(value):\n for v in value:\n if '{' in v:\n return True\n elif isinstance(value, str):\n if '{' in value:\n return True\n return False\n\n\ndef _targets_from(node, enabled, context, name, base_config):\n if not node:\n return\n\n if isinstance(node, list):\n for child in node:\n for target in _targets_from(child, enabled, context, name, base_config):\n yield target\n return\n\n if not isinstance(node, dict):\n return\n\n if 'if' in node:\n if isinstance(node['if'], list):\n condition = set(node['if'])\n else:\n condition = set([node['if']])\n if set(enabled).intersection(condition) != condition:\n return\n\n context = context[:]\n if name:\n context.append(name)\n base_config = dict(base_config)\n for key, value in node.items():\n if key != 'targets' and is_value_type(value):\n base_config[key] = value\n\n for child_name, child in node.items():\n for target in _targets_from(child, enabled, context, child_name, base_config):\n yield target\n\n if 'targets' in node:\n base_config['context'] = context\n for target in node['targets']:\n if isinstance(target, float):\n raise RuntimeError(f\"Target {target} was parsed as a float. Enclose in quotes\")\n if isinstance(target, str):\n target = {'name': target}\n target = ChainMap(target, base_config)\n iterations = 0\n while needs_expansion(target):\n iterations += 1\n if iterations > MAX_ITERS:\n raise RuntimeError(f\"Too many mutual references (in {'/'.join(context)})\")\n for key, value in target.items():\n try:\n if is_list_of_strings(value):\n target[key] = [x.format(**target) for x in value]\n elif isinstance(value, str):\n target[key] = value.format(**target)\n elif isinstance(value, float):\n target[key] = str(value)\n except KeyError as ke:\n raise RuntimeError(f\"Unable to find key {ke} in {target[key]} (in {'/'.join(context)})\")\n yield target\n\n\nINSTALLER_TYPES = {\n 'tarballs': TarballInstallable,\n 's3tarballs': S3TarballInstallable,\n 'nightly': NightlyInstallable,\n 'script': ScriptInstallable,\n 'github': GitHubInstallable,\n 'gitlab': GitLabInstallable,\n 'bitbucket': BitbucketInstallable,\n}\n\n\ndef installers_for(install_context, nodes, enabled):\n for target in targets_from(nodes, enabled, {'staging': install_context.staging, 'now': datetime.now()}):\n assert 'type' in target\n target_type = target['type']\n if target_type not in INSTALLER_TYPES:\n raise RuntimeError(f'Unknown installer type {target_type}')\n installer_type = INSTALLER_TYPES[target_type]\n yield installer_type(install_context, target)\n"
},
{
"alpha_fraction": 0.5289078950881958,
"alphanum_fraction": 0.5378625392913818,
"avg_line_length": 40.42741775512695,
"blob_id": "394643ddae52c1225615f1cf0c4c1b95d831c89a",
"content_id": "a557214ef51f3d151614c7f0ecb6550eb2aab4ee",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5137,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 124,
"path": "/bin/lib/amazon_properties.py",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "import os\nimport tempfile\nimport urllib.parse\nfrom collections import defaultdict\n\nimport requests\n\n\ndef get_properties_compilers_and_libraries(language, logger):\n _compilers = defaultdict(lambda: [])\n _libraries = defaultdict(lambda: [])\n\n encoded_language = urllib.parse.quote(language)\n url = f'https://raw.githubusercontent.com/compiler-explorer/compiler-explorer/master/etc/config/{encoded_language}.amazon.properties'\n lines = []\n with tempfile.TemporaryFile() as fd:\n request = requests.get(url, stream=True)\n if not request.ok:\n raise RuntimeError(f'Fetch failure for {url}: {request}')\n for chunk in request.iter_content(chunk_size=4 * 1024 * 1024):\n fd.write(chunk)\n fd.flush()\n fd.seek(0)\n lines = fd.readlines()\n\n logger.debug('Reading properties for groups')\n groups = defaultdict(lambda: [])\n for line in lines:\n sline = line.decode('utf-8').rstrip('\\n')\n if sline.startswith('group.'):\n keyval = sline.split('=', 1)\n key = keyval[0].split('.')\n val = keyval[1]\n group = key[1]\n if not group in groups:\n groups[group] = defaultdict(lambda: [])\n groups[group]['options'] = \"\"\n groups[group]['compilerType'] = \"\"\n groups[group]['compilers'] = []\n groups[group]['supportsBinary'] = True\n\n if key[2] == \"compilers\":\n groups[group]['compilers'] = val.split(':')\n elif key[2] == \"options\":\n groups[group]['options'] = val\n elif key[2] == \"compilerType\":\n groups[group]['compilerType'] = val\n elif key[2] == \"supportsBinary\":\n groups[group]['supportsBinary'] = val == 'true'\n elif sline.startswith('libs.'):\n keyval = sline.split('=', 1)\n key = keyval[0].split('.')\n val = keyval[1]\n libid = key[1]\n if not libid in _libraries:\n _libraries[libid] = defaultdict(lambda: [])\n\n if key[2] == 'description':\n _libraries[libid]['description'] = val\n elif key[2] == 'name':\n _libraries[libid]['name'] = val\n elif key[2] == 'url':\n _libraries[libid]['url'] = val\n elif key[2] == 'liblink':\n _libraries[libid]['liblink'] = val\n elif key[2] == 'staticliblink':\n _libraries[libid]['staticliblink'] = val\n elif key[2] == 'versions':\n if len(key) > 3:\n versionid = key[3]\n if not 'versionprops' in _libraries[libid]:\n _libraries[libid]['versionprops'] = defaultdict(lambda: [])\n if not versionid in _libraries[libid]['versionprops']:\n _libraries[libid]['versionprops'][versionid] = defaultdict(lambda: [])\n if key[4] == 'path':\n _libraries[libid]['versionprops'][versionid][key[4]] = val.split(':')\n if key[4] == 'libpath':\n _libraries[libid]['versionprops'][versionid][key[4]] = val.split(':')\n else:\n _libraries[libid]['versions'] = val\n\n logger.debug('Setting default values for compilers')\n for group in groups:\n for compiler in groups[group]['compilers']:\n if not compiler in _compilers:\n _compilers[compiler] = defaultdict(lambda: [])\n _compilers[compiler]['options'] = groups[group]['options']\n _compilers[compiler]['compilerType'] = groups[group]['compilerType']\n _compilers[compiler]['supportsBinary'] = groups[group]['supportsBinary']\n _compilers[compiler]['group'] = group\n\n logger.debug('Reading properties for compilers')\n for line in lines:\n sline = line.decode('utf-8').rstrip('\\n')\n if sline.startswith('compiler.'):\n keyval = sline.split('=', 1)\n key = keyval[0].split('.')\n val = keyval[1]\n if not key[1] in _compilers:\n _compilers[key[1]] = defaultdict(lambda: [])\n\n if key[2] == \"supportsBinary\":\n _compilers[key[1]][key[2]] = val == 'true'\n else:\n _compilers[key[1]][key[2]] = val\n\n logger.debug('Removing compilers that are not available or do not support binaries')\n keysToRemove = defaultdict(lambda: [])\n for compiler in _compilers:\n if 'supportsBinary' in _compilers[compiler] and not _compilers[compiler]['supportsBinary']:\n keysToRemove[compiler] = True\n elif _compilers[compiler] == 'wine-vc':\n keysToRemove[compiler] = True\n elif 'exe' in _compilers[compiler]:\n exe = _compilers[compiler]['exe']\n if not os.path.exists(exe):\n keysToRemove[compiler] = True\n else:\n keysToRemove[compiler] = True\n\n for compiler in keysToRemove:\n del _compilers[compiler]\n\n return [_compilers, _libraries]\n"
},
{
"alpha_fraction": 0.6096565127372742,
"alphanum_fraction": 0.6613175868988037,
"avg_line_length": 26.64202308654785,
"blob_id": "39bc6da80a7761a14683bdf45622e1aeeaf57b75",
"content_id": "edc418fcce26d0f8254c460b35fd482ac37b8da1",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 7104,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 257,
"path": "/update_compilers/install_rust_compilers.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSCRIPT_DIR=\"$(cd \"$(dirname \"${BASH_SOURCE[0]}\")\" && pwd)\"\n. ${SCRIPT_DIR}/common.inc\n\ndo_rust_install() {\n local DIR=$1\n local INSTALL=$2\n local IS_STD_LIB=1\n if [[ ${DIR} == rust-std-* ]]; then\n IS_STD_LIB=0\n fi\n fetch http://static.rust-lang.org/dist/${DIR}.tar.gz | tar zxvf - -C /tmp || return ${IS_STD_LIB}\n pushd /tmp/${DIR}\n if [[ ${IS_STD_LIB} -ne 0 ]]; then\n rm -rf ${OPT}/${INSTALL}\n fi\n ./install.sh --prefix=${OPT}/${INSTALL} --verbose --without=rust-docs\n popd\n rm -rf /tmp/${DIR}\n}\n\ninstall_rust() {\n local NAME=$1\n\n if [[ -d ${OPT}/rust-${NAME} ]]; then\n echo Skipping install of rust $NAME as already installed\n return\n fi\n echo Installing rust $NAME\n\n do_rust_install rustc-${NAME}-x86_64-unknown-linux-gnu rust-${NAME}\n\n # workaround for LD_LIBRARY_PATH\n ${PATCHELF} --set-rpath '$ORIGIN/../lib' ${OPT}/rust-${NAME}/bin/rustc\n for to_patch in ${OPT}/rust-${NAME}/lib/*.so; do\n ${PATCHELF} --set-rpath '$ORIGIN' $to_patch\n done\n\n # Don't need docs\n rm -rf ${OPT}/rust-${NAME}/share\n\n do_strip ${OPT}/rust-${NAME}\n}\n\ninstall_new_rust() {\n local NAME=$1\n local -a TARGETS=(\"${!2}\")\n local FORCE=$3\n local DIR=rust-${NAME}\n\n if [[ -n \"$FORCE\" && -d ${DIR} ]]; then\n local time_from=$(date -d \"now - $FORCE\" +%s)\n local dir_time=$(date -r ${DIR} +%s)\n if ((dir_time > time_from)); then\n echo \"Treating ${DIR} as up to date enough, despite force\"\n FORCE=\"\"\n fi\n fi\n\n # force install if asked, or if there's no 'cargo' (which used to happen with older builds)\n if [[ -n \"${FORCE}\" || ! -x ${OPT}/rust-${NAME}/bin/cargo ]]; then\n echo Forcing install of $NAME\n elif [[ -d ${OPT}/rust-${NAME} ]]; then\n echo Skipping install of rust $NAME as already installed\n return\n fi\n echo Installing rust $NAME\n\n do_rust_install rust-${NAME}-x86_64-unknown-linux-gnu rust-${NAME}\n for TARGET in \"${TARGETS[@]}\"; do\n do_rust_install rust-std-${NAME}-${TARGET} rust-${NAME}\n done\n\n # workaround for LD_LIBRARY_PATH\n ${PATCHELF} --set-rpath '$ORIGIN/../lib' ${OPT}/rust-${NAME}/bin/rustc\n ${PATCHELF} --set-rpath '$ORIGIN/../lib' ${OPT}/rust-${NAME}/bin/cargo\n for to_patch in ${OPT}/rust-${NAME}/lib/*.so; do\n ${PATCHELF} --set-rpath '$ORIGIN' $to_patch\n done\n\n # Don't need docs\n rm -rf ${OPT}/rust-${NAME}/share\n\n # Don't strip (llvm SOs don't seem to like it and segfault during startup)\n}\n\nRUST_TARGETS=(\n aarch64-unknown-linux-gnu\n arm-linux-androideabi\n arm-unknown-linux-gnueabi\n arm-unknown-linux-gnueabihf\n i686-apple-darwin\n i686-pc-windows-gnu\n i686-pc-windows-msvc\n i686-unknown-linux-gnu\n mips-unknown-linux-gnu\n mipsel-unknown-linux-gnu\n x86_64-apple-darwin\n x86_64-pc-windows-gnu\n x86_64-pc-windows-msvc\n x86_64-unknown-linux-gnu\n x86_64-unknown-linux-musl\n)\ninstall_new_rust 1.5.0 RUST_TARGETS[@]\ninstall_new_rust 1.6.0 RUST_TARGETS[@]\ninstall_new_rust 1.7.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n aarch64-apple-ios\n armv7-apple-ios\n armv7-unknown-linux-gnueabihf\n armv7s-apple-ios\n i386-apple-ios\n powerpc-unknown-linux-gnu\n powerpc64-unknown-linux-gnu\n powerpc64le-unknown-linux-gnu\n x86_64-apple-ios\n x86_64-rumprun-netbsd\n)\ninstall_new_rust 1.8.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n i586-pc-windows-msvc\n i686-linux-android\n i686-unknown-freebsd\n mips-unknown-linux-musl\n mipsel-unknown-linux-musl\n x86_64-unknown-freebsd\n x86_64-unknown-netbsd\n)\ninstall_new_rust 1.9.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n aarch64-linux-android\n armv7-linux-androideabi\n i586-unknown-linux-gnu\n i686-unknown-linux-musl\n)\ninstall_new_rust 1.10.0 RUST_TARGETS[@]\ninstall_new_rust 1.11.0 RUST_TARGETS[@]\ninstall_new_rust 1.12.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n mips64-unknown-linux-gnuabi64\n mips64el-unknown-linux-gnuabi64\n s390x-unknown-linux-gnu\n)\ninstall_new_rust 1.13.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n arm-unknown-linux-musleabi\n arm-unknown-linux-musleabihf\n armv7-unknown-linux-musleabihf\n asmjs-unknown-emscripten\n wasm32-unknown-emscripten\n)\ninstall_new_rust 1.14.0 RUST_TARGETS[@]\ninstall_new_rust 1.15.1 RUST_TARGETS[@]\ninstall_new_rust 1.16.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n aarch64-unknown-fuchsia\n sparc64-unknown-linux-gnu\n x86_64-unknown-fuchsia\n)\ninstall_new_rust 1.17.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n x86_64-linux-android\n)\ninstall_new_rust 1.18.0 RUST_TARGETS[@]\ninstall_new_rust 1.19.0 RUST_TARGETS[@]\ninstall_new_rust 1.20.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n x86_64-unknown-redox\n)\ninstall_new_rust 1.21.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n aarch64-unknown-linux-musl\n sparcv9-sun-solaris\n x86_64-sun-solaris\n)\ninstall_new_rust 1.22.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n x86_64-unknown-linux-gnux32\n)\ninstall_new_rust 1.23.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n armv5te-unknown-linux-gnueabi\n wasm32-unknown-unknown\n)\ninstall_new_rust 1.24.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n i586-unknown-linux-musl\n x86_64-unknown-cloudabi\n)\ninstall_new_rust 1.25.0 RUST_TARGETS[@]\ninstall_new_rust 1.26.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n armv5te-unknown-linux-musleabi\n thumbv6m-none-eabi\n thumbv7em-none-eabi\n thumbv7em-none-eabihf\n thumbv7m-none-eabi\n)\ninstall_new_rust 1.27.0 RUST_TARGETS[@]\ninstall_new_rust 1.27.1 RUST_TARGETS[@]\ninstall_new_rust 1.28.0 RUST_TARGETS[@]\ninstall_new_rust 1.29.0 RUST_TARGETS[@]\ninstall_new_rust 1.30.0 RUST_TARGETS[@]\ninstall_new_rust 1.31.0 RUST_TARGETS[@]\ninstall_new_rust 1.32.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n thumbv7neon-unknown-linux-gnueabihf\n thumbv7neon-linux-androideabi\n)\ninstall_new_rust 1.33.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n riscv32imac-unknown-none-elf\n riscv32imc-unknown-none-elf\n riscv64imac-unknown-none-elf\n riscv64gc-unknown-none-elf\n)\ninstall_new_rust 1.34.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n armv6-unknown-freebsd-gnueabihf\n armv7-unknown-freebsd-gnueabihf\n wasm32-unknown-wasi\n)\ninstall_new_rust 1.35.0 RUST_TARGETS[@]\ninstall_new_rust 1.36.0 RUST_TARGETS[@]\ninstall_new_rust 1.37.0 RUST_TARGETS[@]\n# Rust 1.38 adds some Tier 3 targets, skipping those for now\ninstall_new_rust 1.38.0 RUST_TARGETS[@]\ninstall_new_rust 1.39.0 RUST_TARGETS[@]\ninstall_new_rust 1.40.0 RUST_TARGETS[@]\nRUST_TARGETS=( \"${RUST_TARGETS[@]/i686-unknown-dragonfly/}\" )\nRUST_TARGETS+=( armv6-unknown-freebsd-gnueabihf )\ninstall_new_rust 1.41.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n armv7a-none-eabi\n riscv64gc-unknown-linux-gnu\n)\ninstall_new_rust 1.42.0 RUST_TARGETS[@]\ninstall_new_rust 1.43.0 RUST_TARGETS[@]\nRUST_TARGETS+=(\n aarch64-unknown-none\n aarch64-unknown-none-softfloat\n arm64-apple-tvos\n x86_64-apple-tvos\n)\ninstall_new_rust 1.44.0 RUST_TARGETS[@]\n\nif install_nightly; then\n install_new_rust nightly RUST_TARGETS[@] '1 day'\n install_new_rust beta RUST_TARGETS[@] '1 week'\nfi\n\ninstall_rust 1.0.0\ninstall_rust 1.1.0\ninstall_rust 1.2.0\ninstall_rust 1.3.0\ninstall_rust 1.4.0\n"
},
{
"alpha_fraction": 0.5183486342430115,
"alphanum_fraction": 0.5642201900482178,
"avg_line_length": 21.244897842407227,
"blob_id": "73c9c04bdd7652711e5ff7d034b0e6961fdc1c67",
"content_id": "59d0cced37c19c810d5f07d65679fc956a4ee4e8",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1090,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 49,
"path": "/update_compilers/install_clean_compilers.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSCRIPT_DIR=\"$(cd \"$(dirname \"${BASH_SOURCE[0]}\")\" && pwd)\"\n. ${SCRIPT_DIR}/common.inc\n\nget_clean32_old() {\n local VER=$1\n local VERNODOTS=$2\n local DIR=clean32-$VER\n\n if [[ ! -d ${DIR} ]]; then\n mkdir ${DIR}\n pushd ${DIR}\n fetch https://ftp.cs.ru.nl/Clean/Clean${VERNODOTS}/linux/clean${VER}.tar.gz | tar xzf - --strip-components 1\n popd\n fi\n}\n\nget_clean32_new() {\n local VER=$1\n local VERNODOTS=$2\n local DIR=clean32-$VER\n\n if [[ ! -d ${DIR} ]]; then\n mkdir ${DIR}\n pushd ${DIR}\n fetch https://ftp.cs.ru.nl/Clean/Clean${VERNODOTS}/linux/clean${VER}_32.tar.gz | tar xzf - --strip-components 1\n popd\n fi\n}\n\nget_clean64() {\n local VER=$1\n local VERNODOTS=$2\n local DIR=clean64-$VER\n\n if [[ ! -d ${DIR} ]]; then\n mkdir ${DIR}\n pushd ${DIR}\n fetch https://ftp.cs.ru.nl/Clean/Clean${VERNODOTS}/linux/clean${VER}_64.tar.gz | tar xzf - --strip-components 1\n popd\n fi\n}\n\nget_clean32_old 2.4 24\nget_clean32_new 3.0 30\n\nget_clean64 2.4 24\nget_clean64 3.0 30\n"
},
{
"alpha_fraction": 0.4984276592731476,
"alphanum_fraction": 0.5691823959350586,
"avg_line_length": 20.200000762939453,
"blob_id": "4500664db4d6d93b34eda0dcb3bcca18372a703e",
"content_id": "1a19bb8e72b1114cb564686a943a7533a258bb29",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 636,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 30,
"path": "/update_compilers/install_haskell_compilers.sh",
"repo_name": "Sameeranjoshi/infra",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nSCRIPT_DIR=\"$(cd \"$(dirname \"${BASH_SOURCE[0]}\")\" && pwd)\"\n. ${SCRIPT_DIR}/common.inc\n\nget_ghc() {\n local VER=$1\n local DIR=ghc-$VER\n\n if [[ ! -d ${DIR} ]]; then\n pushd /tmp\n fetch https://downloads.haskell.org/~ghc/${VER}/ghc-${VER}-x86_64-deb8-linux.tar.xz | tar Jxf -\n cd /tmp/ghc-${VER}\n ./configure --prefix=${OPT}/${DIR}\n make install\n popd\n fi\n}\n\nget_ghc 8.0.2\n# Can't install ghc 8.2.1: https://ghc.haskell.org/trac/ghc/ticket/13945\n# get_ghc 8.2.1\nget_ghc 8.2.2\nget_ghc 8.4.1\nget_ghc 8.4.2\nget_ghc 8.4.3\nget_ghc 8.4.4\nget_ghc 8.6.1\nget_ghc 8.6.2\nget_ghc 8.6.3\n"
}
] | 8 |
rayblick/abstracts_to_wordcloud
|
https://github.com/rayblick/abstracts_to_wordcloud
|
dd18eded583dd52388cd719802e383c51af4a9b0
|
f9bfc55a313266e665aac9a0295bb5a8bb397557
|
ec56ef506c37891544487c85522437341099025c
|
refs/heads/master
| 2021-05-16T01:47:57.551268 | 2017-05-01T06:26:18 | 2017-05-01T06:26:18 | 40,634,651 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6217986345291138,
"alphanum_fraction": 0.6316237449645996,
"avg_line_length": 34.50232696533203,
"blob_id": "4d28764fcbad393c8955433f23401445318e4e37",
"content_id": "99442139da09014a73aba169888a75adcbc96275",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "HTML",
"length_bytes": 15572,
"license_type": "permissive",
"max_line_length": 341,
"num_lines": 430,
"path": "/docs/build/html/pages/project.html",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "\n\n<!DOCTYPE html>\n<!--[if IE 8]><html class=\"no-js lt-ie9\" lang=\"en\" > <![endif]-->\n<!--[if gt IE 8]><!--> <html class=\"no-js\" lang=\"en\" > <!--<![endif]-->\n<head>\n <meta charset=\"utf-8\">\n \n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\n \n <title>Project Layout — Citation Management a documentation</title>\n \n\n \n \n \n \n\n \n\n \n \n \n\n \n\n \n \n <link rel=\"stylesheet\" href=\"../_static/css/theme.css\" type=\"text/css\" />\n \n\n \n\n \n <link rel=\"index\" title=\"Index\"\n href=\"../genindex.html\"/>\n <link rel=\"search\" title=\"Search\" href=\"../search.html\"/>\n <link rel=\"top\" title=\"Citation Management a documentation\" href=\"../index.html\"/>\n <link rel=\"next\" title=\"Data\" href=\"data.html\"/>\n <link rel=\"prev\" title=\"Setup\" href=\"install.html\"/> \n\n \n <script src=\"../_static/js/modernizr.min.js\"></script>\n\n</head>\n\n<body class=\"wy-body-for-nav\" role=\"document\">\n\n \n <div class=\"wy-grid-for-nav\">\n\n \n <nav data-toggle=\"wy-nav-shift\" class=\"wy-nav-side\">\n <div class=\"wy-side-scroll\">\n <div class=\"wy-side-nav-search\">\n \n\n \n <a href=\"../index.html\" class=\"icon icon-home\"> Citation Management\n \n\n \n </a>\n\n \n\n \n<div role=\"search\">\n <form id=\"rtd-search-form\" class=\"wy-form\" action=\"../search.html\" method=\"get\">\n <input type=\"text\" name=\"q\" placeholder=\"Search docs\" />\n <input type=\"hidden\" name=\"check_keywords\" value=\"yes\" />\n <input type=\"hidden\" name=\"area\" value=\"default\" />\n </form>\n</div>\n\n \n </div>\n\n <div class=\"wy-menu wy-menu-vertical\" data-spy=\"affix\" role=\"navigation\" aria-label=\"main navigation\">\n \n \n \n \n \n \n <p class=\"caption\"><span class=\"caption-text\">Contents:</span></p>\n<ul class=\"current\">\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"intro.html\">Citation Manager</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#overview\">Overview</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#aim\">Aim</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#business-rules\">Business Rules</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#scope\">Scope</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#out-of-scope\">Out of scope</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#assumptions\">Assumptions</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#limitations\">Limitations</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#time-management\">Time Management</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"intro.html#milestones\">Milestones</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"install.html\">Setup</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#base-install\">Base Install</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#package-dependencies\">Package Dependencies</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#installing-dependencies\">Installing Dependencies</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#download-repository\">Download Repository</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#jupyter-notebook\">Jupyter Notebook</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#local-install\">Local Install</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#command-line\">Command line</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#additional-notes\">Additional Notes</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"install.html#help\">Help</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1 current\"><a class=\"current reference internal\" href=\"#\">Project Layout</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#modules\">Modules</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#module-helpers\">Module Helpers</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#name-spacing\">Name spacing</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#generic-helpers\">Generic Helpers</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#structure\">Structure</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#documentation\">Documentation</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#updating-documentation\">Updating documentation</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"#docstrings\">Docstrings</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"data.html\">Data</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"data.html#location\">Location</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"data.html#name-spacing\">Name spacing</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"data.html#access\">Access</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"bibtex.html\">Bibtex Module</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#class-name\">Class Name</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#bound-methods\">Bound Methods</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#method-arguments\">Method Arguments</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#usage\">Usage</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#what-is-bibtex\">What is BibTeX?</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#bibtex-format\">BibTeX Format</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"bibtex.html#changes-and-updates\">Changes and Updates</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"wordcloud.html\">Wordcloud</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"wordcloud.html#overview\">Overview</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"wordcloud.html#example\">Example</a></li>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"wordcloud.html#output\">Output</a></li>\n</ul>\n</li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"supplementary.html\">Reference</a><ul>\n<li class=\"toctree-l2\"><a class=\"reference internal\" href=\"supplementary.html#generic-helper-functions\">Generic Helper Functions</a></li>\n</ul>\n</li>\n</ul>\n\n \n \n </div>\n </div>\n </nav>\n\n <section data-toggle=\"wy-nav-shift\" class=\"wy-nav-content-wrap\">\n\n \n <nav class=\"wy-nav-top\" role=\"navigation\" aria-label=\"top navigation\">\n \n <i data-toggle=\"wy-nav-top\" class=\"fa fa-bars\"></i>\n <a href=\"../index.html\">Citation Management</a>\n \n </nav>\n\n\n \n <div class=\"wy-nav-content\">\n <div class=\"rst-content\">\n \n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n<div role=\"navigation\" aria-label=\"breadcrumbs navigation\">\n\n <ul class=\"wy-breadcrumbs\">\n \n <li><a href=\"../index.html\">Docs</a> »</li>\n \n <li>Project Layout</li>\n \n \n <li class=\"wy-breadcrumbs-aside\">\n \n \n <a href=\"../_sources/pages/project.rst.txt\" rel=\"nofollow\"> View page source</a>\n \n \n </li>\n \n </ul>\n\n \n <hr/>\n</div>\n <div role=\"main\" class=\"document\" itemscope=\"itemscope\" itemtype=\"http://schema.org/Article\">\n <div itemprop=\"articleBody\">\n \n <div class=\"section\" id=\"project-layout\">\n<h1>Project Layout<a class=\"headerlink\" href=\"#project-layout\" title=\"Permalink to this headline\">¶</a></h1>\n<div class=\"section\" id=\"modules\">\n<h2>Modules<a class=\"headerlink\" href=\"#modules\" title=\"Permalink to this headline\">¶</a></h2>\n<ul class=\"simple\">\n<li>bibtex</li>\n<li>generic</li>\n</ul>\n</div>\n<div class=\"section\" id=\"module-helpers\">\n<h2>Module Helpers<a class=\"headerlink\" href=\"#module-helpers\" title=\"Permalink to this headline\">¶</a></h2>\n<p>All processing specific to a module is stored in a helper file and the code is reduced to a minimum in the module itself.</p>\n</div>\n<div class=\"section\" id=\"name-spacing\">\n<h2>Name spacing<a class=\"headerlink\" href=\"#name-spacing\" title=\"Permalink to this headline\">¶</a></h2>\n<p>All folders are separated with module level name spacing.</p>\n<p><strong>Examples</strong></p>\n<ul class=\"simple\">\n<li>./data/bibtex/files</li>\n<li>./data/othermodule/files</li>\n<li>./output/bibtex/files</li>\n<li>./output/othermodule/files</li>\n</ul>\n</div>\n<div class=\"section\" id=\"generic-helpers\">\n<h2>Generic Helpers<a class=\"headerlink\" href=\"#generic-helpers\" title=\"Permalink to this headline\">¶</a></h2>\n<p>Generic helpers are not module specific and are implemmented in more than one module. It should be noted here that changes to these functions may affect the performance/functionality of more than one module. Generic helpers live in a neighbouing folder and the relative path names are imported using sys.path.append(‘..’).</p>\n</div>\n<div class=\"section\" id=\"structure\">\n<h2>Structure<a class=\"headerlink\" href=\"#structure\" title=\"Permalink to this headline\">¶</a></h2>\n<div class=\"highlight-bash\"><div class=\"highlight\"><pre><span></span>CitationManager\n │\n ├───bibtex\n │ ├───__init__.py\n │ ├───bibtex.py\n │ └───helpers.py\n │\n ├───data\n │ ├───bibtex\n │ │ ├───test\n │ │ ├───train\n │ │ └───README.txt\n │ │\n │ └───shared\n │\n ├───dev\n │ ├───.ipynb_checkpoints\n │ ├───Exploration.ipynb\n │ └───Testing.ipynb\n │\n ├───docs\n │ ├───build\n │ │ └───html <span class=\"c1\">#Docs start at index.html</span>\n │ └───source\n │ └───pages\n │\n ├───generic\n │ ├───__init__.py\n │ └───helpers.py\n │\n ├───static\n │ └───img\n │\n ├───output\n │ └──bibtex\n │\n ├───__init__.py\n ├───README.md <span class=\"c1\">#Github landing page</span>\n └───...#Project build files\n</pre></div>\n</div>\n</div>\n<div class=\"section\" id=\"documentation\">\n<h2>Documentation<a class=\"headerlink\" href=\"#documentation\" title=\"Permalink to this headline\">¶</a></h2>\n<ul class=\"simple\">\n<li>Github landing page (./README.md)</li>\n<li>Sphinx documentation (./docs)</li>\n<li>Document strings</li>\n<li>Comment lines</li>\n</ul>\n</div>\n<div class=\"section\" id=\"updating-documentation\">\n<h2>Updating documentation<a class=\"headerlink\" href=\"#updating-documentation\" title=\"Permalink to this headline\">¶</a></h2>\n<p><strong>Windows</strong></p>\n<div class=\"highlight-bash\"><div class=\"highlight\"><pre><span></span>git checkout gh-pages\ndel .git<span class=\"se\">\\i</span>ndex\ngit clean -fdx\necho. <span class=\"m\">2</span>>.nojekyll\ngit checkout master docs/build/html\nxcopy .<span class=\"se\">\\d</span>ocs<span class=\"se\">\\b</span>uild<span class=\"se\">\\h</span>tml<span class=\"se\">\\*</span> .<span class=\"se\">\\ </span>/E\nrmdir /S docs\ngit add -A\ngit commit -m <span class=\"s2\">"publishing docs"</span>\ngit push origin gh-pages\n</pre></div>\n</div>\n<p><strong>Linux</strong></p>\n<div class=\"highlight-bash\"><div class=\"highlight\"><pre><span></span>git checkout gh-pages\nrm -rf .\ntouch .nojekyll\ngit checkout master docs/build/html\nmv ./docs/build/html/* ./\nrm -rf ./docs\ngit add --all\ngit commit -m <span class=\"s2\">"publishing docs"</span>\ngit push origin gh-pages\n</pre></div>\n</div>\n</div>\n<div class=\"section\" id=\"docstrings\">\n<h2>Docstrings<a class=\"headerlink\" href=\"#docstrings\" title=\"Permalink to this headline\">¶</a></h2>\n<p>Each method has a break down of its applicaiton.</p>\n<p><strong>Example (generic helper method)</strong></p>\n<div class=\"highlight-python\"><div class=\"highlight\"><pre><span></span><span class=\"k\">def</span> <span class=\"nf\">remove_stopwords</span><span class=\"p\">(</span><span class=\"n\">dictionary</span><span class=\"p\">):</span>\n <span class=\"sd\">"""</span>\n<span class=\"sd\"> Removes single letters (e.g. 'a') and stop words (e.g. 'the').</span>\n\n<span class=\"sd\"> Parameters</span>\n<span class=\"sd\"> ----------</span>\n<span class=\"sd\"> arg1: dictionary of word-count pairs.</span>\n\n<span class=\"sd\"> Exceptions</span>\n<span class=\"sd\"> ----------</span>\n<span class=\"sd\"> Try to stem each word. Exception returns the original word.</span>\n\n<span class=\"sd\"> Usage</span>\n<span class=\"sd\"> -----</span>\n<span class=\"sd\"> remove_stopwords({'running': 5})</span>\n\n<span class=\"sd\"> Returns</span>\n<span class=\"sd\"> -------</span>\n<span class=\"sd\"> Two dictionaries;</span>\n<span class=\"sd\"> 1) original words</span>\n<span class=\"sd\"> 2) stemmed words</span>\n<span class=\"sd\"> ({'running': 5}, {'run': 5})</span>\n\n<span class=\"sd\"> Doctest</span>\n<span class=\"sd\"> -------</span>\n<span class=\"sd\"> >>> remove_stopwords({'this':1, 'running':5, 'testing': 2})</span>\n<span class=\"sd\"> ({'running': 5, 'testing': 2}, {'run': 5, 'test': 2})</span>\n\n<span class=\"sd\"> """</span>\n <span class=\"c1\"># Processing...</span>\n</pre></div>\n</div>\n</div>\n</div>\n\n\n </div>\n <div class=\"articleComments\">\n \n </div>\n </div>\n <footer>\n \n <div class=\"rst-footer-buttons\" role=\"navigation\" aria-label=\"footer navigation\">\n \n <a href=\"data.html\" class=\"btn btn-neutral float-right\" title=\"Data\" accesskey=\"n\" rel=\"next\">Next <span class=\"fa fa-arrow-circle-right\"></span></a>\n \n \n <a href=\"install.html\" class=\"btn btn-neutral\" title=\"Setup\" accesskey=\"p\" rel=\"prev\"><span class=\"fa fa-arrow-circle-left\"></span> Previous</a>\n \n </div>\n \n\n <hr/>\n\n <div role=\"contentinfo\">\n <p>\n © Copyright 2017, Ray Blick.\n\n </p>\n </div>\n Built with <a href=\"http://sphinx-doc.org/\">Sphinx</a> using a <a href=\"https://github.com/snide/sphinx_rtd_theme\">theme</a> provided by <a href=\"https://readthedocs.org\">Read the Docs</a>. \n\n</footer>\n\n </div>\n </div>\n\n </section>\n\n </div>\n \n\n\n \n\n <script type=\"text/javascript\">\n var DOCUMENTATION_OPTIONS = {\n URL_ROOT:'../',\n VERSION:'a',\n COLLAPSE_INDEX:false,\n FILE_SUFFIX:'.html',\n HAS_SOURCE: true,\n SOURCELINK_SUFFIX: '.txt'\n };\n </script>\n <script type=\"text/javascript\" src=\"../_static/jquery.js\"></script>\n <script type=\"text/javascript\" src=\"../_static/underscore.js\"></script>\n <script type=\"text/javascript\" src=\"../_static/doctools.js\"></script>\n\n \n\n \n \n <script type=\"text/javascript\" src=\"../_static/js/theme.js\"></script>\n \n\n \n \n <script type=\"text/javascript\">\n jQuery(function () {\n SphinxRtdTheme.StickyNav.enable();\n });\n </script>\n \n\n</body>\n</html>"
},
{
"alpha_fraction": 0.724693775177002,
"alphanum_fraction": 0.7317859530448914,
"avg_line_length": 25.741378784179688,
"blob_id": "bc0a8dbadff014cc20052963a7663c6bbdd7e24b",
"content_id": "4e714034365e3ff81daef4aacaa81aab406cc930",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1551,
"license_type": "permissive",
"max_line_length": 778,
"num_lines": 58,
"path": "/docs/source/pages/intro.rst",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Citation Manager\n=================\n\n:Authors:\n Ray Blick\n:Version: 0.0.1\n:Last update: 2017/05/01\n\nOverview\n---------\nThe \"Citation Manager\" has two primary objectives. First, to process different types of citation content, such as exported citations from JSTOR (Bitbtex). Second, to provide a text-based prediction algorithm that evaluates titles, abstracts or keywords to predict the labelling of records. For example, evaluate an abstract to identify the most similar journal. This package is compartmentalised into specific standalone modules but share a set of generic helper methods. Setup files are provided for easy install to python. Example data are provided in the /data/ directory and uses namespace convention for module specific content. Share data are stored in /data/shared folder. All of the development for this project was performed using Jupyter Notebook and Atom text editor.\n\nAim\n----\nProcess citations and predict labelling.\n\nBusiness Rules\n-----------------\n- None\n\nScope\n------\n- Python Language\n- Text processing\n- XML processing\n- Text classifiers in Sklearn\n- Data visualisation (wordclouds)\n- Git and Github\n- Sphinx documentation\n- gh-pages\n- Prediction accuracy\n- Example lightweight analysis\n\nOut of scope\n-------------\n- User Interface\n- Web application\n- Deployment on PyPI\n\nAssumptions\n------------\n- None\n\nLimitations\n-----------\n- None\n\nTime Management\n----------------\n- Any free time\n\nMilestones\n------------\n- Build project/package layout\n- Text-based processing\n- Text classifier\n- Documentation\n- Setup files\n"
},
{
"alpha_fraction": 0.6669580340385437,
"alphanum_fraction": 0.6800699234008789,
"avg_line_length": 24.422222137451172,
"blob_id": "33d1b1fbe13e48fbefc9c006dad1de96d1986dfe",
"content_id": "8da224427c80076e7a2f5f4dd57191cfd26d74de",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 1144,
"license_type": "permissive",
"max_line_length": 239,
"num_lines": 45,
"path": "/docs/build/html/_sources/pages/wordcloud.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Wordcloud\n==========\n\nOverview\n----------\nA wordcloud is a visual representation of the words used in a document. This example uses the Bibtex module to process references exported from JSTOR. An image in png format with a transparent background can be used to shape the wordcloud.\n\nExample\n--------\n\n.. code-block:: python\n\n # import wordcloud\n from wordcloud import WordCloud\n from wordcloud import STOPWORDS\n\n # import custom library\n from CitationManager.bibtex import bibtex as bb\n citations = bb.Bibtex()\n citations.process_citations()\n\n # Provide a mask\n clip_mask = imread(\"../static/img/tree.png\")\n\n # Create wordcloud\n wc = WordCloud(background_color=\"white\", width=800,\n height=800, mask=clip_mask, max_words=400, stopwords=STOPWORDS)\n\n # Generate freq from original words form the first article\n wc.generate_from_frequencies(citations.original_words[0][1])\n\n # Plot\n plt.figure(figsize=(16,14))\n plt.imshow(wc)\n plt.axis(\"off\")\n plt.show\n\n # Output to file\n wc.to_file(\"../output/img/bibtex/tree.png\")\n\n\nOutput\n-------\n\n.. image:: ../../../output/img/bibtex/tree.png\n"
},
{
"alpha_fraction": 0.6188870072364807,
"alphanum_fraction": 0.6408094167709351,
"avg_line_length": 21.80769157409668,
"blob_id": "03aab331460151517fa873b4c9804db22cb71b13",
"content_id": "121810038b884489d0b59c0c67f27d371b4d3c9c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 593,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 26,
"path": "/docs/build/html/_sources/index.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": ".. Citation Management documentation master file, created by\n sphinx-quickstart on Fri Apr 28 22:43:11 2017.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\nWelcome to Citation Management's documentation!\n===============================================\n\n.. toctree::\n :maxdepth: 2\n :caption: Contents:\n\n pages/intro\n pages/install\n pages/project\n pages/data\n pages/bibtex\n pages/wordcloud\n pages/supplementary\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.5472754240036011,
"alphanum_fraction": 0.5484536290168762,
"avg_line_length": 25.732282638549805,
"blob_id": "1025bbe67643c44ed7745ef865d6f9f18b6b1750",
"content_id": "816625d9aef9fcaf2909372043ecd489cb6111a9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3395,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 127,
"path": "/bibtex/helpers.py",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "\"\"\"\nHelpers to parse bibtex citations.\n\"\"\"\nimport re\nimport sys\nsys.path.append('..')\nfrom generic import helpers as gh\n\ndef bibtex_splitter(file):\n \"\"\"\n Summary\n --------\n Helper function to splitter text document into citation articles\n and process hard coded parameters. The input txt file needs to be\n a set of citations downloaded in Bibtex format. There are specific\n patterns that are looked for to split the text document such as\n the @article value to separate the primary content. Returns a list\n of dictionaries containing all of the keywords defined in this method.\n\n Parameters\n -----------\n arg1: txt file\n\n Usage\n -----\n text = open('data/more_citations.txt', 'r')\n bibtex_splitter(text)\n\n Example data\n -------------\n\n\n Returns\n ---------\n\n \"\"\"\n # Placeholder\n textcapture = []\n\n # List of items to collect\n items = ['ISSN =', 'URL =','abstract =', 'author =', 'journal =', 'number =',\n 'pages =', 'publisher =', 'title =', 'volume =', 'year =']\n\n # Loop over the file (txt file)\n for doc in file.read().split('@'):\n temp = {}\n for item in items:\n m = re.search(item, doc)\n try:\n item_end = doc[m.end(): ]\n capture = item_end[item_end.find('{') + 1 : item_end.find('}')]\n temp[item[:-2]] = capture\n\n except:\n pass\n\n # Add list\n textcapture.append(temp)\n\n return textcapture\n\n\n\ndef process_citations_handle(docpath, docformat):\n \"\"\"Parse documents containing bibtex citations.\"\"\"\n\n # placeholders\n original_words = []\n stemmed_words = []\n metadata = []\n\n # collect documents\n docs = gh.doc_finder_handle(docpath, docformat)\n\n # loop over docs\n for each_file in docs:\n\n # open text file\n text = open(each_file, 'r', encoding=\"utf8\")\n\n # split text\n bs = bibtex_splitter(text)\n\n # read in each article\n for article in bs:\n\n # skip if no data\n if article == {}:\n continue\n\n else:\n try:\n # temp palce holder\n temp = []\n\n # Convert string to words dictionary\n output_text = gh.word_cleaning_handle(article['abstract'])\n\n # Drop stopwords and apply stemming\n originalwords, stemmedwords = gh.remove_stopwords(output_text)\n\n # collect article attibutes\n #article.pop('abstract', None)\n if article['abstract'] != {}:\n article['abstract'] = \"Y\"\n\n # Append results\n original_words.append([article, originalwords])\n stemmed_words.append([article, stemmedwords])\n\n except:\n pass\n\n finally:\n # Append results\n metadata.append(article)\n\n # Drop duplicates\n metadata = gh.deduplicate_dictionary(metadata)\n stemmed_words = gh.deduplicate_listoflists(stemmed_words)\n original_words = gh.deduplicate_listoflists(original_words)\n\n # Create table for article details\n metadata = gh.list_of_dictionaries_to_dataframe(metadata)\n\n # Return results\n return metadata, stemmed_words, original_words\n"
},
{
"alpha_fraction": 0.5369085073471069,
"alphanum_fraction": 0.5413249135017395,
"avg_line_length": 19.45161247253418,
"blob_id": "0546dfb20e0749b652383596014a99cf958dee40",
"content_id": "3d1a6cd16eaec4868786f330a360e92dce2812b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 3466,
"license_type": "permissive",
"max_line_length": 322,
"num_lines": 155,
"path": "/docs/build/html/_sources/pages/project.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Project Layout\n===============\n\nModules\n--------\n- bibtex\n- generic\n\nModule Helpers\n---------------\nAll processing specific to a module is stored in a helper file and the code is reduced to a minimum in the module itself.\n\nName spacing\n-------------\nAll folders are separated with module level name spacing.\n\n**Examples**\n\n- ./data/bibtex/files\n- ./data/othermodule/files\n- ./output/bibtex/files\n- ./output/othermodule/files\n\nGeneric Helpers\n----------------\nGeneric helpers are not module specific and are implemmented in more than one module. It should be noted here that changes to these functions may affect the performance/functionality of more than one module. Generic helpers live in a neighbouing folder and the relative path names are imported using sys.path.append('..').\n\nStructure\n-----------\n\n.. code-block:: bash\n\n CitationManager\n │\n ├───bibtex\n │ ├───__init__.py\n │ ├───bibtex.py\n │ └───helpers.py\n │\n ├───data\n │ ├───bibtex\n │ │ ├───test\n │ │ ├───train\n │ │ └───README.txt\n │ │\n │ └───shared\n │\n ├───dev\n │ ├───.ipynb_checkpoints\n │ ├───Exploration.ipynb\n │ └───Testing.ipynb\n │\n ├───docs\n │ ├───build\n │ │ └───html #Docs start at index.html\n │ └───source\n │ └───pages\n │\n ├───generic\n │ ├───__init__.py\n │ └───helpers.py\n │\n ├───static\n │ └───img\n │\n ├───output\n │ └──bibtex\n │\n ├───__init__.py\n ├───README.md #Github landing page\n └───...#Project build files\n\n\nDocumentation\n---------------\n\n- Github landing page (./README.md)\n- Sphinx documentation (./docs)\n- Document strings\n- Comment lines\n\n\nUpdating documentation\n------------------------\n\n**Windows**\n\n.. code-block:: bash\n\n git checkout gh-pages\n del .git\\index\n git clean -fdx\n echo. 2>.nojekyll\n git checkout master docs/build/html\n xcopy .\\docs\\build\\html\\* .\\ /E\n rmdir /S docs\n git add -A\n git commit -m \"publishing docs\"\n git push origin gh-pages\n\n\n**Linux**\n\n.. code-block:: bash\n\n git checkout gh-pages\n rm -rf .\n touch .nojekyll\n git checkout master docs/build/html\n mv ./docs/build/html/* ./\n rm -rf ./docs\n git add --all\n git commit -m \"publishing docs\"\n git push origin gh-pages\n\n\n\nDocstrings\n-----------\nEach method has a break down of its applicaiton.\n\n**Example (generic helper method)**\n\n.. code-block:: python\n\n def remove_stopwords(dictionary):\n \"\"\"\n Removes single letters (e.g. 'a') and stop words (e.g. 'the').\n\n Parameters\n ----------\n arg1: dictionary of word-count pairs.\n\n Exceptions\n ----------\n Try to stem each word. Exception returns the original word.\n\n Usage\n -----\n remove_stopwords({'running': 5})\n\n Returns\n -------\n Two dictionaries;\n 1) original words\n 2) stemmed words\n ({'running': 5}, {'run': 5})\n\n Doctest\n -------\n >>> remove_stopwords({'this':1, 'running':5, 'testing': 2})\n ({'running': 5, 'testing': 2}, {'run': 5, 'test': 2})\n\n \"\"\"\n # Processing...\n"
},
{
"alpha_fraction": 0.40789473056793213,
"alphanum_fraction": 0.40789473056793213,
"avg_line_length": 14.199999809265137,
"blob_id": "1e2f66e3b06318bc958420bd35b3c861f91cb503",
"content_id": "a7cb06722d4c808ff031ae185ac47f3e0fa03468",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 76,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 5,
"path": "/docs/build/html/_sources/pages/supplementary.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Reference \n===========\n\nGeneric Helper Functions\n--------------------------\n"
},
{
"alpha_fraction": 0.6296928524971008,
"alphanum_fraction": 0.6348122954368591,
"avg_line_length": 35.625,
"blob_id": "9d577d879a9a7702608c41812e7ee59b717d601b",
"content_id": "4d0ef12ef3acc61730056c59f1054c367a9146d0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 586,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 16,
"path": "/settings.py",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(\n name = \"CitationManager\",\n version = \"0.0.1\",\n packages = ['bibtex', 'generic'],\n long_description = 'Text processing and classification',\n install_requires = ['pandas','sklearn','wordcloud','glob'],\n include_package_data = True,\n package_data = {'CitationManager': ['data/','static/','output/','docs/']},\n author = \"Ray Blick\",\n author_email = \"[email protected]\",\n description = 'Text processing and classification',\n keywords = [\"Text processing\", \"NLTK\", \"natural language\", \"citations\"],\n url = \"rayblick.github.io/\",\n)\n"
},
{
"alpha_fraction": 0.8092783689498901,
"alphanum_fraction": 0.8092783689498901,
"avg_line_length": 63.66666793823242,
"blob_id": "e7a4897ef85ad197d3e582324e18392dd0bf51ec",
"content_id": "d1cd404da8cf131bef79c067b5be4c65b67c2b4f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 194,
"license_type": "permissive",
"max_line_length": 173,
"num_lines": 3,
"path": "/README.md",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "# Citation Manager\n\nThis is a python package that contains convienence wrappers to assess citation exports. [Documentation can be found here.](https://rayblick.github.io/CitationManager/index).\n"
},
{
"alpha_fraction": 0.6681034564971924,
"alphanum_fraction": 0.6681034564971924,
"avg_line_length": 15.571428298950195,
"blob_id": "d299b6e894fa20a56b3d1a69ecbf76b5bff958aa",
"content_id": "ddae54f751edbfec2e1d6f243839bbab0e54b05b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 464,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 28,
"path": "/docs/build/html/_sources/pages/data.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Data\n=====\n\nLocation\n----------\n\n- ./data/\n\nName spacing\n-------------\n\nAll folders are separated with module level name spacing.\n\n**Example**\n\n- ./data/bibtex/train/files\n- ./data/bibtex/test/files\n- ./data/shared/files\n\n\nAccess\n-------\nAccess data using relative links. Default file path and document format are provided.\n\n.. code-block:: python\n\n # Example code block from bibtex module\n process_citations(docpath='../data/bibtex/train', docformat='txt')\n"
},
{
"alpha_fraction": 0.641470193862915,
"alphanum_fraction": 0.6511788964271545,
"avg_line_length": 15.574712753295898,
"blob_id": "afc85df2b6ab76f8542f4329730175a1d57d0ed5",
"content_id": "0059b0bf8fb07929342b8500473e13a56dfaa3ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 1450,
"license_type": "permissive",
"max_line_length": 244,
"num_lines": 87,
"path": "/docs/build/html/_sources/pages/install.rst.txt",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Setup\n======\n\nBase Install\n-------------\n\n- Download/Install Anaconda: https://www.continuum.io/downloads\n\n\nPackage Dependencies\n----------------------\n\n- glob\n- sklearn\n- pandas\n- **wordcloud** (requires install)\n- Jupyter Notebook\n\n\nInstalling Dependencies\n-------------------------\n\n**Install wordcloud (linux)**\n\n.. code-block:: bash\n\n conda install -c amueller wordcloud=1.3.1\n\n\n**Install wordcloud (Windows)**\n\n.. code-block:: bash\n\n #Download from http://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud\n pip install wordcloud‑1.3.1‑cp35‑cp35m‑win_amd64.whl\n\n\nDownload Repository\n---------------------\n\n.. code-block:: bash\n\n git clone https://github.com/rayblick/CitationManager\n\n\nJupyter Notebook\n------------------\n\n.. code-block:: bash\n\n cd CitationManager\n sudo jupyter notebook\n\n # Navigate to module-level examples\n # e.g. /dev/bibtex.ipynb\n\n\nLocal Install\n---------------\nTBA\n\n\nCommand line\n--------------\nTBA\n\n\nAdditional Notes\n-------------------\n\n**Data**\n\nEach module has example data. Default arguments that require data will look in the \"data/module/train\" or \"data/module/test\" folders. To get started, you can add two additional folders and specify the new document path when calling each method.\n\n**Example**\n\n- data/module/test/\n- data/module/train/\n- data/module/yourtestdata/addedfiles\n- data/module/yourtraindata/addedfiles\n\n\nHelp\n------\n\n1. docs/build/html/pages/reference.html\n2. Docstrings\n"
},
{
"alpha_fraction": 0.6638008952140808,
"alphanum_fraction": 0.6638008952140808,
"avg_line_length": 34.64516067504883,
"blob_id": "a4441b6fd8e5aa6156a2f8ed840df8b04a3d0cbe",
"content_id": "9d6f78cd41250d516d3c605db4397d63e4eca423",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2210,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 62,
"path": "/bibtex/bibtex.py",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "# Custom libraries\nimport sys\nsys.path.append('..')\nfrom generic import helpers as gh\nfrom bibtex import helpers as bh\n\n# Existing libraries\nimport glob\nimport pandas as pd\nfrom wordcloud import WordCloud\nfrom sklearn.naive_bayes import MultinomialNB\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.feature_extraction.text import TfidfTransformer\n\nclass Bibtex(object):\n\n def __init__(self):\n self.original_words = []\n self.stemmed_words = []\n self.metadata = []\n self.docformat = \"\"\n\n\n def process_citations(self, docpath='../data/bibtex/train', docformat='txt'):\n self.docformat = docformat\n self.metadata, self.stemmed_words, self.original_words = bh.process_citations_handle(docpath, docformat)\n\n\n def predict_citation_label(self, testpath='../data/bibtex/test',\n pattern='stemmed', targetlabelname='journal'):\n\n # prepare test data\n md, sd, od = bh.process_citations_handle(testpath, self.docformat)\n\n # create identifiers, labels and data\n if pattern == \"original\":\n idtrain, ylabels, xdata = gh.create_labels(self.original_words, targetlabelname)\n idtest, ytest, xtest = gh.create_labels(od, targetlabelname)\n else:\n idtrain, ylabels, xdata = gh.create_labels(self.stemmed_words, targetlabelname)\n idtest, ytest, xtest = gh.create_labels(sd, targetlabelname)\n\n\t # Create array of counts\n vec = DictVectorizer()\n xtrain = vec.fit_transform(xdata)\n xtest = vec.transform(xtest)\n\n # transform by freq and fit\n tf_transformer = TfidfTransformer()\n xtrain_tf = tf_transformer.fit_transform(xtrain)\n xtest_tf = tf_transformer.transform(xtest)\n\n # fit train and predict test data\n clf = MultinomialNB().fit(xtrain_tf, ylabels)\n predicted = clf.predict(xtest_tf)\n\n # print setup\n df = ([y for y in zip(idtest, ytest, [x for x in predicted])])\n resultsDF = pd.DataFrame(df, columns=['URL', targetlabelname, 'prediction'])\n\n # reutrn dataframe\n return pd.merge(md, resultsDF, left_on=['URL', targetlabelname], right_on=['URL', targetlabelname])\n"
},
{
"alpha_fraction": 0.47869423031806946,
"alphanum_fraction": 0.49102914333343506,
"avg_line_length": 21.473388671875,
"blob_id": "a8e385d49386289a9a5ab3092734ae6187409dde",
"content_id": "987ed6d36d62ca9a49a34b37769672df8c4ca5a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8026,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 357,
"path": "/generic/helpers.py",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGeneric helpers not specific to one citation style.\n\"\"\"\nimport glob\nfrom nltk.stem.snowball import SnowballStemmer\nimport re\nfrom wordcloud import STOPWORDS\nimport pandas as pd\nfrom sklearn.feature_extraction import DictVectorizer\nfrom sklearn.feature_extraction.text import TfidfTransformer\n\n# Add stemmer\nstemmer = SnowballStemmer(\"english\")\nstemmer.stem(\"Running\")\n\ndef doc_finder_handle(basepath, fileformat):\n \"\"\"\n Finds files of a particular format in dir that is given in basepath.\n\n Parameters\n ----------\n arg1: String defining a file path\n arg2: String defining document format \n\n Default args\n ------------\n None\n\n Exceptions\n ----------\n None\n\n Usage\n -----\n # add test.txt to data/test dir\n doc_finder_handle(data/test, 'txt')\n\n Returns\n -------\n ['text.txt']\n\n Doctest\n -------\n None\n\n \"\"\"\n # place holder\n docs = []\n\n # Loop over files\n for each_file in glob.glob(basepath + '/*.' + fileformat):\n docs.append(each_file)\n\n # return docs\n return docs\n\n\ndef word_cleaning_handle(string_of_text):\n \"\"\"\n Converts a string to a dictionary of words. \n \n Parameters\n ----------\n arg1: string\n\n Default args\n ------------ \n None\n\n Exceptions\n ----------\n None\n \n Usage\n ------\n word_cleaning_handle('this test')\n \n Returns\n -------\n {'this': 1, 'test': 1}\n \n Doctest\n -------\n >>> word_cleaning_handle('text65[12];:')\n {'text': 1}\n \"\"\"\n # Empty dictionary\n dictionary_of_words ={}\n \n # Regex to process each word\n regex = re.compile(\"[%()^$0-9,'\\.;:!?{}\\]\\[]\")\n \n # loop over a string split by whitespace\n for word in string_of_text.split(' '):\n \n # implement regex from above for each word\n m = regex.sub('', word)\n \n # drop spaces and single letters \n if len(m) > 1:\n # note the use of lower case | add words to dictionary\n dictionary_of_words[m.lower()] = dictionary_of_words.get(m.lower(), 0) + 1\n \n # Return the results\n return dictionary_of_words\n\n\ndef remove_stopwords(dictionary):\n \"\"\"\n Removes single letters (e.g. 'a') and stop words (e.g. 'the').\n\n Parameters\n ----------\n arg1: dictionary of word-count pairs\n\n Exceptions\n ----------\n Try to stem each word. Exception returns the original word.\n\n Usage\n -----\n remove_stopwords({'running': 5})\n\n Returns\n -------\n Two dictionaries; \n 1) original words \n 2) stemmed words\n ({'running': 5}, {'run': 5})\n\n Doctest\n -------\n >>> remove_stopwords({'this':1, 'running':5, 'testing': 2})\n ({'running': 5, 'testing': 2}, {'run': 5, 'test': 2})\n\n \"\"\"\n # Placeholder for output\n stemmed_journal_words = {}\n original_journal_words = {}\n \n # pull key-value pairs from dictionary and parse out stopwords\n for key, value in dictionary.items():\n\n # pass on all stop words\n if re.search(r'\\\\', key) or key in STOPWORDS:\n pass\n\n else: \n try: \n # Add stemmed word \n key_stem = stemmer.stem(key)\n stemmed_journal_words[key_stem] = stemmed_journal_words.get(\n key_stem.lower(), 0) + value\n\n except:\n # If stemming fails enter the original word\n stemmed_journal_words[key] = stemmed_journal_words.get(\n key.lower(), 0) + value\n\n finally: \n # Add in original words \n original_journal_words[key] = original_journal_words.get(\n key.lower(), 0) + value\n \n return original_journal_words, stemmed_journal_words\n\n\n\ndef deduplicate_dictionary(listofdictionaries):\n \"\"\"\n Removes duplicate dictionaries in a list.\n\n Parameters\n ----------\n arg1: list containing dictionaries\n\n Exceptions\n ----------\n None\n\n Usage\n -----\n # list\n list_of_dictionaries = [{'dict1': 2}, \n {'dict1': 2}, \n {'dict2': 3}]\n # run\n deduplicate_dictionary(list_of_dictionaries)\n\n Returns\n -------\n No order is assumed in the output\n [{'dict1': 2}, {'dict2': 3}]\n\n Doctest\n -------\n >>> deduplicate_dictionary([{'test': 2}, {'test': 2}])\n [{'test': 2}]\n\n \"\"\"\n return [dict(tupleized) for tupleized in set(tuple(item.items()) for item in listofdictionaries)]\n\n\ndef deduplicate_listoflists(listoflists):\n \"\"\"\n Remove double ups in lists.\n\n Parameters\n ----------\n arg1: list of lists\n\n Exceptions\n ----------\n None\n\n Usage\n -----\n deduplicate_listoflists([['test'], \n ['test']])\n\n Returns\n -------\n [['test']]\n\n Doctest\n -------\n >>> deduplicate_listoflists([[1,2], [1,2]])\n [[1, 2]]\n \n \"\"\"\n temp=[]\n for i in listoflists:\n if i not in temp:\n temp.append(i)\n return temp\n\n\ndef list_of_dictionaries_to_dataframe(data):\n \"\"\"\n Uses the first dictionary keys to build the headers.\n Then appends all data to the df.\n\n Parameters\n ----------\n arg1: list of dictionaries\n\n Exceptions\n ----------\n None\n\n Usage\n -----\n list_of_dictionaries_to_dataframe([{'Field': 'Science', \"Issue\": 1}, \n {'Field': 'Art', \"Issue\": 23}])\n\n Returns\n -------\n pandas dataframe\n\n output =\n ---------------------------------\n | ID | Field | Issue |\n ---------------------------------\n | 0 | Science | 1.0 |\n | 1 | Art | 23.0 |\n ---------------------------------\n\n\n Mismatch Error\n --------------\n If dictionary keys dont match then ne columns are generated in the output\n Example,\n list_of_dictionaries_to_dataframe([{'Field': 'Science', \"Issue\": 1}, \n {'Topic': 'Art', \"Issue\": 23}]) \n output =\n -------------------------------------------\n | ID | Field | Issue | Topic |\n -------------------------------------------\n | 0 | Science | 1.0 | NaN |\n | 1 | NaN | 23.0 | Art |\n -------------------------------------------\n\n\n Doctest\n -------\n None\n\n \"\"\"\n myDF = pd.DataFrame(columns = data[0].keys())\n for citation in data:\n myDF = myDF.append(citation, ignore_index=True)\n return myDF\n\n\ndef create_labels(data, labelname):\n \"\"\"\n Generates labels, data and identifier fields for analysis. \n\n Parameters\n ----------\n arg1: List of lists, each list contains 2 dictionaries.\n arg2: String specifying a key to use as labels \n\n Exceptions\n ----------\n None\n\n Usage\n -----\n data = [\n [{'URL': '[email protected]',\n 'journal': 'Ecology',\n 'title': 'Home ranges of a bird'},\n {'aerial': 1,\n 'aim': 1,\n 'area': 1,\n 'assemblages': 1}],\n\n [{'URL': '[email protected]',\n 'journal': 'Biology',\n 'title': 'Invasion of a rat'},\n {'cover': 1,\n 'toxic': 1,\n 'prey': 1,\n 'predator': 1}]\n ]\n \n create_labels(data, 'journal')\n\n Returns\n -------\n Three lists each in the order of processing.\n 1) identifier (list)\n 2) labelname (list)\n 3) word counts (dictionary) \n\n (['[email protected]', '[email protected]'],\n ['Ecology', 'Biology'],\n [{'aerial': 1, 'aim': 1, 'area': 1, 'assemblages': 1},\n {'cover': 1, 'predator': 1, 'prey': 1, 'toxic': 1}])\n\n Doctest\n -------\n None\n \n \"\"\"\n ylabels = []\n identifier = []\n xdicts = []\n\n for i in range(len(data)):\n label = data[i][0][labelname]\n ylabels.append(label)\n identifier.append(data[i][0][\"URL\"])\n xdicts.append(data[i][1])\n\n return identifier, ylabels, xdicts\n\n\n\n"
},
{
"alpha_fraction": 0.6368421316146851,
"alphanum_fraction": 0.6540669798851013,
"avg_line_length": 26.866666793823242,
"blob_id": "e7cc56c745db34ac6cf199be634777f14f3bd270",
"content_id": "71fea2bd0779d2f03837a89f24e927a7a877df71",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2091,
"license_type": "permissive",
"max_line_length": 312,
"num_lines": 75,
"path": "/docs/source/pages/bibtex.rst",
"repo_name": "rayblick/abstracts_to_wordcloud",
"src_encoding": "UTF-8",
"text": "Bibtex Module\n===============\n\nClass Name\n-----------\n- Bibtex\n\n\nBound Methods\n--------------\nThe BibTeX module has two methods:\n\n1. process_citations()\n2. predict_citation_label()\n\n\nMethod Arguments\n-----------------\n\n**process_citations**\n\n- docpath (e.g. '../data/bibtex/train' [default])\n- docformat (e.g. txt [default])\n\n**predict_citation_label**\n\n- testpath (e.g. '../data/bibtex/test' [default])\n- pattern ('original' or 'stemmed' [default = stemmed])\n- targetlabelname (e.g. 'journal' [default])\n\n\nUsage\n-------\n\n.. code-block:: python\n\n from CitationManager.bibtex import bibtex as bb\n citations = bb.Bibtex()\n # do processing\n citations.process_citations(docpath='../data/bibtex/train', docformat='txt')\n citations.predict_citation_label(pattern=\"original\")\n\n\nWhat is BibTeX?\n----------------\nBibTeX is a file format that describes references. The format of a BibTex document uses \"@\" syntax such as @article, @book, @inproceedings. A citation export from JSTOR is saved in a txt file format. The special symbols are used in this module to separate the text document prior to text processing and analysis.\n\n\nBibTeX Format\n--------------\n\n.. code-block:: markdown\n\n @article{1970,\n jstor_articletype = {misc},\n title = {Front Matter},\n author = {},\n journal = {Journal of Ecology},\n jstor_issuetitle = {},\n volume = {58},\n number = {1},\n jstor_formatteddate = {Mar., 1970},\n pages = {pp. i-ii},\n url = {http://www.jstor.org/stable/2258166},\n ISSN = {00220477},\n abstract = {This is a replacement string for this abstract.},\n language = {English},\n year = {1970},\n publisher = {British Ecological Society},\n copyright = {Copyright © 1970 British Ecological Society},\n }\n\nChanges and Updates\n---------------------\nIf you need to make changes to this module then you should focus on two scripts only. These scripts include the module (bibtex.py) and the associated helpers (helpers.py). However, the module mostly calls the functions defined in the helper files so changes will mostly occur there.\n"
}
] | 14 |
lipuyu/py_elasticsearch_test
|
https://github.com/lipuyu/py_elasticsearch_test
|
38e2a72308d1f0f19cd2887360c6e715aedff10c
|
9db2c619ce1497cde6692cabc6e0cb7bc00d27a7
|
3886a6d3a7dcaa88c430158535a0928d7903953a
|
refs/heads/master
| 2020-07-02T05:30:34.127266 | 2016-11-21T10:19:50 | 2016-11-21T10:19:50 | 74,320,983 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7132075428962708,
"alphanum_fraction": 0.7811321020126343,
"avg_line_length": 32,
"blob_id": "2cd5727533803eb6c07357a03d334ce9f4fdfd12",
"content_id": "75e39d9bff320903c7d7926ed654c7551dc42d1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 8,
"path": "/ex/ignore.py",
"repo_name": "lipuyu/py_elasticsearch_test",
"src_encoding": "UTF-8",
"text": "from elasticsearch import Elasticsearch\nes = Elasticsearch()\n\n# ignore 400 cause by IndexAlreadyExistsException when creating an index\nes.indices.create(index='test-index', ignore=400)\n\n# ignore 404 and 400\nes.indices.delete(index='test-index', ignore=[400, 404])\n\n"
}
] | 1 |
MugeraH/django_youtube_search
|
https://github.com/MugeraH/django_youtube_search
|
7f984eb93521c93a65e9b519f5589b2cbe4d7a6d
|
658c4be1f1cef12fc9046440922556b673991d59
|
30e357f3a315a4be4be992f386fe0d25e3c4b80a
|
refs/heads/main
| 2023-06-15T19:49:46.805407 | 2021-07-13T03:04:36 | 2021-07-13T03:04:36 | 384,148,039 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49896156787872314,
"alphanum_fraction": 0.5031152367591858,
"avg_line_length": 29.571428298950195,
"blob_id": "4e115a1e2f08bba365b5b9637e6cc8cc0ff8c243",
"content_id": "7778f589ac8dab5a1335b01e3494b22ae9866882",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1926,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 63,
"path": "/youtube/views.py",
"repo_name": "MugeraH/django_youtube_search",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,redirect\nimport requests\nfrom isodate import parse_duration\n\nfrom django.conf import settings\n\n\n\ndef Home(request):\n videos = []\n if request.method == 'POST':\n \n search_url = 'https://www.googleapis.com/youtube/v3/search'\n video_url = 'https://www.googleapis.com/youtube/v3/videos'\n \n search_params = {\n 'part':'snippet',\n 'q':request.POST['search'],\n 'key': settings.YOUTUBE_API_KEY,\n 'maxResults':9,\n 'type':'video'\n }\n \n video_ids = []\n rr = requests.get(search_url,params=search_params)\n # print(rr.json()['items'][0]['id']['videoId'])\n results = rr.json()['items']\n for result in results:\n video_ids.append(result['id']['videoId'])\n \n # function to redirect directly\n # if request.POST['submit'] == 'lucky':\n # return redirect(f'https://www.youtube.com/watch?v={video_ids[0]}')\n \n video_params = {\n 'part':'snippet,contentDetails',\n 'id':','.join(video_ids),\n 'key': settings.YOUTUBE_API_KEY,\n 'maxResults':9,\n \n }\n \n rr= requests.get(video_url,params=video_params)\n results=rr.json()['items']\n \n \n for result in results:\n video_data ={\n 'id':result['id'],\n 'title':result['snippet']['title'],\n 'url':f'https://www.youtube.com/watch?v={result[\"id\"]}',\n 'duration':int(parse_duration(result['contentDetails']['duration']).total_seconds()//60),\n 'thumbnail':result['snippet']['thumbnails']['high']['url']\n }\n videos.append(video_data)\n \n \n ctx={\n 'videos':videos\n } \n \n \n return render(request,\"home.html\",ctx)\n"
}
] | 1 |
subrockmann/image-collector
|
https://github.com/subrockmann/image-collector
|
b5afde5a155432be81add928ddb109814b30dd1f
|
51885e7045ed546feaf89ff42aa23238c7b4579f
|
4a39d4b7d86ce2ae9fe33dc88badf566171955be
|
refs/heads/master
| 2021-07-09T18:32:09.090036 | 2020-02-09T20:40:21 | 2020-02-09T20:40:21 | 238,448,453 | 0 | 0 | null | 2020-02-05T12:46:25 | 2020-02-09T20:40:34 | 2021-03-20T02:51:17 |
Python
|
[
{
"alpha_fraction": 0.650602400302887,
"alphanum_fraction": 0.6512717604637146,
"avg_line_length": 24.3389835357666,
"blob_id": "b8994b7019e8f3c7d2993eeb476f5bffa2b94f5d",
"content_id": "24fe40476702f1243142471c9e727a45cec781b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 59,
"path": "/app/routes.py",
"repo_name": "subrockmann/image-collector",
"src_encoding": "UTF-8",
"text": "from flask import render_template \nfrom flask import request, redirect, flash\nfrom flask_wtf import FlaskForm\n\n\nfrom werkzeug.utils import secure_filename\nfrom app import app\nfrom pathlib import Path\nimport os\nfrom os.path import dirname\n\nUPLOAD_FOLDER = os.path.join(dirname(dirname(os.path.realpath(__file__))), 'uploads')\nALLOWED_EXTENSIONS = {'txt', 'pdf', 'png', 'jpg', 'jpeg', 'gif'}\n\napp.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER\n\n\[email protected]('/')\[email protected]('/index') \ndef index():\n #return \"Index\"\n user = {'username': 'Peter'}\n return render_template('index.html', title='Home', user=user)\n\[email protected]('/about')\ndef about():\n return render_template('about.html')\n\[email protected]('/upload')\ndef upload():\n return render_template('upload.html')\n\n\[email protected](\"/upload-image\", methods=[\"GET\", \"POST\"])\ndef upload_image():\n\n if request.method == \"POST\":\n\n if request.files:\n image = request.files[\"image\"]\n filename = secure_filename(image.filename)\n #flash(\"Image saved.\") # using flash requires setting o a secret key\n\n # TODO: replace this part with a function to upload to s3\n image.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))\n\n #return redirect(request.url)\n \n\n return render_template(\"upload.html\", filename=filename) \n\n\[email protected]('/hello')\ndef hello_world():\n return 'Hello World!'\n\[email protected]('/hello/<name>')\ndef hello_name(name):\n return 'Hello %s!' % name"
},
{
"alpha_fraction": 0.5628742575645447,
"alphanum_fraction": 0.56886225938797,
"avg_line_length": 11,
"blob_id": "52d61f3e4dbc7eab63cd9bbb13292d2d4ba1d472",
"content_id": "da763a8355e825f23d621d3fad1605b6683dbcc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 14,
"path": "/application.py",
"repo_name": "subrockmann/image-collector",
"src_encoding": "UTF-8",
"text": "from app import app\nfrom app import s3\n\[email protected]('/')\ndef home():\n return \"Hello World - Index\"\n\n\n\n\n\nif __name__ == \"__main__\":\n app.debug = True\n app.run()"
},
{
"alpha_fraction": 0.8144329786300659,
"alphanum_fraction": 0.8144329786300659,
"avg_line_length": 47.5,
"blob_id": "7ae020459e2cb384138ae201f61beccfb17fe496",
"content_id": "dee143275215aa956d98614dd1a04a12ace2e585",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 2,
"path": "/README.md",
"repo_name": "subrockmann/image-collector",
"src_encoding": "UTF-8",
"text": "# Image data collector for deep learning projects #\nThis project requires a pipenv installation.\n"
},
{
"alpha_fraction": 0.6660317182540894,
"alphanum_fraction": 0.6850793361663818,
"avg_line_length": 28.716981887817383,
"blob_id": "b44c81f09b884a533f8b6f75d903207737766f12",
"content_id": "55db0906db558f1939b1a0f2f824bd4b095b10bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1575,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 53,
"path": "/app/s3.py",
"repo_name": "subrockmann/image-collector",
"src_encoding": "UTF-8",
"text": "import boto3\nimport botocore\nfrom botocore.exceptions import ClientError\n\nimport logging\nimport pandas as pd\nimport os\nfrom os.path import dirname\n\nCREDENTIALS_FOLDER = os.path.join(dirname(os.path.realpath(__file__)), 'credentials')\nprint(CREDENTIALS_FOLDER)\nCREDENTIALS_FILE = os.path.join(CREDENTIALS_FOLDER,'data-collector-credentials.csv' )\nprint(CREDENTIALS_FILE)\n\n# access AWS credentials\nAWS_KEY_ID = pd.read_csv(CREDENTIALS_FILE)['Access key ID'][0]\nAWS_SECRET = pd.read_csv(CREDENTIALS_FILE)['Secret access key'][0]\n\n# define your preferred region\nMY_REGION = 'eu-central-1'\nBUCKET_NAME = 'data-collector-v1'\n\ns3_resource = boto3.resource('s3')\n\ndef setup_s3():\n # Generate the boto3 client for interacting with S3 and SNS\n s3 = boto3.client('s3', region_name= MY_REGION, \n aws_access_key_id=AWS_KEY_ID, \n aws_secret_access_key=AWS_SECRET)\n return s3\n\ndef create_bucket_if_not_exists(bucket_name): \n exists = True\n try:\n s3.head_bucket(Bucket=bucket_name)\n \n except botocore.exceptions.ClientError as e:\n # If a client error is thrown, then check that it was a 404 error.\n # If it was a 404 error, then the bucket does not exist.\n error_code = e.response['Error']['Code']\n if error_code == '404':\n exists = False\n s3.create_bucket(Bucket=bucket_name,\n CreateBucketConfiguration={'LocationConstraint': MY_REGION})\n return s3_resource.Bucket(name=bucket_name)\n\n\n\n\n\n# connect to S3\ns3 = setup_s3()\ncreate_bucket_if_not_exists(BUCKET_NAME)\n"
}
] | 4 |
AlphaKitty/wechat_spilder
|
https://github.com/AlphaKitty/wechat_spilder
|
e00ff73887560c909c89e71f53366dc4de4d0ed1
|
9532893b3834ea5d7e62645e8f1e39c8878e98ad
|
b738fcb831a735da3cc040a863652d7d7f73f37d
|
refs/heads/master
| 2023-04-18T20:51:09.953203 | 2021-04-24T14:56:46 | 2021-04-24T14:56:46 | 358,275,422 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5566311478614807,
"alphanum_fraction": 0.5963214039802551,
"avg_line_length": 31.080745697021484,
"blob_id": "af0a131029aaad26ec6f7f8dbb8633c3d75ac29b",
"content_id": "5bc119249b501356d582d8c2f56783130da6cbc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5525,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 161,
"path": "/spilder/test/origin.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "import random\nimport re\nimport time\nimport uuid\nfrom urllib.parse import urlencode, quote\n\nimport requests\nfrom pyquery import PyQuery as pq\n\nkey = 'hello world'\n# quote:转义成带%前缀的url样式 这个url是搜狗微信请求的最简格式\nformat_url = 'https://weixin.sogou.com/weixin?type=2&query={}'.format(quote(key))\n\n# User-Agent是必须要有的 不然骗不过目标网站\n# headers_str = 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'\nheaders_str = 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 Edg/89.0.774.77'\n\n\n# headers_str = '''\n# Host: weixin.sogou.com\n# Connection: keep-alive\n# Upgrade-Insecure-Requests: 1\n# User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36\n# Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\n# Accept-Encoding: gzip, deflate, br\n# Accept-Language: zh-CN,zh;q=0.9\n# '''\n\n\ndef headers_to_dict(headers_str):\n headers_str = headers_str.strip()\n # 把header字符串枚举化并转成字典\n headers_dict = dict((i.split(':', 1)[0].strip(), i.split(':', 1)[1].strip()) for i in headers_str.split('\\n'))\n return headers_dict\n\n\na_str = '''\nuigs_cl\tfirst_click\nuigs_refer\thttps://weixin.sogou.com/\nuigs_productid\tvs_web\nterminal\tweb\nvstype\tweixin\npagetype\tresult\nchannel\tresult_article\ns_from\tinput\nsourceid\t\ntype\tweixin_search_pc\nuigs_cookie\tSUID,sct\nquery\thello world\nweixintype\t2\nexp_status\t-1\nexp_id_list\t0_0\nwuid\t0071440178DB40975D3C689EE37C6784\nrn\t1\nlogin\t0\nuphint\t1\nbottomhint\t1\npage\t1\nexp_id\tnull_0-null_1-null_2-null_3-null_4-null_5-null_6-null_7-null_8-null_9\ntime\t20914\n'''\n\n\ndef str_to_dict(a_str):\n '''\n 将a_str形式的字符串转化为字典形式;\n :param a_str:\n :return:\n '''\n str_a = list(i for i in a_str.split('\\n') if i != '')\n str_b = {}\n for a in str_a:\n a1 = a.split('\\t')[0]\n a2 = a.split('\\t')[1]\n str_b[a1] = a2\n\n return str_b\n\n\nb_data = str_to_dict(a_str)\nheaders = headers_to_dict(headers_str)\n\n\ndef get_suva(sunid):\n '''\n 根据sunid来获取suv参数;并添加到cookie\n :param a: sunid\n :return:\n '''\n b_data['snuid'] = sunid.split('=')[-1]\n b_data['uuid'] = uuid.uuid1()\n b_data['uigs_t'] = str(int(round(time.time() * 1000)))\n url_link = 'https://pb.sogou.com/pv.gif?' + urlencode(b_data)\n res = requests.get(url_link)\n cookie_s = res.headers['Set-Cookie'].split(',')\n cookie_list_s = []\n for i in cookie_s:\n for j in i.split(','):\n if 'SUV' in j:\n cookie_list_s.append(j)\n else:\n continue\n print(cookie_list_s[0].split(';')[0])\n headers['Cookie'] = cookie_list_s[0].split(';')[0]\n\n\n# Todo snuid上限大概100次 可以每爬取50页就重新以无cookie身份去获取一次SNUID\ndef get_first_parse(url):\n '''\n 1,构造'真'url;\n 2,获取正确的动态cookie;\n 3,返回真url,访问并解析文章内容\n :param url: 访问的初始url\n :return:\n '''\n # 给headers中添加Referer参数 可以不填\n # headers['Referer'] = url_list\n res = requests.get(url, headers=headers)\n # 访问标准url 获取response中的Set-Cookie\n cookies = res.headers['Set-Cookie'].split(';')\n cookie_list_long = []\n cookie_list2 = []\n for cookie in cookies:\n cookie_list_long.append(str(cookie).split(','))\n for news_list_li in cookie_list_long:\n for set in news_list_li:\n if 'SUID' in set or 'SNUID' in set:\n cookie_list2.append(set)\n sunid = cookie_list2[0].split(';')[0]\n get_suva(sunid)\n # 构造动态Cookies\n headers['Cookie'] = headers['Cookie'] + ';' + ';'.join(cookie_list2)\n news_list_lis = pq(res.text)('.news-list li').items()\n for news_list_li in news_list_lis:\n # 提取href属性标签\n href = pq(news_list_li('.img-box a').attr('href'))\n href = str(href).replace('<p>', '').replace('</p>', '').replace('amp;', '')\n # 构造参数k与h;\n b = int(random.random() * 100) + 1\n a = href.find(\"url=\")\n result_link = href + \"&k=\" + str(b) + \"&h=\" + href[a + 4 + 21 + b: a + 4 + 21 + b + 1]\n a_url = \"https://weixin.sogou.com\" + result_link\n second_url = requests.get(a_url, headers=headers).text\n # 获取真实url\n url_text = re.findall(\"\\'(\\S+?)\\';\", second_url, re.S)\n best_url = ''.join(url_text)\n last_text = requests.get(url=str(best_url.replace('&from=inner', '').replace(\"@\", \"\"))).text\n print('------------------------------------------------------------------------------------')\n print('url: ' + best_url.replace('&from=inner', '').replace(\"@\", \"\"))\n print('标题: ' + pq(last_text)('#activity-name').text())\n # print(pq(last_text)('#js_content > p').text())\n # 二维码链接不显示\n # print(pq(last_text)('.qr_code_pc_img').attr('src').text())\n print('作者: ' + pq(last_text)('#js_name').text())\n # print('发布时间: ' + pq(last_text)('.rich_media_meta_list').text())\n # print(pq(last_text)('#meta_content > span.rich_media_meta.rich_media_meta_text').text())\n\n\nif __name__ == '__main__':\n get_first_parse(\n 'https://weixin.sogou.com/weixin?type=2&query=%E8%B5%A0%E7%A5%A8')\n"
},
{
"alpha_fraction": 0.47103583812713623,
"alphanum_fraction": 0.6536573171615601,
"avg_line_length": 32.95000076293945,
"blob_id": "50239e7d2e5a053ef9c6baf531b04d22ec3532d6",
"content_id": "f1c6a1e905234cc10f3d550590d15c2d63009e76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4314,
"license_type": "no_license",
"max_line_length": 613,
"num_lines": 120,
"path": "/spilder/test/snuid.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "'''\n获取SNUID的值\n'''\nimport requests\nimport json\nimport time\nimport random\n\n'''\n方法(一)通过phantomjs访问sogou搜索结果页面,获取SNUID的值\n'''\n\n\ndef phantomjs_getsnuid():\n from selenium import webdriver\n d = webdriver.PhantomJS('D:\\python27\\Scripts\\phantomjs.exe', service_args=['--load-images=no', '--disk-cache=yes'])\n try:\n d.get(\"https://www.sogou.com/web?query=\")\n Snuid = d.get_cookies()[5][\"value\"]\n except:\n Snuid = \"\"\n d.quit()\n return Snuid\n\n\n'''\n方法(二)通过访问特定url,获取body里面的id\n'''\n\n\ndef Method_one():\n url = \"http://www.sogou.com/antispider/detect.php?sn=E9DA81B7290B940A0000000058BFAB0&wdqz22=12&4c3kbr=12&ymqk4p=37&qhw71j=42&mfo5i5=7&3rqpqk=14&6p4tvk=27&eiac26=29&iozwml=44&urfya2=38&1bkeul=41&jugazb=31&qihm0q=8&lplrbr=10&wo65sp=11&2pev4x=23&4eyk88=16&q27tij=27&65l75p=40&fb3gwq=27&azt9t4=45&yeyqjo=47&kpyzva=31&haeihs=7&lw0u7o=33&tu49bk=42&f9c5r5=12&gooklm=11&_=1488956271683\"\n headers = {\"Cookie\":\n \"ABTEST=0|1488956269|v17;\\\n IPLOC=CN3301;\\\n SUID=E9DA81B7290B940A0000000058BFAB6D;\\\n PHPSESSID=rfrcqafv5v74hbgpt98ah20vf3;\\\n SUIR=1488956269\"\n }\n try:\n f = requests.get(url, headers=headers).content\n f = json.loads(f)\n Snuid = f[\"id\"]\n except:\n Snuid = \"\"\n return Snuid\n\n\n'''\n方法(三)访问特定url,获取header里面的内容\n'''\n\n\ndef Method_two():\n url = \"https://www.sogou.com/web?query=333&_asf=www.sogou.com&_ast=1488955851&w=01019900&p=40040100&ie=utf8&from=index-nologin\"\n headers = {\"Cookie\":\n \"ABTEST=0|1488956269|v17;\\\n IPLOC=CN3301;\\\n SUID=E9DA81B7290B940A0000000058BFAB6D;\\\n PHPSESSID=rfrcqafv5v74hbgpt98ah20vf3;\\\n SUIR=1488956269\"\n }\n f = requests.head(url, headers=headers).headers\n print\n f\n\n\n'''\n方法(四)通过访问需要输入验证码解封的页面,可以获取SNUID\n'''\n\n\ndef Method_three():\n '''\n http://www.sogou.com/antispider/util/seccode.php?tc=1488958062 验证码地址\n '''\n '''\n http://www.sogou.com/antispider/?from=%2fweb%3Fquery%3d152512wqe%26ie%3dutf8%26_ast%3d1488957312%26_asf%3dnull%26w%3d01029901%26p%3d40040100%26dp%3d1%26cid%3d%26cid%3d%26sut%3d578%26sst0%3d1488957299160%26lkt%3d3%2C1488957298718%2C1488957298893\n 访问这个url,然后填写验证码,发送以后就是以下的包内容,可以获取SNUID。\n '''\n import socket\n import re\n res = r\"id\\\"\\: \\\"([^\\\"]*)\\\"\"\n s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n s.connect(('www.sogou.com', 80))\n s.send('''\nPOST http://www.sogou.com/antispider/thank.php HTTP/1.1\nHost: www.sogou.com\nContent-Length: 223\nX-Requested-With: XMLHttpRequest\nContent-Type: application/x-www-form-urlencoded; charset=UTF-8\nCookie: CXID=65B8AE6BEE1CE37D4C63855D92AF339C; SUV=006B71D7B781DAE95800816584135075; IPLOC=CN3301; pgv_pvi=3190912000; GOTO=Af12315; ABTEST=8|1488945458|v17; PHPSESSID=f78qomvob1fq1robqkduu7v7p3; SUIR=D0E3BB8E393F794B2B1B02733A162729; SNUID=B182D8EF595C126A7D67E4E359B12C38; sct=2; sst0=958; ld=AXrrGZllll2Ysfa1lllllVA@rLolllllHc4zfyllllYllllljllll5@@@@@@@@@@; browerV=3; osV=1; LSTMV=673%2C447; LCLKINT=6022; ad=6FwTnyllll2g@popQlSGTVA@7VCYx98tLueNukllll9llllljpJ62s@@@@@@@@@@; SUID=EADA81B7516C860A57B28911000DA424; successCount=1|Wed, 08 Mar 2017 07:51:18 GMT; seccodeErrorCount=1|Wed, 08 Mar 2017 07:51:45 GMT\nc=6exp2e&r=%252Fweb%253Fquery%253Djs%2B%25E6%25A0%25BC%25E5%25BC%258F%25E5%258C%2596%2526ie%253Dutf8%2526_ast%253D1488957312%2526_asf%253Dnull%2526w%253D01029901%2526p%253D40040100%2526dp%253D1%2526cid%253D%2526cid%253D&v=5\n ''')\n buf = s.recv(1024)\n p = re.compile(res)\n L = p.findall(buf)\n if len(L) > 0:\n Snuid = L[0]\n else:\n Snuid = \"\"\n return Snuid\n\n\ndef getsnuid(q):\n while 1:\n if q.qsize() < 10:\n Snuid = random.choice([Method_one(), Method_three(), phantomjs_getsnuid()])\n if Snuid != \"\":\n q.put(Snuid)\n print\n Snuid\n time.sleep(0.5)\n\n\nif __name__ == \"__main__\":\n import Queue\n\n q = Queue.Queue()\n getsnuid(q)\n"
},
{
"alpha_fraction": 0.6309463977813721,
"alphanum_fraction": 0.6464697122573853,
"avg_line_length": 27.126760482788086,
"blob_id": "91f7f463b6b069be9b165b963fd3cc37725e6351",
"content_id": "ec357fb82ea6760e225141d22fc76be990a50f9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2253,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 71,
"path": "/spilder/test/wechatsogo_test.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "import wechatsogou\nfrom cachelib import SimpleCache\nimport json\n\n\n# 获取特定公众号信息\ndef get_gzh_info():\n # 直连\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.get_gzh_info('码猿技术专栏')\n print(json.dumps(info, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\n# 搜索公众号\ndef search_gzh():\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.search_gzh('码猿技术专栏')\n for item in info:\n print(json.dumps(item, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\n# 搜索公众号文章\ndef search_article(keyword):\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.search_article(keyword)\n for item in info:\n print(json.dumps(item, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\n# 联想关键词\ndef get_sugg():\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.get_sugg('Java')\n for item in info:\n print(json.dumps(item, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\n# 搜索热门文章\ndef get_gzh_article_by_hot():\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.get_gzh_article_by_hot('Java多线程')\n print(json.dumps(info, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\n# 搜索公众号文章历史\ndef get_gzh_article_by_history():\n ws_api = wechatsogou.WechatSogouAPI()\n info = ws_api.get_gzh_article_by_history('码猿技术专栏')\n print(json.dumps(info, sort_keys=True, indent=4, separators=(', ', ': '), ensure_ascii=False))\n\n\nif __name__ == '__main__':\n # get_gzh_info()\n # search_gzh()\n search_article('Java多线程')\n # get_gzh_article_by_history()\n # get_gzh_article_by_hot()\n # get_sugg()\n\n# # 验证码输入错误的重试次数,默认为1\n# ws_api = wechatsogou.WechatSogouAPI(captcha_break_time=3)\n#\n# # 所有requests库的参数都能在这用\n# # 如 配置代理,代理列表中至少需包含1个 HTTPS 协议的代理, 并确保代理可用\n# ws_api = wechatsogou.WechatSogouAPI(proxies={\n# \"http\": \"127.0.0.1:8888\",\n# \"https\": \"127.0.0.1:8888\",\n# })\n#\n# # 如 设置超时\n# ws_api = wechatsogou.WechatSogouAPI(timeout=0.1)\n"
},
{
"alpha_fraction": 0.5389821529388428,
"alphanum_fraction": 0.5706191062927246,
"avg_line_length": 123.58169555664062,
"blob_id": "38611ef6b19005d79a1c31ecd628d283dd01ccf2",
"content_id": "1f9d680abc7b06afd4f5cb46a931681614a09247",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 21398,
"license_type": "no_license",
"max_line_length": 4482,
"num_lines": 153,
"path": "/test/puretest/test.html",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "{\"name\":\"Canal\",\"tagline\":\"阿里巴巴mysql数据库binlog的增量订阅&消费组件\",\"body\":\"\n<div class=\\\"blog_content\\\">\\r\\n\n <div class=\\\"iteye-blog-content-contain\\\">\\r\\n<p style=\\\"font-size: 14px;\\\"> </p>\\r\\n<h1>背景</h1>\\r\\n<p\n style=\\\"font-size: 14px;\\\">\n 早期,阿里巴巴B2B公司因为存在杭州和美国双机房部署,存在跨机房同步的业务需求。不过早期的数据库同步业务,主要是基于trigger的方式获取增量变更,不过从2010年开始,阿里系公司开始逐步的尝试基于数据库的日志解析,获取增量变更进行同步,由此衍生出了增量订阅&消费的业务,从此开启了一段新纪元。ps.\n 目前内部使用的同步,已经支持mysql5.x和oracle部分版本的日志解析</p>\\r\\n<p style=\\\"font-size: 14px;\\\"> </p>\\r\\n<p style=\\\"font-size:\n 14px;\\\">基于日志增量订阅&消费支持的业务:</p>\n \\r\\n\n <ol style=\\\"font-size: 14px;\\\n \">\\r\\n\n <li>数据库镜像</li>\n \\r\\n\n <li>数据库实时备份</li>\n \\r\\n\n <li>多级索引 (卖家和买家各自分库索引)</li>\n \\r\\n\n <li>search build</li>\n \\r\\n\n <li>业务cache刷新</li>\n \\r\\n\n <li>价格变化等重要业务消息</li>\n \\r\\n</ol>\\r\\n<h1>项目介绍</h1>\\r\\n<p style=\\\"font-size: 14px;\\\"> 名称:canal [kə'næl]</p>\\r\\n<p style=\\\"font-size:\n 14px;\\\"> 译意:\n 水道/管道/沟渠 </p>\\r\\n<p style=\\\"font-size: 14px;\\\"> 语言: 纯java开发</p>\\r\\n<p style=\\\"font-size: 14px;\\\"> 定位:\n 基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了mysql</p>\\r\\n<p style=\\\"font-size: 14px;\\\"> </p>\\r\\n<h2>工作原理</h2>\\r\\n<h3\n style=\\\"font-size: 14px;\\\">mysql主备复制实现</h3>\\r\\n<p><img\n src=\\\"http://dl.iteye.com/upload/attachment/0080/3086/468c1a14-e7ad-3290-9d3d-44ac501a7227.jpg\\\"\n alt=\\\"\\\"><br> 从上层来看,复制分成三步:</p>\\r\\n\n <ol>\\r\\n\n <li>master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events,可以通过show binlog events进行查看);</li>\n \\r\\n\n <li>slave将master的binary log events拷贝到它的中继日志(relay log);</li>\n \\r\\n\n <li>slave重做中继日志中的事件,将改变反映它自己的数据。</li>\n \\r\\n\n </ol>\n \\r\\n<h3>canal的工作原理:</h3>\\r\\n<p><img width=\\\"590\\\"\n src=\\\"http://dl.iteye.com/upload/attachment/0080/3107/c87b67ba-394c-3086-9577-9db05be04c95.jpg\\\"\n alt=\\\"\\\" height=\\\"273\\\"></p>\\r\\n<p>原理相对比较简单:</p>\\r\\n\n <ol>\\r\\n\n <li>canal模拟mysql slave的交互协议,伪装自己为mysql slave,向mysql master发送dump协议</li>\n \\r\\n\n <li>mysql master收到dump请求,开始推送binary log给slave(也就是canal)</li>\n \\r\\n\n <li>canal解析binary log对象(原始为byte流)</li>\n \\r\\n\n </ol>\n \\r\\n<h1>架构</h1>\\r\\n<p><img width=\\\"548\\\"\n src=\\\"http://dl.iteye.com/upload/attachment/0080/3126/49550085-0cd2-32fa-86a6-f676db5b597b.jpg\\\"\n alt=\\\"\\\" height=\\\"238\\\" style=\\\"line-height: 1.5;\\\"></p>\\r\\n<p style=\\\"color:\n #333333;\n background-image:\n none; margin-top:\n 10px; margin-bottom:\n 10px; font-family:\n Arial, Helvetica,\n FreeSans, sans-serif;\\\n \">说明:</p>\\r\\n\n <ul style=\\\"line-height: 1.5; color: #333333; font-family: Arial, Helvetica, FreeSans, sans-serif;\\\n \">\\r\\n\n <li>server代表一个canal运行实例,对应于一个jvm</li>\n \\r\\n\n <li>instance对应于一个数据队列 (1个server对应1..n个instance)</li>\n \\r\\n</ul>\\r\\n<p>instance模块:</p>\\r\\n\n <ul style=\\\"line-height: 1.5; color: #333333; font-family: Arial, Helvetica, FreeSans, sans-serif;\\\n \">\\r\\n\n <li>eventParser (数据源接入,模拟slave协议和master进行交互,协议解析)</li>\n \\r\\n\n <li>eventSink (Parser和Store链接器,进行数据过滤,加工,分发的工作)</li>\n \\r\\n\n <li>eventStore (数据存储)</li>\n \\r\\n\n <li>metaManager (增量订阅&消费信息管理器)</li>\n \\r\\n</ul>\\r\\n<h3>数据对象格式:<a\n href=\\\"https://github.com/otter-projects/canal/blob/master/protocol/src/main/java/com/alibaba/otter/canal/protocol/EntryProtocol.proto\\\"\n style=\\\"font-size: 14px; line-height: 1.5; color: #bc2a4d; text-decoration: underline;\\\">EntryProtocol.proto</a>\n \\r\\n</h3>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">Entry\\r\\n Header\\r\\n\\t\\tlogfileName [binlog文件名]\\r\\n\\t\\tlogfileOffset [binlog position]\\r\\n\\t\\texecuteTime [发生的变更]\\r\\n\\t\\tschemaName \\r\\n\\t\\ttableName\\r\\n\\t\\teventType [insert/update/delete类型]\\r\\n\\tentryType \\t[事务头BEGIN/事务尾END/数据ROWDATA]\\r\\n\\tstoreValue \\t[byte数据,可展开,对应的类型为RowChange]\\r\\n\\t\\r\\nRowChange\\r\\n\\tisDdl\\t\\t[是否是ddl变更操作,比如create table/drop table]\\r\\n\\tsql\\t\\t[具体的ddl sql]\\r\\n\\trowDatas\\t[具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]\\r\\n\\t\\tbeforeColumns [Column类型的数组]\\r\\n\\t\\tafterColumns [Column类型的数组]\\r\\n\\t\\t\\r\\nColumn \\r\\n\\tindex\\t\\t\\r\\n\\tsqlType\\t\\t[jdbc type]\\r\\n\\tname\\t\\t[column name]\\r\\n\\tisKey\\t\\t[是否为主键]\\r\\n\\tupdated\\t\\t[是否发生过变更]\\r\\n\\tisNull\\t\\t[值是否为null]\\r\\n\\tvalue\\t\\t[具体的内容,注意为文本]</pre>\n \\r\\n<p>说明:</p>\\r\\n\n <ul>\\r\\n\n <li>可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全</li>\n \\r\\n\n <li>可以提供ddl的变更语句</li>\n \\r\\n\n </ul>\n \\r\\n<h1>QuickStart</h1>\\r\\n<h2>几点说明:(mysql初始化)</h2>\\r\\n<p>a. canal的原理是基于mysql\n binlog技术,所以这里一定需要开启mysql的binlog写入功能,并且配置binlog模式为row. </p>\\r\\n\n <pre class=\\\"java\\\" name=\\\"code\\\">[mysqld]\\r\\nlog-bin=mysql-bin #添加这一行就ok\\r\\nbinlog-format=ROW #选择row模式\\r\\nserver_id=1 #配置mysql replaction需要定义,不能和canal的slaveId重复</pre>\n \\r\\nb. canal的原理是模拟自己为mysql slave,所以这里一定需要做为mysql slave的相关权限.\n </div>\n \\r\\n\n <div class=\\\"iteye-blog-content-contain\\\">\\r\\n\n <pre class=\\\"java\\\" name=\\\"code\\\">CREATE USER canal IDENTIFIED BY 'canal'; \\r\\nGRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';\\r\\n-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;\\r\\nFLUSH PRIVILEGES;</pre>\n \\r\\n<p>针对已有的账户可通过grants查询权限:</p>\\r\\n<h2>启动步骤:</h2>\\r\\n<p>1. 下载canal</p>\\r\\n<p>下载部署包</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">wget http://canal4mysql.googlecode.com/files/canal.deployer-1.0.0.tar.gz</pre>\n \\r\\n<p>or </p>\\r\\n<p>自己编译 </p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">git clone [email protected]:otter-projects/canal.git\\r\\ncd canal; \\r\\nmvn clean install -Dmaven.test.skip -Denv=release</pre>\n \\r\\n<p> 编译完成后,会在根目录下产生target/canal.deployer-$version.tar.gz </p>\\r\\n<p></p>\\r\\n<p>2. 解压缩</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">mkdir /tmp/canal\\r\\ntar zxvf canal.deployer-1.0.0.tar.gz -C /tmp/canal</pre>\n \\r\\n<p></p>\\r\\n<p> 解压完成后,进入/tmp/canal目录,可以看到如下结构:</p>\\r\\n<p></p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">drwxr-xr-x 2 jianghang jianghang 136 2013-02-05 21:51 bin\\r\\ndrwxr-xr-x 4 jianghang jianghang 160 2013-02-05 21:51 conf\\r\\ndrwxr-xr-x 2 jianghang jianghang 1.3K 2013-02-05 21:51 lib\\r\\ndrwxr-xr-x 2 jianghang jianghang 48 2013-02-05 21:29 logs</pre>\n \\r\\n<p></p>\\r\\n<p>3. 配置修改</p>\\r\\n<p></p>\\r\\n<p>公用参数: </p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"shell\\\">vi conf/canal.properties</pre>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">#################################################\\r\\n######### common argument ############# \\r\\n#################################################\\r\\ncanal.id= 1\\r\\ncanal.address=\\r\\ncanal.port= 11111\\r\\ncanal.zkServers=\\r\\n# flush data to zk\\r\\ncanal.zookeeper.flush.period = 1000\\r\\n## memory store RingBuffer size, should be Math.pow(2,n)\\r\\ncanal.instance.memory.buffer.size = 32768\\r\\n\\r\\n## detecing config\\r\\ncanal.instance.detecting.enable = false\\r\\ncanal.instance.detecting.sql = insert into retl.xdual values(1,now()) on duplicate key update x=now()\\r\\ncanal.instance.detecting.interval.time = 3 \\r\\ncanal.instance.detecting.retry.threshold = 3 \\r\\ncanal.instance.detecting.heartbeatHaEnable = false\\r\\n\\r\\n# support maximum transaction size, more than the size of the transaction will be cut into multiple transactions delivery\\r\\ncanal.instance.transactionn.size = 1024\\r\\n\\r\\n# network config\\r\\ncanal.instance.network.receiveBufferSize = 16384\\r\\ncanal.instance.network.sendBufferSize = 16384\\r\\ncanal.instance.network.soTimeout = 30\\r\\n\\r\\n#################################################\\r\\n######### destinations ############# \\r\\n#################################################\\r\\ncanal.destinations= example\\r\\n\\r\\ncanal.instance.global.mode = spring \\r\\ncanal.instance.global.lazy = true ##修改为false,代表立马启动\\r\\n#canal.instance.global.manager.address = 127.0.0.1:1099\\r\\ncanal.instance.global.spring.xml = classpath:spring/memory-instance.xml\\r\\n#canal.instance.global.spring.xml = classpath:spring/default-instance.xml</pre>\n \\r\\n<p></p>\\r\\n<p>应用参数:</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"shell\\\">vi conf/example/instance.properties</pre>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"instance.properties\\\">#################################################\\r\\n## mysql serverId\\r\\ncanal.instance.mysql.slaveId = 1234\\r\\n\\r\\n# position info\\r\\ncanal.instance.master.address = 127.0.0.1:3306 #改成自己的数据库地址\\r\\ncanal.instance.master.journal.name = \\r\\ncanal.instance.master.position = \\r\\ncanal.instance.master.timestamp = \\r\\n\\r\\n#canal.instance.standby.address = \\r\\n#canal.instance.standby.journal.name =\\r\\n#canal.instance.standby.position = \\r\\n#canal.instance.standby.timestamp = \\r\\n\\r\\n# username/password\\r\\ncanal.instance.dbUsername = retl #改成自己的数据库信息\\r\\ncanal.instance.dbPassword = retl #改成自己的数据库信息\\r\\ncanal.instance.defaultDatabaseName = #改成自己的数据库信息\\r\\ncanal.instance.connectionCharsetNumber = 33 #改成自己的数据库信息\\r\\ncanal.instance.connectionCharset = UTF-8 #改成自己的数据库信息\\r\\n\\r\\n# table regex\\r\\ncanal.instance.filter.regex = .*\\\\\\\\..*\\r\\n\\r\\n#################################################\\r\\n</pre>\n \\r\\n<p></p>\\r\\n<p></p>\\r\\n<p> 说明:</p>\\r\\n\n <ul>\\r\\n\n <li>canal.instance.connectionCharset 代表数据库的编码方式对应到java中的编码类型,比如UTF-8,GBK , ISO-8859-1</li>\n \\r\\n\n <li>canal.instance.connectionCharsetNumber\n 代表数据库的编码方式对应mysql中的唯一id,详细的映射关系可查看:com.mysql.jdbc.CharsetMapping.INDEX_TO_CHARSET<br>针对常见的编码:<br>utf-8\n <=> 33<br>gb2312 <=> 24<br>gbk <=> 28\n </li>\n \\r\\n\n </ul>\n \\r\\n<p>4. 准备启动</p>\\r\\n<p></p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">sh bin/startup.sh</pre>\n \\r\\n<p></p>\\r\\n<p>5. 查看日志</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">vi logs/canal/canal.log</pre>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">2013-02-05 22:45:27.967 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## start the canal server.\\r\\n2013-02-05 22:45:28.113 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[10.1.29.120:11111]\\r\\n2013-02-05 22:45:28.210 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## the canal server is running now ......</pre>\n \\r\\n<p></p>\\r\\n<p> 具体instance的日志:</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">vi logs/example/example.log</pre>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">2013-02-05 22:50:45.636 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [canal.properties]\\r\\n2013-02-05 22:50:45.641 [main] INFO c.a.o.c.i.spring.support.PropertyPlaceholderConfigurer - Loading properties file from class path resource [example/instance.properties]\\r\\n2013-02-05 22:50:45.803 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example \\r\\n2013-02-05 22:50:45.810 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start successful....</pre>\n \\r\\n<p></p>\\r\\n<p>6. 关闭</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">sh bin/stop.sh</pre>\n \\r\\n<p></p>\\r\\n<p>it's over. </p>\\r\\n\n </div>\n \\r\\n<h1>ClientExample</h1>\\r\\n<p>依赖配置:(目前暂未正式发布到mvn仓库,所以需要各位下载canal源码后手工执行下mvn clean install -Dmaven.test.skip)</p>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\"><dependency>\\r\\n <groupId>com.alibaba.otter</groupId>\\r\\n <artifactId>canal.client</artifactId>\\r\\n <version>1.0.0</version>\\r\\n</dependency></pre>\n \\r\\n<p></p>\\r\\n<p>1. 创建mvn标准工程:</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">mvn archetype:create -DgroupId=com.alibaba.otter -DartifactId=canal.sample</pre>\n \\r\\n<p></p>\\r\\n<p>2. 修改pom.xml,添加依赖</p>\\r\\n<p></p>\\r\\n<p>3. ClientSample代码</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"SimpleCanalClientExample\\\">package com.alibaba.otter.canal.sample;\\r\\n\\r\\nimport java.net.InetSocketAddress;\\r\\nimport java.util.List;\\r\\n\\r\\nimport com.alibaba.otter.canal.common.utils.AddressUtils;\\r\\nimport com.alibaba.otter.canal.protocol.Message;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.Column;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.Entry;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.EntryType;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.EventType;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.RowChange;\\r\\nimport com.alibaba.otter.canal.protocol.CanalEntry.RowData;\\r\\n\\r\\npublic class SimpleCanalClientExample {\\r\\n\\r\\n public static void main(String args[]) {\\r\\n // 创建链接\\r\\n CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),\\r\\n 11111), \\\"example\\\", \\\"\\\", \\\"\\\");\\r\\n int batchSize = 1000;\\r\\n int emptyCount = 0;\\r\\n try {\\r\\n connector.connect();\\r\\n connector.subscribe(\\\".*\\\\\\\\..*\\\");\\r\\n connector.rollback();\\r\\n int totalEmtryCount = 120;\\r\\n while (emptyCount < totalEmtryCount) {\\r\\n Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据\\r\\n long batchId = message.getId();\\r\\n int size = message.getEntries().size();\\r\\n if (batchId == -1 || size == 0) {\\r\\n emptyCount++;\\r\\n System.out.println(\\\"empty count : \\\" + emptyCount);\\r\\n try {\\r\\n Thread.sleep(1000);\\r\\n } catch (InterruptedException e) {\\r\\n }\\r\\n } else {\\r\\n emptyCount = 0;\\r\\n // System.out.printf(\\\"message[batchId=%s,size=%s] \\\\n\\\", batchId, size);\\r\\n printEntry(message.getEntries());\\r\\n }\\r\\n\\r\\n connector.ack(batchId); // 提交确认\\r\\n // connector.rollback(batchId); // 处理失败, 回滚数据\\r\\n }\\r\\n\\r\\n System.out.println(\\\"empty too many times, exit\\\");\\r\\n } finally {\\r\\n connector.disconnect();\\r\\n }\\r\\n }\\r\\n\\r\\n private static void printEntry(List<Entry> entrys) {\\r\\n for (Entry entry : entrys) {\\r\\n if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {\\r\\n continue;\\r\\n }\\r\\n\\r\\n RowChange rowChage = null;\\r\\n try {\\r\\n rowChage = RowChange.parseFrom(entry.getStoreValue());\\r\\n } catch (Exception e) {\\r\\n throw new RuntimeException(\\\"ERROR ## parser of eromanga-event has an error , data:\\\" + entry.toString(),\\r\\n e);\\r\\n }\\r\\n\\r\\n EventType eventType = rowChage.getEventType();\\r\\n System.out.println(String.format(\\\"================> binlog[%s:%s] , name[%s,%s] , eventType : %s\\\",\\r\\n entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),\\r\\n entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),\\r\\n eventType));\\r\\n\\r\\n for (RowData rowData : rowChage.getRowDatasList()) {\\r\\n if (eventType == EventType.DELETE) {\\r\\n printColumn(rowData.getBeforeColumnsList());\\r\\n } else if (eventType == EventType.INSERT) {\\r\\n printColumn(rowData.getAfterColumnsList());\\r\\n } else {\\r\\n System.out.println(\\\"-------> before\\\");\\r\\n printColumn(rowData.getBeforeColumnsList());\\r\\n System.out.println(\\\"-------> after\\\");\\r\\n printColumn(rowData.getAfterColumnsList());\\r\\n }\\r\\n }\\r\\n }\\r\\n }\\r\\n\\r\\n private static void printColumn(List<Column> columns) {\\r\\n for (Column column : columns) {\\r\\n System.out.println(column.getName() + \\\" : \\\" + column.getValue() + \\\" update=\\\" + column.getUpdated());\\r\\n }\\r\\n }\\r\\n}</pre>\n \\r\\n<p></p>\\r\\n<p>4. 运行Client</p>\\r\\n<p>首先启动Canal Server,可参加QuickStart : <a style=\\\"line-height: 1.5;\\\"\n href=\\\"/blogs/1796070\\\">http://agapple.iteye.com/blogs/1796070</a></p>\\r\\n<p>启动Canal Client后,可以从控制台从看到类似消息:</p>\n \\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">empty count : 1\\r\\nempty count : 2\\r\\nempty count : 3\\r\\nempty count : 4</pre>\n \\r\\n<p> 此时代表当前数据库无变更数据</p>\\r\\n<p></p>\\r\\n<p>5. 触发数据库变更</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">mysql> use test;\\r\\nDatabase changed\\r\\nmysql> CREATE TABLE `xdual` (\\r\\n -> `ID` int(11) NOT NULL AUTO_INCREMENT,\\r\\n -> `X` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,\\r\\n -> PRIMARY KEY (`ID`)\\r\\n -> ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 ;\\r\\nQuery OK, 0 rows affected (0.06 sec)\\r\\n\\r\\nmysql> insert into xdual(id,x) values(null,now());Query OK, 1 row affected (0.06 sec)</pre>\n \\r\\n<p></p>\\r\\n<p>可以从控制台中看到:</p>\\r\\n\n <pre name=\\\"code\\\" class=\\\"java\\\">empty count : 1\\r\\nempty count : 2\\r\\nempty count : 3\\r\\nempty count : 4\\r\\n================> binlog[mysql-bin.001946:313661577] , name[test,xdual] , eventType : INSERT\\r\\nID : 4 update=true\\r\\nX : 2013-02-05 23:29:46 update=true</pre>\n \\r\\n<p></p>\\r\\n<h2>最后:</h2>\\r\\n<p> 整个代码在附件中可以下载,如有问题可及时联系。 </p>\\r\\n\n</div>\\r\\n \\r\\n\n<div class=\\\"attachments\\\">\\r\\n<a href=\\\"http://dl.iteye.com/topics/download/7a893f19-bafb-313a-8a7a-e371a4265ad9\\\">canal.sample.tar.gz</a>\n (2.2 KB)\\r\\n\n</div>\\r\\n\",\"google\":\"UA-10379866-5\",\"note\":\"Don't delete this file! It's used internally to help with page regeneration.\"}"
},
{
"alpha_fraction": 0.578110933303833,
"alphanum_fraction": 0.6671664118766785,
"avg_line_length": 37.55491256713867,
"blob_id": "35c41893a875cf6baa261ada1c7085cd593087cf",
"content_id": "dc005dac49787f4e77806d6602efd992c6af13a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7412,
"license_type": "no_license",
"max_line_length": 687,
"num_lines": 173,
"path": "/spilder/test/bs4_test.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "# 请求网页\nimport bs4\nimport requests\n# 解析xpath\nfrom lxml import etree\n# 美化html\nfrom bs4 import BeautifulSoup, Comment\n# 正则表达式\nimport re\n# html转markdown\nimport html2text as ht\n\n\ndef get_html(url):\n response = requests.get(url)\n response.encoding = 'utf8'\n if response.status_code == 200:\n return response.text\n\n\ndef get_content(html):\n soup = BeautifulSoup(html, 'lxml')\n content = soup.find(id='js_content')\n [s.extract() for s in content(\"script\")]\n # 去除注释\n comments = content.findAll(text=lambda text: isinstance(text, Comment))\n [comment.extract() for comment in comments]\n pretty_content = BeautifulSoup(str(content).encode('utf8'), 'lxml')\n return pretty_content.prettify()\n\n\ndef example():\n # print(soup.prettify())\n # 获取文本\n # print(soup.h2.string.strip())\n # 修改属性\n # soup.p['class'] = \"newClass\"\n # 删除属性\n # del soup.p['class']\n # 判断内容是否为注释\n # if type(soup.a.string) == bs4.element.Comment:\n # print(soup.a.string)\n # 列表形式输出子节点\n # print(soup.head.contents)\n # 列表索引获取子元素\n # print(soup.head.contents[1])\n # List形式\n # print(soup.body.children)\n # 遍历List\n # for child in soup.body.children:\n # print(child)\n # 和children的区别是可以递归遍历\n # for child in soup.descendants:\n # print(child)\n # 内容集合\n # for child in soup.div.strings:\n # print(child)\n # 修剪后的内容集合\n # for child in soup.div.stripped_strings:\n # print(child)\n # 直接和递归父节点\n # print(soup.div.parent.name)\n # for parent in soup.div.parents:\n # print(parent.name)\n # 上一个和下一个兄弟节点\n # print(soup.div.next_sibling)\n # print(soup.div.previout_sibling)\n # 上面的和下面的全部兄弟节点\n # for sibling in soup.div.previous_siblings:\n # print(sibling)\n # for sibling in soup.div.next_siblings:\n # print(sibling)\n # 无视层级关系的上一个和下一个节点\n # print(soup.div.previous_element)\n # print(soup.div.next_element)\n # for element in soup.div.previous_elements:\n # print(element)\n # for element in soup.div.next_elements:\n # print(element)\n # 查找当前节点下的所有符合条件的子节点\n # print(soup.div.find_all('section'))\n # print(soup.div.find_all(['section', 'p']))\n # 根据正则表达式搜索\n # for tag in soup.find_all(re.compile('^b')):\n # print(tag)\n # 返回所有tag名字\n # for tag in soup.find_all(True):\n # print(tag.name)\n # 一个标签过滤器 可以作为find_all的参数 返回符合条件的标签\n # def has_class_but_no_id(tag):\n # return tag.has_attr('class') and not tag.has_attr('id')\n # soup.find_all(has_class_but_no_id)\n # 搜索某个特定属性\n # print(soup.find_all(id='activity-name'))\n # 正则配合标签\n # soup.find_all(href=re.compile(\"elsie\"))\n # 多个条件配合\n # soup.find_all(href=re.compile(\"elsie\"), id='link1')\n # class是关键字 应该用class_\n # soup.find_all(\"a\", class_=\"sister\")\n # 特殊符号的需要用attr\n # soup.find_all(attrs={\"data-foo\": \"value\"})\n # 还可以搜索内容\n # soup.find_all(text=\"Elsie\")\n # soup.find_all(text=[\"Tillie\", \"Elsie\", \"Lacie\"])\n # soup.find_all(text=re.compile(\"Dormouse\"))\n # limit限制返回个数\n # soup.find_all(\"a\", limit=2)\n # 关闭默认的递归查找\n # soup.html.find_all(\"title\", recursive=False)\n # 其他的还有:\n # find(和find_all的区别是find直接返回第一个不返回列表 find和find_all都是模糊匹配)\n # find_parent/find_parents\n # find_next_sibling/find_next_siblings\n # find_previous_sibling/find_previous_siblings\n # find_next/find_all_next(element)\n # find_previous/find_all_previous\n # find系列是模糊匹配 多个标签也会匹配 select是精准匹配 返回的是列表 可以直接过滤css\n # print(soup.find(class_='profile_nickname').text)\n # print(soup.select('.profile_nickname')[0].text)\n # print(soup.select('#activity-name')[0].text.strip())\n # 组合查找 多个条件同时满足 比如查找p标签下id为link1的标签等 中间要空格\n # print(soup.select('p #link1'))\n # print(soup.select(\"head > title\"))\n # 组合查找内部标签 中间不空格\n # print(soup.select('a[class=\"sister\"]'))\n # print(soup.select('a[href=\"http://example.com/elsie\"]'))\n # 上面两种可以再组合 缩小范围\n # soup.select('p a[href=\"http://example.com/elsie\"]')\n # text? get_text()?\n # print(soup.select('title')[0].get_text())\n\n # 去除属性script\n # [s.extract() for s in soup(\"script\")]\n # 去除<div class=\"sup--normal“>\n # [s.extract() for s in soup.find_all(\"div\", {\"class\": \"sup--normal\"})]\n\n # tree = etree.HTML(html)\n # title = tree.xpath('//*[@id=\"activity-name\"]/text()')[0].strip()\n # public_from = tree.xpath('//*[@id=\"js_name\"]/text()')[0].strip()\n # # span1 = tree.xpath('//*[@id=\"js_content\"]/p[1]/strong/span/text()')[0].strip()\n # # span2 = tree.xpath('//*[@id=\"js_content\"]/p[2]/strong/span/text()')[0].strip()\n # # span2 = tree.xpath('//*[@id=\"js_content\"]/p[3]/text()')[0].strip()\n # spans = tree.xpath('//*[@id=\"js_content\"]')[0]\n # print(title)\n # print(public_from)\n # print(spans)\n # print(span2)\n pass\n\n\ndef build_markdown(content):\n text_maker = ht.HTML2Text()\n # text_maker.bypass_tables = False\n text = text_maker.handle(content)\n # md = text.split('#')\n return text\n\n\ndef main():\n # 获取原html\n html = get_html(\n # 'https://mp.weixin.qq.com/s?__biz=MzkzODAwMTQwNw==&mid=2247492296&idx=1&sn=30e482203c7fcf924ce223dcca5dfa47')\n 'https://mp.weixin.qq.com/s?__biz=MzU3MDAzNDg1MA==&mid=2247486231&idx=1&sn=e3624c839e8adfec6955dafd7460a5c2&chksm=fcf4d4dacb835dcc6db4573f218e0f5dcfb6b0a4df8396f42bc4e2704b5e92d9fa983a3863ad&scene=126&sessionid=1606669915&key=714c43c4e763db4243694020799bb2ac331c879a97e3850926760e3b9df66b1b1ce2bc8512e5d1cec4d15fe69dc2a4efddfa4a1e440bd732410b9c87f7378abcefeddb40ef5b173dc84c268386fa16abfd70e577da65682eea515ce1828f85eabd1c1986c50cb90313da55ba672281d99df4d50547cc156cd9d51f07227c10a2&ascene=1&uin=MTIxMTIwNjIzNA%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=AxLQ%2F9XCYsuvZ0ktoXSnb7U%3D&pass_ticket=hosf1xh4gpEpplPyin9b6gopmtdGiNUaIPHikWi%2Fa%2FrVc8ApPyI9CKJ3dQPdJX2E&wx_header=0')\n # 'https://mp.weixin.qq.com/s?__biz=MzkzODAwMTQwNw==&mid=2247492267&idx=1&sn=e7865f9f836ed1555030f6a5a285e630&chksm=c284743bf5f3fd2dc975883f6a7e01485a3360d6addf96ef3ba7172c72691ff63e0e5d524d47&scene=126&sessionid=1606644497&key=12842f32187c232df23b9448e3e7611566a3cc9e10533522c37a82a1b2f386c31d85dfa4beab109eab7029b42d239c513679dc34fd3709128ea6975af57ee57e6fa1c73b5c05c17ce6475d154ba273c6283547f9efecf30409b95dd0e2437060b5c75109bedd3ba5dd49aa9f5042238d307e48d625eee3e8a84e01c3df075e78&ascene=1&uin=MTIxMTIwNjIzNA%3D%3D&devicetype=Windows+10+x64&version=6300002f&lang=zh_CN&exportkey=AzmxUtwhAhoK%2Fbib3EKsV5g%3D&pass_ticket=hosf1xh4gpEpplPyin9b6gopmtdGiNUaIPHikWi%2Fa%2FrVc8ApPyI9CKJ3dQPdJX2E&wx_header=0')\n content = get_content(html)\n # print(content)\n md = build_markdown(content)\n print(md)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5063909888267517,
"alphanum_fraction": 0.522686779499054,
"avg_line_length": 40.1677131652832,
"blob_id": "5587538b0b74e7e702afd0c296b2e0b2451c07e2",
"content_id": "0792fb987f1b0b1a4fcee548ab610c41701c3050",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21117,
"license_type": "no_license",
"max_line_length": 358,
"num_lines": 477,
"path": "/spilder/service/wechat_spider.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "# 请求网页\nimport datetime\nimport html\n# json解析\nimport json\nimport time\n\n# html转markdown\nimport html2text as ht\n# 数据库\nimport pymysql\nimport requests\n# 美化html\nfrom bs4 import BeautifulSoup\n\n\nclass WechatSpider:\n\n def __init__(self, biz, cookie, offset, count, log_edit):\n self.biz = biz\n self.cookie = cookie\n self.offset = offset\n self.count = count\n self.total = 0\n self.author_id = ''\n self.author_name = ''\n self.spider_count = 0\n self.log_edit = log_edit\n self.home_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=' + self.biz + '=='\n self.page_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=' + self.biz + '==&offset=' + str(\n self.offset) + '&count=' + str(self.count)\n # self.author_name = ''\n # self.author_avatar = ''\n # self.author_profile = ''\n\n def get_html(self, url, header):\n response = requests.get(url, headers=header)\n response.encoding = 'utf8mb4'\n if response.status_code == 200:\n self.log_edit.insertPlainText(\"[√]网页请求成功\" + \"\\n\")\n print(\"[√]网页请求成功\")\n if \"<title>验证</title>\" in response.text:\n raise Exception(\"需要验证 刷新网页填写必要信息后重试\")\n return response.text\n\n def get_article_url_list(self, page_article_list_html, test):\n # 解析文章主页html\n self.log_edit.insertPlainText(\"[.]正在解析文章列表html...\" + \"\\n\")\n print(\"[.]正在解析文章列表html...\")\n soup = BeautifulSoup(html.unescape(page_article_list_html).encode('utf8'), 'lxml')\n pretty = soup.prettify(formatter='html')\n try:\n # 拆出需要的文章列表json\n self.log_edit.insertPlainText(\"[.]正则提取文章列表json...\" + \"\\n\")\n print(\"[.]正则提取文章列表json...\")\n # split = pretty.split(sep='var msgList = \\'')[1].split(sep='\\';')[0].replace('"', '\\\"')\n split = pretty.split(sep='var msgList = \\'')[1].split(sep='\\';')[0]\n # 格式化json\n self.log_edit.insertPlainText(\"[.]转义json 等待插入数据库...\" + r\"\\n\")\n print(\"[.]转义json 等待插入数据库...\")\n articles_json = json.loads(split)\n if len(articles_json.get('list')) != 0:\n if not test:\n self.offset = self.offset + 10\n self.change_page_url()\n self.spider()\n else:\n return [articles_json['list'][0]]\n else:\n pass\n except Exception as r:\n self.log_edit.insertPlainText(\"异常!\" + str(r) + \"\\n\")\n print(\"异常!\" + str(r))\n return\n return articles_json['list']\n\n @staticmethod\n def has_class_but_no_id(tag):\n return tag.has_attr('data-recommend-type')\n\n def get_article(self, html_str):\n # 解析文章主页html\n soup = BeautifulSoup(html_str.encode('utf8'), 'lxml')\n # 删除所有往期推荐\n [s.extract() for s in soup.find_all(self.has_class_but_no_id)]\n # 删除所有代码块行号\n [s.extract() for s in soup.find_all(\"ul\", {\"class\": \"code-snippet__line-index code-snippet__js\"})]\n # trimmed_soup = soup.find(self.has_class_but_no_id).decompose()\n # 获取js_content\n article_js_content = soup.find(id='js_content')\n pretty_content = BeautifulSoup(str(article_js_content), 'lxml').prettify(formatter='html')\n # 转成markdown\n text_maker = ht.HTML2Text()\n # 设置为true防止content中的大小括号等被转义\n # text_maker.convert_charrefs = True\n text_maker.skip_internal_links = False\n text_maker.br_toggle = '<br>'\n # unescape_content = html.unescape(pretty_content)\n # 这里肯定要自定义一下markdown\n article_content_markdown = text_maker.handle(pretty_content)\n escaped_article_content_markdown = pymysql.escape_string(article_content_markdown)\n return escaped_article_content_markdown\n\n def get_article_list_from_url_list(self, article_list_json):\n if article_list_json is None or article_list_json == '':\n return\n article_list = []\n for article_json in article_list_json:\n # 标题\n title_ = html.unescape(article_json['app_msg_ext_info']['title'])\n # 摘要\n digest_ = html.unescape(article_json['app_msg_ext_info']['digest'])\n # 内容url\n content_url_ = article_json['app_msg_ext_info']['content_url']\n # 封面\n cover_ = article_json['app_msg_ext_info']['cover']\n # 作者\n author_ = article_json['app_msg_ext_info']['author']\n # 发布时间(s时间戳)\n datetime_ = article_json['comm_msg_info']['datetime']\n # 标签\n tag_ = self.choose_tag(title_)\n # 应该可以用来文章去重\n # fakeid_ = article_json['comm_msg_info']['fakeid']\n # 来源网站\n source_url_ = article_json['app_msg_ext_info']['source_url']\n # 多文章\n multi_item_list_ = article_json['app_msg_ext_info']['multi_app_msg_item_list']\n for item in multi_item_list_:\n article = Article()\n article.title = html.unescape(item['title'])\n article.cover = item['cover']\n article.author = item['author']\n article.summary = html.unescape(item['digest'])\n article.tag = self.choose_tag(article.title)\n article.create_at = datetime.datetime.fromtimestamp(datetime_).strftime(\"%Y-%m-%d %H:%M:%S\")\n article.include_at = datetime.datetime.fromtimestamp(round(time.time())).strftime(\"%Y-%m-%d %H:%M:%S\")\n url_ = item['content_url']\n if url_.strip() == '':\n continue\n article.content = self.get_article(self.get_html(url_, ''))\n article_list.append(article)\n if content_url_.strip() == '':\n continue\n html_str = self.get_html(content_url_, '')\n article = Article()\n article.title = title_\n article.cover = cover_\n article.author = author_\n article.summary = digest_\n article.tag = tag_\n article.create_at = datetime.datetime.fromtimestamp(datetime_).strftime(\"%Y-%m-%d %H:%M:%S\")\n article.include_at = datetime.datetime.fromtimestamp(round(time.time())).strftime(\"%Y-%m-%d %H:%M:%S\")\n article.content = self.get_article(html_str)\n article_list.append(article)\n return article_list\n\n # TODO 需要抽取公共方法 游标不参与循环 一次插入多条 https://www.cnblogs.com/jinbuqi/p/11588806.html\n def add_article_list_to_mysql(self, article_list):\n self.log_edit.insertPlainText(\"[.]正在插入数据库...\" + \"\\n\")\n print(\"[.]正在插入数据库...\")\n if article_list is None:\n self.log_edit.insertPlainText(\"记录为0 直接返回\" + \"\\n\")\n print(\"记录为0 直接返回\")\n return\n count = 0\n conn = self.get_mysql_connection()\n cursor = conn.cursor()\n for article in article_list:\n sql = \"insert into article(title,cover,author_id,author_name,summary,create_at,include_at,tag,content) values(\\'\" + article.title + \"\\',\\'\" + article.cover + \"\\',\\'\" + str(\n self.author_id[0]) + \"\\',\\'\" + self.author_name + \"\\',\\'\" + article.summary + \"\\',\\'\" + str(\n article.create_at) + \"\\',\\'\" + article.include_at + \"\\',\\'\" + str(\n article.tag) + \"\\',\\'\" + article.content + \"\\'\" + \")\"\n # unescape_sql = html.unescape(\"sql \")\n try:\n cursor.execute(sql)\n except Exception as r:\n if \"Duplicate\" in str(r):\n self.log_edit.insertPlainText(\"[!]文章重复 已忽略\" + \"\\n\")\n print(\"[!]文章重复 已忽略\")\n continue\n conn.commit()\n count = count + 1\n self.log_edit.insertPlainText(\"[√]当前页第\" + str(count) + \"次插入成功\" + \"\\n\")\n print(\"[√]当前页第\" + str(count) + \"次插入成功\")\n self.total = self.total + count\n return count\n\n def add_user_to_mysql(self, user):\n try:\n self.log_edit.insertPlainText(\"[.]尝试插入作者信息...\" + \"\\n\")\n print(\"[.]尝试插入作者信息...\")\n if user is None:\n return\n sql = \"insert into user(nick_name,avatar,type,signature,qr_code,account) values(\\'\" + user.nickname + \"\\',\\'\" + user.avatar + \"\\',\\'\" + str(\n user.type) + \"\\',\\'\" + user.signature + \"\\',\\'\" + user.qr_code + \"\\',\\'\" + str(\n round(time.time() * 1000)) + \"\\'\" + \")\"\n conn = self.get_mysql_connection()\n cursor = conn.cursor()\n cursor.execute(sql)\n conn.commit()\n\n except Exception as e:\n if \"Duplicate\" in str(e):\n self.log_edit.insertPlainText(\"[*]昵称为\" + user.nickname + \"的作者信息已存在\" + \"\\n\")\n print(\"[*]昵称为\" + user.nickname + \"的作者信息已存在\")\n finally:\n conn = self.get_mysql_connection()\n cursor = conn.cursor()\n get_user_sql = \"select id from user where nick_name = \\'\" + user.nickname + \"\\'\"\n cursor.execute(get_user_sql)\n fetchone = cursor.fetchone()\n conn.commit()\n return fetchone\n\n @staticmethod\n def get_mysql_connection():\n conn = pymysql.connect(\n host='localhost',\n user='root',\n password='root',\n db='tagme3',\n port=3306,\n charset='utf8mb4',\n )\n return conn\n\n def resolve_and_add_to_mysql(self, article_list_json):\n self.log_edit.insertPlainText(\"[.]正在解析偏移量为\" + str(self.offset) + \"的页...\" + \"\\n\")\n print(\"[.]正在解析偏移量为\" + str(self.offset) + \"的页...\")\n self.offset -= self.count\n # 根据文章列表json解析文章实体\n article_list = self.get_article_list_from_url_list(article_list_json)\n if article_list is None:\n self.log_edit.insertPlainText(\"[!]当前页文章数为0\" + \"\\n\")\n print(\"[!]当前页文章数为0\")\n return\n # 把文章实体插入到数据库并返回个数\n self.log_edit.insertPlainText(\"[√]解析成功 共\" + str(len(article_list)) + \"条\" + \"\\n\")\n print(\"[√]解析成功 共\" + str(len(article_list)) + \"条\")\n count = self.add_article_list_to_mysql(article_list)\n return count\n\n def get_header(self):\n header = {\n 'Host': 'mp.weixin.qq.com',\n # 'authority': 'mp.weixin.qq.com',\n # 'cache-control': 'max-age=0',\n # 'upgrade-insecure-requests': '1',\n # 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47',\n 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.116 Safari/537.36 QBCore/4.0.1301.400 QQBrowser/9.0.2524.400 Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36 NetType/WIFI MicroMessenger/7.0.20.1781(0x6700143B) WindowsWechat',\n 'accept': '*/*',\n 'x-requested-with': 'XMLHttpRequest',\n # 'sec-fetch-site': 'none',\n # 'sec-fetch-mode': 'navigate',\n # 'sec-fetch-user': '?1',\n # 'sec-fetch-dest': 'document',\n 'accept-language': 'zh-CN,zh;q=0.8,en-US;q=0.6,en;q=0.5;q=0.4',\n 'cookie': self.cookie\n }\n return header\n\n def change_page_url(self):\n self.page_url = 'https://mp.weixin.qq.com/mp/profile_ext?action=getmsg&__biz=' + self.biz + '==&offset=' + str(\n self.offset) + '&count=' + str(self.count)\n\n # 二维码 头像 昵称 简介\n # var username = \"\" || \"gh_6efb04887fe0\";\n # var headimg = \"http://wx.qlogo.cn/mmhead/Q3auHgzwzM7hYOzDrKzROyuqzoy9yFr1h3Eg43JPafqZ3ibywZT1jhw/0\" || \"\";\n # var nickname = \"码猿技术专栏\".html(false) || \"\";\n # var __biz = \"MzU3MDAzNDg1MA==\";\n def get_author_info(self):\n try:\n header = self.get_header()\n # 根据微信文章列表url获取html\n home_article_list_html = self.get_html(self.home_url, header)\n soup = BeautifulSoup(home_article_list_html.encode('utf8'), 'lxml')\n # 简介\n profile = soup.find(class_=\"profile_desc\").text.strip()\n # 二维码\n qr_code = \"https://open.weixin.qq.com/qr/code?username=\" + \\\n home_article_list_html.split(sep='var username = \"\" || \"')[1].split(sep='\";')[0]\n # 头像\n avatar = home_article_list_html.split(sep='var headimg = \"')[1].split(sep='\" || \"\";')[0]\n # 昵称\n nickname = home_article_list_html.split(sep='var nickname = \"')[1].split(sep='\".html(false) || \"\";')[0]\n user = User()\n user.signature = profile\n user.qr_code = qr_code\n user.avatar = avatar\n user.nickname = nickname\n user.type = 2\n author_id = self.add_user_to_mysql(user)\n self.author_id = author_id\n self.author_name = nickname\n self.log_edit.insertPlainText(\"[√]获取作者信息成功: \" + nickname + \"\" + \"\\n\")\n print(\"[√]获取作者信息成功: \" + nickname + \"\")\n except Exception as r:\n raise Exception(\"获取作者信息失败: \" + str(r) + \"\")\n\n def spider(self):\n self.spider_count += 1\n self.log_edit.insertPlainText(\"-----------------开始第 \" + str(self.spider_count) + \"次爬虫-----------------\" + \"\\n\")\n print(\"-----------------开始第 \" + str(self.spider_count) + \"次爬虫-----------------\")\n self.log_edit.insertPlainText(\"页大小\" + str(self.count) + \",偏移量\" + str(self.offset) + \"\\n\")\n print(\"页大小\" + str(self.count) + \",偏移量\" + str(self.offset))\n\n header = self.get_header()\n # 根据微信文章列表url获取html\n page_article_list_html = self.get_html(self.page_url, header)\n # 睡3秒 不然就封24h\n time.sleep(3)\n # 根据html获取文章列表的json\n article_list_json = self.get_article_url_list(page_article_list_html, False)\n # 根据文章列表json解析文章集合并存入数据库\n count = self.resolve_and_add_to_mysql(article_list_json)\n return count\n\n def test_spider(self):\n self.spider_count += 1\n self.log_edit.insertPlainText(\"-----------------开始第 \" + str(self.spider_count) + \"次爬虫-----------------\" + \"\\n\")\n print(\"-----------------开始第 \" + str(self.spider_count) + \"次爬虫-----------------\")\n self.log_edit.insertPlainText(\"页大小\" + str(self.count) + \",偏移量\" + str(self.offset) + \"\\n\")\n print(\"页大小\" + str(self.count) + \",偏移量\" + str(self.offset))\n\n header = self.get_header()\n # 根据微信文章列表url获取html\n page_article_list_html = self.get_html(self.page_url, header)\n # 根据html获取文章列表的json\n article_list_json = self.get_article_url_list(page_article_list_html, True)\n # 根据文章列表json解析文章集合并存入数据库\n count = self.resolve_and_add_to_mysql(article_list_json)\n return count\n\n @staticmethod\n def choose_tag(title_):\n lower = title_.lower()\n result = 4\n if '前端' in lower or 'html' in lower or 'css' in lower or 'jquery' in lower or 'ajax' in lower or 'vue' in lower or 'webpack' in lower or 'elementui' in lower:\n result = 32\n if '小程序' in lower:\n result = 61\n if '架构' in lower:\n result = 60\n if 'java' in lower or '新特性' in lower:\n result = 44\n if 'spring' in lower or '注解' in lower or 'aop' in lower or 'ioc' in lower or '动态代理' in lower or 'cglib' in lower:\n result = 17\n if '面试题' in lower:\n result = 26\n if 'java基础' in lower or '面向对象' in lower or 'list' in lower or 'collection' in lower \\\n or 'hashmap' in lower or 'object' in lower or '数组' in lower \\\n or '集合' in lower or 'stringbuffer' in lower or 'stringbuilder' in lower \\\n or '循环' in lower or '抽象类' in lower or '切面' in lower or 'gc' in lower or 'oom' in lower or 'stream' in lower \\\n or '反射' in lower or 'switch' in lower or ('if' in lower and 'else' in lower):\n result = 7\n if '职场经验' in lower:\n result = 8\n if '软件安装' in lower:\n result = 10\n if '线程' in lower or '锁' in lower or 'synchronized' in lower or 'thread' in lower or 'volatile' in lower:\n result = 13\n if '数据库' in lower or 'mysql' in lower or 'sql' in lower \\\n or 'oracle' in lower or 'innodb' in lower \\\n or 'truncate' in lower or 'explain' in lower \\\n or ('索引' in lower and '搜索引擎' not in lower):\n result = 11\n if 'redis' in lower:\n result = 9\n if 'linux' in lower:\n result = 15\n if '编程习惯' in lower or ('try' in lower and 'catch' in lower) or '代码审查' in lower or '优雅' in lower:\n result = 16\n if 'maven' in lower:\n result = 19\n if 'swagger' in lower:\n result = 20\n if 'mq' in lower or '消息队列' in lower or '消息中间件' in lower:\n result = 21\n if '分布式' in lower:\n result = 27\n if '微服务' in lower:\n result = 22\n if 'docker' in lower:\n result = 23\n if 'nginx' in lower:\n result = 24\n if 'jvm' in lower:\n result = 28\n if '开源项目' in lower:\n result = 29\n if '高并发' in lower or '秒杀' in lower:\n result = 30\n if 'tomcat' in lower:\n result = 31\n if ('spring' in lower and 'mvc' in lower):\n result = 34\n if 'jwt' in lower:\n result = 36\n if 'elasticsearch' in lower:\n result = 37\n if '分库分表' in lower or '读写分离' in lower:\n result = 38\n if '算法' in lower:\n result = 39\n if 'spring' in lower and 'cloud' in lower:\n result = 40\n if '数据恢复' in lower:\n result = 41\n if 'vue' in lower:\n result = 42\n if 'http' in lower or '次握手' in lower:\n result = 43\n if '性能调优' in lower:\n result = 45\n if '网关' in lower:\n result = 46\n if '框架' in lower:\n result = 47\n if 'dubbo' in lower:\n result = 48\n if 'zookeeper' in lower:\n result = 49\n if 'restful' in lower:\n result = 50\n if '权限认证' in lower or 'oauth' in lower or 'jwt' in lower:\n result = 51\n if 'ssm' in lower:\n result = 52\n if 'eureka' in lower:\n result = 53\n if 'git' in lower:\n result = 54\n if '负载均衡' in lower:\n result = 55\n if 'security' in lower:\n result = 56\n if 'mongodb' in lower:\n result = 57\n if '源码' in lower:\n result = 58\n if '数据结构' in lower or '红黑树' in lower:\n result = 59\n if ('spring' in lower and 'boot' in lower) or '@auto' in lower:\n result = 14\n if '设计模式' in lower:\n result = 25\n if 'jenkins' in lower:\n result = 18\n if 'mybatis' in lower:\n result = 6\n if 'mybatis' in lower and 'plus' in lower:\n result = 62\n # 最后面\n if '插件' in lower or '工具' in lower or '热部署' in lower or '安装' in lower:\n result = 12\n return result\n\n\nclass Article:\n def __init__(self):\n self.title = ''\n self.cover = ''\n self.author = ''\n self.summary = ''\n self.content = ''\n self.create_at = ''\n self.tag = ''\n\n\nclass User:\n def __init__(self):\n self.nickname = ''\n self.avatar = ''\n self.type = ''\n self.signature = ''\n self.qr_code = ''\n"
},
{
"alpha_fraction": 0.5164403319358826,
"alphanum_fraction": 0.5441386699676514,
"avg_line_length": 34.871795654296875,
"blob_id": "496ce3ca49bc909b873b5445097e3d779f3abc92",
"content_id": "4a1b670ba310c509d7f23a59208f0ffe2ab4f70b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5936,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 156,
"path": "/spilder/service/sougou_crawl.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "import random\nimport re\nimport time\nimport uuid\nfrom urllib.parse import urlencode, quote\n\nimport pymysql\nimport requests\nfrom pyquery import PyQuery as pq\n\n\nclass TicketSpider:\n def __init__(self, url):\n self.url = url\n self.key = 'hello world'\n # quote:转义成带%前缀的url样式 这个url是搜狗微信请求的最简格式\n self.format_url = 'https://weixin.sogou.com/weixin?type=2&query={}'.format(quote(self.key))\n # User-Agent是必须要有的 不然骗不过目标网站\n self.headers_str = 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.128 Safari/537.36 Edg/89.0.774.77'\n self.a_str = '''\nuigs_cl\tfirst_click\nuigs_refer\thttps://weixin.sogou.com/\nuigs_productid\tvs_web\nterminal\tweb\nvstype\tweixin\npagetype\tresult\nchannel\tresult_article\ns_from\tinput\nsourceid\t\ntype\tweixin_search_pc\nuigs_cookie\tSUID,sct\nquery\thello world\nweixintype\t2\nexp_status\t-1\nexp_id_list\t0_0\nwuid\t0071440178DB40975D3C689EE37C6784\nrn\t1\nlogin\t0\nuphint\t1\nbottomhint\t1\npage\t1\nexp_id\tnull_0-null_1-null_2-null_3-null_4-null_5-null_6-null_7-null_8-null_9\ntime\t20914\n'''\n self.b_data = self.str_to_dict()\n self.headers = self.headers_to_dict()\n\n def headers_to_dict(self):\n headers_str = self.headers_str.strip()\n # 把header字符串枚举化并转成字典\n headers_dict = dict((i.split(':', 1)[0].strip(), i.split(':', 1)[1].strip()) for i in headers_str.split('\\n'))\n return headers_dict\n\n def str_to_dict(self):\n '''\n 将a_str形式的字符串转化为字典形式;\n :param a_str:\n :return:\n '''\n str_a = list(i for i in self.a_str.split('\\n') if i != '')\n str_b = {}\n for a in str_a:\n a1 = a.split('\\t')[0]\n a2 = a.split('\\t')[1]\n str_b[a1] = a2\n\n return str_b\n\n def get_suva(self, sunid):\n '''\n 根据sunid来获取suv参数;并添加到cookie\n :param a: sunid\n :return:\n '''\n self.b_data['snuid'] = sunid.split('=')[-1]\n self.b_data['uuid'] = uuid.uuid1()\n self.b_data['uigs_t'] = str(int(round(time.time() * 1000)))\n url_link = 'https://pb.sogou.com/pv.gif?' + urlencode(self.b_data)\n res = requests.get(url_link)\n cookie_s = res.headers['Set-Cookie'].split(',')\n cookie_list_s = []\n for i in cookie_s:\n for j in i.split(','):\n if 'SUV' in j:\n cookie_list_s.append(j)\n else:\n continue\n print(cookie_list_s[0].split(';')[0])\n self.headers['Cookie'] = cookie_list_s[0].split(';')[0]\n\n # Todo snuid上限大概100次 可以每爬取50页就重新以无cookie身份去获取一次SNUID\n def get_first_parse(self):\n # 给headers中添加Referer参数 可以不填\n # headers['Referer'] = url_list\n res = requests.get(self.url, headers=self.headers)\n # 访问标准url 获取response中的Set-Cookie\n cookies = res.headers['Set-Cookie'].split(';')\n cookie_list_long = []\n cookie_list2 = []\n for cookie in cookies:\n cookie_list_long.append(str(cookie).split(','))\n for news_list_li in cookie_list_long:\n for set in news_list_li:\n if 'SUID' in set or 'SNUID' in set:\n cookie_list2.append(set)\n sunid = cookie_list2[0].split(';')[0]\n self.get_suva(sunid)\n # 构造动态Cookies\n self.headers['Cookie'] = self.headers['Cookie'] + ';' + ';'.join(cookie_list2)\n news_list_lis = pq(res.text)('.news-list li').items()\n for news_list_li in news_list_lis:\n # 提取href属性标签 得到的url才是能够正确跳转的url\n href = pq(news_list_li('.img-box a').attr('href'))\n href = str(href).replace('<p>', '').replace('</p>', '').replace('amp;', '')\n # 构造参数k与h;\n b = int(random.random() * 100) + 1\n a = href.find(\"url=\")\n result_link = href + \"&k=\" + str(b) + \"&h=\" + href[a + 4 + 21 + b: a + 4 + 21 + b + 1]\n whole_href = \"https://weixin.sogou.com\" + result_link\n logic_url = requests.get(whole_href, headers=self.headers).text\n # 获取真实url\n url_text = re.findall(\"\\'(\\S+?)\\';\", logic_url, re.S)\n best_url = ''.join(url_text)\n real_article_url = best_url.replace('&from=inner', '').replace(\"@\", \"\")\n real_article_text = requests.get(url=str(real_article_url)).text\n print('------------------------------------------------------------------------------------')\n print('url: ' + real_article_url)\n print('标题: ' + pq(real_article_text)('#activity-name').text())\n print('图片: ' + pq(news_list_li('.img-box a img').attr('src')).text().split('url=')[1])\n print('时间戳: ' + pq(news_list_li('.txt-box div span script')).text().split('\\'')[1])\n # 二维码链接不显示\n # print(pq(real_article_text)('.qr_code_pc_img').attr('src').text())\n print('作者: ' + pq(real_article_text)('#js_name').text())\n # print('发布时间: ' + pq(real_article_text)('.rich_media_meta_list').text())\n # print(pq(real_article_text)('#meta_content > span.rich_media_meta.rich_media_meta_text').text())\n\n\nclass DBAccessor:\n\n def __init__(self):\n self.conn = pymysql.connect(\n host='39.107.99.242',\n user='zyl',\n password='zyl',\n db='tagme',\n port=3306,\n charset='utf8mb4',\n )\n\n def exec(self, sql):\n cursor = self.conn.cursor()\n\n\nif __name__ == '__main__':\n ticket = TicketSpider('https://weixin.sogou.com/weixin?type=2&query=%E8%B5%A0%E7%A5%A8')\n ticket.get_first_parse()\n"
},
{
"alpha_fraction": 0.5682926774024963,
"alphanum_fraction": 0.5741463303565979,
"avg_line_length": 34.96491241455078,
"blob_id": "1303a4355f6ff963e33403e2488794bc5453f7bf",
"content_id": "a89beb5068c62e5069f9041ca0914e6c7b1c5c3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2116,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 57,
"path": "/spilder/ui/gui.py",
"repo_name": "AlphaKitty/wechat_spilder",
"src_encoding": "UTF-8",
"text": "from PySide2.QtGui import QIcon\nfrom PySide2.QtWidgets import QApplication, QMessageBox, QFileDialog\nfrom PySide2.QtUiTools import QUiLoader\nimport pymysql\n\nfrom spilder.service.wechat_spider import WechatSpider\n\n\nclass Stats:\n # QMessageBox.about(self.ui, 'tips', biz)\n\n def __init__(self):\n self.ui = QUiLoader().load('wechat_spider.ui')\n self.ui.confirmButton.clicked.connect(self.handle_confirm)\n self.ui.testButton.clicked.connect(self.handle_test)\n self.set_default_text()\n\n def handle_confirm(self):\n print(\"-----------------start-----------------\")\n biz = self.ui.bizEdit.toPlainText()\n cookie = self.ui.cookieEdit.toPlainText()\n spider = WechatSpider(biz, cookie, 0, 10, self.ui.logEdit)\n spider.get_author_info()\n spider.spider()\n print(\"[√]抓取完成共抓取\" + str(spider.total) + \"条\")\n print(\"-----------------end-----------------\")\n QMessageBox.about(self.ui, 'tips', \"共抓取\" + str(spider.total) + \"条\")\n\n def handle_test(self):\n print(\"-----------------start-----------------\")\n biz = self.ui.bizEdit.toPlainText()\n cookie = self.ui.cookieEdit.toPlainText()\n spider = WechatSpider(biz, cookie, 0, 10, self.ui.logEdit)\n spider.get_author_info()\n spider.test_spider()\n print(\"[√]抓取完成共抓取\" + str(spider.total) + \"条\")\n print(\"-----------------end-----------------\")\n QMessageBox.about(self.ui, 'tips', \"共抓取\" + str(spider.total) + \"条\")\n\n def set_default_text(self):\n try:\n conn = WechatSpider.get_mysql_connection()\n cursor = conn.cursor()\n get_cookie_sql = \"select * from spider where active = 1\"\n cursor.execute(get_cookie_sql)\n fetchone = cursor.fetchone()\n conn.commit()\n self.ui.bizEdit.setPlainText(fetchone[1])\n self.ui.cookieEdit.setPlainText(fetchone[2])\n except Exception:\n print(\"[!]默认信息不存在\")\n\n\napp = QApplication([])\nstats = Stats()\nstats.ui.show()\napp.exec_()\n"
}
] | 8 |
dimoka777/Lisa-s-Workbook
|
https://github.com/dimoka777/Lisa-s-Workbook
|
77a13e6123fac6727fec82c3a9a65d62878f66d9
|
ac32f5d6a3fdd64ded8fee1dd48a0caa425b8dd3
|
4d25f01a656d3f7f80853e7f01ef9d377ec5bd4e
|
refs/heads/master
| 2020-06-12T17:23:45.513974 | 2019-06-29T06:10:20 | 2019-06-29T06:10:20 | 194,370,791 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 10.666666984558105,
"blob_id": "152363a43dd379ad7d8832ac2f4651631c09887f",
"content_id": "344de5f4bab32145503993b166dbcdecba4c5874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 18,
"num_lines": 3,
"path": "/test.py",
"repo_name": "dimoka777/Lisa-s-Workbook",
"src_encoding": "UTF-8",
"text": "import numpy as np\na = []\nfor i in\n\n"
},
{
"alpha_fraction": 0.4813167154788971,
"alphanum_fraction": 0.5026690363883972,
"avg_line_length": 22.41666603088379,
"blob_id": "a44db53d0e28becc47b1414d13122e6d3091320a",
"content_id": "675e545bab66fd10b7a9522feb04726623ba2c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1124,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 48,
"path": "/workbook.py",
"repo_name": "dimoka777/Lisa-s-Workbook",
"src_encoding": "UTF-8",
"text": "\"\"\"\n Lisa's WorkBook Hackerrank Max Score 25\n\n\"\"\"\nimport math\nimport os\nimport random\nimport re\nimport sys\nimport numpy\n\n# Complete the workbook function below.\ndef workbook(n, k, arr):\n\n attempt = 0\n counter = 0\n result = []\n for i in range(n):\n temp = 0\n new_list = []\n for j in range(arr[i]):\n new_list.append(temp + 1)\n temp += 1\n while len(new_list) >= k:\n result.append(new_list[:k])\n if counter+1 in result[counter]:\n attempt += 1\n del new_list[:k]\n counter += 1\n if len(new_list) < k and len(new_list) != 0:\n result.append(new_list)\n if counter+1 in result[counter]:\n attempt += 1\n counter += 1\n return attempt\n\n\nif __name__ == '__main__':\n # fptr = open(os.environ['OUTPUT_PATH'], 'w')\n # nk = input().split()\n # n = int(nk[0])\n # k = int(nk[1])\n # arr = list(map(int, input().rstrip().split()))\n result = workbook(5, 3, [4,2,6,1,10])\n print(result)\n # fptr.write(str(result) + '\\n')\n #\n # fptr.close()\n"
}
] | 2 |
rui-silva/analysis_bias_pt_sports_newspapers
|
https://github.com/rui-silva/analysis_bias_pt_sports_newspapers
|
dc553acecd5c1367ef41a022f36468e9a312396a
|
38f31b3636fb7095acf2ac589a6b60a0e54746d3
|
e0ba418da265a0ec85fa418181bc3ba6ae13b83a
|
refs/heads/master
| 2020-12-03T07:31:26.868276 | 2020-01-02T18:58:09 | 2020-01-02T20:19:50 | 231,242,623 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5224586129188538,
"alphanum_fraction": 0.5378250479698181,
"avg_line_length": 15.920000076293945,
"blob_id": "032667a2dc2280bace9e32bb96a61c085d58b013",
"content_id": "d67693d3228b277a47d07ade53c2ebab7fd73933",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 846,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 50,
"path": "/analysis_bias_pt_sports_newspapers/utils.py",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "from enum import Enum\n\n\nclass Newspaper(Enum):\n Abola = 0\n Record = 1\n Ojogo = 2\n\n @staticmethod\n def names():\n return [c.name for c in Newspaper]\n\n\nclass Clubs(Enum):\n BENFICA = (1, 'red')\n PORTO = (2, 'blue')\n SPORTING = (3, 'green')\n OTHER = (5, 'gray')\n\n def __init__(self, id, color):\n self.id = id\n self.color = color\n\n @staticmethod\n def ids():\n return [c.id for c in Clubs]\n\n @staticmethod\n def names():\n return [c.name for c in Clubs]\n\n @staticmethod\n def colors():\n return [c.color for c in Clubs]\n\n\nclass LabelClass(Enum):\n BACKGROUND = 0\n BENFICA = 1\n PORTO = 2\n SPORTING = 3\n PUB = 4\n OTHER = 5\n\n def __init__(self, id):\n self.id = id\n\n @staticmethod\n def names():\n return [c.name for c in LabelClass]\n"
},
{
"alpha_fraction": 0.5874649286270142,
"alphanum_fraction": 0.5965855717658997,
"avg_line_length": 33.48387145996094,
"blob_id": "bed66a9113fa4900c0fcd59433e6c37be9968b82",
"content_id": "eb3244ebf3680c44644c6a766758bec18b40a950",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4276,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 124,
"path": "/analysis_bias_pt_sports_newspapers/categorical_yearplot.py",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "import itertools\nimport datetime as dt\nimport numpy as np\nimport pandas as pd\nfrom matplotlib.colors import ListedColormap\nimport calendar\n\n\ndef cyearplot(data,\n year=None,\n vmin=None,\n vmax=None,\n cmap='Reds',\n fillcolor='whitesmoke',\n linewidth=1,\n linecolor='white',\n daylabels=calendar.day_abbr[:],\n dayticks=True,\n monthlabels=calendar.month_abbr[1:],\n monthticks=True,\n ax=None,\n **kwargs):\n \"\"\"\n Extends ttresslar/calmap to plot (https://github.com/ttresslar/calmap)\n categorical year plots. Each date may be associated with multiple labels.\n The square associated with such dates is filled with multiple colors vertically.\n \"\"\"\n\n if year is None:\n year = data.index.sort_values()[0].year\n\n # Min and max per day.\n if vmin is None:\n vmin = data.min()[0]\n if vmax is None:\n vmax = data.max()[0]\n\n if ax is None:\n ax = plt.gca()\n\n # Filter on year.\n by_day = data[str(year)]\n\n # Add missing days.\n dates_in_year = pd.date_range(start=str(year), end=str(year + 1),\n freq='D')[:-1]\n by_day = by_day.reindex(dates_in_year, fill_value=np.nan)\n\n # Create data frame we can pivot later.\n by_day = pd.DataFrame(\n dict({\n 'day': by_day.index.dayofweek,\n 'week': by_day.index.week,\n 'data': by_day,\n 'fill': 1\n }))\n\n # There may be some days assigned to previous year's last week or\n # next year's first week. We create new week numbers for them so\n # the ordering stays intact and week/day pairs unique.\n by_day.loc[(by_day.index.month == 1) & (by_day.week > 50), 'week'] = 0\n by_day.loc[(by_day.index.month == 12) & (by_day.week < 10), 'week'] \\\n = by_day.week.max() + 1\n\n plot_data = by_day.pivot('day', 'week', 'data')\n\n label_combos = data.map(lambda x: len(x)).unique()\n lcm = np.lcm.reduce(label_combos)\n\n def expand_cols(x):\n if x is np.nan:\n x = (np.nan, )\n return list(\n itertools.chain.from_iterable(\n itertools.repeat(n, lcm // len(x)) for n in x))\n\n # First, expand the labels so that each cell has lcm columns.\n # Then reshape so that the rows correspond to the weekdays.\n # Finally, expand the labels so that each cell has lcm rows.\n plot_data = plot_data.applymap(expand_cols)\n plot_data = np.vstack(plot_data.values.tolist()).reshape(7, -1)\n plot_data = np.repeat(plot_data, lcm, axis=0)\n plot_data = np.ma.masked_where(np.isnan(plot_data), plot_data)\n\n # Compute the cells that dont need to be filled\n fill_data = np.array(by_day.pivot('day', 'week', 'fill').values)\n fill_data = np.repeat(np.repeat(fill_data, lcm, axis=0), lcm, axis=1)\n fill_data = np.ma.masked_where(np.isnan(fill_data), fill_data)\n\n ax.imshow(fill_data, vmin=0, vmax=1, cmap=ListedColormap([fillcolor]))\n ax.imshow(plot_data, vmin=vmin, vmax=vmax, cmap=cmap)\n\n # Get indices for monthlabels.\n if monthticks is True:\n monthticks = range(len(monthlabels))\n elif monthticks is False:\n monthticks = []\n elif isinstance(monthticks, int):\n monthticks = range(len(monthlabels))[monthticks // 2::monthticks]\n\n # Get indices for daylabels.\n if dayticks is True:\n dayticks = range(len(daylabels))\n elif dayticks is False:\n dayticks = []\n elif isinstance(dayticks, int):\n dayticks = range(len(daylabels))[dayticks // 2::dayticks]\n\n # Ticks for x/y axis labels\n ax.set_yticks(np.arange(lcm / 2 - .5, (6 + 1) * lcm, lcm))\n ax.set_yticklabels(daylabels)\n ax.set_xticks([\n by_day.ix[dt.date(year, i + 1, 15)].week * lcm - lcm / 2 - .5\n for i in monthticks\n ])\n ax.set_xticklabels([monthlabels[i] for i in monthticks], ha='center')\n\n # Ticks for the grid-like effect\n ax.set_yticks(np.arange(lcm - .5, (6 + 1) * lcm, lcm), minor=True)\n last_week = by_day['week'].max()\n ax.set_xticks(np.arange(lcm - .5, last_week * lcm, lcm), minor=True)\n ax.grid(which='minor', color=linecolor, linestyle='-', linewidth=linewidth)\n\n return ax\n"
},
{
"alpha_fraction": 0.5699608325958252,
"alphanum_fraction": 0.5756203532218933,
"avg_line_length": 35.11635208129883,
"blob_id": "0edd246d83dba8d4696bd51ee78f411ca4ec0688",
"content_id": "14f31edd6742822ee77499f5e83ca0f835ddf488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11485,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 318,
"path": "/analysis_bias_pt_sports_newspapers/analysis.py",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import ListedColormap\nimport pandas as pd\nimport datetime as dt\nfrom categorical_yearplot import cyearplot\nfrom covers_dataset import CoversDataset, get_file_path_date, get_file_path_newspaper\nfrom utils import LabelClass, Clubs, Newspaper\n\nPT_MONTH_LABELS = [\n 'Jan', 'Fev', 'Mar', 'Abr', 'Mai', 'Jun', 'Jul', 'Ago', 'Set', 'Out',\n 'Nov', 'Dez'\n]\nPT_DAY_LABELS = ['Seg', 'Ter', 'Qua', 'Qui', 'Sex', 'Sab', 'Dom']\n\n\ndef filter_newspapers(df, newspapers):\n return df[df[\"Newspaper\"].isin(newspapers)]\n\n\ndef filter_df_game_data_by_team_and_result(game_data_df, cond_team, cond_result):\n is_home_team_and_wins = (game_data_df['Home_Team'] == cond_team) & (\n game_data_df['Home_Score'] > game_data_df['Away_Score'])\n is_away_team_and_wins = (game_data_df['Away_Team'] == cond_team) & (\n game_data_df['Away_Score'] > game_data_df['Home_Score'])\n is_home_team_and_not_wins = (game_data_df['Home_Team'] == cond_team) & (\n game_data_df['Home_Score'] <= game_data_df['Away_Score'])\n is_away_team_and_not_wins = (game_data_df['Away_Team'] == cond_team) & (\n game_data_df['Away_Score'] <= game_data_df['Home_Score'])\n\n if cond_result == 'win':\n team_idxs = is_home_team_and_wins | is_away_team_and_wins\n elif cond_result == 'non-win':\n team_idxs = is_home_team_and_not_wins | is_away_team_and_not_wins\n return game_data_df[team_idxs]\n\n\ndef produce_cover_counts(df):\n counts = np.zeros(len(LabelClass))\n for index, row in df.iterrows():\n counts[list(row['Highlighted_Labels'])] += 1\n\n return counts[Clubs.ids()]\n\n\ndef cover_data_to_pandas():\n MAX_AREA_TOL = .3\n df = []\n\n dataset = CoversDataset('./data/')\n for i in range(len(dataset)):\n _, target = dataset[i]\n image_path = dataset.images[i]\n date = get_file_path_date(image_path)\n\n newspaper_name = get_file_path_newspaper(image_path).lower()\n areas = target['area']\n\n # Some newspapers dont publish on holidays. Skip those\n if len(areas) == 0:\n continue\n\n labels = target['labels']\n\n benfica_areas = areas[labels == LabelClass.BENFICA.id]\n porto_areas = areas[labels == LabelClass.PORTO.id]\n sporting_areas = areas[labels == LabelClass.SPORTING.id]\n other_areas = areas[labels == LabelClass.OTHER.id]\n cover_total_area = target['image_width'] * target['image_height']\n\n max_area = np.max(target['area'])\n max_coverage_labels = tuple(\n np.unique(labels[np.isclose(areas,\n max_area,\n atol=0,\n rtol=MAX_AREA_TOL)]))\n\n df.append({\n 'Date': dt.datetime.strptime(date, '%Y-%m-%d'),\n 'Newspaper': newspaper_name,\n 'Highlighted_Labels': max_coverage_labels,\n })\n\n df = pd.DataFrame(df)\n return df\n\n\ndef games_data_to_pandas():\n min_date = dt.datetime(year=2019, month=1, day=1)\n max_date = dt.datetime(year=2019, month=12, day=31)\n import csv\n df = []\n with open('./data/games_data.csv', 'r') as csv_file:\n csv_reader = csv.DictReader(csv_file)\n for line_count, row in enumerate(csv_reader):\n date = dt.datetime.strptime(row['date'], '%Y-%m-%d')\n if date < min_date or date > max_date:\n continue\n df.append({\n 'Date': date,\n 'Home_Team': row['home_team'],\n 'Away_Team': row['away_team'],\n 'Home_Score': row['home_score'],\n 'Away_Score': row['away_score']\n })\n\n df = pd.DataFrame(df)\n df = df.drop_duplicates() # paranoid cleanup\n\n return df\n\n\ndef year_calendar_plot(covers_df):\n from matplotlib.patches import Patch\n fig, axes = plt.subplots(nrows=3,\n ncols=1,\n squeeze=False,\n subplot_kw={},\n gridspec_kw={})\n axes = axes.T[0]\n\n for newspaper_idx, newspaper_name in enumerate(Newspaper.names()):\n newspaper_df = filter_newspapers(covers_df, [newspaper_name.lower()])\n total_covers = len(newspaper_df)\n benfica_covers, porto_covers, sporting_covers, other_covers = produce_cover_counts(\n newspaper_df)\n newspaper_df = newspaper_df.set_index('Date')['Highlighted_Labels']\n ax = cyearplot(newspaper_df,\n daylabels=PT_DAY_LABELS,\n monthlabels=PT_MONTH_LABELS,\n linewidth=2,\n cmap=ListedColormap(Clubs.colors()),\n ax=axes[newspaper_idx])\n ax.set_title(newspaper_name.capitalize())\n ax.legend(handles=[\n Patch(facecolor='r',\n edgecolor='r',\n label=f'Benfica {benfica_covers / total_covers:.1%}'),\n Patch(facecolor='b',\n edgecolor='b',\n label=f'Porto {porto_covers / total_covers:.1%}'),\n Patch(facecolor='green',\n edgecolor='green',\n label=f'Sporting {sporting_covers / total_covers:.1%}'),\n Patch(facecolor='gray',\n edgecolor='gray',\n label=f'Other {other_covers / total_covers:.1%}')\n ],\n loc='lower center',\n ncol=4,\n bbox_to_anchor=(0.5, -.5))\n\n fig.set_figheight(10)\n fig.set_figwidth(10)\n plt.tight_layout()\n plt.savefig('./calendar_view.png', bbox_inches='tight')\n\n\ndef tidify_covers_df(df):\n def one_hot(labels, size):\n res = np.zeros(size)\n res[labels] += 1\n return res\n\n df = df.set_index('Date')[['Newspaper', 'Highlighted_Labels']]\n\n # Split labels into columns\n # - one hot encoding of labels\n df['Highlighted_Labels'] = df['Highlighted_Labels'].map(\n lambda x: one_hot(list(x), len(LabelClass))[Clubs.ids()])\n # - split vector to multiple cols\n df[['benfica', 'porto', 'sporting',\n 'other']] = pd.DataFrame(df.Highlighted_Labels.values.tolist(),\n index=df.index)\n df = df.drop(columns=['Highlighted_Labels'])\n return df\n\n\ndef month_plot(data):\n import matplotlib.ticker as mtick\n\n data = tidify_covers_df(data)\n fig, axes = plt.subplots(nrows=1,\n ncols=3,\n squeeze=False,\n subplot_kw={},\n gridspec_kw={})\n axes = axes[0]\n\n for newspaper_idx, n in enumerate(Newspaper.names()):\n newspaper_name = n.lower()\n newspaper_df = filter_newspapers(data, [newspaper_name])\n agg_df = newspaper_df.groupby(\n newspaper_df.index.month)[['benfica', 'porto',\n 'sporting']].agg(['mean'])\n\n agg_df = agg_df\n\n ax = axes[newspaper_idx]\n ax.set_prop_cycle(color=['red', 'blue', 'green'])\n ax.plot(agg_df[['benfica', 'porto', 'sporting']], 'o--', linewidth=2)\n ax.set_title(newspaper_name.capitalize())\n ax.set_xticks([i for i in range(1, 12 + 1)])\n ax.yaxis.set_major_formatter(mtick.PercentFormatter(xmax=1.0))\n ax.set_xticklabels(PT_MONTH_LABELS)\n if newspaper_idx == 0:\n ax.set_ylabel('Percentagem de capas com destaque')\n\n ybot, ytop = ax.set_ylim(0, 1)\n xleft, xright = ax.set_xlim(0.5, 12.5)\n aspect_ratio = 1.0\n ax.set_aspect(aspect=(xright - xleft) / (ytop - ybot) * aspect_ratio)\n\n ax.grid()\n # print(agg_df)\n\n fig.set_figheight(7)\n fig.set_figwidth(23)\n plt.savefig('./month_view.png', bbox_inches='tight')\n\n\ndef next_day_analysis(covers_df, games_df):\n covers_df = tidify_covers_df(covers_df)\n\n for newspaper in Newspaper.names():\n print('=======')\n newspaper = newspaper.lower()\n for club in ['Benfica', 'Porto', 'Sporting']:\n print(f'\\nAnalysis {newspaper} - {club}')\n _next_day_analysis(covers_df, games_df, newspaper, club)\n\n\ndef _next_day_analysis(covers_df, games_df, newspaper, team):\n # Create a DF with the dates after a win or non win of the team\n # - extract wins and non wins\n win_games_df = filter_df_game_data_by_team_and_result(\n games_df, team, 'win')\n no_win_games_df = filter_df_game_data_by_team_and_result(\n games_df, team, 'non-win')\n\n # - compute the dates after events\n dates_after_win = win_games_df['Date'] + dt.timedelta(days=1)\n dates_after_no_win = no_win_games_df['Date'] + dt.timedelta(days=1)\n # - create df\n date_after_win_df = pd.DataFrame({\n 'Date': dates_after_win,\n 'after_win': 1\n }).set_index('Date')\n date_after_no_win_df = pd.DataFrame({\n 'Date': dates_after_no_win,\n 'after_no_win': 1\n }).set_index('Date')\n\n # Get the newspaper covers that highlighted the team\n # - filter newspaper\n covers_df = filter_newspapers(covers_df, [newspaper])\n # - filter only rows for covers where team is highlighted\n club_covers_df = covers_df[covers_df[team.lower()] == 1]\n\n highlighted_wins_df = club_covers_df.join(date_after_win_df, how='inner')\n highlighted_non_wins_df = club_covers_df.join(date_after_no_win_df,\n how='inner')\n\n # Report results\n total_wins = len(dates_after_win)\n total_non_wins = len(dates_after_no_win)\n total_highlighted_wins = highlighted_wins_df['after_win'].sum()\n total_highlighted_non_wins = highlighted_non_wins_df['after_no_win'].sum()\n\n print(f'Number of wins: {total_wins}')\n print(f'Number of non_wins: {total_non_wins}')\n print(f'Pct highlighted wins: {total_highlighted_wins / total_wins:.0%}')\n print(\n f'Pct highlighted non wins: {total_highlighted_non_wins / total_non_wins:.0%}'\n )\n\n # Additional results for debug purposes:\n # - print the highlighted/not highlighted wins and non wins\n print(f'Highlighted wins: {highlighted_wins_df.index}')\n print(f'Highlighted non_wins: {highlighted_non_wins_df.index}')\n\n unhighlighted_wins_df = club_covers_df.join(date_after_win_df, how='right')\n unhighlighted_wins_df = unhighlighted_wins_df[\n unhighlighted_wins_df['Newspaper'].isna()]\n print(f'Unhighlighted wins: {unhighlighted_wins_df.index}')\n\n unhighlighted_non_wins_df = club_covers_df.join(date_after_no_win_df,\n how='right')\n unhighlighted_non_wins_df = unhighlighted_non_wins_df[\n unhighlighted_non_wins_df['Newspaper'].isna()]\n print(f'Unhighlighted non_wins: {unhighlighted_non_wins_df.index}')\n\n\ndef main():\n try:\n covers_df = pd.read_pickle('./data/covers_df.pkl')\n except FileNotFoundError:\n covers_df = cover_data_to_pandas()\n pd.to_pickle(covers_df, './data/covers_df.pkl')\n\n try:\n games_df = pd.read_pickle('./data/games_df.pkl')\n except FileNotFoundError:\n games_df = games_data_to_pandas()\n pd.to_pickle(games_df, './data/games_df.pkl')\n\n print('Creating calendar plot')\n year_calendar_plot(covers_df)\n\n print('Creating month plot')\n month_plot(covers_df)\n\n print('Next day analysis')\n next_day_analysis(covers_df, games_df)\n\n\nmain()\n"
},
{
"alpha_fraction": 0.7365853786468506,
"alphanum_fraction": 0.7463414669036865,
"avg_line_length": 17.303571701049805,
"blob_id": "a378ea24619516a6f610d33f0ded54e581f08058",
"content_id": "84d0cf441bc5052b89d9aed025cc4d4d951313b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 56,
"path": "/README.rst",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "Analysis of biases in portuguese sports newspapers\n========\n\nCode and data used for analyzing the biases in portuguese sports\nnewspapers:\nhttps://ruitsilva.com/pt/post/enviesamento_jornais_desportivos_portugueses/\n(in Portuguese).\n\n\nDependencies\n------------\n\n`poetry` dependency management tool: https://python-poetry.org/\n\npyenv and virtualenv\n\nInstallation\n------------\n\nClone repo\n\ncd into project dir\n\nCreate a virtualenv for the project and activate it\n\n pyenv install 3.6.4\n\n pyenv virtualenv 3.6.4 analysis_bias_pt_sports_newspapers\n\n pyenv activate analysis_bias_pt_sports_newspapers\n\nInstall package with\n\n poetry install\n\n\nRun\n---\n\ncd into the main folder\n\n cd analysis_bias_pt_sports_newspapers\n\nCrawl the covers from banca sapo.\n\n python crawl_covers.py\n\nYou should see a new folder `./data/covers` with the newspaper\ncovers from 2019.\n\nNow run\n\n python analysis.py\n\nThe calendar and month plots will be saved as figures in the current\ndirectory. Other results may be shown on the terminal.\n"
},
{
"alpha_fraction": 0.5615796446800232,
"alphanum_fraction": 0.5934850573539734,
"avg_line_length": 27.730770111083984,
"blob_id": "e89bb333096515782897043aa125329abbac27ed",
"content_id": "1f13191791d53c49bc6702d9348034537bf9c91c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4482,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 156,
"path": "/analysis_bias_pt_sports_newspapers/crawl_covers.py",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "import os\nfrom multiprocessing import Pool\nimport functools\nimport datetime\nfrom enum import Enum\nimport requests\nimport bs4\n\n\nclass Newspaper(Enum):\n \"\"\"\n The ids used by banca sapo for each newspaper.\n \"\"\"\n Abola = 4137\n Record = 4139\n Ojogo = 4138\n\n\nclass Resolution(Enum):\n R320x398 = (320, 398)\n R640x795 = (640, 795)\n R910x1131 = (910, 1131)\n R870x1081 = (870, 1081)\n R1050x1305 = (1050, 1305)\n\n def __init__(self, width, height):\n self.width = width\n self.height = height\n\n def html_str(self):\n return f'W={self.width}&H={self.height}'\n\n\ndef _days_range(start, end):\n day = start\n while day <= end:\n yield day\n day += datetime.timedelta(days=1)\n\n\nclass Crawler(object):\n \"\"\"Crawls the covers of sports newspapers from sapo 24\n\n \"\"\"\n def __init__(self):\n super(Crawler, self).__init__()\n self._newspaper = Newspaper.Abola\n self._start = datetime.date.today()\n self._end = datetime.date.today()\n self._resolution = Resolution.R1050x1305\n\n @property\n def newspaper(self):\n return self._newspaper\n\n @newspaper.setter\n def newspaper(self, np: Newspaper):\n self._newspaper = np\n\n @property\n def resolution(self):\n return self._resolution\n\n @resolution.setter\n def resolution(self, res: Resolution):\n self._resolution = res\n\n def timerange(self,\n start: datetime.date,\n end: datetime.date = datetime.date.today()):\n if start > end:\n raise 'Mispecified time range: start later than end.'\n\n self._start = start\n self._end = end\n\n def crawl(self, out_dir='.'):\n p = Pool(5)\n crawl_fn = functools.partial(Crawler._crawl,\n newspaper=self._newspaper,\n resolution=self._resolution,\n out_dir=out_dir)\n results = p.map(crawl_fn, _days_range(self._start, self._end))\n\n @staticmethod\n def _crawl(day: datetime.date, newspaper, resolution, out_dir):\n filename = f'{newspaper.name}_{day}'\n print(f'{filename}: Downloading')\n response = requests.get(Crawler.url(newspaper, day))\n if response.status_code != 200:\n print(f'{filename}: Error getting page')\n return\n\n soup = bs4.BeautifulSoup(response.text, 'html.parser')\n picture_tag = soup.findAll('picture')[0]\n if not picture_tag:\n print(f'{filename}: No picture tag found. Skipping')\n return\n\n image_url = Crawler.filter_image_sources_by_resolution(\n picture_tag, resolution)\n if not image_url:\n print(f'{filename}: No image url found')\n return\n\n with open(os.path.join(out_dir, filename + '.jpeg'), 'wb') as f:\n f.write(requests.get(image_url).content)\n f.close()\n\n return (filename, image_url)\n\n @staticmethod\n def url(newspaper: Newspaper, date: datetime.date):\n return f'https://24.sapo.pt/jornais/desporto/{newspaper.value}/{date.isoformat()}'\n\n @staticmethod\n def filter_image_sources_by_resolution(pic_tag, res: Resolution):\n for pc in pic_tag.descendants:\n not_html_tag = type(pc) != bs4.element.Tag\n if not_html_tag:\n continue\n jpeg_image = pc['type'] == 'image/jpeg'\n correct_resolution = res.html_str() not in pc['srcset']\n if jpeg_image and correct_resolution:\n return 'http:' + pc['data-srcset']\n\n return None\n\n\ndef main():\n import argparse\n import os\n\n parser = argparse.ArgumentParser(description='')\n parser.add_argument('-o', '--out', type=str, default='./data/covers/')\n args = parser.parse_args()\n\n os.makedirs(args.out, exist_ok=True)\n\n crawler = Crawler()\n crawler.newspaper = Newspaper.Abola\n today = datetime.date.today()\n crawler.timerange(start=datetime.date(2019, 1, 1), end=datetime.date(2019, 12, 31))\n crawler.crawl(out_dir=args.out)\n\n crawler.newspaper = Newspaper.Record\n crawler.timerange(start=datetime.date(2019, 1, 1), end=datetime.date(2019, 12, 31))\n crawler.crawl(out_dir=args.out)\n\n crawler.newspaper = Newspaper.Ojogo\n crawler.timerange(start=datetime.date(2019, 1, 1), end=datetime.date(2019, 12, 31))\n crawler.crawl(out_dir=args.out)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5663265585899353,
"alphanum_fraction": 0.6377550959587097,
"avg_line_length": 17.66666603088379,
"blob_id": "eb85eda4f038cf24cb8c8db61e828c48a6b87fb2",
"content_id": "c433775e5a4d15f58c4e44af62de88e838f2a15d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 21,
"path": "/pyproject.toml",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"analysis_bias_pt_sports_newspapers\"\nversion = \"0.1.0\"\ndescription = \"\"\nauthors = [\"Rui Silva\"]\n\n[tool.poetry.dependencies]\npython = \"^3.6\"\nnumpy = \"^1.18\"\nmatplotlib = \"^3.1\"\npandas = \"^0.25.3\"\nrequests = \"^2.22\"\nbs4 = \"^0.0.1\"\nPillow = \"^6.2\"\n\n[tool.poetry.dev-dependencies]\npytest = \"^3.0\"\n\n[build-system]\nrequires = [\"poetry>=0.12\"]\nbuild-backend = \"poetry.masonry.api\"\n"
},
{
"alpha_fraction": 0.5899224877357483,
"alphanum_fraction": 0.5953488349914551,
"avg_line_length": 30.463415145874023,
"blob_id": "b42d921b9e8e79d1b15b6466c8c212488c4761c6",
"content_id": "57c8d185f3f38df1698286848bcc2bb8fa0191e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2580,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 82,
"path": "/analysis_bias_pt_sports_newspapers/covers_dataset.py",
"repo_name": "rui-silva/analysis_bias_pt_sports_newspapers",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport numpy as np\nfrom PIL import Image\nimport xml.etree.ElementTree as ET\nfrom utils import LabelClass\n\n\ndef get_file_path_newspaper(file_path):\n no_extension = os.path.splitext(file_path)[0]\n newspaper_str = os.path.basename(no_extension).split('_')[0]\n return newspaper_str\n\n\ndef get_file_path_date(file_path):\n no_extension = os.path.splitext(file_path)[0]\n date_str = os.path.basename(no_extension).split('_')[1]\n return date_str\n\n\ndef get_file_path_newspaper_and_date(file_path):\n no_extension = os.path.splitext(file_path)[0]\n filename = os.path.basename(no_extension)\n return filename\n\n\ndef sort_by_filename(l):\n return sorted(\n l,\n key=lambda fname: get_file_path_newspaper_and_date(fname),\n reverse=True)\n\n\nclass CoversDataset(object):\n def __init__(self, root):\n self.images = sort_by_filename(\n glob.glob(os.path.join(root, 'covers', '*.jpeg')))\n self.labels = sort_by_filename(\n glob.glob(os.path.join(root, 'labels', '*.xml')))\n\n def __getitem__(self, idx):\n img_path = self.images[idx]\n label_path = self.labels[idx]\n\n assert get_file_path_newspaper_and_date(img_path) == get_file_path_newspaper_and_date(label_path)\n\n img = Image.open(img_path).convert(\"RGB\")\n\n labels = []\n boxes = []\n areas = []\n tree = ET.parse(label_path)\n for obj in tree.findall('object'):\n obj_name = obj.find('name').text\n\n label_class = LabelClass[obj_name.upper()]\n labels.append(label_class.id)\n box = obj.find('bndbox')\n xmin, ymin = int(box.find('xmin').text), int(box.find('ymin').text)\n xmax, ymax = int(box.find('xmax').text), int(box.find('ymax').text)\n boxes.append([xmin, ymin, xmax, ymax])\n areas.append((xmax - xmin) * (ymax - ymin))\n\n labels = np.array(labels, dtype=np.int64)\n boxes = np.array(boxes, dtype=np.float32)\n areas = np.array(areas, dtype=np.float32)\n image_id = np.array([idx])\n iscrowd = np.zeros((boxes.shape[0], ), dtype=np.int64)\n\n target = {}\n target['boxes'] = boxes\n target['labels'] = labels\n target['area'] = areas\n target[\"image_id\"] = image_id\n target[\"iscrowd\"] = iscrowd\n target[\"image_width\"] = int(tree.find('size').find('width').text)\n target['image_height'] = int(tree.find('size').find('height').text)\n\n return img, target\n\n def __len__(self):\n return len(self.images)\n"
}
] | 7 |
dsczs/python_study
|
https://github.com/dsczs/python_study
|
4631c42b451814f4dedee99d9322e08e1433d766
|
5aed59652083a7f82ed6eb22f143092f7dbd4e9c
|
e9e753cca0b5d5f80fd1820ac548496950051bd8
|
refs/heads/master
| 2020-12-01T17:16:53.531069 | 2020-05-11T03:59:17 | 2020-05-11T03:59:17 | 230,708,795 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5493601560592651,
"alphanum_fraction": 0.5667275786399841,
"avg_line_length": 20.45098114013672,
"blob_id": "260faa70a02b837b2896bb957982f1ac3db0180b",
"content_id": "ecba3958aad686c4df238e4ddafeaadc6c482b17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1094,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 51,
"path": "/tensorflowdemo/Test3.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport tensorflow as tf\n\n\n# tensorflow count demo\ndef test_tf_variable_1():\n\n state = tf.Variable(0, name=\"counter\")\n one = tf.constant(2)\n new_value = tf.add(state, one)\n update = tf.assign(state, new_value)\n\n # init all variables\n init_op = tf.initialize_all_variables()\n\n # run session\n with tf.Session() as sess:\n sess.run(init_op)\n print(\"init state\", sess.run(state))\n for i in range(3):\n sess.run(update)\n print(\"add state\", sess.run(state))\n\n\n# tensorflow fetch demo\ndef test_tf_fetch():\n a = tf.constant(3.0)\n b = tf.constant(2.0)\n c = tf.constant(5.0)\n\n d = tf.add(a, b)\n e = tf.multiply(d, c)\n\n with tf.Session() as sess:\n result = sess.run([d, e])\n print(\"result = \", result)\n\n\n# tensorflow feed demo\ndef test_tf_feed():\n a = tf.placeholder(tf.float32)\n b = tf.placeholder(tf.float32)\n c = tf.multiply(a, b)\n\n with tf.Session() as sess:\n print(sess.run([c], feed_dict={a: [3.0], b: [4.0]}))\n\n\nif __name__ == '__main__':\n test_tf_feed()\n"
},
{
"alpha_fraction": 0.47530537843704224,
"alphanum_fraction": 0.503451943397522,
"avg_line_length": 16.27522850036621,
"blob_id": "261080fa7971424bd651339da211daafdd02240c",
"content_id": "2d06ccd1366a538b697e2ca51efc49b0c27235f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2101,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 109,
"path": "/numpydemo/Test1.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom numpy import *\n\n\n# 打印 eye\ndef print_eye():\n arr = eye(4)\n print(arr)\n\n\n# ndarray\ndef test_ndarray():\n import numpy as np\n\n # 一维数组\n arr = np.array([1, 3, 4])\n print(\"arr = \", arr)\n\n # 二维数组\n arr2 = np.array([[2, 3], [3, 5]])\n print(\"arr2 = \", arr2)\n\n # dtype类型\n arr3 = np.array([2, 4], dtype=float32)\n print(\"arr3 = \", arr3)\n\n # 元祖转np array\n arr4 = np.array((2, 3))\n print(\"arr4 = \", arr4)\n\n# ndarray new\ndef test_ndarray2():\n import numpy as np\n\n arr = np.array([[1, 3, 5], [3, 5, 6]])\n print(\"arr = \", arr)\n print(\"arr.shape = \", arr.shape)\n\n arr2 = arr.reshape((3, 2))\n print(\"arr2 = \", arr2)\n\n\n# test ndarray range\ndef test_nd_array_range():\n import numpy as np\n\n arr = np.arange(1, 10, 2, int32)\n print(\"arr = \", arr)\n\n\n# nd array 四则运算\ndef test_nd_array_4_oper():\n import numpy as np\n # add\n a = np.array([1, 2, 4])\n b = np.array([2, 4, 8])\n c = a + b\n print(\"c = \", c)\n\n # del\n d = a - b\n print(\"d = \", d)\n\n # mulit 每一行乘以每一列的和累加 例如第一行乘以第一列的和累加 第二行乘以第二列的和累加\n e = a * b\n print(\"e = \", e)\n\n # divide\n f = a / b\n print(\"f = \", f)\n\n\n# nd array 遍历\ndef test_nd_array_iterator():\n import numpy as np\n\n arr = np.arange(6).reshape((3, 2))\n print(\"原始arr = \", arr)\n\n print('迭代输出元素:')\n for x in np.nditer(arr):\n print(x, end=',')\n\n\n# 字符串操作\ndef test_char():\n import numpy as np\n a = np.char.add(['hello'], [' numpy'])\n print(\"a = \", a)\n\n # 两个的时候是第一个的第一个与第二个的第一个拼接\n b = np.char.add(['hello', 'hello'], [' numpy', ' python'])\n print(\"b = \", b)\n\n # 重复值\n c = np.char.multiply(' numpy ', 3)\n print(\"c = \", c)\n\n # 首字母大写\n d = np.char.capitalize('numpy')\n print(\"d = \", d)\n\n # 字符串切割\n e = np.char.split('i study python', ' ')\n print(\"e = \", e)\n\n\nif __name__ == '__main__':\n test_char()\n"
},
{
"alpha_fraction": 0.6092256903648376,
"alphanum_fraction": 0.6224052906036377,
"avg_line_length": 29.96938705444336,
"blob_id": "684e312d8a18e26d91045e6be564094a827813c8",
"content_id": "35d3baccc03a4e31517ff8a391f6da7b591c2c36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3261,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 98,
"path": "/taobao/taobaologin.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n用户身份验证\n\nVersion: 0.1\nAuthor: dsczs\n\"\"\"\n\n\ndef login():\n from selenium import webdriver\n import time\n import random\n from browsermobproxy import Server\n from selenium.webdriver.chrome.options import Options\n from selenium.webdriver.common.action_chains import ActionChains\n\n # proxy\n server = Server(r'D:\\FTP\\browsermob-proxy-2.1.4-bin\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy.bat')\n server.start()\n proxy = server.create_proxy()\n\n chrome_options = Options()\n # 不加载图片,加快访问速度\n # chrome_options.add_experimental_option(\"prefs\", {\"profile.managed_default_content_settings.images\": 2})\n # 设置为开发者模式,避免被识别\n chrome_options.add_experimental_option('excludeSwitches',\n ['enable-automation'])\n chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))\n proxy.new_har(\"alimama\", options={'captureHeaders': True, 'captureContent': True})\n\n # 登录\n browser = webdriver.Chrome(chrome_options=chrome_options)\n browser.get(\"https://login.taobao.com/member/login.jhtml?style=minisimple&from=alimama&redirectURL=http://login.taobao.com/member/taobaoke/login.htm?is_login=1&full_redirect=true&disableQuickLogin=true\")\n time.sleep(2)\n\n name = browser.find_element_by_name(\"TPL_username\")\n name.send_keys(\"小刚和婉庆\")\n password = browser.find_element_by_name(\"TPL_password\")\n time.sleep(1)\n password.send_keys(\"\")\n login_button = browser.find_element_by_id(\"J_SubmitStatic\")\n login_button.click()\n\n time.sleep(6)\n # browser.refresh()\n\n huakuai = browser.find_element_by_id(\"nc_1__bg\")\n action = ActionChains(browser)\n\n action.click_and_hold(huakuai).perform()\n action.move_by_offset(10, 0).perform() # 平行移动鼠标\n\n time.sleep(22)\n print(\"滑块完成\")\n # 这里必须休眠 需要跳转\n time.sleep(50)\n\n # 打印cookie\n cookie1 = browser.get_cookies()\n print(\"cookie = \", cookie1)\n\n time.sleep(111)\n # 商品搜索\n browser.get(\"https://pub.alimama.com/myunion.htm\")\n # search = browser.find_elements_by_css_selector(\".search .el-input__inner\")\n # search[0].send_keys(\"南极人10双袜子男四季男士长袜中筒透气吸汗运动商务休闲棉袜保暖长筒棉袜 男士中筒袜10双\")\n # search_button = browser.find_elements_by_css_selector(\".search .el-icon-search\")\n # search_button[0].click()\n time.sleep(2)\n\n # 打开推广地址弹窗\n # js = '$(\"#first_sku_btn\").click()'\n # browser.execute_script(js)\n\n result = proxy.har\n # print(result)\n\n for entry in result['log']['entries']:\n print(entry)\n # if \"mercury.jd.com/log.gif\" in entry['request']['url']:\n # print(\"###############\")\n # # 从头中取cookie\n # header = entry['request']['headers']\n # for h in header:\n # if h['name'] == 'Cookie':\n # print(h['value'])\n # my_cookie = h['value']\n # print(\"my_cookie ->{}\".format(my_cookie))\n\n # 截屏\n # browser.get_screenshot_as_file(\"E:\\\\jd.png\")\n\n time.sleep(11111)\n\n\nif __name__ == '__main__':\n login()\n"
},
{
"alpha_fraction": 0.5540123581886292,
"alphanum_fraction": 0.5879629850387573,
"avg_line_length": 18.606060028076172,
"blob_id": "4fa23f5ddca7af1714c4320b64ea39f51fade6de",
"content_id": "2bcc0f257cbb20bcc84e0f3ffd512d3c506baea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 33,
"path": "/tensorflowdemo/Test2.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport tensorflow as tf\n\n\n# base tensorflow demo\ndef test_tf_1():\n matrix1 = tf.constant([[3., 3.]])\n matrix2 = tf.constant(2., shape=(2, 2))\n\n product = tf.matmul(matrix1, matrix2)\n\n sess = tf.Session()\n result = sess.run(product)\n\n print(result)\n sess.close()\n\n\n# new session this method don't need to close session by you\ndef test_tf_2():\n matrix1 = tf.constant([[3., 3.]])\n matrix2 = tf.constant(2., shape=(2, 2))\n\n product = tf.matmul(matrix1, matrix2)\n\n with tf.Session() as sess:\n result = sess.run(product)\n print(result)\n\n\nif __name__ == '__main__':\n test_tf_2()\n\n"
},
{
"alpha_fraction": 0.6438746452331543,
"alphanum_fraction": 0.6581196784973145,
"avg_line_length": 20.9375,
"blob_id": "d3b2d478e4cc9155e11d45bfc3adb685782e5400",
"content_id": "c0ba05921e03aa8ef18125d37f7581ae2365778b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 16,
"path": "/pythondemo/Test4.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom pythondemo.Student import Student\n\n\nif __name__ == '__main__':\n student = Student('hello', 33, 95)\n # student.test_hello()\n print(student)\n\n # 注意这里不可访问私有的成员变量 但是可以使用这种方式访问 name是private的\n print(student._Student__name)\n\n # score是protected可以直接通过实例访问\n print(student._score)\n\n print(Student.public_var)\n"
},
{
"alpha_fraction": 0.36231884360313416,
"alphanum_fraction": 0.3913043439388275,
"avg_line_length": 8.199999809265137,
"blob_id": "21bf053730bc22146a1f78626663565c32d5b51d",
"content_id": "9bbb2ae89fd9e0c5cdafc7c8fc5e322851bac3e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 15,
"path": "/pythondemo/Test3.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\na = 22\n\n\ndef add():\n global a\n a = a + 1\n\n\nif __name__ == '__main__':\n print(a)\n add()\n print(a)\n"
},
{
"alpha_fraction": 0.4626006782054901,
"alphanum_fraction": 0.5707709789276123,
"avg_line_length": 19.690475463867188,
"blob_id": "7367ef4f582d8557ed91e319fc51707738815ee1",
"content_id": "798ec0e2fba41c8e3b1f8f152f541ee95fd7838f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 42,
"path": "/opencvdemo/Test3.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\ndef zh_ch(string):\n return string.encode(\"gbk\").decode(errors=\"ignore\")\n\n\n# draw line\ndef t1():\n import numpy as np\n import cv2\n img = np.zeros((512, 512, 3), np.uint8)\n cv2.line(img, (0, 0), (511, 511), (255, 0, 0), 2)\n cv2.imshow(zh_ch(\"直线\"), img)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n\n# draw rectangle\ndef t2():\n import numpy as np\n import cv2\n img = np.zeros((512, 512, 3), np.uint8)\n cv2.rectangle(img, (0, 0), (444, 444), (255, 255, 0), 2)\n cv2.imshow(\"rectangle\", img)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n\n# draw cycle\ndef t3():\n import numpy as np\n import cv2\n img = np.zeros((512, 512, 3), np.uint8)\n cv2.circle(img, (222, 222), 150, (255, 255, 0), 2)\n cv2.imshow(\"cycle\", img)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n\nif __name__ == '__main__':\n t3()\n"
},
{
"alpha_fraction": 0.5902883410453796,
"alphanum_fraction": 0.6206373572349548,
"avg_line_length": 20.96666717529297,
"blob_id": "ec54a1eaff97771f7f5d0dfc59760245a9ec57a1",
"content_id": "06aa32a9f9c8ac115482b5fcda659e970d339169",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 691,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 30,
"path": "/opencvdemo/Test1.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\n# 使用opencv操作图像\ndef t1():\n import numpy as np\n import cv2\n image = cv2.imread(\"bd_logo1.png\", cv2.IMREAD_ANYCOLOR)\n print(image)\n cv2.namedWindow('image', cv2.WINDOW_NORMAL)\n cv2.imshow('image', image)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n # 保存图像\n cv2.imwrite('test1.png', image)\n\n\n# 使用 matplotlib 操作图像\ndef t2():\n import numpy as np\n import cv2\n from matplotlib import pyplot as plt\n image = cv2.imread(\"bd_logo1.png\", cv2.IMREAD_ANYCOLOR)\n plt.imshow(image, cmap='gray', interpolation='bicubic')\n plt.xticks([]), plt.yticks([])\n plt.show()\n\n\nif __name__ == '__main__':\n t2()\n"
},
{
"alpha_fraction": 0.593961238861084,
"alphanum_fraction": 0.6110860705375671,
"avg_line_length": 27.81818199157715,
"blob_id": "a05a44784161b83490e3ae8e0e64341566947497",
"content_id": "b1cdfcf741d659bc41fda7d9b5df4286b398bb29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2373,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 77,
"path": "/jd/jdLogin.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n用户身份验证\n\nVersion: 0.1\nAuthor: dsczs\n\"\"\"\n\n\ndef login():\n from selenium import webdriver\n import time\n from browsermobproxy import Server\n from selenium.webdriver.chrome.options import Options\n\n # proxy\n server = Server(r'D:\\FTP\\browsermob-proxy-2.1.4-bin\\browsermob-proxy-2.1.4\\bin\\browsermob-proxy.bat')\n server.start()\n proxy = server.create_proxy()\n\n chrome_options = Options()\n chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy))\n proxy.new_har(\"jd\", options={'captureHeaders': True, 'captureContent': True})\n\n # 登录\n browser = webdriver.Chrome(chrome_options=chrome_options)\n browser.get(\"https://passport.jd.com/common/loginPage?from=media\")\n time.sleep(2)\n name = browser.find_element_by_name(\"loginname\")\n name.send_keys(\"15665549707\")\n password = browser.find_element_by_name(\"nloginpwd\")\n password.send_keys(\"hadoop123\")\n login_button = browser.find_element_by_id(\"paipaiLoginSubmit\")\n login_button.click()\n\n # 这里必须休眠 需要跳转\n time.sleep(5)\n\n # 打印cookie\n cookie1 = browser.get_cookies()\n print(\"cookie = \", cookie1)\n\n # 商品搜索\n browser.get(\"https://union.jd.com/proManager/index?pageNo=1\")\n search = browser.find_elements_by_css_selector(\".search .el-input__inner\")\n search[0].send_keys(\"南极人10双袜子男四季男士长袜中筒透气吸汗运动商务休闲棉袜保暖长筒棉袜 男士中筒袜10双\")\n search_button = browser.find_elements_by_css_selector(\".search .el-icon-search\")\n search_button[0].click()\n time.sleep(2)\n\n # 打开推广地址弹窗\n # js = '$(\"#first_sku_btn\").click()'\n # browser.execute_script(js)\n\n result = proxy.har\n # print(result)\n\n for entry in result['log']['entries']:\n print(entry)\n if \"mercury.jd.com/log.gif\" in entry['request']['url']:\n print(\"###############\")\n # 从头中取cookie\n header = entry['request']['headers']\n for h in header:\n if h['name'] == 'Cookie':\n print(h['value'])\n my_cookie = h['value']\n print(\"my_cookie ->{}\".format(my_cookie))\n\n # 截屏\n # browser.get_screenshot_as_file(\"E:\\\\jd.png\")\n\n time.sleep(11111)\n\n\nif __name__ == '__main__':\n login()\n"
},
{
"alpha_fraction": 0.4564971625804901,
"alphanum_fraction": 0.4734463393688202,
"avg_line_length": 13.258064270019531,
"blob_id": "e54fc4b81b1c76fa97f6c8e35e57c1911aca08e0",
"content_id": "acea50f5082ef3d10bbc0710106e9f18c1a8fb8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 905,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 62,
"path": "/pythondemo/Test1.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom pythondemo.AppLog import AppLog\n\n\ndef test_class():\n pass\n\n\ndef test_func():\n pass\n\n\ndef test_thread():\n pass\n\n\ndef test_hello():\n print(\"hello\")\n\n\ndef test_if():\n if True:\n print(\"true\")\n else:\n print(\"false\")\n\n a = 2\n if a == 3:\n print(\"a = 3\")\n elif a == 2:\n print(\"a = 2\")\n else:\n print(\"a = \", a)\n\n\ndef test_for():\n a = [1, 3, 4, 3]\n for b in a:\n if b % 2 == 1:\n print(\"b = \", b)\n else:\n continue\n\n\ndef test_time():\n import time\n a = time.time()\n print(\"a = \", a)\n\n print(\"格式化时间为 \", time.strftime(\"%Y-%m-%d %H:%M:%S\", time.localtime()))\n\n\n# 处理异常\ndef test_exception():\n try:\n a = 1 / 0\n except Exception as e:\n AppLog('pythondemo test1 test_exception').error(e)\n\n\nif __name__ == '__main__':\n test_exception()\n\n"
},
{
"alpha_fraction": 0.582608699798584,
"alphanum_fraction": 0.591304361820221,
"avg_line_length": 18.16666603088379,
"blob_id": "659e3aa0fe834198a87958e17e7f790293b9dd17",
"content_id": "7fc4a0075767104ac83937046d055dc034e91ca3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 6,
"path": "/pythondemo/Test2.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom pythondemo import support\n\n\nif __name__ == '__main__':\n support.test_print_hello()\n"
},
{
"alpha_fraction": 0.4711751639842987,
"alphanum_fraction": 0.5110864639282227,
"avg_line_length": 21,
"blob_id": "d96c3040d1507adaa3d5377334b1f61139be999c",
"content_id": "16d8be5d24cbbfe48fc4f00ab50d04c534ffadfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 916,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 41,
"path": "/opencvdemo/Test2.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\n# 摄像头 抓取视频\ndef t1():\n import cv2\n cap = cv2.VideoCapture(0)\n\n while(True):\n ret, frame = cap.read()\n gray = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)\n cv2.imshow('frame', gray)\n if cv2.waitKey(1) & 0xff == ord('q'):\n break\n cap.release()\n cv2.destroyAllWindows()\n\n\ndef t2():\n import cv2\n cap = cv2.VideoCapture(0)\n fourcc = cv2.VideoWriter_fourcc(*'XVID')\n out = cv2.VideoWriter('aa.avi', fourcc, 20.0, (640, 480))\n\n while(cap.isOpened()):\n ret, frame = cap.read()\n if ret == True:\n frame = cv2.flip(frame, 0)\n out.write(frame)\n cv2.imshow('frame', frame)\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n else:\n break\n cap.release()\n out.release()\n cv2.destroyAllWindows()\n\n\nif __name__ == '__main__':\n t2()\n"
},
{
"alpha_fraction": 0.5495772361755371,
"alphanum_fraction": 0.5564950108528137,
"avg_line_length": 25.020000457763672,
"blob_id": "a38090dfb72302bf3b87bc4c7e0de1e87b845f81",
"content_id": "64db5d75458d8c439ddfe0cf0d761775d611c4f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1307,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 50,
"path": "/demo/Test1.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n鸢尾花\n\nVersion: 0.1\nAuthor: dsczs\n\"\"\"\n\n\ndef t1():\n from sklearn.datasets import load_iris\n iris_dataset = load_iris()\n print(\"keys of iris_dataset:\\n{}\".format(iris_dataset.keys()))\n for _ in iris_dataset.keys():\n print(\"this is {} : \\n\".format(_))\n print(iris_dataset.get(_))\n\n data = iris_dataset.get(\"data\")\n print(data)\n\n\ndef t2():\n from sklearn.model_selection import train_test_split\n from sklearn.datasets import load_iris\n import numpy as np\n iris_dataset = load_iris()\n x_train, x_test, y_train, y_test = train_test_split(iris_dataset.get(\"data\"),\n iris_dataset.get(\"target\"),\n random_state=0)\n print(\"x_train = \", x_train)\n print(\"x_test = \", x_test)\n print(\"y_train = \", y_train)\n print(\"y_test = \", y_test)\n\n\ndef t3():\n from sklearn.datasets import load_breast_cancer\n iris_dataset = load_breast_cancer()\n print(\"keys of iris_dataset:\\n{}\".format(iris_dataset.keys()))\n for _ in iris_dataset.keys():\n print(\"this is {} : \\n\".format(_))\n print(iris_dataset.get(_))\n\n\ndef t4():\n from sklearn.linear_model import LinearRegression\n\n\nif __name__ == '__main__':\n t3()\n"
},
{
"alpha_fraction": 0.4911591410636902,
"alphanum_fraction": 0.5009823441505432,
"avg_line_length": 22.090909957885742,
"blob_id": "7d4d0ad16fa30a17f92c344cf6187a92ba6dfc8c",
"content_id": "315c278f5fad160eb7ddfe1aaaef4e836fbe8f33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 22,
"path": "/pythondemo/Student.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\nclass Student:\n # 全局变量 public static\n public_var = 22\n # 局部变量 不可直接引用 private\n __name = ''\n __age = 0\n # 局部变量 protected\n _score = 0\n\n def __init__(self, name, age, score):\n self.__name = name\n self.__age = age\n self._score = score\n\n def test_hello(self):\n print(\"this.name = \", self.__name, \"this.age = \", self.__age)\n\n def __str__(self) -> str:\n return \"this.name = \" + self.__name + \" this.age = \" + str(self.__age)\n\n"
},
{
"alpha_fraction": 0.5584415793418884,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 14.399999618530273,
"blob_id": "9857f91f043e9995183f7feb667d834b88a1f3c5",
"content_id": "2e1d6c2e371532faf1009635ad24ead354b23eb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 5,
"path": "/pythondemo/support.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\ndef test_print_hello():\n print(\"Hello support\")\n"
},
{
"alpha_fraction": 0.6246819496154785,
"alphanum_fraction": 0.6450381875038147,
"avg_line_length": 22.117647171020508,
"blob_id": "5753e7aa977df8529be76f9bce29e648f515fdf8",
"content_id": "dd29ef7c3413fa0b92e5b73e93bcdb2d83972d68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 34,
"path": "/demo/Test4.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n用户身份验证\n\nVersion: 0.1\nAuthor: dsczs\n\"\"\"\nif __name__ == '__main__':\n import time\n from selenium import webdriver\n\n login_url = 'https://passport.jd.com/common/loginPage?from=media'\n driver = webdriver.PhantomJS()\n driver.get(login_url)\n time.sleep(5)\n\n account = driver.find_element_by_id('loginname')\n password = driver.find_element_by_id('nloginpwd')\n submit = driver.find_element_by_id('paipaiLoginSubmit')\n\n account.clear()\n password.clear()\n account.send_keys('15665549707')\n password.send_keys('hadoop123')\n\n submit.click()\n time.sleep(5)\n\n # cookie和前面一样的方式获取和保存\n cookies = driver.get_cookies()\n print(cookies)\n web = driver.get(\"https://union.jd.com/overview\")\n print(web)\n driver.close()\n"
},
{
"alpha_fraction": 0.4901960790157318,
"alphanum_fraction": 0.5546218752861023,
"avg_line_length": 18.83333396911621,
"blob_id": "d3381d2cacc1c53e6ae31483c047e60ee01ca60a",
"content_id": "485f665240eaa1dbbd98ea0e1f4fa13a55c5fcc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 357,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 18,
"path": "/pandasdemo/Test1.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport pandas as pd\nimport numpy as np\n\n\ndef test_1():\n s = pd.Series([1, 3, 5])\n d = pd.date_range('20140101', periods=6)\n print(s)\n print(d)\n df = pd.DataFrame(np.random.randn(6, 4),index=d)\n print(df)\n df1 = pd.DataFrame(np.arange(12).reshape((3, 4)))\n print(df1)\n\n\nif __name__ == '__main__':\n test_1()\n"
},
{
"alpha_fraction": 0.5139665007591248,
"alphanum_fraction": 0.5371508598327637,
"avg_line_length": 37.494625091552734,
"blob_id": "9c4c5a3abf9d94b8581e0ee798085c26f0feb148",
"content_id": "bc435cd959b3a1a890c27d4bb07eed918d4f9322",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3606,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 93,
"path": "/demo/Test2.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n\nimport time\nimport requests\nfrom bs4 import BeautifulSoup\n\n\nclass JD_crawl:\n def __init__(self, username, password):\n self.headers = {\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36',\n 'Referer': 'https://passport.jd.com/common/loginPage?from=media',\n 'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8'\n }\n self.login_url = \"https://passport.jd.com/common/loginPage?from=media\"\n self.post_url = \"https://passport.jd.com/uc/loginService\"\n self.auth_url = \"https://passport.jd.com/uc/showAuthCode\"\n self.session = requests.session()\n self.username = username\n self.password = password\n\n def get_login_info(self):\n html = self.session.get(self.login_url, headers=self.headers).content\n soup = BeautifulSoup(html, features=\"html.parser\")\n\n uuid = soup.select('#uuid')[0].get('value')\n t = soup.select('input[name=\"eid\"]')\n eid = soup.select('input[name=\"eid\"]')[0].get('value')\n fp = soup.select('input[name=\"fp\"]')[0].get('value') # session id\n _t = soup.select('input[name=\"_t\"]')[0].get('value') # token\n # login_type = soup.select('input[name=\"loginType\"]')[0].get('value')\n pub_key = soup.select('input[name=\"pubKey\"]')[0].get('value')\n sa_token = soup.select('input[name=\"sa_token\"]')[0].get('value')\n\n auth_page = self.session.post(self.auth_url,\n data={'loginName': self.username, 'nloginpwd': self.password}).text\n # if 'true' in auth_page:\n # auth_code_url = soup.select('#JD_Verification1')[0].get('src2')\n # auth_code = str(self.get_auth_img(auth_code_url))\n # else:\n auth_code = ''\n\n data = {\n 'uuid': uuid,\n 'eid': eid,\n 'fp': fp,\n '_t': _t,\n 'loginname': self.username,\n 'nloginpwd': self.password,\n 'chkRememberMe': True,\n 'pubKey': pub_key,\n 'sa_token': sa_token,\n 'authcode': auth_code,\n 'useSlideAuthCode': 1\n }\n print(\"data = \", data)\n return data\n\n def get_auth_img(self, url):\n auth_code_url = 'http:{}&yys={}'.format(url, str(int(time.time()*1000)))\n auth_img = self.session.get(auth_code_url, headers=self.headers)\n with open('authcode.jpg', 'wb') as f:\n f.write(auth_img.content)\n code_typein = input('请根据下载图片输入验证码:')\n return code_typein\n\n def login(self):\n data = self.get_login_info()\n headers = {\n 'Referer': self.post_url,\n 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36'\n ' (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36',\n 'X-Requested-With': 'XMLHttpRequest'\n }\n try:\n login_page = self.session.post(self.post_url, data=data, headers=headers)\n print(login_page.text)\n except Exception as e:\n print(e)\n\n # self.session.cookies.clear()\n\n def shopping(self):\n login = self.session.post('https://cart.jd.com/cart.action', headers=self.headers)\n print(login.text)\n\n\nif __name__ == '__main__':\n un = '15665549707'\n pwd = 'hadoop123'\n jd = JD_crawl(un, pwd)\n jd.login()\n # jd.shopping()\n"
},
{
"alpha_fraction": 0.5879999995231628,
"alphanum_fraction": 0.5896000266075134,
"avg_line_length": 20.55172348022461,
"blob_id": "52dede2d0348a8d482de0c7071f5e46924e17954",
"content_id": "ab1e413c133db41895e6f30201e07df680948c89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 58,
"path": "/pythondemo/AppLog.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport logging\nfrom enum import Enum\n\n\nclass AppLog:\n level = Enum('level',\n {'debug': logging.DEBUG, 'info': logging.INFO, 'warning': logging.WARNING, 'error': logging.ERROR,\n 'critical': logging.CRITICAL})\n\n logger = None\n\n lvl = None\n\n def __init__(self, name):\n\n self.logger = logging.getLogger(name)\n\n self.logger.setLevel(logging.DEBUG)\n\n self.setLogHandle()\n\n def setLogHandle(self):\n\n fhandler = logging.FileHandler('log/app.log', 'a', 'utf-8')\n\n formatter = logging.Formatter('%(asctime)s %(name)s %(levelname)s %(message)s')\n\n fhandler.setFormatter(formatter)\n\n fhandler.setLevel(logging.DEBUG)\n\n console = logging.StreamHandler()\n\n console.setFormatter(formatter)\n\n console.setLevel(logging.ERROR)\n\n self.logger.addHandler(fhandler)\n\n self.logger.addHandler(console)\n\n def __getattr__(self, name):\n\n if (name in ('debug', 'info', 'warn', 'error', 'critical')):\n\n self.lvl = self.level[name].value\n\n return self\n\n else:\n\n raise AttributeError('Attr not Correct')\n\n def __call__(self, msg):\n\n self.logger.log(self.lvl, msg)\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 8.571428298950195,
"blob_id": "22c59fb88f7a855a6673ed4c56ab2887fd50ce60",
"content_id": "e5f20cb417e152ca847b4f8a60dc517104915b17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 7,
"path": "/taobao/__init__.py",
"repo_name": "dsczs/python_study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n用户身份验证\n\nVersion: 0.1\nAuthor: dsczs\n\"\"\""
}
] | 20 |
RonShalevich/break
|
https://github.com/RonShalevich/break
|
dfe51df421824b413edfea393146a01dfe7b322d
|
0a4889a042eb6bf8a4b49a8f8567bd4a11959c0c
|
e1bd95ce2708f1eae07012a348d88aee52f959b2
|
refs/heads/master
| 2021-01-01T19:17:04.664303 | 2017-07-27T16:24:34 | 2017-07-27T16:24:34 | 98,553,784 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6528925895690918,
"alphanum_fraction": 0.6942148804664612,
"avg_line_length": 21,
"blob_id": "4783fcb308ae797c1e7f9853512aa4f2b19fd3a1",
"content_id": "cbe3f45b7850882f8bcf7c7779e7851c511f3bf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 11,
"path": "/break.py",
"repo_name": "RonShalevich/break",
"src_encoding": "UTF-8",
"text": "import webbrowser\nimport time\n\ntotal = 2\ncounter = 0\n\nprint(\"This program started on \"+time.ctime())\nwhile (counter < total):\n time.sleep(2*60*60)\n webbrowser.open(\"http://www.youtube.com/watch?v=dQw4w9WgXcQ\")\n counter = counter + 1\n"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 22.33333396911621,
"blob_id": "b8e41765b06e29cf5fc857df9ea2052f9abb99cd",
"content_id": "bebc6acf54cc39f9262025959165d8180156ba8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 3,
"path": "/README.md",
"repo_name": "RonShalevich/break",
"src_encoding": "UTF-8",
"text": "# break\n\nThis is a python practice project to create a break reminder\n"
}
] | 2 |
AshishDavid/PythonProject
|
https://github.com/AshishDavid/PythonProject
|
2c2e5428e4b8c6b01896e304bd6a952b2529b8ad
|
18af13d8c9502e3dfde98f8277dd64c233fbbfc5
|
6aa4ebcc0cfc4dbe3b7ffb6bf55325833090df45
|
refs/heads/main
| 2023-01-07T11:02:01.016367 | 2020-11-17T09:34:45 | 2020-11-17T09:34:45 | 313,424,782 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.769911527633667,
"alphanum_fraction": 0.769911527633667,
"avg_line_length": 27.25,
"blob_id": "1d8497161c77886df3f7568dff33b692fab3db76",
"content_id": "4c701ce6039542ba97afea4d793f6c265f6bd72c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 24,
"path": "/README.md",
"repo_name": "AshishDavid/PythonProject",
"src_encoding": "UTF-8",
"text": "# PythonProject\nEncryption\n\nCan only run on windows terminal: \n example on terminal type syntax : python main.py file.txt_location caeser/vignere/vernam encryption/decryption/automatic(only for caeser)\n \n Modes:\n \n python main.py file.txt_location caeser encryption\n \n python main.py file.txt_location caeser decryption\n \n python main.py file.txt_location caeser automatic\n \n python main.py file.txt_location vignere encryption\n \n python main.py file.txt_location vignere decryption\n \n python main.py file.txt_location vernam encryption\n \n python main.py file.txt_location vernam decryption\n \n \n NOTE : It doesnt encyrpts special characters than alphabets.\n"
},
{
"alpha_fraction": 0.42501407861709595,
"alphanum_fraction": 0.44090139865875244,
"avg_line_length": 38.71100997924805,
"blob_id": "b6b1e5a5ff6f556afa9585b5156a6aaea30a29f1",
"content_id": "085957ce0e85ac771a7d13a81d35deaa1eeb44e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8875,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 218,
"path": "/main.py",
"repo_name": "AshishDavid/PythonProject",
"src_encoding": "UTF-8",
"text": "import sys\r\nimport os\r\n\r\n\r\ndef caeser():\r\n file = open(sys.argv[1], 'r')\r\n if sys.argv[3] == 'encryption' or sys.argv[3] == 'decryption':\r\n key = int(input('Enter the key between 0-25 \\n'))\r\n content = file.read()\r\n length = len(content)\r\n if sys.argv[3] == 'encryption':\r\n encrypted_content = ''\r\n for i in range(length):\r\n if content[i].isupper():\r\n encrypted_content += chr((ord(content[i]) + key - 65) % 26 + 65)\r\n if content[i].islower():\r\n encrypted_content += chr((ord(content[i]) + key - 97) % 26 + 97)\r\n elif not content[i].isupper() and not content[i].islower():\r\n encrypted_content += content[i]\r\n print(encrypted_content)\r\n if sys.argv[3] == 'decryption':\r\n decrypted_content = ''\r\n for i in range(length):\r\n if content[i].isupper():\r\n decrypted_content += chr((ord(content[i]) - key - 65) % 26 + 65)\r\n if content[i].islower():\r\n decrypted_content += chr((ord(content[i]) - key - 97) % 26 + 97)\r\n elif not content[i].isupper() and not content[i].islower():\r\n decrypted_content += content[i]\r\n print(decrypted_content)\r\n if sys.argv[3] == 'automatic':\r\n content = file.read()\r\n length = len(content)\r\n most = 'etaoinhsrdlumwc'\r\n most_freq_dict = {}\r\n for i in range(length):\r\n if content[i].isalpha():\r\n if content[i] in most_freq_dict:\r\n most_freq_dict[content[i]] += 1\r\n else:\r\n most_freq_dict[content[i]] = 1\r\n max_key = max(most_freq_dict, key=most_freq_dict.get)\r\n while True:\r\n decrypted_file = ''\r\n for i in most:\r\n for j in range(length):\r\n if content[j].isalpha():\r\n if content[j] == max_key:\r\n decrypted_file += i\r\n else:\r\n decrypted_file += content[j]\r\n else:\r\n decrypted_file += content[j]\r\n print(decrypted_file)\r\n print('Would you like to continue with this or change the most frequent letter ?')\r\n print('Press \"Y\" to continue and guess other letters or \"N\" to change the most frequent letter or '\r\n '\"E\"to exit')\r\n choice = input()\r\n if choice == 'E':\r\n file.close()\r\n return\r\n if choice == 'N':\r\n decrypted_file = ''\r\n continue\r\n if choice == 'Y':\r\n while True:\r\n new_file = decrypted_file\r\n decrypted_file = ''\r\n print('Which letter do you want to replace ?')\r\n print('Input the letter you want to replace')\r\n old_letter = input()\r\n print('Input the new letter')\r\n new_letter = input()\r\n for k in range(length):\r\n if new_file[k].isalpha():\r\n if new_file[k] == old_letter:\r\n decrypted_file += new_letter\r\n else:\r\n decrypted_file += content[k]\r\n else:\r\n decrypted_file += content[k]\r\n print(decrypted_file)\r\n print('Enter \"Yes\" to continue or \"No\" to exit')\r\n choice_again = input()\r\n if choice_again == 'Yes':\r\n continue\r\n if choice_again == 'No':\r\n file.close()\r\n return\r\n elif sys.argv[3] != 'decryption' and sys.argv[3] != 'encryption' and sys.argv[3] != 'automatic':\r\n print(\"No such function available\")\r\n file.close()\r\n\r\n\r\ndef vignere():\r\n file = open(sys.argv[1], 'r')\r\n key = input('Enter the alphabetical key \\n')\r\n content = file.read()\r\n length = len(content)\r\n length_with_only_letters = 0\r\n for x in range(length):\r\n if content[x].isalpha():\r\n length_with_only_letters += 1\r\n count = length_with_only_letters - len(key)\r\n c = 0\r\n for x in range(count):\r\n if c != length:\r\n key += key[c]\r\n c += 1\r\n else:\r\n c = 0\r\n key += key[c]\r\n print(key)\r\n if sys.argv[3] == 'encryption':\r\n encrypted_content = ''\r\n key_count = 0\r\n for i in range(length):\r\n if content[i].isalpha():\r\n encrypted_content += chr(((ord(content[i]) + ord(key[key_count])) % 26) + 65)\r\n key_count += 1\r\n else:\r\n encrypted_content += content[i]\r\n print(encrypted_content)\r\n if sys.argv[3] == 'decryption':\r\n decrypted_content = ''\r\n key_count = 0\r\n for i in range(length):\r\n if content[i].isalpha():\r\n decrypted_content += chr(((ord(content[i]) - ord(key[key_count]) + 26) % 26) + 65)\r\n key_count += 1\r\n else:\r\n decrypted_content += content[i]\r\n print(decrypted_content)\r\n elif sys.argv[3] != 'encryption' and sys.argv[3] != 'decryption':\r\n print('No such function available')\r\n file.close()\r\n\r\n\r\ndef vernam():\r\n file = open(sys.argv[1], 'r')\r\n content = file.read()\r\n count_only_letters = 0\r\n length = len(content)\r\n for x in range(length):\r\n if content[x].isalpha():\r\n count_only_letters += 1\r\n letters = str(count_only_letters)\r\n key = input('Enter the keyword. It should have ' + letters+' alphabets \\n')\r\n if len(key) != count_only_letters:\r\n print('Not a suitable keyword')\r\n return\r\n if sys.argv[3] == 'encryption':\r\n encrypted_content = ''\r\n key_count = 0\r\n for i in range(length):\r\n if content[i].isalpha():\r\n if content[i].islower():\r\n sum_of = ord(content[i]) + ord(key[key_count]) - 194\r\n if sum_of > 25:\r\n encrypted_content += chr(sum_of - 26 + 97)\r\n else:\r\n encrypted_content += chr(sum_of + 97)\r\n key_count += 1\r\n if content[i].isupper():\r\n sum_of = ord(content[i]) + ord(key[key_count]) - 130\r\n if sum_of > 25:\r\n encrypted_content += chr(sum_of - 26 + 65)\r\n else:\r\n encrypted_content += chr(sum_of + 65)\r\n key_count += 1\r\n elif not content[i].isalpha():\r\n encrypted_content += content[i]\r\n print(encrypted_content)\r\n if sys.argv[3] == 'decryption':\r\n decrypted_content = ''\r\n key_count = 0\r\n sum_of_ = 0\r\n for i in range(length):\r\n if content[i].isalpha():\r\n if content[i].islower():\r\n if (ord(content[i]) - 97) - (ord(key[key_count]) - 97) < 0:\r\n sum_of_ = 26 + (ord(content[i]) - 97) - (ord(key[key_count]) - 97)\r\n else:\r\n sum_of_ = (ord(content[i]) - 97) - (ord(key[key_count]) - 97)\r\n decrypted_content += chr(sum_of_ + 97)\r\n key_count += 1\r\n if content[i].isupper():\r\n if (ord(content[i]) - 65) - (ord(key[key_count]) - 65) < 0:\r\n sum_of_ = 26 + (ord(content[i]) - 65) - (ord(key[key_count]) - 65)\r\n else:\r\n sum_of_ = (ord(content[i]) - 97) - (ord(key[key_count]) - 97)\r\n decrypted_content += chr(sum_of_ + 65)\r\n key_count += 1\r\n elif not content[i].isalpha():\r\n decrypted_content += content[i]\r\n print(decrypted_content)\r\n elif sys.argv[3] != 'encryption' and sys.argv[3] != 'decryption':\r\n print('No such function available')\r\n file.close()\r\n\r\n\r\nif len(sys.argv) != 4:\r\n print('Put correct number of arguments')\r\nelse:\r\n if os.path.exists(sys.argv[1]):\r\n if sys.argv[2] == 'caeser':\r\n caeser()\r\n if sys.argv[2] == 'vignere':\r\n vignere()\r\n if sys.argv[2] == 'vernam':\r\n vernam()\r\n else:\r\n print('No such file exists')\r\n\r\n# argv[0] - main.py\r\n# argv[1] - .txt file path\r\n# argv[2] - type of cipher\r\n# argv[3] - encryption/decryption\r\n"
}
] | 2 |
nvthoang/Plant-metabolite-databases
|
https://github.com/nvthoang/Plant-metabolite-databases
|
ea7e191a260465e63bb1399a9117a4d93baf522e
|
cdce6451e2cdbfae7c20a5c360883e02eeb0b113
|
6058891d6fada7648ab1ea7a115cfedfa0502ad3
|
refs/heads/master
| 2020-06-25T02:43:41.978079 | 2019-07-27T14:59:13 | 2019-07-27T14:59:13 | 199,174,662 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.627471923828125,
"alphanum_fraction": 0.6456440687179565,
"avg_line_length": 37.97916793823242,
"blob_id": "ae06103159c6e6eac7f719150f1992bdd47df44d",
"content_id": "b1ece92bc1578216a98875db894ce9df420b7590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1871,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 48,
"path": "/Violin_Plot.R",
"repo_name": "nvthoang/Plant-metabolite-databases",
"src_encoding": "UTF-8",
"text": "# Load data\nDB_druglike = read.csv('~/DB_druglike.csv', header = T)\nhead(DB_druglike)\n\n# Violin plot\nlibrary(ggplot2)\n\n## Partition Coefficient\nSLogP = ggplot(DB_druglike, aes(x = DB, y = SLogP, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept=c(-0.4,5.6), linetype=\"dashed\", color = \"red\", size = 0.7) + \n labs(x = 'Database', y = 'Partition Coefficient (LogP)') + \n theme_minimal()\n\n## Surface Molar Refractivity \nSMR = ggplot(DB_druglike, aes(x = DB, y = SMR, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept=c(40,130), linetype=\"dashed\", color = \"red\", size = 0.7) +\n labs(x = 'Database', y = 'Surface Molar Refractivity (SMR)')+\n theme_minimal()\n\n## Molecular Weight\nMW = ggplot(DB_druglike, aes(x = DB_druglike, y = MW, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept=c(180,500), linetype=\"dashed\", color = \"red\", size = 0.7) +\n labs(x = 'Database', y = 'Molecular Weight (Daltons)') +\n theme_minimal()\n\n## Topological Polar Surface Area\nTopoPSA = ggplot(DB_druglike, aes(x = DB, y = TopoPSA, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept= 140, linetype=\"dashed\", color = \"red\", size = 0.7) +\n labs(x = 'Database', y = 'Topological Polar Surface Area (TPSA)')+\n theme_minimal()\n\n## Number of Hydrogen Bond Donors\nnHBDon = ggplot(DB_druglike, aes(x = DB, y = nHBDon, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept= 5, linetype=\"dashed\", color = \"red\", size = 0.7) +\n labs(x = 'Database', y = 'Number of Hydrogen Bond Donors (nHBDon)')+\n theme_minimal()\n\n## Number of Hydrogen Bond Donors\nnHBAcc = ggplot(DB_druglike, aes(x = DB, y = nHBAcc, fill = DB)) + \n geom_violin(trim=FALSE) + \n geom_hline(yintercept= 10, linetype=\"dashed\", color = \"red\", size = 0.7) +\n labs(x = 'Database', y = 'Number of Hydrogen Bond Acceptors (nHBAcc)')+\n theme_minimal()\n"
},
{
"alpha_fraction": 0.7203728556632996,
"alphanum_fraction": 0.7303594946861267,
"avg_line_length": 29.653060913085938,
"blob_id": "1fe16c8bc649a402d5c2d16134b2c2fa29fdd04f",
"content_id": "e3af49bce22d6e3b5fd84a47cf7dd3fe09aa62bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1502,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 49,
"path": "/SMILE_to_Descriptor.py",
"repo_name": "nvthoang/Plant-metabolite-databases",
"src_encoding": "UTF-8",
"text": "#Import library\nfrom rdkit import Chem\nfrom mordred import Calculator, descriptors, Lipinski\nimport pandas as pd\nimport numpy as np\n\n# Load data\nDB_SMILE = pd.read_csv('Database_SMILE.csv') # Inseart the name of database in csv file\nDB_extracted_list = DB_SMILE.values.tolist()\nDB_SMILE_list = []\n\n# Extract data from list-of-list\nfor compound in DB_extracted_list:\n DB_SMILE_list.append(compound[0])\n\n# Create descriptor calculator with all descriptors\ncalc = Calculator(descriptors, ignore_3D=True, version='1.0.0')\nlen(calc.descriptors)\n\n# Calculate a list of molecule\nmols1 = []\nfor smile in DB_SMILE_list:\n mols1.append(Chem.MolFromSmiles(smile))\nprint(len(mols1))\n\nmols2 = []\nfor smile in mols1:\n if smile != None:\n mols2.append(smile)\nprint(len(mols1))\n\n\n# Run as Pandas dataframe\nDescriptor_full = calc.pandas(mols2) #Should run small number of compound\n\n# Extract a certain column\nDescriptor_full['SMR'] # Druglike Descriptor: nHBDon, nHBAcc, MW, SlogP, SMR, TopoPSA, \n\n# Export to csv file\nDescriptor_full.to_csv('Database_Descriptor.csv', encoding='utf-8', index=False)\n\n# Load dataframe of descriptors\nDB_full_descriptor = pd.read_csv('Database_Descriptor.csv') # Inseart the name of database in csv file\n\n# Extract column in dataframe\nDB_druglike_descriptor = DB_full_descriptor[['nHBDon', 'nHBAcc', 'MW', 'SLogP', 'SMR', 'TopoPSA']]\n\n# Export to csv file\nDB_druglike_descriptor.to_csv('Database_Druglike_Descriptor.csv', encoding='utf-8', index=False)\n"
},
{
"alpha_fraction": 0.6555555462837219,
"alphanum_fraction": 0.6727272868156433,
"avg_line_length": 34.35714340209961,
"blob_id": "27c2153ba7c6ec2bb8dd4c42e794e1de5cca89e9",
"content_id": "0395892270b81dc42bf5e72c196b5e6a90a8d4d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 990,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 28,
"path": "/Heat_Map.R",
"repo_name": "nvthoang/Plant-metabolite-databases",
"src_encoding": "UTF-8",
"text": "# Load data\nhm_data = read.csv('~/data_heatmap.csv', header = T)\nrow.names(hm_data) = hm_data[,1]\nhm_data = hm_data[,-1]\ncolnames(hm_data) = row.names(hm_data)\ndim(hm_data)\nhead(hm_data)\n\n# Reshape data\nlibrary(reshape2)\nmelted_hm_data = melt(hm_data)\nmelted_hm_data\n\nDB_Corr = rep(row.names(hm_data), time = length(hm_data))\nmelted_hm_data = data.frame(melted_hm_data, DB_Corr)\nmelted_hm_data = melted_hm_data[,c(1,3,2)]\ncolnames(melted_hm_data) = c(\"DB_Base\", \"DB_Corr\", \"Value\")\n\n# Set factor type\nmelted_hm_data$DB_Base = factor(melted_hm_data$DB_Base)\nmelted_hm_data$DB_Corr = factor(melted_hm_data$DB_Corr, levels = row.names(hm_data))\n\n# Heatmap\nlibrary(ggplot2)\nggplot(data = melted_hm_data, aes(x = DB_Base, y = DB_Corr)) + geom_tile(aes(fill = Value),colour = \"white\") +\n scale_fill_gradient(low = \"#AED581\", high = \"#E91E63\") + \n labs( x =\"Database (Base)\", y = \"Database (Corresponding)\", fill = 'Overlaping rate') +\n theme(axis.text.x = element_text(angle = 90, hjust = 1))\n"
}
] | 3 |
fillet0117/blockjack
|
https://github.com/fillet0117/blockjack
|
3f73de64d58d337acaa8bfda265f234bb01e87c6
|
7e5471eafab592e9d59decafdb76960a0a6595eb
|
3a26b818f1e80c43a699933747debd39a1a24e27
|
refs/heads/master
| 2020-04-29T23:11:24.728550 | 2019-03-19T09:19:45 | 2019-03-19T09:19:45 | 176,469,649 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.461983323097229,
"alphanum_fraction": 0.48919883370399475,
"avg_line_length": 24.231760025024414,
"blob_id": "6bd80e6182160acca50167fff7b6c5f5488306a1",
"content_id": "b25ac86d16b84ff4a519c44d6d371ae29d802b7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5879,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 233,
"path": "/slapjack.py",
"repo_name": "fillet0117/blockjack",
"src_encoding": "UTF-8",
"text": "import thread\nimport time\nimport random\nimport threading\n\nexitflag = 0\nclass mythread(threading.Thread):\n def __init__(self, threadID, name, threadcard, cangrab, pregrab, score):\n threading.Thread.__init__(self)\n self.name = name\n self.threadcard = []\n self.cangrab = cangrab\n self.score = score\n self.pregrab = pregrab\n def run(self):\n self.threadcard = send3card(self.name)\n abc(self.name, self.threadcard, self.cangrab, self.pregrab, self.score)\n \ncard = []\nfor i in range(1,5):\n for j in range(1,14):\n card.append((i,j))\n \ndef send3card(threadname):\n global card\n threadc = []\n threadlock.acquire()\n print threadname\n for i in range(3):\n a = random.choice(card)\n print a\n threadc.append(a)\n card.remove(a)\n threads.append(threadname)\n threadlock.release()\n return threadc \n\ndef abc(name,threadcard, cangrab, pregrab, score): \n global exitflag\n global count\n global grab\n global banker\n global end_thread\n global threads\n global check_thread\n \n while len(threads) != 4:\n pass \n threadlock.acquire()\n size = len(threads)\n if size == 0:\n pass\n else:\n for i in range(size):\n threads.pop()\n threadlock.release()\n \n while len(end_thread) < 4 or len(card) != 0:\n threadlock.acquire()\n if count == 0:\n exitflag = 1\n count+=1\n threadlock.release()\n time.sleep(1)\n #compare thread's card and banker' card\n while banker == (0,0):\n pass\n threadlock.acquire()\n for a in threadcard:\n if a[0] == banker[0]:\n cangrab = 1\n break\n elif a[1] == banker[1]:\n cangrab = 1\n break\n threadlock.release()\n #if thread can grab\n if cangrab != 0 and (name not in end_thread):\n if pregrab == 1:\n time.sleep(1)\n grab.append(name)\n threadlock.acquire()\n if grab[0] == name:\n for a in threadcard:\n if a[1] == banker[1]:\n score[0] = 30 + score[0]\n threadcard.remove(a)\n break\n elif a[0] == banker[0]:\n score[1] = 10 + score[1]\n threadcard.remove(a)\n break\n pregrab = 1\n print \"who grab the card : %s\" % name\n threadlock.release()\n threadlock.acquire()\n print name\n for i in threadcard:\n print i\n threadlock.release()\n \n threads.append(name)\n while len(threads) != 4:\n pass\n \n #if no thread have same number or color\n if len(grab) == 0 and (name not in end_thread):\n if pregrab == 1:\n time.sleep(1)\n grab.append(name)\n threadlock.acquire()\n if grab[0] == name:\n score[2] = 5 + score[2]\n pregrab = 1\n print \"who grab the card : %s\" % name\n print name\n for i in threadcard:\n print i\n threadlock.release()\n #if thread's card empty,save in end_thread\n threadlock.acquire()\n if len(threadcard) == 0 and (name not in end_thread):\n end_thread.append(name)\n #reset\n if cangrab == 1:\n cangrab = 0\n if len(grab) != 0:\n if grab[0] != name:\n pregrab = 0\n check_thread.append(name)\n threadlock.release()\n while len(check_thread) != 4:\n pass\n \n if pregrab == 1:\n count = 0\n \n \nthreadlock = threading.Lock()\nthreads = []\ngrab = []\ncard1 = []\ncard2 = []\ncard3 = []\ncard4 = []\ncheck_thread = []\ncount2 = 0\n#number,color,grab\nscore1 = [0,0,0]\nscore2 = [0,0,0]\nscore3 = [0,0,0]\nscore4 = [0,0,0]\n\nthreadc = []\nbanker = (0,0)\nend_thread = []\ncount = 0\n\nthread1 = mythread(1,\"thread_1\",card1,0,0,score1)\nthread2 = mythread(2,\"thread_2\",card2,0,0,score2)\nthread3 = mythread(3,\"thread_3\",card3,0,0,score3)\nthread4 = mythread(4,\"thread_4\",card4,0,0,score4)\n\nthread1.start()\nthread2.start()\nthread3.start()\nthread4.start()\n\nwhile 1:\n if exitflag == 1 and len(card) != 0:\n threadlock.acquire()\n banker = random.choice(card)\n card.remove(banker)\n print \"banker's card\"\n print banker\n size = len(grab)\n if size == 0:\n pass\n else:\n for i in range(size):\n grab.pop()\n\n size = len(threads)\n if size == 0:\n pass\n else:\n for i in range(size):\n threads.pop()\n \n size = len(check_thread)\n if size == 0:\n pass\n else:\n for i in range(size):\n check_thread.pop()\n exitflag = 0\n threadlock.release()\n elif len(card) == 0 or len(end_thread) == 4:\n break\nprint \"end\"\nprint \"\"\nscore = [[],[],[],[]]\nscore[0] = score1\nscore[1] = score2\nscore[2] = score3\nscore[3] = score4\n\ncount = 0\nfor i in end_thread:\n total = 0\n print \"player %c : \" % i[7]\n if count == 0:\n print \"first player score + 50\"\n total = total + 50\n \n elif count == 1:\n print \"second player score + 20\"\n total = total + 20\n count2 = 0 \n for a in score[int(i[7]) - 1]:\n if count2 == 0:\n print \"number : \"\n elif count2 == 1:\n print \"color : \"\n elif count2 == 2:\n print \"grab : \"\n print a\n total = total + a\n count2 += 1\n \n print \"total : %d\" % total\n count+=1\n print \"\"\n"
}
] | 1 |
krishpop/Expand
|
https://github.com/krishpop/Expand
|
96ef98d098216fc2d5860a7d7a3ef385fdd38f5d
|
cefb30b41eaeb5ae581cf8c32e121af6ae82ea75
|
d6d94d096d019c9a6c490cff276ef93a1ed08a34
|
refs/heads/master
| 2016-08-05T03:30:49.959256 | 2015-03-17T02:33:06 | 2015-03-17T02:33:06 | 25,441,096 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5697060823440552,
"alphanum_fraction": 0.5779954791069031,
"avg_line_length": 34.704036712646484,
"blob_id": "84b033bb6b65c1f2822eb15672868bbc7a4b2631",
"content_id": "e9a7fdce02362fea4dc95d286d9320e3a0b4d1b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7962,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 223,
"path": "/Expand",
"repo_name": "krishpop/Expand",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n## Submitted by Krishnan Srinivasan\n## Started: 10/15/14\n## Expand: a script to expand and replace environment variables\n\nimport sys\nimport os\nimport re\n\ndef setting(envVar, toValue):\n os.environ[envVar]=toValue\n\ndef matchBraces(match, line, start):\n openBraces = 0\n backslashExpand = re.compile(r\"(\\\\*)([\\$\\{\\}])\")\n # start is index of first \\ (if exists) before next } \n # dollarSign before the brace we are looking at\n dollarSign = True\n start +=1\n if line[start] == '{' and dollarSign:\n openBraces += 1\n start += 1\n dollarSign = False\n while start < len(line) and openBraces > 0:\n precedingBackslash = backslashExpand.match(line[start:])\n if precedingBackslash:\n backslashes = precedingBackslash.group(1)\n # escape brace by skipping it \n if backslashes and len(backslashes)%2:\n start+=precedingBackslash.end()\n continue\n # don't escape brace, cross over all \n else: \n start+=precedingBackslash.end()-1\n if line[start] == '{' and dollarSign:\n openBraces += 1\n if line[start] == '}':\n openBraces -= 1\n if line[start] == '$':\n dollarSign = True\n else:\n dollarSign = False\n if openBraces == 0:\n break\n start += 1\n\n if openBraces == 0:\n allBracesMatchedAt = start\n else: \n raise ValueError(\"Invalid expansion\")\n return allBracesMatchedAt\n\ndef basicPattern(matched, line, pattern, start, end):\n match = matched.group(1)\n try:\n tryMatch = os.environ[match]\n match = tryMatch\n except KeyError:\n match = \"\"\n original = line[start:end]\n line = line.replace(original, match)\n return line\n\ndef decimalPattern(matched, line, pattern, start, end):\n original = line[start:end]\n cmdLineArgs = sys.argv\n digit = int(matched.group(1))\n argToInsert = ''\n if digit < len(cmdLineArgs):\n argToInsert = expand(cmdLineArgs[digit])\n line = line.replace(original, argToInsert)\n return line\n\ndef asteriskPattern(matched, line, pattern, start, end):\n original = line[start:end]\n cmdLineArgs = sys.argv[1:]\n argsToInsert = ''\n space = ' '\n expandedArgs = []\n for arg in cmdLineArgs:\n expandedArgs.append(expand(arg))\n argsToInsert = space.join(expandedArgs)\n line = line.replace(original, argsToInsert)\n return line\n\ndef orPattern(matched, line, pattern, start, end):\n firstMatch = matched.group(1)\n firstLen = len(firstMatch)\n secondMatchIndex = start + firstLen + 3 # to account for $, {, and - characters\n secondMatch = line[secondMatchIndex:end]\n if os.environ.get(firstMatch, ''):\n match = os.environ[firstMatch]\n else:\n secondMatch = expand(secondMatch)\n match = secondMatch\n if os.environ.get(secondMatch, ''):\n match = os.environ[secondMatch]\n line = line.replace(line[start:end + 1], match)\n return (line, match)\n\ndef assignPattern(matched, line, pattern, start, end):\n firstMatch = matched.group(1)\n firstLen = len(firstMatch)\n secondMatchIndex = start + firstLen + 3 # to account for $, {, and = characters\n secondMatch = line[secondMatchIndex:end]\n if os.environ.get(firstMatch, ''):\n match = os.environ[firstMatch]\n else:\n secondMatch = expand(secondMatch)\n match = secondMatch\n if os.environ.get(secondMatch, ''):\n match = os.environ[secondMatch]\n setting(firstMatch, match)\n line = line.replace(line[start:end + 1], match)\n return (line, match)\n\nexpandPatterns = []\nbackslashExpand = re.compile(r\"(\\\\*)(\\$)\") # pattern 0\nexpandPatterns.append(backslashExpand)\nsimpleExpand = re.compile(r\"\\$([a-zA-Z_]+)\") # pattern 1\nexpandPatterns.append(simpleExpand)\nsimpleExpandInBraces = re.compile(r\"\\${([a-zA-Z_]+?)}\") # pattern 2\nexpandPatterns.append(simpleExpandInBraces)\ndecimalExpand = re.compile(r\"\\$(\\d)\") # pattern 3\nexpandPatterns.append(decimalExpand)\ndecimalExpandInBraces = re.compile(r\"\\${(\\d+?)}\") # pattern 4\nexpandPatterns.append(decimalExpandInBraces)\nasteriskExpand = re.compile(r\"\\$(\\*)\") # pattern 5\nexpandPatterns.append(asteriskExpand)\norExpand = re.compile(r\"\\${([a-zA-Z_]+?)-(.*)\") # pattern 6\nexpandPatterns.append(orExpand)\nassignExpand = re.compile(r\"\\${([a-zA-Z_]+?)=(.*)\") # pattern 7\nexpandPatterns.append(assignExpand)\ninvalidChar = re.compile(r\"\\${([a-zA-Z_]*?)([^a-zA-Z_])\") # pattern 8\nexpandPatterns.append(invalidChar)\n\n\ndef expandMatch(match, line, pattern, start, end):\n newLine = line\n if pattern==expandPatterns[1] or pattern==expandPatterns[2]:\n newLine = basicPattern(match, line, pattern, start, end)\n elif pattern == expandPatterns[3] or pattern == expandPatterns[4]:\n newLine = decimalPattern(match, line, pattern, start, end)\n elif pattern == expandPatterns[5]:\n newLine = asteriskPattern(match, line, pattern, start, end)\n return newLine\n\ndef expand(line):\n start = 0\n while start < len(line):\n for pattern in expandPatterns:\n patternFound = pattern.match(line[start:])\n if patternFound:\n if pattern == expandPatterns[0]:\n # if the number of backslashes preceding a \"$\" is even\n # then the $ is negated and ignored\n if patternFound.group(1) and len(patternFound.group(1)) % 2:\n # point right after the $ sign so we ignore it\n start += patternFound.end()-1\n # break so we can retest for leading \"\\\" before next $\n break\n else:\n # point to the $ sign so we can continue to test\n # what the $ refers to\n start += patternFound.end()-1\n # continue so we check the rest of the regexps\n # which specify how to parse \"$\"\n else:\n oldLen=len(line) # length of line before expansion\n if pattern in expandPatterns[1:6]:\n end = start + patternFound.end()\n line = expandMatch(patternFound, line, pattern, start, end)\n lenOfSubStr = len(patternFound.group(0))\n elif pattern in expandPatterns[6:8]:\n end = matchBraces(patternFound, line, start)\n if pattern==expandPatterns[6]:\n expansion = orPattern(patternFound, line, pattern, start, end)\n elif pattern == expandPatterns[7]:\n expansion = assignPattern(patternFound, line, pattern, start, end)\n line = expansion[0]\n lenOfSubStr = len(expansion[1])\n elif pattern == expandPatterns[8]:\n raise ValueError('Invalid expansion')\n start += len(line)-oldLen + lenOfSubStr-1\n break\n start += 1\n return line\n\ndef getInput(linecount):\n try: \n line = raw_input('(%d)$ ' % linecount)\n except EOFError:\n print ''\n sys.exit(0)\n except KeyboardInterrupt:\n print ''\n sys.exit(0)\n return line\n\ndef isInvalidExpansion(line):\n if line == 'quit':\n return True\n else: \n return False\n\ndef main():\n linecount = 1\n quit = False\n while not quit:\n line = getInput(linecount)\n if line:\n try:\n expandedLine = expand(line)\n sys.stdout.flush()\n sys.stdout.write(''.join([\">> \", expandedLine]))\n print ''\n linecount += 1\n except ValueError as err:\n print >>sys.stderr, err\n sys.exit(0)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7382311224937439,
"alphanum_fraction": 0.7432239651679993,
"avg_line_length": 65.71428680419922,
"blob_id": "62889205efe95b5f1bcf7eb3f765f370dfe2e4b7",
"content_id": "bc6debd9ec01b23afe57034dc8da07a0679209cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1416,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 21,
"path": "/README.md",
"repo_name": "krishpop/Expand",
"src_encoding": "UTF-8",
"text": "# Expand\n\n## About\n\nThis assignment was completed for a course I took in Fall 2014: Systems Programming and Computer Organization.\nThe goal of the assignment was to write a script to set and expand environment variables.\n\nIt includes many of the variable expansions that can be carried out in Bash, including:\n - $NAME — Replaced by the value of the environment variable NAME, or by an empty string if name is not defined\n - ${NAME} — Same as above\n - ${NAME-WORD} — Replaced by the value of NAME, or the expansion of WORD, if NAME is not defined\n - ${NAME=WORD} — Replaced by the value of NAME, or the expansion of WORD, if NAME is not defined (in which NAME is immediately assigned to the expansion of WORD)\n - $0, ..., $9 — Replaced $D by the D-th command line argument to Expand, or by an empty string if there is no D-th argument\n - ${N} — Replaced by the Nth argument to expand, or by the empty string if there is no N-th argument\n - $* — Replaced by a list of all arguments to Expand (not including $0), separated by single space characters\n \nThe following constraints are placed on NAME, WORD, and N:\n\n - NAME is a maximal sequence of one or more alphanumeric or _ characters that does not begin with a digit\n - WORD is any sequence of characters that ends with the first } not escaped by a backslash and not within any of the expansions above\n - N is a nonempty sequence of digits\n\n"
}
] | 2 |
ericzhonghou/Horse
|
https://github.com/ericzhonghou/Horse
|
2c98822ede7c57cded8140a274654a82f9a0560a
|
2b81b424d8914f1cd017c4bd217d24366f5019bb
|
382d27fd1b20bd009bf1e43e3d903baa73c60705
|
refs/heads/master
| 2020-06-11T11:34:36.086414 | 2016-12-06T04:16:03 | 2016-12-06T04:16:03 | 75,677,567 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5611628890037537,
"alphanum_fraction": 0.5754251480102539,
"avg_line_length": 19.727272033691406,
"blob_id": "a772a461f03fffb24e57bd7b7375acc666b7fc52",
"content_id": "95245f3e73402e023d5a45b3de00f0ec1fd3407c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1823,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 88,
"path": "/horse.py",
"repo_name": "ericzhonghou/Horse",
"src_encoding": "UTF-8",
"text": "import random\n\ndef open_file(n):\n\tf = open(\"cs170_final_inputs/\"+str(n)+\".in\", \"r\")\n\tsize = f.readline()\n\tg = []\n\te = {}\n\tfor i in range(int(size)):\n\t\tg.append([])\n\t\tcur = f.readline()\n\t\tx = [int(i) for i in cur.split()]\n\t\tg[i] = x\n\tfor j in range(int(size)):\n\t\te[j] = []\n\t\tfor k in range(int(size)):\n\t\t\tif(g[j][k] == 1):\n\t\t\t\te[j].append(k)\n\treturn g, e\n\ndef horse(g, e):\n\tsize = len(g)\n\tresults = []\n\tfor i in range(500):\n\t\tteams = []\n\t\tcurr = random.randint(0, size-1)\n\t\tcurr_team = []\n\t\tseen = []\n\t\twhile (len(seen) != size):\n\t\t\tseen.append(curr)\n\t\t\tcurr_team.append(curr)\n\t\t\tif(len(curr_team) == size):\n\t\t\t\tteams.append(curr_team)\n\t\t\t\tbreak\n\t\t\tneighbors = e[curr]\n\t\t\tnot_seen = [x for x in neighbors if x not in seen]\n\t\t\tif(len(seen) == size):\n\t\t\t\tteams.append(curr_team)\n\t\t\telif (len(not_seen) == 0):\n\t\t\t\tteams.append(curr_team)\n\t\t\t\tcurr_team = []\n\t\t\t\tnot_seen = [x for x in range(0, size) if x not in seen]\n\t\t\t\tcurr = not_seen[random.randint(0, (len(not_seen)-1))]\n\t\t\telse:\n\t\t\t\tcurr = not_seen[random.randint(0, (len(not_seen)-1))]\n\n\t\tif(len(curr_team) == size):\n\t\t\tresults.append(teams)\n\t\t\tbreak\n\t\telse:\t\t\n\t\t\tresults.append(teams)\n\n\tbest_score = -1\n\n\tfor r in results:\n\t\tscore = calculate_score(r, g)\n\t\tif(score > best_score):\n\t\t\tbest_score = score\n\t\t\tbest_lst = r\n\tprint(best_lst)\n\tfor b in range(len(best_lst)):\n\t\tbest_lst[b] = ' '.join(map(str,best_lst[b]))\n\n\treturn (\"; \".join(best_lst), best_score)\n\ndef calculate_score(lst, g):\n\ttotal = 0\n\tfor l in lst:\n\t\ttotal += (len(l) * sum_list(l, g))\n\treturn total\n\ndef sum_list(lst, g):\n\ttotal = 0\n\tfor l in lst:\n\t\ttotal += g[l][l]\n\treturn total\n\ndef main():\n\tf = open('output.out','w')\n\tfor i in range(5, 100):\n\t\tg, e = open_file(i+1)\n\t\tbest = horse(g,e)\n\t\tprint(\"score: \" + str(best[1]))\n\t\tf.write(best[0] + \"\\n\")\n\t\t\nmain()\n\n# g, e = open_file(1)\n# print(horse(g, e))"
}
] | 1 |
dogatuncay/UnWeb
|
https://github.com/dogatuncay/UnWeb
|
7f1a87592d761e74811a1a4628e8bfb5bb99b9cc
|
6143c1fb5d7f4d0183a6ddeda8536259f9f73619
|
63af7fc62a529542180d9a265f10ff1357c7aa9b
|
refs/heads/master
| 2021-01-16T18:29:39.859791 | 2012-11-02T20:26:08 | 2012-11-02T20:26:08 | 2,706,585 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5965569019317627,
"alphanum_fraction": 0.6152694821357727,
"avg_line_length": 32.349998474121094,
"blob_id": "9eb534969838bca03cc0454c1010f23698c350ac",
"content_id": "b5752e64328bd4b20c62b6206b5b8ae638d776ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1336,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 40,
"path": "/code/HDE/scraper_data/update_indexed5.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import csv, os, MySQLdb\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncu=db.cursor()\npath=\"/home/doga/Desktop/scraper_data\"\ndirList=os.listdir(path)\ncu.execute(\"SELECT E_ID FROM hde\")\nrow=0\ncount=0\nfor fname in dirList:\n\tif fname.split(\".\")[1] == \"csv\":\n\t\tdata_path=\"/home/doga/Desktop/scraper_data/\"+fname\n\t\tcsv_data=csv.reader(file(data_path, 'rb'))\n\t\t#headerline=csv_data.next()\n\t\t#r=len(list(csv_data))-1\n\t\tfor row in csv_data:\n\t\t\t#cu.execute(\"UPDATE hde SET INDEXED ='0' WHERE E_ID =%d\" %(count))\n\t\t\tcount+=1\n\t\t\t#db.commit()\n\t\t\tif row[0].startswith(\"https\"):\n\t\t\t\tif row[1] == \"true\":\n\t\t\t\t\tcu.execute(\"UPDATE hde SET INDEXED ='1' WHERE URL =%s\", row[0])\n\t\t\t\t\tdb.commit()\n\t\t\telse:\t\n\t\t\t\t#print 'http://'+row[0]\n\t\t\t\tr=row[0].replace(row[0],\"http://\"+row[0])\n\t\t\t\tif row[1] == \"true\":\n\t\t\t\t\tcu.execute(\"UPDATE hde SET INDEXED ='1' WHERE URL =%s\", r)\t\n\t\t\t\t\tdb.commit()\n\n\t\t\t#if row[1] == \"true\":\n\t\t\t\t#print row[1]\n\t\t\t\t#cu.execute(\"UPDATE hde SET INDEXED ='1' WHERE E_ID =%d\" %(count))\n\t\t\t\t#cu.execute(\"UPDATE hde SET INDEXED ='1' WHERE URL =%s\", row[0])\n\t\t\t\t#cu.execute(\"INSERT INTO test_index(INDEXED) VALUES('1') WHERE URL='%s'\",row[0])\n\t\t\t\t#cu.execute(\"UPDATE test_index SET INDEXED ='0'\")\n\t\t\t\t#cu.execute(\"INSERT INTO test_index(INDEXED) VALUES('1')\")\t\n\t\t\t#db.commit()\n\t\t\t\ncu.close()\ndb.close()\n\t\n"
},
{
"alpha_fraction": 0.6908517479896545,
"alphanum_fraction": 0.6940063238143921,
"avg_line_length": 18.8125,
"blob_id": "81d6820efe21ff3a683b5cd372472da64001e26a",
"content_id": "e714c81b39a81b1b0fe16a8c5756bd8d9cce765a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 16,
"path": "/code/HDE/scraper_data/db_urlto_notepad4.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import MySQLdb\nimport MySQLdb.cursors\n\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\" )\ncursor=db.cursor()\ncursor.execute(\"SELECT URL FROM hde\")\n\nrows=cursor.fetchall()\nf=open('URL.txt','w')\nfor row in rows:\n\tf.write(row[0])\n\tf.write('\\n')\n\nf.close()\t\t\ncursor.close()\t\ndb.close()\n"
},
{
"alpha_fraction": 0.6705107092857361,
"alphanum_fraction": 0.6820428371429443,
"avg_line_length": 27.714284896850586,
"blob_id": "3929a8383c75d132a6dba889cd6c4e004261375d",
"content_id": "7ea518826f61fadf88738a0d8ec109379657d317",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1214,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 42,
"path": "/code/HDE/queries/query2.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "\nimport MySQLdb\nimport struct, os\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncursor=db.cursor()\n\nsql_ses=\"\"\"select DISTINCT SES_ID FROM hde\"\"\"\ncursor.execute(sql_ses)\nses_rows=cursor.fetchall()\nfor srows in ses_rows:\n\tprint srows[0]\nsid=input(\"PICK A SESSION ID FROM THE LIST: \")\n\nsql=\"\"\"select DISTINCT id, url_crawler.url FROM url_crawler , hde WHERE url_crawler.url= hde.URL AND hde.SES_ID=%d AND hde.INDEXED=1; \"\"\" %sid\nx=[]\nm=[]\nc=0\ncursor.execute(sql)\nrows=cursor.fetchall()\nprint \"these URLs are indexed and crawled\"\nfor row in rows:\n\tprint row\n\ta=row[0]\n\tb=row[1]\n\tx.append([a,b])\n\tc+=1\nprint \"lists of childs in first level and their information (only unindexed ones)\"\nfor l in range(0,c):\n\trw=\"\"\"SELECT id_1 FROM Link WHERE Link.id_2=%d\"\"\" % x[l][0]\n\tcursor.execute(rw)\n\tchilds=cursor.fetchall()\n\tprint \"----set-----\"\n\tprint childs \n\tprint \"----info-----\"\n\tfor c in childs :\n\t\tinfo=\"\"\"SELECT url, secured, tld, indexed, http_access FROM url_crawler, Link WHERE id_1 = %d AND url_crawler.id=Link.id_1 AND url_crawler.indexed=0 \"\"\" % c[0] \n\t\tcursor.execute(info)\n\t\tinform=cursor.fetchall()\n\t\tfor inn in inform:\n\t\t\tprint inn\n\t\t\t\t\t\ncursor.close()\ndb.close()\n\n\n\n\n\t\n\n"
},
{
"alpha_fraction": 0.599764347076416,
"alphanum_fraction": 0.6146897077560425,
"avg_line_length": 27.51685333251953,
"blob_id": "8eac1ad4eb1044d46795f02fd249a0df0838f7f9",
"content_id": "781fadfe75bba50c72f23c33c2ffba507223490f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2546,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 89,
"path": "/code/HDE/queries/query.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "\nimport MySQLdb\nimport struct, os\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncursor=db.cursor()\n\nsql_ses=\"\"\"select DISTINCT SES_ID FROM hde\"\"\"\ncursor.execute(sql_ses)\nses_rows=cursor.fetchall()\nfor srows in ses_rows:\n\tprint srows[0]\nsid=input(\"PICK A SESSION ID FROM THE LIST: \")\n\nsql=\"\"\"select S_ID FROM url_crawler , hde WHERE url_crawler.url= hde.URL AND hde.SES_ID=%d\"\"\" %sid\ncursor.execute(sql)\nrows=cursor.fetchall()\n\n#we dont need this right now\n#sql2=\"\"\"select id FROM createt, url_crawler WHERE createt.URL= url_crawler.url\"\"\"\n#cursor.execute(sql2)\n#idss=cursor.fetchall()\n\nx=[]\nm=[]\nc=0\nprint \"-------------------all consecutive pairs-----------------------\"\nfor consecutive in rows:\n\ta=consecutive[0]\n\tx.append(a)\n\nfor i in range(1,len(x)):\n\t#print x[i]\n\tif x[i-1]==x[i]-1:\n\t\ta=x[i]\n\t\tb=x[i-1]\n\t\tprint b,a \n\t\tc+=1\n\t\tm.append([c,b,a])\n#os.system(\"clear\")\nprint \"----------------------------------------------------------------\"\nprint \"You will be asked which consecutive you want to analyze. \\nYou can only enter one of these consecutive pairs \\nPick one number and enter\"\nfor l in range(len(m)):\n\tprint m[l][0]\n\npid=input(\"ENTER A PAIR NUMBER: \")\nfor l in range(len(m)):\n\tif pid == m[l][0]:\n\t\tc1=m[l][1]\n\t\tc2=m[l][2]\nprint \"----------------------------------------------------------------\"\n#print \"=======last consecutive pair is====\" \n#print b,a\n\ncons_crw=\"\"\"select DISTINCT id FROM url_crawler , hde WHERE (url_crawler.url= hde.URL AND hde.S_ID=%d) OR (url_crawler.url= hde.URL AND hde.S_ID=%d)\"\"\" % (c1,c2)\n\ncursor.execute(cons_crw)\nready_to_link=cursor.fetchall()\narr_count=0\na=[]\nb=[]\nfor r in ready_to_link:\n\tarr_count+=1\n\tprint \"--- 1- found the consecutive in the url crawler table\" \n\tprint r[0]\n\tprint \"--- 2- found the first level of childs of the consecutive urls in the link table\" \n\trw=\"\"\"SELECT id_1 FROM Link WHERE Link.id_2=%d\"\"\" % r[0]\n\tcursor.execute(rw)\n\tlists=cursor.fetchall()\n\tif arr_count==1:\n\t\tfor ls in lists:\n\t\t\ta.append(ls[0])\n\t\tprint a\n\telif arr_count==2:\n\t\tfor ls in lists:\n\t\t\tb.append(ls[0])\n\t\tprint b\nfor k in range(len(a)-1):\n\tfor m in range(len(a)-1):\n\t\tif a[k]==b[m]:\n\t\t\tprint \"we have common!\"\n\t\t\tprint a[k], \"=\" , b[m]\n\t\t\tl1=a[k]\n\t\t\tprint \"the info about this url (url, secured, tld, indexed, http_access):\" \n\t\t\tinfo=\"\"\"SELECT url, secured, tld, indexed, http_access FROM url_crawler, Link WHERE id_1 = %d AND id_2= %d AND url_crawler.id=Link.id_1 \"\"\" %(l1, r[0]) \n\t\t\tcursor.execute(info)\n\t\t\tprint cursor.fetchall()\n\t\t\n\t\t\t\ncursor.close()\ndb.close()\n\n\n\n\n\t\n\n"
},
{
"alpha_fraction": 0.6713995933532715,
"alphanum_fraction": 0.6774848103523254,
"avg_line_length": 26.38888931274414,
"blob_id": "4c144f90dec3fd2bfa0401290b8d4494a7da61dc",
"content_id": "6bf73b3287a41a775007a0b388f4f82fe20a7b87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 18,
"path": "/code/HDE/queries/delete_slash.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import MySQLdb\nimport struct, os\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncursor=db.cursor()\n\nslash_control=\"\"\"select URL FROM hde\"\"\"\ncursor.execute(slash_control)\nslash_rows=cursor.fetchall()\nfor slrows in slash_rows:\n\ta=slrows[0]\n\tif a[-1]== '/':\n\t\tb=a[:-1]\n\t\tprint b\n\t\tprint a\n\t\tslash_sql=\"\"\"UPDATE hde SET URL=%s WHERE URL=%s\"\"\" %(b,a)\n\t\t#slash_sql=\"\"\"SELECT URL FROM hde WHERE URL=%s\"\"\" %a\n\t\tcursor.execute(slash_sql)\n\t\tprint cursor.fetchall()\n"
},
{
"alpha_fraction": 0.751091718673706,
"alphanum_fraction": 0.7685589790344238,
"avg_line_length": 24.11111068725586,
"blob_id": "05fb32abc463eac3630692a7f621175a90b11ad7",
"content_id": "8197516956f33e7a4f1b69bb1c555f4c9c592a25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/code/HDE/migrate/bash1.sh",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "\n#!/bin/sh\n\npython /home/doga/Desktop/migrate/create_if_not_exist0.py\n\npython /home/doga/Desktop/migrate/xls_to_csv1.py\n\npython /home/doga/Desktop/migrate/csv_to_db2.py\n\npython /home/doga/Desktop/migrate/update_session_ids3.py\n\n\n"
},
{
"alpha_fraction": 0.6680622100830078,
"alphanum_fraction": 0.6742823123931885,
"avg_line_length": 40.436546325683594,
"blob_id": "9a1b268111cc119464cf5dceb70c819f99a53be9",
"content_id": "d51bd2c0a999e99ad17fbf2b2b08a6eb497e1284",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8360,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 197,
"path": "/code/Crawler/query/nearestNode.java",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import java.awt.Color;\r\nimport java.io.BufferedReader;\r\nimport java.io.File;\r\nimport java.io.IOException;\r\nimport java.io.InputStreamReader;\r\nimport java.sql.DriverManager;\r\n\r\nimport java.sql.Connection;\r\nimport java.sql.DriverManager;\r\nimport java.sql.ResultSet;\r\nimport java.sql.SQLException;\r\nimport java.sql.Statement;\r\n\r\nimport org.gephi.data.attributes.api.AttributeColumn;\r\nimport org.gephi.data.attributes.api.AttributeController;\r\nimport org.gephi.data.attributes.api.AttributeModel;\r\nimport org.gephi.graph.api.DirectedGraph;\r\nimport org.gephi.graph.api.GraphController;\r\nimport org.gephi.graph.api.GraphModel;\r\nimport org.gephi.io.database.drivers.MySQLDriver;\r\nimport org.gephi.io.exporter.api.ExportController;\r\nimport org.gephi.io.importer.api.Container;\r\nimport org.gephi.io.importer.api.EdgeDefault;\r\nimport org.gephi.io.importer.api.ImportController;\r\nimport org.gephi.io.importer.plugin.database.EdgeListDatabaseImpl;\r\nimport org.gephi.io.importer.plugin.database.ImporterEdgeList;\r\nimport org.gephi.io.processor.plugin.DefaultProcessor;\r\nimport org.gephi.layout.plugin.force.StepDisplacement;\r\nimport org.gephi.layout.plugin.force.yifanHu.YifanHuLayout;\r\nimport org.gephi.preview.api.ColorizerFactory;\r\nimport org.gephi.preview.api.EdgeColorizer;\r\nimport org.gephi.preview.api.PreviewController;\r\nimport org.gephi.preview.api.PreviewModel;\r\nimport org.gephi.project.api.ProjectController;\r\nimport org.gephi.project.api.Workspace;\r\nimport org.gephi.ranking.api.ColorTransformer;\r\nimport org.gephi.ranking.api.EdgeRanking;\r\nimport org.gephi.ranking.api.NodeRanking;\r\nimport org.gephi.ranking.api.RankingController;\r\nimport org.gephi.ranking.api.SizeTransformer;\r\nimport org.gephi.statistics.plugin.GraphDistance;\r\nimport org.netbeans.modules.masterfs.providers.Attributes;\r\nimport org.openide.util.Lookup;\r\n\r\npublic class nearestNode {\r\n\r\n\tpublic static void main(String[] argv) {\r\n\r\n\t\t BufferedReader reader;\r\n\t\t reader = new BufferedReader(new InputStreamReader(System.in));\r\n\t\t System.out.println(\"Enter the URL required: \");\r\n\t\t String url_name = null;\r\n\t\t try {\r\n\t\t\turl_name = reader.readLine();\r\n\t\t\t//Throw out any extra backslashes\r\n\t\t\tif(url_name.endsWith(\"/\"))\r\n\t\t\t\turl_name = url_name.substring(0, url_name.length()-1);\r\n\t\t\t}\r\n\t\t catch (IOException e1) {\r\n\t\t\te1.printStackTrace();\r\n\t\t\t} \r\n\t\t \r\n //Init a project - and therefore a workspace\r\n ProjectController pc = Lookup.getDefault().lookup(ProjectController.class);\r\n pc.newProject();\r\n Workspace workspace = pc.getCurrentWorkspace();\r\n\r\n //Get controllers and models\r\n ImportController importController = Lookup.getDefault().lookup(ImportController.class);\r\n GraphModel graphModel = Lookup.getDefault().lookup(GraphController.class).getModel();\r\n AttributeModel attributeModel = Lookup.getDefault().lookup(AttributeController.class).getModel();\r\n PreviewModel pModel = Lookup.getDefault().lookup(PreviewController.class).getModel();\r\n \r\n //Import database\r\n EdgeListDatabaseImpl db = new EdgeListDatabaseImpl();\r\n db.setDBName(\"test\");\r\n db.setHost(\"localhost\");\r\n db.setUsername(\"root\");\r\n db.setPasswd(\"root\");\r\n db.setSQLDriver(new MySQLDriver());\r\n db.setPort(3306);\r\n\r\n //multiple queries\r\n Connection conn = null;\r\n\t\t try {\r\n\t\t\t //Connecting\r\n\t\t\t String userName = \"root\";\r\n String password = \"root\";\r\n Statement stmt;\r\n String url = \"jdbc:mysql://localhost/test\";\r\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance();\r\n conn = DriverManager.getConnection (url, userName, password);\r\n System.out.println (\"Database connection established\");\r\n \r\n //executing query\r\n stmt = conn.createStatement();\r\n\t\t\t String getID_NameQ = \"select id from url_crawler where url = \\\"\" + url_name+\"\\\"\";\r\n\t\t\t ResultSet rs2 = stmt.executeQuery(getID_NameQ);\r\n\t\t\t rs2.next();\r\n\t\t\t int temp_id = rs2.getInt(1);\r\n\t\t\t System.out.println(temp_id);\r\n\t\t\t //incoming edges and outgoing edges\r\n\t\t\t String tempQ = \"SELECT link.id_2 AS source,\" +\r\n\t\t\t\t \t\t\" link.id_1 AS target,\" +\r\n\t\t\t\t \t\t\" link.http_access AS label\" +\r\n\t\t\t\t \t\t\" FROM link Where id_2 = \"+temp_id+\" or id_1 = \"+ temp_id;\r\n\t\t\t \r\n\t\t\t //prepare for the second level\r\n\t\t\t /*\r\n\t\t\t ResultSet rs3 = stmt.executeQuery(\"select id_1 from link where id_2 = \" + temp_id);\r\n\t\t\t \r\n\t\t\t //prepare query for the second level links\r\n\t\t\t int temp_child = 0;\r\n\t\t\t while(rs3.next()) {\r\n\t\t\t\t temp_child = rs3.getInt(1);\r\n\t\t\t\t tempQ = tempQ.concat(\" or id_2 = \"+temp_child);\r\n\t\t\t }\r\n\t\t\t System.out.println(tempQ);\r\n\t\t\t */\r\n\t\t\t //get all the links for Gephi\r\n\t\t\t \r\n\t\t\t db.setEdgeQuery(tempQ);\r\n\t\t\t \r\n conn.close();\r\n\t\t }\r\n\t\t catch (Exception e) {\r\n System.err.println (e.getMessage());\r\n }\r\n\r\n ImporterEdgeList edgeListImporter = new ImporterEdgeList();\r\n Container container = importController.importDatabase(db, edgeListImporter);\r\n //container.setAllowAutoNode(false); //Don't create missing nodes\r\n container.setAllowAutoNode(true);\r\n container.getLoader().setEdgeDefault(EdgeDefault.DIRECTED); //Force UNDIRECTED\r\n \r\n //Append imported data to GraphAPI\r\n importController.process(container, new DefaultProcessor(), workspace);\r\n\r\n //See if graph is well imported\r\n DirectedGraph graph = graphModel.getDirectedGraph();\r\n System.out.println(\"Nodes: \" + graph.getNodeCount());\r\n System.out.println(\"Edges: \" + graph.getEdgeCount());\r\n\r\n //Layout - 100 Yifan Hu passes\r\n YifanHuLayout layout = new YifanHuLayout(null, new StepDisplacement(1f));\r\n layout.setGraphModel(graphModel);\r\n layout.resetPropertiesValues();\r\n for (int i = 0; i < 100 && layout.canAlgo(); i++) {\r\n layout.goAlgo();\r\n }\r\n \r\n //Rank color by Degree\r\n RankingController rankingController = Lookup.getDefault().lookup(RankingController.class);\r\n //AttributeColumn a = attributeModel.getNodeTable().getColumn(\"indexed\");\r\n //NodeRanking degreeRanking = rankingController.getRankingModel().getNodeAttributeRanking(a);\r\n NodeRanking degreeRanking = rankingController.getRankingModel().getInDegreeRanking();\r\n ColorTransformer colorTransformer = rankingController.getObjectColorTransformer(degreeRanking);\r\n colorTransformer.setColors(new Color[]{new Color(0xA4FFF9), new Color(0xFFFF00), new Color(0xF72500)});\r\n rankingController.transform(colorTransformer);\r\n \r\n //Get Centrality\r\n /*\r\n GraphDistance distance = new GraphDistance();\r\n distance.setDirected(true);\r\n distance.execute(graphModel, attributeModel);\r\n \r\n //Rank size by centrality\r\n AttributeColumn centralityColumn = attributeModel.getNodeTable().getColumn(GraphDistance.BETWEENNESS);\r\n NodeRanking centralityRanking = rankingController.getRankingModel().getNodeAttributeRanking(centralityColumn);\r\n SizeTransformer sizeTransformer = rankingController.getObjectSizeTransformer(centralityRanking);\r\n sizeTransformer.setMinSize(3);\r\n sizeTransformer.setMaxSize(10);\r\n rankingController.transform(sizeTransformer);\r\n \r\n //Preview\r\n pModel.getNodeSupervisor().setShowNodeLabels(Boolean.TRUE);\r\n ColorizerFactory colorizerFactory = Lookup.getDefault().lookup(ColorizerFactory.class);\r\n pModel.getSelfLoopSupervisor().setColorizer((EdgeColorizer) colorizerFactory.createCustomColorMode(Color.RED));\r\n pModel.getUniEdgeSupervisor().setEdgeScale(0.1f);\r\n pModel.getBiEdgeSupervisor().setEdgeScale(0.1f);\r\n pModel.getNodeSupervisor().setBaseNodeLabelFont(pModel.getNodeSupervisor().getBaseNodeLabelFont().deriveFont(8));\r\n */\r\n \r\n //Export full graph\r\n ExportController ec = Lookup.getDefault().lookup(ExportController.class);\r\n try {\r\n ec.exportFile(new File(\"C://Users//Eric//Desktop//io_gexf.gexf\"));\r\n //ec.exportFile(new File(\"C://Users//Eric//Desktop//io_gexf.pdf\"));\r\n }\r\n catch (IOException ex) {\r\n ex.printStackTrace();\r\n return;\r\n }\r\n \r\n \r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.6580227017402649,
"alphanum_fraction": 0.664505660533905,
"avg_line_length": 26.954545974731445,
"blob_id": "545391ec6685b8f36e27b50f3a73c611159f3fd2",
"content_id": "c94a4771db1bc0e29b3d771889bc7b0bbfddb36d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 22,
"path": "/code/HDE/migrate/csv_to_db2.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import os\nimport MySQLdb, csv\n\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncursor=db.cursor()\npath=\"/home/doga/Desktop/migrate/\"\ndirList=os.listdir(path)\ncount=1\nfor fname in dirList:\n\tprint fname.split(\".\")[1]\n\tif fname.split(\".\")[1] == \"csv\":\n\t\tdata_path=\"/home/doga/Desktop/migrate/\"+fname\n\t\tcsv_data=csv.reader(file(data_path, 'rb'))\n\t\theaderline=csv_data.next()\n\t\tfor row in csv_data:\n\n\t\t\tcount +=1\n\t\t\tprint count\n\t\t\tcursor.execute(\"INSERT INTO hde (S_ID, URL, Process, Host, IP, Content) VALUES (%s, %s, %s, %s, %s, %s)\",row) \t\n\t\tdb.commit()\ncursor.close()\ndb.close()\n\n\n"
},
{
"alpha_fraction": 0.6126769781112671,
"alphanum_fraction": 0.6192362904548645,
"avg_line_length": 40.65373992919922,
"blob_id": "378a72bb8460a24cab954077a27555cd31893409",
"content_id": "d15ec2631a2e955bfb0d6414180d588bf65daadb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 15398,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 361,
"path": "/code/Crawler/query/isConnect.java",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import java.awt.Color;\r\nimport java.io.*;\r\nimport java.sql.Connection;\r\nimport java.sql.DriverManager;\r\nimport java.sql.ResultSet;\r\nimport java.sql.SQLException;\r\nimport java.sql.PreparedStatement;\r\nimport java.util.LinkedList;\r\nimport java.util.Queue;\r\nimport java.util.Stack;\r\n\r\nimport org.gephi.data.attributes.api.AttributeColumn;\r\nimport org.gephi.data.attributes.api.AttributeController;\r\nimport org.gephi.data.attributes.api.AttributeModel;\r\nimport org.gephi.graph.api.DirectedGraph;\r\nimport org.gephi.graph.api.GraphController;\r\nimport org.gephi.graph.api.GraphModel;\r\nimport org.gephi.io.database.drivers.MySQLDriver;\r\nimport org.gephi.io.exporter.api.ExportController;\r\nimport org.gephi.io.importer.api.Container;\r\nimport org.gephi.io.importer.api.EdgeDefault;\r\nimport org.gephi.io.importer.api.ImportController;\r\nimport org.gephi.io.importer.plugin.database.EdgeListDatabaseImpl;\r\nimport org.gephi.io.importer.plugin.database.ImporterEdgeList;\r\nimport org.gephi.io.processor.plugin.DefaultProcessor;\r\nimport org.gephi.layout.plugin.force.StepDisplacement;\r\nimport org.gephi.layout.plugin.force.yifanHu.YifanHuLayout;\r\nimport org.gephi.preview.api.Colorizer;\r\nimport org.gephi.preview.api.ColorizerClient;\r\nimport org.gephi.preview.api.ColorizerFactory;\r\nimport org.gephi.preview.api.EdgeColorizer;\r\nimport org.gephi.preview.api.NodeChildColorizer;\r\nimport org.gephi.preview.api.PreviewController;\r\nimport org.gephi.preview.api.PreviewModel;\r\nimport org.gephi.project.api.ProjectController;\r\nimport org.gephi.project.api.Workspace;\r\nimport org.gephi.ranking.api.ColorTransformer;\r\nimport org.gephi.ranking.api.NodeRanking;\r\nimport org.gephi.ranking.api.RankingController;\r\nimport org.gephi.ranking.api.SizeTransformer;\r\nimport org.gephi.statistics.plugin.GraphDistance;\r\nimport org.openide.util.Lookup;\r\n\r\nimport com.mysql.jdbc.Statement;\r\n\r\nclass eval {\r\n\tvoid gephiGraph(String query, String nQuery, String innerQuery) {\r\n\t\t//Gephi\r\n\t\t//Init a project - and therefore a workspace\r\n\t\tProjectController pc = Lookup.getDefault().lookup(ProjectController.class);\r\n\t\tpc.newProject();\r\n\t\tWorkspace workspace = pc.getCurrentWorkspace();\r\n\r\n\t\t//Get controllers and models\r\n\t\tImportController importController = Lookup.getDefault().lookup(ImportController.class);\r\n\t\tGraphModel graphModel = Lookup.getDefault().lookup(GraphController.class).getModel();\r\n\t\tAttributeModel attributeModel = Lookup.getDefault().lookup(AttributeController.class).getModel();\r\n\t\tPreviewModel pModel = Lookup.getDefault().lookup(PreviewController.class).getModel();\r\n\t\t\r\n\t\t//Import database for Gephi\r\n EdgeListDatabaseImpl db = new EdgeListDatabaseImpl();\r\n db.setDBName(\"test\");\r\n db.setHost(\"localhost\");\r\n db.setUsername(\"root\");\r\n db.setPasswd(\"root\");\r\n db.setSQLDriver(new MySQLDriver());\r\n db.setPort(3306);\r\n \r\n //query\r\n db.setEdgeQuery(query);\r\n db.setNodeQuery(innerQuery+\" union \"+nQuery);\r\n \r\n ImporterEdgeList edgeListImporter = new ImporterEdgeList();\r\n Container container = importController.importDatabase(db, edgeListImporter);\r\n container.setAllowAutoNode(true);//create missing nodes\r\n container.getLoader().setEdgeDefault(EdgeDefault.DIRECTED); //Force UNDIRECTED\r\n \r\n //Append imported data to GraphAPI\r\n importController.process(container, new DefaultProcessor(), workspace);\r\n\r\n //See if graph is well imported\r\n DirectedGraph graph = graphModel.getDirectedGraph();\r\n System.out.println(\"Nodes: \" + graph.getNodeCount());\r\n System.out.println(\"Edges: \" + graph.getEdgeCount());\r\n\r\n //Layout - 100 Yifan Hu passes\r\n YifanHuLayout layout = new YifanHuLayout(null, new StepDisplacement(1f));\r\n layout.setGraphModel(graphModel);\r\n layout.resetPropertiesValues();\r\n for (int i = 0; i < 100 && layout.canAlgo(); i++) {\r\n layout.goAlgo();\r\n }\r\n \r\n //Rank color by Degree\r\n RankingController rankingController = Lookup.getDefault().lookup(RankingController.class);\r\n AttributeColumn a = attributeModel.getNodeTable().getColumn(\"indexed\");\r\n NodeRanking degreeRanking = rankingController.getRankingModel().getNodeAttributeRanking(a);\r\n //NodeRanking degreeRanking = rankingController.getRankingModel().getDegreeRanking();\r\n ColorTransformer colorTransformer = rankingController.getObjectColorTransformer(degreeRanking);\r\n colorTransformer.setColors(new Color[]{new Color(0xB30000), new Color(0x0000B3)});\r\n rankingController.transform(colorTransformer);\r\n \r\n //Get Centrality\r\n GraphDistance distance = new GraphDistance();\r\n distance.setDirected(true);\r\n distance.execute(graphModel, attributeModel);\r\n \r\n //Rank size by centrality\r\n /*\r\n //AttributeColumn centralityColumn = attributeModel.getNodeTable().getColumn(GraphDistance.BETWEENNESS);\r\n //NodeRanking centralityRanking = rankingController.getRankingModel().getNodeAttributeRanking(centralityColumn);\r\n NodeRanking centralityRanking = rankingController.getRankingModel().getOutDegreeRanking();\r\n SizeTransformer sizeTransformer = rankingController.getObjectSizeTransformer(centralityRanking);\r\n sizeTransformer.setMinSize(10);\r\n sizeTransformer.setMaxSize(12);\r\n rankingController.transform(sizeTransformer);\r\n */\r\n //Preview\r\n /*\r\n pModel.getNodeSupervisor().setShowNodeLabels(Boolean.TRUE);\r\n ColorizerFactory colorizerFactory = Lookup.getDefault().lookup(ColorizerFactory.class);\r\n //Set edges gray\r\n pModel.getUniEdgeSupervisor().setColorizer((EdgeColorizer) colorizerFactory.createCustomColorMode(Color.LIGHT_GRAY));\r\n //Set mutual edges and self loop red\r\n pModel.getBiEdgeSupervisor().setColorizer((EdgeColorizer) colorizerFactory.createCustomColorMode(Color.RED));\r\n pModel.getSelfLoopSupervisor().setColorizer((EdgeColorizer) colorizerFactory.createCustomColorMode(Color.RED));\r\n pModel.getUniEdgeSupervisor().setEdgeScale(0.1f);\r\n pModel.getBiEdgeSupervisor().setEdgeScale(0.1f);\r\n pModel.getNodeSupervisor().setBaseNodeLabelFont(pModel.getNodeSupervisor().getBaseNodeLabelFont().deriveFont(8));\r\n //Set nodes labels white\r\n pModel.getNodeSupervisor().setNodeLabelColorizer((NodeChildColorizer) colorizerFactory.createCustomColorMode(Color.BLUE));\r\n //background color\r\n PreviewController previewController = Lookup.getDefault().lookup(PreviewController.class);\r\n previewController.setBackgroundColor(Color.BLACK);\r\n */\r\n \r\n //Export full graph\r\n ExportController ec = Lookup.getDefault().lookup(ExportController.class);\r\n try {\r\n ec.exportFile(new File(\"C://Users//Eric//Desktop//io_gexf.gexf\"));\r\n //ec.exportFile(new File(\"C://Users//Eric//Desktop//io_gexf.pdf\"));\r\n }\r\n catch (IOException ex) {\r\n ex.printStackTrace();\r\n //return;\r\n }\r\n\t}\r\n\t\r\n\tvoid dest_get_next_level(int url_id, int dest_id, int depth)\r\n\tthrows InstantiationException, IllegalAccessException, ClassNotFoundException {\r\n String userName = \"root\";\r\n String password = \"root\";\r\n String myQuery = \"SELECT link.id_2 AS source, \" +\r\n \t\t\"link.id_1 AS target, \" +\r\n \t\t\"link.http_access AS label \" +\r\n \t\t\"FROM link Where id_2 in (\" + url_id;\r\n String nodeQuery = \"SELECT url_crawler.id AS id, \" +\r\n \t\t\"url_crawler.url AS label, \" +\r\n \t\t\"url_crawler.indexed \" +\r\n \t\t\"FROM url_crawler where id in (\" + url_id;\r\n String innerQuery = \"select url_crawler.id AS id, \" +\r\n \t\t\"url_crawler.url AS label, \" +\r\n \t\t\"url_crawler.indexed \" +\r\n \t\t\"FROM url_crawler where id in (\" +\r\n \t\t\"select distinct id_1 from link where id_2 in (\"+ url_id;\r\n Queue<Integer> queue = new LinkedList<Integer>();\r\n LinkedList<Integer> tempQueue = new LinkedList<Integer>();//use for keeping track of the path\r\n LinkedList<Integer> copyQueue = new LinkedList<Integer>();//use for copy the element\r\n LinkedList<Integer> pathQueue = new LinkedList<Integer>();//path\r\n \r\n try {\r\n //connecting to the database\r\n String url = \"jdbc:mysql://localhost:3306/test\";\r\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance();\r\n\t\t Connection conn = DriverManager.getConnection (url, userName, password);\r\n \r\n\t\t //Search where all the connected indices\r\n\t\t String get_level_stmt = \"SELECT id_1 FROM link WHERE id_2 = ?\";\r\n\t\t PreparedStatement retrieve_parent = conn.prepareStatement(get_level_stmt);\r\n\t\t retrieve_parent.setInt(1, url_id);\r\n\t\t ResultSet rs_level = retrieve_parent.executeQuery();\r\n\r\n\t\t //insert into a queue\r\n\t\t while (rs_level.next()) {\r\n\t\t\t queue.add(rs_level.getInt(1));\r\n\t\t\t tempQueue.add(url_id);\r\n\t\t }\r\n\t\t \r\n\t\t //http://www.computer.org/portal/web/security/home\r\n\t\t //http://www.cl.cam.ac.uk/users/sjm217\r\n\t\t //https://www.easychair.org/account/signin.cgi?conf=fcsprivmod2010\r\n\t\t //http://www.nytimes.com/2010/07/05/nyregion/05cricket.html?_r=2\r\n\t\t //http://www.cl.cam.ac.uk/~srl32/\r\n\t\t //\r\n\t\t //http://www.mdcr.cz/en/HomePage.htm\r\n\t\t int first_item;\r\n\t\t int count = 0;\r\n\t\t int ptr;\r\n\t\t int level_size = queue.size();\r\n\t\t while(!queue.isEmpty() && depth > 0) {\r\n\t\t\t //get the first item in the queue and remove it\r\n\t\t\t first_item = queue.remove();\r\n\t\t\t copyQueue.add(first_item);//keep a copy of them so we can restore the path later\r\n\t\t\t if(first_item == dest_id) {\r\n\t\t\t\t //found it!\r\n\t\t\t\t System.out.println(\"found it! \");\r\n\t\t\t\t System.out.println(count);//print the queue size\r\n\t\t\t\t pathQueue.add(dest_id);\r\n\t\t\t\t ptr = tempQueue.get(copyQueue.indexOf(dest_id));\r\n\t\t\t\t pathQueue.add(ptr);\r\n\t\t\t\t while(ptr != url_id) {\r\n\t\t\t\t\t ptr = tempQueue.get(copyQueue.indexOf(ptr));\r\n\t\t\t\t\t pathQueue.add(ptr);\r\n\t\t\t\t }\r\n\t\t\t\t System.out.println(\"----- path ---------\");\r\n\t\t\t\t while(!pathQueue.isEmpty()) {\r\n\t\t\t\t\t ptr = pathQueue.removeLast();\r\n\t\t\t\t\t myQuery = myQuery.concat(\", \"+ptr);\r\n\t\t\t\t\t nodeQuery = nodeQuery.concat(\", \"+ptr);\r\n\t\t\t\t\t innerQuery = innerQuery.concat(\", \"+ptr);\r\n\t\t\t\t\t System.out.println(ptr);\r\n\t\t\t\t }\r\n\t\t\t\t myQuery = myQuery.concat(\")\");\r\n\t\t\t\t nodeQuery = nodeQuery.concat(\")\");\r\n\t\t\t\t innerQuery = innerQuery.concat(\"))\");\r\n\t\t\t\t conn.close(); \r\n\t\t\t //call gephi\r\n\t\t\t gephiGraph(myQuery, nodeQuery, innerQuery);\r\n\t\t\t\t System.exit(0);\r\n\t\t\t }\r\n\t\t\t else {\r\n\t\t\t\t get_level_stmt = \"SELECT id_1 FROM link WHERE id_2 = ?\";\r\n\t\t\t\t retrieve_parent = conn.prepareStatement(get_level_stmt);\r\n\t\t\t\t retrieve_parent.setInt(1, first_item);\r\n\t\t\t\t rs_level = retrieve_parent.executeQuery();\r\n\t\t\t\t level_size = level_size - 1;\r\n\t\t\t\t \r\n\t\t\t\t //add its children to the end of the queue\r\n\t\t\t\t while (rs_level.next()) {\r\n\t\t\t\t\t //if(!queue.contains(rs_level.getInt(1))) {//this is too expensive!\r\n\t\t\t\t\t \t\tqueue.add(rs_level.getInt(1)); //but could save some space\r\n\t\t\t\t\t \t\ttempQueue.add(first_item);\r\n\t\t\t\t\t //}\r\n\t\t\t\t }\r\n\t\t\t\t //decrease the depth by one since we finished searching this level\r\n\t\t\t\t if(level_size == 0) {\r\n\t\t\t\t\t depth = depth - 1;\r\n\t\t\t\t\t level_size = queue.size(); //reset the level size\r\n\t\t\t\t }\r\n\t\t\t }\r\n\t\t\t count++;\r\n\t\t\t if(count>160000) {\r\n\t\t\t\t conn.close();\r\n\t\t\t\t System.out.println(\"unable to find the item\");\r\n\t\t\t\t System.exit(0);\r\n\t\t\t }\r\n\t\t }\r\n\t\t System.out.println(\"level reached!\");\r\n\t\t System.out.println(\"unable to find the item\");\r\n\t\t conn.close();\r\n }\r\n catch(SQLException ex) {\r\n \t System.err.println(\"SQLException: \" + ex.getMessage()); \r\n }\r\n\t}\r\n}\r\n\r\npublic class isConnect {\r\n\tpublic static void main(String[] args) {\r\n\t\t//eval e1 = new eval();\r\n\t\tConnection conn = null;\r\n try {\r\n \t//e1.dest_get_next_level(1, 707, 5);\r\n String userName = \"root\";\r\n String password = \"root\";\r\n String url = \"jdbc:mysql://localhost/test\";\r\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance ();\r\n conn = DriverManager.getConnection (url, userName, password);\r\n System.out.println (\"Database connection established\");\r\n \r\n try {\r\n \t\t BufferedReader reader;\r\n \t\t reader = new BufferedReader(new InputStreamReader(System.in));\r\n \t\t String line = null;\r\n \t\t String source = null;\r\n \t\t String target = null;\r\n \t\t int limit = 0;\r\n \t\t \r\n \t\t //Enter URL path\r\n \t\t System.out.println(\"Enter the URL required: \");\r\n \t\t source = reader.readLine(); \r\n \t \t if (source.endsWith(\"/\")) {\r\n \t \t\t source = source.substring(0, source.length()-1);\r\n\t \t }\r\n \t\t \r\n \t \t //Enter the destination URL\r\n \t\t System.out.println(\"Enter the destination URL: \");\r\n \t\t target = reader.readLine(); \r\n \t \t if (target.endsWith(\"/\")) {\r\n \t \t\ttarget = target.substring(0, target.length()-1);\r\n\t \t }\r\n \t \t \r\n \t \t //set the limit\r\n \t \t System.out.println(\"Enter the level: \");\r\n \t\t line = reader.readLine();\r\n \t\t try {\r\n \t\t\t limit = Integer.parseInt(line);\r\n \t\t }\r\n \t\t catch(NumberFormatException e) {\r\n \t\t\t System.err.println(\"Not a valid number: \"+line);\r\n \t\t }\r\n \t\t \r\n \t\t //Retrieve the index for source\r\n \t\t String get_id_stmt = \"SELECT id FROM url_crawler WHERE url = ?\";\r\n \t\t PreparedStatement retrieve_id = conn.prepareStatement(get_id_stmt);\r\n \t\t retrieve_id.setString(1, source);\r\n\t\t\t ResultSet rs_id = retrieve_id.executeQuery();\r\n\t\t\t rs_id.first();\r\n\t\t\t int url_id = rs_id.getInt(\"id\");\r\n \t\t System.out.println(\"Source id is \"+url_id);\r\n \t\t \r\n \t\t //Retrieve the index for target\r\n \t\t String get_id_stmt_dest = \"SELECT id FROM url_crawler WHERE url = ?\";\r\n \t\t PreparedStatement dest_retrieve_id = conn.prepareStatement(get_id_stmt_dest);\r\n \t\t dest_retrieve_id.setString(1, target);\r\n \t\t ResultSet dest_rs_id = dest_retrieve_id.executeQuery();\r\n\t\t dest_rs_id.first();\r\n \t\t int dest_url_id = dest_rs_id.getInt(\"id\");\r\n \t\t System.out.println(\"Target id is \"+dest_url_id);\r\n \t\t \r\n \t\t //call BFS\r\n \t\t eval e = new eval(); \r\n \t\t if(limit >4) {\r\n \t\t\t System.out.println(\"Sorry, the maximum level is 4\");\r\n \t\t\t System.exit(0);\r\n \t\t }\r\n \t e.dest_get_next_level(url_id, dest_url_id, limit);\r\n \t\t}\r\n catch(SQLException ex) {\r\n \t System.err.println(\"SQLException: \" + ex.getMessage());\r\n }\r\n \r\n }\r\n catch (Exception e) {\r\n System.err.println (\"Error is \"+e.getMessage());\r\n }\r\n finally {\r\n if (conn != null) {\r\n try {\r\n conn.close ();\r\n System.out.println();\r\n }\r\n catch (Exception e) {\r\n \t System.err.println(\"SQLException: \" + e.getMessage());\r\n }\r\n }\r\n\r\n }\r\n \r\n\t} \r\n}\r\n"
},
{
"alpha_fraction": 0.6813509464263916,
"alphanum_fraction": 0.6864904761314392,
"avg_line_length": 28.586956024169922,
"blob_id": "6cbc01a4e4ca379693ffa6c9913767aa1da63fab",
"content_id": "9c04030931a39c67b17afc4251cac763a0725fc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1362,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 46,
"path": "/code/HDE/queries/query3.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "from Tkinter import *\nimport os, MySQLdb\nimport tkMessageBox\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncu=db.cursor()\n\nclass Quitter(Frame): # subclass our GUI\n\tdef __init__(self, parent=None): # constructor method\n\t\tFrame.__init__(self, parent)\n\t\tself.pack()\n\t\twidget = Button(self, text='Quit', command=self.quit)\n\t\twidget.pack(side=LEFT)\n\tdef quit(self):\n\t\tFrame.quit(self)\n\ndef fetch():\n\tprint 'Input => \"%s\"' % ent.get() # get text\n\tx=int(ent.get())\n\tcu.execute(\"SELECT COUNT(INDEXED) FROM hde WHERE INDEXED=1 AND SES_ID=%s\",x)\n\td=cu.fetchall()\n\tcu.execute(\"SELECT COUNT(INDEXED) FROM hde WHERE INDEXED=0 AND SES_ID=%s\",x)\n\te=cu.fetchall()\n\tprint e\n\ttkMessageBox.showinfo(\"# of Indexed\" , d)\n\ttkMessageBox.showinfo(\"# of Unindexed\", e)\n\t#root=Tk()\n\t#root.title('# of Indexed & Unindexed')\n\t#Message(root,e)\n\t#Message(root,d)\n\t#root.mainloop()\n\ncu.execute(\"SELECT COUNT(DISTINCT SES_ID) FROM hde\")\nd=cu.fetchall()\t\n\nroot = Tk()\nroot.option_add(\"*Dialog.msg.wrapLength\", \"40i\")\nent = Entry(root)\nent.insert(0, 'Select a session id 1-%d' %d[0]) # set text\nent.pack(side=TOP, fill=X) # grow horiz\n\nent.focus() # save a click\nent.bind('<Return>', (lambda event: fetch())) # on enter key\nbtn = Button(root, text='Fetch', command=fetch) # and on button\nbtn.pack(side=LEFT)\nQuitter(root).pack(side=RIGHT)\nroot.mainloop() \n"
},
{
"alpha_fraction": 0.5062094330787659,
"alphanum_fraction": 0.5131244659423828,
"avg_line_length": 33.23671340942383,
"blob_id": "bb6d1586d0f786a7f929325d66777d00f1d42674",
"content_id": "f042e5270535ec386899de8a33c0e0d864640de6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 7086,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 207,
"path": "/code/Crawler/data_collect/link_table.java",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import java.io.DataInputStream;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.sql.Connection;\nimport java.sql.DriverManager;\nimport java.sql.PreparedStatement;\nimport java.sql.ResultSet;\nimport java.sql.SQLException;\nimport java.sql.Statement;\nimport java.util.StringTokenizer;\n\nclass read_for_link\n{\n\t @SuppressWarnings({ \"deprecation\", \"null\" })\n\t void readlinkdata()\n\t {\n\t\t try\n\t\t {\n\t\t\t File folder = new File(\"/home/darkprince/workspace/Data\");\n\t\t\t File[] listOfFiles = folder.listFiles();\n\t\t\t \n\t\t\t for (int i = 0; i < listOfFiles.length; i++)\n\t\t\t {\n\t\t\t\t if (listOfFiles[i].isFile()) \n\t\t\t\t { \n\t\t\t\t\t FileInputStream fstream = new FileInputStream(listOfFiles[i].getPath());\n\t\t\t\t\t //FileInputStream fstream = new FileInputStream(\"C:/Users/Eric/Desktop/b669/1.txt\");\n\t\t\t\t\t DataInputStream in = new DataInputStream(fstream);\n\t\t\t\t\t int count = 0;\n\t\t\t\t\t String child_url = null, parent_url = null, http_access_code = null;\n\t\t\t \n\t\t\t\t\t //Read File Line By Line\n\t\t\t\t\t while (in.available() != 0)\n\t\t\t\t\t {\n\t\t\t\t\t\t count = 0;\n\t\t\t\t\t\t StringTokenizer st = new StringTokenizer(in.readLine());\n\t\t\t\t\t\t while (st.hasMoreTokens()) {\n\t\t\t\t\t\t\t count = count + 1;\n\t\t\t\t\t\t\t String token = st.nextToken();\n\t\t\t\t \n\t\t\t\t\t\t\t switch(count) {\n\t\t\t\t \t\tcase 2://child URL\n\t\t\t\t \t\t\tchild_url = token;\n\t\t\t\t \t\t\tSystem.out.println(\"Accessed URL = \" + token);\n\t\t\t\t \t\t\tbreak;\n\t\t\t\t \t\tcase 6://Access code\n\t\t\t\t \t\t\thttp_access_code = token;\n\t\t\t\t \t\t\tSystem.out.println(\"HTTP Access Code = \" + token);\n\t\t\t\t \t\t\tbreak;\n\t\t\t\t \t\tcase 7://parent URL\n\t\t\t\t \t\t\tparent_url = token;\n\t\t\t\t \t\t\tSystem.out.println(\"Parent URL = \" + token);\n\t\t\t\t \t\t\tbreak;\n\t\t\t\t\t\t\t }\n\t\t\t\t\t\t }\n\t\t\t\t\t\t //call insert\n\t\t\t\t\t\t if(!parent_url.equals(\"NA\")) {\n\t\t\t\t\t\t\t //remove the last \"/\" from url\n\t\t\t\t\t\t\t if(child_url.endsWith(\"/\")) {\n\t\t\t\t\t\t\t\t child_url = child_url.substring(0, child_url.length()-1);\n\t\t\t\t\t\t\t }\n\t\t\t\t\t\t\t if(parent_url.endsWith(\"/\")) {\n\t\t\t\t\t\t\t\t parent_url = parent_url.substring(0, parent_url.length()-1);\n\t\t\t\t\t\t\t }\n\t\t\t\t \t \n\t\t\t\t\t\t\t insert_link_table ins = new insert_link_table();\n\t\t\t\t\t\t\t ins.inserting_url_link(child_url, parent_url, http_access_code);\n\t\t\t\t\t\t }\n\t\t\t\t\t\t //Re-initialize before looping again\n\t\t\t\t\t\t child_url = null;\n\t\t\t\t\t\t parent_url = null;\n\t\t\t\t\t\t http_access_code = null;\n\t\t\t\t\t\t System.out.println(\"-------------------------------------------------\");\n\t\t\t\t\t }\n\t\t\t\t }\n\t\t\t }\n\t\t }\n\t\t catch (Exception e)\n\t\t { \n\t\t\t System.err.println(\"Error: \" + e.getMessage());\n\t\t }\n\t }\n}\n\n//For inserting data into link table table;\nclass insert_link_table\n{\n\t void inserting_url_link(String child_url_name, String parent_url_name, String http_access)\n\t {\n\t\t try\n\t\t {\n String userName = \"root\";\n String password = \"root\";\n \n int id_child = 0;\n int id_parent = 0;\n //connecting to the database\n //String url = \"jdbc:mysql://localhost/test\";\n String url = \"jdbc:mysql://localhost:3306/B669\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance();\n\t\t\t Connection conn = DriverManager.getConnection (url, userName, password);\n\t\t\t \n\t\t\t //Getting the child id from the url_crawler-----------------\n\t\t\t //preparing query\n\t\t\t Statement stmt = null;\n\t\t\t stmt = conn.createStatement();\n\t\t\t String query = \"select id from url_crawler where url = \\\"\"+child_url_name+\"\\\"\";\n\t\t\t //executing query and get the id_1\n\t\t\t ResultSet rs1 = stmt.executeQuery(query);\n\t\t\t rs1.next();\n\t\t\t id_child = rs1.getInt(\"id\");\n\t\t\t \n\t\t\t //Getting the parent id from the url_crawler-----------------\n\t\t\t //preparing query\n\t\t\t String get_id_parent_stmt = \"SELECT id FROM url_crawler WHERE url = ?\";\n\t\t\t PreparedStatement retrieve_parent = conn.prepareStatement(get_id_parent_stmt);\n\t\t\t retrieve_parent.setString(1, parent_url_name);\n\t\t\t //executing query and get the id_2\n\t\t\t ResultSet rs2 = retrieve_parent.executeQuery();\n\t\t\t rs2.next();\n\t\t\t id_parent = rs2.getInt(\"id\");\n\t\t\t System.out.println(id_parent +\" -> \"+ id_child);\n\t\t\t \n\t\t\t //Inserting into link table-----------------------------------\n\t\t\t //preparing query\n\t\t\t String insert_query = \"INSERT INTO Link(id_1, id_2, http_access) values (?,?,?)\";\n\t\t\t PreparedStatement pstmt = conn.prepareStatement(insert_query);\n\t\t\t pstmt.setInt(1, id_child);\n\t\t\t pstmt.setInt(2, id_parent);\n\t\t\t pstmt.setString(3, http_access);\n\t\t\t //executing query and close the connection\n\t\t\t pstmt.executeUpdate();\n\t\t\t pstmt.close();\n\t\t\t conn.close();\n\t\t }\n\t\t catch(Exception url_err)\n\t\t {\n\t\t\t System.err.println(url_err.getMessage());\n\t\t }\n\t }\n}\n\npublic class link_table \n{\n public static void main (String[] args)\n {\n Connection conn = null;\n try\n {\n String userName = \"root\";\n String password = \"root\";\n Statement stmt;\n \n //connect to database\n String url = \"jdbc:mysql://localhost/B669\";\n //String url = \"jdbc:mysql://localhost/test\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance ();\n conn = DriverManager.getConnection (url, userName, password);\n System.out.println (\"Database connection established\");\n System.out.println (\"Creating the Link table\");\n \n try\n {\n \t stmt = conn.createStatement();\n \t String query = \"CREATE TABLE IF NOT EXISTS Link (\" +\n \t \"id_1 INT UNSIGNED not null, \" +\n \"id_2 INT UNSIGNED not null, \"+\n \"http_access VARCHAR(5), \"+\n \"FOREIGN KEY(id_1) REFERENCES url_crawler(id),\" +\n \"FOREIGN KEY(id_2) REFERENCES url_crawler(id),\" +\n \"PRIMARY KEY(id_1, id_2))\";\n \t \n stmt.executeUpdate(query);\n System.out.println(\"Printing all the data first before inserting.....\");\n System.out.println(\".........\");\n System.out.println(\"-------------------------------------------------\");\n \n read_for_link read_links = new read_for_link();\n read_links.readlinkdata();\n }\n catch(SQLException ex)\n {\n \t System.err.println(\"SQLException: \" + ex.getMessage()); \n }\t \n }\n catch (Exception e)\n {\n System.err.println (e.getMessage());\n }\n finally\n {\n if (conn != null)\n {\n try\n {\n conn.close ();\n System.out.println (\"Database connection terminated\");\n }\n catch (Exception e) \n {\n \t System.err.println(\"SQLException: \" + e.getMessage());\n }\n }\n }\n }\n\n}"
},
{
"alpha_fraction": 0.6512455344200134,
"alphanum_fraction": 0.6814946532249451,
"avg_line_length": 30.11111068725586,
"blob_id": "024131c2e9ce6ff94f1eec1f248591026c2c6331",
"content_id": "2e00f1f18366eb66d0b06592847cef01ae4abdcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 562,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 18,
"path": "/code/HDE/migrate/create_if_not_exist0.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "\nimport MySQLdb\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncursor=db.cursor()\n\nsql=\"\"\"CREATE TABLE IF NOT EXISTS `hde`(\n `E_ID` int(11) NOT NULL AUTO_INCREMENT, \n `S_ID` int(11) DEFAULT NULL, \n `URL` text,\n `Process` varchar(45) DEFAULT NULL,\n `Host` varchar(45) DEFAULT NULL,\n `IP` varchar(45) DEFAULT NULL,\n `Content` varchar(45) DEFAULT NULL,\n `SES_ID` int(11) DEFAULT NULL,\n `INDEXED` varchar(2) DEFAULT '0',\n PRIMARY KEY (`E_ID`)\n) ENGINE=MyISAM DEFAULT CHARSET=latin1\"\"\"\ncursor.execute(sql)\ndb.commit()\n\n"
},
{
"alpha_fraction": 0.48459118604660034,
"alphanum_fraction": 0.49245283007621765,
"avg_line_length": 34.32222366333008,
"blob_id": "8499171c9d96045a4aae89a12b9cf4b4e1ffa5b5",
"content_id": "f6b29d34b81deffd0a1f87b7da069226047acd9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6360,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 180,
"path": "/code/Crawler/data_collect/url_crawler.java",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": " import java.sql.*;\n import java.io.*;\n import java.net.*;\n import java.util.StringTokenizer;\n import java.sql.PreparedStatement;\n import java.sql.DriverManager;\n import java.sql.Connection;\n \n class readcrawler \n {\n\t @SuppressWarnings(\"deprecation\")\n\t void readcrawldata()\n\t {\n\t\t try\n\t\t {\n\t\t\t System.out.println(\"* read crawl data v\");\n\t\t\t File folder = new File(\"/home/darkprince/workspace/Data\");\n\t\t\t File[] listOfFiles = folder.listFiles();\n\t\t\t \n\t\t\t for (int i = 0; i < listOfFiles.length; i++)\n\t\t\t {\n\t\t\t\t if (listOfFiles[i].isFile()) \n\t\t\t\t { \n\t\t\t \n\t\t\t\t\t FileInputStream fstream = new FileInputStream(listOfFiles[i].getPath());\n\t\t\t\t\t //FileInputStream fstream = new FileInputStream(\"C:/Users/Eric/Desktop/b669/1.txt\");\n\t\t\t\t\t DataInputStream in = new DataInputStream(fstream);\n\t\t\t\t\t int count = 0;\n\t\t\t \n\t\t\t\t\t //Read File Line By Line\n\t\t\t\t\t while (in.available() != 0)\n\t\t\t\t\t {\n\t\t\t\t\t\t count = 0;\n\t\t\t\t\t\t StringTokenizer st = new StringTokenizer(in.readLine());\n\t\t\t\t\t\t while (st.hasMoreTokens())\n\t\t\t\t\t\t {\n\t\t\t\t\t\t\t count = count + 1;\n\t\t\t\t\t\t\t String token = st.nextToken();\n\t\t\t\t\t\t\t if (count == 2)\n\t\t\t\t\t\t\t { //once we see the URL, we insert it into the database\n\t\t\t\t\t\t\t\t System.out.println(\"Accessed URL = \" + token);\n\t\t\t\t\t\t\t\t insert_url_crawler_table ins = new insert_url_crawler_table();\n\t\t\t\t\t\t\t\t ins.inserting_url_crawler(token, 0);\n\t\t\t\t\t //After we inserted the URL, we don't need to read the rest of data from this line.\n\t\t\t\t\t\t\t\t //Therefore, break the while loop and read the next line of input.\n\t\t\t\t\t\t\t\t break;\n\t\t\t\t\t\t\t }\t\t\t\t \n\t\t\t\t\t\t }\n\t\t\t\t\t\t System.out.println(\"* read crawl data ^\");\n\t\t\t\t\t }\n\t\t\t\t }\n\t\t\t }\n\t\t }\n\t\t catch (Exception e)\n\t\t { \n\t\t\t System.err.println(\"Error: \" + e.getMessage());\n\t\t }\n\t }\n }\n \n //For inserting data into url_crawler table; this takes the input of the crawled data\n class insert_url_crawler_table\n {\n\t void inserting_url_crawler(String url_name, int index)\n\t {\n\t\t try\n\t\t {\n System.out.println(\"* inserting_url_crawler v\");\n\t\t\t String userName = \"root\";\n String password = \"root\";\n int dot = 0;\n //connect to the database\n //String url = \"jdbc:mysql://localhost:3306/test\";\n String url = \"jdbc:mysql://localhost:3306/B669\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance();\n\t\t\t Connection conn = DriverManager.getConnection (url, userName, password);\n\t\t\t String insert_query = \"INSERT INTO url_crawler(url, secured, tld, indexed) values (?,?,?,?)\";\n\t\t\t URL a_URL = new URL(url_name);\n\n\t\t\t StringTokenizer tld = new StringTokenizer(a_URL.getHost(),\".\");\n\t\t\t //Inserting the values one by one\n\t\t\t PreparedStatement pstmt = conn.prepareStatement(insert_query);\n\n\t\t\t //remove the last \"/\" from url since for example, \"www.google.com/\" === \"www.google.com\"\n\t\t\t if(url_name.endsWith(\"/\"))\n\t\t\t\t url_name = url_name.substring(0, url_name.length()-1);\n\n\t\t\t //set url_name and protocol\n\t\t\t pstmt.setString(1, url_name);\n\t\t\t pstmt.setString(2, a_URL.getProtocol());\n\t\t\t \n\t\t\t //set the tld value\n\t\t\t while(tld.hasMoreTokens())\n\t\t\t {\n\t\t\t\t dot = dot + 1;\n\t\t\t\t String tld_value = tld.nextToken();\n\t\t\t\t if (!tld.hasMoreTokens())\n pstmt.setString(3, tld_value);\n\t\t\t }\n\t\t\t //set the indexed? value\n\t\t\t pstmt.setInt(4,0);\n\t\t\t //execute the query and close the connection\n\t\t\t pstmt.executeUpdate();\n\t\t\t pstmt.close();\n\t\t\t conn.close();\n\t\t\t System.out.println(\"** inserted! **\");\n\t\t\t System.out.println(\"* inserting_url_crawler ^\\n\");\n\t\t }\n\t\t catch(Exception url_err)\n\t\t {\n\t\t\t System.err.println(url_err.getMessage());\n\t\t }\n\t }\n }\n\n public class url_crawler\n {\n public static void main (String[] args)\n {\n Connection conn = null;\n\n try\n {\n String userName = \"root\";\n String password = \"root\";\n \n Statement stmt;\n //connect to the database\n //String url = \"jdbc:mysql://localhost:3306/test\";\n String url = \"jdbc:mysql://localhost:3306/B669\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance ();\n conn = DriverManager.getConnection (url, userName, password);\n System.out.println (\"Database connection established!\");\n \n try\n {\n \t stmt = conn.createStatement();\n \t String query = \"CREATE TABLE IF NOT EXISTS url_crawler (\" +\n\t\t\t\t\t \"id INT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY, \" +\n\t\t\t\t\t \"url VARCHAR(700), \"+ //TEXT\n\t\t\t\t\t \"secured VARCHAR(10), \"+\n\t\t\t\t\t \"tld VARCHAR(10), \"+\n\t\t\t\t\t \"indexed INT(1), \" +\n\t\t\t\t\t \"unique (url));\";\n \t \n stmt.executeUpdate(query);\n //close connection\n conn.close();\n System.out.println (\"url_crawler table created\");\n System.out.println(\"Printing all the data first before inserting.....\");\n System.out.println(\".........\");\n System.out.println(\"-------------------------------------------------\");\n \n readcrawler readc = new readcrawler();\n readc.readcrawldata();\n }\n catch(SQLException ex) {\n \t System.err.println(\"SQLException: \" + ex.getMessage()); \n }\t \n }\n catch (Exception e) {\n System.err.println (e.getMessage());\n }\n finally\n {\n if (conn != null)\n {\n try\n {\n conn.close();\n System.out.println (\"Database connection terminated\");\n }\n catch (Exception e) \n {\n \t System.err.println(\"SQLException: \" + e.getMessage());\n }\n }\n }\n }\n }"
},
{
"alpha_fraction": 0.6412213444709778,
"alphanum_fraction": 0.6564885377883911,
"avg_line_length": 20.66666603088379,
"blob_id": "1e4dd0af2912a4ccf730522ebdec7fa202fa1c02",
"content_id": "2e35d1f3d7f1e4271911cd850c7d817df49897f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 18,
"path": "/code/HDE/migrate/update_session_ids3.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import MySQLdb\nimport MySQLdb.cursors\n\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\" )\ncursor=db.cursor()\ncursor.execute(\"SELECT S_ID FROM hde\")\ndb.commit()\nx=0\nz=1\nrows=cursor.fetchall()\nfor row in rows:\n\tif row[0] == 1:\n\t\tx += 1\n\tcursor.execute(\"UPDATE hde SET SES_ID='%d' WHERE E_ID='%d' \" %(x,z))\n\tdb.commit()\n\tz += 1\t\t\t\ncursor.close()\t\ndb.close()\t\t\n\n"
},
{
"alpha_fraction": 0.5232731103897095,
"alphanum_fraction": 0.5290116667747498,
"avg_line_length": 29.75163459777832,
"blob_id": "eb00a0146fd6ba11f0e0631de472fe10be3df030",
"content_id": "729a460d4deb04ce63e7c8f19a27bebd95e59e93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4705,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 153,
"path": "/code/Crawler/query/Link_Back_Count.java",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import java.io.*;\nimport java.sql.Connection;\nimport java.sql.DriverManager;\nimport java.sql.ResultSet;\nimport java.sql.SQLException;\nimport java.sql.PreparedStatement;\nimport java.util.LinkedList;\nimport java.util.Queue;\n\nclass count_broken {\n\t\n\tprivate static int count;\n\t\n\tint redirect_get_next_level(int url_id, int depth, int url_id_constant)\n\tthrows InstantiationException, IllegalAccessException, ClassNotFoundException {\n\t\t\n String userName = \"root\";\n String password = \"root\";\n \n //Assign the values to queue; sort of BFS\n Queue<Integer> queue = new LinkedList<Integer>();\n \n try\n {\n //connecting to the database\n //String url = \"jdbc:mysql://localhost/test\";\n String url = \"jdbc:mysql://localhost:3306/B669\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance();\n\t\t Connection conn = DriverManager.getConnection (url, userName, password);\n \n\t\t\n\t\t //Search where all the connected indices\n\t\t String get_level_stmt = \"SELECT id_1 FROM Link WHERE id_2 = ?\";\n\t\t PreparedStatement retrieve_parent = conn.prepareStatement(get_level_stmt);\n\t\t retrieve_parent.setInt(1, url_id);\n\t\t ResultSet rs_level = retrieve_parent.executeQuery();\n\n\t\t while (rs_level.next())\n\t\t {\n\t\t\t //System.out.println(rs_level.getInt(1));\n\t\t\t try\n\t\t\t {\n\t\t\t if(rs_level.getInt(1) == url_id_constant)\n\t\t\t \t {\n\t\t\t \t //System.out.println(\"-->\"+ rs_level.getInt(1));\n\t\t\t \t\t //System.out.println(\"Redirect Here\");\n\t\t\t \t\t count++;\n\t\t\t \t }\n\t\t\t }\n\t\t\t catch(Exception e) {System.out.println(\"Invalid input\");}\n\t\t\t queue.add(rs_level.getInt(1));\n\t\t }\n\t\t \n\t\t //depth >= 1 because one level is already done\n\t\t while(queue.peek() != null && depth >=1)\n\t\t {\n\t\t\t redirect_get_next_level(queue.remove(), (depth - 1), url_id_constant);\n\t\t\t \n\t\t }\n\t\t\t \n\t\t conn.close();\n }\n catch(SQLException ex)\n {\n \t System.err.println(\"SQLException: \" + ex.getMessage()); \n }\n return count; \n\t}\n\t\n}\n\n\npublic class Link_Back_Count {\n\n\tpublic static void main(String[] args) \n\t{\n\t\tConnection conn = null;\n try\n {\n String userName = \"root\";\n String password = \"root\";\n\t\t\tint output = 0;\n \n \n String url = \"jdbc:mysql://localhost/B669\";\n Class.forName (\"com.mysql.jdbc.Driver\").newInstance ();\n conn = DriverManager.getConnection (url, userName, password);\n System.out.println (\"Database connection established\");\n \n try\n {\n \t\t BufferedReader reader;\n \t\t reader = new BufferedReader(new InputStreamReader(System.in));\n \n \t\t //Enter the enter root URL path\n \t\t System.out.println(\"Enter the URL required:- \\n\");\n \t\t String url_name;\n \t\t url_name = reader.readLine(); \n\n \t \t if (url_name.endsWith(\"/\")) {\n\t \t\t url_name = url_name.substring(0, url_name.length()-1);\n\t \t }\n \t\t \n \t\t //Retrieve the index\n \t\t String get_id_stmt = \"SELECT id FROM url_crawler WHERE url = ?\";\n \t\t PreparedStatement retrieve_id = conn.prepareStatement(get_id_stmt);\n \t\t retrieve_id.setNString(1, url_name);\n \t\t \t\t \n\t\t\t ResultSet rs_id = retrieve_id.executeQuery();\n\t\t\t rs_id.first();\n\t\t\t \n\t\t\t int url_id = rs_id.getInt(\"id\");\n \t\t System.out.println(\"Printing the id for current id: \"+url_id);\n \t\t System.out.println();\n \t\t \n \t\t count_broken c = new count_broken(); \n \t\t \n \t\t //n indicates a level of url_crawler = n+1 \n \t output = c.redirect_get_next_level(url_id, 2, url_id);\n \t System.out.println();\n \t if (output >= 0)\n \t \t System.out.println(\"There are atleast \" +output+\" redirect/s back to the initial URL.\");\n \t else\n \t \t System.out.println(\"No redirects.\");\n \t\t}\n catch(SQLException ex)\n {\n \t System.err.println(\"SQLException: \" + ex.getMessage()); \n }\t \n }\n catch (Exception e)\n {\n System.err.println (e.getMessage());\n }\n finally\n {\n if (conn != null)\n {\n try\n {\n conn.close ();\n System.out.println();\n System.out.println (\"Database connection terminated\");\n }\n catch (Exception e) \n {\n \t System.err.println(\"SQLException: \" + e.getMessage());\n }\n }\n\n }\n\t} \n}\n"
},
{
"alpha_fraction": 0.7527472376823425,
"alphanum_fraction": 0.7637362480163574,
"avg_line_length": 24.571428298950195,
"blob_id": "78f9d809b04a872f9724c948cff345186761fbb2",
"content_id": "0aacfa88e791e14b18ceaf2eb82a45b78023f002",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 7,
"path": "/code/HDE/scraper_data/bash2.sh",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\npython /home/doga/Desktop/scraper_data/db_urlto_notepad4.py\n\njava -cp scrape.jar Scrape.Main URL.txt OUT.csv\n\npython /home/doga/Desktop/scraper_data/update_indexed5.py\n\n\n\n"
},
{
"alpha_fraction": 0.6411824822425842,
"alphanum_fraction": 0.6493374109268188,
"avg_line_length": 28.696969985961914,
"blob_id": "8c975727b2280e422b00598e8d0f6cb80ed54dfc",
"content_id": "e20a4e1a6eca4ca04c728844168604e09638146c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 981,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 33,
"path": "/code/HDE/queries/query4.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "\nimport MySQLdb\nimport string\nimport re\n\ndb=MySQLdb.connect(host=\"localhost\",user=\"root\", passwd=\"root\",db=\"unweb_iub\")\ncu=db.cursor()\n\ncu.execute(\"SELECT DISTINCT SES_ID FROM hde\")\nses=cu.fetchall()\nsarray=[]\t\nfor s in ses:\n\ta=s[0]\n\tsarray.append(a)\n\nfor i in range(len(sarray)):\n\tprint 'the number of indexed URLs in the %d th session #', sarray[i]\n\tcu.execute(\"SELECT COUNT(INDEXED) FROM hde WHERE INDEXED=1 AND SES_ID=%s\",sarray[i])\n\td=cu.fetchall()\n\tprint d\n\tprint 'the number of unindexed URLs in the %d th session #' ,sarray[i]\n\tcu.execute(\"SELECT COUNT(INDEXED) FROM hde WHERE INDEXED=0 AND SES_ID=%s\",sarray[i])\n\te=cu.fetchall()\n\tprint e\n\tprint 'info of the root url of %d th session', sarray[i]\n\tcu.execute(\"SELECT Host FROM hde WHERE S_ID='1' AND SES_ID=%s\",sarray[i])\n\tde=cu.fetchall()\n\tprint de[0][0]\n\tse=de[0][0]\n\tif re.search(\"[google|bing|yahoo]\", se):\n\t\tprint \"root is a search engine\"\n\t\n\n\tprint '-----------------------------------------------------------'\n"
},
{
"alpha_fraction": 0.6013257503509521,
"alphanum_fraction": 0.6070075631141663,
"avg_line_length": 29.08571434020996,
"blob_id": "46345843f3794436a8f32cc2d7c96d3906b13ef3",
"content_id": "7e62014dac20c9d4af26e497af73d8a13981bbef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1056,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 35,
"path": "/code/HDE/migrate/xls_to_csv1.py",
"repo_name": "dogatuncay/UnWeb",
"src_encoding": "UTF-8",
"text": "import os\nimport xlrd\n\npath=\"/home/doga/Desktop/migrate\"\ndirList=os.listdir(path)\nrnum=2\nrow=3\n\nfor fname in dirList:\n\tif fname.split(\".\")[1] == \"xls\":\n\t\txls_file = \"/home/doga/Desktop/migrate/\"+fname\n\t\txls_workbook = xlrd.open_workbook(xls_file)\n\t\txls_sheet = xls_workbook.sheet_by_index(0)\n\n\t\traw_data = [['']*xls_sheet.ncols for _ in range(xls_sheet.nrows)]\n\t\traw_str = ''\n\t\tfeild_delim = ','\n\t\ttext_delim = '\"'\n\n\t\tfor rnum in range(xls_sheet.nrows):\n\t \t\tfor cnum in range(xls_sheet.ncols):\n\t \t\traw_data[rnum][cnum] = str(xls_sheet.cell(rnum,cnum).value)\n\n\t\tfor rnum in range(len(raw_data)):\n\t \t\tfor cnum in range(len(raw_data[rnum])):\n\t \t\t\tif (cnum == len(raw_data[rnum]) - 1):\n\t \t\t\tfeild_delim = '\\n'\n\t \t\telse:\n\t \t\t\tfeild_delim = ','\n\t \t\traw_str += text_delim + raw_data[rnum][cnum] + text_delim + \tfeild_delim\n\t\tfinal_csv_name_splitdot= fname.split(\".\")[0]\n\t\tfinal_csv_name=final_csv_name_splitdot+\".csv\"\n\t\tfinal_csv = open(final_csv_name, 'w')\n\t\tfinal_csv.write(raw_str)\n\t\tfinal_csv.close()\n\n\t\n"
}
] | 18 |
chrisdaly/Computer-Vision
|
https://github.com/chrisdaly/Computer-Vision
|
7ebdbcf0c114572ef0f021972faa3650b5d679f1
|
2136128b9b52a938dc110c012ea2c72d53a8d88f
|
1fba84eb0a8a58373fa011c6f8625798556385a3
|
refs/heads/master
| 2020-03-03T04:36:33.052793 | 2016-12-04T03:26:28 | 2016-12-04T03:27:42 | 65,510,601 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6217917799949646,
"alphanum_fraction": 0.6300241947174072,
"avg_line_length": 26.171052932739258,
"blob_id": "349264257e7c66e79e98688e0206740a3e1034c8",
"content_id": "8da3b5c435cfe4bae6ebee5570e37d9557a78b0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4130,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 152,
"path": "/Assignment 1/cs231n/classifiers/linear_svm.py",
"repo_name": "chrisdaly/Computer-Vision",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom random import shuffle\n\ndef svm_loss_naive(W, X, y, reg):\n \"\"\"\n Structured SVM loss function, naive implementation (with loops).\n\n Inputs have dimension D, there are C classes, and we operate on minibatches\n of N examples.\n\n Inputs:\n - W: A numpy array of shape (D, C) containing weights.\n - X: A numpy array of shape (N, D) containing a minibatch of data.\n - y: A numpy array of shape (N,) containing training labels; y[i] = c means\n that X[i] has label c, where 0 <= c < C.\n - reg: (float) regularization strength\n\n Returns a tuple of:\n - loss as single float\n - gradient with respect to weights W; an array of same shape as W\n \"\"\"\n\n # Initialize the loss as zero.\n loss = 0.0\n\n # Initialize the gradient of weights as zero.\n dW = np.zeros_like(W)\n\n # Get the number of classes and examples.\n num_classes = W.shape[1]\n num_train = X.shape[0]\n \n\n \n # For each of the training examples, calc its score vect, loss & gradient.\n for i in xrange(num_train):\n \n # Calculate the score (X.W)\n scores = X[i].dot(W)\n \n # Get the correct class score from target.\n correct_class_score = scores[y[i]]\n \n # Initialize vector to store derivative of loss to 0s.\n # Remains untouched unless margin isn't met.\n dLi = np.zeros_like(W)\n \n # Keep track of number of classes short of the margin.\n count = 0\n\n # For each value in score row.\n for j in xrange(num_classes):\n \n # Don't calculate loss for correct class.\n if j == y[i]:\n continue\n \n # Find the diff in scores between correct class score and others. \n margin = scores[j] - correct_class_score + 1 # note delta = 1\n \n # If the margin wasn't met.\n # For SVM, only find the gradient of a W class if the margin wasn't met.\n # Otherwise it doesn't need to be improved.\n if margin > 0:\n \n # Add margin to loss.\n loss += margin \n \n # Store the W classifier's gradient. (http://cs231n.github.io/optimization-1/)\n dLi[:,j] = X[i]\n \n # Increment number of classes short of the margin.\n count += 1\n \n # The gradient of the column of W that corresponds to the correct class.\n # Scale the W classifier vector by the number of classes that didnt meet\n # desired margin.\n dLi[:, y[i]] = X[i] * (-count)\n\n # Add the gradient for this row to the entire W gradient.\n dW += dLi \n\n # Right now the loss is a sum over all training examples, but we want it\n # to be an average instead so divide by num_train.\n loss /= num_train\n\n # Add regularization loss.\n loss += 0.5 * reg * np.sum(W * W)\n\n # Average gradient. \n dW /= int(X.shape[0])\n\n # Add in gradient from regularization loss.\n dW += reg*W\n \n return loss, dW\n\n\ndef svm_loss_vectorized(W, X, y, reg):\n \"\"\"\n Structured SVM loss function, vectorized implementation.\n\n Inputs and outputs are the same as svm_loss_naive.\n \"\"\"\n\n # Initialize the loss as zero.\n loss = 0.0\n\n # Initialize the gradient of weights as zero.\n dW = np.zeros_like(W)\n\n # Calculate the scores (X.W).\n S = X.dot(W)\n\n # Subset S on the correct classes.\n s_correct = np.choose(y, S.T)\n\n # Get the diff between correct and incorrect and add delta.\n M = S.T - s_correct + 1\n\n # Hinge the diff at 0.\n M = np.maximum(0, M)\n\n # Get the total loss, subtract 1 for each data vector (correct for +delta).\n loss = np.sum(M) - (X.shape[0] * 1)\n\n # Average loss.\n loss /= X.shape[0]\n\n # Add in regularization loss.\n loss += 0.5 * reg * np.sum(W * W)\n\n # C is a matrix that tracks the status of each classifier.\n # eg if the classifier met the delta.\n C = (M.T > 0).astype(float)\n\n # Count the number of classes in each classifer that didn't meet delta.\n count = C.sum(1) - 1\n\n # Set correct class to the negative count of bad W classifiers.\n C[range(C.shape[0]), y] = -count\n \n # Multiply the tracking matrix by the data vectors to get dW.\n dW = np.dot(X.T, C)\n \n # Average gradient. \n dW /= int(X.shape[0])\n\n # Add in gradient from regularization loss.\n dW += reg*W\n\n return loss, dW\n"
}
] | 1 |
armut/thinkcs-solutions
|
https://github.com/armut/thinkcs-solutions
|
8d219386237b9d743847e78c51bcccc64320259f
|
345cc885aa0d5afb3ab6ad61ab36b2e83a3c1a39
|
7804b8a69725285e88966a703b9e233dcbcb44ed
|
refs/heads/master
| 2021-01-19T00:27:32.678849 | 2016-07-25T08:37:22 | 2016-07-25T08:37:22 | 61,331,096 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4738510251045227,
"alphanum_fraction": 0.5293185710906982,
"avg_line_length": 21.5,
"blob_id": "f8bb654ee28b2d82db71e67999bb0247a2d9ac7d",
"content_id": "39e679882ea277a0e6c5886ecda90f082f92cc8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 631,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 28,
"path": "/chapter-11/11-6.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 11.6\n\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ndef scalar_mult(s, v):\n \"\"\" Takes a number, s, and a list, v and \n returns the scalar multiple of v by s.\n \"\"\"\n for i in range(len(v)):\n v[i] = v[i] * s\n \n return v\n\n\n\ntest(scalar_mult(5, [1, 2]) == [5, 10])\ntest(scalar_mult(3, [1, 0, -1]) == [3, 0, -3])\ntest(scalar_mult(7, [3, 0, 5, 11, 2]) == [21, 0, 35, 77, 14])\n\n"
},
{
"alpha_fraction": 0.6200717091560364,
"alphanum_fraction": 0.6272401213645935,
"avg_line_length": 26.899999618530273,
"blob_id": "320c9efd8ca329aed30c4a60f386b08c11d025c4",
"content_id": "89ccc555f70aa509787ae205b933ff70cfe9a7dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 10,
"path": "/chapter-05/5-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "#exercise 5.1\n\ndef num_to_day(num_of_the_day):\n days = [\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\",\n \"Friday\", \"Saturday\"]\n return days[num_of_the_day]\n\n\nday_number = input(\"Please insert the number of the day: \")\nprint(num_to_day(int(day_number)))\n"
},
{
"alpha_fraction": 0.5328466892242432,
"alphanum_fraction": 0.5810219049453735,
"avg_line_length": 25.346153259277344,
"blob_id": "1b250934cba0655a7f2f606e405d5f1be7da6038",
"content_id": "ec4f7fc5f75cb03d54122cf23873a9207235d4c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 26,
"path": "/chapter-05/5-12.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 5.12\n\ndef insertion_sort(arr):\n for i in range(1, len(arr)):\n key = arr[i]\n index = i\n while index > 0 and arr[index - 1] > key:\n arr[index] = arr[index - 1]\n index = index - 1\n\n arr[index] = key\n\n\ndef is_rightangled(side1, side2, side3):\n sides = [side1, side2, side3]\n insertion_sort(sides)\n if (sides[2]**2) - (sides[0]**2 + sides[1]**2) < 0.000001:\n return True\n else:\n return False\n\ndata1 = input(\"Please enter the first side: \")\ndata2 = input(\"Please enter the second side: \")\ndata3 = input(\"Please enter the third side: \")\n\nprint(is_rightangled(float(data1), float(data2), float(data3)))\n"
},
{
"alpha_fraction": 0.47826087474823,
"alphanum_fraction": 0.5652173757553101,
"avg_line_length": 15.428571701049805,
"blob_id": "3891ec20957a86213993bef3a10e2ba9ce312a3a",
"content_id": "664ea9e42524aba5d7ec526b0f538779c7d3c7c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/chapter-12/mymodule1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.4/5\n\nmyage = 21\nyear = 2016\n\nif __name__ == \"__main__\":\n print(\"This won't run if I'm imported.\")\n"
},
{
"alpha_fraction": 0.6558139324188232,
"alphanum_fraction": 0.6930232644081116,
"avg_line_length": 14.357142448425293,
"blob_id": "b62510f21ed128389bcd67d05f8bc8bde83cdce5",
"content_id": "5babad20c709690b45fd3f2f38ff7ea4b5f1f25d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 14,
"path": "/chapter-03/hello_little_turtles_1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import turtle\nwn = turtle.Screen()\nwn.bgcolor = (\"lightgreen\")\nwn.title = (\"Hello, Tess!\")\n\ntess = turtle.Turtle()\ntess.color(\"blue\")\ntess.pensize(3)\n\ntess.forward(50)\ntess.left(120)\ntess.forward(50)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.48288288712501526,
"alphanum_fraction": 0.50090092420578,
"avg_line_length": 19.55555534362793,
"blob_id": "5069a7aa0404e8c6ffcaf7c290e3fa3c7bed1a13",
"content_id": "75dc68e285643dc6565997503a287c7e4e1bd1be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 27,
"path": "/chapter-08/find.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "def find(strng, ch, start=0, end=None):\n \"\"\"\n Find and return the index of ch in string.\n Return -1 if ch does not occur in string.\n \"\"\"\n ix = 0\n if end is None:\n end = len(strng)\n while ix < end:\n if strng[ix] == ch:\n return ix\n ix += 1\n return -1\n\n\ndef find2(strng, ch, start):\n ix = start\n while ix < len(strng):\n if strng[ix] == ch:\n return ix\n ix += 1\n return -1\n\n\nprint(find(\"Compsci\", \"p\"))\nprint(find(\"Compsci\", \"x\"))\nprint(find2(\"banana\", \"a\", 2))\n"
},
{
"alpha_fraction": 0.5403422713279724,
"alphanum_fraction": 0.5843520760536194,
"avg_line_length": 14.148148536682129,
"blob_id": "884415e6d15a1ede1be4a858231506602cb51221",
"content_id": "cd88c19ee42ba52b776a9dd05f94661df696a516",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 409,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 27,
"path": "/chapter-04/4-2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.2\n\nimport turtle\n\ndef draw_square(t, sz):\n \"\"\"Draws a square with turtle t with size sz of each edge\"\"\"\n t.pendown()\n for i in range(4):\n t.forward(sz)\n t.left(90)\n\n t.right(135)\n t.penup()\n t.forward(14)\n t.left(135)\n\n\nwn = turtle.Screen()\nturtl = turtle.Turtle()\n\nsize = 20\nfor i in range(5):\n draw_square(turtl, size)\n size = size + 20\n\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.7355371713638306,
"alphanum_fraction": 0.7933884263038635,
"avg_line_length": 16.285715103149414,
"blob_id": "b5e6161928a388573930ed2d52e2aa81f3864903",
"content_id": "305c328e68dfbf033221936bced2c3aecf8912b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 7,
"path": "/chapter-12/12-1b.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.1b\n\nimport calendar\n\ncal = calendar.TextCalendar()\ncal.setfirstweekday(calendar.THURSDAY)\ncal.pryear(2016)\n"
},
{
"alpha_fraction": 0.6249144673347473,
"alphanum_fraction": 0.6652977466583252,
"avg_line_length": 18.223684310913086,
"blob_id": "5b1b46cdafe8a775e9309bbdada06bd16f9691c2",
"content_id": "8e7d6a04a691ed35b0f238baa829573081521fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1461,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 76,
"path": "/chapter-10/10-3.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 10.3\nimport turtle\n\nturtle.setup(400, 500)\nwn = turtle.Screen()\nwn.title(\"Turtles becomes a traffic light!\")\nwn.bgcolor(\"lightgreen\")\ngreen = turtle.Turtle()\nred = turtle.Turtle()\norange = turtle.Turtle()\n\ndef draw_housing():\n \"\"\" Draw a nice housing to hold the traffic lights \"\"\"\n green.pensize(3)\n green.color(\"black\", \"darkgrey\")\n green.begin_fill()\n green.forward(80)\n green.left(90)\n green.forward(200)\n green.circle(40, 180)\n green.forward(200)\n green.left(90)\n green.end_fill()\n\ndraw_housing()\n\ngreen.penup()\ngreen.forward(40)\ngreen.left(90)\ngreen.forward(50)\ngreen.shape(\"circle\")\ngreen.shapesize(3)\ngreen.fillcolor(\"green\")\n\norange.hideturtle()\norange.penup()\norange.forward(40)\norange.left(90)\norange.forward(120)\norange.shape(\"circle\")\norange.shapesize(3)\norange.fillcolor(\"orange\")\n\nred.hideturtle()\nred.penup()\nred.forward(40)\nred.left(90)\nred.forward(190)\nred.shape(\"circle\")\nred.shapesize(3)\nred.fillcolor(\"red\")\n\nstate_num = 0\n\n\ndef advance_state_machine():\n global state_num\n if state_num == 0:\n orange.showturtle()\n green.hideturtle()\n state_num = 1\n elif state_num == 1:\n red.showturtle()\n orange.hideturtle()\n state_num = 2\n else:\n green.showturtle()\n red.hideturtle()\n state_num = 0\n\n wn.ontimer(advance_state_machine, 500)\n\n# Bind the event handler to the space key\nadvance_state_machine()\nwn.listen()\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.4131205677986145,
"alphanum_fraction": 0.4822694957256317,
"avg_line_length": 22.45833396911621,
"blob_id": "bc118c4bf1c8a3eafcdc0295873f1d7b53139922",
"content_id": "261400ea8b137f08be9c44f651cb5a2dec8aa30e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 24,
"path": "/chapter-11/11-8.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 11.8\n\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ndef cross_product(u, v):\n x = (u[1] * v[2]) - (u[2] * v[1])\n y = (u[2] * v[0]) - (u[0] * v[2])\n z = (u[0] * v[1]) - (u[1] * v[0])\n\n return [x, y, z]\n\n\ntest(cross_product([2, 3, 4], [5, 6, 7]) == [-3, 6, -3])\ntest(cross_product([5, 7, 2], [2, 7, 5]) == [21, -21, 21])\n\n"
},
{
"alpha_fraction": 0.5707316994667053,
"alphanum_fraction": 0.6170731782913208,
"avg_line_length": 16.08333396911621,
"blob_id": "5527a2e65703ea4d49628a0c19eba06b24863beb",
"content_id": "7ef2ddfa9fa3177d3611f9de24dddfcccfdb1285",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 24,
"path": "/chapter-04/4-10.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.10\n\nimport turtle\n\ndef draw_star(t, l):\n \"\"\"Draw a star with turtle t and length l for each edge\"\"\"\n for x in range(5):\n t.forward(l)\n t.right(144)\n\nwn = turtle.Screen()\nstar = turtle.Turtle()\nstar.penup()\nstar.forward(-200)\nstar.pendown()\n\nfor n in range(5):\n draw_star(star, 80)\n star.penup()\n star.forward(350)\n star.right(144)\n star.pendown()\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.5305197238922119,
"alphanum_fraction": 0.5381932258605957,
"avg_line_length": 28.86458396911621,
"blob_id": "a46eb1d0322a985b0a7257fe650ca95a3628f173",
"content_id": "55865e0e34377e9dc39195b4735bf731811e874c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2867,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 96,
"path": "/chapter-12/wordtools.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.8\n\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test. \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = (\"Test at line {0} FAILED.\".format(linenum))\n print(msg)\n\npunctuation = \"!\\\"#$%&'()*+,-./:;<=>?@[\\\\]^_`{|}~\"\n\ndef cleanword(strng):\n sans_punct = \"\"\n for c in strng:\n if c not in punctuation:\n sans_punct += c\n return sans_punct\n\ndef has_dashdash(strng):\n for c in enumerate(strng):\n if (not c[0] == len(strng)-1) and c[1] == \"-\":\n if strng[c[0]+1] == \"-\":\n return True\n return False\n \ndef extract_words(strng):\n strng_lower = strng.lower()\n strng_nodashes = \"\"\n if has_dashdash(strng_lower):\n strng_nodashes = ' '.join(strng_lower.split(\"--\"))\n else:\n strng_nodashes = strng_lower\n words = strng_nodashes.split()\n strng_clean = []\n for word in words:\n strng_clean.append(cleanword(word))\n\n return strng_clean\n\ndef wordcount(strng, llist):\n count = 0\n for s in llist:\n if s == strng:\n count += 1\n return count\n\ndef wordset(llist):\n word_set = []\n for word in llist:\n if word not in word_set:\n word_set.append(word)\n return sorted(word_set)\n\ndef longestword(llist):\n longest_word = \"\"\n for word in llist:\n if len(word) > len(longest_word):\n longest_word = word\n return len(longest_word)\n\n\ntest(cleanword(\"what?\") == \"what\")\ntest(cleanword(\"'now!'\") == \"now\")\ntest(cleanword(\"?+='w-o-r-d!,@$()'\") == \"word\")\n\ntest(has_dashdash(\"distance--but\"))\ntest(not has_dashdash(\"several\"))\ntest(has_dashdash(\"spoke--\"))\ntest(has_dashdash(\"distance--but\"))\ntest(not has_dashdash(\"-yo-yo-\"))\n\ntest(extract_words(\"Now is the time! 'Now', is the time? Yes, now.\") ==\n ['now','is','the','time','now','is','the','time','yes','now'])\ntest(extract_words(\"she tried to curtsey as she spoke--fancy\") ==\n ['she','tried','to','curtsey','as','she','spoke','fancy'])\n\ntest(wordcount(\"now\", [\"now\",\"is\",\"time\",\"is\",\"now\",\"is\",\"is\"]) == 2)\ntest(wordcount(\"is\", [\"now\",\"is\",\"time\",\"is\",\"now\",\"the\",\"is\"]) == 3)\ntest(wordcount(\"time\", [\"now\",\"is\",\"time\",\"is\",\"now\",\"is\",\"is\"]) == 1)\ntest(wordcount(\"frog\", [\"now\",\"is\",\"time\",\"is\",\"now\",\"is\",\"is\"]) == 0)\n\ntest(wordset([\"now\", \"is\", \"time\", \"is\", \"now\", \"is\", \"is\"]) ==\n [\"is\", \"now\", \"time\"])\ntest(wordset([\"I\", \"a\", \"a\", \"is\", \"a\", \"is\", \"I\", \"am\"]) ==\n [\"I\", \"a\", \"am\", \"is\"])\ntest(wordset([\"or\", \"a\", \"am\", \"is\", \"are\", \"be\", \"but\", \"am\"]) ==\n [\"a\", \"am\", \"are\", \"be\", \"but\", \"is\", \"or\"])\n\ntest(longestword([\"a\", \"apple\", \"pear\", \"grape\"]) == 5)\ntest(longestword([\"a\", \"am\", \"I\", \"be\"]) == 2)\ntest(longestword([\"this\",\"supercalifragilisticexpialidocious\"]) == 34)\ntest(longestword([ ]) == 0)\n"
},
{
"alpha_fraction": 0.6094487905502319,
"alphanum_fraction": 0.6141732335090637,
"avg_line_length": 18.84375,
"blob_id": "81e58fcc8f4dca51fac11e973ed55de35ae51d59",
"content_id": "abb71a70dce8e74c6bb7209fcfe5fae04f46d864",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 635,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/chapter-04/turtles_revisited.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import turtle\n\ndef make_window(colr, ttle):\n \"\"\"\n Set up the window with the given background color and title.\n Returns the new window\n \"\"\"\n w = turtle.Screen()\n w.bgcolor(colr)\n w.title(ttle)\n return w\n\n\ndef make_turtle(colr, sz):\n \"\"\"\n Set up a turtle with the given color and pensize.\n Returns the new turtle\n \"\"\"\n t = turtle.Turtle()\n t.color(colr)\n t.pensize(sz)\n return t\n\n\nwn = make_window(\"lightgreen\", \"Tess and Alex dancing\")\ntess = make_turtle(\"hotpink\", 5)\nalex = make_turtle(\"black\", 1)\ndave = make_turtle(\"yellow\", 2)\n\n# make them dance here\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.7204610705375671,
"alphanum_fraction": 0.740634024143219,
"avg_line_length": 17.263158798217773,
"blob_id": "4a8a7e8c9eb931151f061cdb1d789a527cc44491",
"content_id": "2edb392f70572154ba386c5339e6f7d2aebe021f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 19,
"path": "/chapter-03/hello_little_turtles_1_extended.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import turtle\nwn = turtle.Screen()\n\ntess = turtle.Turtle()\n\nbackground = input(\"Arkaplan rengini giriniz: \")\nwn.bgcolor(background)\n\nforeground = input(\"Tosbanın rengini giriniz: \")\ntess.color(foreground)\n\npen_size = input(\"Kalem kalinligini giriniz: \")\ntess.pensize(int(pen_size))\n\ntess.forward(50)\ntess.left(120)\ntess.forward(50)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.658823549747467,
"avg_line_length": 23.285715103149414,
"blob_id": "b8e2cbf0cb82f4bd7a0e0a903af387905ddc7743",
"content_id": "59ca488300dfacc5591e10bae427be55e03e8f0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 7,
"path": "/chapter-12/namespace_test.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.4/5\n\nimport mymodule1, mymodule2\n\nprint( (mymodule2.myage - mymodule1.myage) ==\n (mymodule2.year - mymodule1.year) )\nprint(\"My name is\",__name__)\n"
},
{
"alpha_fraction": 0.5147058963775635,
"alphanum_fraction": 0.595588207244873,
"avg_line_length": 26.200000762939453,
"blob_id": "9f2754c66c02ca26e407b64354759af835af5068",
"content_id": "05d3bc9d1ca5a7830dda7dd939b2c4254e4d00c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 5,
"path": "/chapter-02/2-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7\n\ncurrent_time = 14\noffset = 51\nprint( \"after \" + str(offset)+ \" hours later the clock shows \" + str((14 + 51)% 24) + \".\" )\n"
},
{
"alpha_fraction": 0.5060975551605225,
"alphanum_fraction": 0.5219511985778809,
"avg_line_length": 23.117647171020508,
"blob_id": "ea69bfbe0b28ed302462a7bd6348472f97b40fb5",
"content_id": "dac1c6d5f362b6ab278a405789ef6d2f9f5983d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1640,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 68,
"path": "/chapter-15/15-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 15.2\n\nclass Point:\n \"\"\" Point class represents and manipulates x, y coords. \"\"\"\n \n def __init__(self, x=0, y=0):\n \"\"\" Create a new point at the origin. \"\"\"\n self.x = x\n self.y = y\n\n def distance_from_origin(self):\n \"\"\" Compute my distance from the origin. \"\"\"\n return ((self.x ** 2) + (self.y ** 2)) ** 0.5\n\n def __str__(self):\n return \"({0}, {1})\".format(self.x, self.y)\n\n def halfway(self, target):\n \"\"\" Return the halfway point between myself and the target. \"\"\"\n mx = (self.x + target.x) / 2\n my = (self.y + target.y) / 2\n return Point(mx, my)\n\n def reflect_x(self):\n return Point(self.x, (-1) * self.y)\n\n def slope_from_origin(self):\n return self.y / self.x\n\n def get_line_to(self, p):\n slope = (p.y - self.y) / (p.x - self.x)\n b = self.y - slope * self.x\n return (slope, b)\n\n\n\ndef find_the_center(p, q, r, s):\n #mid-point of pq:\n mpq = Point((p.x + q.x)/2, (p.y + q.y)/2)\n\n #mid-point of rs:\n mrs = Point((r.x + s.x)/2, (r.y + s.y)/2)\n\n #gradient of pq:\n gpq = (p.y - q.y) / (p.x - q.x)\n\n #gradient of rs:\n grs = (r.y - s.y) / (r.x - s.x)\n\n #x component of the center:\n x = ( (mrs.y-mpq.y)*(gpq*grs)+(gpq*mrs.x)-(grs*mpq.x) ) / (gpq-grs)\n\n #y component of the center:\n y = mpq.y + (mpq.x - x) / gpq\n\n return Point(x, y)\n\n\n\np = Point(2, 1)\nq = Point(0, 5)\nr = Point(-1, 2)\ns = Point(0, 5)\n\nprint(find_the_center(p, q, r, s))\n\n# This method won't work when the two chords pq and rs are parallel and/or\n# when their lengths are different from each other.\n"
},
{
"alpha_fraction": 0.4892086386680603,
"alphanum_fraction": 0.5323740839958191,
"avg_line_length": 11.636363983154297,
"blob_id": "ebc738e6d4a070dfa5ab0f84abcd28f08ea78614",
"content_id": "593952229d390bdda0c78866eb6ea31b4da6c006",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 139,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 11,
"path": "/chapter-04/4-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.7\n\ndef sum_to(n):\n sum = 0;\n for number in range(n + 1):\n sum = sum + number\n\n return sum\n\n\nprint(sum_to(10))\n"
},
{
"alpha_fraction": 0.5563198328018188,
"alphanum_fraction": 0.5623387694358826,
"avg_line_length": 27.75,
"blob_id": "2f31731ed46352e250945385eabd666e7c0964be",
"content_id": "69b2eb1d05a52437d344f28c11963b0cd5d640c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1163,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 40,
"path": "/chapter-16/rectangle.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 16.1\n\nfrom point import Point\n\nclass Rectangle:\n \"\"\" A class to manufacture rectangle objects \"\"\"\n\n def __init__(self, posn, w, h):\n \"\"\" Initialize rectangle at posn, with width w, height h. \"\"\"\n self.corner = posn\n self.width = w\n self.height = h\n\n def __str__(self):\n return \"({0}, {1}, {2})\".format(self.corner, self.width, self.height)\n\n def grow(self, delta_width, delta_height):\n \"\"\" Grow (or shrink) this object by the deltas. \"\"\"\n self.width += delta_width\n self.height += delta_height\n\n def move(self, dx, dy):\n \"\"\" Move this object by the deltas. \"\"\"\n self.corner.x += dx\n self.corner.y += dy\n\n def area(self):\n return self.width * self.height\n\n def perimeter(self):\n return 2 * (self.width + self.height)\n\n def flip(self):\n self.width, self.height = self.height, self.width\n\n def contains(self, pnt):\n if pnt.x >= self.corner.x and pnt.x < self.corner.x + self.width:\n if pnt.y >= self.corner.y and pnt.y < self.corner.y + self.height:\n return True\n return False\n \n"
},
{
"alpha_fraction": 0.5471698045730591,
"alphanum_fraction": 0.5786163806915283,
"avg_line_length": 25.5,
"blob_id": "0df585d6999af876b589b24c01d82757d534c7b7",
"content_id": "096b4d7bc02c186f2f7f269f4a34a60acf1e077f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1908,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 72,
"path": "/chapter-16/16-1-2-3-4.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 16.1\n\nfrom point import Point\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test. \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = (\"Test at line {0} FAILED.\".format(linenum))\n print(msg)\n\n\nclass Rectangle:\n \"\"\" A class to manufacture rectangle objects \"\"\"\n\n def __init__(self, posn, w, h):\n \"\"\" Initialize rectangle at posn, with width w, height h. \"\"\"\n self.corner = posn\n self.width = w\n self.height = h\n\n def __str__(self):\n return \"({0}, {1}, {2})\".format(self.corner, self.width, self.height)\n\n def grow(self, delta_width, delta_height):\n \"\"\" Grow (or shrink) this object by the deltas. \"\"\"\n self.width += delta_width\n self.height += delta_height\n\n def move(self, dx, dy):\n \"\"\" Move this object by the deltas. \"\"\"\n self.corner.x += dx\n self.corner.y += dy\n\n def area(self):\n return self.width * self.height\n\n def perimeter(self):\n return 2 * (self.width + self.height)\n\n def flip(self):\n self.width, self.height = self.height, self.width\n\n def contains(self, pnt):\n if pnt.x >= self.corner.x and pnt.x < self.corner.x + self.width:\n if pnt.y >= self.corner.y and pnt.y < self.corner.y + self.height:\n return True\n return False\n \n\n\nr = Rectangle(Point(0, 0), 10, 5)\ntest(r.area() == 50)\n\nr = Rectangle(Point(0, 0), 10, 5)\ntest(r.perimeter() == 30)\n\nr = Rectangle(Point(100, 50), 10, 5)\ntest(r.width == 10 and r.height == 5)\nr.flip()\ntest(r.width == 5 and r.height == 10)\n\nr = Rectangle(Point(0, 0), 10, 5)\ntest(r.contains(Point(0, 0)))\ntest(r.contains(Point(3, 3)))\ntest(not r.contains(Point(3, 7)))\ntest(not r.contains(Point(3, 5)))\ntest(r.contains(Point(3, 4.99999)))\ntest(not r.contains(Point(-3, -3)))\n"
},
{
"alpha_fraction": 0.5309200882911682,
"alphanum_fraction": 0.5399698615074158,
"avg_line_length": 25.520000457763672,
"blob_id": "2dbc7e49caee9b4a8127a35f553953dbdd9e1487",
"content_id": "44c328ac2b5ca91ca00ed324815e8cc46b50e02b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/chapter-12/12-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.7\n\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\n\ndef myreplace(old, new, s):\n tmp = ' '.join(s.split())\n return new.join(tmp.split(old))\n\n\ntest(myreplace(\",\", \";\", \"this, that, and some other thing\") ==\n \"this; that; and some other thing\")\ntest(myreplace(\" \", \"**\",\n \"Words will now be separated by stars.\") ==\n \"Words**will**now**be**separated**by**stars.\")\n"
},
{
"alpha_fraction": 0.4731707274913788,
"alphanum_fraction": 0.5121951103210449,
"avg_line_length": 19.5,
"blob_id": "b9246d0e5fd5d01cbdff1e0a4daa215ef62fd731",
"content_id": "2b5b59321b5fa31fa1c115ea78b0bf7be6f7b754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 10,
"path": "/chapter-07/7-9.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.9\n\ndef print_triangular_numbers(n):\n for i in range(1, n+1):\n tri = 0\n for j in range(1, i+1):\n tri += j \n print(i,\"\\t\",tri)\n\nprint_triangular_numbers(5)\n"
},
{
"alpha_fraction": 0.555084764957428,
"alphanum_fraction": 0.6398305296897888,
"avg_line_length": 15.857142448425293,
"blob_id": "346084db3b6ec0ef9b5ad304863129a1909c0efb",
"content_id": "d72be604cdc20fc71980d5cb750114c5ea1b0432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 14,
"path": "/chapter-07/7-11.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.11\n\nimport turtle\n\nwn = turtle.Screen()\npirate = turtle.Turtle()\npirate.shape(\"turtle\")\n\ndata = [(160,20), (-43,10), (270,8), (-43,12)]\nfor (turn,step) in data:\n pirate.left(turn)\n pirate.forward(step)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5773955583572388,
"avg_line_length": 30.30769157409668,
"blob_id": "0b87c4f188b00ac335608e3de401d4e3ce24d189",
"content_id": "db6185dfe9b09a93652c02106376104b298cf9ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1221,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 39,
"path": "/chapter-21/21-3.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "class MyTime:\n\n def __init__(self, hrs=0, mins=0, secs=0):\n \"\"\" Create a new MyTime object initialized to hrs, mins, secs.\n The values of mins and secs may be outside the range 0-59,\n but the resulting MyTime object will be normalized.\n \"\"\"\n\n # Calculate total seconds to represent\n totalsecs = hrs*3600 + mins*60 + secs\n self.hours = totalsecs // 3600\n leftoversecs = totalsecs % 3600\n self.minutes = leftoversecs // 60\n self.seconds = leftoversecs & 60\n\n\n def add_time(t1, t2):\n secs = t1.to_seconds() + t2.to_seconds()\n return MyTime(0, 0, secs)\n\n def to_seconds(self):\n \"\"\" Return the number of seconds represented\n by this instance\n \"\"\"\n return self.hours * 3600 + self.minutes * 60 + self.seconds\n\n def after(self, time2):\n return self.to_seconds() > time2.to_seconds()\n\n def __gt__(self, other):\n return self.after(time2)\n\n def __add__(self, other):\n return MyTime(0, 0, self.to_seconds() + other.to_seconds())\n\n def between(self, t1, t2):\n if self.to_seconds() >= t1 and self.to_seconds() < t2:\n return True\n return False\n"
},
{
"alpha_fraction": 0.4842519760131836,
"alphanum_fraction": 0.5255905389785767,
"avg_line_length": 15.387096405029297,
"blob_id": "160fb60353932abab18c4bc29b10f40b4baf93c7",
"content_id": "c11b781b991dfe7a1bfa5a52438f2ffc169db43a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 31,
"path": "/chapter-07/7-14.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.14\n\nimport sys\n\ndef num_digits(n):\n count = 0\n\n if n == 0:\n return 1\n else:\n n = abs(n)\n\n while n != 0:\n count += 1\n n = n//10\n\n return count\n\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ntest(num_digits(0) == 1)\ntest(num_digits(-12345) == 5)\n"
},
{
"alpha_fraction": 0.46616852283477783,
"alphanum_fraction": 0.5367372632026672,
"avg_line_length": 22.23794174194336,
"blob_id": "be5a6e64288382b3268bcc8a6846c2651e1844e9",
"content_id": "4948bd2257b3a2a26a68933f032c7cecaf04211f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7227,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 311,
"path": "/chapter-06/6-all.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test. \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = (\"Test at line {0} FAILED.\".format(linenum))\n print(msg)\n\n# exercise 6.1\ndef turn_clockwise(point):\n if point == \"W\":\n return \"N\"\n elif point == \"N\":\n return \"E\"\n elif point == \"E\":\n return \"S\"\n elif point == \"S\":\n return \"W\"\n\n# exercise 6.2\ndef day_name(num_of_the_day):\n if num_of_the_day == 0:\n return \"Sunday\"\n elif num_of_the_day == 1:\n return \"Monday\"\n elif num_of_the_day == 2:\n return \"Tuesday\"\n elif num_of_the_day == 3:\n return \"Wednesday\"\n elif num_of_the_day == 4:\n return \"Thursday\"\n elif num_of_the_day == 5:\n return \"Friday\"\n elif num_of_the_day == 6:\n return \"Saturday\"\n\n# exercise 6.3\ndef day_num(name_of_the_day):\n if name_of_the_day == \"Sunday\":\n return 0\n elif name_of_the_day == \"Monday\":\n return 1\n elif name_of_the_day == \"Tuesday\":\n return 2\n elif name_of_the_day == \"Wednesday\":\n return 3\n elif name_of_the_day == \"Thursday\":\n return 4\n elif name_of_the_day == \"Friday\":\n return 5\n elif name_of_the_day == \"Saturday\":\n return 6\n\n# exercise 6.4 - 6.5\ndef day_add(name_of_the_day, offset):\n num_of_the_day = day_num(name_of_the_day)\n result = (num_of_the_day + offset) % 7\n return day_name(result)\n\n# exercise 6.6\ndef days_in_month(name_of_the_month):\n if name_of_the_month == \"January\":\n return 31\n elif name_of_the_month == \"February\":\n return 28\n elif name_of_the_month == \"March\":\n return 31\n elif name_of_the_month == \"April\":\n return 30\n elif name_of_the_month == \"May\":\n return 31\n elif name_of_the_month == \"June\":\n return 30\n elif name_of_the_month == \"July\":\n return 31\n elif name_of_the_month == \"August\":\n return 31\n elif name_of_the_month == \"September\":\n return 30\n elif name_of_the_month == \"October\":\n return 31\n elif name_of_the_month == \"November\":\n return 30\n elif name_of_the_month == \"December\":\n return 31\n\n# exercise 6.7 - 6.8\ndef to_secs(h, m, s):\n return int((h*60*60) + (m*60) + s)\n\n# exercise 6.9\ndef hours_in(sec):\n return int(sec/3600)\n\n\ndef minutes_in(sec):\n remaining_sec = sec - (hours_in(sec) * 3600)\n return int(remaining_sec / 60)\n\n\ndef seconds_in(sec):\n remaining_sec = (sec - (hours_in(sec) * 3600)) - (minutes_in(sec) * 60)\n return remaining_sec\n\n# exercise 6.11\ndef compare(a, b):\n if a > b:\n return 1\n elif a == b:\n return 0\n elif a < b:\n return -1\n\n# exercise 6.12\ndef hypotenuse(side1, side2):\n hypot = ((side1 * side1) + (side2 * side2)) ** 0.5\n return hypot\n\n# exercise 6.13\ndef slope(x1, y1, x2, y2):\n d1 = y1 - y2\n d2 = x1 - x2\n return d1 / d2\n\n\ndef intercept(x1, y1, x2, y2):\n m = slope(x1, y1, x2, y2)\n return y1 - m*x1\n\n# exercise 6.14\ndef is_even(n):\n if n % 2 == 0:\n return True\n return False\n\n# exercise 6.15\ndef is_odd(n):\n if is_even(n) == False:\n return True\n else:\n return False\n\n# exercise 6.16\ndef is_factor(f, n):\n if n % f == 0:\n return True\n else:\n return False\n\n# exercise 6.17\ndef is_multiple(n, f):\n if is_factor(f, n):\n return True\n else:\n return False\n\n# exercise 6.18\ndef f2c(t):\n result = (t - 32) / 1.8\n return round(result)\n\n# exercise 6.19\ndef c2f(t):\n result = 1.8 * t + 32\n return round(result)\n\ndef test_suite():\n print(\"exercise 6.1\")\n test(turn_clockwise(\"N\") == \"E\")\n test(turn_clockwise(\"W\") == \"N\")\n test(turn_clockwise(42) == None)\n test(turn_clockwise(\"rubbish\") == None)\n print()\n\n print(\"exercise 6.2\")\n test(day_name(3) == \"Wednesday\")\n test(day_name(6) == \"Saturday\")\n test(day_name(42) == None)\n print()\n \n print(\"exercise 6.3\")\n test(day_num(\"Friday\") == 5)\n test(day_num(\"Sunday\") == 0)\n test(day_num(day_name(3)) == 3)\n test(day_name(day_num(\"Thursday\")) == \"Thursday\")\n test(day_num(\"Halloween\") == None)\n print()\n \n print(\"exercise 6.4\")\n test(day_add(\"Monday\", 4) == \"Friday\")\n test(day_add(\"Tuesday\", 0) == \"Tuesday\")\n test(day_add(\"Tuesday\", 14) == \"Tuesday\")\n test(day_add(\"Sunday\", 100) == \"Tuesday\")\n print()\n\n print(\"exercise 6.5\")\n test(day_add(\"Sunday\", -1) == \"Saturday\")\n test(day_add(\"Sunday\", -7) == \"Sunday\")\n test(day_add(\"Tuesday\", -100) == \"Sunday\")\n print()\n\n print(\"exercise 6.6\")\n test(days_in_month(\"February\") == 28)\n test(days_in_month(\"December\") == 31)\n print()\n\n print(\"exercise 6.7\")\n test(to_secs(2, 30, 10) == 9010)\n test(to_secs(2, 0, 0) == 7200)\n test(to_secs(0, 2, 0) == 120)\n test(to_secs(0, 0, 42) == 42)\n test(to_secs(0, -10, 10) == -590)\n print()\n\n print(\"exercise 6.8\")\n test(to_secs(2.5, 0, 10.71) == 9010)\n test(to_secs(2.433,0,0) == 8758)\n print()\n\n print(\"exercise 6.9\")\n test(hours_in(9010) == 2)\n test(minutes_in(9010) == 30)\n test(seconds_in(9010) == 10)\n print()\n\n print(\"exercise 6.10\")\n test(3 % 4 == 0)\n test(3 % 4 == 3)\n test(3 / 4 == 0)\n test(3 // 4 == 0)\n test(3+4 * 2 == 14)\n test(4-2+2 == 0)\n test(len(\"hello, world!\") == 13)\n print()\n\n print(\"exercise 6.11\")\n test(compare(5, 4) == 1)\n test(compare(7, 7) == 0)\n test(compare(2, 3) == -1)\n test(compare(42, 1) == 1)\n print()\n\n print(\"exercise 6.12\")\n test(hypotenuse(3, 4) == 5.0)\n test(hypotenuse(12, 5) == 13.0)\n test(hypotenuse(24, 7) == 25.0)\n test(hypotenuse(9, 12) == 15.0)\n print()\n\n print(\"exercise 6.13\")\n test(slope(5, 3, 4, 2) == 1.0)\n test(slope(1, 2, 3, 2) == 0.0)\n test(slope(1, 2, 3, 3) == 0.5)\n test(slope(2, 4, 1, 2) == 2.0)\n\n test(intercept(1, 6, 3, 12) == 3.0)\n test(intercept(6, 1, 1, 6) == 7.0)\n test(intercept(4, 6, 12, 8) == 5.0)\n print()\n\n print(\"exercise 6.14\")\n test(is_even(2) == True)\n test(is_even(3) == False)\n print()\n\n print(\"exercise 6.15\")\n test(is_odd(2) == False)\n test(is_odd(3) == True)\n print()\n\n print(\"exercise 6.16\")\n test(is_factor(3, 12))\n test(not is_factor(5, 12))\n test(is_factor(7, 14))\n test(not is_factor(7, 15))\n test(is_factor(1, 15))\n test(is_factor(15, 15))\n test(not is_factor(25, 15))\n print()\n\n print(\"exercise 6.17\")\n test(is_multiple(12, 3))\n test(is_multiple(12, 4))\n test(not is_multiple(12, 5))\n test(is_multiple(12, 6))\n test(not is_multiple(12, 7))\n print()\n\n print(\"exercise 6.18\")\n test(f2c(212) == 100) # Boiling point of water\n test(f2c(32) == 0) # Freezing point of water\n test(f2c(-40) == -40) # Wow, what an interesting case!\n test(f2c(36) == 2)\n test(f2c(37) == 3)\n test(f2c(38) == 3)\n test(f2c(39) == 4)\n print()\n\n print(\"exercise 6.19\")\n test(c2f(0) == 32)\n test(c2f(100) == 212)\n test(c2f(-40) == -40)\n test(c2f(12) == 54)\n test(c2f(18) == 64)\n test(c2f(-48) == -54)\n\n\ntest_suite()\n"
},
{
"alpha_fraction": 0.6085271239280701,
"alphanum_fraction": 0.6279069781303406,
"avg_line_length": 41.83333206176758,
"blob_id": "e015aca4173649df9aa96d52e32facb306e591ce",
"content_id": "434d7589ff5b64ee7b7ef5cb3bcac34e2190d7bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 6,
"path": "/chapter-02/2-8.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 8\n\ncurrent_time = input( \"What time is it now? (hours in 24h format) >>\" )\noffset = input( \"Number of hours to wait >>\" )\nresult = (current_time + offset) % 24\nprint( \"After \" + str(offset) + \" hours later the clock shows \" + str(result) + \".\" )\n\n"
},
{
"alpha_fraction": 0.6020671725273132,
"alphanum_fraction": 0.6614987254142761,
"avg_line_length": 28.769229888916016,
"blob_id": "1e251e0b4c1c89a0b4ce32ee3aeb94c9cd51b2a0",
"content_id": "f80dc95bf651ff863517a7733c9807f97687cad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 13,
"path": "/chapter-05/5-11.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 5.11\n\ndef is_rightangled(side1, side2, longest_side):\n if (longest_side**2) - (side1**2 + side2**2) < 0.000001:\n return True\n else:\n return False\n\ndata1 = input(\"Please enter the first side: \")\ndata2 = input(\"Please enter the second side: \")\ndata3 = input(\"Please enter the longest side: \")\n\nprint(is_rightangled(float(data1), float(data2), float(data3)))\n"
},
{
"alpha_fraction": 0.5788834691047668,
"alphanum_fraction": 0.5958737730979919,
"avg_line_length": 25.580644607543945,
"blob_id": "5e26ac42b51f8e13e9abcf5e8b0d8a827b5774b8",
"content_id": "f87d3b295423bf69ad77ae8c8f167ad8b638d878",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1648,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 62,
"path": "/chapter-15/15-6.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 15.6\n\nclass SMS(object):\n has_been_viewed = False\n from_number = ''\n time_arrived = ''\n text_of_SMS = ''\n\n def __init__(self, from_number, time_arrived, text_of_SMS):\n self.has_been_viewed = False\n self.from_number = from_number\n self.time_arrived = time_arrived\n self.text_of_SMS = text_of_SMS\n\n def __str__(self):\n return self.from_number + \" \" + self.time_arrived + \" \" + self.text_of_SMS\n\n\nclass SMS_store(object):\n\n messages = []\n size = 0\n\n def __init__(self):\n self.messages = []\n self.size = 0\n\n def add_new_arrival(self, from_number, time_arrived, text_of_SMS):\n self.messages.append(SMS(from_number, time_arrived, text_of_SMS))\n self.size += 1\n\n def message_count(self):\n return self.size\n\n def get_unread_indexes(self):\n return [i for i in range(self.size) if not self.messages[i].has_been_viewed]\n\n def get_message(self, i):\n if i > self.size:\n return None\n print(self.messages[i])\n self.messages[i].has_been_viewed = True\n\n def delete(self, i):\n del self.messages[i]\n self.size -= 1\n\n def clear(self):\n del self.messages[:]\n self.size = 0\n \n\nmy_inbox = SMS_store()\nmy_inbox.add_new_arrival(\"11\", \"11\", \"asd\")\nmy_inbox.add_new_arrival(\"111\", \"11\", \"assd\")\nmy_inbox.add_new_arrival(\"111\", \"11\", \"qwer\")\nmy_inbox.add_new_arrival(\"11\", \"11\", \"asda\")\nmy_inbox.delete(2)\nmy_inbox.get_message(2)\nmy_inbox.clear()\nprint(\"Unread messages: \", my_inbox.get_unread_indexes())\n#Although the book recommended to use tuples, here no tuples used.\n"
},
{
"alpha_fraction": 0.5883668661117554,
"alphanum_fraction": 0.6174496412277222,
"avg_line_length": 18.434782028198242,
"blob_id": "b540f7c10cdb6a9911e09e1de962ffcf8e7d8ebe",
"content_id": "e63ee0693b74bac2149d6de5faa25d078f1b6ad5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 23,
"path": "/chapter-04/draw_multicolor.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import turtle\n\ndef draw_multicolor_square(t, sz):\n \"\"\"Make turtle t draw a multi-color square of sz\"\"\"\n for i in [\"red\",\"purple\",\"hotpink\",\"blue\"]:\n t.color(i)\n t.forward(sz)\n t.left(90)\n\nwn = turtle.Screen()\nwn.bgcolor(\"lightgreen\")\n\ntess = turtle.Turtle()\ntess.pensize(3)\n\nsize = 20\nfor i in range(15):\n draw_multicolor_square(tess, size)\n size = size + 10\n tess.forward(10)\n tess.right(18)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.4146341383457184,
"alphanum_fraction": 0.6341463327407837,
"avg_line_length": 9.25,
"blob_id": "6c4cb0083433596984e33b2bd5e1ca7977572aa7",
"content_id": "9e39deb4088a11a51e48b940af549f83e5d4b914",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 4,
"path": "/chapter-12/mymodule2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.4/5\n\nmyage = 0\nyear = 1995\n"
},
{
"alpha_fraction": 0.6284987330436707,
"alphanum_fraction": 0.6361322999000549,
"avg_line_length": 29.230770111083984,
"blob_id": "d10f6673fb9e44a594f455a567e4bdcb8fe88718",
"content_id": "a45403df02a5d72fbacce011d3f9f5519732f4e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 13,
"path": "/chapter-05/5-2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 5.2\n\ndef num_to_day(num_of_the_day):\n days = [\"Sunday\", \"Monday\", \"Tuesday\", \"Wednesday\", \"Thursday\",\n \"Friday\", \"Saturday\"]\n return days[num_of_the_day]\n\n\nstart_day = input(\"Please enter the starting day: \")\nstay_amount = input(\"How many days will you stay?: \")\nreturn_day = int((start_day + stay_amount)) % 7\n\nprint(\"You will return on \", num_to_day(return_day))\n"
},
{
"alpha_fraction": 0.4642857015132904,
"alphanum_fraction": 0.47857141494750977,
"avg_line_length": 14.55555534362793,
"blob_id": "8a896a7bbe6e7eba2d9b95511e270f6c4add8952",
"content_id": "9c4528c40863960c744080b9555fb7bf92e72d24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 9,
"path": "/chapter-08/count_a.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "def count_a(text):\n count = 0\n for c in text:\n if c == \"a\":\n count += 1\n return count\n\n\nprint(count_a(\"banana\"))\n"
},
{
"alpha_fraction": 0.5858895778656006,
"alphanum_fraction": 0.5981594920158386,
"avg_line_length": 19.375,
"blob_id": "b7ac3006b03ec98d9dfc4bdc6e7a02368c71a90f",
"content_id": "d6549106d5c6e86ab358425981814a70bc290904",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 16,
"path": "/chapter-11/double_stuff_pure.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "def double_stuff_pure(a_list):\n \"\"\" Return a new list which contains\n doubles of the elements in a_list.\n \"\"\"\n new_list = []\n for value in a_list:\n new_elem = 2 * value\n new_list.append(new_elem)\n\n return new_list\n\n\nthings = [2, 5, 9]\nxs = double_stuff_pure(things)\nprint(things)\nprint(xs)\n"
},
{
"alpha_fraction": 0.6224489808082581,
"alphanum_fraction": 0.6484230160713196,
"avg_line_length": 25.950000762939453,
"blob_id": "c64449e6fc786ab853a74159f74cb9d344d922fd",
"content_id": "a26224d77d8e3e3421ea38028a2634ce2284718f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 40,
"path": "/chapter-20/alice_words.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 20.3\n\nimport urllib.request\nimport wordtools\n\ndef retrieve_page(url):\n my_socket = urllib.request.urlopen(url)\n dta = str(my_socket.read())\n my_socket.close()\n return dta\n\n\nalice_book = retrieve_page(\"http://www.gutenberg.org/cache/epub/11/pg11.txt\")\nalice_book = alice_book[801:158020]\nrn_removed = ' '.join(alice_book.split(\"\\\\r\\\\n\"))\nwords = wordtools.extract_words(rn_removed)\nword_occurences = {}\nfor word in words:\n if not word == \"\":\n word_occurences[word] = word_occurences.get(word, 0) + 1\n\n\nalice_words = open(\"alice_words.txt\", \"w\")\nalice_words.write(\"Word\\t\\t\\tCount\\n\")\nalice_words.write(\"==============================\\n\")\nfor (u, v) in sorted(word_occurences.items()):\n alice_words.write(\"{0:25}{1}\\n\".format(u, v))\n\n\nprint(\"The word 'alice' occurs {0} times in the book.\".format(word_occurences[\"alice\"]))\n\n\n# exercise 20.4\n\nlongest_word = \"\"\nfor word in words:\n if len(word) > len(longest_word):\n longest_word = word\n\nprint(\"The longest word is {0} and it has {1} letters.\".format(longest_word, len(longest_word)))\n"
},
{
"alpha_fraction": 0.620512843132019,
"alphanum_fraction": 0.6435897350311279,
"avg_line_length": 34.45454406738281,
"blob_id": "2275323d91e671920b2a7307bab301be573e4b1e",
"content_id": "0d6dc04b958fa3451f1e7af2ccf7987de69c7b24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 11,
"path": "/chapter-11/11-4.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 11.4\n\nthis = [\"I\", \"am\", \"not\", \"a\", \"crook\"]\nthat = [\"I\", \"am\", \"not\", \"a\", \"crook\"]\nprint(\"Test 1: {0}\".format(this is that))\nthat = this\nprint(\"Test 2: {0}\".format(this is that))\n\n# this is not that in the first test because lists are mutable and\n# don't refer to the same object. In test 2 after the 6th line, the two lists\n# refer to the same object, so the result is true.\n"
},
{
"alpha_fraction": 0.4936170279979706,
"alphanum_fraction": 0.5404255390167236,
"avg_line_length": 18.58333396911621,
"blob_id": "959e1ec138a99b9160c0236e82b488520cf92f68",
"content_id": "f879f728c6743997c74e4d2c0defaf3c168603c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 235,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 12,
"path": "/chapter-07/7-3.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.3\n\ndef sum_negatives(arr):\n total = 0\n for i in arr:\n if i < 0:\n total += i\n print(\"Sum of the negative numbers in this list is {0}.\".format(total))\n\n\nxs = [1, 2, 3, 4, -5, -9]\nsum_negatives(xs)\n"
},
{
"alpha_fraction": 0.5398229956626892,
"alphanum_fraction": 0.6318584084510803,
"avg_line_length": 12.780488014221191,
"blob_id": "b9189733c1f53099b4a0993fdc9903fe9ac0a471",
"content_id": "6dfe80b95b518b3e1db8232115e87deeb94ef501",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 41,
"path": "/chapter-03/3-6.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.6\n\nimport turtle\n\nwn = turtle.Screen()\ntri = turtle.Turtle()\ntri.shape(\"turtle\")\n\n# triangle\ntri.penup()\ntri.forward(-175)\ntri.pendown()\nfor i in [0,1,2]:\n tri.forward(50)\n tri.left(120)\n\n# square\ntri.penup()\ntri.forward(100)\ntri.pendown()\nfor i in [0,1,2,3]:\n tri.forward(50)\n tri.left(90)\n\n# hexagon\ntri.penup()\ntri.forward(100)\ntri.pendown()\nfor i in [0,1,2,3,4,5]:\n tri.forward(28)\n tri.left(60)\n\n# octagon\ntri.penup()\ntri.forward(100)\ntri.pendown()\nfor i in [0,1,2,3,4,5,6,7]:\n tri.forward(21)\n tri.left(45)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.5593952536582947,
"alphanum_fraction": 0.6047516465187073,
"avg_line_length": 14.433333396911621,
"blob_id": "14f65de0b8243ddbd6b4db433cbe1b5da0172323",
"content_id": "3314626035e32639941a02f07a2660825225e061",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 30,
"path": "/chapter-03/3-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.5\n\nxs = [12, 10, 32, 3, 66, 17, 42, 99, 20]\n\n# each number on a new line:\nfor x in xs:\n print(x)\n\nprint()\n\n# each number and its square on a new line:\nfor x in xs:\n print(x, \" square: \", x*x)\n\nprint()\n\n# loop for adding the numbers:\ntotal = 0;\nfor x in xs:\n total = total + x\n \nprint(\"Total is: \", total)\nprint()\n\n# loop for multiplying the numbers:\nproduct = 1;\nfor x in xs:\n product = product * x\n\nprint(\"The product is: \", product)\n"
},
{
"alpha_fraction": 0.4914933741092682,
"alphanum_fraction": 0.5387523770332336,
"avg_line_length": 19.30769157409668,
"blob_id": "34f8812cb8a381d0180007cd4bbdf24b8fb699f5",
"content_id": "b951db810c321e820a79799c15d3422ce52fd92c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 26,
"path": "/chapter-11/11-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 11.7\n\nimport sys\n\ndef test(did_pass):\n \"\"\" Print the result of the test \"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ndef dot_product(u, v):\n result = 0\n for i in range(len(u)):\n result += u[i] * v[i]\n\n return result\n\n\n\ntest(dot_product([1, 1], [1, 1]) == 2)\ntest(dot_product([1, 2], [1, 4]) == 9)\ntest(dot_product([1, 2, 1], [1, 4, 3]) == 12)\n\n"
},
{
"alpha_fraction": 0.5152173638343811,
"alphanum_fraction": 0.584782600402832,
"avg_line_length": 21.549999237060547,
"blob_id": "f31730783b381bcc4a9846bedfe42c5145a87d1d",
"content_id": "c59a718d41382b18a4bf76105698dcebd3887a1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 20,
"path": "/chapter-16/16-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 16.5\n\nfrom rectangle import *\n\ndef detect_collision(r1, r2):\n if (r1.corner.x + r1.width >= r2.corner.x and\n r1.corner.x <= r2.corner.x + r2.width and\n r1.corner.y + r1.height >= r2.corner.y and\n r1.corner.y <= r2.corner.y + r2.height):\n \n return True\n else:\n return False\n\n\n\nrect1 = Rectangle(Point(0, 0), 10, 10)\nrect2 = Rectangle(Point(9, 10), 5, 7)\n\nprint(detect_collision(rect1, rect2))\n \n"
},
{
"alpha_fraction": 0.5631399154663086,
"alphanum_fraction": 0.6143344640731812,
"avg_line_length": 13.350000381469727,
"blob_id": "3b246f19c48543a89aeeadc1bc9e554cdd46bbd2",
"content_id": "8fef0e0b8241ef93fb3f308238cfb7bc75229ccc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 293,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 20,
"path": "/chapter-03/3-12.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.12\n\nimport turtle\n\nwn = turtle.Screen()\ndot = turtle.Turtle()\ndot.shape(\"turtle\")\ndot.pensize(3)\ndot.penup()\n\nfor i in range(12):\n dot.forward(80)\n dot.pendown()\n dot.forward(20)\n dot.penup()\n dot.stamp()\n dot.forward(-100)\n dot.left(30)\n\nwn.mainloop()\n\n \n"
},
{
"alpha_fraction": 0.6867924332618713,
"alphanum_fraction": 0.7207547426223755,
"avg_line_length": 16.66666603088379,
"blob_id": "5b91f7a965bf461a43d151a6454154d8566bd352",
"content_id": "1ff86e614517cd9b4504e31a2af597def0263251",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/chapter-11/11-2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 11.2\n\nimport turtle\n\nwn = turtle.Screen()\ntess = turtle.Turtle()\nalex = tess\nalex.color(\"blue\")\n\nalex.forward(100)\ntess.forward(-100)\nwn.mainloop()\n\n# Because alex and tess correspond to the same turtle,\n# there is only one turtle, and hence, one color.\n"
},
{
"alpha_fraction": 0.515418529510498,
"alphanum_fraction": 0.634361207485199,
"avg_line_length": 15.214285850524902,
"blob_id": "c2bda2f830f9ee5439a4ef8f1e77dde392aa4ad2",
"content_id": "9b78921c8907e49f34e2c94dfa0d75ef8265567e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 14,
"path": "/chapter-03/3-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.7\n\nimport turtle\n\nwn = turtle.Screen()\npirate = turtle.Turtle()\npirate.shape(\"turtle\")\n\ndata = [160, -43, 270, -97, -43, 200, -940, 17, -86]\nfor i in data:\n pirate.left(i)\n pirate.forward(100)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.4714285731315613,
"alphanum_fraction": 0.5642856955528259,
"avg_line_length": 16.5,
"blob_id": "999c624cbeaa4b64968b29623642c172f3885475",
"content_id": "989dbda604b77e6ac8a0cadda811d06c100125ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 8,
"path": "/chapter-02/2-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 2.5\n\np = 10000\nn = 12\nr = 0.08\nt = input( \"Please enter the number of years: \" )\nresult = p * (1 + (r/n))**(n*t)\nprint( result )\n"
},
{
"alpha_fraction": 0.6045454740524292,
"alphanum_fraction": 0.6136363744735718,
"avg_line_length": 35.5,
"blob_id": "6a4b3d431558ae0bf95cd444b135e304d9aa79a1",
"content_id": "692fc2a01a3fee74f10e4252ec093ada726e0632",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 220,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 6,
"path": "/chapter-03/3-3.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.3\n\ntext = \"One of the months of the year is \"\n\nfor year in [\"January\", \"February\", \"March\", \"April\", \"May\", \"June\", \"July\", \"August\", \"September\", \"October\", \"November\", \"December\"]:\n print(text + year)\n\n"
},
{
"alpha_fraction": 0.4434782564640045,
"alphanum_fraction": 0.5478261113166809,
"avg_line_length": 19.909090042114258,
"blob_id": "bb482ca41ad05a26952fffd01464d1259e60e4d7",
"content_id": "1853238217547be8be6bfb8d8ee4f817172c1e53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 11,
"path": "/chapter-11/f.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "def f(n):\n \"\"\" Find the first positive integer between 101 and less\n than n that is divisible by 21\n \"\"\"\n for i in range(101, n):\n if (i % 21 == 0):\n return i\n\n\nprint(f(110))\nprint(f(1000000000))\n"
},
{
"alpha_fraction": 0.6511628031730652,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 13.333333015441895,
"blob_id": "c9f380d1275485124aed8553279745998fdabfe5",
"content_id": "e11d705dffcb5292d5ea586423566c4986150b81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 6,
"path": "/chapter-12/12-1c.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 12.1c\n\nimport calendar\n\ncal = calendar.TextCalendar()\ncal.prmonth(2016, 3)\n"
},
{
"alpha_fraction": 0.5545171499252319,
"alphanum_fraction": 0.6417445540428162,
"avg_line_length": 17.882352828979492,
"blob_id": "7ac36a2f53ca88937d96cee4acd1e424dbf73e47",
"content_id": "b8bc2c82dd1758e403c02499d58cf482969fa5cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/chapter-03/3-8.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.7\n\nimport turtle\n\nwn = turtle.Screen()\npirate = turtle.Turtle()\npirate.shape(\"turtle\")\n\ndata = [160, -43, 270, -97, -43, 200, -940, 17, -86]\ntotal_turn = 0\nfor i in data:\n pirate.left(i)\n pirate.forward(100)\n total_turn = total_turn + i\n\nprint(\"Pirate's heading is now: \", total_turn)\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.5672727227210999,
"alphanum_fraction": 0.5963636636734009,
"avg_line_length": 12.5,
"blob_id": "e5220a1ad07ac4d1bbed922abb9615b3fe316c35",
"content_id": "6f1d7cf291002630c7df071ab69e779df19f7563",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 20,
"path": "/chapter-04/4-6.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.6\n\nimport turtle\n\ndef draw_poly(t, n, sz):\n for i in range(n):\n t.forward(sz)\n t.left(360//n)\n\ndef draw_equitriangle(t, sz):\n draw_poly(t, 3, sz)\n\n\n\nwn = turtle.Screen()\ntess = turtle.Turtle()\n\ndraw_equitriangle(tess, 50)\n\nwn.mainloop()\n \n"
},
{
"alpha_fraction": 0.5502392053604126,
"alphanum_fraction": 0.5885167717933655,
"avg_line_length": 12.0625,
"blob_id": "a2ee5922c449f2465144488abb03645281a9d166",
"content_id": "558392043b533ca3218db04b717230b047e51eb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 16,
"path": "/chapter-04/4-3.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.3\n\nimport turtle\n\ndef draw_poly(t, n, sz):\n for i in range(n):\n t.forward(sz)\n t.left(360//n)\n\n\nwn = turtle.Screen()\ntess = turtle.Turtle()\n\ndraw_poly(tess, 8, 50)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.540705144405365,
"alphanum_fraction": 0.5557692050933838,
"avg_line_length": 23.280155181884766,
"blob_id": "a6f7b2ce715df05ab4004f3411b22b554cb73c25",
"content_id": "9b9448528d1fc6d940664755239202193c58e398",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6240,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 257,
"path": "/chapter-08/8-all.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\n# exercise 8.2\ndef ex8_2():\n prefixes = \"JKLMNOPQ\"\n suffix = \"ack\"\n\n for letter in prefixes:\n if letter is \"O\" or letter is \"Q\":\n print(letter + \"u\" + suffix)\n else:\n print(letter + suffix)\n\n\n# exercise 8.3\ndef count_letters(strng, ch):\n count = 0\n for char in strng:\n if char == ch:\n count += 1\n return count\n\n\n# exercise 8.4\ndef find(strng, ch, start=0):\n ix = start\n while ix < len(strng):\n if strng[ix] == ch:\n return ix\n ix += 1\n return -1\n\n\ndef count_letterz(strng, ch):\n count = 0\n s_point = find(strng, ch, 0)\n while s_point != -1:\n s_point = find(strng, ch, s_point + 1)\n count += 1\n return count\n\n\n# exercise 8.5\ndef remove_punctuation(s):\n punctuation = \"!\\\"#$%&'()*+,-./:;<=>?@[\\\\]^_`{|}~\"\n sans_punct = \"\"\n for letter in s:\n if letter not in punctuation:\n sans_punct += letter\n return sans_punct\n\n\ndef ex8_5():\n instants = \"\"\" INSTANTS\n\n If I could live again my life,\n In the next - I'll try,\n - to make more mistakes,\n I won't try to be so perfect,\n I'll be more relaxed,\n I'll be more full - than I am now,\n In fact, I'll take fewer things seriously,\n I'll be less hygenic,\n I'll take more risks,\n I'll take more trips,\n I'll watch more sunsets,\n I'll climb more mountains,\n I'll swim more rivers,\n I'll go to more places - I've never been,\n I'll eat more ice creams and less (lime) beans,\n I'll have more real problems - and less imaginary\n ones,\n I was one of those people who live\n prudent and prolific lives -\n each minute of his life,\n Offcourse that I had moments of joy - but,\n if I could go back I'll try to have only good moments,\n\n If you don't know - thats what life is made of,\n Don't lose the now! \n\n I was one of those who never goes anywhere\n without a thermometer,\n without a hot-water bottle,\n and without an umberella and without a parachute,\n\n If I could live again - I will travel light,\n If I could live again - I'll try to work bare feet\n at the beginning of spring till \n the end of autumn,\n I'll ride more carts,\n I'll watch more sunrises and play with more children,\n If I have the life to live - but now I am 85,\n - and I know that I am dying ...\n\n \n\n Jorge Luis BORGES \"\"\"\n \n list_of_words = remove_punctuation(instants).split()\n count_e = 0\n count = 0\n for word in list_of_words:\n if \"e\" in word:\n count_e += 1\n else:\n count += 1\n percentage = (100 * count_e) / (count + count_e)\n print(\"Your text contains {0} words, of which {1} ({2:.1f}%) contain an \\\"e\\\".\".format(count + count_e, count_e, percentage))\n \n\n\n# exercise 8.6\nlayout = \"{0:>3}\"\ndef get_multiplies(n, high):\n table = \"\"\n for i in range(1, high+1):\n table += layout.format(n*i) + \" \"\n return table\n\n\ndef print_mult_table(high):\n lin = \" :\"\n for i in range(1, high+1):\n if i == 1:\n print(\"{0:>8}{1}\".format(\" \", get_multiplies(1, high)))\n for l in range(len(get_multiplies(1, high)) + 4):\n lin += \"-\"\n print(\"{0:<}\".format(lin))\n print(\"{0:>2}{1:<6}{2}\".format(str(i), \":\", get_multiplies(i, high)))\n\n\n\n# exercise 8.7\ndef reverse(strng):\n res = \"\"\n for i in range(1, len(strng)+1):\n res += strng[-i]\n return res\n\n\ntest(reverse(\"happy\") == \"yppah\")\ntest(reverse(\"Python\") == \"nohtyP\")\ntest(reverse(\"\") == \"\")\ntest(reverse(\"a\") == \"a\")\n\n\n\n# exercise 8.8\ndef mirror(strng):\n return strng + reverse(strng)\n\n\ntest(mirror(\"good\") == \"gooddoog\")\ntest(mirror(\"Python\") == \"PythonnohtyP\")\ntest(mirror(\"\") == \"\")\ntest(mirror(\"a\") == \"aa\")\n\n\n\n# exercise 8.9\ndef remove_letter(ch, strng):\n final_string = \"\"\n for c in strng:\n if c is not ch:\n final_string += c\n return final_string\n\n\ntest(remove_letter(\"a\", \"apple\") == \"pple\")\ntest(remove_letter(\"a\", \"banana\") == \"bnn\")\ntest(remove_letter(\"z\", \"banana\") == \"banana\")\ntest(remove_letter(\"i\", \"Mississippi\") == \"Msssspp\")\ntest(remove_letter(\"b\", \"\") == \"\")\ntest(remove_letter(\"b\", \"c\") == \"c\")\n\n\n\n# exercise 8.10\ndef is_palindrome(strng):\n half = strng[0:len(strng)//2]\n if len(strng) % 2 == 0:\n if strng == half + reverse(half):\n return True\n else:\n return False\n else:\n if strng[len(half)+1:] == reverse(half):\n return True\n else:\n return False\n\n\ntest(is_palindrome(\"abba\"))\ntest(not is_palindrome(\"abab\"))\ntest(is_palindrome(\"tenet\"))\ntest(not is_palindrome(\"banana\"))\ntest(is_palindrome(\"straw warts\"))\ntest(is_palindrome(\"a\"))\ntest(is_palindrome(\"\"))\n\n\n\n# exercise 8.11\ndef count(subs, strng):\n tally = 0\n for i in range(len(strng)-len(subs)+1):\n if strng[i:i+len(subs)] == subs:\n tally += 1\n return tally\n\n\ntest(count(\"is\", \"Mississippi\") == 2)\ntest(count(\"an\", \"banana\") == 2)\ntest(count(\"ana\", \"banana\") == 2)\ntest(count(\"nana\", \"banana\") == 1)\ntest(count(\"nanan\", \"banana\") == 0)\ntest(count(\"aaa\", \"aaaaaa\") == 4)\n\n\n\n# exercise 8.12\ndef remove(subs, strng):\n for i in range(len(strng)-len(subs)+1):\n if strng[i:i+len(subs)] == subs:\n return strng[:i] + strng[i+len(subs):]\n\n\ntest(remove(\"an\", \"banana\") == \"bana\")\ntest(remove(\"cyc\", \"bicycle\") == \"bile\")\ntest(remove(\"iss\", \"Mississippi\") == \"Missippi\")\ntest(remove(\"eggs\", \"bicycle\") != \"bicycle\")\n\n\n\n# exercise 8.13\ndef remove_all(subs, strng):\n result = \"\"\n while subs in strng:\n strng = remove(subs, strng)\n return strng\n\n\ntest(remove_all(\"an\", \"banana\") == \"ba\")\ntest(remove_all(\"cyc\", \"bicycle\") == \"bile\")\ntest(remove_all(\"iss\", \"Mississippi\") == \"Mippi\")\ntest(remove_all(\"eggs\", \"bicycle\") == \"bicycle\")\n"
},
{
"alpha_fraction": 0.5400981903076172,
"alphanum_fraction": 0.5564647912979126,
"avg_line_length": 22.5,
"blob_id": "683fb3ec79039a9f5f41d26f7c67714c0b0ec66c",
"content_id": "bac4073f60790f42c3e531c6522959613d5eeace",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 611,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 26,
"path": "/chapter-07/7-6.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.6\nimport sys\n\ndef whereis_sam(arr):\n total_words = 0\n for w in arr:\n total_words += 1\n if w == \"sam\":\n break\n return total_words\n\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\n\ntest(whereis_sam([\"ham\", \"merry\", \"pippin\", \"sam\", \"frodo\"]) == 4)\ntest(whereis_sam([\"ham\", \"merry\", \"pippin\", \"frodo\"]) == 4)\ntest(whereis_sam([\"sam\", \"merry\", \"gandalf\"]) == 1)\n"
},
{
"alpha_fraction": 0.5782312750816345,
"alphanum_fraction": 0.615646243095398,
"avg_line_length": 15.333333015441895,
"blob_id": "deaf64f103a34b6fa11959a1395b170f0507b3c2",
"content_id": "0b106bbfc51c737beda19c3cde72f39927600111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 18,
"path": "/chapter-04/4-9.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.9\n\nimport turtle\n\ndef draw_star(t, l):\n \"\"\"Draw a star with turtle t and length l for each edge\"\"\"\n t.left(36)\n for x in range(5):\n t.left(144)\n t.forward(l)\n\nwn = turtle.Screen()\nstar = turtle.Turtle()\nstar.hideturtle()\n\ndraw_star(star, 100)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.4957627058029175,
"alphanum_fraction": 0.5621469020843506,
"avg_line_length": 16.700000762939453,
"blob_id": "820706b1350191a8ac138ba473f606efe75560f2",
"content_id": "cf5e71318a0a58731b34a769671837fd2f976988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 40,
"path": "/chapter-05/5-8.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 5.8\n\nimport turtle\n\ndef draw_bar(t, height):\n \"\"\"Get turtle t to draw one bar, of height.\"\"\"\n t.begin_fill()\n t.pendown()\n t.left(90)\n t.forward(height)\n t.write(\" \" + str(height))\n t.right(90)\n t.forward(40)\n t.right(90)\n t.forward(height)\n t.left(90)\n t.end_fill()\n t.penup()\n t.forward(10)\n\n\nwn = turtle.Screen()\nwn.bgcolor(\"lightgreen\")\n\nturtl = turtle.Turtle()\nturtl.pensize(3)\n\nxs = [48, 117, 200, 240, 160, 260, 220]\n\nfor v in xs:\n if v >= 200:\n turtl.color(\"black\", \"red\")\n elif v >= 100 and v < 200:\n turtl.color(\"black\", \"yellow\")\n elif v < 100:\n turtl.color(\"black\", \"green\")\n draw_bar(turtl, v)\n\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.5894039869308472,
"alphanum_fraction": 0.6225165724754333,
"avg_line_length": 17.875,
"blob_id": "08c3bf92e172b89bd6649fb5f638a6873b029924",
"content_id": "a540491341b7d1d63052eae3f019ef9f5529a455",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 8,
"path": "/chapter-04/4-8.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.8\n\ndef area_of_circle(r):\n area = 3.14 * r * r\n return area\n\nr = float(input(\"Please enter the radius: \"))\nprint(area_of_circle(r))\n"
},
{
"alpha_fraction": 0.5357723832130432,
"alphanum_fraction": 0.5414634346961975,
"avg_line_length": 23.579999923706055,
"blob_id": "0fa9771bf0b13cf27c3cc6d0ec2f14d57645888e",
"content_id": "602ee031ccb1ce1ac03bfe903e65394246461137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 50,
"path": "/chapter-20/wordtools.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "punctuation = \"!\\\"#$%&'()*+,./:;<=>?@[\\\\]^_`{|}~\"\n\ndef cleanword(strng):\n sans_punct = \"\"\n for c in strng:\n if c not in punctuation:\n sans_punct += c\n return sans_punct\n\ndef has_dashdash(strng):\n for c in enumerate(strng):\n if (not c[0] == len(strng)-1) and c[1] == \"-\":\n if strng[c[0]+1] == \"-\":\n return True\n return False\n \ndef extract_words(strng):\n strng_lower = strng.lower()\n strng_nodashes = \"\"\n if has_dashdash(strng_lower):\n strng_nodashes = ' '.join(strng_lower.split(\"--\"))\n else:\n strng_nodashes = strng_lower\n words = strng_nodashes.split()\n strng_clean = []\n for word in words:\n strng_clean.append(cleanword(word))\n\n return strng_clean\n\ndef wordcount(strng, llist):\n count = 0\n for s in llist:\n if s == strng:\n count += 1\n return count\n\ndef wordset(llist):\n word_set = []\n for word in llist:\n if word not in word_set:\n word_set.append(word)\n return sorted(word_set)\n\ndef longestword(llist):\n longest_word = \"\"\n for word in llist:\n if len(word) > len(longest_word):\n longest_word = word\n return len(longest_word)\n\n"
},
{
"alpha_fraction": 0.5339168310165405,
"alphanum_fraction": 0.5776805281639099,
"avg_line_length": 18.869565963745117,
"blob_id": "f3655901fed36e94b11b2edee600efdfdf04556e",
"content_id": "ec5cebcc76f5c8accc666da85ad2e05884e22c18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 23,
"path": "/chapter-07/7-10.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.10\nimport sys\n\ndef is_prime(n):\n for i in range(2, n):\n if n % i == 0:\n return False\n return True\n\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ntest(is_prime(11))\ntest(not is_prime(35))\ntest(is_prime(19911121))\n"
},
{
"alpha_fraction": 0.4803921580314636,
"alphanum_fraction": 0.5049019455909729,
"avg_line_length": 16,
"blob_id": "7b37e8e1101a21a82b51159045ed9c734dd94a33",
"content_id": "99987fd8811f97f089647e50f70981cc602ad711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 12,
"path": "/chapter-07/7-4.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.4\n\ndef count_word(arr):\n count = 0\n for w in arr:\n if len(w) == 5:\n count += 1\n return count\n\n\nxs = [\"one\", \"two\", \"three\", \"third\", \"fifth\"]\nprint(count_word(xs))\n"
},
{
"alpha_fraction": 0.47297295928001404,
"alphanum_fraction": 0.5202702879905701,
"avg_line_length": 20.925926208496094,
"blob_id": "d42a98bf31ebc1624db3d51dcb138450c87f7aa2",
"content_id": "6f7d560a88f1d0b9a07807358320b18914e17b5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/chapter-07/7-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.5\nimport sys\n\ndef sum_upto_even(arr):\n total = 0\n for i in arr:\n if i % 2 != 0:\n total += i\n else:\n break\n return total\n\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else: \n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ntest(sum_upto_even([1, 3, 5, 4, 6]) == 9)\ntest(sum_upto_even([1, 2, 5, 4, 6]) == 1)\ntest(sum_upto_even([1, 3, 5]) == 9)\ntest(sum_upto_even([2, 4, 6]) == 0)\n"
},
{
"alpha_fraction": 0.5756097435951233,
"alphanum_fraction": 0.6292682886123657,
"avg_line_length": 11.8125,
"blob_id": "0e3704714af55877d10fa748cec69db86b303068",
"content_id": "5f4b15fb49b3cacab3910bb1ad50bc1d047a89e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 16,
"path": "/chapter-04/4-5.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.5\n\nimport turtle\n\nwn = turtle.Screen()\nt = turtle.Turtle()\nt.speed(0)\n\nlength = 3\nfor i in range(99):\n t.right(90)\n t.forward(length)\n length = length + 3\n\nt.right(90)\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.48685404658317566,
"alphanum_fraction": 0.5222121477127075,
"avg_line_length": 25.878047943115234,
"blob_id": "c1aee451875fbd548576ab77a634b24f287c2688",
"content_id": "f84e45d905ca8c9a423ba0378720241499fda7b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1103,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 41,
"path": "/chapter-07/7-17.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.17\n\ndef play_once(human_plays_first):\n import random\n rng = random.Random()\n result = rng.randrange(-1,2)\n print(\"Human plays first={0}, winner={1} \".format(human_plays_first, result))\n return result\n\n\nscore = [0, 0, 0]\nplayer = -1\nwhile True:\n if player == -1:\n player = int(input(\"Who is the first player? Human(1) or Computer(0) : \"))\n elif player == 0:\n player = 1\n else:\n player = 0\n \n result = play_once(player)\n if result == -1:\n print(\"I win!\")\n score[0] += 1\n elif result == 0:\n print(\"Game drawn\")\n score[1] += 1\n else:\n print(\"You win!\")\n score[2] += 1\n\n print(\"Score | I win |\\tYou win | Drawn\")\n print(\"----------------------------\")\n print(\" {0} \\t {1} \\t {2}\".format(score[0], score[2], score[1]))\n percentage = (100 * score[2]) / (score[0] + score[1] + score[2])\n print(\"Percentage of wins for the human: {0}\".format(percentage))\n response = input(\"Do you want to play again? (y/n): \")\n if response != \"y\":\n break\n\nprint(\"Goodbye!\")\n\n"
},
{
"alpha_fraction": 0.5629138946533203,
"alphanum_fraction": 0.5761589407920837,
"avg_line_length": 17.875,
"blob_id": "59fedac8f70f05a9ee1d5209c81bd9f2423ac82a",
"content_id": "43ecd0dd39a7b86cac29cb898ed23d181227a8fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 8,
"path": "/chapter-09/9-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 9.1\ndef print_tuple(a, b):\n print(a + \"---\" + b)\n\n\ntup = (\"I am a\", \" little tuple\")\nprint_tuple(tup)\n# Seems like it is not possible...\n"
},
{
"alpha_fraction": 0.4625000059604645,
"alphanum_fraction": 0.5208333134651184,
"avg_line_length": 19,
"blob_id": "659b3df47489202ad51ab383a761637d61d7cecc",
"content_id": "5ede8e96fd49cd3b97a628bdcb533aa332bd507a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 12,
"path": "/chapter-07/7-2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.2\n\ndef sum_even(arr):\n total_sum = 0\n for i in arr:\n if i % 2 == 0:\n total_sum += i\n print(\"Sum of the even numbers in this list is {0}.\".format(total_sum))\n\n\nxs = [2, 4, 6, 3, 7, 9, 10]\nsum_even(xs)\n"
},
{
"alpha_fraction": 0.5277777910232544,
"alphanum_fraction": 0.5753968358039856,
"avg_line_length": 11.600000381469727,
"blob_id": "7ecc1c16af906a9a41b8ac01a74f158a14ae80e0",
"content_id": "4799b8f108294fe5b120a467b75248bcb3da4cab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 20,
"path": "/chapter-04/4-4.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.4\n\nimport turtle\n\ndef draw_poly(t, n, sz):\n for i in range(n):\n t.forward(sz)\n t.left(360//n)\n\n t.left(18)\n\n\nwn = turtle.Screen()\nturtl = turtle.Turtle()\n\nfor i in range(20):\n draw_poly(turtl, 4, 75)\n\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.59122633934021,
"alphanum_fraction": 0.6201395988464355,
"avg_line_length": 14.920635223388672,
"blob_id": "1be1a8d8f456fefa7db4481682cfa763a3f85c6c",
"content_id": "521641870b84a3156f602f630cbd05e564b8a551",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1003,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 63,
"path": "/chapter-10/10-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 10.1\nimport turtle\n\nturtle.setup(400, 500)\nwn = turtle.Screen()\nwn.title(\"Handling keypresses!\")\nwn.bgcolor(\"lightgreen\")\ntess = turtle.Turtle()\n\ndef h1():\n tess.forward(30)\n\ndef h2():\n tess.left(45)\n\ndef h3():\n tess.right(45)\n\ndef h4():\n wn.bye()\n\ndef make_red():\n tess.color(\"red\")\n\ndef make_green():\n tess.color(\"green\")\n\ndef make_blue():\n tess.color(\"blue\")\n\npen_size = 1\ndef increase_penwidth():\n global pen_size\n if pen_size <= 20:\n pen_size += 1\n tess.pensize(pen_size)\n\ndef decrease_penwidth():\n global pen_size\n if pen_size >= 1:\n pen_size -= 1\n tess.pensize(pen_size)\n\ndef change_title():\n wn.title(\"Tess is now in \" + str(tess.color()))\n\n\nwn.onkey(h1, \"Up\")\nwn.onkey(h2, \"Left\")\nwn.onkey(h3, \"Right\")\nwn.onkey(h4, \"q\")\n\nwn.onkey(make_red, \"r\")\nwn.onkey(make_green, \"g\")\nwn.onkey(make_blue, \"b\")\n\nwn.onkey(increase_penwidth, \"plus\")\nwn.onkey(decrease_penwidth, \"minus\")\n\nwn.onkey(change_title, \"t\")\n\nwn.listen()\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.45045045018196106,
"alphanum_fraction": 0.5135135054588318,
"avg_line_length": 17.5,
"blob_id": "d7c295c9c1094133458fc9b25e68ac4b71e870d6",
"content_id": "1702d6b88dff014a2fc61586fe9ad6d4c9b485d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 12,
"path": "/chapter-07/7-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.1\n\ndef count_odd(arr):\n total = 0\n for i in arr:\n if i % 2 != 0:\n total += 1\n print(\"There are {0} odd numbers in this list.\".format(total))\n\n\nxs = [1, 3, 4, 7, 9, 10]\ncount_odd(xs)\n"
},
{
"alpha_fraction": 0.561904788017273,
"alphanum_fraction": 0.6571428775787354,
"avg_line_length": 16.33333396911621,
"blob_id": "b9f048ae25084668b4e4331aeb76da9d1adaff8d",
"content_id": "4e8da131ae88fafc1631b293c71b9b297c87b80a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 6,
"path": "/chapter-03/3-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.1\n\ntext = \"We like Python's turtles 1000 times! XD\"\n\nfor i in range(1000):\n print(text)\n\n"
},
{
"alpha_fraction": 0.5455893278121948,
"alphanum_fraction": 0.5863602757453918,
"avg_line_length": 22.089284896850586,
"blob_id": "0750c8facec2e521d04712767b933599496935a7",
"content_id": "c52fee9648de0615529a3aea7f26bf422c4eabcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1349,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 56,
"path": "/chapter-20/20-2.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 20.2\r\n\r\n\"\"\"Python 3.5.2 (default, Jul 5 2016, 12:43:10) \r\n[GCC 5.4.0 20160609] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> d = {\"apples\": 15, \"bananas\": 35, \"grapes\": 12}\r\n>>> d[\"bananas\"]\r\n35\r\n>>> d[\"oranges\"] = 20\r\n>>> len(d)\r\n4\r\n>>> \"grapes\" in d\r\nTrue\r\n>>> d[\"pears\"]\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\nKeyError: 'pears'\r\n>>> d.get(\"pears\", 0)\r\n0\r\n>>> fruits = list(d.keys())\r\n>>> fruits.sort()\r\n>>> print(fruits)\r\n['apples', 'bananas', 'grapes', 'oranges']\r\n>>> del d[\"apples\"]\r\n>>> \"apples\" in d\r\nFalse\r\n>>> exit()\"\"\"\r\n\r\nimport sys\r\n\r\ndef test(did_pass):\r\n \"\"\" Print the result of the test \"\"\"\r\n linenum = sys._getframe(1).f_lineno\r\n if did_pass:\r\n msg = \"Test at line {0} ok.\".format(linenum)\r\n else:\r\n msg = \"Test at line {0} FAILED.\".format(linenum)\r\n print(msg)\r\n\r\n\r\n\r\ndef add_fruit(inventory, fruit, quantity=0):\r\n if not len(inventory) == 0:\r\n tmp = inventory[fruit]\r\n inventory[fruit] = quantity + tmp\r\n else:\r\n inventory[fruit] = quantity\r\n\r\n \r\n\r\nnew_inventory = {}\r\nadd_fruit(new_inventory, \"strawberries\", 10)\r\ntest(\"strawberries\" in new_inventory)\r\ntest(new_inventory[\"strawberries\"] == 10)\r\nadd_fruit(new_inventory, \"strawberries\", 25)\r\ntest(new_inventory[\"strawberries\"] == 35)\r\n"
},
{
"alpha_fraction": 0.5607235431671143,
"alphanum_fraction": 0.5736433863639832,
"avg_line_length": 23.125,
"blob_id": "45b118ed3bf663d99333d8a457d2d38a1d58cac0",
"content_id": "547f2f3e51739b15a68cc99414effc5bc87688eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 387,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 16,
"path": "/chapter-20/20-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 20.1\n\ndef letter_count(strng):\n char_counts = {}\n for char in strng.lower():\n if char != \" \":\n char_counts[char] = char_counts.get(char, 0) + 1\n \n letter_items = list(char_counts.items())\n letter_items.sort()\n\n for (u, v) in letter_items:\n print(u + \" \" + str(v))\n\n\nletter_count(\"ThiS is String with Upper and lower case Letters\")\n\n"
},
{
"alpha_fraction": 0.6180904507637024,
"alphanum_fraction": 0.6783919334411621,
"avg_line_length": 12.266666412353516,
"blob_id": "437c4ed7aa5977d487d34ae7d4a9c0c567ffe39d",
"content_id": "bd57339ad29f71dd712c79ff6c29b470f8897860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 15,
"path": "/chapter-03/3-11.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 3.11\n\nimport turtle\n\nwn = turtle.Screen()\nstar = turtle.Turtle()\nstar.hideturtle()\nstar.pensize(3)\n\nstar.left(36)\nfor x in range(5):\n star.left(144)\n star.forward(70)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.4385964870452881,
"alphanum_fraction": 0.6035087704658508,
"avg_line_length": 16.8125,
"blob_id": "32f03f8a5bb896abb186e6556e0d1aaf78d0e29e",
"content_id": "aa3f2009a658d012fae50ff07bd43468d5ce5c1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 16,
"path": "/chapter-07/7-12.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.12\n\nimport turtle\n\nwn = turtle.Screen()\nturtl = turtle.Turtle()\nturtl.pensize(3)\n\ndata = [(135,141), (-135,100), (135,71), (90,71), (45,100), (135,141),\n (-135,100), (-90,100)]\n\nfor (angle,step) in data:\n turtl.left(angle)\n turtl.forward(step)\n\nwn.mainloop()\n"
},
{
"alpha_fraction": 0.40585774183273315,
"alphanum_fraction": 0.41004183888435364,
"avg_line_length": 46.79999923706055,
"blob_id": "856509edfd9616129290ca7f432a6b9c3e7e490e",
"content_id": "f2903bf89c716bfcfc51783ae69332399924b638",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 5,
"path": "/README.md",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "thinkcs-solutions\n=================\n\nHow to Think Like a Computer Scientist Learning with Python 3 (RLE) personal solutions to exercises.\n----------------------------------------------------------------------------------------------------\n"
},
{
"alpha_fraction": 0.5307376980781555,
"alphanum_fraction": 0.5676229596138,
"avg_line_length": 19.33333396911621,
"blob_id": "9c9af64af970f8a59ea4dd47e7ab4d13392fb657",
"content_id": "f6a449ee40b90d8ef9301a7a7ce25a8f93ff1c8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 24,
"path": "/chapter-07/7-16.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.16\n\nimport sys\n\ndef sum_of_squares(xs):\n result = 0\n for i in xs:\n result += i*i\n return result\n\n\ndef test(did_pass):\n \"\"\"Print the result of the test\"\"\"\n linenum = sys._getframe(1).f_lineno\n if did_pass:\n msg = \"Test at line {0} ok.\".format(linenum)\n else:\n msg = \"Test at line {0} FAILED.\".format(linenum)\n print(msg)\n\n\ntest(sum_of_squares([2, 3, 4]) == 29)\ntest(sum_of_squares([ ]) == 0)\ntest(sum_of_squares([2, -3, 4]) == 29)\n"
},
{
"alpha_fraction": 0.5907335877418518,
"alphanum_fraction": 0.6486486196517944,
"avg_line_length": 22.545454025268555,
"blob_id": "10aa85091d18e26d356b2e18b0102e43b0580b2e",
"content_id": "6f0825eb0fef068f098159380066bd5d8c0102f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 11,
"path": "/chapter-05/5-10.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 5.10\n\ndef find_hypot(side1, side2):\n hypot = ((side1 * side1) + (side2 * side2)) ** 0.5\n return hypot\n\n\ndata1 = input(\"Please enter the first side: \")\ndata2 = input(\"Please enter the second side: \")\n\nprint(find_hypot(int(data1), int(data2)))\n"
},
{
"alpha_fraction": 0.4686192572116852,
"alphanum_fraction": 0.5313807725906372,
"avg_line_length": 17.384614944458008,
"blob_id": "70c33bffca867b390b595a3252870b23d444a2ff",
"content_id": "d6408d59e9f2ad776518019cd5636d98b3c7a4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 13,
"path": "/chapter-07/7-7.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 7.7\n\ndef sqrt(n):\n approx = n/2.0\n while True:\n better = (approx + n/approx)/2.0\n print(better)\n if abs(approx - better) < 0.000001:\n return better\n approx = better\n\n\nprint(sqrt(25))\n"
},
{
"alpha_fraction": 0.5722543597221375,
"alphanum_fraction": 0.5953757166862488,
"avg_line_length": 14.727272987365723,
"blob_id": "e241992ffcedb3124aa402f7ee3fa4cb97193b30",
"content_id": "cb1ba105b82c24e4da3e34f23987286f4620eebe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 22,
"path": "/chapter-04/4-1.py",
"repo_name": "armut/thinkcs-solutions",
"src_encoding": "UTF-8",
"text": "# exercise 4.1\n\nimport turtle\n\ndef draw_square(t, sz):\n \"\"\"Draws a square with turtle t with size sz of each edge\"\"\"\n t.pendown()\n for i in range(4):\n t.forward(sz)\n t.left(90)\n\n t.penup()\n t.forward(sz + sz)\n\n\nwn = turtle.Screen()\nturtl = turtle.Turtle()\n\nfor i in range(5):\n draw_square(turtl,20)\n\nwn.mainloop()\n"
}
] | 77 |
Gowthamvenkatesh03/docx-to-pdf
|
https://github.com/Gowthamvenkatesh03/docx-to-pdf
|
62ed388fac4096617166f65f997ea64f4bc7799c
|
0c2ca8bb2f2346b03cea2618ed830373e9968c56
|
fafffc086d0d3691d1147ac1bd250b0c0dfd1a33
|
refs/heads/master
| 2022-11-26T20:52:10.299865 | 2020-08-08T09:06:05 | 2020-08-08T09:06:05 | 286,003,715 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6801470518112183,
"alphanum_fraction": 0.6911764740943909,
"avg_line_length": 32,
"blob_id": "af911bca395edcd9dfb0e07abf2bcf0447ef6005",
"content_id": "d758dc8ff957890fc5f49900cb856d301ed5ebbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 8,
"path": "/convert collection of docx to pdf.py",
"repo_name": "Gowthamvenkatesh03/docx-to-pdf",
"src_encoding": "UTF-8",
"text": "import os\r\nimport docx2pdf\r\nfrom docx2pdf import convert\r\nfolderpath=r\"C:\\Users\\sivacatering\\Desktop\\folder\"\r\nfor files in os.listdir(folderpath):\r\n if \".docx\" not in files:\r\n\t continue\r\n convert(folderpath+\"\\\\\"+files,folderpath+\"\\\\\"+files.split('.')[0]+\".pdf\")\r\n"
},
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 34,
"blob_id": "12cd63c5f697cdf0336f27eba4dc572efe443db8",
"content_id": "e9325b6b1abd38ee7dd21ac22bdfe9dd621679f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Gowthamvenkatesh03/docx-to-pdf",
"src_encoding": "UTF-8",
"text": "# docx-to-pdf\nProgram to convert the collection of docx files to pdf.\n"
}
] | 2 |
EvgeniiMorozov/wb_product_parser
|
https://github.com/EvgeniiMorozov/wb_product_parser
|
b724974612a1643e1eaca3d99f265d2fe3ff1703
|
581a49ab055a88df94ba6e3f07f0ba74d3367048
|
f41d2026a5d19547747e309f7ef4132b54a754e9
|
refs/heads/master
| 2023-07-31T18:30:49.084568 | 2021-09-22T15:17:25 | 2021-09-22T15:17:25 | 407,142,786 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5962343215942383,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 31.590909957885742,
"blob_id": "c04db768521bde6b5f10de63741237547f28800a",
"content_id": "1f5ee68542e6e28bd86cb91828d99dadc27f6fae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1444,
"license_type": "no_license",
"max_line_length": 198,
"num_lines": 44,
"path": "/wb_product_parser/scan_pages.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "from random import randint\nfrom time import sleep\n\nfrom bs4 import BeautifulSoup\nimport requests\nfrom config import HEADERS\n\nproducts = []\n\n\ndef get_content(url):\n return requests.get(url, headers=HEADERS).text\n\n\ndef get_prod_ids(content):\n soup = BeautifulSoup(content, 'html.parser')\n cards = soup.find_all('div', class_='product-card j-card-item')\n products_ids = []\n for card in cards:\n product_id = card.find('a', class_='product-card__main j-open-full-product-card').get('href')\n # '/catalog/15875681/detail.aspx?targetUrl=GP'\n product_id = [el for el in product_id.split('/')]\n products_ids.append(product_id[2])\n\n products.extend(products_ids)\n\n\ndef main():\n pages = 1\n for page in range(1, pages+1):\n print(f'Страница {page} из {pages}...')\n url = f'https://www.wildberries.ru/catalog/elektronika/noutbuki-pereferiya/noutbuki-ultrabuki?page={page}&fbrand=6049%3B24012%3B6667%3B6364%3B19467%3B3859%3B5786'\n # url = f'https://www.wildberries.ru/catalog/elektronika/smartfony-i-telefony/vse-smartfony?sort=popular&page={page}&fbrand=5789%3B6049%3B5786%3B5779%3B16111%3B10883%3B28380%3B132943%3B5772'\n content = get_content(url)\n get_prod_ids(content)\n sleep(randint(8, 12))\n\n with open('notebooks_ids.txt', 'w') as file:\n for product in products:\n file.write(product+'\\n')\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5976526737213135,
"alphanum_fraction": 0.629561722278595,
"avg_line_length": 36.34931564331055,
"blob_id": "8e0f458d98e2da703632d61c298bcbc878f99ad5",
"content_id": "75a5d466d9649fcc503db4c31f80211aff8498b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5522,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 146,
"path": "/wb_product_parser/notebook_page_parser.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nimport time\nfrom random import randint\nimport re\nimport requests\nimport json\nfrom pathlib import Path\n\nfrom bs4 import BeautifulSoup\nfrom config import HEADERS, HTTPS_PREF, notebook_local_path_pref, notebook_spec_pattern\n\nPROD_ID_LIST = [\"29600233\", \"25925048\", \"26009431\", \"34212494\", \"40597292\"]\n\n# PROTO_URL = f\"https://www.wildberries.ru/catalog/{product_id}/detail.aspx?targetUrl=GP\"\n\n# Main page (Oppo, A74, 19990rub): https://images.wbstatic.net/c246x328/new/26820000/26828281-1.jpg\n# Product page: slider main - https://images.wbstatic.net/big/new/26820000/26828281-1.jpg\n# slider nav - https://images.wbstatic.net/tm/new/26820000/26828281-1.jpg\n\nimages_urls = []\n\n\ndef get_html(url):\n return requests.get(url, headers=HEADERS).text\n\n\ndef get_content(html):\n soup = BeautifulSoup(html, \"html.parser\")\n header_soup = soup.find(\"div\", class_=\"same-part-kt__header-wrap\")\n slider_soup = soup.find(\"div\", class_=\"same-part-kt__slider-wrap j-card-left-wrap\")\n price_soup = soup.find(\"div\", class_=\"same-part-kt__info-wrap\")\n details_soup = soup.find(\"section\", class_=\"product-detail__details details\")\n\n # header_soup\n brand = (\n header_soup.find(\"h1\", class_=\"same-part-kt__header\").find_next(\"span\").get_text(strip=True))\n print(brand)\n vendor_code = soup.find(\"div\", class_=\"same-part-kt__common-info\").find(\"span\", class_=\"hide-desktop\")\n vendor_code = vendor_code.find_next(\"span\").get_text(strip=True)\n\n # slider_soup\n swiper_container = slider_soup.find(\"ul\", class_=\"swiper-wrapper\")\n img_links = []\n img_items = swiper_container.find_all(\"img\")\n\n for i in range(min(len(img_items), 3)):\n # <img src=\"//images.wbstatic.net/tm/new/26820000/26828281-1.jpg\" alt=\" Вид 1.\">\n # '//images.wbstatic.net/c324x432/new/23480000/23484561-1.jpg'\n link = img_items[i].get(\"src\")\n image_link = ''.join(re.sub(r\"/tm/\", \"/big/\", link))\n filename = image_link.split('/')[-1]\n image_url_link = HTTPS_PREF + image_link\n image_local_link = notebook_local_path_pref + vendor_code + '/' + filename\n img_links.append(image_local_link)\n images_urls.append(image_url_link)\n\n # price_soup\n if not price_soup.find(\"span\", class_=\"price-block__final-price\"):\n price = None\n else:\n price = price_soup.find(\"span\", class_=\"price-block__final-price\").get_text(strip=True)\n price = price.strip('₽')\n price = int(''.join(el.strip() for el in price))\n\n # details_soup\n description_text = details_soup.find(\"p\", class_=\"collapsable__text\").get_text(strip=True)\n description_text = ' '.join(chunk.strip() for chunk in description_text.split())\n short_description = header_soup.find(\"h1\", class_=\"same-part-kt__header\").find_next(\"span\")\\\n .find_next('span').get_text(strip=True)\n\n # Определяем модель ноутбука (примерно)\n # 'Ноутбук Asus Zenbook Pro 15 OLED UX535LI Intel Core i7 10870H•RAM 16 Гб•SSD 512 Гб•Windows 10 Home'\n # model_proto = short_description.split()\n # stop_list = [brand.lower(), 'ноутбук']\n # model_proto = [el for el in model_proto if el.lower() not in stop_list]\n # model = ' '.join(model_proto[:2])\n\n details_table = details_soup.find(\"div\", class_=\"product-params\")\n table_rows = details_table.find_all(\"tr\", class_=\"product-params__row\")\n\n search_list = notebook_spec_pattern.keys()\n\n specification = defaultdict()\n specification.default_factory = lambda: 'Уточнить'\n # specification['model'] = model\n\n for row in table_rows:\n key_row_text = row.find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text()\n if key_row_text in search_list:\n try:\n spec_key = notebook_spec_pattern[key_row_text]\n specification[spec_key] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n except Exception as ex:\n spec_key = notebook_spec_pattern[key_row_text]\n specification[spec_key] = None\n\n result = {\n \"brand\": brand,\n # \"model\": specification['model'],\n \"vendor\": vendor_code,\n \"short_description\": short_description,\n \"price\": price,\n \"description\": description_text,\n \"specification\": specification,\n \"images_urls\": img_links,\n }\n\n # print(result)\n make_json_file(f\"{vendor_code}\", result)\n\n\ndef make_json_file(filename, data):\n path = f\"source/notebooks/{filename}\"\n if not Path(path).exists():\n Path(path).mkdir()\n with open(path + f\"/{filename}.json\", \"w\", encoding=\"UTF-8\") as file:\n json.dump(data, file, indent=4, ensure_ascii=False)\n\n\ndef main():\n start = time.time()\n\n with open('notebooks_ids.txt', 'r') as file:\n product_ids = file.readlines()\n product_ids = [chunk.strip() for chunk in product_ids]\n # product_ids = PROD_ID_LIST\n\n for idx, product_id in enumerate(product_ids, start=1):\n time.sleep(randint(5, 7))\n print(f'{idx} - {product_id}')\n url = (\n f\"https://www.wildberries.ru/catalog/{product_id}/detail.aspx?targetUrl=GP\"\n )\n html = get_html(url)\n get_content(html)\n\n with open('notebook_images_urls.txt', 'w') as file:\n for url in images_urls:\n file.write(url + '\\n')\n\n end = time.time()\n print(end-start)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6320101022720337,
"alphanum_fraction": 0.6546943783760071,
"avg_line_length": 35.068180084228516,
"blob_id": "bd917face1e3ad4de7698c6346e3968feeb7b864",
"content_id": "fb595361453b446d128013b1289a7c35fdb105c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2007,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 44,
"path": "/wb_product_parser/config.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "HEADERS = {\n \"user agent\": (\n \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like\"\n \" Gecko) Chrome/92.0.4515.131 Safari/537.36\"\n ),\n \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\",\n}\n\nHOST = \"https://www.wildberries.ru\"\nHTTPS_PREF = \"https:\"\n\nphone_spec_pattern = {\n \"Операционная система\": \"operating_system\",\n \"Модель\": \"model\",\n \"Гарантийный срок\": \"guarantee\",\n \"Тип дисплея/экрана\": \"display_type\",\n \"Диагональ экрана\": \"screen_diagonal\",\n \"Разрешение экрана\": \"screen_resolution\",\n \"Процессор\": \"cpu\",\n \"Объем встроенной памяти (Гб)\": \"ROM_size\",\n \"Объем оперативной памяти (Гб)\": \"RAM_size\",\n \"Емкость аккумулятора\": \"battery_capacity\",\n \"Количество мп основной камеры\": \"main_camera_resolution\"\n}\n\nnotebook_spec_pattern = {\n \"Операционная система\": \"operating_system\",\n \"Модель\": \"model\",\n \"Гарантийный срок\": \"guarantee\",\n \"Тип дисплея/экрана\": \"display_type\",\n \"Диагональ экрана\": \"screen_diagonal\",\n \"Разрешение экрана\": \"screen_resolution\",\n \"Тип матрицы\": \"matrix_type\",\n \"Процессор\": \"cpu\",\n \"Количество ядер процессора\": \"cpu_cores\",\n \"Тактовая частота процессора\": \"cpu_clock_speed\",\n \"Объем встроенной памяти (Гб)\": \"ROM_size\",\n \"Объем накопителя SSD\": \"SSD_ROM_size\",\n \"Объем накопителя HDD\": \"HDD_ROM_size\",\n \"Объем оперативной памяти (Гб)\": \"RAM_size\",\n}\n\nphone_local_path_pref = 'source/phones/'\nnotebook_local_path_pref = 'source/notebooks/'\n"
},
{
"alpha_fraction": 0.6830065250396729,
"alphanum_fraction": 0.6830065250396729,
"avg_line_length": 19.399999618530273,
"blob_id": "a239e1c8ec8d1bea3b054ccc7f782084c7338b5f",
"content_id": "b45e860b979f5493f4da65de47102c42c663cbfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 15,
"path": "/wb_product_parser/schemas.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "from pydantic import BaseModel\n\n\nclass Specification(BaseModel):\n operating_system: str\n model: str\n guarantee: str\n display_type: str\n screen_diagonal: str\n screen_resolution: str\n cpu: str\n ROM_size: str\n RAM_size: str\n battery_capacity: str\n main_camera_resolution: str\n"
},
{
"alpha_fraction": 0.6142098307609558,
"alphanum_fraction": 0.6337317228317261,
"avg_line_length": 46.0625,
"blob_id": "704679c7613e2f95e076657c395b4aefbf517eee",
"content_id": "fc64b8b3113ca4a3769361b1c6f8b288be07aa0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7736,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 160,
"path": "/wb_product_parser/old/prod_page_parser.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "# import asyncio\nfrom random import randint\nimport re\nimport requests\nimport json\nfrom pathlib import Path\nfrom time import sleep\n\n# from aiohttp import ClientSession\nfrom bs4 import BeautifulSoup\n\nHEADERS = {\n \"user agent\": (\n \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like\"\n \" Gecko) Chrome/92.0.4515.131 Safari/537.36\"\n ),\n \"Accept\": \"text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9\",\n}\nHOST = \"https://www.wildberries.ru\"\nHOST_PREF = \"https:\"\nPROD_ID_LIST = [\"21264155\", \"26301070\"]\n\n# PROTO_URL = f\"https://www.wildberries.ru/catalog/{product_id}/detail.aspx?targetUrl=GP\"\n\n# Main page (Oppo, A74, 19990rub): https://images.wbstatic.net/c246x328/new/26820000/26828281-1.jpg\n# Product page: slider main - https://images.wbstatic.net/big/new/26820000/26828281-1.jpg\n# slider nav - https://images.wbstatic.net/tm/new/26820000/26828281-1.jpg\n\nfetching_data = []\n\n\n# async def get_html(url: str, session: ClientSession):\n# await asyncio.sleep(5, 15)\n# async with session.get(url=url, headers=HEADERS) as response:\n# if response.status != \"200\":\n# print(f\"Что-то пошло не так! {response.status}\")\n# print(f\"Get data from --> {url}\")\n# response_text = await response.text()\n# fetching_data.append(response_text)\n# return response_text\n\n\n# async def fetch_content():\n# async with ClientSession() as session:\n# tasks = []\n# for product_id in PROD_ID_LIST:\n# url = f\"https://www.wildberries.ru/catalog/{product_id}/detail.aspx?targetUrl=GP\"\n# task = asyncio.create_task(get_html(url, session))\n# tasks.append(task)\n#\n# return await asyncio.gather(*tasks)\n\n\ndef get_html(url, params=None):\n print(f\"{url=}\")\n return requests.get(url, headers=HEADERS, params=None).text\n\n\ndef get_content(html):\n soup = BeautifulSoup(html, \"html.parser\")\n header_soup = soup.find(\"div\", class_=\"same-part-kt__header-wrap\")\n slider_soup = soup.find(\"div\", class_=\"same-part-kt__slider-wrap j-card-left-wrap\")\n price_soup = soup.find(\"div\", class_=\"same-part-kt__info-wrap\")\n details_soup = soup.find(\"section\", class_=\"product-detail__details details\")\n\n # header_soup\n brand = (\n header_soup.find(\"h1\", class_=\"same-part-kt__header\").find_next(\"span\").get_text(strip=True))\n\n vendor_code = soup.find(\"div\", class_=\"same-part-kt__common-info\").find(\"span\", class_=\"hide-desktop\")\n vendor_code = vendor_code.find_next(\"span\").get_text(strip=True)\n\n # slider_soup\n swiper_container = slider_soup.find(\"ul\", class_=\"swiper-wrapper\")\n img_items = swiper_container.find_all(\"li\")\n img_links = []\n for i in range(3):\n # <img src=\"//images.wbstatic.net/tm/new/26820000/26828281-1.jpg\" alt=\" Вид 1.\">\n link = img_items[i].find(\"div\", class_=\"slide__content\").find(\"img\").get(\"src\")\n image_link = re.sub(r\"/tm/\", \"/big/\", link)\n img_links.append(\"\".join(image_link))\n\n # price_soup\n if not price_soup.find(\"span\", class_=\"price-block__final-price\"):\n price = \"-\"\n else:\n price = price_soup.find(\"span\", class_=\"price-block__final-price\").get_text(strip=True)\n\n # details_soup\n description_text = details_soup.find(\"p\", class_=\"collapsable__text\").get_text(strip=True)\n details_table = details_soup.find(\"div\", class_=\"product-params\")\n table_rows = details_table.find_all(\"tr\", class_=\"product-params__row\")\n specification_dict = {}\n for row in table_rows:\n if row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Операционная система\":\n specification_dict[\"operating_system\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Модель\":\n specification_dict[\"model\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Гарантийный срок\":\n specification_dict[\"guarantee\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Тип дисплея/экрана\":\n specification_dict[\"display_type\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Диагональ экрана\":\n specification_dict[\"screen_diagonal\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Разрешение экрана\":\n specification_dict[\"screen_resolution\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Процессор\":\n specification_dict[\"cpu\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Объем встроенной памяти (Гб)\":\n specification_dict[\"ROM_size\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Объем оперативной памяти (Гб)\":\n specification_dict[\"RAM_size\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Емкость аккумулятора\":\n specification_dict[\"battery_capacity\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n elif row.find(\"th\", class_=\"product-params__cell\").find(\"span\", class_=\"product-params__cell-decor\").find(\"span\").get_text() == \"Количество мп основной камеры\":\n specification_dict[\"main_camera_resolution\"] = row.find(\"td\", class_=\"product-params__cell\").get_text(strip=True)\n\n result = {\n \"brand\": brand,\n \"model\": specification_dict[\"model\"],\n \"vendor\": vendor_code,\n \"price\": price,\n \"description\": description_text,\n \"specification\": specification_dict,\n \"images_urls\": img_links,\n }\n print(result)\n make_json_file(f\"{vendor_code}\", result)\n\n\ndef make_json_file(filename, data):\n path = f\"source/json/{filename}\"\n if not Path(path).exists():\n Path(path).mkdir()\n with open(path + f\"/{filename}.json\", \"w\", encoding=\"UTF-8\") as file:\n file.write(json.dumps(data))\n\n\ndef main():\n for product_id in PROD_ID_LIST:\n sleep(randint(8, 12))\n url = (\n f\"https://www.wildberries.ru/catalog/{product_id}/detail.aspx?targetUrl=GP\"\n )\n html = get_html(url)\n get_content(html)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.8684210777282715,
"alphanum_fraction": 0.8684210777282715,
"avg_line_length": 38,
"blob_id": "d4f5c63887fb732b23dd268bd667656166b88de3",
"content_id": "f5b63962f174b04dfa4e21271f91a123f45de070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/wb_product_parser/README.md",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "# Парсер страницы продукта Wildberries"
},
{
"alpha_fraction": 0.6096000075340271,
"alphanum_fraction": 0.6272000074386597,
"avg_line_length": 26.77777862548828,
"blob_id": "14f15b86906309b829d18e5123d2f082573bbbc1",
"content_id": "6aa26e4da3e175c903c007a6724f73b82ec9c61a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 45,
"path": "/wb_product_parser/downloads.py",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom random import randint\nfrom time import sleep\n\nfrom config import HEADERS, phone_local_path_pref, notebook_local_path_pref\nimport requests\n\n\ndef get_content(url):\n return requests.get(url, headers=HEADERS).content\n\n\ndef read_file(filename):\n with open(filename, 'r', encoding='UTF-8') as file:\n data = file.readlines()\n # print(data)\n return [chunk.strip() for chunk in data]\n\n\ndef save_image(filename, binary_content):\n with open(filename, 'wb') as file:\n file.write(binary_content)\n\n\ndef main():\n urls_list = read_file('notebook_images_urls.txt')\n # urls_list = read_file('phone_images_urls.txt')\n # print(urls_list)\n # 'https://images.wbstatic.net/big/new/21260000/21264155-1.jpg'\n for idx, url in enumerate(urls_list):\n sleep(randint(5, 8))\n print(idx)\n print(url)\n filename = url.split('/')[-1]\n directory = filename.split('-')[0]\n path = notebook_local_path_pref + f'{directory}'\n # path = phone_local_path_pref + f'{directory}'\n if not Path(path).exists():\n Path(path).mkdir()\n content = get_content(url)\n save_image(path + f'/{filename}', content)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5298804640769958,
"alphanum_fraction": 0.6254979968070984,
"avg_line_length": 19.079999923706055,
"blob_id": "a836633f9dac54ceb1f71eef6cf7509edf7fcd2b",
"content_id": "939ed03f337d4d50a4c890c1ba489a56762ef67d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 502,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 25,
"path": "/pyproject.toml",
"repo_name": "EvgeniiMorozov/wb_product_parser",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"wb_product_parser\"\nversion = \"0.1.0\"\ndescription = \"\"\nauthors = [\"Evgenii Morozov <[email protected]>\"]\n\n[tool.poetry.dependencies]\npython = \"^3.9\"\nrequests = \"^2.26.0\"\npydantic = \"^1.8.2\"\naiohttp = \"^3.7.4\"\nbeautifulsoup4 = \"^4.10.0\"\nPillow = \"^8.3.2\"\ntypes-requests = \"^2.25.8\"\n\n[tool.poetry.dev-dependencies]\npytest = \"^5.2\"\nblack = \"^21.9b0\"\nflake8 = \"^3.9.2\"\nmypy = \"^0.910\"\ntypes-requests = \"^2.25.8\"\n\n[build-system]\nrequires = [\"poetry-core>=1.0.0\"]\nbuild-backend = \"poetry.core.masonry.api\"\n"
}
] | 8 |
mihai011/EpicShelter
|
https://github.com/mihai011/EpicShelter
|
c0f445483554b11286c924df39fc7df4ab6eb739
|
477df46942af2c6a30cc71c8caff68b08e5fc7a2
|
85ab894464479652c117b3ea3f4bb8842fe64555
|
refs/heads/master
| 2022-12-11T19:50:50.424771 | 2021-02-17T16:20:21 | 2021-02-17T16:20:21 | 238,297,870 | 0 | 0 | null | 2020-02-04T20:19:19 | 2022-07-31T20:06:29 | 2022-12-08T07:51:09 |
Python
|
[
{
"alpha_fraction": 0.662162184715271,
"alphanum_fraction": 0.6714527010917664,
"avg_line_length": 24.630434036254883,
"blob_id": "10c6573049c62a387128d7d07569b4972a7fe9bf",
"content_id": "cf6ef15d7abeda33998cc3d458772e581b503493",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1184,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 46,
"path": "/epicshelter_tested/tests/test_aws_s3.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nfrom aws_s3.aws_s3 import S3\n\nimport pytest\nimport boto3\n\nfrom .aws_utils import boto3_mock\n\[email protected]\ndef make_mock(monkeypatch):\n\n monkeypatch.setattr(boto3, \"client\", boto3_mock)\n\n\ndef test_list_objects(make_mock):\n\n # mock_client = boto3.client('s3')\n # data = mock_client.list_objects(\"test_bucket\")\n my_client = S3()\n\n with pytest.raises(ValueError) as excinfo:\n my_client.list_objects(None)\n\n assert my_client.list_objects(\"test_bucket\") == [\"control.txt\", \"locale.data\", \"mercator\", \"merch.png\"]\n\n\ndef test_download_object(make_mock):\n\n my_client = S3()\n\n with pytest.raises(ValueError) as excinfo:\n my_client.download_fileobj(None, 'control.txt', \"test.txt\")\n\n with pytest.raises(ValueError) as excinfo:\n my_client.download_fileobj(\"mybucket\", None, \"test.txt\")\n\n with pytest.raises(ValueError) as excinfo:\n my_client.download_fileobj(\"mybucket\", 'control.txt', None)\n\n my_client.download_fileobj('mybucket', 'control.txt', \"test.txt\")\n\n assert open(os.path.join(os.getcwd(), \"tests\", \"remote_data\", \"control.txt\")).read() == open(\"test.txt\").read()\n\n os.remove(\"test.txt\")\n\n "
},
{
"alpha_fraction": 0.624365508556366,
"alphanum_fraction": 0.624365508556366,
"avg_line_length": 23.625,
"blob_id": "4b301ac386f9b3dff29c53376bc5516d84ea28aa",
"content_id": "776720f280da27c18d0710c851a5f3630ae8ffd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 24,
"path": "/epicshelter/google_drive/utils/processing_class.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "\nfrom multiprocessing import Process\nfrom multiprocessing.pool import Pool\n\nclass NoDaemonProcess(Process):\n # make 'daemon' attribute always return False\n\n # def __init__(self, **kwargs):\n # super(Processor, self).__init__()\n # self.group = None\n\n def _get_daemon(self):\n return False\n def _set_daemon(self, value):\n pass\n daemon = property(_get_daemon, _set_daemon)\n\n\nclass MyPool(Pool):\n\n def Process(self, *args, **kwds):\n proc = super(MyPool, self).Process(*args, **kwds)\n proc.__class__ = NoDaemonProcess\n\n return proc"
},
{
"alpha_fraction": 0.7558139562606812,
"alphanum_fraction": 0.7558139562606812,
"avg_line_length": 11.428571701049805,
"blob_id": "7415eb3756daca41b7e9f869ebf2bf49cdc6031c",
"content_id": "c432c4f9945d51e645951f38e82bee5038595ffe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 7,
"path": "/epicshelter_tested/tests/test_shelter.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nfrom shelter.shelter import Shelter\n\ndef test():\n assert True"
},
{
"alpha_fraction": 0.6856330037117004,
"alphanum_fraction": 0.720483660697937,
"avg_line_length": 31.697673797607422,
"blob_id": "982ba17dd84d405a57f58c9de53393ebc2cbc662",
"content_id": "9342e3150846d4f6e70cc286fc13976dd47bcca4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 43,
"path": "/epicshelter/main.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from amazon_s3.amazon_s3 import AmazonS3\nfrom google_drive.google_drive import Google_Drive\nfrom azure_blob_storage.azure_blob_storage import AzureStorage\nfrom shelter.shelter import Shelter\n\n# gd1 = Google_Drive(\"credentials_official.json\",\"control_1.pickle\", False)\n# gd2 = Google_Drive(\"credentials_unofficial.json\",\"control_2.pickle\", False)\n# s3 = AmazonS3(\"epic-shelter\", 12)\n# s3.delete_all_files()\n# gd2.delete_all_files()\n# gd.test_method()\n# # gd.show_full_stats()\n# gd1.upload_local(\"/home/mih011/Desktop/TestFinal\")\n# # gd.show_full_stats()\n# gd1.download_local(\"/home/mihai/Desktop/Transfer_test_1\")\n# gd1.delete_all_files()\n\n# s3.upload_local(\"/home/mihai/Desktop/Transfer_test_1\")\n# s3.download_local(\"/home/mihai/Desktop/Transfer_test\")\n# s3.upload_local(\"/home/mih011/Desktop/Transfer_test\")\n# s3.delete_all_files()\n\n# gd = Google_Drive(\"credentials.json\", \"google_types.data\")\n# # s3 = AmazonS3(\"epic-shelter\",12)\n# s3.get_all_file_ids_paths()\n# gd.get_all_file_ids_paths()\n\n# sh = Shelter()\n\n# sh.register(\"google1\",gd1)\n# sh.register(\"google2\",gd2)\n# sh.register(\"s3\",s3)\n\n# sh.transfer(\"google1\", \"google2\",1)\n# s3.delete_all_files()\n# s3.download_local(\"/home/mih011/Desktop/Transfer_test\")\n# gd.delete_all_files()\n\naz = AzureStorage(\"test\", 12)\n\n#az.get_all_file_ids_paths()\naz.upload_local(\"/home/mihai/Desktop/Azure_storage\")\naz.download_local(\"/home/mihai/Desktop/Azure_storage\")\n"
},
{
"alpha_fraction": 0.6032171845436096,
"alphanum_fraction": 0.6032171845436096,
"avg_line_length": 24.724138259887695,
"blob_id": "4c4a28963e04e0bd98964781044bb9436ca16d51",
"content_id": "313602edd6ee78fc23e44c9e2492a20ab5d24bb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1492,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 58,
"path": "/epicshelter/shelter/shelter.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from multiprocessing import Pool\nfrom functools import partial\n\nfrom multiprocessing import Process\nfrom multiprocessing.pool import Pool\n\nclass NoDaemonProcess(Process):\n # make 'daemon' attribute always return False\n def _get_daemon(self):\n return False\n def _set_daemon(self, value):\n pass\n daemon = property(_get_daemon, _set_daemon)\n\nclass MyPool(Pool):\n Process = NoDaemonProcess\n\ndef mass_transfer(index, from_member, to_member):\n\n while True:\n try:\n \n downloader, packet = from_member.create_giver(index)\n uploader = to_member.create_receiver(packet)\n\n done = False\n while done is False:\n status,done = downloader.next_chunk()\n uploader.write(downloader.getvalue())\n uploader.close()\n break\n except Exception as e:\n pass\n\nclass Shelter():\n\n def __init__(self):\n\n self.members = {}\n\n def register(self, name, object):\n\n self.members[name] = object\n\n def transfer(self,_from,_to, workers):\n\n from_member = self.members[_from].make_member()\n to_member = self.members[_to].make_member()\n\n print(\"Transfering {} items\".format(len(from_member)))\n \n target = partial(mass_transfer, from_member=from_member, to_member=to_member) \n p = Pool(workers)\n p.map(target, range(len(from_member)))\n p.close()\n p.join()\n\n print(\"Transfer done\")\n"
},
{
"alpha_fraction": 0.5956140160560608,
"alphanum_fraction": 0.6122807264328003,
"avg_line_length": 26.14285659790039,
"blob_id": "df08ce1bcf9d649e4716c85c8559508754cb8c54",
"content_id": "6e9f1f09a82f3880ed4a3b377ddc5771bcccf381",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2280,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 84,
"path": "/epicshelter/exp_walk.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from googleapiclient.http import MediaIoBaseDownload, MediaIoBaseUpload\nimport io\nimport boto3 \nfrom google_drive.google_drive import Google_Drive\nfrom smart_open import open as s3_open\nimport ntpath\nimport requests\nimport json\nimport magic\n\n\ndef google_to_amazon(file_id):\n \n gd = Google_Drive(\"credentials.json\", \"google_types.data\")\n drive_service = gd.service\n\n request = drive_service.files().get_media(fileId=file_id)\n fh = io.BytesIO()\n downloader = MediaIoBaseDownload(fh, request)\n\n s3 = boto3.client('s3')\n s3.put_object(Bucket=\"epic-shelter\",Key=\"test.mp4\")\n done=False\n with s3_open('s3://epic-shelter/test.mp4', 'wb', transport_params={'session': boto3.session.Session()}) as f:\n while done is False:\n status, done = downloader.next_chunk()\n fh.truncate(0)\n fh.seek(0)\n f.write(fh.getvalue())\n\ndef amazon_to_google(key):\n\n chunk_size = 262144*64\n gd = Google_Drive(\"credentials.json\", \"google_types.data\")\n access_token = gd.creds.token\n\n\n s3 = boto3.resource('s3')\n s3_object = s3.Object('epic-shelter', key)\n filesize = s3_object.content_length\n\n\n amazon = s3_open('s3://epic-shelter/'+key, 'rb', transport_params={'session': boto3.session.Session()})\n\n headers = {\"Authorization\": \"Bearer \"+access_token, \"Content-Type\": \"application/json\"}\n params = {\n \"name\": ntpath.basename(key),\n \"mimeType\": 'application/octet-stream'\n }\n r = requests.post(\n \"https://www.googleapis.com/upload/drive/v3/files?uploadType=resumable\",\n headers=headers,\n data=json.dumps(params)\n )\n\n location = r.headers['Location']\n prev = 0\n\n while True:\n\n piece = amazon.read(chunk_size)\n if not piece:\n break\n \n offset = prev+len(piece)-1\n headers = {\"Content-Range\": \"bytes \"+str(prev)+\"-\" + str(offset) + \"/\" + str(filesize)}\n print(prev,offset)\n prev = offset+1\n r = requests.put(\n location,\n headers=headers,\n data=piece\n )\n print(r.text)\n \n\n\n\n \n\nif __name__ == \"__main__\":\n\n #google_to_amazon(\"1fdhoNqOGBlWy6zV5euhuBahmAfbXMmCg\")\n amazon_to_google(\"GitHub/slamyc/data/test.mp4\")\n"
},
{
"alpha_fraction": 0.6865671873092651,
"alphanum_fraction": 0.700344443321228,
"avg_line_length": 25.42424201965332,
"blob_id": "f8a0811f2d7a7fd5913907b8c8258cffe8baf7f2",
"content_id": "23410c15c77abe3f0df31f14dfd30a64dab975cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 33,
"path": "/epicshelter/test_requests.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nimport requests\n\naccess_token = 'ya29.a0AfH6SMAtV1HcNVXCRMTuag9T0QMT4WC8E36k7mZftFy6S5j8KXHrkmbZPTeHRWwmzDy5_LJL9wLFLgXZpLktVZ1UJJ1JGWnaI7Fo4KUXqJqSMTvX3cVlti9_FqyW07EgoGkw0DZV7HGd_vEfTYspmswIRcS2QwsWxjra' ## Please set the access token.\n\nfilename = '/home/mih011/Downloads/Introduction to Probability and Statistics 15th Edition/Introduction to Probability and Statistics 15th Edition.pdf'\n\nfilesize = os.path.getsize(filename)\n\n# 1. Retrieve session for resumable upload.\n\nheaders = {\"Authorization\": \"Bearer \"+access_token, \"Content-Type\": \"application/json\"}\nparams = {\n \"name\": \"sample.png\",\n \"mimeType\": \"image/png\"\n}\nr = requests.post(\n \"https://www.googleapis.com/upload/drive/v3/files?uploadType=resumable\",\n headers=headers,\n data=json.dumps(params)\n)\nlocation = r.headers['Location']\n\n# 2. Upload the file.\n\nheaders = {\"Content-Range\": \"bytes 0-\" + str(filesize - 1) + \"/\" + str(filesize)}\nr = requests.put(\n location,\n headers=headers,\n data=open(filename, 'rb')\n)\nprint(r.text)"
},
{
"alpha_fraction": 0.5050359964370728,
"alphanum_fraction": 0.7079136967658997,
"avg_line_length": 17.289474487304688,
"blob_id": "c5be3f8abae330e93cf9c2571c2db5393e6ff713",
"content_id": "aab80533746e338a0912d29d63aa0e0a8dd9b945",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 38,
"path": "/epicshelter/requirements.txt",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "boto3==1.17.4\nbotocore==1.20.4\ncachetools==4.2.1\ncertifi==2020.12.5\nchardet==4.0.0\ncycler==0.10.0\ngoogle-api-core==1.26.0\ngoogle-api-python-client==1.12.8\ngoogle-auth==1.25.0\ngoogle-auth-httplib2==0.0.4\ngoogle-auth-oauthlib==0.4.2\ngoogleapis-common-protos==1.52.0\nhttplib2==0.19.0\nidna==3.1\njmespath==0.10.0\nkiwisolver==1.3.1\nmatplotlib==3.3.4\nnumpy==1.20.1\noauthlib==3.1.0\npackaging==20.9\nPillow==8.1.0\nprotobuf==3.14.0\npyasn1==0.4.8\npyasn1-modules==0.2.8\npyparsing==2.4.7\npython-dateutil==2.8.1\npython-magic==0.4.18\npytz==2021.1\nrequests==2.25.1\nrequests-oauthlib==1.3.0\nrsa==4.7\ns3transfer==0.3.4\nsix==1.15.0\nsmart-open==4.1.2\ntermcolor==1.1.0\ntqdm==4.56.0\nuritemplate==3.0.1\nurllib3==1.26.3\n"
},
{
"alpha_fraction": 0.5971128344535828,
"alphanum_fraction": 0.597769021987915,
"avg_line_length": 31.446807861328125,
"blob_id": "55bc4a62b93dbfb12544f93db1a587e7a4a966cb",
"content_id": "54de00a9ae5bb693efefee78bc81966b97acc219",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 47,
"path": "/epicshelter/azure_blob_storage/azure_utils.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from .processing_class import MyPool\nfrom functools import partial\nfrom smart_open import open as open_azure\n\nimport sys\nimport os\n\ndef upload_to_azure(item, container, local_path, cores, transport_params):\n\n if os.path.isdir(item):\n\n files = [os.path.join(item,f) for f in os.listdir(item)]\n target = partial(upload_to_azure, container=container, local_path=local_path, cores=cores, transport_params=transport_params)\n p = MyPool(cores)\n p.map(target, files)\n p.close()\n p.join()\n\n else:\n \n key = os.path.relpath(item, local_path)\n azure_path = os.path.join(\"azure://\", container, key)\n\n with open_azure(azure_path, 'wb', transport_params=transport_params) as azure_in:\n with open(os.path.join(local_path, key)) as local:\n try:\n b = local.read()\n azure_in.write(bytes(b, 'utf-8'))\n except Exception as e :\n print(key, e)\n local.close()\n azure_in.close()\n\n \ndef download_from_azure(item, container, local_path, transport_params):\n\n azure_path = os.path.join(\"azure://\", container, item)\n local_path = os.path.join(local_path, item)\n\n dir_path = os.path.dirname(local_path)\n\n if not os.path.exists(dir_path):\n os.makedirs(dir_path)\n\n with open_azure(azure_path, \"rb\", transport_params=transport_params) as a_out:\n with open(local_path, \"wb+\") as f_in:\n f_in.write(a_out.read())"
},
{
"alpha_fraction": 0.496886670589447,
"alphanum_fraction": 0.529265284538269,
"avg_line_length": 28.759260177612305,
"blob_id": "51401637b41a683b439b6d7965c86e4beb02003e",
"content_id": "acd1f287a5cba9e8e74404efc5d3a8749e3ab69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1606,
"license_type": "no_license",
"max_line_length": 310,
"num_lines": 54,
"path": "/epicshelter_tested/tests/aws_utils.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import os\nimport datetime\n\ndir_test = \"remote_data\"\n\n\ndef boto3_mock(service):\n\n if service == \"s3\":\n return S3Client()\n\n return None\n\n\nclass S3Client():\n\n def __init__(self):\n\n self.dir = dir_test\n self.path = os.path.join(os.getcwd(), \"tests\", self.dir)\n\n def list_objects(self, Bucket=None):\n\n ret_object = {'ResponseMetadata':\n {'RequestId': 'dummy', 'HostId': 'dummy', 'HTTPStatusCode': 200, 'HTTPHeaders':\n {'x-amz-id-2': 'dummy', 'x-amz-request-id': 'A48E3E905674D76E', 'date': 'Tue, 16 Feb 2021 16:18:01 GMT', 'x-amz-bucket-region': 'us-east-1', 'content-type': 'application/xml', 'transfer-encoding': 'chunked', 'server': 'AmazonS3'}, 'RetryAttempts': 0}, 'IsTruncated': False, 'Marker': '',\n 'Contents': [], 'Name': 'elasticbeanstalk-us-east-1-043301319542', 'Prefix': '', 'MaxKeys': 1000, 'EncodingType': 'url'}\n\n key_object = {\n 'Key': '',\n 'LastModified': '',\n 'ETag': '\"5a642684e718afbbadaf179bfd03f0c6\"',\n 'Size': 0,\n 'StorageClass': 'STANDARD',\n 'Owner': {\n 'DisplayName': '',\n 'ID': ''}}\n\n for f in os.listdir(self.path):\n\n key_object[\"Key\"] = f\n key_object[\"Size\"] = os.path.getsize(os.path.join(self.path, f))\n\n ret_object[\"Contents\"].append(key_object.copy())\n\n return ret_object\n\n def download_fileobj(self, Bucket=None, Key=None, fd=None):\n\n with open(os.path.join(self.path,Key), \"rb\") as df:\n\n fd.write(df.read())\n\n return True"
},
{
"alpha_fraction": 0.6155844330787659,
"alphanum_fraction": 0.6246753334999084,
"avg_line_length": 25.44827651977539,
"blob_id": "102f1c8d4a00ff9f3593e1d40b1256e9cb877d81",
"content_id": "6eb3848bddd1ee1adbfe759563e86ca829faf7e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1540,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 58,
"path": "/epicshelter/amazon_s3/utils/amazon_utils.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from .processing_class import MyPool\nfrom functools import partial\n\nimport sys\nimport os\nimport boto3\n\n\n# these objects are pickable\nclient = boto3.client(\"s3\")\ns3 = boto3.resource('s3')\n\ndef get_size_folder(start_path = '.'):\n total_size = 0\n for dirpath, dirnames, filenames in os.walk(start_path):\n for f in filenames:\n fp = os.path.join(dirpath, f)\n # skip if it is symbolic link\n if not os.path.islink(fp):\n total_size += os.path.getsize(fp)\n\n return total_size\n\ndef upload_to_s3(item,bucket,local_path, cores):\n\n if os.path.isdir(item):\n\n files = [os.path.join(item,f) for f in os.listdir(item)]\n target = partial(upload_to_s3, bucket=bucket, local_path=local_path, cores=cores)\n p = MyPool(cores)\n p.map(target, files)\n p.close()\n p.join()\n else:\n key = os.path.relpath(item, local_path)\n client.upload_file(item, bucket, key)\n print(key)\n\ndef download_to_s3(item, bucket, local_path):\n\n filename = os.path.join(local_path,item)\n\n if not os.path.exists(os.path.dirname(filename)):\n try:\n os.makedirs(os.path.dirname(filename))\n except OSError as exc: # Guard against race condition\n pass\n\n s3.meta.client.download_file(bucket, item, filename)\n\n\ndef get_bucket_size(bucket_name):\n\n total_size = 0\n bucket = boto3.resource('s3').Bucket(bucket_name)\n for object in bucket.objects.all():\n total_size += object.size\n return total_size\n\n\n "
},
{
"alpha_fraction": 0.6016190648078918,
"alphanum_fraction": 0.6050276756286621,
"avg_line_length": 22.24752426147461,
"blob_id": "5a440e3c6aeebe3039be6e80435299dbcc5454d2",
"content_id": "f640ddec26ddf61d97f5680ab3c901a6544044ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2347,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 101,
"path": "/epicshelter/azure_blob_storage/azure_blob_storage.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import os \nfrom azure.storage.blob import BlobServiceClient, ContainerClient\nfrom smart_open import open\nfrom .processing_class import MyPool\nfrom .azure_utils import upload_to_azure, download_from_azure\nfrom functools import partial\n\nclass Downloader():\n \n def __init__(self):\n pass\n\n def next_chunk(self):\n pass\n\n def getvalue(self):\n pass\n\nclass Uploader():\n\n def __init__(self):\n pass\n\n def write(self):\n pass\n\n def close(self):\n pass\n\nclass Member():\n\n def __init__(self):\n pass\n\n def __len__(self):\n pass\n\n def create_giver(self):\n pass\n\n def create_receiver(self):\n pass\n\n\nclass AzureStorage:\n\n def __init__(self, container, cores):\n\n self.container = container\n self.cores = cores\n self.data = []\n self.chunk_size = 1024*1024\n\n # make connection \n self.connect_str = os.environ['AZURE_STORAGE_CONNECTION_STRING']\n self.transport_params = {'client': BlobServiceClient.from_connection_string(self.connect_str)}\n print(\"Azure made init!\")\n\n def upload_local(self, local_path):\n\n print(\"Started upload\")\n\n files = [os.path.join(local_path,f) for f in os.listdir(local_path)]\n target = partial(upload_to_azure, container = self.container, local_path = local_path, cores=self.cores, transport_params=self.transport_params)\n p = MyPool(self.cores)\n p.map(target, files)\n p.close()\n p.join()\n\n print(\"Upload done!\")\n\n def download_local(self, local_path):\n\n self.get_all_file_ids_paths()\n \n print(\"Started download!\")\n\n target = partial(download_from_azure, container = self.container, local_path = local_path, transport_params=self.transport_params)\n p = MyPool(self.cores)\n p.map(target, self.data)\n p.close()\n p.join()\n\n\n print(\"Finished download!\")\n \n\n def get_all_file_ids_paths(self):\n \n print(\"Creating the list of blobs\")\n\n client = ContainerClient.from_connection_string(conn_str = self.connect_str , container_name = self.container)\n gen = client.list_blobs()\n\n for blob in gen:\n self.data.append(blob[\"name\"])\n print(\"Made the list of blobs!\")\n\n\n def make_member(self):\n pass"
},
{
"alpha_fraction": 0.5644781589508057,
"alphanum_fraction": 0.581218957901001,
"avg_line_length": 23.658063888549805,
"blob_id": "e5276673adc244aa2fa328ab6a68f88782404531",
"content_id": "7e7fb54b5136dbb61701a74e928af441e3808bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3823,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 155,
"path": "/epicshelter/amazon_s3/amazon_s3.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\n\nimport boto3\nfrom smart_open import open as s3_open\n\nfrom .utils.processing_class import MyPool\nfrom .utils.amazon_utils import *\n\nfrom functools import partial\nimport threading\n\nfrom time import sleep\n\nfrom multiprocessing import cpu_count\n\nclass Downloader():\n\n def __init__(self, bucket, key, chunk_size):\n\n self._fd = s3_open('s3://'+os.path.join(bucket,key), 'rb', transport_params={'session': boto3.session.Session(),\\\n 'buffer_size': chunk_size})\n self.chunk_size = chunk_size\n self.current_data = None\n\n def next_chunk(self):\n \n data = self._fd.read(self.chunk_size)\n if len(data) < self.chunk_size:\n self.current_data = data\n return True, True\n\n self.current_data = data\n \n return True, False\n\n def getvalue(self):\n\n return self.current_data\n\nclass Uploader():\n\n def __init__(self, bucket, packet):\n\n key = packet[\"path\"]\n\n s3 = boto3.client('s3')\n self.bucket = bucket\n self.key = key\n s3.put_object(Bucket=self.bucket,Key=self.key)\n\n self._fd = s3_open('s3://'+os.path.join(self.bucket,self.key), 'wb', transport_params={'session': boto3.session.Session()})\n\n def write(self, data):\n\n self._fd.write(data)\n\n def close(self):\n\n self._fd.close()\n\n \nclass Member():\n\n def __init__(self, bucket, data):\n \n self.bucket = bucket\n self.data = data\n\n def __len__(self):\n \n return len(self.data)\n\n def create_giver(self, index):\n\n downloader = Downloader(self.bucket, self.data[index], 262144*256)\n\n s3 = boto3.resource('s3')\n s3_object = s3.Object(self.bucket, self.data[index])\n filesize = s3_object.content_length\n\n package = {\"path\":self.data[index],\n \"filesize\": filesize\n }\n\n return downloader, package\n\n def create_receiver(self, packet):\n\n return Uploader(self.bucket, packet)\n\nclass AmazonS3():\n \n def __init__(self, bucket, cores):\n \n self.bucket = bucket\n self.client = boto3.client(\"s3\")\n self.s3 = boto3.resource('s3')\n self.cores = cores\n self.data = []\n self.chunk_size = 1024*1024\n\n self.get_all_file_ids_paths()\n\n def upload_local(self, local_path):\n\n print(\"Started upload\")\n\n files = [os.path.join(local_path,f) for f in os.listdir(local_path)]\n target = partial(upload_to_s3, bucket = self.bucket, local_path = local_path, cores=self.cores)\n p = MyPool(self.cores)\n p.map(target, files)\n p.close()\n p.join()\n\n print(\"Upload done!\")\n\n def download_local(self, local_path):\n\n files = self.client.list_objects(Bucket=self.bucket)\n paths = [f[\"Key\"] for f in files[\"Contents\"]]\n target = partial(download_to_s3, bucket=self.bucket, local_path=local_path)\n\n size = get_bucket_size(self.bucket)\n print(\"Started downloading: \"+ str(size/1024/1024/1024) + \" GB\")\n p = MyPool(self.cores)\n p.map(target, paths)\n p.close()\n print(\"Download done!\")\n\n def delete_all_files(self):\n\n s3 = boto3.resource('s3')\n bucket = s3.Bucket(self.bucket)\n bucket.objects.all().delete()\n print(\"Delete all done!\")\n\n def get_all_file_ids_paths(self):\n\n self.data = []\n resp = self.client.list_objects_v2(Bucket=self.bucket)\n if \"Contents\" not in resp:\n return\n for obj in resp['Contents']:\n self.data.append(obj['Key'])\n\n \n def make_member(self):\n\n return Member(self.bucket,self.data)\n\nif __name__ == \"__main__\":\n\n s3 = AmazonS3(\"epic-shelter\")\n s3.upload_local(\"/home/mihai/Desktop/Transfer_test_1\")\n\n"
},
{
"alpha_fraction": 0.7669376730918884,
"alphanum_fraction": 0.7669376730918884,
"avg_line_length": 36,
"blob_id": "083f36c35b7c452484ada3c245432990c77dcf99",
"content_id": "18a1046c4cb94954b3610b2153dc3f6addb50e7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 10,
"path": "/epicshelter/azure_blob_storage/test.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import os\nfrom azure.storage.blob import BlobServiceClient\nfrom smart_open import open\n\nconnect_str = os.environ['AZURE_STORAGE_CONNECTION_STRING']\n\ntransport_params = {'client': BlobServiceClient.from_connection_string(connect_str)}\n\nwith open(\"azure://test/test/a/b/c/something_good_to_look_at.txt\", \"wb\", transport_params=transport_params) as f:\n f.write(b\"test\")"
},
{
"alpha_fraction": 0.42944785952568054,
"alphanum_fraction": 0.4969325065612793,
"avg_line_length": 17.22222137451172,
"blob_id": "1c44a286152f268ac4c1ff209dcf9adef30f78f1",
"content_id": "b7a7c0c73021363e64b23a31f214add5ec097171",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/epicshelter/mp_test.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from multiprocessing import Pool\n\ndef f(x):\n while True:\n x = x + 1\n\nif __name__ == '__main__':\n p = Pool(12)\n print(p.map(f, [1, 2, 3,2,3,4,5,6]))"
},
{
"alpha_fraction": 0.4906269907951355,
"alphanum_fraction": 0.4943635165691376,
"avg_line_length": 29.826171875,
"blob_id": "d4a2fff4f919671881dd89eb2a8716a70983544f",
"content_id": "6905924c2827324baa6d25b371c2be0dddee5d75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15790,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 512,
"path": "/epicshelter/google_drive/google_drive.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nimport pickle\nimport os.path\nfrom googleapiclient.discovery import build\nfrom google_auth_oauthlib.flow import InstalledAppFlow\nfrom google.auth.transport.requests import Request\nimport io\nfrom googleapiclient.http import MediaIoBaseDownload, MediaIoBaseUpload\n\nfrom functools import partial\nfrom tqdm import tqdm\n\nimport matplotlib.pyplot as plt\n\nimport json\nimport os\nimport requests\n\nfrom .utils.google_utils import *\nfrom .utils.processing_class import MyPool\n\nSCOPES = ['https://www.googleapis.com/auth/drive',\\\n 'https://www.googleapis.com/auth/drive.install',\\\n 'https://www.googleapis.com/auth/drive.appdata']\n\nclass Uploader():\n\n def __init__(self, creds, packet, service):\n\n\n while True:\n\n try:\n \n path = packet[\"path\"]\n print(path)\n table_path = os.path.dirname(path)\n last_id, index, final = Google_Drive.get_id(table_path)\n self.filesize = packet['filesize']\n self.path = path.split(\"/\")\n access_token = creds.token\n\n if not final:\n\n level = Google_Drive.get_children(service, last_id)\n \n for i in range(index,len(self.path)-1):\n \n found = False\n for l in level:\n \n if self.path[i] == l['name'] and l['mimeType'] == 'application/vnd.google-apps.folder':\n found=True\n children_response = service.files().list(q=\"'\"+l['id']+\"' in parents\",\n fields='files(id, name, mimeType)').execute()\n children = children_response.get('files',[])\n last_id = l['id']\n new_path = \"/\".join(self.path[:i+1])\n Google_Drive.add_path(new_path ,last_id)\n break\n\n if found:\n level = children\n else:\n if last_id == None:\n\n file_metadata = {\n 'name': self.path[i],\n 'mimeType': 'application/vnd.google-apps.folder'\n }\n \n else:\n file_metadata = {\n 'name': self.path[i],\n 'mimeType': 'application/vnd.google-apps.folder',\n 'parents':[last_id]\n }\n file = service.files().create(body=file_metadata,\n fields='id').execute()\n last_id = file.get('id')\n new_path = \"/\".join(self.path[:i+1])\n Google_Drive.add_path(new_path ,last_id)\n\n\n if last_id == None:\n params = {\n \"name\": self.path[-1],\n \"mimeType\": 'application/octet-stream',\n }\n else:\n params = {\n \"name\": self.path[-1],\n \"mimeType\": 'application/octet-stream',\n \"parents\":[last_id]\n }\n\n headers = {\"Authorization\": \"Bearer \"+access_token, \"Content-Type\": \"application/json\"}\n \n r = requests.post(\n \"https://www.googleapis.com/upload/drive/v3/files?uploadType=resumable\",\n headers=headers,\n data=json.dumps(params)\n )\n\n self.location = r.headers['Location']\n self.prev = 0\n\n break\n except Exception as e:\n print(e)\n \n\n def write(self,piece):\n \n offset = self.prev+len(piece)-1\n headers = {\"Content-Range\": \"bytes \"+str(self.prev)+\"-\" + str(offset) + \"/\" + str(self.filesize)}\n self.prev = offset+1\n\n r = requests.put(\n self.location,\n headers=headers,\n data=piece\n )\n \n def close(self):\n pass\n\nclass Downloader():\n\n def __init__(self, fh, downloader):\n\n self.fh = fh\n self.downloader = downloader\n\n def next_chunk(self):\n\n return self.downloader.next_chunk()\n\n def getvalue(self): \n\n data = self.fh.getvalue()\n self.fh.truncate(0)\n self.fh.seek(0)\n\n return data\n\n\n def close(self):\n\n self.fh.close()\n \n\n\nclass Member():\n\n def __init__(self, data, service, creds):\n \n self.data = data\n self.service = service\n self.creds = creds\n\n def __len__(self):\n \n return len(self.data)\n\n def create_giver(self,index):\n\n request = self.service.files().get_media(fileId=self.data[index][1])\n\n fh = io.BytesIO()\n downloader = MediaIoBaseDownload(fh, request)\n\n f = self.service.files().get(fileId=self.data[index][1], fields='size').execute()\n\n package = {\"path\":self.data[index][0],\"filesize\":f['size']}\n\n print(self.data[index][0])\n \n return Downloader(fh, downloader) , package\n\n def create_receiver(self,packet):\n\n return Uploader(self.creds, packet, self.service)\n\n\nclass Google_Drive():\n\n # g_types = open( \"google_types.data\").read().split(\"\\n\")\n\n lookup_table = {}\n\n def __init__(self, credentials_file, token_file, get_first_level):\n \"\"\"Verifiy credentials and construct and create credentials if necessary\"\"\"\n\n self.creds = None\n if os.path.exists(token_file):\n with open(token_file, 'rb') as token:\n self.creds = pickle.load(token)\n\n if not self.creds or not self.creds.valid:\n if self.creds and self.creds.expired and self.creds.refresh_token:\n self.creds.refresh(Request())\n else:\n flow = InstalledAppFlow.from_client_secrets_file(credentials_file, SCOPES)\n self.creds = flow.run_local_server(port=0)\n \n with open(token_file, 'wb') as token:\n pickle.dump(self.creds,token)\n\n self.service = build('drive', 'v3', credentials=self.creds)\n \n if get_first_level:\n self.first_level = Google_Drive.retrieve_drive_first_level(self.service)\n else:\n self.first_level = None\n\n print(\"Init made!\")\n\n @staticmethod\n def add_path(path,id):\n\n Google_Drive.lookup_table[path] = id\n \n @staticmethod\n def get_id(full_path):\n\n len_path = len(full_path.split(\"/\"))\n full_path = full_path.split(\"/\")\n \n for i in range(len_path,0,-1):\n path = \"/\".join(full_path[:i])\n if path in Google_Drive.lookup_table:\n if len(full_path[i:]) >= 1: \n return Google_Drive.lookup_table[path],i, False\n else:\n return Google_Drive.lookup_table[path],i, True\n \n return None,0,False\n\n @staticmethod\n def get_children(service,id):\n \n if id == None:\n return []\n\n children_response = service.files().list(q=\"'\"+id+\"' in parents\",\n fields='files(id, name, mimeType)').execute()\n children = children_response.get('files',[])\n\n return children\n\n\n def get_files(self, page_size):\n \n items = []\n\n if page_size == 0:\n page_token = None\n \n while True:\n \n response = self.service.files().list(fields='nextPageToken, files(id, name, size, mimeType)',\n pageToken=page_token).execute()\n\n items += response.get('files', [])\n \n page_token = response.get('nextPageToken', None)\n if page_token is None:\n break\n\n else:\n\n results = self.service.files().list(pageSize=page_size, \n fields=\"nextPageToken, files(id, name)\").execute()\n\n items = results.get('files', [])\n\n return items\n\n\n def show_full_stats(self):\n \"\"\" getting some stats about the current state of the drive \"\"\"\n\n stats = {}\n total = 0\n page_token = None\n\n while True:\n\n response = self.service.files().list(fields='nextPageToken, files(size, mimeType)',\n pageToken=page_token).execute()\n\n page_token = response.get('nextPageToken', None)\n if page_token is None:\n break\n\n for f in response.get('files', []):\n\n if 'size' in f:\n if f['mimeType'] not in stats:\n stats[f['mimeType']] = int(f['size'])\n else:\n stats[f['mimeType']] += int(f['size'])\n\n total += int(f['size'])\n\n for s in stats.keys():\n stats[s] = (stats[s]/total) * 100\n\n print(stats)\n plt.xticks(rotation='vertical')\n plt.bar(stats.keys(), stats.values(), 1.0, color='g')\n plt.show()\n\n @staticmethod\n def retrieve_drive_first_level(service):\n \"\"\"getting the first level of the drive file structure\"\"\"\n\n all_items = []\n page_token = None\n\n while True:\n \n response = service.files().list(q=\"'me' in owners and trashed=false\",\n fields='nextPageToken, files(id, name, mimeType)',\n pageToken=page_token).execute()\n\n all_items += response.get('files', [])\n \n page_token = response.get('nextPageToken', None)\n if page_token is None:\n break\n \n page_token = None\n\n while True:\n\n try:\n\n response = service.files().list(q=\"mimeType='application/vnd.google-apps.folder'\",\n pageToken=page_token).execute()\n\n children = []\n for directory in response.get('files',[]):\n\n children_response = service.files().list(q=\"'\"+directory['id']+\"' in parents\",\n fields='files(id, name)').execute()\n children += [r['id'] for r in children_response.get('files',[])]\n \n\n all_items = [a for a in all_items if a['id'] not in children]\n page_token = response.get('nextPageToken',None)\n\n if page_token == None:\n break\n\n except Exception as e:\n pass\n\n #first-level only files, including directors, without google types\n all_items = [a for a in all_items if a['mimeType'] not in Google_Drive.g_types]\n\n\n return all_items\n\n\n def download_local(self, path):\n \"\"\"Download a list of files with id's at a designated path\"\"\"\n \n \n list_id = self.first_level\n if list_id == None:\n self.first_level = Google_Drive.retrieve_drive_first_level(self.service)\n print(\"Started downloading!\")\n p = MyPool(1)\n target = partial(download_file_or_folder,google_types=Google_Drive.g_types, drive_service=self.service, path=path)\n data = p.map(target, list_id)\n data = list(filter(lambda x: x!=None, data))\n while len(data) != 0:\n data = p.map(target, data)\n data = list(filter(lambda x: x!=None, data))\n p.close()\n p.join()\n print(\"Download finished!\")\n\n\n def upload_local(self, local_path):\n \"\"\"Upload all the contents from a local path \"\"\"\n\n files = [os.path.join(local_path,f) for f in os.listdir(local_path)]\n target = partial(upload_file_or_folder,drive_service = self.service,parent_id=None)\n p = MyPool(12)\n data = p.map(target, files)\n data = list(filter(lambda x: x!=None, data))\n while len(data) != 0:\n data = p.map(target, data)\n data = list(filter(lambda x: x!=None, data))\n if len(data) == 1:\n print(data[0])\n p.close()\n p.join()\n print(\"Upload finished!\")\n\n \n def delete_all_files(self):\n\n Google_Drive.lookup_table = {}\n\n page_token = None\n files = []\n\n while True:\n\n response = self.service.files().list(fields='nextPageToken, files(id,name)',\n pageToken=page_token).execute()\n\n page_token = response.get('nextPageToken', None)\n files += response.get('files',[])\n\n if page_token is None:\n break\n \n \n target = partial(delete_file,drive_service = self.service)\n p = MyPool(1)\n data = p.map(target, files)\n data = list(filter(lambda x: x!=None, data))\n while len(data) != 0:\n data = p.map(target, data)\n data = list(filter(lambda x: x!=None, data))\n print(len(data))\n p.close()\n p.join()\n\n print(\"Delete all finished!\")\n\n def get_all_file_ids_paths(self):\n\n all_items = []\n page_token = None\n\n while True:\n \n response = self.service.files().list(q=\"'me' in owners and trashed=false\",\n fields='nextPageToken, files(id, name, mimeType)',\n pageToken=page_token).execute()\n\n all_items += response.get('files', [])\n \n page_token = response.get('nextPageToken', None)\n if page_token is None:\n break\n\n all_items = list(filter(lambda item: item[\"mimeType\"] != \"application/vnd.google-apps.folder\", all_items))\n\n target = partial(get_file_path,drive_service = self.service)\n p = MyPool(12)\n data = p.map(target, all_items)\n data = list(filter(lambda x: x!=None, data))\n p.close()\n p.join()\n self.current_data = data\n\n def upload_file(self, path):\n\n access_token = self.creds.token\n filename = path\n\n filesize = os.path.getsize(filename)\n\n # 1. Retrieve session for resumable upload.\n\n headers = {\"Authorization\": \"Bearer \"+access_token, \"Content-Type\": \"application/json\"}\n params = {\n \"name\": \"br2049.mkv\",\n \"mimeType\": \"video/x-matroska\"\n }\n r = requests.post(\n \"https://www.googleapis.com/upload/drive/v3/files?uploadType=resumable\",\n headers=headers,\n data=json.dumps(params)\n )\n location = r.headers['Location']\n\n # 2. Upload the file.\n chunksize = 262144*64\n prev = 0\n with open(filename,'rb') as f:\n for piece in read_in_chunks(f,chunk_size=chunksize):\n \n offset = prev+len(piece)-1\n headers = {\"Content-Range\": \"bytes \"+str(prev)+\"-\" + str(offset) + \"/\" + str(filesize)}\n prev = offset+1\n r = requests.put(\n location,\n headers=headers,\n data=piece\n )\n print(r.text)\n \n\n def make_member(self):\n\n self.get_all_file_ids_paths()\n return Member(self.current_data, self.service, self.creds)\n\nif __name__ == \"__main__\":\n\n g = Google_Drive()\n g.show_full_stats()\n #path = \"/media/mih01/Mass Storage/Transfer\"\n #g.download_local(path)\n \n\n\n"
},
{
"alpha_fraction": 0.553113579750061,
"alphanum_fraction": 0.5579975843429565,
"avg_line_length": 21.135135650634766,
"blob_id": "8004a97e8ce4dd3b39834304ea883dea19191472",
"content_id": "b0d57fb2bf042460b1441e74c954531f3861833d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 819,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 37,
"path": "/epicshelter_tested/aws_s3/aws_s3.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import boto3\nfrom botocore.client import ClientError\n\n\nclass S3():\n\n def __init__(self):\n\n self.client = boto3.client(\"s3\")\n\n def list_objects(self, bucket=None):\n\n if bucket == None:\n raise ValueError(\"Bucket is None!\")\n\n data = self.client.list_objects(Bucket=bucket)\n\n keys = []\n\n for k in data[\"Contents\"]:\n keys.append(k[\"Key\"])\n \n return keys\n\n def download_fileobj(self, Bucket=None,Key=None, target=None):\n\n if Bucket == None:\n raise ValueError(\"Bucket is None!\")\n\n if Key == None:\n raise ValueError(\"Key is None!\")\n\n if target == None:\n raise ValueError(\"Target is None!\")\n\n with open(target, \"wb+\") as data:\n self.client.download_fileobj(Bucket, Key, data)\n"
},
{
"alpha_fraction": 0.6993007063865662,
"alphanum_fraction": 0.7202796936035156,
"avg_line_length": 17,
"blob_id": "5b4d3d8c1bb53964071de97d3cb3233008ae1a27",
"content_id": "9f769e29c33f33525e82ddbbf63baa00f0c01b31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/epicshelter/amazon_s3/test_amazon.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import boto3\n\n\nclient = boto3.resource(\"s3\")\nbucket = client.Bucket(\"epic-shelter\")\nobj = list(bucket.objects.filter(Prefix=\"df/\"))\n\nprint(obj)"
},
{
"alpha_fraction": 0.49705103039741516,
"alphanum_fraction": 0.5054556131362915,
"avg_line_length": 31.76328468322754,
"blob_id": "8108c00330735850c1f50edeba56b4798896ef9d",
"content_id": "2bd9b88a6f10eb6825bc0ef3c23cd311c54446bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6782,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 207,
"path": "/epicshelter/google_drive/utils/google_utils.py",
"repo_name": "mihai011/EpicShelter",
"src_encoding": "UTF-8",
"text": "import io\nfrom googleapiclient.http import MediaIoBaseDownload, MediaIoBaseUpload\nimport os\nfrom termcolor import colored\nfrom googleapiclient.errors import HttpError\n\nfrom functools import partial\nfrom .processing_class import MyPool\nimport json\nimport ntpath\nimport magic\nimport socket\n\ndef convert_bytes(b, scales):\n return b/(1024**scales)\n\ndef read_in_chunks(file_object, chunk_size=1024):\n while True:\n data = file_object.read(chunk_size)\n if not data:\n break\n yield data\n\ndef download_file_or_folder(item, drive_service, path, google_types):\n \n\n file_id = item['id'] \n item_path = os.path.join(path,item['name'])\n\n if item[\"mimeType\"] == \"application/vnd.google-apps.folder\":\n\n if not os.path.exists(item_path):\n os.makedirs(item_path)\n\n query = \"'\"+file_id+\"' in parents and 'me' in owners and trashed=false\"\n try:\n children_response = drive_service.files().list(q=query,\n fields='files(id, name, mimeType)').execute()\n except HttpError as e:\n if e.resp.status == 416:\n return None\n return item\n children = children_response.get('files',[])\n \n p = MyPool(12)\n target = partial(download_file_or_folder,google_types=google_types, drive_service=drive_service, path=item_path)\n remaining = p.map(target, children)\n remaining = list(filter(lambda x: x!=None, remaining))\n while len(remaining) != 0:\n remaining = p.map(target, remaining)\n remaining = list(filter(lambda x: x!=None, remaining))\n\n p.close()\n p.join()\n \n else:\n\n try:\n request = drive_service.files().get_media(fileId=file_id)\n fh = io.BytesIO()\n downloader = MediaIoBaseDownload(fh, request)\n done = False\n if item['mimeType'] in google_types:\n return \n with open(item_path, \"wb+\") as f:\n while done is False:\n status, done = downloader.next_chunk()\n data = fh.getvalue()\n fh.truncate(0)\n fh.seek(0)\n f.write(data)\n fh.close()\n print(colored(item_path, 'green'))\n except HttpError as e:\n reason = e._get_reason()\n print(reason)\n if reason == \"\":\n return None\n if reason.startswith(\"User Rate Limit Exceeded\"):\n print(colored(str(item['name']) + \" User Rate Limit Exceeded\",\"red\"))\n return item\n if reason.startswith(\"Request range not satisfiable\"):\n print(colored(str(item['name']) +\" Request range not satisfiable\",\"red\"))\n return None\n return None\n except IsADirectoryError as e:\n return item\n\n\ndef upload_file_or_folder(path, drive_service, parent_id):\n\n\n if os.path.isdir(path):\n folder_name = ntpath.basename(path)\n\n if parent_id == None:\n\n file_metadata = {\n 'name': folder_name,\n 'mimeType': 'application/vnd.google-apps.folder'\n }\n else:\n file_metadata = {\n 'name': folder_name,\n 'mimeType': 'application/vnd.google-apps.folder',\n 'parents' :[parent_id]\n }\n try:\n file = drive_service.files().create(body=file_metadata,\n fields='id').execute()\n except HttpError as e:\n if e.resp.status == 416:\n return None\n return path\n\n folder_id = file.get(\"id\")\n children = [os.path.join(path,p) for p in os.listdir(path)]\n p = MyPool(12)\n target = partial(upload_file_or_folder, drive_service=drive_service, parent_id=folder_id)\n remaining = p.map(target, children)\n remaining = list(filter(lambda x: x!=None, remaining))\n while len(remaining) != 0:\n remaining = p.map(target, remaining)\n remaining = list(filter(lambda x: x!=None, remaining))\n if len(remaining) == 1:\n print(remaining[0])\n p.close()\n p.join()\n print(path) \n\n elif os.path.isfile(path):\n\n try:\n mt = magic.Magic(mime=True)\n mt = mt.from_file(path)\n file_name = ntpath.basename(path)\n if parent_id == None:\n file_metadata = {'name': file_name,\n 'mimeType': mt\n }\n else:\n file_metadata = {'name': file_name,\n 'parents' :[parent_id],\n 'mimeType': mt\n }\n \n fh = open(path,\"rb+\")\n media = MediaIoBaseUpload(fh,mimetype=mt,\n chunksize=6024*1024, resumable=True)\n\n request = drive_service.files().create(body=file_metadata,\n media_body=media,\n fields='id').execute()\n\n fh.close()\n print(path)\n except HttpError as e:\n if e.resp.status == 416:\n return None\n if e.resp.status in [403, 404, 500, 512]:\n print(\"error:\"+str(e)+\":\"+path)\n return path\n except IsADirectoryError as e:\n return path\n except socket.timeout as e:\n return path\n\ndef delete_file(file,drive_service):\n\n try:\n drive_service.files().delete(fileId=file['id']).execute()\n print(file['name'])\n except HttpError as e:\n if e.resp.status == 404:\n return None\n if e.resp.status == 403:\n return None\n return file\n\ndef get_file_path(file, drive_service):\n\n id = file['id']\n\n tree = [] # Result\n while True:\n try:\n file = drive_service.files().get(fileId=id, fields='id, name, parents').execute()\n parent = file.get('parents')\n if parent:\n while True:\n folder = drive_service.files().get(\n fileId=parent[0], fields='id, name, parents').execute()\n parent = folder.get('parents')\n if parent is None:\n break\n tree.append(folder.get('name'))\n\n break\n except HttpError as e:\n if e.resp.status == 416:\n return None\n \n tree.reverse()\n tree.append(file[\"name\"])\n path = os.path.join(*tree)\n \n return [path,file['id']]\n"
}
] | 19 |
Santhin/effective-tribble
|
https://github.com/Santhin/effective-tribble
|
1f6130f5034a606006559ea78f193c8c7a60fd1b
|
7156c182c7980474cf620e54c7cdc7fbe02b1aec
|
f20394d78a7f117e1cb8b6f2292c6b94b8c5ca67
|
refs/heads/main
| 2023-04-19T11:47:15.702183 | 2021-05-12T13:08:32 | 2021-05-12T13:08:32 | 366,711,317 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5507377982139587,
"alphanum_fraction": 0.653507649898529,
"avg_line_length": 76.26000213623047,
"blob_id": "02db969294d8db537640768a3c2f876c088c5d4c",
"content_id": "f051f8fb42eb19e8f1e541f593aa8e019c75da97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 7726,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 100,
"path": "/requirements.txt",
"repo_name": "Santhin/effective-tribble",
"src_encoding": "UTF-8",
"text": "appnope==0.1.2; platform_system == \"Darwin\" and python_version >= \"3.7\" and sys_platform == \"darwin\"\nargon2-cffi==20.1.0; python_version >= \"3.6\"\nasync-generator==1.10; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nattrs==21.2.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\" and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\")\nautomat==20.2.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nbackcall==0.2.0; python_version >= \"3.7\"\nbleach==3.3.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\ncffi==1.14.5; implementation_name == \"pypy\" and python_version >= \"3.6\"\ncolorama==0.4.4; python_version >= \"3.7\" and python_full_version < \"3.0.0\" and sys_platform == \"win32\" or sys_platform == \"win32\" and python_version >= \"3.7\" and python_full_version >= \"3.5.0\"\nconstantly==15.1.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\ncryptography==3.4.7; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\ncssselect==1.1.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\ndecorator==5.0.7; python_version >= \"3.7\"\ndefusedxml==0.7.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nentrypoints==0.3; python_version >= \"3.6\"\nh2==3.2.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nhpack==3.0.0; python_version >= \"3.6\"\nhtml-text==0.5.2\nhyperframe==5.2.0; python_version >= \"3.6\"\nhyperlink==21.0.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nidna==3.1; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nincremental==21.3.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nipykernel==5.5.4; python_version >= \"3.6\"\nipython-genutils==0.2.0; python_version >= \"3.7\"\nipython==7.23.1; python_version >= \"3.7\"\nipywidgets==7.6.3\nitemadapter==0.2.0; python_version >= \"3.6\"\nitemloaders==1.0.4; python_version >= \"3.6\"\njedi==0.17.2; python_version >= \"3.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.7\"\njinja2==2.11.3; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\njmespath==0.10.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.3.0\" and python_version >= \"3.6\"\njoblib==1.0.1; python_version >= \"3.6\"\njsonschema==3.2.0; python_version >= \"3.6\"\njupyter-client==6.2.0; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\njupyter-console==6.4.0; python_version >= \"3.6\"\njupyter-core==4.7.1; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\njupyter==1.0.0\njupyterlab-pygments==0.1.2; python_version >= \"3.6\"\njupyterlab-widgets==1.0.0; python_version >= \"3.6\"\nlxml==4.6.3; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nmarkupsafe==1.1.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nmatplotlib-inline==0.1.2; python_version >= \"3.7\"\nmistune==0.8.4; python_version >= \"3.6\"\nnbclient==0.5.3; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nnbconvert==6.0.7; python_version >= \"3.6\"\nnbformat==5.1.3; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nnest-asyncio==1.5.1; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nnotebook==6.3.0; python_version >= \"3.6\"\nnumpy==1.20.3; python_version >= \"3.7\" and python_full_version >= \"3.7.1\"\npackaging==20.9; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\npandas==1.2.4; python_full_version >= \"3.7.1\"\npandocfilters==1.4.3; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\nparsel==1.6.0; python_version >= \"3.6\"\nparso==0.7.1; python_version >= \"3.7\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.7\"\npexpect==4.8.0; sys_platform != \"win32\" and python_version >= \"3.7\"\npickleshare==0.7.5; python_version >= \"3.7\"\npriority==1.3.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nprometheus-client==0.10.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\nprompt-toolkit==3.0.18; python_full_version >= \"3.6.1\" and python_version >= \"3.7\"\nprotego==0.1.16; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nptyprocess==0.7.0; os_name != \"nt\" and python_version >= \"3.7\" and sys_platform != \"win32\"\npy==1.10.0; python_version >= \"3.6\" and python_full_version < \"3.0.0\" and implementation_name == \"pypy\" or implementation_name == \"pypy\" and python_version >= \"3.6\" and python_full_version >= \"3.4.0\"\npyasn1-modules==0.2.8; python_version >= \"3.6\"\npyasn1==0.4.8; python_version >= \"3.6\"\npycparser==2.20; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.4.0\" and python_version >= \"3.6\"\npydispatcher==2.0.5; platform_python_implementation == \"CPython\" and python_version >= \"3.6\"\npygments==2.9.0; python_version >= \"3.7\"\npyopenssl==20.0.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\npyparsing==2.4.7; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\npypydispatcher==2.1.2; platform_python_implementation == \"PyPy\" and python_version >= \"3.6\"\npyrsistent==0.17.3; python_version >= \"3.6\"\npython-dateutil==2.8.1; python_full_version >= \"3.7.1\" and python_version >= \"3.6\"\npytz==2021.1; python_full_version >= \"3.7.1\"\npywin32==300; sys_platform == \"win32\" and python_version >= \"3.6\"\npywinpty==0.5.7; os_name == \"nt\" and python_version >= \"3.6\"\npyzmq==22.0.3; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nqtconsole==5.1.0; python_version >= \"3.6\"\nqtpy==1.9.0; python_version >= \"3.6\"\nqueuelib==1.6.1; python_version >= \"3.6\"\nscikit-learn==0.24.2; python_version >= \"3.6\"\nscipy==1.6.1; python_version >= \"3.7\"\nscrapy-crawl-once==0.1.1\nscrapy==2.5.0; python_version >= \"3.6\"\nsend2trash==1.5.0; python_version >= \"3.6\"\nservice-identity==21.1.0; python_version >= \"3.6\"\nsix==1.16.0; python_full_version >= \"3.7.1\" and python_version >= \"3.6\" and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\") and (python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.3.0\" and python_version >= \"3.6\")\nsklearn==0.0\nsqlitedict==1.7.0\nterminado==0.9.5; python_version >= \"3.6\"\ntestpath==0.4.4; python_version >= \"3.6\"\nthreadpoolctl==2.1.0; python_version >= \"3.6\"\ntornado==6.1; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\ntraitlets==5.0.5; python_full_version >= \"3.6.1\" and python_version >= \"3.7\"\ntwisted-iocpsupport==1.0.1; python_full_version >= \"3.5.4\" and python_version >= \"3.6\" and platform_system == \"Windows\"\ntwisted==21.2.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\nw3lib==1.22.0; python_version >= \"3.6\"\nwcwidth==0.2.5; python_full_version >= \"3.6.1\" and python_version >= \"3.6\"\nwebencodings==0.5.1; python_version >= \"3.6\" and python_full_version < \"3.0.0\" or python_full_version >= \"3.5.0\" and python_version >= \"3.6\"\nwidgetsnbextension==3.5.1\nzope.interface==5.4.0; python_full_version >= \"3.5.4\" and python_version >= \"3.6\"\n"
},
{
"alpha_fraction": 0.4963427484035492,
"alphanum_fraction": 0.5015674233436584,
"avg_line_length": 27.060606002807617,
"blob_id": "6cfb0e1e0effd0dfc8d35986f4df3e386f311d44",
"content_id": "19e6aebab39d7291b0b0baa59586ad1f79c1c672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1211,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 33,
"path": "/README.md",
"repo_name": "Santhin/effective-tribble",
"src_encoding": "UTF-8",
"text": "# Struktura plików:\r\n```\r\n.\r\n├── poetry.lock \r\n├── pyproject.toml\r\n├── README.md\r\n├── requirements.txt - biblioteki zawarte w projekcie \r\n├── zadanie1\r\n│ ├── xkom\r\n│ │ ├── scrapy.cfg\r\n│ │ ├── xkom\r\n│ │ │ ├── __init__.py\r\n│ │ │ ├── items.py\r\n│ │ │ ├── middlewares.py\r\n│ │ │ ├── pipelines.py\r\n│ │ │ ├── settings.py - ustawienia pająka\r\n│ │ │ └── spiders\r\n│ │ │ ├── __init__.py\r\n│ │ │ └── xkomapi.py - crawler\r\n│ │ └── xkomapi.json - plik ze scrawlowanymi danymi\r\n│ └── xkom.postman_collection.json - testowanie api za pomocą postmana\r\n├── zadanie2\r\n│ ├── a.csv\r\n│ ├── b.csv\r\n│ ├── c.csv - plik z miesięcznymi średnimi wartościami\r\n│ └── Notebook_zad2.ipynb\r\n└── zadanie3\r\n ├── Notebook_zad3.ipynb\r\n ├── similarity_with_text.csv - plik z podobieństwem tekstów\r\n ├── vectors.csv - plik z wektorami\r\n ├── x_learn.txt\r\n └── x_test.txt\r\n```"
},
{
"alpha_fraction": 0.5684575438499451,
"alphanum_fraction": 0.6412478089332581,
"avg_line_length": 22.079999923706055,
"blob_id": "e1acca0041ba74dae051409d485f51f6f2e0ffbc",
"content_id": "958c1f704c2e598bbf81bb56f465de404324c216",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/pyproject.toml",
"repo_name": "Santhin/effective-tribble",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"easypartnering\"\nversion = \"0.1.0\"\ndescription = \"\"\nauthors = [\"Santhin <[email protected]>\"]\n\n[tool.poetry.dependencies]\npython = \"^3.8\"\nScrapy = \"^2.5.0\"\nhtml-text = \"^0.5.2\"\njupyter = \"^1.0.0\"\nnotebook = \"^6.3.0\"\npandas = \"^1.2.4\"\nscrapy-crawl-once = \"^0.1.1\"\nsklearn = \"^0.0\"\nscikit-learn = \"^0.24.2\"\n\n[tool.poetry.dev-dependencies]\njupyter-tabnine = \"^1.2.2\"\njupyter_nbextensions_configurator = \"^0.4.1\"\npython-language-server = {extras = [\"all\"], version = \"^0.36.2\"}\n\n[build-system]\nrequires = [\"poetry-core>=1.0.0\"]\nbuild-backend = \"poetry.core.masonry.api\"\n"
},
{
"alpha_fraction": 0.5405982732772827,
"alphanum_fraction": 0.5737179517745972,
"avg_line_length": 44.65853500366211,
"blob_id": "5e75e430c6d29b28166e61e49461d90294667d23",
"content_id": "986fe516ef798f57b92616a966297e8a39fb7a47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1872,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 41,
"path": "/zadanie1/xkom/xkom/spiders/xkomapi.py",
"repo_name": "Santhin/effective-tribble",
"src_encoding": "UTF-8",
"text": "import scrapy\nimport json\nimport html_text\n\nclass XkomapiSpider(scrapy.Spider):\n name = 'xkomapi'\n allowed_domains = ['x-kom.pl']\n start_urls = ['http://x-kom.pl/']\n headers = {\n # 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36',\n 'X-API-Key': 'sJSgnQXySmp6pqNV'\n }\n url = \"https://mobileapi.x-kom.pl/api/v1/xkom/products?productQuery.criteria.groupIds=2,4,7,5,6,8,64,12&productQuery.pagination.currentPage=1&productQuery.pagination.pageSize=100\"\n def start_requests(self):\n yield scrapy.http.Request(url=self.url,\n headers=self.headers,\n callback=self.parse)\n\n def parse(self, response):\n data = json.loads(response.body)\n for product in [x['Id'] for x in data['Items']]:\n yield scrapy.http.Request(url=f\"https://mobileapi.x-kom.pl/api/v1/xkom/products/{product}\",\n headers=self.headers,\n callback=self.parse2,\n meta={\"crawl_once\" : True})\n maxNum = data['TotalPages']\n pageNum = 1\n while pageNum <= maxNum:\n pageNum+=1\n yield scrapy.http.Request(url=f'https://mobileapi.x-kom.pl/api/v1/xkom/products?productQuery.criteria.groupIds=2,4,7,5,6,8,64,12&productQuery.pagination.currentPage={pageNum}&productQuery.pagination.pageSize=100',\n headers=self.headers,\n callback=self.parse)\n\n def parse2(self, response):\n # response.request.meta[\"crawl_once\"] = True\n data = json.loads(response.body)\n yield {\n 'nazwa' : data['Name'],\n 'cena' : data['Price'],\n 'opis' : html_text.extract_text(data['ProductDescription'])\n }\n"
}
] | 4 |
UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1
|
https://github.com/UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1
|
aa27254dcc61fe321655eb96cf1e1038b4350a0b
|
89c4af4ef99c12edb7fec30ade6eba0b47412856
|
43867bd26f0650fdfd6c0f270fa391e93cf4e6ab
|
refs/heads/master
| 2023-03-17T15:48:43.429486 | 2020-07-25T02:54:40 | 2020-07-25T02:58:12 | 348,113,238 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6035503149032593,
"alphanum_fraction": 0.6035503149032593,
"avg_line_length": 27.22222137451172,
"blob_id": "4bd6a5190a15f3373df0062bd0dccc26b8dd33dc",
"content_id": "3130e052758b750ec66b4e9377b3e35f7e13f1f3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 507,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 18,
"path": "/app/model/entity/estado.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "class Estado:\n def __init__(self, id, nome, sigla, iconeEstado, listaNoticias):\n self._id = id\n self._nome = nome\n self._sigla = sigla\n self._iconeEstado = iconeEstado\n self._listaNoticias = listaNoticias\n\n def getId(self):\n return self._id\n def getNome(self):\n return self._nome\n def getSigla(self):\n return self._sigla\n def getIcone(self):\n return self._iconeEstado\n def getNewsList(self):\n return self._listaNoticias"
},
{
"alpha_fraction": 0.6525735259056091,
"alphanum_fraction": 0.654411792755127,
"avg_line_length": 27.6842098236084,
"blob_id": "d84928606dccb6cabb58a75ca8f45f24e6440a36",
"content_id": "c0fd3b6147bda3b87e32bb03442609d7b807298c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 544,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 19,
"path": "/app/model/dao/estadoDao.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "from application.model.entity.estado import Estado\nfrom application import listaEstados\n\n\nclass EstadoDao:\n def __init__(self):\n self._listaEstados = listaEstados\n\n def mostrarEstados(self):\n return self._listaEstados\n\n def mostrarNoticias(self, estado):\n return estado.getListaNoticias()\n \n def busca_por_id(self, id):\n for estado in range(0, len(self._listaEstados)):\n if self._listaEstados[estado].getId() == int(id):\n return self._listaEstados[estado]\n return None"
},
{
"alpha_fraction": 0.7355421781539917,
"alphanum_fraction": 0.740963876247406,
"avg_line_length": 38.5,
"blob_id": "a659b2d437e3d03bda784fea8b35f25ff4cff4ad",
"content_id": "f250050dcdb3ecb569b2043a5d7b2f60a4fe2de8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1660,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 42,
"path": "/app/controller/controllerNoticia.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request\nfrom app import app\nfrom app.model.dao.noticiaDao import NoticiaDAO\nfrom app.model.entity.noticia import Noticia\nfrom app.model.dao.estadoDao import EstadoDAO\nfrom app.model.entity.estado import Estado\nfrom app.model.entity.comment import Comment\nfrom app import listaNoticias\nfrom app import listaEstados\n\[email protected](\"/noticia/<noticia_id>\", methods=['GET'])\ndef noticia(noticia_id):\n noticiaDao = NoticiaDAO()\n noticia = noticiaDao.busca_por_id(noticia_id)\n noticiaDao.armazenar_visualizacao(noticia)\n lista_comentarios = noticia.get_comentarios()\n return render_template(\"noticia.html\", noticia = noticia, listaEstados = listaEstados, listaComments = listaComments)\n\n\[email protected]('/noticia/<noticia_id>/comments', methods=['POST'])\ndef comentar(noticia_id):\n noticiaDao = NoticiaDAO()\n noticia = noticiaDao.busca_por_id(noticia_id)\n autor = request.values.get('nome') \n texto = request.values.get('texto')\n comment = Comment(autor, texto)\n noticia.setComment(comment)\n return render_template('comments.html', noticia = noticia), 201\n\[email protected](\"/noticia/<noticia_id>/curtir\", methods=['POST'])\ndef curtir(noticia_id):\n noticiaDao = NoticiaDAO()\n noticia = noticiaDao.busca_por_id(noticia_id)\n noticiaDao.salvarLike(noticia)\n return render_template(\"curtidas.html\", noticia = noticia), 200\n\[email protected]('/noticia/<noticia_id>/comments', methods=['DELETE'])\ndef apagar(noticia_id):\n noticiaDao = NoticiaDAO()\n noticia = noticiaDao.busca_por_id(noticia_id)\n noticiaDao.apagarComment(noticia)\n return render_template('comments.html', noticia = noticia), 200\n\n"
},
{
"alpha_fraction": 0.5734597444534302,
"alphanum_fraction": 0.5734597444534302,
"avg_line_length": 22.55555534362793,
"blob_id": "34541d5338de1c6487d951c19f2e4a7b6d3833e1",
"content_id": "65058aee1ace752c7c3651d3691bb15405068209",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 9,
"path": "/app/model/entity/comment.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "class comment:\n def __init__(self, autor, texto):\n self._autor = autor\n self._texto = texto\n\n def getAutor(self):\n return self._autor\n def getTexto(self):\n return self._texto"
},
{
"alpha_fraction": 0.5707195997238159,
"alphanum_fraction": 0.5740281343460083,
"avg_line_length": 22.72549057006836,
"blob_id": "95dd601b32e4caead608fe4956e2138bc32c4725",
"content_id": "479fa19391e9bddfbeb79d16afd6bd776e0d732d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1209,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 51,
"path": "/app/model/entity/noticia.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "class Noticia:\n def __init__(self, id, titulo, texto, iconeNoticia, video, dataNoticia, estado):\n self._id = id\n self._titulo = titulo\n self._texto = texto\n self._iconeNoticia = iconeNoticia\n self._video = video\n self._dataNoticia = dataNoticia\n self._estado = estado\n self._qtdView = 0\n self._qtdLike = 0\n self._comments = []\n\n def getId(self):\n return self._id\n \n def getTitulo(self):\n return self._titulo\n \n def getTexto(self):\n return self._texto\n \n def getIconeNoticia(self):\n return self._iconeNoticia\n \n def getVideo(self):\n return self._video\n \n def getDataNoticia(self):\n return self._dataNoticia\n \n def getEstado(self):\n return self._estado\n \n def setQtdView(self):\n self._qtdView = self._qtdView + 1\n \n def getQtdView(self):\n return self._qtdView\n\n def setQtdLike(self):\n self._qtdLike = self._qtdLike + 1\n \n def getQtdLike(self):\n return self._qtdLike \n\n def setComment(self,comment):\n self._comments.append(comment)\n \n def getComment(self):\n return self._comments"
},
{
"alpha_fraction": 0.6423658728599548,
"alphanum_fraction": 0.645116925239563,
"avg_line_length": 28.1200008392334,
"blob_id": "d31b82b1b71ec2c1ffdc310687b0998e899c3e69",
"content_id": "41d064401aa1c75e7bfa2f5d98b6b8bd132cd078",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 727,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 25,
"path": "/app/model/dao/noticiaDao.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "from application.model.entity.noticia import Noticia\nfrom application import listaNoticia\n\nclass NoticiaDao:\n\n def __init__(self):\n self._listaNoticias = listaNoticias\n\n def mostrarNoticias(self, estado):\n return self._listaNoticias\n \n def busca_por_id(self, id):\n for noticia in range(0, len(self._listaNoticias)):\n if self._listaNoticias[noticia].getId() == int(id):\n return self._listaNoticias[noticia]\n return None\n \n def apagarComment(self, noticia):\n noticia.getComment().pop(len(noticia.getComment())-1)\n \n def salvarView(self, noticia):\n noticia.setQtdView()\n \n def salvarLike(self, noticia):\n noticia.setQtdLike()"
},
{
"alpha_fraction": 0.7528917193412781,
"alphanum_fraction": 0.7613039016723633,
"avg_line_length": 46.29999923706055,
"blob_id": "fe0cc5f6ba136cc6f0514e37931d20357600f5bd",
"content_id": "a37144f5476ba411368890d7259c5682a483f6fb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 951,
"license_type": "permissive",
"max_line_length": 166,
"num_lines": 20,
"path": "/app/controller/controllerIndex.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request\nfrom app import app\nfrom app.model.entity.estado import Estado\nfrom app.model.dao.estadoDao import EstadoDAO\nfrom app.model.entity.noticia import Noticia\nfrom app.model.dao.noticiaDao import NoticiaDAO\nfrom app import listaEstados\nfrom app import listaNoticias\n\n\[email protected]('/')\ndef home():\n estadoDao = EstadoDAO()\n for estado in listaEstados:\n estado_id = estado.getId()\n estado = estadoDao.busca_por_id(estado_id) \n listaLatest = [listaNoticias[len(listaNoticias)-1], listaNoticias[len(listaNoticias)-2], listaNoticias[len(listaNoticias)-3], listaNoticias[len(listaNoticias)-4]]\n mostLiked = sorted(listaNoticias, key=Noticia.getQtdLike, reverse=True)\n listaMostLiked = [mostLiked[0], mostLiked[1], mostLiked[2], mostLiked[3]]\n return render_template(\"index.html\", listaEstados = listaEstados, listaLatest = listaLatest, listaMostLiked = listaMostLiked, estado = estado)\n \n"
},
{
"alpha_fraction": 0.7529069781303406,
"alphanum_fraction": 0.7529069781303406,
"avg_line_length": 30.363636016845703,
"blob_id": "6dfa600aea988e098fe3caef4022b1c5d1233413",
"content_id": "df273ce43c3643e8d1650443fa967fe025951d0c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 11,
"path": "/app/controller/controllerEstado.py",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "from app import app\nfrom flask import render_template, request\nfrom app.model.dao.estadoDao import EstadoDao\nfrom app.model.entity.estado import Estado\n\n\[email protected]('/estado/<estado_id>')\ndef estado(estado_id):\n estadoDao = EstadoDao()\n estado = estadoDao.busca_por_id(estado_id)\n return render_template(\"estado.html\", estado = estado)"
},
{
"alpha_fraction": 0.6779661178588867,
"alphanum_fraction": 0.700564980506897,
"avg_line_length": 88,
"blob_id": "87d8fadf2e8cba178d76a39b0fb66f15158772f5",
"content_id": "2b9ac7419197c9bbfe46b0227ca84a3ceb4a7fb0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 179,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 2,
"path": "/app/view/templates/curtidas.html",
"repo_name": "UniversidadeDeVassouras/labproghiper-2020.1-JoaoMarcosGomes-p1",
"src_encoding": "UTF-8",
"text": "<h6 style=\"text-align: center;\">{{noticia.getQtdView()}} visualizações | {{noticia.getQtdLike()}} curtidas</h6>\n<h6 style=\"text-align: center;\">{{noticia.getDataNoticia()}}</h6>"
}
] | 9 |
rob-blackbourn/PyTibrv
|
https://github.com/rob-blackbourn/PyTibrv
|
1658c49b6e033782245ee827f46129256f2e9a56
|
05988a4ba62991b80a80d1e245f5b517429d340b
|
8fbdbe9742d0a3356c04c63772151ffb88c61d4c
|
refs/heads/master
| 2021-01-10T05:17:56.982237 | 2015-09-29T07:16:16 | 2015-09-29T07:16:16 | 43,062,975 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5442177057266235,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 36,
"blob_id": "18de3e28a367c91e1dc1db7b462e91f621a534ec",
"content_id": "208fc0444bd1231bae0acd4c4891bb166c6a3626",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 147,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 4,
"path": "/stdafx.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\n// If you have to ask you're not old enough\nextern \"C\" { FILE _iob[3] = {__iob_func()[0], __iob_func()[1], __iob_func()[2]}; }"
},
{
"alpha_fraction": 0.6910490989685059,
"alphanum_fraction": 0.6910490989685059,
"avg_line_length": 19.372549057006836,
"blob_id": "9029c3718847add7e281391d0b1e1e06487bdaa4",
"content_id": "59aa1a3deedfa9d5c70d1bf0183361dcff4971d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1039,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 51,
"path": "/PyTibrvCallback.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nclass PyTibrvCallback : public TibrvCallback\n{\npublic:\n\tPyTibrvCallback(PyObject* Callback, bool OneOff)\n\t\t:\tm_OneOff(OneOff)\n\t{\n\t\tif (!PyCallable_Check(Callback))\n\t\t\tthrow \"invalid callback\";\n\n\t\tPy_INCREF(Callback);\n\t\tm_Callback = Callback;\n\t}\n\n\t~PyTibrvCallback()\n\t{\n\t\tif (m_Callback != NULL)\n\t\t{\n\t\t\tPy_DECREF(m_Callback);\n\t\t\tm_Callback = NULL;\n\t\t}\n\t}\n\n\tPyObject* getCallback() { return m_Callback; }\n\tconst PyObject* getCallback() const { return m_Callback; }\n\nprivate:\n\tvirtual void onEvent(TibrvEvent* tibevent, TibrvMsg& msg)\n\t{\n\t\tTibrvStatus status;\n\n\t\tPyObject* py_msg = PyObject_From(msg);\n\n\t\tconst char* send_subject, *reply_subject;\n\t\tstatus = msg.getSendSubject(send_subject);\n\t\tstatus = msg.getReplySubject(reply_subject);\n\t\tPyObject* args = Py_BuildValue(\"ssN\", send_subject, reply_subject, py_msg);\n\t\tPyObject* result = PyObject_CallObject(m_Callback, args);\n\t\tPy_DECREF(args);\n\t\tif (result != NULL)\n\t\t\tPy_DECREF(result);\n\n\t\tif (m_OneOff)\n\t\t\tdelete this;\n\t}\n\nprivate:\n\tPyObject* m_Callback;\n\tbool m_OneOff;\n};\n"
},
{
"alpha_fraction": 0.6965174078941345,
"alphanum_fraction": 0.7145849466323853,
"avg_line_length": 32.06926345825195,
"blob_id": "d7b6e3b5248e8a888a64589ceebf752e15fecacb",
"content_id": "4e89990f5299d91ee01d8dbae28b67cb56561016",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7638,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 231,
"path": "/messages.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nstruct message_key\n{\n\tmessage_key(tibrv_u16 id, const char* name) : id(id), name(name) { }\n\tmessage_key(const message_key& key) : id(key.id), name(key.name) { }\n\n\tconst char* name;\n\tconst tibrv_u16 id;\n};\n\ninline PyObject* python_traits<message_key>::PyObject_FromType(const message_key& value)\n{\n\tPyObject* key = PyTuple_New(2);\n\tPyTuple_SetItem(key, 0, python_traits<tibrv_u16>::PyObject_FromType(value.id));\n\tPyTuple_SetItem(key, 1, python_traits<const char*>::PyObject_FromType(value.name));\n\treturn key;\n}\n\ninline message_key python_traits<message_key>::PyObject_AsType(PyObject* value)\n{\n\tif (PyObject_Is<const char*>(value))\n\t\treturn message_key(0, PyObject_As<const char*>(value));\n\telse if (PyObject_Is<tibrv_u16>(value))\n\t\treturn message_key(PyObject_As<tibrv_u16>(value), NULL);\n\telse if (PyObject_Is<tibrv_u16, const char*>(value))\n\t\treturn message_key(python_traits<tibrv_u16>::PyObject_AsType(PySequence_GetItem(value, 0)), python_traits<const char*>::PyObject_AsType(PySequence_GetItem(value, 1)));\n\telse\n\t\tthrow std::exception(\"invalid key\");\n}\n\ninline bool python_traits<message_key>::PyObject_CheckType(PyObject* value)\n{\n\treturn PyObject_Is<const char*>(value) || PyObject_Is<tibrv_u16>(value) || PyObject_Is<tibrv_u16, const char*>(value);\n}\n\ninline PyObject* python_traits<tibrvMsg>::PyObject_FromType(const tibrvMsg& msg)\n{\n\tstd::unique_ptr<TibrvMsg> tibrv_msg(new TibrvMsg(msg, TIBRV_TRUE));\n\tPyObject* py_object = PyObject_From(*tibrv_msg);\n\treturn py_object;\n}\n\ninline PyObject* python_traits<TibrvMsgField>::PyObject_FromType(const TibrvMsgField& msg_field)\n{\n\ttibrv_u8 type = msg_field.getType();\n\tPyObject* value;\n\tswitch (type)\n\t{\n\tcase TIBRVMSG_MSG:\n\t\tvalue = PyObject_From(msg_field.getData().msg);\n\t\tbreak;\n\tcase TIBRVMSG_DATETIME:\n\t\tvalue = PyObject_From(msg_field.getData().date);\n\t\tbreak;\n\tcase TIBRVMSG_OPAQUE:\n\t\tvalue = Py_None;\n\t\tPy_INCREF(value);\n\t\tbreak;\n\tcase TIBRVMSG_STRING:\n\t\tvalue = PyObject_From(msg_field.getData().str);\n\t\tbreak;\n\tcase TIBRVMSG_BOOL:\n\t\tvalue = PyObject_From(msg_field.getData().boolean);\n\t\tbreak;\n\tcase TIBRVMSG_I8:\n\t\tvalue = PyObject_From(msg_field.getData().i8);\n\t\tbreak;\n\tcase TIBRVMSG_U8:\n\t\tvalue = PyObject_From(msg_field.getData().u8);\n\t\tbreak;\n\tcase TIBRVMSG_I16:\n\t\tvalue = PyObject_From(msg_field.getData().i16);\n\t\tbreak;\n\tcase TIBRVMSG_U16:\n\t\tvalue = PyObject_From(msg_field.getData().u16);\n\t\tbreak;\n\tcase TIBRVMSG_I32:\n\t\tvalue = PyObject_From(msg_field.getData().i32);\n\t\tbreak;\n\tcase TIBRVMSG_U32:\n\t\tvalue = PyObject_From(msg_field.getData().u32);\n\t\tbreak;\n\tcase TIBRVMSG_I64:\n\t\tvalue = PyObject_From(msg_field.getData().i64);\n\t\tbreak;\n\tcase TIBRVMSG_U64:\n\t\tvalue = PyObject_From(msg_field.getData().u64);\n\t\tbreak;\n\tcase TIBRVMSG_F32:\n\t\tvalue = PyObject_From(msg_field.getData().f32);\n\t\tbreak;\n\tcase TIBRVMSG_F64:\n\t\tvalue = PyObject_From(msg_field.getData().f64);\n\t\tbreak;\n\tcase TIBRVMSG_I8ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_i8*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_U8ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_u8*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_I16ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_i16*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_U16ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast< const tibrv_u16*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_I32ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_i32*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_U32ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_u32*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_I64ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_i64*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_U64ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_u64*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_F32ARRAY:\n\t\tvalue = PyTuple_From(reinterpret_cast<const tibrv_f32*>(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_F64ARRAY:\n\t\tvalue = PyTuple_From((tibrv_f64*)(msg_field.getData().array), msg_field.getCount());\n\t\tbreak;\n\tcase TIBRVMSG_NONE:\n\t\tvalue = Py_None;\n\t\tPy_INCREF(value);\n\t\tbreak;\n\t}\n\n\ttibrv_u16 id = msg_field.getId();\n\tconst char* name = msg_field.getName();\n\n\tPyObject* key = PyTuple_New(2);\n\tPyTuple_SetItem(key, 0, PyObject_From(msg_field.getId()));\n\tPyTuple_SetItem(key, 1, PyString_FromString(msg_field.getName()));\n\n\tPyObject* item = PyTuple_New(2);\n\tPyTuple_SetItem(item, 0, key);\n\tPyTuple_SetItem(item, 1, value);\n\n\treturn item;\n}\n\ninline PyObject* python_traits<TibrvMsg>::PyObject_FromType(const TibrvMsg& msg)\n{\n\ttibrv_u32 num_fields;\n\tTibrvStatus status = msg.getNumFields(num_fields);\n\tPyObject* py_msg = PyTuple_New(num_fields);\n\tfor (tibrv_u32 field_index = 0; field_index < num_fields; ++field_index)\n\t{\n\t\tTibrvMsgField msg_field;\n\t\tstatus = const_cast<TibrvMsg&>(msg).getFieldByIndex(msg_field, field_index);\n\t\tPyObject* item = PyObject_From(msg_field);\n\t\tPyTuple_SetItem(py_msg, field_index, item);\n\t}\n\treturn py_msg;\n}\n\ninline TibrvStatus add_field(TibrvMsg& msg, const message_key& key, PyObject* value)\n{\n\tif (PyObject_Is<tibrv_i32>(value))\n\t\treturn msg.addI32(key.name, PyObject_As<tibrv_i32>(value), key.id);\n\telse if (PyObject_Is<const char*>(value))\n\t\treturn msg.addString(key.name, PyObject_As<const char*>(value), key.id);\n\telse if (PyObject_Is<tibrv_f64>(value))\n\t\treturn msg.addF64(key.name, PyObject_As<tibrv_f64>(value), key.id);\n\telse if (PyObject_Is<tibrv_bool>(value))\n\t\treturn msg.addBool(key.name, PyObject_As<tibrv_bool>(value), key.id);\n\telse if (PyObject_Is<tibrvMsgDateTime>(value))\n\t\treturn msg.addDateTime(key.name, PyObject_As<tibrvMsgDateTime>(value), key.id);\n\telse if (PySequence_Is<tibrv_i32>(value))\n\t\treturn msg.addI32Array(key.name, PySequence_As<tibrv_i32>(value), PySequence_Size(value), key.id);\n\telse if (PySequence_Is<tibrv_f64>(value))\n\t\treturn msg.addF64Array(key.name, PySequence_As<tibrv_f64>(value), PySequence_Size(value), key.id);\n\telse if (PyObject_Is<TibrvMsg>(value))\n\t\treturn msg.addMsg(key.name, PyObject_As<TibrvMsg>(value), key.id);\n\telse\n\t\treturn TibrvStatus(tibrv_status::TIBRV_INVALID_TYPE);\n}\n\ninline TibrvStatus add_field(TibrvMsg& msg, PyObject* key, PyObject* value)\n{\n\tif (!PyObject_Is<message_key>(key))\n\t\tthrow std::exception(\"invalid key\");\n\n\tTibrvStatus status = add_field(msg, PyObject_As<message_key>(key), value);\n\n\tif (status != TIBRV_OK)\n\t\tthrow tibrv_exception(status, \"failed to create field\");\n}\n\ninline bool python_traits<TibrvMsg>::PyObject_CheckType(PyObject* py_object)\n{\n\treturn PySequence_Check(py_object) || PyDict_Check(py_object);\n}\n\ninline TibrvMsg python_traits<TibrvMsg>::PyObject_AsType(PyObject* fields)\n{\n\tTibrvMsg msg;\n\tTibrvStatus status;\n\n\tif (PyDict_Check(fields))\n\t{\n\t\tPyObject *key, *value;\n\t\tint pos = 0;\n\n\t\twhile (PyDict_Next(fields, &pos, &key, &value))\n\t\t{\n\t\t\tstatus = add_field(msg, key, value);\n\n\t\t\tif (status != TIBRV_OK)\n\t\t\t\tthrow tibrv_exception(status, \"failed to create field\");\n\t\t}\n\t}\n\telse if (PySequence_Check(fields))\n\t{\n\t\tfor (Py_ssize_t i = 0; i < PySequence_Size(fields); ++i)\n\t\t{\n\t\t\tPyObject* item = PySequence_GetItem(fields, i);\n\t\t\tif (!PySequence_Check(item))\n\t\t\t\tthrow std::exception(\"When the fields is a sequence, each item must be a sequence of two elements.\");\n\n\t\t\tstatus = add_field(msg, PySequence_GetItem(item, 0), PySequence_GetItem(item, 1));\n\n\t\t\tif (status != TIBRV_OK)\n\t\t\t\tthrow tibrv_exception(status, \"failed to create field\");\n\t\t}\n\t}\n}"
},
{
"alpha_fraction": 0.6622185111045837,
"alphanum_fraction": 0.6627745628356934,
"avg_line_length": 32,
"blob_id": "a4241a562a5b99108a3f68858b84314b96c8e553",
"content_id": "c4dedbcebe5492e10d0664f997b7ae40e3772c80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3597,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 109,
"path": "/PyTibrvException.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\nstruct { tibrv_status code; char* name; } exceptions[] = {\n\t{TIBRV_INIT_FAILURE,\t\t\t\"INIT_FAILURE\"},\n\t{TIBRV_INVALID_TRANSPORT,\t\t\"INVALID_TRANSPORT\"},\n\t{TIBRV_INVALID_ARG,\t\t\t\t\"INVALID_ARG\"},\n\t{TIBRV_NOT_INITIALIZED,\t\t\t\"NOT_INITIALIZED\"},\n\t{TIBRV_ARG_CONFLICT,\t\t\t\"ARG_CONFLICT\"},\n\n\t{TIBRV_SERVICE_NOT_FOUND,\t\t\"SERVICE_NOT_FOUND\"},\n\t{TIBRV_NETWORK_NOT_FOUND,\t\t\"NETWORK_NOT_FOUND\"},\n\t{TIBRV_DAEMON_NOT_FOUND,\t\t\"DAEMON_NOT_FOUND\"},\n\t{TIBRV_NO_MEMORY,\t\t\t\t\"NO_MEMORY\"},\n\t{TIBRV_INVALID_SUBJECT,\t\t\t\"INVALID_SUBJECT\"},\n\t{TIBRV_DAEMON_NOT_CONNECTED,\t\"DAEMON_NOT_CONNECTED\"},\n {TIBRV_VERSION_MISMATCH,\t\t\"VERSION_MISMATCH\"},\n {TIBRV_SUBJECT_COLLISION,\t\t\"SUBJECT_COLLISION\"},\n {TIBRV_VC_NOT_CONNECTED,\t\t\"VC_NOT_CONNECTED\"},\n\n {TIBRV_NOT_PERMITTED,\t\t\t\"NOT_PERMITTED\"},\n\n {TIBRV_INVALID_NAME,\t\t\t\"INVALID_NAME\"},\n {TIBRV_INVALID_TYPE,\t\t\t\"INVALID_TYPE\"},\n {TIBRV_INVALID_SIZE,\t\t\t\"INVALID_SIZE\"},\n {TIBRV_INVALID_COUNT,\t\t\t\"INVALID_COUNT\"},\n\n {TIBRV_NOT_FOUND,\t\t\t\t\"NOT_FOUND\"},\n {TIBRV_ID_IN_USE,\t\t\t\t\"ID_IN_USE\"},\n {TIBRV_ID_CONFLICT,\t\t\t\t\"ID_CONFLICT\"},\n {TIBRV_CONVERSION_FAILED,\t\t\"CONVERSION_FAILED\"},\n {TIBRV_RESERVED_HANDLER,\t\t\"RESERVED_HANDLER\"},\n {TIBRV_ENCODER_FAILED,\t\t\t\"ENCODER_FAILED\"},\n {TIBRV_DECODER_FAILED,\t\t\t\"DECODER_FAILED\"},\n {TIBRV_INVALID_MSG,\t\t\t\t\"INVALID_MSG\"},\n {TIBRV_INVALID_FIELD,\t\t\t\"INVALID_FIELD\"},\n {TIBRV_INVALID_INSTANCE,\t\t\"INVALID_INSTANCE\"},\n {TIBRV_CORRUPT_MSG,\t\t\t\t\"CORRUPT_MSG\"},\n {TIBRV_ENCODING_MISMATCH,\t\t\"ENCODING_MISMATCH\"},\n\n {TIBRV_TIMEOUT,\t\t\t\t\t\"TIMEOUT\"},\n {TIBRV_INTR,\t\t\t\t\t\"INTR\"},\n\n {TIBRV_INVALID_DISPATCHABLE,\t\"INVALID_DISPATCHABLE\"},\n {TIBRV_INVALID_DISPATCHER,\t\t\"INVALID_DISPATCHER\"},\n\n {TIBRV_INVALID_EVENT,\t\t\t\"INVALID_EVENT\"},\n {TIBRV_INVALID_CALLBACK,\t\t\"INVALID_CALLBACK\"},\n {TIBRV_INVALID_QUEUE,\t\t\t\"INVALID_QUEUE\"},\n {TIBRV_INVALID_QUEUE_GROUP,\t\t\"INVALID_QUEUE_GROUP\"},\n\n {TIBRV_INVALID_TIME_INTERVAL,\t\"INVALID_TIME_INTERVAL\"},\n\n {TIBRV_INVALID_IO_SOURCE,\t\t\"INVALID_IO_SOURCE\"},\n {TIBRV_INVALID_IO_CONDITION,\t\"INVALID_IO_CONDITION\"},\n {TIBRV_SOCKET_LIMIT,\t\t\t\"SOCKET_LIMIT\"},\n\n {TIBRV_OS_ERROR,\t\t\t\t\"OS_ERROR\"},\n\n {TIBRV_INSUFFICIENT_BUFFER,\t\t\"INSUFFICIENT_BUFFER\"},\n {TIBRV_EOF,\t\t\t\t\t\t\"EOF\"},\n {TIBRV_INVALID_FILE,\t\t\t\"INVALID_FILE\"},\n {TIBRV_FILE_NOT_FOUND,\t\t\t\"FILE_NOT_FOUND\"},\n {TIBRV_IO_FAILED,\t\t\t\t\"IO_FAILED\"},\n\n {TIBRV_NOT_FILE_OWNER,\t\t\t\"NOT_FILE_OWNER\"},\n {TIBRV_USERPASS_MISMATCH,\t\t\"USERPASS_MISMATCH\"},\n\n {TIBRV_TOO_MANY_NEIGHBORS,\t\t\"TOO_MANY_NEIGHBORS\"},\n {TIBRV_ALREADY_EXISTS,\t\t\t\"ALREADY_EXISTS\"},\n\n {TIBRV_PORT_BUSY,\t\t\t\t\"PORT_BUSY\"}\n};\n\nPyObject* tibrv_error = PyErr_NewException(\"tibrv.error\", NULL, NULL);\n\ntypedef std::map<tibrv_status,PyObject*> exception_map_t;\nstatic exception_map_t exception_map;\n\nstatic PyObject* GetException(const TibrvStatus& status)\n{\n\texception_map_t::iterator i_map(exception_map.find(status.getCode()));\n\tif (i_map == exception_map.end())\n\t\treturn tibrv_error;\n\telse\n\t\treturn i_map->second;\n}\n\nvoid PyErr_Tibrv(const TibrvStatus& status)\n{\n\tPyErr_SetString(GetException(status), status.getText());\n}\n\nvoid initPyTibrvException(PyObject* module)\n{\n\tPy_INCREF(tibrv_error);\n\tPyModule_AddObject(module, \"error\", tibrv_error);\n\n\tfor (size_t i = 0; i < sizeof(exceptions) / sizeof(exceptions[0]); ++i)\n\t{\n\t\tchar name[BUFSIZ] = \"tibrv.\";\n\t\tstrcat_s(name, BUFSIZ, exceptions[i].name);\n\n\t\tPyObject* error = PyErr_NewException(name, tibrv_error, NULL);\n\t\tPy_INCREF(error);\n\t\tPyModule_AddObject(module, exceptions[i].name, error);\n\n\t\texception_map[exceptions[i].code] = error;\n\t}\n}\n"
},
{
"alpha_fraction": 0.4902411103248596,
"alphanum_fraction": 0.6280137896537781,
"avg_line_length": 23.91428565979004,
"blob_id": "add9866a3bf57e9c70750c499de6120684bbae85",
"content_id": "19dab29b5fa644bab5bbbd71536159af96c12c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 871,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 35,
"path": "/test_publish3.py",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(r\"..\\Debug\")\nsys.path.append(\".\")\n\nimport tibrv\ntibrv.environment.open()\nt = tibrv.transport(\"8650\", \"pc391\", \"pc391.foo.com:7500\")\n\nsubject = \"DATAEXP.VOD LN\"\n\nmessage = {\n\t\"MSG_SRC\"\t\t\t\t: \"GENPUB\",\n\t\"MSG_TYPE\"\t\t\t\t: \"DATAEXP\",\n\t\"EQUITY_TICKER\"\t\t\t: \"VOD LN\",\n\t\"EQUITY_NAME\"\t\t\t: \"VODAFONE GROUP PLC\",\n\t\"ISSUER_TICKER\"\t\t\t: \"VOD LN\",\n\t\"ISSUER_NAME\"\t\t\t: \"Vodafone Group PLC\",\n\t\"LENDERS\"\t\t\t\t: 29 ,\n\t\"AVAILABLE\"\t\t\t\t: 37420270302.427795 ,\n\t\"ON_LOAN\"\t\t\t\t: 10705819494.514700,\n\t\"USAGE_RATIO\"\t\t\t: 0.286097 ,\n\t\"BORROWERS\"\t\t\t\t: 8,\n\t\"BORROWERS_FROM_INV\"\t: 6,\n\t\"BORROWERS_FROM_MKT\"\t: 1,\n\t\"ON_LOAN_FROM_INV\"\t\t: 1142873046.081000,\n\t\"ON_LOAN_FROM_MKT\"\t\t: 9562946448.433701,\n\t\"USAGE_RATIO_FROM_INV\"\t: 0.030542,\n\t\"PCT_MKT_CAP\"\t\t\t: 0.062755,\n\t\"LAST_UPDATE\"\t\t\t: (2007,06,18,18,02,00)}\n\nt.send(subject, message)\n\n\nprint \"press return to exit\"\nsys.__stdin__.readline()"
},
{
"alpha_fraction": 0.6942800879478455,
"alphanum_fraction": 0.7278106212615967,
"avg_line_length": 21.086956024169922,
"blob_id": "3b8c89dea822c2bacf3275d27fa125d557feb15b",
"content_id": "1f3c47376d03e92697686b64255b5798f7bf34f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 507,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 23,
"path": "/test_subscribe.py",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(r\"..\\Debug\")\nsys.path.append(\".\")\n\nimport tibrv\ntibrv.environment.open()\nt = tibrv.transport(\"9650\", \"pc1226\", \"pc1226.foo.com:9765\")\n\ndef cb(send_subject, reply_subject, msg):\n\tprint send_subject, msg\n\t\nsubject=\"TEST.FOO.BAR\"\nl = tibrv.listener(tibrv.environment.defaultqueue, cb, t, subject, None)\n\nwhile True:\n\tprint \"dispatching\"\n\ttry:\n\t\ttibrv.environment.defaultqueue.timeddispatch(1)\n\texcept tibrv.TIMEOUT, e:\n\t\tprint e\n\nprint \"press return to exit\"\nsys.__stdin__.readline()"
},
{
"alpha_fraction": 0.6492929458618164,
"alphanum_fraction": 0.6562626361846924,
"avg_line_length": 24.78125,
"blob_id": "cd6723fa5819512291ee360daf4b69ca9e51186d",
"content_id": "2b3758c434260d6b5e874436fbc77a59f5936edd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9900,
"license_type": "no_license",
"max_line_length": 208,
"num_lines": 384,
"path": "/PyTibrvQueue.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\n#include \"PyTibrvException.h\"\n#include \"PyTibrvQueue.h\"\n\nstatic void\nQueue_dealloc(PyTibrvQueueObject* self)\n{\n\tif (self->queue)\n\t{\n\t\tif (self->queue->isValid() == TIBRV_TRUE && self->queue != Tibrv::defaultQueue())\n\t\t{\n\t\t\tself->queue->destroy();\n\t\t\tdelete self->queue;\n\t\t}\n\t}\n self->ob_type->tp_free((PyObject*)self);\n}\n\nstatic PyObject *\nQueue_new(PyTypeObject *type, PyObject *args, PyObject *kwds)\n{\n PyTibrvQueueObject *self = (PyTibrvQueueObject *)type->tp_alloc(type, 0);\n if (self != NULL)\n\t{\n\t\tself->queue = new TibrvQueue();\n if (self->queue == NULL)\n\t\t{\n Py_DECREF(self);\n return NULL;\n }\n }\n\n return (PyObject *)self;\n}\n\nstatic int\nQueue_init(PyTibrvQueueObject *self, PyObject *args, PyObject *kwds)\n{\n\tchar* name;\n\tint priority = TIBRVQUEUE_DEFAULT_PRIORITY;\n\tPyObject* limit_policy;\n\n static char *kwlist[] = {\"name\", \"priority\", \"limitpolicy\", NULL};\n\n if (! PyArg_ParseTupleAndKeywords(args, kwds, \"s|iO\", kwlist, &name, &priority, &limit_policy))\n return -1; \n\n\tself->queue->setName(name);\n\tself->queue->setPriority(priority);\n\tif (limit_policy)\n\t{\n\t\t// TODO: should return error if tuple wrong length or items incorrect types\n\t\tif (PySequence_Check(limit_policy) && PySequence_Length(limit_policy) == 3)\n\t\t{\n\t\t\ttibrvQueueLimitPolicy policy = static_cast<tibrvQueueLimitPolicy>(PyInt_AsLong(PySequence_GetItem(limit_policy, 0)));\n\t\t\tint max_events = static_cast<int>(PyInt_AsLong(PySequence_GetItem(limit_policy, 1)));\n\t\t\tint discard_amount = static_cast<int>(PyInt_AsLong(PySequence_GetItem(limit_policy, 2)));\n\n\t\t\tself->queue->setLimitPolicy(policy, max_events, discard_amount);\n\t\t}\n\t}\n\n return 0;\n}\n\nstatic PyMemberDef Queue_members[] = {\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\nQueue_getName(PyTibrvQueueObject *self, void *closure)\n{\n\tconst char* queue_name;\n\tTibrvStatus status = self->queue->getName(queue_name);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n return PyString_FromString(queue_name);\n}\n\nstatic PyObject *\nQueue_getPriority(PyTibrvQueueObject *self, void *closure)\n{\n\ttibrv_u32 priority;\n\tTibrvStatus status = self->queue->getPriority(priority);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\treturn PyInt_FromLong(priority);\n}\n\nstatic PyObject *\nQueue_getLimitPolicy(PyTibrvQueueObject *self, void *closure)\n{\n\ttibrvQueueLimitPolicy policy;\n\ttibrv_u32 max_events, discard_amount;\n\tTibrvStatus status = self->queue->getLimitPolicy(policy, max_events, discard_amount);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\tPyObject* tuple = PyTuple_New(3);\n\tif (tuple == NULL)\n\t{\n\t\tPyErr_SetFromErrno(tibrv_error);\n\t\treturn NULL;\n\t}\n\tPyTuple_SetItem(tuple, 0, PyInt_FromLong(static_cast<long>(policy)));\n\tPyTuple_SetItem(tuple, 1, PyInt_FromLong(max_events));\n\tPyTuple_SetItem(tuple, 2, PyInt_FromLong(discard_amount));\n\n\treturn tuple;\n}\nstatic int\nQueue_setLimitPolicy(PyTibrvQueueObject *self, PyObject *value, void *closure)\n{\n\tif (value == NULL)\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"Cannot have an empty policy\");\n\t\treturn -1;\n\t}\n\n\tif (!PySequence_Check(value))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"invalid type\");\n\t\treturn -1;\n\t}\n\n\tif (PySequence_Length(value) != 3)\n\t{\n\t\tPyErr_SetString(PyExc_ValueError, \"expected sequence with three items\");\n\t\treturn -1;\n\t}\n\n\tPyObject* policy = PySequence_GetItem(value, 0);\n\tif (!PyInt_Check(policy))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"expected first item (policy) to be of type int\");\n\t\treturn -1;\n\t}\n\n\tPyObject* max_events = PySequence_GetItem(value, 1);\n\tif (!PyInt_Check(max_events))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"expected first item (max events) to be of type int\");\n\t\treturn -1;\n\t}\n\n\tPyObject *discard_amount = PySequence_GetItem(value, 2);\n\tif (!PyInt_Check(discard_amount))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"expected first item (discard amount) to be of type int\");\n\t\treturn -1;\n\t}\n\n\ttibrvQueueLimitPolicy _policy = static_cast<tibrvQueueLimitPolicy>(PyInt_AsLong(policy));\n\ttibrv_u32 _max_events = static_cast<tibrv_u32>(PyInt_AsLong(max_events));\n\ttibrv_u32 _discard_amount = static_cast<tibrv_u32>(PyInt_AsLong(discard_amount));\n\n\tself->queue->setLimitPolicy(_policy, _max_events, _discard_amount);\n\n\treturn 0;\n}\n\nstatic PyGetSetDef Queue_getseters[] = {\n {\"name\", (getter)Queue_getName, (setter)NULL, \"name\", NULL},\n {\"priority\", (getter)Queue_getPriority, (setter)NULL, \"priority\", NULL},\n {\"limitpolicy\", (getter)Queue_getLimitPolicy, (setter)Queue_setLimitPolicy, \"limit policy\", NULL},\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\nQueue_Count(PyTibrvQueueObject* self)\n{\n\ttibrv_u32 num_events;\n\tTibrvStatus status = self->queue->getCount(num_events);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\treturn PyInt_FromLong(num_events);\n}\n\nstatic PyObject *\nQueue_Create(PyTibrvQueueObject* self)\n{\n\tTibrvStatus status = self->queue->create();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n\treturn Py_None;\n}\n\nstatic PyObject *\nQueue_Destroy(PyTibrvQueueObject* self)\n{\n\tTibrvStatus status = self->queue->destroy();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n\treturn Py_None;\n}\n\nstatic PyObject *\nQueue_Dispatch(PyTibrvQueueObject* self)\n{\n\tTibrvStatus status = self->queue->dispatch();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n\treturn Py_None;\n}\n\nstatic PyObject *\nQueue_IsValid(PyTibrvQueueObject* self)\n{\n\ttibrv_bool is_valid = self->queue->isValid();\n\tPyObject* _is_valid = (is_valid == TIBRV_TRUE ? Py_True : Py_False);\n\tPy_INCREF(_is_valid);\n\treturn _is_valid;\n}\n\nstatic PyObject *\nQueue_Poll(PyTibrvQueueObject* self)\n{\n\tTibrvStatus status = self->queue->poll();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n\treturn Py_None;\n}\n\nstatic PyObject *\nQueue_TimedDispatch(PyTibrvQueueObject* self, PyObject *args, PyObject *kwds)\n{\n double timeout;\n\n static char *kwlist[] = {\"timeout\", NULL};\n\n if (! PyArg_ParseTupleAndKeywords(args, kwds, \"d\", kwlist, &timeout))\n return NULL; \n\n\tTibrvStatus status = self->queue->timedDispatch(timeout);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n\treturn Py_None;\n}\n\nstatic PyMethodDef Queue_methods[] = {\n {\"count\", (PyCFunction)Queue_Count, METH_NOARGS, \"Extract the number of events in a queue.\"},\n {\"create\", (PyCFunction)Queue_Create, METH_NOARGS, \"Create a queue.\"},\n {\"destroy\", (PyCFunction)Queue_Destroy, METH_NOARGS, \"Destroy a queue.\"},\n {\"dispatch\", (PyCFunction)Queue_Dispatch, METH_NOARGS, \"Dispatch an event; if no event is ready, block.\"},\n {\"isvalid\", (PyCFunction)Queue_IsValid, METH_NOARGS, \"Test validity of a queue. \"},\n {\"poll\", (PyCFunction)Queue_Poll, METH_NOARGS, \"Dispatch an event, if possible.\"},\n\t{\"timeddispatch\", (PyCFunction)Queue_TimedDispatch, METH_VARARGS | METH_KEYWORDS, \"Dispatch an event, but if no event is ready to dispatch, limit the time that this call blocks while waiting for an event.\"},\n\t{NULL} /* Sentinel */\n};\n\nPyTypeObject PyTibrvQueue_Type = {\n PyObject_HEAD_INIT(NULL)\n 0,\t\t\t\t\t\t\t/*ob_size*/\n \"tibrv.Queue\",\t\t\t\t/*tp_name*/\n sizeof(PyTibrvQueueObject),\t/*tp_basicsize*/\n 0,\t\t\t\t\t\t\t/*tp_itemsize*/\n (destructor)Queue_dealloc,\t/*tp_dealloc*/\n 0,\t\t\t\t\t\t\t/*tp_print*/\n 0,\t\t\t\t\t\t\t/*tp_getattr*/\n 0,\t\t\t\t\t\t\t/*tp_setattr*/\n 0,\t\t\t\t\t\t\t/*tp_compare*/\n 0,\t\t\t\t\t\t\t/*tp_repr*/\n 0,\t\t\t\t\t\t\t/*tp_as_number*/\n 0,\t\t\t\t\t\t\t/*tp_as_sequence*/\n 0,\t\t\t\t\t\t\t/*tp_as_mapping*/\n 0,\t\t\t\t\t\t\t/*tp_hash */\n 0,\t\t\t\t\t\t\t/*tp_call*/\n 0,\t\t\t\t\t\t\t/*tp_str*/\n 0,\t\t\t\t\t\t\t/*tp_getattro*/\n 0,\t\t\t\t\t\t\t/*tp_setattro*/\n 0,\t\t\t\t\t\t\t/*tp_as_buffer*/\n Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE, /*tp_flags*/\n \"Queue objects\",\t\t\t/* tp_doc */\n 0,\t\t\t\t\t\t\t/* tp_traverse */\n 0,\t\t\t\t\t\t\t/* tp_clear */\n 0,\t\t\t\t\t\t\t/* tp_richcompare */\n 0,\t\t\t\t\t\t\t/* tp_weaklistoffset */\n 0,\t\t\t\t\t\t\t/* tp_iter */\n 0,\t\t\t\t\t\t\t/* tp_iternext */\n Queue_methods,\t\t\t\t/* tp_methods */\n Queue_members,\t\t\t\t/* tp_members */\n Queue_getseters,\t\t\t/* tp_getset */\n 0,\t\t\t\t\t\t\t/* tp_base */\n 0,\t\t\t\t\t\t\t/* tp_dict */\n 0,\t\t\t\t\t\t\t/* tp_descr_get */\n 0,\t\t\t\t\t\t\t/* tp_descr_set */\n 0,\t\t\t\t\t\t\t/* tp_dictoffset */\n (initproc)Queue_init,\t\t/* tp_init */\n 0,\t\t\t\t\t\t\t/* tp_alloc */\n Queue_new,\t\t\t\t\t/* tp_new */\n};\n\nPyObject *\nPyTibrvQueue_FromQueue(TibrvQueue *queue)\n{\n\tPyTibrvQueueObject *q = (PyTibrvQueueObject*)PyTibrvQueue_Type.tp_new(&PyTibrvQueue_Type, NULL, NULL);\n\tif (q != NULL)\n\t{\n\t\tq->queue = queue;\n\t}\n\treturn (PyObject *) q;\n}\n\nTibrvQueue *\nPyTibrvQueue_AsQueue(PyObject *queue)\n{\n\tPyTibrvQueueObject *q = (PyTibrvQueueObject *)queue;\n\tif (q != NULL)\n\t\treturn q->queue;\n\telse\n\t\treturn NULL;\n}\n\nstatic struct { char* name; int id; } IntVars[] = {\n\t{\"QUEUE_DISCARD_NONE\",\t\tTIBRVQUEUE_DISCARD_NONE},\n\t{\"QUEUE_DISCARD_NEW\",\t\tTIBRVQUEUE_DISCARD_NEW},\n\t{\"QUEUE_DISCARD_FIRST\",\t\tTIBRVQUEUE_DISCARD_FIRST},\n\t{\"QUEUE_DISCARD_LAST\",\t\tTIBRVQUEUE_DISCARD_LAST},\n};\n\nstatic struct { char* name; double id; } DblVars[] = {\n\t{\"WAIT_FOREVER\",\t\t\tTIBRV_WAIT_FOREVER},\n\t{\"NO_WAIT\",\t\t\t\t\tTIBRV_NO_WAIT},\n};\n\nvoid initPyTibrvQueue(PyObject* module)\n{\n if (PyType_Ready(&PyTibrvQueue_Type) < 0)\n return;\n\n Py_INCREF(&PyTibrvQueue_Type);\n PyModule_AddObject(module, \"Queue\", (PyObject*)&PyTibrvQueue_Type);\n\n\t// Setup all the integer constants\n\tfor (size_t i = 0; i < sizeof(IntVars) / sizeof(IntVars[0]); ++i)\n\t\tPyModule_AddIntConstant(module, IntVars[i].name, IntVars[i].id);\n\n\t// Setup all the double constants\n\tfor (size_t i = 0; i < sizeof(DblVars) / sizeof(DblVars[0]); ++i)\n\t{\n\t\tPyObject* constant = PyFloat_FromDouble(DblVars[i].id);\n\t\tPyModule_AddObject(module, DblVars[i].name, constant);\n\t\tPy_INCREF(constant);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5563973188400269,
"alphanum_fraction": 0.6372053623199463,
"avg_line_length": 41.46428680419922,
"blob_id": "b8e1ab5ddab900eb7323404d5bf4b4914e296194",
"content_id": "0492bf1cf4cd2df9313d133b63aca14e9e6bb6b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1188,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 28,
"path": "/test_publish2.py",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(r\"..\\Debug\")\nsys.path.append(\".\")\n\nimport tibrv\ntibrv.environment.open()\nt = tibrv.transport(\"8650\", \";239.255.210.1\", \"qsvr02.foo.com:7500\")\n\nsubject='TEST.LIST1'\nmsg = {'MSG_TYPE':'LIST', 'COUNT':4,'ITEM_1':'the', 'ITEM_2':'quick', 'ITEM_3':'brown', 'ITEM_4':'fox'}\nt.send(subject, msg)\nprint subject, msg\n\nsubject='TEST.LIST2'\n#msg = {'MSG_TYPE':'LIST', 'COUNT':4,'ITEM_1':'FOO.CDSCRV.LATEST.VOD LN', 'ITEM_2':'FOO.CDSCRV.LATEST.BAY GR', 'ITEM_3':'FOO.CDSCRV.LATEST.SBRY LN', 'ITEM_4':'FOO.CDSCRV.LATEST.TSCO LN'}\nmsg = {'MSG_TYPE':'LIST', 'COUNT':5,'ITEM_1':'FOO.CDSCRV.LATEST.BAY GR', 'ITEM_2':'FOO.CDSCRV.LATEST.VOD LN', 'ITEM_3':'FOO.CDSCRV.LATEST.SBRY LN', 'ITEM_4':'FOO.CDSCRV.LATEST.TSCO LN', 'ITEM_5':'FOO.CDSCRV.LATEST.TIT IM'}\nt.send(subject, msg)\nprint subject, msg\n\nsubject='TEST.GRID2'\n#msg = {'MSG_TYPE':'GRID', 'ROWS':2, 'COLS':2,'ITEM_1_1':'21-May-2007', 'ITEM_1_2':51.2, 'ITEM_2_1':'21-Mar-2007', 'ITEM_2_2':'55.7'}\nmsg = {'MSG_TYPE':'GRID', 'ROWS':2, 'COLS':2,'ITEM_1_1':(2007, 5, 21), 'ITEM_1_2':51.2, 'ITEM_2_1':(2007, 5, 22), 'ITEM_2_2':55.7}\nt.send(subject, msg)\nprint subject, msg\n\n\nprint \"press return to exit\"\nsys.__stdin__.readline()"
},
{
"alpha_fraction": 0.646064817905426,
"alphanum_fraction": 0.6517361402511597,
"avg_line_length": 24.637981414794922,
"blob_id": "fefb112dbffbda68acdf01dd5ef630d34c57347d",
"content_id": "89ba2e32626dcfb37f6918d2c9271ab246114209",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8640,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 337,
"path": "/PyTibrvNetTransport.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\n#include \"tibrv_exception.h\"\n#include \"traits.h\"\n#include \"types.h\"\n#include \"messages.h\"\n\n#include \"PyTibrvException.h\"\n#include \"PyTibrvNetTransport.h\"\n\n/*\n** NetTransport\n*/\n\nstatic void\ndealloc_method(PyTibrvNetTransportObject* self)\n{\n\tif (self->transport != NULL)\n\t{\n\t\tif (self->transport->isValid() == TIBRV_TRUE)\n\t\t\tself->transport->destroy();\n\n\t\tdelete self->transport;\n\t\tself->transport = NULL;\n\t}\n self->ob_type->tp_free((PyObject*)self);\n}\n\nstatic PyObject *\nnew_method(PyTypeObject *type, PyObject *args, PyObject *kwds)\n{\n PyTibrvNetTransportObject *self = (PyTibrvNetTransportObject*)type->tp_alloc(type, 0);\n\n if (self != NULL)\n\t{\n\t\tself->transport = new TibrvNetTransport();\n if (self->transport == NULL)\n\t\t{\n Py_DECREF(self);\n return NULL;\n\t\t}\n }\n\n return (PyObject *)self;\n}\n\nstatic int\ninit_method(PyTibrvNetTransportObject *self, PyObject *args, PyObject *kwds)\n{\n char *service = NULL, *network = NULL, *daemon = NULL, *license = NULL;\n\n static char *kwlist[] = {\"service\", \"network\", \"daemon\", \"license\", NULL};\n\n if (! PyArg_ParseTupleAndKeywords(args, kwds, \"sss|s\", kwlist, &service, &network, &daemon, &license))\n return -1; \n\n\tTibrvStatus status =\n\t\tlicense == NULL\n\t\t\t? self->transport->create(service, network, daemon)\n\t\t\t: self->transport->createLicensed(service, network, daemon, license);\n\n return 0;\n}\n\nstatic PyMemberDef type_members[] = {\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ngetmember_service(PyTibrvNetTransportObject *self, void *closure)\n{\n\tconst char* service = NULL;\n\tTibrvStatus status = self->transport->getService(service);\n\treturn PyString_FromString(service);\n}\n\nstatic PyObject *\ngetmember_network(PyTibrvNetTransportObject *self, void *closure)\n{\n\tconst char* network = NULL;\n\tTibrvStatus status = self->transport->getNetwork(network);\n\treturn PyString_FromString(network);\n}\n\nstatic PyObject *\ngetmember_daemon(PyTibrvNetTransportObject *self, void *closure)\n{\n\tconst char* daemon = NULL;\n\tTibrvStatus status = self->transport->getDaemon(daemon);\n\treturn PyString_FromString(daemon);\n}\n\nstatic PyObject *\ngetmember_description(PyTibrvNetTransportObject *self, void *closure)\n{\n\tconst char* description = NULL;\n\tTibrvStatus status = self->transport->getDescription(&description);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tif (description != NULL)\n\t\treturn PyString_FromString(description);\n\telse\n\t{\n\t\tPy_INCREF(Py_None);\n\t\treturn Py_None;\n\t}\n}\n\nstatic int\nsetmember_description(PyTibrvNetTransportObject *self, PyObject *value, void *closure)\n{\n\tif (value == NULL)\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"Cannot delete the description\");\n\t\treturn -1;\n\t}\n \n\tif (! PyString_Check(value))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"The last attribute value must be a string\");\n\t\treturn -1;\n\t}\n\n\tchar* description = PyString_AsString(value);\n\tTibrvStatus status = self->transport->setDescription(description);\n\n\treturn 0;\n}\n\nstatic PyGetSetDef type_getseters[] = {\n {\"service\", (getter)getmember_service, NULL, \"service\", NULL},\n {\"network\", (getter)getmember_network, NULL, \"network\", NULL},\n {\"daemon\", (getter)getmember_daemon, NULL, \"daemon\", NULL},\n {\"description\", (getter)getmember_description, (setter)setmember_description, \"description\", NULL},\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ntypemethod_createinbox(PyTibrvNetTransportObject* self)\n{\n\tchar subject[TIBRV_SUBJECT_MAX];\n\tTibrvStatus status = self->transport->createInbox(subject, TIBRV_SUBJECT_MAX);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tif (subject != NULL)\n\t{\n\t\treturn PyString_FromString(subject);\n\t}\n\telse\n\t{\n\t\tPy_INCREF(Py_None);\n\t\treturn Py_None;\n\t}\n}\n\nstatic PyObject *\ntypemethod_destroy(PyTibrvNetTransportObject* self)\n{\n\tTibrvStatus status = self->transport->destroy();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n Py_INCREF(Py_None);\n return Py_None;\n}\n\nstatic PyObject *\ntypemethod_isvalid(PyTibrvNetTransportObject* self)\n{\n\tPyObject* value = (self->transport->isValid() == TIBRV_TRUE ? Py_True : Py_False);\n Py_INCREF(value);\n return value;\n}\n\nstatic PyObject*\ntypemethod_send(PyTibrvNetTransportObject *self, PyObject *args, PyObject *kwds)\n{\n char *send_subject = NULL, *reply_subject = NULL;\n\tPyObject* message_dictionary;\n\n static char *kwlist[] = {\"sendsubject\", \"message\", \"replysubject\", NULL};\n\n if (! PyArg_ParseTupleAndKeywords(args, kwds, \"sO|s\", kwlist, &send_subject, &message_dictionary, &reply_subject))\n return NULL; \n\t\n\tTibrvStatus status;\n\n\tTibrvMsg msg;\n\tstatus = msg.setSendSubject(send_subject);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tif (reply_subject != 0)\n\t\tmsg.setReplySubject(reply_subject);\n\n\tif (!PyDict_Check(message_dictionary))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"expected message to be dictionary\");\n\t\treturn NULL;\n\t}\n\n\tPyObject *key, *value;\n\tint pos = 0;\n\n\twhile (PyDict_Next(message_dictionary, &pos, &key, &value))\n\t{\n\t\tif (PyObject_Is<const char*>(key))\n\t\t{\n\t\t\tconst char* mnemonic = PyObject_As<const char*>(key);\n\n\t\t\tif (PyObject_Is<tibrv_i32>(value))\n\t\t\t\tstatus = msg.addI32(mnemonic, PyObject_As<tibrv_i32>(value));\n\t\t\telse if (PyObject_Is<const char*>(value))\n\t\t\t\tstatus = msg.addString(mnemonic, PyObject_As<const char*>(value));\n\t\t\telse if (PyObject_Is<tibrv_f64>(value))\n\t\t\t\tstatus = msg.addF64(mnemonic, PyObject_As<tibrv_f64>(value));\n\t\t\telse if (PyObject_Is<tibrv_bool>(value))\n\t\t\t\tstatus = msg.addBool(mnemonic, PyObject_As<tibrv_bool>(value));\n\t\t\telse if (PyObject_Is<tibrvMsgDateTime>(value))\n\t\t\t\tstatus = msg.addDateTime(mnemonic, PyObject_As<tibrvMsgDateTime>(value));\n\t\t\telse\n\t\t\t{\n\t\t\t\tPyErr_SetString(PyExc_TypeError, \"invalid type for tibco message\");\n\t\t\t\treturn NULL;\n\t\t\t}\n\n\t\t\tif (status != TIBRV_OK)\n\t\t\t{\n\t\t\t\tPyErr_Tibrv(status);\n\t\t\t\treturn NULL;\n\t\t\t}\n\t\t}\n\t}\n\n\tstatus = self->transport->send(msg);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\tPy_INCREF(Py_None);\n return Py_None;\n}\n\nstatic PyMethodDef type_methods[] = {\n {\"createinbox\", (PyCFunction)typemethod_createinbox, METH_NOARGS, \"Create a unique inbox subject name.\"},\n {\"destroy\", (PyCFunction)typemethod_destroy, METH_NOARGS, \"Destroy a transport.\"},\n {\"isvalid\", (PyCFunction)typemethod_isvalid, METH_NOARGS, \"Destroy a transport.\"},\n {\"send\", (PyCFunction)typemethod_send, METH_VARARGS | METH_KEYWORDS, \"Send a message.\"},\n {NULL} /* Sentinel */\n};\n\nPyTypeObject PyTibrvNetTransport_Type = {\n PyObject_HEAD_INIT(NULL)\n 0,\t\t\t\t\t\t\t\t\t/*ob_size*/\n \"tibrv.nettransport\",\t\t\t\t\t/*tp_name*/\n sizeof(PyTibrvNetTransportObject),\t/*tp_basicsize*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_itemsize*/\n (destructor)dealloc_method,\t\t\t/*tp_dealloc*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_print*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_compare*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_repr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_number*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_sequence*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_mapping*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_hash */\n 0,\t\t\t\t\t\t\t\t\t/*tp_call*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_str*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_buffer*/\n Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE,\t/*tp_flags*/\n \"Tibco Net Transport\",\t\t\t\t/* tp_doc */\n 0,\t\t\t\t\t\t\t\t\t/* tp_traverse */\n 0,\t\t\t\t\t\t\t\t\t/* tp_clear */\n 0,\t\t\t\t\t\t\t\t\t/* tp_richcompare */\n 0,\t\t\t\t\t\t\t\t\t/* tp_weaklistoffset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iter */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iternext */\n type_methods,\t\t\t\t\t\t/* tp_methods */\n type_members,\t\t\t\t\t\t/* tp_members */\n type_getseters,\t\t\t\t\t\t/* tp_getset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_base */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dict */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_get */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_set */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dictoffset */\n (initproc)init_method,\t\t\t\t/* tp_init */\n 0,\t\t\t\t\t\t\t\t\t/* tp_alloc */\n new_method,\t\t\t\t\t\t\t/* tp_new */\n};\n\nPyObject *\nPyTibrvNetTransport_FromTransport(TibrvNetTransport *transport)\n{\n\tPyTibrvNetTransportObject *t = (PyTibrvNetTransportObject*)PyTibrvNetTransport_Type.tp_new(&PyTibrvNetTransport_Type, NULL, NULL);\n\tif (t != NULL)\n\t{\n\t\tt->transport = transport;\n\t}\n\treturn (PyObject *) t;\n}\n\nTibrvNetTransport *\nPyTibrvNetTransport_AsTransport(PyObject *transport)\n{\n\tPyTibrvNetTransportObject *t = (PyTibrvNetTransportObject*)transport;\n\tif (t != NULL)\n\t\treturn t->transport;\n\telse\n\t\treturn NULL;\n}\n\nvoid initPyTibrvNetTransport(PyObject* module) \n{\n if (PyType_Ready(&PyTibrvNetTransport_Type) < 0)\n return;\n Py_INCREF(&PyTibrvNetTransport_Type);\n PyModule_AddObject(module, \"transport\", (PyObject*) &PyTibrvNetTransport_Type);\n}\n"
},
{
"alpha_fraction": 0.7128099203109741,
"alphanum_fraction": 0.7179751992225647,
"avg_line_length": 25.16216278076172,
"blob_id": "be09e7c197f73e5bbda1e6c6c8668b5197d0b98b",
"content_id": "0be6b56b28bc28c84ea658c24bfe6ae05f998f53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1936,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 74,
"path": "/traits.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ntemplate<typename T>\nstruct python_traits\n{\npublic:\n\tstatic PyObject* PyObject_FromType(T const&);\n\tstatic T PyObject_AsType(PyObject*);\n\tstatic bool PyObject_CheckType(PyObject*);\n};\n\ninline PyObject* python_traits<const char*>::PyObject_FromType(const char* const& value) { return PyString_FromString(value); }\ninline const char* python_traits<const char*>::PyObject_AsType(PyObject* value) { return PyString_AsString(value); }\ninline bool python_traits<const char*>::PyObject_CheckType(PyObject* value) { return PyString_Check(value); }\n\ntemplate <typename T>\ninline PyObject* PyObject_From(const T& value)\n{\n\treturn python_traits<T>::PyObject_FromType(value);\n}\n\ntemplate <typename T>\ninline PyObject* PyTuple_From(const T* array, int count)\n{\n\tPyObject* tuple = PyTuple_New(count);\n\tfor (int i = 0; i < count; ++i)\n\t\tPyTuple_SetItem(tuple, i, PyObject_From<T>(array[i]));\n\treturn tuple;\n}\n\ntemplate <typename T>\ninline T PyObject_As(PyObject* item)\n{\n\treturn python_traits<T>::PyObject_AsType(item);\n}\n\ntemplate <typename T>\ninline bool PyObject_Is(PyObject* item)\n{\n\treturn python_traits<T>::PyObject_CheckType(item);\n}\n\ntemplate <typename T>\ninline bool PySequence_Is(PyObject* item)\n{\n\tif (!PySequence_Check(item))\n\t\treturn false;\n\n\tfor (Py_ssize_t i = 0; i < PySequence_Size(item); ++i)\n\t\tif (!python_traits<T>::PyObject_CheckType(PySequence_GetItem(item, i)))\n\t\t\treturn false;\n\n\treturn true;\n}\n\ntemplate <typename T1, typename T2>\ninline bool PyObject_Is(PyObject* item)\n{\n\treturn PySequence_Check(item) && PySequence_Size(item) == 2 && PyObject_Is<T1>(PySequence_GetItem(item, 0)) && PyObject_Is<T2>(PySequence_GetItem(item, 2));\n}\n\ntemplate <typename T>\ninline T* PySequence_As(PyObject* sequence)\n{\n\tint count = PySequence_Size(sequence);\n\tT* array = new T[count];\n\tfor (int i = 0; i < count; ++i)\n\t{\n\t\tPyObject* item = PySequence_GetItem(sequence, i);\n\t\tarray[i] = PyObject_As<T>(item);\n\t}\n\n\treturn array;\n}\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6080519556999207,
"avg_line_length": 25.544828414916992,
"blob_id": "14b4cb9db65e9aaa2fa46da60d6d488847136b6f",
"content_id": "2223d9f6dd6950a49eb5b4c055815efea536559e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3850,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 145,
"path": "/PyTibrvEnvironment.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\n#include \"PyTibrvException.h\"\n#include \"PyTibrvQueue.h\"\n#include \"PyTibrvEnvironment.h\"\n\nstatic void\ndealloc_method(PyTibrvEnvironmentObject* self)\n{\n\tif (self->defaultQueue != NULL)\n\t{\n\t\tPy_DECREF(self->defaultQueue);\n\t\tself->defaultQueue = NULL;\n\t}\n\n self->ob_type->tp_free((PyObject*)self);\n}\n\nstatic PyObject *\nnew_method(PyTypeObject *type, PyObject *args, PyObject *kwds)\n{\n PyTibrvEnvironmentObject *self = (PyTibrvEnvironmentObject *)type->tp_alloc(type, 0);\n\tself->defaultQueue = (PyTibrvQueueObject*) PyTibrvQueue_FromQueue(Tibrv::defaultQueue());\n\n return (PyObject *)self;\n}\n\nstatic int\ninit_method(PyTibrvEnvironmentObject *self, PyObject *args, PyObject *kwds)\n{\n return 0;\n}\n\nstatic PyMemberDef type_members[] = {\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ngetter_getDefaultQueue(PyTibrvEnvironmentObject *self, void *closure)\n{\n Py_INCREF(self->defaultQueue);\n return (PyObject*) self->defaultQueue;\n}\n\nstatic PyGetSetDef type_getseters[] = {\n {\"defaultqueue\", (getter)getter_getDefaultQueue, NULL, \"Extract the default queue object. \", NULL},\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ntypemethod_open(PyTibrvEnvironmentObject* self)\n{\n\tTibrvStatus status = Tibrv::open();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n Py_INCREF(Py_None);\n return Py_None;\n}\n\nstatic PyObject *\ntypemethod_close(PyTibrvEnvironmentObject* self)\n{\n\tTibrvStatus status = Tibrv::close();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n Py_INCREF(Py_None);\n return Py_None;\n}\n\nstatic PyObject *\ntypemethod_version(PyTibrvEnvironmentObject* self)\n{\n return PyString_FromString(Tibrv::version());\n}\n\nstatic PyMethodDef type_methods[] = {\n {\"close\", (PyCFunction)typemethod_close, METH_NOARGS, \"Stop and destroy Rendezvous internal machinery.\"},\n {\"open\", (PyCFunction)typemethod_open, METH_NOARGS, \"Start Rendezvous internal machinery.\"},\n {\"version\", (PyCFunction)typemethod_version, METH_NOARGS, \"Identify the Rendezvous API release number.\"},\n {NULL} /* Sentinel */\n};\n\nPyTypeObject PyTibrvEnvironment_Type = {\n PyObject_HEAD_INIT(NULL)\n 0,\t\t\t\t\t\t\t\t\t/*ob_size*/\n \"tibrv.environment\",\t\t\t\t/*tp_name*/\n sizeof(PyTibrvEnvironmentObject),\t\t\t\t/*tp_basicsize*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_itemsize*/\n (destructor)dealloc_method,\t/*tp_dealloc*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_print*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_compare*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_repr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_number*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_sequence*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_mapping*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_hash */\n 0,\t\t\t\t\t\t\t\t\t/*tp_call*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_str*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_buffer*/\n Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE,\t/*tp_flags*/\n \"Tibco Environment\",\t\t\t\t/* tp_doc */\n 0,\t\t\t\t\t\t\t\t\t/* tp_traverse */\n 0,\t\t\t\t\t\t\t\t\t/* tp_clear */\n 0,\t\t\t\t\t\t\t\t\t/* tp_richcompare */\n 0,\t\t\t\t\t\t\t\t\t/* tp_weaklistoffset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iter */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iternext */\n type_methods,\t\t\t\t\t\t/* tp_methods */\n type_members,\t\t\t\t\t\t/* tp_members */\n type_getseters,\t\t\t\t\t\t/* tp_getset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_base */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dict */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_get */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_set */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dictoffset */\n (initproc)init_method,\t\t\t\t/* tp_init */\n 0,\t\t\t\t\t\t\t\t\t/* tp_alloc */\n new_method,\t\t\t\t\t\t\t/* tp_new */\n};\n\nPyObject *\nPyTibrvEnvironment_New(void)\n{\n\treturn PyTibrvEnvironment_Type.tp_new(&PyTibrvEnvironment_Type, NULL, NULL);\n}\n\nvoid initPyTibrvEnvironment(PyObject* module)\n{\n if (PyType_Ready(&PyTibrvEnvironment_Type) < 0)\n return;\n Py_INCREF(&PyTibrvEnvironment_Type);\n PyModule_AddObject(module, \"environment\", (PyObject *)&PyTibrvEnvironment_Type);\n}\n\n"
},
{
"alpha_fraction": 0.7936962842941284,
"alphanum_fraction": 0.7936962842941284,
"avg_line_length": 25.846153259277344,
"blob_id": "5903dcba72c04138712aeae0b4b7ffc81b467beb",
"content_id": "f66b90581df34368caf4c07c665c487e36227d2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 13,
"path": "/PyTibrvListener.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ntypedef struct {\n PyObject_HEAD\n\tTibrvListener* listener;\n} PyTibrvListenerObject;\n\nextern PyTypeObject PyTibrvListener_Type;\n\n#define PyTibrvListener_Check(op) PyObject_TypeCheck(op, &PyTibrvListener_Type)\n#define PyTibrvListener_CheckExact(op) ((op)->ob_type == &PyTibrvListener_Type)\n\nvoid initPyTibrvListener(PyObject* module);\n"
},
{
"alpha_fraction": 0.6449864506721497,
"alphanum_fraction": 0.6856368780136108,
"avg_line_length": 16.619047164916992,
"blob_id": "71a533cb9cfaf35338fed1f577737b63ed879eba",
"content_id": "c16fd4e8e58d4df97dba0b7be6c79346f18be8b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 21,
"path": "/test_publish.py",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(r\"..\\Debug\")\nsys.path.append(\".\")\n\nimport tibrv\ntibrv.environment.open()\n\nt = tibrv.transport(\"0568\", \"vldntstapp07\", \"vldntstapp07.foo.com:7500\")\n\nimport time\nsubject=\"TEST.FOO.BAR\"\nn = 1\nwhile True:\n\tmsg = {\"COUNT\":n}\n\tt.send(subject, msg)\n\tprint subject, msg\n\ttime.sleep(5)\n\tn = n + 1\n\nprint \"press return to exit\"\nsys.__stdin__.readline()"
},
{
"alpha_fraction": 0.7901785969734192,
"alphanum_fraction": 0.7901785969734192,
"avg_line_length": 27,
"blob_id": "5d01292226335837a0b328bdd3caac1d6da1bb5c",
"content_id": "b2ea0439e51e53279f63380600c8249d89aacd0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 16,
"path": "/PyTibrvQueue.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ntypedef struct {\n PyObject_HEAD\n\tTibrvQueue *queue;\n} PyTibrvQueueObject;\n\nextern PyTypeObject PyTibrvQueue_Type;\n\nextern PyObject *PyTibrvQueue_FromQueue(TibrvQueue *queue);\nextern TibrvQueue *PyTibrvQueue_AsQueue(PyObject *queue);\n\n#define PyTibrvQueue_Check(op) PyObject_TypeCheck(op, &PyTibrvQueue_Type)\n#define PyTibrvQueue_CheckExact(op) ((op)->ob_type == &PyTibrvQueue_Type)\n\nextern void initPyTibrvQueue(PyObject* module);\n"
},
{
"alpha_fraction": 0.8286252617835999,
"alphanum_fraction": 0.8286252617835999,
"avg_line_length": 32.1875,
"blob_id": "02c7e2e287721999c6c16704bd96b4aaf9fd1c20",
"content_id": "f334e98d14b73b299d1a169fc35d76036e7a0af7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 16,
"path": "/PyTibrvNetTransport.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ntypedef struct {\n PyObject_HEAD\n\tTibrvNetTransport* transport;\n} PyTibrvNetTransportObject;\n\nextern PyTypeObject PyTibrvNetTransport_Type;\n\nPyObject *PyTibrvNetTransport_FromTransport(TibrvNetTransport *transport);\nTibrvNetTransport *PyTibrvNetTransport_AsTransport(PyObject *transport);\n\n#define PyTibrvNetTransport_Check(op) PyObject_TypeCheck(op, &PyTibrvNetTransport_Type)\n#define PyTibrvNetTransport_CheckExact(op) ((op)->ob_type == &PyTibrvNetTransport_Type)\n\nvoid initPyTibrvNetTransport(PyObject* module);\n"
},
{
"alpha_fraction": 0.7144169211387634,
"alphanum_fraction": 0.7144169211387634,
"avg_line_length": 21.6875,
"blob_id": "144b18100cdab6c0f1c02f592135917044e79484",
"content_id": "303d1a292a24c212f57fc4721aeeebcbae160298",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1089,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 48,
"path": "/dllmain.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "// dllmain.cpp : Defines the entry point for the DLL application.\n#include \"stdafx.h\"\n\n#include \"tibrv_exception.h\"\n#include \"traits.h\"\n#include \"types.h\"\n#include \"messages.h\"\n\nBOOL APIENTRY DllMain( HMODULE hModule,\n DWORD ul_reason_for_call,\n LPVOID lpReserved\n\t\t\t\t\t )\n{\n\tswitch (ul_reason_for_call)\n\t{\n\tcase DLL_PROCESS_ATTACH:\n\tcase DLL_THREAD_ATTACH:\n\tcase DLL_THREAD_DETACH:\n\tcase DLL_PROCESS_DETACH:\n\t\tbreak;\n\t}\n\treturn TRUE;\n}\n\n#include \"PyTibrvException.h\"\n#include \"PyTibrvQueue.h\"\n#include \"PyTibrvEnvironment.h\"\n#include \"PyTibrvNetTransport.h\"\n#include \"PyTibrvListener.h\"\n\nstatic PyMethodDef module_methods[] = {\n {NULL} /* Sentinel */\n};\n\nPyMODINIT_FUNC inittibrv(void)\n{\n\tPyObject *module = Py_InitModule(\"tibrv\", module_methods);\n\n\tinitPyTibrvException(module);\n\tinitPyTibrvQueue(module);\n\tinitPyTibrvEnvironment(module);\n\tinitPyTibrvNetTransport(module);\n\tinitPyTibrvListener(module);\n\n\tPyObject* environment = PyTibrvEnvironment_New();\n\tPy_INCREF(environment);\n\tPyModule_AddObject(module, \"environment\", environment);\n}\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 21.5,
"blob_id": "2209d5b1a6140e87ea3fed07e92525384af1f1c3",
"content_id": "6aea9f426f16c6c856896cdae74555dccd36722d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 6,
"path": "/PyTibrvException.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nextern PyObject* tibrv_error;\n\nvoid initPyTibrvException(PyObject* module);\nvoid PyErr_Tibrv(const TibrvStatus& status);\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 29.928571701049805,
"blob_id": "1374a5dee9bf1eb1d657ab073b5e4e7131cd7c80",
"content_id": "e124c1ddc5a567d4278ef5528de6bc5b811cd871",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 432,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 14,
"path": "/PyTibrvEnvironment.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ntypedef struct {\n PyObject_HEAD\n\tPyTibrvQueueObject *defaultQueue;\n} PyTibrvEnvironmentObject;\n\nextern PyTypeObject PyTibrvEnvironment_Type;\n\nextern PyObject* PyTibrvEnvironment_New(void);\n#define PyTibrvEnvironment_Check(op) PyObject_TypeCheck(op, &PyTibrvEnvironment_Type)\n#define PyTibrvEnvironment_CheckExact(op) ((op)->ob_type == &PyTibrvEnvironment_Type)\n\nextern void initPyTibrvEnvironment(PyObject* module);"
},
{
"alpha_fraction": 0.7136171460151672,
"alphanum_fraction": 0.7362620830535889,
"avg_line_length": 48.43283462524414,
"blob_id": "f35565d08731553532d86c7026687f4fb8b691e7",
"content_id": "90332b0c6c55c91259639e7b870973af36a95cff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6624,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 134,
"path": "/types.h",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#pragma once\n\ninline PyObject* python_traits<tibrv_f64>::PyObject_FromType(const tibrv_f64& value) { return PyFloat_FromDouble(value); }\ninline tibrv_f64 python_traits<tibrv_f64>::PyObject_AsType(PyObject* value) { return PyFloat_AsDouble(value); }\ninline bool python_traits<tibrv_f64>::PyObject_CheckType(PyObject* value) { return PyFloat_Check(value); }\n\ninline PyObject* python_traits<tibrv_f32>::PyObject_FromType(const tibrv_f32& value) { return PyFloat_FromDouble(static_cast<double>(value)); }\ninline tibrv_f32 python_traits<tibrv_f32>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_f32>(PyFloat_AsDouble(value)); }\ninline bool python_traits<tibrv_f32>::PyObject_CheckType(PyObject* value) { return PyFloat_Check(value); }\n\ninline PyObject* python_traits<tibrv_i8>::PyObject_FromType(const tibrv_i8& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_i8 python_traits<tibrv_i8>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_i8>(PyInt_AsLong(value)); }\ninline bool python_traits<tibrv_i8>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_u8>::PyObject_FromType(const tibrv_u8& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_u8 python_traits<tibrv_u8>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_u8>(PyInt_AsLong(value)); }\ninline bool python_traits<tibrv_u8>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_i16>::PyObject_FromType(const tibrv_i16& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_i16 python_traits<tibrv_i16>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_i16>(PyInt_AsLong(value)); }\ninline bool python_traits<tibrv_i16>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_u16>::PyObject_FromType(const tibrv_u16& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_u16 python_traits<tibrv_u16>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_u16>(PyInt_AsLong(value)); }\ninline bool python_traits<tibrv_u16>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_i32>::PyObject_FromType(const tibrv_i32& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_i32 python_traits<tibrv_i32>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_i32>(PyInt_AsLong(value)); }\ninline bool python_traits<tibrv_i32>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_u32>::PyObject_FromType(const tibrv_u32& value) { return PyInt_FromLong(static_cast<long>(value)); }\ninline tibrv_u32 python_traits<tibrv_u32>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_u32>(PyInt_AsUnsignedLongMask(value)); }\ninline bool python_traits<tibrv_u32>::PyObject_CheckType(PyObject* value) { return PyInt_Check(value); }\n\ninline PyObject* python_traits<tibrv_i64>::PyObject_FromType(const tibrv_i64& value) { return PyLong_FromLong(static_cast<long>(value)); }\ninline tibrv_i64 python_traits<tibrv_i64>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_i64>(PyLong_AsLong(value)); }\ninline bool python_traits<tibrv_i64>::PyObject_CheckType(PyObject* value) { return PyLong_Check(value); }\n\ninline PyObject* python_traits<tibrv_u64>::PyObject_FromType(const tibrv_u64& value) { return PyLong_FromUnsignedLong(static_cast<long>(value)); }\ninline tibrv_u64 python_traits<tibrv_u64>::PyObject_AsType(PyObject* value) { return static_cast<tibrv_u64>(PyLong_AsUnsignedLong(value)); }\ninline bool python_traits<tibrv_u64>::PyObject_CheckType(PyObject* value) { return PyLong_Check(value); }\n\ninline PyObject* python_traits<tibrv_bool>::PyObject_FromType(const tibrv_bool& value)\n{\n\tPyObject* py_value = (value == TIBRV_TRUE ? Py_True : Py_False);\n\tPy_INCREF(py_value);\n\treturn py_value;\n}\ninline tibrv_bool python_traits<tibrv_bool>::PyObject_AsType(PyObject* value) { return PyObject_IsTrue(value) ? TIBRV_TRUE : TIBRV_FALSE; }\ninline bool python_traits<tibrv_bool>::PyObject_CheckType(PyObject* value) { return PyBool_Check(value); }\n\ninline PyObject* python_traits<tibrvMsgDateTime>::PyObject_FromType(const tibrvMsgDateTime& value)\n{\n\ttime_t t = value.sec;\n\n\tstruct tm _tm;\n\t_localtime64_s(&_tm, &t);\n\n\tPyObject* result = PyTuple_New(6);\n\tPyTuple_SetItem(result, 0, PyInt_FromLong(1900 + _tm.tm_year));\n\tPyTuple_SetItem(result, 1, PyInt_FromLong(1 + _tm.tm_mon));\n\tPyTuple_SetItem(result, 2, PyInt_FromLong(_tm.tm_mday));\n\tPyTuple_SetItem(result, 3, PyInt_FromLong(_tm.tm_hour));\n\tPyTuple_SetItem(result, 4, PyInt_FromLong(_tm.tm_min));\n\tPyTuple_SetItem(result, 5, PyInt_FromLong(_tm.tm_sec));\n\n\treturn result;\n}\n\ninline tibrvMsgDateTime python_traits<tibrvMsgDateTime>::PyObject_AsType(PyObject* value)\n{\n\ttibrvMsgDateTime lhs;\n\n\tstruct tm tmbuf;\n\ttmbuf.tm_sec = 0;\n\ttmbuf.tm_min = 0;\n\ttmbuf.tm_hour = 0;\n\ttmbuf.tm_wday = 0;\n\ttmbuf.tm_yday = 0;\n\n\tif (PySequence_Size(value) == 3)\n\t{\n\t\tPyObject* years = PySequence_GetItem(value, 0);\n\t\tPyObject* months = PySequence_GetItem(value, 1);\n\t\tPyObject* days = PySequence_GetItem(value, 2);\n\n\t\tif (PyInt_Check(years) && PyInt_Check(months) && PyInt_Check(days))\n\t\t{\n\t\t\ttmbuf.tm_mday = PyInt_AsLong(days);\n\t\t\ttmbuf.tm_mon = PyInt_AsLong(months) - 1;\n\t\t\ttmbuf.tm_year = PyInt_AsLong(years) - 1900;\n\n\t\t\tlhs.sec = mktime(&tmbuf);\n\t\t\tlhs.nsec = 0;\n\n\t\t\treturn lhs;\n\t\t}\n\t\telse\n\t\t\tthrow \"invalid date time format\";\n\t}\n\telse if (PySequence_Size(value) == 6)\n\t{\n\t\tPyObject* years = PySequence_GetItem(value, 0);\n\t\tPyObject* months = PySequence_GetItem(value, 1);\n\t\tPyObject* days = PySequence_GetItem(value, 2);\n\t\tPyObject* hours = PySequence_GetItem(value, 3);\n\t\tPyObject* minutes = PySequence_GetItem(value, 4);\n\t\tPyObject* seconds = PySequence_GetItem(value, 5);\n\n\t\tif (PyInt_Check(years) && PyInt_Check(months) && PyInt_Check(days) && PyInt_Check(hours) && PyInt_Check(minutes) && PyInt_Check(seconds))\n\t\t{\n\t\t\ttmbuf.tm_sec = PyInt_AsLong(seconds);\n\t\t\ttmbuf.tm_min = PyInt_AsLong(minutes);\n\t\t\ttmbuf.tm_hour = PyInt_AsLong(hours);\n\t\t\ttmbuf.tm_mday = PyInt_AsLong(days);\n\t\t\ttmbuf.tm_mon = PyInt_AsLong(months) - 1;\n\t\t\ttmbuf.tm_year = PyInt_AsLong(years) - 1900;\n\n\t\t\tlhs.sec = mktime(&tmbuf);\n\t\t\tlhs.nsec = 0;\n\n\t\t\treturn lhs;\n\t\t}\n\t\telse\n\t\t\tthrow \"invalid date time format\";\n\t}\n\telse\n\t\tthrow \"invalid date time format\";\n}\n\ninline bool python_traits<tibrvMsgDateTime>::PyObject_CheckType(PyObject* value)\n{\n\treturn PySequence_Check(value) && (PySequence_Size(value) == 3 || PySequence_Size(value) == 6);\n}\n"
},
{
"alpha_fraction": 0.5983624458312988,
"alphanum_fraction": 0.6058862805366516,
"avg_line_length": 24.971263885498047,
"blob_id": "81c2dfdfba06b98fbc200b25494132bcd52b2fb6",
"content_id": "05ee02a479034d67b0d298c90764ae8f421d6998",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4519,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 174,
"path": "/PyTibrvListener.cpp",
"repo_name": "rob-blackbourn/PyTibrv",
"src_encoding": "UTF-8",
"text": "#include \"stdafx.h\"\n\n#include \"tibrv_exception.h\"\n#include \"traits.h\"\n#include \"types.h\"\n#include \"messages.h\"\n#include \"PyTibrvException.h\"\n#include \"PyTibrvListener.h\"\n#include \"PyTibrvNetTransport.h\"\n#include \"PyTibrvQueue.h\"\n#include \"PyTibrvCallback.h\"\n\n/*\n** NetTransport\n*/\n\nstatic void\ndealloc_method(PyTibrvListenerObject* self)\n{\n\tif (self->listener != NULL)\n\t{\n\t\tTibrvStatus status = self->listener->destroy();\n\t\tdelete self->listener;\n\t\tself->listener = NULL;\n\t}\n self->ob_type->tp_free((PyObject*)self);\n}\n\nstatic PyObject *\nnew_method(PyTypeObject *type, PyObject *args, PyObject *kwds)\n{\n PyTibrvListenerObject *self = (PyTibrvListenerObject*)type->tp_alloc(type, 0);\n\n if (self != NULL)\n\t{\n\t\tself->listener = new TibrvListener();\n if (self->listener == NULL)\n\t\t{\n Py_DECREF(self);\n return NULL;\n\t\t}\n }\n\n return (PyObject *)self;\n}\n\nstatic int\ninit_method(PyTibrvListenerObject *self, PyObject *args, PyObject *kwds)\n{\n\tPyObject *queue, *callback, *transport, *closure;\n char *subject = NULL;\n\n static char *kwlist[] = {\"queue\", \"callback\", \"transport\", \"subject\", \"closure\", NULL};\n\n if (! PyArg_ParseTupleAndKeywords(args, kwds, \"OOOs|O\", kwlist, &queue, &callback, &transport, &subject, &closure))\n return -1; \n\n\tif (!PyTibrvQueue_Check(queue))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"queue type invalid\");\n\t\treturn -1;\n\t}\n\n\tif (!PyTibrvNetTransport_Check(transport))\n\t{\n\t\tPyErr_SetString(PyExc_TypeError, \"transport type invalid\");\n\t\treturn -1;\n\t}\n\n\tPyTibrvCallback* cb = new PyTibrvCallback(callback, false);\n\tTibrvStatus status = self->listener->create(PyTibrvQueue_AsQueue(queue), cb, PyTibrvNetTransport_AsTransport(transport), subject, closure);\n\n return 0;\n}\n\nstatic PyMemberDef type_members[] = {\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ngetter_subject(PyTibrvListenerObject *self, void *closure)\n{\n\tconst char* subject = NULL;\n\tTibrvStatus status = self->listener->getSubject(subject);\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n\treturn PyString_FromString(subject);\n}\n\nstatic PyObject *\ngetter_transport(PyTibrvListenerObject *self, void *closure)\n{\n\tTibrvNetTransport* transport = (TibrvNetTransport*) self->listener->getTransport();\n\treturn PyTibrvNetTransport_FromTransport(transport);\n}\n\nstatic PyGetSetDef type_getseters[] = {\n {\"subject\", (getter)getter_subject, NULL, \"service\", NULL},\n {\"transport\", (getter)getter_transport, NULL, \"transport\", NULL},\n {NULL} /* Sentinel */\n};\n\nstatic PyObject *\ntypemethod_destroy(PyTibrvListenerObject* self)\n{\n\tTibrvStatus status = self->listener->destroy();\n\tif (status != TIBRV_OK)\n\t{\n\t\tPyErr_Tibrv(status);\n\t\treturn NULL;\n\t}\n\n Py_INCREF(Py_None);\n return Py_None;\n}\n\nstatic PyMethodDef type_methods[] = {\n {\"destroy\", (PyCFunction)typemethod_destroy, METH_NOARGS, \"Destroy a listener. \"},\n {NULL} /* Sentinel */\n};\n\nPyTypeObject PyTibrvListener_Type = {\n PyObject_HEAD_INIT(NULL)\n 0,\t\t\t\t\t\t\t\t\t/*ob_size*/\n \"tibrv.listener\",\t\t\t\t\t/*tp_name*/\n sizeof(PyTibrvListenerObject),\t\t/*tp_basicsize*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_itemsize*/\n (destructor)dealloc_method,\t\t\t/*tp_dealloc*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_print*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_compare*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_repr*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_number*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_sequence*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_mapping*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_hash */\n 0,\t\t\t\t\t\t\t\t\t/*tp_call*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_str*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_getattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_setattro*/\n 0,\t\t\t\t\t\t\t\t\t/*tp_as_buffer*/\n Py_TPFLAGS_DEFAULT | Py_TPFLAGS_BASETYPE,\t/*tp_flags*/\n \"Tibco Listener\",\t\t\t\t\t/* tp_doc */\n 0,\t\t\t\t\t\t\t\t\t/* tp_traverse */\n 0,\t\t\t\t\t\t\t\t\t/* tp_clear */\n 0,\t\t\t\t\t\t\t\t\t/* tp_richcompare */\n 0,\t\t\t\t\t\t\t\t\t/* tp_weaklistoffset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iter */\n 0,\t\t\t\t\t\t\t\t\t/* tp_iternext */\n type_methods,\t\t\t\t\t\t/* tp_methods */\n type_members,\t\t\t\t\t\t/* tp_members */\n type_getseters,\t\t\t\t\t\t/* tp_getset */\n 0,\t\t\t\t\t\t\t\t\t/* tp_base */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dict */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_get */\n 0,\t\t\t\t\t\t\t\t\t/* tp_descr_set */\n 0,\t\t\t\t\t\t\t\t\t/* tp_dictoffset */\n (initproc)init_method,\t\t\t\t/* tp_init */\n 0,\t\t\t\t\t\t\t\t\t/* tp_alloc */\n new_method,\t\t\t\t\t\t\t/* tp_new */\n};\n\nvoid initPyTibrvListener(PyObject* module) \n{\n if (PyType_Ready(&PyTibrvListener_Type) < 0)\n return;\n Py_INCREF(&PyTibrvListener_Type);\n PyModule_AddObject(module, \"listener\", (PyObject*) &PyTibrvListener_Type);\n}\n"
}
] | 20 |
Hellemos/curso-Python-youtube
|
https://github.com/Hellemos/curso-Python-youtube
|
f4df8c6ff5174cfab6516b697babd34af6cdc6cd
|
cd9ebe19334bfe903d54f1f52b6fa095cf688791
|
c27286e7bf895bd2f8f35eb219c3ea0ed59a44d9
|
refs/heads/master
| 2020-07-03T11:21:06.396709 | 2015-07-22T01:03:58 | 2015-07-22T01:03:58 | 31,380,510 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6060100197792053,
"alphanum_fraction": 0.6360601186752319,
"avg_line_length": 16.114286422729492,
"blob_id": "acbffd730929c8950c4424095e8c727c69f17877",
"content_id": "f8bd83c7d7515e74c1bc24f0b4dc7fdf243f08a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 35,
"path": "/aula16-funções.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "# -*- encoding: UTF-8 -*-\n\ndef aula():\n print('Aula sobre funções')\n\ndef nAula():\n print('Aula 16')\n\ndef cliente(nome):\n print ('Olá,', nome)\n\n#Funções com parâmetros\ndef recebeNome(name):\n print('Olá,', name)\n\nname = input('Entre com o nome: ')\n\n#Funções dinâmicas\ndef soma(n1, n2):\n resultado = n1 + n2\n return resultado\n\nprint('O valor final da soma é:', soma(1, 2))\n\n#Funções com Parâmetros pré-definidos\ndef soma(n1, n2, n3=5):\n resultado = n1 + n2 + n3\n return resultado\n\nprint('O valor final da soma é:', soma(1, 2))\n\naula()\nnAula()\ncliente('Hellen')\nrecebeNome(name)\n"
},
{
"alpha_fraction": 0.7209302186965942,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 20.5,
"blob_id": "bec5aaa407cfeedca8a704e6dd0f112c62ecde17",
"content_id": "dff1894ea310e761ca53facd1124082ecdac4684",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "# curso-Python-youtube\nCódigos da aula 059\n"
},
{
"alpha_fraction": 0.5323193669319153,
"alphanum_fraction": 0.5342205166816711,
"avg_line_length": 28.22222137451172,
"blob_id": "9e573f2091635e75f66127f1bc79223acef8c43d",
"content_id": "1b98b26094bcd7cf43a2204ed80b3fbb7e97eedb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 18,
"path": "/Q9-conta.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Conta(Banco):\n def __init__(self, saldo, ID, senha):\n super(Banco, self).__init__()\n self.__saldo = saldo\n self.ID = ID\n self.senha = senha\n\n def deposito(self, senha, valor):\n self.__saldo += valor\n self.saldo()\n def saque(self, senha, valor):\n if self.__saldo >= valor:\n self.__saldo -= valor\n self.saldo()\n def podeReceberEmprestimo(self, valor):\n pass\n def saldo(self):\n print('Seu saldo atual eh: %.2f' % self.__saldo)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 49.83333206176758,
"blob_id": "4da7068748ff835d63b361308b0c66e8f4099253",
"content_id": "9a6cf1b3ccce9e3d903b384287a77789cf3dd552",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 6,
"path": "/Q6-ciruclo.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Circulo(ObjetoGrafico):\n def __init__(self, raio, cor_de_preenchimento, cor_de_contorno):\n super(Circulo, self).__init__(cor_de_preenchimento, cor_de_contorno)\n self.raio = raio\n self.cor_de_preenchimento = cor_de_preenchimento\n self.cor_de_contorno = cor_de_contorno\n\n"
},
{
"alpha_fraction": 0.6301369667053223,
"alphanum_fraction": 0.6301369667053223,
"avg_line_length": 48.42856979370117,
"blob_id": "e98ede33aa829e8d62060293686132cff7465bca",
"content_id": "9cf4b425323dcc1b1587712463fc8f59244ef682",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 7,
"path": "/Q7-triangulo.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Triangulo(ObjetoGrafico):\n def __init__(self, base, altura, cor_de_preenchimento, cor_de_contorno):\n super(Triangulo, self).__init__(cor_de_preenchimento, cor_de_contorno)\n self.base = base\n self.altura = altura\n self.cor_de_preenchimento = cor_de_preenchimento\n self.cor_de_contorno = cor_de_contorno\n \n \n\n"
},
{
"alpha_fraction": 0.5486842393875122,
"alphanum_fraction": 0.5828947424888611,
"avg_line_length": 23.62295150756836,
"blob_id": "8f3d607e29325a851cdc43a8d1e8f8c510c99cb9",
"content_id": "28b798e5b350b604af0bd5c7841959fb85cf2049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1538,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 61,
"path": "/joguinho.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "# -*- encoding: UTF-8 -*-\ndef soma(n1, n2):\n resultado = n1 + n2\n return resultado\n\ndef subtracao(n1, n2):\n resultado = n1 - n2\n return resultado\n\ndef multiplicacao(n1, n2):\n resultado = n1 * n2\n return resultado\n\ndef divisao(n1, n2):\n resultado = n1 / n2\n return resultado\n\ndef modulo(n1, n2):\n resultado = n1 % n2\n return resultado\n\ndef potenciacao(n1, n2):\n resultado = n1 ** n2\n return resultado\n\nprint('*** Seja bem vindo ao jogo das operações matemática! ***')\ncontador = True\nwhile (contador == True):\n n1 = float(input('Entre com o primeiro valor: '))\n n2 = float(input('Entre com o segundo valor: '))\n\n print('*** Selecione uma das opções: *** ')\n op = int(input('1) Adição \\n2) Subtração \\n3) Multiplicação \\n4) Divisão \\n5) Módulo \\n6) Potenciação \\nR.: '))\n\n if op == 1:\n print('Resultado da soma:', soma(n1, n2))\n\n if op == 2:\n print('Resultado da subtracao:', subtracao(n1, n2))\n\n if op == 3:\n print('Resultado da multiplicacao:', multiplicacao(n1, n2))\n\n if op == 4:\n print('Resultado da divisao:', divisao(n1, n2))\n\n if op == 5:\n print('Resultado do modulo:', modulo(n1, n2))\n\n if op == 6:\n print('Resultado da potenciacao:', potenciacao(n1, n2))\n\n if op > 6:\n print('Opção inválida! Reinicie o jogo!')\n\n continuar = input('Deseja continuar? S/N \\nR.: ')\n if (continuar.upper() == \"S\"):\n continuar = True\n else:\n continuar = False\n break\n \n \n"
},
{
"alpha_fraction": 0.5904255509376526,
"alphanum_fraction": 0.603723406791687,
"avg_line_length": 29.58333396911621,
"blob_id": "39028e6004997957cbdc1c2cfe6be559a0c358bc",
"content_id": "909c0334f9b86cf61c4b2c77eeee3c9414331c9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 12,
"path": "/Q1.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Quadrado:\n def __init__(self):\n self.tamanhoDoLado = 0\n self.area = 0.0\n\n def mudarLado(self, novoValor):\n self.tamanhoDoLado = novoValor\n def retornarValorLado(self):\n return self.tamanhoDoLado\n def calcularArea(self):\n self.area = self.tamanhoDoLado**2\n print('A area do quadrado eh: %.2f' % (self.area))\n \n"
},
{
"alpha_fraction": 0.500954806804657,
"alphanum_fraction": 0.5149586200714111,
"avg_line_length": 40.864864349365234,
"blob_id": "87647eb04dcd20d06ab166c7efe18368d1209424",
"content_id": "99e3c145abf7bbb77742659e3b9a5aa6ec02142d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1571,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 37,
"path": "/Q4-objeto-grafico.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "'''considerando que a cor de preenchimento do retangulo e 1, a do circulo e\n2 e a do triangulo e 3 '''\nclass ObjetoGrafico(object):\n def __init__(self, cor_de_preenchimento, cor_de_contorno):\n self.cor_de_preenchimento = cor_de_preenchimento\n self.preenchida = True\n self.cor_de_contorno = cor_de_contorno\n \n def calcularArea(self):\n if self.cor_de_preenchimento == 1:\n print('A area do retangulo eh: ', self.base * self.altura, 'cm')\n elif self.cor_de_preenchimento == 2:\n print(3.14 * self.raio ** 2)\n elif self.cor_de_preenchimento == 3:\n print(self.base * self.altura / 2)\n else:\n print('figura nao encontrada =/')\n\n def calcularPerimentro(self):\n if self.cor_de_preenchimento == 1:\n print('passou aqui')\n print('O perimetro do retangulo eh: ', 2 * (self.base + self.altura, 'm'))\n elif self.cor_de_preenchimento == 2:\n print('O perimentro do cirulo eh: ', 2* 3.14 * self.raio, 'm') \n elif self.cor_de_preenchimento == 3:\n print('Digite os lados do triangulo: ' )\n a = int(input('Lado A: '))\n b = int(input('Lado B: '))\n c = int(input('Lado C: ')) \n i = 1\n while i <= 3:\n if a == b == c:\n perimetro = a + b + c\n else:\n print('os lados sao diferentes')\n i += 1\n print('O perimetro do triangulo eh: ', perimetro)\n \n \n"
},
{
"alpha_fraction": 0.6130790114402771,
"alphanum_fraction": 0.6171662211418152,
"avg_line_length": 41.35293960571289,
"blob_id": "ba17a94e92bf0620980ecb5796a6acb75d134bc5",
"content_id": "4b4046bdad235e9bcce29f3c4413d0aff9dc495b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 734,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 17,
"path": "/Q2.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Retangulo:\n def __init__(self, base, altura):\n self.base = base\n self.altura = altura\n self.area = 0\n self.perimetro = 0\n def mudarLados(self, novoValorBase, novoValorAltura):\n self.base = novoValorBase\n self.altura = novoValorAltura\n def retornarValorLados(self):\n return 'O novo valor da base eh %d cm e da altura eh %d cm' % (self.base, self.altura)\n def calcularArea(self):\n self.area = self.base * self.altura\n print('A area do retangulo eh: %d cm' %self.area)\n def calcularPerimetro(self):\n self.perimetro = 2 * (self.base + self.altura)\n print('O perimetro deste retangulo tem valor igual a %d' % (self.perimetro))\n \n \n"
},
{
"alpha_fraction": 0.6186186075210571,
"alphanum_fraction": 0.6186186075210571,
"avg_line_length": 40.3125,
"blob_id": "8d6a0e61b4535e7e75d07422baf249d15da84622",
"content_id": "02bbd93f5909a32dd2e485435742030af8c29e79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 16,
"path": "/Q3.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Pessoa:\n def __init__(self, nome, idade, peso, altura):\n self.nome = nome\n self.idade = idade\n self.peso = peso\n self.altura = altura\n\n def ficandoVelho(self, novaIdade):\n self.idade = novaIdade\n print('Ta ficando velho hein? Sua atual idade eh: %d anos' % (self.idade))\n def projetoFicarGordo(self, novoPeso):\n self.peso += novoPeso\n print('Parabens!! Voce conseguiu ganhar peso =D seu peso atual eh: %d kg' %self.peso)\n def projetoFicarMagro(self, pesoPerdido):\n self.peso -= pesoPerdido\n print('E lamentavel, voce emagreceu =/ \\nSeu peso atual eh: %d kg' % (self.peso))\n \n"
},
{
"alpha_fraction": 0.5095890164375305,
"alphanum_fraction": 0.534246563911438,
"avg_line_length": 22.133333206176758,
"blob_id": "5f9d2db3efcb1a7ee624a36196e738cf04cb3753",
"content_id": "20ffe13d5d7d8a69e58fc49e9f7909bfb25a2d2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 15,
"path": "/Q8-banco.py",
"repo_name": "Hellemos/curso-Python-youtube",
"src_encoding": "UTF-8",
"text": "class Banco(object):\n __total = 1000\n taxaReserva = 0.1\n reservaExigida = 100\n def __init__(self):\n pass\n\n def __calcularReserva(self):\n print(Banco.__total * self.taxaReserva)\n\n def podeFazerEmprestimo(self, valor):\n if valor <= Banco.__total:\n return True\n else:\n return False\n \n \n"
}
] | 11 |
vidya/subsets
|
https://github.com/vidya/subsets
|
1dd8b2d6e4e4a6e54bd28dd4523fa47bf88ae000
|
a19f62e45e1940e1a8ba38a508dd995b0ac8bb59
|
5e9db32258e688308b46e61e8690a20106795d45
|
refs/heads/master
| 2020-05-22T18:25:32.458915 | 2019-05-13T18:07:55 | 2019-05-13T18:07:55 | 186,470,762 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.42904841899871826,
"alphanum_fraction": 0.47245410084724426,
"avg_line_length": 19.620689392089844,
"blob_id": "dd610467732919756b0156872b3493fb015d426c",
"content_id": "3b281ce454edd15279b2a1b230e2352dcdef0971",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 29,
"path": "/test_subsets.py",
"repo_name": "vidya/subsets",
"src_encoding": "UTF-8",
"text": "from subsets.subsets import Solution\n\n\ndef test_1_basic():\n nums = [1]\n expected = ((), (1,))\n\n result = Solution().subsets(nums)\n assert set(result) == set(expected)\n\n\ndef test_2_basic():\n nums = [1, 2]\n expected = ((), (1,), (2,), (1, 2))\n\n result = Solution().subsets(nums)\n assert set(result) == set(expected)\n\n\ndef test_3_basic():\n nums = [1, 2, 3]\n expected = ((),\n (1,), (2,), (3,),\n (1, 2), (1, 3), (2, 3),\n (1, 2, 3)\n )\n\n result = Solution().subsets(nums)\n assert set(result) == set(expected)\n\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 26,
"blob_id": "ec5ab050bff49169df29f868990f657582a95994",
"content_id": "84ba4d445873392fbf13199c6c4afb7d3dfe4a04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 2,
"path": "/README.md",
"repo_name": "vidya/subsets",
"src_encoding": "UTF-8",
"text": "# subsets\nSolution to the Subsets problem at LeetCode\n"
}
] | 2 |
pawlooss1/twlab
|
https://github.com/pawlooss1/twlab
|
544f2d48b40d0b539f79efca02cc2a7b693e02d2
|
745e603622b300b611197f08e804dd29c3690b06
|
6800a2e20bb5777552810fe96a6edea7ae440580
|
refs/heads/master
| 2020-08-07T08:37:25.866078 | 2020-01-01T14:54:57 | 2020-01-01T14:54:57 | 213,374,941 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7161354422569275,
"alphanum_fraction": 0.7221115827560425,
"avg_line_length": 42.65217208862305,
"blob_id": "7f865f061b50953a57458028faa39e8401b9b445",
"content_id": "a2449e9eb0bf1ff9fe473a20ca4791bc4f4e2cb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1004,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 23,
"path": "/tw/src/main/java/pl/edu/agh/lab9/standard/SmokersDemo.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab9.standard;\n\nimport java.util.concurrent.Semaphore;\n\npublic class SmokersDemo {\n static Semaphore smokerTobacco = new Semaphore(0);\n static Semaphore smokerPaper = new Semaphore(0);\n static Semaphore smokerMatch = new Semaphore(0);\n static Semaphore agent = new Semaphore(0);\n static Semaphore lock = new Semaphore(1);\n\n public static void main(String[] args) {\n Thread agentThread = new Thread(new Agent(smokerTobacco, smokerPaper, smokerMatch, agent, lock));\n SmokerFactory smokerFactory = new SmokerFactory(smokerTobacco, smokerPaper, smokerMatch, agent, lock);\n Thread smokerTobaccoThread = new Thread(smokerFactory.newSmokerTobacco());\n Thread smokerPaperThread = new Thread(smokerFactory.newSmokerPaper());\n Thread smokerMatchThread = new Thread(smokerFactory.newSmokerMatch());\n agentThread.start();\n smokerMatchThread.start();\n smokerPaperThread.start();\n smokerTobaccoThread.start();\n }\n}\n"
},
{
"alpha_fraction": 0.6005882620811462,
"alphanum_fraction": 0.6023529171943665,
"avg_line_length": 28.824562072753906,
"blob_id": "545cbf4a93527a418dbe6be7407561e94689fc4d",
"content_id": "d81edf10d0d9e3a70cceab7f80be98c1458d6b7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1700,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 57,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad2/NaiveUnorderedBuffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad2;\n\nimport java.util.ArrayList;\nimport java.util.Collection;\nimport java.util.List;\nimport java.util.concurrent.locks.Condition;\nimport java.util.concurrent.locks.Lock;\nimport java.util.concurrent.locks.ReentrantLock;\n\npublic class NaiveUnorderedBuffer implements UnorderedBuffer {\n private final Lock lock = new ReentrantLock();\n private final Condition canPut = lock.newCondition();\n private final Condition canTake = lock.newCondition();\n private int bufferSize;\n private List<Integer> values;\n\n public NaiveUnorderedBuffer(int bufferSize) {\n this.bufferSize = bufferSize;\n this.values = new ArrayList<>(bufferSize);\n }\n\n public void put(Collection<Integer> valuesToPut) {\n lock.lock();\n try {\n while (valuesToPut.size() > availableSpace()) {\n canPut.await();\n }\n values.addAll(valuesToPut);\n canTake.signalAll();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n public Collection<Integer> take(int howMany) {\n lock.lock();\n try {\n while (howMany > values.size()) {\n canTake.await();\n }\n List<Integer> sublist = new ArrayList<>(values.subList(0, howMany));\n values.removeAll(sublist);\n canPut.signalAll();\n return sublist;\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n private int availableSpace() {\n return bufferSize - values.size();\n }\n}\n"
},
{
"alpha_fraction": 0.6206185817718506,
"alphanum_fraction": 0.6371133923530579,
"avg_line_length": 23.25,
"blob_id": "2f00f26f12004a05ac1085a4fb4b2314dd8d5415",
"content_id": "92c4ae567749014bbe33ffb10967713198f8b844",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 20,
"path": "/philosopers_pyt/statistician.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "from functools import reduce\n\nwait_time = {0: [], 1: [], 2: [], 3: [], 4: []}\n\n\ndef add_wait_time(number, measurement):\n wait_time[number].append(measurement)\n\n\ndef wait_time_mean():\n return list(map(lambda t: (t[0], list_mean(t[1])), wait_time.items()))\n\n\ndef list_mean(values):\n return reduce(lambda a, b: a + b, values, 0) / len(values)\n\n\ndef print_measurements(measurements):\n for number, measurement in measurements:\n print('{} {}'.format(number, measurement))\n"
},
{
"alpha_fraction": 0.5786802172660828,
"alphanum_fraction": 0.5812183022499084,
"avg_line_length": 17.761905670166016,
"blob_id": "a3dec7942857543d4f25e7f04ad78adcb6f1a690",
"content_id": "c1e29479b9b180a13bcb2507019a9f3e0cbf09c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/tw/src/main/java/pl/edu/agh/lab2/BinarySemaphore.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab2;\n\nimport pl.edu.agh.util.Utils;\n\npublic class BinarySemaphore implements Semaphore {\n private boolean value = true;\n\n @Override\n public synchronized void p() {\n while (!value) {\n Utils.waitUnchecked(this);\n }\n value = false;\n }\n\n @Override\n public synchronized void v() {\n value = true;\n notify();\n }\n}\n"
},
{
"alpha_fraction": 0.5983436703681946,
"alphanum_fraction": 0.6045548915863037,
"avg_line_length": 23.149999618530273,
"blob_id": "eddfb4b98476d7e66b86305150d3273312c3970c",
"content_id": "10ec7ae23ca802783eb5b171e4a7cdc6966d0a5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 483,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad1/Consumer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad1;\n\npublic class Consumer implements Runnable {\n private int steps;\n private StreamBuffer buffer;\n private int consumerNo;\n\n public Consumer(StreamBuffer buffer, int number) {\n this.buffer = buffer;\n this.steps = buffer.getSize();\n this.consumerNo = number;\n }\n\n @Override\n public void run() {\n for (int i = 0; i < steps; i++) {\n System.out.println(buffer.take(i, consumerNo));\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5058308839797974,
"alphanum_fraction": 0.5262390375137329,
"avg_line_length": 27.58333396911621,
"blob_id": "9a52260762c4f982880543a57e4d635d220b4774",
"content_id": "a2c4b7276a538a10c1b8d10d7a6a3947170cd8aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 48,
"path": "/tw/src/main/java/pl/edu/agh/philosophers/HungerFork.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.philosophers;\n\nimport pl.edu.agh.util.Utils;\n\nimport java.util.List;\nimport java.util.concurrent.locks.Condition;\nimport java.util.concurrent.locks.Lock;\nimport java.util.concurrent.locks.ReentrantLock;\n\npublic class HungerFork implements Fork {\n private final Lock lock = new ReentrantLock();\n private List<Integer> free;\n private List<Condition> philosophers;\n\n public HungerFork() {\n free = Utils.createObjects(5, () -> 2);\n philosophers = Utils.createObjects(5, lock::newCondition);\n }\n\n @Override\n public void take(int i) {\n try {\n lock.lock();\n while (free.get(i) < 2) {\n philosophers.get(i).await();\n }\n free.set((i + 4) % 5, free.get((i + 4) % 5) - 1);\n free.set((i + 1) % 5, free.get((i + 1) % 5) - 1);\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n @Override\n public void putBack(int i) {\n try {\n lock.lock();\n free.set((i + 4) % 5, free.get((i + 4) % 5) + 1);\n free.set((i + 1) % 5, free.get((i + 1) % 5) + 1);\n philosophers.get((i + 4) % 5).signal();\n philosophers.get((i + 1) % 5).signal();\n } finally {\n lock.unlock();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6208251714706421,
"alphanum_fraction": 0.6335952877998352,
"avg_line_length": 29.84848403930664,
"blob_id": "d532d93f3f55c53bd14fb7641a823d5fb7ac592d",
"content_id": "aae73491626d00421f5e4afe57ef17d11bee80c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1018,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 33,
"path": "/tw/src/main/java/pl/edu/agh/lab1/Counter.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab1;\n\nimport pl.edu.agh.util.Utils;\n\nimport java.util.stream.LongStream;\n\npublic class Counter {\n public static final long STEPS = 500_000_000;\n public int value = 0;\n\n public synchronized void increment() {\n value++;\n }\n\n public synchronized void decrement() {\n value--;\n }\n\n public static void main(String[] args) {\n Counter counter = new Counter();\n Runnable incrementor = () -> LongStream.range(0, STEPS).forEach(i -> counter.increment());\n Runnable decrementor = () -> LongStream.range(0, STEPS).forEach(i -> counter.decrement());\n Thread incrementorThread = new Thread(incrementor);\n Thread decrementorThread = new Thread(decrementor);\n Utils.printExecutionTime(() -> {\n incrementorThread.start();\n decrementorThread.start();\n Utils.joinUnchecked(incrementorThread);\n Utils.joinUnchecked(decrementorThread);\n });\n System.out.println(counter.value);\n }\n}\n"
},
{
"alpha_fraction": 0.6023916006088257,
"alphanum_fraction": 0.6068759560585022,
"avg_line_length": 28.733333587646484,
"blob_id": "1611973bbe702f344e9b1238f2a188cdd1fb8bd3",
"content_id": "ecf495c81134b6f85ae57991861f0eb8fd7a5314",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1338,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 45,
"path": "/tw/src/main/java/pl/edu/agh/lab1/SimpleBuffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab1;\n\nimport pl.edu.agh.util.Utils;\n\nimport java.util.List;\nimport java.util.stream.Collectors;\nimport java.util.stream.IntStream;\n\npublic class SimpleBuffer implements Buffer<String> {\n public static final int STEPS = 5;\n private String value;\n private boolean present = false;\n\n public synchronized void put(String value) {\n while (present) {\n Utils.waitUnchecked(this);\n }\n this.value = value;\n present = true;\n notifyAll();\n }\n\n public synchronized String take() {\n while (!present) {\n Utils.waitUnchecked(this);\n }\n present = false;\n notifyAll();\n return value;\n }\n\n public static void main(String[] args) {\n SimpleBuffer buffer = new SimpleBuffer();\n List<Producer> producers = IntStream.range(0, 2).mapToObj(i -> new Producer(buffer))\n .collect(Collectors.toList());\n List<Consumer> consumers = IntStream.range(0, 2).mapToObj(i -> new Consumer(buffer))\n .collect(Collectors.toList());\n Utils.printExecutionTime(() -> {\n consumers.forEach(Thread::start);\n producers.forEach(Thread::start);\n consumers.forEach(Utils::joinUnchecked);\n producers.forEach(Utils::joinUnchecked);\n });\n }\n}\n"
},
{
"alpha_fraction": 0.66796875,
"alphanum_fraction": 0.669921875,
"avg_line_length": 38.38461685180664,
"blob_id": "9b239ec1e276bca4a4e674bbd2af32890ae834ac",
"content_id": "b50c538a31b5e554f5c7705ff1c811848c7c2df3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 512,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/tw/src/main/java/pl/edu/agh/lab9/different/SmokersDemo.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab9.different;\n\npublic class SmokersDemo {\n public static void main(String[] args) {\n Agent.getInstance().getAgents().forEach(r -> new Thread(r).start());\n Pushers pushers = new Pushers();\n pushers.runPushers();\n SmokerFactory smokerFactory = new SmokerFactory(pushers);\n new Thread(smokerFactory.newSmokerMatch()).start();\n new Thread(smokerFactory.newSmokerPaper()).start();\n new Thread(smokerFactory.newSmokerTobacco()).start();\n }\n}\n"
},
{
"alpha_fraction": 0.4856418967247009,
"alphanum_fraction": 0.4991554021835327,
"avg_line_length": 31,
"blob_id": "a1148026a2da2e54557ca28135fc3ec4d5bf1c14",
"content_id": "ba652d5a0831e46e31f59dae7279164d40a7a894",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1184,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 37,
"path": "/philosopers_pyt/waiter_fork.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "import threading\n\n\nclass WaiterFork:\n def __init__(self):\n self.lock = threading.RLock()\n self.occupied = list(map(lambda _: False, range(5)))\n self.forks = list(map(lambda _: threading.Condition(lock=self.lock), range(5)))\n self.waiter = threading.Condition(lock=self.lock)\n self.how_many_present = 0\n\n def take(self, i):\n try:\n self.lock.acquire()\n while self.how_many_present == 4:\n self.waiter.wait()\n self.how_many_present += 1\n while self.occupied[i]:\n self.forks[i].wait()\n self.occupied[i] = True\n while self.occupied[(i + 1) % 5]:\n self.forks[(i + 1) % 5].wait()\n self.occupied[(i + 1) % 5] = True\n finally:\n self.lock.release()\n\n def put_back(self, i):\n try:\n self.lock.acquire()\n self.occupied[i] = False\n self.forks[i].notify()\n self.occupied[(i + 1) % 5] = False\n self.forks[(i + 1) % 5].notify()\n self.how_many_present -= 1\n self.waiter.notify()\n finally:\n self.lock.release()\n"
},
{
"alpha_fraction": 0.6111801266670227,
"alphanum_fraction": 0.6124223470687866,
"avg_line_length": 32.082191467285156,
"blob_id": "8c0f30ab656ee3e53febf326fcba49f1088710d5",
"content_id": "7346e7e944764af041abd77983be99b761d6468e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2415,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 73,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad2/FairUnorderedBuffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad2;\n\nimport java.util.ArrayList;\nimport java.util.Collection;\nimport java.util.List;\nimport java.util.concurrent.locks.Condition;\nimport java.util.concurrent.locks.Lock;\nimport java.util.concurrent.locks.ReentrantLock;\n\npublic class FairUnorderedBuffer implements UnorderedBuffer {\n private final Lock lock = new ReentrantLock();\n private final Condition firstProducer = lock.newCondition();\n private final Condition firstConsumer = lock.newCondition();\n private final Condition remainingProducers = lock.newCondition();\n private final Condition remainingConsumers = lock.newCondition();\n private boolean firstProducerWaiting = false;\n private boolean firstConsumerWaiting = false;\n private int bufferSize;\n private List<Integer> values;\n\n public FairUnorderedBuffer(int bufferSize) {\n this.bufferSize = bufferSize;\n this.values = new ArrayList<>(bufferSize);\n }\n\n public void put(Collection<Integer> valuesToPut) {\n lock.lock();\n try {\n if (firstProducerWaiting) {\n remainingProducers.await();\n }\n firstProducerWaiting = true;\n while (valuesToPut.size() > availableSpace()) {\n firstProducer.await();\n }\n values.addAll(valuesToPut);\n firstProducerWaiting = false;\n remainingProducers.signal();\n firstConsumer.signal();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n public Collection<Integer> take(int howMany) {\n lock.lock();\n try {\n if (firstConsumerWaiting) {\n remainingConsumers.await();\n }\n firstConsumerWaiting = true;\n while (howMany > values.size()) {\n firstConsumer.await();\n }\n List<Integer> sublist = new ArrayList<>(values.subList(0, howMany));\n values.removeAll(sublist);\n firstConsumerWaiting = false;\n remainingConsumers.signal();\n firstProducer.signal();\n return sublist;\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n private int availableSpace() {\n return bufferSize - values.size();\n }\n}\n"
},
{
"alpha_fraction": 0.47671839594841003,
"alphanum_fraction": 0.4900221824645996,
"avg_line_length": 29.066667556762695,
"blob_id": "c6e5756b1ecb70f9e1a157651e2723d2d4e2494a",
"content_id": "37c0859392b132877fe4bc2e4083c981c48c75af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 902,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 30,
"path": "/philosopers_pyt/blocking_fork.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "import threading\n\n\nclass BlockingFork:\n def __init__(self):\n self.lock = threading.RLock()\n self.occupied = list(map(lambda _: False, range(5)))\n self.forks = list(map(lambda _: threading.Condition(lock=self.lock), range(5)))\n\n def take(self, i):\n try:\n self.lock.acquire()\n while self.occupied[i]:\n self.forks[i].wait()\n self.occupied[i] = True\n while self.occupied[(i + 1) % 5]:\n self.forks[(i + 1) % 5].wait()\n self.occupied[(i + 1) % 5] = True\n finally:\n self.lock.release()\n\n def put_back(self, i):\n try:\n self.lock.acquire()\n self.occupied[i] = False\n self.forks[i].notify()\n self.occupied[(i + 1) % 5] = False\n self.forks[(i + 1) % 5].notify()\n finally:\n self.lock.release()\n"
},
{
"alpha_fraction": 0.6170212626457214,
"alphanum_fraction": 0.6276595592498779,
"avg_line_length": 14.666666984558105,
"blob_id": "32cb81b6d68028749168329d189915c25e03a40f",
"content_id": "c989657d8b34ac064536f258647de02b4317da10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/tw/src/main/java/pl/edu/agh/lab1/Buffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab1;\n\npublic interface Buffer<T> {\n void put(T value);\n T take();\n}\n"
},
{
"alpha_fraction": 0.6491405367851257,
"alphanum_fraction": 0.656218409538269,
"avg_line_length": 29.90625,
"blob_id": "b7b3f9bace52eade621d21ca7a3e593ff67422ee",
"content_id": "6a7364124494a56ba8e53f53976900f6e495ad89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 989,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 32,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad2/RandomSizeProducer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad2;\n\nimport org.apache.commons.lang3.RandomUtils;\n\nimport java.util.Collection;\nimport java.util.List;\nimport java.util.stream.Collectors;\nimport java.util.stream.IntStream;\n\npublic class RandomSizeProducer extends Thread {\n private int producerNo;\n private int maxSize;\n private UnorderedBuffer buffer;\n\n public RandomSizeProducer(int producerNo, int maxSize, UnorderedBuffer buffer) {\n this.producerNo = producerNo;\n this.maxSize = maxSize;\n this.buffer = buffer;\n }\n\n @Override\n public void run() {\n for (int i = 0; true; i++) {\n int size = RandomUtils.nextInt(1, maxSize + 1);\n List<Integer> product = IntStream.range(0, size).boxed().collect(Collectors.toList());\n long startTime = System.nanoTime();\n buffer.put(product);\n long endTime = System.nanoTime();\n Statistician.getInstance().addPutTime(size, endTime - startTime);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6057742834091187,
"alphanum_fraction": 0.61312335729599,
"avg_line_length": 30.229507446289062,
"blob_id": "26f1909747d947974c1647b0f2eca43d2f77a50e",
"content_id": "727586a35051c27f1f009801d81f420a8322d782",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1905,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 61,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad1/StreamBuffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad1;\n\nimport io.vavr.Tuple2;\nimport pl.edu.agh.lab1.Buffer;\nimport pl.edu.agh.lab3.BoundedBuffer;\n\nimport java.util.List;\nimport java.util.concurrent.atomic.AtomicInteger;\nimport java.util.concurrent.locks.Condition;\nimport java.util.concurrent.locks.Lock;\nimport java.util.concurrent.locks.ReentrantLock;\nimport java.util.stream.Collectors;\nimport java.util.stream.IntStream;\n\npublic class StreamBuffer {\n private final Lock lock = new ReentrantLock();\n private final Condition canProcess = lock.newCondition();\n private int size;\n private final List<Tuple2<Buffer<String>, AtomicInteger>> array;\n\n public StreamBuffer(int size) {\n this.size = size;\n this.array = IntStream.range(0, size)\n .mapToObj(i -> new Tuple2<Buffer<String>, AtomicInteger>(new BoundedBuffer(), new AtomicInteger(0)))\n .collect(Collectors.toList());\n }\n\n public int getSize() {\n return size;\n }\n\n public void put(String value, int cellNumber, int processorNo) {\n lock.lock();\n try {\n while (array.get(cellNumber)._2.intValue() < processorNo) {\n canProcess.await();\n }\n array.get(cellNumber)._2.incrementAndGet();\n array.get(cellNumber)._1.put(value);\n canProcess.signalAll();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n\n public String take(int cellNumber, int processorNo) {\n lock.lock();\n try {\n while (array.get(cellNumber)._2.intValue() < processorNo) {\n canProcess.await();\n }\n return array.get(cellNumber)._1.take();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n } finally {\n lock.unlock();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6042885184288025,
"alphanum_fraction": 0.61208575963974,
"avg_line_length": 26,
"blob_id": "f8227ec07875abd14516c7e9c7806a941fecf5f9",
"content_id": "48dbd96d690e96bce023b790a542cfcc7e87f184",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 38,
"path": "/tw/src/main/java/pl/edu/agh/lab2/Shopper.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab2;\n\nimport org.apache.commons.lang3.RandomStringUtils;\nimport org.apache.commons.lang3.RandomUtils;\n\npublic class Shopper extends Thread {\n private Shop shop;\n private Cart cart;\n\n public Shopper(Shop shop) {\n this.shop = shop;\n }\n\n @Override\n public void run() {\n goShopping();\n }\n\n private void goShopping() {\n cart = shop.takeCart();\n int cartNumber = cart.getNumber();\n System.out.printf(\"Shopper %d took cart %d%n\", getId(), cartNumber);\n try {\n sleep(RandomUtils.nextInt(1, 100));\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n chooseItem();\n System.out.printf(\"Shopper %d took item %s%n\", getId(), cart.getContent());\n shop.returnCart(cart);\n System.out.printf(\"Shopper %d done with the shopping. Returned cart %d%n\", getId(), cartNumber);\n\n }\n\n private void chooseItem() {\n cart.setContent(RandomStringUtils.random(5));\n }\n}\n"
},
{
"alpha_fraction": 0.5649999976158142,
"alphanum_fraction": 0.574999988079071,
"avg_line_length": 20.052631378173828,
"blob_id": "96d40a4b62e01b58dc8f07fe58e9f1a68bf1769c",
"content_id": "a6d2da954bc379bbe18fcac5a66bb6b5436d3ed2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 19,
"path": "/tw/src/main/java/pl/edu/agh/lab1/Producer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab1;\n\npublic class Producer extends Thread {\n private static final int STEPS = 10;\n private Buffer<String> buffer;\n\n public Producer(Buffer<String> buffer) {\n this.buffer = buffer;\n }\n\n @Override\n public void run() {\n\n for (int i = 0; i < STEPS; i++) {\n buffer.put(String.format(\"message no %d from %d\", i, getId()));\n }\n\n }\n}\n"
},
{
"alpha_fraction": 0.6292682886123657,
"alphanum_fraction": 0.6308943033218384,
"avg_line_length": 20.20689582824707,
"blob_id": "f6446a191340da8a9c5877541b1926cffc321b55",
"content_id": "3c372fc0992d2aaa7a3856bb7bd6b7e5befe7d85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 615,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 29,
"path": "/tw/src/main/java/pl/edu/agh/lab3/Printer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab3;\n\nimport pl.edu.agh.util.Utils;\n\npublic class Printer {\n private int number;\n private boolean available;\n\n public Printer(int number) {\n available = true;\n this.number = number;\n }\n\n public int getNumber() {\n return number;\n }\n\n public boolean isAvailable() {\n return available;\n }\n\n public void setAvailability(boolean available) {\n this.available = available;\n }\n\n public void print(String content) {\n System.out.println(String.format(\"%s (printer no. %d)\", Utils.appendTimestampPrefix(content), number));\n }\n}\n"
},
{
"alpha_fraction": 0.6082739233970642,
"alphanum_fraction": 0.6165477633476257,
"avg_line_length": 32.066036224365234,
"blob_id": "5c86e26f78c3d93177451626f78d7587b30e7830",
"content_id": "e574c683837cf05d7a2436f61bc12cf794008faa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3505,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 106,
"path": "/tw/src/main/java/pl/edu/agh/util/Utils.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.util;\n\nimport io.vavr.Tuple2;\n\nimport java.io.IOException;\nimport java.nio.charset.StandardCharsets;\nimport java.nio.file.Files;\nimport java.nio.file.Paths;\nimport java.text.SimpleDateFormat;\nimport java.util.*;\nimport java.util.function.Function;\nimport java.util.function.Supplier;\nimport java.util.stream.Collectors;\nimport java.util.stream.IntStream;\n\npublic class Utils {\n\n private static final double NANOSECONDS_IN_SECOND = 1_000_000_000;\n\n public static void printExecutionTime(Executable function) {\n long estimatedTime = measureExecutionTime(function);\n System.out.println(String.format(\"It took %f seconds\", estimatedTime / NANOSECONDS_IN_SECOND));\n }\n\n public static long measureExecutionTime(Executable function) {\n long startTime = System.nanoTime();\n function.execute();\n long endTime = System.nanoTime();\n return endTime - startTime;\n }\n\n public static void joinUnchecked(Thread thread) {\n try {\n thread.join();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n }\n\n public static void waitUnchecked(Object object) {\n try {\n object.wait();\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n }\n\n public static void sleepUnchecked(int timeInMillis) {\n try {\n Thread.sleep(timeInMillis);\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n }\n\n public static void sleepUnchecked(Thread thread, int timeInMillis) {\n try {\n thread.sleep(timeInMillis);\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n }\n\n public static String appendTimestampPrefix(String message) {\n String timeStamp = new SimpleDateFormat(\"HH:mm:ss.SSS\").format(Calendar.getInstance().getTime());\n return String.format(\"[%s] %s\", timeStamp, message);\n }\n\n public static <E> String collectionToString(Collection<E> list, String prefix, Function<E, String> mapper) {\n return list.stream().map(mapper).reduce(prefix, (s1, s2) -> String.join(\" \", s1, s2));\n }\n\n public static <E> List<E> createObjects(int howMany, Supplier<E> supplier) {\n return IntStream.range(0, howMany).mapToObj(i -> supplier.get()).collect(Collectors.toList());\n }\n\n public static double listMean(List<Double> list) {\n if (list.size() <= 0) {\n throw new IllegalArgumentException(\"List cannot be empty\");\n }\n Double sum = list.stream().reduce(0.0, Double::sum);\n return sum / list.size();\n }\n\n public static void printMeasurements(List<Tuple2<Integer, Double>> measurements) {\n for (Tuple2<Integer, Double> measurement : measurements) {\n System.out.println(String.format(\"%f\", measurement._2));\n }\n }\n\n public static List<String> loadText(String filePath) {\n Map<Integer, String> map = new HashMap<>();\n map.put(0, \"\");\n map.put(1, \"\");\n map.put(2, \"\");\n map.put(3, \"\");\n try {\n Files.lines(Paths.get(filePath), StandardCharsets.UTF_8)\n .filter(s -> !s.equals(\"\"))\n .forEach(s -> map.put(s.length() % 4, map.get(s.length() % 4) + \" \" + s));\n return new ArrayList<>(map.values());\n } catch (IOException e) {\n throw new RuntimeException(e);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.5102739930152893,
"alphanum_fraction": 0.5188356041908264,
"avg_line_length": 25.545454025268555,
"blob_id": "ab7008f135216a77b7e7455ec863a1419888e2f7",
"content_id": "d06af959c5fc024fb390f4aa34b3d3a1aa13cd41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1168,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 44,
"path": "/philosopers_pyt/asymmetric_fork.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "import threading\n\n\nclass AsymmetricFork:\n def __init__(self):\n self.lock = threading.RLock()\n self.occupied = list(map(lambda _: False, range(5)))\n self.forks = list(map(lambda _: threading.Condition(lock=self.lock), range(5)))\n\n def take(self, i):\n try:\n self.lock.acquire()\n while self.occupied[first_fork(i)]:\n self.forks[first_fork(i)].wait()\n self.occupied[first_fork(i)] = True\n while self.occupied[second_fork(i)]:\n self.forks[second_fork(i)].wait()\n self.occupied[second_fork(i)] = True\n finally:\n self.lock.release()\n\n def put_back(self, i):\n try:\n self.lock.acquire()\n self.occupied[second_fork(i)] = False\n self.forks[second_fork(i)].notify()\n self.occupied[first_fork(i)] = False\n self.forks[first_fork(i)].notify()\n finally:\n self.lock.release()\n\n\ndef first_fork(i):\n if i % 2 == 0:\n return i\n else:\n return (i + 1) % 5\n\n\ndef second_fork(i):\n if i % 2 == 0:\n return (i + 1) % 5\n else:\n return i\n"
},
{
"alpha_fraction": 0.6759259104728699,
"alphanum_fraction": 0.6759259104728699,
"avg_line_length": 14.428571701049805,
"blob_id": "1ba6cf65556c5006aa046fe9464454478ad3c30a",
"content_id": "71fc498fd196081a94551ff35f2090cbda68ea27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/tw/src/main/java/pl/edu/agh/philosophers/Fork.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.philosophers;\n\npublic interface Fork {\n void take(int i);\n\n void putBack(int i);\n}\n"
},
{
"alpha_fraction": 0.4536702632904053,
"alphanum_fraction": 0.4777376651763916,
"avg_line_length": 28.678571701049805,
"blob_id": "f68c884dec0dc4d3169fbd7e8299adb8ecb2f96f",
"content_id": "279296f8b794262c9f674ddfabd3448b846e7512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 831,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 28,
"path": "/philosopers_pyt/hunger_fork.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "import threading\n\n\nclass HungerFork:\n def __init__(self):\n self.lock = threading.RLock()\n self.free = list(map(lambda _: 2, range(5)))\n self.philosophers = list(map(lambda _: threading.Condition(lock=self.lock), range(5)))\n\n def take(self, i):\n try:\n self.lock.acquire()\n while self.free[i] < 2:\n self.philosophers[i].wait()\n self.free[(i + 4) % 5] -= 1\n self.free[(i + 1) % 5] -= 1\n finally:\n self.lock.release()\n\n def put_back(self, i):\n try:\n self.lock.acquire()\n self.free[(i + 4) % 5] += 1\n self.free[(i + 1) % 5] += 1\n self.philosophers[(i + 4) % 5].notify()\n self.philosophers[(i + 1) % 5].notify()\n finally:\n self.lock.release()\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.7606382966041565,
"avg_line_length": 22.5,
"blob_id": "c581d39f6e25306d45b145141640462b3428b1d7",
"content_id": "551c3e02a5f6859b9169099f871d14791f0cb9bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 8,
"path": "/tw/src/main/java/pl/edu/agh/lab4/zad2/UnorderedBuffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab4.zad2;\n\nimport java.util.Collection;\n\npublic interface UnorderedBuffer {\n void put(Collection<Integer> valuesToPut);\n Collection<Integer> take(int howMany);\n}\n"
},
{
"alpha_fraction": 0.5709430575370789,
"alphanum_fraction": 0.5870857834815979,
"avg_line_length": 27.707317352294922,
"blob_id": "3a892ace3d8a9cb1508cc4c13aaf51b7e8c8235e",
"content_id": "9e6a522d483fb5ae98befc5099a06326ccbccfc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1177,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 41,
"path": "/tw/src/main/java/pl/edu/agh/lab3/Client.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab3;\n\nimport org.apache.commons.lang3.RandomStringUtils;\nimport org.apache.commons.lang3.RandomUtils;\nimport pl.edu.agh.util.Utils;\n\npublic class Client extends Thread {\n private boolean requestedTable = false;\n private int pairNumber;\n private Waiter waiter;\n\n public Client(Waiter waiter, int pairNumber) {\n this.waiter = waiter;\n this.pairNumber = pairNumber;\n }\n\n public boolean hasRequestedTable() {\n return requestedTable;\n }\n\n @Override\n public void run() {\n while (true) {\n try {\n sleep(500 + RandomUtils.nextInt(0, 500));\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n requestedTable = true;\n waiter.takeTable(pairNumber);\n System.out.println(Utils.appendTimestampPrefix(pairNumber + \" eating\"));\n try {\n sleep(1000 + RandomUtils.nextInt(0, 1000));\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n requestedTable = false;\n waiter.releaseTable();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6353055238723755,
"alphanum_fraction": 0.6401551961898804,
"avg_line_length": 24.14634132385254,
"blob_id": "4979e227382f390704dd292a6622a01e5a8b027f",
"content_id": "b7fdb8db0fbd2c6892023aca03ef37ed7bdfe257",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1031,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 41,
"path": "/philosopers_pyt/philosopher.py",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "import threading\nimport time\n\nimport statistician\nfrom asymmetric_fork import AsymmetricFork\nfrom blocking_fork import BlockingFork\nfrom hunger_fork import HungerFork\nfrom waiter_fork import WaiterFork\n\n\nclass Philosopher(threading.Thread):\n\n def __init__(self, number, fork):\n super().__init__()\n self.number = number\n self.fork = fork\n\n def think(self):\n pass\n\n def eat(self):\n start = time.clock()\n self.fork.take(self.number)\n end = time.clock()\n statistician.add_wait_time(self.number, end - start)\n self.fork.put_back(self.number)\n\n def run(self):\n for _ in range(1000):\n self.think()\n self.eat()\n\n\nif __name__ == '__main__':\n fork = AsymmetricFork()\n philosophers = list(map(lambda i: Philosopher(i, fork), range(5)))\n for philosopher in philosophers:\n philosopher.start()\n for philosopher in philosophers:\n philosopher.join()\n statistician.print_measurements(statistician.wait_time_mean())\n"
},
{
"alpha_fraction": 0.5329601764678955,
"alphanum_fraction": 0.5366915464401245,
"avg_line_length": 31.816326141357422,
"blob_id": "d86d3bd3242d5a8955673eb485b4df580f01e8ed",
"content_id": "87ecf8dcb604b642dc7edd4e8e5937da9e5ccfa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1608,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 49,
"path": "/tw/src/main/java/pl/edu/agh/lab9/standard/Agent.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab9.standard;\n\nimport org.apache.commons.lang3.RandomUtils;\n\nimport java.util.concurrent.Semaphore;\n\npublic class Agent implements Runnable {\n private Semaphore smokerTobacco;\n private Semaphore smokerPaper;\n private Semaphore smokerMatch;\n private Semaphore agent;\n private Semaphore lock;\n\n public Agent(Semaphore smokerTobacco, Semaphore smokerPaper, Semaphore smokerMatch, Semaphore agent, Semaphore lock) {\n this.smokerTobacco = smokerTobacco;\n this.smokerPaper = smokerPaper;\n this.smokerMatch = smokerMatch;\n this.agent = agent;\n this.lock = lock;\n }\n\n @Override\n public void run() {\n while (true) {\n try {\n lock.acquire();\n int random = RandomUtils.nextInt(0, 3);\n if (random == 0) {\n // Put tobacco on table\n // Put paper on table\n smokerMatch.release(); // Wake up smoker with match\n } else if (random == 1) {\n // Put tobacco on table\n // Put match on table\n smokerPaper.release(); // Wake up smoker with paper\n } else {\n // Put match on table\n // Put paper on table\n smokerTobacco.release(); // Wake up smoker with tobacco\n }\n lock.release();\n agent.acquire(); // Agent sleeps\n } catch (InterruptedException e) {\n throw new RuntimeException(e);\n }\n\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6741041541099548,
"alphanum_fraction": 0.6788370609283447,
"avg_line_length": 32.6136360168457,
"blob_id": "0af1fcd4b272d25ddf0d052cc693af13a1e11f54",
"content_id": "e504b0467c9e4e88dda6aa3c6b8a443253081b54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1479,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 44,
"path": "/tw/src/main/java/pl/edu/agh/lab8/zad3/PriceSniffer.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab8.zad3;\n\nimport pl.edu.agh.util.Utils;\n\nimport java.util.ArrayList;\nimport java.util.List;\nimport java.util.concurrent.CompletableFuture;\nimport java.util.concurrent.ExecutorService;\nimport java.util.concurrent.Executors;\nimport java.util.stream.Collectors;\n\npublic class PriceSniffer {\n private static final int PRODUCTS_NO = 200;\n private ServerMock server = new ServerMock();\n private ExecutorService executorService = Executors.newCachedThreadPool();\n\n public List<Double> sniffSequentially() {\n ArrayList<Double> result = new ArrayList<>();\n for (int i = 0; i < PRODUCTS_NO; i++) {\n result.add(server.getPrice());\n }\n return result;\n }\n\n public List<Double> sniffAsynchronously() {\n ArrayList<CompletableFuture<Double>> result = new ArrayList<>();\n executorService = Executors.newCachedThreadPool();\n for (int i= 0; i < PRODUCTS_NO; i++) {\n result.add(CompletableFuture.supplyAsync(() -> server.getPrice(), executorService));\n }\n return result.stream().map(CompletableFuture::join).collect(Collectors.toList());\n }\n\n public void tearDown() {\n executorService.shutdown();\n }\n\n public static void main(String[] args) {\n PriceSniffer sniffer = new PriceSniffer();\n Utils.printExecutionTime(sniffer::sniffAsynchronously);\n sniffer.tearDown();\n Utils.printExecutionTime(sniffer::sniffSequentially);\n }\n}\n"
},
{
"alpha_fraction": 0.5800865888595581,
"alphanum_fraction": 0.5844155550003052,
"avg_line_length": 17.479999542236328,
"blob_id": "d5b235921fbfe3bb2d545367cb0dae94fc153c25",
"content_id": "01429f45e500e134118ad9fc431373d86b4f21d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 25,
"path": "/tw/src/main/java/pl/edu/agh/lab2/CountingSemaphore.java",
"repo_name": "pawlooss1/twlab",
"src_encoding": "UTF-8",
"text": "package pl.edu.agh.lab2;\n\nimport pl.edu.agh.util.Utils;\n\npublic class CountingSemaphore implements Semaphore{\n private int value;\n\n public CountingSemaphore(int initialValue) {\n value = initialValue;\n }\n\n @Override\n public synchronized void p() {\n while (value < 1) {\n Utils.waitUnchecked(this);\n }\n value--;\n }\n\n @Override\n public synchronized void v() {\n value++;\n notify();\n }\n}\n"
}
] | 28 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.