
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
tizme/pythontest
|
https://github.com/tizme/pythontest
|
b045248fd6308797ab86bd9bb6a48d3ced24d615
|
e2501dccc8e8c9b481b8c786032da7dc7cee2408
|
c3d8408d09c28018a3ce615d14aa5d9fed1e13a1
|
refs/heads/master
| 2021-01-23T19:43:17.399210 | 2017-02-24T21:57:57 | 2017-02-24T21:57:57 | 83,086,178 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6331745386123657,
"alphanum_fraction": 0.6331745386123657,
"avg_line_length": 33.98484802246094,
"blob_id": "ee086f5f7abb4455f1623cc4dfce5c4687cb62a1",
"content_id": "6051533f4e1e42cca0f1f87bda9b7e8888ae6365",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2309,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 66,
"path": "/apps/exam/views.py",
"repo_name": "tizme/pythontest",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom models import User, Travel\nfrom django.contrib import messages\nfrom django.db.models import Count\n\n# Create your views here.\ndef index(request):\n\n return render(request, 'exam/index.html')\n\ndef register(request):\n if request.method == \"POST\":\n user = User.objects.register(request.POST)\n if 'errors' in user:\n for error in user['errors']:\n messages.error(request, error)\n return redirect('/')\n if 'theuser' in user:\n request.session['theuser'] = user['theuser']\n request.session['userid'] = user['userid']\n return redirect('/travels') #where do we want to go on register\n\ndef login(request):\n if request.method == \"POST\":\n user = User.objects.login(request.POST)\n if 'errors' in user:\n for error in user['errors']:\n messages.error(request, error)\n return redirect('/')\n if 'theuser' in user:\n request.session['theuser'] = user['theuser']\n request.session['userid'] = user['userid']\n return redirect('/travels') #where do we want to go on login\n\ndef logout(request):\n del request.session['theuser']\n del request.session['userid']\n return redirect('/') #return to index on logout\n\ndef travels(request):\n context={'travel' :Travel.objects.filter(user_id=request.session['userid']),\n 'everyone' :Travel.objects.exclude(user_id=request.session['userid'])\n }\n return render(request, 'exam/travels.html', context)\n\ndef join(request, id):\n ### section to add another users travel to the current users\n travel = Travel.objects.join(id, request.session['userid'])\n return\n\ndef trip(request, id):\n context={'travel' :Travel.objects.get(id=id), 'user' :User.objects.filter(travel__id=id)}\n return render(request, 'exam/destination.html', context)\n\ndef add(request):\n return render(request, 'exam/add.html')\n\ndef addtravel(request):\n if request.method =='POST':\n travel = Travel.objects.add(request.POST, request.session['userid'])\n if 'errors' in travel:\n for error in travel['errors']:\n messages.error(request, error)\n return redirect('/add')\n\n return redirect('/travels')\n"
},
{
"alpha_fraction": 0.6070562601089478,
"alphanum_fraction": 0.6116347908973694,
"avg_line_length": 36.130001068115234,
"blob_id": "baef400037a4374562c796ddd384745ab832779e",
"content_id": "53717c71955952693b921672906695654d6d8c08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3713,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 100,
"path": "/apps/exam/models.py",
"repo_name": "tizme/pythontest",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\nimport bcrypt, re\nfrom django.db import models\nimport datetime\n# Create your models here.\nclass UserManager(models.Manager):\n def login(self, postData):\n error_msgs = []\n password = bcrypt.hashpw(postData['pass'].encode(), bcrypt.gensalt())\n\n try:\n user = User.objects.get(email=postData['email'])\n except:\n error_msgs.append(\"Invalid user!\")\n return {'errors':error_msgs}\n\n if not bcrypt.hashpw(postData['pass'].encode(), user.password.encode()) == user.password.encode():\n error_msgs.append(\"Wrong Password!\")\n\n if error_msgs:\n return {'errors':error_msgs}\n else:\n return {'theuser':user.name, 'userid':user.id}\n\n def register(self, postData):\n error_msgs = []\n email_regex = re.compile(r'^[a-zA-Z0-9.+_-]+@[a-zA-Z0-9._-]+\\.[a-zA-Z]+$')\n\n try:\n if User.objects.get(email=postData['email']):\n error_msgs.append(\"Email already in use!\")\n except:\n pass\n\n if len(postData['name']) < 2:\n error_msgs.append(\"Name is too short!\")\n\n if not email_regex.match(postData['email']):\n error_msgs.append(\"Invalid email!\")\n\n if len(postData['pass']) < 8:\n error_msgs.append(\"Password is too short!\")\n\n if not postData['pass'] == postData['pass_conf']:\n error_msgs.append(\"Passwords do not match!\")\n\n if error_msgs:\n return {'errors':error_msgs}\n else:\n hashed = bcrypt.hashpw(postData['pass'].encode(), bcrypt.gensalt())\n user = User.objects.create(email=postData['email'],name=postData['name'], password=hashed)\n return {'theuser':user.name, 'userid': user.id}\n\nclass User(models.Model):\n email = models.CharField(max_length=255)\n name = models.CharField(max_length=45)\n password = models.CharField(max_length=45)\n created_at = models.DateTimeField(auto_now_add=True)\n updated_at = models.DateTimeField(auto_now=True)\n objects = UserManager()\n\n\nclass TravelManager(models.Manager):\n def add(self, postData, userid):\n error_msgs = []\n if len(postData['destination']) < 1:\n error_msgs.append('Destination name required')\n\n if len(postData['plan']) < 1:\n error_msgs.append('Travel plans required')\n\n today = datetime.datetime.today()\n start = datetime.datetime.strptime(postData['startdate'], '%Y-%m-%d')\n ##figure out how to convert inputs to unicode to compare\n if start < today:\n error_msgs.append('Must pick a future date')\n #\n\n if postData['enddate'] < postData['startdate']:\n error_msgs.append('Must return after you leave.')\n\n user = {'user': User.objects.get(id=userid)}\n if error_msgs:\n return {'errors':error_msgs}\n else:\n travel = Travel.objects.create(destination=postData['destination'], startdate=postData['startdate'], enddate=postData['enddate'], plan=postData['plan'], user=user['user'])\n return {'destination' :travel.destination}\n\n def join(self, postData, userid):\n travel = Travel.objects.get(id=postData)\n travel = Travel.objects.create(destination=postData['destination'], startdate=postData['startdate'], enddate=postData['enddate'], plan=postData['plan'], user=userid)\n return\n\nclass Travel(models.Model):\n destination = models.CharField(max_length=75)\n startdate = models.DateField()\n enddate = models.DateField()\n plan = models.TextField()\n user = models.ForeignKey(User, related_name=\"travel\")\n objects = TravelManager()\n"
}
] | 2 |
holmeszyx/pyfuckwall
|
https://github.com/holmeszyx/pyfuckwall
|
344f6918912e92919408ad14ddac94f48a00e7f8
|
48b02592c682c7e095fb2351bab4a29c05c809d7
|
ca5b9269fe65062991daca07c532f3d3df2737cc
|
refs/heads/master
| 2016-09-16T10:09:24.272136 | 2012-09-11T09:23:28 | 2012-09-11T09:23:28 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5687074661254883,
"alphanum_fraction": 0.5782312750816345,
"avg_line_length": 21.272727966308594,
"blob_id": "2169988dff3e259ccab11c66c489cbbbd606c84c",
"content_id": "db1d17072785ea747b760ea20f181d822abda2e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1470,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 66,
"path": "/pyfuckw.py",
"repo_name": "holmeszyx/pyfuckwall",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: UTF-8 -*-\n\n\"\"\"\n Auto connect to ssh tunnel\n\"\"\"\n\nimport pexpect\nimport commands\nimport time\n\n__DEBUG__ = False \nexistSSh = \"ssh -qTfnN\"\n\n# fill the exact ssh information below\ninfo = (\"host\", \"username\", \"password\")\n\ndef d(msg):\n \"\"\" print msg when __DEBUG__ is True\"\"\"\n if __DEBUG__ : print msg\n\ndef getPid(process):\n \"\"\" print the first pid associated with the given process\n a empty list will return if process no found\n \"\"\"\n pids = commands.getoutput(r\"pgrep -f '%s'\" % (process))\n pids = pids.split()\n if len(pids) > 1:\n return pids[ : len(pids) - 1]\n else:\n return []\n\ndef connSSH():\n \"\"\" connect to ssh \"\"\"\n cmd = r\"ssh -qTfnN -D 7070 %s@%s\" % (info[1], info[0])\n d(cmd)\n ssh = pexpect.spawn(cmd)\n ssh.expect(\".*password\")\n print \"password sending\"\n time.sleep(0.1)\n ssh.sendline(info[2])\n time.sleep(3)\n # ssh.interact()\n ssh.expect(pexpect.EOF)\n print \"ssh connect done\"\n\ndef main():\n existPid = getPid(existSSh);\n for pid in existPid:\n print (\"will kill a exist ssh which pid is \" + pid)\n commands.getoutput(\"kill %s\" % (pid))\n\n print \"try to connect ssh...\"\n connSSH()\n print \"check...\"\n existPid = getPid(existSSh);\n if len(existPid) > 0:\n print \"ssh opened\"\n else:\n print \"ssh never open\"\n\n\nif __name__ == \"__main__\":\n main();\n # existPid = getPid(\"python\");\n # print existPid\n"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 8.25,
"blob_id": "0fbe9a256cdbd2509c1bcecf82e482d56d0934db",
"content_id": "3590e3c6be85b6021687dfd719e83e78be684047",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 4,
"path": "/README.md",
"repo_name": "holmeszyx/pyfuckwall",
"src_encoding": "UTF-8",
"text": "pyfuckwall\n==========\n\nauto conn ssh"
}
] | 2 |
jibii-george/institute-management-system
|
https://github.com/jibii-george/institute-management-system
|
18612aedf9dbc2cf4da27d47e33d4437ae4f0d9a
|
145cc4dd383b9286a1c4bfbb4fc18780d933c06a
|
19c31e9e0a77a61c72f239cbc172d5d587173a78
|
refs/heads/master
| 2020-09-21T23:15:59.837139 | 2019-12-02T09:45:43 | 2019-12-02T09:45:43 | 224,968,711 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5693974494934082,
"alphanum_fraction": 0.5721056461334229,
"avg_line_length": 27.403846740722656,
"blob_id": "247ab64e9eaf4aa2a54f3c63039668f93fb15843",
"content_id": "b5c488a3d9377901ee2d28468cf4fa34a425c009",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1477,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 52,
"path": "/project/studentapp/forms.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom studentapp.models import student,feedback\nfrom hrapp.models import designation\n\n\n\n\n\nclass Login(forms.ModelForm):\n class Meta():\n model=student,designation\n fields = ['uname','password','dname']\n def clean(self):\n cleaned_data=super().clean()\n # pwd = cleaned_data.get(\"pwd\")\n # cpwd = cleaned_data.get(\"cpwd\")\n # if pwd != cpwd:\n # print(\"password mismatch\")\n # msg = \"password mismatch\"\n # self.add_error('cpwd', msg)\n Name=cleaned_data.get(\"uname\")\n PW=cleaned_data.get(\"password\")\n if student.objects.filter(uname=Name):\n print(\"valid user name\")\n else:\n print(\"invalid username\")\n msg1=\"invalid username\"\n self.add_error('uname',msg1)\n\n if student.objects.filter(password=PW):\n print(\"valid password\")\n else:\n msg2=\"invalid password\"\n self.add_error('password',msg2)\n\nclass Reg_form(forms.ModelForm):\n class Meta():\n model=student\n fields='__all__'\n def clean(self):\n cleaned_data=super().clean()\n Name=cleaned_data.get(\"uname\")\n if student.objects.filter(uname=Name):\n print(\"user name already exists\")\n msg=\"user name already exists!\"\n self.add_error('uname',msg)\n\n\nclass feed_form(forms.ModelForm):\n class Meta():\n model=feedback\n fields='__all__'\n"
},
{
"alpha_fraction": 0.5691527724266052,
"alphanum_fraction": 0.5887038111686707,
"avg_line_length": 31.11627960205078,
"blob_id": "92e04f06d4840727f291304abb87c233b3260b93",
"content_id": "362d2103582b6f81aea76b84d96f2edd155cb4e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1381,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 43,
"path": "/project/studentapp/migrations/0002_auto_20191130_0638.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2019-11-30 06:38\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('hrapp', '0001_initial'),\n ('trainerapp', '0001_initial'),\n ('studentapp', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='student',\n name='tname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='trainerapp.employee'),\n ),\n migrations.AddField(\n model_name='feedback',\n name='bname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.batch'),\n ),\n migrations.AddField(\n model_name='feedback',\n name='cname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.course'),\n ),\n migrations.AddField(\n model_name='feedback',\n name='sname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='studentapp.student'),\n ),\n migrations.AddField(\n model_name='feedback',\n name='tname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='trainerapp.employee'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7418244481086731,
"alphanum_fraction": 0.7521514892578125,
"avg_line_length": 37.70000076293945,
"blob_id": "b4c9e73c3f13915acad61917f0577bba4f2a792b",
"content_id": "6a673a26ae2a6d6211d8a75c5b4c163348260ddc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1162,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 30,
"path": "/project/studentapp/models.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom hrapp.models import gender,course,batch\nfrom trainerapp.models import employee\n# Create your models here.\n\n\n\nclass student(models.Model):\n sname=models.CharField(max_length=100)\n sage=models.IntegerField()\n sphone=models.IntegerField()\n gender=models.ForeignKey(gender,on_delete=models.CASCADE)\n cname=models.ForeignKey(course,on_delete=models.CASCADE)\n bname=models.ForeignKey(batch,on_delete=models.CASCADE)\n tname=models.ForeignKey(employee,on_delete=models.CASCADE)\n uname=models.CharField(max_length=100,default=None)\n password=models.CharField(max_length=100,default=None)\n image = models.ImageField(upload_to='images/')\n status = models.BooleanField(default=False)\n def __str__(self):\n return self.sname\nclass feedback(models.Model):\n cname=models.ForeignKey(course,on_delete=models.CASCADE)\n bname=models.ForeignKey(batch,on_delete=models.CASCADE)\n tname=models.ForeignKey(employee,on_delete=models.CASCADE)\n sname=models.ForeignKey(student,on_delete=models.CASCADE)\n feed_back=models.TextField(max_length=500)\n\n def __str__(self):\n return self.cname\n\n"
},
{
"alpha_fraction": 0.5161895751953125,
"alphanum_fraction": 0.5293289422988892,
"avg_line_length": 33.370967864990234,
"blob_id": "7bb24e7189ef0a31c622fe764d7ea85ed685654d",
"content_id": "de9ef122b6483a4933690162bb06d78b7e02c5ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2131,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 62,
"path": "/project/hrapp/migrations/0001_initial.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2019-11-30 06:38\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='batch',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('bname', models.CharField(max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='classses',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('clname', models.CharField(max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='course',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('cname', models.CharField(max_length=100)),\n ],\n ),\n migrations.CreateModel(\n name='designation',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('dname', models.CharField(max_length=30)),\n ],\n ),\n migrations.CreateModel(\n name='gender',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('gname', models.CharField(max_length=6)),\n ],\n ),\n migrations.CreateModel(\n name='timeslots',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('ts', models.CharField(max_length=3)),\n ],\n ),\n migrations.AddField(\n model_name='batch',\n name='cname',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.course'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7357630729675293,
"alphanum_fraction": 0.7357630729675293,
"avg_line_length": 26.5,
"blob_id": "0eebd52336e9c743575444e7029fbfccb016c489",
"content_id": "5942d29c9eba663d182b83645ce87595c907fea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 16,
"path": "/project/ttapp/views.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.urls import reverse_lazy\nfrom ttapp.models import timetable\nfrom django.views.generic import ListView, CreateView\n\n\n# Create your views here.\nclass tt_list(ListView):\n model = timetable\n template_name = 'timetable/tt.html'\n\nclass tt_create(CreateView):\n model = timetable\n fields='__all__'\n template_name =('timetable/create_tt.html')\n success_url = reverse_lazy('tt_list')"
},
{
"alpha_fraction": 0.5961945056915283,
"alphanum_fraction": 0.6162790656089783,
"avg_line_length": 35.38461685180664,
"blob_id": "7aa8dece59fe08e4ca78a13c2b0ce89f03fa532b",
"content_id": "6276333a176d1f82edd9777797234427f14418d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 946,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 26,
"path": "/project/ttapp/migrations/0001_initial.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0.3 on 2019-11-30 06:39\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('hrapp', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='timetable',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('bname', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.batch')),\n ('clname', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.classses')),\n ('cname', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.course')),\n ('time_slot', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='hrapp.timeslots')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.7602040767669678,
"alphanum_fraction": 0.7678571343421936,
"avg_line_length": 31.58333396911621,
"blob_id": "9f9cfce3845a7aa3adfbb1839e7fc42d6f96e749",
"content_id": "961fc73113e1c9fabdd1d976c2ffd532ae610215",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 12,
"path": "/project/trainerapp/models.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom hrapp.models import gender,course\n# Create your models here.\n\n\nclass employee(models.Model):\n ename=models.CharField(max_length=100)\n eage=models.IntegerField()\n ephone=models.IntegerField()\n gender=models.ForeignKey(gender,on_delete=models.CASCADE)\n course=models.ForeignKey(course,on_delete=models.CASCADE)\n salary=models.IntegerField()\n\n"
},
{
"alpha_fraction": 0.6631578803062439,
"alphanum_fraction": 0.6631578803062439,
"avg_line_length": 18.100000381469727,
"blob_id": "d99027fd00d8cb001ee547d41f93605f5969c25f",
"content_id": "817e7b5975efa3d2dfa4990ffb69c08b9c952a4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 10,
"path": "/project/ttapp/urls.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom ttapp import views\n\n\nurlpatterns=[\n\n path('tt',views.tt_list.as_view(),name='tt_list'),\n path('tt_c', views.tt_create.as_view(), name='tt_create'),\n\n]"
},
{
"alpha_fraction": 0.6552132964134216,
"alphanum_fraction": 0.670616090297699,
"avg_line_length": 23.823530197143555,
"blob_id": "8cd2b80c6c124956929c5e07bf0e33bcbf56accd",
"content_id": "e2929e016f3621715d2114f1d3ccd24d30071a62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 34,
"path": "/project/hrapp/models.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\nclass classses(models.Model):\n clname=models.CharField(max_length=100)\n def __str__(self):\n return self.clname\n\nclass gender(models.Model):\n gname=models.CharField(max_length=6)\n def __str__(self):\n return self.gname\n\nclass designation(models.Model):\n dname=models.CharField(max_length=30)\n def __str__(self):\n return self.dname\n\nclass timeslots(models.Model):\n ts=models.CharField(max_length=3)\n def __str__(self):\n return self.ts\n\nclass course(models.Model):\n cname=models.CharField(max_length=100)\n def __str__(self):\n return self.cname\n\nclass batch(models.Model):\n cname=models.ForeignKey(course,on_delete=models.CASCADE)\n bname=models.CharField(max_length=100)\n def __str__(self):\n return self.bname\n"
},
{
"alpha_fraction": 0.7950000166893005,
"alphanum_fraction": 0.7950000166893005,
"avg_line_length": 48.625,
"blob_id": "616e4e68e89633eeb52c812bbe65c20734d578d4",
"content_id": "33c6f0f991826e22abfe4b5f4d5db45f21808071",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/project/ttapp/models.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom hrapp.models import course,batch,classses,timeslots\n# Create your models here.\nclass timetable(models.Model):\n clname=models.ForeignKey(classses,on_delete=models.CASCADE)\n cname=models.ForeignKey(course,on_delete=models.CASCADE)\n bname=models.ForeignKey(batch,on_delete=models.CASCADE)\n time_slot=models.ForeignKey(timeslots,on_delete=models.CASCADE)\n\n\n\n"
},
{
"alpha_fraction": 0.8098859190940857,
"alphanum_fraction": 0.8098859190940857,
"avg_line_length": 25.200000762939453,
"blob_id": "fb29bc5d6c18721cd9dbc618f51defeee8d6a15c",
"content_id": "9bfa05bc84dd7d31c29b33a611020fc8af0ce4ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 10,
"path": "/project/hrapp/admin.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import *\n\n# Register your models here.\nadmin.site.register(classses)\nadmin.site.register(course)\nadmin.site.register(batch)\nadmin.site.register(timeslots)\nadmin.site.register(gender)\nadmin.site.register(designation)\n\n"
},
{
"alpha_fraction": 0.6467065811157227,
"alphanum_fraction": 0.6467065811157227,
"avg_line_length": 15.699999809265137,
"blob_id": "d9eed9553d18908e62acedc35f1bb92cba77f590",
"content_id": "b2704019f114f4100facf9d87a1e55abe54063c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 10,
"path": "/project/ttapp/forms.py",
"repo_name": "jibii-george/institute-management-system",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom ttapp.models import timetable\n\n\n\n\nclass tt_form(forms.ModelForm):\n class Meta():\n model = timetable\n fields = '__all__'\n"
}
] | 12 |
helenachi/rethink_url_shortener
|
https://github.com/helenachi/rethink_url_shortener
|
6e7c07afed81d316f7d99a3ef8fa613cba37f626
|
ef734bdd43fa8e22d7ef3180dccb49ad3227c465
|
9a5369fbf7739e025b418356446f342e3eb5c93f
|
refs/heads/master
| 2022-12-14T04:54:30.726160 | 2020-09-09T17:13:54 | 2020-09-09T17:13:54 | 294,178,936 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7251309156417847,
"alphanum_fraction": 0.731675386428833,
"avg_line_length": 29.600000381469727,
"blob_id": "8099a6ea91533c32444e023687d6abf87a92c9cd",
"content_id": "8777875f90380fbf483594eebc17709d775adf52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 25,
"path": "/README.md",
"repo_name": "helenachi/rethink_url_shortener",
"src_encoding": "UTF-8",
"text": "# Rethink URL Shortener Challenge [Helena Chi]\n\nA python program that shortens a given valid url.\n\n\nTo run:\n\n- Clone or download this repo and `cd rethink_url_shortener`\n- Run `python3 shortener.py`\n- Enter a valid url\n\n\nAssumptions:\n\n- JSON file initialized to `{ \"counter\": 0, \"directory\": {} }` and gets updated every time you run shortener.py\n- The shortened url will not actually redirect to the given url input if entered in a browser\n- Input URL must be copied and pasted from the url bar in your preferred browser. (i.e. https://www.google.com/)\n- Will not return result for URL's to nonexistent webpages.\n\n\nLimitations:\n\n- The format of the shortened URL will be: `https://hele.na/` + `[an 8-10 digit number]`, and this may be longer than some inputs \n\nHelena Chi"
},
{
"alpha_fraction": 0.6205551028251648,
"alphanum_fraction": 0.626626193523407,
"avg_line_length": 24.065217971801758,
"blob_id": "a6243743356da12704ba07df17a61d045e3100d9",
"content_id": "de0ae8acc87d3f678952b130f310b5bdf5b43117",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2306,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 92,
"path": "/shortner.py",
"repo_name": "helenachi/rethink_url_shortener",
"src_encoding": "UTF-8",
"text": "##############################################################################\n# Helena Chi 2020\n# Rethink URL Shortener Challenge\n##############################################################################\n\nimport json\nimport requests\nimport zlib\nfrom urllib.parse import urlparse\n\nDIRECTORY_FILE = \"directory.json\"\nSHORTENED_HEADER = \"https://hele.na/\"\nENCODING = \"utf-8\"\n\nCDIRECTORY = {}\nCCOUNTER = 0\nwith open(DIRECTORY_FILE, \"r\") as openfile:\n data = json.load(openfile)\n CDIRECTORY = data[\"directory\"]\n CCOUNTER = data[\"counter\"]\n\n\n# isValid\n#\n# RETURNS whether or not the given url leads to an existing webpage\n#\n# Parameters\n# ----------\n# input_url: str\n# the url to check validity\n#\n# Returns\n# -------\n# bool\ndef isValid(input_url):\n request = requests.get(input_url)\n return request.status_code == 200\n\n# shortenedURLFormatter\n#\n# RETURNS a url formatted with the shortened header and unique id, which is obtained\n# by using the Adler-32 checksum algorithm on the given url and its incremented id.\n#\n# Parameters\n# ----------\n# input_url: str\n# the url to shorten\n#\n# Returns\n# -------\n# str\n# the complete url in shortened format\ndef shortnenedURLFormatter(input_url):\n input_str = str(CCOUNTER) + input_url\n adlered = zlib.adler32(bytearray(input_str, ENCODING))\n return SHORTENED_HEADER + str(adlered)\n\n# shorten\n#\n# RETURNS the shortened url for the input url's entry in the directory\n#\n# Parameters\n# ----------\n# input_url: str\n# the url to shorten\n#\n# Returns\n# -------\n# str:\n# a formatted shortened url\ndef shorten(input_url) :\n if (input_url in CDIRECTORY):\n return CDIRECTORY[input_url]\n else:\n new_directory = CDIRECTORY\n new_directory[input_url] = shortnenedURLFormatter(input_url)\n new_counter = CCOUNTER + 1\n new_data = { \n \"counter\": new_counter,\n \"directory\": new_directory\n }\n with open(DIRECTORY_FILE, \"w\") as outfile:\n json.dump(new_data, outfile)\n return new_directory[input_url]\n\n\nif __name__ == \"__main__\":\n input_url = input(\"Pass in the url you want shortened (eg: \\\"https://www.google.com\\\", \\\"https://www.youtube.com/user/crashcourse\\\"):\\n\")\n if (isValid(input_url)):\n print(\"Your shortened url is: \", shorten(input_url))\n else:\n print(\"Your url is not valid, please enter a valid url.\")\n"
}
] | 2 |
Hudson-cyber/Tocador-de-Musica
|
https://github.com/Hudson-cyber/Tocador-de-Musica
|
5534169582fcc08051c545dfe8917b3571486786
|
6804234a3b8b90ae09a9f25a118be8392599c8e8
|
bf4143077df083b2880affe0019c361bb09652a6
|
refs/heads/main
| 2023-06-14T03:26:28.910364 | 2021-07-16T23:56:09 | 2021-07-16T23:56:09 | 386,789,075 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7010101079940796,
"alphanum_fraction": 0.7070707082748413,
"avg_line_length": 28.176469802856445,
"blob_id": "aac135d9040985b4367aa87e26aa5476d914111c",
"content_id": "1830a4a3125b867179535b513d64a1effa3fe789",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 17,
"path": "/Tocador com pygame/TocadorMp3.py",
"repo_name": "Hudson-cyber/Tocador-de-Musica",
"src_encoding": "UTF-8",
"text": "import pygame\nimport time\n# mais informações:https://www.pygame.org/docs/ref/music.html#pygame.mixer.music.get_pos\ntry:\n tempo = int(input(\"\\ndigite o tempo da musica em segundos\\n\"))\n if(tempo <= 5):\n print(\"Digite um tempo maior que 5 segundos\")\n exit()\n\nexcept (ValueError):\n print(\"Ocorreu um erro ao digitar os segundos por favor digite um numero\")\n exit()\n\npygame.init()\npygame.mixer.music.load('harrypotterbugado.mp3')\npygame.mixer.music.play()\ntime.sleep(tempo)"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 42,
"blob_id": "d81cc8bf33fb44bf37a92c19793869ace25d9c80",
"content_id": "30de82a26f6cfb2214cac1d6531f60f72584ab10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 2,
"path": "/Tocador com playsound/TocadorMp3v2.py",
"repo_name": "Hudson-cyber/Tocador-de-Musica",
"src_encoding": "UTF-8",
"text": "from playsound import playsound\nplaysound('theAvengers.mp3', 1) #numero de repetições"
}
] | 2 |
davidparsson/deid
|
https://github.com/davidparsson/deid
|
159479a8c3223a042f4a65869fd5d1ff14a2529e
|
9d28728d175b382915538c2a4e9e463904564e18
|
8b940a129b672bf1ffe540b66d24b99ca2f60bb8
|
refs/heads/master
| 2021-02-17T13:02:04.829207 | 2020-03-04T18:35:05 | 2020-03-04T18:35:05 | 245,098,939 | 0 | 0 |
MIT
| 2020-03-05T07:41:19 | 2020-03-05T07:41:21 | 2020-03-05T10:29:44 | null |
[
{
"alpha_fraction": 0.6047070026397705,
"alphanum_fraction": 0.7280771732330322,
"avg_line_length": 36.14160919189453,
"blob_id": "b70ac204ecc9642f08a363443db5fb43a286f6ac",
"content_id": "57e57bfb43a3c5c4bce0a52bd9bad9b33776cfe7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21245,
"license_type": "permissive",
"max_line_length": 280,
"num_lines": 572,
"path": "/docs/_docs/getting-started/dicom-put.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "---\ntitle: 5. Put Identifiers Back\ncategory: Getting Started\norder: 7\n---\n\n\nAt this point, we want to perform a `put` action, which is generally associated with \nthe `replace_identifiers` function. As a reminder, we are working with a data \nstructure returned from `get_identifiers` in the dicom module, and it is \nindexed first by entity id (`PatientID`) and then item ID \n(`SOPInstanceUID`). A single entry looks like this:\n\n```python\nids['cookie-47']['1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947']\n{'BitsAllocated': 8,\n 'BitsStored': 8,\n 'Columns': 2048,\n 'ConversionType': 'WSD',\n 'HighBit': 7,\n 'ImageComments': 'This is a cookie tumor dataset for testing dicom tools.',\n 'InstitutionName': 'STANFORD',\n 'LossyImageCompression': '01',\n 'LossyImageCompressionMethod': 'ISO_10918_1',\n 'NameOfPhysiciansReadingStudy': 'Dr. damp lake',\n 'OperatorsName': 'nameless voice',\n 'PatientID': 'cookie-47',\n 'PatientName': 'still salad',\n 'PatientSex': 'F',\n 'PhotometricInterpretation': 'YBR_FULL_422',\n 'PixelRepresentation': 0,\n 'PlanarConfiguration': 0,\n 'ReferringPhysicianName': 'Dr. bold moon',\n 'Rows': 1536,\n 'SOPClassUID': '1.2.840.10008.5.1.4.1.1.7',\n 'SOPInstanceUID': '1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947',\n 'SamplesPerPixel': 3,\n 'SeriesInstanceUID': '1.2.276.0.7230010.3.1.3.8323329.5360.1495927170.640945',\n 'SpecificCharacterSet': 'ISO_IR 100',\n 'StudyDate': '20131210',\n 'StudyInstanceUID': '1.2.276.0.7230010.3.1.2.8323329.5360.1495927170.640946',\n 'StudyTime': '191930'}\n```\n\nAt this point, let's walk through a few basic use cases. We again first need to load our dicom files:\n\n```python\nfrom deid.dicom import get_files\nfrom deid.data import get_dataset\nbase = get_dataset('dicom-cookies')\ndicom_files = list(get_files(base))\n```\n\n\n## Default: Remove Everything\nIn this first use case, we extracted identifiers to save to our database, \nand we want to remove everything in the data. To do this, we can use the \ndicom module defaults, and we don't need to give the function anything. Our \ncall would look like this:\n\n```python\nfrom deid.dicom import replace_identifiers\n\ncleaned_files = replace_identifiers(dicom_files=dicom_files)\n\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\n```\n\nYou will notice that by default, the files are written to a temporary directory:\n\n```python\ncleaned_files \n['/tmp/tmphvj05c6y/image4.dcm',\n '/tmp/tmphvj05c6y/image2.dcm',\n '/tmp/tmphvj05c6y/image7.dcm',\n '/tmp/tmphvj05c6y/image6.dcm',\n '/tmp/tmphvj05c6y/image3.dcm',\n '/tmp/tmphvj05c6y/image1.dcm',\n '/tmp/tmphvj05c6y/image5.dcm']\n```\n\nYou can choose to use a custom output folder:\n\n```python\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n output_folder='/home/vanessa/Desktop')\n...python\ncleaned_files\n['/home/vanessa/Desktop/image4.dcm',\n '/home/vanessa/Desktop/image2.dcm',\n '/home/vanessa/Desktop/image7.dcm',\n '/home/vanessa/Desktop/image6.dcm',\n '/home/vanessa/Desktop/image3.dcm',\n '/home/vanessa/Desktop/image1.dcm',\n '/home/vanessa/Desktop/image5.dcm']\n```\n\nOne setting that is important is `overwrite`, which is by default set to False. \nFor example, let's say we decided to run the above again, using the same output \ndirectory of desktop (where the files already exist!)\n\n```python\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nERROR image4.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nERROR image2.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nERROR image7.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nERROR image6.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nERROR image3.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nERROR image1.dcm already exists, overwrite set to False. Not writing.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\nERROR image5.dcm already exists, overwrite set to False. Not writing.\n```\n\nThe function gets angry at us, and returns the list of files that are already \nthere. If you really want to force an overwrite, then you need to do this:\n\n\n```python\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n output_folder='/home/vanessa/Desktop',\n overwrite=True)\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\n```\n\nwherever you dump your new dicoms, it's up to you to decide how to then move \nand store them, and (likely) deal with the original data with identifiers.\n\n## Private Tags\nAn important note is that by default, this function will also remove private tags\n (`remove_private=True`). If you need private tags to determine if there is \nburned pixel data, you would want to set this to False, perform pixel \nidentification, and then remove the private tags yourself:\n\n\n```python\n# Clean the files, but set remove_private to False\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n remove_private=False)\n\nDEBUG Default action is BLANK\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nWARNING Private tags were not removed!\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\nWARNING Private tags were not removed!\n```\n\nNotice how the warning appeared, because we didn't remove private tags? \nNext you would want to do your pixel cleaning, likely using those private\ntags that are still in the data. Then you would go back and remove them.\n\n```python\nfrom deid.dicom import remove_private_identifiers\n\nreally_cleaned = remove_private_identifiers(dicom_files=cleaned_files)\nDEBUG Removed private identifiers for /tmp/tmp2kayz83n/image4.dcm\nDEBUG Removed private identifiers for /tmp/tmp5iadxfb9/image2.dcm\nDEBUG Removed private identifiers for /tmp/tmpk0yii_ya/image7.dcm\nDEBUG Removed private identifiers for /tmp/tmpnxqirboq/image6.dcm\nDEBUG Removed private identifiers for /tmp/tmpp9_tj7zq/image3.dcm\nDEBUG Removed private identifiers for /tmp/tmpo_kwxmlj/image1.dcm\nDEBUG Removed private identifiers for /tmp/tmpf6whw73y/image5.dcm\n\n```\n\nYou could also do pixel scraping first, and then call the function\n(per default) to remove private. These are the first calls that we did, \nnot specifying the variable `remove_private`, and by default it was True. \n\n### Getting Private Tags\nIf you are working within python and want to get private tags for inspection, \nyou can do that too! Let's first load some default data:\n\n\n```python\nfrom deid.dicom import get_files\nfrom deid.data import get_dataset\nbase = get_dataset('dicom-cookies')\ndicom_files = list(get_files(base))\n```\n\nand now the functions we can use. We will look at one dicom_file\n\n```python\nfrom deid.dicom.tags import has_private, get_private\n\nfrom pydicom import read_file\ndicom = read_file(dicom_files[0])\n```\n\nDoes it have private tags?\n\n```python\nhas_private(dicom)\nFound 0 private tags\nFalse\n```\n\nNope! This is a dicom cookie, after all. If we wanted to get the list of tags, we could do:\n\n```python\nprivate_tags = get_private(dicom)\n```\n\nAlthough in this case, the list is empty.\n\n\n## Customize Replacement\nAs we mentioned earlier, if you have a [deid settings]({{ site.baseurl}}/getting-started/dicom-config/) file, \nyou can specify how you want the replacement to work, and in this case, \nyou would want to provide the result `ids` variable from the [previous step]({{ site.baseurl}}/getting-started/dicom-get/)\n\n### Create your deid specification\nFor this example, we will use an example file provided with this package. \nLikely this will be put into a function with easier use, but this will work for now.\n\n```python\nfrom deid.utils import get_installdir\nfrom deid.config import load_deid\nimport os\n\npath = os.path.abspath(\"%s/../examples/deid/\" %get_installdir())\n```\n\nThe above `deid` is just a path to a folder that we have a `deid` file in. \nThe function will find it for us. This function will happen internally, \nbut here is an example of what your loaded `deid` file might look like.\n\n```\ndeid = load_deid(path)\nDEBUG FORMAT set to dicom\nDEBUG Adding ADD PatientIdentityRemoved Yes\nDEBUG Adding REPLACE PatientID var:id\nDEBUG Adding REPLACE SOPInstanceUID var:source_id\ndeid\n\n{\n 'format': 'dicom',\n 'header': [\n {'action': 'ADD','field': 'PatientIdentityRemoved','value': 'Yes'},\n {'action': 'REPLACE', 'field': 'PatientID', 'value': 'var:id'},\n {'action': 'REPLACE', 'field': 'SOPInstanceUID', 'value': 'var:source_id'}\n ]\n}\n```\n\nNotice that under `header` we have a list of actions, each with a `field` \nto be applied to, an `action` type (eg, `REPLACE`), and when relevant \n(for `REPLACE` and `ADD`) we also have a value. If you remember what \nthe `deid` file looked like:\n\n```\nFORMAT dicom\n\n%header\n\nADD PatientIdentityRemoved Yes\nREPLACE PatientID var:id\nREPLACE SOPInstanceUID var:source_id\n```\n\nThe above is a \"coded\" version of that, which has also been validated and checked. In the instruction, written in two forms:\n\n```python\n {'action': 'REPLACE', 'field': 'SOPInstanceUID', 'value': 'var:source_id'}\n \n REPLACE SOPInstanceUID var:source_id\n```\n\nwe are saying that we want to replace the field `SOPInstanceUID` not with a value, \nbut with a **variable** (`var`) that is called `source_id`. The full expression \nthen for value, the third in the row, is `var:source_id`. What this means \nis that when we receive our ids data structure back from get_identifiers, \nwe would need to do whatever lookup is necessary to get that item, and then \nset it for the appropriate item. Eg, for the entity/item showed above, we would do:\n\n```python\nids['cookie-47']['1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947']['source_id'] = 'suid123'\n```\n\n### Add your variables\nLet's walk through that complete example, first getting our identifiers,\n adding some random source_id and id, and then running the function.\n\n```python\nfrom deid.dicom import get_identifiers\nids = get_identifiers(dicom_files)\n```\n\nLet's say that we want to change the `PatientID` `cookie-47` to `cookiemonster`, \nand for each identifier, we will give it a numerically increasing `SOPInstanceUID`.\n\n```python\ncount=0\nfor entity, items in ids.items():\n for item in items:\n ids[entity][item]['id'] = \"cookiemonster\"\n ids[entity][item]['source_id'] = \"cookiemonster-image-%s\" %(count)\n count+=1\n```\n\nAn important note - both fields are added on the level of the item, and not at the \nlevel of the entity! This is because, although we have an entity and item both \nrepresented, they are both represented in a flat hierarchy (on the level of the \nitem) so the final data structure, for each item, should look like this:\n\n```python\nentity = 'cookie-47'\nitem = '1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351'\n\nids[entity][item]\n\n{'BitsAllocated': 8,\n 'BitsStored': 8,h\n 'Columns': 2048,\n 'ConversionType': 'WSD',\n 'HighBit': 7,\n 'ImageComments': 'This is a cookie tumor dataset for testing dicom tools.',\n 'InstitutionName': 'STANFORD',\n 'LossyImageCompression': '01',\n 'LossyImageCompressionMethod': 'ISO_10918_1',\n 'NameOfPhysiciansReadingStudy': 'Dr. lively wind',\n 'OperatorsName': 'curly darkness',\n 'PatientID': 'cookie-47',\n 'PatientName': 'falling disk',\n 'PatientSex': 'M',\n 'PhotometricInterpretation': 'YBR_FULL_422',\n 'PixelRepresentation': 0,\n 'PlanarConfiguration': 0,\n 'ReferringPhysicianName': 'Dr. solitary heart',\n 'Rows': 1536,\n 'SOPClassUID': '1.2.840.10008.5.1.4.1.1.7',\n 'SOPInstanceUID': '1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351',\n 'SamplesPerPixel': 3,\n 'SeriesInstanceUID': '1.2.276.0.7230010.3.1.3.8323329.5329.1495927169.580349',\n 'SpecificCharacterSet': 'ISO_IR 100',\n 'StudyDate': '20131210',\n 'StudyInstanceUID': '1.2.276.0.7230010.3.1.2.8323329.5329.1495927169.580350',\n 'StudyTime': '191929',\n 'id': 'cookiemonster',\n 'id_source': 'cookiemonster-image-6'}\n```\n\nNow we are going to run our function again, but this time providing:\n 1. The path to our deid specification\n 2. the ids data structure we updated above\n\n\n### Replace identifiers\nIt's time to clean our data with the deid specification and ids datastructure we have prepared.\n\n```python\n# path is '/home/vanessa/Documents/Dropbox/Code/som/dicom/deid/examples/deid'\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=path,\n ids=ids)\n\nDEBUG FORMAT set to dicom\nDEBUG Adding ADD PatientIdentityRemoved Yes\nDEBUG Adding REPLACE PatientID var:id\nDEBUG Adding REPLACE SOPInstanceUID var:source_id\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image4.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image2.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image7.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image6.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image3.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image1.dcm.\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image5.dcm.\n```\n\nWe can now read in one of the output files to see the result:\n\n```python\n# We can load in a cleaned file to see what was done\nfrom pydicom import read_file\ntest_file = read_file(cleaned_files[0])\n\ntest_file\n(0008, 0018) SOP Instance UID UI: cookiemonster-image-4\n(0010, 0020) Patient ID LO: 'cookiemonster'\n(0012, 0062) Patient Identity Removed CS: 'Yes'\n(0028, 0002) Samples per Pixel US: 3\n(0028, 0010) Rows US: 1536\n(0028, 0011) Columns US: 2048\n(7fe0, 0010) Pixel Data OB: Array of 738444 bytes\n```\n\nAnd it looks like we are good!\n\nIn this example, we did the more complicated thing of setting the value to be a variable from the ids data structure (specified with `var:id`. We can take an even simpler approach. If we wanted it to be a string value, meaning the same for all items, we would leave out the `var`:\n\n\n```\nREPLACE Modality CT-SPECIAL\n```\n\nThis example would replace the Modality for all items to be the string `CT-SPECIAL`.\n\n#### Define entity or items\nFor this function, if you have set a custom `entity_id` or `item_id` \n(that you used for the first call) you would also want to specify it here. \nAgain, the the defaults are `PatientID` for the entity, and `SOPInstanceUID` for each item. \n\n\n```python\nreplace_identifiers(dicom_files,\n ids=ids,\n entity_id=\"PatientID\",\n item_id=\"SOPInstanceUID\")\n```\n\nFor more refinement of the default config, see the [development]({{ site.baseurl}}/development/) docs.\n\n## Errors During Replacement\nLet's try to break the above. We are going to extract ids, but then define the \n`source_id` at the wrong variable. What happens?\n\n```python\nfrom deid.dicom import get_identifiers\nids = get_identifiers(dicom_files)\n```\n\nLet's be stupid, oops, instead of `source_id` I wrote `source_uid`\n\n```python\ncount=0\nfor entity, items in ids.items():\n for item in items:\n ids[entity][item]['id'] = \"cookiemonster\"\n ids[entity][item]['source_uid'] = \"cookiemonster-image-%s\" %(count)\n count+=1\n```\n\nTry the replacement...\n\n```python\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=path,\n ids=ids)\nDEBUG FORMAT set to dicom\nDEBUG Adding ADD PatientIdentityRemoved Yes\nDEBUG Adding REPLACE PatientID var:id\nDEBUG Adding REPLACE SOPInstanceUID var:source_id\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image4.dcm.\nWARNING REPLACE SOPInstanceUID not done for image4.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image2.dcm.\nWARNING REPLACE SOPInstanceUID not done for image2.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image7.dcm.\nWARNING REPLACE SOPInstanceUID not done for image7.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image6.dcm.\nWARNING REPLACE SOPInstanceUID not done for image6.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image3.dcm.\nWARNING REPLACE SOPInstanceUID not done for image3.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image1.dcm.\nWARNING REPLACE SOPInstanceUID not done for image1.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\nDEBUG Attempting ADDITION of PatientIdentityRemoved to image5.dcm.\nWARNING REPLACE SOPInstanceUID not done for image5.dcm\n```\n\nYou see that we get a warning. As a precaution, since the action wasn't taken, the field is removed from the data.\n\n```python\nfrom pydicom import read_file\ntest_file = read_file(cleaned_files[0])\n\ntest_file\n(0010, 0020) Patient ID LO: 'cookiemonster'\n(0012, 0062) Patient Identity Removed CS: 'Yes'\n(0028, 0002) Samples per Pixel US: 3\n(0028, 0010) Rows US: 1536\n(0028, 0011) Columns US: 2048\n(7fe0, 0010) Pixel Data OB: Array of 738444 bytes\n```\n\n\n```python\nreplace_identifiers(dicom_files,\n ids=ids,\n entity_id=\"PatientID\",\n item_id=\"SOPInstanceUID\")\n```\n\n\n```\nREPLACE Modality CT-SPECIAL\n```\n\n## Developer Replacement\nIf you are a developer, you can create your own config.json and give it to the function above. \nYou can read more about this in the [developers]({{ site.baseurl}}/development/) notes.\n"
},
{
"alpha_fraction": 0.7459349632263184,
"alphanum_fraction": 0.8048780560493469,
"avg_line_length": 121.75,
"blob_id": "cf445c0aed0508d1276dd77f309b9514eea91c2e",
"content_id": "36d01c417a0d6455aec0577475c129637f683347",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 492,
"license_type": "permissive",
"max_line_length": 238,
"num_lines": 4,
"path": "/deid/data/README.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "This folder contains specifications for how to flag a dicom image for a possible burned in annotation. The specification file is called [deid.dicom](deid.dicom) and this README will contain a history of it's updates and changes.\n\n## Deid.dicom Updates\n -'7/2/2017': created with [current CTP](https://github.com/johnperry/CTP/blob/8a3c595b60442e6d74aec4098eaed5dcf8ff8770/source/files/examples/example-dicom-pixel-anonymizer.script) criteria, which are also present on the Stanford run CTP.\n\n"
},
{
"alpha_fraction": 0.6576209664344788,
"alphanum_fraction": 0.6607869863510132,
"avg_line_length": 34.95121765136719,
"blob_id": "edaa5d17e2e0697e04d04ca854d86166295f9d48",
"content_id": "da97089ff27a01d73539c14b67f62902b0dcf28d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4422,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 123,
"path": "/deid/tests/test_dicom_tags.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\nCopyright (c) 2016-2020 Vanessa Sochat\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n\n\"\"\"\n\nimport unittest\nimport tempfile\nimport shutil\nimport json\nimport os\n\nfrom deid.utils import get_installdir\nfrom deid.data import get_dataset\n\n\nclass TestDicomTags(unittest.TestCase):\n def setUp(self):\n self.pwd = get_installdir()\n self.deid = os.path.abspath(\"%s/../examples/deid/deid.dicom\" % self.pwd)\n self.dataset = get_dataset(\"dicom-cookies\")\n self.tmpdir = tempfile.mkdtemp()\n print(\"\\n######################START######################\")\n\n def tearDown(self):\n shutil.rmtree(self.tmpdir)\n print(\"\\n######################END########################\")\n\n def test_add_tag(self):\n print(\"Test deid.dicom.tags add_tag\")\n from deid.dicom.tags import add_tag\n\n dicom = get_dicom(self.dataset)\n self.assertTrue(\"PatientIdentityRemoved\" not in dicom)\n updated = add_tag(dicom=dicom, field=\"PatientIdentityRemoved\", value=\"Yes\")\n self.assertEqual(updated.get(\"PatientIdentityRemoved\"), \"Yes\")\n\n def test_get_tag(self):\n print(\"Test deid.dicom.tags get_tag\")\n from deid.dicom.tags import get_tag\n from pydicom.tag import BaseTag\n\n print(\"Case 1: Ask for known tag\")\n tag = get_tag(\"Modality\")\n self.assertTrue(\"Modality\" in tag)\n self.assertEqual(tag[\"Modality\"][\"VM\"], \"1\")\n self.assertEqual(tag[\"Modality\"][\"VR\"], \"CS\")\n self.assertEqual(tag[\"Modality\"][\"keyword\"], \"Modality\")\n self.assertEqual(tag[\"Modality\"][\"name\"], \"Modality\")\n self.assertTrue(isinstance(tag[\"Modality\"][\"tag\"], BaseTag))\n\n print(\"Case 2: Ask for unknown tag\")\n tag = get_tag(\"KleenexTissue\")\n self.assertTrue(len(tag) == 0)\n\n def test_change_tag(self):\n # Note, update_tag only exists to show different print output\n # so we will not test again.\n print(\"Test deid.dicom.tags change_tag\")\n from deid.dicom.tags import change_tag\n\n dicom = get_dicom(self.dataset)\n\n print(\"Case 1: Change known tag\")\n updated = change_tag(dicom, field=\"PatientID\", value=\"shiny-ham\")\n self.assertEqual(updated.get(\"PatientID\"), \"shiny-ham\")\n\n print(\"Case 2: Change unknown tag\")\n updated = change_tag(dicom, field=\"PatientWazaa\", value=\"shiny-ham\")\n self.assertEqual(updated.get(\"PatientWazaa\"), None)\n\n def test_blank_tag(self):\n # Note that outside of the controlled action\n # functions, user is limited on blanking\n # (eg could produce invalid dicom)\n print(\"Test deid.dicom.tags blank_tag\")\n from deid.dicom.tags import blank_tag\n\n dicom = get_dicom(self.dataset)\n\n updated = blank_tag(dicom, field=\"PatientID\")\n self.assertEqual(updated.get(\"PatientID\"), \"\")\n\n def test_remove_tag(self):\n print(\"Test deid.dicom.tags remove_tag\")\n from deid.dicom.tags import remove_tag\n\n dicom = get_dicom(self.dataset)\n self.assertTrue(\"PatientID\" in dicom)\n updated = remove_tag(dicom, field=\"PatientID\")\n self.assertTrue(\"PatientID\" not in updated)\n\n\ndef get_dicom(dataset):\n \"\"\"helper function to load a dicom\n \"\"\"\n from deid.dicom import get_files\n from pydicom import read_file\n\n dicom_files = get_files(dataset)\n return read_file(next(dicom_files))\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.6254303455352783,
"alphanum_fraction": 0.6267363429069519,
"avg_line_length": 33.239837646484375,
"blob_id": "b439d09a3059a68d4f1595158b9147f425b03904",
"content_id": "d3c91d0a0934da782e2ad463836aa316d252a5a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8423,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 246,
"path": "/deid/dicom/actions.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\nCopyright (c) 2017-2020 Vanessa Sochat\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n\n\"\"\"\n\nfrom deid.logger import bot\nfrom deid.config.standards import actions as valid_actions\n\nfrom .fields import expand_field_expression\n\nfrom deid.utils import get_timestamp, parse_value\n\nfrom pydicom.dataset import Dataset\nfrom pydicom.sequence import Sequence\nfrom .tags import add_tag, update_tag, blank_tag, remove_tag\n\nimport re\n\n# Actions\n\n\ndef perform_action(dicom, action, item=None, fields=None, return_seen=False):\n \"\"\"perform action takes \n\n Parameters\n ==========\n dicom: a loaded dicom file (pydicom read_file)\n item: a dictionary with keys as fields, values as values\n fields: if provided, a filtered list of fields for expand\n action: the action from the parsed deid to take\n \"deid\" (eg, PatientID) the header field to process\n \"action\" (eg, REPLACE) what to do with the field\n \"value\": if needed, the field from the response to replace with\n \"\"\"\n field = action.get(\"field\") # e.g: PatientID, endswith:ID\n value = action.get(\"value\") # \"suid\" or \"var:field\"\n action = action.get(\"action\") # \"REPLACE\"\n\n # Validate the action\n if action not in valid_actions:\n bot.warning(\"%s in not a valid choice. Defaulting to blanked.\" % action)\n action = \"BLANK\"\n\n # If there is an expander applied to field, we iterate over\n fields = expand_field_expression(field=field, dicom=dicom, contenders=fields)\n\n # Keep track of fields we have seen\n seen = []\n\n # An expanded field must END with that field\n expanded_regexp = \"__%s$\" % field\n\n for field in fields:\n seen.append(field)\n\n # Handle top level field\n _perform_action(dicom=dicom, field=field, item=item, action=action, value=value)\n\n # Expand sequences\n if item:\n expanded_fields = [x for x in item if re.search(expanded_regexp, x)]\n\n # FieldA__FieldB\n for expanded_field in expanded_fields:\n _perform_expanded_action(\n dicom=dicom,\n expanded_field=expanded_field,\n item=item,\n action=action,\n value=value,\n )\n\n if return_seen:\n return dicom, seen\n return dicom\n\n\ndef _perform_action(dicom, field, action, value=None, item=None):\n \"\"\"_perform_action is the base function for performing an action.\n perform_action (above) typically is called using a loaded deid,\n and perform_addition is typically done via an addition in a config\n Both result in a call to this function. If an action fails or is not\n done, None is returned, and the calling function should handle this.\n \"\"\"\n if field in dicom and action != \"ADD\":\n\n # Blank the value\n if action == \"BLANK\":\n dicom = blank_tag(dicom, field)\n\n # Code the value with something in the response\n elif action == \"REPLACE\":\n\n value = parse_value(item, value, field)\n if value is not None:\n # If we make it here, do the replacement\n dicom = update_tag(dicom, field=field, value=value)\n else:\n bot.warning(\"REPLACE %s unsuccessful\" % field)\n\n # Code the value with something in the response\n elif action == \"JITTER\":\n value = parse_value(item, value, field)\n if value is not None:\n\n # Jitter the field by the supplied value\n dicom = jitter_timestamp(dicom=dicom, field=field, value=value)\n else:\n bot.warning(\"JITTER %s unsuccessful\" % field)\n\n # elif \"KEEP\" --> Do nothing. Keep the original\n\n # Remove the field entirely\n elif action == \"REMOVE\":\n dicom = remove_tag(dicom, field)\n\n elif action == \"ADD\":\n value = parse_value(item, value, field)\n if value is not None:\n dicom = add_tag(dicom, field, value, quiet=True)\n\n\ndef _perform_expanded_action(dicom, expanded_field, action, value=None, item=None):\n \"\"\"akin to _perform_action, but we expect to be dealing with an expanded\n sequence, and need to step into the Dicom data structure. \n\n Add, jitter, and delete are currently not supported.\n\n The field is expected to have the format FieldA__FieldB where the\n last one is where we want to do the replacement.\n \"\"\"\n field = expanded_field.split(\"__\")[-1]\n\n while field != expanded_field:\n next_field, expanded_field = expanded_field.split(\"__\", 1)\n\n # Case 1: we have a Dataset\n if isinstance(dicom, Dataset):\n dicom = dicom.get(next_field)\n\n elif isinstance(dicom, Sequence):\n for sequence in dicom:\n for subitem in sequence:\n if subitem.keyword == next_field:\n dicom = subitem\n break\n\n # Field should be equal to expanded_field, and in dicom\n if isinstance(dicom, Dataset):\n return _perform_action(\n dicom=dicom, field=field, item=item, action=action, value=value\n )\n\n elif isinstance(dicom, Sequence):\n for sequence in dicom:\n for subitem in sequence:\n if subitem.keyword == field:\n dicom = subitem\n break\n\n if not dicom:\n return\n\n # Not sure if this is possible\n if dicom.keyword != field:\n bot.warning(\"Early return, looking for %s, found %s\" % (field, dicom.keyword))\n return\n\n # Blank the value\n if action == \"BLANK\":\n if dicom.VR not in [\"US\", \"SS\"]:\n dicom.value = \"\"\n\n # Code the value with something in the response\n elif action == \"REPLACE\":\n\n value = parse_value(item, value, field)\n if value is not None:\n dicom.value = value\n\n # elif \"KEEP\" --> Do nothing. Keep the original\n\n\n# Timestamps\n\n\ndef jitter_timestamp(dicom, field, value):\n \"\"\"if present, jitter a timestamp in dicom\n field \"field\" by number of days specified by \"value\"\n The value can be positive or negative.\n \n Parameters\n ==========\n dicom: the pydicom Dataset\n field: the field with the timestamp\n value: number of days to jitter by. Jitter bug!\n\n \"\"\"\n if not isinstance(value, int):\n value = int(value)\n\n original = dicom.get(field, None)\n\n if original is not None:\n dcmvr = dicom.data_element(field).VR\n\n # DICOM Value Representation can be either DA (Date) DT (Timestamp),\n # or something else, which is not supported.\n\n if dcmvr == \"DA\":\n # NEMA-compliant format for DICOM date is YYYYMMDD\n new_value = get_timestamp(original, jitter_days=value, format=\"%Y%m%d\")\n\n elif dcmvr == \"DT\":\n # NEMA-compliant format for DICOM timestamp is\n # YYYYMMDDHHMMSS.FFFFFF&ZZXX\n new_value = get_timestamp(\n original, jitter_days=value, format=\"%Y%m%d%H%M%S.%f%z\"\n )\n else:\n # Do nothing and issue a warning.\n new_value = None\n bot.warning(\"JITTER not supported for %s with VR=%s\" % (field, dcmvr))\n if new_value is not None and new_value != original:\n # Only update if there's something to update AND there's been change\n dicom = update_tag(dicom, field=field, value=new_value)\n return dicom\n"
},
{
"alpha_fraction": 0.7528957724571228,
"alphanum_fraction": 0.7548262476921082,
"avg_line_length": 36,
"blob_id": "d852f6565649c2c5d8920e7699778d526c140aa0",
"content_id": "56c33c5408632d01ba191cd4d4e93845e8039a9d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 518,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 14,
"path": "/docs/_docs/development/index.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "---\ntitle: Development Notes\npermalink: /development/index.html\ncategory: Development\norder: 1\n---\n\nThis readme is intended to explain how the functions work (on the back end) for those \nwishing to create a module for a new image type. The basic idea is that each folder \n(module, eg `dicom`) contains a base processing template that tells the functions to \n`get_identifiers` how to process different header values for the datatype \n(e.g, DICOM). \n\n - [Add an Image Format]({{ site.baseurl }}/development/add-format/)\n"
},
{
"alpha_fraction": 0.7529880404472351,
"alphanum_fraction": 0.7529880404472351,
"avg_line_length": 19.91666603088379,
"blob_id": "a92feacb9842c54445927d952c0ed4a8a0332ed3",
"content_id": "480186bb44f9e508ba6c3cb41f2e7760d279b97b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 251,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 12,
"path": "/deid/dicom/__init__.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "from .header import (\n get_identifiers,\n get_shared_identifiers,\n replace_identifiers,\n remove_private_identifiers,\n)\n\nfrom .utils import get_files\n\nfrom .fields import extract_sequence\n\nfrom .pixels import has_burned_pixels, DicomCleaner\n"
},
{
"alpha_fraction": 0.6360118389129639,
"alphanum_fraction": 0.6555884480476379,
"avg_line_length": 31.540740966796875,
"blob_id": "235044aeb10e0bc9c31e7d1a063a9448b7a44dd7",
"content_id": "d082bd0679ab0342f489f37d8648158d294b6240",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4393,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 135,
"path": "/examples/dicom/header-manipulation/func-replacement.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nfrom deid.dicom import get_files, replace_identifiers\nfrom deid.utils import get_installdir\nfrom deid.data import get_dataset\nimport os\n\n# This is an example of replacing fields in dicom headers,\n# but via a function instead of a preset identifier.\n\n# This will get a set of example cookie dicoms\nbase = get_dataset('dicom-cookies')\ndicom_files = list(get_files(base)) # todo : consider using generator functionality\n\n\n# This is the function to get identifiers\nfrom deid.dicom import get_identifiers\nitems = get_identifiers(dicom_files)\n\n#**\n# The function performs an action to generate a uid, but you can also use\n# it to communicate with databases, APIs, or do something like \n# save the original (and newly generated one) in some (IRB approvied) place\n#**\n\n################################################################################\n# The Deid Recipe\n#\n# The process of updating header values means writing a series of actions\n# in the deid recipe, in this folder the file \"deid.dicom\" that has the\n# following content:\n#\n# FORMAT dicom\n\n# %header\n\n# REPLACE StudyInstanceUID func:generate_uid\n# REPLACE SeriesInstanceUID func:generate_uid\n# ADD FrameOfReferenceUID func:generate_uid\n#\n# In the above we are saying we want to replace the fields above with the\n# output from the generate_uid function, which is expected in the item dict\n##################################\n\n# Create the DeidRecipe Instance from deid.dicom\nfrom deid.config import DeidRecipe\n\nrecipe = DeidRecipe('deid.dicom')\n\n# To see an entire (raw in a dictionary) recipe just look at\nrecipe.deid\n\n# What is the format?\nrecipe.get_format()\n# dicom\n\n# What actions do we want to do on the header?\nrecipe.get_actions()\n\n'''\n[{'action': 'REPLACE',\n 'field': 'StudyInstanceUID',\n 'value': 'func:generate_uid'},\n {'action': 'REPLACE',\n 'field': 'SeriesInstanceUID',\n 'value': 'func:generate_uid'},\n {'action': 'REPLACE',\n 'field': 'FrameOfReferenceUID',\n 'value': 'func:generate_uid'}]\n'''\n\n# We can filter to an action type (not useful here, we only have one type)\nrecipe.get_actions(action='REPLACE')\n\n# or we can filter to a field\nrecipe.get_actions(field='FrameOfReferenceUID')\n\n'''\n[{'action': 'REPLACE',\n 'field': 'FrameOfReferenceUID',\n 'value': 'func:generate_uid'}]\n'''\n\n# and logically, both (not useful here)\nrecipe.get_actions(field='PatientID', action=\"REMOVE\")\n\n\n# Here we need to update each item with the function we want to use!\n\ndef generate_uid(item, value, field):\n '''This function will generate a uuid! You can expect it to be passed\n the dictionary of items extracted from the dicom (and your function)\n and variables, the original value (func:generate_uid) and the field\n name you are applying it to.\n '''\n import uuid\n prefix = field.lower().replace(' ', \" \")\n return prefix + \"-\" + str(uuid.uuid4())\n\n# Remember, the action is: \n# REPLACE StudyInstanceUID func:generate_uid\n# so the key needs to be generate_uid\n\nfor item in items:\n items[item]['generate_uid'] = generate_uid\n\n# Now let's generate the cleaned files! It will output to a temporary directory\n# And then use the deid recipe and updated to create new files\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=recipe,\n ids=items)\n\n\n# We can load in a cleaned file to see what was done\nfrom pydicom import read_file\ntest_file = read_file(cleaned_files[0])\nprint(test_file)\n\n# test_file (subset of changed)\n# (0020, 000d) Study Instance UID UI: studyinstanceuid-022f82f4-e9df-4533-b237-6ab563dfaf56\n# (0020, 000e) Series Instance UID UI: seriesinstanceuid-6a3a0ac8-22fd-449f-9779-2580cf2897bd\n# (0020, 0052) Frame of Reference UID UI: frameofreferenceuid-0693b1fa-9144-4a1d-9cb7-82da56e462ce\n\n# Different output folder\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=recipe,\n ids=items,\n output_folder='/tmp/')\n\n# Force overwrite (be careful!)\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=recipe,\n ids=items,\n output_folder='/tmp/',\n overwrite=True)\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 17.41666603088379,
"blob_id": "d994a2fe2b7f796080a3a07a79f37a2f213c482d",
"content_id": "9dc24817c8821862a3ab334e2608862177cf7df9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 12,
"path": "/deid/utils/__init__.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "from .fileio import (\n get_installdir,\n get_temporary_name,\n write_file,\n write_json,\n read_file,\n read_json,\n recursive_find,\n to_int,\n)\n\nfrom .actions import get_timestamp, get_func, parse_value\n"
},
{
"alpha_fraction": 0.738831639289856,
"alphanum_fraction": 0.7422680258750916,
"avg_line_length": 28.100000381469727,
"blob_id": "5391c70069b21d8cfa5676e35597469150716416",
"content_id": "aa01d7d100a93789587b7cf412bfd4453a1f0e7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 291,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 10,
"path": "/docs/_docs/contributing/code.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "---\ntitle: Github Contribution\ncategory: Contributing\norder: 2\n---\n\n**To be written soon!**\n\n* Filter out long-term GitHub issues with `-label:bucket-list` or focus on active ones with `label:active`\n* If your emacs TeX mode is interfering with viewing Style programs, try `M-x bibtex-mode`\n"
},
{
"alpha_fraction": 0.6604506373405457,
"alphanum_fraction": 0.6705516576766968,
"avg_line_length": 31.9743595123291,
"blob_id": "2d7b4fd5bf47eff62b0a57bc4345b832443935ec",
"content_id": "82ca4b52be5ae9063f87b83e5922d287fe55a8fd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1287,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 39,
"path": "/examples/dicom/header-manipulation/func-sequence-replace/example.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "from deid.dicom import get_identifiers, replace_identifiers\nfrom deid.config import DeidRecipe\n\n# This is supported for deid.dicom version 0.1.34\n\n# This dicom has nested InstanceCreationDate fields\n\ndicom_files = ['MR.dcm']\n\n# They are extracted, and flattened in items\n# 'ReferencedPerformedProcedureStepSequence__InstanceCreationDate': '20091124',\n\nitems = get_identifiers(dicom_files)\n\n# Load in the recipe, we want to REPLACE InstanceCreationDate with a function\n\nrecipe = DeidRecipe('deid.dicom')\n\n# Here is our function\n\ndef generate_uid(item, value, field):\n '''This function will generate a uuid! You can expect it to be passed\n the dictionary of items extracted from the dicom (and your function)\n and variables, the original value (func:generate_uid) and the field\n name you are applying it to.\n '''\n import uuid\n prefix = field.lower().replace(' ', \" \")\n return prefix + \"-\" + str(uuid.uuid4())\n\n# Add the function to each item to be found\nfor item in items:\n items[item]['generate_uid'] = generate_uid\n\n# Clean the files\ncleaned_files = replace_identifiers(dicom_files=dicom_files,\n deid=recipe,\n strip_sequences=False,\n ids=items)\n\n"
},
{
"alpha_fraction": 0.6385706663131714,
"alphanum_fraction": 0.6418191194534302,
"avg_line_length": 33.00581359863281,
"blob_id": "c65d5e4105e3bc58a3009d66212827d0f8a5a6f1",
"content_id": "16c2a44dfbe39fccde0eb78a8dbbb442665bb11d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5849,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 172,
"path": "/deid/dicom/fields.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "\"\"\"\n\nCopyright (c) 2017-2020 Vanessa Sochat\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n\n\"\"\"\n\nfrom deid.logger import bot\nfrom pydicom.sequence import Sequence\nfrom pydicom.dataset import RawDataElement, Dataset\nimport re\n\n\ndef extract_item(item, prefix=None, entry=None):\n \"\"\"a helper function to extract sequence, will extract values from \n a dicom sequence depending on the type.\n\n Parameters\n ==========\n item: an item from a sequence.\n \"\"\"\n # First call, we define entry to be a lookup dictionary\n if entry is None:\n entry = {}\n\n # Skip raw data elements\n if not isinstance(item, RawDataElement):\n header = item.keyword\n\n # If there is no header or field, we can't evaluate\n if header in [None, \"\"]:\n return entry\n\n if prefix is not None:\n header = \"%s__%s\" % (prefix, header)\n\n value = item.value\n if isinstance(value, bytes):\n value = value.decode(\"utf-8\")\n if isinstance(value, Sequence):\n return extract_sequence(value, prefix=header)\n\n entry[header] = value\n return entry\n\n\ndef extract_sequence(sequence, prefix=None):\n \"\"\"return a pydicom.sequence.Sequence recursively\n as a flattened list of items. For example, a nested FieldA and FieldB\n would return as:\n\n {'FieldA__FieldB': '111111'}\n\n Parameters\n ==========\n sequence: the sequence to extract, should be pydicom.sequence.Sequence\n prefix: the parent name\n \"\"\"\n items = {}\n for item in sequence:\n\n # If it's a Dataset, we need to further unwrap it\n if isinstance(item, Dataset):\n for subitem in item:\n items.update(extract_item(subitem, prefix=prefix))\n else:\n bot.warning(\n \"Unrecognized type %s in extract sequences, skipping.\" % type(item)\n )\n return items\n\n\ndef expand_field_expression(field, dicom, contenders=None):\n \"\"\"Get a list of fields based on an expression. If \n no expression found, return single field. Options for fields include:\n\n endswith: filter to fields that end with the expression\n startswith: filter to fields that start with the expression\n contains: filter to fields that contain the expression\n allfields: include all fields\n exceptfields: filter to all fields except those listed ( | separated)\n \n \"\"\"\n # Expanders that don't have a : must be checked for\n expanders = [\"all\"]\n\n # if no contenders provided, use all in dicom headers\n if contenders is None:\n contenders = dicom.dir()\n\n # Case 1: field is an expander without an argument (e.g., no :)\n if field.lower() in expanders:\n\n if field.lower() == \"all\":\n fields = contenders\n return fields\n\n # Case 2: The field is a specific field OR an axpander with argument (A:B)\n fields = field.split(\":\")\n if len(fields) == 1:\n return fields\n\n # if we get down here, we have an expander and expression\n expander, expression = fields\n expression = expression.lower()\n fields = []\n\n # Expanders here require an expression, and have <expander>:<expression>\n if expander.lower() == \"endswith\":\n fields = [x for x in contenders if re.search(\"(%s)$\" % expression, x.lower())]\n elif expander.lower() == \"startswith\":\n fields = [x for x in contenders if re.search(\"^(%s)\" % expression, x.lower())]\n elif expander.lower() == \"except\":\n fields = [x for x in contenders if not re.search(expression, x.lower())]\n elif expander.lower() == \"contains\":\n fields = [x for x in contenders if re.search(expression, x.lower())]\n\n return fields\n\n\ndef get_fields(dicom, skip=None, expand_sequences=True):\n \"\"\"get fields is a simple function to extract a dictionary of fields\n (non empty) from a dicom file.\n\n Parameters\n ==========\n dicom: the dicom file to get fields for.\n skip: an optional list of fields to skip\n expand_sequences: if True, expand values that are sequences.\n \"\"\"\n if skip is None:\n skip = []\n if not isinstance(skip, list):\n skip = [skip]\n\n fields = dict()\n contenders = dicom.dir()\n for contender in contenders:\n if contender in skip:\n continue\n\n try:\n value = dicom.get(contender)\n\n # Adding expanded sequences\n if isinstance(value, Sequence) and expand_sequences is True:\n fields.update(extract_sequence(value, prefix=contender))\n else:\n if value not in [None, \"\"]:\n if isinstance(value, bytes):\n value = value.decode(\"utf-8\")\n fields[contender] = str(value)\n except:\n pass # need to look into this bug\n return fields\n"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 34,
"blob_id": "dac3698e9f8f267a37baf8b482bdafd028838d80",
"content_id": "ca66547a9c30fd5eb3d5368588674009c231e270",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 70,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 2,
"path": "/deid/dicom/pixels/__init__.py",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "from .detect import has_burned_pixels\nfrom .clean import DicomCleaner\n"
},
{
"alpha_fraction": 0.7790697813034058,
"alphanum_fraction": 0.7790697813034058,
"avg_line_length": 50.599998474121094,
"blob_id": "5a145749ca47b876add4b5f3ba54714bfd318a6d",
"content_id": "a01f01f44c6dc12d5e89010e8ac709bb5cd0ebbc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 258,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 5,
"path": "/examples/dicom/README.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "# Examples\n\nThis folder contains examples for interacting with deid! For the basic \ndicom example, see the [recipes](recipes) folder. For tutorials with \nother examples, see [https://pydicom.github.io/deid/examples](https://pydicom.github.io/deid/examples).\n"
},
{
"alpha_fraction": 0.6063492298126221,
"alphanum_fraction": 0.7392290234565735,
"avg_line_length": 36.79999923706055,
"blob_id": "d94b78398bb35389404b801a891e7e0f716e4388",
"content_id": "bb806df869067e5088dd53733ce78ed063f8a3bb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6615,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 175,
"path": "/docs/_docs/getting-started/dicom-get.md",
"repo_name": "davidparsson/deid",
"src_encoding": "UTF-8",
"text": "---\ntitle: 3. Get Identifiers (GET)\ncategory: Getting Started\norder: 5\n---\n\nA get request using the deid module will return the headers found in a particular dataset. \nLet's walk through these steps. As we did in the [loading]({{ site.baseurl }}/getting-started/dicom-loading), \nthe first step was to load a dicom dataset:\n\n\n```python\nfrom deid.data import get_dataset\nfrom deid.dicom import get_files\n\nbase = get_dataset(\"dicom-cookies\")\ndicom_files = list(get_files(base))\nDEBUG Found 7 contender files in dicom-cookies\nDEBUG Checking 7 dicom files for validation.\nFound 7 valid dicom files\n```\n\nWe now have our small dataset that we want to de-identify! The first step is to get \nthe identifiers. By default, we will return all of them. That call will look like this:\n\n```python\nfrom deid.dicom import get_identifiers\nids = get_identifiers(dicom_files)\n```\n\nBy default, any Sequences (lists of items) within the files are expanded and \nprovided. This means that a Sequence with header value `AdditionalData` \nand item `Modality` will be returned as `AdditionalData_Modality`. \nIf you want to disable this and not return expanded sequences:\n\n```python\nids = get_identifiers(dicom_files=dicom_files,\n expand_sequences=False)\n```\n\nWe will see debug output for each, indicating that we found a particular number of fields:\n\n```python\n$ ids=get_identifiers(dicom_files)\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276\nDEBUG Found 27 defined fields for image4.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268\nDEBUG Found 27 defined fields for image2.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866\nDEBUG Found 27 defined fields for image7.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989\nDEBUG Found 27 defined fields for image6.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947\nDEBUG Found 27 defined fields for image3.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131\nDEBUG Found 27 defined fields for image1.dcm\nDEBUG entity id: cookie-47\nDEBUG item id: 1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351\nDEBUG Found 27 defined fields for image5.dcm\n```\n\nSince a data structure is returned indexed by an entity id and then item \n(eg, patient --> image). under the hood this means that we use fields \nfrom the header to use as the index for entity id and item id. \nIf you don't change the defaults, the entity_id is `PatientID` and item \nid is `SOPInstanceUID`. To change this, just specify in the function:\n\n```python\n\nids = get_identifiers(dicom_files,\n entity_id=\"PatientFullName\",\n item_id=\"InstanceUID\")\n```\n\n\n## Organization\nLet's take a closer look at how this is organized. If you notice, the above \nseems to be able to identify entity and items. This is because in the default, \nthe configuration has set an entity id to be the `PatientID` and the item the \n`SOPInstanceUID`. This is how it is organized in the returned result - \nthe entity is the first lookup key:\n\n```python\n# We found one entity\nlen(ids)\n1\n\n# The entity id is cookie-47\nids.keys()\ndict_keys(['cookie-47'])\n```\n\nand then below that, the data is indexed by the item id:\n\n```python\nlist(ids['cookie-47'].keys())\n['1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947',\n '1.2.276.0.7230010.3.1.4.8323329.5348.1495927170.228989',\n '1.2.276.0.7230010.3.1.4.8323329.5329.1495927169.580351',\n '1.2.276.0.7230010.3.1.4.8323329.5342.1495927169.3131',\n '1.2.276.0.7230010.3.1.4.8323329.5354.1495927170.440268',\n '1.2.276.0.7230010.3.1.4.8323329.5323.1495927169.335276',\n '1.2.276.0.7230010.3.1.4.8323329.5335.1495927169.763866']\n```\n**note** that I only made it a list for prettier printing. \n\n\n### Why this organization?\nWe have this organization because by default, the software doesn't know what \nheaders it will find in the dicom files, and it also doesn't know the number \nof (possibly) different entities (eg, a patient) or images (eg, an instance) \nit will find. For this reason, by default, for dicom we have specified that \nthe entity id is the `PatientID` and the `itemID` is the `SOPInstanceUID`. \n\n\n### Header Fields\nThen if we look at the data under a particular item id, we see the dicom fields (and corresponding values) found in the data.\n\n```python\nids['cookie-47']['1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947']\n{'BitsAllocated': 8,\n 'BitsStored': 8,\n 'Columns': 2048,\n 'ConversionType': 'WSD',\n 'HighBit': 7,\n 'ImageComments': 'This is a cookie tumor dataset for testing dicom tools.',\n 'InstitutionName': 'STANFORD',\n 'LossyImageCompression': '01',\n 'LossyImageCompressionMethod': 'ISO_10918_1',\n 'NameOfPhysiciansReadingStudy': 'Dr. damp lake',\n 'OperatorsName': 'nameless voice',\n 'PatientID': 'cookie-47',\n 'PatientName': 'still salad',\n 'PatientSex': 'F',\n 'PhotometricInterpretation': 'YBR_FULL_422',\n 'PixelRepresentation': 0,\n 'PlanarConfiguration': 0,\n 'ReferringPhysicianName': 'Dr. bold moon',\n 'Rows': 1536,\n 'SOPClassUID': '1.2.840.10008.5.1.4.1.1.7',\n 'SOPInstanceUID': '1.2.276.0.7230010.3.1.4.8323329.5360.1495927170.640947',\n 'SamplesPerPixel': 3,\n 'SeriesInstanceUID': '1.2.276.0.7230010.3.1.3.8323329.5360.1495927170.640945',\n 'SpecificCharacterSet': 'ISO_IR 100',\n 'StudyDate': '20131210',\n 'StudyInstanceUID': '1.2.276.0.7230010.3.1.2.8323329.5360.1495927170.640946',\n 'StudyTime': '191930'}\n```\n\n## Save what you need\nPretty neat! At this point, you have a few options:\n\n### Recipe Interaction\nIf you want to do more than load in a basic recipe file (e.g., add new actions, \nuse only a subset of groups, or any customization) then you should read about \nhow to [work with recipes]({{ site.basurl }}/examples/recipe/).\n\n### Clean Pixels\nIt's likely that the pixels in the images have burned in annotations, and we can \nuse the header data to flag these images. Thus, before you replace identifiers, \nyou probably want to do this. We have a DicomCleaner class that can flag images \nfor PHI based on matching some header filter criteria, and you can \n[read about that here]({{site.baseurl}}/getting-started/dicom-pixels/). \n\n### Update Identifiers\nOnce you are finished with any customization of the recipe, updating identifiers,\n and/or potentially flagging and quarantining images that have PHI, you should be \nready to [replace (PUT)]({{ site.baseurl}}/getting-started/dicom-put/) with new\n fields based on the deid recipe.\n"
}
] | 14 |
YasuharaKazuki/make_corpus
|
https://github.com/YasuharaKazuki/make_corpus
|
5cfdc97c208e1cb48683d37d1f7e729b8077e9d0
|
08e265e2680780ac0fd5656818beaad30b9056dc
|
14f5ae1148a7c3a2fa929241b78890f05450601b
|
refs/heads/master
| 2020-04-09T16:19:51.881845 | 2019-04-05T11:15:57 | 2019-04-05T11:15:57 | 160,450,714 | 0 | 0 | null | 2018-12-05T02:49:00 | 2019-04-05T11:15:59 | 2019-04-05T11:25:16 |
Python
|
[
{
"alpha_fraction": 0.525547444820404,
"alphanum_fraction": 0.5313868522644043,
"avg_line_length": 25.346153259277344,
"blob_id": "7fe1adb98725da7dde78dba9d9b5656b14e7f2ce",
"content_id": "e6fc8a0f8bcef06aef04510ec8a690956ad82702",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 26,
"path": "/Make_Corpus/make_id_list.py",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport argparse\n\ndef main():\n parser = argparse.ArgumentParser()\n\n parser.add_argument('--text_file', type=str,\n help='File of path')\n parser.add_argument('--output_file', type=str,\n help='output file name')\n args = parser.parse_args()\n\n # get text_list\n with open(args.text_file, 'r') as f:\n text_list = [line.rstrip() for line in f]\n\n with open(args.output_file, 'w') as f:\n for index in range(len(text_list)):\n f.write('ID' + str(index + 1).zfill(7) + ',')\n f.write(text_list[index] + '\\n')\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7413793206214905,
"alphanum_fraction": 0.75,
"avg_line_length": 18.33333396911621,
"blob_id": "9379c81f130fbdbd1deea89e1bf464190283d9a9",
"content_id": "07534f92726fbc9b49a7a0be5cea675a658885bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 6,
"path": "/README.md",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "# make_corpus\n\nI'm making Japanese corpus. This corpus takes into account 2 mora.\n\n## Todo\nmake selected text list.\n"
},
{
"alpha_fraction": 0.4162735939025879,
"alphanum_fraction": 0.42393869161605835,
"avg_line_length": 30.407407760620117,
"blob_id": "282b39609bfdd989a8ba32284063057b16d964e4",
"content_id": "9b3ddf2f42fdffb8eb0a1ea288808bd1d3bb007f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2049,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 54,
"path": "/Make_Corpus/data_preprocess.sh",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nlast_character='s/[!?。「」]/h/g'\nold_character='[ゝヱゑゐヰ]'\nall_symbol='s/[!\\.\\(\\)\\?,├─┌┐┼。,.・:;?!゛゜´`¨^ ̄_ヽヾゝゞ〃仝々〆◯〇—‐/\~〜∥|…‥‘’“”()〔〕[]{}〈〉《》「」『』【】+-±×÷=≠<>≦≧∞∴♂♀°′″℃¥$¢£%#&*@§☆★○●◎◇◆□■△▲▽▼※〒→←↑↓〓∈∋⊆⊇⊂⊃∪∩∧∨¬⇒⇔∀∃∠⊥⌒∂∇≡≒≪≫√∽∝∵∫∬ʼn♯♭♪]//g'\naozora_dir=Aozorabunko\npreprocess_dir=Data_preprocess\n\n[ ! -e ${preprocess_dir} ] && mkdir ${preprocess_dir}\n\nfor file_path in `find ${aozora_dir} | grep txt`; do\n\n text_tail=`cat -n ${file_path} | grep 底本:| awk '{print $1}'`\n if [ -z \"${text_tail}\" ];then\n text_tail=`cat ${file_path} | wc -l`\n else\n text_tail=`expr ${text_tail} - 1`\n fi\n\n text_head=`cat -n ${file_path} | grep -E '\\-\\-\\-\\-\\-\\-\\-\\-\\-\\-' | awk '{print $1}' | tail -n1`\n if [ -z \"${text_head}\" ];then\n text_head=0\n else\n text_head=`expr ${text_head} + 1`\n fi\n\n [ -e temp.txt ] && rm temp.txt\n\n cat ${file_path} | head -${text_tail} | tail -`expr ${text_tail} - ${text_head} + 1` > temp.txt\n\n\n preprocess_file=`basename ${file_path}`\n\n [ -e ${preprocess_dir}/${preprocess_file} ] && rm ${preprocess_dir}/${preprocess_file}\n\n old_flug=`grep -E ${old_character} temp.txt | wc -l`\n if [ ${old_flug} -eq 0 ];then\n sed 's/([^\\)]*)//g' temp.txt | \\\n sed 's/《[^\\》]*》//g' | \\\n sed 's/〔[^\\〕]*〕//g' | \\\n sed 's/[#[^\\]*]//g' | \\\n sed ${last_character} | \\\n tr 'h' '\\n' | \\\n tr '\\r' 'h' | \\\n sed ${all_symbol} | \\\n sed 's/〜/h/g'| \\\n sed 's/h//g' | \\\n grep -v -E '[a-zA-Z0-90-9a-zA-Z]' | \\\n grep -v '^\\s*$'| \\\n sed 's/ //g' > ${preprocess_dir}/${preprocess_file}\n fi\ndone\n\nrm temp.txt\n"
},
{
"alpha_fraction": 0.5135307312011719,
"alphanum_fraction": 0.5198981165885925,
"avg_line_length": 29.201923370361328,
"blob_id": "35f4ad46b96e1e50abef2e4fa15196098be8d1b0",
"content_id": "5cacec92cfccb076140870b4d48444c9eb899f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3143,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 104,
"path": "/Make_Corpus/run.sh",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# [ USER SETTING ]\n# 0: data preprocess\n# 1: text extraction\n\nstage=2\n\n# [ PREPROCESS SETTING ]\nN_GRAM_DIR=N_gram\nDATA_PREPROCESS=Data_preprocess\n# [ EXTRACTION SETTING ]\nn_jobs=4\nmax_mora=30\nmin_mora=20\npath_file=path_list.txt\noutput_dir=mora_${min_mora}_${max_mora}\nextraction_text=extraction_text.txt\n# [ SELECTION SETTING ]\nSELECT_DIR=Select_text_data\nselected_text=selected_text.txt\nselect_num=5000\n\n# [ STAGE 0 ]\nif echo ${stage} | grep -q 0; then\n echo \"########################################\"\n echo \"# DATA PREPROCESS #\"\n echo \"########################################\"\n\n ./data_preprocess.sh\n\n # make bigram list\n python make_bigram_list.py \\\n --unigram_file ${N_GRAM_DIR}/unigram_list.txt \\\n --outdir ${N_GRAM_DIR}/\n\nfi\n\n# [ STAGE 1 ]\nif echo ${stage} | grep -q 1; then\n echo \"########################################\"\n echo \"# TEXT EXTRACTION #\"\n echo \"########################################\"\n\n [ -e ${path_file} ] && rm ${path_file}\n find ${DATA_PREPROCESS} | grep txt > ${path_file}\n\n [ ! -e ${output_dir} ] && mkdir ${output_dir}\n\n python extraction_text.py \\\n --n_jobs ${n_jobs} \\\n --path_file ${path_file} \\\n --max_mora ${max_mora} \\\n --min_mora ${min_mora} \\\n --output_file ${output_dir}/${extraction_text}\n\n sed 's/、//g' ${output_dir}/${extraction_text} > tmp.txt\n sort tmp.txt | uniq > ${output_dir}/${extraction_text}\n rm tmp.txt\n\n python make_id_list.py \\\n --text_file ${output_dir}/${extraction_text} \\\n --output_file ${output_dir}/${extraction_text}\nfi\n\n# [ STAGE 2 ]\nif echo ${stage} | grep -q 2; then\n echo \"########################################\"\n echo \"# SERECT TEXT #\"\n echo \"########################################\"\n\n [ ! -e ${output_dir}/${SELECT_DIR} ] && mkdir ${output_dir}/${SELECT_DIR}\n\n if [ -f ${output_dir}/${SELECT_DIR}/${selected_text} ]; then\n cat ${output_dir}/${extraction_text} ${output_dir}/${SELECT_DIR}/${selected_text} | \\\n sort | uniq -u > ${output_dir}/${SELECT_DIR}/candidate_text.txt\n fi\n\n for bigram in `cat ${N_GRAM_DIR}/bigram_list.txt`; do\n shuf ${output_dir}/${SELECT_DIR}/candidate_text.txt | \\\n grep ${bigram} | \\\n head -n1 >> ${output_dir}/${SELECT_DIR}/tmp.txt\n done\n\n sort ${output_dir}/${SELECT_DIR}/tmp.txt | \\\n uniq > ${output_dir}/${SELECT_DIR}/select_text.txt\n\n for bigram in `cat ${N_GRAM_DIR}/bigram_list.txt`; do\n shuf ${output_dir}/${SELECT_DIR}/select_text.txt | \\\n grep ${bigram} | \\\n head -n1 >> ${output_dir}/${SELECT_DIR}/tmp.txt\n done\n\n sort ${output_dir}/${SELECT_DIR}/tmp.txt | \\\n uniq > ${output_dir}/${SELECT_DIR}/select_text.csv\n\n python calculate_bigram.py \\\n --csv_file ${output_dir}/${SELECT_DIR}/select_text.csv \\\n --bigram_file ${N_GRAM_DIR}/bigram_list.txt \\\n --output_file ${output_dir}/${SELECT_DIR}/select_text.txt \\\n --select_num ${select_num}\n\n rm ${output_dir}/${SELECT_DIR}/tmp.txt\nfi\n"
},
{
"alpha_fraction": 0.5678831934928894,
"alphanum_fraction": 0.5759124159812927,
"avg_line_length": 30.494253158569336,
"blob_id": "2682a82e6aef0acaef10f9196050bf99b33a018b",
"content_id": "674e92b9e6cf4c1e3e4b27c34882e1257851e73a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2740,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 87,
"path": "/Make_Corpus/calculate_bigram.py",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport argparse\nimport pandas as pd\nimport numpy as np\nfrom pprint import pprint\nimport re\n\n\ndef main():\n\n np.set_printoptions(threshold=np.inf)\n parser = argparse.ArgumentParser()\n\n parser.add_argument('--csv_file', nargs='?',\n help='Csv-file')\n parser.add_argument('--bigram_file', type=str,\n help='Bigram-file')\n parser.add_argument('--output_file', type=str,\n help='Output_file')\n parser.add_argument('--select_num', type=int,\n help='Select number of text')\n args = parser.parse_args()\n\n # read csv-file\n text_csv = pd.read_csv(args.csv_file, header=None).values\n\n # read data\n id_list = text_csv[:, 0]\n real_text_list = text_csv[:, 1]\n read_text_list = text_csv[:, 2]\n\n # make dictionary for text\n text_dict = {}\n text_index = 0\n for id, read_text, real_text in zip(id_list, read_text_list, real_text_list):\n text_dict.update({text_index: (id, read_text, real_text,)})\n text_index += 1\n\n # make dictionary for bigram\n bigram_dict = {}\n bigram_index = 0\n with open(args.bigram_file, 'r') as f:\n for line in f:\n bigram_dict.update({line.rstrip(): bigram_index})\n bigram_index += 1\n\n # difine vecter of bigram\n bigram_vecter = np.zeros((len(bigram_dict), len(text_dict)))\n\n select_text_dict = {}\n\n # count mora\n for read_text_index, read_text_value in text_dict.items():\n vecter = np.array([len(re.findall('(?={0})'.format(re.escape(bigram_key)),\n read_text_value[1])) for bigram_key in bigram_dict])\n bigram_vecter[:, read_text_index] = vecter\n\n while len(select_text_dict) < args.select_num:\n # sum bigram\n sum_vecter = np.sum(bigram_vecter, axis=1)\n\n # get after index (except sum = 0)\n sum_vecter_sort_index = np.argsort(sum_vecter)\n sum_vecter_except_zero = np.where(sum_vecter > 0)\n sum_vecter_sort_index = sum_vecter_sort_index[len(sum_vecter) - len(sum_vecter_except_zero[0]):]\n\n # index of mora\n index = sum_vecter_sort_index[0]\n\n # get text index including mora\n index_serch = np.where(bigram_vecter[index] > 0)[0]\n\n # get text\n for text_index in index_serch:\n select_text_dict.update({text_index: text_dict[text_index]})\n bigram_vecter[:, text_index] = 0\n del text_dict[text_index]\n\n with open(args.output_file, 'w') as f:\n for select in select_text_dict.values():\n pprint(select[0] + ',' + select[2] + ',' + select[1], stream=f)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5539942979812622,
"alphanum_fraction": 0.556856632232666,
"avg_line_length": 24.282894134521484,
"blob_id": "eacd9f12c7746d8109402502bbef076c80062f51",
"content_id": "a181ce3b41a5c77992ee8212a5ed0d66e17457c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3843,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 152,
"path": "/Make_Corpus/extraction_text.py",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport argparse\nimport MeCab\nfrom itertools import chain\nimport re\nfrom pykakasi import kakasi\nfrom joblib import Parallel, delayed\n\ndef read_path_list(path_file):\n \"\"\"READ FILE PATH AND MAKE PATH LIST\n\n Parameter\n ---------\n path_file: str\n file name of path\n\n Return\n ---------\n path_list: list of str\n path list\n \"\"\"\n with open(path_file) as f:\n # read files and make list\n path_list = [line.rstrip() for line in f]\n\n return path_list\n\n\ndef read_text_file(path):\n \"\"\"READ TEXT FILE\n\n Parameter\n ---------\n path: str\n path of text file\n\n Return\n ---------\n text_list: list of str\n text list\n \"\"\"\n\n with open(path, 'r') as f:\n # read text file and make text list\n text_list = [line.strip() for line in f.readlines()]\n\n return text_list\n\n\ndef analysis_text(text_list):\n \"\"\"ANALYZE TEXT USING MECAB AND PYKAKASI\n\n Parameter\n ---------\n text_list: list of str\n text list\n\n Return\n ---------\n analysis_list: list of str\n analyzed text list\n \"\"\"\n # define MeCab\n mecab = MeCab.Tagger(\"-Oyomi\")\n\n # analyze text using MeCab\n analysis_list = [re.sub(r'\\n', '', mecab.parse(line)) for line in text_list]\n\n # define converter\n converter = kakasi()\n\n # set converter Kanji > Katakana\n converter.setMode('J', 'K')\n conv = converter.getConverter()\n\n # analyze text using Pykakasi\n try:\n analysis_list = [conv.do(line) for line in analysis_list]\n except Exception:\n print('pykakasi error')\n\n return analysis_list\n\n\ndef extract_text(pair_text, max_mora, min_mora):\n \"\"\"EXTRACT TEXT\n\n Parameter\n ---------\n pair_text: tuple of str\n pair text\n max_mora: int\n max length of mora\n min_mora: int\n min length of mora\n\n Return\n ---------\n pair_text: tuple of str\n pair text\n \"\"\"\n if len(pair_text[1]) >= min_mora and len(pair_text[1]) <= max_mora:\n return pair_text\n\n\ndef main():\n parser = argparse.ArgumentParser()\n\n parser.add_argument('--n_jobs', type=int, default=1,\n help='number of using CPU')\n parser.add_argument('--path_file', type=str,\n help='File of path')\n parser.add_argument('--max_mora', type=int, default=30,\n help='max number of mora')\n parser.add_argument('--min_mora', type=int, default=20,\n help='minimum number of mora')\n parser.add_argument('--output_file', type=str,\n help='output file name')\n args = parser.parse_args()\n\n # get path_list\n path_list = read_path_list(args.path_file)\n\n # get all text\n all_text_list = Parallel(n_jobs=args.n_jobs)([delayed(read_text_file)\n (path) for path in path_list])\n # analyze all text\n analysis_list = Parallel(n_jobs=args.n_jobs)([delayed(analysis_text)\n (text_list) for text_list in all_text_list])\n # flatten list\n all_text_list = list(chain.from_iterable(all_text_list))\n analysis_list = list(chain.from_iterable(analysis_list))\n\n # make pair list\n pair_text_list = list(zip(all_text_list, analysis_list))\n\n # extraction text\n text_list = Parallel(n_jobs=args.n_jobs)([delayed(extract_text)\n (pair_text, args.max_mora, args.min_mora)\n for pair_text in pair_text_list])\n # remove None data\n text_list = list(filter(None.__ne__, text_list))\n\n with open(args.output_file, 'w') as f:\n for text in text_list:\n f.write(text[0] + ',' + text[1] + '\\n')\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5545851588249207,
"alphanum_fraction": 0.5633187890052795,
"avg_line_length": 25.423076629638672,
"blob_id": "95485e41baaaaa4e61342934025b4a62dfef8ef8",
"content_id": "83574bfdb76e61cb9cbb7d5ba49e850d1993d52f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 687,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 26,
"path": "/Make_Corpus/make_bigram_list.py",
"repo_name": "YasuharaKazuki/make_corpus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport argparse\n\n\ndef main():\n parser = argparse.ArgumentParser()\n\n parser.add_argument('--unigram_file', type=str,\n help='unigram-file')\n parser.add_argument('--outdir', type=str,\n help='output directory')\n args = parser.parse_args()\n\n with open(args.unigram_file, 'r') as unigram_file:\n unigram = [line.rstrip() for line in unigram_file]\n\n with open(args.outdir + 'bigram_list.txt', 'w') as w_file:\n for unigram1 in unigram:\n for unigram2 in unigram:\n w_file.write(unigram1 + unigram2 + '\\n')\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 7 |
Diliscara/Minecraft
|
https://github.com/Diliscara/Minecraft
|
3df706ce1de0bce49474008d474d97030c957816
|
c96e949cf782340e027ac08330b920037c188ac2
|
b1563d15a5247349156e5565409a9b6b57422b9c
|
refs/heads/master
| 2021-01-20T03:21:22.007625 | 2017-11-27T21:08:31 | 2017-11-27T21:08:31 | 89,525,580 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.454693078994751,
"alphanum_fraction": 0.6420915722846985,
"avg_line_length": 32.10752868652344,
"blob_id": "c8826e3e5f0caabf7421a57a1364320cb50d3aeb",
"content_id": "7745c9a011bba641c5bb7af51c5ffb9b7159c47e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3079,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 93,
"path": "/1.py",
"repo_name": "Diliscara/Minecraft",
"src_encoding": "UTF-8",
"text": "from mcpi.minecraft import Minecraft\nfrom mcpi import block\nfrom time import sleep\nfrom random import randint\n\ndef init():\n\tmc = Minecraft.create()\n\tx,y,z=mc.player.getPos()\n\treturn mc\n\n#def main():\n\t#flower=18\n\t#mc=Minecraft.create()\n\t#while True:\n\t\t#x,y,z = mc.player.getPos()\n\t\t#mc.setBlock(x,y-1,z,flower)\n\t\t#sleep (0.1)\n\ndef makeBigBuilding(mc, x, y, z):\n\t#Base Foundation\n\tmc.setBlocks(x+1,y,z+1,x+21,y,z+20,1)\n\t#Left Wall\n\tmc.setBlocks(x+1,y+1,z+1,x+21,y+21,z+1,1)\n\t#Right Wall\n\tmc.setBlocks(x+1,y+1,z+20,x+21,y+21,z+20,1)\n\t#Far Wall\n\tmc.setBlocks(x+21,y+1,z+1,x+21,y+21,z+20,1)\n\t#Front Wall\n\tmc.setBlocks(x+1,y+1,z+1,x+1,y+21,z+20,1)\n\t#Ceiling\n\tmc.setBlocks(x+1,y+21,z+1,x+21,y+21,z+20,1)\n\t#Door\n\tmc.setBlocks(x+1,y+1,z+10,x+1,y+3,z+10,51)\n\tmc.setBlocks(x+1,y+1,z+11,x+1,y+3,z+11,51)\n\t#Left Windows\n\tmc.setBlocks(x+3,y+3,z+1,x+3,y+18,z+1,20)\n\tmc.setBlocks(x+6,y+3,z+1,x+6,y+18,z+1,20)\n\tmc.setBlocks(x+9,y+3,z+1,x+9,y+18,z+1,20)\n\tmc.setBlocks(x+12,y+3,z+1,x+12,y+18,z+1,20)\n\tmc.setBlocks(x+15,y+3,z+1,x+15,y+18,z+1,20)\n\tmc.setBlocks(x+18,y+3,z+1,x+18,y+18,z+1,20)\n\t#Right Windows\n\tmc.setBlocks(x+3,y+3,z+20,x+3,y+18,z+20,20)\n\tmc.setBlocks(x+6,y+3,z+20,x+6,y+18,z+20,20)\n\tmc.setBlocks(x+9,y+3,z+20,x+9,y+18,z+20,20)\n\tmc.setBlocks(x+12,y+3,z+20,x+12,y+18,z+20,20)\n\tmc.setBlocks(x+15,y+3,z+20,x+15,y+18,z+20,20)\n\tmc.setBlocks(x+18,y+3,z+20,x+18,y+18,z+20,20)\n\t#Back Windows\n\tmc.setBlocks(x+21,y+3,z+3,x+21,y+18,z+3,20)\n\tmc.setBlocks(x+21,y+3,z+6,x+21,y+18,z+6,20)\n\tmc.setBlocks(x+21,y+3,z+9,x+21,y+18,z+9,20)\n\tmc.setBlocks(x+21,y+3,z+12,x+21,y+18,z+12,20)\n\tmc.setBlocks(x+21,y+3,z+15,x+21,y+18,z+15,20)\n\tmc.setBlocks(x+21,y+3,z+18,x+21,y+18,z+18,20)\n\t#Front Windows\n\tmc.setBlocks(x+1,y+3,z+3,x+1,y+18,z+3,20)\n\tmc.setBlocks(x+1,y+3,z+6,x+1,y+18,z+6,20)\n\tmc.setBlocks(x+1,y+3,z+9,x+1,y+18,z+9,20)\n\tmc.setBlocks(x+1,y+3,z+18,x+1,y+18,z+18,20)\n\tmc.setBlocks(x+1,y+3,z+15,x+1,y+18,z+15,20)\n\tmc.setBlocks(x+1,y+3,z+12,x+1,y+18,z+12,20)\n\t#Roof 1 Layer\n\tmc.setBlocks(x+2,y+22,z+2,x+20,y+22,z+19,1)\n\tmc.setBlocks(x+2,y+22,z+2,x+2,y+22,z+19,1)\n\tmc.setBlocks(x+20,y+22,z+2,x+20,y+22,z+19,1)\n\tmc.setBlocks(x+2,y+22,z+19,x+20,y+22,z+19,1)\n\t#Roof 2 Layer\n\tmc.setBlocks(x+3,y+23,z+3,x+19,y+23,z+18,1)\n\tmc.setBlocks(x+3,y+23,z+3,x+3,y+23,z+18,1)\n\tmc.setBlocks(x+19,y+23,z+3,x+19,y+23,z+18,1)\n\tmc.setBlocks(x+3,y+23,z+18,x+19,y+23,z+18,1)\n\t#Roof 3 Layer\n\tmc.setBlocks(x+4,y+24,z+4,x+18,y+24,z+17,1)\n\tmc.setBlocks(x+4,y+24,z+4,x+4,y+24,z+17,1)\n\tmc.setBlocks(x+18,y+24,z+4,x+18,y+24,z+17,1)\n\tmc.setBlocks(x+4,y+24,z+17,x+18,y+24,z+17,1)\n\t#Roof 4 Layer\n\tmc.setBlocks(x+5,y+25,z+5,x+17,y+25,z+16,1)\n\tmc.setBlocks(x+5,y+25,z+5,x+5,y+25,z+16,1)\n\tmc.setBlocks(x+17,y+25,z+5,x+17,y+25,z+16,1)\n\tmc.setBlocks(x+5,y+25,z+16,x+17,y+25,z+16,1)\n\t#Roof 5 Layer\n\tmc.setBlocks(x+6,y+26,z+6,x+16,y+26,z+15,1)\n\tmc.setBlocks(x+6,y+26,z+6,x+6,y+26,z+15,1)\n\tmc.setBlocks(x+16,y+26,z+6,x+16,y+26,z+15,1)\n\tmc.setBlocks(x+6,y+26,z+15,x+16,y+26,z+15,1)\n\nmc = init()\nx,y,z=mc.player.getTilePos()\nmakeBigBuilding(mc, x, y, z)\nmakeBigBuilding(mc, x, y, z)\n#https://www.jayconsystems.com/tutorials/pythonprogramminecraft/\n"
},
{
"alpha_fraction": 0.5289329290390015,
"alphanum_fraction": 0.5860909819602966,
"avg_line_length": 41.81060791015625,
"blob_id": "19cfe3703debff10be13e7c67f0c81f287df9ae7",
"content_id": "4bacc9886b34c144edf9447ced12e36c410bf3e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5651,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 132,
"path": "/village.py",
"repo_name": "Diliscara/Minecraft",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom mcpi.minecraft import Minecraft\nfrom mcpi import block\n\n###########################################################\n#\n# Initialise the Village. A clearing is made in front of the player.\n# A road is placed along the z axis with grass either side of it.\n# The Minecraft connection is returned.\n#\n###########################################################\ndef init():\n mc = Minecraft.create()\n x, y, z = mc.player.getTilePos()\n if z > 70:\n # We need room along the z axis for the steet\n z = 9999\n mc.setBlocks(x-15, -1, z-2, x+15, 50, z+58, block.AIR.id)\n mc.setBlocks(x-9999, -0.7, z-9999, x+9999, -0.7, z+9999, block.WATER.id)\n mc.setBlocks(x-9999, -0.0, z-9999, x+9999, -0.0, z+9999, block.ICE.id)\n mc.player.setPos(x, 0, z)\n return mc\n\n###########################################################\n#\n# Construct a House centered on coordinates x, y, z.\n# The house is 6 blocks deep and 7 blocks wide.\n#\n###########################################################\ndef makeHouse(mc, x, y, z):\n # Build the shell\n mc.setBlocks(x-2, y, z-3, x+3, y+2, z+3, block.ICE.id)\n mc.setBlocks(x-1, y, z-2, x+2, y+2, z+2, block.WATER.id)\n\n # Add the roof\n mc.setBlocks(x-2, y+3, z-3, x-2, y+3, z+3, block.ICE.id, 0)\n mc.setBlocks(x+3, y+3, z-3, x+3, y+3, z+3, block.ICE.id, 1)\n mc.setBlocks(x-1, y+4, z-3, x-1, y+4, z+3, block.ICE.id, 0)\n mc.setBlocks(x+2, y+4, z-3, x+2, y+4, z+3, block.ICE.id, 1)\n mc.setBlocks(x, y+5, z-3, x, y+5, z+3, block.ICE.id, 0)\n mc.setBlocks(x+1, y+5, z-3, x+1, y+5, z+3, block.ICE.id, 1)\n\n # Fill in each end of the roof\n mc.setBlocks(x-1, y+3, z-3, x+2, y+3, z-3, block.ICE.id)\n mc.setBlocks(x, y+4, z-3, x+1, y+4, z-3, block.ICE.id)\n mc.setBlocks(x-1, y+3, z+3, x+2, y+3, z+3, block.ICE.id)\n mc.setBlocks(x, y+4, z+3, x+1, y+4, z+3, block.ICE.id)\n \n # Add doors front and rear and pathways\n mc.setBlock(x-2, y, z-1, block.AIR.id, 0)\n mc.setBlock(x-2, y+1, z-1, block.AIR.id, 8)\n mc.setBlock(x+3, y, z+1, block.AIR.id, 2)\n mc.setBlock(x+3, y+1, z+1, block.AIR.id, 10)\n mc.setBlocks(x-3, y-1, z-1, x-4, y-1, z-1, block.ICE.id)\n mc.setBlocks(x+4, y-1, z+1, x+5, y-1, z+1, block.ICE.id)\n\n # Add Windows\n mc.setBlocks(x-2, y+1, z, x-2, y+1, z+1, block.FENCE.id)\n mc.setBlocks(x+3, y+1, z, x+3, y+1, z-1, block.FENCE.id)\n mc.setBlocks(x, y+1, z-3, x+1, y+1, z-3, block.FENCE.id)\n mc.setBlocks(x, y+1, z+3, x+1, y+1, z+3, block.FENCE.id)\n \n#def makeHouse(mc, x, y, z):\n\t# Build the shell\n mc.setBlocks(x-4, y, z-6, x+6, y+4, z+6, block.LAVA.id)\n mc.setBlocks(x-2, y, z-4, x+4, y+4, z+4, block.WATER.id)\n\n # Add the roof\n mc.setBlocks(x-4, y+6, z-6, x-4, y+6, z+6, block.GLOWING_OBSIDIAN.id, 0)\n mc.setBlocks(x+6, y+6, z-6, x+6, y+6, z+6, block.GLOWING_OBSIDIAN.id, 1)\n mc.setBlocks(x-4, y+8, z-6, x-2, y+8, z+6, block.GLOWING_OBSIDIAN.id, 0)\n mc.setBlocks(x+4, y+8, z-6, x+4, y+8, z+6, block.GLOWING_OBSIDIAN.id, 1)\n mc.setBlocks(x, y+10, z-6, x, y+10, z+6, block.GLOWING_OBSIDIAN.id, 0)\n mc.setBlocks(x+2, y+10, z-6, x+2, y+10, z+6, block.GLOWING_OBSIDIAN.id, 1)\n\n # Fill in each end of the roof\n mc.setBlocks(x-2, y+6, z-6, x+4, y+6, z-6, block.GLOWING_OBSIDIAN.id)\n mc.setBlocks(x, y+8, z-6, x+2, y+8, z-6, block.GLOWING_OBSIDIAN.id)\n mc.setBlocks(x-2, y+6, z+6, x+4, y+6, z+6, block.GLOWING_OBSIDIAN.id)\n mc.setBlocks(x, y+8, z+6, x+2, y+8, z+6, block.GLOWING_OBSIDIAN.id)\n \n # Add doors front and rear and pathways\n mc.setBlock(x-4, y, z-2, block.AIR.id, 0)\n mc.setBlock(x-4, y+2, z-2, block.AIR.id, 8)\n mc.setBlock(x+6, y, z+2, block.AIR.id, 2)\n mc.setBlock(x+6, y+2, z+2, block.AIR.id, 10)\n mc.setBlocks(x-6, y-2, z-2, x-8, y-2, z-2, block.GLOWING_OBSIDIAN.id)\n mc.setBlocks(x+8, y-2, z+2, x+10, y-2, z+2, block.GLOWING_OBSIDIAN.id)\n\n # Add Windows\n mc.setBlocks(x-4, y+2, z, x-4, y+2, z+2, block.FENCE_GATE.id)\n mc.setBlocks(x+6, y+2, z, x+6, y+2, z-2, block.FENCE_GATE.id)\n mc.setBlocks(x, y+2, z-6, x+2, y+2, z-6, block.FENCE_GATE.id)\n mc.setBlocks(x, y+2, z+6, x+2, y+2, z+6, block.FENCE_GATE.id)\n \n\n\n\nmc = init()\nx, y, z = mc.player.getTilePos()\nmakeHouse(mc, x+7, y, z+4)\nmakeHouse(mc, x+17, y, z+14)\n\n##################################################\n#\n# Exercises:\n#\n# 1. Run this code and explore the world in Minecraft, see the road\n# and the house that have been built.\n#\n# 2. Make a copy of the above line of code \"makeHouse...\" and\n# change it so that a second house is build on the other side of the road.\n# Hint: You will have to change the location of the new house.\n#\n# 3. Wrap both of the \"makeHouse...\" lines in a for loop to create \n# a row of houses along each side of the road. You should be able to make\n# 6 houses spaced 10 blocks apart. You will have to change the arguments\n# supplied to both \"makeHouse...\" calls so that the houses are built\n# all along the road. Refer to last week's \"Steps\" exercise for an\n# example of building things inside a for loop.\n#\n# 4. Copy and Paste the whole \"makeHouse...\" function and change the name\n# of it to something else (for example \"makeShop\"). Now change the code\n# inside the copied function so that it creates your new design (for\n# example, a shop will have large windows, a pavement all the way across\n# the front and an awning.\n#\n# 5. Change your for loop so that is uses both \"makeHouse\" and \"makeShop\"\n# (for example the houses on one side of the street and the shops on the\n# other).\n#\n# Code source: http://www.cotswoldjam.org/downloads/2017-01/minecraft-village/village.py\n"
},
{
"alpha_fraction": 0.7068965435028076,
"alphanum_fraction": 0.7068965435028076,
"avg_line_length": 23.85714340209961,
"blob_id": "56fc59138dfb4469ab16e20fb2992602ab1b646e",
"content_id": "c24f1f3558ae2bfc77b2e730d06b9954469f97df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 7,
"path": "/trails.py",
"repo_name": "Diliscara/Minecraft",
"src_encoding": "UTF-8",
"text": "from mcpi.minecraft import Minecraft\nfrom mcpi import block\ndef init():\n\tmc = Minecraft.create()\n\tx, y, z = mc.player.getPos()\n\tmc.setBlock(x, y, z, block.ICE.id)\n\treturn mc\n"
},
{
"alpha_fraction": 0.4658430218696594,
"alphanum_fraction": 0.5428779125213623,
"avg_line_length": 39.47058868408203,
"blob_id": "9ea010eb6eb7d456e60811e39fc1ab9470afe818",
"content_id": "dc8bcf568f567a7306ed9045f5095ad1c37f9091",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4128,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 102,
"path": "/experiment.py",
"repo_name": "Diliscara/Minecraft",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nfrom mcpi.minecraft import Minecraft\nfrom mcpi import block\n\n###########################################################\n#\n# Initialise the Village. A clearing is made in front of the player.\n# A road is placed along the z axis with grass either side of it.\n# The Minecraft connection is returned.\n#\n###########################################################\ndef init():\n mc = Minecraft.create()\n x, y, z = mc.player.getTilePos()\n if z > 70:\n # We need room along the z axis for the steet\n z = 9999\n mc.setBlocks(x-9999, -1, z-9999, x+9999, 50, z+9999, block.WATER.id)\n mc.setBlocks(x-9999, -0.7, z-9999, x+9999, -0.7, z+9999, block.WATER.id)\n mc.setBlocks(x-9999, -0.0, z-9999, x+9999, -0.0, z+9999, block.ICE.id)\n mc.player.setPos(x, 0, z)\n return mc\n\n###########################################################\n#\n# Construct a House centered on coordinates x, y, z.\n# The house is 6 blocks deep and 7 blocks wide.\n#\n###########################################################\ndef makeHouse(mc, x, y, z):\n # Build the shell\n mc.setBlocks(x-2, y, z-3, x+3, y+2, z+3, block.ICE.id)\n mc.setBlocks(x-1, y, z-2, x+2, y+2, z+2, block.WATER.id)\n\n # Add the roof\n mc.setBlocks(x-2, y+3, z-3, x-2, y+3, z+3, block.ICE.id, 0)\n mc.setBlocks(x+3, y+3, z-3, x+3, y+3, z+3, block.ICE.id, 1)\n mc.setBlocks(x-1, y+4, z-3, x-1, y+4, z+3, block.ICE.id, 0)\n mc.setBlocks(x+2, y+4, z-3, x+2, y+4, z+3, block.ICE.id, 1)\n mc.setBlocks(x, y+5, z-3, x, y+5, z+3, block.ICE.id, 0)\n mc.setBlocks(x+1, y+5, z-3, x+1, y+5, z+3, block.ICE.id, 1)\n\n # Fill in each end of the roof\n mc.setBlocks(x-1, y+3, z-3, x+2, y+3, z-3, block.ICE.id)\n mc.setBlocks(x, y+4, z-3, x+1, y+4, z-3, block.ICE.id)\n mc.setBlocks(x-1, y+3, z+3, x+2, y+3, z+3, block.ICE.id)\n mc.setBlocks(x, y+4, z+3, x+1, y+4, z+3, block.ICE.id)\n \n # Add doors front and rear and pathways\n mc.setBlock(x-2, y, z-1, block.AIR.id, 0)\n mc.setBlock(x-2, y+1, z-1, block.AIR.id, 8)\n mc.setBlock(x+3, y, z+1, block.AIR.id, 2)\n mc.setBlock(x+3, y+1, z+1, block.AIR.id, 10)\n mc.setBlocks(x-3, y-1, z-1, x-4, y-1, z-1, block.ICE.id)\n mc.setBlocks(x+4, y-1, z+1, x+5, y-1, z+1, block.ICE.id)\n\n # Add Windows\n mc.setBlocks(x-2, y+1, z, x-2, y+1, z+1, block.FENCE.id)\n mc.setBlocks(x+3, y+1, z, x+3, y+1, z-1, block.FENCE.id)\n mc.setBlocks(x, y+1, z-3, x+1, y+1, z-3, block.FENCE.id)\n mc.setBlocks(x, y+1, z+3, x+1, y+1, z+3, block.FENCE.id)\n \n#def makeHouse(mc, x, y, z):\n\t# Build the shell\n mc.setBlocks(x-4, y, z-6, x+6, y+4, z+6, block.ICE.id)\n mc.setBlocks(x-2, y, z-4, x+4, y+4, z+4, block.WATER.id)\n\n # Add the roof\n mc.setBlocks(x-4, y+6, z-6, x-4, y+6, z+6, block.SNOW.id, 0)\n mc.setBlocks(x+6, y+6, z-6, x+6, y+6, z+6, block.SNOW.id, 1)\n mc.setBlocks(x-4, y+8, z-6, x-2, y+8, z+6, block.SNOW.id, 0)\n mc.setBlocks(x+4, y+8, z-6, x+4, y+8, z+6, block.SNOW.id, 1)\n mc.setBlocks(x, y+10, z-6, x, y+10, z+6, block.SNOW.id, 0)\n mc.setBlocks(x+2, y+10, z-6, x+2, y+10, z+6, block.SNOW.id, 1)\n\n # Fill in each end of the roof\n mc.setBlocks(x-2, y+6, z-6, x+4, y+6, z-6, block.SNOW.id)\n mc.setBlocks(x, y+8, z-6, x+2, y+8, z-6, block.SNOW.id)\n mc.setBlocks(x-2, y+6, z+6, x+4, y+6, z+6, block.SNOW.id)\n mc.setBlocks(x, y+8, z+6, x+2, y+8, z+6, block.SNOW.id)\n \n # Add doors front and rear and pathways\n mc.setBlock(x-4, y, z-2, block.AIR.id, 0)\n mc.setBlock(x-4, y+2, z-2, block.AIR.id, 8)\n mc.setBlock(x+6, y, z+2, block.AIR.id, 2)\n mc.setBlock(x+6, y+2, z+2, block.AIR.id, 10)\n mc.setBlocks(x-6, y-2, z-2, x-8, y-2, z-2, block.SNOW.id)\n mc.setBlocks(x+8, y-2, z+2, x+10, y-2, z+2, block.SNOW.id)\n\n # Add Windows\n mc.setBlocks(x-4, y+2, z, x-4, y+2, z+2, block.FENCE_GATE.id)\n mc.setBlocks(x+6, y+2, z, x+6, y+2, z-2, block.FENCE_GATE.id)\n mc.setBlocks(x, y+2, z-6, x+2, y+2, z-6, block.FENCE_GATE.id)\n mc.setBlocks(x, y+2, z+6, x+2, y+2, z+6, block.FENCE_GATE.id)\n \n\n\n\nmc = init()\nx, y, z = mc.player.getTilePos()\nmakeHouse(mc, x+7, y, z+4)\nmakeHouse(mc, x+17, y, z+14)\n"
}
] | 4 |
MeepMoop/roombas
|
https://github.com/MeepMoop/roombas
|
13edb0a4147b04858496c867a33cfcedf429da93
|
65034b9fe216516ba9ed36bda7853e4e92e56cda
|
5c43afb1c1e2d5a7c738e4d20904c0956212d686
|
refs/heads/master
| 2021-01-22T04:18:03.656256 | 2017-05-26T00:06:45 | 2017-05-26T00:06:45 | 92,450,815 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.671219527721405,
"alphanum_fraction": 0.6731707453727722,
"avg_line_length": 27.5,
"blob_id": "924ad64976189fb8b7b581368a9cc61e0d960e21",
"content_id": "bdc7974cb27403b85993d07478b599f90935838d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 36,
"path": "/GameObjects.py",
"repo_name": "MeepMoop/roombas",
"src_encoding": "UTF-8",
"text": "class Room:\n # init, base class sets up room's entity list\n def __init__(self):\n self.entities = []\n # update loop, base class calls update() of each entity in room\n def update(self):\n for entity in self.entities:\n entity.update()\n # draw event, base class calls draw() of each entity in room\n def draw(self):\n for entity in self.entities:\n entity.draw()\n # called when room starts, typically create initial entities here\n def roomStart(self):\n pass\n # called when room ends, base class clears room's entity list\n def roomEnd(self):\n self.entities = []\n\nclass Entity:\n # init, base class stores entity's coordinates\n def __init__(self, x=0, y=0):\n self.x = x\n self.y = y\n # create event, called when instance makes it out of the instance creation queue\n def create(self):\n pass\n # update loop\n def update(self):\n pass\n # destroy event, called when instance makes it out of the instance removal queue\n def destroy(self):\n pass\n # draw event\n def draw(self):\n pass"
},
{
"alpha_fraction": 0.7395833134651184,
"alphanum_fraction": 0.7447916865348816,
"avg_line_length": 16.454545974731445,
"blob_id": "ea1aee27cca027320856135034528da614b429d6",
"content_id": "0e470fcc3a83a45cd44ca41f43c4592d1c5f7110",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 11,
"path": "/README.md",
"repo_name": "MeepMoop/roombas",
"src_encoding": "UTF-8",
"text": "# Roombas\nRoomba simulator built around [meepgame](https://github.com/MeepMoop/meepgame)\n\n# Dependencies\n* Pygame\n\n# Usage\n```\ngit clone http://github.com/MeepMoop/roombas\npython3 Game.py\n```\n"
},
{
"alpha_fraction": 0.3165210485458374,
"alphanum_fraction": 0.4281175434589386,
"avg_line_length": 39.629032135009766,
"blob_id": "2e1e9a74f980e408d0841b038f54856c6ad699a9",
"content_id": "8b7e9dedd289ea19b0469ffd2f2d28a446b62aac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2518,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 62,
"path": "/GameUtil.py",
"repo_name": "MeepMoop/roombas",
"src_encoding": "UTF-8",
"text": "def collisionCircleLine(C, r, A, B):\n LAB = ((B[0] - A[0]) ** 2 + (B[1] - A[1]) ** 2) ** 0.5\n m0 = (B[0] - A[0])/LAB\n m1 = (B[1] - A[1])/LAB\n t = (C[0] - A[0]) * m0 + (C[1] - A[1]) * m1\n if t < 0 or t > LAB:\n return False\n return (C[0] - (A[0] + t * m0)) ** 2 + (C[1] - (A[1] + t * m1)) ** 2 <= r ** 2\n\ndef collisionCircleRectangle(C, r, RA, RB):\n return collisionCircleLine(C, r, (RA[0], RA[1]), (RB[0], RA[1])) or \\\n collisionCircleLine(C, r, (RA[0], RA[1]), (RA[0], RB[1])) or \\\n collisionCircleLine(C, r, (RB[0], RB[1]), (RB[0], RA[1])) or \\\n collisionCircleLine(C, r, (RB[0], RB[1]), (RA[0], RB[1])) or \\\n (C[0] > RA[0] and C[0] < RB[0] and C[1] > RA[1] and C[1] < RB[1])\n\ndef collisionCircleCircle(C1, r1, C2, r2):\n return (C2[0] - C1[0]) ** 2 + (C2[1] - C1[1]) ** 2 <= (r1 + r2) ** 2\n\ndef collisionLineLine(A1, B1, A2, B2):\n den = ((B1[0] - A1[0]) * (B2[1] - A2[1])) - ((B1[1] - A1[1]) * (B2[0] - A2[0]))\n r = ((A1[1] - A2[1]) * (B2[0] - A2[0])) - ((A1[0] - A2[0]) * (B2[1] - A2[1]))\n s = ((A1[1] - A2[1]) * (B1[0] - A1[0])) - ((A1[0] - A2[0]) * (B1[1] - A1[1]))\n if den == 0:\n if r == 0 and s == 0:\n c = (A2[0] - A1[0]) / (B1[0] - A1[0])\n d = (B2[0] - A1[0]) / (B1[0] - A1[0])\n return (c >= 0 and c <= 1) or (d >= 0 and d <= 1)\n else:\n return False\n r /= den\n s /= den\n return (r >= 0 and r <= 1) and (s >= 0 and s <= 1)\n\ndef collisionLineRectangle(A, B, RA, RB):\n return collisionLineLine(A, B, (RA[0], RA[1]), (RB[0], RA[1])) or \\\n collisionLineLine(A, B, (RA[0], RA[1]), (RA[0], RB[1])) or \\\n collisionLineLine(A, B, (RB[0], RB[1]), (RB[0], RA[1])) or \\\n collisionLineLine(A, B, (RB[0], RB[1]), (RA[0], RB[1]))\n\ndef collisionPtLineLine(A1, B1, A2, B2):\n den = ((B1[0] - A1[0]) * (B2[1] - A2[1])) - ((B1[1] - A1[1]) * (B2[0] - A2[0]))\n r = ((A1[1] - A2[1]) * (B2[0] - A2[0])) - ((A1[0] - A2[0]) * (B2[1] - A2[1]))\n s = ((A1[1] - A2[1]) * (B1[0] - A1[0])) - ((A1[0] - A2[0]) * (B1[1] - A1[1]))\n if den == 0:\n if r == 0 and s == 0:\n c = (A2[0] - A1[0]) / (B1[0] - A1[0])\n d = (B2[0] - A1[0]) / (B1[0] - A1[0])\n if c >= 0 and c <= 1:\n return (A1[0] + c * (B1[0] - A1[0]), A1[1] + c * (B1[1] - A1[1]))\n elif d >= 0 and d <= 1:\n return (A1[0] + d * (B1[0] - A1[0]), A1[1] + d * (B1[1] - A1[1]))\n else:\n return None\n else:\n return None\n r /= den\n s /= den\n if (r >= 0 and r <= 1) and (s >= 0 and s <= 1):\n return (A1[0] + r * (B1[0] - A1[0]), A1[1] + r * (B1[1] - A1[1]))\n else:\n return None"
},
{
"alpha_fraction": 0.599023163318634,
"alphanum_fraction": 0.6193630695343018,
"avg_line_length": 35.90370559692383,
"blob_id": "2ed97bc272ca6ee52562a9bc50369a07849c0161",
"content_id": "d0b28fabffa5a077a8f477cb270e67c113320bef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14946,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 405,
"path": "/Game.py",
"repo_name": "MeepMoop/roombas",
"src_encoding": "UTF-8",
"text": "import sys, pygame\nfrom GameObjects import *\nfrom GameUtil import *\nfrom math import *\nimport numpy as np\nfrom random import random, randint\n\n### main game class - edit settings\n\nclass Game:\n # settings\n _WINDOW_CAPTION = \"Game\"\n _FPS = 30\n _FPS_DISPLAY = False\n _WIDTH = 320\n _HEIGHT = 320\n _BGCOL = (255, 255, 255)\n\n # initialization\n _DIAG = (_WIDTH ** 2 + _HEIGHT ** 2) ** 0.5\n _DISPLAY = pygame.display.set_mode((_WIDTH, _HEIGHT), pygame.RESIZABLE)\n _GFX = pygame.Surface((_WIDTH, _HEIGHT), pygame.SRCALPHA)\n pygame.display.set_caption(_WINDOW_CAPTION)\n _CLOCK = pygame.time.Clock()\n\n _CREATION_QUEUE = []\n _DELETION_QUEUE = []\n\n _ROOMS = [Room()]\n _ACTIVE_ROOM = _ROOMS[0]\n\n @staticmethod\n def gameLoop():\n while True:\n # window closed\n for event in pygame.event.get():\n if event.type == pygame.QUIT: sys.exit()\n # create queued instances\n for instance in Game._CREATION_QUEUE:\n instance.create()\n Game._ACTIVE_ROOM.entities.append(instance)\n Game._CREATION_QUEUE.clear()\n # update active room\n Game._ACTIVE_ROOM.update()\n # delete queued instances\n for instance in Game._DELETION_QUEUE:\n instance.destroy()\n Game._ACTIVE_ROOM.entities.remove(instance)\n Game._DELETION_QUEUE.clear()\n # draw\n Game._DISPLAY.fill(Game._BGCOL)\n Game._GFX.fill(Game._BGCOL)\n Game._ACTIVE_ROOM.draw()\n Game._DISPLAY.blit(Game._GFX, (0, 0))\n pygame.display.update()\n # manage framerate\n Game._CLOCK.tick(Game._FPS)\n if Game._FPS_DISPLAY: print('FPS:', Game._CLOCK.get_fps())\n\n @staticmethod\n def instanceCreate(instance):\n Game._CREATION_QUEUE.append(instance)\n return instance\n\n @staticmethod\n def instanceDestroy(instance):\n Game._DELETION_QUEUE.append(instance)\n \n @staticmethod\n def gotoRoom(roomNumber):\n Game._ACTIVE_ROOM.roomEnd()\n Game._ACTIVE_ROOM = Game._ROOMS[roomNumber]\n Game._ACTIVE_ROOM.roomStart()\n \n @staticmethod\n def entityExists(entity_class):\n for entity in Game._ACTIVE_ROOM.entities:\n if type(entity) == entity_class:\n return true\n return false\n \n @staticmethod\n def getEntities(entity_class):\n entities = []\n for entity in Game._ACTIVE_ROOM.entities:\n if type(entity) == entity_class:\n entities.append(entity)\n return entities\n \n @staticmethod\n def getEntitiesUnderParent(parent_class):\n entities = []\n for entity in Game._ACTIVE_ROOM.entities:\n if entity.__class__.__bases__[0] == parent_class or type(entity) == parent_class:\n entities.append(entity)\n return entities\n\n### new rooms - inherit from base class (See GameObjects.py)\n\n'''\nclass NewRoom(Room):\n def __init__(self): \n super().__init__()\n def update(self):\n super().update()\n def draw(self):\n super().draw()\n def roomStart(self):\n super().roomStart()\n def roomEnd(self):\n super().roomEnd()\n'''\n\nclass Environment(Room):\n def roomStart(self):\n super().roomStart()\n # build environment here - add obstacles, roombas, etc\n wallWidth = 32\n wallColorTop = [128, 128, 128]\n wallColorBottom = [128, 128, 128]\n wallColorLeft = [128, 128, 128]\n wallColorRight = [128, 128, 128]\n ballColor = [255, 128, 0]\n\n self.obstacles = []\n self.obstacles.append(Game.instanceCreate(ObstacleLine(wallWidth, wallWidth, Game._WIDTH - wallWidth, wallWidth, wallColorTop)))\n self.obstacles.append(Game.instanceCreate(ObstacleLine(wallWidth, wallWidth, wallWidth, Game._HEIGHT - wallWidth, wallColorLeft)))\n self.obstacles.append(Game.instanceCreate(ObstacleLine(Game._WIDTH - wallWidth, Game._HEIGHT - wallWidth, wallWidth, Game._HEIGHT - wallWidth, wallColorBottom)))\n self.obstacles.append(Game.instanceCreate(ObstacleLine(Game._WIDTH - wallWidth, Game._HEIGHT - wallWidth, Game._WIDTH - wallWidth, wallWidth, wallColorRight)))\n for i in range(3):\n self.obstacles.append(Game.instanceCreate(ObstacleCircle(1.5 * wallWidth + random() * (Game._WIDTH - 3 * wallWidth), 1.5 * wallWidth + random() * (Game._HEIGHT - 3 * wallWidth), wallWidth / 2, ballColor)))\n \n Game.instanceCreate(Roomba(160, 160, 16, 12, [32, 32, 32], random() * 2 * pi, 0.0, 0.5))\n\n\n### new entities - inherit from base class (See GameObjects.py)\n\n'''\nclass NewEntity(Entity):\n def __init__(self, x=0, y=0):\n super().__init__(x, y)\n def create(self):\n super().create()\n def update(self):\n super().update()\n def destroy(self):\n super().destroy()\n def draw(self):\n super().draw()\n'''\n\nclass Roomba(Entity):\n sprFace = pygame.image.load('agent_face.png')\n\n ## events\n\n def __init__(self, x, y, r, rW, color, ang=0, lvel=0, rvel=0):\n super().__init__(x, y)\n self.r = r # roomba radius\n self.rW = rW # wheel distance from center\n self.color = color # [R, G, B]\n self.ang = ang # angle in radians\n self.lvel = lvel # linear velocity of left wheel\n self.rvel = rvel # linear velocity of right wheel\n self.xRem = 0 # x-remainder to account for rounding errors\n self.yRem = 0 # y-remainder ''\n self.bumpSensor = 0 # bump sensor\n # vision\n self.viewRays = 12 # number of rays\n self.viewRayDist = Game._DIAG # ray distance\n self.viewAngle = pi / 3 # field of view\n self.visRGB = [[0, 0, 0] for i in range(self.viewRays)] # vision RGB array\n self.visD = [0.0 for i in range(self.viewRays)] # vision depth array\n \n ### init RL stuff here ###\n self.S = np.zeros(3 * self.viewRays)\n self.wl = np.random.randn(3 * self.viewRays + 1) / np.sqrt(self.viewRays)\n self.wr = np.random.randn(3 * self.viewRays + 1) / np.sqrt(self.viewRays)\n \n def update(self):\n super().update()\n self.bumpSensor = 0 # reset bump sensor\n vel = (self.lvel + self.rvel) / 2 # compute linear velocity\n omega = (self.rvel - self.lvel) / self.rW # compute angular velocity\n self.ang += omega # increment angle\n self.ang = self.ang - 2 * pi if self.ang >= pi else self.ang + 2 * pi if self.ang < -pi else self.ang # wrap angle\n xvel = vel * cos(self.ang) # compute x-velocity\n yvel = vel * sin(self.ang) # compute y-velocity\n self.bumpSensor = self.moveX(xvel) or self.moveY(yvel) # adjust position and update bump sensor\n self.visRGB, self.visD = self.getVision(self.viewAngle, self.viewRays) # get RGBD information\n\n ### update RL stuff here ###\n ''' ignore this hacky genetic alg + backprop monster '''\n R = -2 * self.bumpSensor + abs(self.lvel + self.rvel)\n Sp = (np.array(self.visRGB) * (1 - np.array([self.visD]).T / Game._DIAG)).flatten() / 255\n phi = np.hstack((Sp, 1))\n self.lvel = tanh(np.dot(self.wl, phi))\n self.rvel = tanh(np.dot(self.wr, phi))\n self.S = Sp\n if R < 0.5:\n lvelTarget = 2 * randint(0, 1) - 1\n rvelTarget = 2 * randint(0, 1) - 1\n self.wl += 0.1 * (lvelTarget - self.lvel) * (1 - self.lvel ** 2) * phi\n self.wr += 0.1 * (rvelTarget - self.rvel) * (1 - self.rvel ** 2) * phi\n \n def draw(self):\n super().draw()\n pos = (int(self.x), int(self.y))\n self.drawVisionRays(self.viewAngle, self.viewRays) # draw vision rays\n pygame.draw.circle(Game._GFX, self.color, pos, self.r) # draw roomba color\n sprRotate = pygame.transform.rotate(Roomba.sprFace, self.ang * 180 / pi) # draw roomba face\n Game._GFX.blit(sprRotate, sprRotate.get_rect(center=pos))\n self.drawVision(8, 8, 8, self.visRGB, self.visD) # display vision RGB info\n self.drawBumpSensor(16 + 8 * self.viewRays, 8, 8) # display vision depth info\n self.drawState(8, 304, 8) # draw agent's state\n \n ## methods\n\n # set linear velocity of each wheel\n def setWheelVel(self, lvel, rvel):\n self.lvel = lvel\n self.rvel = rvel\n \n # set linear and angular velocity of roomba\n def setVel(self, vel, omega):\n self.lvel = vel - omega * self.rW / 2\n self.rvel = vel + omega * self.rW / 2\n \n # get vision RGB, D arrays\n def getVision(self, viewAngle, rays):\n vis = [[0, 0, 0] for i in range(rays)]\n depth = [Game._DIAG + 1 for i in range(rays)]\n if rays == 1:\n rayPts = [(self.x + self.viewRayDist + cos(self.ang), self.y - self.viewRayDist + sin(self.ang))]\n else:\n rayPts = [(self.x + self.viewRayDist * cos(self.ang + viewAngle * (0.5 - i / (rays - 1))), \\\n self.y - self.viewRayDist * sin(self.ang + viewAngle * (0.5 - i / (rays - 1)))) for i in range(rays)]\n for i, ray in enumerate(rayPts):\n for obstacle in Game._ACTIVE_ROOM.obstacles:\n if type(obstacle) == ObstacleRect:\n if collisionLineRectangle((self.x, self.y), ray, obstacle.rect.topleft, obstacle.rect.bottomright):\n dsqr = (obstacle.x - self.x) ** 2 + (obstacle.y - self.y) ** 2\n if dsqr < depth[i] ** 2:\n depth[i] = dsqr ** 0.5\n vis[i] = obstacle.color\n elif type(obstacle) == ObstacleCircle:\n if collisionCircleLine(obstacle.pos, obstacle.r, (self.x, self.y), ray):\n dsqr = (obstacle.x - self.x) ** 2 + (obstacle.y - self.y) ** 2\n if dsqr < depth[i] ** 2:\n depth[i] = dsqr ** 0.5\n vis[i] = obstacle.color\n elif type(obstacle) == ObstacleLine:\n pt = collisionPtLineLine(obstacle.A, obstacle.B, (self.x, self.y), ray)\n if pt != None:\n dsqr = (pt[0] - self.x) ** 2 + (pt[1] - self.y) ** 2\n if dsqr < depth[i] ** 2:\n depth[i] = dsqr ** 0.5\n vis[i] = obstacle.color\n return vis, depth\n \n # draw vision rays relative to roomba\n def drawVisionRays(self, viewAngle, rays):\n if rays == 1:\n rayPts = [(self.x + self.viewRayDist + cos(self.ang), self.y - self.viewRayDist + sin(self.ang))]\n else:\n rayPts = [(self.x + self.viewRayDist * cos(self.ang + viewAngle * (0.5 - i / (rays - 1))), \\\n self.y - self.viewRayDist * sin(self.ang + viewAngle * (0.5 - i / (rays - 1)))) for i in range(rays)]\n for ray in rayPts:\n pygame.draw.line(Game._GFX, [0, 0, 0], (self.x, self.y), ray)\n \n # draw RGBD visualization given coordinates and pixel width\n def drawVision(self, x, y, w, colors, depths):\n for i, color in enumerate(colors):\n pygame.draw.rect(Game._GFX, color, pygame.Rect(x + i * w, y, w, w))\n for i, depth in enumerate(depths):\n pygame.draw.rect(Game._GFX, [int(255 * (1 - min(1, depth / (Game._DIAG)))) for ray in range(3)], pygame.Rect(x + i * w, y + w, w, w))\n \n # draw bump sensor visualization given coordinates and pixel width\n def drawBumpSensor(self, x, y, w):\n pygame.draw.rect(Game._GFX, [(1 - self.bumpSensor) * 255, self.bumpSensor * 255, 0], pygame.Rect(x, y, w, w))\n \n # draw agent's state given coordinates and pixel width\n def drawState(self, x, y, w):\n for i, val in enumerate(self.S):\n pygame.draw.rect(Game._GFX, [val * 255 for ch in range(3)], pygame.Rect(x + i * w, y, w, w))\n \n # update roomba's x-position given x-velocity, return updated bump sensor\n def moveX(self, xvel):\n self.xRem += xvel\n amt = round(self.xRem)\n sgn = 1 if amt > 0 else -1 if amt < 0 else 0\n self.xRem -= amt\n for step in range(abs(amt)):\n if not self.collideObstacle(self.x + sgn, self.y):\n self.x += sgn\n else:\n self.xRem = 0\n return 1\n if amt == 0:\n sgn = 1 if self.xRem > 0 else -1 if self.xRem < 0 else 0\n if self.collideObstacle(self.x + sgn, self.y):\n self.xRem = 0\n return 1\n return 0\n\n # update roomba's y-position given y-velocity, return updated bump sensor\n def moveY(self, yvel):\n self.yRem += yvel\n amt = round(self.yRem)\n sgn = 1 if amt > 0 else -1 if amt < 0 else 0\n self.yRem -= amt\n for step in range(abs(amt)):\n if not self.collideObstacle(self.x, self.y - sgn):\n self.y -= sgn\n else:\n self.yRem = 0\n return 1\n if amt == 0:\n sgn = 1 if self.yRem > 0 else -1 if self.yRem < 0 else 0\n if self.collideObstacle(self.x, self.y - sgn):\n self.yRem = 0\n return 1\n return 0\n \n # check if roomba collided with an obstacle\n def collideObstacle(self, x, y):\n for obstacle in Game._ACTIVE_ROOM.obstacles:\n if type(obstacle) == ObstacleRect:\n if collisionCircleRectangle((x, y), self.r, obstacle.rect.topleft, obstacle.rect.bottomright):\n return True\n elif type(obstacle) == ObstacleCircle:\n if collisionCircleCircle((x, y), self.r, obstacle.pos, obstacle.r):\n return True\n elif type(obstacle) == ObstacleLine:\n if collisionCircleLine((x, y), self.r, obstacle.A, obstacle.B):\n return True\n return False\n \n # check if roomba collided with another roomba\n def collideRoomba(self, x, y):\n for roomba in Game.getEntities(Roomba):\n if self != roomba:\n if collisionCircle((x, y), self.r, (roomba.x, roomba.y), roomba.r):\n return True\n return False\n \n # bounce off of other roombas\n def bounceRoomba(self):\n for roomba in Game.getEntities(Roomba):\n if self != roomba:\n if collisionCircle((self.x, self.y), self.r, (roomba.x, roomba.y), roomba.r):\n self.x = self.x + 1 if self.x - roomba.x > 0 else self.x - 1 if self.x - roomba.x < 0 else self.x\n self.y = self.y + 1 if self.y - roomba.y > 0 else self.y - 1 if self.y - roomba.y < 0 else self.y\n \n # make the room wrap around \n def wrapPos(self):\n self.x = self.x - Game._WIDTH if self.x >= Game._WIDTH else self.x + Game._WIDTH if self.x < 0 else self.x\n self.y = self.y - Game._HEIGHT if self.y >= Game._HEIGHT else self.y + Game._HEIGHT if self.y < 0 else self.y\n\n# base obstacle entity\nclass Obstacle(Entity):\n def __init__(self, x=0, y=0):\n super().__init__(x, y)\n\n# rectangle obstacle given top left coordinate, width, height\nclass ObstacleRect(Obstacle):\n def __init__(self, x1, y1, w, h, color=(0, 0, 0)):\n super().__init__(x1 + w/2, y1 + h/2)\n self.rect = pygame.Rect(int(x1), int(y1), int(w), int(h))\n self.color = color\n def draw(self):\n super().draw()\n pygame.draw.rect(Game._GFX, self.color, self.rect)\n\n# circle obstacle given center coordinate and radius\nclass ObstacleCircle(Obstacle):\n def __init__(self, x1, y1, r, color=(0, 0, 0)):\n super().__init__(x1, y1)\n self.pos = (int(x1), int(y1))\n self.r = int(r)\n self.color = color\n def draw(self):\n super().draw()\n pygame.draw.circle(Game._GFX, self.color, self.pos, self.r)\n\n# line segment obstacle given two end points\nclass ObstacleLine(Obstacle):\n def __init__(self, x1, y1, x2, y2, color=(0, 0, 0)):\n super().__init__((x1 + x2)/2, (y1 + y2)/2)\n self.A = (int(x1), int(y1))\n self.B = (int(x2), int(y2))\n self.color = color\n def draw(self):\n super().draw()\n pygame.draw.line(Game._GFX, self.color, self.A, self.B)\n\n### entry point - add rooms here\nif __name__ == '__main__':\n Game._ROOMS.clear()\n # add rooms\n Game._ROOMS.append(Environment())\n # set starting room\n Game.gotoRoom(0)\n # start game\n Game.gameLoop()\n"
}
] | 4 |
pankajanand18/python-tests
|
https://github.com/pankajanand18/python-tests
|
19fabe4474e0e95abe02dc42f3c70ba08e87aa68
|
3e58a274463692a2552efd3a05393683567dac6e
|
151f26c650d4253acfabb239f2c87c908f9233f1
|
refs/heads/master
| 2021-01-15T21:50:24.462289 | 2014-11-16T08:17:56 | 2014-11-16T08:17:56 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5779221057891846,
"alphanum_fraction": 0.5974025726318359,
"avg_line_length": 22.049999237060547,
"blob_id": "a3891ca0181e4ab606b256d7bd1be86abcf62f89",
"content_id": "39cbee8ec60a1109f0f324e46dc0b3d4f21e7157",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 20,
"path": "/ugly.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\nn = 15\nbases = [2, 3, 5]\n\nnums = [1] * n\ncandidates_indexes = [0 for _ in bases]\ncandidates = [base for base in bases]\n\nfor i in range(1, n):\n nextn = min(candidates)\n nums[i] = nextn\n\n for index, val in enumerate(candidates):\n if val == nextn:\n candidates_indexes[index] += 1\n candidates[index] = bases[index] * nums[candidates_indexes[index]]\n print nextn,candidates[index]\n\nprint(nums)\n\n"
},
{
"alpha_fraction": 0.521181583404541,
"alphanum_fraction": 0.5330891013145447,
"avg_line_length": 41.813724517822266,
"blob_id": "7275da2c27fafea3f6745078adbaf08ffd3443d2",
"content_id": "3143ff9a37b81c6f21e067a92220e8b9eb0df370",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4367,
"license_type": "permissive",
"max_line_length": 186,
"num_lines": 102,
"path": "/devikatest.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport threading\nimport time\nimport psycopg2\n\nexitFlag = 0\nconnections = [{'server':'dw-rsm-010','db':'dwrsm010'}]\nfor connection in connections:\n print \"Starting connection string \"\n conn_string = \"host='%s.cv63a8urwqge.us-east-1.redshift.amazonaws.com' dbname='%s' user='dw_rs_admin' password='Adm1n001' port='8192'\" % (connection['server'],connection['db'])\n\nfor i in range(0,2):\n try:\n print \"Getting conn varialble \"\n conn = psycopg2.connect(conn_string)\n except:\n continue\n break\n\ncursor = conn.cursor()\nconn.set_isolation_level( psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT )\n\n\nclass myThread (threading.Thread):\n def __init__(self, threadID, name, counter):\n threading.Thread.__init__(self)\n self.threadID = threadID\n self.name = name\n self.counter = counter\n def run(self):\n print \"Starting \" + self.name\n if self.threadID == 1:\n print \"I am polling thread\"\n connect_db(self.name, self.counter, 5)\n if self.threadID == 2:\n print \"I am deep copy thread to print time\"\n deep_copy(self.name, self.counter, 5)\n print \"Exiting \" + self.name\n\ndef print_time(threadName, delay, counter):\n while (exitFlag == 0):\n print \"%s:exitFlag \" % (exitFlag)\n if exitFlag:\n thread.exit()\n time.sleep(delay)\n print \"%s:Inside wile loop %s\" % (threadName, time.ctime(time.time()))\n counter -= 1\n\ndef connect_db(threadName, delay, counter):\n cursor.execute(\"set query_group to 'superuser'\")\n print \"Inside connect_db\"\n while (exitFlag == 0):\n print \"%s:exitFlag \" % (exitFlag)\n if exitFlag:\n thread.exit()\n time.sleep(delay)\n cursor.execute(\"select 'thread13_try2'||sysdate\")\n records = cursor.fetchall()\n if cursor.rowcount==0:\n print \"Nothing to CANCEL in %s database\" % connection['db']\n else:\n for pid in records:\n print 'On database: '+connection['db']+\", sysdate : \" + str(pid[0])\n print \"%s:exitFlag \" % (exitFlag)\n\ndef deep_copy(threadName, delay, counter):\n print \"Inside deep copy module \"\n cursor.execute(\"set query_group to 'superuser'\")\n cursor.execute(\"select sysdate\")\n records = cursor.fetchall()\n if cursor.rowcount==0:\n print \"Nothing to CANCEL in %s database\" % connection['db']\n else:\n for pid in records:\n print 'On database: '+connection['db']+\", sysdate : \" + str(pid[0])\n print \"Inside the deep_copy module.. waiting \"\n time.sleep(12);\n try:\n conn.set_isolation_level( psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT )\n print \"Executing insert into booker.vacuum_d_daily_buyer_effectiveness (select * from booker.d_daily_buyer_effectiveness)\"\n cursor.execute(\"insert into booker.vacuum_d_daily_buyer_effectiveness (select * from booker.d_daily_buyer_effectiveness)\")\n# print \"Executing create table booker.vacuum_ddbe ( like booker.d_daily_buyer_effectiveness)\"\n# cursor.execute(\"create table booker.vacuum_ddbe ( like booker.d_daily_buyer_effectiveness)\")\n# print \"Done insert into booker.vacuum_d_daily_buyer_effectiveness (select * from booker.d_daily_buyer_effectiveness)\"\n time.sleep(12);\n global exitFlag\n exitFlag = 1\n print \"%s:exitFlag \" % (exitFlag)\n except:\n print \"Exception\"\n global exitFlag\n exitFlag = 1\n\n# Create new threads\nthread1 = myThread(1, \"Thread-1\", 1)\nthread1.setDaemon(True)\nthread2 = myThread(2, \"Thread-2\", 2)\n\n# Start new Threads\nthread1.start()\nthread2.start()\n"
},
{
"alpha_fraction": 0.49585404992103577,
"alphanum_fraction": 0.5174129605293274,
"avg_line_length": 18.483871459960938,
"blob_id": "93a60102cb77330840e8df8874eccbee35892436",
"content_id": "420b54f7d26f23c1c5c43e848fcc4e06d85e18cb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 31,
"path": "/mastermind.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "import math\n\nprimes = {}\n\n\ndef is_prime(n):\n global primes\n if primes.get(n, False) == True:\n return True\n\n if n % 2 == 0 and n > 2:\n return False\n return all(n % i for i in range(3, int(math.sqrt(n)) + 1, 2))\n\n\nt = int(raw_input())\n\nwhile t > 0:\n input_range = raw_input()\n start = int(input_range.split(' ')[0])\n end = int(input_range.split(' ')[1])\n count = end - start + 1\n while start <= end:\n if is_prime(start) == True:\n primes.update({start: True})\n count = count - 1\n\n start = start + 1\n print count\n\n t = t - 1"
},
{
"alpha_fraction": 0.5758354663848877,
"alphanum_fraction": 0.5826906561851501,
"avg_line_length": 27.108434677124023,
"blob_id": "e4dc59260da0fc091832f570df618784396e41cf",
"content_id": "1fc2e80285571fb1be1f1baade1fca75920f377e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2334,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 83,
"path": "/generate_category.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from sre_parse import isident\n\n__author__ = 'pankaj'\n\nimport csv\nimport json\n\nfile_path = '/home/pankaj/Documents/Latest_Categories-10.csv'\ndef toTitleWord(words):\n words_array=words.split(' ')\n new_array=[word.title() for word in words_array]\n\n # for word in words_array:\n # word=word.title()\n # new_array.append(word)\n return \" \".join(new_array)\n\ndef chopArray(array,titleCase):\n new_array=[]\n if titleCase:\n new_array = [item.strip() for item in array]\n else:\n new_array = [ toTitleWord(item.strip()) for item in array]\n\n\n # for item in array:\n # item=item.strip()\n # if(titleCase):\n # item=toTitleWord(item)\n # new_array.append(item)\n return new_array\n\ndef getSortedArray(array,titlecase=True,sortdata=True):\n data=array\n if type(array) is list:\n data=array\n else:\n data=chopArray(array.split(','),titlecase)\n if(sortdata):\n data.sort()\n return data\n\ndef generateJson(filepath):\n with open(filepath, \"rb\") as csvfile:\n csvreader = csv.reader(csvfile, delimiter=',')\n count = 0\n sts_categories = []\n subcategories = {}\n brands = {}\n keywords = {}\n\n for row in csvreader:\n if count < 2:\n count = count + 1\n continue\n category = row[0]\n sts_categories.append(category)\n if len(row[1]) > 0:\n subcategories.update({category: getSortedArray(row[1].strip(),False)})\n # if len(row[3]) > 3:\n # brands.update({category: getSortedArray(row[3],False)})\n if len(row[2]) > 0:\n keywords.update({category: getSortedArray(row[2],False,False)})\n #print row\n\n\n # print sts_categories\n # print subcategories\n # print brands\n # print keywords\n final_json={}\n sts_categories=getSortedArray(sts_categories)\n\n final_json.update({'categories':sts_categories})\n final_json.update({'subCategories':subcategories})\n final_json.update({'brands':brands})\n final_json.update({'keywords':keywords})\n print json.dumps(final_json,sort_keys=True,indent=4,separators=(',', ': '))\n\n\n\ngenerateJson(file_path)\n#print getSortedArray(\"pankaj,anand,Karol,Bagh\")\n\n"
},
{
"alpha_fraction": 0.4459124803543091,
"alphanum_fraction": 0.46160197257995605,
"avg_line_length": 18.819671630859375,
"blob_id": "3b7e3b9ff05764bf38a6d49539645cc1e9a4cf7d",
"content_id": "7a81ce2bd5909affa98802c9c3011e109dd088d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1211,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 61,
"path": "/trees/pallindrome_count.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\ndef getPallindromeCount(string):\n\n mid=0\n right=0\n left=0\n counter =0\n longest_length=0\n while mid < len(string):\n right=mid\n left=mid\n found = True\n while right >=0 and left < len(string):\n if string[right] == string[left]:\n if left - right >longest_length:\n longest_length= left-right\n counter=1\n elif left-right == longest_length:\n counter+=1\n else:\n break\n\n left+=1\n right-=1\n\n\n\n right=mid\n left=mid+1\n while right >=0 and left < len(string):\n if string[right] == string[left]:\n if left - right >longest_length:\n longest_length= left-right\n counter=1\n elif left-right == longest_length:\n counter+=1\n else:\n break\n\n left+=1\n right-=1\n\n\n\n\n\n\n mid+=1\n print longest_length\n print counter\n\n\ngetPallindromeCount('ababbacababbad')\n# tests=int(raw_input())\n#\n# while tests > 0:\n# t=raw_input()\n#\n# tests-=1\n\n\n"
},
{
"alpha_fraction": 0.6222222447395325,
"alphanum_fraction": 0.6320987939834595,
"avg_line_length": 16.478260040283203,
"blob_id": "a44a00601ee22fa21d4a7eeb5e2598d9072c3fcb",
"content_id": "ffd69ae9000fb25d683c0cb498e7628c08d37e61",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 23,
"path": "/trees/tries.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\nclass TriesNode:\n object_count =0\n def __init__(self):\n self.data = None\n self.links={}\n TriesNode.object_count+=1\n\n def getObjectCount(self):\n return TriesNode.object_count\n\n\ndef newFun():\n print 'hello world '\n\nnode = TriesNode()\nnode.getSize = newFun\nnode.object_count =5\n\nnode.getSize()\nnode1 = TriesNode()\nprint node.getObjectCount()\n\n\n\n"
},
{
"alpha_fraction": 0.6617100238800049,
"alphanum_fraction": 0.6741015911102295,
"avg_line_length": 15.100000381469727,
"blob_id": "6fb7cfd91bc149f5643ce39c900da60d3f7ccfcb",
"content_id": "70d01ead265cad8ebd31d3071660ecc4c50bc89a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 807,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 50,
"path": "/fun_with_sequence.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from fractions import gcd\n\ndef getIntegerInput():\n\tinputs = raw_input()\n\tinput_int_list=[]\n\tglobal original_numbers\n\n\tfor data in inputs.split(' '):\n\t\tdata = int(data)\n\t\tinput_int_list.append(data)\n\t\t\n\t#print input_int_list\n\treturn input_int_list\n\n\nt_str = raw_input()\nt= int(t_str)\noriginal_numbers = range(1,t+1)\ninputs = raw_input()\n\n\nitem_found= None\n\nfor data in inputs.split(' '):\n\tdata = int(data)\t\n\tif original_numbers[data-1] > data:\n\t\titem_found = data\n\t\tbreak\n\telse:\n\t\toriginal_numbers[data-1] = data + 1 \n\n\n#print item_found\n# for i in xrange(0,t):\n# \tif original_numbers[i] == i+1:\n# \t\tmissing_found = i+ 1\n# \t\tbreak\n\noriginal_numbers = range(1,t+1)\t\n\n\n#original_numbers.remove(missing_found)\n\n#print missing_found\n#print item_found\n\nprint item_found,\n\nfor i in original_numbers:\t\n\t\tprint i,\n\n\n"
},
{
"alpha_fraction": 0.4607190489768982,
"alphanum_fraction": 0.4860186278820038,
"avg_line_length": 19.324323654174805,
"blob_id": "c74e7f4cb8af686cfe689836a9561b679f49ea91",
"content_id": "35ad97c029b3533313b0068371382fba443e3c7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 751,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 37,
"path": "/rangemax1.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from itertools import izip\n\n\ndef printRange(birth_event, death):\n birth_event.sort()\n death.sort()\n b = 0\n d = 0\n\n count = 0\n max_count = 0\n start_date = birth_event[0]\n end_date = 0\n\n while b < len(birth_event) and d < len(death):\n if birth_event[b] < death[d]:\n count = count + 1\n b += 1\n if count > max_count:\n start_date = birth_event[b - 1]\n max_count = count\n else:\n print 'death'\n if count == max_count:\n end_date = death[d]\n count = -1\n d += 1\n\n print birth_event\n\n print death\n print max_count\n print start_date\n print end_date\n\n\nprintRange([5, 6, 2], [10, 15, 7])"
},
{
"alpha_fraction": 0.572311520576477,
"alphanum_fraction": 0.6155747771263123,
"avg_line_length": 18.7560977935791,
"blob_id": "28983e063ffbb65a267bb5b339bc268468e8087f",
"content_id": "b76b6ed00dbe0a3d5e34373dc149afcf289e7be6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 809,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 41,
"path": "/heap.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "a=[20,16,14,6,13,10,1,5,7,12,19]\n\n\n\n\n\ndef doHeapifyMax(list,i):\n\tprint 'inside doHeapifyMax'\n\tright = 2 * i + 1 \n\tleft = 2 * i + 2 ;\n\tlargest = i\n\tlength = len(list)\n\tif left < length and list[left] > list [ i]:\n\t\tlargest = left\n\tif right < length and list[right] > list[i]:\n\t\tlargest = right\n\tif largest != i:\n\t\tlist[i], list[largest] = list[largest],list[i]\t\n\t\tdoHeapifyMax(list,largest)\n\n\ndef convertToHeap(list):\n\tlength = len(list)\n\tfor i in xrange(len(list)/2,-1,-1):\n\t\tprint \"%s : %s\"%(i,length)\n\t\tdoHeapifyMax(list,i)\n\n\ndef isMaxHeap(list):\n\tfor i in range(0,len(list)/2):\n\t\tnode = i \t\n\t\tif list[i] > list[(2*node)+1] and list [i] > list[(2*node)+2]:\n\t\t\tcontinue\n\t\telse:\n\t\t\tprint 'not a max heap'\n\t\t\tprint \"%s %s %s\"%(i,list[2*i+1],list[2*i+2])\n\t\t\tbreak\nprint a \nconvertToHeap(a)\nprint a \nisMaxHeap(a)"
},
{
"alpha_fraction": 0.6222222447395325,
"alphanum_fraction": 0.6555555462837219,
"avg_line_length": 16.600000381469727,
"blob_id": "efd574a32c772e7b9515c3c8eb9e5a4b159f26bf",
"content_id": "a22a45c72e0816e34240066102106c20fd38abac",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 5,
"path": "/smaller_number.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "\n\ndef nextSmaller(number):\n\tnumber = number % 10\n\t\n\twhile number > 0:\n\t\tnext_int = number "
},
{
"alpha_fraction": 0.5752961039543152,
"alphanum_fraction": 0.6395938992500305,
"avg_line_length": 23.54166603088379,
"blob_id": "c24358e6ca45ac7e473fe0164b149c9ae0733642",
"content_id": "0b2b8e9b2d443ba422403952df0d9a03bd0f0538",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 24,
"path": "/summing.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "\n\n\ndef getSum(list,start_index,end_index):\n\treturn sum(list[start_index:end_index+1])\n\n\n# print getSum([0,1, 2, 3, 4, 5],1,2)\n# print getSum([0,1, 2, 3, 4, 5],1,3)\n# print getSum([0,1, 2, 3, 4, 5],2,3)\n# print getSum([0,1, 2, 3, 4, 5],3,4)\n\ninput_array=[0]\narray_size=input()\ninput_data = raw_input()\ninput_array=[int(i) for i in input_data.split(' ')]\n\ntest_cases= input()\ninput_size=[]\nfor i in xrange(test_cases):\n\n\tstart = raw_input()\n\tactual_data= start.split(' ')\t\n\tinput_size.append((actual_data[0],actual_data[1]))\n\nfor data in input_size:\n\tprint getSum(input_array, data[0],data[1])"
},
{
"alpha_fraction": 0.6355932354927063,
"alphanum_fraction": 0.6593220233917236,
"avg_line_length": 13.774999618530273,
"blob_id": "28915245c590c486c5da47048003ccf718f602ba",
"content_id": "2fe7176406509c090b8c8f3979728cb1a6c3797c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 590,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 40,
"path": "/sortedarraytobst.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "class TreeNode:\n\tdef __init__(self):\n\t\tself.right = None\n\t\tself.left= None\n\t\tself. data= None\n\tdef __str__(self):\n\t\treturn \"%s\"%self.data\n\n\t\n\n\n\ndef preorder(root):\n\tif root is None or root.data is None:\n\t\treturn\n\t\n\tpreorder(root.left)\n\tprint root.data\n\tpreorder(root.right)\n\n\ndef createBst(list,start,end):\n\n\tif start > end: \n\t\treturn None\n\n\troot = TreeNode()\n\tmid = (start+end)/2\t\n\troot.data = list[mid]\n\t\n\t\n\n\troot.left = createBst(list,start,mid-1)\n\troot.right = createBst ( list,mid+1,end)\n\treturn root\n\nlist=[1,2,3,4,5,6,7,8,9]\n\nroot = createBst(list,0,len(list)-1)\nprint preorder(root)"
},
{
"alpha_fraction": 0.6320000290870667,
"alphanum_fraction": 0.6399999856948853,
"avg_line_length": 11.5,
"blob_id": "ff0831c6343a2ace5a0635bfb57ef895b338676d",
"content_id": "5c003a6b6a56e476b2a5e0b5c90868b0622faebf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 125,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 10,
"path": "/yield.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "def generator():\n\tmylist = range(5)\n\tfor i in mylist:\n\t\tyield i*i\n\n\ngen = generator()\nfor i in gen:\n\tprint \" start\"\n\tprint i "
},
{
"alpha_fraction": 0.5724090337753296,
"alphanum_fraction": 0.5765271186828613,
"avg_line_length": 15.5,
"blob_id": "c5c227e32d66a41851877816d2495b61afbdd664",
"content_id": "0ffd900e1ae4970fd82520a76c55f4af9a9dd99d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1457,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 88,
"path": "/linkedlists/reverserlist.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "\n\nfrom linkedlist import SinglyLinkedListNode\n\n\n\n\ndef reverseList(head):\n\n tail=None\n last=None\n tempNode = head\n while tempNode is not None:\n currentNode, tempNode = tempNode, tempNode.next\n currentNode.next = tail\n tail = currentNode\n\n\n return tail\n\ndef reverseListKNode(head,k):\n tempHead= None\n tempTail= None\n while head is not None:\n tempNode = head\n last = None\n tk=k\n while tempNode is not None and tk > 0:\n currentNode,nextNode = tempNode,tempNode.next\n currentNode.next = last\n last=currentNode\n tempNode = nextNode\n tk-=1\n if tempHead is not None:\n tempTail.next = last\n head.next = nextNode\n else:\n tempHead = last\n head.next= nextNode\n\n\n tempTail = head\n head=nextNode\n\n return tempHead\n\n\n\n\n\n\n\n\n\n\n\n\n\ndef printLinkedList(head):\n\n while head is not None:\n print head.data,\n head=head.next\n print ''\n\n\n\n\n\ndef createList(list):\n\n lastNode=None\n head=None\n for i in list:\n node= SinglyLinkedListNode(i)\n if lastNode == None:\n lastNode = node\n head = node\n else:\n lastNode.next = node\n lastNode=node\n\n return head\n\n\na=(i for i in xrange(1,11))\nlist = createList(a)\nprintLinkedList(list)\nnewList=reverseListKNode(list,2)\nprintLinkedList(newList)\n\n\n\n"
},
{
"alpha_fraction": 0.5458823442459106,
"alphanum_fraction": 0.5976470708847046,
"avg_line_length": 18.31818199157715,
"blob_id": "f71506975604a66971fdd7b069f8332b378d4bac",
"content_id": "dc55c3028d00716d5a1a59bb09ce33a69df489b7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 22,
"path": "/coinchange.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "coins=[1,2,5,10]\n\ndef getDenomination(coins,sum):\n\tmin_deno=[0] * (sum + 1 )\n\n\tfor amt in xrange(1,sum+1):\n\t\tmin_deno[amt]= 30000\n\t\ttemp= 30000\n\t\tfor i in xrange(len(coins)):\n\t\t\tif amt >= coins[i]:\n\t\t\t\ttemp_amt = min_deno[amt-coins[i]] + 1 \n\t\t\t\t#print temp_amt\n\t\t\t\tif temp_amt < temp:\n\t\t\t\t\ttemp = temp_amt\n\t\t\t\t\tmin_deno[amt] = temp\n\t\t\tprint \"%s %s %s\"%(coins[i],amt,min_deno)\n\n\t\t\t\n\n\tprint min_deno\n\ngetDenomination(coins,23)\n"
},
{
"alpha_fraction": 0.5589519739151001,
"alphanum_fraction": 0.5589519739151001,
"avg_line_length": 15.285714149475098,
"blob_id": "20088662929327d2e662e995178430b57fe4b20b",
"content_id": "bce53bb58969a1a0311261364f81ad6e31eaff2e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 229,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 14,
"path": "/test_with.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\nclass control:\n def __enter__(self):\n\n return \"Enter data\"\n\n def __exit__(self, exc_type, exc_val, exc_tb):\n print \"exit\"\n\n\nwith control() as str:\n print str\n print 'hello world'\n\n"
},
{
"alpha_fraction": 0.6068660020828247,
"alphanum_fraction": 0.6190476417541504,
"avg_line_length": 16.269229888916016,
"blob_id": "542940e91e55a748f1142112253371f169366316",
"content_id": "160f0a6c78b22f1dcb8ccf09a1134ecfd7abc1f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 903,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 52,
"path": "/trees/trees1.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "class Tree(object):\n def __init__(self,data,left,right):\n self.left = left\n self.right = right\n self.data = data\n def __str__(self):\n \treturn \"[Data : %s, R : %s, L %s]\"%(self.data,self.right,self.left)\n\n\n\ndef getHeight(root_node):\n\tif root_node is None:\n\t\treturn 0\n\tr_height= 1 + getHeight(root_node.right);\n\tl_height= 1 + getHeight(root_node.left)\n\n\tif r_height > l_height:\n\t\treturn r_height\n\telse:\n\t\treturn l_height\n\t\ninput=[1,5,5,2,2,-1,3]\nhash={}\nroot_node=None\nfor i in xrange(len(input)):\n\ttree_node= Tree(i,None,None)\n\thash.update({i:tree_node})\n\n\nfor i in xrange(len(input)):\n\t\n\n\n\tnode = hash[i]\n\tif input[i] == -1:\n\t\troot_node = node\n\t\tcontinue\n\n\tparent = hash[input[i]]\n\tif parent.left is None:\n\t\tparent.left = node\n\telse:\n\t\tparent.right= node\n\n\n\n\t\n\n# for item in hash.keys():\n# \tprint \"%s : %s\"%(item,hash[item])\nprint root_node\nprint getHeight(root_node)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6897469758987427,
"alphanum_fraction": 0.7163781523704529,
"avg_line_length": 28.920000076293945,
"blob_id": "18b71f487b552f3a51bffed810a23e007f032840",
"content_id": "2776f08110f57079e6c34ccba9a808bec88438b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 751,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 25,
"path": "/stockmax.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "input=[1,2,100]\ncounter = 0\ninput_result=[-1] * 3 \ndef getStockMax(input,index,current_stocks,current_profit):\n\tglobal counter\n\n\tprint \"%s index: %s current_stocks: %s current_profit: %s \" % (counter,index,current_stocks,current_profit)\n\tcounter = counter + 1 \n\tif index <= len(input)-1:\t\t\n\t\tcurrent_value_sell = current_stocks * input[index]\n\n\t\tcurrent_profit = current_profit-(input[index])\n\t\tif current_profit < 0:\n\t\t\tcurrent_profit = 0\n\n\t\tnext_value_with_buy = getStockMax(input,index+1,current_stocks+1,current_profit)\n\t\tnext_value_with_sell = getStockMax(input,index+1,0,current_profit+current_value_sell)\n\n\t\t\n\t\treturn max(max(current_value_sell,next_value_with_buy),next_value_with_sell)\n\telse:\n\t\treturn 0 \n\n\nprint getStockMax(input,0,1,0)\t\n\n\n"
},
{
"alpha_fraction": 0.6127819418907166,
"alphanum_fraction": 0.6240601539611816,
"avg_line_length": 17.964284896850586,
"blob_id": "fd071f09d7fb9dfb95e9ce399eadc08dedc05f72",
"content_id": "b8bc44f54519429f62e79f937766052c480d369d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "permissive",
"max_line_length": 156,
"num_lines": 28,
"path": "/trees/sachin.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "# Question 1: Given a string of words return all words which have their reverse present in the string as ( (word1 , reverseword1 ) , (word2 ,reverseword2) )\n\n# eg .\n# Input - \n# Sachin tendulkar is the best tseb eth nihcaS \ninput='Sachin tendulkar is the best tseb eth nihcaS'\nhash={}\nword=''\nfor char in input:\n\tprint char\n\n\tif char == ' ':\n\t\tif len(word) > 0:\n\t\t\tword_list= hash.get(len(word),[])\n\t\t\tword_list.append(word)\n\t\t\thash[len(word)]= word_list\n\n\t\t\tword=''\n\n\telse:\n\t\tword = word + char;\n\nhash[len(word)].append(word)\n\n\n\n\nhash\n\n"
},
{
"alpha_fraction": 0.6353383660316467,
"alphanum_fraction": 0.6503759622573853,
"avg_line_length": 21.08333396911621,
"blob_id": "93f8e9c13a4b78cc7159626c117af2afe8513348",
"content_id": "92ce3f5d05d86f676193aba82619052d5db06f45",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 12,
"path": "/pythontest.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "\na='Mahendra Singh Dhoni'\naStriped = a.split(' ');\nlength = len(aStriped)\nnewString=[]\nfor i in xrange(0,length):\n\tif len(aStriped[i].strip())>0:\n\t\tif i < length-1:\n\t\t\tnewString.append(aStriped[i][0])\n\t\telse:\n\t\t\tnewString.append(aStriped[i])\n\nprint \" \".join(newString)\n"
},
{
"alpha_fraction": 0.4750957787036896,
"alphanum_fraction": 0.540229856967926,
"avg_line_length": 13.5,
"blob_id": "bde56154dd5e263f37d4f026a51b153fc708d2b2",
"content_id": "a0cdf39020fa1e75d2f2b281c17e9cfbefff6e1d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 18,
"path": "/even_odd_list.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\n\ndef getEvenOddLists(ints):\n oddList=set()\n\n for i in ints:\n if i%2==0:\n continue\n else:\n oddList.add(i)\n print ints\n print oddList\n\n\nints = [1,21,53,84,50,66,7,38,9]\ngetEvenOddLists(ints)\n"
},
{
"alpha_fraction": 0.592644989490509,
"alphanum_fraction": 0.6096181273460388,
"avg_line_length": 19.764705657958984,
"blob_id": "dc408ef5f9c1b0a6a7e2bd53161d38ed90205a6c",
"content_id": "0af6537400b18695742df7ae38fca07d10d6e0e9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 707,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 34,
"path": "/name_directory.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\nfrom operator import itemgetter\n\ndef formatName(input):\n\n def printName(personData):\n if personData[3] == 'M':\n return input(\"%s %s %s\"%('Mr.',personData[0],personData[1]))\n else:\n return input(\"%s %s %s\"%('Ms.',personData[0],personData[1]))\n return printName\n\n\n@formatName\ndef showName(dataList):\n print dataList\n\n\nn=int(raw_input())\ntemp = 0\ninput_list= []\nwhile temp < n:\n temp+=1\n input_data= raw_input()\n input_data = input_data.split(\" \")\n input_list.append(input_data)\n\n\ninput_list.sort(key=itemgetter(2))\nfor i in input_list:\n showName(i)\n\n# showName(['Mike','Thomson',20,'M'])\n# showName(['Lily','Thomson',20,'F'])\n\n"
},
{
"alpha_fraction": 0.5429782271385193,
"alphanum_fraction": 0.5508474707603455,
"avg_line_length": 23.65671730041504,
"blob_id": "26aa7891e8a2b6ecc1351d8aa0434eb134186939",
"content_id": "9ccffb8dfae0113b9138c8e221f9d74e4dd74b8a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1652,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 67,
"path": "/alien_words.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from itertools import izip\n\n__author__ = 'pankaj'\n\nimport numpy as np\n\nclass Graph(object):\n\n def __init__(self,total_vertices):\n self.edge_list=[None]*total_vertices\n self.total_vertices = total_vertices\n\n def add_edge(self,v,w):\n edge = self.edge_list[v]\n if edge==None:\n edge = []\n edge.append(w)\n self.edge_list[v]=edge\n else:\n edge.append(w)\n\n\n def buildGraph(self,input_words):\n a=ord('a')\n for i in xrange(0,len(input_words)-1):\n for char1,char2 in izip(input_words[i],input_words[i+1]):\n if char1 != char2:\n self.add_edge(ord(char1)-a,ord(char2)-a)\n break\n\n\n\n def topologicalSortUtil(self,index,visited,stack):\n edge_list = self.edge_list[index]\n visited[index] = True\n if edge_list is not None:\n for i in edge_list:\n if visited[i] is False:\n self.topologicalSortUtil(i,visited,stack)\n stack.append(index)\n\n def topoLogicalSort(self):\n visited = [False] * self.total_vertices\n stack =[]\n i=0\n for i in xrange(0,self.total_vertices):\n if visited[i] is False:\n self.topologicalSortUtil(i,visited,stack)\n\n\n stack.reverse()\n print stack\n\ninput_words = (\"baa\", \"abcd\", \"abca\", \"cab\", \"cad\")\ndata=\"\".join(input_words)\ndict={}\nfor i in data:\n hash = dict.get(i,None)\n if hash == None:\n dict.update({i:0})\n else:\n hash+=1\n\nprint input_words\ng = Graph(len(dict.keys()))\ng.buildGraph(input_words)\ng.topoLogicalSort()\n"
},
{
"alpha_fraction": 0.556851327419281,
"alphanum_fraction": 0.564723014831543,
"avg_line_length": 25.519380569458008,
"blob_id": "81687173d9da182eb0146844fa5d5785c9fa5919",
"content_id": "ddba65a7773b1171695ce94bb050d1919d57710d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3430,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 129,
"path": "/trees/word_count_heap.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\nclass HeapNode(object):\n def __init__(self,data):\n self.data= data\n self.count = 0\n self.nodeLocation = None\n\n\nclass Heap(object):\n capacity=10\n def __init__(self):\n self.nodes=[None] * (Heap.capacity+1)\n self.size= 1\n\n def maxHeapify(self,index):\n\n # do heapify here\n left = 2 * index\n right = 2 * index + 1\n largest = index\n if left <= self.size and self.nodes[left].count > self.nodes[largest].count:\n largest = left\n if right <= self.size and self.nodes[right].count > self.nodes[largest].count:\n largest = right\n\n if largest is not index:\n tempNode = self.nodes[largest]\n self.nodes[largest] = self.nodes[index]\n self.nodes[index] = tempNode\n self.nodes[index].nodeLocation.minHeapLoc = index\n self.nodes[largest].nodeLocation.minHeapLoc = largest\n self.maxHeapify(largest)\n\n def getElement(self,index):\n return self.nodes[index]\n\n def insertElement(self,heapNode):\n\n if self.size < self.capacity:\n self.nodes[self.size] = heapNode\n self.size+=1\n elif self.size == self.capacity:\n # check leaf nodes\n size =self.size -1\n while size > (self.size-1)/2 :\n if self.nodes[size].count < heapNode.count:\n self.nodes[size] = heapNode\n self.maxHeapify(size)\n break\n size-=1\n\n\n\nclass Tries(object):\n max_nodes= 26;\n def __init__(self,rootNode=False):\n self.nodes=[None]*Tries.max_nodes # an array of 26 characters\n self.data=None\n self.leaf=False\n self.rootNode=rootNode\n self.minHeapLoc=-1\n\n def __str__(self):\n return self.data\n\n\n def populateNextElment(self,string):\n index=ord(string[0])-ord('a')\n node = self.nodes[index]\n if node == None:\n node = Tries()\n self.nodes[index] =node\n return node.insert_element(string)\n\n\n def insert_element(self,string):\n if self.rootNode == True:\n self.data=''\n return self.populateNextElment(string)\n\n\n if self.data==None:\n self.data= string[0]\n\n if len(string) == 1:\n self.leaf = True\n return self\n else:\n return self.populateNextElment(string[1:])\n\n def printAllString(self,string=None):\n if string is None:\n string=''\n\n if self.rootNode == False and self.leaf == True:\n print string+self.data\n i=0\n while i < Tries.max_nodes:\n node = self.nodes[i]\n if node is not None:\n node.printAllString('%s%s'%(string,self.data))\n i+=1\n\ndef insertIntoHeap(trieNode,heapRoot,data):\n if trieNode.minHeapLoc == -1:\n # No data inserted into Heap as of now\n heapNode = HeapNode()\n heapNode.data = data\n heapNode.nodeLocation = trieNode\n heapNode.count = 0\n\n else:\n heapNode= heapRoot.getElement(trieNode.minHeapLoc)\n heapNode.count += 1\n\n\n\n\n\nheap=Heap()\nrootNode=Tries(True)\nrootNode.insert_element(\"a\")\nrootNode.insert_element(\"pankaj\")\nrootNode.insert_element(\"pankaja\")\nrootNode.insert_element(\"anand\")\nrootNode.insert_element(\"amand\")\nrootNode.printAllString('')\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5342163443565369,
"alphanum_fraction": 0.5342163443565369,
"avg_line_length": 12.058823585510254,
"blob_id": "78aafa64a1986b33094f2c351adfcd7076ff9351",
"content_id": "d47857df4c9f3c1607ba78bf4994ce78829d8bd4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 453,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 34,
"path": "/linkedlists/linkedlist.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\n\nclass SinglyLinkedListNode(object):\n\n def __init__(self,data):\n self.data= data\n self.next=None\n\n\n def addAfter(self,node):\n node.next = self\n\n\n\n\n\n\n\n\n\n\n\nclass DoublyLinkedListNode(object):\n def __init__(self):\n self.data = None\n self.next = None\n self.prev= None\n\n def __init__(self,data):\n self.data = data\n self.prev = None\n self.next = None\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5387523770332336,
"alphanum_fraction": 0.553875207901001,
"avg_line_length": 22.04347801208496,
"blob_id": "86451e7bba32609eb8cc3c896dae60ce4b7f2e4b",
"content_id": "2d3456ddb2864ff68315757e065812ad77c1066d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 23,
"path": "/inverse_list.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "test_case = int(raw_input())\n\nwhile test_case > 0:\n length = int(raw_input())\n index = 1\n input_data = raw_input()\n list = []\n original_list = []\n counter = 0\n input_data = input_data.split(' ')\n print input_data\n for data in input_data:\n data = int(data)\n list.append(data)\n original_list.insert(data - 1, counter + 1)\n counter = counter + 1\n\n if cmp(list, original_list) == 0:\n print \"inverse\"\n else:\n print \"not inverse\"\n\n test_case = test_case - 1"
},
{
"alpha_fraction": 0.5841584205627441,
"alphanum_fraction": 0.6150990128517151,
"avg_line_length": 17.720930099487305,
"blob_id": "ec7f7594add570ff65bc382eb7276dbe0ae9e54e",
"content_id": "e2b52e89ba9ebec9246025ee83fe12cc4923c00c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 808,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 43,
"path": "/jamun.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\nfrom fractions import gcd\ndef getCommonDivisior(dataList):\n\n #dataList.sort()\n\n length = len(dataList)\n temp = 1\n g= dataList[0]\n while temp < length -1 and g!=1:\n #print g\n g = gcd(g,dataList[temp])\n temp +=1\n print g\n\n\ntests=int(raw_input())\n\nwhile tests > 0:\n\n num_input=int(raw_input())\n dataListPlain = raw_input()\n dataListPlain = dataListPlain.split(' ')\n input_list=[]\n\n for data in dataListPlain:\n input_list.append(int(data))\n input_list.sort()\n if len(input_list) != num_input:\n raise AssertionError()\n\n\n getCommonDivisior(input_list)\n tests-=1\n\n# input1=[5,15,10]\n# input2=[3,1,2]\n# input3=[15,9,6]\n# getCommonDivisior(input1)\n# getCommonDivisior(input3)\n# getCommonDivisior(input2)\n\n\n\n"
},
{
"alpha_fraction": 0.5284768342971802,
"alphanum_fraction": 0.5483443737030029,
"avg_line_length": 22.5625,
"blob_id": "aadddc7669a5d076fa79c4d30bd20053a8240cd5",
"content_id": "83bfc059e528e0276a410d14ac30c06be76bfe91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 755,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 32,
"path": "/rangemax.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "def getMax(list):\n max = list[0]\n for item in list:\n if item > max:\n max = item\n\n return max\n\n\ndef printRange(start_list, end_list):\n max = getMax(end_list)\n\n count_array = [0] * max;\n for i in xrange(len(start_list)):\n for item in xrange(start_list[i] - 1, end_list[i]):\n count_array[item] = count_array[item] + 1\n\n max_age = count_array[0]\n max_age_index = []\n print count_array\n for item in xrange(len(count_array)):\n\n if count_array[item] > max_age:\n max_age = count_array[item]\n max_age_index = [item + 1]\n elif max_age == count_array[item]:\n max_age_index.append(item + 1)\n\n print max_age_index\n\n\nprintRange([5, 6, 2], [10, 15, 7])\n\n"
},
{
"alpha_fraction": 0.6140651702880859,
"alphanum_fraction": 0.6300743222236633,
"avg_line_length": 23.577465057373047,
"blob_id": "aee821372b7e439ebaf13f6108c8f5f9d14edca2",
"content_id": "a58c4a5c63f6909cd15f6983e73ded15b884dc06",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1749,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 71,
"path": "/databasetest.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\nimport threading\nimport time\nimport psycopg2\n\n\nconn= psycopg2.connect(dbname='devikadb', user='devikatest1', password='asdf1234',host='localhost')\ncur=conn.cursor()\n\n\nexit_thread=0\nclass myThread (threading.Thread):\n def __init__(self, threadID, name, counter):\n threading.Thread.__init__(self)\n self.threadID = threadID\n self.name = name\n self.counter = counter\n def run(self):\n print \"Starting \" + self.name\n if self.threadID == 1:\n print \"I am polling thread\"\n do_poll(self.name, self.counter, 5)\n if self.threadID == 2:\n print \"I am deep copy\"\n deep_copy(self.name, self.counter, 5)\n print \"Exiting \" + self.name\n\n\ndef do_poll(name,counter,int):\n global exit_thread\n global conn\n cursor=conn.cursor()\n\n while exit_thread==0:\n print 'do poll %s'%exit_thread\n cursor.execute(\"select * from test limit 1\");\n print 'poll value %s'%exit_thread\n\n\n\ndef deep_copy(name,counter,int):\n global conn\n print 'drop table'\n cur.execute(\"DROP TABLE test3\")\n conn.commit()\n print 'creating table'\n cur.execute(\"CREATE TABLE test3 (id serial PRIMARY KEY, num integer, data varchar);\")\n conn.commit()\n print 'Thread Deep Copy : starting copy'\n cur.execute(\"insert into test3 (select * from test)\")\n print 'Thread Deep Copy : copy finished'\n conn.commit()\n print 'Thread Deep Copy : commit finised'\n global exit_thread\n exit_thread=1\n\n\n\nthread1 = myThread(1, \"Thread-1\", 1)\n#thread1.setDaemon(True)\nthread2 = myThread(2, \"Thread-2\", 2)\n\n# Start new Threads\nthread1.start()\nthread2.start()\n\n\n# thread1.join()\n# thread2.join()\n#exit_thread=1\n\n\n\n\n"
},
{
"alpha_fraction": 0.5472972989082336,
"alphanum_fraction": 0.5859073400497437,
"avg_line_length": 36,
"blob_id": "dd17ea1bd71a471391c2e57b74f644510181da21",
"content_id": "8bee664fe31446085a873f86f6b7c1d9e1165ade",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1036,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 28,
"path": "/speed.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport itertools\n\nn=6\niters = 1000\nfirstzero = 0\nbothzero = 0\n\"\"\" The next line iterates over arrays of length n+1 which contain only -1s and 1s \"\"\"\nfor S in itertools.product([-1,1], repeat = n+1):\n \"\"\"For i from 0 to iters -1 \"\"\"\n for i in xrange(iters):\n \"\"\" Choose a random array of length n.\n Prob 1/4 of being -1, prob 1/4 of being 1 and prob 1/2 of being 0. \"\"\"\n F = np.random.choice(np.array([-1,0,0,1], dtype=np.int8), size = n)\n \"\"\"The next loop just makes sure that F is not all zeros.\"\"\"\n while np.all(F ==0):\n F = np.random.choice(np.array([-1,0,0,1], dtype=np.int8), size = n)\n \"\"\"np.convolve(F,S,'valid') computes two inner products between\n F and the two successive windows of S of length n.\"\"\"\n FS = np.convolve(F,S, 'valid')\n if (FS[0] == 0):\n firstzero += 1\n if np.all(FS==0):\n bothzero += 1\n\nprint \"firstzero\", firstzero\nprint \"bothzero\", bothzero\n"
},
{
"alpha_fraction": 0.5361093282699585,
"alphanum_fraction": 0.5556278228759766,
"avg_line_length": 26.10714340209961,
"blob_id": "b896e0515066fb0509dd1bf574978e36be7dbaea",
"content_id": "7aeb52c20279d94c0ef4e182f51489bbe8f53cfd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1537,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 56,
"path": "/mrx.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "def getIntegerInput():\n inputs = raw_input()\n input_int_list = [int(i) for i in inputs.split(' ')]\n\n # print input_int_list\n return input_int_list\n\n\ndef solve(input_list, index, result_store, k):\n if index >= len(input_list):\n return 0\n if result_store[index] is not -1:\n return result_store[index]\n ret = max(-500000, solve(input_list, index + 1, result_store, k))\n ret = max(ret, input_list[index] + solve(input_list, index + k + 1, result_store, k))\n result_store[index] = ret\n return ret\n\n\ndef getCalculateMaxTime(list, k):\n length = len(list)\n result_store = [0] * len(list)\n\n result_store[0] = max(list[0], list[1])\n\n for i in xrange(2, len(list)):\n life = list[i]\n\n if life < 0:\n result_store[i] = result_store[i - 1]\n elif i - k - 1 < 0:\n result_store[i] = max(result_store[i - 1], list[i])\n else:\n # print i-k-1\n result_store[i] = max(result_store[i - 1], list[i] + result_store[i - k - 1])\n print result_store[-1]\n\n\nt = input()\nlist_of_input = []\nfor i in xrange(t):\n inputs = getIntegerInput()\n array_size = inputs[0]\n k = inputs[1]\n input_array = getIntegerInput()\n list_of_input.append((input_array, k))\n\nfor i in list_of_input:\n try:\n input_list = i[0]\n k = i[1]\n result_store = [-1] * len(input_list)\n print solve(input_list, 0, result_store, k)\n except Exception, e:\n print 'exception came %s' % e\n pass\n\t\n\n\n\t\n\n\t\n\n\t\t\t\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6278409361839294,
"alphanum_fraction": 0.6306818127632141,
"avg_line_length": 16.5,
"blob_id": "abe6742e008e5eac70b9cd289d8edec94ebd81e1",
"content_id": "f1ce2a9183aa34fb6824b23c7685311b85de19d6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 20,
"path": "/pangrams.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\ninput_array='abcdefghijklmnopqrstuvwxyz'\n\ndef check_panagrams(str):\n global input_array\n str=str.lower()\n for ch in input_array:\n if str.find(ch)==-1:\n return False\n\n return True\n\n\ninput_line= raw_input()\n\nif check_panagrams(input_line) == True:\n print 'pangram'\nelse:\n print 'not pangram'\n\n\n"
},
{
"alpha_fraction": 0.6538461446762085,
"alphanum_fraction": 0.6606335043907166,
"avg_line_length": 18.173913955688477,
"blob_id": "ba67540bbf985abd2c5c74213761d4e4a82cde38",
"content_id": "9215c19b815a3cbf1f291dba47cc7a247e7aa488",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 23,
"path": "/jhools_browser.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "\n\ndef getString(website_name_orig):\n\t\n\twebsite_name = website_name_orig[4:-4]\n\n\n\tfor char in ['a','i','e','o','u']:\n\t\twebsite_name = website_name.replace(char,'')\n\n\tlength = len(website_name)\t\n\tprint website_name\n\treturn \"%s/%s\"%(length+4,len(website_name_orig))\n\n# print getString(\"www.google.com\")\n# print getString(\"www.o.com\")\n# print getString(\"www.hackerearth.com\")\n\n\n\nt=input()\n\nfor i in xrange(t):\n\tn = raw_input()\n\tprint getString(n)"
},
{
"alpha_fraction": 0.5673162341117859,
"alphanum_fraction": 0.570416271686554,
"avg_line_length": 24.56818199157715,
"blob_id": "c214c97a6cc82d6fd6287fbcf44f6ed46d6810bc",
"content_id": "aeb74e57bf8669eea4be07bc029998cec007586e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2258,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 88,
"path": "/trees/flipkart.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from collections import deque\n__author__ = 'pankaj'\n\n# class to hold the Tree's Nodes Structure\nclass Tree(object):\n def __init__(self,data,left,right):\n self.left = left\n self.right = right\n self.data = data\n def __str__(self):\n \treturn \"[Data : %s, R : %s, L %s]\"%(self.data,self.right,self.left)\n\n\n\n\n\n# function to build the tree with given input array with each element point to its root\ndef buildTree(input):\n hash={}\n root_node=None\n for i in xrange(len(input)):\n tree_node= Tree(i,None,None)\n hash.update({i:tree_node})\n for i in xrange(len(input)):\n node = hash[i]\n if input[i] == -1:\n root_node = node\n continue\n\n parent = hash[input[i]]\n if parent.left is None:\n parent.left = node\n else:\n\t parent.right= node\n return root_node\n\n\n\n\n#function to print the tree in reverse level order traversal\ndef printReverseOrder(root_node):\n queue=deque()\n queue.append(root_node) # Insert Root node first\n stack=[]\n\n # this will create an stack with boundary of levels marked as None Items in stack\n while True:\n nodeCount = len(queue)\n if nodeCount == 0:\n break\n stack.append(None)\n while nodeCount > 0:\n node = queue.popleft()\n stack.append(node.data)\n if node.left != None:\n queue.append(node.left)\n if node.right != None:\n queue.append(node.right)\n nodeCount-=1\n\n\n dup_stack=[]\n while len(stack) > 0:\n item = stack.pop()\n if item == None:\n # Once the boundary is found reverse the found elements and print\n dup_stack.reverse()\n for i in dup_stack:\n print '%s'%(i),\n print ''\n dup_stack=[]\n else:\n # As we are reading elements from the end keep it as it is to print in reverse form later on\n dup_stack.append(item)\n\n\n\ntotal_nodes = int(raw_input())\ntemp = 0\nnodes = raw_input()\nnodes = nodes.split(' ')\nnode_list=[]\nwhile temp < total_nodes:\n node_list.append(int(nodes[temp].strip()))\n temp+=1\n\nroot_node=buildTree(node_list)\nprintReverseOrder(root_node)\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5518010258674622,
"alphanum_fraction": 0.5737564563751221,
"avg_line_length": 20.101449966430664,
"blob_id": "822ed9b404790462239555936af19331f145dfd9",
"content_id": "2154f027f1f03caa4b34132d761b8423df245338",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5830,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 276,
"path": "/joy_counts.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "import yappi\nimport math\n\nclass Memoize:\n def __init__(self, f):\n self.f = f\n self.memo = {}\n def __call__(self, *args):\n if not args in self.memo:\n self.memo[args] = self.f(*args)\n return self.memo[args]\n\ndef mergelist(a,b):\n count = len(b) -1\n while count >= 0:\n a.pop()\n count-=1\n a.extend(b)\n return a\n\n\n# a=[1,2,3,]\n# b=[5,6,3,4]\n# print mergelist(a,b)\n\n# def getkthelementrecursiveDriver(k):\n# list = getkthelementrecursive(k)\n# for i in list:\n# print i,\n# print ''\n\n\ninitial_list=[2,3,4]\n\n\n\ndef getkthElementIterative(k,array=None):\n global initial_list\n if k < 4:\n return [initial_list[k-1]]\n\n power_list=[1]\n boundry_list=[(0,3)]\n\n num = bucket_start= j= num_trail = 3\n element_count=1\n while j < k:\n num_trail = num\n power_list.append(num_trail)\n bucket_start = j\n num = num * 3\n j += (num)\n bucket_end = j\n boundry_list.append((bucket_start,bucket_end))\n element_count+=1\n\n data_list = [2] * element_count\n temp = 0\n offset = k - bucket_start\n while temp < element_count and offset > 0:\n\n num_trail= power_list[element_count-1-temp]\n data_list[temp]= initial_list[ ((offset-1)/num_trail) ]\n temp +=1\n new_offset= (bucket_start - num_trail) + ( offset - ((num_trail)*((offset-1)/num_trail)))\n bucket_start = boundry_list[element_count-1-temp][0]\n\n if new_offset < 3 and bucket_start == 0:\n if new_offset == offset:\n data_list[temp] = initial_list[new_offset-1]\n\n\n\n\n\n offset = new_offset - bucket_start\n\n #bucket_end = boundry_list[element_count-1-temp][1]\n\n return data_list\n\n\n\ndef getkthelementrecursive(k,array=None):\n global initial_list\n if k < 4 :\n if array is not None:\n array[-1] = initial_list[k-1]\n return array\n return [initial_list[k-1]]\n num = bucket_start= j= num_trail = 3\n element_count=1\n\n while j < k:\n num_trail = num\n bucket_start = j\n num = num * 3\n j += (num)\n bucket_end = j\n element_count+=1\n\n offset = k - bucket_start\n# print offset\n data_list = [2] * element_count\n if array is not None:\n array[len(array)-element_count]= initial_list[ ((offset-1)/num_trail) ]\n data_list = array\n else:\n data_list[0] = initial_list[ ((offset-1)/num_trail) ]\n #print data_list\n # if array is not None:\n # data_list = mergelist(array,data_list)\n #print data_list\n\n #print \"start : %s | end : %s | length : %s | bucket offset %s %s\"%(bucket_start,bucket_end,element_count,offset,num_trail)\n new_offset= (bucket_start - num_trail) + ( offset - ((num_trail)*((offset-1)/num_trail)))\n\n return getkthelementrecursive(new_offset,data_list)\n\n\n\n\n\n\n\n\n\n\n\n #return getkthelementrecursive(offset)\n\ndef getkthelement(k):\n j = 3\n num = 3\n element_count = 2\n\n while j < k:\n num = num * 3\n\n j += num\n element_count += 1\n #print element_count\n #print j\n left = j - k\n\n\n left_item = element_count -2\n list = [4] * element_count\n while left > 0:\n temp_left_item = left_item\n\n while temp_left_item >= 0:\n if list[temp_left_item] > 2:\n break\n else:\n temp_left_item -= 1\n\n list[temp_left_item] -= 1\n\n p = temp_left_item + 1\n\n while p <= left_item:\n list[p] = 4\n p+=1\n left -= 1\n #print list\n item =0\n # while item < len(list)-1:\n # print list[item],\n # item+=1\n # print \"\"\n return list[0:-1]\n\n# print getkthelementrecursive(29)\n# print getkthElementIterative(29)\n\n#tests=int(raw_input())\n\n# while tests > 0:\n# t=int(raw_input())\n# getkthelement(t)\n# tests-=1\n# getkthelement(29)\n# print getkthelementrecursive(29)\n# getkthelement(21)\n\nyappi.start()\n#\ncount=9999999\nnumber=count\nwhile number > 0:\n #getkthelementrecursive(number)\n getkthElementIterative(number)\n #getkthelement(number)\n number-=1\n #print number\n#yappi.get_func_stats().print_all()\n\n# yappi.stop()\n# yappi.start()\n#\n# number=count\n# while number > 0:\n# #getkthelementrecursive(number)\n# getkthElementIterative(number)\n# #getkthelement(number)\n# number-=1\n# #print number\nyappi.get_func_stats().print_all()\ntemp =0\n# while temp < number:\n#\n# try:\n# first_result = getkthElementIterative(temp)\n# second_result = getkthelementrecursive(temp)\n#\n# if first_result != second_result:\n# print \" number : %s , first_result: %s second_result: %s\"%(temp,first_result,second_result)\n# except Exception as e:\n# print \"error in number %s , %s \"%(temp, e)\n# temp+=1\n\n\n\n\n# print getkthelement(21)\n# print getkthelementrecursive(21)\n# getkthelement(141)\n# getkthelementrecursiveDriver(141)\n# getkthelement(119)\n# getkthelementrecursiveDriver(119)\n# getkthelement(30)\n# getkthelementrecursiveDriver(30)\n# getkthelement(6)\n# getkthelementrecursiveDriver(6)\n\n\n\n\n\n\n\n# ********************\n# tests=int(raw_input())\n# #print tests\n# while tests > 0:\n# t=int(raw_input())\n# \t#print t\n# \tresult = t\n# \tinitial_list=[2,3,4]\n# \tnew_list=[]\n# \tnew_list.extend(initial_list)\n# \tcondition= true\n# \tfinal_list=[2,3,4]\n# \twhile t >= 1:\n# \t\ttemp_list=[]\n# \t\tfor i in initial_list:\t\t\n\n# \t\t\tfor data in new_list:\n# \t\t\t\tnew_str=\"%s%s\"%(i,data)\n# \t\t\t\ttemp_list.append(new_str)\n# \t\t\t\t# print new_str,\n# \t\t#print new_list\t\t\n# \t\tnew_list=temp_list\n# \t\tfinal_list.extend(new_list)\n# \t\tif len(new_list) > t:\n# \t\t\tcondition = false\n# \t\t\t#print 'breaking'\n# \t\t\tbreak\n# \t\tt-= 1\n# \t#print len(final_list)\n# \t#print final_list\n\n# \tprint final_list[result-1]\n\n# \ttests-=1\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6904761791229248,
"avg_line_length": 14.6875,
"blob_id": "999adaec4c01cc8944c56c9ac8f387c6d57c0f98",
"content_id": "01d591d5d2d7dfa5cc4030c6a7aa43197de38034",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 16,
"path": "/validstrings.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "intputs=[\"0123456789\",\"0123456789a\"]\n\ndef verifyString(input):\n\tfor i in xrange(len(input)):\n\t\ttry:\n\t\t\tif i is not int(input[i]):\n\t\t\t\treturn False\n\t\texcept Exception:\n\t\t\treturn False\n\n\t\t\n\treturn True\n\n\nfor input in intputs:\n\tprint verifyString(input)\n\n"
},
{
"alpha_fraction": 0.5148279666900635,
"alphanum_fraction": 0.5338078141212463,
"avg_line_length": 18.045454025268555,
"blob_id": "9576beae04c963a46297b4fb10477fb9ad0197d9",
"content_id": "daf9231fc84c067661ad0a407c5132bc61209b89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 843,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 44,
"path": "/pallindrom.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "__author__ = 'pankaj'\n\n\n\ndef isPallindrome(str,length):\n temp=0\n while temp <= length/2:\n if str[temp] != str[length-temp-1]:\n return False\n temp+=1\n\n return True\n\ndef checkPallindrome(str):\n\n if isPallindrome(str,len(str)) == True:\n return -1\n temp =0\n while temp < len(str):\n if str[temp] != str[-(temp+1)]:\n\n new_str=('%s%s')%(str[0:temp],str[temp+1:len(str)])\n if isPallindrome(new_str,len(new_str)) == True:\n return temp\n else:\n return len(str)-temp-1;\n temp+=1\n #print new_str\n\n return -1\n\n\n\n\nn= int(raw_input())\ntemp = 0\nwhile temp < n:\n temp+=1\n line = raw_input()\n print checkPallindrome(line)\n\n# print isPallindrome(\"aa\",2)\n# print isPallindrome(\"aab\",3)\n#print isPallindrome(\"a\",)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.647398829460144,
"alphanum_fraction": 0.676300585269928,
"avg_line_length": 14.727272987365723,
"blob_id": "6879fc88aeada82b46d9e1f201103795ea19146a",
"content_id": "b29cc0929ad6654d82e4d3c9c3fba10602300490",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 173,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 11,
"path": "/generator.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "from guppy import hpy\nnum=10000\n#mygenerator = (x*x for x in range(num))\nmygenerator = [x*x for x in range(num)]\n\n\nfor i in mygenerator:\n\tprint(i)\n\nh = hpy()\nprint h.heap()\n"
},
{
"alpha_fraction": 0.6192893385887146,
"alphanum_fraction": 0.6362097859382629,
"avg_line_length": 14.972972869873047,
"blob_id": "4e78e7d24680afb1d6269e7f4e9fae1177cfc383",
"content_id": "17cd5f178331c0326088f85356a3f4ca330a06fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 37,
"path": "/ankit_numbers.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "n=1\n\n\nimport copy\n\ndef ankitSum(target,data,sum_total):\n\t#print data\n\tfor i in xrange(len(data)):\n\t\tnew_target = list(target)\n\t\tnew_data = list(data)\n\t\tnew_target.append(data[i])\n\t\tnew_data = data[i+1:]\n\t\t#print new_target\n\t\tsum_total = sum_total + sum(new_target)\n\n\t\tsum_total = ankitSum(new_target,new_data,sum_total)\n\t#print sum_total\n\treturn sum_total\n\n\n\n\n# def getSum(n,t):\n# \tsum = 0\n# \tfor i in xrange(1,t+1):\n# \t\tprint i\n# \t\tfor j in xrange(1,t+1):\n# \t\t\tsum += j\n# \treturn sum\n\nt=input()\n\nfor i in xrange(t):\n\tn=input()\n\ttarget=[]\n\tdata= range(1,n+1)\t\n\tprint ankitSum(target,data,0)\n"
},
{
"alpha_fraction": 0.6614173054695129,
"alphanum_fraction": 0.6614173054695129,
"avg_line_length": 12.666666984558105,
"blob_id": "dedfb376d8b477e95d6c4f77a107f4842bcf6582",
"content_id": "60cb1020fffc31bb5b6c28c73746198f5735bc05",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 127,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 9,
"path": "/test_exception_else.py",
"repo_name": "pankajanand18/python-tests",
"src_encoding": "UTF-8",
"text": "data={'Hello':'Data'}\n\ntry:\n# data.Hello='hello'\n print 'hello'\nexcept Exception as ex:\n raise\nelse:\n print \"reached rase\"\n\n\t\n\n"
}
] | 40 |
PiotrWolinski/Weather-App
|
https://github.com/PiotrWolinski/Weather-App
|
5bb829d6aeb24490bdefd170be0b9de43ed541f5
|
37cbf011dd2b3340f5f84c25dd2e3d774071989f
|
3b1a4510f05bf0496dfa55b6657a1ee09e588c3e
|
refs/heads/main
| 2023-03-11T21:57:17.002331 | 2021-03-03T19:16:05 | 2021-03-03T19:16:05 | 338,052,161 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5507998466491699,
"alphanum_fraction": 0.5546908974647522,
"avg_line_length": 28.66666603088379,
"blob_id": "ed303c7569f2418e579a7c0bc1ec5e032f3e0f75",
"content_id": "3be6784c8c8b5b86a9102c37e7fea8e4cd02bd91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2313,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 78,
"path": "/app.py",
"repo_name": "PiotrWolinski/Weather-App",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom datetime import datetime, timezone\nimport requests\n\nfrom config import OPENWEATHER_KEY\n\napp = Flask(__name__, template_folder='templates')\nOW_BASE = 'https://api.openweathermap.org/data/2.5/weather'\nICON_BASE = 'http://openweathermap.org/img/w/'\n\n# ensures that the first letter will be capital and other small\ndef parse_name(s: str) -> str:\n words = s.split(' ')\n output = []\n for w in words:\n low_word = w.lower()\n tmp_word = list(low_word)\n tmp_word[0] = tmp_word[0].upper()\n output.append(''.join(tmp_word))\n\n return ' '.join(output)\n\n# parses current date to format: \"WEEKDAY, DD MM YYYY\"\ndef show_date() -> str:\n output = datetime.today().strftime(\"%A, %d %B %Y\")\n return output\n\n# gets weather info based on the city name\ndef get_weather(city: str) -> dict:\n url = f'{OW_BASE}?q={city}&appid={OPENWEATHER_KEY}&units=metric'\n\n response = requests.get(url)\n\n if response.status_code == 200:\n weather_data = response.json()\n data = {}\n data['city'] = parse_name(city)\n data['temp_min'] = weather_data['main']['temp_min']\n data['temp_max'] = weather_data['main']['temp_max']\n data['country'] = weather_data['sys']['country']\n data['weather'] = weather_data['weather'][0]['description']\n icon_id = weather_data['weather'][0]['icon']\n data['icon'] = f'{ICON_BASE}{icon_id}.png'\n\n data['day'] = show_date()\n return data\n else:\n return None\n\[email protected]('/', methods=['GET'])\ndef index():\n city = request.args.get('city')\n initial = True\n success = False\n\n if city is None:\n return render_template('index.html', \n success=success, \n initial=initial)\n\n initial = False\n \n data = get_weather(city)\n\n if data is not None:\n success = True\n return render_template('index.html', \n data=data,\n success=success,\n initial=initial)\n else:\n return render_template('index.html', \n success=success,\n initial=initial)\n\n\nif __name__ == '__main__':\n app.run()"
},
{
"alpha_fraction": 0.7464212775230408,
"alphanum_fraction": 0.7464212775230408,
"avg_line_length": 42.45454406738281,
"blob_id": "169ec8d42b35ef875a9c823ebebd510af4715eee",
"content_id": "da509aa1b9e7d9b8cb33a513ea89bf8bb1681172",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 243,
"num_lines": 11,
"path": "/README.md",
"repo_name": "PiotrWolinski/Weather-App",
"src_encoding": "UTF-8",
"text": "# Weather-App\r\n\r\nThis Flask web-app shows usage of [openweathermap](https://openweathermap.org/current) API with simple styling in vanilla CSS and Bootstrap.\r\n\r\n## Configuration\r\n\r\nThis app needs an openweathermap API key which can be generated after signing up [here](https://openweathermap.org/). After generating one it should be placed as the **OPENWEATHER_KEY** variable in the **config.py** file in the main directory.\r\n\r\n## Usage\r\n\r\nSimply run an **app.py** from the command line.\r\n"
}
] | 2 |
robertsoh/sise
|
https://github.com/robertsoh/sise
|
26641fef61788a179e9cca527b076d1f061002fa
|
e4d2099d1dc222190edfa16f23cd7e50a904c7f0
|
52a764d7cb61f48c89ee8cde4015a75a55aea9a8
|
refs/heads/master
| 2020-03-23T15:12:51.454154 | 2018-07-21T07:08:54 | 2018-07-21T07:08:54 | 141,730,790 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6516913175582886,
"alphanum_fraction": 0.663847804069519,
"avg_line_length": 27.66666603088379,
"blob_id": "75a5f96c1888478617ca1d85952d33a968ab3298",
"content_id": "74b5d7160e470a28aa35baaa9b8cae8a4a7bc175",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1892,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 66,
"path": "/apps/ubigeo/models.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models\nfrom django.utils.encoding import python_2_unicode_compatible\n\n\nclass Departamento(models.Model):\n\n nombre = models.CharField('Nombre', max_length=255)\n cod_inei = models.CharField('INEI', max_length=10)\n cod_reniec = models.CharField('RENIEC', max_length=10, null=True)\n\n created = models.DateTimeField(auto_now_add=True)\n modified = models.DateTimeField(auto_now=True)\n\n class Meta:\n verbose_name = 'Departamento'\n verbose_name_plural = 'Departamentos'\n default_related_name = 'departamentos'\n ordering = ('nombre',)\n\n def __str__(self):\n return self.nombre\n\n\nclass Provincia(models.Model):\n\n departamento = models.ForeignKey('Departamento')\n\n nombre = models.CharField('Nombre', max_length=255)\n cod_inei = models.CharField('INEI', max_length=10)\n cod_reniec = models.CharField('RENIEC', max_length=10, null=True)\n\n created = models.DateTimeField(auto_now_add=True)\n modified = models.DateTimeField(auto_now=True)\n\n class Meta:\n verbose_name = 'Provincia'\n verbose_name_plural = 'Provincias'\n default_related_name = 'provincias'\n ordering = ('nombre',)\n\n def __str__(self):\n return self.nombre\n\n\nclass Distrito(models.Model):\n\n provincia = models.ForeignKey('Provincia')\n\n nombre = models.CharField('Nombre', max_length=255)\n cod_inei = models.CharField('INEI', max_length=10)\n cod_reniec = models.CharField('RENIEC', max_length=10, null=True)\n\n created = models.DateTimeField(auto_now_add=True)\n modified = models.DateTimeField(auto_now=True)\n\n class Meta:\n verbose_name = 'Distrito'\n verbose_name_plural = 'Distritos'\n default_related_name = 'distritos'\n ordering = ('nombre',)\n\n def __str__(self):\n return self.nombre\n"
},
{
"alpha_fraction": 0.6195651888847351,
"alphanum_fraction": 0.6521739363670349,
"avg_line_length": 12.142857551574707,
"blob_id": "9589368b64dd2bae32f83fa167b8c31673c4e61e",
"content_id": "8ab213f087515f7c895440fd3f5063e0ff658dd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/CHANGELOG.md",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# CHANGELOG\n\n\n## 0.1.0 - Fecha de creación, en: YYYY-MM-DD\n\n### Agregado\n- Proyecto inicial\n"
},
{
"alpha_fraction": 0.7699999809265137,
"alphanum_fraction": 0.7699999809265137,
"avg_line_length": 19,
"blob_id": "86b96e4ed5fa936b463d9c5904b31f812da7c591",
"content_id": "dd6a259b36ff0af1b758efaa5996fbfd78d595ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 5,
"path": "/apps/facultades/apps.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass FacultadesConfig(AppConfig):\n name = 'apps.facultades'\n"
},
{
"alpha_fraction": 0.65625,
"alphanum_fraction": 0.677734375,
"avg_line_length": 36.925926208496094,
"blob_id": "bb07b3d79d1db5e7f8d40d23a9beae38df9cd1d5",
"content_id": "e8e3bf3738fbbb4fec8292e6283b7ca81a9b914d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1024,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 27,
"path": "/apps/estudiantes/migrations/0002_auto_20180721_0142.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.14 on 2018-07-21 01:42\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\nimport django.db.models.deletion\nimport smart_selects.db_fields\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('estudiantes', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='estudiante',\n name='direccion_distrito',\n field=smart_selects.db_fields.ChainedForeignKey(auto_choose=True, chained_field='direccion_provincia', chained_model_field='provincia', on_delete=django.db.models.deletion.CASCADE, to='ubigeo.Distrito'),\n ),\n migrations.AlterField(\n model_name='estudiante',\n name='direccion_provincia',\n field=smart_selects.db_fields.ChainedForeignKey(auto_choose=True, chained_field='direccion_departamento', chained_model_field='departamento', on_delete=django.db.models.deletion.CASCADE, to='ubigeo.Provincia'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5767530202865601,
"alphanum_fraction": 0.5915982127189636,
"avg_line_length": 46.969696044921875,
"blob_id": "dfc7309e281722e0371fe46ae33cc7f260b73020",
"content_id": "d2fbc9a371f970dfa0fd1545c1eca364dd502083",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3166,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 66,
"path": "/apps/estudiantes/migrations/0001_initial.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.11.14 on 2018-07-20 17:17\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ('facultades', '0001_initial'),\n ('ubigeo', '0001_initial'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Estudiante',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nombre', models.CharField(max_length=100)),\n ('apellido_paterno', models.CharField(max_length=100)),\n ('apellido_materno', models.CharField(max_length=100)),\n ('fecha_nacimiento', models.DateField(verbose_name='Fecha de nacimiento')),\n ('direccion', models.CharField(max_length=254)),\n ('telefono', models.CharField(max_length=9)),\n ('correo', models.EmailField(max_length=254)),\n ('direccion_departamento', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='ubigeo.Departamento')),\n ('direccion_distrito', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='ubigeo.Distrito')),\n ('direccion_provincia', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='ubigeo.Provincia')),\n ],\n ),\n migrations.CreateModel(\n name='EstudianteEAP',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('fecha_inicio', models.DateField(verbose_name='Fecha inicio')),\n ('fecha_fin', models.DateField(blank=True, null=True, verbose_name='Fecha fin')),\n ('eap', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='facultades.EAP')),\n ('estudiante', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='estudiante_eaps', to='estudiantes.Estudiante')),\n ],\n ),\n migrations.CreateModel(\n name='EstudianteGrado',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('fecha', models.DateField()),\n ('estudiante', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='estudiante_grados', to='estudiantes.Estudiante')),\n ],\n ),\n migrations.CreateModel(\n name='Grado',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nombre', models.CharField(max_length=254)),\n ('codigo', models.CharField(max_length=20)),\n ],\n ),\n migrations.AddField(\n model_name='estudiantegrado',\n name='grado',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, related_name='+', to='estudiantes.Grado'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.713302731513977,
"alphanum_fraction": 0.7545871734619141,
"avg_line_length": 32.53845977783203,
"blob_id": "453b137a7504e29c0e7aedd7d946b58baba05ab8",
"content_id": "e66748f35c840020178a9cc3005005e8a533a0b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 13,
"path": "/config/urls.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom django.contrib import admin\nfrom django.views.generic import TemplateView\n\n\nurlpatterns = [\n url(r'^admin/', admin.site.urls),\n url(r'^chaining/', include('smart_selects.urls')),\n]\n\nhandler403 = TemplateView.as_view(template_name='errors/403.html')\nhandler404 = TemplateView.as_view(template_name='errors/404.html')\nhandler500 = TemplateView.as_view(template_name='errors/500.html')\n"
},
{
"alpha_fraction": 0.649193525314331,
"alphanum_fraction": 0.6693548560142517,
"avg_line_length": 22.619047164916992,
"blob_id": "a2499d718c8db9ab9b18ef2ab1ee4161d6a35b54",
"content_id": "e5a37b7bce09b50deee5ba2c0d9cebd6592cd917",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 21,
"path": "/apps/facultades/models.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n\nclass Facultad(models.Model):\n nombre = models.CharField(max_length=254)\n codigo = models.CharField(max_length=20)\n\n class Meta:\n verbose_name_plural = 'Facultades'\n\n def __str__(self):\n return self.nombre\n\n\nclass EAP(models.Model):\n nombre = models.CharField(max_length=254)\n codigo = models.CharField(max_length=20)\n facultad = models.ForeignKey(Facultad, related_name='eaps')\n\n def __str__(self):\n return self.nombre\n"
},
{
"alpha_fraction": 0.5879059433937073,
"alphanum_fraction": 0.5890257358551025,
"avg_line_length": 23.135135650634766,
"blob_id": "aceffab6ebe38a7b673496e31e27c715faa0efed",
"content_id": "c56a1a48ee444c8a4c4cf6ba6defab05bfe2ee60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 37,
"path": "/apps/ubigeo/views.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.views.generic import View\nfrom django.http import JsonResponse\n\nfrom .models import Provincia, Distrito\n\n\nclass UbigeoView(View):\n\n model = None\n parent_field = None\n\n def get(self, request, *args, **kwargs):\n data = []\n params = {}\n if self.parent_field in request.GET:\n params[self.parent_field] = request.GET.get(self.parent_field)\n for obj in self.model.objects.filter(**params):\n data.append({\n 'id': obj.id,\n 'nombre': obj.nombre,\n 'cod_inei': obj.cod_inei,\n 'cod_reniec': obj.cod_reniec\n })\n return JsonResponse({'data': data})\n\n\nclass ProvinciaView(UbigeoView):\n\n model = Provincia\n parent_field = 'departamento_id'\n\n\nclass DistritoView(UbigeoView):\n\n model = Distrito\n parent_field = 'provincia_id'\n"
},
{
"alpha_fraction": 0.6735537052154541,
"alphanum_fraction": 0.78925621509552,
"avg_line_length": 21,
"blob_id": "1c5caffb308bb8c27c5f03a05c18c872b02eefa2",
"content_id": "229e1a96b60934575b0c36b5e7f6024043fec767",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/requirements.txt",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "django<1.12\ndjangorestframework<3.8\ndjango-crispy-forms<1.8\npsycopg2-binary<2.8\npython-dateutil<2.8\nrequests<2.2\nflake8<3.6\nisort<4.4\ngunicorn==19.6.0\nwhitenoise==3.2\ngit+https://github.com/digi604/django-smart-selects.git@js-unlinting-fixes\n"
},
{
"alpha_fraction": 0.679665744304657,
"alphanum_fraction": 0.6810584664344788,
"avg_line_length": 27.520000457763672,
"blob_id": "432cd8ff6a0888308009090208b8f003d16e749e",
"content_id": "ef4b820625f667a9553875f623fdf0d120526f5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 25,
"path": "/apps/estudiantes/admin.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom apps.estudiantes.models import Estudiante, EstudianteEAP, Grado\n\n\[email protected](Estudiante)\nclass EstudiantedAdmin(admin.ModelAdmin):\n list_display = ('nombre', 'apellido_paterno', 'apellido_materno', 'telefono', 'correo')\n\n class Media:\n js = (\n 'smart-selects/admin/js/chainedfk.js',\n 'smart-selects/admin/js/chainedm2m.js',\n 'smart-selects/admin/js/bindfields.js',\n )\n\n\[email protected](EstudianteEAP)\nclass EstudianteEAPAdmin(admin.ModelAdmin):\n list_display = ('estudiante', 'eap', 'fecha_inicio', 'fecha_fin')\n\n\[email protected](Grado)\nclass GradoAdmin(admin.ModelAdmin):\n list_display = ('nombre', 'codigo')\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7400000095367432,
"alphanum_fraction": 0.7400000095367432,
"avg_line_length": 22.076923370361328,
"blob_id": "0b336f43503082407bf5d81a504c3cabed6438c7",
"content_id": "dea584cd0b4bada213e4b62c1d5c2683c01cbd1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 13,
"path": "/apps/facultades/admin.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n\nfrom apps.facultades.models import Facultad, EAP\n\n\[email protected](Facultad)\nclass FacultadAdmin(admin.ModelAdmin):\n list_display = ('nombre', 'codigo')\n\n\[email protected](EAP)\nclass EAPdAdmin(admin.ModelAdmin):\n list_display = ('nombre', 'codigo', 'facultad')\n"
},
{
"alpha_fraction": 0.6757493019104004,
"alphanum_fraction": 0.6771117448806763,
"avg_line_length": 26.185184478759766,
"blob_id": "1ab5d4b89bfc92d207a207ae1c931d207734a870",
"content_id": "bc9b9b45e0b9452d5fd71994a855a52138af50c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 734,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/apps/ubigeo/admin.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.contrib import admin\n\nfrom .models import Departamento, Provincia, Distrito\n\n\[email protected](Departamento)\nclass DepartamentoAdmin(admin.ModelAdmin):\n\n list_display = ('nombre', 'cod_inei', 'cod_reniec')\n search_fields = ('nombre', 'cod_inei', 'cod_reniec')\n\n\[email protected](Provincia)\nclass ProvinciaAdmin(admin.ModelAdmin):\n\n list_display = ('nombre', 'cod_inei', 'cod_reniec')\n search_fields = ('nombre', 'cod_inei', 'cod_reniec')\n list_filter = ('departamento',)\n\n\[email protected](Distrito)\nclass DistritoAdmin(admin.ModelAdmin):\n\n list_display = ('nombre', 'cod_inei', 'cod_reniec')\n search_fields = ('nombre', 'cod_inei', 'cod_reniec')\n list_filter = ('provincia',)\n"
},
{
"alpha_fraction": 0.6922246217727661,
"alphanum_fraction": 0.7035636901855469,
"avg_line_length": 32.672725677490234,
"blob_id": "7aad2f699679873b57c804e2f3a970bb87a17f4d",
"content_id": "fdb8d77b06f3ace0d3fc1565a103cf6a11db3740",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1852,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 55,
"path": "/apps/estudiantes/models.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom smart_selects.db_fields import ChainedForeignKey\n\nfrom apps.facultades.models import EAP\nfrom apps.ubigeo.models import Departamento, Provincia, Distrito\n\n\nclass Grado(models.Model):\n nombre = models.CharField(max_length=254)\n codigo = models.CharField(max_length=20)\n\n def __str__(self):\n return self.nombre\n\n\nclass Estudiante(models.Model):\n\n nombre = models.CharField(max_length=100)\n apellido_paterno = models.CharField(max_length=100)\n apellido_materno = models.CharField(max_length=100)\n fecha_nacimiento = models.DateField('Fecha de nacimiento')\n direccion_departamento = models.ForeignKey(Departamento)\n direccion_provincia = ChainedForeignKey(\n Provincia,\n chained_field=\"direccion_departamento\",\n chained_model_field=\"departamento\",\n show_all=False,\n auto_choose=True,\n sort=True)\n direccion_distrito = ChainedForeignKey(\n Distrito,\n chained_field=\"direccion_provincia\",\n chained_model_field=\"provincia\",\n show_all=False,\n auto_choose=True,\n sort=True)\n direccion = models.CharField(max_length=254)\n telefono = models.CharField(max_length=9)\n correo = models.EmailField(max_length=254)\n\n def __str__(self):\n return '{} {} {}'.format(self.nombre, self.apellido_paterno, self.apellido_materno)\n\n\nclass EstudianteEAP(models.Model):\n eap = models.ForeignKey(EAP)\n estudiante = models.ForeignKey(Estudiante, related_name='estudiante_eaps')\n fecha_inicio = models.DateField('Fecha inicio')\n fecha_fin = models.DateField('Fecha fin', blank=True, null=True)\n\n\nclass EstudianteGrado(models.Model):\n estudiante = models.ForeignKey(Estudiante, related_name='estudiante_grados')\n grado = models.ForeignKey(Grado, related_name='+')\n fecha = models.DateField()\n"
},
{
"alpha_fraction": 0.654618501663208,
"alphanum_fraction": 0.6586345434188843,
"avg_line_length": 23.899999618530273,
"blob_id": "1644d183eba102ee3a1355321d7fd4ad20c84d31",
"content_id": "41ca14eb21f9f72dfea2799300754622fed60146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 10,
"path": "/apps/ubigeo/urls.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom django.conf.urls import url\n\nfrom . import views\n\n\nurlpatterns = [\n url(r'^provincias/$', views.ProvinciaView.as_view(), name='provincias'),\n url(r'^distritos/$', views.DistritoView.as_view(), name='distritos'),\n]\n"
},
{
"alpha_fraction": 0.7745097875595093,
"alphanum_fraction": 0.7745097875595093,
"avg_line_length": 19.399999618530273,
"blob_id": "04820d7dd94b04e62a4de86aa9be8f3ef69d3b03",
"content_id": "78016e802beb232a66fa4fdc4f80a786c9ef017f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 5,
"path": "/apps/estudiantes/apps.py",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass EstudiantesConfig(AppConfig):\n name = 'apps.estudiantes'\n"
},
{
"alpha_fraction": 0.6973684430122375,
"alphanum_fraction": 0.6973684430122375,
"avg_line_length": 49.33333206176758,
"blob_id": "05079940c2b8f969ab1cf29e984db5b92636690c",
"content_id": "d5a3b0051350ee83612d7cd84cc746e184be6500",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 152,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 3,
"path": "/apps/static/js/estudiante-admin.js",
"repo_name": "robertsoh/sise",
"src_encoding": "UTF-8",
"text": "\n$(document).ready(function () {\n ubigeoSetup('ubigeo/', '#id_direccion_departamento', '#id_provincia_departamento', '#id_distrito_departamento');\n});\n"
}
] | 16 |
Irving-ren/Audio-Super-Resolution-Python3-TF
|
https://github.com/Irving-ren/Audio-Super-Resolution-Python3-TF
|
1d87afef414e986f78cf87722bccf88a97996085
|
37cb46c37bde183392dc6109a6309330f24c6dcf
|
b58120281069d1cf0423be2cf317c6e8fb0ecea2
|
refs/heads/master
| 2021-09-18T05:32:07.070529 | 2018-07-10T06:53:23 | 2018-07-10T06:53:23 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48797735571861267,
"alphanum_fraction": 0.5054219961166382,
"avg_line_length": 24.2261905670166,
"blob_id": "1f1df20c784d7ee1182a0b728bc8c7e091349034",
"content_id": "e6c1dee369ab9d3f6a3d166aa04974825788b9ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2121,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 84,
"path": "/03_predict_and_return_output_wav_files.py",
"repo_name": "Irving-ren/Audio-Super-Resolution-Python3-TF",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# #### referenced by - https://github.com/kuleshov/audio-super-res\n# # Predict & Get output files\n# \n\n# In[1]:\n\n\nimport os\nos.sys.path.append(os.path.abspath('.'))\nos.sys.path.append(os.path.dirname(os.path.abspath('.')))\nimport numpy as np\nimport matplotlib\nfrom asr_model import ASRNet, default_opt\nfrom io_utils import upsample_wav\nfrom io_utils import load_h5\nimport tensorflow as tf\n\n\n# In[2]:\n\n\nargs = {\n 'ckpt' : './default_log_name.lr0.000100.1.g4.b100/model.ckpt',\n 'wav_file_list' : './data/test.txt',\n 'r' : 6,\n 'sr' : 16000,\n 'alg' : 'adam',\n 'epochs' : 5,\n 'logname' : 'default_log_name',\n 'layers' : 4,\n 'lr' : 1e-3,\n 'batch_size' : 4,\n 'out_label' : 'asr_pred',\n 'in_dir' : './data/test'\n}\nprint(tf.__version__)\n\n\n# In[3]:\n\n\ndef evaluate(args):\n # load model\n model = get_model(args, 0, args['r'], from_ckpt=False, train=True)\n model.load(args['ckpt']) # from default checkpoint\n\n if args['wav_file_list']:\n with open(args['wav_file_list']) as f:\n for line in f:\n try:\n filename = line.strip()\n print(filename)\n filename = os.path.join(args['in_dir'], filename)\n upsample_wav(filename, args, model)\n except EOFError:\n print('WARNING: Error reading file:', line.strip())\n\n\ndef get_model(args, n_dim, r, from_ckpt=False, train=True):\n \"\"\"Create a model based on arguments\"\"\" \n if train:\n opt_params = {\n 'alg' : args['alg'], \n 'lr' : args['lr'], \n 'b1' : 0.9, \n 'b2' : 0.999,\n 'batch_size': args['batch_size'], \n 'layers': args['layers']}\n else: \n opt_params = default_opt\n\n # create model & init\n model = ASRNet(\n from_ckpt=from_ckpt, \n n_dim=n_dim, \n r=r,\n opt_params=opt_params, \n log_prefix=args['logname'])\n \n return model\n\nevaluate(args)\n\n"
},
{
"alpha_fraction": 0.5512122511863708,
"alphanum_fraction": 0.5700148344039917,
"avg_line_length": 19.602041244506836,
"blob_id": "b384db157abc254b62c31e4ff825ee1d469be32e",
"content_id": "36ba90127abd1a67d94048aed8676ca105a36c40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2021,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 98,
"path": "/02_training_model.py",
"repo_name": "Irving-ren/Audio-Super-Resolution-Python3-TF",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# #### referenced by - https://github.com/kuleshov/audio-super-res\n\n# # Training ASR model\n\n# In[1]:\n\n\nimport os\nos.sys.path.append(os.path.abspath('.'))\nos.sys.path.append(os.path.dirname(os.path.abspath('.')))\nimport numpy as np\nimport matplotlib\nfrom asr_model import ASRNet, default_opt\nfrom io_utils import upsample_wav\nfrom io_utils import load_h5\nimport tensorflow as tf\n#matplotlib.use('Agg')\n\n\n# In[2]:\n\n\nargs = {\n 'train' : 'train.h5',\n 'val' : 'valid.h5',\n 'alg' : 'adam',\n 'epochs' : 10,\n 'logname' : 'default_log_name',\n 'layers' : 4,\n 'lr' : 0.0005,\n 'batch_size' : 100\n}\nprint(tf.__version__)\n\n\n# In[3]:\n\n\n# get data\nX_train, Y_train = load_h5(args['train'])\nX_val, Y_val = load_h5(args['val'])\n\n\n# In[4]:\n\n\n# determine super-resolution level\nn_dim_y, n_chan_y = Y_train[0].shape\nn_dim_x, n_chan_x = X_train[0].shape\nprint('number of dimension Y:',n_dim_y)\nprint('number of channel Y:',n_chan_y)\nprint('number of dimension X:',n_dim_x)\nprint('number of channel X:',n_chan_x)\nr = int(Y_train[0].shape[0] / X_train[0].shape[0])\nprint('r:',r)\nn_chan = n_chan_y\nn_dim = n_dim_y\nassert n_chan == 1 # if not number of channel is not 0 -> Error assert!\n\n\n# In[5]:\n\n\n# create model\ndef get_model(args, n_dim, r, from_ckpt=False, train=True):\n \"\"\"Create a model based on arguments\"\"\"\n \n if train:\n opt_params = {\n 'alg' : args['alg'], \n 'lr' : args['lr'], \n 'b1' : 0.9, \n 'b2' : 0.999,\n 'batch_size': args['batch_size'], \n 'layers': args['layers']}\n else: \n opt_params = default_opt\n\n # create model & init\n model = ASRNet(\n from_ckpt=from_ckpt, \n n_dim=n_dim, \n r=r,\n opt_params=opt_params, \n log_prefix=args['logname'])\n \n return model\n\nmodel = get_model(args, n_dim, r, from_ckpt=False, train=True)\n\n\n# In[ ]:\n\n\n# train model\nmodel.fit(X_train, Y_train, X_val, Y_val, n_epoch=args['epochs'])\n\n"
}
] | 2 |
czbiohub/mm2python
|
https://github.com/czbiohub/mm2python
|
07e4397d6f2181ee576eefda2c8e4f088cab164c
|
3e224a9ec934407e1c99915abd730e6d061ceed5
|
2ab40a5c896ab6e571246c8f8a51434da98bbcbb
|
refs/heads/master
| 2022-11-13T02:00:57.667653 | 2022-10-30T16:23:55 | 2022-10-30T16:23:55 | 190,825,002 | 0 | 0 |
NOASSERTION
| 2019-06-07T23:49:47 | 2020-07-29T01:12:35 | 2020-07-31T21:53:50 |
Java
|
[
{
"alpha_fraction": 0.5795336961746216,
"alphanum_fraction": 0.5867875814437866,
"avg_line_length": 39.20833206176758,
"blob_id": "248299cf358b37d2851d62e43dd3ae63291a4973",
"content_id": "182dbcfa27e1cee04c1652c2bd8758d79158f599",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3860,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 96,
"path": "/src/main/java/org/mm2python/mmDataHandler/ramDisk/ramDiskConstructor.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage org.mm2python.mmDataHandler.ramDisk;\n\nimport org.mm2python.UI.reporter;\nimport org.micromanager.Studio;\n\nimport javax.swing.JPanel;\nimport javax.swing.JOptionPane;\nimport java.util.concurrent.TimeUnit;\n\n/**\n *\n * @author bryant.chhun\n */\npublic class ramDiskConstructor {\n\n private static final JPanel panel = new JPanel();\n\n // modify later to actually create a ramdisk\n public ramDiskConstructor(Studio mm_) {\n Studio mm;\n String command;\n// String command2;\n mm = mm_;\n\n String OS = System.getProperty(\"os.name\").toLowerCase();\n\n /**\n * check for operating system\n * establish commands needed to create RAMDISK based on that OS\n */\n if (OS.indexOf(\"win\") >= 0) {\n reporter.set_report_area(true, false, false, \"Windows system detected\");\n reporter.set_report_area(\"Windows system detected, be sure imdisk is installed\");\n JOptionPane.showMessageDialog(panel, \"Windows system detected, \\n\" +\n \"Please be sure imdisk is installed\\n\" +\n \"https://sourceforge.net/projects/imdisk-toolkit/\");\n\n command = \"imdisk -a -s 4096M -m Q: -p \\\"/fs:ntfs /q /y\\\"\";\n// command2 = \"mkdir JavaPlugin_temp_folder\";\n\n } else if (OS.indexOf(\"mac\") >= 0) {\n reporter.set_report_area(true, false, false, \"Mac system detected, creating 4gb RAM disk at 'RAM_Disk'\");\n reporter.set_report_area(\"Mac system detected, creating 4gb RAM disk at 'RAM_Disk'\");\n\n command = String.format(\"diskutil erasevolume HFS+ '%s' `hdiutil attach -nomount ram://8388608`\", \"RAM_disk\");\n// command2 = \"mkdir /Volumes/RAM_disk\";\n\n } else if (OS.indexOf(\"nix\") >= 0) {\n reporter.set_report_area(true, false, false, \"Unix or Linux system detected\");\n reporter.set_report_area(\"RAMdisk for unix system not supported\");\n JOptionPane.showMessageDialog(panel, \"Current OS does not support Ram disk, or imdisk is not installed\");\n\n command = \"\";\n// command2 = \"\";\n\n } else {\n reporter.set_report_area(true, false, false, \"Current OS is not supported\");\n reporter.set_report_area(\"current OS is not supported\");\n JOptionPane.showMessageDialog(panel, \"Current OS does not support Ram disk, or imdisk is not installed\");\n\n command = \"\";\n// command2 = \"\";\n\n }\n\n try {\n reporter.set_report_area(true, false, false, \"creating RAM disk using command: \");\n reporter.set_report_area(true, false, false, command);\n if (OS.indexOf(\"mac\") >= 0) {\n // because making ramdisk requires parsing used by shell. We must use String[] object\n reporter.set_report_area(\"(mac): Creating Ramdisk as drive Q\");\n Process p = Runtime.getRuntime().exec(new String[] { \"bash\", \"-c\", command});\n// TimeUnit.SECONDS.sleep(3);\n// Process p2 = Runtime.getRuntime().exec(new String[] { \"bash\", \"-c\", command2});\n } else if (OS.indexOf(\"win\") >= 0) {\n reporter.set_report_area(\"(win): Creating Ramdisk as drive Q\");\n try {\n Process p = Runtime.getRuntime().exec(new String[] {\"cmd.exe\", \"/c\", command});\n } catch (Exception ex) {\n reporter.set_report_area(ex.toString());\n }\n }\n\n } catch (Exception ex) {\n mm.logs().showError(ex);\n reporter.set_report_area(\"exception during ramdisk construction\");\n }\n \n }\n \n}\n"
},
{
"alpha_fraction": 0.5975773930549622,
"alphanum_fraction": 0.6195603609085083,
"avg_line_length": 23.228260040283203,
"blob_id": "ff9935f3ce98aa0b2ec58e292896a63be433b2f4",
"content_id": "23fa35b413bdd1071511eee879d3ddc038d62f75",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2229,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 92,
"path": "/src/test/java/Tests/DataStructuresTests/ConstantsTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.DataStructuresTests;\n\nimport org.mm2python.DataStructures.Constants;\nimport org.junit.jupiter.api.Test;\n\nimport static junit.framework.TestCase.assertTrue;\nimport static org.junit.jupiter.api.Assertions.assertEquals;\n\npublic class ConstantsTests {\n\n @Test\n void testTempFile() {\n Constants c = new Constants();\n Constants.tempFilePath = \"testpath\";\n assertEquals(\"testpath\", Constants.tempFilePath);\n\n new Constants();\n assertEquals(\"testpath\", Constants.tempFilePath);\n }\n\n @Test\n void testbitDepth() {\n Constants c = new Constants();\n Constants.bitDepth = 16;\n assertEquals(16, Constants.bitDepth);\n\n new Constants();\n assertEquals(16, Constants.bitDepth);\n }\n\n @Test\n void testHeight() {\n Constants c = new Constants();\n Constants.height = 2048;\n assertEquals(2048, Constants.height);\n\n new Constants();\n assertEquals(2048, Constants.height);\n }\n\n @Test\n void testWidth() {\n Constants c = new Constants();\n Constants.width = 1024;\n assertEquals(1024, Constants.width);\n\n new Constants();\n assertEquals(1024, Constants.width);\n }\n\n @Test\n void testPorts() {\n Constants c = new Constants();\n Constants.ports.add(1001);\n assertEquals(1001, Constants.ports.get(0).intValue());\n\n new Constants();\n assertEquals(1001, Constants.ports.get(0).intValue());\n }\n\n @Test\n void testfixedMemMap() {\n Constants c = new Constants();\n Constants.setFixedMemMap(true);\n assertTrue(Constants.getFixedMemMap());\n\n Constants p = new Constants();\n assertTrue(Constants.getFixedMemMap());\n }\n\n @Test\n void testpy4JRadioButton() {\n Constants c = new Constants();\n Constants.setPy4JRadioButton(true);\n assertTrue(Constants.getPy4JRadioButton());\n\n Constants p = new Constants();\n assertTrue(Constants.getPy4JRadioButton());\n }\n\n @Test\n void testOS() {\n Constants c = new Constants();\n\n assertEquals(\"mac\", Constants.getOS());\n\n new Constants();\n assertEquals(\"mac\", Constants.getOS());\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.7159090638160706,
"alphanum_fraction": 0.7175324559211731,
"avg_line_length": 29.799999237060547,
"blob_id": "27e260476832cc6f8dfa7526f3bd675fb18e9b1a",
"content_id": "0dc401a6e66bad2b3545f544338636881f047bf3",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 616,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 20,
"path": "/src/test/java/Tests/DataStructuresTests/OSTypeExceptionTest.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.DataStructuresTests;\n\nimport org.mm2python.DataStructures.Exceptions.OSTypeException;\nimport org.junit.jupiter.api.Test;\n\nimport static org.junit.jupiter.api.Assertions.assertThrows;\n\npublic class OSTypeExceptionTest {\n\n @Test\n void testOSTypeException() {\n assertThrows(OSTypeException.class, () -> {throw new OSTypeException(\"testing custom exception\"); });\n }\n\n @Test\n void testOSTypeExceptionWithCause() {\n assertThrows(OSTypeException.class, () -> {throw new OSTypeException(\"custom exception message\",\n new Throwable(\"custom type cause\")); });\n }\n}\n"
},
{
"alpha_fraction": 0.8153846263885498,
"alphanum_fraction": 0.8153846263885498,
"avg_line_length": 15.25,
"blob_id": "b6f4a48ef2e2f71898ade189186cc5fef5afa935",
"content_id": "fcbc872da339d3beea3e963326e7926b6e5b1832",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 65,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 4,
"path": "/src/test/java/Tests/EventHandlerTests/ExecutorTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.EventHandlerTests;\n\npublic class ExecutorTests {\n}\n"
},
{
"alpha_fraction": 0.541218638420105,
"alphanum_fraction": 0.5501791834831238,
"avg_line_length": 28.680850982666016,
"blob_id": "94c742aea9ef84f2e4ecc74ea1bbd97856ab4dab",
"content_id": "95027ff0460e4ac9dea8adbaee0422debf9a915b",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2790,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 94,
"path": "/examples/mm2python_snap_live_display.py",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "from py4j.java_gateway import JavaGateway, CallbackServerParameters, GatewayParameters\nimport numpy as np\nfrom PyQt5.QtCore import QRunnable, QThreadPool, QObject, pyqtSlot, pyqtSignal\n\nimport napari\n\n\ndef pull_memmap(entry_point):\n meta = entry_point.getLastMeta()\n if meta is None:\n return None\n else:\n data = np.memmap(meta.getFilepath(), dtype=\"uint16\", mode='r+', offset=meta.getBufferPosition(),\n shape=(meta.getxRange(), meta.getyRange()))\n return data\n\n# =======================================================\n# =========== Visualization classes =====================\n# =======================================================\n\n\nclass SimpleNapariWindow(QObject):\n\n def __init__(self):\n super().__init__()\n print('setting up napari window')\n self.viewer = napari.Viewer()\n\n N = 2048\n\n # init image data\n self.init_data_1 = 2 ** 16 * np.random.rand(N, N)\n\n # init layers with vector data and subscribe to gui notifications\n self.layer1 = self.viewer.add_image(self.init_data_1)\n\n @pyqtSlot(object)\n def update(self, data: object):\n # print('gui is notified of new data')\n try:\n self.layer1.data = data\n # self.layer1._node.set_data(data)\n # self.layer1._node.update()\n self.layer1.name = \"snap\"\n except Exception as ex:\n print(\"exception while updating gui \"+str(ex))\n\n\n# =======================================================\n# ============== mm2python data retrieval ===============\n# =======================================================\n\nclass ImplementPy4J(QObject):\n\n send_data_to_display = pyqtSignal(object)\n\n def __init__(self, gate):\n super().__init__()\n self.gateway = gate\n self.ep = self.gateway.entry_point\n listener = self.ep.getListener()\n listener.registerListener(self)\n\n class Java:\n implements = [\"org.mm2python.MPIMethod.Py4J.Py4JListenerInterface\"]\n\n def notify(self, obj):\n \"\"\"\n When notified by java, this event is called\n \"\"\"\n\n print(\"notified by java via java interface\")\n\n dat = pull_memmap(self.ep)\n\n while dat is None:\n dat = pull_memmap(self.ep)\n\n self.send_data_to_display.emit(dat)\n\n\nif __name__ == '__main__':\n\n with napari.gui_qt():\n\n # connect to org.mm2python\n gateway = JavaGateway(gateway_parameters=GatewayParameters(auto_field=True),\n callback_server_parameters=CallbackServerParameters())\n\n window = SimpleNapariWindow()\n imp = ImplementPy4J(gateway)\n\n # connect the window's slot with the monitor's signal\n imp.send_data_to_display.connect(window.update)\n"
},
{
"alpha_fraction": 0.6123752593994141,
"alphanum_fraction": 0.6139720678329468,
"avg_line_length": 38.761905670166016,
"blob_id": "ffb96f5a9f881b2797c8de3f328f737258d72728",
"content_id": "fd5921a7b1aa2e1f5e8ea0ed95ceda7866a4ab76",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2505,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 63,
"path": "/src/main/java/org/mm2python/mmEventHandler/displayEventsThread.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage org.mm2python.mmEventHandler;\n\nimport org.mm2python.UI.reporter;\nimport org.micromanager.Studio;\nimport org.micromanager.display.DisplayManager;\n\n/**\n *\n * @author bryant.chhun\n */\npublic class displayEventsThread implements Runnable {\n private Studio mm;\n private DisplayManager dm;\n private displayEvents display_events;\n private static int old_window_count;\n \n public displayEventsThread(Studio mm_, DisplayManager dm_) {\n mm = mm_;\n dm = dm_;\n }\n \n @Override\n public void run() {\n /**\n * To keep track of the number of active windows in micromanager.\n * **** This was deemed entirely unnecessary as micromanager already handles window counts ****\n */\n// while(Constants.current_window_count <= dm.getAllImageWindows().size()) {\n//\n// reporter.set_report_area(true, false, \"current window count = \"+Constants.current_window_count);\n// int num_windows = dm.getAllImageWindows().size();\n// reporter.set_report_area(true, false, \"num of image windows = \"+num_windows);\n// //System.out.println(\"old window counter = \"+old_window_count);\n//\n// if(num_windows > Constants.current_window_count){\n// reporter.set_report_area(true, false, \"num windows increased = \"+num_windows);\n// DisplayWindow dw = dm.getAllImageWindows().get(num_windows-1);\n// reporter.set_report_area(true, false,\"new displaywindow exists = \"+dw);\n//\n// display_events = new displayEvents(mm, Constants.current_window_count, dw);\n// display_events.registerThisDisplay();\n//\n// Constants.current_window_count += 1;\n// reporter.set_report_area(\"current window count = \"+Constants.current_window_count);\n// old_window_count = Constants.current_window_count;\n// break;\n//\n// } else if (old_window_count == dm.getAllImageWindows().size()){\n// //old_window_count = current_window_count;\n// break;\n// } else {\n// reporter.set_report_area(true, false, \"num_windows not incremented yet\");\n// }\n// }\n reporter.set_report_area(true, true, true, \"displayevents not supported\");\n }\n \n}\n"
},
{
"alpha_fraction": 0.6002358198165894,
"alphanum_fraction": 0.6008254885673523,
"avg_line_length": 23.579710006713867,
"blob_id": "e14cc2816a5dc9ac6b43319af73e5020c9120963",
"content_id": "9ccd8085458d2e7649989588e4a7713590067683",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1696,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 69,
"path": "/src/main/java/org/mm2python/DataStructures/Builders/MDSParamObject.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python.DataStructures.Builders;\n\nimport java.security.InvalidParameterException;\n\n/**\n * a custom Object that accepts two types:\n * Integer\n * String\n * Used as two-type element for arraylist\n */\npublic class MDSParamObject {\n\n private Integer intValue=null;\n private String strValue=null;\n private String label;\n\n /**\n * String constructor useful for MDS values like filenames\n * @param label_ : Name of parameter\n * @param str : Value of parameter\n */\n public MDSParamObject(String label_, String str) {\n this.label = label_;\n this.strValue = str;\n }\n\n /**\n * Intenger constructor for MDS searches\n * @param label_ : Name of parameter like 'Z', \"TIME\", \"POSITION\"\n * @param i : value\n */\n public MDSParamObject(String label_, Integer i) {\n this.label = label_;\n this.intValue = i;\n }\n\n public MDSParamObject(String str) {\n this.strValue = str;\n }\n\n public MDSParamObject(Integer i) {\n this.intValue = i;\n }\n\n public String getStr() {\n if(this.strValue!=null) {\n return this.strValue;\n } else {\n throw new InvalidParameterException(\"MDSParamObject is not a Str object\");\n }\n }\n\n public Integer getInt() {\n if(this.intValue!=null) {\n return this.intValue;\n } else {\n throw new InvalidParameterException(\"MDSParamObject is not an Int object\");\n }\n }\n\n public String getLabel() {\n if(this.label!=null) {\n return this.label;\n } else {\n throw new InvalidParameterException(\"MDSParamObject has no assigned label\");\n }\n }\n\n}\n"
},
{
"alpha_fraction": 0.5367403030395508,
"alphanum_fraction": 0.548895001411438,
"avg_line_length": 28.19354820251465,
"blob_id": "c4513d1aeb151a4dc2cfe7036843384a2b58278a",
"content_id": "966b4195fb66c05b6426cd62744c96608b22b227",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3620,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 124,
"path": "/examples/mm2python_snap_live_display_monitor.py",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "from py4j.java_gateway import JavaGateway, CallbackServerParameters, GatewayParameters\nimport numpy as np\nfrom PyQt5.QtCore import QRunnable, QThreadPool, QObject, pyqtSlot, pyqtSignal\nimport time\n\nimport napari\n\n\ndef pull_memmap(entry_point):\n meta = entry_point.getLastMeta()\n if meta is None:\n return None\n else:\n data = np.memmap(meta.getFilepath(), dtype=\"uint16\", mode='r+', offset=meta.getBufferPosition(),\n shape=(meta.getxRange(), meta.getyRange()))\n return data\n\n# =======================================================\n# =========== Visualization classes =====================\n# =======================================================\n\n\nclass SimpleNapariWindow(QObject):\n\n def __init__(self):\n super().__init__()\n print('setting up napari window')\n self.viewer = napari.Viewer()\n\n N = 2048\n\n # init image data\n self.init_data_1 = 2 ** 16 * np.random.rand(N, N)\n\n # init layers with vector data and subscribe to gui notifications\n self.layer1 = self.viewer.add_image(self.init_data_1)\n\n @pyqtSlot(object)\n def update(self, data: object):\n # print('gui is notified of new data')\n try:\n self.layer1.data = data\n # self.layer1._node.set_data(data)\n # self.layer1._node.update()\n self.layer1.name = \"snap\"\n except Exception as ex:\n print(\"exception while updating gui \"+str(ex))\n\n\n# =======================================================\n# ============== mm2python data retrieval ===============\n# =======================================================\n\"\"\"\nThe \"ProcessRunnable\" class launches the monitor in another thread.\nOtherwise, the while loop will prevent the display from updating until everything is done\n\"\"\"\n\nclass ProcessRunnable(QRunnable):\n def __init__(self, target, args):\n super().__init__()\n self.t = target\n self.args = args\n\n def run(self):\n self.t(*self.args)\n\n def start(self):\n QThreadPool.globalInstance().start(self)\n\n\"\"\"\nSimple monitor to send new data to napari window\n\"\"\"\n\n\nclass MonitorPy4j(QObject):\n\n send_data_to_display = pyqtSignal(object)\n\n def __init__(self, gateway_):\n super(MonitorPy4j, self).__init__()\n self.gateway = gateway_\n self.ep = self.gateway.entry_point\n\n def launch_monitor_in_process(self,):\n p = ProcessRunnable(target=self.monitor_process, args=())\n p.start()\n\n def monitor_process(self):\n print('monitor launched')\n self.ep.clearQueue()\n count = 0\n while True:\n time.sleep(0.001)\n\n data = pull_memmap(self.ep)\n while data is None:\n data = pull_memmap(self.ep)\n self.send_data_to_display.emit(data)\n\n if count >= 1000:\n # timeout is 2.5 minutes = 15000\n print(\"timeout waiting for more data\")\n break\n else:\n count += 1\n if count % 100 == 0:\n print('waiting')\n\n\nif __name__ == '__main__':\n\n with napari.gui_qt():\n\n # connect to org.mm2python\n gateway = JavaGateway(gateway_parameters=GatewayParameters(auto_field=True),\n callback_server_parameters=CallbackServerParameters())\n\n window = SimpleNapariWindow()\n monitor = MonitorPy4j(gateway)\n\n # connect the window's slot with the monitor's signal\n monitor.send_data_to_display.connect(window.update)\n\n monitor.launch_monitor_in_process()\n"
},
{
"alpha_fraction": 0.6485294103622437,
"alphanum_fraction": 0.6647058725357056,
"avg_line_length": 22.05084800720215,
"blob_id": "917e0b5bff37f95c4bd3580776a9a76a334a36e3",
"content_id": "615e9380858e0d1d3344688209c985ad59815ed4",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1360,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 59,
"path": "/examples/python_hardware_control.py",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "# import\nfrom py4j.java_gateway import JavaGateway, GatewayParameters\nimport numpy as np\n\n# connect to org.mm2python\ngateway = JavaGateway(gateway_parameters=GatewayParameters(auto_field=True))\n\n# link to class\nep = gateway.entry_point\nmm = ep.getStudio()\nmmc = ep.getCMMCore()\n\n# ===========================================================\n# ====== micro-manager core or studio control with py4j =====\n# ===========================================================\n\n# https://valelab4.ucsf.edu/~MM/doc-2.0.0-beta/mmstudio/org/micromanager/Studio.html\n# https://valelab4.ucsf.edu/~MM/doc-2.0.0-beta/mmcorej/mmcorej/CMMCore.html\n\n\n\n# DEVICE CONTROL USING CORE\n\n# Z stage\nmmc.getPosition()\nmmc.getPosition(\"Z\")\nmmc.setPosition(5.9999)\n\n# XY Stage\nmmc.getXPosition()\nmmc.getYPosition()\n\n# camera\nmmc.setCameraDevice(\"camera name\")\nmmc.setExposure(100.0)\n\n# set any general device's property\nmmc.setProperty(\"device name\", \"device property\", \"value\")\n\n\n\n# DEVICE CONTROL USING STUDIO\n\naf = mm.getAutofocusManager()\nafp = af.getAutofocusMethod()\n\n\n\n# RETRIEVING DATA\n\n# get metadata of the most recent image taken\nmeta = ep.getLastMeta()\n\n# get path of memory mapped file\nmeta.getFilepath()\n\n# load the file\ndata = np.memmap(meta.getFilepath(), dtype=\"uint16\", mode='r+', offset=meta.getBufferPosition(),\n shape=(meta.getxRange(), meta.getyRange()))\n"
},
{
"alpha_fraction": 0.6229782104492188,
"alphanum_fraction": 0.624118983745575,
"avg_line_length": 32.76203536987305,
"blob_id": "16cb1cfb332dcd360a2b1e2e503568c2abc97ade",
"content_id": "36f279f54a278b3dc180806cc33cbee246bcd1e4",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 24545,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 727,
"path": "/src/main/java/org/mm2python/MPIMethod/Py4J/Py4JEntryPoint.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage org.mm2python.MPIMethod.Py4J;\n\nimport mmcorej.TaggedImage;\nimport org.micromanager.data.Image;\nimport org.mm2python.DataStructures.Builders.MDSBuilder;\nimport org.mm2python.DataStructures.Builders.MDSParamBuilder;\nimport org.mm2python.DataStructures.Builders.MDSParameters;\nimport org.mm2python.DataStructures.Constants;\nimport org.mm2python.DataStructures.Maps.MDSMap;\nimport org.mm2python.DataStructures.MetaDataStore;\n//import org.mm2python.DataStructures.Queues.DynamicMemMapReferenceQueue;\nimport org.mm2python.DataStructures.Queues.FixedMemMapReferenceQueue;\nimport org.mm2python.DataStructures.Queues.MDSQueue;\nimport org.mm2python.MPIMethod.zeroMQ.zeroMQ;\nimport org.mm2python.UI.reporter;\nimport org.mm2python.mmDataHandler.DataPathInterface;\nimport org.mm2python.mmDataHandler.DataMapInterface;\nimport mmcorej.CMMCore;\nimport org.micromanager.Studio;\nimport org.mm2python.mmDataHandler.Exceptions.NoImageException;\nimport org.mm2python.mmDataHandler.memMapWriter;\nimport org.zeromq.ZContext;\nimport org.zeromq.ZMQ;\n\nimport java.io.FileNotFoundException;\nimport java.io.IOException;\nimport java.nio.MappedByteBuffer;\nimport java.security.InvalidParameterException;\nimport java.util.ArrayList;\n\n\n/**\n * \n * @author bryant.chhun\n */\npublic class Py4JEntryPoint implements DataMapInterface, DataPathInterface {\n private static Studio mm;\n private static CMMCore mmc;\n private static Py4JListener listener;\n\n /**\n * constructor\n * @param mm_: the parent studio object.\n */\n Py4JEntryPoint(Studio mm_){\n mm = mm_;\n mmc = mm_.getCMMCore();\n listener = new Py4JListener();\n }\n\n /**\n * retrieve the micro-manager GUI object\n * @return : Studio\n */\n public Studio getStudio() {\n return mm;\n }\n\n /**\n * retrieve the micro-manager CORE object\n * @return : CMMCore\n */\n public CMMCore getCMMCore() {\n return mmc;\n }\n\n /**\n * retrieve the py4j listener object (for implementing java interfaces from python)\n * @return : Py4JListener\n */\n public Py4JListener getListener() {\n return listener;\n }\n\n /**\n * current camera's image bitdepth\n * @return : int\n */\n public int getBitDepth() {return (int)Constants.bitDepth;}\n\n /**\n * current camera's image height\n * @return : int\n */\n public int getHeight() {return (int) Constants.height;}\n\n /**\n * current camera's image width\n * @return : int\n */\n public int getWidth() {return (int) Constants.width;}\n\n //============== provide utility functions for system management ====//\n\n /**\n * utility for resetting the queue of acquired images\n * useful when scripting acquisition\n */\n public void clearQueue(){\n MDSQueue.resetQueue();\n }\n\n /**\n * query if acquired image queue is empty\n * @return : boolean\n */\n public boolean isQueueEmpty(){\n return MDSQueue.isQueueEmpty();\n }\n\n /**\n * clears the MDSMap store\n * the MDSMap store holds all acquired metadata in no particular order\n */\n public void clearMaps() {\n MDSMap.clearData();\n }\n\n /**\n * query if MDSMap is empty\n * @return : boolean\n */\n public boolean isMapEmpty() {\n return MDSMap.isEmpty();\n }\n\n /**\n * clear both MDSQueue and MDSMaps\n */\n public void clearAll() {\n MDSQueue.resetQueue();\n MDSMap.clearData();\n }\n\n //============== zmq data retrieval methods ==================================//\n /**\n * return either the metadata for the last image or send the raw image to zmq ports\n */\n public boolean sendLastImage() {\n try {\n MetaDataStore mds = this.getLastMeta();\n Object rawpixels = mds.getDataProvider().getImage(mds.getCoord()).getRawPixels();\n zeroMQ.send(rawpixels);\n return true;\n } catch (Exception ex) {\n return false;\n }\n }\n\n /**\n * send the first image (as determined by MDS Queue) out via zeroMQ port\n */\n public boolean sendFirstImage() {\n try {\n MetaDataStore mds = this.getFirstMeta();\n Object rawpixels = mds.getImage();\n zeroMQ.send(rawpixels);\n return true;\n } catch (Exception ex) {\n return false;\n }\n }\n\n /**\n * send the image (as determined by supplied MDS) out via zeroMQ port\n * @param mds\n */\n public boolean sendImage(MetaDataStore mds) {\n try {\n Object rawpixels = mds.getDataProvider().getImage(mds.getCoord()).getRawPixels();\n zeroMQ.send(rawpixels);\n return true;\n } catch (Exception ex) {\n return false;\n }\n }\n\n public boolean sendImage(TaggedImage tm) {\n try {\n Object rawpixels = tm.pix;\n zeroMQ.send(rawpixels);\n return true;\n } catch (Exception ex) {\n reporter.set_report_area(\"Exception sending TaggedImage to zmq socket: \"+ex.toString());\n return false;\n }\n }\n\n public boolean sendImage(Image im) {\n try {\n zeroMQ.send(im.getRawPixels());\n return true;\n } catch (Exception ex) {\n reporter.set_report_area(\"Exception sending Image to zmq socket: \"+ex.toString());\n return false;\n }\n }\n\n public boolean sendImage(Object obj) {\n try{\n if (obj instanceof short[] || obj instanceof byte[]){\n zeroMQ.send(obj);\n return true;\n } else {\n reporter.set_report_area(\"object representing internal image Buffer is not an instance of Short[] or byte[]\");\n return false;\n }\n } catch (Exception ex) {\n reporter.set_report_area(\"Exception sending short[] or byte[] object to zmq socket: \"+ex.toString());\n return false;\n }\n }\n\n /**\n * get the zeroMQ port\n * @return : String\n */\n public String getZMQPort() {\n return zeroMQ.getPort();\n }\n\n public ZMQ.Socket getZMQSocket() {\n return zeroMQ.socket;\n }\n\n public ZContext getZMQContext() {\n return zeroMQ.getContext();\n }\n\n // =====================================\n // MDSQueue retrieval interface methods\n\n public MetaDataStore getLastMeta() {\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDS());\n }\n\n public MetaDataStore getFirstMeta() {\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDS());\n }\n\n /**\n * If the supplied MDS was generated in \"on demand\" mode, it would not have a filepath but WILL have a datastore\n * this method will take the data, write it to a memory map, and return a new MDS that includes the filepath\n *\n * @param mds_: MetaDataStore\n * @return MetaDataStore with filepath\n */\n private MetaDataStore checkMDS(MetaDataStore mds_) {\n\n if(mds_.getFilepath() == null && mds_.getDataProvider() != null) {\n // mds was acquired by \"on demand\" method\n // we must write it to the next mem map file and modify the MDS\n try{\n if(FixedMemMapReferenceQueue.isFileQueueEmpty()){\n FixedMemMapReferenceQueue.createFileNames(Constants.getNumTempFiles());\n }\n } catch(FileNotFoundException FNF) {\n reporter.set_report_area(\"FileNotFound while creating memory mapped files\");\n }\n MappedByteBuffer buffer = FixedMemMapReferenceQueue.getNextBuffer();\n String filename = FixedMemMapReferenceQueue.getNextFileName();\n// String filename = FixedMemMapReferenceQueue.getBufferFileName(buffer);\n\n try {\n Image im = mds_.getDataProvider().getImage(mds_.getCoord());\n memMapWriter.writeToMemMap(im, buffer, 0);\n return new MDSBuilder()\n .position(mds_.getPosition())\n .time(mds_.getTime())\n .z(mds_.getZ())\n .channel(mds_.getChannel())\n .xRange(mds_.getxRange())\n .yRange(mds_.getyRange())\n .bitDepth(mds_.getBitDepth())\n .prefix(mds_.getPrefix())\n .windowname(mds_.getWindowName())\n .channel_name(mds_.getChannelName())\n .filepath(filename)\n .buffer_position(mds_.getBufferPosition())\n .dataprovider(mds_.getDataProvider())\n .coord(mds_.getCoord())\n .summaryMetadata(mds_.getSummaryMetadata())\n .buildMDS();\n\n } catch (IOException ioe) {\n reporter.set_report_area(\"IOException while getting image from DataProvider: \" + ioe.toString());\n } catch (NoImageException nie) {\n reporter.set_report_area(\"NoImageException while writing image to memory mapped file\");\n } catch (IllegalAccessException ilex) {\n reporter.set_report_area(String.format(\"Fail to build MDS for c%d, z%d, p%d, t%d, filepath=%s\",\n mds_.getChannel(), mds_.getZ(), mds_.getPosition(), mds_.getTime(), filename));\n }\n }\n return mds_;\n }\n\n\n // =============================================================================\n\n\n /**\n * Core Images do not automatically generate MetaData Files.\n * - Creates MDS based on next available memory mapped file name\n * - write this MDS to queues/maps, and return this to users\n * @param objim : image Object of type Image, TaggedImage, or Object\n * @return MetaDataStore\n */\n public MetaDataStore getCoreMeta(Object objim) {\n\n MetaDataStore mds = createMDS();\n MappedByteBuffer buffer = null;\n if(!Constants.getZMQButton()) {\n buffer = FixedMemMapReferenceQueue.getNextBuffer();\n } else {\n reporter.set_report_area(\"Data transfer mode is set to ZMQ not memory map\");\n return null;\n }\n\n try {\n if(!Constants.getZMQButton()) {\n memMapWriter.writeToMemMap(objim, buffer, mds.getBufferPosition());\n }\n MDSMap.putMDS(mds);\n MDSQueue.putMDS(mds);\n } catch (NoImageException nie) {\n reporter.set_report_area(\"Attempted to write image, but no image data exists! \"\n +nie.toString());\n } catch (InvalidParameterException ipe) {\n reporter.set_report_area(\"InvalidParameterException while writing to MetaDataStore HashMap: \"\n +ipe.toString());\n } catch (NullPointerException npe){\n reporter.set_report_area(\"NullPointerException while writing to MetaDataStore HashMap: \"\n +npe.toString());\n } catch (Exception ex) {\n reporter.set_report_area(\"General Exception during getCoreMeta \"+ex.toString());\n }\n return mds;\n }\n\n /**\n * build a MDS using:\n * - memory mapped filename retrieved from queues\n * - image width, height, bitdepth retrieved from core\n * - buffer position based on mem map writing type\n * @return MetaDataStore\n */\n private MetaDataStore createMDS() {\n MetaDataStore mds_;\n String filename = null;\n\n // evaluate data transfer method\n if(!Constants.getZMQButton()) {\n filename = FixedMemMapReferenceQueue.getNextFileName();\n } else {\n reporter.set_report_area(\"Data transfer mode is set to ZMQ not memory map\");\n }\n\n // create metadata\n try {\n mds_ = new MDSBuilder()\n .filepath(filename)\n .buffer_position(0)\n .xRange((int) mmc.getImageWidth())\n .yRange((int) mmc.getImageHeight())\n .bitDepth((int) mmc.getImageBitDepth())\n .buildMDS();\n } catch (Exception ex) {\n reporter.set_report_area(ex.toString());\n return null;\n }\n return mds_;\n }\n\n// /**\n// * Query the Memory Mapped Reference Queues for the next available memmap file\n// *\n// * @return MappedByteBuffer : the next available memory mapped file\n// */\n// private MappedByteBuffer getNextBuffer() {\n// MappedByteBuffer buffer = null;\n// // evaluate data transfer method\n// if(!Constants.getZMQButton()) {\n// buffer = FixedMemMapReferenceQueue.getNextBuffer();\n// } else {\n// reporter.set_report_area(\"Data transfer mode is set to ZMQ not memory map\");\n// }\n// return buffer;\n// }\n\n // ==========================================================================================\n\n @Override\n public MetaDataStore getLastMetaByChannelName(String channelName) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getLastMetaByChannelIndex(int channelIndex) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getLastMetaByZ(int z) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getLastMetaByPosition(int pos) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getLastMetaByTime(int time) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getLastMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getFirstMetaByChannelName(String channelName) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getFirstMetaByChannelIndex(int channelIndex) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getFirstMetaByZ(int z) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getFirstMetaByPosition(int pos) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDSByParam(params));\n }\n\n @Override\n public MetaDataStore getFirstMetaByTime(int time) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return checkMDS(MDSQueue.getFirstMDSByParam(params));\n }\n\n// public void removeFirstMetaByChannelName(String channelName) throws IllegalAccessException {\n// MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n//\n// MDSQueue.removeFirstMDSByParam(params));\n// }\n//\n// public void removeLastMetaByChannelName(String channelName) throws IllegalAccessException {\n// MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n//\n// MDSQueue.removeFirstMDSByParam(params));\n// }\n\n //============== Data Path interface methods ====================//\n //== For retrieving Filepaths to mmap files =====================//\n\n\n // Path retrieval interface methods\n\n @Override\n public String getLastFileByChannelName(String channelName) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get last file by channel\n @Override\n public String getLastFileByChannelIndex(int channelIndex) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get last file by z\n @Override\n public String getLastFileByZ(int z) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get last file by p\n @Override\n public String getLastFileByPosition(int pos) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get last file by t\n @Override\n public String getLastFileByTime(int time) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get first file by channel_name\n @Override\n public String getFirstFileByChannelName(String channelName) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get first file by channel\n @Override\n public String getFirstFileByChannelIndex(int channelIndex) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get first file by z\n @Override\n public String getFirstFileByZ(int z) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get first file by p\n @Override\n public String getFirstFileByPosition(int pos) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n // get first file by t\n @Override\n public String getFirstFileByTime(int time) throws IllegalAccessException {\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n\n if(MDSQueue.isQueueEmpty()) {\n return null;\n }\n return MDSQueue.getLastFilenameByParam(params);\n }\n\n //============== Data Map interface methods ====================//\n //== For retrieving MetaDataStore objects and Filenames ======================//\n //== Useful for retrieving but not removing references to existing data ======//\n\n // Map retrieval interface methods\n\n @Override\n public ArrayList<String> getAllFilesByChannelName(String channelName) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n\n return MDSMap.getFilenamesByParams(params);\n }\n\n @Override\n public ArrayList<String> getAllFilesByChannelIndex(int channelIndex) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n\n return MDSMap.getFilenamesByParams(params);\n }\n\n @Override\n public ArrayList<String> getAllFilesByZ(int z) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n\n return MDSMap.getFilenamesByParams(params);\n }\n\n @Override\n public ArrayList<String> getAllFilesByPosition(int pos) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n\n return MDSMap.getFilenamesByParams(params);\n }\n\n @Override\n public ArrayList<String> getAllFilesByTime(int time) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n\n return MDSMap.getFilenamesByParams(params);\n }\n\n @Override\n public ArrayList<MetaDataStore> getAllMetaByChannelName(String channelName) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel_name(channelName).buildMDSParams();\n\n return MDSMap.getMDSByParams(params);\n }\n\n @Override\n public ArrayList<MetaDataStore> getAllMetaByChannelIndex(int channelIndex) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().channel(channelIndex).buildMDSParams();\n\n return MDSMap.getMDSByParams(params);\n }\n\n @Override\n public ArrayList<MetaDataStore> getAllMetaByZ(int z) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().z(z).buildMDSParams();\n\n return MDSMap.getMDSByParams(params);\n }\n\n @Override\n public ArrayList<MetaDataStore> getAllMetaByPosition(int pos) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().position(pos).buildMDSParams();\n\n return MDSMap.getMDSByParams(params);\n }\n\n @Override\n public ArrayList<MetaDataStore> getAllMetaByTime(int time) throws IllegalAccessException{\n MDSParameters params = new MDSParamBuilder().time(time).buildMDSParams();\n\n return MDSMap.getMDSByParams(params);\n }\n\n\n // ==============================================================\n // Methods to return metadatastores based on arbitrary parameters //\n /**\n * get the parameter builder to search on custom subset of parameters\n * useful if you want to search on 2 or more parameters\n * @return : MDSParamBuilder object\n */\n @Override\n public MDSParamBuilder getParameterBuilder() {\n return new MDSParamBuilder();\n }\n\n /**\n * get a list of MetaDataStore objects that match the supplied parameters\n * note: to extract on unhashed parameters, you must filter the results externally\n * i.e.: arraylist.get(0).windowname == \"specific window name\"\n * @param mdsp : MDSParameters object\n * @return : Arraylist of MDS (or list in python)\n */\n @Override\n public ArrayList<MetaDataStore> getMetaByParameters(MDSParameters mdsp) {\n return MDSMap.getMDSByParams(mdsp);\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.5943138599395752,
"alphanum_fraction": 0.5954073071479797,
"avg_line_length": 26.712121963500977,
"blob_id": "4287b4585f1adce3e9fa52c45e5f257895b51e97",
"content_id": "bf11071bf07922917a5804539daf79a289b484e8",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1829,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 66,
"path": "/src/main/java/org/mm2python/DataStructures/Builders/MDSParamBuilder.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python.DataStructures.Builders;\n\nimport org.mm2python.DataStructures.MetaDataStore;\n\nimport java.util.ArrayList;\n\n/**\n * build an arraylist of parameters (String)\n * parameters are simply T, P, Z, C, C_name\n * used when querying MDSMap or MDSQueue for MetaDataStores\n */\npublic class MDSParamBuilder extends MDSBuilderBase {\n\n private ArrayList<MDSParamObject> params;\n\n public MDSParamBuilder() {\n params = new ArrayList<>();\n }\n\n public MDSParameters buildMDSParams() {\n\n if(time!=null) {\n params.add(new MDSParamObject(\"TIME\", time));\n }\n if(pos!=null) {\n params.add(new MDSParamObject(\"POSITION\", pos));\n }\n if(z!=null) {\n params.add(new MDSParamObject(\"Z\", z));\n }\n if(channel!=null) {\n params.add(new MDSParamObject(\"CHANNEL\", channel));\n }\n\n if(channel_name!=null) {\n params.add(new MDSParamObject(\"CHANNELNAME\", channel_name));\n }\n\n if(xRange!=null) {\n params.add(new MDSParamObject(\"XRANGE\", xRange));\n }\n if(yRange!=null) {\n params.add(new MDSParamObject(\"YRANGE\", yRange));\n }\n if(bitDepth!=null) {\n params.add(new MDSParamObject(\"BITDEPTH\", bitDepth));\n }\n\n if(prefix!=null) {\n params.add(new MDSParamObject(\"PREFIX\", prefix));\n }\n if(windowname!=null) {\n params.add(new MDSParamObject(\"WINDOWNAME\", windowname));\n }\n if(filepath!=null) {\n params.add(new MDSParamObject(\"FILEPATH\", filepath));\n }\n\n return new MDSParameters(params);\n }\n\n public MetaDataStore buildMDS() throws IllegalAccessException{\n throw new IllegalAccessException(\"buildMDS not allowed from ParamBuilder\");\n }\n\n}\n"
},
{
"alpha_fraction": 0.7259036302566528,
"alphanum_fraction": 0.7289156913757324,
"avg_line_length": 19.75,
"blob_id": "a49ad01db70b50b958da914ed800859b248f54bc",
"content_id": "fece15f9b8570837a32de6e2af62168979c7b4a8",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 332,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 16,
"path": "/src/main/java/org/mm2python/mmEventHandler/Exceptions/NotImplementedException.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python.mmEventHandler.Exceptions;\n\n\npublic class NotImplementedException extends Exception{\n\n public NotImplementedException(String pString)\n {\n super(pString);\n }\n\n public NotImplementedException(String pErrorMessage, Throwable pThrowable)\n {\n super(pErrorMessage, pThrowable);\n }\n\n}\n"
},
{
"alpha_fraction": 0.6929556131362915,
"alphanum_fraction": 0.6956355571746826,
"avg_line_length": 31.24691390991211,
"blob_id": "c8ed19410f20ad232dcbaf8c25d21b02ee0b7c3b",
"content_id": "150a65c75f6e3f8a2ea884b5519c543244eec819",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2612,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 81,
"path": "/src/main/java/org/mm2python/mmEventHandler/displayEvents.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage org.mm2python.mmEventHandler;\n\nimport org.mm2python.UI.reporter;\nimport org.mm2python.mmEventHandler.Exceptions.NotImplementedException;\n\nimport com.google.common.eventbus.Subscribe;\nimport org.micromanager.Studio;\nimport org.micromanager.display.*;\n\n/**\n * used to track display windows\n * number of windows is tracked using static field in \"Constants\" class.\n * @author bryant.chhun\n */\npublic class displayEvents {\n private final Studio mm;\n private final DisplayWindow window;\n\n\n /**\n * For registering micro-manager display events\n * See here for more details about mm API events:\n * https://micro-manager.org/wiki/Version_2.0_API_Events\n *\n * @param mm_ parent micro-manager Studio object\n * @param window_ DisplayWindow whose construction triggered this class's construction\n */\n public displayEvents(Studio mm_, DisplayWindow window_) {\n mm = mm_;\n window = window_;\n }\n\n public displayEvents(Studio mm_, int current_window_count_, DisplayWindow window_) {\n mm = mm_;\n window = window_;\n }\n\n /**\n * Register this class for notifications from micro-manager.\n */\n public void registerThisDisplay(){\n window.registerForEvents(this);\n }\n\n// @Subscribe\n// public void monitor_DisplayDestroyedEvent(DisplayDestroyedEvent event){\n// reporter.set_report_area(\"display destroyed\");\n// window.unregisterForEvents(this);\n// }\n \n// @Subscribe\n// public void monitor_NewDisplaySettingsEvent(NewDisplaySettingsEvent event) throws NotImplementedException{\n// throw new NotImplementedException(\"NewDisplaySettingsEvent not implemented\");\n// }\n \n// @Subscribe\n// public void monitor_NewImagePlusEvent(NewImagePlusEvent event) throws NotImplementedException{\n// throw new NotImplementedException(\"NewImagePlusEvent not implemented\");\n// }\n \n// @Subscribe\n// public void monitor_PixelsSetEvent(PixelsSetEvent event) throws NotImplementedException{\n// throw new NotImplementedException(\"PixelsSetEvent not implemented\");\n// }\n\n// /**\n// * RequestToDrawEvent appears in the online documentation: https://micro-manager.org/wiki/Version_2.0_API_Events\n// * but it does not appear in the code!\n// * @param event\n// */\n// @Subscribe\n// public void monitor_RequestToDrawEvent(RequestToDrawEvent event){\n//\n// }\n \n}\n"
},
{
"alpha_fraction": 0.5594237446784973,
"alphanum_fraction": 0.5594237446784973,
"avg_line_length": 13.614034652709961,
"blob_id": "54343f3ce149f4a4553c94132e48a2c32c04b52d",
"content_id": "091fb4983f5bd59dfb27b02a58ced979a0831928",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 833,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 57,
"path": "/src/test/java/Tests/EventHandlerTests/mmDataHandlerTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.EventHandlerTests;\n\nimport org.junit.jupiter.api.Test;\n\npublic class mmDataHandlerTests {\n\n // ============ Tests for memMapImage ======================\n @Test\n void test_memMapImage_byteimg() {\n\n }\n\n @Test\n void test_memMapImage_shortimg() {\n\n }\n\n @Test\n void test_memMapImage_MetaStoreCreation() {\n\n }\n\n @Test\n void test_memMapImage_MetaToFilename() {\n\n }\n\n @Test\n void test_memMapImage_ChanToMeta() {\n\n }\n\n //========== Tests for MetadataStore information =========\n\n @Test\n void test_MetaDataStore_elements() {\n\n }\n\n @Test\n void test_MetaDataStore_hashCode() {\n\n }\n\n @Test\n void test_MetaDataStore_equality() {\n\n }\n\n //========== Tests for integration of writing and data store =======\n\n @Test\n void test_process() {\n\n }\n\n}\n"
},
{
"alpha_fraction": 0.6556394100189209,
"alphanum_fraction": 0.6600799560546875,
"avg_line_length": 28.05806541442871,
"blob_id": "77ea5d20bcfbe448752f4cf5b58402dd302c31c0",
"content_id": "8bb51201a6ec04f3b5bb468acbb6bef29ee8320f",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4504,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 155,
"path": "/src/test/java/Tests/EventHandlerTests/DatastoreEventsThreadTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.EventHandlerTests;\n\nimport org.junit.jupiter.api.Test;\nimport org.micromanager.LogManager;\nimport org.micromanager.Studio;\nimport org.micromanager.acquisition.AcquisitionManager;\nimport org.micromanager.acquisition.SequenceSettings;\nimport org.micromanager.data.Coords;\nimport org.micromanager.data.Datastore;\nimport org.micromanager.data.Image;\nimport org.micromanager.data.SummaryMetadata;\nimport org.mm2python.DataStructures.Maps.MDSMap;\nimport org.mm2python.DataStructures.Queues.DynamicMemMapReferenceQueue;\nimport org.mm2python.DataStructures.Queues.FixedMemMapReferenceQueue;\nimport org.mm2python.DataStructures.Queues.MDSQueue;\nimport org.mm2python.UI.reporter;\nimport org.mm2python.mmEventHandler.datastoreEventsThread;\n\nimport javax.swing.*;\nimport javax.swing.text.Document;\n\nimport java.nio.MappedByteBuffer;\n\nimport static org.junit.jupiter.api.Assertions.assertEquals;\nimport static org.mockito.ArgumentMatchers.anyString;\nimport static org.mockito.ArgumentMatchers.anyInt;\nimport static org.mockito.Mockito.*;\n\n\nclass DatastoreEventsThreadTests {\n\n private Studio mm;\n private Datastore ds;\n private Coords coord;\n private Image im;\n private SummaryMetadata smd;\n private DynamicMemMapReferenceQueue dynamic;\n private FixedMemMapReferenceQueue fixed;\n private MDSMap mdsm;\n private MDSQueue mdsq;\n\n private void setUp() {\n mm = mock(Studio.class);\n\n // mocking methods needed by reporter\n // JText Area\n JTextArea jta = mock(JTextArea.class);\n doNothing().when(jta).append(anyString());\n Document doc = mock(Document.class);\n when(jta.getDocument()).thenReturn(doc);\n when(doc.getLength()).thenReturn(0);\n doNothing().when(jta).setCaretPosition(anyInt());\n new reporter(jta, mm);\n\n // mm log manager\n LogManager lm = mock(LogManager.class);\n when(mm.logs()).thenReturn(lm);\n doNothing().when(lm).logMessage(anyString());\n\n // mocking methods needed by testrunnable\n ds = mock(Datastore.class);\n SequenceSettings ss = mock(SequenceSettings.class);\n AcquisitionManager aq = mock(AcquisitionManager.class);\n when(mm.acquisitions()).thenReturn(aq);\n when(aq.getAcquisitionSettings()).thenReturn(ss);\n\n // mock for constructor\n coord = mock(Coords.class);\n im = mock(Image.class);\n smd = mock(SummaryMetadata.class);\n when(smd.getChannelNames()).thenReturn(new String[] {\"mock ch0\", \"mock ch1\"});\n when(coord.getChannel()).thenReturn(1);\n when(im.getWidth()).thenReturn(2048);\n when(im.getHeight()).thenReturn(2048);\n when(im.getBytesPerPixel()).thenReturn(2);\n\n // not possible to mock\n // mock fixed and dynamic memmap reference\n datastoreEventsThread det = spy(new datastoreEventsThread(ds,\n coord,\n im,\n smd,\n \"chan\",\n \"prefix\",\n \"window\"));\n fixed = mock(FixedMemMapReferenceQueue.class);\n\n when(fixed.getNextFileName()).thenReturn(\"mocked_fixed_filename\");\n MappedByteBuffer mbb = mock(MappedByteBuffer.class);\n when(fixed.getNextBuffer()).thenReturn(mbb);\n\n dynamic = mock(DynamicMemMapReferenceQueue.class);\n when(dynamic.getCurrentFileName()).thenReturn(\"mocked_dyanmic_filename\");\n when(dynamic.getCurrentBuffer()).thenReturn(mbb);\n when(dynamic.getCurrentPosition()).thenReturn(0);\n\n // mock MDSMap, MDSQueue\n mdsm = mock(MDSMap.class);\n mdsq = mock(MDSQueue.class);\n\n }\n\n @Test\n void testConstructor() {\n// setUp();\n//\n// datastoreEventsThread deth = new datastoreEventsThread(ds,\n// coord,\n// im,\n// smd,\n// \"current channel\",\n// \"prefix\",\n// \"window name\");\n//\n// assertEquals(deth, datastoreEventsThread.class);\n\n\n }\n\n /**\n * need to test sub methods using multiple constructors with different passed parameters\n * \"testing private methods through the public methods\"\n */\n\n @Test\n void testRunnableWriteToMemMap() {\n\n }\n\n @Test\n void testRunnableMakeMDS() {\n\n }\n\n @Test\n void testRunnableWriteToHashMap() {\n\n }\n\n @Test\n void testRunnableWriteToQueues() {\n\n }\n\n @Test\n void testRunnableNotifyListeners() {\n\n }\n\n @Test\n void testGetFileName() {\n\n }\n\n}\n"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 16.5,
"blob_id": "037b422a198afa5d424fd2eb1816bb8e0e2eed5d",
"content_id": "7ef6781e1408ad34fba226726e619cf154d39bbb",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 70,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 4,
"path": "/src/test/java/Tests/EventHandlerTests/DisplayEventsTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.EventHandlerTests;\n\npublic class DisplayEventsTests {\n}\n"
},
{
"alpha_fraction": 0.6393952965736389,
"alphanum_fraction": 0.6456202864646912,
"avg_line_length": 25.162790298461914,
"blob_id": "99757cd05e66745cfc5aa7c48f5567e42a088868",
"content_id": "44c6c8f9abcdec3c03e85300b5689ff94f652b30",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2249,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 86,
"path": "/src/main/java/org/mm2python/mm2PythonPlugin.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python;\n\n/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\n\n/**\n *\n * @author bryant.chhun\n */\n\nimport org.mm2python.UI.pythonBridgeUI_dialog;\nimport mmcorej.CMMCore;\nimport org.micromanager.MenuPlugin;\nimport org.micromanager.Studio;\nimport org.scijava.plugin.Plugin;\nimport org.scijava.plugin.SciJavaPlugin;\n\n@Plugin(type = MenuPlugin.class)\npublic class mm2PythonPlugin implements MenuPlugin, SciJavaPlugin{\n private static final String menuName = \"mm2python_v0.0.2\";\n private static final String tooltipDescription = \"Establishes a Py4J gateway for Python control of Micro-Manager and access to data\";\n private static final String version = \"0.0.1\";\n private static final String copyright = \"CZ Biohub\";\n\n // Provides access to the Micro-Manager Core API (for direct hardware\n // control)\n private CMMCore mmc_;\n\n // Provides access to the Micro-Manager Java API (for GUI control and high-\n // level functions).\n private Studio mm_;\n\n private pythonBridgeUI_dialog myFrame_;\n\n @Override\n public String getSubMenu() {\n return \"mm2python\";\n }\n\n @Override\n public void onPluginSelected() {\n if (myFrame_ == null) {\n try {\n myFrame_ = new pythonBridgeUI_dialog(mm_, mmc_);\n// mm_.events().registerForEvents(myFrame_);\n } catch (Exception e) {\n mm_.logs().showError(e);\n }\n }\n myFrame_.pack();\n myFrame_.setVisible(true);\n\n /* if necessary, we can launch the mm2python plugin UI in another thread */\n// MainExecutor.getExecutor().execute(new mm2pythonGUIRunnable(mm_, mmc_));\n }\n\n @Override\n public void setContext(Studio app) {\n mm_ = app;\n mmc_ = app.getCMMCore();\n }\n\n @Override\n public String getName() {\n return menuName;\n }\n\n @Override\n public String getHelpText() {\n return tooltipDescription;\n }\n\n @Override\n public String getVersion() {\n return version;\n }\n\n @Override\n public String getCopyright() {\n return copyright;\n }\n\n}"
},
{
"alpha_fraction": 0.7558997273445129,
"alphanum_fraction": 0.7566371560096741,
"avg_line_length": 30.534883499145508,
"blob_id": "76b5ed7a13533ab20e82c2eb286a580084f00d6e",
"content_id": "ec4aeffa0bf8b85dcb759e7ca805043faad014c1",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1356,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 43,
"path": "/src/main/java/org/mm2python/mmDataHandler/DataPathInterface.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python.mmDataHandler;\n\n/**\n *\n * @author bryant.chhun\n */\npublic interface DataPathInterface {\n\n // methods to retrieve from queue\n // these call PathQueue\n // return a single string\n // get last file by channel_name\n public String getLastFileByChannelName(String channelName) throws IllegalAccessException;\n\n // get last file by channel\n public String getLastFileByChannelIndex(int channelIndex) throws IllegalAccessException;\n\n // get last file by z\n public String getLastFileByZ(int z) throws IllegalAccessException;\n\n // get last file by p\n public String getLastFileByPosition(int pos) throws IllegalAccessException;\n\n // get last file by t\n public String getLastFileByTime(int time) throws IllegalAccessException;\n\n // get first file by channel_name\n public String getFirstFileByChannelName(String channelName) throws IllegalAccessException;\n\n // get first file by channel\n public String getFirstFileByChannelIndex(int channelIndex) throws IllegalAccessException;\n\n // get first file by z\n public String getFirstFileByZ(int z) throws IllegalAccessException;\n\n // get first file by p\n public String getFirstFileByPosition(int pos) throws IllegalAccessException;\n\n // get first file by t\n public String getFirstFileByTime(int time) throws IllegalAccessException;\n\n\n}\n"
},
{
"alpha_fraction": 0.5979883074760437,
"alphanum_fraction": 0.6155093908309937,
"avg_line_length": 29.205883026123047,
"blob_id": "782eb09b08705bc816992d7e4a3507ecc5956a03",
"content_id": "c12f6f18aa02d14a0cd2a7c35fda37e30fe8ff59",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3082,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 102,
"path": "/examples/python_basic.py",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "# bchhun, {2019-06-18}\n\n# import\nfrom py4j.java_gateway import JavaGateway, GatewayParameters\nimport numpy as np\n\n# connect to org.mm2python\ngateway = JavaGateway(gateway_parameters=GatewayParameters(auto_field=True))\n\n# link to class\nep = gateway.entry_point\nmm = ep.getStudio()\nmmc = ep.getCMMCore()\n\n# ===========================================================\n# ====== micro-manager core or studio control with py4j =====\n# ===========================================================\n\n# https://valelab4.ucsf.edu/~MM/doc-2.0.0-beta/mmstudio/org/micromanager/Studio.html\n# https://valelab4.ucsf.edu/~MM/doc-2.0.0-beta/mmcorej/mmcorej/CMMCore.html\n\n#device control\nmmc.setPosition(5.9999)\n\naf = mm.getAutofocusManager()\nafp = af.getAutofocusMethod()\nafp.fullFocus()\n\n# standard Micro-manager 2.0 api for creating a datastore, snapping an image, and placing the data\nautosavestore = mm.data().createMultipageTIFFDatastore(\"path_to_your_savefile\", True, True)\nmm.displays().createDisplay(autosavestore)\n\nc, z, p = 1.0, 1.0, 1.0\nmmc.snapImage()\ntmp1 = mmc.getTaggedImage()\nchannel0 = mm.data().convertTaggedImage(tmp1)\nchannel0 = channel0.copyWith(\n channel0.getCoords().copy().channel(c).z(z).stagePosition(p).build(),\n channel0.getMetadata().copy().positionName(\"\" + str(p)).build())\nautosavestore.putImage(channel0)\n\n\n# ===========================================\n# ===== access org.mm2python MetaDataStores =====\n# ===========================================\n\n# retrieve MetaData object for the most recent image\nmeta = ep.getLastMeta()\n\n# retrieve MetaData object for the oldest image\nmeta = ep.getFirstMeta()\n\nmeta.getChannel()\nmeta.getZ()\nmeta.getPosition()\nmeta.getTime()\nmeta.getxRange()\nmeta.getyRange()\nmeta.getBitDepth()\nmeta.getChannelName()\nmeta.getPrefix()\nmeta.getWindowName()\nmeta.getFilepath()\n\n# also have\n# [\"mmap filepath1\", \"mmap filepath2\", ...] = ep.getFilesByChannel( <int> )\n# [\"mmap filepaths\", \"mmap filepath2\", ...] = ep.getFilesByTime( <int> )\n\n# [MDS1, MDS2, ...] = ep.getMetaByChannel(<int>)\n# [MDS1, MDS2, ...] = ep.getMetaByTime(<int>)\n\n# ===========================================================\n# ===== given an mmap path, load the data in python =========\n#============================================================\n\npath = meta.getFilepath()\nnumpy_array = np.memmap(meta.getFilepath(), dtype=\"uint16\", mode='r+', offset=0,\n shape=(meta.getxRange(), meta.getyRange()))\n\n\n# =========================\n# ======== example ========\n\naq = mm.getAcquisitionManager()\naq.runAcquisitionNonblocking()\n\n# wait some time for several cycles\nch = ep.getMetaByChannelName(\"Rhodamine\")\nfor i in range(len(ch)):\n print(ch[i].getZ())\n\n# convenience function\ndef get_snap_data(mm, gate):\n # Snaps and writes to snap/live view\n mm.live().snap(True)\n\n # Retrieve data from memory mapped files, np.memmap is functionally same as np.array\n meta = gate.getLastMeta()\n dat = np.memmap(meta.getFilepath(), dtype=\"uint16\", mode='r+', offset=0,\n shape=(meta.getxRange(), meta.getyRange()))\n\n return dat\n\n"
},
{
"alpha_fraction": 0.6035740375518799,
"alphanum_fraction": 0.6207147836685181,
"avg_line_length": 25.882352828979492,
"blob_id": "ad3739a07b2e0bcbf9c1eee16c670350a956fc89",
"content_id": "8c09b4d1aa89e69ca3f75cd6fbe1bc944e140d30",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2742,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 102,
"path": "/src/test/java/Tests/MPIMethodTests/EntryPointTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.MPIMethodTests;\n\nimport mmcorej.CMMCore;\nimport mmcorej.TaggedImage;\nimport org.junit.jupiter.api.Test;\nimport org.micromanager.Studio;\nimport org.micromanager.data.DataProvider;\nimport org.mm2python.DataStructures.Builders.MDSBuilder;\nimport org.mm2python.DataStructures.Constants;\nimport org.mm2python.DataStructures.MetaDataStore;\nimport org.mm2python.MPIMethod.Py4J.Py4JEntryPoint;\n\nimport static org.junit.Assert.assertFalse;\nimport static org.junit.Assert.assertNull;\nimport static org.junit.jupiter.api.Assertions.assertEquals;\nimport static org.junit.jupiter.api.Assertions.fail;\nimport static org.mockito.Mockito.mock;\nimport static org.mockito.Mockito.when;\n\n\nclass EntryPointTests {\n\n private Py4JEntryPoint ep;\n private Studio mm;\n private CMMCore mmc;\n private MetaDataStore mds, mds_bad;\n private TaggedImage tm;\n private DataProvider provider;\n private short[] im1;\n private byte[] im2;\n private float[] im3;\n\n private void setUp() {\n mm = mock(Studio.class);\n mmc = mock(CMMCore.class);\n ep = mock(Py4JEntryPoint.class);\n provider = mock(DataProvider.class);\n when(mm.getCMMCore()).thenReturn(mmc);\n }\n\n private void setupFakeData() {\n try{\n mds = new MDSBuilder().position(0).z(1).time(2).channel(3).\n xRange(1024).yRange(1024).bitDepth(16).\n channel_name(\"DAPI\").prefix(\"prefix_\").windowname(\"window\").\n filepath(\"/path/to/this/memorymapfile.dat\")\n .dataprovider(provider)\n .buildMDS();\n tm = mock(TaggedImage.class);\n im1 = new short[] {1,2,3,4};\n im2 = new byte[] {5,6,7,8};\n im3 = new float[] {9,10,11,12};\n } catch (Exception ex) {\n fail(ex);\n }\n }\n\n private void breakDown() { }\n\n @Test\n void testConstructor() {\n setUp();\n assertEquals(Py4JEntryPoint.class, ep.getClass());\n }\n\n @Test\n void testSendImageMDS() {\n setUp();\n setupFakeData();\n assertFalse(ep.sendImage(mds));\n }\n\n @Test\n void testSendImageTM() {\n setUp();\n setupFakeData();\n assertFalse(ep.sendImage(tm));\n }\n\n @Test\n void testSendImageObj() {\n setUp();\n setupFakeData();\n assertFalse(ep.sendImage(im1));\n assertFalse(ep.sendImage(im2));\n ep.sendImage(im3);\n\n }\n\n @Test\n void testEPGetCoreMeta() {\n setUp();\n setupFakeData();\n\n Constants.setZMQButton(true);\n assertNull(ep.getCoreMeta(mds));\n\n// Constants.setZMQButton(false);\n// assertEquals(MetaDataStore.class, ep.getCoreMeta(mds).getClass());\n }\n\n}\n"
},
{
"alpha_fraction": 0.5459227561950684,
"alphanum_fraction": 0.5523605346679688,
"avg_line_length": 24.985130310058594,
"blob_id": "1deca08aca390b6c94e534e79af1a73d1321bb25",
"content_id": "23c72da6ab4be0abe3268751ecb7977d4a662eba",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6990,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 269,
"path": "/src/test/java/Tests/DataStructuresTests/DynamicMemMapReferenceQueueTests.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package Tests.DataStructuresTests;\n\nimport org.mm2python.DataStructures.Constants;\nimport org.mm2python.DataStructures.Queues.DynamicMemMapReferenceQueue;\nimport org.junit.jupiter.api.Test;\n\nimport java.io.File;\nimport java.util.ArrayList;\nimport java.util.Collection;\nimport java.util.HashSet;\nimport java.util.Set;\nimport java.util.concurrent.CountDownLatch;\nimport java.util.concurrent.ExecutorService;\nimport java.util.concurrent.Executors;\nimport java.util.concurrent.Future;\n\nimport static org.junit.jupiter.api.Assertions.*;\nimport java.nio.MappedByteBuffer;\n\n//todo: write data placement tests\n//todo: rewrite offset tests\nclass DynamicMemMapReferenceQueueTests {\n\n private int NUM_CHANNELS = 2;\n private int NUM_Z = 10;\n private DynamicMemMapReferenceQueue dynamic;\n\n // ========= SETUP CODE =====================\n /**\n * to delete generated temp files and temp directory\n */\n private void clearTempFiles() {\n File index = new File(Constants.tempFilePath);\n String[] entries = index.list();\n\n for(String s: entries) {\n try {\n File currentFile = new File(index.getPath(), s);\n currentFile.delete();\n } catch (Exception ex) {\n System.out.println(\"skipped a file\");\n }\n }\n File dir = new File(Constants.tempFilePath);\n dir.delete();\n }\n\n /**\n * to initialize the constants with reasonable image values and temp file directory\n */\n private void initializeConstants() {\n Constants.setFixedMemMap(false);\n Constants.bitDepth=16;\n Constants.width=2048;\n Constants.height=2048;\n switch(Constants.getOS()) {\n case \"win\":\n Constants.tempFilePath = \"C:\\\\mm2pythonTemp\";\n break;\n case \"mac\":\n String username = System.getProperty(\"user.name\");\n Constants.tempFilePath =\n String.format(\"/Users/%s/Desktop/mm2pythonTemp\",\n username);\n break;\n default:\n fail(\"no OS found\");\n }\n }\n\n private void setUp() {\n dynamic = new DynamicMemMapReferenceQueue();\n }\n\n // ========= TESTS =====================\n\n /**\n * test creation of memory maps\n */\n @Test\n void testCreateMMap() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n assertFalse(dynamic.isEmpty());\n assertEquals(0, dynamic.getCurrentPosition());\n assertEquals(16*2048*2048/8, dynamic.getCurrentByteLength());\n\n clearTempFiles();\n\n }\n\n /**\n * test resetQueues\n */\n @Test\n void testClear() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n dynamic.resetQueue();\n assertTrue(dynamic.isEmpty());\n\n clearTempFiles();\n }\n\n /**\n * test simple retrieval of next file\n */\n @Test\n void testGetNextFileName() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n String next = dynamic.getCurrentFileName();\n assertEquals(String.class, next.getClass());\n\n clearTempFiles();\n }\n\n /**\n * test position automatic increment after current block is filled\n */\n @Test\n void testPositionIncrement() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n int bytelength = dynamic.getCurrentByteLength();\n\n int i = 0;\n while(!dynamic.isEmpty()) {\n int off = dynamic.getCurrentPosition();\n assertEquals(i, off);\n i += bytelength;\n }\n assertEquals(NUM_CHANNELS*NUM_Z*bytelength, i);\n\n clearTempFiles();\n }\n\n /**\n * test that new files are created when current file is filled\n */\n @Test\n void testDynamicCreation() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n int position = -1;\n String firstFileName = dynamic.getCurrentFileName();\n\n for(int i =0; i < NUM_CHANNELS*NUM_Z + 1; i++) {\n MappedByteBuffer buf = dynamic.getCurrentBuffer();\n position = dynamic.getCurrentPosition();\n }\n assertEquals(0, position);\n assertNotEquals(firstFileName, dynamic.getCurrentFileName());\n\n clearTempFiles();\n }\n\n /**\n * test simple data placement\n */\n @Test\n void testDataPlacement() {\n initializeConstants();\n setUp();\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n byte[] array = new byte[512*512];\n MappedByteBuffer buf = dynamic.getCurrentBuffer();\n int pos = dynamic.getCurrentPosition();\n buf.put(array, 0 , pos);\n buf.force();\n\n clearTempFiles();\n\n }\n\n\n\n /**\n * test looping and concurrency : finite number of positions retrieved\n * - concurrent threads will not retrieve the same position\n *\n */\n @Test\n void testGetNextConcurrent() {\n // follow: https://dzone.com/articles/how-i-test-my-java-classes-for-thread-safety\n initializeConstants();\n setUp();\n\n // make sure num is < num_channels*num_z\n int num = 10;\n\n try {\n dynamic.createFileNames(NUM_CHANNELS, NUM_Z);\n } catch (Exception ex) {\n fail(ex);\n }\n\n // create threads and submit getNextFileName\n CountDownLatch latch = new CountDownLatch(1);\n ExecutorService service = Executors.newFixedThreadPool(num);\n Collection<Future<Integer>> futures = new ArrayList<>(num);\n for (int t = 0; t < num; ++t) {\n futures.add(service.submit(\n () -> {\n latch.await();\n return dynamic.getCurrentPosition();\n }\n ));\n }\n latch.countDown();\n\n // retrieve number of unique hashes from futures\n Set<Integer> ids = new HashSet<>();\n for (Future<Integer> f : futures) {\n try {\n ids.add(f.get());\n } catch (Exception ex) {\n System.out.println(\"exception checking unique threads \"+ex);\n }\n }\n\n // unlike in the FixedMemmap case,\n assertEquals(num, ids.size());\n\n clearTempFiles();\n }\n\n}\n"
},
{
"alpha_fraction": 0.7301115393638611,
"alphanum_fraction": 0.7338290214538574,
"avg_line_length": 28.2391300201416,
"blob_id": "5af6342911e6412a4616c849f33740fd572e492c",
"content_id": "b176e819ca21f70b6cdd081867809297fa695094",
"detected_licenses": [
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1345,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 46,
"path": "/src/main/java/org/mm2python/DataStructures/Maps/RegisteredGlobalEvents.java",
"repo_name": "czbiohub/mm2python",
"src_encoding": "UTF-8",
"text": "package org.mm2python.DataStructures.Maps;\n\nimport org.micromanager.data.DataProvider;\nimport org.mm2python.mmEventHandler.globalEvents;\n\nimport java.util.concurrent.LinkedBlockingQueue;\nimport java.util.concurrent.TimeUnit;\n\n/**\n * to keep track of globalEvents that are registered to EventBus\n * These must be manually unregistered upon disconnection, or they will always receive events.\n */\npublic class RegisteredGlobalEvents {\n\n private static LinkedBlockingQueue<globalEvents> RegisteredGlobalEvents;\n\n static {\n RegisteredGlobalEvents = new LinkedBlockingQueue<>(1);\n }\n\n public static void put(globalEvents ge) throws InterruptedException {\n RegisteredGlobalEvents.offer(ge, 1, TimeUnit.SECONDS);\n }\n\n public static globalEvents get(globalEvents ge) {\n return RegisteredGlobalEvents.peek();\n }\n\n public static void remove(globalEvents ge) {\n RegisteredGlobalEvents.remove(ge);\n }\n\n public static void reset() {\n RegisteredGlobalEvents.clear();\n RegisteredGlobalEvents = null;\n RegisteredGlobalEvents = new LinkedBlockingQueue<>(1);\n }\n\n public static int getSize() {\n return RegisteredGlobalEvents.size();\n }\n\n public static LinkedBlockingQueue<globalEvents> getAllRegisteredGlobalEvents() {\n return RegisteredGlobalEvents;\n }\n}\n"
}
] | 22 |
scuy/pix_docker
|
https://github.com/scuy/pix_docker
|
46cc712b9b726deabcc49f0ef19462babba9fa86
|
f77c11732c1ced97313cd9833024e84b9e28550e
|
ef951acf193d372f6360f8660412b3794380c36b
|
refs/heads/master
| 2021-05-20T21:20:21.643236 | 2020-04-02T12:51:58 | 2020-04-02T12:51:58 | 252,421,044 | 0 | 0 | null | 2020-04-02T10:12:10 | 2020-04-02T07:57:30 | 2020-04-02T07:57:27 | null |
[
{
"alpha_fraction": 0.6685393452644348,
"alphanum_fraction": 0.7247191071510315,
"avg_line_length": 34.79999923706055,
"blob_id": "8bc655ebcc52377799313c901ec53d8b243115c6",
"content_id": "941be534142596ae8812a0ba5a6d73e92d7264bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 5,
"path": "/docker/entrypoint.sh",
"repo_name": "scuy/pix_docker",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\npython pixplot.py --images \"/home/images/*.jpg\" --metadata \"/home/metadata.csv\" --image_size 299 299 --model inception\necho \"Start server\"\npython -m http.server 5000"
},
{
"alpha_fraction": 0.5830985903739929,
"alphanum_fraction": 0.611267626285553,
"avg_line_length": 22.600000381469727,
"blob_id": "62309ff94fedb95e16e1535dcc4b2d356a32d659",
"content_id": "5daaee6b6359116e24a7d41888d6b29e6492fef9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 15,
"path": "/docker-compose.yml",
"repo_name": "scuy/pix_docker",
"src_encoding": "UTF-8",
"text": "version: '3.5'\n\nservices:\n pixplot:\n container_name: pixplot\n build:\n context: ./docker\n network: host\n ports:\n - \"5000:5000\"\n volumes:\n - /home/michael/Documents/pix-plot/pixplot/:/home\n - /home/michael/Desktop/test_oeff/:/home/images\n #- /home/michael/Desktop/test_oeff/:/home/images\n working_dir: /home\n\n"
},
{
"alpha_fraction": 0.7291666865348816,
"alphanum_fraction": 0.737500011920929,
"avg_line_length": 25.77777862548828,
"blob_id": "7aeb480efcc701d10a253d334517bb027cf986b5",
"content_id": "677e71e61c139855e38f3233dbf7acc8109bb5f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 9,
"path": "/docker/Dockerfile",
"repo_name": "scuy/pix_docker",
"src_encoding": "UTF-8",
"text": "FROM python:3.7-slim-stretch\n\nRUN apt update -y && apt install build-essential -y && apt-get install manpages-dev -y\nRUN pip install --upgrade pip\nRUN pip install pixplot\n\nCOPY entrypoint.sh /root\n\nENTRYPOINT [ \"sh\" ,\"/root/entrypoint.sh\"]"
},
{
"alpha_fraction": 0.5883892178535461,
"alphanum_fraction": 0.5954824090003967,
"avg_line_length": 37.930294036865234,
"blob_id": "481b5716ab75b6a5f4a91197c38988a512af7b62",
"content_id": "f6660be1bdb156ff73ff250236c01b4307a56ec8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29042,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 746,
"path": "/pixplot/pixplot.py",
"repo_name": "scuy/pix_docker",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport os\nimport csv\nimport sys\nimport json\nimport gzip\nimport math\nimport uuid\nimport glob2\nimport shutil\nimport random\nimport argparse\nimport datetime\nimport numpy as np\nimport rasterfairy\nimport pkg_resources\nimport multiprocessing\nfrom umap import UMAP\nimport tensorflow as tf\nfrom hdbscan import HDBSCAN\nfrom scipy.stats import kde\nfrom residualunit import ResidualUnit\nfrom clusteringlayer import ClusteringLayer\nimport matplotlib.pyplot as plt\nfrom rasterfairy import coonswarp\nfrom iiif_downloader import Manifest\nfrom distutils.dir_util import copy_tree\nfrom pointgrid import align_points_to_grid\nfrom collections import defaultdict\nfrom keras_preprocessing.image import load_img\nfrom sklearn.preprocessing import minmax_scale\nfrom tensorflow import keras\nfrom sklearn.metrics import pairwise_distances_argmin_min\nfrom os.path import join, exists, dirname, realpath\nimport warnings\nwarnings.filterwarnings('ignore')\n\n# pylint: disable=W0633 \n# pylint: disable=W0702\n# pylint: disable=W0621\n# pylint: disable=W0613\n\ntry:\n from MulticoreTSNE import MulticoreTSNE as TSNE\nexcept:\n from sklearn.manifold import TSNE\n\ntry:\n from urllib.parse import unquote # python 3\nexcept:\n from urllib import unquote # python 2\n\n# handle dynamic GPU memory allocation\ntf_config = tf.compat.v1.ConfigProto()\ntf_config.gpu_options.allow_growth = True\ntf_config.log_device_placement = True\nsess = tf.compat.v1.Session(config=tf_config)\n\n'''\nNB: Keras Image class objects return image.size as w,h\n Numpy array representations of images return image.shape as h,w,c\n'''\n\nconfig = {\n 'images': None,\n 'metadata': None,\n 'out_dir': 'output',\n 'use_cache': True,\n 'encoding': 'utf8',\n 'min_cluster_size': 20,\n 'atlas_size': 2048,\n 'cell_size': 32,\n 'lod_cell_height': 128,\n 'n_neighbors': 6,\n 'min_dist': 0.001,\n 'metric': 'correlation',\n 'pointgrid_fill': 0.05,\n 'square_cells': False,\n 'gzip': False,\n 'plot_id': str(uuid.uuid1()),\n}\n\n##\n# Main\n##\n\ndef process_images(**kwargs):\n '''Main method for processing user images and metadata'''\n copy_web_assets(**kwargs)\n kwargs['out_dir'] = join(kwargs['out_dir'], 'data')\n kwargs['image_paths'] = filter_images(**kwargs)\n kwargs['atlas_dir'] = get_atlas_data(**kwargs)\n get_manifest(**kwargs)\n write_images(**kwargs)\n print(' * done!')\n\n\ndef stream_images(*args, **kwargs):\n '''Read in all images from args[0], a list of image paths'''\n images = []\n for idx, i in enumerate(kwargs['image_paths']):\n try:\n image = Image(i)\n yield image\n except:\n print(' * image', i, 'could not be processed')\n\n\ndef write_images(**kwargs):\n '''Write all originals and thumbs to the output dir'''\n for i in stream_images(**kwargs):\n # copy original for lightbox\n out_dir = join(kwargs['out_dir'], 'originals')\n if not exists(out_dir):\n os.makedirs(out_dir)\n out_path = join(out_dir, clean_filename(i.path))\n shutil.copy(i.path, out_path)\n # copy thumb for lod texture\n out_dir = join(kwargs['out_dir'], 'thumbs')\n if not exists(out_dir):\n os.makedirs(out_dir)\n out_path = join(out_dir, clean_filename(i.path))\n img = keras.preprocessing.image.array_to_img(\n i.resize_to_max(kwargs['lod_cell_height']))\n keras.preprocessing.image.save_img(out_path, img)\n\n\ndef get_manifest(**kwargs):\n '''Create and return the base object for the manifest output file'''\n # load the atlas data\n atlas_data = json.load(\n open(join(kwargs['atlas_dir'], 'atlas_positions.json')))\n # store each cell's size and atlas position\n atlas_ids = set([i['idx'] for i in atlas_data])\n sizes = [[] for _ in atlas_ids]\n pos = [[] for _ in atlas_ids]\n for idx, i in enumerate(atlas_data):\n sizes[i['idx']].append([i['w'], i['h']])\n pos[i['idx']].append([i['x'], i['y']])\n # obtain the paths to each layout's JSON positions\n layouts = get_layouts(**kwargs)\n # create a heightmap for each layout\n for i in layouts:\n for j in layouts[i]:\n get_heightmap(layouts[i][j], i + '-' + j, **kwargs)\n # create manifest json\n point_size = 1 / math.ceil(len(kwargs['image_paths'])**(1/2))\n manifest = {\n 'layouts': layouts,\n 'initial_layout': 'umap',\n 'point_size': {\n 'min': 0,\n 'max': 1.2 * point_size,\n 'initial': 0.18 * point_size,\n },\n 'imagelist': get_path('imagelists', 'imagelist', **kwargs),\n 'atlas_dir': kwargs['atlas_dir'],\n 'config': {\n 'sizes': {\n 'atlas': kwargs['atlas_size'],\n 'cell': kwargs['cell_size'],\n 'lod': kwargs['lod_cell_height'],\n },\n },\n 'metadata': True if kwargs['metadata'] else False,\n 'centroids': get_centroids(vecs=read_json(layouts['umap']['layout'], **kwargs), **kwargs),\n 'creation_date': datetime.datetime.today().strftime('%d-%B-%Y-%H:%M:%S'),\n 'version': get_version(),\n }\n path = get_path('manifests', 'manifest', **kwargs)\n write_json(path, manifest, **kwargs)\n path = get_path(None, 'manifest', add_hash=False, **kwargs)\n write_json(path, manifest, **kwargs)\n # create images json\n imagelist = {\n 'cell_sizes': sizes,\n 'images': [clean_filename(i) for i in kwargs['image_paths']],\n 'atlas': {\n 'count': len(atlas_ids),\n 'positions': pos,\n },\n }\n write_json(manifest['imagelist'], imagelist)\n\n\ndef filter_images(**kwargs):\n '''Main method for filtering images given user metadata (if provided)'''\n image_paths = []\n for i in stream_images(image_paths=get_image_paths(**kwargs)):\n # get image height and width\n w, h = i.original.size\n # remove images with 0 height or width when resized to lod height\n if (h == 0) or (w == 0):\n print(' * skipping {} because it contains 0 height or width'.format(i.path))\n continue\n # remove images that have 0 height or width when resized\n try:\n resized = i.resize_to_max(kwargs['lod_cell_height'])\n except ValueError:\n print(\n ' * skipping {} because it contains 0 height or width when resized'.format(i.path))\n continue\n # remove images that are too wide for the atlas\n if (w/h) > (kwargs['atlas_size']/kwargs['cell_size']):\n print(' * skipping {} because its dimensions are oblong'.format(i.path))\n continue\n image_paths.append(i.path)\n # handle the case user provided no metadata\n if not kwargs.get('metadata', False):\n return image_paths\n # handle csv metadata\n l = []\n if kwargs['metadata'].endswith('.csv'):\n headers = ['filename', 'tags', 'description', 'permalink']\n with open(kwargs['metadata']) as f:\n for i in list(csv.reader(f)):\n l.append({headers[j]: i[j] for j, _ in enumerate(headers)})\n # handle json metadata\n else:\n for i in glob2.glob(kwargs['metadata']):\n with open(i) as f:\n l.append(json.load(f))\n # retain only records with image and metadata\n img_bn = set([clean_filename(i) for i in image_paths])\n meta_bn = set([clean_filename(i.get('filename', '')) for i in l])\n both = img_bn.intersection(meta_bn)\n no_meta = list(img_bn - meta_bn)\n if no_meta:\n print(' ! Some images are missing metadata:\\n -',\n '\\n - '.join(no_meta[:10]))\n if len(no_meta) > 10:\n print(' ...', len(no_meta)-10, 'more')\n with open('missing-metadata.txt', 'w') as out:\n out.write('\\n'.join(no_meta))\n kwargs['metadata'] = [\n i for i in l if clean_filename(i['filename']) in both]\n write_metadata(**kwargs)\n return [i for i in image_paths if clean_filename(i) in both]\n\n\ndef get_image_paths(**kwargs):\n '''Called once to provide a list of image paths--handles IIIF manifest input'''\n # handle case where --images points to iiif manifest\n image_paths = None\n if not kwargs['images']:\n print('\\nError: please provide an images argument, e.g.:')\n print('pixplot --images \"cat_pictures/*.jpg\"\\n')\n sys.exit()\n if os.path.exists(kwargs['images']):\n with open(kwargs['images']) as f:\n f = [i.strip() for i in f.read().split('\\n') if i.strip()]\n if [i.startswith('http') for i in f]:\n for i in f:\n Manifest(url=i).save_images(limit=1)\n image_paths = sorted(glob2.glob(\n os.path.join('iiif-downloads', 'images', '*')))\n # handle case where --images points to a glob of images\n if not image_paths:\n image_paths = sorted(glob2.glob(kwargs['images']))\n if not image_paths:\n print('\\nError: No input images were found. Please check your --images glob\\n')\n sys.exit()\n # optional shuffle that mutates image_paths\n if kwargs['shuffle']:\n print(' * shuffling input images')\n random.shuffle(image_paths)\n return image_paths\n\n\ndef clean_filename(s):\n '''Given a string that points to a filename, return a clean filename'''\n return unquote(os.path.basename(s))\n\n\ndef write_metadata(**kwargs):\n if not kwargs.get('metadata', []):\n return\n out_dir = join(kwargs['out_dir'], 'metadata')\n for i in ['filters', 'options', 'file']:\n out_path = join(out_dir, i)\n if not exists(out_path):\n os.makedirs(out_path)\n # find images with each tag\n d = defaultdict(list)\n for i in kwargs['metadata']:\n filename = clean_filename(i['filename'])\n tags = [j.strip() for j in i['tags'].split('|')]\n i['tags'] = tags\n for j in tags:\n d['__'.join(j.split())].append(filename)\n write_json(os.path.join(out_dir, 'file',\n filename + '.json'), i, **kwargs)\n filters = [{'filter_name': 'select', 'filter_values': list(d.keys())}]\n write_json(os.path.join(out_dir, 'filters',\n 'filters.json'), filters, **kwargs)\n # create the options\n for i in d:\n write_json(os.path.join(out_dir, 'options',\n i + '.json'), d[i], **kwargs)\n\n\ndef get_atlas_data(**kwargs):\n '''\n Generate and save to disk all atlases to be used for this visualization\n If square, center each cell in an nxn square, else use uniform height\n '''\n # if the atlas files already exist, load from cache\n out_dir = os.path.join(kwargs['out_dir'], 'atlases', kwargs['plot_id'])\n if os.path.exists(out_dir) and kwargs['use_cache']:\n print(' * loading saved atlas data')\n return out_dir\n if not os.path.exists(out_dir):\n os.makedirs(out_dir)\n # else create the atlas images and store the positions of cells in atlases\n print(' * creating atlas files')\n n = 0 # number of atlases\n x = 0 # x pos in atlas\n y = 0 # y pos in atlas\n positions = [] # l[cell_idx] = atlas data\n atlas = np.zeros((kwargs['atlas_size'], kwargs['atlas_size'], 3))\n for idx, i in enumerate(stream_images(**kwargs)):\n if kwargs['square_cells']:\n cell_data = i.resize_to_square(kwargs['cell_size'])\n else:\n cell_data = i.resize_to_height(kwargs['cell_size'])\n _, v, _ = cell_data.shape\n appendable = False\n if (x + v) <= kwargs['atlas_size']:\n appendable = True\n elif (y + (2*kwargs['cell_size'])) <= kwargs['atlas_size']:\n y += kwargs['cell_size']\n x = 0\n appendable = True\n if not appendable:\n save_atlas(atlas, out_dir, n)\n n += 1\n atlas = np.zeros((kwargs['atlas_size'], kwargs['atlas_size'], 3))\n x = 0\n y = 0\n atlas[y:y+kwargs['cell_size'], x:x+v] = cell_data\n # find the size of the cell in the lod canvas\n lod_data = i.resize_to_max(kwargs['lod_cell_height'])\n h, w, _ = lod_data.shape # h,w,colors in lod-cell sized image `i`\n positions.append({\n 'idx': n, # atlas idx\n 'x': x, # x offset of cell in atlas\n 'y': y, # y offset of cell in atlas\n 'w': w, # w of cell at lod size\n 'h': h, # h of cell at lod size\n })\n x += v\n save_atlas(atlas, out_dir, n)\n out_path = os.path.join(out_dir, 'atlas_positions.json')\n with open(out_path, 'w') as out:\n json.dump(positions, out)\n return out_dir\n\n\ndef save_atlas(atlas, out_dir, n):\n '''Save an atlas to disk'''\n out_path = join(out_dir, 'atlas-{}.jpg'.format(n))\n keras.preprocessing.image.save_img(out_path, atlas)\n\n\ndef get_layouts(*args, **kwargs):\n '''Get the image positions in each projection'''\n vecs = vectorize_images(**kwargs)\n umap = get_umap_projection(vecs=vecs, **kwargs)\n raster = get_rasterfairy_projection(umap=umap, **kwargs)\n grid = get_grid_projection(**kwargs)\n umap_grid = get_pointgrid_projection(umap, 'umap', **kwargs)\n return {\n 'umap': {\n 'layout': umap,\n 'jittered': umap_grid,\n },\n 'grid': {\n 'layout': grid,\n },\n 'rasterfairy': {\n 'layout': raster,\n },\n }\n\n\ndef vectorize_images(**kwargs):\n '''Create and return vector representation of Image() instances'''\n print(\n ' * preparing to vectorize {} images'.format(len(kwargs['image_paths'])))\n vector_dir = os.path.join(kwargs['out_dir'], 'image-vectors')\n if not os.path.exists(vector_dir):\n os.makedirs(vector_dir)\n resnet = \"resnet\"\n resnet_trained = \"resnet_trained\"\n inception = \"inception\"\n weights = kwargs['weights']\n clusters = int(kwargs['cnn_clusters'])\n image_size = tuple([int(i) for i in kwargs['image_size']])\n \n if kwargs['model'].lower() == resnet:\n model = keras.models.Sequential()\n model.add(keras.layers.Conv2D(64, kernel_size=7,\n strides=2, input_shape=(*image_size, 3)))\n model.add(keras.layers.BatchNormalization())\n model.add(keras.layers.Activation(\"relu\"))\n model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding=\"SAME\"))\n prev_filters = 64\n # for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:\n for filters in [64] * 1 + [128] * 2 + [256] * 3 + [512] * 3:\n strides = 1 if filters == prev_filters else 2\n model.add(ResidualUnit(filters, strides=strides))\n prev_filters = filters\n model.add(keras.layers.GlobalAvgPool2D())\n model.add(keras.layers.Flatten())\n model.add(keras.layers.Dense(units=clusters, name='embedding'))\n model.add(ClusteringLayer(clusters))\n model.load_weights(weights)\n elif kwargs['model'].lower() == inception:\n image_size = (299,299)\n base = keras.applications.InceptionV3(include_top=True, weights='imagenet',)\n model = keras.models.Model(inputs=base.input, outputs=base.get_layer('avg_pool').output)\n elif kwargs['model'].lower() == resnet_trained:\n resnet = keras.applications.ResNet50(\n weights=None, include_top=False, input_shape=(*image_size, 3))\n x = keras.layers.Flatten()(resnet.output)\n x = keras.layers.Dense(units=clusters, name='embedding')(x)\n x = ClusteringLayer(clusters)(x)\n model = keras.models.Model(inputs=resnet.input,outputs = [x])\n model.load_weights(weights)\n else:\n raise ValueError(\"Unknown CNN network model!\")\n\n print(' * creating image array')\n vecs = []\n for idx, i in enumerate(stream_images(**kwargs)):\n vector_path = os.path.join(\n vector_dir, os.path.basename(i.path) + '.npy')\n if os.path.exists(vector_path) and kwargs['use_cache']:\n vec = np.load(vector_path)\n else:\n im = keras.applications.inception_v3.preprocess_input(keras.preprocessing.image.img_to_array(\n i.original.resize(image_size)))\n vec = model.predict(np.expand_dims(im, 0)).squeeze()\n np.save(vector_path, vec)\n vecs.append(vec)\n print(' * vectorized {}/{} images'.format(idx +\n 1, len(kwargs['image_paths'])))\n return np.array(vecs)\n\n\ndef get_umap_projection(**kwargs):\n '''Get the x,y positions of images passed through a umap projection'''\n print(' * creating UMAP layout')\n out_path = get_path('layouts', 'umap', **kwargs)\n if os.path.exists(out_path) and kwargs['use_cache']:\n return out_path\n model = UMAP(n_neighbors=kwargs['n_neighbors'],\n min_dist=kwargs['min_dist'],\n metric=kwargs['metric'])\n z = model.fit_transform(kwargs['vecs'])\n return write_layout(out_path, z, **kwargs)\n\n\ndef get_tsne_projection(**kwargs):\n '''Get the x,y positions of images passed through a TSNE projection'''\n print(' * creating TSNE layout with ' +\n str(multiprocessing.cpu_count()) + ' cores...')\n out_path = get_path('layouts', 'tsne', **kwargs)\n if os.path.exists(out_path) and kwargs['use_cache']:\n return out_path\n model = TSNE(perplexity=kwargs.get('perplexity', 2),\n n_jobs=multiprocessing.cpu_count())\n z = model.fit_transform(kwargs['vecs'])\n return write_layout(out_path, z, **kwargs)\n\n\ndef get_rasterfairy_projection(**kwargs):\n '''Get the x, y position of images passed through a rasterfairy projection'''\n print(' * creating rasterfairy layout')\n out_path = get_path('layouts', 'rasterfairy', **kwargs)\n if os.path.exists(out_path) and kwargs['use_cache']:\n return out_path\n umap = np.array(read_json(kwargs['umap'], **kwargs))\n umap = (umap + 1)/2 # scale 0:1\n try:\n umap = coonswarp.rectifyCloud(umap, # stretch the distribution\n perimeterSubdivisionSteps=4,\n autoPerimeterOffset=False,\n paddingScale=1.05)\n except: #pylint: disable=W0702\n print(' * coonswarp rectification could not be performed')\n pos = rasterfairy.transformPointCloud2D(umap)[0]\n return write_layout(out_path, pos, **kwargs)\n\n\ndef get_grid_projection(**kwargs):\n '''Get the x,y positions of images in a grid projection'''\n print(' * creating grid layout')\n out_path = get_path('layouts', 'grid', **kwargs)\n if os.path.exists(out_path) and kwargs['use_cache']:\n return out_path\n paths = kwargs['image_paths']\n n = math.ceil(len(paths)**(1/2))\n l = [] # positions\n for i, _ in enumerate(paths):\n x = i % n\n y = math.floor(i/n)\n l.append([x, y])\n z = np.array(l)\n return write_layout(out_path, z, **kwargs)\n\n\ndef get_pointgrid_projection(path, label, **kwargs):\n '''Gridify the positions in `path` and return the path to this new layout'''\n print(' * creating {} pointgrid'.format(label))\n out_path = get_path('layouts', label + '-jittered', **kwargs)\n if os.path.exists(out_path) and kwargs['use_cache']:\n return out_path\n arr = np.array(read_json(path, **kwargs))\n z = align_points_to_grid(arr)\n return write_layout(out_path, z, **kwargs)\n\n\ndef add_z_dim(X, val=0.001):\n '''Given X with shape (n,2) return (n,3) with val as X[:,2]'''\n if X.shape[1] == 2:\n z = np.zeros((X.shape[0], 3)) + val\n for idx, i in enumerate(X):\n z[idx] += np.array((i[0], i[1], 0))\n return z.tolist()\n return X.tolist()\n\n\ndef get_path(*args, **kwargs):\n '''Return the path to a JSON file with conditional gz extension'''\n sub_dir, filename = args\n out_dir = join(kwargs['out_dir'],\n sub_dir) if sub_dir else kwargs['out_dir']\n if kwargs.get('add_hash', True):\n filename += '-' + kwargs['plot_id']\n path = join(out_dir, filename + '.json')\n return path + '.gz' if kwargs.get('gzip', False) else path\n\n\ndef write_layout(path, obj, **kwargs):\n '''Write layout json `obj` to disk and return the path to the saved file'''\n obj = (minmax_scale(obj)-0.5)*2 # scale -1:1\n obj = [[round(float(j), 5) for j in i] for i in obj]\n return write_json(path, obj, **kwargs)\n\n\ndef write_json(path, obj, **kwargs):\n '''Write json object `obj` to disk and return the path to that file'''\n out_dir, _ = os.path.split(path)\n if not os.path.exists(out_dir):\n os.makedirs(out_dir)\n if kwargs.get('gzip', False):\n with gzip.GzipFile(path, 'w') as out:\n out.write(json.dumps(obj).encode(kwargs['encoding']))\n return path\n else:\n with open(path, 'w') as out:\n json.dump(obj, out)\n return path\n\n\ndef read_json(path, **kwargs):\n '''Read and return the json object written by the current process at `path`'''\n if kwargs.get('gzip', False):\n with gzip.GzipFile(path, 'r') as f:\n return json.loads(f.read().decode(kwargs['encoding']))\n with open(path) as f:\n return json.load(f)\n\n\ndef get_centroids(**kwargs):\n '''Return the stable clusters from the condensed tree of connected components from the density graph'''\n print(' * HDBSCAN clustering data with ' +\n str(multiprocessing.cpu_count()) + ' cores...')\n config = {\n 'min_cluster_size': kwargs['min_cluster_size'],\n 'cluster_selection_epsilon': 0.01,\n 'min_samples': 1,\n 'core_dist_n_jobs': multiprocessing.cpu_count(),\n }\n z = HDBSCAN(**config).fit(kwargs['vecs'])\n # find the centroids for each cluster\n d = defaultdict(list)\n for idx, i in enumerate(z.labels_):\n d[i].append(kwargs['vecs'][idx])\n centroids = []\n for i in d:\n x, y = np.array(d[i]).T\n centroids.append(np.array([np.sum(x)/len(x), np.sum(y)/len(y)]))\n closest, _ = pairwise_distances_argmin_min(centroids, kwargs['vecs'])\n closest = set(closest)\n print(' * found', len(closest), 'clusters')\n paths = [kwargs['image_paths'][i] for i in closest]\n data = [{\n 'img': clean_filename(paths[idx]),\n 'label': 'Cluster {}'.format(idx+1),\n } for idx, i in enumerate(closest)]\n # save the centroids to disk and return the path to the saved json\n return write_json(get_path('centroids', 'centroid', **kwargs), data, **kwargs)\n\n\ndef copy_web_assets(**kwargs):\n '''Copy the /web directory from the pixplot source to the users cwd'''\n src = join(dirname(realpath(__file__)), 'web')\n dest = join(os.getcwd(), kwargs['out_dir'])\n copy_tree(src, dest)\n # write version numbers into output\n for i in ['index.html', os.path.join('assets', 'js', 'tsne.js')]:\n path = os.path.join(dest, i)\n with open(path, 'r') as f:\n f = f.read().replace('VERSION_NUMBER', get_version())\n with open(path, 'w') as out:\n out.write(f)\n if kwargs['copy_web_only']:\n sys.exit()\n\n\ndef get_version():\n '''Return the version of pixplot installed'''\n return pkg_resources.get_distribution('pixplot').version\n\n\ndef get_heightmap(path, label, **kwargs):\n '''Create a heightmap using the distribution of points stored at `path`'''\n X = np.array(read_json(path, **kwargs))\n # create kernel density estimate of distribution X\n nbins = 200 #pylint: disable=unpacking-non-sequence\n x, y = X.T\n xi, yi = np.mgrid[x.min():x.max():nbins*1j, y.min():y.max():nbins*1j]\n zi = kde.gaussian_kde(X.T)(np.vstack([xi.flatten(), yi.flatten()]))\n # create the plot\n fig, _ = plt.subplots(nrows=1, ncols=1, figsize=(5, 5))\n fig.subplots_adjust(0, 0, 1, 1)\n plt.pcolormesh(xi, yi, zi.reshape(xi.shape),\n shading='gouraud', cmap=\"gray\")\n plt.axis('off')\n # save the plot\n out_dir = os.path.join(kwargs['out_dir'], 'heightmaps')\n if not os.path.exists(out_dir):\n os.makedirs(out_dir)\n out_path = os.path.join(out_dir, label + '-heightmap.png')\n plt.savefig(out_path, pad_inches=0)\n\n\nclass Image:\n\n def __init__(self, *args, **kwargs):\n self.path = args[0]\n self.original = load_img(self.path)\n\n def resize_to_max(self, n):\n '''\n Resize self.original so its longest side has n pixels (maintain proportion)\n '''\n w, h = self.original.size\n size = (n, int(n * h/w)) if w > h else (int(n * w/h), n)\n return keras.preprocessing.image.img_to_array(self.original.resize(size))\n\n def resize_to_height(self, height):\n '''\n Resize self.original into an image with height h and proportional width\n '''\n w, h = self.original.size\n if (w/h*height) < 1:\n resizedwidth = 1\n else:\n resizedwidth = int(w/h*height)\n size = (resizedwidth, height)\n return keras.preprocessing.image.img_to_array(self.original.resize(size))\n\n def resize_to_square(self, n, center=False):\n '''\n Resize self.original to an image with nxn pixels (maintain proportion)\n if center, center the colored pixels in the square, else left align\n '''\n a = self.resize_to_max(n)\n h, w, _ = a.shape\n pad_lr = int((n-w)/2) # left right pad\n pad_tb = int((n-h)/2) # top bottom pad\n b = np.zeros((n, n, 3))\n if center:\n b[pad_tb:pad_tb+h, pad_lr:pad_lr+w, :] = a\n else:\n b[:h, :w, :] = a\n return b\n\n\n##\n# Entry Point\n##\n\n\ndef parse():\n '''Read command line args and begin data processing'''\n description = 'Generate the data required to create a PixPlot viewer'\n parser = argparse.ArgumentParser(\n description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument(\n '--images', type=str, default=config['images'], help='path to a glob of images to process', required=False)\n parser.add_argument('--metadata', type=str, default=config['metadata'],\n help='path to a csv or glob of JSON files with image metadata (see readme for format)', required=False)\n parser.add_argument('--use_cache', type=bool, default=config['use_cache'],\n help='given inputs identical to prior inputs, load outputs from cache', required=False)\n parser.add_argument('--encoding', type=str,\n default=config['encoding'], help='the encoding of input metadata', required=False)\n parser.add_argument('--min_cluster_size', type=int,\n default=config['min_cluster_size'], help='the minimum number of images in a cluster', required=False)\n parser.add_argument('--out_dir', type=str, default=config['out_dir'],\n help='the directory to which outputs will be saved', required=False)\n parser.add_argument('--cell_size', type=int,\n default=config['cell_size'], help='the size of atlas cells in px', required=False)\n parser.add_argument('--n_neighbors', type=int,\n default=config['n_neighbors'], help='the n_neighbors argument for UMAP')\n parser.add_argument('--min_dist', type=float,\n default=config['min_dist'], help='the min_dist argument for umap')\n parser.add_argument(\n '--metric', type=str, default=config['metric'], help='the metric argument for umap')\n parser.add_argument('--pointgrid_fill', type=float, default=config['pointgrid_fill'],\n help='float 0:1 that determines sparsity of jittered distributions (lower means more sparse)')\n parser.add_argument('--copy_web_only', action='store_true',\n help='update ./output/web without reprocessing data')\n parser.add_argument('--gzip', action='store_true',\n help='save outputs with gzip compression')\n parser.add_argument('--shuffle', action='store_true',\n help='shuffle the input images before data processing begins')\n parser.add_argument('--plot_id', type=str, default=config['plot_id'],\n help='unique id for a plot; useful for resuming processing on a started plot')\n parser.add_argument('--model', type=str, default='resnet',\n help = 'cnn network to vectorize image. 1. inception \\n2. resnet \\n3. resnet_trained')\n parser.add_argument('--image_size', nargs=\"+\", required=True,\n help = 'image size of input images')\n parser.add_argument('--cnn_clusters', type=str, default=100,\n help= 'Number of clusters of CNN output layer. Only reqired for Deep embedded models')\n parser.add_argument('--weights', type=str,\n help='Weights to be loaded to model. Should be a keras model file in .h5 file format')\n config.update(vars(parser.parse_args()))\n process_images(**config)\n\n\nif __name__ == '__main__':\n parse()\n"
}
] | 4 |
p-lambda/gradual_domain_adaptation
|
https://github.com/p-lambda/gradual_domain_adaptation
|
c70a7929d3eb4fefda9b4e8049417aad31600a51
|
aba1b7c9c3cc38a363099b60ccfa15ad4e923dcd
|
58e223774faba8e57584c3eee919c5edfab8a04a
|
refs/heads/master
| 2023-04-11T11:31:59.108007 | 2020-02-27T23:40:10 | 2020-02-27T23:40:10 | 204,068,553 | 35 | 16 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6439054012298584,
"alphanum_fraction": 0.6684662699699402,
"avg_line_length": 43.276092529296875,
"blob_id": "f947159118ad15e839f11cb6f815334d2f330afc",
"content_id": "10496185cf29cc59eef011d075c9abc664ad5666",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13151,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 297,
"path": "/gradual_shift_better.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\nimport utils\nimport models\nimport datasets\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.keras import metrics\nfrom tensorflow.keras.datasets import mnist\nfrom tensorflow.keras.utils import to_categorical\nimport pickle\n\n\ndef compile_model(model, loss='ce'):\n loss = models.get_loss(loss, model.output_shape[1])\n model.compile(optimizer='adam',\n loss=[loss],\n metrics=[metrics.sparse_categorical_accuracy])\n\n\ndef train_model_source(model, split_data, epochs=1000):\n model.fit(split_data.src_train_x, split_data.src_train_y, epochs=epochs, verbose=False)\n print(\"Source accuracy:\")\n _, src_acc = model.evaluate(split_data.src_val_x, split_data.src_val_y)\n print(\"Target accuracy:\")\n _, target_acc = model.evaluate(split_data.target_val_x, split_data.target_val_y)\n return src_acc, target_acc\n\n\ndef run_experiment(\n dataset_func, n_classes, input_shape, save_file, model_func=models.simple_softmax_conv_model,\n interval=2000, epochs=10, loss='ce', soft=False, conf_q=0.1, num_runs=20, num_repeats=None):\n (src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y, dir_inter_x, dir_inter_y,\n trg_val_x, trg_val_y, trg_test_x, trg_test_y) = dataset_func()\n if soft:\n src_tr_y = to_categorical(src_tr_y)\n src_val_y = to_categorical(src_val_y)\n trg_eval_y = to_categorical(trg_eval_y)\n dir_inter_y = to_categorical(dir_inter_y)\n inter_y = to_categorical(inter_y)\n trg_test_y = to_categorical(trg_test_y)\n if num_repeats is None:\n num_repeats = int(inter_x.shape[0] / interval)\n def new_model():\n model = model_func(n_classes, input_shape=input_shape)\n compile_model(model, loss)\n return model\n def student_func(teacher):\n return teacher\n def run(seed):\n utils.rand_seed(seed)\n trg_eval_x = trg_val_x\n trg_eval_y = trg_val_y\n # Train source model.\n source_model = new_model()\n source_model.fit(src_tr_x, src_tr_y, epochs=epochs, verbose=False)\n _, src_acc = source_model.evaluate(src_val_x, src_val_y)\n _, target_acc = source_model.evaluate(trg_eval_x, trg_eval_y)\n # Gradual self-training.\n print(\"\\n\\n Gradual self-training:\")\n teacher = new_model()\n teacher.set_weights(source_model.get_weights())\n gradual_accuracies, student = utils.gradual_self_train(\n student_func, teacher, inter_x, inter_y, interval, epochs=epochs, soft=soft,\n confidence_q=conf_q)\n _, acc = student.evaluate(trg_eval_x, trg_eval_y)\n gradual_accuracies.append(acc)\n # Train to target.\n print(\"\\n\\n Direct boostrap to target:\")\n teacher = new_model()\n teacher.set_weights(source_model.get_weights())\n target_accuracies, _ = utils.self_train(\n student_func, teacher, dir_inter_x, epochs=epochs, target_x=trg_eval_x,\n target_y=trg_eval_y, repeats=num_repeats, soft=soft, confidence_q=conf_q)\n print(\"\\n\\n Direct boostrap to all unsup data:\")\n teacher = new_model()\n teacher.set_weights(source_model.get_weights())\n all_accuracies, _ = utils.self_train(\n student_func, teacher, inter_x, epochs=epochs, target_x=trg_eval_x,\n target_y=trg_eval_y, repeats=num_repeats, soft=soft, confidence_q=conf_q)\n return src_acc, target_acc, gradual_accuracies, target_accuracies, all_accuracies\n results = []\n for i in range(num_runs):\n results.append(run(i))\n print('Saving to ' + save_file)\n pickle.dump(results, open(save_file, \"wb\"))\n\n\ndef experiment_results(save_name):\n results = pickle.load(open(save_name, \"rb\"))\n src_accs, target_accs = [], []\n final_graduals, final_targets, final_alls = [], [], []\n best_targets, best_alls = [], []\n for src_acc, target_acc, gradual_accuracies, target_accuracies, all_accuracies in results:\n src_accs.append(100 * src_acc)\n target_accs.append(100 * target_acc)\n final_graduals.append(100 * gradual_accuracies[-1])\n final_targets.append(100 * target_accuracies[-1])\n final_alls.append(100 * all_accuracies[-1])\n best_targets.append(100 * np.max(target_accuracies))\n best_alls.append(100 * np.max(all_accuracies))\n num_runs = len(src_accs)\n mult = 1.645 # For 90% confidence intervals\n print(\"\\nNon-adaptive accuracy on source (%): \", np.mean(src_accs),\n mult * np.std(src_accs) / np.sqrt(num_runs))\n print(\"Non-adaptive accuracy on target (%): \", np.mean(target_accs),\n mult * np.std(target_accs) / np.sqrt(num_runs))\n print(\"Gradual self-train accuracy (%): \", np.mean(final_graduals),\n mult * np.std(final_graduals) / np.sqrt(num_runs))\n print(\"Target self-train accuracy (%): \", np.mean(final_targets),\n mult * np.std(final_targets) / np.sqrt(num_runs))\n print(\"All self-train accuracy (%): \", np.mean(final_alls),\n mult * np.std(final_alls) / np.sqrt(num_runs))\n print(\"Best of Target self-train accuracies (%): \", np.mean(best_targets),\n mult * np.std(best_targets) / np.sqrt(num_runs))\n print(\"Best of All self-train accuracies (%): \", np.mean(best_alls),\n mult * np.std(best_alls) / np.sqrt(num_runs))\n\n\ndef rotated_mnist_60_conv_experiment():\n run_experiment(\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\n save_file='saved_files/rot_mnist_60_conv.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=10, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef portraits_conv_experiment():\n run_experiment(\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\n save_file='saved_files/portraits.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=20, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef gaussian_linear_experiment():\n d = 100 \n run_experiment(\n dataset_func=lambda: datasets.gaussian_data_func(d), n_classes=2, input_shape=(d,),\n save_file='saved_files/gaussian.dat',\n model_func=models.linear_softmax_model, interval=500, epochs=100, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\n# Ablations below.\n\ndef rotated_mnist_60_conv_experiment_noconf():\n run_experiment(\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\n save_file='saved_files/rot_mnist_60_conv_noconf.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=10, loss='ce',\n soft=False, conf_q=0.0, num_runs=5)\n\n\ndef portraits_conv_experiment_noconf():\n run_experiment(\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\n save_file='saved_files/portraits_noconf.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=20, loss='ce',\n soft=False, conf_q=0.0, num_runs=5)\n\n\ndef gaussian_linear_experiment_noconf():\n d = 100 \n run_experiment(\n dataset_func=lambda: datasets.gaussian_data_func(d), n_classes=2, input_shape=(d,),\n save_file='saved_files/gaussian_noconf.dat',\n model_func=models.linear_softmax_model, interval=500, epochs=100, loss='ce',\n soft=False, conf_q=0.0, num_runs=5)\n\n\ndef portraits_64_conv_experiment():\n run_experiment(\n dataset_func=datasets.portraits_64_data_func, n_classes=2, input_shape=(64, 64, 1),\n save_file='saved_files/portraits_64.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=20, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef dialing_ratios_mnist_experiment():\n run_experiment(\n dataset_func=datasets.rotated_mnist_60_dialing_ratios_data_func,\n n_classes=10, input_shape=(28, 28, 1),\n save_file='saved_files/dialing_rot_mnist_60_conv.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=10, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef portraits_conv_experiment_more():\n run_experiment(\n dataset_func=datasets.portraits_data_func_more, n_classes=2, input_shape=(32, 32, 1),\n save_file='saved_files/portraits_more.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=20, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef rotated_mnist_60_conv_experiment_smaller_interval():\n run_experiment(\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\n save_file='saved_files/rot_mnist_60_conv_smaller_interval.dat',\n model_func=models.simple_softmax_conv_model, interval=1000, epochs=10, loss='ce',\n soft=False, conf_q=0.1, num_runs=5, num_repeats=7)\n\n\ndef portraits_conv_experiment_smaller_interval():\n run_experiment(\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\n save_file='saved_files/portraits_smaller_interval.dat',\n model_func=models.simple_softmax_conv_model, interval=1000, epochs=20, loss='ce',\n soft=False, conf_q=0.1, num_runs=5, num_repeats=7)\n\n\ndef gaussian_linear_experiment_smaller_interval():\n d = 100 \n run_experiment(\n dataset_func=lambda: datasets.gaussian_data_func(d), n_classes=2, input_shape=(d,),\n save_file='saved_files/gaussian_smaller_interval.dat',\n model_func=models.linear_softmax_model, interval=250, epochs=100, loss='ce',\n soft=False, conf_q=0.1, num_runs=5, num_repeats=7)\n\n\n\ndef rotated_mnist_60_conv_experiment_more_epochs():\n run_experiment(\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\n save_file='saved_files/rot_mnist_60_conv_more_epochs.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=15, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef portraits_conv_experiment_more_epochs():\n run_experiment(\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\n save_file='saved_files/portraits_more_epochs.dat',\n model_func=models.simple_softmax_conv_model, interval=2000, epochs=30, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\ndef gaussian_linear_experiment_more_epochs():\n d = 100 \n run_experiment(\n dataset_func=lambda: datasets.gaussian_data_func(d), n_classes=2, input_shape=(d,),\n save_file='saved_files/gaussian_more_epochs.dat',\n model_func=models.linear_softmax_model, interval=500, epochs=150, loss='ce',\n soft=False, conf_q=0.1, num_runs=5)\n\n\nif __name__ == \"__main__\":\n # Main paper experiments.\n portraits_conv_experiment()\n print(\"Portraits conv experiment\")\n experiment_results('saved_files/portraits.dat')\n rotated_mnist_60_conv_experiment()\n print(\"Rot MNIST conv experiment\")\n experiment_results('saved_files/rot_mnist_60_conv.dat')\n gaussian_linear_experiment()\n print(\"Gaussian linear experiment\")\n experiment_results('saved_files/gaussian.dat')\n print(\"Dialing MNIST ratios conv experiment\")\n dialing_ratios_mnist_experiment()\n experiment_results('saved_files/dialing_rot_mnist_60_conv.dat')\n\n # Without confidence thresholding.\n portraits_conv_experiment_noconf()\n print(\"Portraits conv experiment no confidence thresholding\")\n experiment_results('saved_files/portraits_noconf.dat')\n rotated_mnist_60_conv_experiment_noconf()\n print(\"Rot MNIST conv experiment no confidence thresholding\")\n experiment_results('saved_files/rot_mnist_60_conv_noconf.dat')\n gaussian_linear_experiment_noconf()\n print(\"Gaussian linear experiment no confidence thresholding\")\n experiment_results('saved_files/gaussian_noconf.dat')\n\n # Try predicting for next set of data points on portraits.\n portraits_conv_experiment_more()\n print(\"Portraits next datapoints conv experiment\")\n experiment_results('saved_files/portraits_more.dat')\n\n # Try smaller window sizes.\n portraits_conv_experiment_smaller_interval()\n print(\"Portraits conv experiment smaller window\")\n experiment_results('saved_files/portraits_smaller_interval.dat')\n rotated_mnist_60_conv_experiment_smaller_interval()\n print(\"Rot MNIST conv experiment smaller window\")\n experiment_results('saved_files/rot_mnist_60_conv_smaller_interval.dat')\n gaussian_linear_experiment_smaller_interval()\n print(\"Gaussian linear experiment smaller window\")\n experiment_results('saved_files/gaussian_smaller_interval.dat')\n\n # Try training more epochs.\n portraits_conv_experiment_more_epochs()\n print(\"Portraits conv experiment train longer\")\n experiment_results('saved_files/portraits_more_epochs.dat')\n rotated_mnist_60_conv_experiment_more_epochs()\n print(\"Rot MNIST conv experiment train longer\")\n experiment_results('saved_files/rot_mnist_60_conv_more_epochs.dat')\n gaussian_linear_experiment_more_epochs()\n print(\"Gaussian linear experiment train longer\")\n experiment_results('saved_files/gaussian_more_epochs.dat')\n"
},
{
"alpha_fraction": 0.6148648858070374,
"alphanum_fraction": 0.6248648762702942,
"avg_line_length": 34.959999084472656,
"blob_id": "a9768781c8b1b6cda36af7b3c3337e34e8d73b25",
"content_id": "81a2f90d2b4f41ad0f06844e66b5e86156435503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3700,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 100,
"path": "/utils.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\r\nimport numpy as np\r\nfrom tensorflow.keras.models import load_model\r\nimport tensorflow as tf\r\n\r\ndef rand_seed(seed):\r\n np.random.seed(seed)\r\n tf.compat.v1.set_random_seed(seed)\r\n\r\n\r\ndef self_train_once(student, teacher, unsup_x, confidence_q=0.1, epochs=20):\r\n # Do one bootstrapping step on unsup_x, where pred_model is used to make predictions,\r\n # and we use these predictions to update model.\r\n logits = teacher.predict(np.concatenate([unsup_x]))\r\n confidence = np.amax(logits, axis=1) - np.amin(logits, axis=1)\r\n alpha = np.quantile(confidence, confidence_q)\r\n indices = np.argwhere(confidence >= alpha)[:, 0]\r\n preds = np.argmax(logits, axis=1)\r\n student.fit(unsup_x[indices], preds[indices], epochs=epochs, verbose=False)\r\n\r\n\r\ndef soft_self_train_once(student, teacher, unsup_x, epochs=20):\r\n probs = teacher.predict(np.concatenate([unsup_x]))\r\n student.fit(unsup_x, probs, epochs=epochs, verbose=False)\r\n\r\n\r\ndef self_train(student_func, teacher, unsup_x, confidence_q=0.1, epochs=20, repeats=1,\r\n target_x=None, target_y=None, soft=False):\r\n accuracies = []\r\n for i in range(repeats):\r\n student = student_func(teacher)\r\n if soft:\r\n soft_self_train_once(student, teacher, unsup_x, epochs)\r\n else:\r\n self_train_once(student, teacher, unsup_x, confidence_q, epochs)\r\n if target_x is not None and target_y is not None:\r\n _, accuracy = student.evaluate(target_x, target_y, verbose=True)\r\n accuracies.append(accuracy)\r\n teacher = student\r\n return accuracies, student\r\n\r\n\r\ndef gradual_self_train(student_func, teacher, unsup_x, debug_y, interval, confidence_q=0.1,\r\n epochs=20, soft=False):\r\n upper_idx = int(unsup_x.shape[0] / interval)\r\n accuracies = []\r\n for i in range(upper_idx):\r\n student = student_func(teacher)\r\n cur_xs = unsup_x[interval*i:interval*(i+1)]\r\n cur_ys = debug_y[interval*i:interval*(i+1)]\r\n # _, student = self_train(\r\n # student_func, teacher, unsup_x, confidence_q, epochs, repeats=2)\r\n if soft:\r\n soft_self_train_once(student, teacher, cur_xs, epochs)\r\n else:\r\n self_train_once(student, teacher, cur_xs, confidence_q, epochs)\r\n _, accuracy = student.evaluate(cur_xs, cur_ys)\r\n accuracies.append(accuracy)\r\n teacher = student\r\n return accuracies, student\r\n\r\n\r\ndef split_data(xs, ys, splits):\r\n return np.split(xs, splits), np.split(ys, splits)\r\n\r\n\r\ndef train_to_acc(model, acc, train_x, train_y, val_x, val_y):\r\n # Modify steps per epoch to be around dataset size / 10\r\n # Keep training until accuracy \r\n batch_size = 32\r\n data_size = train_x.shape[0]\r\n steps_per_epoch = int(data_size / 50.0 / batch_size)\r\n logger.info(\"train_xs size is %s\", str(train_x.shape))\r\n while True:\r\n model.fit(train_x, train_y, batch_size=batch_size, steps_per_epoch=steps_per_epoch, verbose=False)\r\n val_accuracy = model.evaluate(val_x, val_y, verbose=False)[1]\r\n logger.info(\"validation accuracy is %f\", val_accuracy)\r\n if val_accuracy >= acc:\r\n break\r\n return model\r\n\r\n\r\ndef save_model(model, filename):\r\n model.save(filename)\r\n\r\n\r\ndef load_model(filename):\r\n model = load_model(filename)\r\n\r\n\r\ndef rolling_average(sequence, r):\r\n N = sequence.shape[0]\r\n assert r < N\r\n assert r > 1\r\n rolling_sums = []\r\n cur_sum = sum(sequence[:r])\r\n rolling_sums.append(cur_sum)\r\n for i in range(r, N):\r\n cur_sum = cur_sum + sequence[i] - sequence[i-r]\r\n rolling_sums.append(cur_sum)\r\n return np.array(rolling_sums) * 1.0 / r\r\n\r\n"
},
{
"alpha_fraction": 0.6266171336174011,
"alphanum_fraction": 0.6534200310707092,
"avg_line_length": 45.094276428222656,
"blob_id": "fcf3220e03becc7571958aad808f54c743e0e8a2",
"content_id": "dbd44b9faba0a51cd687939e6c182d3711a0950d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13991,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 297,
"path": "/regularization_helps.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\r\nimport datasets\r\nimport models\r\nimport utils\r\nimport tensorflow as tf\r\nfrom tensorflow.keras import metrics\r\nimport pickle\r\nimport numpy as np\r\nfrom tensorflow.keras.utils import to_categorical\r\n\r\n\r\ndef compile_model(model, loss='ce'):\r\n loss = models.get_loss(loss, model.output_shape[1])\r\n model.compile(optimizer='adam',\r\n loss=[loss],\r\n metrics=['accuracy'])\r\n\r\n\r\ndef student_func_gen(model_func, retrain, loss):\r\n iters = 0\r\n def student_func(teacher):\r\n nonlocal iters\r\n iters += 1\r\n if iters == 1 or retrain:\r\n model = model_func()\r\n compile_model(model, loss)\r\n return model\r\n return teacher\r\n return student_func\r\n\r\n\r\ndef reg_vs_unreg_experiment(\r\n src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y, trg_eval_x, trg_eval_y,\r\n n_classes, input_shape, save_file, unreg_model_func, reg_model_func,\r\n interval=2000, epochs=10, loss='ce', retrain=False, soft=False, num_runs=20):\r\n if soft:\r\n src_tr_y = to_categorical(src_tr_y)\r\n src_val_y = to_categorical(src_val_y)\r\n trg_eval_y = to_categorical(trg_eval_y)\r\n inter_y = to_categorical(inter_y)\r\n def teacher_model():\r\n model = unreg_model_func(n_classes, input_shape=input_shape)\r\n compile_model(model, loss)\r\n return model\r\n def run(seed):\r\n utils.rand_seed(seed)\r\n # Train source model.\r\n source_model = teacher_model()\r\n source_model.fit(src_tr_x, src_tr_y, epochs=epochs, verbose=False)\r\n _, src_acc = source_model.evaluate(src_val_x, src_val_y)\r\n _, target_acc = source_model.evaluate(trg_eval_x, trg_eval_y)\r\n # Gradual self-training.\r\n def gradual_train(regularize):\r\n teacher = teacher_model()\r\n teacher.set_weights(source_model.get_weights())\r\n if regularize:\r\n model_func = reg_model_func\r\n else:\r\n model_func = unreg_model_func\r\n student_func = student_func_gen(\r\n model_func=lambda: model_func(n_classes, input_shape=input_shape),\r\n retrain=retrain, loss=loss)\r\n accuracies, student = utils.gradual_self_train(\r\n student_func, teacher, inter_x, inter_y, interval, epochs=epochs, soft=soft)\r\n _, acc = student.evaluate(trg_eval_x, trg_eval_y)\r\n accuracies.append(acc)\r\n return accuracies\r\n # Regularized gradual self-training.\r\n print(\"\\n\\n Regularized gradual self-training:\")\r\n reg_accuracies = gradual_train(regularize=True)\r\n # Unregularized\r\n print(\"\\n\\n Unregularized gradual self-training:\")\r\n unreg_accuracies = gradual_train(regularize=False)\r\n return src_acc, target_acc, reg_accuracies, unreg_accuracies\r\n results = []\r\n for i in range(num_runs):\r\n results.append(run(i))\r\n print('Saving to ' + save_file)\r\n pickle.dump(results, open(save_file, \"wb\"))\r\n\r\n\r\ndef rotated_mnist_regularization_experiment(\r\n unreg_model_func, reg_model_func, loss, save_name_base, N=2000, delta_angle=3, num_angles=21,\r\n retrain=False, num_runs=20):\r\n # Get data.\r\n (train_x, train_y), _ = datasets.get_preprocessed_mnist()\r\n orig_x, orig_y = train_x[:N], train_y[:N]\r\n inter_x, inter_y = datasets.make_population_rotated_dataset(\r\n orig_x, orig_y, delta_angle, num_angles)\r\n trg_x, trg_y = inter_x[-N:], inter_y[-N:]\r\n n_classes = 10\r\n input_shape = (28, 28, 1)\r\n loss = 'ce'\r\n epochs = 20\r\n interval = N\r\n save_file = (save_name_base + '_' + str(N) + '_' + str(delta_angle) + '_' + str(num_angles) +\r\n '.dat')\r\n reg_vs_unreg_experiment(\r\n orig_x, orig_y, orig_x, orig_y, inter_x, inter_y, trg_x, trg_y,\r\n n_classes, input_shape, save_file, unreg_model_func, reg_model_func,\r\n interval, epochs, loss, retrain, soft=False, num_runs=num_runs)\r\n\r\n\r\ndef finite_data_experiment(\r\n dataset_func, n_classes, input_shape, save_file, unreg_model_func, reg_model_func,\r\n interval=2000, epochs=10, loss='ce', retrain=False, soft=False, num_runs=20):\r\n (src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y, dir_inter_x, dir_inter_y,\r\n trg_val_x, trg_val_y, trg_test_x, trg_test_y) = dataset_func()\r\n reg_vs_unreg_experiment(\r\n src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y, trg_val_x, trg_val_y,\r\n n_classes, input_shape, save_file, unreg_model_func, reg_model_func,\r\n interval, epochs, loss, retrain, soft=soft, num_runs=num_runs)\r\n\r\n\r\ndef regularization_results(save_name):\r\n results = pickle.load(open(save_name, \"rb\"))\r\n src_accs, target_accs, reg_accs, unreg_accs = [], [], [], []\r\n for src_acc, target_acc, reg_accuracies, unreg_accuracies in results:\r\n src_accs.append(100 * src_acc)\r\n target_accs.append(100 * target_acc)\r\n reg_accs.append(100 * reg_accuracies[-1])\r\n unreg_accs.append(100 * unreg_accuracies[-1])\r\n num_runs = len(src_accs)\r\n mult = 1.645 # For 90% confidence intervals\r\n print(\"\\nNon-adaptive accuracy on source (%): \", np.mean(src_accs),\r\n mult * np.std(src_accs) / np.sqrt(num_runs))\r\n print(\"Non-adaptive accuracy on target (%): \", np.mean(target_accs),\r\n mult * np.std(target_accs) / np.sqrt(num_runs))\r\n print(\"Reg accuracy (%): \", np.mean(reg_accs),\r\n mult * np.std(reg_accs) / np.sqrt(num_runs))\r\n print(\"Unreg accuracy (%): \", np.mean(unreg_accs),\r\n mult * np.std(unreg_accs) / np.sqrt(num_runs))\r\n\r\n\r\ndef rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\r\n save_file='saved_files/reg_vs_unreg_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.unregularized_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=10, loss='ce', soft=False, num_runs=5)\r\n\r\n\r\ndef soft_rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\r\n save_file='saved_files/reg_vs_unreg_soft_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.unregularized_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=10, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef retrain_soft_rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\r\n save_file='saved_files/reg_vs_unreg_retrain_soft_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.unregularized_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=10, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef keras_retrain_soft_rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\r\n save_file='saved_files/reg_vs_unreg_keras_retrain_soft_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.unregularized_keras_mnist_model,\r\n reg_model_func=models.keras_mnist_model,\r\n interval=2000, epochs=10, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef deeper_retrain_soft_rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_data_func, n_classes=10, input_shape=(28, 28, 1),\r\n save_file='saved_files/deeper_retrain_soft_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.deeper_softmax_conv_model,\r\n reg_model_func=models.deeper_softmax_conv_model,\r\n interval=2000, epochs=10, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef portraits_data_func():\r\n return datasets.make_portraits_data(1000, 1000, 14000, 2000, 1000, 1000)\r\n\r\n\r\ndef portraits_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\r\n save_file='saved_files/reg_vs_unreg_portraits.dat',\r\n unreg_model_func=models.unregularized_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=20, loss='ce', soft=False, num_runs=5)\r\n\r\n\r\ndef soft_portraits_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.portraits_data_func, n_classes=2, input_shape=(32, 32, 1),\r\n save_file='saved_files/reg_vs_unreg_soft_portraits.dat',\r\n unreg_model_func=models.unregularized_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=20, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef gaussian_data_func(d):\r\n return datasets.make_high_d_gaussian_data(\r\n d=d, min_var=0.05, max_var=0.1,\r\n source_alphas=[0.0, 0.0], inter_alphas=[0.0, 1.0], target_alphas=[1.0, 1.0],\r\n n_src_tr=500, n_src_val=1000, n_inter=5000, n_trg_val=1000, n_trg_tst=1000)\r\n\r\n\r\ndef gaussian_linear_experiment():\r\n d = 100 \r\n finite_data_experiment(\r\n dataset_func=lambda: gaussian_data_func(d), n_classes=2, input_shape=(d,),\r\n save_file='saved_files/reg_vs_unreg_gaussian.dat',\r\n unreg_model_func=lambda k, input_shape: models.linear_softmax_model(k, input_shape, l2_reg=0.0),\r\n reg_model_func=models.linear_softmax_model,\r\n interval=500, epochs=100, loss='ce', soft=False, num_runs=5)\r\n\r\ndef soft_gaussian_linear_experiment():\r\n d = 100 \r\n finite_data_experiment(\r\n dataset_func=lambda: gaussian_data_func(d), n_classes=2, input_shape=(d,),\r\n save_file='saved_files/reg_vs_unreg_soft_gaussian.dat',\r\n unreg_model_func=lambda k, input_shape: models.linear_softmax_model(k, input_shape, l2_reg=0.0),\r\n reg_model_func=models.linear_softmax_model,\r\n interval=500, epochs=100, loss='categorical_ce', soft=True, num_runs=5)\r\n\r\n\r\ndef dialing_rotated_mnist_60_conv_experiment():\r\n finite_data_experiment(\r\n dataset_func=datasets.rotated_mnist_60_dialing_ratios_data_func, n_classes=10,\r\n input_shape=(28, 28, 1),\r\n save_file='saved_files/reg_vs_unreg_dialing_rot_mnist_60_conv.dat',\r\n unreg_model_func=models.simple_softmax_conv_model,\r\n reg_model_func=models.simple_softmax_conv_model,\r\n interval=2000, epochs=10, loss='ce', soft=False, num_runs=5)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n rotated_mnist_regularization_experiment(\r\n models.unregularized_softmax_conv_model, models.simple_softmax_conv_model, 'ce',\r\n save_name_base='saved_files/inf_reg_mnist', N=2000, delta_angle=3, num_angles=20,\r\n retrain=False, num_runs=5)\r\n print(\"Rot MNIST experiment 2000 points rotated\")\r\n regularization_results('saved_files/inf_reg_mnist_2000_3_20.dat')\r\n\r\n rotated_mnist_regularization_experiment(\r\n models.unregularized_softmax_conv_model, models.simple_softmax_conv_model, 'ce',\r\n save_name_base='saved_files/inf_reg_mnist', N=5000, delta_angle=3, num_angles=20,\r\n retrain=False, num_runs=5)\r\n print(\"Rot MNIST experiment 5000 points rotated\")\r\n regularization_results('saved_files/inf_reg_mnist_5000_3_20.dat')\r\n\r\n rotated_mnist_regularization_experiment(\r\n models.unregularized_softmax_conv_model, models.simple_softmax_conv_model, 'ce',\r\n save_name_base='saved_files/inf_reg_mnist', N=20000, delta_angle=3, num_angles=20,\r\n retrain=False, num_runs=5)\r\n print(\"Rot MNIST experiment 20k points rotated\")\r\n regularization_results('saved_files/inf_reg_mnist_20000_3_20.dat')\r\n\r\n # Run all experiments comparing regularization vs no regularization.\r\n portraits_conv_experiment()\r\n print(\"Portraits conv experiment reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_portraits.dat')\r\n rotated_mnist_60_conv_experiment()\r\n print(\"Rotating MNIST conv experiment reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_rot_mnist_60_conv.dat')\r\n gaussian_linear_experiment()\r\n print(\"Gaussian linear experiment reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_gaussian.dat')\r\n\r\n # Run all experiments, soft labeling, comparing regularization vs no regularization.\r\n soft_portraits_conv_experiment()\r\n print(\"Portraits conv experiment soft labeling reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_soft_portraits.dat')\r\n soft_rotated_mnist_60_conv_experiment()\r\n print(\"Rot MNIST conv experiment soft labeling reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_soft_rot_mnist_60_conv.dat')\r\n soft_gaussian_linear_experiment()\r\n print(\"Gaussian linear experiment soft labeling reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_soft_gaussian.dat')\r\n\r\n # Dialing ratios results.\r\n dialing_rotated_mnist_60_conv_experiment()\r\n print(\"Dialing rations MNIST experiment reg vs no reg\")\r\n regularization_results('saved_files/reg_vs_unreg_dialing_rot_mnist_60_conv.dat')\r\n\r\n # Try retraining the model each iteration.\r\n retrain_soft_rotated_mnist_60_conv_experiment()\r\n print(\"Rot MNIST conv experiment reset model when self-training\")\r\n regularization_results('saved_files/reg_vs_unreg_retrain_soft_rot_mnist_60_conv.dat')\r\n # Use the Keras MNIST model.\r\n keras_retrain_soft_rotated_mnist_60_conv_experiment()\r\n print(\"Rot MNIST conv experiment use Keras MNIST model\")\r\n regularization_results('saved_files/reg_vs_unreg_keras_retrain_soft_rot_mnist_60_conv.dat')\r\n # Use a deeper (4 layer) conv net model.\r\n deeper_retrain_soft_rotated_mnist_60_conv_experiment()\r\n print(\"Rot MNIST conv experiment use deeper model\")\r\n regularization_results('saved_files/deeper_retrain_soft_rot_mnist_60_conv.dat')\r\n\r\n"
},
{
"alpha_fraction": 0.5977948307991028,
"alphanum_fraction": 0.6251198649406433,
"avg_line_length": 33.196720123291016,
"blob_id": "cc49898844b9427bded84177ed8dd1d22a3508ac",
"content_id": "ec6a90c64f51fdf875888a1e0a6813a1efae0248",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4172,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 122,
"path": "/dataset_test.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\nfrom scipy.io import loadmat, savemat\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom tensorflow.keras.datasets import mnist\nfrom skimage.transform import resize\n\n\ndef shuffle(xs, ys):\n indices = list(range(len(xs)))\n np.random.shuffle(indices)\n return xs[indices], ys[indices]\n\ndef mnist_resize(x):\n H, W, C = 32, 32, 3\n x = x.reshape(-1, 28, 28)\n resized_x = np.empty((len(x), H, W), dtype='float32')\n for i, img in enumerate(x):\n if i % 1000 == 0:\n print(i)\n # resize returns [0, 1]\n resized_x[i] = resize(img, (H, W), mode='reflect')\n\n # Retile to make RGB\n resized_x = resized_x.reshape(-1, H, W, 1)\n resized_x = np.tile(resized_x, (1, 1, 1, C))\n return resized_x\n\ndef save_mnist_32():\n (mnist_x, mnist_y), (_, _) = mnist.load_data()\n mnist_x = mnist_resize(mnist_x / 255.0)\n savemat('mnist32_train.mat', {'X': mnist_x, 'y': mnist_y})\n\n\ndef make_mnist_svhn_dataset(num_examples, mnist_start_prob, mnist_end_prob):\n data = loadmat('mnist32_train.mat')\n mnist_x = data['X']\n mnist_y = data['y']\n mnist_y = np.squeeze(mnist_y)\n mnist_x, mnist_y = shuffle(mnist_x, mnist_y)\n print(np.min(mnist_x), np.max(mnist_x))\n\n data = loadmat('svhn_train_32x32.mat')\n svhn_x = data['X']\n svhn_x = svhn_x / 255.0\n svhn_x = np.transpose(svhn_x, [3, 0, 1, 2])\n svhn_y = data['y']\n svhn_y = np.squeeze(svhn_y)\n svhn_y[(svhn_y == 10)] = 0\n svhn_x, svhn_y = shuffle(svhn_x, svhn_y)\n print(svhn_x.shape, svhn_y.shape)\n print(np.min(svhn_x), np.max(svhn_x))\n\n delta = float(mnist_end_prob - mnist_start_prob) / (num_examples - 1)\n mnist_probs = np.array([mnist_start_prob + delta * i for i in range(num_examples)])\n # assert((np.all(mnist_end_prob >= mnist_probs) and np.all(mnist_probs >= mnist_start_prob)) or\n # (np.all(mnist_start_prob >= mnist_probs) and np.all(mnist_probs >= mnist_end_prob)))\n domains = np.random.binomial(n=1, p=mnist_probs)\n assert(domains.shape == (num_examples,))\n mnist_indices = np.arange(num_examples)[domains == 1]\n svhn_indices = np.arange(num_examples)[domains == 0]\n print(svhn_x.shape, mnist_x.shape)\n assert(svhn_x.shape[1:] == mnist_x.shape[1:])\n print(mnist_indices[:10], svhn_indices[:10], svhn_indices[-10:])\n xs = np.empty((num_examples,) + tuple(svhn_x.shape[1:]), dtype='float32')\n ys = np.empty((num_examples,), dtype='int32')\n xs[mnist_indices] = mnist_x[:mnist_indices.size]\n xs[svhn_indices] = svhn_x[:svhn_indices.size]\n ys[mnist_indices] = mnist_y[:mnist_indices.size]\n ys[svhn_indices] = svhn_y[:svhn_indices.size]\n return xs, ys\n\n\n\nsave_mnist_32()\n# xs, ys = make_mnist_svhn_dataset(10000, 0.9, 0.1)\n# print(xs.shape, ys.shape)\n# ex_0 = xs[ys == 0][0]\n# plt.imshow(ex_0)\n# plt.show()\n# ex_0 = xs[ys == 0][-1]\n# plt.imshow(ex_0)\n# plt.show()\n\n\n # Read and process MNIST images\n # Read and process SVHN images\n # Shuffle MNIST and SVHN images\n # First generate an array of datasets\n # Interpolate between start and end prob\n # Use that to pick and index from a Bernoulli\n # Then select the images (could do some fancy indexing, or just do it manually, append images)\n # Should be fast enough, did that in rotated dataset\n # Return this\n\n# data = loadmat('svhn_train_32x32.mat')\n# Xs = data['X']\n# Xs = np.transpose(Xs, [3, 0, 1, 2])\n# Ys = data['y']\n# Ys = np.squeeze(Ys)\n# print(Xs.shape, Ys.shape)\n# print(np.min(Ys), np.max(Ys))\n# Ys[(Ys == 10)] = 0\n# print(np.min(Ys), np.max(Ys))\n# print(np.min(Xs), np.max(Xs))\n\n# Resize MNIST images to make them colored. Just add extra channels.\n# Need to check min and max for MNIST and SVHN, preprocess them as needed\n# Could add instance normalization as well, if we think that helps.\n# (train_x, train_y), (_, _) = mnist.load_data()\n# print(np.min(train_x), np.max(train_x))\n# train_x = np.tile(np.expand_dims(train_x, axis=-1), (1, 1, 1, 3))\n# print(np.min(train_y), np.max(train_y))\n# print(train_y.shape)\n# ex_0 = train_x[train_y == 0][0]\n# plt.imshow(ex_0)\n# plt.show()\n# print(train_x.shape)\n\n# X10s = Xs[y10s]\n# print(X10s.shape)\n# plt.imshow(X10s[0])\n# plt.show()"
},
{
"alpha_fraction": 0.5804511308670044,
"alphanum_fraction": 0.62556391954422,
"avg_line_length": 25.625,
"blob_id": "14467ff65fd38563755b659c8b3ecbd624d9458e",
"content_id": "6a24ce4921eda63088feb9e682075307049d0a8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 665,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 24,
"path": "/make_plots.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\r\nimport pickle\r\nimport utils\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom matplotlib import rc\r\n\r\nfont = {'family' : 'normal',\r\n 'size' : 16}\r\nrc('font', **font)\r\nbinary_genders = pickle.load(open('portraits_gender_stats', 'rb'))\r\nr = 1000\r\nN = 18000\r\ny = utils.rolling_average(binary_genders, r)[:N-r] * 100\r\nx = np.array(list(range(N-r)))\r\nyerr = 0.5 / np.sqrt(r) * 1.645 * 100\r\n# plt.errorbar(\r\n# x, y, yerr=yerr,\r\n# barsabove=True, color='blue', capsize=4, linestyle='--')\r\nplt.ylim([0, 100])\r\nplt.plot(y)\r\nplt.fill_between(x, y-yerr, y+yerr, facecolor='blue', alpha=0.2)\r\nplt.xlabel(\"Time\")\r\nplt.ylabel(\"% Female\")\r\nplt.show()\r\n"
},
{
"alpha_fraction": 0.6100472807884216,
"alphanum_fraction": 0.6280527114868164,
"avg_line_length": 40.36008071899414,
"blob_id": "adb1609ad209d73a8f5f468571e67614b9122019",
"content_id": "70792302a0100754d927b03b6af76c420f195a60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20105,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 486,
"path": "/datasets.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\nimport collections\nimport numpy as np\nfrom tensorflow.keras.preprocessing.image import ImageDataGenerator\nfrom tensorflow.keras.datasets import mnist\nfrom tensorflow.keras.datasets import cifar10\nimport scipy.io\nfrom scipy import ndimage\nfrom scipy.stats import ortho_group\nimport sklearn.preprocessing\nimport pickle\nimport utils\n\nDataset = collections.namedtuple('Dataset',\n 'get_data n_src_train n_src_valid n_target_unsup n_target_val n_target_test target_end '\n 'n_classes input_shape')\n\nSplitData = collections.namedtuple('SplitData',\n ('src_train_x src_val_x src_train_y src_val_y target_unsup_x target_val_x final_target_test_x '\n 'debug_target_unsup_y target_val_y final_target_test_y inter_x inter_y'))\n\n\nimage_options = {\n 'batch_size': 100,\n 'class_mode': 'binary',\n 'color_mode': 'grayscale',\n}\n\n\ndef split_sizes(array, sizes):\n indices = np.cumsum(sizes)\n return np.split(array, indices)\n\n\ndef shuffle(xs, ys):\n indices = list(range(len(xs)))\n np.random.shuffle(indices)\n return xs[indices], ys[indices]\n\n\ndef get_split_data(dataset):\n Xs, Ys = dataset.get_data()\n n_src = dataset.n_src_train + dataset.n_src_valid\n n_target = dataset.n_target_unsup + dataset.n_target_val + dataset.n_target_test\n src_x, src_y = shuffle(Xs[:n_src], Ys[:n_src])\n target_x, target_y = shuffle(\n Xs[dataset.target_end-n_target:dataset.target_end],\n Ys[dataset.target_end-n_target:dataset.target_end])\n [src_train_x, src_val_x] = split_sizes(src_x, [dataset.n_src_train])\n [src_train_y, src_val_y] = split_sizes(src_y, [dataset.n_src_train])\n [target_unsup_x, target_val_x, final_target_test_x] = split_sizes(\n target_x, [dataset.n_target_unsup, dataset.n_target_val])\n [debug_target_unsup_y, target_val_y, final_target_test_y] = split_sizes(\n target_y, [dataset.n_target_unsup, dataset.n_target_val])\n inter_x, inter_y = Xs[n_src:dataset.target_end-n_target], Ys[n_src:dataset.target_end-n_target]\n return SplitData(\n src_train_x=src_train_x,\n src_val_x=src_val_x,\n src_train_y=src_train_y,\n src_val_y=src_val_y,\n target_unsup_x=target_unsup_x,\n target_val_x=target_val_x,\n final_target_test_x=final_target_test_x,\n debug_target_unsup_y=debug_target_unsup_y,\n target_val_y=target_val_y,\n final_target_test_y=final_target_test_y,\n inter_x=inter_x,\n inter_y=inter_y,\n )\n\n\n# Gaussian dataset.\n\ndef shape_means(means):\n means = np.array(means)\n if len(means.shape) == 1:\n means = np.expand_dims(means, axis=-1)\n else:\n assert(len(means.shape) == 2)\n return means\n\n\ndef shape_sigmas(sigmas, means):\n sigmas = np.array(sigmas)\n shape_len = len(sigmas.shape)\n assert(shape_len == 1 or shape_len == 3)\n new_sigmas = sigmas\n if shape_len == 1:\n c = np.expand_dims(np.expand_dims(sigmas, axis=-1), axis=-1)\n d = means.shape[1]\n new_sigmas = c * np.eye(d)\n assert(new_sigmas.shape == (sigmas.shape[0], d, d))\n return new_sigmas\n\n\ndef get_gaussian_at_alpha(source_means, source_sigmas, target_means, target_sigmas, alpha):\n num_classes = source_means.shape[0]\n class_prob = 1.0 / num_classes\n y = np.argmax(np.random.multinomial(1, [class_prob] * num_classes))\n mean = source_means[y] * (1 - alpha) + target_means[y] * alpha\n sigma = source_sigmas[y] * (1 - alpha) + target_sigmas[y] * alpha\n x = np.random.multivariate_normal(mean, sigma)\n return x, y\n\n\ndef sample_gaussian_alpha(source_means, source_sigmas, target_means, target_sigmas,\n alpha_low, alpha_high, N):\n source_means = shape_means(source_means)\n target_means = shape_means(target_means)\n source_sigmas = shape_sigmas(source_sigmas, source_means)\n target_sigmas = shape_sigmas(target_sigmas, target_means)\n xs, ys = [], []\n for i in range(N):\n if alpha_low == alpha_high:\n alpha = alpha_low\n else:\n alpha = np.random.uniform(low=alpha_low, high=alpha_high)\n x, y = get_gaussian_at_alpha(\n source_means, source_sigmas, target_means, target_sigmas, alpha)\n xs.append(x)\n ys.append(y)\n return np.array(xs), np.array(ys)\n\n\ndef continual_gaussian_alpha(source_means, source_sigmas, target_means, target_sigmas,\n alpha_low, alpha_high, N):\n source_means = shape_means(source_means)\n target_means = shape_means(target_means)\n source_sigmas = shape_sigmas(source_sigmas, source_means)\n target_sigmas = shape_sigmas(target_sigmas, target_means)\n xs, ys = [], []\n for i in range(N):\n alpha = float(alpha_high - alpha_low) / N * i + alpha_low\n x, y = get_gaussian_at_alpha(\n source_means, source_sigmas, target_means, target_sigmas, alpha)\n xs.append(x)\n ys.append(y)\n return np.array(xs), np.array(ys)\n\n\ndef make_moving_gaussian_data(\n source_means, source_sigmas, target_means, target_sigmas,\n source_alphas, inter_alphas, target_alphas,\n n_src_tr, n_src_val, n_inter, n_trg_val, n_trg_tst):\n src_tr_x, src_tr_y = sample_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n source_alphas[0], source_alphas[1], N=n_src_tr)\n src_val_x, src_val_y = sample_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n source_alphas[0], source_alphas[1], N=n_src_val)\n inter_x, inter_y = continual_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n inter_alphas[0], inter_alphas[1], N=n_inter)\n dir_inter_x, dir_inter_y = sample_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n target_alphas[0], target_alphas[1], N=n_inter)\n trg_val_x, trg_val_y = sample_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n target_alphas[0], target_alphas[1], N=n_trg_val)\n trg_test_x, trg_test_y = sample_gaussian_alpha(\n source_means, source_sigmas, target_means, target_sigmas,\n target_alphas[0], target_alphas[1], N=n_trg_tst)\n return (src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y,\n dir_inter_x, dir_inter_y, trg_val_x, trg_val_y, trg_test_x, trg_test_y)\n\n\ndef make_high_d_gaussian_data(\n d, min_var, max_var, source_alphas, inter_alphas, target_alphas,\n n_src_tr, n_src_val, n_inter, n_trg_val, n_trg_tst):\n assert(min_var > 0)\n means, var_list = [], []\n for i in range(4):\n means.append(np.random.multivariate_normal(np.zeros(d), np.eye(d)))\n means[i] = means[i] / np.linalg.norm(means[i])\n # Generate diagonal.\n diag = np.diag(np.random.uniform(min_var, max_var, size=d))\n rot = ortho_group.rvs(d)\n var = np.matmul(rot, np.matmul(diag, np.linalg.inv(rot)))\n var_list.append(var)\n return make_moving_gaussian_data(\n source_means=[means[0], means[1]], source_sigmas=[var_list[0], var_list[1]],\n target_means=[means[2], means[3]], target_sigmas=[var_list[2], var_list[3]],\n source_alphas=source_alphas, inter_alphas=inter_alphas, target_alphas=target_alphas,\n n_src_tr=n_src_tr, n_src_val=n_src_val, n_inter=n_inter,\n n_trg_val=n_trg_val, n_trg_tst=n_trg_tst)\n\n\ndef make_moving_gaussians(source_means, source_sigmas, target_means, target_sigmas, steps):\n source_means = shape_means(source_means)\n target_means = shape_means(target_means)\n source_sigmas = shape_sigmas(source_sigmas, source_means)\n target_sigmas = shape_sigmas(target_sigmas, target_means)\n for i in range(steps):\n alpha = float(i) / (steps - 1)\n mean = source_means[y] * (1 - alpha) + target_means[y] * alpha\n sigma = source_sigmas[y] * (1 - alpha) + target_sigmas[y] * alpha\n x, y = get_gaussian_at_alpha()\n xs.append(x)\n ys.append(y)\n return np.array(xs), np.array(ys)\n\n\ndef high_d_gaussians(d, var, n):\n # Choose random direction.\n v = np.random.multivariate_normal(np.zeros(d), np.eye(d))\n v = v / np.linalg.norm(v)\n # Choose random perpendicular direction.\n perp = np.random.multivariate_normal(np.zeros(d), np.eye(d))\n perp = perp - np.dot(perp, v) * v\n perp = perp / np.linalg.norm(perp)\n assert(abs(np.dot(perp, v)) < 1e-8)\n assert(abs(np.linalg.norm(v) - 1) < 1e-8)\n assert(abs(np.linalg.norm(perp) - 1) < 1e-8)\n s_a = 2 * perp - v\n s_b = -2 * perp + v\n t_a = -2 * perp - v\n t_b = 2 * perp + v\n return lambda: make_moving_gaussians([s_a, s_b], [var, var], [t_a, t_b], [var, var], n)\n\n\n# MNIST datasets.\n\ndef get_preprocessed_mnist():\n (train_x, train_y), (test_x, test_y) = mnist.load_data()\n train_x, test_x = train_x / 255.0, test_x / 255.0\n train_x, train_y = shuffle(train_x, train_y)\n train_x = np.expand_dims(np.array(train_x), axis=-1)\n test_x = np.expand_dims(np.array(test_x), axis=-1)\n return (train_x, train_y), (test_x, test_y)\n\n\ndef sample_rotate_images(xs, start_angle, end_angle):\n new_xs = []\n num_points = xs.shape[0]\n for i in range(num_points):\n if start_angle == end_angle:\n angle = start_angle\n else:\n angle = np.random.uniform(low=start_angle, high=end_angle)\n img = ndimage.rotate(xs[i], angle, reshape=False)\n new_xs.append(img)\n return np.array(new_xs)\n\n\ndef continually_rotate_images(xs, start_angle, end_angle):\n new_xs = []\n num_points = xs.shape[0]\n for i in range(num_points):\n angle = float(end_angle - start_angle) / num_points * i + start_angle\n img = ndimage.rotate(xs[i], angle, reshape=False)\n new_xs.append(img)\n return np.array(new_xs)\n\n\ndef _transition_rotation_dataset(train_x, train_y, test_x, test_y,\n source_angles, target_angles, inter_func,\n src_train_end, src_val_end, inter_end, target_end):\n assert(target_end <= train_x.shape[0])\n assert(train_x.shape[0] == train_y.shape[0])\n src_tr_x, src_tr_y = train_x[:src_train_end], train_y[:src_train_end]\n src_tr_x = sample_rotate_images(src_tr_x, source_angles[0], source_angles[1])\n src_val_x, src_val_y = train_x[src_train_end:src_val_end], train_y[src_train_end:src_val_end]\n src_val_x = sample_rotate_images(src_val_x, source_angles[0], source_angles[1])\n tmp_inter_x, inter_y = train_x[src_val_end:inter_end], train_y[src_val_end:inter_end]\n inter_x = inter_func(tmp_inter_x)\n dir_inter_x = sample_rotate_images(tmp_inter_x, target_angles[0], target_angles[1])\n dir_inter_y = np.array(inter_y)\n assert(inter_x.shape == dir_inter_x.shape)\n trg_val_x, trg_val_y = train_x[inter_end:target_end], train_y[inter_end:target_end]\n trg_val_x = sample_rotate_images(trg_val_x, target_angles[0], target_angles[1])\n trg_test_x, trg_test_y = test_x, test_y\n trg_test_x = sample_rotate_images(trg_test_x, target_angles[0], target_angles[1])\n return (src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y,\n dir_inter_x, dir_inter_y, trg_val_x, trg_val_y, trg_test_x, trg_test_y)\n\n\ndef dial_rotation_proportions(xs, source_angles, target_angles):\n N = xs.shape[0]\n new_xs = []\n rotate_ps = np.arange(N) / float(N - 1)\n is_target = np.random.binomial(n=1, p=rotate_ps)\n assert(is_target.shape == (N,))\n for i in range(N):\n if is_target[i]:\n angle = np.random.uniform(low=target_angles[0], high=target_angles[1])\n else:\n angle = np.random.uniform(low=source_angles[0], high=source_angles[1])\n cur_x = ndimage.rotate(xs[i], angle, reshape=False)\n new_xs.append(cur_x)\n return np.array(new_xs)\n\n\ndef dial_proportions_rotated_dataset(train_x, train_y, test_x, test_y,\n source_angles, target_angles,\n src_train_end, src_val_end, inter_end, target_end):\n inter_func = lambda x: dial_rotation_proportions(\n x, source_angles, target_angles)\n return _transition_rotation_dataset(\n train_x, train_y, test_x, test_y, source_angles, target_angles,\n inter_func, src_train_end, src_val_end, inter_end, target_end)\n\n\ndef make_rotated_dataset(train_x, train_y, test_x, test_y,\n source_angles, inter_angles, target_angles,\n src_train_end, src_val_end, inter_end, target_end):\n inter_func = lambda x: continually_rotate_images(x, inter_angles[0], inter_angles[1])\n return _transition_rotation_dataset(\n train_x, train_y, test_x, test_y, source_angles, target_angles,\n inter_func, src_train_end, src_val_end, inter_end, target_end)\n\n\ndef make_population_rotated_dataset(xs, ys, delta_angle, num_angles):\n images, labels = [], []\n for i in range(num_angles):\n cur_angle = i * delta_angle\n cur_images = sample_rotate_images(xs, cur_angle, cur_angle)\n images.append(cur_images)\n labels.append(ys)\n images = np.concatenate(images, axis=0)\n labels = np.concatenate(labels, axis=0)\n assert images.shape[1:] == xs.shape[1:]\n assert labels.shape[1:] == ys.shape[1:]\n return images, labels\n\n\ndef make_rotated_dataset_continuous(dataset, start_angle, end_angle, num_points):\n images, labels = [], []\n (train_x, train_y), (_, _) = dataset.load_data()\n train_x, train_y = shuffle(train_x, train_y)\n train_x = train_x / 255.0\n assert(num_points < train_x.shape[0])\n indices = np.random.choice(train_x.shape[0], size=num_points, replace=False)\n for i in range(num_points):\n angle = float(end_angle - start_angle) / num_points * i + start_angle\n idx = indices[i]\n img = ndimage.rotate(train_x[idx], angle, reshape=False)\n images.append(img)\n labels.append(train_y[idx])\n return np.array(images), np.array(labels)\n\n\ndef make_rotated_mnist(start_angle, end_angle, num_points, normalize=False):\n Xs, Ys = make_rotated_dataset(mnist, start_angle, end_angle, num_points)\n if normalize:\n Xs = np.reshape(Xs, (Xs.shape[0], -1))\n old_mean = np.mean(Xs)\n Xs = sklearn.preprocessing.normalize(Xs, norm='l2')\n new_mean = np.mean(Xs)\n Xs = Xs * (old_mean / new_mean)\n return np.expand_dims(np.array(Xs), axis=-1), Ys\n\n\ndef make_rotated_cifar10(start_angle, end_angle, num_points):\n return make_rotated_dataset(cifar10, start_angle, end_angle, num_points) \n\n\ndef make_mnist():\n (train_x, train_y), (_, _) = mnist.load_data()\n train_x = train_x / 255.0\n return np.expand_dims(train_x, axis=-1), train_y\n\n\ndef make_mnist_svhn_dataset(num_examples, mnist_start_prob, mnist_end_prob):\n data = scipy.io.loadmat('mnist32_train.mat')\n mnist_x = data['X']\n mnist_y = data['y']\n mnist_y = np.squeeze(mnist_y)\n mnist_x, mnist_y = shuffle(mnist_x, mnist_y)\n\n data = scipy.io.loadmat('svhn_train_32x32.mat')\n svhn_x = data['X']\n svhn_x = svhn_x / 255.0\n svhn_x = np.transpose(svhn_x, [3, 0, 1, 2])\n svhn_y = data['y']\n svhn_y = np.squeeze(svhn_y)\n svhn_y[(svhn_y == 10)] = 0\n svhn_x, svhn_y = shuffle(svhn_x, svhn_y)\n\n delta = float(mnist_end_prob - mnist_start_prob) / (num_examples - 1)\n mnist_probs = np.array([mnist_start_prob + delta * i for i in range(num_examples)])\n # assert((np.all(mnist_end_prob >= mnist_probs) and np.all(mnist_probs >= mnist_start_prob)) or\n # (np.all(mnist_start_prob >= mnist_probs) and np.all(mnist_probs >= mnist_end_prob)))\n domains = np.random.binomial(n=1, p=mnist_probs)\n assert(domains.shape == (num_examples,))\n mnist_indices = np.arange(num_examples)[domains == 1]\n svhn_indices = np.arange(num_examples)[domains == 0]\n assert(svhn_x.shape[1:] == mnist_x.shape[1:])\n xs = np.empty((num_examples,) + tuple(svhn_x.shape[1:]), dtype='float32')\n ys = np.empty((num_examples,), dtype='int32')\n xs[mnist_indices] = mnist_x[:mnist_indices.size]\n xs[svhn_indices] = svhn_x[:svhn_indices.size]\n ys[mnist_indices] = mnist_y[:mnist_indices.size]\n ys[svhn_indices] = svhn_y[:svhn_indices.size]\n return xs, ys\n\n\n# Portraits dataset.\n\ndef save_data(data_dir='dataset_32x32', save_file='dataset_32x32.mat', target_size=(32, 32)):\n Xs, Ys = [], []\n datagen = ImageDataGenerator(rescale=1./255)\n data_generator = datagen.flow_from_directory(\n data_dir, shuffle=False, target_size=target_size, **image_options)\n while True:\n next_x, next_y = data_generator.next()\n Xs.append(next_x)\n Ys.append(next_y)\n if data_generator.batch_index == 0:\n break\n Xs = np.concatenate(Xs)\n Ys = np.concatenate(Ys)\n filenames = [f[2:] for f in data_generator.filenames]\n assert(len(set(filenames)) == len(filenames))\n filenames_idx = list(zip(filenames, range(len(filenames))))\n filenames_idx = [(f, i) for f, i in zip(filenames, range(len(filenames)))]\n # if f[5:8] == 'Cal' or f[5:8] == 'cal']\n indices = [i for f, i in sorted(filenames_idx)]\n genders = np.array([f[:1] for f in data_generator.filenames])[indices]\n binary_genders = (genders == 'F')\n pickle.dump(binary_genders, open('portraits_gender_stats', \"wb\"))\n print(\"computed gender stats\")\n # gender_stats = utils.rolling_average(binary_genders, 500)\n # print(filenames)\n # sort_indices = np.argsort(filenames)\n # We need to sort only by year, and not have correlation with state.\n # print state stats? print gender stats? print school stats?\n # E.g. if this changes a lot by year, then we might want to do some grouping.\n # Maybe print out number per year, and then we can decide on a grouping? Or algorithmically decide?\n Xs = Xs[indices]\n Ys = Ys[indices]\n scipy.io.savemat('./' + save_file, mdict={'Xs': Xs, 'Ys': Ys})\n\n\ndef load_portraits_data(load_file='dataset_32x32.mat'):\n data = scipy.io.loadmat('./' + load_file)\n return data['Xs'], data['Ys'][0]\n\n\ndef make_portraits_data(n_src_tr, n_src_val, n_inter, n_target_unsup, n_trg_val, n_trg_tst,\n load_file='dataset_32x32.mat'):\n xs, ys = load_portraits_data(load_file)\n src_end = n_src_tr + n_src_val\n inter_end = src_end + n_inter\n trg_end = inter_end + n_trg_val + n_trg_tst\n src_x, src_y = shuffle(xs[:src_end], ys[:src_end])\n trg_x, trg_y = shuffle(xs[inter_end:trg_end], ys[inter_end:trg_end])\n [src_tr_x, src_val_x] = split_sizes(src_x, [n_src_tr])\n [src_tr_y, src_val_y] = split_sizes(src_y, [n_src_tr])\n [trg_val_x, trg_test_x] = split_sizes(trg_x, [n_trg_val])\n [trg_val_y, trg_test_y] = split_sizes(trg_y, [n_trg_val])\n inter_x, inter_y = xs[src_end:inter_end], ys[src_end:inter_end]\n dir_inter_x, dir_inter_y = inter_x[-n_target_unsup:], inter_y[-n_target_unsup:]\n return (src_tr_x, src_tr_y, src_val_x, src_val_y, inter_x, inter_y,\n dir_inter_x, dir_inter_y, trg_val_x, trg_val_y, trg_test_x, trg_test_y)\n\n\ndef rotated_mnist_60_data_func():\n (train_x, train_y), (test_x, test_y) = get_preprocessed_mnist()\n return make_rotated_dataset(\n train_x, train_y, test_x, test_y, [0.0, 5.0], [5.0, 60.0], [55.0, 60.0],\n 5000, 6000, 48000, 50000)\n\n\ndef rotated_mnist_60_dialing_ratios_data_func():\n (train_x, train_y), (test_x, test_y) = get_preprocessed_mnist()\n return dial_proportions_rotated_dataset(\n train_x, train_y, test_x, test_y, [0.0, 5.0], [55.0, 60.0],\n 5000, 6000, 48000, 50000)\n\n\ndef portraits_data_func():\n return make_portraits_data(1000, 1000, 14000, 2000, 1000, 1000)\n\n\ndef portraits_data_func_more():\n return make_portraits_data(1000, 1000, 20000, 2000, 1000, 1000)\n\n\ndef portraits_64_data_func():\n return make_portraits_data(1000, 1000, 14000, 2000, 1000, 1000, load_file='dataset_64x64.mat')\n\n\ndef gaussian_data_func(d):\n return make_high_d_gaussian_data(\n d=d, min_var=0.05, max_var=0.1,\n source_alphas=[0.0, 0.0], inter_alphas=[0.0, 1.0], target_alphas=[1.0, 1.0],\n n_src_tr=500, n_src_val=1000, n_inter=5000, n_trg_val=1000, n_trg_tst=1000)\n\n\n\n"
},
{
"alpha_fraction": 0.6105342507362366,
"alphanum_fraction": 0.6409330368041992,
"avg_line_length": 40.01234436035156,
"blob_id": "11cfad49c3d8d6b3e08eb10b6eb80fe73c80180f",
"content_id": "990fc4111e816f4baa7757f598ffb78177433f48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6645,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 162,
"path": "/models.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\nimport tensorflow as tf\nimport tensorflow.keras as keras\nfrom tensorflow.keras import regularizers\nfrom tensorflow.keras import losses\n\n\n# Models.\n\ndef linear_model(num_labels, input_shape, l2_reg=0.02):\n linear_model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=input_shape),\n keras.layers.Dense(num_labels, activation=None, name='out',\n kernel_regularizer=regularizers.l2(l2_reg))\n ])\n return linear_model\n\n\ndef linear_softmax_model(num_labels, input_shape, l2_reg=0.02):\n linear_model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=input_shape),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out',\n kernel_regularizer=regularizers.l2(l2_reg))\n ])\n return linear_model\n\n\ndef mlp_softmax_model(num_labels, input_shape, l2_reg=0.02):\n linear_model = keras.models.Sequential([\n keras.layers.Flatten(input_shape=input_shape),\n keras.layers.Dense(32, activation=tf.nn.relu,\n kernel_regularizer=regularizers.l2(0.0)),\n keras.layers.Dense(32, activation=tf.nn.relu,\n kernel_regularizer=regularizers.l2(0.0)),\n keras.layers.BatchNormalization(),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out',\n kernel_regularizer=regularizers.l2(l2_reg))\n ])\n return linear_model\n\n\ndef simple_softmax_conv_model(num_labels, hidden_nodes=32, input_shape=(28,28,1), l2_reg=0.0):\n return keras.models.Sequential([\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same', input_shape=input_shape),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Dropout(0.5),\n keras.layers.BatchNormalization(),\n keras.layers.Flatten(name='after_flatten'),\n # keras.layers.Dense(64, activation=tf.nn.relu),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out')\n ])\n\n\ndef deeper_softmax_conv_model(num_labels, hidden_nodes=32, input_shape=(28,28,1), l2_reg=0.0):\n return keras.models.Sequential([\n keras.layers.Conv2D(hidden_nodes, (5,5), (1, 1), activation=tf.nn.relu,\n padding='same', input_shape=input_shape),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same', input_shape=input_shape),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Dropout(0.5),\n keras.layers.BatchNormalization(),\n keras.layers.Flatten(name='after_flatten'),\n # keras.layers.Dense(64, activation=tf.nn.relu),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out')\n ])\n\n\ndef unregularized_softmax_conv_model(num_labels, hidden_nodes=32, input_shape=(28,28,1), l2_reg=0.0):\n return keras.models.Sequential([\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same', input_shape=input_shape),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Conv2D(hidden_nodes, (5,5), (2, 2), activation=tf.nn.relu,\n padding='same'),\n keras.layers.Flatten(name='after_flatten'),\n # keras.layers.Dense(64, activation=tf.nn.relu),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out')\n ])\n\n\ndef keras_mnist_model(num_labels, input_shape=(28,28,1)):\n model = keras.models.Sequential()\n model.add(keras.layers.Conv2D(32, kernel_size=(3, 3),\n activation='relu',\n input_shape=input_shape))\n model.add(keras.layers.Conv2D(64, (3, 3), activation='relu'))\n model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))\n model.add(keras.layers.Dropout(0.25))\n model.add(keras.layers.Flatten())\n model.add(keras.layers.Dense(128, activation='relu'))\n model.add(keras.layers.Dropout(0.5))\n model.add(keras.layers.Dense(num_labels, activation='softmax'))\n return model\n\n\ndef unregularized_keras_mnist_model(num_labels, input_shape=(28,28,1)):\n model = keras.models.Sequential()\n model.add(keras.layers.Conv2D(32, kernel_size=(3, 3),\n activation='relu',\n input_shape=input_shape))\n model.add(keras.layers.Conv2D(64, (3, 3), activation='relu'))\n model.add(keras.layers.MaxPooling2D(pool_size=(2, 2)))\n model.add(keras.layers.Flatten())\n model.add(keras.layers.Dense(128, activation='relu'))\n model.add(keras.layers.Dense(num_labels, activation='softmax'))\n return model\n\n\ndef papernot_softmax_model(num_labels, input_shape=(28,28,1), l2_reg=0.0):\n papernot_conv_model = keras.models.Sequential([\n keras.layers.Conv2D(64, (8, 8), (2,2), activation=tf.nn.relu,\n padding='same', input_shape=input_shape),\n keras.layers.Conv2D(128, (6,6), (2,2), activation=tf.nn.relu,\n padding='valid'),\n keras.layers.Conv2D(128, (5,5), (1,1), activation=tf.nn.relu,\n padding='valid'),\n keras.layers.BatchNormalization(),\n keras.layers.Flatten(name='after_flatten'),\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out')\n ])\n return papernot_conv_model\n\n\n# Losses.\n\ndef sparse_categorical_hinge(num_classes):\n def loss(y_true,y_pred):\n y_true = tf.reduce_mean(y_true, axis=1)\n y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=num_classes)\n return losses.categorical_hinge(y_true, y_pred)\n return loss\n\n\ndef sparse_categorical_ramp(num_classes):\n def loss(y_true,y_pred):\n y_true = tf.reduce_mean(y_true, axis=1)\n y_true = tf.one_hot(tf.cast(y_true, dtype=tf.int32), depth=num_classes)\n return tf.sqrt(losses.categorical_hinge(y_true, y_pred))\n return loss\n\n\ndef get_loss(loss_name, num_classes):\n if loss_name == 'hinge':\n loss = sparse_categorical_hinge(num_classes)\n elif loss_name == 'ramp':\n loss = sparse_categorical_ramp(num_classes)\n elif loss_name == 'ce':\n loss = losses.sparse_categorical_crossentropy\n elif loss_name == 'categorical_ce':\n loss = losses.categorical_crossentropy\n else:\n raise ValueError(\"Cannot parse loss %s\", loss_name)\n return loss\n"
},
{
"alpha_fraction": 0.5910824537277222,
"alphanum_fraction": 0.6133763790130615,
"avg_line_length": 39.54878234863281,
"blob_id": "1cba4f935aae929215060049b40c9acbb16ac14a",
"content_id": "2d3792295551ec27a62dd7961203c9c272b40bc5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3409,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 82,
"path": "/pseudolabel_ss.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\r\nimport tensorflow.keras as keras\r\nimport tensorflow as tf\r\nimport numpy as np\r\nfrom tensorflow.keras.datasets import mnist\r\n\r\n\r\ndef simple_conv_model(num_labels, hidden_nodes=64, input_shape=(28,28,1), l2_reg=0.0):\r\n return keras.models.Sequential([\r\n keras.layers.Conv2D(hidden_nodes, (5,5), (2,2), activation=tf.nn.relu,\r\n padding='same', input_shape=input_shape),\r\n keras.layers.Conv2D(hidden_nodes, (5,5), (2,2), activation=tf.nn.relu,\r\n padding='same'),\r\n # keras.layers.SpatialDropout2D(0.5),\r\n # keras.layers.Conv2D(hidden_nodes, (5,5), (2,2), activation=tf.nn.relu,\r\n # padding='same'),\r\n keras.layers.BatchNormalization(),\r\n keras.layers.Flatten(name='after_flatten'),\r\n # keras.layers.Dense(150, activation=tf.nn.relu),\r\n # keras.layers.Dense(64, activation=tf.nn.relu),\r\n keras.layers.Dense(num_labels, activation=tf.nn.softmax, name='out')\r\n ])\r\n\r\n\r\ndef split_dataset(num_labeled, num_classes, train_x, train_y):\r\n assert(num_labeled % num_classes == 0)\r\n assert(np.min(train_y) == 0 and np.max(train_y) == num_classes - 1)\r\n per_class = num_labeled // 9\r\n labeled_x, labeled_y = [], []\r\n unlabeled_x, unlabeled_y = [], []\r\n for i in range(num_classes):\r\n class_filter = (train_y == i)\r\n class_x = train_x[class_filter]\r\n class_y = train_y[class_filter]\r\n labeled_x.append(class_x[:per_class])\r\n labeled_y.append(class_y[:per_class])\r\n unlabeled_x.append(class_x[per_class:])\r\n unlabeled_y.append(class_y[per_class:])\r\n labeled_x = np.concatenate(labeled_x)\r\n labeled_y = np.concatenate(labeled_y)\r\n unlabeled_x = np.concatenate(unlabeled_x)\r\n unlabeled_y = np.concatenate(unlabeled_y)\r\n assert(labeled_x.shape[0] == labeled_y.shape[0])\r\n assert(labeled_x.shape[1:] == train_x.shape[1:])\r\n return labeled_x, labeled_y, unlabeled_x, unlabeled_y\r\n\r\n\r\n\r\ndef pseudolabel(model, num_labeled, train_x, train_y, test_x, test_y):\r\n model.compile(loss='sparse_categorical_crossentropy',\r\n optimizer='adam',\r\n metrics=['accuracy'])\r\n # labeled_x, labeled_y = train_x[:num_labeled], train_y[:num_labeled]\r\n labeled_x, labeled_y, unlabeled_x, _ = split_dataset(\r\n num_labeled, 10, train_x, train_y)\r\n train_x = train_x / 255.0\r\n print(labeled_x.shape, labeled_y.shape)\r\n print(labeled_y[:10], labeled_y[100:110])\r\n print([np.sum(labeled_y == i) for i in range(10)])\r\n model.fit(labeled_x, labeled_y, epochs=10)\r\n model.evaluate(test_x, test_y)\r\n\r\n # Unlabeled.\r\n confidence_q = 0.1\r\n epochs = 10\r\n for i in range(epochs):\r\n logits = model.predict(np.concatenate([unlabeled_x]))\r\n confidence = np.amax(logits, axis=1) - np.amin(logits, axis=1)\r\n alpha = np.quantile(confidence, confidence_q)\r\n indices = np.argwhere(confidence >= alpha)[:, 0]\r\n preds = np.argmax(logits, axis=1)\r\n model.fit(unlabeled_x[indices], preds[indices], epochs=1, verbose=False)\r\n model.evaluate(test_x, test_y)\r\n\r\n\r\ndef main():\r\n (train_x, train_y), (test_x, test_y) = mnist.load_data()\r\n train_x = np.expand_dims(train_x, axis=-1)\r\n test_x = np.expand_dims(test_x, axis=-1)\r\n conv_model = simple_conv_model(10)\r\n pseudolabel(conv_model, 1000, train_x, train_y, test_x, test_y)\r\n\r\nmain()\r\n"
},
{
"alpha_fraction": 0.5786163806915283,
"alphanum_fraction": 0.6163522005081177,
"avg_line_length": 29.700000762939453,
"blob_id": "6bea5a99499088ab0d8ce99a0b4c711970e95865",
"content_id": "61245ced39cb732eb3bbf89bf005acfd47fc59be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 20,
"path": "/create_dataset.py",
"repo_name": "p-lambda/gradual_domain_adaptation",
"src_encoding": "UTF-8",
"text": "\r\nfrom PIL import Image\r\nimport os, sys\r\nfrom shutil import copyfile\r\nimport numpy as np\r\nimport datasets\r\n\r\n# Resize images.\r\ndef resize(path, size=64):\r\n dirs = os.listdir(path)\r\n for item in dirs:\r\n if os.path.isfile(path+item):\r\n im = Image.open(path+item)\r\n f, e = os.path.splitext(path+item)\r\n imResize = im.resize((size,size), Image.ANTIALIAS)\r\n imResize.save(f + '.png', 'PNG')\r\n\r\nfor folder in ['./dataset_32x32/M/', './dataset_32x32/F/']:\r\n resize(folder, size=32)\r\n\r\ndatasets.save_data(data_dir='dataset_32x32', save_file='dataset_32x32.mat', target_size=(32,32))\r\n"
}
] | 9 |
shekkbuilder/crypto
|
https://github.com/shekkbuilder/crypto
|
12a479ca9c1bf2e4eb4311c606e3f0f2b6c2c0a3
|
2e8fa11f707db92e604fb5afc4082107fce72b39
|
686f0b3e923d3da7663e697e8c59758c1aa122d4
|
refs/heads/master
| 2021-01-19T17:33:08.364446 | 2017-02-18T00:33:47 | 2017-02-18T00:33:47 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5777027010917664,
"alphanum_fraction": 0.5979729890823364,
"avg_line_length": 16.41176414489746,
"blob_id": "2b84aa9490887f9350c0fd9094301f69ca3fc9e4",
"content_id": "ec02781faa4a5c3ee0e992f3f699f5ff10d91abe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 17,
"path": "/rot.py",
"repo_name": "shekkbuilder/crypto",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys, string\n\ncipher = sys.argv[1].upper()\n\nfor rot in range(1, 27):\n\tplain = \"\"\n\tfor c in cipher:\n\t\ttry:\n\t\t\ti = string.uppercase.index(c)\n\t\t\ti = (i + rot) % len(string.uppercase)\n\t\t\tplain += string.uppercase[i]\n\t\texcept:\n\t\t\tplain += c\n\n\tprint \"[%02d] %s\" % (rot, plain)\n"
},
{
"alpha_fraction": 0.6652329564094543,
"alphanum_fraction": 0.6681003570556641,
"avg_line_length": 28.08333396911621,
"blob_id": "fb4810ace1d46cd435c83befc55c15339c684b7b",
"content_id": "983f153409e2bf3d80c58413452836b018217f58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1395,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 48,
"path": "/vigenere.py",
"repo_name": "shekkbuilder/crypto",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport string, argparse\nfrom itertools import cycle\n\nargsParser = argparse.ArgumentParser(description=\"Vigenere Encrypt/Decrypt\")\nargsParser.add_argument(\"file\", metavar=\"text file\", nargs=\"?\")\nargsParser.add_argument(\"key\", metavar=\"key\", nargs=\"?\")\nargs = argsParser.parse_args()\n\n\ndef encrypt(key, plaintext):\n \"\"\"\n Encrypt the string and return the ciphertext\n http://programeveryday.com/post/implementing-a-basic-vigenere-cipher-in-python/\n \"\"\"\n pairs = zip(plaintext, cycle(key))\n result = ''\n\n for pair in pairs:\n total = reduce(lambda x, y: string.uppercase.index(x) + string.uppercase.index(y), pair)\n result += string.uppercase[total % 26]\n\n return result\n\n\ndef decrypt(key, ciphertext):\n \"\"\"\n Decrypt the string and return the plaintext\n http://programeveryday.com/post/implementing-a-basic-vigenere-cipher-in-python/\n \"\"\"\n pairs = zip(ciphertext, cycle(key))\n result = ''\n\n for pair in pairs:\n total = reduce(lambda x, y: string.uppercase.index(x) - string.uppercase.index(y), pair)\n result += string.uppercase[total % 26]\n\n return result\n\n\nwith open(args.file, \"r\") as f:\n\ttxt = f.read().strip().replace(\" \",\"\").replace(\"\\n\", \"\").upper()\n\nprint 'Key: %s' % args.key\nprint 'Plaintext: %s' % txt\nprint 'Encrypted: %s' % encrypt(args.key, txt)\nprint 'Decrypted: %s' % decrypt(args.key, txt)"
},
{
"alpha_fraction": 0.64682537317276,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 22,
"blob_id": "78a34fb9b22552ad39c481cec8b4c87578c99b3a",
"content_id": "244dc5fb25c69d80aff2cf830b7c43f154dfb547",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 11,
"path": "/caesar.py",
"repo_name": "shekkbuilder/crypto",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys, string\n\ncipher = sys.argv[1].upper()\n\ncharset = string.uppercase\n\nfor shift in range(27):\n\tplain = [charset[(string.uppercase.index(c) + shift) % len(charset)] for c in cipher]\n\tprint \"[%02d] %s\" % (shift, \"\".join(plain))"
}
] | 3 |
galaxycorpforce/gumball_testy_flask
|
https://github.com/galaxycorpforce/gumball_testy_flask
|
94304f64a238abdc29bd0a9b1052889444f58357
|
b9f2ca9c1f1d1b152a1bc9bfba98431c3e27060b
|
b0f074b66ac0c1c2eca537afd047e2bd5546511a
|
refs/heads/main
| 2023-01-07T04:38:18.016319 | 2020-11-03T06:53:49 | 2020-11-03T06:53:49 | 309,599,388 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5816555023193359,
"alphanum_fraction": 0.6029082536697388,
"avg_line_length": 23.83333396911621,
"blob_id": "07ed0518768da0f26afac1e9d7a5afa0e8d1d5d5",
"content_id": "66a4d25db6b9bf6c75a2f0edc137220baf45fa46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 894,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 36,
"path": "/test_runner.py",
"repo_name": "galaxycorpforce/gumball_testy_flask",
"src_encoding": "UTF-8",
"text": "from gumball_env import *\nimport random\n\nenv = GumballEnv()\nconfig = {}\nstate, _, _, info = env.reset()\nrewards = 0\nsteps = 0\nsample_obs = state\nprint('sample_obs:\\n')\nprint(sample_obs)\np1_rewards = []\np2_rewards = []\nprint('valid_actions', info['valid_actions'])\nfor i in range(3):\n player='p1'\n done = False\n state, _, _, _ = env.reset()\n while not done:\n # action1 = env.sample_actions()\n action = env.sample_actions()\n obs, reward, done, info = env.step(action)\n if player == 'p1':\n p1_rewards.append(reward)\n else:\n p2_rewards.append(reward)\n player=info['player']\n steps += 1\n print('finished match:', i)\n\nprint('reward', rewards)\nprint('steps', steps)\nprint('p1_rewards', (p1_rewards))\nprint('p2_rewards', (p2_rewards))\nprint('sum p1_rewards', sum(p1_rewards))\nprint('sum p2_rewards', sum(p2_rewards))\n"
},
{
"alpha_fraction": 0.5833802819252014,
"alphanum_fraction": 0.5881690382957458,
"avg_line_length": 22.825504302978516,
"blob_id": "11415e65412fa51a7fff4b465433b56cbf51c489",
"content_id": "20013899403b91244851ec559e6fbcc3d5110123",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3550,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 149,
"path": "/app.py",
"repo_name": "galaxycorpforce/gumball_testy_flask",
"src_encoding": "UTF-8",
"text": "import flask\nfrom flask import Flask, request, Response\nfrom flask import request\nimport time\nfrom flask_cors import CORS,cross_origin\nimport gumball_lite_environ as env\n\napp = Flask(__name__)\nCORS(app)\napp.config['CORS_HEADERS'] = 'Content-Type'\n\ngumball_envs = {}\nenvs_last_used_timers = {}\n\nBOT_COUNT = 15\nfor i in range(BOT_COUNT):\n bot_id = str(i)\n gumball_envs[bot_id] = env.make_env()\n envs_last_used_timers[bot_id] = time.time()\n\nimport numpy as np\nimport os\nimport json\n\nFLASK_PORT = int(os.environ.get('FLASK_PORT', 12231))\nDEBUG = bool(int(os.environ.get('DEBUG', 1)))\n\nclass NpEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.integer):\n return int(obj)\n elif isinstance(obj, np.floating):\n return float(obj)\n elif isinstance(obj, np.ndarray):\n return obj.tolist()\n else:\n return super(NpEncoder, self).default(obj)\n\n\[email protected]('/api/reset',methods=['POST', 'OPTIONS'])\n@cross_origin()\ndef reset_env():\n print('enter reset_env')\n payload = {}\n\n # let's say how long to stay on\n params = request.get_json()\n\n bot_id = params['bot_id']\n # reset last used timer\n envs_last_used_timers[bot_id] = time.time()\n\n env = gumball_envs[bot_id]\n\n obs, reward, done, info = env.reset()\n resp = {\n 'obs': obs,\n 'reward': reward,\n 'done': done,\n 'info': info\n }\n\n print(obs)\n print('exit step', resp)\n return json.dumps(resp, cls=NpEncoder)\n\[email protected]('/api/step',methods=['POST', 'OPTIONS'])\n@cross_origin()\ndef step():\n print('enter step')\n payload = {}\n\n # let's say how long to stay on\n params = request.get_json()\n\n bot_id = params['bot_id']\n env = gumball_envs[bot_id]\n\n action_as_int = params['action']\n\n try:\n obs, reward, done, info = env.step(action_as_int)\n resp = {\n 'obs': obs,\n 'reward': reward,\n 'done': done,\n 'info': info\n }\n except Exception as e:\n print(e)\n raise e\n\n# return jsonify(resp)\n# print(resp)\n# print('exit step', resp)\n return json.dumps(resp, cls=NpEncoder)\n\[email protected]('/api/get_next_bot_id',methods=['GET', 'POST', 'OPTIONS'])\n@cross_origin()\ndef get_next_bot_id():\n print('enter get_next_bot_id')\n payload = {}\n\n bot_id = 0\n min_time = envs_last_used_timers[\"0\"]\n\n for i in range(BOT_COUNT):\n new_time = envs_last_used_timers[str(i)]\n if new_time < min_time:\n min_time = new_time\n bot_id = i\n\n resp = {\n 'bot_id':str(bot_id)\n }\n\n print('exit get_next_bot_id', resp)\n return json.dumps(resp, cls=NpEncoder)\n\n\[email protected]('/api/get_sample_action',methods=['GET', 'POST', 'OPTIONS'])\n@cross_origin()\ndef get_sample_action():\n payload = {}\n\n params = request.get_json()\n bot_id = params['bot_id']\n env = gumball_envs[bot_id]\n\n action_as_int = env.sample_actions()\n resp = {\n 'action':action_as_int,\n }\n\n return json.dumps(resp, cls=NpEncoder)\n\n\nif __name__ == '__main__':\n app.run(debug=DEBUG,host='0.0.0.0', port=FLASK_PORT, threaded=True)\n\n\ndef jsonify(obj, status=200, headers=None):\n \"\"\" Custom JSONificaton to support obj.to_dict protocol. \"\"\"\n data = NpEncoder().encode(obj)\n if 'callback' in request.args:\n cb = request.args.get('callback')\n data = '%s && %s(%s)' % (cb, cb, data)\n return Response(data, headers=headers, status=status,\n mimetype='application/json')\n"
}
] | 2 |
iCodeIN/cocass
|
https://github.com/iCodeIN/cocass
|
09f39f02e58f43e8572a99670106d93b863cab9d
|
5f38dd732ecb659fb75c13293d4e44b57d36e2da
|
9c8921b8cc2b442c565fa93d763666f671612d2b
|
refs/heads/master
| 2023-08-18T20:26:44.836261 | 2021-01-18T07:08:46 | 2021-01-18T07:08:46 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5465116500854492,
"alphanum_fraction": 0.569767415523529,
"avg_line_length": 16.200000762939453,
"blob_id": "e2f81150a839c0fcc633e0d7279b334bfea7fac0",
"content_id": "644363b7fcef6ecb8951bf62828c6a60d593f9f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 5,
"path": "/tests/call/exit.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n fprintf(stderr, \"AAAAAAAAAA\\n\");\n fflush(stderr);\n exit(42);\n}\n"
},
{
"alpha_fraction": 0.25448235869407654,
"alphanum_fraction": 0.31521111726760864,
"avg_line_length": 34.28571319580078,
"blob_id": "79c423ed51aa9f8d7b17ef74678708db18701aaf",
"content_id": "ad8cfec62cccc0162a93c7ffa127a5f1941bee80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1729,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 49,
"path": "/tests/ptr/extended_assign.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = malloc(QSIZE*3);\n int j = 1;\n i[0] = 5; i[1] = 7; i[2] = 3;\n\n printf(\"ADD\\n\");\n j += 1; printf(\"%d ?= 2\\n\", j);\n i[0] += 1; printf(\"%d ?= 6\\n\", i[0]);\n *i += 1; printf(\"%d ?= 7\\n\", *i);\n printf(\"\\nMUL\\n\");\n j *= 2; printf(\"%d ?= 4\\n\", j);\n i[0] *= 2; printf(\"%d ?= 14\\n\", i[0]);\n *i *= 2; printf(\"%d ?= 28\\n\", *i);\n printf(\"\\nSUB\\n\");\n j -= -15; printf(\"%d ?= 19\\n\", j);\n i[0] -= 1; printf(\"%d ?= 27\\n\", i[0]);\n *i -= 2; printf(\"%d ?= 25\\n\", *i);\n printf(\"\\nDIV\\n\");\n j /= 2; printf(\"%d ?= 9\\n\", j);\n i[0] /= 5; printf(\"%d ?= 5\\n\", i[0]);\n *i /= 2; printf(\"%d ?= 2\\n\", *i);\n printf(\"\\nMOD\\n\");\n j = 5;\n j %= 3; printf(\"%d ?= 2\\n\", j);\n i[0] = 10;\n i[0] %= 4; printf(\"%d ?= 2\\n\", i[0]);\n *i = 15;\n *i %= 6; printf(\"%d ?= 3\\n\", *i);\n printf(\"\\nSHL\\n\");\n j <<= 2; printf(\"%d ?= 8\\n\", j);\n i[0] <<= 1; printf(\"%d ?= 6\\n\", i[0]);\n *i <<= 2; printf(\"%d ?= 24\\n\", *i);\n printf(\"\\nSHR\\n\");\n j >>= 1; printf(\"%d ?= 4\\n\", j);\n i[0] >>= 1; printf(\"%d ?= 12\\n\", i[0]);\n *i >>= 1; printf(\"%d ?= 6\\n\", *i);\n printf(\"\\nOR\\n\");\n j |= 1; printf(\"%d ?= 5\\n\", j);\n i[0] |= 5; printf(\"%d ?= 7\\n\", i[0]);\n *i |= 9; printf(\"%d ?= 15\\n\", *i);\n printf(\"\\nAND\\n\");\n j &= 3; printf(\"%d ?= 1\\n\", j);\n i[0] &= 11; printf(\"%d ?= 11\\n\", i[0]);\n *i &= 7; printf(\"%d ?= 3\\n\", *i);\n printf(\"\\nXOR\\n\");\n j ^= 5; printf(\"%d ?= 4\\n\", j);\n i[0] ^= 6; printf(\"%d ?= 5\\n\", i[0]);\n *i ^= 6; printf(\"%d ?= 3\\n\", *i);\n}\n"
},
{
"alpha_fraction": 0.375,
"alphanum_fraction": 0.4027777910232544,
"avg_line_length": 11,
"blob_id": "09889b61b93831a8802b981b837930bd2c0f635a",
"content_id": "5c50d253aa5731d379f820f1cfb85ad8e2b51fd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 6,
"path": "/tests/boot/ex7.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int x;\nint main() {\n x = 3;\n printf(\"%d\", x + 2);\n return x;\n}\n"
},
{
"alpha_fraction": 0.4719626307487488,
"alphanum_fraction": 0.49065420031547546,
"avg_line_length": 20.399999618530273,
"blob_id": "14f4e740dc93a1ab94bb299f755cf40f435d12ca",
"content_id": "999b09183663da3b8a5c5c5c28555896a87fb261",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 10,
"path": "/tests/except/uncaught-str.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "char* s = \"foo\";\n\nint main(int argc, char** argv) {\n char* z = \"bar\";\n switch (atol(argv[1])) {\n case 0: throw Zero(\"Hello, World\");\n case 1: throw One(s);\n case 2: throw Two(z);\n }\n}\n"
},
{
"alpha_fraction": 0.41163793206214905,
"alphanum_fraction": 0.4288793206214905,
"avg_line_length": 26.294116973876953,
"blob_id": "9d9147a55ecaac498526bbb0c84968bfc06fce16",
"content_id": "7a96c914883995f0fa5181fced9a2976e638443e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 464,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 17,
"path": "/tests/calc/wmean.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n int* items = malloc(QSIZE*argc);\n int mask = ('-' | ('w'<<8));\n int total = 0, count = 0;\n for (int i = 1; i < argc; i++) {\n int wht = 1;\n if ((*argv[i] & WORD) == mask) {\n wht = atol(argv[i++]+WSIZE);\n }\n int itm = atol(argv[i]);\n count += wht;\n total += wht * itm;\n }\n int mean = (count == 0) ? 0 : total / count;\n printf(\"%d\\n\", mean);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.44999998807907104,
"alphanum_fraction": 0.4611110985279083,
"avg_line_length": 14,
"blob_id": "d365fdb23318247f7e7b2a2c7e95695da1044510",
"content_id": "0ef6a0c35a5113664c1e16e77ac6568616845a29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 12,
"path": "/failures/return_try.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n try {\n return 42; //!inside//\n } catch (Wrong _) {\n printf(\"Should not have caught.\\n\");\n }\n}\n\nint main() {\n foo();\n throw Wrong(NULL);\n}\n"
},
{
"alpha_fraction": 0.3195876181125641,
"alphanum_fraction": 0.39175257086753845,
"avg_line_length": 15.166666984558105,
"blob_id": "50762e3bbf8b37403189d8c88742f84bc2e82cf6",
"content_id": "ea39e26f8ce0d5040e962bc9c3d016679c1842e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 6,
"path": "/verify/calc/cmp_order.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"i is 4 ?= 4\\n\"*2 + \"i is 3 ?= 3\\n\"*3, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.40625,
"alphanum_fraction": 0.421875,
"avg_line_length": 11.800000190734863,
"blob_id": "0034db182492c3c24e17646b32e3ceb417ecb250",
"content_id": "517e4b75aa1a5bc2eb5d1348d7dc6141072d8428",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 5,
"path": "/failures/decl_alternate.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i;\n j = 1; //!undeclared//\n int j;\n}\n"
},
{
"alpha_fraction": 0.41025641560554504,
"alphanum_fraction": 0.41025641560554504,
"avg_line_length": 15.714285850524902,
"blob_id": "d0e798a6515d9ebb771529dced12a39cd8ca802c",
"content_id": "5b406a6b0755e723f711fb8ea6e394b722f6c7d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/tests/sys/fork.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n if (fork()) {\n printf(\"I am parent\\n\");\n } else {\n printf(\"I am child\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.4200518727302551,
"alphanum_fraction": 0.4356093406677246,
"avg_line_length": 21.6862735748291,
"blob_id": "e8b62ec7295c9341a1789863f494158dcc654c2e",
"content_id": "2cd2fe7709875e5d89b7ef449b941f6bc22cadc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1157,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 51,
"path": "/tests/string/memlib.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int strpref (char* src, char* pref) {\n while (1) {\n if ((*pref & BYTE) == 0) {\n return 0;\n } else if ((*src & BYTE) < (*pref & BYTE)) {\n return 1;\n } else if ((*src & BYTE) > (*pref & BYTE)) {\n return -1;\n }\n pref++;\n src++;\n }\n}\n\nvoid* memchr (void* s, char c, int n) {\n while (n > 0) {\n if ((*s & BYTE) == c) { return s; }\n s++;\n n--;\n }\n return NULL;\n}\n\nchar* strchr (char* s, char c) {\n while (1) {\n if ((*s & BYTE) == c) { return s; }\n s++;\n if ((*s & BYTE) == 0) { return NULL; }\n }\n return NULL;\n}\n\nchar* strstr (char* src, char* pat) {\n while (*src != 0) {\n if (strpref(src, pat) == 0) { return src; }\n src++;\n }\n}\n\nint main() {\n char* arr = \"aaoeu-a/lrcakblcroadksaotelrcdakrcraxracx,.r\";\n char* foo = \"foo\";\n assert(arr+7 == memchr(arr, '/', 50));\n assert(NULL == strchr(arr, 'z'));\n int i = strpref(arr, \"aaob\");\n assert(-1 == i);\n assert(1 == strpref(arr, \"aazzzz\"));\n assert(0 == strpref(foo, \"foo\"));\n assert(arr+8 == strstr(arr, \"lrc\"));\n return 0;\n}\n"
},
{
"alpha_fraction": 0.27785059809684753,
"alphanum_fraction": 0.3263433873653412,
"avg_line_length": 23.612903594970703,
"blob_id": "9e535e59ae9451e5b87366c6b9ba3562e9c1e434",
"content_id": "f361fc53c038a77351541c1b586fc2c36b1b1a3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 31,
"path": "/tests/ptr/additions.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = malloc(QSIZE*3);\n *i = 52;\n printf(\"%d ?= 52\\n\", *i);\n *(i+QSIZE) = (*i)++ + 2;\n printf(\"%d ?= 53, %d ?= 54\\n\", *i, *(i+QSIZE));\n *(i+2*QSIZE) = ++(*(i+QSIZE)) + 2;\n printf(\"%d ?= 53, %d ?= 55, %d ?= 57\\n\\n\", *i, *(i+QSIZE), *(i+2*QSIZE));\n\n int k = &i[1];\n printf(\"%d ?= %d ?= 55\\n\", i[1], *k);\n *k = 3;\n printf(\"%d ?= %d ?= 3\\n\", i[1], *k);\n k = &i;\n printf(\"%d ?= 53\\n\\n\", **k);\n free(i);\n\n int j = 1;\n i = &j;\n printf(\"%d ?= %d ?= 1\\n\", *i, j);\n j = 3;\n printf(\"%d ?= %d ?= 3\\n\", *i, j);\n j++;\n printf(\"%d ?= %d ?= 4\\n\", *i, j);\n (*i)++;\n printf(\"%d ?= %d ?= 5\\n\", *i, j);\n *i = 3;\n printf(\"%d ?= %d ?= 3\\n\", *i, j);\n k = &i;\n printf(\"%d ?= 3\\n\", **k);\n}\n"
},
{
"alpha_fraction": 0.47826087474823,
"alphanum_fraction": 0.4945652186870575,
"avg_line_length": 22,
"blob_id": "067a3d97586b6f8f1385ff2aeb82ca5eb47aa005",
"content_id": "1a4d3e2f60e70f7f07fdc0814a4081e0a2cfc0fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 8,
"path": "/tests/string/sprintf.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n char* s = malloc(100*BSIZE);\n strcpy(s, \"Formatting string: <%s> <%s> <%s>\");\n printf(s, s, \"foo\", \"bar\");\n putchar('\\n');\n free(s);\n fflush(stdout);\n}\n"
},
{
"alpha_fraction": 0.5041322112083435,
"alphanum_fraction": 0.5144628286361694,
"avg_line_length": 32.76744079589844,
"blob_id": "60da3a56a77a5f493537ff0edc195b718833994a",
"content_id": "e905e3ba231ca8ee393958ad7ac616333a15b24e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1452,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 43,
"path": "/verify/misc/mwc.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ninfo_str = \"\\nusage: mwc [-l|-w|-c] FILE\\n count (l)ines, (w)ords, (c)haracters in FILE (default -w)\\n\"\n\n\ndef expect(*args):\n if len(args) == 1: return (2, \"Not enough arguments\" + info_str, \"\")\n file = None\n mode = None\n for a in args[1:]:\n if a[0] == '-':\n if mode is not None: return (1, \"Too many optional arguments\" + info_str, \"\")\n if a[1] in ['w', 'c', 'l']:\n mode = a[1]\n else: return (1, \"Invalid optional argument\" + info_str, \"\")\n if len(a) > 2: return (2, \"Optional argument too long\" + info_str, \"\")\n elif file is not None: return (2, \"Too many positional arguments\" + info_str, \"\")\n else: file = a\n if file is None: return (2, \"Not enough positional arguments\" + info_str, \"\")\n if mode is None: mode = 'w'\n try:\n with open(file, 'r') as f:\n pass\n except FileNotFoundError:\n return (3, \"File does not exist\" + info_str, \"\")\n cproc = Popen([\"wc\", '-' + mode, file], stdin=PIPE, stdout=PIPE, stderr=PIPE)\n cout, _ = cproc.communicate()\n return (0, cout.decode('utf-8'), \"\")\n\ndata = [\n [\"-l\", \"Makefile\"],\n [\"Makefile\", \"-l\"],\n [\"-w\", \"compile.ml\"],\n [\"-c\", \"cparse.mly\"],\n [\"-foo\", \"Makefile\"],\n [\"-f\", \"Makefile\"],\n [],\n [\"-c\", \"-c\", \"cparse.ml\"],\n [\"-l\", \"inexistant.file\"],\n [\"Makefile\"],\n [\"Makefile\", \"Makefile\"],\n [\"-c\"],\n]\n"
},
{
"alpha_fraction": 0.4631936550140381,
"alphanum_fraction": 0.4711211919784546,
"avg_line_length": 21.64102554321289,
"blob_id": "869515c3b4893ec362bcf3092de7753fe1f2d3c4",
"content_id": "c7162063d870fbb8c31282a867b856670fabf862",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 39,
"path": "/tests/call/bsearch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int cmp(int* a, int* b) {\n return (*a - *b);\n}\n\nvoid assert_increase(int* arr, int len) {\n for (int i = 1; i < len; i++) {\n assert(arr[i-1] < arr[i]);\n }\n}\n\nint main(int argc, char** argv) {\n int* items = malloc(QSIZE*argc);\n int key;\n int j = 0;\n for (int i = 1; i < argc; i++) {\n if (strcmp(argv[i], \"--key\") == 0) {\n key = atol(argv[++i]);\n } else {\n items[j++] = atol(argv[i]);\n }\n }\n\n try {\n assert_increase(items, j);\n } catch (AssertionFailure) {\n fprintf(stderr, \"List is not increasing\");\n exit(1);\n }\n\n int* item = bsearch(&key, items, j, QSIZE, cmp);\n if (item != NULL) {\n printf(\"Found item = %d at position %d\\n\", *item, (item - items) / QSIZE);\n } else {\n printf(\"Item = %d could not be found\\n\", key);\n }\n\n free(items);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.45285359025001526,
"alphanum_fraction": 0.46029776334762573,
"avg_line_length": 28.851852416992188,
"blob_id": "7ce1468dfb384c8db8a5c437ede293485a295b97",
"content_id": "f15bc7e456bc1bb18f2e543844472216e3f2001d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 27,
"path": "/verify/sys/read.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd, data):\n proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate(bytes(data, 'utf-8'))\n status = True\n if proc.returncode != 0:\n print(\"Nonzero return code\")\n status = False\n if err != b'':\n print(\"Expected empty stderr\")\n status = False\n cmp = bytes(\"\".join(data[i:i+3] + '\\n' for i in range(0, len(data), 3)), 'utf-8')\n if out != cmp:\n print(\"Wrong split\")\n print(\" [{}]\\n expect[{}]\".format(out, cmp))\n status = False\n return status\n\ncfg = [\n [\"...\"],\n [\"......\"],\n [\"foobarbazbaz\"],\n [\"AaaBbbCccDddEeeFffGgg\"],\n [\".?!.?!.?!.?!\"],\n [\"....................................................................................\"],\n]\n"
},
{
"alpha_fraction": 0.3267108201980591,
"alphanum_fraction": 0.3421633541584015,
"avg_line_length": 16.423076629638672,
"blob_id": "a8e2f12a18e3d4667869da4284b81c8d2a1f668e",
"content_id": "705281a65f525ae51aa7f23d92afb39d484577df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 26,
"path": "/tests/calc/bitwise.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int and(int x, int y) {\n printf(\"%d & %d = %d\\n\", x, y, x & y);\n}\n\nint or(int x, int y) {\n printf(\"%d | %d = %d\\n\", x, y, x | y);\n}\n\nint xor(int x, int y) {\n printf(\"%d ^ %d = %d\\n\", x, y, x ^ y);\n}\n\nint not(int x) {\n printf(\"~%d = %d\\n\", x, ~x);\n}\n\nint main() {\n for (int i = 0; i < 200; i++) {\n for (int j = i; j < 200; j++) {\n and(i, j);\n or(i, j);\n xor(i, j);\n }\n not(i);\n }\n}\n"
},
{
"alpha_fraction": 0.2578125,
"alphanum_fraction": 0.390625,
"avg_line_length": 20.33333396911621,
"blob_id": "7a610356a2bbec5029e99ed338f137f00de6a7d5",
"content_id": "aab9a74797072ade01d704aae360ad90f716841f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 6,
"path": "/tests/reduce/reduce_eif.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x = 1 ? 42 : 666;\n int y = 0 ? 42 : 666;\n int z = x ? 42 : 666;\n printf(\"%d %d %d\\n\", x, y, z);\n}\n"
},
{
"alpha_fraction": 0.39897698163986206,
"alphanum_fraction": 0.42966753244400024,
"avg_line_length": 18.549999237060547,
"blob_id": "83e89c3eef7498d200ac40af78f226f87d7b61ac",
"content_id": "526e313f0f7fdf7e42077f6096c080060d48ca91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 20,
"path": "/failures/arity.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {}\nint bar(int a) {}\nint baz(int a, int b) {}\n\nint main() {\n foo();\n foo(1); //?arity//\n foo(1, 1); //?arity//\n bar(); //?arity//\n bar(1);\n bar(1, 2); //?arity//\n baz(); //?arity//\n baz(1); //?arity//\n baz(1, 2);\n malloc(); //?arity//\n malloc(0, 1, 2); //?arity//\n printf(); //?arity//\n fprintf(stdout); //?arity//\n quux(); //?unknown//\n}\n"
},
{
"alpha_fraction": 0.4864864945411682,
"alphanum_fraction": 0.5064011216163635,
"avg_line_length": 17.5,
"blob_id": "7e0b9041f5483d057f4ae0649e7de3f66ad32ccb",
"content_id": "e8fb6fe6cd9b935358aa46e47d84b1ae3b76cda3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 38,
"path": "/tests/sys/pipe-simple.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int* p;\nint q;\n\n// On simule la commande \"cat Makefile | wc\" avec deux processus et un pipe.\n\nvoid pere () {\n // greffer stdout sur l'entrée du pipe\n dup2(p[1], 1);\n close(p[0]);\n close(p[1]);\n\n // exec cat toto\n execlp(\"cat\", \"cat\", \"Makefile\", NULL);\n printf(\"cat failed\\n\"); // never happens\n}\n\nvoid fils () {\n // faire en sorte que stdin lise dans le pipe\n dup2(p[0], 0);\n close(p[0]);\n close(p[1]);\n\n // exec wc\n execlp(\"wc\", \"wc\", NULL);\n printf(\"wc failed\\n\"); // never happens\n}\n\nint main() {\n p = malloc(2*QSIZE);\n pipe(&q);\n p[0] = q & DOUBLE;\n p[1] = q >> (8*DSIZE);\n if (fork()) {\n pere();\n } else {\n fils();\n }\n}\n"
},
{
"alpha_fraction": 0.5680000185966492,
"alphanum_fraction": 0.5759999752044678,
"avg_line_length": 16.85714340209961,
"blob_id": "9fa66fc15ac02976cacba4b14d22f90bf6b83b59",
"content_id": "7e2d3e4595f3d812a86da891bca3c39f3caf0289",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 7,
"path": "/tests/call/argcount.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int offset;\nint main(int argc, char** argv) {\n int count;\n offset = -1;\n count = argc;\n return count + offset;\n}\n"
},
{
"alpha_fraction": 0.4126984179019928,
"alphanum_fraction": 0.4444444477558136,
"avg_line_length": 17.899999618530273,
"blob_id": "caa1f2e58f954553a67a29186b619d162f047648",
"content_id": "0dcdfce09408137ab675ffdda2e118eb8fee3ad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 10,
"path": "/verify/except/try_loop.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n for i in range(8):\n if i != 5:\n res += \"i = {}\\n\".format(i)\n return (111, res, \"Unhandled exception Exit(0)\\n\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3265306055545807,
"alphanum_fraction": 0.442176878452301,
"avg_line_length": 21.615385055541992,
"blob_id": "123e8f5e34d7de56f5bc8ec3d9f6c49d2caabb1e",
"content_id": "7ba93bf4f1a8e0a22bbfbac4a5c9305f61716ea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/verify/calc/minimax.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n l = [int(i) for i in args[1:]]\n res = \"min = {}\\nmax = {}\\n\".format(min(l), max(l))\n return (0, res, \"\")\n\ndata = [\n \"0\".split(),\n \"1 2 8 3 9\".split(),\n \"41 589 -12 -56 0 1 500\".split(),\n \"1 8 9 -1\".split(),\n \"10 9 8\".split(),\n \"8 9 10\".split(),\n]\n"
},
{
"alpha_fraction": 0.3417721390724182,
"alphanum_fraction": 0.3445850908756256,
"avg_line_length": 29.913043975830078,
"blob_id": "7066a2d2f74f7eb994858a1992adc1c6c61458a9",
"content_id": "d629babb8ee5a475352d3a7058203dc9a132740c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 711,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 23,
"path": "/tests/calc/cmp.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int i;\nint main() {\n i = 5;\n int j = 6;\n printf(\"Yes:\\n\");\n printf(\"\\ti < j: %d\\n\", i < j);\n printf(\"\\ti <= j: %d\\n\", i <= j);\n printf(\"\\ti == i: %d\\n\", i == i);\n printf(\"\\t!(j <= i): %d\\n\", !(j <= i));\n printf(\"\\t!(j < i): %d\\n\", !(j < i));\n printf(\"\\tj > i: %d\\n\", j > i);\n printf(\"\\tj >= i: %d\\n\", j >= i);\n printf(\"\\tj != i: %d\\n\", j != i);\n printf(\"No:\\n\");\n printf(\"\\tj < i: %d\\n\", j < i);\n printf(\"\\tj <= i: %d\\n\", j <= i);\n printf(\"\\ti == j: %d\\n\", i == j);\n printf(\"\\t!(i < j): %d\\n\", !(i < j));\n printf(\"\\t!(i <= j): %d\\n\", !(i <= j));\n printf(\"\\ti > j: %d\\n\", i > j);\n printf(\"\\ti >= j: %d\\n\", i >= j);\n printf(\"\\ti != i: %d\\n\", i != i);\n}\n"
},
{
"alpha_fraction": 0.3287671208381653,
"alphanum_fraction": 0.4383561611175537,
"avg_line_length": 11.166666984558105,
"blob_id": "18a670cd9da600a20ad0ac6c5ea88e9e28730998",
"content_id": "c4f39cd43d1a07d538c0ce09435b68afc750e428",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 6,
"path": "/verify/reduce/reduce_eif.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"42 666 42\\n\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4798206388950348,
"alphanum_fraction": 0.5336322784423828,
"avg_line_length": 12.9375,
"blob_id": "4607548c426248bd168dbc514dc3a8dab1a1da73",
"content_id": "8a24506b6f6a4e6fd9674cbdd5254cbcf0ef9d93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 16,
"path": "/tests/decl/typedef.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "long i1;\nlong j1 = 3;\nvoid* i3;\nvoid f1 ();\nvoid* f2 ();\nvoid f4 ();\nvoid f5 ();\n\nint g1() {}\nvoid* g2() {}\nvoid g3() {}\nvoid g4(void* foo()) {}\n\nvoid qsort (void* ptr, int len, int size, int cmp ()) {}\n\nint main (void) {}\n"
},
{
"alpha_fraction": 0.4367816150188446,
"alphanum_fraction": 0.4482758641242981,
"avg_line_length": 20.75,
"blob_id": "c73903e19162d1ad07d4bf738d82b9cb314f86f4",
"content_id": "61dfb36168078de79b9ad4d4d1d816a8c1167352",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 4,
"path": "/tests/boot/isdigit.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n printf(\"%d\\n\", !!isdigit('a'));\n printf(\"%d\\n\", !!isdigit('0'));\n}\n"
},
{
"alpha_fraction": 0.3065049648284912,
"alphanum_fraction": 0.37816980481147766,
"avg_line_length": 35.279998779296875,
"blob_id": "0b478b83f86fc025a23e2187ca99703c8588e3a0",
"content_id": "5c84c741fa2d0a0ba3c1d7a29f8b0a9bd7bea06d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 907,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 25,
"path": "/verify/reduce/reduce_cmp.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n res += \"Yes:\\n\"\n res += \"\\t5 < 6: {}\\n\".format(int(5 < 6))\n res += \"\\t5 <= 6: {}\\n\".format(int(5 <= 6))\n res += \"\\t5 == 5: {}\\n\".format(int(5 == 5))\n res += \"\\t!(6 <= 5): {}\\n\".format(int(not (6 <= 5)))\n res += \"\\t!(6 < 5): {}\\n\".format(int(not (6 < 5)))\n res += \"\\t6 > 5: {}\\n\".format(int(6 > 5))\n res += \"\\t6 >= 5: {}\\n\".format(int(6 >= 5))\n res += \"\\t6 != 5: {}\\n\".format(int(6 != 5))\n res += \"No:\\n\"\n res += \"\\t6 < 5: {}\\n\".format(int(6 < 5))\n res += \"\\t6 <= 5: {}\\n\".format(int(6 <= 5))\n res += \"\\t5 == 6: {}\\n\".format(int(5 == 6))\n res += \"\\t!(5 < 6): {}\\n\".format(int(not (5 < 6)))\n res += \"\\t!(5 <= 6): {}\\n\".format(int(not (5 <= 6)))\n res += \"\\t5 > 6: {}\\n\".format(int(5 > 6))\n res += \"\\t5 >= 6: {}\\n\".format(int(5 >= 6))\n res += \"\\t5 != 5: {}\\n\".format(int(5 != 5))\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.38461539149284363,
"alphanum_fraction": 0.4423076808452606,
"avg_line_length": 12,
"blob_id": "74e1df242b2d4d1ef271e148d65a6bb3c387e31e",
"content_id": "da04d7e0c360aa07bef22a31ec96f75f5d03bb17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/tests/boot/ex12.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n write(1, \"ok\", 2);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4472222328186035,
"alphanum_fraction": 0.4472222328186035,
"avg_line_length": 20.176469802856445,
"blob_id": "243549d939ba8651f72c0baa564c7bfeee85b55e",
"content_id": "286415e207d8bda24ac6db6e2f41c7f088dbff0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 17,
"path": "/failures/duplicate_catch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n throw Foo(NULL);\n throw _(NULL); //!wildcard//\n\n try {}\n catch (Foo _) {}\n catch (Bar _) {}\n catch (Bar _) {} //?duplicate//\n catch (Foo _) {} //?duplicate//\n catch (_ _) {}\n catch (Baz _) {} //?unreachable//\n catch (Quux _) {} //?unreachable//\n\n try {}\n catch (Foo _) {}\n catch (Foo _) {} //?duplicate//\n}\n"
},
{
"alpha_fraction": 0.5234042406082153,
"alphanum_fraction": 0.5404255390167236,
"avg_line_length": 17.076923370361328,
"blob_id": "641d3e9f321339fe50cc96734e9a0ad1b0cc4550",
"content_id": "87e7eac3170bf959d2ce6d6d67616622e8c2d399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 235,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 13,
"path": "/tests/sys/survive.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "void ignore_sigint() {\n printf(\"You can't kill me !\\n\");\n fflush(stdout);\n}\n\nint main() {\n printf(\"I am %d\\n\", getpid());\n fflush(stdout);\n signal(SIGINT, ignore_sigint);\n while (true) {\n usleep(1000);\n }\n}\n"
},
{
"alpha_fraction": 0.34549516439437866,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 23.870370864868164,
"blob_id": "c4c28144bcbfdedfa3c62f68a822acc13ca49aa6",
"content_id": "44beb07f84a85c49af3bb2ec596539601c9ca90a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1343,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 54,
"path": "/tests/call/varargs.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo(int x1, int x2, int x3, int x4, ...) {\n int* ap;\n int arg;\n printf(\"1:%d 2:%d 3:%d 4:%d\\n\", x1, x2, x3, x4);\n va_start(ap);\n while ((arg = va_arg(ap)) != NULL) {\n printf(\"Next: %d\\n\", arg);\n }\n printf(\"Done.\\n\\n\");\n}\n\nint bar(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8, ...) {\n int* ap;\n int arg;\n printf(\"1:%d 2:%d 3:%d 4:%d\\n\", x1, x2, x3, x4);\n printf(\"5:%d 6:%d 7:%d 8:%d\\n\", x5, x6, x7, x8);\n va_start(ap);\n while ((arg = va_arg(ap)) != NULL) {\n printf(\"Next: %d\\n\", arg);\n }\n printf(\"Done.\\n\\n\");\n}\n\nvoid write(int nb, ...) {\n int* ap;\n va_start(ap);\n for (int i = 0; i < nb; i++) {\n printf(\"argument #%d: %d\\n\", i, va_arg(ap));\n }\n putchar('\\n');\n}\n\nvoid twice(int nb, ...) {\n int* ap1, ap2;\n va_start(ap1);\n va_start(ap2);\n for (int i = 0; i < nb; i++) {\n printf(\"two at once: %d %d\\n\", va_arg(ap1), va_arg(ap2));\n }\n putchar('\\n');\n}\n\nint main() {\n // foo(1,2,3); // KO\n foo(1,2,3,4, NULL);\n foo(1,2,3,4,5,6, NULL);\n foo(1,2,3,4,5,6,7,8,9,10,11,12, NULL);\n // bar(1,2,3); // KO\n bar(1,2,3,4,5,6,7,8,9,10,11,12,13, NULL);\n write(2, 101,102);\n write(5, 101,102,103,104,105);\n write(15, 101,102,103,104,105,106,107,108,109,110,111,112,113,114,115);\n twice(5, 1,2,3,4,5);\n}\n"
},
{
"alpha_fraction": 0.5856741666793823,
"alphanum_fraction": 0.5856741666793823,
"avg_line_length": 29.95652198791504,
"blob_id": "95faa3e20fef5d02c7b9880d3f801fe3237f0ff4",
"content_id": "222a2ba571e49d6f541a5770d6500d6517446ba7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 712,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 23,
"path": "/verify/sys/exec.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd):\n proc = Popen(cmd, stdout=PIPE, stdin=PIPE, stderr=PIPE)\n cproc = Popen([\"ls\", \"-l\"], stdout=PIPE, stdin=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n cout, cerr = cproc.communicate()\n status = True\n if proc.returncode != cproc.returncode:\n print(\"Wrong return code: [{}]; expect[{}]\".format(proc.returncode, cproc.returncode))\n status = False\n if err != cerr:\n print(\"Wrong error:\\n [{}]\\nexpect[{}]\".format(err, cerr))\n status = False\n if out != cout + b'[pere] le fils a termine !\\n':\n print(\"Wrong output\")\n print(out)\n status = False\n return status\n\ncfg = [\n [],\n]\n"
},
{
"alpha_fraction": 0.6589524745941162,
"alphanum_fraction": 0.6601704955101013,
"avg_line_length": 35.761192321777344,
"blob_id": "6e01df4b87f2c4c4dd5203d9fa841c5f0ebe962c",
"content_id": "b54e45f1fb7c3a94faf3a98bf52e1025f92f545b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2591,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 67,
"path": "/README.md",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "# COCass\n\nNeven Villani, ENS Paris-Saclay\n\n## Build\n\nMake targets:\n- `make` builds `mcc`\n- `make test` runs `mcc` on the tests: test files in `assets/`, verifiers in `verify/`. Each test is a `.c` file and a `.py` verifier, the output of the compiled executable is checked against the verifier for each set of command line arguments.\n\nNote: `make test` executes `./check.py`, which you can also invoke directly:\n`./check.py [TESTS]` where `TESTS` is a list of\n- `category/` (e.g. `except/`) to run a full category of tests\n- `file` (e.g. `except/exc1`) to run a single test\nor is left empty to run all tests.\n\n\n## Usage\n\n`mcc [OPTIONS] [FILE]`\n\nWhere options are:\n- `-D` print declarations and exit\n- `-A` print AST and exit\n- `-S` dump assembler and exit\n- `-v`, `-v1` report structural items\n- `-v2` report details\n- `--no-reduce` disables reduction of expressions whose result is known at compile-time\n (added because reduction was required for toplevel initialisation, and I decided to make it available for all expressions. Nevertheless having the ability to turn it on and off is useful for verification)\n- `--no-color` turn off syntax highlighting\n (added because I wanted to add color, but still needed the option of turning it off if the terminal doesn't support it or in order to pipe the output to a file)\n\n## Requirements\n\n`cpp` for the preprocessing, `gcc` for the linking.\n\n## Structure\n\n```\n─┐\n ├─ assets\n │ ├─ calc/*.c arithmetic tests\n │ ├─ call/*.c function call tests\n │ ├─ decl/*.c variable declaration tests\n │ ├─ boot/*.c tests to get started\n │ ├─ except/*.c exception tests\n │ ├─ flow/*.c control flow tests\n │ ├─ misc/*.c tests that are difficult to automate\n │ ├─ ptr/*.c array access and dereferences\n │ ├─ reduce/*.c optimization tests\n │ └─ string/*.c char* manipulation\n ├─ failures/*.c files that are expected to be rejected or issue a warning\n ├─ verify/*/*.py Python verifiers\n ├─ cAST.ml syntax tree builder\n ├─ clex.mll lexer\n ├─ compile.ml AST -> simplified assembler\n ├─ cparse.mly source -> AST\n ├─ cprint.ml AST pretty-print\n ├─ error.ml error reporting\n ├─ generate.ml simplified assembler -> asm source code\n ├─ main.ml argument parsing\n ├─ pigment.ml color abstraction\n ├─ reduce.ml ASM simplifier\n ├─ test.py automatic tester\n ├─ verbose.ml verbosity control\n └─ *.mli\n```\n"
},
{
"alpha_fraction": 0.4189944267272949,
"alphanum_fraction": 0.44054269790649414,
"avg_line_length": 35.85293960571289,
"blob_id": "d1f02531fc5552a5b3c853fc4194d78e1fc4cf25",
"content_id": "239d7fc791bf915a7390a7099602708fe0a28ed6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1253,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 34,
"path": "/tests/misc/rsort.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "void rsort (int N, int lg, int* tab) {\n int m = tab[0];\n for (int n = 0; n < N; n++) (m < tab[n]) ? m = tab[n] : 0;\n int M = 1 << lg;\n int* access = malloc(M*QSIZE);\n int* cpy = malloc(N*QSIZE);\n for (int i = 0; i < N; i++) cpy[i] = malloc(2*QSIZE);\n int b = 0;\n for (int n = 0; n < N; n++) cpy[n][0] = tab[n];\n for (int filter = M-1, d = 0; filter <= 4*m; filter <<= lg, b = 1-b, d += lg) {\n for (int m = 0; m < M; m++) access[m] = 0;\n for (int n = 0; n < N; n++) access[((cpy[n][b])&filter)>>d]++;\n for (int m = 1; m < M; m++) access[m] += access[m-1];\n for (int n = N-1; n >=0; n--) cpy[--access[((cpy[n][b])&filter)>>d]][1-b] = cpy[n][b];\n }\n for (int n = 0; n < N; n++) tab[n] = cpy[n][b];\n free(access);\n for (int i = 0; i < N; i++) free(cpy[i]);\n free(cpy);\n}\n\nint main () {\n int N ;\n printf(\"Enter array size: \"); scanf(\"%ld\", &N) ;\n int* tab = malloc(N*QSIZE) ;\n printf(\"Enter %d elements:\\n\", N);\n for (int n = 0; n < N; n++) scanf(\"%ld\", &tab[n]);\n for (int n = 0; n < N; n++) printf(\"%d \", tab[n]);\n printf(\"\\nNow sorting\\n\");\n rsort(N, 2, tab) ;\n printf(\"Done!\\n\");\n for (int n = 0; n < N; n++) printf(\"%d \", tab[n]);\n putchar('\\n') ;\n}\n"
},
{
"alpha_fraction": 0.2921348214149475,
"alphanum_fraction": 0.3820224702358246,
"avg_line_length": 13.833333015441895,
"blob_id": "cdab1444fc4a60d7c126102efbfa4d929ffc3c8f",
"content_id": "9fac9be50103e62bbc741fb276a4b380e13cbbf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 6,
"path": "/tests/reduce/reduce_monops.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x = ~10;\n assert(x == ~10);\n x = -12;\n assert(x == -12);\n}\n"
},
{
"alpha_fraction": 0.2929936349391937,
"alphanum_fraction": 0.36305731534957886,
"avg_line_length": 21.428571701049805,
"blob_id": "0e0a9c778cc304581834657877d5418af5596c09",
"content_id": "05d42a0093137f28971015a14ed3d4b3df41ee6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 314,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 14,
"path": "/tests/reduce/single_step.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x = 3, y = 4;\n assert(x + y == 7);\n assert((x+1) + y == 8);\n assert(x + (y+1) == 8);\n assert(x * y == 12);\n assert((x+1) * y == 16);\n assert(x * (y+1) == 15);\n assert(x - y == -1);\n assert((x+1) - y == 0);\n assert(x - (y+1) == -2);\n x += 3;\n assert(x == 6);\n}\n"
},
{
"alpha_fraction": 0.409494549036026,
"alphanum_fraction": 0.4269125759601593,
"avg_line_length": 26.62264060974121,
"blob_id": "46c492067353bf38b046507d72e78cc40963c678",
"content_id": "2d366052a158c6537624035a631ccf87d68437f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2928,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 106,
"path": "/tests/misc/sudoku_solver.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define LEN 9\n\nint main(int argc, char** argv) {\n int nb_solve = (argc >= 2) ? atol(argv[1]) : 1;\n for (int n = 0; n < nb_solve; n++) {\n printf(\"Solving sudoku n# %d\\n\", n);\n int nb_filled = 0;\n int** root_sudoku = allocate_sudoku();\n for (int i = 0; i < LEN; i++) {\n for (int j = 0; j < LEN; j++) {\n int next;\n scanf(\"%d\", &next);\n root_sudoku[i][j] = next;\n if (next != 0) nb_filled++;\n }\n }\n printf(\"Done reading sudoku...\\n\");\n // display grid\n for (int i = 0; i < LEN; i++) {\n for (int j = 0; j < LEN; j++) {\n printf(\"%d \", root_sudoku[i][j]);\n }\n printf(\"\\n\") ;\n }\n // solve and check\n int info = routine(root_sudoku, 81 - nb_filled);\n if (info) {\n printf(\"Solved !\\n\");\n } else {\n printf(\"Error : failed to solve\\n\");\n }\n // print final result\n for (int i = 0; i < LEN; i++) {\n for (int j = 0; j < 9; j++) {\n printf(\"%d \", root_sudoku[i][j]) ;\n }\n printf(\"\\n\") ;\n }\n free_sudoku(root_sudoku);\n }\n return 0 ;\n}\n\nint** allocate_sudoku() {\n int** grid = malloc(LEN*QSIZE);\n for (int i = 0; i < LEN; i++) {\n grid[i] = malloc(LEN*QSIZE);\n }\n return grid;\n}\n\nvoid free_sudoku(int** grid) {\n for (int i = 0; i < LEN; i++) {\n free(grid[i]);\n }\n free(grid);\n}\n\nint full_check(int line, int col, int** sudoku) {\n // check that no mistakes were introduced\n int digit = sudoku[line][col];\n for (int other = 0; other < 9; other++) {\n if (sudoku[other][col] == digit && other != line) {\n return 0;\n }\n if (sudoku[line][other] == digit && other != col) {\n return 0;\n }\n }\n for (int other_line = (line / 3) * 3; other_line < (line / 3 + 1) * 3; other_line++) {\n for (int other_col = (col / 3) * 3; other_col < (col / 3 + 1) * 3; other_col++) {\n if (sudoku[other_line][other_col] == digit && (other_line != line || other_col != col)) {\n return 0;\n }\n }\n }\n return 1;\n}\n\nint routine(int** sudoku, int nb_unknown) {\n // make guesses recursively until something works\n if (nb_unknown == 0) return 1;\n int found = 0;\n int i = 0, j = 0;\n // find first blank\n while (!found) {\n if (sudoku[i][j] == 0) {\n found = 1;\n } else if (j < 8) {\n j++;\n } else {\n j = 0;\n i++;\n }\n }\n // guess next number\n for (int digit = 1; digit < 10; digit++) {\n sudoku[i][j] = digit;\n if (full_check(i, j, sudoku)) {\n int info = routine(sudoku, nb_unknown - 1);\n if (info) return 1;\n }\n }\n sudoku[i][j] = 0;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.25555557012557983,
"alphanum_fraction": 0.35555556416511536,
"avg_line_length": 14,
"blob_id": "9ec5bc324bebb9ace47e65bc0cd7693f402e7274",
"content_id": "1bd1c720d5d5840ebc7e0fa1f3b58bd0b758e434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 6,
"path": "/verify/boot/ex11.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"5 = 5? 6 = 6? 4 = 4? 5 = 5? \", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3305785059928894,
"alphanum_fraction": 0.3595041334629059,
"avg_line_length": 21,
"blob_id": "aee216bbfa426b93af9c8d81f2ef17f9d6cac2b1",
"content_id": "39090a01b2d04d22234ea0b27081260626246d53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 11,
"path": "/tests/flow/switch_loop.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n for (int i = 0; 1; i++) {\n switch (i) {\n case 1: continue;\n case 3:\n case 5: putchar('\\n'); break;\n case 10: return;\n default: printf(\"%d \", i);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6034482717514038,
"alphanum_fraction": 0.6120689511299133,
"avg_line_length": 18.33333396911621,
"blob_id": "5cd2cbacba4022b95da58c233473af507edf5226",
"content_id": "1942a81f9f8ce6636422d4dc91a747e63c204c58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 116,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 6,
"path": "/verify/except/try_switch.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"Exited switch normally\\nExited switch with exception\\n\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3932584226131439,
"alphanum_fraction": 0.4606741666793823,
"avg_line_length": 13.833333015441895,
"blob_id": "df5b028b30bfa7e9e3b6254c842cc2e639a75f7e",
"content_id": "99fbb9d54498a56d17fa63cc57442ef469d1a9df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 6,
"path": "/tests/call/assert.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n assert(1 == 1);\n assert(true);\n assert(52);\n assert(0 == 1);\n}\n"
},
{
"alpha_fraction": 0.4160178005695343,
"alphanum_fraction": 0.43492770195007324,
"avg_line_length": 22.657894134521484,
"blob_id": "f215e2987a5f4de461594cb74140e54d1c95744c",
"content_id": "b62034b43164a7cd526b938e36b0e845c8ed1a1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 899,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 38,
"path": "/tests/string/concise.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int mstrlen (char * str) {\n int i = -1;\n while (*(str+(++i)) & BYTE) {}\n return i;\n}\n\nint mstrcmp (char * lt, char * rt) {\n while ((*lt & BYTE) && ((*lt & BYTE) == (*rt & BYTE))) {\n lt++; rt++;\n }\n return (*lt & BYTE) - (*rt & BYTE);\n}\n\nvoid mstrcpy (char* src, char* dest) {\n while ((*dest &= ~BYTE), (*dest++ |= (*src++ & BYTE)) & BYTE) {}\n return --dest;\n}\n\nint main (int argc, char** argv) {\n if (argc == 2) {\n printf(\"%d\\n\", mstrlen(argv[1]));\n return 0;\n } else if (argc == 3) {\n printf(\"%d\\n\", mstrcmp(argv[1], argv[2]));\n return 0;\n } else if (argc == 4) {\n char* s = malloc(100);\n char* tmp = s;\n tmp = mstrcpy(argv[1], tmp);\n tmp = mstrcpy(argv[2], tmp);\n tmp = mstrcpy(argv[3], tmp);\n printf(\"%s\\n\", s);\n free(s);\n return 0;\n } else {\n return 1;\n }\n}\n"
},
{
"alpha_fraction": 0.3709677457809448,
"alphanum_fraction": 0.3870967626571655,
"avg_line_length": 9.333333015441895,
"blob_id": "3872f634372dfb4db9bf1905fb829242b920bfb2",
"content_id": "498880685d527e40b20c2101de24e4c631446b69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 6,
"path": "/verify/string/memlib.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4527558982372284,
"alphanum_fraction": 0.46259841322898865,
"avg_line_length": 23.190475463867188,
"blob_id": "66ecd617e8549cc8dba3a114c4efcbef79565a20",
"content_id": "4678c9c1549b4c67a000d53b7690f45f3edbcebf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/tests/calc/minimax.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define DISPLAY(X) printf(#X\" = %d\\n\", (X));\n\nvoid minimax (int* tab, int len, int* min, int* max) {\n *min = *max = *tab;\n for (int i = 1; i < len; i++) {\n if (tab[i] < *min) { *min = tab[i]; }\n if (tab[i] > *max) { *max = tab[i]; }\n }\n}\n\n\nint main (int argc, char** argv) {\n int* tab = malloc((argc-1)*QSIZE);\n for (int i = 1; i < argc; i++) {\n tab[i-1] = atol(argv[i]);\n }\n int min, max;\n minimax(tab, argc-1, &min, &max);\n DISPLAY(min);\n DISPLAY(max);\n}\n"
},
{
"alpha_fraction": 0.3526569902896881,
"alphanum_fraction": 0.43478259444236755,
"avg_line_length": 22,
"blob_id": "222a487772c957411118eb18db15748db2ebd47f",
"content_id": "79cd733e7646e18f34a096d692c1f0f903e7d88d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/tests/boot/ex9.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x = 12;\n int y = 10;\n printf(\"%d = 12? \", 1 ? x : y);\n printf(\"%d = 10? \", 0 ? x : y);\n printf(\"%d = 12?, if 10 not false but not the gcc one\", 18 ? x : y);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3650793731212616,
"alphanum_fraction": 0.3968254029750824,
"avg_line_length": 9.5,
"blob_id": "56412b757d7841d693b954cd808dabd05c6e21c8",
"content_id": "534675f8a8706e6e0826903970ee5930f2a4af16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 6,
"path": "/verify/boot/ex7.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (3, \"5\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3364197611808777,
"alphanum_fraction": 0.3858024775981903,
"avg_line_length": 22.14285659790039,
"blob_id": "02bd648a8018984ff9f1c079910adc5eb2aa5a17",
"content_id": "c0c38542eb6a512679896ce2a52c7b9b3610fd39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 14,
"path": "/failures/assignment.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {}\n\nint main() {\n 1 = 1; //!lvalue|address//\n int x, y;\n (x+1) = 1; //!lvalue//\n -x = 1; //!lvalue//\n (x = 1) = 1; //!lvalue//\n (1 < 2) = 1; //!lvalue|address//\n \"foo\" = 1; //!lvalue|addressed//\n foo() = 1; //!lvalue//\n (x ? y : x) = 1; //!lvalue//\n (x = 1, x = 2) = 1; //!lvalue//\n}\n"
},
{
"alpha_fraction": 0.3427947461605072,
"alphanum_fraction": 0.35807859897613525,
"avg_line_length": 18.913043975830078,
"blob_id": "35ee4fba357cd80e53824a52b742888ca0b6bc47",
"content_id": "dc2782e3b9b1874c150dc61c7096769ac30998d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/verify/string/paren.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def bien_parentesee(s):\n diff = 0\n for c in s:\n if c == '(': diff += 1\n elif c == ')':\n if diff == 0: return False\n else: diff -= 1\n return diff == 0\n\ndef expect(*args):\n res = \"\"\n for s in args[1:]:\n res += \"{} -> {}\\n\".format(s, int(bien_parentesee(s)))\n return (0, res, \"\")\n\ndata = [\n [\"(())\"],\n [\"(foo(bar)(baz)q()uux)\"],\n [\")(\"],\n [\"((((()\"],\n [\"()))))\"],\n [\"[(]{)}{()\"],\n]\n"
},
{
"alpha_fraction": 0.277372270822525,
"alphanum_fraction": 0.30656933784484863,
"avg_line_length": 14.222222328186035,
"blob_id": "1c40a1ce81dfca760d582c446c7b1fdd3f9252b3",
"content_id": "06fbd22e4ceb5f3076bf04cc9b055e2aa1113388",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/tests/decl/alternate.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main () {\n int i, j;\n i = 1;\n int k, l;\n i = i + 1;\n k = j = 3;\n l = 3;\n printf(\"%d %d %d %d\\n\", i, j, k, l);\n}\n"
},
{
"alpha_fraction": 0.4866666793823242,
"alphanum_fraction": 0.4933333396911621,
"avg_line_length": 17.75,
"blob_id": "66008dd4eac271cff325d863d887a4bff2e60936",
"content_id": "87e1bf757106376600059b3c963ee8b13cc207eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 8,
"path": "/failures/init_declaration.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int i;\nint j = i; //!compile-time//\n\nint main(int argc, char** argv) {\n int i = k; //!undeclared//\n int l = m, //!undeclared//\n m = 1;\n}\n"
},
{
"alpha_fraction": 0.3218574821949005,
"alphanum_fraction": 0.6589271426200867,
"avg_line_length": 43.60714340209961,
"blob_id": "70c03a4acf1a5c1e0cb7ff16a4af57cb5be13d20",
"content_id": "f27d60b7ae8ed06f2f820d543186d27386b3ed31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2498,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 56,
"path": "/verify/misc/sudoku_solver.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd, puzzle):\n proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate(bytes(' '.join(c for c in puzzle), 'utf-8'))\n status = True\n if err != b'':\n print(\"Did not expect anything on stderr\")\n status = False\n s = out.decode('utf-8').split('\\n')\n if s[0] != \"Solving sudoku n# 0\" or s[1] != \"Done reading sudoku...\":\n print(\"Header not properly printed\")\n status = False\n if s[11] != \"Solved !\":\n print(\"Solution not announced\")\n status = False\n unsolved = \"\".join(s[2:11]).replace(' ', '')\n solved = \"\".join(s[12:21]).replace(' ', '')\n if unsolved != puzzle:\n print(\"Error reading data\")\n status = False\n for (c,d) in zip(unsolved, solved):\n if c != '0' and c != d:\n print(\"Nonzero value changed\")\n status = False\n if not ('1' <= d <= '9'):\n print(\"Value out of range\")\n status = False\n for i in range(9):\n if len(set(solved[i*9+j] for j in range(9))) != 9:\n print(\"Duplicate number in line\")\n status = False\n if len(set(solved[j*9+i] for j in range(9))) != 9:\n print(\"Duplicate number in column\")\n status = False\n for si in range(3):\n for sj in range(3):\n if len(set(solved[(3*si+i)*9 + (3*sj+j)] for i in range(3) for j in range(3))) != 9:\n print(\"Duplicate number in block\")\n status = False\n if not status: print(out)\n return status\n\n\ncfg = [\n [\"001900003900700160030005007050000009004302600200000070600100030042007006500006800\"],\n [\"000125400008400000420800000030000095060902010510000060000003049000007200001298000\"],\n [\"062340750100005600570000040000094800400000006005830000030000091006400007059083260\"],\n [\"300000000005009000200504000020000700160000058704310600000890100000067080000005437\"],\n [\"630000000000500008005674000000020000003401020000000345000007004080300902947100080\"],\n [\"000020040008035000000070602031046970200000000000501203049000730000000010800004000\"],\n [\"361025900080960010400000057008000471000603000259000800740000005020018060005470329\"],\n [\"050807020600010090702540006070020301504000908103080070900076205060090003080103040\"],\n [\"080005000000003457000070809060400903007010500408007020901020000842300000000100080\"],\n [\"003502900000040000106000305900251008070408030800763001308000104000020000005104800\"],\n]\n"
},
{
"alpha_fraction": 0.49238577485084534,
"alphanum_fraction": 0.49238577485084534,
"avg_line_length": 20.88888931274414,
"blob_id": "faf0a05c93375f081bb6361965b7b909ad392171",
"content_id": "3fecdc32e63c8b26c66cc69a27285268a41a9b31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 9,
"path": "/tests/except/nothrow.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n try {\n printf(\"This may not fail, despite the try block.\\n\");\n } catch (Unreachable _) {\n printf(\"Never.\\n\");\n } finally {\n printf(\"Always.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.3559870421886444,
"alphanum_fraction": 0.4207119643688202,
"avg_line_length": 27.090909957885742,
"blob_id": "4cfe733410e8d7f6f1abad048d315e2405b6f7ee",
"content_id": "4c1d794a49ba6794638632b1aee55a3dd15f9cc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 11,
"path": "/failures/divzero.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x;\n x = 1 / 0; //?division by zero//\n x = 1 / (2 - 2); //?division by zero//\n x = 1 % 0; //?division by zero//\n x = 1 % (2 - 2); //?division by zero//\n x = 1 / (0 * 2 + 2 - 2); //?division by zero//\n\n x = 1 << -4; //?shift amount//\n x = 56 >> -2; //?shift amount//\n}\n"
},
{
"alpha_fraction": 0.4943883419036865,
"alphanum_fraction": 0.5056116580963135,
"avg_line_length": 20.731706619262695,
"blob_id": "eac9fead5caec1159c242c8558a94a3b04e06bca",
"content_id": "cd9514dbea85cac375fef9c340cb3d12b5244aee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1782,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 82,
"path": "/tests/misc/guessnum.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#ifndef MCC\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <stdbool.h>\n#define QSIZE 8\n#define int long\n#endif\n\nint max;\n\nint choose() {\n return rand() % max;\n}\n\nint strindex(char* str, int index) {\n int base = index / QSIZE;\n int loc = index % QSIZE;\n int val = str[base];\n while (loc--) {\n val = val / 256;\n }\n return val % 256;\n}\n\nint isnumber(char* str) {\n int len = strlen(str);\n for (int i = 0; i < len; i++) {\n int val = strindex(str, i);\n if (!('0' <= val && val <= '9' && val)) {\n return false;\n }\n }\n return true;\n}\n\nint compare(int guess, int real) {\n if (guess < 0) {\n printf(\"The number has to be positive, are you even trying ?\\n\");\n } else if (guess > max) {\n printf(\"Come on, I said it wouldn't be any greater than %d...\\n\", max);\n } else if (guess == real) {\n printf(\"You guessed it! Good job.\\n\");\n return true;\n } else if (guess < real) {\n printf(\"A bit bigger...\\n\");\n } else {\n printf(\"Slightly smaller...\\n\");\n }\n return false;\n}\n\nint play() {\n int real = choose();\n int found = false;\n int* guess = malloc(QSIZE);\n printf(\"I want to make you guess a number.\\n\");\n printf(\"It's between 0 and %d.\\n\", max);\n while (!found) {\n printf(\" > \");\n scanf(\"%ld\", guess);\n found = compare(guess[0], real);\n }\n free(guess);\n}\n\nint check(char* str) {\n int len = strlen(str);\n for (int i = 0; i < len; i++) {\n int val = strindex(str, i),\n printf(\"str[%d] = <%c> (%d)\\n\", i, val, val);\n }\n}\n\nint main(int argc, char** argv) {\n if (argc > 1 && isnumber(argv[1])) {\n max = atol(argv[1]);\n } else {\n max = 100;\n }\n play();\n}\n"
},
{
"alpha_fraction": 0.5044247508049011,
"alphanum_fraction": 0.517699122428894,
"avg_line_length": 24.11111068725586,
"blob_id": "ff7b5a6360677299a85472000e5ee9d1868201eb",
"content_id": "4d1ceeb963849a7d6dae77f41e0b68c204000270",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 9,
"path": "/failures/invalid_va.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main (int argc, char** argv, ...) {} //!may not//\n\nint foo() {\n int* ap;\n va_start(ap); //!non-variadic//\n va_start(101); //!no address//\n va_start(ap, ap); //!exactly one//\n va_arg(ap); //!non-variadic//\n}\n"
},
{
"alpha_fraction": 0.551948070526123,
"alphanum_fraction": 0.5649350881576538,
"avg_line_length": 29.799999237060547,
"blob_id": "fef3af5c85ee4387b944902df9685083da453bcd",
"content_id": "e0f4e32bab666d0b622c3a5117639da6c893dfe6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 5,
"path": "/tests/call/hello.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n printf(\"Hello, World!\\n\");\n printf(\"My name is %s.\\n\", argv[0]);\n printf(\"I have %d arguments.\\n\", argc-1);\n}\n"
},
{
"alpha_fraction": 0.49444442987442017,
"alphanum_fraction": 0.5095959305763245,
"avg_line_length": 29.9375,
"blob_id": "6b1b580fb438de38fdfad02e5a3b3de8795def2d",
"content_id": "6304ae06e7e9ad98863d503eb48c6dc15e2f26ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1982,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 64,
"path": "/tests/misc/sieve.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main (int argc, char **argv) {\n if (argc != 2) {\n fprintf (stderr, \"Usage: ./sieve <n>\\ncalcule et affiche les nombres premiers inferieurs a <n>.\\n\");\n fflush (stderr);\n exit (10); /* non mais! */\n }\n int n = atoi (argv[1]); // conversion chaine -> entier.\n if (n < 2) {\n fprintf (stderr, \"Ah non, quand meme, un nombre >=2, s'il-vous-plait...\\n\");\n fflush (stderr);\n exit (10);\n }\n int* bits = malloc (QSIZE*n); // allouer de la place pour n entiers (booleens).\n // Ca prend 64 foit trop de place, mais ce serait compliqué de traiter des bits individuels\n if (bits==NULL) {\n fprintf (stderr, \"%d est trop gros, je n'ai pas assez de place memoire...\\n\");\n fflush (stderr);\n exit (10);\n }\n zero_sieve (bits, n);\n bits[0] = bits[1] = 1;\n fill_sieve (bits, n);\n print_sieve (bits, n);\n free (bits); // et on libere la place memoire allouee pour bits[].\n return 0;\n}\n\nint zero_sieve (int *bits, int n) {\n for (int i = 0; i < n; i++) bits[i] = 0;\n return 0;\n}\n\nint fill_sieve (int *bits, int n) {\n for (int last_prime = 2; last_prime < n;){\n cross_out_prime (bits, n, last_prime);\n while (++last_prime < n && bits[last_prime]);\n }\n return 0;\n}\n\nint cross_out_prime (int *bits, int n, int prime) {\n for (int delta = prime; (prime = prime + delta) < n;) bits[prime] = 1;\n return 0;\n}\n\nint print_sieve (int *bits, int n) {\n printf(\"Les nombres premiers inferieurs a %d sont:\\n\", n);\n char* delim = \" \";\n int k = 0;\n for (int i = 0; i < n; i++) {\n if (bits[i]==0) {\n printf (\"%s%8d\", delim, i);\n if (++k >= 4) {\n printf(\"\\n\"); // retour à la ligne.\n k = 0;\n delim = \" \";\n } else {\n printf (\" \"); // espace.\n }\n }\n }\n fflush (stdout); // on vide le tampon de stdout, utilise par printf().\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5643203854560852,
"alphanum_fraction": 0.5655339956283569,
"avg_line_length": 31.959999084472656,
"blob_id": "6335ddd8484b484e120a956ea7d43f7a447ea638",
"content_id": "ed856349c60a4d85872db0b073491f9aeefdc89b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 25,
"path": "/verify/sys/execvp.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd, *args):\n proc = Popen([cmd, *args], stdin=PIPE, stdout=PIPE, stderr=PIPE)\n cproc = Popen(args, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n cout, cerr = cproc.communicate()\n status = True\n if cout != out:\n print(\"Wrong output:\\n [{}]\\nexpect[{}]\".format(out, cout))\n status = False\n if cerr != err:\n print(\"Wrong error:\\n [{}]\\nexpect[{}]\".format(err, cerr))\n status = False\n if proc.returncode != cproc.returncode:\n print(\"Wrong return code: [{}]; expect[{}]\".format(proc.returncode, cproc.returncode))\n status = False\n return status\n\ncfg = [\n [\"ls\", \"-la\"],\n [\"cat\", \"Makefile\", \"compile.ml\"],\n [\"bash\", \"-c\", \"exit 1\"],\n [\"wc\", \"-wl\", \"compile.ml\"],\n]\n"
},
{
"alpha_fraction": 0.4552397131919861,
"alphanum_fraction": 0.4815443456172943,
"avg_line_length": 21.44761848449707,
"blob_id": "f0ff95941b3257a6f0c2dce8cb124face3b5600a",
"content_id": "b539405459bed554e0f48568ac92dee963757a72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2357,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 105,
"path": "/tests/except/except.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int test_throw(int i) {\n if (i == 0) {\n throw Foo(0);\n } else if (i == 1) {\n throw Bar(1);\n }\n return 42;\n}\n\nint test_catch(int i) {\n int j = -1;\n try {\n j = test_throw(i);\n } catch (Foo x) {\n printf(\"Failed n.1 with Foo(%d)\\n\", x);\n }\n return j;\n}\n\nint test_catch_finally (int i) {\n int j = -1;\n try {\n j = test_throw(i);\n } catch (Bar x) {\n printf(\"Failed n.2 with Bar(%d)\\n\", x);\n } finally {\n printf(\"Ended n.2\\n\");\n }\n return j;\n}\n\nint test_finally (int i) {\n int j = -1;\n try {\n j = test_throw(i);\n } finally {\n printf(\"Ended n.2\\n\");\n }\n return j;\n}\n\nint test_multi_catch (int i) {\n int j = -1;\n try {\n j = test_throw(i);\n } catch (Foo x) {\n printf(\"Caught Foo(%d)\\n\", x);\n } catch (Bar y) {\n printf(\"Caught Bar(%d)\\n\", y);\n throw Bar(y);\n } catch (Unreachable _) {\n printf(\"AAAAAAAAAA\\n\");\n } finally {\n printf(\"Finally...\\n\");\n }\n return j;\n}\n\nint test_no_error (int i) {\n try {\n printf(\"Everything is fine.\\n\");\n } catch (Foo x) {\n printf(\"Unreachable.\\n\");\n } finally {\n printf(\"No error occurred.\\n\");\n }\n return 10;\n}\n\nint test_string () {\n try {\n try {\n throw Foo(\"Hello, World!\");\n } catch (Foo x) {\n printf(\"Caught %s\\n\", x);\n throw Foo(x);\n }\n } catch (Foo x) {\n printf(\"Caught %s again\\n\", x);\n }\n}\n\nint main(int argc, char** argv) {\n switch (atoi(argv[1])) {\n case 1: throw Foo(15); break;\n case 2: test_throw(0); break;\n case 3: test_throw(1); break;\n case 4: test_throw(2); break;\n case 5: test_catch(0); break;\n case 6: test_catch(1); break;\n case 7: test_catch(2); break;\n case 8: test_catch_finally(0); break;\n case 9: test_catch_finally(1); break;\n case 10: test_catch_finally(2); break;\n case 11: test_finally(0); break;\n case 12: test_finally(1); break;\n case 13: test_finally(2); break;\n case 14: test_multi_catch(0); break;\n case 15: test_string(); break;\n case 16: test_multi_catch(1); break;\n case 17: test_multi_catch(2); break;\n case 18: test_no_error(0); break;\n }\n printf(\"Normal exit\\n\");\n}\n"
},
{
"alpha_fraction": 0.30000001192092896,
"alphanum_fraction": 0.3333333432674408,
"avg_line_length": 14,
"blob_id": "05b0a48af5b8bb4cb9e62079ff411a90adc1a3f5",
"content_id": "4e41fdae75dc21529e940792273ec1b8b0177888",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 8,
"path": "/tests/ptr/addr-deref.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x = 1;\n int* y = &x;\n int* z = &*y;\n assert(*z == 1);\n *&x = 3;\n assert(*z == 3);\n}\n"
},
{
"alpha_fraction": 0.5496183037757874,
"alphanum_fraction": 0.5511450171470642,
"avg_line_length": 25.200000762939453,
"blob_id": "e3ffdae83a921c43bc93d9940f65cd17272a4ef3",
"content_id": "65c8eeefc42a1d8f15cb8a54aab8d6299931ea9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 655,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 25,
"path": "/verify/sys/dup-redir.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd):\n proc = Popen(cmd, stdout=PIPE, stdin=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n status = True\n if err != b'':\n print(\"Expected empty stderr\")\n status = False\n if out != b'This goes to stdout.\\n':\n print(\"Wrong stdout: [{}]\".format(out))\n status = False\n if proc.returncode != 0:\n print(\"Nonzero exit code\")\n status = False\n with open(\"dump.log\", 'r') as f:\n s = f.read()\n if s != \"This goes to the log.\\n\":\n print(\"Wrong file contents: [{}]\".format(s))\n status = False\n return status\n\ncfg = [\n [],\n]\n"
},
{
"alpha_fraction": 0.7180762887001038,
"alphanum_fraction": 0.7197346687316895,
"avg_line_length": 66,
"blob_id": "e90234de652f97a6ea0346193b93e55fa5662997",
"content_id": "537da4d2d2f39538269ddbeaf424d2e434c7bb20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 459,
"num_lines": 9,
"path": "/verify/string/argsort.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \" \".join(sorted(args)) + \" \\n\", \"\")\n\ndata = [\n [],\n [\"frobnify\"],\n [\"bar\", \"quux\", \"baz\", \"foo\"],\n [*\"Lorem ipsum dolor sit amet consectetur adipiscing elit sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur Excepteur sint occaecat cupidatat non proident sunt in culpa qui officia deserunt mollit anim id est laborum\".split(' ')],\n]\n"
},
{
"alpha_fraction": 0.3505154550075531,
"alphanum_fraction": 0.4041237235069275,
"avg_line_length": 22.095237731933594,
"blob_id": "288cfb0ceea1ffb59a2028ed462eb08328f94005",
"content_id": "7abb71fd77be69cbb057cfb000e10e2d25d85482",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 21,
"path": "/tests/call/max.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int max(int count, ...) {\n int* ap;\n int best;\n va_start(ap);\n for (int j = 0; j < count; j++) {\n int arg = va_arg(ap);\n if (j > 0) {\n best = (best > arg) ? best : arg;\n } else {\n best = arg;\n }\n }\n return best;\n}\n\nint main(int argc, char** argv) {\n printf(\"%d == 9\\n\", max(7, 5,4,9,3,5,0,7));\n printf(\"%d == 6\\n\", max(1, 6));\n printf(\"%d == 8\\n\", max(2, 4,8));\n printf(\"%d == 10\\n\", max(4, 2,5,8,10));\n}\n"
},
{
"alpha_fraction": 0.3720000088214874,
"alphanum_fraction": 0.45133334398269653,
"avg_line_length": 27.30188751220703,
"blob_id": "37e76c448647e392dddf07856715220939003668",
"content_id": "b695a958ded98517a25deb2358624da0e51f009e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1500,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 53,
"path": "/tests/reduce/array.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "void strset(char* str, int index, int newval) {\n int arr = str + index;\n *(str+index) = (*(str+index) & ~BYTE) + (newval & BYTE);\n}\n\nint main() {\n char* s = malloc(100);\n for (int i = 0; i < 100; i++) strset(s, i, i);\n printf(\"0x%08X\\n\", *(s+BSIZE));\n printf(\"0x%08X\\n\", *(s+WSIZE));\n printf(\"0x%08X\\n\", *(s+DSIZE));\n printf(\"0x%08X\\n\", *(s+QSIZE));\n printf(\"0x%08X\\n\", *(s+2*BSIZE));\n printf(\"0x%08X\\n\", *(s+BSIZE*2));\n printf(\"0x%08X\\n\", *(s+2*WSIZE));\n printf(\"0x%08X\\n\", *(s+WSIZE*2));\n printf(\"0x%08X\\n\", *(s+2*DSIZE));\n printf(\"0x%08X\\n\", *(s+DSIZE*2));\n printf(\"0x%08X\\n\", *(s+2*QSIZE));\n printf(\"0x%08X\\n\", *(s+QSIZE*2));\n *(s+BSIZE) += 1;\n *(s+WSIZE) += 1;\n *(s+DSIZE) += 1;\n *(s+QSIZE) += 1;\n *(s+2*BSIZE) += 1;\n *(s+BSIZE*2) += 1;\n *(s+2*WSIZE) += 1;\n *(s+WSIZE*2) += 1;\n *(s+2*DSIZE) += 1;\n *(s+DSIZE*2) += 1;\n *(s+2*QSIZE) += 1;\n *(s+QSIZE*2) += 1;\n printf(\"0x%08X\\n\", *(s+BSIZE));\n printf(\"0x%08X\\n\", *(s+WSIZE));\n printf(\"0x%08X\\n\", *(s+DSIZE));\n printf(\"0x%08X\\n\", *(s+QSIZE));\n printf(\"0x%08X\\n\", *(s+2*BSIZE));\n printf(\"0x%08X\\n\", *(s+2*WSIZE));\n printf(\"0x%08X\\n\", *(s+2*DSIZE));\n printf(\"0x%08X\\n\", *(s+2*QSIZE));\n *(s+BSIZE) = 1;\n *(s+WSIZE) = 1;\n *(s+DSIZE) = 1;\n *(s+QSIZE) = 1;\n *(s+2*BSIZE) = 1;\n *(s+BSIZE*2) = 1;\n *(s+2*WSIZE) = 1;\n *(s+WSIZE*2) = 1;\n *(s+2*DSIZE) = 1;\n *(s+DSIZE*2) = 1;\n *(s+2*QSIZE) = 1;\n *(s+QSIZE*2) = 1;\n}\n"
},
{
"alpha_fraction": 0.3362445533275604,
"alphanum_fraction": 0.3624454140663147,
"avg_line_length": 18.08333396911621,
"blob_id": "228e194c7f5d9d05237d882dd37e9f813c9ac385",
"content_id": "c78b297239b97fd46976d092c5b01850c81c40be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 12,
"path": "/verify/calc/shifts.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n for i in range(1000):\n for j in range(5):\n res += \"{} \".format(i << j)\n res += \"{} \".format(i >> j)\n res += '\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.30392158031463623,
"alphanum_fraction": 0.4215686321258545,
"avg_line_length": 19.399999618530273,
"blob_id": "b291fbb8ea81ac239d43ca28c7146956701c4fec",
"content_id": "cdaf78d55a075de13f5f39a5644e5f70974c49af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/verify/ptr/multifnptr.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n res += \"foo1(5) = 15 ?= 15\\n\"\n res += \"foo1(bar1(5)) = 12 ?= 12\\n\"\n res += \"foo2(foo0(), bar1(bar0()) = 375 ?= 375\\n\"\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.49135446548461914,
"alphanum_fraction": 0.5100864768028259,
"avg_line_length": 22.133333206176758,
"blob_id": "5f444ab5314a3ad346c10822e0a16e26e0847c9e",
"content_id": "d2c69f4499ec3a513f04717431c6a99e9b687460",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 694,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 30,
"path": "/tests/calc/fact.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#ifndef MCC\n#include <stdio.h>\n#include <stdlib.h>\n#endif\n\nint fact (int n) {\n int res = 1;\n while (n != 0) {\n res *= n;\n n--;\n }\n return res;\n}\n\nint main (int argc, char **argv) {\n if (argc != 2) {\n fprintf(stderr, \"Usage: ./fact <n>\\ncalcule et affiche la factorielle de <n>.\\n\");\n fflush(stderr);\n exit(10); /* non mais! */\n }\n int n = atoi(argv[1]);\n if (n < 0) {\n fprintf(stderr, \"Ah non, quand meme, un nombre positif ou nul, s'il-vous-plait...\\n\");\n fflush(stderr);\n exit(10);\n }\n int res = fact(n);\n printf(\"La factorielle de %d vaut %d (en tout cas, modulo 2^32...).\\n\", n, res);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.33796295523643494,
"alphanum_fraction": 0.3611111044883728,
"avg_line_length": 15.615385055541992,
"blob_id": "36aacf9d04799b363b006f4d0c98812bea285056",
"content_id": "b53cf7cf984a61f9d5259712d924c0252bbdc6b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 13,
"path": "/verify/ptr/dbl-array.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n cnt = 0\n res = \"\"\n for i in range(5):\n for j in range(6):\n res += \"{} \".format(cnt)\n cnt += 1\n res += '\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4864864945411682,
"alphanum_fraction": 0.4954954981803894,
"avg_line_length": 12.875,
"blob_id": "15b49c0e2e65608f54ac7e5611ce0a045e6218f8",
"content_id": "9c7406ea3d38a57fb1ae1c82ab9c7c2fcaf812d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 8,
"path": "/verify/string/path.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "import os\n\ndef expect(*args):\n return (0, \"$PATH = {}\\n\".format(os.getenv(\"PATH\")), \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3890339434146881,
"alphanum_fraction": 0.4360313415527344,
"avg_line_length": 20.27777862548828,
"blob_id": "9e4c8d50de71d5b6180975a531442441f43e5b9c",
"content_id": "32d6d898eb84a9aafe5ed35368ce5e4ce8369255",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 18,
"path": "/verify/except/uncaught-str.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n n = int(args[1])\n if n == 0:\n return (111, \"\", \"Unhandled exception Zero(\\\"Hello, World\\\")\\n\")\n elif n == 1:\n return (111, \"\", \"Unhandled exception One(\\\"foo\\\")\\n\")\n elif n == 2:\n return (111, \"\", \"Unhandled exception Two(\\\"bar\\\")\\n\")\n else:\n return (0, \"\", \"\")\n\n\ndata = [\n [\"-1\"],\n [\"0\"],\n [\"1\"],\n [\"2\"],\n]\n"
},
{
"alpha_fraction": 0.4399999976158142,
"alphanum_fraction": 0.4399999976158142,
"avg_line_length": 9.714285850524902,
"blob_id": "a9a9a9d298c563376020cafff0ed143a326d80ac",
"content_id": "839b0b8c49aa3597c35f74b8b2a9d21848349144",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 7,
"path": "/tests/string/strret.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n return \"bar\";\n}\n\nint main() {\n printf(\"%s\\n\", foo());\n}\n"
},
{
"alpha_fraction": 0.5108910799026489,
"alphanum_fraction": 0.5277227759361267,
"avg_line_length": 30.5625,
"blob_id": "18f5ae54cb20f85ba3b4cddfb18e20886db2e687",
"content_id": "334a4f5bd751a43cdb2688538858fae43c917e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1010,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 32,
"path": "/verify/misc/sort.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd, size):\n proc = Popen([cmd, str(size)], stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n status = True\n if proc.returncode != 0:\n print(\"Wrong return code: [{}]; expect[0]\".format(proc.returncode))\n status = False\n if err != b'':\n print(\"Expected no stderr, got [{}]\".format(err))\n lst, srt = out.decode('utf-8').rstrip().split(\"\\n\")\n lst = [int(s) for s in lst.rstrip().split(' ')]\n srt = [int(s) for s in srt.rstrip().split(' ')]\n lst.sort()\n if lst != srt:\n print(\"Output does not match\")\n if len(lst) != len(srt):\n print(\"Not the same size: [{}]; expect[{}]\".format(len(lst), len(srt)))\n for i in range(len(lst)):\n if lst[i] != srt[i]:\n print(\"Values differ at position {}: [{}]; expect[{}]\".format(i, lst[i], srt[i]))\n status = False\n return status\n\ncfg = [\n [1],\n [10],\n [100],\n [1000],\n [5000],\n]\n"
},
{
"alpha_fraction": 0.34210526943206787,
"alphanum_fraction": 0.37368419766426086,
"avg_line_length": 13.615385055541992,
"blob_id": "128dd920bf75f6578aeecef0b66dba468b58b0f7",
"content_id": "be3f0f54ecf89e19fa6727f387246f09a6a441b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 13,
"path": "/tests/decl/init.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int i = 1;\nint j = 2, k = 3 * QSIZE;\n\nint foo() {\n int l = 1;\n int m = 2, n = 3;\n int o = n;\n printf(\"%d %d %d %d %d %d %d\\n\", i, j, k, l, m, n, o);\n}\n\nint main() {\n foo();\n}\n"
},
{
"alpha_fraction": 0.2857142984867096,
"alphanum_fraction": 0.4166666567325592,
"avg_line_length": 13,
"blob_id": "1c122d7aa1a9106a1c0e91f22c25343952f90371",
"content_id": "abe568e1c5b632970cd3f4f2c485f37db17c485a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 84,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 6,
"path": "/verify/decl/ptr.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"0 1 2 3 4 5 6 7 8 9 \\n\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.41897234320640564,
"alphanum_fraction": 0.43478259444236755,
"avg_line_length": 13.882352828979492,
"blob_id": "176fede8891e20b1e7b252b10f38d519bd10d3e1",
"content_id": "618959665bdd6549d71dda10980a0c752c06be9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 253,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 17,
"path": "/tests/ptr/swap.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define DISPLAY(X) printf(#X\" = %d\\n\", (X));0\n\nvoid swap (int* a, int* b) {\n int tmp = *a;\n *a = *b;\n *b = tmp;\n}\n\nint main () {\n int a = 5;\n int b = 10;\n DISPLAY(a);\n DISPLAY(b);\n swap(&a, &b);\n DISPLAY(a);\n DISPLAY(b);\n}\n"
},
{
"alpha_fraction": 0.2723666727542877,
"alphanum_fraction": 0.4041427969932556,
"avg_line_length": 24.211111068725586,
"blob_id": "a272614c3f2b2758dbbc99214a0734053272e0d5",
"content_id": "9320e57edd33819d1ec8cf4abef4e9eea28dbc51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2269,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 90,
"path": "/verify/reduce/reduce_binops.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n ret = \"\"\n\n ret += \"ADD \"\n ret += \"{} \".format(1656 + 4582)\n ret += \"{} \".format(18 + -78)\n ret += \"{} \".format(-482 + -7569)\n ret += \"{} \".format(15 + 45 + 689 + 96 + 47 + 45)\n ret += '\\n'\n\n ret += \"SUB \"\n ret += \"{} \".format(4693 - 7582)\n ret += \"{} \".format(482 - -15)\n ret += \"{} \".format(-1445 - 4782)\n ret += \"{} \".format(45 - 5 - -12 - 5)\n ret += '\\n'\n\n ret += \"MUL \"\n ret += \"{} \".format(425 * 736)\n ret += \"{} \".format(72 * -15)\n ret += \"{} \".format(-452 * -69)\n ret += \"{} \".format(-45 * 5 * 2 * 4 * -7)\n ret += '\\n'\n\n ret += \"DIV \"\n ret += \"{} \".format(15266 // 45)\n ret += \"{} \".format(-144443 // 889 + 1) # difference here\n ret += \"{} \".format(-496854 // -321)\n ret += \"{} \".format(42659 // -152 + 1) # difference here\n ret += '\\n'\n\n ret += \"MOD \"\n ret += \"{} \".format(1236546 % 156)\n ret += \"{} \".format(695816 % 54)\n ret += \"{} \".format(-(654 % 52)) # difference here\n ret += \"{} \".format(4546986 % 45) # difference here\n ret += \"{} \".format(-558 % -54)\n ret += '\\n'\n\n ret += \"AND \"\n ret += \"{} \".format(1236546 & 156)\n ret += \"{} \".format(695816 & 54)\n ret += \"{} \".format(-654 & 52)\n ret += \"{} \".format(4546986 & -45)\n ret += \"{} \".format(-558 & -54)\n ret += '\\n'\n\n ret += \"XOR \"\n ret += \"{} \".format(1236546 ^ 156)\n ret += \"{} \".format(695816 ^ 54)\n ret += \"{} \".format(-654 ^ 52)\n ret += \"{} \".format(4546986 ^ -45)\n ret += \"{} \".format(-558 ^ -54)\n ret += '\\n'\n\n ret += \"OR \"\n ret += \"{} \".format(1236546 | 156)\n ret += \"{} \".format(695816 | 54)\n ret += \"{} \".format(-654 | 52)\n ret += \"{} \".format(4546986 | -45)\n ret += \"{} \".format(-558 | -54)\n ret += '\\n'\n\n ret += \"NEG \"\n ret += \"{} \".format(-0)\n ret += \"{} \".format(-15)\n ret += \"{} \".format(-(-152))\n ret += '\\n'\n\n ret += \"NOT \"\n ret += \"{} \".format(~0)\n ret += \"{} \".format(~1584)\n ret += \"{} \".format(~(-1474))\n ret += '\\n'\n\n ret += \"SHR \"\n ret += \"{} \".format(15246 >> 2)\n ret += \"{} \".format(-426 >> 3)\n ret += '\\n'\n\n ret += \"SHL \"\n ret += \"{} \".format(15246 << 2)\n ret += \"{} \".format(-426 << 3)\n ret += '\\n'\n\n return (0, ret, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3614034950733185,
"alphanum_fraction": 0.39298245310783386,
"avg_line_length": 20.923076629638672,
"blob_id": "93286f783548f5f328c44e75410cde41688ff9be",
"content_id": "ecc85cb62b5f213331f780fe479d61818ae98806",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 285,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/verify/except/loop_try.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n for i in range(12):\n res += \"i = {}\\n\".format(i)\n if i == 3:\n res += \"Found 3\\n\"\n if i != 7:\n res += \"Always except 7 ({}).\\n\".format(i)\n return (0, res + \"Loop exited at 11.\\n\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.34302327036857605,
"alphanum_fraction": 0.36627906560897827,
"avg_line_length": 14.636363983154297,
"blob_id": "d9f8db891b4063cb914dab823c1b9663d2afe5f0",
"content_id": "d103d0e85ef651c9ca589c8b4cf9bd3820fec49f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 11,
"path": "/tests/boot/ex10.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int y = 7;\n if (true) {\n printf(\"on est dans le if\");\n int y = 3;\n } else {\n y = 4;\n }\n printf(\"%d\", y);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.28383922576904297,
"alphanum_fraction": 0.4109926223754883,
"avg_line_length": 31.945945739746094,
"blob_id": "80249b877040e043e2703bb3e22b3687c31e5864",
"content_id": "a6cc9bf9b7d0d11fe61bf1c6bcbf328a7bf4aa55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 37,
"path": "/tests/calc/binops.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x, y;\n printf(\"ADDITION \");\n x = 1656; y = 4582; printf(\"%d \", x + y);\n x = 18; y = -78; printf(\"%d \", x + y);\n x = -482; y = -7569; printf(\"%d \", -482 + -7569);\n x = 45; y = 47; printf(\"%d \", 15 + x + 689 + 96 + y + 45);\n putchar('\\n');\n\n printf(\"SUBTRACTION \");\n x = 4693; y = 7582; printf(\"%d \", x - y);\n x = 482; y = -15; printf(\"%d \", x - y);\n x = -1445; y = 4782; printf(\"%d \", x - y);\n x = 5; y = -12; printf(\"%d \", 45 - x - y - 5);\n putchar('\\n');\n\n printf(\"MULTIPLICATION \");\n x = 425; y = 736; printf(\"%d \", 425 * 736);\n x = 72; y = -15; printf(\"%d \", x * y);\n x = -452; y = -69; printf(\"%d \", x * y);\n x = 5; y = 4; printf(\"%d \", -45 * x * 2 * y * -7);\n putchar('\\n');\n\n printf(\"DIVISION \");\n x = 15266; y = 45; printf(\"%d \", x / y);\n x = -144443; y = 889; printf(\"%d \", x / y);\n x = -496854; y = -321; printf(\"%d \", x / y);\n putchar('\\n');\n\n printf(\"MODULUS \");\n x = 1236546; y = 156; printf(\"%d \", x % y);\n x = 695816; y = 54; printf(\"%d \", x % y);\n x = -654; y = 52; printf(\"%d \", x % y);\n x = 4546986; y = -45; printf(\"%d \", x % y);\n x = -558; y = -54; printf(\"%d \", x % y);\n putchar('\\n');\n}\n"
},
{
"alpha_fraction": 0.2998204529285431,
"alphanum_fraction": 0.4290843904018402,
"avg_line_length": 24.9069766998291,
"blob_id": "f93642beb60fce18f0e250fd7075c9bd33f80e73",
"content_id": "3c71087327bb8ccc8c10a691bdf3e1108a4a539e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 43,
"path": "/verify/calc/binops.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n ret = \"\"\n\n ret += \"ADDITION \"\n ret += \"{} \".format(1656 + 4582)\n ret += \"{} \".format(18 + -78)\n ret += \"{} \".format(-482 + -7569)\n ret += \"{} \".format(15 + 45 + 689 + 96 + 47 + 45)\n ret += '\\n'\n\n ret += \"SUBTRACTION \"\n ret += \"{} \".format(4693 - 7582)\n ret += \"{} \".format(482 - -15)\n ret += \"{} \".format(-1445 - 4782)\n ret += \"{} \".format(45 - 5 - -12 - 5)\n ret += '\\n'\n\n ret += \"MULTIPLICATION \"\n ret += \"{} \".format(425 * 736)\n ret += \"{} \".format(72 * -15)\n ret += \"{} \".format(-452 * -69)\n ret += \"{} \".format(-45 * 5 * 2 * 4 * -7)\n ret += '\\n'\n\n ret += \"DIVISION \"\n ret += \"{} \".format(15266 // 45)\n ret += \"{} \".format(-144443 // 889 + 1) # difference here\n ret += \"{} \".format(-496854 // -321)\n ret += '\\n'\n\n ret += \"MODULUS \"\n ret += \"{} \".format(1236546 % 156)\n ret += \"{} \".format(695816 % 54)\n ret += \"{} \".format(-(654 % 52)) # difference here\n ret += \"{} \".format(4546986 % 45) # difference here\n ret += \"{} \".format(-558 % -54)\n ret += '\\n'\n\n return (0, ret, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3702906370162964,
"alphanum_fraction": 0.3735199272632599,
"avg_line_length": 33.407405853271484,
"blob_id": "98fd6d83fe65edb58c29305665b1175dc466f0c8",
"content_id": "967b245f912f36b4af3a396ad3a4dbd15fbe7ce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 929,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/verify/calc/cmp.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n i = 5;\n j = 6;\n res = \"\"\n res += \"Yes:\\n\"\n res += \"\\ti < j: {}\\n\".format(int(i < j))\n res += \"\\ti <= j: {}\\n\".format(int(i <= j))\n res += \"\\ti == i: {}\\n\".format(int(i == i))\n res += \"\\t!(j <= i): {}\\n\".format(int(not (j <= i)))\n res += \"\\t!(j < i): {}\\n\".format(int(not (j < i)))\n res += \"\\tj > i: {}\\n\".format(int(j > i))\n res += \"\\tj >= i: {}\\n\".format(int(j >= i))\n res += \"\\tj != i: {}\\n\".format(int(j != i))\n res += \"No:\\n\"\n res += \"\\tj < i: {}\\n\".format(int(j < i))\n res += \"\\tj <= i: {}\\n\".format(int(j <= i))\n res += \"\\ti == j: {}\\n\".format(int(i == j))\n res += \"\\t!(i < j): {}\\n\".format(int(not (i < j)))\n res += \"\\t!(i <= j): {}\\n\".format(int(not (i <= j)))\n res += \"\\ti > j: {}\\n\".format(int(i > j))\n res += \"\\ti >= j: {}\\n\".format(int(i >= j))\n res += \"\\ti != i: {}\\n\".format(int(i != i))\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.37775444984436035,
"alphanum_fraction": 0.4134312570095062,
"avg_line_length": 25.47222137451172,
"blob_id": "f1f784fcecdf3626c0f44729fa8380a7051d7ab2",
"content_id": "1023c9eb3dfbdc844bba19b5204e01db769bd5f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 953,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 36,
"path": "/verify/misc/sieve.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n if len(args) != 2:\n return (10, \"\", \"Usage: ./sieve <n>\\ncalcule et affiche les nombres premiers inferieurs a <n>.\\n\")\n n = int(args[1])\n if n < 2:\n return (10, \"\", \"Ah non, quand meme, un nombre >=2, s'il-vous-plait...\\n\")\n ok = [True] * n\n ok[0] = ok[1] = False\n for i in range(2, n):\n if ok[i]:\n for j in range(i*2, n, i):\n ok[j] = False\n res = \"Les nombres premiers inferieurs a {} sont:\\n\".format(n)\n delim = \" \";\n primes = [p for p in range(n) if ok[p]]\n for i in range(0, len(primes), 4):\n for j in range(4):\n if i+j >= len(primes):\n break\n res += \" {: 8}\".format(primes[i+j])\n if j != 3:\n res += ' '\n else:\n res += '\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n [\"0\"],\n [\"2\"],\n [\"10\"],\n [\"50\"],\n [\"100\"],\n [\"500\"],\n [\"1000\"],\n]\n"
},
{
"alpha_fraction": 0.3828125,
"alphanum_fraction": 0.4140625,
"avg_line_length": 19.645160675048828,
"blob_id": "6410cc922b1cae9c630cb1456955d53abbe24f6a",
"content_id": "a277d43fe0e6a81e82630c74acdb110148eb3f3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 640,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/verify/flow/count.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(args):\n j = 0\n i = 1\n res = \"\"\n fmtloop = \"i = {}\\n\"\n fmtend = \"i ended at {}\\n\\n\"\n while (j != 10):\n res += fmtloop.format(i)\n res += \"j = {}\\n\".format(j)\n j = i\n i += 1\n res += \"j ended at {}\\n\".format(j)\n res += fmtend.format(i)\n for i in range(10):\n res += \"i = {}\\n\".format(i)\n res += \"i at 10\\n\\n\"\n for i in range(15, -1, -1):\n res += fmtloop.format(i)\n res += fmtend.format(-1)\n i = -25;\n while (i != -3):\n i += 1\n res += fmtloop.format(i)\n i += 1\n res += fmtend.format(i)\n return (0, res, \"\")\n\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4353233873844147,
"alphanum_fraction": 0.4527363181114197,
"avg_line_length": 20.157894134521484,
"blob_id": "72624ee5274a5b2d9107574d6e50b7bc6f97c6d5",
"content_id": "c1c85ef0434a9d432ff30eb8e89c6cb80d6aab5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 402,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 19,
"path": "/tests/calc/mean.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int mean(int* items, int len) {\n int total = 0;\n for (int i = 0; i < len; i++) {\n total += items[i];\n }\n if (len > 0) {\n return (total / len);\n } else {\n return 0;\n }\n}\n\nint main(int argc, char** argv) {\n int* items = malloc(QSIZE*argc);\n for (int i = 1; i < argc; i++) {\n items[i-1] = atol(argv[i]);\n }\n printf(\"%d\\n\", mean(items, argc-1));\n}\n"
},
{
"alpha_fraction": 0.4034653604030609,
"alphanum_fraction": 0.4183168411254883,
"avg_line_length": 12.931034088134766,
"blob_id": "426e2d36c4a2f6e5f2844ad9ec04fbf8310b1561",
"content_id": "d21d1ebe4e9c197fefac0a8062175cf9905ec518",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 404,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 29,
"path": "/verify/call/multicall.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def bar1(x, y):\n return x + y\n\ndef bar2(x, y):\n return y - x\n\ndef foo(x):\n z = x\n z = bar1(x, z)\n z = bar2(x, z)\n return z\n\ndef main(argc):\n x = foo(argc)\n y = 3\n y = foo(y)\n x = x + y\n return x\n\ndef expect(*args):\n return (main(len(args)), \"\", \"\")\n\ndata = [\n [],\n [\"1\"],\n [\"hello\", \"world\"],\n [\"eggs\", \"and\", \"spam\"],\n [\"foo\", \"bar\", \"baz\", \"quux\"],\n]\n"
},
{
"alpha_fraction": 0.36284151673316956,
"alphanum_fraction": 0.37595629692077637,
"avg_line_length": 24.41666603088379,
"blob_id": "3d9dbb472a55731cae2b8e932a52a161e052edd5",
"content_id": "e1f87e5a4ba2b65600ff67fb70860c4fdce22620",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 915,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 36,
"path": "/tests/except/loop_try.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n for (int i = 0; 1; i++) {\n try {\n printf(\"i = %d\\n\", i);\n switch (i) {\n case 7: throw Seven; // abbreviation for `throw Seven(NULL)`\n case 3: throw Three;\n case 11: throw Eleven;\n }\n } catch (Three) { // abbreviation for `catch (Three _)`\n printf(\"Found 3\\n\");\n } catch (Seven) {\n continue; // OK\n // break; // OK\n // return; // OK\n // return 1; // OK\n } finally {\n printf(\"Always except 7 (%d).\\n\", i);\n // continue; // OK\n // break; // OK\n // return; // OK\n // return 1; // OK\n }\n }\n printf(\"End.\\n\");\n}\n\nint main() {\n try {\n foo();\n } catch (Three _) {\n printf(\"Never.\\n\");\n } catch (Eleven _) {\n printf(\"Loop exited at 11.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.28313252329826355,
"alphanum_fraction": 0.3192771077156067,
"avg_line_length": 19.75,
"blob_id": "a525f424a51dd48f49cfba6a615753cd930a70ec",
"content_id": "753b52c279fbe67a2282de4d471d679e7bb4e28d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 8,
"path": "/tests/flow/seq.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = 0, j = 1;\n i++, j++;\n printf(\"%d %d\\n\", i, j);\n for (int i = 0, j = 0; i < 10; i++, j--) {\n printf(\"%d %d\\n\", i, j);\n }\n}\n"
},
{
"alpha_fraction": 0.40659821033477783,
"alphanum_fraction": 0.4937732219696045,
"avg_line_length": 36.826446533203125,
"blob_id": "44cd6927c91fcfba651a34455846b7e88dedf7bd",
"content_id": "1797d0f8538c32cf7f01f76f18d560d1760bea0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4577,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 121,
"path": "/tests/reduce/big_switch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo(int i) {\n switch (i) {\n case -9: printf(\"-9\\n\"); break;\n case -8: printf(\"-8\\n\"); break;\n case -7: printf(\"-7\\n\"); break;\n case -6: printf(\"-6\\n\"); break;\n case -5: printf(\"-5\\n\"); break;\n case -4: printf(\"-4\\n\"); break;\n case -3: printf(\"-3\\n\"); break;\n case -2: printf(\"-2\\n\"); break;\n case -1: printf(\"-1\\n\"); break;\n case 0: printf(\"0\\n\"); break;\n case 1: printf(\"1\\n\"); break;\n case 2: printf(\"2\\n\"); break;\n case 3: printf(\"3\\n\"); break;\n case 4: printf(\"4\\n\"); break;\n case 5: printf(\"5\\n\"); break;\n case 6: printf(\"6\\n\"); break;\n case 7: printf(\"7\\n\"); break;\n case 8: printf(\"8\\n\"); break;\n case 9: printf(\"9\\n\"); break;\n case 10: printf(\"10\\n\"); break;\n case 11: printf(\"11\\n\"); break;\n case 12: printf(\"12\\n\"); break;\n case 13: printf(\"13\\n\"); break;\n case 14: printf(\"14\\n\"); break;\n case 15: printf(\"15\\n\"); break;\n case 16: printf(\"16\\n\"); break;\n case 17: printf(\"17\\n\"); break;\n case 18: printf(\"18\\n\"); break;\n case 19: printf(\"19\\n\"); break;\n case 20: printf(\"20\\n\"); break;\n case 21: printf(\"21\\n\"); break;\n case 22: printf(\"22\\n\"); break;\n case 23: printf(\"23\\n\"); break;\n case 24: printf(\"24\\n\"); break;\n case 25: printf(\"25\\n\"); break;\n case 26: printf(\"26\\n\"); break;\n case 27: printf(\"27\\n\"); break;\n case 28: printf(\"28\\n\"); break;\n case 29: printf(\"29\\n\"); break;\n case 30: printf(\"30\\n\"); break;\n case 31: printf(\"31\\n\"); break;\n case 32: printf(\"32\\n\"); break;\n case 33: printf(\"33\\n\"); break;\n case 34: printf(\"34\\n\"); break;\n case 35: printf(\"35\\n\"); break;\n case 36: printf(\"36\\n\"); break;\n case 37: printf(\"37\\n\"); break;\n case 38: printf(\"38\\n\"); break;\n case 39: printf(\"39\\n\"); break;\n case 40: printf(\"40\\n\"); break;\n case 41: printf(\"41\\n\"); break;\n case 42: printf(\"42\\n\"); break;\n case 43: printf(\"43\\n\"); break;\n case 44: printf(\"44\\n\"); break;\n case 45: printf(\"45\\n\"); break;\n case 46: printf(\"46\\n\"); break;\n case 47: printf(\"47\\n\"); break;\n case 48: printf(\"48\\n\"); break;\n case 49: printf(\"49\\n\"); break;\n case 50: printf(\"50\\n\"); break;\n case 51: printf(\"51\\n\"); break;\n case 52: printf(\"52\\n\"); break;\n case 53: printf(\"53\\n\"); break;\n case 54: printf(\"54\\n\"); break;\n case 55: printf(\"55\\n\"); break;\n case 56: printf(\"56\\n\"); break;\n case 57: printf(\"57\\n\"); break;\n case 58: printf(\"58\\n\"); break;\n case 59: printf(\"59\\n\"); break;\n case 60: printf(\"60\\n\"); break;\n case 61: printf(\"61\\n\"); break;\n case 62: printf(\"62\\n\"); break;\n case 63: printf(\"63\\n\"); break;\n case 64: printf(\"64\\n\"); break;\n case 65: printf(\"65\\n\"); break;\n case 66: printf(\"66\\n\"); break;\n case 67: printf(\"67\\n\"); break;\n case 68: printf(\"68\\n\"); break;\n case 69: printf(\"69\\n\"); break;\n case 70: printf(\"70\\n\"); break;\n case 71: printf(\"71\\n\"); break;\n case 72: printf(\"72\\n\"); break;\n case 73: printf(\"73\\n\"); break;\n case 74: printf(\"74\\n\"); break;\n case 75: printf(\"75\\n\"); break;\n case 76: printf(\"76\\n\"); break;\n case 77: printf(\"77\\n\"); break;\n case 78: printf(\"78\\n\"); break;\n case 79: printf(\"79\\n\"); break;\n case 80: printf(\"80\\n\"); break;\n case 81: printf(\"81\\n\"); break;\n case 82: printf(\"82\\n\"); break;\n case 83: printf(\"83\\n\"); break;\n case 84: printf(\"84\\n\"); break;\n case 85: printf(\"85\\n\"); break;\n case 86: printf(\"86\\n\"); break;\n case 87: printf(\"87\\n\"); break;\n case 88: printf(\"88\\n\"); break;\n case 89: printf(\"89\\n\"); break;\n case 90: printf(\"90\\n\"); break;\n case 91: printf(\"91\\n\"); break;\n case 92: printf(\"92\\n\"); break;\n case 93: printf(\"93\\n\"); break;\n case 94: printf(\"94\\n\"); break;\n case 95: printf(\"95\\n\"); break;\n case 96: printf(\"96\\n\"); break;\n case 97: printf(\"97\\n\"); break;\n case 98: printf(\"98\\n\"); break;\n case 99: printf(\"99\\n\"); break;\n default: printf(\"Other\\n\"); break;\n }\n}\n\nint main(int argc, char** argv) {\n for (int i = 1; i < argc; i++) {\n foo(atoi(argv[i]));\n }\n fprintf(stderr, \"No more arguments\\n\");\n}\n"
},
{
"alpha_fraction": 0.4784946143627167,
"alphanum_fraction": 0.49462366104125977,
"avg_line_length": 22.25,
"blob_id": "d8b7f14598c9c466f86b1e41dd2826dbf5dcdbed",
"content_id": "c264deefacddd04a608924705e98b8adf5047d34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 8,
"path": "/verify/call/hello.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"Hello, World!\\nMy name is {}.\\nI have {} arguments.\\n\".format(args[0], len(args)-1), \"\")\n\ndata = [\n [],\n [\"foo\"],\n [\"eggs\", \"and\", \"spam\"],\n]\n"
},
{
"alpha_fraction": 0.4134078323841095,
"alphanum_fraction": 0.44134077429771423,
"avg_line_length": 18.88888931274414,
"blob_id": "28c86e9655c879769b8d8ddadb182db16d3334cd",
"content_id": "382413cd24c112088028d3e67267e99c1c9ee040",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 9,
"path": "/tests/sys/read.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n char* c = malloc(3);\n while (read(0, c, 3)) {\n write(1, c, 3);\n putchar('\\n');\n fflush(stdout);\n }\n free(c);\n}\n"
},
{
"alpha_fraction": 0.41644561290740967,
"alphanum_fraction": 0.4270557165145874,
"avg_line_length": 21.176469802856445,
"blob_id": "7f27c8f11a92e3f51b62505a82d05456b04d6dd3",
"content_id": "54f8a27a31fefa7b84263cc62beefc242bf2df01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 17,
"path": "/tests/except/any_catch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n int i;\n i = atoi(argv[1]);\n try {\n switch (i) {\n case 0: throw Zero(NULL);\n case 1: throw One(NULL);\n case 2: throw Two(NULL);\n }\n } catch (Zero _) {\n printf(\"Zero\\n\");\n } catch (_ _) {\n printf(\"Something else\\n\");\n } finally {\n printf(\"Exit.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.48507463932037354,
"alphanum_fraction": 0.49253731966018677,
"avg_line_length": 19.615385055541992,
"blob_id": "5300723094333de9fc13c0b286e2dc339e616f3d",
"content_id": "10f4a1f2b9201fbc32d55b6bbc773213feda6db5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 13,
"path": "/tests/except/assert-catch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int assert_eq(int i, int j) {\n try {\n assert(i == j);\n } catch (AssertionFailure _) {\n printf(\"%d is not equal to %d\\n\", i, j);\n }\n}\n\nint main(int argc, char** argv) {\n int i = atol(argv[1]);\n int j = atol(argv[2]);\n assert_eq(i, j);\n}\n"
},
{
"alpha_fraction": 0.40192925930023193,
"alphanum_fraction": 0.42122185230255127,
"avg_line_length": 19.733333587646484,
"blob_id": "a332a5d8db54175527ab1f877c22a31da36a5b60",
"content_id": "69cb42947f4f52848ac4c496a0ee3af3c95a8042",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 311,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 15,
"path": "/tests/string/cat.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define FILE char\n\nint main (int argc, char **argv) {\n for (int i = 1; i < argc; i++) {\n FILE* f = fopen(argv[i], \"r\");\n int c;\n while ((c = fgetc(f)) != EOF) {\n\t fputc(c, stdout);\n // usleep(1000);\n }\n fclose(f);\n }\n fflush(stdout);\n exit(0);\n}\n"
},
{
"alpha_fraction": 0.29729729890823364,
"alphanum_fraction": 0.342342346906662,
"avg_line_length": 12.875,
"blob_id": "fb533ba8cc7ec40c9d810dbe9b067d4e921096fe",
"content_id": "a7a9e933d89ac925a8c370aa5777799ee59bedba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 8,
"path": "/verify/call/argcount.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (len(args)-1, \"\", \"\")\n\ndata = [\n [],\n [\"foo\"],\n [\"1\", \"2\", \"3\", \"4\"],\n]\n"
},
{
"alpha_fraction": 0.47727271914482117,
"alphanum_fraction": 0.47727271914482117,
"avg_line_length": 13.666666984558105,
"blob_id": "03c7ffbe1f523005fe7ede3c2e42a0cb244e6c6a",
"content_id": "c4181e45d2b86548f81cf86b86dd35535217e427",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 9,
"path": "/failures/break.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n break; //!no loop//\n continue; //!no loop//\n}\n\nint main() {\n break; //!no loop//\n continue; //!no loop//\n}\n"
},
{
"alpha_fraction": 0.3657689094543457,
"alphanum_fraction": 0.43788009881973267,
"avg_line_length": 22.97916603088379,
"blob_id": "d822d04a3c9d492bb5910b1c87ca10f1d6fbdee1",
"content_id": "c19ab8ed99cd68d8ea7fb102e8d3b197562c7ea7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 48,
"path": "/verify/call/varargs.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def foo(x1, x2, x3, x4, *rest):\n res = \"\"\n res += \"1:{} 2:{} 3:{} 4:{}\\n\".format(x1, x2, x3, x4)\n for a in rest:\n if a != 0:\n res += \"Next: {}\\n\".format(a)\n res += \"Done.\\n\\n\"\n return res\n\ndef bar(x1, x2, x3, x4, x5, x6, x7, x8, *rest):\n res = \"\"\n res += \"1:{} 2:{} 3:{} 4:{}\\n\".format(x1, x2, x3, x4)\n res += \"5:{} 6:{} 7:{} 8:{}\\n\".format(x5, x6, x7, x8)\n for a in rest:\n if a != 0:\n res += \"Next: {}\\n\".format(a)\n res += \"Done.\\n\\n\"\n return res\n\ndef write(nb, *rest):\n res = \"\"\n for i in range(nb):\n res += \"argument #{}: {}\\n\".format(i, rest[i])\n res += '\\n'\n return res\n\ndef twice(nb, *rest):\n res = \"\"\n for i in range(nb):\n res += \"two at once: {} {}\\n\".format(rest[i], rest[i])\n res += '\\n'\n return res\n\ndef expect(*args):\n res = \"\"\n res += foo(1,2,3,4, 0)\n res += foo(*range(1,7), 0)\n res += foo(*range(1,13), 0)\n res += bar(*range(1,14), 0)\n res += write(2, 101,102)\n res += write(5, *range(101,106))\n res += write(15, *range(101,116))\n res += twice(5, 1,2,3,4,5)\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.49142760038375854,
"alphanum_fraction": 0.5039891600608826,
"avg_line_length": 26.919431686401367,
"blob_id": "a6f511ce52752a2a78e4efb29128f5e55da572b3",
"content_id": "e9c1975aacd67eefb743b2c67345aa191242a924",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5891,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 211,
"path": "/tests/misc/mwc.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "// exit codes :: arguments\n#define WR_OPT 1 // invalid option\n#define WR_ARG 2 // badly formatted argument\n#define WR_FILE 3 // file does not exist\n\n// exit codes :: syscalls\n#define ERR_RD 101 // read failed\n#define ERR_OP 102 // open failed\n#define ERR_SK 103 // lseek failed\n\n// error handlers\n#define VERIFY_READ(X) { \\\n if ((X) == -1) { \\\n perror(\"Failed to read. \"); \\\n exit(ERR_RD); \\\n } \\\n}\n\n#define VERIFY_OPEN(X) { \\\n if ((X) == -1) { \\\n perror(\"Failed to open. \"); \\\n exit(ERR_OP); \\\n } \\\n}\n\n#define VERIFY_LSEEK(X) { \\\n if ((X) == -1) { \\\n perror(\"Failed to seek. \"); \\\n exit(ERR_SK); \\\n } \\\n}\n\n#define NB_THREADS 4\n#define BUFSIZE (64 * 1024)\n#define SEEK_END 2\n#define R_OK 4\n#define SEEK_CUR 1\n\nvoid invalid (char* msg, int retcode) {\n printf(msg);\n printf(\"usage: mwc [-l|-w|-c] FILE\\n\");\n printf(\" count (l)ines, (w)ords, (c)haracters in FILE (default -w)\\n\");\n exit(retcode);\n}\n\nint main (int argc, char** argv) {\n if (argc == 1) invalid(\"Not enough arguments\\n\", WR_ARG);\n char* file = NULL;\n char mode = 0;\n for (int i = 1; i < argc; i++) {\n if ((*argv[i] & BYTE) == '-') { // treat as an argument\n if (mode != 0) invalid(\"Too many optional arguments\\n\", WR_OPT); // already have an option\n switch (*(argv[i]+1) & BYTE) {\n case 'w': case 'c': case 'l':\n mode = *(argv[i]+1) & BYTE;\n break;\n default: invalid(\"Invalid optional argument\\n\", WR_OPT); // unknown option: not w/l/c\n }\n if ((*(argv[i]+2) & BYTE) != 0) invalid(\"Optional argument too long\\n\", WR_OPT); // option is not -w/-l/-c\n } else {\n if (file != NULL) invalid(\"Too many positional arguments\\n\", WR_ARG);\n file = argv[i];\n }\n }\n if (file == NULL) invalid(\"Not enough positional arguments\\n\", WR_ARG);\n if (mode == 0) mode = 'w'; // default is -w\n\n if (access(file, R_OK) == 0) { // thanks to this we don't have to handle errors for open()\n switch (mode) {\n case 'c': {\n int n = count_bytes(file);\n printf(\"%d %s\\n\", n, file);\n break;\n }\n case 'w': {\n int n = dispatch(file, count_words);\n printf(\"%d %s\\n\", n, file);\n break;\n }\n case 'l': {\n int n = dispatch(file, count_lines);\n printf(\"%d %s\\n\", n, file);\n break;\n }\n }\n } else {\n invalid(\"File does not exist\\n\", WR_FILE);\n }\n return 0;\n}\n\nchar* z_file;\nint* z_start, z_end, z_count;\n\nint* counters;\n\nint dispatch (char* file, void* counter) {\n // open to determine length -> distribution of ranges\n int fd = open(file, O_RDONLY, 0444);\n VERIFY_OPEN(fd);\n int length = lseek(fd, 0, SEEK_END);\n close(fd);\n\n // launch threads\n z_file = file;\n z_start = malloc(QSIZE*NB_THREADS);\n z_end = malloc(QSIZE*NB_THREADS);\n z_count = malloc(QSIZE*NB_THREADS);\n counters = malloc(QSIZE*NB_THREADS);\n for (int i = 0; i < NB_THREADS; i++) {\n z_start[i] = (i * length) / NB_THREADS;\n z_end[i] = ((i+1) * length) / NB_THREADS;\n pthread_create(&counters[i], NULL, counter, i);\n }\n\n // terminate threads and calculate sum\n int sum = 0;\n for (int i = 0; i < NB_THREADS; i++) pthread_join(counters[i], NULL);\n for (int i = 0; i < NB_THREADS; i++) sum += z_count[i];\n return sum;\n}\n\nint count_bytes (char* file) {\n int fd = open(file, O_RDONLY, 0444);\n int pos = lseek(fd, 0, SEEK_END);\n VERIFY_LSEEK(pos);\n close(fd);\n return pos;\n}\n\n// A line is any number of characters followed by a '\\n'\nvoid* count_lines (int id) {\n // open file and init variables\n int fd = open(z_file, O_RDONLY, 0444);\n int pos = lseek(fd, z_start[id], SEEK_CUR);\n VERIFY_LSEEK(pos);\n char* buf = malloc(BUFSIZE);\n int length = z_end[id] - z_start[id];\n int count = 0;\n\n // count by BUFSIZE intervals\n while (length > 0) {\n int iter = BUFSIZE < length ? BUFSIZE : length;\n int err = read(fd, buf, iter);\n VERIFY_READ(err);\n for (int i = 0; i < iter; i++) {\n if ((*(buf+i) & BYTE) == '\\n') count++;\n }\n length -= BUFSIZE;\n }\n\n // terminate\n close(fd);\n free(buf);\n z_count[id] = count;\n pthread_exit(NULL);\n}\n\nint is_endword (char c) {\n switch (c) {\n case ' ': case '\\t': case '\\n': return 1;\n default: return 0;\n }\n}\n\n// A word is any non-is_endword() followed by a is_endword()\nvoid* count_words (int id) {\n // open file and init variables\n int fd = open(z_file, O_RDONLY, 0444);\n int pos = lseek(fd, z_start[id], SEEK_CUR);\n VERIFY_LSEEK(pos);\n char* buf = malloc(BUFSIZE);\n int length = z_end[id] - z_start[id];\n int count = 0;\n int prev_blank = 1;\n\n // count by BUFSIZE intervals\n while (length > 0) {\n int iter = BUFSIZE < length ? BUFSIZE : length;\n int err = read(fd, buf, iter);\n VERIFY_READ(err);\n for (int i = 0; i < iter; i++) {\n if (is_endword(*(buf+i) & BYTE)) {\n if (!prev_blank) {\n prev_blank = 1;\n count++;\n }\n } else {\n prev_blank = 0;\n }\n }\n length -= BUFSIZE;\n }\n if (!prev_blank) {\n // last character of the zone could be the end of a word\n char c = 0;\n read(fd, &c, 1);\n c &= BYTE;\n // we don't check here because failure means end of file,\n // which is detected by (c == 0).\n if (is_endword(c) || c == 0) {\n count++;\n }\n }\n\n // terminate\n close(fd);\n free(buf);\n z_count[id] = count;\n pthread_exit(NULL);\n}\n"
},
{
"alpha_fraction": 0.4314868748188019,
"alphanum_fraction": 0.46793001890182495,
"avg_line_length": 23.5,
"blob_id": "b96df4b7e2b513e9ae0971642697b067c169441d",
"content_id": "20da4899996f010a15716443ef8b0440bd2fc592",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 28,
"path": "/tests/string/binconv.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define DISPLAY(X) printf(#X\" = %d\\n\", (X))\n#define DECLARE(X) X; printf(#X\"\\n\")\n\nint bin_to_int (char* t, int len) {\n int r = 0;\n int p = 1;\n for (int i = 0; i < len; i++) {\n switch (*(t+i) & BYTE) {\n case '1': r += p; break;\n case '0': break;\n default: throw InvalidBinary(*(t+i) & BYTE);\n }\n p *= 2;\n }\n return r;\n}\n\nint main () {\n DECLARE(char* a = \"101\");\n DISPLAY(bin_to_int(a, 3));\n DISPLAY(bin_to_int(a, 2));\n try {\n DISPLAY(bin_to_int(\"110f2o\", 6));\n } catch (InvalidBinary c) {\n printf(\"Invalid character '%c' in \\\"110f2o\\\"\\n\", c);\n }\n DISPLAY(bin_to_int(\"110f2o\", 3));\n}\n"
},
{
"alpha_fraction": 0.37142857909202576,
"alphanum_fraction": 0.38367345929145813,
"avg_line_length": 15.333333015441895,
"blob_id": "d1750f0426ce0982058ef72a7a36078c472c0998",
"content_id": "e7213e7ccc5ec15f8604cbc9e82d84b062fd6002",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 15,
"path": "/failures/break_try.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n int i;\n for (i = 0; i < 10; i++) {\n try {\n break; //!outside//\n } catch (Wrong _) {\n printf(\"Should not have caught.\\n\");\n }\n }\n throw Wrong(NULL);\n}\n\nint main() {\n foo();\n}\n"
},
{
"alpha_fraction": 0.41228070855140686,
"alphanum_fraction": 0.4385964870452881,
"avg_line_length": 18,
"blob_id": "53b53f99494b509f88554aad640b7f5a63fa53a6",
"content_id": "1aa061e067cb9c5fcb4885c43c3e0cf45d2feb5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 12,
"path": "/failures/undeclared.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i;\n i = j; //!undeclared//\n j = 1; //!undeclared//\n { int k; }\n i = k; //!undeclared//\n k = 1; //!undeclared//\n\n arr[0] = 1; //!undeclared//\n i = arr[0]; //!undeclared//\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3831440508365631,
"alphanum_fraction": 0.3968918025493622,
"avg_line_length": 33.14285659790039,
"blob_id": "f062a42cdbdb1dd22abcf4f97c8fdf6baed0f740",
"content_id": "a89e48f0d9ea6f73076ff8d9e770699209928596",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1673,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 49,
"path": "/tests/calc/calc.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int str_to_int(char* s) {\n int acc = 0;\n int len = strlen(s);\n int i = ((*s&BYTE) == '-');\n for (; i < len; i++) {\n if (isdigit(*(s+i)&BYTE)) {\n acc = acc * 10 + (*(s+i)&BYTE) - '0';\n } else {\n throw InvalidInt(s);\n }\n }\n return ((*s&BYTE) == '-') ? -acc : acc;\n}\n\nint main(int argc, char** argv) {\n if (argc == 1 || argc % 3 != 1) {\n fprintf(stderr, \"Usage: calc <op> <m> <n> [<op> <m> <n> ...]\\n where <m>, <n>: integers; <op>: +, x, /, %, -\");\n exit(1);\n }\n for (int i = 0; 3*i+1 < argc; i++) {\n int m, n;\n int result;\n try {\n m = str_to_int(argv[3*i+2]);\n n = str_to_int(argv[3*i+3]);\n int op = *argv[3*i+1]&BYTE;\n switch (op) {\n case '+': result = m + n; break;\n case '-': result = m - n; break;\n case 'x': result = m * n; break;\n case '/':\n if (n == 0) throw ZeroDivisionError;\n result = m / n; break;\n case '%':\n if (n == 0) throw ZeroDivisionError;\n result = m % n; break;\n default:\n throw InvalidOperation(op);\n }\n printf(\"%d %c %d = %d\\n\", m, op, n, result);\n } catch (ZeroDivisionError) {\n fprintf(stderr, \"Cannot divide by zero: %d %c %d\\n.\", m, *argv[3*i+1], n);\n } catch (InvalidInt s) {\n fprintf(stderr, \"%s is not a valid base 10 integer.\\n\", s);\n } catch (InvalidOperation op) {\n fprintf(stderr, \"Unknown operator %c.\\n\", op);\n }\n }\n}\n"
},
{
"alpha_fraction": 0.4388609826564789,
"alphanum_fraction": 0.4522612988948822,
"avg_line_length": 26.136363983154297,
"blob_id": "0b471e7280827748fb7f82342febc873e90cba5d",
"content_id": "1b17d90e9e9704fd763798260bc0bac96baf609d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 22,
"path": "/verify/call/has_args.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*argv):\n res = \"\"\n argc = len(argv)\n if argc > 2:\n res += \"I have at least two args: {}, {}\\n\".format(argv[1], argv[2])\n if (argc > 3):\n res += \"I even have one more: {}\\n\".format(argv[3])\n else:\n res += \"...nevermind, I have only two.\\n\"\n elif argc > 1:\n res += \"I have just a single argument: {}\\n\".format(argv[1])\n else:\n res += \"I have no args other than my own name.\\n\"\n return (0, res, \"\")\n\ndata = [\n [],\n [\"foo\"],\n [\"foo\", \"bar\"],\n [\"foo\", \"bar\", \"baz\"],\n [\"foo\", \"bar\", \"baz\", \"quux\"],\n]\n"
},
{
"alpha_fraction": 0.32743361592292786,
"alphanum_fraction": 0.36283186078071594,
"avg_line_length": 13.125,
"blob_id": "92048d8dd44432928b2eaca5362df7003720c73a",
"content_id": "1bd2c027bae890ee04a16d0b044ba1ddf4883392",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 8,
"path": "/failures/incompatible.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int tab;\n\n 0++; //!lvalue//\n ++0; //!lvalue//\n 0--; //!lvalue//\n --0; //!lvalue//\n}\n"
},
{
"alpha_fraction": 0.5126436948776245,
"alphanum_fraction": 0.5321838855743408,
"avg_line_length": 23.85714340209961,
"blob_id": "7bdc7020a87fcd29fc98c5c863e4f3cd222350fd",
"content_id": "2611e2359771a0a48f25074b72007a98ed4e6158",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 35,
"path": "/verify/sys/survive.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE, signal\nimport time as t\n\ndef verify(cmd, iter):\n proc = Popen(cmd, stdout=PIPE, stderr=PIPE)\n for i in range(iter):\n t.sleep(0.05)\n proc.send_signal(signal.SIGINT);\n t.sleep(0.05)\n proc.send_signal(signal.SIGTERM);\n t.sleep(0.05)\n out = proc.stdout.read().decode('utf-8').rstrip().split(\"\\n\")\n err = proc.stderr.read()\n status = True\n if err != b'':\n print(\"Non-empty stderr '{}'\".format(err))\n status = False\n if \"I am \" not in out[0]:\n print(\"Wrong header\")\n status = False\n if len(out) != iter + 1:\n print(\"Too few messages\")\n status = False\n for x in out[1:]:\n if x != \"You can't kill me !\":\n print(\"Wrong text '{}'\".format(x))\n status = False\n return status\n\ncfg = [\n [0],\n [1],\n [2],\n [5],\n]\n"
},
{
"alpha_fraction": 0.49312376976013184,
"alphanum_fraction": 0.5068762302398682,
"avg_line_length": 35.35714340209961,
"blob_id": "c08982251721a51330603b094b5c9c1c3394291c",
"content_id": "a787d2e5be6d74ea61d1e6829d4b6b802f608125",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 14,
"path": "/tests/call/has_args.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n if (argc > 2) {\n fprintf(stdout, \"I have at least two args: %s, %s\\n\", argv[1], argv[2]);\n if (argc > 3) {\n fprintf(stdout, \"I even have one more: %s\\n\", argv[3]);\n } else {\n fprintf(stdout, \"...nevermind, I have only two.\\n\");\n }\n } else if (argc > 1) {\n fprintf(stdout, \"I have just a single argument: %s\\n\", argv[1]);\n } else {\n fprintf(stdout, \"I have no args other than my own name.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.43478259444236755,
"alphanum_fraction": 0.45150500535964966,
"avg_line_length": 12.590909004211426,
"blob_id": "13602449dd66fcfaaec2d02ca9b4e3fec4c9bf45",
"content_id": "c6a670bb577b9650949dd90daa1a7df6698feec9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 22,
"path": "/tests/call/multicall.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int bar1(int x, int y) {\n return x + y;\n}\n\nint bar2(int x, int y) {\n return y - x;\n}\n\nint foo(int x) {\n int z = x;\n z = bar1(x, z);\n z = bar2(x, z);\n return z;\n}\n\nint main(int argc, char**argv) {\n int x = foo(argc);\n int y = 3;\n y = foo(y);\n x = x + y;\n return x;\n}\n"
},
{
"alpha_fraction": 0.36581921577453613,
"alphanum_fraction": 0.39830508828163147,
"avg_line_length": 21.125,
"blob_id": "3ef4179775e6472dccfa31e2d6bd873fbb250a2f",
"content_id": "fa47b301b423ff53ed74f153c410a0adb3dae563",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 32,
"path": "/tests/calc/syracuse.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#define MAXTEST 1000\n#define MAXVAL 1000000\n\nint syracuse() {\n for (int nombre = 1; nombre <= MAXTEST; nombre++) {\n int vol = nombre;\n int i;\n for (i = 0; i <= MAXVAL; i++) {\n if (vol == 1) break;\n if (vol >= MAXVAL) break;\n if (vol & 1) {\n vol = 3 * vol + 1;\n } else {\n vol = vol / 2;\n }\n }\n if (i == MAXVAL + 1) return 1;\n if (vol == 1) {\n printf(\"Ok %d\\n\", nombre);\n } else {\n printf(\"Not found %d\\n\", nombre);\n }\n }\n return 0;\n}\n\nint main() {\n if (syracuse()) {\n printf(\"Contre-exemple trouve !\\n\");\n }\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5538461804389954,
"alphanum_fraction": 0.5846154093742371,
"avg_line_length": 20.66666603088379,
"blob_id": "101d4dce26bfb289df402da7b75eca4c2da00186",
"content_id": "25d36a83e570c72d644cd344ae0b0dc294dbd7d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 3,
"path": "/tests/sys/execvp.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n execvp(argv[1], argv+8);\n}\n"
},
{
"alpha_fraction": 0.40857142210006714,
"alphanum_fraction": 0.4414285719394684,
"avg_line_length": 21.580644607543945,
"blob_id": "7e92762fa21d1b47154966ec24ea5eb31c763439",
"content_id": "9e5358a95db7b8bc33f29ad83cc134ea79d004c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 700,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 31,
"path": "/verify/calc/fact.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "exec(open(\"verify/overflow.py\").read())\n\ndef factorial(n):\n f = 1\n for i in range(1, n+1):\n f *= i\n return f\n\ndef expect(*args):\n if len(args) != 2:\n return (10, \"\", \"Usage: ./fact <n>\\ncalcule et affiche la factorielle de <n>.\\n\")\n else:\n try:\n n = int(args[1])\n except:\n n = 0\n if n < 0:\n return (10, \"\", \"Ah non, quand meme, un nombre positif ou nul, s'il-vous-plait...\\n\")\n f = sdword(factorial(n))\n return (0, \"La factorielle de {} vaut {} (en tout cas, modulo 2^32...).\\n\".format(n, f), \"\")\n\ndata = [\n [],\n [\"0\"],\n [\"1\"],\n [\"4\"],\n [\"20\"],\n [\"foo\"],\n [\"-1\"],\n [\"2\", \"1\"],\n]\n"
},
{
"alpha_fraction": 0.4189189076423645,
"alphanum_fraction": 0.45945945382118225,
"avg_line_length": 17.5,
"blob_id": "1e50c24276c263893241d595ae7043395e7dc777",
"content_id": "0742ddb4b1f806f2677f9d707fb4f931c3c3f5b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 8,
"path": "/verify/calc/ordre.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"Valeur de j=7 (normalement 7), valeur de i=3.\\n\", \"\")\n\ndata = [\n [],\n [\"42\"],\n [\"foo\", \"bar\", \"baz\"],\n]\n"
},
{
"alpha_fraction": 0.280303031206131,
"alphanum_fraction": 0.3712121248245239,
"avg_line_length": 17.85714340209961,
"blob_id": "3e6c240c70c64e85af2daec0548509177cc25b0c",
"content_id": "83d1f973503359c99ca85dde1d57c02d9f12bfc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 14,
"path": "/verify/except/assert-catch.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n i = int(args[1])\n j = int(args[2])\n if i != j:\n return (0, \"{} is not equal to {}\\n\".format(i, j), \"\")\n else:\n return (0, \"\", \"\")\n\ndata = [\n [\"0\", \"1\"],\n [\"0\", \"0\"],\n [\"1524\", \"12\"],\n [\"85696\", \"85696\"],\n]\n"
},
{
"alpha_fraction": 0.6804075837135315,
"alphanum_fraction": 0.6845762133598328,
"avg_line_length": 22.988889694213867,
"blob_id": "0bea0aaf7d5cfb670c38f559600220003683f29b",
"content_id": "b6eebfa899c7c586db28c04d4b6ec1040b913c12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2161,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 90,
"path": "/Makefile",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "# Copyright (c) 2020 by Laboratoire Spécification et Vérification (LSV),\n# CNRS UMR 8643 & ENS Paris-Saclay.\n# Written by Amélie Ledein\n# Adapted by Neven Villani\n\n%.cmo: %.ml\n\tocamlc -g -c $<\n\n%.cmi: %.mli\n\tocamlc -g -c $<\n\n# build artifacts\nCAMLOBJS=error.cmo cAST.cmo pigment.cmo reduce.cmo cprint.cmo \\\n\tcparse.cmo clex.cmo verbose.cmo generate.cmo compile.cmo \\\n\tmain.cmo\n\n# src files\nCAMLSRC=$(addsuffix .ml,$(basename $(CAMLOBJS)))\n\n# archive directory\nPJ=VILLANI_NEVEN-FULL\n\n# non-generated files\nSRC=clex.mll cAST.ml cAST.mli cparse.mly \\\n\tpigment.ml pigment.mli cprint.ml cprint.mli \\\n\tgenerate.ml generate.mli reduce.ml reduce.mli \\\n\tverbose.ml verbose.mli compile.ml compile.mli \\\n\terror.ml main.ml\nAUX=Makefile README.md check.py\nDOCS=report.pdf semantics.pdf\nTESTS=tests failures verify\n\n# main build\nmcc: $(CAMLOBJS)\n\tocamlc -g -o mcc unix.cma $(CAMLOBJS)\n\nclean:\n\trm -f mcc *.cmi *.cmo || echo \"Nothing to remove\"\n\trm -f cparse.ml cparse.mli clex.ml || echo \"Nothing to remove\"\n\trm -f cparse.output || echo \"Nothing to remove\"\n\trm -f depend || echo \"Nothing to remove\"\n\trm -rf $(PJ).tar.gz $(PJ) || echo \"Nothing to remove\"\n\tfind . -name '*.s' -type f -exec rm {} +\n\tfind tests ! -name '*.*' -type f -exec rm {} +\n\tfind failures ! -name '*.*' -type f -exec rm {} +\n\trm docs/*.log docs/*.aux docs/*.out || echo \"Nothing to remove\"\n\n# create and compress final assignment\nproject:\n\tmake clean\n\tmkdir $(PJ)\n\tcp -r $(TESTS) $(PJ)/\n\tcp $(SRC) $(PJ)/\n\tcp $(AUX) $(PJ)/\n\tcp -r $(DOCS) $(PJ)/\n\ttar czf $(PJ).tar.gz $(PJ)\n\n# automatic tester\ntest: mcc\n\tpython3 check.py\n\n# LaTeX arguments\nTEX_ARGS=--interaction=nonstopmode --halt-on-error\nPDFLATEX_ARGS=$(TEX_ARGS)\nLUALATEX_ARGS=$(TEX_ARGS) --shell-escape\n\nsemantics:\n\tcd docs ; \\\n\t\tpdflatex $(PDFLATEX_ARGS) semantics.tex\n\tmv docs/semantics.pdf .\n\nreport:\n\tcd docs ; \\\n\t\tlualatex $(LUALATEX_ARGS) report.tex\n\tmv docs/report.pdf .\n\n# lex & parse\ncparse.ml: cparse.mly\n\tocamlyacc -v cparse.mly\n\nclex.ml: clex.mll\n\tocamllex clex.mll\n\ncompile.cmi: compile.mli\ncompile.cmo: compile.ml compile.cmi\n\ndepend: Makefile $(wildcard *.ml) $(wildcard *.mli) cparse.ml clex.ml\n\tocamldep *.mli *.ml > depend\n\n-include depend\n"
},
{
"alpha_fraction": 0.43706294894218445,
"alphanum_fraction": 0.45104894042015076,
"avg_line_length": 16.875,
"blob_id": "20ecc01c72fd8d13681beb28b16e68a260d0d842",
"content_id": "58125114f2e13b844c65abe3b3be4d2e5d060a8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 16,
"path": "/tests/except/try_switch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo(int i) {\n try {\n switch (i) {\n case 0: break;\n case 1: throw One(NULL);\n }\n printf(\"Exited switch normally\\n\");\n } catch (One _) {\n printf(\"Exited switch with exception\\n\");\n }\n}\n\nint main() {\n foo(0);\n foo(1);\n}\n"
},
{
"alpha_fraction": 0.4423076808452606,
"alphanum_fraction": 0.45384615659713745,
"avg_line_length": 15.25,
"blob_id": "c37779693d1a6846244925d870b4d8ed718b7d51",
"content_id": "87c789d5fc169e36c9c23ca175924afbd40eceb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 16,
"path": "/tests/flow/triangle.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "char chr = '*';\nint amount = 1;\n\nvoid line() {\n for (int i = 0; i < amount; i++) {\n putchar(chr);\n }\n putchar('\\n');\n}\n\nint main(int argc, char** argv) {\n int max = atol(argv[1]);\n for (; amount < max; amount++) {\n line();\n }\n}\n"
},
{
"alpha_fraction": 0.37707948684692383,
"alphanum_fraction": 0.39926064014434814,
"avg_line_length": 21.54166603088379,
"blob_id": "898c9f2fc374d57b9b9c56fec7cd0b3c7af3debb",
"content_id": "8e6f8d30765b9b6a2d5eb78b04c0d3d38d4bb03c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 24,
"path": "/tests/flow/count.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = 0, j;\n char* fmtloop = \"i = %d\\n\";\n char* fmtend = \"i ended at %d\\n\\n\";\n while ((j = i++) != 10) {\n printf(fmtloop, i);\n printf(\"j = %d\\n\", j);\n }\n printf(\"j ended at %d\\n\", j);\n printf(fmtend, i);\n for (i = 0; i < 10; i++) {\n printf(\"i = %d\\n\", i);\n }\n printf(\"i at %d\\n\\n\", i);\n for (i = 15; i != -1; i--) {\n printf(fmtloop, i);\n }\n printf(fmtend, i);\n i = -25;\n while ((i++) != -3) {\n printf(fmtloop, i);\n }\n printf(fmtend, i);\n}\n"
},
{
"alpha_fraction": 0.4572271406650543,
"alphanum_fraction": 0.4690265357494354,
"avg_line_length": 21.600000381469727,
"blob_id": "357f612a766bcb382fa5315962984aba0c2f24e4",
"content_id": "092d0862499ecb690f5e52acbef3d02498acbc8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 30,
"path": "/tests/string/string.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int strget(char* str, int index) {\n return *(str+index) & BYTE;\n}\nvoid strset(char* str, int index, int newval) {\n int arr = str + index;\n *arr = (*arr & ~BYTE) + (newval & BYTE);\n}\n\nchar* fmt;\n\nint check(char* str) {\n fmt = \"str[%*d] = <%c> (%*d)\\n\";\n int len = strlen(str);\n for (int i = 0; i < len; i++) {\n char val = strget(str, i);\n printf(fmt, 2, i, val, 3, val);\n }\n putchar('\\n');\n for (int i = 0; i < len; i++) {\n strset(str, i, 'a' + i);\n }\n for (int i = 0; i < len; i++) {\n char val = strget(str, i);\n printf(fmt, 2, i, val, 3, val);\n }\n}\n\nint main(int argc, char** argv) {\n check(argv[0]);\n}\n"
},
{
"alpha_fraction": 0.35970786213874817,
"alphanum_fraction": 0.3980523347854614,
"avg_line_length": 32.53061294555664,
"blob_id": "b0647af583c913749de2865496cb465e492789a6",
"content_id": "d2bda23490918ae9a7b64a44b2b6036f9877c005",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1643,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 49,
"path": "/verify/calc/calc.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def calculate(op, lhs, rhs):\n if op == '-':\n return (\"{} - {} = {}\\n\".format(lhs, rhs, lhs - rhs), \"\")\n elif op == '+':\n return (\"{} + {} = {}\\n\".format(lhs, rhs, lhs + rhs), \"\")\n elif op == 'x':\n return (\"{} x {} = {}\\n\".format(lhs, rhs, lhs * rhs), \"\")\n elif op == '/':\n if rhs == 0:\n return (\"\", \"Cannot divide by zero: {} / {}\\n.\".format(lhs, rhs))\n return (\"{} / {} = {}\\n\".format(lhs, rhs, lhs // rhs), \"\")\n elif op == '%':\n if rhs == 0:\n return (\"\", \"Cannot divide by zero: {} % {}\\n.\".format(lhs, rhs))\n return (\"{} % {} = {}\\n\".format(lhs, rhs, lhs % rhs), \"\")\n else:\n return (\"\", \"Unknown operator {}.\\n\".format(op))\n\ndef expect(*args):\n out = \"\"\n err = \"\"\n if len(args) == 1 or len(args) % 3 != 1:\n return (1, \"\", \"Usage: calc <op> <m> <n> [<op> <m> <n> ...]\\n where <m>, <n>: integers; <op>: +, x, /, %, -\")\n for i in range(len(args) // 3):\n try:\n m = int(args[3*i+2])\n except:\n err += \"{} is not a valid base 10 integer.\\n\".format(args[3*i+2])\n continue\n try:\n n = int(args[3*i+3])\n except:\n err += \"{} is not a valid base 10 integer.\\n\".format(args[3*i+3])\n continue\n (o, e) = calculate(args[3*i+1], m, n)\n out += o\n err += e\n return (0, out, err)\n\ndata = [\n [],\n [\"~\"],\n [*\"- 52\".split(' ')],\n [*\"- 45 86\".split(' ')],\n [*\"+ 10 12 + 5 15 + 2 -154 + -145 -85\".split(' ')],\n [*\"x 45 86 x 78 -4 x -10 -10\".split(' ')],\n [*\"/ 76 3\".split(' ')],\n [*\"% 7654 7\".split(' ')],\n]\n"
},
{
"alpha_fraction": 0.4822334945201874,
"alphanum_fraction": 0.5025380849838257,
"avg_line_length": 12.133333206176758,
"blob_id": "32754b189c6bdc9a540ab0f3d70636dd590e9851",
"content_id": "9ce6372bca86fd17cc878437fcb72d28b0522908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 15,
"path": "/tests/ptr/fnptr.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo(int x) {\n printf(\"I am foo and I have received %d\\n\", x);\n}\n\nint apply(void fn(), int arg) {\n fn(arg);\n}\n\nint g ();\n\nint main() {\n apply(foo, 10);\n g = foo;\n apply(g, 20);\n}\n"
},
{
"alpha_fraction": 0.5689980983734131,
"alphanum_fraction": 0.5765595436096191,
"avg_line_length": 22,
"blob_id": "e6f47bc57e05ce701b22f90214480bb4d21ca144",
"content_id": "3a0c0568e4210b64bb1646797e03be8ea6240f89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 23,
"path": "/verify/sys/alarm.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\nimport time as t\n\ndef verify(cmd):\n start = t.time()\n proc = Popen(cmd, stdout=PIPE, stdin=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n end = t.time()\n status = True\n if end - start < 0.9:\n print(\"Process exited too quickly\")\n status = False\n if err != b'':\n print(\"Did not expect any stderr\")\n status = False\n if proc.returncode != 0:\n print(\"Expected return code 0\")\n status = false\n return status\n\ncfg = [\n [],\n]\n"
},
{
"alpha_fraction": 0.40909090638160706,
"alphanum_fraction": 0.43939393758773804,
"avg_line_length": 17.85714340209961,
"blob_id": "c51850ce625a1463472720efe64735b5cf79b84d",
"content_id": "868d53b916ffa3a74c9ee8e3b7a4e5bcd67df893",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 7,
"path": "/verify/flow/infinite.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n line = \"\".join(\"{} \".format(i) for i in range(10))\n return (0, (line + '\\n') * 2, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.4821428656578064,
"avg_line_length": 17.66666603088379,
"blob_id": "549e1af1e37fb664f13990a2c0d4eb39e45569b0",
"content_id": "f7ef9aeca1134c4ad756e8938ff60c2d5833d72b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 6,
"path": "/verify/calc/syracuse.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"\".join(\"Ok {}\\n\".format(i) for i in range(1, 1001)), \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.5942857265472412,
"alphanum_fraction": 0.5942857265472412,
"avg_line_length": 18.44444465637207,
"blob_id": "f5a830cbe4d8d9abb66b2ac44a342dd9cb0c0bac",
"content_id": "394134286703b3190ce9e409e29ac65992cfddfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 350,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 18,
"path": "/failures/multidecl.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argc) {} //!twice//\n\nint foo() {}\nint bar() {}\nint baz() {}\nint foo() {} //!redefinition//\nint foo() {} //!redefinition//\n\nint main() {} //!redefinition//\n\nint x;\nint foo; //!redefinition//\nint x; //!redefinition//\nint main; //!redefinition//\n\nint va_arg; //!reserved//\nint assert; //!reserved//\nint va_start; //!reserved//\n"
},
{
"alpha_fraction": 0.3782542049884796,
"alphanum_fraction": 0.4042879045009613,
"avg_line_length": 21.517240524291992,
"blob_id": "fcea80e386febd66cc9a77603ed3264cdd18d26f",
"content_id": "8ede0ae2bd66025c28d788c3fa69d42c3737fae3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 653,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 29,
"path": "/verify/string/concise.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def strcmp(lt, rt):\n for cl,cr in zip(lt + '\\000'*len(rt), rt + '\\000'*len(lt)):\n if cl != cr:\n return ord(cl) - ord(cr)\n return 0\n\n\ndef expect(*args):\n if len(args) == 2:\n return (0, \"{}\\n\".format(len(args[1])), \"\")\n elif len(args) == 3:\n return (0, \"{}\\n\".format(strcmp(*args[1:])), \"\")\n elif len(args) == 4:\n return (0, \"\".join(args[1:]) + '\\n', \"\")\n else:\n return (1, \"\", \"\")\n\ndata = [\n [],\n [\"\"],\n [\"aoeuhtns\"],\n [\"fffff\"],\n [\"abc\", \"def\"],\n [\"abc\", \"abcd\"],\n [\"abc\", \"ab\"],\n [\"fffffff\", \"fffffff\"],\n [\"foo\", \"bar\", \"baz\"],\n [\"Hell\", \"o, Wor\", \"ld!\"],\n]\n"
},
{
"alpha_fraction": 0.2726806700229645,
"alphanum_fraction": 0.424397736787796,
"avg_line_length": 22.506023406982422,
"blob_id": "9c9916178dc5ac9efb4e05a1cd1f651b9688887d",
"content_id": "5e13fdcf3c28b83e47dbfa8adaa31d24b4f65ddf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1951,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 83,
"path": "/tests/reduce/reduce_binops.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n printf(\"ADD \");\n printf(\"%d \", 1656 + 4582);\n printf(\"%d \", 18 + -78);\n printf(\"%d \", -482 + -7569);\n printf(\"%d \", 15 + 45 + 689 + 96 + 47 + 45);\n putchar('\\n');\n\n printf(\"SUB \");\n printf(\"%d \", 4693 - 7582);\n printf(\"%d \", 482 - -15);\n printf(\"%d \", -1445 - 4782);\n printf(\"%d \", 45 - 5 - -12 - 5);\n putchar('\\n');\n\n printf(\"MUL \");\n printf(\"%d \", 425 * 736);\n printf(\"%d \", 72 * -15);\n printf(\"%d \", -452 * -69);\n printf(\"%d \", -45 * 5 * 2 * 4 * -7);\n putchar('\\n');\n\n printf(\"DIV \");\n printf(\"%d \", 15266 / 45);\n printf(\"%d \", -144443 / 889);\n printf(\"%d \", -496854 / -321);\n printf(\"%d \", 42659 / -152);\n putchar('\\n');\n\n printf(\"MOD \");\n printf(\"%d \", 1236546 % 156);\n printf(\"%d \", 695816 % 54);\n printf(\"%d \", -654 % 52);\n printf(\"%d \", 4546986 % -45);\n printf(\"%d \", -558 % -54);\n putchar('\\n');\n\n printf(\"AND \");\n printf(\"%d \", 1236546 & 156);\n printf(\"%d \", 695816 & 54);\n printf(\"%d \", -654 & 52);\n printf(\"%d \", 4546986 & -45);\n printf(\"%d \", -558 & -54);\n putchar('\\n');\n\n printf(\"XOR \");\n printf(\"%d \", 1236546 ^ 156);\n printf(\"%d \", 695816 ^ 54);\n printf(\"%d \", -654 ^ 52);\n printf(\"%d \", 4546986 ^ -45);\n printf(\"%d \", -558 ^ -54);\n putchar('\\n');\n\n printf(\"OR \");\n printf(\"%d \", 1236546 | 156);\n printf(\"%d \", 695816 | 54);\n printf(\"%d \", -654 | 52);\n printf(\"%d \", 4546986 | -45);\n printf(\"%d \", -558 | -54);\n putchar('\\n');\n\n printf(\"NEG \");\n printf(\"%d \", -0);\n printf(\"%d \", -15);\n printf(\"%d \", -(-152));\n putchar('\\n');\n\n printf(\"NOT \");\n printf(\"%d \", ~0);\n printf(\"%d \", ~1584);\n printf(\"%d \", ~(-1474));\n putchar('\\n');\n\n printf(\"SHR \");\n printf(\"%d \", 15246 >> 2);\n printf(\"%d \", -426 >> 3);\n putchar('\\n');\n\n printf(\"SHL \");\n printf(\"%d \", 15246 << 2);\n printf(\"%d \", -426 << 3);\n putchar('\\n');\n}\n"
},
{
"alpha_fraction": 0.37062937021255493,
"alphanum_fraction": 0.3916083872318268,
"avg_line_length": 14.88888931274414,
"blob_id": "94819255b3e6ee794b0a1e550612e3f79397d8cb",
"content_id": "a7929f952488c3bd8a34d7b5e788286e1dc91c45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/verify/call/call.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n ret = \"\"\n for i in range(1, 9):\n ret += \"x{} = {}\\n\".format(i, i)\n return (0, ret, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.47413793206214905,
"alphanum_fraction": 0.47413793206214905,
"avg_line_length": 24.77777862548828,
"blob_id": "defe11e52dcab3654bac27a1be9804a6bb772824",
"content_id": "96bb082a40d6335fb755811c43aa9921542adc9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 9,
"path": "/tests/sys/exec.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main (int argc, char **argv) {\n if (fork()) {\n wait(NULL);\n printf(\"[pere] le fils a termine !\\n\");\n } else {\n execlp(\"ls\", \"ls\", \"-l\", NULL);\n printf(\"Ceci ne devrait pas arriver.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.35913312435150146,
"alphanum_fraction": 0.37770897150039673,
"avg_line_length": 23.846153259277344,
"blob_id": "1c820fc8d5cfc78876dc034e84409f348354f8ec",
"content_id": "af2811e3235ed10b173917f2a970c11a9e9e58fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 13,
"path": "/verify/string/string.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n s = args[0]\n res = \"\"\n for i,c in enumerate(s):\n res += \"str[{: >2}] = <{}> ({: >3})\\n\".format(i, c, ord(c))\n res += '\\n'\n for i in range(len(s)):\n res += \"str[{: >2}] = <{}> ({: >3})\\n\".format(i, chr(ord('a') + i), ord('a') + i)\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.31611570715904236,
"alphanum_fraction": 0.3429751992225647,
"avg_line_length": 18.360000610351562,
"blob_id": "f18ca456fa1f7b2ffee6a82409a4f3ce93462e49",
"content_id": "f3b322606139cc312150ff9cb6699210f3e9b5d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 484,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 25,
"path": "/verify/flow/break.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n for i in range(10):\n if i == 5: break\n res += \"{} \".format(i)\n res += '\\n'\n for i in range(10):\n if i == 7: break\n for j in range(10):\n if i == j: break;\n res += \"({},{}) \".format(i, j)\n res += '\\n'\n\n i = 0;\n while True:\n if i == 10:\n res += \"exit.\\n\"\n break;\n res += \"{} \".format(i)\n i += 1\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.5273631811141968,
"alphanum_fraction": 0.5522388219833374,
"avg_line_length": 15.75,
"blob_id": "5f70fe46a255d8c6ec089d83cd30347cf2b79cf0",
"content_id": "3f45cd91b9047f1daa24c97e58caa6c1a677b17a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 12,
"path": "/verify/ptr/fnptr.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def foo(x):\n return \"I am foo and I have received {}\\n\".format(x)\n\ndef apply(fn, arg):\n return fn(arg)\n\ndef expect(*args):\n return (0, apply(foo, 10) + apply(foo, 20), \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.48663100600242615,
"alphanum_fraction": 0.5080214142799377,
"avg_line_length": 25.714284896850586,
"blob_id": "8a278a4b133ad350bff51ed6f95b3efe576de03b",
"content_id": "b3537fe9f18ccb9fa675d5702301e9fb83498920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 7,
"path": "/tests/calc/ordre.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main (int argc, char **argv) {\n int i, j;\n int j = (i = 3) + (i = 4);\n printf(\"Valeur de j=%d (normalement 7), valeur de i=%d.\\n\", j, i);\n fflush(stdout);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5391969680786133,
"alphanum_fraction": 0.5487571954727173,
"avg_line_length": 18.370370864868164,
"blob_id": "b524c1316e22d8fbf3cca4df49a5b35901fd7810",
"content_id": "069686a848998459d843420a1543626ad8c7ecfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 27,
"path": "/tests/sys/alarm.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int keep_going = 1;\n\nvoid catch_alarm (int sig) {\n /* Clear the flag. */\n printf(\"caught alarm signal\\n\");\n keep_going = 0;\n}\n\nint main () {\n int i = 0;\n\n /* Establish a handler for SIGALRM signals. */\n signal(SIGALRM, catch_alarm);\n\n /* Set an alarm to go off in a little while. */\n alarm(1);\n\n /* Check the flag once in a while to see when to quit. */\n while (keep_going) {\n /* do something */\n printf(\"i = %d\\n\", ++i);\n }\n\n printf(\"loop terminated\\n\");\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3709677457809448,
"alphanum_fraction": 0.3870967626571655,
"avg_line_length": 9.333333015441895,
"blob_id": "2839c2e20d34989b30f7205636f0ad5fdab81aa2",
"content_id": "b75399d83b5ef373f149f19133e84281d8c3789d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 6,
"path": "/verify/boot/scoped_ret.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (5, \"\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3030303120613098,
"alphanum_fraction": 0.3393939435482025,
"avg_line_length": 14,
"blob_id": "3b572ec4abb4348ab8a881058ef72cd6583c249e",
"content_id": "4d7e636c8c0ae050abf6754d9a84560e211bd34b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 11,
"path": "/tests/decl/override.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = 1;\n int* x = &i;\n int i = 2;\n assert(i == 2);\n assert(*x == 1);\n i++;\n (*x)--;\n assert(i == 3);\n assert(*x == 0);\n}\n"
},
{
"alpha_fraction": 0.48051947355270386,
"alphanum_fraction": 0.4848484992980957,
"avg_line_length": 20,
"blob_id": "8c680dbe94267cd3b7142a75feb22fa8220ccf5c",
"content_id": "5fcc5d6091a1b59f398162a37ed1b3b3d7a2dc7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 11,
"path": "/tests/string/argsort.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int cmp(void* a, void* b) {\n return strcmp(*a, *b);\n}\n\nint main(int argc, char** argv) {\n qsort(argv, argc, QSIZE, cmp);\n for (int i = 0; i < argc; i++) {\n printf(\"%s \", *(argv+i*QSIZE));\n }\n putchar('\\n');\n}\n"
},
{
"alpha_fraction": 0.5729323029518127,
"alphanum_fraction": 0.5759398341178894,
"avg_line_length": 30.66666603088379,
"blob_id": "b80adb5b4c9e2b71ef5abc67ae095e446b630df5",
"content_id": "4de12d22a147478c33e48fcf5ae033293a7ef826",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 665,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 21,
"path": "/verify/sys/fork.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd):\n proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n expected = [b'I am parent\\nI am child\\n', b'I am child\\nI am parent\\n']\n status = True\n if out not in expected:\n print(\"Wrong output:\\n [{}] is not one of the expected results\".format(out))\n status = False\n if err != b'':\n print(\"Wrong error:\\n [{}]\\nexpect[{}]\".format(err, ''))\n status = False\n if proc.returncode != 0:\n print(\"Wrong return code: [{}]; expect[{}]\".format(proc.returncode, 0))\n status = False\n return status\n\ncfg = [\n [],\n]\n"
},
{
"alpha_fraction": 0.47270116209983826,
"alphanum_fraction": 0.49425286054611206,
"avg_line_length": 25.769229888916016,
"blob_id": "af5c433ded7e1a2101510cbe47ccc7f51787f6ec",
"content_id": "77b0b9a9d4d64102df58bbc3e854b7fa7fb98caa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 26,
"path": "/tests/except/exc1.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int f (int n, int i) {\n if (i == 0) throw Zero(n);\n if (i == 1) throw Trouve(n);\n if (i % 2) {\n return f(n + 1, 3 * i + 1);\n } else {\n return f(n + 1, i / 2);\n }\n}\n\nint main (int argc, char **argv) {\n if (argc != 2) {\n fprintf(stderr, \"Usage: ./exc1 <n>\\ncalcule a quelle iteration une suite mysterieuse termine, en partant de <n>.\\n\");\n fflush(stderr);\n exit(10); /* non mais! */\n }\n int j = atoi(argv[1]);\n try {\n f(0, j);\n fprintf(stderr, \"Pas trouve...\\n\");\n } catch (Trouve n) {\n fprintf(stderr, \"La suite termine apres %d iterations en partant de %d.\\n\", n, j);\n }\n fflush(stderr);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5089285969734192,
"alphanum_fraction": 0.5089285969734192,
"avg_line_length": 17.66666603088379,
"blob_id": "8f5931657f03c89d54234e22ba53d12d202e9797",
"content_id": "9e3a367a1206ec8fae23807541874386300b1d29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 6,
"path": "/tests/string/scan.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int x;\n scanf(\"%ld\", &x);\n printf(\"You gave me the number %d\", x);\n fflush(stdout);\n}\n"
},
{
"alpha_fraction": 0.2907488942146301,
"alphanum_fraction": 0.3171806037425995,
"avg_line_length": 16.461538314819336,
"blob_id": "a3d755d1088a634c09969be3d9ae0bfa55485d55",
"content_id": "5149a0919c16b5753a2247450f87cb81316e136f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 13,
"path": "/tests/flow/infinite.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = 0;\n for (;;) {\n printf(\"%d \", i++);\n if (i == 10) break;\n }\n putchar('\\n');\n for (i = 0;;) {\n printf(\"%d \", i++);\n if (i == 10) break;\n }\n putchar('\\n');\n}\n"
},
{
"alpha_fraction": 0.3985561728477478,
"alphanum_fraction": 0.411039263010025,
"avg_line_length": 29.29157257080078,
"blob_id": "e3faff710e8f8804a19ab380779a0fead05635c3",
"content_id": "6257d481877ad4f291e00a57249df033fde63ad5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13298,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 439,
"path": "/check.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nfrom subprocess import run, Popen, PIPE\nimport sys\n\nassets = [\n (\"boot\", [\n \"ex0\",\n \"ex1\",\n \"ex2\",\n \"ex3\",\n \"ex4\",\n \"ex5\",\n \"ex6\",\n \"ex7\",\n \"ex8\",\n \"ex9\",\n \"ex10\",\n \"ex11\",\n \"ex12\",\n \"add\",\n \"ret\",\n \"scoped_ret\",\n \"isdigit\",\n ]),\n (\"call\", [\n \"hello\",\n \"has_args\",\n \"argcount\",\n \"max\",\n \"noreturn\",\n \"exit\",\n \"multicall\",\n \"call\",\n \"assert\",\n \"printglob\",\n \"bsearch\",\n \"varargs\",\n ]),\n (\"calc\", [\n \"cmp\",\n \"calc\",\n \"shifts\",\n \"binops\",\n \"bitwise\",\n \"incdec\",\n \"ordre\",\n \"minimax\",\n \"cmp_order\",\n \"syracuse\",\n \"mean\",\n \"wmean\",\n \"fact\",\n ]),\n (\"ptr\", [\n \"array\",\n \"swap\",\n \"dbl-array\",\n \"additions\",\n \"addr-deref\",\n \"extended_assign\",\n \"fnptr\",\n \"multifnptr\",\n ]),\n (\"string\", [\n \"put\",\n \"quine\",\n \"sprintf\",\n \"scan\",\n \"scan-fun\",\n \"string\",\n \"strret\",\n \"path\",\n \"argsort\",\n \"paren\",\n \"binconv\",\n \"cat\",\n \"memlib\",\n \"concise\",\n ]),\n (\"flow\", [\n \"loops\",\n \"count\",\n \"seq\",\n \"break\",\n \"continue\",\n \"switch_loop\",\n \"triangle\",\n \"dowhile\",\n \"infinite\",\n ]),\n (\"reduce\", [\n \"reduce_eif\",\n \"reduce_monops\",\n \"reduce_binops\",\n \"reduce_cmp\",\n \"big_switch\",\n \"single_step\",\n \"array\",\n ]),\n (\"except\", [\n \"exc1\",\n \"exc2\",\n \"exc3\",\n \"except\",\n \"loop_try\",\n \"try_loop\",\n \"try_switch\",\n \"any_catch\",\n \"nothrow\",\n \"uncaught-str\",\n \"assert-catch\",\n ]),\n (\"decl\", [\n \"init\",\n \"ptr\",\n \"typedef\",\n \"alternate\",\n \"scope-switch\",\n \"override\",\n \"string\",\n ]),\n (\"sys\", [\n \"fork\",\n \"execvp\",\n \"exec\",\n \"alarm\",\n \"survive\",\n \"dup-redir\",\n \"pipe-simple\",\n \"read\",\n ]),\n (\"misc\", [\n \"mwc\",\n \"sieve\",\n \"sort\",\n \"rsort\",\n \"sudoku_solver\",\n ]),\n]\n\nfailures = [\n \"arity\",\n \"assignment\",\n \"break_try\",\n \"break\",\n \"decl_alternate\",\n \"divzero\",\n \"duplicate_catch\",\n \"incompatible\",\n \"init_declaration\",\n \"invalid_va\",\n \"loop_try\",\n \"multidecl\",\n \"return_try\",\n \"switch\",\n \"undeclared\",\n]\n\nclass Module:\n def __init__(self, path, **kwargs):\n d = kwargs\n src = open(path).read()\n exec(src, d)\n # d.pop(\"__builtins__\")\n for k in d.keys():\n instr = \"self.{elem} = d['{elem}']\".format(elem=k)\n exec(instr)\n\ndef compile(cc, fbase, more=[]):\n print(\" compile: {} tests/{}.c {}\".format(cc, fbase, \"\".join(more)))\n res = run([cc, \"tests/{}.c\".format(fbase), *more], stdout=PIPE, stderr=PIPE)\n success = True\n if res.returncode != 0:\n print(\"Errored: retcode {}\".format(res.returncode))\n success = False\n for (data, stream) in zip([res.stderr, res.stdout], [\"Err\", \"Out\"]):\n if len(data) > 0:\n print(\"{} :: {}\".format(stream, data.decode('UTF-8')))\n if len(res.stderr) > 0:\n success = False\n return success\n\ndef compare(lt, rt):\n if lt == rt:\n return None\n def context(s, pos, l):\n return s[max(0, pos-l) : min(len(s)+1, pos+l)]\n for i in range(max(len(lt), len(rt))):\n if i >= len(lt) or i >= len(rt) or lt[i] != rt[i]:\n return (i, context(lt, i, 10), context(rt, i, 10))\n\ndef check(fbase):\n module = Module(\"verify/{}.py\".format(fbase))\n ok = 0\n ko = 0\n prog = \"./tests/{}\".format(fbase)\n try:\n _ = module.expect\n expect = True\n except AttributeError:\n expect = False\n if expect:\n for d in module.data:\n (expect_code, expect_out, expect_err) = module.expect(prog, *d)\n expect_out, expect_err = bytes(expect_out, 'UTF-8'), bytes(expect_err, 'UTF-8')\n res = run([prog, *d], stdout=PIPE, stderr=PIPE)\n code, out, err = res.returncode, res.stdout, res.stderr\n if expect_code == code and expect_err == err and expect_out == out:\n print(\" \\x1b[32m[OK]\\x1b[0m {}\".format(d))\n ok += 1\n else:\n print(\" \\x1b[31m[KO]\\x1b[0m {}\".format(d))\n ko += 1\n if expect_code != code:\n print(\" \\x1b[33mWrong code:\")\n print(\" \\x1b[32m[{}]\".format(expect_code))\n print(\" \\x1b[31m[{}]\\x1b[0m\".format(code))\n diff = compare(expect_out, out)\n if diff is not None:\n print(\" \\x1b[33mWrong stdout:\")\n print(\" \\x1b[32m[{}]\".format(expect_out))\n print(\" \\x1b[31m[{}]\\x1b[0m\".format(out))\n print(\" Difference at {}: [{}] vs [{}]\".format(*diff))\n diff = compare(expect_err, err)\n if diff is not None:\n print(\" \\x1b[33mWrong stderr:\")\n print(\" \\x1b[32m[{}]\".format(expect_err))\n print(\" \\x1b[31m[{}]\\x1b[0m\".format(err))\n print(\" Difference at {}: [{}] vs [{}]\".format(*diff))\n else:\n for d in module.cfg:\n res = module.verify(prog, *d)\n if res:\n ok += 1\n print(\" \\x1b[32m[OK]\\x1b[0m {}\".format(d))\n else:\n ko += 1\n print(\" \\x1b[31m[KO]\\x1b[0m {}\".format(d))\n return (ok, ko)\n\ndef fulltest(cc, fbase, more=[]):\n try:\n with open(\"verify/{}.py\".format(fbase)) as f:\n pass\n except FileNotFoundError:\n print(\"No such test: {}\".format(fbase))\n exit(50)\n print(\"Checking {}:\".format(fbase))\n if compile(cc, fbase, more=more):\n ok, ko = check(fbase)\n return (ok, ko)\n else:\n exit(100)\n return False\n\ndef verify_failure(cc, fbase):\n print(\"Checking {}\".format(fbase))\n okE = koE = 0\n okW = koW = 0\n fname = \"{}.c\".format(fbase)\n print(\" compile: {} {}\".format(cc, fname))\n msg = run([cc, fname], stderr=PIPE, stdout=PIPE).stderr.decode('utf-8')\n fails = {}\n for l in msg.split('\\n'):\n if \"parser:\" in l:\n ff, more = l.split(', line')\n loc, msg = more.split('): ')\n line = int(loc.split('(')[0])\n if \"FATAL\" in l:\n fails[(line, \"err\")] = [msg, False]\n else:\n fails[(line, \"wrn\")] = [msg, False]\n with open(fname, 'r') as f:\n for j,l in enumerate(f.readlines()):\n i = j + 1\n if '//!' in l:\n kws = l.split('//!')[-1].split('//')[0].split('|')\n if (i, \"err\") in fails:\n for kw in kws:\n if kw in fails[(i, \"err\")][0]:\n fails[(i, \"err\")][1] = True\n break\n else:\n print(\" Error at line {} does not have keyword '{}': '{}'\".format(i, kw, fails[(i, \"err\")][0]))\n else:\n print(\" Expected an error at line {}\".format(i))\n koE += 1\n elif '//?' in l:\n kws = l.split('//?')[-1].split('//')[0].split('|')\n if (i, \"wrn\") in fails:\n for kw in kws:\n if kw in fails[(i, \"wrn\")][0]:\n fails[(i, \"wrn\")][1] = True\n break\n else:\n print(\" Warning at line {} does not have keyword '{}': '{}'\".format(i, kw, fails[(i, \"wrn\")][0]))\n else:\n print(\" Expected a warning at line {}\".format(i))\n koW += 1\n for key in fails:\n (line, type) = key\n msg, handled = fails[key]\n if handled:\n if type == \"err\":\n okE += 1\n else:\n okW += 1\n else:\n if type == \"err\":\n print(\" Did not expect the error '{}' at line {}\".format(msg, line))\n koE += 1\n else:\n print(\" Did not expect the warning '{}' at line {}\".format(msg, line))\n koW += 1\n if koE + koW == 0:\n print(\" \\x1b[32m[OK]\\x1b[0m {}\".format(fbase))\n else:\n print(\" \\x1b[31m[KO]\\x1b[0m {}\".format(fbase))\n return ((okW, koW), (okE, koE))\n\ndef main():\n if len(sys.argv) >= 2:\n if sys.argv[1] in [\"--help\", \"-h\"]:\n print(\"\"\"Automated tester for a C-- compiler\n usage:\n check [TARGET ...]\n either:\n - compare the compiled output by mcc of tests/(TARGET).c\n against the specification in verify/(TARGET).py\n where TARGET is one of\n CATEGORY/ a registered category\n CATEGORY/FILE a single file path\n - assert that all warnings and errors have been emitted\n by scanning the source file for //! and //? comments\n check [-h|--help]\n print this help message\n check [-c|--categ]\n print all categories\n check [-l|--list] [CATEGORY ...]\n print all available files, only list those in certain categories\n if extra arguments are provided\n\n examples:\n check -l\n check -l sys ptr decl\n check sys/alarm string/ ptr/additions\n check failures/undeclared\n \"\"\")\n return\n elif sys.argv[1] in [\"--categ\", \"-c\"]:\n for (category, _) in assets:\n print(category)\n return\n elif sys.argv[1] in [\"--list\", \"-l\"]:\n categs = sys.argv[2:]\n for (category, tests) in assets:\n if categs == [] or category in categs:\n print(\"{}: {}\".format(category, \", \".join(tests)))\n return\n\n cc = \"./mcc\"\n args = sys.argv[1:]\n\n nb_files = nb_tests = nb_error = 0\n nb_okC = nb_koC = 0\n nb_okE = nb_koE = 0\n nb_okW = nb_koW = 0\n logs = []\n\n if len(args) >= 1:\n for fbase in args:\n if len(fbase) >= 1 and fbase[-1] == \"/\":\n if fbase[:-1] == \"failures\":\n for f in failures:\n nb_files += 1\n wrn, err = verify_failure(cc, \"failures/\" + f)\n logs.append((2, wrn, err))\n else:\n for (category, tests) in assets:\n if category == fbase[:-1]:\n for fbase in tests:\n nb_files += 1\n for more in [[\"--no-reduce\"], []]:\n ok, ko = fulltest(cc, category + '/' + fbase, more=more)\n logs.append((1, ok, ko))\n else:\n if \"failures/\" in fbase:\n nb_files += 1\n wrn, err = verify_failure(cc, fbase)\n logs.append((2, wrn, err))\n else:\n nb_files += 1\n for more in [[\"--no-reduce\"], []]:\n ok, ko = fulltest(cc, fbase, more=more)\n logs.append((1, ok, ko))\n else:\n for (category, tests) in assets:\n print(\"\\n\\n <<< category: {} >>>\\n\".format(category))\n for fbase in tests:\n nb_files += 1\n for more in [[\"--no-reduce\"], []]:\n ok, ko = fulltest(cc, category + '/' + fbase, more=more)\n logs.append((1, ok, ko))\n print(\"\\n\\n <<< fail >>>\\n\")\n for f in failures:\n nb_files += 1\n wrn, err = verify_failure(cc, \"failures/\" + f)\n logs.append((2, wrn, err))\n\n for res in logs:\n if res[0] == 2:\n _, wrn, err = res\n okW, koW = wrn\n okE, koE = err\n nb_okE += okE\n nb_okW += okW\n nb_koE += koE\n nb_koW += koW\n nb_error += koE + koW\n else:\n _, ok, ko = res\n nb_error += ko\n nb_tests += ok\n nb_okC += ok\n nb_koC += ko\n\n print(\"\\x1b[32m\" if nb_error == 0 else \"\\x1b[31m\")\n print(\"=====================================\")\n print(\"Ran tests on {} files\".format(nb_files))\n print(\" {} failed tests\".format(nb_error))\n print()\n print(\" {} calculation checks, {} incorrect\".format(nb_okC, nb_koC))\n print(\" {} warning checks, {} incorrect\".format(nb_okW, nb_koW))\n print(\" {} error checks, {} incorrect\".format(nb_okE, nb_koE))\n print(\"=====================================\")\n print(\"\\x1b[0m\", end=\"\")\n\nmain()\n"
},
{
"alpha_fraction": 0.6022988557815552,
"alphanum_fraction": 0.6160919666290283,
"avg_line_length": 30.071428298950195,
"blob_id": "37acf40f2fa512ae842c5cd52afbf7749a5c90f7",
"content_id": "ef379cb18fc47e385c838344b09ded091ff8c07a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 14,
"path": "/tests/sys/dup-redir.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "void main () {\n // This line goes to standard output as usual.\n printf(\"This goes to stdout.\\n\");\n fflush(stdout);\n\n // We open a new file and make standard output write into it\n int f = open(\"dump.log\", O_WRONLY | O_CREAT | O_TRUNC, 0666);\n dup2(f, 1); // override stdout\n close(f); // we do not need this anymore\n\n // this line ends up in the file\n printf(\"This goes to the log.\\n\");\n fflush(stdout);\n}\n"
},
{
"alpha_fraction": 0.32311978936195374,
"alphanum_fraction": 0.42339831590652466,
"avg_line_length": 21.4375,
"blob_id": "6f7b5ebff3077a0e394dcc1a3ff4039d01938203",
"content_id": "b5c1340c179f11a1251242801149355d2c1bf7b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/verify/calc/wmean.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def mean(arr):\n if arr == []: return 0\n return sum(arr) // len(arr)\n\ndef expect(*args):\n i = 1\n n = len(args)\n count = 0\n total = 0\n while i < n:\n if '-w' in args[i]:\n weight = int(args[i][2:])\n i += 1\n else:\n weight = 1\n item = int(args[i])\n count += weight\n total += item * weight\n i += 1\n if count == 0: return (0, \"0\\n\", \"\")\n return (0, \"{}\\n\".format(total // count), \"\")\n\ndata = [\n [],\n [\"10\"],\n \"-w3 10 20\".split(),\n \"1 10 -w10 100 1000\".split(),\n \"5 7 9 -w2 3 5 1 8 2 -w3 9 3 5 1 2 -w2 7 8 4 5 -w9 6 9 9 3 2\".split(),\n \"-w1000 20 0\".split(),\n \"-w0 50 10\".split(),\n \"-w0 10\".split(),\n]\n"
},
{
"alpha_fraction": 0.3050847351551056,
"alphanum_fraction": 0.4648910462856293,
"avg_line_length": 25.645160675048828,
"blob_id": "3352a35e3309ba783b7857e763a6f6b7f166f6f0",
"content_id": "51b32b932aba139b290e6f1b0138ae9c58e68b4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 826,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 31,
"path": "/tests/call/printglob.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int i;\nint j;\nint *k;\n\nint foo() {\n printf(\"foo: %d + %d -> %d\\n\", i, j, k[i+j]);\n}\n\nint bar() {\n printf(\"0:%d\\n1:%d\\n2:%d\\n3:%d\\n4:%d\\n5:%d\\n6:%d\\n7:%d\\n8:%d\\n9:%d\\nA:%d\\nB:%d\\nC:%d\\n\", 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12);\n}\n\nint baz(int x0, int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8, int x9, int xA, int xB, int xC) {\n printf(\"0:%d\\n1:%d\\n2:%d\\n3:%d\\n4:%d\\n5:%d\\n6:%d\\n7:%d\\n8:%d\\n9:%d\\nA:%d\\nB:%d\\nC:%d\\n\", x0, x1, x2, x3, x4, x5, x6, x7, x8, x9, xA, xB, xC);\n}\n\nint main() {\n i = 0;\n j = 0;\n k = malloc(6*QSIZE);\n k[0] = 1000; k[1] = 100; k[2] = 200;\n k[3] = 300; k[4] = 400;\n foo(); i++;\n foo(); j++;\n foo(); j++;\n foo(); i++;\n foo();\n bar();\n baz(1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010, 1011, 1012);\n fflush(stdout);\n}\n"
},
{
"alpha_fraction": 0.45548388361930847,
"alphanum_fraction": 0.4929032325744629,
"avg_line_length": 24.83333396911621,
"blob_id": "dbbf2796e88d5906b4f62c3d65e84f232cb98a8d",
"content_id": "0053f685b34f458e032b0037cbb422ecb0f14f5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 30,
"path": "/verify/except/exc3.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def syracuse(n):\n if n == 1:\n return 0\n elif n % 2 == 0:\n return 1 + syracuse(n // 2)\n else:\n return 1 + syracuse(3*n + 1)\n\n\ndef expect(*args):\n always = \"*Fin* (ce message doit toujours s'afficher).\\n\"\n if len(args) != 2:\n return (10, \"\", \"Usage: ./exc1 <n>\\ncalcule a quelle iteration une suite mysterieuse termine, en partant de <n>.\\n\")\n n = int(args[1])\n if n < 0:\n return (0, \"\", \"Pas trouvé...\\n\" + always)\n if n == 0:\n return (0, \"\", \"Le nombre d'entree est nul.\\n\" + always)\n else:\n return (0, \"\", \"La suite termine apres {} iterations en partant de {}.\\n\".format(syracuse(n), n) + always)\n\ndata = [\n [],\n [\"0\"],\n [\"1\"],\n [\"5\"],\n [\"521\"],\n [\"6521\"],\n [\"foo\", \"bar\"],\n]\n"
},
{
"alpha_fraction": 0.4110032320022583,
"alphanum_fraction": 0.4190938472747803,
"avg_line_length": 29.899999618530273,
"blob_id": "97aa26131decb41ffff1b107f65456e481f2bc58",
"content_id": "a513b95a9bd01cb6877ab439606d65ea66571a5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 618,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 20,
"path": "/tests/string/paren.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int bien_parentesee (char* str) {\n for (int cnt = 0;;) { // cnt counts the number of '(' more than ')'\n switch (*str++ & BYTE) {\n case 0: return !cnt; // cnt != 0 iff there is an unclosed paren\n case '(': cnt++; break; // open paren\n case ')':\n if (cnt) {\n cnt--; break; // close paren\n } else {\n return 0; // unopened paren\n }\n }\n }\n}\n\nint main (int argc, char** argv) {\n for (int i = 1; i < argc; i++) {\n printf(\"%s -> %d\\n\", argv[i], bien_parentesee(argv[i]));\n }\n}\n"
},
{
"alpha_fraction": 0.3382352888584137,
"alphanum_fraction": 0.37867647409439087,
"avg_line_length": 17.133333206176758,
"blob_id": "c654aad75b8e44bc5d227c937d18666d131c2063",
"content_id": "31fbdd02c6e74837ff4c83833fb0577756ab104a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 15,
"path": "/verify/except/any_catch.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n i = int(args[1])\n if i == 0:\n return (0, \"Zero\\nExit.\\n\", \"\")\n elif i == 1 or i == 2:\n return (0, \"Something else\\nExit.\\n\", \"\")\n else:\n return (0, \"Exit.\\n\", \"\")\n\ndata = [\n [\"0\"],\n [\"1\"],\n [\"2\"],\n [\"3\"],\n]\n"
},
{
"alpha_fraction": 0.3650793731212616,
"alphanum_fraction": 0.3968254029750824,
"avg_line_length": 9.5,
"blob_id": "e88ec37ffefc86299cde4caaab571c5ec8353d82",
"content_id": "49b3feaf8416defa07d21453428c475554ccf32b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 6,
"path": "/verify/boot/add.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (13, \"\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.28125,
"alphanum_fraction": 0.3958333432674408,
"avg_line_length": 15,
"blob_id": "9d42a76778f553735eadbb59c47a287af5b898bd",
"content_id": "9e9e45381ebcd91de3e64bf3e5389054eff46060",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 6,
"path": "/verify/call/max.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"9 == 9\\n6 == 6\\n8 == 8\\n10 == 10\\n\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.29595014452934265,
"alphanum_fraction": 0.32398754358291626,
"avg_line_length": 19.0625,
"blob_id": "6744d7529624f4d3c93be91d3686934686b44317",
"content_id": "67031bec867f57f1a2798a82ded5c555f0fd69df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 16,
"path": "/tests/decl/scope-switch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main(int argc, char** argv) {\n int x = atoi(argv[1]);\n switch (x) {\n case 0:\n int y = 1;\n printf(\"%d\\n\", y);\n break;\n case 1:\n // y = 1; // KO\n case 2:\n case 3:\n case 4:\n int y = 2;\n printf(\"%d\\n\", y);\n }\n}\n"
},
{
"alpha_fraction": 0.2916666567325592,
"alphanum_fraction": 0.3375000059604645,
"avg_line_length": 17.461538314819336,
"blob_id": "aa17dcf6053bc302a9ce2ff3e2fc09e73bdecb00",
"content_id": "5c11758bab930f60927a5457c69c666bf096da3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 13,
"path": "/tests/calc/incdec.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int* arr = malloc(10*QSIZE);\n for (int i = 0; i < 10; i++) {\n arr[i] = i;\n }\n int i = 0;\n while (i < 10) {\n --arr[i++];\n }\n for (i = 0; i < 10; i++) {\n printf(\"%d\\n\", arr[i]);\n }\n}\n"
},
{
"alpha_fraction": 0.3711538314819336,
"alphanum_fraction": 0.4038461446762085,
"avg_line_length": 19.799999237060547,
"blob_id": "f08b4ba14e633988dabd95af8ab7943c6db993dc",
"content_id": "a844d4308ee23e30c246b3e7d550f8be0f6cb026",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 25,
"path": "/tests/misc/sort.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int cmp (int* a, int* b) {\n if (*a > *b) {\n return 1;\n } else {\n return -1;\n }\n}\n\nint main(int argc, char** argv) {\n int len = 5000;\n if (argc > 1) len = atol(argv[1]);\n int* arr = malloc(len*QSIZE);\n for (int i = 0; i < len; i++) {\n arr[i] = rand() % 10000;\n }\n for (int i = 0; i < len; i++) {\n printf(\"%d \", arr[i]);\n }\n printf(\"\\n\");\n qsort(arr, len, 8, cmp);\n for (int i = 0; i < len; i++) {\n printf(\"%d \", arr[i]);\n }\n printf(\"\\n\");\n}\n"
},
{
"alpha_fraction": 0.3684210479259491,
"alphanum_fraction": 0.4035087823867798,
"avg_line_length": 10.399999618530273,
"blob_id": "0731ce17773a1e45da2d0f84ec23c3dd49b9d310",
"content_id": "ad6077cf25a2e61aba14be3436657e8e51a10921",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/tests/decl/string.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "char* s = \"<<%d>>\\n\";\n\nint main() {\n printf(s, 42);\n}\n"
},
{
"alpha_fraction": 0.312834233045578,
"alphanum_fraction": 0.3288770020008087,
"avg_line_length": 19.77777862548828,
"blob_id": "f051777f7514549cb60478ff8441ba36c53778d2",
"content_id": "43216b823de187679edb01d00b9e1ec420153203",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 18,
"path": "/tests/ptr/dbl-array.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int W = 6;\nint H = 5;\n\nint main() {\n int* arr = malloc(H*QSIZE);\n for (int i = 0; i < H; i++) {\n arr[i] = malloc(W*QSIZE);\n for (int j = 0; j < W; j++) {\n arr[i][j] = i*W + j;\n }\n }\n for (int i = 0; i < H; i++) {\n for (int j = 0; j < W; j++) {\n printf(\"%d \", arr[i][j]);\n }\n putchar('\\n');\n }\n}\n"
},
{
"alpha_fraction": 0.5850622653961182,
"alphanum_fraction": 0.5933610200881958,
"avg_line_length": 23.100000381469727,
"blob_id": "4087e4786280c507295259cda751f499fc76e992",
"content_id": "43bbdd395ec9ecc0815a539d931b7d03c088ff7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 10,
"path": "/verify/sys/pipe-simple.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef expect(*args):\n proc = Popen([\"bash\", \"-c\", \"cat Makefile | wc\"], stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate()\n return (0, out.decode('utf-8'), \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.27986347675323486,
"alphanum_fraction": 0.3071672320365906,
"avg_line_length": 16.235294342041016,
"blob_id": "a79d8ede9eb51e5392266d1fe91e260532acc6f9",
"content_id": "13e00b5a00fdcdbbf79a90761b4d484420ede5b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 293,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 17,
"path": "/verify/flow/switch_loop.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n i = -1\n while True:\n i += 1\n if i == 1:\n continue\n elif i == 3 or i == 5:\n res += '\\n'\n elif i == 10:\n return (0, res, \"\")\n else:\n res += \"{} \".format(i)\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.36231884360313416,
"alphanum_fraction": 0.37681159377098083,
"avg_line_length": 8.857142448425293,
"blob_id": "d52d32cca93b858435349f25d9bbfa79c8c026b4",
"content_id": "1bd8301525ae5c198395427efc0f80c437d46013",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 7,
"path": "/tests/boot/ex2.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int x;\nint main() {\n int y;\n y = 3;\n x = y;\n return x;\n}\n"
},
{
"alpha_fraction": 0.36403509974479675,
"alphanum_fraction": 0.44078946113586426,
"avg_line_length": 29.399999618530273,
"blob_id": "26a711f332957db87634cf533a11ff457b64e736",
"content_id": "149eedde3414fdac6e5caef9869f3b803f5d3588",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 456,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 15,
"path": "/tests/ptr/array.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i = 0;\n long* arr = malloc(3*QSIZE);\n arr[i++] = 100;\n arr[i++] = 200;\n arr[i] = arr[0]++;\n fprintf(stdout, \"arr[2] = %d ?= 101; \", ++arr[2]);\n fprintf(stdout, \"arr[2] = %d ?= 101; \", arr[2]);\n fprintf(stdout, \"arr[1] = %d ?= 200; \", arr[1]);\n fprintf(stdout, \"arr[0] = %d ?= 101; \", arr[0]);\n int k = &arr[1];\n (*k)++;\n fprintf(stdout, \"arr[1] = %d ?= %d ?= 201; \", arr[1], *k);\n fflush(stdout);\n}\n"
},
{
"alpha_fraction": 0.42391303181648254,
"alphanum_fraction": 0.42934781312942505,
"avg_line_length": 19.44444465637207,
"blob_id": "0d444dafb202ee997af1a595518a7caefb1fe81d",
"content_id": "0808ede0aff6d3e741975e899360bf4d1211e0c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 9,
"path": "/verify/string/sprintf.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n s = \"Formatting string: <%s> <%s> <%s>\"\n fmt = s.replace(\"%s\", \"{}\")\n res = fmt.format(s, \"foo\", \"bar\") + '\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.41822174191474915,
"alphanum_fraction": 0.4654226005077362,
"avg_line_length": 23.62162208557129,
"blob_id": "457fcc79885086b31f020277f05a6840b9551f36",
"content_id": "1f81d27f241f11b4905b36c381bed95745ae6823",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 37,
"path": "/verify/call/bsearch.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def search(arr, item):\n # (NOT a bsearch)\n return arr.index(item)\n\ndef is_inc(arr):\n for i in range(1, len(arr)):\n if arr[i-1] >= arr[i]:\n return False\n return True\n\ndef expect(*args):\n i = 1\n n = len(args)\n items = []\n while i < n:\n if args[i] == \"--key\":\n key = int(args[i+1])\n i += 1\n else:\n items.append(int(args[i]))\n i += 1\n if not is_inc(items):\n return (1, \"\", \"List is not increasing\")\n try:\n p = search(items, key)\n return (0, \"Found item = {} at position {}\\n\".format(key, p), \"\")\n except ValueError:\n return (0, \"Item = {} could not be found\\n\".format(key), \"\")\n\ndata = [\n \"1 2 3 5 8 9 --key 10\".split(),\n \"1 2 5 --key 2 6 7\".split(),\n \"5 4 3\".split(),\n \"--key 10 1\".split(),\n \"2 2 4 6 8\".split(),\n \"--key 5 1 3 5 6 --key 7 8 9 --key 3\".split(),\n]\n"
},
{
"alpha_fraction": 0.3006681501865387,
"alphanum_fraction": 0.3229398727416992,
"avg_line_length": 20.380952835083008,
"blob_id": "f690fe334a25c3fd071b8ed550b3452d3ce28f69",
"content_id": "122047c4070a51ae4c1a27c31bc1be2580ec21d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 21,
"path": "/verify/flow/continue.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n for i in range(10):\n if (i == 5): continue\n res += \"{} \".format(i)\n res += '\\n'\n for i in range(10):\n if (i == 7 or i == 3):\n res += '\\n'\n continue\n for j in range(10):\n if (i == j):\n res += \" \"\n continue\n res += \"({},{}) \".format(i, j)\n res += '\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.5149253606796265,
"alphanum_fraction": 0.5597015023231506,
"avg_line_length": 21.33333396911621,
"blob_id": "e82abf4ce17a71ffbe26dbeee223eb8744b7e0bc",
"content_id": "32a1b36821a0c018a39b609a1ac11fe6e703115f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 6,
"path": "/verify/call/assert.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (111, \"\", \"Unhandled exception AssertionFailure(\\\"{}.c:5\\\")\\n\".format(args[0][2:]))\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.295908659696579,
"alphanum_fraction": 0.3339676558971405,
"avg_line_length": 24.0238094329834,
"blob_id": "db2d258b133ba227c87aff0d1b51bf21a51db220",
"content_id": "89b925d3bc203d7b762d5ee3f94a0f740dd69886",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1051,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 42,
"path": "/tests/flow/loops.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n printf(\"1. for \");\n for (int i = 0; i < 10; i++) {\n printf(\"%d \", i);\n }\n printf(\"\\n2. one-line for \");\n for (int i = 0; i < 10; i++) printf(\"%d \", i);\n printf(\"\\n3. for no-inc \");\n for (int i = 0; i < 10;) {\n printf(\"%d \", i);\n i++;\n }\n printf(\"\\n4. for no-init \");\n int i = 0;\n for (; i < 10; i++) {\n printf(\"%d \", i);\n }\n printf(\"\\n5. for only-cond \");\n int i = 0;\n for (; i < 10;) {\n printf(\"%d \", i);\n i++;\n }\n printf(\"\\n6. while \");\n int i = 1;\n while (i % 10 != 0) {\n printf(\"%d \", i);\n i++;\n }\n printf(\"\\n7. do-while \");\n int i = 0;\n do {\n printf(\"%d \", i);\n i++;\n } while (i % 10 != 0);\n printf(\"\\n8. one-line while \");\n int i = 1;\n while (i % 10 != 0) printf(\"%d \", i++);\n printf(\"\\n9. one-line do-while \");\n int i = 0;\n do printf(\"%d \", i); while (++i % 10 != 0);\n}\n"
},
{
"alpha_fraction": 0.3962264060974121,
"alphanum_fraction": 0.42767295241355896,
"avg_line_length": 16.66666603088379,
"blob_id": "b250762bfc7670c6ce0149acc2e746ca0fc72774",
"content_id": "79946e780afd54f41f989f5c20d13b6aad20cebc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 9,
"path": "/failures/switch.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n switch (5) {\n case 1: return;\n case 1: break; //!duplicate//\n }\n switch (5) {\n case 1: continue; //!loop//\n }\n}\n"
},
{
"alpha_fraction": 0.37728938460350037,
"alphanum_fraction": 0.4432234466075897,
"avg_line_length": 21.75,
"blob_id": "10eee04754d71e9fe9b0f0cb73158586b2460713",
"content_id": "5f7418c32750c9f36c28709d8b173fd26e6ab7e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 12,
"path": "/verify/string/binconv.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n res += 'char* a = \"101\"\\n'\n res += 'bin_to_int(a, 3) = 5\\n'\n res += 'bin_to_int(a, 2) = 1\\n'\n res += 'Invalid character \\'f\\' in \"110f2o\"\\n'\n res += 'bin_to_int(\"110f2o\", 3) = 3\\n'\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.33898305892944336,
"alphanum_fraction": 0.38983049988746643,
"avg_line_length": 13.75,
"blob_id": "d22cd1c9ccc72b83cfb7393a2e5c28d92a73292d",
"content_id": "8ae0a67b290425683e704c103bd052d0081bf43c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 4,
"path": "/tests/boot/add.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int a = 3 + 4, b = 6;\n return a + b;\n}\n"
},
{
"alpha_fraction": 0.3076923191547394,
"alphanum_fraction": 0.4375,
"avg_line_length": 28.714284896850586,
"blob_id": "e320f0792cc032d11aef0344a72a33841e30abdc",
"content_id": "2ebcf29fbc328ee3e7e448ec0d4b1941a8355c00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 14,
"path": "/tests/call/call.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int nth(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) {\n printf(\"x1 = %d\\n\", x1);\n printf(\"x2 = %d\\n\", x2);\n printf(\"x3 = %d\\n\", x3);\n printf(\"x4 = %d\\n\", x4);\n printf(\"x5 = %d\\n\", x5);\n printf(\"x6 = %d\\n\", x6);\n printf(\"x7 = %d\\n\", x7);\n printf(\"x8 = %d\\n\", x8);\n}\n\nint main() {\n nth(3/(2+1), 1+72*0+1*1, 7%(2*2), 2*(3-1), (2*5)/3+2, 2*(2+1), (-2)*2*(-2)-1, 1+1+2*3);\n}\n"
},
{
"alpha_fraction": 0.6424778699874878,
"alphanum_fraction": 0.6690265536308289,
"avg_line_length": 50.3636360168457,
"blob_id": "1c4b87ef81ada4beabc9c5d13941dab13ac4ae5b",
"content_id": "cbf3cb4c957d1eb9a92d85756426c7ab153ebbf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 11,
"path": "/verify/overflow.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def overflow_correct(value, bits, signed):\n base = 1 << bits\n value %= base\n return value - base if signed and value.bit_length() == bits else value\n\nbyte, sbyte, word, sword, dword, sdword, qword, sqword = (\n lambda v: overflow_correct(v, 8, False), lambda v: overflow_correct(v, 8, True),\n lambda v: overflow_correct(v, 16, False), lambda v: overflow_correct(v, 16, True),\n lambda v: overflow_correct(v, 32, False), lambda v: overflow_correct(v, 32, True),\n lambda v: overflow_correct(v, 64, False), lambda v: overflow_correct(v, 64, True)\n)\n"
},
{
"alpha_fraction": 0.3464788794517517,
"alphanum_fraction": 0.4732394218444824,
"avg_line_length": 19.882352828979492,
"blob_id": "ee2cf42487f30fb8f8cbde089b9084184daf32a3",
"content_id": "ffe01cc89413e2b6ce5f052d34b114ff5eae7559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 17,
"path": "/verify/calc/mean.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def mean(arr):\n if arr == []: return 0\n return sum(arr) // len(arr)\n\ndef expect(*args):\n items = []\n for i in args[1:]:\n items.append(int(i))\n return (0, \"{}\\n\".format(mean(items)), \"\")\n\ndata = [\n [],\n [\"10\"],\n \"10 10 10 20\".split(),\n \"1 10 100 1000\".split(),\n \"5 7 9 3 5 1 8 2 9 3 5 1 2 7 8 4 5 6 9 9 3 2\".split(),\n]\n"
},
{
"alpha_fraction": 0.26376810669898987,
"alphanum_fraction": 0.3072463870048523,
"avg_line_length": 23.64285659790039,
"blob_id": "35536bd5ca72757d83936472701ea508a44100bc",
"content_id": "aa262e4ac8695b8fbd7f8a64059f786b893f8fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 14,
"path": "/tests/calc/cmp_order.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i;\n\n if ((i = 3) > (i = 4)) {}\n printf(\"i is %d ?= 4\\n\", i);\n if ((i = 3) >= (i = 4)) {}\n printf(\"i is %d ?= 4\\n\", i);\n if ((i = 3) < (i = 4)) {}\n printf(\"i is %d ?= 3\\n\", i);\n if ((i = 3) <= (i = 4)) {}\n printf(\"i is %d ?= 3\\n\", i);\n if ((i = 3) == (i = 4)) {}\n printf(\"i is %d ?= 3\\n\", i);\n}\n"
},
{
"alpha_fraction": 0.3922330141067505,
"alphanum_fraction": 0.40582525730133057,
"avg_line_length": 19.600000381469727,
"blob_id": "89f42e8350a6a056a2898f0237653c3535591526",
"content_id": "3238500c6c3be9f2849723294c6f8c887432748d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 25,
"path": "/verify/calc/bitwise.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def bit_and(x, y):\n return \"{} & {} = {}\\n\".format(x, y, x & y)\n\ndef bit_or(x, y):\n return \"{} | {} = {}\\n\".format(x, y, x | y)\n\ndef bit_xor(x, y):\n return \"{} ^ {} = {}\\n\".format(x, y, x ^ y)\n\ndef bit_not(x):\n return \"~{} = {}\\n\".format(x, ~x)\n\ndef expect(*args):\n ret = \"\"\n for i in range(200):\n for j in range(i, 200):\n ret += bit_and(i, j)\n ret += bit_or(i, j)\n ret += bit_xor(i, j)\n ret += bit_not(i)\n return (0, ret, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3709677457809448,
"alphanum_fraction": 0.3870967626571655,
"avg_line_length": 9.333333015441895,
"blob_id": "202f676072b31739b45d74e482f0c29363f66376",
"content_id": "e83f4bedb607769f44b14df83a07f52b963928da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 6,
"path": "/verify/boot/ex2.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (3, \"\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.35333332419395447,
"alphanum_fraction": 0.3683333396911621,
"avg_line_length": 20.428571701049805,
"blob_id": "f2dfaf03aed736145f9036bb43da68aaad1cb147",
"content_id": "c0acf3066fa756536710d424f6b1d2a95a4809ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 600,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 28,
"path": "/failures/loop_try.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n int i;\n for (i = 0; 1; i++) {\n try {\n printf(\"i = %d\\n\", i);\n switch (i) {\n case 7: continue; //!outside//\n case 3: throw Three(NULL);\n case 11: throw Eleven(NULL);\n }\n } catch (Three _) {\n printf(\"Found 3\\n\");\n } finally {\n printf(\"Always (%d).\\n\", i);\n }\n }\n printf(\"Never.\\n\");\n}\n\nint main() {\n try {\n foo();\n } catch (Three _) {\n printf(\"Never.\\n\");\n } catch (Eleven _) {\n printf(\"Loop exited at 11.\\n\");\n }\n}\n"
},
{
"alpha_fraction": 0.49152541160583496,
"alphanum_fraction": 0.49152541160583496,
"avg_line_length": 18.66666603088379,
"blob_id": "976ce531d74a5135fef9e7f89e122242ff5493b4",
"content_id": "51f6960721028653f40e298e957023e342a4af7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 3,
"path": "/tests/string/path.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n printf(\"$PATH = %s\\n\", getenv(\"PATH\"));\n}\n"
},
{
"alpha_fraction": 0.5356164574623108,
"alphanum_fraction": 0.5575342178344727,
"avg_line_length": 29.41666603088379,
"blob_id": "7175ca416e9866325109d9f30d68317c95197d64",
"content_id": "d1372f5d96332d09b44676d9dab3b72e84bfa3be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 730,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 24,
"path": "/verify/string/scan.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\n\ndef verify(cmd, param):\n proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n out, err = proc.communicate(input=bytes(\"{}\\n\".format(param), 'utf-8'))\n expected = bytes(\"You gave me the number {}\".format(param), 'utf-8')\n status = True\n if expected != out:\n print(\"Wrong output:\\n [{}]\\nexpect[{}]\".format(expected, out))\n status = False\n if err != b'':\n print(\"Wrong error:\\n [{}]\\nexpect[{}]\".format(err, b''))\n status = False\n if proc.returncode != 0:\n print(\"Wrong return code: [{}]; expect[{}]\".format(proc.returncode, 0))\n status = False\n return status\n\ncfg = [\n [15],\n [-1],\n [0],\n [50666584],\n]\n"
},
{
"alpha_fraction": 0.2659793794155121,
"alphanum_fraction": 0.2969072163105011,
"avg_line_length": 20.086956024169922,
"blob_id": "520948ea59dad2909a1cec87aa841dffbd53c7d5",
"content_id": "ea1fe79d396b656eec10c2e844bf2ac44acd012c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 23,
"path": "/tests/flow/break.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n for (int i = 0; i < 10; i++) {\n if (i == 5) break;\n printf(\"%d \", i);\n }\n putchar('\\n');\n for (int i = 0; i < 10; i++) {\n if (i == 7) break;\n for (int j = 0; j < 10; j++) {\n if (i == j) break;\n printf(\"(%d,%d) \", i, j);\n }\n putchar('\\n');\n }\n int i = 0;\n while (1) {\n if (i == 10) {\n printf(\"exit.\\n\");\n break;\n }\n printf(\"%d \", i++);\n }\n}\n"
},
{
"alpha_fraction": 0.5015151500701904,
"alphanum_fraction": 0.5787878632545471,
"avg_line_length": 37.82352828979492,
"blob_id": "14021e1a980fc232f5c5b7f62a6c715bc8efceeb",
"content_id": "b8446ede0270d4953779f43dc997e34314a1d356",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 660,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 17,
"path": "/tests/ptr/multifnptr.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int apply0(int fn()) { return fn(); }\nint apply1(int fn(), int x) { return fn(x); }\nint apply2(int fn(), int x, int y) { return fn(x, y); }\nint apply1bis(int fn(), int x) { return apply1(fn, x); }\n\nint foo0() { return 42; }\nint bar0() { return 666; }\nint foo1(int x) { return x+10; }\nint bar1(int x) { return x/2; }\nint foo2(int x, int y) { return x + y; }\nint bar2(int x, int y) { return x - y; }\n\nint main() {\n printf(\"foo1(5) = %d ?= 15\\n\", apply1(foo1, 5));\n printf(\"foo1(bar1(5)) = %d ?= 12\\n\", apply1bis(foo1, apply1bis(bar1, 5)));\n printf(\"foo2(foo0(), bar1(bar0()) = %d ?= 375\\n\", apply2(foo2, apply0(foo0), apply1bis(bar1, apply0(bar0))));\n}\n"
},
{
"alpha_fraction": 0.3288888931274414,
"alphanum_fraction": 0.3733333349227905,
"avg_line_length": 15.071428298950195,
"blob_id": "ba3820f7373aebce58d87df5901d13bb60b93ac5",
"content_id": "87791e34fb9a2f8ef09437fed3519cec4ad683ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 14,
"path": "/verify/calc/incdec.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n arr = [*range(10)]\n i = 0\n while (i < 10):\n arr[i] -= 1\n i += 1\n res = \"\"\n for i in range(10):\n res += \"{}\\n\".format(arr[i])\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.403292179107666,
"alphanum_fraction": 0.4485596716403961,
"avg_line_length": 14.1875,
"blob_id": "1f021256d3a2d344a6454dfe59a4e1744aacb9d3",
"content_id": "6cb60f33ee19335d39ca40aa6f57f7a00ff2b1e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 16,
"path": "/verify/flow/triangle.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "chr = '*'\n\ndef line(amount):\n return chr * amount + '\\n'\n\ndef expect(*args):\n max = int(args[1])\n return (0, \"\".join(line(amount) for amount in range(1, max)), \"\")\n\ndata = [\n [\"1\"],\n [\"4\"],\n [\"5\"],\n [\"10\"],\n [\"100\"],\n]\n"
},
{
"alpha_fraction": 0.3866666555404663,
"alphanum_fraction": 0.4000000059604645,
"avg_line_length": 17.75,
"blob_id": "bf4cc7f8a5741b2de0d46e7933ce3478f37b9b64",
"content_id": "7a4178857c9554aece3233ca9ecf634ed9561e4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 8,
"path": "/tests/flow/dowhile.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n int i;\n do {\n scanf(\"%ld\", &i);\n printf(\"I got %ld\\n\", i);\n } while (i != -1);\n printf(\"Ended after -1\\n\");\n}\n"
},
{
"alpha_fraction": 0.3195876181125641,
"alphanum_fraction": 0.4613402187824249,
"avg_line_length": 24.866666793823242,
"blob_id": "9d7a011a3aeb0091a48386877f08f8cc3f5d0267",
"content_id": "c5ed905783861878bc9022231b95d0d3506d4444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 15,
"path": "/verify/reduce/big_switch.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def foo(i):\n if -9 <= int(i) <= 99:\n return i\n else:\n return \"Other\"\n\ndef expect(*args):\n return (0, \"\\n\".join([foo(x) for x in args[1:]]) + \"\\n\", \"No more arguments\\n\")\n\ndata = [\n [*\"0 1 2 3 4 5 6\".split(\" \")],\n [*\"-11 -10 -9 -8 -7 -6 97 98 99 100 101\".split(\" \")],\n [*\"15 12 5 78 96 32 4 0 -9 85 96\".split(\" \")],\n [str(i) for i in range(-15, 105)],\n]\n"
},
{
"alpha_fraction": 0.3405405282974243,
"alphanum_fraction": 0.5351351499557495,
"avg_line_length": 36,
"blob_id": "10d20a07092bc1500225e302c0bde0045b172e56",
"content_id": "4fe5608492d30f9bae955911a6faa07dffd693ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 5,
"path": "/tests/string/quine.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n char* c = \"int main() {%c%cchar* c = %c%s%c;%c%cprintf(c,10,9,34,c,34,10,9,10,9,10,10);%c%creturn 0;%c}%c\";\n printf(c,10,9,34,c,34,10,9,10,9,10,10);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.25,
"alphanum_fraction": 0.2671568691730499,
"avg_line_length": 18.428571701049805,
"blob_id": "42df43a4ba48e199ed712ac9e6b2468b2cddfa2f",
"content_id": "82c9f8be6c9ec1a6bd9b27cbfdee30e487a86eb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/tests/except/try_loop.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int foo() {\n try {\n for (int i = 0; i < 10; i++) {\n if (i == 5) {\n // break; // OK\n continue; // OK\n // return; // KO\n // return 1; // KO\n }\n printf(\"i = %d\\n\", i);\n if (i == 7) {\n throw Exit(NULL);\n }\n }\n }\n return 0;\n}\n\nint main() {\n return foo();\n}\n"
},
{
"alpha_fraction": 0.504119873046875,
"alphanum_fraction": 0.5460674166679382,
"avg_line_length": 28.66666603088379,
"blob_id": "2f69823ff45f0ac0ffb1ebf8644c845701d65b84",
"content_id": "4df639c5b92d1d5c813a7b8b048367eb1cfcef8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 45,
"path": "/verify/misc/rsort.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE\nimport random as rnd\n\ndef verify(cmd, size, maxi):\n proc = Popen(cmd, stdin=PIPE, stdout=PIPE, stderr=PIPE)\n data = \"{} \".format(size)\n numbers = [rnd.randint(0, maxi) for i in range(size)]\n data += \" \".join(str(i) for i in numbers)\n out, err = proc.communicate(data.encode('utf-8'))\n ret = proc.returncode\n status = True\n if ret != 0:\n print(\"Nonzero return code: {}\".format(ret))\n status = False\n if err != b'':\n print(\"Non-empty stderr: '{}'\".format(err))\n status = False\n out = out.decode('utf-8').rstrip().split('\\n')\n if out[0] != \"Enter array size: Enter {} elements:\".format(size):\n print(\"Wrong header '{}'\".format(out[0]))\n status = False\n if out[1] != \" \".join(str(i) for i in numbers) + ' ':\n print(\"Error reading numbers\")\n status = False\n if out[2] != \"Now sorting\":\n print(\"Wrong announcement\")\n status = False\n if out[3] != \"Done!\":\n print(\"Did not announce sort\")\n status = False\n if out[4] != \" \".join(str(i) for i in sorted(numbers)):\n print(\"Did not sort properly\")\n status = False\n return status\n\ncfg = [\n [10, 10],\n [100, 10],\n [10, 100],\n [100, 100],\n [1000, 1],\n [1000, 10],\n [1000, 100],\n [1000, 1000],\n]\n"
},
{
"alpha_fraction": 0.4531802237033844,
"alphanum_fraction": 0.5061837434768677,
"avg_line_length": 42.53845977783203,
"blob_id": "5d211b2fdae3dc41c6bd9e9cd17f64fdf6990451",
"content_id": "a655c723376fcda4a724405d0509251719590d2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1132,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 26,
"path": "/verify/except/except.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n i = int(args[1])\n return [\n (0, \"\", \"\"),\n (111, \"\", \"Unhandled exception Foo(15)\\n\"),\n (111, \"\", \"Unhandled exception Foo(0)\\n\"),\n (111, \"\", \"Unhandled exception Bar(1)\\n\"),\n (0, \"Normal exit\\n\", \"\"),\n (0, \"Failed n.1 with Foo(0)\\nNormal exit\\n\", \"\"),\n (111, \"\", \"Unhandled exception Bar(1)\\n\"),\n (0, \"Normal exit\\n\", \"\"),\n (111, \"Ended n.2\\n\", \"Unhandled exception Foo(0)\\n\"),\n (0, \"Failed n.2 with Bar(1)\\nEnded n.2\\nNormal exit\\n\", \"\"),\n (0, \"Ended n.2\\nNormal exit\\n\", \"\"),\n (111, \"Ended n.2\\n\", \"Unhandled exception Foo(0)\\n\"),\n (111, \"Ended n.2\\n\", \"Unhandled exception Bar(1)\\n\"),\n (0, \"Ended n.2\\nNormal exit\\n\", \"\"),\n (0, \"Caught Foo(0)\\nFinally...\\nNormal exit\\n\", \"\"),\n (0, \"Caught Hello, World!\\nCaught Hello, World! again\\nNormal exit\\n\", \"\"),\n (111, \"Caught Bar(1)\\n\", \"Unhandled exception Bar(1)\\n\"),\n (0, \"Finally...\\nNormal exit\\n\", \"\"),\n (0, \"Everything is fine.\\nNo error occurred.\\nNormal exit\\n\", \"\")\n ][i]\n\n\ndata = [[str(i)] for i in range(1, 19)]\n"
},
{
"alpha_fraction": 0.3611111044883728,
"alphanum_fraction": 0.5079365372657776,
"avg_line_length": 18.384614944458008,
"blob_id": "84dc790d419fe2ddcdf60f0e41b27a66332571cc",
"content_id": "ac52acc057bfe1c5a7cc339d6e62a296054815c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 13,
"path": "/verify/string/quine.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "q = \"\"\"int main() {\n\\tchar* c = \"int main() {%c%cchar* c = %c%s%c;%c%cprintf(c,10,9,34,c,34,10,9,10,9,10,10);%c%creturn 0;%c}%c\";\n\\tprintf(c,10,9,34,c,34,10,9,10,9,10,10);\n\\treturn 0;\n}\n\"\"\"\n\ndef expect(*args):\n return (0, q, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.4533333480358124,
"alphanum_fraction": 0.47999998927116394,
"avg_line_length": 11.5,
"blob_id": "b1cf32adec0361d8e6198e789935527a0a6963a9",
"content_id": "11c5a492f8f8fa0e1ba6526de76a10d4d6f93cff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 6,
"path": "/verify/call/exit.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (42, \"\", \"AAAAAAAAAA\\n\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3024691343307495,
"alphanum_fraction": 0.34567901492118835,
"avg_line_length": 13.727272987365723,
"blob_id": "9879d7a62ada98642a03fd3199d726f0009d970e",
"content_id": "47b7c8c830a0c2101648c9d3d5de0863340a2f6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 11,
"path": "/verify/ptr/swap.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n res = \"\"\n res += \"a = 5\\n\"\n res += \"b = 10\\n\"\n res += \"a = 10\\n\"\n res += \"b = 5\\n\"\n return (0, res, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.44999998807907104,
"alphanum_fraction": 0.4749999940395355,
"avg_line_length": 12.333333015441895,
"blob_id": "b91d08e19555f0b60885ef66004c4e748a55ba5e",
"content_id": "f24e414df9d304f387498ceb31224537fb5bfa6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 6,
"path": "/verify/boot/ex10.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"on est dans le if7\", \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.2507374584674835,
"alphanum_fraction": 0.3451327383518219,
"avg_line_length": 32.900001525878906,
"blob_id": "e0154ed6f4a9a46ed03e284755dc77623d67303c",
"content_id": "ce27c742f3b74e548d77c15ad95c332f68001948",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 20,
"path": "/tests/reduce/reduce_cmp.c",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "int main() {\n printf(\"Yes:\\n\");\n printf(\"\\t5 < 6: %d\\n\", 5 < 6);\n printf(\"\\t5 <= 6: %d\\n\", 5 <= 6);\n printf(\"\\t5 == 5: %d\\n\", 5 == 5);\n printf(\"\\t!(6 <= 5): %d\\n\", !(6 <= 5));\n printf(\"\\t!(6 < 5): %d\\n\", !(6 < 5));\n printf(\"\\t6 > 5: %d\\n\", 6 > 5);\n printf(\"\\t6 >= 5: %d\\n\", 6 >= 5);\n printf(\"\\t6 != 5: %d\\n\", 6 != 5);\n printf(\"No:\\n\");\n printf(\"\\t6 < 5: %d\\n\", 6 < 5);\n printf(\"\\t6 <= 5: %d\\n\", 6 <= 5);\n printf(\"\\t5 == 6: %d\\n\", 5 == 6);\n printf(\"\\t!(5 < 6): %d\\n\", !(5 < 6));\n printf(\"\\t!(5 <= 6): %d\\n\", !(5 <= 6));\n printf(\"\\t5 > 6: %d\\n\", 5 > 6);\n printf(\"\\t5 >= 6: %d\\n\", 5 >= 6);\n printf(\"\\t5 != 5: %d\\n\", 5 != 5);\n}\n"
},
{
"alpha_fraction": 0.5023696422576904,
"alphanum_fraction": 0.5118483304977417,
"avg_line_length": 18.18181800842285,
"blob_id": "c869cd03799b697ca3ca21176f564a5bfedc6a14",
"content_id": "8e884ab592063e233a14cfa3b01339f424af9291",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 11,
"path": "/verify/string/cat.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def cat(name):\n with open(name) as f:\n return f.read()\n\ndef expect(*args):\n return (0, ''.join(cat(f) for f in args[1:]), \"\")\n\ndata = [\n [\"Makefile\"],\n [\"README.md\", \"main.ml\", \"error.ml\"],\n]\n"
},
{
"alpha_fraction": 0.3468531370162964,
"alphanum_fraction": 0.39020979404449463,
"avg_line_length": 17.33333396911621,
"blob_id": "05748c45937d146cf813ca4177eaf5af295faa29",
"content_id": "5ef752a623796e4bad48b4524507c8cd1a7b9143",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 39,
"path": "/verify/call/printglob.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "global i, j, k\n\ndef foo():\n return \"foo: {} + {} -> {}\\n\".format(i, j, k[i + j])\n\ndef bar():\n ret = \"\"\n for i in zip([*range(0, 10),'A','B','C','D'], [*range(0, 13)]):\n ret += \"{}:{}\\n\".format(*i)\n return ret\n\ndef baz(*x):\n ret = \"\"\n for i in zip([*range(0, 10),'A','B','C','D'], x):\n ret += \"{}:{}\\n\".format(*i)\n return ret\n\ndef expect(*args):\n global i, j, k\n i = 0\n j = 0\n k = [1000] + [100 * i for i in range(1, 5)]\n ret = \"\"\n ret += foo()\n i += 1\n ret += foo()\n j += 1\n ret += foo()\n j += 1\n ret += foo()\n i += 1\n ret += foo()\n ret += bar()\n ret += baz(*[1000+i for i in range(13)])\n return (0, ret, \"\")\n\ndata = [\n [],\n]\n"
},
{
"alpha_fraction": 0.3840000033378601,
"alphanum_fraction": 0.5040000081062317,
"avg_line_length": 19.83333396911621,
"blob_id": "a44b9cf0cc7a78581f323fdd403c25cac022ff73",
"content_id": "a019908bddb4d7255ace186783a9be14a9cc65c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 6,
"path": "/verify/boot/ex9.py",
"repo_name": "iCodeIN/cocass",
"src_encoding": "UTF-8",
"text": "def expect(*args):\n return (0, \"12 = 12? 10 = 10? 12 = 12?, if 10 not false but not the gcc one\", \"\")\n\ndata = [\n [],\n]\n"
}
] | 191 |
mortie23/teradata-geo
|
https://github.com/mortie23/teradata-geo
|
83293e59a5701c8d0d99403b6e4ad320529d20b1
|
e75997ea7955970a5395044cf248aea0578e470c
|
18eb1f3afa3446da5ccac2d20468bdb5892d91ea
|
refs/heads/master
| 2022-11-28T17:05:23.321901 | 2020-08-05T22:35:19 | 2020-08-05T22:35:19 | 285,182,731 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7204301357269287,
"alphanum_fraction": 0.7688171863555908,
"avg_line_length": 30.16666603088379,
"blob_id": "d1fc1971c2c883675be5874609e06c4c7d4d0b91",
"content_id": "14a0115d1097fffb9e0771a17fa612dd6d86351f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 6,
"path": "/geo-convert.py",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport geopandas\n\nmyshpfile = geopandas.read_file('/mnt/d/data/geo/modified-monash-model/MMM2019Final.shp')\nmyshpfile.to_file('mmm-2019-final.json', driver='GeoJSON')"
},
{
"alpha_fraction": 0.8275862336158752,
"alphanum_fraction": 0.8275862336158752,
"avg_line_length": 18.33333396911621,
"blob_id": "01729419878e4d73269ffbd9f120dc9849eade72",
"content_id": "6ddacbcb6f920c65a5d3587a77afbecf07fc5cf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 3,
"path": "/README.md",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "# teradata-geospatial\n\nTutorial on Geospatial in Teradata\n"
},
{
"alpha_fraction": 0.6531901359558105,
"alphanum_fraction": 0.6766898036003113,
"avg_line_length": 25.921768188476562,
"blob_id": "ca35ea20469f62e96bb9c7274e98c19c3e222cff",
"content_id": "398a093a0055a3140cfe0f47109d5f03ee4bb3ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7915,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 294,
"path": "/tutorial.md",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "Document Control\n================\n\nAuthors\n-------\n\n Business Term | Title | Date |Role\n ----------------------| ----------------| ------------| ------------\n Christopher Mortimer | Data Analyst |2017-08-07 | Dev\n\nVersion Management\n------------------\n\n Version |Author | Date | Content\n --------- |--------------------- |------------ | -------------------------------------\n V1.0 | Christopher Mortimer | 2017-08-07 | Dev\n\n \n\nTable of Contents\n-----------------\n\n[Document Control](#document-control)\n\n[Authors ](#authors)\n\n[Version Management](#version-management)\n\n[Introduction](#introduction)\n\n[Prerequisite](#prerequisite)\n\n[Content](#content)\n\n[Tutorial](#tutorial)\n\n[Convert from GeoJSON to ST_Geometry](#Convert-from-GeoJSON-to-ST_Geometry)\n\n\nIntroduction\n============\n\nThis Teradata Geospatial Tutorial covers \n\n1. geospatial data loading\n1. geospatial queries\n\nThe tutorial currently works Teradata 16.20 version.\n\nPrerequisite \n------------\n\nThis tutorial was designed on a Windows 10 computer with:\n1. Download Teradata express 16.20 VM (http://downloads.teradata.com/download)\n1. Download Teradata Tools and Utilities 16.20 (http://downloads.teradata.com/download)\n1. Teradata Studio 16.20 (http://downloads.teradata.com/download)\n1. Python 3.8.2\n\nContent\n----------------\n\nThe following components are provided with this tutorial:\n\n- tutorial.md (instructions)\n- geo-convert.py (script to convert shape file to GeoJSON)\n - ./data (where the GeoJSON is written to)\n - ./load-geojson (the load scripts to get the GeoJSON into Teradata)\n - ./shape-files (source Shape Files)\n - ./dba (setup of the database)\n\nTutorial\n========\n\nTutorial Scenario\n-----------------\n\nWe have a shape file and we want to load it to a ST_Geometry field in Teradata.\nWe do not have access to a 32bit OS or java CLI so using the Teradata java tool is not an option.\nWe do have access to Python.\n\nDatabase Creation and Grants\n----------------------------\n\nA database needs to be created to contain the geospatial data and access to geospatial features.\nExample that needs to be run as DBC against your VM.\n\n```sql\n-- Create database with 100 Mb\nCREATE DATABASE PRD_ADS_HWD_WDAPGRP_DB FROM DBC AS PERM = 100000000;\n\n-- General database grants\nGRANT DROP DATABASE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT DROP DATABASE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT CREATE TABLE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT CREATE PROCEDURE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT SELECT ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT UPDATE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT DELETE ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\nGRANT INSERT ON PRD_ADS_HWD_WDAPGRP_DB TO DBC;\n\n-- Geospatial specific grants\nGRANT EXECUTE FUNCTION ON SYSSPATIAL TO PRD_ADS_HWD_WDAPGRP_DB WITH GRANT OPTION;\nGRANT SELECT ON SYSSPATIAL TO PRD_ADS_HWD_WDAPGRP_DB; \nGRANT EXECUTE PROCEDURE ON SYSSPATIAL TO PRD_ADS_HWD_WDAPGRP_DB;\nGRANT EXECUTE FUNCTION ON SYSSPATIAL.TESSELLATE_SEARCH TO PRD_ADS_HWD_WDAPGRP_DB WITH GRANT OPTION;\nGRANT EXECUTE FUNCTION ON SYSSPATIAL.TESSELLATE_INDEX TO PRD_ADS_HWD_WDAPGRP_DB WITH GRANT OPTION;\nGRANT UDTUSAGE ON SYSUDTLIB TO PRD_ADS_HWD_WDAPGRP_DB;\n```\n\nTable Creation and Data Loading\n-------------------------------\n\n### Staging Table\n\nStaging table captures the JSON data.\n\n```sql\n-- Create the staging table\nCREATE TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_JSON_STAGING (\n ID_COL VARCHAR(100)\n , JSON_DATA JSON(16776192)\n)\n;\n```\n\n#### Alternative Using TDGeoImport\n\nIf you have a 32 bit OS and Java you can try this.\nUse the loading utility `TDGeoImport`. \nIt loads directly from \"ESRI Shape files\".\n\n> Command line arguments \n> -l \\<system name or ip address\\>/\\<user name\\>,\\<user password\\> \n> -f filename of shape file to be loaded (extension .shp) \n> -b is followed by the database name \n\nTDGeoImport should be run from the `TDGeoimportexport/bin` directory.\n\nTo do this:\n\nCreate a different staging table:\n\n```sql\n-- Create the staging table\nCREATE TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_STAGING (\n ID_COL VARCHAR(100)\n , JSON_DATA ST_Geometry\n)\n;\n```\n\n- Open a command window (I use the Microsoft Terminal from Windows Store)\n- Go to the TDGeoimportexport/bin directory by typing cd c:\\...\\<>\\..\\TDGeoimportexport/bin\n- Run the TDGeoimport from the directory\n\n```sh\njava -Xms256m -Xmx512m -classpath .;tdgssconfig.jar;terajdbc4.jar com.teradata.geo.TDGeoImport -l 192.168.0.28/dbc,dbc -s PRD_ADS_HWD_WDAPGRP_DB -f \".\\shape-fIles\\shape-file.shp\" -n GEO_STAGING\n```\n\nThis will populate the `GEO_STAGING` table with the geospatial column.\n\n### Convert from Shape file to GeoJSON\n\nYou will need to have the `geopandas` package in your python environment.\n\n```sh\npip install geopandas\n```\n\nFor this tutorial we will use the Modified Monash Model shape file that is open data availabel at: \n\n[Download from data.gov.au](https://data.gov.au/data/dataset/modified-monash-model-mmm-2019)\n\n\n\nFrom the zip, extract the files somewhere, and then modify the Python script `geo-convert.py` to point to your file. \n\nRun the Python script.\n\n```sh\n./geo-convery.py\n```\n\nGitHub has a great feature that will automatically show GeoJSON files as polygons on a map.\nThis is a sample of the records that was create using the following script for testing purposes.\n\n```sh\n# Write the first 10 lines to a new file\nhead mmm-2019-final.json > mmm-2019-sample.json\n# Append the last 10 lines to the file created before\ntail mmm-2019-final.json >> mmm-2019-sample.json\n```\n\n\n\n### Load the GeoJSON\n\nRun the TPT script using command line (in this instance using PowerShell in Windows Terminal).\nYou will need to have installed the Teradata Tools an Utilities to use the `tbuild` CLI application.\n\n```sh\ntbuild -f .\\loadJSON.tpt -v .\\loadJSON-jobvars-mmm.jvar\n```\n\n\n\nConvert from GeoJSON to ST_Geometry\n-----------------------------------\n\nThe access layer script can be used to:\n1. Parse the JSON using native Teradata JSON syntax\n1. Use the Teradata function `GeomFromGeoJSON` to convert the GeoJSON to `ST_Geometry`.\n\n```sql\n-- Get the features and geography\nSELECT\n A.ID_COL\n , A.OBJECTID\n , GeomFromGeoJSON(A.GEOMETRY_CHAR,4326) AS GEOMETRY\nFROM (\n SELECT \n T.ID_COL\n , T.OBJECTID\n , T.SA1_MAIN16\n , T.MMM2019\n , T.SHAPE_Leng\n , T.SHAPE_Area\n , TRIM(TRAILING ' ' FROM T.GEOMETRY_CHAR) AS GEOMETRY_CHAR\n FROM \n JSON_TABLE (\n ON PRD_ADS_HWD_WDAPGRP_DB.GEO_JSON_STAGING\n USING \n ROWEXPR('$.features[*]')\n colexpr('[ \n { \"jsonpath\" : \"$.properties.OBJECTID\",\"type\" : \"BIGINT\"}\n , { \"jsonpath\" : \"$.properties.SA1_MAIN16\",\"type\" : \"BIGINT\"}\n , { \"jsonpath\" : \"$.properties.MMM2019\",\"type\" : \"INTEGER\"}\n , { \"jsonpath\" : \"$.properties.SHAPE_Leng\",\"type\" : \"FLOAT\"}\n , { \"jsonpath\" : \"$.properties.SHAPE_Area\",\"type\" : \"FLOAT\"}\n , { \"jsonpath\" : \"$.geometry\",\"type\" : \"CHAR(63000)\"}\n ]'\n )\n ) AS T (\n ID_COL\n , OBJECTID\n , SA1_MAIN16\n , MMM2019\n , SHAPE_Leng\n , SHAPE_Area\n , GEOMETRY_CHAR\n )\n) AS A\n;\n```\n\nPoints in Polygons\n------------------\n\nOnce the polygon data is available in Teradata we can use it to find what polygons a point is in.\n\n### Create a sample point\n\n```sql\nCREATE TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS (\n ID_COL VARCHAR(100) \n , POINT_GEOMETRY ST_GEOMETRY\n)\nPRIMARY INDEX(ID_COL)\n;\n\n-- Insert sample \nINSERT INTO PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS VALUES ('1','POINT (149.0723375605 -35.4349675974999)');\n```\n\nNow we have the point we can use a spatial join to find what polugon the point is in.\n\n```sql\nSELECT \n POINT.ID_COL\n , POLY.OBJECTID\nFROM \n PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS POINT\nINNER JOIN \n PRD_ADS_HWD_WDAPGRP_DB.GEO POLY\nON \n POINT.POINT_GEOMETRY.ST_WITHIN(POLY.GEOMETRY)= 1\n;\n```\n\nResult\n\n ID_COL |OBJECTID \n ------ |-------- \n 1 | 57487\n"
},
{
"alpha_fraction": 0.6286764740943909,
"alphanum_fraction": 0.6985294222831726,
"avg_line_length": 23.81818199157715,
"blob_id": "d2b40eecd0494ea98c13472cd459ca20dadec6f9",
"content_id": "de66198f4699f76d16ca010e2abc7aad88ea4605",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 11,
"path": "/load-geojson/ddl.sql",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "-- Author:\tChristopher Mortimer\n-- Date:\t 2020-08-05\n-- Desc:\t Create staging table for GeoJSON\n\nDROP TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_JSON_STAGING;\nCREATE TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_JSON_STAGING (\n ID_COL VARCHAR(100) \n , JSON_DATA JSON (16776192) \n)\nPRIMARY INDEX(ID_COL)\n;"
},
{
"alpha_fraction": 0.6023916006088257,
"alphanum_fraction": 0.7025411128997803,
"avg_line_length": 39.8125,
"blob_id": "c6cd2be799a0ec077d71b3587af2a78370533dbf",
"content_id": "cf503fe2a17947b4b2ab51df071bc50b35a286b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 16,
"path": "/data/test-points.sql",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "-- Author:\tChristopher Mortimer\r\n-- Date:\t 2020-08-05\r\n-- Desc:\t Create some test points\r\n\r\nDROP TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS;\r\nCREATE TABLE PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS (\r\n ID_COL VARCHAR(100) \r\n , POINT_GEOMETRY ST_GEOMETRY\r\n)\r\nPRIMARY INDEX(ID_COL)\r\n;\r\n--CALL SYSSPATIAL.AddGeometryColumn('','PRD_ADS_HWD_WDAPGRP_DB','GEO_POINTS','POINT_GEOMETRY',4283,'ST_POINT', 0.0, 1.0, 1000.0, 1001.0,s);\r\n-- Executed as Single statement. Failed [3523 : 42000] The user does not have EXECUTE PROCEDURE access to SYSSPATIAL.AddGeometryColumn. \r\n\r\n-- Insert sample \r\nINSERT INTO PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS VALUES ('1','POINT (149.0723375605 -35.4349675974999)');\r\n"
},
{
"alpha_fraction": 0.5355902910232544,
"alphanum_fraction": 0.5659722089767456,
"avg_line_length": 25.159090042114258,
"blob_id": "080980b9dae25b3a481497b6a8e2d718f0201036",
"content_id": "ee328037309acd4529492c3ab3fbe8b6d2e00f39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1152,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 44,
"path": "/access-layer/access-layer.sql",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "\n-- Author: Christopher Mortimer\n-- Date: 2020-08-05\n-- Desc: Parsing a GeoJSON JSON file in native Teradata to ST_Geometry\n\n-- Get the features and geography\nREPLACE VIEW PRD_ADS_HWD_WDAPGRP_DB.GEO AS\nSELECT\n A.ID_COL\n , A.OBJECTID\n , GeomFromGeoJSON(A.GEOMETRY_CHAR,0) AS GEOMETRY\nFROM (\n SELECT \n T.ID_COL\n , T.OBJECTID\n , T.SA1_MAIN16\n , T.MMM2019\n , T.SHAPE_Leng\n , T.SHAPE_Area\n , TRIM(TRAILING ' ' FROM T.GEOMETRY_CHAR) AS GEOMETRY_CHAR\n FROM \n JSON_TABLE (\n ON PRD_ADS_HWD_WDAPGRP_DB.GEO_JSON_STAGING\n USING \n ROWEXPR('$.features[*]')\n colexpr('[ \n { \"jsonpath\" : \"$.properties.OBJECTID\",\"type\" : \"BIGINT\"}\n , { \"jsonpath\" : \"$.properties.SA1_MAIN16\",\"type\" : \"BIGINT\"}\n , { \"jsonpath\" : \"$.properties.MMM2019\",\"type\" : \"INTEGER\"}\n , { \"jsonpath\" : \"$.properties.SHAPE_Leng\",\"type\" : \"FLOAT\"}\n , { \"jsonpath\" : \"$.properties.SHAPE_Area\",\"type\" : \"FLOAT\"}\n , { \"jsonpath\" : \"$.geometry\",\"type\" : \"CHAR(63000)\"}\n ]'\n )\n ) AS T (\n ID_COL\n , OBJECTID\n , SA1_MAIN16\n , MMM2019\n , SHAPE_Leng\n , SHAPE_Area\n , GEOMETRY_CHAR\n )\n) AS A\n;\n"
},
{
"alpha_fraction": 0.619528591632843,
"alphanum_fraction": 0.6498316526412964,
"avg_line_length": 19.214284896850586,
"blob_id": "c30f0027bfe4d4c6651b2206c11366fd464d172f",
"content_id": "a05fc7c9174d0f445a9a28c3909fd5b556632a89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 297,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/access-layer/point-in.sql",
"repo_name": "mortie23/teradata-geo",
"src_encoding": "UTF-8",
"text": "-- Author: Christopher Mortimer\r\n-- Date: 2020-08-05\r\n-- Desc: Find the polygon that a point is in\r\n\r\nSELECT \r\n POINT.ID_COL\r\n , POLY.OBJECTID\r\nFROM \r\n PRD_ADS_HWD_WDAPGRP_DB.GEO_POINTS POINT\r\nINNER JOIN \r\n PRD_ADS_HWD_WDAPGRP_DB.GEO POLY\r\nON \r\n POINT.POINT_GEOMETRY.ST_WITHIN(POLY.GEOMETRY)= 1\r\n;\r\n"
}
] | 7 |
yantongw/MODIS_tools
|
https://github.com/yantongw/MODIS_tools
|
d96473b66329a9a614a271af5885eeb13bdeda6b
|
e66e1b427994d1e4e4a04069bac7ed5e402b74f4
|
5a7371e7d93f2cee7056cef592a0896bce0bc1d8
|
refs/heads/master
| 2021-09-10T21:58:07.929400 | 2018-04-03T03:48:11 | 2018-04-03T03:48:11 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6849478483200073,
"alphanum_fraction": 0.6971684098243713,
"avg_line_length": 22.97142791748047,
"blob_id": "7ff48b1487e5e4c174f3ca0384b25b73145232da",
"content_id": "5fa9b6fa7ea25fb844dcb8308969394918c8f64b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3355,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 140,
"path": "/calc_avg.py",
"repo_name": "yantongw/MODIS_tools",
"src_encoding": "UTF-8",
"text": "'''\nThis program should be run after the \"fetch_historic_8d.py\" program.\nThe program loops through a directory of NDVI files (\"historic\"), calculates the average per-pixel NDVI,\nand stores one .tif file each for Aqua and Terra in a directory called \"reference_files\"\n\nDeveloper: Aakash Ahamed ([email protected])\nNASA Goddard Space Flight Center\nApplied Sciences Program\nHydrological Sciences Laboratory \n'''\n\nfrom osgeo import gdal\nimport numpy as np\nimport os\nimport shutil\n\n# Functions \n\ndef read_as_array(raster):\n\tds = gdal.Open(raster)\n\tarray = np.array(ds.GetRasterBand(1).ReadAsArray())\n\treturn array\n\ndef chunks(r,n):\n\tfor i in range (0,len(r),n):\n\t\tyield r[i:i+n]\n\t\t\ndef array2raster(rasterfn,newRasterfn,array):\n\traster = gdal.Open(rasterfn)\n\tgeotransform = raster.GetGeoTransform()\n\tproj = raster.GetProjection()\n\toriginX = geotransform[0]\n\toriginY = geotransform[3]\n\tpixelWidth = geotransform[1]\n\tpixelHeight = geotransform[5]\n\tcols = raster.RasterXSize\n\trows = raster.RasterYSize\n\n\tdriver = gdal.GetDriverByName('GTiff')\n\toutRaster = driver.Create(newRasterfn, cols, rows, 1, gdal.GDT_Float32) # Change dtype here\n\toutRaster.SetGeoTransform((originX, pixelWidth, 0, originY, 0, pixelHeight))\n\toutband = outRaster.GetRasterBand(1)\n\toutband.WriteArray(array)\n\t\t\n\toutRaster.SetProjection(proj)\n\toutband.FlushCache()\n\t\ndef calc_average(chunk_list):\n\n\taverages = []\n\tvariances = []\n\n\tfor chunk in chunk_list:\n\t\tarrays = []\n\t\ttemp = chunk\n\t\tfor i in temp:\n\t\t\tarrays.append(read_as_array(i))\n\t\t\tprint(\"reading....\" + i)\n\t\t\n\t\tfor array in arrays: # mask\n\t\t\tarray[array == 0] = np.nan\n\t\t\n\t\ttime_array = np.array(arrays)\n\t\taverage = np.nanmean(time_array,axis = 0)\n\t\taverages.append(average)\n\t\tvariance= np.nanvar(time_array,axis = 0)\n\t\tvariances.append(variance)\n\n\tfin_array = np.array(averages)\n\tfin_variance = np.array(variances)\n\n\ttrue_average = np.nanmean(fin_array, axis = 0)\n\t\n\treturn (true_average)\n\t\n\ndef main():\n\tdir = os.getcwd()\n\t\n\t# make dir for averages\n\tref_dir = os.path.join(dir,\"reference_files\")\n\t\n\tif os.path.exists(ref_dir):\n\t\tpass\n\telse: \n\t\tos.mkdir(ref_dir)\n\t\t\n\tresults_dir = os.path.join(dir,\"results\")\n\n\tif os.path.exists(results_dir):\n\t\tpass\n\telse: \n\t\tos.mkdir(results_dir)\n\t\t\n\t# Set dir with historic files (created automatically from fetch_8d scripts)\n\thistoric_dir = os.path.join(dir,\"historic\")\n\tos.chdir(historic_dir)\n\n\t# Aqua \n\tfiles = [x for x in os.listdir(os.getcwd()) if x.endswith(\".tif\") and \"Aqua\" in x] #and \"2011\" not in x]\n\n\tchunk_list = list(chunks(files,2))\n\n\taqua_average = calc_average(chunk_list)\n\t\n\tdel chunk_list\n\t\n\tmatch_raster = \"\".join(files[0])\n\tdoy = match_raster[10:13]\n\t\n\tarray2raster(match_raster, doy+\"_aqua_average.tif\", aqua_average)\n\t\n\tdel aqua_average\n\n\tfile = [x for x in os.listdir(os.getcwd()) if x.endswith(\"average.tif\")]\n\tfile = \"\".join(file)\n\n\tshutil.copy(file,ref_dir)\n\tos.remove(file)\n\t\n\t# Terra\n\tfiles = [x for x in os.listdir(os.getcwd()) if x.endswith(\".tif\") and \"Terra\" in x]# and \"2011\" not in x]\n\n\tchunk_list = list(chunks(files,2))\n\t\n\tterra_average = calc_average(chunk_list)\n\t\n\tmatch_raster = \"\".join(files[0])\n\tdoy = match_raster[11:14]\n\t\n\tarray2raster(match_raster, doy+\"_terra_average.tif\", terra_average)\n\t\n\tfile = [x for x in os.listdir(os.getcwd()) if x.endswith(\"average.tif\")]\n\tfile = \"\".join(file)\n\n\tshutil.copy(file,ref_dir)\n\tos.remove(file)\n\t\nif __name__ == '__main__':\n\tmain()"
},
{
"alpha_fraction": 0.7093476057052612,
"alphanum_fraction": 0.7254137992858887,
"avg_line_length": 66.5,
"blob_id": "dde64ef6d514a99f7e1b68e76ddb61cb774e434a",
"content_id": "21abe77f80bb2fdd5afb65beaaa18debc3de5a65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 4108,
"license_type": "no_license",
"max_line_length": 485,
"num_lines": 60,
"path": "/README.txt",
"repo_name": "yantongw/MODIS_tools",
"src_encoding": "UTF-8",
"text": "This readme describes the software routines for a regional flood detection and impact assessment module for Southeast Asia.\r\n\r\nDeveloper: Aakash Ahamed ([email protected]; [email protected]; 908 370 7738)\r\nContact and PI: John D. Bolten ([email protected])\r\nDate: 1/2017\r\n\r\nNASA Goddard Space Flight Center\r\nHydrological Sciences Laboratory (Code 617)\r\nApplied Sciences Program \r\n\r\nDISCLAIMER: THIS SOFTWARE IS PROVIDED \"AS IS\" AND ANY EXPRESSED OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)\r\nHOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\r\n\r\nThis system has been tested, ported, and run successfully on Ubuntu 14.04 OS with 16 GB ram. Initial storage requirements are ~ 30 GB, but accumulated results will soon exceed this. As such, either more storage or maintenance scripts are recommended. \r\n\r\n################################\r\n##### Install Instructions #####\r\n################################ \r\n\r\n1) Start with a fresh install of Ubuntu 14.04 (16 GB ram, 50+ GB storage, 1 core required)\r\n2) Install the gdal library and its dependencies by running (from command line)\r\n\r\n\tsudo add-apt-repository ppa:ubuntugis/ppa && sudo apt-get update\r\n\r\n\tsudo apt-get install gdal-bin python3-gdal\r\n\r\n3) Test the gdal install by entering the python shell and typing \"from osgeo import gdal\"\r\n\r\n\tpython3\r\n\r\n\t> from osgeo import gdal\r\n\r\n4) If there are no error messages, the software libraries and dependencies are correctly configured.\r\n\r\n5) Install the crontab commands in the crontab.txt file. Relative file paths and execution times may have to be altered.\r\n\r\n##############################\r\n##### Usage Instructions #####\r\n##############################\r\n\r\n**************************************\r\n******** Folder : NRT_Flood **********\r\n**************************************\r\n\r\nDescription: This set of programs downloads, processes, and applies classification algorithm to MODIS data to determine flooded areas, non-flooded areas, and areas where there is not enough data (due to cloud obscuration) to make a determination.\r\n\r\nPrograms in this module and descriptions:\r\n1) fetch_historic.py - determines the day of the year and downloads M*D09Q1 products for the length of the MODIS Aqua and Terra record for the nearest available date on each year. If products in the \"historic\" directory are current, the program does not run. For each image, clouds are masked and per-pixel NDVI is calculated (250m resolution).\r\n2) calc_avg.py - averages the Aqua / Terra files in the \"historic\" dir to construct a combined MODIS Aqua / Terra average NDVI composite for that day of the year. Outputs are stored in the \"reference_files\" directory\r\n3) fetch_NRT.py - fetches the latest MODIS Aqua / Terra data available on the NASA nrt servers. Clouds are filtered and NDVI is calculated at 250m resolution. Outputs are stored in the \"daily_files_nrt\" directory.\r\n4) calc_anom.py - calculates the NDVI of permanent water bodies using the \"permanent_water_mask.tif\" file and the historic NDVI composite. Pixels below the mean H2O NDVI threshold are classified \"surface water\". Outputs are surface water extent products (0 = No water, 1 = water, NaN = clouds/permanent water) generated for the day of year (avg_SW) and the latest NRT 4-day composite (SW_doy_year).\r\n\r\nThe programs should be run in numerical order: \r\n\r\n(1) --> (2) --> (3) --> (4)\r\n\r\nRequired static file: \r\n1) permanent_water_mask.tif - This file is a binary .tiff raster of the MOD44 Permanent water mask \r\n\r\nEach program contains a more detailed description within the docstring of the .py file as well as in-line comments for code clarity"
},
{
"alpha_fraction": 0.690796434879303,
"alphanum_fraction": 0.7044247984886169,
"avg_line_length": 32.83233642578125,
"blob_id": "df5a4d412e55eeda28f3fd577d009f176a9a401e",
"content_id": "9ee9184b207e6fb82ee9dba91a4d4a25f5439d0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5650,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 167,
"path": "/calc_anom.py",
"repo_name": "yantongw/MODIS_tools",
"src_encoding": "UTF-8",
"text": "'''\nThis program should be run after the \"fetch_historic_8d.py\" and \"calc_avg.py\" programs\nThe program calculates the NDVI of permanent water bodies using the \"permanent_water_mask.tif\" file.\nNext, 1/2 SD is added to the mean NDVI of permanent water, and pixels below this threshold are classified \"surface water\"\nSurface water products are generated for the day of year (avg_SW) and the year of interest\n\nDeveloper: Aakash Ahamed ([email protected])\nNASA Goddard Space Flight Center\nApplied Sciences Program\nHydrological Sciences Laboratory \n'''\n\nfrom osgeo import gdal\nimport numpy as np\nimport os\nimport shutil\n\n# Functions \n\ndef read_as_array(raster):\n\tds = gdal.Open(raster)\n\tarray = np.array(ds.GetRasterBand(1).ReadAsArray())\n\treturn array\n\ndef chunks(r,n):\n\tfor i in range (0,len(r),n):\n\t\tyield r[i:i+n]\n\t\t\ndef array2raster(rasterfn,newRasterfn,array):\n\traster = gdal.Open(rasterfn)\n\tgeotransform = raster.GetGeoTransform()\n\tproj = raster.GetProjection()\n\toriginX = geotransform[0]\n\toriginY = geotransform[3]\n\tpixelWidth = geotransform[1]\n\tpixelHeight = geotransform[5]\n\tcols = raster.RasterXSize\n\trows = raster.RasterYSize\n\n\tdriver = gdal.GetDriverByName('GTiff')\n\toutRaster = driver.Create(newRasterfn, cols, rows, 1, gdal.GDT_Float32) # Change dtype here\n\toutRaster.SetGeoTransform((originX, pixelWidth, 0, originY, 0, pixelHeight))\n\toutband = outRaster.GetRasterBand(1)\n\toutband.WriteArray(array)\n\t\t\n\toutRaster.SetProjection(proj)\n\toutband.FlushCache()\n\t\ndef main():\n\n\t# dirs\n\tdir = os.getcwd()\n\tref_dir = os.path.join(dir,\"reference_files\")\n\thistoric_dir = os.path.join(dir,\"historic\")\n\tresults_dir = os.path.join(dir,\"results\")\n\tproducts_dir = os.path.join(dir,\"products\")\n\n\t# create \"products\" dir\n\tif os.path.exists(products_dir):\n\t\tpass\n\telse:\n\t\tos.mkdir(products_dir)\n\t\t\n\t# Read the water mask and remove nodata values\n\twater = [x for x in os.listdir(os.getcwd()) if \"water\" in x]\n\twater = \"\".join(water)\n\twater_array = read_as_array(water)\n\twater_array[water_array<0] = np.nan\n\twater_array[water_array>1] = np.nan\n\n\t# make a new object for the invert \n\tinverted_water_array = [x for x in os.listdir(os.getcwd()) if \"water\" in x]\n\tinverted_water_array = \"\".join(inverted_water_array)\n\tinverted_water_array = read_as_array(inverted_water_array)\n\t\n\twater_array_fin = inverted_water_array\n\twater_array_fin[water_array_fin < 0] = np.nan\n\twater_array_fin[water_array_fin > 1] = np.nan\n\twater_array_fin[water_array_fin == 1] = np.nan\n\twater_array_fin[water_array_fin == 0] = 1\n\t\t\n\t# Read the images of flood years \n\t# Terra\n\tcomparison_img = [x for x in os.listdir(historic_dir) if \"2013\" in x and \"Terra\" in x]\n\tcomparison_img = os.path.join(historic_dir,\"\".join(comparison_img))\n\tterra_comparison_arr = read_as_array(comparison_img)\n\t\n\tyear = \"\".join(comparison_img)\n\tyear = year[-20:-16]\n\t\n\tdoy = \"\".join(comparison_img)\n\tdoy = doy[-15:-12]\n\t\n\t# Aqua\n\tcomparison_img = [x for x in os.listdir(historic_dir) if \"2013\" in x and \"Aqua\" in x]\n\tcomparison_img = os.path.join(historic_dir,\"\".join(comparison_img))\n\taqua_comparison_arr = read_as_array(comparison_img)\n\t\n\tyear_average = np.nanmean(np.array([aqua_comparison_arr,terra_comparison_arr]), axis = 0)\n\t\n\t# Write the average NDVI for that year \n\toutfile = \"MCD_{}_ndvi_{}.tif\".format(year,doy)\n\toutfile = os.path.join(products_dir,outfile)\n\tarray2raster(comparison_img,outfile, year_average)\n\t\n\t# Read the average ndvi files and smash them together\n\t# Terra\n\tterra = [x for x in os.listdir(ref_dir) if \"terra\" in x]\n\tterra = (os.path.join(ref_dir,\"\".join(terra)))\n\tterra_average = read_as_array(terra)\n\t\t\n\t# aqua\n\taqua = [x for x in os.listdir(ref_dir) if \"aqua\" in x]\n\taqua = (os.path.join(ref_dir,\"\".join(aqua)))\n\taqua_average = read_as_array(aqua)\n\t\t\n\taverage = np.nanmean(np.array([aqua_average,terra_average]), axis = 0)\n\t\n\toutfile = '''MCD_avg_ndvi_{}.tif'''.format(doy)\n\toutfile = os.path.join(products_dir,outfile)\n\tarray2raster(comparison_img,outfile, average)\n\n\t# CALCULATE THE NDVI VALUES OF PERMANENT WATER using the INVERTED water mask\n\th2o = np.multiply(water_array_fin,average)\n\th2o[h2o < -1.0] = np.nan\n\th2o[h2o > 1.0] = np.nan\n\tprint(np.nanmean(h2o))\n\tprint(\"H20 average\")\n\t\n\tf = h2o[np.logical_not(np.isnan(h2o))]\n\t\n\toutfile = 'average_h2o_vals.csv'\n\toutfile = os.path.join(results_dir,outfile)\n\tnp.savetxt(outfile, f, delimiter = \",\", fmt = \"%f\")\n\t\n\toutfile = \"h2o.tif\"\n\toutfile = os.path.join(results_dir,outfile)\n\tarray2raster(comparison_img,outfile, h2o)\n\t\n\t# CLASSIFY SURFACE WATER BASED ON PERMANENT WATER NDVI AVGs for average image. Write out as water extetn\n\thalf_sd = np.nanstd(h2o)/ 2\n\tupper_bound = np.nanmean(h2o) + half_sd\n\tprint(upper_bound)\n\tprint(\"upper bound\")\n\tterrestrial_avg = np.multiply(average,water_array) # Mask ocean water\t\n\ta = np.where(terrestrial_avg > upper_bound, 0, terrestrial_avg)\n\ta = np.where(water_array_fin == 1 , 1, a) # add the SW back in \n\ta = np.ma.array(a, mask=np.isnan(a))\n\ta = np.where(a != 0, 1, a)\n\n\tarray2raster(comparison_img, os.path.join(products_dir,'''avg_SW_{}.tif'''.format(doy)), a.data) # write \n\n\t# Now do it for year of interest \n\tyear_average = np.nanmean(np.array([aqua_comparison_arr,terra_comparison_arr]), axis = 0) # smash the aqua and terra NDVIs together\n\tyear_terrestrial = np.multiply(year_average,water_array) # mask ocean water \n\tx = np.where(year_terrestrial > upper_bound, 0, year_terrestrial)\n\tx = np.where(water_array_fin == 1 , 1, x) # add the SW back in \n\ty = np.ma.array(x, mask=np.isnan(x))\n\ty = np.where(y != 0, 1, y)\n\t\t\n\toutfile = '''{}_SW_{}.tif'''.format(year,doy)\n\toutfile = os.path.join(products_dir,outfile)\n\tarray2raster(comparison_img, outfile, y.data)\n\t\n\t\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.6319245100021362,
"alphanum_fraction": 0.647876501083374,
"avg_line_length": 28.405731201171875,
"blob_id": "9ccadc7abd2630b918353ccff65ab5127360ff6e",
"content_id": "f52d3c3f985d531aa5879b81300dd20b410db6eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19496,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 663,
"path": "/fetch_historic.py",
"repo_name": "yantongw/MODIS_tools",
"src_encoding": "UTF-8",
"text": "'''\nThis file fetches the historic MOD09 and MYD09 (Q1 or GQ) surface reflectance data for the length of the MODIS record. \nClouds are masked using the A1 bit fields for the Q1 product and the GA bit fields for the GQ product.\nNDVI is calculated and files are stored in a directory called \"historic\"\nTo select specific products (Q1, GQ) and / or years (2000 - ), change the \"product\" and \"doy\" variables in the params section \n\nDeveloper: Aakash Ahamed ([email protected])\nNASA Goddard Space Flight Center\nApplied Sciences Program\nHydrological Sciences Laboratory \n'''\n\nimport os\nimport ftplib\nimport datetime\nfrom osgeo import gdal\nimport numpy as np\nfrom numpy import *\nimport shutil\nimport itertools\n\n###########################################\n# Small function to grab the current date #\n###########################################\n\ndef get_dates ():\n year = str(datetime.datetime.now().year)\n month = str(datetime.datetime.now().month)\n day = str(datetime.datetime.now().day)\n day_of_year = datetime.datetime.now().timetuple().tm_yday\n doy = str(day_of_year - 0) # set this to go back x number of days\n\n date= {\n \"year\" : year,\n \"month\": month,\n \"day\" : day,\n \"doy\" : doy}\n\n return date\n\ndates = get_dates()\n\n#############################\n########## Params ###########\n#############################\n\n# Set these to the dates and products you wish to analyze \nproduct = \"Q1\"\ndoy = dates['doy']\n\nyears = [x for x in range(2000,2017)] # does not look for 2016 data\n\naqua_years = [x for x in range(2003,2017)] # does not look for 2002 historic data \n\n#############################\n########## Classes ##########\n#############################\n\nclass NDVI_8day():\n\n\tdef __init__ (self, year, doy, sat, product):\n\t\tself.year = year\n\t\tself.doy = doy\n\t\tself.sat = sat\n\t\tself.product = product\n\t\t\n\tdef get_current_directory(self):\n\t\treturn(os.path.dirname(os.path.realpath(__file__)))\t\n\t\t\t\n\tdef get_dates (self): # Leave blank to select the current day or alter the dict to pick a date\n\t\tyear = str(datetime.datetime.now().year)\n\t\tmonth = str(datetime.datetime.now().month)\n\t\tday = str(datetime.datetime.now().day)\n\t\tday_of_year = datetime.datetime.now().timetuple().tm_yday\n\t\tdoy = str(day_of_year - 0) \n\t\t\n\t\tdate= {\n\t\t\"year\" : year,\n\t\t\"month\": month,\n\t\t\"day\" : day,\n\t\t\"doy\" : doy}\n\t\t\t\n\t\treturn date\n\n\tdef ftp_protocols(self,sat,product):\n\t\tprint(\"Performing analysis for \" + sat + \" \" + product)\n\t\tftp = ftplib.FTP('ladsweb.nascom.nasa.gov') # https://ladsweb.nascom.nasa.gov\n\t\tftp.login(\"anonymous\",\"anonymous\")\n\t\tif sat == \"Terra\" and product == \"Q1\": \n\t\t\tftp.cwd('allData/6/MOD09Q1')\n\t\telif sat == \"Terra\" and product == \"A1\":\n\t\t\tftp.cwd('allData/6/MOD09A1')\n\t\telif sat == \"Aqua\" and product == \"Q1\":\n\t\t\tftp.cwd('allData/6/MYD09Q1')\n\t\telif sat == \"Aqua\" and product == \"A1\":\n\t\t\tftp.cwd('allData/6/MYD09A1')\n\t\t\t\n\t\telse: \n\t\t\tprint(\"COULDN'T LOCATE MODIS PRODUCT, TRY AGAIN\")\n\t\tftp.set_pasv(True)\n\t\t\n\t\treturn(ftp)\n\n\tdef get_nearest_date(self, base, dates):\n\t\tnearness = { abs(base.timestamp() - date.timestamp()) : date for date in dates }\n\t\treturn nearness[min(nearness.keys())]\t\n\t\t\n\tdef get_combo_list(self):\n\t\th = ['h26','h27','h28'] # Change to go to a different area of the world\n\t\tv = ['v06','v07','v08'] # These too \n\t\tcombinations = list(itertools.product(*[h,v]))\n\t\tcombo_strings = []\n\t\tfor combo in combinations:\n\t\t\tcombo_strings.append(''.join(combo))\n\t\treturn combo_strings\n\t\n\tdef hdf_to_gtiff_8day(self, file, band):\n\t\tif \"Q1\" in file and band == \"b01\" or \"b02\":\n\t\t\tcommand = '''gdal_translate -of Gtiff HDF4_EOS:EOS_GRID:\"{}\":MOD_Grid_250m_Surface_Reflectance:sur_refl_{} {}_{}.tif '''.format(file,band,file[0:23],band)\n\t\t\tprint(command)\n\t\t\tos.system(command)\n\t\t# GQ command \n\t\n\tdef build_vrt_string(self, dir, band):\n\t\tfiles = os.listdir(dir)\n\t\tlist = [x for x in files if x.endswith(band+\".tif\")]\n\t\tstring = \" \".join(list)\n\t\treturn string\n\n\tdef build_vrt_table(self, file_string):\n\t\toutfile = file_string[0:16] + \"_\" + file_string[-7:-4]\n\t\tcommand = '''gdalbuildvrt {}.vrt {}'''.format(outfile, file_string)\n\t\tos.system(command)\n\t\treturn [x for x in os.listdir(os.getcwd()) if file_string[0:16] in x]\n\n\tdef mosaic(self, vrt):\n\t\tmosaic_cmd = '''gdalwarp {} {}.tif -t_srs EPSG:4326 -dstnodata \"-999\" -overwrite'''.format(vrt,vrt[0:-4])\n\t\tos.system(mosaic_cmd)\n\n\tdef cleanup_hdf(self, dir, combo):\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if x.endswith(\".hdf\")]\n\t\tfor i in files:\n\t\t\tos.remove (i)\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if combo in x]\n\t\tfor i in files:\n\t\t\tos.remove(i)\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if \".vrt\" in x]\n\t\tfor i in files:\n\t\t\tos.remove(i)\n\t\n\tdef read_bits(self, array):\n\t\tbitlist = []\n\t\t\n\t\tfor i in np.nditer(array):\n\t\t\tbitlist.append(bin(i)[2:].zfill(16))\n\t\t\n\t\tcloudmask = []\n\t\t\n\t\tfor item in bitlist:\n\t\t\tif item[-4:-2] == \"01\" or item[-4:-2] == \"10\" :# These are the MODIS bit fields \n\t\t\t\tcloudmask.append(0)\n\t\t\telse:\n\t\t\t\tcloudmask.append(1)\n\t\t\n\t\tcloud_array = np.array(cloudmask).reshape(array.shape[0],array.shape[1])\n\t\treturn(cloud_array)\t\t\n\t\t\n\tdef get_raster_extent(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\n\t\treturn(extent)\n\t\n\tdef get_raster_resolution(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\n\t\treturn(pixelX,pixelY)\n\t\n\tdef clip(self, extent, raster, outfiles):\n\t\tstr_extent = ' '.join(map(str,extent))\n\t\tcommand = '''gdal_translate -projwin {} {} {}'''.format(str_extent, raster, outfiles)\n\t\tos.system(command)\n\t\treturn(outfiles)\n\t\n\tdef resample(self, resolution, raster, outfiles):\n\t\tstr_resolution = ' '.join(map(str,resolution))\n\t\tcommand = '''gdalwarp -tr {} {} {}'''.format(str_resolution, raster, outfiles)\n\t\tprint(command)\n\t\tos.system(command)\n\n\tdef read_as_array(self, raster):\n\t\tds = gdal.Open(raster)\n\t\tarray = np.array(ds.GetRasterBand(1).ReadAsArray())\n\t\treturn array\n\t\t\n\tdef array2raster(self, rasterfn,newRasterfn,array):\n\t\traster = gdal.Open(rasterfn)\n\t\tgeotransform = raster.GetGeoTransform()\n\t\tproj = raster.GetProjection()\n\t\toriginX = geotransform[0]\n\t\toriginY = geotransform[3]\n\t\tpixelWidth = geotransform[1]\n\t\tpixelHeight = geotransform[5]\n\t\tcols = raster.RasterXSize\n\t\trows = raster.RasterYSize\n\n\t\tdriver = gdal.GetDriverByName('GTiff')\n\t\toutRaster = driver.Create(newRasterfn, cols, rows, 1, gdal.GDT_Float32) # Change dtype here\n\t\toutRaster.SetGeoTransform((originX, pixelWidth, 0, originY, 0, pixelHeight))\n\t\toutband = outRaster.GetRasterBand(1)\n\t\toutband.WriteArray(array)\n\t\t\n\t\toutRaster.SetProjection(proj)\n\t\toutband.FlushCache()\n\t\n\nclass CloudMask8day():\n\n\tdef __init__ (self, year, doy, sat, product):\n\t\tself.year = year\n\t\tself.doy = doy\n\t\tself.sat = sat\n\t\tself.product = product\n\t\t\n\tdef get_current_directory(self):\n\t\treturn(os.path.dirname(os.path.realpath(__file__)))\t\n\t\t\t\n\tdef get_dates (self): # Leave blank to select the current day or alter the dict to pick a date\n\t\tyear = str(datetime.datetime.now().year)\n\t\tmonth = str(datetime.datetime.now().month)\n\t\tday = str(datetime.datetime.now().day)\n\t\tday_of_year = datetime.datetime.now().timetuple().tm_yday\n\t\tdoy = str(day_of_year - 0) #str(doy) #\n\t\t\n\t\tdate= {\n\t\t\"year\" : year,\n\t\t\"month\": month,\n\t\t\"day\" : day,\n\t\t\"doy\" : doy}\n\t\t\t\n\t\treturn date\n\n\tdef ftp_protocols(self,sat,product):\n\t\tprint(\"Performing analysis for \" + sat + \" \" + product)\n\t\tftp = ftplib.FTP('ladsweb.nascom.nasa.gov') # https://ladsweb.nascom.nasa.gov\n\t\tftp.login(\"anonymous\",\"anonymous\")\n\t\tif sat == \"Terra\" and product == \"Q1\": \n\t\t\tftp.cwd('allData/6/MOD09Q1')\n\t\telif sat == \"Terra\" and product == \"A1\":\n\t\t\tftp.cwd('allData/6/MOD09A1')\n\t\telif sat == \"Aqua\" and product == \"Q1\":\n\t\t\tftp.cwd('allData/6/MYD09Q1')\n\t\telif sat == \"Aqua\" and product == \"A1\":\n\t\t\tftp.cwd('allData/6/MYD09A1')\n\t\t\t\n\t\telse: \n\t\t\tprint(\"COULDN'T LOCATE MODIS PRODUCT, TRY AGAIN\")\n\t\tftp.set_pasv(True)\n\t\t\n\t\treturn(ftp)\n\n\tdef get_combo_list(self):\n\t\th = ['h26','h27','h28'] # Change to go to a different area of the world\n\t\tv = ['v06','v07','v08'] # These too \n\t\tcombinations = list(itertools.product(*[h,v]))\n\t\tcombo_strings = []\n\t\tfor combo in combinations:\n\t\t\tcombo_strings.append(''.join(combo))\n\t\treturn combo_strings\n\t\n\tdef hdf_to_gtiff(self, file, band):\n\t\tif \"A1\" in file:\n\t\t\tcommand = '''gdal_translate -of Gtiff HDF4_EOS:EOS_GRID:\"{}\":MOD_Grid_500m_Surface_Reflectance:sur_refl_state_500m {}_{}.tif '''.format(file,file[0:23],\"bqa\")\n\t\t\tos.system(command)\n\n\t\treturn([x for x in os.listdir(os.getcwd()) if x.endswith((band)+\".tif\")])\n\t\n\tdef build_vrt_string(self, dir, band):\n\t\tfiles = os.listdir(dir)\n\t\tlist = [x for x in files if x.endswith(band+\".tif\")]\n\t\tstring = \" \".join(list)\n\t\treturn string\n\n\tdef build_vrt_table(self, file_string):\n\t\toutfile = file_string[0:16] + \"_\" + file_string[-7:-4]\n\t\tcommand = '''gdalbuildvrt {}.vrt {}'''.format(outfile, file_string)\n\t\tos.system(command)\n\t\treturn [x for x in os.listdir(os.getcwd()) if file_string[0:16] in x]\n\n\tdef mosaic(self, vrt):\n\t\tmosaic_cmd = '''gdalwarp {} {}.tif -t_srs EPSG:4326 -dstnodata \"-999\" -overwrite'''.format(vrt,vrt[0:-4])\n\t\tos.system(mosaic_cmd)\n\t\t\n\tdef read_bits(self, array):\n\t\tbitlist = []\n\t\t\n\t\tfor i in np.nditer(array):\n\t\t\tbitlist.append(bin(i)[2:].zfill(16))\n\t\t\n\t\tcloudmask = []\n\t\t\n\t\tfor item in bitlist:\n\t\t\tif item[-2:] == \"01\" or item[-2:] == \"10\" or item[-3] == \"1\":# These are the MODIS bit fields \n\t\t\t\tcloudmask.append(0)\n\t\t\telse:\n\t\t\t\tcloudmask.append(1)\n\t\t\n\t\tcloud_array = np.array(cloudmask).reshape(array.shape[0],array.shape[1])\n\t\treturn(cloud_array)\t\n\t\t\n\tdef cleanup_hdf(self, dir, combo):\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if x.endswith(\".hdf\")]\n\t\tfor i in files:\n\t\t\tos.remove (i)\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if combo in x]\n\t\tfor i in files:\n\t\t\tos.remove(i)\n\t\tfiles = [x for x in os.listdir(os.getcwd()) if \".vrt\" in x]\n\t\tfor i in files:\n\t\t\tos.remove(i)\n\t\t\t\n\tdef get_raster_extent(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\n\t\treturn(extent)\n\t\t\n\tdef get_raster_resolution(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\n\t\treturn(pixelX,pixelY)\n\t\t\n\tdef clip(self, extent, raster, outfiles):\n\t\tstr_extent = ' '.join(map(str,extent))\n\t\tcommand = '''gdal_translate -projwin {} {} {}'''.format(str_extent, raster, outfiles)\n\t\tos.system(command)\n\t\treturn(outfiles)\n\t\t\n\tdef resample(self, resolution, raster, outfiles):\n\t\tstr_resolution = ' '.join(map(str,resolution))\n\t\tcommand = '''gdalwarp -tr {} {} {}'''.format(str_resolution, raster, outfiles)\n\t\tprint(command)\n\t\tos.system(command)\n\n\tdef read_as_array(self, raster):\n\t\tds = gdal.Open(raster)\n\t\tarray = np.array(ds.GetRasterBand(1).ReadAsArray())\n\t\treturn array\n\t\t\n\tdef array2raster(self, rasterfn,newRasterfn,array):\n\t\traster = gdal.Open(rasterfn)\n\t\tgeotransform = raster.GetGeoTransform()\n\t\tproj = raster.GetProjection()\n\t\toriginX = geotransform[0]\n\t\toriginY = geotransform[3]\n\t\tpixelWidth = geotransform[1]\n\t\tpixelHeight = geotransform[5]\n\t\tcols = raster.RasterXSize\n\t\trows = raster.RasterYSize\n\n\t\tdriver = gdal.GetDriverByName('GTiff')\n\t\toutRaster = driver.Create(newRasterfn, cols, rows, 1, gdal.GDT_Float32) # Change dtype here\n\t\toutRaster.SetGeoTransform((originX, pixelWidth, 0, originY, 0, pixelHeight))\n\t\toutband = outRaster.GetRasterBand(1)\n\t\toutband.WriteArray(array)\n\t\t\n\t\toutRaster.SetProjection(proj)\n\t\toutband.FlushCache()\n\t\t\n#############################\n########### Main ############\n#############################\n\ndef ndvi_8day(product,year,doy,satellite):\n\timage = NDVI_8day(year, doy , satellite, product)\n\tyear = image.year\n\tdoy = image.doy\n\tsat = image.sat\n\tprod = image.product\n\n\tprint(\"YEAR IS : \" + str(year))\n\tprint(\"DOY IS : \" + str(doy))\n\tprint(\"SATELLITE IS : \" + str(sat))\n\tprint(\"PRODUCT IS : \" + image.product)\n\n\tftp = image.ftp_protocols(image.sat,image.product)\n\tfiles = ftp.nlst()\n\n\tdir = ftp.cwd(\"\".join(image.year)) # cd to year \n\tfiles = ftp.nlst()\n\t\n\tdates = [int(f) for f in files] # Grab the nearest window to input date \n\t\n\tnearest = min(dates, key=lambda x:abs(x-int(image.doy)))\n\t\n\tnearest = str(nearest)\n\t\n\t# Make sure \"nearest\" is 3 characters long \n\tnearest = nearest.zfill(3)\n\t\t\n\tdir = ftp.cwd(\"\".join(nearest)) # cd to day \n\t\n\tfiles = ftp.nlst()\n\n\tcombos = image.get_combo_list() # get list of tiles \n\t\n\tfiles_of_interest = []\n\n\tfor file in files:\n\t\tfor combo in combos:\n\t\t\tif \"\".join(combo) in \"\".join(file):\n\t\t\t\tfiles_of_interest.append(file)\n\t\t\t\n\tif len(files_of_interest) !=9:\n\t\tprint('''TILES OF INTEREST DO NOT EXIST FOR {}... MOVING TO NEXT YEAR'''.format(str(year)))\n\t\treturn\n\t\t\t\t\n\t# Download\n\tfor i in files_of_interest:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\n\tfiles = [x for x in os.listdir(image.get_current_directory()) if x.endswith('.hdf')]\n\tprint(files)\n\n\tfor file in files:\n\t\tprint(file[0:23])\n\t\timage.hdf_to_gtiff_8day(\"\".join(file),\"b01\")\n\t\timage.hdf_to_gtiff_8day(\"\".join(file),\"b02\")\n\t\timage.hdf_to_gtiff_8day(\"\".join(file),\"bqa\")\n\n\t# Now you have the .tiff files. Mosaic them\t\n\tb1 = image.build_vrt_string(image.get_current_directory(),\"b01\")\n\tb2 = image.build_vrt_string(image.get_current_directory(),\"b02\")\n\n\timage.build_vrt_table(b1)\n\timage.build_vrt_table(b2)\n\n\tvrt_files = [x for x in os.listdir(image.get_current_directory()) if x.endswith(\".vrt\")]\n\n\tfor file in vrt_files:\n\t\timage.mosaic(file)\n\t\t\n\tfor combo in combos:\n\t\timage.cleanup_hdf(os.listdir(image.get_current_directory()),\"\".join(combo))\n\n\t# Clip\n\treference_file = [x for x in os.listdir(image.get_current_directory()) if \"water_mask.tif\" in x]\n\treference_file = \"\".join(reference_file)\n\n\textent = image.get_raster_extent(reference_file)\n\t# resolution = image.get_raster_resolution(reference_file)\n\n\t# Clip\n\tfiles = [x for x in os.listdir(image.get_current_directory()) if nearest in x]\n\tfor i in files:\n\t\timage.clip (extent, \"\".join(i), \"\".join(i[:-4])+\"_clip.tif\") \n\n\t# Cleanup \n\tfiles = [x for x in os.listdir(image.get_current_directory()) if not os.path.isdir(x) and nearest in x and \"clip\" not in x]\n\tfor i in files:\n\t\tos.remove(i)\n\n\t# Calculate NDVI with checks for funky data \n\tb2 = \"\".join([x for x in os.listdir(image.get_current_directory()) if \"b02\" in x])\n\tb2 = os.path.join(image.get_current_directory(),b2)\n\tb1 = \"\".join([x for x in os.listdir(image.get_current_directory()) if \"b01\" in x])\n\tb1 = os.path.join(image.get_current_directory(),b1)\n\n\tg = gdal.Open(b1)\n\tred = g.ReadAsArray()\t\n\tred.astype(float32)\n\n\tg = gdal.Open(b2)\n\tnir = g.ReadAsArray()\n\tnir.astype(float32)\n\t\t\t\n\tcheck = np.logical_and ( red > 0, nir > 0 )\n\tndvi = np.where ( check, (nir - red ) / ( nir + red ), -999)\n\t\t\t\n\tndvi[ndvi>1] = 0\n\tndvi[ndvi < -1] =0\n\n\tprint(\"################## NDVI ##############\")\n\n\tprint(ndvi)\n\tprint(ndvi.shape)\n\tprint(np.min(ndvi))\n\tprint(np.max(ndvi))\n\tprint(np.mean(ndvi))\n\n\t\n\t''' Cloud '''\n\n\tyear = image.year\n\tdoy = image.doy\n\tsat = image.sat\n\tif image.product == \"GQ\":\n\t\tproduct = \"GA\"\n\tif image.product == \"Q1\":\n\t\tproduct = \"A1\"\n\t\t\n\tprint(year,doy,sat,product)\n\t\t\n\tmask = CloudMask8day(year,doy,sat,product)\n\n\tftp = mask.ftp_protocols(sat,product)\n\tfiles = ftp.nlst()\n\n\tdir = ftp.cwd(\"\".join(mask.year)) # Cd to a year\n\tfiles = ftp.nlst()\n\n\tdir = ftp.cwd(\"\".join(nearest)) # Cd to a day\n\tfiles = ftp.nlst()\n\n\tcombos = image.get_combo_list() # get relevant path/row combinations \n\n\tfiles_of_interest = []\n\n\tfor file in files:\n\t\tfor combo in combos:\n\t\t\tif \"\".join(combo) in \"\".join(file):\n\t\t\t\tfiles_of_interest.append(file)\n\t\t\t\t\n\t# Download\n\tfor i in files_of_interest:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\n\tfiles = [x for x in os.listdir(image.get_current_directory()) if x.endswith('.hdf')]\n\n\tfor file in files:\n\t\tmask.hdf_to_gtiff(\"\".join(file),\"bqc\")\n\n\t# Mosaic \n\tqc = mask.build_vrt_string(mask.get_current_directory(),\"bqa\")\n\n\tmask.build_vrt_table(qc)\n\n\tvrt_files = [x for x in os.listdir(mask.get_current_directory()) if x.endswith(\".vrt\")]\n\n\tfor file in vrt_files:\n\t\tmask.mosaic(file)\n\n\tfor combo in combos:\n\t\tmask.cleanup_hdf(os.listdir(mask.get_current_directory()),\"\".join(combo))\n\t\t\n\t# Clip\n\treference_file = [x for x in os.listdir(mask.get_current_directory()) if \"water_mask.tif\" in x] # \"b01\" in x] # dryBaseSEA.tif reference.tif \n\treference_file = \"\".join(reference_file)\n\n\textent = mask.get_raster_extent(reference_file)\n\n\t# Clip\n\tfiles = [x for x in os.listdir(mask.get_current_directory()) if nearest and \"bqa\" in x]\n\tfor i in files:\n\t\tmask.clip (extent, \"\".join(i), \"\".join(i[:-4])+\"_clip.tif\") \n\n\t# Cleanup \n\tfiles = [x for x in os.listdir(mask.get_current_directory()) if not os.path.isdir(x) and nearest in x and \"clip\" not in x]\n\tprint(files)\n\tfor i in files:\n\t\tos.remove(i)\n\n\t# Build cloud mask\n\tfile = [x for x in os.listdir(mask.get_current_directory()) if \"clip\" in x and \"bqa\" in x]\n\tfile = \"\".join(file)\n\tfile = os.path.join(mask.get_current_directory(),file)\n\tprint(file)\n\n\tcloud_array = mask.read_as_array(file)\n\tcloud_array = mask.read_bits(cloud_array)\n\n\tcloud_array = np.repeat(cloud_array,2, axis = 0)\n\tcloud_array = np.repeat(cloud_array,2, axis = 1)\n\n\t# Apply cloud mask\n\talmost_fin_array = np.multiply(cloud_array,ndvi)\n\n\t# Apply water mask\n\twater_array = [x for x in os.listdir(os.getcwd()) if \"water\" in x]\n\twater_array = \"\".join(water_array)\n\twater_array = image.read_as_array(water_array)\n\n\tfin_array = np.multiply(almost_fin_array,1)#water_array)\n\n\tfin_array[fin_array == 0] = np.nan\n\n\t# TODO: make some stats about image. 1) cloud fraction, 2) cloud free avg NDVI value \n\n\t# Write NDVI raster \n\tmatch_raster = [x for x in os.listdir(os.getcwd()) if \"b01\" in x and \"clip\" in x]\n\tmatch_raster = \"\".join(match_raster)\n\n\tmask.array2raster(match_raster,image.sat+\"_\"+image.year+ \"_\"+nearest+\"_ndvi_8d.tif\", fin_array)\n\n\t# Cleanup \n\tfiles = [x for x in os.listdir(image.get_current_directory()) if not os.path.isdir(x) and \"clip\" in x]\n\tprint(files)\n\tfor f in files:\n\t\tos.remove(f)\n\t\t\n\t# Move to new directory \t\n\tfile = [x for x in os.listdir(image.get_current_directory()) if x.endswith(\".tif\") and \"ndvi\" in x]\n\tprint(file)\n\tfile = \"\".join(file)\n\tprint(file)\n\n\tif os.path.exists(os.path.join(image.get_current_directory(),\"historic\")):\n\t\tpass\n\telse:\n\t\tos.mkdir(os.path.join(image.get_current_directory(),\"historic\"))\n\t\t\t\n\tnew_dir = os.path.join(image.get_current_directory(),\"historic\")\n\n\tshutil.copy(file,new_dir)\n\tos.remove(file)\n\t\n###########################################\n# Small function to grab the current date #\n###########################################\n\n\n\t\n# dates = get_dates()\n\nfor year in aqua_years:\n\tndvi_8day(product,str(year),str(doy),\"Aqua\")\n\t\nfor year in years:\n\tndvi_8day(product,str(year),str(doy),\"Terra\")\n"
},
{
"alpha_fraction": 0.6285694241523743,
"alphanum_fraction": 0.6511757969856262,
"avg_line_length": 28.042682647705078,
"blob_id": "663e338bca5b5c8f65c765d8eaba93a072289ff8",
"content_id": "61a6fa86e2d080fd3872411d5e015becf99d368e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14288,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 492,
"path": "/fetch_NRT.py",
"repo_name": "yantongw/MODIS_tools",
"src_encoding": "UTF-8",
"text": "'''\nThis program does the following:\n1) Fetch the most recent MOD09GQ Surface Reflectance files from LANCE\n2) Fetch the most recent MOD35_L2 cloud mask files from LANCE\n3) Calculates NDVI, masks clouds, resamples, clips to SE Asia region. \n4) Deposits files in the \"daily_files_nrt\" directory\n\nYou must sign up for an account and supply credentials at L 63\nIf this script ever breaks for inexplicable reasons, try changing to nrt4, nrt2, nrt1 in previous line\n\nDeveloper: Aakash Ahamed ([email protected])\nNASA Goddard Space Flight Center\nApplied Sciences Program\nHydrological Sciences Laboratory \n'''\n\n#############\n# Libraries #\n#############\n\nimport os\nimport ftplib\nimport datetime\nfrom time import gmtime, strftime\nfrom osgeo import gdal\nimport numpy as np\nfrom numpy import *\nimport shutil\nimport argparse\n\n#############\n# Functions #\n#############\n\nclass NDVI_NRT():\n\t\n\tdef __init__ (self):\n\t\tpass\n\t\n\tdef get_current_directory(self):\n\t\treturn(os.path.dirname(os.path.realpath(__file__)))\t\n\t\t\t\t\n\tdef get_dates(self):\n\t\tyear = str(datetime.datetime.now().year)\n\t\tmonth = str(datetime.datetime.now().month)\n\t\tday = str(datetime.datetime.now().day)\n\t\tday_of_year = datetime.datetime.now().timetuple().tm_yday\n\t\thour = str(datetime.datetime.now().hour)\n\t\tminute = str(datetime.datetime.now().minute)\n\t\tdoy = str(day_of_year - 0) # <-- Change this to go back x days \n\t\t\n\t\tdate= {\n\t\t\"year\" : year,\n\t\t\"month\": month,\n\t\t\"day\" : day,\n\t\t\"doy\" : doy,\n\t\t\"hour\" : hour,\n\t\t\"minute\" : minute}\n\t\t\t\n\t\treturn date\n\n\tdef ftp_protocols(self):\n\t\tftp = ftplib.FTP('nrt3.modaps.eosdis.nasa.gov')\n\t\tftp.login(\"username\",\"password\") # ENTER USERNAME HERE\n\t\tftp.cwd('orders/flood_watch')\n\t\tftp.set_pasv(True)\n\t\treturn(ftp)\n\t\n\tdef get_latest_files(self, files_list, product):\n\t\n\t\tlatest_list = []\n\t\tfor file in files_list:\n\t\t\tlatest_files = []\n\t\t\tfor i in file:\n\t\t\t\tif i.startswith(product):\n\t\t\t\t\tlatest_files.append(i[24:36]) # This is the time string in the files \n\t\t\tlatest_list.append(latest_files)\n\t\t\t\t\t\n\t\tlatest_images = []\n\t\tfor list in latest_list:\n\t\t\tlist.sort() \n\t\t\tlatest_images.append(list[-1])\n\n\t\tfinal_prods = []\n\t\tfor image in latest_images:\n\t\t\tfor list in files_list:\n\t\t\t\tfor item in list:\n\t\t\t\t\tif image in item:\n\t\t\t\t\t\tfinal_prods.append(item)\n\n\t\treturn(final_prods)\n\t\t\n\t\t\n\tdef get_latest_cloud_files(self, files_list, product):\n\t\n\t\tlatest_list = []\n\t\tfor file in files_list:\n\t\t\tlatest_files = []\n\t\t\tfor i in file:\n\t\t\t\tif i.startswith(product):\n\t\t\t\t\tlatest_files.append(i[27:39]) # Same as above function \n\t\t\tlatest_list.append(latest_files)\n\t\t\t\t\t\n\t\tlatest_images = []\n\t\tfor list in latest_list:\n\t\t\tlist.sort() \n\t\t\tlatest_images.append(list[-1])\n\n\t\tfinal_prods = []\n\t\tfor image in latest_images:\n\t\t\tfor list in files_list:\n\t\t\t\tfor item in list:\n\t\t\t\t\tif image in item:\n\t\t\t\t\t\tfinal_prods.append(item)\n\n\t\treturn(final_prods)\n\t\t\n\tdef build_vrt_string(self, dir, band, product):\n\t\tfiles = os.listdir(dir)\n\t\tlist = [x for x in files if x.endswith(band+\".tif\") and product in x]\n\t\tstring = \" \".join(list)\n\t\treturn string\n\n\tdef build_vrt_table(self, file_string):\n\t\toutfile = file_string[0:14] + \"_\" + file_string[-10:-4]\n\t\tcommand = '''gdalbuildvrt {}.vrt {}'''.format(outfile, file_string)\n\t\tos.system(command)\n\t\treturn [x for x in os.listdir(os.getcwd()) if file_string[0:16] in x]\n\t\t\n\tdef build_cloud_vrt_table(self, file_string):\n\t\toutfile = file_string[0:17] + \"_\" + file_string[-6:-4]\n\t\tcommand = '''gdalbuildvrt {}.vrt {}'''.format(outfile, file_string)\n\t\tos.system(command)\n\t\treturn [x for x in os.listdir(os.getcwd()) if file_string[0:16] in x]\n\t\t\n\tdef mosaic(self, vrt):\n\t\tmosaic_cmd = '''gdalwarp {} {}.tif -t_srs EPSG:4326 -dstnodata \"-999\" -overwrite'''.format(vrt,vrt[0:-4])\n\t\tos.system(mosaic_cmd)\n\t\n\tdef get_raster_extent(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\n\t\treturn(extent)\n\t\n\tdef clip(self, extent, raster, outfiles):\n\t\tstr_extent = ' '.join(map(str,extent))\n\t\tcommand = '''gdal_translate -projwin {} {} {}'''.format(str_extent, raster, outfiles)\n\t\tos.system(command)\n\t\treturn(outfiles)\n\t\t\n\tdef read_as_array(self, raster):\n\t\tds = gdal.Open(raster)\n\t\tflood_array = np.array(ds.GetRasterBand(1).ReadAsArray())\n\t\treturn flood_array\n\n\tdef calc_NDVI(self, list, sat): \n\t\tif sat == \"MOD\": \n\t\t\tb1 = [x for x in list if x.startswith(\"MOD09\") if \"Band_1\" in x]\n\t\t\tb1 = \"\".join(b1)\t\t\t\n\t\t\tb2 = [x for x in list if x.startswith(\"MOD09\") if \"Band_2\" in x]\n\t\t\tb2 = \"\".join(b2)\n\n\t\t\t# Read as array \n\t\t\tg = gdal.Open(b1)\n\t\t\tred = g.ReadAsArray()\n\n\t\t\tg = gdal.Open(b2)\n\t\t\tnir = g.ReadAsArray()\n\n\t\t\tred = array(red, dtype = float32)\n\t\t\tnir = array(nir, dtype = float32)\n\n\t\t\tcheck = np.logical_and ( red > 0, nir > 0 )\n\t\t\tndvi = np.where ( check, (nir - red ) / ( nir + red ), -999)\n\t\t\t\n\t\t\tndvi[ndvi>1] = np.nan #0\n\t\t\tndvi[ndvi < -1] = np.nan #0\n\t\t\t\n\t\t\treturn(ndvi)\n\t\t\t\n\t\tif sat == \"MYD\":\n\t\t\tb1 = [x for x in list if x.startswith(\"MYD09\") if \"Band_1\" in x]\n\t\t\tb1 = \"\".join(b1)\n\t\t\tb2 = [x for x in list if x.startswith(\"MYD09\") if \"Band_2\" in x]\n\t\t\tb2 = \"\".join(b2)\n\t\t\t\n\t\t\t# Read as array \n\t\t\tg = gdal.Open(b1)\n\t\t\tred = g.ReadAsArray()\n\t\t\t\n\t\t\tred.astype(float32)\n\n\t\t\tg = gdal.Open(b2)\n\t\t\tnir = g.ReadAsArray()\n\t\t\t\n\t\t\tnir.astype(float32)\n\t\t\t\n\t\t\tcheck = np.logical_and ( red > 0, nir > 0 )\n\t\t\tndvi = np.where ( check, (nir - red ) / ( nir + red ), -999)\n\t\t\t\n\t\t\tndvi[ndvi>1] = np.nan #0\n\t\t\tndvi[ndvi < -1] = np.nan #0\n\t\t\t\n\t\t\treturn(ndvi)\n\t\t\t\n\tdef write_raster(self, array, raster, dates, satellite):\n\t\tmatch_raster = gdal.Open(raster)\n\t\tcols = array.shape[0]\n\t\trows = array.shape[1]\n\t\ttrans=match_raster.GetGeoTransform()\n\t\tproj=match_raster.GetProjection()\n\t\t# nodatav = array.GetNoDataValue()\n\t\t\n\t\toutfile = satellite+dates['year']+dates['doy']+\".tif\"\n\t\t\n\t\t# Create the file, using the information from the original file\n\t\toutdriver = gdal.GetDriverByName(\"GTiff\")\n\t\toutdata = outdriver.Create(str(outfile), rows, cols, 1, gdal.GDT_Float32)\n\n\t\t# Write the array to the file\n\t\toutdata.GetRasterBand(1).WriteArray(array)\n\t\t\n\t\t# Georeference the image\n\t\toutdata.SetGeoTransform(trans)\n\n\t\t# Write projection information\n\t\toutdata.SetProjection(proj)\n\t\treturn outfile\n\t\t\n\tdef array2raster(self, rasterfn,newRasterfn,array):\n\t\traster = gdal.Open(rasterfn)\n\t\tgeotransform = raster.GetGeoTransform()\n\t\tproj = raster.GetProjection()\n\t\toriginX = geotransform[0]\n\t\toriginY = geotransform[3]\n\t\tpixelWidth = geotransform[1]\n\t\tpixelHeight = geotransform[5]\n\t\tcols = raster.RasterXSize\n\t\trows = raster.RasterYSize\n\n\t\tdriver = gdal.GetDriverByName('GTiff')\n\t\toutRaster = driver.Create(newRasterfn, cols, rows, 1, gdal.GDT_Float32) # Change dtype here\n\t\toutRaster.SetGeoTransform((originX, pixelWidth, 0, originY, 0, pixelHeight))\n\t\toutband = outRaster.GetRasterBand(1)\n\t\toutband.WriteArray(array)\n\t\t\t\n\t\toutRaster.SetProjection(proj)\n\t\toutband.FlushCache()\n\t\t\n\tdef build_cloud_tiff(self, list):\n\t\tcommand = '''gdal_translate -ot \"Byte\" -of \"Gtiff\" -b \"5\" {} {}.tif '''.format(\"\".join(list),\"\".join(list[0:26]) + \"_b5\")\n\t\tprint(command)\n\t\tos.system(command)\n\t\t\n\tdef read_bits (self, sat):\n\t\tmask = [x for x in os.listdir(os.getcwd()) if x.startswith(sat+\"35\") if x.endswith(\"b5.tif\")]\n\t\tmask = \"\".join(mask)\n\t\tmask = os.path.join(os.getcwd(),mask)\n\t\tmask = gdal.Open(mask)\n\t\tmask = mask.ReadAsArray()\n\t\t\n\t\t# read the bits \n\t\tbitlist = []\n\n\t\tfor x in np.nditer(mask):\n\t\t\tbitlist.append(bin(x)[2:].zfill(8)) # change to zpad different lengths \n\t\t\n\t\tcloudmask = []\n\n\t\tfor item in bitlist:\n\t\t\tif item[5:7] == \"00\" or item[5:7] == \"01\" or item[5:7] == \"10\":\n\t\t\t\tcloudmask.append(0)\n\t\t\telse:\n\t\t\t\tcloudmask.append(1)\n\n\t\tcloud_array = np.array(cloudmask).reshape(mask.shape[0],mask.shape[1])\n\t\treturn(cloud_array)\n\t\t\n\tdef get_raster_resolution(self, raster):\n\t\tr = gdal.Open(raster)\n\t\tgeoTransform = r.GetGeoTransform()\n\t\tulx = geoTransform[0]\n\t\tuly = geoTransform[3]\n\t\tlrx = ulx + geoTransform[1]*r.RasterXSize\n\t\tlry = uly + geoTransform[5]*r.RasterYSize\n\t\tpixelX=geoTransform[1]\n\t\tpixelY=geoTransform[5]\n\t\textent = [ulx,uly,lrx,lry] \n\t\tdel geoTransform\n\t\treturn(pixelX,pixelY)\n\t\t\n\tdef resample(self, resolution, raster, outfiles):\n\t\tstr_resolution = ' '.join(map(str,resolution))\n\t\tcommand = '''gdalwarp -tr {} {} {} -overwrite'''.format(str_resolution, raster, outfiles)\n\t\tprint(command)\n\t\tos.system(command)\n\t\treturn(outfiles)\n\n\tdef cleanup(self, directory):\n\t\tfiles = [x for x in os.listdir(directory) if \"water_mask\" not in x and x.endswith(\".tif\") or x.endswith(\".hdf\")]\n\t\tfor i in files:\n\t\t\tos.remove(i)\n\t\tvrts = [x for x in os.listdir(os.getcwd()) if x.endswith(\".vrt\")]\n\t\tfor vrt in vrts:\n\t\t\tos.remove(vrt)\n\t\t\t\n########\n# MAIN #\n########\n\ndef main():\n\n\t#######################\n\t# NRT NDVI (M*D09) GQ #\n\t#######################\n\t\n\t# Make class instance\n\timage = NDVI_NRT()\n\n\t# Connect to FTP and cd to relevant dir \n\tftp = image.ftp_protocols()\n\tdates = image.get_dates()\n\tstarttime = strftime(\"%Y-%m-%d %H:%M:%S\", gmtime()) # print start time for logs \n\tprint(starttime)\n\n\ttile_dict = {\n\t\t\"1\" : \"*100E010N*\",\n\t\t\"2\" : \"*100E020N*\",\n\t\t\"3\" : \"*100E030N*\",\n\t\t\"4\" : \"*090E010N*\",\n\t\t\"5\" : \"*090E020N*\",\n\t\t\"6\" : \"*090E030N*\",\n\t\t\"7\" : \"*110E010N*\",\n\t\t\"8\" : \"*110E020N*\",\n\t\t\"9\" : \"*110E030N*\"\n\t\t}\n\n\tfiles_list = []\t\n\n\t# Make list of lists containing files for each tile\n\tfor k,v in tile_dict.items():\n\t\tfiles_list.append(ftp.nlst(\"*\"+dates['year']+dates['doy']+v))\n\n\t# Filter those lists for the latest files\n\tMOD09_prods = image.get_latest_files(files_list, \"MOD09\")\n\tMOD09_prods = [x for x in MOD09_prods if \"Band_7\" not in x]\n\n\tfor i in MOD09_prods:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\n\tMYD09_prods = image.get_latest_files(files_list, \"MYD09\")\n\tMYD09_prods = [x for x in MYD09_prods if \"Band_7\" not in x]\n\n\tfor i in MYD09_prods:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\t\t\n\t# Build VRTs for b1 and b2 and Mosaic\n\tMYD_b1 = image.build_vrt_string(os.getcwd(),\"Band_1\",\"MYD\")\n\tMYD_b2 = image.build_vrt_string(os.getcwd(),\"Band_2\",\"MYD\")\n\n\timage.build_vrt_table(MYD_b1)\n\timage.build_vrt_table(MYD_b2)\n\n\tMOD_b1 = image.build_vrt_string(os.getcwd(),\"Band_1\",\"MOD\")\n\tMOD_b2 = image.build_vrt_string(os.getcwd(),\"Band_2\",\"MOD\")\n\n\timage.build_vrt_table(MOD_b1)\n\timage.build_vrt_table(MOD_b2)\n\n\tvrt_files = [x for x in os.listdir(image.get_current_directory()) if x.endswith(\".vrt\")]\n\tfor file in vrt_files:\n\t\timage.mosaic(file)\n\t\t\n\t# Clean up\n\ttrash = [x for x in os.listdir(os.getcwd()) if \"250m\" in x or x.endswith(\".vrt\")]\n\tfor i in trash:\n\t\tos.remove(i)\n\n\t# Calculate NDVI \n\tMYD_mosaics = [x for x in os.listdir(os.getcwd()) if x.startswith(\"MYD09\")] #x.endswith(\"clip.tif\")]\t\n\tMYD_ndvi = image.calc_NDVI(MYD_mosaics, \"MYD\")\n\n\tMOD_mosaics = [x for x in os.listdir(os.getcwd()) if x.startswith(\"MOD09\")] #x.endswith(\"clip.tif\")]\t\n\tMOD_ndvi = image.calc_NDVI(MOD_mosaics, \"MOD\")\n\n\t###############\n\t# Cloud Masks #\n\t###############\n\t\n\t# Grab the cloud masks\n\tMOD35_prods = image.get_latest_cloud_files(files_list, \"MOD35_L2\")\n\n\tfor i in MOD35_prods:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\t\t\n\tMYD35_prods = image.get_latest_cloud_files(files_list, \"MYD35_L2\")\n\n\tfor i in MYD35_prods:\n\t\tftp.retrbinary('RETR %s' % i, open(i,\"wb\").write)\n\t\n\t# Convert the HDF files to tiffs\n\tcloud_files_aqua = [x for x in os.listdir(os.getcwd()) if \"MYD35_L2\" in x]\n\tfor file in cloud_files_aqua:\n\t\timage.build_cloud_tiff(file)\n\n\tcloud_files_terra = [x for x in os.listdir(os.getcwd()) if \"MOD35_L2\" in x]\t\n\tfor file in cloud_files_terra:\n\t\timage.build_cloud_tiff(file)\n\t\t\n\t# Mosaic\n\tMYD_35 = image.build_vrt_string(os.getcwd(), \"b5\", \"MYD35_L2\")\n\tMOD_35 = image.build_vrt_string(os.getcwd(), \"b5\", \"MOD35_L2\")\n\n\timage.build_cloud_vrt_table(MYD_35)\n\timage.build_cloud_vrt_table(MOD_35)\n\n\tcloud_vrt = [x for x in os.listdir(os.getcwd()) if \"35\" in x if x.endswith(\".vrt\")]\n\tfor i in cloud_vrt:\n\t\timage.mosaic(i)\n\t\n\t# Clean up \n\tcloud_trash = [x for x in os.listdir(os.getcwd()) if \"N\" in x if \"E\" in x]\n\tfor i in cloud_trash:\n\t\tos.remove(i)\n\t\n\tmod_mask = image.read_bits(\"MOD\")\n\tmyd_mask = image.read_bits(\"MYD\")\n\n\tmod_mask = np.repeat(mod_mask, 4, axis = 0)\n\tmod_mask = np.repeat(mod_mask, 4, axis = 1)\n\n\tmyd_mask = np.repeat(myd_mask, 4, axis = 0)\n\tmyd_mask = np.repeat(myd_mask, 4, axis = 1)\n\t\n\t# Apply cloud masks\n\tmod_product = np.multiply(MOD_ndvi,mod_mask) \n\tmod_product[mod_product == 0] = np.nan\n\n\tmyd_product = np.multiply(MYD_ndvi,myd_mask)\n\tmyd_product[myd_product == 0] = np.nan\n\n\tmatch_raster = [x for x in os.listdir(os.getcwd()) if \"MOD09\" in x if \"Band_1\" in x if \"E\" not in x if \"vrt\" not in x]\n\tmatch_raster = \"\".join(match_raster)\n\tmatch_raster = os.path.join(os.getcwd(),match_raster) \n\t\n\tmod_tiff = image.write_raster(mod_product,match_raster,dates,\"MOD_NDVI_temp\")\n\tmyd_tiff = image.write_raster(myd_product,match_raster,dates,\"MYD_NDVI_temp\")\n\t\n\t# Resample to the water mask resolution \n\treference_file = [x for x in os.listdir(os.getcwd()) if \"water_mask\" in x]\n\treference_file = \"\".join(reference_file)\n\treference_file = os.path.join(os.getcwd(),reference_file)\n\tresolution = image.get_raster_resolution(reference_file)\n\t\n\tfinal_prod_mod = image.resample(resolution, mod_tiff, \"MOD_resampled.tif\")\n\tfinal_prod_myd = image.resample(resolution, myd_tiff, \"MYD_resampled.tif\")\n\t\n\t# Clip to water mask extent\n\textent = image.get_raster_extent(reference_file)\n\timage.clip(extent, os.path.join(os.getcwd(),\"MOD_resampled.tif\"), \"MOD_NDVI_\"+dates['year']+dates['doy']+\".tif\")\n\timage.clip(extent, os.path.join(os.getcwd(),\"MYD_resampled.tif\"), \"MYD_NDVI_\"+dates['year']+dates['doy']+\".tif\")\n\t\n\t# Select the clipped products \n\tfinal_prods = [x for x in os.listdir(os.getcwd()) if dates['year'] in x and \"temp\" not in x and \"Band\" not in x and \"35\" not in x]\n\t\n\t# Create the daily NRT dir \n\tif os.path.exists(os.path.join(os.getcwd(),\"daily_files_nrt\")):\n\t\tpass\n\telse:\n\t\tos.mkdir(os.path.join(os.getcwd(),\"daily_files_nrt\"))\n\tdaily_dir = os.path.join(os.getcwd(),\"daily_files_nrt\")\n\n\t# Copy over the final prods \n\tfor prod in final_prods:\n\t\tshutil.copy(prod,daily_dir)\n\n\t#Cleanup\n\tgarbage = [x for x in os.listdir(os.getcwd()) if \"MOD\" in x or \"MYD\" in x]\n\tfor i in garbage:\n\t\tos.remove(i)\n\t\nif __name__ == '__main__':\n\tmain()"
}
] | 5 |
Kaedone/Password-Hashes
|
https://github.com/Kaedone/Password-Hashes
|
52def8d7a5b715451a69850f18d6bf6fa71d733c
|
242cbf0348cfeb0ce661b0803a2018343609071e
|
b62bceca24a985da0443b2aecef024fd2635416b
|
refs/heads/main
| 2023-01-02T13:29:58.556204 | 2020-10-24T20:06:10 | 2020-10-24T20:06:10 | 306,960,555 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7635604739189148,
"alphanum_fraction": 0.7649513483047485,
"avg_line_length": 64.36363983154297,
"blob_id": "61add2c74a4011596d7a318a107b1da043081a7a",
"content_id": "fcb5c68fcfe691f4dba4efaf4fc89a0e4ef0b9f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 449,
"num_lines": 11,
"path": "/README.md",
"repo_name": "Kaedone/Password-Hashes",
"src_encoding": "UTF-8",
"text": "# Password-Hashes\nWhen you sign up for an account somewhere, some websites do not actually store your password in their databases. Instead, they will transform your password into something else using a cryptographic hashing algorithm. After the password is transformed, it is then called a password hash. Whenever you try to login, the website will transform the password you tried using the same hashing algorithm and simply see if the password hashes are the same.\n\n# Instructions\nCreate the function that converts a given string into an `md5` hash. The return value should be encoded in `hexadecimal`.\n\n# Code Examples\n```\n passHash(\"password\") // --> \"5f4dcc3b5aa765d61d8327deb882cf99\"\n passHash(\"abc123\") // --> \"e99a18c428cb38d5f260853678922e03\"\n```\n"
},
{
"alpha_fraction": 0.650943398475647,
"alphanum_fraction": 0.6886792182922363,
"avg_line_length": 34.33333206176758,
"blob_id": "669e4a1374ac9367a9bfbd3d9ca2da6ac73118f6",
"content_id": "552eeff8b742b7d945ec047e01e40f464d667a69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 12,
"path": "/test_main.py",
"repo_name": "Kaedone/Password-Hashes",
"src_encoding": "UTF-8",
"text": "Test.describe(\"Basic tests\")\nTest.assert_equals(pass_hash('password'), '5f4dcc3b5aa765d61d8327deb882cf99');\nTest.assert_equals(pass_hash('abc123'), 'e99a18c428cb38d5f260853678922e03');\n\nimport random\nimport hashlib\nTest.describe(\"Random Tests\")\nfor _ in range(198):\n _s=''.join(random.choice('0123456789abcdefghijklmnopqrstuvwxyz') for i in range(5))\n _m=hashlib.md5()\n _m.update(_s.encode('utf-8'))\n Test.assert_equals(pass_hash(_s), _m.hexdigest());\n"
}
] | 2 |
Aljosa12/WebForum
|
https://github.com/Aljosa12/WebForum
|
829e2efeed5df13a20c74b7d4ec19b0c67435a9a
|
5a9156db1b341898c1fccd04441e2b0367990180
|
59945b166ea2fd16ab38079de108d8170322bf5b
|
refs/heads/master
| 2022-11-26T21:19:37.676460 | 2020-08-11T19:24:07 | 2020-08-11T19:24:07 | 284,702,214 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7346241474151611,
"alphanum_fraction": 0.7346241474151611,
"avg_line_length": 27.29032325744629,
"blob_id": "e5c508f4095ac414dc8dba8669b2fdeaba83ac4d",
"content_id": "a460000c30d231d02beeb3e91a815db74936b39d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 878,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/main.py",
"repo_name": "Aljosa12/WebForum",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\n\nfrom models.user import User\nfrom models.settings import db\nfrom models.topic import Topic\n\nfrom handlers.auth import auth_handlers\nfrom handlers.topic import topic_handlers\nfrom handlers.comment import comment_handlers\n\napp = Flask(__name__)\napp.register_blueprint(auth_handlers)\napp.register_blueprint(topic_handlers)\napp.register_blueprint(comment_handlers)\ndb.create_all()\n\n# Handler/controller\[email protected]('/', methods=[\"GET\", \"POST\"])\ndef index():\n # check if user is authenticated based on session_token\n session_token = request.cookies.get(\"session_token\")\n user = db.query(User).filter_by(session_token=session_token).first()\n\n # get all topics from db\n topics = db.query(Topic).all()\n\n return render_template(\"topics/index.html\", user=user, topics=topics)\n\n\nif __name__ == '__main__':\n app.run()\n\n"
},
{
"alpha_fraction": 0.6696891188621521,
"alphanum_fraction": 0.6696891188621521,
"avg_line_length": 30.510204315185547,
"blob_id": "d1de7b2662ffe77c5307407bb3da0f5df4f4bc04",
"content_id": "92942bb2b567e3183ec9b1cd61fd60d281d644fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3088,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 98,
"path": "/handlers/comment.py",
"repo_name": "Aljosa12/WebForum",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request, redirect, url_for, Blueprint\n\nfrom models.settings import db\nfrom models.topic import Topic\nfrom models.user import User\nfrom models.comment import Comment\n\nfrom utils.redis_helper import create_csrf_token, validate_csrf\nfrom utils.auth_helper import user_from_session_token\n\ncomment_handlers = Blueprint(\"comment\", __name__)\n\n\n@comment_handlers.route(\"/topic/<topic_id>/create-comment\", methods=[\"POST\"])\ndef comment_create(topic_id):\n user = user_from_session_token()\n\n if not user:\n return redirect(url_for('auth.login'))\n\n csrf = request.form.get(\"csrf\")\n\n if not validate_csrf(csrf, user.username):\n return \"CSRF token is not valid!\"\n\n text = request.form.get(\"text\")\n topic = Topic.read(topic_id)\n\n Comment.create(topic=topic, text=text, author=user)\n\n return redirect(url_for('topic.topic_details', topic_id=topic_id))\n\n\n@comment_handlers.route(\"/topic/<comment_id>/delete\", methods=[\"GET\"])\ndef topic_delete(comment_id):\n comment = db.query(Comment).get(int(comment_id))\n\n if request.method == \"GET\":\n\n db.delete(comment)\n db.commit()\n\n return redirect(url_for('index', comment=comment))\n\n\n@comment_handlers.route(\"/comment/<comment_id>/delete\", methods=[\"POST\"])\ndef comment_delete(comment_id):\n comment = db.query(Comment).get(int(comment_id)) # get comment from db by ID\n\n # get current user\n session_token = request.cookies.get(\"session_token\")\n user = db.query(User).filter_by(session_token=session_token).first()\n\n # check if user logged in & if user is author\n if not user:\n return redirect(url_for('auth.login'))\n elif comment.author.id != user.id:\n return \"You can only delete your own comments!\"\n\n # check CSRF tokens\n csrf = request.form.get(\"csrf\")\n\n if validate_csrf(csrf, user.username):\n # if it validates, delete the comment\n topic_id = comment.topic.id # save the topic ID in a variable before you delete the comment\n\n db.delete(comment)\n db.commit()\n return redirect(url_for('topic.topic_details', topic_id=topic_id))\n else:\n return \"CSRF error: tokens don't match!\"\n\n\n@comment_handlers.route(\"/comment/<comment_id>/edit\", methods=[\"GET\", \"POST\"])\ndef comment_edit(comment_id):\n comment = db.query(Comment).get(int(comment_id)) # get comment from db by ID\n\n # get current user\n session_token = request.cookies.get(\"session_token\")\n user = db.query(User).filter_by(session_token=session_token).first()\n\n # check if user is logged in and user is author\n if not user:\n redirect(url_for(\"auth/login\"))\n elif comment.author.id != user.id:\n return \"You are not an author\"\n\n if request.method == \"GET\":\n return render_template(\"topics/comment_edit.html\", comment=comment)\n\n # POST request\n elif request.method == \"POST\":\n text = request.form.get(\"text\")\n\n comment.text = text\n db.add(comment)\n db.commit()\n return redirect(url_for('topic.topic_details', topic_id=comment.topic.id))\n"
},
{
"alpha_fraction": 0.8656716346740723,
"alphanum_fraction": 0.8805969953536987,
"avg_line_length": 8.714285850524902,
"blob_id": "c63682d89c981b55796294aa43fe5adb4a6985e0",
"content_id": "d1edb50a4e99bb12009f943fb4d1233b1ab72db5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "Aljosa12/WebForum",
"src_encoding": "UTF-8",
"text": "Flask\npsycopg2\nsqla-wrapper\nsmartninja-redis\ngunicorn\nrequests\nhuey"
},
{
"alpha_fraction": 0.6214098930358887,
"alphanum_fraction": 0.6214098930358887,
"avg_line_length": 30.14634132385254,
"blob_id": "9a38242e8ae6023aad9abeae00f9c2d4c5984dbe",
"content_id": "e0795a1a9a9148353fda3b284cd6976f3c5ce045",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3834,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 123,
"path": "/handlers/topic.py",
"repo_name": "Aljosa12/WebForum",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import render_template, request, redirect, url_for, Blueprint\n\nfrom models.settings import db\nfrom models.topic import Topic\nfrom models.comment import Comment\n\nfrom utils.redis_helper import create_csrf_token, validate_csrf\nfrom utils.auth_helper import user_from_session_token\n\n\ntopic_handlers = Blueprint(\"topic\", __name__)\n\n\n@topic_handlers.route(\"/create-topic\", methods=[\"GET\", \"POST\"])\ndef topic_create():\n user = user_from_session_token()\n\n # only logged in users can create topic\n if not user:\n return redirect(url_for('auth/login'))\n\n if request.method == \"GET\":\n csrf_token = create_csrf_token(user.username)\n\n return render_template(\"topics/topic_create.html\", user=user, csrf_token=csrf_token) # send CSRF token into HTML template\n\n elif request.method == \"POST\":\n csrf = request.form.get(\"csrf\") # csrf from HTML\n\n if validate_csrf(csrf, user.username): # if they match, allow user to create a topic\n title = request.form.get(\"title\")\n text = request.form.get(\"text\")\n\n # create a topic object\n topic = Topic.create(title=title, text=text, author=user)\n\n return redirect(url_for('index'))\n\n else:\n return \"CSRF token is not valid\"\n\n\n@topic_handlers.route(\"/topic/<topic_id>\", methods=[\"GET\"])\ndef topic_details(topic_id):\n topic = db.query(Topic).get(int(topic_id))\n\n user = user_from_session_token()\n comments = db.query(Comment).filter_by(topic=topic).all()\n\n # START test background tasks (TODO: delete this code later)\n if os.getenv('REDIS_URL'):\n from task import get_random_num\n get_random_num()\n # END test background tasks €wsee¸dx;:\n\n return render_template(\"topics/topic_details.html\", topic=topic, user=user,\n csrf_token=create_csrf_token(user.username), comments=comments)\n\n\n@topic_handlers.route(\"/topic/<topic_id>/edit\", methods=[\"GET\", \"POST\"])\ndef topic_edit(topic_id):\n topic = db.query(Topic).get(int(topic_id))\n\n if request.method == \"GET\":\n return render_template(\"topics/topic_edit.html\", topic=topic)\n\n elif request.method == \"POST\":\n title = request.form.get(\"title\")\n text = request.form.get(\"text\")\n\n user = user_from_session_token()\n\n # check if user is logged in and user is author\n if not user:\n redirect(url_for(\"auth/login\"))\n elif topic.author_id != user.id:\n return \"You are not an author\"\n else:\n # update the topic fields\n topic.title = title\n topic.text = text\n db.add(topic)\n db.commit()\n\n return redirect(url_for('topic.topic_details', topic_id=topic_id))\n\n\n@topic_handlers.route(\"/topic/<topic_id>/delete\", methods=[\"GET\", \"POST\"])\ndef topic_delete(topic_id):\n topic = db.query(Topic).get(int(topic_id))\n\n if request.method == \"GET\":\n return render_template(\"topics/topic_delete.html\", topic=topic)\n\n elif request.method == \"POST\":\n # get current user (author)\n user = user_from_session_token()\n\n # check if user is logged in and user is author\n if not user:\n return redirect(url_for('auth/login'))\n elif topic.author_id != user.id:\n return \"You are not the author!\"\n else: # if user IS logged in and current user IS author\n # delete topic\n db.delete(topic)\n db.commit()\n return redirect(url_for('index'))\n\n\n\"\"\" Moj način deletanja topica \[email protected](\"/topic/<topic_id>/delete\", methods=[\"GET\"])\ndef topic_delete(topic_id):\n topic = db.query(Topic).get(int(topic_id))\n\n if request.method == \"GET\":\n\n db.delete(topic)\n db.commit()\n\n return redirect(url_for('index'))\"\"\""
}
] | 4 |
LiuFang816/ProgramClassification
|
https://github.com/LiuFang816/ProgramClassification
|
6b097e3c00fead1856f11e1372f6ec09344a6e2a
|
d80ce624f9fc660e68e4afad9910733bbc064728
|
3a539dfe8253d8a7d0cb58867e255df601b69500
|
refs/heads/master
| 2021-05-08T21:47:42.586644 | 2018-01-31T07:39:55 | 2018-01-31T07:39:55 | 119,651,973 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5570228099822998,
"alphanum_fraction": 0.5648259520530701,
"avg_line_length": 40.911949157714844,
"blob_id": "c78487f4418c5c948c60c4f6d16bdb57fd2026ae",
"content_id": "bd0d74e3efbc53d687b139e7212d08c7f172fe74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6698,
"license_type": "no_license",
"max_line_length": 229,
"num_lines": 159,
"path": "/model/run_lstm_model.py",
"repo_name": "LiuFang816/ProgramClassification",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport tensorflow as tf\nimport os\nfrom model.LSTM import *\nfrom tools import data_reader\nimport time\nfrom datetime import timedelta\nimport numpy as np\nMODE='train'\nflags=tf.flags\nflags.DEFINE_string('data_path','../data','data path')\nflags.DEFINE_string('save_path','../data/checkpoints/lstm/best_validation','best val save path')\nflags.DEFINE_string('save_dir','../data/checkpoints/lstm','save dir')\nflags.DEFINE_string('tensorboard_dir','../data/tensorboard/lstm','tensorboard path')\nflags.DEFINE_string('MODE','train','mode')\nflags=flags.FLAGS\n\ndef get_time_dif(start_time):\n end_time=time.time()\n time_dif=end_time-start_time\n return timedelta(seconds=int(round(time_dif)))\n\ndef feed_data(x_batch,y_batch,keep_prob):\n feed_dict={\n model.input:x_batch,\n model.label:y_batch,\n model.keep_prob:keep_prob\n }\n return feed_dict\n\ndef evaluate(sess,x_,y_):\n data_len=len(x_)\n eval_batch=data_reader.batch_iter(x_,y_,config.batch_size)\n total_loss=0.0\n total_acc=0.0\n for x_batch,y_batch in eval_batch:\n batch_len=len(x_batch)\n feed_dict=feed_data(x_batch,y_batch,1.0)\n loss,acc=sess.run([model.loss,model.acc],feed_dict=feed_dict)\n total_loss+=loss*batch_len\n total_acc+=acc*batch_len\n return total_loss/data_len,total_acc/data_len\n\ndef train(id_to_word):\n tensorboard_dir=flags.tensorboard_dir\n if not os.path.exists(tensorboard_dir):\n os.makedirs(tensorboard_dir)\n tf.summary.scalar('loss',model.loss)\n tf.summary.scalar('accuracy',model.acc)\n merged_summary=tf.summary.merge_all()\n writer=tf.summary.FileWriter(tensorboard_dir)\n\n saver=tf.train.Saver()\n if not os.path.exists(flags.save_dir):\n os.makedirs(flags.save_dir)\n Config = tf.ConfigProto()\n Config.gpu_options.allow_growth = True\n with tf.Session(config=Config) as sess:\n sess.run(tf.global_variables_initializer())\n writer.add_graph(sess.graph)\n print('training and evaluating...')\n start_time=time.time()\n total_batch=0\n best_eval_acc=0.0\n last_improved=0\n required_improvement=1000 #超过1000轮未提升则提前结束训练\n flag=False\n for epoch in range(config.num_epochs):\n print('Epoch:',epoch+1)\n train_batch=data_reader.batch_iter(train_inputs,train_labels,config.batch_size)\n for x_batch,y_batch in train_batch:\n feed_dict=feed_data(x_batch,y_batch,config.dropout_keep_prob)\n if total_batch%config.save_per_batch==0:\n s=sess.run(merged_summary,feed_dict=feed_dict)\n writer.add_summary(s,total_batch)\n if total_batch%config.print_per_batch==0:\n\n loss,acc,prediction=sess.run([model.loss,model.acc,model.predict_class],feed_dict=feed_dict)\n loss_val,acc_val=evaluate(sess,val_inputs,val_labels)\n if acc_val>best_eval_acc:\n best_eval_acc=acc_val\n last_improved=total_batch\n saver.save(sess,flags.save_path)\n improved_str='*'\n else:\n improved_str=''\n time_dif=get_time_dif(start_time)\n msg='Iter:{0:>6}, Train Loss:{1:>6.2}, Train Acc:{2:>7.2%},' \\\n 'Val Loss:{3:>6.2}, Val Acc:{4:>7.2%}, Time:{5} {6}'\n print(msg.format(total_batch,loss,acc,loss_val,acc_val,time_dif,improved_str))\n # for i in range(2):#print 2 个example (≤batch_size)\n # input_=''\n # target_=''\n # predic_=''\n # for j in range(config.num_steps-1):\n # input_+=id_to_word[x_batch[i][j]]+' '\n # target_+=id_to_word[y_batch[i][j]]+' '\n # predic_+=id_to_word[prediction[i][j]]+' '\n # print('input: %s\\n\\nTarget: %s\\n\\nPrediction: %s \\n\\n'%(input_,target_,predic_))\n\n sess.run(model._train_op,feed_dict=feed_dict)\n total_batch+=1\n\n if total_batch-last_improved>required_improvement:\n print('No optimization dor a long time, stop training...')\n flag=True\n break\n if flag:\n break\nimport json\ndef test(save_path,N):\n Config = tf.ConfigProto()\n Config.gpu_options.allow_growth = True\n with tf.Session(config=Config) as sess:\n sess.run(tf.global_variables_initializer())\n saver=tf.train.Saver()\n saver.restore(sess,flags.save_path)\n test_loss,test_acc=evaluate(sess,test_inputs,test_labels)\n msg='Test Loss:{0:>6.2}, Test Acc:{1:>7.2%}'\n print(msg.format(test_loss,test_acc))\n test_batch=data_reader.batch_iter(test_inputs,test_labels,config.batch_size)\n with open(save_path,'w') as f:\n for x_batch,y_batch in test_batch:\n feed_dict=feed_data(x_batch,y_batch,config.dropout_keep_prob)\n loss,acc,logits=sess.run([model.loss,model.acc,model.logits],feed_dict=feed_dict)\n for i in range(config.batch_size):\n target=[]\n prediction=[]\n for j in range(config.num_steps):\n prediction.append([])\n target.append(logits[i][j])\n tmp = list(logits[i][j])\n for m in range(N):\n index=tmp.index(max(tmp))\n prediction[j].append(index)\n tmp[index]=-100\n\n # target=json.dumps(target)\n # # print(target)\n # prediction=json.dumps(prediction)\n # # print(prediction)\n # f.write(target+'\\n')\n # f.write(prediction+'\\n')\n\n\n\nif __name__ == '__main__':\n config=LSTMConfig()\n word_to_id=data_reader._build_vocab(os.path.join(flags.data_path,\"pro_cla/train.txt\"),config.vocab_size,config.num_steps)\n\n train_inputs,train_labels,val_inputs,val_labels,test_inputs,test_labels,left_id, right_id, PAD_ID=data_reader.raw_data(data_path=flags.data_path,word_to_id=word_to_id,num_steps=config.num_steps,num_classes=config.num_classes)\n print(np.shape(train_inputs))\n print(np.shape(train_labels))\n model=LSTM(config)\n id_to_word=data_reader.reverseDic(word_to_id)\n if MODE=='train':\n train(id_to_word)\n else:\n test('test.txt',1)\n"
},
{
"alpha_fraction": 0.5184023380279541,
"alphanum_fraction": 0.5315767526626587,
"avg_line_length": 48.0461540222168,
"blob_id": "952071daa2dd1e8b9b9e039739919fb86eb4c9b3",
"content_id": "dcd4479cca6ad6890b83b3c5c8414276f13cbc96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9660,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 195,
"path": "/model/new_SLSTM.py",
"repo_name": "LiuFang816/ProgramClassification",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport tensorflow as tf\nimport numpy as np\nfrom Stack import *\nclass LSTMConfig(object):\n embedding_size=256\n vocab_size=1000\n num_layers=2\n num_classes=104\n num_steps=400\n hidden_size=256\n dropout_keep_prob=1.0\n learning_rate=1e-4\n batch_size=32 #无法并行,因此只能为1\n num_epochs=50\n print_per_batch=200\n save_per_batch=200\n max_grad_norm=5\n rnn='lstm'\n\nclass StackLSTM(object):\n def __init__(self,config,start_mark,end_mark):\n self.config=config\n self.input=tf.placeholder(tf.int64,[config.batch_size,self.config.num_steps],name='input')\n self.label=tf.placeholder(tf.int64,[config.batch_size,self.config.num_classes],name='label')\n self.keep_prob=tf.placeholder(tf.float32,name='keep_prob')\n self.start=start_mark\n self.end=end_mark\n self.rnn()\n def rnn(self):\n def lstm_cell():\n return tf.contrib.rnn.BasicLSTMCell(self.config.hidden_size,state_is_tuple=True)\n def gru_cell():\n return tf.contrib.rnn.GRUCell(self.config.hidden_size)\n with tf.device('/cpu:0'):\n embedding=tf.get_variable('embedding',[self.config.vocab_size,self.config.embedding_size])\n embedding_inputs=tf.nn.embedding_lookup(embedding,self.input)\n embedding_inputs=tf.nn.dropout(embedding_inputs,0.8)\n with tf.name_scope('rnn'):\n outputs,_=self._build_rnn_graph_lstm(embedding_inputs,self.config)\n # print(outputs)\n last=outputs\n # print(last)\n # output = tf.reshape(tf.concat(outputs, 1), [-1, self.config.hidden_size])\n with tf.name_scope('score'):\n #全连接层\n fc=tf.layers.dense(last,self.config.hidden_size,name='fc1')\n fc=tf.contrib.layers.dropout(fc,self.keep_prob)\n fc=tf.nn.relu(fc)\n #输出层\n self.logits=tf.layers.dense(fc,self.config.num_classes,name='fc2')\n self.predict_class=tf.argmax(tf.nn.softmax(self.logits),1)\n\n with tf.name_scope('optimize'):\n cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits=self.logits,labels=self.label)\n self.loss=tf.reduce_mean(cross_entropy)\n tvars = tf.trainable_variables()\n grads, _ = tf.clip_by_global_norm(tf.gradients(self.loss, tvars),\n self.config.max_grad_norm)\n optimizer = tf.train.AdamOptimizer(self.config.learning_rate)\n self._train_op = optimizer.apply_gradients(\n zip(grads, tvars),\n global_step=tf.train.get_or_create_global_step())\n\n with tf.name_scope('accuracy'):\n correct_pre=tf.equal(tf.argmax(self.label,1),self.predict_class)\n self.acc=tf.reduce_mean(tf.cast(correct_pre,tf.float32))\n\n\n def _build_rnn_graph_lstm(self, inputs, config):\n \"\"\"Build the inference graph using canonical LSTM cells.\"\"\"\n # Slightly better results can be obtained with forget gate biases\n # initialized to 1 but the hyperparameters of the model would need to be\n # different than reported in the paper.\n def make_cell():\n cell = tf.contrib.rnn.BasicLSTMCell(config.hidden_size, forget_bias=0.0, state_is_tuple=True)\n cell = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=config.dropout_keep_prob)\n return cell\n\n cell = tf.contrib.rnn.MultiRNNCell(\n [make_cell() for _ in range(config.num_layers)], state_is_tuple=True)\n\n self._initial_state = cell.zero_state(config.batch_size, tf.float32)\n state = self._initial_state\n # Simplified version of tensorflow_models/tutorials/rnn/rnn.py's rnn().\n # This builds an unrolled LSTM for tutorial purposes only.\n # In general, use the rnn() or state_saving_rnn() from rnn.py.\n #\n # The alternative version of the code below is:\n #\n # inputs = tf.unstack(inputs, num=num_steps, axis=1)\n # outputs, state = tf.contrib.rnn.static_rnn(cell, inputs,\n # initial_state=self._initial_state)\n outputs = []\n\n def func_push(state_i,i):\n self.state_stack[i].push(state_i)\n return state_i\n\n\n #-----------------特殊情况需要保留名称------------------\n # def updateState(state,time_step):\n # # state = ((state[0][0], state[0][1]), (state[1][0],state[1][1]))\n #\n # (out, newstate) = cell(inputs[:, time_step, :], state)\n # # print('------------------------------hhhhhh----------------------------')\n # tf.get_variable_scope().reuse_variables()\n # return newstate\n # nameSet=[word_to_id['Import'],word_to_id['ClassDef'],word_to_id['FunctionDef'],word_to_id['Assign'],word_to_id['AsyncFunctionDef'],word_to_id['Attribute']]\n # def f_default(state):\n # return state,state\n #\n # def func_push(state, time_step):\n # #add特殊情况需要保留名称\n # state,newState = tf.cond(tf.logical_or(\n # tf.logical_or(tf.equal(self._input_data[0][time_step-1], nameSet[0]), tf.equal(self._input_data[0][time_step-1], nameSet[1])),\n # tf.logical_or(tf.equal(self._input_data[0][time_step-1], nameSet[2]), tf.equal(self._input_data[0][time_step-1], nameSet[3])),\n # ),lambda: updateState(state, time_step), lambda: f_default(state))\n #\n # self.state_stack.push(newState)\n # return state[0][0], state[0][1], state[1][0], state[1][1]\n # #-------------------------------------------------------------\n\n def func_pop(i):\n # (cell_output,state)=cell(inputs[:,time_step,:],state)\n state_i=self.state_stack[i].pop()\n # (cell_output,state)=cell(cell_output,state)\n return state_i\n #def func_pop(state):\n # #------增加一层---------------#\n # w = tf.get_variable(\n # \"state_w\", [2*config.hidden_size, config.hidden_size], dtype=tf.float32)\n # # b = tf.get_variable(\"state_b\", [1,config.hidden_size], dtype=data_type())\n # old_state=self.state_stack.pop()\n # concat_state=[[],[]]\n # new_state=[[],[]]\n # # concat_state=tf.concat([old_state,state],1)\n # # concat_state=tf.reshape(concat_state,[1,-1])\n # for i in range(2):\n # for j in range(2):\n # concat_state[i].append(tf.concat([old_state[i][j],state[i][j]],1))\n # new_state[i].append(tf.matmul(concat_state[i][j], w))\n # return new_state[0][0], new_state[0][1], new_state[1][0], new_state[1][1]\n\n def func_default(state_i):\n return state_i\n\n with tf.variable_scope(\"RNN\"):\n self.state_stack=[Stack() for _ in range(self.config.batch_size)]\n # for time_step in range(self.config.num_steps):\n # if time_step > 0: tf.get_variable_scope().reuse_variables()\n # # print(self.input)\n # new_state=tf.cond(tf.equal(self.input[0][time_step],self.start),\n # lambda:func_push(state),lambda:func_default(state))\n # new_state=tf.cond(tf.equal(self.input[0][time_step],self.end),\n # lambda:func_pop(time_step,state),lambda:func_default(state))\n # state=((new_state[0],new_state[1]),(new_state[2],new_state[3]))\n #\n # (outputs, state) = cell(inputs[:, time_step, :], state)\n # #outputs.append(cell_output)\n # # output = tf.reshape(tf.concat(outputs, 1), [-1, config.hidden_size])\n\n #----------------------------------------------------------------------\n for time_step in range(self.config.num_steps):\n if time_step > 0: tf.get_variable_scope().reuse_variables()\n STATES=[]\n NEW_STATES=[]\n for i in range(config.batch_size):\n # print(state)\n state_i=[]\n for m in range(len(state)):#layers\n for n in range(len(state[m])):# c & h\n # print(new_state[m][n][i])\n state_i.append(tf.reshape(state[m][n][i],[1,-1]))\n STATES.append(state_i)\n # print(STATES)\n\n for i in range(config.batch_size):\n new_state_i=tf.cond(tf.equal(self.input[i][time_step],self.start),\n lambda:func_push(STATES[i],i),lambda:func_default(STATES[i]))\n new_state_i=tf.cond(tf.equal(self.input[i][time_step],self.end),\n lambda:func_pop(i),lambda:func_default(STATES[i]))\n state_i=new_state_i\n # state_i=((new_state_i[0],new_state_i[1]),(new_state_i[2],new_state_i[3]))\n NEW_STATES.append(state_i)\n # print(NEW_STATES)\n NEW_STATES=tf.concat(NEW_STATES,1)\n # print(tf.concat(NEW_STATES,1)[0])\n state=((NEW_STATES[0],NEW_STATES[1]),(NEW_STATES[2],NEW_STATES[3]))\n print(state)\n #只需要最后一个step的output\n # print(state)\n (outputs, state) = cell(inputs[:, time_step, :], state)\n #-----------------------------------------------------------------------------\n return outputs, state\n"
},
{
"alpha_fraction": 0.5816022753715515,
"alphanum_fraction": 0.5953090190887451,
"avg_line_length": 32.80143737792969,
"blob_id": "20820366c8fea59526c658bf1dd66bc4acdd9d55",
"content_id": "0a255768dd410fc747a0924829daf07618a46ecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23640,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 695,
"path": "/model/SLSTM_add_input_info.py",
"repo_name": "LiuFang816/ProgramClassification",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport sys\nimport time\n\nimport numpy as np\nimport tensorflow as tf\nfrom lstm.tools import Stack\n\nfrom lstm.tools import data_reader\nfrom lstm.tools.generate_test_data import is_nonterminal, is_terminal, stop_words\n\nflags = tf.flags\nlogging = tf.logging\n\nflags.DEFINE_string(\n \"model\", \"small\",\n \"A type of model. Possible options are: small, medium, large.\")\nflags.DEFINE_string(\"data_path\", '../data/',\n \"Where the training/test data is stored.\")\nflags.DEFINE_string(\"save_path\", '../data/test/',\n \"Model output directory.\")\nflags.DEFINE_bool(\"use_fp16\", False,\n \"Train using 16-bit floats instead of 32bit floats\")\nflags.DEFINE_bool(\"decode\", False,\n \"Set to True for interactive decoding.\")\nflags.DEFINE_bool(\"generate\", False, \"Set to True for interactive generating.\")\nflags.DEFINE_bool(\"test\", False, \"Set to True for interactive generating.\")\n\nFLAGS = flags.FLAGS\n\nword_to_id = data_reader.get_word_to_id(FLAGS.data_path)\nnameSet = [word_to_id['ClassDef'], word_to_id['FunctionDef'], word_to_id['Assign'], word_to_id['AsyncFunctionDef']]\n\n\ndef data_type():\n return tf.float16 if FLAGS.use_fp16 else tf.float32\n\n\nclass NoInitInput(object):\n \"\"\"The input data.\"\"\"\n\n def __init__(self, config, data, name=None, isDecode=False):\n if isDecode:\n self.num_steps = len(data) + 1\n X = [[0]]\n X[0] = data\n data = tf.convert_to_tensor(X, name=\"data\", dtype=tf.int32)\n self.input_data = data\n self.targets = data # 这个没有用\n self.batch_size = 1\n self.epoch_size = 1\n else:\n self.batch_size = batch_size = config.batch_size\n self.num_steps = num_steps = config.num_steps\n self.epoch_size = ((len(data) // batch_size) - 1) // num_steps\n self.input_data, self.targets = data_reader.data_producer(\n data, batch_size, num_steps, name=name)\n\n\nclass NoInitModel(object):\n \"\"\"The NoInit model.\"\"\"\n\n def __init__(self, is_training, config, input_, START_MARK, END_MARK, PAD_MARK):\n self._input = input_\n\n batch_size = input_.batch_size\n num_steps = input_.num_steps - 1\n size = config.hidden_size\n vocab_size = config.vocab_size\n\n # Slightly better results can be obtained with forget gate biases\n # initialized to 1 but the hyperparameters of the model would need to be\n # different than reported in the paper.\n lstm_cell = tf.contrib.rnn.BasicLSTMCell(size, forget_bias=0.0, state_is_tuple=True)\n if is_training and config.keep_prob < 1:\n lstm_cell = tf.contrib.rnn.DropoutWrapper(\n lstm_cell, output_keep_prob=config.keep_prob)\n # cell=lstm_cell\n cell = tf.contrib.rnn.MultiRNNCell([lstm_cell] * config.num_layers, state_is_tuple=True)\n\n self._initial_state = cell.zero_state(batch_size, data_type())\n self.state_stack = Stack.Stack()\n\n with tf.device(\"/cpu:0\"):\n embedding = tf.get_variable(\n \"embedding\", [vocab_size, size], dtype=data_type())\n inputs = tf.nn.embedding_lookup(embedding, input_.input_data)\n\n if is_training and config.keep_prob < 1:\n inputs = tf.nn.dropout(inputs, config.keep_prob)\n self._input_data = input_.input_data\n\n test = []\n self._test = test\n # self._inputs=inputs\n # Simplified version of tensorflow.models.rnn.rnn.py's rnn().\n # This builds an unrolled LSTM for tutorial purposes only.\n # In general, use the rnn() or state_saving_rnn() from rnn.py.\n #\n # The alternative version of the code below is:\n #\n # inputs = tf.unstack(inputs, num=num_steps, axis=1)\n # outputs, state = tf.nn.rnn(cell, inputs, initial_state=self._initial_state)\n outputs = []\n state = self._initial_state # [1,hidden_size]\n\n # def func_push(state,batch):\n # self.state_stack.push(state)\n # return state[0][0][batch], state[0][1][batch], state[1][0][batch], state[1][1][batch]\n #\n # def func_pop(batch):\n # state = self.state_stack.pop()\n # return state[0][0][batch], state[0][1][batch], state[1][0][batch], state[1][1][batch]\n #\n # def func_default(state,batch):\n # return state[0][0][batch], state[0][1][batch], state[1][0][batch], state[1][1][batch]\n\n def updateState(state, time_step):\n state = ((state[0][0], state[0][1]), (state[1][0], state[1][1]))\n\n (out, newstate) = cell(inputs[:, time_step, :], state)\n\n # print('------------------------------hhhhhh----------------------------')\n tf.get_variable_scope().reuse_variables()\n return newstate\n\n def f_default(state):\n return state\n\n def func_proceed_name(state, time_step):\n (cell_output, newstate) = cell(inputs[:, time_step, :], state)\n tf.get_variable_scope().reuse_variables()\n (cell_output, newstate) = cell(inputs[:, time_step, :], newstate)\n tf.get_variable_scope().reuse_variables()\n\n return newstate\n\n def func_not_proceed_name(state):\n return state\n\n def func_push(state):\n \"\"\"\n 传入一个LSTMTuple\n 1. push\n 2. 返回4个state\n :param state:\n :param time_step:\n :return:\n \"\"\"\n\n self.state_stack.push(state)\n return state[0][0], state[0][1], state[1][0], state[1][1]\n\n def func_pop(time_step,state):\n (cell_output,state)=cell(inputs[:,time_step,:],state)\n state=self.state_stack.pop()\n (cell_output,state)=cell(cell_output,state)\n return state[0][0],state[0][1],state[1][0],state[1][1]\n\n def func_default(state):\n return state[0][0], state[0][1], state[1][0], state[1][1]\n\n with tf.variable_scope(\"RNN\"):\n for time_step in range(num_steps):\n if time_step > 0: tf.get_variable_scope().reuse_variables()\n # if time_step<num_steps/2:\n # new_state=func_push(state,time_step)\n # else:\n # new_state=func_default(state)\n #\n # if time_step>=num_steps/2:\n # new_state=func_pop()\n # else:\n # new_state=func_default(state)\n\n maybeUpdateState = tf.cond(tf.logical_or(\n tf.logical_or(tf.equal(self._input_data[0][time_step-1], nameSet[0]), tf.equal(self._input_data[0][time_step-1], nameSet[1])),\n tf.logical_or(tf.equal(self._input_data[0][time_step-1], nameSet[2]), tf.equal(self._input_data[0][time_step-1], nameSet[3])),\n ),lambda: func_proceed_name(state, time_step),lambda: func_not_proceed_name(state))\n\n new_state = tf.cond(tf.equal(self._input_data[0][time_step], START_MARK),\n lambda: func_push(maybeUpdateState), lambda: func_default(maybeUpdateState))\n #state经过push更新之后需要回到初始时的状态,然后进行后续的cell计算\n new_state=state[0][0], state[0][1], state[1][0], state[1][1]\n # # fixme : func_default(state) 是不是应该是func_default(new_state)?\n new_state = tf.cond(tf.equal(self._input_data[0][time_step], END_MARK), lambda: func_pop(),\n lambda: func_default(state))\n\n state = ((new_state[0], new_state[1]), (new_state[2], new_state[3]))\n\n (cell_output, state) = cell(inputs[:, time_step, :], state)\n outputs.append(cell_output)\n\n output = tf.reshape(tf.concat(outputs, 1), [-1, size])\n softmax_w = tf.get_variable(\n \"softmax_w\", [size, vocab_size], dtype=data_type())\n softmax_b = tf.get_variable(\"softmax_b\", [vocab_size], dtype=data_type())\n logits = tf.matmul(output, softmax_w) + softmax_b\n loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example(\n [logits],\n [tf.reshape(input_.targets, [-1])],\n [tf.ones([batch_size * num_steps], dtype=data_type())])\n self._cost = cost = tf.reduce_sum(loss) / batch_size\n self._final_state = state\n self._targets = input_.targets\n self._logits = logits\n\n if not is_training:\n return\n\n self._lr = tf.Variable(0.0, trainable=False)\n tvars = tf.trainable_variables()\n grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars),\n config.max_grad_norm)\n optimizer = tf.train.GradientDescentOptimizer(self._lr)\n self._train_op = optimizer.apply_gradients(\n zip(grads, tvars),\n global_step=tf.contrib.framework.get_or_create_global_step())\n\n self._new_lr = tf.placeholder(\n tf.float32, shape=[], name=\"new_learning_rate\")\n self._lr_update = tf.assign(self._lr, self._new_lr)\n\n def assign_lr(self, session, lr_value):\n session.run(self._lr_update, feed_dict={self._new_lr: lr_value})\n\n def step(self, session):\n output = session.run(self._logits)\n return output\n\n @property\n def input(self):\n return self._input\n\n @property\n def initial_state(self):\n return self._initial_state\n\n @property\n def cost(self):\n return self._cost\n\n @property\n def final_state(self):\n return self._final_state\n\n @property\n def lr(self):\n return self._lr\n\n @property\n def train_op(self):\n return self._train_op\n\n\nclass SmallConfig(object):\n \"\"\"Small config.\"\"\"\n init_scale = 0.1\n learning_rate = 0.1\n max_grad_norm = 5\n num_layers = 2\n max_data_row = None\n num_steps = 60\n hidden_size = 200\n max_epoch = 4\n max_max_epoch = 13\n keep_prob = 1.0\n lr_decay = 0.5\n batch_size = 1\n vocab_size = 5000\n\n\nclass MediumConfig(object):\n \"\"\"Medium config.\"\"\"\n init_scale = 0.05\n learning_rate = 1\n max_grad_norm = 5\n num_layers = 2\n num_steps = 35\n hidden_size = 1024\n max_epoch = 6\n max_max_epoch = 39\n keep_prob = 0.5\n lr_decay = 0.8\n batch_size = 200\n vocab_size = 10000\n\n\nclass LargeConfig(object):\n \"\"\"Large config.\"\"\"\n init_scale = 0.04\n learning_rate = 1.0\n max_grad_norm = 10\n num_layers = 2\n num_steps = 35\n hidden_size = 1024\n max_epoch = 14\n max_max_epoch = 55\n keep_prob = 0.35\n lr_decay = 1 / 1.15\n batch_size = 200\n vocab_size = 10000\n\n\nclass TestConfig(object):\n \"\"\"Tiny config, for testing.\"\"\"\n init_scale = 0.1\n learning_rate = 1.0\n max_grad_norm = 1\n num_layers = 1\n num_steps = 2\n hidden_size = 2\n max_epoch = 1\n max_max_epoch = 1\n keep_prob = 1.0\n lr_decay = 0.5\n batch_size = 20\n vocab_size = 10000\n\n\ndef run_epoch(session, model, eval_op=None, verbose=False, id_to_word=None, end_id=None, isDecode=False):\n \"\"\"Runs the model on the given data.\"\"\"\n if isDecode:\n output = model.step(session)\n return output\n start_time = time.time()\n costs = 0.0\n iters = 0\n state = session.run(model.initial_state)\n\n SUM = 0\n correct_tok = 0\n\n fetches = {\n \"cost\": model.cost,\n \"final_state\": model.final_state,\n \"input_data\": model._input_data,\n \"targets\": model._targets,\n \"pred_output\": model._logits\n }\n if eval_op is not None:\n fetches[\"eval_op\"] = eval_op\n\n for step in range(model.input.epoch_size):\n feed_dict = {}\n for i, (c, h) in enumerate(model.initial_state):\n feed_dict[c] = state[i].c\n feed_dict[h] = state[i].h\n\n vals = session.run(fetches, feed_dict)\n cost = vals[\"cost\"]\n state = vals[\"final_state\"]\n\n costs += cost\n iters += model.input.num_steps\n\n # todo add 计算accuracy\n midInputData = vals[\"input_data\"]\n midTargets = vals[\"targets\"]\n pred_output = vals[\"pred_output\"]\n try:\n for i in range(model.input.batch_size):\n for j in range(model.input.num_steps - 1):\n SUM += 1\n trueOutput = id_to_word[midTargets[i][j]]\n tmp = list(pred_output[i * (model.input.num_steps - 1) + j])\n # todo topN这里注释\n predOutput = id_to_word[tmp.index(max(tmp))]\n if midInputData[i][j] == end_id:\n SUM -= 1\n break\n if trueOutput == predOutput:\n correct_tok += 1\n # todo topN使用这里\n # predOutput=[]\n # for m in range(N):\n # index=tmp.index(max(tmp))\n # predOutput.append(id_to_word[index])\n # tmp[index]=-100\n # if trueOutput in predOutput:\n # correct_tok+=1\n except:\n print(\"--------ERROR 计算acc----\")\n pass\n\n if verbose and step % (model.input.epoch_size // 10) == 10:\n print(\"%.3f perplexity: %.3f speed: %.0f wps\" %\n (step * 1.0 / model.input.epoch_size, np.exp(costs / iters),\n iters * model.input.batch_size / (time.time() - start_time)))\n\n if True:\n midInputData = vals[\"input_data\"]\n midTargets = vals[\"targets\"]\n pred_output = vals[\"pred_output\"]\n global num_steps\n try:\n for i in range(1):\n inputStr = ''\n trueOutput = ''\n predOutput = ''\n for j in range(num_steps):\n inputStr += id_to_word[midInputData[i][j]] + ' '\n\n trueOutput += id_to_word[midTargets[i][j]] + ' '\n\n tmp = list(pred_output[i * num_steps + j])\n predOutput += id_to_word[tmp.index(max(tmp))] + ' '\n print('Input: %s \\n True Output: %s \\n Pred Output: %s \\n' % (inputStr, trueOutput, predOutput))\n except:\n pass\n\n acc = correct_tok * 1.0 / SUM\n print(\"Accuracy : %.3f\" % acc)\n return np.exp(costs / iters)\n\n\ndef get_config():\n if FLAGS.model == \"small\":\n return SmallConfig()\n elif FLAGS.model == \"medium\":\n return MediumConfig()\n elif FLAGS.model == \"large\":\n return LargeConfig()\n elif FLAGS.model == \"test\":\n return TestConfig()\n else:\n raise ValueError(\"Invalid model: %s\", FLAGS.model)\n\n\nnum_steps = 0\n\n\ndef train():\n if not FLAGS.data_path:\n raise ValueError(\"Must set --data_path to PTB data directory\")\n config = get_config()\n\n word_to_id = data_reader.get_word_to_id(FLAGS.data_path)\n # todo raw_data还应包含weights\n raw_data = data_reader.raw_data(max_data_row=config.max_data_row, data_path=FLAGS.data_path, word_to_id=word_to_id,\n max_length=config.num_steps)\n train_data, test_data, voc_size, end_id, _, START_MARK, END_MARK, PAD_MARK = raw_data\n id_to_word = data_reader.reverseDic(word_to_id)\n\n config = get_config()\n global num_steps\n num_steps = config.num_steps - 1\n\n eval_config = get_config()\n # eval_config.batch_size = 1\n # eval_config.num_steps = 1\n\n # 使用动态vocab_size\n # config.vocab_size=voc_size\n # eval_config.voc_size=voc_size\n\n\n with tf.Graph().as_default():\n initializer = tf.random_uniform_initializer(-config.init_scale,\n config.init_scale)\n\n with tf.name_scope(\"Train\"):\n train_input = NoInitInput(config=config, data=train_data, name=\"TrainInput\")\n with tf.variable_scope(\"Model\", reuse=None, initializer=initializer):\n m = NoInitModel(is_training=True, config=config, input_=train_input,\n START_MARK=START_MARK, END_MARK=END_MARK, PAD_MARK=PAD_MARK)\n tf.summary.scalar(\"Training Loss\", m.cost)\n tf.summary.scalar(\"Learning Rate\", m.lr)\n\n # with tf.name_scope(\"Valid\"):\n # valid_input = NoInitInput(config=config, data=valid_data, name=\"ValidInput\")\n # with tf.variable_scope(\"Model\", reuse=True, initializer=initializer):\n # mvalid = NoInitModel(is_training=False, config=config, input_=valid_input)\n # tf.scalar_summary(\"Validation Loss\", mvalid.cost)\n\n with tf.name_scope(\"Test\"):\n test_input = NoInitInput(config=eval_config, data=test_data, name=\"TestInput\")\n with tf.variable_scope(\"Model\", reuse=True, initializer=initializer):\n mtest = NoInitModel(is_training=False, config=eval_config, input_=test_input,\n START_MARK=START_MARK, END_MARK=END_MARK, PAD_MARK=PAD_MARK)\n\n sv = tf.train.Supervisor(logdir=FLAGS.save_path)\n with sv.managed_session() as session:\n for i in range(config.max_max_epoch):\n lr_decay = config.lr_decay ** max(i + 1 - config.max_epoch, 0.0)\n m.assign_lr(session, config.learning_rate * lr_decay)\n\n print(\"Epoch: %d Learning rate: %.3f\" % (i + 1, session.run(m.lr)))\n train_perplexity = run_epoch(session, m, eval_op=m.train_op, verbose=True, id_to_word=id_to_word,\n end_id=end_id)\n print(\"Epoch: %d Train Perplexity: %.3f\" % (i + 1, train_perplexity))\n # valid_perplexity = run_epoch(session, mvalid, id_to_word=id_to_word)\n # print(\"Epoch: %d Valid Perplexity: %.3f\" % (i + 1, valid_perplexity))\n\n test_perplexity = run_epoch(session, mtest, id_to_word=id_to_word, end_id=end_id)\n print(\"Test Perplexity: %.3f\" % test_perplexity)\n\n if FLAGS.save_path:\n print(\"Saving model to %s.\" % FLAGS.save_path)\n sv.saver.save(session, FLAGS.save_path, global_step=sv.global_step)\n\n\ndef decode():\n choice = ['1', '2', '3', '4', '5', 'q']\n if not FLAGS.data_path:\n raise ValueError(\"Must set --data_path to PTB data directory\")\n config = get_config()\n\n word_to_id = data_reader.get_word_to_id(FLAGS.data_path)\n # todo raw_data还应包含weights\n raw_data = data_reader.raw_data(max_data_row=config.max_data_row, data_path=FLAGS.data_path, word_to_id=word_to_id,\n max_length=config.num_steps)\n train_data, test_data, voc_size, end_id, _, START_MARK, END_MARK, PAD_MARK = raw_data\n id_to_word = data_reader.reverseDic(word_to_id)\n\n config = get_config()\n global num_steps\n num_steps = config.num_steps - 1\n\n sys.stdout.write(\"> \")\n sys.stdout.flush()\n token = sys.stdin.readline().strip('\\n').split(' ')\n for i in range(len(token)):\n if token[i] not in word_to_id:\n token[i] = word_to_id['UNK']\n else:\n token[i] = word_to_id[token[i]]\n\n while True:\n with tf.Graph().as_default():\n initializer = tf.random_uniform_initializer(-config.init_scale,\n config.init_scale)\n\n with tf.name_scope(\"Train\"):\n decode_input = NoInitInput(config=config, data=token, name=\"TrainInput\", isDecode=True)\n with tf.variable_scope(\"Model\", reuse=None, initializer=initializer):\n decode_model = NoInitModel(is_training=False, config=config, input_=decode_input,\n START_MARK=START_MARK, END_MARK=END_MARK, PAD_MARK=PAD_MARK)\n\n # ckpt = tf.train.get_checkpoint_state(FLAGS.save_path)\n # if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):\n # print(\"Reading model parameters from %s\" % ckpt.model_checkpoint_path)\n # # model.saver.restore(session, ckpt.model_checkpoint_path)\n # else:\n # print(\"Created model with fresh parameters.\")\n Config = tf.ConfigProto()\n Config.gpu_options.allow_growth = True\n sv = tf.train.Supervisor(logdir=FLAGS.save_path)\n with sv.managed_session(config=Config) as session:\n output = run_epoch(session, decode_model, id_to_word, end_id=end_id, isDecode=True)\n # output = decode_model.step(session)\n # print(output)\n tmp = list(output[-1])\n\n # output=id_to_word[tmp.index(max(tmp))]\n # print('next token --> %s'%output)\n # ------------\n\n # todo 输出top5\n predOutput = []\n count = 0\n while count < 5:\n index = tmp.index(max(tmp))\n if index == PAD_MARK:\n tmp[index] = -100\n continue\n predOutput.append(id_to_word[index])\n count += 1\n tmp[index] = -100\n\n print('next token --> ')\n for i in range(len(predOutput)):\n print('%d: %s' % (i + 1, predOutput[i]))\n print('You Choose: ')\n x = sys.stdin.readline().strip('\\n')\n if x != 'q' and x in choice:\n token.append(word_to_id[predOutput[int(x) - 1]])\n elif x not in choice:\n if x not in word_to_id:\n token.append(word_to_id['UNK'])\n else:\n token.append(word_to_id[x])\n else:\n break\n\n\ndef test(type, filename):\n # wfname='data/'+type+'.txt'\n # wf=open(wfname,'w')\n if not FLAGS.data_path:\n raise ValueError(\"Must set --data_path to PTB data directory\")\n config = get_config()\n\n word_to_id = data_reader.get_word_to_id(FLAGS.data_path)\n # todo raw_data还应包含weights\n raw_data = data_reader.raw_data(FLAGS.data_path, word_to_id, config.num_steps)\n train_data, test_data, voc_size, end_id, _, START_MARK, END_MARK, PAD_MARK = raw_data\n id_to_word = data_reader.reverseDic(word_to_id)\n\n config = get_config()\n global num_steps\n num_steps = config.num_steps - 1\n SUM = 0\n correct_tok = 0\n\n f = open(filename)\n data = f.readlines()\n for i in range(len(data)):\n try:\n SUM += 1\n code = data[i].strip('\\n').split(' ')\n # print(data)\n testInput = code[0:len(code) - 1]\n testTarget = code[-1]\n if testTarget not in word_to_id:\n testTarget = 'UNK'\n for j in range(len(testInput)):\n if testInput[j] not in word_to_id:\n testInput[j] = word_to_id['UNK']\n else:\n testInput[j] = word_to_id[testInput[j]]\n\n with tf.Graph().as_default():\n initializer = tf.random_uniform_initializer(-config.init_scale,\n config.init_scale)\n with tf.name_scope(\"Train\"):\n decode_input = NoInitInput(config=config, data=testInput, name=\"TrainInput\", isDecode=True)\n with tf.variable_scope(\"Model\", reuse=None, initializer=initializer):\n decode_model = NoInitModel(is_training=True, config=config, input_=decode_input,\n START_MARK=START_MARK, END_MARK=END_MARK, PAD_MARK=PAD_MARK)\n\n # ckpt = tf.train.get_checkpoint_state(FLAGS.save_path)\n # if ckpt and tf.train.checkpoint_exists(ckpt.model_checkpoint_path):\n # print(\"Reading model parameters from %s\" % ckpt.model_checkpoint_path)\n # # model.saver.restore(session, ckpt.model_checkpoint_path)\n # else:\n # print(\"Created model with fresh parameters.\")\n\n sv = tf.train.Supervisor(logdir=FLAGS.save_path)\n with sv.managed_session() as session:\n output = run_epoch(session, decode_model, id_to_word, end_id=end_id, isDecode=True)\n tmp = list(output[-1])\n\n # top10\n predOutput = []\n count = 0\n while count < 10:\n index = tmp.index(max(tmp))\n # todo fix me\n if index == PAD_MARK or id_to_word[index] in stop_words:\n tmp[index] = -100\n continue\n predOutput.append(id_to_word[index])\n count += 1\n tmp[index] = -100\n # sv.saver.save(session, FLAGS.save_path, global_step=sv.global_step)\n\n if type == 'T':\n for i in range(len(predOutput)):\n if is_terminal(predOutput[i]):\n print(\"%s,%s\" % (predOutput[i], testTarget))\n if (predOutput[i] == testTarget):\n correct_tok += 1\n break\n else:\n for i in range(len(predOutput)):\n if is_nonterminal(predOutput[i]):\n print(\"%s,%s\" % (predOutput[i], testTarget))\n if (predOutput[i] == testTarget):\n correct_tok += 1\n break\n print(' %d %d' % (correct_tok, SUM))\n acc = correct_tok * 1.0 / SUM\n print(\"Accuracy : %.3f\" % acc)\n except:\n pass\n acc = correct_tok * 1.0 / SUM\n print(\"Final Accuracy : %.3f\" % acc)\n\n\ndef main(_):\n if FLAGS.decode:\n decode()\n if FLAGS.test:\n test('NT', r'../data/train_nonterminal-60-60.txt')\n else:\n train()\n\n\nif __name__ == \"__main__\":\n tf.app.run()\n"
},
{
"alpha_fraction": 0.6082066893577576,
"alphanum_fraction": 0.6139817833900452,
"avg_line_length": 33.61052703857422,
"blob_id": "5a0a37952bc090a77c721d6cfd3c9bb8ae6772c8",
"content_id": "a2b414ccac64cb3c65a5410f0f8ca28de6d43bb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3298,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 95,
"path": "/tools/data_reader.py",
"repo_name": "LiuFang816/ProgramClassification",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport tensorflow as tf\nimport os\nimport collections\nimport numpy as np\nimport tensorflow.contrib.keras as kr\n\n#seq length 为num_step-1\ndef batch_iter(x,y,batch_size):\n data_len=len(x)\n num_batch=int((data_len-1)/batch_size)+1\n\n for i in range(num_batch):\n start_id=i*batch_size\n end_id=min((i+1)*batch_size,data_len)\n if end_id-start_id<batch_size:\n break\n yield x[start_id:end_id],y[start_id:end_id]\n\ndef read_data(file,seq_len):\n with open(file,'r',encoding='utf-8',errors='ignore') as f:\n contents,labels=[],[]\n lines=f.readlines()\n for line in lines:\n try:\n label,content=line.split('\\t')\n content=content.replace('\\n','')\n content=content.split(' ')\n if len(content)>seq_len:\n continue\n labels.append(int(label)-1)#label从0开始\n contents.append(content)\n except:\n pass\n return contents,labels\n# contents,labels=read_data('../data/pro_cla/val.txt',500)\n# print(contents[0])\n# print(labels[0])\n\ndef file_to_id(word_to_id,data,num_steps):\n for i in range(len(data)):\n for j in range(len(data[i])):\n data[i][j]=word_to_id[data[i][j]] if data[i][j] in word_to_id else word_to_id['UNK']\n if num_steps:\n for _ in range(num_steps - len(data[i])):\n data[i].append(word_to_id['PAD'])\n # print(len(data[i]))\n return data\n\n\ndef raw_data(data_path=None, word_to_id=None, num_steps=None,num_classes=None):\n train_path = os.path.join(data_path,\"pro_cla/train.txt\")\n val_path=os.path.join(data_path,'pro_cla/val.txt')\n test_path = os.path.join(data_path, \"pro_cla/test.txt\")\n\n train_data,train_label=read_data(train_path,num_steps)\n test_data,test_label=read_data(test_path,num_steps)\n val_data,val_label=read_data(val_path,num_steps)\n train_data=np.asarray(file_to_id(word_to_id,train_data,num_steps))\n val_data=np.asarray(file_to_id(word_to_id,val_data,num_steps))\n test_data=np.asarray(file_to_id(word_to_id,test_data,num_steps))\n train_label=kr.utils.to_categorical(train_label,num_classes)\n val_label=kr.utils.to_categorical(val_label,num_classes)\n test_label=kr.utils.to_categorical(test_label,num_classes)\n left_id = word_to_id['{']\n right_id = word_to_id['}']\n PAD_ID = word_to_id['PAD']\n return train_data,train_label,val_data,val_label,test_data,test_label,left_id, right_id, PAD_ID\n\n# def get_pair(data):\n# labels=data[:,1:]\n# inputs=data[:,:-1]\n# return inputs,labels\n\n\ndef _build_vocab(filename,vocab_size,seq_len):\n data,label = read_data(filename,seq_len)\n words=[]\n for content in data:\n words.extend(content)\n counter = collections.Counter(words)\n count_pairs = sorted(counter.items(), key=lambda x: (-x[1], x[0]))\n words, values = list(zip(*count_pairs))\n words = words[0:vocab_size-2]\n word_to_id = dict(zip(words, range(len(words))))\n word_to_id['UNK'] = len(word_to_id)\n word_to_id['PAD'] = len(word_to_id)\n return word_to_id\n\n\ndef reverseDic(curDic):\n newmaplist = {}\n for key, value in curDic.items():\n newmaplist[value] = key\n return newmaplist\n\n\n"
}
] | 4 |
LootToken/Loot-Marketplace-Framework
|
https://github.com/LootToken/Loot-Marketplace-Framework
|
296e96473f5bc257a26eb175b1794e72974d602b
|
24e98857201afab39683f2c095d1023abf95875e
|
87d4cf31bac37d36fcc77064960ad2096f6afabd
|
refs/heads/master
| 2020-03-26T00:27:22.509702 | 2018-08-16T21:00:49 | 2018-08-16T21:00:49 | 144,321,360 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6741045713424683,
"alphanum_fraction": 0.7214249968528748,
"avg_line_length": 46.344261169433594,
"blob_id": "b052501a70682104775fbb62185b6761d50cd8f8",
"content_id": "489dcb54aa9dbccf24bb790b77a010884980f013",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25997,
"license_type": "permissive",
"max_line_length": 502,
"num_lines": 549,
"path": "/README.md",
"repo_name": "LootToken/Loot-Marketplace-Framework",
"src_encoding": "UTF-8",
"text": "# Loot Marketplace Framework & LootClicker\n\n#### We are bringing blockchain gaming to the mainstream, providing a complete and viable solution to digitalizing assets in fast paced large scale commercial games without hindering the end user.\n\n#### At its core we are targeting the gaming industry; allowing the trading of digitalized assets instantly and securely for the end user, through the utilization of the NEO blockchain, smart contracts and a front-running incentivized relaying network. \n\n#### Producers and developers can simply integrate with the network, registering their marketplace in the smart contract. They will then be able to leverage exclusive management rights to their assets, without needing to trust a third party. \n\n#### The framework and decentralized game modes are built upon our open source smart contract.\n#### https://github.com/LootToken/Loot-Marketplace-Framework/blob/master/LootMarketsContract.py\n#### All framework interaction occurs on our public API listed at the bottom of this document. Upon the completion of a review by a certified NEO development group, our wallet will be open sourced and released in this repository.\n\n\n## LootClicker (ALPHA) - Play at http://www.lootclicker.online\n\n\n##### NOTE: As we are in alpha testing, only whitelisted emails will be able to register and login. We have sent accounts and wallets to the judges of the NEO Game competition. You can sign up for this on our website.\n\n\n\n\n\n\n\n\n\n\n\n#### Overview\n- LootClicker is a f2p MMO casual clicker game. \n- It was built from the ground up specifically for the NEO blockchain and as a game to play casually or on the side while trading cryptocurrencies.\n- The centralized aspect of game logic itself is managed by an authoritative server, every action which may effect the in game economy and value of assets is verified and accepted by the server, this will attempt to remove all cheating from the game to properly simulate an in game economy.\n- Players can earn items from crates, or in decentralized game modes. \n- The in game equippable assets are all integrated into the framework and therefore registered on the NEO blockchain.\n\n#### Game Features\n\nA list of some of the features that are currently working:\n\n- Singleplayer mode in which the player can fight enemies and defeat powerful bosses to advance stages.\n- Offline bounty (soft currency) and experience generation that is claimed upon login, this is scaled dependent on your idle damage and stage.\n- Find rare gems in combat that can be spent to perform actions such as creating guilds, starting events and rerolling your class.\n- In game digital assets all are given stats and/or abilities according to their rarity along with unique sounds and effects.\n- There are 7 weapon classes to use, equipping a weapon class with give you an additional active skill to use in combat.\n- Unlock mercenaries with bounty in single player mode that will increase damage output.\n- At level 100+ you can \"Server Hop\". You will gain passive bonuses and be able to unlock active/passive skills, but in turn will be stripped of your current rank, currency and stage.\n- At higher levels you may choose and unlock from 3 talent classes; beserker, specialist and lawless. These each have their own unique active and passive skills. \n- Join a guild, with up to 50 members to chat, rank up, and complete timed events to earn rewards.\n- Daily rewards can be collected on a login streak over 30 days.\n- Unlock over 100 achievements which yield unique rewards and titles.\n- Enter our first decentralized game mode \"Blockchain Royale\", all logic is resolved on the blockchain in a smart contract.\n- A friends list, global online chat with channels and private messaging.\n- Search the gear and stats of any other player.\n- Equip pets, cosmetics and weapons to use in battle.\n- Reroll the stats of weapons.\n- Leaderboards for guilds and players.\n- Progress is never lost, and bound to your account/blockchain.\n- A full functioning in game marketplace has been integrated to showcase how assets can be sold, bought and traded on the Loot marketplace framework.\n\n#### Accessing LootClicker items in the wallet\n- You may register an account with a pre-existing private key, or else a new one will be created for you.\n - You can copy this private key, and with it log into the wallet with the first option on the menu.\n - In the \"Settings\", you can click \"Save Wallet\" to enable easy access into the wallet where you can access your items.\n- Any items in your wallet are cross synced with an integrated game, so purchased marketplace items in the wallet will be available for use in LootClicker without an effort on the players part.\n\n### Next release - Patch 1.1\n\nWe aim to have the following released by the next patch as we transition into open beta.\n\n- Fixing any residual alpha bugs.\n- Standalone builds for mac/pc. \n- Add new cosmetics, mercenaries and items.\n- Perfect the in game scaling algorithms for the best player experience.\n- Support for WebGL uploading profile pictures.\n- Android/Mac build begins.\n\n## Decentralized Game Modes\n\n### Blockchain Royale\n\n#### As a part of the NEO-Game competition, we wanted to really showcase the potential of what a smart contract is capable of. We have decided to release our first decentralized game mode based on the popular \"Battle Royale\" gamemode. \n\n\n\n- For a player to perform an action, they must sign and send an invocation transaction with their private key and the ensure the required parameters of what they want to do are in the script.\n- Every single action of this game mode is decided and resolved inside the smart contract and output through ```Notify``` events which are relayed to the game including:\n\n - Movement: moving the player in a direction along a map.\n - Map boundaries: defining where the player is allowed to move along a map.\n - Random in game events: dynamically spawning areas on the map that are randomly marked off and destroyed.\n - Timeouts: ensuring inactive players can be removed.\n - Looting and fighting: random rolls decided on the blockchain result in public and fair results.\n - Rewards: the smart contract can be programmed to give rewards to addresses based on certain conditions.\n\n- Smart contracts are able to emit ```Notify``` events so we know what occurred on the blockchain such as the following from our contract:\n```\ndetails = [\"BR\", event_code,\"BR_sign_up\",address, result]\nNotify(details)\n``` \nHere we can see that an address has signed up, and what the result was.\n\n- Important game information is caught by our API, stored and able to be publicly queryable through the API calls listed below.\n- We can then from in game, call the API and show the player game logic based on the results decided in a smart contract by querying these logs back in order.\n\n\n#### Phases\n\n##### Creation: \nContract call: ``` BR_create [UniqueGameID,Address,Marketplace,Items] ```\n- A marketplace owner may create an event, and pass in x rewards, which will be given to the last x players of the match.\n\n##### Sign Up: \nContract call: ``` BR_sign_up [UniqueGameID,Address] ```\n- Players may sign up to the event, this registers them into the event in the smart contract itself.\n\n##### Start: \nContract call: ``` BR_start [UniqueGameID,Address] ```\n- The owner of the event can start the event, each round has a timeout period, in which players who do not move will be eliminated.\n\n##### Round 0 (Landing):\nContract call: ``` BR_choose_initial_zone [UniqueGameID,Address,Zone] ```\n\n- The player can \"spawn\" in, choosing a zone to initially be on, if it is in the constraints of the grid created.\n\n##### Round 1+: \nContract call: ``` BR_do_action [UniqueGameID,Address,Action,Direction] ```\n\nA registered and not yet eliminated address may do one of the following recognized actions each round:\n - \"Move\",\"Hide\",\"Loot\". \n - If a player is hiding, they have the advantage, 60% chance to win.\n - If a player is looting, they can find untradeable in game items in their current zone, although this will yield a disadvantage, a 40% chance to win.\n - A player can move to a square, 40 % chance to win.\n - If percentages are the same, it will go to a 50-50 roll.\n - To encourage movement and unique gameplay, after round 4, every round a new side of the grid map will be randomly chosen to be destroyed. This event is notified and will be seen in game.\n\n##### Finish Round:\nContract call: ``` BR_finish_round [UniqueGameID] ```\n\n- This can be called by anyone and will resolve the round on the condition that; all the players have made an action for the round, or the round has timed out. \n- If the event is complete, being there is <= 1 player, the smart contract will automatically finish the event and give the prizes to the x amount players as specified in the creation stage.\n\n\n## Wallet \n\nThe LOOT wallet is a tool used to securely store game assets.\nIt provides the following functionality:\n\n- Secure offline wallet creation and saving which includes NEP-2 support.\n- Signing and sending transactions.\n- Claiming and redeeming generated GAS.\n- Address book.\n- Switch between mainnet/testnet/privatenet.\n- Viewing names, stats, descriptions and photos of any registered games marketplace assets.\n- Viewing prices and balances of system assets and NEP-5 tokens.\n- Tracking the 24 hour change of your balance and individual NEO assets.\n- Full interaction with the LOOT Marketplace framework, including trading, buying, selling, cancelling, and removing registered game assets.\n- Two currently registered titles, LootClicker and Project: MEYSA with more to be announced soon.\n- A network monitor for the framework in which all data is publicly queryable.\n\n### Screenshots\n\n\n\n\n\n\n\n\n\n\n### Download Links\n\n#### Wallet release: TBA\n\n- Upon completion of code review by a NEO development group, the download links and source code will be MIT licensed and placed in this repository.\n\n## Framework & LootMarketsContract\n\n#### Overview\n\n- We intially wanted to integrate digital assets into LootClicker and saw a potential for targeting a larger audience.\n- The problem we have noticed with some decentralized exchanges and NFT contracts is the speed at which transactions occur. This can be a major inconvenience on a players gaming experience and is the main reason we decided to build the Loot framework.\n- The main necessity of our smart contract is to act as the foundation of our framework, it allows completely decentralized ownership and the exchange of assets for a token pegged to a fiat value. \n- The utility NEP-5 token contract has been slightly edited to allow deposit/withdrawal in and out of the smart contract, so that funds can be managed by the framework. This functionality is currently built in to the wallet.\n- Transactions can be relayed by any party, upon mainnet release, this will be a completely open network where anyone can be rewarded for powering the network. The fees are payed out decidedly by publicly viewable algorithms converting gas costs to LOOT fees by several variables.\n- To add to further decentralization on this front-running incentivized network, the framework is currently being extended into many nodes which communicate to eachother to ensure no downtime.\n- In depth details are being documented in our whitepaper which will be released.\n\n##### Marketplace\n\n- A marketplace defined in our smart contract is essentially a class of assets in the contract that address/addresses have exclusive ownership over. This means they are able to create and distribute assets to players of their game.\n- These distributed assets can then be bought, sold, traded and/or removed by a NEO address.\n- A marketplace can be created dynamically at any time by the contract owner, which will immediately give them exclusive asset rights over their named marketplace assets.\n- The economic value of these assets is decided upon by the community of an integrated title.\n- It is important to note however this does not allow the marketplace owner to take items from the player at any time or have any control of the players assets once given to them.\n\n##### General\n\n- The way our framework functions, a marketplace owner must sign these transactions to let them occur such that everything is ordered correctly. \n- These orders get packaged into transactions by the framework and distributed to the network and end up being invoked inside the smart contract for final resolution.\n - While trading is active in the contract, they must have the final say in when a transaction is allowed to occur. \n - This is automatically done for the registered marketplace owner when a valid order is posted to ```/add_order/``` through the API, on the condition they have signed the parameters with their private key, attaching this signature and their public key. We can quickly check if they are a marketplace owner by querying the smart contract.\n- As seen in the smart contract, we can verify parameters signed by private keys to ensure all parties involved in the transaction want an order to occur.\n\n##### Unforseen Occurrence\n\n- It should be noted that in the case of an emergency, we have added methods to allow termination of trading, in which everyone will be able to use functions normally, verified by ```CheckWitness```.\n- If a relayed transaction was ever to fail during the testing stages of development, our framework contains a quick emergency chain rebuilding method, picking out faulty transactions.\n- As orders are signed to exact parameters by a users private key, there is no possible way a user will ever lose their digital assets or tokens. \n- We have multiple measures in place to ensure a faulty transaction or bad actor transaction that is relayed is never sent to a NEO node.\n\n#### Network Order Format\n\nAn order can be sent via a raw string in JSON format in the body of a POST request through the route ```/add_order/``` to the public API with the following details of what order an address would like to place.\n\n- The API spec can be found at the bottom of this page.\n\nNOTE: There is a 5 second timeout between orders for players to discourage spam before fees are introduced.\n\n\n```\n{\n \"operation\": # The operation the maker of this order wants to perform. \n \"put_offer,buy_offer,cancel_offer,give_item,remove_item,withdraw\"\n \"address\": # The address of the maker of the order.\n \"taker_address\": # Optionally the address the maker of the order specifies.\n \"tokens\": # How many tokens the originator is spending.\n \"item_id\": # The id of the item the maker is performing the operation on. \n \"marketplace\": # Which marketplace this is occurring on.\n \"signature\": # The signature of this signed order.\n \"public_key\": # The public key of the maker.\n \"salt\": # A unique GUID so that this order may only occur once.\n}\n```\n\n\n## Framework API - http://lootmarketplacenode.com:8090/\n\n### Framework API Routes\n\n#### POST /add_order/\n- Add an order to the framework, if in the proper format and allowed to occur these changes will be reflected immediately.\n\nExample: http://lootmarketplacenode.com:8090/add_order/\n\nRequest body:\n```\n{\n \"operation\": \"buy_item\",\n \"address\": \"AK2nJJpJr6o664CWJKi1QRXjqeic2zRp8y\",\n \"taker_address\": \"\",\n \"tokens\": 2, \n \"item_id\": 101, \n \"marketplace\": \"LootClicker\" \n \"signature\": \"8932a691788c2ac8489812a291523ad2ee878306a0f9dc15e676f7f3c01eff00f8a294ee6804f44a1c15e0762de128cdd2f60525f4e199c7e630732dbb7ef9ce\" \n \"public_key\": \"02c190a00cb234adf6763e5f6ac5a45cc0eaaf442f881f7e329359625dcc9bc671\",\n \"salt\": \"307128a7e69547a59cb7bc49a198759a\" \n}\n```\n\nResponse body:\n```\n{\n \"result\": True,\n \"error_code\": 0\n}\n```\n\n#### GET /marketplaces/get\n- Query a list of registered games/marketplaces.\n\nExample: http://lootmarketplacenode.com:8090/marketplaces/get\n\n\nResponse body:\n\n```\n{\n \"marketplaces\": [\n \"LootClicker\",\n \"Project_MEYSA\"\n ]\n}\n```\n\n\n#### GET /market/get/[marketplace]\n- Query a list of items being sold on a marketplace.\n\nExample: http://lootmarketplacenode.com:8090/market/get/LootClicker\n\nResponse body:\n```\n{\n \"marketplace\": \"LootClicker\",\n \"offers\": [\n \"{\\\"marketplace\\\": \\\"LootClicker\\\", \\\"offer_id\\\": \\\"07db509b3a1e4e0ab990519055328a1c\\\", \\\"address\\\": \\\"AdRpcifzm36LGRcVhfeC2YmsoPARNLTQ3j\\\", \\\"item_id\\\": 735, \\\"price\\\": 112345678, \\\"tag\\\": \\\"\\\", \\\"type\\\": \\\"Shotgun\\\", \\\"slug\\\": 2017, \\\"name\\\": \\\"TCR-37 Skyforged Cinder\\\", \\\"rarity\\\": 2, \\\"description\\\": \\\"A cruel looking design favoured by those who like to intimidate their comrades as well as their foes.\\\", \\\"misc\\\": \\\"20 DPC / 4.16 CD\\\\n-2 % DPS / 2 % IDLE / 2 % XP / 2 % Bounty\\\"}\",\n \"{\\\"marketplace\\\": \\\"LootClicker\\\", \\\"offer_id\\\": \\\"7378e1bbbf4749e5abf058bb1a922769\\\", \\\"address\\\": \\\"AdRpcifzm36LGRcVhfeC2YmsoPARNLTQ3j\\\", \\\"item_id\\\": 737, \\\"price\\\": 543520000000, \\\"tag\\\": \\\"\\\", \\\"type\\\": \\\"Pistol\\\", \\\"slug\\\": 2004, \\\"name\\\": \\\"R9-360 Atomic Prism\\\", \\\"rarity\\\": 4, \\\"description\\\": \\\"This laser hand-cannon has several aftermarket parts, cobbled together from all sorts of other models.\\\", \\\"misc\\\": \\\"18 DPC / .03 CD\\\\n-6 % DPS / 2 % IDLE / 2 % XP / 2 % Bounty\\\"}\"\n ]\n}\n```\n\n#### GET /market/get_offer/[offer_id]\n- Query a specific offer by its offer_id value.\n\nExample: http://lootmarketplacenode.com:8090/market/get/LootClicker\n\nResponse body:\n```\n{\n \"offer\": \"{\\\"marketplace\\\": \\\"LootClicker\\\", \\\"offer_id\\\": \\\"07db509b3a1e4e0ab990519055328a1c\\\", \\\"address\\\": \\\"AdRpcifzm36LGRcVhfeC2YmsoPARNLTQ3j\\\", \\\"item_id\\\": 735, \\\"price\\\": 112345678, \\\"tag\\\": \\\"\\\", \\\"type\\\": \\\"Shotgun\\\", \\\"slug\\\": 2017, \\\"name\\\": \\\"TCR-37 Skyforged Cinder\\\", \\\"rarity\\\": 2, \\\"description\\\": \\\"A cruel looking design favoured by those who like to intimidate their comrades as well as their foes.\\\", \\\"misc\\\": \\\"20 DPC / 4.16 CD\\\\n-2 % DPS / 2 % IDLE / 2 % XP / 2 % Bounty\\\"}\"\n}\n```\n\n\n#### GET /inventory/[marketplace]/[address]\n- Query the inventory of an address on a specific marketplace.\n\nExample: http://lootmarketplacenode.com:8090/inventory/Project_MEYSA/AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\n\nResponse body:\n```\n{\n \"address\": \"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\",\n \"inventory\": [\n 100000,\n 100002,\n 100003,\n 100005,\n 100000,\n 100002,\n 100003,\n 100005,\n 100004\n ]\n}\n```\n\n#### GET /item/[marketplace]/[id]\n- Query the details of an item on a specific marketplace with its id value.\n\nExample: http://lootmarketplacenode.com:8090/item/Project_MEYSA/100000\n\nResponse body:\n```\n{\n \"id\": 100000,\n \"marketplace\": \"Project_MEYSA\",\n \"name\": \"SunSpring, the Fatherly\",\n \"description\": \"SunSpring is a hippie who truly believes he has “transcended” the island, becoming some kind of deity and that everyone on the island is his child.\",\n \"slug\": 1,\n \"type\": \"Skin\",\n \"misc\": \"\",\n \"rarity\": 5\n}\n```\n\n\n#### GET /history/address/[address]\n- Query the framework network history of an address.\n\nExample: http://lootmarketplacenode.com:8090/history/address/AK2nJJpJr6o664CWJKi1QRXjqeic2zRp8y\n\nResponse body:\n```\n{\n \"address\": \"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\",\n \"history\": [\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": null,\\n \\\"offer_id\\\": null,\\n \\\"operation\\\": \\\"cancel_offer\\\",\\n \\\"salt\\\": null,\\n \\\"slug\\\": -1,\\n \\\"timestamp\\\": 1534112429.046384,\\n \\\"tokens\\\": 100000000000\\n}\",\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": null,\\n \\\"offer_id\\\": null,\\n \\\"operation\\\": \\\"put_offer\\\",\\n \\\"salt\\\": null,\\n \\\"slug\\\": -1,\\n \\\"timestamp\\\": 1534112387.7050304,\\n \\\"tokens\\\": 100000000000\\n}\"\n ]\n}\n```\n\n\n#### GET /history/marketplace/[marketplace]\n- Query the framework network history of marketplace.\n\nExample: http://lootmarketplacenode.com:8090/history/all/LootClicker\n\nResponse body:\n\nResponse body:\n```\n{\n \"history\": [\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": \\\"Penny\\\",\\n \\\"offer_id\\\": \\\"572ed69f4188468cab3c112e523ff8a0\\\",\\n \\\"operation\\\": \\\"cancel_offer\\\",\\n \\\"salt\\\": \\\"e6a6bde631974c8d84e0494c386cb541\\\",\\n \\\"slug\\\": 3,\\n \\\"timestamp\\\": 1534112429.046384,\\n \\\"tokens\\\": 100000000000\\n}\",\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": \\\"Penny\\\",\\n \\\"offer_id\\\": null,\\n \\\"operation\\\": \\\"put_offer\\\",\\n \\\"salt\\\": \\\"572ed69f4188468cab3c112e523ff8a0\\\",\\n \\\"slug\\\": 3,\\n \\\"timestamp\\\": 1534112387.7050304,\\n \\\"tokens\\\": 100000000000\\n}\"\n ]\n}\n```\n\n#### GET /history/all/[number]\n- Query the complete marketplace history with the specified number of values being returned, ordered by the newest first.\n\nExample: http://lootmarketplacenode.com:8090/history/all/2\n\nResponse body:\n```\n{\n \"history\": [\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": \\\"Penny\\\",\\n \\\"offer_id\\\": \\\"572ed69f4188468cab3c112e523ff8a0\\\",\\n \\\"operation\\\": \\\"cancel_offer\\\",\\n \\\"salt\\\": \\\"e6a6bde631974c8d84e0494c386cb541\\\",\\n \\\"slug\\\": 3,\\n \\\"timestamp\\\": 1534112429.046384,\\n \\\"tokens\\\": 100000000000\\n}\",\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_to\\\": \\\"\\\",\\n \\\"item_id\\\": 100004,\\n \\\"marketplace\\\": \\\"Project_MEYSA\\\",\\n \\\"name\\\": \\\"Penny\\\",\\n \\\"offer_id\\\": null,\\n \\\"operation\\\": \\\"put_offer\\\",\\n \\\"salt\\\": \\\"572ed69f4188468cab3c112e523ff8a0\\\",\\n \\\"slug\\\": 3,\\n \\\"timestamp\\\": 1534112387.7050304,\\n \\\"tokens\\\": 100000000000\\n}\"\n ]\n}\n```\n\n#### GET /wallet/[address]\n- Query the amount of LOOT an address has deposited into the smart contract.\n\nExample: http://lootmarketplacenode.com:8090/wallet/AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\n\nResponse body:\n\n```\n{\n \"balance\": 3300000000\n}\n```\n\n\n\n#### GET /wallet/withdrawing/[address]\n- Query the amount of LOOT an address is currently withdrawing from the smart contract.\n\nExample: http://lootmarketplacenode.com:8090/wallet/withdrawing/AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\n\nResponse body:\n\n```\n{\n \"balance\": 0\n}\n```\n\n#### GET /network/information\n- Query any additional network information of the framework.\n\nExample: http://lootmarketplacenode.com:8090/network/information\n\nResponse body:\n\n```\n{\n \"relayers\": 1,\n \"transactions_pending\": 0,\n \"payout_ratio\": 0,\n \"fee_ratio\": 0\n}\n```\n\n### Utility Routes\n\n#### POST /wallets/create\n- Create a NEP-2 key and address with the password specified in the request body.\n- Integrated titles can use this as a way to give a wallet to their players without needing any heavier frameworks involved.\n\nExample: http://lootmarketplacenode.com:8090/wallets/create\n\nRequest body:\n```\n{\n \"password\":\"password123\"\n}\n```\n\nResponse body:\n```\n{\n \"address\": \"AYjiaSfysSxsxATzH2gRiGWTvmLfmu65Us\",\n \"nep2_key\": \"6PYKNmC7Dzoq1JXVjjkrGzwdKS7N2U2vkKtP1G8rUXLHm4d16HQ1RAXMzN\"\n}\n```\n\n\n#### POST /send_raw_tx/\n- For convenience, post a raw transaction to the NEO node with the highest synced block height.\n\nExample: http://lootmarketplacenode.com:8090/send_raw_tx/\n\nRequest body:\n```\nd1013d511423ba2703c53263e8d6e522dc32203339dcd8eee9044c6f6f7453c10a676976655f6974656d73676916b6583fad1b36b25476896cbdd2c9645070b1000000000000000000000001414015abcfca9ed66738f71feef13d90cfb58ac7e97745b6a0c089c1d25cf3dd1f8c464c28eb92c04eefa4507e17db1ecf87aacbdecbf37aef516c9914ad1ffdde9c2321031a6c6fbbdf02ca351745fa86b9ba5a9452d785ac4f7fc2b7548ca2a46c4fcf4aac\n```\n\nResponse body:\n```\n{\n \"result\": false\n}\n```\n#### GET /get_node_height\n- Get the height of the blockchain this marketplace node is listening for events on.\n\nExample: http://lootmarketplacenode.com:8090/get_node_height\n\nResponse body:\n\n```\n{\n \"height\": \"137116\"\n}\n```\n\n### Decentralized Game Mode Routes\n\n#### GET /battle_royale/logs\n- Query the log of all the smart contract events caught from ```Notify```.\n- Games can query this to understand exactly what was resolved in the smart contract.\n\nExample: http://lootmarketplacenode.com:8090/battle_royale/logs\n\nResponse body:\n\n```\n{\n \"logs\": [\n \"{\\n \\\"address\\\": \\\"AaeGQWooqqyTe65GGNcsEU9Nn7VArY64Ne\\\",\\n \\\"address_vs\\\": null,\\n \\\"event_code\\\": \\\"697\\\",\\n \\\"message\\\": 0,\\n \\\"result\\\": true,\\n \\\"round\\\": 0,\\n \\\"salt\\\": \\\"36ab7595059844c6a436c9260c6494af\\\",\\n \\\"type\\\": \\\"BR_sign_up\\\",\\n \\\"zone\\\": 0\\n}\",\n \"{\\n \\\"address\\\": \\\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\\\",\\n \\\"address_vs\\\": null,\\n \\\"event_code\\\": \\\"697\\\",\\n \\\"message\\\": 0,\\n \\\"result\\\": true,\\n \\\"round\\\": 0,\\n \\\"salt\\\": \\\"3f20ade7726148e98bdc828c21ba1210\\\",\\n \\\"type\\\": \\\"BR_create\\\",\\n \\\"zone\\\": 0\\n}\"\n ]\n}\n```\n\n#### GET /battle_royale/leaderboard/[event_code]\n- Query the leaderboard of an event royale match.\n\nExample: http://lootmarketplacenode.com:8090/battle_royale/leaderboard/697\n\nResponse body:\n```\n{\n \"leaderboard\": \"[\"AaeGQWooqqyTe65GGNcsEU9Nn7VArY64Ne\",\"AM1px3B3GWNP3sXZTdcHYhpKzDL8xrg3Mr\"]\"\n}\n```\n\n\n## Acknowledgements\n\nWithout the following this project would not be possible.\nWe offer a sincere thank you and hope we will be able to give something back.\n\n- NEO\n- NGD\n- NEL\n- CoZ\n- NEO-python\n- NEO-lux \n- @metachris\n- @localhuman\n\n"
},
{
"alpha_fraction": 0.6222750544548035,
"alphanum_fraction": 0.6283805966377258,
"avg_line_length": 34.505332946777344,
"blob_id": "a0b234917e23908e223f85aaaa9141de5dc5b982",
"content_id": "8680469db94d610c4d30be88d312e34a3b1ae4e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73212,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 2062,
"path": "/LootMarketsContract.py",
"repo_name": "LootToken/Loot-Marketplace-Framework",
"src_encoding": "UTF-8",
"text": "\"\"\"\n===== LootMarketExchange =====\n\nMIT License\n\nCopyright 2018 LOOT Token Inc. & Warped Gaming LLC\n\nAuthor: @poli\nEmail: [email protected]\n\nThis smart contract is the foundation of the Loot Framework.\nIt enables the creation of marketplaces for games, that is, it\nintegrates a storage system for items on the NEO blockchain as \"digital assets\" where\nthey are tradeable for the NEP-5 asset LOOT tied to a fiat value. A marketplace is registered\nwith owners, who have exclusive permissions to create and give players assets on this marketplace.\n\nFor our proof of concept game LootClicker, this contract includes its first decentralized game mode \ninspired by the \"Battle Royale\" genre of games. \nAll aspects of game logic are decided in this contract and it aims to show what a NEO smart contract is capable of.\n\"\"\"\n\nfrom boa.builtins import concat, list, range, take, substr, verify_signature, sha256, hash160, hash256\nfrom boa.interop.System.ExecutionEngine import GetScriptContainer, GetExecutingScriptHash, GetCallingScriptHash,GetEntryScriptHash\nfrom boa.interop.Neo.Transaction import Transaction, TransactionInput, GetReferences, GetOutputs, GetUnspentCoins,GetAttributes, GetInputs\nfrom boa.interop.Neo.Output import GetValue, GetAssetId, GetScriptHash\nfrom boa.interop.Neo.Attribute import TransactionAttribute\nfrom boa.interop.Neo.TriggerType import Application, Verification\nfrom boa.interop.Neo.Storage import Get, Put, Delete, GetContext\nfrom boa.interop.Neo.Action import RegisterAction\nfrom boa.interop.Neo.Blockchain import GetHeight, ShowAllContracts, GetContract, GetHeader\nfrom boa.interop.Neo.Runtime import Notify, Serialize, Deserialize, CheckWitness, GetTrigger\nfrom boa.interop.Neo.App import RegisterAppCall, DynamicAppCall\nfrom boa.interop.Neo.Header import Header\n\n# region Marketplace Variables\n\n# Wallet hash of the owner of the contract.\ncontract_owner = b'9|3W[\\xec\\r\\xe7\\xd8\\x03\\xd8\\xe9\\x15\\xe1\\x933\\x92P\\xfc\\xb0'\n\n# Hash of the NEP-5 loot token contract.\nLootTokenHash = b'i\\x9b\\xf7\\x17L\\xd7\\x0f\\xbe\\xea\\xe4\\xc5R\\xe7\\xb0\\xddX\\x8a\\x89\\xca\\xcb'\n\n# Register the hash of the NEP-5 LOOT token contract to enable cross contract operations.\nLootContract = RegisterAppCall('cbca898a58ddb0e752c5e4eabe0fd74c17f79b69', 'operation', 'args')\n\n# Storage keys\ncontract_state_key = b'State' # Stores the state of the contract.\ninventory_key = b'Inventory' # The inventory of an address.\nmarketplace_key = b'Marketplace' # The owner of a marketplace\noffers_key = b'Offers' # All the offers available on a marketplace.\norder_key = b'Order' # Mark an order as complete so it is not completed.\n\n# Fee variables\nfeeFactor = 10000\nMAX_FEE = 10000000\n\n# Contract States\nTERMINATED = b'\\x01' # Anyone may do any core operations without owners permission e.g. emergency button.\nPENDING = b'\\x02' # The contract needs to be initialized before trading is opened.\nACTIVE = b'\\03' # All operations are active and managed by the LOOT Marketplace framework.\n\n# endregion\n\n\n# region Decentralized Game variables\n\n# Stores the rewards that competition owner has placed.\nbattle_royale_rewards_key = b'BattleRoyaleRewards'\n# A list of the destroyed zones.\nbattle_royale_destroyed_zones_key = b'BattleRoyaleGas'\n# The zone which is marked to be destroyed.\nbattle_royale_marked_destroyed_zone_key = b\"BRMarkedZone\"\n# For more information about every entrant.\nbattle_royale_entrant_key = b'BattleRoyaleInformation'\n# A list of players so we can easily iterate through the remaining players.\nbattle_royale_current_players_key = b'BattleRoyaleCurrentPlayers'\n# The details of the event.\nbattle_royale_details_key = b'BattleRoyaleDetails'\n# Leaderboard results of the event.\nbattle_royale_event_results_key = b'BREventResults'\n\n# Zones start being destroyed at round 4.\nROUND_DESTROYED_ZONES_GENERATE = 4\n\n# 5% chance to find loot per \"loot\" roll each round, increases + 5% each round.\nBR_CHANCE_TO_FIND_LOOT = 5\nBR_CHANCE_INCREASE_PER_ROUND = 5\n# The round will timeout after 10 blocks.\nBR_ROUND_TIMEOUT = 10\nBR_UNTRADEABLE_REWARDS = [\"Gem\", \"Ammo\", \"Crate\", \"Bounty\"]\n\n# endregion\n\n\ndef Main(operation, args):\n \"\"\"\n The entry point for the smart contract.\n :param operation: str The operation to invoke.\n :param args: list A list of arguments for the operation.\n :return:\n bytearray: The result of the operation. \"\"\"\n\n print(\"LootMarketExchange: Version 2.5: Testnet\")\n trigger = GetTrigger()\n if trigger == Application():\n\n # ========= Marketplace Operations ==========\n\n # Fill the order on the blockchain.\n if operation == \"exchange\":\n if len(args) == 14:\n marketplace = args[0]\n marketplace_owner_address = args[1]\n marketplace_owner_signature = args[2]\n marketplace_owner_public_key = args[3]\n originator_address = args[4]\n originator_signature = args[5]\n originator_public_key = args[6]\n taker_address = args[7]\n taker_signature = args[8]\n taker_public_key = args[9]\n item_id = args[10]\n price = args[11]\n originator_order_salt = args[12]\n taker_order_salt = args[13]\n\n operation_result = exchange(marketplace, marketplace_owner_address, marketplace_owner_signature,\n marketplace_owner_public_key, originator_address, originator_signature,\n originator_public_key, taker_address, taker_signature, taker_public_key,\n originator_order_salt, taker_order_salt, item_id, price)\n\n payload = [\"exchange\", originator_order_salt, marketplace, operation_result]\n Notify(payload)\n\n return operation_result\n\n if operation == \"trade\":\n # Trade must have an terminated implementation so users will never lose access to their assets.\n if get_contract_state() == TERMINATED:\n if len(args) == 4:\n marketplace = args[0]\n originator_address = args[1]\n taker_address = args[2]\n item_id = args[3]\n\n if not CheckWitness(originator_address):\n return False\n\n operation_result = trade(marketplace, originator_address, taker_address, item_id)\n return operation_result\n\n if len(args) == 10:\n marketplace = args[0]\n originator_address = args[1]\n taker_address = args[2]\n item_id = args[3]\n originator_signature = args[4]\n originator_public_key = args[5]\n marketplace_owner_address = args[6]\n marketplace_owner_signature = args[7]\n marketplace_owner_public_key = args[8]\n originator_order_salt = args[9]\n\n operation_result = trade_verified(marketplace, originator_address, taker_address, item_id,\n marketplace_owner_address, marketplace_owner_signature,\n marketplace_owner_public_key, originator_signature,\n originator_public_key, originator_order_salt)\n transaction_details = [\"trade\", originator_order_salt, marketplace, operation_result]\n Notify(transaction_details)\n\n return operation_result\n\n if operation == \"give_item\":\n # Marketplace owners must be able to still give items without the framework.\n if get_contract_state() == TERMINATED:\n if len(args) == 4:\n marketplace = args[0]\n originator_address = args[1]\n taker_address = args[2]\n item_id = args[3]\n\n if not CheckWitness(originator_address):\n return False\n if not is_marketplace_owner(marketplace, originator_address):\n return False\n\n operation_result = trade(marketplace, originator_address, taker_address, item_id)\n return operation_result\n\n if len(args) == 7:\n marketplace = args[0]\n address_to = args[1]\n item_id = args[2]\n marketplace_owner = args[3]\n marketplace_owner_signature = args[4]\n marketplace_owner_public_key = args[5]\n originator_order_salt = args[6]\n\n operation_result = give_item_verified(marketplace, address_to, item_id, marketplace_owner,\n marketplace_owner_signature, marketplace_owner_public_key,\n originator_order_salt)\n payload = [\"give_item\", originator_order_salt, marketplace, operation_result]\n Notify(payload)\n return operation_result\n\n\n if operation == \"remove_item\":\n # Remove item must have a terminated implementation so users can still access their assets.\n if get_contract_state() == TERMINATED:\n if len(args) == 3:\n marketplace = args[0]\n originator_address = args[1]\n item_id = args[2]\n\n if CheckWitness(originator_address):\n return False\n operation_result = remove_item(marketplace, originator_address, item_id)\n return operation_result\n\n if len(args) == 9:\n marketplace = args[0]\n originator_address = args[1]\n item_id = args[2]\n originator_signature = args[3]\n originator_public_key = args[4]\n marketplace_owner_address = args[5]\n marketplace_owner_signature = args[6]\n marketplace_owner_public_key = args[7]\n originator_order_salt = args[8]\n\n operation_result = remove_item_verified(marketplace, originator_address, item_id,\n originator_order_salt, marketplace_owner_address\n , marketplace_owner_signature, marketplace_owner_public_key,\n originator_signature, originator_public_key)\n payload = [\"remove_item\", originator_order_salt, marketplace, operation_result]\n Notify(payload)\n return operation_result\n\n # Queries\n\n if operation == \"get_inventory\":\n if len(args) == 2:\n marketplace = args[0]\n address = args[1]\n inventory_s = get_inventory(marketplace, address)\n if inventory_s == b'':\n inventory = []\n else:\n inventory = Deserialize(inventory_s)\n\n payload = [\"get_inventory\", marketplace, address, inventory]\n Notify(payload)\n return True\n\n if operation == \"marketplace_owner\":\n if len(args) == 2:\n marketplace = args[0]\n address = args[1]\n result = is_marketplace_owner(marketplace, address)\n\n payload = [\"marketplace_owner\", marketplace, address, result]\n Notify(payload)\n return result\n\n # ========= Administration, Crowdsale & NEP-5 Specific Operations ==========\n\n if operation == \"receiving\":\n if len(args) == 3:\n # Get the script hash of the address calling this.\n caller = GetCallingScriptHash()\n\n # Must be from the LOOT nep-5 contract.\n if caller != LootTokenHash:\n return False\n\n return handle_deposit(args)\n\n if operation == \"withdraw\":\n # Users will be able to withdraw their funds in a terminated state.\n if get_contract_state() == TERMINATED:\n if len(args) == 2:\n originator_address = args[0]\n amount = args[1]\n my_hash = GetExecutingScriptHash()\n\n if not CheckWitness(originator_address):\n return False\n\n operation_result = withdrawal(my_hash, originator_address, amount)\n return operation_result\n\n if len(args) == 8:\n originator_address = args[0]\n tokens = args[1]\n originator_signature = args[2]\n originator_public_key = args[3]\n owner_address = args[4]\n owner_signature = args[5]\n owner_public_key = args[6]\n originator_order_salt = args[7]\n\n my_hash = GetExecutingScriptHash()\n\n if withdrawal_verified(my_hash, originator_address, tokens, originator_signature, originator_public_key,\n owner_address, owner_signature, owner_public_key, originator_order_salt):\n order_complete(originator_order_salt)\n payload = [\"withdraw\", originator_order_salt, originator_address, tokens]\n Notify(payload)\n return True\n\n return False\n\n if operation == \"transfer\":\n if len(args) == 9:\n originator_address = args[0]\n taker_address = args[1]\n tokens = args[2]\n originator_signature = args[3]\n originator_public_key = args[4]\n marketplace_owner_address = args[5]\n marketplace_owner_signature = args[6]\n marketplace_owner_public_key = args[7]\n originator_order_salt = args[8]\n\n operation_result = transfer_token_verified(originator_address, taker_address, tokens,\n originator_signature, originator_public_key,\n marketplace_owner_address, marketplace_owner_signature,\n marketplace_owner_public_key, originator_order_salt)\n\n transaction_details = [\"transfer\", originator_order_salt, operation_result]\n Notify(transaction_details)\n return operation_result\n\n if operation == \"add_owner_wallet\":\n marketplace = args[0]\n address = args[1]\n return add_owner_wallet(marketplace, address)\n\n if operation == \"set_maker_fees\":\n if len(args) == 2:\n marketplace = args[0]\n fee = args[1]\n return set_maker_fee(marketplace, fee)\n\n if operation == \"set_taker_fees\":\n if len(args) == 2:\n marketplace = args[0]\n fee = args[1]\n return set_taker_fee(marketplace, fee)\n\n if operation == \"get_maker_fee\":\n if len(args) == 1:\n marketplace = args[0]\n return get_maker_fee(marketplace)\n\n if operation == \"get_taker_fee\":\n if len(args) == 1:\n marketplace = args[0]\n return get_taker_fee(marketplace)\n\n # Query the LOOT balance of an address.\n if operation == \"balance_of\":\n if len(args) == 1:\n address = args[0]\n balance = balance_of(address)\n # Notify the API with the LOOT balance of the address.\n transaction_details = [\"balance_of\", address, balance]\n Notify(transaction_details)\n return balance\n\n # OWNER only\n if CheckWitness(contract_owner):\n\n # Register a new marketplace on the blockchain.\n if operation == \"register_marketplace\":\n if len(args) == 4:\n marketplace = args[0]\n address = args[1]\n maker_fee = args[2]\n taker_fee = args[3]\n return register_marketplace(marketplace, address, maker_fee, taker_fee)\n\n if operation == \"set_contract_state\":\n contract_state = args[0]\n set_contract_state(contract_state)\n return True\n\n # State of the contract.\n if operation == \"get_state\":\n return get_contract_state()\n\n # ========= Decentralized Games ==========\n\n # Battle Royale\n\n if operation == \"BR_create\":\n # To start the event, the marketplace owner, uploads rewards and requirements.\n event_code = args[0]\n marketplace_owner_address = args[1]\n marketplace = args[2]\n\n # Remove the first 3 keyword args, the following should be items.\n for i in range(0, 3):\n args.remove(0)\n\n result = BR_create(event_code, marketplace, marketplace_owner_address, args)\n\n payload = [\"BR\", event_code, \"BR_create\", marketplace_owner_address, result]\n Notify(payload)\n\n return result\n\n if operation == \"BR_sign_up\":\n if len(args) == 2:\n event_code = args[0]\n address = args[1]\n\n result = BR_sign_up(event_code, address)\n details = [\"BR\", event_code, \"BR_sign_up\", address, result]\n Notify(details)\n\n return result\n\n if operation == \"BR_start\":\n if len(args) == 2:\n event_code = args[0]\n address = args[1]\n\n result = BR_start(event_code, address)\n\n details = [\"BR\", event_code, \"BR_start\", address, result]\n Notify(details)\n\n return result\n\n if operation == \"BR_choose_initial_zone\":\n if len(args) == 3:\n event_code = args[0]\n address = args[1]\n zone = args[2]\n\n # The first action which will be resolved the next round.\n return BR_choose_initial_grid_position(event_code, address, zone)\n\n if operation == \"BR_do_action\":\n if len(args) == 4:\n event_code = args[0]\n address = args[1]\n action = args[2]\n direction = args[3]\n\n return BR_do_action(event_code, address, action, direction)\n\n if operation == \"BR_finish_round\":\n if len(args) == 1:\n event_code = args[0]\n\n return BR_finish_round(event_code)\n\n if operation == \"BR_get_leaderboard\":\n if len(args) == 1:\n context = GetContext()\n event_code = args[0]\n leaderboard = get_BR_leaderboard(context, event_code)\n if leaderboard != b'':\n leaderboard = Deserialize(leaderboard)\n else:\n leaderboard = []\n payload = [\"BR\", event_code, 'leaderboard', leaderboard]\n Notify(payload)\n\n return True\n\n if operation == \"BR_get_event_details\":\n if len(args) == 1:\n context = GetContext()\n\n event_code = args[0]\n event_details = get_BR_event_details(context, event_code)\n payload = [\"BR\", event_code, \"event_details\", event_details]\n Notify(payload)\n\n return True\n\n return False\n\n # Owner will not be allowed to withdraw anything.\n if trigger == Verification():\n pass\n # check if the invoker is the owner of this contract\n # is_owner = CheckWitness(contract_owner)\n\n # If owner, proceed\n # if is_owner:\n # return True\n\n return False\n\n\ndef exchange(marketplace, marketplace_owner_address, marketplace_owner_signature,\n marketplace_owner_public_key, originator_address, originator_signature,\n originator_public_key, taker_address, taker_signature, taker_public_key,\n originator_order_salt, taker_order_salt, item_id, price):\n \"\"\"\n Verify the signatures of two parties and securely swap the item, and tokens between them.\n \"\"\"\n\n if order_complete(originator_order_salt):\n print(\"ERROR! This transaction has already occurred!\")\n return False\n\n if order_complete(taker_order_salt):\n print(\"ERROR! This transaction has already occurred!\")\n return False\n\n originator_args = [\"put_offer\", marketplace, item_id, price, originator_order_salt]\n\n if not verify_order(originator_address, originator_signature, originator_public_key, originator_args):\n print(\"ERROR! originator has not signed the order\")\n return False\n\n taker_args = [\"buy_offer\", marketplace, item_id, price, taker_order_salt]\n if not verify_order(taker_address, taker_signature, taker_public_key, taker_args):\n print(\"ERROR! Taker has not signed the order!\")\n return False\n\n # A marketplace owner must verify so there are no jumps in the queue.\n marketplace_owner_args = [\"exchange\", marketplace, item_id, price, originator_address, taker_address]\n\n if not verify_order(marketplace_owner_address, marketplace_owner_signature, marketplace_owner_public_key,\n marketplace_owner_args):\n print(\"ERROR! Marketplace owner has not signed the order!\")\n return False\n\n if not trade(marketplace, originator_address, taker_address, item_id):\n print(\"ERROR! Items could not be transferred.\")\n return False\n\n if not transfer_token(taker_address, originator_address, price):\n print(\"ERROR! Tokens could not be transferred.\")\n return False\n\n # Set the orders as complete so they can only occur once.\n set_order_complete(originator_order_salt)\n set_order_complete(taker_order_salt)\n\n return True\n\n\n\ndef trade_verified(marketplace, originator_address, taker_address, item_id,\n marketplace_owner_address, marketplace_owner_signature,\n marketplace_owner_public_key, originator_signature,\n originator_public_key, salt):\n \"\"\"\n Transfer an item from an address, to an address on a marketplace.\n \"\"\"\n\n if not is_marketplace_owner(marketplace, marketplace_owner_address):\n print(\"ERROR! Only a marketplace owner is allowed to give items.\")\n return False\n\n if order_complete(salt):\n print(\"ERROR! This order has already occurred!\")\n return False\n\n args = [\"trade\", marketplace, originator_address, taker_address, item_id, salt]\n\n if not verify_order(marketplace_owner_address, marketplace_owner_signature, marketplace_owner_public_key, args):\n print(\"ERROR! The marketplace owner has not permitted the transaction.\")\n return False\n\n if not verify_order(originator_address, originator_signature, originator_public_key, args):\n print(\"ERROR! The address removing has not signed this!\")\n return False\n\n if trade(marketplace, originator_address, taker_address, item_id):\n set_order_complete(salt)\n return True\n\n print(\"ERROR! Could not complete the trade\")\n return False\n\n\ndef trade(marketplace, originator_address, taker_address, item_id):\n \"\"\"\n Trade an item from one address to another, on a specific marketplace.\n \"\"\"\n # If the item is being transferred to the same address, don't waste gas and return True.\n if originator_address == taker_address:\n return True\n\n # If the removal of the item from the address sending is successful, give the item to the address receiving.\n if remove_item(marketplace, originator_address, item_id):\n if give_item(marketplace, taker_address, item_id):\n return True\n\n\n\n\ndef give_item_verified(marketplace, taker_address, item_id,\n owner_address, owner_signature,\n owner_public_key, salt):\n \"\"\"\n Give an item to an address on a specific marketplace, verified by a marketplace owner.\n \"\"\"\n\n if not is_marketplace_owner(marketplace, owner_address):\n print(\"Only a marketplace owner is allowed to give items.\")\n return False\n\n if order_complete(salt):\n print(\"This order has already occurred!\")\n return False\n\n args = [\"give_item\", marketplace, taker_address, item_id, 0, salt]\n if not verify_order(owner_address, owner_signature, owner_public_key, args):\n print(\"A marketplace owner has not signed this order.\")\n return False\n\n set_order_complete(salt)\n\n give_item(marketplace, taker_address, item_id)\n\n return True\n\ndef give_item(marketplace, taker_address, item_id):\n \"\"\"\n Give an item to an address on a specific marketplace.\n \"\"\"\n # Get the players inventory from storage.\n inventory_s = get_inventory(marketplace, taker_address)\n\n # If the address owns no items create a new list, else grab the pre-existing list and append the new item.\n if inventory_s == b'':\n inventory = [item_id]\n else:\n inventory = Deserialize(inventory_s)\n inventory.append(item_id)\n\n # Serialize and save the inventory back to the storage.\n inventory_s = Serialize(inventory)\n save_inventory(marketplace, taker_address, inventory_s)\n\n return True\n\n\ndef remove_item_verified(marketplace, address, item_id, salt, owner_address,\n owner_signature, owner_public_key, signature, public_key):\n \"\"\"\n Remove an item from an address on a marketplace.\n \"\"\"\n\n if not is_marketplace_owner(marketplace, owner_address):\n print(\"ERROR! Only a marketplace owner is allowed to give items.\")\n return False\n\n if order_complete(salt):\n print(\"ERROR! This order has already occurred!\")\n return False\n\n args = [\"remove_item\", marketplace, address, item_id, 0, salt]\n if not verify_order(owner_address, owner_signature, owner_public_key, args):\n print(\"ERROR! A marketplace owner has not signed this order.\")\n return False\n\n owner_args = [\"remove_item\", marketplace, address, item_id, 0, salt]\n if not verify_order(address, signature, public_key, owner_args):\n print(\"ERROR! The address removing has not signed this!\")\n return False\n\n if remove_item(marketplace, address, item_id):\n set_order_complete(salt)\n return True\n\n return False\n\n\ndef remove_item(marketplace, address, item_id):\n \"\"\"\n Remove an item from an address on a specific marketplace.\n \"\"\"\n inventory_s = get_inventory(marketplace, address)\n if inventory_s != b'':\n inventory = Deserialize(inventory_s)\n current_index = 0\n\n for item in inventory:\n if item == item_id:\n inventory.remove(current_index)\n inventory_s = Serialize(inventory)\n save_inventory(marketplace, address, inventory_s)\n return True\n current_index += 1\n\n return False\n\n\ndef verify_order(address, signature, public_key, args):\n \"\"\"\n Verify that an order is properly signed by a signature and public key.\n We also ensure the public key can be recreated into the script hash\n so we know that it is the address that signed it.\n \"\"\"\n\n message = \"\"\n for arg in args:\n message = concat(message, arg)\n\n # Create the script hash from the given public key, to verify the address.\n redeem_script = b'21' + public_key + b'ac'\n script_hash = hash160(redeem_script)\n\n # Must verify the address we are doing something for is the public key whom signed the order.\n if script_hash != address:\n print(\"ERROR! The public key does not match with the address who signed the order.\")\n return False\n\n if not verify_signature(public_key, signature, message):\n print(\"ERROR! Signature has not signed the order.\")\n return False\n\n return True\n\n\ndef get_contract_state():\n \"\"\"Current state of the contract.\"\"\"\n context = GetContext()\n state = Get(context, contract_state_key)\n return state\n\n\ndef set_contract_state(state):\n \"\"\" Set the state of the contract. \"\"\"\n context = GetContext()\n Delete(context, contract_state_key)\n Put(context, contract_state_key, state)\n\n return True\n\n\ndef set_order_complete(salt):\n \"\"\" So an order is not repeated, user has signed a salt. \"\"\"\n context = GetContext()\n key = concat(order_key, salt)\n Put(context, key, True)\n\n return True\n\n\ndef order_complete(salt):\n \"\"\" Check if an order has already been completed.\"\"\"\n context = GetContext()\n key = concat(order_key, salt)\n exists = Get(context, key)\n if exists != b'':\n return True\n\n return False\n # return exists != b''\n\n\ndef increase_balance(address, amount):\n \"\"\"\n Called on deposit to increase the amount of LOOT in storage of an address.\n \"\"\"\n context = GetContext()\n\n # LOOT balance is mapped directly to an address\n key = address\n\n current_balance = Get(context, key)\n new_balance = current_balance + amount\n\n Put(context, key, new_balance)\n\n # Notify that address there deposit is complete\n evt = [\"deposit\", address, amount]\n Notify(evt)\n\n return True\n\n\ndef reduce_balance(address, amount):\n \"\"\"\n Called on withdrawal, to reduce the amount of LOOT in storage of an address.\n \"\"\"\n context = GetContext()\n if amount < 1:\n print(\"ERROR! Can only reduce a balance >= 1. \")\n return False\n\n # LOOT is mapped directly to address\n key = address\n\n current_balance = Get(context, key)\n new_balance = current_balance - amount\n\n if new_balance < 0:\n print(\"ERROR! Not enough balance to reduce!\")\n return False\n\n if new_balance > 0:\n Put(context, key, new_balance)\n else:\n Delete(context, key)\n\n return True\n\n\n\ndef transfer_token_verified(originator_address, taker_address, tokens, originator_signature, originator_public_key,\n owner_address, owner_signature, owner_public_key, salt):\n \"\"\"\n Transfer tokens on the framework.\n\n Token transfers within this contract are only meant to be done for purchasing items with MTX.\n This must be allowed through by the contract owner.\n\n NOTE: Funds will always still be able to be withdrawn by a user back into the NEP-5 contract\n if the contract is in a terminated state.\n \"\"\"\n\n if owner_address != contract_owner:\n print(\"ERROR! Address specified is not the contract owner.\")\n return False\n\n if order_complete(salt):\n print(\"ERROR! This order has already occurred!\")\n return False\n\n order_args = [\"transfer\", originator_address, taker_address, tokens, salt]\n\n if not verify_order(owner_address, owner_signature, owner_public_key, order_args):\n print(\"ERROR! The contract owner has not signed this order.\")\n return False\n\n if not verify_order(originator_address, originator_signature, originator_public_key, order_args):\n print(\"ERROR! The address transferring tokens has not signed this!\")\n return False\n\n if transfer_token(originator_address, taker_address, tokens):\n order_complete(salt)\n return True\n\n return False\n\n\ndef transfer_token_to(address_to, amount):\n \"\"\"\n Transfer the specified amount of LOOT to an address within the smart contract..\n \"\"\"\n context = GetContext()\n\n # The amount being transferred must be >= 1.\n if amount < 1:\n print(\"ERROR! Can only transfer an amount >= 1. \")\n return False\n\n # Add the LOOT to the address receiving the tokens and save it to storage.\n balance_to = balance_of(address_to)\n balance_to += amount\n Delete(context, address_to)\n Put(context, address_to, balance_to)\n\n return True\n\n\ndef transfer_token(address_from, address_to, amount):\n \"\"\"\n Transfer the specified amount of LOOT from an address, to an address.\n \"\"\"\n context = GetContext()\n\n # The amount being transferred must be > 0.\n if amount <= 0:\n return False\n\n # If the address is sending LOOT to itself, save on gas and return True.\n if address_from == address_to:\n return True\n\n # If the balance of the address sending the LOOT does not have enough, return False.\n balance_from = balance_of(address_from)\n if balance_from < amount:\n return False\n\n # Subtract the amount from the address sending the LOOT and save it to storage.\n balance_from -= amount\n Delete(context, address_from)\n Put(context, address_from, balance_from)\n\n # Add the LOOT to the address receiving the tokens and save it to storage.\n balance_to = balance_of(address_to)\n balance_to += amount\n Delete(context, address_to)\n Put(context, address_to, balance_to)\n\n return True\n\n\ndef handle_deposit(args):\n \"\"\"\n Called when the NEP-5 LOOT contract calls this contract, we handle the deposited LOOT token.\n \"\"\"\n address_from = args[0]\n address_to = args[1]\n amount = args[2]\n\n if len(address_from) != 20:\n return False\n\n if len(address_to) != 20:\n return False\n\n return increase_balance(address_from, amount)\n\n\ndef withdrawal_verified(my_hash, originator_address, tokens, originator_signature, originator_public_key,\n owner_address, owner_signature, owner_public_key, salt):\n \"\"\"\n Withdrawal on the framework must be verified.\n\n NOTE: Funds will always still be able to be withdrawn by a user back into the NEP-5 contract by other means.\n \"\"\"\n\n if owner_address != contract_owner:\n print(\"ERROR! Owner address specified is not the contract owner.\")\n return False\n\n if order_complete(salt):\n print(\"ERROR! This order has already occurred!\")\n return False\n\n order_args = [\"withdraw\", originator_address, tokens, salt]\n\n if not verify_order(owner_address, owner_signature, owner_public_key, order_args):\n print(\"ERROR! The contract owner has not signed this order.\")\n return False\n\n if not verify_order(originator_address, originator_signature, originator_public_key, order_args):\n print(\"ERROR! The address transferring tokens has not signed this!\")\n return False\n\n return withdrawal(my_hash, originator_address, tokens)\n\n\ndef withdrawal(my_hash, originator_address, tokens):\n \"\"\" Withdraw from the smart contract, invoking the Loot NEP-5 contract. \"\"\"\n\n balance = balance_of(originator_address)\n if tokens < 1 or tokens > balance:\n print(\"ERROR!: Unable to withdraw from contract!\")\n return False\n\n params = [my_hash, originator_address, tokens]\n # if the transfer to the nep5 contract was successful, reduce the balance of their address in this contract\n if LootContract('transfer', params):\n reduce_balance(originator_address, tokens)\n return True\n\n return False\n\n\ndef balance_of(address):\n \"\"\"\n Query the LOOT balance of an address.\n \"\"\"\n context = GetContext()\n balance = Get(context, address)\n return balance\n\n\n# endregion\n\n\ndef calculate_fees_of_order(marketplace, maker_address, taker_address, amount):\n \"\"\"When an order has been filled between two parties, the owner of the\n marketplace can optionally take some fees.\n Maker gets charged once the order is filled.\n Taker get charged upon buying the order.\"\"\"\n\n # Get the fees for this marketplace\n fee_address = get_fee_address(marketplace)\n maker_fee_rate = get_maker_fee(marketplace)\n taker_fee_rate = get_taker_fee(marketplace)\n\n # When a user buys -> they are charged a little extra\n # When a user sells -> they receive the price they put - some fees\n maker_fee = (amount * maker_fee_rate) / feeFactor\n taker_fee = (amount * taker_fee_rate) / feeFactor\n\n print(\"Maker fee: \" + maker_fee)\n print(\"Taker fee: \" + taker_fee)\n # Give funds to the marketplace owner.\n if not transfer_token(maker_address, fee_address, maker_fee):\n return False\n if not transfer_token(taker_address, fee_address, taker_fee):\n return False\n\n return True\n\n\ndef save_inventory(marketplace, address, inventory):\n \"\"\"\n Helper method for inventory operations, saves a serialized list of items to storage.\n \"\"\"\n context = GetContext()\n\n # Concatenate the specific storage key, delete the old storage\n # and add the updated inventory into storage.\n inventory_marketplace_key = concat(inventory_key, marketplace)\n storage_key = concat(inventory_marketplace_key, address)\n Delete(context, storage_key)\n Put(context, storage_key, inventory)\n\n return True\n\n\ndef get_inventory(marketplace, address):\n \"\"\"\n Get the items the address owns on a marketplace.\n \"\"\"\n context = GetContext()\n\n # Return the serialized inventory for the address.\n inventory_marketplace_key = concat(inventory_key, marketplace)\n storage_key = concat(inventory_marketplace_key, address)\n items_serialized = Get(context, storage_key)\n\n return items_serialized\n\n\n# Marketplace Administration\n\ndef register_marketplace(marketplace, address, taker_fee, maker_fee):\n \"\"\"\n Register a new marketplace on the blockchain.\n They can set their fees and the address the fees go to.\n \"\"\"\n if not set_maker_fee(marketplace, maker_fee):\n return False\n if not set_taker_fee(marketplace, taker_fee):\n return False\n if not set_fee_address(marketplace, address):\n return False\n if not add_owner_wallet(marketplace, address):\n return False\n # Concatenate the owner key and save the address into storage.\n\n print(\"Successfully registered marketplace!\")\n return True\n\n\ndef set_maker_fee(marketplace, fee):\n \"\"\"\n Maker fees, fees for selling.\n \"\"\"\n if fee > MAX_FEE:\n return False\n if fee < 0:\n return False\n context = GetContext()\n\n key = concat(\"makerFee\", marketplace)\n Put(context, key, fee)\n\n return True\n\n\ndef set_taker_fee(marketplace, fee):\n \"\"\"\n Taker fees, fees for buying.\n \"\"\"\n if fee > MAX_FEE:\n return False\n if fee < 0:\n return False\n\n context = GetContext()\n key = concat(\"takerFee\", marketplace)\n Put(context, key, fee)\n\n return True\n\n\ndef set_fee_address(marketplace, address):\n \"\"\"\n Set who will receive the fees for this marketplace.\n \"\"\"\n if len(address) != 20:\n return False\n context = GetContext()\n key = concat(\"feeAddress\", marketplace)\n Put(context, key, address)\n\n return True\n\n\ndef get_fee_address(marketplace):\n \"\"\"\n Get the taker fees set in a marketplace.\n \"\"\"\n context = GetContext()\n key = concat(\"feeAddress\", marketplace)\n fee_address = Get(context, key)\n return fee_address\n\n\ndef get_maker_fee(marketplace):\n \"\"\"\n Get the maker fees set in a marketplace.\n \"\"\"\n context = GetContext()\n key = concat(\"makerFee\", marketplace)\n maker_fee = Get(context, key)\n return maker_fee\n\n\ndef get_taker_fee(marketplace):\n \"\"\"\n Get the taker fees set in a marketplace.\n \"\"\"\n context = GetContext()\n key = concat(\"takerFee\", marketplace)\n taker_fee = Get(context, key)\n return taker_fee\n\n\ndef add_owner_wallet(marketplace, address):\n \"\"\"\n Add an owner wallet, giving them exclusive rights to their marketplace.\n \"\"\"\n context = GetContext()\n key_part1 = concat(\"key\", address)\n owner_key = concat(marketplace, key_part1)\n owner = Get(context, owner_key)\n\n if owner == b'':\n Put(context, owner_key, address)\n return True\n\n return False\n\n\n# Saving marketplace owners in seperate storage, costs less to search rather than a less.\ndef is_marketplace_owner(marketplace, address):\n \"\"\"\n Check if the address is an owner of a marketplace.\n \"\"\"\n context = GetContext()\n key_part1 = concat(\"key\", address)\n owner_key = concat(marketplace, key_part1)\n owner = Get(context, owner_key)\n\n return owner != b''\n\n\n# endregion\n\n\n# region Decentralized GameModes & events.\n\n\ndef BR_create(event_code, marketplace, marketplace_owner_address, rewards):\n '''\n Create a new battle royale decentralized event, with the given rewards as prizes for the winners.\n :param event_code: The unique code of the event.\n :param marketplace: The game being hosted on.\n :param marketplace_owner_address: The address creating this event.\n :param rewards: A list of rewards given to the top players.\n :return: If created event successfully.\n '''\n\n # Currently only an owner can give out rewards for testing.\n if not is_marketplace_owner(marketplace, marketplace_owner_address):\n print(\"ERROR! Cannot start event: must be an owner of the marketplace.\")\n return False\n\n if not CheckWitness(marketplace_owner_address):\n print(\"ERROR! Cannot start event: address is not a witness of the transaction.\")\n return False\n\n context = GetContext()\n\n # Ensure an event with this code does not already exist.\n br_details_s = get_BR_event_details(context, event_code)\n\n if br_details_s != b'':\n print(\"ERROR! Cannot start event: event code is not unique.\")\n return False\n\n # Create a new set of details for the event, and save this to storage to be queryable.\n # TODO lists suffice for building, but if necessary these lists can be more neatly done with dictionaries.\n br_details = [0, 0, marketplace_owner_address, False, 0, 0, 10, marketplace, 0]\n set_BR_event_details(context, event_code, br_details)\n\n # Add rewards at stake for the contest, may be any number n, s.t. n <= 12 (16 max parameters, 4 used).\n set_BR_rewards(context, event_code, rewards)\n\n return True\n\n\ndef BR_start(event_code, address):\n \"\"\"\n Start the BR event.\n :param event_code: The unique code of the event.\n :param address: The address which is starting the event.\n :return: True if the event starts.\n \"\"\"\n\n if not CheckWitness(address):\n print(\"ERROR: Cannot start event, no witness of this address attached to the transaction.\")\n return False\n\n context = GetContext()\n\n br_details = get_BR_event_details(context, event_code)\n\n if br_details == b'':\n print(\"ERROR! Cannot start event, it does not exist.\")\n return False\n\n br_details = Deserialize(br_details)\n\n if br_details[2] != address:\n print(\"ERROR! Cannot start event, is not the owner of the event.\")\n return False\n\n player_list = get_BR_player_list(context, event_code)\n if player_list == b'':\n print(\"ERROR! No players, cannot start the match.\")\n return False\n\n player_list = Deserialize(player_list)\n player_count = len(player_list)\n # Determine how large the x * y grid will be.\n # Starts at 3 x 3 currently for each player to keep a square shaped grid.\n player_count -= 1\n grid_length = 3 + player_count\n br_details[8] = grid_length # Must store the grid length for calculations with boundaries and movement.\n grid_capacity = grid_length * grid_length\n # Take one as player can land at zones 0-15.\n grid_capacity -= 1\n br_details[1] = grid_capacity\n # Set the event to has begun.\n br_details[3] = True\n # Set the block in which the round has started, used an approximate time reference.\n br_details[4] = GetHeight()\n set_BR_event_details(context, event_code, br_details)\n\n return True\n\n\ndef BR_sign_up(event_code, address):\n \"\"\"\n Currently anyone may sign up to the BR, it is a public decentralized contest.\n :param event_code: The unique code of the event.\n :param address: The address wanting to sign up.\n :return: If signed up successfully.\n \"\"\"\n context = GetContext()\n\n # Get the stored details of the event.\n br_details = get_BR_event_details(context, event_code)\n\n if br_details == b'':\n print(\"ERROR! Cannot sign up to the event, there is no event running with this code.\")\n return False\n\n br_details = Deserialize(br_details)\n\n if br_details[3]:\n print(\"ERROR! Event has begun can not sign up!\")\n return False\n\n if not CheckWitness(address):\n print(\"ERROR! Cannot sign up to an event, witness is not attached to tx.\")\n return False\n\n stored_entrant = get_BR_entrant_details(context, event_code, address)\n\n if stored_entrant != b'':\n print(\"ERROR! Cannot sign up to event, this address is already signed up.\")\n return False\n\n # Add this player to a list of the active players and save into storage.\n list_of_players = get_BR_player_list(context, event_code)\n if list_of_players == b'':\n list_of_players = []\n else:\n list_of_players = Deserialize(list_of_players)\n list_of_players.append(address)\n set_BR_player_list(context, event_code, list_of_players)\n\n # Create a new entrant information list, and add it into storage so it may be queried.\n entrant_information = [0, 0, \"\", 0]\n set_BR_entrant_details(context, event_code, address, entrant_information)\n\n return True\n\n\ndef BR_choose_initial_grid_position(event_code, address, zone):\n \"\"\"\n Every player is required to choose their initial position they will \"land\" in.\n :param event_code: The unique code of the event.\n :param address: The address performing the action.\n :param zone: The zone/grid position they want to be put in.\n :return: True if chooses initial zone/grid position.\n \"\"\"\n context = GetContext()\n\n if not CheckWitness(address):\n print(\"ERROR! Cannot sign up to an event, witness is not attached to tx.\")\n return False\n\n # Ensure the event exists.\n event_details = get_BR_event_details(context, event_code)\n\n if event_details == b'':\n print(\"ERROR! Cannot perform initial grid choice, event does not exist.\")\n return False\n\n event_details = Deserialize(event_details)\n\n # Ensure the round is at 0.\n current_event_round = event_details[0]\n if current_event_round != 0:\n print(\"ERROR! Cannot perform spawn, round 0 has finished.\")\n return False\n\n entrant_details = get_BR_entrant_details(context, event_code, address)\n\n if entrant_details == b'':\n print(\"ERROR! Cannot perform spawn, entrant does not exist in this event.\")\n return False\n\n entrant_details = Deserialize(entrant_details)\n\n # Ensure the entrant is in round 0, e.g. they have not already landed.\n if entrant_details[1] > 0:\n print(\"ERROR! Cannot perform spawn, entrant current round is > 0.\")\n return False\n\n # Ensure the player is not landing in a zone that is out of bounds.\n capacity = event_details[1]\n if zone > capacity or zone < 0:\n print(\"ERROR! Cannot perform spawn, landing zone is outside the bounds.\")\n return False\n\n # Move and update the player to the next position, and place them into round 1.\n entrant_details[1] = 1\n # Move them to the zone.\n entrant_details[0] = zone\n set_BR_entrant_details(context, event_code, address, entrant_details)\n\n return True\n\n\ndef BR_do_action(event_code, address, action, direction):\n '''\n Perform an action, in the event, logic of the game is is all determined here.\n :param event_code: The unique code of the event.\n :param address: The address performing the action.\n :param action: The action being performed.\n :param direction: The direction the player wants to move.\n :return: True if the action was locked in, and the round resolved.\n '''\n\n context = GetContext()\n\n if not CheckWitness(address):\n print(\"ERROR: Cannot sign up to an event, witness is not attached to tx.\")\n return False\n\n event_details = get_BR_event_details(context, event_code)\n\n if event_details == b'':\n print(\"ERROR: Cannot perform action, event does not exist.\")\n return False\n\n event_details = Deserialize(event_details)\n\n entrant_details = get_BR_entrant_details(context, event_code, address)\n\n if entrant_details == b'':\n print(\"ERROR: Cannot perform action, entrant does not exist in this event.\")\n return False\n\n entrant_details = Deserialize(entrant_details)\n\n if not event_details[3]:\n print(\"ERROR: Cannot resolve action, event has not begun.\")\n return False\n\n # Must be > round 0, i.e. must spawn into the game first.\n if event_details[0] <= 0:\n print(\"ERROR: No action is available on round 0.\")\n return False\n\n # The event current round must be lower or equal to the players recorded round.\n if event_details[0] < entrant_details[1]:\n print(\"ERROR: Player has already completed an action this round.\")\n return False\n\n # Update player details which will be resolved next.\n entrant_details[1] = event_details[0] + 1\n entrant_details[2] = action\n entrant_details[3] = direction\n\n # Save details and resolve the round.\n set_BR_entrant_details(context, event_code, address, entrant_details)\n\n BR_resolve_round(event_code, address, event_details, entrant_details)\n\n return True\n\n\ndef BR_resolve_round(event_code, address, event_details, entrant_details):\n \"\"\"\n Called internally by the smart contract to resolve a round after an address completes an action.\n :param event_code: The unique code of the event.\n :param address: The address performing the action.\n :param event_details: The stored details of the event.\n :param entrant_details: The stored details of the entrant.\n \"\"\"\n\n context = GetContext()\n\n zone_caller_in = entrant_details[0]\n round_in = event_details[0]\n # This is why we have to store how many players we started the game so we can calculate boundaries.\n grid_side_length = event_details[8]\n caller_action = entrant_details[2]\n\n # Firstly, if the player is moving, perform that action.\n if caller_action == 'move':\n\n # Get the direction we are moving.\n direction_moving = entrant_details[3]\n\n print(direction_moving)\n\n # Traverse the grid in the direction we are moving.\n zone_to = zone_caller_in\n # UP\n if direction_moving == 0:\n zone_to += grid_side_length\n # DOWN\n elif direction_moving == 1:\n zone_to -= grid_side_length\n # RIGHT\n elif direction_moving == 2:\n zone_to += 1\n # LEFT\n elif direction_moving == 3:\n zone_to -= 1\n\n # If doing this move has not made us out of bounds, we can move the player.\n if not is_player_out_of_bounds(zone_to, grid_side_length, direction_moving, 0):\n # Move zone and save details.\n entrant_details[0] = zone_to\n set_BR_entrant_details(context, event_code, address, entrant_details)\n zone_caller_in = zone_to\n\n # Find the complete list of players who are not this address in the same zone.\n list_of_players_in_zone = []\n list_of_player_details_in_zone = []\n list_of_players = get_BR_player_list(context, event_code)\n list_of_players = Deserialize(list_of_players)\n\n for player in list_of_players: # ~ 10\n if player != address:\n entrant = get_BR_entrant_details(context, event_code, player)\n if entrant != b'':\n entrant = Deserialize(entrant)\n # They must be in the same zone as the caller,\n # and they must of had a chance to perform a move for this round.\n if entrant[0] == zone_caller_in and entrant[1] == round_in + 1:\n list_of_players_in_zone.append(player)\n list_of_player_details_in_zone.append(entrant)\n\n # Resolve the combat for the round, if there is at least one other player in the grid.\n player_count_in_zone = len(list_of_players_in_zone)\n\n if player_count_in_zone > 0:\n # Get a random player in the zone to fight, and their details.\n player_index_vs = random_number_upper_limit(player_count_in_zone)\n\n address_vs = list_of_players_in_zone[player_index_vs]\n player_vs_details = list_of_player_details_in_zone[player_index_vs]\n opponent_action = player_vs_details[2]\n\n # Fight and publish the results.\n battle_result = BR_roll_combat(caller_action, opponent_action)\n\n payload = [\"BR\", event_code, \"fight\", round_in, address, address_vs, battle_result]\n Notify(payload)\n\n if battle_result:\n print(\"BATTLE! Win -> removing opponent from battle!\")\n BR_remove_player(event_code, address_vs)\n\n else:\n print(\"BATTLE! Lost -> removing caller from battle!\")\n # Remove and return true as complete.\n BR_remove_player(event_code, address)\n return False\n\n # If a player is looting and survived the round, we can loot items.\n if caller_action == \"loot\":\n BR_loot_action(event_code, round_in, address)\n\n return True\n\n\ndef BR_remove_player(event_code, address):\n '''\n Remove a player from the BR, after they lose determined by the sc.\n :param event_code:\n :param address:\n :return:\n '''\n # remove or mark as destroyed?\n context = GetContext()\n\n # Simply add the address to the leaderboard list,\n # and we display them in order of being knocked out, last player wins.\n leaderboard = get_BR_leaderboard(context, event_code)\n\n if leaderboard == b'':\n leaderboard = [address]\n else:\n leaderboard = Deserialize(leaderboard)\n leaderboard.append(address)\n\n set_BR_leaderboard(context, event_code, leaderboard)\n\n # Delete the entrant details so they can not perform any other action.\n half_key = concat(battle_royale_entrant_key, event_code)\n complete_key = concat(half_key, address)\n Delete(context, complete_key)\n\n # Finally remove the address from the list of active players.\n list_of_all_players = get_BR_player_list(context, event_code)\n list_of_all_players = Deserialize(list_of_all_players)\n\n current_index = 0\n\n for player in list_of_all_players:\n if player == address:\n list_of_all_players.remove(current_index)\n set_BR_player_list(context, event_code, list_of_all_players)\n return list_of_all_players\n current_index += 1\n\n return list_of_all_players\n\n\ndef BR_loot_action(event_code, current_round, address):\n \"\"\"\n Called internally by the smart contract when a user performs a loot action.\n These events are caught and if the user found an item they are given in the game.\n :param event_code: The unique code of the event.\n :param current_round: The current round to calculate the drop chance.\n :param address: The address performing the loot action.\n :return: True\n \"\"\"\n\n # Calculate the current chance to find loot and roll it.\n chance_to_find_loot = BR_CHANCE_TO_FIND_LOOT + (BR_CHANCE_INCREASE_PER_ROUND * current_round)\n\n rolled_item = random_number_0_100() <= chance_to_find_loot\n rolled_reward = -1\n\n if rolled_item:\n upper_limit = len(BR_UNTRADEABLE_REWARDS) - 1\n rolled_reward = random_number_upper_limit(upper_limit)\n\n # Notify if an item was rolled.\n payload = [\"BR\", event_code, \"loot\", address, rolled_reward]\n Notify(payload)\n\n return True\n\n\ndef BR_roll_combat(caller_action, opponent_action):\n \"\"\"\n Internally called by the smart contract to fairly decide the outcome of combat between players.\n :param caller_action: The action being performed by the caller.\n :param opponent_action: The action being performed by the opponent.\n :return: True if the caller wins.\n \"\"\"\n\n if caller_action == \"loot\" or caller_action == \"move\":\n # If the caller is looting or moving they are at a disadvantage.\n if opponent_action == \"hide\":\n caller_win_chance = 40\n else:\n caller_win_chance = 50\n\n elif caller_action == \"hide\":\n # If the opponent is hiding they are at the advantage.\n if opponent_action == \"hide\":\n caller_win_chance = 50\n # If the caller is hiding and opponent is not hiding, caller has 60% chance to win\n else:\n caller_win_chance = 60\n else:\n # if unknown command, the caller loses, as they did not select a valid action.\n return False\n\n return random_number_0_100() <= caller_win_chance\n\n\ndef BR_finish_round(event_code):\n \"\"\"\n Called by anyone to finish an event, will only finish if the conditions are met.\n # Best case, ~30s each round.\n # Worst case, ~3min each round.\n :param event_code: The unique code of the event.\n :return: True if the event was finished.\n \"\"\"\n\n context = GetContext()\n height = GetHeight()\n\n br_details = get_BR_event_details(context, event_code)\n\n if br_details == b'':\n print(\"ERROR! Cannot end round, event does not exist.\")\n return False\n\n br_details = Deserialize(br_details)\n\n # If the battle has not started, return false.\n if not br_details[3]:\n print(\"ERROR! Cannot end round, battle royale event has not begun!\")\n return False\n\n round_start_height = br_details[4]\n\n # If 10 blocks have past, the round has timed out.\n if height - round_start_height >= BR_ROUND_TIMEOUT:\n return BR_on_round_finish(event_code, br_details, context, height)\n # If we have not timed out we check if every player has completed an action for this round so we can finish early.\n else:\n list_of_players = get_BR_player_list(context, event_code)\n list_of_players = Deserialize(list_of_players)\n\n for player in list_of_players:\n entrant = get_BR_entrant_details(context, event_code, player)\n if entrant != b'':\n entrant = Deserialize(entrant)\n if entrant[1] <= br_details[0]:\n print(\"ERROR! A player has not made a move for this round.\")\n payload = ['BR', event_code, 'round_end', br_details[0], False]\n Notify(payload)\n return False\n\n # All players are done!\n return BR_on_round_finish(event_code, br_details, context, height)\n\n\ndef BR_on_round_finish(event_code, br_details, context, height):\n \"\"\"\n Called internally by the smart contract to conclude a round.\n :param event_code: The unique code of the event.\n :param br_details: The details of the BR event.\n :param context: The storage context.\n :param height: The current height of the blockchain.\n :return: True if the round was resolved.\n \"\"\"\n\n # Set the height and increment the round.\n br_details[4] = height\n br_details[0] = br_details[0] + 1\n\n # Update BR details to next round.\n set_BR_event_details(context, event_code, br_details)\n\n # Get the list of active players.\n list_of_players = get_BR_player_list(context, event_code)\n list_of_players = Deserialize(list_of_players)\n\n # Check if zone needs to be destroyed now,\n # we can bundle that up with checking if they have moved to save gas.\n if br_details[0] >= ROUND_DESTROYED_ZONES_GENERATE:\n # Returns a list of players that survived through the destroyed zones.\n list_of_players = BR_destroy_next_zone(event_code, br_details[0], br_details[8])\n # If we have not checked players that have not moved yet, do so.\n else:\n # Remove players that did not perform an action this turn.\n # This has to occur is seperate steps or will not work as we cannot mutate a list during iteration.\n removed_players_address = []\n\n for player in list_of_players:\n entrant = get_BR_entrant_details(context, event_code, player)\n if entrant != b'':\n entrant = Deserialize(entrant)\n if entrant[1] != br_details[0]:\n removed_players_address.append(player)\n\n for i in range(0, len(removed_players_address)):\n # Now we can remove players without mutating the original list during iteration.\n list_of_players = BR_remove_player(event_code, removed_players_address[i])\n\n payload = [\"BR\", event_code, \"removed_player\", removed_players_address[i]]\n Notify(payload)\n\n remaining_player_count = len(list_of_players)\n\n print(\"----- Remaining player count -----\")\n print(remaining_player_count)\n print(\"----------------------------------\")\n # If there are <= one player, we should end the event.\n if remaining_player_count <= 1:\n # If there is a final playing remaining, remove him and end the match.\n if remaining_player_count > 0:\n last_player_address = list_of_players[0]\n BR_remove_player(event_code, last_player_address)\n\n return BR_end_event(event_code, br_details, context)\n\n payload = ['BR', event_code, 'round_end', br_details[0], True]\n Notify(payload)\n\n return True\n\n\ndef BR_end_event(event_code, event_details, context):\n \"\"\"\n Called from within the contract when the event ends.\n Pays out items to the top x players dependent on the length\n of rewards the event was initialized with.\n :param event_code: The unique event code of the event.\n :param event_details: The details of the event.\n :param context: The storage context.\n :return: True if the event ended.\n \"\"\"\n\n # Remove the event as it is complete to clean up storage.\n # The leaderboard remains.\n remove_BR_event_details(context, event_code)\n\n leaderboard = get_BR_leaderboard(context, event_code)\n leaderboard = Deserialize(leaderboard)\n\n # Get the rewards of the event.\n rewards = get_BR_rewards(context, event_code)\n\n if rewards == b'':\n print(\"ERROR: No rewards exist for this event.\")\n return True\n\n rewards = Deserialize(rewards)\n\n for i in range(0, len(rewards)):\n # As we are giving it to the last added addresses to the list, those whom survived the longest.\n if len(leaderboard) > 0 and i <= len(leaderboard) - 1:\n # Winners are the last x players s.t. x == len(rewards) for now.\n index = len(leaderboard) - 1\n # Get the last player - i in the list.\n index = index - i\n address = leaderboard[index]\n reward = rewards[i]\n marketplace = event_details[7]\n\n give_item(marketplace, address, reward)\n\n # Acknowledge that a user received a reward.\n payload = [\"BR\", event_code, \"received_reward\", address, reward]\n Notify(payload)\n\n # Can then query the leaderboard to see winners outside.\n payload = [\"BR\", event_code, \"event_complete\", True]\n Notify(payload)\n\n return True\n\n\ndef BR_destroy_next_zone(event_code, round_on, grid_length):\n \"\"\"\n This is only called after advancing a zone.\n Mark a zone for destruction, and destroy a previous\n zone if there is one.\n This encourages the player to move from their zone.\n This way, the next side that will be stripped from the map will always be random .\n :param event_code: The unique code of the event.\n :param round_on: The current round the event is on.\n :param grid_length: The length of a side of the grid map.\n :return: List of players which were not in a destroyed zone.\n \"\"\"\n\n context = GetContext()\n\n print(\"-----Destroying next marked zone.-----\")\n\n # Check if there is a previous marked zone.\n # Marked zone will be a marked side, so the side the gas is coming in on.\n current_destroyed_depths = get_BR_destroyed_zone_depths(context, event_code)\n\n # Grab the list of remaining players.\n player_list = get_BR_player_list(context, event_code)\n player_list = Deserialize(player_list)\n\n # If the depths have been initialized.\n if current_destroyed_depths != b'':\n current_destroyed_depths = Deserialize(current_destroyed_depths)\n\n removed_address_list = []\n\n # The grid has 4 sides that can be marked off, iterate through these.\n for i in range(0, 4):\n # If the current depth is > 0, meaning the side has been destroyed.\n current_depth = current_destroyed_depths[i]\n if current_depth > 0:\n # If there is a depth change here, we can check once per side if the player is out of range.\n # We are now checking to see if the player is out of bounds.\n for player in player_list: # ~10\n entrant = get_BR_entrant_details(context, event_code, player)\n if entrant != b'':\n entrant = Deserialize(entrant)\n zone_entrant_is_in = entrant[0]\n # Out of bounds ? if so remove them.\n entrant_out_of_bounds = is_player_out_of_bounds(zone_entrant_is_in, grid_length, i,\n current_destroyed_depths[i])\n # Did they perform an action this round before it timed out ? if not, remove them.\n entrant_did_not_do_action = entrant[1] != round_on\n if entrant_out_of_bounds or entrant_did_not_do_action:\n removed_address_list.append(player)\n\n # Remove the list of players for the remaining players list and notify each removal.\n for i in range(0, len(removed_address_list)):\n player_list = BR_remove_player(event_code, removed_address_list[i])\n\n payload = [\"BR\", event_code, \"removed_player\", removed_address_list[i]]\n Notify(payload)\n\n else:\n # Initialize the list of depths the \"poison\" has consumed the sides,\n # and has in turn stripped down the grid map area.\n current_destroyed_depths = [0, 0, 0, 0]\n\n # Pick a new random side for the gas to come from next round, and notify the event.\n # So we can increment to say the depth of that row has increased, that will be checked next round to give players\n # a chance to move.\n side_gas_is_coming = random_number_upper_limit(4)\n value = current_destroyed_depths[side_gas_is_coming]\n current_destroyed_depths[side_gas_is_coming] = value + 1\n set_BR_destroyed_zone_depths(context, event_code, current_destroyed_depths)\n\n # Notify players that a zone has been marked so they have a chance to move.\n payload = [\"BR\", event_code, \"zone_marked\", side_gas_is_coming]\n Notify(payload)\n\n return player_list\n\n\ndef is_player_out_of_bounds(zone_on, grid_length, side, depth):\n \"\"\"\n Check if a player is outside the bounds of the map.\n :param zone_on: The zone the player is currently on.\n :param grid_length: The length of the grid, determined at the beginning of the match.\n :param side: The side we are checking if out of bounds. As a player can only move one square at a time.\n :param depth: The depth of the side that is \"eliminated\", essentially how many times the \"poison\" has occurred.\n The players row/column must be within this depth.\n Can check if the player is out of bounds of the normal map with depth = 0.\n :return: True if out of bounds.\n \"\"\"\n # We can calculate the boundaries of the grid and check if the player is out of bounds.\n\n # TOP\n if side == 0:\n row_in = zone_on / grid_length\n\n row_in = (grid_length - row_in) - 1\n\n if row_in <= depth - 1:\n return True\n # BOTTOM\n elif side == 1:\n row_in = zone_on / grid_length\n # e.g. if we are row 0, and depth is 1, we are out\n # if we are row 1 and depth is 1 we are fine\n if row_in <= depth - 1:\n return True\n # EAST\n elif side == 2:\n\n t = grid_length - 1\n b = zone_on % grid_length\n column_in = t - b\n # If the column we are in is\n if column_in <= depth - 1:\n return True\n # WEST\n elif side == 3:\n column_in = zone_on % grid_length\n\n if column_in <= depth - 1:\n return True\n\n return False\n\n\n# BR Mutators\n\ndef set_BR_event_details(context, event_code, details):\n ''' Details of the BR event, capacity, owner, etc.'''\n key = concat(battle_royale_details_key, event_code)\n br_details_s = Get(context, key)\n if br_details_s != b'':\n Delete(context, key)\n br_details_s = Serialize(details)\n Put(context, key, br_details_s)\n return True\n\n\ndef set_BR_entrant_details(context, event_code, address, details):\n ''' Details of the entrant, round action, action, etc.'''\n half_key = concat(battle_royale_entrant_key, event_code)\n complete_key = concat(half_key, address)\n stored_entrant_s = Get(context, complete_key)\n if stored_entrant_s != b'':\n Delete(context, complete_key)\n details_s = Serialize(details)\n Put(context, complete_key, details_s)\n return True\n\n\ndef set_BR_destroyed_zone_depths(context, event_code, zones):\n ''' A list of zones that any player on them will be disqualified. '''\n br_destroyed_zones_key = concat(battle_royale_destroyed_zones_key, event_code)\n destroyed_zones_s = Get(context, br_destroyed_zones_key)\n if destroyed_zones_s != b'':\n Delete(context, br_destroyed_zones_key)\n zones_s = Serialize(zones)\n Put(context, br_destroyed_zones_key, zones_s)\n return True\n\n\ndef set_BR_rewards(context, event_code, rewards):\n ''' A list of the rewards of a BR event.'''\n rewards_s = Serialize(rewards)\n key = concat(battle_royale_rewards_key, event_code)\n Put(context, key, rewards_s)\n return True\n\n\ndef set_BR_marked_zone(context, event_code, zone):\n key = concat(battle_royale_marked_destroyed_zone_key, event_code)\n Put(context, key, zone)\n return True\n\n\ndef set_BR_leaderboard(context, event_code, leaders):\n key = concat(battle_royale_event_results_key, event_code)\n leaderboard_s = Get(context, key)\n if leaderboard_s != b'':\n Delete(context, key)\n leaders_s = Serialize(leaders)\n Put(context, key, leaders_s)\n return True\n\n\ndef set_BR_player_list(context, event_code, players):\n key = concat(battle_royale_current_players_key, event_code)\n players_s = Get(context, key)\n if players_s != b'':\n Delete(context, key)\n players_s = Serialize(players)\n Put(context, key, players_s)\n return True\n\n\n# BR Accessors\n\n\"\"\"\nNote: When getting from storage we must send these values in the serialized form,\n and deserialize at the initial method call.\n\"\"\"\n\n\ndef get_BR_event_details(context, event_code):\n ''' Details of the BR event, capacity, owner, etc.'''\n key = concat(battle_royale_details_key, event_code)\n br_details = Get(context, key)\n return br_details\n\n\ndef get_BR_entrant_details(context, event_code, address):\n ''' Details of the entrant, round action, action, etc.'''\n half_key = concat(battle_royale_entrant_key, event_code)\n complete_key = concat(half_key, address)\n stored_entrant = Get(context, complete_key)\n # stored_entrant = Deserialize(stored_entrant_s)\n return stored_entrant\n\n\ndef get_BR_destroyed_zone_depths(context, event_code):\n ''' A list of zones that any player on them will be disqualified. '''\n br_destroyed_zones_key = concat(battle_royale_destroyed_zones_key, event_code)\n destroyed_zones = Get(context, br_destroyed_zones_key)\n # destroyed_zones = [] if destroyed_zones_s == b'' else Deserialize(destroyed_zones_s)\n return destroyed_zones\n\n\ndef get_BR_rewards(context, event_code):\n ''' A list of the rewards of a BR event.'''\n key = concat(battle_royale_rewards_key, event_code)\n rewards = Get(context, key)\n # rewards = [] if rewards_s == b'' else Deserialize(rewards_s)\n return rewards\n\n\ndef get_BR_marked_zones(context, event_code):\n key = concat(battle_royale_marked_destroyed_zone_key, event_code)\n zone = Get(context, key)\n return zone\n\n\ndef get_BR_player_list(context, event_code):\n key = concat(battle_royale_current_players_key, event_code)\n players = Get(context, key)\n return players\n\n\ndef get_BR_leaderboard(context, event_code):\n key = concat(battle_royale_event_results_key, event_code)\n leaderboard = Get(context, key)\n # leaderboard = [] if leaderboard_s == b'' else Deserialize(leaderboard_s)\n return leaderboard\n\n\ndef remove_BR_event_details(context, event_code):\n key = concat(battle_royale_details_key, event_code)\n br_details_s = Get(context, key)\n if br_details_s != b'':\n Delete(context, key)\n return True\n\n\n# Random number generation\n\ndef random_number_0_100():\n height = GetHeight()\n header = GetHeader(height)\n index = header.ConsensusData\n random_number = index % 99\n return random_number\n\n\ndef random_number_upper_limit(limit):\n height = GetHeight()\n header = GetHeader(height)\n random_number = header.ConsensusData >> 32\n result = (random_number * limit) >> 32\n\n return result\n\n# endregion\n"
}
] | 2 |
handabaldeep/Wifi-fingerprinting
|
https://github.com/handabaldeep/Wifi-fingerprinting
|
c51b7b023dbfdb906b03670214d9686e4505648b
|
e94b24890774deda610422849255cf984be90fc9
|
7b8a6e63ae82d6e47902392a91acfe9976d82639
|
refs/heads/master
| 2020-06-19T21:26:01.113426 | 2019-09-04T14:25:28 | 2019-09-04T14:25:28 | 196,880,048 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4139110743999481,
"alphanum_fraction": 0.44355759024620056,
"avg_line_length": 25.590909957885742,
"blob_id": "aa31777320f865f9f0b7e27f5e9991f17728b64d",
"content_id": "9bd4e9900dc1407a8ec80d34485b9a111de3485b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1754,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 66,
"path": "/kMeans.py",
"repo_name": "handabaldeep/Wifi-fingerprinting",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jul 2 20:16:52 2019\n\n@author: handabaldeep\n\"\"\"\nimport random\nimport numpy as np\nimport sys\n\nclass kMeans:\n \n def __init__(self, tolerance=0.01, max_iterations=10):\n self.tolerance = tolerance\n self.max_iterations = max_iterations\n \n def dist(self,a,b):\n self._sum = 0\n for i in range(len(a)):\n self._sum += (a[i] - b[i])**2\n return self._sum**0.5\n \n def centroid_dist(self,cent,p):\n min_dist = sys.maxsize\n pos = -1\n for i in range(len(cent)):\n #d = dist(p,cent[i])\n d = abs(p-cent[i])\n if d < min_dist:\n min_dist = d\n pos = i+1\n return pos\n \n def kmeans(self,input_arr,k=3):\n k_values = np.zeros(input_arr.shape[0],dtype=int)\n for i in range(len(k_values)):\n k_values[i] = random.randint(1,k)\n \n c = sorted(zip(k_values,input_arr))\n print(c)\n \n centroids = np.zeros(k)\n for j in range(self.max_iterations):\n k,i = 0,0\n while i<len(c):\n _sum,num = 0,0\n while i<len(c) and c[i][0] == k+1:\n _sum += c[i][1]\n num += 1\n i += 1\n centroids[k] = _sum/num\n #print(centroids[k],_sum,num,k)\n k += 1\n \n #print(centroids)\n for i in range(len(c)):\n c[i] = (self.centroid_dist(centroids,c[i][1]),c[i][1])\n \n c.sort()\n #print(c)\n return c\n \n# a = np.array([1,2,3,4,5,6,7,8,9,10])\n# k1 = kMeans()\n# print(k1.kmeans(a))"
},
{
"alpha_fraction": 0.5367550849914551,
"alphanum_fraction": 0.5876467823982239,
"avg_line_length": 25.136363983154297,
"blob_id": "84be0e4280c095eb481a3491a6bd6e60cef1a570",
"content_id": "ed576620fff43382199b87c5b9e473ccbb300539",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2299,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 88,
"path": "/KNN.py",
"repo_name": "handabaldeep/Wifi-fingerprinting",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Jul 1 16:15:22 2019\n\n@author: handabaldeep\n\"\"\"\n\nimport numpy as np\n\nclass KNN:\n\n\tdef knn_classification(input_arr, output_arr, test_arr, k=1):\n\t\t\n\t\tdist_list = np.zeros(input_arr.shape[0])\n\t\tvals_list = np.zeros(input_arr.shape[0])\n\t\tfor i in range(input_arr.shape[0]):\n\t\t\tdist = 0\n\t\t\tfor j in range(input_arr.shape[1]):\n\t\t\t\tdist += (input_arr[i][j]-test_arr[j])**2\n\t\t\tdist_list[i] = dist**(0.5)\n\t\t\tvals_list[i] = output_arr[i]\n\t\t\n\t\t#print(dist_list,vals_list)\n\t\tvalues = sorted(zip(dist_list,vals_list))\n\t\t#print(values)\n\t\tv = []\n\t\tfor i in range(k):\n\t\t\tv.append(values[i][1])\n\t\tv.sort()\n\t\t#print(v)\n\n\t\trepeat, max_iter = 1,1\n\t\tret = v[0]\n\t\tfor j in range(len(v)-1):\n\t\t\tif j == k:\n\t\t\t\tbreak\n\t\t\tif v[j] == v[j+1]:\n\t\t\t\trepeat += 1\n\t\t\telse:\n\t\t\t\trepeat = 1\n\t\t\tif repeat >= max_iter:\n\t\t\t\tmax_iter = repeat\n\t\t\t\tret = v[j]\n\t\t\t#print(repeat,max_iter)\n\t\t\n\t\treturn ret\n\n\tdef knn_regression(input_arr, output_arr, test_arr, k=1):\n\t\t \n\t\tdist_list = np.zeros(input_arr.shape[0])\n\t\tvals_list = np.zeros(input_arr.shape[0])\n\t\tfor i in range(input_arr.shape[0]):\n\t\t\tdist = 0\n\t\t\tfor j in range(input_arr.shape[1]):\n\t\t\t\tdist += (input_arr[i][j]-test_arr[j])**2\n\t\t\tdist_list[i] = dist**(0.5)\n\t\t\tvals_list[i] = output_arr[i]\n\t\t\n\t\t#print(sorted(zip(dist_list,vals_list)))\n\t\tvalues = sorted(zip(dist_list,vals_list))\n\t\t#print(values)\n\t\tv = []\n\t\tfor i in range(k):\n\t\t\tv.append(values[i][1])\n\t\t#print(v)\n\t\t\n\t\treturn sum(v)/len(v)\n\n# input_a = np.array([[0,3],[2,2],[3,3],[-1,1],[-1,-1],[0,1]])\n# output_a = np.array([1,1,1,-1,-1,-1])\n# test_a = np.array([1,2])\n# print('For k=1:',KNN.knn_classification(input_a,output_a,test_a))\n# print('For k=3:',KNN.knn_classification(input_a,output_a,test_a,3))\n# print()\n\n# input_b = np.array([[1,2,3,0],[1,4,2,3],[-2,3,-4,3],[-1,1,-3,2]])\n# output_b = np.array([1,1,-1,-1])\n# test_b = np.array([0,1,0,1])\n# print('For k=1:',KNN.knn_classification(input_b,output_b,test_b))\n# print('For k=3:',KNN.knn_classification(input_b,output_b,test_b,3))\n# print()\n\n# input_c = np.array([[1,2,3,0],[1,4,2,3],[-2,3,-4,3],[-1,1,-3,2]])\n# output_c = np.array([-2,2,0,1])\n# test_c = np.array([0,1,0,1])\n# print('For k=1:',KNN.knn_regression(input_c,output_c,test_c))\n# print('For k=3:',KNN.knn_regression(input_c,output_c,test_c,3))"
},
{
"alpha_fraction": 0.8167939186096191,
"alphanum_fraction": 0.8238402605056763,
"avg_line_length": 242.2857208251953,
"blob_id": "7bbff0af60e7b8b81838c480074a1606a75903c7",
"content_id": "d9aed88ee36b71393a13631aeaf655ef9a1cf43c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1703,
"license_type": "no_license",
"max_line_length": 595,
"num_lines": 7,
"path": "/README.md",
"repo_name": "handabaldeep/Wifi-fingerprinting",
"src_encoding": "UTF-8",
"text": "# Wifi-fingerprinting\n\nWi-Fi fingerprinting is one of the indoor localization techniques which uses the intensity of the Received Signal Strength (RSS) from the wireless access points distributed around the building as the measurement for determining the receiver's position. In the past, various machine learning algorithms have been used to resolve the indoor positioning problem which has resulted in different accuracies and processing time. This dissertation presents a localization model employing K- Nearest Neighbours (KNN) regression and K-means clustering to give a much better accuracy of the user location.\n\nAfter implementing the hybrid model, the model is experimented with a public database that was collected at Jaume I University in Spain. The results show that the hybrid model has outperformed the individual KNN model by 120%, achieving the position accuracy of 5 meters in contrast to the 11 meters accuracy achieved by the solo KNN model deployed with an optimal value of k. While the KNN model improves the performance by 90% when the value of k is optimised from k=300 to k=5, the KNN and k-means hybrid algorithm further enhances the localization accuracy.\n\nThe position of the targets were determined by first predicting the cluster it belongs to and then locating the coordinates by applying KNN only to the predicted cluster. This indicates that the error difference increases gradually with an increase in the number of positions that have been entered in the database. Thus segregating them into groups or clusters would result in a decrease in error. In this dissertation we use the Cumulative Distribution Function (CDF) plots for comparing the accuracy of these models.\n"
}
] | 3 |
ShipXu/PointsTrackDemo
|
https://github.com/ShipXu/PointsTrackDemo
|
c0ada884f4127e9e90c3f23d222ea464a19e9f63
|
63baab0be1b2efaa9e8cc33de3043dbaecfd6bbd
|
062315f4d331a2c468763b9f4b76a84a3d801528
|
refs/heads/master
| 2022-07-22T20:45:31.669218 | 2020-05-20T03:40:04 | 2020-05-20T03:40:04 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5713418126106262,
"alphanum_fraction": 0.5913782715797424,
"avg_line_length": 26.450000762939453,
"blob_id": "b8d24c962b2bcae1ea11c40e88dfd024aa3a543d",
"content_id": "03a5fa403ad5a6b053dc4a5bcf3d438d61657887",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1783,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 60,
"path": "/evaluate.py",
"repo_name": "ShipXu/PointsTrackDemo",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport sys\n\nLINE_ITEMS_LEN = 5\nCOORDS_LEN = 8\n\nLINE_ERROR_STR = \"行的格式不正确,正确格式如: \" \\\n \"\\n\\\"n x1,y1 x2,y2, x3,y3 x4,y4\\\"\\n\" \\\n \"[备注:所有项都应该是数字格式]\\n\"\nNUM_FRAMES_ERROR_STR = \"提供的结果文件帧数目与视频帧数不一致,请检查\"\nFRAME_IDX_ERROR_STR = \"行号需与帧序号一致\"\n\ndef readfile(filename):\n coords_list = []\n with open(filename, 'r') as fr:\n lines = fr.readlines()\n for idx, line in enumerate(lines):\n frame_idx, coords = readline(line)\n if idx != frame_idx:\n raise Exception(FRAME_IDX_ERROR_STR)\n coords_list.append(coords)\n coords_array = np.array(coords_list)\n return coords_array\n\n\ndef readline(line):\n items = line.strip('\\n').split()\n # print(len(items))\n if len(items) != LINE_ITEMS_LEN:\n raise Exception(LINE_ERROR_STR)\n frame_idx = int(items[0])\n try:\n points = [tuple([float(i) for i in xy_str.split(',')]) for xy_str in items[1:]]\n points = np.array(points).reshape((-1, ))\n if len(points) != COORDS_LEN:\n raise Exception(\"需要确保每行只有四点\")\n except Exception as e:\n raise Exception(LINE_ERROR_STR)\n return frame_idx, points\n\n\ndef calc_mse(coords_1, coords_2):\n if coords_1.shape != coords_2.shape:\n raise Exception(NUM_FRAMES_ERROR_STR)\n if coords_1.shape[0] < 1:\n raise Exception()\n mse = np.square(coords_1 - coords_2).mean() * 2\n return mse\n\n\ndef main():\n filepath1 = sys.argv[1]\n filepath2 = sys.argv[2]\n coords1 = readfile(filepath1)\n coords2 = readfile(filepath2)\n print(calc_mse(coords1, coords2))\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.2911275327205658,
"alphanum_fraction": 0.7684842944145203,
"avg_line_length": 27.8266658782959,
"blob_id": "bc83b46ea2892b9bc74e0532fa273f6fc1898536",
"content_id": "3cb2c8ebc9ac5b4e1ed30d26ccd5f3a5f4383b5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2564,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 75,
"path": "/README.md",
"repo_name": "ShipXu/PointsTrackDemo",
"src_encoding": "UTF-8",
"text": "# PointsTrackDemo\n2020“马栏山”杯国际音视频算法大赛图像赛道demo\n\n## 依赖\n* [OpenCV](https://opencv.org/) python >= 3.4.2\n* [OpenCV-Contrib-Python](https://pytorch.org/) >= 3.4.2\n\n安装依赖\n```sh\npip install -r requirements.txt\n```\n\n## 介绍与使用\n1. baseline.py baseline脚本\n2. baseline.mp4 示例视频文件\n3. target_points.txt 跟踪目标点,格式为: frame_index x1,y1 x2,y2 x3,y3 x4,y4 (frame_index=0)\n4. groundtruth.txt gt 文件\n4. results.txt 结果输出\n5. preview.py 预览输出结果脚本\n6. evaluate.py 评估单个结果脚本\n\n### 运行 baseline.py:\n\n```\npython baseline.py baseline.mp4 target_points.txt results.txt\n```\n将得到 results.txt 且格式如下: \n\n格式如下:\n```\nframe_index x1,y1 x2,y2 x3,y3 x4,y4\nframe_index 从0帧到最后一帧。\nx{n},y{n} 代表四个点位,x与y之间,分隔;点位与点位以及与frame_index之间以单个空格分隔\n```\n示例内容如下:\n```\n0 503.8940124511719,639.3179931640625 1187.550048828125,633.2730102539062 1188.4599609375,987.6669921875 506.3169860839844,984.4979858398438\n1 504.137939453125,639.2542114257812 1187.40087890625,633.1990356445312 1188.3466796875,987.4276123046875 506.54583740234375,984.2858276367188\n2 504.4727783203125,639.2118530273438 1187.2799072265625,633.1328125 1188.2421875,987.1868896484375 506.9146728515625,984.0758056640625\n3 504.7879943847656,639.1420288085938 1187.2020263671875,633.0950927734375 1188.15234375,986.9442138671875 507.22686767578125,983.8025512695312\n4 505.0701904296875,639.1002197265625 1187.05078125,633.007080078125 1188.01953125,986.653564453125 507.496337890625,983.5907592773438\n5 505.3311462402344,639.0217895507812 1186.8768310546875,632.93212890625 1187.8094482421875,986.3496704101562 507.75726318359375,983.26708984375\n6 505.62005615234375,638.96337890625 1186.7620849609375,632.8793334960938 1187.7109375,986.0864868164062 508.0498046875,983.011474609375\n7 505.88250732421875,638.8890380859375 1186.6134033203125,632.800537109375 1187.5517578125,985.7926635742188 508.31353759765625,982.7230224609375\n...\n```\n\n### 运行 preview.py:\n\n```\npython preview.py baseline.mp4 results.txt\n```\n\n### 运行 evaluate.py:\n\n```\npython evaluate.py groundtruth.txt results.txt\n```\n\n## 提交注意事项\n\n结果结构如下组织:\n```\n/\n├── predict\n│ ├── 0.txt\n│ ├── 1.txt\n│ ├── 2.txt\n│ ├── 3.txt\n│ ├── ...\n│ └── n.txt\n```\ntxt文件前缀名需与视频文件夹名保持一致\n\n并打包成 predict.zip 提交\n\n\n"
},
{
"alpha_fraction": 0.4826827943325043,
"alphanum_fraction": 0.5057724118232727,
"avg_line_length": 27,
"blob_id": "3a322fb49adcf80d5be5947934b1007fc700a8d0",
"content_id": "0f8e26f4966ec50199f84ecbca3f230c08a9b03f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1881,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 65,
"path": "/preview.py",
"repo_name": "ShipXu/PointsTrackDemo",
"src_encoding": "UTF-8",
"text": "import cv2\nimport sys\nimport numpy as np\n\n'''\n 浏览验证跟踪结果在视频中的跟踪效果\n'''\ndef main(video_path,results_txt):\n # Create a VideoCapture object and read from input file\n cap = cv2.VideoCapture(video_path) \n \n points_lines = list()\n with open(results_txt,\"r\") as f:\n points_lines = f.readlines()\n\n if (cap.isOpened()== False):\n print(\"Error opening video stream or file\")\n\n ind = 0\n while(cap.isOpened()):\n # Capture frame-by-frame\n ret, frame = cap.read()\n if ret == True:\n # Draw rectangle\n line = points_lines[ind]\n pt_tuple = line.strip('\\n').split()\n pt_1 = list(map(int,list(map(float, pt_tuple[1].split(\",\")))))\n pt_2 = list(map(int,list(map(float, pt_tuple[2].split(\",\")))))\n pt_3 = list(map(int,list(map(float, pt_tuple[3].split(\",\")))))\n pt_4 = list(map(int,list(map(float, pt_tuple[4].split(\",\")))))\n pts = np.array([[pt_1,pt_2,pt_3,pt_4]], dtype = np.int32)\n cv2.fillPoly(frame, pts, 255) \n # Display videp\n cv2.imshow('Preview',frame)\n \n # flush\n cv2.waitKey(10)\n ind += 1\n \n # q quit\n if cv2.waitKey(25) & 0xFF == ord('q'):\n break\n\n \n # Break the loop\n else:\n break\n \n if cv2.waitKey(0) == 27: \n cv2.destroyAllWindows() \n \n cap.release()\n\n \n'''\n param 1:目标视频文件\n param 1:跟踪点位文件\n''' \nif __name__ == '__main__':\n try: \n main(sys.argv[1],sys.argv[2])\n #main(\"baseline.mp4\",'results.txt')\n except IndexError:\n print (\"Please input baseline.mp4 , results.txt: \")\n print (\"For example: python preview.py 'baseline.mp4' 'results.txt'\")"
},
{
"alpha_fraction": 0.4865890145301819,
"alphanum_fraction": 0.5074505805969238,
"avg_line_length": 27.796875,
"blob_id": "59a56d4668f39662032ea860adbe2290a2214d3e",
"content_id": "b13cf3707d74f140edf10a0c5f8350c2cc2ea8a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3989,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 128,
"path": "/baseline.py",
"repo_name": "ShipXu/PointsTrackDemo",
"src_encoding": "UTF-8",
"text": "# coding=utf-8\n# points tracing baseline\n\nimport cv2\nimport numpy as np\nimport sys\n\n'''\n Baseline 通过特征点匹配计算单应性矩形来完成点位跟踪。\n'''\nclass Points_Tracing():\n def __init__(self) :\n self.ratio = 0.85\n self.min_match = 4\n self.sift = cv2.xfeatures2d.SIFT_create()\n self.matcher = cv2.BFMatcher()\n\n # 单应性矩阵计算\n def get_homography(self,img1,img2):\n # 提取特征点\n kp1, des1 = self.sift.detectAndCompute(img1, None)\n kp2, des2 = self.sift.detectAndCompute(img2, None)\n \n # 匹配\n raw_matches = self.matcher.knnMatch(des1, des2, k=2)\n good_points = []\n good_matches = []\n for m1, m2 in raw_matches:\n if m1.distance < self.ratio * m2.distance:\n good_points.append((m1.trainIdx, m1.queryIdx))\n good_matches.append([m1])\n \n if len(good_points) >= self.min_match:\n image1_kp = np.float32(\n [kp1[i].pt for (_, i) in good_points])\n image2_kp = np.float32(\n [kp2[i].pt for (i, _) in good_points])\n \n H, status = cv2.findHomography(image1_kp, image2_kp, cv2.RANSAC,5.0)\n \n return H\n else:\n return np.eye(3,3)\n \n # 跟踪点位\n def tracing(self,video_path,points_txt,result_txt):\n # 结果列表\n points_results = list()\n \n # 初始单应\n M = np.eye(3,3)\n \n # 加载视频文件\n video_cap = cv2.VideoCapture(video_path)\n \n # 加载目标跟踪点位\n first_points = read_txt(points_txt)\n \n # 读取第一帧\n video_cap.set(cv2.CAP_PROP_POS_FRAMES, 0)\n ret, pre_frame = video_cap.read()\n \n points_results.append((0,first_points))\n \n # 循环\n while video_cap.isOpened():\n \n index = video_cap.get(cv2.CAP_PROP_POS_FRAMES)\n ret, frame = video_cap.read()\n \n if ret == True:\n # 获取相邻两帧单应性矩阵\n H = self.get_homography(pre_frame,frame)\n \n # 计算到首帧的单应性矩阵\n M = np.matmul(H,M) \n \n # 根据单应性矩阵跟踪目标点位\n dst = cv2.perspectiveTransform(first_points, M)\n \n points_results.append((int(index),dst))\n \n pre_frame = frame\n\n else:\n break\n \n # 释放cap\n video_cap.release()\n \n # 存储跟踪结果到结果文件\n store_txt(points_results,result_txt)\n \n# 读取目标跟踪点位\ndef read_txt(points_txt):\n points = None\n with open(points_txt,\"r\") as p:\n points = np.float32(list(map(lambda x: list(map(float,x.split(\",\"))),p.readline().split()[1:]))).reshape(-1, 1, 2)\n return points\n\n# 存储结果 \ndef store_txt(points_results,result_txt):\n with open(result_txt,\"w\") as w:\n for result in points_results:\n frame_id = result[0]\n points = result[1]\n a = points.flatten().tolist()\n b = [str(frame_id)]\n b.extend([\",\".join(list(map(str,a[i:i+2]))) for i in range(0,len(a),2)])\n w.write(\" \".join(b)+\"\\n\") \n\n\ndef main(argv1,argv2,argv3):\n # 跟踪\n Points_Tracing().tracing(argv1,argv2,argv3)\n \n'''\n param 1:目标视频文件\n param 2:目标点位文件\n param 3:跟踪点位文件\n'''\nif __name__ == '__main__':\n try: \n main(sys.argv[1],sys.argv[2],sys.argv[3])\n #main(\"baseline.mp4\",'target_points.txt','results.txt')\n except IndexError:\n print (\"Please input baseline.mp4 , target_points.txt and results.txt: \")\n print (\"For example: python baseline.py 'baseline.mp4' 'target_points.txt' 'results.txt'\")\n \n"
}
] | 4 |
Flavx/Matrix-Processor
|
https://github.com/Flavx/Matrix-Processor
|
be3630a725832c498d2350283f294ff8c5abfd18
|
6894cfc4b910c7cef7b7db412c151c6b08220fca
|
433721a50ffa8aade9a65b12c6f8768a34b82d01
|
refs/heads/master
| 2022-11-12T18:53:02.923144 | 2020-06-29T18:51:35 | 2020-06-29T18:51:35 | 275,899,508 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8117647171020508,
"avg_line_length": 41.5,
"blob_id": "e77d26eda4ca64d4f3393c07f851016ca7045d7c",
"content_id": "68e92999e21caf1b252e4997f6434b0d995639b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Flavx/Matrix-Processor",
"src_encoding": "UTF-8",
"text": "# Matrix-Processor\nRequires writing of the last 6th step, Invert Matrix calculation.\n"
},
{
"alpha_fraction": 0.5587324500083923,
"alphanum_fraction": 0.5780319571495056,
"avg_line_length": 31.28461456298828,
"blob_id": "ea3001f1f643822985f566fb745d22775d8b140e",
"content_id": "8d363abf002a6d665020123864a0e3f225666259",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4197,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 130,
"path": "/processor.py",
"repo_name": "Flavx/Matrix-Processor",
"src_encoding": "UTF-8",
"text": "import math\n\nclass Matrix:\n\n def __init__(self):\n self.nm = list(input().split())\n self.rows, self.cols = map(int, self.nm)\n self.mat = [input().split() for _ in range(int(self.nm[0]))]\n self.e_mat = [n for row in self.mat for n in row]\n\n def transposed_main(self):\n main = list(map(list, zip(*self.mat)))\n return main\n\n def transposed_side(self):\n side = [[self.mat[j][i] for j in reversed(range(len(self.mat)))] for i in reversed(range(len(self.mat)))]\n return side\n\n def transposed_vertical(self):\n vertical = [[self.mat[i][j] for j in reversed(range(len(self.mat)))] for i in range(len(self.mat))]\n return vertical\n\n def transposed_horizontal(self):\n hor = [[self.mat[i][j] for j in range(len(self.mat))] for i in reversed(range(len(self.mat)))]\n return hor\n\n\ndef matrix_determinant(matrix):\n row = len(matrix)\n col = len(matrix[0])\n if row == 1:\n return matrix[0][0]\n if row == 2:\n return float(matrix[0][0]) * float(matrix[1][1]) - float(matrix[0][1]) * float(matrix[1][0])\n else:\n determinant = 0\n for i in range(row):\n minor = [[matrix[k][j] for j in range(col) if j != i] for k in range(1, row)]\n determinant += float(matrix[0][i]) * matrix_determinant(minor) * (-1)**(1+i+1)\n return determinant\n\n\ndef matrix_addition(matrix_a, matrix_b):\n return list(map(lambda x, y: float(x) + float(y), matrix_a, matrix_b))\n\n\ndef matrix_multiplier(extracted_matrix, multiplier):\n return [float(item) * float(multiplier) for item in extracted_matrix]\n\n\ndef matrices_multiplication(matrix_a, matrix_b):\n return [[sum(float(a) * float(b) for a, b in zip(row_a, col_b)) for col_b in zip(*matrix_b)] for row_a in matrix_a]\n\n\ndef matrix_recostituent(extracted_matrix, cols):\n re_mat = [extracted_matrix[x:x + cols] for x in range(0, len(extracted_matrix), cols)]\n return re_mat\n\n\ndef matrix_printer(matrix):\n print(\"The result is:\")\n for list_ in matrix:\n print(*list_)\n\n\ndef menu_1():\n print(\"1. Add matrices\\n\"\n \"2. Multiply matrix by a constant\\n\"\n \"3. Multiply matrices\\n\"\n \"4. Transpose matrices\\n\"\n \"5. Calculate a determinant\\n\"\n \"6. Inverse matrix\\n\"\n \"0. Exit\")\n\n\ndef menu_2():\n print(\"\\n1. Main diagonal\\n\"\n \"2. Side diagonal\\n\"\n \"3. Vertical line\\n\"\n \"4. Horizontal line\")\n\n\nwhile True:\n menu_1()\n choice = int(input())\n\n if choice not in [0, 1, 2, 3, 4, 5]:\n print(\"Sorry unknown selection\")\n elif choice == 1:\n matrix_1 = Matrix()\n matrix_2 = Matrix()\n if matrix_1.nm != matrix_2.nm:\n print(\"The operation cannot be performed.\")\n else:\n new_matrix = matrix_addition(matrix_1.e_mat, matrix_2.e_mat)\n re_matrix = matrix_recostituent(new_matrix, matrix_1.cols)\n matrix_printer(re_matrix)\n elif choice == 2:\n matrix_1 = Matrix()\n result = matrix_multiplier(matrix_1.e_mat, float(input()))\n re_matrix = matrix_recostituent(result, matrix_1.cols)\n matrix_printer(re_matrix)\n elif choice == 3:\n matrix_1 = Matrix()\n matrix_2 = Matrix()\n if matrix_1.cols != matrix_2.rows:\n print(\"The operation cannot be performed.\")\n else:\n result = matrices_multiplication(matrix_1.mat, matrix_2.mat)\n matrix_printer(result)\n elif choice == 4:\n menu_2()\n new_choice = int(input())\n matrix_1 = Matrix()\n if new_choice not in [1, 2, 3, 4]:\n print(\"Sorry unknown selection\")\n elif new_choice == 1:\n matrix_printer(matrix_1.transposed_main())\n elif new_choice == 2:\n matrix_printer(matrix_1.transposed_side())\n elif new_choice == 3:\n matrix_printer(matrix_1.transposed_vertical())\n elif new_choice == 4:\n matrix_printer(matrix_1.transposed_horizontal())\n elif choice == 5:\n matrix_1 = Matrix()\n print(matrix_determinant(matrix_1.rows, matrix_1.cols, matrix_1.mat))\n print()\n elif choice == 0:\n break\n"
}
] | 2 |
losinggeneration/kos
|
https://github.com/losinggeneration/kos
|
34895d010b519fd3d1255b7518a43c68165dda32
|
7c19668b7bef90c06d9419dca3abae86ac542feb
|
8524994a2c32cee6c133c08b9bd902f2006a20e5
|
refs/heads/master
| 2016-09-05T10:34:31.240458 | 2008-05-05T22:51:41 | 2008-05-11T07:08:49 | 7,083 | 8 | 3 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4986301362514496,
"alphanum_fraction": 0.5643835663795471,
"avg_line_length": 13,
"blob_id": "29043e83722776d01c38e2369f3b37424dbac19e",
"content_id": "6f46a9e2594c2b6ed76e7a016babb51e4fbcc2ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 26,
"path": "/libc/time/time.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n time.c\n (c)2002 Dan Potter\n\n $Id: time.c,v 1.1 2002/02/24 01:24:00 bardtx Exp $\n*/\n\n#include <time.h>\n#include <arch/rtc.h>\n\n/* time() */\ntime_t time(time_t *ptr) {\n\ttime_t t;\n\n\tt = rtc_unix_secs();\n\tif (ptr) {\n\t\t*ptr = t;\n\t}\n\treturn t;\n}\n\n/* time() */\ndouble difftime(time_t time1, time_t time0) {\n\treturn (double)(time1 - time0);\n}\n\n"
},
{
"alpha_fraction": 0.5526315569877625,
"alphanum_fraction": 0.5789473652839661,
"avg_line_length": 11,
"blob_id": "8a7a3a25b3aa273f4194d9d2d4f8ee703395111c",
"content_id": "7dd545b2a4faf833ae5f3e487d7d6a1f1ef03eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 3,
"path": "/kernel/arch/gba/kernel/irq.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "\nint irq_inside_int() {\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6213063597679138,
"alphanum_fraction": 0.6454121470451355,
"avg_line_length": 21.543859481811523,
"blob_id": "4e24409888d6a371441e6577075515c546a19b5f",
"content_id": "ff67655a9a1ba7e73bdb3430d9b1b37ef0549ad9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1286,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 57,
"path": "/include/arch/ps2/arch/spinlock.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/spinlock.h\n (c)2001-2002 Dan Potter\n \n $Id: spinlock.h,v 1.3 2002/11/06 08:41:03 bardtx Exp $\n*/\n\n#ifndef __ARCH_SPINLOCK_H\n#define __ARCH_SPINLOCK_H\n\n/* Defines processor specific spinlocks */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/thread.h>\n\n/* Spinlock data type */\ntypedef volatile int spinlock_t;\n\n/* Value initializer */\n#define SPINLOCK_INITIALIZER 0\n\n/* Initialize a spinlock */\n#define spinlock_init(A) *(A) = SPINLOCK_INITIALIZER\n\n/* Note here that even if threads aren't enabled, we'll still set the\n lock so that it can be used for anti-IRQ protection (e.g., malloc) */\n\n/* Spin on a lock; we should probably get something a bit more elegant\n here, but what the heck... ll/sc are pretty ridiculously complicated\n and the manual doesn't say for sure if they prevent interrupts anyway. */\n#define spinlock_lock(A) do { \\\n\tspinlock_t * __lock = A; \\\n try_again: \\\n\tirq_disable(); \\\n\tif (*__lock) { \\\n\t\tirq_enable(); \\\n\t\tthd_pass(); \\\n\t\tgoto try_again; \\\n\t} else { \\\n\t\t*__lock = 1; \\\n\t} \\\n} while (0)\n\n/* Free a lock */\n#define spinlock_unlock(A) do { \\\n\t\t*(A) = 0; \\\n\t} while (0)\n\n__END_DECLS\n\n/* Determine if a lock is locked */\n#define spinlock_is_locked(A) ( *(A) != 0 )\n\n#endif\t/* __ARCH_SPINLOCK_H */\n\n"
},
{
"alpha_fraction": 0.5487179756164551,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 15.208333015441895,
"blob_id": "f863f031f8891c899807305488fc1ab7a3505252",
"content_id": "3caa6701384684804e0e15d65644993b5b737e7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 390,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 24,
"path": "/libc/stdlib/rand.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n rand.c\n (c)2000-2001 Dan Potter\n\n Slightly less than optimal random number function\n*/\n\n#include <stdlib.h>\n\nCVSID(\"$Id: rand.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\");\n\nstatic unsigned long seed=123;\n#define RNDC 1013904223\n#define RNDM 1164525\n\nvoid srand(unsigned int s) {\n\tseed = s;\n}\n\nint rand() {\n\tseed = seed * RNDM + RNDC;\n\treturn seed & RAND_MAX;\n}\n\n"
},
{
"alpha_fraction": 0.6301615834236145,
"alphanum_fraction": 0.6660681962966919,
"avg_line_length": 16.967741012573242,
"blob_id": "466f67192082dbfad95d33d4507d5ac05302469f",
"content_id": "3d5fcdee945883c9c5f1bc871b1f54feb11c5482",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 557,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 31,
"path": "/kernel/net/net_icmp.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_icmp.h\n Copyright (C) 2002 Dan Potter\n Copyright (C) 2005, 2007 Lawrence Sebald\n\n*/\n\n#ifndef __LOCAL_NET_ICMP_H\n#define __LOCAL_NET_ICMP_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/net.h>\n#include \"net_ipv4.h\"\n\n#define packed __attribute__((packed))\ntypedef struct {\n\tuint8\ttype\t\tpacked;\n\tuint8\tcode\t\tpacked;\n\tuint16\tchecksum\tpacked;\n\tuint8\tmisc[4]\t\tpacked;\n} icmp_hdr_t;\n#undef packed\n\nint net_icmp_input(netif_t *src, ip_hdr_t *ih, const uint8 *data, int size);\n\n__END_DECLS\n\n#endif\t/* __LOCAL_NET_ICMP_H */\n"
},
{
"alpha_fraction": 0.6698841452598572,
"alphanum_fraction": 0.6920849680900574,
"avg_line_length": 22.545454025268555,
"blob_id": "8cb4b2b753334708c76ecd1c7cac241cfc0a7b30",
"content_id": "9b78410ac04fcd01f23c00885c645cf6b9fe84d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1036,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 44,
"path": "/kernel/arch/ia32/kernel/rtc.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n rtc.c\n Copyright (C)2003 Dan Potter\n*/\n\n/* Real Time Clock support\n\n The functions in here return various info about the real-world time and\n date stored in the machine. The general process here is to retrieve\n the date/time value and then use the other functions to interpret it.\n\n rtc_get_time() should return a UNIX-epoch time stamp, and then the normal\n BSD library functions can be used to interpret that time stamp.\n\n */\n\n#include <arch/rtc.h>\n\nCVSID(\"$Id: rtc.c,v 1.1 2003/08/01 03:18:37 bardtx Exp $\");\n\n/* The boot time; we'll save this in rtc_init() */\nstatic time_t boot_time = 0;\n\n/* Returns the date/time value as a UNIX epoch time stamp */\ntime_t rtc_unix_secs() {\n\treturn 0;\n}\n\n\n/* Returns the date/time that the system was booted as a UNIX epoch time\n stamp. Adding this to the value from timer_ms_gettime() will\n produce a current timestamp. */\ntime_t rtc_boot_time() {\n\treturn boot_time;\n}\n\nint rtc_init() {\n\tboot_time = rtc_unix_secs();\n\treturn 0;\n}\n\nvoid rtc_shutdown() {\n}\n"
},
{
"alpha_fraction": 0.62687748670578,
"alphanum_fraction": 0.6395257115364075,
"avg_line_length": 18.312976837158203,
"blob_id": "57bc4e6e9650614aa2b6939eac7ee69693e5772e",
"content_id": "163ba11ac6843245bcf5a2ed858fb45ba3d17bbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2530,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 131,
"path": "/kernel/thread/cond.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n cond.c\n Copyright (c)2001,2003 Dan Potter\n*/\n\n/* Defines condition variables, which are like semaphores that automatically\n signal all waiting processes when a signal() is called. */\n\n#include <string.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <assert.h>\n#include <errno.h>\n\n#include <kos/thread.h>\n#include <kos/limits.h>\n#include <kos/cond.h>\n#include <kos/genwait.h>\n#include <sys/queue.h>\n\nCVSID(\"$Id: cond.c,v 1.8 2003/02/17 04:41:58 bardtx Exp $\");\n\n/**************************************/\n\n/* Global list of condvars */\nstatic struct condlist cond_list;\n\n/* Allocate a new condvar; the condvar will be assigned\n to the calling process and when that process dies, the condvar\n will also die. */\ncondvar_t *cond_create() {\n\tcondvar_t\t*cv;\n\tint\t\told = 0;\n\n\t/* Create a condvar structure */\n\tcv = (condvar_t*)malloc(sizeof(condvar_t));\n\tif (!cv) {\n\t\terrno = ENOMEM;\n\t\treturn NULL;\n\t}\n\n\t/* Add to the global list */\n\told = irq_disable();\n\tLIST_INSERT_HEAD(&cond_list, cv, g_list);\n\tirq_restore(old);\n\n\treturn cv;\n}\n\n/* Free a condvar */\nvoid cond_destroy(condvar_t *cv) {\n\tint\t\told = 0;\n\n\t/* XXX Do something better with queued threads */\n\tgenwait_wake_all(cv);\n\n\t/* Remove it from the global list */\n\told = irq_disable();\n\tLIST_REMOVE(cv, g_list);\n\tirq_restore(old);\n\n\t/* Free the memory */\n\tfree(cv);\n}\n\nint cond_wait_timed(condvar_t *cv, mutex_t *m, int timeout) {\n\tint old, rv;\n\n\tif (irq_inside_int()) {\n\t\tdbglog(DBG_WARNING, \"cond_wait: called inside interrupt\\n\");\n\t\terrno = EPERM;\n\t\treturn -1;\n\t}\n\n\told = irq_disable();\n\n\t/* First of all, release the associated mutex */\n\tassert( mutex_is_locked(m) );\n\tmutex_unlock(m);\n\n\t/* Now block us until we're signaled */\n\trv = genwait_wait(cv, timeout ? \"cond_wait_timed\" : \"cond_wait\", timeout, NULL);\n\n\t/* Re-lock our mutex */\n\tif (rv >= 0 || errno == EAGAIN) {\n\t\tmutex_lock(m);\n\t}\n\n\t/* Ok, ready to return */\n\tirq_restore(old);\n\n\treturn rv;\n}\n\nint cond_wait(condvar_t *cv, mutex_t *m) {\n\treturn cond_wait_timed(cv, m, 0);\n}\n\nvoid cond_signal(condvar_t *cv) {\n\tint old = 0;\n\n\told = irq_disable();\n\n\t/* Wake any one thread who's waiting */\n\tgenwait_wake_one(cv);\n\n\tirq_restore(old);\n}\n\nvoid cond_broadcast(condvar_t *cv) {\n\tint old = 0;\n\n\told = irq_disable();\n\n\t/* Wake all threads who are waiting */\n\tgenwait_wake_all(cv);\n\n\tirq_restore(old);\n}\n\n/* Initialize condvar structures */\nint cond_init() {\n\tLIST_INIT(&cond_list);\n\treturn 0;\n}\n\n/* Shut down condvar structures */\nvoid cond_shutdown() {\n\t/* XXX Destroy all condvars here */\n}\n"
},
{
"alpha_fraction": 0.6174609065055847,
"alphanum_fraction": 0.6422575116157532,
"avg_line_length": 21.571428298950195,
"blob_id": "bb964c4878f39443f5aabf0e09fd4fde41cc8799",
"content_id": "82d9492309c25cac8a82ecaf275951b5da4c54db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7743,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 343,
"path": "/kernel/arch/dreamcast/hardware/cdrom.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n cdrom.c\n\n (c)2000 Dan Potter\n\n */\n\n#include <dc/cdrom.h>\n#include <kos/thread.h>\n#include <kos/mutex.h>\n\nCVSID(\"$Id: cdrom.c,v 1.8 2003/04/24 03:25:27 bardtx Exp $\");\n\n/*\n\nThis module contains low-level primitives for accessing the CD-Rom (I\nrefer to it as a CD-Rom and not a GD-Rom, because this code will not\naccess the GD area, by design). Whenever a file is accessed and a new\ndisc is inserted, it reads the TOC for the disc in the drive and\ngets everything situated. After that it will read raw sectors from \nthe data track on a standard DC bootable CDR (one audio track plus\none data track in xa1 format).\n\nMost of the information/algorithms in this file are thanks to\nMarcus Comstedt. Thanks to Maiwe for the verbose command names and\nalso for the CDDA playback routines.\n\nNote that these functions may be affected by changing compiler options...\nthey require their parameters to be in certain registers, which is \nnormally the case with the default options. If in doubt, decompile the\noutput and look to make sure.\n\n*/\n\n\n/* GD-Rom BIOS calls... named mostly after Marcus' code. None have more\n than two parameters; R7 (fourth parameter) needs to describe\n which syscall we want. */\n\n#define MAKE_SYSCALL(rs, p1, p2, idx) \\\n\tuint32 *syscall_bc = (uint32*)0x8c0000bc; \\\n\tint (*syscall)() = (int (*)())(*syscall_bc); \\\n\trs syscall((p1), (p2), 0, (idx));\n\n/* Reset system functions */\nstatic void gdc_init_system() {\tMAKE_SYSCALL(/**/, 0, 0, 3); }\n\n/* Submit a command to the system */\nstatic int gdc_req_cmd(int cmd, void *param) { MAKE_SYSCALL(return, cmd, param, 0); }\n\n/* Check status on an executed command */\nstatic int gdc_get_cmd_stat(int f, void *status) { MAKE_SYSCALL(return, f, status, 1); }\n\n/* Execute submitted commands */\nstatic void gdc_exec_server() { MAKE_SYSCALL(/**/, 0, 0, 2); }\n\n/* Check drive status and get disc type */\nstatic int gdc_get_drv_stat(void *param) { MAKE_SYSCALL(return, param, 0, 4); }\n\n/* Set disc access mode */\nstatic int gdc_change_data_type(void *param) { MAKE_SYSCALL(return, param, 0, 10); }\n\n/* Reset the GD-ROM */\nstatic void gdc_reset() { MAKE_SYSCALL(/**/, 0, 0, 9); }\n\n/* Abort the current command */\nstatic void gdc_abort_cmd(int cmd) { MAKE_SYSCALL(/**/,cmd, 0, 8); }\n\n/* The CD access mutex */\nstatic mutex_t * mutex = NULL;\nstatic int sector_size = 2048; /*default 2048, 2352 for raw data reading*/\n\nvoid set_sector_size (int size) {\n\tsector_size = size;\n\tcdrom_reinit();\n} \n\n/* Command execution sequence */\nint cdrom_exec_cmd(int cmd, void *param) {\n\tint status[4] = {0};\n\tint f, n;\n\n\t/* Submit the command and wait for it to finish */\n\tf = gdc_req_cmd(cmd, param);\n\tdo {\n\t\tgdc_exec_server();\n\t\tn = gdc_get_cmd_stat(f, status);\n\t\tif (n == PROCESSING)\n\t\t\tthd_pass();\n\t} while (n == PROCESSING);\n\n\tif (n == COMPLETED)\n\t\treturn ERR_OK;\n\telse if (n == ABORTED)\n\t\treturn ERR_ABORTED;\n\telse if (n == NO_ACTIVE)\n\t\treturn ERR_NO_ACTIVE;\n\telse {\n\t\tswitch(status[0]) {\n\t\t\tcase 2: return ERR_NO_DISC;\n\t\t\tcase 6: return ERR_DISC_CHG;\n\t\t\tdefault:\n\t\t\t\treturn ERR_SYS;\n\t\t}\n\t}\n}\n\n/* Return the status of the drive as two integers (see constants) */\nint cdrom_get_status(int *status, int *disc_type) {\n\tint \trv = ERR_OK;\n\tuint32\tparams[2];\n\n\t/* We might be called in an interrupt to check for ISO cache\n\t flushing, so make sure we're not interrupting something\n\t already in progress. */\n\tif (irq_inside_int()) {\n\t\tif (mutex_is_locked(mutex))\n\t\t\treturn -1;\n\t} else {\n\t\tmutex_lock(mutex);\n\t}\n\n\trv = gdc_get_drv_stat(params);\n\tif (rv >= 0) {\n\t\tif (status != NULL)\n\t\t\t*status = params[0];\n\t\tif (disc_type != NULL)\n\t\t\t*disc_type = params[1];\n\t} else {\n\t\tif (status != NULL)\n\t\t\t*status = -1;\n\t\tif (disc_type != NULL)\n\t\t\t*disc_type = -1;\n\t}\n\n\tif (!irq_inside_int())\n\t\tmutex_unlock(mutex);\n\n\treturn rv;\n}\n\n/* Re-init the drive, e.g., after a disc change, etc */\nint cdrom_reinit() {\n\tint\trv = ERR_OK;\n\tint\tr = -1, cdxa;\n\tuint32\tparams[4];\n\tint\ttimeout;\n\n\tmutex_lock(mutex);\n\n\t/* Try a few times; it might be busy. If it's still busy\n\t after this loop then it's probably really dead. */\n\ttimeout = 10*1000/20;\t/* 10 second timeout */\n\twhile (timeout > 0) {\n\t\tr = cdrom_exec_cmd(CMD_INIT, NULL);\n\t\tif (r == 0) break;\n\t\tif (r == ERR_NO_DISC) {\n\t\t\trv = r;\n\t\t\tgoto exit;\n\t\t} else if (r == ERR_SYS) {\n\t\t\trv = r;\n\t\t\tgoto exit;\n\t\t}\n\n\t\t/* Still trying.. sleep a bit and check again */\n\t\tthd_sleep(20);\n\t\ttimeout--;\n\t}\n\tif (timeout <= 0) {\n\t\trv = r;\n\t\tgoto exit;\n\t}\n\n\t/* Check disc type and set parameters */\n\tgdc_get_drv_stat(params);\n\tcdxa = params[1] == 32;\n\tparams[0] = 0;\t\t\t\t/* 0 = set, 1 = get */\n\tparams[1] = 8192;\t\t\t/* ? */\n\tparams[2] = cdxa ? 2048 : 1024;\t\t/* CD-XA mode 1/2 */\n\tparams[3] = sector_size;\t\t/* sector size */\n\tif (gdc_change_data_type(params) < 0) { rv = ERR_SYS; goto exit; }\n\nexit:\n\tmutex_unlock(mutex);\n\treturn rv;\n}\n\n/* Read the table of contents */\nint cdrom_read_toc(CDROM_TOC *toc_buffer, int session) {\n\tstruct {\n\t\tint\tsession;\n\t\tvoid\t*buffer;\n\t} params;\n\tint rv;\n\t\n\tmutex_lock(mutex);\n\t\n\tparams.session = session;\n\tparams.buffer = toc_buffer;\n\trv = cdrom_exec_cmd(CMD_GETTOC2, ¶ms);\n\t\n\tmutex_unlock(mutex);\n\treturn rv;\n}\n\n/* Read one or more sectors */\nint cdrom_read_sectors(void *buffer, int sector, int cnt) {\n\tstruct {\n\t\tint\tsec, num;\n\t\tvoid\t*buffer;\n\t\tint\tdunno;\n\t} params;\n\tint rv;\n\n\tmutex_lock(mutex);\n\t\n\tparams.sec = sector;\t/* Starting sector */\n\tparams.num = cnt;\t/* Number of sectors */\n\tparams.buffer = buffer;\t/* Output buffer */\n\tparams.dunno = 0;\t/* ? */\n\trv = cdrom_exec_cmd(CMD_PIOREAD, ¶ms);\n\t\n\tmutex_unlock(mutex);\n\treturn rv;\n}\n\n/* Locate the LBA sector of the data track; use after reading TOC */\nuint32 cdrom_locate_data_track(CDROM_TOC *toc) {\n\tint i, first, last;\n\t\n\tfirst = TOC_TRACK(toc->first);\n\tlast = TOC_TRACK(toc->last);\n\t\n\tif (first < 1 || last > 99 || first > last)\n\t\treturn 0;\n\t\n\t/* Find the last track which as a CTRL of 4 */\n\tfor (i=last; i>=first; i--) {\n\t\tif (TOC_CTRL(toc->entry[i - 1]) == 4)\n\t\t\treturn TOC_LBA(toc->entry[i - 1]);\n\t}\n\t\n\treturn 0;\n}\n\n/* Play CDDA tracks\n start -- track to play from\n end -- track to play to\n repeat -- number of times to repeat (0-15, 15=infinite)\n mode -- CDDA_TRACKS or CDDA_SECTORS\n */\nint cdrom_cdda_play(uint32 start, uint32 end, uint32 repeat, int mode) {\n\tstruct {\n\t\tint start;\n\t\tint end;\n\t\tint repeat;\n\t} params;\n\tint rv;\n\n\t/* Limit to 0-15 */\n\tif (repeat > 15)\n\t\trepeat = 15;\n\n\tparams.start = start;\n\tparams.end = end;\n\tparams.repeat = repeat;\n\n\tmutex_lock(mutex);\n\tif (mode == CDDA_TRACKS)\n\t\trv = cdrom_exec_cmd(CMD_PLAY, ¶ms);\n\telse\n\t\trv = cdrom_exec_cmd(CMD_PLAY2, ¶ms);\n\tmutex_unlock(mutex);\n\n\treturn rv;\n}\n\n/* Pause CDDA audio playback */\nint cdrom_cdda_pause() {\n\tint rv;\n\n\tmutex_lock(mutex);\n\trv = cdrom_exec_cmd(CMD_PAUSE, NULL);\n\tmutex_unlock(mutex);\n\n\treturn rv;\n}\n\n/* Resume CDDA audio playback */\nint cdrom_cdda_resume() {\n\tint rv;\n\n\tmutex_lock(mutex);\n\trv = cdrom_exec_cmd(CMD_RELEASE, NULL);\n\tmutex_unlock(mutex);\n\n\treturn rv;\n}\n\n/* Spin down the CD */\nint cdrom_spin_down() {\n\tint rv;\n\n\tmutex_lock(mutex);\n\trv = cdrom_exec_cmd(CMD_STOP, NULL);\n\tmutex_unlock(mutex);\n\n\treturn rv;\n}\n\n/* Initialize: assume no threading issues */\nint cdrom_init() {\n\tuint32 p, x;\n\tvolatile uint32 *react = (uint32*)0xa05f74e4,\n\t\t*bios = (uint32*)0xa0000000;\n\n\tif (mutex != NULL)\n\t\treturn -1;\n\n\t/* Reactivate drive: send the BIOS size and then read each\n\t word across the bus so the controller can verify it. */\n\t*react = 0x1fffff;\n\tfor (p=0; p<0x200000/4; p++) { x = bios[p]; }\n\n\t/* Reset system functions */\n\tgdc_init_system();\n\n\t/* Initialize mutex */\n\tmutex = mutex_create();\n\n\t/* Do an initial initialization */\n\tcdrom_reinit();\n\t\n\treturn 0;\n}\n\nvoid cdrom_shutdown() {\n\tif (mutex == NULL)\n\t\treturn;\n\tmutex_destroy(mutex);\n\tmutex = NULL;\n}\n\n"
},
{
"alpha_fraction": 0.48363494873046875,
"alphanum_fraction": 0.5862533450126648,
"avg_line_length": 25.20707130432129,
"blob_id": "f3b289321fb52d276959e66c3ccd0b0252654b84",
"content_id": "3ed66cf2d3cf6fd7c040009d7de9f408fb17d038",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5194,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 198,
"path": "/examples/dreamcast/sound/ghettoplay-vorbis/ghettoplay.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* GhettoPlay: an Ogg Vorbis browser and playback util\n (c)2000-2002 Dan Potter\n (c)2001 Thorsten Titze\n\n Distributed as an example for libdream 0.7\n Ported up to libdream 0.95\n Ported up to KOS 1.1.x\n Converted to OggVorbis\n\n Historical note: this is _really_ 2.0. There was an internally\n created Ghetto Play that I made to browse and test various S3Ms\n with early versions of the player. It _really_ deserved the name\n GHETTO Play =). This one, like Ghetto Pong, is a 2.0 that is more\n like \"Pimpin' Play\" ;-). However, sticking with tradition... \n \n*/\n\n#include <oggvorbis/sndoggvorbis.h>\n#include <stdio.h>\n#include \"gp.h\"\n\nlong bitrate;\n\nint check_start() {\n\tMAPLE_FOREACH_BEGIN(MAPLE_FUNC_CONTROLLER, cont_state_t, st)\n\t\tif (st->buttons & CONT_START) {\n\t\t\tprintf(\"Pressed start\\n\");\n\t\t\treturn 1;\n\t\t}\n\tMAPLE_FOREACH_END()\n\n\treturn 0;\n}\n\n/* Render the mouse if they have one attached */\nstatic int mx = 320, my = 240;\nstatic int lmx[5] = {320, 320, 320, 320, 320},\n\tlmy[5] = {240, 240, 240, 240, 240};\nvoid mouse_render() {\n\tint i;\n\tint atall = 0;\n\t\n\tMAPLE_FOREACH_BEGIN(MAPLE_FUNC_MOUSE, mouse_state_t, st)\n\t\tatall = 1;\n\t\tif (st->dx || st->dy) {\n\t\t\n\t\t\tmx += st->dx;\n\t\t\tmy += st->dy;\n\t\t\n\t\t\tif (mx < 0) mx = 0;\n\t\t\tif (mx > 640) mx = 640;\n\t\t\tif (my < 0) my = 0;\n\t\t\tif (my > 480) my = 480;\n\n\t\t\tlmx[0] = mx;\n\t\t\tlmy[0] = my;\n\t\t}\n\tMAPLE_FOREACH_END()\n\n\tif (atall) {\n\t\tfor (i=4; i>0; i--) {\n\t\t\tlmx[i] = lmx[i-1];\n\t\t\tlmy[i] = lmy[i-1];\n\t\t}\n\n\t\tdraw_poly_mouse(mx, my, 1.0f);\n\t\tfor (i=1; i<5; i++)\n\t\t\tdraw_poly_mouse(lmx[i], lmy[i], 0.8f * (5-i) / 6.0f);\n\t}\n}\n\n/* Update the VMU LCD */\n#include \"vmu_ghetto.h\"\n#include \"vmu_play.h\"\n#include \"vmu_ghettoplay.h\"\nstatic int cycle = 0, phase = 1;\nvoid vmu_lcd_update() {\n\tswitch(cycle) {\n\t\tcase 0: {\t/* Getto/Play/GettoPlay */\n\t\t\tif (phase == 1) {\n\t\t\t\tvmu_set_icon(vmu_ghetto_xpm);\n\t\t\t} else if (phase == 60) {\n\t\t\t\tvmu_set_icon(vmu_play_xpm);\n\t\t\t} else if (phase == 120) {\n\t\t\t\tvmu_set_icon(vmu_ghettoplay_xpm);\n\t\t\t} else if (phase == 180) {\n\t\t\t\tphase = 0;\n\t\t\t\tcycle = 1;\n\t\t\t}\n\t\t} break;\n\t\tcase 1: {\t/* Flashing */\n\t\t\tif ((phase % 20) == 0) {\n\t\t\t\tvmu_set_icon(vmu_ghettoplay_xpm);\n\t\t\t} else if ((phase % 20) == 10) {\n\t\t\t\tvmu_set_icon(NULL);\n\t\t\t}\n\t\t\t\n\t\t\tif (phase == 60) {\n\t\t\t\tcycle = 0;\n\t\t\t\tphase = 0;\n\t\t\t}\n\t\t} break;\n\t}\n\tphase++;\n}\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\n/* Program entry */\nint main(int argc, char **argv) {\n\t/* Do basic setup */\n\tpvr_init_defaults();\n\n\t/* Initialize oggvorbis player thread */\n\tsnd_stream_init();\n\tsndoggvorbis_init();\n\n\t/* Setup the mouse/font texture */\n\tsetup_util_texture();\n\n\t/* Setup background display */\n\tbkg_setup();\n\n\twhile (!check_start()) {\n\t\tpvr_wait_ready();\n\t\tpvr_scene_begin();\n\t\tpvr_list_begin(PVR_LIST_OP_POLY);\n\n\t\t/* Opaque list *************************************/\n\t\tbkg_render();\n\n\t\t/* End of opaque list */\n\t\tpvr_list_finish();\n\t\tpvr_list_begin(PVR_LIST_TR_POLY);\n\n\t\t/* Translucent list ********************************/\n\n\t\t/* Top Banner */\n\t\tdraw_poly_box(0.0f, 10.0f, 640.0f, 20.0f+(24.0f*2.0f)+10.0f, 90.0f, \n\t\t\t0.3f, 0.2f, 0.5f, 0.0f, 0.5f, 0.1f, 0.8f, 0.2f);\n\t\tdraw_poly_strf(5.0f, 20.0f, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,\n\t\t\t\" GhettoPlay (C)2000-2002 by Dan Potter \");\n\t\tdraw_poly_strf(5.0f, 48.0f, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,\n\t\t\t\" sndoggvorbis (C)2001 by Thorsten Titze \");\n\n\t\t/* Song menu */\n\t\tsong_menu_render();\n\t\t\n\t\t/* File Information */\n\t\tdraw_poly_box(20.0f, 440.0f-96.0f+4, 640.0f-20.0f, 440.0f, 90.0f, \n\t\t\t0.3f, 0.2f, 0.5f, 0.0f, 0.5f, 0.1f, 0.8f, 0.2f);\n\t\t\n\t\tdraw_poly_strf(30.0f,440.0f-96.0f+6,100.0f,1.0f,1.0f,1.0f,1.0f,\"File Information:\");\n\t\tdraw_poly_strf(640.0f-180.0f-12.0f+(6*12.0f),440.0f-96.0f+6,100.0f,1.0f,1.0f,1.0f,1.0f,\"bit/s\");\n\t\tdraw_poly_strf(30.0f,440.0f-96.0f+6+24.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,\"Author:\");\n\t\tdraw_poly_strf(30.0f,440.0f-96.0f+6+48.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,\"Title:\");\n\t\tdraw_poly_strf(320.0f,440.0f-96.0f+6+24.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,\"Genre:\");\n\n\t\t/* If we're playing a file fill out the File information */\n\t\tif(sndoggvorbis_isplaying())\n\t\t{\n\t\t\tchar bitrate[6];\n\t\t\tlong bitrateval=sndoggvorbis_getbitrate();\n\t\t\tsprintf(bitrate,\"%6ld\",bitrateval);\n\t\t\tchar * artist, * title, * genre;\n\n\t\t\tartist = sndoggvorbis_getartist(); if (!artist) artist = \"[none]\";\n\t\t\ttitle = sndoggvorbis_gettitle(); if (!title) title = \"[none]\";\n\t\t\tgenre = sndoggvorbis_getgenre(); if (!genre) genre = \"[none]\";\n\t\t\n\t\t\tdraw_poly_strf(640.0f-180.0f-12.0f -12.0f, 440.0f-96.0f+6, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,bitrate);\n\t\t\tdraw_poly_strf(30.0f+(12.0f*7),440.0f-96.0f+6+24.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,artist);\n\t\t\tdraw_poly_strf(30.0f+(12.0f*6),440.0f-96.0f+6+48.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,title);\n\t\t\tdraw_poly_strf(320.0f+(12.0f*6),440.0f-96.0f+6+24.0f+10.0f,100.0f,1.0f,1.0f,1.0f,1.0f,genre);\n\t\t}\n\n\t\t/* Render the mouse if they move it.. it doesn't do anything\n\t\t but it's cool looking ^_^ */\n\t\tmouse_render();\n\n\t\t/* End of translucent list */\n\t\tpvr_list_finish();\n\n\t\t/* Finish the frame *******************************/\n\t\tpvr_scene_finish();\n\t\t\n\t\t/* Update the VMU LCD */\n\t\tvmu_lcd_update();\n\t}\n\t\n\tsndoggvorbis_shutdown();\n\n\t/* Stop the sound */\n\tspu_disable();\n\n\treturn 0;\n}\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6162201166152954,
"alphanum_fraction": 0.650253415107727,
"avg_line_length": 19.909090042114258,
"blob_id": "0c3d74aacddf0f63f185d7a3a2604adbdb5f0720",
"content_id": "2698ae9ded7530b34e1170d1ac2a9066b71b3f61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1381,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 66,
"path": "/libc/include/time.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n time.h\n (c)2000 Dan Potter\n\n $Id: time.h,v 1.3 2002/03/15 06:45:42 bardtx Exp $\n\n*/\n\n#ifndef __TIME_H\n#define __TIME_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\ntypedef uint32 time_t;\ntypedef uint32 clock_t;\n\n/* POSIX states that CLOCKS_PER_SEC must be 1000000 */\n#ifndef CLOCKS_PER_SEC\n# define CLOCKS_PER_SEC 1000000\n#endif\n\ntime_t time(time_t *t);\nclock_t clock(void);\ndouble difftime(time_t time1, time_t time0);\n\n/* Time value */\nstruct timeval {\n\tlong\ttv_sec;\t\t/* Seconds */\n\tlong\ttv_usec;\t/* Microseconds */\n};\n\n/* We don't support time zones, but put it here for compatability */\nstruct timezone {\n\tint\ttz_minuteswest;\n\tint\ttz_dsttime;\n};\n\n/* Return the number of seconds and microseconds since 1970 */\nint gettimeofday(struct timeval *tv, struct timezone *tz);\n\n/* Time struct */\nstruct tm {\n\tint\ttm_sec;\t\t/* seconds */\n\tint\ttm_min;\t\t/* minutes */\n\tint\ttm_hour;\t/* hours */\n\tint\ttm_mday;\t/* day of the month */\n\tint\ttm_mon;\t\t/* month (0 - 11) */\n\tint\ttm_year;\t/* year */\n\tint\ttm_wday;\t/* day of the week */\n\tint\ttm_yday;\t/* day of the year */\n\tint\ttm_isdst;\t/* daylight savings time */\n};\n\n/* Convert a struct tm into a time_t */\ntime_t mktime(struct tm *timeptr);\n\n/* Convert a time_t into a struct tm (thread-safe) */\nstruct tm *localtime_r(const time_t *timep, struct tm * dst);\n\n__END_DECLS\n\n#endif\t/* __TIME_H */\n\n"
},
{
"alpha_fraction": 0.7049180269241333,
"alphanum_fraction": 0.709601879119873,
"avg_line_length": 28.744186401367188,
"blob_id": "487619859010b877c4b0ee03c5f3081ad0160daf",
"content_id": "99d021031b2d7ac971411527e315bfd67ed855e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1281,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 43,
"path": "/include/arch/dreamcast/dc/fs_dclnative.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/fs_dclnative.h\n Copyright (C)2003 Dan Potter\n\n*/\n\n#ifndef __DC_FS_DCLNATIVE_H\n#define __DC_FS_DCLNATIVE_H\n\n/* Definitions for the \"dcload-ip native\" file system. This is like,\n dc-load, but it uses KOS' ethernet drivers to talk directly to the\n installed network adapter. This is far faster and more reliable as\n long as you're not debugging interrupts or something. :) When KOS\n exits, control will be handed back to the resident dcload-ip\n instance. */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <dc/fs_dcload.h>\n\n/* Printk replacement */\nvoid dclnative_printk(const char *str);\n\n/* File functions */\nfile_t\tdclnative_open(vfs_handler_t * vfs, const char *fn, int mode);\nvoid\tdclnative_close(file_t hnd);\nssize_t\tdclnative_read(file_t hnd, void *buf, size_t cnt);\noff_t\tdclnative_seek(file_t hnd, off_t offset, int whence);\noff_t\tdclnative_tell(file_t hnd);\nsize_t\tdclnative_total(file_t hnd);\ndirent_t* dclnative_readdir(file_t hnd);\nint dclnative_rename(vfs_handler_t * vfs, const char *fn1, const char *fn2);\nint dclnative_unlink(vfs_handler_t * vfs, const char *fn);\n\n/* Init/Shutdown */\nint fs_dclnative_init();\nint fs_dclnative_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_FS_DCLNATIVE_H */\n\n\n"
},
{
"alpha_fraction": 0.6216350793838501,
"alphanum_fraction": 0.6407444477081299,
"avg_line_length": 36.14814758300781,
"blob_id": "5b3508d3cf43e7cc60ed433c82964a35215eedc7",
"content_id": "a28150ab4934e1e7b2aec3133113d019a6a9e4e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6018,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 162,
"path": "/kernel/arch/dreamcast/fs/dcload-commands.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-commands.c\n\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible \n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#include <dc/fs_dclnative.h>\n#include \"dcload-commands.h\"\n#include \"dcload-packet.h\"\n#include \"dcload-net.h\"\n#include \"dcload-syscalls.h\"\n\n/* #include \"commands.h\"\n#include \"packet.h\"\n#include \"net.h\"\n#include \"video.h\"\n#include \"rtl8139.h\"\n#include \"syscalls.h\"\n#include \"cdfs.h\"\n#include \"dcload.h\"\n#include \"go.h\"\n#include \"disable.h\"\n#include \"scif.h\" */\n\n#define NAME \"dcload-ip-native 1.0.3\"\n\ntypedef struct {\n unsigned int load_address;\n unsigned int load_size;\n unsigned char map[16384];\n} bin_info_t;\n\nstatic bin_info_t bin_info;\n\nstatic unsigned char buffer[COMMAND_LEN + 1024]; /* buffer for response */\nstatic command_t * response = (command_t *)buffer;\n\n/* void cmd_reboot(ether_header_t * ether, ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n booted = 0;\n running = 0;\n\n disable_cache();\n go(0x8c004000);\n} */\n\nvoid dcln_cmd_loadbin(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n bin_info.load_address = ntohl(command->address);\n bin_info.load_size = ntohl(command->size);\n memset(bin_info.map, 0, 16384);\n\n dcln_our_ip = ntohl(ip->dest);\n \n dcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n dcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) command, COMMAND_LEN, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n dcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN);\n}\n \nvoid dcln_cmd_partbin(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{ \n int index = 0;\n\n memcpy((unsigned char *)ntohl(command->address), command->data, ntohl(command->size));\n \n index = (ntohl(command->address) - bin_info.load_address) >> 10;\n bin_info.map[index] = 1;\n}\n\nvoid dcln_cmd_donebin(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n int i;\n \n for(i = 0; i < (bin_info.load_size + 1023)/1024; i++)\n\tif (!bin_info.map[i])\n\t break;\n if ( i == (bin_info.load_size + 1023)/1024 ) {\n\tcommand->address = htonl(0);\n\tcommand->size = htonl(0);\n }\telse {\n\tcommand->address = htonl( bin_info.load_address + i * 1024);\n\tif ( i == ( bin_info.load_size + 1023)/1024 - 1)\n\t command->size = htonl(bin_info.load_size % 1024);\n\telse\n\t command->size = htonl(1024);\n }\n \n dcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n dcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) command, COMMAND_LEN, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n dcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN);\n}\n\nvoid dcln_cmd_sendbinq(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n int numpackets, i;\n unsigned char *ptr;\n unsigned int bytes_left;\n unsigned int bytes_thistime;\n\n bytes_left = ntohl(command->size);\n numpackets = (ntohl(command->size)+1023) / 1024;\n ptr = (unsigned char *)ntohl(command->address);\n \n memcpy(response->id, DCLN_CMD_SENDBIN, 4);\n for(i = 0; i < numpackets; i++) {\n\tif (bytes_left >= 1024)\n\t bytes_thistime = 1024;\n\telse\n\t bytes_thistime = bytes_left;\n\tbytes_left -= bytes_thistime;\n\t\t\n\tresponse->address = htonl((unsigned int)ptr);\n\tmemcpy(response->data, ptr, bytes_thistime);\n\tresponse->size = htonl(bytes_thistime);\n\tdcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN + bytes_thistime, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n\tdcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) response, COMMAND_LEN + bytes_thistime, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n\tdcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN + bytes_thistime);\n\tptr += bytes_thistime;\n }\n \n memcpy(response->id, DCLN_CMD_DONEBIN, 4);\n response->address = htonl(0);\n response->size = htonl(0);\n dcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n dcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) response, COMMAND_LEN, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n dcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN);\n}\n\nvoid dcln_cmd_sendbin(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n dcln_our_ip = ntohl(ip->dest);\n dcln_cmd_sendbinq(ip, udp, command);\n}\n\nvoid dcln_cmd_version(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n int i;\n\n i = strlen(NAME) + 1;\n memcpy(response, command, COMMAND_LEN);\n strcpy(response->data, NAME);\n dcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN + i, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n dcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) response, COMMAND_LEN + i, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n dcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN + i);\n}\n\nvoid dcln_cmd_retval(ip_header_t * ip, udp_header_t * udp, command_t * command)\n{\n\tdcln_make_ip(ntohl(ip->src), ntohl(ip->dest), UDP_H_LEN + COMMAND_LEN, 17, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN));\n\tdcln_make_udp(ntohs(udp->src), ntohs(udp->dest),(unsigned char *) command, COMMAND_LEN, (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN), (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN));\n\tdcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + COMMAND_LEN);\n\n\tdcln_syscall_retval = ntohl(command->address);\n\tdcln_syscall_data = command->data;\n\tdcln_escape_loop = 1;\n}\n"
},
{
"alpha_fraction": 0.5819581747055054,
"alphanum_fraction": 0.6347634792327881,
"avg_line_length": 20.595237731933594,
"blob_id": "439e60bd07fceae3fac8100d9236918e184356a5",
"content_id": "14fd6e3bd262fc6c2850b2e84e56f070c61a9446",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 42,
"path": "/kernel/arch/gba/kernel/mm.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n mm.c\n (c)2000-2001 Dan Potter\n*/\n\nstatic char id[] = \"KOS $Id: mm.c,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\";\n\n\n/* Defines a simple UNIX-style memory pool system. */\n\n#include <arch/types.h>\n\n/* The end of the program is always marked by the '_end' symbol. So we'll\n longword-align that and add a little for safety. sbrk() calls will\n move up from there. */\nextern unsigned long end;\nstatic void *sbrk_base;\n\n/* MM-wide initialization */\nint mm_init() {\n\tint base = (int)(&end);\n\tbase = (base/4)*4 + 4;\t\t/* longword align */\n\tsbrk_base = (void*)base;\n\t\n\treturn 0;\n}\n\n/* Simple sbrk function */\nvoid* sbrk(unsigned long increment) {\n\tvoid *base = sbrk_base;\n\n\tif (increment & 3)\n\t\tincrement = (increment + 4) & ~3;\n\tsbrk_base += increment;\n\n\tif ( ((uint32)sbrk_base) >= (0x02040000 - 4096) ) {\n\t\tpanic(\"out of memory; about to run over kernel stack\");\n\t}\n\t\n\treturn base;\n}\n\n\n"
},
{
"alpha_fraction": 0.6256454586982727,
"alphanum_fraction": 0.6372633576393127,
"avg_line_length": 22.474746704101562,
"blob_id": "84590a031ddb3c1acb2e9b904c520c2d090d4f68",
"content_id": "f58ca1ddaedca04619887f5128d9b6f85c364e12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2324,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 99,
"path": "/kernel/arch/dreamcast/hardware/maple/maple_driver.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n maple_driver.c\n (c)2002 Dan Potter\n */\n\n#include <string.h>\n#include <stdlib.h>\n#include <dc/maple.h>\n\n/* Register a maple device driver; do this before maple_init() */\nint maple_driver_reg(maple_driver_t *driver) {\n\t/* Insert it into the device list */\n\tLIST_INSERT_HEAD(&maple_state.driver_list, driver, drv_list);\n\treturn 0;\n}\n\n/* Unregister a maple device driver */\nint maple_driver_unreg(maple_driver_t *driver) {\n\t/* Remove it from the list */\n\tLIST_REMOVE(driver, drv_list);\n\treturn 0;\n}\n\n/* Attach a maple device to a driver, if possible */\nint maple_driver_attach(maple_frame_t *det) {\n\tmaple_driver_t\t\t*i;\n\tmaple_response_t\t*resp;\n\tmaple_devinfo_t\t\t*devinfo;\n\tmaple_device_t\t\t*dev;\n\tint\t\t\tattached;\n\n\t/* Resolve some pointers first */\n\tresp = (maple_response_t *)det->recv_buf;\n\tdevinfo = (maple_devinfo_t *)resp->data;\n\tattached = 0;\n\tdev = &maple_state.ports[det->dst_port].units[det->dst_unit];\n\tmemcpy(&dev->info, devinfo, sizeof(maple_devinfo_t));\n\tdev->info.product_name[29] = 0;\n\tdev->info.product_license[59] = 0;\n\tdev->drv = NULL;\n\n\t/* Go through the list and look for a matching driver */\n\tLIST_FOREACH(i, &maple_state.driver_list, drv_list) {\n\t\t/* For now we just pick the first matching driver */\n\t\tif (i->functions & devinfo->functions) {\n\t\t\t/* Driver matches, try an attach */\n\t\t\tif (i->attach(i, dev) >= 0) {\n\t\t\t\t/* Success: make it permanent */\n\t\t\t\tattached = 1;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n\n\t/* Did we get any hits? */\n\tif (!attached)\n\t\treturn -1;\n\n\t/* Finish setting stuff up */\n\tdev->drv = i;\n\tdev->status_valid = 0;\n\tdev->valid = 1;\n\n\treturn 0;\n}\n\n/* Detach an attached maple device */\nint maple_driver_detach(int p, int u) {\n\tmaple_device_t\t*dev;\n\n\tdev = &maple_state.ports[p].units[u];\n\tif (!dev->valid)\n\t\treturn -1;\n\tif (dev->drv && dev->drv->detach)\n\t\tdev->drv->detach(dev->drv, dev);\n\tdev->valid = 0;\n\n\treturn 0;\n}\n\n/* For each device which the given driver controls, call the callback */\nint maple_driver_foreach(maple_driver_t *drv, int (*callback)(maple_device_t *)) {\n\tint\t\tp, u;\n\tmaple_device_t\t*dev;\n\n\tfor (p=0; p<MAPLE_PORT_COUNT; p++) {\n\t\tfor (u=0; u<MAPLE_UNIT_COUNT; u++) {\n\t\t\tdev = &maple_state.ports[p].units[u];\n\t\t\tif (!dev->valid) continue;\n\n\t\t\tif (dev->drv == drv && !dev->frame.queued)\n\t\t\t\tif (callback(dev) < 0)\n\t\t\t\t\treturn -1;\n\t\t}\n\t}\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.4404272735118866,
"alphanum_fraction": 0.4700082242488861,
"avg_line_length": 22.86274528503418,
"blob_id": "9b36dc8850cfa1d5a9ff5bd50c165bb02766977b",
"content_id": "6daf6f704f9586e6fe4e926d0a4c66617e4918ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1217,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 51,
"path": "/kernel/libc/koslib/inet_pton.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n inet_pton.c\n Copyright (C) 2007 Lawrence Sebald\n\n*/\n\n#include <arpa/inet.h>\n#include <errno.h>\n\nint inet_pton(int af, const char *src, void *dst) {\n int parts[4] = { 0 };\n int count = 0;\n struct in_addr *addr = (struct in_addr *)dst;\n\n if(af != AF_INET) {\n errno = EAFNOSUPPORT;\n return -1;\n }\n\n for(; *src && count < 4; ++src) {\n if(*src == '.') {\n ++count;\n }\n /* Unlike inet_aton(), inet_pton() only supports decimal parts */\n else if(*src >= '0' && *src <= '9') {\n parts[count] *= 10;\n parts[count] += *src - '0';\n }\n else {\n /* Invalid digit, and not a dot... bail */\n return 0;\n }\n }\n\n if(count != 3) {\n /* Not the right number of parts, bail */\n return 0;\n }\n\n /* Validate each part, note that unlike inet_aton(), inet_pton() only\n supports the standard xxx.xxx.xxx.xxx addresses. */\n if(parts[0] > 0xFF || parts[1] > 0xFF ||\n parts[2] > 0xFF || parts[3] > 0xFF)\n return 0;\n\n addr->s_addr = htonl(parts[0] << 24 | parts[1] << 16 |\n parts[2] << 8 | parts[3]);\n\n return 1;\n}\n"
},
{
"alpha_fraction": 0.6296296119689941,
"alphanum_fraction": 0.6296296119689941,
"avg_line_length": 12.5,
"blob_id": "304dd5a0808ea3a1bc500fcac606956c0d6a944a",
"content_id": "521e58bd3ad1d9aa7ef63211bc88a04841f7f9de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-objcopy",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_OBJCOPY} \"$@\"\n"
},
{
"alpha_fraction": 0.5581773519515991,
"alphanum_fraction": 0.5744507908821106,
"avg_line_length": 21.72222137451172,
"blob_id": "4c222bfccef94140e7086b914d141dfec56df0a7",
"content_id": "195b0cd8cc6d6e20ddcf2d6d906ee53aa82362a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 54,
"path": "/libc/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KOS libc ##version##\n#\n# Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.5 2002/06/13 09:55:49 bardtx Exp $\n\n# gen\nOBJS_GEN := $(patsubst %.c,%.o,$(wildcard gen/*.c))\nOBJS := $(OBJS_GEN)\n\n# locale\nOBJS_LOCALE := $(patsubst %.c,%.o,$(wildcard locale/*.c))\nOBJS += $(OBJS_LOCALE)\n\n# net\nOBJS_NET := $(patsubst %.c,%.o,$(wildcard net/*.c))\nOBJS += $(OBJS_NET)\n\n# stdio\nOBJS_STDIO := $(patsubst %.c,%.o,$(wildcard stdio/*.c))\nOBJS += $(OBJS_STDIO)\n\n# stdlib\nOBJS_STDLIB := $(patsubst %.c,%.o,$(wildcard stdlib/*.c))\nOBJS += $(OBJS_STDLIB)\n\n# string\nOBJS_STRING := $(patsubst %.c,%.o,$(wildcard string/*.c))\nOBJS += $(OBJS_STRING)\n\n# time\nOBJS_TIME := $(patsubst %.c,%.o,$(wildcard time/*.c))\nOBJS += $(OBJS_TIME)\n\n# C++\nOBJS_CPP := $(patsubst %.c,%.o,$(wildcard cpp/*.c))\nOBJS += $(OBJS_CPP)\n\n# arch\nifeq ($(KOS_ARCH), dreamcast)\n\tOBJS_ARCH := $(patsubst %.c,%.o,$(wildcard arch/dreamcast/*.c))\n\tOBJS_ARCH := $(OBJS_ARCH) $(patsubst %.s,%.o,$(wildcard arch/dreamcast/*.s))\n\tOBJS += $(OBJS_ARCH)\nendif\n\nSUBDIRS =\n\nall: $(OBJS)\n\t-rm -f $(TOPDIR)/kernel/build/libc/*.o\n\t-cp $(OBJS) $(TOPDIR)/kernel/build/libc/\n\n# Grab the shared Makefile pieces\ninclude $(TOPDIR)/Makefile.prefab\n\n\n"
},
{
"alpha_fraction": 0.5134615302085876,
"alphanum_fraction": 0.5846154093742371,
"avg_line_length": 20.66666603088379,
"blob_id": "cbbea1325ebf696f390b28479ef74b945dd9ac34",
"content_id": "507d05b6bb2fedf026454b53226efbdd3c730ff8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 24,
"path": "/examples/dreamcast/libdream/rgb888/rgb888.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* This isn't a very well supported mode under KOS but it's here\n for completeness. This is kind of cool actually because thanks to the\n extra pixel precision you can see further into the XOR pattern. */\n\n#include <kos.h>\n\nint main(int argc, char **argv) {\n\tint x, y;\n\n\t/* Do initial setup */\t\n\tvid_set_mode(DM_640x480, PM_RGB888);\n\t\n\tfor (y=0; y<480; y++)\n\t\tfor (x=0; x<640; x++) {\n\t\t\tint c = (x ^ y) & 255;\n\t\t\tvram_l[y*640+x] = (c << 17)\n\t\t\t\t| (c << 8)\n\t\t\t\t| (c << 0);\n\t\t}\n\n\tusleep(5 * 1000 * 1000);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6736441254615784,
"alphanum_fraction": 0.694576621055603,
"avg_line_length": 24.634145736694336,
"blob_id": "6672ab65fa489cf1bdbc575995378586f294a582",
"content_id": "c12bc8396b9906f88e7999d89a8f1eef4cc0e19f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1051,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 41,
"path": "/kernel/arch/ia32/kernel/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ia32/kernel/Makefile\n# Copyright (C)2003 Dan Potter\n# \n# $Id: Makefile,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n\n# Generic kernel abstraction layer: this provides a set of routines\n# that the portable part of the kernel expects to find on every\n# target processor. Other routines may be present as well, but\n# that minimum set must be present.\n\nCOPYOBJS = banner.o cache.o dbgio.o entry.o irq.o init.o panic.o\nCOPYOBJS += rtc.o timer.o\nCOPYOBJS += init_flags_default.o # init_romdisk_default.o\nCOPYOBJS += mmu.o\nCOPYOBJS += exec.o stack.o thdswitch.o arch_exports.o\nCOPYOBJS += gdt.o\nOBJS = $(COPYOBJS) startup.o\nSUBDIRS = \n\nmyall: $(OBJS)\n\t-cp $(COPYOBJS) ../../../../kernel/build/\n\t-rm banner.c banner.o\n\ninclude ../../../../Makefile.prefab\n\nbanner.o: banner.c\n\nbanner.c: make_banner.sh\n\t./make_banner.sh\n\narch_exports.o: arch_exports.c\n\narch_exports.c: ../exports.txt\n\t../../../../utils/genexports/genexports.sh ../exports.txt arch_exports.c arch_symtab\n\nclean:\n\t-rm -f banner.c\n\t-rm -f $(OBJS)\n\t-rm -f arch_exports.c\n"
},
{
"alpha_fraction": 0.6353591084480286,
"alphanum_fraction": 0.7237569093704224,
"avg_line_length": 21.625,
"blob_id": "ce6f9f3737c8b65a3bb0f94a88f8c62eb1961cf5",
"content_id": "21a9c028ad8d00022b66a885b1d5e895e4dc2171",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 8,
"path": "/addons/libkosutils/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# libkosutils Makefile\n#\n# $Id: Makefile,v 1.2 2003/02/27 04:25:40 bardtx Exp $\n\nTARGET = libkosutils.a\nOBJS = bspline.o img.o pcx_small.o\n\ninclude $(TOPDIR)/addons/Makefile.prefab\n"
},
{
"alpha_fraction": 0.4395604431629181,
"alphanum_fraction": 0.5494505763053894,
"avg_line_length": 11.928571701049805,
"blob_id": "3bb0eb7f105154f2613fabb85eda75d300c55d52",
"content_id": "8ef2b7135e2afb9fb72b8a5bbafc58f1c63745e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 14,
"path": "/libc/stdlib/exit.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n exit.c\n (c)2001 Dan Potter\n\n $Id: exit.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n#include <arch/arch.h>\n\n/* exit() */\nvoid exit() {\n\tarch_exit();\n}\n\n"
},
{
"alpha_fraction": 0.5979955196380615,
"alphanum_fraction": 0.6314030885696411,
"avg_line_length": 12.606060981750488,
"blob_id": "34ee27da8255d579f60706c9a4d648316f3d1a9a",
"content_id": "132475d678f0244a6b559a6432f8ce7c11d7fa20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 898,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 66,
"path": "/examples/dreamcast/kgl/demos/tunnel/menu.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* Kallistios ##version##\n\n menu.h\n (c)2001,2002 Paul Boese a.k.a. Axlen\n\n A cheap little menu class\n\n $Id: menu.h,v 1.1 2002/03/04 02:57:32 axlen Exp $\n*/\n\n#ifndef __MENU_H\n#define __MENU_H\n\n#ifndef NULL\n#define NULL 0\n#endif\n#define FLOAT_T 0\n#define INTEGER_T 1\n\ntypedef struct Menuitem_t {\n\tint type;\n\tint min;\n\tint max;\n\tint amt;\n\tint* pvalue;\n\tchar* pformat;\n\tMenuitem_t* prev;\n\tMenuitem_t* next;\n};\n\nunion uf2i_t {\n\tint i;\n\tfloat f;\n};\n\nclass Menu {\n\n\tprotected:\n\n\tstatic Menuitem_t* mlist;\n\tstatic Menuitem_t* mtail;\n\tstatic Menuitem_t* mcur;\n\tstatic union uf2i_t uf2i;\n\n\tpublic:\n\n\tMenu () {\n\t\tmlist = mtail = mcur = NULL;\n\t}\n\n\tvoid add(int min, int max, int amt, int* pval, char *pformat);\n\n\tvoid add(float min, float max, float amt, float* pval, char *pformat);\n\t\n\tvoid next();\n\n\tvoid prev();\n\n\tvoid inc();\n\n\tvoid dec();\n\n\tvoid draw(int x, int y, int yinc);\n};\n\n#endif /* __MENU_H */\n"
},
{
"alpha_fraction": 0.6669505834579468,
"alphanum_fraction": 0.686541736125946,
"avg_line_length": 19.241378784179688,
"blob_id": "d0c64af49e674f052f4999d969aa9ad4a84fbbc0",
"content_id": "409cd4260fb3055af8fed2f67062492213f4b058",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 58,
"path": "/include/sys/sched.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#ifndef __SYS_SCHED_H\n#define __SYS_SCHED_H\n\n#include <kos/cdefs.h>\n__BEGIN_DECLS\n\n// These are copied from Newlib to make stuff compile as expected.\n\n#define SCHED_OTHER 0\n#define SCHED_FIFO 1\n#define SCHED_RR 2\n\n/* Scheduling Parameters, P1003.1b-1993, p. 249\n NOTE: Fields whose name begins with \"ss_\" added by P1003.4b/D8, p. 33. */\n\nstruct sched_param {\n int sched_priority; /* Process execution scheduling priority */\n};\n\n\n// And all this maps pthread types to KOS types for pthread.h.\n#include <kos/thread.h>\n#include <kos/sem.h>\n#include <kos/cond.h>\n#include <kos/mutex.h>\n\n// Missing structs we don't care about in this impl.\ntypedef struct {\n\t// Empty\n} pthread_mutexattr_t;\n\ntypedef struct {\n\t// Empty\n} pthread_condattr_t;\n\ntypedef struct {\n\t// Empty\n} pthread_attr_t;\n\ntypedef struct {\n\tint initialized;\n\tint run;\n} pthread_once_t;\n\ntypedef struct {\n\t// Empty\n} pthread_key_t;\n\n// Map over KOS types. The mutex/condvar maps have to be pointers\n// because we allow _INIT #defines to work.\ntypedef kthread_t * pthread_t;\ntypedef mutex_t * pthread_mutex_t;\ntypedef condvar_t * pthread_cond_t;\n\n\n__END_DECLS\n\n#endif\t/* __SYS_SCHED_H */\n"
},
{
"alpha_fraction": 0.6637524962425232,
"alphanum_fraction": 0.6812373995780945,
"avg_line_length": 25.535715103149414,
"blob_id": "a2a0863eaa558a0052f8c27f8393b493cdcb023f",
"content_id": "18a9aadf34646c091575b54f4b7f29452591ba0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1487,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 56,
"path": "/include/kos/mutex.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/mutex.h\n Copyright (C)2001,2003 Dan Potter\n\n $Id: mutex.h,v 1.2 2003/07/31 00:38:00 bardtx Exp $\n\n*/\n\n#ifndef __KOS_MUTEX_H\n#define __KOS_MUTEX_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* These are just wrappers around semaphores */\n#include <kos/sem.h>\n\ntypedef semaphore_t mutex_t;\n\n/* Create a mutex. Sets errno to ENOMEM on failure. */\nmutex_t * mutex_create();\n\n/* Destroy a mutex */\nvoid mutex_destroy(mutex_t * m);\n\n/* Attempt to lock the mutex; if it's busy, then block. Returns 0 on\n success, -1 on error.\n EPERM - called inside interrupt\n EINTR - wait was interrupted */\nint mutex_lock(mutex_t * m);\n\n/* Attempt to lock the mutex; if it's busy and it takes longer than the\n timeout (milliseconds) then return an error.\n EPERM - called inside interrupt\n EINTR - wait was interrupted\n EAGAIN - timed out */\nint mutex_lock_timed(mutex_t * m, int timeout);\n\n/* Check to see whether the mutex is available; note that this is not\n a threadsafe way to figure out if it _will_ be locked by the time you\n get to locking it. */\nint mutex_is_locked(mutex_t * m);\n\n/* Attempt to lock the mutex. If the mutex would block, then return an\n error instead of actually blocking. Note that this function, unlike\n the other waits, DOES work inside an interrupt.\n EAGAIN - would block */\nint mutex_trylock(mutex_t * m);\n\n/* Unlock the mutex */\nvoid mutex_unlock(mutex_t * m);\n\n__END_DECLS\n\n#endif\t/* __KOS_MUTEX_H */\n\n"
},
{
"alpha_fraction": 0.5926034450531006,
"alphanum_fraction": 0.6130026578903198,
"avg_line_length": 28.370689392089844,
"blob_id": "ab91166c1da9ec36cb8a677aadb52eac0a0fc438",
"content_id": "6b7761b2671581897c6d82107a7530c5d15b3a57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6814,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 232,
"path": "/kernel/arch/dreamcast/fs/dcload-net.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-net.c\n\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#include <dc/fs_dclnative.h>\n#include \"dcload-commands.h\"\n#include \"dcload-packet.h\"\n#include \"dcload-net.h\"\n\nstatic unsigned char broadcast[6] = { 0xff, 0xff, 0xff, 0xff, 0xff, 0xff };\n\nstatic void process_broadcast(unsigned char *pkt, int len)\n{\n ether_header_t *ether_header = (ether_header_t *)pkt;\n arp_header_t *arp_header = (arp_header_t *)(pkt + ETHER_H_LEN);\n unsigned char tmp[10];\n unsigned int ip = htonl(dcln_our_ip);\n\n if (ether_header->type[1] != 0x06) /* ARP */\n\treturn; \n\n /* hardware address space = ethernet */\n if (arp_header->hw_addr_space != 0x0100)\n\treturn;\n\n /* protocol address space = IP */\n if (arp_header->proto_addr_space != 0x0008)\n\treturn;\n\n if (arp_header->opcode == 0x0100) { /* arp request */\n\tif (dcln_our_ip == 0) /* return if we don't know our ip */\n\t return;\n\tif (!memcmp(arp_header->proto_target, &ip, 4)) { /* for us */\n\t /* put src hw address into dest hw address */\n\t memcpy(ether_header->dest, ether_header->src, 6);\n\t /* put our hw address into src hw address */\n\t memcpy(ether_header->src, dcln_our_mac, 6);\n\t arp_header->opcode = 0x0200; /* arp reply */\n\t /* swap sender and target addresses */\n\t memcpy(tmp, arp_header->hw_sender, 10);\n\t memcpy(arp_header->hw_sender, arp_header->hw_target, 10);\n\t memcpy(arp_header->hw_target, tmp, 10);\n\t /* put our hw address into sender hw address */\n\t memcpy(arp_header->hw_sender, dcln_our_mac, 6);\n\t /* transmit */\n\t dcln_tx(pkt, ETHER_H_LEN + ARP_H_LEN);\n\t}\n }\n}\n\nstatic void process_icmp(ether_header_t *ether, ip_header_t *ip, icmp_header_t *icmp)\n{\n unsigned int i;\n unsigned char tmp[6];\n\n memset(dcln_pkt_buf, 0, ntohs(ip->length) + (ntohs(ip->length)%2) - 4*(ip->version_ihl & 0x0f));\n\n /* check icmp checksum */\n i = icmp->checksum;\n icmp->checksum = 0;\n memcpy(dcln_pkt_buf, icmp, ntohs(ip->length) - 4*(ip->version_ihl & 0x0f));\n icmp->checksum = dcln_checksum((unsigned short *)dcln_pkt_buf, (ntohs(ip->length)+1)/2 - 2*(ip->version_ihl & 0x0f));\n if (i != icmp->checksum)\n return;\n \n if (icmp->type == 8) { /* echo request */\n icmp->type = 0; /* echo reply */\n /* swap src and dest hw addresses */\n memcpy(tmp, ether->dest, 6);\n memcpy(ether->dest, ether->src, 6);\n memcpy(ether->src, tmp, 6);\n /* swap src and dest ip addresses */\n memcpy(&i, &ip->src, 4);\n memcpy(&ip->src, &ip->dest, 4);\n memcpy(&ip->dest, &i, 4);\n /* recompute ip header checksum */\n ip->checksum = 0;\n ip->checksum = dcln_checksum((unsigned short *)ip, 2*(ip->version_ihl & 0x0f));\n /* recompute icmp checksum */\n icmp->checksum = 0;\n icmp->checksum = dcln_checksum((unsigned short *)icmp, ntohs(ip->length)/2 - 2*(ip->version_ihl & 0x0f));\n /* transmit */\n dcln_tx((uint8 *)ether, ETHER_H_LEN + ntohs(ip->length));\n }\n}\n\n/* typedef struct {\n unsigned int load_address;\n unsigned int load_size;\n unsigned char map[16384];\n} bin_info_t;\n\nstatic bin_info_t bin_info; */\n\nstatic void process_udp(ether_header_t *ether, ip_header_t *ip, udp_header_t *udp)\n{\n ip_udp_pseudo_header_t *pseudo;\n unsigned short i;\n command_t *command;\n\n pseudo = (ip_udp_pseudo_header_t *)dcln_pkt_buf;\n pseudo->src_ip = ip->src;\n pseudo->dest_ip = ip->dest;\n pseudo->zero = 0;\n pseudo->protocol = ip->protocol;\n pseudo->udp_length = udp->length;\n pseudo->src_port = udp->src;\n pseudo->dest_port = udp->dest;\n pseudo->length = udp->length;\n pseudo->checksum = 0;\n memset(pseudo->data, 0, ntohs(udp->length) - 8 + (ntohs(udp->length)%2));\n memcpy(pseudo->data, udp->data, ntohs(udp->length) - 8);\n\n /* checksum == 0 means no checksum */\n if (udp->checksum != 0)\n i = dcln_checksum((unsigned short *)pseudo, (sizeof(ip_udp_pseudo_header_t) + ntohs(udp->length) - 9 + 1)/2);\n else\n i = 0;\n /* checksum == 0xffff means checksum was really 0 */\n if (udp->checksum == 0xffff)\n udp->checksum = 0;\n\n if (i != udp->checksum) {\n/* scif_puts(\"UDP CHECKSUM BAD\\n\"); */\n return;\n }\n\n dcln_make_ether(ether->src, ether->dest, (ether_header_t *)dcln_pkt_buf);\n\n command = (command_t *)udp->data;\n\n /* Some of these aren't applicable at this point. */\n /* if (!memcmp(command->id, DCLN_CMD_EXECUTE, 4)) {\n dcln_cmd_execute(ether, ip, udp, command);\n } */\n\n if (!memcmp(command->id, DCLN_CMD_LOADBIN, 4)) {\n dcln_cmd_loadbin(ip, udp, command);\n }\n \n if (!memcmp(command->id, DCLN_CMD_PARTBIN, 4)) {\n dcln_cmd_partbin(ip, udp, command);\n }\n\n if (!memcmp(command->id, DCLN_CMD_DONEBIN, 4)) {\n dcln_cmd_donebin(ip, udp, command);\n }\n\n if (!memcmp(command->id, DCLN_CMD_SENDBINQ, 4)) {\n dcln_cmd_sendbinq(ip, udp, command);\n }\n\n if (!memcmp(command->id, DCLN_CMD_SENDBIN, 4)) {\n dcln_cmd_sendbin(ip, udp, command);\n }\n\n if (!memcmp(command->id, DCLN_CMD_VERSION, 4)) {\n dcln_cmd_version(ip, udp, command);\n }\n\n if (!memcmp(command->id, DCLN_CMD_RETVAL, 4)) {\n dcln_cmd_retval(ip, udp, command);\n }\n\n /* if (!memcmp(command->id, DCLN_CMD_REBOOT, 4)) {\n dcln_cmd_reboot(ip, udp, command);\n } */\n}\n\nstatic void process_mine(unsigned char *pkt, int len)\n{\n ether_header_t *ether_header = (ether_header_t *)pkt;\n ip_header_t *ip_header = (ip_header_t *)(pkt + 14);\n icmp_header_t *icmp_header;\n udp_header_t *udp_header;\n /* ip_udp_pseudo_header_t *ip_udp_pseudo_header;\n unsigned char tmp[6]; */\n int i;\n \n if (ether_header->type[1] != 0x00)\n\treturn;\n\n /* ignore fragmented packets */\n\n if (ntohs(ip_header->flags_frag_offset) & 0x3fff)\n\treturn;\n \n /* check ip header checksum */\n i = ip_header->checksum;\n ip_header->checksum = 0;\n ip_header->checksum = dcln_checksum((unsigned short *)ip_header, 2*(ip_header->version_ihl & 0x0f));\n if (i != ip_header->checksum)\n return;\n\n switch (ip_header->protocol) {\n case 1: /* icmp */\n\ticmp_header = (icmp_header_t *)(pkt + ETHER_H_LEN + 4*(ip_header->version_ihl & 0x0f));\n\tprocess_icmp(ether_header, ip_header, icmp_header);\n\tbreak;\n case 17: /* udp */\n udp_header = (udp_header_t *)(pkt + ETHER_H_LEN + 4*(ip_header->version_ihl & 0x0f));\n process_udp(ether_header, ip_header, udp_header);\n default:\n break;\n }\n}\n\nvoid dcln_process_pkt(unsigned char *pkt, int len)\n{\n ether_header_t *ether_header = (ether_header_t *)pkt;\n\n if (ether_header->type[0] != 0x08)\n\treturn;\n\n if (!memcmp(ether_header->dest, broadcast, 6)) {\n\tprocess_broadcast(pkt, len);\n\treturn;\n }\n\n if (!memcmp(ether_header->dest, dcln_our_mac, 6)) {\n\tprocess_mine(pkt, len);\n\treturn;\n }\n}\n"
},
{
"alpha_fraction": 0.6101694703102112,
"alphanum_fraction": 0.6779661178588867,
"avg_line_length": 16.352941513061523,
"blob_id": "952c828ad0e20eae7bbc7b36483b726e4ea214a9",
"content_id": "2ebad1b3b17de806b9514bbab6989241863acefa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/kernel/arch/dreamcast/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.4 2002/05/05 22:17:06 bardtx Exp $\n\t\nSUBDIRS=fs hardware kernel math sound util\n\nifeq ($(KOS_SUBARCH), navi)\n\tSUBDIRS += navi\nendif\n\ninclude ../../../Makefile.rules\n\nall: subdirs\nclean: clean_subdirs\n"
},
{
"alpha_fraction": 0.5025380849838257,
"alphanum_fraction": 0.6142131686210632,
"avg_line_length": 16.81818199157715,
"blob_id": "23e5ddd0689a07df72cf9fca083175e9592ee967",
"content_id": "3e7b145897bbb0a1477371b8ff7a0f2bd39b2636",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 11,
"path": "/kernel/arch/ps2/fs/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ps2/fs/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/11/06 08:36:40 bardtx Exp $\n\nOBJS = fs_ps2load.o\nSUBDIRS = \n\ninclude ../../../../Makefile.prefab\n\n"
},
{
"alpha_fraction": 0.6407506465911865,
"alphanum_fraction": 0.6630920171737671,
"avg_line_length": 29.216217041015625,
"blob_id": "2f8f85b7dcafcad0e50b919db26afb68f734bdb1",
"content_id": "96d8a3f1f5e18a5558f140e8a6505435f88df2cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 37,
"path": "/kernel/arch/ia32/kernel/stack.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n stack.c\n Copyright (C)2003 Dan Potter\n*/\n\n/* Functions to tinker with the stack, includeing obtaining a stack\n trace when frame pointers are enabled. If frame pointers are enabled,\n then you'll need to also define FRAME_POINTERS to get support for stack\n traces.\n\n We could probably technically move this into arch indep with a bit more\n work... */\n\n#include <arch/arch.h>\n#include <arch/dbgio.h>\n#include <arch/stack.h>\n\nCVSID(\"$Id: stack.c,v 1.2 2003/08/02 09:14:46 bardtx Exp $\");\n\n/* Do a stack trace from the current function; leave off the first n frames\n (i.e., in assert()). */\nvoid arch_stk_trace(int n) {\n}\n\n/* Do a stack trace from the given frame pointer (useful for things like\n tracing from an ISR); leave off the first n frames. */\nvoid arch_stk_trace_at(uint32 fp, int n) {\n\tuint32 foo = fp + 5;\n\tdbgio_printf(\"%d\\n\", foo);\n#ifdef FRAME_POINTERS\n\tdbgio_printf(\"-------- Stack Trace (innermost first) ---------\\n\");\n\tdbgio_printf(\"-------------- End Stack Trace -----------------\\n\");\n#else\n\tdbgio_printf(\"Stack Trace: frame pointers not enabled!\\n\");\n#endif\n}\n\n"
},
{
"alpha_fraction": 0.5672268867492676,
"alphanum_fraction": 0.6554622054100037,
"avg_line_length": 17.076923370361328,
"blob_id": "630f1e517173d905d7e67b03345ac18616cf5fab",
"content_id": "f09ff3a4933220abef404795a4e55eac9ec859dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/kernel/arch/ps2/sbios/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ps2/sbios/Makefile\n# (c)2002 Dan Potter\n#\n# $Id: Makefile,v 1.1 2002/10/27 23:39:23 bardtx Exp $\n\n# Main SBIOS support routines\nOBJS = sbios_init_shutdown.o\n\nSUBDIRS =\n\ninclude ../../../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.5121951103210449,
"alphanum_fraction": 0.6244376301765442,
"avg_line_length": 25.55974769592285,
"blob_id": "20fc0fe939874a843c9ded334b73e771ef5a84d2",
"content_id": "6909ea302f5109b6a9b3850a0ddf6ab640539627",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4223,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 159,
"path": "/examples/dreamcast/kgl/basic/vq/vq-example.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n vq-example.c\n\n This is a modified nehe06.c that shows the capabilities of\n VQ compression. Original code (c)2001 Benoit Miller\n Modified version (c)2002 Gil Megidish\n \n Texture is copyright (c)2002 Mayang Murni Adnin; for more\n incredible textures, go to www.mayang.com\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <math.h>\n\nGLfloat xrot;\t/* X Rotation */\nGLfloat yrot;\t/* Y Rotation */\nGLfloat zrot;\t/* Z Rotation */\n\nGLuint texture[1];\t\n\n/* external vq-texture storage */\nextern unsigned char fruit[];\nextern unsigned char fruit_end[];\n\n/* Load a texture and glKosTex2D */\nstatic int loadtxr() {\n\tGLuint size;\n\tpvr_ptr_t txaddr;\n\n\tsize = fruit_end - fruit;\n\ttxaddr = pvr_mem_malloc(size);\n\tif (txaddr == NULL)\n\t\treturn -1;\n\n\t/* all writes to vram must be 16/32 bit */\n\tmemcpy2(txaddr, fruit, size);\t\n\n\tglGenTextures(1, texture);\n\tglBindTexture(GL_TEXTURE_2D, texture[0]);\n\tglKosTex2D(GL_RGB565_TWID | GL_VQ_ENABLE, 512, 512, txaddr);\n\treturn 0;\n}\n\nvoid draw_gl(void) {\n\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\tglLoadIdentity();\n\tglTranslatef(0.0f, 0.0f, -5.0f);\n\n\tglRotatef(xrot, 1.0f, 0.0f, 0.0f);\n\tglRotatef(yrot, 0.0f, 1.0f, 0.0f);\n\tglRotatef(zrot, 0.0f, 0.0f, 1.0f);\n\n\tglBindTexture(GL_TEXTURE_2D, texture[0]);\n\t\n\tglBegin(GL_QUADS);\n\t\t\n\t\t/* Front Face */\n\t\tglColor3f(1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\n\t\t/* Back Face */\n\t\tglColor3f(1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\n\t\t/* Top Face */\n\t\tglColor3f(0.0f, 1.0f, 0.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\n\t\t/* Bottom Face */\n\t\tglColor3f(1.0f, 0.0f, 0.0f); \n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\n\t\t/* Right face */\n\t\tglColor3f(0.0f, 1.0f, 0.0f); glTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglColor3f(0.3f, 0.5f, 1.0f); glTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglColor3f(1.0f, 0.3f, 0.5f); glTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglColor3f(0.5f, 0.5f, 0.5f); glTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\n\t\t/* Left Face */\n\t\tglColor3f(1.0f, 0.0f, 0.0f); glTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglColor3f(1.0f, 1.0f, 0.0f); glTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglColor3f(0.0f, 1.0f, 1.0f); glTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglColor3f(0.0f, 0.0f, 1.0f); glTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\n\tglEnd();\n\n\txrot+=0.3f;\n\tyrot+=0.2f;\n\tzrot+=0.4f;\n}\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\t\n\t/* Initialize KOS */\n\tpvr_init_defaults();\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f, 640.0f/480.0f, 0.1f, 100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\t\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.0f, 0.0f, 0.0f, 0.5f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LEQUAL);\n\t\n\t/* Set up the texture */\n\tif (loadtxr() < 0) { \n\t\tprintf(\"loadtxr() failed\\n\");\n\t\treturn 0;\n\t}\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\t\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\t\t\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw the GL \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6605555415153503,
"alphanum_fraction": 0.6961110830307007,
"avg_line_length": 26.25757598876953,
"blob_id": "9d05b808dc8a5ecba59e85e32845c6599c0a318b",
"content_id": "75bc99031ace4c8bd5f410e97cf7092c7e3b525d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1800,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 66,
"path": "/include/addons/kos/netcfg.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n kos/netcfg.h\n Copyright (C)2003 Dan Potter\n\n $Id: netcfg.h,v 1.1 2003/07/15 07:58:28 bardtx Exp $\n\n*/\n\n#ifndef __KOS_NETCFG_H\n#define __KOS_NETCFG_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Network configuration info. This holds the information about how we\n will start the networking and what settings to use. */\n#define NETCFG_METHOD_DHCP\t0\n#define NETCFG_METHOD_STATIC\t1\n#define NETCFG_METHOD_PPPOE\t4\n#define NETCFG_SRC_VMU\t\t0\n#define NETCFG_SRC_FLASH\t1\n#define NETCFG_SRC_CWD\t\t2\n#define NETCFG_SRC_CDROOT\t3\ntypedef struct netcfg {\n\tint\tsrc;\t\t\t// Config source\n\tint\tmethod;\t\t\t// Configuration method\n\tuint32\tip;\t\t\t// IP addresses\n\tuint32\tgateway;\n\tuint32\tnetmask;\n\tuint32\tbroadcast;\n\tuint32\tdns[2];\t\t\t// DNS servers\n\tchar\thostname[64];\t\t// DHCP hostname\n\tchar\temail[64];\t\t// E-Mail address\n\tchar\tsmtp[64];\t\t// SMTP server\n\tchar\tpop3[64];\t\t// POP3 server\n\tchar\tpop3_login[64];\t\t// POP3 login name\n\tchar\tpop3_passwd[64];\t// POP3 password\n\tchar\tproxy_host[64];\t\t// Proxy server hostname\n\tint\tproxy_port;\t\t// Proxy server port\n\tchar\tppp_login[64];\t\t// PPP login\n\tchar\tppp_passwd[64];\t\t// PPP password\n\tchar\tdriver[64];\t\t// Driver program filename (if any)\n} netcfg_t;\n\n// Load a network config from a specific file.\nint netcfg_load_from(const char * fn, netcfg_t * out);\n\n// Load a network config from the DC flash.\nint netcfg_load_flash(netcfg_t * out);\n\n// Load a network config. Tries the VMUs first, then the current\n// directory, and finally /cd.\nint netcfg_load(netcfg_t * out);\n\n// Save a network config to a specific file.\nint netcfg_save_to(const char * fn, const netcfg_t * cfg);\n\n// Save a network config. Always goes for the first available VMU.\nint netcfg_save(const netcfg_t * cfg);\n\n__END_DECLS\n\n#endif\t/* __KOS_NETCFG_H */\n\n"
},
{
"alpha_fraction": 0.494915246963501,
"alphanum_fraction": 0.6169491410255432,
"avg_line_length": 17.4375,
"blob_id": "d515f957cc468725109dc27fba7b443b995736f7",
"content_id": "263d6f0140a4fe4a608286800537a52aab50531c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/libc/gen/errno.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n errno.c\n Copyright (C)2003 Dan Potter\n\n $Id: errno.c,v 1.2 2003/06/23 05:21:30 bardtx Exp $\n*/\n\n#include <errno.h>\n#include <kos/thread.h>\n\nCVSID(\"$Id: errno.c,v 1.2 2003/06/23 05:21:30 bardtx Exp $\");\n\nint * __error() {\n\treturn thd_get_errno(thd_get_current());\n}\n"
},
{
"alpha_fraction": 0.5856319069862366,
"alphanum_fraction": 0.6375253200531006,
"avg_line_length": 19.242902755737305,
"blob_id": "3717ab90c085d4895386121478dc9e1f8ced8575",
"content_id": "7908977288e104de0dcbffb76501efbcba58d777",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6417,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 317,
"path": "/utils/wav2adpcm/wav2adpcm.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n\taica adpcm <-> wave converter;\n\n\t(c) 2002 BERO <[email protected]>\n\tunder GPL or notify me\n\n\taica adpcm seems same as YMZ280B adpcm\n\tadpcm->pcm algorithm can found MAME/src/sound/ymz280b.c by Aaron Giles\n\n\tthis code is for little endian machine\n\n\tModified by Dan Potter to read/write ADPCM WAV files, and to\n\thandle stereo (though the stereo is very likely KOS specific\n\tsince we make no effort to interleave it). Please see README.GPL\n\tin the KOS docs dir for more info on the GPL license.\n*/\n\n#include <stdio.h>\n#include <stdlib.h>\n\nstatic int diff_lookup[16] = {\n\t1,3,5,7,9,11,13,15,\n\t-1,-3,-5,-7,-9,-11,-13,-15,\n};\n\nstatic int index_scale[16] = {\n\t0x0e6, 0x0e6, 0x0e6, 0x0e6, 0x133, 0x199, 0x200, 0x266,\n\t0x0e6, 0x0e6, 0x0e6, 0x0e6, 0x133, 0x199, 0x200, 0x266 //same value for speedup\n};\n\nstatic inline int limit(int val,int min,int max)\n{\n\tif (val<min) return min;\n\telse if (val>max) return max;\n\telse return val;\n}\n\nvoid pcm2adpcm(unsigned char *dst,const short *src,size_t length)\n{\n\tint signal,step;\n\tsignal = 0;\n\tstep = 0x7f;\n\n\t// length/=4;\n\tlength = (length+3)/4;\n\tdo {\n\t\tint data,val,diff;\n\n\t\t/* hign nibble */\n\t\tdiff = *src++ - signal;\n\t\tdiff = (diff*8)/step;\n\n\t\tval = abs(diff)/2;\n\t\tif (val>7) val = 7;\n\t\tif (diff<0) val+=8;\n\n\t\tsignal += (step*diff_lookup[val])/8;\n\t\tsignal = limit(signal,-32768,32767);\n\n\t\tstep = (step * index_scale[val]) >> 8;\n\t\tstep = limit(step,0x7f,0x6000);\n\n\t\tdata = val;\n\n\t\t/* low nibble */\n\t\tdiff = *src++ - signal;\n\t\tdiff = (diff*8)/step;\n\n\t\tval = (abs(diff))/2;\n\t\tif (val>7) val = 7;\n\t\tif (diff<0) val+=8;\n\n\t\tsignal += (step*diff_lookup[val])/8;\n\t\tsignal = limit(signal,-32768,32767);\n\n\t\tstep = (step * index_scale[val]) >> 8;\n\t\tstep = limit(step,0x7f,0x6000);\n\n\t\tdata |= val << 4;\n\n\t\t*dst++ = data;\n\n\t} while(--length);\n}\n\nvoid adpcm2pcm(short *dst,const unsigned char *src,size_t length)\n{\n\tint signal,step;\n\tsignal = 0;\n\tstep = 0x7f;\n\n\tdo {\n\t\tint data,val;\n\n\t\tdata = *src++;\n\n\t\t/* low nibble */\n\t\tval = data & 15;\n\n\t\tsignal += (step*diff_lookup[val])/8;\n\t\tsignal = limit(signal,-32768,32767);\n\n\t\tstep = (step * index_scale[val & 7]) >> 8;\n\t\tstep = limit(step,0x7f,0x6000);\n\n\t\t*dst++= signal;\n\n\t\t/* high nibble */\n\t\tval = (data >> 4)&15;\n\n\t\tsignal += (step*diff_lookup[val])/8;\n\t\tsignal = limit(signal,-32768,32767);\n\n\t\tstep = (step * index_scale[val & 7]) >> 8;\n\t\tstep = limit(step,0x7f,0x6000);\n\n\t\t*dst++ = signal;\n\n\t} while(--length);\n}\n\nvoid deinterleave(void *buffer, size_t size) {\n\tshort * buf;\n\tshort * buf1, * buf2;\n\tint i;\n\n\tbuf = (short *)buffer;\n\tbuf1 = malloc(size / 2);\n\tbuf2 = malloc(size / 2);\n\n\tfor (i=0; i<size/4; i++) {\n\t\tbuf1[i] = buf[i*2+0];\n\t\tbuf2[i] = buf[i*2+1];\n\t}\n\n\tmemcpy(buf, buf1, size/2);\n\tmemcpy(buf + size/4, buf2, size/2);\n\n\tfree(buf1);\n\tfree(buf2);\n}\n\nvoid interleave(void *buffer, size_t size) {\n\tshort * buf;\n\tshort * buf1, * buf2;\n\tint i;\n\n\tbuf = malloc(size);\n\tbuf1 = (short *)buffer;\n\tbuf2 = buf1 + size/4;\n\n\tfor (i=0; i<size/4; i++) {\n\t\tbuf[i*2+0] = buf1[i];\n\t\tbuf[i*2+1] = buf2[i];\n\t}\n\n\tmemcpy(buffer, buf, size);\n\n\tfree(buf);\n}\n\nstruct wavhdr_t {\n\tchar hdr1[4];\n\tlong totalsize;\n\n\tchar hdr2[8];\n\tlong hdrsize;\n \tshort format;\n\tshort channels;\n\tlong freq;\n\tlong byte_per_sec;\n\tshort blocksize;\n\tshort bits;\n\n\tchar hdr3[4];\n\tlong datasize;\n};\n\nint wav2adpcm(const char *infile,const char *outfile)\n{\n\tstruct wavhdr_t wavhdr;\n\tFILE *in,*out;\n\tsize_t pcmsize,adpcmsize;\n\tshort *pcmbuf;\n\tunsigned char *adpcmbuf;\n\n\tin = fopen(infile,\"rb\");\n\tif (in==NULL) {\n\t\tprintf(\"can't open %s\\n\",infile);\n\t\treturn -1;\n\t}\n\tfread(&wavhdr,1,sizeof(wavhdr),in);\n\n\tif(memcmp(wavhdr.hdr1,\"RIFF\",4)\n\t|| memcmp(wavhdr.hdr2,\"WAVEfmt \",8)\n\t|| memcmp(wavhdr.hdr3,\"data\",4)\n\t|| wavhdr.hdrsize!=0x10\n\t|| wavhdr.format!=1\n\t|| (wavhdr.channels!=1 && wavhdr.channels!=2)\n\t|| wavhdr.bits!=16) {\n\t\tprintf(\"unsupport format\\n\");\n\t\tfclose(in);\n\t\treturn -1;\n\t}\n\n\tpcmsize = wavhdr.datasize;\n\n\tadpcmsize = pcmsize/4;\n\tpcmbuf = malloc(pcmsize);\n\tadpcmbuf = malloc(adpcmsize);\n\n\tfread(pcmbuf,1,pcmsize,in);\n\tfclose(in);\n\n\tif (wavhdr.channels == 1) {\n\t\tpcm2adpcm(adpcmbuf,pcmbuf,pcmsize);\n\t} else {\n\t\t/* For stereo we just deinterleave the input and store the\n\t\t left and right channel of the ADPCM data separately. */\n\t\tdeinterleave(pcmbuf, pcmsize);\n\t\tpcm2adpcm(adpcmbuf, pcmbuf, pcmsize/2);\n\t\tpcm2adpcm(adpcmbuf + adpcmsize/2, pcmbuf+pcmsize/4, pcmsize/2);\n\t}\n\n\tout = fopen(outfile,\"wb\");\n\twavhdr.datasize = adpcmsize;\n\twavhdr.format = 20;\t/* ITU G.723 ADPCM (Yamaha) */\n\twavhdr.bits = 4;\n\twavhdr.totalsize = wavhdr.datasize + sizeof(wavhdr)-8;\n\tfwrite(&wavhdr, 1, sizeof(wavhdr), out);\n\tfwrite(adpcmbuf,1,adpcmsize,out);\n\tfclose(out);\n\n\treturn 0;\n}\n\nint adpcm2wav(const char *infile,const char *outfile)\n{\n\tstruct wavhdr_t wavhdr;\n\tFILE *in,*out;\n\tsize_t pcmsize,adpcmsize;\n\tshort *pcmbuf;\n\tunsigned char *adpcmbuf;\n\n\tin = fopen(infile,\"rb\");\n\tif (in==NULL) {\n\t\tprintf(\"can't open %s\\n\",infile);\n\t\treturn -1;\n\t}\n\tfread(&wavhdr, 1, sizeof(wavhdr), in);\n\t\n\tif(memcmp(wavhdr.hdr1,\"RIFF\",4)\n\t|| memcmp(wavhdr.hdr2,\"WAVEfmt \",8)\n\t|| memcmp(wavhdr.hdr3,\"data\",4)\n\t|| wavhdr.hdrsize!=0x10\n\t|| wavhdr.format!=20\n\t|| (wavhdr.channels!=1 && wavhdr.channels!=2)\n\t|| wavhdr.bits!=4) {\n\t\tprintf(\"unsupport format\\n\");\n\t\tfclose(in);\n\t\treturn -1;\n\t}\n\n\tadpcmsize = wavhdr.datasize;\n\tpcmsize = adpcmsize*4;\n\tadpcmbuf = malloc(adpcmsize);\n\tpcmbuf = malloc(pcmsize);\n\n\tfread(adpcmbuf,1,adpcmsize,in);\n\tfclose(in);\n\n\tif (wavhdr.channels == 1) {\n\t\tadpcm2pcm(pcmbuf,adpcmbuf,adpcmsize);\n\t} else {\n\t\tadpcm2pcm(pcmbuf, adpcmbuf, adpcmsize/2);\n\t\tadpcm2pcm(pcmbuf+pcmsize/4, adpcmbuf + adpcmsize/2, adpcmsize/2);\n\t\tinterleave(pcmbuf, pcmsize);\n\t}\n\n\twavhdr.blocksize = wavhdr.channels*sizeof(short);\n\twavhdr.byte_per_sec = wavhdr.freq*wavhdr.blocksize;\n\twavhdr.datasize = pcmsize;\n\twavhdr.totalsize = wavhdr.datasize + sizeof(wavhdr)-8;\n\twavhdr.format = 1;\n\twavhdr.bits = 16;\n\n\tout = fopen(outfile,\"wb\");\n\tfwrite(&wavhdr,1,sizeof(wavhdr),out);\n\tfwrite(pcmbuf,1,pcmsize,out);\n\tfclose(out);\n\n\treturn 0;\n}\n\nvoid usage() {\n\tprintf( \"wav2adpcm: 16bit mono wav to aica adpcm and vice-versa (c)2002 BERO\\n\"\n\t\t\" wav2adpcm -t <infile.wav> <outfile.wav> (To adpcm)\\n\"\n\t\t\" wav2adpcm -f <infile.wav> <outfile.wav> (From adpcm)\\n\"\n\t);\n}\n\nint main(int argc,char **argv)\n{\n\tif (argc == 4) {\n\t\tif (!strcmp(argv[1], \"-t\")) {\n\t\t\treturn wav2adpcm(argv[2], argv[3]);\n\t\t} else if (!strcmp(argv[1], \"-f\")) {\n\t\t\treturn adpcm2wav(argv[2], argv[3]);\n\t\t} else {\n\t\t\tusage();\n\t\t\treturn -1;\n\t\t}\n\t} else {\n\t\tusage();\n\t\treturn -1;\n\t}\n}\n"
},
{
"alpha_fraction": 0.5173395872116089,
"alphanum_fraction": 0.5724600553512573,
"avg_line_length": 19.316116333007812,
"blob_id": "c29793657484207a28342d292e9e144d06b5e385",
"content_id": "8efb0c02131c5fb9e110f580880786cf5fdef754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9833,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 484,
"path": "/examples/dreamcast/kgl/demos/tunnel/tunnel.cpp",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n tunnel.cpp\n (c)2002 Paul Boese\n \n Adapted from the Mesa tunnel demo by David Bucciarelli\n*/\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <kos.h>\n#include <pcx/pcx.h>\n#include \"plprint.h\"\n#include \"menu.h\"\n\nCVSID(\"$Id: tunnel.cpp,v 1.7 2003/03/09 01:20:06 bardtx Exp $\");\n\n#define DPAD_REPEAT_INTERVAL 7 /* frames */\n\n/* tunnel */\n#define NUMBLOC 11 \nextern int striplength_skin_13[];\nextern float stripdata_skin_13[];\n\nextern int striplength_skin_12[];\nextern float stripdata_skin_12[];\n\nextern int striplength_skin_11[];\nextern float stripdata_skin_11[];\n\nextern int striplength_skin_9[];\nextern float stripdata_skin_9[];\n\nstatic float obs[3] = { 1000.0, 0.0, 2.0 };\nstatic float dir[3];\nstatic int velocity = 10;\nstatic float v = 0.1;\nstatic float alpha = 90.0;\nstatic float beta = 90.0;\n\n/* fog */\nstatic float density = 0.04;\nstatic float fogcolor[4] = { 0.7, 0.7, 0.7, 1.0 };\nstatic float last_density = density;\n\n/* misc state */\nstatic int usefog = 1;\nstatic int textog = 1;\nstatic int cstrip = 0;\nstatic int cullface = 0;\nstatic int help = 1;\nstatic int joyactive = 0;\n\n/* texture */\nstatic GLuint t1id, t2id;\n\nstatic Menu* fm;\n\n/* our own fmod cuz the newlib ieee32 version is broken! */\nstatic float fmod(float x, float y) {\n\tint n;\n\tn = (int)(x/y);\n\treturn x - (float)n*y;\n}\n\n#define FABS(n) ((((n) < 0.0) ? (-1.0*(n)) : (n)))\n\n/*************************************************************************/\n\nstatic void\ndrawobjs(int *l, float *f)\n{\n\tint mend, j;\n\n\tif (cstrip) {\n\t\tfloat r = 0.33, g = 0.33, b = 0.33;\n\n\t\tfor (; (*l) != 0;) {\n\t\t\tmend = *l++;\n\n\t\t\tr += 0.33;\n\t\t\tif (r > 1.0) {\n\t\t\t\tr = 0.33;\n\t\t\t\tg += 0.33;\n\t\t\t\tif (g > 1.0) {\n\t\t\t\t\tg = 0.33;\n\t\t\t\t\tb += 0.33;\n\t\t\t\t\tif (b > 1.0)\n\t\t\t\t\t\tb = 0.33;\n\t\t\t\t}\n\t\t\t}\n\t\t\t\n\t\t\tglColor3f(r, g, b);\n\t\t\tglBegin(GL_TRIANGLE_STRIP);\n\t\t\tfor (j = 0; j < mend; j++) {\n\t\t\t\tf += 4;\n\t\t\t\tglTexCoord2fv(f);\n\t\t\t\tf += 2;\n\t\t\t\tglVertex3fv(f);\n\t\t\t\tf += 3;\n\t\t\t}\n\t\t\tglEnd();\n\t\t}\n\t}\n\telse\n\t\tfor (; (*l) != 0;) {\n\t\t\tmend = *l++;\n\t\t\t\n\t\t\tglBegin(GL_TRIANGLE_STRIP);\n\t\t\tfor (j = 0; j < mend; j++) {\n\t\t\t\tglColor4fv(f);\n\t\t\t\tf += 4;\n\t\t\t\tglTexCoord2fv(f);\n\t\t\t\tf += 2;\n\t\t\t\tglVertex3fv(f);\n\t\t\t\tf += 3;\n\t\t\t}\n\t\t\tglEnd();\n\t\t}\n}\n\nstatic void calcposobs(void) {\n\tdir[0] = fsin(alpha * F_PI / 180.0);\n\tdir[1] = fcos(alpha * F_PI / 180.0) * fsin(beta * F_PI / 180.0);\n\tdir[2] = fcos(beta * F_PI / 180.0);\n\n\tobs[0] += v * dir[0];\n\tobs[1] += v * dir[1];\n\tobs[2] += v * dir[2];\n}\n\nstatic void draw(void)\n{\n\tint i;\n\tfloat base, offset;\n\tif (usefog & 1) {\n\t\tglEnable(GL_FOG);\n\t} else\n\t\tglDisable(GL_FOG);\n\t\t\n\tif (textog & 1) {\n\t\tglEnable(GL_TEXTURE_2D);\n\t} else\n\t\tglDisable(GL_TEXTURE_2D);\n\n\tif (cullface & 1) {\n\t\tglEnable(GL_CULL_FACE);\n\t} else\n\t\tglDisable(GL_CULL_FACE);\n\n\tglPushMatrix();\n\tcalcposobs();\n\tgluLookAt(obs[0], obs[1], obs[2],\n\t\tobs[0] + dir[0], obs[1] + dir[1], obs[2] + dir[2],\n\t\t0.0, 0.0, 1.0);\n\n\tif (dir[0] > 0) {\n\t\toffset = 8.0;\n\t\tbase = obs[0] - fmod(obs[0], 8.0);\n\t} else {\n\t\toffset = -8.0;\n\t\tbase = obs[0] + (8.0 - fmod(obs[0], 8.0));\n\t}\n\n\tglPushMatrix();\n\tglTranslatef((base - offset / 2.0), 0.0, 0.0);\n\tfor (i = 0; i < NUMBLOC; i++) {\n\t\tglTranslatef(offset, 0.0, 0.0);\n\t\tglBindTexture(GL_TEXTURE_2D, t1id);\n\t\tdrawobjs(striplength_skin_11, stripdata_skin_11);\n\t\tglBindTexture(GL_TEXTURE_2D, t2id);\n\t\tdrawobjs(striplength_skin_12, stripdata_skin_12);\n\t\tdrawobjs(striplength_skin_9, stripdata_skin_9);\n\t\tdrawobjs(striplength_skin_13, stripdata_skin_13);\n\t}\n\tglPopMatrix();\n\tglPopMatrix();\n}\n\n/*************************************************************************/\n\nstatic void rect(int x, int y, int w, int h) {\n\tglBegin(GL_QUADS);\n\tglVertex3f(x,y,0);\n\tglVertex3f(x+w,y,0);\n\tglVertex3f(x+w,y+h,0);\n\tglVertex3f(x,y+h,0);\n\tglEnd();\n}\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\t\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\npvr_init_params_t params = {\n /* Enable opaque and punchthru polygons with size 16 */\n { PVR_BINSIZE_32, PVR_BINSIZE_0, PVR_BINSIZE_32, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nstatic void do_init() {\n pvr_init(¶ms);\n\tprintf(\"[DCTunnel] KGL Initialing\\n\");\n\n\t/* Setup KGL */\n\tglKosInit();\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0, 640.0f/480.0f, 1.0, 50.0);\n\tglMatrixMode(GL_MODELVIEW);\n\tglEnable(GL_TEXTURE_2D);\n\tglClearColor(0.7f, 0.7f, 0.7f, 1.0f);\n\tglShadeModel(GL_SMOOTH);\n\tglDisable(GL_DEPTH_TEST);\n\tglDepthMask(GL_TRUE);\n\tglDepthFunc(GL_LESS);\n\t\n\t/* fog */\n\tglEnable(GL_FOG);\n\tglFogi(GL_FOG_MODE, GL_EXP2);\n\tglFogfv(GL_FOG_COLOR, fogcolor);\n\tglFogf(GL_FOG_DENSITY, density);\n\tglHint(GL_FOG_HINT, GL_NICEST);\n\t\n\t/* textures */\n\tprintf(\"[DCTunnel] Loading Textures\\n\");\n\tloadtxr(\"/rd/tile.pcx\", &t1id);\n\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n\tloadtxr(\"/rd/bw.pcx\", &t2id);\n\n\t/* PLIB for fonts */\n\tplinit();\n\n\t/* Setup Menu */\n\tprintf(\"[DCTunnel] Initializing Menu\\n\");\n\tfm = (Menu*) malloc(sizeof(Menu));\n\t/* min max amt pvalue format */\n\tfm->add(0, 1, 1, &cstrip,\t\"See Strips....... %d\");\n\tfm->add(0, 1, 1, &usefog,\t\"Fog.............. %d\");\n\tfm->add(0.0, 1.0, 0.001, &density,\t\"Fog Density...... %1.3f\");\n\tfm->add(0, 1, 1, &textog, \t\"Texture.......... %d\");\n\tfm->add(0, 1, 1, &cullface, \t\"Cull Backface.... %d\");\n\tfm->add(-100, 100, 1, &velocity,\t\"Velocity......... %+03d\");\n\n\tcalcposobs();\n}\n\nstatic void reset_view() {\n\tvelocity = 10;\n\talpha = 90.0;\n\tbeta = 90.0;\n\tobs[0] = 1000.0;\n\tobs[1] = 0.0;\n\tobs[2] = 2.0;\n}\n\nvoid do_help() {\n\tglPushMatrix();\n\tglLoadIdentity();\n\tglOrtho(0,640,0,480,-1,0);\n\tglMatrixMode(GL_PROJECTION);\n\tglPushMatrix();\n\tglLoadIdentity();\n\n\tglDisable(GL_TEXTURE_2D);\n\tglBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);\n\tglColor4f(0.0, 0.0, 0.0, 0.5);\n\trect(150, 120, 340, 220);\n\n\tglPopMatrix();\n\tglMatrixMode(GL_MODELVIEW);\n\tglPopMatrix();\n\n\tglEnable(GL_TEXTURE_2D);\n\tfm->draw(11, 11, 2);\n}\n\nstatic void do_text() {\n\tplprint(1, 1, 1.0f, 0.0f, 0.0f,\n\t\t\t\"Tunnel V1.5 Written by David Bucciarelli\", 0);\n\tif (help) {\n\t\tplprint(1, 29, 1.0f, 0.0f, 0.0f,\n\t\t\t\"[Y][D-Pad] help [A] Reset [L/R] Velocity\", 0);\n\t\tplprint(1, 27, 1.0f, 0.0f, 0.0f, \"[Joystick]\", 0);\n\t}\n}\n\ntypedef struct JOYINFO {\n\tfloat wXpos;\n\tfloat wYpos;\n};\n\nstatic float max[2] = { 0.0, 0.0 };\nstatic float min[2] = { 255.0, 255.0 }, center[2];\nstatic void do_joy(cont_cond_t *cond) {\n\t\n\tJOYINFO joy;\n\n\tjoy.wXpos = (float)cond->joyx;\n\tjoy.wYpos = (float)cond->joyy;\n\n\tif (!joyactive) {\n\t\t/* save joystick center */\n\t\tif (max[0] < joy.wXpos)\n\t\t\tmax[0] = joy.wXpos;\n\t\tif (min[0] > joy.wXpos)\n\t\t\tmin[0] = joy.wXpos;\n\t\tcenter[0] = (max[0] + min[0]) / 2.0;\n\n\t\tif (max[1] < joy.wYpos)\n\t\t\tmax[1] = joy.wYpos;\n\t\tif (min[1] > joy.wYpos)\n\t\t\tmin[1] = joy.wYpos;\n\t\tcenter[1] = (max[1] + min[1]) / 2.0;\n\t\tjoyactive = 1;\n\t} \n\n\tif (joyactive){\n\t\t/* use joystick values */\n\t\tif (FABS(center[0] - joy.wXpos) > 5.0 )\n\t\t\talpha -= (center[0] - joy.wXpos)/100.0f;\n\t\tif (FABS(center[1] - joy.wYpos) > 5.0 )\n\t\t\tbeta += (center[1] - joy.wYpos)/100.0f;\n\t}\n\t\t\n\t\n\t/* left/right trigger control velocity */\n\tif ((cond->rtrig > 128) && (velocity < 100))\n\t\tvelocity += 1;\n\tif ((cond->ltrig > 128) && (velocity > -100))\n\t\tvelocity -= 1;\n\t/* both triggers - full stop */\n\tif ((cond->ltrig > 128) && (cond->rtrig > 128))\n\t\tvelocity = 0;\n}\n\nstatic GLboolean yp = GL_FALSE;\nint do_controller(uint8 c) {\n\tstatic int dpad = 0;\n\tstatic int dpadrep = DPAD_REPEAT_INTERVAL;\n\tstatic cont_cond_t cond;\n\n\t/* Check key status */\n\tif (cont_get_cond(c, &cond) < 0)\n\t\treturn 0;\n\tif (!(cond.buttons & CONT_START))\n\t\treturn 0;\n\n\t/* DPAD Menu controls */\n\tif (!(cond.buttons & CONT_DPAD_UP)) {\n\t\tif (dpad == 0) {\n\t\t\tdpad |= 0x1000;\n\t\t\tif (help) {\n\t\t\t\tfm->prev();\n\t\t\t} else\n\t\t\t\t;\n\t\t}\n\t} else\n\t\tdpad &= ~0x1000;\n\n\tif (!(cond.buttons & CONT_DPAD_DOWN)) {\n\t\tif (dpad == 0) {\n\t\t\tdpad |= 0x0100;\n\t\t\tif (help) {\n\t\t\t\tfm->next();\n\t\t\t} else\n\t\t\t\t;\n\t\t}\n\t} else\n\t\tdpad &= ~0x0100;\n\t\n\tif (!(cond.buttons & CONT_DPAD_LEFT)) {\n\t\tif (dpad == 0) {\n\t\t\tdpad |= 0x0001;\n\t\t\tif (help) {\n\t\t\t\tfm->dec();\n\t\t\t} else\n\t\t\t\t;\n\t\t}\n\t} else\n\t\tdpad &= ~0x0001;\n\n\tif (!(cond.buttons & CONT_DPAD_RIGHT)) {\n\t\tif (dpad == 0) {\n\t\t\tdpad |= 0x0010;\n\t\t\tif (help) {\n\t\t\t\tfm->inc();\n\t\t\t} else\n\t\t\t\t;\n\t\t}\n\t} else\n\t\tdpad &= ~0x0010;\n\t\n\t// cheap dpad hold and repeat...\n\tif (dpad != 0) {\n\t\tdpadrep--;\n\t\tif (dpadrep < 0) {\n\t\t\tdpadrep = DPAD_REPEAT_INTERVAL;\n\t\t\tdpad = 0;\n\t\t}\n\t} else\n\t\tdpadrep = DPAD_REPEAT_INTERVAL;\n\t\n\t/* Help toggle */\n\tif (!(cond.buttons & CONT_Y) && !yp) {\n\t\typ = GL_TRUE;\n\t\thelp = !help;\n\t}\n\tif (cond.buttons & CONT_Y)\n\t\typ = GL_FALSE;\n\n\t/* Reset view */\n\tif (!(cond.buttons & CONT_A))\n\t\treset_view();\n\t\n\tdo_joy(&cond);\n\t\n\tv = (float)(velocity/100.0f);\n\t\t\n\tif (last_density != density) {\n\t\tglFogf(GL_FOG_DENSITY, density);\n\t\tlast_density = density;\n\t}\n\treturn 1;\n} /* do_controller */\n\nextern uint8 romdisk[];\nint main(void) {\n\tuint8 c;\n\tpvr_stats_t stats;\n\n\tdo_init();\n\n\tc = maple_first_controller();\n\t\n\tprintf(\"[DCTunnel] Entering Main Loop\\n\");\n\twhile(1) {\n\t\tif (!do_controller(c))\n\t\t\tbreak;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\t\tglLoadIdentity();\n\n\t\tdraw();\n\n\t\t/* Done with Opaque Polys */\n\t\tglKosFinishList();\n\t\tglDisable(GL_FOG);\n\t\t\n\t\tif (help)\n\t\t\tdo_help();\n\t\tdo_text();\n\t\t\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\tpvr_get_stats(&stats);\n\tprintf(\"VBL Count: %d, last_time: %f, frame rate: %f fps\\n\",\n\t\tstats.vbl_count, stats.frame_last_time, stats.frame_rate);\n\n\tprintf(\"[DCTunnel] Exited main loop\\n\");\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.49249908328056335,
"alphanum_fraction": 0.5298206806182861,
"avg_line_length": 25.02857208251953,
"blob_id": "3308d4e5cb0762967b884148e57eff9f8077ab33",
"content_id": "e6d3eb6e256042ec1213aab4e462b2dbd2bc26f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5466,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 210,
"path": "/kernel/net/net_ipv4.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_ipv4.c\n\n Copyright (C) 2005, 2006, 2007, 2008 Lawrence Sebald\n\n Portions adapted from KOS' old net_icmp.c file:\n Copyright (c) 2002 Dan Potter\n\n*/\n\n#include <stdio.h>\n#include <string.h>\n#include <errno.h>\n#include <arpa/inet.h>\n#include <kos/net.h>\n#include \"net_ipv4.h\"\n#include \"net_icmp.h\"\n#include \"net_udp.h\"\n\n/* Perform an IP-style checksum on a block of data */\nuint16 net_ipv4_checksum(const uint8 *data, int bytes) {\n uint32 sum = 0;\n int i;\n\n /* Make sure we don't do any unaligned memory accesses */\n if(((uint32)data) & 0x01) {\n for(i = 0; i < bytes; i += 2) {\n sum += (data[i]) | (data[i + 1] << 8);\n\n if(sum & 0xFFFF0000) {\n sum &= 0xFFFF;\n ++sum;\n }\n }\n }\n else {\n uint16 *ptr = (uint16 *)data;\n\n for(i = 0; i < (bytes >> 1); ++i) {\n sum += ptr[i];\n\n if(sum & 0xFFFF0000) {\n sum &= 0xFFFF;\n ++sum;\n }\n }\n }\n\n /* Handle the last byte, if we have an odd byte count */\n if(bytes & 0x01) {\n sum += data[bytes - 1];\n\n if(sum & 0xFFFF0000) {\n sum &= 0xFFFF;\n ++sum;\n }\n }\n\n return sum ^ 0xFFFF;\n}\n\n/* Determine if a given IP is in the current network */\nstatic int is_in_network(const uint8 src[4], const uint8 dest[4],\n const uint8 netmask[4]) {\n int i;\n\n for(i = 0; i < 4; i++) {\n if((dest[i] & netmask[i]) != (src[i] & netmask[i]))\n return 0;\n }\n\n return 1;\n}\n\n/* Send a packet on the specified network adapter */\nint net_ipv4_send_packet(netif_t *net, ip_hdr_t *hdr, const uint8 *data,\n int size) {\n uint8 dest_ip[4];\n uint8 dest_mac[6];\n uint8 pkt[size + sizeof(ip_hdr_t) + sizeof(eth_hdr_t)];\n eth_hdr_t *ehdr;\n int err;\n\n if(net == NULL) {\n net = net_default_dev;\n }\n\n net_ipv4_parse_address(ntohl(hdr->dest), dest_ip);\n\n /* Is this the loopback address (127.0.0.1)? */\n if(ntohl(hdr->dest) == 0x7F000001) {\n /* Put the IP header / data into our packet */\n memcpy(pkt, hdr, 4 * (hdr->version_ihl & 0x0f));\n memcpy(pkt + 4 * (hdr->version_ihl & 0x0f), data, size);\n \n /* Send it \"away\" */\n net_ipv4_input(NULL, pkt, 4 * (hdr->version_ihl & 0x0f) + size);\n\n return 0;\n }\n \n /* Is it in our network? */\n if(!is_in_network(net->ip_addr, dest_ip, net->netmask)) {\n memcpy(dest_ip, net->gateway, 4);\n }\n\n /* Get our destination's MAC address. If we do not have the MAC address\n cached, return a distinguished error to the upper-level protocol so\n that it can decide what to do. */\n err = net_arp_lookup(net, dest_ip, dest_mac);\n if(err == -1) {\n errno = ENETUNREACH;\n return -1;\n }\n else if(err == -2) {\n return -2;\n }\n\n /* Fill in the ethernet header */\n ehdr = (eth_hdr_t *)pkt;\n memcpy(ehdr->dest, dest_mac, 6);\n memcpy(ehdr->src, net->mac_addr, 6);\n ehdr->type[0] = 0x08;\n ehdr->type[1] = 0x00;\n\n /* Put the IP header / data into our ethernet packet */\n memcpy(pkt + sizeof(eth_hdr_t), hdr, 4 * (hdr->version_ihl & 0x0f));\n memcpy(pkt + sizeof(eth_hdr_t) + 4 * (hdr->version_ihl & 0x0f), data,\n size);\n\n /* Send it away */\n net->if_tx(net, pkt, sizeof(ip_hdr_t) + size + sizeof(eth_hdr_t),\n NETIF_BLOCK);\n\n return 0;\n}\n\nint net_ipv4_send(netif_t *net, const uint8 *data, int size, int id, int ttl,\n int proto, uint32 src, uint32 dst) {\n ip_hdr_t hdr;\n\n /* Fill in the IPv4 Header */\n hdr.version_ihl = 0x45;\n hdr.tos = 0;\n hdr.length = htons(size + 20);\n hdr.packet_id = id;\n hdr.flags_frag_offs = htons(0x4000);\n hdr.ttl = ttl;\n hdr.protocol = proto;\n hdr.checksum = 0;\n hdr.src = src;\n hdr.dest = dst;\n\n hdr.checksum = net_ipv4_checksum((uint8 *)&hdr, sizeof(ip_hdr_t));\n\n return net_ipv4_send_packet(net, &hdr, data, size);\n}\n\nint net_ipv4_input(netif_t *src, const uint8 *pkt, int pktsize) {\n ip_hdr_t\t*ip;\n int\t\ti;\n uint8 *data;\n int hdrlen;\n\n if(pktsize < sizeof(ip_hdr_t))\n /* This is obviously a bad packet, drop it */\n return -1;\n\n ip = (ip_hdr_t*) pkt;\n hdrlen = (ip->version_ihl & 0x0F) << 2;\n\n if(pktsize < hdrlen)\n /* The packet is smaller than the listed header length, bail */\n return -1;\n\n data = (uint8 *) (pkt + hdrlen);\n\n /* Check ip header checksum */\n i = ip->checksum;\n ip->checksum = 0;\n ip->checksum = net_ipv4_checksum((uint8 *)ip, hdrlen);\n\n if(i != ip->checksum) {\n /* The checksums don't match, bail */\n return -1;\n }\n\n switch(ip->protocol) {\n case IPPROTO_ICMP:\n return net_icmp_input(src, ip, data, ntohs(ip->length) - hdrlen); \n\n case IPPROTO_UDP:\n return net_udp_input(src, ip, data, ntohs(ip->length) - hdrlen);\n }\n\n /* There's no handler for this packet type, bail out */\n return -1;\n}\n\nuint32 net_ipv4_address(const uint8 addr[4]) {\n return (addr[0] << 24) | (addr[1] << 16) | (addr[2] << 8) | (addr[3]);\n}\n\nvoid net_ipv4_parse_address(uint32 addr, uint8 out[4]) {\n out[0] = (uint8) ((addr >> 24) & 0xFF);\n out[1] = (uint8) ((addr >> 16) & 0xFF);\n out[2] = (uint8) ((addr >> 8) & 0xFF);\n out[3] = (uint8) (addr & 0xFF);\n}\n"
},
{
"alpha_fraction": 0.5905077457427979,
"alphanum_fraction": 0.6346578598022461,
"avg_line_length": 18.255319595336914,
"blob_id": "bf5ee281bfbc6eaf0cbde8c6942c7288077188ec",
"content_id": "489e9b19c6947af9107bee232b413003b09f82f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 906,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 47,
"path": "/examples/dreamcast/kgl/demos/tunnel/plprint.cpp",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n plprint.cpp\n (c)2002 Paul Boese\n\n Uses Steve Baker's PLIB that was ported by Peter Hatch.\n*/\n\n#include <kos.h>\n#include <time.h>\n#include <dcplib/fnt.h>\n#include \"plprint.h\"\n\nCVSID(\"$Id: plprint.cpp,v 1.2 2002/04/12 01:05:12 axlen Exp $\");\n\nextern uint8 romdisk[];\n\nstatic fntRenderer *text;\nstatic fntTexFont *font;\n\nstatic int filter_mode = 1;\n\nvoid plinit() {\n\ttext = new fntRenderer ();\n\tfont = new fntTexFont(\"/rd/courier-bold.txf\");\n\tprintf(\"Loading font\\n\");\n}\n\nvoid plprint(int x, int y, float r, float g, float b, const char *s, int fp) {\n\ttext->setFilterMode(filter_mode);\n\tfont->setFixedPitch(fp);\n\tif ((fp) == 1) {\n\t\tfont->setGap(0.1);\n\t\tfont->setWidth(0.5);\n\t}\n\telse {\n\t\tfont->setGap(0.1);\n\t\tfont->setWidth(1.0);\n\t}\n\ttext->setFont(font);\n\ttext->setPointSize(20);\n\ttext->begin();\n\ttext->setColor(r, g, b, 0.8f);\n\ttext->start2f(x*16, y*16);\n\ttext->puts(s);\n\ttext->end();\n}\n\n"
},
{
"alpha_fraction": 0.6913907527923584,
"alphanum_fraction": 0.6993377208709717,
"avg_line_length": 19.405405044555664,
"blob_id": "1b0659f8af2f9b4a744e1ff4e4882c15a4c71845",
"content_id": "550214665795f4e4d445e30533e3513aeb6757fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 755,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 37,
"path": "/kernel/arch/dreamcast/hardware/maple/dreameye.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dreameye.c\n Copyright (C) 2005 Lawrence Sebald\n*/\n\n#include <dc/maple.h>\n#include <dc/maple/dreameye.h>\n\nstatic void dreameye_periodic(maple_driver_t *drv) {\n}\n\nstatic int dreameye_attach(maple_driver_t *drv, maple_device_t *dev) {\n\tdev->status_valid = 1;\n\treturn 0;\n}\n\nstatic void dreameye_detach(maple_driver_t *drv, maple_device_t *dev) {\n}\n\n/* Device Driver Struct */\nstatic maple_driver_t dreameye_drv = {\n\tfunctions:\tMAPLE_FUNC_CAMERA,\n\tname:\t\t\"Dreameye (Camera)\",\n\tperiodic:\tdreameye_periodic,\n\tattach:\t\tdreameye_attach,\n\tdetach:\t\tdreameye_detach\n};\n\n/* Add the DreamEye to the driver chain */\nint dreameye_init() {\n\treturn maple_driver_reg(&dreameye_drv);\n}\n\nvoid dreameye_shutdown() {\n\tmaple_driver_unreg(&dreameye_drv);\n}\n"
},
{
"alpha_fraction": 0.5116279125213623,
"alphanum_fraction": 0.6569767594337463,
"avg_line_length": 23.571428298950195,
"blob_id": "bedc6ff4af01e80ad1d313f2f726cfd79f922295",
"content_id": "5c6d9140300c8ee2b7e0fbaaf954cb7344e4c17a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/utils/dc-chain/unpack.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nrm -rf binutils-2.17 gcc-3.4.6 newlib-1.15.0\n\ntar jxf binutils-2.17.tar.bz2 || exit 1\ntar jxf gcc-3.4.6.tar.bz2 || exit 1\ntar zxf newlib-1.12.0.tar.gz || exit 1\n"
},
{
"alpha_fraction": 0.6605839133262634,
"alphanum_fraction": 0.6861313581466675,
"avg_line_length": 16.677419662475586,
"blob_id": "5e1819a6e78a298be08373e879bba4e76841cc5b",
"content_id": "e7b6f4e6651a31c23ded33c23c4b0423aa94516d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 548,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 31,
"path": "/kernel/arch/dreamcast/fs/dcload-net.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-net.h\n\n Copyright (C)2003 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#ifndef __NET_H__\n#define __NET_H__\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\nvoid dcln_process_pkt(unsigned char *pkt, int len);\nvoid dcln_tx(uint8 * pkt, int len);\nvoid dcln_rx_loop();\n\nextern uint32 dcln_our_ip;\nextern uint8 dcln_our_mac[6];\nextern uint8 dcln_pkt_buf[1600];\n\n__END_DECLS\n\n#endif\n"
},
{
"alpha_fraction": 0.6110210418701172,
"alphanum_fraction": 0.65153968334198,
"avg_line_length": 17.66666603088379,
"blob_id": "955ee77be4a994bdff52bed5167dc1962b85cc5d",
"content_id": "4d9d322862842153ebd74562ad2fe4f4ad1c0b0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 33,
"path": "/include/addons/kos/vector.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n kos/vector.h\n (c)2002 Dan Potter\n\n $Id: vector.h,v 1.1 2002/09/05 07:31:55 bardtx Exp $\n\n*/\n\n#ifndef __KOS_VECTOR_H\n#define __KOS_VECTOR_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/**\n KOS Platform independent 4-part vector data types. These are used by\n the matrix routines in the DC, and by bsplines in misc. */\n\n/* Matrix definition (4x4) */\ntypedef float matrix_t[4][4];\n\n/* Vector definition */\ntypedef struct vectorstr { float x, y, z, w; } vector_t;\n\n/* Points are just vectors */\ntypedef vector_t point_t;\n\n__END_DECLS\n\n#endif\t/* __KOS_VECTOR_H */\n\n"
},
{
"alpha_fraction": 0.6068052649497986,
"alphanum_fraction": 0.6578450202941895,
"avg_line_length": 18.55555534362793,
"blob_id": "f5735064a2891278c28be41aa2cafbadab8346c2",
"content_id": "fbd5270dd5e852e5e6b619dfeab48d85c6c3743d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 27,
"path": "/include/arch/dreamcast/navi/flash.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n navi/flash.h\n (c)2002 Dan Potter\n \n $Id: flash.h,v 1.1 2002/05/05 22:17:51 bardtx Exp $\n*/\n\n#ifndef __NAVI_FLASH_H\n#define __NAVI_FLASH_H\n\n#include <arch/types.h>\n\n/* Return 0 if we successfully detect a compatible device */\nint nvflash_detect();\n\n/* Erase a block of flash */\nint nvflash_erase_block(uint32 addr);\n\n/* Write a block of data */\nint nvflash_write_block(uint32 addr, void * data, uint32 len);\n\n/* Erase the whole flash chip */\nint nvflash_erase_all();\n\n\n#endif\t/* __NAVI_FLASH_H */\n\n"
},
{
"alpha_fraction": 0.6862227916717529,
"alphanum_fraction": 0.7046802639961243,
"avg_line_length": 26.089284896850586,
"blob_id": "adada634c23fabe30a305e82e6d9bd4ec610b9ee",
"content_id": "2289336ed8ef47bde257df492b54a40fadab0283",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1517,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 56,
"path": "/include/sys/socket.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sys/socket.h\n Copyright (C)2006 Lawrence Sebald\n\n*/\n\n#ifndef __SYS_SOCKET_H\n#define __SYS_SOCKET_H\n\n#include <sys/cdefs.h>\n#include <arch/types.h>\n\n__BEGIN_DECLS\n\ntypedef uint32 socklen_t;\n\n#ifndef __SA_FAMILY_T_DEFINED\n#define __SA_FAMILY_T_DEFINED\ntypedef uint32 sa_family_t;\n#endif\n\nstruct sockaddr {\n sa_family_t sa_family;\n char sa_data[];\n};\n\n/* Socket types, currently only SOCK_DGRAM is available */\n#define SOCK_DGRAM 1\n\n/* Socket address families. Currently only AF_INET is available */\n#define AF_INET 1\n\n#define PF_INET AF_INET\n\n/* Socket shutdown macros. */\n#define SHUT_RD 0x00000001\n#define SHUT_WR 0x00000002\n#define SHUT_RDWR (SHUT_RD | SHUT_WR)\n\nint accept(int socket, struct sockaddr *address, socklen_t *address_len);\nint bind(int socket, const struct sockaddr *address, socklen_t address_len);\nint connect(int socket, const struct sockaddr *address, socklen_t address_len);\nint listen(int socket, int backlog);\nssize_t recv(int socket, void *buffer, size_t length, int flags);\nssize_t recvfrom(int socket, void *buffer, size_t length, int flags,\n struct sockaddr *address, socklen_t *address_len);\nssize_t send(int socket, const void *message, size_t length, int flags);\nssize_t sendto(int socket, const void *message, size_t length, int flags,\n const struct sockaddr *dest_addr, socklen_t dest_len);\nint shutdown(int socket, int how);\nint socket(int domain, int type, int protocol);\n\n__END_DECLS\n\n#endif /* __SYS_SOCKET_H */\n"
},
{
"alpha_fraction": 0.5656830072402954,
"alphanum_fraction": 0.6242265701293945,
"avg_line_length": 20.212121963500977,
"blob_id": "5047a8f1dfb172cf04abecc7105975c588e86c21",
"content_id": "748715270e58b4d8fab628bd8dc0632d9fc47f2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4202,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 198,
"path": "/examples/dreamcast/kgl/basic/vfzclip/vfzclip.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n vfzclip.c\n (c)2001, 2002 [email protected], Paul Boese\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n#define SDIFF 0.001f\n\n#define true (1 == 1)\n#define false (1 == 0)\n\nCVSID(\"$Id\");\n\n/*\n A demonstration of Trilinear's NEAR-Z-Clipper that has been\n incorporated into KGL. Use the joystick to rotate the view, the D-Pad\n to move forward and back, and the A button to toggle the Z-Clipper\n on or off. Please note that the code only works with GL_TRIANGLES.\n\n Thanks to NeHe's tutorials for the crate image.\n*/\n\nvoid quad() {\n\tfloat x=-1.0f;\n\tfloat y=-1.0f;\n\n\tfloat incr=2.0f;\n\n\n\tglBegin(GL_TRIANGLES);\n\n\n\twhile (x<=1.0f-incr) {\n\t\twhile (y<=1.0f-incr) {\n\t\t\t/* Front face */\n\t\t\tglTexCoord2f(1.0f-SDIFF,0.0f+SDIFF);\n\t\t\tglVertex3f(x, y+incr, 0.0f);\n\t\t\tglTexCoord2f(0.0f+SDIFF,0.0f+SDIFF);\n\t\t\tglVertex3f(x+incr, y+incr, 0.0f);\n\t\t\tglTexCoord2f(0.0f+SDIFF,1.0f-SDIFF);\n\t\t\tglVertex3f(x+incr, y, 0.0f);\n\n\t\t\tglTexCoord2f(1.0f-SDIFF,0.0f+SDIFF);\n\t\t\tglVertex3f(x, y+incr, 0.0f);\n\t\t\tglTexCoord2f(0.0f+SDIFF,1.0f-SDIFF);\n\t\t\tglVertex3f(x+incr, y, 0.0f);\n\t\t\tglTexCoord2f(1.0f-SDIFF,1.0f-SDIFF);\n\t\t\tglVertex3f(x, y, 0.0f);\n\t\t\ty+=incr;\n\t\t}\n\t\ty=-1.0f;\n\t\tx+=incr;\n\t}\n\tglEnd();\n}\n\nvoid cube() {\n\n\t\tglPushMatrix();\n\t\tglTranslatef(0.0f, 0.0f, 1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglTranslatef(0.0f, 0.0f, -1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglRotatef(90, 1.0f, 0.0f, 0.0f);\n\t\tglTranslatef(0.0f, 0.0f, 1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglRotatef(-90, 1.0f, 0.0f, 0.0f);\n\t\tglTranslatef(0.0f, 0.0f,1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglRotatef(90, 0.0f, 1.0f, 0.0f);\n\t\tglTranslatef(0.0f, 0.0f, 1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglRotatef(-90, 0.0f, 1.0f, 0.0f);\n\t\tglTranslatef(0.0f, 0.0f, 1.0f);\n\t\tquad();\n\t\tglPopMatrix();\n}\n\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nextern uint8 romdisk[];\nKOS_INIT_FLAGS(INIT_DEFAULT);\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tmaple_device_t * caddr;\n\tcont_state_t * cont;\n\tGLuint\ttexture;\n\tfloat\tz = -1.0f;\n\tfloat\trx = 0.0f;\n\tfloat\try = 0.0f;\n\tint\tzclip = true;\n\tint\ta_pressed = false;\n\n\t/* Normal init */\n\tpvr_init_defaults();\n\n\t/* Get KGL stuff initialized */\n\tglKosInit();\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglEnable(GL_TEXTURE_2D);\n\tglEnable(GL_KOS_AUTO_UV);\n\n\t/* Expect CW verts */\n\tglFrontFace(GL_CW);\n\n\t/* Load a texture and make to look nice */\n\tloadtxr(\"/rd/crate.pcx\", &texture);\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n\n\tglClearColor(0.3f, 0.4f, 0.5f, 1.0f);\n\n\twhile(1) {\n\t\t/* Check controller/key status */\n\t\tif ((caddr = maple_enum_type(0, MAPLE_FUNC_CONTROLLER)) == NULL)\n\t\t\tbreak;\n\t\t\n\t\tcont = (cont_state_t *)maple_dev_status(caddr);\n\t\tif ((cont->buttons & CONT_START))\n\t\t\tbreak;\n\t\t\n\t\tif ((cont->buttons & CONT_DPAD_UP))\n\t\t\tz -= 0.3f;\n\t\tif ((cont->buttons & CONT_DPAD_DOWN))\n\t\t\tz += 0.3f;\n\t\tif ((cont->buttons & CONT_A) && !a_pressed) {\n\t\t\ta_pressed = true;\n\t\t\tzclip = !zclip;\n\t\t}\n\t\tif (!(cont->buttons & CONT_A))\n\t\t\ta_pressed = false;\n\t\t\n\t\trx+=((float)cont->joyy)/100.0f;\n\t\try+=((float)cont->joyx)/100.0f;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\tglLoadIdentity();\n\n\t\tglTranslatef(0.0f, 0.0f, -50-z);\n\n\t\tglRotatef(-90, 1.0f, 0.0f, 0.0f);\n\t\tglRotatef(rx, 1.0f, 0.0f, 0.0f);\n\t\tglRotatef(ry, 0.0f, 0.0f, 1.0f);\n\n\t\tglPushMatrix();\n\t\tglBindTexture( GL_TEXTURE_2D, texture);\n\t\tglScalef(50.0f, 50.0f, 50.0f);\n\t\tglTranslatef(0.0f, 0.0f, 0.75f);\n\n\t\tif (zclip) glEnable(GL_KOS_NEARZ_CLIPPING);\n\t\tcube();\n\t\tglDisable(GL_KOS_NEARZ_CLIPPING);\n\n\t\tglPopMatrix();\n\t\t\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6024096608161926,
"alphanum_fraction": 0.6626505851745605,
"avg_line_length": 19.6875,
"blob_id": "c69208d63334bf2d79e274e29b1d82c9e1d340f0",
"content_id": "d101a7e5bd11c68e44e005cc55214a0cc40da4d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/libk++/pure_virtual.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pure_virtual.c\n Copyright (C)2003 Dan Potter\n\n Provides a libsupc++ function for using pure virtuals. Thanks to\n Bero for the info.\n */\n\n#include <arch/arch.h>\n\nCVSID(\"$Id: pure_virtual.c,v 1.1 2003/05/23 02:26:50 bardtx Exp $\");\n\nvoid __cxa_pure_virtual() {\n\tpanic(\"Pure virtual method called\");\n}\n\n"
},
{
"alpha_fraction": 0.6394811868667603,
"alphanum_fraction": 0.6746624112129211,
"avg_line_length": 28.9255313873291,
"blob_id": "7b8aca2bdbccc991592f0f3285c2e883d3c0525f",
"content_id": "2acb919a7bb9e3fad8f277045a7f19c9cb13e7fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5628,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 188,
"path": "/examples/dreamcast/parallax/delay_cube/delay_cube.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n delay_cube.c\n Copyright (C)2003 Dan Potter\n*/\n\n#include <kos.h>\n#include <math.h>\n#include <plx/texture.h>\n#include <plx/context.h>\n#include <plx/prim.h>\n\nKOS_INIT_FLAGS(INIT_DEFAULT | INIT_MALLOCSTATS);\n\n/*\n\nThe third demo effect in my series of Parallax demo effects. This one\nmight actually be of practical interest to people still. This effect\ngenerates a cube out of a 3D grid of dots and then does something that\nlooks somewhat like motion blurring on it. The trick here is that we're\nusing alpha blended copies of the object instead of doing raster effects,\nso it becomes feasible on the PVR.\n\nThis works by saving the last N modelview matrices and then restoring\neach one for each \"delay\" cube. Each \"delay\" cube has a successively\nlower alpha value as well.\n\nThis is very rendering stage intensive due to the alpha blending. It\nmight be made faster by switching entirely to opaque polys, but I'll\nleave the working out of that as an exercise to the reader ;)\n\nAnother exercise for the reader... it is possible (and not too difficult)\nto modify this code so that you have many geometric objects and morph\nbetween them. The key is to have the same number of points in each object\nand then have a \"delta\" array to tell you how much to move each point\neach frame.\n\n*/\n\n// Generate a cube object for our usage. This could really be anything, I\n// just like cubes. :)\nvector_t cube[6*6*6];\nint cubepnts = 6*6*6;\nvoid makecube() {\n\tint x, y, z;\n\n\tfor (x=-3; x<3; x++) {\n\t\tfor (y=-3; y<3; y++) {\n\t\t\tfor (z=-3; z<3; z++) {\n\t\t\t\tcube[(x+3)*36+(y+3)*6+(z+3)].x = x;\n\t\t\t\tcube[(x+3)*36+(y+3)*6+(z+3)].y = y;\n\t\t\t\tcube[(x+3)*36+(y+3)*6+(z+3)].z = z;\n\t\t\t}\n\t\t}\n\t}\n}\n\n// Draw a single point in 3D space. Uses the currently loaded matrix.\nvoid drawpnt(float x, float y, float z, float a, float r, float g, float b) {\n\tuint32 col = plx_pack_color(a, r, g, b);\n\n\t// Transform the point, clip the Z plane to avoid artifacts.\n\tplx_mat_tfip_3d(x, y, z);\n\tif (z <= 0.00001f) z = 0.00001f;\n\n\t// Draw it.\n\tplx_vert_inp(PLX_VERT, x, y+1.0f, z, col);\n\tplx_vert_inp(PLX_VERT, x, y, z, col);\n\tplx_vert_inp(PLX_VERT, x+1.0f, y+1.0f, z, col);\n\tplx_vert_inp(PLX_VERT_EOS, x+1.0f, y, z, col);\n}\n\n// Draws the full cube at the current position.\nvoid drawcube(float b) {\n\tint i;\n\n\tfor (i=0; i<cubepnts; i++)\n\t\tdrawpnt(cube[i].x, cube[i].y, cube[i].z, b, 1.0f, 1.0f, 1.0f);\n}\n\n// Temporary matrix so we don't have to keep recalculating our\n// screenview and projection matrices. This has to be declared out\n// here or GCC will ignore your aligned(32) request (potentially\n// causing crashage).\nstatic matrix_t tmpmat __attribute__((aligned(32)));\n\nint main(int argc, char **argv) {\n\tint done, i;\n\tint theta;\n\tpvr_stats_t stats;\n\tint delays = 8;\n\tmatrix_t oldmats[delays];\n\n\tmemset(&oldmats, 0, sizeof(oldmats));\n\n\t// Init PVR\n\tpvr_init_defaults();\n\tpvr_set_bg_color(0.0f, 1.0f*0x49/0xff, 1.0f*0x6b/0xff);\n\n\t// Setup the context\n\tplx_cxt_init();\n\tplx_cxt_texture(NULL);\n\tplx_cxt_culling(PLX_CULL_NONE);\n\n\t// Init 3D stuff. mat3d is like KGL.\n\tplx_mat3d_init();\n\tplx_mat3d_mode(PLX_MAT_PROJECTION);\n\tplx_mat3d_identity();\n\tplx_mat3d_perspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tplx_mat3d_mode(PLX_MAT_MODELVIEW);\n\n\t// Create our model\n\tmakecube();\n\n\t// Until the user hits start...\n\tfor (done = 0, theta = 0; !done; ) {\n\t\t// Check for start\n\t\tMAPLE_FOREACH_BEGIN(MAPLE_FUNC_CONTROLLER, cont_state_t, st)\n\t\t\tif (st->buttons & CONT_START)\n\t\t\t\tdone = 1;\n\t\tMAPLE_FOREACH_END()\n\n\t\t// Setup the frame\n\t\tpvr_wait_ready();\n\t\tpvr_scene_begin();\n\t\tpvr_list_begin(PVR_LIST_OP_POLY);\n\n\t\t// Submit the context\n\t\tplx_cxt_send(PVR_LIST_OP_POLY);\n\n\t\t// Setup some rotations/translations. These are \"executed\" from\n\t\t// bottom to top. So we rotate the cube in place on all three\n\t\t// axes a bit, then translate it to the left by 10, and rotate\n\t\t// the whole deal (so it zooms around the screen a bit). Finally\n\t\t// we translate the whole mess back by 30 so it's visible.\n\t\tplx_mat3d_identity();\n\t\tplx_mat3d_translate(0.0f, 0.0f, -30.0f);\n\t\tplx_mat3d_rotate(theta*0.3f, 1.0f, 0.0f, 0.0f);\n\t\tplx_mat3d_rotate(theta*1.5f, 0.0f, 1.0f, 0.0f);\n\t\tplx_mat3d_translate(10.0f, 0.0f, 0.0f);\n\t\tplx_mat3d_rotate(theta, 1.0f, 0.0f, 0.0f);\n\t\tplx_mat3d_rotate(theta*0.5f, 0.0f, 0.1f, 0.0f);\n\t\tplx_mat3d_rotate(theta*0.3f, 0.0f, 0.0f, 0.1f);\n\n\t\t// Save this latest modelview matrix\n\t\tfor (i=0; i<delays-1; i++)\n\t\t\tmemcpy(&oldmats[i], &oldmats[i+1], sizeof(matrix_t));\n\t\tplx_mat3d_store(&oldmats[delays-1]);\n\n\t\t// Draw a cube at our current position/rotation. We make a snapshot\n\t\t// of the full translation matrix after projection so that we can\n\t\t// just apply new modelview matrices for the delay cubes.\n\t\tplx_mat_identity();\n\t\tplx_mat3d_apply(PLX_MAT_SCREENVIEW);\n\t\tplx_mat3d_apply(PLX_MAT_PROJECTION);\n\t\tplx_mat_store(&tmpmat);\n\t\tplx_mat3d_apply(PLX_MAT_MODELVIEW);\n\t\tdrawcube(1.0f);\n\n\t\t// Translucent list for delay cubes\n\t\tplx_list_begin(PVR_LIST_TR_POLY);\n\t\tplx_cxt_send(PVR_LIST_TR_POLY);\n\n\t\t// Now go back and draw the delay cubes\n\t\tfor (i=0; i<delays-1; i++) {\n\t\t\t// Load the old matrix\n\t\t\tplx_mat3d_load(&oldmats[(delays-2)-i]);\n\n\t\t\t// Apply it and draw the cube\n\t\t\tplx_mat_load(&tmpmat);\n\t\t\tplx_mat3d_apply(PLX_MAT_MODELVIEW);\n\t\t\tdrawcube(1.0f - (i+2)*(0.8f / delays));\n\t\t}\n\n\t\tpvr_scene_finish();\n\n\t\t// Move our counters\n\t\ttheta++;\n\t}\n\n\t// You have to keep a watch on these, especially the vertex used\n\t// for really poly intensive effects.\n\tpvr_get_stats(&stats);\n\tdbglog(DBG_DEBUG, \"3D Stats: %ld vblanks, frame rate ~%f fps, max vertex used %d bytes\\n\",\n\t\tstats.vbl_count, (double)stats.frame_rate, stats.vtx_buffer_used_max);\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.7025102972984314,
"alphanum_fraction": 0.7152491807937622,
"avg_line_length": 30.388235092163086,
"blob_id": "cb43cb653492cf6dd215cde2f2c82f454ba074aa",
"content_id": "cfa3f7a24eedd6bbf771016e4e128ee1ee47af2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2669,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 85,
"path": "/include/arch/dreamcast/dc/sound/stream.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/sound/stream.h\n Copyright (C)2002,2004 Dan Potter\n\n $Id: stream.h,v 1.6 2003/03/09 01:26:36 bardtx Exp $\n\n*/\n\n#ifndef __DC_SOUND_STREAM_H\n#define __DC_SOUND_STREAM_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* The maximum number of streams which can be allocated at once */\n#define SND_STREAM_MAX 4\n\n/* The maximum buffer size for a stream */\n#define SND_STREAM_BUFFER_MAX 0x10000\n\n/* A stream handle */\ntypedef int snd_stream_hnd_t;\n\n/* An invalid stream handle */\n#define SND_STREAM_INVALID -1\n\n/* Set \"get data\" callback */\ntypedef void* (*snd_stream_callback_t)(snd_stream_hnd_t hnd, int smp_req, int * smp_recv);\nvoid snd_stream_set_callback(snd_stream_hnd_t hnd, snd_stream_callback_t cb);\n\n/* Add an effect filter to the sound stream chain. When the stream\n buffer filler needs more data, it starts out by calling the initial\n callback (set above). It then calls each function in the effect\n filter chain, which can modify the buffer and the amount of data\n available as well. Filters persist across multiple calls to _init()\n but will be emptied by _shutdown(). */\ntypedef void (*snd_stream_filter_t)(snd_stream_hnd_t hnd, void * obj, int hz, int channels, void **buffer, int *samplecnt);\nvoid snd_stream_filter_add(snd_stream_hnd_t hnd, snd_stream_filter_t filtfunc, void * obj);\n\n/* Remove a filter added with the above function */\nvoid snd_stream_filter_remove(snd_stream_hnd_t hnd, snd_stream_filter_t filtfunc, void * obj);\n\n/* Prefill buffers -- do this before calling start() */\nvoid snd_stream_prefill(snd_stream_hnd_t hnd);\n\n/* Initialize stream system */\nint snd_stream_init();\n\n/* Shut everything down and free mem */\nvoid snd_stream_shutdown();\n\n/* Allocate and init a stream channel */\nsnd_stream_hnd_t snd_stream_alloc(snd_stream_callback_t cb, int bufsize);\n\n/* Re-init a stream channel */\nint snd_stream_reinit(snd_stream_hnd_t hnd, snd_stream_callback_t cb);\n\n/* Destroy a stream channel */\nvoid snd_stream_destroy(snd_stream_hnd_t hnd);\n\n/* Enable / disable stream queueing */ \nvoid snd_stream_queue_enable(snd_stream_hnd_t hnd);\nvoid snd_stream_queue_disable(snd_stream_hnd_t hnd);\n\n/* Actually make it go (in queued mode) */\nvoid snd_stream_queue_go(snd_stream_hnd_t hnd);\n\n/* Start streaming */\nvoid snd_stream_start(snd_stream_hnd_t hnd, uint32 freq, int st);\n\n/* Stop streaming */\nvoid snd_stream_stop(snd_stream_hnd_t hnd);\n\n/* Poll streamer to load more data if neccessary */\nint snd_stream_poll(snd_stream_hnd_t hnd);\n\n/* Set the volume on the streaming channels */\nvoid snd_stream_volume(snd_stream_hnd_t hnd, int vol);\n\n__END_DECLS\n\n#endif\t/* __DC_SOUND_STREAM_H */\n\n"
},
{
"alpha_fraction": 0.6563876867294312,
"alphanum_fraction": 0.700440526008606,
"avg_line_length": 22.482759475708008,
"blob_id": "30d2af0095fe6985fcd88bc24f31cc297ab4adf0",
"content_id": "70c83b2db5477fd12564d0ca72938fef60b64f17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 29,
"path": "/kernel/libc/pthreads/pthread_tls.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <pthread.h>\n#include <errno.h>\n\n/* Dynamic Package Initialization */\nint pthread_once(pthread_once_t *once_control, void (*init_routine)(void)) {\n\treturn EINVAL;\n}\n\n/* Thread-Specific Data Key Create, P1003.1c/Draft 10, p. 163 */\n\nint pthread_key_create(pthread_key_t *key, void (*destructor)( void * )) {\n\treturn EINVAL;\n}\n\n/* Thread-Specific Data Management, P1003.1c/Draft 10, p. 165 */ \n\nint pthread_setspecific(pthread_key_t key, const void *value) {\n\treturn EINVAL;\n}\n\nvoid * pthread_getspecific(pthread_key_t key) {\n\treturn NULL;\n}\n\n/* Thread-Specific Data Key Deletion, P1003.1c/Draft 10, p. 167 */\n\nint pthread_key_delete(pthread_key_t key) {\n\treturn EINVAL;\n}\n"
},
{
"alpha_fraction": 0.6623255610466003,
"alphanum_fraction": 0.6809302568435669,
"avg_line_length": 20.039215087890625,
"blob_id": "32a3bc468b22c6c38814f39a4fe5dde5a1fea0b8",
"content_id": "1ccf7d73e58862299b22d5aa058706e6337831af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1075,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 51,
"path": "/kernel/arch/ps2/kernel/atexit.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n atexit.c\n (c)2002 Florian Schulze\n*/\n\n#include <arch/arch.h>\n#include <arch/atexit.h>\n#include <malloc.h>\n#include <stdio.h>\n\nCVSID(\"$Id: atexit.c,v 1.1 2002/10/26 08:04:00 bardtx Exp $\");\n\n/* atexit() handling\n\n Note: we may eventually move this into libc */\n\nstruct arch_atexit_handler *arch_atexit_handlers = NULL;\n\nvoid atexit(void (*func)(void)) {\n\tstruct arch_atexit_handler *new_handler;\n\n\tif (!func)\n\t\treturn;\n\t\n\tnew_handler = malloc(sizeof(struct arch_atexit_handler));\n\tif (!new_handler)\n\t\treturn; /* TODO: error handling? */\n\t\n\tnew_handler->handler = func;\n\tnew_handler->next = arch_atexit_handlers;\n\t\n\tarch_atexit_handlers = new_handler;\n}\n\n/* Call all the atexit() handlers */\nvoid arch_atexit() {\n\tstruct arch_atexit_handler *exit_handler;\n\n\tdbglog(DBG_CRITICAL, \"arch: calling atexit functions\\n\");\n\n\texit_handler = arch_atexit_handlers;\n\twhile (exit_handler) {\n\t\tif (exit_handler->handler)\n\t\t\texit_handler->handler();\n\t\t\n\t\texit_handler = exit_handler->next;\n\t\tfree(arch_atexit_handlers);\n\t\tarch_atexit_handlers = exit_handler;\n\t}\n}\n\n\n"
},
{
"alpha_fraction": 0.6205085515975952,
"alphanum_fraction": 0.7020453214645386,
"avg_line_length": 34.81188201904297,
"blob_id": "61734bb75bf6b0ae1e41d47e23ef1ebd44be2caa",
"content_id": "ed9d510ea2a2398fb4d4215151ef9f4797930b88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3618,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 101,
"path": "/include/arch/dreamcast/dc/asic.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/asic.h\n (c)2001-2002 Dan Potter\n\n $Id: asic.h,v 1.4 2003/02/25 07:39:37 bardtx Exp $\n \n*/\n\n#ifndef __DC_ASIC_H\n#define __DC_ASIC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* All event codes are two 8-bit integers; the top integer is the event code\n register to look in to check the event (and to acknolwedge it). The\n register to check is 0xa05f6900+4*regnum. The bottom integer is the\n bit index within that register. */\n\n/* Event codes for the PVR chip */\n#define ASIC_EVT_PVR_RENDERDONE\t\t0x0002\t\t/* Render completed */\n#define ASIC_EVT_PVR_SCANINT1\t\t0x0003\t\t/* Scanline interrupt 1 */\n#define ASIC_EVT_PVR_SCANINT2\t\t0x0004\t\t/* Scanline interrupt 2 */\n#define ASIC_EVT_PVR_VBLINT\t\t0x0005\t\t/* VBL interrupt */\n#define ASIC_EVT_PVR_OPAQUEDONE\t\t0x0007\t\t/* Opaque list completed */\n#define ASIC_EVT_PVR_OPAQUEMODDONE\t0x0008\t\t/* Opaque modifiers completed */\n#define ASIC_EVT_PVR_TRANSDONE\t\t0x0009\t\t/* Transparent list completed */\n#define ASIC_EVT_PVR_TRANSMODDONE\t0x000a\t\t/* Transparent modifiers completed */\n#define ASIC_EVT_PVR_DMA\t\t0x0013\t\t/* PVR DMA complete */\n#define ASIC_EVT_PVR_PTDONE\t\t0x0015\t\t/* Punch-thrus completed */\n#define ASIC_EVT_PVR_PRIMOUTOFMEM\t0x0202\t\t/* Out of primitive memory */\n#define ASIC_EVT_PVR_MATOUTOFMEM\t0x0203\t\t/* Out of matrix memory */\n\n/* Event codes for the GD controller */\n#define ASIC_EVT_GD_COMMAND\t\t0x0100\t\t/* GD-Rom Command Status */\n#define ASIC_EVT_GD_DMA\t\t\t0x000e\t\t/* GD-Rom DMA complete */\n\n/* Event codes for the Maple controller */\n#define ASIC_EVT_MAPLE_DMA\t\t0x000c\t\t/* Maple DMA complete */\n#define ASIC_EVT_MAPLE_ERROR\t\t0x000d\t\t/* Maple error (?) */\n\n/* Event codes for the SPU */\n#define ASIC_EVT_SPU_DMA\t\t0x000f\t\t/* SPU (G2 chnl 0) DMA complete */\n#define ASIC_EVT_SPU_IRQ\t\t0x0101\t\t/* SPU interrupt */\n\n/* Event codes for G2 bus DMA */\n#define ASIC_EVT_G2_DMA0\t\t0x000f\t\t/* G2 DMA chnl 0 complete */\n#define ASIC_EVT_G2_DMA1\t\t0x0010\t\t/* G2 DMA chnl 1 complete */\n#define ASIC_EVT_G2_DMA2\t\t0x0011\t\t/* G2 DMA chnl 2 complete */\n#define ASIC_EVT_G2_DMA3\t\t0x0012\t\t/* G2 DMA chnl 3 complete */\n\n/* Event codes for the external port */\n#define ASIC_EVT_EXP_8BIT\t\t0x0102\t\t/* Modem / Lan Adapter */\n#define ASIC_EVT_EXP_PCI\t\t0x0103\t\t/* BBA IRQ */\n\n/* ASIC registers */\n#define ASIC_IRQD_A\t\t(*(vuint32*)0xa05f6910)\n#define ASIC_IRQD_B\t\t(*(vuint32*)0xa05f6914)\n#define ASIC_IRQD_C\t\t(*(vuint32*)0xa05f6918)\n#define ASIC_IRQB_A\t\t(*(vuint32*)0xa05f6920)\n#define ASIC_IRQB_B\t\t(*(vuint32*)0xa05f6924)\n#define ASIC_IRQB_C\t\t(*(vuint32*)0xa05f6928)\n#define ASIC_IRQ9_A\t\t(*(vuint32*)0xa05f6930)\n#define ASIC_IRQ9_B\t\t(*(vuint32*)0xa05f6934)\n#define ASIC_IRQ9_C\t\t(*(vuint32*)0xa05f6938)\n\n#define ASIC_ACK_A\t\t(*(vuint32*)0xa05f6900)\n#define ASIC_ACK_B\t\t(*(vuint32*)0xa05f6904)\n#define ASIC_ACK_C\t\t(*(vuint32*)0xa05f6908)\n\n/* ASIC IRQ priorities (pick one at hook time, or don't choose anything and\n we'll choose a default) */\n#define ASIC_IRQ9\t\t1\n#define ASIC_IRQB\t\t2\n#define ASIC_IRQD\t\t3\n#define ASIC_IRQ_DEFAULT\t0\n\n/* The type of a ASIC event handler */\ntypedef void (*asic_evt_handler)(uint32 code);\n\n/* Set a handler, or remove a handler (see codes above); handler\n functions have one parameter, which is the exception code. */\nint asic_evt_set_handler(uint32 code, asic_evt_handler handler);\n\n/* Enable/Disable ASIC events; only enable a given event on one irqlevel! */\nvoid asic_evt_disable_all();\nvoid asic_evt_disable(uint32 code, int irqlevel);\nvoid asic_evt_enable(uint32 code, int irqlevel);\n\n/* Init routine */\nvoid asic_init();\n\n/* Shutdown */\nvoid asic_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_ASIC_H */\n\n"
},
{
"alpha_fraction": 0.5621933341026306,
"alphanum_fraction": 0.5862433910369873,
"avg_line_length": 26.278215408325195,
"blob_id": "f1b0790c316a96369557396bc197b3676e4fcba9",
"content_id": "4720e48ec86531855859e382789be3ce079cfc07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 10395,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 381,
"path": "/examples/dreamcast/kgl/nehe/nehe26/nehe26.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe02.c\n (c)2002 Paul Boese\n\n Parts (c)2001 Benoit Miller\n Major Parts (c)1999 Jeff Molofee\n*/\n\n#include <kos.h>\n#include <stdio.h>\n#include <math.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n\n/* Morphing Points!\n\n Essentially the same thing as NeHe's lesson26 code. \n To learn more, go to http://nehe.gamedev.net/.\n\n Buttons A X Y B are used to choose the sphere, torus, tube, and random\n point cloud respectively. DPAD and Right/Left triggers control object\n rotation.\n*/\n\n/* screen width, height, and bit depth */\n#define SCREEN_WIDTH 640\n#define SCREEN_HEIGHT 400\n\n/* Set up some booleans */\n#define TRUE 1\n#define FALSE 0\ntypedef unsigned int bool;\n\n/* Build Our Vertex Structure */\ntypedef struct {\n\tfloat x, y, z; /* 3D Coordinates */\n} vertex;\n\n/* Build Our Object Structure */\ntypedef struct {\n\tint verts; /* Number Of Vertices For The Object */\n\tvertex *points; /* One Vertice (Vertex x,y & z) */\n} object;\n\nGLfloat xrot, yrot, zrot; /* Camera rotation variables */\nGLfloat cx, cy, cz = -15; /* Camera pos variable */\nGLfloat xspeed, yspeed, zspeed; /* Spin Speed */\n\nint key = 1; /* Make Sure Same Morph Key Not Pressed */\nint step = 0, steps = 200; /* Step Counter And Maximum Number Of Steps */\nbool morph = FALSE; /* Default morph To False (Not Morphing) */\n\nint maxver; /* Holds The Max Number Of Vertices */\nobject morph1, morph2, morph3, morph4, /* Our 4 Morphable Objects */\n\thelper, *sour, *dest; /* Helper, Source, Destination Object */\n\n#define MORPHS 4\n\n/* function to allocate memory for an object */\nvoid objallocate( object *k, int n ) {\n\n\t/* Sets points Equal To VERTEX * Number Of Vertices */\n\tk->points = ( vertex* )malloc( sizeof( vertex ) * n );\n}\n\n/* function deallocate memory for an object */\nvoid objfree( object *k ) {\n\n\tfree( k->points );\n}\n\n\n/* function to release/destroy our resources and restoring the old desktop */\nvoid Quit( int returnCode ) {\n\n\t/* deallocate the objects' memory */\n\tobjfree( &morph1 );\n\tobjfree( &morph2 );\n\tobjfree( &morph3 );\n\tobjfree( &morph4 );\n\tobjfree( &helper );\n}\n\n/* function Loads Object From File (name) */\nvoid objload( char *name, object *k ) {\n\n\tint ver; /* Will Hold Vertice Count */\n\tfloat rx, ry, rz; /* Hold Vertex X, Y & Z Position */\n\tFILE *filein; /* Filename To Open */\n\tint i; /* Simple loop variable */\n \n\tprintf(\" [objload] file: %s\\n\", name);\n\n\t/* Opens The File For Reading */\n\tfilein = fopen( name, \"r\" );\n\t/* Reads the number of verts in the file */\n\tfread(&ver, sizeof(int), 1, filein);\n\t/* Sets Objects verts Variable To Equal The Value Of ver */\n\tk->verts = ver;\n\t/* Jumps To Code That Allocates Ram To Hold The Object */\n\tobjallocate( k,ver );\n \n\t/* Loops Through The Vertices */\n\tfor ( i = 0; i < ver; i++ ) {\n\t\t/* Reads the next three verts */\n\t\tfread(&rx, sizeof(float), 1, filein);\n\t\tfread(&ry, sizeof(float), 1, filein);\n\t\tfread(&rz, sizeof(float), 1, filein);\n\t\t/* Set our object's x, y, z points */\n\t\tk->points[i].x = rx;\n\t\tk->points[i].y = ry;\n\t\tk->points[i].z = rz;\n\t}\n\n\t/* Close The File */\n\tfclose( filein );\n\n\t/* If ver Is Greater Than maxver Set maxver Equal To ver */\n\tif( ver > maxver )\n\t\tmaxver = ver;\n}\n\n/* function to calculate Movement Of Points During Morphing */\nvertex calculate( int i ) {\n\n\tvertex a; /* Temporary Vertex Called a */\n\n\t/* Calculate x, y, and z movement */\n\ta.x = ( sour->points[i].x - dest->points[i].x ) / steps;\n\ta.y = ( sour->points[i].y - dest->points[i].y ) / steps;\n\ta.z = ( sour->points[i].z - dest->points[i].z ) / steps;\n\n\treturn a;\n} \n\n/* general OpenGL initialization function */\nint initGL( GLvoid ) {\n\n\tint i; /* Simple Looping variable */\n\n\t/* Height / width ration */\n\tGLfloat ratio;\n\n\tratio = SCREEN_WIDTH / SCREEN_HEIGHT;\n\n\t/* change to the projection matrix and set our viewing volume. */\n\tglMatrixMode( GL_PROJECTION );\n\tglLoadIdentity( );\n\n\t/* Set our perspective */\n\tgluPerspective( 45.0f, ratio, 0.1f, 100.0f );\n\n\t/* Make sure we're chaning the model view and not the projection */\n\tglMatrixMode( GL_MODELVIEW );\n\n\t/* Reset The View */\n\tglLoadIdentity( );\n\n\t/* Set The Blending Function For Translucency */\n\tglBlendFunc( GL_SRC_ALPHA, GL_ONE );\n\n\t/* This Will Clear The Background Color To Black */\n\tglClearColor( 0.0f, 0.0f, 0.0f, 0.0f );\n\n\t/* Enables Clearing Of The Depth Buffer */\n\tglClearDepth( 1.0 );\n\n\t/* The Type Of Depth Test To Do */\n\tglDepthFunc( GL_LESS );\n\n\t/* Enables Depth Testing */\n\tglEnable( GL_DEPTH_TEST );\n\n\t/* Enables Smooth Color Shading */\n\tglShadeModel( GL_SMOOTH );\n \n\t/* Sets Max Vertices To 0 By Default */\n\tmaxver = 0;\n\t/* Load The First Object Into morph1 From File sphere.txt */\n\tobjload( \"/rd/sphere.bin\", &morph1 );\n\t/* Load The Second Object Into morph2 From File torus.txt */\n\tobjload( \"/rd/torus.bin\", &morph2 );\n\t/* Load The Third Object Into morph3 From File tube.txt */\n\tobjload( \"/rd/tube.bin\", &morph3 );\n\n\t/* Manually Reserve Ram For A 4th 486 Vertice Object (morph4) */\n\tobjallocate( &morph4, 486 );\n\t/* Loop Through All 468 Vertices */\n\tfor( i = 0; i < 486; i++ ) {\n\t\t/* Generate a random point in xyz space for each vertex */\n\t\t/* Values range from -7 to 7 */\n\t\tmorph4.points[i].x = (( float )( rand( ) % 14000 ) / 1000 ) - 7;\n\t\tmorph4.points[i].y = (( float )( rand( ) % 14000 ) / 1000 ) - 7;\n\t\tmorph4.points[i].z = (( float )( rand( ) % 14000 ) / 1000 ) - 7;\n\t}\n\n\t/* Load sphere.txt Object Into Helper (Used As Starting Point) */\n\tobjload( \"/rd/sphere.bin\", &helper );\n\t/* Source & Destination Are Set To Equal First Object (morph1) */\n\tsour = dest = &morph1;\n\n\treturn( TRUE );\n}\n\nvoid draw_gl(void) {\n \n\tGLfloat tx, ty, tz; /* Temp X, Y & Z Variables */\n\tvertex q; /* Holds Returned Calculated Values For One Vertex */\n\tint i; /* Simple Looping Variable */\n\n\t/* Clear The Screen And The Depth Buffer */\n\tglClear( GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT );\n\t/* Reset The View */\n\tglLoadIdentity( );\n\t/* Translate The The Current Position To Start Drawing */\n\tglTranslatef( cx, cy, cz );\n\t/* Rotate On The X Axis By xrot */\n\tglRotatef( xrot, 1.0f, 0.0f, 0.0f );\n\t/* Rotate On The Y Axis By yrot */\n\tglRotatef( yrot, 0.0f, 1.0f, 0.0f );\n\t/* Rotate On The Z Axis By zrot */\n\tglRotatef( zrot, 0.0f, 0.0f, 1.0f );\n\n\t/* Increase xrot,yrot & zrot by xspeed, yspeed & zspeed */\n\txrot += xspeed;\n\tyrot += yspeed;\n\tzrot += zspeed;\n\n\t/* Begin Drawing Points */\n\tglBegin( GL_POINTS );\n\t/* Loop Through All The Verts Of morph1 (All Objects Have\n\t * * The Same Amount Of Verts For Simplicity, Could Use maxver Also)\n\t * */\n\tfor( i = 0; i < morph1.verts; i++ ) {\n\t\t/* If morph Is True Calculate Movement Otherwise Movement=0 */\n\t\tif ( morph )\n\t\t\tq = calculate( i );\n\t\telse\n\t\t\tq.x = q.y = q.z = 0.0f;\n\n\t\t/* Subtract the calculated unitx from the point's xyz coords */\n\t\thelper.points[i].x -= q.x;\n\t\thelper.points[i].y -= q.y;\n\t\thelper.points[i].z -= q.z;\n\n\t\t/* Set the temp xyz vars the the helper's xyz vars */\n\t\ttx = helper.points[i].x;\n\t\tty = helper.points[i].y;\n\t\ttz = helper.points[i].z;\n\n\t\t/* Set Color To A Bright Shade Of Off Blue */\n\t\tglColor3f( 0.0f, 1.0f, 1.0f );\n\t\t/* Draw A Point At The Current Temp Values (Vertex) */\n\t\tglVertex3f( tx, ty, tz );\n\t\t/* Darken Color A Bit */\n\t\tglColor3f( 0.0f, 0.5f, 1.0f );\n\t\t/* Calculate Two Positions Ahead */\n\t\ttx -= 2.0f * q.x;\n\t\tty -= 2.0f * q.y;\n\t\ttz -= 2.0f * q.z;\n\n\t\t/* Draw A Second Point At The Newly Calculate Position */\n\t\tglVertex3f( tx, ty, tz );\n\t\t/* Set Color To A Very Dark Blue */\n\t\tglColor3f( 0.0f, 0.0f, 1.0f );\n\n\t\t/* Calculate Two More Positions Ahead */\n\t\ttx -= 2.0f * q.x;\n\t\tty -= 2.0f * q.y;\n\t\ttz -= 2.0f * q.z;\n\n\t\t/* Draw A Third Point At The Second New Position */\n\t\tglVertex3f( tx, ty, tz );\n\t}\n\tglEnd( );\n\n\t/* If We're Morphing And We Haven't Gone Through All 200 Steps\n\t * Increase Our Step Counter\n\t * Otherwise Set Morphing To False, Make Source=Destination And\n\t * Set The Step Counter Back To Zero.\n\t */\n\t\n\tif( morph && step <= steps ) {\n\t\tstep++;\n\t}\n\telse {\n\t\tmorph = FALSE;\n\t\tsour = dest;\n\t\tstep = 0;\n\t}\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n#define NOT_LAST (cond.buttons & last)\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tuint16\tlast = CONT_A;\n\n\txrot = yrot = zrot = 0.0f;\n\txspeed = yspeed = zspeed = 0.0f;\n\n\t/* Initialize KOS */\n\tpvr_init(¶ms);\n\n\tprintf(\"nehe26 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\tinitGL();\n\n\tc = maple_first_controller();\n\n\tprintf(\"Entering main loop\\n\");\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n if (!(cond.buttons & CONT_A) && !morph && NOT_LAST) {\n morph = TRUE;\n\t\t\tdest = &morph1;\n\t\t\tlast = CONT_A;\n\t\t}\n if (!(cond.buttons & CONT_X) && !morph && NOT_LAST) {\n morph = TRUE;\n\t\t\tdest = &morph2;\n\t\t\tlast = CONT_X;\n\t\t}\n if (!(cond.buttons & CONT_Y) && !morph && NOT_LAST) {\n morph = TRUE;\n\t\t\tdest = &morph3;\n\t\t\tlast = CONT_Y;\n\t\t}\n if (!(cond.buttons & CONT_B) && !morph && NOT_LAST) {\n morph = TRUE;\n\t\t\tdest = &morph4;\n\t\t\tlast = CONT_B;\n\t\t}\n if (!(cond.buttons & CONT_DPAD_UP))\n xspeed -= 0.01f;\n if (!(cond.buttons & CONT_DPAD_DOWN))\n xspeed += 0.01f;\n if (!(cond.buttons & CONT_DPAD_LEFT))\n yspeed -= 0.01f;\n if (!(cond.buttons & CONT_DPAD_RIGHT))\n yspeed += 0.01f;\n\t\tif (cond.rtrig > 0x7f)\n\t\t\tzspeed += 0.01f;\n\t\tif (cond.ltrig > 0x7f)\n\t\t\tzspeed -= 0.01f;\n\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw the \"scene\" */\n\t\tglKosFinishList();\n\t\tdraw_gl();\n\t\t\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\tQuit(0);\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5580110549926758,
"alphanum_fraction": 0.6270717978477478,
"avg_line_length": 14.69565200805664,
"blob_id": "43109d8868f3e283d4a6a9136c155aaf6e759878",
"content_id": "02f2cb781f531d83247ac3d224ee9aac9419d8a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 23,
"path": "/include/arch/ps2/arch/rtc.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/rtc.h\n (c)2000-2002 Dan Potter\n\n $Id: rtc.h,v 1.1 2002/10/26 08:04:00 bardtx Exp $\n\n */\n\n#ifndef __ARCH_RTC_H\n#define __ARCH_RTC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <time.h>\n\n/* Returns the date/time value as a UNIX epoch time stamp */\ntime_t rtc_unix_secs();\n\n__END_DECLS\n\n#endif\t/* __ARCH_RTC_H */\n\n"
},
{
"alpha_fraction": 0.6035503149032593,
"alphanum_fraction": 0.6094674468040466,
"avg_line_length": 14.272727012634277,
"blob_id": "b6008e843a11d740ed68fc8c2b776ff1291ff919",
"content_id": "a153e1af58464218e2b26ba7c5fc16a624384e90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 169,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 11,
"path": "/utils/gba-crcfix/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "\nCFLAGS = -O2 -g -Wall -DINLINE=inline #-g#\nLDFLAGS = -s -g #-g\n\nTARGET=gba-crcfix\nOBJS=gba-crcfix.o\n\nall: $(TARGET)\n$(TARGET): $(OBJS)\n\nclean:\n\trm -f $(TARGET) $(OBJS)\n"
},
{
"alpha_fraction": 0.5645805597305298,
"alphanum_fraction": 0.5872170329093933,
"avg_line_length": 14.957447052001953,
"blob_id": "922a0e95dc1861d546100c49497a57ed8dea4b8d",
"content_id": "a0a8531bddc5e2708981a40acf611b862f7009b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 751,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 47,
"path": "/examples/dreamcast/sound/hello-ogg/display.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#define XPOS_INIT 1\n#define YPOS_INIT 1\n#define SCREENWIDTH 640\n\nint disp_xpos=XPOS_INIT;\nint disp_ypos=YPOS_INIT;\n\nvoid printpos_d(int xpos, int ypos, char *str)\n{\n\tint offset;\n\tchar current;\n\twhile(*str)\n\t{\n\t\toffset = (xpos*12) + ((ypos* (24+4)) * SCREENWIDTH);\n\t\tcurrent=*str++;\n\t\tif(current != '\\n')\n\t\t{\n\t\t\tbfont_draw(vram_s + offset,SCREENWIDTH, 0, current);\n\t\t\txpos++;\n\t\t}\n\t\telse\n\t\t{\n\t\t\txpos = XPOS_INIT;\n\t\t\typos ++;\n\t\t}\n\t}\n}\nvoid print_d(char *str)\n{\n\tint offset;\n\tchar current;\n\twhile(*str)\n\t{\n\t\toffset = (disp_xpos*12) + ((disp_ypos* (24+4)) * SCREENWIDTH);\n\t\tcurrent=*str++;\n\t\tif(current != '\\n')\n\t\t{\n\t\t\tbfont_draw(vram_s + offset,SCREENWIDTH, 0, current);\n\t\t\tdisp_xpos++;\n\t\t}\n\t\telse\n\t\t{\n\t\t\tdisp_xpos = XPOS_INIT;\n\t\t\tdisp_ypos ++;\n\t\t}\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.5950362086296082,
"alphanum_fraction": 0.6107616424560547,
"avg_line_length": 22.897058486938477,
"blob_id": "e2aa7131227cfe588f653d248b1046a9bccaf192",
"content_id": "9529c7b3dabec2bb57e1e1e54848dafa5786855c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 14626,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 612,
"path": "/kernel/arch/dreamcast/fs/fs_vmu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n fs_vmu.c\n Copyright (C)2003 Dan Potter\n\n*/\n\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <malloc.h>\n#include <time.h>\n#include <arch/types.h>\n#include <kos/mutex.h>\n#include <dc/fs_vmu.h>\n#include <dc/vmufs.h>\n#include <dc/maple.h>\n#include <dc/maple/vmu.h>\n#include <sys/queue.h>\n\nCVSID(\"$Id: fs_vmu.c,v 1.4 2003/07/31 00:48:42 bardtx Exp $\");\n\n/*\n\nThis is the vmu filesystem module. Because there are no directories on vmu's\nit's pretty simple, however the filesystem uses a seperate directory for each\nof the vmu slots, so if vmufs were mounted on /vmu, /vmu/a1/ is the dir for \nslot 1 on port a, and /vmu/c2 is slot 2 on port c, etc.\n\nAt the moment this FS is kind of a hack because of the simplicity (and weirdness)\nof the VMU file system. For one, all files must be pretty small, so it loads\nand caches the entire file on open. For two, all files are a multiple of 512\nbytes in size (no way around this one). On top of it all, files may have an \nobnoxious header and you can't just read and write them with abandon like\na normal file system. We'll have to find ways around this later on, but for\nnow it gives the file data to you raw.\n\nNote: this new version now talks directly to the vmufs module and doesn't do\nany block-level I/O anymore. This layer and that one are interchangeable\nand may be used pretty much simultaneously in the same program.\n\n*/\n\n/* Enable this if you want copious debug output */\n/* #define VMUFS_DEBUG */\n\n#define VMU_DIR \t0\n#define VMU_FILE\t1\n#define VMU_ANY\t\t-1\t/* Used for checking validity */\n\n/* File handles */\ntypedef struct vmu_fh_str {\n\tuint32\t\tstrtype;\t\t/* 0==dir, 1==file */\n\tTAILQ_ENTRY(vmu_fh_str)\tlistent;\t/* list entry */\n\n\tint\t\tmode;\t\t\t/* mode the file was opened with */\n\tchar\t\tpath[17];\t\t/* full path of the file */\n\tchar\t\tname[13];\t\t/* name of the file */\n\toff_t\t\tloc;\t\t\t/* current position in the file (bytes) */\n\tmaple_device_t\t* dev;\t\t\t/* maple address of the vmu to use */\n\tint\t\tfilesize;\t\t/* file length from dirent (in 512-byte blks) */\n\tuint8\t\t*data;\t\t\t/* copy of the whole file */\n} vmu_fh_t;\n\n/* Directory handles */\ntypedef struct vmu_dh_str {\n\tuint32\t\tstrtype;\t\t/* 0==dir, 1==file */\n\tTAILQ_ENTRY(vmu_dh_str) listent;\t/* list entry */\n\n\tint\t\trootdir;\t\t/* 1 if we're reading /vmu */\n\tdirent_t\tdirent;\t\t\t/* Dirent to pass back */\n\tvmu_dir_t\t* dirblocks;\t\t/* Copy of all directory blocks */\n\tuint16\t\tentry;\t\t\t/* Current dirent */\n\tuint16\t\tdircnt;\t\t\t/* Count of dir entries */\t\n\tmaple_device_t\t* dev;\t\t\t/* VMU address */\n} vmu_dh_t;\n\n/* Linked list of open files (controlled by \"mutex\") */\nTAILQ_HEAD(vmu_fh_list, vmu_fh_str) vmu_fh;\n\n/* Thread mutex for vmu_fh access */\nstatic mutex_t * fh_mutex;\n\n\n/* Take a VMUFS path and return the requested address */\nstatic maple_device_t * vmu_path_to_addr(const char *p) {\n\tchar port;\n\n\tif (p[0] != '/') return NULL;\t\t\t/* Only absolute paths */\n\tport = p[1] | 32;\t\t\t\t/* Lowercase the port */\n\tif (port < 'a' || port > 'd') return NULL;\t/* Unit A-D, device 0-5 */\n\tif (p[2] < '0' || p[2] > '5') return NULL;\n\t\n\treturn maple_enum_dev(port - 'a', p[2] - '0');\n}\n\n/* Open the fake vmu root dir /vmu */\nvmu_fh_t *vmu_open_vmu_dir() {\n\tint p, u;\n\tunsigned int num = 0;\n\tchar names[MAPLE_PORT_COUNT * MAPLE_UNIT_COUNT][2];\n\tvmu_dh_t *dh;\n\tmaple_device_t * dev;\n\n\t/* Determine how many VMUs are connected */\n\tfor (p=0; p<MAPLE_PORT_COUNT; p++) {\n\t\tfor (u=0; u<MAPLE_UNIT_COUNT; u++) {\n\t\t\tdev = maple_enum_dev(p, u);\n\t\t\tif (!dev) continue;\n\n\t\t\tif (dev->info.functions & MAPLE_FUNC_MEMCARD) {\n\t\t\t\tnames[num][0] = p+'a';\n\t\t\t\tnames[num][1] = u+'0';\n\t\t\t\tnum++;\n#ifdef VMUFS_DEBUG\n\t\t\t\tdbglog(DBG_KDEBUG, \"vmu_open_vmu_dir: found memcard (%c%d)\\n\", 'a'+p, u);\n#endif\n\t\t\t}\n\t\t}\n\t}\n\n#ifdef VMUFS_DEBUG\n\tdbglog(DBG_KDEBUG, \"# of memcards found: %d\\n\", num);\n#endif\n\n\tdh = malloc(sizeof(vmu_dh_t));\n\tmemset(dh, 0, sizeof(vmu_dh_t));\n\tdh->strtype = VMU_DIR;\n\tdh->dirblocks = malloc(num * sizeof(vmu_dir_t));\n\tif (!dh->dirblocks) {\n\t\tfree(dh);\n\t\treturn NULL;\n\t}\n\tdh->rootdir = 1;\n\tdh->entry = 0;\n\tdh->dircnt = num;\n\tdh->dev = NULL;\n\n\t/* Create the directory entries */\n\tfor (u=0; u<num; u++) {\n\t\tmemset(dh->dirblocks + u, 0, sizeof(vmu_dir_t));\t/* Start in a clean room */\n\t\tmemcpy(dh->dirblocks[u].filename, names+u, 2);\n\t\tdh->dirblocks[u].filetype = 0xff;\n\t}\n\treturn (vmu_fh_t *)dh;\n}\n\n/* opendir function */\nstatic vmu_fh_t *vmu_open_dir(maple_device_t * dev) {\n\tvmu_dir_t\t* dirents;\n\tint\t\tdircnt;\n\tvmu_dh_t\t* dh;\n\n\t/* Read the VMU's directory */\n\tif (vmufs_readdir(dev, &dirents, &dircnt) < 0)\n\t\treturn NULL;\n\n\t/* Allocate a handle for the dir blocks */\n\tdh = malloc(sizeof(vmu_dh_t));\n\tdh->strtype = VMU_DIR;\n\tdh->dirblocks = dirents;\n\tdh->rootdir = 0;\n\tdh->entry = 0;\n\tdh->dircnt = dircnt;\n\tdh->dev = dev;\n\t\n\treturn (vmu_fh_t *)dh;\n}\n\n/* openfile function */\nstatic vmu_fh_t *vmu_open_file(maple_device_t * dev, const char *path, int mode) {\n\tvmu_fh_t\t* fd;\t\t/* file descriptor */\n\tint\t\trealmode, rv;\n\tvoid\t\t* data;\n\tint\t\tdatasize;\n\n\t/* Malloc a new fh struct */\n\tfd = malloc(sizeof(vmu_fh_t));\n\n\t/* Fill in the filehandle struct */\n\tfd->strtype = VMU_FILE;\n\tfd->mode = mode;\n\tstrncpy(fd->path, path, 16);\n\tstrncpy(fd->name, path + 4, 12);\n\tfd->loc = 0;\n\tfd->dev = dev;\n\n\t/* What mode are we opening in? If we're reading or writing without O_TRUNC\n\t then we need to read the old file if there is one. */\n\trealmode = mode & O_MODE_MASK;\n\tif (realmode == O_RDONLY || ((realmode == O_RDWR || realmode == O_WRONLY) && !(mode & O_TRUNC))) {\n\t\t/* Try to open it */\n\t\trv = vmufs_read(dev, fd->name, &data, &datasize);\n\n\t\tif (rv < 0) {\n\t\t\tif (realmode == O_RDWR || realmode == O_WRONLY) {\n\t\t\t\t/* In some modes failure is ok -- just setup a blank first block. */\n\t\t\t\tdata = malloc(512);\n\t\t\t\tdatasize = 512;\n\t\t\t\tmemset(data, 0, 512);\n\t\t\t} else {\n\t\t\t\tfree(fd);\n\t\t\t\treturn NULL;\n\t\t\t}\n\t\t}\n\t} else {\n\t\t/* We're writing with truncate... just setup a blank first block. */\n\t\tdata = malloc(512);\n\t\tdatasize = 512;\n\t\tmemset(data, 0, 512);\n\t}\n\n\tfd->data = (uint8 *)data;\n\tfd->filesize = datasize/512;\n\n\tif (fd->filesize == 0) {\n\t\tdbglog(DBG_WARNING, \"VMUFS: can't open zero-length file %s\\n\", path);\n\t\tfree(fd);\n\t\treturn NULL;\n\t}\n\t\n\treturn fd;\n}\n\n/* open function */\nstatic void * vmu_open(vfs_handler_t * vfs, const char *path, int mode) {\n\tmaple_device_t\t* dev;\t\t/* maple bus address of the vmu unit */\n\tvmu_fh_t\t*fh;\n\n\tif (!*path || (path[0] == '/' && !path[1])) {\n\t\t/* /vmu should be opened */\n\t\tfh = vmu_open_vmu_dir();\n\t} else {\n\t\t/* Figure out which vmu slot is being opened */\n\t\tdev = vmu_path_to_addr(path);\n\t\t/* printf(\"VMUFS: card address is %02x\\n\", addr); */\n\t\tif (dev == NULL) return 0;\n\n\t\t/* Check for open as dir */\n\t\tif (strlen(path) == 3 || (strlen(path) == 4 && path[3] == '/')) {\n\t\t\tif (!(mode & O_DIR)) return 0;\n\t\t\tfh = vmu_open_dir(dev);\n\t\t} else {\n\t\t\tif (mode & O_DIR) return 0;\n\t\t\tfh = vmu_open_file(dev, path, mode);\n\t\t}\n\t}\n\tif (fh == NULL) return 0;\n\n\t/* link the fh onto the top of the list */\n\tmutex_lock(fh_mutex);\n\tTAILQ_INSERT_TAIL(&vmu_fh, fh, listent);\n\tmutex_unlock(fh_mutex);\n\n\treturn (void *)fh;\n}\n\n/* Verify that a given hnd is actually in the list */\nstatic int vmu_verify_hnd(void * hnd, int type) {\n\tvmu_fh_t\t*cur;\n\tint\t\trv;\n\n\trv = 0;\n\t\n\tmutex_lock(fh_mutex);\n\tTAILQ_FOREACH(cur, &vmu_fh, listent) {\n\t\tif ((void *)cur == hnd) {\n\t\t\trv = 1;\n\t\t\tbreak;\n\t\t}\n\t}\n\tmutex_unlock(fh_mutex);\n\t\n\tif (rv)\n\t\treturn type == VMU_ANY ? 1 : (cur->strtype == type);\n\telse\n\t\treturn 0;\n}\n\n/* write a file out before closing it: we aren't perfect on error handling here */\nstatic int vmu_write_close(void * hnd) {\n\tvmu_fh_t\t*fh;\n\n\tfh = (vmu_fh_t*)hnd;\n\treturn vmufs_write(fh->dev, fh->name, fh->data, fh->filesize*512, VMUFS_OVERWRITE);\n}\n\n/* close a file */\nstatic void vmu_close(void * hnd) {\n\tvmu_fh_t *fh;\n\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(hnd, VMU_ANY))\n\t\treturn;\n\n\tfh = (vmu_fh_t *)hnd;\n\n\tswitch (fh->strtype) {\n\tcase VMU_DIR: {\n\t\tvmu_dh_t * dir = (vmu_dh_t *)hnd;\n\t\tif (dir->dirblocks)\n\t\t\tfree(dir->dirblocks);\n\t\tbreak;\n\t}\n\n\tcase VMU_FILE:\n\t\tif ((fh->mode & O_MODE_MASK) == O_WRONLY ||\n\t\t\t(fh->mode & O_MODE_MASK) == O_RDWR)\n\t\t{\n\t\t\tvmu_write_close(hnd);\n\t\t}\n\t\tfree(fh->data);\n\t\tbreak;\n\t\n\t}\n\t/* Look for the one to get rid of */\n\tmutex_lock(fh_mutex);\n\tTAILQ_REMOVE(&vmu_fh, fh, listent);\n\tmutex_unlock(fh_mutex);\n\n\tfree(fh);\n}\n\n/* read function */\nstatic ssize_t vmu_read(void * hnd, void *buffer, size_t cnt) {\n\tvmu_fh_t *fh;\n\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(hnd, VMU_FILE))\n\t\treturn -1;\n\n\tfh = (vmu_fh_t *)hnd;\n\n\t/* make sure we're opened for reading */\n\tif ((fh->mode & O_MODE_MASK) != O_RDONLY && (fh->mode & O_MODE_MASK) != O_RDWR)\n\t\treturn 0;\n\n\t/* Check size */\n\tcnt = (fh->loc + cnt) > (fh->filesize*512) ?\n\t\t(fh->filesize*512 - fh->loc) : cnt;\n\n\t/* Reads past EOF return 0 */\n\tif ((long)cnt < 0)\n\t\treturn 0;\n\n\t/* Copy out the data */\n\tmemcpy(buffer, fh->data+fh->loc, cnt);\n\tfh->loc += cnt;\n\t\n\treturn cnt;\n}\n\n/* write function */\nstatic ssize_t vmu_write(void * hnd, const void *buffer, size_t cnt) {\n\tvmu_fh_t\t*fh;\n\tvoid\t\t*tmp;\n\tint\t\tn;\n\n\t/* Check the handle we were given */\n\tif (!vmu_verify_hnd(hnd, VMU_FILE))\n\t\treturn -1;\n\n\tfh = (vmu_fh_t *)hnd;\n\n\t/* Make sure we're opened for writing */\n\tif ((fh->mode & O_MODE_MASK) != O_WRONLY && (fh->mode & O_MODE_MASK) != O_RDWR)\n\t\treturn -1;\n\n\t/* Check to make sure we have enough room in data */\n\tif (fh->loc + cnt > fh->filesize * 512) {\n\t\t/* Figure out the new block count */\n\t\tn = ((fh->loc + cnt) - (fh->filesize * 512));\n\t\tif (n & 511)\n\t\t\tn = (n+512) & ~511;\n\t\tn = n / 512;\n\n#ifdef VMUFS_DEBUG\n\t\tdbglog(DBG_KDEBUG, \"VMUFS: extending file's filesize by %d\\n\", n);\n#endif\n\t\t\n\t\t/* We alloc another 512*n bytes for the file */\n\t\ttmp = realloc(fh->data, (fh->filesize + n) * 512);\n\t\tif (!tmp) {\n\t\t\tdbglog(DBG_ERROR, \"VMUFS: unable to realloc another 512 bytes\\n\");\n\t\t\treturn -1;\n\t\t}\n\n\t\t/* Assign the new pointer and clear out the new space */\n\t\tfh->data = tmp;\n\t\tmemset(fh->data + fh->filesize * 512, 0, 512*n);\n\t\tfh->filesize += n;\n\t}\n\n\t/* insert the data in buffer into fh->data at fh->loc */\n#ifdef VMUFS_DEBUG\n\tdbglog(DBG_KDEBUG, \"VMUFS: adding %d bytes of data at loc %d (%d avail)\\n\",\n\t\tcnt, fh->loc, fh->filesize * 512);\n#endif\n\tmemcpy(fh->data + fh->loc, buffer, cnt);\n\tfh->loc += cnt;\n\n\treturn cnt;\n}\n\n/* mmap a file */\n/* note: writing past EOF will invalidate your pointer */\nstatic void *vmu_mmap(void * hnd) {\n\tvmu_fh_t *fh;\n\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(hnd, VMU_FILE))\n\t\treturn NULL;\n\n\tfh = (vmu_fh_t *)hnd;\n\n\treturn fh->data;\n}\n\n/* Seek elsewhere in a file */\nstatic off_t vmu_seek(void * hnd, off_t offset, int whence) {\n\tvmu_fh_t *fh;\n\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(hnd, VMU_FILE))\n\t\treturn -1;\n\n\tfh = (vmu_fh_t *)hnd;\n\n\t/* Update current position according to arguments */\n\tswitch (whence) {\n\t\tcase SEEK_SET: break;\n\t\tcase SEEK_CUR: offset += fh->loc; break;\n\t\tcase SEEK_END: offset = fh->filesize * 512 - offset; break;\n\t\tdefault:\n\t\t\treturn -1;\n\t}\n\t\n\t/* Check bounds; allow seek past EOF. */\n\tif (offset < 0) offset = 0;\n\tfh->loc = offset;\n\t\n\treturn fh->loc;\n}\n\n/* tell the current position in the file */\nstatic off_t vmu_tell(void * hnd) {\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(hnd, VMU_FILE))\n\t\treturn -1;\n\n\treturn ((vmu_fh_t *) hnd)->loc;\n}\n\n/* return the filesize */\nstatic size_t vmu_total(void * fd) {\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(fd, VMU_FILE))\n\t\treturn -1;\n\n\t/* note that all filesizes are multiples of 512 for the vmu */\n\treturn (((vmu_fh_t *) fd)->filesize) * 512;\n}\n\n/* read a directory handle */\nstatic dirent_t *vmu_readdir(void * fd) {\n\tvmu_dh_t\t*dh;\n\tvmu_dir_t\t*dir;\n\n\t/* Check the handle */\n\tif (!vmu_verify_hnd(fd, VMU_DIR)) {\n\t\treturn NULL;\n\t}\n\n\tdh = (vmu_dh_t*)fd;\n\n\t/* printf(\"VMUFS: readdir on entry %d of %d\\n\", dh->entry, dh->dircnt); */\n\n\t/* Check if we have any entries left */\n\tif (dh->entry >= dh->dircnt)\n\t\treturn NULL;\n\t\n\t/* printf(\"VMUFS: reading non-null entry %d\\n\", dh->entry); */\n\t\t\n\t/* Ok, extract it and fill the dirent struct */\n\tdir = dh->dirblocks + dh->entry;\n\tif (dh->rootdir)\n\t\tdh->dirent.size = -1;\n\telse\n\t\tdh->dirent.size = dir->filesize*512;\n\tstrncpy(dh->dirent.name, dir->filename, 12);\n\tdh->dirent.name[12] = 0;\n\tdh->dirent.time = 0;\t/* FIXME */\n\tdh->dirent.attr = 0;\n\n\t/* Move to the next entry */\n\tdh->entry++;\n\n\treturn &dh->dirent;\n}\n\n/* Delete a file */\nstatic int vmu_unlink(vfs_handler_t * vfs, const char *path) {\n\tmaple_device_t\t* dev = NULL;\t/* address of VMU */\n\n\t/* convert path to valid VMU address */\n\tdev = vmu_path_to_addr(path);\n\tif (dev == NULL) {\n\t\tdbglog(DBG_ERROR, \"VMUFS: vmu_unlink on invalid path '%s'\\n\", path);\n\t\treturn -1;\n\t}\n\n\treturn vmufs_delete(dev, path + 4);\n}\n\nstatic int vmu_stat(vfs_handler_t * vfs, const char * fn, stat_t * rv) {\n\tmaple_device_t * dev;\n\n\tif (rv == NULL) {\n\t\tdbglog(DBG_ERROR, \"vmu_stat: null output pointer\\n\");\n\t\treturn -1;\n\t}\n\t\n\t/* The only thing we can stat right now is full VMUs, and what that\n\t will get you is a count of free blocks in \"size\". */\n\tdev = vmu_path_to_addr(fn);\n\tif (dev == NULL) {\n\t\tdbglog(DBG_ERROR, \"vmu_stat: couldn't resolve VMU name '%s'\\n\", fn);\n\t\treturn -1;\n\t}\n\n\t/* Get the number of free blocks */\n\trv->size = vmufs_free_blocks(dev);\n\trv->dev = NULL;\n\trv->unique = 0;\n\trv->type = STAT_TYPE_DIR;\n\trv->attr = STAT_ATTR_RW;\n\trv->time = 0;\n\n\treturn (rv->size < 0) ? -1 : 0;\n}\n\n/* handler interface */\nstatic vfs_handler_t vh = {\n\t/* Name handler */\n\t{\n\t\t\"/vmu\",\t\t/* name */\n\t\t0,\t\t/* tbfi */\n\t\t0x00010000,\t/* Version 1.0 */\n\t\t0,\t\t/* flags */\n\t\tNMMGR_TYPE_VFS,\t/* VFS handler */\n\t\tNMMGR_LIST_INIT\n\t},\n\t0, NULL,\t/* In-kernel, privdata */\n\t\n\tvmu_open,\n\tvmu_close,\n\tvmu_read,\n\tvmu_write,\t/* the write function */\n\tvmu_seek,\t/* the seek function */\n\tvmu_tell,\n\tvmu_total,\n\tvmu_readdir,\t/* readdir */\n\tNULL,\t\t/* ioctl */\n\tNULL,\t\t/* rename/move */\n\tvmu_unlink,\t/* unlink */\t\t\n\tvmu_mmap,\t/* mmap */\n\tNULL,\t\t/* complete */\n\tvmu_stat,\t/* stat */\n\tNULL,\t\t/* mkdir */\n\tNULL\t\t/* rmdir */\n};\n\nint fs_vmu_init() {\n\tTAILQ_INIT(&vmu_fh);\n\tfh_mutex = mutex_create();\n\treturn nmmgr_handler_add(&vh.nmmgr);\n}\n\nint fs_vmu_shutdown() {\n\tvmu_fh_t * c, * n;\n\n\tc = TAILQ_FIRST(&vmu_fh);\n\twhile (c) {\n\t\tn = TAILQ_NEXT(c, listent);\n\t\t\n\t\tswitch (c->strtype) {\n\t\tcase VMU_DIR: {\n\t\t\tvmu_dh_t * dir = (vmu_dh_t *)c;\n\t\t\tfree(dir->dirblocks);\n\t\t\tbreak;\n\t\t}\n\n\t\tcase VMU_FILE:\n\t\t\tif ((c->mode & O_MODE_MASK) == O_WRONLY ||\n\t\t\t\t(c->mode & O_MODE_MASK) == O_RDWR)\n\t\t\t{\n\t\t\t\tdbglog(DBG_ERROR, \"fs_vmu_shutdown: still-open file '%s' not written!\\n\", c->path);\n\t\t\t}\n\t\t\tfree(c->data);\n\t\t\tbreak;\n\t\t}\n\n\t\tfree(c);\n\t\tc = n;\n\t}\n\t\n\tif (fh_mutex != NULL)\n\t\tmutex_destroy(fh_mutex);\n\tfh_mutex = NULL;\n\t\n\treturn nmmgr_handler_remove(&vh.nmmgr);\n}\n\n"
},
{
"alpha_fraction": 0.5894554853439331,
"alphanum_fraction": 0.6093344688415527,
"avg_line_length": 20.811321258544922,
"blob_id": "1b13087b7432a0cbfbc4f77e2c8cdaf1e32fe139",
"content_id": "35b42c9586de466506b5fb1b0651015365ce5a6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1157,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 53,
"path": "/kernel/thread/mutex.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n mutex.c\n (c)2002 Dan Potter\n*/\n\n/* Defines a mutex: these are just wrappers around count-1\n semaphore objects. */\n\n/**************************************/\n\n#include <kos/mutex.h>\n\nCVSID(\"$Id: mutex.c,v 1.2 2003/02/17 04:20:30 bardtx Exp $\");\n\n/**************************************/\n\n/* Create a mutex */\nmutex_t * mutex_create() {\n\treturn sem_create(1);\n}\n\n/* Destroy a mutex */\nvoid mutex_destroy(mutex_t * m) {\n\tsem_destroy(m);\n}\n\n/* Attempt to lock the mutex; if it's busy, then block */\nint mutex_lock(mutex_t * m) {\n\treturn sem_wait(m);\n}\n\n/* Attempt to lock the mutex; if it's busy and it takes longer than the\n timeout (milliseconds) then return an error. */\nint mutex_lock_timed(mutex_t * m, int timeout) {\n\treturn sem_wait_timed(m, timeout);\n}\n\n/* Check to see whether the mutex is available; note that this is not\n a threadsafe way to figure out if it _will_ be locked by the time you\n get to locking it. */\nint mutex_is_locked(mutex_t * m) {\n\treturn sem_count(m) <= 0;\n}\n\nint mutex_trylock(mutex_t * m) {\n\treturn sem_trywait(m);\n}\n\n/* Unlock the mutex */\nvoid mutex_unlock(mutex_t * m) {\n\tsem_signal(m);\n}\n\n"
},
{
"alpha_fraction": 0.49462366104125977,
"alphanum_fraction": 0.6236559152603149,
"avg_line_length": 13.307692527770996,
"blob_id": "1e474ad6646904bb9c5f88dd7bd263e9b0987a51",
"content_id": "7bc21de68a9e1b3401c6897294b4af56b51062c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/examples/dreamcast/kgl/nehe/nehe26/data/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# Kallistios - txt2bin Makefile\n# \n# (c)2002, Paul Boese\n#\n# $Id: Makefile,v 1.1 2002/02/23 05:20:36 axlen Exp $\n\nCC = gcc -Wall\n\nall:\n\t$(CC) -o txt2bin txt2bin.c\n\nclean:\n\t@rm txt2bin *.bin\n"
},
{
"alpha_fraction": 0.6474112272262573,
"alphanum_fraction": 0.6747967600822449,
"avg_line_length": 18,
"blob_id": "c2b163ebaae369ab66f7fc06228f23c92a53df2a",
"content_id": "6f247591f54505e64b40275826358666e8fbafa5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2337,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 123,
"path": "/kernel/libc/pthreads/pthread_cond.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <pthread.h>\n#include <errno.h>\n#include <assert.h>\n#include <sys/time.h>\n\n/* Condition Variable Initialization Attributes, P1003.1c/Draft 10, p. 96 */\n\nint pthread_condattr_init(pthread_condattr_t *attr) {\n\treturn 0;\n}\n\nint pthread_condattr_destroy(pthread_condattr_t *attr) {\n\treturn 0;\n}\n\nint pthread_condattr_getpshared(const pthread_condattr_t *attr, int *pshared) {\n\treturn 0;\n}\n\nint pthread_condattr_setpshared(pthread_condattr_t *attr, int pshared) {\n\treturn 0;\n}\n\n/* Initializing and Destroying a Condition Variable, P1003.1c/Draft 10, p. 87 */\n\nint pthread_cond_init(pthread_cond_t *cond, const pthread_condattr_t *attr) {\n\tassert( cond );\n\n\t*cond = cond_create();\n\tif (*cond)\n\t\treturn 0;\n\telse\n\t\treturn EAGAIN;\n}\n\nint pthread_cond_destroy(pthread_cond_t * cond) {\n\tassert( cond );\n\n\tcond_destroy(*cond);\n\n\treturn 0;\n}\n\n// XXX condvars made this way should probably be nuked at shutdown\n#define CHK_AND_CREATE \\\n\tif (*cond == PTHREAD_COND_INITIALIZER) { \\\n\t\tint rv = pthread_cond_init(cond, NULL); \\\n\t\tif (rv != 0) \\\n\t\t\treturn rv; \\\n\t}\n\n/* Broadcasting and Signaling a Condition, P1003.1c/Draft 10, p. 101 */\n\nint pthread_cond_signal(pthread_cond_t *cond) {\n\tassert( cond );\n\n\tCHK_AND_CREATE;\n\n\tcond_signal(*cond);\n\treturn 0;\n}\n\nint pthread_cond_broadcast(pthread_cond_t *cond) {\n\tassert( cond );\n\n\tCHK_AND_CREATE;\n\n\tcond_broadcast(*cond);\n\treturn 0;\n}\n\n/* Waiting on a Condition, P1003.1c/Draft 10, p. 105 */\n\nint pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex) {\n\tint rv;\n\n\tassert( cond );\n\tassert( mutex );\n\n\tCHK_AND_CREATE;\n\n\trv = cond_wait(*cond, *mutex);\n\n\t// XXX this probably isn't proper\n\tif (rv)\n\t\treturn EINVAL;\n\telse\n\t\treturn 0;\n}\n\nint pthread_cond_timedwait(pthread_cond_t *cond, pthread_mutex_t *mutex,\n\tconst struct timespec *abstime)\n{\n\tint rv, tmo;\n\tstruct timeval ctv;\n\n\tassert( cond );\n\tassert( mutex );\n\tassert( abstime );\n\n\tCHK_AND_CREATE;\n\n\t// We have to calculate this...\n\tgettimeofday(&ctv, NULL);\n\n\t// Milliseconds, Microseconds, Nanoseconds, oh my!\n\ttmo = abstime->tv_sec - ctv.tv_sec;\n\ttmo += abstime->tv_nsec / (1000*1000) - ctv.tv_usec / 1000;\n\tassert( tmo >= 0 );\n\n\tif (tmo == 0)\n\t\treturn ETIMEDOUT;\n\n\trv = cond_wait_timed(*cond, *mutex, tmo);\n\tif (rv >= 0)\n\t\treturn 0;\n\n\t// XXX this probably isn't proper\n\tif (errno == EAGAIN)\n\t\treturn ETIMEDOUT;\n\telse\n\t\treturn EINVAL;\n}\n"
},
{
"alpha_fraction": 0.46943971514701843,
"alphanum_fraction": 0.5730050802230835,
"avg_line_length": 29.205127716064453,
"blob_id": "a2fea2d1841d1d34704c06995d08efec81e0affa",
"content_id": "f843479fdb3d0f872bf07fec9bdb99a9baec81df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1220,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 39,
"path": "/examples/dreamcast/video/bfont/bfont.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "WINDOWS-1252",
"text": "/* Very simple test for bfont (and its various encodings) */\n\n#include <kos.h>\n\nint main(int argc, char **argv) {\n\tint x, y, o;\n\n\tfor (y=0; y<480; y++)\n\t\tfor (x=0; x<640; x++) {\n\t\t\tint c = (x ^ y) & 255;\n\t\t\tvram_s[y*640+x] = ((c >> 3) << 12)\n\t\t\t\t| ((c >> 2) << 5)\n\t\t\t\t| ((c >> 3) << 0);\n\t\t}\n\n\to = 20*640 + 20;\n\n\t/* Test with ISO8859-1 encoding */\n\tbfont_set_encoding(BFONT_CODE_ISO8859_1);\n\tbfont_draw_str(vram_s + o, 640, 1, \"Test of basic ASCII\"); o += 640*24;\n\tbfont_draw_str(vram_s + o, 640, 1, \"Parlez-vous français?\"); o += 640*24;\n\tbfont_draw_str(vram_s + o, 640, 0, \"Test of basic ASCII\"); o += 640*24;\n\tbfont_draw_str(vram_s + o, 640, 0, \"Parlez-vous français?\"); o += 640*24;\n\n\t/* Test with EUC encoding */\n\tbfont_set_encoding(BFONT_CODE_EUC);\n\tbfont_draw_str(vram_s + o, 640, 1, \"¤³¤ó¤Ë¤Á¤Ï EUC!\"); o += 640*24;\n\tbfont_draw_str(vram_s + o, 640, 0, \"¤³¤ó¤Ë¤Á¤Ï EUC!\"); o += 640*24;\n\n\t/* Test with Shift-JIS encoding */\n\tbfont_set_encoding(BFONT_CODE_SJIS);\n\tbfont_draw_str(vram_s + o, 640, 1, \"ƒAƒhƒŒƒX•ÏŠ· SJIS\"); o += 640*24;\n\tbfont_draw_str(vram_s + o, 640, 0, \"ƒAƒhƒŒƒX•ÏŠ· SJIS\"); o += 640*24;\n\n\t/* Pause to see the results */\n\tusleep(5*1000*1000);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5696594715118408,
"alphanum_fraction": 0.6439628601074219,
"avg_line_length": 16.83333396911621,
"blob_id": "73eca8c411d1f40fbaf43f8688bd39f6667891f1",
"content_id": "49f87adf1d3d05f4026ee0a7dbff14c8804100a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 18,
"path": "/examples/dreamcast/kgl/benchmarks/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/kgl/benchmarks/Makefile\n# (c)2001-2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/04/20 03:51:45 axlen Exp $\n\nall:\n\t$(MAKE) -C quadmark\n\t$(MAKE) -C trimark\n\nclean:\n\t$(MAKE) -C quadmark clean\n\t$(MAKE) -C trimark clean\n\t\t\ndist:\n\t$(MAKE) -C quadmark dist\n\t$(MAKE) -C trimark dist\n\n\n"
},
{
"alpha_fraction": 0.5542168617248535,
"alphanum_fraction": 0.6345381736755371,
"avg_line_length": 15.466666221618652,
"blob_id": "b36c6b1a199b028ef6ef2c9e9dacb663d93e752d",
"content_id": "eab74a53c28890f602a461a64d9279c6afd1c01d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 15,
"path": "/examples/dreamcast/sound/cdda/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/sound/cdda/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/07/17 15:14:16 axlen Exp $\n\nall:\n\t$(MAKE) -C basic_cdda\n\nclean:\n\t$(MAKE) -C basic_cdda clean\n\t\t\ndist:\n\t$(MAKE) -C basic_cdda dist\n\n\n"
},
{
"alpha_fraction": 0.6861042380332947,
"alphanum_fraction": 0.7022332549095154,
"avg_line_length": 46.411766052246094,
"blob_id": "4c07aabfafb9fda49a0eb8fe1b497e3c0a161184",
"content_id": "d7575c376625d45178120a05c23a38c1bc4541b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 17,
"path": "/environ_dreamcast.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS environment variable settings. These are the shared pieces\n# for the Dreamcast(tm) platform.\n\nexport KOS_CFLAGS=\"${KOS_CFLAGS} -ml -m4-single-only -fno-optimize-sibling-calls\"\nexport KOS_AFLAGS=\"${KOS_AFLAGS} -little\"\nexport KOS_LDFLAGS=\"${KOS_LDFLAGS} -ml -m4-single-only -Wl,-Ttext=0x8c010000\"\n\n# If we're building for DC, we need the ARM compiler paths as well.\nif [ x${KOS_ARCH} = xdreamcast ]; then\n\texport DC_ARM_CC=\"${DC_ARM_BASE}/bin/${DC_ARM_PREFIX}-gcc\"\n\texport DC_ARM_AS=\"${DC_ARM_BASE}/bin/${DC_ARM_PREFIX}-as\"\n\texport DC_ARM_AR=\"${DC_ARM_BASE}/bin/${DC_ARM_PREFIX}-ar\"\n\texport DC_ARM_OBJCOPY=\"${DC_ARM_BASE}/bin/${DC_ARM_PREFIX}-objcopy\"\n\texport DC_ARM_LD=\"${DC_ARM_BASE}/bin/${DC_ARM_PREFIX}-ld\"\n\texport DC_ARM_CFLAGS=\"-mcpu=arm7 -Wall -O2\"\n\texport DC_ARM_AFLAGS=\"-mcpu=arm7\"\nfi\n"
},
{
"alpha_fraction": 0.5902391076087952,
"alphanum_fraction": 0.6081250905990601,
"avg_line_length": 20.899606704711914,
"blob_id": "47db549f55ecf8b7234c88a1c7abd9ffb14b9103",
"content_id": "48c4daed7233e137e454a9d7f5de87770c83b5ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 11126,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 508,
"path": "/kernel/arch/dreamcast/fs/fs_dclnative.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/fs_dclnative.c\n Copyright (C)2003 Dan Potter\n\n Portions of various supporting modules are\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n \n*/\n\n\n#include <arch/dbgio.h>\n#include <dc/fs_dclnative.h>\n#include <kos/thread.h>\n#include <kos/sem.h>\n#include <kos/mutex.h>\n#include <kos/fs.h>\n#include <kos/net.h>\n\n#include <stdio.h>\n#include <ctype.h>\n#include <string.h>\n#include <malloc.h>\n\n#include \"dcload-commands.h\"\n#include \"dcload-net.h\"\n#include \"dcload-packet.h\"\n#include \"dcload-syscalls.h\"\n\nCVSID(\"$Id: fs_dclnative.c,v 1.1 2003/04/24 03:03:33 bardtx Exp $\");\n\n/*****************************************************************/\n/* Administrative details */\n\n/* dcload-ip variables used by all the modules */\nuint32\tdcln_our_ip;\nuint8\tdcln_our_mac[6];\nuint8\tdcln_pkt_buf[1600];\nuint32\tdcln_tool_ip;\nuint8\tdcln_tool_mac[6];\nuint16\tdcln_tool_port;\nint\tdcln_syscall_retval;\nunsigned char *dcln_syscall_data;\nint\tdcln_escape_loop;\n\n// #define DEBUG\n// #define DEBUG_VERBOSE\n\n/* This uses an addition to dc-load-ip 1.0.3 */\ntypedef struct {\n\tuint32\ttoolip;\n\tuint32\ttoolport;\n\tuint32\tourip;\n\tuint8\ttoolmac[6];\n} hostinfo_t;\nstatic void get_tool_ip() {\n\thostinfo_t hi;\n\n\t/* Call down to dcload-ip to get the tool IP/port. */\n\tdcloadsyscall(DCLOAD_GETHOSTINFO, &hi);\n\n\tdcln_tool_ip = hi.toolip;\n\tdcln_tool_port = hi.toolport;\n\tdcln_our_ip = hi.ourip;\n\tmemcpy(dcln_tool_mac, hi.toolmac, 6);\n\n#ifdef DEBUG\n\tprintf(\"tool = %08lx/%d, us = %08lx\\n\",\n\t\tdcln_tool_ip, dcln_tool_port, dcln_our_ip);\n#endif\n}\n\n/* Our output device. This is kind of a turbo hack, but it works since\n the DC only has one possible network device at once. */\nstatic netif_t * outdev = NULL;\n\n/* Packet buffers. We hold these buffers separately to make sure that\n we don't have to use malloc in an interrupt. It's possible, but it\n may fail and we may drop packets that way. As long as we're high\n enough priority, 64 ought to be plenty for anything. */\n#define PKT_BUF_CNT 64\nstatic int pkt_tail, pkt_head;\nstatic uint8 * pkt_bufs[PKT_BUF_CNT];\nstatic int pkt_sizes[PKT_BUF_CNT];\nstatic int pkt_cnt;\nstatic semaphore_t * pkt_sem;\n\n/* Network receive. This function will receive all ethernet packets\n destined for our MAC address and process them accordingly. What we'll\n really do here is just queue them up and wake our thread. */\nstatic net_input_func ni_old;\nstatic int dcln_input(netif_t * src, uint8 * pkt, int pktsize) {\n\tint idx = pkt_head;\n\n#ifdef DEBUG\n\tprintf(\"received a packet\\n\");\n#endif\n\n\t/* No more room to store packets... silently drop it */\n\tif (pkt_cnt >= PKT_BUF_CNT)\n\t\treturn 0;\n\n#ifdef DEBUG\n\tprintf(\"storing it as index %d\\n\", idx);\n#endif\n\n\tmemcpy(pkt_bufs[idx], pkt, pktsize);\n\tpkt_sizes[idx] = pktsize;\n\n\tpkt_head = (pkt_head + 1) % PKT_BUF_CNT;\n\tpkt_cnt++;\n\n\tsem_signal(pkt_sem);\n\tthd_schedule(1, 0);\n\n\treturn 0;\n}\n\n/* Transmission function. This is a super turbo hack, but it works. If\n we don't have an output device yet, just scan for the single present\n device and cache it. */\nvoid dcln_tx(uint8 * pkt, int len) {\n#ifdef DEBUG\n\tint i;\n\t\n\tprintf(\"transmitting a packet of len %d:\\n\", len);\n#ifdef DEBUG_VERBOSE\n\tfor (i=0; i<len; i++) {\n\t\tprintf(\"%02x \", pkt[i]);\n\t\tif (i && !(i % 16))\n\t\t\tprintf(\"\\n\");\n\t}\n\tprintf(\"\\n\");\n#endif\n#endif\n\t\n\toutdev->if_tx(outdev, pkt, len, NETIF_BLOCK);\n}\n\n/* Our network-receive loop. This thing wakes when there's something\n to process in the packet queue, and presumably will exit back to\n some code at some point. */\nvoid dcln_rx_loop() {\n\tint old, i;\n\t\n\twhile (!dcln_escape_loop) {\n\t\t/* Wait for some data to arrive */\n#ifdef DEBUG\n\t\tprintf(\"waiting for a packet\\n\");\n#endif\n\t\tsem_wait(pkt_sem);\n\n#ifdef DEBUG\n\t\tprintf(\"received a packet on slot %d w/size %d:\\n\", pkt_tail, pkt_sizes[pkt_tail]);\n#ifdef DEBUG_VERBOSE\n\t\tfor (i=0; i<pkt_sizes[pkt_tail]; i++) {\n\t\t\tprintf(\"%02x \", pkt_bufs[pkt_tail][i]);\n\t\t\tif (i && !(i % 16))\n\t\t\t\tprintf(\"\\n\");\n\t\t}\n\t\tprintf(\"\\n\");\n#endif\n#endif\n\n\t\t/* Process the incoming packet */\n\t\tdcln_process_pkt(pkt_bufs[pkt_tail], pkt_sizes[pkt_tail]);\n\n\t\t/* Pull it off the queue */\n\t\told = irq_disable();\n\t\tpkt_sizes[pkt_tail] = -1;\n\t\tpkt_tail = (pkt_tail + 1) % PKT_BUF_CNT;\n\t\tpkt_cnt--;\n\t\tirq_restore(old);\n\t}\n\tdcln_escape_loop = 0;\n}\n\n\n/*****************************************************************/\n/* Actual printk and VFS functionality */\n\n/* Mutex to make sure we don't try to perform more than one op at\n once. There's no technical reason against it, but the protocol\n doesn't assign tags to commands. */\nstatic mutex_t * mutex;\n\n/* Printk replacement */\nstatic dbgio_printk_func old_printk = 0;\nvoid dclnative_printk(const char *str) {\n\tif (irq_inside_int()) {\n\t\tdbgio_write_str(str);\n\t\treturn;\n\t}\n\tmutex_lock(mutex);\n\tdcln_write(1, str, strlen(str));\n\tmutex_unlock(mutex);\n}\n\nstatic char *dcload_path = NULL;\nuint32 dclnative_open(vfs_handler_t * vfs, const char *fn, int mode) {\n int hnd = 0;\n uint32 h;\n int dcload_mode = 0;\n\n mutex_lock(mutex);\n \n if (mode & O_DIR) {\n if (fn[0] == '\\0') {\n fn = \"/\";\n }\n hnd = dcln_opendir(fn);\n\tif (hnd) {\n\t if (dcload_path)\n\t\tfree(dcload_path);\n\t if (fn[strlen(fn) - 1] == '/') {\n\t\tdcload_path = malloc(strlen(fn)+1);\n\t\tstrcpy(dcload_path, fn);\n\t } else {\n\t\tdcload_path = malloc(strlen(fn)+2);\n\t\tstrcpy(dcload_path, fn);\n\t\tstrcat(dcload_path, \"/\");\n\t }\n\t}\n } else { /* hack */\n\tif ((mode & O_MODE_MASK) == O_RDONLY)\n\t dcload_mode = 0;\n\tif ((mode & O_MODE_MASK) == O_RDWR)\n\t dcload_mode = 2 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_WRONLY)\n\t dcload_mode = 1 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_APPEND)\n\t dcload_mode = 2 | 8 | 0x0200;\n\tif (mode & O_TRUNC)\n\t dcload_mode |= 0x0400;\n\thnd = dcln_open(fn, dcload_mode, 0644);\n\thnd++; /* KOS uses 0 for error, not -1 */\n }\n \n h = hnd;\n\n mutex_unlock(mutex);\n return h;\n}\n\nvoid dclnative_close(uint32 hnd) {\n mutex_lock(mutex);\n \n if (hnd) {\n\tif (hnd > 100) /* hack */\n\t dcln_closedir(hnd);\n\telse {\n\t hnd--; /* KOS uses 0 for error, not -1 */\n\t dcln_close(hnd);\n\t}\n }\n mutex_unlock(mutex);\n}\n\nssize_t dclnative_read(uint32 hnd, void *buf, size_t cnt) {\n ssize_t ret = -1;\n \n mutex_lock(mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dcln_read(hnd, buf, cnt);\n }\n \n mutex_unlock(mutex);\n\n return ret;\n}\n\nssize_t dclnative_write(uint32 hnd, const void *buf, size_t cnt) {\n ssize_t ret = -1;\n \t\n mutex_lock(mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dcln_write(hnd, buf, cnt);\n }\n\n mutex_unlock(mutex);\n return ret;\n}\n\noff_t dclnative_seek(uint32 hnd, off_t offset, int whence) {\n off_t ret = -1;\n\n mutex_lock(mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dcln_lseek(hnd, offset, whence);\n }\n\n mutex_unlock(mutex);\n return ret;\n}\n\noff_t dclnative_tell(uint32 hnd) {\n off_t ret = -1;\n \n mutex_lock(mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dcln_lseek(hnd, 0, SEEK_CUR);\n }\n\n mutex_unlock(mutex);\n return ret;\n}\n\nsize_t dclnative_total(uint32 hnd) {\n size_t ret = -1;\n size_t cur;\n\t\n mutex_lock(mutex);\n\t\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tcur = dcln_lseek(hnd, 0, SEEK_CUR);\n\tret = dcln_lseek(hnd, 0, SEEK_END);\n\tdcln_lseek(hnd, cur, SEEK_SET);\n }\n\t\n mutex_unlock(mutex);\n return ret;\n}\n\n/* Not thread-safe, but that's ok because neither is the FS */\nstatic dirent_t dirent;\ndirent_t *dclnative_readdir(uint32 hnd) {\n dirent_t *rv = NULL;\n dcload_dirent_t *dcld;\n dcload_stat_t filestat;\n char *fn;\n\n if (hnd < 100) return NULL; /* hack */\n\n mutex_lock(mutex);\n\n dcld = (dcload_dirent_t *)dcln_readdir(hnd);\n \n if (dcld) {\n\trv = &dirent;\n\tstrcpy(rv->name, dcld->d_name);\n\trv->size = 0;\n\trv->time = 0;\n\trv->attr = 0; /* what the hell is attr supposed to be anyways? */\n\n\tfn = malloc(strlen(dcload_path)+strlen(dcld->d_name)+1);\n\tstrcpy(fn, dcload_path);\n\tstrcat(fn, dcld->d_name);\n\n\tif (!dcln_stat(fn, &filestat)) {\n\t if (filestat.st_mode & S_IFDIR)\n\t\trv->size = -1;\n\t else\n\t\trv->size = filestat.st_size;\n\t rv->time = filestat.st_mtime;\n\t \n\t}\n\t\n\tfree(fn);\n }\n \n mutex_unlock(mutex);\n return rv;\n}\n\nint dclnative_rename(vfs_handler_t * vfs, const char *fn1, const char *fn2) {\n int ret;\n\n mutex_lock(mutex);\n\n /* really stupid hack, since I didn't put rename() in dcload */\n\n ret = dcln_link(fn1, fn2);\n\n if (!ret)\n\tret = dcln_unlink(fn1);\n\n mutex_unlock(mutex);\n return ret;\n}\n\nint dclnative_unlink(vfs_handler_t * vfs, const char *fn) {\n int ret;\n\n mutex_lock(mutex);\n\n ret = dcln_unlink(fn);\n\n mutex_unlock(mutex);\n return ret;\n}\n\n/* Pull all that together */\nstatic vfs_handler_t vh = {\n { \"/pc\" }, /* path prefix */\n 0, 0,\t\t/* In-kernel, no cacheing */\n NULL, /* privdata */\n VFS_LIST_INIT, /* linked list pointer */\n dclnative_open, \n dclnative_close,\n dclnative_read,\n dclnative_write,\n dclnative_seek,\n dclnative_tell,\n dclnative_total,\n dclnative_readdir,\n NULL, /* ioctl */\n dclnative_rename,\n dclnative_unlink,\n NULL /* mmap */\n};\n\n\n/*****************************************************************/\n/* Init/shutdown */\n\nint fs_dclnative_init() {\n\tint i;\n\tnetif_t * n;\n\n\t/* Find our output device */\n#ifdef DEBUG\n\tprintf(\"finding device:\\n\");\n#endif\n\tLIST_FOREACH(n, &net_if_list, if_list) {\n\t\tif (n->flags & NETIF_RUNNING) {\n\t\t\toutdev = n;\n\t\t\tbreak;\n\t\t}\n\t}\n\tif (!outdev) {\n\t\t/* Shouldn't happen... */\n\t\tdbgio_write_str(\"fs_dclnative_init: couldn't find an output device!\\n\");\n\t\treturn -1;\n\t}\n#ifdef DEBUG\n\tprintf(\"found device at %p (%s)\\n\", outdev, outdev->descr);\n#endif\n\n\t/* Setup our packet buffers */\n\tpkt_tail = pkt_head = 0;\n\tfor (i=0; i<PKT_BUF_CNT; i++) {\n\t\tpkt_bufs[i] = malloc(1600);\n\t\tpkt_sizes[i] = -1;\n\t}\n\tpkt_cnt = 0;\n\tpkt_sem = sem_create(0);\n\n\t/* Setup other misc variables */\n\tdcln_tool_ip = 0;\n\tmemset(dcln_tool_mac, 0, 6);\n\tdcln_tool_port = 0;\n\tmemcpy(dcln_our_mac, outdev->mac_addr, 6);\n\tdcln_syscall_retval = 0;\n\tdcln_escape_loop = 0;\n\n\tmutex = mutex_create();\n\n\t/* Get the tool IP/port */\n\tget_tool_ip();\n\n\t/* Enable us on the networking. I have no idea why this stupid\n\t line warns without the cast. */\n#ifdef DEBUG\n\tprintf(\"setting net target\\n\");\n#endif\n\tni_old = net_input_set_target((net_input_func)dcln_input);\n\n\t/* Hook printk */\n//#ifndef DEBUG\n//#else\n\tthd_sleep(1000);\n\tdclnative_printk(\"Test through dcl_native\\n\");\n\tdclnative_printk(\"switching printfs!\\n\");\n\told_printk = dbgio_set_printk(dclnative_printk);\n//#endif\n\n\t/* Register with VFS */\n\treturn fs_handler_add(\"/pc\", &vh);\n}\n\nint fs_dclnative_shutdown() {\n\tint i;\n\n\tdbgio_set_printk(old_printk);\n\n\tnet_input_set_target(ni_old);\n\t\n\tfor (i=0; i<PKT_BUF_CNT; i++)\n\t\tfree(pkt_bufs[i]);\n\n\tmutex_destroy(mutex);\n\tsem_destroy(pkt_sem);\n\n\toutdev = NULL;\n\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6467106342315674,
"alphanum_fraction": 0.668889582157135,
"avg_line_length": 30.252927780151367,
"blob_id": "d6330aa7f4acf1d3e72fe0a37f52ba9502c6e476",
"content_id": "3d81219e9c211609701fb2f25b83729153dab649",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 13346,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 427,
"path": "/include/arch/dreamcast/dc/maple.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/maple.h\n (C)2002 Dan Potter\n\n $Id: maple.h,v 1.10 2003/04/24 03:14:47 bardtx Exp $\n\n This new driver's design is based loosely on the LinuxDC maple\n bus driver.\n*/\n\n#ifndef __DC_MAPLE_H\n#define __DC_MAPLE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/queue.h>\n\n/* Enabling this line will add massive amounts of processing time\n to the maple system, but it can verify DMA errors */\n#define MAPLE_DMA_DEBUG\t0\n\n/* Enabling this will turn on intra-interrupt debugging messages, which\n can cause problems if you're using a dc-load console rather than raw\n serial output. Disable for normal usage. */\n#define MAPLE_IRQ_DEBUG 0\n\n/* Maple Bus registers */\n#define MAPLE_BASE\t0xa05f6c00\n#define MAPLE_DMAADDR\t(MAPLE_BASE+0x04)\n#define MAPLE_RESET2\t(MAPLE_BASE+0x10)\n#define MAPLE_ENABLE\t(MAPLE_BASE+0x14)\n#define MAPLE_STATE\t(MAPLE_BASE+0x18)\n#define MAPLE_SPEED\t(MAPLE_BASE+0x80)\n#define MAPLE_RESET1\t(MAPLE_BASE+0x8c)\n\n/* Some register define values */\n#define MAPLE_RESET2_MAGIC\t0\n#define MAPLE_ENABLE_ENABLED\t1\n#define MAPLE_ENABLE_DISABLED\t0\n#define MAPLE_STATE_IDLE\t0\n#define MAPLE_STATE_DMA\t\t1\n#define MAPLE_SPEED_2MBPS\t0\n#define MAPLE_SPEED_TIMEOUT(n)\t((n) << 16)\n#define MAPLE_RESET1_MAGIC\t0x6155404f\n\n/* Command and response codes */\n#define MAPLE_RESPONSE_FILEERR\t\t-5\n#define MAPLE_RESPONSE_AGAIN \t\t-4\n#define MAPLE_RESPONSE_BADCMD\t\t-3\n#define MAPLE_RESPONSE_BADFUNC\t\t-2\n#define MAPLE_RESPONSE_NONE\t\t-1\n#define MAPLE_COMMAND_DEVINFO\t\t1\n#define MAPLE_COMMAND_ALLINFO\t\t2\n#define MAPLE_COMMAND_RESET\t\t3\n#define MAPLE_COMMAND_KILL\t\t4\n#define MAPLE_RESPONSE_DEVINFO\t\t5\n#define MAPLE_RESPONSE_ALLINFO\t\t6\n#define MAPLE_RESPONSE_OK\t\t7\n#define MAPLE_RESPONSE_DATATRF\t\t8\n#define MAPLE_COMMAND_GETCOND\t\t9\n#define MAPLE_COMMAND_GETMINFO\t\t10\n#define MAPLE_COMMAND_BREAD\t\t11\n#define MAPLE_COMMAND_BWRITE\t\t12\n#define MAPLE_COMMAND_BSYNC\t\t13\n#define MAPLE_COMMAND_SETCOND\t\t14\n#define MAPLE_COMMAND_MICCONTROL 15\n\n/* Function codes; most sources claim that these numbers are little\n endian, and for all I know, they might be; but since it's a bitmask\n it doesn't really make much different. We'll just reverse our constants\n from the \"big-endian\" version. */\n#define MAPLE_FUNC_PURUPURU\t\t0x00010000\n#define MAPLE_FUNC_MOUSE\t\t0x00020000\n#define MAPLE_FUNC_CAMERA\t\t0x00080000\n#define MAPLE_FUNC_CONTROLLER\t\t0x01000000\n#define MAPLE_FUNC_MEMCARD\t\t0x02000000\n#define MAPLE_FUNC_LCD\t\t\t0x04000000\n#define MAPLE_FUNC_CLOCK\t\t0x08000000\n#define MAPLE_FUNC_MICROPHONE\t\t0x10000000\n#define MAPLE_FUNC_ARGUN\t\t0x20000000\n#define MAPLE_FUNC_KEYBOARD\t\t0x40000000\n#define MAPLE_FUNC_LIGHTGUN\t\t0x80000000\n\n/* Pre-define list/queue types */\nstruct maple_frame;\nTAILQ_HEAD(maple_frame_queue, maple_frame);\n\nstruct maple_driver;\nLIST_HEAD(maple_driver_list, maple_driver);\n\n/* Maple frame to be queued for transport */\ntypedef struct maple_frame {\n\t/* Send queue handle */\n\tTAILQ_ENTRY(maple_frame)\tframeq;\n\n\tint\tcmd;\t\t\t/* Command (defined above) */\n\tint\tdst_port, dst_unit;\t/* Maple destination address */\n\tint\tlength;\t\t\t/* Data transfer length in 32-bit words */\n\tvolatile int\tstate;\t\t\t/* Has this frame been sent / responded to? */\n\tvolatile int\tqueued;\t\t\t/* Are we on the queue? */\n\n\tvoid\t*send_buf;\t\t/* The data which will be sent (if any) */\n\tuint8\t*recv_buf;\t\t/* Points into recv_buf_arr, but 32-byte aligned */\n\n\tstruct maple_device\t*dev;\t/* Does this belong to a device? */\n\n\tvoid\t(*callback)(struct maple_frame *);\t/* Response callback */\n\n#if MAPLE_DMA_DEBUG\n\tuint8\trecv_buf_arr[1024 + 1024 + 32];\t\t/* Response receive area */\n#else\n\tuint8\trecv_buf_arr[1024 + 32];\t\t/* Response receive area */\n#endif\n} maple_frame_t;\n\n#define MAPLE_FRAME_VACANT\t0\t/* Ready to be used */\n#define MAPLE_FRAME_UNSENT\t1\t/* Ready to be sent */\n#define MAPLE_FRAME_SENT\t2\t/* Frame has been sent, but no response yet */\n#define MAPLE_FRAME_RESPONDED\t3\t/* Frame has a response */\n\n/* Maple device info structure (used by hardware) */\ntypedef struct maple_devinfo {\n\tuint32\t\tfunctions;\n\tuint32\t\tfunction_data[3];\n\tuint8\t\tarea_code;\n\tuint8\t\tconnector_direction;\n\tchar\t\tproduct_name[30];\n\tchar\t\tproduct_license[60];\n\tuint16\t\tstandby_power;\n\tuint16\t\tmax_power;\n} maple_devinfo_t;\n\n/* Response frame structure (used by hardware) */\ntypedef struct maple_response {\n\tint8\t\tresponse;\t\t/* Response */\n\tuint8\t\tdst_addr;\t\t/* Destination address */\n\tuint8\t\tsrc_addr;\t\t/* Source address */\n\tuint8\t\tdata_len;\t\t/* Data length (in 32-bit words) */\n\tuint8\t\tdata[0];\t\t/* Data (if any) */\n} maple_response_t;\n\n/* One maple device; note that we duplicate the port/unit info which\n is normally somewhat implicit so that we can pass around a pointer\n to a particular device struct. */\ntypedef struct maple_device {\n\t/* Public */\n\tint\t\t\tvalid;\t\t/* Is this a valid device? */\n\tint\t\t\tport, unit;\t/* Maple address */\n\tmaple_devinfo_t\t\tinfo;\t\t/* Device info struct */\n\n\t/* Private */\n\tint\t\t\tdev_mask;\t/* Device-present mask for unit 0's */\n\tmaple_frame_t\t\tframe;\t\t/* Give each device one rx/tx frame */\n\tstruct maple_driver *\tdrv;\t\t/* Driver which handles this device */\n\n\tvolatile int\t\tstatus_valid;\t/* Have we got our first status update? */\n\tuint8\t\t\tstatus[1024];\t/* Status buffer (for pollable devices) */\n} maple_device_t;\n\n/* One maple port; each maple port can contain up to 6 devices, the first\n one of which is always the port itself. */\n#define MAPLE_PORT_COUNT\t4\n#define MAPLE_UNIT_COUNT\t6\ntypedef struct maple_port {\n\tint\t\tport;\t\t\t\t/* Port ID */\n\tmaple_device_t\tunits[MAPLE_UNIT_COUNT];\t/* Pointers to active units */\n} maple_port_t;\n\n/* A maple device driver; anything which is added to this list is capable\n of handling one or more maple device types. When a device of the given\n type is connected (includes startup \"connection\"), the driver is\n invoked. This same process happens for disconnection, response\n receipt, and on a periodic interval (for normal updates). */\ntypedef struct maple_driver {\n\t/* Driver list handle */\n\tLIST_ENTRY(maple_driver)\tdrv_list;\n\n\tuint32\t\tfunctions;\t/* One or more MAPLE_FUNC_* or'd together */\n\tconst char *\tname;\t\t/* The driver name */\n\n\t/* Callbacks, to be filled in by the driver */\n\tvoid\t(*periodic)(struct maple_driver *drv);\n\tint\t(*attach)(struct maple_driver *drv, maple_device_t *dev);\n\tvoid\t(*detach)(struct maple_driver *drv, maple_device_t *dev);\n} maple_driver_t;\n\n/* Maple state structure; we put everything in here to keep from\n polluting the global namespace too much */\ntypedef struct maple_state_str {\n\t/* Maple device driver list; NOTE: Do not manipulate directly */\n\tstruct maple_driver_list\tdriver_list;\n\n\t/* Maple frame submission queue; NOTE: Do not manipulate directly */\n\tstruct maple_frame_queue\tframe_queue;\n\n\t/* Maple device info structure */\n\tmaple_port_t\t\t\tports[MAPLE_PORT_COUNT];\n\n\t/* Interrupt counters */\n\tvolatile int\t\t\tdma_cntr, vbl_cntr;\n\n\t/* DMA send buffer */\n\tuint8\t\t\t\t*dma_buffer;\n\tvolatile int\t\t\tdma_in_progress;\n\n\t/* Next unit which will be auto-detected */\n\tint\t\t\t\tdetect_port_next;\n\tint\t\t\t\tdetect_unit_next;\n\tvolatile int\t\t\tdetect_wrapped;\n\n\t/* Our vblank handler handle */\n\tint\t\t\t\tvbl_handle;\n} maple_state_t;\n\n/* Maple DMA buffer size; increase if you do a _LOT_ of maple stuff\n on every periodic interrupt */\n#define MAPLE_DMA_SIZE 16384\n\n/* Maple memory read/write functions; these are just hooks in case\n we need to do something else later */\n#define maple_read(A) ( *((vuint32*)(A)) )\n#define maple_write(A, V) ( *((vuint32*)(A)) = (V) )\n\n/* Return codes from maple access functions */\n#define MAPLE_EOK\t0\n#define MAPLE_EFAIL\t-1\n#define MAPLE_EAGAIN\t-2\n#define MAPLE_EINVALID\t-3\n#define MAPLE_ENOTSUPP\t-4\n#define MAPLE_ETIMEOUT\t-5\n\n/**************************************************************************/\n/* maple_globals.c */\n\n/* Global state info */\nextern maple_state_t maple_state;\n\n/**************************************************************************/\n/* maple_utils.c */\n\n/* Enable / Disable the bus */\nvoid maple_bus_enable();\nvoid maple_bus_disable();\n\n/* Start / Stop DMA */\nvoid maple_dma_start();\nvoid maple_dma_stop();\nint maple_dma_in_progress();\n\n/* Set DMA address */\nvoid maple_dma_addr(void *ptr);\n\n/* Return a \"maple address\" for a port,unit pair */\nuint8 maple_addr(int port, int unit);\n\n/* Decompose a \"maple address\" into a port,unit pair */\n/* WARNING: Won't work on multi-cast addresses! */\nvoid maple_raddr(uint8 addr, int * port, int * unit);\n\n/* Return a string with the capabilities of a given driver; NOT THREAD SAFE */\nconst char * maple_pcaps(uint32 functions);\n\n/* Return a string representing the maple response code */\nconst char * maple_perror(int response);\n\n/* Determine if a given device is valid */\nint maple_dev_valid(int p, int u);\n\n#if MAPLE_DMA_DEBUG\n/* Debugging help */\nvoid maple_sentinel_setup(void * buffer, int bufsize);\nvoid maple_sentinel_verify(const char * bufname, void * buffer, int bufsize);\n#endif\n\n/**************************************************************************/\n/* maple_queue.c */\n\n/* Send all queued frames */\nvoid maple_queue_flush();\n\n/* Submit a frame for queueing; this will generally be called inside the\n periodic interrupt; however, if you need to do something asynchronously\n (e.g., VMU access) then it might cause some problems. In this case, the\n function will automatically do locking by disabling interrupts \n temporarily. In any case, the callback will be done inside an IRQ context. */\nint maple_queue_frame(maple_frame_t *frame);\n\n/* Remove a used frame from the queue; same semantics as above */\nint maple_queue_remove(maple_frame_t *frame);\n\n/* Initialize a new frame to prepare it to be placed on the queue; call\n this _before_ you fill it in */\nvoid maple_frame_init(maple_frame_t *frame);\n\n/* Lock a frame so that someone else can't use it in the mean time; if the\n frame is already locked, an error will be returned. */\nint maple_frame_lock(maple_frame_t *frame);\n\n/* Unlock a frame */\nvoid maple_frame_unlock(maple_frame_t *frame);\n\n/**************************************************************************/\n/* maple_driver.c */\n\n/* Register a maple device driver; do this before maple_init() */\nint maple_driver_reg(maple_driver_t *driver);\n\n/* Unregister a maple device driver */\nint maple_driver_unreg(maple_driver_t *driver);\n\n/* Attach a maple device to a driver, if possible */\nint maple_driver_attach(maple_frame_t *det);\n\n/* Detach an attached maple device */\nint maple_driver_detach(int p, int u);\n\n/* For each device which the given driver controls, call the callback */\nint maple_driver_foreach(maple_driver_t *drv, int (*callback)(maple_device_t *));\n\n/**************************************************************************/\n/* maple_irq.c */\n\n/* Called on every VBL (~60fps) */\nvoid maple_vbl_irq_hnd(uint32 code);\n\n/* Called after a Maple DMA send / receive pair completes */\nvoid maple_dma_irq_hnd(uint32 code);\n\n/**************************************************************************/\n/* maple_enum.c */\n\n/* Return the number of connected devices */\nint maple_enum_count();\n\n/* Return a raw device info struct for the given device */\nmaple_device_t * maple_enum_dev(int p, int u);\n\n/* Return the Nth device of the requested type (where N is zero-indexed) */\nmaple_device_t * maple_enum_type(int n, uint32 func);\n\n/* Get the status struct for the requested maple device; wait until it's\n valid before returning. Cast to the appropriate type you're expecting. */\nvoid * maple_dev_status(maple_device_t *dev);\n\n/**************************************************************************/\n/* maple_compat.h */\n\n/* Utility function used by other compat functions */\nint maple_compat_resolve(uint8 addr, maple_device_t **dev, uint32 funcs);\n\n/* Retrieve function code... */\nuint32 maple_device_func(int port, int unit);\n\n/* First with a given function code... */\nuint8 maple_first_device(int code);\n\n/* First controller */\nuint8 maple_first_controller();\n\n/* First mouse */\nuint8 maple_first_mouse();\n\n/* First keyboard */\nuint8 maple_first_kb();\n\n/* First LCD unit */\nuint8 maple_first_lcd();\n\n/* First VMU */ \nuint8 maple_first_vmu();\n\n/* NOP now */\n#define maple_rescan_bus(Q)\t/* NADA */\n\n/* Renamed */\n#define maple_create_addr(A, B) maple_addr(A, B)\n\n/**************************************************************************/\n/* maple_init.c */\n\n/* Init / Shutdown */\nint\tmaple_init();\nvoid\tmaple_shutdown();\n\n/* Wait for the initial bus scan to complete */\nvoid\tmaple_wait_scan();\n\n/**************************************************************************/\n/* Convienence macros */\n\n/* A \"foreach\" loop to scan all maple devices of a given type. It is used\n like this:\n\n MAPLE_FOREACH_BEGIN(MAPLE_FUNC_CONTROLLER, cont_state_t, st)\n \tif (st->buttons & CONT_START)\n \t\treturn -1;\n MAPLE_FOREACH_END()\n\n The peripheral index can be obtained with __i, and the raw device struct\n with __dev. The code inside the loop is guaranteed to be inside a block\n (i.e., { code })\n */\n\n#define MAPLE_FOREACH_BEGIN(TYPE, VARTYPE, VAR) \\\ndo { \\\n\tmaple_device_t\t* __dev; \\\n\tVARTYPE * VAR; \\\n\tint\t__i; \\\n\\\n\t__i = 0; \\\n\twhile ( (__dev = maple_enum_type(__i, TYPE)) ) { \\\n\t\tVAR = (VARTYPE *)maple_dev_status(__dev); \\\n\t\tdo {\n\t\t\n#define MAPLE_FOREACH_END() \\\n\t\t} while(0); \\\n\t\t__i++; \\\n\t} \\\n} while(0);\n\t\n\n__END_DECLS\n\n#endif /* __DC_MAPLE_H */\n\n"
},
{
"alpha_fraction": 0.6057825684547424,
"alphanum_fraction": 0.6177369952201843,
"avg_line_length": 28.47541046142578,
"blob_id": "febe5b01da498b83889cdb80dd0f697e38027357",
"content_id": "61e273d4e269c53068c39b92905c3685ce7c6bd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3597,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 122,
"path": "/libc/include/stdio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n stdio.h\n (c)2000-2002 Dan Potter\n\n $Id: stdio.h,v 1.3 2003/06/23 05:21:31 bardtx Exp $\n\n*/\n\n#ifndef __STDIO_H\n#define __STDIO_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <unistd.h>\n#include <stdarg.h>\n#include <kos/fs.h>\n\n/* ANSI style wrappers for some of the fileio functions */\n\n/* BUFSIZ for ANSI compliance; note that we actually don't have any\n sort of buffering */\n#ifndef BUFSIZ\n#define BUFSIZ 1024\n#endif\n\n#ifndef EOF\n#define EOF (-1)\n#endif\n\ntypedef struct _FILE_t FILE;\ntypedef off_t fpos_t;\n\n/* For ANSI compatability */\n#define stdin ( (FILE *)1 )\n#define stdout ( (FILE *)2 )\n#define stderr ( (FILE *)2 )\n\nvoid clearerr(FILE *);\nint fclose(FILE *);\nFILE *fdopen(int, const char *);\nint feof(FILE *);\nint ferror(FILE *);\nint fflush(FILE *);\nint fgetc(FILE *);\nint getc(FILE *);\t/* This can't be a macro thanks to broken g++v3 libs */\nint fgetpos(FILE *, fpos_t *);\nchar *fgets(char *, int, FILE *);\nint fileno(FILE *);\nFILE *fopen(const char *, const char *);\nint fprintf(FILE *, const char *, ...);\nint fputc(int, FILE *);\nint fputs(const char *, FILE *);\nsize_t fread(void *, size_t, size_t, FILE *);\nFILE *freopen(const char *, const char *, FILE *);\nint fscanf(FILE *, const char *, ...);\nint fseek(FILE *, long int, int);\nint fseeko(FILE *, off_t, int);\nint fsetpos(FILE *, const fpos_t *);\nlong int ftell(FILE *);\noff_t ftello(FILE *);\nsize_t fwrite(const void *, size_t, size_t, FILE *);\nint getc(FILE *);\nint getchar(void);\nchar *gets(char *);\nint getw(FILE *);\nint pclose(FILE *);\nvoid perror(const char *);\nFILE *popen(const char *, const char *);\nint printf(const char *, ...);\nint putc(int, FILE *);\nint putchar(int);\nint puts(const char *);\nint putw(int, FILE *);\nint remove(const char *);\nint rename(const char *, const char *);\nvoid rewind(FILE *);\nint scanf(const char *, ...);\nvoid setbuf(FILE *, char *);\nint setvbuf(FILE *, char *, int, size_t);\nint snprintf(char *, size_t, const char *, ...);\nint sprintf(char *, const char *, ...);\nint sscanf(const char *, const char *, ...);\nchar *tempnam(const char *, const char *);\nFILE *tmpfile(void);\nchar *tmpnam(char *);\nint ungetc(int, FILE *);\nint vfprintf(FILE *, const char *, va_list);\nint vprintf(const char *, va_list);\nint vsnprintf(char *, size_t, const char *, va_list);\nint vsprintf(char *, const char *, va_list);\n\n/* strerror list */\nextern const char * const sys_errlist[];\nextern const int sys_nerr;\n\n/* To make porting programs a bit easier.. WARNING: only works on GCC */\n#define fprintf(BLAGH, ARGS...) printf(ARGS)\n\n/* Kernel debugging printf; all output sent to this is filtered through\n a kernel log level check before actually being printed. This way, you\n can set the level of debug info you want to see (or want your users\n to see). */\nvoid dbglog(int level, const char *fmt, ...) __printflike(2, 3);\n\n/* Log levels for the above */\n#define DBG_DEAD\t0\t\t/* The system is dead */\n#define DBG_CRITICAL\t1\t\t/* A critical error message */\n#define DBG_ERROR\t2\t\t/* A normal error message */\n#define DBG_WARNING\t3\t\t/* Potential problem */\n#define DBG_NOTICE\t4\t\t/* Normal but significant */\n#define DBG_INFO\t5\t\t/* Informational messages */\n#define DBG_DEBUG\t6\t\t/* User debug messages */\n#define DBG_KDEBUG\t7\t\t/* Kernel debug messages */\n\n/* Set debug level */\nvoid dbglog_set_level(int level);\n\n__END_DECLS\n\n#endif\t/* __STDIO_H */\n\n"
},
{
"alpha_fraction": 0.5880322456359863,
"alphanum_fraction": 0.6093210577964783,
"avg_line_length": 16.3799991607666,
"blob_id": "90e9fbc00a0e73a2ba9d22e69fcbf43590f54ca4",
"content_id": "c1a3828ab4c5ad6e9f61e44d12e850c4ec214634",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1738,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 100,
"path": "/utils/gba-crcfix/gba-crcfix.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gba-crcfix.c\n (c)2002 Gil Megidish\n \n Calculate the header checksum (complement check)\n\n $id: \n*/\n\n#include <stdio.h>\n#include <string.h>\n#include <errno.h>\n\n/* We do this instead of stdint.h since that (ironically) seems to be\n non-portable */\n#define uint8_t unsigned char\n\n#define HEADER_SIZE 0xc0\n\nstatic void fix_header(uint8_t *header) {\n\n\tuint8_t sum = 0;\n\tuint8_t count = 0xbc - 0xa0;\n\t\n\t/* complement check of 0xa0 - 0xbc */\n\theader = header + 0xa0;\n\t\n\twhile (count-- > 0) {\n\t\tsum = sum - *header++;\n\t}\n\t\n\tsum = (sum - 0x19);\n\t*header = sum;\n}\n\nstatic int process(const char *filename) {\n\n\tFILE *fp;\n\tuint8_t header[HEADER_SIZE];\n\t\n\tfp = fopen(filename, \"r+b\");\n\tif (fp == NULL) {\n\t\tfprintf(stderr, \"Failed to open %s for reading/writing\\n\", filename);\n\t\treturn -errno;\n\t}\n\t\n\tif (fread(header, 1, HEADER_SIZE, fp) != HEADER_SIZE) {\n\t\tfclose(fp);\n\t\tfprintf(stderr, \"Error reading from %s\\n\", filename);\n\t\treturn -errno;\n\t}\n\t\n\tfix_header(header);\n\tif (fseek(fp, 0, SEEK_SET) < 0) {\n\t\tfclose(fp);\n\t\tfprintf(stderr, \"Failed to rewind file %s\\n\", filename);\n\t\treturn -errno;\n\t}\n\t\n\tif (fwrite(header, 1, HEADER_SIZE, fp) != HEADER_SIZE) {\n\t\tfclose(fp);\n\t\tfprintf(stderr, \"Error writing header back to file %s\\n\", filename);\n\t\treturn -errno;\n\t}\n\t\n\tfclose(fp);\n\treturn 0;\n}\n\nstatic void usage(const char *ego) {\n\tconst char *name;\n\t\n\tname = strrchr(ego, '/');\n\tif (name == NULL)\n\t\tname = ego;\n\telse\n\t\tname++;\n\t\t\n\tprintf(\"GBA Complement Check fix\\n\");\n\tprintf(\"Usage: %s file1 [file2...]\\n\", name);\n}\n\nint main(int argc, char *argv[]) {\n\n\tint i;\n\t\n\tif (argc < 2) {\n\t\tusage(argv[0]);\n\t\treturn 0;\n\t}\n\n\tfor (i=1; i<argc; i++) {\n\t\tint ok = process(argv[i]);\n\t\tif (ok != 0)\n\t\t\treturn ok;\n\t}\t\n\t\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5482625365257263,
"alphanum_fraction": 0.6254826188087463,
"avg_line_length": 14.058823585510254,
"blob_id": "ca03e24238c631d179f8837af67826e5e4b1c32e",
"content_id": "0c3cb46b1ff3fc10a06b81e623f1b24dc689c093",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/kernel/arch/dreamcast/navi/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast/navi/Makefile\n# (c)2002 Dan Potter\n#\n# $Id: Makefile,v 1.1 2002/05/05 22:16:49 bardtx Exp $\n\n# IDE\nOBJS += navi_ide.o\n\n# Flash BIOS\nOBJS += navi_flash.o\n\n# SUBDIRS = fs\nSUBDIRS =\n\ninclude ../../../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.6116071343421936,
"alphanum_fraction": 0.653124988079071,
"avg_line_length": 22.578947067260742,
"blob_id": "a68d7b3a796bacb22c1436b79ea003be71283e94",
"content_id": "e223fbefc2cdd2f1ad4c61215c26442cd4678ec0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2240,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 95,
"path": "/kernel/arch/dreamcast/fs/dcload-packet.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-net.h\n\n Copyright (C)2003 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#ifndef __PACKET_H__\n#define __PACKET_H__\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <endian.h>\n\n#define __PACKED__ __attribute__((packed))\n\ntypedef struct {\n\tuint8\tdest[6];\n\tuint8\tsrc[6];\n\tuint8\ttype[2];\n} ether_header_t;\n\ntypedef struct {\n\tuint8\tversion_ihl\t\t__PACKED__;\n\tuint8\ttos\t\t\t__PACKED__;\n\tuint16\tlength\t\t\t__PACKED__;\n\tuint16\tpacket_id\t\t__PACKED__;\n\tuint16\tflags_frag_offset\t__PACKED__;\n\tuint8\tttl\t\t\t__PACKED__;\n\tuint8\tprotocol\t\t__PACKED__;\n\tuint16\tchecksum\t\t__PACKED__;\n\tuint32\tsrc\t\t\t__PACKED__;\n\tuint32\tdest\t\t\t__PACKED__;\n} ip_header_t;\n\ntypedef struct {\n\tuint16\tsrc\t\t\t__PACKED__;\n\tuint16\tdest\t\t\t__PACKED__;\n\tuint16\tlength\t\t\t__PACKED__;\n\tuint16\tchecksum\t\t__PACKED__;\n\tuint8\tdata[0]\t\t\t__PACKED__;\n} udp_header_t;\n\ntypedef struct {\n\tuint8\ttype\t\t\t__PACKED__;\n\tuint8\tcode\t\t\t__PACKED__;\n\tuint16\tchecksum\t\t__PACKED__;\n\tuint32\tmisc\t\t\t__PACKED__;\n} icmp_header_t;\n\ntypedef struct {\n\tuint16\thw_addr_space\t\t__PACKED__;\n\tuint16\tproto_addr_space\t__PACKED__;\n\tuint8\thw_addr_len\t\t__PACKED__;\n\tuint8\tproto_addr_len\t\t__PACKED__;\n\tuint16\topcode\t\t\t__PACKED__;\n\tuint8\thw_sender[6]\t\t__PACKED__;\n\tuint8\tproto_sender[4]\t\t__PACKED__;\n\tuint8\thw_target[6]\t\t__PACKED__;\n\tuint8\tproto_target[4]\t\t__PACKED__;\n} arp_header_t;\n\ntypedef struct {\n\tuint32\tsrc_ip\t\t\t__PACKED__;\n\tuint32\tdest_ip\t\t\t__PACKED__;\n\tuint8\tzero\t\t\t__PACKED__;\n\tuint8\tprotocol\t\t__PACKED__;\n\tuint16\tudp_length\t\t__PACKED__;\n\tuint16\tsrc_port\t\t__PACKED__;\n\tuint16\tdest_port\t\t__PACKED__;\n\tuint16\tlength\t\t\t__PACKED__;\n\tuint16\tchecksum\t\t__PACKED__;\n\tuint8\tdata[0]\t\t\t__PACKED__;\n} ip_udp_pseudo_header_t;\n\nuint16 dcln_checksum(uint16 *buf, int count);\nvoid dcln_make_ether(char *dest, char *src, ether_header_t *ether);\nvoid dcln_make_ip(int dest, int src, int length, char protocol, ip_header_t *ip);\nvoid dcln_make_udp(uint16 dest, uint16 src, uint8 * data, int length, ip_header_t *ip, udp_header_t *udp);\n\n#define ETHER_H_LEN 14\n#define IP_H_LEN 20\n#define UDP_H_LEN 8\n#define ICMP_H_LEN 8\n#define ARP_H_LEN 28\n\n#endif\n__END_DECLS\n"
},
{
"alpha_fraction": 0.5347580313682556,
"alphanum_fraction": 0.6319295763969421,
"avg_line_length": 22.882883071899414,
"blob_id": "1bb9fefa3f43d18526e833b6f0c527cfd9d4ed92",
"content_id": "ebbc24ea03c8ca2c3706cb128fe18c0161cede6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7955,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 333,
"path": "/examples/dreamcast/kgl/basic/scissor/scissor.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n scissor.c\n (c)2002 Paul Boese\n\n Demonstrates the use of glScissor( ) using both the normal\n GL_SCISSOR_TEST and GL_KOS_USERCLIP_OUTSIDE clip modes.\n\n Use the 'A' button to cycle though the following demos.\n Use the 'DPAD' to move the clip rectangle in the first two demos.\n Demos:\n \tGL_SCISSOR_TEST\n\tGL_KOS_USERCLIP_OUTSIDE\n\tDISABLE glScissor\n\t4 viewports not clipped\n\t4 viewports clipped\n\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\nCVSID(\"$Id: scissor.c,v 1.4 2002/06/30 16:28:34 axlen Exp $\");\n\n#define NUM_DEMOS 5\nenum { USERCLIP_INSIDE = 0, USERCLIP_OUTSIDE, USERCLIP_DISABLED,\n\tQUAD_SCREEN_UNCLIPPED, QUAD_SCREEN_CLIPPED };\nstatic char demo[NUM_DEMOS][80] = {\n\t{ \"glEnable( GL_SCISSOR_TEST )\" },\n\t{ \"glEnable( GL_KOS_USERCLIP_OUTSIDE )\" },\n\t{ \"glDisable( GL_SCISSOR_TEST )\" },\n\t{ \"Four viewports >>> no clipping <<<\" },\n\t{ \"Four viewports >>> clipped <<<\" }\n};\nstatic int selected = USERCLIP_INSIDE;\nstatic GLint x = 0, y = 0;\nstatic GLfloat rot = 0.0f;\nstatic GLfloat rtri = 0.0f, rquad = 0.0f;\nstatic GLuint texture;\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid quad(int x, int y) {\n\tglBegin(GL_QUADS);\n\tglColor4f(1,1,1,0.5f);\n\tglTexCoord2f(0.0f, 0.0f);\n\tglVertex3f(x,y,0);\n\tglTexCoord2f(4.0f, 0.0f);\n\tglVertex3f(x+128,y,0);\n\tglTexCoord2f(4.0f, 4.0f);\n\tglVertex3f(x+128,y+128,0);\n\tglTexCoord2f(0.0f, 4.0f);\n\tglVertex3f(x,y+128,0);\n\tglEnd();\n}\n\nvoid rect(int x, int y, int width, int height) {\n\tglBegin(GL_QUADS);\n\tglColor4f(1,1,1,0.5f);\n\tglTexCoord2f(0.0f, 0.0f);\n\tglVertex3f(x,y,0);\n\tglTexCoord2f(4.0f, 0.0f);\n\tglVertex3f(x+width,y,0);\n\tglTexCoord2f(4.0f, 4.0f);\n\tglVertex3f(x+width,y+height,0);\n\tglTexCoord2f(0.0f, 4.0f);\n\tglVertex3f(x,y+height,0);\n\tglEnd();\n}\n\nstatic void draw_gl(float rot, float x, float y) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\n\tglLoadIdentity();\n\tglTranslatef(0.0f, 0.0f, -4.0f);\n\tglRotatef(rot, x, y, 0.0f);\n\n\tglPushMatrix();\n\tglTranslatef(-1.5f,0.0f,0.0);\n\tglRotatef(rtri,0.0f,1.0f,0.0f);\n\n\tglBegin(GL_TRIANGLES);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, -1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, -1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, -1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\tglEnd();\n\n\tglPopMatrix();\n\tglPushMatrix();\n\tglTranslatef(1.5f,0.0f,0.0f);\n\tglRotatef(rquad,1.0f,1.0f,1.0f);\n\t\t\n\tglBegin(GL_QUADS);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.5f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\tglEnd();\n\n\tglPopMatrix();\n}\n\nstatic void draw_ortho_scene() {\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\tglOrtho(0,640,0,480,-1,1);\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_FLAT);\n\tglDepthFunc(GL_LESS);\n\tglClearColor(0.8f, 0.4f, 0.4f, 1.0f);\n\t\n\tglViewport(0, 0, 640, 480);\n\tglScissor(x, y, 320, 240); \n\t/* draw a nice 32x32 bitsize square checkered\n\t background */\n\tglBindTexture(GL_TEXTURE_2D, texture);\n\trect(0, 0, 512, 512);\n\trect(512, 0, 512, 512);\n}\n\nstatic void draw_perspective_scene() {\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,320.0f/240.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\tglDisable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.1f, 0.1f, 0.1f, 1.0f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LESS);\n\n\t/* Draw scene - bottom left */\n\tglViewport(0, 0, 320, 240);\n\tglScissor(0, 0, 320, 240);\n\tdraw_gl(rot, 1.0, 1.0);\n\n\t/* Draw scene - upper left */\n\tglScissor(0, 240, 320, 240);\n\tglViewport(0, 240, 320, 240);\n\tdraw_gl(rot, -1.0f, 1.0f);\n\n\t/* Draw scene - bottom right */\n\tglScissor(320, 0, 320, 240);\n\tglViewport(320, 0, 320, 240);\n\tdraw_gl(rot, 1.0f, -1.0f);\n\t\t\n\t/* Draw scene - upper right */\n\tglScissor(320, 240, 320, 240);\n\tglViewport(320, 240, 320, 240);\n\tdraw_gl(rot, -1.0f, -1.0f);\n\t\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tstatic GLboolean ap = GL_FALSE;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"texwrap beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\t/* Set up the texture */\n\tloadtxr(\"/rd/checker.pcx\", &texture);\n\n\tprintf(\"\\n[glScissor Demo]\\n\");\n\tprintf(\"DPAD moves glScissor( ) defined rectangle.\\n\");\n\tprintf(\"A button selects demo.\\n\");\n\tprintf(\" %s\\n\", demo[selected]);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\n\t\tif (cond.buttons & CONT_DPAD_UP)\n\t\t\ty-=8; if (y < -224) y = -224;\n\t\tif (cond.buttons & CONT_DPAD_DOWN)\n\t\t\ty+=8; if (y > 448) y = 448;\n\t\tif (cond.buttons & CONT_DPAD_LEFT)\n\t\t\tx+=8; if (x > 632) x = 632; \n\t\tif (cond.buttons & CONT_DPAD_RIGHT)\n\t\t\tx-=8; if (x < -288) x = -288;\n\t\t\n\t\t/* Demo select button */\n\t\tif (!(cond.buttons & CONT_A) && !ap) {\n\t\t\tap = GL_TRUE;\n\t\t\tselected++;\n\t\t\tselected %= NUM_DEMOS;\n\t\t\tprintf(\" %s\\n\", demo[selected]);\n\t\t}\n\t\tif (cond.buttons & CONT_A)\n\t\t\tap = GL_FALSE;\n\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* top row, non-alpha texture */\n\t\tglBindTexture(GL_TEXTURE_2D, texture);\n\n\t\tswitch (selected) {\n\t\tcase USERCLIP_INSIDE:\n\t\tcase QUAD_SCREEN_CLIPPED:\n\t\t\tglEnable(GL_SCISSOR_TEST);\n\t\t\tbreak;\n\t\tcase USERCLIP_OUTSIDE:\n\t\t\tglEnable(GL_KOS_USERCLIP_OUTSIDE);\n\t\t\tbreak;\n\t\tcase USERCLIP_DISABLED:\n\t\tcase QUAD_SCREEN_UNCLIPPED:\n\t\t\tglDisable(GL_SCISSOR_TEST);\n\t\t\t/* or \n\t\t\tglDisable(GL_KOS_USERCLIP_OUTSIDE);\n\t\t\t*/\n\t\t\tbreak;\n\t\t}\n\t\t\n\t\tswitch (selected) {\n\t\tcase USERCLIP_INSIDE:\n\t\tcase USERCLIP_OUTSIDE:\n\t\tcase USERCLIP_DISABLED:\n\t\t\t\n\t\t\tdraw_ortho_scene();\n\t\t\t\n\t\t\tbreak;\n\t\tcase QUAD_SCREEN_UNCLIPPED:\n\t\tcase QUAD_SCREEN_CLIPPED:\n\t\t\t\n\t\t\tdraw_perspective_scene();\n\t\t\t\n\t\t\trot += 2.0f;\n\t\t\trtri += 3.0f;\n\t\t\trquad += -2.5f;\n\t\t\tbreak;\n\t\t}\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6604329347610474,
"alphanum_fraction": 0.6934284567832947,
"avg_line_length": 37.09758758544922,
"blob_id": "fa72f9e4e706d811a049a2798a75f91bb0281465",
"content_id": "70ef156c0d15af67a394531e4d0e8bc2444a21fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 36308,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 953,
"path": "/include/arch/dreamcast/dc/pvr.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/pvr.h\n (C)2002 Dan Potter\n\n $Id: pvr.h,v 1.28 2003/04/24 03:13:45 bardtx Exp $\n\n Low-level PVR 3D interface for the DC\n Note: this API does _not_ handle any sort of transformations\n (including perspective!) so for that, you should look to KGL.\n*/\n\n\n#ifndef __DC_PVR_H\n#define __DC_PVR_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <dc/sq.h>\n#include <kos/img.h>\n\n/* Data types ********************************************************/\n\n/* PVR texture memory pointer; unlike the old \"TA\" system, PVR pointers\n in the new system are actually SH-4 compatible pointers and can\n be used directly in place of ta_txr_map(). */\ntypedef void * pvr_ptr_t;\n\n/* PVR list specification */\ntypedef uint32 pvr_list_t;\n\n/* Polygon context; you should use this more human readable format for\n specifying your polygon contexts, and then compile them into polygon\n headers (below) when you are ready to start using them.\n\n This has embedded structures in it for two reasons; the first reason\n is to make it easier for me to add new stuff later without breaking\n existing code. The second reason is to make it more readable and\n usable.\n*/ \ntypedef struct {\n\tint\t\tlist_type;\n\tstruct {\n\t\tint\t\talpha;\n\t\tint\t\tshading;\n\t\tint\t\tfog_type;\n\t\tint\t\tculling;\n\t\tint\t\tcolor_clamp;\n\t\tint\t\tclip_mode;\n\t\tint\t\tmodifier_mode;\n\t} gen;\n\tstruct {\n\t\tint\t\tsrc, dst;\n\t\tint\t\tsrc_enable, dst_enable;\n\t} blend;\n\tstruct {\n\t\tint\t\tcolor;\n\t\tint\t\tuv;\n\t\tint\t\tmodifier;\n\t} fmt;\n\tstruct {\n\t\tint\t\tcomparison;\n\t\tint\t\twrite;\n\t} depth;\n\tstruct {\n\t\tint\t\tenable;\n\t\tint\t\tfilter;\t\t/* none, bi-linear, tri-linear, etc */\n\t\tint\t\tmipmap;\n\t\tint\t\tmipmap_bias;\n\t\tint\t\tuv_flip;\n\t\tint\t\tuv_clamp;\n\t\tint\t\talpha;\n\t\tint\t\tenv;\n\t\tint\t\twidth;\n\t\tint\t\theight;\n\t\tint\t\tformat;\t\t/* bit format, vq, twiddle, stride */\n\t\tpvr_ptr_t\tbase;\t\t/* texture location */\n\t} txr;\n} pvr_poly_cxt_t;\n\n/* Sprite context; use this somewhat readable format to specify your\n sprites before compiling them into polygon headers.\n*/\ntypedef struct {\n\tint\t\tlist_type;\n\tstruct {\n\t\tint\t\talpha;\n\t\tint\t\tfog_type;\n\t\tint\t\tculling;\n\t\tint\t\tcolor_clamp;\n\t\tint\t\tclip_mode;\n\t} gen;\n\tstruct {\n\t\tint\t\tsrc, dst;\n\t\tint\t\tsrc_enable, dst_enable;\n\t} blend;\n\tstruct {\n\t\tint\t\tcomparison;\n\t\tint\t\twrite;\n\t} depth;\n\tstruct {\n\t\tint\t\tfilter;\n\t\tint\t\tmipmap;\n\t\tint\t\tmipmap_bias;\n\t\tint\t\tuv_flip;\n\t\tint\t\tuv_clamp;\n\t\tint\t\talpha;\n\t\tint\t\twidth;\n\t\tint\t\theight;\n\t\tint\t\tformat;\n\t\tpvr_ptr_t\tbase;\n\t} txr;\n} pvr_sprite_cxt_t;\n\n/* Constants for the above structure; thanks to Benoit Miller for these */\n/* list_type */\n#define PVR_LIST_OP_POLY\t\t0\t/* opaque poly */\n#define PVR_LIST_OP_MOD\t\t\t1\t/* opaque modifier */\n#define PVR_LIST_TR_POLY\t\t2\t/* translucent poly */\n#define PVR_LIST_TR_MOD\t\t\t3\t/* translucent modifier */\n#define PVR_LIST_PT_POLY\t\t4\t/* punch-thru poly */\n\n#define PVR_SHADE_FLAT\t\t\t0\t/* shading */\n#define PVR_SHADE_GOURAUD\t\t1\n\n#define PVR_DEPTHCMP_NEVER\t\t0\t/* depth_comparison */\n#define PVR_DEPTHCMP_LESS\t\t1\n#define PVR_DEPTHCMP_EQUAL\t\t2\n#define PVR_DEPTHCMP_LEQUAL\t\t3\n#define PVR_DEPTHCMP_GREATER\t\t4\n#define PVR_DEPTHCMP_NOTEQUAL\t\t5\n#define PVR_DEPTHCMP_GEQUAL\t\t6\n#define PVR_DEPTHCMP_ALWAYS\t\t7\n\n#define PVR_CULLING_NONE\t\t0\t/* culling */\n#define PVR_CULLING_SMALL\t\t1\n#define PVR_CULLING_CCW\t\t\t2\n#define PVR_CULLING_CW\t\t\t3\n\n#define PVR_DEPTHWRITE_ENABLE\t\t0\t/* depth_write */\n#define PVR_DEPTHWRITE_DISABLE\t\t1\n\n#define PVR_TEXTURE_DISABLE\t\t0\t/* txr_enable */\n#define PVR_TEXTURE_ENABLE\t\t1\n\n#define PVR_BLEND_ZERO\t\t\t0\t/* src_blend / dst_blend */\n#define PVR_BLEND_ONE\t\t\t1\n#define PVR_BLEND_DESTCOLOR\t\t2\n#define PVR_BLEND_INVDESTCOLOR\t\t3\n#define PVR_BLEND_SRCALPHA\t\t4\n#define PVR_BLEND_INVSRCALPHA\t\t5\n#define PVR_BLEND_DESTALPHA\t\t6\n#define PVR_BLEND_INVDESTALPHA\t\t7\n\n#define PVR_BLEND_DISABLE\t\t0\t/* src_blend_enable / dst_blend_enable */\n#define PVR_BLEND_ENABLE\t\t1\n\n#define PVR_FOG_TABLE\t\t\t0\t/* fog_type */\n#define PVR_FOG_VERTEX\t\t\t1\n#define PVR_FOG_DISABLE\t\t\t2\n#define PVR_FOG_TABLE2\t\t\t3\n\n#define PVR_USERCLIP_DISABLE\t\t0\t/* clip_mode */\n#define PVR_USERCLIP_INSIDE\t\t2\n#define PVR_USERCLIP_OUTSIDE\t\t3\n\n#define PVR_CLRCLAMP_DISABLE\t\t0\t/* color_clamp */\n#define PVR_CLRCLAMP_ENABLE\t\t1\n\n#define PVR_ALPHA_DISABLE\t\t0\t/* alpha */\n#define PVR_ALPHA_ENABLE\t\t1\n\n#define PVR_TXRALPHA_ENABLE\t\t0\t/* txr_alpha */\n#define PVR_TXRALPHA_DISABLE\t\t1\n\n#define PVR_UVFLIP_NONE\t\t\t0\t/* txr_uvflip */\n#define PVR_UVFLIP_V\t\t\t1\n#define PVR_UVFLIP_U\t\t\t2\n#define PVR_UVFLIP_UV\t\t\t3\n\n#define PVR_UVCLAMP_NONE\t\t0\t/* txr_uvclamp */\n#define PVR_UVCLAMP_V\t\t\t1\n#define PVR_UVCLAMP_U\t\t\t2\n#define PVR_UVCLAMP_UV\t\t\t3\n\n#define PVR_FILTER_NONE\t\t\t0\t/* txr_filter */\n#define PVR_FILTER_NEAREST\t\t0\n#define PVR_FILTER_BILINEAR\t\t2\n#define PVR_FILTER_TRILINEAR1\t\t4\n#define PVR_FILTER_TRILINEAR2\t\t6\n\n#define PVR_MIPBIAS_NORMAL\t\tPVR_MIPBIAS_1_00\t/* txr_mipmap_bias */\n#define PVR_MIPBIAS_0_25\t\t1\n#define PVR_MIPBIAS_0_50\t\t2\n#define PVR_MIPBIAS_0_75\t\t3\n#define PVR_MIPBIAS_1_00\t\t4\n#define PVR_MIPBIAS_1_25\t\t5\n#define PVR_MIPBIAS_1_50\t\t6\n#define PVR_MIPBIAS_1_75\t\t7\n#define PVR_MIPBIAS_2_00\t\t8\n#define PVR_MIPBIAS_2_25\t\t9\n#define PVR_MIPBIAS_2_50\t\t10\n#define PVR_MIPBIAS_2_75\t\t11\n#define PVR_MIPBIAS_3_00\t\t12\n#define PVR_MIPBIAS_3_25\t\t13\n#define PVR_MIPBIAS_3_50\t\t14\n#define PVR_MIPBIAS_3_75\t\t15\n\n/* txr_env */\n#define PVR_TXRENV_REPLACE\t\t0\t/* C = Ct, A = At */\n#define PVR_TXRENV_MODULATE\t\t1\t/* C = Cs * Ct, A = At */\n#define PVR_TXRENV_DECAL\t\t2\t/* C = (Cs * At) + (Cs * (1-At)), A = As */\n#define PVR_TXRENV_MODULATEALPHA\t3\t/* C = Cs * Ct, A = As * At */\n\n#define PVR_MIPMAP_DISABLE\t\t0\t/* txr_mipmap */\n#define PVR_MIPMAP_ENABLE\t\t1\n\n#define PVR_TXRFMT_NONE\t\t\t0\t\t/* txr_format */\n#define PVR_TXRFMT_VQ_DISABLE\t\t(0 << 30)\n#define PVR_TXRFMT_VQ_ENABLE\t\t(1 << 30)\n#define PVR_TXRFMT_ARGB1555\t\t(0 << 27)\n#define PVR_TXRFMT_RGB565\t\t(1 << 27)\n#define PVR_TXRFMT_ARGB4444\t\t(2 << 27)\n#define PVR_TXRFMT_YUV422\t\t(3 << 27)\n#define PVR_TXRFMT_BUMP\t\t\t(4 << 27)\n#define PVR_TXRFMT_PAL4BPP\t\t(5 << 27)\n#define PVR_TXRFMT_PAL8BPP\t\t(6 << 27)\n#define PVR_TXRFMT_TWIDDLED\t\t(0 << 26)\n#define PVR_TXRFMT_NONTWIDDLED\t\t(1 << 26)\n#define PVR_TXRFMT_NOSTRIDE\t\t(0 << 21)\n#define PVR_TXRFMT_STRIDE\t\t(1 << 21)\n\n/* OR one of these into your texture format if you need it. Note that\n these coincide with the twiddled/stride bits, so you can't have a \n non-twiddled/strided texture that's paletted! */\n#define PVR_TXRFMT_8BPP_PAL(x)\t\t((x) << 25)\n#define PVR_TXRFMT_4BPP_PAL(x)\t\t((x) << 21)\n\n#define PVR_CLRFMT_ARGBPACKED\t\t0\t/* color_format */\n#define PVR_CLRFMT_4FLOATS\t\t1\n#define PVR_CLRFMT_INTENSITY\t\t2\n#define PVR_CLRFMT_INTENSITY_PREV\t3\n\n#define PVR_UVFMT_32BIT\t\t\t0\t/* txr_uv_format */\n#define PVR_UVFMT_16BIT\t\t\t1\n\n#define PVR_MODIFIER_DISABLE\t\t0\t/* modifier_format */\n#define PVR_MODIFIER_ENABLE\t\t1\n\n#define PVR_MODIFIER_CHEAP_SHADOW\t0\t\n#define PVR_MODIFIER_NORMAL\t\t1\n\n#define PVR_MODIFIER_OTHER_POLY\t\t0\t/* PM1 modifer instruction */\n#define PVR_MODIFIER_FIRST_POLY\t\t1\t/* ...in inclusion vol */\n#define PVR_MODIFIER_LAST_POLY\t\t2\t/* ...in exclusion vol */\n\n\n/* \"Polygon header\" -- this is the hardware equivalent of a rendering\n context; you'll create one of these from your pvr_poly_context_t and\n use it for submission to the hardware. */\ntypedef struct {\n\tuint32\t\tcmd;\t\t\t/* TA command */\n\tuint32\t\tmode1, mode2, mode3;\t/* mode parameters */\n\tuint32\t\td1, d2, d3, d4;\t\t/* dummies */\n} pvr_poly_hdr_t;\n\n/* Polygon header with intensity color. This is the equivalent of\n pvr_poly_hdr_t, but for use with intensity color (sprites). */\ntypedef struct {\n\tuint32\t\tcmd;\t\t\t\t\t/* TA command */\n\tuint32\t\tmode1, mode2, mode3;\t/* mode parameters */\n\tfloat\t\ta, r, g, b;\t\t\t\t/* color */\n} pvr_poly_ic_hdr_t;\n\n/* Generic vertex type; the PVR chip itself supports many more vertex\n types, but this is the main one that can be used with both textured\n and non-textured polygons, and is fairly fast. You can find other\n variants below. */\ntypedef struct {\n\tuint32\t\tflags;\t\t\t/* vertex flags */\n\tfloat\t\tx, y, z;\t\t/* the coodinates */\n\tfloat\t\tu, v;\t\t\t/* texture coords */\n\tuint32\t\targb;\t\t\t/* vertex color */\n\tuint32\t\toargb;\t\t\t/* offset color */\n} pvr_vertex_t;\n\n/* Textured, packed color, affected by modifer volume. Note that this\n vertex type has two copies of colors, offset colors and texture \n coords. The second set of texture coords, colors, and offset colors\n are used when enclosed within a modifer volume */\ntypedef struct {\n\tuint32 flags;\t\t\t\t/* vertex flags */\n\tfloat x, y, z;\t\t\t\t/* the coordinates */\n\tfloat u0, v0;\t\t\t\t/* texture coords 0 */\n\tuint32 argb0;\t\t\t\t/* vertex color 0 */\n\tuint32 oargb0;\t\t\t\t/* offset color 0 */\n\tfloat u1, v1;\t\t\t\t/* texture coords 1 */\n\tuint32 argb1;\t\t\t\t/* vertex color 1 */\n\tuint32 oargb1;\t\t\t\t/* offset color 1 */\n\tuint32 d1, d2, d3, d4;\t\t\t/* dummies */\n} pvr_vertex_tpcm_t;\n\n/* Textured sprite. This vertex type is to be used with the intensity\n colored polygon header and the sprite related commands to draw\n hardware accelerated, textured sprites. */\ntypedef struct {\n\tuint32 flags;\n\tfloat ax, ay, az;\n\tfloat bx, by, bz;\n\tfloat cx, cy, cz;\n\tfloat dx, dy;\n\tuint32 dummy;\n\tuint32 auv;\n\tuint32 buv;\n\tuint32 cuv;\n} pvr_sprite_txr_t;\n\n/* This vertex is only for modifer volumes */\ntypedef struct {\n\tuint32 flags;\t\t\t\t/* vertex flags */\n\tfloat ax, ay, az;\t\t\t/* 3 sets of coordinates */\n\tfloat bx, by, bz;\n\tfloat cx, cy, cz;\n\tuint32 d1, d2, d3, d4, d5, d6;\t\t/* dummies */\n} pvr_modifier_vol_t;\n\n/* Small macro for packing float color values */\n#define PVR_PACK_COLOR(a, r, g, b) ( \\\n\t( ((uint8)( a * 255 ) ) << 24 ) | \\\n\t( ((uint8)( r * 255 ) ) << 16 ) | \\\n\t( ((uint8)( g * 255 ) ) << 8 ) | \\\n\t( ((uint8)( b * 255 ) ) << 0 ) )\n\n/* Small function for packing two 32-bit u/v values into\n two 16-bit u/v values. */\nstatic inline uint32 PVR_PACK_16BIT_UV(float u, float v) {\n\treturn ( ((*((uint32 *) &u)) >> 0 ) & 0xFFFF0000 ) |\n\t ( ((*((uint32 *) &v)) >> 16 ) & 0x0000FFFF );\n}\n\n/* ... other vertex structs omitted for now ... */\n\n/* Constants that apply to all primitives */\n#define PVR_CMD_POLYHDR\t\t0x80840000\t/* sublist, striplength=2 */\n#define PVR_CMD_VERTEX\t\t0xe0000000\n#define PVR_CMD_VERTEX_EOL\t0xf0000000\n#define PVR_CMD_USERCLIP\t0x20000000\n#define PVR_CMD_MODIFIER\t0x80040000\n#define PVR_CMD_SPRITE\t\t0xA0000000\n\n/* Constants and bitmasks for handling polygon headers; note that thanks\n to the arrangement of constants above, this is mainly a matter of bit\n shifting to compile it... */\n#define PVR_TA_CMD_TYPE_SHIFT\t\t24\n#define PVR_TA_CMD_TYPE_MASK\t\t(7 << PVR_TA_CMD_TYPE_SHIFT)\n\n#define PVR_TA_CMD_USERCLIP_SHIFT\t16\n#define PVR_TA_CMD_USERCLIP_MASK\t(3 << PVR_TA_CMD_USERCLIP_SHIFT) \n\t\n#define PVR_TA_CMD_CLRFMT_SHIFT\t\t4\n#define PVR_TA_CMD_CLRFMT_MASK\t\t(7 << PVR_TA_CMD_CLRFMT_SHIFT)\n\n#define PVR_TA_CMD_SHADE_SHIFT\t\t1\n#define PVR_TA_CMD_SHADE_MASK\t\t(1 << PVR_TA_CMD_SHADE_SHIFT)\n\n#define PVR_TA_CMD_UVFMT_SHIFT\t\t0\n#define PVR_TA_CMD_UVFMT_MASK\t\t(1 << PVR_TA_CMD_UVFMT_SHIFT)\n\t\n#define PVR_TA_CMD_MODIFIER_SHIFT\t7\n#define PVR_TA_CMD_MODIFIER_MASK\t(1 << PVR_TA_CMD_MODIFIER_SHIFT)\n\t\n#define PVR_TA_CMD_MODIFIERMODE_SHIFT\t6\n#define PVR_TA_CMD_MODIFIERMODE_MASK\t(1 << PVR_TA_CMD_MODIFIERMODE_SHIFT)\n\n#define PVR_TA_PM1_DEPTHCMP_SHIFT\t29\n#define PVR_TA_PM1_DEPTHCMP_MASK\t(7 << PVR_TA_PM1_DEPTHCMP_SHIFT)\n\n#define PVR_TA_PM1_CULLING_SHIFT\t27\n#define PVR_TA_PM1_CULLING_MASK\t\t(3 << PVR_TA_PM1_CULLING_SHIFT)\n\n#define PVR_TA_PM1_DEPTHWRITE_SHIFT\t26\n#define PVR_TA_PM1_DEPTHWRITE_MASK\t(1 << PVR_TA_PM1_DEPTHWRITE_SHIFT)\n\n#define PVR_TA_PM1_TXRENABLE_SHIFT\t25\n#define PVR_TA_PM1_TXRENABLE_MASK\t(1 << PVR_TA_PM1_TXRENABLE_SHIFT)\n\n#define PVR_TA_PM1_MODIFIERINST_SHIFT\t29 \n#define PVR_TA_PM1_MODIFIERINST_MASK\t(2 << PVR_TA_PM1_MODIFIERINST_SHIFT)\n\n#define PVR_TA_PM2_SRCBLEND_SHIFT\t29\n#define PVR_TA_PM2_SRCBLEND_MASK\t(7 << PVR_TA_PM2_SRCBLEND_SHIFT)\n\n#define PVR_TA_PM2_DSTBLEND_SHIFT\t26\n#define PVR_TA_PM2_DSTBLEND_MASK\t(7 << PVR_TA_PM2_DSTBLEND_SHIFT)\n\n#define PVR_TA_PM2_SRCENABLE_SHIFT\t25\n#define PVR_TA_PM2_SRCENABLE_MASK\t(1 << PVR_TA_PM2_SRCENABLE_SHIFT)\n\n#define PVR_TA_PM2_DSTENABLE_SHIFT\t24\n#define PVR_TA_PM2_DSTENABLE_MASK\t(1 << PVR_TA_PM2_DSTENABLE_SHIFT)\n\n#define PVR_TA_PM2_FOG_SHIFT\t\t22\n#define PVR_TA_PM2_FOG_MASK\t\t(3 << PVR_TA_PM2_FOG_SHIFT)\n\n#define PVR_TA_PM2_CLAMP_SHIFT\t\t21\n#define PVR_TA_PM2_CLAMP_MASK\t\t(1 << PVR_TA_PM2_CLAMP_SHIFT)\n\n#define PVR_TA_PM2_ALPHA_SHIFT\t\t20\n#define PVR_TA_PM2_ALPHA_MASK\t\t(1 << PVR_TA_PM2_ALPHA_SHIFT)\n\n#define PVR_TA_PM2_TXRALPHA_SHIFT\t19\n#define PVR_TA_PM2_TXRALPHA_MASK\t(1 << PVR_TA_PM2_TXRALPHA_SHIFT)\n\n#define PVR_TA_PM2_UVFLIP_SHIFT\t\t17\n#define PVR_TA_PM2_UVFLIP_MASK\t\t(3 << PVR_TA_PM2_UVFLIP_SHIFT)\n\n#define PVR_TA_PM2_UVCLAMP_SHIFT\t15\n#define PVR_TA_PM2_UVCLAMP_MASK\t\t(3 << PVR_TA_PM2_UVCLAMP_SHIFT)\n\n#define PVR_TA_PM2_FILTER_SHIFT\t\t12\n#define PVR_TA_PM2_FILTER_MASK\t\t(7 << PVR_TA_PM2_FILTER_SHIFT)\n\n#define PVR_TA_PM2_MIPBIAS_SHIFT\t8\n#define PVR_TA_PM2_MIPBIAS_MASK\t\t(15 << PVR_TA_PM2_MIPBIAS_SHIFT)\n\n#define PVR_TA_PM2_TXRENV_SHIFT\t\t6\n#define PVR_TA_PM2_TXRENV_MASK\t\t(3 << PVR_TA_PM2_TXRENV_SHIFT)\n\n#define PVR_TA_PM2_USIZE_SHIFT\t\t3\n#define PVR_TA_PM2_USIZE_MASK\t\t(7 << PVR_TA_PM2_USIZE_SHIFT)\n\n#define PVR_TA_PM2_VSIZE_SHIFT\t\t0\n#define PVR_TA_PM2_VSIZE_MASK\t\t(7 << PVR_TA_PM2_VSIZE_SHIFT)\n\n#define PVR_TA_PM3_MIPMAP_SHIFT\t\t31\n#define PVR_TA_PM3_MIPMAP_MASK\t\t(1 << PVR_TA_PM3_MIPMAP_SHIFT)\n\n#define PVR_TA_PM3_TXRFMT_SHIFT\t\t0\n#define PVR_TA_PM3_TXRFMT_MASK\t\t0xffffffff\n\n\n\n/**** Register macros ***************************************************/\n\n/* We use these macros to do all PVR register access, so that it's\n simple later on to hook them for debugging or whatnot. */\n\n#define PVR_GET(REG) (* ( (uint32*)( 0xa05f8000 + (REG) ) ) )\n#define PVR_SET(REG, VALUE) PVR_GET(REG) = (VALUE)\n\n/* The registers themselves; these are from Maiwe's powervr-reg.txt */\n/* Note that 2D specific registers have been excluded for now (like\n vsync, hsync, v/h size, etc) */\n\n#define PVR_ID\t\t\t0x0000\t\t/* Chip ID */\n#define PVR_REVISION\t\t0x0004\t\t/* Chip revision */\n#define PVR_RESET\t\t0x0008\t\t/* Reset pins */\n#define PVR_ISP_START\t\t0x0014\t\t/* Start the ISP/TSP */\n#define PVR_UNK_0018\t\t0x0018\t\t/* ?? */\n#define PVR_ISP_VERTBUF_ADDR\t0x0020\t\t/* Vertex buffer address for scene rendering */\n#define PVR_ISP_TILEMAT_ADDR\t0x002c\t\t/* Tile matrix address for scene rendering */\n#define PVR_SPANSORT_CFG\t0x0030\t\t/* ?? -- write 0x101 for now */\n#define PVR_FB_CFG_1\t\t0x0044\t\t/* Framebuffer config 1 */\n#define PVR_FB_CFG_2\t\t0x0048\t\t/* Framebuffer config 2 */\n#define PVR_RENDER_MODULO\t0x004c\t\t/* Render modulo */\n#define PVR_RENDER_ADDR\t\t0x0060\t\t/* Render output address */\n#define PVR_RENDER_ADDR_2\t0x0064\t\t/* Output for strip-buffering */\n#define PVR_PCLIP_X\t\t0x0068\t\t/* Horizontal clipping area */\n#define PVR_PCLIP_Y\t\t0x006c\t\t/* Vertical clipping area */\n#define PVR_CHEAP_SHADOW\t0x0074\t\t/* Cheap shadow control */\n#define PVR_OBJECT_CLIP\t\t0x0078\t\t/* Distance for polygon culling */\n#define PVR_UNK_007C\t\t0x007c\t\t/* ?? -- write 0x0027df77 for now */\n#define PVR_UNK_0080\t\t0x0080\t\t/* ?? -- write 7 for now */\n#define PVR_TEXTURE_CLIP\t0x0084\t\t/* Distance for texture clipping */\n#define PVR_BGPLANE_Z\t\t0x0088\t\t/* Distance for background plane */\n#define PVR_BGPLANE_CFG\t\t0x008c\t\t/* Background plane config */\n#define PVR_UNK_0098\t\t0x0098\t\t/* ?? -- write 0x00800408 for now */\n#define PVR_UNK_00A0\t\t0x00a0\t\t/* ?? -- write 0x20 for now */\n#define PVR_UNK_00A8\t\t0x00a8\t\t/* ?? -- write 0x15d1c951 for now */\n#define PVR_FOG_TABLE_COLOR\t0x00b0\t\t/* Table fog color */\n#define PVR_FOG_VERTEX_COLOR\t0x00b4\t\t/* Vertex fog color */\n#define PVR_FOG_DENSITY\t\t0x00b8\t\t/* Fog density coefficient */\n#define PVR_COLOR_CLAMP_MAX\t0x00bc\t\t/* RGB Color clamp max */\n#define PVR_COLOR_CLAMP_MIN\t0x00c0\t\t/* RGB Color clamp min */\n#define PVR_GUN_POS\t\t0x00c4\t\t/* Light gun position */\n#define PVR_UNK_00C8\t\t0x00c8\t\t/* ?? -- write same as border H in 00d4 << 16 */\n#define PVR_VPOS_IRQ\t\t0x00cc\t\t/* Vertical position IRQ */\n#define PVR_TEXTURE_MODULO\t0x00e4\t\t/* Output texture width modulo */\n#define PVR_VIDEO_CFG\t\t0x00e8\t\t/* Misc video config */\n#define PVR_SCALER_CFG\t\t0x00f4\t\t/* Smoothing scaler */\n#define PVR_PALETTE_CFG\t\t0x0108\t\t/* Palette format */\n#define PVR_SYNC_STATUS\t\t0x010c\t\t/* V/H blank status */\n#define PVR_UNK_0110\t\t0x0110\t\t/* ?? -- write 0x93f39 for now */\n#define PVR_UNK_0114\t\t0x0114\t\t/* ?? -- write 0x200000 for now */\n#define PVR_UNK_0118\t\t0x0118\t\t/* ?? -- write 0x8040 for now */\n#define PVR_TA_OPB_START\t0x0124\t\t/* Object Pointer Buffer start for TA usage */\n#define PVR_TA_VERTBUF_START\t0x0128\t\t/* Vertex buffer start for TA usage */\n#define PVR_TA_OPB_END\t\t0x012c\t\t/* OPB end for TA usage */\n#define PVR_TA_VERTBUF_END\t0x0130\t\t/* Vertex buffer end for TA usage */\n#define PVR_TA_OPB_POS\t\t0x0134\t\t/* Top used memory location in OPB for TA usage */\n#define PVR_TA_VERTBUF_POS\t0x0138\t\t/* Top used memory location in vertbuf for TA usage */\n#define PVR_TILEMAT_CFG\t\t0x013c\t\t/* Tile matrix size config */\n#define PVR_OPB_CFG\t\t0x0140\t\t/* Active lists / list size */\n#define PVR_TA_INIT\t\t0x0144\t\t/* Initialize vertex reg. params */\n#define PVR_YUV_ADDR\t\t0x0148\t\t/* YUV conversion destination */\n#define PVR_YUV_CFG_1\t\t0x014c\t\t/* YUV configuration */\n#define PVR_UNK_0160\t\t0x0160\t\t/* ?? */\n#define PVR_TA_OPB_INIT\t\t0x0164\t\t/* Object pointer buffer position init */\n#define PVR_FOG_TABLE_BASE\t0x0200\t\t/* Base of the fog table */\n#define PVR_PALETTE_TABLE_BASE\t0x1000\t\t/* Base of the palette table */\n\n/* Useful memory locations */\n#define PVR_TA_INPUT\t\t0x10000000\t/* TA command input */\n#define PVR_RAM_BASE\t\t0xa5000000\t/* PVR RAM (raw) */\n#define PVR_RAM_INT_BASE\t0xa4000000\t/* PVR RAM (interleaved) */\n#define PVR_RAM_SIZE\t\t(8*1024*1024)\t/* RAM size in bytes */\n#define PVR_RAM_TOP\t\t(PVR_RAM_BASE + PVR_RAM_SIZE)\t\t/* Top of raw PVR RAM */\n#define PVR_RAM_INT_TOP\t\t(PVR_RAM_INT_BASE + PVR_RAM_SIZE)\t/* Top of int PVR RAM */\n\n/* Register content defines, as needed; these will be filled in over time\n as the implementation requires them. There's too many to do otherwise. */\n\n#define PVR_RESET_ALL\t\t0xffffffff\t/* PVR_RESET */\n#define PVR_RESET_NONE\t\t0x00000000\n#define PVR_RESET_TA\t\t0x00000001\n#define PVR_RESET_ISPTSP\t0x00000002\n\n#define PVR_ISP_START_GO\t0xffffffff\t/* PVR_ISP_START */\n\n#define PVR_TA_INIT_GO\t\t0x80000000\t/* PVR_TA_INIT */\n\n\n/* Initialization ****************************************************/\n\n/* Initialization and shutdown: stuff you should only ever have to do\n once in your program. */\n\n/* Bin sizes */\n#define PVR_BINSIZE_0\t\t\t0\n#define PVR_BINSIZE_8\t\t\t8\n#define PVR_BINSIZE_16\t\t\t16\n#define PVR_BINSIZE_32\t\t\t32\n\n/* You'll fill in this structure before calling init */\ntypedef struct {\n\t/* Bin sizes: opaque polygons, opaque modifiers, translucent\n\t polygons, translucent modifiers, punch-thrus */\n\tint\t\topb_sizes[5];\n\n\t/* Vertex buffer size (should be a nice round number) */\n\tint\t\tvertex_buf_size;\n\n\t/* Non-zero if we want to enable vertex DMA mode. Note that\n\t if this is set, then _all_ enabled lists need to have a\n\t vertex buffer assigned. */\n\tint\t\tdma_enabled;\n\n\t/* Non-zero if horizontal scaling is to be enabled. By enabling\n\t this setting and stretching your image to double the native\n\t screen width, you can get horizontal full-screen anti-aliasing. */\n\tint\t\tfsaa_enabled;\n} pvr_init_params_t;\n\n/* Initialize the PVR chip to ready status, enabling the specified lists\n and using the specified parameters; note that bins and vertex buffers\n come from the texture memory pool! Expects that a 2D mode was \n initialized already using the vid_* API. */\nint pvr_init(pvr_init_params_t *params);\n\n/* Simpler function which initializes the PVR using 16/16 for the opaque\n and translucent lists, and 0's for everything else; 512k of vertex\n buffer. This is equivalent to the old ta_init_defaults() for now. */\nint pvr_init_defaults();\n\n/* Shut down the PVR chip from ready status, leaving it in 2D mode as it\n was before the init. */\nint pvr_shutdown();\n\n\n/* Misc parameters ***************************************************/\n\n/* These are miscellaneous parameters you can set which affect the\n rendering process. */\n\n/* Set the background plane color (the area of the screen not covered by\n any other polygons) */\nvoid pvr_set_bg_color(float r, float g, float b);\n\n/* Return the current VBlank count */\nint pvr_get_vbl_count();\n\n/* Statistics structure */\ntypedef struct pvr_stats {\n\tuint32\t\tenabled_list_mask;\t/* Which lists are enabled? */\n\tuint32\t\tvbl_count;\t\t/* VBlank count */\n\tint\t\tframe_last_time;\t/* Ready-to-Ready length for the last frame in milliseconds */\n\tfloat\t\tframe_rate;\t\t/* Current frame rate (per second) */\n\tint\t\treg_last_time;\t\t/* Registration time for the last frame in milliseconds */\n\tint\t\trnd_last_time;\t\t/* Rendering time for the last frame in milliseconds */\n\tint\t\tvtx_buffer_used;\t/* Number of bytes used in the vertex buffer for the last frame */\n\tint\t\tvtx_buffer_used_max;\t/* Number of bytes used in the vertex buffer for the largest frame */\n\tint\t\tbuf_last_time;\t\t/* DMA buffer file time for the last frame in milliseconds */\n\tuint32\t\tframe_count;\t\t/* Total number of rendered/viewed frames */\n\t/* ... more later as it's implemented ... */\n} pvr_stats_t;\n\n/* Fill in a statistics structure (above) from current data. This\n is a super-set of frame count. */\nint pvr_get_stats(pvr_stats_t *stat);\n\n\n/* Palette management ************************************************/\n\n/* In addition to its 16-bit truecolor modes, the PVR also supports some\n nice paletted modes. These aren't useful for super high quality images\n most of the time, but they can be useful for doing some interesting\n special effects, like the old cheap \"worm hole\". */\n\n/* Palette formats */\n#define PVR_PAL_ARGB1555\t0\n#define PVR_PAL_RGB565\t\t1\n#define PVR_PAL_ARGB4444\t2\n#define PVR_PAL_ARGB8888\t3\n\n/* Set the palette format */\nvoid pvr_set_pal_format(int fmt);\n\n/* Set a palette value; note that the format of the table is variable,\n so for maximum speed we simply let the user decide what to do here. */\nstatic inline void pvr_set_pal_entry(uint32 idx, uint32 value) {\n\tPVR_SET(PVR_PALETTE_TABLE_BASE + 4*idx, value);\n}\n\n\n/* Hardware Fog parameters *******************************************/\n\n/* Thanks to Paul Boese for figuring this stuff out */\n\n/* Set the fog table color */\nvoid pvr_fog_table_color(float a, float r, float g, float b);\n\n/* Set the fog vertex color */\nvoid pvr_fog_vertex_color(float a, float r, float g, float b);\n\n/* Set the fog far depth */\nvoid pvr_fog_far_depth(float d);\n\n/* Initialize the fog table using an exp2 algorithm (like GL_EXP2) */\nvoid pvr_fog_table_exp2(float density);\n\n/* Initialize the fog table using an exp algorithm (like GL_EXP) */\nvoid pvr_fog_table_exp(float density);\n\n/* Initialize the fog table using a linear algorithm (like GL_LINEAR) */\nvoid pvr_fog_table_linear(float start, float end);\n\n/* Set a custom fog table from float values */\nvoid pvr_fog_table_custom(float tbl1[]);\n\n\n/* Memory management *************************************************/\n\n/* PVR memory management in KOS uses a modified dlmalloc; see the\n source file pvr_mem_core.c for more info. */\n\n/* Allocate a chunk of memory from texture space; the returned value\n will be relative to the base of texture memory (zero-based) */\npvr_ptr_t pvr_mem_malloc(size_t size);\n\n/* Free a previously allocated chunk of memory */\nvoid pvr_mem_free(pvr_ptr_t chunk);\n\n/* Return the number of bytes available still in the memory pool */\nuint32 pvr_mem_available();\n\n/* Reset the memory pool, equivalent to freeing all textures currently\n residing in RAM. */\nvoid pvr_mem_reset();\n\n/* Check the memory block list to see what's allocated */\n/* Only available if you've enabled KM_DBG in pvr_mem.c */\nvoid pvr_mem_print_list();\n\n/* Print some statistics (like mallocstats) */\nvoid pvr_mem_stats();\n\n/* Scene rendering ***************************************************/\n\n/* This API is used to submit triangle strips to the PVR via the TA\n interace in the chip. \n\n An important side note about the PVR is that all primitive types\n must be submitted grouped together. If you have 10 polygons for each\n list type, then the PVR must receive them via the TA by list type,\n with a list delimiter in between.\n\n So there are two modes you can use here. The first mode allows you to\n submit data directly to the TA. Your data will be forwarded to the\n chip for processing as it is fed to the PVR module. If your data\n is easily sorted into the primitive types, then this is the fastest\n mode for submitting data.\n\n The second mode allows you to submit data via main-RAM vertex buffers,\n which will be queued until the proper primitive type is active. In this\n case, each piece of data is copied into the vertex buffer while the\n wrong list is activated, and when the proper list becomes activated,\n the data is all sent at once. Ideally this would be via DMA, right \n now it is by store queues. This has the advantage of allowing you to\n send data in any order and have the PVR functions resolve how it should\n get sent to the hardware, but it is slower.\n\n The nice thing is that any combination of these modes can be used. You\n can assign a vertex buffer for any list, and it will be used to hold the\n incoming vertex data until the proper list has come up. Or if the proper\n list is already up, the data will be submitted directly. So if most of\n your polygons are opaque, and you only have a couple of translucents,\n you can set a small buffer to gather translucent data and then it will\n get sent when you do a pvr_end_scene().\n\n Thanks to Mikael Kalms for the idea for this API.\n\n Another somewhat subtle point that bears mentioning is that in the normal\n case (interrupts enabled) an interrupt handler will automatically take\n care of starting a frame rendering (after scene_finish()) and also\n flipping pages when appropriate. */\n\n/* Returns non-zero if vertex DMA was enabled at init time. */\nint pvr_vertex_dma_enabled();\n\n/* Setup a vertex buffer for one of the list types. If the specified list type\n already has a vertex buffer, it will be replaced by the new one; if NULL\n is specified as a buffer location, the list type will be switched to direct\n mode. The old buffer location will be returned (if any). Note that each\n buffer should actually be twice as long (to hold two frames' worth of\n data). The 'len' should be a multiple of 64, and the pointer should be\n aligned to a 32-byte boundary. 'len' also may not be smaller than 128\n bytes, even if you have no intention of using the given list. Also you\n should generally not try to do this at any time besides before a frame\n is begin, or Bad Things May Happen. */\nvoid * pvr_set_vertbuf(pvr_list_t list, void * buffer, int len);\n\n/* Return a pointer to the current output location in the DMA buffer for\n the requested list. DMA must globally be enabled for this to work. Data\n may be added to this buffer by the user program directly. */\nvoid * pvr_vertbuf_tail(pvr_list_t list);\n\n/* Notify the PVR system that data have been written into the output buffer\n for the given list. This should always be done after writing data directly\n to these buffers or it will get overwritten by other data. 'amt' is in\n bytes and should _always_ be a multiple of 32. */\nvoid pvr_vertbuf_written(pvr_list_t list, uint32 amt);\n\n/* Begin collecting data for a frame of 3D output to the off-screen\n frame buffer */\nvoid pvr_scene_begin();\n\n/* Begin collecting data for a frame of 3D output to the specified texture;\n pass in the size of the buffer in rx and ry, and the return values in\n rx and ry will be the size actually used (if changed). Note that\n currently this only supports screen-sized output! */\nvoid pvr_scene_begin_txr(pvr_ptr_t txr, uint32 *rx, uint32 *ry);\n\n/* Begin collecting data for the given list type. Lists do not have to be\n submitted in any particular order, but all types of a list must be \n submitted at once (unless vertex DMA mode is enabled). If the given list\n has already been closed, then an error (-1) is returned. Note that there\n is no need to call this function in DMA mode unless you want to make use\n of pvr_prim for compatibility. */\nint pvr_list_begin(pvr_list_t list);\n\n/* End collecting data for the current list type. Lists can never be opened\n again within a single frame once they have been closed. Thus submitting\n a primitive that belongs in a closed list is considered an error. Closing\n a list that is already closed is also an error (-1). Note that if you open\n a list but do not submit any primitives, a blank one will be submitted to\n satisfy the hardware. If vertex DMA mode is enabled, then this simply\n sets the current list pointer to no list, and none of the above restrictions\n apply. */\nint pvr_list_finish();\n\n/* Submit a primitive of the _current_ list type; note that any values\n submitted in this fashion will go directly to the hardware without any\n sort of buffering, and submitting a primitive of the wrong type will\n quite likely ruin your scene. Note that this also will not work if you\n haven't begun any list types (i.e., all data is queued). If DMA is enabled,\n the primitive will be appended to the end of the currently selected list's\n buffer. Returns -1 for failure. */\nint pvr_prim(void * data, int size);\n\n/* Initialize a state variable for Direct Rendering; variable should be\n of the type pvr_dr_state_t */\n#define pvr_dr_init(vtx_buf_ptr) do { \\\n\t(vtx_buf_ptr) = 0; \\\n\tQACR0 = ((((uint32)PVR_TA_INPUT) >> 26) << 2) & 0x1c; \\\n\tQACR1 = ((((uint32)PVR_TA_INPUT) >> 26) << 2) & 0x1c; \\\n} while (0)\n#define pvr_dr_state_t uint32\n\n/* Obtain the target address for Direct Rendering; this will return a\n write-only destination address where a primitive should be written to get\n ready to submit it to the TA in DR mode. You must pass in a variable\n which was initialized with pvr_dr_init(). */\n#define pvr_dr_target(vtx_buf_ptr) \\\n\t({ (vtx_buf_ptr) ^= 32; \\\n\t (pvr_vertex_t *)(0xe0000000 | (vtx_buf_ptr)); \\\n\t})\n\n/* Commit a primitive written into the Direct Rendering target address; pass\n the address returned by pvr_dr_target(). */\n#define pvr_dr_commit(addr) __asm__ __volatile__(\"pref @%0\" : : \"r\" (addr))\n\n/* Submit a primitive of the given list type; if the requested list is not\n the current list, then the data will be queued in a vertex buffer if\n available, otherwise it will be submitted directly. If a vertex buffer\n doesn't exist when one is needed, an error (-1) is returned. */\nint pvr_list_prim(pvr_list_t list, void * data, int size);\n\n/* Called to flush buffered data of the given list type to the hardware\n processor. If there is no vertex buffer for the given type, then an error\n (-1) is returned. The list must have been started with pvr_begin_list().\n This is intended to be used later in a \"hybrid\" mode where both direct\n and DMA TA submission is possible. */\nint pvr_list_flush(pvr_list_t list);\n\n/* Call this after you have finished submitting all data for a frame; once\n this has been called, you can not submit any more data until one of the\n pvr_scene_begin() functions is called again. An error (-1) is returned if\n you have not started a scene already. */\nint pvr_scene_finish();\n\n/* Block the caller until the PVR system is ready for another frame to be\n submitted. The PVR system allocates enough space for two frames: one in\n data collection mode, and another in rendering mode. If a frame is \n currently rendering, and another frame has already been closed, then the\n caller cannot do anything else until the rendering frame completes. Note\n also that the new frame cannot be activated except during a vertical\n blanking period, so this essentially waits until a rendered frame is\n complete _AND_ a vertical blank happens. Returns -1 if the wait times\n out. Note that once this returns, the PVR system is ready for another\n frame's data to be collected. */\nint pvr_wait_ready();\n\n/* Same thing as above, but in non-blocking form; returns -1 if the PVR isn't\n ready; returns 0 when the PVR has accepted your frame and is ready for\n more. If this returns 0 then you _must_ call pvr_wait_ready afterwards\n to clear the condition. */\nint pvr_check_ready();\n\n\n/* Primitive handling ************************************************/\n\n/* These functions help you prepare primitives for loading into the\n PVR for scene processing. */\n\n/* Compile a polygon context into a polygon header */\nvoid pvr_poly_compile(pvr_poly_hdr_t *dst, pvr_poly_cxt_t *src);\n\n/* Create a colored polygon context with parameters similar to\n the old \"ta\" function `ta_poly_hdr_col' */\nvoid pvr_poly_cxt_col(pvr_poly_cxt_t *dst, pvr_list_t list);\n\n/* Create a textured polygon context with parameters similar to\n the old \"ta\" function `ta_poly_hdr_txr' */\nvoid pvr_poly_cxt_txr(pvr_poly_cxt_t *dst, pvr_list_t list,\n\tint textureformat, int tw, int th, pvr_ptr_t textureaddr,\n\tint filtering);\n\n/* Compile a sprite context into a colored polygon header */\nvoid pvr_sprite_compile(pvr_poly_ic_hdr_t *dst,\n\tpvr_sprite_cxt_t *src);\n\n/* Create a textured sprite context */\nvoid pvr_sprite_cxt_txr(pvr_sprite_cxt_t *dst, pvr_list_t list,\n\tint textureformat, int tw, int th, pvr_ptr_t textureaddr,\n\tint filtering);\n\n/* Texture handling **************************************************/\n\n/* Helper functions for handling texture tasks of various kinds. */\n\n/* Load raw texture data from an SH-4 buffer into PVR RAM */\nvoid pvr_txr_load(void * src, pvr_ptr_t dst, uint32 count);\n\n/* Constants for texture loading */\n#define PVR_TXRLOAD_4BPP\t0x01\t/* Basic pixel formats */\n#define PVR_TXRLOAD_8BPP\t0x02\n#define PVR_TXRLOAD_16BPP\t0x03\n#define PVR_TXRLOAD_FMT_MASK\t0x0f\n\n#define PVR_TXRLOAD_VQ_LOAD\t\t0x10\t/* Do VQ encoding (not supported yet, if ever) */\n#define PVR_TXRLOAD_INVERT_Y\t\t0x20\t/* Invert the Y axis while loading */\n#define PVR_TXRLOAD_FMT_VQ\t\t0x40\t/* Texture is already VQ encoded */\n#define PVR_TXRLOAD_FMT_TWIDDLED\t0x80\t/* Texture is already twiddled */\n#define PVR_TXRLOAD_FMT_NOTWIDDLE\t0x80\t/* Same sorta thing -- don't twiddle it */\n#define PVR_TXRLOAD_DMA\t\t\t0x8000\t/* Use DMA to load the texture */\n#define PVR_TXRLOAD_NONBLOCK\t\t0x4000\t/* Use non-blocking loads (only for DMA) */\n#define PVR_TXRLOAD_SQ\t\t\t0x2000\t/* Use store queues to load */\n\n/* Load texture data from an SH-4 buffer into PVR RAM, twiddling it\n in the process, among other things (see pvr_texture.c for more\n details) */\nvoid pvr_txr_load_ex(void * src, pvr_ptr_t dst, uint32 w, uint32 h, uint32 flags);\n\n/* Load a KOS Platform Independent Image (subject to restraint checking) */\nvoid pvr_txr_load_kimg(kos_img_t *img, pvr_ptr_t dst, uint32 flags);\n\n\n/* PVR DMA ***********************************************************/\n\n/** Interrupt callback type */\ntypedef void (*pvr_dma_callback_t)(ptr_t data);\n\n/** Perform a DMA transfer to the PVR. The source pointer must be 32-byte\n aligned, and the count should be a multiple of 32 bytes. Type should\n be one of the constants below. If block is non-zero, then the function\n will only return when the DMA operation has completed. If callback is\n non-NULL, then the function will be called on completion (in an interrupt\n context!). Returns <0 for failure. */\nint pvr_dma_transfer(void * src, uint32 dest, uint32 count, int type,\n\tint block, pvr_dma_callback_t callback, ptr_t cbdata);\n\n#define PVR_DMA_VRAM64\t0\t/*< Transfer to VRAM in interleaved mode */\n#define PVR_DMA_VRAM32\t1\t/*< Transfer to VRAM in linear mode */\n#define PVR_DMA_TA\t2\t/*< Transfer to the tile accelerator */\n\n/** Load a texture using PVR DMA. If block is non-zero, then the function\n will not return until the texture DMA is complete. Otherwise, check\n the value of pvr_dma_ready() to see if things are ready. */\nint pvr_txr_load_dma(void * src, pvr_ptr_t dest, uint32 count, int block,\n\tpvr_dma_callback_t callback, ptr_t cbdata);\n\n/** Loads a block of vertex data to the tile accelerator. Same semantics as\n the above stuff. */\nint pvr_dma_load_ta(void * src, uint32 count, int block,\n\tpvr_dma_callback_t callback, ptr_t cbdata);\n\n/** Returns non-zero if PVR DMA is inactive. */\nint pvr_dma_ready();\n\n/** Initialize PVR DMA */\nvoid pvr_dma_init();\n\n/** Shut down PVR DMA */\nvoid pvr_dma_shutdown();\n\n/*********************************************************************/\n\n\n__END_DECLS\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5428446531295776,
"alphanum_fraction": 0.550859808921814,
"avg_line_length": 20.78412628173828,
"blob_id": "8f2253dba9a694a513a0433620c1caab2edb041b",
"content_id": "359aa9dfacb6ff295bcb422f5c543b6ae6a2b869",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6862,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 315,
"path": "/kernel/fs/fs_socket.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n fs_socket.c\n Copyright (C) 2006 Lawrence Sebald\n\n*/\n\n#include <kos/mutex.h>\n#include <arch/spinlock.h>\n#include <kos/dbgio.h>\n#include <kos/fs.h>\n#include <kos/fs_socket.h>\n#include <kos/net.h>\n\n#include <errno.h>\n#include <string.h>\n#include <malloc.h>\n#include <sys/queue.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <arpa/inet.h>\n\n#include \"../net/net_ipv4.h\"\n#include \"../net/net_udp.h\"\n\n/* Define the socket list type */\nLIST_HEAD(socket_list, net_socket);\n\nstatic struct socket_list sockets;\nstatic mutex_t *list_mutex;\n\nstatic void fs_socket_close(void *hnd) {\n net_socket_t *sock = (net_socket_t *) hnd;\n\n mutex_lock(list_mutex);\n LIST_REMOVE(sock, sock_list);\n mutex_unlock(list_mutex);\n\n net_udp_close(hnd);\n\n free(sock);\n}\n\nstatic ssize_t fs_socket_read(void *hnd, void *buffer, size_t cnt) {\n net_socket_t *sock = (net_socket_t *)hnd;\n\n return net_udp_recv(sock, buffer, cnt, 0);\n}\n\nstatic off_t fs_socket_seek(void *hnd, off_t offset, int whence) {\n errno = ESPIPE;\n return (off_t) -1;\n}\n\nstatic off_t fs_socket_tell(void *hnd) {\n errno = ESPIPE;\n return (off_t) -1;\n}\n\nstatic ssize_t fs_socket_write(void *hnd, const void *buffer, size_t cnt) {\n net_socket_t *sock = (net_socket_t *)hnd;\n\n return net_udp_send(sock, buffer, cnt, 0);\n}\n\n/* VFS handler */\nstatic vfs_handler_t vh = {\n /* Name handler */\n {\n \"/sock\", /* Name */\n 0, /* tbfi */\n 0x00010000, /* Version 1.0 */\n 0, /* Flags */\n NMMGR_TYPE_VFS,\n NMMGR_LIST_INIT,\n },\n\n 0, NULL, /* No cache, privdata */\n\n NULL, /* open */\n fs_socket_close, /* close */\n fs_socket_read, /* read */\n fs_socket_write, /* write */\n fs_socket_seek, /* seek */\n fs_socket_tell, /* tell */\n NULL, /* total */\n NULL, /* readdir */\n NULL, /* ioctl */\n NULL, /* rename */\n NULL, /* unlink */\n NULL, /* mmap */\n NULL, /* complete */\n NULL, /* stat */\n NULL, /* mkdir */\n NULL /* rmdir */\n};\n\n/* Have we been initialized? */\nstatic int initted = 0;\n\nint fs_socket_init() {\n if(initted == 1)\n return 0;\n\n LIST_INIT(&sockets);\n\n if(nmmgr_handler_add(&vh.nmmgr) < 0)\n return -1;\n\n list_mutex = mutex_create();\n initted = 1;\n\n return 0;\n}\n\nint fs_socket_shutdown() {\n net_socket_t *c, *n;\n\n if(initted == 0)\n return 0;\n\n mutex_lock(list_mutex);\n c = LIST_FIRST(&sockets);\n while(c != NULL) {\n n = LIST_NEXT(c, sock_list);\n\n vh.close(c);\n\n free(c);\n c = n;\n }\n\n if(nmmgr_handler_remove(&vh.nmmgr) < 0)\n return -1;\n\n mutex_destroy(list_mutex);\n\n initted = 0;\n\n return 0;\n}\n\nint fs_socket_setflags(int sock, int flags) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_setflags(hnd, flags);\n}\n\nint socket(int domain, int type, int protocol) {\n net_socket_t *sock;\n file_t hnd;\n\n /* First, check the arguments for validity */\n if(domain != AF_INET) {\n errno = EAFNOSUPPORT;\n return -1;\n }\n\n if(type != SOCK_DGRAM) {\n errno = EPROTONOSUPPORT;\n return -1;\n }\n\n if(protocol != 0 && protocol != IPPROTO_UDP) {\n errno = EPROTONOSUPPORT;\n return -1;\n }\n\n /* Allocate the socket structure, if we have the space */\n sock = (net_socket_t *) malloc(sizeof(net_socket_t));\n if(!sock) {\n errno = ENOMEM;\n return -1;\n }\n\n /* Attempt to get a handle for this socket */\n hnd = fs_open_handle(&vh, sock);\n if(hnd < 0) {\n free(sock);\n return -1;\n }\n\n /* We only support UDP right now, so this is ok... */\n sock->protocol = IPPROTO_UDP;\n\n /* Initialize protocol-specific data */\n if(net_udp_socket(sock, domain, type, protocol) == -1) {\n fs_close(hnd);\n return -1;\n }\n\n /* Add this socket into the list of sockets, and return */\n mutex_lock(list_mutex);\n LIST_INSERT_HEAD(&sockets, sock, sock_list);\n mutex_unlock(list_mutex);\n\n return hnd;\n}\n\nint accept(int sock, struct sockaddr *address, socklen_t *address_len) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_accept(hnd, address, address_len);\n}\n\nint bind(int sock, const struct sockaddr *address, socklen_t address_len) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_bind(hnd, address, address_len);\n}\n\nint connect(int sock, const struct sockaddr *address, socklen_t address_len) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_connect(hnd, address, address_len);\n}\n\nint listen(int sock, int backlog) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_listen(hnd, backlog);\n}\n\nssize_t recv(int sock, void *buffer, size_t length, int flags) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_recv(hnd, buffer, length, flags);\n}\n\nssize_t recvfrom(int sock, void *buffer, size_t length, int flags,\n struct sockaddr *address, socklen_t *address_len) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_recvfrom(hnd, buffer, length, flags, address,\n address_len);\n}\n\nssize_t send(int sock, const void *message, size_t length, int flags) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_send(hnd, message, length, flags);\n}\n\nssize_t sendto(int sock, const void *message, size_t length, int flags,\n const struct sockaddr *dest_addr, socklen_t dest_len) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_sendto(hnd, message, length, flags, dest_addr, dest_len);\n}\n\nint shutdown(int sock, int how) {\n net_socket_t *hnd;\n\n hnd = (net_socket_t *) fs_get_handle(sock);\n if(hnd == NULL) {\n errno = EBADF;\n return -1;\n }\n\n return net_udp_shutdownsock(hnd, how);\n}\n"
},
{
"alpha_fraction": 0.5081570744514465,
"alphanum_fraction": 0.5564954876899719,
"avg_line_length": 28.339284896850586,
"blob_id": "1af369a68542440c71d1c931d6aa133cff46602c",
"content_id": "2dc4bc8573d4a1ea0287058bd7253a4ec50cc81c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1655,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 56,
"path": "/addons/libkosutils/bspline.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n bspline.c\n (c)2000 Dan Potter\n\n For generating B-Spline curves \n\n This math info is from Leendert Ammeraal's \"Programming Principles in\n Computer Graphics\". \n*/\n\n#include <kos/bspline.h>\n\n/* Pass it an array of points and it will calculate a set of B-spline\n co-efficients for generating a curve. There must be at least one point\n before the \"current\" one, and at least two after the \"current\" one (a\n total of four points required). These values will be used in the \n function below. */\nstatic float bc_x[4], bc_y[4], bc_z[4];\nvoid bspline_coeff(const point_t * pnt) {\n\tfloat a, b, c, d;\n\t\n\t/* First calculate the X coefficients */\n\ta = pnt[-1].x; b = pnt[0].x; c = pnt[1].x; d = pnt[2].x;\n\tbc_x[3] = (-a+3*(b-c)+d) / 6.0f;\n\tbc_x[2] = (a-2*b+c)/2.0f;\n\tbc_x[1] = (c-a)/2.0f;\n\tbc_x[0] = (a+4*b+c)/6.0f;\n\t\n\t/* Next, the Y coefficients */\n\ta = pnt[-1].y; b = pnt[0].y; c = pnt[1].y; d = pnt[2].y;\n\tbc_y[3] = (-a+3*(b-c)+d) / 6.0f;\n\tbc_y[2] = (a-2*b+c)/2.0f;\n\tbc_y[1] = (c-a)/2.0f;\n\tbc_y[0] = (a+4*b+c)/6.0f;\n\n\t/* Finally, the Z coefficients */\n\ta = pnt[-1].z; b = pnt[0].z; c = pnt[1].z; d = pnt[2].z;\n\tbc_z[3] = (-a+3*(b-c)+d) / 6.0f;\n\tbc_z[2] = (a-2*b+c)/2.0f;\n\tbc_z[1] = (c-a)/2.0f;\n\tbc_z[0] = (a+4*b+c)/6.0f;\n}\n\n/* Given a 't' (between 0.0f and 1.0f) this will generate the next point\n values for the current set of coefficients. */\nvoid bspline_get_point(float t, point_t *p) {\n\t/* Generate X */\n\tp->x = ((bc_x[3]*t+bc_x[2])*t+bc_x[1])*t + bc_x[0];\n\t\n\t/* Generate Y */\n\tp->y = ((bc_y[3]*t+bc_y[2])*t+bc_y[1])*t + bc_y[0];\n\t\n\t/* Generate Z */\n\tp->z = ((bc_z[3]*t+bc_z[2])*t+bc_z[1])*t + bc_z[0];\n}\n\n \n \n\n\n\n"
},
{
"alpha_fraction": 0.5699658989906311,
"alphanum_fraction": 0.6604095697402954,
"avg_line_length": 17.870967864990234,
"blob_id": "766644483115b76e7cb0a506776bff217371e934",
"content_id": "eb7a08208a10e1c39b08f79c08379d640f89fc73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 31,
"path": "/include/arch/dreamcast/dc/fs_iso9660.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/fs/iso9660.h\n (c)2000-2001 Dan Potter\n\n $Id: fs_iso9660.h,v 1.5 2003/04/24 03:14:20 bardtx Exp $\n*/\n\n#ifndef __DC_FS_ISO9660_H\n#define __DC_FS_ISO9660_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n\n#define MAX_ISO_FILES 8\n\n/* Call to reset the cache and generally assume that a new disc\n has been (or will be) inserted. This is equivalent to the old\n iso_ioctl() call. */\nint iso_reset();\n\nint fs_iso9660_init();\nint fs_iso9660_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_FS_ISO9660_H */\n\n"
},
{
"alpha_fraction": 0.5798525810241699,
"alphanum_fraction": 0.6289926171302795,
"avg_line_length": 18.285715103149414,
"blob_id": "83b7c5054a326e6cf425afc3981bc02f8e74442d",
"content_id": "d0d8077e0a6dd02ab12223c453255d8eccfd6eba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/examples/dreamcast/network/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/network/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.5 2002/06/11 06:14:39 bardtx Exp $\n\nall:\n\t$(MAKE) -C basic\n\t$(MAKE) -C httpd\n#\t$(MAKE) -C dcload-ip-lwip-test\n\nclean:\n\t$(MAKE) -C basic clean\n\t$(MAKE) -C httpd clean\n#\t$(MAKE) -C dcload-ip-lwip-test clean\n\t\t\ndist:\n\t$(MAKE) -C basic dist\n\t$(MAKE) -C httpd dist\n#\t$(MAKE) -C dcload-ip-lwip-test dist\n\n\n"
},
{
"alpha_fraction": 0.6120783686637878,
"alphanum_fraction": 0.6305767297744751,
"avg_line_length": 35.039215087890625,
"blob_id": "b52931d9ce28cd43419312b30a0a8f5285b64622",
"content_id": "2424a3d3280afd2194bd9f70b739244d23e773ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1838,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 51,
"path": "/kernel/net/net_udp.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_udp.h\n Copyright (C) 2005, 2006, 2007, 2008 Lawrence Sebald\n\n*/\n\n#ifndef __LOCAL_NET_UDP_H\n#define __LOCAL_NET_UDP_H\n\n#include <sys/socket.h>\n#include <kos/fs_socket.h>\n\n#define packed __attribute__((packed))\ntypedef struct {\n uint16 src_port packed;\n uint16 dst_port packed;\n uint16 length packed;\n uint16 checksum packed;\n} udp_hdr_t;\n#undef packed\n\nint net_udp_input(netif_t *src, ip_hdr_t *ih, const uint8 *data, int size);\nint net_udp_send_raw(netif_t *net, uint32 src_ip, uint16 src_port,\n uint32 dst_ip, uint16 dst_port, const uint8 *data,\n int size, int flags);\n\n/* Sockets */\nint net_udp_accept(net_socket_t *hnd, struct sockaddr *addr,\n socklen_t *addr_len);\nint net_udp_bind(net_socket_t *hnd, const struct sockaddr *addr,\n socklen_t addr_len);\nint net_udp_connect(net_socket_t *hnd, const struct sockaddr *addr,\n socklen_t addr_len);\nint net_udp_listen(net_socket_t *hnd, int backlog);\nssize_t net_udp_recv(net_socket_t *hnd, void *buffer, size_t length, int flags);\nssize_t net_udp_recvfrom(net_socket_t *hnd, void *buffer, size_t length,\n int flags, struct sockaddr *addr, socklen_t *addr_len);\nssize_t net_udp_send(net_socket_t *hnd, const void *message, size_t length,\n int flags);\nssize_t net_udp_sendto(net_socket_t *hnd, const void *message, size_t length,\n int flags, const struct sockaddr *addr,\n socklen_t addr_len);\nint net_udp_shutdownsock(net_socket_t *hnd, int how);\nint net_udp_socket(net_socket_t *hnd, int domain, int type, int protocol);\n\nvoid net_udp_close(net_socket_t *hnd);\n\nint net_udp_setflags(net_socket_t *hnd, int flags);\n\n#endif /* __LOCAL_NET_UDP_H */\n"
},
{
"alpha_fraction": 0.6495813727378845,
"alphanum_fraction": 0.7094139456748962,
"avg_line_length": 31.639999389648438,
"blob_id": "f5cf283a9ae253c10113b93384b40c237bf1dfac",
"content_id": "03b08b5397fb4024fef5bbf17e9360c112e0e0ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4897,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 150,
"path": "/include/arch/ps2/arch/irq.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/irq.h\n (c)2000-2002 Dan Potter\n\n $Id: irq.h,v 1.3 2002/11/03 03:40:55 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_IRQ_H\n#define __ARCH_IRQ_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* The number of bytes required to save thread context. This should\n include all general CPU registers, FP registers, and status regs (even\n if not all of these are actually used). */\n#define REG_BYTE_CNT (32*16 + 2*16 + 8 + 6*4 + 32*4 + 2*4)\n\n/* Architecture-specific structure for holding the processor state (register\n values, etc). The size of this structure should be less than or equal\n to the above value. We currently don't save the full 128-bit GPRs. */\ntypedef struct irq_context {\n\tuint128\t\tr[32];\t\t\t/* 31 general purpose regs (+ $zero) */\n\tuint128\t\tlo, hi;\t\t\t/* LO, HI */\n\tuint64\t\tsa;\t\t\t/* Shift amount */\n\tuint32\t\tstatus, pc;\t\t/* COP0 regs relevant to context */\n\tuint32\t\tcause, config,\t\t/* Not really part of context, but kernel will need them */\n\t\t\tbadvaddr,badpaddr;\n\tuint32\t\tfr[32];\t\t\t/* 32 floating point regs */\n\tuint32\t\tfcr31, facc;\t\t/* Control/Status, Accumulator */\n} irq_context_t;\n\n/* A couple of architecture independent access macros. For PS2 these\n are a bit nastier because of the data widths. */\n#define CONTEXT_128_TO_32(c) (*((uint32 *)&(c)))\n#define CONTEXT_PC(c)\t(CONTEXT_128_TO_32((c).pc))\n#define CONTEXT_FP(c)\t(CONTEXT_128_TO_32((c).r[30]))\t/* $fp */\n#define CONTEXT_SP(c)\t(CONTEXT_128_TO_32((c).r[29]))\t/* $sp */\n\n/* Catchable exceptions -- the 0xf0 digit refers to the vector index (where\n the exception is vectered to) while the 0x0f digit is ExcCode. */\n#define EXC_TLB_REFILL\t\t0x0000\n#define EXC_PERF_COUNTER\t0x0010\n#define EXC_DEBUG\t\t0x0020\n#define EXC_COMMON\t\t0x0030\n#define EXC_TLB_MODIFIED\t0x0031\n#define EXC_TLB_INVALID_IL\t0x0032\n#define EXC_TLB_INVALID_S\t0x0033\n#define EXC_ADDR_ERROR_IL\t0x0034\n#define EXC_ADDR_ERROR_S\t0x0035\n#define EXC_BUS_ERROR_IL\t0x0036\n#define EXC_BUS_ERROR_S\t\t0x0037\n#define EXC_SYSCALL\t\t0x0038\n#define EXC_BREAK\t\t0x0039\n#define EXC_COP_UNUSABLE\t0x003b\n#define EXC_OVERFLOW\t\t0x003c\n#define EXC_TRAP\t\t0x003d\n#define EXC_INTR\t\t0x0040\n#define EXC_INTR_0\t\t0x0040\t\t/* Used for INTC */\n#define EXC_INTR_1\t\t0x0041\t\t/* Used for DMAC */\n\n/* INT0-based interrupts; we encode the actual processor interrupt as the\n bottom byte here, and the top byte will be used as an index into a\n secondary table. This is somewhat like the ASIC module on the DC. */\n#define EXC_INTR_GS\t\t0x0040\n#define EXC_INTR_SBUS\t\t0x0140\n#define EXC_INTR_VB_ON\t\t0x0240\t\t/* Vertical blank start */\n#define EXC_INTR_VB_OFF\t\t0x0340\t\t/* Vertical blank end */\n#define EXC_INTR_VIF0\t\t0x0440\n#define EXC_INTR_VIF1\t\t0x0540\n#define EXC_INTR_VU0\t\t0x0640\n#define EXC_INTR_VU1\t\t0x0740\n#define EXC_INTR_IPU\t\t0x0840\n#define EXC_INTR_TIMER0\t\t0x0940\n#define EXC_INTR_TIMER1\t\t0x0a40\n#define EXC_INTR_TIMER2\t\t0x0b40\n#define EXC_INTR_TIMER3\t\t0x0c40\n#define EXC_INTR_SFIFO\t\t0x0d40\t\t/* SFIFO transfer error */\n#define EXC_INTR_VU0WD\t\t0x0e40\t\t/* VU0 watchdog */\n\n/* INT1-based interrupts. */\n#define EXC_INTR_DMAC\t\t0x0041\n\n/* This is a software-generated one (double-fault) for when an exception\n happens inside an ISR. */\n#define EXC_DOUBLE_FAULT\t0x00ff\n\n/* Software-generated for unhandled exception */\n#define EXC_UNHANDLED_EXC\t0x00fe\n\n/* The value of the timer IRQ */\n#define TIMER_IRQ\t\tEXC_INTR_TIMER0\n\n/* The type of an interrupt identifier */\ntypedef uint32 irq_t;\n\n/* The type of an IRQ handler */\ntypedef void (*irq_handler)(irq_t source, irq_context_t *context);\n\n/* Are we inside an interrupt handler? */\nint irq_inside_int();\n\n/* Pretend like we just came in from an interrupt and force\n a context switch back to the \"current\" context. Make sure\n you've called irq_set_context()! */\nvoid irq_force_return();\n\n/* Set a handler, or remove a handler (see codes above) */\nint irq_set_handler(irq_t source, irq_handler hnd);\n\n/* Get the address of the current handler */\nirq_handler irq_get_handler(irq_t source);\n\n/* Set a global exception handler */\nint irq_set_global_handler(irq_handler hnd);\n\n/* Get the global exception handler */\nirq_handler irq_get_global_handler();\n\n/* Switch out contexts (for interrupt return) */\nvoid irq_set_context(irq_context_t *regbank);\n\n/* Return the current IRQ context */\nirq_context_t *irq_get_context();\n\n/* Fill a newly allocated context block for usage with supervisor/kernel\n or user mode. The given parameters will be passed to the called routine (up\n to the architecture maximum). */\nvoid irq_create_context(irq_context_t *context, ptr_t stack_pointer,\n\tptr_t routine, uint64 *args, int usermode);\n\n/* Enable/Disable interrupts */\nint irq_disable();\nvoid irq_enable();\nstatic inline void irq_enable_exc() { }\t\t/* NOP on MIPS */\nvoid irq_restore(int v);\n\n/* Init routine */\nint irq_init();\n\n/* Shutdown */\nvoid irq_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_IRQ_H */\n\n"
},
{
"alpha_fraction": 0.645846426486969,
"alphanum_fraction": 0.7133417129516602,
"avg_line_length": 32.98395538330078,
"blob_id": "67c9a343de68f314d73b422ea1ce379734c85c3c",
"content_id": "1bb01dbd02c4a17245aab743d2c3ce8f21b7e7f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6356,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 187,
"path": "/include/arch/dreamcast/arch/irq.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/irq.h\n (c)2000-2001 Dan Potter\n\n $Id: irq.h,v 1.9 2003/02/14 06:33:47 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_IRQ_H\n#define __ARCH_IRQ_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* The number of bytes required to save thread context. This should\n include all general CPU registers, FP registers, and status regs (even\n if not all of these are actually used). */\n#define REG_BYTE_CNT 256\t\t\t/* Currently really 228 */\n\n/* Architecture-specific structure for holding the processor state (register\n values, etc). The size of this structure should be less than or equal\n to the above value. */\ntypedef struct irq_context {\n\tuint32\t\tr[16];\t\t\t/* 16 general purpose regs */\n\tuint32\t\tpc, pr, gbr, vbr;\t/* Various system words */\n\tuint32\t\tmach, macl, sr;\n\tuint32\t\tfrbank[16];\t\t/* Secondary float regs */\n\tuint32\t\tfr[16];\t\t\t/* Primary float regs */\n\tuint32\t\tfpscr, fpul;\t\t/* Float control regs */\n} irq_context_t;\n\n/* A couple of architecture independent access macros */\n#define CONTEXT_PC(c)\t((c).pc)\n#define CONTEXT_FP(c)\t((c).r[14])\n#define CONTEXT_SP(c)\t((c).r[15])\n#define CONTEXT_RET(c)\t((c).r[0])\n\n/* Dreamcast-specific exception codes.. use these when getting or setting an\n exception code value. */\n\n/* Reset type */\n#define EXC_RESET_POWERON\t0x0000\t/* Power-on reset */\n#define EXC_RESET_MANUAL\t0x0020\t/* Manual reset */\n#define EXC_RESET_UDI\t\t0x0000\t/* Hitachi UDI reset */\n#define EXC_ITLB_MULTIPLE\t0x0140\t/* Instruction TLB multiple hit */\n#define EXC_DTLB_MULTIPLE\t0x0140\t/* Data TLB multiple hit */\n\n/* Re-Execution type */\n#define EXC_USER_BREAK_PRE\t0x01e0\t/* User break before instruction */\n#define EXC_INSTR_ADDRESS\t0x00e0\t/* Instruction address */\n#define EXC_ITLB_MISS\t\t0x0040\t/* Instruction TLB miss */\n#define EXC_ITLB_PV\t\t0x00a0\t/* Instruction TLB protection violation */\n#define EXC_ILLEGAL_INSTR\t0x0180\t/* Illegal instruction */\n#define EXC_SLOT_ILLEGAL_INSTR\t0x01a0\t/* Slot illegal instruction */\n#define EXC_GENERAL_FPU\t\t0x0800\t/* General FPU exception */\n#define EXC_SLOT_FPU\t\t0x0820\t/* Slot FPU exception */\n#define EXC_DATA_ADDRESS_READ\t0x00e0\t/* Data address (read) */\n#define EXC_DATA_ADDRESS_WRITE\t0x0100\t/* Data address (write) */\n#define EXC_DTLB_MISS_READ\t0x0040\t/* Data TLB miss (read) */\n#define EXC_DTLB_MISS_WRITE\t0x0060\t/* Data TLB miss (write) */\n#define EXC_DTLB_PV_READ\t0x00a0\t/* Data TLB P.V. (read) */\n#define EXC_DTLB_PV_WRITE\t0x00c0\t/* Data TLB P.V. (write) */\n#define EXC_FPU\t\t\t0x0120\t/* FPU exception */\n#define EXC_INITIAL_PAGE_WRITE\t0x0080\t/* Initial page write exception */\n\n/* Completion type */\n#define EXC_TRAPA\t\t0x0160\t/* Unconditional trap */\n#define EXC_USER_BREAK_POST\t0x01e0\t/* User break after instruction */\n\n/* Interrupt (completion type) */\n#define EXC_NMI\t\t\t0x01c0\t/* Nonmaskable interrupt */\n#define EXC_IRQ0\t\t0x0200\t/* External IRL requests */\n#define EXC_IRQ1\t\t0x0220\n#define EXC_IRQ2\t\t0x0240\n#define EXC_IRQ3\t\t0x0260\n#define EXC_IRQ4\t\t0x0280\n#define EXC_IRQ5\t\t0x02a0\n#define EXC_IRQ6\t\t0x02c0\n#define EXC_IRQ7\t\t0x02e0\n#define EXC_IRQ8\t\t0x0300\n#define EXC_IRQ9\t\t0x0320\n#define EXC_IRQA\t\t0x0340\n#define EXC_IRQB\t\t0x0360\n#define EXC_IRQC\t\t0x0380\n#define EXC_IRQD\t\t0x03a0\n#define EXC_IRQE\t\t0x03c0\n#define EXC_TMU0_TUNI0\t\t0x0400\t/* TMU0 underflow */\n#define EXC_TMU1_TUNI1\t\t0x0420\t/* TMU1 underflow */\n#define EXC_TMU2_TUNI2\t\t0x0440\t/* TMU2 underflow */\n#define EXC_TMU2_TICPI2\t\t0x0460\t/* TMU2 input capture */\n#define EXC_RTC_ATI\t\t0x0480\n#define EXC_RTC_PRI\t\t0x04a0\n#define EXC_RTC_CUI\t\t0x04c0\n#define EXC_SCI_ERI\t\t0x04e0\t/* SCI Error receive */\n#define EXC_SCI_RXI\t\t0x0500\t/* Receive ready */\n#define EXC_SCI_TXI\t\t0x0520\t/* Transmit ready */\n#define EXC_SCI_TEI\t\t0x0540\t/* Transmit error */\n#define EXC_WDT_ITI\t\t0x0560\t/* Watchdog timer */\n#define EXC_REF_RCMI\t\t0x0580\n#define EXC_REF_ROVI\t\t0x05a0\n#define EXC_UDI\t\t\t0x0600\t/* Hitachi UDI */\n#define EXC_GPIO_GPIOI\t\t0x0620\n#define EXC_DMAC_DMTE0\t\t0x0640\n#define EXC_DMAC_DMTE1\t\t0x0660\n#define EXC_DMAC_DMTE2\t\t0x0680\n#define EXC_DMAC_DMTE3\t\t0x06a0\n#define EXC_DMA_DMAE\t\t0x06c0\n#define EXC_SCIF_ERI\t\t0x0700\t/* SCIF Error receive */\n#define EXC_SCIF_RXI\t\t0x0720\n#define EXC_SCIF_BRI\t\t0x0740\n#define EXC_SCIF_TXI\t\t0x0760\n\n/* This is a software-generated one (double-fault) for when an exception\n happens inside an ISR. */\n#define EXC_DOUBLE_FAULT\t0x0ff0\n\n/* Software-generated for unhandled exception */\n#define EXC_UNHANDLED_EXC\t0x0fe0\n\n/* The following are a table of \"type offsets\" (see the Hitachi PDF).\n These are the 0x000, 0x100, 0x400, and 0x600 offsets. */\n#define EXC_OFFSET_000\t\t0\n#define EXC_OFFSET_100\t\t1\n#define EXC_OFFSET_400\t\t2\n#define EXC_OFFSET_600\t\t3\n\n/* The value of the timer IRQ */\n#define TIMER_IRQ\t\tEXC_TMU0_TUNI0\n\n/* The type of an interrupt identifier */\ntypedef uint32 irq_t;\n\n/* The type of an IRQ handler */\ntypedef void (*irq_handler)(irq_t source, irq_context_t *context);\n\n/* Are we inside an interrupt handler? */\nint irq_inside_int();\n\n/* Pretend like we just came in from an interrupt and force\n a context switch back to the \"current\" context. Make sure\n you've called irq_set_context()! */\nvoid irq_force_return();\n\n/* Set a handler, or remove a handler (see codes above) */\nint irq_set_handler(irq_t source, irq_handler hnd);\n\n/* Get the address of the current handler */\nirq_handler irq_get_handler(irq_t source);\n\n/* Set or remove a trapa handler */\nint trapa_set_handler(irq_t code, irq_handler hnd);\n\n/* Set a global exception handler */\nint irq_set_global_handler(irq_handler hnd);\n\n/* Get the global exception handler */\nirq_handler irq_get_global_handler();\n\n/* Switch out contexts (for interrupt return) */\nvoid irq_set_context(irq_context_t *regbank);\n\n/* Return the current IRQ context */\nirq_context_t *irq_get_context();\n\n/* Fill a newly allocated context block for usage with supervisor/kernel\n or user mode. The given parameters will be passed to the called routine (up\n to the architecture maximum). */\nvoid irq_create_context(irq_context_t *context, uint32 stack_pointer,\n\tuint32 routine, uint32 *args, int usermode);\n\n/* Enable/Disable interrupts */\nint irq_disable();\t\t/* Will leave exceptions enabled */\nvoid irq_enable();\t\t/* Enables all ints including external */\nvoid irq_restore(int v);\n\n/* Init routine */\nint irq_init();\n\n/* Shutdown */\nvoid irq_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_IRQ_H */\n\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.632478654384613,
"avg_line_length": 15.714285850524902,
"blob_id": "88c4ebdb2b36cba8df761722c4ff5676059c9d2b",
"content_id": "ec4245427291ec0c37344fadc5624fda955d3f85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 14,
"path": "/kernel/libc/newlib/newlib_link.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n newlib_link.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <sys/reent.h>\n#include <errno.h>\n\nint _link_r(struct _reent * reent, const char * oldf, const char * newf) {\n\treent->_errno = EMLINK;\n\treturn -1;\n}\n"
},
{
"alpha_fraction": 0.6536231637001038,
"alphanum_fraction": 0.665217399597168,
"avg_line_length": 27.70833396911621,
"blob_id": "a3ed5f61b971bbb91ef54677f99ecf8ba53c5463",
"content_id": "78c821f3fada2591022f65fd1e7334047bd2c0f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 690,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 24,
"path": "/kernel/libc/koslib/crtend.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n crtend.c\n Copyright (C)2002 Dan Potter\n*/\n\n/* Handles ctors and dtors (for C++ programs). This is modeled on the \n FreeBSD crtend.c code. Note that the default linker scripts for\n GCC will automatically put our ctors at the end of the list. */\n\n#include <sys/cdefs.h>\n\n/* Here we gain access to the ctor and dtor sections of the program by\n defining new data in them. */\ntypedef void (*fptr)(void);\n\nstatic fptr ctor_list[1] __attribute__((section(\".ctors\"))) = { (fptr) 0 };\nstatic fptr dtor_list[1] __attribute__((section(\".dtors\"))) = { (fptr) 0 };\n\n/* Ensures that this gets linked in */\nvoid __crtend_pullin() {\n\t(void)ctor_list;\n\t(void)dtor_list;\n}\n\n"
},
{
"alpha_fraction": 0.6491228342056274,
"alphanum_fraction": 0.6917293071746826,
"avg_line_length": 22.441177368164062,
"blob_id": "a7737130366dba4fb63a5356385412583bc284ab",
"content_id": "eef27c3ae1f1d824d016ec8bc64a795f1c740e3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 34,
"path": "/include/arch/ps2/arch/cache.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/cache.h\n (c)2001 Dan Potter\n \n $Id: cache.h,v 1.3 2002/11/03 03:40:55 bardtx Exp $\n*/\n\n#ifndef __ARCH_CACHE_H\n#define __ARCH_CACHE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n#if 0\n/* Flush a range of i-cache, given a physical address range */\nvoid icache_flush_range(uint32 start, uint32 count);\n\n/* Invalidate a range of o-cache/d-cache, given a physical address range */\nvoid dcache_inval_range(uint32 start, uint32 count);\n\n/* Flush a range of o-cache/d-cache, given a physical address range */\nvoid dcache_flush_range(uint32 start, uint32 count);\n#endif\n\n/* Sync, disable, invalidate, and re-enable all caches; use after rewriting\n some bit of code. */\nvoid cache_flush_all();\n\n__END_DECLS\n\n#endif\t/* __ARCH_CACHE_H */\n\n"
},
{
"alpha_fraction": 0.5297619104385376,
"alphanum_fraction": 0.601190447807312,
"avg_line_length": 12.958333015441895,
"blob_id": "84136b9913a88e2f93ab32b8bdf669eb8c619090",
"content_id": "2ca4f08b349626741d5e23ecd75963425fc76594",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 24,
"path": "/include/arch/dreamcast/dc/fs_vmu.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/fs_vmu.h\n (c)2000-2001 Jordan DeLong\n\n $Id: fs_vmu.h,v 1.3 2002/08/12 07:25:58 bardtx Exp $\n\n*/\n\n#ifndef __DC_FS_VMU_H\n#define __DC_FS_VMU_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/fs.h>\n\n/* Initialization */\nint fs_vmu_init();\nint fs_vmu_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_FS_VMU_H */\n\n"
},
{
"alpha_fraction": 0.5507246255874634,
"alphanum_fraction": 0.6376811861991882,
"avg_line_length": 18.714284896850586,
"blob_id": "eca1cc0fd1a1d6c2b72bdba808cbc8de67b9a969",
"content_id": "621dca6262cc92efde834101b52aed350345b9ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 14,
"path": "/libc/string/strcoll.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n strcoll.c\n Copyright (C)2003 Dan Potter\n\n $Id: strnicmp.c,v 1.2 2002/02/13 10:44:50 andrewk Exp $\n*/\n\n#include <string.h>\n\n/* We don't have locales, so just call strcmp */\nint strcoll(const char * c1, const char * c2) {\n\treturn strcmp(c1, c2);\n}\n"
},
{
"alpha_fraction": 0.5102040767669678,
"alphanum_fraction": 0.6122449040412903,
"avg_line_length": 15,
"blob_id": "65bea9905a7cf5e7a9b7876804b74d344b5a8931",
"content_id": "1262012bd782197d312c7d599d5994aad82ff9c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/examples/gba/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/gba/Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/09/23 23:35:40 bardtx Exp $\n\nall:\n\t$(MAKE) -C pogo-keen\n\nclean:\n\t$(MAKE) -C pogo-keen clean\n\t\t\n\n"
},
{
"alpha_fraction": 0.5609756112098694,
"alphanum_fraction": 0.642276406288147,
"avg_line_length": 15.266666412353516,
"blob_id": "6d7ccfe5fe769769421a705ddc9e70ab0bfc7791",
"content_id": "fdfd794bbef9b54db71275669371851873c9bb20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 246,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/dreamcast/basic/threading/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/basic/threading/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/04/19 07:53:52 bardtx Exp $\n\nall:\n\t$(MAKE) -C general\n\nclean:\n\t$(MAKE) -C general clean\n\t\t\ndist:\n\t$(MAKE) -C general dist\n\n\n"
},
{
"alpha_fraction": 0.5849462151527405,
"alphanum_fraction": 0.6365591287612915,
"avg_line_length": 19.217391967773438,
"blob_id": "5402ab235c631a006affc5ca5dfee36ce6254f9d",
"content_id": "d770b3efa3c7e3a2b2877e885ac6959dbd93f85b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 23,
"path": "/libc/string/memcpy2.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n memcpy2.c\n (c)2001 Dan Potter\n\n $Id: memcpy2.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n#include <string.h>\n\n/* This variant was added by Dan Potter for its usefulness in \n working with GBA external hardware. */\nvoid * memcpy2(void *dest, const void *src, size_t count)\n{\n\tunsigned short *tmp = (unsigned short *) dest;\n\tunsigned short *s = (unsigned short *) src;\n\tcount = count/2;\n\n\twhile (count--)\n\t\t*tmp++ = *s++;\n\n\treturn dest;\n}\n"
},
{
"alpha_fraction": 0.512440025806427,
"alphanum_fraction": 0.6782074570655823,
"avg_line_length": 30.91866111755371,
"blob_id": "2aa313350054addab94e3d4e6146226eac221cee",
"content_id": "b87763e0435f2b08e643b944732b52122e15994c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6672,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 209,
"path": "/include/arch/ps2/ps2/ioports.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/ioports.h\n (c)2002 Dan Potter\n \n $Id: ioports.h,v 1.1 2002/11/03 03:40:55 bardtx Exp $\n*/\n\n#ifndef __PS2_IOPORTS_H\n#define __PS2_IOPORTS_H\n\n/* Define __ASM__ before including this file if you want to use it\n from an assembly file. The register definitions will become\n just raw addresses. */\n\n#ifndef __ASM__\n#\tinclude <sys/cdefs.h>\n\t__BEGIN_DECLS\n#\tinclude <arch/types.h>\n#\tdefine _IOPORT128(x) (*((vuint128 *)(x)))\n#\tdefine _IOPORT32(x) (*((vuint32 *)(x)))\n#\tdefine _IOPORT8(x) (*((vuint8 *)(x)))\n#\tdefine _IOPTR32(x) ((vuint32 *)(x))\n#else\t/* !__ASM__ */\n#\tdefine _IOPORT128(x) x\n#\tdefine _IOPORT32(x) x\n#\tdefine _IOPORT8(x) x\n#\tdefine _IOPTR32(x) x\n#endif\t/* __ASM__ */\n\n\n/* If there are any misc hardware port definitions, then they'll go here.\n Each major subsystem (e.g., GS) may have its own set of definitions\n elsewhere as well. */\n\n/* Timers */\n#define TIMER_COUNT(x)\t_IOPORT32((x)*0x800+0xb0000000)\n#define TIMER_MODE(x)\t_IOPORT32((x)*0x800+0xb0000010)\n#define TIMER_COMP(x)\t_IOPORT32((x)*0x800+0xb0000020)\n#define TIMER_HOLD(x)\t_IOPORT32((x)*0x800+0xb0000030)\n\n/* Timer constants for TIMER_MODE */\n#define TIMER_CLKS_BUSCLK\t0\n#define TIMER_CLKS_BUSCLK16\t1\n#define TIMER_CLKS_BUSCLK256\t2\n#define TIMER_CLKS_HBLNK\t3\n#define TIMER_GATE_DISABLE\t0\n#define TIMER_GATE_ENABLE\t(1 << 2)\n#define TIMER_GATS_HBLNK\t0\n#define TIMER_GATS_VBLNK\t(1 << 3)\n#define TIMER_GATM_00\t\t0\t\t/* Can't even think of good names */\n#define TIMER_GATM_01\t\t(1 << 4)\t/* for these weird-ass modes... look */\n#define TIMER_GATM_10\t\t(2 << 4)\t/* in the EE manual on pg 36 */\n#define TIMER_GATM_11\t\t(3 << 4)\n#define TIMER_ZRET_DISABLE\t0\n#define TIMER_ZRET_ENABLE\t(1 << 6)\n#define TIMER_CUE_DISABLE\t0\n#define TIMER_CUE_ENABLE\t(1 << 7)\n#define TIMER_CMPE_DISABLE\t0\n#define TIMER_CMPE_ENABLE\t(1 << 8)\n#define TIMER_OVFE_DISABLE\t0\n#define TIMER_OVFE_ENABLE\t(1 << 9)\n#define TIMER_EQUF\t\t(1 << 10)\n#define TIMER_OVFF\t\t(1 << 11)\n\n/* IPU */\n#define IPU_CMD\t\t_IOPORT32(0xb0002000)\n#define IPU_CTRL\t_IOPORT32(0xb0002010)\n#define IPU_BP\t\t_IOPORT32(0xb0002020)\n#define IPU_TOP\t\t_IOPORT32(0xb0002030)\n\n/* GIF */\n#define GIF_CTRL\t_IOPORT32(0xb0003000)\n#define GIF_MODE\t_IOPORT32(0xb0003010)\n#define GIF_STAT\t_IOPORT32(0xb0003020)\n#define GIF_TAG(x)\t_IOPORT32((x)*0x10+0xb0003070)\n#define GIF_CNT\t\t_IOPORT32(0xb0003080)\n#define GIF_P3CNT\t_IOPORT32(0xb0003090)\n#define GIF_P3TAG\t_IOPORT32(0xb00030a0)\n\n/* VIF0/1: x in [0..1] and y in [0..3] */\n#define VIF_STAT(x)\t_IOPORT32((x)*0x400 + 0xb0003800)\n#define VIF_FBRST(x)\t_IOPORT32((x)*0x400 + 0xb0003810)\n#define VIF_ERR(x)\t_IOPORT32((x)*0x400 + 0xb0003820)\n#define VIF_MARK(x)\t_IOPORT32((x)*0x400 + 0xb0003830)\n#define VIF_CYCLE(x)\t_IOPORT32((x)*0x400 + 0xb0003840)\n#define VIF_MODE(x)\t_IOPORT32((x)*0x400 + 0xb0003850)\n#define VIF_NUM(x)\t_IOPORT32((x)*0x400 + 0xb0003860)\n#define VIF_MASK(x)\t_IOPORT32((x)*0x400 + 0xb0003870)\n#define VIF_CODE(x)\t_IOPORT32((x)*0x400 + 0xb0003880)\n#define VIF_ITOPS(x)\t_IOPORT32((x)*0x400 + 0xb0003890)\n#define VIF_ITOP(x)\t_IOPORT32((x)*0x400 + 0xb00038d0)\n#define VIF_ROW(x,y)\t_IOPORT32((x)*0x400 + (y)*0x10 + 0xb0003900)\n#define VIF_COL(x,y)\t_IOPORT32((x)*0x400 + (y)*0x10 + 0xb0003940)\n\n/* FIFO */\n#define FIFO_VIF0\t_IOPORT128(0xb0004000)\n#define FIFO_VIF1\t_IOPORT128(0xb0005000)\n#define FIFO_GIF\t_IOPORT128(0xb0006000)\n#define FIFO_IPU_OUT\t_IOPORT128(0xb0007000)\n#define FIFO_IPU_IN\t_IOPORT128(0xb0007010)\n\n/* DMAC: x in [0..9] with the following support:\n\n CHCR MADR QWC TADR ASR0 ASR1 SADR\n0 x x x x x x\n1 x x x x x x\n2 x x x x x x\n3 x x x\n4 x x x x\n5 x x x\n6 x x x x\n7 x x x\n8 x x x x\n9 x x x x x\n\n */\n#define DMAC_CHCR(x)\t_IOPORT32((x)*0x1000 + 0xb0008000)\n#define DMAC_MADR(x)\t_IOPORT32((x)*0x1000 + 0xb0008010)\n#define DMAC_QWC(x)\t_IOPORT32((x)*0x1000 + 0xb0008020)\n#define DMAC_TADR(x)\t_IOPORT32((x)*0x1000 + 0xb0008030)\n#define DMAC_ASR0(x)\t_IOPORT32((x)*0x1000 + 0xb0008040)\n#define DMAC_ASR1(x)\t_IOPORT32((x)*0x1000 + 0xb0008050)\n#define DMAC_SADR(x)\t_IOPORT32((x)*0x1000 + 0xb0008080)\n\n/* INTC status/mask registers */\n#define INTC_STAT\t_IOPORT32(0xb000f000)\n#define INTC_MASK\t_IOPORT32(0xb000f010)\n\n#ifndef __ASM__\n/* These macros are needed to toggle the bits since they\n toggle when written to, as opposed to simply accepting the value\n written to them. Only pass one bit at a time. */\n#define INTC_MASK_SET(x) do {\t\t\\\n\tif (!(INTC_MASK & (x)))\t\t\\\n\t\tINTC_MASK |= (x);\t\\\n} while (0)\n#define INTC_MASK_CLEAR(x) do {\t\t\\\n\tif (INTC_MASK & (x))\t\t\\\n\t\tINTC_MASK |= (x);\t\\\n} while (0)\n\n#endif\t/* __ASM__ */\n\n/* Bits for the INTC registers */\n#define INTM_GS\t\t0x00000001\n#define INTM_SBUS\t0x00000002\n#define INTM_VBON\t0x00000004\n#define INTM_VBOFF\t0x00000008\n#define INTM_VIF0\t0x00000010\n#define INTM_VIF1\t0x00000020\n#define INTM_VU0\t0x00000040\n#define INTM_VU1\t0x00000080\n#define INTM_IPU\t0x00000100\n#define INTM_TIMER0\t0x00000200\n#define INTM_TIMER1\t0x00000400\n#define INTM_TIMER2\t0x00000800\n#define INTM_TIMER3\t0x00001000\n#define INTM_SFIFO\t0x00002000\n#define INTM_VU0WD\t0x00004000\n\n/* SIF */\n#define SIF_SMFLG\t_IOPORT32(0xb000f230)\n\n/* DMAC */\n#define DMAC_ENABLER\t_IOPORT32(0xb000f520)\n#define DMAC_ENABLEW\t_IOPORT32(0xb000f590)\n\n/* VU0/VU1 memory regions */\n#define VU0_MICROMEM\t_IOPTR32(0xb1000000)\n#define VU0_VUMEM\t_IOPTR32(0xb1004000)\n#define VU1_MICROMEM\t_IOPTR32(0xb1008000)\n#define VU1_VUMEM\t_IOPTR32(0xb100c000)\n\n/* GS */\n#define GS_PMODE\t_IOPTR128(0xb2000000)\n#define GS_SMODE1\t_IOPTR128(0xb2000010)\n#define GS_SMODE2\t_IOPTR128(0xb2000020)\n#define GS_SRFSH\t_IOPTR128(0xb2000030)\n#define GS_SYNCH1\t_IOPTR128(0xb2000040)\n#define GS_SYNCH2\t_IOPTR128(0xb2000050)\n#define GS_SYNCV\t_IOPTR128(0xb2000060)\n#define GS_DISPFB1\t_IOPTR128(0xb2000070)\n#define GS_DISPLAY1\t_IOPTR128(0xb2000080)\n#define GS_DISPFB2\t_IOPTR128(0xb2000090)\n#define GS_DISPLAY2\t_IOPTR128(0xb20000a0)\n#define GS_EXTBUF\t_IOPTR128(0xb20000b0)\n#define GS_EXTDATA\t_IOPTR128(0xb20000c0)\n#define GS_EXTWRITE\t_IOPTR128(0xb20000d0)\n#define GS_BGCOLOR\t_IOPTR128(0xb20000e0)\n#define GS_CSR\t\t_IOPTR128(0xb2001000)\n#define GS_IMR\t\t_IOPTR128(0xb2001010)\n#define GS_BUSDIR\t_IOPTR128(0xb2001040)\n#define GS_SIGLBLID\t_IOPTR128(0xb2001080)\n\n/* Misc PIO registers */\n#define PIO_DIR\t\t_IOPORT8(0xb400002c)\n#define PIO_DATA\t_IOPORT8(0xb400002e)\n\n/* Bits for the PIO registers */\n#define PIO_DIR_OUT\t\t1\n#define PIO_DATA_LED_ON\t\t0\n#define PIO_DATA_LED_OFF\t1\n\n#ifndef __ASM__\n\t__END_DECLS\n#endif\t/* __ASM__ */\n\n#endif\t/* __PS2_SBIOS_H */\n\n"
},
{
"alpha_fraction": 0.5448673367500305,
"alphanum_fraction": 0.5968924760818481,
"avg_line_length": 22.471311569213867,
"blob_id": "05fd05d79d0aef0cd64c89b0b2b0ea946122032d",
"content_id": "737049ace1c02b5ac1c51982c7ad9eed612b9327",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5728,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 244,
"path": "/examples/dreamcast/parallax/bubbles/bubbles.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n KallistiOS ##version##\n bubbles.c\n\n (c)2002 Dan Potter\n*/\n\n#include <kos.h>\n#include <math.h>\n#include <plx/matrix.h>\n#include <plx/prim.h>\n\n/*\n\nThis is a Parallax version of the \"bubbles\" KGL demo. The speed is about\nthe same, but it uses the Parallax functions instead of KGL.\n\n*/\n\n/* Draws a sphere out of GL_QUADS according to the syntax of glutSolidSphere\n\n This now uses triangle strips and PVR Direct Rendering for the best\n possible performance.\n\n Based very loosely on a routine from James Susinno.\n*/\nstatic float phase = 0.0f;\nstatic pvr_poly_cxt_t cxt;\nstatic pvr_poly_hdr_t hdr;\nstatic void sphere( float radius, int slices, int stacks ) {\n\tint\ti, j;\n\tfloat\tpitch, pitch2;\n\tfloat\tx, y, z, g, b;\n\tfloat\tyaw, yaw2;\n\tpvr_dr_state_t\tdr_state;\n\n\t/* Setup our Direct Render state: pick a store queue and setup QACR0/1 */\n\tpvr_dr_init(dr_state);\n\n\t/* Initialize xmtrx with the values from KGL */\n\tplx_mat_identity();\n\tplx_mat3d_apply(PLX_MAT_SCREENVIEW);\n\tplx_mat3d_apply(PLX_MAT_PROJECTION);\n\tplx_mat3d_apply(PLX_MAT_MODELVIEW);\n\n\t/* Put our own polygon header */\n\tpvr_prim(&hdr, sizeof(hdr));\n\n\t/* Iterate over stacks */\n\tfor ( i=0; i<stacks; i++ ) {\n\t\tpitch = 2*M_PI * ( (float)i/(float)stacks );\n\t\tpitch2 = 2*M_PI * ( (float)(i+1)/(float)stacks );\n\n\t\t/* Iterate over slices: each entire stack will be one\n\t\t long triangle strip. */\n\t\tfor ( j=0; j<=slices/2; j++ ) {\n\t\t\tyaw = 2*M_PI * ( (float)j/(float)slices );\n\t\t\tyaw2 = 2*M_PI * ( (float)(j+1)/(float)slices );\n\n\t\t\t/* x, y+1 */\n\t\t\tx = radius * fcos( yaw ) * fcos( pitch2 );\n\t\t\ty = radius * fsin( pitch2 );\n\t\t\tz = radius * fsin( yaw ) * fcos( pitch2 );\n\t\t\tmat_trans_single(x, y, z);\t\t\t/* Use ftrv to transform */\n\t\t\tg = fcos( yaw*2 ) / 2.0f + 0.5f;\n\t\t\tb = fsin( phase + pitch2 ) / 2.0f + 0.5f;\n\t\t\tplx_vert_fnd(&dr_state, PVR_CMD_VERTEX,\n\t\t\t\tx, y, z, 0.5f,\n\t\t\t\t0.0f, g, b);\n \n\t\t\t/* x, y */\n\t\t\tx = radius * fcos( yaw ) * fcos( pitch );\n\t\t\ty = radius * fsin( pitch );\n\t\t\tz = radius * fsin( yaw ) * fcos( pitch );\n\t\t\tmat_trans_single(x, y, z);\n\t\t\tg = fcos( yaw*2 ) / 2.0f + 0.5f;\n\t\t\tb = fsin( phase + pitch ) / 2.0f + 0.5f;\n\n\t\t\tif (j == (slices/2)) {\n\t\t\t\tplx_vert_fnd(&dr_state, PVR_CMD_VERTEX_EOL,\n\t\t\t\t\tx, y, z, 0.5f,\n\t\t\t\t\t0.0f, g, b);\n\t\t\t} else {\n\t\t\t\tplx_vert_fnd(&dr_state, PVR_CMD_VERTEX,\n\t\t\t\t\tx, y, z, 0.5f,\n\t\t\t\t\t0.0f, g, b);\n\t\t\t}\n\t\t}\n\t}\n}\n\n#define SPHERE_CNT 12\nstatic float r = 0;\nstatic void sphere_frame_opaque() {\n\tint i;\n\n\tvid_border_color(255, 0, 0);\n\tpvr_wait_ready();\n\tvid_border_color(0, 255, 0);\n\n\tpvr_scene_begin();\n\tpvr_list_begin(PVR_LIST_OP_POLY);\n\n\tplx_mat3d_identity();\n\tplx_mat3d_translate(0.0f, 0.0f, -12.0f);\n\tplx_mat3d_rotate(r * 2, 0.75f, 1.0f, 0.5f);\n\tplx_mat3d_push();\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tplx_mat3d_translate(6.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 6.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tplx_mat3d_rotate(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(1.2f, 20, 20);\n\t\tif (i < (SPHERE_CNT-1))\n\t\t\tplx_mat3d_peek();\n\t}\n\tplx_mat3d_pop();\n\n\tplx_mat3d_identity();\n\tplx_mat3d_translate(0.0f, 0.0f, -12.0f);\n\tplx_mat3d_rotate(-r * 2, 0.75f, 1.0f, 0.5f);\n\tplx_mat3d_push();\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tplx_mat3d_translate(3.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 3.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tplx_mat3d_rotate(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(0.8f, 20, 20);\n\t\tif (i < (SPHERE_CNT-1))\n\t\t\tplx_mat3d_peek();\n\t}\n\tplx_mat3d_pop();\n\n\tvid_border_color(0, 0, 255);\n\tpvr_scene_finish();\n\n\tr++;\n\tphase += 2*M_PI / 240.0f;\n}\n\nstatic void sphere_frame_trans() {\n\tint i;\n\n\tvid_border_color(255, 0, 0);\n\tpvr_wait_ready();\n\tvid_border_color(0, 255, 0);\n\n\tpvr_scene_begin();\n\tpvr_list_begin(PVR_LIST_TR_POLY);\n\n\tplx_mat3d_identity();\n\tplx_mat3d_translate(0.0f, 0.0f, -12.0f);\n\tplx_mat3d_rotate(r * 2, 0.75f, 1.0f, 0.5f);\n\tplx_mat3d_push();\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tplx_mat3d_translate(4.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 4.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tplx_mat3d_rotate(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(1.0f, 20, 20);\n\t\tif (i < (SPHERE_CNT-1))\n\t\t\tplx_mat3d_peek();\n\t}\n\n\tplx_mat3d_pop();\n\n\tvid_border_color(0, 0, 255);\n\tpvr_scene_finish();\n\n\tr++;\n\tphase += 2*M_PI / 240.0f;\n}\n\nvoid do_sphere_test() {\n\tuint8\t\taddr;\n\tcont_cond_t\tcond;\n\tint\t\tmode = 0;\n\tint\t\ta_was_down = 0;\n\n\tpvr_set_bg_color(0.2f, 0.0f, 0.4f);\n\n\tpvr_poly_cxt_col(&cxt, PVR_LIST_OP_POLY);\n\tcxt.gen.culling = PVR_CULLING_NONE;\n\tpvr_poly_compile(&hdr, &cxt);\n\n\tfor (;;) {\n\t\tif (!mode)\n\t\t\tsphere_frame_opaque();\n\t\telse\n\t\t\tsphere_frame_trans();\n\t\n\t\taddr = maple_first_controller();\n\t\tif (addr == 0)\n\t\t\tcontinue;\n\t\tif (cont_get_cond(addr, &cond) < 0)\n\t\t\tcontinue;\n\t\tif (!(cond.buttons & CONT_START)) {\n\t\t\treturn;\n\t\t}\n\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\tif (a_was_down) continue;\n\t\t\ta_was_down = 1;\n\t\t\tmode ^= 1;\n\t\t\tswitch(mode) {\n\t\t\tcase 0:\t/* Opaque */\n\t\t\t\tpvr_poly_cxt_col(&cxt, PVR_LIST_OP_POLY);\n\t\t\t\tcxt.gen.culling = PVR_CULLING_NONE;\n\t\t\t\tpvr_poly_compile(&hdr, &cxt);\n\t\t\t\tbreak;\n\t\t\tcase 1:\t/* Translucent */\n\t\t\t\tpvr_poly_cxt_col(&cxt, PVR_LIST_TR_POLY);\n\t\t\t\tcxt.gen.culling = PVR_CULLING_NONE;\n\t\t\t\tpvr_poly_compile(&hdr, &cxt);\n\t\t\t\tbreak;\n\t\t\t}\n\t\t} else {\n\t\t\ta_was_down = 0;\n\t\t}\n\t}\n}\n\npvr_init_params_t params = {\n\t/* Enable opaque and translucent polygons with size 16 */\n\t{ PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\t\n\t/* Vertex buffer size 512K */\n\t512*1024\n};\n\t\nint main(int argc, char **argv) {\n\t/* Init PVR API */\n\tif (pvr_init(¶ms) < 0)\n\t\treturn -1;\n\n\t/* Init matrices */\n\tplx_mat3d_init();\n\tplx_mat3d_mode(PLX_MAT_PROJECTION);\n\tplx_mat3d_identity();\n\tplx_mat3d_perspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tplx_mat3d_mode(PLX_MAT_MODELVIEW);\n\n\t/* Do the test */\n\tprintf(\"Bubbles KGL sample: press START to exit, A to toggle sphere type\\n\");\n\tdo_sphere_test();\n\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6112092733383179,
"alphanum_fraction": 0.6238323450088501,
"avg_line_length": 18.894472122192383,
"blob_id": "a799c89712d69aa9977ce88409c3decb55e09353",
"content_id": "9825f67652126ededcf94229335520ae81d47851",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3961,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 199,
"path": "/kernel/thread/sem.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sem.c\n Copyright (c)2001,2002,2003 Dan Potter\n*/\n\n/* Defines semaphores */\n\n/**************************************/\n\n#include <string.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <assert.h>\n#include <errno.h>\n\n#include <kos/thread.h>\n#include <kos/limits.h>\n#include <kos/sem.h>\n#include <kos/genwait.h>\n#include <sys/queue.h>\n#include <arch/spinlock.h>\n\nCVSID(\"$Id: sem.c,v 1.13 2003/02/15 02:47:04 bardtx Exp $\");\n\n/**************************************/\n\n/* Semaphore list spinlock */\nstatic spinlock_t mutex;\n\n/* Global list of semaphores */\nstatic struct semlist sem_list;\n\n/* Allocate a new semaphore; the semaphore will be assigned\n to the calling process and when that process dies, the semaphore\n will also die. */\nsemaphore_t *sem_create(int value) {\n\tsemaphore_t\t*sm;\n\n\t/* Create a semaphore structure */\n\tsm = (semaphore_t*)malloc(sizeof(semaphore_t));\n\tif (!sm) {\n\t\terrno = ENOMEM;\n\t\treturn NULL;\n\t}\n\tsm->count = value;\n\n\t/* Add to the global list */\n\tspinlock_lock(&mutex);\n\tLIST_INSERT_HEAD(&sem_list, sm, g_list);\n\tspinlock_unlock(&mutex);\n\n\treturn sm;\n}\n\n/* Take care of destroying a semaphore */\nvoid sem_destroy(semaphore_t *sm) {\n\t/* XXX Do something with queued threads */\n\n\t/* Remove it from the global list */\n\tspinlock_lock(&mutex);\n\tLIST_REMOVE(sm, g_list);\n\tspinlock_unlock(&mutex);\n\n\t/* Free the memory */\n\tfree(sm);\n}\n\nint sem_wait(semaphore_t *sm) {\n\tint old, rv = 0;\n\t\n\tif (irq_inside_int()) {\n\t\tdbglog(DBG_WARNING, \"sem_wait: called inside interrupt\\n\");\n\t\terrno = EPERM;\n\t\treturn -1;\n\t}\n\n\told = irq_disable();\n\n\t/* If there's enough count left, then let the thread proceed */\n\tif (sm->count > 0) {\n\t\tsm->count--;\n\t} else {\n\t\t/* Block us until we're signaled */\n\t\tsm->count--;\n\t\trv = genwait_wait(sm, \"sem_wait\", 0, NULL);\n\n\t\t/* Did we get interrupted? */\n\t\tif (rv < 0) {\n\t\t\tassert( errno == EINTR );\n\t\t\trv = -1;\n\t\t}\n\t}\n\n\tirq_restore(old);\n\n\treturn rv;\n}\n\n/* This function will be called by genwait if we timeout. */\nstatic void sem_timeout(void * obj) {\n\t/* Convert it back to a semaphore ptr */\n\tsemaphore_t * s = (semaphore_t *)obj;\n\n\t/* Release a thread from the count */\n\ts->count++;\n}\n\n/* Wait on a semaphore, with timeout (in milliseconds) */\nint sem_wait_timed(semaphore_t *sem, int timeout) {\n\tint old = 0, rv = 0;\n\n\t/* Make sure we're not inside an interrupt */\n\tif (irq_inside_int()) {\n\t\tdbglog(DBG_WARNING, \"sem_wait_timed: called inside interrupt\\n\");\n\t\terrno = EPERM;\n\t\treturn -1;\n\t}\n\n\t/* Check for smarty clients */\n\tif (timeout <= 0) {\n\t\treturn sem_wait(sem);\n\t}\n\n\t/* Disable interrupts */\n\told = irq_disable();\n\n\t/* If there's enough count left, then let the thread proceed */\n\tif (sem->count > 0) {\n\t\tsem->count--;\n\t\trv = 0;\n\t} else {\n\t\t/* Block us until we're signaled */\n\t\tsem->count--;\n\t\trv = genwait_wait(sem, \"sem_wait_timed\", timeout, sem_timeout);\n\t}\n\n\tirq_restore(old);\n\n\treturn rv;\n}\n\n/* Attempt to wait on a semaphore. If the semaphore would block,\n then return an error instead of actually blocking. */\nint sem_trywait(semaphore_t *sm) {\n\tint old = 0;\n\tint succeeded;\n\n\told = irq_disable();\n\n\t/* Is there enough count left? */\n\tif (sm->count > 0) {\n\t\tsm->count--;\n\t\tsucceeded = 0;\n\t} else {\n\t\tsucceeded = -1;\n\t\terrno = EAGAIN;\n\t}\n\n\t/* Restore interrupts */\n\tirq_restore(old);\n\n\treturn succeeded;\n}\n\n/* Signal a semaphore */ \nvoid sem_signal(semaphore_t *sm) {\n\tint\t\told = 0, woken;\n\t\n\told = irq_disable();\n\n\t/* Is there anyone waiting? If so, pass off to them */\n\tif (sm->count < 0) {\n\t\twoken = genwait_wake_cnt(sm, 1);\n\t\tassert( woken == 1 );\n\t\tsm->count++;\n\t} else {\n\t\t/* No one is waiting, so just add another tick */\n\t\tsm->count++;\n\t}\n\n\tirq_restore(old);\n}\n\n/* Return the semaphore count */\nint sem_count(semaphore_t *sm) {\n\t/* Look for the semaphore */\n\treturn sm->count;\n}\n\n/* Initialize semaphore structures */\nint sem_init() {\n\tLIST_INIT(&sem_list);\n\tspinlock_init(&mutex);\n\treturn 0;\n}\n\n/* Shut down semaphore structures */\nvoid sem_shutdown() { }\n\n\n"
},
{
"alpha_fraction": 0.6344696879386902,
"alphanum_fraction": 0.6837121248245239,
"avg_line_length": 22.954545974731445,
"blob_id": "105f53fd6c24863ac7ecd2376eac5fb75ffdff00",
"content_id": "1972480254553986beb290ecd64159aa946e597b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 528,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 22,
"path": "/include/arch/ia32/arch/exec.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/arch/exec.h\n (c)2002 Dan Potter\n \n $Id: exec.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n*/\n\n#ifndef __ARCH_EXEC_H\n#define __ARCH_EXEC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* Replace the currently running image with whatever is at\n the pointer; note that this call will never return. */\nvoid arch_exec_at(const void *image, uint32 length, uint32 address) __noreturn;\nvoid arch_exec(const void *image, uint32 length) __noreturn;\n\n__END_DECLS\n\n#endif\t/* __ARCH_EXEC_H */\n\n"
},
{
"alpha_fraction": 0.5663716793060303,
"alphanum_fraction": 0.6106194853782654,
"avg_line_length": 10.300000190734863,
"blob_id": "c0b8e060802c8b6c935abb2d51ddc22795c18988",
"content_id": "7779bf9337d1d2b67a92beaf81b083c857c7a69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 10,
"path": "/kernel/libc/newlib/newlib_isatty.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n newlib_isatty.c\n Copyright (C)2004 Dan Potter\n\n*/\n\nint isatty(int fd) {\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6061946749687195,
"alphanum_fraction": 0.6283186078071594,
"avg_line_length": 15.142857551574707,
"blob_id": "14328f200c49f8a1210f808b800c7702b1a50ce8",
"content_id": "7ad5f2e2d885f2a064acf33912a155c183c8d6a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 14,
"path": "/kernel/libc/newlib/newlib_stat.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n newlib_stat.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <unistd.h>\n#include <sys/stat.h>\n\nint _stat_r(void * reent, const char * fn, struct stat * pstat) {\n\tpstat->st_mode = S_IFCHR;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6417277455329895,
"alphanum_fraction": 0.6918627023696899,
"avg_line_length": 22.770641326904297,
"blob_id": "c1f57d77c3cf00fec1f34a03793a66508dcd5118",
"content_id": "f0c59c07f43ccfc647590b3ae186c60877609d42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2593,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 109,
"path": "/include/arch/ps2/ps2/fs_ps2load.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/ps2/include/ps2/fs_ps2load.h\n Copyright (c)2002 Andrew Kieschnick\n Copyright (c)2002 Dan Potter\n\n*/\n\n#ifndef __PS2_FS_PS2LOAD_H\n#define __PS2_FS_PS2LOAD_H\n\n/* Definitions for the \"dcload\" file system */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n\n/* dcload magic value */\n#define PS2LOADMAGICVALUE 0xdeadbeef\n#define PS2LOADBLOCKPTR ((uint32 *)0x81fff800)\n\n/* Available ps2load console commands */\n\n#define PS2LOAD_READ\t\t0\n#define PS2LOAD_WRITE\t\t1\n#define PS2LOAD_OPEN\t\t2\n#define PS2LOAD_CLOSE\t\t3\n#define PS2LOAD_CREAT\t\t4\n#define PS2LOAD_LINK\t\t5\n#define PS2LOAD_UNLINK\t\t6\n#define PS2LOAD_CHDIR\t\t7\n#define PS2LOAD_CHMOD\t\t8 \n#define PS2LOAD_LSEEK\t\t9\n#define PS2LOAD_FSTAT\t\t10\n#define PS2LOAD_TIME\t\t11\n#define PS2LOAD_STAT\t\t12\n#define PS2LOAD_UTIME\t\t13\n#define PS2LOAD_GSCONSPRINT\t14\n#define PS2LOAD_EXIT\t\t15\n#define PS2LOAD_OPENDIR\t\t16\n#define PS2LOAD_CLOSEDIR\t17\n#define PS2LOAD_READDIR\t\t18\n\n/* ps2load dirent */\n\nstruct ps2load_dirent {\n long d_ino; /* inode number */\n off_t d_off; /* offset to the next dirent */\n unsigned short d_reclen;/* length of this record */\n unsigned char d_type; /* type of file */\n char d_name[256]; /* filename */\n};\n\ntypedef struct ps2load_dirent ps2load_dirent_t;\n\n/* ps2load stat */\n\nstruct ps2load_stat { \n unsigned short st_dev;\n unsigned short st_ino;\n int st_mode;\n unsigned short st_nlink;\n unsigned short st_uid;\n unsigned short st_gid;\n unsigned short st_rdev;\n long st_size;\n long st_atime;\n long st_spare1;\n long st_mtime;\n long st_spare2;\n long st_ctime;\n long st_spare3;\n long st_blksize;\n long st_blocks;\n long st_spare4[2];\n};\n\ntypedef struct ps2load_stat ps2load_stat_t;\n\n#define S_IFDIR 0040000 /* directory */\n\n/* Printk replacement */\nvoid ps2load_printk(const char *str);\n\n/* File functions */\nuint32\tps2load_open(vfs_handler_t * vfs, const char *fn, int mode);\nvoid\tps2load_close(uint32 hnd);\nssize_t\tps2load_read(uint32 hnd, void *buf, size_t cnt);\noff_t\tps2load_seek(uint32 hnd, off_t offset, int whence);\noff_t\tps2load_tell(uint32 hnd);\nsize_t\tps2load_total(uint32 hnd);\ndirent_t* ps2load_readdir(uint32 hnd);\nint ps2load_rename(vfs_handler_t * vfs, const char *fn1, const char *fn2);\nint ps2load_unlink(vfs_handler_t * vfs, const char *fn);\n\n/* Init func */\nvoid fs_ps2load_init_console();\nint fs_ps2load_init();\nint fs_ps2load_shutdown();\n\n/* Init func for ps2load-ip + lwIP */\nint fs_ps2load_init_lwip(void *p);\n\n__END_DECLS\n\n#endif\t/* __PS2_FS_PS2LOAD_H */\n\n\n"
},
{
"alpha_fraction": 0.6173285245895386,
"alphanum_fraction": 0.6191335916519165,
"avg_line_length": 18.034482955932617,
"blob_id": "bf7a99b5bb66256e764dff797c41ecee228bb4ce",
"content_id": "d325c2857aff4b054a786936400b8c0d0b1393e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 554,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 29,
"path": "/examples/dreamcast/kgl/basic/vq/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "\nTARGET = vq-example.elf\nOBJS = vq-example.o fruit.o \n\nall: rm-elf $(TARGET)\n\ninclude $(KOS_PATH)/scripts/Makefile.rules\n\nclean:\n\t-rm -f $(TARGET) $(OBJS) fruit.vq\n\nrm-elf:\n\t-rm -f $(TARGET) \n\n$(TARGET): $(OBJS) \n\t$(KOS_CC) $(KOS_CFLAGS) $(KOS_LDFLAGS) -o $(TARGET) $(KOS_START) \\\n\t\t$(OBJS) $(OBJEXTRA) -L$(TOPDIR)/lib -lgl $(KOS_LIBS) -lm\n\nfruit.o: fruit.vq\n\t$(KOS_PATH)/bin/bin2o fruit.vq fruit fruit.o\n\nfruit.vq: fruit.jpg\n\t$(KOS_PATH)/bin/vqenc -t -v fruit.jpg\n\nrun: $(TARGET)\n\t$(KOS_LOADER) $(TARGET)\n\ndist:\n\trm -f $(OBJS) \n\t$(KOS_STRIP) $(TARGET)\n\n"
},
{
"alpha_fraction": 0.612649142742157,
"alphanum_fraction": 0.663484513759613,
"avg_line_length": 23.219654083251953,
"blob_id": "92c29f4b4fdbf6229489c878db9ef095dd1419e3",
"content_id": "90fb5288ce1a109f42a2b54a6a9af056b06760be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4190,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 173,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_dma.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n pvr_dma.c\n Copyright (C)2002 Roger Cattermole\n Copyright (C)2004 Dan Potter\n http://www.boob.co.uk\n */\n\n#include <stdio.h>\n#include <errno.h>\n#include <dc/pvr.h>\n#include <dc/asic.h>\n#include <kos/thread.h>\n#include <kos/sem.h>\n\n#include \"pvr_internal.h\"\n\n/* Modified for inclusion into KOS by Dan Potter */\n\nCVSID(\"$Id: pvr_dma.c,v 1.5 2003/02/25 07:39:37 bardtx Exp $\");\n\n/* Signaling semaphore */\nstatic semaphore_t * dma_done;\nstatic int dma_blocking;\nstatic pvr_dma_callback_t dma_callback;\nstatic ptr_t dma_cbdata;\n\n/* DMA registers */\nstatic vuint32\t* const pvrdma = (vuint32 *)0xa05f6800;\nstatic vuint32\t* const shdma = (vuint32 *)0xffa00000;\n\n/* DMAC registers */\n#define DMAC_SAR2\t0x20/4\n#define DMAC_DMATCR2\t0x28/4\n#define DMAC_CHCR2\t0x2c/4\n#define DMAC_DMAOR\t0x40/4\n\n/* PVR Dma registers - Offset by 0xA05F6800 */\n#define PVR_STATE\t0x00\n#define PVR_LEN\t\t0x04/4\n#define PVR_DST\t\t0x08/4\n#define PVR_LMMODE0\t0x84/4\n#define PVR_LMMODE1\t0x88/4\n\nstatic void pvr_dma_irq_hnd(uint32 code) {\n\tif (shdma[DMAC_DMATCR2] != 0)\n\t\tdbglog(DBG_INFO,\"pvr_dma: The dma did not complete successfully\\n\");\n\n\t// DBG((\"pvr_dma_irq_hnd\\n\"));\n\n\t// Call the callback, if any.\n\tif (dma_callback) {\n\t\t// This song and dance is necessary because the handler\n\t\t// could chain to itself.\n\t\tpvr_dma_callback_t cb = dma_callback;\n\t\tptr_t d = dma_cbdata;\n\n\t\tdma_callback = NULL;\n\t\tdma_cbdata = 0;\n\n\t\tcb(d);\n\t}\n\t\n\t// Signal the calling thread to continue, if any.\n\tif (dma_blocking) {\n\t\tsem_signal(dma_done);\n\t\tthd_schedule(1, 0);\n\t\tdma_blocking = 0;\n\t}\n}\n\nint pvr_dma_transfer(void * src, uint32 dest, uint32 count, int type,\n\tint block, pvr_dma_callback_t callback, ptr_t cbdata)\n{\n\tuint32 val;\n\tuint32 src_addr = ((uint32)src); \n\tuint32 dest_addr;\n\n\t// Send the data to the right place\n\tif (type == PVR_DMA_TA)\n\t\tdest_addr = (((unsigned long)dest) & 0xFFFFFF) | 0x10000000;\n\telse\n\t\tdest_addr = (((unsigned long)dest) & 0xFFFFFF) | 0x11000000;\n\n\t// Make sure we're not already DMA'ing\n\tif (pvrdma[PVR_DST] != 0) { \n\t\tdbglog(DBG_ERROR, \"pvr_dma: PVR_DST != 0\\n\");\n\t\terrno = EINPROGRESS;\n\t\treturn -1;\n\t}\n\n\tval = shdma[DMAC_CHCR2];\n\n\tif (val & 0x1) /* DE bit set so we must clear it */\n\t\tshdma[DMAC_CHCR2] = val | 0x1;\n\tif (val & 0x2) /* TE bit set so we must clear it */\n\t\tshdma[DMAC_CHCR2] = val | 0x2;\n\t\n\t/* Check for 32-byte alignment */\n\tif (src_addr & 0x1F)\n\t\tdbglog(DBG_WARNING, \"pvr_dma: src is not 32-byte aligned\\n\");\n\tsrc_addr &= 0x0FFFFFE0;\n\n\tif (src_addr < 0x0c000000) {\n\t\tdbglog(DBG_ERROR, \"pvr_dma: src address < 0x0c000000\\n\");\n\t\terrno = EFAULT;\n\t\treturn -1;\n\t}\n\t\n\tshdma[DMAC_SAR2] = src_addr;\n\tshdma[DMAC_DMATCR2] = count/32;\n\tshdma[DMAC_CHCR2] = 0x12c1;\n\n\tval = shdma[DMAC_DMAOR];\n\n\tif ((val & 0x8007) != 0x8001) {\n\t\tdbglog(DBG_ERROR, \"pvr_dma: Failed DMAOR check\\n\");\n\t\terrno = EIO;\n\t\treturn -1;\n\t}\n\n\tdma_blocking = block;\n\tdma_callback = callback;\n\tdma_cbdata = cbdata;\n\n\tpvrdma[PVR_LMMODE0] = type == PVR_DMA_VRAM64 ? 0 : 1;\n\tpvrdma[PVR_STATE] = dest_addr;\n\tpvrdma[PVR_LEN] = count;\n\tpvrdma[PVR_DST] = 0x1;\n\n\t/* Wait for us to be signaled */\n\tif (block)\n\t\tsem_wait(dma_done);\n\n\treturn 0;\n}\n\n/* Count is in bytes. */\nint pvr_txr_load_dma(void * src, pvr_ptr_t dest, uint32 count, int block,\n\tpvr_dma_callback_t callback, ptr_t cbdata)\n{\n\treturn pvr_dma_transfer(src, (uint32)dest, count, PVR_DMA_VRAM64, block, callback, cbdata);\n}\n\nint pvr_dma_load_ta(void * src, uint32 count, int block, pvr_dma_callback_t callback, ptr_t cbdata) {\n\treturn pvr_dma_transfer(src, 0, count, PVR_DMA_TA, block, callback, cbdata);\n}\n\nint pvr_dma_ready() {\n\treturn pvrdma[PVR_DST] == 0;\n}\n\nvoid pvr_dma_init() {\n\t/* Create an initially blocked semaphore */\n\tdma_done = sem_create(0);\n\tdma_blocking = 0;\n\tdma_callback = NULL;\n\tdma_cbdata = 0;\n\n\t/* Hook the neccessary interrupts */\n\tasic_evt_set_handler(ASIC_EVT_PVR_DMA, pvr_dma_irq_hnd);\tasic_evt_enable(ASIC_EVT_PVR_DMA, ASIC_IRQ_DEFAULT);\n}\n\nvoid pvr_dma_shutdown() {\n\t/* XXX Need to ensure that no DMA is in progress, does this work?? */\n\tif (!pvr_dma_ready()) {\n\t\tpvrdma[PVR_DST] = 0;\n\t}\n\n\t/* Clean up */\n\tasic_evt_disable(ASIC_EVT_PVR_DMA, ASIC_IRQ_DEFAULT);\t\tasic_evt_set_handler(ASIC_EVT_PVR_DMA, NULL);\n\tsem_destroy(dma_done);\n}\n"
},
{
"alpha_fraction": 0.6616809368133545,
"alphanum_fraction": 0.6695156693458557,
"avg_line_length": 22.779661178588867,
"blob_id": "b9cc20fe52b7bd8fe96d4cd57a7b9c0e26d17774",
"content_id": "fc3de35e4d6a05d6e5a4646995f6c018f13b0383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1404,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 59,
"path": "/include/arch/dreamcast/dc/maple/sip.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/sip.h\n Copyright (C) 2005 Lawrence Sebald\n\n*/\n\n#ifndef __DC_MAPLE_SIP_H\n#define __DC_MAPLE_SIP_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <sys/types.h>\n\n/* This driver controls the Sound Input Peripheral for the maple\n bus (the microphone). Many thanks go out to ZeZu for pointing\n me towards what some commands actually do.\n*/\n\n/* SIP Status structure */\ntypedef struct\tsip_state {\n\tuint8 amp_gain;\n\tuint8 is_sampling;\n\tsize_t buf_len;\n\toff_t buf_pos;\n\tuint8 *samples_buf;\n} sip_state_t;\n\n/* The maximum gain value to be passed to the function\n below. */\n#define SIP_MAX_GAIN 0x1F\n\n/* Set the amplifier's gain. This should only be called prior\n to sampling, to ensure that the sound returned is of the\n same volume. */\nint sip_set_gain(maple_device_t *dev, uint8 g);\n\n/* Start sampling. */\nint sip_start_sampling(maple_device_t *dev);\n\n/* Stop sampling. */\nint sip_stop_sampling(maple_device_t *dev);\n\n/* Get samples out of the buffer. This can ONLY be called after\n sampling has been stopped. Returns the size in bytes of the\n filled buffer. */\nint sip_get_samples(maple_device_t *dev, uint8 *buf, size_t len);\n\n/* Clear the internal sample buffer. */\nint sip_clear_samples(maple_device_t *dev);\n\n/* Init / Shutdown */\nint sip_init();\nvoid sip_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_SIP_H */\n\n"
},
{
"alpha_fraction": 0.6421529650688171,
"alphanum_fraction": 0.6725286245346069,
"avg_line_length": 24.18120765686035,
"blob_id": "ac89579c51374f6e4d6bd816e3b0dce28244160f",
"content_id": "f0ea66f69518cb39079a41eecff35c7ccc3921d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3753,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 149,
"path": "/include/arch/ps2/arch/arch.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/arch.h\n (c)2001-2002 Dan Potter\n \n $Id: arch.h,v 1.2 2002/10/27 23:39:23 bardtx Exp $\n*/\n\n#ifndef __ARCH_ARCH_H\n#define __ARCH_ARCH_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* This stuff is all wrong... probably needs to be updated for PS2 */\n#if 0\n/* Page size info (for MMU) */\n#define PAGESIZE\t4096\n#define PAGESIZE_BITS\t12\n#define PAGEMASK\t(PAGESIZE - 1)\n\n/* Page count variable; in this case it's static, so we can\n optimize this quite a bit. */\n#define page_count ((16*1024*1024 - 0x10000) / PAGESIZE)\n\n/* Base address of available physical pages */\n#define page_phys_base 0x8c010000\n#endif\t/* 0 */\n\n/* Number of timer ticks per second */\n#define HZ\t\t100\n\n/* Default thread stack size */\n#define THD_STACK_SIZE\t65536\n\n/* More DC specific stuff, though we'll probably want equivalents\n eventually, so I'm leaving it here as a reminder. */\n#if 0\n/* Default video mode */\n#define DEFAULT_VID_MODE\tDM_640x480\n#define DEFAULT_PIXEL_MODE\tPM_RGB565\n\n/* Default serial parameters */\n#define DEFAULT_SERIAL_BAUD\t57600\n#define DEFAULT_SERIAL_FIFO\t1\n#endif\t/* 0 */\n\n/* Panic function */\nvoid panic(const char *str) __noreturn;\n\n/* Kernel C-level entry point */\nvoid arch_main();\n\n/* Potential exit paths from the kernel on arch_exit() */\n#define ARCH_EXIT_RETURN\t1\n\n/* Set the exit path (default is RETURN) */\nvoid arch_set_exit_path(int path);\n\n/* Generic kernel \"exit\" point */\nvoid arch_exit() __noreturn;\n\n/* Kernel \"return\" point */\nvoid arch_return() __noreturn;\n\n/* Kernel \"abort\" point */\nvoid arch_abort() __noreturn;\n\n/* Call to run all ctors / dtors */\nvoid arch_ctors();\nvoid arch_dtors();\n\n/* Hook to ensure linking of crtend.c */\nvoid __crtend_pullin();\n\n/* Use this macro to determine the level of initialization you'd like in\n your program by default. The defaults line will be fine for most things. */\n#define KOS_INIT_FLAGS(flags)\tuint32 __kos_init_flags = (flags)\n\nextern uint32 __kos_init_flags;\n\n/* Defaults */\n#define INIT_DEFAULT \\\n\t(INIT_IRQ | INIT_THD_PREEMPT)\n\n/* Define a romdisk for your program, if you'd like one */\n#define KOS_INIT_ROMDISK(rd)\tvoid * __kos_romdisk = (rd)\n\nextern void * __kos_romdisk;\n\n/* State that you don't want a romdisk */\n#define KOS_INIT_ROMDISK_NONE\tNULL\n\n/* Constants for the above */\n#define INIT_NONE\t\t0\t\t/* Kernel enables */\n#define INIT_IRQ\t\t1\n#define INIT_THD_PREEMPT\t2\n#define INIT_NET\t\t4\n#define INIT_MALLOCSTATS\t8\n#define INIT_OCRAM\t\t16\n\n/* PS2-specific arch init things */\nvoid arch_real_exit() __noreturn;\nint hardware_init();\nvoid hardware_shutdown();\nvoid syscall_init();\n\n/* PS2-specific sleep mode function */\n#define arch_sleep() do { \\\n\t/* XXX WRITE ME */ \\\n\t} while(0)\n\n/* PS2-specific function to get the return address from the current function */\n#define arch_get_ret_addr() ({ \\\n\t\tptr_t pr; \\\n\t\t__asm__ __volatile__(\"sd\t$31,%0\\n\" \\\n\t\t\t: \"=&z\" (pr) \\\n\t\t\t: /* no inputs */ \\\n\t\t\t: \"memory\" ); \\\n\tpr; })\n\n#if 0\t/* Not ported yet */\n\n/* Please note that all of the following frame pointer macros are ONLY\n valid if you have compiled your code WITHOUT -fomit-frame-pointer. These\n are mainly useful for getting a stack trace from an error. */\n\n/* DC specific function to get the frame pointer from the current function */\n#define arch_get_fptr() ({ \\\n\t\tuint32 fp; \\\n\t\t__asm__ __volatile__(\"mov\tr14,%0\\n\" \\\n\t\t\t: \"=&z\" (fp) \\\n\t\t\t: /* no inputs */ \\\n\t\t\t: \"memory\" ); \\\n\tfp; })\n\n/* Pass in a frame pointer value to get the return address for the given frame */\n#define arch_fptr_ret_addr(fptr) (*((uint32*)fptr))\n\n/* Pass in a frame pointer value to get the previous frame pointer for the given frame */\n#define arch_fptr_next(fptr) (*((uint32*)(fptr+4)))\n\n#endif\n\n__END_DECLS\n\n#endif\t/* __ARCH_ARCH_H */\n\n"
},
{
"alpha_fraction": 0.48985958099365234,
"alphanum_fraction": 0.5429016947746277,
"avg_line_length": 20.33333396911621,
"blob_id": "caee5806320ae81fd0e3e4bf42161b2c62801695",
"content_id": "2fb36cdc1f171b618f2d14ed091fe640be4cdc3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 30,
"path": "/libc/string/strnicmp.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n strnicmp.c\n (c)2000 Dan Potter\n\n $Id: strnicmp.c,v 1.2 2002/02/13 10:44:50 andrewk Exp $\n*/\n\n#include <string.h>\n\n/* Works like strncmp, but not case sensitive */\nint strnicmp(const char * cs, const char * ct, int count) {\n\tint c1, c2, res = 0;\n\n\twhile(count) {\n\t\tc1 = *cs++; c2 = *ct++;\n\t\tif (c1 >= 'A' && c1 <= 'Z') c1 += 'a' - 'A';\n\t\tif (c2 >= 'A' && c2 <= 'Z') c2 += 'a' - 'A';\n\t\tif ((res = c1 - c2) != 0 || (!*cs && !*ct))\n\t\t\tbreak;\n\t\tcount--;\n\t}\n\n\treturn res;\n}\n\n/* Provides strncasecmp also (same thing) */\nint strncasecmp(const char *cs, const char *ct, int count) {\n\treturn strnicmp(cs, ct, count);\n}\n\n"
},
{
"alpha_fraction": 0.580930233001709,
"alphanum_fraction": 0.6009302139282227,
"avg_line_length": 17.859649658203125,
"blob_id": "c4500ccc065600dd824c6772852bee450e31a29f",
"content_id": "5f4409d9d6133ea149fd13ceed23016d64859317",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2150,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 114,
"path": "/kernel/fs/fs_utils.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n fs_utils.c\n Copyright (C)2002 Dan Potter\n\n*/\n\n/*\n\nA couple of helpful utility functions for VFS usage.\nXXX This probably belongs in something like libc...\n\n*/\n\n#include <kos/fs.h>\n#include <stdio.h>\n#include <malloc.h>\n#include <assert.h>\n\nCVSID(\"$Id: fs_utils.c,v 1.2 2002/08/19 08:10:07 bardtx Exp $\");\n\n/* Copies a file from 'src' to 'dst'. The amount of the file\n actually copied without error is returned. */\nssize_t fs_copy(const char * src, const char * dst) {\n\tchar\t*buff;\n\tssize_t\tleft, total, r;\n\tfile_t\tfs, fd;\n\n\t/* Try to open both files */\n\tfs = fs_open(src, O_RDONLY);\n\tif (fs == FILEHND_INVALID) {\n\t\treturn -1;\n\t}\n\n\tfd = fs_open(dst, O_WRONLY | O_TRUNC);\n\tif (fd == FILEHND_INVALID) {\n\t\tfs_close(fs);\n\t\treturn -2;\n\t}\n\n\t/* Get the source size */\n\tleft = fs_total(fs);\n\ttotal = 0;\n\n\t/* Allocate a buffer */\n\tbuff = malloc(65536);\n\n\t/* Do the copy */\n\twhile (left > 0) {\n\t\tr = fs_read(fs, buff, 65536);\n\t\tif (r <= 0)\n\t\t\tbreak;\n\t\tfs_write(fd, buff, r);\n\t\tleft -= r;\n\t\ttotal += r;\n\t}\n\n\t/* Free the buffer */\n\tfree(buff);\n\n\t/* Close both files */\n\tfs_close(fs);\n\tfs_close(fd);\n\n\treturn total;\n}\n\n/* Opens a file, allocates enough RAM to hold the whole thing,\n reads it into RAM, and closes it. The caller owns the allocated\n memory (and must free it). The file size is returned, or -1 \n on failure; on success, out_ptr is filled with the address \n of the loaded buffer. */\nssize_t fs_load(const char * src, void ** out_ptr) {\n\tfile_t\tf;\n\tvoid\t* data;\n\tuint8\t* out;\n\tssize_t\ttotal, left, r;\n\n\tassert( out_ptr != NULL );\n\t*out_ptr = NULL;\n\n\t/* Try to open the file */\n\tf = fs_open(src, O_RDONLY);\n\tif (f == FILEHND_INVALID)\n\t\treturn -1;\n\n\t/* Get the size and alloc a buffer */\n\tleft = fs_total(f);\n\ttotal = 0;\n\tdata = malloc(left);\n\tout = (uint8 *)data;\n\n\t/* Load the data */\n\twhile (left > 0) {\n\t\tr = fs_read(f, out, left);\n\t\tif (r <= 0)\n\t\t\tbreak;\n\t\tleft -= r;\n\t\ttotal += r;\n\t\tout += r;\n\t}\n\n\t/* Did we get it all? If not, realloc the buffer */\n\tif (left > 0) {\n\t\t*out_ptr = realloc(data, total);\n\t\tif (*out_ptr == NULL)\n\t\t\t*out_ptr = data;\n\t} else\n\t\t*out_ptr = data;\n\n\tfs_close(f);\n\n\treturn total;\n}\n"
},
{
"alpha_fraction": 0.6853084564208984,
"alphanum_fraction": 0.7035064101219177,
"avg_line_length": 26.80246925354004,
"blob_id": "f2ae3735b961092fdc656094a4a9a311fe3b3582",
"content_id": "1897092179ae9dde1faeb240f52b79e62c4c536a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2253,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 81,
"path": "/include/arch/gba/arch/irq.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/include/irq.h\n (c)2000-2001 Dan Potter\n\n $Id: irq.h,v 1.2 2003/02/17 00:47:38 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_IRQ_H\n#define __ARCH_IRQ_H\n\n#include <arch/types.h>\n\n/* The number of bytes required to save thread context. This should\n include all general CPU registers, FP registers, and status regs (even\n if not all of these are actually used). */\n#define REG_BYTE_CNT 256\t\t\t/* Currently really 228 */\n\n/* Architecture-specific structure for holding the processor state (register\n values, etc). The size of this structure should be less than or equal\n to the above value. */\ntypedef struct irq_context {\n\tuint32\tstuff;\n} irq_context_t;\n\n/* A couple of architecture independent access macros */\n#define CONTEXT_PC(c)\t((c).stuff)\n#define CONTEXT_FP(c)\t((c).stuff)\n#define CONTEXT_SP(c)\t((c).stuff)\n#define CONTEXT_RET(c)\t((c).stuff)\n\n/* GBA-specific exception codes */\n\n/* The value of the timer IRQ */\n#define TIMER_IRQ\t\t0\n\n/* The type of an interrupt identifier */\ntypedef uint32 irq_t;\n\n/* The type of an IRQ handler */\ntypedef void (*irq_handler)(irq_t source, irq_context_t *context);\n\n/* Are we inside an interrupt handler? */\nint irq_inside_int();\n\n/* Pretend like we just came in from an interrupt and force\n a context switch back to the \"current\" context. Make sure\n you've called irq_set_context()! */\nvoid irq_force_return();\n\n/* Set a handler, or remove a handler (see codes above) */\nint irq_set_handler(irq_t source, irq_handler hnd);\n\n/* Set a global exception handler */\nint irq_set_global_handler(irq_handler hnd);\n\n/* Switch out contexts (for interrupt return) */\nvoid irq_set_context(irq_context_t *regbank);\n\n/* Return the current IRQ context */\nirq_context_t *irq_get_context();\n\n/* Fill a newly allocated context block for usage with supervisor/kernel\n or user mode. The given parameters will be passed to the called routine (up\n to the architecture maximum). */\nvoid irq_create_context(irq_context_t *context, uint32 stack_pointer,\n\tuint32 routine, uint32 *args, int usermode);\n\n/* Enable/Disable interrupts */\nint irq_disable();\nvoid irq_enable();\nvoid irq_restore(int v);\n\n/* Init routine */\nint irq_init();\n\n/* Shutdown */\nvoid irq_shutdown();\n\n#endif\t/* __ARCH_IRQ_H */\n\n"
},
{
"alpha_fraction": 0.6499999761581421,
"alphanum_fraction": 0.6772727370262146,
"avg_line_length": 25.80487823486328,
"blob_id": "60e194b6eb84f9f912ea176add82bb100d8345e9",
"content_id": "156cf2b69f58bdd10546bd1827d60b6527d1507e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1100,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 41,
"path": "/include/kos/dbglog.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/dbglog.h\n Copyright (C)2004 Dan Potter\n\n $Id: stdio.h,v 1.3 2003/06/23 05:21:31 bardtx Exp $\n\n*/\n\n#ifndef __KOS_DBGLOG_H\n#define __KOS_DBGLOG_H\n\n#include <kos/cdefs.h>\n__BEGIN_DECLS\n\n#include <unistd.h>\n#include <stdarg.h>\n#include <kos/fs.h>\n\n/* Kernel debugging printf; all output sent to this is filtered through\n a kernel log level check before actually being printed. This way, you\n can set the level of debug info you want to see (or want your users\n to see). */\nvoid dbglog(int level, const char *fmt, ...) __printflike(2, 3);\n\n/* Log levels for the above */\n#define DBG_DEAD\t0\t\t/* The system is dead */\n#define DBG_CRITICAL\t1\t\t/* A critical error message */\n#define DBG_ERROR\t2\t\t/* A normal error message */\n#define DBG_WARNING\t3\t\t/* Potential problem */\n#define DBG_NOTICE\t4\t\t/* Normal but significant */\n#define DBG_INFO\t5\t\t/* Informational messages */\n#define DBG_DEBUG\t6\t\t/* User debug messages */\n#define DBG_KDEBUG\t7\t\t/* Kernel debug messages */\n\n/* Set debug level */\nvoid dbglog_set_level(int level);\n\n__END_DECLS\n\n#endif\t/* __KOS_DBGLOG_H */\n\n"
},
{
"alpha_fraction": 0.5934820175170898,
"alphanum_fraction": 0.645797610282898,
"avg_line_length": 24.91111183166504,
"blob_id": "c68f24fe0b0a7e57fae765a2403a5fb0e5d56ef4",
"content_id": "b1143fcb5ce0c351273f593be09ef884b038c325",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1166,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 45,
"path": "/kernel/arch/ps2/kernel/syscall.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n syscall.c\n (c)2002 Dan Potter\n*/\n\n#include <arch/syscall.h>\n#include <arch/irq.h>\n\nCVSID(\"$Id: syscall.c,v 1.1 2002/11/03 03:40:55 bardtx Exp $\");\n\n/* The actual syscall handler */\nextern void syscall_entry(irq_t source, irq_context_t *cxt);\n/* T0 will contain the address to which we should jump. When that\n routine returns, we will context switch back into the\n original caller (or some other scheduled thread). Called\n routines can pass up to four parameters in A0-A3. */\nasm(\n\"\t.text\\n\"\n\"syscall_entry:\\n\"\n\"\tld\t$4,(16*4)($5)\\n\"\t// Load A0\n\"\tld\t$6,(16*6)($5)\\n\"\t// Load A2\n\"\tld\t$7,(16*7)($5)\\n\"\t// Load A3\n\"\tld\t$8,(16*8)($5)\\n\"\t// Load T0\n\"\tjr\t$8\\n\"\t\t\t// Branch to routine\n\"\tld\t$7,(16*7)($5)\\n\"\t// Load A1\n);\n\n/* Set the return value for a syscall for a dormant thread */\nvoid syscall_set_return(irq_context_t *context, int value) {\n\tCONTEXT_128_TO_32(context->r[2]) = value;\n}\n\n/* Init routine */\nint syscall_init() {\n\t/* Hook the IRQ handler for SYSCALL */\n\tirq_set_handler(EXC_SYSCALL, syscall_entry);\n\treturn 0;\n}\n\n/* Shutdown */\nvoid syscall_shutdown() {\n\t/* Unhook the IRQ handler */\n\tirq_set_handler(EXC_SYSCALL, NULL);\n}\n"
},
{
"alpha_fraction": 0.6258277893066406,
"alphanum_fraction": 0.6622516512870789,
"avg_line_length": 21.33333396911621,
"blob_id": "e0b630e6c9a5ae3ed33c99801b55dc0072fc3320",
"content_id": "ec45f9b280de31eac0e10b9075841e564616bc42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 27,
"path": "/include/arch/ia32/arch/stack.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/arch/stack.h\n (c)2002 Dan Potter\n \n $Id: stack.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n*/\n\n#ifndef __ARCH_STACK_H\n#define __ARCH_STACK_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Do a stack trace from the current function; leave off the first n frames\n (i.e., in assert()). */\nvoid arch_stk_trace(int n);\n\n/* Do a stack trace from the given frame pointer (useful for things like\n tracing from an ISR); leave off the first n frames. */\nvoid arch_stk_trace_at(uint32 fp, int n);\n\n__END_DECLS\n\n#endif\t/* __ARCH_EXEC_H */\n\n"
},
{
"alpha_fraction": 0.5732483863830566,
"alphanum_fraction": 0.6326963901519775,
"avg_line_length": 19.434782028198242,
"blob_id": "d8b9830f344a9fe0cb06e07e50f795109ad466d8",
"content_id": "5f048b0b30d9ee34b3aa818715c15e13cf050313",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 471,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 23,
"path": "/libc/stdio/floatio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n floatio.h\n (c)2001 Vincent Penne\n\n $Id: floatio.h,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n#ifndef __LIBC_FLOATIO_H\n#define __LIBC_FLOATIO_H\n\n/* More or less random values, are they safe ? */\n#define MAXEXP 100\n#define MAXFRACT 100\n\n/* we haven't them yet ... */\n/* static int isinf(double d) { return 0; }\nstatic int isnan(double d) { return 0; } */\n\n/* use a very basic dtoa function */\n#define __dtoa dtoa \n\n#endif\t/* __LIBC_FLOATIO_H */\n\n"
},
{
"alpha_fraction": 0.7019608020782471,
"alphanum_fraction": 0.70686274766922,
"avg_line_length": 26.567567825317383,
"blob_id": "a5110f1cf8c8e4974a800d2c464a21a9d21d2b13",
"content_id": "149ddb901b4f8f6ee2402bacf9f7bfcab0ccad0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1020,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 37,
"path": "/kernel/libc/newlib/lock_common.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n lock_common.h\n Copyright (C)2004 Dan Potter\n\n*/\n\n#ifndef __NEWLIB_LOCK_COMMON_H\n#define __NEWLIB_LOCK_COMMON_H\n\n#include <arch/spinlock.h>\n\ntypedef struct {\n\tvoid\t* owner;\n\tint\tnest;\n\tspinlock_t lock;\n} __newlib_recursive_lock_t;\n\n#define __NEWLIB_RECURSIVE_LOCK_INIT { NULL, 0, SPINLOCK_INITIALIZER }\n\ntypedef spinlock_t __newlib_lock_t;\n#define __NEWLIB_LOCK_INIT SPINLOCK_INITIALIZER\n\nvoid __newlib_lock_init(__newlib_lock_t *);\nvoid __newlib_lock_close(__newlib_lock_t *);\nvoid __newlib_lock_acquire(__newlib_lock_t *);\nvoid __newlib_lock_try_acquire(__newlib_lock_t *);\nvoid __newlib_lock_release(__newlib_lock_t *);\n\nvoid __newlib_lock_init_recursive(__newlib_recursive_lock_t *);\nvoid __newlib_lock_close_recursive(__newlib_recursive_lock_t *);\nvoid __newlib_lock_acquire_recursive(__newlib_recursive_lock_t *);\nvoid __newlib_lock_try_acquire_recursive(__newlib_recursive_lock_t *);\nvoid __newlib_lock_release_recursive(__newlib_recursive_lock_t *);\n\n\n#endif // __NEWLIB_LOCK_COMMON_H\n"
},
{
"alpha_fraction": 0.6039885878562927,
"alphanum_fraction": 0.6096866130828857,
"avg_line_length": 17.945945739746094,
"blob_id": "192ad74c0c02a5380d1c5a99660aa53d971874f0",
"content_id": "2fc61505d5021f59bbfccdf79287499f859b02d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 702,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 37,
"path": "/include/kos/fs_socket.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs_socket.h\n Copyright (C) 2006 Lawrence Sebald\n\n*/\n\n#ifndef __KOS_FS_SOCKET_H\n#define __KOS_FS_SOCKET_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n#include <sys/queue.h>\n\ntypedef struct net_socket {\n /* List handle */\n LIST_ENTRY(net_socket) sock_list;\n \n /* Protocol of this socket. This corresponds to the IP protocol number */\n int protocol;\n \n /* Protocol specific data */\n void *data;\n} net_socket_t;\n\nint fs_socket_init();\nint fs_socket_shutdown();\n\nint fs_socket_setflags(int sock, int flags);\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_SOCKET_H */\n\n"
},
{
"alpha_fraction": 0.5184651017189026,
"alphanum_fraction": 0.5455856919288635,
"avg_line_length": 28.615385055541992,
"blob_id": "0338880a299c21ef2edc99d8a6bf4f05e237981f",
"content_id": "5125c78064b9b4e7d2f8d710a86933ea3e635eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3466,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 117,
"path": "/include/arch/dreamcast/dc/matrix.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n matrix.h\n (c)2000 Dan Potter\n\n $Id: matrix.h,v 1.2 2002/09/06 06:29:08 bardtx Exp $\n*/\n\n#ifndef __DC_MATRIX_H\n#define __DC_MATRIX_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/vector.h>\n\n/* Copy the internal matrix out to a memory one */\nvoid mat_store(matrix_t *out);\n\n/* Copy a memory matrix into the internal one */\nvoid mat_load(matrix_t *out);\n\n/* Clear internal to an identity matrix */\nvoid mat_identity();\n\n/* \"Apply\" a matrix: multiply a matrix onto the \"internal\" one */\nvoid mat_apply(matrix_t *src);\n\n/* Transform zero or more sets of vectors using the current internal\n matrix. Each vector is three floats long. */\nvoid mat_transform(vector_t *invecs, vector_t *outvecs, int veccnt, int vecskip);\n\n/* Transform zero or more sets of vertices using the current internal\n matrix, directly to the store queues. Each vertex is 32 bytes long.\n All non-xyz data will be copied over along with the transformed\n coordinates. Minimum number of vertices: 1.\n\n Note taht the QACRx registers must have already been set.\n\n This was contributed by Jim Ursetto. */\nvoid mat_transform_sq(void * input, void * output, int veccnt);\n\n/* Inline mat_transform which works on the three coordinates passed in;\n this works most efficiently if you've already got the three numbers\n (x,y,z) in the right registers (fr0,fr1,fr2). */\n#define mat_trans_single(x, y, z) { \\\n\tregister float __x __asm__(\"fr0\") = (x); \\\n\tregister float __y __asm__(\"fr1\") = (y); \\\n\tregister float __z __asm__(\"fr2\") = (z); \\\n\t__asm__ __volatile__( \\\n\t\t\"fldi1\tfr3\\n\" \\\n\t\t\"ftrv\txmtrx,fv0\\n\" \\\n\t\t\"fldi1\tfr2\\n\" \\\n\t\t\"fdiv\tfr3,fr2\\n\" \\\n\t\t\"fmul\tfr2,fr0\\n\" \\\n\t\t\"fmul\tfr2,fr1\\n\" \\\n\t\t: \"=f\" (__x), \"=f\" (__y), \"=f\" (__z) \\\n\t\t: \"0\" (__x), \"1\" (__y), \"2\" (__z) \\\n\t\t: \"fr3\" ); \\\n\tx = __x; y = __y; z = __z; \\\n}\n\n/* Same as above, but allows an input to and preserves the Z/W value */\n#define mat_trans_single4(x, y, z, w) { \\\n\tregister float __x __asm__(\"fr0\") = (x); \\\n\tregister float __y __asm__(\"fr1\") = (y); \\\n\tregister float __z __asm__(\"fr2\") = (z); \\\n\tregister float __w __asm__(\"fr3\") = (w); \\\n\t__asm__ __volatile__( \\\n\t\t\"ftrv\txmtrx,fv0\\n\" \\\n\t\t\"fdiv\tfr3,fr0\\n\" \\\n\t\t\"fdiv\tfr3,fr1\\n\" \\\n\t\t\"fdiv\tfr3,fr2\\n\" \\\n\t\t\"fldi1\tfr4\\n\" \\\n\t\t\"fdiv\tfr3,fr4\\n\" \\\n\t\t\"fmov\tfr4,fr3\\n\" \\\n\t\t: \"=f\" (__x), \"=f\" (__y), \"=f\" (__z), \"=f\" (__w) \\\n\t\t: \"0\" (__x), \"1\" (__y), \"2\" (__z), \"3\" (__w) \\\n\t\t: \"fr4\" ); \\\n\tx = __x; y = __y; z = __z; w = __w; \\\n}\n\n/* This is like mat_trans_single, but it leaves z/w instead of 1/w\n for the z component. */\n#define mat_trans_single3(x, y, z) { \\\n\tregister float __x __asm__(\"fr0\") = (x); \\\n\tregister float __y __asm__(\"fr1\") = (y); \\\n\tregister float __z __asm__(\"fr2\") = (z); \\\n\t__asm__ __volatile__( \\\n\t\t\"fldi1\tfr3\\n\" \\\n\t\t\"ftrv\txmtrx,fv0\\n\" \\\n\t\t\"fdiv\tfr3,fr0\\n\" \\\n\t\t\"fdiv\tfr3,fr1\\n\" \\\n\t\t\"fdiv\tfr3,fr2\\n\" \\\n\t\t: \"=f\" (__x), \"=f\" (__y), \"=f\" (__z) \\\n\t\t: \"0\" (__x), \"1\" (__y), \"2\" (__z) \\\n\t\t: \"fr3\" ); \\\n\tx = __x; y = __y; z = __z; \\\n}\n\n/* Transform vector, without any perspective division. */\n#define mat_trans_nodiv(x, y, z, w) { \\\n\tregister float __x __asm__(\"fr0\") = (x); \\\n\tregister float __y __asm__(\"fr1\") = (y); \\\n\tregister float __z __asm__(\"fr2\") = (z); \\\n\tregister float __w __asm__(\"fr3\") = (w); \\\n\t__asm__ __volatile__( \\\n\t\t\"ftrv xmtrx,fv0\\n\" \\\n\t\t: \"=f\" (__x), \"=f\" (__y), \"=f\" (__z), \"=f\" (__w) \\\n\t\t: \"0\" (__x), \"1\" (__y), \"2\" (__z), \"3\" (__w) ); \\\n\tx = __x; y = __y; z = __z; w = __w; \\\n}\n\n\n__END_DECLS\n\n#endif\t/* __DC_MATRIX_H */\n\n"
},
{
"alpha_fraction": 0.539170503616333,
"alphanum_fraction": 0.6313363909721375,
"avg_line_length": 16.91666603088379,
"blob_id": "48396aeca4753985a6d8fa13c80056d525571174",
"content_id": "4d8a4ca88aafa6ff3941d5a1ef661bfab90385c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/kernel/arch/dreamcast/util/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast/util/Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/03/23 07:11:43 bardtx Exp $\n\n\nOBJS = vmu_pkg.o screenshot.o\nSUBDIRS = \n\ninclude ../../../../Makefile.prefab\n\n\n"
},
{
"alpha_fraction": 0.6018432974815369,
"alphanum_fraction": 0.634101390838623,
"avg_line_length": 21.54166603088379,
"blob_id": "a981ad9524c209851de03ac74b1e36fc80bd8e09",
"content_id": "6d037e6eec100caf78005ff6644567e5f918b771",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 48,
"path": "/include/arch/ps2/arch/syscall.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/syscall.h\n (c)2000-2002 Dan Potter\n\n $Id: syscall.h,v 1.3 2002/11/14 06:50:06 bardtx Exp $\n\n*/\n\n#ifndef __ARCH_SYSCALL_H\n#define __ARCH_SYSCALL_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <arch/irq.h>\n\n/* Set the return value for a syscall for a dormant thread */\nvoid syscall_set_return(irq_context_t *context, int value);\n\n/* Handles all the nasty work */\n#define SET_RETURN(thread, value) \\\n\tsyscall_set_return(&(thread->context), (value))\n\n/* Ditto */\n#define SET_MY_RETURN(value) \\\n\tSET_RETURN(thd_current, value)\n\n/* Ditto */\n#define RETURN(value) do { \\\n\tSET_RETURN(thd_current, value); \\\n\t/* if (thd_current->state != STATE_RUNNING) */ \\\n\t\tthd_schedule(0); \\\n\treturn; } while(0)\n\n\n/* This macro can be used in normal mode to jump into kernel\n mode convienently. XXX Need to update for new syntax usage. */\n#define SYSCALL(routine, p1, p2, p3, p4) do { \\\n\t__asm__(\"la\t$8,0(%0);\" \\\n\t \"syscall;\" \\\n\t \"nop;\" : : \"r\"(routine)); \\\n\t} while(0)\n\n__END_DECLS\n\n#endif\t/* __ARCH_SYSCALL_H */\n\n\n\n"
},
{
"alpha_fraction": 0.6273885369300842,
"alphanum_fraction": 0.6464968323707581,
"avg_line_length": 28.880952835083008,
"blob_id": "d7c9e58d2b759ccb5a8a6571d43add2975304802",
"content_id": "508bbce561477b5667a345cf2adcd08d2da7c2c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1256,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 42,
"path": "/libc/include/assert.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n assert.h\n (c)2002 Dan Potter\n\n $Id: assert.h,v 1.2 2002/09/13 04:41:57 bardtx Exp $\n*/\n\n#ifndef __ASSERT_H\n#define __ASSERT_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* This is nice and simple, modeled after the BSD one like most of KOS;\n the addition here is assert_msg(), which allows you to provide an\n error message. */\n#define _assert(e) assert(e)\n\n/* __FUNCTION__ is not ANSI, it's GCC, but we depend on GCC anyway.. */\n#ifdef NDEBUG\n#\tdefine assert(e) ((void)0)\n#\tdefine assert_msg(e, m) ((void)0)\n#else\n#\tdefine assert(e) ((e) ? (void)0 : __assert(__FILE__, __LINE__, #e, NULL, __FUNCTION__))\n#\tdefine assert_msg(e, m) ((e) ? (void)0 : __assert(__FILE__, __LINE__, #e, m, __FUNCTION__))\n#endif\n\n/* Defined in assert.c */\nvoid __assert(const char *file, int line, const char *expr,\n\tconst char *msg, const char *func);\n\n/* Set an \"assert handler\" which is called whenever an assert happens.\n By default, this will print a message and call abort(). Returns the old\n handler's address. */\ntypedef void (*assert_handler_t)(const char * file, int line, const char * expr,\n\tconst char * msg, const char * func);\nassert_handler_t assert_set_handler(assert_handler_t hnd);\n\n__END_DECLS\n\n#endif\t/* __ASSERT_H */\n\n"
},
{
"alpha_fraction": 0.6114577651023865,
"alphanum_fraction": 0.6993760466575623,
"avg_line_length": 29.48214340209961,
"blob_id": "9d0fd965d22e0a924def1ab766858398fcd9679f",
"content_id": "faae765c4e238294ddcb48f7b29ce41ce5a187b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1763,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 56,
"path": "/include/arch/dreamcast/dc/modem/mconst.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\r\n\r\n mconst.h\r\n Copyright (C)2002, 2004 Nick Kochakian\r\n\r\n Distributed under the terms of the KOS license.\r\n\r\n $Id: mconst.h,v 1.1 2003/05/23 02:05:02 bardtx Exp $\r\n*/\r\n\r\n/* Modem constants are defined here. Automatically included by modem.h */\r\n#ifndef __MODEM_MCONST_H\r\n#define __MODEM_MCONST_H\r\n\r\n/* Each speed constant contains information about the data rate in bps and the\r\n protocol that's being used. The first 4 bits identify the the speed that's\r\n being used, and the last 4 bits identify the protocol.\r\n\r\n And don't try to create your own custom speeds from these, you'll cause\r\n something very bad to happen. Only use the MODEM_SPEED_* constants defined\r\n in modem.h! */\r\n\r\n/* Speeds */\r\n#define MODEM_SPEED_AUTO 0x0\r\n#define MODEM_SPEED_1200 0x0\r\n#define MODEM_SPEED_2400 0x1\r\n#define MODEM_SPEED_4800 0x2\r\n#define MODEM_SPEED_7200 0x3\r\n#define MODEM_SPEED_9600 0x4\r\n#define MODEM_SPEED_12000 0x5\r\n#define MODEM_SPEED_14400 0x6\r\n#define MODEM_SPEED_16800 0x7\r\n#define MODEM_SPEED_19200 0x8\r\n#define MODEM_SPEED_21600 0x9\r\n#define MODEM_SPEED_24000 0xA\r\n#define MODEM_SPEED_26400 0xB\r\n#define MODEM_SPEED_28000 0xC\r\n#define MODEM_SPEED_31200 0xD\r\n#define MODEM_SPEED_33600 0xE\r\n\r\n/* Protocols */\r\n#define MODEM_PROTOCOL_V17 0x0\r\n#define MODEM_PROTOCOL_V22 0x1\r\n#define MODEM_PROTOCOL_V22BIS 0x2\r\n#define MODEM_PROTOCOL_V32 0x3\r\n#define MODEM_PROTOCOL_V32BIS 0x4\r\n#define MODEM_PROTOCOL_V34 0x5\r\n#define MODEM_PROTOCOL_V8 0x6\r\n\r\n#define MODEM_SPEED_GET_PROTOCOL(x) ((modem_speed_t)(x) >> 4)\r\n#define MODEM_SPEED_GET_SPEED(x) ((modem_speed_t)(x) & 0xF)\r\n#define MODEM_MAKE_SPEED(p, s) ((modem_speed_t)((((p) & 0xF) << 4) | ((s) & 0xF)))\r\n\r\ntypedef unsigned char modem_speed_t;\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.5115207433700562,
"alphanum_fraction": 0.6082949042320251,
"avg_line_length": 13.399999618530273,
"blob_id": "90e4e2c7484dd1664881f2a7ddb58a64ea20696a",
"content_id": "66a7067e8314e8baf626bf09abd4ebc2cfef6e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/ps2/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/ps2/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/10/27 23:41:13 bardtx Exp $\n\nall:\n\t$(MAKE) -C basic\n\nclean:\n\t$(MAKE) -C basic clean\n\t\t\ndist:\n\t$(MAKE) -C basic dist\n\n"
},
{
"alpha_fraction": 0.6047120690345764,
"alphanum_fraction": 0.6675392389297485,
"avg_line_length": 14.833333015441895,
"blob_id": "22c86a77a728eb11887f2dcbef9edd62c9abcb77",
"content_id": "31c6b742971c0a48a60f9a87b7519520dbfe7508",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 24,
"path": "/examples/dreamcast/kgl/demos/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/kgl/demos/Makefile\n# (c)2001-2002 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/03/04 05:00:45 bardtx Exp $\n\nall:\nifdef KOS_CCPLUS\n\t$(MAKE) -C tunnel\nendif\n\t$(MAKE) -C bubbles\n\nclean:\nifdef KOS_CCPLUS\n\t$(MAKE) -C tunnel clean\nendif\n\t$(MAKE) -C bubbles clean\n\t\t\ndist:\nifdef KOS_CCPLUS\n\t$(MAKE) -C tunnel dist\nendif\n\t$(MAKE) -C bubbles dist\n\n\n"
},
{
"alpha_fraction": 0.5938739776611328,
"alphanum_fraction": 0.6264874339103699,
"avg_line_length": 22.391752243041992,
"blob_id": "b795180953e59dedbb860c517f7f03875a3050bd",
"content_id": "3d30153571e9e61b97fe1757ae8e7e5006dbc2a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4538,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 194,
"path": "/examples/dreamcast/basic/threading/general/general_threading_test.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n general_threading_test.c \n\n (c)2000-2002 Dan Potter\n\n A simple thread example\n\n This small program shows off the threading (and also is used as\n a regression test to make sure threading is still approximately\n working =). See below for some more specific notes.\n\n */\n\n#include <kos.h>\n\n/* Semaphore used for timing below */\nsemaphore_t *sem;\n\n/* This routine will be started as thread #0 */\nvoid thd_0(void *v) {\n\tint x, y;\n\n\tprintf(\"Thread 0 started\\n\");\n\tfor (y=0; y<480; y++)\n\t\tfor (x=0; x<320; x++)\n\t\t\tvram_s[y*640+x] = (((x*x) + (y*y)) & 0x1f) << 11;\n\tprintf(\"Thread 0 finished\\n\");\n}\n\n/* This routine will be started as thread #1 */\nvoid thd_1(void *v) {\n\tint i;\n\n\tfor (i=0; i<30; i++) {\n\t\tprintf(\"Hi from thread 1\\n\");\n\t\tthd_sleep(100);\n\t\tsem_signal(sem);\n\t}\n\tprintf(\"Thread 1 waiting:\\n\");\n\tthd_sleep(5000);\n\tprintf(\"Thread 1 exiting\\n\");\n}\n\n/* This routine will be started as thread #2 */\nvoid thd_2(void *v) {\n\tint i;\n\t\n\tthd_sleep(50);\n\tfor (i=0; i<29; i++) {\n\t\tsem_wait(sem);\n\t\tprintf(\"Hi from thread 2\\n\");\n\t}\n\tprintf(\"sem_wait_timed returns %d\\n\", sem_wait_timed(sem, 200));\n\tprintf(\"sem_wait_timed returns %d\\n\", sem_wait_timed(sem, 200));\n\tprintf(\"sem_wait_timed returns %d\\n\", sem_wait_timed(sem, 200));\n\tprintf(\"Thread 2 exiting\\n\");\n}\n\n/* Condvar/mutex used for timing below */\nmutex_t * mut;\ncondvar_t * cv;\nvolatile int cv_ready = 0, cv_cnt = 0, cv_quit = 0;\n\n/* This routine will be started N times for the condvar testing */\nvoid thd_3(void *v) {\n\tprintf(\"Thread %d started\\n\", (int)v);\n\n\tmutex_lock(mut);\n\tfor ( ; ; ) {\n\t\twhile (!cv_ready && !cv_quit) {\n\t\t\tcond_wait(cv, mut);\n\t\t}\n\n\t\tif (!cv_quit) {\n\t\t\tprintf(\"Thread %d re-activated. Count is now %d.\\n\",\n\t\t\t\t(int)v, ++cv_cnt);\n\t\t\tcv_ready = 0;\n\t\t} else\n\t\t\tbreak;\n\n\t}\n\tmutex_unlock(mut);\n\n\tprintf(\"Thread %d exiting\\n\", (int)v);\n}\n\n/* Hardware / basic OS init: IRQs disabled, threads enabled,\n no initial romdisk */\nKOS_INIT_FLAGS(INIT_THD_PREEMPT);\n\n/* The main program */\nint main(int argc, char **argv) {\n\tint x, y, i;\n\tkthread_t * t0, * t1, * t2, *t3[10];\n\n\tcont_btn_callback(0, CONT_START | CONT_A | CONT_B | CONT_X | CONT_Y, arch_exit);\n\n\t/* Print a banner */\t\n\tprintf(\"KOS 1.1.x thread program:\\n\");\n\n\t/* Create two threads, but don't start them yet. Note that at this\n\t point in your program, IRQs are still disabled. This is so that you\n\t have full control over what happens to the threads. */\n\tt0 = thd_create(thd_0, NULL);\n\tt1 = thd_create(thd_1, NULL);\n\tt2 = thd_create(thd_2, NULL);\n\n\t/* Create a semaphore for timing purposes */\n\tsem = sem_create(1);\n\t/* Enabling IRQs starts the thread scheduler */\n\tirq_enable();\n\n\t/* In the foreground, draw a moire pattern on the screen */\n\tfor (y=0; y<480; y++)\n\t\tfor (x=320; x<640; x++)\n\t\t\tvram_s[y*640+x] = ((x*x) + (y*y)) & 0x1f;\n\n\ttimer_spin_sleep(1000);\n\tthd_pslist(printf);\n\tthd_pslist_queue(printf);\n\n\tprintf(\"Waiting for the death of thread 1:\\n\");\n\tx = thd_wait(t1);\n\n\tprintf(\"Retval was %d. Waiting for the death of thread 2:\\n\", x);\n\tx = thd_wait(t2);\n\tprintf(\"Retval was %d.\\n\", x);\n\n\tprintf(\"Testing idle sleeping:\\n\");\n\tthd_pslist(printf);\n\tthd_sleep(1000);\n\tprintf(\"Test succeeded\\n\");\n\n\tthd_wait(t0);\n\n\tprintf(\"\\n\\nCondvar test; starting threads\\n\");\n\tprintf(\"Main thread is %08lx\\n\", thd_current);\n\tmut = mutex_create();\n\tcv = cond_create();\n\tfor (i=0; i<10; i++) {\n\t\tt3[i] = thd_create(thd_3, (void *)i);\n\t\tprintf(\"Thread %d is %08lx\\n\", i, t3[i]);\n\t}\n\tthd_sleep(500);\n\n\tprintf(\"\\nOne-by-one test:\\n\");\n\tfor (i=0; i<10; i++) {\n\t\tmutex_lock(mut);\n\t\tcv_ready = 1;\n\t\tprintf(\"Signaling %d:\\n\", i);\n\t\tcond_signal(cv);\n\t\tmutex_unlock(mut);\n\t\tthd_sleep(100);\n\t}\n\n\tprintf(\"\\nAgain, without waiting:\\n\");\n\tfor (i=0; i<10; i++) {\n\t\tmutex_lock(mut);\n\t\tcv_ready = 1;\n\t\tprintf(\"Signaling %d:\\n\", i);\n\t\tcond_signal(cv);\n\t\tmutex_unlock(mut);\n\t}\n\tthd_sleep(100);\n\tprintf(\" (might not be the full 10)\\n\");\n\t\n\tprintf(\"\\nBroadcast test:\\n\");\n\tmutex_lock(mut);\n\tcv_ready = 1;\n\tcond_broadcast(cv);\n\tmutex_unlock(mut);\n\tthd_sleep(100);\n\tprintf(\" (only one should have gotten through)\\n\");\n\n\tprintf(\"\\nKilling all condvar threads:\\n\");\n\tmutex_lock(mut);\n\tcv_quit = 1;\n\tcond_broadcast(cv);\n\tmutex_unlock(mut);\n\tfor (i=0; i<10; i++)\n\t\tthd_wait(t3[i]);\n\n\t/* Disable IRQs, thus turning off threading. All threads that were\n\t running are now gone. If your threads were doing anything like\n\t PowerVR or other hardware access, I recommend avoiding this sort\n\t of brute-force shutdown approach =) */\n\tirq_disable();\n\n\t/* Shut it all down */\n\tprintf(\"Done.\\n\");\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6148232221603394,
"alphanum_fraction": 0.6308789849281311,
"avg_line_length": 21.176258087158203,
"blob_id": "cc1bf272158f86c55fc0a1b95fa5887813ce2b0c",
"content_id": "e37ef8810ce1a40c1d168427ead4c6a7d6bcd3a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6166,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 278,
"path": "/kernel/arch/dreamcast/hardware/maple/sip.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sip.c\n Copyright (C) 2005 Lawrence Sebald\n*/\n\n#include <assert.h>\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <kos/genwait.h>\n#include <dc/maple.h>\n#include <dc/maple/sip.h>\n\nstatic void sip_generic_cb(maple_frame_t *frame)\t{\n\t/* Unlock the frame */\n\tmaple_frame_unlock(frame);\n\t\n\t/* Wake up! */\n\tgenwait_wake_all(frame);\n}\n\nint sip_set_gain(maple_device_t *dev, uint8 g)\t{\n\tsip_state_t *sip;\n\n\tassert( dev != NULL );\n\t\n\tsip = (sip_state_t *)dev->status;\n\n\t/* Check the gain value for validity */\n\tif(g > 0x1F)\n\t\treturn MAPLE_EINVALID;\n\n\tsip->amp_gain = g;\n\n\treturn MAPLE_EOK;\n}\n\nint sip_start_sampling(maple_device_t *dev)\t{\n\tsip_state_t *sip;\n\tuint32 *send_buf;\n\t\n\tassert( dev != NULL );\n\t\n\tsip = (sip_state_t *)dev->status;\n\t\n\t/* Make sure we aren't yet sampling */\n\tif(sip->is_sampling)\n\t\treturn MAPLE_EFAIL;\n\t\n\t/* Lock the frame */\n\tif(maple_frame_lock(&dev->frame) < 0)\n\t\treturn MAPLE_EAGAIN;\n\t\n\t/* Reset the frame */\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MICROPHONE;\n\tsend_buf[1] = 0x02 | (0x80 << 8); /* Start sampling */\n\tdev->frame.cmd = MAPLE_COMMAND_MICCONTROL;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2;\n\tdev->frame.callback = sip_generic_cb;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\t\n\t/* Wait for the SIP to accept it */\n\tif(genwait_wait(&dev->frame, \"sip_start_sampling\", 500, NULL) < 0) {\n\t\tif(dev->frame.state != MAPLE_FRAME_VACANT)\t{\n\t\t\t/* Something went wrong.... */\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\tdbglog(DBG_ERROR, \"sip_start_sampling: timeout to unit %c%c\\n\",\n\t\t\t dev->port + 'A', dev->unit + '0');\n\t\t\treturn MAPLE_ETIMEOUT;\n\t\t}\n\t}\n\t\n\tsip->is_sampling = 1;\n\t\n\treturn MAPLE_EOK;\n}\n\nint sip_stop_sampling(maple_device_t *dev)\t{\n\tsip_state_t *sip;\n\tuint32 *send_buf;\n\n\tassert( dev != NULL );\n\n\tsip = (sip_state_t *)dev->status;\n\n\t/* Make sure we actually are sampling */\n\tif(!sip->is_sampling)\n\t\treturn MAPLE_EFAIL;\n\n\t/* Lock the frame */\n\tif(maple_frame_lock(&dev->frame) < 0)\n\t\treturn MAPLE_EAGAIN;\n\n\t/* Reset the frame */\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MICROPHONE;\n\tsend_buf[1] = 0x02; /* Stop sampling */\n\tdev->frame.cmd = MAPLE_COMMAND_MICCONTROL;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2;\n\tdev->frame.callback = sip_generic_cb;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\t/* Wait for the SIP to accept it */\n\tif(genwait_wait(&dev->frame, \"sip_stop_sampling\", 500, NULL) < 0) {\n\t\tif(dev->frame.state != MAPLE_FRAME_VACANT)\t{\n\t\t\t/* Something went wrong.... */\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\tdbglog(DBG_ERROR, \"sip_stop_sampling: timeout to unit %c%c\\n\",\n\t\t\t dev->port + 'A', dev->unit + '0');\n\t\t\treturn MAPLE_ETIMEOUT;\n\t\t}\n\t}\n\n\tsip->is_sampling = 0;\n\n\treturn MAPLE_EOK;\n}\n\nint sip_get_samples(maple_device_t *dev, uint8 *buf, size_t len)\t{\n\tsip_state_t *sip;\n\tsize_t sz;\n\n\tsip = (sip_state_t *)dev->status;\n\n\tif(sip->is_sampling)\n\t\treturn MAPLE_EFAIL;\n\n\tsz = sip->buf_pos > len ? len : sip->buf_pos;\n\n\tmemcpy(buf, sip->samples_buf, sz);\n\n\tif(sz == sip->buf_pos)\t{\n\t\tsip->buf_pos = 0;\n\t}\n\telse\t{\n\t\tmemcpy(sip->samples_buf + sz, sip->samples_buf, sip->buf_pos - sz);\n\t\tsip->buf_pos -= sz;\n\t}\n\n\treturn sz;\n}\n\nint sip_clear_samples(maple_device_t *dev)\t{\n\tsip_state_t *sip;\n\n\tsip = (sip_state_t *)dev->status;\n\n\tif(sip->is_sampling)\n\t\treturn MAPLE_EFAIL;\n\n\tsip->buf_pos = 0;\n\n\treturn MAPLE_EOK;\n}\n\nstatic void sip_reply(maple_frame_t *frm)\t{\n\tmaple_response_t *resp;\n\tuint32 *respbuf;\n\tsize_t sz, i;\n\tsip_state_t *sip;\n\t\n\t/* Unlock the frame now (it's ok, we're in an IRQ) */\n\tmaple_frame_unlock(frm);\n\t\n\t/* Make sure we got a valid response */\n\tresp = (maple_response_t *)frm->recv_buf;\n\t\n\tif (resp->response != MAPLE_RESPONSE_DATATRF)\n\t\treturn;\n\trespbuf = (uint32 *)resp->data;\n\tif (respbuf[0] != MAPLE_FUNC_MICROPHONE)\n\t\treturn;\n\t\n\tif(frm->dev)\t{\n\t\tsip = (sip_state_t *)frm->dev->status;\n\t\tfrm->dev->status_valid = 1;\n\n\t\tif(sip->is_sampling)\t{\n\t\t\tsz = resp->data_len * 4 - 8;\n\n\t\t\t/* Make sure we don't overflow the buffer */\n\t\t\tif(sz + sip->buf_pos <= sip->buf_len)\t{\n\t\t\t\tfor(i = 0; i < sz; i++)\t{\n\t\t\t\t\tsip->samples_buf[i + sip->buf_pos] = resp->data[i + 8];\n\t\t\t\t}\n\t\t\t\tsip->buf_pos += sz;\n\t\t\t}\n\t\t}\n\t}\n}\n\n\nstatic int sip_poll(maple_device_t *dev)\t{\n\tsip_state_t *sip;\n\tuint32 *send_buf;\n\n\t/* Test to make sure that the particular mic is enabled */\n\tsip = (sip_state_t *)dev->status;\n\n\t/* Lock the frame, or die trying */\n\tif(maple_frame_lock(&dev->frame) < 0)\n\t\treturn 0;\n\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MICROPHONE;\n\tsend_buf[1] = 0x01 | (sip->amp_gain << 8); /* Get samples/status */\n\tdev->frame.cmd = MAPLE_COMMAND_MICCONTROL;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2;\n\tdev->frame.callback = sip_reply;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\treturn 0;\n}\n\nstatic void sip_periodic(maple_driver_t *drv) {\n\tmaple_driver_foreach(drv, sip_poll);\n}\n\nstatic int sip_attach(maple_driver_t *drv, maple_device_t *dev) {\n\tsip_state_t *sip;\n\n\t/* Allocate the sample buffer for 10 seconds worth of samples */\n\tsip = (sip_state_t *)dev->status;\n\tsip->is_sampling = 0;\n\tsip->amp_gain = 0;\n\tsip->buf_pos = 0;\n\tsip->samples_buf = (uint8 *)malloc(11025 * 2 * 10);\n\n\tif(sip->samples_buf == NULL)\t{\n\t\tdev->status_valid = 0;\n\t\tsip->buf_len = 0;\n\t\treturn -1;\n\t}\n\telse\t{\n\t\tdev->status_valid = 1;\n\t\tsip->buf_len = 11025 * 2 * 10;\n\t\treturn 0;\n\t}\n}\n\nstatic void sip_detach(maple_driver_t *drv, maple_device_t *dev) {\n\tsip_state_t *sip;\n\n\tsip = (sip_state_t *)dev->status;\n\tfree(sip->samples_buf);\n}\n\n/* Device Driver Struct */\nstatic maple_driver_t sip_drv = {\n\tfunctions:\tMAPLE_FUNC_MICROPHONE,\n\tname:\t\t\"Sound Input Peripheral\",\n\tperiodic:\tsip_periodic,\n\tattach:\t\tsip_attach,\n\tdetach:\t\tsip_detach\n};\n\n/* Add the SIP to the driver chain */\nint sip_init() {\n\treturn maple_driver_reg(&sip_drv);\n}\n\nvoid sip_shutdown() {\n\tmaple_driver_unreg(&sip_drv);\n}\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5751879811286926,
"avg_line_length": 12.947368621826172,
"blob_id": "7d4416bca9181de27851fdd64c87ede9043c5e36",
"content_id": "36527f81c2c1969a5a9acc0d6f3daeac75ae0b48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/libc/string/_strupr.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n _strupr.c\n (c)2002 Brian Peek\n\n $Id: _strupr.c,v 1.1 2002/07/27 00:52:08 bardtx Exp $\n*/\n\n#include <string.h>\n#include <ctype.h>\n\nchar *_strupr(char *string)\n{\n\tchar *s;\n\n\tfor(s = string; *s; s++)\n\t\t*s = toupper(*s);\n\treturn string;\n}\n\n"
},
{
"alpha_fraction": 0.6540540456771851,
"alphanum_fraction": 0.7027027010917664,
"avg_line_length": 14.333333015441895,
"blob_id": "3ca896bda541d6d5c155e1b5988da8b64426a921",
"content_id": "086a65b50b2bec4c8b70946cfc8f5f93b6d3d433",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 12,
"path": "/utils/wav2adpcm/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "\n# Makefile for the wav2adpcm program.\n\nCFLAGS = -O2 -Wall -g\nLDFLAGS = -g\n\ninstall: all\n\tinstall -m 755 wav2adpcm $(KOS_PATH)/bin\n\nall: wav2adpcm\n\nclean:\n\t-rm -f wav2adpcm.o wav2adpcm\n"
},
{
"alpha_fraction": 0.6398515105247498,
"alphanum_fraction": 0.6615098714828491,
"avg_line_length": 25.899999618530273,
"blob_id": "8672bfaa2963c189371038be3db7600e3eac4589",
"content_id": "aadfd8322b832a72af79ad85c12b1dba466c25c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1616,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 60,
"path": "/examples/ps2/basic/hello/hello.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n hello.c\n (c)2001 Dan Potter\n*/\n\n#include <kos.h>\n\n/* You can safely remove this line if you don't use a ROMDISK */\nextern uint8 romdisk[];\n\n/* These macros tell KOS how to initialize itself. All of this initialization\n happens before main() gets called, and the shutdown happens afterwards. So\n you need to set any flags you want here. Here are some possibilities:\n\n INIT_NONE\t\t-- don't do any auto init\n INIT_IRQ\t\t-- Enable IRQs\n INIT_THD_PREEMPT\t-- Enable pre-emptive threading\n INIT_NET\t\t-- Enable networking (doesn't imply lwIP!)\n INIT_MALLOCSTATS\t-- Enable a call to malloc_stats() right before shutdown\n\n You can OR any or all of those together. If you want to start out with\n the current KOS defaults, use INIT_DEFAULT (or leave it out entirely). */\nKOS_INIT_FLAGS(INIT_DEFAULT | INIT_MALLOCSTATS);\n\n/* And specify a romdisk, if you want one (or leave it out) */\n// KOS_INIT_ROMDISK(romdisk);\n\n/* Your program's main entry point */\nint main(int argc, char **argv) {\n\tuint8 * b;\n\tint i;\n\t\n\t/* The requisite line */\n\tprintf(\"\\nHello world!\\n\\n\");\n\n\t/* Exercise the malloc/free calls a bit */\n\tprintf(\"Allocating some ram:\\n\");\n\tb = malloc(64*1024);\n\tprintf(\"Allocated 64k at %p\\n\", b);\n\n\tfor (i=0; i<64*1024; i++)\n\t\tb[i] = i & 255;\n\n\tfor (i=0; i<64*1024; i++)\n\t\tif (b[i] != (i & 255))\n\t\t\tprintf(\"mismatch at %d\\n\", i);\n\n\tprintf(\"Memory block checked ok, freeing\\n\");\n\tfree(b);\n\n\t/* Manually cause an interrupt to test IRQs */\n\tprintf(\"Doing syscall...\\n\");\n\tasm(\"syscall\\n nop\\n\");\n\n\t/* Print a banner so we know we succeeded */\n\tprintf(\"Done!\\n\");\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6467990875244141,
"alphanum_fraction": 0.6644591689109802,
"avg_line_length": 18.60869598388672,
"blob_id": "de6dabf84d608da468fe706fd119f02447263827",
"content_id": "4fcd2d48be0455084a0aadfd3bf95e4397a543d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 23,
"path": "/include/kos/string.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/string.h\n Copyright (C)2004 Dan Potter\n\n*/\n\n#ifndef __KOS_STRING_H\n#define __KOS_STRING_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <string.h>\n\nvoid * memcpy4(void * dest,const void *src,size_t count);\nvoid * memset4(void * s,unsigned long c,size_t count);\nvoid * memcpy2(void * dest,const void *src,size_t count);\nvoid * memset2(void * s,unsigned short c,size_t count);\n\n__END_DECLS\n\n#endif\t/* __KOS_STRING_H */\n\n\n"
},
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.6140350699424744,
"avg_line_length": 14.066666603088379,
"blob_id": "31997297f830feed11b165755bdb7f7d8aaeae74",
"content_id": "c5594df8fc155cc1f5b2fddac7dd0e37b682e2cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/dreamcast/basic/fpu/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/basic/fpu/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/05/18 07:08:35 bardtx Exp $\n\nall:\n\t$(MAKE) -C exc\n\nclean:\n\t$(MAKE) -C exc clean\n\t\t\ndist:\n\t$(MAKE) -C exc dist\n\n\n"
},
{
"alpha_fraction": 0.5771647095680237,
"alphanum_fraction": 0.5960119962692261,
"avg_line_length": 21.323171615600586,
"blob_id": "6ef6ac1ef02ea69c79a11423d68b05bf20367269",
"content_id": "e7c7f7892bc8a0ca5de49a843f5130b31a96bfb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3661,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 164,
"path": "/examples/dreamcast/kgl/demos/tunnel/menu.cpp",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* Kallistios ##version##\n\n menu.cpp\n (c)2001,2002 Paul Boese a.k.a. Axlen\n\n A cheap little menu class\n*/\n\n#include <string.h>\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include \"plprint.h\"\n#include \"menu.h\"\n\nCVSID(\"$Id: menu.cpp,v 1.1 2002/03/04 02:57:32 axlen Exp $\");\n\nvoid Menu::add(int min, int max, int amt, int* pval, char *pformat) {\n\tMenuitem_t* madd;\t\n\tif (mlist == NULL) {\n\t\tmlist = (Menuitem_t*) malloc(sizeof(Menuitem_t));\n\t\tmlist->prev = NULL;\n\t\tmlist->next = NULL;\n\t\tmadd = mcur = mtail = mlist;\n\t} else {\n\t\tmadd = (Menuitem_t*) malloc(sizeof(Menuitem_t));\n\t\tmtail->next = madd;\n\t\tmadd->prev = mtail;\n\t\tmadd->next = NULL;\n\t\tmtail = madd;\n\t}\n\tmadd->type = INTEGER_T;\n\tmadd->min = min;\n\tmadd->max = max;\n\tmadd->amt = amt;\n\tmadd->pvalue = pval;\n\tmadd->pformat = (char*) malloc(strlen(pformat)+1); \n\tmemcpy(madd->pformat, pformat, strlen(pformat)+1);\n\tprintf(\"[i**]menu->add = %d\\n\", strlen(pformat)+1);\n}\n\n// lvalue cast fix for C++, as proposed by Jim Ursetto\n// http://sourceforge.net/mailarchive/message.php?msg_id=9293303\ntemplate <typename T, typename X> inline T& lvalue_cast(X& x) {\n return *( reinterpret_cast<T*>(&x) ); // *((T *)& x)\n}\n\nvoid Menu::add(float min, float max, float amt, float* pval, char *pformat) {\n\tMenuitem_t* madd;\n\tif (mlist == NULL) {\n\t\tmlist = (Menuitem_t*) malloc(sizeof(Menuitem_t));\n\t\tmlist->prev = NULL;\n\t\tmlist->next = NULL;\n\t\tmadd = mcur = mtail = mlist;\n\t} else {\n\t\tmadd = (Menuitem_t*) malloc(sizeof(Menuitem_t));\n\t\tmtail->next = madd;\n\t\tmadd->prev = mtail;\n\t\tmadd->next = NULL;\n\t\tmtail = madd;\n\t}\n\tmadd->type = FLOAT_T;\n\tuf2i.f = min; madd->min = uf2i.i;\n\tuf2i.f = max; madd->max = uf2i.i;\n\tuf2i.f = amt; madd->amt = uf2i.i;\n\tlvalue_cast<float *>(madd->pvalue) = pval;\n\tmadd->pformat = (char*) malloc(strlen(pformat)+1); \n\tmemcpy(madd->pformat, pformat, strlen(pformat)+1);\n\tprintf(\"[f**]menu->add = %d\\n\", strlen(pformat)+1);\n}\nvoid Menu::next() {\n\tif (mcur == NULL) return;\n\tif (mcur->next != NULL) {\n\t\t// point to next menu item\n\t\tmcur = mcur->next;\n\t} else {\n\t\t// wrap around to first menu item\n\t\tmcur = mlist;\n\t}\n}\n\nvoid Menu::prev() {\n\tif (mcur == NULL) return;\n\tif (mcur->prev != NULL) {\n\t\t// point to prev menu item\n\t\tmcur = mcur->prev;\n\t} else {\n\t\t// wrap around to last menu item\n\t\tmcur = mtail;\n\t}\n}\n\t\nvoid Menu::inc() {\n\tint tmp;\n\tfloat fmp;\n\n\tif (mcur == NULL) return;\n\tswitch(mcur->type) {\n\tcase INTEGER_T:\n\t\ttmp = *mcur->pvalue;\n\t\ttmp += mcur->amt;\n\t\tif (tmp > mcur->max)\n\t\t\treturn;\n\t\t(*mcur->pvalue) = tmp;\n\t\tbreak;\n\tcase FLOAT_T:\n\t\tfmp = (float)*(float *)mcur->pvalue;\n\t\tuf2i.i = mcur->amt; fmp += uf2i.f;\n\t\tuf2i.i = mcur->max;\n\t\tif (fmp > uf2i.f)\n\t\t\treturn;\n\t\t(*(float *)mcur->pvalue) = fmp;\n\t\tbreak;\n\t}\n}\n\nvoid Menu::dec() {\n\tint tmp;\n\tfloat fmp;\n\t\n\tif (mcur == NULL) return;\n\tswitch(mcur->type) {\n\tcase INTEGER_T:\n\t\ttmp = *mcur->pvalue;\n\t\ttmp -= mcur->amt;\n\t\tif (tmp < mcur->min)\n\t\t\treturn;\n\t\t(*mcur->pvalue) = tmp;\n\t\tbreak;\n\tcase FLOAT_T:\n\t\tfmp = (float)*(float *)mcur->pvalue;\n\t\tuf2i.i = mcur->amt; fmp -= uf2i.f;\n\t\tuf2i.i = mcur->min;\n\t\tif (fmp < uf2i.f)\n\t\t\treturn;\n\t\t(*(float *)mcur->pvalue) = fmp;\n\t\tbreak;\n\t}\n}\n\nvoid Menu::draw(int x, int y, int yinc) {\n\tMenuitem_t* pmi = mlist;\n\tint cy = y;\n\tchar buf[80];\n\t\n\twhile (pmi != NULL) {\n\t\tif(pmi->type == INTEGER_T)\n\t\t\tsprintf(buf, pmi->pformat, *pmi->pvalue);\n\t\telse\n\t\t\tsprintf(buf, pmi->pformat, (float)*(float*)pmi->pvalue);\n\t\tif (pmi == mcur) {\n\t\t plprint(x,cy, 1.0f, 1.0f, 0.0f, buf, 1);\n\t\t} else {\n\t\t plprint(x,cy, 0.8f, 0.8f, 0.8f, buf, 1);\n\t\t}\n\t\tcy += yinc;\n\t\tpmi = pmi->next;\n\t}\n}\n\nMenuitem_t* Menu::mlist = NULL;\nMenuitem_t* Menu::mtail = NULL;\nMenuitem_t* Menu::mcur = NULL;\nunion uf2i_t Menu::uf2i;\n"
},
{
"alpha_fraction": 0.6798349022865295,
"alphanum_fraction": 0.7040094137191772,
"avg_line_length": 26.338708877563477,
"blob_id": "ea6bb7928e6ed23c898f2d83a69de2b2ea76bd61",
"content_id": "ae48108dce9d85422b118130a117388ab89e26d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1696,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 62,
"path": "/include/arch/dreamcast/dc/sound/sound.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/sound/sound.h\n (c)2002 Dan Potter\n\n $Id: sound.h,v 1.2 2002/07/06 07:57:32 bardtx Exp $\n\n*/\n\n#ifndef __DC_SOUND_SOUND_H\n#define __DC_SOUND_SOUND_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Allocate a chunk of SPU RAM; we will return an offset into SPU RAM. */\nuint32 snd_mem_malloc(size_t size);\n\n/* Free a previously allocated chunk of memory */\nvoid snd_mem_free(uint32 addr);\n\n/* Return the number of bytes available in the largest free chunk */\nuint32 snd_mem_available();\n\n/* Reinitialize the pool with the given RAM base offset */\nint snd_mem_init(uint32 reserve);\n\n/* Shut down the SPU allocator */\nvoid snd_mem_shutdown();\n\n/* Initialize driver; note that this replaces the AICA program so that\n if you had anything else going on, it's gone now! */\nint snd_init();\n\n/* Shut everything down and free mem */\nvoid snd_shutdown();\n\n/* Queue up a request to the SH4->AICA queue; size is in uint32's */\nint snd_sh4_to_aica(void *packet, uint32 size);\n\n/* Start processing requests in the queue */\nvoid snd_sh4_to_aica_start();\n\n/* Stop processing requests in the queue */\nvoid snd_sh4_to_aica_stop();\n\n/* Transfer one packet of data from the AICA->SH4 queue. Expects to\n find AICA_CMD_MAX_SIZE dwords of space available. Returns -1\n if failure, 0 for no packets available, 1 otherwise. Failure\n might mean a permanent failure since the queue is probably out of sync. */\nint snd_aica_to_sh4(void *packetout);\n\n/* Poll for responses from the AICA. We assume here that we're not\n running in an interrupt handler (thread perhaps, of whoever\n is using us). */\nvoid snd_poll_resp();\n\n__END_DECLS\n\n#endif\t/* __DC_SOUND_SOUND_H */\n\n"
},
{
"alpha_fraction": 0.550061821937561,
"alphanum_fraction": 0.5862175822257996,
"avg_line_length": 28.26244354248047,
"blob_id": "45dfb8c58aba563ae3a2099cbcf7c1c2cb0969c2",
"content_id": "c0166283d17cf4eba59b3f1eb64f7ab4d8f2a40a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6472,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 221,
"path": "/kernel/arch/dreamcast/hardware/asic.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n asic.c\n Copyright (c)2000,2001,2002,2003 Dan Potter\n*/\n\n/* \n This module contains low-level ASIC handling. Right now this is just for\n ASIC interrupts, but it will eventually include DMA as well.\n\n The DC's System ASIC is integrated with the 3D chip and serves as the\n Grand Central Station for the interaction of all the various peripherals\n (which really means that it allows the SH-4 to control all of them =).\n The basic block diagram looks like this:\n\n +-----------+ +--------+ +-----------------+\n | 16MB Ram | | |----| 8MB Texture Ram |\n +-----------+ | System | +-----------------+\n | | ASIC | +--------------------+ +-------------+\n +-------------+ +-+--+ AICA SPU |--+ 2MB SPU RAM |\n |A | PVR2DC | | +-------------------++ +-------------+\n +-------+ | | |C +-----------------+ |\n | SH-4 | | | \\--+ Expansion Port | |\n +-------+ +---+----+ +-----------------+ |\n |B +------------+ |D\n +---------+ GD-Rom +------/\n | +------------+\n | +----------------------+\n \\---------+ 2MB ROM + 256K Flash |\n +----------------------+\n\n A: Main system bus -- connects the SH-4 to the ASIC and its main RAM\n B: \"G1\" bus -- connects the ASIC to the GD-Rom and the ROM/Flash\n C: \"G2\" bus -- connects the ASIC to the SPU and Expansion port\n D: Not entirely verified connection for streaming audio data\n\n All buses can simultaneously transmit data via PIO and/or DMA. This\n is where the ridiculous bandwidth figures come from that you see in\n marketing literature. In reality, each bus isn't terribly fast on\n its own -- they tend to have high bandwidth but high latency.\n\n The \"G2\" bus is notoriously flaky. Specifically, one should ensure\n to write the proper data size for the peripheral you are accessing\n (32-bits for SPU, 8-bits for 8-bit peripherals, etc). Every 8\n 32-bit words written to the SPU must be followed by a g2_fifo_wait().\n Additionally, if SPU or Expansion Port DMA is being used, only one\n of these may proceed at once and any PIO access _must_ pause the\n DMA and disable interrupts. Any other treatment may cause serious\n data corruption between the ASIC and the G2 peripherals.\n\n For more information on all of this see:\n\n http://www.segatech.com/technical/dcblock/index.html\n http://mc.pp.se/dc/\n\n */\n\n/* Small interrupt listing (from the two Marcus's =)\n\n 691x -> irq 13\n 692x -> irq 11\n 693x -> irq 9\n\n 69x0\n bit 2\trender complete\n 3\tscanline 1\n 4\tscanline 2\n 5\tvsync\n 7\topaque polys accepted\n 8\topaque modifiers accepted\n 9\ttranslucent polys accepted\n 10\ttranslucent modifiers accepted\n 12\tmaple dma complete\n 13\tmaple error(?)\n 14\tgd-rom dma complete\n 15\taica dma complete\n 16\texternal dma 1 complete\n 17\texternal dma 2 complete\n 18\t??? dma complete\n 21\tpunch-thru polys accepted\n\n 69x4\n bit 0\tgd-rom command status\n 1\tAICA\n 2 modem?\n 3 expansion port (PCI bridge)\n\n 69x8\n bit 2\tout of primitive memory\n bit 3\tout of matrix memory\n\n */\n\n#include <string.h>\n#include <stdio.h>\n#include <arch/irq.h>\n#include <dc/asic.h>\n#include <arch/spinlock.h>\n\nCVSID(\"$Id: asic.c,v 1.3 2003/02/25 07:39:36 bardtx Exp $\");\n\n/* Exception table -- this table matches each potential G2 event to a function\n pointer. If the pointer is null, then nothing happens. Otherwise, the\n function will handle the exception. */\nstatic asic_evt_handler asic_evt_handlers[0x4][0x20];\n\n/* Set a handler, or remove a handler */\nint asic_evt_set_handler(uint32 code, asic_evt_handler hnd) {\n\tuint32 evtreg, evt;\n\t\n\tevtreg = (code >> 8) & 0xff;\n\tevt = code & 0xff;\n\t\n\tif (evtreg > 0x4)\n\t\treturn -1;\n\tif (evt > 0x20)\n\t\treturn -1;\n\n\tasic_evt_handlers[evtreg][evt] = hnd;\n\t\n\treturn 0;\n}\n\n/* The ASIC event handler; this is called from the global IRQ handler\n to handle external IRQ 9. */\nstatic void handler_irq9(irq_t source, irq_context_t *context) {\n\tint\treg, i;\n\tvuint32\t*asicack = (vuint32*)0xa05f6900;\n\tuint32\tmask;\n\n\t/* Go through each event register and look for pending events */\n\tfor (reg=0; reg<3; reg++) {\n\t\t/* Read the event mask and clear pending */\n\t\tmask = asicack[reg]; asicack[reg] = mask;\n\t\t\n\t\t/* Search for relevant handlers */\n\t\tfor (i=0; i<32; i++) {\n\t\t\tif (mask & (1 << i)) {\n\t\t\t\tif (asic_evt_handlers[reg][i] != NULL) {\n\t\t\t\t\tasic_evt_handlers[reg][i]( (reg << 8) | i );\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n}\n\n\n/* Disable all G2 events */\nvoid asic_evt_disable_all() {\n\tvuint32 * asicen;\n\tint irq, sub;\n\n\tfor (irq=0; irq<3; irq++) {\n\t\tasicen = (vuint32*)(0xa05f6910 + irq*0x10);\n\t\tfor (sub=0; sub<3; sub++) {\n\t\t\tasicen[sub] = 0;\n\t\t}\n\t}\n}\n\n/* Disable a particular G2 event */\nvoid asic_evt_disable(uint32 code, int irqlevel) {\n\tvuint32 *asicen;\n\n\t/* Did the user choose an IRQ level? If not, give them 9 by default */\n\tif (irqlevel == ASIC_IRQ_DEFAULT)\n\t\tirqlevel = ASIC_IRQ9;\n\t\n\tasicen = (vuint32*)(0xa05f6900 + irqlevel*0x10);\n\tasicen[((code >> 8) & 0xff)] &= ~(1 << (code & 0xff));\n}\n\n/* Enable a particular G2 event */\nvoid asic_evt_enable(uint32 code, int irqlevel) {\n\tvuint32 *asicen;\n\n\t/* Did the user choose an IRQ level? If not, give them 9 by default */\n\tif (irqlevel == ASIC_IRQ_DEFAULT)\n\t\tirqlevel = ASIC_IRQ9;\n\t\n\tasicen = (vuint32*)(0xa05f6900 + irqlevel*0x10);\n\tasicen[((code >> 8) & 0xff)] |= (1 << (code & 0xff));\n}\n\n/* Initialize events */\nvoid asic_evt_init() {\n\t/* Clear any pending interrupts and disable all events */\n\tasic_evt_disable_all();\n\tASIC_ACK_A = 0xffffffff;\n\tASIC_ACK_B = 0xffffffff;\n\tASIC_ACK_C = 0xffffffff;\n\t\n\t/* Clear out the event table */\n\tmemset(asic_evt_handlers, 0, sizeof(asic_evt_handlers));\n\t\n\t/* Hook IRQ9,B,D */\n\tirq_set_handler(EXC_IRQ9, handler_irq9);\n\tirq_set_handler(EXC_IRQB, handler_irq9);\n\tirq_set_handler(EXC_IRQD, handler_irq9);\n}\n\n/* Shutdown events */\nvoid asic_evt_shutdown() {\n\t/* Disable all events */\n\tasic_evt_disable_all();\n\t\n\t/* Unhook handlers */\n\tirq_set_handler(EXC_IRQ9, NULL);\n\tirq_set_handler(EXC_IRQB, NULL);\n\tirq_set_handler(EXC_IRQD, NULL);\n}\n\n/* Init routine */\nvoid asic_init() {\n\tasic_evt_init();\n}\n\n\nvoid asic_shutdown() {\n\tasic_evt_shutdown();\n}\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6420931816101074,
"alphanum_fraction": 0.6940412521362305,
"avg_line_length": 20.45081901550293,
"blob_id": "f895f9305756e755ba8b19e7ab565d01e0f70bf3",
"content_id": "b5c3dc63e62bc4c316f4e9d173dcdd212f4d7b6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2618,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 122,
"path": "/include/arch/dreamcast/dc/cdrom.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/cdrom.h\n (c)2000-2001 Dan Potter\n\n $Id: cdrom.h,v 1.4 2002/09/13 05:11:43 bardtx Exp $\n\n*/\n\n#ifndef __DC_CDROM_H\n#define __DC_CDROM_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Command codes (thanks maiwe) */\n#define CMD_PIOREAD\t16\n#define CMD_DMAREAD\t17\n#define CMD_GETTOC\t18\n#define CMD_GETTOC2\t19\n#define CMD_PLAY\t20\n#define CMD_PLAY2\t21\n#define CMD_PAUSE\t22\n#define CMD_RELEASE\t23\n#define CMD_INIT\t24\n#define CMD_SEEK\t27\n#define CMD_READ\t28\n#define CMD_STOP\t33\n#define CMD_GETSCD\t34\n#define CMD_GETSES\t35\n\n/* Command responses */\n#define ERR_OK\t\t0\n#define ERR_NO_DISC\t1\n#define ERR_DISC_CHG\t2\n#define ERR_SYS\t\t3\n#define ERR_ABORTED\t4\n#define ERR_NO_ACTIVE\t5\n\n/* Command Status responses */\n#define FAILED\t\t-1\n#define NO_ACTIVE\t0\n#define PROCESSING\t1\n#define COMPLETED\t2\n#define ABORTED\t\t3\n\n/* CDDA Read Modes */\n#define CDDA_TRACKS\t1\n#define CDDA_SECTORS\t2\n\n/* Status values */\n#define CD_STATUS_BUSY\t\t0\n#define CD_STATUS_PAUSED\t1\n#define CD_STATUS_STANDBY\t2\n#define CD_STATUS_PLAYING\t3\n#define CD_STATUS_SEEKING\t4\n#define CD_STATUS_SCANNING\t5\n#define CD_STATUS_OPEN\t\t6\n#define CD_STATUS_NO_DISC\t7\n\n/* Disk types */\n#define CD_CDDA\t\t0\n#define CD_CDROM\t0x10\n#define CD_CDROM_XA\t0x20\n#define CD_CDI\t\t0x30\n#define CD_GDROM\t0x80\n\n/* TOC structure returned by the BIOS */\ntypedef struct {\n\tuint32\tentry[99];\n\tuint32\tfirst, last;\n\tuint32\tleadout_sector;\n} CDROM_TOC;\n\n/* TOC access macros */\n#define TOC_LBA(n) ((n) & 0x00ffffff)\n#define TOC_ADR(n) ( ((n) & 0x0f000000) >> 24 )\n#define TOC_CTRL(n) ( ((n) & 0xf0000000) >> 28 )\n#define TOC_TRACK(n) ( ((n) & 0x00ff0000) >> 16 )\n\n/* Sets the sector size */\nvoid set_sector_size (int size);\n\n/* Command execution sequence */\nint cdrom_exec_cmd(int cmd, void *param);\n\n/* Return the status of the drive as two integers (see constants) */\nint cdrom_get_status(int *status, int *disc_type);\n\n/* Re-init the drive, e.g., after a disc change, etc */\nint cdrom_reinit();\n\n/* Read the table of contents */\nint cdrom_read_toc(CDROM_TOC *toc_buffer, int session);\n\n/* Read one or more sectors */\nint cdrom_read_sectors(void *buffer, int sector, int cnt);\n\n/* Locate the LBA sector of the data track */\nuint32 cdrom_locate_data_track(CDROM_TOC *toc);\n\n/* Play CDDA audio tracks or sectors */\nint cdrom_cdda_play(uint32 start, uint32 end, uint32 loops, int mode);\n\n/* Pause CDDA audio playback */\nint cdrom_cdda_pause();\n\n/* Resume CDDA audio playback */\nint cdrom_cdda_resume();\n\n/* Spin down the CD */\nint cdrom_spin_down();\n\n/* Initialize */\nint cdrom_init();\nvoid cdrom_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_CDROM_H */\n\n"
},
{
"alpha_fraction": 0.6452096104621887,
"alphanum_fraction": 0.68113774061203,
"avg_line_length": 17.55555534362793,
"blob_id": "6f5a963105a5455a889954b40c27fd903841da5d",
"content_id": "e1c1e7086d6b646ef148a34f47da89bca65a272c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 36,
"path": "/include/arpa/inet.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arpa/inet.h\n Copyright (C) 2006, 2007 Lawrence Sebald\n\n*/\n\n#ifndef __ARPA_INET_H\n#define __ARPA_INET_H\n\n#include <sys/cdefs.h>\n\n__BEGIN_DECLS\n\n#include <sys/types.h>\n#include <netinet/in.h>\n#include <sys/socket.h>\n\nuint32 htonl(uint32 value);\nuint32 ntohl(uint32 value);\n\nuint16 htons(uint16 value);\nuint16 ntohs(uint16 value);\n\nin_addr_t inet_addr(const char *cp);\nint inet_aton(const char *cp, struct in_addr *pin);\n\nint inet_pton(int af, const char *src, void *dst);\nconst char *inet_ntop(int af, const void *src, char *dst, socklen_t size);\n\n/* Non-reentrant */\nchar *inet_ntoa(struct in_addr addr);\n\n__END_DECLS\n\n#endif /* __ARPA_INET_H */\n"
},
{
"alpha_fraction": 0.5642828941345215,
"alphanum_fraction": 0.729581892490387,
"avg_line_length": 25.93684196472168,
"blob_id": "ac1c9ff8f7c6b9decc97238fa0d0380e169f2ccf",
"content_id": "8f606aaaffdd5913b94ff20030b2ed0133895e2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2559,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 95,
"path": "/include/arch/gba/gba/video.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gba/video.h\n (c)2001 Dan Potter\n \n $Id: video.h,v 1.2 2002/12/12 21:48:14 gilm Exp $\n*/\n\n/* Thanks to Dovoto's tutorial for these numbers */\n\n#ifndef __GBA_VIDEO_H\n#define __GBA_VIDEO_H\n\n#include <arch/types.h>\n\n/* Display mode register */\n#define REG_DISPCNT\t(*(vu16*)0x04000000)\n\n/* Display status register (vsync) */\n#define REG_DISPSTAT\t(*(vu16*)0x04000004)\n\n/* Scanline counter */\n#define REG_VCOUNT\t(*(vu16*)0x04000006)\n\n/* Background controls */\n#define REG_BG0CNT\t(*(vu16*)0x04000008)\n#define REG_BG1CNT\t(*(vu16*)0x0400000a)\n#define REG_BG2CNT\t(*(vu16*)0x0400000c)\n#define REG_BG3CNT\t(*(vu16*)0x0400000e)\n\n/* Background offsets */\n#define REG_BG0HOFS\t(*(vu16*)0x04000010)\n#define REG_BG0VOFS\t(*(vu16*)0x04000012)\n#define REG_BG1HOFS\t(*(vu16*)0x04000014)\n#define REG_BG1VOFS\t(*(vu16*)0x04000016)\n#define REG_BG2HOFS\t(*(vu16*)0x04000018)\n#define REG_BG2VOFS\t(*(vu16*)0x0400001a)\n#define REG_BG3HOFS\t(*(vu16*)0x0400001c)\n#define REG_BG3VOFS\t(*(vu16*)0x0400001e)\n\n/* The two display buffers */\n#define PTR_VID_0\t((vu16*)0x06000000)\n#define PTR_VID_1\t((vu16*)0x0600A000)\t/* Valid only in Mode 4 */\n\n/* Background palete memory (in indexed mode) */\n#define PTR_BG_PAL\t((vu16*)0x05000000)\n\n/* Basic display mode (\"background type\") */\n#define DISP_MODE_0\t\t0x0000\n#define DISP_MODE_1\t\t0x0001\n#define DISP_MODE_2\t\t0x0002\n#define DISP_MODE_3\t\t0x0003\n#define DISP_MODE_4\t\t0x0004\n#define DISP_MODE_5\t\t0x0005\n\n/* Misc options */\n#define DISP_BUFFER_0\t\t0x0000\n#define DISP_BUFFER_1\t\t0x0010\n#define DISP_HBLANK_OAM\t\t0x0020\n#define DISP_OBJ_2D\t\t0x0000\n#define DISP_OBJ_1D\t\t0x0040\n#define DISP_FORCE_BLANK\t0x0080\n\n/* Tile layer enable/disable */\n#define DISP_BG0_DISABLE\t0x0000\n#define DISP_BG0_ENABLE\t\t0x0100\n#define DISP_BG1_DISABLE\t0x0000\n#define DISP_BG1_ENABLE\t\t0x0200\n#define DISP_BG2_DISABLE\t0x0000\n#define DISP_BG2_ENABLE\t\t0x0400\n#define DISP_BG3_DISABLE\t0x0000\n#define DISP_BG3_ENABLE\t\t0x0800\n\n/* Sprite enable/disable */\n#define DISP_OBJ_ENABLE\t\t0x1000\n#define DISP_OBJ_DISABLE\t0x0000\n#define DISP_WIN1_ENABLE\t0x2000\n#define DISP_WIN1_DISABLE\t0x0000\n#define DISP_WIN2_ENABLE\t0x4000\n#define DISP_WIN2_DISABLE\t0x0000\n#define DISP_WINOBJ_ENABLE\t0x8000\n#define DISP_WINOBJ_DISABLE\t0x0000\n\n/* Display status flags (DISPSTAT) */\n#define DISP_VBLANK\t\t0x0001\n#define DISP_HBLANK\t\t0x0002\n#define DISP_VCOUNTER\t\t0x0004\n#define DISP_VBLANK_IRQ\t\t0x0008\n#define DISP_HBLANK_IRQ\t\t0x0010\n#define DISP_VCOUNTER_IRQ\t0x0020\n\n/* Shifts required before OR'ing value with DISPSTAT */\n#define DISP_VCOUNTER_SHIFT\t0x0008\n\n#endif\t/* __GBA_VIDEO_H */\n"
},
{
"alpha_fraction": 0.6216216087341309,
"alphanum_fraction": 0.6652806401252747,
"avg_line_length": 16.77777862548828,
"blob_id": "bd9ad55a435721ff7ef6bd0a2d6eeb013cc6cf34",
"content_id": "0f2439419163f454c50179a0d3fa5562d4d727b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 27,
"path": "/include/arch/ps2/arch/atexit.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/arch/atexit.h\n (c)2002 Florian Schulze\n \n $Id: atexit.h,v 1.1 2002/10/26 08:04:00 bardtx Exp $\n*/\n\n#ifndef __ARCH_ATEXIT_H\n#define __ARCH_ATEXIT_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\nstruct arch_atexit_handler {\n\tstruct arch_atexit_handler *next;\n\tvoid (*handler)(void);\n};\n\nextern struct arch_atexit_handler *arch_atexit_handlers;\n\n/* Call all the atexit() handlers */\nvoid arch_atexit();\n\n__END_DECLS\n\n#endif\t/* __ARCH_ATEXIT_H */\n\n"
},
{
"alpha_fraction": 0.6445497870445251,
"alphanum_fraction": 0.6856240034103394,
"avg_line_length": 21.60714340209961,
"blob_id": "06922e4ae644ff462dbd5ff38949e836047fa73e",
"content_id": "810f06c3732a2f719281f53d32fe96569365e0c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 28,
"path": "/kernel/arch/ia32/kernel/exec.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n exec.c\n Copyright (C)2003 Dan Potter\n*/\n\n#include <arch/arch.h>\n#include <arch/exec.h>\n#include <arch/irq.h>\n#include <arch/cache.h>\n#include <assert.h>\n#include <string.h>\n#include <stdio.h>\n\nCVSID(\"$Id: exec.c,v 1.1 2003/08/01 03:18:37 bardtx Exp $\");\n\n/* Pull the shutdown function in from main.c */\nvoid arch_shutdown();\n\n/* Replace the currently running image with whatever is at\n the pointer; note that this call will never return. */\nvoid arch_exec_at(const void *image, uint32 length, uint32 address) {\n\tpanic(\"ENOSYS\");\n}\n\nvoid arch_exec(const void *image, uint32 length) {\n\tpanic(\"ENOSYS\");\n}\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.629539966583252,
"avg_line_length": 17.727272033691406,
"blob_id": "04226017e687b580a0784c73250b6968dcf2fc5f",
"content_id": "3699a255dbd0a250a7551905416e778363e224e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 22,
"path": "/kernel/libc/koslib/memset4.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n memset4.c\n (c)2000 Dan Potter\n\n $Id: memset4.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n#include <string.h>\n\n/* This variant was added by Dan Potter for its usefulness in \n working with Dreamcast external hardware. */\nvoid * memset4(void *s, unsigned long c, size_t count)\n{\n\tunsigned long *xs = (unsigned long *) s;\n\tcount = count / 4;\n\n\twhile (count--)\n\t\t*xs++ = c;\n\n\treturn s;\n}\n\n"
},
{
"alpha_fraction": 0.6392694115638733,
"alphanum_fraction": 0.6575342416763306,
"avg_line_length": 15.84615421295166,
"blob_id": "5d0f243dd846f1fb1237db448d2e75a3d43eb55b",
"content_id": "c274e8f77847067bac231e26914c9866ea60eb56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/kernel/libc/koslib/rewinddir.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n rewinddir.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <kos/dbglog.h>\n\n// This isn't properly prototyped... sosume :)\nvoid rewinddir() {\n\tdbglog(DBG_WARNING, \"rewinddir: call ignored\\n\");\n}\n"
},
{
"alpha_fraction": 0.5958395004272461,
"alphanum_fraction": 0.6359583735466003,
"avg_line_length": 17.63888931274414,
"blob_id": "fd4840045bf9138f11e94254b9d6e729eb9759e4",
"content_id": "9ad2f1b688a1a180c2e4646bf5a8bd93d27e2142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 36,
"path": "/include/kos/fs_builtin.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs_builtin.h\n (c)2000-2001 Dan Potter\n\n $Id: fs_builtin.h,v 1.3 2002/08/12 18:43:53 bardtx Exp $\n*/\n\n#ifndef __KOS_FS_BUILTIN_H\n#define __KOS_FS_BUILTIN_H\n\n/* Definitions for the \"built-in\" file system */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/limits.h>\n#include <kos/fs.h>\n\ntypedef struct {\n\tchar\tname[MAX_FN_LEN];\t/* File's full path name */\n\tuint8\t*data;\t\t\t/* Data for the file */\n\tuint32\tsize;\t\t\t/* Data size */\n} fs_builtin_ent;\n\n\n/* Set a table */\nint fs_builtin_set_table(fs_builtin_ent *tbl, int cnt);\n\n/* Init func */\nint fs_builtin_init();\nint fs_builtin_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_BUILTIN_H */\n\n\n"
},
{
"alpha_fraction": 0.6671732664108276,
"alphanum_fraction": 0.697568416595459,
"avg_line_length": 27.521739959716797,
"blob_id": "a8b80f04e5493ea457eaf514331af9f91fc92c21",
"content_id": "a60b7268129d90a8802e1b2d239f6ac434b10e6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 658,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 23,
"path": "/kernel/arch/gba/kernel/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/gba/kernel/Makefile\n# (c)2000 Dan Potter\n# \n# $Id: Makefile,v 1.3 2003/01/10 13:03:40 gilm Exp $\n\n# Generic kernel abstraction layer: this provides a set of routines\n# that the portable part of the kernel expects to find on every\n# target processor. Other routines may be present as well, but\n# that minimum set must be present.\n\nCOPYOBJS = dbgio.o main.o mm.o panic.o\nCOPYOBJS += syscalls.o timer.o irq.o\nCOPYOBJS += init_romdisk_default.o init_flags_default.o\nCOPYOBJS += lazy_porting.o\nOBJS = $(COPYOBJS) startup.o\nSUBDIRS = \n\nmyall: $(OBJS)\n\tcp $(COPYOBJS) ../../../../kernel/build/\n\ninclude ../../../../Makefile.prefab\n\n\n"
},
{
"alpha_fraction": 0.5284132957458496,
"alphanum_fraction": 0.6263222694396973,
"avg_line_length": 25.38311767578125,
"blob_id": "8e18731c94988c8cd0242655be12fb4ef21d9e70",
"content_id": "4bc8a71ad13413d33e9f9686923998baa3640f0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4065,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 154,
"path": "/examples/dreamcast/kgl/nehe/nehe06/nehe06.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe06.c\n (c)2001 Benoit Miller\n\n Parts (c)2000 Jeff Molofee\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/* Simple KGL example to demonstrate texturing. \n\n Essentially the same thing as NeHe's lesson06 code.\n To learn more, go to http://nehe.gamedev.net/.\n*/\n\nGLfloat xrot;\t/* X Rotation */\nGLfloat yrot;\t/* Y Rotation */\nGLfloat zrot;\t/* Z Rotation */\n\nGLuint texture[1];\t/* Storage For One Texture */\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid draw_gl(void) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\tglLoadIdentity();\n\tglTranslatef(0.0f,0.0f,-5.0f);\n\n\tglRotatef(xrot,1.0f,0.0f,0.0f);\n\tglRotatef(yrot,0.0f,1.0f,0.0f);\n\tglRotatef(zrot,0.0f,0.0f,1.0f);\n\n\tglBindTexture(GL_TEXTURE_2D, texture[0]);\n\n\tglBegin(GL_QUADS);\n\t\t/* Front Face */\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t/* Back Face */\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\t/* Top Face */\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\t/* Bottom Face */\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\t/* Right face */\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\t/* Left Face */\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\tglEnd();\n\n\txrot+=0.3f;\n\tyrot+=0.2f;\n\tzrot+=0.4f;\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\n\t/* Initialize KOS */\n\tpvr_init(¶ms);\n\n\tprintf(\"nehe06 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,640.0f/480.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.0f, 0.0f, 0.0f, 0.5f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LEQUAL);\n\n\t/* Set up the texture */\n\tloadtxr(\"/rd/NeHe.pcx\", &texture[0]);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw the GL \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5900900959968567,
"avg_line_length": 13.800000190734863,
"blob_id": "51a6b778087293cef138d26d2367f45da6a36d39",
"content_id": "b9d8ab6193f5a7e5e15c687acf16be477456d139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/libc/include/wchar.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n wchar.h\n (c)2001 Dan Potter\n\n $Id: wchar.h,v 1.1 2002/02/09 06:15:42 bardtx Exp $\n*/\n\n#ifndef __WCHAR_H\n#define __WCHAR_H\n\n#define __need_wchar_t\n#include <stddef.h>\n\n#endif /* __WCHAR_H */\n"
},
{
"alpha_fraction": 0.6617915630340576,
"alphanum_fraction": 0.6892138719558716,
"avg_line_length": 19.961538314819336,
"blob_id": "8a75280a1131a493fc9c0ce7c7a59684717a0651",
"content_id": "b5bcbe933e898ed0be102bb48ea50d4f304858e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 26,
"path": "/examples/dreamcast/network/basic/basic.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n network.c\n (c)2002 Dan Potter\n*/\n\n#include <kos.h>\n\n/*\n\nThis is a simple network test example. All it does is bring up the\nnetworking system and wait for a bit to let you have a chance to\nping it, etc. Note that this program is totally portable as long\nas your KOS platform has networking capabilities, but I'm leaving\nit in \"dreamcast\" for now.\n \n*/\n\nKOS_INIT_FLAGS(INIT_DEFAULT | INIT_NET);\n\nint main(int argc, char **argv) {\n\t/* Wait for a bit so the user can ping, etc */\n\tusleep(10 * 1000 * 1000);\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5773584842681885,
"alphanum_fraction": 0.6188679337501526,
"avg_line_length": 10.52173900604248,
"blob_id": "5b19d5e07b1f209b13076d4b25dbae676e9f0224",
"content_id": "cb3e1cd03a0667c08f08fcfa48a13a1358d1717a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 23,
"path": "/libm/common/sf_nan.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n * nanf () returns a nan.\n * Added by Cygnus Support.\n */\n\n#include \"fdlibm.h\"\n\n\tfloat nanf()\n{\n\tfloat x;\n\n\tSET_FLOAT_WORD(x,0x7fc00000);\n\treturn x;\n}\n\n#ifdef _DOUBLE_IS_32BITS\n\n\tdouble nan()\n{\n\treturn (double) nanf();\n}\n\n#endif /* defined(_DOUBLE_IS_32BITS) */\n"
},
{
"alpha_fraction": 0.6239120364189148,
"alphanum_fraction": 0.6558253169059753,
"avg_line_length": 24.8853759765625,
"blob_id": "cdbff3ae2256263b78b1516304cf2d1317f6f05c",
"content_id": "04eee460fca2c48aead0e43ab0233d87bfe5cdf1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6549,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 253,
"path": "/kernel/arch/ps2/kernel/irq.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/kernel/irq.c\n (c)2002 Dan Potter\n*/\n\n/* This module contains low-level handling for IRQs and related exceptions. */\n\n#include <string.h>\n#include <stdio.h>\n#include <assert.h>\n#include <arch/irq.h>\n#include <arch/cache.h>\n#include <ps2/ioports.h>\n#include <arch/dbgio.h>\n#include <arch/arch.h>\n\n/* Exception table */\nstatic irq_handler irq_handlers[0x100];\n\n/* INTC table */\nstatic irq_handler intc_handlers[0x10];\n\n/* Global exception handler -- hook this if you want to get each and every\n exception; you might get more than you bargained for, but it can be useful. */\nstatic irq_handler irq_hnd_global;\n\n/* Default IRQ context location (until threading is up) */\nstatic irq_context_t irq_context_default;\n\n/* Are we inside an interrupt? */\nstatic int inside_int;\nint irq_inside_int() {\n\treturn inside_int;\n}\n\n/* Set a handler, or remove a handler */\nint irq_set_handler(irq_t code, irq_handler hnd) {\n\tif ((code & 0xff) == EXC_INTR_0) {\n\t\tintc_handlers[(code >> 8) & 0xff] = hnd;\n\t} else {\n\t\tirq_handlers[code & 0xff] = hnd;\n\t}\n\treturn 0;\n}\n\n/* Get the address of the current handler */\nirq_handler irq_get_handler(irq_t code) {\n\tif ((code & 0xff) == EXC_INTR_0) {\n\t\treturn intc_handlers[(code >> 8) & 0xff];\n\t} else {\n\t\treturn irq_handlers[code & 0xff];\n\t}\n}\n\n/* Set a global handler */\nint irq_set_global_handler(irq_handler hnd) {\n\tirq_hnd_global = hnd;\n\treturn 0;\n}\n\n/* Get the global exception handler */\nirq_handler irq_get_global_handler() {\n\treturn irq_hnd_global;\n}\n\n/* Print a kernel panic reg dump */\nextern irq_context_t *irq_srt_addr;\nvoid irq_dump_regs(int code, int evt) {\n\tdbglog(DBG_DEAD, \"Unhandled exception\\n\");\n}\n\n/* IRQ save-regs table (in entry.S) */\nextern irq_context_t *irq_srt_addr;\n\n/* The C-level routine that processes context switching and other\n types of interrupts. Note: we are running on the stack of the\n process that was interrupted! */\nvolatile uint32 jiffies = 0;\nvoid irq_handle_exception() {\n\tint\ti, vtype, exccode, idx;\n\tuint32\tis;\n\n\tinside_int = 1;\n\n\t/* Dig the vector type out of k1 */\n\tvtype = (CONTEXT_128_TO_32(irq_srt_addr->r[27]) << 4) & 0xf0;\n\n\t/* Get ExcCode */\n\texccode = (irq_srt_addr->cause >> 2) & 0x0f;\n\n\t/* Put those two together to get the exception index */\n\tidx = vtype | exccode;\n\n\t/* If it was a syscall, then increase PC before returning */\n\tif (idx == EXC_SYSCALL)\n\t\tCONTEXT_128_TO_32(irq_srt_addr->pc) += 4;\n\n\tif (vtype == 0x40) {\n\t\t/* Interrupt -- call the handlers for any active bits and ack all */\n\t\tis = INTC_STAT;\n\t\tfor (i=0; i<15; i++) {\n\t\t\tif (is & (1<<i)) {\n\t\t\t\tif (intc_handlers[i])\n\t\t\t\t\tintc_handlers[i](idx, irq_srt_addr);\n\t\t\t\tswitch (i) {\n\t\t\t\tcase 9:\t\t/* TIMER0 */\n\t\t\t\t\ttimer_clear(0); break;\n\t\t\t\tcase 10:\t/* TIMER1 */\n\t\t\t\t\ttimer_clear(1); break;\n\t\t\t\tcase 11:\t/* TIMER2 */\n\t\t\t\t\ttimer_clear(2); break;\n\t\t\t\tcase 12:\t/* TIMER3 */\n\t\t\t\t\ttimer_clear(3); jiffies++; break;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tINTC_STAT = is;\n\t} else if (irq_handlers[idx]) {\n\t\tirq_handlers[idx](idx, irq_srt_addr);\n\t} else {\n\t\t/* Some other type of interrupt which we can't handle... die the\n\t\t hard way */\n\t\tdbgio_printf(\"Unhandled exception type %04x\\n\", idx);\n\t\tarch_exit();\n\t}\n\n\tinside_int = 0;\n}\n\n/* Switches register banks; call this outside of exception handling\n (but make sure interrupts are off!!) to change where registers will\n go to, or call it inside an exception handler to switch contexts. \n Make sure you have at least REG_BYTE_CNT bytes available. DO NOT\n ALLOW ANY INTERRUPTS TO HAPPEN UNTIL THIS HAS BEEN CALLED AT \n LEAST ONCE! */\nvoid irq_set_context(irq_context_t *regbank) {\n\tirq_srt_addr = regbank;\n}\n\n/* Return the current IRQ context */\nirq_context_t *irq_get_context() {\n\treturn irq_srt_addr;\n}\n\n/* Fill a newly allocated context block for usage with supervisor/kernel\n or user mode. The given parameters will be passed to the called routine (up\n to the architecture maximum). */\nvoid irq_create_context(irq_context_t *context, ptr_t stkpntr,\n\tptr_t routine, uint64 *args, int usermode)\n{\n\tint i;\n\n\t/* We don't support user mode at this point */\n\tassert( usermode == 0 );\n\n\t/* Clear out the context */\n\tmemset(context, 0, sizeof(irq_context_t));\n\n\t/* Copy all of these regs from the current context (we should probably\n\t do something a bit more intelligent here, but this ought to do for now) */\n\tcontext->status = irq_srt_addr->status;\n\tcontext->cause = irq_srt_addr->cause;\n\tcontext->config = irq_srt_addr->config;\n\tcontext->badvaddr = irq_srt_addr->badvaddr;\n\tcontext->badpaddr = irq_srt_addr->badpaddr;\n\tcontext->fcr31 = irq_srt_addr->fcr31;\n\n\t/* Initialize the PC and stack */\n\tCONTEXT_PC(*context) = routine;\n\tCONTEXT_SP(*context) = stkpntr;\n\n\t/* Copy up to 4 args */\n\tfor (i=0; i<4; i++) {\n\t\tCONTEXT_128_TO_32(context->r[4+i]) = args[i];\n\t}\n}\n\n/* Are we initted? */\nstatic int initted = 0;\n\n/* Refs to our exception vector templates */\nextern void _ps2ev_tlb_refill(), _ps2ev_counter(), _ps2ev_debug(), _ps2ev_common(),\n\t_ps2ev_interrupt();\n\n/* A default syscall implementation for testing */\n#if 0\nstatic void irq_sc_def(irq_t src, irq_context_t * cxt) {\n\t/* Syscall -- Toggle the internal LED for the amusement of the user */\n\tint i, j, k, type;\n\ttype = (src >> 4) & 0x0f;\n\tfor (i=0; i<5; i++) {\n\t\tfor (j=0; j<type+1; j++) {\n\t\t\tPIO_DIR = PIO_DIR_OUT;\n\t\t\tPIO_DATA = PIO_DATA_LED_ON;\n\t\t\tfor (k=0; k<2500000; k++)\n\t\t\t\t;\n\t\t\tPIO_DIR = PIO_DIR_OUT;\n\t\t\tPIO_DATA = PIO_DATA_LED_OFF;\n\t\t\tfor (k=0; k<2500000; k++)\n\t\t\t\t;\n\t\t}\n\t\tfor (k=0; k<10000000; k++)\n\t\t\t;\n\t}\n\tif (src == EXC_SYSCALL)\n\t\tcxt->pc += 4;\n}\n#endif\n\n/* Init */\nint irq_init() {\n\tif (initted)\n\t\treturn 0;\n\n\t/* Default to not in an interrupt */\n\tinside_int = 1;\n\n\t/* Setup a default SRT location */\n\tirq_set_context(&irq_context_default);\n\n\t/* Start out with no handlers */\n\tmemset(irq_handlers, 0, sizeof(irq_handlers));\n\tmemset(intc_handlers, 0, sizeof(intc_handlers));\n\n\t/* Load new IRQ handlers */\n\tmemcpy((void *)0x80000000, &_ps2ev_tlb_refill, 0x80);\n\tmemcpy((void *)0x80000080, &_ps2ev_counter, 0x80);\n\tmemcpy((void *)0x80000100, &_ps2ev_debug, 0x80);\n\tmemcpy((void *)0x80000180, &_ps2ev_common, 0x80);\n\tmemcpy((void *)0x80000200, &_ps2ev_interrupt, 0x80);\n\tcache_flush_all();\n\n\t/* Start out with no INTC interrupts enabled */\n\tINTC_MASK = INTC_MASK;\n\tINTC_STAT = 0x7fff;\n\n\t/* Set a default syscall */\n\t// irq_set_handler(EXC_SYSCALL, irq_sc_def);\n\n\tinitted = 1;\n\n\treturn 0;\n}\n\n/* Shutdown */\nvoid irq_shutdown() {\n\t/* No need to reset our IRQ handlers, startup.S will do it. */\n\tinitted = 0;\n\tirq_disable();\n\tINTC_STAT = 0x7fff;\n\tINTC_MASK = INTC_MASK;\n}\n"
},
{
"alpha_fraction": 0.5450270175933838,
"alphanum_fraction": 0.6255007982254028,
"avg_line_length": 26.328571319580078,
"blob_id": "44277b6ef5ad6a632b2607ecd291137e622c6594",
"content_id": "8b0e6bec2bebd7ddf8fc48dab76faccb508f7b54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5741,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 210,
"path": "/examples/dreamcast/kgl/nehe/nehe08/nehe08.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe08.c\n (c)2001 Benoit Miller\n\n Parts (c)2000 Tom Stanis/Jeff Molofee\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/* Simple KGL example to demonstrate blending.\n\n Essentially the same thing as NeHe's lesson08 code.\n To learn more, go to http://nehe.gamedev.net/.\n\n There is no lighting yet in KGL, so it has not been included.\n\n DPAD controls the cube rotation, button A & B control the depth\n of the cube, button X toggles filtering, and button Y toggles alpha \n blending.\n*/\n\nstatic GLfloat xrot;\t\t/* X Rotation */\nstatic GLfloat yrot;\t\t/* Y Rotation */\nstatic GLfloat xspeed;\t\t/* X Rotation Speed */\nstatic GLfloat yspeed;\t\t/* Y Rotation Speed */\nstatic GLfloat z=-5.0f;\t\t/* Depth Into The Screen */\n\nstatic GLuint filter;\t\t/* Which Filter To Use */\nstatic GLuint texture[2];\t/* Storage For Two Textures */\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid draw_gl(void) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\tglLoadIdentity();\n\tglTranslatef(0.0f,0.0f,z);\n\n\tglRotatef(xrot,1.0f,0.0f,0.0f);\n\tglRotatef(yrot,0.0f,1.0f,0.0f);\n\n\tglBindTexture(GL_TEXTURE_2D, texture[filter]);\n\n\tglBegin(GL_QUADS);\n\t\t/* Front Face */\n\t\tglNormal3f( 0.0f, 0.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t/* Back Face */\n\t\tglNormal3f( 0.0f, 0.0f,-1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\t/* Top Face */\n\t\tglNormal3f( 0.0f, 1.0f, 0.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\t/* Bottom Face */\n\t\tglNormal3f( 0.0f,-1.0f, 0.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\t/* Right face */\n\t\tglNormal3f( 1.0f, 0.0f, 0.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\t/* Left Face */\n\t\tglNormal3f(-1.0f, 0.0f, 0.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\tglEnd();\n\n\txrot+=xspeed;\n\tyrot+=yspeed;\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tGLboolean xp = GL_FALSE;\n\tGLboolean yp = GL_FALSE;\n\tGLboolean blend = GL_FALSE;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"nehe06 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,640.0f/480.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.0f, 0.0f, 0.0f, 0.5f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LEQUAL);\n\n\tglColor4f(1.0f, 1.0f, 1.0f, 0.5);\n\tglBlendFunc(GL_SRC_ALPHA,GL_ONE);\n\n\t/* Set up the textures */\n\tloadtxr(\"/rd/glass.pcx\", &texture[0]);\n\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_NONE);\n\tloadtxr(\"/rd/glass.pcx\", &texture[1]);\n\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\tif (!(cond.buttons & CONT_A))\n\t\t\tz -= 0.02f;\n\t\tif (!(cond.buttons & CONT_B))\n\t\t\tz += 0.02f;\n\t\tif (!(cond.buttons & CONT_X) && !xp) {\n\t\t\txp = GL_TRUE;\n\t\t\tfilter += 1;\n\t\t\tif (filter > 1)\n\t\t\t\tfilter = 0;\n\t\t}\n\t\tif (cond.buttons & CONT_X)\n\t\t\txp = GL_FALSE;\n\t\tif (!(cond.buttons & CONT_Y) && !yp) {\n\t\t\typ = GL_TRUE;\n\t\t\tblend = !blend;\n\t\t}\n\t\tif (cond.buttons & CONT_Y)\n\t\t\typ = GL_FALSE;\n\t\tif (!(cond.buttons & CONT_DPAD_UP))\n\t\t\txspeed -= 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_DOWN))\n\t\t\txspeed += 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_LEFT))\n\t\t\tyspeed -= 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_RIGHT))\n\t\t\tyspeed += 0.01f;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Switch to the blended polygon list if needed */\n\t\tif (blend) {\n\t\t\tglKosFinishList();\n\t\t\tglDepthMask(0);\n\t\t} else {\n\t\t\tglDepthMask(1);\n\t\t}\n\n\t\t/* Draw the GL \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6818830370903015,
"alphanum_fraction": 0.7085116505622864,
"avg_line_length": 35.67441940307617,
"blob_id": "01eedd93a850f0bb050cc07311da24e53a781e14",
"content_id": "147de2d7bb76fc88cc82f0291e7d24d2eecb0f9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6309,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 172,
"path": "/include/arch/ia32/arch/mmu.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/arch/mmu.h\n (c)2001 Dan Potter\n \n $Id: mmu.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n*/\n\n#ifndef __ARCH_MMU_H\n#define __ARCH_MMU_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/iovec.h>\n\n/* Since the software has to handle TLB misses on the SH-4, we have freedom\n to use any page table format we want (and thus save space), but we must\n make it quick to access. The SH-4 can address a maximum of 512M of address\n space per \"area\", but we only care about one area, so this is the total\n maximum addressable space. With 4K pages, that works out to 2^17 pages\n that must be mappable, or 17 bits. We use 18 bits just to be sure (there\n are a few left over).\n\n Page tables (per-process) are a sparse two-level array. The virtual address\n space is actually 2^30 bytes, or 2^(30-12)=2^18 pages, so there must be\n a possibility of having that many page entries per process space. A full\n page table for a process would be 1M, so this is obviously too big!! Thus\n the sparse array.\n\n The bottom layer of the page tables consists of a sub-context array for\n 512 pages, which translates into 2K of storage space. The process then\n has the possibility of using one or more of the 512 top-level slots. For\n a very small process (using one page for code/data and one for stack), it\n should be possible to achieve a page table footprint of one page. The tables\n can grow from there as neccessary.\n\n Virtual addresses are broken up as follows:\n\n Bits 31 - 22\t\t10 bits top-level page directory\n Bits 21 - 13\t\t9 bits bottom-level page entry\n Bits 11 - 0\t\tByte index into page\n\n */\n\n#define MMU_TOP_SHIFT 21\n#define MMU_TOP_BITS 10\n#define MMU_TOP_MASK ((1 << MMU_TOP_BITS) - 1)\n#define MMU_BOT_SHIFT 12\n#define MMU_BOT_BITS 9\n#define MMU_BOT_MASK ((1 << MMU_BOT_BITS) - 1)\n#define MMU_IND_SHIFT 0\n#define MMU_IND_BITS 12\n#define MMU_IND_MASK ((1 << MMU_IND_BITS) - 1)\n\n/* MMU TLB entry for a single page (one 32-bit word) */\ntypedef struct mmupage {\n\t/* Explicit pieces, used for reference */\n\t/*uint32\tvirtual; */\t/* implicit */\n\tuint32\t\tphysical:18;\t/* Physical page ID\t-- 18 bits */\n\tuint32\t\tprkey:2;\t/* Protection key data\t-- 2 bits */\n\tuint32\t\tvalid:1;\t/* Valid mapping\t-- 1 bit */\n\tuint32\t\tshared:1;\t/* Shared between procs\t-- 1 bit */\n\tuint32\t\tcache:1;\t/* Cacheable\t\t-- 1 bit */\n\tuint32\t\tdirty:1;\t/* Dirty\t\t-- 1 bit */\n\tuint32\t\twthru:1;\t/* Write-thru enable\t-- 1 bit */\n\tuint32\t\tblank:7;\t/* Reserved\t\t-- 7 bits */\n\n\t/* Pre-compiled pieces. These waste a bit of ram, but they also\n\t speed loading immensely at runtime. */\n\tuint32\t\tpteh, ptel;\n} mmupage_t;\n\n/* MMU sub-context type. We have two-level page tables on\n SH-4, and each sub-context contains 512 entries. */\n#define MMU_SUB_PAGES\t512\ntypedef struct mmusubcontext {\n\tmmupage_t\tpage[MMU_SUB_PAGES];\t/* 512 pages */\n} mmusubcontext_t;\n\n/* MMU Context type */\n#define MMU_PAGES\t1024\ntypedef struct mmucontext {\n\tmmusubcontext_t\t*sub[MMU_PAGES];\t/* 1024 sub-contexts */\n\tint\t\tasid;\t\t\t/* Address Space ID */\n} mmucontext_t;\n\n/* \"Current\" page tables (for TLB exception handling) */\nextern mmucontext_t *mmu_cxt_current;\n\n/* Set the \"current\" page tables for TLB handling */\nvoid mmu_use_table(mmucontext_t *context);\n\n/* Allocate a new MMU context; each process should have exactly one of\n these, and these should not exist without a process. */\nmmucontext_t *mmu_context_create(int asid);\n\n/* Destroy an MMU context when a process is being destroyed. */\nvoid mmu_context_destroy(mmucontext_t *context);\n\n/* Using the given page tables, translate the virtual page ID to a \n physical page ID. Return -1 on failure. */\nint mmu_virt_to_phys(mmucontext_t *context, int virtpage);\n\n/* Using the given page tables, translate the physical page ID to a\n virtual page ID. Return -1 on failure. */\nint mmu_phys_to_virt(mmucontext_t *context, int physpage);\n\n/* Switch to the given context; invalidate any caches as neccessary */\nvoid mmu_switch_context(mmucontext_t *context);\n\n/* Set the given virtual page as invalid (unmap it) */\nvoid mmu_page_invalidate(mmucontext_t *context, int virtpage, int count);\n\n/* Set the given virtual page to map to the given physical page; implies\n turning on the \"valid\" bit. Also sets the other named attributes.*/\nvoid mmu_page_map(mmucontext_t *context, int virtpage, int physpage,\n\tint count, int prot, int cache, int share, int dirty);\n\n/* Set the page protection to the given values */\n#define MMU_KERNEL_RDONLY\t0\n#define MMU_KERNEL_RDWR\t\t1\n#define MMU_ALL_RDONLY\t\t2\n#define MMU_ALL_RDWR\t\t3\nvoid mmu_page_protect(mmucontext_t *context, int virtpage, int count,\n\tint prot);\n\n/* Set the cacheing type to the given values */\n#define MMU_NO_CACHE\t\t1\n#define MMU_CACHE_BACK\t\t2\t/* Write-back */\n#define MMU_CACHE_WT\t\t3\t/* Write-thru */\n#define MMU_CACHEABLE\t\tMMU_CACHE_BACK\nvoid mmu_page_cache(mmucontext_t *context, int virtpage, int count, int cache);\n\n/* Set a page as shared or not */\n#define MMU_NOT_SHARED\t\t0\n#define MMU_SHARED\t\t1\nvoid mmu_page_share(mmucontext_t *context, int virtpage, int count, int share);\n\n/* Read the \"dirty\" bit of the page; potentially reset the bit. */\n#define MMU_NO_CHANGE\t\t0\n#define MMU_CLEAN\t\t1\n#define MMU_DIRTY\t\t2\nint mmu_page_dirty(mmucontext_t *context, int virtpage, int count, int reset);\n\n/* Copy a chunk of data from a process' address space into a\n kernel buffer, taking into account page mappings. */\nint mmu_copyin(mmucontext_t *context, uint32 srcaddr, uint32 srccnt, void *buffer);\n\n/* Copy a chunk of data from one process' address space to another\n process' address space, taking into account page mappings. */\nint mmu_copyv(mmucontext_t *context1, iovec_t *iov1, int iovcnt1,\n\tmmucontext_t *context2, iovec_t *iov2, int iovcnt2);\n\n/* MMU syscalls */\nvoid sc_mmu_mmap(uint32 dst, size_t len, uint32 src);\n\n/* Get/set thefunction to handle virt->phys page mapping; the function\n should return a pointer to an mmupage_t on success, or NULL on\n failure. */\ntypedef mmupage_t * (*mmu_mapfunc_t)(mmucontext_t * context, int virtpage);\nmmu_mapfunc_t mmu_map_get_callback();\nmmu_mapfunc_t mmu_map_set_callback(mmu_mapfunc_t newfunc);\n\n/* Init / shutdown MMU */\nint mmu_init();\nvoid mmu_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_MMU_H */\n\n"
},
{
"alpha_fraction": 0.7021034955978394,
"alphanum_fraction": 0.7021034955978394,
"avg_line_length": 42.974998474121094,
"blob_id": "48b0852f773d3682d2d6f886bed003c433cc187d",
"content_id": "19a0c7acc9c558f18a8241d71adb9c267d83efcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1759,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 40,
"path": "/environ_base.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS environment variable settings. These are the shared pieces\n# that are generated from the user config. Configure if you like.\n\n# Pull in the arch environ file\n. environ_${KOS_ARCH}.sh\n\n# Add the gnu wrappers dir to the path\n#export PATH=\"${PATH}:${KOS_BASE}/utils/gnu_wrappers\"\n\n# Base include path\nexport KOS_INC_BASE=\"${KOS_PATH}/include\"\nexport KOS_INC_ADDONS=\"${KOS_PATH}/include/addons\"\n\n# Our includes\nexport KOS_INC_PATHS=\"${KOS_INC_PATHS} -I${KOS_INC_BASE} \\\n-I${KOS_PATH}/include/arch/${KOS_ARCH} -I${KOS_INC_ADDONS}\"\n\n#export KOS_INC_PATHS_CPP=\"${KOS_INC_PATHS_CPP} -I${KOS_BASE}/libk++/stlport\"\n\n# \"System\" libraries\nexport KOS_LIB_PATHS=\"-L${KOS_PATH}/lib -L${KOS_PATH}/lib/addons\"\nexport KOS_LIBS=\"-Wl,--start-group -lkallisti -lc -lgcc -Wl,--end-group\"\n\n# Main arch compiler paths\nexport KOS_CC=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-gcc\"\nexport KOS_CCPLUS=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-g++\"\nexport KOS_AS=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-as\"\nexport KOS_AR=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-ar\"\nexport KOS_OBJCOPY=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-objcopy\"\nexport KOS_LD=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-ld\"\nexport KOS_RANLIB=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-ranlib\"\nexport KOS_STRIP=\"${KOS_CC_BASE}/bin/${KOS_CC_PREFIX}-strip\"\nexport KOS_CFLAGS=\"${KOS_CFLAGS} ${KOS_INC_PATHS} -D_arch_${KOS_ARCH} -D_arch_sub_${KOS_SUBARCH} -Wall -g -fno-builtin -fno-strict-aliasing\"\nexport KOS_CPPFLAGS=\"${KOS_CPPFLAGS} ${KOS_INC_PATHS_CPP} -fno-operator-names -fno-rtti -fno-exceptions\"\n#export KOS_AFLAGS=\"${KOS_AFLAGS}\"\nexport KOS_LDFLAGS=\"${KOS_LDFLAGS} -nostartfiles -nostdlib ${KOS_LIB_PATHS}\"\n\n# Some extra vars based on architecture\nexport KOS_ARCH_DIR=\"${KOS_PATH}/lib\"\nexport KOS_START=\"${KOS_ARCH_DIR}/startup.o\"\n"
},
{
"alpha_fraction": 0.5624399781227112,
"alphanum_fraction": 0.5919788479804993,
"avg_line_length": 20.970975875854492,
"blob_id": "580e73c348a7570f2c3aac7330a0ecd1afe91a46",
"content_id": "04ad5ec3389d44f2e180b8b37a7cf08cb0d8c7ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8328,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 379,
"path": "/kernel/arch/ps2/fs/fs_ps2load.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/ps2/fs/fs_ps2load.c\n Copyright (c)2002 Andrew Kieschnick\n Copyright (c)2002 Dan Potter\n\n*/\n\n/*\n\nThis is a rewrite of Dan Potter's fs_serconsole to use the dcload / dc-tool\nfileserver and console. \n\nprintf goes to the dc-tool console\n/pc corresponds to / on the system running dc-tool\n\nModified for ps2-load-ip by Dan Potter.\n\n*/\n\n#include <ps2/fs_ps2load.h>\n#include <kos/thread.h>\n#include <arch/spinlock.h>\n#include <arch/dbgio.h>\n#include <kos/fs.h>\n\n#include <stdio.h>\n#include <ctype.h>\n#include <string.h>\n#include <malloc.h>\n\nCVSID(\"$Id: fs_ps2load.c,v 1.1 2002/11/06 08:36:40 bardtx Exp $\");\n\nstatic spinlock_t mutex = SPINLOCK_INITIALIZER;\n\nstatic uint32 * ps2lip_block = NULL;\nstatic int (*ps2lip_syscall)(int code, ...) = NULL;\n\nstatic dbgio_printk_func old_printk = 0;\n\n/* static void * lwip_dclsc = 0;\n\n#define dclsc(...) ({ \\\n int rv; \\\n if (lwip_dclsc) \\\n\trv = (*(int (*)()) lwip_dclsc)(__VA_ARGS__); \\\n else \\\n\trv = plain_dclsc(__VA_ARGS__); \\\n rv; \\\n}) */\n\n/* Printk replacement */\n\nvoid ps2load_printk(const char *str) {\n /* if (lwip_dclsc && irq_inside_int())\n\treturn; */\n spinlock_lock(&mutex);\n ps2lip_syscall(PS2LOAD_WRITE, 1, str, strlen(str));\n spinlock_unlock(&mutex);\n}\n\nstatic char *ps2load_path = NULL;\nuint32 ps2load_open(vfs_handler_t * vfs, const char *fn, int mode) {\n int hnd = 0;\n uint32 h;\n int ps2load_mode = 0;\n \n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n \n if (mode & O_DIR) {\n if (fn[0] == '\\0') {\n fn = \"/\";\n }\n\thnd = ps2lip_syscall(PS2LOAD_OPENDIR, fn);\n\tif (hnd) {\n\t if (ps2load_path)\n\t\tfree(ps2load_path);\n\t if (fn[strlen(fn) - 1] == '/') {\n\t\tps2load_path = malloc(strlen(fn)+1);\n\t\tstrcpy(ps2load_path, fn);\n\t } else {\n\t\tps2load_path = malloc(strlen(fn)+2);\n\t\tstrcpy(ps2load_path, fn);\n\t\tstrcat(ps2load_path, \"/\");\n\t }\n\t}\n } else { /* hack */\n\tif ((mode & O_MODE_MASK) == O_RDONLY)\n\t ps2load_mode = 0;\n\tif ((mode & O_MODE_MASK) == O_RDWR)\n\t ps2load_mode = 2 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_WRONLY)\n\t ps2load_mode = 1 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_APPEND)\n\t ps2load_mode = 2 | 8 | 0x0200;\n\tif (mode & O_TRUNC)\n\t ps2load_mode |= 0x0400;\n\thnd = ps2lip_syscall(PS2LOAD_OPEN, fn, ps2load_mode, 0644);\n\thnd++; /* KOS uses 0 for error, not -1 */\n }\n \n h = hnd;\n\n spinlock_unlock(&mutex);\n return h;\n}\n\nvoid ps2load_close(uint32 hnd) {\n /* if (lwip_dclsc && irq_inside_int())\n\treturn; */\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\tif (hnd > 100) /* hack */\n\t ps2lip_syscall(PS2LOAD_CLOSEDIR, hnd);\n\telse {\n\t hnd--; /* KOS uses 0 for error, not -1 */\n\t ps2lip_syscall(PS2LOAD_CLOSE, hnd);\n\t}\n }\n spinlock_unlock(&mutex);\n}\n\nssize_t ps2load_read(uint32 hnd, void *buf, size_t cnt) {\n ssize_t ret = -1;\n \n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = ps2lip_syscall(PS2LOAD_READ, hnd, buf, cnt);\n }\n \n spinlock_unlock(&mutex);\n return ret;\n}\n\nssize_t ps2load_write(uint32 hnd, const void *buf, size_t cnt) {\n ssize_t ret = -1;\n \t\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = ps2lip_syscall(PS2LOAD_WRITE, hnd, buf, cnt);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\noff_t ps2load_seek(uint32 hnd, off_t offset, int whence) {\n off_t ret = -1;\n\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = ps2lip_syscall(PS2LOAD_LSEEK, hnd, offset, whence);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\noff_t ps2load_tell(uint32 hnd) {\n off_t ret = -1;\n \n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = ps2lip_syscall(PS2LOAD_LSEEK, hnd, 0, SEEK_CUR);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\nsize_t ps2load_total(uint32 hnd) {\n size_t ret = -1;\n size_t cur;\n\t\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n\t\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tcur = ps2lip_syscall(PS2LOAD_LSEEK, hnd, 0, SEEK_CUR);\n\tret = ps2lip_syscall(PS2LOAD_LSEEK, hnd, 0, SEEK_END);\n\tps2lip_syscall(PS2LOAD_LSEEK, hnd, cur, SEEK_SET);\n }\n\t\n spinlock_unlock(&mutex);\n return ret;\n}\n\n/* Not thread-safe, but that's ok because neither is the FS */\nstatic dirent_t dirent;\ndirent_t *ps2load_readdir(uint32 hnd) {\n dirent_t *rv = NULL;\n ps2load_dirent_t *dcld;\n ps2load_stat_t filestat;\n char *fn;\n\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n if (hnd < 100) return NULL; /* hack */\n\n spinlock_lock(&mutex);\n\n dcld = (ps2load_dirent_t *)ps2lip_syscall(PS2LOAD_READDIR, hnd);\n \n if (dcld) {\n\trv = &dirent;\n\tstrcpy(rv->name, dcld->d_name);\n\trv->size = 0;\n\trv->time = 0;\n\trv->attr = 0; /* what the hell is attr supposed to be anyways? */\n\n\tfn = malloc(strlen(ps2load_path)+strlen(dcld->d_name)+1);\n\tstrcpy(fn, ps2load_path);\n\tstrcat(fn, dcld->d_name);\n\n\tif (!ps2lip_syscall(PS2LOAD_STAT, fn, &filestat)) {\n\t if (filestat.st_mode & S_IFDIR)\n\t\trv->size = -1;\n\t else\n\t\trv->size = filestat.st_size;\n\t rv->time = filestat.st_mtime;\n\t \n\t}\n\t\n\tfree(fn);\n }\n \n spinlock_unlock(&mutex);\n return rv;\n}\n\nint ps2load_rename(vfs_handler_t * vfs, const char *fn1, const char *fn2) {\n int ret;\n\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n\n /* really stupid hack, since I didn't put rename() in dcload */\n\n ret = ps2lip_syscall(PS2LOAD_LINK, fn1, fn2);\n\n if (!ret)\n\tret = ps2lip_syscall(PS2LOAD_UNLINK, fn1);\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\nint ps2load_unlink(vfs_handler_t * vfs, const char *fn) {\n int ret;\n\n /* if (lwip_dclsc && irq_inside_int())\n\treturn 0; */\n\n spinlock_lock(&mutex);\n\n ret = ps2lip_syscall(PS2LOAD_UNLINK, fn);\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\n/* Pull all that together */\nstatic vfs_handler_t vh = {\n { \"/pc\" }, /* path prefix */\n 0, 0,\t\t/* In-kernel, no cacheing */\n NULL, /* privdata */\n VFS_LIST_INIT, /* linked list pointer */\n ps2load_open, \n ps2load_close,\n ps2load_read,\n ps2load_write,\n ps2load_seek,\n ps2load_tell,\n ps2load_total,\n ps2load_readdir,\n NULL, /* ioctl */\n ps2load_rename,\n ps2load_unlink,\n NULL /* mmap */\n};\n\n/* Call this before arch_init_all (or any call to dbgio_*) to use ps2load's\n console output functions. */\nvoid fs_ps2load_init_console() {\n\t/* Check for ps2load */\n\tif (!ps2lip_block) {\n\t\tps2lip_block = (uint32 *)(*PS2LOADBLOCKPTR);\n\t\tif (ps2lip_block == NULL)\n\t\t\treturn;\n\t\tif (ps2lip_block[0] != PS2LOADMAGICVALUE) {\n\t\t\tps2lip_block = NULL;\n\t\t\treturn;\n\t\t}\n\t}\n\tps2lip_syscall = (int (*)(int, ...))ps2lip_block[2];\n\n\t// This still sucks\n\t// old_printk = dbgio_set_printk(ps2load_printk);\n}\n\n/* Call fs_ps2load_init_console() before calling fs_ps2load_init() */\nint fs_ps2load_init() {\n\t/* Check for ps2load */\n\tif (!ps2lip_block)\n\t\treturn -1;\n\n /* Check for combination of KOS networking and dcload-ip */\n /* if ((dcload_type == DCLOAD_TYPE_IP) && (__kos_init_flags & INIT_NET)) {\n\tdbglog(DBG_INFO, \"dc-load console support disabled (network enabled)\\n\");\n\tif (old_printk) {\n\t dbgio_set_printk(old_printk);\n\t old_printk = 0;\n\t}\n\treturn -1;\n } */\n\n\t/* Register with VFS */\n\treturn fs_handler_add(\"/pc\", &vh);\n}\n\nint fs_ps2load_shutdown() {\n\t/* Check for ps2load */\n\tif (!ps2lip_block)\n\t\treturn -1;\n\n\treturn fs_handler_remove(&vh);\n}\n\n#if 0\n/* used for dcload-ip + lwIP\n * assumes fs_dcload_init() was previously called\n */\nint fs_dcload_init_lwip(void *p)\n{\n /* Check for combination of KOS networking and dcload-ip */\n if ((dcload_type == DCLOAD_TYPE_IP) && (__kos_init_flags & INIT_NET)) {\n\tlwip_dclsc = p;\n\n\told_printk = dbgio_set_printk(dcload_printk);\n\n\tdbglog(DBG_INFO, \"dc-load console support enabled (lwIP)\\n\");\n } else\n\treturn -1;\n\n /* Register with VFS */\n return fs_handler_add(\"/pc\", &vh);\n}\n#endif\n\n"
},
{
"alpha_fraction": 0.5880733728408813,
"alphanum_fraction": 0.6119266152381897,
"avg_line_length": 16.225807189941406,
"blob_id": "8b2ce65ef906fcb32551ce72f9b38998d29a8b9b",
"content_id": "d68eb867dd23f77e6886574daedd265f57d5228f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1090,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 62,
"path": "/libk++/mem.cc",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n libk++/mem.cc\n\n (c)2002 Gil Megidish\n*/\n\n#include <sys/cdefs.h>\n#include <arch/arch.h>\n#include <stdio.h>\n#include <sys/types.h>\n\nCVSID(\"$Id: mem.cc,v 1.2 2002/09/23 23:03:34 gilm Exp $\");\n\n/* This file contains definitions for the basic malloc/free operations\n in C++. You can use this tiny replacement for libstdc++ when you\n don't need the whole thing. */\n\nextern \"C\" void free(void*);\nextern \"C\" void *malloc(unsigned);\n\nasm(\n\".text\\n\"\n\".global __ZdlPv\\n\"\n\".global __Znwj\\n\"\n\".global __ZdaPv\\n\"\n\".global __Znaj\\n\"\n\".extern _free\\n\"\n\".extern _malloc\\n\"\n\"__ZdlPv:\\n\"\n\"__ZdaPv:\\n\"\n\"\tmov.l\tfreeaddr,r0\\n\"\n\"\tjmp\t@r0\\n\"\n\"\tnop\\n\"\n\".align 2\\n\"\n\"freeaddr:\t.long\t_free\\n\"\n\"__Znwj:\\n\"\n\"__Znaj:\\n\"\n\"\tmov.l\tmallocaddr,r0\\n\"\n\"\tjmp\t@r0\\n\"\n\"\tnop\\n\"\n\".align 2\\n\"\n\"mallocaddr:\t.long\t_malloc\\n\"\n);\n\n/* void operator delete(void *ptr) {\n\tif (ptr)\n\t\tfree(ptr);\n}\n\nvoid* operator new(size_t len) {\n\treturn malloc(len);\n}\n\n\nvoid operator delete[](void *ptr) {\n\t::operator delete(ptr);\n}\n\nvoid* operator new[](size_t len) {\n\treturn ::operator new(len);\n} */\n \n"
},
{
"alpha_fraction": 0.5548387169837952,
"alphanum_fraction": 0.625806450843811,
"avg_line_length": 17.176469802856445,
"blob_id": "b722876b7156a3f7437ccfc37150e5fe0a2e0b91",
"content_id": "13afbda1a5db530c313b3cb2fbfa5db3db1e2801",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 17,
"path": "/libc/time/clock.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n clock.c\n (c)2002 Jeffrey McBeth\n\n $Id: clock.c,v 1.1 2002/03/15 06:45:42 bardtx Exp $\n*/\n\n#include <time.h>\n\n/* clock() */\n/* According to the POSIX standard, if the process time can't be determined\n * clock should return (clock_t)-1\n */\nclock_t clock(void) {\n\treturn (clock_t)-1;\n}\n\n"
},
{
"alpha_fraction": 0.6679104566574097,
"alphanum_fraction": 0.6865671873092651,
"avg_line_length": 20,
"blob_id": "22c0f244426ac6533841fa097f34340a86aafee7",
"content_id": "1e8e5468e7d6c966e81565340703af1af55f061d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1072,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 51,
"path": "/include/kos/exports.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/exports.h\n Copyright (C)2003 Dan Potter\n\n $Id: exports.h,v 1.1 2003/06/19 04:30:23 bardtx Exp $\n\n*/\n\n#ifndef __KOS_EXPORTS_H\n#define __KOS_EXPORTS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* This struct holds one export symbol that will be patched into\n loaded ELF files. */\ntypedef struct export_sym {\n\tconst char\t* name;\n\tptr_t\t\tptr;\n} export_sym_t;\n\n/* These are the platform-independent exports */\nextern export_sym_t kernel_symtab[];\n\n/* And these are the arch-specific exports */\nextern export_sym_t arch_symtab[];\n\n#ifndef __EXPORTS_FILE\n#include <kos/nmmgr.h>\n/* This struct defines a symbol table \"handler\" for nmmgr. */\ntypedef struct symtab_handler {\n\t/* Name manager handler header */\n\tstruct nmmgr_handler\tnmmgr;\n\n\t/* Location of the first entry */\n\texport_sym_t\t\t* table;\n} symtab_handler_t;\n#endif\n\n/* Setup our initial exports */\nint export_init();\n\n/* Look up a symbol by name. Returns the struct. */\nexport_sym_t * export_lookup(const char * name);\n\n__END_DECLS\n\n#endif\t/* __KOS_EXPORTS_H */\n\n"
},
{
"alpha_fraction": 0.6904453635215759,
"alphanum_fraction": 0.7235261797904968,
"avg_line_length": 39.37313461303711,
"blob_id": "dd9bd724a12af13b060caaaf5a7507e9210e044c",
"content_id": "01cad46f0d69235bc96f7593eb58d57f665cf125",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 5411,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 134,
"path": "/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# Root Makefile\n# Copyright (C)2003 Dan Potter\n# \n# $Id: Makefile,v 1.5 2002/04/20 17:23:31 bardtx Exp $\n\n# Add stuff to DIRS to auto-compile it with the big tree.\nDIRS = utils\nifdef KOS_CCPLUS\n\tDIRS += libk++\nendif\nDIRS += kernel addons # examples\n\nexport TOPDIR=${PWD}\n\n# Detect a non-working or missing environ.sh file.\nifndef KOS_PATH\nerror:\n\t@echo You don\\'t seem to have a working environ.sh file. Please take a look at\n\t@echo doc/README for more info.\n\t@echo\n\t@echo Perhaps you need to run kos-make instead.\n\t@echo Usually you should first run\n\t@echo utils/gnu_wrappers/kos-make install-tools\n\t@exit 0\nelse\n\nall: pre-make\n\tfor i in $(DIRS); do $(MAKE) -C $$i || exit -1; done\n\nclean:\n\tfor i in $(DIRS); do $(MAKE) -C $$i clean || exit -1; done\n\ndistclean: clean\n\t-rm -f lib/$(KOS_ARCH)/*.a\n\t-rm -f lib/$(KOS_ARCH)/addons/*.a\n\npre-make: install-headers\n\tinstall -m 755 utils/bin2o/bin2o ${KOS_PATH}/bin/bin2o\n\ninstall-tools:\n\t@echo Installing tools\n\tinstall -m 660 environ.sh ${KOS_PATH}/bin/environ.sh\n\tinstall -m 660 environ_base.sh ${KOS_PATH}/bin/environ_base.sh\n\tinstall -m 660 environ_${KOS_ARCH}.sh ${KOS_PATH}/bin/environ_${KOS_ARCH}.sh\n\tinstall -m 755 utils/gnu_wrappers/kos-ar ${KOS_PATH}/bin/kos-ar\n\tinstall -m 755 utils/gnu_wrappers/kos-as ${KOS_PATH}/bin/kos-as\n\tinstall -m 755 utils/gnu_wrappers/kos-c++ ${KOS_PATH}/bin/kos-c++\n\tinstall -m 755 utils/gnu_wrappers/kos-cc ${KOS_PATH}/bin/kos-cc\n\tinstall -m 755 utils/gnu_wrappers/kos-ld ${KOS_PATH}/bin/kos-ld\n\tinstall -m 755 utils/gnu_wrappers/kos-make ${KOS_PATH}/bin/kos-make\n\tinstall -m 755 utils/gnu_wrappers/kos-objcopy ${KOS_PATH}/bin/kos-objcopy\n\tinstall -m 755 utils/gnu_wrappers/kos-ranlib ${KOS_PATH}/bin/kos-ranlib\n\tinstall -m 755 utils/gnu_wrappers/kos-strip ${KOS_PATH}/bin/kos-strip\n\t@echo Installing Makefile.rules\n\tinstall -d ${KOS_PATH}/scripts\n\tinstall -m 660 Makefile.rules ${KOS_PATH}/scripts/Makefile.rules\n\ninstall-libs:\n\t@echo Installing libraries\n\tinstall -m 660 lib/${KOS_ARCH}/libkallisti.a ${KOS_PATH}/lib/libkallisti.a\n\tinstall -m 660 lib/${KOS_ARCH}/libkallisti_exports.a ${KOS_PATH}/lib/libkallisti_exports.a\n\tinstall -m 770 -d ${KOS_PATH}/lib/addons\n\tinstall -m 660 lib/${KOS_ARCH}/addons/libkosutils.a ${KOS_PATH}/lib/addons/libkosutils.a\n\tinstall -m 660 kernel/arch/${KOS_ARCH}/kernel/startup.o ${KOS_PATH}/lib/startup.o\nifdef KOS_CCPLUS\n\tinstall -m 660 lib/$(KOS_ARCH)/libk++.a ${KOS_PATH}/lib/libk++.a\nendif\n\ninstall: all install-tools install-libs\n\ninstall-headers: install-standard-headers install-${KOS_ARCH}-headers\n\ninstall-standard-headers:\n\tinstall -d ${KOS_PATH}/include/kos\n\tinstall -d ${KOS_PATH}/include/kos\n\tinstall -d ${KOS_PATH}/include/sys\n\tinstall -d ${KOS_PATH}/include/arch\n\tinstall -d ${KOS_PATH}/include/arpa\n\tinstall -d ${KOS_PATH}/include/addons\n\tinstall -d ${KOS_PATH}/include/addons/kos\n\tinstall -d ${KOS_PATH}/include/netinet\n\tinstall -d ${KOS_PATH}/include/machine\n\tinstall -m 660 include/*.h ${KOS_PATH}/include/\n\tinstall -m 660 include/kos/*.h ${KOS_PATH}/include/kos/\n\tinstall -m 660 include/arpa/*.h ${KOS_PATH}/include/arpa\n\tinstall -m 660 include/netinet/*.h ${KOS_PATH}/include/netinet\n\tinstall -m 660 include/sys/*.h ${KOS_PATH}/include/sys/\n\tinstall -m 660 include/addons/kos/*.h ${KOS_PATH}/include/addons/kos\n\tinstall -m 660 include/machine/*.h ${KOS_PATH}/include/machine\n\ninstall-gba-headers:\n\tinstall -d ${KOS_PATH}/include/arch/gba\n\tinstall -d ${KOS_PATH}/include/arch/gba/gba\n\tinstall -d ${KOS_PATH}/include/arch/gba/arch\n\tinstall -m 660 include/arch/gba/gba/*.h ${KOS_PATH}/include/arch/gba/gba/\n\tinstall -m 660 include/arch/gba/arch/*.h ${KOS_PATH}/include/arch/gba/arch/\n\ninstall-ps2-headers:\n\tinstall -d ${KOS_PATH}/include/arch/ps2\n\tinstall -d ${KOS_PATH}/include/arch/ps2/ps2\n\tinstall -d ${KOS_PATH}/include/arch/ps2/arch\n\tinstall -m 660 include/arch/ps2/ps2/*.h ${KOS_PATH}/include/arch/ps2/ps2\n\tinstall -m 660 include/arch/ps2/arch/*.h ${KOS_PATH}/include/arch/ps2/arch\n\ninstall-ia32-headers:\n\tinstall -d ${KOS_PATH}/include/arch/ia32\n\tinstall -d ${KOS_PATH}/include/arch/ia32/arch\n\tinstall -d ${KOS_PATH}/include/arch/ia32/ia32\n\tinstall -m 660 include/arch/ia32/arch/*.h ${KOS_PATH}/include/arch/ia32/arch\n\tinstall -m 660 include/arch/ia32/ia32/*.h ${KOS_PATH}/include/arch/ia32/ia32\n\ninstall-dreamcast-headers:\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/dc\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/dc/net\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/dc/maple\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/dc/modem\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/dc/sound\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/arch\n\tinstall -d ${KOS_PATH}/include/arch/dreamcast/navi\n\tinstall -m 660 include/arch/dreamcast/dc/*.h ${KOS_PATH}/include/arch/dreamcast/dc\n\tinstall -m 660 include/arch/dreamcast/dc/net/*.h ${KOS_PATH}/include/arch/dreamcast/dc/net\n\tinstall -m 660 include/arch/dreamcast/dc/maple/*.h ${KOS_PATH}/include/arch/dreamcast/dc/maple\n\tinstall -m 660 include/arch/dreamcast/dc/modem/*.h ${KOS_PATH}/include/arch/dreamcast/dc/modem\n\tinstall -m 660 include/arch/dreamcast/dc/sound/*.h ${KOS_PATH}/include/arch/dreamcast/dc/sound\n\tinstall -m 660 include/arch/dreamcast/arch/*.h ${KOS_PATH}/include/arch/dreamcast/arch\n\tinstall -m 660 include/arch/dreamcast/navi/*.h ${KOS_PATH}/include/arch/dreamcast/navi\n\nexamples:\n\t$(MAKE) -C examples/${KOS_ARCH} all\n\nendif\n\n"
},
{
"alpha_fraction": 0.6625403761863708,
"alphanum_fraction": 0.6683261394500732,
"avg_line_length": 27.258554458618164,
"blob_id": "ce76b7038134b1de3d70ae79222929be59a24b64",
"content_id": "dc5fc4f0bec0acec64764bfb5902948c693ab9d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7432,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 263,
"path": "/utils/svn_utils/svnpull.py",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# This script implements the client side of the Subversion repository dump\n# \"push\" system, the server side of which is implemented in svnpush.py.\n#\n# Copyright (C)2003 Dan Potter\n#\n\n# Usage:\n# svnpull.py <repo path> <svnpush URL>\n#\n# A Subversion repository should exist at <repo path> and not be in use by\n# any other client at the time (e.g., stop your Apache instance if you are\n# using one, most people won't; make sure other users aren't using it, etc). \n# The <svnpush URL> should be the URL where updates are being posted on\n# the web. This should contain one or more xxx_full.dump.bz2 files and zero\n# or more xxx_incr.dump.bz2 files. It can be hand-maintained, but will\n# generally be maintined by the svnpush.py script.\n#\n# When the script is run, it will go out to the URL and check the available\n# revisions there. This will be compared against the revisions present in the\n# local repository. If there are newer revisions present on the site, they\n# will be downloaded and applied locally.\n#\n# Note that this goes only by version numbers -- you are required by this\n# currently to not check in anything to your repository locally! If you do\n# then strange things may start to happen. Perhaps this can be fixed later.\n\nimport sys, string, svnpush, urllib2, popen2, thread\n\n########################################################################\n# Configuration\n\n# All configuration is done in the svnpush.py module. Please look in that\n# file for config options.\n\n########################################################################\n# Implicit config globals, from cmdline. Set these to something besides\n# None if you want to have parameter defaults. If you set one, you must\n# set them all.\n\nglobal path_svnrepo, path_srcurl\n\n# path_svnrepo - path to the SVN repo we're working on\npath_svnrepo = None\n\n# path_srcurl - URL to pull updates from\n#path_srcurl = 'http://gamedev.allusion.net/svn/'\npath_srcurl = None\n\n# Verify the defaulted parameters\ntry:\n\tif (path_svnrepo is not None) or (path_srcurl is not None):\n\t\tassert path_svnrepo is not None\n\t\tassert path_srcurl is not None\nexcept AssertionError:\n\tprint \"Some parameters were defaulted, others were not.\"\n\tprint \"Please correct this in svnpull.py and try again.\"\n\tsys.exit(-1)\n\n########################################################################\n# SVN Utility funcs\n# These supplement what's in svnpush.py. Perhaps not the greatest code\n# layout but it works and is simple.\n\n# Merge one Subversion revision from the web server. This uses 'svnadmin\n# load' and 'bzip2' to decrunch and load the dump.\ndef svnLoadRevision(revFn):\n\t# Grab the revision\n\trd = urlGet(path_srcurl + '/' + revFn)\n\n\t# Open up a pipe to svnadmin to write it out\n\tprint \"Loading '%s' into the repo...\" % revFn\n\tp = popen2.Popen3('bzip2 -cd | ' + svnpush.svnadmin_bin \\\n\t\t+ ' load %s' % path_svnrepo, 1)\n\n\t# Start threads to give the user a running display of stdout/stderr\n\tdef dispthread(fd):\n\t\twhile 1:\n\t\t\tf = fd.readline()\n\t\t\tif f == '':\n\t\t\t\treturn\n\tthread.start_new_thread(dispthread, (p.fromchild,))\n\tthread.start_new_thread(dispthread, (p.childerr,))\n\n\t# Write all of our data into the pipe\n\tp.tochild.write(rd)\n\tp.tochild.close()\n\n\t# Get the return code\n\trc = p.wait()\n\n\treturn rc\n\n\n########################################################################\n# HTTP utility funcs\n# These are analogous to the SCP utility funcs in svnpush.py, but they use\n# URLs and urllib as a transport.\n\n# Open a URL and return the file contents as a string.\ndef urlGet(src):\n\tprint \"Downloading %s\" % src\n\n\t# Open a connection\n\th = urllib2.urlopen(src)\n\n\t# Copy the contents\n\tcont = h.read()\n\n\t# Close out\n\th.close()\n\n\treturn cont\n\n# Copy down one file from the given URL.\ndef urlCopy(src, dst):\n\t# Get the file data\n\th = urlGet(src)\n\n\t# Open the destination file\n\tf = open(dst, \"wb\")\n\n\t# Copy the contents from h to f\n\tf.write(h)\n\n\t# Close out\n\tf.close()\n\n# Go out to the URL and find the latest full dump revision.\ndef urlLatestFullRevision():\n\treturn int(string.strip(urlGet(path_srcurl + \"/highest_full\")))\n\n# Go out to the URL and find the latest incremental dump revision.\ndef urlLatestIncrRevision():\n\treturn int(string.strip(urlGet(path_srcurl + \"/highest_incr\")))\n\n# Go out to the URL and find the latest revision available. Returns both\n# the revision and the type string.\ndef urlLatestRevision():\n\t# Get the latest full revision\n\tlf = urlLatestFullRevision()\n\n\t# And the latest incremental revision\n\tli = urlLatestIncrRevision()\n\n\t# Make sure it's valid\n\tif lf < 0:\n\t\tprint \"Latest full revision is -1, which is invalid.\"\n\t\tsys.exit(-1)\n\tif li > 0 and lf > li:\n\t\tprint \"Full revisions exist without incrementals, which is invalid.\"\n\t\tsys.exit(-1)\n\n\t# If there is an incremental revision available, return that.\n\tif li > 0:\n\t\treturn li, 'incr'\n\telse:\n\t\treturn lf, 'full'\n\n# Grab the specified revision (as 'full' or 'incr') and load it up.\ndef urlLoadRevision(rev, type):\n\t# Commit it\n\trc = svnLoadRevision(\"%d_%s.dump.bz2\" % (rev, type))\n\tif rc != 0:\n\t\tprint \"Couldn't load revision %d/%s, exit code %d\" \\\n\t\t\t% (rev, type, rc)\n\t\tsys.exit(-1)\n\n#######################################################################\n# Main\n\ndef help():\n\tglobal path_srcurl\n\n\t# Preamble is always the same\n\tprint \"usage: svnpull.py \",\n\n\t# Do we have defaults?\n\tif path_svnrepo is not None:\n\t\tprint \"[<local repo path> <src URL>]\"\n\t\tprint \"<local repo path> defaults to '%s'\" % path_svnrepo\n\t\tprint \"<src URL> defaults to '%s'\" % path_srcurl\n\telse:\n\t\tprint \"<local repo path> <src URL>\"\n\ndef main(argv):\n\tglobal path_svnrepo, path_srcurl\n\n\tprint \"\"\"svnpull.py\nSubversion push-based repository \"client\"\nCopyright (C)2003 Dan Potter\n\"\"\"\n\n\t# Make sure we're called with enough parameters\n\tif path_svnrepo is None:\n\t\tif len(argv) < 3:\n\t\t\thelp()\n\t\t\tsys.exit(-1)\n\t\telse:\n\t\t\t# Set our globals\n\t\t\tpath_svnrepo = argv[1]\n\t\t\tpath_srcurl = argv[2]\n\telse:\n\t\tif len(argv) > 1 and len(argv) < 3:\n\t\t\thelp()\n\t\t\tsys.exit(-1)\n\n\t# Fill in the defaults in svnpush.py that we use as a module.\n\tsvnpush.path_svnrepo = path_svnrepo\n\n\tprint \"Repo at %s, source at %s\" % (path_svnrepo, path_srcurl)\n\n\t# Find the latest revision of the local repo (and also verify its\n\t# integrity)\n\tprint \"Finding latest local revision.\"\n\tlv = svnpush.getLatestRevision()\n\n\tprint \"Verified repository integrity, latest revision is %d.\" % lv\n\n\t# Get the latest URL target revision\n\tprint \"Finding latest public revision.\"\n\tpv, ptype = urlLatestRevision()\n\n\tprint \"Latest public revision is %d/%s.\" % (pv, ptype)\n\n\tif lv > pv:\n\t\tprint \"ERROR: Somehow the local repo is past the public one!\"\n\t\tsys.exit(-1)\n\tif lv == pv:\n\t\tprint \"Local repo is up to date.\"\n\t\tsys.exit(0)\n\n\t# Do we need to do a full import first?\n\tif lv == 0:\n\t\tfpv = urlLatestFullRevision()\n\t\tprint \"Local repo is completely empty, importing full dump %d.\" % fpv\n\t\turlLoadRevision(fpv, 'full')\n\t\tlv = fpv\n\n\tprint \"Full repo is now to %d.\" % lv\n\n\t# Do incrementals if necessary\n\tif lv < pv:\n\t\tprint \"Applying incrementals...\"\n\n\twhile lv < pv:\n\t\tlv = lv + 1\n\t\ttry:\n\t\t\turlLoadRevision(lv, 'incr')\n\t\texcept urllib2.HTTPError:\n\t\t\tprint \"Couldn't get incremental %d -- perhaps your repo is too old?\" % lv\n\t\t\tprint \"If you have no local data in it, try deleting your repo and\"\n\t\t\tprint \"creating it again with 'svnadmin create'.\"\n\t\t\tsys.exit(-1)\n\n\tprint \"Repo is now patched to %d.\" % lv\n\n\tprint \"Done.\"\n\treturn 0\n\nif __name__=='__main__':\n\tsys.exit(main(sys.argv))\n"
},
{
"alpha_fraction": 0.6372846961021423,
"alphanum_fraction": 0.6656534671783447,
"avg_line_length": 25.648649215698242,
"blob_id": "f8fe0a800d51b798021f2e9ab284f6f89d5fbf02",
"content_id": "5dd836d5305649ef55a9f3427aab4518fd71836c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 37,
"path": "/include/addons/kos/pcx.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n kos/pcx.h\n (c)2000-2001 Dan Potter\n\n $Id: pcx.h,v 1.2 2002/01/05 07:23:32 bardtx Exp $\n\n*/\n\n#ifndef __KOS_PCX_H\n#define __KOS_PCX_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* These first two versions are mainly for use with the GBA, and they are\n defined in the \"pcx_small\" file. They can be used on any architecture of\n course. */\n \n/* Flat 15-bit BGR load of the PCX data into whatever buffer -- assumes the\n buffer is the same width as the PCX */\nint pcx_load_flat(const char *fn, int *w_out, int *h_out, void *pic_out);\n\n/* Palettized load of the PCX data -- the picture data will go into the\n picture output buffer, and the palette will go into pal_out as\n 15-bit BGR data. */\nint pcx_load_palette(const char *fn, int *w_out, int *h_out, void *pic_out, void *pal_out);\n\n\n/* This last version is the larger memory version (for use on DC, etc) */\n/* XXX insert definition */\n\n__END_DECLS\n\n#endif\t/* __KOS_PCX_H */\n\n"
},
{
"alpha_fraction": 0.5768757462501526,
"alphanum_fraction": 0.6011685132980347,
"avg_line_length": 22.366907119750977,
"blob_id": "6db6a41cf15db79cfc2d8d566b866090cfcae913",
"content_id": "3342facea566e4fc9f862d65f545b928757b5527",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3252,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 139,
"path": "/kernel/arch/dreamcast/hardware/maple/maple_compat.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n maple_compat.c\n (C)2002 Dan Potter\n\n */\n\n#include <assert.h>\n#include <string.h>\n#include <dc/maple.h>\n#include <dc/maple/controller.h>\n#include <dc/maple/mouse.h>\n\nCVSID(\"$Id: maple_compat.c,v 1.3 2002/05/24 06:47:26 bardtx Exp $\");\n\n/* Utility function used by other compat functions */\nint maple_compat_resolve(uint8 addr, maple_device_t **dev, uint32 funcs) {\n\tint\tp, u;\n\n\tmaple_raddr(addr, &p, &u);\n\tif (!maple_dev_valid(p, u))\n\t\treturn MAPLE_EINVALID;\n\t*dev = &maple_state.ports[p].units[u];\n\tif (! ((*dev)->info.functions & funcs) )\n\t\treturn MAPLE_ENOTSUPP;\n\n\treturn 0;\n}\n\n/****************************************************************************/\n/* maple.c */\n\n/* Retrieve function code... */\nuint32 maple_device_func(int p, int u) {\n\tmaple_device_t\t*dev;\n\tdev = &maple_state.ports[p].units[u];\n\tif (!dev->valid)\n\t\treturn 0;\n\telse\n\t\treturn dev->info.functions;\n}\n\n/* First with a given function code... */\nuint8 maple_first_device(int code) {\n\tint\t\tp, u;\n\tuint32\t\tfunc;\n\n\tfor (p=0; p<MAPLE_PORT_COUNT; p++)\n\t\tfor (u=0; u<MAPLE_UNIT_COUNT; u++) {\n\t\t\tfunc = maple_device_func(p, u);\n\t\t\tif (func & code)\n\t\t\t\treturn maple_addr(p, u);\n\t\t}\n\treturn 0;\n}\n\n/* First controller */\nuint8 maple_first_controller() {\n\treturn maple_first_device(MAPLE_FUNC_CONTROLLER);\n}\n\n/* First mouse */\nuint8 maple_first_mouse() {\n\treturn maple_first_device(MAPLE_FUNC_MOUSE);\n}\n\n/* First keyboard */\nuint8 maple_first_kb() {\n\treturn maple_first_device(MAPLE_FUNC_KEYBOARD);\n}\n\n/* First LCD unit */\nuint8 maple_first_lcd() {\n\treturn maple_first_device(MAPLE_FUNC_LCD);\n}\n\n/* First VMU */\nuint8 maple_first_vmu() {\n\treturn maple_first_device(MAPLE_FUNC_MEMCARD);\n}\n\n/****************************************************************************/\n/* controller.c */\n\n/* Get the old compatible condition structure for controller on port\n and fill in cond with it, ret -1 on error. */\nint cont_get_cond(uint8 addr, cont_cond_t *cond) {\n\tint\t\trv;\n\tmaple_device_t\t*dev;\n\tcont_state_t\t*stat;\n\n\t/* Resolve a status struct */\n\tassert( addr != 0 );\n\trv = maple_compat_resolve(addr, &dev, MAPLE_FUNC_CONTROLLER);\n\tif (rv < 0)\n\t\treturn rv;\n\n\tstat = maple_dev_status(dev);\n\tassert(stat != NULL);\n\n\t/* Copy out the pieces into an old compat struct */\n\tcond->buttons = (uint16)(~stat->buttons);\n\tcond->ltrig = (uint8)(stat->ltrig);\n\tcond->rtrig = (uint8)(stat->rtrig);\n\tcond->joyx = (uint8)(stat->joyx+128);\n\tcond->joyy = (uint8)(stat->joyy+128);\n\tcond->joy2x = (uint8)(stat->joy2x+128);\n\tcond->joy2y = (uint8)(stat->joy2y+128);\n\t\t\n\treturn 0;\n}\n\n/****************************************************************************/\n/* mouse.c */\n\n/* get the condition structure for a mouse at address addr. return a\n -1 if an error occurs. */\nint mouse_get_cond(uint8 addr, mouse_cond_t *cond) {\n\tint\t\trv;\n\tmaple_device_t\t*dev;\n\tmouse_state_t\t*stat;\n\n\tassert( addr != 0 );\n\trv = maple_compat_resolve(addr, &dev, MAPLE_FUNC_MOUSE);\n\tif (rv < 0)\n\t\treturn rv;\n\n\tstat = maple_dev_status(dev);\n\tassert(stat != NULL);\n\n\t/* Copy out the pieces into an old compat struct */\n\tcond->buttons = (uint16)(~stat->buttons);\n\tcond->dummy1 = cond->dummy2 = cond->dummy3 = cond->dummy4 = 0;\n\tcond->dx = stat->dx;\n\tcond->dy = stat->dy;\n\tcond->dz = stat->dz;\n\n\treturn 0;\n} \n\n"
},
{
"alpha_fraction": 0.6925230026245117,
"alphanum_fraction": 0.7125149965286255,
"avg_line_length": 27.409090042114258,
"blob_id": "dafb046a81c4eafe5a12ba846632f23ad8917661",
"content_id": "bad1272e2c9de960297ca7a01f31470af10109f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2501,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 88,
"path": "/include/arch/ia32/arch/timer.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/timer.h\n (c)2000-2001 Dan Potter\n\n $Id: timer.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n\n*/\n\n#ifndef __ARCH_TIMER_H\n#define __ARCH_TIMER_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <arch/irq.h>\n\n/* Timer sources -- we get four on the SH4 */\n#define TMU0\t0\t/* Off limits during thread operation */\n#define TMU1\t1\t/* Used for timer_spin_sleep() */\n#define TMU2\t2\t/* Used for timer_get_ticks() */\n#define WDT\t3\t/* Not supported yet */\n\n/* The main timer for the task switcher to use */\n#define TIMER_ID TMU0\n\n/* Pre-initialize a timer; set values but don't start it */\nint timer_prime(int which, uint32 speed, int interrupts);\n\n/* Start a timer -- starts it running (and interrupts if applicable) */\nint timer_start(int which);\n\n/* Stop a timer -- and disables its interrupt */\nint timer_stop(int which);\n\n/* Returns the count value of a timer */\nuint32 timer_count(int which);\n\n/* Clears the timer underflow bit and returns what its value was */\nint timer_clear(int which);\n\n/* Spin-loop kernel sleep func: uses the secondary timer in the\n SH-4 to very accurately delay even when interrupts are disabled */\nvoid timer_spin_sleep(int ms);\n\n/* Enable timer interrupts (high priority); needs to move\n to irq.c sometime. */\nvoid timer_enable_ints(int which);\n\n/* Disable timer interrupts; needs to move to irq.c sometime. */\nvoid timer_disable_ints(int which);\n\n/* Check whether ints are enabled */\nint timer_ints_enabled(int which);\n\n/* Enable the millisecond timer */\nvoid timer_ms_enable();\nvoid timer_ms_disable();\n\n/* Return the number of ticks since KOS was booted */\nvoid timer_ms_gettime(uint32 *secs, uint32 *msecs);\n\n/* Does the same as timer_ms_gettime(), but it merges both values\n into a single 64-bit millisecond counter. May be more handy\n in some situations. */\nuint64 timer_ms_gettime64();\n\n/* Set the callback target for the primary timer. Set to NULL\n to disable callbacks. Returns the address of the previous\n handler. */\ntypedef void (*timer_primary_callback_t)(irq_context_t *);\ntimer_primary_callback_t timer_primary_set_callback(timer_primary_callback_t callback);\n\n/* Request a wakeup in approximately N milliseconds. You only get one\n simultaneous wakeup. Any subsequent calls here will replace any \n pending wakeup. */\nvoid timer_primary_wakeup(uint32 millis);\n\n/* Init function */\nint timer_init();\n\n/* Shutdown */\nvoid timer_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_TIMER_H */\n\n"
},
{
"alpha_fraction": 0.6277695894241333,
"alphanum_fraction": 0.6479566693305969,
"avg_line_length": 18.528846740722656,
"blob_id": "eb69b0bbc9e96e73cad93ff367cc6024f12cf279",
"content_id": "84db970affe0a43066f46ad8e06dd6f2bb3b5f51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2031,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 104,
"path": "/examples/dreamcast/cpp/modplug_test/example.cpp",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <kos.h>\n#include <modplug/stdafx.h>\n#include <modplug/sndfile.h>\n\nuint16 sound_buffer[65536] = {0};\nCSoundFile *soundfile;\n\nvoid *mod_callback(snd_stream_hnd_t hnd, int len, int * actual)\n{\n\tint res;\n\t\n\tres=soundfile->Read(sound_buffer, len)*4/*samplesize*/;\n\t//printf(\"res: %i, len: %i\\n\",res,len);\n\tif (res<len)\n\t{\n\t\tsoundfile->SetCurrentPos(0);\n\t\tsoundfile->Read(&sound_buffer[res], len-res);\n\t}\n\t*actual = len;\n\t\n\treturn sound_buffer;\n}\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tuint8 *mod_buffer;\n\tuint32 hnd;\n\tchar filename[]=\"/rd/test.s3m\";\n\n\tprintf(\"modplug_test beginning\\n\");\n\n\tsnd_stream_init();\n\n\thnd=fs_open(filename, O_RDONLY);\n\tif (!hnd) {\n\t\tprintf(\"Error reading %s\\n\",filename);\n\t\treturn 0;\n\t}\n\n\tprintf(\"Filesize: %i\\n\",fs_total(hnd));\n\tmod_buffer=(uint8 *)malloc(fs_total(hnd));\n\tif (!mod_buffer) {\n\t\tprintf(\"Not enough memory\\n\");\n\t\treturn 0;\n\t}\n\tprintf(\"Memory allocated\\n\");\n\t\n\tif (fs_read(hnd,mod_buffer,fs_total(hnd))!=fs_total(hnd))\n\t{\n\t\tprintf(\"Read error\\n\");\n\t\tfree(mod_buffer);\n\t\treturn 0;\n\t}\n\tprintf(\"File read\\n\");\n\t\n\tsoundfile = new CSoundFile;\n\tif (!soundfile) {\n\t\tprintf(\"Not enough memory\\n\");\n\t\tfree(mod_buffer);\n\t\treturn 0;\n\t}\n\tprintf(\"CSoundFile created\\n\");\n\tif (!soundfile->Create(mod_buffer,fs_total(hnd))) {\n\t\tprintf(\"Mod not loaded\\n\");\n\t\tfree(mod_buffer);\n\t\tdelete soundfile;\n\t\treturn 0;\n\t}\n\tprintf(\"Mod loaded\\n\");\n\tsoundfile->SetWaveConfig(44100,16,2);\n\tprintf(\"Type: %i\\n\",soundfile->GetType());\n\tprintf(\"Title: %s\\n\",soundfile->GetTitle());\n\n\t/*fs_close(hnd);\n\tfree(mod_buffer);*/\n\n\tsnd_stream_hnd_t shnd = snd_stream_alloc(mod_callback, SND_STREAM_BUFFER_MAX);\n\tsnd_stream_start(shnd, 44100, 1);\n\n\twhile(1) {\n\t\t/* Check key status */\n\t\tc = maple_first_controller();\n\t\tif (cont_get_cond(c, &cond) >= 0) {\n\t\t\tif (!(cond.buttons & CONT_START))\n\t\t\t\tbreak;\n\t\t}\n\n\t\tsnd_stream_poll(shnd);\n\t\t\n\t\ttimer_spin_sleep(10);\n\t}\n\n\tdelete soundfile;\n\n\tsnd_stream_destroy(shnd);\n\n\tsnd_stream_shutdown();\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6632952690124512,
"alphanum_fraction": 0.6858075261116028,
"avg_line_length": 28.757282257080078,
"blob_id": "85c2b0aa5c94a927de267782b0127040fc34bd86",
"content_id": "020b6ec28e25a98bbfd3f842f9bf6fc2d85e397e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3065,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 103,
"path": "/kernel/arch/dreamcast/fs/dcload-syscalls.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-commands.h\n\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#ifndef __SYSCALLS_H__\n#define __SYSCALLS_H__\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n#define DCLN_CMD_EXIT \"DC00\"\n#define DCLN_CMD_FSTAT \"DC01\"\n#define DCLN_CMD_WRITE \"DD02\"\n#define DCLN_CMD_READ \"DC03\"\n#define DCLN_CMD_OPEN \"DC04\"\n#define DCLN_CMD_CLOSE \"DC05\"\n#define DCLN_CMD_CREAT \"DC06\"\n#define DCLN_CMD_LINK \"DC07\"\n#define DCLN_CMD_UNLINK \"DC08\"\n#define DCLN_CMD_CHDIR \"DC09\"\n#define DCLN_CMD_CHMOD \"DC10\"\n#define DCLN_CMD_LSEEK \"DC11\"\n#define DCLN_CMD_TIME \"DC12\"\n#define DCLN_CMD_STAT \"DC13\"\n#define DCLN_CMD_UTIME \"DC14\"\n#define DCLN_CMD_BAD \"DC15\"\n#define DCLN_CMD_OPENDIR \"DC16\"\n#define DCLN_CMD_CLOSEDIR \"DC17\"\n#define DCLN_CMD_READDIR \"DC18\"\n#define DCLN_CMD_CDFSREAD \"DC19\"\n#define DCLN_CMD_GDBPACKET \"DC20\"\n\nextern int dcln_syscall_retval;\nextern unsigned char *dcln_syscall_data;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int value0 __attribute__ ((packed));\n unsigned int value1 __attribute__ ((packed));\n unsigned int value2 __attribute__ ((packed));\n} command_3int_t;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int value0 __attribute__ ((packed));\n unsigned int value1 __attribute__ ((packed));\n unsigned char string[1] __attribute__ ((packed));\n} command_2int_string_t;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int value0 __attribute__ ((packed));\n} command_int_t;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int value0 __attribute__ ((packed));\n unsigned char string[1] __attribute__ ((packed));\n} command_int_string_t;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned char string[1] __attribute__ ((packed));\n} command_string_t;\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int value0 __attribute__ ((packed));\n unsigned int value1 __attribute__ ((packed));\n unsigned int value2 __attribute__ ((packed));\n unsigned char string[1] __attribute__ ((packed));\n} command_3int_string_t;\n\nvoid dcln_build_send_packet(int command_len);\nvoid dcln_exit();\nint dcln_read(int fd, void * buf, size_t count);\nint dcln_write(int fd, const void *buf, size_t count);\nint dcln_open(const char *pathname, int flags, int perms);\nint dcln_close(int fd);\nint dcln_link(const char *oldpath, const char *newpath);\nint dcln_unlink(const char *pathname);\nint dcln_chdir(const char *path);\noff_t dcln_lseek(int fildes, off_t offset, int whence);\ntime_t dcln_time(time_t * t);\nint dcln_stat(const char *file_name, dcload_stat_t *buf);\nint dcln_opendir(const char *name);\nint dcln_closedir(int dir);\ndcload_dirent_t *dcln_readdir(int dir);\nsize_t dcln_gdbpacket(const char *in_buf, size_t in_size, char *out_buf, size_t out_size);\n\n__END_DECLS\n\n#endif\n"
},
{
"alpha_fraction": 0.5953654050827026,
"alphanum_fraction": 0.6390374302864075,
"avg_line_length": 20.576923370361328,
"blob_id": "cc8d651707391323615c7fb8e9bfb8bb5b5f08de",
"content_id": "6ae2cf537231a660e2acd7ed907a074406a82ac7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1122,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 52,
"path": "/kernel/net/net_input.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_input.c\n Copyright (C) 2002 Dan Potter\n Copyright (C) 2005 Lawrence Sebald\n*/\n\n#include <stdio.h>\n#include <kos/net.h>\n#include \"net_ipv4.h\"\n\nCVSID(\"$Id: net_input.c,v 1.2 2002/03/24 00:27:05 bardtx Exp $\");\n\n/*\n\n Main packet input system\n \n*/\n\nstatic int net_default_input(netif_t *nif, const uint8 *data, int len) {\n\tuint16 proto = (uint16)((data[12] << 8) | (data[13]));\n\n\tswitch(proto) {\n\t\tcase 0x0800:\n\t\t\treturn net_ipv4_input(nif, data + sizeof(eth_hdr_t),\n len - sizeof(eth_hdr_t));\n\n\t\tcase 0x0806:\n\t\t\treturn net_arp_input(nif, data, len);\n\n\t\tdefault:\n\t\t\treturn 0;\n\t}\n}\n\n/* Where will input packets be routed? */\nnet_input_func net_input_target = net_default_input;\n\n/* Process an incoming packet */\nint net_input(netif_t *device, const uint8 *data, int len) {\n\tif (net_input_target != NULL)\n\t\treturn net_input_target(device, data, len);\n\telse\n\t\treturn 0;\n}\n\n/* Setup an input target; returns the old target */\nnet_input_func net_input_set_target(net_input_func t) {\n\tnet_input_func old = net_input_target;\n\tnet_input_target = t;\n\treturn old;\n}\n"
},
{
"alpha_fraction": 0.6811715364456177,
"alphanum_fraction": 0.701255202293396,
"avg_line_length": 26.76744270324707,
"blob_id": "f3149897e80d239da3e8eddcbc67587e61971040",
"content_id": "2bf38cd751dfe7dc5e82567444b5c257f6a986af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1195,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 43,
"path": "/include/kos/fs_romdisk.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs_romdisk.h\n (c)2001 Dan Potter\n\n $Id: fs_romdisk.h,v 1.4 2002/08/13 04:54:22 bardtx Exp $\n*/\n\n#ifndef __KOS_FS_ROMDISK_H\n#define __KOS_FS_ROMDISK_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n\n#define MAX_RD_FILES 16\n\n/* Initialize the file system */\nint fs_romdisk_init();\n\n/* De-init the file system; also unmounts any mounted images. */\nint fs_romdisk_shutdown();\n\n/* NOTE: the mount/unmount are _not_ thread safe as regards doing multiple\n mounts/unmounts in different threads at the same time, and they don't\n check for open files currently either. Caveat emptor! */\n\n/* Mount a romdisk image; must have called fs_romdisk_init() earlier.\n Also note that we do _not_ take ownership of the image data if\n own_buffer is 0, so if you malloc'd that buffer, you must\n also free it after the unmount. If own_buffer is non-zero, then\n we free the buffer when it is unmounted. */\nint fs_romdisk_mount(const char * mountpoint, const uint8 *img, int own_buffer);\n\n/* Unmount a romdisk image */\nint fs_romdisk_unmount(const char * mountpoint);\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_ROMDISK_H */\n\n"
},
{
"alpha_fraction": 0.6734104156494141,
"alphanum_fraction": 0.6890173554420471,
"avg_line_length": 23.35211181640625,
"blob_id": "f41069c68e59306c246a09e0b4c171aa55cdd2a1",
"content_id": "11ec280c09f7c49df30b5ef6a32b2c23b7c82672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1730,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 71,
"path": "/include/kos/sem.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/sem.h\n Copyright (C)2001,2003 Dan Potter\n\n $Id: sem.h,v 1.7 2003/07/31 00:38:00 bardtx Exp $\n\n*/\n\n#ifndef __KOS_SEM_H\n#define __KOS_SEM_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/queue.h>\n#include <kos/thread.h>\n\n/* Semaphore structure definition */\ntypedef struct semaphore {\n\t/* List entry for the global list of semaphores */\n\tLIST_ENTRY(semaphore)\tg_list;\n\n\t/* Basic semaphore info */\n\tint\t\tcount;\t\t/* The semaphore count */\n} semaphore_t;\n\nLIST_HEAD(semlist, semaphore);\n\n/* Allocate a new semaphore. Sets errno to ENOMEM on failure. */\nsemaphore_t *sem_create(int value);\n\n/* Free a semaphore */\nvoid sem_destroy(semaphore_t *sem);\n\n/* Wait on a semaphore. Returns -1 on error:\n EPERM - called inside interrupt\n EINTR - wait was interrupted */\nint sem_wait(semaphore_t *sem);\n\n/* Wait on a semaphore, with timeout (in milliseconds); returns -1\n on failure, otherwise 0.\n EPERM - called inside interrupt\n EINTR - wait was interrupted\n EAGAIN - timed out */\nint sem_wait_timed(semaphore_t *sem, int timeout);\n\n/* Attempt to wait on a semaphore. If the semaphore would block,\n then return an error instead of actually blocking. Note that this\n function, unlike the other waits, DOES work inside an interrupt.\n EAGAIN - would block */\nint sem_trywait(semaphore_t *sem);\n\n/* Signal a semaphore */\nvoid sem_signal(semaphore_t *sem);\n\n/* Return the semaphore count */\nint sem_count(semaphore_t *sem);\n\n/* Called by the periodic thread interrupt to look for timed out\n sem_wait_timed calls */\nvoid sem_check_timeouts();\n\n/* Init / shutdown */\nint sem_init();\nvoid sem_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_SEM_H */\n\n"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6480186581611633,
"avg_line_length": 35.75714111328125,
"blob_id": "dd34fba6c0ff99218b0f2fa3fbb30541ef37f188",
"content_id": "0849ce126f1a49cf750a26c7c1174bf1e19111a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2574,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 70,
"path": "/include/addons/kos/img.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n kos/img.h\n (c)2002 Dan Potter\n\n $Id: img.h,v 1.4 2003/04/24 03:00:44 bardtx Exp $\n\n*/\n\n#ifndef __KOS_IMG_H\n#define __KOS_IMG_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* KOS Platform independent image struct; you can use this for textures or\n whatever you feel it's appropriate for. \"width\" and \"height\" are as you\n would expect. \"format\" has a lower-half which is platform independent\n and used to basically describe the contained data; the upper-half is\n platform dependent and can hold anything (so AND it off if you want\n the bottom part). Note that in some of the more obscure formats (like\n the paletted formats) the data interpretation _may_ be platform dependent.\n Thus we also provide a data-length field. */\ntypedef struct kos_img {\n\tvoid\t* data;\n\tuint32\tw, h;\n\tuint32\tfmt;\n\tuint32\tbyte_count;\n} kos_img_t;\n\n/* Access to the upper and lower pieces of the format word */\n#define KOS_IMG_FMT_I(x) ((x) & 0xffff)\t\t/* Platform independent part */\n#define KOS_IMG_FMT_D(x) (((x) >> 16) & 0xffff)\n\n/* Macro to create a new format word */\n#define KOS_IMG_FMT(i, d) ( ((i) & 0xffff) | (((d) & 0xffff) << 16) )\n\n/* Definitions for the plat independent part *************************************/\n\n/* Bitmap formats */\n#define KOS_IMG_FMT_NONE\t0x00\t/* Undefined */\n#define KOS_IMG_FMT_RGB888\t0x01\t/* Interleaved r/g/b bytes (24-bit) */\n#define KOS_IMG_FMT_ARGB8888\t0x02\t/* Interleaved a/r/g/b bytes (32-bit) */\n#define KOS_IMG_FMT_RGB565\t0x03\t/* r/g/b 5/6/5 (16-bit) */\n#define KOS_IMG_FMT_ARGB4444\t0x04\t/* a/r/g/b 4/4/4/4 (16-bit) */\n#define KOS_IMG_FMT_ARGB1555\t0x05\t/* a/r/g/b 1/5/5/5 (16-bit) */\n#define KOS_IMG_FMT_PAL4BPP\t0x06\t/* Paletted (4-bit) */\n#define KOS_IMG_FMT_PAL8BPP\t0x07\t/* Paletted (8-bit) */\n#define KOS_IMG_FMT_YUV422\t0x08\t/* y/u/v 4/2/2 (8-bit) */\n#define KOS_IMG_FMT_BGR565\t0x09\t/* b/g/r 5/6/5 (16-bit) */\n#define KOS_IMG_FMT_RGBA8888\t0x10\t/* Interleaved r/g/b/a bytes (32-bit) */\n#define KOS_IMG_FMT_MASK\t0xff\n\n/* Misc attributes */\n#define KOS_IMG_INVERTED_X\t0x0100\t/* X axis is inverted */\n#define KOS_IMG_INVERTED_Y\t0x0200\t/* Y axis is inverted */\n#define KOS_IMG_NOT_OWNER\t0x0400\t/* We don't own the buffer containing\n\t\t\t\t\t the data (ROM or similar) */\n\n/* Util functions ****************************************************************/\n\n/* Free a kos_img_t which was created by an image loader; set struct_also to non-zero\n if you want it to free the struct itself as well. */\nvoid kos_img_free(kos_img_t *img, int struct_also);\n\n__END_DECLS\n\n#endif\t/* __KOS_IMG_H */\n\n"
},
{
"alpha_fraction": 0.6546762585639954,
"alphanum_fraction": 0.6828536987304688,
"avg_line_length": 21.835617065429688,
"blob_id": "de5601bdff9ea6deacdda9de634121e2cf561d20",
"content_id": "5a287a35d013064f2073746b1b322405c03478f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1668,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 73,
"path": "/include/malloc.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n malloc.h\n Copyright (C)2003 Dan Potter\n\n $Id: malloc.h,v 1.6 2003/06/19 04:31:26 bardtx Exp $\n\n*/\n\n#ifndef __MALLOC_H\n#define __MALLOC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Unlike previous versions, we totally decouple the implementation from\n the declarations. */\n\n/* ANSI C functions */\nstruct mallinfo {\n\tint arena; /* non-mmapped space allocated from system */\n\tint ordblks; /* number of free chunks */\n\tint smblks; /* number of fastbin blocks */\n\tint hblks; /* number of mmapped regions */\n\tint hblkhd; /* space in mmapped regions */\n\tint usmblks; /* maximum total allocated space */\n\tint fsmblks; /* space available in freed fastbin blocks */\n\tint uordblks; /* total allocated space */\n\tint fordblks; /* total free space */\n\tint keepcost; /* top-most, releasable (via malloc_trim) space */\n};\n\nvoid * malloc(size_t size);\nvoid * calloc(size_t nmemb, size_t size);\nvoid free(void * ptr);\nvoid * realloc(void * ptr, size_t size);\nvoid * memalign(size_t alignment, size_t size);\nvoid * valloc(size_t size);\n\nstruct mallinfo mallinfo();\n\n/* mallopt defines */\n#define M_MXFAST 1\n#define DEFAULT_MXFAST 64\n\n#define M_TRIM_THRESHOLD -1\n#define DEFAULT_TRIM_THRESHOLD (256*1024)\n\n#define M_TOP_PAD -2\n#define DEFAULT_TOP_PAD 0\n\n#define M_MMAP_THRESHOLD -3\n#define DEFAULT_MMAP_THRESHOLD (256*1024)\n\n#define M_MMAP_MAX -4\n#define DEFAULT_MMAP_MAX 65536\nint mallopt(int, int);\n\n/* Debug function */\nvoid malloc_stats();\n\n/* KOS specfic calls */\nint malloc_irq_safe();\n\n/* Only available with KM_DBG */\nint mem_check_block(void *p);\nint mem_check_all();\n\n__END_DECLS\n\n#endif\t/* __MALLOC_H */\n\n"
},
{
"alpha_fraction": 0.673154354095459,
"alphanum_fraction": 0.6899328827857971,
"avg_line_length": 23.016128540039062,
"blob_id": "18b79b265790e22f640e932e75588e23fea1f9ad",
"content_id": "582deab5786ea569e2ba3f86fcf8d7015dcaf9d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1490,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 62,
"path": "/include/arch/ia32/arch/dbgio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/dbgio.h\n (c)2000 Dan Potter\n\n $Id: dbgio.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_DBGIO_H\n#define __ARCH_DBGIO_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Set another function to capture all debug output */\ntypedef void (*dbgio_printk_func)(const char *);\ndbgio_printk_func dbgio_set_printk(dbgio_printk_func func);\n\nextern dbgio_printk_func dbgio_printk;\n\n\n/* Set serial parameters; this is not platform independent like I want \n it to be, but it should be generic enough to be useful. */\nvoid dbgio_set_parameters(int baud, int fifo);\n\n/* Initialize the SCIF port */\nvoid dbgio_init();\n\n/* Write one char to the serial port (call serial_flush()!)*/\nvoid dbgio_write(int c);\n\n/* Flush all FIFO'd bytes out of the serial port buffer */\nvoid dbgio_flush();\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer(const uint8 *data, int len);\n\n/* Read an entire buffer (block) */\nvoid dbgio_read_buffer(uint8 *data, int len);\n\n/* Send a string (null-terminated) */\nvoid dbgio_write_str(const char *str);\n\n/* Null write-string function for pre-init */\nvoid dbgio_null_write(const char *str);\n\n/* Read one char from the serial port (-1 if nothing to read) */\nint dbgio_read();\n\n/* Enable / Disable debug I/O globally */\nvoid dbgio_disable();\nvoid dbgio_enable();\n\n/* Printf functionality */\nint dbgio_printf(const char *fmt, ...) __printflike(1, 2);\n\n__END_DECLS\n\n#endif\t/* __ARCH_DBGIO_H */\n\n"
},
{
"alpha_fraction": 0.6122152209281921,
"alphanum_fraction": 0.6282113194465637,
"avg_line_length": 35.513275146484375,
"blob_id": "cf3129d780d0a930e0cee0829e024b60c0bdfebe",
"content_id": "1db9453e920f7916427eed1173d4da1ab516fb3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8252,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 226,
"path": "/examples/dreamcast/conio/adventure/hdr.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*-\n * Copyright (c) 1991, 1993\n *\tThe Regents of the University of California. All rights reserved.\n *\n * The game adventure was originally written in Fortran by Will Crowther\n * and Don Woods. It was later translated to C and enhanced by Jim\n * Gillogly. This code is derived from software contributed to Berkeley\n * by Jim Gillogly at The Rand Corporation.\n *\n * Redistribution and use in source and binary forms, with or without\n * modification, are permitted provided that the following conditions\n * are met:\n * 1. Redistributions of source code must retain the above copyright\n * notice, this list of conditions and the following disclaimer.\n * 2. Redistributions in binary form must reproduce the above copyright\n * notice, this list of conditions and the following disclaimer in the\n * documentation and/or other materials provided with the distribution.\n * 3. All advertising materials mentioning features or use of this software\n * must display the following acknowledgement:\n *\tThis product includes software developed by the University of\n *\tCalifornia, Berkeley and its contributors.\n * 4. Neither the name of the University nor the names of its contributors\n * may be used to endorse or promote products derived from this software\n * without specific prior written permission.\n *\n * THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND\n * ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n * ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE\n * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS\n * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)\n * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY\n * OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\n * SUCH DAMAGE.\n *\n *\t@(#)hdr.h\t8.1 (Berkeley) 5/31/93\n */\n\n/* ADVENTURE -- Jim Gillogly, Jul 1977\n * This program is a re-write of ADVENT, written in FORTRAN mostly by\n * Don Woods of SAIL. In most places it is as nearly identical to the\n * original as possible given the language and word-size differences.\n * A few places, such as the message arrays and travel arrays were changed\n * to reflect the smaller core size and word size. The labels of the\n * original are reflected in this version, so that the comments of the\n * fortran are still applicable here.\n *\n * The data file distributed with the fortran source is assumed to be called\n * \"glorkz\" in the directory where the program is first run.\n *\n * $FreeBSD: src/games/adventure/hdr.h,v 1.5.2.1 2001/03/05 11:43:11 kris Exp $\n */\n\n/* hdr.h: included by c advent files */\n#ifdef SETUP\n#include <sys/types.h>\n#include <signal.h>\n#else\n#include \"porthelper.h\"\n#endif\n\nint datfd; /* message file descriptor */\n/* volatile sig_atomic_t delhit; */\nint yea;\nextern char data_file[]; /* Virtual data file */\n\n#define TAB '\\t'\n#define LF '\\n'\n#define FLUSHLINE do { int flushline_ch; while ((flushline_ch = getchar()) != EOF && flushline_ch != '\\n'); } while (0)\n#define FLUSHLF while (next()!=LF)\n\n\nint loc,newloc,oldloc,oldlc2,wzdark,gaveup,kq,k,k2;\nchar *wd1,*wd2; /* the complete words */\nint verb,obj,spk;\nextern int blklin;\nint saved,savet,mxscor,latncy;\n\n#define SHORT 50 /* How short is a demo game? */\n\n#define MAXSTR 20 /* max length of user's words */\n\n#define HTSIZE 512 /* max number of vocab words */\nstruct hashtab /* hash table for vocabulary */\n{ int val; /* word type &index (ktab) */\n\tchar *atab; /* pointer to actual string */\n} voc[HTSIZE];\n\n#define SEED 1815622 /* \"Encryption\" seed */\n\nstruct text\n#ifdef OLDSTUFF\n{ int seekadr; /* DATFILE must be < 2**16 */\n#endif /* !OLDSTUFF */\n{ char *seekadr; /* Msg start in virtual disk */\n\tint txtlen; /* length of msg starting here */\n};\n\n#define RTXSIZ 205\nstruct text rtext[RTXSIZ]; /* random text messages */\n\n#define MAGSIZ 35\nstruct text mtext[MAGSIZ]; /* magic messages */\n\nint clsses;\n#define CLSMAX 12\nstruct text ctext[CLSMAX]; /* classes of adventurer */\nint cval[CLSMAX];\n\nstruct text ptext[101]; /* object descriptions */\n\n#define LOCSIZ 141 /* number of locations */\nstruct text ltext[LOCSIZ]; /* long loc description */\nstruct text stext[LOCSIZ]; /* short loc descriptions */\n\nstruct travlist /* direcs & conditions of travel*/\n{ struct travlist *next; /* ptr to next list entry */\n\tint conditions; /* m in writeup (newloc / 1000) */\n\tint tloc; /* n in writeup (newloc % 1000) */\n\tint tverb; /* the verb that takes you there*/\n} *travel[LOCSIZ],*tkk; /* travel is closer to keys(...)*/\n\nint atloc[LOCSIZ];\n\nint plac[101]; /* initial object placement */\nint fixd[101],fixed[101]; /* location fixed? */\n\nint actspk[35]; /* rtext msg for verb <n> */\n\nint cond[LOCSIZ]; /* various condition bits */\n\nextern int setbit[16]; /* bit defn masks 1,2,4,... */\n\nint hntmax;\nint hints[20][5]; /* info on hints */\nint hinted[20],hintlc[20];\n\nint place[101], prop[101],linkx[201];\nint abb[LOCSIZ];\n\nint maxtrs,tally,tally2; /* treasure values */\n\n#define FALSE 0\n#define TRUE 1\n\nint keys,lamp,grate,cage,rod,rod2,steps,/* mnemonics */\n\tbird,door,pillow,snake,fissur,tablet,clam,oyster,magzin,\n\tdwarf,knife,food,bottle,water,oil,plant,plant2,axe,mirror,dragon,\n\tchasm,troll,troll2,bear,messag,vend,batter,\n\tnugget,coins,chest,eggs,tridnt,vase,emrald,pyram,pearl,rug,chain,\n\tspices,\n\tback,look,cave,null,entrnc,dprssn,\n\tenter, stream, pour,\n\tsay,lock,throw,find,invent;\n\nint chloc,chloc2,dseen[7],dloc[7], /* dwarf stuff */\n\todloc[7],dflag,daltlc;\n\nint tk[21],stick,dtotal,attack;\nint turns,lmwarn,iwest,knfloc,detail, /* various flags & counters */\n\tabbnum,maxdie,numdie,holdng,dkill,foobar,bonus,clock1,clock2,\n\tclosng,apanic,closed,scorng;\n\nint demo,limit;\n\nint at (int objj);\nint bug (int n);\nvoid carry (int, int);\nvoid caveclose (void);\nvoid checkhints (void);\nvoid ciao (void);\nvoid closing (void);\nu_long crc (const char *ptr, int nr);\nvoid crc_start (void);\nint dark (void);\nvoid datime (int *d, int *t);\nchar *decr (int, int, int, int, int);\nvoid die (int entry);\nvoid done (int entry);\nvoid drop (int object,int where);\nvoid dstroy (int);\nint fdwarf (void);\nint forced (int locc);\nvoid getin (char **wrd1, char **wrd2);\nint here (int objj);\nvoid init (void);\nvoid juggle (int);\nint liq (void);\nint liqloc (int locc);\nint march (void);\nvoid move (int, int);\nvoid mspeak (int);\nint pct (int n);\nvoid poof (void);\nvoid pspeak (int m, int skip);\nint put (int, int, int);\nint ran (int range);\nvoid rdata (void);\nint restore (const char *infile);\nvoid rspeak (int);\nint save (const char *);\nint score (void);\nvoid speak (const struct text *);\nint Start (void);\nvoid startup (void);\nint toting (int objj);\nvoid trapdel (int sig);\nint trdrop (void);\nint trfeed (void);\nint trfill (void);\nint trkill (void);\nint tropen (void);\nint trsay (void);\nint trtake (void);\nint trtoss (void);\nint vocab (const char *,int,int);\nint yes (int x, int y, int z);\nint yesm (int x, int y, int z);\n\n/* We need to get a little tricky to avoid strings */\n/* #define DECR(a,b,c,d,e) decr('a'+'+','b'+'-','c'+'#','d'+'&','e'+'%') */\n#define DECR(a,b,c,d,e) ( #a #b #c #d #e )\n\n/* gid_t\tegid; */\n"
},
{
"alpha_fraction": 0.6051282286643982,
"alphanum_fraction": 0.6307692527770996,
"avg_line_length": 14,
"blob_id": "b5ea76881c0fa14967c503a2c6352d79e84276f3",
"content_id": "aa61f0414f66ccc94e81aae9903e5f40129d6b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/kernel/libc/newlib/newlib_times.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n newlib_times.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <sys/reent.h>\n#include <sys/times.h>\n\nint _times_r(struct _reent * re, struct tms * tmsbuf) {\n\treturn -1;\n}\n"
},
{
"alpha_fraction": 0.6323686838150024,
"alphanum_fraction": 0.6655948758125305,
"avg_line_length": 16.27777862548828,
"blob_id": "a6e5ecaaf5607609558c042de77dbc985ed56676",
"content_id": "1b3d5ae19d810e75a1ffefaf7ed50b08072a3112",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 933,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 54,
"path": "/include/netinet/in.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n netinet/in.h\n Copyright (C) 2006, 2007 Lawrence Sebald\n\n*/\n\n#ifndef __NETINET_IN_H\n#define __NETINET_IN_H\n\n#include <sys/cdefs.h>\n#include <arch/types.h>\n\n__BEGIN_DECLS\n\n#ifndef __IN_PORT_T_DEFINED\n#define __IN_PORT_T_DEFINED\ntypedef uint16 in_port_t;\n#endif\n\n#ifndef __IN_ADDR_T_DEFINED\n#define __IN_ADDR_T_DEFINED\ntypedef uint32 in_addr_t;\n#endif\n\n#ifndef __SA_FAMILY_T_DEFINED\n#define __SA_FAMILY_T_DEFINED\ntypedef uint32 sa_family_t;\n#endif\n\nstruct in_addr {\n in_addr_t s_addr;\n};\n\nstruct sockaddr_in {\n sa_family_t sin_family;\n in_port_t sin_port;\n struct in_addr sin_addr;\n unsigned char sin_zero[8];\n};\n\n#define INADDR_ANY 0x00000000\n#define INADDR_BROADCAST 0xFFFFFFFF\n#define INADDR_NONE 0xFFFFFFFF\n\n/* IP Protocols */\n#define IPPROTO_IP 0\n#define IPPROTO_ICMP 1\n#define IPPROTO_TCP 6\n#define IPPROTO_UDP 17\n\n__END_DECLS\n\n#endif /* __NETINET_IN_H */\n"
},
{
"alpha_fraction": 0.6023080348968506,
"alphanum_fraction": 0.6209498643875122,
"avg_line_length": 23.21505355834961,
"blob_id": "d1c553c14aafe7a6fda1a06b103d8088852c51a1",
"content_id": "249e06b53e9e490e8bce610d69ea0048376cac34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2253,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 93,
"path": "/utils/cvs_utils/vcheck.py",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# A simple little script which takes the output of a \"cvs status\" command\n# and parses it into a more usable format for a large number of files.\n#\n# (c)2002 Dan Potter\n#\n# $Id: vcheck.py,v 1.3 2002/10/26 08:03:18 bardtx Exp $\n#\n\nimport sys, string, os, re\n\n# Exclude any files which match these patterns\nexclude_files = [\n\t\".*elf\", \".*bz2\", \".*run.gdb\", \".*romdisk.*img\",\n\t\".*environ.*\"\n]\n\ndef main():\n\t# Run cvs status and get the output\n\tp = os.popen(\"cvs status\")\n\t# p = os.popen(\"cat test.txt\")\n\tcvs_output = p.read()\n\tp.close()\n\n\t# Parse the output into lines\n\tlines = string.split(cvs_output, \"\\n\")\n\tline_count = len(lines)\n\n\t# Get the unknown file names and remove them from the main list\n\tunknown_lines = filter(lambda x:len(x)>0 and x[0]=='?', lines)\n\tunknown_names = map(lambda x:x[2:], unknown_lines)\n\tlines = filter(lambda x,l=unknown_lines:x not in l, lines)\n\tassert ( len(lines) + len(unknown_lines) ) == line_count\n\n\t# Now seperate everything else into buckets\n\tbuckets = [ ]\n\tcur_bucket = None\n\tfor i in range(len(lines)):\n\t\tline = lines[i]\n\t\tif line[:4] == \"====\":\n\t\t\tif cur_bucket is not None:\n\t\t\t\tbuckets.append(cur_bucket)\n\t\t\tcur_bucket = [ ]\n\t\telse:\n\t\t\tif len(line) > 0:\n\t\t\t\tcur_bucket.append(line)\n\tif len(cur_bucket) > 0:\n\t\tbuckets.append(cur_bucket)\n\n\tprint \"Processed %d files\" % ( len(buckets) + len(unknown_names) )\n\n\t# Now for each bucket, extract the filename and the version\n\tif len(unknown_names) > 0:\n\t\tfiles = { 'Unknown': unknown_names }\n\telse:\n\t\tfiles = { }\n\tfor i in buckets:\n\t\tj = i[0]\n\t\tw = string.find(j, \"Status:\");\n\t\tassert w != -1\n\t\tstatus = j[w+8:]\n\n\t\tj = i[2]\n\t\tw = string.split(j, \"\\t\")\n\t\tif len(w) == 3:\n\t\t\tfile = w[2]\n\t\telse:\n\t\t\tfile = string.split(i[0])[1]\n\n\t\tif files.has_key(status):\n\t\t\tfiles[status].append(file)\n\t\telse:\n\t\t\tfiles[status] = [ file ] \n\n\t# Output a list of each file not in the Up-to-date status\n\tfor i in files.keys():\n\t\tif i == \"Up-to-date\": continue\n\t\tprint \"Files with status '%s':\" % i\n\t\tskipped_cnt = 0\n\t\tfor j in files[i]:\n\t\t\tpas = 1\n\t\t\tfor k in exclude_files:\n\t\t\t\tif re.compile(k).match(j, 1):\n\t\t\t\t\tpas = 0\n\t\t\tif pas:\n\t\t\t\tprint \" %s\" % j\n\t\t\telse:\n\t\t\t\tskipped_cnt = skipped_cnt + 1\n\t\tif skipped_cnt > 0:\n\t\t\tprint \" (%d files excluded)\" % skipped_cnt\n\nmain()\n\n"
},
{
"alpha_fraction": 0.713936448097229,
"alphanum_fraction": 0.713936448097229,
"avg_line_length": 20.526315689086914,
"blob_id": "99a5583b4fc84c8671c5c90fa7ce92d21d28ea9b",
"content_id": "94f35b5e6d8fe41aff2f9b82f66d8d8ed00c7b2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 409,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 19,
"path": "/include/sys/stdio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#ifndef _NEWLIB_STDIO_H\n#define _NEWLIB_STDIO_H\n\n// Cribbed from newlib sys/stdio.h\n\n/* Internal locking macros, used to protect stdio functions. In the\n general case, expand to nothing. */\n#if !defined(_flockfile)\n# define _flockfile(fp)\n#endif\n\n#if !defined(_funlockfile)\n# define _funlockfile(fp)\n#endif\n\n// Added for old KOS source compatability\n#include <kos/dbglog.h>\n\n#endif /* _NEWLIB_STDIO_H */\n"
},
{
"alpha_fraction": 0.6187613010406494,
"alphanum_fraction": 0.6355983018875122,
"avg_line_length": 24.16666603088379,
"blob_id": "2bb2658e5f02309e427435113fdfc94a24a20dd2",
"content_id": "b78e2af0a071109cfb18690aa2fef8bb6d86bcc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1663,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 66,
"path": "/libc/include/sys/cdefs.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sys/cdefs.h\n (c)2002 Dan Potter\n\n $Id: cdefs.h,v 1.2 2002/10/26 08:01:34 bardtx Exp $\n\n Based loosely around some stuff in BSD's sys/cdefs.h\n*/\n\n#ifndef __SYS_CDEFS_H\n#define __SYS_CDEFS_H\n\n/* Check GCC version */\n#ifndef _arch_ps2\n#\tif __GNUC__ < 2\n#\t\twarning Your GCC is too old. This will probably not work right.\n#\tendif\n\n#\tif __GNUC__ == 2 && __GNUC_MINOR__ < 97\n#\t\twarning Your GCC is too old. This will probably not work right.\n#\tendif\n#endif\t/* _arch_ps2 */\n\n/* Special function/variable attributes */\n#define __noreturn\t__attribute__((__noreturn__))\n#define __pure\t\t__attribute__((__const__))\n#define __unused\t__attribute__((__unused__))\n\n#define __dead2\t\t__noreturn\t/* BSD compat */\n#define __pure2\t\t__pure\t\t/* ditto */\n\n/* Printf/Scanf-like declaration */\n#define __printflike(fmtarg, firstvararg) \\\n\t__attribute__((__format__ (__printf__, fmtarg, firstvararg)))\n\n#define __scanflike(fmtarg, firstvararg) \\\n\t__attribute__((__format__ (__printf__, fmtarg, firstvararg)))\n\n/* C++ compatability support */\n#ifdef __cplusplus\n#\tdefine __BEGIN_DECLS\textern \"C\" {\n#\tdefine __END_DECLS\t}\n#else\n#\tdefine __BEGIN_DECLS\n#\tdefine __END_DECLS\n#endif\n\n/* GCC macros for special cases */\n/* #if __GNUC__ == */\n\n/* Optional CVS ID tags, without warnings */\n#if defined(__GNUC__) && defined(__ELF__)\n#\tdefine __IDSTRING(name, string) __asm__(\".ident\\t\\\"\" string \"\\\"\")\n#else\n#\tdefine __IDSTRING(name, string) static const char name[] __unused = string;\n#endif\n\n#ifndef NO_CVS_ID\n#\tdefine IDSTRING(name, s) __IDSTRING(name, s)\n#\tdefine CVSID(s) __IDSTRING(cvsid, \"KOS \" s)\n#else\n#\tdefine IDSTRING(s)\n#endif\n\n#endif\t/* __SYS_CDEFS_H */\n\n\n"
},
{
"alpha_fraction": 0.6287228465080261,
"alphanum_fraction": 0.7057042121887207,
"avg_line_length": 45.16666793823242,
"blob_id": "eff9a2936b1569e241afa21cf99440a7e02eb14a",
"content_id": "7d9fa4c5e3b06097f4e3017cee43ea4644fb7ec5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3962,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 84,
"path": "/include/arch/dreamcast/dc/modem/modem.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\r\n\r\n modem.h\r\n Copyright (C)2002, 2004 Nick Kochakian\r\n\r\n Distributed under the terms of the KOS license.\r\n\r\n $Id: modem.h,v 1.1 2003/05/23 02:05:02 bardtx Exp $\r\n*/\r\n\r\n#ifndef __DC_MODEM_MODEM_H\r\n#define __DC_MODEM_MODEM_H\r\n\r\n#include \"mconst.h\"\r\n\r\n#define MODEM_MODE_REMOTE 0 /* Connect to a remote modem */\r\n#define MODEM_MODE_ANSWER 1 /* Answer a call when a ring is detected */\r\n#define MODEM_MODE_NULL 255 /* Not doing anything. Don't give this to\r\n any function! */\r\n\r\n/* V.22 bis modes */\r\n#define MODEM_SPEED_V22BIS_1200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V22BIS, MODEM_SPEED_1200)\r\n#define MODEM_SPEED_V22BIS_2400 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V22BIS, MODEM_SPEED_2400)\r\n\r\n/* V.22 modes */\r\n#define MODEM_SPEED_V22_1200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V22, MODEM_SPEED_1200)\r\n\r\n/* V.32 modes */\r\n#define MODEM_SPEED_V32_4800 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V32, MODEM_SPEED_4800)\r\n#define MODEM_SPEED_V32_9600 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V32, MODEM_SPEED_9600)\r\n\r\n/* V.32 bis modes */\r\n#define MODEM_SPEED_V32BIS_7200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V32BIS, MODEM_SPEED_7200)\r\n#define MODEM_SPEED_V32BIS_12000 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V32BIS, MODEM_SPEED_12000)\r\n#define MODEM_SPEED_V32BIS_14400 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V32BIS, MODEM_SPEED_14400)\r\n\r\n/* V.8 modes */\r\n#define MODEM_SPEED_V8_2400 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_2400)\r\n#define MODEM_SPEED_V8_4800 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_4800)\r\n#define MODEM_SPEED_V8_7200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_7200)\r\n#define MODEM_SPEED_V8_9600 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_9600)\r\n#define MODEM_SPEED_V8_12000 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_12000)\r\n#define MODEM_SPEED_V8_14400 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_14400)\r\n#define MODEM_SPEED_V8_16800 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_16800)\r\n#define MODEM_SPEED_V8_19200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_19200)\r\n#define MODEM_SPEED_V8_21600 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_21600)\r\n#define MODEM_SPEED_V8_24000 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_24000)\r\n#define MODEM_SPEED_V8_26400 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_26400)\r\n#define MODEM_SPEED_V8_28000 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_28000)\r\n#define MODEM_SPEED_V8_31200 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_31200)\r\n#define MODEM_SPEED_V8_33600 MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_33600)\r\n#define MODEM_SPEED_V8_AUTO MODEM_MAKE_SPEED(MODEM_PROTOCOL_V8, MODEM_SPEED_1200)\r\n\r\n/* Event constants */\r\ntypedef enum\r\n{\r\n MODEM_EVENT_CONNECTION_FAILED = 0, /* The modem tried to establish a connection but failed */\r\n MODEM_EVENT_CONNECTED, /* A connection has been established */\r\n MODEM_EVENT_DISCONNECTED, /* The remote modem dropped the connection */\r\n MODEM_EVENT_RX_NOT_EMPTY, /* New data has entered the previously empty receive buffer */\r\n MODEM_EVENT_OVERFLOW, /* The receive buffer overflowed and was cleared */\r\n MODEM_EVENT_TX_EMPTY /* The transmission buffer has been emptied */\r\n} modemEvent_t;\r\n\r\ntypedef void (*MODEMEVENTHANDLERPROC)(modemEvent_t event);\r\n\r\n/* From modem.c */\r\nint modem_init(void);\r\nvoid modem_shutdown(void);\r\nint modem_set_mode(int mode, modem_speed_t speed);\r\nint modem_wait_dialtone(int ms_timeout);\r\nint modem_dial(const char *digits);\r\nvoid modem_set_event_handler(MODEMEVENTHANDLERPROC eventHandler);\r\nvoid modem_disconnect(void);\r\nint modem_is_connecting(void);\r\nint modem_is_connected(void);\r\nunsigned long modem_get_connection_rate(void);\r\n\r\n/* From mdata.c */\r\nint modem_read_data(unsigned char *data, int size);\r\nint modem_write_data(unsigned char *data, int size);\r\nint modem_has_data(void);\r\n\r\n#endif\r\n"
},
{
"alpha_fraction": 0.6489591002464294,
"alphanum_fraction": 0.6733668446540833,
"avg_line_length": 20.41538429260254,
"blob_id": "b0304bf1966e9a653f84293a201e3de48919b76d",
"content_id": "d229a727938db15745a07d2ab2060ef3cebbb63a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1393,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 65,
"path": "/include/arch/gba/arch/arch.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/arch.h\n (c)2001 Dan Potter\n \n $Id: arch.h,v 1.4 2003/02/17 00:47:38 bardtx Exp $\n*/\n\n#ifndef __ARCH_ARCH_H\n#define __ARCH_ARCH_H\n\n#include <arch/types.h>\n\n/* Number of timer ticks per second (if using threads) */\n#define HZ\t\t100\n\n/* Default thread stack size (if using threads) */\n#define THD_STACK_SIZE\t8192\n\n/* Default video mode */\n\n/* Default serial parameters */\n\n/* Panic function */\nvoid panic(char *str);\n\n/* Prototype for the portable kernel main() */\nint kernel_main(const char *args);\n\n/* Kernel C-level entry point */\nint arch_main();\n\n/* Kernel \"quit\" point */\nvoid arch_exit();\n\n/* Kernel \"reboot\" call */\nvoid arch_reboot();\n\n/* Use this macro to determine the level of initialization you'd like in\n your program by default. The defaults line will be fine for most things. */\n#define KOS_INIT_FLAGS(flags)\tuint32 __kos_init_flags = (flags)\n\nextern uint32 __kos_init_flags;\n\n/* Defaults */\n#define INIT_DEFAULT \\\n\tINIT_IRQ\n\n/* Define a romdisk for your program, if you'd like one */\n#define KOS_INIT_ROMDISK(rd)\tvoid * __kos_romdisk = (rd)\n\nextern void * __kos_romdisk;\n\n/* State that you don't want a romdisk */\n#define KOS_INIT_ROMDISK_NONE\tNULL\n\n/* Constants for the above */\n#define INIT_NONE\t\t0\t\t/* Kernel enables */\n#define INIT_IRQ\t\t1\n#define INIT_MALLOCSTATS\t8\n\n/* CPU sleep */\n#define arch_sleep()\n\n#endif\t/* __ARCH_ARCH_H */\n\n"
},
{
"alpha_fraction": 0.4030769169330597,
"alphanum_fraction": 0.5030769109725952,
"avg_line_length": 16.078947067260742,
"blob_id": "d7f331a60c85ec63b17bd959bbae8dea0e3dc1db",
"content_id": "7dd4e5dbfd9933cef1444a219404e5e8cb47879d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 650,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 38,
"path": "/examples/dreamcast/libdream/320x240/320x240.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <kos.h>\n\n#define W 320\n#define H 240\n\nKOS_INIT_FLAGS(INIT_IRQ);\n\nint main(int argc, char **argv) {\n\tint x, y;\n\n\t/* Set the video mode */\n\tvid_set_mode(DM_320x240, PM_RGB565);\n\t\n\tfor (y=0; y<240; y++)\n\t\tfor (x=0; x<320; x++) {\n\t\t\tint c = (x ^ y) & 255;\n\t\t\tvram_s[y*320+x] = ((c >> 3) << 12)\n\t\t\t\t| ((c >> 2) << 5)\n\t\t\t\t| ((c >> 3) << 0);\n\t\t}\n\n\tfor (y=0; y<H; y+=24) {\n\t\tchar tmp[16];\n\t\tsprintf(tmp, \"%d\", y);\n\t\tbfont_draw_str(vram_s+y*W+10, W, 0, tmp);\n\t}\n\n\tfor (x=0; x<W; x+=100) {\n\t\tchar tmp[16];\n\t\tsprintf(tmp, \"%d\", x/10);\n\t\tbfont_draw_str(vram_s+10*W+x, W, 0, tmp);\n\t}\n\n\t/* Pause to see the results */\n\tusleep(5*1000*1000);\n\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6602162718772888,
"alphanum_fraction": 0.6994877457618713,
"avg_line_length": 26.23255729675293,
"blob_id": "5b3611b6d7ce361c1e77e037382916100c161521",
"content_id": "6a3aaa8135840ca465f4095f6b5ae5738117c727",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3514,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 129,
"path": "/include/arch/ia32/arch/arch.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ia32/include/arch.h\n Copyright (C)2001,2003 Dan Potter\n \n $Id: arch.h,v 1.2 2003/08/02 23:09:26 bardtx Exp $\n*/\n\n#ifndef __ARCH_ARCH_H\n#define __ARCH_ARCH_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Page size info (for MMU) */\n#define PAGESIZE\t4096\n#define PAGESIZE_BITS\t12\n#define PAGEMASK\t(PAGESIZE - 1)\n\n/* Page count variable; in this case it's static, so we can\n optimize this quite a bit. */\n// XXX Need to ask the BIOS at start time\n#define page_count ((32*1024*1024 - 0x10000) / PAGESIZE)\n\n/* Base address of available physical pages */\n#define page_phys_base 0x00010000\n\n/* Number of timer ticks per second */\n#define HZ\t\t100\n\n/* Default thread stack size */\n#define THD_STACK_SIZE\t8192\n\n/* Default serial parameters */\n#define DEFAULT_SERIAL_BAUD\t57600\n#define DEFAULT_SERIAL_FIFO\t1\n\n/* Do we need symbol prefixes? */\n#define ELF_SYM_PREFIX \"\"\n#define ELF_SYM_PREFIX_LEN 0\n\n/* Panic function */\nvoid panic(const char *str) __noreturn;\n\n/* Prototype for the portable kernel main() */\nint kernel_main(const char *args);\n\n/* Kernel C-level entry point */\nint arch_main();\n\n/* Generic kernel \"exit\" point */\nvoid arch_exit() __noreturn;\n\n/* Kernel \"return\" point */\nvoid arch_return() __noreturn;\n\n/* Kernel \"abort\" point */\nvoid arch_abort() __noreturn;\n\n/* Kernel \"reboot\" call */\nvoid arch_reboot() __noreturn;\n\n/* Call to run all ctors / dtors */\nvoid arch_ctors();\nvoid arch_dtors();\n\n/* Hook to ensure linking of crtend.c */\nvoid __crtend_pullin();\n\n/* Use this macro to determine the level of initialization you'd like in\n your program by default. The defaults line will be fine for most things. */\n#define KOS_INIT_FLAGS(flags)\tuint32 __kos_init_flags = (flags)\n\nextern uint32 __kos_init_flags;\n\n/* Defaults */\n#define INIT_DEFAULT \\\n\t(INIT_IRQ | INIT_THD_PREEMPT)\n\n/* Define a romdisk for your program, if you'd like one */\n#define KOS_INIT_ROMDISK(rd)\tvoid * __kos_romdisk = (rd)\n\nextern void * __kos_romdisk;\n\n/* State that you don't want a romdisk */\n#define KOS_INIT_ROMDISK_NONE\tNULL\n\n/* Constants for the above */\n#define INIT_NONE\t\t0x0000\t\t/* Kernel enables */\n#define INIT_IRQ\t\t0x0001\n#define INIT_THD_PREEMPT\t0x0002\n#define INIT_NET\t\t0x0004\n#define INIT_MALLOCSTATS\t0x0008\n#define INIT_QUIET\t\t0x0010\n\n/* Call this function to remove all arch-specific traces of a process */\nstruct kprocess;\nvoid arch_remove_process(struct kprocess * proc);\n\n/* ia32 specific sleep mode function */\n#define arch_sleep() do { \\\n\t\t__asm__ __volatile__(\"hlt\"); \\\n\t} while(0)\n\n/* ia32 specific function to get the return address from the current function */\n#define arch_get_ret_addr() (0)\n\n/* Please note that all of the following frame pointer macros are ONLY\n valid if you have compiled your code WITHOUT -fomit-frame-pointer. These\n are mainly useful for getting a stack trace from an error. */\n\n/* ia32 specific function to get the frame pointer from the current function */\n#define arch_get_fptr() (0)\n\n/* Pass in a frame pointer value to get the return address for the given frame */\n#define arch_fptr_ret_addr(fptr) (*((uint32*)fptr))\n\n/* Pass in a frame pointer value to get the previous frame pointer for the given frame */\n#define arch_fptr_next(fptr) (*((uint32*)(fptr+4)))\n\n/* Returns true if the passed address is likely to be valid. Doesn't\n have to be exact, just a sort of general idea. */\n#define arch_valid_address(ptr) ((ptr_t)(ptr) >= 0x00010000 && (ptr_t)(ptr) < 0x01000000)\n\n__END_DECLS\n\n#endif\t/* __ARCH_ARCH_H */\n\n"
},
{
"alpha_fraction": 0.639053225517273,
"alphanum_fraction": 0.6576500535011292,
"avg_line_length": 23.38144302368164,
"blob_id": "c0b4b5ffa3a3e15d18def0e4d007af5e7a35fa64",
"content_id": "2afe64b5c591fd2b38c7cdeafdcd02e23a891705",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2366,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 97,
"path": "/kernel/arch/dreamcast/hardware/maple/mouse.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n mouse.c\n (C)2002 Dan Potter\n*/\n\n#include <dc/maple.h>\n#include <dc/maple/mouse.h>\n#include <string.h>\n#include <assert.h>\n\nCVSID(\"$Id: mouse.c,v 1.3 2002/05/24 06:47:26 bardtx Exp $\");\n\nstatic void mouse_reply(maple_frame_t *frm) {\n\tmaple_response_t\t*resp;\n\tuint32\t\t\t*respbuf;\n\tmouse_cond_t\t\t*raw;\n\tmouse_state_t\t\t*cooked;\n\n\t/* Unlock the frame now (it's ok, we're in an IRQ) */\n\tmaple_frame_unlock(frm);\n\n\t/* Make sure we got a valid response */\n\tresp = (maple_response_t *)frm->recv_buf;\n\tif (resp->response != MAPLE_RESPONSE_DATATRF)\n\t\treturn;\n\trespbuf = (uint32 *)resp->data;\n\tif (respbuf[0] != MAPLE_FUNC_MOUSE)\n\t\treturn;\n\n\t/* Update the status area from the response */\n\tif (frm->dev) {\n\t\t/* Verify the size of the frame and grab a pointer to it */\n\t\tassert( sizeof(mouse_cond_t) == ((resp->data_len-1) * 4) );\n\t\traw = (mouse_cond_t *)(respbuf+1);\n\n\t\t/* Fill the \"nice\" struct from the raw data */\n\t\tcooked = (mouse_state_t *)(frm->dev->status);\n\t\tcooked->buttons = (~raw->buttons) & 14;\n\t\tcooked->dx = raw->dx - MOUSE_DELTA_CENTER;\n\t\tcooked->dy = raw->dy - MOUSE_DELTA_CENTER;\n\t\tcooked->dz = raw->dz - MOUSE_DELTA_CENTER;\n\t\tfrm->dev->status_valid = 1;\n\t}\n}\n\nstatic int mouse_poll(maple_device_t *dev) {\n\tuint32 * send_buf;\n\n\tif (maple_frame_lock(&dev->frame) < 0)\n\t\treturn 0;\n\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MOUSE;\n\tdev->frame.cmd = MAPLE_COMMAND_GETCOND;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 1;\n\tdev->frame.callback = mouse_reply;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\treturn 0;\n}\n\nstatic void mouse_periodic(maple_driver_t *drv) {\n\tmaple_driver_foreach(drv, mouse_poll);\n}\n\nstatic int mouse_attach(maple_driver_t *drv, maple_device_t *dev) {\n\tmemset(dev->status, 0, sizeof(dev->status));\n\tdev->status_valid = 0;\n\treturn 0;\n}\n\nstatic void mouse_detach(maple_driver_t *drv, maple_device_t *dev) {\n\tdev->status_valid = 0;\n}\n\n/* Device Driver Struct */\nstatic maple_driver_t mouse_drv = {\n\tfunctions:\tMAPLE_FUNC_MOUSE,\n\tname:\t\t\"Mouse Driver\",\n\tperiodic:\tmouse_periodic,\n\tattach:\t\tmouse_attach,\n\tdetach:\t\tmouse_detach\n};\n\n/* Add the mouse to the driver chain */\nint mouse_init() {\n\treturn maple_driver_reg(&mouse_drv);\n}\n\nvoid mouse_shutdown() {\n\tmaple_driver_unreg(&mouse_drv);\n}\n\n"
},
{
"alpha_fraction": 0.43798118829727173,
"alphanum_fraction": 0.4927288293838501,
"avg_line_length": 15.464788436889648,
"blob_id": "d767678578df35b15da5f24c55729bdf947b93e6",
"content_id": "df5cc189fdc53d1135b2414ced6afbd2db975299",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1169,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 71,
"path": "/examples/dreamcast/libdream/keyboard/keyboard.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <kos.h>\n\nvoid kb_test() {\n\tuint8 mcont, mkb;\n\tcont_cond_t cond;\n\tint k, x = 20, y = 20+24;\n\n\tprintf(\"Now doing keyboard test\\n\");\t\n\n\twhile (1) {\n\t\tmcont = maple_first_controller();\n\t\tif (!mcont) continue;\n\t\tmkb = maple_first_kb();\n\t\tif (!mkb) continue;\n\t\t\n\t\t/* Check for start on the controller */\n\t\tif (cont_get_cond(mcont, &cond) < 0) {\n\t\t\treturn;\n\t\t}\n\t\t\n\t\tif (!(cond.buttons & CONT_START)) {\n\t\t\tprintf(\"Pressed start\\n\");\n\t\t\treturn;\n\t\t}\n\t\t\n\t\tusleep(10 * 1000);\n\t\t\n\t\t/* Check for keyboard input */\n\t\t/* if (kbd_poll(mkb)) {\n\t\t\tprintf(\"Error checking keyboard status\\n\");\n\t\t\treturn;\n\t\t} */\n\n\t\t/* Get queued keys */\n\t\twhile ( (k = kbd_get_key()) != -1) {\n\t\t\tif (k > 0xff)\n\t\t\t\tprintf(\"Special key %04x\\n\", k);\n\t\t\t\n\t\t\tif (k != 13) {\n\t\t\t\tbfont_draw(vram_s + y*640+x, 640, 0, k);\n\t\t\t\tx += 12;\n\t\t\t} else {\n\t\t\t\tx = 20;\n\t\t\t\ty += 24;\n\t\t\t}\n\t\t}\n\t\t\n\t\tif (k == 27) {\n\t\t\tprintf(\"ESC pressed\\n\");\n\t\t\tbreak;\n\t\t}\n\n\t\tusleep(10 * 1000);\n\t}\n}\n\nint main(int argc, char **argv) {\n\tint x, y;\n\n\tfor (y=0; y<480; y++)\n\t\tfor (x=0; x<640; x++) {\n\t\t\tint c = (x ^ y) & 255;\n\t\t\tvram_s[y*640+x] = ((c >> 3) << 12)\n\t\t\t\t| ((c >> 2) << 5)\n\t\t\t\t| ((c >> 3) << 0);\n\t\t}\n\n\tkb_test();\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6027397513389587,
"alphanum_fraction": 0.6301369667053223,
"avg_line_length": 17.774192810058594,
"blob_id": "bfb1059083be11c12b0a112cb61f7aefd63757b2",
"content_id": "84b9396fab11c1d76baf8aff1a8c056be44026c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 31,
"path": "/examples/dreamcast/kgl/demos/tunnel/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n# \n# tunnel Makefile\n#\n# $Id: Makefile,v 1.4 2002/09/05 07:40:48 bardtx Exp $\n# \n\nTARGET = tunnel.elf\nOBJS = tunnel.o plprint.o menu.o tunneldat.o\n\nKOS_ROMDISK_DIR=romdisk\n\nall: rm-elf $(TARGET)\n\ninclude $(KOS_PATH)/scripts/Makefile.rules\n\nclean:\n\t-rm -f $(TARGET) $(BIN) $(OBJS) romdisk.*\n\nrm-elf:\n\t-rm -f $(TARGET) $(BIN) romdisk.*\n\n$(TARGET): $(OBJS) romdisk.o\n\tkos-c++ -o $(TARGET) $(OBJS) romdisk.o $(OBJEXTRA) -ldcplib -lk++ -lgl -lpcx -lkosutils -lm\n\nrun: $(TARGET)\n\t$(KOS_LOADER) $(TARGET)\n\ndist: \n\trm -f $(OBJS) romdisk.*\n\t$(KOS_STRIP) $(TARGET)\n\n\n"
},
{
"alpha_fraction": 0.6593647599220276,
"alphanum_fraction": 0.6659364700317383,
"avg_line_length": 21.564102172851562,
"blob_id": "735d819107331b0bab482b33b82b1352dd65ab71",
"content_id": "17633ddceb6a23faad73833252e8bf9184a694a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 913,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 39,
"path": "/include/sys/dirent.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#ifndef __SYS_DIRENT_H\n#define __SYS_DIRENT_H\n\n#include <unistd.h>\n#include <arch/types.h>\n#include <kos/fs.h>\n\nstruct dirent {\n\tint\td_ino;\n\toff_t\td_off;\n\tuint16\td_reclen;\n\tuint8\td_type;\n\tchar\td_name[256];\n};\n\n// In KOS, DIR* is just an fd. We'll use a real struct here anyway so we\n// can store the POSIX dirent.\ntypedef struct {\n\tfile_t\t\tfd;\n\tstruct dirent\td_ent;\n} DIR;\n\n// Standard UNIX dir functions. Not all of these are fully functional\n// right now due to lack of support in KOS.\n\n// All of these work.\nDIR *opendir(const char *name);\nint closedir(DIR *dir);\nstruct dirent *readdir(DIR *dir);\n\n// None of these work.\nvoid rewinddir(DIR *dir);\nint scandir(const char *dir, struct dirent ***namelist,\n\tint(*filter)(const struct dirent *),\n\tint(*compar)(const struct dirent **, const struct dirent **));\nvoid seekdir(DIR *dir, off_t offset);\noff_t telldir(DIR *dir);\n\n#endif\n \n"
},
{
"alpha_fraction": 0.6190622448921204,
"alphanum_fraction": 0.6395372748374939,
"avg_line_length": 29.335403442382812,
"blob_id": "96bf91143eb64b9a28cc39ee3633522af84d9c96",
"content_id": "4ca32ecee1ba98a48b511ab54b86fa5d6bfed745",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9768,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 322,
"path": "/kernel/arch/dreamcast/hardware/maple/vmu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n vmu.c\n Copyright (C)2002,2003 Dan Potter\n */\n\n#include <assert.h>\n#include <string.h>\n#include <stdio.h>\n#include <kos/thread.h>\n#include <kos/genwait.h>\n#include <dc/maple.h>\n#include <dc/maple/vmu.h>\n#include <arch/timer.h>\n\nCVSID(\"$Id: vmu.c,v 1.9 2003/04/25 04:13:12 bardtx Exp $\");\n\n/*\n This module deals with the VMU. It provides functionality for\n memorycard access, and for access to the lcd screen.\n \n Thanks to Marcus Comstedt for VMU/Maple information.\n */\n\nstatic int vmu_attach(maple_driver_t *drv, maple_device_t *dev) {\n\tdev->status_valid = 1;\n\treturn 0;\n}\n\nstatic void vmu_detach(maple_driver_t *drv, maple_device_t *dev) {\n}\n\n/* Device Driver Struct */\nstatic maple_driver_t vmu_drv = {\n\tfunctions:\tMAPLE_FUNC_MEMCARD | MAPLE_FUNC_LCD | MAPLE_FUNC_CLOCK,\n\tname:\t\t\"VMU Driver\",\n\tperiodic:\tNULL,\n\tattach:\t\tvmu_attach,\n\tdetach:\t\tvmu_detach\n};\n\n/* Add the VMU to the driver chain */\nint vmu_init() {\n\treturn maple_driver_reg(&vmu_drv);\n}\n\nvoid vmu_shutdown() {\n\tmaple_driver_unreg(&vmu_drv);\n}\n\n/* These interfaces will probably change eventually, but for now they\n can stay the same */\n\n/* Completion callback for the draw_lcd function below */\nstatic void draw_lcd_callback(maple_frame_t * frame) {\n\t/* Unlock the frame for the next usage */\n\tmaple_frame_unlock(frame);\n\n\t/* Wakey, wakey! */\n\tgenwait_wake_all(frame);\n}\n\n/* Draw a 1-bit bitmap on the LCD screen (48x32). return a -1 if\n an error occurs */\nint vmu_draw_lcd(maple_device_t * dev, void *bitmap) {\n\tuint32 *\tsend_buf;\n\n\tassert( dev != NULL );\n \n\t/* Lock the frame */\n\tif (maple_frame_lock(&dev->frame) < 0)\n\t\treturn MAPLE_EAGAIN;\n\n\t/* Reset the frame */\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_LCD;\n\tsend_buf[1] = 0;\t/* Block / phase / partition */\n\tmemcpy(send_buf+2, bitmap, 48 * 4);\n\tdev->frame.cmd = MAPLE_COMMAND_BWRITE;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2 + 48;\n\tdev->frame.callback = draw_lcd_callback;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\t/* Wait for the LCD to accept it */\n\tif (genwait_wait(&dev->frame, \"vmu_draw_lcd\", 500, NULL) < 0) {\n\t\tif (dev->frame.state != MAPLE_FRAME_VACANT) {\n\t\t\t/* It's probably never coming back, so just unlock the frame */\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\tdbglog(DBG_ERROR, \"vmu_draw_lcd: timeout to unit %c%c\\n\",\n\t\t\t\tdev->port+'A', dev->unit+'0');\n\t\t\treturn MAPLE_ETIMEOUT;\n\t\t}\n\t}\n\treturn MAPLE_EOK;\n}\n\n/* Read the data in block blocknum into buffer, return a -1\n if an error occurs, for now we ignore MAPLE_RESPONSE_FILEERR,\n which will be changed shortly */\nstatic void vmu_block_read_callback(maple_frame_t *frm) {\n\t/* Wakey, wakey! */\n\tgenwait_wake_all(frm);\n}\n\nint vmu_block_read(maple_device_t * dev, uint16 blocknum, uint8 *buffer) {\n\tmaple_response_t\t*resp;\n\tint\t\t\trv;\n\tuint32\t\t\t*send_buf;\n\tuint32\t\t\tblkid;\n\n\tassert( dev != NULL );\n\n\t/* Lock the frame. XXX: Priority inversion issues here. */\n\twhile (maple_frame_lock(&dev->frame) < 0)\n\t\tthd_pass();\n\t\t\n\t/* This is (block << 24) | (phase << 8) | (partition (0 for all vmu)) */\n\tblkid = ((blocknum & 0xff) << 24) | ((blocknum >> 8) << 16);\n\t\n\t/* Reset the frame */\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MEMCARD;\n\tsend_buf[1] = blkid;\n\tdev->frame.cmd = MAPLE_COMMAND_BREAD;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2;\n\tdev->frame.callback = vmu_block_read_callback;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\t/* Wait for the VMU to accept it */\n\tif (genwait_wait(&dev->frame, \"vmu_block_read\", 100, NULL) < 0) {\n\t\tif (dev->frame.state != MAPLE_FRAME_RESPONDED) {\n\t\t\t/* It's probably never coming back, so just unlock the frame */\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\tdbglog(DBG_ERROR, \"vmu_block_read: timeout to unit %c%c, block %d\\n\",\n\t\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum);\n\t\t\treturn MAPLE_ETIMEOUT;\n\t\t}\n\t}\n\tif (dev->frame.state != MAPLE_FRAME_RESPONDED) {\n\t\tdbglog(DBG_ERROR, \"vmu_block_read: incorrect state for unit %c%c, block %d (%d)\\n\",\n\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum, dev->frame.state);\n\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\treturn MAPLE_EFAIL;\n\t}\n\n\t/* Copy out the response */\n\tresp = (maple_response_t *)dev->frame.recv_buf;\n\tsend_buf = (uint32 *)resp->data;\n\tif (resp->response != MAPLE_RESPONSE_DATATRF\n\t\t\t|| send_buf[0] != MAPLE_FUNC_MEMCARD\n\t\t\t|| send_buf[1] != blkid) {\n\t\trv = MAPLE_EFAIL;\n\t\tdbglog(DBG_ERROR, \"vmu_block_read failed: %s(%d)/%08lx\\r\\n\",\n\t\t\tmaple_perror(resp->response), resp->response, send_buf[0]);\n\t} else {\n\t\trv = MAPLE_EOK;\n\t\tmemcpy(buffer, send_buf + 2, (resp->data_len - 2) * 4);\n\t}\n\n\tmaple_frame_unlock(&dev->frame);\n\n\treturn rv;\n}\n\n/* writes buffer into block blocknum. ret a -1 on error. We don't do anything about the\n maple bus returning file errors, etc, right now, but that will change soon. */\nstatic void vmu_block_write_callback(maple_frame_t *frm) {\n\t/* Reset the frame status (but still keep it for us to use) */\n\tfrm->state = MAPLE_FRAME_UNSENT;\n\n\t/* Wakey, wakey! */\n\tgenwait_wake_all(frm);\n}\nstatic int vmu_block_write_internal(maple_device_t * dev, uint16 blocknum, uint8 *buffer) {\n\tmaple_response_t\t*resp;\n\tint\t\t\trv, phase, r;\n\tuint32\t\t\t*send_buf;\n\tuint32\t\t\tblkid;\n\n\tassert( dev != NULL );\n\n\t/* Assume success */\n\trv = MAPLE_EOK;\n\n\t/* Lock the frame. XXX: Priority inversion issues here. */\n\twhile (maple_frame_lock(&dev->frame) < 0)\n\t\tthd_pass();\n\n\t/* Writes have to occur in four phases per block -- this is the\n\t way of flash memory, which you must erase an entire block \n\t at once to write; the blocks in this case are 128 bytes long. */\n\tfor (phase=0; phase<4; phase++) {\n\t\t/* this is (block << 24) | (phase << 8) | (partition (0 for all vmu)) */\n\t\tblkid = ((blocknum & 0xff) << 24) | ((blocknum >> 8) << 16) | (phase << 8);\n\t\n\t\t/* Reset the frame */\n\t\tmaple_frame_init(&dev->frame);\n\t\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\t\tsend_buf[0] = MAPLE_FUNC_MEMCARD;\n\t\tsend_buf[1] = blkid;\n\t\tmemcpy(send_buf + 2, buffer + 128*phase, 128);\n\t\tdev->frame.cmd = MAPLE_COMMAND_BWRITE;\n\t\tdev->frame.dst_port = dev->port;\n\t\tdev->frame.dst_unit = dev->unit;\n\t\tdev->frame.length = 2 + (128 / 4);\n\t\tdev->frame.callback = vmu_block_write_callback;\n\t\tdev->frame.send_buf = send_buf;\n\t\tmaple_queue_frame(&dev->frame);\n\n\t\t/* Wait for the VMU to accept it */\n\t\tif (genwait_wait(&dev->frame, \"vmu_block_write\", 100, NULL) < 0) {\n\t\t\tif (dev->frame.state != MAPLE_FRAME_UNSENT) {\n\t\t\t\t/* It's probably never coming back, so just unlock the frame */\n\t\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\t\tdbglog(DBG_ERROR, \"vmu_block_write: timeout to unit %c%c, block %d\\n\",\n\t\t\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum);\n\t\t\t\treturn MAPLE_ETIMEOUT;\n\t\t\t}\n\t\t}\n\t\tif (dev->frame.state != MAPLE_FRAME_UNSENT) {\n\t\t\tdbglog(DBG_ERROR, \"vmu_block_read: incorrect state for unit %c%c, block %d (%d)\\n\",\n\t\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum, dev->frame.state);\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\treturn MAPLE_EFAIL;\n\t\t}\n\n\t\t/* Check the response */\n\t\tresp = (maple_response_t *)dev->frame.recv_buf;\n\t\tr = resp->response;\n\t\tif (r != MAPLE_RESPONSE_OK) {\n\t\t\trv = MAPLE_EFAIL;\n\t\t\tdbglog(DBG_ERROR, \"Incorrect response writing phase %d:\\n\", phase);\n\t\t\tdbglog(DBG_ERROR, \"response: %s(%d)\\n\", maple_perror(resp->response), resp->response);\n\t\t\tdbglog(DBG_ERROR, \"datalen: %d\\n\", resp->data_len);\n\t\t}\n\t}\n\n\t/* Finally a \"sync\" command -- thanks Nagra */\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_MEMCARD;\n\tsend_buf[1] = ((blocknum & 0xff) << 24)\n\t\t| (((blocknum >> 8) & 0xff) << 16)\n\t\t| (4 << 8);\n\tdev->frame.cmd = MAPLE_COMMAND_BSYNC;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 2;\n\tdev->frame.callback = vmu_block_write_callback;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\t/* Wait for the VMU to accept it */\n\tif (genwait_wait(&dev->frame, \"vmu_block_write\", 100, NULL) < 0) {\n\t\tif (dev->frame.state != MAPLE_FRAME_UNSENT) {\n\t\t\t/* It's probably never coming back, so just unlock the frame */\n\t\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\t\tdbglog(DBG_ERROR, \"vmu_block_write: timeout to unit %c%c, block %d\\n\",\n\t\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum);\n\t\t\treturn MAPLE_ETIMEOUT;\n\t\t}\n\t}\n\tif (dev->frame.state != MAPLE_FRAME_UNSENT) {\n\t\tdbglog(DBG_ERROR, \"vmu_block_read: incorrect state for unit %c%c, block %d (%d)\\n\",\n\t\t\tdev->port+'A', dev->unit+'0', (int)blocknum, dev->frame.state);\n\t\tdev->frame.state = MAPLE_FRAME_VACANT;\n\t\treturn MAPLE_EFAIL;\n\t}\n\tdev->frame.state = MAPLE_FRAME_VACANT;\n\n\treturn rv;\n}\n\n// Sometimes a flaky or stubborn card can be recovered by trying a couple\n// of times...\nint vmu_block_write(maple_device_t * dev, uint16 blocknum, uint8 *buffer) {\n\tint i, rv;\n\tfor (i=0; i<4; i++) {\n\t\t// Try the write.\n\t\trv = vmu_block_write_internal(dev, blocknum, buffer);\n\t\tif (rv == MAPLE_EOK)\n\t\t\treturn rv;\n\n\t\t// It failed -- wait a bit and try again.\n\t\tthd_sleep(100);\n\t}\n\n\t// Well, looks like it's really toasty... return the most recent error.\n\treturn rv;\n}\n\n/* Utility function which sets the icon on all available VMUs\n from an Xwindows XBM. Imported from libdcutils. */\nvoid vmu_set_icon(const char *vmu_icon) {\n\tint\tx, y, xi, xb, i;\n\tuint8\tbitmap[48*32/8];\n\tmaple_device_t * dev;\n\n\tmemset(bitmap, 0, 48*32/8);\n\tif (vmu_icon) {\n\t\tfor (y=0; y<32; y++)\n\t\t\tfor (x=0; x<48; x++) {\n\t\t\t\txi = x / 8;\n\t\t\t\txb = 0x80 >> (x % 8);\n\t\t\t\tif (vmu_icon[(31-y)*48+(47-x)] == '.')\n\t\t\t\t\tbitmap[y*(48/8)+xi] |= xb;\n\t\t\t}\n\t}\n\n\ti = 0;\n\twhile ( (dev = maple_enum_type(i++, MAPLE_FUNC_LCD)) ) {\n\t\tvmu_draw_lcd(dev, bitmap);\n\t}\n}\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6622788906097412,
"avg_line_length": 25.129032135009766,
"blob_id": "3614e0a740827c2824ed68d32e69f7ab1da67b3f",
"content_id": "db3d3843cbfaeef6b58c039653eb42f7e7ce9e58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2431,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 93,
"path": "/kernel/arch/ia32/kernel/mmu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ia32/kernel/mmu.c\n Copyright (c)2003 Dan Potter\n*/\n\n#include <string.h>\n#include <malloc.h>\n\n#include <kos/thread.h>\n#include <arch/arch.h>\n#include <arch/types.h>\n#include <arch/irq.h>\n#include <arch/mmu.h>\n#include <arch/dbgio.h>\n#include <arch/cache.h>\n\nCVSID(\"$Id: mmu.c,v 1.1 2003/08/01 03:18:37 bardtx Exp $\");\n\nvoid mmu_reset_itlb() {\n}\n\nvoid mmu_use_table(mmucontext_t *context) {\n}\n\n/* Allocate a page table shell; no actual sub-contexts will be allocated\n until a mapping is performed. */\nmmucontext_t *mmu_context_create(int asid) {\n\treturn NULL;\n}\n\n/* Destroy an MMU context when a process is being destroyed. */\nvoid mmu_context_destroy(mmucontext_t *context) {\n}\n\n/* Using the given page tables, translate the virtual page ID to a \n physical page ID. Return -1 on failure. */\nint mmu_virt_to_phys(mmucontext_t *context, int virtpage) {\n\treturn 0;\n}\n\n/* Switch to the given context; invalidate any caches as neccessary */\nvoid mmu_switch_context(mmucontext_t *context) {\n}\n\n/* Map N pages sequentially */\nvoid mmu_page_map(mmucontext_t *context,\n\t\tint virtpage, int physpage, int count,\n\t\tint prot, int cache, int share, int dirty) {\n}\n\n/* Copy a chunk of data from a process' address space into a\n kernel buffer, taking into account page mappings.\n\n This routine is pretty nasty.. this is completely platform\n generic but should probably be replaced by a nice assembly\n routine for each platform as appropriate. */\nint mmu_copyin(mmucontext_t *context, uint32 srcaddr, uint32 srccnt, void *buffer) {\n\treturn -1;\n}\n\n/* Copy a chunk of data from one process' address space to another\n process' address space, taking into account page mappings.\n\n This routine is pretty nasty.. this is completely platform\n generic but should probably be replaced by a nice assembly\n routine for each platform as appropriate. */\nint mmu_copyv(mmucontext_t *context1, iovec_t *iov1, int iovcnt1,\n\t\tmmucontext_t *context2, iovec_t *iov2, int iovcnt2) {\n\treturn -1;\n}\n\t\t\n\n/********************************************************************************/\n/* Exception handlers */\n\nmmu_mapfunc_t mmu_map_get_callback() {\n\treturn NULL;\n}\n\nmmu_mapfunc_t mmu_map_set_callback(mmu_mapfunc_t newfunc) {\n\treturn NULL;\n}\n\n/********************************************************************************/\n/* Init routine */\nint mmu_init() {\n\treturn 0;\n}\n\n/* Shutdown */\nvoid mmu_shutdown() {\n}\n\n"
},
{
"alpha_fraction": 0.5623058080673218,
"alphanum_fraction": 0.5987228155136108,
"avg_line_length": 24.98206329345703,
"blob_id": "c3afad2acd30dd6a31e43bc9f38e0de129e24731",
"content_id": "10de6119b559318fba50344fc18638b68d77827c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5794,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 223,
"path": "/kernel/net/net_icmp.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_icmp.c\n\n Copyright (C) 2002 Dan Potter\n Copyright (C) 2005, 2006, 2007 Lawrence Sebald\n\n */\n\n#include <stdio.h>\n#include <string.h>\n#include <malloc.h>\n#include <sys/queue.h>\n#include <kos/net.h>\n#include <kos/thread.h>\n#include <arch/timer.h>\n#include <arpa/inet.h>\n#include \"net_icmp.h\"\n#include \"net_ipv4.h\"\n\nCVSID(\"$Id: net_icmp.c,v 1.2 2002/03/24 00:27:05 bardtx Exp $\");\n\n/*\nThis file implements RFC 792, the Internet Control Message Protocol.\nCurrently implemented message types are:\n 0 - Echo Reply\n 8 - Echo\n\nMessage types that are not implemented yet (if ever):\n 3 - Destination Unreachable\n 4 - Source Quench\n 5 - Redirect\n 11 - Time Exceeded\n 12 - Parameter Problem\n 14 - Timestamp Reply\n 13 - Timestamp\n 15 - Information Request\n 16 - Information Reply\n*/\n\nstruct __ping_pkt {\n\tLIST_ENTRY(__ping_pkt) pkt_list;\n\tuint8 ip[4];\n\tuint8 *data;\n\tint data_sz;\n\tuint16 icmp_seq;\n\tuint64 usec;\n};\n\nLIST_HEAD(__ping_pkt_list, __ping_pkt);\n\nstatic struct __ping_pkt_list pings = LIST_HEAD_INITIALIZER(0);\nstatic uint8 pktbuf[1514];\nstatic uint16 icmp_echo_seq = 1;\n\nstatic void icmp_default_echo_cb(const uint8 *ip, uint16 seq, uint64 delta_us,\n uint8 ttl, const uint8* data, int data_sz) {\n\tprintf(\"%d bytes from %d.%d.%d.%d: icmp_seq=%d ttl=%d time=%.2f ms\\n\",\n\t data_sz, ip[0], ip[1], ip[2], ip[3], seq, ttl,\n\t delta_us / 1000.0f);\n}\n\n/* The default echo (ping) callback */\nnet_echo_cb net_icmp_echo_cb = icmp_default_echo_cb;\n\n/* Handle Echo Reply (ICMP type 0) packets */\nstatic void net_icmp_input_0(netif_t *src, ip_hdr_t *ip, icmp_hdr_t *icmp,\n const uint8 *d, int s) {\n\tuint64 tmr;\n\tstruct __ping_pkt *ping;\n\tuint16 seq;\n\n\ttmr = timer_us_gettime64();\n\n\tLIST_FOREACH(ping, &pings, pkt_list) {\n\t\tseq = (d[7] | (d[6] << 8));\n\t\tif(ping->icmp_seq == seq) {\n\t\t\tnet_icmp_echo_cb((uint8 *)&ip->src, seq, \n\t\t\t tmr - ping->usec, ip->ttl, d, s);\n\n\t\t\tLIST_REMOVE(ping, pkt_list);\n\t\t\tfree(ping->data);\n\t\t\tfree(ping);\n\n\t\t\treturn;\n\t\t}\n\t}\n}\n\n/* Handle Echo (ICMP type 8) packets */\nstatic void net_icmp_input_8(netif_t *src, ip_hdr_t *ip, icmp_hdr_t *icmp,\n const uint8 *d, int s) {\n\tint i;\n\n\t/* Set type to echo reply */\n\ticmp->type = 0;\n\n\t/* Swap source and dest ip addresses */\n\ti = ip->src;\n\tip->src = ip->dest;\n\tip->dest = i;\n\n\t/* Recompute the IP header checksum */\n\tip->checksum = 0;\n\tip->checksum = net_ipv4_checksum((uint8 *)ip,\n\t 4 * (ip->version_ihl & 0x0f));\n\n\t/* Recompute the ICMP header checksum */\n\ticmp->checksum = 0;\n\ticmp->checksum = net_ipv4_checksum((uint8 *)icmp, ntohs(ip->length) -\n\t 4 * (ip->version_ihl & 0x0f));\n\n\t/* Send it */\n\tmemcpy(pktbuf, ip, 20);\n\tmemcpy(pktbuf + 20, d, ntohs(ip->length) - 4 * (ip->version_ihl & 0x0F));\n\tnet_ipv4_send_packet(src, ip, pktbuf + 20, ntohs(ip->length) -\n\t 4 * (ip->version_ihl & 0x0F));\n}\n\nint net_icmp_input(netif_t *src, ip_hdr_t *ip, const uint8 *d, int s) {\n\ticmp_hdr_t *icmp;\n\tint i;\n\n\t/* Find ICMP header */\n\ticmp = (icmp_hdr_t*) d;\n\n\t/* Check icmp checksum */\n\tmemset(pktbuf, 0, 1514);\n\ti = icmp->checksum;\n\ticmp->checksum = 0;\n\tmemcpy(pktbuf, icmp, ntohs(ip->length) - 4 * (ip->version_ihl & 0x0f));\n\ticmp->checksum = net_ipv4_checksum(pktbuf, (ntohs(ip->length) + 1) -\n\t 4 * (ip->version_ihl & 0x0f));\n\n\tif (i != icmp->checksum) {\n\t\tdbglog(DBG_KDEBUG, \"net_icmp: icmp with invalid checksum\\n\");\n\t\treturn -1;\n\t}\n\n\tswitch(icmp->type) {\n\t\tcase 0: /* Echo reply */\n\t\t\tnet_icmp_input_0(src, ip, icmp, d, s);\n\t\t\tbreak;\n\t\tcase 3: /* Destination unreachable */\n\t\t\tdbglog(DBG_KDEBUG, \"net_icmp: Destination unreachable,\"\n\t\t\t \" code %d\\n\", icmp->code);\n\t\t\tbreak;\n\n\t\tcase 8: /* Echo */\n\t\t\tnet_icmp_input_8(src, ip, icmp, d, s);\n\t\t\tbreak;\n\n\t\tdefault:\n\t\t\tdbglog(DBG_KDEBUG, \"net_icmp: unknown icmp type: %d\\n\",\n\t\t\t icmp->type);\n\t}\n\n\treturn 0;\n}\n\n/* Send an ICMP Echo (PING) packet to the specified device */\nint net_icmp_send_echo(netif_t *net, const uint8 ipaddr[4], const uint8 *data,\n int size) {\n\ticmp_hdr_t *icmp;\n\tip_hdr_t ip;\n\tstruct __ping_pkt *newping;\n\tint r = -1;\n\tuint8 databuf[sizeof(icmp_hdr_t) + size];\n\n\ticmp = (icmp_hdr_t *)databuf;\n\n\t/* Fill in the ICMP Header */\n\ticmp->type = 8; /* Echo */\n\ticmp->code = 0;\n\ticmp->checksum = 0;\n\ticmp->misc[0] = (uint8) 'D';\n\ticmp->misc[1] = (uint8) 'C';\n\ticmp->misc[2] = (uint8) (icmp_echo_seq >> 8);\n\ticmp->misc[3] = (uint8) (icmp_echo_seq & 0xFF);\n\tmemcpy(databuf + sizeof(icmp_hdr_t), data, size);\n\n\t/* Fill in the IP Header */\n\tip.version_ihl = 0x45; /* 20 byte header, ipv4 */\n\tip.tos = 0;\n\tip.length = htons(sizeof(icmp_hdr_t) + size + 20);\n\tip.packet_id = 0;\n\tip.flags_frag_offs = 0x0040;\n\tip.ttl = 64;\n\tip.protocol = 1; /* ICMP */\n\tip.checksum = 0;\n\n\tif(net_ipv4_address(ipaddr) == 0x7F000001)\n\t\tip.src = htonl(net_ipv4_address(ipaddr));\n\telse\n\t\tip.src = htonl(net_ipv4_address(net->ip_addr));\n\n\tip.dest = htonl(net_ipv4_address(ipaddr));\n\n\t/* Compute the ICMP Checksum */\n\ticmp->checksum = net_ipv4_checksum(databuf, sizeof(icmp_hdr_t) + size);\n\n\t/* Compute the IP Checksum */\n\tip.checksum = net_ipv4_checksum((uint8 *)&ip, sizeof(ip_hdr_t));\n\n\tnewping = (struct __ping_pkt*) malloc(sizeof(struct __ping_pkt));\n\tnewping->data = (uint8 *)malloc(size);\n\tnewping->data_sz = size;\n\tnewping->icmp_seq = icmp_echo_seq;\n\tmemcpy(newping->data, data, size);\n\tmemcpy(newping->ip, ipaddr, 4);\n\tLIST_INSERT_HEAD(&pings, newping, pkt_list);\n\n\t++icmp_echo_seq;\n\n\twhile(r == -1)\t{\n\t\tnewping->usec = timer_us_gettime64();\n\t\tr = net_ipv4_send_packet(net, &ip, databuf,\n\t\t sizeof(icmp_hdr_t) + size);\n\t\tthd_sleep(10);\n\t}\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6339622735977173,
"alphanum_fraction": 0.6396226286888123,
"avg_line_length": 17.928571701049805,
"blob_id": "52e7bf9b06dc9ac7d9a050b4d1490ea7d894aba5",
"content_id": "bd11226722e174c3c38f6b24d2f27c77da9add96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 28,
"path": "/examples/dreamcast/network/dns-client/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# Put the filename of the output binary here\nTARGET = dns-client.elf\n\n# List all of your C files here, but change the extension to \".o\"\nOBJS = dnslookup.o\n\nLWIPDIR = $(KOS_PATH)/include/addons/lwip\nARCHDIR = $(LWIPDIR)/kos\n\nall: rm-elf $(TARGET)\n\ninclude ../../../../Makefile.rules\n\nCFLAGS += -DIPv4 \\\n\t-I$(LWIPDIR) -I$(ARCHDIR) \\\n\t-I$(LWIPDIR)/ipv4\n\nclean:\n\trm -f $(TARGET) $(OBJS)\n\nrm-elf:\n\trm -f $(TARGET)\n\n$(TARGET): $(OBJS)\n\tkos-cc -o $(TARGET) $(OBJS) $(OBJEXTRA) -llwip4 -lkosutils\n\nrun: $(TARGET)\n\tdc-tool -n -x $(TARGET)\n"
},
{
"alpha_fraction": 0.6336154937744141,
"alphanum_fraction": 0.6541717052459717,
"avg_line_length": 18.23255729675293,
"blob_id": "b0e0f277856c358c5a49f41156bb8ea74e7323ce",
"content_id": "65a3aedf0e2e600e0597dc402331ab73c68a0ef4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 827,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 43,
"path": "/include/sys/_types.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#ifndef _SYS__TYPES_H\n#define _SYS__TYPES_H\n\n// This part copied from newlib's sys/_types.h.\ntypedef long _off_t;\n__extension__ typedef long long _off64_t;\n\n#if defined(__INT_MAX__) && __INT_MAX__ == 2147483647\ntypedef int _ssize_t;\n#else\ntypedef long _ssize_t;\n#endif\n\n#define __need_wint_t\n#include <stddef.h>\n\n/* Conversion state information. */\ntypedef struct\n{\n int __count;\n union\n {\n wint_t __wch;\n unsigned char __wchb[4];\n } __value; /* Value so far. */\n} _mbstate_t;\n\ntypedef int _flock_t;\n\n/* Iconv descriptor type */\ntypedef void *_iconv_t;\n\n\n// This part inserted to fix newlib brokenness.\n#define FD_SETSIZE 1024\n\n// And this is for old KOS source compatability.\n#include <arch/types.h>\n\n// Include stuff to make pthreads work as well.\n#include <sys/_pthread.h>\n\n#endif\t/* _SYS__TYPES_H */\n"
},
{
"alpha_fraction": 0.5506893992424011,
"alphanum_fraction": 0.5868613123893738,
"avg_line_length": 26.75225257873535,
"blob_id": "197c969f837a44988306cc31814988d4f3a7f023",
"content_id": "46c20d6d13569d1acc1accf643c74f821ce51481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6165,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 222,
"path": "/kernel/arch/dreamcast/hardware/maple/keyboard.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n keyboard.c\n (C)2002 Dan Potter\n*/\n\n#include <assert.h>\n#include <string.h>\n#include <stdio.h>\n#include <dc/maple.h>\n#include <dc/maple/keyboard.h>\n\nCVSID(\"$Id: keyboard.c,v 1.4 2002/05/18 07:11:24 bardtx Exp $\");\n\n/*\n\nThis module is an (almost) complete keyboard system. It handles key\ndebouncing and queueing so you don't miss any pressed keys as long\nas you poll often enough. The only thing missing currently is key\nrepeat handling.\n\n*/\n\n\n/* The keyboard queue (global for now) */\n#define KBD_QUEUE_SIZE 16\nstatic volatile int\tkbd_queue_active = 1;\nstatic volatile int\tkbd_queue_tail = 0, kbd_queue_head = 0;\nstatic volatile uint16\tkbd_queue[KBD_QUEUE_SIZE];\n\n/* Turn keyboard queueing on or off. This is mainly useful if you want\n to use the keys for a game where individual keypresses don't mean\n as much as having the keys up or down. Setting this state to\n a new value will clear the queue. */\nvoid kbd_set_queue(int active) {\n\tif (kbd_queue_active != active) {\n\t\tkbd_queue_head = kbd_queue_tail = 0;\n\t}\n\tkbd_queue_active = active;\n}\n\n/* Take a key scancode, encode it appropriately, and place it on the\n keyboard queue. At the moment we assume no key overflows. */\nstatic int kbd_enqueue(kbd_state_t *state, uint8 keycode) {\n\tstatic char keymap_noshift[] = {\n\t/*0*/\t0, 0, 0, 0, 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i',\n\t\t'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't',\n\t\t'u', 'v', 'w', 'x', 'y', 'z',\n\t/*1e*/\t'1', '2', '3', '4', '5', '6', '7', '8', '9', '0',\n\t/*28*/\t13, 27, 8, 9, 32, '-', '=', '[', ']', '\\\\', 0, ';', '\\'',\n\t/*35*/\t'`', ',', '.', '/', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n\t/*46*/\t0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n\t/*53*/\t0, '/', '*', '-', '+', 13, '1', '2', '3', '4', '5', '6',\n\t/*5f*/\t'7', '8', '9', '0', '.', 0\n\t};\n\tstatic char keymap_shift[] = {\n\t/*0*/\t0, 0, 0, 0, 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I',\n\t\t'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T',\n\t\t'U', 'V', 'W', 'X', 'Y', 'Z',\n\t/*1e*/\t'!', '@', '#', '$', '%', '^', '&', '*', '(', ')',\n\t/*28*/\t13, 27, 8, 9, 32, '_', '+', '{', '}', '|', 0, ':', '\"',\n\t/*35*/\t'~', '<', '>', '?', 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n\t/*46*/\t0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\n\t/*53*/\t0, '/', '*', '-', '+', 13, '1', '2', '3', '4', '5', '6',\n\t/*5f*/\t'7', '8', '9', '0', '.', 0\n\t};\n\tuint16 ascii;\n\n\t/* If queueing is turned off, don't bother */\n\tif (!kbd_queue_active)\n\t\treturn 0;\n\n\t/* Figure out its key queue value */\t\n\tif (state->shift_keys & (KBD_MOD_LSHIFT|KBD_MOD_RSHIFT))\n\t\tascii = keymap_shift[keycode];\n\telse\n\t\tascii = keymap_noshift[keycode];\n\t\n\tif (ascii == 0)\n\t\tascii = ((uint16)keycode) << 8;\n\t\t\n\t/* Ok... now do the enqueue */\n\tkbd_queue[kbd_queue_head] = ascii;\n\tkbd_queue_head = (kbd_queue_head + 1) & (KBD_QUEUE_SIZE-1);\n\n\treturn 0;\n}\t\n\n/* Take a key off the key queue, or return -1 if there is none waiting */\nint kbd_get_key() {\n\tint rv;\n\n\t/* If queueing isn't active, there won't be anything to get */\n\tif (!kbd_queue_active)\n\t\treturn -1;\n\t\n\t/* Check available */\n\tif (kbd_queue_head == kbd_queue_tail)\n\t\treturn -1;\n\t\n\trv = kbd_queue[kbd_queue_tail];\n\tkbd_queue_tail = (kbd_queue_tail + 1) & (KBD_QUEUE_SIZE - 1);\n\t\n\treturn rv;\n}\n\n/* Update the keyboard status; this will handle debounce handling as well as\n queueing keypresses for later usage. The key press queue uses 16-bit\n words so that we can store \"special\" keys as such. This needs to be called\n fairly periodically if you're expecting keyboard input. */\nstatic void kbd_check_poll(maple_frame_t *frm) {\n\tkbd_state_t\t*state;\n\tkbd_cond_t\t*cond;\n\tint\t\ti, p;\n\n\tstate = (kbd_state_t *)frm->dev->status;\n\tcond = (kbd_cond_t *)&state->cond;\n\n\t/* Check the shift state */\n\tstate->shift_keys = cond->modifiers;\n\t\n\t/* Process all pressed keys */\n\tfor (i=0; i<6; i++) {\n\t\tif (cond->keys[i] != 0) {\n\t\t\tp = state->matrix[cond->keys[i]];\n\t\t\tstate->matrix[cond->keys[i]] = 2;\t/* 2 == currently pressed */\n\t\t\tif (p == 0)\n\t\t\t\tkbd_enqueue(state, cond->keys[i]);\n\t\t}\n\t}\n\t\n\t/* Now normalize the key matrix */\n\tfor (i=0; i<256; i++) {\n\t\tif (state->matrix[i] == 1)\n\t\t\tstate->matrix[i] = 0;\n\t\telse if (state->matrix[i] == 2)\n\t\t\tstate->matrix[i] = 1;\n\t\telse if (state->matrix[i] != 0) {\n\t\t\tassert_msg(0, \"invalid key matrix array detected\");\n\t\t}\n\t}\n}\n\nstatic void kbd_reply(maple_frame_t *frm) {\n\tmaple_response_t\t*resp;\n\tuint32\t\t\t*respbuf;\n\tkbd_state_t\t\t*state;\n\tkbd_cond_t\t\t*cond;\n\n\t/* Unlock the frame (it's ok, we're in an IRQ) */\n\tmaple_frame_unlock(frm);\n\n\t/* Make sure we got a valid response */\n\tresp = (maple_response_t *)frm->recv_buf;\n\tif (resp->response != MAPLE_RESPONSE_DATATRF)\n\t\treturn;\n\trespbuf = (uint32 *)resp->data;\n\tif (respbuf[0] != MAPLE_FUNC_KEYBOARD)\n\t\treturn;\n\n\t/* Update the status area from the response */\n\tif (frm->dev) {\n\t\tstate = (kbd_state_t *)frm->dev->status;\n\t\tcond = (kbd_cond_t *)&state->cond;\n\t\tmemcpy(cond, respbuf+1, (resp->data_len-1) * 4);\n\t\tfrm->dev->status_valid = 1;\n\t\tkbd_check_poll(frm);\n\t}\n}\n\nstatic int kbd_poll_intern(maple_device_t *dev) {\n\tuint32 * send_buf;\n\n\tif (maple_frame_lock(&dev->frame) < 0)\n\t\treturn 0;\n\n\tmaple_frame_init(&dev->frame);\n\tsend_buf = (uint32 *)dev->frame.recv_buf;\n\tsend_buf[0] = MAPLE_FUNC_KEYBOARD;\n\tdev->frame.cmd = MAPLE_COMMAND_GETCOND;\n\tdev->frame.dst_port = dev->port;\n\tdev->frame.dst_unit = dev->unit;\n\tdev->frame.length = 1;\n\tdev->frame.callback = kbd_reply;\n\tdev->frame.send_buf = send_buf;\n\tmaple_queue_frame(&dev->frame);\n\n\treturn 0;\n}\n\nstatic void kbd_periodic(maple_driver_t *drv) {\n\tmaple_driver_foreach(drv, kbd_poll_intern);\n}\n\nstatic int kbd_attach(maple_driver_t *drv, maple_device_t *dev) {\n\tmemset(dev->status, 0, sizeof(dev->status));\n\tdev->status_valid = 0;\n\treturn 0;\n}\n\nstatic void kbd_detach(maple_driver_t *drv, maple_device_t *dev) {\n\tmemset(dev->status, 0, sizeof(dev->status));\n\tdev->status_valid = 0;\n}\n\n/* Device driver struct */\nstatic maple_driver_t kbd_drv = {\n\tfunctions:\tMAPLE_FUNC_KEYBOARD,\n\tname:\t\t\"Keyboard Driver\",\n\tperiodic:\tkbd_periodic,\n\tattach:\t\tkbd_attach,\n\tdetach:\t\tkbd_detach\n};\n\n/* Add the keyboard to the driver chain */\nint kbd_init() {\n\treturn maple_driver_reg(&kbd_drv);\n}\n\nvoid kbd_shutdown() {\n\tmaple_driver_unreg(&kbd_drv);\n}\n\n\n\n\n"
},
{
"alpha_fraction": 0.671007513999939,
"alphanum_fraction": 0.6888279914855957,
"avg_line_length": 25.035715103149414,
"blob_id": "a3d774daaf1b81a472b8cc40e4c7eec5dd1e6a56",
"content_id": "c28fcc18f96b2fd6f7e082bd90e9dd1ed0917802",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1459,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 56,
"path": "/include/arch/dreamcast/dc/sound/sfxmgr.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/sound/sfxmgr.h\n (c)2002 Dan Potter\n\n $Id: sfxmgr.h,v 1.6 2003/04/24 03:15:09 bardtx Exp $\n\n*/\n\n#ifndef __DC_SOUND_SFXMGR_H\n#define __DC_SOUND_SFXMGR_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Sound effect handle type */\ntypedef uint32 sfxhnd_t;\n#define SFXHND_INVALID 0\n\n/* Load a sound effect from a WAV file and return a handle to it */\nsfxhnd_t snd_sfx_load(const char *fn);\n\n/* Unload a single sample */\nvoid snd_sfx_unload(sfxhnd_t idx);\n\n/* Unload all loaded samples and free their SPU RAM */\nvoid snd_sfx_unload_all();\n\n/* Play a sound effect with the given volume and panning; if the sound\n effect is in stereo, the panning is ignored. Returns the used channel\n ID (or the left channel, if stereo). */\nint snd_sfx_play(sfxhnd_t idx, int vol, int pan);\n\n/* Works like snd_sfx_play, but selects a specific channel. If the sample\n is stereo, the next channel will also be used. */\nint snd_sfx_play_chn(int chn, sfxhnd_t idx, int vol, int pan);\n\n/* Stops a single sound effect from playing. */\nvoid snd_sfx_stop(int chn);\n\n/* Stop all playing sound effects. Doesn't stop channels 0 or 1, which\n are assumed to be for streaming. */\nvoid snd_sfx_stop_all();\n\n/* Allocate a channel for non-sfx usage (e.g. streams). Returns -1\n on failure. */\nint snd_sfx_chn_alloc();\n\n/* Free a channel for non-sfx usage. */\nvoid snd_sfx_chn_free(int chn);\n\n__END_DECLS\n\n#endif\t/* __DC_SOUND_SFXMGR_H */\n\n"
},
{
"alpha_fraction": 0.4827781021595001,
"alphanum_fraction": 0.6157538294792175,
"avg_line_length": 22.600000381469727,
"blob_id": "4f0a19da5be9b75d64c22ac001dae27cc8d46267",
"content_id": "50e16cece3eab87d08a02d8a515b385509624473",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3542,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 150,
"path": "/examples/dreamcast/kgl/nehe/nehe05/nehe05.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe02.c\n (c)2001 Benoit Miller\n\n Parts (c)2000 Jeff Molofee\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n\n/* Another simple example in KGL.\n\n Essentially the same thing as NeHe's lesson05 code. \n To learn more, go to http://nehe.gamedev.net/.\n*/\n\nstatic GLfloat rtri; \t/* Rotation angle for the triangle */\nstatic GLfloat rquad;\t/* Rotation angle for the quad */\n\nvoid draw_gl(void) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\n\tglLoadIdentity();\n\tglTranslatef(-1.5f,0.0f,-6.0f);\n\tglRotatef(rtri,0.0f,1.0f,0.0f);\n\n\tglBegin(GL_TRIANGLES);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, -1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, -1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, -1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 0.0f, 1.0f, 0.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\tglEnd();\n\n\tglLoadIdentity();\n\tglTranslatef(1.5f,0.0f,-7.0f);\n\tglRotatef(rquad,1.0f,1.0f,1.0f);\n\n\tglBegin(GL_QUADS);\n\t\tglColor3f(0.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.5f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\t\tglColor3f(1.0f,0.0f,0.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,1.0f,0.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglColor3f(0.0f,0.0f,1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f,-1.0f);\n\t\tglVertex3f(-1.0f,-1.0f, 1.0f);\n\t\tglColor3f(1.0f,0.0f,1.0f);\n\t\tglVertex3f( 1.0f, 1.0f,-1.0f);\n\t\tglVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f, 1.0f);\n\t\tglVertex3f( 1.0f,-1.0f,-1.0f);\n\tglEnd();\n\n\trtri+=0.2f;\n\trquad-=0.15f;\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"nehe05 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,640.0f/480.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.0f, 0.0f, 0.0f, 0.0f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LEQUAL);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw the \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6296296119689941,
"alphanum_fraction": 0.6683695316314697,
"avg_line_length": 28.350000381469727,
"blob_id": "14f1256eddf84c2ed6e2cccd694d00a1dda8da6f",
"content_id": "23be6a260249ec19873fca5a1dae31c84a765a3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2349,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 80,
"path": "/include/arch/dreamcast/dc/maple/controller.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/controller.h\n (C)2000-2002 Jordan DeLong, Dan Potter\n\n $Id: controller.h,v 1.4 2002/05/24 06:47:26 bardtx Exp $\n\n Thanks to Marcus Comstedt for information on the controller.\n*/\n\n#ifndef __DC_MAPLE_CONTROLLER_H\n#define __DC_MAPLE_CONTROLLER_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Buttons bitfield defines */\n#define CONT_C\t\t\t(1<<0)\n#define CONT_B\t\t\t(1<<1)\n#define CONT_A\t\t\t(1<<2)\n#define CONT_START\t\t(1<<3)\n#define CONT_DPAD_UP\t\t(1<<4)\n#define CONT_DPAD_DOWN\t\t(1<<5)\n#define CONT_DPAD_LEFT\t\t(1<<6)\n#define CONT_DPAD_RIGHT\t\t(1<<7)\n#define CONT_Z\t\t\t(1<<8)\n#define CONT_Y\t\t\t(1<<9)\n#define CONT_X\t\t\t(1<<10)\n#define CONT_D\t\t\t(1<<11)\n#define CONT_DPAD2_UP\t\t(1<<12)\n#define CONT_DPAD2_DOWN\t\t(1<<13)\n#define CONT_DPAD2_LEFT\t\t(1<<14)\n#define CONT_DPAD2_RIGHT\t(1<<15)\n\n/* Raw controller condition structure */\ntypedef struct {\n\tuint16 buttons;\t\t\t/* buttons bitfield */\n\tuint8 rtrig;\t\t\t/* right trigger */\n\tuint8 ltrig;\t\t\t/* left trigger */\n\tuint8 joyx;\t\t\t/* joystick X */\n\tuint8 joyy;\t\t\t/* joystick Y */\n\tuint8 joy2x;\t\t\t/* second joystick X */\n\tuint8 joy2y;\t\t\t/* second joystick Y */\n} cont_cond_t;\n\n/* Our more civilized structure. Note that there are some fairly\n significant differences in value interpretations here between\n this struct and the old one: \n\n - \"buttons\" is zero based: a 1-bit means the button is PRESSED.\n - \"joyx\", \"joyy\", \"joy2x\", and \"joy2y\" are all zero based: zero\n means they are in the center, negative values are up/left,\n and positive values are down/right.\n\n Note also that this is the struct you will get back if you call\n maple_dev_status(), NOT a cont_cond_t. However, cont_get_cond() will\n return the old compatible struct for now. */\ntypedef struct {\n\tuint32\tbuttons;\t\t/* Buttons bitfield */\n\tint\tltrig, rtrig;\t\t/* Triggers */\n\tint\tjoyx, joyy;\t\t/* Joystick X/Y */\n\tint\tjoy2x, joy2y;\t\t/* Second Joystick X/Y (if applicable) */\n} cont_state_t;\n\n/* Init / Shutdown */\nint\tcont_init();\nvoid\tcont_shutdown();\n\n/* Compat function */\nint\tcont_get_cond(uint8 addr, cont_cond_t *cond);\n\n/* Set a controller callback for a button combo; set addr=0 for any controller */\ntypedef void (*cont_btn_callback_t)(uint8 addr, uint32 btns);\nvoid\tcont_btn_callback(uint8 addr, uint32 btns, cont_btn_callback_t cb);\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_CONTROLLER_H */\n\n"
},
{
"alpha_fraction": 0.6078431606292725,
"alphanum_fraction": 0.6078431606292725,
"avg_line_length": 11.75,
"blob_id": "a2f27cf2b434d258edb83bc2a96179d6c75cda2a",
"content_id": "8fb9668aa8affee4a4f54a0923b84f8dce9620c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-make",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_MAKE} \"$@\"\n"
},
{
"alpha_fraction": 0.624871015548706,
"alphanum_fraction": 0.6398348808288574,
"avg_line_length": 16.779815673828125,
"blob_id": "23064db4f5183115df99d25f9213a09341ef356f",
"content_id": "87c334280dcb3413ec2644ff368763fb2a9f199a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1938,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 109,
"path": "/kernel/arch/ia32/kernel/init.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ia32/kernel/init.c\n Copyright (c)2003 Dan Potter\n*/\n\n#include <string.h>\n#include <arch/arch.h>\n#include <arch/dbgio.h>\n#include <arch/irq.h>\n#include <arch/timer.h>\n//#include <sys/process.h>\n//#include <kos/mm.h>\n#include <kos/nmmgr.h>\n#include <kos/fs.h>\n#include <kos/fs_romdisk.h>\n#include <kos/fs_pty.h>\n#include <kos/net.h>\n\nvoid arch_abort() {\n\tdbgio_printk(\"Halted.\\n\");\n\tasm(\"cli\");\n\tasm(\"hlt\");\n}\n\nvoid arch_reboot() {\n}\n\nvoid arch_exit() {\n\tarch_abort();\n}\n\nvoid arch_remove_process(kprocess_t * proc) {\n\tirq_remove_process(proc);\n}\n\nextern const char banner[];\nextern uint8 edata, end;\nint main(int argc, char **argv);\n\nint arch_main() {\n\t// Clear out BSS\n\tuint8 *bss_start = (uint8 *)(&edata);\n\tuint8 *bss_end = (uint8 *)(&end);\n\tmemset(bss_start, 0, bss_end - bss_start);\n\n\t// Ensure we pull in crtend.c\n\t__crtend_pullin();\n\n\t// Print out a welcome banner\n\tdbgio_init();\n\tif (__kos_init_flags & INIT_QUIET) {\n\t\tdbgio_set_printk(dbgio_null_write);\n\t} else {\n\t\tdbgio_printk(\"\\n--\\n\");\n\t\tdbgio_printk(banner);\n\t}\n\n\t// Initialize memory management\n\tmm_init();\n\n\t// Setup hardware basics\n\tirq_init();\n\tdbgio_init_2();\n\ttimer_init();\n\ttimer_ms_enable();\n\trtc_init();\n\n\t// Switch on interrupts\n\tirq_enable();\n\n\t// Threads\n\tif (__kos_init_flags & INIT_THD_PREEMPT)\n\t\tthd_init(THD_MODE_PREEMPT);\n\telse\n\t\tthd_init(THD_MODE_COOP);\n\n\t// Mark a few regions unusable (thanks IBM!)\n\t// XXX Can't do this anymore, need to use the MMU.\n\t// mm_palloc(0x000a0000, 0x60000/PAGESIZE, _local_process);\n\n\t// VFS facilities\n\tnmmgr_init();\n\tfs_init();\n\tfs_romdisk_init();\n\tfs_pty_init();\n\n\tif (__kos_romdisk != NULL) {\n\t\tfs_romdisk_mount(\"/rd\", __kos_romdisk);\n\t}\n\n\t// Enable IRQs to start the whole shebang rolling\n\tif (__kos_init_flags & INIT_IRQ)\n\t\tirq_enable();\n\n\t// Enable networking\n\tnet_init();\n\n\t// Run ctors\n\tarch_ctors();\n\n\t// Call main.\n\tmain(0, NULL);\n\n\t// Call kernel exit.\n\tarch_exit();\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6656723022460938,
"alphanum_fraction": 0.6782675981521606,
"avg_line_length": 43.367645263671875,
"blob_id": "3daf1a459925855f79153b7f02360fce12024d55",
"content_id": "ad65076b27ad6d49389226c4831d7ca00fe3eca9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9051,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 204,
"path": "/include/arch/dreamcast/dc/vmufs.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/vmufs.h\n Copyright (C)2003 Dan Potter\n\n*/\n\n#ifndef __DC_VMUFS_H\n#define __DC_VMUFS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <dc/maple.h>\n\n#define __packed__ __attribute__((packed))\n/** BCD timestamp, used several places below */\ntypedef struct {\n\tuint8\tcent\t\t__packed__;\n\tuint8\tyear\t\t__packed__;\n\tuint8\tmonth\t\t__packed__;\n\tuint8\tday\t\t__packed__;\n\tuint8\thour\t\t__packed__;\n\tuint8\tmin\t\t__packed__;\n\tuint8\tsec\t\t__packed__;\n\tuint8\tdow\t\t__packed__;\t/* Day of week (0 = monday, etc) */\n} vmu_timestamp_t;\n\n/** Root block layout */\ntypedef struct {\n\tuint8\t\tmagic[16]\t__packed__;\t/*< All should contain 0x55 */\n\tuint8\t\tuse_custom\t__packed__;\t/*< 0 = standard, 1 = custom */\n\tuint8\t\tcustom_color[4] __packed__;\t/*< blue, green, red, alpha */\n\tuint8\t\tpad1[27]\t__packed__;\t/*< All zeros */\n\tvmu_timestamp_t\ttimestamp\t__packed__;\t/*< BCD timestamp */\n\tuint8\t\tpad2[8]\t\t__packed__;\t/*< All zeros */\n\tuint8\t\tunk1[6]\t\t__packed__;\t/*< ??? */\n\tuint16\t\tfat_loc\t\t__packed__;\t/*< FAT location */\n\tuint16\t\tfat_size\t__packed__;\t/*< FAT size in blocks */\n\tuint16\t\tdir_loc\t\t__packed__;\t/*< Directory location */\n\tuint16\t\tdir_size\t__packed__;\t/*< Directory size in blocks */\n\tuint16\t\ticon_shape\t__packed__;\t/*< Icon shape for this VMS */\n\tuint16\t\tblk_cnt\t\t__packed__;\t/*< Number of user blocks */\n\tuint8\t\tunk2[430]\t__packed__;\t/*< ??? */\n} vmu_root_t;\n\n/** Directory entries, 32 bytes each */\ntypedef struct {\n\tuint8\t\tfiletype\t__packed__;\t/*< 0x00 = no file; 0x33 = data; 0xcc = a game */\n\tuint8\t\tcopyprotect\t__packed__;\t/*< 0x00 = copyable; 0xff = copy protected */\n\tuint16\t\tfirstblk\t__packed__;\t/*< Location of the first block in the file */\n\tchar\t\tfilename[12]\t__packed__;\t/*< Note: there is no null terminator */\n\tvmu_timestamp_t\ttimestamp\t__packed__;\t/*< File time */\n\tuint16\t\tfilesize\t__packed__;\t/*< Size of the file in blocks */\n\tuint16\t\thdroff\t\t__packed__;\t/*< Offset of header, in blocks from start of file */\n\tuint8\t\tdirty\t\t__packed__;\t/*< See header notes */\n\tuint8\t\tpad1[3]\t\t__packed__;\t/*< All zeros */\n} vmu_dir_t;\n#undef __packed__\n\n/* Notes about the \"dirty\" field on vmu_dir_t :)\n\n This byte should always be zero when written out to the VMU. What this\n lets us do, though, is conserve on flash writes. If you only want to\n modify one single file (which is the standard case) then re-writing all\n of the dir blocks is a big waste. Instead, you should set the dirty flag\n on the in-mem copy of the directory, and writing it back out will only\n flush the containing block back to the VMU, setting it back to zero\n in the process. Loaded blocks should always have zero here (though we\n enforce that in the code to make sure) so it will be non-dirty by\n default.\n */\n\n\n/* ****************** Low level functions ******************** */\n\n/** Fill in the date on a vmu_dir_t for writing */\nvoid vmufs_dir_fill_time(vmu_dir_t *d);\n\n/** Reads a selected VMU's root block. Assumes the mutex is held. */\nint vmufs_root_read(maple_device_t * dev, vmu_root_t * root_buf);\n\n/** Writes a selected VMU's root block. Assumes the mutex is held. */\nint vmufs_root_write(maple_device_t * dev, vmu_root_t * root_buf);\n\n/** Given a VMU's root block, return the amount of space in bytes required\n to hold its directory. */\nint vmufs_dir_blocks(vmu_root_t * root_buf);\n\n/** Given a VMU's root block, return the amount of space in bytes required\n to hold its FAT. */\nint vmufs_fat_blocks(vmu_root_t * root_buf);\n\n/** Given a selected VMU's root block, read its directory. Assumes the mutex\n is held. There must be at least the number of bytes returned by\n vmufs_dir_blocks() available in the buffer for this to succeed. */\nint vmufs_dir_read(maple_device_t * dev, vmu_root_t * root_buf, vmu_dir_t * dir_buf);\n\n/** Given a selected VMU's root block and dir blocks, write the dirty dir blocks\n back to the VMU. Assumes the mutex is held. */\nint vmufs_dir_write(maple_device_t * dev, vmu_root_t * root, vmu_dir_t * dir_buf);\n\n/** Given a selected VMU's root block, read its FAT. Assumes the mutex is held.\n There must be at least the number of bytes returned by vmufs_fat_blocks()\n available in the buffer for this to succeed. */\nint vmufs_fat_read(maple_device_t * dev, vmu_root_t * root, uint16 * fat_buf);\n\n/** Given a selected VMU's root block and its FAT, write the FAT blocks\n back to the VMU. Assumes the mutex is held. */\nint vmufs_fat_write(maple_device_t * dev, vmu_root_t * root, uint16 * fat_buf);\n\n/** Given a previously-read directory, locate a file by filename. The index into\n the directory array will be returned on success, or <0 on failure. 'fn' will\n be checked up to 12 characters. */\nint vmufs_dir_find(vmu_root_t * root, vmu_dir_t * dir, const char * fn);\n\n/** Given a previously-read directory, add a new dirent to the dir. Another file\n with the same name should not exist (delete it first if it does). This function\n will _not_ check for dups! Returns 0 on success, or <0 on failure. */\nint vmufs_dir_add(vmu_root_t * root, vmu_dir_t * dir, vmu_dir_t * newdirent);\n\n/** Given a pointer to a directory struct and a previously loaded FAT, load\n the indicated file from the VMU. An appropriate amount of space must\n have been allocated previously in the buffer. Assumes the mutex is held.\n Returns 0 on success, <0 on failure. */\nint vmufs_file_read(maple_device_t * dev, uint16 * fat, vmu_dir_t * dirent, void * outbuf);\n\n/** Given a pointer to a mostly-filled directory struct and a previously loaded\n directory and FAT, write the indicated file to the VMU. The named file\n should not exist in the directory already. The directory and FAT will _not_\n be sync'd back to the VMU, this must be done manually. Assumes the mutex\n is held. Returns 0 on success, <0 on failure. The 'size' parameter is in\n blocks (512-bytes each). */\nint vmufs_file_write(maple_device_t * dev, vmu_root_t * root, uint16 * fat,\n\tvmu_dir_t * dir, vmu_dir_t * newdirent, void * filebuf, int size);\n\n/** Given a previously-read FAT and directory, delete the named file. No changes are\n made to the VMU itself, just the in-memory structs. */\nint vmufs_file_delete(vmu_root_t * root, uint16 * fat, vmu_dir_t * dir, const char *fn);\n\n/** Given a previously-read FAT, return the number of blocks available to write\n out new file data. */\nint vmufs_fat_free(vmu_root_t * root, uint16 * fat);\n\n/** Given a previously-read directory, return the number of dirents available\n for new files. */\nint vmufs_dir_free(vmu_root_t * root, vmu_dir_t * dir);\n\n/** Lock the mutex. This should be done before you attempt any low-level ops. */\nint vmufs_mutex_lock();\n\n/** Unlock the mutex. This should be done once you're done with any low-level ops. */\nint vmufs_mutex_unlock();\n\n\n/* ****************** Higher level functions ******************** */\n\n/** Reads the directory from a VMU. The output buffer will be allocated for\n you using malloc(), and the number of entries will be returned. Returns\n 0 on success, or <0 on failure. On failure, 'outbuf' will not contain\n a dangling buffer that needs to be freed (no further action required). */\nint vmufs_readdir(maple_device_t * dev, vmu_dir_t ** outbuf, int * outcnt);\n\n/** Reads a file from the VMU. The output buffer will be allocated for you\n using malloc(), and the size of the file will be returned. Returns 0 on\n success, or <0 on failure. On failure, 'outbuf' will not contain\n a dangling buffer that needs to be freed (no further action required). */\nint vmufs_read(maple_device_t * dev, const char * fn, void ** outbuf, int * outsize);\n\n/** Same as vmufs_read, but takes a pre-read dirent to speed things up when you\n have already done a lookup. */\nint vmufs_read_dirent(maple_device_t * dev, vmu_dir_t * dirent, void ** outbuf, int * outsize);\n\n/* Flags for vmufs_write */\n#define VMUFS_OVERWRITE\t\t1\t/*< Overwrite existing files */\n#define VMUFS_VMUGAME\t\t2\t/*< This file is a VMU game */\n#define VMUFS_NOCOPY\t\t4\t/*< Set the no-copy flag */\n\n/** Writes a file to the VMU. If the named file already exists, then the\n function checks 'flags'. If VMUFS_OVERWRITE is set, then the old\n file is deleted first before the new one is written (this all happens\n atomically). On partial failure, some data blocks may have been written,\n but in general the card should not be damaged. Returns 0 on success,\n or <0 for failure. */\nint vmufs_write(maple_device_t * dev, const char * fn, void * inbuf, int insize, int flags);\n\n/** Deletes a file from the VMU. Returns 0 on success, -1 if the file can't be\n found, or -2 for some other error. */\nint vmufs_delete(maple_device_t * dev, const char * fn);\n\n/** Returns the number of user blocks free for file writing. You should check this\n number before attempting to write. */\nint vmufs_free_blocks(maple_device_t * dev);\n\n\n/** Initialize vmufs. Must be called before anything else is useful. */\nint vmufs_init();\n\n/** Shutdown vmufs. Must be called after everything is finished. */\nint vmufs_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_VMUFS_H */\n"
},
{
"alpha_fraction": 0.5643789172172546,
"alphanum_fraction": 0.594441294670105,
"avg_line_length": 25.68181800842285,
"blob_id": "6a849563f3d2b8df866011de640c724351d83bfb",
"content_id": "b77873ef8b270070c75b5c6ba9c9c787f1a273a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1763,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 66,
"path": "/libc/include/ctype.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n ctype.h\n (c)2000-2001 Jordan DeLong and Dan Potter\n\n $Id: ctype.h,v 1.1 2002/02/09 06:15:42 bardtx Exp $\n*/\n\n#ifndef __CTYPE_H\n#define __CTYPE_H\n\n#include <sys/cdefs.h>\n\n__BEGIN_DECLS\n\n/* Unix specification requires the definition of these as functions too */\nint isalpha(int);\nint isupper(int);\nint islower(int);\nint isdigit(int);\nint isxdigit(int);\nint isspace(int);\nint ispunct(int);\nint isalnum(int);\nint isblank(int);\nint isprint(int);\nint isgraph(int);\nint iscntrl(int);\nint isascii(int);\nint toascii(int);\nint tolower(int);\nint toupper(int);\n\n#define _U\t0x01\t/* upper */\n#define _L\t0x02\t/* lower */\n#define _N\t0x04\t/* number */\n#define _S\t0x08\t/* space */\n#define _P\t0x10\t/* punct */\n#define _C\t0x20\t/* control */\n#define _X\t0x40\t/* hex number */\n#define _B\t0x80\t/* blank */\n\nextern const char _ctype_[];\n\n#define isalpha(c) (_ctype_[(unsigned)(c)] & (_U|_L))\n#define isupper(c) (_ctype_[(unsigned)(c)] & _U)\n#define islower(c) (_ctype_[(unsigned)(c)] & _L)\n#define isdigit(c) (_ctype_[(unsigned)(c)] & _N)\n#define isxdigit(c) (_ctype_[(unsigned)(c)] & (_X|_N))\n#define isspace(c) (_ctype_[(unsigned)(c)] & _S)\n#define ispunct(c) (_ctype_[(unsigned)(c)] & _P)\n#define isalnum(c) (_ctype_[(unsigned)(c)] & (_U|_L|_N))\n#define isblank(c) (_ctype_[(unsigned)(c)] & _B)\n#define isprint(c) (_ctype_[(unsigned)(c)] & (_P|_U|_L|_N|_B))\n#define isgraph(c) (_ctype_[(unsigned)(c)] & (_P|_U|_L|_N))\n#define iscntrl(c) (_ctype_[(unsigned)(c)] & _C)\n#define isascii(c) (((c) & ~0x7F) == 0)\n#define toascii(c) ((c) & 0x7f)\n#define tolower(c) (isupper(c) ? ((c) + ('a' - 'A')) : (c))\n#define toupper(c) (islower(c) ? ((c) - ('a' - 'A')) : (c))\n#define _tolower(c) ((c) + ('a' - 'A'))\n#define _toupper(c) ((c) - ('a' - 'A'))\n\n__END_DECLS\n\n#endif\n\n\n"
},
{
"alpha_fraction": 0.5462831258773804,
"alphanum_fraction": 0.5887211561203003,
"avg_line_length": 17.972972869873047,
"blob_id": "27f0c985fef0eb3313a0ab1d7f70710492757a99",
"content_id": "45edcab4427937750de7246de71a7ccd83c2e746",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3511,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 185,
"path": "/examples/gba/pogo-keen/pogo.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "\n/* KallistiOS ##version##\n\n pogo.c\n (c)2002 Gil Megidish\n\n*/\n\n/*\n\nThis is an inefficient example of how to get your KOS GBA code kicking; it\nshows Commander Keen (animation by Blackeye Software,) jumping around with\nhis pogo stick. \n\nAbsolutely not the way to write games; but this is just to show basic\nguidelines of initializing and using the romdisk filesystem with the gba,\nand the use of video registers directly.\n\n*/\n\n#include <gba/video.h>\n#include <gba/keys.h>\n#include <kos.h>\n#include <kos/pcx.h>\n\nextern uint8 romdisk_boot[];\n\nvoid arm_irq_handler() { }\n\nstatic uint16 pogo_bitmaps[7][48*48];\n\nstatic uint16 *get_pogo_bitmap(int index) {\n\treturn pogo_bitmaps[index];\n}\t\n\nvoid gba_setmode(int mode, int bg) {\n\tREG_DISPCNT = mode | (1 << (bg + 8));\n}\n\nstatic int sequence = 0;\nstatic int pogo_x = (240 + 48)/2;\nstatic int pogo_y = (160 - 48);\nstatic int pogo_xmax = 240 - 48 - 1;\nstatic int pogo_ymax = 160 - 48;\nstatic int pogo_dir = 0;\n\n#define RGB16(r,g,b) ((r>>3) | ((g>>3) << 5) | ((b>>3) << 10))\n\nstatic void draw_bitmap(uint16 *rgb) {\n\t/* this will draw a 48x48 rgb bitmap onto a 16bit video buffer */\n\tuint16 color;\n\tuint16 *ptr;\n\tint direction;\n\tint i, j;\n\t\n\tptr = (uint16*)PTR_VID_0 + (pogo_y * 240) + pogo_x;\n\t\n\tif (pogo_dir == 0)\n\t\tdirection = 1;\n\telse {\n\t\t/* facing right */\n\t\tdirection = -1;\n\t\tptr = ptr + 48;\n\t}\n\t\t\n\tfor (j=0; j<48; j++) {\n\t\tfor (i=0; i<48; i++) {\n\t\t\tcolor = *rgb++;\n\t\t\tif (color == RGB16(0xff, 0, 0xff))\n\t\t\t\tcolor = 0;\n\t\t\t\t\n\t\t\t*ptr = color;\n\t\t\tptr = ptr + direction;\n\t\t}\n\n\t\tptr = ptr + 240 - (48 * direction);\n\t}\n}\n\nstatic void animate() {\n\tuint16 *bitmap;\n\t\n\tbitmap = get_pogo_bitmap(sequence);\n\tdraw_bitmap(bitmap);\n}\n\nstatic void wait() {\n\tvolatile uint32 *status;\n\t\n\t/* wait for a full vsync */\n\tstatus = (uint32*)0x4000004;\n\twhile ((*status & 1) == 0);\n\twhile ((*status & 1) == 1);\n}\n\nstatic void sleep(int n) {\n\twhile (n > 0) {\n\t\twait();\n\t\t--n;\n\t}\n}\n\nstatic void check_keys() {\n\tint keys;\n\t\n\tkeys = REG_KEYS;\n\tif ((keys & KEY_LEFT) == 0) {\n\t\t/* left */\n\t\t--pogo_x;\n\t\tif (pogo_x < 0) \n\t\t\tpogo_x = 0;\n\t\tpogo_dir = 0;\n\t}\n\t\n\tif ((keys & KEY_RIGHT) == 0) {\n\t\t/* right */\n\t\t++pogo_x;\n\t\tif (pogo_x > pogo_xmax)\n\t\t\tpogo_x = pogo_xmax;\n\t\tpogo_dir = 1;\n\t}\n\n\tif ((keys & KEY_UP) == 0) {\n\t\t/* up */\n\t\t--pogo_y;\n\t\tif (pogo_y < 0)\n\t\t\tpogo_y = 0;\n\t}\n\n\tif ((keys & KEY_DOWN) == 0) {\n\t\t/* down */\n\t\t++pogo_y;\n\t\tif (pogo_y > pogo_ymax)\n\t\t\tpogo_y = pogo_ymax;\n\t}\n}\n\nstatic void prepare() {\n\tint w, h;\n\n\t/* load all 7 bitmaps */\t\n\tpcx_load_flat(\"/rd/1.pcx\", &w, &h, get_pogo_bitmap(0));\n\tpcx_load_flat(\"/rd/2.pcx\", &w, &h, get_pogo_bitmap(1));\n\tpcx_load_flat(\"/rd/3.pcx\", &w, &h, get_pogo_bitmap(2));\n\tpcx_load_flat(\"/rd/4.pcx\", &w, &h, get_pogo_bitmap(3));\n\tpcx_load_flat(\"/rd/5.pcx\", &w, &h, get_pogo_bitmap(4));\n\tpcx_load_flat(\"/rd/6.pcx\", &w, &h, get_pogo_bitmap(5));\n\tpcx_load_flat(\"/rd/7.pcx\", &w, &h, get_pogo_bitmap(6));\n}\n\nKOS_INIT_FLAGS(INIT_DEFAULT);\nKOS_INIT_ROMDISK(romdisk_boot);\n\nint main() {\n\t/* initialize romdisk filesystem */\n\t\n\t/* initialize video mode (raw, 16 bit) */\n\tgba_setmode(3, 2);\n\t\n\tmemset(PTR_VID_0, 0, 240*160);\t\n\t\n\t/* preload pogo animation */\n\tprepare();\n\t\n\t/* main loop */\n\tsequence = 0;\n\twhile (REG_KEYS & KEY_A) {\n\t\n\t\t/* show current frame of animation, and sleep for some period */\n\t\tanimate();\n\t\tsleep(2);\n\t\t\n\t\t/* next frame in animation (only 7 pictures in set) */\n\t\tsequence++;\n\t\tsequence = sequence % 7;\n\t\t\n\t\t/* probe keypad */\n\t\tcheck_keys();\n\t}\n\t\n\t/* go back to neverever land */\n\tarch_reboot();\n\t\n\t/* keep compiler happy(R) */\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.4726027250289917,
"alphanum_fraction": 0.5308219194412231,
"avg_line_length": 19.13793182373047,
"blob_id": "9858e3a5756bc29d9c4f53329e84c90dac7df2cc",
"content_id": "5ad838845ac7d37bd7625e11b42423d46f3afae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 29,
"path": "/libc/string/stricmp.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n stricmp.c\n (c)2000 Dan Potter\n\n $Id: stricmp.c,v 1.2 2002/02/13 10:44:09 andrewk Exp $\n*/\n\n#include <string.h>\n\n/* Works like strcmp, but not case sensitive */\nint stricmp(const char * cs,const char * ct) {\n\tint c1, c2, res;\n\n\twhile(1) {\n\t\tc1 = *cs++; c2 = *ct++;\n\t\tif (c1 >= 'A' && c1 <= 'Z') c1 += 'a' - 'A';\n\t\tif (c2 >= 'A' && c2 <= 'Z') c2 += 'a' - 'A';\n\t\tif ((res = c1 - c2) != 0 || (!*cs && !*ct))\n\t\t\tbreak;\n\t}\n\n\treturn res;\n}\n\n/* Also provides strcasecmp (same thing) */\nint strcasecmp(const char *cs, const char *ct) {\n\treturn stricmp(cs, ct);\n}\n"
},
{
"alpha_fraction": 0.6398963928222656,
"alphanum_fraction": 0.674870491027832,
"avg_line_length": 23.09375,
"blob_id": "64caae4b7ff0144e9e9ebb78a53cb0518549fdfd",
"content_id": "ff033703b5da63e6076c8f12bae38f5bec9f42b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 32,
"path": "/examples/gba/pogo-keen/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS 1.1.6\n#\n# pogo-keen/Makefile\n# (c)2002 Gil Megidish\n# \n# $Id: Makefile,v 1.1 2002/09/23 19:30:27 gilm Exp $\n\nall: pogo-keen.gba\n\ninclude $(TOPDIR)/Makefile.rules\n\nOBJS = pogo.o\n\nclean:\n\t-rm -f $(OBJS)\n\t-rm -f pogo-keen.gba\n\t-rm -f pogo-keen.elf\n\t-rm -f romdisk_boot.o\n\t-rm -f romdisk_boot.img\n\npogo-keen.gba: pogo-keen.elf\n\t$(TOPDIR)/utils/gba-elf2bin/gba-elf2bin pogo-keen.elf pogo-keen.gba\n\t-rm -f pogo-keen.elf\n\nDATAOBJS = romdisk_boot.o\npogo-keen.elf: $(OBJS) $(DATAOBJS)\n\t$(KOS_CC) $(KOS_CFLAGS) $(KOS_LDFLAGS) -o pogo-keen.elf \\\n\t\t$(KOS_START) $(OBJS) $(DATAOBJS) $(OBJEXTRA) -L$(TOPDIR)/lib -lkallisti -lgcc\n\nromdisk_boot.o:\n\t$(KOS_GENROMFS) -f romdisk_boot.img -d romdisk_boot -v\n\t$(TOPDIR)/utils/bin2o/bin2o romdisk_boot.img romdisk_boot romdisk_boot.o\n\n"
},
{
"alpha_fraction": 0.6317262053489685,
"alphanum_fraction": 0.707705557346344,
"avg_line_length": 26,
"blob_id": "868daf02c226ea0ddc3bab24e02fdd6ba6ae43fc",
"content_id": "e128149545ce2f306e4ea600c86fd2ae600789e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4646,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 172,
"path": "/include/arch/dreamcast/dc/maple/keyboard.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/keyboard.h\n (C)2000-2002 Jordan DeLong and Dan Potter\n\n $Id: keyboard.h,v 1.3 2002/05/18 07:11:44 bardtx Exp $\n*/\n\n#ifndef __DC_MAPLE_KEYBOARD_H\n#define __DC_MAPLE_KEYBOARD_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* modifier keys */\n#define KBD_MOD_LCTRL \t\t(1<<0)\n#define KBD_MOD_LSHIFT\t\t(1<<1)\n#define KBD_MOD_LALT\t\t(1<<2)\n#define KBD_MOD_S1\t\t(1<<3)\n#define KBD_MOD_RCTRL\t\t(1<<4)\n#define KBD_MOD_RSHIFT\t\t(1<<5)\n#define KBD_MOD_RALT\t\t(1<<6)\n#define KBD_MOD_S2\t\t(1<<7)\n\n/* bits for leds : this is not comprensive (need for japanese kbds also) */\n#define KBD_LED_NUMLOCK\t\t(1<<0)\n#define KBD_LED_CAPSLOCK\t(1<<1)\n#define KBD_LED_SCRLOCK\t\t(1<<2)\n\n/* defines for the keys (argh...) */\n#define KBD_KEY_NONE\t\t0x00\n#define KBD_KEY_ERROR\t\t0x01\n#define KBD_KEY_A\t\t0x04\n#define KBD_KEY_B\t\t0x05\n#define KBD_KEY_C\t\t0x06\n#define KBD_KEY_D\t\t0x07\n#define KBD_KEY_E\t\t0x08\n#define KBD_KEY_F\t\t0x09\n#define KBD_KEY_G\t\t0x0a\n#define KBD_KEY_H\t\t0x0b\n#define KBD_KEY_I\t\t0x0c\n#define KBD_KEY_J\t\t0x0d\n#define KBD_KEY_K\t\t0x0e\n#define KBD_KEY_L\t\t0x0f\n#define KBD_KEY_M\t\t0x10\n#define KBD_KEY_N\t\t0x11\n#define KBD_KEY_O\t\t0x12\n#define KBD_KEY_P\t\t0x13\n#define KBD_KEY_Q\t\t0x14\n#define KBD_KEY_R\t\t0x15\n#define KBD_KEY_S\t\t0x16\n#define KBD_KEY_T\t\t0x17\n#define KBD_KEY_U\t\t0x18\n#define KBD_KEY_V\t\t0x19\n#define KBD_KEY_W\t\t0x1a\n#define KBD_KEY_X\t\t0x1b\n#define KBD_KEY_Y\t\t0x1c\n#define KBD_KEY_Z\t\t0x1d\n#define KBD_KEY_1\t\t0x1e\n#define KBD_KEY_2\t\t0x1f\n#define KBD_KEY_3\t\t0x20\n#define KBD_KEY_4\t\t0x21\n#define KBD_KEY_5\t\t0x22\n#define KBD_KEY_6\t\t0x23\n#define KBD_KEY_7\t\t0x24\n#define KBD_KEY_8\t\t0x25\n#define KBD_KEY_9\t\t0x26\n#define KBD_KEY_0\t\t0x27\n#define KBD_KEY_ENTER\t\t0x28\n#define KBD_KEY_ESCAPE\t\t0x29\n#define KBD_KEY_BACKSPACE\t0x2a\n#define KBD_KEY_TAB\t\t0x2b\n#define KBD_KEY_SPACE\t\t0x2c\n#define KBD_KEY_MINUS\t\t0x2d\n#define KBD_KEY_PLUS\t\t0x2e\n#define KBD_KEY_LBRACKET\t0x2f\n#define KBD_KEY_RBRACKET\t0x30\n#define KBD_KEY_BACKSLASH\t0x31\n#define KBD_KEY_SEMICOLON\t0x33\n#define KBD_KEY_QUOTE\t\t0x34\n#define KBD_KEY_TILDE\t\t0x35\n#define KBD_KEY_COMMA\t\t0x36\n#define KBD_KEY_PERIOD\t\t0x37\n#define KBD_KEY_SLASH\t\t0x38\n#define KBD_KEY_CAPSLOCK\t0x39\n#define KBD_KEY_F1\t\t0x3a\n#define KBD_KEY_F2\t\t0x3b\n#define KBD_KEY_F3\t\t0x3c\n#define KBD_KEY_F4\t\t0x3d\n#define KBD_KEY_F5\t\t0x3e\n#define KBD_KEY_F6\t\t0x3f\n#define KBD_KEY_F7\t\t0x40\n#define KBD_KEY_F8\t\t0x41\n#define KBD_KEY_F9\t\t0x42\n#define KBD_KEY_F10\t\t0x43\n#define KBD_KEY_F11\t\t0x44\n#define KBD_KEY_F12\t\t0x45\n#define KBD_KEY_PRINT\t\t0x46\n#define KBD_KEY_SCRLOCK\t\t0x47\n#define KBD_KEY_PAUSE\t\t0x48\n#define KBD_KEY_INSERT\t\t0x49\n#define KBD_KEY_HOME\t\t0x4a\n#define KBD_KEY_PGUP\t\t0x4b\n#define KBD_KEY_DEL\t\t0x4c\n#define KBD_KEY_END\t\t0x4d\n#define KBD_KEY_PGDOWN\t\t0x4e\n#define KBD_KEY_RIGHT\t\t0x4f\n#define KBD_KEY_LEFT\t\t0x50\n#define KBD_KEY_DOWN\t\t0x51\n#define KBD_KEY_UP\t\t0x52\n#define KBD_KEY_PAD_NUMLOCK\t0x53\n#define KBD_KEY_PAD_DIVIDE\t0x54\n#define KBD_KEY_PAD_MULTIPLY\t0x55\n#define KBD_KEY_PAD_MINUS\t0x56\n#define KBD_KEY_PAD_PLUS\t0x57\n#define KBD_KEY_PAD_ENTER\t0x58\n#define KBD_KEY_PAD_1\t\t0x59\n#define KBD_KEY_PAD_2\t\t0x5a\n#define KBD_KEY_PAD_3\t\t0x5b\n#define KBD_KEY_PAD_4\t\t0x5c\n#define KBD_KEY_PAD_5\t\t0x5d\n#define KBD_KEY_PAD_6\t\t0x5e\n#define KBD_KEY_PAD_7\t\t0x5f\n#define KBD_KEY_PAD_8\t\t0x60\n#define KBD_KEY_PAD_9\t\t0x61\n#define KBD_KEY_PAD_0\t\t0x62\n#define KBD_KEY_PAD_PERIOD\t0x63\n#define KBD_KEY_S3\t\t0x65\n\n/* Raw condition structure */\ntypedef struct {\n\tuint8 modifiers;\t/* bitmask of shift keys/etc */\n\tuint8 leds;\t\t/* bitmask of leds that are lit */\n\tuint8 keys[6];\t\t/* codes for up to 6 currently pressed keys */\n} kbd_cond_t;\n\n/* This is the structure of the 'state' space. This is what you will\n get back if you call maple_dev_state(). */\ntypedef struct kbd_state {\n\t/* The latest raw keyboard condition */\n\tkbd_cond_t cond;\n\t\n\t/* The key matrix array -- this is an array that lists the status of all\n\t keys on the keyboard. This is mainly used for key repeat and debouncing. */\n\tuint8\tmatrix[256];\n\n\t/* Shift key status */\n\tint\tshift_keys;\n} kbd_state_t;\n\n/* Turn keyboard queueing on or off. This is mainly useful if you want\n to use the keys for a game where individual keypresses don't mean\n as much as having the keys up or down. Setting this state to\n a new value will clear the queue. */\nvoid kbd_set_queue(int active);\n\n/* Take a key scancode, encode it appropriate, and place it on the\n keyboard queue. At the moment we assume no key overflows. */\n/* int kbd_enqueue(uint8 keycode); */\n\n/* Take a key off the key queue, or return -1 if there is none waiting */\nint kbd_get_key();\n\n/* Init / Shutdown */\nint\tkbd_init();\nvoid\tkbd_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_KEYBOARD_H */\n\n\n"
},
{
"alpha_fraction": 0.5739030241966248,
"alphanum_fraction": 0.6050808429718018,
"avg_line_length": 19.595237731933594,
"blob_id": "c79cc4bb7181a1306f1ec22f4bfbeabe6263486c",
"content_id": "2b93d448ca2a9ba60445477c4d959298a1469361",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 42,
"path": "/include/arch/gba/arch/spinlock.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/include/spinlock.h\n (c)2001 Dan Potter\n \n $Id: spinlock.h,v 1.2 2002/11/06 08:34:54 bardtx Exp $\n*/\n\n#ifndef __ARCH_SPINLOCK_H\n#define __ARCH_SPINLOCK_H\n\n/* Defines processor specific spinlocks; if you include this file, you\n must first include kos/thread.h. */\n\n/* Spinlock data type */\n/* typedef int spinlock_t; */\ntypedef char spinlock_t;\n\n/* Value initializer */\n#define SPINLOCK_INITIALIZER 0\n\n/* Initialize a spinlock */\n#define spinlock_init(A) *(A) = SPINLOCK_INITIALIZER\n\n/* Spin on a lock */\n/* #define spinlock_lock(A) do { \\\n\t\tif (*(A)) { \\\n\t\t\twhile (*(A)) \\\n\t\t\t\t; \\\n\t\t\t*(A) = 1; \\\n\t\t} \\\n\t} while (0) */\n#define spinlock_lock(A) do { } while (0)\n\n/* Free a lock */\n/* #define spinlock_unlock(A) do { \\\n\t\t*(A) = 0; \\\n\t} while (0) */\n#define spinlock_unlock(A) do { } while (0)\n\n\n#endif\t/* __ARCH_SPINLOCK_H */\n\n"
},
{
"alpha_fraction": 0.5396153926849365,
"alphanum_fraction": 0.6061538457870483,
"avg_line_length": 21.798246383666992,
"blob_id": "702fc4ee1ddc35ccbbf1fc409b15d9858398818b",
"content_id": "e9bb595264d4c06e4377371101188d5bae548230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5200,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 228,
"path": "/examples/dreamcast/kgl/basic/gl/gltest.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gltest.c\n (c)2001 Dan Potter\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/*\n\nThis is a really simple KallistiGL example. It shows off several things:\nbasic matrix control, perspective, the AUTO_UV feature, and controlling\nthe image with maple input.\n\nThanks to NeHe's tutorials for the crate image.\n\n*/\n\n/* Draw a cube centered around 0,0,0. Note the total lack of glTexCoord2f(),\n even though the cube is in fact getting textured! This is KGL's AUTO_UV\n feature: turn it on and it assumes you're putting on the texture on\n the quad in the order 0,0; 1,0; 1,1; 0,1. This only works for quads. */\nvoid cube(float r) {\n\tglRotatef(r, 1.0f, 0.0f, 1.0f);\n\t\n\tglBegin(GL_QUADS);\n\n\t\t/* Front face */\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\n\t\t/* Back face */\n\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\t\t\t\n\t\t/* Left face */\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\n\t\t/* Right face */\n\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\n\t\t/* Top face */\n\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\n\t\t/* Bottom face */\n\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\tglEnd();\n}\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tfloat\tr = 0.0f;\n\tfloat\tdr = 2;\n\tfloat\tz = -14.0f;\n\tGLuint\ttexture;\n\tGLuint dummy;\n\tint\ttrans = 0;\n\tpvr_stats_t\tstats;\n\n\t/* Initialize KOS */\n\n\t/* Use this to test other video modes */\n\t/* vid_init(DM_320x240, PM_RGB565); */\n\n\t/* Normal init */\n\tpvr_init(¶ms);\n\n\tprintf(\"gltest beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglEnable(GL_TEXTURE_2D);\n\tglEnable(GL_KOS_AUTO_UV);\n\n\t/* Expect CW verts */\n\tglFrontFace(GL_CW);\n\n /* Enable Transparancy */\n glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);\n\t\n\t/* Load a texture and make to look nice */\n\tloadtxr(\"/rd/crate.pcx\", &texture);\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n glTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATEALPHA);\n\n\tglClearColor(0.3f, 0.4f, 0.5f, 1.0f);\n\n\twhile(1) {\n\t\t/* Check key status */\n\t\tc = maple_first_controller();\n\t\tif (c) {\n\t\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\t}\n\t\t\tif (!(cond.buttons & CONT_START))\n\t\t\t\tbreak;\n\t\t\tif (!(cond.buttons & CONT_DPAD_UP))\n\t\t\t\tz -= 0.1f;\n\t\t\tif (!(cond.buttons & CONT_DPAD_DOWN))\n\t\t\t\tz += 0.1f;\n\t\t\tif (!(cond.buttons & CONT_DPAD_LEFT)) {\n\t\t\t\t/* If manual rotation is requested, then stop\n\t\t\t\t the automated rotation */\n\t\t\t\tdr = 0.0f;\n\t\t\t\tr -= 2.0f;\n\t\t\t}\n\t\t\tif (!(cond.buttons & CONT_DPAD_RIGHT)) {\n\t\t\t\tdr = 0.0f;\n\t\t\t\tr += 2.0f;\n\t\t\t}\n\t\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\t\t/* This weird logic is to avoid bouncing back\n\t\t\t\t and forth before the user lets go of the\n\t\t\t\t button. */\n\t\t\t\tif (!(trans & 0x1000)) {\n\t\t\t\t\tif (trans == 0)\n\t\t\t\t\t\ttrans = 0x1001;\n\t\t\t\t\telse\n\t\t\t\t\t\ttrans = 0x1000;\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\ttrans &= ~0x1000;\n\t\t\t}\n\t\t}\n\n\t\tr += dr;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw four cubes */\n\t\tglLoadIdentity();\n\t\tglTranslatef(0.0f, 0.0f, z);\n\t\tglRotatef(r, 0.0f, 1.0f, 0.5f);\n\t\tglPushMatrix();\n\t\t\n\t\tglTranslatef(-5.0f, 0.0f, 0.0f);\n\t\tcube(r);\n\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglTranslatef(5.0f, 0.0f, 0.0f);\n\t\tcube(r);\n\n\t\t/* Potentially do two as translucent */\n\t\tif (trans & 1) {\n\t\t\tglKosFinishList();\n\t\t\tglColor4f(1.0f, 1.0f, 1.0f, 0.5f);\n\t\t\tglDisable(GL_CULL_FACE);\n\t\t}\n\n\t\tglPopMatrix();\n\t\tglPushMatrix();\n\t\tglTranslatef(0.0f, 5.0f, 0.0f);\n\t\tcube(r);\n\n\t\tglPopMatrix();\n\t\tglTranslatef(0.0f, -5.0f, 0.0f);\n\t\tcube(r);\n\n\t\tif (trans & 1) {\n\t\t glEnable(GL_CULL_FACE);\n\t\t}\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\tpvr_get_stats(&stats);\n\tprintf(\"VBL Count: %d, last_time: %f, frame rate: %f fps\\n\",\n\t\tstats.vbl_count, stats.frame_last_time, stats.frame_rate);\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5559350848197937,
"alphanum_fraction": 0.6046114563941956,
"avg_line_length": 19.172412872314453,
"blob_id": "dc7d644e1ddbc51eae0f752d8796f54d42fd75fa",
"content_id": "87ac32336cdcb89539c3db47a34abb8d5157b12f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1171,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 58,
"path": "/include/arch/ia32/ia32/ports.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n ports.h\n Copyright (C)2003 Dan Potter\n \n $Id: ports.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n*/\n\n#ifndef __IA32_PORTS_H\n#define __IA32_PORTS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n// These macros determine if the port number is small enough to do it\n// directly. If so it save some code space and registers.\n#define inb(port) ({ \\\n\tuint8 _data; \\\n\tif (((port) & 0xffff) < 0x100) \\\n\t\t_data = inbc(port); \\\n\telse \\\n\t\t_data = inbv(port); \\\n\t_data; })\n\n#define outb(port, data) ({ \\\n\tif (((port) & 0xffff) < 0x100) \\\n\t\toutbc(port, data); \\\n\telse \\\n\t\toutbv(port, data); })\n\nstatic inline uint8 inbc(int port) {\n\tuint8 data;\n\n\tasm volatile(\"inb %1,%0\" : \"=a\" (data) : \"id\" ((uint16)port));\n\treturn data;\n}\n\nstatic inline void outbc(int port, uint8 data) {\n\tasm volatile(\"outb %0,%1\" : : \"a\" (data), \"id\" ((uint16)port));\n}\n\nstatic inline uint8 inbv(int port) {\n\tuint8 data;\n\n\tasm volatile(\"inb %%dx,%0\" : \"=a\" (data) : \"d\" ((uint16)port));\n\treturn data;\n}\n\nstatic inline void outbv(int port, uint8 data) {\n\tasm volatile(\"outb %0,%%dx\" : : \"a\" (data), \"d\" ((uint16)port));\n}\n\n\n__END_DECLS\n\n#endif\t/* __IA32_PORTS_H */\n\n"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.6074073910713196,
"avg_line_length": 12.449999809265137,
"blob_id": "e0f8770ccf46e4a711480d738eaa4945f8fd3e12",
"content_id": "ee2344e8f7ddfa094ba0f5aed133508880445719",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 20,
"path": "/libc/include/sys/types.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sys/types.h\n (c)2002 Dan Potter\n\n $Id: types.h,v 1.1 2002/04/20 22:08:43 bardtx Exp $\n\n*/\n\n#ifndef __SYS_TYPES_H\n#define __SYS_TYPES_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n__END_DECLS\n\n#endif\t/* __SYS_TYPES_H */\n\n"
},
{
"alpha_fraction": 0.6041666865348816,
"alphanum_fraction": 0.6041666865348816,
"avg_line_length": 15,
"blob_id": "764f9229671cbedddbb8169fa2014500ef8479f4",
"content_id": "97bad5419a6bf61972c4bdd79406319f77a7e112",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 3,
"path": "/utils/gnu_wrappers/kos-ar",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\nexec ${KOS_AR} \"$@\"\n"
},
{
"alpha_fraction": 0.5710930824279785,
"alphanum_fraction": 0.6298035979270935,
"avg_line_length": 23.51308822631836,
"blob_id": "72e2dc8a37293da1f5cebd929b900e14f81b8262",
"content_id": "788e04810ab8a4a9876586e7b9ae89dd9d29bae5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4684,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 191,
"path": "/examples/dreamcast/kgl/nehe/nehe09/nehe09.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe09.c\n (c)2001 Benoit Miller\n\n Parts (c)2000 Jeff Molofee\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/* Simple KGL example to demonstrate texturing. \n\n Essentially the same thing as NeHe's lesson06 code.\n To learn more, go to http://nehe.gamedev.net/.\n*/\n\n#define NUM_STARS 50\t\t/* Number Of Stars To Draw */\n\ntypedef struct\t\t\t/* Create A Structure For Star */\n{\n\tint r, g, b;\t\t/* Stars Color */\n\tGLfloat dist,\t\t/* Stars Distance From Center */\n\t\tangle; \t/* Stars Current Angle */\n} stars;\nstatic stars star[NUM_STARS];\t/* Need To Keep Track Of 'NUM_STARS' Stars */\n\nstatic GLboolean twinkle;\t/* Twinkling Stars */\n\nstatic GLfloat zoom=-15.0f;\t/* Distance Away From Stars */\nstatic GLfloat tilt=90.0f;\t/* Tilt The View */\nstatic GLfloat spin;\t\t/* Spin Stars */\n\nstatic GLuint loop;\t\t/* General Loop Variable */\nstatic GLuint texture[1];\t/* Storage For One textures */\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid draw_gl(void) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\tglBindTexture(GL_TEXTURE_2D, texture[0]);\n\n\tfor (loop=0; loop<NUM_STARS; loop++) {\n\t\tglLoadIdentity();\n\t\tglTranslatef(0.0f,0.0f,zoom);\n\t\tglRotatef(tilt,1.0f,0.0f,0.0f);\n\t\tglRotatef(star[loop].angle,0.0f,1.0f,0.0f);\n\t\tglTranslatef(star[loop].dist,0.0f,0.0f);\n\t\tglRotatef(-star[loop].angle,0.0f,1.0f,0.0f);\n\t\tglRotatef(-tilt,1.0f,0.0f,0.0f);\n\t\t\n\t\tif (twinkle)\n\t\t{\n\t\t\tglColor4ub(star[(NUM_STARS-loop)-1].r,star[(NUM_STARS-loop)-1].g,star[(NUM_STARS-loop)-1].b,255);\n\t\t\tglBegin(GL_QUADS);\n\t\t\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f,-1.0f, 0.0f);\n\t\t\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f,-1.0f, 0.0f);\n\t\t\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 0.0f);\n\t\t\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 0.0f);\n\t\t\tglEnd();\n\t\t}\n\n\t\tglRotatef(spin,0.0f,0.0f,1.0f);\n\t\tglColor4ub(star[loop].r,star[loop].g,star[loop].b,255);\n\t\tglBegin(GL_QUADS);\n\t\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f,-1.0f, 0.0f);\n\t\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f,-1.0f, 0.0f);\n\t\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 0.0f);\n\t\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 0.0f);\n\t\tglEnd();\n\n\t\tspin+=0.01f;\n\t\tstar[loop].angle+=(float)(loop)/NUM_STARS;\n\t\tstar[loop].dist-=0.01f;\n\t\tif (star[loop].dist<0.0f)\n\t\t{\n\t\t\tstar[loop].dist+=5.0f;\n\t\t\tstar[loop].r=rand()%256;\n\t\t\tstar[loop].g=rand()%256;\n\t\t\tstar[loop].b=rand()%256;\n\t\t}\n\t}\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tGLboolean yp = GL_FALSE;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"nehe09 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,640.0f/480.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.0f, 0.0f, 0.0f, 0.5f);\n\tglClearDepth(1.0f);\n\tglBlendFunc(GL_SRC_ALPHA,GL_ONE);\n\t//glEnable(GL_BLEND);\n\n\tfor (loop=0; loop<NUM_STARS; loop++)\n\t{\n\t\tstar[loop].angle=0.0f;\n\t\tstar[loop].dist=((float)(loop)/NUM_STARS)*5.0f;\n\t\tstar[loop].r=rand()%256;\n\t\tstar[loop].g=rand()%256;\n\t\tstar[loop].b=rand()%256;\n\t}\n\n\t/* Set up the texture */\n\tloadtxr(\"/rd/Star.pcx\", &texture[0]);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\tif (!(cond.buttons & CONT_DPAD_UP))\n\t\t\ttilt -= 0.5f;\n\t\tif (!(cond.buttons & CONT_DPAD_DOWN))\n\t\t\ttilt += 0.5f;\n\t\tif (!(cond.buttons & CONT_A))\n\t\t\tzoom -= 0.2f;\n\t\tif (!(cond.buttons & CONT_B))\n\t\t\tzoom += 0.2f;\n\t\tif (!(cond.buttons & CONT_Y) && !yp) {\n\t\t\typ = GL_TRUE;\n\t\t\ttwinkle = !twinkle;\n\t\t}\n\t\tif (cond.buttons & CONT_Y)\n\t\t\typ = GL_FALSE;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Switch to blended polygon list */\n\t\tglKosFinishList();\n\n\t\t/* Draw the GL \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6547619104385376,
"alphanum_fraction": 0.6642857193946838,
"avg_line_length": 15.760000228881836,
"blob_id": "017fbe0c2f3d13b2417691a34344a573d4882909",
"content_id": "35ab87a9a3e36963c7a5f0c1f92e3d798374e5e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 25,
"path": "/include/arch/dreamcast/dc/maple/dreameye.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/dreameye.h\n Copyright (C) 2005 Lawrence Sebald\n\n*/\n\n#ifndef __DC_MAPLE_DREAMEYE_H\n#define __DC_MAPLE_DREAMEYE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* There's nothing much here to see right now, just stuff\n to make the detection work. */\n\n/* Init / Shutdown */\nint dreameye_init();\nvoid dreameye_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_DREAMEYE_H */\n\n"
},
{
"alpha_fraction": 0.5899280309677124,
"alphanum_fraction": 0.6258992552757263,
"avg_line_length": 16.375,
"blob_id": "d3e832a338c69ea0bf64c81e8b25a25581f6aa84",
"content_id": "85224306b27b1d42c7b6b0f0f51a7e0033ce4362",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 32,
"path": "/examples/dreamcast/lua/basic/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# lua/basic/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/06/30 06:33:38 bardtx Exp $\n\nall: rm-elf lua.elf\n\nKOS_LOCAL_CFLAGS := -I$(KOS_PATH)/addons/lua/include\n\n\ninclude $(KOS_PATH)/scripts/Makefile.rules\n\nOBJS = lua.o\n\nclean:\n\t-rm -f lua.elf $(OBJS)\n\nrm-elf:\n\t-rm -f lua.elf\n\nlua.elf: $(OBJS) \n\t$(KOS_CC) $(KOS_CFLAGS) $(KOS_LDFLAGS) -o lua.elf $(KOS_START) $(OBJS) $(DATAOBJS) \\\n\t\t$(OBJEXTRA) -llua -llualib -lconio $(KOS_LIBS) -lm\n\nrun: lua.elf\n\t$(KOS_LOADER) lua.elf\n\ndist:\n\t-rm -f $(OBJS)\n\t$(KOS_STRIP) lua.elf\n"
},
{
"alpha_fraction": 0.5740131735801697,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 17.84375,
"blob_id": "148503ba61782769abd64c575656eae22079e83f",
"content_id": "bcc6c48615c7c3a067604d58b8419bd45e538a07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/examples/dreamcast/network/httpd/simhost.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <kos.h>\n#include <lwip/lwip.h>\n#include <unistd.h>\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nvoid httpd();\nvoid do_httpd(void * foo) {\n\thttpd();\n}\n\nint main(int argc, char **argv) {\n\tnet_init();\n\tlwip_kos_init();\n\tthd_create(do_httpd, NULL);\n\n\tvid_clear(50,0,70);\n\tbfont_draw_str(vram_s + 20*640+20, 640, 0, \"KOSHttpd active\");\n\tbfont_draw_str(vram_s + 44*640+20, 640, 0, \"Press START to quit.\");\n\n\tthd_sleep(1000*5);\n\n\tfor ( ; ; ) {\n\t\tMAPLE_FOREACH_BEGIN(MAPLE_FUNC_CONTROLLER, cont_state_t, st)\n\t\t\tif (st->buttons & CONT_START)\n\t\t\t\treturn 0;\n\t\tMAPLE_FOREACH_END()\n\t}\n\n\treturn 0;\n}\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5875831246376038,
"alphanum_fraction": 0.635254979133606,
"avg_line_length": 20.95121955871582,
"blob_id": "c5b900e9155ba1b36ca68954885fe8745ab6fc9f",
"content_id": "052ae9b68189dff70bd259d0af4289d252081d90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 902,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 41,
"path": "/kernel/arch/ps2/kernel/mm.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n mm.c\n (c)2000-2002 Dan Potter\n*/\n\n#include <arch/types.h>\n#include <arch/arch.h>\n\nCVSID(\"$Id: mm.c,v 1.2 2002/11/03 03:40:55 bardtx Exp $\");\n\n/* The end of the program is always marked by the '_end' symbol. So we'll\n longword-align that and add a little for safety. sbrk() calls will\n move up from there. */\nextern unsigned long end;\nstatic void *sbrk_base;\n\n/* MM-wide initialization */\nint mm_init() {\n\tint base = (int)(&end);\n\tbase = (base/4)*4 + 4;\t\t/* longword align */\n\tsbrk_base = (void*)base;\n\t\n\treturn 0;\n}\n\n/* Simple sbrk function */\nvoid* sbrk(unsigned long increment) {\n\tvoid *base = sbrk_base;\n\n\tif (increment & 3)\n\t\tincrement = (increment + 4) & ~3;\n\tsbrk_base += increment;\n\n\t/* Hard-coded for RedBoot usage right now */\n\tif ( ((ptr_t)sbrk_base) >= (0x81ff0000 - 65536) ) {\n\t\tpanic(\"out of memory; about to run over kernel stack\");\n\t}\n\t\n\treturn base;\n}\n\n\n"
},
{
"alpha_fraction": 0.5414937734603882,
"alphanum_fraction": 0.6161825656890869,
"avg_line_length": 20.567163467407227,
"blob_id": "0de9a58d77fc13ede916f8378a12ed04e56e8fbb",
"content_id": "c3da93b54c6d6be533db00612215b9393d5d384c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1446,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 67,
"path": "/include/arch/dreamcast/dc/ubc.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/ubc.h\n (C)2002 Dan Potter\n\n $Id: ubc.h,v 1.1 2002/03/16 19:22:03 bardtx Exp $\n*/\n\n\n#ifndef __DC_UBC_H\n#define __DC_UBC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* From the SH-4 PDF */\n#define BARA (*((vuint32*)0xFF200000))\n#define BASRA (*((vuint8*)0xFF000014))\n#define BAMRA (*((vuint8*)0xFF200004))\n#define BBRA (*((vuint16*)0xFF200008))\n#define BARB (*((vuint32*)0xFF20000C))\n#define BASRB (*((vuint8*)0xFF000018))\n#define BAMRB (*((vuint8*)0xFF200010))\n#define BBRB (*((vuint16*)0xFF200014))\n#define BRCR (*((vuint16*)0xFF200020))\n\n/* These are inlined to avoid complications with using them */\n\n/* Pause after setting UBC parameters */\nstatic inline void ubc_pause() {\n\t__asm__ __volatile__(\"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\"\n\t \"nop\\n\");\n}\n\n/* Disable all UBC breakpoints */\nstatic inline void ubc_disable_all() {\n\tBBRA = 0;\n\tBBRB = 0;\n\tubc_pause();\n}\n\n/* Set a UBC data-write breakpoint at the given address */\nstatic inline void ubc_break_data_write(uint32 address) {\n\tBASRA = 0;\t\t/* ASID = 0 */\n\tBARA = address;\t\t/* Break address */\n\tBAMRA = 4;\t\t/* Mask the ASID */\n\tBRCR = 0;\t\t/* Nothing special, clear all flags */\n\tBBRA = 0x28;\t\t/* Operand write cycle, no size constraint */\n\tubc_pause();\n}\n\n/* More to come.... */\n\n__END_DECLS\n\n#endif\t/* __DC_UBC_H */\n\n"
},
{
"alpha_fraction": 0.6253164410591125,
"alphanum_fraction": 0.6860759258270264,
"avg_line_length": 25.133333206176758,
"blob_id": "cd0fa190ebb5802678473ab1d70609bb0bf6f6a6",
"content_id": "fd0c6ddbe34edaa2506ea24fcd2c7ce49611decd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 15,
"path": "/kernel/arch/dreamcast/fs/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast/fs/Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.3 2003/04/24 03:03:32 bardtx Exp $\n\n# Dreamcast-specific file systems\n\nOBJS = fs_iso9660.o fs_vmu.o fs_dcload.o dcload-syscall.o vmufs.o \\\n fs_dclsocket.o\n# OBJS += fs_dclnative.o dcload-commands.o dcload-net.o dcload-packet.o dcload-syscalls.o\nSUBDIRS = \n\ninclude ../../../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.5759999752044678,
"alphanum_fraction": 0.656000018119812,
"avg_line_length": 19.75,
"blob_id": "b1ffe59ad547dd983ec1cfc0b43bf28a3dad18db",
"content_id": "dd102608fff9034e83904da1fc2f1adfb9e9dde3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/kernel/arch/dreamcast/hardware/modem/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast/hardware/modem/Makefile\n# Copyright (C)2003 Dan Potter\n# \n# $Id: Makefile,v 1.1 2003/05/23 02:04:42 bardtx Exp $\n\nOBJS = mdata.o mintr.o modem.o chainbuf.o\n\nSUBDIRS =\n\ninclude ../../../../../Makefile.prefab\n\n"
},
{
"alpha_fraction": 0.6490797400474548,
"alphanum_fraction": 0.6736196279525757,
"avg_line_length": 23.66666603088379,
"blob_id": "f4c4d3931da0b5827b14f15ee4df42e6185d210c",
"content_id": "4f7fdb2b5e91bbf1816f951b16a0691e1e02cb49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 33,
"path": "/include/kos/fs_ramdisk.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs_ramdisk.h\n (c)2002 Dan Potter\n\n $Id: fs_ramdisk.h,v 1.2 2003/04/24 03:00:02 bardtx Exp $\n*/\n\n#ifndef __KOS_FS_RAMDISK_H\n#define __KOS_FS_RAMDISK_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n\n/* Call this function to have the ramdisk fs take over a piece\n of memory from you and turn it into a ramdisk file. This is handy\n if you have some loaded object but need to use it as a file.\n XXX Doesn't work with multiple ramdisks... do we care? */\nint fs_ramdisk_attach(const char * fn, void * obj, size_t size);\n\n/* Does the opposite of attach */\nint fs_ramdisk_detach(const char * fn, void ** obj, size_t * size);\n\nint fs_ramdisk_init();\nint fs_ramdisk_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_RAMDISK_H */\n\n"
},
{
"alpha_fraction": 0.5794205665588379,
"alphanum_fraction": 0.6063936352729797,
"avg_line_length": 17.518518447875977,
"blob_id": "03c7e44c0ef9c999ecb0b36c0582a7ade8af3c2b",
"content_id": "00c291b0b1ee72003084fed49cff26a80024ea23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 54,
"path": "/kernel/arch/gba/kernel/main.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n main.c\n (c)2001 Dan Potter\n*/\n\nstatic char id[] = \"KOS $Id: main.c,v 1.2 2002/09/23 23:03:33 gilm Exp $\";\n\n#include <string.h>\n#include <kos.h>\n#include <kos/fs.h>\n\n/* Auto-init stuff: comment out here if you don't like this stuff\n to be running in your build, and also below in arch_main() */\nint arch_auto_init() {\n\n\tfs_init();\t\t\t/* VFS */\n//\tfs_ramdisk_init();\t\t/* Ramdisk */\n\tfs_romdisk_init();\t\t/* Romdisk */\n\n\tif (__kos_romdisk != NULL) {\n\t\tfs_romdisk_mount(\"/rd\", __kos_romdisk, 0);\n\t}\n\t\n\treturn 0;\n}\n\n/* This is the entry point inside the C program */\nint arch_main() {\n\n\tif (mm_init() < 0)\n\t\treturn 0;\n\t\t\n\tarch_auto_init();\n\n\treturn main(0, NULL);\n}\n\n/* Called to shut down the system */\nvoid arch_exit() {\n}\n\n/* Called from syscall to reboot the system */\nvoid arch_reboot() {\n}\n\n\n/* When you make a function called main() in a GCC program, it wants\n this stuff too. */\nvoid _main() { }\nvoid atexit() { }\n\n/* GCC 3.0 also wants these */\nvoid __gccmain() { }\n\n"
},
{
"alpha_fraction": 0.6309012770652771,
"alphanum_fraction": 0.6849467754364014,
"avg_line_length": 27.33333396911621,
"blob_id": "7c1013d2dca30673a80c162604f9fece5a62dca3",
"content_id": "125758eba6402ccd14e4da3286a6a77f903c7a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6291,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 222,
"path": "/include/arch/ps2/ps2/sbios.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/sbios.h\n (c)2002 Dan Potter\n \n $Id: sbios.h,v 1.1 2002/10/27 23:39:23 bardtx Exp $\n*/\n\n#ifndef __PS2_SBIOS_H\n#define __PS2_SBIOS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n#ifdef _arch_sub_rte\t/* Only applies to the RTE */\n\n/* Everything you ever wanted to know about the SBIOS interface and more! */\n\n/* Misc notes divined by studying various code and mem dumps....\n\n Basic memory layout when booted from the RTE (either directly or via\n RedBoot:\n\n 0x80000000 - 0x80000280: MIPS exception vectors (can be user-programmed)\n 0x80000280 - 0x80010000: RTE kernel (called via SBIOS interface func)\n 0x80001000: RTE kernel SBIOS interface\n\n under RedBoot:\n 0x80010000 - 0x80f00000: Available for usage\n 0x80f00000 - 0x81000000: Reserved for eCos/RedBoot usage\n 0x81000000 - 0x81fff000: Available for usage\n under raw RTE:\n 0x80010000 - 0x81fff000: Available for usage\n\n 0x81fff000 - 0x82000000: RTE bootstrap info (cmdline args, etc)\n\n When booted directly from the RTE, the standard MIPS prom boot\n convention is generally used, which is to pass in an argc, argv,\n and envp using the standard calling conventions. The PS2 cheats\n a little by overloading 'envp' to point to a full-sized ps2_bootinfo_t\n struct (below). You can verify that this is what you have for envp\n by checking the magic value against the constants below.\n\n When booting from RedBoot with 'go', you probably won't get those\n args (though I haven't checked for 100% sure). Instead, you can\n get a slightly truncated version of the ps2_bootinfo_t struct\n by peeking directly at the SBIOS interface at 0x80001000. This\n contains a 32-bit function pointer to the \"sbios\" function, which\n is what you talk to in order to do just about anything with the\n RTE. This is followed by a 32-bit magic value (constant below)\n which you can check to make sure nothing weird is going on.\n\n */\n\n/****************************************** SBIOS Structs/Constants *****/\n\n/* Real-time clock struct; used below in the boot time member. Everything\n in here is pretty obvious, except \"year\", which is 2000+year. Doesn't\n anyone EVER learn from their mistakes?! */\ntypedef struct ps2_rtc {\n\tuint8\tjunk1;\n\tuint8\tsec;\n\tuint8\tmin;\n\tuint8\thour;\n\tuint8\tjunk2;\n\tuint8\tday;\n\tuint8\tmon;\n\tuint8\tyear;\t/* <-- Y2K/Y2.1K non-compliant!! */\n} ps2_rtc_t;\n\n/* System configuration values; used below in the sysconf member. \n I suppose that somewhere something describes what exactly these\n members mean... about the only thing I can guess at is \"spdif\",\n which is probably non-zero if using SPDIF audio output. Other\n than that... who knows. */\ntypedef struct ps2_sysconf {\n\tint16\ttime_zone;\n\tuint8\taspect;\n\tuint8\tdatenotation;\n\tuint8\tlanguage;\n\tuint8\tspdif;\n\tuint8\tsummertime;\n\tuint8\ttimenotation;\n\tuint8\tvideo;\n} ps2_sysconf_t;\n\n/* Boot info struct */\ntypedef struct ps2_bootinfo {\n\t/* Basic info */\n\tuint32\t\tpccard_type;\t\t/* ? */\n\tchar\t\t* args;\t\t\t/* Command line args */\n\tuint32\t\tres[2];\t\t\t/* Reserved */\n\tps2_rtc_t\tboot_time;\t\t/* Time when the system booted */\n\tuint32\t\tmach_type;\t\t/* Machine type (T10K, PS2) */\n\tuint32\t\tpcic_type;\t\t/* ? */\n\tps2_sysconf_t\tsysconf;\t\t/* System config settings */\n\n\t/* \"old\" bootinfo struct stops here */\n\t\n\tuint32\t\tmagic;\t\t\t/* Should be \"P2LB\" */\n\tint32\t\tsize;\t\t\t/* Size of the bootinfo struct */\n\tuint32\t\tsbios_base;\t\t/* Base of the SBIOS structs */\n\tuint32\t\tmemsize;\t\t/* Size of available memory (?) */\n\t\n\t/* Version strings */\n\tuint32\t\tver_stringsize;\t\t/* Size of the total version string buffer */\n\tchar \t\t* ver_string;\t\t/* Pointer to the total version string buffer */\n\tchar *\t\tver_strings[10];\t/* Version strings for individual pieces */\n} ps2_bootinfo_t;\n\n/* Magic value for \"new\" bootinfo struct (when directly booting on RTE\n as opposed to under RedBoot, etc). \"P2LB\" == \"PS2 Linux Boot\"? */\n#define PS2_BOOTINFO_MAGIC\t\t0x50324c42\t/* \"P2LB\" */\n\n/* Machine types */\nenum {\n\tPS2_MACH_TYPE_PS2 = 0,\n\tPS2_MACH_TYPE_T10K\n};\n\n/* Version string indeces */\nenum {\n\tPS2_VER_VM = 0,\n\tPS2_VER_RB,\n\tPS2_VER_MODEL,\n\tPS2_VER_PS1DRV_ROM,\n\tPS2_VER_PS1DRV_HDD,\n\tPS2_VER_PS1DRV_PATH,\n\tPS2_VER_DVD_ID,\n\tPS2_VER_DVD_ROM,\n\tPS2_VER_DVD_HDD,\n\tPS2_VER_DVD_PATH\n};\n\n/* SBIOS-related constants */\n#define PS2_SBIOS_BASE\t\t0x80001000\t/* Base of the SBIOS \"old bootinfo\" */\n#define PS2_SBIOS_ENTRY_OFFS\t0\t\t/* SBIOS entry function */\n#define PS2_SBIOS_MAGIC_OFFS\t4\t\t/* SBIOS magic offset */\n\n/* We'll set these up in sbios_init(). */\nint \t\t(* sbios_call)(int, void *);\t/* SBIOS entry function */\nps2_bootinfo_t \tsbios_bootinfo;\t\t\t/* Our bootinfo struct */\nint\t\tsbios_bootinfo_old;\t\t/* Old-style bootinfo? */\n\n/************************************************* SBIOS Calls/Args *****/\n\nenum {\n\tPS2_SB_GETVER = 0,\n\tPS2_SB_HALT,\n\tPS2_SB_SETDVE,\n\tPS2_SB_PUTCHAR,\n\tPS2_SB_GETCHAR,\n\tPS2_SB_SETGSCRT,\n\t\n\tPS2_SB_SIFINIT = 0x10,\n\tPS2_SB_SIFEXIT,\n\tPS2_SB_SIFSETDMA,\n\tPS2_SB_SIFDMASTART,\n\tPS2_SB_SIFSETDCHAIN,\n\t\n\tPS2_SB_SIFINITCMD = 0x20,\n\tPS2_SB_SIFEXITCMD,\n\tPS2_SB_SIFSENDCMD,\n\tPS2_SB_SIFCMDINTRHDLR,\n\tPS2_SB_SIFADDCMDHANDLER,\n\tPS2_SB_SIFREMOVECMDHANDLER,\n\tPS2_SB_SIFSETCMDBUFFER,\n\n\tPS2_SB_SIFINITRPC = 0x30,\n\tPS2_SB_SIFEXITRPC,\n\tPS2_SB_SIFGETOTHERDATA,\n\tPS2_SB_SIFBINDRPC,\n\tPS2_SB_SIFCALLRPC,\n\tPS2_SB_SIFCHECKSTATRPC,\n\tPS2_SB_SIFSETRPCQUEUE,\n\tPS2_SB_SIFREGISTERRPC,\n\tPS2_SB_SIFREMOVERPC,\n\tPS2_SB_SIFREMOVERPCQUEUE,\n\tPS2_SB_SIFGETNEXTREQUEST,\n\tPS2_SB_SIFEXECREQUEST,\n\n\tPS2_SB_IOPH_INIT = 0x40,\n\tPS2_SB_IOPH_ALLOC,\n\tPS2_SB_IOPH_FREE,\n\n\tPS2_SB_PAD_INIT = 0x50,\n\tPS2_SB_PAD_END,\n\tPS2_SB_PAD_PORTOPEN,\n\tPS2_SB_PAD_PORTCLOSE,\n\tPS2_SB_PAD_SETMAINMODE,\n\tPS2_SB_PAD_SETACTDIRECT,\n\tPS2_SB_PAD_SETACTALIGN,\n\tPS2_SB_PAD_INFOPRESSMODE,\n\tPS2_SB_PAD_ENTERPRESSMODE,\n\tPS2_SB_PAD_EXITPRESSMODE,\n\tPS2_SB_PAD_READ,\n\tPS2_SB_PAD_GETSTATE,\n\tPS2_SB_PAD_GETREQSTATE,\n\tPS2_SB_PAD_INFOACT,\n\tPS2_SB_PAD_INFOCOMB,\n\tPS2_SB_PAD_INFOMODE\n\n\t// XXX More to add.. hands tired ;)\n};\n\n\n/********************************************* SBIOS Util Functions *****/\n\n/* Initialize the SBIOS interface. If an SBIOS is properly detected and\n initialized, then we'll return 0; otherwise -1. */\nint\t\tsbios_init();\n\n/* Shut down the SBIOS interface. */\nvoid\t\tsbios_shutdown();\n\n#endif\t/* _arch_sub_rte */\n\n__END_DECLS\n\n#endif\t/* __PS2_SBIOS_H */\n\n"
},
{
"alpha_fraction": 0.6696260571479797,
"alphanum_fraction": 0.6828086972236633,
"avg_line_length": 29.211381912231445,
"blob_id": "af178ce16e281ed0166434c5373d2ebea2c1d659",
"content_id": "191721fd286ffaf0f6c1f656acfaf8acc22c70c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3717,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 123,
"path": "/include/kos/dbgio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/include/dbgio.h\n Copyright (C)2000,2004 Dan Potter\n\n $Id: dbgio.h,v 1.4 2002/04/06 23:40:32 bardtx Exp $\n \n*/\n\n#ifndef __KOS_DBGIO_H\n#define __KOS_DBGIO_H\n\n#include <kos/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/** This struct represents a single dbgio interface. This should represent\n a generic pollable console interface. We will store an ordered list of\n these statically linked into the program and fall back from one to the\n next until one returns true for detected(). Note that the last device in\n this chain is the null console, which will always return true. */\ntypedef struct dbgio_handler {\n\t/** Name of the dbgio handler */\n\tconst char\t* name;\n\n\t/** Returns 1 if the device is available and usable, or 0 if it\n\t appears not to be. */\n\tint\t(*detected)();\n\n\t/** Init the interface with default parameters. */\n\tint\t(*init)();\n\n\t/** Shut down the interface */\n\tint\t(*shutdown)();\n\n\t/** Set polled/IRQ usage */\n\tint\t(*set_irq_usage)(int mode);\n\n\t/** Read one char from the console or -1 if there's nothing to read,\n\t or an error condition exists (check errno). */\n\tint\t(*read)();\n\t\n\t/** Write one char to the console (may need to call flush()).\n\t Returns the number of chars written or -1 on error. */\n\tint\t(*write)(int c);\n\n\t/** Flush any queued written bytes. Returns -1 on error. */\n\tint\t(*flush)();\n\n\t/** Send an entire buffer. Returns the number of chars written or\n\t -1 on error. If xlat is non-zero, then newline transformations\n\t may occur. */\n\tint\t(*write_buffer)(const uint8 *data, int len, int xlat);\n\n\t/** Read a buffer (block). Returns the number of chars read or\n\t -1 on error. */\n\tint\t(*read_buffer)(uint8 *data, int len);\n} dbgio_handler_t;\n\n/* These two should be initialized in arch. */\nextern dbgio_handler_t * dbgio_handlers[];\nextern int dbgio_handler_cnt;\n\n/* This is defined by the shared code, in case there's no valid handler. */\nextern dbgio_handler_t dbgio_null;\n\n/** Manually select a new dbgio interface by name. Returns 0 on success or\n -1 on error. Note that even if the given device isn't detected, this\n will still let you select it. */\nint dbgio_dev_select(const char * name);\n\n/** Returns the name of the currently selected device. */\nconst char * dbgio_dev_get();\n\n/** Initialize the dbgio console. The device selection process is as\n described above. */\nint dbgio_init();\n\n/** Set IRQ usage - we default to polled */\nint dbgio_set_irq_usage(int mode);\n#define DBGIO_MODE_POLLED 0\n#define DBGIO_MODE_IRQ 1\n\n/** Read one char from the console or -1 if there's nothing to read,\n or an error condition exists (check errno). */\nint dbgio_read();\n\n/** Write one char to the console (may need to call flush()).\n Returns the number of chars written or -1 on error. */\nint dbgio_write(int c);\n\n/** Flush any queued written bytes. Returns -1 on error. */\nint dbgio_flush();\n\n/** Send an entire buffer. Returns the number of chars written or\n -1 on error. */\nint dbgio_write_buffer(const uint8 *data, int len);\n\n/** Read a buffer (block). Returns the number of chars read or\n -1 on error. */\nint dbgio_read_buffer(uint8 *data, int len);\n\n/** Send an entire buffer. Returns the number of chars written or\n -1 on error. Newline translations may occur. */\nint dbgio_write_buffer_xlat(const uint8 *data, int len);\n\n/** Send a string (null-terminated). Returns the number of chars\n written or -1 on error. */\nint dbgio_write_str(const char *str);\n\n/** Disable debug I/O globally */\nvoid dbgio_disable();\n\n/** Enable debug I/O globally */\nvoid dbgio_enable();\n\n/** Printf functionality */\nint dbgio_printf(const char *fmt, ...) __printflike(1, 2);\n\n__END_DECLS\n\n#endif\t/* __KOS_DBGIO_H */\n\n"
},
{
"alpha_fraction": 0.5980839133262634,
"alphanum_fraction": 0.6535127758979797,
"avg_line_length": 22.06315803527832,
"blob_id": "a66632ceaefcb1cf08f4ef11e426a7318042a9b0",
"content_id": "da891ff2fb4d0fd8ac84d3779fdaae8f8d073271",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4384,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 190,
"path": "/examples/dreamcast/kgl/basic/texenv/texenv.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n texenv.c\n (c)2001 Benoit Miller\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n#include <tga/tga.h>\n\n/* Really simple KGL example to demonstrate the various glTexEnv modes. \n\n The top row shows what happens with a texture without any alpha \n components (RGB565 in this case). The bottom row shows the same thing\n but with a texture that includes alpha information (ARGB4444).\n\n Press button A to toggle alpha blending on/off, start to quit.\n*/\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid loadtxr_tga(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (tga_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_ARGB4444_TWID, img.w, img.h, txaddr);\n}\n\nvoid quad(int x, int y) {\n\tglBegin(GL_QUADS);\n\tglColor4f(1,0,0,0.75);\n\tglVertex3f(x,y,0);\n\tglColor4f(0,1,0,0.75);\n\tglVertex3f(x+150,y,0);\n\tglColor4f(0,0,1,0.75);\n\tglVertex3f(x+150,y+150,0);\n\tglColor4f(1,1,1,0.75);\n\tglVertex3f(x,y+150,0);\n\tglEnd();\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tint trans = 0;\n\tGLuint\ttexture1, texture2, texture3;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"texenv beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\tglOrtho(0,640,0,480,0,-1);\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);\n\tglDepthMask(GL_FALSE);\n\n\t/* Set up the textures */\n\tloadtxr(\"/rd/checker.pcx\", &texture1);\n\tloadtxr(\"/rd/crate.pcx\", &texture2);\n\tloadtxr_tga(\"/rd/kgl.tga\", &texture3);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\t/* This weird logic is to avoid bouncing back\n\t\t\t and forth before the user lets go of the\n\t\t\t button. */\n\t\t\tif (!(trans & 0x1000)) {\n\t\t\t\tif (trans == 0)\n\t\t\t\t\ttrans = 0x1001;\n\t\t\t\telse\n\t\t\t\t\ttrans = 0x1000;\n\t\t\t}\n\t\t} else {\n\t\t\ttrans &= ~0x1000;\n\t\t}\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\tglDisable(GL_KOS_AUTO_UV);\n\t\tglBindTexture(GL_TEXTURE_2D, texture1);\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_REPLACE);\n\t\tglColor4f(0,0,0,0);\n\t\tglBegin(GL_QUADS);\n\t\tglTexCoord2f(0,0);\n\t\tglVertex3f(0,0,0);\n\t\tglTexCoord2f(20,0);\n\t\tglVertex3f(640,0,0);\n\t\tglTexCoord2f(20,15);\n\t\tglVertex3f(640,480,0);\n\t\tglTexCoord2f(0,15);\n\t\tglVertex3f(0,480,0);\n\t\tglEnd();\n\n\t\tif (trans & 1) {\n\t\t\tglKosFinishList();\n\t\t}\n\n\t\t/* top row, non-alpha texture */\n\t\tglEnable(GL_KOS_AUTO_UV);\n\t\tglBindTexture(GL_TEXTURE_2D, texture2);\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_REPLACE);\n\t\tquad(5,250);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATE);\n\t\tquad(165,250);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_DECAL);\n\t\tquad(325,250);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATEALPHA);\n\t\tquad(485,250);\n\n\t\t/* bottom row, alpha texture */\n\t\tglBindTexture(GL_TEXTURE_2D, texture3);\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_REPLACE);\n\t\tquad(5,50);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATE);\n\t\tquad(165,50);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_DECAL);\n\t\tquad(325,50);\n\n\t\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATEALPHA);\n\t\tquad(485,50);\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.469072163105011,
"alphanum_fraction": 0.5824742317199707,
"avg_line_length": 15,
"blob_id": "f013e9e149eaa783738f850148745cbe22c418fd",
"content_id": "fdbe2af1cf6349c0622897f0ee062e1792f68ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 12,
"path": "/kernel/arch/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\n\nall:\n\t$(MAKE) -C $(KOS_ARCH)\n\nclean:\n\t$(MAKE) -C $(KOS_ARCH) clean\n\t\n"
},
{
"alpha_fraction": 0.5184575915336609,
"alphanum_fraction": 0.5290570259094238,
"avg_line_length": 22.683982849121094,
"blob_id": "6b2b8fd8c274054306f86aeee30938fbddfe517d",
"content_id": "556e8c7dd211915edcf8052c195d670271a0d944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5472,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 231,
"path": "/examples/dreamcast/lua/basic/lua.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n** $Id: lua.c,v 1.2 2002/06/30 06:33:38 bardtx Exp $\n** Lua stand-alone interpreter\n** See Copyright Notice in lua.h\n*/\n\n/* Ported to KOS conio by Dan Potter */\n\n#include <kos.h>\n#include <conio/conio.h>\n\n#include <assert.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\n/* #include \"lua.h\"\n\n#include \"luadebug.h\"\n#include \"lualib.h\" */\n#include <lua/lua.h>\n\n\nstatic lua_State *L = NULL;\n\n\n#ifndef PROMPT\n#define PROMPT\t\t\"> \"\n#endif\n\nstatic void laction (int i);\n\n\nstatic lua_Hook old_linehook = NULL;\nstatic lua_Hook old_callhook = NULL;\n\nstatic void userinit (void) {\n lua_baselibopen(L);\n lua_iolibopen(L);\n lua_strlibopen(L);\n lua_mathlibopen(L);\n lua_dblibopen(L);\n /* add your libraries here */\n}\n\nstatic int ldo (int (*f)(lua_State *l, const char *), const char *name) {\n int res;\n int top = lua_gettop(L);\n res = f(L, name); /* dostring | dofile */\n lua_settop(L, top); /* remove eventual results */\n /* Lua gives no message in such cases, so lua.c provides one */\n if (res == LUA_ERRMEM) {\n conio_printf(\"lua: memory allocation error\\n\");\n }\n else if (res == LUA_ERRERR)\n conio_printf(\"lua: error in error message\\n\");\n return res;\n}\n\n\nstatic void print_version (void) {\n conio_printf(\"%.80s %.80s\\n\", LUA_VERSION, LUA_COPYRIGHT);\n}\n\n\nstatic void assign (char *arg) {\n char *eq = strchr(arg, '=');\n *eq = '\\0'; /* spilt `arg' in two strings (name & value) */\n lua_pushstring(L, eq+1);\n lua_setglobal(L, arg);\n}\n\n\nstatic void getargs (char *argv[]) {\n int i;\n lua_newtable(L);\n for (i=0; argv[i]; i++) {\n /* arg[i] = argv[i] */\n lua_pushnumber(L, i);\n lua_pushstring(L, argv[i]);\n lua_settable(L, -3);\n }\n /* arg.n = maximum index in table `arg' */\n lua_pushstring(L, \"n\");\n lua_pushnumber(L, i-1);\n lua_settable(L, -3);\n}\n\n\nstatic int l_getargs (lua_State *l) {\n char **argv = (char **)lua_touserdata(l, -1);\n getargs(argv);\n return 1;\n}\n\n\n/* maximum length of an input string */\n#ifndef MAXINPUT\n#define MAXINPUT\tBUFSIZ\n#endif\n\nstatic void manual_input (int version, int prompt) {\n int cont = 1, r;\n if (version) print_version();\n while (cont) {\n char buffer[MAXINPUT];\n int i = 0;\n if (prompt) {\n const char *s;\n lua_getglobal(L, \"_PROMPT\");\n s = lua_tostring(L, -1);\n if (!s) s = PROMPT;\n conio_printf(s);\n lua_pop(L, 1); /* remove global */\n }\n r = conio_input_getline(-1, buffer, MAXINPUT);\n assert( r >= 0 );\n if (strlen(buffer)) {\n \tldo(lua_dostring, buffer);\n \tlua_settop(L, 0); /* remove eventual results */\n }\n }\n conio_printf(\"\\n\");\n}\n\n#if 0\nstatic int handle_argv (char *argv[], struct Options *opt) {\n if (opt->stacksize > 0) argv++; /* skip option `-s' (if present) */\n if (*argv == NULL) { /* no more arguments? */\n if (isatty(0)) {\n manual_input(1, 1);\n }\n else\n ldo(lua_dofile, NULL); /* executes stdin as a file */\n }\n else { /* other arguments; loop over them */\n int i;\n for (i = 0; argv[i] != NULL; i++) {\n if (argv[i][0] != '-') { /* not an option? */\n if (strchr(argv[i], '='))\n assign(argv[i]);\n else\n if (file_input(argv[i]) != EXIT_SUCCESS)\n return EXIT_FAILURE; /* stop if file fails */\n }\n else switch (argv[i][1]) { /* option */\n case 0: {\n ldo(lua_dofile, NULL); /* executes stdin as a file */\n break;\n }\n case 'i': {\n manual_input(0, 1);\n break;\n }\n case 'q': {\n manual_input(0, 0);\n break;\n }\n case 'c': {\n opt->toclose = 1;\n break;\n }\n case 'v': {\n print_version();\n break;\n }\n case 'e': {\n i++;\n if (argv[i] == NULL) {\n print_message();\n return EXIT_FAILURE;\n }\n if (ldo(lua_dostring, argv[i]) != 0) {\n fprintf(stderr, \"lua: error running argument `%.99s'\\n\", argv[i]);\n return EXIT_FAILURE;\n }\n break;\n }\n case 'f': {\n i++;\n if (argv[i] == NULL) {\n print_message();\n return EXIT_FAILURE;\n }\n getargs(argv+i); /* collect remaining arguments */\n lua_setglobal(L, \"arg\");\n return file_input(argv[i]); /* stop scanning arguments */\n }\n case 's': {\n fprintf(stderr, \"lua: stack size (`-s') must be the first option\\n\");\n return EXIT_FAILURE;\n }\n default: {\n print_message();\n return EXIT_FAILURE;\n }\n }\n }\n }\n return EXIT_SUCCESS;\n}\n#endif\n\nstatic void register_getargs (char *argv[]) {\n lua_pushlightuserdata(L, argv);\n lua_pushcclosure(L, l_getargs, 1);\n lua_setglobal(L, \"getargs\");\n}\n\n\nint main (int argc, char *argv[]) {\n int status;\n\n cont_btn_callback(0, CONT_START, (cont_btn_callback_t)arch_exit);\n pvr_init_defaults();\n conio_init(CONIO_TTY_SERIAL, CONIO_INPUT_LINE);\n\n luaB_set_fputs((void (*)(const char *))conio_printf);\n \n L = lua_open(); /* create state */\n if (L == NULL) {\n printf(\"Invalid state.. giving up\\n\");\n return -1;\n }\n userinit(); /* open libraries */\n register_getargs(argv); /* create `getargs' function */\n manual_input(1, 1);\n /* status = handle_argv(argv+1, &opt); */\n lua_close(L);\n return status;\n}\n\n"
},
{
"alpha_fraction": 0.5338694453239441,
"alphanum_fraction": 0.6082586050033569,
"avg_line_length": 27.72888946533203,
"blob_id": "b60faacce443b5e88d80fb7cbd5a7318855ae42a",
"content_id": "8f2319f92e40b7a940157e6e73e6028dc20ea3d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6466,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 225,
"path": "/examples/dreamcast/kgl/nehe/nehe16/nehe16.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n nehe16.c\n (c)2001 Paul Boese\n\n Parts (c)2000 Tom Stanis/Jeff Molofee/Benoit Miller\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/* Simple GL example to demonstrate fog (PVR table fog).\n\n Essentially the same thing as NeHe's lesson16 code.\n To learn more, go to http://nehe.gamedev.net/.\n\n There is no lighting yet in GL, so it has not been included.\n\n DPAD controls the cube rotation, button A & B control the depth\n of the cube, button X toggles fog on/off, and button Y toggles fog type. \n*/\n\nstatic GLfloat xrot;\t\t/* X Rotation */\nstatic GLfloat yrot;\t\t/* Y Rotation */\nstatic GLfloat xspeed;\t\t/* X Rotation Speed */\nstatic GLfloat yspeed;\t\t/* Y Rotation Speed */\nstatic GLfloat z=-5.0f;\t\t/* Depth Into The Screen */\n\nstatic GLuint texture;\t /* Storage For Texture */\n\n/* Storage For Three Types Of Fog */\nGLuint fogType = 0; /* use GL_EXP initially */\nGLuint fogMode[] = { GL_EXP, GL_EXP2, GL_LINEAR };\nchar cfogMode[3][10] = {\"GL_EXP \", \"GL_EXP2 \", \"GL_LINEAR\" };\nGLfloat fogColor[4] = { 0.5f, 0.5f, 0.5f, 1.0f }; /* Fog Color */\nint fog = GL_TRUE;\n\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid draw_gl(void) {\n\tglClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);\n\tglLoadIdentity();\n\tglTranslatef(0.0f,0.0f,z);\n\n\tglRotatef(xrot,1.0f,0.0f,0.0f);\n\tglRotatef(yrot,0.0f,1.0f,0.0f);\n\n\tglBindTexture(GL_TEXTURE_2D, texture);\n\n\tglBegin(GL_QUADS);\n\t\t/* Front Face */\n\t\tglNormal3f( 0.0f, 0.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t/* Back Face */\n\t\tglNormal3f( 0.0f, 0.0f,-1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\t/* Top Face */\n\t\tglNormal3f( 0.0f, 1.0f, 0.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\t/* Bottom Face */\n\t\tglNormal3f( 0.0f,-1.0f, 0.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\t/* Right face */\n\t\tglNormal3f( 1.0f, 0.0f, 0.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f( 1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f( 1.0f, 1.0f, -1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f( 1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f( 1.0f, -1.0f, 1.0f);\n\t\t/* Left Face */\n\t\tglNormal3f(-1.0f, 0.0f, 0.0f);\n\t\tglTexCoord2f(0.0f, 0.0f); glVertex3f(-1.0f, -1.0f, -1.0f);\n\t\tglTexCoord2f(1.0f, 0.0f); glVertex3f(-1.0f, -1.0f, 1.0f);\n\t\tglTexCoord2f(1.0f, 1.0f); glVertex3f(-1.0f, 1.0f, 1.0f);\n\t\tglTexCoord2f(0.0f, 1.0f); glVertex3f(-1.0f, 1.0f, -1.0f);\n\tglEnd();\n\n\txrot+=xspeed;\n\tyrot+=yspeed;\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tGLboolean xp = GL_FALSE;\n\tGLboolean yp = GL_FALSE;\n\tGLboolean ap = GL_FALSE;\n\tGLboolean bp = GL_FALSE;\n\tGLboolean blend = GL_FALSE;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"nehe16 beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f,640.0f/480.0f,0.1f,100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglShadeModel(GL_SMOOTH);\n\tglClearColor(0.5f, 0.5f, 0.5f, 1.0f);\n\tglClearDepth(1.0f);\n\tglEnable(GL_DEPTH_TEST);\n\tglDepthFunc(GL_LEQUAL);\n\n\tglColor4f(1.0f, 1.0f, 1.0f, 0.5);\n\tglBlendFunc(GL_SRC_ALPHA,GL_ONE);\n\n\t/* Set up the fog */\n\tglFogi( GL_FOG_MODE, fogMode[fogType] ); /* Fog Mode */\n\tglFogfv( GL_FOG_COLOR, fogColor ); /* Set Fog Color */\n\tglFogf (GL_FOG_DENSITY, 0.35f ); /* How Dense The Fog is */\n\tglHint( GL_FOG_HINT, GL_DONT_CARE ); /* Fog Hint Value */\n\tglFogf( GL_FOG_START, 0.0f ); /* Fog Start Depth */\n\tglFogf( GL_FOG_END, 5.0f ); /* Fog End Depth */\n\tglEnable( GL_FOG ); /* Enables GL_FOG */\n\n\t/* Set up the textures */\n\tloadtxr(\"/rd/crate.pcx\", &texture);\n\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\tif (z >= -15.0f) z -= 0.02f;\n\t\t}\n\t\tif (!(cond.buttons & CONT_B)) {\n\t\t\tif (z <= 0.0f) z += 0.02f;\n\t\t}\n\t\tif (!(cond.buttons & CONT_X) && !xp) {\n\t\t\txp = GL_TRUE;\n\t \t\tfogType = ( ++fogType ) % 3;\n\t \t\tglFogi( GL_FOG_MODE, fogMode[fogType] );\n\t \t\tprintf(\"%s\\n\", cfogMode[fogType]);\n\t\t}\n\t\tif (cond.buttons & CONT_X)\n\t\t\txp = GL_FALSE;\n\t\tif (!(cond.buttons & CONT_Y) && !yp) {\n\t\t\typ = GL_TRUE;\n\t\t\tfog = !fog;\n\t\t}\n\t\tif (cond.buttons & CONT_Y)\n\t\t\typ = GL_FALSE;\n\t\tif (!(cond.buttons & CONT_DPAD_UP))\n\t\t\txspeed -= 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_DOWN))\n\t\t\txspeed += 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_LEFT))\n\t\t\tyspeed -= 0.01f;\n\t\tif (!(cond.buttons & CONT_DPAD_RIGHT))\n\t\t\tyspeed += 0.01f;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Switch fog off/on */\n\t\tif (fog) {\n\t\t\tglEnable(GL_FOG);\n\t\t} else {\n\t\t\tglDisable(GL_FOG);\n\t\t}\n\n\t\t/* Draw the GL \"scene\" */\n\t\tdraw_gl();\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.5641385912895203,
"alphanum_fraction": 0.6638576984405518,
"avg_line_length": 24.117647171020508,
"blob_id": "880498edadafd15f8549c752a9320d08fddd002c",
"content_id": "e115acaa74e4060ca83d821e523eef654e902a44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2136,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 85,
"path": "/include/arch/gba/gba/sprite.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gba/sprite.h\n (c)2001 Dan Potter\n \n $Id: sprite.h,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\n*/\n\n/* Thanks to Dovoto's tutorial for these numbers */\n\n#ifndef __GBA_SPRITE_H\n#define __GBA_SPRITE_H\n\n#include <arch/types.h>\n\n/* Object Attribute Memory */\n#define PTR_OAM\t\t((vu16*)0x07000000)\n\n/* Object data memory */\n#define PTR_OBJ_DATA\t((vu16*)0x06010000)\n\n/* Object palette memory */\n#define PTR_OBJ_PAL\t((vu16*)0x05000200)\n\n/* I chose to make two seperate structures here because using a union is\n probably going to result in awful looking code, and the common case\n is going to be #2 anyway... */\n\n/* Object Attribute entry definition (bitfield version) */\ntypedef struct {\n\t/* Attribute 0 */\n\tu16\ty:9;\t\t/* Y coordinate */\n\tu16\tr:1;\t\t/* Rotation / Scaling flag */\n\tu16\tsd:1;\t\t/* Size Double */\n\tu16\tmode:2;\t\t/* Mode / Alpha */\n\tu16\tm:1;\t\t/* Mosaic flag */\n\tu16\tc:1;\t\t/* Color mode */\n\tu16\tshape:2;\t/* Object shape */\n\n\t/* Attribute 1 */\n\tu16\tx:9;\t\t/* X coordinate */\n\tu16\trdi:5;\t\t/* Rotation data index / flip flags*/\n\tu16\tsize:2;\t\t/* Size */\n\n\t/* Attribute 2 */\n\tu16\tname:10;\t/* Character name / sprite index */\n\tu16\tprio:2;\t\t/* Layer priority */\n\tu16\tpal:4;\t\t/* Palette index */\n\n\t/* Attribute 3 */\n\tu16\tattr3;\t\t/* ? Set to zero */\n} __attribute__((packed)) oam_entry_bf;\n\n/* Object Attribute entry definition (raw version) */\ntypedef struct {\n\tu16\tattr0, attr1, attr2, attr3;\n} __attribute__((packed)) oam_entry_t;\n\n/* Attribute 0 constants */\n#define SPR_ROTATION\t0x0100\n#define SPR_SIZE_DOUBLE\t0x0200\n#define SPR_MODE_NORMAL\t0x0000\n#define SPR_MODE_TRANS\t0x0400\n#define SPR_MODE_WND\t0x0800\n#define SPR_MOSAIC\t0x1000\n#define SPR_COLOR_16\t0x0000\n#define SPR_COLOR_256\t0x2000\n#define SPR_SQUARE\t0x0000\n#define SPR_TALL\t0x4000\n#define SPR_WIDE\t0x8000\n\n/* Attribute 1 constants */\n#define SPR_ROT_DATA(n)\t((n) << 9)\n#define SPR_H_FLIP\t0x1000\n#define SPR_V_FLIP\t0x2000\n#define SPR_SIZE_8\t0x0000\n#define SPR_SIZE_16\t0x4000\n#define SPR_SIZE_32\t0x8000\n#define SPR_SIZE_64\t0xC000\n\n/* Attribute 2 constants */\n#define SPR_PRIO(n)\t((n) << 10)\n#define SPR_PAL(n)\t((n) << 12)\n\n#endif\t/* __GBA_SPRITE_H */\n\n"
},
{
"alpha_fraction": 0.5745454430580139,
"alphanum_fraction": 0.6127272844314575,
"avg_line_length": 21.83333396911621,
"blob_id": "5cf174cdb1e9cbcd67b491fe4a917ded2f51c344",
"content_id": "02eadcb58c148d478bef3a729de5d0035a1e5730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 550,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 24,
"path": "/libm/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KOS libm ##version##\n#\n# Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/03/04 06:07:39 bardtx Exp $\n\n# math\nOBJS_MATH := $(patsubst %.c,%.o,$(wildcard math/*.c))\nOBJS := $(OBJS_MATH)\n\n# common\nOBJS_COMMON := $(patsubst %.c,%.o,$(wildcard common/*.c))\nOBJS += $(OBJS_COMMON)\n\nSUBDIRS =\n\nKOS_CFLAGS := $(KOS_CFLAGS) -I$(TOPDIR)/libm -I$(TOPDIR)/libm/common -I../include/newlib-libm-sh4\n\nall: $(OBJS)\n\t$(KOS_AR) rcs $(TOPDIR)/lib/$(KOS_ARCH)/libm.a $(OBJS)\n\n# Grab the shared Makefile pieces\ninclude $(TOPDIR)/Makefile.prefab\n\n\n"
},
{
"alpha_fraction": 0.6144667863845825,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 24.30188751220703,
"blob_id": "c34fa2f94d6f219566c0e2fa7495a609bc638603",
"content_id": "72d4045088d3a7d214de7531abed7bcd09ba5df8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1341,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 53,
"path": "/kernel/net/net_ipv4.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_ipv4.h\n Copyright (C) 2005, 2007, 2008 Lawrence Sebald\n\n*/\n\n#ifndef __LOCAL_NET_IPV4_H\n#define __LOCAL_NET_IPV4_H\n\n/* These structs are from AndrewK's dcload-ip. */\n#define packed __attribute__((packed))\ntypedef struct {\n\tuint8\tdest[6]\t\tpacked;\n\tuint8\tsrc[6]\t\tpacked;\n\tuint8\ttype[2]\t\tpacked;\n} eth_hdr_t;\n\ntypedef struct {\n\tuint8\tversion_ihl\tpacked;\n\tuint8\ttos\t\tpacked;\n\tuint16\tlength\t\tpacked;\n\tuint16\tpacket_id\tpacked;\n\tuint16\tflags_frag_offs\tpacked;\n\tuint8\tttl\t\tpacked;\n\tuint8\tprotocol\tpacked;\n\tuint16\tchecksum\tpacked;\n\tuint32\tsrc\t\tpacked;\n\tuint32\tdest\t\tpacked;\n} ip_hdr_t;\n\ntypedef struct {\n\tuint32 src_addr packed;\n\tuint32 dst_addr packed;\n\tuint8 zero packed;\n\tuint8 proto packed;\n\tuint16 length packed;\n\tuint16 src_port packed;\n\tuint16 dst_port packed;\n\tuint16 hdrlength packed;\n\tuint16 checksum packed;\n\tuint8 data[1] packed;\n} ip_pseudo_hdr_t;\n#undef packed\n\nuint16 net_ipv4_checksum(const uint8 *data, int bytes);\nint net_ipv4_send_packet(netif_t *net, ip_hdr_t *hdr, const uint8 *data,\n int size);\nint net_ipv4_send(netif_t *net, const uint8 *data, int size, int id, int ttl,\n int proto, uint32 src, uint32 dst);\nint net_ipv4_input(netif_t *src, const uint8 *pkt, int pktsize);\n\n#endif /* __LOCAL_NET_IPV4_H */\n"
},
{
"alpha_fraction": 0.64552241563797,
"alphanum_fraction": 0.6679104566574097,
"avg_line_length": 21.157894134521484,
"blob_id": "236e9bd1d5567ce47350ce99b41a7d0b302b0691",
"content_id": "38b4c0d6faf37092c83c07bb387a53bdbbfc1d7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2948,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 133,
"path": "/kernel/arch/ps2/kernel/dbgio.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dbgio.c\n (c)2002 Dan Potter\n*/\n\n#include <string.h>\n#include <stdio.h>\n#include <stdarg.h>\n#include <arch/arch.h>\n#include <arch/dbgio.h>\n#include <arch/spinlock.h>\n\nCVSID(\"$Id: dbgio.c,v 1.2 2002/11/03 03:40:55 bardtx Exp $\");\n\n/*\n\nThis module assumes the existance of ps2-load-ip. If ps2-load-ip\nisn't present, then it just disables itself.\n\nThere's no support for non-RTE targets right now, but eventually it\nshould probably hook up to something like NapLink's USB client.\n\n*/\n\n/* This redirect is here to allow you to hook the debug output in your \n program if you want to do that. */\ndbgio_printk_func dbgio_printk = dbgio_null_write;\n\n/* Set serial parameters; this is not platform independent like I want\n it to be, but it should be generic enough to be useful. */\nvoid dbgio_set_parameters(int baud, int fifo) { }\n\n/* Enable serial support */\nvoid dbgio_enable() { }\n\n/* Disable serial support */\nvoid dbgio_disable() { }\n\n/* Set another function to capture all debug output */\ndbgio_printk_func dbgio_set_printk(dbgio_printk_func func) {\n\tdbgio_printk_func rv = dbgio_printk;\n\tdbgio_printk = func;\n\treturn rv;\n}\n\n/* This should probably hook up to a ps2-load-ip module at some point */\nstatic uint32 * ps2lip_block;\nstatic int (*ps2lip_syscall)(int code, ...);\n\nvoid dbgio_init() {\n\tdbgio_printk = dbgio_null_write;\n\n\tif (!ps2lip_block) {\n\t\tps2lip_block = (uint32 *)((uint32 *)0x81fff800)[0];\n\t\tif (ps2lip_block == NULL)\n\t\t\treturn;\n\t\tif (ps2lip_block[0] != 0xdeadbeef) {\n\t\t\tps2lip_block = NULL;\n\t\t\treturn;\n\t\t}\n\t}\n\n\tps2lip_syscall = (int (*)(int, ...))ps2lip_block[2];\n\t\n\tdbgio_set_printk(dbgio_write_str);\n}\n\nvoid dbgio_write(int c) {\n\tchar str[2] = { c, 0 };\n\tif (ps2lip_syscall != NULL)\n\t\tps2lip_syscall(14, str);\n}\n\n/* Flush all FIFO'd bytes out of the serial port buffer */\nvoid dbgio_flush() {\n}\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer(const uint8 *data, int len) {\n\twhile (len-- > 0)\n\t\tdbgio_write(*data++);\n}\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer_xlat(const uint8 *data, int len) {\n\twhile (len-- > 0) {\n\t\tif (*data == '\\n')\n\t\t\tdbgio_write('\\r');\n\t\tdbgio_write(*data++);\n\t}\n}\n\n/* Send a string (null-terminated) */\nvoid dbgio_write_str(const char *str) {\n\tdbgio_write_buffer_xlat((const uint8*)str, strlen(str));\n}\n\n/* Null write-string function for pre-init */\nvoid dbgio_null_write(const char *str) {\n}\n\n/* Read one char from the serial port (-1 if nothing to read) */\nint dbgio_read() {\n\treturn -1;\n}\n\n/* Read an entire buffer (block) */\nvoid dbgio_read_buffer(uint8 *data, int len) {\n}\n\n/* Not re-entrant */\nstatic char printf_buf[1024];\nstatic spinlock_t lock = SPINLOCK_INITIALIZER;\n\nint dbgio_printf(const char *fmt, ...) {\n\tva_list args;\n\tint i;\n\n\tif (!irq_inside_int())\n\t\tspinlock_lock(&lock);\n\n\tva_start(args, fmt);\n\ti = vsprintf(printf_buf, fmt, args);\n\tva_end(args);\n\n\tdbgio_printk(printf_buf);\n\n\tif (!irq_inside_int())\n\t\tspinlock_unlock(&lock);\n\n\treturn i;\n}\n\n"
},
{
"alpha_fraction": 0.5958498120307922,
"alphanum_fraction": 0.6284584999084473,
"avg_line_length": 21.741573333740234,
"blob_id": "79150bab8786e60b1afca68357165981e697a66d",
"content_id": "d91fe53777c8f582e18f0d0df4fa41e4295747b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2024,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 89,
"path": "/kernel/arch/dreamcast/util/screenshot.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n \n screenshot.c\n (c)2002 Dan Potter\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <dc/video.h>\n#include <kos/fs.h>\n#include <arch/irq.h>\n\nCVSID(\"$Id: screenshot.c,v 1.3 2003/02/14 08:13:18 bardtx Exp $\");\n\n/*\n\nProvides a very simple screen shot facility (dumps raw RGB PPM files from the\ncurrently viewed framebuffer).\n\nDestination file system must be writeable and have enough free space.\n\nAssumes display is in 16-bit mode.\n\n*/\n\nint vid_screen_shot(const char *destfn) {\n\tfile_t\tf;\n\tint\ti, bsize;\n\tuint8\t*buffer;\n\tuint16\tpixel;\n\tuint8\tr, g, b;\n\tchar\theader[256];\n\tuint32\tsave;\n\n\t/* Allocate a new buffer so we can blast it all at once */\n\tbsize = vid_mode->width * vid_mode->height * 3;\n\tbuffer = (uint8 *)malloc(bsize);\n\tif (buffer == NULL) {\n\t\tdbglog(DBG_ERROR, \"video_screen_shot: can't allocate ss memory\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Disable interrupts */\n\tsave = irq_disable();\n\n\t/* Write out each 16-bit pixel as 24 bits */\n\tfor (i=0; i<vid_mode->width*vid_mode->height; i++) {\n\t\tpixel = vram_s[i];\n\t\tr = ((pixel >> 11) & 0x1f) << 3;\n\t\tg = ((pixel >> 5) & 0x3f) << 2;\n\t\tb = ((pixel >> 0) & 0x1f) << 3;\n\t\tbuffer[i*3+0] = r;\n\t\tbuffer[i*3+1] = g;\n\t\tbuffer[i*3+2] = b;\n\t}\n\n\tirq_restore(save);\n\n\t/* Open output file */\n\tf = fs_open(destfn, O_WRONLY | O_TRUNC);\n\tif (!f) {\n\t\tdbglog(DBG_ERROR, \"video_screen_shot: can't open output file '%s'\\n\", destfn);\n\t\tfree(buffer);\n\t\treturn -1;\n\t}\n\n\t/* Write a small header */\n\tsprintf(header, \"P6\\n#KallistiOS Screen Shot\\n%d %d\\n255\\n\", vid_mode->width, vid_mode->height);\n\tif (fs_write(f, header, strlen(header)) != strlen(header)) {\n\t\tdbglog(DBG_ERROR, \"video_screen_shot: can't write header to output file '%s'\\n\", destfn);\n\t\tfs_close(f);\n\t\tfree(buffer);\n\t\treturn -1;\n\t}\n\n\t/* Write the data */\n\tif (fs_write(f, buffer, bsize) != (ssize_t)bsize) {\n\t\tdbglog(DBG_ERROR, \"video_screen_shot: can't write data to output file '%s'\\n\", destfn);\n\t\tfs_close(f);\n\t\tfree(buffer);\n\t\treturn -1;\n\t}\n\n\tfs_close(f);\n\tfree(buffer);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6233603954315186,
"alphanum_fraction": 0.684572160243988,
"avg_line_length": 30.382352828979492,
"blob_id": "8994e8c17e0c8d0610dc50c5a769163654821ce3",
"content_id": "bf23690e2e23fc109e98987bd654c6654ad37518",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3202,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 102,
"path": "/include/arch/dreamcast/dc/g2bus.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n g2bus.h\n (c)2002 Dan Potter\n \n $Id: g2bus.h,v 1.5 2002/09/13 06:44:41 bardtx Exp $\n*/\n\n#ifndef __DC_G2BUS_H\n#define __DC_G2BUS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* DMA copy from SH-4 RAM to G2 bus (dir = 0) or the opposite; \n length must be a multiple of 32,\n and the source and destination addresses must be aligned on 32-byte\n boundaries. If block is non-zero, this function won't return until\n the transfer is complete. If callback is non-NULL, it will be called\n upon completion (in an interrupt context!). Returns <0 on error. \n\n Known working combination :\n \n g2chn = 0, sh4chn = 3 --> mode = 5 (but many other value seems OK ?)\n g2chn = 1, sh4chn = 1 --> mode = 0 (or 4 better ?)\n g2chn = 1, sh4chn = 0 --> mode = 3\n \n It seems that g2chn is not important when choosing mode, so this mode parameter is probably \n how we actually connect the sh4chn to the g2chn.\n\n Update : looks like there is a formula, mode = 3 + shchn\n\n*/\n\n/* We use sh channel 3 here to avoid conflicts with the PVR. */\n#define SPU_DMA_MODE 6 /* should we use 6 instead, so that the formula is 3+shchn ? \n\t\t\t 6 works too, so ... */\n#define SPU_DMA_G2CHN 0\n#define SPU_DMA_SHCHN 3\n\n/* For BBA : sh channel 1 (doesn't seem used) and g2 channel 1 to no conflict with SPU */\n#define BBA_DMA_MODE 4\n#define BBA_DMA_G2CHN 1\n#define BBA_DMA_SHCHN 1\n\n/* For BBA2 : sh channel 0 (doesn't seem used) and g2 channel 2 to no conflict with SPU */\n/* This is a second DMA channels used for the BBA, just for fun and see if we can initiate\n two DMA transfers with the BBA concurently. */\n#define BBA_DMA2_MODE 3\n#define BBA_DMA2_G2CHN 2\n#define BBA_DMA2_SHCHN 0\n\ntypedef void (*g2_dma_callback_t)(ptr_t data);\nint g2_dma_transfer(void *from, void * dest, uint32 length, int block,\n\tg2_dma_callback_t callback, ptr_t cbdata, \n\tuint32 dir, uint32 mode, uint32 g2chn, uint32 sh4chn);\n\n/* Read one byte from G2 */\nuint8 g2_read_8(uint32 address);\n\n/* Write one byte to G2 */\nvoid g2_write_8(uint32 address, uint8 value);\n\n/* Read one word from G2 */\nuint16 g2_read_16(uint32 address);\n\n/* Write one word to G2 */\nvoid g2_write_16(uint32 address, uint16 value);\n\n/* Read one dword from G2 */\nuint32 g2_read_32(uint32 address);\n\n/* Write one dword to G2 */\nvoid g2_write_32(uint32 address, uint32 value);\n\n/* Read a block of 8-bit values from G2 */\nvoid g2_read_block_8(uint8 * output, uint32 address, int amt);\n\n/* Write a block 8-bit values to G2 */\nvoid g2_write_block_8(const uint8 * input, uint32 address, int amt);\n\n/* Read a block of 16-bit values from G2 */\nvoid g2_read_block_16(uint16 * output, uint32 address, int amt);\n\n/* Write a block of 16-bit values to G2 */\nvoid g2_write_block_16(const uint16 * input, uint32 address, int amt);\n\n/* Read a block of 32-bit values from G2 */\nvoid g2_read_block_32(uint32 * output, uint32 address, int amt);\n\n/* Write a block of 32-bit values to G2 */\nvoid g2_write_block_32(const uint32 * input, uint32 address, int amt);\n\n/* When writing to the SPU RAM, this is required at least every 8 32-bit\n writes that you execute */\nvoid g2_fifo_wait();\n\n__END_DECLS\n\n#endif\t/* __DC_G2BUS_H */\n\n"
},
{
"alpha_fraction": 0.5837019681930542,
"alphanum_fraction": 0.6351571679115295,
"avg_line_length": 24.553571701049805,
"blob_id": "124083c92f78241dbfc10e36f994a0a7f44e7ad0",
"content_id": "aecdc2ff23fad476a8cd113d9174430038844345",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4295,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 168,
"path": "/examples/dreamcast/kgl/basic/texwrap/texwrap.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n texwrap.c\n (c)2002 Paul Boese\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\nCVSID(\"$Id: texwrap.c,v 1.2 2002/04/07 02:54:04 bardtx Exp $\");\n\n/* Really simple KGL example to demonstrate the glTexParameter\n texture wrapping modes. \n\n A Picture is worth a thousand words...\n \n | top row\n | |--------- |--------- |-------- |-------- |\n | |S Repeat| |S Clamp | |S Repeat| |S Clamp | |\n | |T Repeat| |T Repeat| |T Clamp | |T Clamp | |\n | | | | | | | | | |\n | ---------| ---------| ---------| ---------| |\n | \n | bottom row\n | ...Same only transparent\n |\n\n To see the effects of wrapping you must use S T values greater than\n [0,1]. In this exmaple we are using 4x4 checkered pattern that is\n repeated 4 times. That is the S T (U, V) texture coordinates used\n are [0,4]. \n\n e.g.:\n\tglTexCoord2f(0.0f, 0.0f); glVertex3f(0,0,0);\n\tglTexCoord2f(4.0f, 0.0f); glVertex3f(1,0,0);\n\tglTexCoord2f(4.0f, 4.0f); glVertex3f(1,1,0);\n\tglTexCoord2f(0.0f, 4.0f); glVertex3f(0,1,0);\n \n Press start to quit.\n*/\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nvoid quad(int x, int y) {\n\tglBegin(GL_QUADS);\n\tglColor4f(1,1,1,0.5f);\n\tglTexCoord2f(0.0f, 0.0f);\n\tglVertex3f(x,y,0);\n\tglTexCoord2f(4.0f, 0.0f);\n\tglVertex3f(x+128,y,0);\n\tglTexCoord2f(4.0f, 4.0f);\n\tglVertex3f(x+128,y+128,0);\n\tglTexCoord2f(0.0f, 4.0f);\n\tglVertex3f(x,y+128,0);\n\tglEnd();\n}\n\npvr_init_params_t params = {\n /* Enable opaque and translucent polygons with size 16 */\n { PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\n /* Vertex buffer size 512K */\n 512*1024\n};\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tGLuint\ttexture;\n\n\t/* Initialize KOS */\n pvr_init(¶ms);\n\n\tprintf(\"texwrap beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\tglMatrixMode(GL_MODELVIEW);\n\tglLoadIdentity();\n\tglOrtho(0,640,0,480,0,-1);\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\n\tglEnable(GL_TEXTURE_2D);\n\tglBlendFunc(GL_SRC_ALPHA, GL_ONE);\n\n\t/* Set up the textures */\n\tloadtxr(\"/rd/checker.pcx\", &texture);\n\n\tglClearColor(0.4f, 0.4f, 0.8f, 1.0f);\n\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* top row, non-alpha texture */\n\t\tglBindTexture(GL_TEXTURE_2D, texture);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);\n\t\tquad(16,275);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);\n\t\tquad(176,275);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP);\n\t\tquad(336,275);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP);\n\t\tquad(496,275);\n\t\t\n\t\t/* bottom row, alpha texture */\n\t\tglKosFinishList();\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);\n\t\tquad(16,75);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);\n\t\tquad(176,75);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP);\n\t\tquad(336,75);\n\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP);\n\t\tglTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP);\n\t\tquad(496,75);\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6220755577087402,
"alphanum_fraction": 0.6513197422027588,
"avg_line_length": 27.86147117614746,
"blob_id": "89879e02383a075e50c663d51526d4ef21d8a272",
"content_id": "631471804b7ea4779b2908de8c97f6f4d3b5956d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6668,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 231,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_misc.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvr_misc.c\n (C)2002 Dan Potter\n\n */\n\n#include <assert.h>\n#include <string.h>\n#include <arch/timer.h>\n#include <dc/pvr.h>\n#include <dc/video.h>\n#include \"pvr_internal.h\"\n\n/*\n These are miscellaneous parameters you can set which affect the\n rendering process.\n*/\n\nCVSID(\"$Id: pvr_misc.c,v 1.12 2003/04/24 03:12:26 bardtx Exp $\");\n\n/* Set the background plane color (the area of the screen not covered by\n any other polygons) */\nvoid pvr_set_bg_color(float r, float g, float b) {\n\tint ir, ig, ib;\n\n\tir = (int)(255 * r);\n\tig = (int)(255 * g);\n\tib = (int)(255 * b);\n\n\tpvr_state.bg_color = (ir << 16) | (ig << 8) | (ib << 0);\n}\n\n/* Return the current VBlank count */\nint pvr_get_vbl_count() {\n\treturn pvr_state.vbl_count;\n}\n\n/* Fill in a statistics structure (above) from current data. This\n is a super-set of frame count. */ \nint pvr_get_stats(pvr_stats_t *stat) {\n\tif (!pvr_state.valid)\n\t\treturn -1;\n\n\tassert(stat != NULL);\n\n\tstat->enabled_list_mask = pvr_state.lists_enabled;\n\tstat->vbl_count = pvr_state.vbl_count;\n\tstat->frame_last_time = pvr_state.frame_last_len;\n\tstat->reg_last_time = pvr_state.reg_last_len;\n\tstat->rnd_last_time = pvr_state.rnd_last_len;\n\tif (stat->frame_last_time != 0)\n\t\tstat->frame_rate = 1000.0f / stat->frame_last_time;\n\telse\n\t\tstat->frame_rate = -1.0f;\n\tstat->vtx_buffer_used = pvr_state.vtx_buf_used;\n\tstat->vtx_buffer_used_max = pvr_state.vtx_buf_used_max;\n\tstat->buf_last_time = pvr_state.buf_last_len;\n\tstat->frame_count = pvr_state.frame_count;\n\n\treturn 0;\n}\n\nint pvr_vertex_dma_enabled() {\n\treturn pvr_state.dma_mode;\n}\n\n/******** INTERNAL STUFF ************************************************/\n\n/* Update statistical counters */\nvoid pvr_sync_stats(int event) {\n\tuint64\tt;\n\tvolatile pvr_ta_buffers_t *buf;\n\n\n\t/* Get the current time */\n\tt = timer_ms_gettime64();\n\n\tswitch (event) {\n\tcase PVR_SYNC_VBLANK:\n\t\tpvr_state.vbl_count++;\n\t\tbreak;\n\n\tcase PVR_SYNC_REGSTART:\n\t\tpvr_state.reg_start_time = t;\n\t\tbreak;\n\n\tcase PVR_SYNC_REGDONE:\n\t\tpvr_state.reg_last_len = (uint32)(t - pvr_state.reg_start_time);\n\n\t\tbuf = pvr_state.ta_buffers + pvr_state.ta_target;\n\t\tpvr_state.vtx_buf_used = PVR_GET(PVR_TA_VERTBUF_POS) - buf->vertex;\n\t\tif (pvr_state.vtx_buf_used > pvr_state.vtx_buf_used_max)\n\t\t\tpvr_state.vtx_buf_used_max = pvr_state.vtx_buf_used;\n\t\tbreak;\n\n\tcase PVR_SYNC_RNDSTART:\n\t\tpvr_state.rnd_start_time = t;\n\t\tbreak;\n\n\tcase PVR_SYNC_RNDDONE:\n\t\tpvr_state.rnd_last_len = (uint32)(t - pvr_state.rnd_start_time);\n\t\tbreak;\n\n\tcase PVR_SYNC_BUFSTART:\n\t\tpvr_state.buf_start_time = t;\n\t\tbreak;\n\n\tcase PVR_SYNC_BUFDONE:\n\t\tpvr_state.buf_last_len = (uint32)(t - pvr_state.buf_start_time);\n\t\tbreak;\n\n\tcase PVR_SYNC_PAGEFLIP:\n\t\tpvr_state.frame_last_len = (uint32)(t - pvr_state.frame_last_time);\n\t\tpvr_state.frame_last_time = t;\n\t\tpvr_state.frame_count++;\n\t\tbreak;\n\n\t}\n}\n\n/* Synchronize the viewed page with what's in pvr_state */\nvoid pvr_sync_view() {\n\tvid_set_start(pvr_state.frame_buffers[pvr_state.view_target].frame);\n}\n\n/* Synchronize the registration buffer with what's in pvr_state */\nvoid pvr_sync_reg_buffer() {\n\tvolatile pvr_ta_buffers_t *buf;\n\n\tbuf = pvr_state.ta_buffers + pvr_state.ta_target;\n\n\t/* Reset TA */\n\t//PVR_SET(PVR_RESET, PVR_RESET_TA);\n\t//PVR_SET(PVR_RESET, PVR_RESET_NONE);\n\n\t/* Set buffer pointers */\n\tPVR_SET(PVR_TA_OPB_START,\tbuf->opb);\n\tPVR_SET(PVR_TA_OPB_END,\t\tbuf->opb - buf->opb_size);\n\tPVR_SET(PVR_TA_VERTBUF_START,\tbuf->vertex);\n\tPVR_SET(PVR_TA_VERTBUF_END,\tbuf->vertex + buf->vertex_size);\n\tPVR_SET(PVR_TA_OPB_INIT,\tbuf->opb);\n\n\t/* Misc config parameters */\n\tPVR_SET(PVR_TILEMAT_CFG,\tpvr_state.tsize_const);\t\t/* Tile count: (H/32-1) << 16 | (W/32-1) */\n\tPVR_SET(PVR_OPB_CFG,\t\tpvr_state.list_reg_mask);\t/* List enables */\n\tPVR_SET(PVR_TA_INIT,\t\tPVR_TA_INIT_GO);\t\t/* Confirm settings */\n\t(void)PVR_GET(PVR_TA_INIT);\n}\n\n/* Begin a render operation that has been queued completely (i.e., the\n opposite of ta_target) */\nvoid pvr_begin_queued_render() {\n\tvolatile pvr_ta_buffers_t\t* tbuf;\n\tvolatile pvr_frame_buffers_t\t* rbuf;\n\tpvr_bkg_poly_t\tbkg;\n\tuint32\t\t*vrl, *bkgdata;\n\tuint32\t\tvert_end;\n\tint\t\ti;\n\n\t/* Get the appropriate buffer */\n\ttbuf = pvr_state.ta_buffers + (pvr_state.ta_target ^ 1);\n\trbuf = pvr_state.frame_buffers + (pvr_state.view_target ^ 1);\n\n\t/* Calculate background value for below */\n\t/* Small side note: during setup, the value is originally\n\t 0x01203000... I'm thinking that the upper word signifies\n\t the length of the background plane list in dwords\n\t shifted up by 4. */\n\tvert_end = 0x01000000 | ((PVR_GET(PVR_TA_VERTBUF_POS) - tbuf->vertex) << 1);\n\t\n\t/* Throw the background data on the end of the TA's list */\n\tbkg.flags1 = 0x90800000;\t/* These are from libdream.. ought to figure out */\n\tbkg.flags2 = 0x20800440;\t/* what they mean for sure... heh =) */\n\tbkg.dummy = 0;\n\tbkg.x1 = 0.0f; bkg.y1 = 480.0f; bkg.z1 = 0.2f; bkg.argb1 = pvr_state.bg_color;\n\tbkg.x2 = 0.0f; bkg.y2 = 0.0f; bkg.z2 = 0.2f; bkg.argb2 = pvr_state.bg_color;\n\tbkg.x3 = 640.0f; bkg.y3 = 480.0f; bkg.z3 = 0.2f; bkg.argb3 = pvr_state.bg_color;\n\tbkgdata = (uint32 *)&bkg;\n\tvrl = (uint32*)(PVR_RAM_BASE | PVR_GET(PVR_TA_VERTBUF_POS));\n\tfor (i=0; i<0x10; i++)\n\t\tvrl[i] = bkgdata[i];\n\tvrl[0x11] = 0;\n\n\t/* Reset the ISP/TSP, just in case */\n\t//PVR_SET(PVR_RESET, PVR_RESET_ISPTSP);\n\t//PVR_SET(PVR_RESET, PVR_RESET_NONE);\n\n\t/* Finish up rendering the current frame (into the other buffer) */\n\tPVR_SET(PVR_ISP_TILEMAT_ADDR, tbuf->tile_matrix);\n\tPVR_SET(PVR_ISP_VERTBUF_ADDR, tbuf->vertex);\n\tif (!pvr_state.to_texture)\n\t\tPVR_SET(PVR_RENDER_ADDR, rbuf->frame);\n\telse {\n\t\tPVR_SET(PVR_RENDER_ADDR, pvr_state.to_txr_addr | (1 << 24));\n\t\tPVR_SET(PVR_RENDER_ADDR_2, pvr_state.to_txr_addr | (1 << 24));\n\t}\n\tPVR_SET(PVR_BGPLANE_CFG, vert_end);\t/* Bkg plane location */\n\tPVR_SET(PVR_BGPLANE_Z, *((uint32*)&pvr_state.zclip));\n\tPVR_SET(PVR_PCLIP_X, pvr_state.pclip_x);\n\tPVR_SET(PVR_PCLIP_Y, pvr_state.pclip_y);\n\tif (!pvr_state.to_texture)\n\t\tPVR_SET(PVR_RENDER_MODULO, (pvr_state.w * 2) / 8);\n\telse\n\t\tPVR_SET(PVR_RENDER_MODULO, pvr_state.to_txr_rp);\n\t// XXX Do we _really_ need this every time?\n\t// SETREG(PVR_FB_CFG_2, 0x00000009);\t\t/* Alpha mode */\n\tPVR_SET(PVR_ISP_START, PVR_ISP_START_GO);\t/* Start render */\n}\n\nvoid pvr_blank_polyhdr(int type) {\n\tpvr_poly_hdr_t poly;\n\n\t// Make it.\n\tpvr_blank_polyhdr_buf(type, &poly);\n\n\t// Submit it\n\tpvr_prim(&poly, sizeof(poly));\n}\n\nvoid pvr_blank_polyhdr_buf(int type, pvr_poly_hdr_t * poly) {\n\t/* Empty it out */\n\tmemset(poly, 0, sizeof(pvr_poly_hdr_t));\n\n\t/* Put in the list type */\n\tpoly->cmd = (type << PVR_TA_CMD_TYPE_SHIFT) | 0x80840012;\n\n\t/* Fill in dummy values */\n\tpoly->d1 = poly->d2 = poly->d3 = poly->d4 = 0xffffffff;\n\n}\n\n"
},
{
"alpha_fraction": 0.5162528157234192,
"alphanum_fraction": 0.5263388752937317,
"avg_line_length": 23.323999404907227,
"blob_id": "6919b133c129afc849810b639bf1357dd2b7b68d",
"content_id": "185ea8585b093b0f2e7e5e4a57e94f44a47411dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 18243,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 750,
"path": "/kernel/net/net_udp.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_udp.c\n Copyright (C) 2005, 2006, 2007, 2008 Lawrence Sebald\n\n*/\n\n#include <stdio.h>\n#include <string.h>\n#include <malloc.h>\n#include <arpa/inet.h>\n#include <kos/net.h>\n#include <kos/mutex.h>\n#include <kos/genwait.h>\n#include <sys/queue.h>\n#include <kos/dbgio.h>\n#include <kos/fs_socket.h>\n#include <arch/irq.h>\n#include <sys/socket.h>\n#include <errno.h>\n#include \"net_ipv4.h\"\n#include \"net_udp.h\"\n\nstruct udp_pkt {\n TAILQ_ENTRY(udp_pkt) pkt_queue;\n struct sockaddr_in from;\n uint8 *data;\n uint16 datasize;\n};\n\nTAILQ_HEAD(udp_pkt_queue, udp_pkt);\n\nstruct udp_sock {\n LIST_ENTRY(udp_sock) sock_list;\n struct sockaddr_in local_addr;\n struct sockaddr_in remote_addr;\n\n int flags;\n\n struct udp_pkt_queue packets;\n};\n\nLIST_HEAD(udp_sock_list, udp_sock);\n\nstatic struct udp_sock_list net_udp_sockets = LIST_HEAD_INITIALIZER(0);\nstatic mutex_t *udp_mutex = NULL;\n\nint net_udp_accept(net_socket_t *hnd, struct sockaddr *addr,\n socklen_t *addr_len) {\n errno = EOPNOTSUPP;\n return -1;\n}\n\nint net_udp_bind(net_socket_t *hnd, const struct sockaddr *addr,\n socklen_t addr_len) {\n struct udp_sock *udpsock, *iter;\n struct sockaddr_in *realaddr;\n\n /* Verify the parameters sent in first */\n if(addr == NULL) {\n errno = EFAULT;\n return -1;\n }\n\n if(addr->sa_family != AF_INET) {\n errno = EAFNOSUPPORT;\n return -1;\n }\n\n /* Get the sockaddr_in structure, rather than the sockaddr one */\n realaddr = (struct sockaddr_in *) addr;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n /* See if we requested a specific port or not */\n if(realaddr->sin_port != 0) {\n /* Make sure we don't already have a socket bound to the\n port specified */\n\n LIST_FOREACH(iter, &net_udp_sockets, sock_list) {\n if(iter->local_addr.sin_port == realaddr->sin_port) {\n mutex_unlock(udp_mutex);\n errno = EADDRINUSE;\n return -1;\n }\n }\n\n udpsock->local_addr = *realaddr;\n }\n else {\n uint16 port = 1024, tmp = 0;\n\n /* Grab the first unused port >= 1024. This is, unfortunately, O(n^2) */\n while(tmp != port) {\n tmp = port;\n\n LIST_FOREACH(iter, &net_udp_sockets, sock_list) {\n if(iter->local_addr.sin_port == port) {\n ++port;\n break;\n }\n }\n }\n\n udpsock->local_addr = *realaddr;\n udpsock->local_addr.sin_port = htons(port);\n }\n\n mutex_unlock(udp_mutex);\n\n return 0;\n}\n\nint net_udp_connect(net_socket_t *hnd, const struct sockaddr *addr,\n socklen_t addr_len) {\n struct udp_sock *udpsock;\n struct sockaddr_in *realaddr;\n\n if(addr == NULL) {\n errno = EFAULT;\n return -1;\n }\n\n if(addr->sa_family != AF_INET) {\n errno = EAFNOSUPPORT;\n return -1;\n }\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(udpsock->remote_addr.sin_addr.s_addr != INADDR_ANY) {\n mutex_unlock(udp_mutex);\n errno = EISCONN;\n return -1;\n }\n\n realaddr = (struct sockaddr_in *) addr;\n if(realaddr->sin_port == 0 || realaddr->sin_addr.s_addr == INADDR_ANY) {\n mutex_unlock(udp_mutex);\n errno = EADDRNOTAVAIL;\n return -1;\n }\n\n udpsock->remote_addr.sin_addr.s_addr = realaddr->sin_addr.s_addr;\n udpsock->remote_addr.sin_port = realaddr->sin_port;\n\n mutex_unlock(udp_mutex);\n\n return 0;\n}\n\nint net_udp_listen(net_socket_t *hnd, int backlog) {\n errno = EOPNOTSUPP;\n return -1;\n}\n\nssize_t net_udp_recv(net_socket_t *hnd, void *buffer, size_t length, int flags) {\n struct udp_sock *udpsock;\n struct udp_pkt *pkt;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(udpsock->remote_addr.sin_addr.s_addr == INADDR_ANY ||\n udpsock->remote_addr.sin_port == 0) {\n mutex_unlock(udp_mutex);\n errno = ENOTCONN;\n return -1;\n }\n\n if(udpsock->flags & SHUT_RD) {\n mutex_unlock(udp_mutex);\n return 0;\n }\n\n if(buffer == NULL) {\n mutex_unlock(udp_mutex);\n errno = EFAULT;\n return -1;\n }\n\n if(TAILQ_EMPTY(&udpsock->packets) && ((udpsock->flags & O_NONBLOCK) ||\n irq_inside_int())) {\n mutex_unlock(udp_mutex);\n errno = EWOULDBLOCK;\n return -1;\n }\n\n if(TAILQ_EMPTY(&udpsock->packets)) {\n mutex_unlock(udp_mutex);\n genwait_wait(udpsock, \"net_udp_recv\", 0, NULL);\n mutex_lock(udp_mutex);\n }\n\n pkt = TAILQ_FIRST(&udpsock->packets);\n\n if(pkt->datasize > length) {\n memcpy(buffer, pkt->data, length);\n }\n else {\n memcpy(buffer, pkt->data, pkt->datasize);\n length = pkt->datasize;\n }\n\n TAILQ_REMOVE(&udpsock->packets, pkt, pkt_queue);\n free(pkt->data);\n free(pkt);\n\n mutex_unlock(udp_mutex);\n\n return length;\n}\n\nssize_t net_udp_recvfrom(net_socket_t *hnd, void *buffer, size_t length,\n int flags, struct sockaddr *addr,\n socklen_t *addr_len) {\n struct udp_sock *udpsock;\n struct udp_pkt *pkt;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(udpsock->flags & SHUT_RD) {\n mutex_unlock(udp_mutex);\n return 0;\n }\n\n if(buffer == NULL || addr_len == NULL) {\n mutex_unlock(udp_mutex);\n errno = EFAULT;\n return -1;\n }\n\n if(TAILQ_EMPTY(&udpsock->packets) && ((udpsock->flags & O_NONBLOCK) ||\n irq_inside_int())) {\n mutex_unlock(udp_mutex);\n errno = EWOULDBLOCK;\n return -1;\n }\n\n while(TAILQ_EMPTY(&udpsock->packets)) {\n mutex_unlock(udp_mutex);\n genwait_wait(udpsock, \"net_udp_recvfrom\", 0, NULL);\n mutex_lock(udp_mutex);\n }\n\n pkt = TAILQ_FIRST(&udpsock->packets);\n\n if(pkt->datasize > length) {\n memcpy(buffer, pkt->data, length);\n }\n else {\n memcpy(buffer, pkt->data, pkt->datasize);\n length = pkt->datasize;\n }\n\n if(addr != NULL) {\n struct sockaddr_in realaddr;\n\n realaddr.sin_family = AF_INET;\n realaddr.sin_addr.s_addr = pkt->from.sin_addr.s_addr;\n realaddr.sin_port = pkt->from.sin_port;\n memset(realaddr.sin_zero, 0, 8);\n\n if(*addr_len < sizeof(struct sockaddr_in)) {\n memcpy(addr, &realaddr, *addr_len);\n }\n else {\n memcpy(addr, &realaddr, sizeof(struct sockaddr_in));\n *addr_len = sizeof(struct sockaddr_in);\n }\n }\n\n TAILQ_REMOVE(&udpsock->packets, pkt, pkt_queue);\n free(pkt->data);\n free(pkt);\n\n mutex_unlock(udp_mutex);\n\n return length;\n}\n\nssize_t net_udp_send(net_socket_t *hnd, const void *message, size_t length,\n int flags) {\n struct udp_sock *udpsock;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(udpsock->flags & SHUT_WR) {\n mutex_unlock(udp_mutex);\n errno = EPIPE;\n return -1;\n }\n\n if(udpsock->remote_addr.sin_addr.s_addr == INADDR_ANY ||\n udpsock->remote_addr.sin_port == 0) {\n mutex_unlock(udp_mutex);\n errno = ENOTCONN;\n return -1;\n }\n\n if(message == NULL) {\n mutex_unlock(udp_mutex);\n errno = EFAULT;\n return -1;\n }\n\n if(udpsock->local_addr.sin_port == 0) {\n uint16 port = 1024, tmp = 0;\n struct udp_sock *iter;\n\n /* Grab the first unused port >= 1024. This is, unfortunately, O(n^2) */\n while(tmp != port) {\n tmp = port;\n\n LIST_FOREACH(iter, &net_udp_sockets, sock_list) {\n if(iter->local_addr.sin_port == port) {\n ++port;\n break;\n }\n }\n }\n\n udpsock->local_addr.sin_port = htons(port);\n }\n\n mutex_unlock(udp_mutex);\n\n return net_udp_send_raw(NULL, udpsock->local_addr.sin_addr.s_addr,\n udpsock->local_addr.sin_port,\n udpsock->remote_addr.sin_addr.s_addr,\n udpsock->remote_addr.sin_port, (uint8 *) message,\n length, udpsock->flags);\n}\n\nssize_t net_udp_sendto(net_socket_t *hnd, const void *message, size_t length,\n int flags, const struct sockaddr *addr,\n socklen_t addr_len) {\n struct udp_sock *udpsock;\n struct sockaddr_in *realaddr;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(udpsock->flags & SHUT_WR) {\n mutex_unlock(udp_mutex);\n errno = EPIPE;\n return -1;\n }\n\n if(message == NULL || addr == NULL) {\n mutex_unlock(udp_mutex);\n errno = EFAULT;\n return -1;\n }\n\n realaddr = (struct sockaddr_in *) addr;\n\n if(udpsock->local_addr.sin_port == 0) {\n uint16 port = 1024, tmp = 0;\n struct udp_sock *iter;\n\n /* Grab the first unused port >= 1024. This is, unfortunately, O(n^2) */\n while(tmp != port) {\n tmp = port;\n\n LIST_FOREACH(iter, &net_udp_sockets, sock_list) {\n if(iter->local_addr.sin_port == port) {\n ++port;\n break;\n }\n }\n }\n\n udpsock->local_addr.sin_port = htons(port);\n }\n\n mutex_unlock(udp_mutex);\n\n return net_udp_send_raw(NULL, udpsock->local_addr.sin_addr.s_addr,\n udpsock->local_addr.sin_port,\n realaddr->sin_addr.s_addr, realaddr->sin_port,\n (uint8 *) message, length, udpsock->flags);\n}\n\nint net_udp_shutdownsock(net_socket_t *hnd, int how) {\n struct udp_sock *udpsock;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(how & 0xFFFFFFFC) {\n mutex_unlock(udp_mutex);\n errno = EINVAL;\n }\n\n udpsock->flags |= how;\n\n mutex_unlock(udp_mutex);\n\n return 0;\n}\n\nint net_udp_socket(net_socket_t *hnd, int domain, int type, int protocol) {\n struct udp_sock *udpsock;\n\n udpsock = (struct udp_sock *) malloc(sizeof(struct udp_sock));\n if(udpsock == NULL) {\n errno = ENOMEM;\n return -1;\n }\n\n udpsock->remote_addr.sin_family = AF_INET;\n udpsock->remote_addr.sin_addr.s_addr = INADDR_ANY;\n udpsock->remote_addr.sin_port = 0;\n\n udpsock->local_addr.sin_family = AF_INET;\n udpsock->local_addr.sin_addr.s_addr = INADDR_ANY;\n udpsock->local_addr.sin_port = 0;\n\n udpsock->flags = 0;\n\n TAILQ_INIT(&udpsock->packets);\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n LIST_INSERT_HEAD(&net_udp_sockets, udpsock, sock_list);\n mutex_unlock(udp_mutex);\n\n hnd->data = udpsock;\n\n return 0;\n}\n\nvoid net_udp_close(net_socket_t *hnd) {\n struct udp_sock *udpsock;\n struct udp_pkt *pkt;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *)hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return;\n }\n\n TAILQ_FOREACH(pkt, &udpsock->packets, pkt_queue) {\n free(pkt->data);\n TAILQ_REMOVE(&udpsock->packets, pkt, pkt_queue);\n free(pkt);\n }\n\n LIST_REMOVE(udpsock, sock_list);\n\n free(udpsock);\n mutex_unlock(udp_mutex);\n}\n\nint net_udp_setflags(net_socket_t *hnd, int flags) {\n struct udp_sock *udpsock;\n\n if(irq_inside_int()) {\n if(mutex_trylock(udp_mutex) == -1) {\n errno = EWOULDBLOCK;\n return -1;\n }\n }\n else {\n mutex_lock(udp_mutex);\n }\n\n udpsock = (struct udp_sock *) hnd->data;\n if(udpsock == NULL) {\n mutex_unlock(udp_mutex);\n errno = EBADF;\n return -1;\n }\n\n if(flags & (~O_NONBLOCK)) {\n mutex_unlock(udp_mutex);\n errno = EINVAL;\n return -1;\n }\n\n udpsock->flags |= flags;\n mutex_unlock(udp_mutex);\n\n return 0;\n}\n\nint net_udp_input(netif_t *src, ip_hdr_t *ip, const uint8 *data, int size) {\n uint8 buf[size + 12];\n ip_pseudo_hdr_t *ps = (ip_pseudo_hdr_t *)buf;\n uint16 checksum;\n struct udp_sock *sock;\n struct udp_pkt *pkt;\n\n if(size <= sizeof(udp_hdr_t)) {\n /* Discard the packet, since it is too short to be of any interest. */\n return -1;\n }\n\n ps->src_addr = ip->src;\n ps->dst_addr = ip->dest;\n ps->zero = 0;\n ps->proto = ip->protocol;\n memcpy(&ps->src_port, data, size);\n ps->length = htons(size);\n\n checksum = ps->checksum;\n ps->checksum = 0;\n ps->checksum = net_ipv4_checksum(buf, size + 12);\n\n if(checksum != ps->checksum) {\n /* The checksums don't match, bail out */\n return -1;\n }\n\n if(mutex_trylock(udp_mutex)) {\n /* Considering this function is usually called in an IRQ, if the\n mutex is locked, there isn't much that can be done. */\n return -1;\n }\n\n LIST_FOREACH(sock, &net_udp_sockets, sock_list) {\n /* See if we have a socket matching the description provided */\n if(sock->local_addr.sin_port == ps->dst_port &&\n ((sock->remote_addr.sin_port == ps->src_port &&\n sock->remote_addr.sin_addr.s_addr == ps->src_addr) ||\n (sock->remote_addr.sin_port == 0 &&\n sock->remote_addr.sin_addr.s_addr == INADDR_ANY))) {\n pkt = (struct udp_pkt *) malloc(sizeof(struct udp_pkt));\n\n pkt->datasize = size - sizeof(udp_hdr_t);\n pkt->data = (uint8 *) malloc(pkt->datasize);\n\n pkt->from.sin_family = AF_INET;\n pkt->from.sin_addr.s_addr = ip->src;\n pkt->from.sin_port = ps->src_port;\n\n memcpy(pkt->data, ps->data, pkt->datasize);\n\n TAILQ_INSERT_TAIL(&sock->packets, pkt, pkt_queue);\n\n genwait_wake_one(sock);\n\n mutex_unlock(udp_mutex);\n\n return 0;\n }\n }\n\n mutex_unlock(udp_mutex);\n\n return -1;\n}\n\nint net_udp_send_raw(netif_t *net, uint32 src_ip, uint16 src_port,\n uint32 dst_ip, uint16 dst_port, const uint8 *data,\n int size, int flags) {\n uint8 buf[size + 12 + sizeof(udp_hdr_t)];\n ip_pseudo_hdr_t *ps = (ip_pseudo_hdr_t *) buf;\n int err;\n\n if(net == NULL && net_default_dev == NULL) {\n errno = ENETDOWN;\n return -1;\n }\n\n if(src_ip == INADDR_ANY) {\n if(net == NULL && net_default_dev != NULL) {\n ps->src_addr = htonl(net_ipv4_address(net_default_dev->ip_addr));\n }\n else if(net != NULL) {\n ps->src_addr = htonl(net_ipv4_address(net->ip_addr));\n }\n }\n else {\n ps->src_addr = src_ip;\n }\n\n memcpy(ps->data, data, size);\n size += sizeof(udp_hdr_t);\n\n ps->dst_addr = dst_ip;\n ps->zero = 0;\n ps->proto = 17;\n ps->length = htons(size);\n ps->src_port = src_port;\n ps->dst_port = dst_port;\n ps->hdrlength = ps->length;\n ps->checksum = 0;\n ps->checksum = net_ipv4_checksum(buf, size + 12);\n\nretry_send:\n /* Pass everything off to the network layer to do the rest. */\n err = net_ipv4_send(net, buf + 12, size, 0, 64, IPPROTO_UDP, ps->src_addr,\n ps->dst_addr);\n \n /* If the IP layer returns that the ARP cache didn't have the entry for the\n destination, sleep for a little bit, and try again (as long as the\n non-blocking flag was not set). */\n if(err == -2 && !(flags & O_NONBLOCK)) {\n thd_sleep(100);\n goto retry_send;\n }\n else if(err == -2) {\n errno = ENETUNREACH;\n return -1;\n }\n else if(err < 0) {\n return -1;\n }\n else {\n return size - sizeof(udp_hdr_t);\n }\n}\n\nint net_udp_init() {\n udp_mutex = mutex_create();\n\n if(udp_mutex == NULL) {\n return -1;\n }\n\n return 0;\n}\n\nvoid net_udp_shutdown() {\n if(udp_mutex != NULL)\n mutex_destroy(udp_mutex);\n}\n"
},
{
"alpha_fraction": 0.5057471394538879,
"alphanum_fraction": 0.5876436829566956,
"avg_line_length": 20.75,
"blob_id": "4c87999dcca23724e58fd293e49eefe084461279",
"content_id": "dc60fcc9c88845f11f6e85b3ea8397bcbd8c1f8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 696,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 32,
"path": "/libc/net/byteorder.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n byteorder.c\n (c)2001 Dan Potter\n\n $Id: byteorder.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n */\n\n/* Byte-order translation functions */\n#include <arch/types.h>\n\n/* XXX needs to be in arch */\n\n/* Network to Host short */\nuint16 ntohs(uint16 value) {\n\treturn ((value >> 8) & 0xff)\n\t\t| ((value << 8) & 0xff00);\n}\n\n/* Network to Host long */\nuint32 ntohl(uint32 value) {\n\treturn ((value >> 24) & 0xff)\n\t\t| (( (value >> 16) & 0xff ) << 8)\n\t\t| (( (value >> 8) & 0xff) << 16)\n\t\t| (( (value >> 0) & 0xff) << 24);\n}\n\n/* Host to Network short */\nuint32 htons(uint32 value) { return ntohs(value); }\n\n/* Host to Network long */\nuint32 htonl(uint32 value) { return ntohl(value); }\n"
},
{
"alpha_fraction": 0.5197415351867676,
"alphanum_fraction": 0.5784278512001038,
"avg_line_length": 20.102272033691406,
"blob_id": "fa6f0b390ed82a42934713903daaf2d937c6d221",
"content_id": "94de1e910e1a43d46daa512390d5c1062fe1e84a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5572,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 264,
"path": "/kernel/arch/dreamcast/hardware/biosfont.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n biosfont.c\n\n (c)2000-2002 Dan Potter\n Japanese code (c) Kazuaki Matsumoto\n */\n\n#include <assert.h>\n#include <dc/biosfont.h>\n\n/*\n\nThis module handles interfacing to the bios font. It supports the standard\nEuropean encodings via ISO8859-1, and Japanese in both Shift-JIS and EUC\nmodes. For Windows/Cygwin users, you'll probably want to call\nbfont_set_encoding(BFONT_CODE_SJIS) so that your messages are displayed\nproperly; otherwise it will default to EUC (for *nix).\n\nThanks to Marcus Comstedt for the bios font information.\n\nAll the Japanese code is by Kazuaki Matsumoto.\n\n*/\n\n/* Our current conversion mode */\nint bfont_code_mode = BFONT_CODE_ISO8859_1;\n\n/* Select an encoding for Japanese (or disable) */\nvoid bfont_set_encoding(int enc) {\n\tif (enc < BFONT_CODE_ISO8859_1 || enc > BFONT_CODE_SJIS) {\n\t\tassert_msg( 0, \"Unknown bfont encoding mode\" );\n\t}\n\tbfont_code_mode = enc;\n}\n\n/* A little assembly that grabs the font address */\nextern uint8* get_font_address();\nasm(\n\"\t.text\\n\"\n\"\t.align 2\\n\"\n\"_get_font_address:\\n\"\n\"\tmov.l\tsyscall_b4,r0\\n\"\n\"\tmov.l\t@r0,r0\\n\"\n\"\tjmp\t@r0\\n\"\n\"\tmov\t#0,r1\\n\"\n\"\\n\" \n\"\t.align 4\\n\"\n\"syscall_b4:\\n\"\n\"\t.long\t0x8c0000b4\\n\"\n);\n\n\n/* Shift-JIS -> JIS conversion */\nunsigned int sjis2jis(unsigned int sjis) {\n\tunsigned int hib, lob;\n\n\thib = (sjis >> 8) & 0xff;\n\tlob = sjis & 0xff;\n\thib -= (hib <= 0x9f) ? 0x71 : 0xb1;\n\thib = (hib << 1) + 1;\n\tif (lob > 0x7f) lob--;\n\tif (lob >= 0x9e) {\n\t\tlob -= 0x7d;\n\t\thib++;\n\t} else\n\t\tlob -= 0x1f;\n\n\treturn (hib << 8) | lob;\n}\n\n\n/* EUC -> JIS conversion */\nunsigned int euc2jis(unsigned int euc) {\n\treturn euc & ~0x8080;\n}\n\n/* Given an ASCII character, find it in the BIOS font if possible */\nuint8 *bfont_find_char(int ch) {\n\tint\tindex = -1;\n\tuint8\t*fa = get_font_address();\n\t\n\t/* 33-126 in ASCII are 1-94 in the font */\n\tif (ch >= 33 && ch <= 126)\n\t\tindex = ch - 32;\n\t\n\t/* 160-255 in ASCII are 96-161 in the font */\n\tif (ch >= 160 && ch <= 255)\n\t\tindex = ch - (160 - 96);\n\t\n\t/* Map anything else to a space */\n\tif (index == -1)\n\t\tindex = 72 << 2;\n\n\treturn fa + index*36;\n}\n\n/* JIS -> (kuten) -> address conversion */\nuint8 *bfont_find_char_jp(int ch) {\n\tuint8\t*fa = get_font_address();\n\tint\tku, ten, kuten = 0;\n\n\t/* Do the requested code conversion */\n\tswitch(bfont_code_mode) {\n\tcase BFONT_CODE_ISO8859_1:\n\t\treturn NULL;\n\tcase BFONT_CODE_EUC:\n\t\tch = euc2jis(ch);\n\t\tbreak;\n\tcase BFONT_CODE_SJIS:\n\t\tch = sjis2jis(ch);\n\t\tbreak;\n\tdefault:\n\t\tassert_msg( 0, \"Unknown bfont encoding mode\" );\n\t}\n\t\n\tif (ch > 0) {\n\t\tku = ((ch >> 8) & 0x7F);\n\t\tten = (ch & 0x7F);\n\t\tif (ku >= 0x30)\n\t\t\tku -= 0x30 - 0x28;\n\t\tkuten = (ku - 0x21) * 94 + ten - 0x21;\n\t}\n\treturn fa + (kuten + 144)*72;\n}\n\n\n/* Half-width kana -> address conversion */\nuint8 *bfont_find_char_jp_half(int ch) {\n\tuint8 *fa = get_font_address();\n\treturn fa + (32 + ch)*36;\n}\n\n/* Draw half-width kana */\nvoid bfont_draw_thin(uint16 *buffer, int bufwidth, int opaque, int c, int iskana) {\n\tuint8\t*ch;\n\tuint16\tword;\n\tint\tx, y;\n\n\tif (iskana)\n\t\tch = bfont_find_char_jp_half(c);\n\telse\n\t\tch = bfont_find_char(c);\n\n\tfor (y=0; y<24; ) {\n\t\t/* Do the first row */\n\t\tword = (((uint16)ch[0]) << 4) | ((ch[1] >> 4) & 0x0f);\n\t\tfor (x=0; x<12; x++) {\n\t\t\tif (word & (0x0800 >> x))\n\t\t\t\t*buffer = 0xffff;\n\t\t\telse {\n\t\t\t\tif (opaque)\n\t\t\t\t\t*buffer = 0x0000;\n\t\t\t}\n\t\t\tbuffer++;\n\t\t}\n\t\tbuffer += bufwidth - 12;\n\t\ty++;\n\n\t\t/* Do the second row */\n\t\tword = ( (((uint16)ch[1]) << 8) & 0xf00 ) | ch[2];\n\t\tfor (x=0; x<12; x++) {\n\t\t\tif (word & (0x0800 >> x))\n\t\t\t\t*buffer = 0xffff;\n\t\t\telse {\n\t\t\t\tif (opaque)\n\t\t\t\t\t*buffer = 0x0000;\n\t\t\t}\n\t\t\tbuffer++;\n\t\t}\n\t\tbuffer += bufwidth - 12;\n\t\ty++;\n\n\t\tch += 3;\n\t}\n}\n\n/* Compat function */\nvoid bfont_draw(uint16 *buffer, int bufwidth, int opaque, int c) {\n\tbfont_draw_thin(buffer, bufwidth, opaque, c, 0);\n}\n\n/* Draw wide character */\nvoid bfont_draw_wide(uint16 *buffer, int bufwidth, int opaque, int c) {\n\tuint8\t*ch = bfont_find_char_jp(c);\n\tuint16\tword;\n\tint\tx, y;\n\n\tfor (y=0; y<24; ) {\n\t\t/* Do the first row */\n\t\tword = (((uint16)ch[0]) << 4) | ((ch[1] >> 4) & 0x0f);\n\t\tfor (x=0; x<12; x++) {\n\t\t\tif (word & (0x0800 >> x))\n\t\t\t\t*buffer = 0xffff;\n\t\t\telse {\n\t\t\t\tif (opaque)\n\t\t\t\t\t*buffer = 0x0000;\n\t\t\t}\n\t\t\tbuffer++;\n\t\t}\n\n\t\tword = ( (((uint16)ch[1]) << 8) & 0xf00 ) | ch[2];\n\t\tfor (x=0; x<12; x++) {\n\t\t\tif (word & (0x0800 >> x))\n\t\t\t\t*buffer = 0xffff;\n\t\t\telse {\n\t\t\t\tif (opaque)\n\t\t\t\t*buffer = 0x0000;\n\t\t\t}\n\t\t\tbuffer++;\n\t\t}\n\t\tbuffer += bufwidth - 24;\n\t\ty++;\n\n\t\tch += 3;\n\t}\n}\n\n\n/* Draw string of full-width (wide) and half-width (thin) characters\n Note that this handles the case of mixed encodings unless Japanese\n support is disabled (BFONT_CODE_ISO8859_1). */\nvoid bfont_draw_str(uint16 *buffer, int width, int opaque, char *str) {\n\tuint16 nChr, nMask, nFlag;\n\n\twhile (*str) {\n\t\tnFlag = 0;\n\t\tnChr = *str & 0xff;\n\t\tif (bfont_code_mode != BFONT_CODE_ISO8859_1 && (nChr & 0x80)) {\n\t\t\tswitch (bfont_code_mode) {\n\t\t\tcase BFONT_CODE_EUC:\n\t\t\t\tif (nChr == 0x8e) {\n\t\t\t\t\tstr++;\n\t\t\t\t\tnChr = *str & 0xff;\n\t\t\t\t\tif ( (nChr < 0xa1) || (nChr > 0xdf) )\n\t\t\t\t\t\tnChr = 0xa0;\t/* Blank Space */\n\t\t\t\t} else\n\t\t\t\t\tnFlag = 1;\n\t\t\t\tbreak;\n\t\t\tcase BFONT_CODE_SJIS:\n\t\t\t\tnMask = nChr & 0xf0;\n\t\t\t\tif ( (nMask == 0x80) || (nMask == 0x90) || (nMask == 0xe0) )\n\t\t\t\t\tnFlag = 1;\n\t\t\t\tbreak;\n\t\t\tdefault:\n\t\t\t\tassert_msg( 0, \"Unknown bfont encoding mode\" );\n\t\t\t}\n\t\t\t\n\t\t\tif (nFlag == 1) {\n\t\t\t\tstr++;\n\t\t\t\tnChr = (nChr << 8) | (*str & 0xff);\n\t\t\t\tbfont_draw_wide(buffer, width, opaque, nChr);\n\t\t\t\tbuffer += 24;\n\t\t\t} else {\n\t\t\t\tbfont_draw_thin(buffer, width, opaque, nChr, 1);\n\t\t\t\tbuffer += 12;\n\t\t\t}\n\t\t} else {\n\t\t\tbfont_draw_thin(buffer, width, opaque, nChr, 0);\n\t\t\tbuffer += 12;\n\t\t}\n\t\tstr++;\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.594357967376709,
"alphanum_fraction": 0.6084630489349365,
"avg_line_length": 23.176469802856445,
"blob_id": "30ef1f6e7802b8034c6268b7260f3f032151de67",
"content_id": "1cab909e470e74e57b84a0de27b7adcdbc0faa81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2056,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 85,
"path": "/libc/include/stdlib.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n stdlib.h\n (c)2001-2002 Dan Potter\n\n $Id: stdlib.h,v 1.5 2003/06/19 04:31:26 bardtx Exp $\n\n*/\n\n#ifndef __STDLIB_H\n#define __STDLIB_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <unistd.h>\n\n/* To be compatible with newer ANSI C */\n#include <malloc.h>\n\n/* To make future porting efforts simpler */\n#define __P(x) x\n\n#include <stddef.h>\n/* From BSD */\n/* #define offsetof(type, field) ((size_t)(&((type *)0)->field)) */\n\n/* random number functions */\n#define RAND_MAX 0x7fffffff\n\n#define EXIT_FAILURE\t1\t/* Failing exit status. */\n#define EXIT_SUCCESS\t0\t/* Successful exit status. */\n\ntypedef struct\n{\n\tint quot;\t/* quotient */\n\tint rem;\t/* remainder */\n} div_t;\n\ntypedef struct\n{\n\tlong quot;\t/* quotient */\n\tlong rem;\t/* remainder */\n} ldiv_t;\n\nvoid abort(void) __noreturn;\nint abs(int);\nint atexit(void (*)(void));\nvoid\t_atexit_call_all();\ndouble atof(const char *);\nint atoi(const char *);\nlong atol(const char *);\nvoid *bsearch(const void *, const void *, size_t, size_t,\n\t\tint (*)(const void *, const void *));\nvoid *calloc(size_t, size_t);\ndiv_t div(int, int);\nvoid exit(int) __noreturn;\nchar *getenv(const char *);\nlong labs(long);\nldiv_t ldiv(long, long);\nint mblen(const char *, size_t);\nsize_t mbstowcs(wchar_t *, const char *, size_t);\nint mbtowc(wchar_t *, const char *, size_t);\nchar *mktemp(char *);\nint mkstemp(char *);\nint putenv(char *);\nvoid qsort(void *, size_t, size_t, int (*)(const void *,\n\t\tconst void *));\nint rand(void);\nint rand_r(unsigned int *);\nlong random(void);\nint randnum(int limit);\t/* Not ANSI C */\nvoid *realloc(void *, size_t);\nchar *realpath(const char *, char *);\nvoid srand(unsigned int);\ndouble strtod(const char *, char **);\nlong strtol(const char *, char **, int);\nunsigned long strtoul(const char *, char **, int);\nint system(const char *);\nsize_t wcstombs(char *, const wchar_t *, size_t);\nint wctomb(char *, wchar_t);\n\n__END_DECLS\n\n#endif\t/* __STDLIB_H */\n\n"
},
{
"alpha_fraction": 0.6671069860458374,
"alphanum_fraction": 0.689564049243927,
"avg_line_length": 13.557692527770996,
"blob_id": "29a3c185aab731dd64182e4f6e0a490dff72a0a5",
"content_id": "3cd36a4a1c82c1d9e481d70b72ef2f806e12c9a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 52,
"path": "/kernel/arch/gba/kernel/lazy_porting.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <arch/timer.h>\n\nint spinlock_is_locked() {\n\treturn 0;\n}\n\nvoid arch_sleep(int x) {\n\treturn;\n}\n\nvoid irq_restore(int x) {\n\treturn;\n}\n\nint irq_disable() {\n\treturn 0;\n}\n\nvoid irq_create_context(irq_context_t *context, uint32 stack_pointer,\n\tuint32 routine, uint32 *args, int usermode)\n{\n\treturn;\n}\n\nvoid irq_set_context(irq_context_t * c) {\n\treturn;\n}\n\nuint64 timer_ms_gettime64() { return 0; }\n\ntimer_primary_callback_t timer_primary_set_callback(timer_primary_callback_t callback) {\n\treturn NULL;\n}\n\nvoid timer_primary_wakeup(uint32 millis) {\n}\n\nvoid timer_spin_sleep(int x) {\n\treturn;\n}\n\nint irq_set_handler(irq_t source, irq_handler hnd) {\n\treturn 0;\n}\n\nvoid timer_primary_enable() {\n\treturn;\n}\n\nint thd_block_now(irq_context_t * c) {\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.7020162343978882,
"alphanum_fraction": 0.7064676880836487,
"avg_line_length": 29.79032325744629,
"blob_id": "232a33f69777b6ac63167f4b6dee5d0ffe9f146c",
"content_id": "442d9b191375b6a54925d9c168784ce04ed55a97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3819,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 124,
"path": "/include/kos/library.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/library.h\n Copyright (C)2003 Dan Potter\n\n $Id$\n\n*/\n\n#ifndef __KOS_LIBRARY_H\n#define __KOS_LIBRARY_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos/thread.h>\n#include <kos/elf.h>\n#include <kos/fs.h>\n\n/* Pre-define list/queue types */\nstruct klibrary;\nTAILQ_HEAD(klqueue, klibrary);\nLIST_HEAD(kllist, klibrary);\n\n/* Thread IDs are ok for us */\ntypedef tid_t libid_t;\n\n/* Structure describing one loaded library. Each lib basically consists of\n a set of loaded program code and a set of standard exported entry points. */\ntypedef struct klibrary {\n\t/* Library list handle */\n\tLIST_ENTRY(klibrary)\tlist;\n\n\t/* Kernel library id */\n\tlibid_t\tlibid;\n\n\t/* Flags */\n\tuint32\tflags;\n\n\t/* ELF program image for this library */\n\telf_prog_t image;\n\n\t/* The library's reference count. If it is opened more than once, this\n\t will go to >1 values. The library is actually shut down and removed\n\t if this reaches zero. */\n\tint refcnt;\n\n\t/* Standard library entry points. Every loaded library must provide\n\t at least these things. */\n\n\t/* Return a pointer to a string containing the library's symbolic\n\t name. Must work before calling lib_open. */\n\tconst char * (*lib_get_name)();\n\n\t/* Return an integer containing the library's version ID. Must work\n\t before calling lib_open. */\n\tuint32 (*lib_get_version)();\n\n\t/* \"Open\" the library (i.e., init and/or increase ref count). Return\n\t >= 0 value here to signal success. If failure is signaled on the\n\t first lib_open, it is assumed we can remove this library from memory. */\n\tint (*lib_open)(struct klibrary * lib);\n\n\t/* \"Close\" the library (i.e., dec ref count and/or shut down). Return\n\t >= 0 on success or < 0 on failure. */\n\tint (*lib_close)(struct klibrary * lib);\n} klibrary_t;\n\n/* Library flag values */\n#define LIBRARY_DEFAULTS\t0\t/* Defaults: no flags */\n\n/* Library list; note: do not manipulate directly */\nextern struct kllist library_list;\n\n/* Given a library ID, locates the lib structure */\nklibrary_t *library_by_libid(libid_t libid);\n\n/* New library shell function. When you want to load a new library, this\n function will handle that for you. This will generally only be used by\n the library code internally. */\nklibrary_t *library_create(int flags);\n\n/* Given a library handle, this function removes the library from the library\n list. Any remaining resources assigned to this library will be freed. This\n will generally only be used by the library code internally. */\nint library_destroy(klibrary_t *lib);\n\n/* Try to open a library by symbolic name. If the library open fails, then\n attempt to load the library from the given filename. If this fails, then\n return NULL for error. On success, return a handle to the library;\n lib_open will already have been called. */\nklibrary_t * library_open(const char * name, const char * fn);\n\n/* Look up a library by name without trying to load or open it. This is\n useful if you want to open a library in one place and not have to keep\n track of the handle to close it later. */\nklibrary_t * library_lookup(const char * name);\n\n/* Close a previously opened library. If this fails, return < 0 for error. If\n it succeeds, return > 0; lib_close will already have been called, and the\n library may have been destroyed as well (do NOT try to use it again). */\nint library_close(klibrary_t * lib);\n\n/* Retrieve library's libid (runtime ID) */\nlibid_t library_get_libid(klibrary_t * lib);\n\n/* Retrieve library's reference count */\nint library_get_refcnt(klibrary_t * lib);\n\n/* Retrieve library's name */\nconst char * library_get_name(klibrary_t * lib);\n\n/* Retrieve library's version */\nuint32 library_get_version(klibrary_t * lib);\n\n/* Init */\nint library_init();\n\n/* Shutdown */\nvoid library_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_LIBRARY_H */\n\n"
},
{
"alpha_fraction": 0.5523012280464172,
"alphanum_fraction": 0.6359832882881165,
"avg_line_length": 14.866666793823242,
"blob_id": "956fa7c50db28c006adebb3831f4ec8c794050c9",
"content_id": "30224f552d3497c3ec610a507ac253ccbf8923c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/dreamcast/modem/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/modem/Makefile\n# Copyright (C)2003 Dan Potter\n# \n# $Id: Makefile,v 1.1 2003/05/23 02:05:41 bardtx Exp $\n\nall:\n\t$(MAKE) -C basic\n\nclean:\n\t$(MAKE) -C basic clean\n\t\t\ndist:\n\t$(MAKE) -C basic dist\n\n"
},
{
"alpha_fraction": 0.6362437605857849,
"alphanum_fraction": 0.6642047166824341,
"avg_line_length": 21.414201736450195,
"blob_id": "e300c3fbce0ce562cd426dc2e0548c27fd6e746b",
"content_id": "31393df1ddcf4a92dfe26380f3ca7d3bc9130ec2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3791,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 169,
"path": "/kernel/arch/ps2/kernel/timer.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n timer.c\n (c)2002 Dan Potter\n*/\n\n#include <assert.h>\n#include <stdio.h>\n#include <arch/arch.h>\n#include <arch/timer.h>\n#include <arch/irq.h>\n#include <ps2/ioports.h>\n\nCVSID(\"$Id: timer.c,v 1.1 2002/11/03 03:40:55 bardtx Exp $\");\n\n/* Pre-initialize a timer; set values but don't start it */\nint timer_prime(int which, uint32 speed, int interrupts) {\n\t/* Note: speed must be at least 100 here! Otherwise,\n\t the count value will overflow. */\n\tassert( speed >= 100 );\n\n\tif (interrupts)\n\t\ttimer_enable_ints(which);\n\telse\n\t\ttimer_disable_ints(which);\n\n\tTIMER_COMP(which) = TIMER_BUSCLK256 / speed;\n\tTIMER_COUNT(which) = 0;\n\tTIMER_HOLD(which) = 0;\n\tTIMER_MODE(which) = TIMER_CLKS_BUSCLK256\n\t\t| TIMER_ZRET_ENABLE\n\t\t| TIMER_CMPE_ENABLE\n\t\t| TIMER_EQUF\n\t\t| TIMER_OVFF;\n\n\treturn 0;\n}\n\n/* Start a timer -- starts it running (and interrupts if applicable) */\nint timer_start(int which) {\n\tTIMER_MODE(which) |= TIMER_CUE_ENABLE;\n\treturn 0;\n}\n\n/* Stop a timer -- and disables its interrupt */\nint timer_stop(int which) {\n\tTIMER_MODE(which) &= ~TIMER_CUE_ENABLE;\n\treturn 0;\n}\n\n/* Returns the count value of a timer */\nuint32 timer_count(int which) {\n\treturn TIMER_COUNT(which);\n}\n\n/* Clears the timer EQUF bit and returns what its value was */\nint timer_clear(int which) {\n\tuint32 tmp = TIMER_MODE(which);\n\tTIMER_MODE(which) = tmp | TIMER_EQUF;\n\n\treturn (tmp & TIMER_EQUF) != 0;\n}\n\n/* Spin-loop kernel sleep func: uses timer 1 in the\n EE to very accurately delay even when interrupts are disabled */\nvoid timer_spin_sleep(int ms) {\n\ttimer_prime(1, 1000, 0);\n\ttimer_start(1);\n\n\twhile (ms > 0) {\n\t\twhile (!(TIMER_MODE(1) & TIMER_EQUF))\n\t\t\t;\n\t\ttimer_clear(1);\n\t\tms--;\n\t}\n\n\ttimer_stop(1);\n}\n\n/* Enable timer interrupts (high priority); needs to move\n to irq.c sometime. */\nvoid timer_enable_ints(int which) {\n\tINTC_MASK_SET(INTM_TIMER0 << which);\n}\n\n/* Disable timer interrupts; needs to move to irq.c sometime. */\nvoid timer_disable_ints(int which) {\n\tINTC_MASK_CLEAR(INTM_TIMER0 << which);\n}\n\n/* Check whether ints are enabled */\nint timer_ints_enabled(int which) {\n\treturn (INTC_MASK & (INTM_TIMER0) << which) != 0;\n}\n\n/* Millisecond timer -- this is unfunctional right now because we can't\n get a timer slower than about 100Hz (might as well piggyback on jiffies).\n Probably should set it up later to trigger on VSYNC or something. */\nstatic uint32 timer_ms_counter = 0;\nstatic uint32 timer_ms_countdown;\nstatic void timer_ms_handler(irq_t source, irq_context_t *context) {\n\ttimer_ms_counter++;\n}\n\nvoid timer_ms_enable() {\n\t/* irq_set_handler(EXC_INTR_TIMER2, timer_ms_handler);\n\ttimer_prime(2, 100, 1);\n\ttimer_ms_countdown = TIMER_COMP(2);\n\ttimer_clear(2);\n\ttimer_start(2); */\n}\n\nvoid timer_ms_disable() {\n\t/* timer_stop(2);\n\ttimer_disable_ints(2); */\n}\n\n/* Return the number of ticks since KOS was booted */\nvoid timer_ms_gettime(uint32 *secs, uint32 *msecs) {\n\tuint32 used;\n\n\t/* Seconds part comes from ms_counter / 100 */\n\tif (secs) {\n\t\t*secs = timer_ms_counter;\n\t}\n\n\t/* Milliseconds, we check how much of the timer has elapsed */\n\tif (msecs) {\n\t\t// used = timer_ms_countdown - timer_count(TMU2);\n\t\tused = 0;\n\t\t*msecs = (uint32)(used * 1000.0 / timer_ms_countdown);\n\t}\n}\n\n/* Enable / Disable primary kernel timer */\nvoid timer_primary_enable() {\n\t/* Preinit and enable timer with interrupts, with HZ for jiffies */\n\ttimer_prime(TIMER_ID, HZ, 0);\n\ttimer_start(TIMER_ID);\n}\n\nvoid timer_primary_disable() {\n\ttimer_disable_ints(TIMER_ID);\n\ttimer_stop(TIMER_ID);\n}\n\n/* Init */\nint timer_init() {\n\tint i;\n\t\n\t/* Disable all timers */\n\tfor (i=0; i<4; i++) {\n\t\tTIMER_MODE(i) = 0;\n\t\ttimer_disable_ints(i);\n\t}\n\t\n\treturn 0;\n}\n\n/* Shutdown */\nvoid timer_shutdown() {\n\tint i;\n\t\n\t/* Disable all timers */\n\tfor (i=0; i<4; i++) {\n\t\tTIMER_MODE(i) = 0;\n\t\ttimer_disable_ints(i);\n\t}\n}\n\n\n\n"
},
{
"alpha_fraction": 0.5693548321723938,
"alphanum_fraction": 0.5693548321723938,
"avg_line_length": 21.925926208496094,
"blob_id": "11ac6a909b74cd1358dbbb2c8d89ce2cbf489711",
"content_id": "66ecd044a80f894ed96fc22ca8c808fe460623b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 620,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 27,
"path": "/kernel/arch/ps2/kernel/make_banner.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Re-creates the banner.c file for each compilation run\n\necho 'char banner[] = ' > banner.c\n\nif [ \"${KOS_SUBARCH}\" != \"\" ]; then\n\techo -n '\"KOS for '${KOS_ARCH}'['${KOS_SUBARCH}'] ##version##: ' >> banner.c\nelse\n\techo -n '\"KOS for '${KOS_ARCH}' ##version##: ' >> banner.c\nfi\necho -n `date` >> banner.c\necho '\\n\"' >> banner.c\n\necho -n '\" ' >> banner.c\necho -n `whoami` >> banner.c\necho -n '@' >> banner.c\nif [ `uname` = Linux ]; then\n\techo -n `hostname -f` >> banner.c\nelse\n\techo -n `hostname` >> banner.c\nfi\necho -n ':' >> banner.c\necho -n $KOS_BASE >> banner.c\necho '\\n\"' >> banner.c\n\necho ';' >> banner.c\n\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.5751391649246216,
"avg_line_length": 14.399999618530273,
"blob_id": "aa7532830b610d4269a9d2eafb15a1a998100159",
"content_id": "7e3ba217363207675576e71042aea322e2542199",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 35,
"path": "/kernel/libc/koslib/readdir.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n readdir.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <dirent.h>\n#include <errno.h>\n#include <string.h>\n#include <kos/fs.h>\n\nstruct dirent * readdir(DIR * dir) {\n\tdirent_t * d;\n\n\tif (!dir) {\n\t\terrno = EBADF;\n\t\treturn NULL;\n\t}\n\td = fs_readdir(dir->fd);\n\n\tif (!d)\n\t\treturn NULL;\n\n\tdir->d_ent.d_ino = 0;\n\tdir->d_ent.d_off = 0;\n\tdir->d_ent.d_reclen = 0;\n\tif (d->size < 0)\n\t\tdir->d_ent.d_type = 4;\t// DT_DIR\n\telse\n\t\tdir->d_ent.d_type = 8;\t// DT_REG\n\tstrncpy(dir->d_ent.d_name, d->name, 255);\n\n\treturn &dir->d_ent;\n}\n"
},
{
"alpha_fraction": 0.5662983655929565,
"alphanum_fraction": 0.6243094205856323,
"avg_line_length": 22.60869598388672,
"blob_id": "78ef370bd315b9434875f98c5506d34f6c283696",
"content_id": "dfa435ecbc4941c72d94351a5bb33763d87be809",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1086,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 46,
"path": "/examples/dreamcast/libdream/800x608/800x608.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* This sample program shows off 800x608, the mythical \"unsupported\" video\n mode that Sega will probably complain doesn't work (like they did for\n our 320x240 modes earlier on ;-). This will probably only work on a VGA\n monitor and I highly recommend that you don't try it on a non-multisync.\n Still needs some tweaking.\n\n In here I also demonstrate how to use the bfont BIOS font routines, and\n how to initialize only selected parts of KOS (resulting in a much \n smaller and less polluted binary).\n\n */\n\n#include <kos.h>\n\n#define W 800\n#define H 608\n\nint main(int argc, char **argv) {\n\tint x, y;\n\n\t/* Set video mode */\n\tvid_set_mode(DM_800x608, PM_RGB565);\n\t\n\tfor (y=0; y<H; y++)\n\t\tfor (x=0; x<W; x++) {\n\t\t\tint c = (x ^ y) & 255;\n\t\t\tvram_s[y*W+x] = ((c >> 3) << 0);\n\t\t}\n\n\tfor (y=0; y<H; y+=24) {\n\t\tchar tmp[16];\n\t\tsprintf(tmp, \"%d\", y);\n\t\tbfont_draw_str(vram_s+y*W+10, W, 0, tmp);\n\t}\n\n\tfor (x=0; x<W; x+=100) {\n\t\tchar tmp[16];\n\t\tsprintf(tmp, \"%d\", x/10);\n\t\tbfont_draw_str(vram_s+10*W+x, W, 0, tmp);\n\t}\n\n\t/* Pause to see the results */\n\tusleep(5*1000*1000);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6153846383094788,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 12,
"blob_id": "95c94c7193c0f6099880c6c4abe73814fed2c250",
"content_id": "15021321eef7c012bc1fa3de2596d8fc50800415",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-strip",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_STRIP} \"$@\"\n"
},
{
"alpha_fraction": 0.5942519307136536,
"alphanum_fraction": 0.649196982383728,
"avg_line_length": 18.71666717529297,
"blob_id": "e39682a8fdcb9c081fa8e97acf14087bcf8c9ba3",
"content_id": "e194f9b54d108fc2a98ef6c74e948c030c79186a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1183,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 60,
"path": "/kernel/libc/pthreads/pthread_thd.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <pthread.h>\n#include <errno.h>\n#include <assert.h>\n\n/* Thread Creation, P1003.1c/Draft 10, p. 144 */\n\nint pthread_create(pthread_t *thread, const pthread_attr_t *attr,\n\tvoid *(*start_routine)( void * ), void *arg)\n{\n\tkthread_t * nt;\n\n\tassert( thread );\n\tassert( start_routine );\n\n\tnt = thd_create( (void (*)(void *))start_routine, arg );\n\tif (nt) {\n\t\t*thread = nt;\n\t\treturn 0;\n\t} else {\n\t\treturn EAGAIN;\n\t}\n}\n\n/* Wait for Thread Termination, P1003.1c/Draft 10, p. 147 */\n\nint pthread_join(pthread_t thread, void **value_ptr) {\n\tassert( thread );\n\n\t// XXX Need to get return value if value_ptr != NULL.\n\tif (thd_wait(thread) < 0)\n\t\treturn ESRCH;\n\telse\n\t\treturn 0;\n}\n\n/* Detaching a Thread, P1003.1c/Draft 10, p. 149 */\n\nint pthread_detach(pthread_t thread) {\n\t// Currently meaningless.\n\treturn 0;\n}\n\n/* Thread Termination, p1003.1c/Draft 10, p. 150 */\n\nvoid pthread_exit(void *value_ptr) {\n\t// XXX Need to get return value.\n\tthd_exit();\n}\n\n/* Get Calling Thread's ID, p1003.1c/Draft 10, p. XXX */\n\npthread_t pthread_self(void) {\n\treturn thd_current;\n}\n\n/* Compare Thread IDs, p1003.1c/Draft 10, p. 153 */\n\nint pthread_equal(pthread_t t1, pthread_t t2) {\n\treturn t1 == t2;\n}\n"
},
{
"alpha_fraction": 0.6232430338859558,
"alphanum_fraction": 0.6455585956573486,
"avg_line_length": 27.51239585876465,
"blob_id": "7214401586c19eb7e183361eb5eec9c6fa8a196d",
"content_id": "b10724332adda36aab780e7063dbe1960398dd40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6901,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 242,
"path": "/include/kos/net.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/net.h\n (c)2002 Dan Potter\n\n $Id: net.h,v 1.8 2003/06/19 04:30:23 bardtx Exp $\n\n*/\n\n#ifndef __KOS_NET_H\n#define __KOS_NET_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/queue.h>\n\n/* All functions in this header return < 0 on failure, and 0 on success. */\n\n\n\n/* Structure describing one usable network device; this is pretty ethernet\n centric, though I suppose you could stuff other things into this system\n like PPP. */\ntypedef struct knetif {\n\t/* Device list handle */\n\tLIST_ENTRY(knetif)\t\tif_list;\n\n\t/* Device name (\"bba\", \"la\", etc) */\n\tconst char \t\t\t*name;\n\n\t/* Long description of the device */\n\tconst char\t\t\t*descr;\n\n\t/* Unit index (starts at zero and counts upwards for multiple\n\t network devices of the same type) */\n\tint\t\t\t\tindex;\n\n\t/* Internal device ID (for whatever the driver wants) */\n\tuint32\t\t\t\tdev_id;\n\n\t/* Interface flags */\n\tuint32\t\t\t\tflags;\n\n\t/* The device's MAC address */\n\tuint8\t\t\t\tmac_addr[6];\n\n\t/* The device's IP address (if any) */\n\tuint8\t\t\t\tip_addr[4];\n\n /* The device's netmask */\n uint8 netmask[4];\n\n /* The device's gateway's IP address */\n uint8 gateway[4];\n\n\t/* All of the following callback functions should return a negative\n\t value on failure, and a zero or positive value on success. Some\n\t functions have special values, as noted. */\n\n\t/* Attempt to detect the device */\n\tint (*if_detect)(struct knetif * self);\n\n\t/* Initialize the device */\n\tint (*if_init)(struct knetif * self);\n\n\t/* Shutdown the device */\n\tint (*if_shutdown)(struct knetif * self);\n\n\t/* Start the device (after init or stop) */\n\tint (*if_start)(struct knetif * self);\n\n\t/* Stop (hibernate) the device */\n\tint (*if_stop)(struct knetif * self);\n\n\t/* Queue a packet for transmission; see special return values\n\t below the structure */\n\tint (*if_tx)(struct knetif * self, const uint8 * data, int len, int blocking);\n\n\t/* Commit any queued output packets */\n\tint (*if_tx_commit)(struct knetif * self);\n\n\t/* Poll for queued receive packets, if neccessary */\n\tint (*if_rx_poll)(struct knetif * self);\n\n\t/* Set flags; you should generally manipulate flags through here so that\n\t the driver gets a chance to act on the info. */\n\tint (*if_set_flags)(struct knetif * self, uint32 flags_and, uint32 flags_or);\n} netif_t;\n\n/* Flags for netif_t */\n#define NETIF_NO_FLAGS\t\t0x00000000\n#define NETIF_REGISTERED\t0x00000001\t\t/* Is it registered? */\n#define NETIF_DETECTED\t\t0x00000002\t\t/* Is it detected? */\n#define NETIF_INITIALIZED\t0x00000004\t\t/* Has it been initialized? */\n#define NETIF_RUNNING\t\t0x00000008\t\t/* Has start() been called? */\n#define NETIF_PROMISC\t\t0x00010000\t\t/* Promiscuous mode */\n#define NETIF_NEEDSPOLL\t\t0x01000000\t\t/* Needs to be polled for input */\n\n/* Return types for if_tx */\n#define NETIF_TX_OK\t\t0\n#define NETIF_TX_ERROR\t\t-1\n#define NETIF_TX_AGAIN\t\t-2\n\n/* Blocking types */\n#define NETIF_NOBLOCK\t\t0\n#define NETIF_BLOCK\t\t1\n\n\n/* Define the list type */\nLIST_HEAD(netif_list, knetif);\n\n\n/* Structure describing an ARP entry; each entry contains a MAC address,\n an IP address, and a timestamp from 'jiffies'. The timestamp allows\n aging and eventual removal. */\ntypedef struct netarp {\n\t/* ARP cache list handle */\n\tLIST_ENTRY(netarp)\t\tac_list;\n\n\t/* Mac address */\n\tuint8\t\t\t\tmac[6];\n\n\t/* Associated IP address */\n\tuint8\t\t\t\tip[4];\n\n\t/* Cache entry time; if zero, this entry won't expire */\n\tuint32\t\t\t\ttimestamp;\n} netarp_t;\n\n/* Define the list type */\nLIST_HEAD(netarp_list, netarp);\n\n/***** net_arp.c **********************************************************/\n\n/* ARP cache */\nextern struct netarp_list net_arp_cache;\n\n\n/* Init */\nint net_arp_init();\n\n/* Shutdown */\nvoid net_arp_shutdown();\n\n/* Garbage collect timed out entries */\nint net_arp_gc();\n\n/* Add an entry to the ARP cache manually */\nint net_arp_insert(netif_t *nif, uint8 mac[6], uint8 ip[4], uint32 timestamp);\n\n/* Look up an entry from the ARP cache; if no entry is found, then an ARP\n query will be sent and an error will be returned. Thus your packet send\n should also fail. Later when the transmit retries, hopefully the answer\n will have arrived. */\nint net_arp_lookup(netif_t *nif, uint8 ip_in[4], uint8 mac_out[6]);\n\n/* Do a reverse ARP lookup: look for an IP for a given mac address; note\n that if this fails, you have no recourse. */\nint net_arp_revlookup(netif_t *nif, uint8 ip_out[4], uint8 mac_in[6]);\n\n/* Receive an ARP packet and process it (called by net_input) */\nint net_arp_input(netif_t *nif, const uint8 *pkt, int len);\n\n/* Generate an ARP who-has query on the given device */\nint net_arp_query(netif_t *nif, uint8 ip[4]);\n\n\n/***** net_input.c *********************************************************/\n\n/* Type of net input callback */\ntypedef int (*net_input_func)(netif_t *, const uint8 *, int);\n\n/* Where will input packets be routed? */\nextern net_input_func net_input_target;\n\n/* Device drivers should call this function to submit packets received\n in the background; this function may or may not return immidiately\n but it won't take an infinitely long time (so it's safe to call inside\n interrupt handlers, etc) */\nint net_input(netif_t *device, const uint8 *data, int len);\n\n/* Setup an input target; returns the old target */\nnet_input_func net_input_set_target(net_input_func t);\n\n/***** net_icmp.c *********************************************************/\n\n/* Type of ping reply callback */\ntypedef void (*net_echo_cb)(const uint8 *, uint16, uint64, uint8, const uint8 *, int);\n\n/* Where will we handle possibly notifying the user of ping replies? */\nextern net_echo_cb net_icmp_echo_cb;\n\n/***** net_ipv4.c *********************************************************/\n\n/* Create a 32-bit IP address, based on the individual numbers contained\n within the ip. */\nuint32 net_ipv4_address(const uint8 addr[4]);\n\n/* Parse an IP address that is packet into a uint32 into an array of the\n individual bytes */\nvoid net_ipv4_parse_address(uint32 addr, uint8 out[4]);\n\n/***** net_udp.c **********************************************************/\n\n/* Init */\nint net_udp_init();\n\n/* Shutdown */\nvoid net_udp_shutdown();\n\n/***** net_core.c *********************************************************/\n\n/* Interface list; note: do not manipulate directly */\nextern struct netif_list net_if_list;\n\n/* Function to retrieve the list. Again, do not manipulate directly. */\nstruct netif_list * net_get_if_list();\n\n/* The default network device, used with sockets. */\nextern netif_t *net_default_dev;\n\n/* Set our default device to an arbitrary device, returns the old device */\nnetif_t *net_set_default(netif_t *n);\n\n/* Register a network device */\nint net_reg_device(netif_t *device);\n\n/* Unregister a network device */\nint net_unreg_device(netif_t *device);\n\n\n/* Init */\nint net_init();\n\n/* Shutdown */\nvoid net_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_NET_H */\n\n"
},
{
"alpha_fraction": 0.7189873456954956,
"alphanum_fraction": 0.7696202397346497,
"avg_line_length": 55.42856979370117,
"blob_id": "6fc1cdf3b05a76b89cf93ea77d266925f467e943",
"content_id": "259a1e82876d94719c84b2d293856d59539c6a3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 7,
"path": "/environ_gba.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS environment variable settings. These are the shared pieces\n# for the GBA(tm) platform.\n\n# This is currently configured to produce only Thumb code\nexport KOS_CFLAGS=\"${KOS_CFLAGS} -mcpu=arm7tdmi -mthumb -ffreestanding\"\nexport KOS_AFLAGS=\"${KOS_AFLAGS} -marm7tdmi\"\nexport KOS_LDFLAGS=\"${KOS_LDFLAGS} -Wl,-Ttext=0x08000000,-Tdata=0x02000000,-T,$KOS_BASE/kernel/arch/gba/gba.ld.script\"\n"
},
{
"alpha_fraction": 0.6332487463951111,
"alphanum_fraction": 0.6662436723709106,
"avg_line_length": 23.625,
"blob_id": "5c43ddfcb343d55a40b8c8ac807232d41e90ff07",
"content_id": "abf267a55ad80388b2fd18cb64f7a225060123aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 32,
"path": "/kernel/arch/ps2/sbios/sbios_init_shutdown.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sbios_init_shutdown.c\n Copyright (c)2002 Dan Potter\n*/\n\n#include <ps2/sbios.h>\n\n/* SBIOS is the PS2RTE runtime kernel that resides in the lower 64k of\n RAM after it boots an image. The SBIOS handles all interactions with\n the IOP, which includes:\n\n - Hard disk(?)\n - Memory card\n - CD/DVD drive\n - Firewire\n - PS2 pads (controllers)\n - Audio output\n\n And probably other stuff I don't know about yet. To call into the\n SBIOS, we have to dig into the first of it for the boot info, and\n get an entry proc address (\"sbios_call\"). This will be used\n for all interactions with the SBIOS. */\n\nCVSID(\"$Id: sbios_init_shutdown.c,v 1.2 2002/11/06 08:40:08 bardtx Exp $\");\n\nint sbios_init() {\n\treturn -1;\n}\n\nvoid sbios_shutdown() {\n}\n"
},
{
"alpha_fraction": 0.6328461170196533,
"alphanum_fraction": 0.6827170848846436,
"avg_line_length": 18.366666793823242,
"blob_id": "b4ed096d42d0b72f980c6673c5ca0fe552a17ccd",
"content_id": "daf5b9132f4eaeeb4e6cd9220972105ddcc505b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1163,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 60,
"path": "/include/arch/dreamcast/dc/maple/mouse.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/mouse.h\n (C)2000-2002 Jordan DeLong and Dan Potter\n\n $Id: mouse.h,v 1.3 2002/05/24 06:47:26 bardtx Exp $\n\n*/\n\n#ifndef __DC_MAPLE_MOUSE_H\n#define __DC_MAPLE_MOUSE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* mouse defines */\n#define MOUSE_RIGHTBUTTON\t(1<<1)\n#define MOUSE_LEFTBUTTON\t(1<<2)\n#define MOUSE_SIDEBUTTON\t(1<<3)\n\n#define MOUSE_DELTA_CENTER 0x200\n\n/* Raw mouse condition structure */\ntypedef struct {\n\tuint16 buttons;\n\tuint16 dummy1;\n\tint16 dx;\n\tint16 dy;\n\tint16 dz;\n\tuint16 dummy2;\n\tuint32 dummy3;\n\tuint32 dummy4;\n} mouse_cond_t;\n\n/* More civilized mouse structure. There are several significant\n differences in data interpretation between the \"cooked\" and\n the old \"raw\" structs:\n\n - buttons are zero-based: a 1-bit means the button is PRESSED\n - no dummy values\n\n Note that this is what maple_dev_status() will return.\n */\ntypedef struct {\n\tuint32\tbuttons;\n\tint\tdx, dy, dz;\n} mouse_state_t;\n\n/* Old maple interface */\nint mouse_get_cond(uint8 addr, mouse_cond_t *cond);\n\n/* Init / Shutdown */\nint\tmouse_init();\nvoid\tmouse_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_MOUSE_H */\n\n"
},
{
"alpha_fraction": 0.6445147395133972,
"alphanum_fraction": 0.6940928101539612,
"avg_line_length": 23.30769157409668,
"blob_id": "f1d57b2deabc2e48d413ad15d6e657bbf85ffd6b",
"content_id": "f248bcaa814bb01c1569e377e74d2ae8b101e330",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 39,
"path": "/include/arch/dreamcast/dc/biosfont.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/biosfont.h\n (c)2000-2001 Dan Potter\n Japanese Functions (c)2002 Kazuaki Matsumoto\n\n $Id: biosfont.h,v 1.3 2002/06/27 23:24:43 bardtx Exp $\n\n*/\n\n\n#ifndef __DC_BIOSFONT_H\n#define __DC_BIOSFONT_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Constants for the function below */\n#define BFONT_CODE_ISO8859_1\t0\t/* DEFAULT */\n#define BFONT_CODE_EUC\t\t1\n#define BFONT_CODE_SJIS\t\t2\n\n/* Select an encoding for Japanese (or disable) */\nvoid bfont_set_encoding(int enc);\n\nuint8 *bfont_find_char(int ch);\nuint8 *bfont_find_char_jp(int ch);\nuint8 *bfont_find_char_jp_half(int ch);\n\nvoid bfont_draw(uint16 *buffer, int bufwidth, int opaque, int c);\nvoid bfont_draw_thin(uint16 *buffer, int bufwidth, int opaque, int c, int iskana);\nvoid bfont_draw_wide(uint16 *buffer, int bufwidth, int opaque, int c);\nvoid bfont_draw_str(uint16 *buffer, int width, int opaque, char *str);\n\n__END_DECLS\n\n#endif /* __DC_BIOSFONT_H */\n"
},
{
"alpha_fraction": 0.5976331233978271,
"alphanum_fraction": 0.6213017702102661,
"avg_line_length": 24.037036895751953,
"blob_id": "b854051b829448d73e2b13861e48d0e5be3764fc",
"content_id": "3d3f618aab14d8a57d82e710d77274ddcfeee8fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2028,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 81,
"path": "/kernel/arch/dreamcast/fs/dcload-packet.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-packet.c\n\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#include \"dcload-packet.h\"\n\nunsigned short dcln_checksum(unsigned short *buf, int count)\n{\n unsigned long sum = 0;\n\n while (count--) {\n\tsum += *buf++;\n\tif (sum & 0xffff0000) {\n\t sum &= 0xffff;\n\t sum++;\n\t}\n }\n return ~(sum & 0xffff);\n}\n\nvoid dcln_make_ether(char *dest, char *src, ether_header_t *ether)\n{\n memcpy(ether->dest, dest, 6);\n memcpy(ether->src, src, 6);\n ether->type[0] = 8;\n ether->type[1] = 0;\n}\n\nvoid dcln_make_ip(int dest, int src, int length, char protocol, ip_header_t *ip)\n{\n ip->version_ihl = 0x45;\n ip->tos = 0;\n ip->length = htons(20 + length);\n ip->packet_id = 0;\n ip->flags_frag_offset = htons(0x4000);\n ip->ttl = 0x40;\n ip->protocol = protocol;\n ip->checksum = 0;\n ip->src = htonl(src);\n ip->dest = htonl(dest);\n\n ip->checksum = dcln_checksum((unsigned short *)ip, sizeof(ip_header_t)/2);\n}\n\n/* umm.... :) */\nstatic unsigned char crap[1514];\n\nvoid dcln_make_udp(unsigned short dest, unsigned short src, unsigned char * data, int length, ip_header_t *ip, udp_header_t *udp)\n{\n ip_udp_pseudo_header_t *pseudo = (ip_udp_pseudo_header_t *)crap;\n\n udp->src = htons(src);\n udp->dest = htons(dest);\n udp->length = htons(length + 8);\n udp->checksum = 0;\n memcpy(udp->data, data, length);\n\n pseudo->src_ip = ip->src;\n pseudo->dest_ip = ip->dest;\n pseudo->zero = 0;\n pseudo->protocol = ip->protocol;\n pseudo->udp_length = udp->length;\n pseudo->src_port = udp->src;\n pseudo->dest_port = udp->dest;\n pseudo->length = udp->length;\n pseudo->checksum = 0;\n memset(pseudo->data, 0, length + (length%2));\n memcpy(pseudo->data, udp->data, length);\n\n udp->checksum = dcln_checksum((unsigned short *)pseudo, (sizeof(ip_udp_pseudo_header_t) + length)/2);\n if (udp->checksum == 0)\n udp->checksum = 0xffff;\n}\n"
},
{
"alpha_fraction": 0.6328233480453491,
"alphanum_fraction": 0.6745479702949524,
"avg_line_length": 21.4375,
"blob_id": "d1bffc00edfc6bcb064d722da7a093ae1548616a",
"content_id": "4bf8857c2b3cd9688286940e7d9347d7edec3b9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/include/arch/dreamcast/dc/maple/vmu.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/vmu.h\n (C)2000-2002 Jordan DeLong and Dan Potter\n\n $Id: vmu.h,v 1.3 2002/09/04 03:38:42 bardtx Exp $\n\n*/\n\n#ifndef __DC_MAPLE_VMU_H\n#define __DC_MAPLE_VMU_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\nint vmu_draw_lcd(maple_device_t * dev, void *bitmap);\nint vmu_block_read(maple_device_t * dev, uint16 blocknum, uint8 *buffer);\nint vmu_block_write(maple_device_t * dev, uint16 blocknum, uint8 *buffer);\n\n/* Utility function which sets the icon on all available VMUs \n from an Xwindows XBM. Imported from libdcutils. */\nvoid vmu_set_icon(const char *vmu_icon);\n\n/* Init / Shutdown */\nint vmu_init();\nvoid vmu_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_VMU_H */\n\n"
},
{
"alpha_fraction": 0.651448667049408,
"alphanum_fraction": 0.6665496230125427,
"avg_line_length": 21.599206924438477,
"blob_id": "c486ba885debdcb4493a7c093d311cb9b88a5816",
"content_id": "3cc6a3548ec1cd05b6a96dba8e7524779c2f0cc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5695,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 252,
"path": "/kernel/arch/ia32/kernel/irq.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ia32/kernel/irq.c\n Copyright (c)2003 Dan Potter\n*/\n \n#include <errno.h>\n#include <string.h>\n#include <arch/irq.h>\n#include <arch/dbgio.h>\n#include <kos/process.h>\n\n// Exception table. This table matches an exception/IRQ to a function\n// pointer and a process handle. If the pointer is null, then nothing\n// happens. Otherwise, the function will handle the exception.\nstatic irq_handler irq_handlers[0x102];\nstatic kprocess_t * irq_handlers_procs[0x102];\n\n// Global exception handler -- hook this if you want to get each and every\n// exception; you might get more than you bargained for, but it can be useful.\nstatic irq_handler irq_hnd_global;\nstatic kprocess_t * irq_hnd_global_proc;\n\n// Default IRQ context location\nstatic irq_context_t irq_context_default;\n\n// Defined in the asm file: what's our current context?\nextern irq_context_t * irq_srt_addr;\n\n// Are we inside an interrupt?\nstatic int inside_int;\nint irq_inside_int() {\n\treturn inside_int;\n}\n\n// List of strings for CPU faults\nstatic const char * faultnames[] = {\n\t\"Divide error\",\n\t\"Debug\",\n\t\"Nonmaskable Interrupt\",\n\t\"Breakpoint\",\n\t\"Overflow\",\n\t\"Bound\",\n\t\"Invalid opcode\",\n\t\"Device not available\",\n\t\"Double fault\",\n\t\"Coprocessor overrun\",\n\t\"Invalid TSS\",\n\t\"Segment not present\",\n\t\"Stack fault\",\n\t\"General protection fault\",\n\t\"Page fault\",\n\t\"Reserved\",\n\t\"Coprocessor Error\"\n};\n\n// Do a little debug dump of the current task.\nvoid irq_dump_regs(int code, uint32 errcode) {\n\tirq_context_t * t = irq_srt_addr;\n\n\tdbgio_printf(\"Unhandled exception: EIP %08lx, code %d error %08lx\\n\", t->eip, code, errcode);\n\tif (code >= 0 && code <= 16) {\n\t\tdbgio_printf(\"%s\\n\", faultnames[code]);\n\t}\n\tdbgio_printf(\" EAX %08lx EBX %08lx ECX %08lx EDX %08lx\\n\", t->eax, t->ebx, t->ecx, t->edx);\n\tdbgio_printf(\" ESI %08lx EDI %08lx EBP %08lx ESP %08lx\\n\", t->esi, t->edi, t->ebp, t->esp);\n\tdbgio_printf(\" EFLAGS %08lx\\n\", t->eflags);\n\tif (thd_current) {\n\t\tdbgio_printf(\"Died in thread %d\\n\", thd_current->tid);\n\t\tif (thd_current->pshell) {\n\t\t\tdbgio_printf(\"Which is in process %d (base %p)\\n\", thd_current->pshell->pid,\n\t\t\t\tthd_current->pshell->image.data);\n\t\t}\n\t}\n\t// arch_stk_trace_at(t->ebp, 0);\n}\n\n// C-Level interrupt/exception handler. NOTE: We are running on the stack\n// of the thread that was interrupted!\nvoid irq_handle_exception(int code, uint32 errcode) {\n\tint handled = 0;\n\n\t// Nested exception?\n\tif (inside_int) {\n\t\tirq_handler hnd = irq_handlers[EXC_DOUBLE_FAULT];\n\t\tif (hnd != NULL)\n\t\t\thnd(EXC_DOUBLE_FAULT, irq_srt_addr);\n\t\telse\n\t\t\tirq_dump_regs(code, errcode);\n\t\tthd_pslist(dbgio_printf);\n\t\tprocess_print_list(dbgio_printf);\n\t\tpanic(\"double fault\");\n\t}\n\tinside_int = 1;\n\n\t// If there's a global handler, call it\n\tif (irq_hnd_global) {\n\t\tirq_hnd_global(code, irq_srt_addr);\n\t\thandled = 1;\n\t}\n\n\t// If there's a handler, call it\n\t{\n\t\tirq_handler hnd = irq_handlers[code];\n\t\tif (hnd != NULL) {\n\t\t\thnd(code, irq_srt_addr);\n\t\t\thandled = 1;\n\t\t}\n\t}\n\n\t// Did it get handled?\n\tif (!handled) {\n\t\tirq_handler hnd = irq_handlers[EXC_UNHANDLED_EXC];\n\t\tif (hnd != NULL)\n\t\t\thnd(code, irq_srt_addr);\n\t\telse\n\t\t\tirq_dump_regs(code, errcode);\n\t\tpanic(\"unhandled IRQ/Exception\");\n\t}\n\n\tinside_int = 0;\n}\n\n// Set or remove a handler\nint _irq_set_handler(kprocess_t * proc, irq_t src, irq_handler hnd) {\n\tint old;\n\n\t// Make sure they don't do something crackheaded\n\tif (src > 0x102) {\n\t\terrno = EINVAL;\n\t\treturn -1;\n\t}\n\n\told = irq_disable();\n\n\tirq_handlers[src] = hnd;\n\tirq_handlers_procs[src] = proc;\n\n\tirq_restore(old);\n\t\n\treturn 0;\n}\n\n// Get a handler\nirq_handler irq_get_handler(irq_t source) {\n\t// Make sure they don't do something crackheaded\n\tif (source > 0x102) {\n\t\terrno = EINVAL;\n\t\treturn NULL;\n\t}\n\n\treturn irq_handlers[source];\n}\n\n// Set or remove global handler\nint _irq_set_global_handler(struct kprocess * proc, irq_handler hnd) {\n\tint old;\n\n\told = irq_disable();\n\n\tirq_hnd_global = hnd;\n\tirq_hnd_global_proc = proc;\n\n\tirq_restore(old);\n\treturn 0;\n}\n\n// Get global handler\nirq_handler irq_get_global_handler() {\n\treturn irq_hnd_global;\n}\n\nvoid irq_create_context(irq_context_t *context, ptr_t stkpntr,\n\tptr_t routine, uint32 *args, int usermode)\n{\n\tuint32\t* stk;\n\n\t// Clear out the struct to start with\n\tmemset(context, 0, sizeof(irq_context_t));\n\n\t// Start the task with interrupts enabled\n\tcontext->eflags = 1 << 9;\n\n\t// Setup the program frame\n\tcontext->eip = routine;\n\tcontext->ebp = 0xffffffff;\n\n\t// Copy the program args onto the stack\n\tstk = (uint32 *)stkpntr;\n\tstk--; *stk = args[3];\n\tstk--; *stk = args[2];\n\tstk--; *stk = args[1];\n\tstk--; *stk = args[0];\n\tstk--; *stk = 0;\t// Bogus ret addr\n\tcontext->esp = (uint32)stk;\n}\n\nvoid irq_set_context(irq_context_t *regbank) {\n\tirq_srt_addr = regbank;\n}\n\nirq_context_t * irq_get_context() {\n\treturn irq_srt_addr;\n}\n\nvoid irq_remove_process(struct kprocess * proc) {\n\tint old, i;\n\n\told = irq_disable();\n\n\tfor (i=0; i<0x100; i++) {\n\t\tif (irq_handlers_procs[i] == proc) {\n\t\t\tirq_handlers[i] = NULL;\n\t\t\tirq_handlers_procs[i] = NULL;\n\t\t}\n\t}\n\n\tif (irq_hnd_global_proc == proc) {\n\t\tirq_hnd_global = NULL;\n\t\tirq_hnd_global_proc = NULL;\n\t}\n\n\tirq_restore(old);\n}\n\nint irq_init() {\n\t// Make sure interrupts are disabled\n\tirq_disable();\n\n\t// Blank the exception handler tables\n\tmemset(irq_handlers, 0, sizeof(irq_handlers));\n\tmemset(irq_handlers_procs, 0, sizeof(irq_handlers_procs));\n\tirq_hnd_global = NULL;\n\tirq_hnd_global_proc = NULL;\n\n\t// Default to not inside an int\n\tinside_int = 0;\n\n\t// Set a default context (will be superceded if threads are\n\t// enabled later)\n\tirq_set_context(&irq_context_default);\n\n\t// Do the low-level setup to get us hooked into an IDT\n\tirq_low_setup();\n\n\treturn 0;\n}\n\nvoid irq_shutdown() {\n\t// Disable interrupts\n\tirq_disable();\n}\n"
},
{
"alpha_fraction": 0.5719394683837891,
"alphanum_fraction": 0.6185235977172852,
"avg_line_length": 23.560810089111328,
"blob_id": "95a492c42a6642d6c00a7c50f8c20a7a9a608182",
"content_id": "70606a7b77fabe79a10bb3fb1a4a1d14179523a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 10905,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 444,
"path": "/kernel/arch/dreamcast/hardware/flashrom.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n flashrom.c\n Copyright (c)2003 Dan Potter\n*/\n\n/*\n\n This module implements the stuff enumerated in flashrom.h. \n\n Writing to the flash is disabled by default. To re-enable it, uncomment\n the #define below.\n\n Thanks to Marcus Comstedt for the info about the flashrom and syscalls.\n\n */\n\n#include <string.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <dc/flashrom.h>\n#include <arch/irq.h>\n\nCVSID(\"$Id: flashrom.c,v 1.4 2003/03/10 01:45:31 bardtx Exp $\");\n\n/* This is the fateful define. Re-enable this at the peril of your\n Dreamcast's soul ;) */\n/* #define ENABLE_WRITES 1 */\n\n\n/* First, implementation of the syscall wrappers. */\n\nint flashrom_info(int part, int * start_out, int * size_out) {\n\tint\t(*sc)(int, uint32*, int, int);\n\tuint32\tptrs[2];\n\tint\trv;\n\n\t*((uint32 *)&sc) = *((uint32 *)0x8c0000b8);\n\tif (sc(part, ptrs, 0, 0) == 0) {\n\t\t*start_out = ptrs[0];\n\t\t*size_out = ptrs[1];\n\t\trv = 0;\n\t} else\n\t\trv = -1;\n\treturn rv;\n}\n\nint flashrom_read(int offset, void * buffer_out, int bytes) {\n\tint\t(*sc)(int, void*, int, int);\n\tint\trv;\n\n\t*((uint32 *)&sc) = *((uint32 *)0x8c0000b8);\n\trv = sc(offset, buffer_out, bytes, 1);\n\treturn rv;\n}\n\nint flashrom_write(int offset, void * buffer, int bytes) {\n#ifdef ENABLE_WRITES\n\tint\t(*sc)(int, void*, int, int);\n\tint\told, rv;\n\n\told = irq_disable();\n\t*((uint32 *)&sc) = *((uint32 *)0x8c0000b8);\n\trv = sc(offset, buffer, bytes, 2);\n\tirq_restore(old);\n\treturn rv;\n#else\n\treturn -1;\n#endif\n}\n\nint flashrom_delete(int offset) {\n#ifdef ENABLE_WRITES\n\tint\t(*sc)(int, int, int, int);\n\tint\told, rv;\n\n\told = irq_disable();\n\t*((uint32 *)&sc) = *((uint32 *)0x8c0000b8);\n\trv = sc(offset, 0, 0, 3);\n\tirq_restore(old);\n\treturn rv;\n#else\n\treturn -1;\n#endif\n}\n\n\n\n/* Higher level stuff follows */\n\n/* Internal function calculates the checksum of a flashrom block. Thanks\n to Marcus Comstedt for this code. */\nstatic int flashrom_calc_crc(uint8 * buffer) {\n\tint i, c, n = 0xffff;\n\n\tfor (i=0; i<62; i++) {\n\t\tn ^= buffer[i] << 8;\n\t\tfor (c=0; c<8; c++) {\n\t\t\tif (n & 0x8000)\n\t\t\t\tn = (n << 1) ^ 4129;\n\t\t\telse\n\t\t\t\tn = (n << 1);\n\t\t}\n\t}\n\n\treturn (~n) & 0xffff;\n}\n\n\nint flashrom_get_block(int partid, int blockid, uint8 * buffer_out) {\n\tint\tstart, size;\n\tint\tbmcnt;\n\tchar\tmagic[18];\n\tuint8\t* bitmap;\n\tint\ti, rv;\n\n\t/* First, figure out where the partition is located. */\n\tif (flashrom_info(partid, &start, &size) < 0)\n\t\treturn -2;\n\n\t/* Verify the partition */\n\tif (flashrom_read(start, magic, 18) < 0) {\n\t\tdbglog(DBG_ERROR, \"flashrom_get_block: can't read part %d magic\\n\", partid);\n\t\treturn -3;\n\t}\n\tif (strncmp(magic, \"KATANA_FLASH____\", 16) || *((uint16*)(magic+16)) != partid) {\n\t\tbmcnt = *((uint16*)(magic+16));\n\t\tmagic[16] = 0;\n\t\tdbglog(DBG_ERROR, \"flashrom_get_block: invalid magic '%s' or id %d in part %d\\n\", magic, bmcnt, partid);\n\t\treturn -4;\n\t}\n\n\t/* We need one bit per 64 bytes of partition size. Figure out how\n\t many blocks we have in this partition (number of bits needed). */\n\tbmcnt = size / 64;\n\n\t/* Round it to an even 64-bytes (64*8 bits). */\n\tbmcnt = (bmcnt + (64*8)-1) & ~(64*8 - 1);\n\n\t/* Divide that by 8 to get the number of bytes from the end of the\n\t partition that the bitmap will be located. */\n\tbmcnt = bmcnt / 8;\n\n\t/* This is messy but simple and safe... */\n\tif (bmcnt > 65536) {\n\t\tdbglog(DBG_ERROR, \"flashrom_get_block: bogus part %p/%d\\n\", (void *)start, size);\n\t\treturn -5;\n\t}\n\tbitmap = (uint8 *)malloc(bmcnt);\n\n\tif (flashrom_read(start+size-bmcnt, bitmap, bmcnt) < 0) {\n\t\tdbglog(DBG_ERROR, \"flashrom_get_block: can't read part %d bitmap\\n\", partid);\n\t\trv = -6; goto ex;\n\t}\n\n\t/* Go through all the allocated blocks, and look for the latest one\n\t that has a matching logical block ID. We'll start at the end since\n\t that's easiest to deal with. Block 0 is the magic block, so we\n\t won't check that. */\n\tfor (i=0; i<bmcnt*8; i++) {\n\t\t/* Little shortcut */\n\t\tif (bitmap[i / 8] == 0)\n\t\t\ti += 8;\n\t\t\n\t\tif (bitmap[i / 8] & (0x80 >> (i % 8)))\n\t\t\tbreak;\n\t}\n\n\t/* All blocks unused -> file not found. Note that this is probably\n\t a very unusual condition. */\n\tif (i == 0) {\n\t\trv = -1; goto ex;\n\t}\n\n\ti--;\t/* 'i' was the first unused block, so back up one */\n\tfor ( ; i>0; i--) {\n\t\t/* Read the block; +1 because bitmap block zero is actually\n\t\t _user_ block zero, which is physical block 1. */\n\t\tif (flashrom_read(start+(i+1)*64, buffer_out, 64) < 0) {\n\t\t\tdbglog(DBG_ERROR, \"flashrom_get_block: can't read part %d phys block %d\\n\", partid, i+1);\n\t\t\trv = -6; goto ex;\n\t\t}\n\n\t\t/* Does the block ID match? */\n\t\tif (*((uint16*)buffer_out) != blockid)\n\t\t\tcontinue;\n\n\t\t/* Check the checksum to make sure it's valid */\n\t\tbmcnt = flashrom_calc_crc(buffer_out);\n\t\tif (bmcnt != *((uint16*)(buffer_out+62))) {\n\t\t\tdbglog(DBG_WARNING, \"flashrom_get_block: part %d phys block %d has invalid checksum %04x (should be %04x)\\n\",\n\t\t\t\tpartid, i+1, *((uint16*)(buffer_out+62)), bmcnt);\n\t\t\tcontinue;\n\t\t}\n\n\t\t/* Ok, looks like we got it! */\n\t\trv = 0; goto ex;\n\t}\n\n\t/* Didn't find anything */\n\trv = -1;\n\t\nex:\n\tfree(bitmap);\n\treturn rv;\n}\n\n/* This internal function returns the system config block. As far as I\n can determine, this is always partition 2, logical block 5. */\nstatic int flashrom_load_syscfg(uint8 * buffer) {\n\treturn flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_SYSCFG, buffer);\n}\n\n/* Structure of the system config block (as much as we know anyway). */\ntypedef struct {\n\tuint16\tblock_id;\t/* Should be 5 */\n\tuint8\tdate[4];\t/* Last set time (secs since 1/1/1950 in LE) */\n\tuint8\tunk1;\t\t/* Unknown */\n\tuint8\tlang;\t\t/* Language ID */\n\tuint8\tmono;\t\t/* Mono/stereo setting */\n\tuint8\tautostart;\t/* Auto-start setting */\n\tuint8\tunk2[4];\t/* Unknown */\n\tuint8\tpadding[50];\t/* Should generally be all 0xff */\n} syscfg_t;\n\nint flashrom_get_syscfg(flashrom_syscfg_t * out) {\n\tuint8 buffer[64];\n\tsyscfg_t *sc = (syscfg_t *)buffer;\n\n\t/* Get the system config block */\n\tif (flashrom_load_syscfg(buffer) < 0)\n\t\treturn -1;\n\n\t/* Fill in values from it */\n\tout->language = sc->lang;\n\tout->audio = sc->mono == 1 ? 0 : 1;\n\tout->autostart = sc->autostart == 1 ? 0 : 1;\n\n\treturn 0;\n}\n\nint flashrom_get_region() {\n\tint start, size;\n\tchar region[6] = { 0 };\n\n\t/* Find the partition */\n\tif (flashrom_info(FLASHROM_PT_SYSTEM, &start, &size) < 0) {\n\t\tdbglog(DBG_ERROR, \"flashrom_get_region: can't find partition 0\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Read the first 5 characters of that partition */\n\tif (flashrom_read(start, region, 5) < 0) {\n\t\tdbglog(DBG_ERROR, \"flashrom_get_region: can't read partition 0\\n\");\n\t\treturn -1;\n\t}\n\n\t/* Now compare against known codes */\n\tif (!strcmp(region, \"00000\"))\n\t\treturn FLASHROM_REGION_JAPAN;\n\telse if (!strcmp(region, \"00110\"))\n\t\treturn FLASHROM_REGION_US;\n\telse if (!strcmp(region, \"00211\"))\n\t\treturn FLASHROM_REGION_EUROPE;\n\telse {\n\t\tdbglog(DBG_WARNING, \"flashrom_get_region: unknown code '%s'\\n\", region);\n\t\treturn FLASHROM_REGION_UNKNOWN;\n\t}\n}\n\n/* Structure of the ISP config blocks (as much as we know anyway). \n Thanks to Sam Steele for this info. */\ntypedef struct {\n\tunion {\n\t\tstruct {\n\t\t\t/* Block 0xE0 */\n\t\t\tuint16\tblockid;\t\t/* Should be 0xE0 */\n\t\t\tuint8\tprodname[4];\t/* SEGA */\n\t\t\tuint8\tunk1;\t\t\t/* 0x13 */\n\t\t\tuint8\tmethod;\t\n\t\t\tuint8\tunk2[2];\t\t/* 0x00 0x00 */\n\t\t\tuint8\tip[4];\t\t\t/* These are all in big-endian notation */\n\t\t\tuint8\tnm[4];\n\t\t\tuint8\tbc[4];\n\t\t\tuint8\tdns1[4];\n\t\t\tuint8\tdns2[4];\n\t\t\tuint8\tgw[4];\n\t\t\tuint8\tunk3[4];\t\t/* All zeros */\n\t\t\tchar\thostname[24];\t/* Host name */\n\t\t\tuint16\tcrc;\n\t\t} e0;\n\n\t\tstruct {\n\t\t\t/* Block E2 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE2 */\n\t\t\tuint8\tunk[12];\n\t\t\tchar\temail[48];\n\t\t\tuint16\tcrc;\n\t\t} e2;\n\n\t\tstruct {\n\t\t\t/* Block E4 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE4 */\n\t\t\tuint8\tunk[32];\n\t\t\tchar\tsmtp[28];\n\t\t\tuint16\tcrc;\n\t\t} e4;\n\n\t\tstruct {\n\t\t\t/* Block E5 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE5 */\n\t\t\tuint8\tunk[36];\n\t\t\tchar\tpop3[24];\n\t\t\tuint16\tcrc;\n\t\t} e5;\n\n\t\tstruct {\n\t\t\t/* Block E6 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE6 */\n\t\t\tuint8\tunk[40];\n\t\t\tchar\tpop3_login[20];\n\t\t\tuint16\tcrc;\n\t\t} e6;\n\n\t\tstruct {\n\t\t\t/* Block E7 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE7 */\n\t\t\tuint8\tunk[12];\n\t\t\tchar\tpop3_passwd[32];\n\t\t\tchar\tproxy_host[16];\n\t\t\tuint16\tcrc;\n\t\t} e7;\n\n\t\tstruct {\n\t\t\t/* Block E8 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE8 */\n\t\t\tuint8\tunk1[48];\n\t\t\tuint16\tproxy_port;\n\t\t\tuint16\tunk2;\n\t\t\tchar\tppp_login[8];\n\t\t\tuint16\tcrc;\n\t\t} e8;\n\n\t\tstruct {\n\t\t\t/* Block E9 */\n\t\t\tuint16\tblockid;\t/* Should be 0xE9 */\n\t\t\tuint8\tunk[40];\n\t\t\tchar\tppp_passwd[20];\n\t\t\tuint16\tcrc;\n\t\t} e9;\n\t};\n} isp_settings_t;\n\nint flashrom_get_ispcfg(flashrom_ispcfg_t * out) {\n\tuint8\t\tbuffer[64];\n\tisp_settings_t\t* isp = (isp_settings_t *)buffer;\n\tint\t\tfound = 0;\n\n\t/* Clean out the output config buffer. */\n\tmemset(out, 0, sizeof(flashrom_ispcfg_t));\n\n\t/* Get the E0 config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_IP_SETTINGS, buffer) >= 0) {\n\t\t/* Fill in values from it */\n\t\tout->method = isp->e0.method;\n\t\tmemcpy(out->ip, isp->e0.ip, 4);\n\t\tmemcpy(out->nm, isp->e0.nm, 4);\n\t\tmemcpy(out->bc, isp->e0.bc, 4);\n\t\tmemcpy(out->gw, isp->e0.gw, 4);\n\t\tmemcpy(out->dns[0], isp->e0.dns1, 4);\n\t\tmemcpy(out->dns[1], isp->e0.dns2, 4);\n\t\tmemcpy(out->hostname, isp->e0.hostname, 24);\n\n\t\tout->ip_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the email config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_EMAIL, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->email, isp->e2.email, 48);\n\n\t\tout->email_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the smtp config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_SMTP, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->smtp, isp->e4.smtp, 28);\n\n\t\tout->smtp_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the pop3 config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_POP3, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->pop3, isp->e5.pop3, 24);\n\n\t\tout->pop3_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the pop3 login config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_POP3LOGIN, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->pop3_login, isp->e6.pop3_login, 20);\n\n\t\tout->pop3_login_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the pop3 passwd config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_POP3PASSWD, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->pop3_passwd, isp->e7.pop3_passwd, 32);\n\t\tmemcpy(out->proxy_host, isp->e7.proxy_host, 16);\n\n\t\tout->pop3_passwd_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the PPP login config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_PPPLOGIN, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tout->proxy_port = isp->e8.proxy_port;\n\t\tmemcpy(out->ppp_login, isp->e8.ppp_login, 8);\n\n\t\tout->ppp_login_valid = 1;\n\t\tfound++;\n\t}\n\n\t/* Get the PPP passwd config block */\n\tif (flashrom_get_block(FLASHROM_PT_BLOCK_1, FLASHROM_B1_PPPPASSWD, buffer) >= 0) {\n\t\t/* Fill in the values from it */\n\t\tmemcpy(out->ppp_passwd, isp->e9.ppp_passwd, 20);\n\n\t\tout->ppp_passwd_valid = 1;\n\t\tfound++;\n\t}\n\n\treturn found > 0 ? 0 : -1;\n}\n"
},
{
"alpha_fraction": 0.5431472063064575,
"alphanum_fraction": 0.6548223495483398,
"avg_line_length": 16.81818199157715,
"blob_id": "cd196830ee77b8b4945d3b72d3cb538b6ae79a09",
"content_id": "69eeb8f0c2368e8efc06a5b181442da7c3f83994",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/utils/isotest/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# utils/isotest/Makefile\n# (c)2000 Dan Potter\n# \n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:01 bardtx Exp $\n\nall: isotest\n\nisotest: isotest.c\n\tgcc -g -o isotest isotest.c\n\n"
},
{
"alpha_fraction": 0.5776640772819519,
"alphanum_fraction": 0.5958257913589478,
"avg_line_length": 20.71023941040039,
"blob_id": "52c3b57c89631b4a43854705fa67989cea89ff7d",
"content_id": "c6228413d263fa1bb0ea50a5b61a3db853e1646a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9966,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 459,
"path": "/kernel/arch/dreamcast/fs/fs_dcload.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/fs_dcload.c\n Copyright (C)2002 Andrew Kieschnick\n Copyright (C)2004 Dan Potter\n \n*/\n\n/*\n\nThis is a rewrite of Dan Potter's fs_serconsole to use the dcload / dc-tool\nfileserver and console. \n\nprintf goes to the dc-tool console\n/pc corresponds to / on the system running dc-tool\n\n*/\n\n#include <dc/fs_dcload.h>\n#include <kos/thread.h>\n#include <arch/spinlock.h>\n#include <kos/dbgio.h>\n#include <kos/fs.h>\n\n#include <errno.h>\n#include <stdio.h>\n#include <ctype.h>\n#include <string.h>\n#include <malloc.h>\n\nCVSID(\"$Id: fs_dcload.c,v 1.14 2003/04/24 03:05:49 bardtx Exp $\");\n\nstatic spinlock_t mutex = SPINLOCK_INITIALIZER;\n\n#define plain_dclsc(...) ({ \\\n\tint old = 0, rv; \\\n\tif (!irq_inside_int()) { \\\n\t\told = irq_disable(); \\\n\t} \\\n\twhile ((*(vuint32 *)0xa05f688c) & 0x20) \\\n\t\t; \\\n\trv = dcloadsyscall(__VA_ARGS__); \\\n\tif (!irq_inside_int()) \\\n\t\tirq_restore(old); \\\n\trv; \\\n})\n\n// #define plain_dclsc(...) dcloadsyscall(__VA_ARGS__)\n\nstatic void * lwip_dclsc = 0;\n\n#define dclsc(...) ({ \\\n int rv; \\\n if (lwip_dclsc) \\\n\trv = (*(int (*)()) lwip_dclsc)(__VA_ARGS__); \\\n else \\\n\trv = plain_dclsc(__VA_ARGS__); \\\n rv; \\\n})\n\n/* Printk replacement */\n\nint dcload_write_buffer(const uint8 *data, int len, int xlat) {\n if (lwip_dclsc && irq_inside_int()) {\n\terrno = EAGAIN;\n\treturn -1;\n }\n spinlock_lock(&mutex);\n dclsc(DCLOAD_WRITE, 1, data, len);\n spinlock_unlock(&mutex);\n\n return len;\n}\n\nint dcload_read_cons() {\n return -1;\n}\n\nsize_t dcload_gdbpacket(const char* in_buf, size_t in_size, char* out_buf, size_t out_size) {\n size_t ret = -1;\n\n if (lwip_dclsc && irq_inside_int())\n return 0;\n\n spinlock_lock(&mutex);\n\n /* we have to pack the sizes together because the dcloadsyscall handler\n can only take 4 parameters */\n \tret = dclsc(DCLOAD_GDBPACKET, in_buf, (in_size << 16) | (out_size & 0xffff), out_buf);\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\nstatic char *dcload_path = NULL;\nuint32 dcload_open(vfs_handler_t * vfs, const char *fn, int mode) {\n int hnd = 0;\n uint32 h;\n int dcload_mode = 0;\n \n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n \n if (mode & O_DIR) {\n if (fn[0] == '\\0') {\n fn = \"/\";\n }\n\thnd = dclsc(DCLOAD_OPENDIR, fn);\n\tif (hnd) {\n\t if (dcload_path)\n\t\tfree(dcload_path);\n\t if (fn[strlen(fn) - 1] == '/') {\n\t\tdcload_path = malloc(strlen(fn)+1);\n\t\tstrcpy(dcload_path, fn);\n\t } else {\n\t\tdcload_path = malloc(strlen(fn)+2);\n\t\tstrcpy(dcload_path, fn);\n\t\tstrcat(dcload_path, \"/\");\n\t }\n\t}\n } else { /* hack */\n\tif ((mode & O_MODE_MASK) == O_RDONLY)\n\t dcload_mode = 0;\n\tif ((mode & O_MODE_MASK) == O_RDWR)\n\t dcload_mode = 2 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_WRONLY)\n\t dcload_mode = 1 | 0x0200;\n\tif ((mode & O_MODE_MASK) == O_APPEND)\n\t dcload_mode = 2 | 8 | 0x0200;\n\tif (mode & O_TRUNC)\n\t dcload_mode |= 0x0400;\n\thnd = dclsc(DCLOAD_OPEN, fn, dcload_mode, 0644);\n\thnd++; /* KOS uses 0 for error, not -1 */\n }\n \n h = hnd;\n\n spinlock_unlock(&mutex);\n return h;\n}\n\nvoid dcload_close(uint32 hnd) {\n if (lwip_dclsc && irq_inside_int())\n\treturn;\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\tif (hnd > 100) /* hack */\n\t dclsc(DCLOAD_CLOSEDIR, hnd);\n\telse {\n\t hnd--; /* KOS uses 0 for error, not -1 */\n\t dclsc(DCLOAD_CLOSE, hnd);\n\t}\n }\n spinlock_unlock(&mutex);\n}\n\nssize_t dcload_read(uint32 hnd, void *buf, size_t cnt) {\n ssize_t ret = -1;\n \n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dclsc(DCLOAD_READ, hnd, buf, cnt);\n }\n \n spinlock_unlock(&mutex);\n return ret;\n}\n\nssize_t dcload_write(uint32 hnd, const void *buf, size_t cnt) {\n ssize_t ret = -1;\n \t\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n \n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dclsc(DCLOAD_WRITE, hnd, buf, cnt);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\noff_t dcload_seek(uint32 hnd, off_t offset, int whence) {\n off_t ret = -1;\n\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dclsc(DCLOAD_LSEEK, hnd, offset, whence);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\noff_t dcload_tell(uint32 hnd) {\n off_t ret = -1;\n \n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tret = dclsc(DCLOAD_LSEEK, hnd, 0, SEEK_CUR);\n }\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\nsize_t dcload_total(uint32 hnd) {\n size_t ret = -1;\n size_t cur;\n\t\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n\t\n if (hnd) {\n\thnd--; /* KOS uses 0 for error, not -1 */\n\tcur = dclsc(DCLOAD_LSEEK, hnd, 0, SEEK_CUR);\n\tret = dclsc(DCLOAD_LSEEK, hnd, 0, SEEK_END);\n\tdclsc(DCLOAD_LSEEK, hnd, cur, SEEK_SET);\n }\n\t\n spinlock_unlock(&mutex);\n return ret;\n}\n\n/* Not thread-safe, but that's ok because neither is the FS */\nstatic dirent_t dirent;\ndirent_t *dcload_readdir(uint32 hnd) {\n dirent_t *rv = NULL;\n dcload_dirent_t *dcld;\n dcload_stat_t filestat;\n char *fn;\n\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n if (hnd < 100) return NULL; /* hack */\n\n spinlock_lock(&mutex);\n\n dcld = (dcload_dirent_t *)dclsc(DCLOAD_READDIR, hnd);\n \n if (dcld) {\n\trv = &dirent;\n\tstrcpy(rv->name, dcld->d_name);\n\trv->size = 0;\n\trv->time = 0;\n\trv->attr = 0; /* what the hell is attr supposed to be anyways? */\n\n\tfn = malloc(strlen(dcload_path)+strlen(dcld->d_name)+1);\n\tstrcpy(fn, dcload_path);\n\tstrcat(fn, dcld->d_name);\n\n\tif (!dclsc(DCLOAD_STAT, fn, &filestat)) {\n\t if (filestat.st_mode & S_IFDIR) {\n\t\trv->size = -1;\n\t\trv->attr = O_DIR;\n\t } else\n\t\trv->size = filestat.st_size;\n\t rv->time = filestat.st_mtime;\n\t \n\t}\n\t\n\tfree(fn);\n }\n \n spinlock_unlock(&mutex);\n return rv;\n}\n\nint dcload_rename(vfs_handler_t * vfs, const char *fn1, const char *fn2) {\n int ret;\n\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n\n /* really stupid hack, since I didn't put rename() in dcload */\n\n ret = dclsc(DCLOAD_LINK, fn1, fn2);\n\n if (!ret)\n\tret = dclsc(DCLOAD_UNLINK, fn1);\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\nint dcload_unlink(vfs_handler_t * vfs, const char *fn) {\n int ret;\n\n if (lwip_dclsc && irq_inside_int())\n\treturn 0;\n\n spinlock_lock(&mutex);\n\n ret = dclsc(DCLOAD_UNLINK, fn);\n\n spinlock_unlock(&mutex);\n return ret;\n}\n\n\n\n/* Pull all that together */\nstatic vfs_handler_t vh = {\n\t/* Name handler */\n\t{\n\t\t\"/pc\",\t\t/* name */\n\t\t0,\t\t/* tbfi */\n\t\t0x00010000,\t/* Version 1.0 */\n\t\t0,\t\t/* flags */\n\t\tNMMGR_TYPE_VFS,\n\t\tNMMGR_LIST_INIT\n\t},\n\n\t0, NULL,\t/* no cache, privdata */\n\n\tdcload_open, \n\tdcload_close,\n\tdcload_read,\n\tdcload_write,\n\tdcload_seek,\n\tdcload_tell,\n\tdcload_total,\n\tdcload_readdir,\n\tNULL, /* ioctl */\n\tdcload_rename,\n\tdcload_unlink,\n\tNULL /* mmap */\n};\n\n// We have to provide a minimal interface in case dcload usage is\n// disabled through init flags.\nstatic int never_detected() { return 0; }\ndbgio_handler_t dbgio_dcload = {\n\t\"fs_dcload_uninit\",\n\tnever_detected\n};\n\nint fs_dcload_detected() {\n /* Check for dcload */\n if (*DCLOADMAGICADDR == DCLOADMAGICVALUE)\n\treturn 1;\n else\n\treturn 0;\n}\n\nstatic int *dcload_wrkmem = NULL;\nint dcload_type = DCLOAD_TYPE_NONE;\n\n/* Call this before arch_init_all (or any call to dbgio_*) to use dcload's\n console output functions. */\nvoid fs_dcload_init_console() {\n /* Setup our dbgio handler */\n memcpy(&dbgio_dcload, &dbgio_null, sizeof(dbgio_dcload));\n dbgio_dcload.detected = fs_dcload_detected;\n dbgio_dcload.write_buffer = dcload_write_buffer;\n // dbgio_dcload.read = dcload_read_cons;\n\n // We actually need to detect here to make sure we're not on\n // dcload-serial, or scif_init must not proceed.\n if (*DCLOADMAGICADDR != DCLOADMAGICVALUE)\n\treturn;\n\n /* Give dcload the 64k it needs to compress data (if on serial) */\n dcload_wrkmem = malloc(65536);\n if (dcload_wrkmem) {\n \tif (dclsc(DCLOAD_ASSIGNWRKMEM, dcload_wrkmem) == -1) {\n \t free(dcload_wrkmem);\n \t dcload_type = DCLOAD_TYPE_IP;\n \t dcload_wrkmem = NULL;\n \t} else {\n \t dcload_type = DCLOAD_TYPE_SER;\n \t}\n }\n}\n\n/* Call fs_dcload_init_console() before calling fs_dcload_init() */\nint fs_dcload_init() {\n // This was already done in init_console.\n if (dcload_type == DCLOAD_TYPE_NONE)\n\treturn -1;\n\n /* Check for combination of KOS networking and dcload-ip */\n if ((dcload_type == DCLOAD_TYPE_IP) && (__kos_init_flags & INIT_NET)) {\n\tdbglog(DBG_INFO, \"dc-load console+kosnet, will switch to internal ethernet\\n\");\n\treturn -1;\n\t/* if (old_printk) {\n\t dbgio_set_printk(old_printk);\n\t old_printk = 0;\n\t}\n\treturn -1; */\n }\n\n /* Register with VFS */\n return nmmgr_handler_add(&vh.nmmgr);\n}\n\nint fs_dcload_shutdown() {\n /* Check for dcload */\n if (*DCLOADMAGICADDR != DCLOADMAGICVALUE)\n\treturn -1;\n\n /* Free dcload wrkram */\n if (dcload_wrkmem) {\n dclsc(DCLOAD_ASSIGNWRKMEM, 0);\n free(dcload_wrkmem);\n }\n\n /* If we're not on lwIP, we can continue using the debug channel */\n if (lwip_dclsc) {\n dcload_type = DCLOAD_TYPE_NONE;\n dbgio_dev_select(\"scif\");\n }\n\n return nmmgr_handler_remove(&vh.nmmgr);\n}\n\n/* used for dcload-ip + lwIP\n * assumes fs_dcload_init() was previously called\n */\nint fs_dcload_init_lwip(void *p)\n{\n /* Check for combination of KOS networking and dcload-ip */\n if ((dcload_type == DCLOAD_TYPE_IP) && (__kos_init_flags & INIT_NET)) {\n\tlwip_dclsc = p;\n\n\tdbglog(DBG_INFO, \"dc-load console support enabled (lwIP)\\n\");\n } else\n\treturn -1;\n\n /* Register with VFS */\n return nmmgr_handler_add(&vh.nmmgr);\n}\n\n"
},
{
"alpha_fraction": 0.6315576434135437,
"alphanum_fraction": 0.6400648355484009,
"avg_line_length": 19.827003479003906,
"blob_id": "7c28f91ddce1b1aacb57525a80415419eff12d40",
"content_id": "bbbc8b84028d33e0d2edaa589d1cdfb4cb0ed5a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4937,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 237,
"path": "/kernel/arch/ps2/kernel/main.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n main.c\n (c)2000 Dan Potter\n*/\n\n#include <stdio.h>\n#include <malloc.h>\n#include <arch/syscall.h>\n#include <arch/dbgio.h>\n#include <arch/timer.h>\n#include <arch/arch.h>\n#include <arch/atexit.h>\n#include <arch/irq.h>\n\n#include \"initall_hdrs.h\"\n\nCVSID(\"$Id: main.c,v 1.4 2002/11/06 08:36:00 bardtx Exp $\");\n\n/* This really ought to be prototyped in a header */\nint\tmm_init();\n\n/* Ditto */\nint\tmain(int argc, char **argv);\n\n/* Double-ditto */\nextern const char banner[];\n\n/* For some reason, the linker won't pull in _start() from startup.o\n unless you explicitly link to it, even though it'll give an error\n about a missing _start. -_- */\nvoid _start();\nvoid __help_dumb_compiler__() {\n\t_start();\n}\n\n/* Auto-init stuff: comment out here if you don't like this stuff\n to be running in your build, and also below in arch_main() */\n/* #if 0 */\nint arch_auto_init() {\n\tdbgio_init();\t\t\t/* Init debug IO and print a banner */\n\tfs_ps2load_init_console();\n\tdbglog(DBG_INFO, \"\\n--\\n\");\n\tdbglog(DBG_INFO, banner);\n\n\ttimer_init();\t\t\t/* Timers */\n\tirq_init();\t\t\t/* IRQs */\n\tsyscall_init();\t\t\t/* System call interface */\n#if 0\t\n\thardware_init();\t\t/* DC Hardware init */\n#endif\n\n\t/* Threads */\n#if 0\n\tif (__kos_init_flags & INIT_THD_PREEMPT)\n\t\tthd_init(THD_MODE_PREEMPT);\n\telse\n#endif\n\t\tthd_init(THD_MODE_COOP);\n\n\tfs_init();\t\t\t/* VFS */\n\tfs_ramdisk_init();\t\t/* Ramdisk */\n\tfs_romdisk_init();\t\t/* Romdisk */\n\n\tif (__kos_romdisk != NULL) {\n\t\tfs_romdisk_mount(\"/rd\", __kos_romdisk, 0);\n\t}\n\tif (fs_ps2load_init() >= 0) {\n\t\tdbglog(DBG_INFO, \"ps2-load console support enabled\\n\");\n\t}\n#if 0\n\tfs_iso9660_init();\n\tfs_vmu_init();\n\n\t/* Now comes the optional stuff */\n\tif (__kos_init_flags & INIT_IRQ) {\n\t\tirq_enable();\t\t/* Turn on IRQs */\n\t\tmaple_wait_scan();\t/* Wait for the maple scan to complete */\n\t}\n\tif (__kos_init_flags & INIT_NET) {\n\t\tnet_init();\t\t/* Enable networking (and drivers) */\n\t}\n\n\t/* And one more mandatory thing */\n\ttimer_ms_enable();\n#endif\n\n\treturn 0;\n}\n\nvoid arch_auto_shutdown() {\n\tirq_disable();\n\ttimer_shutdown();\n#if 0\n\tsnd_shutdown();\n\thardware_shutdown();\n\tnet_shutdown();\n\tpvr_shutdown();\n\tfs_dcload_shutdown();\n\tfs_vmu_shutdown();\n\tfs_iso9660_shutdown();\n#endif\n\tfs_ramdisk_shutdown();\n\tfs_romdisk_shutdown();\n\tfs_shutdown();\n\tthd_shutdown();\n}\n/* #endif */\n\n/* This is the entry point inside the C program */\nvoid arch_main() {\n\tint rv;\n\n\t/* Ensure that we pull in crtend.c in the linking process */\n\t__crtend_pullin();\n\n\t/* Ensure that UBC is not enabled from a previous session */\n\t// ubc_disable_all();\n\n\t/* Initialize memory management */\n\tmm_init();\n\n\t/* Do auto-init stuff */\n\tarch_auto_init();\n\n\t/* Run ctors */\n\tarch_ctors();\n\n\t/* Call the user's main function */\n\trv = main(0, NULL);\n\n\t/* Call kernel exit */\n\tarch_exit();\n}\n\n/* Set the exit path (default is RETURN) */\nint arch_exit_path = ARCH_EXIT_RETURN;\nvoid arch_set_exit_path(int path) {\n\tassert(path == ARCH_EXIT_RETURN);\n\tarch_exit_path = path;\n}\n\n/* Does the actual shutdown stuff for a proper shutdown */\nvoid arch_shutdown() {\n\t/* Run dtors */\n\tarch_atexit();\n\tarch_dtors();\n\n\tdbglog(DBG_CRITICAL, \"arch: shutting down kernel\\n\");\n\n\t/* Turn off UBC breakpoints, if any */\n\t// ubc_disable_all();\n\t\n\t/* Do auto-shutdown... or use the \"light weight\" version underneath */\n#if 1\n\tarch_auto_shutdown();\n#else\n\t/* Ensure that interrupts are disabled */\n\tirq_disable();\n\tirq_enable_exc();\n\n\t/* Make sure that PVR and Maple are shut down */\n\tpvr_shutdown();\n\tmaple_shutdown();\n\n\t/* Shut down any other hardware things */\n\thardware_shutdown();\n#endif\n\n\tif (__kos_init_flags & INIT_MALLOCSTATS) {\n\t\tmalloc_stats();\n\t}\n\n\t/* Shut down IRQs */\n\t// irq_shutdown();\n}\n\n/* Generic kernel exit point (configurable) */\nvoid arch_exit() {\n\t/* switch (arch_exit_path) {\n\tdefault:\n\t\tdbglog(DBG_CRITICAL, \"arch: arch_exit_path has invalid value!\\n\");\n\tcase ARCH_EXIT_RETURN:\n\t\tarch_return();\n\t\tbreak;\n\tcase ARCH_EXIT_MENU:\n\t\tarch_menu();\n\t\tbreak;\n\tcase ARCH_EXIT_REBOOT:\n\t\tarch_shutdown();\n\t\tarch_reboot();\n\t\tbreak;\n\t} */\n\tarch_return();\n}\n\n/* Called to shut down the system and return to the debug handler (if any) */\nvoid arch_return() {\n\t/* Shut down */\n\tarch_shutdown();\n\t\n\t/* Jump back to the boot loader */\n\tarch_real_exit();\n}\n\n/* Called to shut down non-gracefully; assume the system is in peril\n and don't try to call the dtors */\nvoid arch_abort() {\n\t/* Turn off UBC breakpoints, if any */\n\t// ubc_disable_all();\n\t\n\tdbglog(DBG_CRITICAL, \"arch: aborting the system\\n\");\n\n#if 0\n\t/* PVR disable-by-fire */\n\tPVR_SET(PVR_RESET, PVR_RESET_ALL);\n\tPVR_SET(PVR_RESET, PVR_RESET_NONE);\n\n\t/* Maple disable-by-fire */\n\tmaple_dma_stop();\n\n\t/* Sound disable (nothing weird done in here) */\n\tspu_disable();\n\n\t/* Turn off any IRQs */\t\n\tirq_disable();\n#endif\n\n\tarch_real_exit();\n}\n\n/* When you make a function called main() in a GCC program, it wants\n this stuff too. */\nvoid _main() { }\n\n/* And some library funcs from newlib want this */\nint __errno;\n\n"
},
{
"alpha_fraction": 0.5324789881706238,
"alphanum_fraction": 0.581087052822113,
"avg_line_length": 20.55238151550293,
"blob_id": "3cda29c77d0052a2666589b25b7670a16df87739",
"content_id": "c3ad6a6d164a053b55237aa255feac10afce1703",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2263,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 105,
"path": "/libc/time/localtime.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n * localtime_r.c\n * Original Author:\tAdapted from tzcode maintained by Arthur David Olson.\n *\n * Converts the calendar time pointed to by tim_p into a broken-down time\n * expressed as local time. Returns a pointer to a structure containing the\n * broken-down time.\n */\n\n/* Imported to KOS from Newlib 0.9.0 */\n\n#include <stdlib.h>\n#include <time.h>\n\nCVSID(\"$Id: localtime.c,v 1.1 2002/02/24 01:24:00 bardtx Exp $\");\n\n#define SECSPERMIN\t60L\n#define MINSPERHOUR\t60L\n#define HOURSPERDAY\t24L\n#define SECSPERHOUR\t(SECSPERMIN * MINSPERHOUR)\n#define SECSPERDAY\t(SECSPERHOUR * HOURSPERDAY)\n#define DAYSPERWEEK\t7\n#define MONSPERYEAR\t12\n\n#define YEAR_BASE\t1900\n#define EPOCH_YEAR 1970\n#define EPOCH_WDAY 4\n\n#define isleap(y) ((((y) % 4) == 0 && ((y) % 100) != 0) || ((y) % 400) == 0)\n\nstatic const int mon_lengths[2][MONSPERYEAR] = {\n {31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31},\n {31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31}\n} ;\n\nstatic const int year_lengths[2] = {\n 365,\n 366\n} ;\n\nstruct tm * localtime_r(const time_t * tim_p, struct tm *res)\n{\n long days, rem;\n int y;\n int yleap;\n const int *ip;\n\n days = ((long) *tim_p) / SECSPERDAY;\n rem = ((long) *tim_p) % SECSPERDAY;\n while (rem < 0) \n {\n rem += SECSPERDAY;\n --days;\n }\n while (rem >= SECSPERDAY)\n {\n rem -= SECSPERDAY;\n ++days;\n }\n \n /* compute hour, min, and sec */ \n res->tm_hour = (int) (rem / SECSPERHOUR);\n rem %= SECSPERHOUR;\n res->tm_min = (int) (rem / SECSPERMIN);\n res->tm_sec = (int) (rem % SECSPERMIN);\n\n /* compute day of week */\n if ((res->tm_wday = ((EPOCH_WDAY + days) % DAYSPERWEEK)) < 0)\n res->tm_wday += DAYSPERWEEK;\n\n /* compute year & day of year */\n y = EPOCH_YEAR;\n if (days >= 0)\n {\n for (;;)\n\t{\n\t yleap = isleap(y);\n\t if (days < year_lengths[yleap])\n\t break;\n\t y++;\n\t days -= year_lengths[yleap];\n\t}\n }\n else\n {\n do\n\t{\n\t --y;\n\t yleap = isleap(y);\n\t days += year_lengths[yleap];\n\t} while (days < 0);\n }\n\n res->tm_year = y - YEAR_BASE;\n res->tm_yday = days;\n ip = mon_lengths[yleap];\n for (res->tm_mon = 0; days >= ip[res->tm_mon]; ++res->tm_mon)\n days -= ip[res->tm_mon];\n res->tm_mday = days + 1;\n\n /* set daylight saving time flag */\n res->tm_isdst = -1;\n \n return (res);\n}\n"
},
{
"alpha_fraction": 0.46276596188545227,
"alphanum_fraction": 0.5744680762290955,
"avg_line_length": 14.583333015441895,
"blob_id": "42de81ece754e17c358d9511a3d43ddd8e99905f",
"content_id": "b2696e91c093681d48c80429c82d53ed51365371",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 12,
"path": "/libc/stdlib/getenv.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n getenv.c\n (c)2001 Dan Potter\n\n $Id: getenv.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n/* getenv() */\nchar *getenv(const char *name) {\n\treturn (char *)0;\n}\n\n"
},
{
"alpha_fraction": 0.513830304145813,
"alphanum_fraction": 0.559931218624115,
"avg_line_length": 19.440895080566406,
"blob_id": "223069175cbfd01728cdfe35862f940d7abef6a5",
"content_id": "8dfae91ede8a84a6cbeebca4875f459d138d387c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6399,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 313,
"path": "/kernel/arch/ia32/kernel/dbgio.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dbgio.c\n Copyright (C)2003 Dan Potter\n*/\n\n#include <string.h>\n#include <stdio.h>\n#include <stdarg.h>\n#include <arch/arch.h>\n#include <arch/dbgio.h>\n#include <arch/spinlock.h>\n#include <ia32/ports.h>\n\nCVSID(\"$Id: dbgio.c,v 1.3 2003/08/02 23:11:43 bardtx Exp $\");\n\n/*\n\n*/\n\nstatic ptr_t scrn_mem;\nstatic int output_attr;\nstatic int curs_x,curs_y;\n\nvoid vga_set_mem(uint32 base) { scrn_mem=base; }\n\nvoid vga_clear() {\n\tmemset2((void *)scrn_mem, 0x0700, 80*50);\n}\n\nvoid vga_move_cursor(uint32 x, uint32 y) {\n\tuint32\taddr = y*80+x;\n\n\tcurs_x = x;\n\tcurs_y = y;\n\n\toutb(0x3d4, 0xe);\n\toutb(0x3d5, addr >> 8);\n\toutb(0x3d4, 0xf);\n\toutb(0x3d5, addr & 0xff);\n}\n\nvoid vga_scroll(uint32 ystart, uint32 numrows) {\n\tmemcpy((void *)(scrn_mem + (ystart) * 160),\n\t\t(void *)(scrn_mem + (ystart+1) * 160),\n\t\t(numrows-1) * 160);\n\tmemset((void *)(scrn_mem + (ystart + numrows - 1) * 160),\n\t\t0,160);\n}\n\nvoid vga_print_at(uint32 x, uint32 y, uint32 f, uint32 b, const char * string) {\n\tchar\t*output = (char *)(scrn_mem + y*160 + x*2);\t\n\tint8\tattr = (b << 4) | f;\n\n\twhile (*string) {\n\t\toutput[0] = *string;\n\t\toutput[1] = attr;\n\t\toutput += 2;\n\t\tstring++;\n\t}\n}\n\nvoid vga_setcolor(uint32 f, uint32 b) {\n\toutput_attr = (b<<4) | f;\n}\n\nvoid vga_print(const char *string) {\n\tuint8\t*output = (uint8 *)scrn_mem;\n\tuint8\tattr = output_attr;\n\tuint32\tx = curs_x, y = curs_y;\n\n\twhile (*string) {\n\t\tif (*string == '\\n') {\n\t\t\tx=0; y++;\n\t\t} else if (*string == '\\r') {\n\t\t\tx = 0;\n\t\t} else if (*string == '\\t') {\n\t\t\tx = (x + 7) & ~7;\n\t\t\tif (x >= 80) { x-=80; y++; }\n\t\t} else {\n\t\t\toutput[(y*160+x*2)] = *string;\n\t\t\toutput[(y*160+x*2)+1] = attr;\n\n\t\t\tx++;\n\t\t\tif (x >= 80) { x=0; y++; }\n\t\t}\n\n\t\tif (y >= 25) {\n\t\t\tvga_scroll(1,24);\n\t\t\ty=24;\n\t\t}\n\n\t\tstring++;\n\t}\n\n\tvga_move_cursor(x,y);\n}\n\nvoid vga_wait() {\n\twhile ((inb(0x3da) & 8))\n\t\t;\n\twhile (!(inb(0x3da) & 8))\n\t\t;\n}\n\nvoid vga_get_cursor(uint32 * cx, uint32 * cy) {\n\t*cx = curs_x;\n\t*cy = curs_y;\n}\n\nint vga_init() {\n\t// Do some initial setup\n\tvga_set_mem(0xb8000);\n\tvga_clear();\t\t// clear the screen\n\tvga_move_cursor(0,1);\t// put the cursor on the second row\n\tvga_setcolor(7,0);\n\n\t// Print a banner so we can see what's going on\n\tvga_print_at(0,0,15,1,\" KallistiOS/ia32 \");\n\tvga_print(\"Startup console output initialized.\\n\");\n\n\treturn 0;\n}\n\nint vga_shutdown() {\n return 0;\n}\n\n///////////////////////////////////////////////////////////////////////\n\n/* This redirect is here to allow you to hook the debug output in your \n program if you want to do that. */\ndbgio_printk_func dbgio_printk = dbgio_null_write;\n\n/* Enable serial support */\nvoid dbgio_enable() { }\n\n/* Disable serial support */\nvoid dbgio_disable() { }\n\n/* Set another function to capture all debug output */\ndbgio_printk_func dbgio_set_printk(dbgio_printk_func func) {\n\tdbgio_printk_func rv = dbgio_printk;\n\tdbgio_printk = func;\n\treturn rv;\n}\n\n/* Write one char to the serial port (call serial_flush()!) */\nvoid dbgio_write(int c) {\n\tchar foo[2] = { c, 0 };\n\tvga_print(foo);\n}\n\n/* Flush all FIFO'd bytes out of the serial port buffer */\nvoid dbgio_flush() {\n}\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer(const uint8 *data, int len) {\n\twhile (len-- > 0)\n\t\tdbgio_write(*data++);\n}\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer_xlat(const uint8 *data, int len) {\n\tdbgio_write_buffer(data, len);\n}\n\n/* Send a string (null-terminated) */\nvoid dbgio_write_str(const char *str) {\n\tdbgio_write_buffer((const uint8*)str, strlen(str));\n}\n\n/* Null write-string function for pre-init */\nvoid dbgio_null_write(const char *str) {\n}\n\n///////////////////////////////////////////////////////////////////////\n\n// Ring buffer\nstatic uint8 buffer[32];\nstatic int buf_head, buf_tail, buf_cnt;\n\n// Scancode translator\nstatic uint8 scans[256] = {\n\t0,\n\t27,\n\t'1', '2', '3', '4', '5', '6', '7', '8', '9', '0', '-', '=', 8,\t\t// 2+\n\t9, 'q', 'w', 'e', 'r', 't', 'y', 'u', 'i', 'o', 'p', '[', ']', 13,\t// 15+\n\t0, 'a', 's', 'd', 'f', 'g', 'h', 'j', 'k', 'l', ';', '\\'',\t\t// 29+\n\t'`', 0, 0, 'z', 'x', 'c', 'v', 'b', 'n', 'm', ',', '.', '/', 0,\t\t// 41+\n\t'*', 0, 32\n};\n\n// IRQ9 handler\nstatic void kb_hnd(irq_t src, irq_context_t * cxt) {\n\tint sc, oc;\n\n\t// Read the input value\n\tsc = inb(0x60);\n\n\t// Ack the KB controller\n\toc = inb(0x61);\n\toutb(0x61, oc | 0x80);\n\toutb(0x61, oc & ~0x80);\n\t// outb(0x20, 0x61);\n\n\t// Ignore release codes\n\tif (sc & 0x80)\n\t\treturn;\n\n\t// Translate it to ASCII if possible\n\tif (scans[sc]) {\n\t\tsc = scans[sc];\n\n\t\t// Store it in the buffer\n\t\tbuffer[buf_head] = sc;\n\t\tbuf_head = (buf_head + 1) % 32;\n\t\tbuf_cnt++;\n\t}\n}\n\n/* Read one char from the serial port (-1 if nothing to read) */\nint dbgio_read() {\n\tint old = irq_disable();\n\tint rv = -1;\n\n\tif (buf_cnt > 0) {\n\t\trv = buffer[buf_tail];\n\t\tbuf_tail = (buf_tail + 1) % 32;\n\t\tbuf_cnt--;\n\t}\n\n\tirq_restore(old);\n\n\treturn rv;\n}\n\n/* Read an entire buffer (block) */\nvoid dbgio_read_buffer(uint8 *data, int len) {\n\tint c;\n\twhile (len-- > 0) {\n\t\twhile ( (c = dbgio_read()) == -1)\n\t\t\t;\n\t\t*data++ = c;\n\t}\n}\n\n///////////////////////////////////////////////////////////////////////\n\n// First init, handles only output\nvoid dbgio_init() {\n\tvga_init();\n\tdbgio_printk = vga_print;\n}\n\n// Second init, also sets up keyboard input\nvoid dbgio_init_2() {\n\tint oc;\n\n\t// Clear any pending keyboard input, in case...\n\tinb(0x60);\n\tinb(0x60);\n\tinb(0x60);\n\n\t// Send an enable command\n\twhile (inb(0x64) & 2)\n\t\t;\n\toutb(0x64,0xae);\n\twhile (inb(0x64) & 2)\n\t\t;\n\n\t// ACK the response\n\toc = inb(0x61);\n\toutb(0x61, oc | 0xc0);\n\toutb(0x61, oc & ~0xc0);\n\n\t// Reset the queues and hook interrupts\n\tbuf_head = buf_tail = buf_cnt = 0;\n\tirq_set_handler(EXC_IRQ1, kb_hnd);\n\toutb(0x21, inb(0x21) & ~2);\n\n\tdbgio_printk(\"PC/AT keyboard input enabled.\\n\");\n}\n\n\n///////////////////////////////////////////////////////////////////////\n\n/* Not re-entrant */\nstatic char printf_buf[1024];\nstatic spinlock_t lock = SPINLOCK_INITIALIZER;\n\nint dbgio_printf(const char *fmt, ...) {\n\tva_list args;\n\tint i;\n\n\t/* XXX This isn't correct. We could be inside an int with IRQs\n\t enabled, and we could be outside an int with IRQs disabled, which\n\t would cause a deadlock here. We need an irq_is_enabled()! */\n\t//if (!irq_inside_int())\n\t//\tspinlock_lock(&lock);\n\n\tva_start(args, fmt);\n\ti = vsprintf(printf_buf, fmt, args);\n\tva_end(args);\n\n\tdbgio_printk(printf_buf);\n\n\t//if (!irq_inside_int())\n\t//\tspinlock_unlock(&lock);\n\n\treturn i;\n}\n\n"
},
{
"alpha_fraction": 0.6175243258476257,
"alphanum_fraction": 0.6620305776596069,
"avg_line_length": 21.375,
"blob_id": "fe5742b2fc8c451143bfd9a788a97157fcea49df",
"content_id": "2770da18867993a72d4bcb91b9d645ee164b2956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 719,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 32,
"path": "/include/arch/gba/arch/syscall.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/include/syscall.h\n (c)2000-2001 Dan Potter\n\n $Id: syscall.h,v 1.3 2002/12/09 06:29:19 bardtx Exp $\n\n*/\n\n#ifndef __ARCH_SYSCALL_H\n#define __ARCH_SYSCALL_H\n\n#include <arch/types.h>\n#include <arch/irq.h>\n\n/* Set the return value for a syscall for a dormant thread */\nvoid syscall_set_return(irq_context_t *context, int value);\n\n/* Handles all the nasty work */\n#define SET_RETURN(thread, value) do { } while(0)\n\n/* Ditto */\n#define SET_MY_RETURN(value) do { } while(0)\n\n/* Ditto */\n#define RETURN(value) do { } while(0)\n\n/* This macro can be used in normal mode to jump into kernel\n mode convienently */\n#define SYSCALL(routine, p1, p2, p3, p4) 0\n\n#endif\t/* __ARCH_SYSCALL_H */\n\n\n\n"
},
{
"alpha_fraction": 0.6136865615844727,
"alphanum_fraction": 0.6710816621780396,
"avg_line_length": 15.071428298950195,
"blob_id": "f03b2cbe773b64a1c6b42cc6c86e6f247452b386",
"content_id": "4d9b422008e0b55b8faaed45a0ad4d7334c8f8cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 28,
"path": "/kernel/arch/dreamcast/hardware/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/dreamcast/hardware/Makefile\n# (c)2000-2001 Dan Potter\n#\n# $Id: Makefile,v 1.12 2003/05/23 02:04:42 bardtx Exp $\n\n# Init wrapper\nOBJS = hardware.o\n\n# BIOS services\nOBJS += biosfont.o cdrom.o flashrom.o\n\n# Sound\nOBJS += spu.o spudma.o\n\n# Bus support\nOBJS += asic.o g2bus.o\n\n# Video-related\nOBJS += video.o vblank.o\n\n# CPU-related\nOBJS += sq.o scif.o\n\nSUBDIRS = pvr network maple modem\n\ninclude ../../../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.5644699335098267,
"alphanum_fraction": 0.6217765212059021,
"avg_line_length": 14.17391300201416,
"blob_id": "779f1d405b3e7077ecde1a92170edd7201723bf0",
"content_id": "2d1ec806335425754ae794435e4efc9c368ca827",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 23,
"path": "/examples/dreamcast/kgl/demos/tunnel/plprint.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n plprint.h\n (c)2002 Paul Boese\n\n $Id: plprint.h,v 1.1 2002/03/04 02:57:32 axlen Exp $\n*/\n\n#ifndef __PLPRINT_H\n#define __PLPRINT_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <kos.h>\n\nvoid plinit();\n\nvoid plprint(int x, int y, float r, float g, float b, const char *s, int fp);\n\n__END_DECLS\n\n#endif /* __PLPRINT_H */\n"
},
{
"alpha_fraction": 0.6771653294563293,
"alphanum_fraction": 0.7086614370346069,
"avg_line_length": 25.710525512695312,
"blob_id": "6f3f59c932a3d7311de8ddae7fcbd41b10233615",
"content_id": "6f82abcba8c5ac84694a459bf14146c8577ad602",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1016,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 38,
"path": "/include/arch/gba/arch/timer.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/include/timer.h\n (c)2000-2001 Dan Potter\n\n $Id: timer.h,v 1.2 2003/02/17 00:47:38 bardtx Exp $\n\n*/\n\n#ifndef __ARCH_TIMER_H\n#define __ARCH_TIMER_H\n\n#include <arch/types.h>\n#include <arch/irq.h>\n\n/* Does the same as timer_ms_gettime(), but it merges both values\n into a single 64-bit millisecond counter. May be more handy \n in some situations. */\nuint64 timer_ms_gettime64();\n\n/* Set the callback target for the primary timer. Set to NULL\n to disable callbacks. Returns the address of the previous\n handler. */\ntypedef void (*timer_primary_callback_t)(irq_context_t *);\ntimer_primary_callback_t timer_primary_set_callback(timer_primary_callback_t callback);\n\n/* Request a wakeup in approximately N milliseconds. You only get one\n simultaneous wakeup. Any subsequent calls here will replace any \n pending wakeup. */\nvoid timer_primary_wakeup(uint32 millis);\n\n/* Init function */\nint timer_init();\n\n/* Shutdown */\nvoid timer_shutdown();\n\n#endif\t/* __ARCH_TIMER_H */\n\n"
},
{
"alpha_fraction": 0.5361841917037964,
"alphanum_fraction": 0.6052631735801697,
"avg_line_length": 17.75,
"blob_id": "5269b4ee5dfc005d2aab6c4c05406bf9bd93807c",
"content_id": "fd59ef612f879295ff1221623d9e33be7e7561cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 16,
"path": "/utils/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# utils/Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.5 2002/12/12 20:35:48 gilm Exp $\n\nDIRS = genromfs wav2adpcm vqenc gba-crcfix\n\n# Ok for these to fail atm...\n\nall:\n\tfor i in $(DIRS); do $(MAKE) -C $$i; done\n\nclean:\n\tfor i in $(DIRS); do $(MAKE) -C $$i clean; done\n\t\t\n\n"
},
{
"alpha_fraction": 0.6775956153869629,
"alphanum_fraction": 0.6994535326957703,
"avg_line_length": 14.166666984558105,
"blob_id": "d8235289e8511942db32a031e01fdf9c453089c3",
"content_id": "6471771a9e2b2503e1b4c28423089b2a04920550",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 12,
"path": "/kernel/libc/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# kernel/libc/Makefile\n# Copyright (C)2004 Dan Potter\n# \n\nSUBDIRS = koslib newlib pthreads\n\nall: subdirs\nclean: clean_subdirs\n\ninclude ../../Makefile.prefab\n\n"
},
{
"alpha_fraction": 0.5310254693031311,
"alphanum_fraction": 0.5950359106063843,
"avg_line_length": 21.850746154785156,
"blob_id": "a3de35413807802b5c5d2687c713eee301c05cfb",
"content_id": "5a7d51b874de1450c32bbedc56bcd5e402e1f700",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3062,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 134,
"path": "/examples/dreamcast/libdream/vmu/vmu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* Note: this is just a low-level example; in theory you can use\n the fs_vmu functions to do file-level VMU access. Of course\n that is probably not working at the moment.. ^_^; */\n\n/* Thanks to Marcus Comstedt for this VMU format info. */\n\n#include <kos.h>\n\n\n/* Draws one file entry, along with its \"description\" in the\n boot rom file manager. */\nint y1 = 20+36;\nvoid draw_one(uint8 addr, char *fn, uint16 hdrblock) {\n\tbfont_draw_str(vram_s+y1*640+10, 640, 0, \"File \");\n\tbfont_draw_str(vram_s+y1*640+10+5*12, 640, 0, fn);\n\n\tif (hdrblock) {\n\t\tuint8 buf[1024];\n\n\t\tif (vmu_block_read(addr, hdrblock, buf)) {\n\t\t\tprintf(\"Can't read file header at %d\\n\", hdrblock);\n\t\t\treturn;\n\t\t}\n\n\t\tbuf[0x10+32] = 0;\n\t\tbfont_draw_str(vram_s+y1*640+10+(6+strlen(fn))*12, 640, 0, \n\t\t\tbuf+0x10);\n\t}\n\ty1 += 24;\n}\n\n/* We only do the monochrome one here to avoid having to\n parse through the FAT. */\nvoid draw_icondata(uint8 addr, uint16 block) {\n\tuint8 buf[512], *icon;\n\tuint16 *buf16 = (uint16*)buf, *vr = vram_s + 20*640+20;\n\tuint16 monoicon;\n\tint x, y;\n\n\tif (vmu_block_read(addr, block, buf)) {\n\t\tprintf(\"Can't read ICONDATA block %d\\n\", block);\n\t\treturn;\n\t}\n\n\tmonoicon = buf16[0x10/2];\n\tif (monoicon > (512 - 128)) {\n\t\tprintf(\"Monochrome icon is too far in\\n\");\n\t\treturn;\n\t}\n\n\ticon = buf + monoicon;\n\n\tfor (y=0; y<32; y++)\n\t\tfor (x=0; x<32; x++) {\n\t\t\tif (icon[(y*32+x)/8] & (0x80 >> (x&7)))\n\t\t\t\tvr[y*640+x] = 0;\n\t\t\telse\n\t\t\t\tvr[y*640+x] = 0xffff;\n\t\t}\n}\n\n/* The full read test */\nvoid vmu_read_test() {\n\tint i, n, drawn = 0;\n\tuint8 addr = maple_first_vmu(), *ent;\n\tuint8 buf[512];\n\n\tuint16 *buf16 = (uint16*)buf, dirblock, dirlength, *ent16;\n\n\tuint16 icondata = 0;\n\n\t/* Make sure we have a VMU */\n\tif (!addr) {\n\t\tprintf(\"No VMU present!\\n\");\n\t\treturn;\n\t}\n\n\t/* Read the root block and find out where the directory is located */\n\tif (vmu_block_read(addr, 255, buf)) {\n\t\tprintf(\"Can't read VMU root block\\n\");\n\t}\n\n\tdirblock = buf16[0x4a/2]; dirlength = buf16[0x4c/2];\n\n\t/* Draw entries and look for the ICONDATA.VMS entry */\n\tfor (n=dirlength; n>0; n--) {\n\t\t/* Read one dir block */\n\t\tif (vmu_block_read(addr, dirblock, buf) != 0) {\n\t\t\tprintf(\"Can't read VMU block %d\\n\", dirblock);\n\t\t\treturn;\n\t\t}\n\n\t\t/* Each block has 16 entries */\n\t\tfor (i=0; i<16; i++) {\n\t\t\tent = buf+i*32;\n\t\t\tif (!*ent) continue;\n\n\t\t\t/* Check the filename; for normal files, draw an\n\t\t\t entry on the screen. If it's ICONDATA_VMS then\n\t\t\t just keep track of the block. */\n\t\t\tent16 = (uint16*)ent;\n\t\t\tent[4+12] = 0;\n\t\t\tif (!strcmp(ent+4, \"ICONDATA_VMS\"))\n\t\t\t\ticondata = ent16[1];\n\t\t\telse {\n\t\t\t\t/* We don't handle FAT traversal... */\n\t\t\t\tif (ent16[0x1a/2]) {\n\t\t\t\t\tdraw_one(0, (char*)(ent+4), 0);\n\t\t\t\t} else {\n\t\t\t\t\tdraw_one(addr, (char*)(ent+4), ent16[1]);\n\t\t\t\t}\n\n\t\t\t\t/* More than 16 won't fit. */\n\t\t\t\tif ((drawn++) >= 16) {\n\t\t\t\t\tdirblock = 0; i = 16; break;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tdirblock--;\n\t}\n\n\t/* Did we find the ICONDATA_VMS file? If so, draw it.. */\n\tif (icondata)\n\t\tdraw_icondata(addr, icondata);\n}\n\nint main(int argc, char **argv) {\n\t/* Do VMU read test */\n\tvmu_read_test();\n\n\tusleep(5 * 1000 * 1000);\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6901408433914185,
"alphanum_fraction": 0.7070422768592834,
"avg_line_length": 58.16666793823242,
"blob_id": "44411471b8b8fb9348018bd52701d27fa8fe1074",
"content_id": "e8130e148e5886caecb88e0494996aab8bc2d697",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 6,
"path": "/environ_ps2.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS environment variable settings. These are the shared pieces\n# for the PS2(tm) platform.\n\n#export KOS_CFLAGS=\"${KOS_CFLAGS}\"\nexport KOS_AFLAGS=\"${KOS_AFLAGS} -Wa,-EL -Wa,-mips3 -Wa,-mcpu=r5900 -I${KOS_BASE}/kernel/arch/${KOS_ARCH}/include -c\"\nexport KOS_LDFLAGS=\"${KOS_LDFLAGS} -Wl,-T${KOS_BASE}/kernel/arch/${KOS_ARCH}/link-${KOS_SUBARCH}.ld\"\n"
},
{
"alpha_fraction": 0.5893420577049255,
"alphanum_fraction": 0.6331633925437927,
"avg_line_length": 29.8464412689209,
"blob_id": "b277ac64ad3f76b197482218294e7ea2c16e1426",
"content_id": "1f290034cae503a6d9c08dadab1d6b7188bf466f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8238,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 267,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_buffers.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvr_buffers.c\n Copyright (C)2002,2004 Dan Potter\n\n */\n\n#include <assert.h>\n#include <stdio.h>\n#include <dc/pvr.h>\n#include <dc/video.h>\n#include \"pvr_internal.h\"\n\n/*\n\n This module handles buffer allocation for the structures that the\n TA feed into, and which the ISP/TSP read from during the scene\n rendering.\n\n*/\n\nCVSID(\"$Id: pvr_buffers.c,v 1.6 2003/04/24 03:10:54 bardtx Exp $\");\n\n\n/* Fill Tile Matrix buffers. This function takes a base address and sets up\n the rendering structures there. Each tile of the screen (32x32) receives\n a small buffer space. */\nvoid pvr_init_tile_matrix(int which) {\n\tvolatile pvr_ta_buffers_t\t*buf;\n\tint\t\tx, y;\n\tuint32\t\t*vr;\n\tvolatile int\t*opbs;\n\tuint32\t\tmatbase, opbbase;\n\n\tvr = (uint32*)PVR_RAM_BASE;\n\tbuf = pvr_state.ta_buffers + which;\n\topbs = pvr_state.opb_size;\n\n\tmatbase = buf->tile_matrix;\n\topbbase = buf->opb;\n\t\n\t/* Header of zeros */\n\tvr += buf->tile_matrix/4;\n\tfor (x=0; x<0x48; x+=4)\n\t\t*vr++ = 0;\n\t\t\n\t/* Initial init tile */\n\tvr[0] = 0x10000000;\n\tvr[1] = 0x80000000;\n\tvr[2] = 0x80000000;\n\tvr[3] = 0x80000000;\n\tvr[4] = 0x80000000;\n\tvr[5] = 0x80000000;\n\tvr += 6;\n\t\n\t/* Now the main tile matrix */\n#if 0\n\tdbglog(DBG_KDEBUG, \" Using poly buffers %08lx/%08lx/%08lx/%08lx/%08lx\\r\\n\",\n\t\tbuf->opb_type[0],\n\t\tbuf->opb_type[1],\n\t\tbuf->opb_type[2],\n\t\tbuf->opb_type[3],\n\t\tbuf->opb_type[4]);\n#endif\t/* !NDEBUG */\n\tfor (x=0; x<pvr_state.tw; x++) {\n\t\tfor (y=0; y<pvr_state.th; y++) {\n\t\t\t/* Control word */\n\t\t\tvr[0] = (y << 8) | (x << 2);\n\n\t\t\t/* Opaque poly buffer */\n\t\t\tvr[1] = buf->opb_type[0] + opbs[0]*pvr_state.tw*y + opbs[0]*x;\n\t\t\t\n\t\t\t/* Opaque volume mod buffer */\n\t\t\tvr[2] = buf->opb_type[1] + opbs[1]*pvr_state.tw*y + opbs[1]*x;\n\t\t\t\n\t\t\t/* Translucent poly buffer */\n\t\t\tvr[3] = buf->opb_type[2] + opbs[2]*pvr_state.tw*y + opbs[2]*x;\n\t\t\t\n\t\t\t/* Translucent volume mod buffer */\n\t\t\tvr[4] = buf->opb_type[3] + opbs[3]*pvr_state.tw*y + opbs[3]*x;\n\t\t\t\n\t\t\t/* Punch-thru poly buffer */\n\t\t\tvr[5] = buf->opb_type[4] + opbs[4]*pvr_state.tw*y + opbs[4]*x;\n\t\t\tvr += 6;\n\t\t}\n\t}\n\tvr[-6] |= 1<<31;\n\n\t/* Must skip over zeroed header for actual usage */\n\tbuf->tile_matrix += 0x48;\n}\n\n/* Fill all tile matrices */\nvoid pvr_init_tile_matrices() {\n\tint i;\n\n\tfor (i=0; i<2; i++)\n\t\tpvr_init_tile_matrix(i);\n}\n\n\n/* Allocate PVR buffers given a set of parameters\n\nThere's some confusion in here that is explained more fully in pvr_internal.h.\n\nThe other confusing thing is that texture ram is a 64-bit multiplexed space\nrather than a copy of the flat 32-bit VRAM. So in order to maximize the\navailable texture RAM, the PVR structures for the two frames are broken\nup and placed at 0x000000 and 0x400000.\n\n*/\n#define BUF_ALIGN 128\n#define BUF_ALIGN_MASK (BUF_ALIGN - 1)\nvoid pvr_allocate_buffers(pvr_init_params_t *params) {\n\tvolatile pvr_ta_buffers_t\t*buf;\n\tvolatile pvr_frame_buffers_t\t*fbuf;\n\tint\ti, j;\n\tuint32\toutaddr, polybuf, sconst, polybuf_alloc;\n\n\t/* Set screen sizes; pvr_init has ensured that we have a valid mode\n\t and all that by now, so we can freely dig into the vid_mode\n\t structure here. */\n\tpvr_state.w = vid_mode->width;\t\tpvr_state.h = vid_mode->height;\n\tpvr_state.tw = pvr_state.w / 32;\tpvr_state.th = pvr_state.h / 32;\n\n\t/* FSAA -> double the tile buffer width */\n\tif (pvr_state.fsaa)\n\t\tpvr_state.tw *= 2;\n\n\t/* We can actually handle non-mod-32 heights pretty easily -- just extend\n\t the frame buffer a bit, but use a pixel clip for the real mode. */\n\tif ((pvr_state.h % 32) != 0) {\n\t\tpvr_state.h = (pvr_state.h + 32) & ~31;\n\t\tpvr_state.th++;\n\t}\n\t\n\tpvr_state.tsize_const = ((pvr_state.th - 1) << 16)\n\t\t| ((pvr_state.tw - 1) << 0);\n\n\t/* Set clipping parameters */\n\tpvr_state.zclip = 0.0001f;\n\tpvr_state.pclip_left = 0;\tpvr_state.pclip_right = vid_mode->width - 1;\n\tpvr_state.pclip_top = 0;\tpvr_state.pclip_bottom = vid_mode->height - 1;\n\tpvr_state.pclip_x = (pvr_state.pclip_right << 16) | (pvr_state.pclip_left);\n\tpvr_state.pclip_y = (pvr_state.pclip_bottom << 16) | (pvr_state.pclip_top);\n\t\n\t/* Look at active lists and figure out how much to allocate\n\t for each poly type */\n\tpolybuf = 0;\n\tpvr_state.list_reg_mask = 1 << 20;\n\tfor (i=0; i<PVR_OPB_COUNT; i++) {\n\t\tpvr_state.opb_size[i] = params->opb_sizes[i] * 4;\t/* in bytes */\n\t\tpvr_state.opb_ind[i] = pvr_state.opb_size[i] * pvr_state.tw * pvr_state.th;\n\t\tpolybuf += pvr_state.opb_ind[i];\n\n\t\tswitch (params->opb_sizes[i]) {\n\t\tcase PVR_BINSIZE_0:\tsconst = 0; break;\n\t\tcase PVR_BINSIZE_8:\tsconst = 1; break;\n\t\tcase PVR_BINSIZE_16:\tsconst = 2; break;\n\t\tcase PVR_BINSIZE_32:\tsconst = 3; break;\n\t\tdefault:\t\tassert_msg(0, \"invalid poly_buf_size\"); sconst = 2; break;\n\t\t}\n\n\t\tif (sconst > 0) {\n\t\t\tpvr_state.lists_enabled |= (1 << i);\n\t\t\tpvr_state.list_reg_mask |= sconst << (4 * i);\n\t\t}\n\t}\n\t\n\t/* Initialize each buffer set */\n\tfor (i=0; i<2; i++) {\n\t\t/* Frame 0 goes at 0, Frame 1 goes at 0x400000 (half way) */\n\t\tif (i == 0)\n\t\t\toutaddr = 0;\n\t\telse\n\t\t\toutaddr = 0x400000;\n\n\t\t/* Select a pvr_buffers_t. Note that there's no good reason\n\t\t to allocate the frame buffers at the same time as the TA\n\t\t buffers except that it's handy to do it all in one place. */\n\t\tbuf = pvr_state.ta_buffers + i;\n\t\tfbuf = pvr_state.frame_buffers + i;\n\t\n\t\t/* Vertex buffer */\n\t\tbuf->vertex = outaddr;\n\t\tbuf->vertex_size = params->vertex_buf_size;\n\t\toutaddr += buf->vertex_size;\n\t\n\t\t/* N-byte align */\n\t\toutaddr = (outaddr + BUF_ALIGN_MASK) & ~BUF_ALIGN_MASK;\n\n\t\t/* Object Pointer Buffers */\n\t\t/* XXX What the heck is this 0x50580 magic value?? All I \n\t\t remember about it is that removing it makes it fail. */\n\t\tbuf->opb_size = 0x50580 + polybuf;\n\t\toutaddr += buf->opb_size;\n\t\t// buf->poly_buf_size = (outaddr - polybuf) - buf->vertex;\n\t\tpolybuf_alloc = buf->opb = outaddr - polybuf;\n\n\t\tfor (j=0; j<PVR_OPB_COUNT; j++) {\n\t\t\tif (pvr_state.opb_size[j] > 0) {\n\t\t\t\tbuf->opb_type[j] = polybuf_alloc;\n\t\t\t\tpolybuf_alloc += pvr_state.opb_ind[j];\n\t\t\t} else {\n\t\t\t\tbuf->opb_type[j] = 0x80000000;\n\t\t\t}\n\t\t}\n\t\toutaddr += buf->opb_size;\t/* Do we _really_ need this twice? */\n\t\n\t\t/* N-byte align */\n\t\toutaddr = (outaddr + BUF_ALIGN_MASK) & ~BUF_ALIGN_MASK;\n\n\t\t/* Tile Matrix */\n\t\tbuf->tile_matrix = outaddr;\n\t\tbuf->tile_matrix_size = (18 + 6 * pvr_state.tw * pvr_state.th) * 4;\n\t\toutaddr += buf->tile_matrix_size;\n\t\n\t\t/* N-byte align */\n\t\toutaddr = (outaddr + BUF_ALIGN_MASK) & ~BUF_ALIGN_MASK;\n\t\t\n\t\t/* Output buffer */\n\t\tfbuf->frame = outaddr;\n\t\tfbuf->frame_size = pvr_state.w * pvr_state.h * 2;\n\t\toutaddr += fbuf->frame_size;\n\t\t\n\t\t/* N-byte align */\n\t\toutaddr = (outaddr + BUF_ALIGN_MASK) & ~BUF_ALIGN_MASK;\n\t}\n\n\t/* Texture ram is whatever is left */\n\tpvr_state.texture_base = (outaddr - 0x400000) * 2;\n\n#if 0\n\tdbglog(DBG_KDEBUG, \"pvr: initialized PVR buffers:\\n\");\n\tdbglog(DBG_KDEBUG, \" texture RAM begins at %08lx\\n\", pvr_state.texture_base);\n\tfor (i=0; i<2; i++) {\t\t\n\t\tbuf = pvr_state.ta_buffers+i;\n\t\tfbuf = pvr_state.frame_buffers+i;\n\t\tdbglog(DBG_KDEBUG, \" vertex/vertex_size: %08lx/%08lx\\n\", buf->vertex, buf->vertex_size);\n\t\tdbglog(DBG_KDEBUG, \" opb base/opb_size: %08lx/%08lx\\n\", buf->opb, buf->opb_size);\n\t\tdbglog(DBG_KDEBUG, \" opbs per type: %08lx %08lx %08lx %08lx %08lx\\n\",\n\t\t\tbuf->opb_type[0],\n\t\t\tbuf->opb_type[1],\n\t\t\tbuf->opb_type[2],\n\t\t\tbuf->opb_type[3],\n\t\t\tbuf->opb_type[4]);\n\t\tdbglog(DBG_KDEBUG, \" tile_matrix/tile_matrix_size: %08lx/%08lx\\n\", buf->tile_matrix, buf->tile_matrix_size);\n\t\tdbglog(DBG_KDEBUG, \" frame/frame_size: %08lx/%08lx\\n\", fbuf->frame, fbuf->frame_size);\n\t}\n\t\n\tdbglog(DBG_KDEBUG, \" list_mask %08lx\\n\", pvr_state.list_reg_mask);\n\tdbglog(DBG_KDEBUG, \" opb sizes per type: %08lx/%08lx/%08lx/%08lx/%08lx\\n\",\n\t\tpvr_state.opb_ind[0],\n\t\tpvr_state.opb_ind[1],\n\t\tpvr_state.opb_ind[2],\n\t\tpvr_state.opb_ind[3],\n\t\tpvr_state.opb_ind[4]);\n\tdbglog(DBG_KDEBUG, \" w/h = %d/%d, tw/th = %d/%d\\n\", pvr_state.w, pvr_state.h,\n\t\tpvr_state.tw, pvr_state.th);\n\tdbglog(DBG_KDEBUG, \" zclip %08lx\\n\", *((uint32*)&pvr_state.zclip));\n\tdbglog(DBG_KDEBUG, \" pclip_left/right %08lx/%08lx\\n\", pvr_state.pclip_left, pvr_state.pclip_right);\n\tdbglog(DBG_KDEBUG, \" pclip_top/bottom %08lx/%08lx\\n\", pvr_state.pclip_top, pvr_state.pclip_bottom);\n\tdbglog(DBG_KDEBUG, \" lists_enabled %08lx\\n\", pvr_state.lists_enabled);\n\tdbglog(DBG_KDEBUG, \"Free texture memory: %ld bytes\\n\",\n\t\t0x800000 - pvr_state.texture_base);\n#endif\t/* !NDEBUG */\n}\n\n\n"
},
{
"alpha_fraction": 0.6190476417541504,
"alphanum_fraction": 0.6626983880996704,
"avg_line_length": 25.473684310913086,
"blob_id": "f0ad974a83b121828558a7f3023ea54c0127259d",
"content_id": "3ac84e574ef941a3a50473088e915c63e529aca0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 19,
"path": "/kernel/arch/gba/kernel/panic.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n panic.c\n (c)2001 Dan Potter\n*/\n\nstatic char id[] = \"KOS $Id: panic.c,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\";\n\n/* Setup basic kernel services (printf, etc) */\n#include <stdio.h>\n#include <malloc.h>\n\n/* If something goes badly wrong in the kernel and you don't think you\n can recover, call this. This is a pretty standard tactic from *nixy\n kernels which ought to be avoided if at all possible. */\nvoid panic(const char *msg) {\n\tprintf(\"%s\\r\\n\", msg);\n\tarch_exit();\n}\n\n"
},
{
"alpha_fraction": 0.4425634741783142,
"alphanum_fraction": 0.4945586323738098,
"avg_line_length": 10.328766822814941,
"blob_id": "f99a422bc7c057de841130f39c77d67d3285cd1f",
"content_id": "1e06e117e153982dac4b85c1f0e2871dacb9f9aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 827,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 73,
"path": "/libc/stdlib/dtoa.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dtoa.c\n (c)2001 Vincent Penne\n\n $Id: dtoa.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n\n/*\n\n Very simple and inacurate dtoa function. \n We do not consider the \"mode\" parameter ...\n\n */\n\n#include <math.h>\n\nchar * \ndtoa(double d, \n int mode, \n int ndigits, \n int *decpt, \n int *sign, \n char **rve)\n{\n\tstatic char result[256];\n\tchar * s;\n\n\tdouble tmp;\n\n\tint ex;\n\n\n\tif (d < 0) {\n\t\t*sign = 1;\n\t\td = -d;\n\t} else\n\t\t*sign = 0;\n\n\tex = 0;\n\ttmp = d; \n\n\twhile (tmp >= 10) {\n\t\ttmp /= 10;\n\t\tex++;\n\t}\n\twhile (tmp > 0 && tmp < 1) {\n\t\ttmp *= 10;\n\t\tex--;\n\t}\n\n\t*decpt = ex+1;\n\n\ts = result;\n\tif (ndigits > sizeof(result)-1)\n\t\tndigits = sizeof(result)-1;\n\twhile (ndigits--) {\n\t\tint i = tmp;\n \n\t\t*s++ = '0'+i;\n\n\t\ttmp -= i;\n\t\ttmp *= 10;\n\t}\n\n\t*s++ = 0;\n\n\tif (rve)\n\t\t*rve = s-1;\n \n\treturn result;\n}\n"
},
{
"alpha_fraction": 0.5996240377426147,
"alphanum_fraction": 0.6259398460388184,
"avg_line_length": 24.309524536132812,
"blob_id": "295077b0fa5a6d931c890bdb102e91dbb27b0da5",
"content_id": "04a9a4c66d65ac7c0c66d17c46e04d50ec3be03c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 42,
"path": "/kernel/arch/ps2/kernel/crtbegin.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n crtbegin.c\n (c)2002 Dan Potter\n*/\n\n/* Handles ctors and dtors (for C++ programs). This is modeled on the \n FreeBSD crtbegin.c code. Note that the default linker scripts for\n GCC will automatically put our ctors at the front of the list. */\n\n#include <arch/types.h>\n\nCVSID(\"$Id: crtbegin.c,v 1.1 2002/10/26 08:04:00 bardtx Exp $\");\n\n/* Here we gain access to the ctor and dtor sections of the program by\n defining new data in them. */\ntypedef void (*fptr)(void);\n\nstatic fptr ctor_list[1] __attribute__((section(\".ctors\"))) = { (fptr) -1 };\nstatic fptr dtor_list[1] __attribute__((section(\".dtors\"))) = { (fptr) -1 };\n\n/* Call this to execute all ctors */\nvoid arch_ctors() {\n\tfptr *fpp;\n\n\t/* Run up to the end of the list (defined by crtend) */\n\tfor (fpp=ctor_list + 1; *fpp != 0; ++fpp)\n\t\t;\n\n\t/* Now run the ctors backwards */\n\twhile (--fpp > ctor_list)\n\t\t(**fpp)();\n}\n\n/* Call this to execute all dtors */\nvoid arch_dtors() {\n\tfptr *fpp;\n\n\t/* Do the dtors forwards */\n\tfor (fpp=dtor_list + 1; *fpp != 0; ++fpp )\n\t\t(**fpp)();\n}\n\n"
},
{
"alpha_fraction": 0.6399394869804382,
"alphanum_fraction": 0.6913766860961914,
"avg_line_length": 22.571428298950195,
"blob_id": "a7d58b65113a39de65aaf55d85c84dbe0ff5be48",
"content_id": "59b042389dd415f8a9ab79aa8600c46f617e38e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 28,
"path": "/include/arch/ia32/arch/cache.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ia32/include/cache.h\n (c)2001 Dan Potter\n \n $Id: cache.h,v 1.1 2003/08/01 03:18:37 bardtx Exp $\n*/\n\n#ifndef __ARCH_CACHE_H\n#define __ARCH_CACHE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Flush a range of i-cache, given a physical address range */\nvoid icache_flush_range(uint32 start, uint32 count);\n\n/* Invalidate a range of o-cache/d-cache, given a physical address range */\nvoid dcache_inval_range(uint32 start, uint32 count);\n\n/* Flush a range of o-cache/d-cache, given a physical address range */\nvoid dcache_flush_range(uint32 start, uint32 count);\n\n__END_DECLS\n\n#endif\t/* __ARCH_CACHE_H */\n\n"
},
{
"alpha_fraction": 0.6734875440597534,
"alphanum_fraction": 0.708185076713562,
"avg_line_length": 26.072288513183594,
"blob_id": "8d9f851bd00513e280ffea7c1ea3b274eeff97a2",
"content_id": "14e9ad7845382b3ea39042d045e477fed0eea07d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2248,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 83,
"path": "/include/arch/ps2/arch/timer.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/timer.h\n (c)2000-2002 Dan Potter\n\n $Id: timer.h,v 1.2 2002/11/03 03:40:55 bardtx Exp $\n\n*/\n\n#ifndef __ARCH_TIMER_H\n#define __ARCH_TIMER_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Bus clock speed on the PS2 is 147.456MHz; these are spelt out here\n so that it's easier to calculate the type you need. Unfortunately the\n next slowest thing you can latch to is HSYNC, which is based on\n refresh rates and not real time. -_- */\n#define TIMER_BUSCLK\t147456000\n#define TIMER_BUSCLK16\t9216000\n#define TIMER_BUSCLK256\t576000\n\n/* Timer sources -- we get four on the SH4 */\n#define TIMER0\t0\t/* Unused */\n#define TIMER1\t1\t/* Used for timer_spin_sleep() */\n#define TIMER2\t2\t/* Will for timer_ms_gettime() maybe */\n#define TIMER3\t3\t/* Off limits during thread operation */\n\n/* The main timer for the task switcher to use */\n#define TIMER_ID TIMER3\n\n/* Pre-initialize a timer; set values but don't start it */\nint timer_prime(int which, uint32 speed, int interrupts);\n\n/* Start a timer -- starts it running (and interrupts if applicable) */\nint timer_start(int which);\n\n/* Stop a timer -- and disables its interrupt */\nint timer_stop(int which);\n\n/* Returns the count value of a timer */\nuint32 timer_count(int which);\n\n/* Clears the timer underflow bit and returns what its value was */\nint timer_clear(int which);\n\n/* Spin-loop kernel sleep func: uses the secondary timer in the\n SH-4 to very accurately delay even when interrupts are disabled */\nvoid timer_spin_sleep(int ms);\n\n/* Enable timer interrupts (high priority); needs to move\n to irq.c sometime. */\nvoid timer_enable_ints(int which);\n\n/* Disable timer interrupts; needs to move to irq.c sometime. */\nvoid timer_disable_ints(int which);\n\n/* Check whether ints are enabled */\nint timer_ints_enabled(int which);\n\n/* Enable the millisecond timer */\nvoid timer_ms_enable();\nvoid timer_ms_disable();\n\n/* Return the number of ticks since KOS was booted */\nvoid timer_ms_gettime(uint32 *secs, uint32 *msecs);\n\n/* Enable the main kernel timer */\nvoid timer_primary_enable();\nvoid timer_primary_disable();\n\n/* Init function */\nint timer_init();\n\n/* Shutdown */\nvoid timer_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_TIMER_H */\n\n"
},
{
"alpha_fraction": 0.640671968460083,
"alphanum_fraction": 0.6557028889656067,
"avg_line_length": 28.2901554107666,
"blob_id": "43e7bd4bc428858fb5599d1352bad45f91861db0",
"content_id": "53866ea30f9abc49d425968da585d2ab5068cc39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5655,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 193,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_irq.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvr_irq.c\n Copyright (C)2002,2004 Dan Potter\n\n */\n\n#include <assert.h>\n#include <dc/pvr.h>\n#include <dc/video.h>\n#include <dc/asic.h>\n#include <arch/cache.h>\n#include \"pvr_internal.h\"\n\n/*\n PVR interrupt handler; the way things are setup, we're gonna get\n one of these for each full vertical refresh and at the completion\n of TA data acceptance. The timing here is pretty critical. We need\n to flip pages during a vertical blank, and then signal to the program\n that it's ok to start playing with TA registers again, or we waste\n rendering time.\n*/\n\nCVSID(\"$Id: pvr_irq.c,v 1.10 2003/04/24 03:12:25 bardtx Exp $\");\n\n// Find the next list to DMA out. If we have none left to do, then do\n// nothing. Otherwise, start the DMA and chain back to us upon completion.\nstatic void dma_next_list(ptr_t data) {\n\tint i, did = 0;\n\tvolatile pvr_dma_buffers_t * b;\n\n\t// DBG((\"dma_next_list\\n\"));\n\n\tfor (i=0; i<PVR_OPB_COUNT; i++) {\n\t\tif ((pvr_state.lists_enabled & (1 << i))\n\t\t\t&& !(pvr_state.lists_dmaed & (1 << i)))\n\t\t{\n\t\t\t// Get the buffers for this frame.\n\t\t\tb = pvr_state.dma_buffers + (pvr_state.ram_target ^ 1);\n\n\t\t\t// Flush the last 32 bytes out of dcache, just in case.\n\t\t\t// dcache_flush_range((ptr_t)(b->base[i] + b->ptr[i] - 32), 32);\n\t\t\tdcache_flush_range((ptr_t)(b->base[i]), b->ptr[i] + 32);\n\t\t\t//amt = b->ptr[i] > 16384 ? 16384 : b->ptr[i];\n\t\t\t//dcache_flush_range((ptr_t)(b->base[i] + b->ptr[i] - amt), amt);\n\n\t\t\t// Start the DMA transfer, chaining to ourselves.\n\t\t\t//DBG((\"dma_begin(buf %d, list %d, base %p, len %d)\\n\",\n\t\t\t//\tpvr_state.ram_target ^ 1, i,\n\t\t\t//\tb->base[i], b->ptr[i]));\n\t\t\tpvr_dma_load_ta(b->base[i], b->ptr[i], 0, dma_next_list, 0);\n\n\t\t\t// Mark this list as done, and break out for now.\n\t\t\tpvr_state.lists_dmaed |= 1 << i;\n\t\t\tdid++;\n\n\t\t\tbreak;\n\t\t}\n\t}\n\n\t// If that was the last one, then free up the DMA channel.\n\tif (!did) {\n\t\t//DBG((\"dma_complete(buf %d)\\n\", pvr_state.ram_target ^ 1));\n\n\t\t// Unlock\n\t\tmutex_unlock(pvr_state.dma_lock);\n\t\tpvr_state.lists_dmaed = 0;\n\n\t\t// Buffers are now empty again\n\t\tpvr_state.dma_buffers[pvr_state.ram_target ^ 1].ready = 0;\n\n\t\t// Signal the client code to continue onwards.\n\t\tsem_signal(pvr_state.ready_sem);\n\t\tthd_schedule(1,0);\n\t}\n}\n\nvoid pvr_int_handler(uint32 code) {\n\t// What kind of event did we get?\n\tswitch(code) {\n\tcase ASIC_EVT_PVR_OPAQUEDONE:\n\t\t//DBG((\"irq_opaquedone\\n\"));\n\t\tpvr_state.lists_transferred |= 1 << PVR_OPB_OP;\n\t\tbreak;\n\tcase ASIC_EVT_PVR_TRANSDONE:\n\t\t//DBG((\"irq_transdone\\n\"));\n\t\tpvr_state.lists_transferred |= 1 << PVR_OPB_TP;\n\t\tbreak;\n\tcase ASIC_EVT_PVR_OPAQUEMODDONE:\n\t\tpvr_state.lists_transferred |= 1 << PVR_OPB_OM;\n\t\tbreak;\n\tcase ASIC_EVT_PVR_TRANSMODDONE:\n\t\tpvr_state.lists_transferred |= 1 << PVR_OPB_TM;\n\t\tbreak;\n\tcase ASIC_EVT_PVR_PTDONE:\n\t\tpvr_state.lists_transferred |= 1 << PVR_OPB_PT;\n\t\tbreak;\n\tcase ASIC_EVT_PVR_RENDERDONE:\n\t\t//DBG((\"irq_renderdone\\n\"));\n\t\tpvr_state.render_busy = 0;\n\t\tpvr_state.render_completed = 1;\n\t\tpvr_sync_stats(PVR_SYNC_RNDDONE);\n\t\tbreak;\n\tcase ASIC_EVT_PVR_VBLINT:\n\t\tpvr_sync_stats(PVR_SYNC_VBLANK);\n\t\tbreak;\n\t}\n\n\t/* Update our stats if we finished all registration */\n\tswitch (code) {\n\tcase ASIC_EVT_PVR_OPAQUEDONE:\n\tcase ASIC_EVT_PVR_TRANSDONE:\n\tcase ASIC_EVT_PVR_OPAQUEMODDONE:\n\tcase ASIC_EVT_PVR_TRANSMODDONE:\n\tcase ASIC_EVT_PVR_PTDONE:\n\t\tif (pvr_state.lists_transferred == pvr_state.lists_enabled) {\n\t\t\tpvr_sync_stats(PVR_SYNC_REGDONE);\n\t\t}\n\t\treturn;\n\t}\n\n\t// If it's not a vblank, ignore for now for the rest of this.\n\tif (code != ASIC_EVT_PVR_VBLINT)\n\t\treturn;\n\n\t// If the render-done interrupt has fired then we are ready to flip to the\n\t// new frame buffer.\n\tif (pvr_state.render_completed) {\n\t\t//DBG((\"view(%d)\\n\", pvr_state.view_target ^ 1));\n\n\t\t// Handle PVR stats\n\t\tpvr_sync_stats(PVR_SYNC_PAGEFLIP);\n\n\t\t// Switch view address to the \"good\" buffer\n\t\tif(pvr_state.to_texture != 2)\n\t\t\tpvr_state.view_target ^= 1;\n\t\tpvr_sync_view();\n\n\t\t// Clear the render completed flag.\n\t\tpvr_state.render_completed = 0;\n\n\t\t// Set the fact that the next frame should be texture rendered, if it is the case\n\t\tpvr_state.to_texture = pvr_state.to_texture == 1 ? 2 : 0;\n\t}\n\n\t// If all lists are fully transferred and a render is not in progress,\n\t// we are ready to start rendering.\n\tif (!pvr_state.render_busy\t\n\t\t&& pvr_state.lists_transferred == pvr_state.lists_enabled)\n\t{\n\t\t/* XXX Note:\n\t\t For some reason, the render must be started _before_ we sync\n\t\t to the new reg buffers. The only reasons I can think of for this\n\t\t are that there may be something in the reg sync that messes up\n\t\t the render in progress, or we are misusing some bits somewhere. */\n\n\t\t// Begin rendering from the dirty TA buffer into the clean\n\t\t// frame buffer.\n\t\t//DBG((\"start_render(%d -> %d)\\n\", pvr_state.ta_target, pvr_state.view_target ^ 1));\n\t\tpvr_state.ta_target ^= 1;\n\t\tpvr_begin_queued_render();\n\t\tpvr_state.render_busy = 1;\n\t\tpvr_sync_stats(PVR_SYNC_RNDSTART);\n\n\t\t// If we're not in DMA mode, then signal the client code\n\t\t// to continue onwards.\n\t\tif (!pvr_state.dma_mode) {\n\t\t\tsem_signal(pvr_state.ready_sem);\n\t\t\tthd_schedule(1,0);\n\t\t}\n\n\t\t// Switch to the clean TA buffer.\n\t\tpvr_state.lists_transferred = 0;\n\t\tpvr_sync_reg_buffer();\n\n\t\t// The TA is no longer busy.\n\t\tpvr_state.ta_busy = 0;\n\t}\n\n\t// If we're in DMA mode, the DMA source buffers are ready, and a DMA\n\t// is not in progress, then we are ready to start DMAing.\n\tif (pvr_state.dma_mode\n\t\t&& !pvr_state.ta_busy\n\t\t&& pvr_state.dma_buffers[pvr_state.ram_target ^ 1].ready\n\t\t&& mutex_trylock(pvr_state.dma_lock) >= 0)\n\t{\n\t\tpvr_sync_stats(PVR_SYNC_REGSTART);\n\n\t\t// Begin DMAing the first list.\n\t\tpvr_state.ta_busy = 1;\n\t\tdma_next_list(0);\n\t}\n}\n\n\n"
},
{
"alpha_fraction": 0.6755852699279785,
"alphanum_fraction": 0.6906354427337646,
"avg_line_length": 26.16666603088379,
"blob_id": "18924f35d2c8bc6e9df4593c176805bf2e637b01",
"content_id": "65bc089e696216ae6ef7117550021cc1b08b110e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1794,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 66,
"path": "/include/kos/cond.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/cond.h\n Copyright (C)2001,2003 Dan Potter\n\n $Id: cond.h,v 1.4 2003/07/31 00:38:00 bardtx Exp $\n\n*/\n\n#ifndef __KOS_COND_H\n#define __KOS_COND_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/queue.h>\n#include <kos/thread.h>\n#include <kos/mutex.h>\n\n/* Condition structure */\ntypedef struct condvar {\n\t/* List entry for the global list of condvars */\n\tLIST_ENTRY(condvar)\tg_list;\n} condvar_t;\n\nLIST_HEAD(condlist, condvar);\n\n/* Allocate a new condvar. Sets errno to ENOMEM on failure. */\ncondvar_t *cond_create();\n\n/* Free a condvar */\nvoid cond_destroy(condvar_t *cv);\n\n/* Wait on a condvar; if there is an associated mutex to unlock\n while waiting, then pass that as well. Returns -1 on error.\n EPERM - called inside interrupt\n EINTR - wait was interrupted */\nint cond_wait(condvar_t *cv, mutex_t * m);\n\n/* Wait on a condvar; if there is an associated mutex to unlock\n while waiting, then pass that as well. If more than 'timeout'\n milliseconds passes and we still haven't been signaled, return\n an error code (-1). Return success (0) when we are woken normally.\n Note: if 'timeout' is zero, this call is equivalent to \n cond_wait above.\n EPERM - called inside interrupt\n EAGAIN - timed out\n EINTR - was interrupted */\nint cond_wait_timed(condvar_t *cv, mutex_t * m, int timeout);\n\n/* Signal a single thread waiting on the condvar; you should be\n holding any associated mutex before doing this! */\nvoid cond_signal(condvar_t *cv);\n\n/* Signal all threads waiting on the condvar; you should be holding\n any associated mutex before doing this! */\nvoid cond_broadcast(condvar_t *cv);\n\n/* Init / shutdown */\nint cond_init();\nvoid cond_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_COND_H */\n\n"
},
{
"alpha_fraction": 0.6111111044883728,
"alphanum_fraction": 0.6340388059616089,
"avg_line_length": 19.600000381469727,
"blob_id": "ce383d7b8d8b39e551caa3b2848363a8284345ec",
"content_id": "891501fb1baece7ea881a1fcff0768c995565b66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 55,
"path": "/include/arch/ia32/arch/spinlock.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/spinlock.h\n (c)2001 Dan Potter\n \n $Id: spinlock.h,v 1.2 2003/08/02 09:14:46 bardtx Exp $\n*/\n\n#ifndef __ARCH_SPINLOCK_H\n#define __ARCH_SPINLOCK_H\n\n/* Defines processor specific spinlocks */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* DC implementation uses threads most of the time */\n#include <kos/thread.h>\n#include <arch/irq.h>\n\n/* Spinlock data type */\ntypedef volatile int spinlock_t;\n\n/* Value initializer */\n#define SPINLOCK_INITIALIZER 0\n\n/* Initialize a spinlock */\n#define spinlock_init(A) *(A) = SPINLOCK_INITIALIZER\n\n/* Note here that even if threads aren't enabled, we'll still set the\n lock so that it can be used for anti-IRQ protection (e.g., malloc) */\n\n/* Spin on a lock */\n#define spinlock_lock(A) do { \\\n\tint __x = irq_disable(); \\\n\twhile (*A) { \\\n\t\tirq_restore(__x); \\\n\t\tthd_pass(); \\\n\t\tirq_disable(); \\\n\t} \\\n\t*A = 1; \\\n\tirq_restore(__x); \\\n} while(0)\n\n/* Free a lock */\n#define spinlock_unlock(A) do { \\\n\t\t*(A) = 0; \\\n\t} while (0)\n\n__END_DECLS\n\n/* Determine if a lock is locked */\n#define spinlock_is_locked(A) ( *(A) != 0 )\n\n#endif\t/* __ARCH_SPINLOCK_H */\n\n"
},
{
"alpha_fraction": 0.44205862283706665,
"alphanum_fraction": 0.4505794048309326,
"avg_line_length": 26.485437393188477,
"blob_id": "3496d794962c27d84b3cbd7979e655381ef87f2c",
"content_id": "37fd92d77b96433b7450eb3cbf2415682a63f057",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2934,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 103,
"path": "/examples/dreamcast/modem/basic/example1.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\r\n\r\n example1.c\r\n Copyright (C)2004 Nick Kochakian\r\n\r\n Connecting without events\r\n*/\r\n\r\n#include <stdio.h>\r\n#include <kos.h>\r\n#include \"dc/modem/modem.h\"\r\n\r\n#define DATA_BUFFER_LENGTH 128\r\n\r\nint buttonPressed(int button)\r\n{\r\n cont_cond_t controller;\r\n\r\n cont_get_cond(maple_addr(0, 0), &controller);\r\n\r\n return !(controller.buttons & button);\r\n}\r\n\r\nint main()\r\n{\r\n int answerMode = 0;\r\n unsigned char data[DATA_BUFFER_LENGTH];\r\n int i;\r\n int byteCount;\r\n\r\n if (!modem_init())\r\n {\r\n printf(\"modem_init failed!\\n\");\r\n return 1;\r\n }\r\n\r\n printf(\"\\nDreamcast modem - example 1\\n\");\r\n printf(\"Press START to exit\\n\\n\");\r\n\r\n if (answerMode)\r\n printf(\"Answer mode - Call the Dreamcast. It will pick up after one ring.\\n\\n\");\r\n else\r\n printf(\"Remote mode - Connect the phone line to your computer's modem and use ATA to\\n \\\"answer\\\" the Dreamcast.\\n\\n\");\r\n\r\n printf(\"Once the modems are connected you can send data to the Dreamcast,\\n\");\r\n printf(\"and the Dreamcast can send data to the remote modem by pressing the\\n\");\r\n printf(\"A button.\\n\\n\");\r\n\r\n while (!buttonPressed(CONT_START))\r\n {\r\n modem_set_mode(answerMode ? MODEM_MODE_ANSWER :\r\n MODEM_MODE_REMOTE,\r\n MODEM_SPEED_V8_AUTO);\r\n\r\n printf(\"Waiting for a connection..\\n\");\r\n while (modem_is_connecting())\r\n {\r\n if (buttonPressed(CONT_START))\r\n {\r\n printf(\"Connection aborted\\n\");\r\n return 0;\r\n }\r\n }\r\n\r\n if (modem_is_connected())\r\n {\r\n printf(\"Connected at %dbps\\n\", (int)modem_get_connection_rate());\r\n\r\n while (!buttonPressed(CONT_START) && modem_is_connected())\r\n {\r\n /* Receive data */\r\n if (modem_has_data())\r\n {\r\n byteCount = modem_read_data(data, DATA_BUFFER_LENGTH);\r\n for (i=0; i<byteCount; i++)\r\n printf(\"%c\", (data[i] >= 32 && data[i] <= 126) ?\r\n data[i] : ' ');\r\n }\r\n\r\n /* Send data */\r\n if (buttonPressed(CONT_A))\r\n {\r\n for (i=0; i<8; i++)\r\n data[i] = (int)'a' + i;\r\n\r\n modem_write_data(data, 8);\r\n }\r\n }\r\n\r\n if (modem_is_connected())\r\n {\r\n printf(\"Disconnecting..\\n\");\r\n modem_disconnect();\r\n\r\n while (buttonPressed(CONT_START));\r\n } else\r\n printf(\"Disconnected\\n\");\r\n } else\r\n printf(\"Connection failed\\n\");\r\n }\r\n\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5736604332923889,
"alphanum_fraction": 0.5933113694190979,
"avg_line_length": 22.54310417175293,
"blob_id": "503a3e417f17db2c0ea2a56cdff251edcf91632a",
"content_id": "db8476062f3ac421842968cbd99398b1b77e5880",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8193,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 348,
"path": "/addons/libkosutils/netcfg.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n netcfg.c\n Copyright (C)2003,2004 Dan Potter\n\n*/\n\n#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <kos/netcfg.h>\n#include <dc/flashrom.h>\n#include <dc/vmu_pkg.h>\n\n#include \"netcfg_icon.h\"\n\n#if 0\n#define dbgp printf\n#else\n#define dbgp(x...)\n#endif\n\nvoid netcfg_vmuify(const char *filename_in, const char *filename_out) {\n\tint\tfd, pkg_size;\n\tuint8\t*buf;\n\tuint8\t*pkg_out;\n\tvmu_pkg_t pkg;\n\n\tdbgp(\"Opening source file\\n\");\n\tfd = fs_open(filename_in, O_RDONLY);\n\tbuf = (uint8 *) malloc(fs_total(fd));\n\tfs_read(fd, buf, fs_total(fd));\n\tdbgp(\"Read %i bytes\\n\", fs_total(fd));\n\n\tstrcpy(pkg.desc_short, \"KallistiOS 1.3\");\n\tstrcpy(pkg.desc_long, \"KOS Network Settings\");\n\tstrcpy(pkg.app_id, \"KOS\");\n\tpkg.icon_cnt = 1;\n\tpkg.icon_anim_speed = 1;\n\tmemcpy(&pkg.icon_pal[0], netcfg_icon, 32);\n\tpkg.icon_data = netcfg_icon + 32;\n\tpkg.eyecatch_type = VMUPKG_EC_NONE;\n\tpkg.data_len = fs_total(fd);\n\tpkg.data = buf;\n\tdbgp(\"Building package\\n\");\n\tvmu_pkg_build(&pkg, &pkg_out, &pkg_size);\n\tfs_close(fd);\n\tdbgp(\"Closing source file\\n\");\n\n\tdbgp(\"Opening output file\\n\");\n\tfd = fs_open(filename_out, O_WRONLY);\n\tdbgp(\"Writing..\\n\");\n\tfs_write(fd, pkg_out, pkg_size);\n\tdbgp(\"Closing output file\\n\");\n\tfs_close(fd);\n\tfree(buf);\n\tdbgp(\"VMUification complete\\n\");\n}\n\n/* This module attempts to ferret out a valid network configuration by\n drawing on all available sources. A file stored on the VMU is tried\n first, followed by reading the settings from the DC's flashrom. If\n this fails, we try reading settings from the current dir in the VFS,\n and then from the root of the CD. If that fails, we give up. */\n\nint netcfg_load_from(const char * fn, netcfg_t * out) {\n\tFILE * f;\n\tchar buf[64], *b;\n\tint l;\n\n\tassert( out );\n\n\t// Open the file\n\tf = fopen(fn, \"rb\");\n\tif (!f)\n\t\treturn -1;\n\n\t// If we're reading from a VMU, seek past the header\n\t// In the future, we could read this and use data_len to\n\t// know how big the file really is\n\tif (fn[0]=='/' && fn[1]=='v' && fn[2] == 'm' && fn[3] == 'u') {\n\t\t// Make sure there's a VMU header to skip. If so, skip it.\n\t\tfread(buf, 4, 1, f); buf[4] = 0;\n\t\tif (strcmp(buf, \"# KO\"))\n\t\t\tfseek(f, 128+512, SEEK_SET);\n\t}\n\n\t// Read each line...\n\twhile (fgets(buf, 64, f)) {\n\t\t// Skip comments and blank lines\n\t\tif (buf[0] == 0 || buf[0] == '#')\n\t\t\tcontinue;\n\n\t\t// Strip newlines\n\t\tl = strlen(buf);\n\t\tif (buf[l-1] == '\\n') {\n\t\t\tbuf[l-1] = 0;\n\t\t\tl--;\n\t\t}\n\t\tif (buf[l-1] == '\\r') {\n\t\t\tbuf[l-1] = 0;\n\t\t\tl--;\n\t\t}\n\n\t\t// Look for an equals\n\t\tb = strchr(buf, '=');\n\t\tif (!b)\n\t\t\tcontinue;\n\n\t\t*b = 0; b++;\n\n\t\t// What was the line type?\n\t\tif (!strcmp(buf, \"driver\")) {\n\t\t\tstrcpy(out->driver, b);\n\t\t} else if (!strcmp(buf, \"ip\")) {\n\t\t\tout->ip = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"gateway\")) {\n\t\t\tout->gateway = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"netmask\")) {\n\t\t\tout->netmask = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"broadcast\")) {\n\t\t\tout->broadcast = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"dns1\")) {\n\t\t\tout->dns[0] = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"dns2\")) {\n\t\t\tout->dns[1] = strtoul(b, NULL, 16);\n\t\t} else if (!strcmp(buf, \"hostname\")) {\n\t\t\tstrcpy(out->hostname, b);\n\t\t} else if (!strcmp(buf, \"email\")) {\n\t\t\tstrcpy(out->email, b);\n\t\t} else if (!strcmp(buf, \"smtp\")) {\n\t\t\tstrcpy(out->smtp, b);\n\t\t} else if (!strcmp(buf, \"pop3\")) {\n\t\t\tstrcpy(out->pop3, b);\n\t\t} else if (!strcmp(buf, \"pop3_login\")) {\n\t\t\tstrcpy(out->pop3_login, b);\n\t\t} else if (!strcmp(buf, \"pop3_passwd\")) {\n\t\t\tstrcpy(out->pop3_passwd, b);\n\t\t} else if (!strcmp(buf, \"proxy_host\")) {\n\t\t\tstrcpy(out->proxy_host, b);\n\t\t} else if (!strcmp(buf, \"proxy_port\")) {\n\t\t\tout->proxy_port = strtoul(b, NULL, 10);\n\t\t} else if (!strcmp(buf, \"ppp_login\")) {\n\t\t\tstrcpy(out->ppp_login, b);\n\t\t} else if (!strcmp(buf, \"ppp_passwd\")) {\n\t\t\tstrcpy(out->ppp_passwd, b);\n\t\t} else if (!strcmp(buf, \"method\")) {\n\t\t\tif (!strcmp(b, \"dhcp\"))\n\t\t\t\tout->method = NETCFG_METHOD_DHCP;\n\t\t\telse if (!strcmp(b, \"static\"))\n\t\t\t\tout->method = NETCFG_METHOD_STATIC;\n\t\t\telse if (!strcmp(b, \"pppoe\"))\n\t\t\t\tout->method = NETCFG_METHOD_PPPOE;\n\t\t}\n\t}\n\n\tfclose(f);\n\n\treturn 0;\n}\n\nint netcfg_load_flash(netcfg_t * out) {\n\tflashrom_ispcfg_t cfg;\n\n\tif (flashrom_get_ispcfg(&cfg) < 0)\n\t\treturn -1;\n\n\t// Start out with a clean config\n\tmemset(out, 0, sizeof(netcfg_t));\n\n#define READIP(dst, src) \\\n\tdst = ((src[0]) << 24) | \\\n\t\t((src[1]) << 16) | \\\n\t\t((src[2]) << 8) | \\\n\t\t((src[3]) << 0)\n\n\tif (cfg.ip_valid) {\n\t\tREADIP(out->ip, cfg.ip);\n\t\tREADIP(out->gateway, cfg.gw);\n\t\tREADIP(out->netmask, cfg.nm);\n\t\tREADIP(out->broadcast, cfg.bc);\n\t\tREADIP(out->dns[0], cfg.dns[0]);\n\t\tREADIP(out->dns[1], cfg.dns[1]);\n\t\tstrcpy(out->hostname, cfg.hostname);\n\t}\n\tif (cfg.email_valid)\n\t\tstrcpy(out->email, cfg.email);\n\tif (cfg.smtp_valid)\n\t\tstrcpy(out->smtp, cfg.smtp);\n\tif (cfg.pop3_valid)\n\t\tstrcpy(out->pop3, cfg.pop3);\n\tif (cfg.pop3_login_valid)\n\t\tstrcpy(out->pop3_login, cfg.pop3_login);\n\tif (cfg.pop3_passwd_valid) {\n\t\tstrcpy(out->pop3_passwd, cfg.pop3_passwd);\n\t\tout->proxy_port = cfg.proxy_port;\n\t}\n\tif (cfg.ppp_login_valid) {\n\t\tstrcpy(out->proxy_host, cfg.proxy_host);\n\t\tstrcpy(out->ppp_login, cfg.ppp_login);\n\t}\n\tif (cfg.ppp_passwd_valid)\n\t\tstrcpy(out->ppp_passwd, cfg.ppp_passwd);\n\n#undef READIP\n\n\treturn 0;\n}\n\nint netcfg_load(netcfg_t * out) {\n\tfile_t f;\n\tdirent_t * d;\n\tchar buf[64];\n\n\t// Scan for VMUs\n\tf = fs_open(\"/vmu\", O_RDONLY | O_DIR);\n\tif (f >= 0) {\n\t\tfor ( ; ; ) {\n\t\t\td = fs_readdir(f);\n\t\t\tif (!d) {\n\t\t\t\tfs_close(f);\n\t\t\t\tbreak;\n\t\t\t}\n\n\t\t\tsprintf(buf, \"/vmu/%s/net.cfg\", d->name);\n\t\t\tif (netcfg_load_from(buf, out) >= 0) {\n\t\t\t\tout->src = NETCFG_SRC_VMU;\n\t\t\t\tfs_close(f);\n\t\t\t\treturn 0;\n\t\t\t}\n\t\t}\n\t}\n\n\t// Couldn't find anything. Try reading the config\n\t// from flash.\n\tif (netcfg_load_flash(out) >= 0) {\n\t\tout->src = NETCFG_SRC_FLASH;\n\t\treturn 0;\n\t}\n\n\t// Didn't work out->. try the current dir.\n\tif (netcfg_load_from(\"net.cfg\", out) >= 0) {\n\t\tout->src = NETCFG_SRC_CWD;\n\t\treturn 0;\n\t}\n\n\t// Finally, try the CD\n\tif (netcfg_load_from(\"/cd/net.cfg\", out) >= 0) {\n\t\tout->src = NETCFG_SRC_CDROOT;\n\t\treturn 0;\n\t}\n\n\treturn -1;\n}\n\nint netcfg_save_to(const char * fn, const netcfg_t * cfg) {\n\tFILE * f;\n\tchar buf[64];\n\n\tassert( cfg );\n\n\tdbgp(\"Saving: %s\\n\",fn);\n\t// Open the output file\n\tif (fn[0]=='/' && fn[1]=='v' && fn[2] == 'm' && fn[3] == 'u') {\n\t\tdbgp(\"Saving to VMU\\n\");\n\t\tf = fopen(\"/ram/netcfg.tmp\", \"wb\");\n\t} else {\n\t\tf = fopen(fn, \"wb\");\n\t}\n\tif (!f)\n\t\treturn -1;\n\n\t// Write out each line...\n\tsprintf(buf, \"# KOS Network Config written by netcfg_save_to\\n\");\n\tif (fwrite(buf, strlen(buf), 1, f) != 1)\n\t\tgoto error;\n\n#define WRITESTR(fmt, data) \\\n\tsprintf(buf, fmt, data); \\\n\tif (fwrite(buf, strlen(buf), 1, f) != 1) \\\n\t\tgoto error;\n\n\tWRITESTR(\"driver=%s\\n\", cfg->driver);\n\tWRITESTR(\"ip=%08lx\\n\", cfg->ip);\n\tWRITESTR(\"gateway=%08lx\\n\", cfg->gateway);\n\tWRITESTR(\"netmask=%08lx\\n\", cfg->netmask);\n\tWRITESTR(\"broadcast=%08lx\\n\", cfg->broadcast);\n\tWRITESTR(\"dns1=%08lx\\n\", cfg->dns[0]);\n\tWRITESTR(\"dns2=%08lx\\n\", cfg->dns[1]);\n\tWRITESTR(\"hostname=%s\\n\", cfg->hostname);\n\tWRITESTR(\"email=%s\\n\", cfg->email);\n\tWRITESTR(\"smtp=%s\\n\", cfg->smtp);\n\tWRITESTR(\"pop3=%s\\n\", cfg->pop3);\n\tWRITESTR(\"pop3_login=%s\\n\", cfg->pop3_login);\n\tWRITESTR(\"pop3_passwd=%s\\n\", cfg->pop3_passwd);\n\tWRITESTR(\"proxy_host=%s\\n\", cfg->proxy_host);\n\tWRITESTR(\"proxy_port=%d\\n\", cfg->proxy_port);\n\tWRITESTR(\"ppp_login=%s\\n\", cfg->ppp_login);\n\tWRITESTR(\"ppp_passwd=%s\\n\", cfg->ppp_passwd);\n\tswitch (cfg->method) {\n\tcase 0:\n\t\tWRITESTR(\"method=%s\\n\", \"dhcp\");\n\t\tbreak;\n\tcase 1:\n\t\tWRITESTR(\"method=%s\\n\", \"static\");\n\t\tbreak;\n\tcase 4:\n\t\tWRITESTR(\"method=%s\\n\", \"pppoe\");\n\t\tbreak;\n\t}\n#undef WRITESTR\n\n\tfclose(f);\n\n\t//If we're saving to a VMU, tack on the header and send it out\n\tif (fn[0]=='/' && fn[1]=='v' && fn[2] == 'm' && fn[3] == 'u') {\n\t\tnetcfg_vmuify(\"/ram/netcfg.tmp\", fn);\n\t\tunlink(\"/ram/netcfg.tmp\");\n\t}\n\treturn 0;\n\nerror:\n\tfclose(f);\n\treturn -1;\n}\n\nint netcfg_save(const netcfg_t * cfg) {\n\tfile_t f;\n\tdirent_t * d;\n\tchar buf[64];\n\n\t// Scan for a VMU\n\tf = fs_open(\"/vmu\", O_RDONLY | O_DIR);\n\tif (f < 0)\n\t\treturn -1;\n\n\td = fs_readdir(f);\n\tif (!d) {\n\t\tfs_close(f);\n\t\treturn -1;\n\t}\n\n\tsprintf(buf, \"/vmu/%s/net.cfg\", d->name);\n\tfs_close(f);\n\n\treturn netcfg_save_to(buf, cfg);\n}\n"
},
{
"alpha_fraction": 0.5375407934188843,
"alphanum_fraction": 0.5588372349739075,
"avg_line_length": 15.577319145202637,
"blob_id": "b295fae87d0ba32523fc816f8ee3ba62a55c55b9",
"content_id": "50182a444ae3596d43e5a8684552675e9de8ef11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6433,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 388,
"path": "/libc/stdio/stdio.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n stdio.c\n (c)2000-2001 Tobias Gloth\n\n*/\n\n#include <kos/fs.h>\n\nCVSID(\"$Id: stdio.c,v 1.6 2003/06/19 04:31:26 bardtx Exp $\");\n\n#define MAX_FILE 16\n\ntypedef struct _FILE_t {\n\tfile_t file;\n\tuint8 used;\n\tuint8 owner;\n\tuint8 error;\n\tuint8 eof;\n\tuint8 putback;\n\tuint8 has_putback;\n} _FILE_t;\n\n#include <stdio.h>\n#include <string.h>\n#include <arch/spinlock.h>\n\nstatic FILE f[MAX_FILE];\nstatic int f_used = 0;\n\n/* Thread mutex */\nstatic spinlock_t mutex;\n\n#define VALID_FILE(X) (((X) >= &f[0]) && ((X) < &f[MAX_FILE]) && ((X)->used))\n\nstatic FILE *alloc_file() {\n\tFILE *result = 0;\n\tspinlock_lock(&mutex);\n\tif (f_used <= MAX_FILE) {\n\t\tint i;\n\t\tfor (i=0; i<MAX_FILE; i++) {\n\t\t\tif (!f[i].used) {\n\t\t\t\tf[i].file = 0;\n\t\t\t\tf[i].used = 1;\n\t\t\t\tf[i].owner = 1;\n\t\t\t\tf[i].eof = 0;\n\t\t\t\tf[i].error = 0;\n\t\t\t\tf[i].putback = 0;\n\t\t\t\tf[i].has_putback = 0;\n\t\t\t\tresult = f+i;\n\t\t\t\tf_used++;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n\tspinlock_unlock(&mutex);\n\treturn result;\n}\n\nstatic void release_file(FILE *file) {\n\tspinlock_lock(&mutex);\n\tif (VALID_FILE(file)) {\n\t\tfile->used = 0;\n\t\tf_used--;\n\t}\n\tspinlock_unlock(&mutex);\n}\n\nstatic int convert_mode(const char *mode) {\n\n\t/* try to parse it corrrectly */\n\tint mode_r = 0, mode_a = 0, mode_w = 0, mode_b = 0, mode_p = 0;\n\n\tif (mode == (char *)0) {\n\t\treturn -1;\n\t}\n\tif (*mode == 'r') {\n\t\tmode_r=1;\n\t} else if (*mode == 'w') {\n\t\tmode_w=1;\n\t} else if (*mode == 'a') {\n\t\tmode_w=1;\n\t} else {\n\t\treturn -1;\n\t}\n\tmode++;\n\tif (*mode == 'b') {\n\t\tmode_b = 1;\n\t\tmode++;\n\t}\n\tif (*mode == '+') {\n\t\tmode_p = 1;\n\t\tmode++;\n\t}\n\tif ((*mode == 'b') && (mode_b == 0)) {\n\t\tmode_b = 1;\n\t\tmode++;\n\t} else if (*mode != '\\0') {\n\t\treturn -1;\n\t}\n\n\tif (mode_r && !mode_p) {\n\t\treturn O_RDONLY;\n\t} else if (mode_r && mode_p) {\n\t\treturn O_RDWR;\n\t} else if (mode_w && !mode_p) {\n\t\treturn O_WRONLY | O_TRUNC;\n\t} else if (mode_w && mode_p) {\n\t\treturn O_RDWR | O_TRUNC;\n\t} else if (mode_a && !mode_p) {\n\t\treturn O_APPEND;\n\t} else if (mode_a && mode_p) {\n\t\treturn O_APPEND;\n\t}\n\n\treturn -1;\n}\n\nFILE *fopen(const char *path, const char *mode) {\n\n\tfile_t file;\n\tint fsMode;\n\tFILE *result;\n\n\tfsMode = convert_mode (mode);\n\tif (fsMode == -1) {\n\t\treturn (FILE *)0;\n\t}\n\tresult = alloc_file();\n\tif (!result) {\n\t\treturn (FILE *)0;\n\t}\n\n\tfile = fs_open (path, fsMode);\n\tif (file < 0) {\n\t\trelease_file(result);\n\t\treturn (FILE *)0;\n\t}\n\n\tresult->file = file;\n\n\treturn result;\n}\n\nFILE *fdopen(int file, const char *mode) {\n\n\tFILE *result;\n\n\tif (file < 0) {\n\t\treturn (FILE *)0;\n\t}\n\tresult = alloc_file();\n\tif (!result) {\n\t\treturn (FILE *)0;\n\t}\n\n\tresult->file = file;\n\tresult->owner = 1;\n\n\treturn result;\n}\n\nFILE *freopen(const char *path, const char *mode, FILE *file) {\n\n\tint fsMode;\n\n\tif (VALID_FILE(file)) {\n\t\tif (file->owner) {\n\t\t\tfs_close(file->file);\n\t\t}\n\t}\n\n\tfsMode = convert_mode (mode);\n\tif (fsMode == -1) {\n\t\tif (VALID_FILE(file)) {\n\t\t\trelease_file(file);\n\t\t}\n\t\treturn (FILE *)0;\n\t}\n\n\tif (!VALID_FILE(file)) {\n\t\tfile = alloc_file();\n\t}\n\tif (!VALID_FILE(file)) {\n\t\treturn (FILE *)0;\n\t}\n\n\tfile->file = fs_open (path, fsMode);\n\tif (file->file == 0) {\n\t\trelease_file(file);\n\t\treturn (FILE *)0;\n\t}\n\n\tfile->owner = 1;\n\tfile->eof = 0;\n\tfile->error = 0;\n\treturn file;\n}\n\nint fclose(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn EOF;\n\t}\n\tif (file->owner) {\n\t\tfs_close(file->file);\n\t}\n\trelease_file (file);\n\treturn 0;\n}\n\nsize_t fread(void *ptr, size_t size, size_t nmemb, FILE *file) {\n\tsize_t result = 0, to_read = size * nmemb;\n\tif (!VALID_FILE(file) || (to_read == 0)) {\n\t\treturn 0;\n\t}\n\tif (file->has_putback) {\n\t\tunsigned char *tmp = (unsigned char *)ptr;\n\t\t*tmp = file->putback;\n\t\tptr = tmp+1;\n\t\tfile->has_putback = 0;\n\t\tresult++;\n\t\tto_read--;\n\t}\n\tresult += fs_read(file->file, ptr, to_read);\n\tresult = result / size;\n\tif (result < 0) {\n\t\tfile->error = 1;\n\t\treturn 0;\n\t}\n\tif (result < nmemb) {\n\t\tfile->eof = 1;\n\t}\n\treturn result;\n}\n\nint fgetc(FILE *file) {\n\tunsigned char ch;\n\tif (!fread(&ch, 1, 1, file)) {\n\t\treturn EOF;\n\t}\n\treturn (int)ch;\n}\n\nint getc(FILE * file) {\n\treturn fgetc(file);\n}\n\nint ungetc(int c, FILE *file) {\n\tif (!VALID_FILE(file) || (file->has_putback) ||\n\t\t(fs_tell(file->file) <= 0)) {\n\t\treturn EOF;\n\t}\n\tfile->putback = c;\n\tfile->has_putback = 1;\n\treturn c;\n}\n\nchar *fgets(char *s, int size, FILE *file) {\n\n\tint i, ch;\n\n\tif (!VALID_FILE(file) || !s) {\n\t\treturn (char *)0;\n\t}\n\tfor (i=0; i<size-1; i++) {\n\t\tch = s[i] = fgetc (file);\n\t\tif (ch == EOF) {\n\t\t\tbreak;\n\t\t}\n\t\tif (ch == '\\n') {\n\t\t\ti++;\n\t\t\tbreak;\n\t\t}\n\t}\n\ts[i] = '\\0';\n\treturn (i == 0) ? (char *)0 : s;\n}\n\nsize_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn 0;\n\t}\n\tif (file->has_putback) {\n\t\tfs_seek(file->file, -1, SEEK_CUR);\n\t\tfile->has_putback = 0;\n\t}\n\treturn fs_write(file->file, ptr, size*nmemb)/size;\n}\n\nint fputc(int ch, FILE *file) {\n\tunsigned char c = (unsigned char)ch;\n\tif (!fwrite(&c, 1, 1, file)) {\n\t\treturn EOF;\n\t}\n\treturn ch;\n}\n\nint puts(const char *str) {\n\tsize_t size = str ? strlen(str) : 0;\n\tsize_t written = printf (\"%s\\n\", str);\n\treturn (written == size+1) ? 0 : EOF;\n}\n\nint fputs(const char *s, FILE *file) {\n\n\tint len;\n\n\tif (!VALID_FILE(file) || !s) {\n\t\treturn -1;\n\t}\n\tlen = strlen(s);\n\tif (fs_write(file->file, s, len) != len) {\n\t\treturn -1;\n\t}\n\treturn 0;\n}\n\nint fflush(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\t/* I think everything is flushed anyway */\n\treturn 0;\n}\n\nint fseek(FILE *file, long offset, int whence) {\n\tif (!VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\tfile->has_putback = 0;\n\treturn fs_seek(file->file, offset, whence) == -1 ? -1 : 0;\n}\n\nlong ftell(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\treturn (long)fs_tell(file->file) - (file->has_putback ? 1 : 0);\n}\n\nvoid rewind(FILE *file) {\n\tfseek(file, 0, SEEK_SET);\n}\n\nint fgetpos(FILE *file, fpos_t *pos) {\n\tif (!pos || !VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\t*pos = fs_tell(file->file) - (file->has_putback ? 1 : 0);\n\treturn (*pos == -1) ? -1 : 0;\n}\n\nint fsetpos(FILE *file, const fpos_t *pos) {\n\tif (!pos || !VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\tfile->has_putback = 0;\n\treturn fs_seek(file->file, *pos, SEEK_SET) == -1 ? -1 : 0;\n}\n\nvoid clearerr(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn;\n\t}\n\tfile->error = 0;\n\tfile->eof = 0;\n}\n\nint ferror(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\treturn (int)file->error;\n}\n\nint feof(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn -1;\n\t}\n\treturn (int)file->eof;\n}\n\nint fileno(FILE *file) {\n\tif (!VALID_FILE(file)) {\n\t\treturn 0;\n\t}\n\treturn file->file;\n}\n\n"
},
{
"alpha_fraction": 0.6170557141304016,
"alphanum_fraction": 0.6258377432823181,
"avg_line_length": 22.906076431274414,
"blob_id": "06cf52f7af620038a53b76ff1675854bce951f2c",
"content_id": "c95464e12ef8ace30ec3db50acabc90cf988d80d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4327,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 181,
"path": "/kernel/net/net_core.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_core.c\n\n Copyright (C) 2002 Dan Potter\n Copyright (C) 2005 Lawrence Sebald\n*/\n\n#include <string.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <kos/net.h>\n#include <kos/fs_socket.h>\n\nCVSID(\"$Id: net_core.c,v 1.5 2002/10/26 07:59:50 bardtx Exp $\");\n\n/*\n\nThis module, and others in this tree, handle the architecture-independent\npart of the networking system of KOS. They serve the following purposes:\n\n- Specific network card drivers may register themselves using the functions\n here, if their hardware is present\n- Link-level messages will be handled here, such as ARP\n- The whole networking system can be enabled or disabled from here\n \n*/\n\n/**************************************************************************/\n/* Variables */\n\n/* Active network devices list */\nstruct netif_list net_if_list = LIST_HEAD_INITIALIZER(0);\n\n/* ARP cache */ \nstruct netarp_list net_arp_cache = LIST_HEAD_INITIALIZER(0);\n\n/* Default net device */\nnetif_t *net_default_dev = NULL;\n\n/**************************************************************************/\n/* Driver list management\n Note that this stuff might be used before net_core is actually\n itself initialized. This lets us let the drivers build up the available\n driver list, and then we'll come back later and look through them all. */\n\n/* Register a network device */\nint net_reg_device(netif_t *device) {\n\t/* Make sure it's not already registered */\n\tif (device->flags & NETIF_REGISTERED) {\n\t\tdbglog(DBG_WARNING, \"net_reg_device: '%s' is already registered\\n\",\n\t\t\tdevice->name);\n\t\treturn -1;\n\t}\n\n\t/* Insert it into the interface list */\n\tLIST_INSERT_HEAD(&net_if_list, device, if_list);\n\n\t/* Mark it as registered */\n\tdevice->flags |= NETIF_REGISTERED;\n\n\t/* We need to do more processing in here eventually like looking for\n\t duplicate device IDs and assigning new indeces, but that can\n\t wait until we're actually supporting a box with the possibility\n\t of more than one network interface... which probably won't happen\n\t any time soon... */\n\n\t/* Success */\n\treturn 0;\n}\n\n/* Unregister a network device */\nint net_unreg_device(netif_t *device) {\n\t/* Make sure it really was registered */\n\tif (!(device->flags & NETIF_REGISTERED)) {\n\t\tdbglog(DBG_WARNING, \"net_unreg_device: '%s' isn't registered\\n\",\n\t\t\tdevice->name);\n\t\treturn -1;\n\t}\n\n\t/* Remove it from the list */\n\tLIST_REMOVE(device, if_list);\n\n\t/* Mark it as unregistered */\n\tdevice->flags &= ~NETIF_REGISTERED;\n\n\t/* Success */\n\treturn 0;\n}\n\nstruct netif_list * net_get_if_list() {\n\treturn &net_if_list;\n}\n\n/*****************************************************************************/\n/* Init/shutdown */\n\n/* Set default */\nnetif_t *net_set_default(netif_t *n)\t{\n netif_t *olddev = net_default_dev;\n\n\tnet_default_dev = n;\n\n\treturn olddev;\n}\n\n/* Device detect / init */\nint net_dev_init() {\n\tint detected = 0;\n\tnetif_t *cur;\n\n\tLIST_FOREACH(cur, &net_if_list, if_list) {\n\t\t/* Make sure we have one */\n\t\tif (cur->if_detect(cur) < 0)\n\t\t\tcontinue;\n\n\t\t/* Ok, we do -- initialize it */\n\t\tif (cur->if_init(cur) < 0)\n\t\t\tcontinue;\n\n\t\t/* It's initialized, so now enable it */\n\t\tif (cur->if_start(cur) < 0) {\n\t\t\tcur->if_shutdown(cur);\n\t\t\tcontinue;\n\t\t}\n\n /* Set the first detected device to be the default */\n if(net_default_dev == NULL)\n net_set_default(cur);\n\n\t\tdetected++;\n\t}\n\n\tdbglog(DBG_DEBUG, \"net_dev_init: detected %d usable network device(s)\\n\", detected);\n\n\treturn 0;\n}\n\n/* Init */\nint net_init() {\n\t/* Detect and potentially initialize devices */\n\tif (net_dev_init() < 0)\n\t\treturn -1;\n\t\n\t/* Initialize the ARP cache */\n\tnet_arp_init();\n\n\t/* Initialize the UDP system */\n\tnet_udp_init();\n\n\t/* Initialize the sockets-like interface */\n\tfs_socket_init();\n\n\treturn 0;\n}\n\n/* Shutdown */\nvoid net_shutdown() {\n\tnetif_t *cur;\n\n\t/* Shut down the sockets-like interface */\n\tfs_socket_shutdown();\n\n\t/* Shut down the UDP system */\n\tnet_udp_shutdown();\n\n\t/* Shut down the ARP cache */\n\tnet_arp_shutdown();\n\n\t/* Shut down all activated network devices */\n\tLIST_FOREACH(cur, &net_if_list, if_list) {\n\t\tif (cur->flags & NETIF_RUNNING && cur->if_stop)\n\t\t\tcur->if_stop(cur);\n\t\tif (cur->flags & NETIF_INITIALIZED && cur->if_shutdown)\n\t\t\tcur->if_shutdown(cur);\n\t\tcur->flags &= ~NETIF_REGISTERED;\n\t}\n\n\t/* Blank out the list */\n\tLIST_INIT(&net_if_list);\n}\n"
},
{
"alpha_fraction": 0.64833003282547,
"alphanum_fraction": 0.699410617351532,
"avg_line_length": 23.238094329833984,
"blob_id": "c01aefa1398dcc3a29a2c3399b2f358399540d5d",
"content_id": "9f8aaa652f9fe66ecf442d5adc66f544d31ea56f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 21,
"path": "/kernel/arch/ia32/boot/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ia32/loader/Makefile\n#\n# $Id: Makefile,v 1.2 2003/08/02 09:14:11 bardtx Exp $\n\nall:\n\tnasm loader.asm -o loader.bin\n\ninstall: all\n\t$(KOS_OBJCOPY) -O binary ../../../../lib/kernel.elf kernel.bin\n\tcat kernel.bin >> loader.bin\n\tdd if=loader.bin of=/home/bard/.bochs/hd0 seek=4032 bs=512 conv=notrunc\n\n# Use this if you want a kosher binary for disassembly, for checking exactly\n# what nasm did.\ntestbin:\n\tnasm -g -felf loader.asm -o loader.o\n\nclean:\n\trm -f loader.bin kernel.bin\n"
},
{
"alpha_fraction": 0.6622516512870789,
"alphanum_fraction": 0.695364236831665,
"avg_line_length": 26.05128288269043,
"blob_id": "90708b2cbf06bb73e3da2936853d9a88da9bb0dc",
"content_id": "b4fe3bd98f1e9948e6780de26efd11f41a32bb0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 39,
"path": "/include/arch/dreamcast/dc/matrix3d.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n matrix3d.h\n (c)2000 Dan Potter and Jordan DeLong\n\n $Id: matrix3d.h,v 1.1 2002/09/05 07:32:57 bardtx Exp $\n\n*/\n\n#ifndef __KOS_MATRIX3D_H\n#define __KOS_MATRIX3D_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <dc/matrix.h>\n\nvoid mat_rotate_x(float r);\nvoid mat_rotate_y(float r);\nvoid mat_rotate_z(float r);\nvoid mat_rotate(float xr, float yr, float zr);\nvoid mat_translate(float x, float y, float z);\nvoid mat_scale(float x, float y, float z);\n\n/**\n This sets up a perspective view frustum for basic 3D usage. The xcenter\n and ycenter parameters are dependent on your screen resolution (or however\n you want to do it); cot_fovy_2 is 1.0/tan(view_angle/2). Use 1.0 for a\n normal 90' view. znear and zfar are what they sound like. */\nvoid mat_perspective(float xcenter, float ycenter, float cot_fovy_2,\n\tfloat znear, float zfar);\n\n/**\n Performs a \"camera\" function with rotations and translations. */\nvoid mat_lookat(const point_t * eye, const point_t * center, const vector_t * up);\n\n__END_DECLS\n\n#endif\t/* __KOS_MATRIX3D_H */\n\n\n"
},
{
"alpha_fraction": 0.5939341187477112,
"alphanum_fraction": 0.6290639042854309,
"avg_line_length": 30.606897354125977,
"blob_id": "861b9e69ec5bcdb03cebfe5ed0f65ff3cb351119",
"content_id": "a94e509b0e41cff38560f8642a37eb39598e1da2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4583,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 145,
"path": "/examples/dreamcast/conio/adventure/done.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*-\n * Copyright (c) 1991, 1993\n *\tThe Regents of the University of California. All rights reserved.\n *\n * The game adventure was originally written in Fortran by Will Crowther\n * and Don Woods. It was later translated to C and enhanced by Jim\n * Gillogly. This code is derived from software contributed to Berkeley\n * by Jim Gillogly at The Rand Corporation.\n *\n * Redistribution and use in source and binary forms, with or without\n * modification, are permitted provided that the following conditions\n * are met:\n * 1. Redistributions of source code must retain the above copyright\n * notice, this list of conditions and the following disclaimer.\n * 2. Redistributions in binary form must reproduce the above copyright\n * notice, this list of conditions and the following disclaimer in the\n * documentation and/or other materials provided with the distribution.\n * 3. All advertising materials mentioning features or use of this software\n * must display the following acknowledgement:\n *\tThis product includes software developed by the University of\n *\tCalifornia, Berkeley and its contributors.\n * 4. Neither the name of the University nor the names of its contributors\n * may be used to endorse or promote products derived from this software\n * without specific prior written permission.\n *\n * THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND\n * ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n * IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n * ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE\n * FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n * DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS\n * OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)\n * HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT\n * LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY\n * OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF\n * SUCH DAMAGE.\n */\n\n#ifndef lint\n#if 0\nstatic char sccsid[] = \"@(#)done.c\t8.1 (Berkeley) 5/31/93\";\n#endif\nstatic const char rcsid[] =\n \"$FreeBSD: src/games/adventure/done.c,v 1.7 1999/12/19 00:21:50 billf Exp $\";\n#endif /* not lint */\n\n/* Re-coding of advent in C: termination routines */\n\n#include <stdio.h>\n#include \"hdr.h\"\n\nint\nscore() /* sort of like 20000 */\n{ int scor,i;\n\tmxscor=scor=0;\n\tfor (i=50; i<=maxtrs; i++)\n\t{\tif (ptext[i].txtlen==0) continue;\n\t\tk=12;\n\t\tif (i==chest) k=14;\n\t\tif (i>chest) k=16;\n\t\tif (prop[i]>=0) scor += 2;\n\t\tif (place[i]==3&&prop[i]==0) scor += k-2;\n\t\tmxscor += k;\n\t}\n\tscor += (maxdie-numdie)*10;\n\tmxscor += maxdie*10;\n\tif (!(scorng||gaveup)) scor += 4;\n\tmxscor += 4;\n\tif (dflag!=0) scor += 25;\n\tmxscor += 25;\n\tif (closng) scor += 25;\n\tmxscor += 25;\n\tif (closed)\n\t{ if (bonus==0) scor += 10;\n\t\tif (bonus==135) scor += 25;\n\t\tif (bonus==134) scor += 30;\n\t\tif (bonus==133) scor += 45;\n\t}\n\tmxscor += 45;\n\tif (place[magzin]==108) scor++;\n\tmxscor++;\n\tscor += 2;\n\tmxscor += 2;\n\tfor (i=1; i<=hntmax; i++)\n\t\tif (hinted[i]) scor -= hints[i][2];\n\treturn(scor);\n}\n\nvoid\ndone(entry) /* entry=1 means goto 13000 */ /* game is over */\nint entry; /* entry=2 means goto 20000 */ /* 3=19000 */\n{ int i,sc;\n\tif (entry==1) mspeak(1);\n\tif (entry==3) rspeak(136);\n\tprintf(\"\\n\\n\\nYou scored %d out of a \",(sc=score()));\n\tprintf(\"possible %d using %d turns.\\n\",mxscor,turns);\n\tfor (i=1; i<=clsses; i++)\n\t\tif (cval[i]>=sc)\n\t\t{ speak(&ctext[i]);\n\t\t\tif (i==clsses-1)\n\t\t\t{ printf(\"To achieve the next higher rating\");\n\t\t\t\tprintf(\" would be a neat trick!\\n\\n\");\n\t\t\t\tprintf(\"Congratulations!!\\n\");\n\t\t\t\texit(0);\n\t\t\t}\n\t\t\tk=cval[i]+1-sc;\n\t\t\tprintf(\"To achieve the next higher rating, you need\");\n\t\t\tprintf(\" %d more point\",k);\n\t\t\tif (k==1) printf(\".\\n\");\n\t\t\telse printf(\"s.\\n\");\n\t\t\texit(0);\n\t\t}\n\tprintf(\"You just went off my scale!!!\\n\");\n\texit(0);\n}\n\n\nvoid\ndie(entry) /* label 90 */\nint entry;\n{ int i;\n\tif (entry != 99)\n\t{ rspeak(23);\n\t\toldlc2=loc;\n\t}\n\tif (closng) /* 99 */\n\t{ rspeak(131);\n\t\tnumdie++;\n\t\tdone(2);\n\t}\n\tyea=yes(81+numdie*2,82+numdie*2,54);\n\tnumdie++;\n\tif (numdie==maxdie || !yea) done(2);\n\tplace[water]=0;\n\tplace[oil]=0;\n\tif (toting(lamp)) prop[lamp]=0;\n\tfor (i=100; i>=1; i--)\n\t{ if (!toting(i)) continue;\n\t\tk=oldlc2;\n\t\tif (i==lamp) k=1;\n\t\tdrop(i,k);\n\t}\n\tloc=3;\n\toldloc=loc;\n}\n"
},
{
"alpha_fraction": 0.5201793909072876,
"alphanum_fraction": 0.6143497824668884,
"avg_line_length": 13.800000190734863,
"blob_id": "ed0b008817c298315b47666ea34fd758705c0bb0",
"content_id": "2524a9643a9a8ca830a92d359d66b20df68cd7d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/ps2/basic/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/ps2/basic/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/10/27 23:41:13 bardtx Exp $\n\nall:\n\t$(MAKE) -C hello\n\nclean:\n\t$(MAKE) -C hello clean\n\t\t\ndist:\n\t$(MAKE) -C hello dist\n\n"
},
{
"alpha_fraction": 0.5472901463508606,
"alphanum_fraction": 0.5802338123321533,
"avg_line_length": 17.81999969482422,
"blob_id": "b2d161b2dcc7c4c4f139959d169107307969857e",
"content_id": "313ea1afee1bd38e08f8b7dbec711ed10004e41c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 50,
"path": "/examples/dreamcast/libdream/mouse/mouse.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#include <kos.h>\n\nvoid mouse_test() {\n\tmouse_cond_t mcond;\n\tcont_cond_t cond;\n\tuint8 mcont, mmouse;\n\tint c = 'M', x = 20, y = 20;\n\n\tprintf(\"Now doing mouse test\\n\");\t\n\twhile (1) {\n\t\tmcont = maple_first_controller();\n\t\tif (!mcont) continue;\n\t\tmmouse = maple_first_mouse();\n\t\tif (!mmouse) continue;\n\t\t\n\t\t/* Check for start on the controller */\n\t\tif (cont_get_cond(mcont, &cond) < 0) {\n\t\t\tprintf(\"Error getting controller status\\n\");\n\t\t\treturn;\n\t\t}\n\t\t\n\t\tif (!(cond.buttons & CONT_START)) {\n\t\t\tprintf(\"Pressed start\\n\");\n\t\t\treturn;\n\t\t}\n\t\t\n\t\tusleep(10 * 1000);\n\t\t\n\t\t/* Check for mouse input */\n\t\tif (mouse_get_cond(mmouse, &mcond) < 0)\n\t\t\tcontinue;\n\n\t\t/* Move the cursor if applicable */\n\t\tif (mcond.dx || mcond.dy || mcond.dz) {\n\t\t\tvid_clear(0,0,0);\n\t\t\tx += mcond.dx;\n\t\t\ty += mcond.dy;\n\t\t\tc += mcond.dz;\n\t\t\tbfont_draw(vram_s + (y*640+x), 640, 0, c);\n\t\t}\n\n\t\tusleep(10 * 1000);\n\t}\n}\n\nint main(int argc, char **argv) {\n\tmouse_test();\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6129032373428345,
"alphanum_fraction": 0.6129032373428345,
"avg_line_length": 22.25,
"blob_id": "b3c632d93ccd3d2bb0eba60acfe095e2e68e52e6",
"content_id": "528f397d4e9108faa4e3736fb72484ee5f905413",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 93,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-ld",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_LD} ${KOS_LDFLAGS} \"$@\" ${KOS_LIB_PATHS} ${KOS_LIBS}\n"
},
{
"alpha_fraction": 0.5504201650619507,
"alphanum_fraction": 0.6386554837226868,
"avg_line_length": 20.363636016845703,
"blob_id": "4215bc415e4e706f087760b57f3890fbabcfc824",
"content_id": "90c07fc69ebc8184433a87368c6201f99baf9414",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/kernel/net/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# net/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/02/10 20:31:43 bardtx Exp $\n\nOBJS = net_core.o net_arp.o net_input.o net_icmp.o net_ipv4.o net_udp.o\nSUBDIRS = \n\ninclude ../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.6198723912239075,
"alphanum_fraction": 0.6654512286186218,
"avg_line_length": 30.782608032226562,
"blob_id": "c4576b01aac81494ddd3f7b3345037130b402476",
"content_id": "a70d768db08ed3025bcabcaea9f2461d5af5bb4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2194,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 69,
"path": "/include/arch/dreamcast/dc/vmu_pkg.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/vmu_pkg.h\n (c)2002 Dan Potter\n\n $Id: vmu_pkg.h,v 1.2 2002/06/11 05:55:36 bardtx Exp $\n\n*/\n\n#ifndef __DC_VMU_PKG_H\n#define __DC_VMU_PKG_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* Anyone wanting to package a VMU file should create one of these\n somewhere; eventually it will be turned into a flat file that you\n can save using fs_vmu. */\ntypedef struct vmu_pkg {\n\tchar\t\tdesc_short[20];\t\t/* Short file description */\n\tchar\t\tdesc_long[36];\t\t/* Long file description */\n\tchar\t\tapp_id[20];\t\t/* Application ID */\n\tint\t\ticon_cnt;\t\t/* Number of icons */\n\tint\t\ticon_anim_speed;\t/* Icon animation speed */\n\tint\t\teyecatch_type;\t\t/* \"Eyecatch\" type */\n\tint\t\tdata_len;\t\t/* Number of data (payload) bytes */\n\tuint16\t\ticon_pal[16];\t\t/* Icon palette (ARGB4444) */\n\tconst uint8\t*icon_data;\t\t/* 512*n bytes of icon data */\n\tconst uint8\t*eyecatch_data;\t\t/* Eyecatch data */\n\tconst uint8\t*data;\t\t\t/* Payload data */\n} vmu_pkg_t;\n\n/* Final header format (will go into the VMU file itself) */\ntypedef struct vmu_hdr {\n\tchar\t\tdesc_short[16];\t\t/* Space-padded */\n\tchar\t\tdesc_long[32];\t\t/* Space-padded */\n\tchar\t\tapp_id[16];\t\t/* Null-padded */\n\tuint16\t\ticon_cnt;\n\tuint16\t\ticon_anim_speed;\n\tuint16\t\teyecatch_type;\n\tuint16\t\tcrc;\n\tuint32\t\tdata_len;\n\tuint8\t\treserved[20];\n\tuint16\t\ticon_pal[16];\n\t/* 512*n Icon Bitmaps */\n\t/* Eyecatch palette + bitmap */\n} vmu_hdr_t;\n\n/* Eyecatch types: all eyecatches are 72x56, but the pixel format is variable: */\n#define VMUPKG_EC_NONE\t\t0\n#define VMUPKG_EC_16BIT\t\t1\t/* 16-bit ARGB4444 */\n#define VMUPKG_EC_256COL\t2\t/* 256-color palette */\n#define VMUPKG_EC_16COL\t\t3\t/* 16-color palette */\n/* Note that in all of the above cases which use a palette, the palette entries\n are in ARGB4444 format and come directly before the pixel data itself. */\n\n/* Converts a vmu_pkg_t structure into an array of uint8's which may be\n written to a VMU file via fs_vmu, or whatever. */\nint vmu_pkg_build(vmu_pkg_t *src, uint8 ** dst, int * dst_size);\n/* Parse an array of uint8's (i.e. a VMU data file) into a \n * vmu_pkg_t package structure. */\nint vmu_pkg_parse(uint8 *data, vmu_pkg_t *pkg);\n\n\n__END_DECLS\n\n#endif\t/* __DC_VMU_PKG_H */\n\n"
},
{
"alpha_fraction": 0.4516417384147644,
"alphanum_fraction": 0.5378601551055908,
"avg_line_length": 22.687829971313477,
"blob_id": "4f0bf76f19615f80f945dba075cd92733fe8f40c",
"content_id": "9c31fa4b0bc88c3691d494ba079c7cfba548399b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4477,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 189,
"path": "/kernel/arch/dreamcast/math/matrix3d.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n matrix3d.c\n (c)2000-2002 Dan Potter and Jordan DeLong\n\n Some 3D utils to use with the matrix functions\n Based on example code by Marcus Comstedt\n*/\n\n#include <assert.h>\n#include <dc/fmath.h>\n#include <dc/matrix.h>\n#include <dc/matrix3d.h>\n\nCVSID(\"$Id: matrix3d.c,v 1.1 2002/09/05 07:32:13 bardtx Exp $\");\n\nstatic matrix_t tr_m __attribute__((aligned(32))) = {\n\t{ 1.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 1.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 1.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\nvoid mat_translate(float x, float y, float z) {\n\ttr_m[3][0] = x;\n\ttr_m[3][1] = y;\n\ttr_m[3][2] = z;\n\tmat_apply(&tr_m);\n}\n\nstatic matrix_t sc_m __attribute__((aligned(32))) = {\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\nvoid mat_scale(float xs, float ys, float zs) {\n\tsc_m[0][0] = xs;\n\tsc_m[1][1] = ys;\n\tsc_m[2][2] = zs;\n\tmat_apply(&sc_m);\n}\n\nstatic matrix_t rx_m __attribute__((aligned(32))) = {\n\t{ 1.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\nvoid mat_rotate_x(float r) {\n\trx_m[1][1] = rx_m[2][2] = fcos(r);\n\trx_m[2][1] = fsin(r);\n\trx_m[1][2] = -fsin(r);\n\tmat_apply(&rx_m);\n}\n\nstatic matrix_t ry_m __attribute__((aligned(32))) = {\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 1.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\nvoid mat_rotate_y(float r) {\n\try_m[0][0] = ry_m[2][2] = fcos(r);\n\try_m[2][0] = -fsin(r);\n\try_m[0][2] = fsin(r);\n\tmat_apply(&ry_m);\n}\n\nstatic matrix_t rz_m __attribute__((aligned(32))) = {\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 1.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\nvoid mat_rotate_z(float r) {\n\trz_m[0][0] = rz_m[1][1] = fcos(r);\n\trz_m[1][0] = fsin(r);\n\trz_m[0][1] = -fsin(r);\n\tmat_apply(&rz_m);\n}\n\nvoid mat_rotate(float xr, float yr, float zr) {\n\tmat_rotate_x(xr);\n\tmat_rotate_y(yr);\n\tmat_rotate_z(zr);\n}\n\n/* Some #define's so we can keep the nice looking matrices for reference */\n#define XCENTER 0.0f\n#define YCENTER 0.0f\n#define COT_FOVY_2 1.0f\n#define ZNEAR 1.0f\n#define ZFAR 100.0f\n\n/* Screen view matrix (used to transform to screen space) */\nstatic matrix_t sv_mat = {\n\t{ YCENTER, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, YCENTER, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 1.0f, 0.0f },\n\t{ XCENTER, YCENTER, 0.0f, 1.0f }\n};\n\n/* Frustum matrix (does perspective) */\nstatic matrix_t fr_mat = {\n\t{ COT_FOVY_2, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, COT_FOVY_2, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, (ZFAR+ZNEAR)/(ZNEAR-ZFAR), -1.0f },\n\t{ 0.0f, 0.0f, 2*ZFAR*ZNEAR/(ZNEAR-ZFAR), 1.0f }\n};\n\nvoid mat_perspective(float xcenter, float ycenter, float cot_fovy_2,\n\tfloat znear, float zfar)\n{\n\t/* Setup the screenview matrix */\n\tsv_mat[0][0] = sv_mat[1][1] = sv_mat[3][1] = ycenter;\n\tsv_mat[3][0] = xcenter;\n\tmat_apply(&sv_mat);\n\n\t/* Setup the frustum matrix */\n\tassert( (znear - zfar) != 0 );\n\tfr_mat[0][0] = fr_mat[1][1] = cot_fovy_2;\n\tfr_mat[2][2] = (zfar + znear) / (znear - zfar);\n\tfr_mat[3][2] = 2*zfar*znear / (znear - zfar);\n\tmat_apply(&fr_mat);\n}\n\n\n/* The following lookat code is based heavily on KGL's gluLookAt */\n\n/* Should these be publically accessible somewhere? */\nstatic void normalize(vector_t * p) {\n\tfloat r;\n\n\tr = fsqrt( p->x*p->x + p->y*p->y + p->z*p->z );\n\tif (r == 0.0) return;\n\n\tp->x /= r;\n\tp->y /= r;\n\tp->z /= r;\n}\n\nstatic void cross(const vector_t * v1, const vector_t * v2, vector_t * r) {\n\tr->x = v1->y*v2->z - v1->z*v2->y;\n\tr->y = v1->z*v2->x - v1->x*v2->z;\n\tr->z = v1->x*v2->y - v1->y*v2->x;\n}\n\nstatic matrix_t ml __attribute__((aligned(32))) = {\n\t{ 1.0f, 0.0f, 0.0f, 0.0f },\n\t{ 0.0f, 1.0f, 0.0f, 0.0f },\n\t{ 0.0f, 0.0f, 1.0f, 0.0f },\n\t{ 0.0f, 0.0f, 0.0f, 1.0f }\n};\n\nvoid mat_lookat(const point_t * eye, const point_t * center, const vector_t * upi) {\n\tpoint_t forward, side, up;\n\n\tforward.x = center->x - eye->x;\n\tforward.y = center->y - eye->y;\n\tforward.z = center->z - eye->z;\n\n\tup.x = upi->x;\n\tup.y = upi->y;\n\tup.z = upi->z;\n\n\tnormalize(&forward);\n\n\t/* Side = forward x up */\n\tcross(&forward, &up, &side);\n\tnormalize(&side);\n\n\t/* Recompute up as: up = side x forward */\n\tcross(&side, &forward, &up);\n\n\tml[0][0] = side.x;\n\tml[1][0] = side.y;\n\tml[2][0] = side.z;\n\n\tml[0][1] = up.x;\n\tml[1][1] = up.y;\n\tml[2][1] = up.z;\n\n\tml[0][2] = -forward.x;\n\tml[1][2] = -forward.y;\n\tml[2][2] = -forward.z;\n\n\tmat_apply(&ml);\n\tmat_translate(-eye->x, -eye->y, -eye->z);\n}\n"
},
{
"alpha_fraction": 0.6700767278671265,
"alphanum_fraction": 0.7028985619544983,
"avg_line_length": 31.56944465637207,
"blob_id": "6590333a2f3b8cffd526c5fbb14377770931c0f4",
"content_id": "7aa61c5a0b23e0075cf23e8385c79a3343d2bf9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2346,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 72,
"path": "/include/kos/nmmgr.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/nmmgr.h\n Copyright (C)2003 Dan Potter\n\n $Id: nmmgr.h,v 1.1 2003/06/19 04:30:23 bardtx Exp $\n\n*/\n\n#ifndef __KOS_NMMGR_H\n#define __KOS_NMMGR_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <sys/queue.h>\n\n/* Pre-define list types */\nstruct nmmgr_handler;\ntypedef LIST_HEAD(nmmgr_list, nmmgr_handler) nmmgr_list_t;\n\n/* List entry initializer for static structs */\n#define NMMGR_LIST_INIT { NULL }\n\n/* Handler interface; all name handlers' must structs must begin with this\n prefix. If the handler conforms to some particular interface, then the\n struct must more specifically be of that type. */\ntypedef struct nmmgr_handler {\n\tchar\tpathname[MAX_FN_LEN];\t/* Path name */\n\tint\tpid;\t\t\t/* Process table ID for handler (0 == static) */\n\tuint32\tversion;\t\t/* Version code */\n\tuint32\tflags;\t\t\t/* Bitmask of flags */\n\tuint32\ttype;\t\t\t/* Type of handler */\n\tLIST_ENTRY(nmmgr_handler)\tlist_ent;\t/* Linked list entry */\n} nmmgr_handler_t;\n\n/* Version codes ('version') have two pieces: a major and minor revision.\n A major revision (top 16 bits) means that the interfaces are totally\n incompatible. A minor revision (lower 16 bits) diffrentiates between\n mostly-compatible but newer/older revisions of the implementing code. */\n\n/* Flag bits */\n#define NMMGR_FLAGS_NEEDSFREE\t0x00000001\t/* We need to free() this struct on remove */\n\n/* Name handler types. All \"system\" types are defined below 0x10000. */\n#define NMMGR_TYPE_UNKNOWN\t0x0000\t\t/* ? */\n#define NMMGR_TYPE_VFS\t\t0x0010\t\t/* Mounted file system */\n#define NMMGR_TYPE_BLOCKDEV\t0x0020\t\t/* Block device */\n#define NMMGR_TYPE_SINGLETON\t0x0030\t\t/* Singleton service (e.g., /dev/irq) */\n#define NMMGR_TYPE_SYMTAB\t0x0040\t\t/* Symbol table */\n#define NMMGR_SYS_MAX\t\t0x10000\t\t/* Here and above are user types */\n\n/* Given a pathname, return the name handler corresponding to it\n (or NULL if there is none). */\nnmmgr_handler_t * nmmgr_lookup(const char *name);\n\n/* Get the head element of our name list. This is for READ-ONLY PURPOSES ONLY. */\nnmmgr_list_t * nmmgr_get_list();\n\n/* Add/Remove a name handler module */\nint\tnmmgr_handler_add(nmmgr_handler_t *hnd);\nint\tnmmgr_handler_remove(nmmgr_handler_t *hnd);\n\n/* Name manager init */\nint\tnmmgr_init();\nvoid \tnmmgr_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_NMMGR_H */\n\n"
},
{
"alpha_fraction": 0.6939501762390137,
"alphanum_fraction": 0.6975088715553284,
"avg_line_length": 20.615385055541992,
"blob_id": "d65b42577b0b22284f071ff1f79303ac619651ca",
"content_id": "6521320a1e82066cc684d2d3232626cbd7ef9daf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 281,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/utils/gnu_wrappers/kos-c++",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\nexport KOS_CPP=1\nsource kos-cc\n\n# This may actually require bash...\n\n# Just supplement the standard C flags and call down.\nexport KOS_CC=\"${KOS_CCPLUS}\"\nexport KOS_CFLAGS=\"${KOS_CFLAGS} ${KOS_CPPFLAGS}\"\nexport KOS_LIBS=\"-lstdc++ ${KOS_LIBS}\"\n\nmain \"$@\"\n"
},
{
"alpha_fraction": 0.6631723046302795,
"alphanum_fraction": 0.6773017048835754,
"avg_line_length": 21.15151596069336,
"blob_id": "f0ebe01dbc410b488aac909896efb2c7c0612f53",
"content_id": "6c1dde543f515bc275ee133bfdacbc80f5175b25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2194,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 99,
"path": "/include/kos.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos.h\n (c)2001 Dan Potter\n\n $Id: kos.h,v 1.25 2003/05/23 02:18:45 bardtx Exp $\n*/\n\n#ifndef __KOS_H\n#define __KOS_H\n\n/* The ultimate for the truly lazy: include and go! No more figuring out\n which headers to include for your project. */\n\n#include <kos/cdefs.h>\n__BEGIN_DECLS\n\n#include <ctype.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <string.h>\n#include <unistd.h>\n\n#include <kos/fs.h>\n#include <kos/fs_builtin.h>\n#include <kos/fs_romdisk.h>\n#include <kos/fs_ramdisk.h>\n#include <kos/fs_pty.h>\n#include <kos/limits.h>\n#include <kos/thread.h>\n#include <kos/sem.h>\n#include <kos/mutex.h>\n#include <kos/cond.h>\n#include <kos/genwait.h>\n#include <kos/library.h>\n#include <kos/net.h>\n#include <kos/nmmgr.h>\n#include <kos/exports.h>\n#include <kos/dbgio.h>\n\n#include <arch/arch.h>\n#include <arch/cache.h>\n#include <arch/irq.h>\n#include <arch/spinlock.h>\n#include <arch/timer.h>\n#include <arch/types.h>\n#include <arch/exec.h>\n#include <arch/stack.h>\n\n#ifdef _arch_dreamcast\n#\tinclude <arch/mmu.h>\n\n#\tinclude <dc/biosfont.h>\n#\tinclude <dc/cdrom.h>\n#\tinclude <dc/fs_dcload.h>\n#\tinclude <dc/fs_iso9660.h>\n#\tinclude <dc/fs_vmu.h>\n#\tinclude <dc/asic.h>\n#\tinclude <dc/maple.h>\n#\tinclude <dc/maple/controller.h>\n#\tinclude <dc/maple/keyboard.h>\n#\tinclude <dc/maple/mouse.h>\n#\tinclude <dc/maple/vmu.h>\n#\tinclude <dc/maple/sip.h>\n#\tinclude <dc/maple/purupuru.h>\n#\tinclude <dc/vmu_pkg.h>\n#\tinclude <dc/spu.h>\n#\tinclude <dc/pvr.h>\n#\tinclude <dc/video.h>\n#\tinclude <dc/fmath.h>\n#\tinclude <dc/matrix.h>\n#\tinclude <dc/sound/stream.h>\n#\tinclude <dc/sound/sfxmgr.h>\n#\tinclude <dc/net/broadband_adapter.h>\n#\tinclude <dc/net/lan_adapter.h>\n#\tinclude <dc/modem/modem.h>\n#\tinclude <dc/sq.h>\n#\tinclude <dc/ubc.h>\n#\tinclude <dc/flashrom.h>\n#\tinclude <dc/vblank.h>\n#\tinclude <dc/vmufs.h>\n#\tinclude <dc/scif.h>\n#elif _arch_gba\t/* _arch_dreamcast */\n#\tinclude <gba/keys.h>\n#\tinclude <gba/sprite.h>\n#\tinclude <gba/video.h>\n#\tinclude <gba/dma.h>\n#\tinclude <gba/sound.h>\n#elif _arch_ps2 /* _arch_gba */\n#\tinclude <ps2/ioports.h>\n#\tinclude\t<ps2/fs_ps2load.h>\n#\tinclude <ps2/sbios.h>\n#else\t/* _arch_ps2 */\n#\terror Invalid architecture or no architecture specified\n#endif\n\n__END_DECLS\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5995057225227356,
"alphanum_fraction": 0.6422997117042542,
"avg_line_length": 25.415807723999023,
"blob_id": "3576fa51a3c019da2464df42451648c7b0b82417",
"content_id": "10061aa0307db9ad4f56c1a900e84a94dec2816b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7688,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 291,
"path": "/examples/dreamcast/kgl/demos/bubbles/bubbles.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/*\n KallistiOS ##version##\n bubbles.c\n\n (c)2002 Dan Potter\n*/\n\n#include <kos.h>\n#include <math.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n\n/*\n\nThis example shows off something truly evil ;-)\n\nKGL is a really nice API for doing some quick graphics work without having\nto worry about the little issues like vertex structures, 3D rotations, etc.\nBut sometimes KGL just isn't fast enough for what you want to do. This came\nup recently during an effect I was working on for a game project. So for this\ncase, the Direct Rendering macros were created.\n\nThe basic problem is that the DC's SH-4 makes very inefficient use of the\nRAM, and has no L2 cache. So if you use RAM in your PVR-feeding loop, you're\nlikely to blow 3-4 times as many cycles as you really need to. What we really\nwant to do is eliminate all function calls, all RAM access, and streamline\neverything as much as possible. So here's the basic idea:\n\n- Inline all access to hardware rather than calling functions; so store queue\n functions, TA submission, etc, are all handled inline by the macros\n- Do not involve RAM at all, except maybe a small stack page if neccessary\n for each variables; a memory stucture is not even used for storing vertex\n data while it is being prepared -- it is written directly into the store\n queues as it's generated.\n- Bypass KGL entirely for transformations and data submission\n\nObviously as KGL becomes more complex, this means you have more and more of\na burden to shoulder to do it this way, but sometimes you just need more\ndirect access, and this is a good way.\n\nThis sample uses 4800 triangles per frame, for 288000 per second at 60fps\nfor the translucent version, and 9600 per frame, for 576000 per\nsecond at 60fps.\n\nPre-DR, I was able to barely maintain 30fps with 6 spheres, and with this\nnew optimized version, I can now easily do 12 spheres at 60fps even with\ntranslucent polys, so the difference is quite marked.\n\n*/\n\n\n/* Draws a sphere out of GL_QUADS according to the syntax of glutSolidSphere\n\n This now uses triangle strips and KGL/PVR Direct Rendering for the best\n possible performance.\n\n Based very loosely on a routine from James Susinno.\n*/\nstatic float phase = 0.0f;\nstatic pvr_poly_cxt_t cxt;\nstatic pvr_poly_hdr_t hdr;\nstatic void sphere( float radius, int slices, int stacks ) {\n\tint\ti, j;\n\tfloat\tpitch, pitch2;\n\tfloat\tx, y, z, g, b;\n\tfloat\tyaw, yaw2;\n\tpvr_vertex_t\t*vert;\n\tpvr_dr_state_t\tdr_state;\n\n\t/* Setup our Direct Render state: pick a store queue and setup QACR0/1 */\n\tpvr_dr_init(dr_state);\n\n\t/* Initialize xmtrx with the values from KGL */\n\tglKosMatrixIdent();\n\tglKosMatrixApply(GL_KOS_SCREENVIEW);\n\tglKosMatrixApply(GL_PROJECTION);\n\tglKosMatrixApply(GL_MODELVIEW);\n\n\t/* Put our own polygon header */\n\tpvr_prim(&hdr, sizeof(hdr));\n\n\t/* Iterate over stacks */\n\tfor ( i=0; i<stacks; i++ ) {\n\t\tpitch = 2*M_PI * ( (float)i/(float)stacks );\n\t\tpitch2 = 2*M_PI * ( (float)(i+1)/(float)stacks );\n\n\t\t/* Iterate over slices: each entire stack will be one\n\t\t long triangle strip. */\n\t\tfor ( j=0; j<=slices/2; j++ ) {\n\t\t\tyaw = 2*M_PI * ( (float)j/(float)slices );\n\t\t\tyaw2 = 2*M_PI * ( (float)(j+1)/(float)slices );\n\n\t\t\t/* x, y+1 */\n\t\t\tx = radius * fcos( yaw ) * fcos( pitch2 );\n\t\t\ty = radius * fsin( pitch2 );\n\t\t\tz = radius * fsin( yaw ) * fcos( pitch2 );\n\t\t\tmat_trans_single(x, y, z);\t\t\t/* Use ftrv to transform */\n\t\t\tg = fcos( yaw*2 ) / 2.0f + 0.5f;\n\t\t\tb = fsin( phase + pitch2 ) / 2.0f + 0.5f;\n\t\t\tvert = pvr_dr_target(dr_state);\t\t\t/* Get a store queue address */\n\t\t\tvert->flags = PVR_CMD_VERTEX;\n\t\t\tvert->x = x;\n\t\t\tvert->y = y;\n\t\t\tvert->z = z;\n\t\t\tvert->u = 0.0f;\n\t\t\tvert->v = 0.0f;\n\t\t\tvert->argb = PVR_PACK_COLOR(0.5f, 0.0f, g, b);\n\t\t\tvert->oargb = 0xff000000;\n\t\t\tpvr_dr_commit(vert);\t\t\t\t/* Prefetch the SQ */\n \n\t\t\t/* x, y */\n\t\t\tx = radius * fcos( yaw ) * fcos( pitch );\n\t\t\ty = radius * fsin( pitch );\n\t\t\tz = radius * fsin( yaw ) * fcos( pitch );\n\t\t\tmat_trans_single(x, y, z);\n\t\t\tg = fcos( yaw*2 ) / 2.0f + 0.5f;\n\t\t\tb = fsin( phase + pitch ) / 2.0f + 0.5f;\n\t\t\tvert = pvr_dr_target(dr_state);\n\t\t\tif (j == (slices/2))\n\t\t\t\tvert->flags = PVR_CMD_VERTEX_EOL;\n\t\t\telse\n\t\t\t\tvert->flags = PVR_CMD_VERTEX;\n\t\t\tvert->x = x;\n\t\t\tvert->y = y;\n\t\t\tvert->z = z;\n\t\t\tvert->u = 0.0f;\n\t\t\tvert->v = 0.0f;\n\t\t\tvert->argb = PVR_PACK_COLOR(0.5f, 0.0f, g, b);\n\t\t\tvert->oargb = 0xff000000;\n\t\t\tpvr_dr_commit(vert);\n\t\t}\n\t}\n}\n\n#define SPHERE_CNT 12\nstatic int r = 0;\n\nstatic void sphere_frame_opaque() {\n\tint i;\n\n\tvid_border_color(255, 0, 0);\n\tglKosBeginFrame();\n\n\tvid_border_color(0, 255, 0);\n\n\tglLoadIdentity();\n\tglTranslatef(0.0f, 0.0f, -12.0f);\n\tglRotatef(r * 2, 0.75f, 1.0f, 0.5f);\n\tglDisable(GL_CULL_FACE);\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tglPushMatrix();\n\t\tglTranslatef(6.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 6.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tglRotatef(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(1.2f, 20, 20);\n\t\tglPopMatrix();\n\t}\n\n\tglLoadIdentity();\n\tglTranslatef(0.0f, 0.0f, -12.0f);\n\tglRotatef(-r * 2, 0.75f, 1.0f, 0.5f);\n\tglDisable(GL_CULL_FACE);\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tglPushMatrix();\n\t\tglTranslatef(3.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 3.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tglRotatef(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(0.8f, 20, 20);\n\t\tglPopMatrix();\n\t}\n\n\tglKosFinishList();\n\n\tvid_border_color(0, 0, 255);\n\tglKosFinishFrame();\n\tr++;\n\tphase += 2*M_PI / 240.0f;\n}\n\nstatic void sphere_frame_trans() {\n\tint i;\n\n\tglKosBeginFrame();\n\n\tglKosFinishList();\n\n\tvid_border_color(0, 255, 0);\n\tglLoadIdentity();\n\tglTranslatef(0.0f, 0.0f, -10.0f);\n\tglRotatef(15, 1.0f, 0.0f, 0.0f);\n\tglRotatef(r * 2, 0.75f, 1.0f, 0.5f);\n\tglDisable(GL_CULL_FACE);\n\n\tfor (i=0; i<SPHERE_CNT; i++) {\n\t\tglPushMatrix();\n\t\tglTranslatef(4.0f * fcos(i * 2*M_PI / SPHERE_CNT), 0.0f, 4.0f * fsin(i * 2*M_PI / SPHERE_CNT));\n\t\tglRotatef(r, 1.0f, 1.0f, 1.0f);\n\t\tsphere(1.0f, 20, 20);\n\t\tglPopMatrix();\n\t}\n\n\tvid_border_color(0, 0, 255);\n\tglKosFinishFrame();\n\tvid_border_color(255, 0, 0);\n\tr++;\n\tphase += 2*M_PI / 240.0f;\n}\n\nvoid do_sphere_test() {\n\tuint8\t\taddr;\n\tcont_cond_t\tcond;\n\tint\t\tmode = 0;\n\tint\t\ta_was_down = 0;\n\n\tglClearColor(0.2f, 0.0f, 0.4f, 1.0f);\n\tglDisable(GL_TEXTURE_2D);\n\n\tpvr_poly_cxt_col(&cxt, PVR_LIST_OP_POLY);\n\tcxt.gen.culling = PVR_CULLING_NONE;\n\tpvr_poly_compile(&hdr, &cxt);\n\n\tfor (;;) {\n\t\tif (!mode)\n\t\t\tsphere_frame_opaque();\n\t\telse\n\t\t\tsphere_frame_trans();\n\t\n\t\taddr = maple_first_controller();\n\t\tif (addr == 0)\n\t\t\tcontinue;\n\t\tif (cont_get_cond(addr, &cond) < 0)\n\t\t\tcontinue;\n\t\tif (!(cond.buttons & CONT_START)) {\n\t\t\treturn;\n\t\t}\n\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\tif (a_was_down) continue;\n\t\t\ta_was_down = 1;\n\t\t\tmode ^= 1;\n\t\t\tswitch(mode) {\n\t\t\tcase 0:\t/* Opaque */\n\t\t\t\tpvr_poly_cxt_col(&cxt, PVR_LIST_OP_POLY);\n\t\t\t\tcxt.gen.culling = PVR_CULLING_NONE;\n\t\t\t\tpvr_poly_compile(&hdr, &cxt);\n\t\t\t\tbreak;\n\t\t\tcase 1:\t/* Translucent */\n\t\t\t\tpvr_poly_cxt_col(&cxt, PVR_LIST_TR_POLY);\n\t\t\t\tcxt.gen.culling = PVR_CULLING_NONE;\n\t\t\t\tpvr_poly_compile(&hdr, &cxt);\n\t\t\t\tbreak;\n\t\t\t}\n\t\t} else {\n\t\t\ta_was_down = 0;\n\t\t}\n\t}\n}\n\npvr_init_params_t params = {\n\t/* Enable opaque and translucent polygons with size 16 */\n\t{ PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_16, PVR_BINSIZE_0, PVR_BINSIZE_0 },\n\t\n\t/* Vertex buffer size 512K */\n\t512*1024\n};\n\t\nint main(int argc, char **argv) {\n\t/* Init PVR API */\n\tif (pvr_init(¶ms) < 0)\n\t\treturn -1;\n\n\t/* Init KGL */\n\tglKosInit();\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglEnable(GL_TEXTURE_2D);\n\n\t/* Expect CW verts */\n\tglFrontFace(GL_CW);\n\n\t/* Enable Transparancy */\n\tglBlendFunc(GL_SRC_ALPHA, GL_ONE);\n\tglEnable(GL_DEPTH_TEST);\n\n\t/* Do the test */\n\tprintf(\"Bubbles KGL sample: press START to exit, A to toggle sphere type\\n\");\n\tdo_sphere_test();\n\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.5347825884819031,
"alphanum_fraction": 0.6217391490936279,
"avg_line_length": 14.199999809265137,
"blob_id": "99a460ad43ba0606b61238d63cc4290772bd4269",
"content_id": "6dadf68390c49e64043336bef1943408862b064d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 15,
"path": "/examples/dreamcast/video/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/video/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.1 2002/07/10 16:51:42 bardtx Exp $\n\nall:\n\t$(MAKE) -C bfont\n\nclean:\n\t$(MAKE) -C bfont clean\n\t\t\ndist:\n\t$(MAKE) -C bfont dist\n\n\n"
},
{
"alpha_fraction": 0.5408163070678711,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 19.63157844543457,
"blob_id": "c16c0f03e967999c2140e2e5068deb3e7a7faf70",
"content_id": "c5fe7e2440b8b5dc1b4fd81df5c2875a48d8b764",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 19,
"path": "/libc/stdio/perror.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n perror.c\n Copyright (C)2003 Dan Potter\n\n $Id: perror.c,v 1.1 2003/06/23 05:22:14 bardtx Exp $\n*/\n\n#include <stdlib.h>\n#include <stdio.h>\n#include <string.h>\n#include <errno.h>\n\nCVSID(\"$Id: perror.c,v 1.1 2003/06/23 05:22:14 bardtx Exp $\");\n\nvoid perror(const char * msg) {\n\t/* XXX: Should probably write to stderr */\n\tprintf(\"%s: %s\\n\", msg, strerror(errno));\n}\n"
},
{
"alpha_fraction": 0.6766794323921204,
"alphanum_fraction": 0.6843255162239075,
"avg_line_length": 30.016948699951172,
"blob_id": "864978bb415566a3a3205f945e422262ec6c1dae",
"content_id": "5c7f864ef86a22dd8c7e8abe737f86cde4d5c603",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1831,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 59,
"path": "/kernel/arch/dreamcast/fs/dcload-commands.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-commands.h\n\n Copyright (C)2003 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n#ifndef __COMMANDS_H__\n#define __COMMANDS_H__\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n#include \"dcload-packet.h\"\n\ntypedef struct {\n unsigned char id[4] __attribute__ ((packed));\n unsigned int address __attribute__ ((packed));\n unsigned int size __attribute__ ((packed));\n unsigned char data[1] __attribute__ ((packed));\n} command_t;\n\n#define DCLN_CMD_EXECUTE \"EXEC\" /* execute */\n#define DCLN_CMD_LOADBIN \"LBIN\" /* begin receiving binary */\n#define DCLN_CMD_PARTBIN \"PBIN\" /* part of a binary */\n#define DCLN_CMD_DONEBIN \"DBIN\" /* end receiving binary */\n#define DCLN_CMD_SENDBIN \"SBIN\" /* send a binary */\n#define DCLN_CMD_SENDBINQ \"SBIQ\" /* send a binary, quiet */\n#define DCLN_CMD_VERSION \"VERS\" /* send version info */\n\n#define DCLN_CMD_RETVAL \"RETV\" /* return value */\n\n#define DCLN_CMD_REBOOT \"RBOT\" /* reboot */\n\n#define COMMAND_LEN 12\n\nextern uint32 dcln_tool_ip;\nextern uint8 dcln_tool_mac[6];\nextern uint16 dcln_tool_port;\nextern int dcln_escape_loop;\n\nvoid dcln_cmd_loadbin(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_partbin(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_donebin(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_sendbinq(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_sendbin(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_version(ip_header_t * ip, udp_header_t * udp, command_t * command);\nvoid dcln_cmd_retval(ip_header_t * ip, udp_header_t * udp, command_t * command);\n\n__END_DECLS\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5733333230018616,
"alphanum_fraction": 0.6711111068725586,
"avg_line_length": 16.30769157409668,
"blob_id": "b49a4f2f97663ab9dd3fc292159b6e6cdbb96690",
"content_id": "81ceeef93b73d17c4d2998f230eddc2e7e923f5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/kernel/arch/ia32/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ia32 Makefile\n# Copyright (C)2003 Dan Potter\n# \n# $Id: Makefile,v 1.1 2003/08/01 03:18:36 bardtx Exp $\n\t\nSUBDIRS=kernel boot\n\ninclude ../../../Makefile.rules\n\nall: subdirs\nclean: clean_subdirs\n"
},
{
"alpha_fraction": 0.6744269132614136,
"alphanum_fraction": 0.7020057439804077,
"avg_line_length": 19.8358211517334,
"blob_id": "7879fcd195f3f7e8a0b12198c0c198c526f0cb80",
"content_id": "0d6b60c3f89430873bb4ee7330e6adac461b4f41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2792,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 134,
"path": "/kernel/libc/pthreads/pthread_mutex.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "// This can be useful for checking whether some pthread program compiled\n// correctly (e.g. libstdc++).\n// #define MUTEX_DEBUG 1\n\n#include <pthread.h>\n#include <errno.h>\n#include <assert.h>\n\n#if MUTEX_DEBUG == 1\n#include <stdio.h>\n#endif\n\n// XXX Recursive mutexes are not supported ... this could cause deadlocks\n// in code expecting it. Where do you set that!?\n\n/* Mutex Initialization Attributes, P1003.1c/Draft 10, p. 81 */ \n\nint pthread_mutexattr_init(pthread_mutexattr_t *attr) {\n\treturn 0;\n}\n\nint pthread_mutexattr_destroy(pthread_mutexattr_t *attr) {\n\treturn 0;\n}\n\nint pthread_mutexattr_getpshared(const pthread_mutexattr_t *attr, int *pshared) {\n\treturn 0;\n}\n\nint pthread_mutexattr_setpshared(pthread_mutexattr_t *attr, int pshared) {\n\treturn 0;\n}\n\n/* Initializing and Destroying a Mutex, P1003.1c/Draft 10, p. 87 */\n\nint pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *attr) {\n\tassert( mutex );\n\n\t*mutex = mutex_create();\n\tif (*mutex)\n\t\treturn 0;\n\telse\n\t\treturn EAGAIN;\n}\n\nint pthread_mutex_destroy(pthread_mutex_t *mutex) {\n\tassert( mutex );\n\n\tmutex_destroy(*mutex);\n\n\treturn 0;\n}\n\n// XXX mutexes made this way should probably be nuked at shutdown\n#define CHK_AND_CREATE \\\n\tif (*mutex == PTHREAD_MUTEX_INITIALIZER) { \\\n\t\tint rv = pthread_mutex_init(mutex, NULL); \\\n\t\tif (rv != 0) \\\n\t\t\treturn rv; \\\n\t}\n\n/* Locking and Unlocking a Mutex, P1003.1c/Draft 10, p. 93\n NOTE: P1003.4b/D8 adds pthread_mutex_timedlock(), p. 29 */\n\nint pthread_mutex_lock(pthread_mutex_t *mutex) {\n\tassert( mutex );\n\n\tCHK_AND_CREATE;\n\n\tmutex_lock(*mutex);\n\n#if MUTEX_DEBUG == 1\n\tprintf(\"locked %08x\\n\", mutex);\n#endif\n\n\treturn 0;\n}\n\nint pthread_mutex_trylock(pthread_mutex_t *mutex) {\n\tassert( mutex );\n\n\tCHK_AND_CREATE;\n\n\tif (mutex_trylock(*mutex) < 0) {\n\t\tif (errno == EAGAIN)\n\t\t\treturn EBUSY;\n\t\telse\n\t\t\treturn EINVAL;\n\t}\n\n\treturn 0;\n}\n\nint pthread_mutex_unlock(pthread_mutex_t *mutex) {\n\tassert( mutex );\n\n\tCHK_AND_CREATE;\n\n\tmutex_unlock(*mutex);\n\n#if MUTEX_DEBUG == 1\n\tprintf(\"locked %08x\\n\", mutex);\n#endif\n\n\treturn 0;\n}\n\n/* Mutex Initialization Scheduling Attributes, P1003.1c/Draft 10, p. 128 */\n\nint pthread_mutexattr_setprotocol(pthread_mutexattr_t *attr, int protocol) {\n\treturn 0;\n}\n\nint pthread_mutexattr_getprotocol(const pthread_mutexattr_t *attr, int *protocol) {\n\treturn EINVAL;\n}\n\nint pthread_mutexattr_setprioceiling(pthread_mutexattr_t *attr, int prioceiling) {\n\treturn 0;\n}\n\nint pthread_mutexattr_getprioceiling(const pthread_mutexattr_t *attr, int *prioceiling) {\n\treturn EINVAL;\n}\n\n/* Change the Priority Ceiling of a Mutex, P1003.1c/Draft 10, p. 131 */\n\nint pthread_mutex_setprioceiling(pthread_mutex_t *mutex, int prioceiling, int *old_ceiling) {\n\treturn 0;\n}\n\nint pthread_mutex_getprioceiling(pthread_mutex_t *mutex, int *prioceiling) {\n\treturn EINVAL;\n}\n"
},
{
"alpha_fraction": 0.4318181872367859,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 15.375,
"blob_id": "0330f6dd1be4bc1a2c20fea492ac7bb917e7d5c1",
"content_id": "562acfb8f35a3af35c481769e82b6286260d0a1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 8,
"path": "/utils/bin2c/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# bin2c util\n# (c)2000 Dan Potter\n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:00 bardtx Exp $\n\nall: bin2c\n\nbin2c:\n\tgcc -o bin2c bin2c.c\n\n"
},
{
"alpha_fraction": 0.6259884238243103,
"alphanum_fraction": 0.65375155210495,
"avg_line_length": 35.59807205200195,
"blob_id": "fd0e00aedb229633f64262d163239686cc2382bd",
"content_id": "18c0e2f53e3d07e17b7a1a53616218242f9e5b1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 11382,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 311,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_prim.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvr_prim.c\n (C)2002 Dan Potter\n\n */\n\n#include <assert.h>\n#include <string.h>\n#include <dc/pvr.h>\n#include \"pvr_internal.h\"\n\n/*\n\n Primitive handling\n\n These functions help you prepare primitives for loading into the\n PVR for scene processing.\n\n*/\n\nCVSID(\"$Id: pvr_prim.c,v 1.8 2002/09/13 04:38:41 bardtx Exp $\");\n\n/* Compile a polygon context into a polygon header */\nvoid pvr_poly_compile(pvr_poly_hdr_t *dst, pvr_poly_cxt_t *src) {\n\tint\tu, v;\n\tuint32\ttxr_base;\n\t\n\t/* Basically we just take each parameter, clip it, shift it\n\t into place, and OR it into the final result. */\n\n\t/* The base values for CMD */\n\tdst->cmd = PVR_CMD_POLYHDR;\n\tif (src->txr.enable == PVR_TEXTURE_ENABLE)\n\t\tdst->cmd |= 8;\n\n\t/* Or in the list type, shading type, color and UV formats */\n\tdst->cmd |= (src->list_type << PVR_TA_CMD_TYPE_SHIFT) & PVR_TA_CMD_TYPE_MASK;\n\tdst->cmd |= (src->fmt.color << PVR_TA_CMD_CLRFMT_SHIFT) & PVR_TA_CMD_CLRFMT_MASK;\n\tdst->cmd |= (src->gen.shading << PVR_TA_CMD_SHADE_SHIFT) & PVR_TA_CMD_SHADE_MASK;\n\tdst->cmd |= (src->fmt.uv << PVR_TA_CMD_UVFMT_SHIFT) & PVR_TA_CMD_UVFMT_MASK;\n\tdst->cmd |= (src->gen.clip_mode << PVR_TA_CMD_USERCLIP_SHIFT) & PVR_TA_CMD_USERCLIP_MASK;\n\tdst->cmd |= (src->fmt.modifier << PVR_TA_CMD_MODIFIER_SHIFT) & PVR_TA_CMD_MODIFIER_MASK;\n\tdst->cmd |= (src->gen.modifier_mode << PVR_TA_CMD_MODIFIERMODE_SHIFT) & PVR_TA_CMD_MODIFIERMODE_MASK;\n\n\t/* Polygon mode 1 */\n\tdst->mode1 = (src->depth.comparison << PVR_TA_PM1_DEPTHCMP_SHIFT) & PVR_TA_PM1_DEPTHCMP_MASK;\n\tdst->mode1 |= (src->gen.culling << PVR_TA_PM1_CULLING_SHIFT) & PVR_TA_PM1_CULLING_MASK;\n\tdst->mode1 |= (src->depth.write << PVR_TA_PM1_DEPTHWRITE_SHIFT) & PVR_TA_PM1_DEPTHWRITE_MASK;\n\tdst->mode1 |= (src->txr.enable << PVR_TA_PM1_TXRENABLE_SHIFT) & PVR_TA_PM1_TXRENABLE_MASK;\n\n\t/* Polygon mode 2 */\n\tdst->mode2 = (src->blend.src << PVR_TA_PM2_SRCBLEND_SHIFT) & PVR_TA_PM2_SRCBLEND_MASK;\n\tdst->mode2 |= (src->blend.dst << PVR_TA_PM2_DSTBLEND_SHIFT) & PVR_TA_PM2_DSTBLEND_MASK;\n\tdst->mode2 |= (src->blend.src_enable << PVR_TA_PM2_SRCENABLE_SHIFT) & PVR_TA_PM2_SRCENABLE_MASK;\n\tdst->mode2 |= (src->blend.dst_enable << PVR_TA_PM2_DSTENABLE_SHIFT) & PVR_TA_PM2_DSTENABLE_MASK;\n\tdst->mode2 |= (src->gen.fog_type << PVR_TA_PM2_FOG_SHIFT) & PVR_TA_PM2_FOG_MASK;\n\tdst->mode2 |= (src->gen.color_clamp << PVR_TA_PM2_CLAMP_SHIFT) & PVR_TA_PM2_CLAMP_MASK;\n\tdst->mode2 |= (src->gen.alpha << PVR_TA_PM2_ALPHA_SHIFT) & PVR_TA_PM2_ALPHA_MASK;\n\n\tif (src->txr.enable == PVR_TEXTURE_DISABLE) {\n\t\tdst->mode3 = 0;\n\t} else {\n\t\tdst->mode2 |= (src->txr.alpha << PVR_TA_PM2_TXRALPHA_SHIFT) & PVR_TA_PM2_TXRALPHA_MASK;\n\t\tdst->mode2 |= (src->txr.uv_flip << PVR_TA_PM2_UVFLIP_SHIFT) & PVR_TA_PM2_UVFLIP_MASK;\n\t\tdst->mode2 |= (src->txr.uv_clamp << PVR_TA_PM2_UVCLAMP_SHIFT) & PVR_TA_PM2_UVCLAMP_MASK;\n\t\tdst->mode2 |= (src->txr.filter << PVR_TA_PM2_FILTER_SHIFT) & PVR_TA_PM2_FILTER_MASK;\n\t\tdst->mode2 |= (src->txr.mipmap_bias << PVR_TA_PM2_MIPBIAS_SHIFT) & PVR_TA_PM2_MIPBIAS_MASK;\n\t\tdst->mode2 |= (src->txr.env << PVR_TA_PM2_TXRENV_SHIFT) & PVR_TA_PM2_TXRENV_MASK;\n\n\t\tswitch (src->txr.width) {\n\t\tcase 8:\t\tu = 0; break;\n\t\tcase 16:\tu = 1; break;\n\t\tcase 32:\tu = 2; break;\n\t\tcase 64:\tu = 3; break;\n\t\tcase 128:\tu = 4; break;\n\t\tcase 256:\tu = 5; break;\n\t\tcase 512:\tu = 6; break;\n\t\tcase 1024:\tu = 7; break;\n\t\tdefault:\tassert_msg(0, \"Invalid texture U size\"); u = 0; break;\n\t\t}\n\n\t\tswitch (src->txr.height) {\n\t\tcase 8:\t\tv = 0; break;\n\t\tcase 16:\tv = 1; break;\n\t\tcase 32:\tv = 2; break;\n\t\tcase 64:\tv = 3; break;\n\t\tcase 128:\tv = 4; break;\n\t\tcase 256:\tv = 5; break;\n\t\tcase 512:\tv = 6; break;\n\t\tcase 1024:\tv = 7; break;\n\t\tdefault:\tassert_msg(0, \"Invalid texture V size\"); v = 0; break;\n\t\t}\n\n\t\tdst->mode2 |= (u << PVR_TA_PM2_USIZE_SHIFT) & PVR_TA_PM2_USIZE_MASK;\n\t\tdst->mode2 |= (v << PVR_TA_PM2_VSIZE_SHIFT) & PVR_TA_PM2_VSIZE_MASK;\n\n\t\t/* Polygon mode 3 */\n\t\tdst->mode3 = (src->txr.mipmap << PVR_TA_PM3_MIPMAP_SHIFT) & PVR_TA_PM3_MIPMAP_MASK;\n\t\tdst->mode3 |= (src->txr.format << PVR_TA_PM3_TXRFMT_SHIFT) & PVR_TA_PM3_TXRFMT_MASK;\n\n\t\t/* Convert the texture address */\n\t\ttxr_base = (uint32)src->txr.base;\n\t\ttxr_base = (txr_base & 0x00fffff8) >> 3;\n\t\tdst->mode3 |= txr_base;\n\t}\n\n\t/* Dummy values */\n\tdst->d1 = dst->d2 = dst->d3 = dst->d4 = 0xffffffff;\n}\n\n/* Create a colored polygon context with parameters similar to\n the old \"ta\" function `ta_poly_hdr_col' */\nvoid pvr_poly_cxt_col(pvr_poly_cxt_t *dst, pvr_list_t list) {\n\tint alpha;\n\n\t/* Start off blank */\n\tmemset(dst, 0, sizeof(pvr_poly_cxt_t));\n\n\t/* Fill in a few values */\n\tdst->list_type = list;\n\talpha = list > PVR_LIST_OP_MOD;\n\tdst->fmt.color = PVR_CLRFMT_ARGBPACKED;\n\tdst->fmt.uv = PVR_UVFMT_32BIT;\n\tdst->gen.shading = PVR_SHADE_GOURAUD;\n\tdst->depth.comparison = PVR_DEPTHCMP_GREATER;\n\tdst->depth.write = PVR_DEPTHWRITE_ENABLE;\n\tdst->gen.culling = PVR_CULLING_CCW;\n\tdst->txr.enable = PVR_TEXTURE_DISABLE;\n\tif (!alpha) {\n\t\tdst->gen.alpha = PVR_ALPHA_DISABLE;\n\t\tdst->blend.src = PVR_BLEND_ONE;\n\t\tdst->blend.dst = PVR_BLEND_ZERO;\n\t} else {\n\t\tdst->gen.alpha = PVR_ALPHA_ENABLE;\n\t\tdst->blend.src = PVR_BLEND_SRCALPHA;\n\t\tdst->blend.dst = PVR_BLEND_INVSRCALPHA;\n\t}\n\tdst->blend.src_enable = PVR_BLEND_DISABLE;\n\tdst->blend.dst_enable = PVR_BLEND_DISABLE;\n\tdst->gen.fog_type = PVR_FOG_DISABLE;\n\tdst->gen.color_clamp = PVR_CLRCLAMP_DISABLE;\n}\n\n/* Create a textured polygon context with parameters similar to\n the old \"ta\" function `ta_poly_hdr_txr' */\nvoid pvr_poly_cxt_txr(pvr_poly_cxt_t *dst, pvr_list_t list,\n\t\tint textureformat, int tw, int th, pvr_ptr_t textureaddr,\n\t\tint filtering) {\n\tint alpha;\n\t\n\t/* Start off blank */\n\tmemset(dst, 0, sizeof(pvr_poly_cxt_t));\n\n\t/* Fill in a few values */\n\tdst->list_type = list;\n\talpha = list > PVR_LIST_OP_MOD;\n\tdst->fmt.color = PVR_CLRFMT_ARGBPACKED;\n\tdst->fmt.uv = PVR_UVFMT_32BIT;\n\tdst->gen.shading = PVR_SHADE_GOURAUD;\n\tdst->depth.comparison = PVR_DEPTHCMP_GREATER;\n\tdst->depth.write = PVR_DEPTHWRITE_ENABLE;\n\tdst->gen.culling = PVR_CULLING_CCW;\n\tdst->txr.enable = PVR_TEXTURE_ENABLE;\n\tif (!alpha) {\n\t\tdst->gen.alpha = PVR_ALPHA_DISABLE;\n\t\tdst->txr.alpha = PVR_TXRALPHA_ENABLE;\n\t\tdst->blend.src = PVR_BLEND_ONE;\n\t\tdst->blend.dst = PVR_BLEND_ZERO;\n\t\tdst->txr.env = PVR_TXRENV_MODULATE;\n\t} else {\n\t\tdst->gen.alpha = PVR_ALPHA_ENABLE;\n\t\tdst->txr.alpha = PVR_TXRALPHA_ENABLE;\n\t\tdst->blend.src = PVR_BLEND_SRCALPHA;\n\t\tdst->blend.dst = PVR_BLEND_INVSRCALPHA;\n\t\tdst->txr.env = PVR_TXRENV_MODULATEALPHA;\n\t}\n\tdst->blend.src_enable = PVR_BLEND_DISABLE;\n\tdst->blend.dst_enable = PVR_BLEND_DISABLE;\n\tdst->gen.fog_type = PVR_FOG_DISABLE;\n\tdst->gen.color_clamp = PVR_CLRCLAMP_DISABLE;\n\tdst->txr.uv_flip = PVR_UVFLIP_NONE;\n\tdst->txr.uv_clamp = PVR_UVCLAMP_NONE;\n\tdst->txr.filter = filtering;\n\tdst->txr.mipmap_bias = PVR_MIPBIAS_NORMAL;\n\tdst->txr.width = tw;\n\tdst->txr.height = th;\n\tdst->txr.base = textureaddr;\n\tdst->txr.format = textureformat;\n}\n\n/* Create a textured sprite context with parameters similar to\n the old \"ta\" function `ta_poly_hdr_txr' */\nvoid pvr_sprite_cxt_txr(pvr_sprite_cxt_t *dst, pvr_list_t list,\n\t\t\t\t\t int textureformat, int tw, int th, pvr_ptr_t textureaddr,\n\t\t\t\t\t int filtering) {\n\tint alpha;\n\n\t/* Start off blank */\n\tmemset(dst, 0, sizeof(pvr_sprite_cxt_t));\n\n\t/* Fill in a few values */\n\tdst->list_type = list;\n\talpha = list > PVR_LIST_OP_MOD;\n\tdst->depth.comparison = PVR_DEPTHCMP_GREATER;\n\tdst->depth.write = PVR_DEPTHWRITE_ENABLE;\n\tdst->gen.culling = PVR_CULLING_CCW;\n\tif (!alpha) {\n\t\tdst->gen.alpha = PVR_ALPHA_DISABLE;\n\t\tdst->txr.alpha = PVR_TXRALPHA_ENABLE;\n\t\tdst->blend.src = PVR_BLEND_ONE;\n\t\tdst->blend.dst = PVR_BLEND_ZERO;\n\t} else {\n\t\tdst->gen.alpha = PVR_ALPHA_ENABLE;\n\t\tdst->txr.alpha = PVR_TXRALPHA_ENABLE;\n\t\tdst->blend.src = PVR_BLEND_SRCALPHA;\n\t\tdst->blend.dst = PVR_BLEND_INVSRCALPHA;\n\t}\n\tdst->blend.src_enable = PVR_BLEND_DISABLE;\n\tdst->blend.dst_enable = PVR_BLEND_DISABLE;\n\tdst->gen.fog_type = PVR_FOG_DISABLE;\n\tdst->gen.color_clamp = PVR_CLRCLAMP_DISABLE;\n\tdst->txr.uv_flip = PVR_UVFLIP_NONE;\n\tdst->txr.uv_clamp = PVR_UVCLAMP_NONE;\n\tdst->txr.filter = filtering;\n\tdst->txr.mipmap_bias = PVR_MIPBIAS_NORMAL;\n\tdst->txr.width = tw;\n\tdst->txr.height = th;\n\tdst->txr.base = textureaddr;\n\tdst->txr.format = textureformat;\n}\n\nvoid pvr_sprite_compile(pvr_poly_ic_hdr_t *dst,\n\t\tpvr_sprite_cxt_t *src) {\n\tint u, v;\n\tuint32 txr_base;\n\n\t/* Basically we just take each parameter, clip it, shift it\n\t into place, and OR it into the final result. */\n\n\t/* The base values for CMD */\n\tdst->cmd = PVR_CMD_SPRITE | 8;\n\n\t/* Or in the list type, clipping mode, and UV formats */\n\tdst->cmd |= (src->list_type << PVR_TA_CMD_TYPE_SHIFT) & PVR_TA_CMD_TYPE_MASK;\n\tdst->cmd |= (PVR_UVFMT_16BIT << PVR_TA_CMD_UVFMT_SHIFT) & PVR_TA_CMD_UVFMT_MASK;\n\tdst->cmd |= (src->gen.clip_mode << PVR_TA_CMD_USERCLIP_SHIFT) & PVR_TA_CMD_USERCLIP_MASK;\n\n\t/* Polygon mode 1 */\n\tdst->mode1 = (src->depth.comparison << PVR_TA_PM1_DEPTHCMP_SHIFT) & PVR_TA_PM1_DEPTHCMP_MASK;\n\tdst->mode1 |= (src->gen.culling << PVR_TA_PM1_CULLING_SHIFT) & PVR_TA_PM1_CULLING_MASK;\n\tdst->mode1 |= (src->depth.write << PVR_TA_PM1_DEPTHWRITE_SHIFT) & PVR_TA_PM1_DEPTHWRITE_MASK;\n\tdst->mode1 |= (1 << PVR_TA_PM1_TXRENABLE_SHIFT) & PVR_TA_PM1_TXRENABLE_MASK;\n\n\t/* Polygon mode 2 */\n\tdst->mode2 = (src->blend.src << PVR_TA_PM2_SRCBLEND_SHIFT) & PVR_TA_PM2_SRCBLEND_MASK;\n\tdst->mode2 |= (src->blend.dst << PVR_TA_PM2_DSTBLEND_SHIFT) & PVR_TA_PM2_DSTBLEND_MASK;\n\tdst->mode2 |= (src->blend.src_enable << PVR_TA_PM2_SRCENABLE_SHIFT) & PVR_TA_PM2_SRCENABLE_MASK;\n\tdst->mode2 |= (src->blend.dst_enable << PVR_TA_PM2_DSTENABLE_SHIFT) & PVR_TA_PM2_DSTENABLE_MASK;\n\tdst->mode2 |= (src->gen.fog_type << PVR_TA_PM2_FOG_SHIFT) & PVR_TA_PM2_FOG_MASK;\n\tdst->mode2 |= (src->gen.color_clamp << PVR_TA_PM2_CLAMP_SHIFT) & PVR_TA_PM2_CLAMP_MASK;\n\tdst->mode2 |= (src->gen.alpha << PVR_TA_PM2_ALPHA_SHIFT) & PVR_TA_PM2_ALPHA_MASK;\n\n\tassert_msg(src->txr.base != NULL, \"Sprites must be textured\");\n\n\tdst->mode2 |= (src->txr.alpha << PVR_TA_PM2_TXRALPHA_SHIFT) & PVR_TA_PM2_TXRALPHA_MASK;\n\tdst->mode2 |= (src->txr.uv_flip << PVR_TA_PM2_UVFLIP_SHIFT) & PVR_TA_PM2_UVFLIP_MASK;\n\tdst->mode2 |= (src->txr.uv_clamp << PVR_TA_PM2_UVCLAMP_SHIFT) & PVR_TA_PM2_UVCLAMP_MASK;\n\tdst->mode2 |= (src->txr.filter << PVR_TA_PM2_FILTER_SHIFT) & PVR_TA_PM2_FILTER_MASK;\n\tdst->mode2 |= (src->txr.mipmap_bias << PVR_TA_PM2_MIPBIAS_SHIFT) & PVR_TA_PM2_MIPBIAS_MASK;\n\n\tswitch (src->txr.width) {\n\t\tcase 8:\t\tu = 0; break;\n\t\tcase 16:\tu = 1; break;\n\t\tcase 32:\tu = 2; break;\n\t\tcase 64:\tu = 3; break;\n\t\tcase 128:\tu = 4; break;\n\t\tcase 256:\tu = 5; break;\n\t\tcase 512:\tu = 6; break;\n\t\tcase 1024:\tu = 7; break;\n\t\tdefault:\tassert_msg(0, \"Invalid texture U size\"); u = 0; break;\n\t}\n\n\tswitch (src->txr.height) {\n\t\tcase 8:\t\tv = 0; break;\n\t\tcase 16:\tv = 1; break;\n\t\tcase 32:\tv = 2; break;\n\t\tcase 64:\tv = 3; break;\n\t\tcase 128:\tv = 4; break;\n\t\tcase 256:\tv = 5; break;\n\t\tcase 512:\tv = 6; break;\n\t\tcase 1024:\tv = 7; break;\n\t\tdefault:\tassert_msg(0, \"Invalid texture V size\"); v = 0; break;\n\t}\n\n\tdst->mode2 |= (u << PVR_TA_PM2_USIZE_SHIFT) & PVR_TA_PM2_USIZE_MASK;\n\tdst->mode2 |= (v << PVR_TA_PM2_VSIZE_SHIFT) & PVR_TA_PM2_VSIZE_MASK;\n\n\t/* Polygon mode 3 */\n\tdst->mode3 = (src->txr.mipmap << PVR_TA_PM3_MIPMAP_SHIFT) & PVR_TA_PM3_MIPMAP_MASK;\n\tdst->mode3 |= (src->txr.format << PVR_TA_PM3_TXRFMT_SHIFT) & PVR_TA_PM3_TXRFMT_MASK;\n\t\t\n\ttxr_base = (uint32)src->txr.base;\n\ttxr_base = (txr_base & 0x00fffff8) >> 3;\n\tdst->mode3 |= txr_base;\n\n\tdst->a = 1.0f;\n\tdst->r = 1.0f;\n\tdst->g = 1.0f;\n\tdst->b = 1.0f;\n}\n"
},
{
"alpha_fraction": 0.5533333420753479,
"alphanum_fraction": 0.6366666555404663,
"avg_line_length": 19,
"blob_id": "c684b88268831dc92ca0bc888d8a81d988633284",
"content_id": "861e047a285c63ac8a9d26e4935daf8bd2ab11c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 15,
"path": "/libc/stdlib/randnum.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n randnum.c\n (c)2000-2001 Dan Potter\n\n Utility function to pick a random number in a range\n*/\n\n#include <stdlib.h>\n\nCVSID(\"$Id: randnum.c,v 1.1 2002/09/08 06:56:02 bardtx Exp $\");\n\nint randnum(int limit) {\n\treturn (int)((double)rand() / ((double)RAND_MAX + 1) * limit);\n}\n"
},
{
"alpha_fraction": 0.5372340679168701,
"alphanum_fraction": 0.6542553305625916,
"avg_line_length": 16,
"blob_id": "d8ecc0171541efcad43d192f7892fb6db34a61db",
"content_id": "870571d69390bdd94fa2162c8fafd164dfb7b24e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 188,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/utils/bincnv/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# utils/bincnv/Makefile\n# (c)2000 Dan Potter\n#\n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:01 bardtx Exp $\n\nall: bincnv\n\nbincnv: bincnv.c\n\tgcc -g -o bincnv bincnv.c\n\n"
},
{
"alpha_fraction": 0.5775400996208191,
"alphanum_fraction": 0.6310160160064697,
"avg_line_length": 15.217391014099121,
"blob_id": "1ee5e0fc3f02b3d7c999f2309a0f8565e7e060af",
"content_id": "c20d03d49d46be07f15582e055f1210c7fabf98d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 23,
"path": "/include/arch/dreamcast/arch/gdb.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/arch/gdb.h\n (c)2002 Dan Potter\n \n $Id: gdb.h,v 1.1 2002/09/13 05:19:39 bardtx Exp $\n*/\n\n#ifndef __ARCH_GDB_H\n#define __ARCH_GDB_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* Initialize the GDB stub */\nvoid gdb_init();\n\n/* Manually raise a GDB breakpoint */\nvoid gdb_breakpoint();\n\n__END_DECLS\n\n#endif\t/* __ARCH_GDB_H */\n\n"
},
{
"alpha_fraction": 0.5553727149963379,
"alphanum_fraction": 0.6108276844024658,
"avg_line_length": 21.171533584594727,
"blob_id": "455da001213c3601d55bad8a3d813b23de64f1a4",
"content_id": "c581c19a4344467ce93ef423f8b8411a4633a1de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6077,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 274,
"path": "/examples/dreamcast/cpp/gltest/gltest.cpp",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gltest.cpp\n (c)2001-2002 Dan Potter\n*/\n\n#include <kos.h>\n#include <GL/gl.h>\n#include <GL/glu.h>\n#include <pcx/pcx.h>\n\n/*\n\nThis is a really simple KallistiGL example. It shows off several things:\nbasic matrix control, perspective, the AUTO_UV feature, and controlling\nthe image with maple input.\n\nThanks to NeHe's tutorials for the crate image.\n\nThis version is written in C++ and uses some basic C++ operations to test\nvarious things about C++ functionality.\n\n*/\n\nclass Object {\nprotected:\n\tfloat\ttx, ty, tz;\n\npublic:\n\tObject(float dtx, float dty, float dtz) {\n\t\ttx = dtx;\n\t\tty = dty;\n\t\ttz = dtz;\n\t\tprintf(\"Object::Object called\\n\");\n\t}\n\n\tvirtual ~Object() {\n\t\tprintf(\"Object::~Object called\\n\");\n\t}\n\n\tvirtual void draw() {\n\t}\n};\n\nclass Cube : public Object {\nprivate:\n\tfloat r;\n\t\npublic:\n\tCube(float px, float py, float pz)\n\t\t\t: Object(px, py, pz) {\n\t\tr = 0.0f;\n\t\tprintf(\"Cube::Cube called\\n\");\n\t}\n\n\tvirtual ~Cube() {\n\t\tprintf(\"Cube::~Cube called\\n\");\n\t}\n\n\tvoid rotate(float dr) {\n\t\tr += dr;\n\t}\n\n\t/* Draw a cube centered around 0,0,0. Note the total lack of glTexCoord2f(),\n\t even though the cube is in fact getting textured! This is KGL's AUTO_UV\n\t feature: turn it on and it assumes you're putting on the texture on\n\t the quad in the order 0,0; 1,0; 1,1; 0,1. This only works for quads. */\n\tvirtual void draw() {\n\t\tglPushMatrix();\n\t\tglTranslatef(tx, ty, tz);\n\t\tglRotatef(r, 1.0f, 0.0f, 1.0f);\n\t\t\n\t\tglBegin(GL_QUADS);\n\n\t\t\t/* Front face */\n\t\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\t\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\t\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\n\t\t\t/* Back face */\n\t\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\t\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\t\t\t\n\t\t\t/* Left face */\n\t\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\t\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\n\t\t\t/* Right face */\n\t\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\t\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\t\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\n\t\t\t/* Top face */\n\t\t\tglVertex3f(1.0f, 1.0f, 1.0f);\n\t\t\tglVertex3f(-1.0f, 1.0f, 1.0f);\n\t\t\tglVertex3f(-1.0f, 1.0f, -1.0f);\n\t\t\tglVertex3f(1.0f, 1.0f, -1.0f);\n\n\t\t\t/* Bottom face */\n\t\t\tglVertex3f(1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(-1.0f, -1.0f, -1.0f);\n\t\t\tglVertex3f(-1.0f, -1.0f, 1.0f);\n\t\t\tglVertex3f(1.0f, -1.0f, 1.0f);\n\t\tglEnd();\n\t\t\n\t\tglPopMatrix();\n\t}\n};\t\n\n/* Note that ctors/dtors aren't really supported right now because of the\n problems related to initialization; i.e., when main() is called, ctors\n ought to have been called, but if they do any KOS specific stuff, it\n will work (or worse, crash). I'm open to suggestions on fixing it. */\nclass CtorDtorTest {\npublic:\n\tCtorDtorTest() {\n\t\tprintf(\"CtorDtorTest::CtorDtorTest called\\n\");\n\t}\n\tvirtual ~CtorDtorTest() {\n\t\tprintf(\"CtorDtorTest::~CtorDtorTest called\\n\");\n\t}\n} test_object, test_object2;\n\n/* Load a texture using pcx_load_texture and glKosTex2D */\nvoid loadtxr(const char *fn, GLuint *txr) {\n\tkos_img_t img;\n\tpvr_ptr_t txaddr;\n\n\tif (pcx_to_img(fn, &img) < 0) {\n\t\tprintf(\"can't load %s\\n\", fn);\n\t\treturn;\n\t}\n\n\ttxaddr = pvr_mem_malloc(img.w * img.h * 2);\n\tpvr_txr_load_kimg(&img, txaddr, PVR_TXRLOAD_INVERT_Y);\n\tkos_img_free(&img, 0);\n\n\tglGenTextures(1, txr);\n\tglBindTexture(GL_TEXTURE_2D, *txr);\n\tglKosTex2D(GL_RGB565_TWID, img.w, img.h, txaddr);\n}\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nint main(int argc, char **argv) {\n\tcont_cond_t cond;\n\tuint8\tc;\n\tfloat\tr = 0.0f;\n\tfloat\tdr = 2.0f;\n\tfloat\tz = -14.0f;\n\tGLuint\ttexture;\n\tint\ttrans = 0;\n\n\t/* Initialize KOS */\n\tdbglog_set_level(DBG_WARNING);\n\tpvr_init_defaults();\n\n\tprintf(\"gltest beginning\\n\");\n\n\t/* Get basic stuff initialized */\n\tglKosInit();\n\tglMatrixMode(GL_PROJECTION);\n\tglLoadIdentity();\n\tgluPerspective(45.0f, 640.0f / 480.0f, 0.1f, 100.0f);\n\tglMatrixMode(GL_MODELVIEW);\n\tglEnable(GL_TEXTURE_2D);\n\tglEnable(GL_KOS_AUTO_UV);\n\t\n\t/* Expect CW vertex order */\n\tglFrontFace(GL_CW);\n\n\t/* Enable Transparancy */\n glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA);\n\t\n\t/* Load a texture and make it look nice */\n\tloadtxr(\"/rd/crate.pcx\", &texture);\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_FILTER, GL_FILTER_BILINEAR);\n\tglTexEnvi(GL_TEXTURE_2D, GL_TEXTURE_ENV_MODE, GL_MODULATEALPHA);\n\n\n\tprintf(\"texture is %08x\\n\", texture);\n\n\tCube *cubes[4] = {\n\t\tnew Cube(-5.0f, 0.0f, 0.0f),\n\t\tnew Cube(5.0f, 0.0f, 0.0f),\n\t\tnew Cube(0.0f, 5.0f, 0.0f),\n\t\tnew Cube(0.0f, -5.0f, 0.0f)\n\t};\n\tc = maple_first_controller();\n\twhile(1) {\n\t\t/* Check key status */\n\t\tif (cont_get_cond(c, &cond) < 0) {\n\t\t\tprintf(\"Error reading controller\\n\");\n\t\t\tbreak;\n\t\t}\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\tbreak;\n\t\tif (!(cond.buttons & CONT_DPAD_UP))\n\t\t\tz -= 0.1f;\n\t\tif (!(cond.buttons & CONT_DPAD_DOWN))\n\t\t\tz += 0.1f;\n\t\tif (!(cond.buttons & CONT_DPAD_LEFT)) {\n\t\t\t/* If manual rotation is requested, then stop\n\t\t\t the automated rotation */\n\t\t\tdr = 0.0f;\n\t\t\tfor (int i=0; i<4; i++)\n\t\t\t\tcubes[i]->rotate(- 2.0f);\n\t\t\tr -= 2.0f;\n\t\t}\n\t\tif (!(cond.buttons & CONT_DPAD_RIGHT)) {\n\t\t\tdr = 0.0f;\n\t\t\tfor (int i=0; i<4; i++)\n\t\t\t\tcubes[i]->rotate(+ 2.0f);\n\t\t\tr += 2.0f;\n\t\t}\n\t\tif (!(cond.buttons & CONT_A)) {\n\t\t\t/* This weird logic is to avoid bouncing back\n\t\t\t and forth before the user lets go of the\n\t\t\t button. */\n\t\t\tif (!(trans & 0x1000)) {\n\t\t\t\tif (trans == 0)\n\t\t\t\t\ttrans = 0x1001;\n\t\t\t\telse\n\t\t\t\t\ttrans = 0x1000;\n\t\t\t}\n\t\t} else {\n\t\t\ttrans &= ~0x1000;\n\t\t}\n\n\t\tfor (int i=0; i<4; i++)\n\t\t\tcubes[i]->rotate(dr);\n\t\tr += dr;\n\n\t\t/* Begin frame */\n\t\tglKosBeginFrame();\n\n\t\t/* Draw four objects */\n\t\tglLoadIdentity();\n\t\tglTranslatef(0.0f, 0.0f, z);\n\t\tglRotatef(r, 0.0f, 1.0f, 0.5f);\n\n\t\tcubes[0]->draw();\n\t\tcubes[1]->draw();\n\n\t\t/* Potentially do two as translucent */\n\t\tif (trans & 1) {\n\t\t\tglKosFinishList();\n\t\t\tglColor4f(1.0f, 1.0f, 1.0f, 0.5f);\n\t\t\tglDisable(GL_CULL_FACE);\n\t\t}\n\n\t\tcubes[2]->draw();\n\t\tcubes[3]->draw();\n\n\t\tif (trans & 1) {\n\t\t glEnable(GL_CULL_FACE);\n\t\t}\n\n\t\t/* Finish the frame */\n\t\tglKosFinishFrame();\n\t}\n\n\tfor (int i=0; i<4; i++)\n\t\tdelete cubes[i];\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6551305651664734,
"alphanum_fraction": 0.6717263460159302,
"avg_line_length": 22.98058319091797,
"blob_id": "f304dfc0648702cc836dad4c3a04cf0eed47df49",
"content_id": "01aadb365583273c46f88e1e12839ab1aa15ca93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4941,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 206,
"path": "/kernel/arch/dreamcast/hardware/pvr/pvr_mem.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvr_mem.c\n (C)2002 Dan Potter\n\n */\n\n#include <assert.h>\n#include <dc/pvr.h>\n#include \"pvr_internal.h\"\n#include <stdio.h>\n\n#include <malloc.h>\t/* For the struct mallinfo defs */\n\n/*\n\nThis module basically serves as a KOS-friendly front end and support routines\nfor the pvr_mem_core module, which is a dlmalloc-derived malloc for use with\nthe PVR memory pool.\n\nI was originally going to make a totally seperate thing that could be used\nto generically manage any memory pool, but then I realized what a gruelling\nand thankless task that would be when starting with dlmalloc, so we have this\ninstead. ^_^;\n \n*/\n\n/* Uncomment this line to enable leak checking */\n/* #define KM_DBG */\n\n/* Uncomment this if you want REALLY verbose debugging (print\n every time a block is allocated or freed) */\n/* #define KM_DBG_VERBOSE */\n\nCVSID(\"$Id: pvr_mem.c,v 1.7 2003/04/24 03:10:08 bardtx Exp $\");\n\n/* Bring in some prototypes from pvr_mem_core.c */\n/* We can't directly include its header because of name clashes with\n the real malloc header */\nextern void * pvr_int_malloc(size_t bytes);\nextern void pvr_int_free(void *ptr);\nextern struct mallinfo pvr_int_mallinfo();\nextern void pvr_int_mem_reset();\nextern void pvr_int_malloc_stats();\n\n\n#ifdef KM_DBG\n\n#include <kos/thread.h>\n#include <arch/arch.h>\n\n/* List of allocated memory blocks for leak checking */\ntypedef struct memctl {\n\tuint32\t\t\tsize;\n\ttid_t\t\t\tthread;\n\tuint32\t\t\taddr;\n\tpvr_ptr_t\t\tblock;\n\tLIST_ENTRY(memctl)\tlist;\n} memctl_t;\n\nstatic LIST_HEAD(memctl_list, memctl) block_list;\n\n#endif\t/* KM_DBG */\n\n\n/* PVR RAM base; NULL is considered invalid */\nstatic pvr_ptr_t pvr_mem_base = NULL;\n#define CHECK_MEM_BASE assert_msg(pvr_mem_base != NULL, \\\n\t\"pvr_mem_* used, but PVR hasn't been initialized yet\")\n\n/* Used in pvr_mem_core.c */\nvoid * pvr_int_sbrk(size_t amt) {\n\tuint32 old, n;\n\t\n\t/* Are we valid? */\n\tCHECK_MEM_BASE;\n\n\t/* Try to increment it */\n\told = (uint32)pvr_mem_base;\n\tn = old + amt;\n\n\t/* Did we run over? */\n\tif (n > PVR_RAM_INT_TOP)\n\t\treturn (void *)-1;\n\n\t/* Nope, everything's cool */\n\tpvr_mem_base = (pvr_ptr_t)n;\n\treturn (pvr_ptr_t)old;\n}\n\n/* Allocate a chunk of memory from texture space; the returned value\n will be relative to the base of texture memory (zero-based) */\npvr_ptr_t pvr_mem_malloc(size_t size) {\n\tuint32 rv32;\n#ifdef KM_DBG\n\tuint32\t\tra = arch_get_ret_addr();\n\tmemctl_t \t* ctl;\n#endif\t/* KM_DBG */\n\t\n\tCHECK_MEM_BASE;\n\n\trv32 = (uint32)pvr_int_malloc(size);\n\tassert_msg( (rv32 & 0x1f) == 0,\n\t\t\"dlmalloc's alignment is broken; please make a bug report\");\n\n#ifdef KM_DBG\n\tctl = malloc(sizeof(memctl_t));\n\tctl->size = size;\n\tctl->thread = thd_current->tid;\n\tctl->addr = ra;\n\tctl->block = (pvr_ptr_t)rv32;\n\tLIST_INSERT_HEAD(&block_list, ctl, list);\n#endif\t/* KM_DBG */\n\n#ifdef KM_DBG_VERBOSE\n\tprintf(\"Thread %d/%08lx allocated %d bytes at %08lx\\n\",\n\t\tctl->thread, ctl->addr, ctl->size, rv32);\n#endif\n\n\treturn (pvr_ptr_t)rv32;\n}\n\n/* Free a previously allocated chunk of memory */\nvoid pvr_mem_free(pvr_ptr_t chunk) {\n#ifdef KM_DBG\n\tuint32\t\tra = arch_get_ret_addr();\n\tmemctl_t\t* ctl;\n\tint\t\tfound;\n#endif\t/* KM_DBG */\n\n\tCHECK_MEM_BASE;\n\n#ifdef KM_DBG_VERBOSE\n\tprintf(\"Thread %d/%08lx freeing block @ %08lx\\n\",\n\t\tthd_current->tid, ra, (uint32)chunk);\n#endif\n\n#ifdef KM_DBG\n\tfound = 0;\n\t\n\tLIST_FOREACH(ctl, &block_list, list) {\n\t\tif (ctl->block == chunk) {\n\t\t\tLIST_REMOVE(ctl, list);\n\t\t\tfree(ctl);\n\t\t\tfound = 1;\n\t\t\tbreak;\n\t\t}\n\t}\n\n\tif (!found) {\n\t\tdbglog(DBG_ERROR, \"pvr_mem_free: trying to free non-alloc'd block %08lx (called from %d/%08lx\\n\",\n\t\t\t(uint32)chunk, thd_current->tid, ra);\n\t}\n#endif\t/* KM_DBG */\n\t\t\n\tpvr_int_free((void *)chunk);\n}\n\n/* Check the memory block list to see what's allocated */\nvoid pvr_mem_print_list() {\n#ifdef KM_DBG\n\tmemctl_t\t* ctl;\n\n\tprintf(\"pvr_mem_print_list block list:\\n\");\n\tLIST_FOREACH(ctl, &block_list, list) {\n\t\tprintf(\" unfreed block at %08lx size %d, allocated by thread %d/%08lx\\n\",\n\t\t\tctl->block, ctl->size, ctl->thread, ctl->addr);\n\t}\n\tprintf(\"pvr_mem_print_list end block list\\n\");\n#endif\t/* KM_DBG */\n}\n\n/* Return the number of bytes available still in the memory pool */\nstatic uint32 pvr_mem_available_int() {\n\tstruct mallinfo mi = pvr_int_mallinfo();\n\n\t/* This magic formula is modeled after mstats() */\n\treturn mi.arena - mi.uordblks;\n}\nuint32 pvr_mem_available() {\n\tCHECK_MEM_BASE;\n\n\treturn pvr_mem_available_int();\n}\n\n/* Reset the memory pool, equivalent to freeing all textures currently\n residing in RAM. This _must_ be done on a mode change, configuration\n change, etc. */\nvoid pvr_mem_reset() {\n\tif (!pvr_state.valid)\n\t\tpvr_mem_base = NULL;\n\telse {\n\t\tpvr_mem_base = (pvr_ptr_t)(PVR_RAM_INT_BASE + pvr_state.texture_base);\n\t\tpvr_int_mem_reset();\n\t}\n}\n\n/* Print some statistics (like mallocstats) */\nvoid pvr_mem_stats() {\n\tprintf(\"pvr_mem_stats():\\n\");\n\tpvr_int_malloc_stats();\n\tprintf(\"max sbrk base: %08lx\\n\", (uint32)pvr_mem_base);\n#ifdef KM_DBG\n\tpvr_mem_print_list();\n#endif\n}\n\n"
},
{
"alpha_fraction": 0.6223999857902527,
"alphanum_fraction": 0.6607999801635742,
"avg_line_length": 18.5,
"blob_id": "46f0c394652a2a08e94326f30440c92fc1646ce9",
"content_id": "50acd55ba0e1f4f68a40938b091cebdc1caab3a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 625,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 32,
"path": "/include/arch/dreamcast/arch/rtc.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/rtc.h\n (c)2000-2001 Dan Potter\n\n $Id: rtc.h,v 1.4 2002/11/16 02:11:58 bardtx Exp $\n\n */\n\n#ifndef __ARCH_RTC_H\n#define __ARCH_RTC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <time.h>\n\n/* Returns the date/time value as a UNIX epoch time stamp */\ntime_t rtc_unix_secs();\n\n/* Returns the date/time that the system was booted as a UNIX epoch time\n stamp. Adding this to the value from timer_ms_gettime() will\n produce a current timestamp. */\ntime_t rtc_boot_time();\n\n/* Init / Shutdown */\nint rtc_init();\nvoid rtc_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_RTC_H */\n\n"
},
{
"alpha_fraction": 0.6743002533912659,
"alphanum_fraction": 0.7010177969932556,
"avg_line_length": 26.034482955932617,
"blob_id": "f1850668198f0411b636d561d7f3241070678cd2",
"content_id": "45b409660e53cf9e585648dba9383b838114ce85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 29,
"path": "/kernel/arch/ps2/kernel/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ps2/kernel/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.3 2002/11/03 03:40:55 bardtx Exp $\n\n# Generic kernel abstraction layer: this provides a set of routines\n# that the portable part of the kernel expects to find on every\n# target processor. Other routines may be present as well, but\n# that minimum set must be present.\n\nCOPYOBJS = banner.o dbgio.o main.o irq.o panic.o entry.o\nCOPYOBJS += init_flags_default.o init_romdisk_default.o\nCOPYOBJS += crtbegin.o crtend.o atexit.o mm.o startup.o\nCOPYOBJS += cache.o syscall.o timer.o\nOBJS = $(COPYOBJS)\nSUBDIRS = \n\nmyall: $(OBJS)\n\t-cp $(COPYOBJS) ../../../../kernel/build/\n\t-rm banner.c banner.o\n\ninclude ../../../../Makefile.prefab\n\nbanner.o: banner.c\n\nbanner.c: make_banner.sh\n\t./make_banner.sh\n\n\n"
},
{
"alpha_fraction": 0.60317462682724,
"alphanum_fraction": 0.60317462682724,
"avg_line_length": 14.75,
"blob_id": "96a2880ca97cbbe5a5c399110f25d112f30cd1e0",
"content_id": "e97b5e7faf3aeb1f6b2f912f5a92bedb181a244d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-as",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_AS} ${KOS_AFLAGS} \"$@\"\n"
},
{
"alpha_fraction": 0.5581395626068115,
"alphanum_fraction": 0.6511628031730652,
"avg_line_length": 20.41666603088379,
"blob_id": "90557ed706ba9dff2f202e38bea2e76de20182aa",
"content_id": "8848fa5cfbb194f2358ad68e32723b3b4c82cbe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/kernel/fs/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# kernel/fs/Makefile\n# (c)2000-2001 Dan Potter\n# \n# $Id: Makefile,v 1.3 2002/08/13 04:54:22 bardtx Exp $\n\nOBJS = fs.o fs_romdisk.o fs_ramdisk.o fs_pty.o\nOBJS += fs_utils.o elf.o fs_socket.o\nSUBDIRS = \n\ninclude ../../Makefile.prefab\n\n"
},
{
"alpha_fraction": 0.6017315983772278,
"alphanum_fraction": 0.6082251071929932,
"avg_line_length": 16.769229888916016,
"blob_id": "1e3403028dc496b297d294bbf6d2a788657d302a",
"content_id": "17e0db3026a5f7fe584a9e28a3b64631965be99a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 26,
"path": "/examples/dreamcast/network/dcload-ip-lwip-test/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "TARGET = dcload-lwip.elf\n\nOBJS = main.o\n\nLWIPDIR := $(KOS_PATH)/include/addons/lwip\nLWIPARCH := $(LWIPDIR)/kos\nCFLAGS := $(KOS_CFLAGS) -DIPv4 -DLWIP_DEBUG \\\n\t-I$(LWIPDIR) -I$(LWIPARCH) \\\n\t-I$(LWIPDIR)/ipv4 \n\nall: rm-elf $(TARGET)\n\ninclude ../../../../Makefile.rules\n\nclean:\n\t-rm -f $(TARGET) $(OBJS) romdisk.*\n\nrm-elf:\n\t-rm -f $(TARGET) romdisk.*\n\n$(TARGET): $(OBJS)\n\tkos-cc -o $(TARGET) $(OBJS) $(OBJEXTRA) -llwip4\n\ndist:\n\trm -f $(OBJS)\n\t$(KOS_STRIP) $(TARGET)\n"
},
{
"alpha_fraction": 0.674632728099823,
"alphanum_fraction": 0.723744809627533,
"avg_line_length": 28.610389709472656,
"blob_id": "0493c4c81a794afe0cd42fb837f47f3db9b92b19",
"content_id": "b4492ac04370aa7aacacf7931caaf7f623f2b0e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4561,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 154,
"path": "/include/arch/ia32/arch/irq.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n ia32/irq.h\n Copyright (C)2000,2001,2003 Dan Potter\n\n $Id: irq.h,v 1.2 2003/08/02 09:14:46 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_IRQ_H\n#define __ARCH_IRQ_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* The number of bytes required to save thread context. This should\n include all general CPU registers, FP registers, and status regs (even\n if not all of these are actually used). */\n#define REG_BYTE_CNT 256\n\n/* Architecture-specific structure for holding the processor state (register\n values, etc). The size of this structure should be less than or equal\n to the above value. */\ntypedef struct irq_context {\n\tuint32\t\teax, ebx, ecx, edx;\t// GPRs\n\tuint32\t\tesi, edi;\t\t// String regs\n\tuint32\t\tebp, esp;\t\t// Stack\n\tuint32\t\teip;\t\t\t// Program counter\n\tuint32\t\teflags;\t\t\t// CPU flags\n\t// We'll certainly need more later (FPRs, LDT, etc) but that's a\n\t// good enough start.\n} irq_context_t;\n\n// A couple of architecture independent access macros\n#define CONTEXT_PC(c)\t((c).eip)\n#define CONTEXT_FP(c)\t((c).ebp)\n#define CONTEXT_SP(c)\t((c).esp)\n#define CONTEXT_RET(c)\t((c).eax)\n\n// ia32-specific exception codes\n#define EXC_DIVIDE_ERROR\t0x0000\n#define EXC_DEBUG\t\t0x0001\n#define EXC_NMI\t\t\t0x0002\n#define EXC_BREAKPOINT\t\t0x0003\n#define EXC_OVERFLOW\t\t0x0004\n#define EXC_BOUND\t\t0x0005\n#define EXC_INVALID_OPCODE\t0x0006\n#define EXC_DEV_NOT_AVAILABLE\t0x0007\n#define EXC_EXC_DOUBLE_FAULT\t0x0008\t// Error code\n#define EXC_COPROC_OVERRUN\t0x0009\n#define EXC_INVALID_TSS\t\t0x000a\t// Error code\n#define EXC_SEG_NOT_PRESENT\t0x000b\n#define EXC_STACK_FAULT\t\t0x000c\t// Error code\n#define EXC_GEN_PROT_FAULT\t0x000d\t// Error code\n#define EXC_PAGE_FAULT\t\t0x000e\n#define EXC_COPROC_ERROR\t0x0010\n\n// We will assign hardware interrupts to 0x70 - 0x7f using the PIC.\n#define EXC_IRQ0\t\t0x0070\n#define EXC_IRQ1\t\t0x0071\n#define EXC_IRQ2\t\t0x0072\n#define EXC_IRQ3\t\t0x0073\n#define EXC_IRQ4\t\t0x0074\n#define EXC_IRQ5\t\t0x0075\n#define EXC_IRQ6\t\t0x0076\n#define EXC_IRQ7\t\t0x0077\n#define EXC_IRQ8\t\t0x0078\n#define EXC_IRQ9\t\t0x0079\n#define EXC_IRQA\t\t0x007a\n#define EXC_IRQB\t\t0x007b\n#define EXC_IRQC\t\t0x007c\n#define EXC_IRQD\t\t0x007d\n#define EXC_IRQE\t\t0x007e\n#define EXC_IRQF\t\t0x007f\n\n// This is a software-generated one (double-fault) for when an exception\n// happens inside an ISR. This is different from the hardware-generated\n// \"double fault\" that happens above when the processor is trying to\n// service an exception and gets an exception.\n#define EXC_DOUBLE_FAULT\t0x0100\n\n/* Software-generated for unhandled exception */\n#define EXC_UNHANDLED_EXC\t0x0101\n\n/* The value of the timer IRQ */\n#define TIMER_IRQ\t\tEXC_IRQ0\n\n/* The type of an interrupt identifier */\ntypedef uint32 irq_t;\n\n/* The type of an IRQ handler */\ntypedef void (*irq_handler)(irq_t source, irq_context_t *context);\n\n/* Are we inside an interrupt handler? */\nint irq_inside_int();\n\n/* Pretend like we just came in from an interrupt and force\n a context switch back to the \"current\" context. Make sure\n you've called irq_set_context()! */\nvoid irq_force_return();\n\n/* Set a handler, or remove a handler (see codes above) */\nint irq_set_handler(irq_t source, irq_handler hnd);\n\n/* Non-public function */\nstruct kprocess;\nint _irq_set_handler(struct kprocess * proc, irq_t src, irq_handler hnd);\n\n/* Get the address of the current handler */\nirq_handler irq_get_handler(irq_t source);\n\n/* Set a global exception handler */\nint irq_set_global_handler(irq_handler hnd);\n\n/* Non-public version */\nint _irq_set_global_handler(struct kprocess * proc, irq_handler hnd);\n\n/* Get the global exception handler */\nirq_handler irq_get_global_handler();\n\n/* Switch out contexts (for interrupt return) */\nvoid irq_set_context(irq_context_t *regbank);\n\n/* Return the current IRQ context */\nirq_context_t *irq_get_context();\n\n/* Fill a newly allocated context block for usage with supervisor/kernel\n or user mode. The given parameters will be passed to the called routine (up\n to the architecture maximum). */\nvoid irq_create_context(irq_context_t *context, ptr_t stack_pointer,\n\tptr_t routine, uint32 *args, int usermode);\n\n/* Enable/Disable interrupts */\nint irq_disable();\t\t/* Will leave exceptions enabled */\nint irq_enable();\t\t/* Enables all ints including external */\nvoid irq_restore(int v);\n\n/* Remove all IRQ handlers for the named process */\nvoid irq_remove_process(struct kprocess * proc);\n\n/* Low-level IRQ/Exception setup, located in entry.s */\nvoid irq_low_setup();\n\n/* Init routine */\nint irq_init();\n\n/* Shutdown */\nvoid irq_shutdown();\n\n__END_DECLS\n\n#endif\t/* __ARCH_IRQ_H */\n\n"
},
{
"alpha_fraction": 0.6898068189620972,
"alphanum_fraction": 0.7031568884849548,
"avg_line_length": 28.47222137451172,
"blob_id": "ce9b74a8f9b82eb6564ff89e055099a4a3132864",
"content_id": "3c2544641b09ebfdfe7be194d424a87cbcf899e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6367,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 216,
"path": "/include/kos/thread.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/thread.h\n Copyright (C)2000,2001,2002,2003 Dan Potter\n\n $Id: thread.h,v 1.13 2003/06/23 05:19:50 bardtx Exp $\n\n*/\n\n#ifndef __KOS_THREAD_H\n#define __KOS_THREAD_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <arch/irq.h>\n#include <arch/arch.h>\n#include <sys/queue.h>\n#include <sys/reent.h>\n\n/* Priority values */\n#define PRIO_MAX 4096\n#define PRIO_DEFAULT 10\n\n/* Pre-define list/queue types */\nstruct kthread;\nTAILQ_HEAD(ktqueue, kthread);\nLIST_HEAD(ktlist, kthread);\n\n/* Structure describing one running thread */\ntypedef struct kthread {\n\t/* Thread list handle */\n\tLIST_ENTRY(kthread)\t\tt_list;\n\n\t/* Run/Wait queue handle */\n\tTAILQ_ENTRY(kthread)\t\tthdq;\n\n\t/* Timer queue handle (if applicable) */\n\tTAILQ_ENTRY(kthread)\t\ttimerq;\n\n\t/* Kernel thread id */\n\ttid_t\ttid;\n\n\t/* Static priority: 0..PRIO_MAX (higher means lower priority) */\n\tprio_t\tprio;\n\n\t/* Flags */\n\tuint32\tflags;\n\n\t/* Process state */\n\tint\tstate;\n\n\t/* Generic wait target and message, if applicable */\n\tvoid\t\t* wait_obj;\n\tconst char\t* wait_msg;\n\n\t/* Wait timeout callback: if the genwait times out, this function\n\t will be called. This allows hooks for things like fixing up\n\t semaphore count values, etc. */\n\tvoid (*wait_callback)(void * obj);\n\n\t/* Next scheduled time; used for sleep and timed block\n\t operations. This value is in milliseconds since the start of\n\t timer_ms_gettime(). This should be enough for something like\n\t 2 million years of wait time ;) */\n\tuint64\t\twait_timeout;\n\n\t/* Thread label; used when printing out a user-readable\n\t process listing. */\n\t/* XXX: Move to TLS */\n\tchar\tlabel[256];\n\n\t/* Current file system path */\n\t/* XXX: Move to TLS */\n\tchar\tpwd[256];\n\n\t/* Register store; used to save thread context */\n\tirq_context_t\tcontext;\n\n\t/* Thread private stack; this should be a pointer to the base\n\t of a stack page. */\n\tuint32\t*stack;\n\tuint32\tstack_size;\n\n\t/* Our errno variable */\n\t/* XXX: Move to TLS */\n\tint\tthd_errno;\n\n\t/* Our re-ent struct for newlib */\n\tstruct _reent thd_reent;\n} kthread_t;\n\n/* Thread flag values */\n#define THD_DEFAULTS\t0\t/* Defaults: no flags */\n#define THD_USER\t1\t/* Thread runs in user mode */\n#define THD_QUEUED\t2\t/* Thread is in the run queue */\n\n/* Thread state values */\n#define STATE_ZOMBIE\t\t0x0000\t/* Waiting to die */\n#define STATE_RUNNING\t\t0x0001\t/* Process is \"current\" */\n#define STATE_READY\t\t0x0002\t/* Ready to be scheduled */\n#define STATE_WAIT\t\t0x0003\t/* Blocked on a genwait */\n\n/* Are threads cooperative or pre-emptive? */\nextern int thd_mode;\n#define THD_MODE_NONE\t\t-1\t/* Threads not running */\n#define THD_MODE_COOP\t\t0\n#define THD_MODE_PREEMPT\t1\n\n/* Thread list; note: do not manipulate directly */\nextern struct ktlist thd_list;\n\n/* Run queue; note: do not manipulate directly */\nextern struct ktqueue run_queue;\n\n/* The currently executing thread */\nextern kthread_t *thd_current;\n\n/* \"Jiffy\" count; just counts context switches */\n/* XXX: Deprecated! */\nextern vuint32 jiffies;\n\n/* Blocks the calling thread and performs a reschedule as if a context\n switch timer had been executed. This is useful for, e.g., blocking\n on sync primitives. The param 'mycxt' should point to the calling\n thread's context block. This is implemented in arch-specific code. \n The meaningfulness of the return value depends on whether the\n unblocker set a return value or not. */\nint thd_block_now(irq_context_t * mycxt);\n\n/* This function looks at the state of the system and returns a new\n thread context to swap in. This is called from thd_block_now() and\n from the pre-emptive context switcher. Note that thd_current might\n be NULL on entering this function, if the caller blocked itself.\n It is assumed that by the time this returns, the irq_srt_addr and\n thd_current will be updated.*/\nirq_context_t * thd_choose_new();\n\n/* Given a thread ID, locates the thread structure */\nkthread_t *thd_by_tid(tid_t tid);\n\n/* Enqueue a process in the runnable queue; adds it right after the\n process group of the same priority if front_of_line is zero,\n otherwise queues it at the front of its priority group. */\nvoid thd_add_to_runnable(kthread_t *t, int front_of_line);\n\n/* Removes a thread from the runnable queue, if it's there. */\nint thd_remove_from_runnable(kthread_t *thd);\n \n/* New thread function; given a routine address, it will create a\n new kernel thread with a default stack. When the routine\n returns, the thread will exit. Returns the new thread id. */\nkthread_t *thd_create(void (*routine)(void *param), void *param);\n\n/* Given a thread id, this function removes the thread from\n the execution chain. */\nint thd_destroy(kthread_t *thd);\n\n/* Thread exit syscall (for use in user-mode processes, but can be used\n anywhere). */\nvoid thd_exit() __noreturn;\n\n/* Force a re-schedule; for most cases, you'll want to set front_of_line\n to zero, but read the comments in kernel/thread/thread.c for more\n info, especially if you need to guarantee low latencies. This just\n updates irq_srt_addr and thd_current. Set 'now' to non-zero if you want\n thd_schedule() to use a particular system time for checking timeouts. */\nvoid thd_schedule(int front_of_line, uint64 now);\n\n/* Force a given thread to the front of the queue */\nvoid thd_schedule_next(kthread_t *thd);\n\n/* Throw away the curren thread's timeslice */\nvoid thd_pass();\n\n/* Sleep for a given number of milliseconds */\nvoid thd_sleep(int ms);\n\n/* Set a thread's priority value; if it is scheduled already, it will be\n rescheduled with the new priority value. */\nint thd_set_prio(kthread_t *thd, prio_t prio);\n\n/* Return the current thread's kthread struct */\nkthread_t *thd_get_current();\n\n/* Retrive / set thread label */\nconst char *thd_get_label(kthread_t *thd);\nvoid thd_set_label(kthread_t *thd, const char *label);\n\n/* Retrieve / set thread pwd */\nconst char *thd_get_pwd(kthread_t *thd);\nvoid thd_set_pwd(kthread_t *thd, const char *pwd);\n\n/* Retrieve a pointer to the thread errno */\nint * thd_get_errno(kthread_t *thd);\n\n/* Retrieve a pointer to the thread reent struct */\nstruct _reent * thd_get_reent(kthread_t *thd);\n\n/* Change threading modes */\nint thd_set_mode(int mode);\n\n/* Wait for a thread to exit */\nint thd_wait(kthread_t * thd);\n\n\n/* Init */\nint thd_init(int mode);\n\n/* Shutdown */\nvoid thd_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_THREAD_H */\n\n"
},
{
"alpha_fraction": 0.6489637494087219,
"alphanum_fraction": 0.6904144883155823,
"avg_line_length": 29.84000015258789,
"blob_id": "901da7fe5c5cb2aa870006b948084ace56ad3406",
"content_id": "b0d89c4b2334ddc532be86818bca5b7c913fa02e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 25,
"path": "/utils/gba-elf2bin/gba-elf2bin",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\n# Converts an ELF file to a GBA-compatible ROM file\n# (c)2001 Chuck mason\n#\n# This program was originally included as part of the libgba\n# library for GBA development, and is probably covered under\n# the GPL or LGPL license.\n#\n# usage: gba-elf2bin <elf> <bin>\n# \n# $Id: gba-elf2bin,v 1.1.1.1 2001/09/26 07:05:00 bardtx Exp $\n\nrm -f /tmp/tmp.{text,rodata,data,bss}\n\nOBJCOPY=arm-elf-objcopy\n\n$OBJCOPY -O binary -j .text $1 /tmp/tmp.text\n$OBJCOPY -O binary -j .sarm --change-section-lma .sarm=0 $1 /tmp/tmp.data\n$OBJCOPY -O binary -j .data --change-section-lma .data=0 $1 /tmp/tmp.data\n$OBJCOPY -O binary -j .rodata $1 /tmp/tmp.rodata\n$OBJCOPY -O binary -j .bss $1 /tmp/tmp.bss\ncat /tmp/tmp.{text,rodata,data,bss} > $2\n\nrm -f /tmp/tmp.{text,data,rodata,bss}\n\n"
},
{
"alpha_fraction": 0.5197685360908508,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 27.77777862548828,
"blob_id": "c336044c7625392eca8a4711d62f061ef7be1fa7",
"content_id": "3f00f8d45a188922d490a1c5fe983b826d5fedc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 36,
"path": "/include/arch/gba/gba/dma.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gba/dma.h\n (c)2002 Gil Megidish\n \n $Id: dma.h,v 1.1 2002/12/12 21:48:14 gilm Exp $\n*/\n\n#ifndef __GBA_DMA_H\n#define __GBA_DMA_H\n\n#include <arch/types.h>\n\n/* There are four dma channels; All source addresses and destination\n * addresses are 24bit only. Consult proper documentation about\n * the properties of each channel.\n */\n\n#define REG_DMA0SAD\t(*(vu32*)0x040000b0)\n#define REG_DMA0DAD\t(*(vu32*)0x040000b4)\n#define REG_DMA0CNT_L\t(*(vu16*)0x040000b8)\n#define REG_DMA0CNT_H\t(*(vu16*)0x040000ba)\n#define REG_DMA1SAD\t(*(vu32*)0x040000bc)\n#define REG_DMA1DAD\t(*(vu32*)0x040000c0)\n#define REG_DMA1CNT_L\t(*(vu16*)0x040000c4)\n#define REG_DMA1CNT_H\t(*(vu16*)0x040000c6)\n#define REG_DMA2SAD\t(*(vu32*)0x040000c8)\n#define REG_DMA2DAD\t(*(vu32*)0x040000cc)\n#define REG_DMA2CNT_L\t(*(vu16*)0x040000d0)\n#define REG_DMA2CNT_H\t(*(vu16*)0x040000d2)\n#define REG_DMA3SAD\t(*(vu32*)0x040000d4)\n#define REG_DMA3DAD\t(*(vu32*)0x040000d8)\n#define REG_DMA3CNT_L\t(*(vu16*)0x040000dc)\n#define REG_DMA3CNT_H\t(*(vu16*)0x040000de)\n\n#endif\n\n"
},
{
"alpha_fraction": 0.6717850565910339,
"alphanum_fraction": 0.6948176622390747,
"avg_line_length": 24.414634704589844,
"blob_id": "9064f11b4edd50051b01ac66882a5f999b1a2263",
"content_id": "80de457511d34aec5365a89497c42ba46fdcd575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1042,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 41,
"path": "/include/addons/kos/bspline.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n bspline.h\n (c)2000 Dan Potter\n\n $Id: bspline.h,v 1.1 2002/09/05 07:31:55 bardtx Exp $\n*/\n\n#ifndef __KOS_BSPLINE_H\n#define __KOS_BSPLINE_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/** \\file\n This module provides utility functions to generate b-spline\n curves in your program. It is used by passing in a set of\n control points to bspline_coeff, and then querying for\n individual points using bspline_get_point.\n*/\n\n#include <kos/vector.h>\n\n/**\n Pass it an array of points and it will calculate a set of B-spline\n co-efficients for generating a curve. There must be at least one point\n before the \"current\" one, and at least two after the \"current\" one (a\n total of four points required). These values will be used in the \n function below.\n*/\nvoid bspline_coeff(const point_t *pnt);\n\n/**\n Given a 't' (between 0.0f and 1.0f) this will generate the next point\n values for the current set of coefficients.\n*/\nvoid bspline_get_point(float t, point_t *p);\n\n__END_DECLS\n\n#endif\t/* __KOS_BSPLINE_H */\n"
},
{
"alpha_fraction": 0.6583769917488098,
"alphanum_fraction": 0.6688481569290161,
"avg_line_length": 18.58974266052246,
"blob_id": "9b7db206f140d8f1381fa137d7b4a332f0687129",
"content_id": "69da8433b4ffb972583d3aa4d954b27ab0cdb62e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 39,
"path": "/examples/dreamcast/network/httpd/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#\n# KallistiOS lwIP test program\n# (c)2002 Dan Potter\n# \n\n# Put the filename of the output binary here\nTARGET = httpd.elf\n\n# List all of your C files here, but change the extension to \".o\"\nOBJS = simhost.o httpd.o romdisk.o\n\nall: rm-elf $(TARGET)\n\ninclude $(KOS_PATH)/scripts/Makefile.rules\n\nLWIPDIR = $(KOS_PATH)/include/addons/lwip\nARCHDIR = $(LWIPDIR)/kos\n\nCFLAGS += -DIPv4 \\\n\t-I$(LWIPDIR) -I$(ARCHDIR) \\\n\t-I$(LWIPDIR)/ipv4\n\nclean:\n\trm -f $(TARGET) $(OBJS) romdisk.img\n\nrm-elf:\n\trm -f $(TARGET) romdisk.*\n\n$(TARGET): $(OBJS)\n\tkos-cc -o $(TARGET) $(OBJS) $(OBJEXTRA) -llwip4 -lkosutils\n\nromdisk.img:\n\t$(KOS_GENROMFS) -f romdisk.img -d romdisk -v\n\nromdisk.o: romdisk.img\n\t$(KOS_PATH)/bin/bin2o romdisk.img romdisk romdisk.o\n\nrun: $(TARGET)\n\tdc-tool -n -x $(TARGET)\n"
},
{
"alpha_fraction": 0.6658647060394287,
"alphanum_fraction": 0.6807246208190918,
"avg_line_length": 32.325469970703125,
"blob_id": "f0cfbd99fa42c71979ee2f812151604d449f3b1e",
"content_id": "21d7141d28958328bfc7ced093a672d702f8c06b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7066,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 212,
"path": "/include/kos/fs.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs.h\n Copyright (C)2000,2001,2002,2003 Dan Potter\n\n $Id: fs.h,v 1.11 2003/07/31 00:38:00 bardtx Exp $\n\n*/\n\n#ifndef __KOS_FS_H\n#define __KOS_FS_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <sys/types.h>\n#include <kos/limits.h>\n#include <time.h>\n#include <sys/queue.h>\n\n#include <kos/nmmgr.h>\n\n/* Directory entry; all handlers must conform to this interface */\ntypedef struct kos_dirent {\n\tint\tsize;\n\tchar\tname[MAX_FN_LEN];\n\ttime_t\ttime;\n\tuint32\tattr;\n} dirent_t;\n\n/* File status information; like dirent, this is not the same as the *nix\n variation but it has similar information. */\nstruct vfs_handler;\ntypedef struct /*stat*/ {\n\tstruct vfs_handler\t* dev;\t\t/* The VFS handler for this file/dir */\n\tuint32\t\t\tunique;\t\t/* A unique identifier on the VFS for this file/dir */\n\tuint32\t\t\ttype;\t\t/* File/Dir type */\n\tuint32\t\t\tattr;\t\t/* Attributes */\n\toff_t\t\t\tsize;\t\t/* Total file size, if applicable */\n\ttime_t\t\t\ttime;\t\t/* Last access/mod/change time (depends on VFS) */\n} stat_t;\n\n/* stat_t.unique */\n#define STAT_UNIQUE_NONE\t0\t/* Constant to use denoting the file has no unique ID */\n\n/* stat_t.type */\n#define STAT_TYPE_NONE\t\t0\t/* Unknown / undefined / not relevant */\n#define STAT_TYPE_FILE\t\t1\t/* Standard file */\n#define STAT_TYPE_DIR\t\t2\t/* Standard directory */\n#define STAT_TYPE_PIPE\t\t3\t/* A virtual device of some sort (pipe, socket, etc) */\n#define STAT_TYPE_META\t\t4\t/* Meta data */\n\n/* stat_t.attr */\n#define STAT_ATTR_NONE\t\t0x00\t/* No attributes */\n#define STAT_ATTR_R\t\t0x01\t/* Read-capable */\n#define STAT_ATTR_W\t\t0x02\t/* Write-capable */\n#define STAT_ATTR_RW\t\t(STAT_ATTR_R | STAT_ATTR_W)\t/* Read/Write capable */\n\n/* File descriptor type */\ntypedef int file_t;\n\n/* Invalid file handle constant (for open failure, etc) */\n#define FILEHND_INVALID\t((file_t)-1)\n\n/* Handler interface; all VFS handlers must implement this interface. */\ntypedef struct vfs_handler {\n\t/* Name manager handler header */\n\tnmmgr_handler_t\t\tnmmgr;\n\n\t/* Some VFS-specific pieces */\n\tint\tcache;\t\t\t/* Allow VFS cacheing; 0=no, 1=yes */\n\tvoid\t* privdata;\t\t/* Pointer to private data for the handler */\n\n\t/* Open a file on the given VFS; return a unique identifier */\n\tvoid *\t(*open)(struct vfs_handler * vfs, const char *fn, int mode);\n\n\t/* Close a previously opened file */\n\tvoid\t(*close)(void * hnd);\n\n\t/* Read from a previously opened file */\n\tssize_t\t(*read)(void * hnd, void *buffer, size_t cnt);\n\n\t/* Write to a previously opened file */\n\tssize_t\t(*write)(void * hnd, const void *buffer, size_t cnt);\n\n\t/* Seek in a previously opened file */\n\toff_t\t(*seek)(void * hnd, off_t offset, int whence);\n\n\t/* Return the current position in a previously opened file */\n\toff_t\t(*tell)(void * hnd);\n\n\t/* Return the total size of a previously opened file */\n\tsize_t\t(*total)(void * hnd);\n\n\t/* Read the next directory entry in a directory opened with O_DIR */\n\tdirent_t* (*readdir)(void * hnd);\n\n\t/* Execute a device-specific call on a previously opened file */\n\tint\t(*ioctl)(void * hnd, void *data, size_t size);\n\n\t/* Rename/move a file on the given VFS */\n\tint\t(*rename)(struct vfs_handler * vfs, const char *fn1, const char *fn2);\n\n\t/* Delete a file from the given VFS */\n\tint\t(*unlink)(struct vfs_handler * vfs, const char *fn);\n\n\t/* \"Memory map\" a previously opened file */\n\tvoid*\t(*mmap)(void * fd);\n\n\t/* Perform an I/O completion (async I/O) for a previously opened file */\n\tint\t(*complete)(void * fd, ssize_t * rv);\n\n\t/* Get status information on a file on the given VFS */\n\tint\t(*stat)(struct vfs_handler * vfs, const char * fn, stat_t * rv);\n\n\t/* Make a directory on the given VFS */\n\tint\t(*mkdir)(struct vfs_handler * vfs, const char * fn);\n\n\t/* Remove a directory from the given VFS */\n\tint\t(*rmdir)(struct vfs_handler * vfs, const char * fn);\n} vfs_handler_t;\n\n/* This is the number of distinct file descriptors the global table\n has in it. */\n#define FD_SETSIZE\t1024\n\n/* This is the private struct that will be used as raw file handles\n underlying descriptors. */\nstruct fs_hnd;\n\n/* The kernel-wide file descriptor table. These will reference to open files. */\nextern struct fs_hnd * fd_table[FD_SETSIZE];\n\n/* Open modes */\n#include <sys/fcntl.h>\n#if 0\n#define O_RDONLY\t1\t\t/* Read only */\n#define O_RDWR\t\t2\t\t/* Read-write */\n#define O_APPEND\t3\t\t/* Append to an existing file */\n#define O_WRONLY\t4\t\t/* Write-only */\n#endif\n//#define O_MODE_MASK\t7\t\t/* Mask for mode numbers */\n#define O_MODE_MASK\t0x0f\t\t/* Mask for mode numbers */\n//#define O_TRUNC\t\t0x0100\t\t/* Truncate */\n#define O_ASYNC\t\t0x0200\t\t/* Open for asynchronous I/O */\n//#define O_NONBLOCK\t0x0400\t\t/* Open for non-blocking I/O */\n#define O_DIR\t\t0x1000\t\t/* Open as directory */\n#define O_META\t\t0x2000\t\t/* Open as metadata */\n\n/* Seek modes */\n#define SEEK_SET 0\n#define SEEK_CUR 1\n#define SEEK_END 2\n\n/* Standard file descriptor functions */\nfile_t\tfs_open(const char *fn, int mode);\nvoid\tfs_close(file_t hnd);\nssize_t\tfs_read(file_t hnd, void *buffer, size_t cnt);\nssize_t\tfs_write(file_t hnd, const void *buffer, size_t cnt);\noff_t\tfs_seek(file_t hnd, off_t offset, int whence);\noff_t\tfs_tell(file_t hnd);\nsize_t\tfs_total(file_t hnd);\ndirent_t* fs_readdir(file_t hnd);\nint\tfs_ioctl(file_t hnd, void *data, size_t size);\nint\tfs_rename(const char *fn1, const char *fn2);\nint\tfs_unlink(const char *fn);\nint\tfs_chdir(const char *fn);\nvoid*\tfs_mmap(file_t hnd);\nint\tfs_complete(file_t fd, ssize_t * rv);\nint\tfs_stat(const char * fn, stat_t * rv);\nint\tfs_mkdir(const char * fn);\nint\tfs_rmdir(const char * fn);\nfile_t\tfs_dup(file_t oldfd);\nfile_t\tfs_dup2(file_t oldfd, file_t newfd);\n\n/* Call this function to create a \"transient\" file descriptor. What this\n does for you is let you setup ad-hoc VFS integration for libs that\n have their own open mechanism (e.g., TCP/IP sockets). It could also be\n used to do things like generic resource management. Calling this\n function is functionally identical to fs_open, except it doesn't\n require registering a full VFS or doing a name lookup. */\nfile_t\tfs_open_handle(vfs_handler_t * vfs, void * hnd);\n\n/* These two functions are used to reveal \"internal\" info about a file\n descriptor, so that libraries can provide their own facilities using\n VFS-sponsored file descriptors (e.g., TCP/IP bind, connect, etc). */\nvfs_handler_t * fs_get_handler(file_t fd);\nvoid * fs_get_handle(file_t fd);\n\n/* Returns the working directory of the current thread */\nconst char *fs_getwd();\n\n/* Couple of util functions */\n\n/* Copies a file from 'src' to 'dst'. The amount of the file\n actually copied without error is returned. */\nssize_t\tfs_copy(const char * src, const char * dst);\n\n/* Opens a file, allocates enough RAM to hold the whole thing,\n reads it into RAM, and closes it. The caller owns the allocated\n memory (and must free it). The file size is returned, or -1\n on failure; on success, out_ptr is filled with the address\n of the loaded buffer, and on failure it is set to NULL. */\nssize_t fs_load(const char * src, void ** out_ptr);\n\n/* VFS init */\nint\tfs_init();\nvoid \tfs_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_H */\n\n"
},
{
"alpha_fraction": 0.5642201900482178,
"alphanum_fraction": 0.6605504751205444,
"avg_line_length": 15.769230842590332,
"blob_id": "95d7412c83bca954ba54649b89ae4415157df562",
"content_id": "78e81cd31bf00ff36fc3ffefe875e9c5981bbceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/kernel/arch/ps2/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/ps2 Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.3 2002/11/06 08:36:40 bardtx Exp $\n\t\nSUBDIRS=kernel sbios fs\n\ninclude ../../../Makefile.rules\n\nall: subdirs\nclean: clean_subdirs\n"
},
{
"alpha_fraction": 0.6713124513626099,
"alphanum_fraction": 0.6957026720046997,
"avg_line_length": 22.88888931274414,
"blob_id": "fbdb6daf07d86e4e0e76302406b2c0e2da8826b9",
"content_id": "2ba78223379c641f15231dffd60296da7805a868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 861,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 36,
"path": "/include/arch/dreamcast/dc/vblank.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/vblank.h\n Copyright (C)2003 Dan Potter\n\n $Id: vblank.h,v 1.1 2003/04/24 03:07:20 bardtx Exp $\n*/\n\n#ifndef __DC_VBLANK_H\n#define __DC_VBLANK_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <dc/asic.h>\n\n/** Add a vblank handler. The function will be called at the start of every\n vertical blanking period with the same parameters that were passed to\n the original ASIC handler. Returns <0 on failure or a handle otherwise. */\nint vblank_handler_add(asic_evt_handler hnd);\n\n/** Remove a vblank handler. Pass the handle returned from\n vblank_handler_add. */\nint vblank_handler_remove(int handle);\n\n/** Initialize the vblank handler. This must be called after the asic module\n is initialized. */\nint vblank_init();\n\n/** Shut down the vblank handler. */\nint vblank_shutdown();\n\n\n__END_DECLS\n\n#endif\t/* __DC_VBLANK_H */\n\n"
},
{
"alpha_fraction": 0.6849817037582397,
"alphanum_fraction": 0.7002441883087158,
"avg_line_length": 29.314815521240234,
"blob_id": "86c8d924cf54c1b89398afcf2ce285e72fad16e4",
"content_id": "b3eb3a9b5f36a82c278ea37114d6bca348df6b9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1638,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 54,
"path": "/include/kos/genwait.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n include/kos/genwait.h\n Copyright (c)2003 Dan Potter\n\n $Id: genwait.h,v 1.2 2003/02/16 04:55:24 bardtx Exp $\n\n*/\n\n#ifndef __KOS_GENWAIT_H\n#define __KOS_GENWAIT_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <sys/queue.h>\n#include <kos/thread.h>\n\n/* Sleep on the object \"obj\". The sleep status will be listed in any\n textual displays as \"mesg\". If \"timeout\" is non-zero, then the thread\n will be woken again after timeout milliseconds even if it hasn't\n been signaled manually. If \"callback\" is non-NULL, then the given\n function will be called with \"obj\" as its parameter if the wait\n times out (but before the thread is re-scheduled). */\nint genwait_wait(void * obj, const char * mesg, int timeout, void (*callback)(void *));\n\n/* Wake up N threads waiting on the given object. If cnt is <=0, then we\n wake all threads. Returns the number of threads actually woken. */\nint genwait_wake_cnt(void * obj, int cnt);\n\n/* Wake up all threads waiting on the given object. */\nvoid genwait_wake_all(void * obj);\n\n/* Wake up one thread waiting on the given object. */\nvoid genwait_wake_one(void * obj);\n\n/* Called by the scheduler to look for timed out genwait_wait calls. \n Pass the current system clock as \"now\". */\nvoid genwait_check_timeouts(uint64 now);\n\n/* Returns the time of the next timeout event. If there are no pending\n timeout events, then we return zero. Called by the scheduler. */\nuint64 genwait_next_timeout();\n\n/* Initialize the genwait system */\nint genwait_init();\n\n/* Shut down the genwait system */\nvoid genwait_shutdown();\n \n\n__END_DECLS\n\n#endif\t/* __KOS_GENWAIT_H */\n\n"
},
{
"alpha_fraction": 0.6226415038108826,
"alphanum_fraction": 0.6226415038108826,
"avg_line_length": 12.25,
"blob_id": "799ae4ec3d682a6dee97b520b0ef9f68b50769fc",
"content_id": "efd4735dbb14adf67bebe5c8bdcf78027ca6e07d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/utils/gnu_wrappers/kos-ranlib",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nsource environ.sh\n\nexec ${KOS_RANLIB} \"$@\"\n"
},
{
"alpha_fraction": 0.5630630850791931,
"alphanum_fraction": 0.662162184715271,
"avg_line_length": 16.076923370361328,
"blob_id": "17a63745f91cb394e1d26da4e0b3477f77b87441",
"content_id": "d7c7cbd49c69747c64cbc2fcf17e0c3ce6c05cf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 13,
"path": "/kernel/arch/gba/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# arch/gba Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\n\t\nSUBDIRS=hardware kernel\n\ninclude ../../../Makefile.rules\n\nall: subdirs\nclean: clean_subdirs\n"
},
{
"alpha_fraction": 0.5343915224075317,
"alphanum_fraction": 0.5740740895271301,
"avg_line_length": 15.06382942199707,
"blob_id": "ac0e59bbf83d51eecec95f5803318f12c32e7c44",
"content_id": "352ea506f42f37de559f3ead43df1efa0e469332",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 756,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 47,
"path": "/kernel/arch/dreamcast/math/fmath.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/fmath.c\n (C)2001 Andrew Kieschnick\n*/\n\n#include <dc/fmath.h>\n\n/* Returns sin(r), where r is [0..2*PI] */\nfloat fsin(float r) {\n\treturn __fsin(r);\n}\n\n/* Returns cos(r), where r is [0..2*PI] */\nfloat fcos(float r) {\n\treturn __fcos(r);\n}\n\n/* Returns tan(r), where r is [0..2*PI] */\nfloat ftan(float r) {\n\treturn __ftan(r);\n}\n\n/* Returns sin(d), where d is [0..65535] */\nfloat fisin(int d) {\n\treturn __fisin(d);\n}\n\n/* Returns cos(d), where d is [0..65535] */\nfloat ficos(int d) {\n\treturn __ficos(d);\n}\n\n/* Returns tan(d), where d is [0..65535] */\nfloat fitan(int d) {\n\treturn __fitan(d);\n}\n\n/* Returns sqrt(f) */\nfloat fsqrt(float f) {\n\treturn __fsqrt(f);\n}\n\n/* Returns 1.0f / sqrt(f) */\nfloat frsqrt(float f) {\n\treturn __frsqrt(f);\n}\n\n"
},
{
"alpha_fraction": 0.6350914835929871,
"alphanum_fraction": 0.6620021462440491,
"avg_line_length": 20.581396102905273,
"blob_id": "f3af5945f81507a84d836f0a86b9f26beb1a81bc",
"content_id": "889faec1e67d31c2b7bea51276f206525429d8b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 929,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 43,
"path": "/include/arch/gba/arch/dbgio.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/gba/include/dbgio.h\n (c)2000 Dan Potter\n\n $Id: dbgio.h,v 1.1.1.1 2001/09/26 07:05:11 bardtx Exp $\n \n*/\n\n#ifndef __ARCH_DBGIO_H\n#define __ARCH_DBGIO_H\n\n#include <arch/types.h>\n\n/* Initialize the SCIF port */\nvoid dbgio_init();\n\n/* Write one char to the serial port (call serial_flush()!)*/\nvoid dbgio_write(int c);\n\n/* Flush all FIFO'd bytes out of the serial port buffer */\nvoid dbgio_flush();\n\n/* Send an entire buffer */\nvoid dbgio_write_buffer(uint8 *data, int len);\n\n/* Read an entire buffer (block) */\nvoid dbgio_read_buffer(uint8 *data, int len);\n\n/* Send a string (null-terminated) */\nvoid dbgio_write_str(char *str);\n\n/* Read one char from the serial port (-1 if nothing to read) */\nint dbgio_read();\n\n/* Enable / Disable debug I/O globally */\nvoid dbgio_disable();\nvoid dbgio_enable();\n\n/* Printf functionality */\nint dbgio_printf(const char *fmt, ...);\n\n#endif\t/* __ARCH_DBGIO_H */\n\n"
},
{
"alpha_fraction": 0.5245459079742432,
"alphanum_fraction": 0.5761287212371826,
"avg_line_length": 21.29861068725586,
"blob_id": "0f76d5f06003f24c743ffdfe62e1e2e2f7b032e6",
"content_id": "4fb96ea32be39bc6848d4166d2aabc79e76d4e42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9635,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 432,
"path": "/examples/dreamcast/sound/ghettoplay-vorbis/songmenu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* GhettoPlay: an S3M browser and playback util\n (c)2000 Dan Potter\n*/\n\n#include <oggvorbis/sndoggvorbis.h>\n#include <string.h>\n#include \"gp.h\"\n\n/* Takes care of the song menu */\n\n\n/* Song menu choices */\ntypedef struct {\n\tchar\tfn[256];\n\tint\tsize;\n} entry;\ntypedef struct {\n\tchar\tfn[256];\n\tint\tsize;\n} lst_entry;\n\n///////// Mutex protected /////////\nstatic mutex_t * mut = NULL;\n\nchar curdir[1024] = \"/\";\nchar playdir[1024] = \"/\";\nchar loadme[256] = \"\";\nchar workstring[256] =\"\";\n\nstatic entry entries[200];\nstatic int num_entries = 0;\n//////// Mutex protected //////////\nstatic volatile int load_queued = 0;\n\nstatic int selected = 0, top = 0, iplaying = 0;\n\nstatic int framecnt = 0;\nstatic float throb = 0.2f, dthrob = 0.01f;\n\n/* Here we hold the playlist */\nstatic int lst_size = 0;\nstatic lst_entry lst_entries[200];\nstatic int lst_playing = -1;\n\n\n/* Code to draw a nice o-scope on the background during playback :) */\nstatic mutex_t * hookmut = NULL;\nstatic int16 sndbuffer[2][16384];\nstatic int sndbuffer_cnt = 0;\nstatic uint64 last_time = 0;\nstatic int takeframes = 0;\nstatic int curpos = 0;\nstatic int filtinitted = 0;\n\nstatic void snd_hook(int strm, void * obj, int freq, int chn, void ** buf, int *req) {\n\tint actual;\n\tuint64 t;\n\n\tmutex_lock(hookmut);\n\tactual = *req;\n\tif (actual > 16384*2)\n\t\tactual = 16384*2;\n\tmemcpy(sndbuffer+0, sndbuffer+1, sndbuffer_cnt*4);\n\tmemcpy(sndbuffer+1, *buf, actual);\n\tsndbuffer_cnt = actual/4;\n\n\tt = timer_ms_gettime64();\n\tif (last_time != 0) {\n\t\tuint32 elapsed = (uint32)(t - last_time);\n\t\ttakeframes = elapsed * 60 / 1000;\n\t}\n\tlast_time = t;\n\tcurpos = 0;\n\tmutex_unlock(hookmut);\n}\n\n#include <plx/dr.h>\n#include <plx/prim.h>\nstatic void draw_wave() {\n\tint idx, cnt;\n\tfloat x, p, y, z = 80.0f;\n\n\tmutex_lock(hookmut);\n\tif (takeframes != 0 && sndbuffer_cnt != 0) {\n\t\tplx_dr_state_t dr; plx_dr_init(&dr);\n\t\tcnt = sndbuffer_cnt * takeframes / 60;\n\t\t\n\t\tplx_vert_ind(&dr, PLX_VERT, 0.0f, 240.0f, z, 0xffffffff);\n\t\tplx_vert_ind(&dr, PLX_VERT, 0.0f, 235.0f, z, 0xffffffff);\n\t\tfor (x = 20.0f, p = 0.0f; x < 620.0f; x += 4.0f, p+=4.0f/(620.0f - 20.0f)) {\n\t\t\tidx = curpos + ((int)(p*cnt)) * 2;\n\t\t\ty = 240.0f + sndbuffer[0][idx] * 120.0f / 32768.0f;\n\t\t\tplx_vert_ind(&dr, PLX_VERT, x, y+5.0f, z, 0xffffffff);\n\t\t\tplx_vert_ind(&dr, PLX_VERT, x, y, z, 0xffffffff);\n\t\t}\n\t\tplx_vert_ind(&dr, PLX_VERT, 640.0f, 240.0f, z, 0xffffffff);\n\t\tplx_vert_ind(&dr, PLX_VERT_EOS, 640.0f, 235.0f, z, 0xffffffff);\n\n\t\tcurpos += cnt;\n\t\tif (curpos >= (sndbuffer_cnt + sndbuffer_cnt * takeframes / 60))\n\t\t\tcurpos = 0;\n\t}\n\tmutex_unlock(hookmut);\n}\n\n\nstatic void load_song_list(void * p) {\n\tfile_t d;\n\n\td = fs_open(curdir, O_RDONLY | O_DIR);\n\tif (!d) {\n\t\tstrcpy(curdir, \"/\");\n\t\td = fs_open(curdir, O_RDONLY | O_DIR);\n\t\tif (!d) {\n\t\t\tmutex_lock(mut);\n\t\t\tnum_entries = 1;\n\t\t\tstrcpy(entries[0].fn,\"Error!\");\n\t\t\tentries[0].size = 0;\n\t\t\tmutex_unlock(mut);\n\t\t\treturn;\n\t\t}\n\t}\n\t{\n\t\tdirent_t *de;\n\t\tnum_entries = 0;\n\t\tif (strcmp(curdir, \"/\")) {\n\t\t\tmutex_lock(mut);\n\t\t\tstrcpy(entries[0].fn, \"<..>\"); entries[0].size = -1;\n\t\t\tnum_entries++;\n\t\t\tmutex_unlock(mut);\n\t\t}\n\t\twhile ( (de = fs_readdir(d)) && num_entries < 200) {\n\t\t\tprintf(\"read entry '%s'\\n\", de->name);\n\t\t\tif (strcmp(de->name, \".\") && strcmp(de->name, \"..\")) {\n\t\t\t\tmutex_lock(mut);\n\t\t\t\tstrcpy(entries[num_entries].fn, de->name);\n\t\t\t\tentries[num_entries].size = de->size;\n\t\t\t\tnum_entries++;\n\t\t\t\tmutex_unlock(mut);\n\t\t\t}\n\t\t}\n\t}\n\tfs_close(d);\n\tload_queued = 0;\n}\n\n/* Draws the song listing */\nstatic void draw_listing() {\n\tfloat y = 92.0f;\n\tint i, esel;\n\n//\tprintf(\"DEBUG: List size %d\\r\\n\",lst_size);\n\n\t/* Draw all the song titles */\t\n//\tfor (i=0; i<14 && (top+i)<num_entries; i++) {\n\tfor (i=0; i<10 && (top+i)<num_entries; i++) {\n\t\tint li;\n\t\tdraw_poly_strf(32.0f, y, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,\n\t\t\t\"%s\", entries[top+i].fn);\n\t\tif (entries[top+i].size >= 0) {\n\t\t\tdraw_poly_strf(32.0f+240.0f, y, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,\n\t\t\t\t\"%d bytes\", entries[top+i].size);\n\t\t} else {\n\t\t\tdraw_poly_strf(32.0f+240.0f, y, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f, \"<DIR>\");\n\t\t}\n\n\t\t/* Check for playlist entries */\n\t\tfor(li = 0; li<lst_size;li++)\n\t\t{\n\t\t\tstrcat(workstring,curdir);\n\t\t\tstrcat(workstring,\"/\");\n\t\t\tstrcat(workstring,entries[top+i].fn);\n\t\n//\t\t\tprintf(\"%s =? %s \\r\\n\",workstring,lst_entries[li].fn);\n\n\t\t\tif(!(strcmp(workstring,lst_entries[li].fn)))\n\t\t\t{\n\t\t\t\tdraw_poly_strf(36.0f+32.0f+360.0f, y, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f, \"%2d\", li+1);\n\t\t\t}\t\t\t\t\n\t\t\tif(!(strcmp(workstring,lst_entries[lst_playing].fn)))\n\t\t\t{\n\t\t\t\tdraw_poly_box (31.0f, y - 1.0f,\n\t\t\t\t\t\t609.0f, y + 25.0f, 90.0f,\n\t\t\t\t\t\tthrob, 0.0f, 0.2f, 0.2f, \n\t\t\t\t\t\tthrob, 0.0f, throb, 0.2f);\n\n\t\t\t}\n\t\t\t\n\t\t\tworkstring[0]=0;\n\t\t}\t\t\n\t\t\n\t\t\n\t\ty += 24.0f;\n\t}\n\t\n\t/* Put a highlight bar under one of them */\n\tesel = (selected - top);\n\tdraw_poly_box(31.0f, 92.0f+esel*24.0f - 1.0f,\n\t\t609.0f, 92.0f+esel*24.0f + 25.0f, 95.0f,\n\t\tthrob, throb, 0.2f, 0.2f, throb, throb, 0.2f, 0.2f);\n\n\t/* Put a hightlight bar under the playing file */\n\t/* Only works correctly if you're in the same dir as the played file */\n\tif( (sndoggvorbis_isplaying() && !(strcmp(playdir,curdir)) && (lst_size==0)) )\n\t{\n\t\tesel = (iplaying - top);\n\t\tdraw_poly_box(31.0f, 92.0f+esel*24.0f - 1.0f,\n\t\t\t609.0f, 92.0f+esel*24.0f + 25.0f, 90.0f,\n\t\t\tthrob, 0.0f, 0.2f, 0.2f, \n\t\t\tthrob, 0.0f, throb, 0.2f);\n\t}\n\n\tif (sndoggvorbis_isplaying()) {\n\t\tdraw_wave();\n\t}\n\n}\n\nstatic void start(char *fn) {\n\tif (!sndoggvorbis_isplaying()) {\n\t\tsndoggvorbis_start(fn,0);\n\t}\n}\n\nstatic void stop() {\n\tif (sndoggvorbis_isplaying()) {\n\t\tsndoggvorbis_stop();\n\t}\n}\n\n/* Handle controller input */\nstatic uint8 mcont = 0;\nvoid check_controller() {\n\tstatic int up_moved = 0, down_moved = 0, a_pressed = 0, y_pressed = 0;\n\tcont_cond_t cond;\n\n\tif ((!(sndoggvorbis_isplaying())) && (lst_playing != -1))\n\t{\n\t\tlst_playing++;\n\t\tif (lst_playing == lst_size)\n\t\t{\n\t\t\tprintf(\"DEBUG: Reached end of playlist...\\r\\n\");\n\t\t\tlst_playing = -1;\n\t\t\tlst_size = 0;\n\t\t}\n\t\telse\n\t\t{\n\t\t\tprintf(\"DEBUG: Next song in playlist...\\r\\n\");\n\t\t\tstart(lst_entries[lst_playing].fn);\n\t\t}\n\t}\n\t\t\t\t\n\tif (!mcont) {\n\t\tmcont = maple_first_controller();\n\t\tif (!mcont) { return; }\n\t}\n\tif (cont_get_cond(mcont, &cond)) { return; }\n\n\tif (!(cond.buttons & CONT_DPAD_UP)) {\n\t\tif ((framecnt - up_moved) > 10) {\n\t\t\tif (selected > 0) {\n\t\t\t\tselected--;\n\t\t\t\tif (selected < top) {\n\t\t\t\t\ttop = selected;\n\t\t\t\t}\n\t\t\t}\n\t\t\tup_moved = framecnt;\n\t\t}\n\t}\n\tif (!(cond.buttons & CONT_DPAD_DOWN)) {\n\t\tif ((framecnt - down_moved) > 10) {\n\t\t\tif (selected < (num_entries - 1)) {\n\t\t\t\tselected++;\n//\t\t\t\tif (selected >= (top+14)) {\n\t\t\t\tif (selected >= (top+10)) {\n\t\t\t\t\ttop++;\n\t\t\t\t}\n\t\t\t}\n\t\t\tdown_moved = framecnt;\n\t\t}\n\t}\n\tif (cond.ltrig > 0) {\n\t\tif ((framecnt - up_moved) > 10) {\n//\t\t\tselected -= 14;\n\t\t\tselected -= 10;\n\n\t\t\tif (selected < 0) selected = 0;\n\t\t\tif (selected < top) top = selected;\n\t\t\tup_moved = framecnt;\n\t\t}\n\t}\n\tif (cond.rtrig > 0) {\n\t\tif ((framecnt - down_moved) > 10) {\n//\t\t\tselected += 14;\n\t\t\tselected += 10;\n\t\t\tif (selected > (num_entries - 1))\n\t\t\t\tselected = num_entries - 1;\n//\t\t\tif (selected >= (top+14))\n\t\t\tif (selected >= (top+10))\n\t\t\t\ttop = selected;\n\t\t\tdown_moved = framecnt;\n\t\t}\n\t}\n\tif (!(cond.buttons & CONT_B) && sndoggvorbis_isplaying()) {\n\t\tstop();\n\t}\n\n\tif (!(cond.buttons & CONT_Y)) {\n\t\tif ((framecnt - y_pressed) > 10)\n\t\t{\n\t\tstrcat(workstring,curdir);\n\t\tstrcat(workstring,\"/\");\n\t\tstrcat(workstring,entries[selected].fn);\t\t\n\t\tstrcpy(lst_entries[lst_size].fn,workstring);\n\t\t\n\t\tprintf(\"DEBUG: Entry %d : %s\\r\\n\",lst_size,lst_entries[lst_size].fn);\n\n\t\tworkstring[0]=0;\n\t\t\n\t\tlst_size++;\n\n\t\t}\n\t\ty_pressed=framecnt;\n\t}\n\n\tif (!(cond.buttons & CONT_A) && !load_queued) {\n\t\tif ((framecnt - a_pressed) > 10)\n\t\t{\n\t\t\tif (!strcmp(entries[selected].fn, \"Error!\"))\n\t\t\t{\n\t\t\t\tnum_entries = 0;\n\t\t\t}\n\t\t\telse if (lst_size > 0)\n\t\t\t{\n\t\t\t\tprintf(\"DEBUG: Playing playlist...\\r\\n\");\n\t\t\t\tlst_playing=0;\n\t\t\t\tstop();\n\t\t\t\tstart(lst_entries[lst_playing].fn);\n\t\t\t\t// sndoggvorbis_wait_play();\n\t\t\t}\n\t\t\telse if (entries[selected].size >= 0)\n\t\t\t{\n\t\t\t\tstop();\n\t\t\t\tstrcpy(playdir,curdir);\n\t\t\t\tstrcat(loadme,curdir);\n\t\t\t\tstrcat(loadme,\"/\");\n\t\t\t\tstrcat(loadme,entries[selected].fn);\n\t\t\t\tstart(loadme);\n\t\t\t\tloadme[0]=0;\n\t\t\t\tiplaying=selected;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\tif (!strcmp(entries[selected].fn, \"<..>\"))\n\t\t\t\t{\n\t\t\t\t\tint i;\n\t\t\t\t\tfor (i=strlen(curdir); i>0; i--)\n\t\t\t\t\t{\n\t\t\t\t\t\tif (curdir[i] == '/')\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcurdir[i] = 0;\n\t\t\t\t\t\t\tbreak;\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcurdir[i] = 0;\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t} \n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (strcmp(curdir, \"/\"))\n\t\t\t\t\tstrcat(curdir, \"/\");\n\t\t\t\t\tstrcat(curdir, entries[selected].fn);\n\t\t\t\t}\n\t\t\t\tmutex_lock(mut);\n\t\t\t\tselected = top = num_entries = 0;\n\t\t\t\tmutex_unlock(mut);\n\t\t\t\tprintf(\"current directory is now '%s'\\n\", curdir);\n\t\t\t}\n\t\t}\n\t\ta_pressed = framecnt;\n\t}\n}\n\n/* Check maple bus inputs */\nvoid check_inputs() {\n\tcheck_controller();\n}\n\n/* Main rendering of the song menu */\nvoid song_menu_render() {\n\tif (mut == NULL) {\n\t\tmut = mutex_create();\n\t\thookmut = mutex_create();\n\t}\n\tif (!filtinitted) {\n\t\tsnd_stream_filter_add(0, snd_hook, NULL);\n\t\tfiltinitted = 1;\n\t}\n\n\t/* Draw a background box */\n\tdraw_poly_box(30.0f, 80.0f, 610.0f, 440.0f-96.0f, 90.0f, \n\t\t0.2f, 0.8f, 0.5f, 0.0f, 0.2f, 0.8f, 0.8f, 0.2f);\n\t\t\n\t/* If we don't have a file listing, get it now */\n\tif (num_entries == 0 && !load_queued) {\n\t\tload_queued = 1;\n\t\tthd_create(load_song_list, NULL);\n\t}\n\n\t/* if (load_queued)\n\t\tdraw_poly_strf(32.0f, 82.0f, 100.0f, 1.0f, 1.0f, 1.0f, 1.0f,\n\t\t\t\"Scanning Directory...\"); */\n\t\n\t/* Draw the song listing */\n\tmutex_lock(mut);\n\tdraw_listing();\n\tmutex_unlock(mut);\n\t\n\t/* Adjust the throbber */\n\tthrob += dthrob;\n\tif (throb < 0.2f || throb > 0.8f) {\n\t\tdthrob = -dthrob;\n\t\tthrob += dthrob;\n\t}\n\t\n\t/* Check maple inputs */\n\tcheck_inputs();\n\t\n\tframecnt++;\n}\n\n\n"
},
{
"alpha_fraction": 0.5877862572669983,
"alphanum_fraction": 0.6030534505844116,
"avg_line_length": 15.25,
"blob_id": "fc1e2dcaa665bc49ecce89783aa0423d68eb6224",
"content_id": "633d93ee85666890998c454396d59514cf99e5ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 262,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 16,
"path": "/libk++/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#\n# libk++\n#\n# Simplified libstdc++ for KOS\n#\n# Makefile (c)2002 Dan Potter\n# \n\nOBJS = mem.o pure_virtual.o\nSUBDIRS =\n\nmyall: $(OBJS)\n\trm -f $(TOPDIR)/lib/$(KOS_ARCH)/libk++.a\n\t$(KOS_AR) rcs $(TOPDIR)/lib/$(KOS_ARCH)/libk++.a $(OBJS)\n\ninclude ../Makefile.prefab\n\n\n"
},
{
"alpha_fraction": 0.6234464049339294,
"alphanum_fraction": 0.6315957307815552,
"avg_line_length": 25.784147262573242,
"blob_id": "af815eb48473107cb23341b0aaea7a1dc92d312c",
"content_id": "45d0c6be02f42be6017d0ce142769d17dfd57ac7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 21965,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 820,
"path": "/kernel/thread/thread.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/thread.c\n Copyright (c)2000,2001,2002,2003 Dan Potter\n*/\n\n#include <stdlib.h>\n#include <assert.h>\n#include <string.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <reent.h>\n#include <kos/thread.h>\n#include <kos/sem.h>\n#include <kos/cond.h>\n#include <kos/genwait.h>\n#include <arch/irq.h>\n#include <arch/timer.h>\n#include <arch/arch.h>\n\nCVSID(\"$Id: thread.c,v 1.22 2003/04/08 05:29:46 bardtx Exp $\");\n\n/*\n\nThis module supports thread scheduling in KOS. The timer interrupt is used\nto re-schedule the processor HZ times per second in pre-emptive mode. \nThis is a fairly simplistic scheduler, though it does employ some \nstandard advanced OS tactics like priority scheduling and semaphores.\n\nSome of this code ought to look familiar to BSD-heads; I studied the\nBSD kernel quite a bit to get some ideas on priorities, and I am\nalso using their queue library verbatim (sys/queue.h).\n \n*/\n\n/* Uncomment the following line to enable experimental jiffyless thread\n switching support. Doesn't work very well right now. */\n/* #define JIFFYLESS */\n\n/*****************************************************************************/\n/* Thread scheduler data */\n\n/* Thread list. This includes all threads except dead ones. */\nstatic struct ktlist thd_list;\n\n/* Run queue. This is more like on a standard time sharing system than the\n previous versions. The top element of this priority queue should be the\n thread that is ready to run next. When a thread is scheduled, it will be\n removed from this queue. When it's de-scheduled, it will be re-inserted\n by its priority value at the end of its priority group. Note that right\n now this condition is being broken because sleeping threads are on the\n same queue. We deal with those in thd_switch below. */\nstatic struct ktqueue run_queue;\n\n/* \"Jiffy\" count: this is basically a counter that gets incremented each\n time a timer interrupt happens. XXX: Deprecated. */\nvuint32 jiffies;\n\n#ifdef JIFFYLESS\n/* Next pre-emption wake up time. If we are in pre-emptive threading mode and\n there are multiple tasks contending for the CPU, then this var will have\n the next system time that we need to wake up for a context switch. */\nuint64 thd_next_switch;\n#endif\n\n/* The currently executing thread. This thread should not be on any queues. */\nkthread_t *thd_current = NULL;\n\n/* Thread mode: cooperative or pre-emptive. */\nint thd_mode = THD_MODE_NONE;\n\n/*****************************************************************************/\n/* Debug */\n#include <kos/dbgio.h>\n\nstatic const char *thd_state_to_str(kthread_t * thd) {\n\tswitch(thd->state) {\n\t\tcase STATE_ZOMBIE:\n\t\t\treturn \"zombie\";\n\t\tcase STATE_RUNNING:\n\t\t\treturn \"running\";\n\t\tcase STATE_READY:\n\t\t\treturn \"ready\";\n\t\tcase STATE_WAIT:\n\t\t\tif (thd->wait_msg)\n\t\t\t\treturn thd->wait_msg;\n\t\t\telse\n\t\t\t\treturn \"wait\";\n\t\tdefault:\n\t\t\treturn \"unknown\";\n\t}\n}\n\nint thd_pslist(int (*pf)(const char *fmt, ...)) {\n\tkthread_t *cur;\n\n\tpf(\"All threads (may not be deterministic):\\n\");\n\tpf(\"addr\\t\\ttid\\tprio\\tflags\\twait_timeout\\tstate name\\n\");\n\t\n\tLIST_FOREACH(cur, &thd_list, t_list) {\n\t\tpf(\"%08lx\\t\", CONTEXT_PC(cur->context));\n\t\tpf(\"%d\\t\", cur->tid);\n\t\tif (cur->prio == PRIO_MAX)\n\t\t\tpf(\"MAX\\t\");\n\t\telse\n\t\t\tpf(\"%d\\t\", cur->prio);\n\t\tpf(\"%08lx\\t\", cur->flags);\n\t\tpf(\"%ld\\t\\t\", (uint32)cur->wait_timeout);\n\t\tpf(\"%10s\", thd_state_to_str(cur));\n\t\tpf(\"%s\\n\", cur->label);\n\t}\n\tpf(\"--end of list--\\n\");\n\n\treturn 0;\n}\n\nint thd_pslist_queue(int (*pf)(const char *fmt, ...)) {\n\tkthread_t *cur;\n\n\tpf(\"Queued threads:\\n\");\n\tpf(\"addr\\t\\ttid\\tprio\\tflags\\twait_timeout\\tstate name\\n\");\n\tTAILQ_FOREACH(cur, &run_queue, thdq) {\n\t\tpf(\"%08lx\\t\", CONTEXT_PC(cur->context));\n\t\tpf(\"%d\\t\", cur->tid);\n\t\tif (cur->prio == PRIO_MAX)\n\t\t\tpf(\"MAX\\t\");\n\t\telse\n\t\t\tpf(\"%d\\t\", cur->prio);\n\t\tpf(\"%08lx\\t\", cur->flags);\n\t\tpf(\"%ld\\t\\t\", (uint32)cur->wait_timeout);\n\t\tpf(\"%10s\", thd_state_to_str(cur));\n\t\tpf(\"%s\\n\", cur->label);\n\t}\n\n\treturn 0;\n}\n\n/*****************************************************************************/\n/* Returns a fresh thread ID for each new thread */\n\n/* Highest thread id (used when assigning next thread id) */\nstatic tid_t tid_highest;\n\n\n/* Return the next available thread id (assumes wraparound will not run\n into old processes). */\nstatic tid_t thd_next_free() {\n\tint id;\n\tid = tid_highest++;\n\treturn id;\n}\n\n/* Given a thread ID, locates the thread structure */\nkthread_t *thd_by_tid(tid_t tid) {\n\tkthread_t *np;\n\n\tLIST_FOREACH(np, &thd_list, t_list) {\n\t\tif (np->tid == tid)\n\t\t\treturn np;\n\t}\n\n\treturn NULL;\n}\n\n\n/*****************************************************************************/\n/* Thread support routines: idle task and start task wrapper */\n\n/* An idle function. This function literally does nothing but loop\n forever. It's meant to be used for an idle task. */\nstatic void thd_idle_task(void *param) {\n\t/* Uncomment these if you want some debug for deadlocking */\n/*\tint old = irq_disable();\n#ifndef NDEBUG\n\tthd_pslist();\n\tprintf(\"Inside idle task now\\n\");\n#endif\n\tirq_restore(old); */\n\tfor (;;) {\n\t\tarch_sleep();\t/* We can safely enter sleep mode here */\n\t}\n}\n\n/* Thread execution wrapper; when the thd_create function below\n adds a new thread to the thread chain, this function is the one\n that gets called in the new context. */\nvoid thd_birth(void (*routine)(void *param), void *param) {\n\t/* Call the thread function */\n\troutine(param);\n\n\t/* Die */\n\tthd_exit();\n}\n\n/* Terminate the current thread */\nvoid thd_exit() {\n\t/* Call Dr. Kevorkian; after this executes we could be killed\n\t at any time. */\n\tthd_current->state = STATE_ZOMBIE;\n\n\t/* Manually reschedule */\n\tthd_block_now(&thd_current->context);\n\n\t/* not reached */\n\tabort();\n}\n\n\n/*****************************************************************************/\n/* Thread creation and deletion */\n\n/* Enqueue a process in the runnable queue; adds it right after the\n process group of the same priority (front_of_line==0) or\n right before the process group of the same priority (front_of_line!=0). \n See thd_schedule for why this is helpful. */\nvoid thd_add_to_runnable(kthread_t *t, int front_of_line) {\n\tkthread_t\t*i;\n\tint\t\tdone;\n\n\tif (t->flags & THD_QUEUED)\n\t\treturn;\n\n\tdone = 0;\n\n\tif (!front_of_line) {\n\t\t/* Look for a thread of lower priority and insert\n\t \t before it. If there is nothing on the run queue, we'll \n\t \t fall through to the bottom. */\n\t\tTAILQ_FOREACH(i, &run_queue, thdq) {\n\t\t\tif (i->prio > t->prio) {\n\t\t\t\tTAILQ_INSERT_BEFORE(i, t, thdq);\n\t\t\t\tdone = 1;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t} else {\n\t\t/* Look for a thread of the same or lower priority and\n\t\t insert before it. If there is nothing on the run queue,\n\t\t we'll fall through to the bottom. */\n\t\tTAILQ_FOREACH(i, &run_queue, thdq) {\n\t\t\tif (i->prio >= t->prio) {\n\t\t\t\tTAILQ_INSERT_BEFORE(i, t, thdq);\n\t\t\t\tdone = 1;\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t}\n\n\t/* Didn't find one, put it at the end */\n\tif (!done)\n\t\tTAILQ_INSERT_TAIL(&run_queue, t, thdq);\n\n\tt->flags |= THD_QUEUED;\n}\n\n/* Removes a thread from the runnable queue, if it's there. */\nint thd_remove_from_runnable(kthread_t *thd) {\n\tif (!(thd->flags & THD_QUEUED)) return 0;\n\tthd->flags &= ~THD_QUEUED;\n\tTAILQ_REMOVE(&run_queue, thd, thdq);\n\treturn 0;\n}\n\n/* New thread function; given a routine address, it will create a\n new kernel thread with a default stack. When the routine\n returns, the thread will exit. Returns the new thread struct. */\nkthread_t *thd_create(void (*routine)(void *param), void *param) {\n\tkthread_t\t*nt;\n\ttid_t\t\ttid;\n\tuint32\t\tparams[2];\n\tint\t\toldirq = 0;\n\n\tnt = NULL;\n\n\toldirq = irq_disable();\n\n\t/* Get a new thread id */\n\ttid = thd_next_free();\n\tif (tid >= 0) {\n\t\t/* Create a new thread structure */\n\t\tnt = malloc(sizeof(kthread_t));\n\t\tif (nt != NULL) {\n\t\t\t/* Clear out potentially unused stuff */\n\t\t\tmemset(nt, 0, sizeof(kthread_t));\n\t\t\n\t\t\t/* Create a new thread stack */\n\t\t\tnt->stack = (uint32*)malloc(THD_STACK_SIZE);\n\t\t\tnt->stack_size = THD_STACK_SIZE;\n\t\n\t\t\t/* Populate the context */\n\t\t\tparams[0] = (uint32)routine;\n\t\t\tparams[1] = (uint32)param;\n\t\t\tirq_create_context(&nt->context,\n\t\t\t\t((uint32)nt->stack)+nt->stack_size,\n\t\t\t\t(uint32)thd_birth, params, 0);\n\n\t\t\tnt->tid = tid;\n\t\t\tnt->prio = PRIO_DEFAULT;\n\t\t\tnt->flags = THD_DEFAULTS;\n\t\t\tnt->state = STATE_READY;\n\t\t\tstrcpy(nt->label, \"[un-named kernel thread]\");\n\t\t\tif (thd_current)\n\t\t\t\tstrcpy(nt->pwd, thd_current->pwd);\n\t\t\telse\n\t\t\t\tstrcpy(nt->pwd, \"/\");\n\n\t\t\t_REENT_INIT_PTR((&(nt->thd_reent)));\n\n\t\t\t/* Insert it into the thread list */\n\t\t\tLIST_INSERT_HEAD(&thd_list, nt, t_list);\n\n\t\t\t/* Schedule it */\n\t\t\tthd_add_to_runnable(nt, 0);\n\t\t}\n\t}\n\n\tirq_restore(oldirq);\n\treturn nt;\n}\n\n/* Given a thread id, this function removes the thread from\n the execution chain. */\nint thd_destroy(kthread_t *thd) {\n\tint oldirq = 0;\n\n\t/* Make sure there are no ints */\n\toldirq = irq_disable();\n\n\t/* If any threads were waiting on this one, then go ahead\n\t and unblock them. */\n\tgenwait_wake_all(thd);\n\n\t/* De-schedule the thread if it's scheduled and free the\n\t thread structure */\n\tthd_remove_from_runnable(thd);\n\tLIST_REMOVE(thd, t_list);\n\n\t/* Free its stack */\n\tfree(thd->stack);\n\n\t/* Free the thread */\n\tfree(thd);\n\n\t/* Put ints back the way they were */\n\tirq_restore(oldirq);\n\n\treturn 0;\n}\n\n/*****************************************************************************/\n/* Thread attribute functions */\n\n/* Set a thread's priority */\nint thd_set_prio(kthread_t *thd, prio_t prio) {\n\t/* Set the new priority */\n\tthd->prio = prio;\n\treturn 0;\n}\n\n/*****************************************************************************/\n/* Scheduling routines */\n\n/* Thread scheduler; this function will find a new thread to run when a \n context switch is requested. No work is done in here except to change\n out the thd_current variable contents. Assumed that we are in an \n interrupt context.\n\n In the normal operation mode, the current thread is pushed back onto\n the run queue at the end of its priority group. This implements the\n standard round robin scheduling within priority groups. If you set the\n front_of_line parameter to non-zero, then this behavior is modified:\n the current thread is pushed onto the run queue at the _front_ of its\n priority group. The effect is that no context switching is done, but\n priority groups are re-checked. This is useful when returning from an\n IRQ after doing something like a sem_signal, where you'd ideally like\n to make sure the priorities are all straight before returning, but you\n don't want a full context switch inside the same priority group.\n */\nvoid thd_schedule(int front_of_line, uint64 now) {\n\tint\t\tdontenq, count;\n\tkthread_t\t*thd, *tnext;\n\n\tif (now == 0)\n\t\tnow = timer_ms_gettime64();\n\n\t/* We won't re-enqueue the current thread if it's NULL (i.e., the\n\t thread blocked itself somewhere) or if it's a zombie (below) */\n\tdontenq = thd_current == NULL ? 1 : 0;\n\t\n\t/* Destroy all threads marked STATE_ZOMBIE */\n\tthd = LIST_FIRST(&thd_list);\n\tcount = 0;\n\twhile (thd != NULL) {\n\t\ttnext = LIST_NEXT(thd, t_list);\n\n\t\tif (thd->state == STATE_ZOMBIE) {\n\t\t\tif (thd == thd_current)\n\t\t\t\tdontenq = 1;\n\t\t\tthd_destroy(thd);\n\t\t}\n\n\t\tthd = tnext;\n\t\tcount++;\n\t}\n\n\t/* If there's only one thread left, it's the idle task: exit the OS */\n\tif (count == 1) {\n\t\tdbgio_printf(\"\\nthd_schedule: idle task is the only thing left; exiting\\n\");\n\t\tarch_exit();\n\t}\n\n\t/* Re-queue the last \"current\" thread onto the run queue if\n\t it didn't die */\n\tif (!dontenq && thd_current->state == STATE_RUNNING) {\n\t\tthd_current->state = STATE_READY;\n\t\tthd_add_to_runnable(thd_current, front_of_line);\n\t}\n\n\t/* Look for timed out waits */\n\tgenwait_check_timeouts(now);\n\n\t/* Search downwards through the run queue for a runnable thread; if\n\t we don't find a normal runnable thread, the idle process will\n\t always be there at the bottom. */\n\tTAILQ_FOREACH(thd, &run_queue, thdq) {\n\t\t/* Is it runnable? If not, keep going */\n\t\tif (thd->state == STATE_READY)\n\t\t\tbreak;\n\t}\n\n\t/* Didn't find one? Big problem here... */\n\tif (thd == NULL) {\n\t\tthd_pslist(printf);\n\t\tpanic(\"couldn't find a runnable thread\");\n\t}\n\t\t\n\t/* We should now have a runnable thread, so remove it from the\n\t run queue and switch to it. */\n\tthd_remove_from_runnable(thd);\n\n\tthd_current = thd;\n\t_impure_ptr = &thd->thd_reent;\n\tthd->state = STATE_RUNNING;\n\n\t/* Make sure the thread hasn't underrun its stack */\n\tif (thd_current->stack && thd_current->stack_size) {\n\t\tif ( CONTEXT_SP(thd_current->context) < (ptr_t)(thd_current->stack) ) {\n\t\t\tthd_pslist(printf);\n\t\t\tthd_pslist_queue(printf);\n\t\t\tassert_msg( 0, \"Thread stack underrun\" );\n\t\t}\n\t}\n\n\tirq_set_context(&thd_current->context);\n}\n\n/* Temporary priority boosting function: call this from within an interrupt\n to boost the given thread to the front of the queue. This will cause the\n interrupt return to jump back to the new thread instead of the one that\n was executing (unless it was already executing). */\nvoid thd_schedule_next(kthread_t *thd) {\n\t/* Can't boost a blocked thread */\n\tif (thd_current->state != STATE_READY)\n\t\treturn;\n\n\t/* Unfortunately we have to take care of this here */\n\tif (thd_current->state == STATE_ZOMBIE) {\n\t\tthd_destroy(thd);\n\t} else if (thd_current->state == STATE_RUNNING) {\n\t\tthd_current->state = STATE_READY;\n\t\tthd_add_to_runnable(thd_current, 0);\n\t}\n\n\tthd_remove_from_runnable(thd);\n\tthd_current = thd;\n\t_impure_ptr = &thd->thd_reent;\n\tthd_current->state = STATE_RUNNING;\n\tirq_set_context(&thd_current->context);\n}\n\n#ifdef JIFFYLESS\n/* Looks at our queues and determines when we need to wake up next. */\nstatic void thd_schedule_switch(uint64 now) {\n\tuint64 nexttmr;\n\tkthread_t * nt;\n\n\tassert( thd_current != NULL );\n\n\t/* When is the next timer event due? */\n\tnexttmr = genwait_next_timeout();\n\n\t/* Are we in cooperative threading? If so, we never need a context\n\t switch timeout. */\n\tif (thd_mode == THD_MODE_COOP) {\n\t\t/* Just wake up for the timer event */\n\t\tif (nexttmr != 0) {\n\t\t\tassert( nexttmr != now );\n\t\t\ttimer_primary_wakeup(nexttmr - now);\n\t\t}\n\t} else {\n\t\t/* We already should have a runnable task in thd_current. Look also\n\t\t at the run queue. Is there anything at the same priority level\n\t\t as the current thread? */\n\t\tnt = TAILQ_FIRST(&run_queue);\n\t\tif (nt != NULL && nt->prio <= thd_current->prio) {\n\t\t\t/* Is the timeslice time more than the next timer event? If so\n\t\t\t then don't bother with a pre-emption timer. */\n\t\t\tif ((nexttmr - now) >= thd_next_switch) {\n\t\t\t\t/* We need a timeslice pre-emption. Make it so! */\n\t\t\t\tassert( thd_next_switch != now );\n\t\t\t\ttimer_primary_wakeup(thd_next_switch - now);\n\t\t\t} else {\n\t\t\t\t/* Just wake up for the timer event. */\n\t\t\t\tassert( nexttmr != now );\n\t\t\t\ttimer_primary_wakeup(nexttmr - now);\n\t\t\t}\n\t\t} else {\n\t\t\t/* Just wake up for the next timer event */\n\t\t\tif (nexttmr != 0) {\n\t\t\t\tassert( nexttmr != now );\n\t\t\t\ttimer_primary_wakeup(nexttmr - now);\n\t\t\t} else {\n\t\t\t\tthd_next_switch = 0;\n\t\t\t}\n\t\t}\n\t}\n}\n#endif /* JIFFYLESS */\n\n/* See kos/thread.h for description */\nirq_context_t * thd_choose_new() {\n\tuint64 now = timer_ms_gettime64();\n\n\t//printf(\"thd_choose_new() woken at %d\\n\", (uint32)now);\n\n\t/* Do any re-scheduling */\n\tthd_schedule(0, now);\n\n#ifdef JIFFYLESS\n\t/* Increment the context switch counter */\n\tjiffies++;\n\n\t/* Schedule a new next-switch event */\n\tthd_next_switch = now + 1000/HZ;\n\t//printf(\" resetting thd_next_switch to %d\\n\", (uint32)thd_next_switch);\n\tthd_schedule_switch(now);\n#endif\n\n\t/* Return the new IRQ context back to the caller */\n\treturn &thd_current->context;\n}\n\n/*****************************************************************************/\n\n/* Timer function. Check to see if we were woken because of a timeout event\n or because of a pre-empt. For timeouts, just go take care of it and sleep\n again until our next context switch (if any). For pre-empts, re-schedule\n threads, swap out contexts, and sleep. */\nstatic void thd_timer_hnd(irq_context_t *context) {\n\t/* Get the system time */\n\tuint64 now = timer_ms_gettime64();\n\n\t//printf(\"timer woke at %d\\n\", (uint32)now);\n\n#ifdef JIFFYLESS\n\t/* Did we wake up for a timer event or a context switch? */\n\tif (thd_next_switch && now >= thd_next_switch) {\n\t\t/* Do any re-scheduling. Note that thd_schedule() also checks\n\t\t for timeouts, so if we had those simultaneous with a context\n\t\t switch it'll get caught here. */\n\t\tthd_schedule(0, now);\n\n\t\t/* Schedule the next context switch. */\n\t\tthd_next_switch = now + 1000/HZ;\n\t\t//printf(\"resetting thd_next_switch to %ld\\n\", (uint32)thd_next_switch);\n\t} else {\n\t\t/* Just deal with timers */\n\t\tgenwait_check_timeouts(now);\n\t}\n\n\t/* Request a wakeup at the next time we will need to re-schedule. */\n\tthd_schedule_switch(now);\n#else\n\tthd_schedule(0, now);\n\ttimer_primary_wakeup(1000/HZ);\n#endif\n}\n\n/*****************************************************************************/\n\n/* Thread blocking based sleeping; this is the preferred way to\n sleep because it eases the load on the system for the other\n threads. */\nvoid thd_sleep(int ms) {\n\tif (thd_mode == THD_MODE_NONE) {\n\t\ttimer_spin_sleep(ms);\n\t\treturn;\n\t}\n\n\t/* A timeout of zero is the same as thd_pass() and passing zero\n\t down to genwait_wait() causes bad juju. */\n\tif (!ms) {\n\t\tthd_pass();\n\t\treturn;\n\t}\n\n\t/* We can genwait on a non-existant object here with a timeout and\n\t have the exact same effect; as a nice bonus, this collapses both\n\t sleep cases into a single case, which is nice for scheduling\n\t purposes. 0xffffffff definitely doesn't exist as an object, so we'll\n\t use that for straight up timeouts. */\n\tgenwait_wait((void *)0xffffffff, \"thd_sleep\", ms, NULL);\n}\n\n/* Manually cause a re-schedule */\nvoid thd_pass() {\n\t/* Makes no sense inside int */\n\tif (irq_inside_int()) return;\n\n\t/* Pass off control manually */\n\tthd_block_now(&thd_current->context);\n}\n\n/* Wait for a thread to exit */\nint thd_wait(kthread_t * thd) {\n\tint\t\told, rv;\n\tkthread_t\t* t = NULL;\n\n\t/* Can't scan for NULL threads */\n\tif (thd == NULL)\n\t\treturn -1;\n\n\tif (irq_inside_int()) {\n\t\tdbglog(DBG_WARNING, \"thd_wait(%p) called inside an interrupt!\\n\", thd);\n\t\treturn -1;\n\t}\n\n\told = irq_disable();\n\t\n\t/* Search the thread list and make sure that this thread hasn't\n\t already died and been deallocated. */\n\tLIST_FOREACH(t, &thd_list, t_list) {\n\t\tif (t == thd)\n\t\t\tbreak;\n\t}\n\n\t/* Did we find anything? */\n\tif (t != thd) {\n\t\trv = -2;\n\t} else {\n\t\t/* Wait for the target thread to die */\n\t\tgenwait_wait(thd, \"thd_wait\", 0, NULL);\n\n\t\t/* Ok, we're all clear */\n\t\trv = 0;\n\t}\n\n\tirq_restore(old);\n\treturn rv;\n}\n\n/*****************************************************************************/\n/* Retrive / set thread label */ \nconst char *thd_get_label(kthread_t *thd) {\n\treturn thd->label;\n}\n\nvoid thd_set_label(kthread_t *thd, const char *label) {\n\tstrncpy(thd->label, label, sizeof(thd->label) - 1);\n}\n\n/* Find the current thread */\nkthread_t *thd_get_current() {\n\treturn thd_current;\n}\n\n/* Retrieve / set thread pwd */ \nconst char *thd_get_pwd(kthread_t *thd) {\n\treturn thd->pwd;\n}\n\nvoid thd_set_pwd(kthread_t *thd, const char *pwd) {\n\tstrncpy(thd->pwd, pwd, sizeof(thd->pwd) - 1);\n}\n\nint * thd_get_errno(kthread_t * thd) {\n\treturn &thd->thd_errno;\n}\n\nstruct _reent * thd_get_reent(kthread_t *thd) {\n\treturn &thd->thd_reent;\n}\n\n/*****************************************************************************/\n\n/* Change threading modes */\nint thd_set_mode(int mode) {\n\tint old = thd_mode;\n\n\t/* Nothing to change? */\n\tif (thd_mode == mode)\n\t\treturn thd_mode;\n\n\tif (thd_mode == THD_MODE_COOP) {\n\t\t/* Schedule our first pre-emption wakeup */\n#ifdef JIFFYLESS\n\t\tthd_next_switch = timer_ms_gettime64() + 1000/HZ;\n#endif\n\t\ttimer_primary_wakeup(1000/HZ);\n\t} else {\n#ifdef JIFFYLESS\n\t\t/* Don't do any more pre-empt wakeups */\n\t\tthd_next_switch = 0;\n#endif\n\t}\n\n\tthd_mode = mode;\n\n\treturn old;\n}\n\n/*****************************************************************************/\n/* Init/shutdown */\n\n/* Init */\nint thd_init(int mode) {\n\tkthread_t *idle, *kern;\n\n\t/* Make sure we're not already running */\n\tif (thd_mode != THD_MODE_NONE)\n\t\treturn -1;\n\n\t/* Setup our mode as appropriate */\n\tthd_mode = mode;\n\n\t/* Initialize handle counters */\n\ttid_highest = 1;\n\n\t/* Initialize the thread list */\n\tLIST_INIT(&thd_list);\n\n\t/* Initialize the run queue */\n\tTAILQ_INIT(&run_queue);\n\n\t/* Start off with no \"current\" thread */\n\tthd_current = NULL;\n\n\t/* Setup a kernel task for the currently running \"main\" thread */\n\tkern = thd_create(NULL, NULL);\n\tstrcpy(kern->label, \"[kernel]\");\n\tkern->state = STATE_RUNNING;\n\n\t/* De-scehdule the thread (it's STATE_RUNNING) */\n\tthd_remove_from_runnable(kern);\n\t\n\t/* Setup an idle task that is always ready to run, in case everyone\n\t else is blocked on something. */\n\tidle = thd_create(thd_idle_task, NULL);\n\tstrcpy(idle->label, \"[idle]\");\n\tthd_set_prio(idle, PRIO_MAX);\n\tidle->state = STATE_READY;\n\n\t/* Main thread -- the kern thread */\n\tthd_current = kern;\n\tirq_set_context(&kern->context);\n\n\t/* Re-initialize jiffy counter */\n\tjiffies = 0;\n\n\t/* Initialize thread sync primitives */\n\tgenwait_init();\n\tsem_init();\n\tcond_init();\n\n\t/* Setup our pre-emption handler */\n\ttimer_primary_set_callback(thd_timer_hnd);\n\n\t/* If we're in pre-emptive mode, then schedule the first context switch */\n\tif (thd_mode == THD_MODE_PREEMPT) {\n\t\t/* Schedule our first wakeup */\n#ifdef JIFFYLESS\n\t\tthd_next_switch = timer_ms_gettime64() + 1000/HZ;\n#endif\n\t\ttimer_primary_wakeup(1000/HZ);\n\n\t\tprintf(\"thd: pre-emption enabled, HZ=%d\\n\", HZ);\n\t} else\n\t\tprintf(\"thd: pre-emption disabled\\n\");\n\n\treturn 0;\n}\n\n/* Shutdown */\nvoid thd_shutdown() {\n\tkthread_t *n1, *n2;\n\n\t/* Disable pre-emption, if neccessary */\n\tif (thd_mode == THD_MODE_PREEMPT) {\n\t\ttimer_primary_set_callback(NULL);\n\t}\n\n\t/* Kill remaining live threads */\n\tn1 = LIST_FIRST(&thd_list);\n\twhile (n1 != NULL) {\n\t\tn2 = LIST_NEXT(n1, t_list);\n\t\tfree(n1->stack);\n\t\tfree(n1);\n\t\tn1 = n2;\n\t}\n\n\t/* Shutdown thread sync primitives */\n\tsem_shutdown();\n\tcond_shutdown();\n\tgenwait_shutdown();\n\n\t/* Not running */\n\tthd_mode = THD_MODE_NONE;\n\n\t// XXX _impure_ptr is borked\n}\n\n\n"
},
{
"alpha_fraction": 0.6290655732154846,
"alphanum_fraction": 0.6418430805206299,
"avg_line_length": 27.277372360229492,
"blob_id": "520101e975d116eb063c90a81aa61afa03a1cdf7",
"content_id": "953ace8d98bbdbe6b3ed0e7231d81575f6c1a03e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7748,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 274,
"path": "/kernel/arch/dreamcast/fs/dcload-syscalls.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/fs/dcload-net.c\n\n Copyright (C)2001 Andrew Kieschnick, imported\n from the GPL'd dc-load-ip sources to a BSD-compatible\n license with permission.\n\n Adapted to KOS by Dan Potter.\n\n*/\n\n/* #include <unistd.h>\n#include <sys/types.h>\n#include <sys/stat.h>\n#include <fcntl.h>\n#include <utime.h>\n#include <stdarg.h>\n#include <dirent.h> */\n\n#include <string.h>\n#include <dc/fs_dclnative.h>\n#include \"dcload-syscalls.h\"\n#include \"dcload-packet.h\"\n#include \"dcload-net.h\"\n#include \"dcload-commands.h\"\n\nstatic ether_header_t * ether = (ether_header_t *)dcln_pkt_buf;\nstatic ip_header_t * ip = (ip_header_t *)(dcln_pkt_buf + ETHER_H_LEN);\nstatic udp_header_t * udp = (udp_header_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN);\n\n/* send command, enable bb, bb_loop(), then return */\n\nvoid dcln_build_send_packet(int command_len)\n{\n unsigned char * command = dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN;\n/*\n scif_puts(\"build_send_packet\\n\");\n scif_putchar(command[0]);\n scif_putchar(command[1]);\n scif_putchar(command[2]);\n scif_putchar(command[3]);\n scif_puts(\"\\n\");\n*/\n dcln_make_ether(dcln_tool_mac, dcln_our_mac, ether);\n dcln_make_ip(dcln_tool_ip, dcln_our_ip, UDP_H_LEN + command_len, 17, ip);\n dcln_make_udp(dcln_tool_port, 31313, command, command_len, ip, udp);\n dcln_tx(dcln_pkt_buf, ETHER_H_LEN + IP_H_LEN + UDP_H_LEN + command_len);\n}\n\nvoid dcln_exit(void)\n{\n command_t * command = (command_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_EXIT, 4); \n command->address = htonl(0);\n command->size = htonl(0);\n dcln_build_send_packet(COMMAND_LEN);\n}\n\nint dcln_read(int fd, void *buf, size_t count)\n{\n command_3int_t * command = (command_3int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_READ, 4); \n command->value0 = htonl(fd);\n command->value1 = htonl((uint32)buf);\n command->value2 = htonl(count);\n dcln_build_send_packet(sizeof(command_3int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_write(int fd, const void *buf, size_t count)\n{\n command_3int_t * command = (command_3int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_WRITE, 4); \n command->value0 = htonl(fd);\n command->value1 = htonl((uint32)buf);\n command->value2 = htonl(count);\n dcln_build_send_packet(sizeof(command_3int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_open(const char *pathname, int flags, int perms)\n{\n command_2int_string_t * command = (command_2int_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n\n int namelen = strlen(pathname);\n \n memcpy(command->id, DCLN_CMD_OPEN, 4); \n\n command->value0 = htonl(flags);\n command->value1 = htonl(perms);\n\n memcpy(command->string, pathname, namelen+1);\n \n dcln_build_send_packet(sizeof(command_2int_string_t)+namelen);\n dcln_rx_loop();\n\n return dcln_syscall_retval;\n}\n\nint dcln_close(int fd)\n{\n command_int_t * command = (command_int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n\n memcpy(command->id, DCLN_CMD_CLOSE, 4); \n command->value0 = htonl(fd);\n\n dcln_build_send_packet(sizeof(command_int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_link(const char *oldpath, const char *newpath)\n{\n command_string_t * command = (command_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n int namelen1 = strlen(oldpath);\n int namelen2 = strlen(newpath);\n \n memcpy(command->id, DCLN_CMD_LINK, 4); \n\n memcpy(command->string, oldpath, namelen1 + 1);\n memcpy(command->string + namelen1 + 1, newpath, namelen2 + 1); \n \n dcln_build_send_packet(sizeof(command_string_t)+namelen1+namelen2+1);\n dcln_rx_loop();\n\n return dcln_syscall_retval;\n\n}\n\nint dcln_unlink(const char *pathname)\n{\n command_string_t * command = (command_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n int namelen = strlen(pathname);\n \n memcpy(command->id, DCLN_CMD_UNLINK, 4); \n\n memcpy(command->string, pathname, namelen + 1);\n \n dcln_build_send_packet(sizeof(command_string_t)+namelen);\n dcln_rx_loop();\n\n return dcln_syscall_retval;\n}\n\nint dcln_chdir(const char *path)\n{\n command_string_t * command = (command_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n int namelen = strlen(path);\n \n memcpy(command->id, DCLN_CMD_CHDIR, 4); \n\n memcpy(command->string, path, namelen + 1);\n\n dcln_build_send_packet(sizeof(command_string_t)+namelen);\n dcln_rx_loop();\n\n return dcln_syscall_retval;\n}\n\noff_t dcln_lseek(int fildes, off_t offset, int whence)\n{\n command_3int_t * command = (command_3int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_LSEEK, 4); \n command->value0 = htonl(fildes);\n command->value1 = htonl(offset);\n command->value2 = htonl(whence);\n\n dcln_build_send_packet(sizeof(command_3int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\ntime_t dcln_time(time_t * t)\n{\n command_int_t * command = (command_int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n\n \n memcpy(command->id, DCLN_CMD_TIME, 4); \n dcln_build_send_packet(sizeof(command_int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_stat(const char *file_name, dcload_stat_t *buf)\n{\n command_2int_string_t * command = (command_2int_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n int namelen = strlen(file_name);\n\n memcpy(command->id, DCLN_CMD_STAT, 4); \n memcpy(command->string, file_name, namelen+1);\n\n command->value0 = htonl((uint32)buf);\n command->value1 = htonl(sizeof(struct stat));\n \n dcln_build_send_packet(sizeof(command_2int_string_t)+namelen);\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_opendir(const char *name)\n{\n command_string_t * command = (command_string_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n int namelen = strlen(name);\n \n memcpy(command->id, DCLN_CMD_OPENDIR, 4); \n memcpy(command->string, name, namelen+1);\n\n dcln_build_send_packet(sizeof(command_string_t)+namelen);\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nint dcln_closedir(int dir)\n{\n command_int_t * command = (command_int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_CLOSEDIR, 4); \n command->value0 = htonl(dir);\n\n dcln_build_send_packet(sizeof(command_int_t));\n dcln_rx_loop();\n \n return dcln_syscall_retval;\n}\n\nstatic dcload_dirent_t our_dir;\n\ndcload_dirent_t *dcln_readdir(int dir)\n{\n command_3int_t * command = (command_3int_t *)(dcln_pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n \n memcpy(command->id, DCLN_CMD_READDIR, 4); \n command->value0 = htonl(dir);\n command->value1 = htonl((uint32)&our_dir);\n command->value2 = htonl(sizeof(struct dirent));\n\n dcln_build_send_packet(sizeof(command_3int_t));\n dcln_rx_loop();\n \n if (dcln_syscall_retval)\n\treturn &our_dir;\n else\n\treturn 0;\n}\n\t\nsize_t dcln_gdbpacket(const char *in_buf, size_t in_size, char *out_buf, size_t out_size)\n{\n command_2int_string_t * command = (command_2int_string_t *)(pkt_buf + ETHER_H_LEN + IP_H_LEN + UDP_H_LEN);\n\n memcpy(command->id, CMD_GDBPACKET, 4);\n command->value0 = htonl(in_size);\n command->value1 = htonl(out_size);\n memcpy(command->string, in_buf, in_size);\n dcln_build_send_packet(sizeof(command_2int_string_t)-1 + in_size);\n dcln_rx_loop();\n\n memcpy(out_buf, dcln_syscall_data, dcln_syscall_retval);\n\n return dcln_syscall_retval;\n}\n"
},
{
"alpha_fraction": 0.5341914892196655,
"alphanum_fraction": 0.6017699241638184,
"avg_line_length": 23.372549057006836,
"blob_id": "42eb3796ac1175602777cba12b2282114af4cbf2",
"content_id": "d9fdae49ac9ae5d1d3b01653b55357353382dfc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1243,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 51,
"path": "/examples/dreamcast/sound/ghettoplay-vorbis/texture.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* GhettoPlay: an S3M browser and playback util\n (c)2000 Dan Potter\n*/\n\n#include \"gp.h\"\n\n/* Creates the utility texture used for the font and mouse cursor. The\n resulting texture will be 256x256. */\n#include \"mouse1.h\"\npvr_ptr_t util_texture;\npvr_poly_hdr_t util_txr_hdr;\nvoid setup_util_texture() {\n\tuint16\t*vram;\n\tint\tx, y;\n\tpvr_poly_cxt_t\tcxt;\n\n\tutil_texture = pvr_mem_malloc(256*256*2);\n\tprintf(\"util_texture at %08x\\n\", util_texture);\n\tvram = (uint16 *)util_texture;\n\t\n\t/* First dump in the mouse cursor */\n\tfor (y=0; y<16; y++) {\n\t\tfor (x=0; x<10; x++) {\n\t\t\tif (mouse1_xpm[y*10+x] == '.')\n\t\t\t\t*vram = 0xffff;\n\t\t\telse if (mouse1_xpm[y*10+x] == '+')\n\t\t\t\t*vram = 0xf000;\n\t\t\telse\n\t\t\t\t*vram = 0x0000;\n\t\t\tvram++;\n\t\t}\n\t\tvram += 256 - 10;\n\t}\n\t\n\t/* Now add the rest as ASCII characters */\n\tvram = (uint16 *)util_texture;\n\tfor (y=0; y<8; y++) {\n\t\tfor (x=0; x<16; x++) {\n\t\t\t/* Skip the first (it's a mouse pointer) */\n\t\t\tif (x != 0 || y != 0) \n\t\t\t\tbfont_draw(vram, 256, 0, y*16+x);\n\t\t\tvram += 16;\n\t\t}\n\t\tvram += 23*256;\n\t}\n\n\t/* Setup a polygon header for the util texture */\n\tpvr_poly_cxt_txr(&cxt, PVR_LIST_TR_POLY, PVR_TXRFMT_ARGB4444 | PVR_TXRFMT_NONTWIDDLED,\n\t\t256, 256, util_texture, PVR_FILTER_NONE);\n\tpvr_poly_compile(&util_txr_hdr, &cxt);\n}\n"
},
{
"alpha_fraction": 0.6600000262260437,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 14.384614944458008,
"blob_id": "c4754dfc81db7671565f4ac326e5c86fcfcf9913",
"content_id": "54004be8a475afc8e7082d699d838f3b40766727",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 26,
"path": "/kernel/arch/dreamcast/include/dc/fs_dclsocket.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/fs_dclsocket.h\n Copyright (C) 2007, 2008 Lawrence Sebald\n\n*/\n\n#ifndef __DC_FSDCLSOCKET_H\n#define __DC_FSDCLSOCKET_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <dc/fs_dcload.h>\n\nextern dbgio_handler_t dbgio_dcls;\n\n/* Initialization */\nvoid fs_dclsocket_init_console();\nint fs_dclsocket_init();\n\nint fs_dclsocket_shutdown();\n\n__END_DECLS\n\n#endif /* __DC_FSDCLSOCKET_H */\n"
},
{
"alpha_fraction": 0.49172577261924744,
"alphanum_fraction": 0.6985815763473511,
"avg_line_length": 24.606060028076172,
"blob_id": "994784bc04e9e890a33d0774ed86791df17ef658",
"content_id": "3eabaa0c8b5b508a506716889761a84e6fdd6175",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 846,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 33,
"path": "/include/arch/gba/gba/sound.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n gba/sound.h\n (c)2002 Gil Megidish\n \n $Id: \n*/\n\n#ifndef __GBA_SOUND_H\n#define __GBA_SOUND_H\n\n#include <arch/types.h>\n\n#define REG_SOUND1CNT_L\t(*(vu16*)0x04000060)\n#define REG_SOUND1CNT_H\t(*(vu16*)0x04000062)\n#define REG_SOUND1CNT_X\t(*(vu16*)0x04000064)\n#define REG_SOUND2CNT_L\t(*(vu16*)0x04000068)\n#define REG_SOUND2CNT_H\t(*(vu16*)0x0400006C)\n#define REG_SOUND3CNT_L\t(*(vu16*)0x04000070)\n#define REG_SOUND3CNT_H\t(*(vu16*)0x04000072)\n#define REG_SOUND3CNT_X\t(*(vu16*)0x04000074)\n#define REG_SOUND4CNT_L\t(*(vu16*)0x04000078)\n#define REG_SOUND4CNT_H\t(*(vu16*)0x0400007C)\n\n/* Master registers */\n#define REG_SOUNDCNT_L\t(*(vu16*)0x04000080)\n#define REG_SOUNDCNT_H\t(*(vu16*)0x04000082)\n#define REG_SOUNDCNT_X\t(*(vu16*)0x04000084)\n#define REG_SOUNDBIAS\t(*(vu16*)0x04000088)\n\n#define PTR_WAVE_RAM\t((vu8*)0x0400008a)\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5917481184005737,
"alphanum_fraction": 0.6558089256286621,
"avg_line_length": 23.210525512695312,
"blob_id": "2bdddd0137de1f95be1fcdf6b676ac6146a39456",
"content_id": "a2482535b57a46abfeb42fe4ec1109c48f2f2f84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 921,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 38,
"path": "/include/arch/dreamcast/dc/sq.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/sq.h\n (C)2000-2001 Andrew Kieschnick\n\n $Id: sq.h,v 1.2 2002/01/05 07:33:51 bardtx Exp $\n*/\n\n\n#ifndef __DC_SQ_H\n#define __DC_SQ_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n#define QACR0 (*(volatile unsigned int *)(void *)0xff000038)\n#define QACR1 (*(volatile unsigned int *)(void *)0xff00003c)\n\n/* clears n bytes at dest, dest must be 32-byte aligned */\nvoid sq_clr(void *dest, int n);\n\n/* copies n bytes from src to dest, dest must be 32-byte aligned */\nvoid * sq_cpy(void *dest, void *src, int n);\n\n/* fills n bytes at s with byte c, s must be 32-byte aligned */\nvoid * sq_set(void *s, uint32 c, int n);\n\n/* fills n bytes at s with short c, s must be 32-byte aligned */\nvoid * sq_set16(void *s, uint32 c, int n);\n\n/* fills n bytes at s with int c, s must be 32-byte aligned */\nvoid * sq_set32(void *s, uint32 c, int n);\n\n__END_DECLS\n\n#endif\n\n"
},
{
"alpha_fraction": 0.5446428656578064,
"alphanum_fraction": 0.6339285969734192,
"avg_line_length": 17.41666603088379,
"blob_id": "85567c11b313235542ec1ec61b37ccab3e78a65f",
"content_id": "e6938bdfdec21ab503bc876f7f1f6ece9deb28a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/kernel/thread/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# thread/Makefile\n# (c)2001 Dan Potter\n# \n# $Id: Makefile,v 1.4 2003/02/14 08:25:07 bardtx Exp $\n\nOBJS = sem.o cond.o mutex.o genwait.o\nOBJS += thread.o\nSUBDIRS = \n\ninclude ../../Makefile.prefab\n\n\n\n"
},
{
"alpha_fraction": 0.5889621376991272,
"alphanum_fraction": 0.6128500699996948,
"avg_line_length": 20.660715103149414,
"blob_id": "c1a36ebd04ee8b51d12cb9583ce2286c9bea78dd",
"content_id": "b736e216062d2c1ec5bf8f440322a43e6e081b67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1214,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 56,
"path": "/include/arch/dreamcast/arch/spinlock.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/dreamcast/include/spinlock.h\n (c)2001 Dan Potter\n \n $Id: spinlock.h,v 1.6 2002/11/13 02:05:15 bardtx Exp $\n*/\n\n#ifndef __ARCH_SPINLOCK_H\n#define __ARCH_SPINLOCK_H\n\n/* Defines processor specific spinlocks */\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n/* DC implementation uses threads most of the time */\n#include <kos/thread.h>\n\n/* Spinlock data type */\ntypedef volatile int spinlock_t;\n\n/* Value initializer */\n#define SPINLOCK_INITIALIZER 0\n\n/* Initialize a spinlock */\n#define spinlock_init(A) *(A) = SPINLOCK_INITIALIZER\n\n/* Note here that even if threads aren't enabled, we'll still set the\n lock so that it can be used for anti-IRQ protection (e.g., malloc) */\n\n/* Spin on a lock */\n#define spinlock_lock(A) do { \\\n\tspinlock_t * __lock = A; \\\n\tint __gotlock = 0; \\\n\twhile(1) { \\\n\t\tasm volatile (\"tas.b @%1\\n\\t\" \\\n\t\t\t \"movt %0\\n\\t\" \\\n\t\t\t\t: \"=r\" (__gotlock) : \"r\" (__lock) : \"t\", \"memory\"); \\\n\t\tif (!__gotlock) \\\n\t\t\tthd_pass(); \\\n\t\telse break; \\\n\t} \\\n} while (0)\n\n/* Free a lock */\n#define spinlock_unlock(A) do { \\\n\t\t*(A) = 0; \\\n\t} while (0)\n\n/* Determine if a lock is locked */\n#define spinlock_is_locked(A) ( *(A) != 0 )\n\n__END_DECLS\n\n#endif\t/* __ARCH_SPINLOCK_H */\n\n"
},
{
"alpha_fraction": 0.6321321129798889,
"alphanum_fraction": 0.6766766905784607,
"avg_line_length": 18.558822631835938,
"blob_id": "27640ef64aef53d0db7a3272417b264dc5a4130b",
"content_id": "437a933438ab436309646d1716ef9359a4156d83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1998,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 102,
"path": "/kernel/arch/ia32/kernel/timer.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n timer.c\n Copyright (c)2003 Dan Potter\n*/\n\n#include <assert.h>\n\n#include <stdio.h>\n#include <arch/arch.h>\n#include <arch/timer.h>\n#include <arch/irq.h>\n#include <ia32/ports.h>\n\nCVSID(\"$Id: timer.c,v 1.3 2003/08/02 23:11:43 bardtx Exp $\");\n\nvolatile uint32 jiffies = 0;\n\n// Set the PIC Timer 0 speed\nvoid timer_set_speed(int tps) {\n\tuint32 factor;\n\n\tassert( tps != 0 ); if (!tps) tps++;\n\tfactor = 1193181 / tps;\n\n\toutb(0x43, 0x34);\n\toutb(0x40, factor & 0xff);\n\toutb(0x40, (factor >> 8) & 0xff);\n}\n\n/* Spin-loop kernel sleep func: uses the secondary timer in the\n SH-4 to very accurately delay even when interrupts are disabled */\nvoid timer_spin_sleep(int ms) {\n}\n\n\n/* Millisecond timer */\nstatic uint32 timer_ms_counter = 0;\nstatic uint32 timer_ms_countdown;\nstatic void timer_ms_handler(irq_t source, irq_context_t *context) {\n\ttimer_ms_counter++;\n}\n\nvoid timer_ms_enable() {\n}\n\nvoid timer_ms_disable() {\n}\n\n/* Return the number of ticks since KOS was booted */\nvoid timer_ms_gettime(uint32 *secs, uint32 *msecs) {\n\t*secs = jiffies / HZ;\n\t*msecs = (jiffies % HZ) * 1000 / HZ;\n}\n\nuint64 timer_ms_gettime64() {\n\treturn (uint64)jiffies * 1000 / HZ;\n}\n\ntimer_primary_callback_t tp_callback;\nstatic void tp_handler(irq_t src, irq_context_t * cxt) {\n\tif (tp_callback)\n\t\ttp_callback(cxt);\n\tjiffies++;\n}\n\nstatic void timer_primary_init() {\n\t// Clear out our vars\n\ttp_callback = NULL;\n\n\t// Hook the timer IRQ\n\tirq_set_handler(TIMER_IRQ, tp_handler);\n\n\t// Enable the external interrupt\n\toutb(0x21, inb(0x21) & ~1);\n}\n\ntimer_primary_callback_t timer_primary_set_callback(timer_primary_callback_t cb) {\n\ttimer_primary_callback_t cbold = tp_callback;\n\ttp_callback = cb;\n\treturn cbold;\n}\n\nvoid timer_primary_wakeup(uint32 millis) {\n\t// We always wakeup after 1000/HZ millis for now\n}\n\n\n/* Init */\nint timer_init() {\n\t// Set the primary timer speed\n\ttimer_set_speed(HZ);\n\n\t// Hook the timer interrupt\n\ttimer_primary_init();\n\n\treturn 0;\n}\n\n/* Shutdown */\nvoid timer_shutdown() {\n}\n\n\n\n"
},
{
"alpha_fraction": 0.5557103157043457,
"alphanum_fraction": 0.6051532030105591,
"avg_line_length": 21.40625,
"blob_id": "3aff65e1415b82a0b3393b7fe727acb17fd9b9ea",
"content_id": "75275af5bceaeac86c909d67e3a23989d135feae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1436,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 64,
"path": "/examples/dreamcast/basic/mmu/pvrmap/pvrmap.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n pvrmap.c\n (c)2002 Dan Potter\n*/\n\n#include <kos.h>\n\n/* This sample doesn't particularly do anything helpful, but it shows off\n the basic usage of the built-in page table functions for remapping\n regions of memory. That main drawing code should certainly pull\n a double-take from any good coder ;) */\n\nKOS_INIT_FLAGS(INIT_DEFAULT | INIT_MALLOCSTATS);\n\nint main(int argc, char **argv) {\n\tmmucontext_t * cxt;\n\tuint16 * vr;\n\tint x, y, done = 0;\n\t\n\t/* Initialize MMU support */\n\tmmu_init();\n\n\t/* Setup a context */\n\tcxt = mmu_context_create(0);\n\tmmu_use_table(cxt);\n\tmmu_switch_context(cxt);\n\n\t/* Map the PVR video memory to 0 */\n\tmmu_page_map(cxt, 0, 0x05000000 >> PAGESIZE_BITS, (8*1024*1024) >> PAGESIZE_BITS,\n\t\tMMU_ALL_RDWR, MMU_NO_CACHE, MMU_NOT_SHARED, MMU_DIRTY);\n\n\t/* Draw a nice pattern to the NULL space */\n\tvr = NULL;\n\tfor (y=0; y<480; y++) {\n\t\tfor (x=0; x<640; x++) {\n\t\t\tint v = ((x*x+y*y) & 255);\n\t\t\tif (v >= 128)\n\t\t\t\tv = 127 - (v-128);\n\t\t\tvr[y*640+x] = ((v >> 3) << 11)\n\t\t\t\t| ((v >> 2) << 5)\n\t\t\t\t| ((v >> 3) << 0);\n\t\t}\n\t}\n\n\t/* Draw some text */\n\tbfont_draw_str(vr + 20*640+20, 640, 0, \"Press START!\");\n\n\t/* Wait for start */\n\twhile (!done) {\n\t\tMAPLE_FOREACH_BEGIN(MAPLE_FUNC_CONTROLLER, cont_state_t, st)\n\t\t\tif (st->buttons & CONT_START)\n\t\t\t\tdone = 1;\n\t\tMAPLE_FOREACH_END()\n\t}\n\n\t/* Destroy the context */\n\tmmu_context_destroy(cxt);\n\n\t/* Shutdown MMU support */\n\tmmu_shutdown();\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.48288974165916443,
"alphanum_fraction": 0.5627376437187195,
"avg_line_length": 14.470588684082031,
"blob_id": "cc51e3abc1f60207124b70c114154d6733dc586f",
"content_id": "0f0d458deb5d6a7a197e18730185190fa4365f46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 17,
"path": "/libc/string/strnlen.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n strnlen.c\n (c)2000 Dan Potter\n\n $Id: strnlen.c,v 1.1 2002/02/09 06:15:43 bardtx Exp $\n*/\n\n\n#include <string.h>\n\nsize_t strnlen(const char * s, size_t count) {\n\tconst char *t = s;\n\n\twhile (count-- && *t != '\\0') t++;\n\treturn t - s;\n}\n"
},
{
"alpha_fraction": 0.5287958383560181,
"alphanum_fraction": 0.6439790725708008,
"avg_line_length": 16.272727966308594,
"blob_id": "bfa50b94eb6b35a0d6e7c71de0084c50bd3e8c5f",
"content_id": "1abcbab7d2ba65a09095945de74f1d41069c35aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/utils/rdtest/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# utils/rdtest/Makefile\n# (c)2000 Dan Potter\n# \n# $Id: Makefile,v 1.1.1.1 2001/09/26 07:05:01 bardtx Exp $\n\nall: rdtest\n\nrdtest: rdtest.c\n\tgcc -g -o rdtest rdtest.c\n\n"
},
{
"alpha_fraction": 0.5081967115402222,
"alphanum_fraction": 0.6163934469223022,
"avg_line_length": 18.0625,
"blob_id": "fd97fb6c0b6e58fd9b096f4f7ded695d63d4c5a0",
"content_id": "0081c9240894f9d4f6d7910fa35b8fe50ef4a83b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 16,
"path": "/include/kos/limits.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/limits.h\n (c)2000-2001 Dan Potter\n\n $Id: limits.h,v 1.1.1.1 2001/09/26 07:05:20 bardtx Exp $\n \n*/\n\n#ifndef __KOS_LIMITS_H\n#define __KOS_LIMITS_H\n\n#define MAX_FN_LEN\t256\t\t/* Max filename length */\n#define PATH_MAX\t4095\t\t/* Max path length */\n\n#endif\t/* __KOS_LIMITS_H */\n"
},
{
"alpha_fraction": 0.6382660865783691,
"alphanum_fraction": 0.6681614518165588,
"avg_line_length": 22.034482955932617,
"blob_id": "492900a92fdf062c2755241c3e0b5525a43acc22",
"content_id": "0bc8a2b7b82fd0d24f357311a80804c32bcc5a79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 29,
"path": "/include/kos/fs_pty.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/fs_pty.h\n Copyright (C)2003 Dan Potter\n\n $Id: fs_pty.h,v 1.1 2003/06/19 04:30:23 bardtx Exp $\n*/\n\n#ifndef __KOS_FS_PTY_H\n#define __KOS_FS_PTY_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <kos/limits.h>\n#include <kos/fs.h>\n\n/* Call this function to create a new pty. The name of the pty is written\n into the user-provided buffer (if non-NULL) and two open file descriptors\n pointing to the two ends of the pty are returned. */\nint fs_pty_create(char * buffer, int maxbuflen, file_t * master_out, file_t * slave_out);\n\nint fs_pty_init();\nint fs_pty_shutdown();\n\n__END_DECLS\n\n#endif\t/* __KOS_FS_PTY_H */\n\n"
},
{
"alpha_fraction": 0.5615637898445129,
"alphanum_fraction": 0.5930197834968567,
"avg_line_length": 23.544116973876953,
"blob_id": "c74c0d4fbe70d58a71d9242832077546be3d766f",
"content_id": "69a41aa460876f1bc3baec795916c14cf918a814",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6676,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 272,
"path": "/kernel/net/net_arp.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/net/net_arp.c\n\n Copyright (C) 2002 Dan Potter\n Copyright (C) 2005 Lawrence Sebald\n*/\n\n#include <string.h>\n#include <malloc.h>\n#include <stdio.h>\n#include <kos/net.h>\n#include <kos/thread.h>\n#include \"net_ipv4.h\"\n\nCVSID(\"$Id: net_arp.c,v 1.1 2002/01/30 06:54:27 bardtx Exp $\");\n\n/*\n\n ARP handling system\n \n*/\n\n/* ARP Packet Structre */\n#define packed __attribute__((packed))\ntypedef struct {\n\tuint8 hw_type[2] packed;\n\tuint8 pr_type[2] packed;\n\tuint8 hw_size packed;\n\tuint8 pr_size packed;\n\tuint8 opcode[2] packed;\n\tuint8 hw_send[6] packed;\n\tuint8 pr_send[4] packed;\n\tuint8 hw_recv[6] packed;\n\tuint8 pr_recv[6] packed;\n} arp_pkt_t;\n#undef packed\n\n/**************************************************************************/\n/* Variables */\n\n/* ARP cache */ \nstruct netarp_list net_arp_cache;\n\n/**************************************************************************/\n/* Cache management */\n\n/* Garbage collect timed out entries */\nint net_arp_gc() {\n\tnetarp_t *a1, *a2;\n\n\ta1 = LIST_FIRST(&net_arp_cache);\n\twhile (a1 != NULL) {\n\t\ta2 = LIST_NEXT(a1, ac_list);\n\t\tif (a1->timestamp && jiffies >= (a1->timestamp + 600*HZ)) {\n\t\t\tLIST_REMOVE(a1, ac_list);\n\t\t\tfree(a1);\n\t\t}\n\t\ta1 = a2;\n\t}\n\n\treturn 0;\n}\n\n/* Add an entry to the ARP cache manually */\nint net_arp_insert(netif_t *nif, uint8 mac[6], uint8 ip[4], uint32 timestamp) {\n\tnetarp_t *cur;\n\t\n\t/* First make sure the entry isn't already there */\n\tLIST_FOREACH(cur, &net_arp_cache, ac_list) {\n\t\tif (!memcmp(ip, cur->ip, 4)) {\n\t\t\tmemcpy(cur->mac, mac, 6);\n\t\t\tcur->timestamp = timestamp;\n\t\t\treturn 0;\n\t\t}\n\t}\n\n\t/* It's not there, add an entry */\n\tcur = (netarp_t *)malloc(sizeof(netarp_t));\n\tmemcpy(cur->mac, mac, 6);\n\tmemcpy(cur->ip, ip, 4);\n\tcur->timestamp = timestamp;\n\tLIST_INSERT_HEAD(&net_arp_cache, cur, ac_list);\n\n\t/* Garbage collect expired entries */\n\tnet_arp_gc();\n\n\treturn 0;\n}\n\n/* Look up an entry from the ARP cache; if no entry is found, then an ARP\n query will be sent and an error will be returned. Thus your packet send\n should also fail. Later when the transmit retries, hopefully the answer\n will have arrived. */\nint net_arp_lookup(netif_t *nif, uint8 ip_in[4], uint8 mac_out[6]) {\n\tnetarp_t *cur;\n\n\t/* Garbage collect expired entries */\n\tnet_arp_gc();\n\n\t/* Look for the entry */\n\tLIST_FOREACH(cur, &net_arp_cache, ac_list) {\n\t\tif (!memcmp(ip_in, cur->ip, 4)) {\n\t\t\tif(cur->mac[0] == 0 && cur->mac[1] == 0 && \n\t\t\t cur->mac[2] == 0 && cur->mac[3] == 0 &&\n\t\t\t cur->mac[4] == 0 && cur->mac[5] == 0) {\n\t\t\t\treturn -1;\n\t\t\t}\n\n\t\t\tmemcpy(mac_out, cur->mac, 6);\n\t\t\tif (cur->timestamp != 0)\n\t\t\t\tcur->timestamp = jiffies;\n\t\t\treturn 0;\n\t\t}\n\t}\n\n\t/* It's not there... Add an incomplete ARP entry */\n\tmemset(mac_out, 0, 6);\n\tnet_arp_insert(nif, mac_out, ip_in, jiffies);\n\t\n\t/* Generate an ARP who-has packet */\n\tnet_arp_query(nif, ip_in);\n\n\t/* Return failure */\n\treturn -2;\n}\n\n/* Do a reverse ARP lookup: look for an IP for a given mac address; note\n that if this fails, you have no recourse. */\nint net_arp_revlookup(netif_t *nif, uint8 ip_out[4], uint8 mac_in[6]) {\n\tnetarp_t *cur;\n\n\t/* Look for the entry */\n\tLIST_FOREACH(cur, &net_arp_cache, ac_list) {\n\t\tif (!memcmp(mac_in, cur->mac, 6)) {\n\t\t\tmemcpy(ip_out, cur->ip, 4);\n\t\t\tif (cur->timestamp != 0)\n\t\t\t\tcur->timestamp = jiffies;\n\t\t\treturn 0;\n\t\t}\n\t}\n\n\treturn -1;\n}\n\n/* Send an ARP reply packet on the specified network adapter */\nstatic int net_arp_send(netif_t *nif, arp_pkt_t *pkt)\t{\n\tarp_pkt_t pkt_out;\n\teth_hdr_t eth_hdr;\n\tuint8 buf[sizeof(arp_pkt_t) + sizeof(eth_hdr_t)];\n\n\t/* First, fill in the ARP packet. */\n\tpkt_out.hw_type[0] = 0;\n\tpkt_out.hw_type[1] = 1;\n\tpkt_out.pr_type[0] = 0x08;\n\tpkt_out.pr_type[1] = 0x00;\n\tpkt_out.hw_size = 6;\n\tpkt_out.pr_size = 4;\n\tpkt_out.opcode[0] = 0;\n\tpkt_out.opcode[1] = 2;\n\tmemcpy(pkt_out.hw_send, nif->mac_addr, 6);\n\tmemcpy(pkt_out.pr_send, nif->ip_addr, 4);\n\tmemcpy(pkt_out.pr_recv, pkt->pr_send, 4);\n\tmemcpy(pkt_out.hw_recv, pkt->hw_send, 6);\n\n\t/* Fill in the ethernet header. */\n\tmemcpy(eth_hdr.src, nif->mac_addr, 6);\n\tmemcpy(eth_hdr.dest, pkt->hw_send, 6);\n\teth_hdr.type[0] = 0x08; /* ARP */\n\teth_hdr.type[1] = 0x06;\n\n\tmemcpy(buf, ð_hdr, sizeof(eth_hdr_t));\n\tmemcpy(buf + sizeof(eth_hdr_t), &pkt_out, sizeof(arp_pkt_t));\n\n\t/* Send it away */\n\tnif->if_tx(nif, buf, sizeof(eth_hdr_t) + sizeof(arp_pkt_t), NETIF_BLOCK);\n\t\n\treturn 0;\n}\n \n/* Receive an ARP packet and process it (called by net_input) */\nint net_arp_input(netif_t *nif, const uint8 *pkt_in, int len) {\n\teth_hdr_t *eth_hdr;\n\tarp_pkt_t *pkt;\n\n\teth_hdr = (eth_hdr_t *)pkt_in;\n\tpkt = (arp_pkt_t *)(pkt_in + sizeof(eth_hdr_t));\n\n\tswitch(pkt->opcode[1]) {\n\t\tcase 1: /* ARP Request */\n\t\t\tnet_arp_send(nif, pkt);\n\t\tcase 2: /* ARP Reply */\n\t\t\t/* Insert into ARP cache */\n\t\t\tnet_arp_insert(nif, pkt->hw_send, pkt->pr_send, jiffies);\n\t\t\tbreak;\n\t\tdefault:\n\t\t\tdbglog(DBG_KDEBUG, \"net_arp: Unknown ARP Opcode: %d\\n\", pkt->opcode[1]);\n\t}\n\n\treturn 0;\n}\n\n/* Generate an ARP who-has query on the given device */\nint net_arp_query(netif_t *nif, uint8 ip[4]) {\n\tarp_pkt_t pkt_out;\n\teth_hdr_t eth_hdr;\n\tuint8 buf[sizeof(arp_pkt_t) + sizeof(eth_hdr_t)];\n\n\t/* First, fill in the ARP packet. */\n\tpkt_out.hw_type[0] = 0;\n\tpkt_out.hw_type[1] = 1;\n\tpkt_out.pr_type[0] = 0x08;\n\tpkt_out.pr_type[1] = 0x00;\n\tpkt_out.hw_size = 6;\n\tpkt_out.pr_size = 4;\n\tpkt_out.opcode[0] = 0;\n\tpkt_out.opcode[1] = 1;\n\tmemcpy(pkt_out.hw_send, nif->mac_addr, 6);\n\tmemcpy(pkt_out.pr_send, nif->ip_addr, 4);\n\tmemcpy(pkt_out.pr_recv, ip, 4);\n\tpkt_out.hw_recv[0] = 0xFF; /* Ethernet broadcast address */\n\tpkt_out.hw_recv[1] = 0xFF;\n\tpkt_out.hw_recv[2] = 0xFF;\n\tpkt_out.hw_recv[3] = 0xFF;\n\tpkt_out.hw_recv[4] = 0xFF;\n\tpkt_out.hw_recv[5] = 0xFF;\n\n\t/* Fill in the ethernet header. */\n\tmemcpy(eth_hdr.src, nif->mac_addr, 6);\n\teth_hdr.dest[0] = 0xFF; /* Ethernet broadcast address */\n\teth_hdr.dest[1] = 0xFF;\n\teth_hdr.dest[2] = 0xFF;\n\teth_hdr.dest[3] = 0xFF;\n\teth_hdr.dest[4] = 0xFF;\n\teth_hdr.dest[5] = 0xFF;\n\teth_hdr.type[0] = 0x08; /* ARP */\n\teth_hdr.type[1] = 0x06;\n\n\tmemcpy(buf, ð_hdr, sizeof(eth_hdr_t));\n\tmemcpy(buf + sizeof(eth_hdr_t), &pkt_out, sizeof(arp_pkt_t));\n\n\t/* Send it away */\n\tnif->if_tx(nif, buf, sizeof(eth_hdr_t) + sizeof(arp_pkt_t), NETIF_BLOCK);\n\t\n\treturn 0;\n}\n\n/*****************************************************************************/\n/* Init/shutdown */\n\n/* Init */\nint net_arp_init() {\n\t/* Initialize the ARP cache */\n\tLIST_INIT(&net_arp_cache);\n\n\treturn 0;\n}\n\n/* Shutdown */\nvoid net_arp_shutdown() {\n\t/* Free all ARP entries */\n\tnetarp_t *a1, *a2;\n\n\ta1 = LIST_FIRST(&net_arp_cache);\n\twhile (a1 != NULL) {\n\t\ta2 = LIST_NEXT(a1, ac_list);\n\t\tfree(a1);\n\t\ta1 = a2;\n\t}\n\n\tLIST_INIT(&net_arp_cache);\n}\n"
},
{
"alpha_fraction": 0.522251307964325,
"alphanum_fraction": 0.5842059254646301,
"avg_line_length": 18.572649002075195,
"blob_id": "06c8081c1e14e17ec191ac428c19760750fd8f5c",
"content_id": "bb9fde68b63d9371d6ed343fafa00ba956823eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2292,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 117,
"path": "/examples/dreamcast/vmu/vmu_pkg/vmu.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n vmu.c\n (c)2002 Dan Potter\n*/\n\n/* This simple example shows how to use the vmu_pkg_* functions to write \n a file to a VMU with a DC-compatible header so it can be managed like\n any other VMU file from the BIOS menus. */\n\n#include <kos.h>\n\nextern uint8 romdisk[];\nKOS_INIT_ROMDISK(romdisk);\n\nvoid draw_dir() {\n\tfile_t\t\td;\n\tint\t\ty = 88;\n\tdirent_t\t*de;\n\n\td = fs_open(\"/vmu/a1\", O_RDONLY | O_DIR);\n\tif (!d) {\n\t\tbfont_draw_str(vram_s + y*640+10, 640, 0, \"Can't read VMU\");\n\t} else {\n\t\twhile ( (de = fs_readdir(d)) ) {\n\t\t\tbfont_draw_str(vram_s + y*640+10, 640, 0, de->name);\n\t\t\ty += 24;\n\t\t\tif (y >= (480 - 24))\n\t\t\t\tbreak;\n\t\t}\n\n\t\tfs_close(d);\n\t}\n}\n\nint dev_checked = 0;\nvoid new_vmu() {\n\tmaple_device_t * dev;\n\n\tdev = maple_enum_dev(0, 1); \n\tif (dev == NULL) {\n\t\tif (dev_checked) {\n\t\t\tmemset4(vram_s + 88 * 640, 0, 640*(480 - 64)*2);\n\t\t\tbfont_draw_str(vram_s + 88*640+10, 640, 0, \"No VMU\");\n\t\t\tdev_checked = 0;\n\t\t}\n\t} else if (dev_checked) {\n\t} else {\n\t\tmemset4(vram_s + 88 * 640, 0, 640*(480 - 88));\n\t\tdraw_dir();\n\t\tdev_checked = 1;\n\t}\n}\n\nint wait_start() {\n\tuint8 cont;\n\tcont_cond_t cond;\n\n\tfor(;;) {\n\t\tnew_vmu();\n\t\t\n\t\tcont = maple_first_controller();\n\t\tif (cont == 0) continue;\n\n\t\tif (cont_get_cond(cont, &cond) < 0)\n\t\t\tcontinue;\n\n\t\tif (!(cond.buttons & CONT_START))\n\t\t\treturn 0;\n\t}\n}\n\n/* Here's the actual meat of it */\nvoid write_entry() {\n\tvmu_pkg_t\tpkg;\n\tuint8\t\tdata[4096], *pkg_out;\n\tint\t\tpkg_size;\n\tint\t\ti;\n\tfile_t\t\tf;\n\n\tstrcpy(pkg.desc_short, \"VMU Test\");\n\tstrcpy(pkg.desc_long, \"This is a test VMU file\");\n\tstrcpy(pkg.app_id, \"KOS\");\n\tpkg.icon_cnt = 0;\n\tpkg.icon_anim_speed = 0;\n\tpkg.eyecatch_type = VMUPKG_EC_NONE;\n\tpkg.data_len = 4096;\n\tpkg.data = data;\n\n\tfor (i=0; i<4096; i++)\n\t\tdata[i] = i & 255;\n\n\tvmu_pkg_build(&pkg, &pkg_out, &pkg_size);\n\n\tfs_unlink(\"/vmu/a1/TESTFILE\");\n\tf = fs_open(\"/vmu/a1/TESTFILE\", O_WRONLY);\n\tif (!f) {\n\t\tprintf(\"error writing\\n\");\n\t\treturn;\n\t}\n\tfs_write(f, pkg_out, pkg_size);\n\tfs_close(f);\n}\n\nint main(int argc, char **argv) {\n\tbfont_draw_str(vram_s + 20 * 640 + 20, 640, 0,\n\t\t\"Put a VMU you don't care too much about\");\n\tbfont_draw_str(vram_s + 42 * 640 + 20, 640, 0,\n\t\t\"in slot A1 and press START\");\n\tbfont_draw_str(vram_s + 88*640+10, 640, 0, \"No VMU\");\n\n\tif (wait_start() < 0) return 0;\n\n\twrite_entry();\n\n\treturn 0;\n}\n\n\n"
},
{
"alpha_fraction": 0.6113536953926086,
"alphanum_fraction": 0.6331877708435059,
"avg_line_length": 15.357142448425293,
"blob_id": "fa0131b9bcd398926fc730935a260f07d8252259",
"content_id": "d0a290ce6733837151cf24664fac45c2e33b6abc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 14,
"path": "/kernel/libc/newlib/newlib_fstat.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n newlib_fstat.c\n Copyright (C)2004 Dan Potter\n\n*/\n\n#include <unistd.h>\n#include <sys/stat.h>\n\nint _fstat_r(struct _reent * reent, int fd, struct stat * pstat) {\n\tpstat->st_mode = S_IFCHR;\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6931859850883484,
"alphanum_fraction": 0.7171270847320557,
"avg_line_length": 34.24675369262695,
"blob_id": "bb72068348afa32fbb96cd7584b5cd82226ddf12",
"content_id": "26bccb35b48374758e56711ca8477c673170b796",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2715,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 77,
"path": "/include/arch/dreamcast/dc/maple/purupuru.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/maple/purupuru.h\n Copyright (C) 2003 Dan Potter\n Copyright (C) 2005 Lawrence Sebald\n\n $Id: purupuru.h,v 1.1 2003/03/15 00:47:24 bardtx Exp $\n\n*/\n\n#ifndef __DC_MAPLE_PURUPURU_H\n#define __DC_MAPLE_PURUPURU_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/* These defines are based off of information that Kamjin provided on the \n DCEmulation forums. They may or may not act the same on all purus.\n For instance, on my official Sega Purupuru, the decay setting seems\n to make many if not all effects do nothing. Don't be surprised if\n your initial effect does nothing for you, its to be expected. Using\n the purupuru seems to be very much a guess-and-test situation. */\n\n/* Effect Generation structure, use with the defines below. */\ntypedef struct purupuru_effect {\n\tuint8 duration;\n\tuint8 effect2;\n\tuint8 effect1;\n\tuint8 special;\n} purupuru_effect_t;\n\n/* Set one of each of the following in the effect2 field of the\n purupuru_effect_t. Valid values for each are 0-7. The LINTENSITY\n value works with the INTENSITY of effect1 to increase the intensity\n of the rumble, where UINTENSITY apparently lowers the rumble's\n intensity somewhat. */\n#define PURUPURU_EFFECT2_UINTENSITY(x) (x << 4)\n#define PURUPURU_EFFECT2_LINTENSITY(x) (x)\n\n/* OR these in with your effect2 value if you feel so inclined.\n if you or the PULSE effect in here, you probably should also\n do so with the effect1 one below. */\n#define PURUPURU_EFFECT2_DECAY (8 << 4)\n#define PURUPURU_EFFECT2_PULSE (8)\n\n/* Set one value for this in the effect1 field of the effect structure. */\n#define PURUPURU_EFFECT1_INTENSITY(x) (x << 4)\n\n/* OR these in with your effect1 value, if you need them. PULSE\n should probably be used with the PULSE in effect2, as well.\n POWERSAVE will probably make your purupuru ignore that command. */\n#define PURUPURU_EFFECT1_PULSE (8 << 4)\n#define PURUPURU_EFFECT1_POWERSAVE (15)\n\n/* Special Effects and motor select. The normal purupuru packs will\n only have one motor. Selecting MOTOR2 for these is probably not\n a good idea. The PULSE setting here supposably creates a sharp\n pulse effect, when ORed with the special field. */\n#define PURUPURU_SPECIAL_MOTOR1 (1 << 4)\n#define PURUPURU_SPECIAL_MOTOR2 (1 << 7)\n#define PURUPURU_SPECIAL_PULSE (1)\n\n/* Send a specified effect to a specified purupuru */\nint purupuru_rumble(maple_device_t *dev, purupuru_effect_t *effect);\n\n/* Send a raw effect to a specified purupuru */\nint purupuru_rumble_raw(maple_device_t *dev, uint32 effect);\n\n/* Init / Shutdown */\nint purupuru_init();\nvoid purupuru_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_MAPLE_PURUPURU_H */\n\n"
},
{
"alpha_fraction": 0.5864197611808777,
"alphanum_fraction": 0.6378600597381592,
"avg_line_length": 19.16666603088379,
"blob_id": "a990675514d6e191d21d7c0276b4f6d2b5db049f",
"content_id": "d2862ae0fb51e44a9a5f28901e81b74077f299f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 486,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 24,
"path": "/examples/dreamcast/sound/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/sound/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.2.2.1 2003/06/20 06:31:15 bardtx Exp $\n\nall:\n\t$(MAKE) -C ghettoplay-vorbis\n\t$(MAKE) -C hello-ogg\n\t$(MAKE) -C hello-mp3\n\t$(MAKE) -C cdda\n\nclean:\n\t$(MAKE) -C ghettoplay-vorbis clean\n\t$(MAKE) -C hello-ogg clean\n\t$(MAKE) -C hello-mp3 clean\n\t$(MAKE) -C cdda clean\n\t\t\ndist:\n\t$(MAKE) -C ghettoplay-vorbis dist\n\t$(MAKE) -C hello-ogg dist\n\t$(MAKE) -C hello-mp3 dist\n\t$(MAKE) -C cdda dist\n\n\n"
},
{
"alpha_fraction": 0.5328983068466187,
"alphanum_fraction": 0.6258836388587952,
"avg_line_length": 17.3799991607666,
"blob_id": "60258dd688e5ab5cee1ec511172fb6587465b075",
"content_id": "484a16050d81f825a88b992931159a1020cff946",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1839,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 100,
"path": "/include/arch/ps2/ps2/asmregs.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n arch/ps2/include/asmregs.h\n (c)2002 Dan Potter\n \n $Id: asmregs.h,v 1.1 2002/10/27 23:39:23 bardtx Exp $\n*/\n\n#ifndef __PS2_ASMREGS_H\n#define __PS2_ASMREGS_H\n\n/* This is meant to be included from a .S files for human-readable\n register names. */\n\n/******************************************************** CPU Regs ****/\n\n/* Hard-wired to zero */\n#define zero\t$0\n\n/* Assembler temp register */\n#define at\t$1\n\n/* Return value(s) */\n#define v0\t$2\n#define v1\t$3\n\n/* Arguments/parameters */\n#define a0\t$4\n#define a1\t$5\n#define a2\t$6\n#define a3\t$7\n\n/* Temp (caller saved) registers */\n#define t0\t$8\n#define t1\t$9\n#define t2\t$10\n#define t3\t$11\n#define t4\t$12\n#define t5\t$13\n#define t6\t$14\n#define t7\t$15\n#define t8\t$24\n#define t9\t$25\t/* Shared with JP */\n\n/* (Callee) saved registers */\n#define s0\t$16\n#define s1\t$17\n#define s2\t$18\n#define s3\t$19\n#define s4\t$20\n#define s5\t$21\n#define s6\t$22\n#define s7\t$23\n#define s8\t$30\t/* Shared with FP */\n\n/* PIC Jump register */\n#define jp\t$25\t/* Shared with T9 */\n\n/* Kernel scratch regs */\n#define k0\t$26\n#define k1\t$27\n\n/* Global pointer */\n#define gp\t$28\n\n/* Stack pointer */\n#define sp\t$29\n\n/* Frame pointer */\n#define fp\t$30\t/* Shared with S8 */\n\n/* Return address */\n#define ra\t$31\n\n/******************************************************** COP0 regs ****/\n\n#define cp0index\t$0\n#define cp0random\t$1\n#define cp0entrylo0\t$2\n#define cp0entrylo1\t$3\n#define cp0context\t$4\n#define cp0pagemask\t$5\n#define cp0wired\t$6\n#define cp0badvaddr\t$8\n#define cp0count\t$9\n#define cp0entryhi\t$10\n#define cp0compare\t$11\n#define cp0status\t$12\n#define cp0cause\t$13\n#define cp0epc\t\t$14\n#define cp0prid\t\t$15\n#define cp0config\t$16\n#define cp0badpaddr\t$23\n#define cp0debug\t$24\n#define cp0perf\t\t$25\n#define cp0taglo\t$28\n#define cp0taghi\t$29\n#define cp0errorepc\t$30\n\n#endif\t/* __PS2_ASMREGS_H */\n\n"
},
{
"alpha_fraction": 0.6398804187774658,
"alphanum_fraction": 0.6477622985839844,
"avg_line_length": 29.5761775970459,
"blob_id": "b0b7397004b0c192a859e14c665a3e979995e010",
"content_id": "ca30764e641725fae4bedf04d71e3dad52866881",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11038,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 361,
"path": "/utils/svn_utils/svnpush.py",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# This script implements a very simple Subversion repository dump \"push\",\n# which is a cheap (the only?) way to publically host Subversion without\n# needing dedicated Apache support.\n#\n# Copyright (C)2003 Dan Potter\n#\n\n# Usage:\n# svnpush.py <repo path> <output path> <output scp target>\n#\n# The repository at <repo path> will be queried for the latest version. If\n# it is higher than what is available at <output scp target>, then each\n# new version will be dumped as xxx_incr.dump.bz2, where xxx is the revision\n# number. These files will be placed in <output path>. Once all new versions\n# are dumped, these files will be uploaded to <output scp target> using\n# scp, and the administrative files there (highest_full, highest_incr) will\n# be updated.\n#\n# The repository MUST be accessed only by us while we're working on it.\n# Subversion may handle this gracefully, and it may not. Your best bet is\n# not to bet your data on it. To facilitate this, apache_initrc may be\n# set in the config below to stop and start Apache 2 around the operations.\n#\n\nimport popen2, sys, string, os, smtplib, time\n\n#######################################################################\n# Configuration\n\n# Path to the 'svn' binary, or just 'svn' if it's in the PATH\nsvn_bin = 'svn'\n\n# Path to the 'svnadmin' binary, or just 'svnadmin' if it's in the PATH\nsvnadmin_bin = 'svnadmin'\n\n# Set to non-none if you want to auto stop and start Apache 2 around the\n# operation (it must be stopped while you're running this script). The\n# command will be run with a single parameter of 'start' or 'stop'.\napache_initrc = '/etc/init.d/apache2'\n\n# Set this to a string if we should send out a notification email for each\n# new revision to the repository. The string will be the email address\n# to send messages to. If this feature is enabled, notify_from will\n# set the \"from\" address as well. Note that in these strings the '#'\n# character will be changed to '@', so that posting this script on\n# a web page won't result in spam. notify_smtp is the server to use\n# for sending messages.\nnotify_to = None\nnotify_from = None\nnotify_smtp = None\n\n# Dan's config ;)\n#notify_to = 'cadcdev-svn-commits#lists.sourceforge.net'\n#notify_from = 'bard-dcdev#allusion.net'\n#notify_smtp = 'localhost'\n\n#######################################################################\n# Implicit config globals, from cmdline. Set these to something besides\n# None if you want to have parameter defaults. If you set one, you must\n# set them all.\n\nglobal path_svnrepo, path_output, path_scp\n\n# path_svnrepo - path to the SVN repo we're working on\npath_svnrepo = None\n\n# path_output - path to write incr files to\npath_output = None\n\n# path_scp - scp target to compare against / update\npath_scp = None\n\n# Verify the defaulted parameters\ntry:\n\tif (path_svnrepo is not None) or (path_output is not None) \\\n\t\t\tor (path_scp is not None):\n\t\tassert path_svnrepo is not None\n\t\tassert path_output is not None\n\t\tassert path_scp is not None\nexcept AssertionError:\n\tprint \"Some parameters were defaulted, others were not.\"\n\tprint \"Please correct this in svnpush.py and try again.\"\n\tsys.exit(-1)\n\n#######################################################################\n# Version\n\n# Modify this line if you fork the program, please.\nversion = 'SvnPush.py v1.0'\n\n#######################################################################\n# SVN Utility funcs\n\n# Run svnadmin with the given parameters, and return the output as a tuple:\n# (error code int, stdout string array, stderr string array). We assume\n# here that the majority of the output we're concerned about will go onto\n# stderr. If this turns out not to be true, a deadlock can happen.\ndef runSvnAdmin(cmd):\n\t# Spawn the process and get pipes\n\tp = popen2.Popen3(svnadmin_bin + ' ' + cmd, 1)\n\n\t# Read all of stderr first\n\tse = p.childerr.readlines()\n\n\t# Read all of stdout\n\tso = p.fromchild.readlines()\n\n\t# Get the return code\n\trc = p.wait()\n\n\t# Return it all\n\treturn (rc, so, se)\n\t\n\n# Query an SVN repo for the latest available revision. We assume here that\n# the root dir '/' is always updated whenever there is any commit. I believe\n# this is always true.\n#\n# Older svnadmin versions had a nice \"lscr\" command, but that was removed\n# for some inexplicable reason by 0.32.1, so we have to use verify (slow).\ndef getLatestRevision():\n\t# Do an svnadmin verify command on the repo\n\trs = runSvnAdmin(\"verify \" + path_svnrepo)\n\tif rs[0] != 0:\n\t\tprint \"svnadmin verify command failed with code %d\" % rs[0]\n\t\tsys.exit(-1)\n\n\t# The last line of the stderr should be the version string.\n\tse = rs[2]\n\tif len(se) < 1:\n\t\tprint \"svnadmin verify failed:\"\n\t\tprint string.join(se, '\\n')\n\t\tsys.exit(-1)\n\tvs = se[-1]\n\n\t# Make sure the format is comprehensible\n\tprefix = '* Verified revision '\n\tif vs[:len(prefix)] != prefix:\n\t\tprint \"svnadmin returned incomprehensible output:\"\n\t\tprint vs\n\t\tsys.exit(-1)\n\n\t# Should be in the form '* Verified revision xxx.'\n\tvs = string.strip(vs)\n\tvs = vs[len(prefix):-1]\n\treturn int(vs)\n\n# Dump one Subversion revision from the local repository. This uses\n# 'svnadmin dump' and 'bzip2' to create the file.\ndef svnDumpRevision(rev):\n\t# Gruesome UNIX pipe :)\n\tcmd = \"dump \" + path_svnrepo + \" -r %d:%d \" % (rev,rev) \\\n\t\t+ \"--incremental | bzip2 -c > \" \\\n\t\t+ path_output + \"/%d_incr.dump.bz2\" % rev\n\tprint \"svnadmin \" + cmd\n\trs = runSvnAdmin(cmd)\n\n\t# Make sure it succeeded\n\tif rs[0] != 0:\n\t\tprint \"svnadmin verify command failed with code %d\" % rs[0]\n\t\tsys.exit(-1)\n\n#######################################################################\n# SCP utility funcs\n\n# Invoke scp to copy some files from src to dst.\ndef scpCopy(src, dst):\n\t# Run SCP with src and dst\n\trv = os.system(\"scp '%s' '%s'\" % (src, dst))\n\n\t# Return the return value\n\treturn rv\n\n# Copy up one revision to the scp target point.\ndef scpCopyRevision(rev):\n\tprint path_output + \"/%d_incr.dump.bz2\" % rev,path_output+\"/\"\n\trv = scpCopy(path_output + \"/%d_incr.dump.bz2\" % rev, path_scp+\"/\")\n\tif rv != 0:\n\t\tprint \"Couldn't copy rev %d to scp target (%d)\" % (rev, rv)\n\t\tsys.exit(-1)\n\n\n# Go out to the scp target point and grab highest_incr. Returns an integer\n# with the highest publically available revision number.\ndef scpLatestRevision():\n\t# Pull down our push control file from the scp target loc.\n\trv = scpCopy(path_scp + \"/highest_incr\", path_output + \"/\")\n\tif rv != 0:\n\t\tprint \"Couldn't retrieve highest_incr from scp target (%d)\" % rv\n\t\tsys.exit(-1)\n\n\t# Read the data (should be a single number)\n\tf = open(path_output + \"/highest_incr\", \"rb\")\n\tval = int(string.strip(f.read()))\n\tf.close()\n\n\treturn val\n\n# Set a new revision on the scp target.\ndef scpSetRevision(rev):\n\t# Make a new revision code file\n\tf = open(path_output + \"/highest_incr\", \"wb\")\n\tf.write(\"%d\\n\" % rev)\n\tf.close()\n\n\t# Copy it up\n\trv = scpCopy(path_output+\"/highest_incr\", path_scp+\"/\")\n\tif rv != 0:\n\t\tprint \"Couldn't update highest_incr to scp target (%d)\" % rv\n\t\tsys.exit(-1)\n\n#######################################################################\n# Mail utilities\n\n# Given a revision code, look up the dump file we created for that revision\n# and ferret out the changelog message. Send this as an email to the\n# target address. Assumes SVN dump format version 2.\ndef sendNotifyEmail(rev):\n\t# Load up the generated dump file\n\tfn = \"%s/%d_incr.dump.bz2\" % (path_output, rev)\n\tstdo, stdi = popen2.popen2(\"bzip2 -cd %s\" % fn)\n\tdata = stdo.read()\n\tstdi.close()\n\tstdo.close()\n\n\t# Find the log message. This is really wasteful for large dumps\n\t# but I don't really care :)\n\tw = string.find(data, \"K 7\\nsvn:log\\nV \")\n\tif w == -1:\n\t\tprint \"Can't find log message in '%s'.\" % fn\n\t\tsys.exit(-1)\n\tw = w + len(\"K 7\\nsvn:log\\nV \")\n\tcnt = string.split(data[w:])\n\tcnt = int(cnt[0])\n\tw = w + len(str(cnt))\n\twhile data[w] == '\\r' or data[w] == '\\n':\n\t\tw = w + 1\n\tlogmsg = data[w:w+cnt]\n\n\t# Figure out the timezone poo (why is there no func for this...)\n\ttzoffs = -time.timezone / 3600\n\tif tzoffs < 0:\n\t\ttzstr = \"-%04d\" % (-tzoffs * 100)\n\telse:\n\t\ttzstr = \"+%04d\" % (tzoffs * 100)\n\n\t# Build up the message\n\tfrommail = string.replace(notify_from, '#', '@')\n\ttomail = string.replace(notify_to, '#', '@')\n\tmsg = \"From: %s\\r\\n\" % frommail\n\tmsg = msg + \"To: %s\\r\\n\" % tomail\n\tmsg = msg + \"Subject: Repo revision %d\\r\\n\" % rev\n\tmsg = msg + \"Date: %s\\r\\n\" % time.strftime(\"%a, %d %b %Y %H:%M:%S \" + tzstr)\n\tmsg = msg + \"User-Agent: %s\\r\\n\" % version\n\tmsg = msg + \"\\r\\n\"\n\tmsg = msg + \"A new revision has been checked into the Subversion repository.\\r\\n\"\n\tmsg = msg + \"\\r\\n\"\n\tmsg = msg + \"Revision %d:\\r\\n\" % rev\n\tmsg = msg + logmsg + \"\\r\\n\"\n\tmsg = msg + \"This message was generated by %s.\\r\\n\" % version\n\n\t#print \"----------------------------\"\n\t#print \"Sending SMTP message:\"\n\t#print \"\"\n\t#print msg\n\t#print \"----------------------------\"\n\n\t# Send the message\n\tsmtp = smtplib.SMTP(notify_smtp)\n\tsmtp.sendmail(frommail, tomail, msg)\n\tsmtp.quit()\n\n\n#######################################################################\n# Main\n\ndef help():\n\tglobal path_svnrepo, path_output, path_scp\n\n\t# Preamble is always the same\n\tprint \"usage: svnpush.py \",\n\n\t# Do we have defaults?\n\tif path_svnrepo is not None:\n\t\tprint \"[<local repo path> <dump output path> <scp target>]\"\n\t\tprint \"<local repo path> defaults to '%s'\" % path_svnrepo\n\t\tprint \"<dump output path> defaults to '%s'\" % path_output\n\t\tprint \"<scp target> defaults to '%s'\" % path_scp\n\telse:\n\t\tprint \"<local repo path> <dump output path> <scp target>\"\n\ndef main(argv):\n\tglobal path_svnrepo, path_output, path_scp\n\n\tprint \"\"\"%s\nSubversion push-based repository \"server\"\nCopyright (C)2003 Dan Potter\n\"\"\" % version\n\n\t# Make sure we're called with enough parameters\n\tif path_svnrepo is None:\n\t\tif len(argv) < 4:\n\t\t\thelp()\n\t\t\tsys.exit(-1)\n\t\telse:\n\t\t\t# Set our globals\n\t\t\tpath_svnrepo = argv[1]\n\t\t\tpath_output = argv[2]\n\t\t\tpath_scp = argv[3]\n\telse:\n\t\tif len(argv) > 1 and len(argv) < 4:\n\t\t\thelp()\n\t\t\tsys.exit(-1)\n\n\tprint \"Repo at %s, output at %s, scp at %s\" \\\n\t\t% (path_svnrepo, path_output, path_scp)\n\n\t# Find the latest revision of the local repo (and also verify its\n\t# integrity)\n\tprint \"Finding latest local revision.\"\n\tlv = getLatestRevision()\n\n\tprint \"Verified repository integrity, latest revision is %d.\" % lv\n\n\t# Get the latest scp target revision.\n\tprint \"Finding latest public revision.\"\n\tsv = scpLatestRevision()\n\n\tprint \"Latest public revision is %d.\" % sv\n\n\tif sv > lv:\n\t\tprint \"ERROR: Somehow the public repo is past the local one!\"\n\t\tsys.exit(-1)\n\tif sv == lv:\n\t\tprint \"Public repo is up to date.\"\n\t\tsys.exit(0)\n\n\t# Ok, looks like we need to do something. For each missing revision,\n\t# do an svnadmin dump into a file we can upload.\n\tfor i in range(sv+1, lv+1):\n\t\tprint \"Dumping revision %d.\" % i\n\t\tsvnDumpRevision(i)\n\t\tprint \"Uploading revision %d.\" % i\n\t\tscpCopyRevision(i)\n\n\t\tif notify_to is not None:\n\t\t\tprint \"Sending notification email...\"\n\t\t\tsendNotifyEmail(i)\n\n\t# Finally write out a new control file.\n\tprint \"Updating highest revision file.\"\n\tscpSetRevision(lv)\n\n\tprint \"Done.\"\n\n\treturn 0\n\nif __name__=='__main__':\n\tsys.exit(main(sys.argv))\n"
},
{
"alpha_fraction": 0.557692289352417,
"alphanum_fraction": 0.6367521286010742,
"avg_line_length": 18.5,
"blob_id": "dfe2f1ff52304d945be99232f5b609b8a2af3e45",
"content_id": "4d7c0a006e7e6dfd436a7163cd750fb862c4bf4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 468,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 24,
"path": "/libc/string/strerror.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n strerror.c\n Copyright (C)2003 Dan Potter\n\n $Id: strerror.c,v 1.1 2003/06/23 05:22:15 bardtx Exp $\n*/\n\n#include <stdlib.h>\n#include <string.h>\n#include <errno.h>\n#include <stdio.h>\n\nCVSID(\"$Id: strerror.c,v 1.1 2003/06/23 05:22:15 bardtx Exp $\");\n\nstatic const char unkerr[] = \"Unknown error code\";\n\nchar * strerror(int num) {\n\tif (num >= 0 && num < sys_nerr)\n\t\treturn (char *)sys_errlist[num];\n\n\terrno = EINVAL;\n\treturn (char *)unkerr;\n}\n"
},
{
"alpha_fraction": 0.5295723676681519,
"alphanum_fraction": 0.5641492009162903,
"avg_line_length": 22.12631607055664,
"blob_id": "0f33819a1736e15f351ad10d5f2968a5cbb10b59",
"content_id": "6951b5bb244dc1c72f1eecdc8073c58aa59aa19e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2198,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 95,
"path": "/utils/vqenc/get_image_png.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos_img.c\n (c)2002 Jeffrey McBeth, Dan Potter\n\n Based on Jeff's png_load_texture routine, but loads into a\n KOS plat-independent image.\n*/\n \n#include <assert.h>\n#include <png.h>\n#include <stdlib.h>\n#include \"readpng.h\"\n#include \"get_image.h\"\n\n/* load an n x n texture from a png */\n\n/* not to be used outside of here */\nvoid _png_copy_texture(uint8 *buffer, uint8 *temp_tex,\n uint32 channels, uint32 stride,\n uint32 w, uint32 h)\n{\n uint32 i,j;\n uint8 *ourbuffer;\n uint8 *pRow;\n \n for(i = 0; i < h; i++) {\n pRow = &buffer[i*stride];\n ourbuffer = &temp_tex[i*w*4];\n \n if (channels == 3) {\n for (j=0; j<w; j++) {\n ourbuffer[j*4+0] = 0xff;\n ourbuffer[j*4+1] = pRow[j*3];\n ourbuffer[j*4+2] = pRow[j*3+1];\n ourbuffer[j*4+3] = pRow[j*3+2];\n }\n }\n else if (channels == 4) {\n for (j=0; j<w; j++) {\n ourbuffer[j*4+0] = pRow[j*4+3];\n ourbuffer[j*4+1] = pRow[j*4+0];\n ourbuffer[j*4+2] = pRow[j*4+1];\n ourbuffer[j*4+3] = pRow[j*4+2];\n }\n }\n }\n}\n\nint get_image_png(const char * filename, image_t * image) {\n\tuint8 *temp_tex;\n\n\t/* More stuff */\n\tuint8\t*buffer;\t/* Output row buffer */\n\tuint32\trow_stride;\t/* physical row width in output buffer */\n\tuint32\tchannels;\t/* 3 for RGB 4 for RGBA */\n\n\tFILE\t*infile;\t/* source file */\n\n\tassert( image != NULL );\n\n\tif ((infile = fopen(filename, \"r\")) == 0) {\n\t\tprintf(\"png_to_texture: can't open %s\\n\", filename);\n\t\treturn -1;\n\t}\n\n\t/* Step 1: Initialize loader */\n\tif (readpng_init(infile)) {\n\t\tfclose(infile);\n\t\treturn -2;\n\t}\n\n\t/* Step 1.5: Create output kos_img_t */\n\t/* rv = (kos_img_t *)malloc(sizeof(kos_img_t)); */\n\n\t/* Step 2: Read file */\n\tbuffer = readpng_get_image(&channels, &row_stride, &image->w, &image->h);\n\ttemp_tex = (uint8 *)malloc(sizeof(uint8) * 4 * image->w * image->h);\n\timage->data = (unsigned char *)temp_tex;\n\timage->bpp = 4;\n\timage->stride = image->w*4;\n\n\t_png_copy_texture(buffer, temp_tex,\n\t\tchannels, row_stride,\n\t\timage->w, image->h);\n\n\t/* Step 3: Finish decompression */\n\tfree(buffer);\n\treadpng_cleanup();\n\n\tfclose(infile);\n\n\t/* And we're done! */\n\treturn 0;\n}\n\n"
},
{
"alpha_fraction": 0.6685508489608765,
"alphanum_fraction": 0.701438844203949,
"avg_line_length": 28.923076629638672,
"blob_id": "e7d510b10900f0f67a22f92ca462f49cf4d92f54",
"content_id": "2a21025be8ca8b7b8ec672d5290c387376ea7ad9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1946,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 65,
"path": "/include/arch/dreamcast/dc/spu.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n dc/spu.h\n (c)2000-2001 Dan Potter\n\n $Id: spu.h,v 1.7 2002/10/17 06:10:39 bardtx Exp $\n\n*/\n\n#ifndef __DC_SPU_H\n#define __DC_SPU_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <dc/g2bus.h>\n\n/* Waits for the sound FIFO to empty */\nvoid spu_write_wait();\n\n/* memcpy and memset designed for sound RAM; for addresses, don't\n bother to include the 0xa0800000 offset that is implied. 'length'\n must be a multiple of 4, but if it is not it will be rounded up. */\nvoid spu_memload(uint32 to, void *from, int length);\nvoid spu_memread(void *to, uint32 from, int length);\nvoid spu_memset(uint32 to, uint32 what, int length);\n\n/* DMA copy from SH-4 RAM to SPU RAM; length must be a multiple of 32,\n and the source and destination addresses must be aligned on 32-byte\n boundaries. If block is non-zero, this function won't return until\n the transfer is complete. If callback is non-NULL, it will be called\n upon completion (in an interrupt context!). Returns <0 on error. */\ntypedef g2_dma_callback_t spu_dma_callback_t;\nint spu_dma_transfer(void * from, uint32 dest, uint32 length, int block,\n\tspu_dma_callback_t callback, ptr_t cbdata);\n\n/* Enable/disable the SPU; note that disable implies reset of the\n ARM CPU core. */\nvoid spu_enable();\nvoid spu_disable();\n\n/* Set CDDA volume: values are 0-15 */\nvoid spu_cdda_volume(int left_volume, int right_volume);\n\n/* Set CDDA panning: values are 0-31, 16=center */\nvoid spu_cdda_pan(int left_pan, int right_pan);\n\n/* Set master volume (0..15) and mono/stereo settings */\nvoid spu_master_mixer(int volume, int stereo);\n\n/* Initialize the SPU; by default it will be left in a state of\n reset until you upload a program. */\nint spu_init();\n\n/* Shutdown SPU */\nint spu_shutdown();\n\n/* These two are seperate because they have to be done at a different time */\nint spu_dma_init();\nvoid spu_dma_shutdown();\n\n__END_DECLS\n\n#endif\t/* __DC_SPU_H */\n\n"
},
{
"alpha_fraction": 0.6268625259399414,
"alphanum_fraction": 0.6709339022636414,
"avg_line_length": 26.859649658203125,
"blob_id": "dbde45ab0cc24df5dd6805e730e5d0e205e9cb6c",
"content_id": "dc179575b4042f40669e523e80904061278500da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4765,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 171,
"path": "/include/kos/elf.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kos/elf.h\n Copyright (C)2000,2001,2003 Dan Potter\n\n $Id: elf.h,v 1.3 2003/08/02 23:08:36 bardtx Exp $\n\n*/\n\n#ifndef __KOS_ELF_H\n#define __KOS_ELF_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n#include <sys/queue.h>\n\n/* ELF file header */\nstruct elf_hdr_t {\n\tunsigned char\tident[16];\t/* For elf32-shl, 0x7f+\"ELF\"+1+1 */\n\tuint16\t\ttype;\t\t/* 0x02 for ET_EXEC */\n\tuint16\t\tmachine;\t/* 0x2a for elf32-shl */\n\tuint32\t\tversion;\n\tuint32\t\tentry;\t\t/* Entry point */\n\tuint32\t\tphoff;\t\t/* Program header offset */\n\tuint32\t\tshoff;\t\t/* Section header offset */\n\tuint32\t\tflags;\t\t/* Processor flags */\n\tuint16\t\tehsize;\t\t/* ELF header size in bytes */\n\tuint16\t\tphentsize;\t/* Program header entry size */\n\tuint16\t\tphnum;\t\t/* Program header entry count */\n\tuint16\t\tshentsize;\t/* Section header entry size */\n\tuint16\t\tshnum;\t\t/* Section header entry count */\n\tuint16\t\tshstrndx;\t/* String table section index */\n};\n\n/* ELF architecture types */\n#define EM_386\t\t3\t\t/* ia32 */\n#define EM_SH\t\t42\t\t/* sh */\n\n/* Section header types */\n#define SHT_NULL\t0\t\t/* Inactive */\n#define SHT_PROGBITS\t1\t\t/* Program code/data */\n#define SHT_SYMTAB\t2\t\t/* Full symbol table */\n#define SHT_STRTAB\t3\t\t/* String table */\n#define SHT_RELA\t4\t\t/* Relocation table, with addends */\n#define SHT_HASH\t5\t\t/* Sym tab hashtable */\n#define SHT_DYNAMIC\t6\t\t/* Dynamic linking info */\n#define SHT_NOTE\t7\t\t/* Notes */\n#define SHT_NOBITS\t8\t\t/* Occupies no space in the file */\n#define SHT_REL\t\t9\t\t/* Relocation table, no addends */\n#define SHT_SHLIB\t10\t\t/* Invalid.. hehe */\n#define SHT_DYNSYM\t11\t\t/* Dynamic-only sym tab */\n#define SHT_LOPROC\t0x70000000\t/* Processor specific */\n#define SHT_HIPROC\t0x7fffffff\n#define SHT_LOUSER\t0x80000000\t/* Program specific */\n#define SHT_HIUSER\t0xffffffff\n\n/* Section header flags */\n#define SHF_WRITE\t1\t\t/* Writable data */\n#define SHF_ALLOC\t2\t\t/* Resident */\n#define SHF_EXECINSTR\t4\t\t/* Executable instructions */\n#define SHF_MASKPROC\t0xf0000000\t/* Processor specific */\n\n/* Special section indeces */\n#define SHN_UNDEF\t0\t\t/* Undefined, missing, irrelevant */\n#define SHN_ABS\t\t0xfff1\t\t/* Absolute values */\n\n/* Section header */\nstruct elf_shdr_t {\n\tuint32\t\tname;\t\t/* Index into string table */\n\tuint32\t\ttype;\t\t/* See constants above */\n\tuint32\t\tflags;\n\tuint32\t\taddr;\t\t/* In-memory offset */\n\tuint32\t\toffset;\t\t/* On-disk offset */\n\tuint32\t\tsize;\t\t/* Size (if SHT_NOBITS, zero file len */\n\tuint32\t\tlink;\t\t/* See below */\n\tuint32\t\tinfo;\t\t/* See below */\n\tuint32\t\taddralign;\t/* Alignment constraints */\n\tuint32\t\tentsize;\t/* Fixed-size table entry sizes */\n};\n/* Link and info fields:\n\nswitch (sh_type) {\n\tcase SHT_DYNAMIC:\n\t\tlink = section header index of the string table used by\n\t\t\tthe entries in this section\n\t\tinfo = 0\n\tcase SHT_HASH:\n\t\tilnk = section header index of the string table to which\n\t\t\tthis info applies\n\t\tinfo = 0\n\tcase SHT_REL, SHT_RELA:\n\t\tlink = section header index of associated symbol table\n\t\tinfo = section header index of section to which reloc applies\n\tcase SHT_SYMTAB, SHT_DYNSYM:\n\t\tlink = section header index of associated string table\n\t\tinfo = one greater than the symbol table index of the last\n\t\t\tlocal symbol (binding STB_LOCAL)\n}\n\n*/\n\n#define STB_LOCAL\t0\n#define STB_GLOBAL\t1\n#define STB_WEAK\t2\n\n#define STT_NOTYPE\t0\n#define STT_OBJECT\t1\n#define STT_FUNC\t2\n#define STT_SECTION\t3\n#define STT_FILE\t4\n\n/* Symbol table entry */\nstruct elf_sym_t {\n\tuint32\t\tname;\t\t/* Index into stringtab */\n\tuint32\t\tvalue;\n\tuint32\t\tsize;\n\tuint8\t\tinfo;\t\t/* type == info & 0x0f */\n\tuint8\t\tother;\t\t\n\tuint16\t\tshndx;\t\t/* Section index */\n};\n#define ELF32_ST_BIND(info)\t((info) >> 4)\n#define ELF32_ST_TYPE(info)\t((info) & 0xf)\n\n/* Relocation-A Entries */\nstruct elf_rela_t {\n\tuint32\t\toffset;\t\t/* Offset within section */\n\tuint32\t\tinfo;\t\t/* Symbol and type */\n\tint32\t\taddend;\t\t/* \"A\" constant */\n};\n\n/* Relocation Entries */\nstruct elf_rel_t {\n\tuint32\t\toffset;\t\t/* Offset within section */\n\tuint32\t\tinfo;\t\t/* Symbol and type */\n};\n\n/* Relocation-related defs */\n#define R_SH_DIR32\t\t1\n#define R_386_32\t\t1\n#define R_386_PC32\t\t2\n#define ELF32_R_SYM(i) ((i) >> 8)\n#define ELF32_R_TYPE(i) ((uint8)(i))\n\n\n/* Kernel-specific definition of a loaded ELF binary */\nstruct klibrary;\ntypedef struct elf_prog {\n\tvoid\t*data;\t\t/* Data block containing the program */\n\tuint32\tsize;\t\t/* Memory image size (rounded up to page size) */\n\n\t/* Library exports */\n\tptr_t\tlib_get_name;\n\tptr_t\tlib_get_version;\n\tptr_t\tlib_open;\n\tptr_t\tlib_close;\n\n\t/* Library filename */\n\tchar\tfn[256];\n} elf_prog_t;\n\n/* Load an ELF binary and return the relevant data in an elf_prog_t structure. */\nint elf_load(const char *fn, struct klibrary * shell, elf_prog_t * out);\n\n/* Free a loaded ELF program */\nvoid elf_free(elf_prog_t *prog);\n\n__END_DECLS\n\n#endif\t/* __OS_ELF_H */\n\n"
},
{
"alpha_fraction": 0.555858314037323,
"alphanum_fraction": 0.6103542447090149,
"avg_line_length": 13.640000343322754,
"blob_id": "09ccbbeaaa95c4bc1dab75bb5347504e41899708",
"content_id": "23e5f3cd8efb63cdbdf3c419e42202408d3b4a14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 25,
"path": "/libc/include/sys/iovec.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n sys/iovec.h\n (c)2001 Dan Potter\n\n $Id: iovec.h,v 1.1 2002/02/09 06:15:42 bardtx Exp $\n\n*/\n\n#ifndef __SYS_IOVEC_H\n#define __SYS_IOVEC_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <stddef.h>\n\ntypedef struct iovec {\n\tchar\t*iov_base;\t/* Base address */\n\tsize_t\tiov_len;\t/* Length */\n} iovec_t;\n\n__END_DECLS\n\n#endif\t/* __SYS_IOVEC_H */\n\n"
},
{
"alpha_fraction": 0.5566219091415405,
"alphanum_fraction": 0.5885659456253052,
"avg_line_length": 19.546478271484375,
"blob_id": "80e35fcff773be73e1a0a8d2fa1c8a5e2d93cae0",
"content_id": "04442953eb8059a79a969e9b36b70e680e5b0d10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7294,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 355,
"path": "/kernel/arch/dreamcast/sound/snd_sfxmgr.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n snd_sfxmgr.c\n Copyright (c)2000,2001,2002,2003,2004 Dan Potter\n\n Sound effects management system; this thing loads and plays sound effects\n during game operation.\n*/\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <assert.h>\n#include <string.h>\n\n#include <sys/queue.h>\n#include <kos/fs.h>\n#include <arch/irq.h>\n#include <dc/spu.h>\n#include <dc/sound/sound.h>\n#include <dc/sound/sfxmgr.h>\n\n#include \"arm/aica_cmd_iface.h\"\n\nCVSID(\"$Id: snd_sfxmgr.c,v 1.11 2003/04/24 03:17:08 bardtx Exp $\");\n\nstruct snd_effect;\nLIST_HEAD(selist, snd_effect);\n\ntypedef struct snd_effect {\n\tuint32\tlocl, locr;\n\tuint32\tlen;\n\tuint32\trate;\n\tuint32\tused;\n\tint\tstereo;\n\tuint32\tfmt;\n\n\tLIST_ENTRY(snd_effect)\tlist;\n} snd_effect_t;\n\nstruct selist snd_effects;\n\n// The next channel we'll use to play sound effects.\nstatic int sfx_nextchan = 0;\n\n// Our channel-in-use mask.\nstatic uint64 sfx_inuse = 0;\n\n/* Unload all loaded samples and free their SPU RAM */\nvoid snd_sfx_unload_all() {\n\tsnd_effect_t * t, * n;\n\n\tt = LIST_FIRST(&snd_effects);\n\twhile (t) {\n\t\tn = LIST_NEXT(t, list);\n\n\t\tsnd_mem_free(t->locl);\n\t\tif (t->stereo)\n\t\t\tsnd_mem_free(t->locr);\n\t\tfree(t);\n\n\t\tt = n;\n\t}\n\n\tLIST_INIT(&snd_effects);\n}\n\n/* Unload a single sample */\nvoid snd_sfx_unload(sfxhnd_t idx) {\n\tsnd_effect_t * t = (snd_effect_t *)idx;\n\n\tsnd_mem_free(t->locl);\n\tif (t->stereo)\n\t\tsnd_mem_free(t->locr);\n\n\tLIST_REMOVE(t, list);\n\tfree(t);\n}\n\n/* WAV header:\n\t0x08\t-- \"WAVE\"\n\t0x14\t-- 1 for PCM, 20 for ADPCM\n\t0x16\t-- short num channels (1/2)\n\t0x18\t-- long HZ\n\t0x22\t-- short 8 or 16 (bits)\n\t0x28\t-- long data length\n\t0x2c\t-- data start\n\n */\n\n/* Load a sound effect from a WAV file and return a handle to it */\nsfxhnd_t snd_sfx_load(const char *fn) {\n\tuint32\tfd, len, hz;\n\tuint16\t*tmp, chn, bitsize, fmt;\n\tsnd_effect_t *t;\n\tint\townmem;\n\n\tdbglog(DBG_DEBUG, \"snd_sfx: loading effect %s\\n\", fn);\n\n\tfd = fs_open(fn, O_RDONLY);\n\tif (fd == 0) {\n\t\tdbglog(DBG_WARNING, \"snd_sfx: can't open sfx %s\\n\", fn);\n\t\treturn 0;\n\t}\n\n\t/* Check file magic */\n\thz = 0;\n\tfs_seek(fd, 8, SEEK_SET);\n\tfs_read(fd, &hz, 4);\n\tif (strncmp((char*)&hz, \"WAVE\", 4)) {\n\t\tdbglog(DBG_WARNING, \"snd_sfx: file is not RIFF WAVE\\n\");\n\t\tfs_close(fd);\n\t\treturn 0;\n\t}\n\t\n\t\n\t/* Read WAV header info */\n\tfs_seek(fd, 0x14, SEEK_SET);\n\tfs_read(fd, &fmt, 2);\n\tfs_read(fd, &chn, 2);\n\tfs_read(fd, &hz, 4);\n\tfs_seek(fd, 0x22, SEEK_SET);\n\tfs_read(fd, &bitsize, 2);\n\t\n\t/* Read WAV data */\n\tfs_seek(fd, 0x28, SEEK_SET);\n\tfs_read(fd, &len, 4);\n\n\tprintf(\"WAVE file is %s, %dHZ, %d bits/sample, %d bytes total, format %d\\n\",\n\t\tchn==1 ? \"mono\" : \"stereo\", hz, bitsize, len, fmt);\n\n\t/* Try to mmap it and if that works, no need to copy it again */\n\townmem = 0;\n\ttmp = (uint16 *)fs_mmap(fd);\n\tif (!tmp) {\n\t\ttmp = malloc(len);\n\t\tfs_read(fd, tmp, len);\n\t\townmem = 1;\n\t} else {\n\t\ttmp = (uint16 *)( ((uint8 *)tmp) + fs_tell(fd) );\n\t}\n\tfs_close(fd);\n\n\tt = malloc(sizeof(snd_effect_t));\n\tmemset(t, 0, sizeof(snd_effect_t));\n\n\tif (chn == 1) {\n\t\t/* Mono PCM/ADPCM */\n\t\tt->len = len/2;\t/* 16-bit samples */\n\t\tt->rate = hz;\n\t\tt->used = 1;\n\t\tt->locl = snd_mem_malloc(len);\n\t\tif (t->locl)\n\t\t\tspu_memload(t->locl, tmp, len);\n\t\tt->locr = 0;\n\t\tt->stereo = 0;\n\n\t\tif (fmt == 20) {\n\t\t\tt->fmt = AICA_SM_ADPCM;\n\t\t\tt->len *= 4;\t/* 4-bit packed samples */\n\t\t} else\n\t\t\tt->fmt = AICA_SM_16BIT;\n\t} else if (chn == 2 && fmt == 1) {\n\t\t/* Stereo PCM */\n\t\tint i;\n\t\tuint16 * sepbuf;\n\n\t\tsepbuf = malloc(len/2);\n\t\tfor (i=0; i<len/2; i+=2) {\n\t\t\tsepbuf[i/2] = tmp[i+1];\n\t\t}\n\t\tfor (i=0; i<len/2; i+=2) {\n\t\t\ttmp[i/2] = tmp[i];\n\t\t}\n\t\t\n\t\tt->len = len/4;\t/* Two stereo, 16-bit samples */\n\t\tt->rate = hz;\n\t\tt->used = 1;\n\t\tt->locl = snd_mem_malloc(len/2);\n\t\tt->locr = snd_mem_malloc(len/2);\n\t\tif (t->locl)\n\t\t\tspu_memload(t->locl, tmp, len/2);\n\t\tif (t->locr)\n\t\t\tspu_memload(t->locr, sepbuf, len/2);\n\t\tt->stereo = 1;\n\t\tt->fmt = AICA_SM_16BIT;\n\n\t\tfree(sepbuf);\n\t} else if (chn == 2 && fmt == 20) {\n\t\t/* Stereo ADPCM */\n\n\t\t/* We have to be careful here, because the second sample might not\n\t\t start on a nice even dword boundary. We take the easy way out\n\t\t and just malloc a second buffer. */\n\t\tuint8 * buf2 = malloc(len/2);\n\t\tmemcpy(buf2, ((uint8*)tmp) + len/2, len/2);\n\n\t\tt->len = len;\t/* Two stereo, 4-bit samples */\n\t\tt->rate = hz;\n\t\tt->used = 1;\n\t\tt->locl = snd_mem_malloc(len/2);\n\t\tt->locr = snd_mem_malloc(len/2);\n\t\tif (t->locl)\n\t\t\tspu_memload(t->locl, tmp, len/2);\n\t\tif (t->locr)\n\t\t\tspu_memload(t->locr, buf2, len/2);\n\t\tt->stereo = 1;\n\t\tt->fmt = AICA_SM_ADPCM;\n\n\t\tfree(buf2);\n\t} else {\n\t\tfree(t);\n\t\tt = NULL;\n\t}\n\n\tif (ownmem)\n\t\tfree(tmp);\n\n\tif (t) {\n\t\tLIST_INSERT_HEAD(&snd_effects, t, list);\n\t}\n\t\n\treturn (sfxhnd_t)t;\n}\n\nint snd_sfx_play_chn(int chn, sfxhnd_t idx, int vol, int pan) {\n\tint size;\n\tsnd_effect_t * t = (snd_effect_t *)idx;\n\tAICA_CMDSTR_CHANNEL(tmp, cmd, chan);\n\n\tsize = t->len;\n\tif (size >= 65535) size = 65534;\n\n\t/* printf(\"sndstream: playing effect %p on chan %d, loc %x/%x, rate %d, size %d, vol %d, pan %d\\r\\n\",\n\t\tidx, sfx_lastchan, t->locl, t->locr, t->rate, size, vol, pan); */\n\tif (!t->stereo) {\n\t\tcmd->cmd = AICA_CMD_CHAN;\n\t\tcmd->timestamp = 0;\n\t\tcmd->size = AICA_CMDSTR_CHANNEL_SIZE;\n\t\tcmd->cmd_id = chn;\n\t\tchan->cmd = AICA_CH_CMD_START;\n\t\tchan->base = t->locl;\n\t\tchan->type = t->fmt;\n\t\tchan->length = size;\n\t\tchan->loop = 0;\n\t\tchan->loopstart = 0;\n\t\tchan->loopend = size;\n\t\tchan->freq = t->rate;\n\t\tchan->vol = vol;\n\t\tchan->pan = pan;\n\t\tsnd_sh4_to_aica(tmp, cmd->size);\n\t} else {\n\t\tcmd->cmd = AICA_CMD_CHAN;\n\t\tcmd->timestamp = 0;\n\t\tcmd->size = AICA_CMDSTR_CHANNEL_SIZE;\n\t\tcmd->cmd_id = chn;\n\t\tchan->cmd = AICA_CH_CMD_START;\n\t\tchan->base = t->locl;\n\t\tchan->type = t->fmt;\n\t\tchan->length = size;\n\t\tchan->loop = 0;\n\t\tchan->loopstart = 0;\n\t\tchan->loopend = size;\n\t\tchan->freq = t->rate;\n\t\tchan->vol = vol;\n\t\tchan->pan = 0;\n\n\t\tsnd_sh4_to_aica_stop();\n\t\tsnd_sh4_to_aica(tmp, cmd->size);\n\n\t\tcmd->cmd_id = chn + 1;\n\t\tchan->base = t->locr;\n\t\tchan->pan = 255;\n\t\tsnd_sh4_to_aica(tmp, cmd->size);\n\t\tsnd_sh4_to_aica_start();\n\t}\n\n\treturn chn;\n}\n\nint snd_sfx_play(sfxhnd_t idx, int vol, int pan) {\n\tint chn, moved, old;\n\n\t// This isn't perfect.. but it should be good enough.\n\told = irq_disable();\n\tchn = sfx_nextchan;\n\tmoved = 0;\n\twhile (sfx_inuse & (1 << chn)) {\n\t\tchn = (chn + 1) % 64;\n\t\tif (sfx_nextchan == chn)\n\t\t\tbreak;\n\t\tmoved++;\n\t}\n\tirq_restore(old);\n\n\tif (moved && chn == sfx_nextchan) {\n\t\treturn -1;\n\t} else {\n\t\tsfx_nextchan = (chn + 2) % 64;\t// in case of stereo\n\t\treturn snd_sfx_play_chn(chn, idx, vol, pan);\n\t}\n}\n\nvoid snd_sfx_stop(int chn) {\n\tAICA_CMDSTR_CHANNEL(tmp, cmd, chan);\n\tcmd->cmd = AICA_CMD_CHAN;\n\tcmd->timestamp = 0;\n\tcmd->size = AICA_CMDSTR_CHANNEL_SIZE;\n\tcmd->cmd_id = chn;\n\tchan->cmd = AICA_CH_CMD_STOP;\n\tchan->base = 0;\n\tchan->type = 0;\n\tchan->length = 0;\n\tchan->loop = 0;\n\tchan->loopstart = 0;\n\tchan->loopend = 0;\n\tchan->freq = 44100;\n\tchan->vol = 0;\n\tchan->pan = 0;\n\tsnd_sh4_to_aica(tmp, cmd->size);\n}\n\nvoid snd_sfx_stop_all() {\n\tint i;\n\t\n\tfor (i=0; i<64; i++) {\n\t\tif (sfx_inuse & (1 << i))\n\t\t\tcontinue;\n\n\t\tsnd_sfx_stop(i);\n\t}\n}\n\nint snd_sfx_chn_alloc() {\n\tint old, chn;\n\n\told = irq_disable();\n\tfor (chn=0; chn<64; chn++)\n\t\tif (!(sfx_inuse & (1 << chn)))\n\t\t\tbreak;\n\tif (chn >= 64)\n\t\tchn = -1;\n\telse\n\t\tsfx_inuse |= 1 << chn;\n\tirq_restore(old);\n\n\treturn chn;\n}\n\nvoid snd_sfx_chn_free(int chn) {\n\tint old;\n\n\told = irq_disable();\n\tsfx_inuse &= ~(1 << chn);\n\tirq_restore(old);\n}\n"
},
{
"alpha_fraction": 0.4483816921710968,
"alphanum_fraction": 0.5147879719734192,
"avg_line_length": 27.663999557495117,
"blob_id": "09c82f2aa768e2d509bb4f644aa779d2a83835f2",
"content_id": "775bf9a29fd9c96896e5f521aa0a1c7c9e3f94f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3584,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 125,
"path": "/include/arch/dreamcast/dc/video.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n *\n * dc/video.h\n * (c)2001 Anders Clerwall (scav)\n *\n * $Id: video.h,v 1.6.2.1 2003/07/10 02:20:23 bardtx Exp $\n */\n\n#ifndef __DC_VIDEO_H\n#define __DC_VIDEO_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n//-----------------------------------------------------------------------------\n#define CT_ANY\t\t-1 // <-- Used ONLY internally with vid_mode\n#define CT_VGA\t\t0\n#define CT_RGB\t\t2\n#define CT_COMPOSITE\t3\n\n//-----------------------------------------------------------------------------\n#define PM_RGB555\t0\n#define PM_RGB565\t1\n#define PM_RGB888\t3\n\n//-----------------------------------------------------------------------------\n// These are more generic modes\n\nenum {\n\tDM_GENERIC_FIRST = 0x1000,\n\tDM_320x240 = 0x1000,\n\tDM_640x480,\n\tDM_800x608,\n\tDM_256x256,\n\tDM_768x480,\n\tDM_768x576,\n\tDM_GENERIC_LAST = DM_768x576\n};\n\n//-----------------------------------------------------------------------------\n// More specific modes (and actual indeces into the mode table)\n\nenum {\n\tDM_INVALID = 0,\n\t// Valid modes below\n\tDM_320x240_VGA = 1,\n\tDM_320x240_NTSC,\n\tDM_640x480_VGA,\n\tDM_640x480_NTSC_IL,\n\tDM_800x608_VGA,\n\tDM_640x480_PAL_IL,\n\tDM_256x256_PAL_IL,\n\tDM_768x480_NTSC_IL,\n\tDM_768x576_PAL_IL,\n\tDM_768x480_PAL_IL,\n\tDM_320x240_PAL,\n\t// The below is only for counting..\n\tDM_SENTINEL,\n\tDM_MODE_COUNT\n};\n\n//-----------------------------------------------------------------------------\n#define VID_MAX_FB\t4\t// <-- This should be enough\n\n//-----------------------------------------------------------------------------\n// These are for the \"flags\" field of \"vid_mode_t\"\n#define VID_INTERLACE\t\t0x00000001\n#define VID_LINEDOUBLE\t\t0x00000002\t// <-- For 240 scanlines on VGA cable\n#define VID_PIXELDOUBLE\t\t0x00000004\t// <-- For low-res modes (320)\n#define VID_PAL\t\t\t0x00000008\t// <-- This sets output to 50Hz PAL if not CT_VGA\n\n//-----------------------------------------------------------------------------\nstruct vid_mode {\n\tint generic;\t\t\t\t// <-- Generic mode identifier (for vid_set_mode)\n\tuint16 width, height;\t\t\t// <-- With and height of screen in pixels\n\tuint32 flags;\t\t\t\t// <-- Combination of one or more VID_* flags\n\t\n\tint16 cable_type;\t\t\t// <-- One of CT_*\n\tuint16 pm;\t\t\t\t// <-- Pixel Mode\n\t\n\tuint16 scanlines, clocks;\t\t// <-- Scanlines/frame and clocks per scanline.\n\tuint16 bitmapx, bitmapy;\t\t// <-- Bitmap window position (bitmapy is automatically increased for PAL)\n\tuint16 scanint1, scanint2;\t\t// <-- Scanline interrupt positions (scanint2 automatically doubled for VGA)\n\tuint16 borderx1, borderx2;\t\t// <-- Border x start/stop\n\tuint16 bordery1, bordery2;\t\t// <-- Border y start/stop\n\t\n\tuint16 fb_curr, fb_count;\n\tuint32 fb_base[VID_MAX_FB];\n};\n\ntypedef struct vid_mode vid_mode_t;\n\nextern vid_mode_t vid_builtin[DM_MODE_COUNT];\nextern vid_mode_t *vid_mode;\n\n//-----------------------------------------------------------------------------\nextern uint16 *vram_s;\nextern uint32 *vram_l;\n\n//-----------------------------------------------------------------------------\nint vid_check_cable();\n\nvoid vid_set_start(uint32 base);\nvoid vid_flip(int fb);\nvoid vid_border_color(int r, int g, int b);\nvoid vid_clear(int r, int g, int b);\nvoid vid_empty();\nvoid vid_waitvbl();\nvoid vid_set_mode(int dm, int pm);\nvoid vid_set_mode_ex(vid_mode_t *mode);\n\nvoid vid_init(int disp_mode, int pixel_mode);\nvoid vid_shutdown();\n\n//-----------------------------------------------------------------------------\n\nint vid_screen_shot(const char * destfn);\n\n//-----------------------------------------------------------------------------\n\n__END_DECLS\n\n#endif\t// __DC_VIDEO_H\n\n"
},
{
"alpha_fraction": 0.6883116960525513,
"alphanum_fraction": 0.7489177584648132,
"avg_line_length": 37.5,
"blob_id": "2188b9e7df52a661556c9db929b9ba726ec53288",
"content_id": "816d6fd6ad387f42f59f422d83eb85e442614e78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 6,
"path": "/environ_ia32.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS environment variable settings. These are the shared pieces\n# for the ia32/i386 platform.\n\n#export KOS_CFLAGS=\"${KOS_CFLAGS}\"\n#export KOS_AFLAGS=\"${KOS_AFLAGS}\"\nexport KOS_LDFLAGS=\"${KOS_LDFLAGS} -Wl,-Ttext=0x00010000\"\n"
},
{
"alpha_fraction": 0.6782488822937012,
"alphanum_fraction": 0.7030460834503174,
"avg_line_length": 34.5,
"blob_id": "7871db9039ff3650852bbb0345ead204005c52d7",
"content_id": "13ad398a74a4b613632946dcfe3ab40f96b1793a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 6533,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 184,
"path": "/include/arch/dreamcast/dc/flashrom.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n kernel/arch/dreamcast/include/dc/flashrom.h\n Copyright (C)2003 Dan Potter\n\n $Id: flashrom.h,v 1.4 2003/03/10 01:45:32 bardtx Exp $\n*/\n\n\n#ifndef __DC_FLASHROM_H\n#define __DC_FLASHROM_H\n\n#include <sys/cdefs.h>\n__BEGIN_DECLS\n\n#include <arch/types.h>\n\n/**\n \\file Implements wrappers for the BIOS flashrom syscalls, and some\n utilities to make it easier to use the flashrom info. Note that\n because the flash writing can be such a dangerous thing potentially\n (I haven't deleted my flash to see what happens, but given the\n info stored here it sounds like a Bad Idea(tm)) the syscalls for\n the WRITE and DELETE operations are not enabled by default. If you\n are 100% sure you really want to be writing to the flash and you\n know what you're doing, then you can edit flashrom.c and re-enable\n them there. */\n\n/**\n An enumeration of partitions available in the flashrom. */\n#define FLASHROM_PT_SYSTEM\t\t0\t/*< Factory settings (read-only, 8K) */\n#define FLASHROM_PT_RESERVED\t1\t/*< reserved (all 0s, 8K) */\n#define FLASHROM_PT_BLOCK_1\t\t2\t/*< Block allocated (16K) */\n#define FLASHROM_PT_SETTINGS\t3\t/*< Game settings (block allocated, 32K) */\n#define FLASHROM_PT_BLOCK_2\t\t4\t/*< Block allocated (64K) */\n\n/**\n An enumeration of logical blocks available in the flashrom. */\n#define FLASHROM_B1_SYSCFG\t\t0x05\t/*< System config (BLOCK_1) */\n#define FLASHROM_B1_IP_SETTINGS\t0xE0\t/*< IP settings for BBA (BLOCK_1) */\n#define FLASHROM_B1_EMAIL\t\t0xE2\t/*< Email address (BLOCK_1) */\n#define FLASHROM_B1_SMTP\t\t0xE4\t/*< SMTP server setting (BLOCK_1) */\n#define FLASHROM_B1_POP3\t\t0xE5\t/*< POP3 server setting (BLOCK_1) */\n#define FLASHROM_B1_POP3LOGIN\t0xE6\t/*< POP3 login setting (BLOCK_1) */\n#define FLASHROM_B1_POP3PASSWD\t0xE7\t/*< POP3 password setting + proxy (BLOCK_1) */\n#define FLASHROM_B1_PPPLOGIN\t0xE8\t/*< PPP username + proxy (BLOCK_1) */\n#define FLASHROM_B1_PPPPASSWD\t0xE9\t/*< PPP passwd (BLOCK_1) */\n\n/**\n Implements the FLASHROM_INFO syscall; given a partition ID,\n return two ints specifying the beginning and the size of\n the partition (respectively) inside the flashrom. Returns zero\n if successful, -1 otherwise. */\nint flashrom_info(int part, int * start_out, int * size_out);\n\n/**\n Implements the FLASHROM_READ syscall; given a flashrom offset,\n an output buffer, and a count, this reads data from the\n flashrom. Returns the number of bytes read if successful,\n or -1 otherwise. */\nint flashrom_read(int offset, void * buffer_out, int bytes);\n\n/**\n Implements the FLASHROM_WRITE syscall; given a flashrom offset,\n an input buffer, and a count, this writes data to the flashrom.\n Returns the number of bytes written if successful, -1 otherwise.\n\n NOTE: It is not possible to write ones to the flashrom over zeros.\n If you want to do this, you must save the old data in the flashrom,\n delete it out, and save the new data back. */\nint flashrom_write(int offset, void * buffer, int bytes);\n\n/**\n Implements the FLASHROM_DELETE syscall; given a partition offset,\n that entire partition of the flashrom will be deleted and all data\n will be reset to FFs. Returns zero if successful, -1 on failure. */\nint flashrom_delete(int offset);\n\n\n/* Medium-level functions */\n/**\n Returns a numbered logical block from the requested partition. The newest\n data is returned. 'buffer_out' must have enough room for 60 bytes of\n data. */\nint flashrom_get_block(int partid, int blockid, uint8 * buffer_out);\n\n\n/* Higher level functions */\n\n/**\n Language settings possible in the BIOS menu. These will be returned\n from flashrom_get_language(). */\n#define FLASHROM_LANG_JAPANESE\t0\n#define FLASHROM_LANG_ENGLISH\t1\n#define FLASHROM_LANG_GERMAN\t2\n#define FLASHROM_LANG_FRENCH\t3\n#define FLASHROM_LANG_SPANISH\t4\n#define FLASHROM_LANG_ITALIAN\t5\n\n/**\n This struct will be filled by calling the flashrom_get_syscfg call\n below. */\ntypedef struct flashrom_syscfg {\n\tint\tlanguage;\t/*< Language setting (see defines above) */\n\tint\taudio;\t\t/*< 0 == mono, 1 == stereo */\n\tint\tautostart;\t/*< 0 == off, 1 == on */\n} flashrom_syscfg_t;\n\n/**\n Retrieves the current syscfg settings and fills them into the struct\n passed in to us. */\nint flashrom_get_syscfg(flashrom_syscfg_t * out);\n\n\n/**\n Region settings possible in the system flash (partition 0). */\n#define FLASHROM_REGION_UNKNOWN\t0\n#define FLASHROM_REGION_JAPAN\t1\n#define FLASHROM_REGION_US\t2\n#define FLASHROM_REGION_EUROPE\t3\n\n/**\n Retrieves the console's region code. This is still somewhat \n experimental, it may not function 100% on all DCs. Returns\n one of the codes above or -1 on error. */\nint flashrom_get_region();\n\n/**\n Method constants for the ispcfg struct */\n#define FLASHROM_ISP_DHCP\t0\n#define FLASHROM_ISP_STATIC\t1\n#define FLASHROM_ISP_DIALUP\t2\n#define FLASHROM_ISP_PPPOE\t4\n\n/**\n This struct will be filled by calling flashrom_get_isp_settings below.\n Thanks to Sam Steele for this info. */\ntypedef struct flashrom_ispcfg {\n\tint\tip_valid;\t\t/*< >0 if the IP settings are valid */\n\tint\tmethod;\t\t\t/*< DHCP, Static, dialup(?), PPPoE */\n\tuint8\tip[4];\t\t/*< Host IP address */\n\tuint8\tnm[4];\t\t/*< Netmask */\n\tuint8\tbc[4];\t\t/*< Broadcast address */\n\tuint8\tgw[4];\t\t/*< Gateway address */\n\tuint8\tdns[2][4];\t/*< DNS servers (2) */\n\tchar\thostname[24];\t/*< DHCP/Host name */\n\n\tint\temail_valid;\t/*< >0 if the email setting is valid */\n\tchar\temail[48];\t/*< Email address */\n\n\tint\tsmtp_valid;\t\t/*< >0 if the smtp setting is valid */\n\tchar\tsmtp[28];\t/*< SMTP server */\n\n\tint\tpop3_valid;\t\t/*< >0 if the pop3 setting is valid */\n\tchar\tpop3[24];\t/*< POP3 server */\n\n\tint\tpop3_login_valid;\t\t/*< >0 if the login setting is valid */\n\tchar\tpop3_login[20];\t\t/*< POP3 login */\n\n\tint\tpop3_passwd_valid;\t\t/*< >0 if the passwd/proxy setting is valid */\n\tchar\tpop3_passwd[32];\t/*< POP3 passwd */\n\tchar\tproxy_host[16];\t\t/*< Proxy server hostname */\n\n\tint\tppp_login_valid;\t/*< >0 if the PPP login/proxy setting is valid */\n\tint\tproxy_port;\t\t\t/*< Proxy server port */\n\tchar\tppp_login[8];\t/*< PPP login */\n\n\tint\tppp_passwd_valid;\t/*< >0 if the PPP passwd setting is valid */\n\tchar\tppp_passwd[20];\t/*< PPP password */\n} flashrom_ispcfg_t;\n\n/**\n Retrieves the console's ISP settings, if they exist. These are set by\n programs like Dream Passport 3. Returns -1 on error (none of the settings\n can be found, or some other error), or >=0 on success. You should check\n the _valid member of the matching part of the struct before relying on\n the data. */\nint flashrom_get_ispcfg(flashrom_ispcfg_t * out);\n\n/* More to come later */\n\n__END_DECLS\n\n#endif\t/* __DC_FLASHROM_H */\n\n"
},
{
"alpha_fraction": 0.6277128458023071,
"alphanum_fraction": 0.6611018180847168,
"avg_line_length": 21.11111068725586,
"blob_id": "37941da025fffbbe344fc9a8929ba6ea9fa04488",
"content_id": "781e9d0d24e57364b081ecdebe2299812c413869",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 599,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 27,
"path": "/examples/dreamcast/pvr/Makefile",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "# KallistiOS ##version##\n#\n# examples/dreamcast/pvr/Makefile\n# (c)2002 Dan Potter\n# \n# $Id: Makefile,v 1.2 2002/09/28 04:18:55 bardtx Exp $\n\nall:\n\t$(MAKE) -C plasma\n\t$(MAKE) -C pvrmark\n\t$(MAKE) -C pvrmark_strips\n\t$(MAKE) -C pvrmark_strips_direct\n\t$(MAKE) -C texture_render\n\nclean:\n\t$(MAKE) -C plasma clean\n\t$(MAKE) -C pvrmark clean\n\t$(MAKE) -C pvrmark_strips clean\n\t$(MAKE) -C pvrmark_strips_direct clean\n\t$(MAKE) -C texture_render clean\n\t\t\ndist:\n\t$(MAKE) -C plasma dist\n\t$(MAKE) -C pvrmark dist\n\t$(MAKE) -C pvrmark_strips dist\n\t$(MAKE) -C pvrmark_strips_direct dist\n\t$(MAKE) -C texture_render dist\n\n\n"
},
{
"alpha_fraction": 0.5938864350318909,
"alphanum_fraction": 0.6724891066551208,
"avg_line_length": 56,
"blob_id": "45ec42d6bb6929307d7687e2b8094fc65bd09ce6",
"content_id": "f7a627d4fccbcbd91a2d0b255b0c501ce23b8983",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/utils/dc-chain/download.sh",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nwget -c ftp://ftp.gnu.org/gnu/binutils/binutils-2.17.tar.bz2 || exit 1\nwget -c ftp://ftp.gnu.org/gnu/gcc/gcc-3.4.6/gcc-3.4.6.tar.bz2 || exit 1\nwget -c ftp://sources.redhat.com/pub/newlib/newlib-1.12.0.tar.gz || exit 1\n\n"
},
{
"alpha_fraction": 0.6134510636329651,
"alphanum_fraction": 0.6317934989929199,
"avg_line_length": 21.984375,
"blob_id": "9feacb13cd56275196d9255413ebaac88fc386dd",
"content_id": "a8f76593ff01a2f6d7c0768810b9e52461fd4629",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1472,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 64,
"path": "/kernel/arch/dreamcast/hardware/maple/maple_enum.c",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "/* KallistiOS ##version##\n\n maple_enum.c\n (c)2002 Dan Potter\n */\n\n#include <dc/maple.h>\n#include <kos/thread.h>\n\nCVSID(\"$Id: maple_enum.c,v 1.2 2002/05/18 07:11:24 bardtx Exp $\");\n\n/* Return the number of connected devices */\nint maple_enum_count() {\n\tint p, u, cnt;\n\n\tfor (cnt=0, p=0; p<MAPLE_PORT_COUNT; p++)\n\t\tfor (u=0; u<MAPLE_UNIT_COUNT; u++) {\n\t\t\tif (maple_state.ports[p].units[u].valid)\n\t\t\t\tcnt++;\n\t\t}\n\n\treturn cnt;\n}\n\n/* Return a raw device info struct for the given device */\nmaple_device_t * maple_enum_dev(int p, int u) {\n\tif (maple_dev_valid(p, u))\n\t\treturn &maple_state.ports[p].units[u];\n\telse\n\t\treturn NULL;\n}\n\n/* Return the Nth device of the requested type (where N is zero-indexed) */\nmaple_device_t * maple_enum_type(int n, uint32 func) {\n\tint p, u;\n\tmaple_device_t *dev;\n\n\tfor (p=0; p<MAPLE_PORT_COUNT; p++) {\n\t\tfor (u=0; u<MAPLE_UNIT_COUNT; u++) {\n\t\t\tdev = maple_enum_dev(p, u);\n\t\t\tif (dev != NULL && dev->info.functions & func) {\n\t\t\t\tif (!n) return dev;\n\t\t\t\tn--;\n\t\t\t}\n\t\t}\n\t}\n\n\treturn NULL;\n}\n\n/* Get the status struct for the requested maple device; wait until it's\n valid before returning. Cast to the appropriate type you're expecting. */\nvoid * maple_dev_status(maple_device_t *dev) {\n\t/* Is the device valid? */\n\tif (!dev->valid)\n\t\treturn NULL;\n\n\t/* Waits until the first DMA happens: crude but effective (replace me later) */\n\twhile (!dev->status_valid)\n\t\tthd_pass();\n\n\t/* Cast and return the status buffer */\n\treturn (void *)(dev->status);\n}\n\n"
},
{
"alpha_fraction": 0.7055837512016296,
"alphanum_fraction": 0.710659921169281,
"avg_line_length": 20.88888931274414,
"blob_id": "691e9437da79f5257f634a34bd59f753f987f26f",
"content_id": "6e8c9874ca3eedcb3a1b8654b94bf2a013ef0ea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 9,
"path": "/include/sys/_pthread.h",
"repo_name": "losinggeneration/kos",
"src_encoding": "UTF-8",
"text": "#ifndef __SYS__PTHREAD_H\n#define __SYS__PTHREAD_H\n\n// Make sure pthreads compile ok.\n#define _POSIX_THREADS\n#define _POSIX_TIMEOUTS\n#define PTHREAD_MUTEX_RECURSIVE 0\n\n#endif\t/* __SYS__PTHREAD_H */\n"
}
] | 344 |
dietrannies/memento-convert
|
https://github.com/dietrannies/memento-convert
|
2120ebef02243f36068033fae5a958458f078839
|
e4aa1e2a9ee77d7355cd49e18bd93ff362186f51
|
6792607abcafa3b3fa2faebbd43c63a9013f8ec3
|
refs/heads/master
| 2022-12-01T10:43:51.820904 | 2020-08-16T17:12:59 | 2020-08-16T17:12:59 | 287,989,158 | 3 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6418918967247009,
"alphanum_fraction": 0.6520270109176636,
"avg_line_length": 25.909090042114258,
"blob_id": "60b6f6ea44f4277fbe0a6e3cca872b9f05368c32",
"content_id": "9b547543b59f0bf92a5eb54f8f73484461534be6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 11,
"path": "/setup.py",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\n\nsetup(\n name=\"memento_convert\",\n version=\"0.1.0\",\n packages=find_packages(where=\"./src\"),\n package_dir={\"\": \"src\"},\n install_requires=[\"pandas\"],\n entry_points={\"console_scripts\": [\"memento-convert = memento_convert.main:main\"]},\n)\n"
},
{
"alpha_fraction": 0.7680981755256653,
"alphanum_fraction": 0.7705521583557129,
"avg_line_length": 31.600000381469727,
"blob_id": "936443f7252872075fa974e8b548fd2cf5e60b5e",
"content_id": "a5dbf272ed92dc154d6831e1482e869065ef67f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 332,
"num_lines": 25,
"path": "/README.md",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "# Memento Database Converter\n\n## Introduction\n\nOn the go, I use the excellent [Memento Database](https://mementodatabase.com) application for Android for keeping track of things, but I was in need of a way to easily pull out an SQLite3 database with my data so I could further process it on my computer. This is a *very* preliminary version of a conversion tool for this purpose.\n\n## Installation\n\nGit clone the repo and install from the root folder using the following command:\n\n```bash\npip install .\n```\n\n## Usage\n\nIn the Memento Database application, make a backup from the Settings menu, pull the backup file to the computer and unzip.\n\nExecute the command, example:\n\n```bash\nmemento-convert -i memento.db -o extract.db\n```\n\nThe resulting file is a SQLite3 database containing your libraries as regular tables.\n"
},
{
"alpha_fraction": 0.6510500907897949,
"alphanum_fraction": 0.6607431173324585,
"avg_line_length": 21.925926208496094,
"blob_id": "f843f35190d0558ce13e87c29971fb442355937f",
"content_id": "d3029ead71529d44ab0a8b58d1b50f923323eae4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 619,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 27,
"path": "/src/memento_convert/dtypes.py",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom dataclasses import dataclass\nfrom typing import Callable\n\n\n@dataclass\nclass DType:\n memento_type_code: str = None\n pandas_dtype: str = \"object\"\n sqlite_type: str = \"TEXT\"\n transform_func: Callable = lambda x: x\n\n\ndtypes = [\n DType(\n memento_type_code=\"ft_date\",\n sqlite_type=\"DATE\",\n transform_func=lambda x: datetime.utcfromtimestamp(int(x) // 1000).strftime(\"%Y-%m-%d\"),\n ),\n DType(memento_type_code=\"ft_int\", pandas_dtype=\"int32\", sqlite_type=\"INTEGER\"),\n]\n\n\ndtypes_map = {t.memento_type_code: t for t in dtypes}\n\n\ndefault_dtype = DType()\n"
},
{
"alpha_fraction": 0.5090275406837463,
"alphanum_fraction": 0.510611355304718,
"avg_line_length": 23.6640625,
"blob_id": "5aa23fc0b25aa74dca2dd87b95d2c96691596c7c",
"content_id": "0958b1124ddbb2a110c6ad0055aa8551dcfb1bf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3157,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 128,
"path": "/src/memento_convert/memento.py",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nfrom dataclasses import dataclass\nimport sqlite3\n\nimport pandas as pd\n\n\n@dataclass\nclass Field:\n uuid: str\n title: str\n type_code: str\n\n\n@dataclass\nclass Value:\n field_uuid: str\n item_uuid: str\n value_str: str\n value_float: float\n value_int: int\n\n\n@dataclass\nclass Item:\n uuid: str\n creation_date: datetime\n\n\n@dataclass\nclass Library:\n uuid: str\n title: str\n\n\nclass MementoDB:\n def __init__(self, filename):\n self.db = sqlite3.connect(filename)\n\n def __enter__(self):\n return self\n\n def __exit__(self, type, value, traceback):\n self.close()\n\n def query(self, query):\n return pd.read_sql(query, self.db)\n\n @property\n def tbl_library(self):\n return self.query(\"SELECT * FROM tbl_library\")\n\n @property\n def tbl_library_item(self):\n return self.query(\"SELECT * FROM tbl_library_item\")\n\n @property\n def tbl_flex_template(self):\n return self.query(\"SELECT * FROM tbl_flex_template\")\n\n @property\n def tbl_flex_content2(self):\n return self.query(\"SELECT * FROM tbl_flex_content2\")\n\n def get_libraries(self):\n return [\n Library(uuid=l.UUID, title=l.TITLE)\n for _, l in self.query(\n \"\"\"\n SELECT *\n FROM tbl_library\n WHERE NOT REMOVED\n \"\"\"\n ).iterrows()\n ]\n\n def get_fields(self, library_uuid):\n return [\n Field(uuid=f.UUID, title=f.title, type_code=f.type_code)\n for _, f in self.query(\n f\"\"\"\n SELECT *\n FROM tbl_flex_template\n WHERE LIB_UUID = '{library_uuid}'\n ORDER BY sortorder\n \"\"\"\n ).iterrows()\n ]\n\n def get_items(self, library_uuid):\n return [\n Item(uuid=i.UUID, creation_date=i.creation_date)\n for _, i in self.query(\n f\"\"\"\n SELECT *\n FROM tbl_library_item\n WHERE LIB_UUID = '{library_uuid}'\n AND NOT REMOVED\n \"\"\"\n ).iterrows()\n ]\n\n def get_values(self, library_uuid):\n return [\n Value(\n field_uuid=v.templateUUID,\n item_uuid=v.ownerUUID,\n value_str=None if pd.isnull(v.stringContent) else str(v.stringContent),\n value_float=None if pd.isnull(v.realContent) else float(v.realContent),\n value_int=None if pd.isnull(v.intContent) else int(v.intContent),\n )\n for _, v in self.query(\n f\"\"\"\n SELECT v.*\n FROM tbl_flex_content2 v\n INNER JOIN tbl_library_item i\n ON v.ownerUUID = i.UUID\n AND NOT i.REMOVED\n INNER JOIN tbl_flex_template f\n ON v.templateUUID = f.UUID\n WHERE i.LIB_UUID = '{library_uuid}'\n AND f.LIB_UUID = '{library_uuid}'\n \"\"\"\n ).iterrows()\n ]\n\n def close(self):\n self.db.close()\n"
},
{
"alpha_fraction": 0.6721311211585999,
"alphanum_fraction": 0.6721311211585999,
"avg_line_length": 23.399999618530273,
"blob_id": "6e296a17842ac3c08eafb69848b9bac83a131867",
"content_id": "8f94127b09d15912fc5d381461a4fd3b769ca4f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 20,
"path": "/src/memento_convert/helper.py",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "import re\n\nfrom memento_convert.dtypes import dtypes_map, default_dtype\n\n\ndef normalize_name(s):\n return re.sub(r\"[\\-_\\s]\", \"_\", s.lower())\n\n\ndef coalesce(*elements):\n for element in elements:\n if element is None:\n continue\n return element\n\n\ndef transform(column, memento_type_code):\n return column.apply(dtypes_map.get(memento_type_code, default_dtype).transform_func).astype(\n dtypes_map.get(memento_type_code, default_dtype).pandas_dtype\n )\n"
},
{
"alpha_fraction": 0.6303580403327942,
"alphanum_fraction": 0.6333837509155273,
"avg_line_length": 32.61016845703125,
"blob_id": "dc1ee23bab3b78e691e781ecc911f5decc6b3ca3",
"content_id": "7d3bb441f958422d67af890ad8b120342541b4f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1983,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 59,
"path": "/src/memento_convert/main.py",
"repo_name": "dietrannies/memento-convert",
"src_encoding": "UTF-8",
"text": "import os\nfrom datetime import datetime\nimport sqlite3\nimport argparse\n\nimport pandas as pd\n\nfrom memento_convert.memento import MementoDB\nfrom memento_convert.helper import normalize_name, coalesce, transform\n\n\ndef main():\n\n parser = argparse.ArgumentParser(description=\"Convert Memento Database db files to regular SQLite databases\")\n parser.add_argument(\n \"-i\", \"--input\", type=str, help=\"input file (Memento Database db file)\", default=\"memento.db\",\n )\n parser.add_argument(\n \"-o\", \"--output\", type=str, help=\"output file (SQLite db file)\", default=\"extract.db\",\n )\n args = parser.parse_args()\n\n memento_filename = args.input\n export_filename = args.output\n\n if os.path.exists(export_filename):\n os.remove(export_filename)\n\n with MementoDB(memento_filename) as memento, sqlite3.connect(export_filename) as export:\n\n for library in memento.get_libraries():\n\n fields = memento.get_fields(library.uuid)\n items = memento.get_items(library.uuid)\n values = memento.get_values(library.uuid)\n\n df = pd.DataFrame(columns=[f.uuid for f in fields], index=[i.uuid for i in items])\n\n for value in values:\n df.loc[value.item_uuid, value.field_uuid] = coalesce(\n value.value_str, value.value_float, value.value_int\n )\n\n for field in fields:\n df[field.uuid] = transform(df[field.uuid], field.type_code)\n df.rename(columns={field.uuid: normalize_name(field.title)}, inplace=True)\n\n df[\"creation_date\"] = None\n for item in items:\n df.loc[item.uuid, \"creation_date\"] = datetime.utcfromtimestamp(item.creation_date // 1000)\n\n df.sort_values(\"creation_date\", inplace=True)\n df.reset_index(inplace=True, drop=True)\n\n df.to_sql(name=normalize_name(library.title), index=False, con=export)\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 6 |
amanda7641/disks
|
https://github.com/amanda7641/disks
|
773478c3760cb64df375beb4641289a758b81249
|
4d0f0d38845ae48448051187ab73933a541bdf9d
|
c8778e714b0d36ae9fc46858acb6bb787358924c
|
refs/heads/master
| 2020-03-27T06:28:01.543139 | 2018-09-03T20:58:34 | 2018-09-03T20:58:34 | 146,108,275 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5917431116104126,
"alphanum_fraction": 0.6092316508293152,
"avg_line_length": 41.43902587890625,
"blob_id": "3d9bc178f2e594744979b92fe523a06ea4cebfd7",
"content_id": "04f30264afa0c7c3928368948cdfc2d29fda96b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3488,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 82,
"path": "/main.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import xygame\nimport overlapData\nimport itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\n\n#Builds general overlapData for all annular disks with these p and q values\noverlapData = []\nfor i in range(1,p*q+1):\n if i % p == 0:\n overlapData.append([(i%(p*q),'r'),((i+q-1)%(p*q),'l'),((i+q)%(p*q),'r'),((i+1)%(p*q),'l')])\n overlapData.append([(i%(p*q),'l'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'r')])\n elif i % p == 1:\n overlapData.append([(i%(p*q),'l'),((i-1)%(p*q),'r'),((i+q)%(p*q),'r'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-q+1)%(p*q),'l'),((i-q)%(p*q),'r'),((i+1)%(p*q),'r')])\n elif i % p == (p-1):\n overlapData.append([(i%(p*q),'l'),((i+q)%(p*q),'l'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'l'),((i+1)%(p*q),'l')])\n else:\n overlapData.append([(i%(p*q),'l'),((i+q)%(p*q),'r'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'l'),((i+1)%(p*q),'r')])\n \n\n#Gets more info from user\ndisks = int(input(\"How many disks will you use? \"))\nwhile disks > p*q:\n disks = int(input(\"How many disks will you use? \"))\ndiskNumbers = []\nfor i in range(int(disks)):\n m = int(input(\"Next disk number!: \"))\n while m < 1 or m > p*q or diskNumbers.count(m) > 0:\n if m < 1 or m > p*q:\n m = int(input(\"There are a maximum of \" + str(p*q) + \" disks. Choose a new one: \"))\n if diskNumbers.count(m) > 0:\n m = int(input(\"You have already added that disk, choose a new one: \"))\n diskNumbers.append(int(m))\n#You can comment out the above, if you wish to supply the diskNumbers in a list like below\n #diskNumbers = [1,2,3,12,9,10,11,13,15,17,19]\n #disks = len(diskNumbers)\n\n#Sort diskNumbers for easy viewing, replace any p*q with 0 so that indexing is easier in future functions/methods\nsortedDiskNumbers = sorted(diskNumbers)\nfor disk in sortedDiskNumbers:\n if disk == p*q:\n sortedDiskNumbers.remove(disk)\n sortedDiskNumbers.insert(0,0)\nprint(sortedDiskNumbers)\n\n\n#Prune overlapData rows based on sortedDiskNumbers and pairs from each row with a number that is not in sortedDiskNumbers\nitemCount = 0\nwhile itemCount < len(overlapData):\n if sortedDiskNumbers.count(overlapData[itemCount][0][0]) <= 0:\n overlapData.remove(overlapData[itemCount])\n itemCount = itemCount - 1\n else:\n pairCount = 0\n while pairCount < len(overlapData[itemCount]):\n if sortedDiskNumbers.count(overlapData[itemCount][pairCount][0]) <= 0:\n overlapData[itemCount].remove(overlapData[itemCount][pairCount])\n pairCount = pairCount - 1\n pairCount = pairCount + 1\n itemCount = itemCount + 1\n\norientationConfigurations = list(itertools.product([0,1], repeat=disks))\n#In the above configurations: 1 is positive, 0 is negative\n\n#If we are going to be reading overlapData from a .dat file use the below\n #overlapData = overlapData.OverlapData(\"allOverlap.dat\", sortedDiskNumbers)\n #overlapDataForDiskChoices = overlapData.findOverlapDataForDiskChoices()\n\ngame = xygame.XYGame(p,q,overlapData, len(sortedDiskNumbers), sortedDiskNumbers, orientationConfigurations)\ngame.play()\n\n\nprint(\"Runtime: \" + str(datetime.now()-startTime))\n\n\n\n "
},
{
"alpha_fraction": 0.6047377586364746,
"alphanum_fraction": 0.6152284145355225,
"avg_line_length": 41.21428680419922,
"blob_id": "ab293eece5f2bd1f2b15aa5cf69baa239bb159d4",
"content_id": "93ef5d7cfd29d0dcc798bf94239ab7e9d482da03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2955,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 70,
"path": "/iterable.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import xygame\nimport overlapData\nimport itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\ndisks = p*q - (p+q)\n\n#Builds general overlapData for all annular disks with these p and q values\noverlapData = []\nfor i in range(1,p*q+1):\n if i % p == 0:\n overlapData.append([(i%(p*q),'r'),((i+q-1)%(p*q),'l'),((i+q)%(p*q),'r'),((i+1)%(p*q),'l')])\n overlapData.append([(i%(p*q),'l'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'r')])\n elif i % p == 1:\n overlapData.append([(i%(p*q),'l'),((i-1)%(p*q),'r'),((i+q)%(p*q),'r'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-q+1)%(p*q),'l'),((i-q)%(p*q),'r'),((i+1)%(p*q),'r')])\n elif i % p == (p-1):\n overlapData.append([(i%(p*q),'l'),((i+q)%(p*q),'l'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'l'),((i+1)%(p*q),'l')])\n else:\n overlapData.append([(i%(p*q),'l'),((i+q)%(p*q),'r'),((i+q-1)%(p*q),'r')])\n overlapData.append([(i%(p*q),'r'),((i-1)%(p*q),'r'),((i-q)%(p*q),'l'),((i-q+1)%(p*q),'l'),((i+1)%(p*q),'r')])\noverlapDataTuple = tuple(overlapData)\n\n\n\n#Can get more info from user to let them decide how many disks to try\n #disks = int(input(\"How many disks will you use? \"))\n\norientationConfigurations = list(itertools.product([0,1], repeat=disks))\n#In the above configurations: 1 is positive, 0 is negative\n\n#Generate all possible choices of disks\nmyNumbers = range(p*q)\nmyList = list(itertools.combinations(myNumbers, disks))\n\n#Prune overlapData rows based on sortedDiskNumbers and pairs from each row with a number that is not in sortedDiskNumbers\ndef prune(myOverlapData, diskChoice):\n prunedOverlapData = []\n for overlapDataItem in myOverlapData:\n if diskChoice.count(overlapDataItem[0][0]) > 0:\n prunedOverlapDataItem = []\n for pair in overlapDataItem:\n if diskChoice.count(pair[0]) > 0:\n prunedOverlapDataItem.append(pair)\n prunedOverlapData.append(prunedOverlapDataItem)\n return prunedOverlapData\n\n#Loop through all disk choices to play xygame for each choice\nhasConfiguration = []\nfor sortedDiskNumbers in myList:\n prunedOverlapData = prune(overlapData, sortedDiskNumbers)\n print(str(sortedDiskNumbers) + \", overlap: \" + str(prunedOverlapData))\n game = xygame.XYGame(p,q,prunedOverlapData,len(sortedDiskNumbers),sortedDiskNumbers, orientationConfigurations)\n xyList = game.getXYList()\n if xyList:\n configs = []\n for config in xyList:\n configs.append(config[0])\n hasConfiguration.append((sortedDiskNumbers, configs))\nfor configuration in hasConfiguration:\n print(configuration)\nprint(\"Number of configurations that work: \" + str(len(hasConfiguration)))\nprint(\"Runtime: \" + str(datetime.now()-startTime))\n"
},
{
"alpha_fraction": 0.5332629084587097,
"alphanum_fraction": 0.5477447509765625,
"avg_line_length": 41.774192810058594,
"blob_id": "bbbfbcbf44486e88adda050916d5459eb3d13f70",
"content_id": "99eac1053f2aab42b5e605234ac6e54cc8e2fd6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6629,
"license_type": "no_license",
"max_line_length": 212,
"num_lines": 155,
"path": "/new_isotopy_fullGame_Filter.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import xygame\nimport overlapData\nimport itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\ndisks = p*q - (p+q)\n\n#Builds general overlapData for all annular disks with these p and q values\noverlapData = []\nfor i in range(p):\n for j in range(q):\n overlapData.append([((i%p,j%q),'l'),(((i)%p,(j-1)%q),'r'),(((i+1)%p,(j)%q),'r')])\n overlapData.append([((i%p,j%q),'r'),(((i-1)%p,(j)%q),'l'),(((i)%p,(j+1)%q),'l')])\n\n#Generate all possible choices of disks\ndiskNumbers = []\nfor i in range(p):\n for j in range(q):\n diskNumbers.append((i,j))\ndiskNumbers.pop(0)\ndiskOptions = list(itertools.combinations(diskNumbers, (disks-1)))\ndiskChoices = []\nfor z in range(len(diskOptions)):\n diskChoices.append(list(diskOptions[z]))\n diskChoices[z].insert(0,(0,0))\n\nnumberOfDiskChoices = len(diskChoices)\n\norientationConfigurations = list(itertools.product([0,1], repeat=disks))\n#In the above configurations: 1 is positive, 0 is negative\n\nfilename = str(p)+\",\"+str(q)+\"_xyResults_New_Isotopy_FullGame_Filtered\"\nfile = open(filename,\"w+\")\n\n#Prune overlapData rows based on sortedDiskNumbers and pairs from each row with a number that is not in sortedDiskNumbers\ndef prune(myOverlapData, diskChoice):\n prunedOverlapData = []\n for overlapDataItem in myOverlapData:\n if diskChoice.count(overlapDataItem[0][0]) > 0:\n prunedOverlapDataItem = []\n for pair in overlapDataItem:\n if diskChoice.count(pair[0]) > 0:\n prunedOverlapDataItem.append(pair)\n prunedOverlapData.append(prunedOverlapDataItem)\n return prunedOverlapData\n\ncount = 0\nconfigurationsCount = 0\ndisksThatWork = []\nfor diskChoice in diskChoices:\n #check that the diskChoice wasn't already added in a transformed version\n alreadyCounted = False\n for i in range(p):\n for j in range(q):\n if i==0 and j==0:\n continue\n else:\n tempList = []\n for m in range(disks):\n temp1 = (diskChoice[m][0]+i)%(p)\n temp2 = (diskChoice[m][1])+j)%(q)\n tempList.append((temp1,temp2))\n tempList = sorted(tempList)\n if disksThatWork.count(tempList) > 0:\n alreadyCounted = True\n break\n if alreadyCounted:\n break\n if alreadyCounted:\n break\n #loop through each orientation configuration\n prunedOverlapData = prune(overlapData, diskChoice)\n configurationsList = []\n for configuration in orientationConfigurations:\n #play the xygame\n tooManyYTest = False\n for overlapDataList in prunedOverlapData:\n xyList = []\n for overlapDataItem in overlapDataList:\n if configuration[diskChoice.index(overlapDataItem[0])] == 1:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"x\")\n else:\n xyList.append(\"y\")\n else:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"y\")\n else:\n xyList.append(\"x\")\n if xyList[0] == \"y\" and xyList.count(\"y\") >= 2:\n tooManyYTest = True\n break\n if tooManyYTest:\n continue\n else:\n #check if the constraints make the orientation config fail\n thisDoesNotWork = False\n matrixForm = [[0 for col in range(q)]for row in range(p)]\n configurationCounter = 0 #Use to track which index in configuration we should be using\n #While placing a 1 (negative) or 2 (positive) into the matrix, check whether any surrounding places in the matrix cause a problem\n for disk in diskChoice:\n newValue = matrixForm[disk[0]][disk[1]] + configuration[configurationCounter] + 1\n matrixForm[disk[0]][disk[1]] = newValue\n if newValue == 2 and (matrixForm[disk[0]][(disk[1]+1)%q]==1 or matrixForm[(disk[0]-1)%p][disk[1]]==1 or matrixForm[(disk[0]-1)%p][(disk[1]-1)%q]==2 or matrixForm[(disk[0]+1)%p][(disk[1]+1)%q]==2):\n thisDoesNotWork = True\n break\n if newValue == 1 and (matrixForm[disk[0]][(disk[1]-1)%q]==2 or matrixForm[(disk[0]+1)%p][disk[1]]==2 or matrixForm[(disk[0]-1)%p][(disk[1]-1)%q]==1 or matrixForm[(disk[0]+1)%p][(disk[1]+1)%q]==1):\n thisDoesNotWork = True\n break\n configurationCounter = configurationCounter + 1\n #If no problems arise above, check to be sure there are no rows of all 1 (negative) or columns of all 2 (positive)\n if not thisDoesNotWork:\n for j in range(q):\n positive = False\n if matrixForm[0][j] == 2:\n positive = True\n for i in range(p):\n if matrixForm[i][j]==1 or matrixForm[i][j]==0:\n positive = False\n break\n if positive:\n thisDoesNotWork = True\n break\n for i in range(p):\n negative = False\n if matrixForm[i][0] == 1:\n negative = True\n for j in range(q):\n if matrixForm[i][j]==2 or matrixForm[i][j]==0:\n negative = False\n break\n if negative:\n thisDoesNotWork = True\n break\n #If no problems arise above, all this configuration to the list of configurations that work for this diskchoice\n if not thisDoesNotWork:\n disksThatWork.append(diskChoice)\n configurationsList.append(configuration)\n configurationsCount = configurationsCount + 1\n if len(configurationsList) > 0:\n file.write(\"Disk Choice: \" + str(diskChoice)+ \"\\n\")\n for workingConfiguration in configurationsList:\n file.write(str(workingConfiguration)+ \"\\n\")\n count = count + 1\n file.write(\"\\n\")\nfile.write(\"There are \" + str(count)+ \" disk choices that produce \" + str(configurationsCount) + \" possible configurations.\")\nfile.close()\n\nprint(\"Runtime: \" + str(datetime.now()-startTime))"
},
{
"alpha_fraction": 0.58275306224823,
"alphanum_fraction": 0.5886448621749878,
"avg_line_length": 29.129032135009766,
"blob_id": "91d7b79444be15c68127dc4982c8536edb10605a",
"content_id": "58bb052e470f1ab70813dbbcabb47fe7ea66f4cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1867,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 62,
"path": "/filter.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\n#Read file\ndef readxyFile(filename):\n text_file = open(filename, \"r\")\n lineData = text_file.read().splitlines()\n lines = lineData[:len(lineData)-1]\n text_file.close()\n allDiskChoices = []\n for line in lines:\n fullLine = eval(line)\n allDiskChoices.append(fullLine[0])\n return allDiskChoices\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\ndisks = p*q - (p+q)\n\n#Use the method above to read the file\nfileName = \"\" + str(p)+\",\"+str(q)+\"_xyResults_New_Isotopy_After_Constraints\"\ndiskChoices = readxyFile(fileName)\n\nprint(\"Original # of diskChoices: \" + str(len(diskChoices)))\n\n#Create a new file to store the new xyResults\nnewFilename = str(p)+\",\"+str(q)+\"_xyResults_New_Isotopy_After_Constraints_and_Filtered\"\nfile = open(newFilename,\"w+\")\n\ndisksThatWork = []\nfor diskChoice in diskChoices:\n alreadyCounted = False\n for i in range(p):\n for j in range(q):\n if i==0 and j==0:\n continue\n else:\n tempList = []\n for m in range(disks):\n temp1 = (int(diskChoice[m][0])+i)%(p)\n temp2 = (int(diskChoice[m][1])+j)%(q)\n tempList.append((temp1,temp2))\n tempList = sorted(tempList)\n if disksThatWork.count(tempList) > 0:\n alreadyCounted = True\n break\n if alreadyCounted:\n break\n else:\n disksThatWork.append(diskChoice)\n\nfor item in disksThatWork:\n file.write(str(item)+ \"\\n\")\nfile.write(\"New # of diskChoices: \" + str(len(disksThatWork)))\nfile.close()\nprint(\"New # of diskChoices: \" + str(len(disksThatWork)))\n\nprint(\"Runtime: \" + str(datetime.now()-startTime))"
},
{
"alpha_fraction": 0.6013916730880737,
"alphanum_fraction": 0.6170477271080017,
"avg_line_length": 34.57522201538086,
"blob_id": "d2a53c3f836a8145a0405807a40444ba85ac9b08",
"content_id": "b3a656d8629613a48b916b0bc9abc1efa35ae29f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4024,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 113,
"path": "/originalIsotopyXYGame.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import xygame\nimport overlapData\nimport itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\n\n#Builds general overlapData for all annular disks with these p and q values\noverlapData = []\ndiskNumbers = []\nfor i in range(p):\n for j in range(q):\n overlapData.append([((i%p,j%q),'l'),(((i+1)%p,j%q),'r'),((i%p,(j-1)%q),'r')])\n overlapData.append([((i%p,j%q),'r'),(((i-1)%p,(j-1)%q),'r'),(((i-1)%p,j%q),'l'),(((i)%p,(j+1)%q),'l'),(((i+1)%p,(j+1)%q),'r')])\n\n#Gets more info from user\ndisks = int(input(\"How many disks will you use? \"))\nwhile disks > p*q:\n disks = int(input(\"How many disks will you use? \"))\ndiskNumbers = []\nfor i in range(int(disks)):\n m = input(\"Enter disk number in form 'i,j': \")\n mList = m.split(',')\n iTH = int(mList[0])\n jTH = int(mList[1])\n while iTH < 0 or iTH > p-1 or jTH < 0 or jTH > q-1 or diskNumbers.count((iTH,jTH)) > 0:\n if iTH < 0 or iTH > p-1 or jTH < 0 or jTH > q-1:\n m = input(\"Error, one of those is not possible. Choose a new disk: \")\n mList = m.split(',')\n iTH = int(mList[0])\n jTH = int(mList[1])\n if diskNumbers.count((iTH,jTH)) > 0:\n m = input(\"You have already added that disk, choose a new one: \")\n mList = m.split(',')\n iTH = int(mList[0])\n jTH = int(mList[1])\n diskNumbers.append((iTH,jTH))\n#You can comment out the above, if you wish to supply the diskNumbers in a list like below\n #diskNumbers = [1,2,3,12,9,10,11,13,15,17,19]\n #disks = len(diskNumbers)\n\n#Sort diskNumbers for easy viewing\nsortedDiskNumbers = sorted(diskNumbers)\nprint(sortedDiskNumbers)\n\n# for i in overlapData:\n# print(i)\n# print(\"There are: \" + str(len(overlapData)))\n\n#Prune overlapData rows based on sortedDiskNumbers and pairs from each row with a number that is not in sortedDiskNumbers\nitemCount = 0\nwhile itemCount < len(overlapData):\n if sortedDiskNumbers.count(overlapData[itemCount][0][0]) <= 0:\n overlapData.remove(overlapData[itemCount])\n itemCount = itemCount - 1\n else:\n pairCount = 0\n while pairCount < len(overlapData[itemCount]):\n if sortedDiskNumbers.count(overlapData[itemCount][pairCount][0]) <= 0:\n overlapData[itemCount].remove(overlapData[itemCount][pairCount])\n pairCount = pairCount - 1\n pairCount = pairCount + 1\n itemCount = itemCount + 1\n\n\n\norientationConfigurations = list(itertools.product([0,1], repeat=disks))\n#In the above configurations: 1 is positive, 0 is negative\n\n#If we are going to be reading overlapData from a .dat file use the below\n #overlapData = overlapData.OverlapData(\"allOverlap.dat\", sortedDiskNumbers)\n #overlapDataForDiskChoices = overlapData.findOverlapDataForDiskChoices()\n\nprint(\"Overlap Data: \" + str(overlapData))\nprint()\n\nprint(\"Configurations that work: \")\nconfigurationsList = []\nfor configuration in orientationConfigurations:\n\n tooManyYTest = False\n for overlapDataList in overlapData:\n xyList = []\n for overlapDataItem in overlapDataList:\n if configuration[sortedDiskNumbers.index(overlapDataItem[0])] == 1:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"x\")\n else:\n xyList.append(\"y\")\n else:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"y\")\n else:\n xyList.append(\"x\")\n if xyList[0] == \"y\" and xyList.count(\"y\") >= 2:\n tooManyYTest = True\n break\n if tooManyYTest:\n continue\n else:\n configurationsList.append(configuration)\n\n\nfor workingConfiguration in configurationsList:\n print(\"Configuration: \" + str(workingConfiguration))\nprint(\"Number of working configuration: \" + str(len(configurationsList)))\n\nprint(\"Runtime: \" + str(datetime.now()-startTime))\n\n\n\n "
},
{
"alpha_fraction": 0.5988242030143738,
"alphanum_fraction": 0.6024636030197144,
"avg_line_length": 39.602272033691406,
"blob_id": "fec61485775de2ecdb3a7f7151154593ab2dd622",
"content_id": "da57dc9348733d5d49bcc8dd447f2a5b303014de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3572,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 88,
"path": "/xygame.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import itertools\n\nclass XYGame:\n\n def __init__(self, p, q, overlapData, numberOfDisks, diskChoices, orientationConfigurations):\n self.p = int(p)\n self.q = int(q)\n self.overlapData = overlapData\n self.numberOfDisks = numberOfDisks\n self.diskChoices = diskChoices\n self.orientationConfigurations = orientationConfigurations\n\n #This function is not currently used since a list is being passed in instead of a .dat file\n #Read overlap data from file\n def readOverlapFile(self, overlapData):\n text_file = open(overlapData, \"r\")\n lines = text_file.read().splitlines()\n text_file.close()\n overlapData = []\n for line in lines:\n overlapItems = []\n items = line.split(',')\n for i in range(len(items)):\n if i % 2 == 0:\n overlapItems.append((int(items[i]), str(items[i+1])))\n overlapData.append(overlapItems)\n return overlapData\n\n #Tests one configuration to see if it works\n def singleConfigurationXY(self, configuration, overlapData):\n xyFullList = []\n tooManyYTest = False\n for overlapDataList in overlapData:\n xyList = []\n for overlapDataItem in overlapDataList:\n #make if for when overlapDataItem[0] % self.p == 0, then the below rules reverse\n if configuration[self.diskChoices.index(overlapDataItem[0])] == 1:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"x\")\n else:\n xyList.append(\"y\")\n else:\n if overlapDataItem[1] == \"l\":\n xyList.append(\"y\")\n else:\n xyList.append(\"x\")\n if xyList[0] == \"y\" and xyList.count(\"y\") >= 2:\n tooManyYTest = True\n break\n xyFullList.append(xyList)\n if tooManyYTest:\n return None\n return xyFullList\n\n #Loop through all configurations to test using singleConfigurationXY function\n def allConfigurationsXY(self, configurations, overlapData):\n configurationPairingList = []\n for configuration in configurations:\n xyList = self.singleConfigurationXY(configuration, overlapData)\n if xyList == None:\n continue\n else:\n configurationPairingList.append((configuration, xyList))\n return configurationPairingList\n\n #Print the pairings of configurations that work and the xy list to go with the configuration\n def printAllConfigurationsXY(self, list):\n for item in list:\n print(\"Configuration: \" + str(item[0]) + \", XYList: \" + str(item[1]))\n\n def play(self):\n #A change can be made here if you wish to go back to reading an overlap .dat file\n #overlapData = self.readOverlapFile(self.overlapData)\n overlapData = self.overlapData\n print(\"Overlap Data: \" + str(self.overlapData))\n print()\n\n\n print(\"Configurations that work: \")\n XYList = self.allConfigurationsXY(self.orientationConfigurations, self.overlapData)\n self.printAllConfigurationsXY(XYList)\n print(\"Number of working configuration: \" + str(len(XYList)))\n\n #Play the XYGame, but instead of printing results return the XYList\n def getXYList(self):\n overlapData = self.overlapData\n XYList = self.allConfigurationsXY(self.orientationConfigurations, self.overlapData)\n return XYList"
},
{
"alpha_fraction": 0.5740858316421509,
"alphanum_fraction": 0.5888818502426147,
"avg_line_length": 48.29166793823242,
"blob_id": "0794175e77255bfd52f09a7ff9bfd53db378ca8a",
"content_id": "a98eec25df186d208cddcfc681b7a2d30dc1ccbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4731,
"license_type": "no_license",
"max_line_length": 208,
"num_lines": 96,
"path": "/readxyResults.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nstartTime = datetime.now()\n\n#Read file and build list of allxyResults where each item is a list with the first item being the diskchoice and the following items are configuration configurations\ndef readxyFile(filename):\n text_file = open(filename, \"r\")\n lines = text_file.read().splitlines()\n lines.pop(len(lines)-1)\n text_file.close()\n allxyResults = []\n onexyResult = []\n count = 0\n for line in lines:\n if line == \"\":\n count = count + 1\n allxyResults.append(onexyResult)\n onexyResult = []\n continue\n else:\n if not onexyResult:\n onexyResult.append(eval(line[13:]))\n else:\n onexyResult.append(eval(line))\n return allxyResults\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\ndisks = p*q - (p+q)\n\n#Use the method above to read the file\nfilename = \"\" + str(p)+\",\"+str(q)+\"_xyResults_New_Isotopy\"\nxyResults = readxyFile(filename)\n\n#Create a new file to store the new xyResults\nnewFilename = str(p)+\",\"+str(q)+\"_xyResults_New_Isotopy_After_Constraints\"\nfile = open(newFilename,\"w+\")\n\n\nxyResultCount = 0 #Use to track how many diskChoices still have configurations that could work\nconfigurationsCount = 0 #Use to track how many total possible configurations there are\n#Loop through each diskchoice and its configurations\nfor xyResult in xyResults:\n configurationsList = [] #This will keep all configurations that could still work for this disk choice\n for configuration in xyResult[1:]:\n thisDoesNotWork = False\n matrixForm = [[0 for col in range(q)]for row in range(p)]\n configurationCounter = 0 #Use to track which index in configuration we should be using\n #While placing a 1 (negative) or 2 (positive) into the matrix, check whether any surrounding places in the matrix cause a problem\n for disk in xyResult[0]:\n newValue = matrixForm[disk[0]][disk[1]] + configuration[configurationCounter] + 1\n matrixForm[disk[0]][disk[1]] = newValue\n if newValue == 2 and (matrixForm[disk[0]][(disk[1]+1)%q]==1 or matrixForm[(disk[0]-1)%p][disk[1]]==1 or matrixForm[(disk[0]-1)%p][(disk[1]-1)%q]==2 or matrixForm[(disk[0]+1)%p][(disk[1]+1)%q]==2):\n thisDoesNotWork = True\n break\n if newValue == 1 and (matrixForm[disk[0]][(disk[1]-1)%q]==2 or matrixForm[(disk[0]+1)%p][disk[1]]==2 or matrixForm[(disk[0]-1)%p][(disk[1]-1)%q]==1 or matrixForm[(disk[0]+1)%p][(disk[1]+1)%q]==1):\n thisDoesNotWork = True\n break\n configurationCounter = configurationCounter + 1\n #If no problems arise above, check to be sure there are no rows of all 1 (negative) or columns of all 2 (positive)\n if not thisDoesNotWork:\n for j in range(q):\n positive = False\n if matrixForm[0][j] == 2:\n positive = True\n for i in range(p):\n if matrixForm[i][j]==1 or matrixForm[i][j]==0:\n positive = False\n break\n if positive:\n thisDoesNotWork = True\n break\n for i in range(p):\n negative = False\n if matrixForm[i][0] == 1:\n negative = True\n for j in range(q):\n if matrixForm[i][j]==2 or matrixForm[i][j]==0:\n negative = False\n break\n if negative:\n thisDoesNotWork = True\n break\n #If no problems arise above, all this configuration to the list of configurations that work for this diskchoice\n if not thisDoesNotWork:\n configurationsList.append(configuration)\n configurationsCount = configurationsCount + 1\n #If there are configurations that pass all tests for this diskchoice, write to the file the disk choice followed by all possible configurations that are remaining\n if configurationsList:\n file.write(str(xyResult[0]) + \",\" + str(configurationsList) + \"\\n\")\n xyResultCount = xyResultCount + 1\nfile.write(\"There are \" + str(xyResultCount) + \" disk choices that produce \" + str(configurationsCount) + \" possible configurations.\")\nfile.close()\nprint(\"There are \" + str(xyResultCount) + \" disk choices that produce \" + str(configurationsCount) + \" possible configurations.\")\nprint(\"Runtime: \" + str(datetime.now()-startTime))"
},
{
"alpha_fraction": 0.4939005374908447,
"alphanum_fraction": 0.5060994625091553,
"avg_line_length": 26.101694107055664,
"blob_id": "a52a8be713b4a2c3cd8f7c7be7146ae53899d08a",
"content_id": "103e720d925a19eacad3ed295fe1b7698194514b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3197,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 118,
"path": "/combinations.py",
"repo_name": "amanda7641/disks",
"src_encoding": "UTF-8",
"text": "import itertools\n\nfrom datetime import datetime\nstartTime = datetime.now()\n\np = input(\"What is your P value: \")\nq = input(\"What is your Q value: \")\np = int(p)\nq = int(q)\ndisks = p*q - (p+q)\n\ndiskOptions = range(p*q)\n\ndef combinations(iterable, r):\n # combinations('ABCD', 2) --> AB AC AD BC BD CD\n # combinations(range(4), 3) --> 012 013 023 123\n pool = tuple(iterable)\n n = len(pool)\n if r > n:\n return\n indices = list(range(r))\n yield tuple(pool[i] for i in indices)\n while True:\n for i in reversed(range(r)):\n if indices[i] != i + n - r:\n break\n else:\n return\n indices[i] += 1\n for j in range(i+1, r):\n indices[j] = indices[j-1] + 1\n yield tuple(pool[i] for i in indices)\n\n# diskChoices = combinations(diskOptions,disks)\n# for i in diskChoices:\n# print(i)\n\ndiskNumbers = []\nfor i in range(p):\n for j in range(q):\n diskNumbers.append((i,j))\nprint(diskNumbers)\ndiskChoices = list(itertools.combinations(range(p*q), disks))\nnumberOfDiskChoices = len(diskChoices)\nprint(\"Original # of diskChoices: \" + str(numberOfDiskChoices))\n\ncount = 0\nwhile count < len(diskChoices)-(p*q)+2:\n whereWShouldStart = count+1\n for l in range(1, len(diskNumbers)):\n tempList = []\n for m in range(disks):\n temp = (diskChoices[count][m]+l)%(p*q)\n tempList.append(temp)\n tempList = sorted(tempList)\n n = whereWShouldStart\n if n >= len(diskChoices):\n n = count+1\n for s in range((len(diskChoices)-count)):\n match = True\n r=0\n while r < len(tempList):\n if diskChoices[n][r] == tempList[r]:\n r = r+1\n continue\n else:\n match = False\n r = r+1\n if match: \n diskChoices.pop(n)\n whereWShouldStart=n#\n break\n n = n+1\n if n >= len(diskChoices):\n n = count+1\n count = count+1\n\n# count = 0\n# while count < len(diskChoices)-(p*q)+2:\n# for l in range(1, len(diskNumbers)):\n# tempList = []\n# for m in range(disks):\n# temp = (diskChoices[count][m]+l)%(p*q)\n# tempList.append(temp)\n# tempList = sorted(tempList)\n# n=count+1\n# while n < len(diskChoices):\n# match = True\n# r=0\n# while r < len(tempList):\n# if diskChoices[n][r] == tempList[r]:\n# r = r+1\n# continue\n# else:\n# match = False\n# r = r+1\n# if match: \n# diskChoices.pop(n)\n# break\n# n = n+1\n# count = count+1\n\n\n\nfor a in range(len(diskChoices)):\n tempList = []\n for b in range(disks):\n tempPair = diskNumbers[diskChoices[a][b]]\n tempList.append(tempPair)\n diskChoices[a]=tempList\n \n\n\n# for item in diskChoices:\n# print(item)\nprint(\"New # of diskChoices: \" + str(len(diskChoices)))\n\nprint(\"Runtime: \" + str(datetime.now()-startTime))"
}
] | 8 |
prajwalkm/insta_Ecommerce
|
https://github.com/prajwalkm/insta_Ecommerce
|
580b22982ca768dc9ee3d09e58a3d664ebcd6e52
|
9d321d1219fd82c7de81e93fbf7800dcd6fb0ef0
|
dbede606d3f45485b33c4e2dbaee1ad00aa822f2
|
refs/heads/master
| 2020-06-29T05:18:59.086813 | 2016-11-22T08:05:55 | 2016-11-22T08:05:55 | 74,447,320 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5309734344482422,
"alphanum_fraction": 0.7079645991325378,
"avg_line_length": 16.384614944458008,
"blob_id": "0947236ae67840672970ff09f1e87798ca560c7f",
"content_id": "715025f345e239e27dde5c4f8a71abf319f3e101",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 226,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "prajwalkm/insta_Ecommerce",
"src_encoding": "UTF-8",
"text": "cffi==1.7.0\ncryptography==1.4\nDjango==1.8.4\ndjango-crispy-forms==1.6.0\ndjango-registration-redux==1.4\nidna==2.1\nndg-httpsclient==0.4.1\nPillow==3.3.0\npyasn1==0.1.9\npycparser==2.14\npyOpenSSL==16.0.0\nrequests==2.10.0\nsix==1.10.0\n"
},
{
"alpha_fraction": 0.7032213807106018,
"alphanum_fraction": 0.7066484093666077,
"avg_line_length": 23.09917449951172,
"blob_id": "f5a36d84f88a90eec7f47a323230ff38bc3a63c1",
"content_id": "c67d3443cef792968642933efc70aae38075646e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5836,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 242,
"path": "/carts/views.py",
"repo_name": "prajwalkm/insta_Ecommerce",
"src_encoding": "UTF-8",
"text": "\nfrom django.http import HttpResponseRedirect,Http404, JsonResponse\nfrom django.shortcuts import render,get_object_or_404,redirect\n\nfrom django.core.urlresolvers import reverse\n\nfrom django.contrib.auth.forms import AuthenticationForm\n\nfrom django.views.generic.base import View\nfrom django.views.generic.detail import SingleObjectMixin,DetailView\nfrom django.views.generic.edit import FormMixin\n\nfrom products.models import variation\nfrom carts.models import Cart,CartItem\n\nfrom orders.forms import GuestCheckoutForm\nfrom orders.models import UserCheckout,Order,UserAddress\n\nfrom orders.mixins import CartOrderMixin\n\n\n# Create your views here.\n\n\nclass ItemCountView(View):\n\n\n\tdef get(self,request,*args,**kwargs):\n\n\t\tif request.is_ajax:\n\t\t\tcart_id=self.request.session.get(\"cart_id\")\n\t\t\tif cart_id==None:\n\t\t\t\tcount= 0\n\t\t\telse:\n\t\t\t\tcart=Cart.objects.get(id=cart_id)\n\t\t\t\tcount=cart.items.count()\n\t\t\trequest.session[\"cart_item_count\"]=count\n\n\t\t\treturn JsonResponse({\"count\":count})\n\t\telse:\n\t\t\traise Http404\n\n\n\n\nclass cartview(SingleObjectMixin,View):\n\tmodel = Cart\n\ttemplate_name=\"carts/view.html\"\n\tdef get_object(self,*args,**kwargs):\n\t\tself.request.session.set_expiry(0)\n\t\tcart_id=self.request.session.get(\"cart_id\")\n\t\tif cart_id == None:\n\t\t\tcart = Cart()\n\t\t\tcart.save()\n\t\t\tcart_id = cart.id\n\t\t\tself.request.session[\"cart_id\"] = cart_id\n\n\t\tcart=Cart.objects.get(id=cart_id)\n\n\t\tif self.request.user.is_authenticated():\n\t\t\tcart.user=self.request.user\n\t\t\tcart.save()\n\t\treturn cart \n\n\tdef get(self,request,*args,**kwargs):\n\t\tcart=self.get_object()\n\t\t\n\n\t\titem_id=request.GET.get(\"item\")\n\t\tdelete_item=request.GET.get(\"delete\",False)\n\t\tif item_id:\n\t\t\titem_instance=get_object_or_404(variation,id=item_id)\n\t\t\tqty=request.GET.get(\"qty\",1)\n\t\t\tflash_message=\"\"\n\t\t\titem_added=False\n\t\t\ttry:\n\t\t\t\tif int(qty)<1:\n\t\t\t\t\tdelete_item=True\n\t\t\texcept:\n\t\t\t\traise Http404\n\t\t\t\n\t\t\tcart_item,created=CartItem.objects.get_or_create(cart=cart,item=item_instance)\n\t\t\t\n\t\t\tif created:\n\t\t\t\titem_added=True\n\t\t\t\tflash_message=\"Product sucessfully added !!\"\n\t\t\tif delete_item:\n\t\t\t\tflash_message=\"Item removed sucessfully\"\n\t\t\t\tcart_item.delete()\n\t\t\telse:\n\t\t\t\tif not created:\n\t\t\t\t\tflash_message=\"quantity has been updated sucessfully\"\n\t\t\t\tcart_item.quantity=qty\n\t\t\t\tcart_item.save()\n\t\t\tif not request.is_ajax():\n\t\t\t\treturn HttpResponseRedirect(reverse(\"carts\"))\n\t\tif request.is_ajax():\n\t\t\ttry:\n\t\t\t\ttotal=cart_item.line_item_total\n\t\t\texcept:\n\t\t\t\ttotal=None\n\t\t\ttry:\n\t\t\t\tsubtotal=cart_item.cart.subtotal\n\t\t\texcept:\n\t\t\t\tsubtotal=None\n\t\t\ttry:\n\t\t\t\ttotal_items=cart_item.cart.items.count()\n\t\t\texcept:\n\t\t\t\ttotal_items=0\n\n\t\t\ttry:\n\t\t\t\ttaxtotal=cart_item.cart.taxtotal\n\t\t\texcept:\n\t\t\t\ttaxtotal=None\n\t\t\ttry:\n\t\t\t\ttotal=cart_item.cart.total\n\t\t\texcept:\n\t\t\t\ttotal=None\n\n\n\t\t\tdata={\n\t\t\t\t\"deleted\":delete_item,\n\t\t\t\t\"item_added\":item_added,\n\t\t\t\t\"line_total\": total,\n\t\t\t\t\"subtotal\":subtotal,\n\t\t\t\t\"flash_message\":flash_message,\n\t\t\t\t\"total_items\":total_items,\n\t\t\t\t\"taxtotal\":taxtotal,\n\t\t\t\t\"total\":total\n\t\t\t\t}\n\n\t\t\treturn JsonResponse(data)\t\n\n\t\tcontext={\n\t\t\t\t\"object\": self.get_object()\n\n\t\t}\n\t\ttemplate=self.template_name\n\t\treturn render(request,template,context)\n\n\n\nclass CheckoutView(CartOrderMixin,FormMixin,DetailView):\n\tmodel=Cart\n\ttemplate_name=\"carts/checkout_view.html\"\n\tform_class=GuestCheckoutForm\n\n\n\tdef get_object(self,*args,**kwargs):\n\t\tcart=self.get_cart()\n\t\tif cart == None:\n\t\t\treturn None\n\t\treturn cart \n\n\tdef get_context_data(self,*args,**kwargs):\n\t\tcontext=super(CheckoutView,self).get_context_data(*args,**kwargs)\n\n\t\t#cart=self.get_object()\n \n\t\tuser_can_continue=False\n\t\tuser_check_id=self.request.session.get('user_checkout_id')\n\t\t\n\t\t# if not self.request.user.is_authenticated() or user_check_id==None:\n\t\t# \tcontext['login_form']=AuthenticationForm()\n\t\t# \tcontext['next_url']=self.request.build_absolute_uri()\n\t\t# elif self.request.user.is_authenticated() or user_check_id!=None:\n\t\t# \tuser_can_continue=True\n\t\t# else:\n\t\t# \tpass\n\t\tif self.request.user.is_authenticated():\n\t\t\tuser_can_continue=True\n\t\t\tuser_checkout,created=UserCheckout.objects.get_or_create(email=self.request.user.email)\n\t\t\tuser_checkout.user=self.request.user\n\t\t\tuser_checkout.save()\n\t\t\tself.request.session['user_checkout_id']=user_checkout.id\n\n\t\telif not self.request.user.is_authenticated() and user_check_id==None:\n\t\t\tcontext['login_form']=AuthenticationForm()\n\t\t\tcontext['next_url']=self.request.build_absolute_uri()\n\t\telse:\n\t\t\tpass\n\n\t\tif user_check_id!=None:\n\t\t\tuser_can_continue=True\n\n\n\n\n\n\n\n\n\t\tcontext['order']=self.get_order()\n\t\tcontext['user_can_continue']=user_can_continue\n\t\tcontext['form']=self.get_form()\t\n\t\treturn context\n\n\tdef post(self,request,*args,**kwargs):\n\t\tself.object=self.get_object()\n\t\tform=self.get_form()\n\t\tif form.is_valid():\n\t\t\temail = (form.cleaned_data.get('email'))\n\t\t\tuser_checkout,created=UserCheckout.objects.get_or_create(email=email)\n\t\t\trequest.session['user_checkout_id']=user_checkout.id\n\t\t\treturn self.form_valid(form)\n\t\telse:\n\t\t\treturn self.form_invalid(form)\n\n\tdef get_success_url(self):\n\t\treturn reverse('checkout')\n\n\tdef get(self,request,*args,**kwargs):\n\t\tget_data=super(CheckoutView,self).get(request,*args,**kwargs)\n\t\tcart=self.get_object() \n\t\tif cart==None:\n\t\t\treturn redirect(\"carts\")\n\t\tnew_order=self.get_order()\n\t\tuser_checkout_id=request.session.get(\"user_checkout_id\")\n\t\tif user_checkout_id !=None:\n\t\t\tuser_checkout =UserCheckout.objects.get(id=user_checkout_id)\n\t\t\tif new_order.billing_address==None or new_order.shipping_address==None:\n\t\t\t \treturn redirect(\"order_address\")\n\t\t\n\t\t\t\n\t\t\tnew_order.user=user_checkout\n\t\t\tnew_order.save()\n\n\n\t\treturn get_data\n\n\n \n\n\nclass CheckoutFinalView(CartOrderMixin,View):\n\tdef post(self,request,*args,**kwargs):\n\t\torder=self.get_order()\n\t\tif (request.POST.get(\"payment_token\"))==\"ABC\":\n\t\t\tprint(order.cart.items.all())\n\t\treturn redirect(\"checkout\")\n\n\tdef get(self,request,*args,**kwargs):\n\t\treturn redirect(\"checkout\")\n\n\n\n"
}
] | 2 |
newtfrank/Twitter-Streaming-
|
https://github.com/newtfrank/Twitter-Streaming-
|
ea8e8ba98ecf4fad9fe9454b47c283129e100d00
|
e0bce770ba266b20b1d91e0fabb38785bba976c4
|
1a6acf9d95cedf6e6f6c6121214c91da44483366
|
refs/heads/master
| 2020-03-22T18:02:49.225401 | 2018-07-19T19:10:15 | 2018-07-19T19:10:15 | 134,836,180 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7126436829566956,
"alphanum_fraction": 0.7126436829566956,
"avg_line_length": 33.79999923706055,
"blob_id": "4dd74c98f0d801cfcb7ae87655d13e7ab19468a5",
"content_id": "6d885f3f81583e0fc13e3a692deac0b875460641",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 5,
"path": "/twitter_credentials.py",
"repo_name": "newtfrank/Twitter-Streaming-",
"src_encoding": "UTF-8",
"text": "# variables that contain the user credentials to access the twitter API\nACCESS_TOKEN = \"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\"\nACCESS_TOKEN_SECRET = \"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\"\nCONSUMER_KEY = \"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\"\nCONSUMER_SECRET = \"xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\"\n"
},
{
"alpha_fraction": 0.6605806350708008,
"alphanum_fraction": 0.6626758575439453,
"avg_line_length": 33.03061294555664,
"blob_id": "9b2becb24d7d01a8828ab7b2221b57ea52dc6ec4",
"content_id": "a510c763cd564cf1e21c0feb8372cc7bb280e395",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3341,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 98,
"path": "/tweepy_streamer.py",
"repo_name": "newtfrank/Twitter-Streaming-",
"src_encoding": "UTF-8",
"text": "from tweepy import API\nfrom tweepy import Cursor\nfrom tweepy.streaming import StreamListener\nfrom tweepy import OAuthHandler\nfrom tweepy import Stream\n\nimport json\nimport twitter_credentials\n\n\n# class for authentication\nclass Twitter_Authenticator():\n\n def authenticate_twitter_app(self):\n auth = OAuthHandler(twitter_credentials.CONSUMER_KEY, twitter_credentials.CONSUMER_SECRET)\n auth.set_access_token(twitter_credentials.ACCESS_TOKEN, twitter_credentials.ACCESS_TOKEN_SECRET)\n return auth\n\n\n####### Twitter Client ######\nclass TwitterClient():\n def __init__ (self, twitter_user=None):\n self.auth = Twitter_Authenticator().authenticate_twitter_app()\n self.twitter_client = API(self.auth)\n\n self.twitter_user = twitter_user\n\n def get_user_timeline_tweets(self, num_tweets):\n tweets = []\n for tweet in Cursor(self.twitter_client.user_timeline, id=self.twitter_user).items(num_tweets):\n tweets.append(tweet)\n return tweets\n\n def get_friend_list(self, num_friends):\n friend_list = []\n for friend in Cursor(self.twitter_client.friends, id=self.twitter_user).items(num_friends):\n friend_list.append(friend)\n return friend_list\n\n def get_home_timeline_tweets(self, num_tweets):\n home_timeline_tweets = []\n for tweet in Cursor(self.twitter_client.home_timeline, id=self.twitter_user).items(num_tweets):\n home_timeline_tweets.append(tweet)\n return home_timeline_tweets\n\n\n\nclass TwitterStreamer():\n # class for streaming and process live tweets\n def __init__(self):\n self.twitter_authenticator = Twitter_Authenticator()\n\n def stream_tweets(self, fetched_tweets_filename, hash_tag_list):\n #handles twitter authentication and the connection to the twitter steaming API\n listener = Twitter_Listener(fetched_tweets_filename)\n auth = self.twitter_authenticator.authenticate_twitter_app()\n stream = Stream(auth, listener)\n\n stream.filter(track=hash_tag_list)\n\nclass Twitter_Listener(StreamListener):\n # basic listener class that prints received tweets \n def __init__(self, fetched_tweets_filename):\n self.fetched_tweets_filename = fetched_tweets_filename\n\n def on_data(self,data):\n try:\n print(data)\n\n #with open('tweets.txt', 'w') as tweet_data:\n # json.dumps(data, tweet_data, ensure_ascii=False)\n \n with open(self.fetched_tweets_filename, 'a') as tf:\n tf.write(data)\n return True\n except BaseException as e:\n print(\"Error on data: %s\" % str(e))\n return True\n\n \n def on_error(self, status):\n if status == 420:\n # Returning False on_data method in case rate limit occurs\n return False\n print(status)\n\n\n\nif __name__ == \"__main__\":\n hash_tag_list = ['Product', 'Smartphone', 'Jumia Travel', 'Appliances']\n fetched_tweets_filename = 'tweets.json'\n\n twitter_client = TwitterClient('Jumia')\n print(twitter_client.get_user_timeline_tweets(5))\n #print(twitter_client.get_friend_list(10))\n #print(twitter_client.get_home_timeline_tweets(5))\n # twitter_streamer = TwitterStreamer()\n #TwitterStreamer.stream_tweets(fetched_tweets_filename, hash_tag_list)\n \n\n"
}
] | 2 |
jamieapps101/Bio-Mech-Assignment
|
https://github.com/jamieapps101/Bio-Mech-Assignment
|
10aa017bbd8bedb50e13f308dc90fcc03f2eca65
|
ab6583ec728627c7b67e4c15e8a96b1bf75c36e7
|
3b3f9d2e713c974a9a543ff0d0d0aaebb87a6dfe
|
refs/heads/master
| 2020-05-03T02:27:15.924399 | 2019-05-14T18:46:43 | 2019-05-14T18:46:43 | 178,369,905 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5164514183998108,
"alphanum_fraction": 0.5219864845275879,
"avg_line_length": 39.14814758300781,
"blob_id": "1b43c05318599eb54ae90c3787d8cd4f3204acb5",
"content_id": "3798f4d07a8bf80205dee3cf38034c9e4d7ff3bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6504,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 162,
"path": "/src/leapInterfaces2.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport sys, thread, time\n\nimport threading\n\nimport sys\nsys.path.insert(0, \"../lib\")\nimport Leap\nimport math\nimport numpy as np\nimport Queue\nimport warnings\nimport os\nimport csv\n\n\nclass SampleListener(Leap.Listener):\n finger_names = ['Thumb', 'Index', 'Middle', 'Ring', 'Pinky']\n bone_names = ['Metacarpal', 'Proximal', 'Intermediate', 'Distal']\n state_names = ['STATE_INVALID', 'STATE_START', 'STATE_UPDATE', 'STATE_END']\n\n def __init__(self, lockVariable, q):\n super(SampleListener,self).__init__()\n self.internalLockVariable = lockVariable\n self.internalQueue = q\n self.filename = \"trainingData/leapOutput.csv\"\n with open(self.filename, \"w+\") as outputFile:\n writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n dataLabels = []\n #for a in range(8):\n dataLabels.append(\"time\")\n\n finger_names = ['Thumb', 'Index', 'Middle', 'Ring', 'Pinky']\n #bone_names = ['Metacarpal', 'Proximal', 'Intermediate', 'Distal']\n bone_names = ['Proximal', 'Intermediate', 'Distal'] # 3 angles are calculated, which are considered to be at the bases of each bone\n for a in finger_names:\n for b in bone_names:\n dataLabels.append(a+\"_\"+b)\n writer.writerow(dataLabels)\n\n def on_init(self, controller):\n print(\"Initialized\")\n\n def on_connect(self, controller):\n print(\"Connected\")\n\n # Enable gestures\n controller.enable_gesture(Leap.Gesture.TYPE_CIRCLE);\n controller.enable_gesture(Leap.Gesture.TYPE_KEY_TAP);\n controller.enable_gesture(Leap.Gesture.TYPE_SCREEN_TAP);\n controller.enable_gesture(Leap.Gesture.TYPE_SWIPE);\n\n def on_disconnect(self, controller):\n # Note: not dispatched when running in a debugger.\n print(\"Disconnected\")\n\n def on_exit(self, controller):\n print(\"Exited\")\n\n\n def getAngle(self,a,b):\n #print(\"a: {}\".format(a))\n #print(\"b: {}\".format(b))\n aDotb = 0\n magProd = 0\n g = 0\n angle = 0\n try:\n aDotb = np.dot(a,b)\n #print(\"aDotb {}\".format(aDotb))\n magProd = (np.linalg.norm(a)*np.linalg.norm(b))\n #print(\"magProd {}\".format(magProd))\n g = aDotb/magProd # G\n angle = np.arccos(g)*(180.0/3.14) # getAngle\n angle = angle.reshape((1,1))\n except RuntimeWarning:\n print(\"aDotb {}\".format(aDotb))\n print(\"magProd {}\".format(magProd))\n print(\"g {}\".format(g))\n print(\"angle {}\".format(angle))\n return angle\n\n\n def on_frame(self, controller):\n # Get the most recent frame and report some basic information\n print(\"leap running\")\n frame = controller.frame()\n if (len(frame.hands) == 0):\n pass\n elif (len(frame.hands) > 1):\n print(\"There are too many hands in the frame\")\n else:\n for hand in frame.hands: # for each hand, should only have one entry by this point\n handAngles = None\n for finger in hand.fingers: # for each finger\n boneDirections = np.array([0])\n for boneIndex in range(0,4): # for each bone in each finger\n bone = finger.bone(boneIndex)\n start = np.array(bone.prev_joint.to_float_array()).reshape((1,3))\n end = np.array(bone.next_joint.to_float_array()).reshape((1,3))\n boneVector = end-start\n try:\n boneDirections = np.concatenate((boneDirections,boneVector),axis=0)\n except ValueError:\n boneDirections = boneVector\n fingerJointAngles = np.array([])\n for joint in range(len(boneDirections)-1): # for each joint in each finger\n try:\n angle = self.getAngle(boneDirections[joint,:],boneDirections[joint+1,:]) # get a joint angle\n except ValueError:\n print(\"Value Error boneDirections: {}\".format(boneDirections))\n except IndexError:\n print(\"Index Error boneDirections: {}\".format(boneDirections))\n\n try: # append it to joint angle record\n fingerJointAngles = np.concatenate((fingerJointAngles,angle),axis=1)\n except ValueError:\n fingerJointAngles = angle\n try: # for each finger, append joint data to hand angles variable\n handAngles = np.concatenate((handAngles,fingerJointAngles),axis=0)\n except ValueError:\n handAngles = fingerJointAngles\n\n outputData = [int(time.time())*1000]\n outputData = outputData + list(handAngles.flatten())\n with open(self.filename, \"a\") as outputFile:\n writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n writer.writerow(outputData)\n\n # write to file!\n\ndef main():\n # Create a sample listener and controller\n print(\"PID: {}\".format(os.getpid()))\n lock = threading.Lock()\n q = Queue.LifoQueue(maxsize=1)\n listener = SampleListener(lock,q)\n controller = Leap.Controller()\n\n # Have the sample listener receive events from the controller\n controller.add_listener(listener)\n\n # Keep this process running until Enter is pressed\n print(\"Press Enter to quit...\")\n try:\n while True:\n time.sleep(1)\n try:\n data = q.get(block=True)\n print(\"Hand data:\")\n print(data)\n except QueueEmpty:\n pass\n\n except KeyboardInterrupt:\n print(\"time to go to sleep!\")\n finally:\n controller.remove_listener(listener)\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5558739304542542,
"alphanum_fraction": 0.5830945372581482,
"avg_line_length": 14.863636016845703,
"blob_id": "ae6b780b5323653a41bfcc8c570dcfbec368c1ba",
"content_id": "4f88cec99b63a65d6807fd0a50970e3033d3d790",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 44,
"path": "/referenceMaterial/unlimitedHand/testArduinoSketch.ino/testArduinoSketch.ino",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#include \"string.h\"\n\nvoid setup() \n{\n Serial.begin(9600);\n pinMode(13, HIGH);\n}\n\nint counter = 0;\n\nvoid loop() \n{\n Serial.println(++counter);\n delay(1000);\n}\n\nvoid serialEvent()\n{\n delay(10);\n String input = \"\";\n while(Serial.available())\n {\n char inChar = (char)Serial.read();\n if(inChar != '\\n')\n {\n input.concat(inChar);\n //Serial.println(input);\n }\n }\n //Serial.print(input);\n String onString = \"on\";\n String offString = \"off\";\n if(input.compareTo(onString) == 0)\n {\n //Serial.println(\"Turning LED On\");\n digitalWrite(13, HIGH);\n }\n \n if(input.compareTo(offString) == 0)\n {\n //Serial.println(\"Turning LED Off\");\n digitalWrite(13, LOW);\n }\n}\n"
},
{
"alpha_fraction": 0.6198871731758118,
"alphanum_fraction": 0.6386929750442505,
"avg_line_length": 30.511110305786133,
"blob_id": "c61870f2e73bc5e9160e58d1107b703e8320ea59",
"content_id": "2387557ad422bcb0386cd974413ffe0f34eb137d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4254,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 135,
"path": "/src/netTester.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n\nimport argparse\nimport tensorflow as tf\nimport pandas as pd\nimport numpy as np\nfrom scipy import stats\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport time\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--batch_size', default=1000, type=int, help='batch size')\nparser.add_argument('--train_steps', default=1000, type=int,\n help='number of training steps')\n\n\ndef amalgamateData(files=[\"outputLong01.csv\"]):\n totalData = np.array([8])\n for file in files:\n if files.index(file) == 0:\n path = \"trainingData/\" + file\n fileData = pd.read_csv(path)\n totalData = fileData.to_numpy()\n else:\n path = \"trainingData/\" + file\n fileData = pd.read_csv(path)\n tempData = fileData.to_numpy()\n totalData = np.concatenate((totalData,tempData),axis=0)# ie going down\n\n np.random.shuffle(totalData)\n x = totalData[:,:8]\n y = totalData[:,8:]\n #y = totalData[:,9:] # bc lower joint of thumb (ie first entry) has value nan\n return x,y\n\ndef processData(x,y):\n y = y[:,1:] # to eliminate nan\n y = y.mean(axis=1)\n length = y.size\n print(\"Using {} samples\".format(length))\n A = y.reshape(length,1)\n B = []\n meanData = y.mean()\n print(\"mean angle: {}\".format(y.mean()))\n print(\"median angle: {}\".format(np.median(y)))\n print(\"mode angle: {}\".format(stats.mode(y)))\n sns.distplot(y)\n\n for a in A:\n if a > meanData:\n B.append(1)\n else:\n B.append(0)\n return x,B\n\ndef train_input_fn(features, labels, batch_size): #\"\"\"An input function for training\"\"\"\n dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))\n dataset = dataset.shuffle(1000).repeat().batch(batch_size)\n return dataset\n\ndef eval_input_fn(features, labels, batch_size):\n \"\"\"An input function for evaluation or prediction\"\"\"\n features=dict(features)\n if labels is None:\n inputs = features\n else:\n inputs = (features, labels)\n\n dataset = tf.data.Dataset.from_tensor_slices(inputs)\n assert batch_size is not None, \"batch_size must not be None\"\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef main(argv):\n\n args = parser.parse_args(argv[1:])\n #https://www.tensorflow.org/guide/feature_columns\n my_feature_columns = []\n\n inputDataLabels = []\n for a in range(8):\n inputDataLabels.append(\"data\"+str(a))\n\n for key in inputDataLabels:\n my_feature_columns.append(tf.feature_column.numeric_column(key=key))\n\n outputDataLabels = [\"output\"]\n\n\n classifier = tf.estimator.LinearClassifier(\n feature_columns=my_feature_columns,\n #hidden_units=[8,4],\n n_classes=2,\n #model_dir='neuralNetdata'\n )\n\n trainDataSize = 18000\n testDataSize = 1000\n secondDimension = 8\n print(\"lets make some data!\")\n start = time.time()*1000\n numberOfWeights = 8\n maxWeight = 8\n #weights = np.random.uniform(size=(numberOfWeights,1))*maxWeight\n weights = np.array([[1],[2],[3],[4],[5],[6],[7],[8]])\n x = np.random.uniform(size=(secondDimension,trainDataSize))\n xTest = np.random.uniform(size=(secondDimension,testDataSize))\n y = np.round(np.divide(np.sum(np.multiply(x,weights),axis=0),np.sum(weights)))\n yTest = np.round(np.divide(np.sum(np.multiply(xTest,weights),axis=0),np.sum(weights)))\n end = time.time()*1000\n print(\"Done, that took {}ms\".format(end-start))\n print()\n x = pd.DataFrame(x.transpose(), columns = inputDataLabels)\n y = pd.DataFrame(y.transpose(), columns = outputDataLabels)\n xTest = pd.DataFrame(xTest.transpose(), columns = inputDataLabels)\n yTest = pd.DataFrame(yTest.transpose(), columns = outputDataLabels)\n print(\"mean: {}\".format(np.mean(y)))\n start = time.time()*1000\n a=classifier.train(input_fn=lambda:train_input_fn(x, y, 18000),steps=10000)\n print(\"Done, that took {}ms\".format(end-start))\n\n eval_result = classifier.evaluate(\n input_fn=lambda:eval_input_fn(xTest, yTest,10))\n\n print('\\nTest set accuracy: {accuracy:0.3f}\\n'.format(**eval_result))\n #plt.show()\n\n\n\nif __name__ == '__main__':\n tf.logging.set_verbosity(tf.logging.INFO)\n tf.app.run(main)\n"
},
{
"alpha_fraction": 0.6954243779182434,
"alphanum_fraction": 0.7052043080329895,
"avg_line_length": 29.78494644165039,
"blob_id": "56f6b26fea6d5c6d9b803f57d32e48426d03b593",
"content_id": "18beed1eb21fae5f87fe0f0a8733fe2f2fee06f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2863,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 93,
"path": "/referenceMaterial/unlimitedHand/deepNetBuilder.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n#useful: https://missinglink.ai/guides/neural-network-concepts/7-types-neural-network-activation-functions-right/\n\nimport tensorflow as tf\nfrom tensorflow import keras\nimport numpy as np\nfrom tensorflow.keras import backend as K\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n#openHandDataFile = input(\"Enter name of open hand data file\")\n#if openHandDataFile == \"\" or openHandDataFile == \"\\n\":\nopenHandDataFile = 'open.csv'\n\nopenHandDataInput = np.genfromtxt(openHandDataFile, delimiter=',')\nshape = openHandDataInput.shape\nopenHandData = np.zeros((shape[0],shape[1]+1))\nopenHandData[:,:-1] = openHandDataInput # concat-ed with ones to indicate classified closed dataset\n\n#closedHandDataFile = input(\"Enter name of closed hand data file\")\n#if closedHandDataFile == \"\" or closedHandDataFile == \"\\n\":\nclosedHandDataFile = 'closed.csv'\n\nclosedHandDataInput = np.genfromtxt(closedHandDataFile, delimiter=',')\nshape = closedHandDataInput.shape\nclosedHandData = np.ones((shape[0],shape[1]+1))\nclosedHandData[:,:-1] = closedHandDataInput # concat-ed with ones to indicate classified closed dataset\n\ntotalData = np.concatenate((openHandData,closedHandData),axis=0) # stack datasets vertically\nnp.random.shuffle(totalData) # randomly shuffle data avoid biasing initial or final epochs\n#print(totalData)\ntrainX = totalData[:,:-1]\ntrainY = totalData[:,-1]\nprint(trainX.shape)\nprint(trainY.shape)\n\n#graph inputs/outpu\n#X = tf.placeholder(\"int\", shape=(1,8))\n#Y = tf.placeholder(\"float\")\n\n#graph design\nmodel = keras.Sequential([\n keras.layers.Dense(8, input_dim=8),\n keras.layers.Dense(8, activation='sigmoid'),\n #keras.layers.Dense(8, activation=tf.nn.relu),\n keras.layers.Dense(1, activation=tf.nn.softmax)\n])\n\n\nmodel.compile(optimizer='adam',\nloss='mean_squared_error',\nmetrics=['accuracy'])\n\nmodel.summary()\n#exit()\n#exit()\n\n\ndef plot_history(history):\n hist = pd.DataFrame(history.history)\n hist['epoch'] = history.epoch\n\n plt.figure()\n plt.xlabel('Epoch')\n plt.ylabel('Mean Abs Error [MPG]')\n plt.plot(hist['epoch'], hist['mean_absolute_error'],\n label='Train Error')\n plt.plot(hist['epoch'], hist['val_mean_absolute_error'],\n label = 'Val Error')\n plt.ylim([0,5])\n plt.legend()\n\n plt.figure()\n plt.xlabel('Epoch')\n plt.ylabel('Mean Square Error [$MPG^2$]')\n plt.plot(hist['epoch'], hist['mean_squared_error'],\n label='Train Error')\n plt.plot(hist['epoch'], hist['val_mean_squared_error'],\n label = 'Val Error')\n plt.ylim([0,20])\n plt.legend()\n plt.show()\n\n\n#with tf.Graph().as_default():\n# with tf.Session() as sess:\n #sess.run(tf.global_variables_intializer())\n# K.set_session(sess)\n #model = load_model(model_path)\n #preds = model.predict(in_data)\nhistory = model.fit(x=trainX, y=trainY, epochs=5)#, batch_size=1)\n#plot_history(history)\n"
},
{
"alpha_fraction": 0.6619718074798584,
"alphanum_fraction": 0.6760563254356384,
"avg_line_length": 13.199999809265137,
"blob_id": "a9bc256bdfc99a40b2df35912222f2227a8eb93f",
"content_id": "c362e4d6f35c5fa551080f462a23297a1c21262a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 5,
"path": "/referenceMaterial/leapMotion/src/test",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport sys\nsys.path.insert(0, \"../lib\")\nimport Leap\n"
},
{
"alpha_fraction": 0.5690305829048157,
"alphanum_fraction": 0.6233234405517578,
"avg_line_length": 38.27760314941406,
"blob_id": "debf7c42cf160bdfed3cd7752eae087a418f40a5",
"content_id": "ab40519cbe68c052bc052fbea23337f702508ebe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12451,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 317,
"path": "/src/trainNet.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n#\n#\n# [[2], [3], [4], [5], [6], [7], [8], [2, 2], [4, 4], [6, 6], [8, 8], [8, 2, 2], [8, 4, 4], [8, 6, 6]]\n# [0.5530086, 0.63419294, 0.64565426, 0.64374405, 0.62750715, 0.63514805, 0.63037246, 0.5530086, 0.5530086, 0.6150907, 0.62750715, 0.5530086, 0.61604583, 0.63801336]\n#\n# [[4, 4, 4, 4], [8, 8, 4, 4], [13, 4], [13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13, 13]]\n# [0.64374405, 0.65234, 0.63228273, 0.6618911]\n\n\nimport argparse\nimport tensorflow as tf\nfrom tensorflow import keras\nimport pandas as pd\nimport numpy as np\nfrom scipy import stats\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom scipy import signal\nimport time\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--batch_size', default=10000, type=int, help='batch size')\nparser.add_argument('--train_steps', default=100, type=int,\n help='number of training steps')\n\ncp_callback = tf.keras.callbacks.ModelCheckpoint(\"kerasModels/cp.ckpt\",\n save_weights_only=True,\n verbose=1)\n\ndef plot_history(histories, key='binary_crossentropy'):\n plt.figure(1)\n\n for name, history in histories:\n val = plt.plot(history.epoch, history.history['acc'],\n '--', label=name.title()+' Val')\n\n plt.xlabel('Epochs')\n # plt.ylabel(key.replace('_',' ').title())\n plt.ylabel(\"acc\")\n plt.legend()\n plt.xlim([0,max(history.epoch)])\n plt.grid(which=\"both\")\n\n plt.figure(2)\n for name, history in histories:\n val = plt.plot(history.epoch, history.history['val_'+key],\n '--', label=name.title()+' Val')\n plt.plot(history.epoch, history.history[key], color=val[0].get_color(),\n label=name.title()+' Train')\n # plt.plot(history.epoch, , color='g',\n # label=name.title()+' Train')\n\n plt.xlabel('Epochs')\n plt.ylabel(key.replace('_',' ').title())\n plt.legend()\n plt.xlim([0,max(history.epoch)])\n plt.grid(which=\"both\")\n\n\n\ndef amalgamateData():\n path = \"/home/jamie/storageDrive/Drive/Uni/Third Year/ACS340 - Biomechatronics/Bio-Mech Assignment Windows/src/trainingData/combinedData.csv\"\n fileData = pd.read_csv(path)\n totalData = fileData.to_numpy()\n np.random.shuffle(totalData)\n x = totalData[:,1:((5*8)+1)] #ignore time col, get 8*5 emg col\n print(\"x shape: {}\".format(x.shape))\n y = totalData[:,-1] # get last col\n print(\"y shape: {}\".format(y.shape))\n return x,y\n\ndef processData(x,y):\n #x = np.divide(x,1024)\n #y = y[:,1:] # to eliminate nan\n #y = y[:,3:6] # look only at Index_Proximal Index_Intermediate,Index_Distal (end not inclusive)\n #y = y.mean(axis=1)\n #length = y.size\n #print(\"Using {} samples\".format(length))\n #A = y.reshape(length,1)\n #B = []\n #meanData = y.mean()\n #print(\"mean angle: {}\".format(y.mean()))\n #print(\"median angle: {}\".format(np.median(y)))\n #print(\"mode angle: {}\".format(stats.mode(y)))\n #plt.figure(1)\n #sns.distplot(y) # for plotting initial data distribution\n #return x,y\n #yMax = np.max(y)\n #y = np.divide(y,yMax) # normalise\n bins = 10\n #y = np.multiply(y,bins-1)\n #y = np.round(y)\n #print(\"mean angle translated: {}\".format(y.mean()))\n #dataBins = [[],[],[],[],[],[],[],[],[],[]]\n #tempBin = []\n #sizes = []\n #y = y.reshape(len(y),1)\n #data = np.append(x,y,axis=1)\n #print(\"mean angle translated: {}\".format(data[:,8].mean()))\n #for a in range(bins):\n #print(\"a = {}\".format(a))\n# for sample in data:\n # dataBins[int(sample[8])].append(sample)\n #sum = 0\n #for bin in dataBins:\n #print(len(bin))\n #sum += len(bin)\n\n # print(\"Total: {}\".format(sum))\n # newSamples = 20000\n # newData = [] # np.array([]).reshape(0,9)\n # #print(\"newData shape:{}\".format(newData.shape))\n # sampleIndexes = np.random.randint(bins,size=newSamples)\n # print(\"mean index = {}\".format(np.mean(sampleIndexes)))\n # for sampleIndex in sampleIndexes:\n # sampleBin = dataBins[sampleIndex]\n # if len(sampleBin) != 0:\n # sampleNumber = np.random.randint(len(sampleBin))\n # sample = sampleBin[sampleNumber]\n # newData.append(sample)\n # newData = np.array(newData).astype(np.int64)\n # print(\"newData shape; {}\".format(newData.shape))\n # print(\"newData distplot shape; {}\".format(newData[:,8].shape))\n # print(\"newData example: \\n{}\".format(newData[:4,:]))\n # print(\"classification mean: {}\".format(np.mean(newData[:,8])))\n # #plt.figure(2)\n #sns.distplot(newData[:,8]) # for fitting corrected distribution\n #plt.show()\n # x = newData[:,:8]\n # y = newData[:,8:]\n\n newY = []\n for sample in y:\n # if sample > (bins-1)/2:\n # newY.append(1)\n # else:\n # newY.append(0)\n newY.append(int(sample/3))\n y = np.array(newY)\n sns.distplot(y) # for fitting corrected distribution\n return x,y\n # exit()\n\ndef train_input_fn(features, labels, batch_size): #\"\"\"An input function for training\"\"\"\n # Convert the inputs to a Dataset.\n dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))\n # Shuffle, repeat, and batch the examples.\n dataset = dataset.shuffle(20000).repeat().batch(batch_size)\n # Return the dataset.\n return dataset\n\ndef eval_input_fn(features, labels, batch_size):\n \"\"\"An input function for evaluation or prediction\"\"\"\n features=dict(features)\n if labels is None:\n # No labels, use only features.\n inputs = features\n else:\n inputs = (features, labels)\n\n # Convert the inputs to a Dataset.\n dataset = tf.data.Dataset.from_tensor_slices(inputs)\n\n # Batch the examples\n assert batch_size is not None, \"batch_size must not be None\"\n dataset = dataset.batch(batch_size)\n\n # Return the dataset.\n return dataset\n\n\ndef main(argv):\n\n args = parser.parse_args(argv[1:])\n #https://www.tensorflow.org/guide/feature_columns\n my_feature_columns = []\n inputDataLabels = []\n for a in range(8):\n for b in range(5):\n inputDataLabels.append(\"emg\"+str(a)+\"fft\"+str(b))\n\n outputDataLabels = ['aveAngle']\n for key in inputDataLabels:\n my_feature_columns.append(tf.feature_column.numeric_column(key=key))\n\n accuracies = []\n #path = \"/home/jamie/storageDrive/Drive/Uni/Third Year/ACS340 - Biomechatronics/Bio-Mech Assignment Windows/src/trainingData/combinedData.csv\"\n dataX,dataY = amalgamateData() # maybe search through .csv files in trainingData folder\n dataX,dataY = processData(dataX,dataY)\n print(\"dataY mean:{}\".format(dataY.mean()))\n\n #plt.show()\n #exit()\n proportionTrain = 16/20\n print(\"proportionTrain type: {}\".format(type(proportionTrain)))\n length,width = dataX.shape\n trainIndex = int(length*proportionTrain)\n print(\"trainIndex type: {}\".format(type(trainIndex)))\n train_x = dataX[:trainIndex,:]\n train_y = dataY[:trainIndex]\n test_x = dataX[trainIndex:,:]\n test_y = dataY[trainIndex:]\n train_x = pd.DataFrame(train_x, columns = inputDataLabels)\n train_y = pd.DataFrame(train_y, columns = outputDataLabels)\n test_x = pd.DataFrame(test_x, columns = inputDataLabels)\n test_y = pd.DataFrame(test_y, columns = outputDataLabels)\n print(\"shape: {}\".format(train_x.shape))\n print(\"shape: {}\".format(train_y.shape))\n print(\"shape: {}\".format(test_x.shape))\n print(\"shape: {}\".format(test_y.shape))\n plt.show()\n time.sleep(5)\n# structures = [[50],[100],[150],[200],[250],[300],[350],[400],[450],[500],\n# [50,50],[100,100],[200,200],[250,250],[300,300],[400,400]]\n# [0.685063, 0.68686265, 0.68326336, 0.71025795, 0.69526094, 0.7006599, 0.69286144, 0.7024595, 0.7132574, 0.7132574, 0.71385723, 0.72645473, 0.7306539, 0.7396521, 0.7324535, 0.73425317]\n\n\n #structure = [300]\n\n # classifier = tf.estimator.DNNClassifier(\n # feature_columns=my_feature_columns,\n # hidden_units=structure,\n # n_classes=2,\n # #model_dir='neuralNetdata'\n # )\n #\n # a=classifier.train(input_fn=lambda:train_input_fn(train_x, train_y, args.batch_size),steps=epoch)\n #\n # eval_result = classifier.evaluate(\n # input_fn=lambda:eval_input_fn(test_x, test_y,\n # args.batch_size))\n # val = eval_result[\"accuracy\"]\n # accuracies.append(val)\n # print('\\nTest set accuracy: {}\\n'.format(val))\n model1 = keras.Sequential([\n #keras.layers.Flatten(input_shape=(1, 8)),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002), activation=tf.nn.relu,input_shape=(40,)),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(2, activation=tf.nn.softmax)\n ])\n\n model2 = keras.Sequential([\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.002), activation=tf.nn.relu,input_shape=(8,)),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(2, activation=tf.nn.softmax)\n ])\n\n model3 = keras.Sequential([\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.001), activation=tf.nn.relu,input_shape=(8,)),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.001),activation=tf.nn.softmax),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.001),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(120, kernel_regularizer=keras.regularizers.l2(0.001),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(2, activation=tf.nn.softmax)\n ])\n\n model1.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy','binary_crossentropy'])\n\n model2.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy','binary_crossentropy'])\n\n model3.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy','binary_crossentropy'])\n tf.logging.set_verbosity(tf.logging.ERROR)\n #model1.summary()\n history1 = model1.fit(train_x, train_y, epochs=500,batch_size=20000,validation_data=(test_x, test_y),verbose=2, callbacks=[cp_callback])\n #history2 = model2.fit(train_x, train_y, epochs=600,batch_size=20000,validation_data=(test_x, test_y),verbose=2)\n #history3 = model3.fit(train_x, train_y, epochs=700,batch_size=20000,validation_data=(test_x, test_y),verbose=2)\n\n plot_history([('model1', history1)])#,('model2', history2),('model3', history3)])\n #test_loss, test_acc, bin_cross = model1.evaluate(test_x, test_y)\n #print(\"model1: {} \".format(test_acc))\n #test_loss, test_acc, bin_cross = model2.evaluate(test_x, test_y)\n #print(\"model2: {} \".format(test_acc))\n plt.show()\n\n\n\n\n\n\nif __name__ == '__main__':\n tf.logging.set_verbosity(tf.logging.INFO)\n tf.app.run(main)\n"
},
{
"alpha_fraction": 0.5491416454315186,
"alphanum_fraction": 0.5710300207138062,
"avg_line_length": 34.037593841552734,
"blob_id": "99d4dfc846e9756c28b0a8e3e905a0ff358be53a",
"content_id": "f05dde594c6b56d49bfcfbf98cb117335a30ba9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4660,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 133,
"path": "/src/KNNClassifier.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport argparse\n#import tensorflow as tf\nimport pandas as pd\nimport numpy as np\nfrom scipy import stats\n#import seaborn as sns\nimport matplotlib.pyplot as plt\n\n\n\ndef amalgamateData(files=[\"outputLong01.csv\"]):\n totalData = np.array([8])\n for file in files:\n if files.index(file) == 0:\n path = \"trainingData/\" + file\n fileData = pd.read_csv(path)\n totalData = fileData.to_numpy()\n else:\n path = \"trainingData/\" + file\n fileData = pd.read_csv(path)\n tempData = fileData.to_numpy()\n totalData = np.concatenate((totalData,tempData),axis=0)# ie going down\n\n np.random.shuffle(totalData)\n x = totalData[:,:8]\n y = totalData[:,8:]\n #y = totalData[:,9:] # bc lower joint of thumb (ie first entry) has value nan\n return x,y\n\ndef processData(x,y):\n y = y[:,1:] # to eliminate nan\n y = y[:,3:6] # look only at Index_Proximal Index_Intermediate,Index_Distal (end not inclusive)\n y = y.mean(axis=1)\n length = y.size\n print(\"Using {} samples\".format(length))\n A = y.reshape(length,1)\n B = []\n meanData = y.mean()\n #print(\"mean angle: {}\".format(y.mean()))\n #print(\"median angle: {}\".format(np.median(y)))\n #print(\"mode angle: {}\".format(stats.mode(y)))\n #sns.distplot(y)\n\n for a in A:\n if a > meanData:\n B.append(1)\n else:\n B.append(0)\n\n #print(\"mean class: {}\".format(np.array(B).mean()))\n #print(\"B: \\n{}\".format(np.array(B)))\n return x,np.array(B)\n\nclass KNNClassifier:\n def __init__(self):\n self.refDataX = None\n self.refDataY = None\n\n def setReferenceData(self,inputx,inputy):\n self.refDataX = inputx\n #print(\"self.refDataX: \\n{}\".format(self.refDataX))\n self.refDataY = inputy\n #print(\"self.refDataY: \\n{}\".format(self.refDataY))\n\n def classify(self,inputx):\n if(type(self.refDataX) == type(None) or type(self.refDataY) == type(None)):\n print(\"KNN Classify called with no reference data input\")\n return None\n else:\n differences = np.subtract(self.refDataX,inputx)\n squared_differences = np.power(differences,2)\n summed_squared_differences = np.sum(squared_differences,axis=1).reshape(len(squared_differences),1)\n totalDataSet=np.append(summed_squared_differences,self.refDataY.reshape(len(self.refDataY),1),axis=1)\n totalDataSet = pd.DataFrame(data=totalDataSet,columns=[\"diff\",\"class\"])\n #exit()\n sortedData = totalDataSet.sort_values(by=\"diff\",axis=0)\n sortedData = sortedData.values\n topSortedResult=sortedData[:10,:]# take top 10 closest points\n res = np.histogram(topSortedResult[:,1],bins=(0,0.5,1),density=True)\n res = res[0]\n dist = res/np.sum(res)\n probClassA,probClassB = dist[0],dist[1]\n if probClassA > probClassB:\n return 0\n elif probClassA < probClassB:\n return 1\n\ndef main():\n dataX,dataY = amalgamateData() # maybe search through .csv files in trainingData folder\n dataX,dataY = processData(dataX,dataY)\n proportionTrain = 99/100\n #print(\"proportionTrain type: {}\".format(type(proportionTrain)))\n length,width = dataX.shape\n trainIndex = int(length*proportionTrain)\n #print(\"trainIndex: \\n{}\".format(trainIndex))\n #print(\"trainIndex type: {}\".format(type(trainIndex)))\n train_x = dataX[:trainIndex,:]\n #print(\"train_x: \\n{}\".format(train_x))\n train_y = dataY[:trainIndex]\n test_x = dataX[trainIndex:,:]\n test_y = dataY[trainIndex:]\n classifier = KNNClassifier()\n print(\"importing training data\")\n classifier.setReferenceData(train_x,train_y)\n print(\"running {} samples\".format(len(test_x)))\n # results\n AC0PC0 = 0\n AC0PC1 = 0\n AC1PC0 = 0\n AC1PC1 = 0\n for sample in zip(test_x,test_y):\n result = classifier.classify(sample[0])\n if sample[1] == 1:\n if result == 1:\n AC1PC1 += 1\n else:\n AC1PC0 += 1\n else:\n if result == 1:\n AC0PC1 += 1\n else:\n AC0PC0 += 1\n print(\"good:\")\n print(AC0PC0+AC1PC1)\n print((AC0PC0+AC1PC1)/((AC0PC0+AC1PC1)+(AC0PC1+AC1PC0)))\n print(\"bad\")\n print(AC0PC1+AC1PC0)\n print((AC0PC1+AC1PC0)/((AC0PC0+AC1PC1)+(AC0PC1+AC1PC0)))\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.670431911945343,
"alphanum_fraction": 0.7009966969490051,
"avg_line_length": 22.88888931274414,
"blob_id": "1b2ad583f5559da6c786d6ea8c6d637e2f70ae57",
"content_id": "fb48e6a6cbc091766ab3b1e2c67c9bcff5e071f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1505,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 63,
"path": "/src/myoSampleFtest.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# ave sample freq: 58.7015798967\n# std dev: 0.00800620253063\n\nimport threading\nimport sys, time, thread\nimport math\nimport numpy as np\nfrom leapInterfaces2 import SampleListener\nimport Queue\nfrom myoConnectFunctions import *\nimport csv\nsys.path.insert(0, \"../lib\")\nimport Leap\n\nsampleTimesOriginal = []\n\ndef proc_emg(emg, moving, times=[]):\n global sampleTimesOriginal\n sampleTimesOriginal.append(time.time())\n #print(\"sample\")\n\n\n\n# Myo setup\nm = MyoRaw(sys.argv[1] if len(sys.argv) >= 2 else None)\nm.add_emg_handler(proc_emg)\nprint(\"Connecting to Myo Band\")\nm.connect()\nprint(\"Myo Connected\")\ntime.sleep(1)\nprint(\"running\")\nrunMode = True\ninit = time.time()\ntry:\n while runMode:\n m.run()\n if len(sampleTimesOriginal) > 300:\n runMode = False\n else:\n print(300 - len(sampleTimesOriginal))\n #time.sleep(0.1)\nexcept KeyboardInterrupt:\n print(\"\\ntime to go to sleep!\")\n stop = time.time()\n duration = stop - init\n print(\"{}\".format(sampleCounter) + \" myo samples in {}ms\".format(int(duration*1000)))\nfinally:\n pass\n\nsampleTimes = sampleTimesOriginal\n#print(sampleTimes)\n#print(len(sampleTimes))\nbaseTime = sampleTimes[0]\n#print(baseTime)\nsampleTimes = np.array(sampleTimes) - baseTime\nsamplePeriods = np.diff(sampleTimes)\nsampleFreqs = 1/np.array(samplePeriods).mean()\naveSamplePeriod = np.array(samplePeriods).mean()\naveSampleFreq = sampleFreqs.mean()\nprint(\"ave sample freq: {}\".format(sampleFreqs))\nexit()\n"
},
{
"alpha_fraction": 0.6647354364395142,
"alphanum_fraction": 0.6799922585487366,
"avg_line_length": 30.962963104248047,
"blob_id": "857f6e546463cca1236ace89bc387bb84aa2b4b4",
"content_id": "c5ab7bafbbd904a5b0421e9dfdfb76f82daead27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5178,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 162,
"path": "/src/gatherData.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# to run this, run:\n# sudo leapd\n# LeapControlPanel\n### try LeapControlPanel --showsettings if not working\n#\n\n# https://www.blog.pythonlibrary.org/2016/07/28/python-201-a-tutorial-on-threads/\n\n# myo connect came from: http://www.fernandocosentino.net/pyoconnect/\n\n# ave sample freq: 52.0070258816\n# std dev: 0.00443972074748\n\n# plan of action\n# independently sample myo and leapmotion\n# produce script to go though slower sampled sensor, combine with data from high sampled sensor using linear interpolation\n# pass through fft with window of 0.2-3.0 seconds\n# output new data\n# train neural net\n\nimport pandas as pd\nimport threading\nimport sys, time, thread\nimport math\nimport numpy as np\nfrom leapInterfaces2 import SampleListener\nimport Queue\nfrom myoConnectFunctions import *\nimport csv\nsys.path.insert(0, \"../lib\")\nimport Leap\n# import seaborn as sns\n# import matplotlib.pyplot as plt\n#\n# sampleTimesOriginal = []\n# samples = 0\n#\n# print(\"Beginning\")\n#\n# enableCollection = True\n# leapMotionDetection = False\n# q = Queue.LifoQueue(maxsize=1)\n#\n# myoFileName = \"trainingData/myoOutput.csv\"\n# leapFilename = \"trainingData/leapOutput.csv\"\n# with open(myoFileName, \"w+\") as outputFile:\n# writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n# dataLabels = []\n# for a in range(8):\n# dataLabels.append(\"emg\"+str(a))\n# writer.writerow(dataLabels)\n\n\n\n\n# averageList = []\nsampleCounter = 0\ndataStore = []\n\ndef proc_emg(emg, moving, times=[]):\n global dataStore\n global sampleCounter\n #print(\"myo running\")\n sampleCounter+= 1\n dataStore.append(list(emg))\n#\n#\n# print(\"Please put on myo band, and place hand above leapmotion sensor\")\n# print(\"if leap motion cannot properly track hand, recording will be \")\n# print(\"paused and automatically resumed on recognition. Press enter\")\n# print(\"when ready to connect\")\n# rubbish = raw_input()\n\n# Myo setup\nm = MyoRaw(sys.argv[1] if len(sys.argv) >= 2 else None)\nm.add_emg_handler(proc_emg)\nprint(\"Connecting to Myo Band\")\nm.connect()\nprint(\"Myo Connected\")\n#\n#\n# # leap setup\n# lock = threading.Lock()\n# listener = SampleListener(lock,q)\n# controller = Leap.Controller()\n# controller.add_listener(listener)\n\n# Keep this process running until Enter is pressed\nprint(\"Press Enter to quit...\")\ninit = time.time()\ntry:\n while True:\n m.run(1)\n if len(dataStore) >= 100:\n temp = dataStore\n # with open(myoFileName, mode = 'a') as outputFile:\n # writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n # for data in temp:\n # writer.writerow(data)\n\nexcept KeyboardInterrupt:\n print(\"\\ntime to go to sleep!\")\n stop = time.time()\n duration = stop - init\n print(\"{}\".format(sampleCounter) + \" myo samples in {}ms\".format(int(duration*1000)))\nfinally:\n pass\n #controller.remove_listener(listener)\n\n\n# now to process the data\ndef aveFreq(data):\n myoTimes = data[:,0]\n myoTimes = np.diff(myoTimes)\n myoTimes = [time for time in myoTimes if time < (myoTimes.mean()+2*myoTimes.std()) and time > (myoTimes.mean()-2*myoTimes.std())] # remove top and bottom 2.2% of values\n myoAveSampleTimes = np.array(myoTimes).mean()\n myoAveFreq = 1/(myoAveSampleTimes * 1000)\n return myoAveFreq\n\nmyoData = pd.read_csv(\"trainingData/myoOutput.csv\")\nmyoFs = aveFreq(myoData)\nprint(\"Myo average sampling freq = {}Hz\".format(myoFs))\nleapData = pd.read_csv(\"trainingData/leapOutput.csv\")\nleapFs = aveFreq(leapData)\nprint(\"Myo average sampling freq = {}Hz\".format(leapFs))\n#\n# combinedData = []\n#\n# def interpolateData(preserveTime, superSample):\n# combinedData = []\n# leapData = preserveTime\n# myoData = superSample\n# for leapRow in leapData:\n# leapRowTime = leapRow[0]\n# myoRowCount,myoColCount = myoData.shape\n# for rowIndex in (range(myoRowCount)-1):\n# myoRowTime = myoData[rowIndex,0]\n# nextMyoRowTime = myoData[rowIndex+1,0]\n# if (myoRowTime <= leapRowTime) and (nextMyoRowTime >= leapRowTime): # ie we've found the samples either side of the sample in the leap data\n# myoRowData = myoData[rowIndex,1:]\n# nextMyoRowData = myoData[rowIndex+1,1:]\n# myoGradient = (np.array(nextMyoRowData) - np.array(myoRowData))/(nextMyoRowTime-myoRowTime)\n# interpolatedMyoData = (myoGradient * (leapRowTime-myoRowTime)) + np.array(myoRowData)\n# combinedData.append(list(leapRow) + list(interpolatedMyoData))\n# if myoRowTime >= leapRowTime and nextMyoRowTime >= leapRowTime: # somehow we've gone past it\n# break\n#\n#\n# if myoFs > leapFs:\n# print(\"leap sampled slower, super sampling myo\")\n# combinedData = interpolateData(leapData, myoData)\n# else:\n# print(\"myo sampled slower, super sampling leap\")\n# combinedData = interpolateData(myoData, leapData)\n#\n# dataToWrite = np.array(combinedData[0])\n#\n# for row in combinedData[1:]:\n# dataToWrite = np.vstack((dataToWrite,row))\n#\n# np.savetxt(\"combinedData.csv\", dataToWrite, delimiter=\",\")\n"
},
{
"alpha_fraction": 0.6137930750846863,
"alphanum_fraction": 0.6179310083389282,
"avg_line_length": 20.969696044921875,
"blob_id": "d292789e78a539c95c28b28c03bf05d52bd5543d",
"content_id": "8a1802c1070a9efc0e5f1fc4342ce156973f0686",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 725,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 33,
"path": "/referenceMaterial/myoband/main.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nfrom myoConnectFunctions import *\nimport sys\nimport csv\n\nm = MyoRaw(sys.argv[1] if len(sys.argv) >= 2 else None)\n\nfileName = raw_input(\"specify filename (*.csv)\")\nif fileName == \"\" or fileName == \"\\n\":\n fileName = 'output'\nfileName += \".csv\"\n\ndef proc_emg(emg, moving, times=[]):\n with open(fileName, mode = 'a') as outputFile:\n writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n try:\n print(emg)\n writer.writerow(emg)\n except KeyboardInterrupt:\n pass\n\nm.add_emg_handler(proc_emg)\nm.connect()\n\ntry:\n while True:\n m.run(1)\nexcept KeyboardInterrupt:\n pass\nfinally:\n m.disconnect()\n print()\n"
},
{
"alpha_fraction": 0.436899870634079,
"alphanum_fraction": 0.4588477313518524,
"avg_line_length": 26.50943374633789,
"blob_id": "ba87dcad6b70d9378b644d1f164c4986bf81adf0",
"content_id": "367ca44a68f5d327dda08334e213d28a6bd9f4a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1458,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 53,
"path": "/referenceMaterial/unlimitedHand/unlimitedhandFirmware/unlimitedhandFirmware.ino",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "/*\n * Example: PhotoReflectors\n * To print out PhotoReflectors via Serial Connection(115200).\n * The PhotoReflectors' values are printed out on your serial monitor.\n * 2016.10.22 \n * http://dev.unlimitedhand.com\n */\n \n#include <UH.h>\nUH uh; // create uh object to control a uh\n\nint PRValues[PR_CH_NUM];// channel number of PhotoReflectors\n\n///////////////////////////////////////////////////////////\n// SET UP\n///////////////////////////////////////////////////////////\nvoid setup()\n{\n Serial.begin(115200); // initialize serial communication:\n uh.initPR(); // initialize PhotoReflectors\n}\n\n///////////////////////////////////////////////////////////\n// LOOP \n///////////////////////////////////////////////////////////\nvoid loop()\n{\n uh.readPR(PRValues);\n for(int i = 0; i < PR_CH_NUM; i ++)\n {\n //Serial.print(\"CH\"); \n //Serial.print(i);\n //Serial.print(\":\");\n Serial.print(PRValues[i]); \n Serial.print(\" \");\n }\n Serial.println(\"\");\n delay(100);\n}\n\n///////////////////////////////////////////////////////////\n// SERIAL EVENT FUNCTION \n///////////////////////////////////////////////////////////\n/*\nvoid serialEvent(){\n if(Serial.available()>0){\n if((char)Serial.read()==118){ // if you type 'v' \n char sketch_name[] = \"PhotoReflectors__0043\";//Patch to probe sketch version\n Serial.print(\"Version:\");Serial.println(sketch_name);// retrun the version\n }\n }\n}\n*/\n"
},
{
"alpha_fraction": 0.6015424132347107,
"alphanum_fraction": 0.6323907375335693,
"avg_line_length": 24.933332443237305,
"blob_id": "a0d8aea26cfa3d67f737c6437cdf59df231f3770",
"content_id": "3ca78c8b278632ac2f2a6bc3c49e893b68544a60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 389,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 15,
"path": "/src/angleTest.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nimport numpy as np\n\n\na = np.array([0,1,1])\nb = np.array([0,1,0])\naDotb = np.dot(-a,b)\nprint(\"a*b :{}\".format(aDotb))\nmagProd = (np.linalg.norm(a)*np.linalg.norm(b))\nprint(\"magProd :{}\".format(magProd))\ng = aDotb/magProd # G\nprint(\"g:{}\".format(g))\nangle = np.arccos(g) # getAngles\nprint(\"angle(rads):{}\".format(angle))\nprint(\"angle(degrees):{}\".format(angle*(180/3.14)))\n"
},
{
"alpha_fraction": 0.5589353442192078,
"alphanum_fraction": 0.5855513215065002,
"avg_line_length": 14.939393997192383,
"blob_id": "da500338879f81617f6506b7189d6dbf85ad5954",
"content_id": "581452369d9b22b7790933f325cd63366f111adf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 33,
"path": "/src/arduinoSerialTester/arduinoSerialTester.ino",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "void setup() \n{\n Serial.begin(115200);\n pinMode(13, OUTPUT);\n}\n\nvoid loop() {\n // put your main code here, to run repeatedly:\n\n}\n\nvoid serialEvent()\n{\n delay(10);\n String inputString = \"\";\n while(Serial.available())\n {\n char character = (char)Serial.read();\n if(character != '\\n')\n {\n inputString += character;\n }\n }\n Serial.println(\"I received: \" + inputString);\n if(inputString == \"open\")\n {\n digitalWrite(13, HIGH);\n }\n else if(inputString == \"close\")\n {\n digitalWrite(13, LOW);\n }\n}\n"
},
{
"alpha_fraction": 0.6180645227432251,
"alphanum_fraction": 0.639032244682312,
"avg_line_length": 30.31313133239746,
"blob_id": "f0f1780a0717597b57a4472e2b71f0259fba53b5",
"content_id": "613532280e500f1641e50e8ad413d04d22fb98f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3100,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 99,
"path": "/src/interpreter.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n#import threading\nimport os\nimport sys, time\nimport math\nimport numpy as np\n#import Queue\nsys.path.insert(0, \"/home/jamie/Coding/projects/Bio-Mech Assignment/lib\")\n\nfrom myoConnectFunctions import *\n#import lib\nimport serial\nimport argparse\nimport tensorflow as tf\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'\nimport pandas as pd\nimport numpy as np\n\nport = serial.Serial(\"/dev/ttyACM1\",115200)\n\ninputDataLabels = []\nfor a in range(8):\n inputDataLabels.append(\"emg\"+str(a))\n\nmy_feature_columns=[]\nfor key in inputDataLabels:\n my_feature_columns.append(tf.feature_column.numeric_column(key=key))\n\nclassifier = tf.estimator.DNNClassifier(\nfeature_columns=my_feature_columns,\nhidden_units=[10, 10],\nn_classes=2,\nmodel_dir='neuralNetdata'\n)\n\n\ndef eval_input_fn(features, labels, batch_size):\n features=dict(features)\n if labels is None:\n # No labels, use only features.\n inputs = features\n else:\n inputs = (features, labels)\n dataset = tf.data.Dataset.from_tensor_slices(inputs)# Convert the inputs to a Dataset.\n assert batch_size is not None, \"batch_size must not be None\" # Batch the examples\n dataset = dataset.batch(batch_size)\n return dataset\n\n\ndef proc_emg(emg, moving, times=[]):\n try:\n emgDataList = np.array(list(emg))\n #print(\"emgDataList: {}\".format(emgDataList))\n input_x = pd.DataFrame([emgDataList], columns = inputDataLabels)\n #print(\"input_x: {}\".format(input_x))\n model1 = keras.Sequential([\n #keras.layers.Flatten(input_shape=(1, 8)),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002), activation=tf.nn.relu,input_shape=(8,)),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(100, kernel_regularizer=keras.regularizers.l2(0.002),activation=tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.2),\n keras.layers.Dense(2, activation=tf.nn.softmax)\n ])\n model.load_weights(checkpoint_path)\n pre\n for a in output:\n classID = a['class_ids'][0]\n print(classID)\n\n\n\n except KeyboardInterrupt:\n exit()\n\n\nm = MyoRaw(sys.argv[1] if len(sys.argv) >= 2 else None)\nm.add_emg_handler(proc_emg)\nprint(\"Connecting to Myo Band\")\nm.connect()\nprint(\"Myo Connected\")\n\npause = input(\"press enter when ready to begin\")\n\nprint(\"Press Enter to quit...\")\ntry:\n internalAngles = None\n while True:\n m.run(1)\nexcept KeyboardInterrupt:\n print(\"time to go to sleep!\")\n"
},
{
"alpha_fraction": 0.5901926159858704,
"alphanum_fraction": 0.6094570755958557,
"avg_line_length": 23.826086044311523,
"blob_id": "8f7ec392545d4ffccf336553a4cdc66fc6727589",
"content_id": "265a906bfe1b7e986125f2b02b7ea0f9617f728b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 571,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 23,
"path": "/referenceMaterial/unlimitedHand/.goutputstream-RD0TXZ",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport time\nimport serial\nimport csv\n\nname = raw_input(\"Specify Serial Port\")\nif name == \"\" || name == \"\\n\"\n name = '/dev/ttyACM0'\n\nser = serial.Serial(port=name,baudrate=115200) # open serial port\nprint(ser.name) # check which port was really used\nfileName = raw_input(\"specify filename (*.txt)\")\n\nwith open(fileName, mode = 'w') as outputFile:\n try:\n while(1 == 1):\n output = ser.read_until()\n print(output.decode(\"utf-8\"))\n\n except KeyboardInterrupt:\n pass\n\nser.close() # close port\n"
},
{
"alpha_fraction": 0.5866388082504272,
"alphanum_fraction": 0.6002087593078613,
"avg_line_length": 26.371429443359375,
"blob_id": "5f0e456f44c3d25a7330e6c6109495b2c7d34536",
"content_id": "681bbf3f33631563679f64b3d1a7775fbbb51a09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 958,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 35,
"path": "/referenceMaterial/unlimitedHand/sampleUH.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport time\nimport serial\nimport csv\nfrom io import StringIO\nimport re\n\nname = input(\"Specify Serial Port\")\nif name == \"\" or name == \"\\n\":\n name = '/dev/ttyUSB0'\n\nser = serial.Serial(port=name,baudrate=115200) # open serial port\nprint(ser.name) # check which port was really used\nfileName = input(\"specify filename (*.csv)\")\nif fileName == \"\" or fileName == \"\\n\":\n fileName = 'output'\nfileName += \".csv\"\n\nwith open(fileName, mode = 'w') as outputFile:\n writer = csv.writer(outputFile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)\n try:\n while(1 == 1):\n output = ser.read_until()\n outputString = output.decode(\"utf-8\")\n #print(outputString)\n data = re.findall(\"[0-9]+\",outputString)\n print(\"Extracted:\")\n print(data)\n writer.writerow(data)\n\n\n except KeyboardInterrupt:\n pass\n\nser.close() # close port\n"
},
{
"alpha_fraction": 0.6120401620864868,
"alphanum_fraction": 0.648829460144043,
"avg_line_length": 26.18181800842285,
"blob_id": "bed030ddf5c3fb593ac11f0821e83f1cd873235b",
"content_id": "c04c723e2831d96ca30a1617e652999ce3c4edd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 11,
"path": "/referenceMaterial/unlimitedHand/testSerial.py",
"repo_name": "jamieapps101/Bio-Mech-Assignment",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport time\nimport serial\n\nser = serial.Serial(port='/dev/ttyUSB0',baudrate=115200) # open serial port\nprint(ser.name) # check which port was really used\nwhile(1 == 1):\n output = ser.read_until()\n print(output.decode(\"utf-8\"))\n\nser.close() # close port\n"
}
] | 17 |
Solopie/password-protected-website
|
https://github.com/Solopie/password-protected-website
|
958f2a1852b4c404f96dded7eea7c29dcdf81f29
|
fcd6750d8fffde19fa17bcd1ffd817d6042b4e67
|
3c13dd4d1de34fe54e96e15da83e0ef9abf7476c
|
refs/heads/master
| 2023-08-06T19:29:48.013722 | 2021-10-07T05:18:10 | 2021-10-07T05:18:10 | 413,252,793 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5656623244285583,
"alphanum_fraction": 0.5707788467407227,
"avg_line_length": 33.490196228027344,
"blob_id": "8ed46a7688a14cd5bb7b0b1177f1b8f4ad136b57",
"content_id": "43187583f3dcf2e924efec2c1d43681041ca9436",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1759,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 51,
"path": "/main.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request, session, render_template, redirect, url_for\nfrom blueprints.access import access_bp\nfrom db import access_db\nimport config\n\napp = Flask(__name__)\napp.secret_key = config.APP_KEY\n\n# Only enable access functionality if enabled\nif config.ENABLE_TOKEN:\n @app.before_first_request\n def setup():\n # ----- CHECK IF ACCESS (SETUP) REQUIRED -----\n # Check if token is set already for application (incase of restart)\n if len(access_db.query(\"SELECT * FROM tokens\")) > 0:\n config.SETUP_REQUIRED = False\n # ----- ------------------------------ -----\n\n @app.before_request\n def hook():\n # ----- ACCESS ROUTE PROTECTION -----\n # Only check for access if token is enabled\n # Check if token setup has been done\n if config.SETUP_REQUIRED:\n if request.endpoint not in [\"access.setup\", \"static\", None]:\n return redirect(url_for(\"access.setup\"))\n else:\n # Don't want to allow access to setup when setup already done\n if request.endpoint == \"access.setup\":\n return redirect(url_for(\"access.login\"))\n\n # Check if user has access\n if \"access\" not in session and request.endpoint not in [\"access.login\", \"static\", None]:\n return redirect(url_for(\"access.login\"))\n # ----- ----------------------- -----\n\n # ----- ACCESS BLUEPRINT -----\n # Sorry you can't use the /access route :'(\n app.register_blueprint(access_bp, url_prefix=\"/access\")\n # ----- ---------------- -----\n\n# You can write your routes here!\n\[email protected](\"/\")\ndef index():\n return render_template(\"index.html\")\n\n\n\nif __name__ == \"__main__\":\n app.run(host=\"0.0.0.0\", port=8000)\n"
},
{
"alpha_fraction": 0.6753246784210205,
"alphanum_fraction": 0.6753246784210205,
"avg_line_length": 18.25,
"blob_id": "f4969dd2dbb1a1558fd6414b4e3c34a60af2781d",
"content_id": "a76f70dde5e422b8456c5d90aacc9c02b9a2cd28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/init.sql",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "CREATE TABLE tokens (\n token_hash TEXT NOT NULL,\n salt TEXT NOT NULL\n)\n"
},
{
"alpha_fraction": 0.7365269660949707,
"alphanum_fraction": 0.742514967918396,
"avg_line_length": 26.91666603088379,
"blob_id": "305817b0a3f83bafb9bf9630b810481c77280530",
"content_id": "35b53e3f65640b08ee662f6a2d96cbfd0705866f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 12,
"path": "/config.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "from dotenv import load_dotenv \nfrom secrets import token_bytes\nfrom os import getenv\n\nload_dotenv()\n\nAPP_KEY = getenv(\"DEV_APP_KEY\") or token_bytes(24)\nENABLE_TOKEN = True if getenv(\"ENABLE_TOKEN\").lower() == \"true\" else False\nACCESS_DB_PATH = getenv(\"ACCESS_DB_PATH\")\nSETUP_REQUIRED = True \n\n# Write your environment variables here!"
},
{
"alpha_fraction": 0.6370250582695007,
"alphanum_fraction": 0.6370250582695007,
"avg_line_length": 33.36111068725586,
"blob_id": "1ba808c7020e7efccf3004c1587f06897ccf49c2",
"content_id": "9dae17a884c5803ce15f4ed2b230847c62d89051",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1237,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 36,
"path": "/blueprints/access/__init__.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, render_template, request, redirect ,url_for, session\nfrom util import generate_hash, verify_access\nfrom db import access_db\nimport config\n\naccess_bp = Blueprint(\"access\", __name__, template_folder=\"templates\")\n\n@access_bp.route(\"/\", methods=[\"GET\", \"POST\"])\ndef login():\n if \"access\" in session and session[\"access\"] == True:\n return redirect(url_for(\"index\"))\n\n if request.method == \"POST\":\n token = request.form.get(\"token\")\n if verify_access(token):\n session[\"access\"] = True \n return redirect(url_for(\"index\"))\n else:\n return render_template(\"login.html\", error=\"Access failed\")\n\n return render_template(\"login.html\")\n\n@access_bp.route(\"/setup\", methods=[\"GET\", \"POST\"])\ndef setup():\n # Shouldn't be able to setup token if already set\n if config.SETUP_REQUIRED == False:\n return \"Setup already completed\"\n\n if request.method == \"POST\":\n token = request.form.get(\"token\")\n key,salt = generate_hash(token)\n access_db.query(\"INSERT INTO tokens VALUES (?,?)\", (key,salt), True)\n config.SETUP_REQUIRED = False\n return redirect(url_for(\".login\"))\n\n return render_template(\"setup.html\")\n"
},
{
"alpha_fraction": 0.5172004699707031,
"alphanum_fraction": 0.518386721611023,
"avg_line_length": 29.10714340209961,
"blob_id": "268db76b989a86e28b531b83e0e7939ecc0b50f0",
"content_id": "3299ce8d1d1898b287a7db54f70259b38b732249",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 843,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 28,
"path": "/db/Database.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "import sqlite3 as sql\nimport logging\n\nclass Database:\n def __init__(self, path):\n # I don't know if I'm doing the logging right :)\n logging.basicConfig(level=logging.DEBUG)\n self.logger = logging.getLogger(__name__)\n self.path = path\n\n def query(self,query, params=(), commit=False):\n rows = []\n try:\n with sql.connect(self.path) as con:\n con.row_factory = sql.Row\n cur = con.cursor()\n cur.execute(query, params)\n\n # If we're running insert or update we commit and don't return anything\n if commit:\n con.commit()\n else:\n rows = cur.fetchall()\n con.close()\n except Exception as e:\n self.logger.exception(e)\n\n return rows\n"
},
{
"alpha_fraction": 0.7542856931686401,
"alphanum_fraction": 0.7542856931686401,
"avg_line_length": 28.33333396911621,
"blob_id": "2cf8859c2d0b45f3ba7412c620d6203dd686b884",
"content_id": "01cbc3af474ae1122765d7b27615b12c28663951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 6,
"path": "/db/__init__.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "from .Database import Database\nimport config\n\n# List of databases (you can create your own here!)\naccess_db = Database(config.ACCESS_DB_PATH)\n# my_db = Database(\"database.db\")"
},
{
"alpha_fraction": 0.5587761402130127,
"alphanum_fraction": 0.5974234938621521,
"avg_line_length": 27.227272033691406,
"blob_id": "b486f175ca972626e5c4a7c59bff70dfac297c42",
"content_id": "11f4f1d9d90dfdfc589fb8a232f53b1b829ee54b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 621,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 22,
"path": "/util.py",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "from secrets import token_bytes\nfrom db import access_db\nimport hashlib\n\n# ----- ACCESS HELPER FUNCTIONS -----\ndef generate_hash(content):\n salt = token_bytes(32)\n key = hashlib.pbkdf2_hmac('sha256', content.encode('utf-8'), salt, 100000)\n\n return (key,salt)\n\ndef verify_access(token):\n rows = access_db.query(\"SELECT token_hash,salt FROM tokens\")\n\n for r in rows:\n curSalt = r[\"salt\"]\n temp_key = hashlib.pbkdf2_hmac('sha256', token.encode('utf-8'), curSalt, 100000)\n if temp_key == r[\"token_hash\"]:\n return True \n \n return False\n# ----- ---------------------- -----\n"
},
{
"alpha_fraction": 0.730526328086853,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 18.79166603088379,
"blob_id": "af7587cb88729e7b313ff94871ef237e70546609",
"content_id": "24156161afd10577e895ed94fa3e231feb6cbbff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 950,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 48,
"path": "/README.md",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "# Password Protected Website Template\n\nTemplate repository to create websites that required a password to access. You may want only certain people to access the website but still want the website to be open publicly.\n\nBuilt with:\n\n- Python 3\n- Flask\n- SQLite\n\n## Environment variables\n\nCheck out \".env.sample\" file\n\n**ENABLE_TOKEN**\n\n- Values: True | False\n - Default: True \n- Description: Enable the password protection\n\n**ACCESS_DB_PATH**\n- Values: String of path\n - Default: access.db\n- Description: Path of the database file\n\n## Deployment\n\n### Manual\n\n*Should only be used for testing*\n\nInstall dependencies \n\n pip install -r requirements.txt\n\nEnsure you initialise your SQLite database using the `init.sql` script before running app\n\n sqlite3 access.db < init.sql\n\nRun `main.py`\n\n python main.py\n\nApplication will be running on port 8000 (or whatever port you have specified in `main.py`)\n\n### Docker\n\n*Docker file coming soon!*\n"
},
{
"alpha_fraction": 0.5021459460258484,
"alphanum_fraction": 0.7038626670837402,
"avg_line_length": 16.923076629638672,
"blob_id": "669dd35bfdadd70a08009540659c968cb273dc94",
"content_id": "9681e0af3ec1973288c59e614244835ccc5db77e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 13,
"path": "/requirements.txt",
"repo_name": "Solopie/password-protected-website",
"src_encoding": "UTF-8",
"text": "click==8.0.1\nFlask==2.0.1\nitsdangerous==2.0.1\nJinja2==3.0.1\nMarkupSafe==2.0.1\nmypy-extensions==0.4.3\npathspec==0.9.0\nplatformdirs==2.4.0\npython-dotenv==0.19.0\nregex==2021.9.30\ntomli==1.2.1\ntyping-extensions==3.10.0.2\nWerkzeug==2.0.1\n"
}
] | 9 |
abe-winter/mitiewrap
|
https://github.com/abe-winter/mitiewrap
|
a51eded854fea501be80ec8c4176a493467b11e8
|
0cdcfdfbee256958301243ec3f465b0d46ebc9ea
|
4f07752470fbc16a2be8c7eb8d43e10c694034c6
|
refs/heads/master
| 2016-09-06T06:13:27.454730 | 2015-01-18T22:54:27 | 2015-01-18T22:54:27 | 29,315,086 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6434370875358582,
"alphanum_fraction": 0.6488497853279114,
"avg_line_length": 29.79166603088379,
"blob_id": "9c564ad6eebc7339d5bf7beb00b1e53b6653b724",
"content_id": "98c8c6c88206712d811d861712b3c371312f47cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1478,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 48,
"path": "/setup.py",
"repo_name": "abe-winter/mitiewrap",
"src_encoding": "UTF-8",
"text": "\"python wrapper for MIT's information extractor (MITIE)\"\n\nimport os, functools\nfrom distutils.core import setup, Extension\nfrom Cython.Build import cythonize\n\nmitiewrap = Extension(\n 'mitiewrap',\n sources=sum([\n ['mitiewrap.pyx'],\n map(functools.partial(os.path.join,'MITIE/mitielib/src'),[\n 'mitie.cpp',\n 'named_entity_extractor.cpp',\n 'ner_feature_extraction.cpp',\n 'binary_relation_detector.cpp',\n 'binary_relation_detector_trainer.cpp',\n 'stem.c',\n 'stemmer.cpp',\n 'conll_parser.cpp',\n 'ner_trainer.cpp',\n ]),\n map(functools.partial(os.path.join,'MITIE/dlib/dlib/threads'),[\n 'multithreaded_object_extension.cpp',\n 'threaded_object_extension.cpp',\n 'threads_kernel_1.cpp',\n 'threads_kernel_2.cpp',\n 'threads_kernel_shared.cpp',\n 'thread_pool_extension.cpp',\n ]),\n map(functools.partial(os.path.join,'MITIE/dlib/dlib/misc_api'),[\n 'misc_api_kernel_1.cpp',\n 'misc_api_kernel_2.cpp',\n ]),\n ],[]),\n extra_compile_args=['-fpic','-Wall','-W','-O3','-IMITIE/mitielib/include','-IMITIE/dlib'],\n)\n\nsetup(\n name='mitie',\n version='0.0.0',\n description='python wrapper for mitie cpp lib',\n ext_modules=cythonize([mitiewrap]),\n author='Abe Winter',\n author_email='[email protected]',\n url='https://github.com/abe-winter/mitie-py',\n license='MIT (but MITIE is licensed under the boost license)',\n keywords=['MITIE','NER','named entity extraction','information extraction','nlp'],\n)\n"
},
{
"alpha_fraction": 0.6853932738304138,
"alphanum_fraction": 0.7078651785850525,
"avg_line_length": 10.125,
"blob_id": "0ae9ee5832e8b10e56df9b4ca80c5f1d260f78a2",
"content_id": "ee1fec57d2af765c10cbf06fd81ae4bf8ef3d912",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 89,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 8,
"path": "/tox.ini",
"repo_name": "abe-winter/mitiewrap",
"src_encoding": "UTF-8",
"text": "[tox]\nenvlist = py27\n\n[pytest]\nnorecursedirs = env\n\n[testenv]\ncommands = py.test test.py\n"
},
{
"alpha_fraction": 0.7384898662567139,
"alphanum_fraction": 0.7449355721473694,
"avg_line_length": 62.882354736328125,
"blob_id": "8fdf8af75dea41f84843d0eed582c6aa366fa8bb",
"content_id": "f50ab4fc95df2558ca14a17c8e7d7eede359a037",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1086,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 17,
"path": "/test.py",
"repo_name": "abe-winter/mitiewrap",
"src_encoding": "UTF-8",
"text": "\"\"\"This is exercising the wrapper, not testing model accuracy.\nThis assumes you've downloaded http://sourceforge.net/projects/mitie/files/binaries/MITIE-models-v0.2.tar.bz2 to ~/mitie-models and unpacked it there.\n\"\"\"\n# todo: the test should have a tiny corpus on which it trains a tiny model to use as a fixture; not good to have a data dependency\n\nimport os\nimport mitiewrap # note: this will only succeed if the module has been installed. It won't automatically update to changes\n\nMODELS_PATH = os.path.expanduser('~/mitie-models/english/ner_model.dat')\n\ndef test_tokenize():\n assert mitiewrap.tokenize('It was the best of times, it was the worst of times.')==['It','was','the','best','of','times',',','it','was','the','worst','of','times','.']\n\ndef test_ner():\n ner = mitiewrap.NamedEntityExtractor(MODELS_PATH)\n tags = ner.extract_entities(mitiewrap.tokenize('Later that month in Chicago, the Council on Foreign Relations met to decide how to avert a second recession in the 2010s.'))\n assert all(isinstance(slice_,slice) and isinstance(tag,basestring) for slice_,tag in tags)\n"
},
{
"alpha_fraction": 0.7678207755088806,
"alphanum_fraction": 0.7678207755088806,
"avg_line_length": 27.882352828979492,
"blob_id": "97a14bf600be41394ede2eea86be3c39162b81e5",
"content_id": "b7e29264bd9055ca4a3d7fd7ed4cd2d228de670f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 491,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 17,
"path": "/README.md",
"repo_name": "abe-winter/mitiewrap",
"src_encoding": "UTF-8",
"text": "# mitiewrap\n\nMITIE is a C++ library for named entity recognition with a permissive license. More here: https://github.com/mit-nlp/mitie\n\nThis is a python wrapper for MITIE. MITIE already has a python wrapper, but this one is pip-compatible (sdist and bdist).\n\n# installation\n```shell\ngit clone --recursive https://github.com/abe-winter/mitiewrap.git\ncd mitiewrap\nvirtualenv env\npip install cython # needs to present for setup to run\npython -m setup install\n```\n\n# issues\nNot heavily tested.\n"
}
] | 4 |
amandagodoy/python3
|
https://github.com/amandagodoy/python3
|
040d739cc603716613a6fc1431a39790ed56b70c
|
3e900af66950ea14953c3bcedfb9fbc5abd0fb0d
|
b4f3f262fb8025abf139f4a437a15172238fc31f
|
refs/heads/main
| 2023-03-07T20:12:58.599237 | 2021-02-22T12:04:46 | 2021-02-22T12:04:46 | 341,186,697 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5575757622718811,
"alphanum_fraction": 0.5787878632545471,
"avg_line_length": 30.967741012573242,
"blob_id": "764ef5307bbbaac7ab75d90d393524aa15987f03",
"content_id": "d3495b38de89c7e4a7b622ee01c4072f2ec10980",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1000,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 31,
"path": "/jogos/for-adivinha.py",
"repo_name": "amandagodoy/python3",
"src_encoding": "UTF-8",
"text": "print(\"**********************************\")\nprint(\"bem vindos ao jogo de adivinhação!\")\nprint(\"**********************************\")\n\n\nnumero_secreto = 42\ntotal_de_tentativas = 3\n\nfor rodada in range(1, total_de_tentativas + 1):\n print(\"Tentativas {} de {}\".format(rodada, total_de_tentativas))\n chute = int(input(\"Digite um valor entre 1 e 100: \"))\n print(\"VocÊ digitou \", chute)\n#valores c/ ponto flutuante pode ser usado \"R$ {:.2f}\".format(1.59)\n if(chute < 1 or chute > 100): #or || and\n print(\"Warning: É necessário digitar valores entre 1 e 100!\")\n continue\n\n acertou = numero_secreto == chute\n maior = chute > numero_secreto\n menor = chute < numero_secreto\n\n if(acertou):\n print(\"Você acertou\")\n break\n else:\n if(maior):\n print(\"Você errou! O seu chute foi maior do que o número secreto\")\n elif(menor):\n print(\"Você errou! O seu chute foi menor do que o número secreto\")\n\nprint(\"Fim de jogo!\")"
},
{
"alpha_fraction": 0.4607645869255066,
"alphanum_fraction": 0.46881288290023804,
"avg_line_length": 21.636363983154297,
"blob_id": "69431692989972c220f936d3b7d74703de748439",
"content_id": "8ddb18304919814805d839bbfbd562a4c358bae1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 22,
"path": "/jogos/jogo.py",
"repo_name": "amandagodoy/python3",
"src_encoding": "UTF-8",
"text": "import forca\nimport adivinhacaoniveis\n\ndef escolher_jogo():\n print(\"**********************************\")\n print(\"********Choice your game!*********\")\n print(\"**********************************\")\n\n\n print(\"(1) hangman (2) divination\")\n\n jogo = int(input(\"Qual jogo?\"))\n\n if(jogo == 1):\n print(\"jogando hangman\")\n forca.jogar()\n elif(jogo == 2):\n print(\"jogando divination\")\n adivinhacaoniveis.jogar()\n\nif(__name__ == \"__main__\"):\n escolher_jogo()"
},
{
"alpha_fraction": 0.33039647340774536,
"alphanum_fraction": 0.33039647340774536,
"avg_line_length": 19.636363983154297,
"blob_id": "e21c2305f9190249a3071de4f0eb7e4055e4a346",
"content_id": "f3f9cbeae12871ca283e8d430b913a9525e24b99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 11,
"path": "/jogos/forca.py",
"repo_name": "amandagodoy/python3",
"src_encoding": "UTF-8",
"text": "\ndef jogar():\n print(\"**********************************\")\n print(\"***Welcome in the hangman game!***\")\n print(\"**********************************\")\n\n\n\n print(\"Fim de jogo!\")\n\nif(__name__ == \"__main__\"):\n jogar()"
}
] | 3 |
alxsoares/project-euler-3
|
https://github.com/alxsoares/project-euler-3
|
e10d290c353e55eeff7b5028018fd99a1af9dce4
|
87de3745f1f5ad00c9379395b4c2780351208cc3
|
bd18696d1c0f9a28a1774e0fec89b3f2e00ee676
|
refs/heads/master
| 2021-01-01T20:49:55.384784 | 2017-07-20T13:58:19 | 2017-07-20T13:58:19 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.37637564539909363,
"alphanum_fraction": 0.44167277216911316,
"avg_line_length": 18.753623962402344,
"blob_id": "7c0c6fa5ac5f8d6a756d0810d23cfc4af8c96141",
"content_id": "bc229e0393e29b681d437583169fcfded86035cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1363,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 69,
"path": "/project-euler/546/euler_546_v1.py",
"repo_name": "alxsoares/project-euler-3",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nimport sys\nif sys.version_info > (3,):\n long = int\n xrange = range\n\n\nsum_cache = {}\nk = 2\n\n\ndef _reset(new_k):\n \"\"\"reset the caches.\"\"\"\n global k, sum_cache\n sum_cache = {(-1): 0, 0: 1}\n k = new_k\n return\n\n\n_reset(2)\n\n# s(n) = sum_k=0^k=n(f(k)) = f(0)+f(1)+f(2)...+f(n)\n# f(n) = s(n)-s(n-1)\n# s(n) = f(kn) / k\n# f(n) = [ f(k(n+1)) - f(kn) ] / k\n# f(kn) = k * s(n)\n# s(kn)-s(kn-1) = k * s(n)\n#\n# For k=2:\n# s(2n) = s(n) + s(n/2) * 2 * n + 2 * n * f(n/2+1) + 2 * (n-2) * f(n/2+2) +\n# 2 * (n-4) * f(n/2+3) ... + 2 * f(n) =\n# s(2n) = s(n) + s(n/2) * 2 * n + 2 * n * [s(n/2+2)-s(n/2-1)] +\n# 2 * (n-2) * [s(n/2+3)-s(n/2+2)] ... + 2 * [s(n+1) - s(n)] =\n# s(2n) = s(n) + s(n/2) * 2 * n +\n\n\ndef my_s(n):\n global sum_cache, k\n if n not in sum_cache:\n x = int(n/k)\n sum_cache[n] = long(((my_s(n-1)) << 1)-my_s(n-2) + my_s(x)-my_s(x-1))\n return sum_cache[n]\n\n\ndef f(n):\n return my_s(n)-my_s(n-1)\n\n\ndef calc(new_k, n):\n _reset(new_k)\n for i in xrange(n):\n f(i)\n return f(n)\n\n\ndef is_good(k, n, expected):\n got = calc(k, n)\n if got != expected:\n print(\"f_%d(%d) = %d != %d\" % (k, n, got, expected))\n raise Exception\n return\n\n\nis_good(5, 10, 18)\nis_good(7, 100, 1003)\nis_good(2, 1000, long('264830889564'))\n\nfor i in xrange(1000):\n print((\"f(%d) = %d\") % (i, f(i)))\n"
},
{
"alpha_fraction": 0.4356093406677246,
"alphanum_fraction": 0.4459809958934784,
"avg_line_length": 27.219512939453125,
"blob_id": "2ec1169f3ceb5c310e905117152bd94a19f36912",
"content_id": "05e45a4d5726963f57c327fb9cba911b944735c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1157,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 41,
"path": "/project-euler/518/gen-pivots.py",
"repo_name": "alxsoares/project-euler-3",
"src_encoding": "UTF-8",
"text": "import re\nimport sys\n\nif sys.version_info > (3,):\n long = int\n\n\ndef main():\n factor_counts = {}\n by_pivots = {}\n l_re = re.compile(r'^[0-9]+: ([0-9 ]+)$')\n with open('./factored.txt') as fh:\n for line in fh:\n l = line.rstrip('\\n')\n m = l_re.match(l)\n if not m:\n raise BaseException\n factors = m.group(1).split(' ')\n for f in factors:\n if f not in factor_counts:\n factor_counts[f] = 0\n factor_counts[f] += 1\n pivot = factors[-1]\n if pivot not in by_pivots:\n by_pivots[pivot] = []\n by_pivots[pivot].append(l)\n for pivot, numbers in by_pivots.iteritems():\n filtered = []\n for l in numbers:\n if all(factor_counts[x] > 2 for x\n in l_re.match(l).group(1).split(' ')):\n filtered.append(l)\n if len(filtered) > 0:\n with open('./by-pivot-factor/%s.txt' % (pivot), 'w') as o:\n for l in filtered:\n o.write(l + \"\\n\")\n return\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 2 |
Whoam11/MacMan
|
https://github.com/Whoam11/MacMan
|
c4196ab0d49039ba2df4b92344746f87a56c6be8
|
3d8dd1c740d8a31212d3c6ade84a56f7076f6789
|
f7975fde7ad22654409eaaf4830600d2be1a6fea
|
refs/heads/master
| 2020-07-14T07:20:27.410571 | 2019-08-30T00:15:07 | 2019-08-30T00:15:07 | 205,271,827 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7932960987091064,
"alphanum_fraction": 0.7932960987091064,
"avg_line_length": 28.83333396911621,
"blob_id": "1813ea8976f9c45669148628f6323a6e9bb93c67",
"content_id": "957042f58f7532120d47ea54e631837aefded481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Whoam11/MacMan",
"src_encoding": "UTF-8",
"text": "# MacMan\nSimple Python Mac Address Changer\n\n\nThis python script will change your mac address to your desire mac address. Works only for Linux systems!\nScript must be run as root.\n"
},
{
"alpha_fraction": 0.6129032373428345,
"alphanum_fraction": 0.6137303709983826,
"avg_line_length": 26.386363983154297,
"blob_id": "35e7351d4e06c3cdab0b72b496403f4a9c136962",
"content_id": "52c6c6607e08c3b844ec340aa136f99f242d9558",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1209,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 44,
"path": "/macman.py",
"repo_name": "Whoam11/MacMan",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\nimport os\nimport termcolor\nimport time\n\n\ndef change_mac(interf, mac):\n#Sending commands to change the mac address\n \n os.system(\"ifconfig \" + interf + \" down\")\n print \"[+] Interface Down\"\n os.system(\"ifconfig \" + interf + \" hw\" + \" ether \" + mac )\n print \"[+] Mac address got changed!\"\n os.system(\"ifconfig \" + interf + \" up\")\n print \"[+] Interface Up!\"\n\n\n\n\ndef main():\n\n print termcolor.colored(\"MacMan - Mac Address Changer\", \"green\")\n time.sleep(2)\n print termcolor.colored(\"[!] Make sure to run it as root!\", \"red\")\n getin = termcolor.colored(\"[*] Enter Interface To Change Mac Addres On: \", \"blue\")\n interface = raw_input(getin)\n mc = termcolor.colored(\"[*] Enter Mac Address To change To: \", \"blue\")\n new_mac_ad = raw_input(mc)\n \n \n\n bf = os.system(\"ifconfig \" + interface)\n change_mac(interface,new_mac_ad)\n termcolor.colored(\"[*] Checking New Mac Address\", \"blue\")\n after = os.system(\"ifconfig \" + interface)\n \n \n if bf == after:\n termcolor.colored(\"[!] Failed To Change Mac Address\", \"blue\")\n else:\n termcolor.colored(\"[+] Mac Address Got Change With New Mac \" + new_mac + \" Address!\")\n \nmain()\n \n"
}
] | 2 |
yoh786/HFHSpy
|
https://github.com/yoh786/HFHSpy
|
d47f8497e7a6b080a6d1124d8279c826e4afea87
|
ac6bca18b66cba19ed46ec7b9f701dc58b53fd80
|
fcf73787c130477feacd53ff2a773073009a280c
|
refs/heads/master
| 2020-09-21T23:13:08.144512 | 2019-12-25T07:35:07 | 2019-12-25T07:35:07 | 224,968,306 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6596194505691528,
"alphanum_fraction": 0.6744186282157898,
"avg_line_length": 25.705883026123047,
"blob_id": "0dbc466e96c80b29b68915c885c3b17d652d49d4",
"content_id": "1a05e4b5210eb40dbd4e7318b46f1ed48f90715e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 17,
"path": "/hworldParse.py",
"repo_name": "yoh786/HFHSpy",
"src_encoding": "UTF-8",
"text": "import time\r\nprint(\"init parser\")\r\n\r\n#remember filepath runs from root directory of Python? or OS?\r\n#defintely python in our case \r\nfilepath = 'yoScripts/twocities.txt'\r\n\r\n#note in below that we need to specify encoding or else it fails with charmap error\r\nwith open(filepath, encoding=\"utf-8\") as fp:\r\n\tline = fp.readline()\r\n\tnumwords = 0\r\n\tcnt = 1\r\n\twhile line:\r\n\t\tprint(\"Line {}: {}\".format(cnt, line.strip()))\r\n\t\ttime.sleep(.125)\r\n\t\tline = fp.readline()\r\n\t\tcnt += 1\r\n\t\t"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.7259259223937988,
"avg_line_length": 37.42856979370117,
"blob_id": "81bcd7e71ad1bd9da424bc1c13e9c33f028fffe6",
"content_id": "8aa71f1c2a68b86a582f3539d259d15d35f84e42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 7,
"path": "/snip.py",
"repo_name": "yoh786/HFHSpy",
"src_encoding": "UTF-8",
"text": "\n#here is a list\nalist = [\"name\", \"KB3456 - there are extraenuous characters after the first 6\", \"another field\"]\n#now we will take one of the strings from the list and then only keep a few of the characters.\nstrip = alist[1]\nparse = strip[:6]\nprint(strip)\nprint(parse)\n"
},
{
"alpha_fraction": 0.5678704977035522,
"alphanum_fraction": 0.5778331160545349,
"avg_line_length": 19.70270347595215,
"blob_id": "10b8ab2d74230e7e1f0e683733b7b1ac79164eae",
"content_id": "0e55d315b1d7d3295d2b13995351ddb5fb0beb6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 803,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 37,
"path": "/Playground.py",
"repo_name": "yoh786/HFHSpy",
"src_encoding": "UTF-8",
"text": "sumlist = []\r\n\r\nfor x in range (10):\r\n sumlist.append(str(x))\r\n\r\nprint(str(sumlist))\r\n\r\ndef split_list(alist, size):\r\n list_of_lists = []\r\n while len(alist) > size:\r\n abit = alist[:size]\r\n list_of_lists.append(abit)\r\n alist = alist[size:]\r\n list_of_lists.append(alist)\r\n return list_of_lists\r\n\r\ndef a_new_dict(alist):\r\n new_object = {}\r\n new_object[\"first\"] = alist[0]\r\n new_object[\"second\"] = alist[1]\r\n new_object[\"third\"] = alist[2]\r\n new_object[\"fourth\"] = alist[3]\r\n new_object[\"fifth\"] = alist[4]\r\n print(str(new_object))\r\n return new_object\r\n\r\nanswer = split_list(sumlist, 5)\r\nprint(str(answer))\r\n\r\nendArray = []\r\n\r\nfor v in answer:\r\n print(\"mark\")\r\n one_obj = a_new_dict(v)\r\n endArray.append(one_obj)\r\n\r\nprint(str(endArray))\r\n"
},
{
"alpha_fraction": 0.5881447196006775,
"alphanum_fraction": 0.5966127514839172,
"avg_line_length": 23.47058868408203,
"blob_id": "5bff8a400064d9a19ad5c13404329cb1583d8c5b",
"content_id": "528c2a9adc88e21932891c9a9a5d9b1900a6638e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 51,
"path": "/prod.py",
"repo_name": "yoh786/HFHSpy",
"src_encoding": "UTF-8",
"text": "#INIT VARS\r\ndesiredresult = []\r\nlistresult = []\r\n\r\ndef split_list(alist, size):\r\n list_of_lists = []\r\n while len(alist) > size:\r\n abit = alist[:size]\r\n list_of_lists.append(abit)\r\n alist = alist[size:]\r\n list_of_lists.append(alist)\r\n return list_of_lists\r\n\r\ndef a_new_dict(alist):\r\n new_object = {}\r\n new_object[\"Article Name\"] = alist[0]\r\n kbcut = alist[1]\r\n kb = kbcut[:7]\r\n new_object[\"KB Number\"] = kb\r\n new_object[\"Description\"] = alist[2]\r\n print(str(new_object))\r\n return new_object\r\n#END VARS\r\n#set filepath\r\nfilepath = 'entriesshort.txt'\r\n#Open file, push lines to an array\r\nwith open(filepath, encoding=\"utf-8\") as fp:\r\n line = fp.readline()\r\n cnt = 1\r\n while line:\r\n popin = line.strip()\r\n listresult.append(popin)\r\n print(\".\")\r\n line = fp.readline()\r\n cnt += 1\r\n print(\"done with line loop\")\r\n#split said array\r\nlines_per_object = 4\r\nanswer = split_list(listresult, lines_per_object)\r\n#convert Lists to Dictionaries\r\ncount = 0\r\nfor e in answer:\r\n print(\"{} made\".format(str(count)))\r\n one_entry = a_new_dict(e)\r\n desiredresult.append(one_entry)\r\n count += 1\r\n#output a file\r\nf = open(\"result.txt\", \"a\", encoding=\"utf-8\")\r\nf.write(str(desiredresult))\r\nf.close()\r\n#el fin\r\n"
}
] | 4 |
alishalabi/herd-immunity
|
https://github.com/alishalabi/herd-immunity
|
4e26ac673a303a5be8e5fcaef569bf387851d48a
|
53585fb07c4f41eac2d1a41f197186bd96eedec2
|
19f150d2b4540b618b4467592615a39ba8d594c1
|
refs/heads/master
| 2020-03-30T21:05:04.700833 | 2018-10-15T18:40:37 | 2018-10-15T18:40:37 | 151,616,006 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6991304159164429,
"alphanum_fraction": 0.7078260779380798,
"avg_line_length": 30.94444465637207,
"blob_id": "dbc8be03c2cbaf9171d87e65ad808151c0e0f94d",
"content_id": "a58e768413931ce78200ee4b76133d1fff4d14ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1150,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 36,
"path": "/virus.py",
"repo_name": "alishalabi/herd-immunity",
"src_encoding": "UTF-8",
"text": "class Virus(object):\n '''\n Because every one of our simulations and tests will be\n utilizing specific virus paramters, it will be helpful\n for us to create a simple Virus class to minimize\n boilerplate code\n Plus... it is good practice :)\n\n We will be passing an intialize method into this class,\n taking in the following parameters:\n\n name: the name of the virus\n mortality_rate: the deadliness of the virus\n contagiousness: the contagiousness of the virus\n\n In our simulations, we will be using statistics from:\n https://www.theguardian.com/news/datablog/ng-interactive/2014/oct/15/visualised-how-ebola-compares-to-other-infectious-diseases\n\n We will also include a simple test to see if our viruse\n objects are properly being created\n '''\n\n def __init__(self, name, mortality_rate, contagiousness):\n self.name = name\n self.mortality_rate = mortality_rate\n self.contagiousness = contagiousness\n\n\ndef test_was_virus_created():\n virus = Virus(\"HIV\", 0.8, 3.5)\n print(virus.name)\n print(virus.mortality_rate)\n print(virus.contagiousness)\n\n\n# test_was_virus_created()\n"
},
{
"alpha_fraction": 0.6615201830863953,
"alphanum_fraction": 0.6698337197303772,
"avg_line_length": 31.384614944458008,
"blob_id": "26a008c1bc6e8c9421527a1aeeb7737b404e99f8",
"content_id": "1fac351df628fe10e72b87a8214236fb8db2e510",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 842,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 26,
"path": "/person_test.py",
"repo_name": "alishalabi/herd-immunity",
"src_encoding": "UTF-8",
"text": "import unittest\n# import virus.py\n# Still need to install\nimport person\n\n\nclass PersonTest(unittest.TestCase):\n def test_is_alive_and_is_vaccinated(self):\n testPerson = person.Person(1, True)\n assert testPerson.is_vaccinated == True\n assert testPerson.is_alive == True\n\n def test_is_alive_and_is_not_vaccinated(self):\n testPerson = person.Person(1, False)\n assert testPerson.is_vaccinated == False\n assert testPerson.is_alive == True\n\n def test_died_from_infection(self):\n testPerson = person.Person(1, False, 1.1)\n testPerson.did_survive_infection()\n assert testPerson.is_alive == False\n\n def test_did_not_die_from_infection(self):\n testPerson = person.Person(1, False, 0)\n testPerson.did_survive_infection()\n assert testPerson.is_alive == True\n"
}
] | 2 |
briefmnews/django-ip-access
|
https://github.com/briefmnews/django-ip-access
|
9c95b79e86e90730804bd137f76ef9c7e8a7f626
|
55d5ce8068f3f9ff99f817aa389e398a7c54b4ae
|
7aad29b5ea153c9af6f963a423ba137cd908f55f
|
refs/heads/master
| 2023-07-27T02:57:16.394186 | 2023-05-05T14:18:14 | 2023-05-05T14:18:14 | 206,255,606 | 1 | 0 | null | 2019-09-04T07:12:31 | 2022-06-20T13:25:55 | 2023-07-05T23:26:43 |
Python
|
[
{
"alpha_fraction": 0.6159822344779968,
"alphanum_fraction": 0.6259711384773254,
"avg_line_length": 32.37036895751953,
"blob_id": "b8ba2b044cbaff8aba3c220f6a25a753a647d1c5",
"content_id": "c4c20b21254d965b939f330dcf95698b49e27525",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 901,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 27,
"path": "/setup.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nfrom django_ip_access import __version__\n\nsetup(\n name=\"django-ip-access\",\n version=__version__,\n description=\"Access a Django app with authorized IP address\",\n url=\"https://github.com/briefmnews/django-ip-access\",\n author=\"Brief.me\",\n author_email=\"[email protected]\",\n packages=[\"django_ip_access\", \"django_ip_access.migrations\"],\n python_requires=\">=3.7\",\n install_requires=[\"Django>=3.2\", \"django-ipware>=2.1\"],\n classifiers=[\n \"Environment :: Web Environment\",\n \"Framework :: Django\",\n \"Framework :: Django :: 3.2\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3\",\n ],\n include_package_data=True,\n zip_safe=False,\n)\n"
},
{
"alpha_fraction": 0.7051886916160583,
"alphanum_fraction": 0.7051886916160583,
"avg_line_length": 23.941177368164062,
"blob_id": "502af0851da2089845edac655e59b2bc4e1948af",
"content_id": "dbea675d1b81cd36e67a487d5b2e617d870f2b18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/django_ip_access/admin.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin, messages\n\nfrom .forms import EditIpAddressForm\nfrom .models import EditIpAddress\n\n\nclass EditIpAddressAdmin(admin.ModelAdmin):\n raw_id_fields = (\"user\",)\n list_select_related = (\"user\",)\n list_display = (\"ips\", \"user\")\n ordering = (\"user__email\",)\n search_fields = (\"ips\", \"user__email\")\n\n form = EditIpAddressForm\n\n\nadmin.site.register(EditIpAddress, EditIpAddressAdmin)\n"
},
{
"alpha_fraction": 0.6835066676139832,
"alphanum_fraction": 0.6835066676139832,
"avg_line_length": 28.2608699798584,
"blob_id": "71aec4165049c603673c4d854fd5d844f7267c95",
"content_id": "7630c15672f3a457a41951daeb0b9cfd59e8ee2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 23,
"path": "/django_ip_access/middleware.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import login\nfrom ipware import get_client_ip\n\nfrom .backends import IpAccessBackend\n\n\nclass IpAccessMiddleware:\n \"\"\"Middleware that allows Ip address authentication\"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def __call__(self, request):\n if request.user and request.user.is_authenticated:\n return self.get_response(request)\n\n ip, is_routable = get_client_ip(request)\n user = IpAccessBackend.authenticate(request, ip=ip)\n\n if user:\n login(request, user, backend=\"django_ip_access.backends.IpAccessBackend\")\n\n return self.get_response(request)\n"
},
{
"alpha_fraction": 0.6157728433609009,
"alphanum_fraction": 0.6157728433609009,
"avg_line_length": 25.86440658569336,
"blob_id": "291bcab66c1daf132ac03bf9eda4cb7ef196213d",
"content_id": "60230febf2a7f65eebe02c91445d7c2bc19faadf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1585,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 59,
"path": "/django_ip_access/models.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import ipaddress\n\nfrom django.db import models\n\nfrom django.contrib.auth import get_user_model\n\nUser = get_user_model()\n\n\nclass EditIpAddress(models.Model):\n ips = models.TextField()\n user = models.OneToOneField(User, on_delete=models.CASCADE)\n\n class Meta:\n verbose_name = \"Edit Authorized IP address\"\n verbose_name_plural = \"Edit Authorized IP addresses\"\n\n def __str__(self):\n return str(self.user)\n\n def _generate_ips_list(self):\n ips_list = []\n for ip in self.ips.split():\n try:\n ips_list.append(str(ipaddress.ip_address(ip)))\n except ValueError:\n ips_list += [str(el) for el in ipaddress.ip_network(ip).hosts()]\n\n return ips_list\n\n def save(self, *args, **kwargs):\n self.ipaddress_set.all().delete()\n\n super().save(*args, **kwargs)\n\n ips_list = self._generate_ips_list()\n\n ip_addresses_to_create = []\n for ip in ips_list:\n ip_addresses_to_create.append(\n IpAddress(user=self.user, ip=ip, edit_ip_address=self)\n )\n\n IpAddress.objects.bulk_create(ip_addresses_to_create)\n\n\nclass IpAddress(models.Model):\n ip = models.GenericIPAddressField(unique=True)\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n edit_ip_address = models.ForeignKey(\n \"EditIpAddress\", on_delete=models.CASCADE, null=True\n )\n\n class Meta:\n verbose_name = \"Authorized IP address\"\n verbose_name_plural = \"Authorized IP addresses\"\n\n def __str__(self):\n return self.ip\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 17,
"blob_id": "54d2f941d5970211088b2861dff651e701a5379c",
"content_id": "3db1c54b1485e8bb0b111baef37a861bb4113c0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/requirements.txt",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "Django==3.2.19\ndjango-ipware==5.0.0\n"
},
{
"alpha_fraction": 0.6496815085411072,
"alphanum_fraction": 0.6496815085411072,
"avg_line_length": 28.4375,
"blob_id": "c370b0c78475fdb63c9c645fbf6ccf76c236aefe",
"content_id": "5fdd9315924b08f40e2c6c881f032dd6d9aacea7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1413,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 48,
"path": "/tests/test_middleware.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom django_ip_access.middleware import IpAccessMiddleware\n\npytestmark = pytest.mark.django_db\n\n\nclass TestIpAccessMiddleware:\n @staticmethod\n def test_init():\n # GIVEN / WHEN\n ip_access_middleware = IpAccessMiddleware(\"dump response\")\n\n # THEN\n assert ip_access_middleware.get_response == \"dump response\"\n\n def test_anonymous_user_without_existing_ip_address(self, request_builder):\n request = request_builder.get\n ip_access_middleware = IpAccessMiddleware(request)\n\n ip_access_middleware(request())\n\n assert ip_access_middleware.get_response().path == \"/\"\n\n def test_anonymous_user_with_existing_ip_address(self, ip, mocker, request_builder):\n # GIVEN\n request = request_builder.get\n ip_access_middleware = IpAccessMiddleware(request)\n\n # WHEN\n mocker.patch(\n \"django_ip_access.middleware.get_client_ip\", return_value=(ip.ip, False)\n )\n ip_access_middleware(request())\n\n # THEN\n assert ip_access_middleware.get_response().path == \"/\"\n\n def test_authenticated_user(self, user, request_builder):\n # GIVEN\n request = request_builder.get\n ip_access_middleware = IpAccessMiddleware(request)\n\n # WHEN\n ip_access_middleware(request(user=user))\n\n # THEN\n assert ip_access_middleware.get_response().path == \"/\"\n"
},
{
"alpha_fraction": 0.4385061264038086,
"alphanum_fraction": 0.45911139249801636,
"avg_line_length": 30.059999465942383,
"blob_id": "f746dd24efe389269a263b16280f12cf6a90908c",
"content_id": "9fef095f67c7d3447c8b1dd2bdd5374b6311cf5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1553,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 50,
"path": "/django_ip_access/migrations/0003_auto_20200320_1148.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.11 on 2020-03-20 10:48\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n (\"django_ip_access\", \"0002_auto_20200204_1233\"),\n ]\n\n operations = [\n migrations.CreateModel(\n name=\"EditIpAddress\",\n fields=[\n (\n \"id\",\n models.AutoField(\n auto_created=True,\n primary_key=True,\n serialize=False,\n verbose_name=\"ID\",\n ),\n ),\n (\"ips\", models.TextField()),\n (\n \"user\",\n models.OneToOneField(\n on_delete=django.db.models.deletion.CASCADE,\n to=settings.AUTH_USER_MODEL,\n ),\n ),\n ],\n options={\n \"verbose_name\": \"Edit Authorized IP address\",\n \"verbose_name_plural\": \"Edit Authorized IP addresses\",\n },\n ),\n migrations.AddField(\n model_name=\"ipaddress\",\n name=\"edit_ip_address\",\n field=models.ForeignKey(\n null=True,\n on_delete=django.db.models.deletion.CASCADE,\n to=\"django_ip_access.EditIpAddress\",\n ),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7113950848579407,
"alphanum_fraction": 0.7113950848579407,
"avg_line_length": 20.340909957885742,
"blob_id": "87960c587e56324bb29e9ea2e88d1b8b5d337f56",
"content_id": "aa6ff84efe6e1457d02f44b7e1b7ae309eb3500b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 44,
"path": "/tests/conftest.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom django.contrib.auth.models import AnonymousUser\nfrom django.contrib.sessions.middleware import SessionMiddleware\nfrom django.test import RequestFactory\n\nfrom .factories import EditIpAddressFactory, IpAddressFactory, UserFactory\n\n\[email protected]\ndef user():\n return UserFactory()\n\n\[email protected]\ndef ip():\n user = UserFactory()\n return IpAddressFactory(user=user)\n\n\[email protected]\ndef edit_ip():\n user = UserFactory()\n return EditIpAddressFactory(user=user)\n\n\[email protected]\ndef request_builder():\n \"\"\"Create a request object\"\"\"\n return RequestBuilder()\n\n\nclass RequestBuilder(object):\n @staticmethod\n def get(path=\"/\", user=None):\n rf = RequestFactory()\n request = rf.get(path)\n request.user = user or AnonymousUser()\n\n middleware = SessionMiddleware(\"dummy\")\n middleware.process_request(request)\n request.session.save()\n\n return request\n"
},
{
"alpha_fraction": 0.6325823068618774,
"alphanum_fraction": 0.6325823068618774,
"avg_line_length": 22.079999923706055,
"blob_id": "e9c28f7e41694b1ae53e8988588f01bfec52c179",
"content_id": "50b586b24273eaac7801ecf311e1c9e41dc242a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 25,
"path": "/django_ip_access/backends.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import get_user_model\n\nfrom .models import IpAddress\n\nUser = get_user_model()\n\n\nclass IpAccessBackend:\n \"\"\"Authentication with IP address\"\"\"\n\n @staticmethod\n def authenticate(request, ip=None):\n try:\n ip_address = IpAddress.objects.get(ip=ip, user__is_active=True)\n except IpAddress.DoesNotExist:\n return None\n\n return ip_address.user\n\n @staticmethod\n def get_user(user_id):\n try:\n return User.objects.get(pk=user_id)\n except User.DoesNotExist:\n return None\n"
},
{
"alpha_fraction": 0.7165898680686951,
"alphanum_fraction": 0.7281106114387512,
"avg_line_length": 31.388059616088867,
"blob_id": "0f06cb3904af084cd97b94ba4cbf0f986d8d9d5c",
"content_id": "0001bd6a5de5ed7228356228929ca7a4c74e89fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2170,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 67,
"path": "/README.md",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "# django-ip-access\n[](https://www.python.org/downloads/release/python-270/) \n[](https://docs.djangoproject.com/en/3.2/)\n[](https://github.com/briefmnews/django-ip-access/actions/workflows/workflow.yaml)\n[](https://codecov.io/gh/briefmnews/django-ip-access)\n[](https://github.com/psf/black)\n\nAccess a Django app with authorized IP address\n\n\n## Installation\nInstall with [pip](https://pip.pypa.io/en/stable/)\n```shell script\npip install -e git://github.com/briefmnews/django-ip-access.git@master#egg=django_ip_access\n```\n\n\n## Setup \nIn order to make `django-ip-access` works, you'll need to follow the steps below.\n\n### Settings\nFirst you need to add the following to your setings:\n```python\nINSTALLED_APPS = (\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n\n 'django_ip_access',\n ...\n)\n\nMIDDLEWARE_CLASSES = (\n 'django.middleware.common.CommonMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n \n 'django_ip_access.middleware.IpAccessMiddleware',\n ...\n)\n\nAUTHENTICATION_BACKENDS = (\n 'django.contrib.auth.backends.ModelBackend',\n \n 'django_ip_access.backends.IpAccessBackend',\n ...\n)\n```\n\n### Migrations\nNext, you need to run the migrations in order to update your database schema.\n```shell script\npython manage.py migrate\n```\n\n## How to use ?\nOnce you are all set up, when a request to your app is made, the `IpAccessMiddleware` checks\nfor if the IP address of the request exists in the admin panel and\nif the user associated to the IP address is active.\n\n\n## Tests\nTesting is managed by `pytest`. required packages for testing can be installed with:\n```shell script\npytest\n```\n"
},
{
"alpha_fraction": 0.6949569582939148,
"alphanum_fraction": 0.6961869597434998,
"avg_line_length": 26.100000381469727,
"blob_id": "ad610b7334b5325ba84f3c60bbefb19156da4762",
"content_id": "f69e4c9d516991979b0f6827b657aa494c27017d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 813,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 30,
"path": "/tests/test_backends.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom django_ip_access.backends import IpAccessBackend\n\npytestmark = pytest.mark.django_db\n\n\nclass TestIpAccessBackend:\n @staticmethod\n def test_get_user_user_exists(user):\n user = IpAccessBackend.get_user(user.id)\n assert user\n\n @staticmethod\n def test_get_user_without_existing_user(user):\n user = IpAccessBackend.get_user(user.id + 1)\n assert not user\n\n @staticmethod\n def test_authenticate_with_inactive_user(request_builder, user):\n user.is_active = False\n user = IpAccessBackend.authenticate(request_builder.get(user))\n\n assert not user\n\n @staticmethod\n def test_authenticate_with_active_user(request_builder, ip):\n user = IpAccessBackend.authenticate(request_builder.get(ip.user), ip=ip.ip)\n\n assert user\n"
},
{
"alpha_fraction": 0.5513333082199097,
"alphanum_fraction": 0.5526666641235352,
"avg_line_length": 27.846153259277344,
"blob_id": "5099f02a362e0574731fb4c7669b7f7fb6a777cc",
"content_id": "139d30baa918e8030041719494895a7189e90dab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1500,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 52,
"path": "/django_ip_access/forms.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import ipaddress\n\nfrom django import forms\nfrom django.core.exceptions import ValidationError\nfrom django.utils.translation import gettext_lazy as _\n\nfrom .models import EditIpAddress, IpAddress\n\n\nclass EditIpAddressForm(forms.ModelForm):\n class Meta:\n model = EditIpAddress\n help_texts = {\"ips\": _(\"One ip address per row.\")}\n fields = \"__all__\"\n\n def clean_ips(self):\n return self._get_cleaned_ips()\n\n def _get_cleaned_ips(self):\n ips = self.cleaned_data.get(\"ips\")\n\n # Validate ips\n list_ips = []\n\n for ip in ips.split():\n try:\n ipaddress.ip_network(ip)\n except ValueError:\n raise ValidationError(_(f\"{ip} is not well-formatted.\"))\n\n list_ips.append(ip)\n\n # Remove duplicates\n duplicate_ips = set(\n [(ip, list_ips.count(ip)) for ip in list_ips if list_ips.count(ip) > 1]\n )\n for ip, count in duplicate_ips:\n ips = ips.replace(ip, \"\", count - 1)\n\n # Remove existing ips from another user\n for ip in ips.split():\n try:\n ip_address = IpAddress.objects.exclude(\n edit_ip_address=self.instance or None\n ).get(ip=ip)\n raise ValidationError(\n _(f\"{ip_address.ip} already exists for user {ip_address.user}.\")\n )\n except IpAddress.DoesNotExist:\n pass\n\n return ips.strip()\n"
},
{
"alpha_fraction": 0.7685950398445129,
"alphanum_fraction": 0.7685950398445129,
"avg_line_length": 21,
"blob_id": "0cbd073d89683e7ad28241a1e2eca0513816900e",
"content_id": "8168b3cbbdde870da15af2cfd277f2dc6ce5e399",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 11,
"path": "/tests/test_apps.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom django_ip_access.apps import DjangoIpAccessConfig\n\npytestmark = pytest.mark.django_db\n\n\nclass TestDjangoIpAccessConfig:\n @staticmethod\n def test_apps():\n assert \"django_ip_access\" in DjangoIpAccessConfig.name\n"
},
{
"alpha_fraction": 0.7287449240684509,
"alphanum_fraction": 0.7300944924354553,
"avg_line_length": 22.15625,
"blob_id": "7540ca18b6a3067be0b82c2b0ddb2d214c6fba44",
"content_id": "f8589637414b13b5941fbb365e59403e0042870b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 32,
"path": "/tests/factories.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import factory\nfrom faker import Faker\n\nfrom django.contrib.auth import get_user_model\n\nfrom django_ip_access.models import EditIpAddress, IpAddress\n\nfaker = Faker()\n\n\nclass UserFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = get_user_model()\n\n email = factory.Sequence(lambda n: \"hubert{0}@delabatte.fr\".format(n))\n username = email\n\n\nclass EditIpAddressFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = EditIpAddress\n\n user = factory.SubFactory(UserFactory)\n\n\nclass IpAddressFactory(factory.django.DjangoModelFactory):\n class Meta:\n model = IpAddress\n\n ip = faker.ipv4()\n edit_ip_address = factory.SubFactory(EditIpAddressFactory)\n user = factory.SubFactory(UserFactory)\n"
},
{
"alpha_fraction": 0.6173633337020874,
"alphanum_fraction": 0.6205787658691406,
"avg_line_length": 22.037036895751953,
"blob_id": "ff5cc40fb09a82eeafeebe151ed7dae91b1fdbef",
"content_id": "6120c572c250fdb36ec75389e725779e5cd61908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 27,
"path": "/tests/test_models.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom faker import Faker\nfrom django_ip_access.models import IpAddress, EditIpAddress\n\nfaker = Faker()\npytestmark = pytest.mark.django_db\n\n\nclass TestEditIpAddress:\n def test_str(self, edit_ip):\n assert edit_ip.__str__() == str(edit_ip.user)\n\n\nclass TestIpAddress:\n def test_str(self, ip):\n assert ip.__str__() == ip.ip\n\n def test_one_user_can_have_multiple_ip_access(self, ip):\n # GIVEN\n user = ip.user\n\n # WHEN\n second_ip = IpAddress(user=user, ip=faker.ipv4())\n second_ip.save()\n\n # THEN\n assert user.ipaddress_set.all().count() == 2\n"
},
{
"alpha_fraction": 0.5295180678367615,
"alphanum_fraction": 0.5602409839630127,
"avg_line_length": 27.13559341430664,
"blob_id": "293a8b8affd0c84dbfcb8d23dbf0ab31e3fac7aa",
"content_id": "1695bdce5e737bfb6d22f206d0e0b0e9f1553d92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1660,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 59,
"path": "/tests/test_forms.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom django_ip_access.forms import EditIpAddressForm\nfrom django_ip_access.models import IpAddress\n\npytestmark = pytest.mark.django_db\n\n\nclass TestEditIpAddressForm:\n def test_form_works(self, user):\n # GIVEN\n ips = [\"127.0.0.1\", \"127.0.0.2\", \"128.0.0.0/24\"]\n data = {\"ips\": \"\\n\".join(ips), \"user\": user.pk}\n\n # WHEN\n form = EditIpAddressForm(data=data)\n\n # THEN\n assert form.is_valid()\n form.save()\n assert IpAddress.objects.all().count() == 256\n\n def test_form_with_wrong_ip_formatting(self, user):\n # GIVEN\n ips = [\"127.0.0.1\", \"wrong.ip\"]\n data = {\"ips\": \"\\n\".join(ips), \"user\": user.pk}\n\n # WHEN\n form = EditIpAddressForm(data=data)\n\n # THEN\n assert not form.is_valid()\n assert \"wrong.ip is not well-formatted.\" in form.errors[\"ips\"]\n\n def test_remove_duplicates(self, user):\n # GIVEN\n ips = [\"127.0.0.1\", \"127.0.0.1\", \"127.0.0.2\"]\n data = {\"ips\": \"\\n\".join(ips), \"user\": user.pk}\n\n # WHEN\n form = EditIpAddressForm(data=data)\n\n # THEN\n assert form.is_valid()\n form.save()\n assert IpAddress.objects.filter(ip__in=ips).count() == 2\n\n def test_ip_already_exists(self, user, ip):\n \"\"\"Raise a validation error in case the ip exists for another user\"\"\"\n # GIVEN\n ips = [ip.ip]\n data = {\"ips\": \"\\n\".join(ips), \"user\": user.pk}\n\n # WHEN\n form = EditIpAddressForm(data=data)\n\n # THEN\n assert not form.is_valid()\n assert f\"{ip.ip} already exists for user {ip.user}.\" in form.errors[\"ips\"]\n"
},
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 20,
"blob_id": "623a443b12dad23e133d54b0bc32f99858b8b80d",
"content_id": "626cbcb3ccb05d091cde2a589f6dd3ea214c46e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 5,
"path": "/django_ip_access/apps.py",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass DjangoIpAccessConfig(AppConfig):\n name = \"django_ip_access\"\n"
},
{
"alpha_fraction": 0.6761904954910278,
"alphanum_fraction": 0.6761904954910278,
"avg_line_length": 22.33333396911621,
"blob_id": "73904bb233f8c3cac839c72d33d08b55afa9136d",
"content_id": "0ad8c49e0caf9f7bb17c5424c6b1348265e19e0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 18,
"path": "/Makefile",
"repo_name": "briefmnews/django-ip-access",
"src_encoding": "UTF-8",
"text": "clean:\n\trm -rf *.egg-info .pytest_cache\n\trm -rf htmlcov\n\tfind . -name '*.pyc' -delete\n\tfind . -name '__pycache__' -delete\n\ncoverage:\n\tpytest --cov=django_ip_access tests\n\nreport:\n\tpytest --cov=django_ip_access --cov-report=html tests\n\ninstall:\n\tpip install -r test_requirements.txt\n\nrelease:\n\tgit tag -a $(shell python -c \"from django_ip_access import __version__; print(__version__)\") -m \"$(m)\"\n\tgit push origin --tags\n"
}
] | 18 |
pandumagdum/AbstractiveTextSummarization
|
https://github.com/pandumagdum/AbstractiveTextSummarization
|
39d79622cfbc7a1ec69c82163966f592f1921d97
|
8b6c0ea1d17330276ba61e2ed473743b2ccd5fd9
|
09f292c3987ce62ab6e68f381f5d213f283aaf97
|
refs/heads/master
| 2020-07-11T01:18:53.052003 | 2019-02-02T08:05:48 | 2019-02-02T08:05:48 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7523616552352905,
"alphanum_fraction": 0.7746288776397705,
"avg_line_length": 58.279998779296875,
"blob_id": "e95c2388100660e79674cffa6323ee381f56a06f",
"content_id": "8d5e0d3bb555de5f6991ef48c47a514b652de6e7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1482,
"license_type": "permissive",
"max_line_length": 291,
"num_lines": 25,
"path": "/README.md",
"repo_name": "pandumagdum/AbstractiveTextSummarization",
"src_encoding": "UTF-8",
"text": "This is an implementation of the abstractive text summarization model described in https://arxiv.org/pdf/1704.04368.pdf\n\nCode creds go to https://github.com/abisee/pointer-generator\n\nThis is built to run with Python3 and Tensorflow 1.5.0+\n\n## Pre-processing\nGet the dataset folder from Google Drive. Name this folder `dataset` and put it inside the current directory\n\nAlso create a folder `logs` in the current directory\n\nEach time, make sure to name your experiment uniquely (shouldn't share name with an experiment already in logs/)\n\n## Training\nSimply run the following, you can tune the experiment name:\n`python3 run_summarization.py --mode=train --data_path=dataset/finished_files/chunked/train_* --vocab_path=dataset/finished_files/vocab --log_root=logs/ --exp_name=exp1`\n\n## Hyperparameter Tuning\nHyperparameters that you can tune: `max_enc_steps`, `max_dec_steps` (both of these can be found in run_summarization.py, on lines 50 and 51). The original values were max_enc_steps = 400, max_dec_steps = 100, but this takes a while to train. Reduced them both to 10 to improve training time.\n\nOther hyperparameters that you can tune are `num_epochs_train` and `num_epochs_eval`, found on lines 47-48 of run_summarization.py\n\n## Evaluation\nSimply run the following, experiment name must be same as training run:\n`python3 run_summarization.py --mode=eval --data_path=dataset/finished_files/chunked/val_* --vocab_path=dataset/finished_files/vocab --log_root=logs/ --exp_name=exp1`\n"
},
{
"alpha_fraction": 0.7534246444702148,
"alphanum_fraction": 0.7534246444702148,
"avg_line_length": 20,
"blob_id": "bcc40dcfe74c3bff15226e4d341d4158afcac262",
"content_id": "456590520350b2a0da294779e217b3020ad54283",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 146,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 7,
"path": "/get_dataset.sh",
"repo_name": "pandumagdum/AbstractiveTextSummarization",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nmkdir dataset\ncd dataset\ngit clone https://github.com/ArvindSridhar/CNN-DM-Dataset.git\nmv CNN-DM-Dataset .\nrm -rf CNN-DM-Dataset\ncd .."
},
{
"alpha_fraction": 0.6224286556243896,
"alphanum_fraction": 0.6529529094696045,
"avg_line_length": 26.399999618530273,
"blob_id": "e13e2a24a452fba0119d2fad3a6596bc637fd584",
"content_id": "a260e11dd8a18f498714ce8f978ea10a892ed479",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1507,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 55,
"path": "/prepare_for_rouge.py",
"repo_name": "pandumagdum/AbstractiveTextSummarization",
"src_encoding": "UTF-8",
"text": "from rouge import Rouge\nimport glob\n\nBASE_DIR = \"./logs/pretrained_model_tf1.2.1/decode_val_400maxenc_4beam_35mindec_100maxdec_ckpt-238518/\"\n\nrouge = Rouge()\n\ngenerated_abs = []\nactual_abs = []\n\ngenerated_files = sorted(glob.glob(BASE_DIR + \"decoded/*.txt\"))\nfor name in generated_files:\n\twith open(name) as f:\n\t\tdata = f.read().replace('\\n', '')\n\t\tgenerated_abs.append(data)\n\nactual_files = sorted(glob.glob(BASE_DIR + \"reference/*.txt\"))\nfor name in actual_files:\n\twith open(name) as f:\n\t\tdata = f.read().replace('\\n', '')\n\t\tactual_abs.append(data)\n\nnum_docs_using = len(generated_abs)\n\nval_rouge_f = {'rouge-1': 0,'rouge-2': 0,'rouge-l': 0}\nval_rouge_p = {'rouge-1': 0,'rouge-2': 0,'rouge-l': 0}\nval_rouge_r = {'rouge-1': 0,'rouge-2': 0,'rouge-l': 0}\n\nfor i in range(num_docs_using):\n\tgenerated = generated_abs[i]\n\treference = actual_abs[i]\n\trouge_scores = rouge.get_scores(generated, reference)[0]\n\tfor r in ['rouge-1','rouge-2','rouge-l']:\n\t\tval_rouge_f[r] += rouge_scores[r]['f']\n\t\tval_rouge_p[r] += rouge_scores[r]['p']\n\t\tval_rouge_r[r] += rouge_scores[r]['r']\n\nfor i in val_rouge_f:\n\tval_rouge_f[i] /= num_docs_using\n\tval_rouge_p[i] /= num_docs_using\n\tval_rouge_r[i] /= num_docs_using\n\tval_rouge_f[i] *= 100\n\tval_rouge_p[i] *= 100\n\tval_rouge_r[i] *= 100\n\nprint(\"Precision:\", val_rouge_p)\nprint(\"Recall:\", val_rouge_r)\nprint(\"F score:\", val_rouge_f)\n\nlength = 0\nfor i in range(num_docs_using):\n\tgenerated = generated_abs[i].split(\" \")\n\tlength += len(generated)\nlength /= num_docs_using\nprint(length)\n"
}
] | 3 |
Erkin97-zz/youtubepp
|
https://github.com/Erkin97-zz/youtubepp
|
0edfb1f9045de881d6022e6d29257b0298be223d
|
14f953ad02e1c02d25e87e42b15cf511ff2f6ed1
|
1840d2b0b65d63f06ee8e0ab7d9cff2befedfc72
|
refs/heads/master
| 2022-12-28T20:15:07.430720 | 2020-08-07T06:31:53 | 2020-08-07T06:31:53 | 266,012,734 | 0 | 0 |
MIT
| 2020-05-22T03:51:55 | 2020-08-07T06:31:56 | 2022-12-12T21:44:13 |
JavaScript
|
[
{
"alpha_fraction": 0.7682926654815674,
"alphanum_fraction": 0.7804877758026123,
"avg_line_length": 26.33333396911621,
"blob_id": "8104c58e9edcf0ef218be7cef9b5708049ba71d2",
"content_id": "c04f572235790327c265e659fa7af06f455b4220",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 82,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Erkin97-zz/youtubepp",
"src_encoding": "UTF-8",
"text": "# Youtube Comments Translator\n\nDemo - https://www.youtube.com/watch?v=PdNE3nTYCfo\n"
},
{
"alpha_fraction": 0.779552698135376,
"alphanum_fraction": 0.779552698135376,
"avg_line_length": 21.428571701049805,
"blob_id": "f7ec01ed66290eafc04a195bfca131a102d0c0e3",
"content_id": "33efb91886b871df2109f57ee7ec567357ae8c59",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 14,
"path": "/api/translate.py",
"repo_name": "Erkin97-zz/youtubepp",
"src_encoding": "UTF-8",
"text": "from googletrans import Translator\nimport argparse\n\ntranslator = Translator()\nparser = argparse.ArgumentParser()\nparser.add_argument(\"text\")\nparser.add_argument(\"destination\")\n\nargs = parser.parse_args()\ntext = args.text\ndest = args.destination\n\nresult = translator.translate(text, dest = dest)\nprint(result.text)"
},
{
"alpha_fraction": 0.5976154804229736,
"alphanum_fraction": 0.6039493083953857,
"avg_line_length": 30.57647132873535,
"blob_id": "eae0f1c368df1934e49323fcf3c3d8eca3b3f41c",
"content_id": "364661ac0dd23beadbd616f894c8d43bcbe40b7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2690,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 85,
"path": "/src/content.js",
"repo_name": "Erkin97-zz/youtubepp",
"src_encoding": "UTF-8",
"text": "chrome.runtime.sendMessage({\n todo: \"showPageAction\",\n});\n\n// reference: https://stackoverflow.com/questions/30578673/is-it-possible-to-make-queryselectorall-live-like-getelementsbytagname\nfunction querySelectorAllLive(element, selector) {\n // Initialize results with current nodes.\n const result = Array.prototype.slice.call(element.querySelectorAll(selector));\n\n // Create observer instance.\n const observer = new MutationObserver((mutations) => {\n mutations.forEach((mutation) => {\n [].forEach.call(mutation.addedNodes, function (node) {\n if (node.nodeType === Node.ELEMENT_NODE && node.matches(selector)) {\n result.push(node);\n }\n });\n });\n });\n\n // Set up observer.\n observer.observe(element, { childList: true, subtree: true });\n\n return result;\n}\n\n// Update comments when new comes\nlet commentsSize = 0;\nlet needToReload = false;\nsetInterval(() => {\n const elms = querySelectorAllLive(document, \"[id='content-text']\");\n if (elms.length === commentsSize) return;\n commentsSize = elms.length;\n\n elms.forEach((elem) => {\n if (elem.getAttribute(\"isChanged\") !== \"yes\") {\n const translateButton = document.createElement(\"span\");\n const text = elem.textContent;\n translateButton.innerHTML = \" 🌎 TRANSLATE 🌏 \";\n translateButton.style.cursor = \"pointer\";\n translateButton.style.color = \"#113d4f\";\n needToReload = true;\n translateButton.addEventListener(\"click\", () => {\n chrome.storage.local.get([\"destination\"], function (result) {\n const dest = result.destination ? result.destination : \"en\";\n fetch(\"\", {\n // ngrok tunneling to my api\n method: \"POST\",\n headers: {\n \"Content-Type\": \"application/json\",\n },\n body: JSON.stringify({ text, dest }),\n })\n .then((response) => response.json())\n .then(({ message }) => {\n elem.textContent = message;\n })\n .catch((error) => {\n console.log(error);\n });\n });\n });\n translateButton.style.display = \"none\";\n elem.parentNode.onmouseover = () => {\n translateButton.style.display = \"inline\";\n };\n elem.parentNode.onmouseleave = () => {\n translateButton.style.display = \"none\";\n };\n elem.appendChild(translateButton);\n elem.setAttribute(\"isChanged\", \"yes\");\n }\n });\n}, 2000);\n\nchrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {\n if (request.todo == \"reloadPage\") {\n if (needToReload) {\n needToReload = false;\n document.location.reload(true);\n }\n }\n});\n\nchrome.run;\n"
}
] | 3 |
fengzilaolei/ZJU_Teacher_Cluster
|
https://github.com/fengzilaolei/ZJU_Teacher_Cluster
|
881f7858b4f52d341c0ee6ed810ded3823a957d5
|
9b4165db079bfed039c23a8b7becfc3d43ae2687
|
c9d38369f42efe9cb939651ce2f1aedf0506f7c8
|
refs/heads/master
| 2022-01-10T20:00:31.760254 | 2019-01-05T05:47:17 | 2019-01-05T05:50:11 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6059238314628601,
"alphanum_fraction": 0.6152327060699463,
"avg_line_length": 30.78923797607422,
"blob_id": "d502abc23cadc562df3e4519af3e85c55ff1b065",
"content_id": "a854904443f54612c1e65eff2abb52a2668a0138",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9054,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 223,
"path": "/Test/jieba_Kmeans_Cluster.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\nimport sys, os\nimport numpy as np\nfrom numpy import *\nimport jieba\nimport math\nimport jieba.analyse\n\n#载入用户自定义的吃点,以便包含jieba词库里没有的词\n#词典格式:一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒\njieba.load_userdict(\"E:/WorkSpace/PycharmProject/Crawling_NLP/Data/userdict.txt\")\n\ndef read_from_file(file_name):\n \"\"\"\n 读取语料中的内容,并存放于words中\n :param file_name: 语料文件的路径\n :return: words\n \"\"\"\n with open(file_name) as fp:\n words = fp.read()\n return words\n\ndef stop_words(stop_word_file):\n \"\"\"\n #对停用词进行,并存放于new_words列表中\n :param stop_word_file:\n #set() 函数创建一个无序不重复元素集合{},可进行关系测试,删除重复数据,还可以计算交集&、差集-、并集|等。\n :return: set(new_words)\n \"\"\"\n words = read_from_file(stop_word_file)\n result = jieba.cut(words)\n new_words = []\n for r in result:\n new_words.append(r)\n return set(new_words)\n\ndef del_stop_words(words, stop_words_set):\n \"\"\"\n :param words: 未分词的文档\n :param stop_words_set: 停用词文档\n :return: 去除停用词后的文档\n \"\"\"\n result = jieba.cut(words)\n new_words = []\n for r in result:\n if r not in stop_words_set:\n new_words.append(r)\n # print r.encode(\"utf-8\"),\n # print len(new_words),len(set(new_words))\n return new_words\n\ndef tfidf(term, doc, word_dict, docset):\n tf = float(doc.count(term)) / (len(doc) + 0.001)\n idf = math.log(float(len(docset)) / word_dict[term])\n return tf * idf\n\ndef idf(term, word_dict, docset):\n idf = math.log(float(len(docset)) / word_dict[term])\n return idf\n\ndef word_in_docs(word_set, docs):\n word_dict = {}\n for word in word_set:\n # print word.encode(\"utf-8\")\n word_dict[word] = len([doc for doc in docs if word in doc])\n # print word_dict[word],\n return word_dict\n\n#构建词袋空间VSM(vector space model)\ndef get_all_vector(file_path, stop_words_set):\n \"\"\"\n 最终得到的矩阵的性质为:\n 列是所有文档总共的词的集合;每行代表一个文档;每行是一个向量,向量的每个值是这个词的权值。\n :param file_path:\n :param stop_words_set:\n :return:names:文本路径\n tfidf:权值\n \"\"\"\n #os.path.join(path1[, path2[, ...]]) 把目录和文件名合成一个路径\n #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。\n\n # 1.将所有文档读入到程序中\n #names为构建的语料库中每个txt文件对应的路径列表\n names = [os.path.join(file_path, f) for f in os.listdir(file_path)]\n posts = [open(name, encoding='utf-8').read() for name in names]\n\n # 2.对每个文档进行切词,并去除文档中的停用词。 3. 统计所有文档的词集合\n docs = []\n word_set = set()\n #将所有文档分词后的结果都存放于word_set集合当中,并将一个文档作为一个列表项存放于docs列表中\n for post in posts:\n doc = del_stop_words(post, stop_words_set)\n docs.append(doc)\n word_set |= set(doc)\n # print len(doc),len(word_set)\n\n # 4. 对每个文档,都将构建一个向量,向量的值是词语在本文档中出现的次数。\n word_set = list(word_set) #转换为列表\n docs_vsm = []\n # for word in word_set[:30]:\n # print word.encode(\"utf-8\"),\n for doc in docs:\n temp_vector = []\n for word in word_set:\n temp_vector.append(doc.count(word) * 1.0) #统计词在文档中出现的次数\n # print temp_vector[-30:-1]\n docs_vsm.append(temp_vector)\n\n docs_matrix = np.array(docs_vsm) #将词频列表转换为矩阵\n # print docs_matrix.shape\n # print len(np.nonzero(docs_matrix[:,3])[0])\n\n # 5.将单词出现的次数转换为权值(TF-IDF)\n column_sum = [float(len(np.nonzero(docs_matrix[:, i])[0])) for i in range(docs_matrix.shape[1])]\n column_sum = np.array(column_sum)\n column_sum = docs_matrix.shape[0] / column_sum\n idf = np.log(column_sum)\n idf = np.diag(idf)\n # print idf.shape\n # row_sum = [ docs_matrix[i].sum() for i in range(docs_matrix.shape[0]) ]\n # print idf\n # print column_sum\n for doc_v in docs_matrix:\n if doc_v.sum() == 0:\n doc_v = doc_v / 1\n else:\n doc_v = doc_v / (doc_v.sum())\n\n tfidf = np.dot(docs_matrix, idf)\n\n return names, tfidf\n\ndef gen_sim(A, B):\n \"\"\"\n 文本相似度计算,该函数计算余弦相似度\n 余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体差异的大小。\n 相比欧氏距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上的差异。\n 相对于欧氏距离,余弦相似度更适合计算文本的相似度。首先将文本转换为权值向量,\n 通过计算两个向量的夹角余弦值,就可以评估他们的相似度。\n 余弦值的范围在[-1,1]之间,值越趋近于1,代表两个向量方向越接近;越趋近于-1,代表他们的方向越相反。\n 为了方便聚类分析,我们将余弦值做归一化处理,将其转换到[0,1]之间,并且值越小距离越近。\n :param A:\n :param B:\n :return:\n \"\"\"\n num = float(np.dot(A, B.T))\n denum = np.linalg.norm(A) * np.linalg.norm(B)\n if denum == 0:\n denum = 1\n cosn = num / denum\n sim = 0.5 + 0.5 * cosn # 余弦值为[-1,1],归一化为[0,1],值越大相似度越大\n return sim\n\ndef randCent(dataSet, k):\n \"\"\"\n 该函数为给定数据集构建一个包含k个随机初始聚类中心的集合\n :param dataSet:数据集合,矩阵\n :param k: 初始聚类中心个数\n :return:\n \"\"\"\n n = shape(dataSet)[1]\n centroids = mat(zeros((k, n))) # create centroid mat\n for j in range(n): # create random cluster centers, within bounds of each dimension\n minJ = min(dataSet[:, j])\n rangeJ = float(max(dataSet[:, j]) - minJ)\n centroids[:, j] = mat(minJ + rangeJ * random.rand(k, 1))\n return centroids\n\n\ndef kMeans(dataSet, k, distMeas=gen_sim, createCent=randCent):\n \"\"\"\n 该算法会创建k个质心,然后将每个点分配到最近的质心,再重新计算质心。\n 这个过程重复数次,直到数据点的簇分配结果不再改变为止。\n\n 该函数接受4个参数,只有数据集及簇的数目是必选的参数,用来计算距离和创建初始质心的函数都是可选的。\n :param dataSet:数据集合,矩阵\n :param k:初始聚类中心个数\n :param distMeas: 计算距离的函数\n :param createCent: 创建初始质心的函数\n :return:clusterAssment:簇分配结果矩阵,包含两列:一列记录簇索引值,\n 第二列存储误差(这里的误差是指当前点到簇质心的距离,可用该误差来评价聚类效果)\n centroids:簇中心的结果\n \"\"\"\n m = shape(dataSet)[0]\n clusterAssment = mat(zeros((m, 2))) # create mat to assign data points\n # to a centroid, also holds SE of each point\n centroids = createCent(dataSet, k)\n clusterChanged = True\n counter = 0\n while counter <= 50:\n counter += 1\n clusterChanged = False\n for i in range(m): # for each data point assign it to the closest centroid\n minDist = inf;\n minIndex = -1\n #寻找最近的质心\n for j in range(k):\n distJI = distMeas(centroids[j, :], dataSet[i, :])\n if distJI < minDist:\n minDist = distJI;\n minIndex = j\n if clusterAssment[i, 0] != minIndex:\n clusterChanged = True\n clusterAssment[i, :] = minIndex, minDist ** 2\n #更新质心的位置\n # print centroids\n for cent in range(k): # recalculate centroids\n ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]] # get all the point in this cluster\n centroids[cent, :] = mean(ptsInClust, axis=0) # assign centroid to mean\n return centroids, clusterAssment\n\nif __name__ == \"__main__\":\n stop_words = stop_words(\"E:/WorkSpace/PycharmProject/Crawling_NLP/Data/stopwords.txt\")\n names, tfidf_mat = get_all_vector(\"E:/WorkSpace/PycharmProject/Crawling_NLP/Data/Teacher_Data2/\", stop_words)\n print(tfidf_mat)\n # file = open(\"E:/WorkSpace/PycharmProject/Crawling_NLP/Data/result.txt\" , 'w', encoding='utf-8')\n # file.write(tfidf_mat)\n # file.close()\n np.savetxt(\"E:/WorkSpace/PycharmProject/Crawling_NLP/Data/result.txt\", tfidf_mat)\n myCentroids, clustAssing = kMeans(tfidf_mat, 5, gen_sim, randCent)\n for label, name in zip(clustAssing[:, 0], names):\n print(label, name)\n\n"
},
{
"alpha_fraction": 0.606620192527771,
"alphanum_fraction": 0.6411150097846985,
"avg_line_length": 20.58646583557129,
"blob_id": "d5d3005b1bee8896e9da62722189393446c0b8ff",
"content_id": "95d79dece35395e64014536f3ccf7a281503ca86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3424,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 133,
"path": "/Test/TextAnalysis1.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Sep 09 15:18:29 2016\n\n@author: Administrator\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport codecs\nfrom scipy import ndimage\nfrom sklearn import manifold, datasets\nfrom sklearn import feature_extraction\nfrom sklearn.feature_extraction.text import TfidfTransformer\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.feature_extraction.text import HashingVectorizer\n\n####第一步 计算TFIDF####\n\n# 文档预料 空格连接\ncorpus = []\n\n# 读取预料 一行预料为一个文档\nfor line in open('E:/WorkSpace/PycharmProject/Text_cluster/Data/Teacher_Data.txt', 'r',encoding='utf-8').readlines():\n # print line\n corpus.append(line.strip())\n# print corpus\n# 将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频\nvectorizer = CountVectorizer()\n\n# 该类会统计每个词语的tf-idf权值\ntransformer = TfidfTransformer()\n\n# 第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵\ntfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))\n\n# 获取词袋模型中的所有词语\nword = vectorizer.get_feature_names()\n\n# 将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重\nweight = tfidf.toarray()\n\n# 打印特征向量文本内容\n#print('Features length:' + str(len(word)))\nresName = \"BHTfidf_Result.txt\"\nresult = codecs.open(resName, 'w', 'utf-8')\nfor j in range(len(word)):\n result.write(word[j] + ' ')\nresult.write('\\r\\n\\r\\n')\n\n# 打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重\nfor i in range(len(weight)):\n # print u\"-------这里输出第\", i, u\"类文本的词语tf-idf权重------\"\n for j in range(len(word)):\n # print weight[i][j],\n result.write(str(weight[i][j]) + ' ')\n result.write('\\r\\n\\r\\n')\n\nresult.close()\n\n####第二步 聚类Kmeans####\nprint('Start Kmeans:')\nfrom sklearn.cluster import KMeans\n\nclf = KMeans(n_clusters=50) # 景区 动物 人物 国家\ns = clf.fit(weight)\nprint(s)\n\n# 中心点\nprint(clf.cluster_centers_)\n\n# 每个样本所属的簇\n# label = [] # 存储1000个类标 4个类\n# print(clf.labels_)\n# i = 1\n# while i <= len(clf.labels_):\n# print(i, clf.labels_[i - 1])\n# label.append(clf.labels_[i - 1])\n# i = i + 1\n\n# 用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数 958.137281791\nprint(clf.inertia_)\n\n# ####第三步 图形输出 降维####\n# from sklearn.decomposition import PCA\n#\n# pca = PCA(n_components=2) # 输出两维\n# newData = pca.fit_transform(weight) # 载入N维\n# print(newData)\n#\n# # 5A景区\n# x1 = []\n# y1 = []\n# i = 0\n# while i < 400:\n# x1.append(newData[i][0])\n# y1.append(newData[i][1])\n# i += 1\n#\n# # 动物\n# x2 = []\n# y2 = []\n# i = 400\n# while i < 600:\n# x2.append(newData[i][0])\n# y2.append(newData[i][1])\n# i += 1\n#\n# # 人物\n# x3 = []\n# y3 = []\n# i = 600\n# while i < 800:\n# x3.append(newData[i][0])\n# y3.append(newData[i][1])\n# i += 1\n#\n# # 国家\n# x4 = []\n# y4 = []\n# i = 800\n# while i < 1000:\n# x4.append(newData[i][0])\n# y4.append(newData[i][1])\n# i += 1\n#\n# # 四种颜色 红 绿 蓝 黑\n# plt.plot(x1, y1, 'or')\n# plt.plot(x2, y2, 'og')\n# plt.plot(x3, y3, 'ob')\n# plt.plot(x4, y4, 'ok')\n# plt.show()"
},
{
"alpha_fraction": 0.6476906538009644,
"alphanum_fraction": 0.6573576927185059,
"avg_line_length": 28.125,
"blob_id": "e2148cbbfc0fa4a6ac8fba6a31526897e40bba1e",
"content_id": "62ed7078804d281dbc17ad7448cf09f1f4ab4989",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 32,
"path": "/Practice_demo/Text_cluster.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import jieba.analyse\nimport codecs\nfile = codecs.open(\"E:/WorkSpace/PycharmProject/Text_cluster/Data/Teacher_Data/宋广华.txt\",'rb',encoding='utf-8').read()\n# print(file)\n# str = ''\n# for line in file:\n# str = line\n# print(str)\n#content_str = \" \".join(str)\nprint(\" \".join(jieba.analyse.extract_tags(file,topK=10,withWeight=False)))\n# -*- coding: UTF-8 -*-\nimport codecs\nimport jieba\nimport jieba.analyse\n#添加用户自定义的词典\n# jieba.load_userdict(\"E:/WorkSpace/PycharmProject/Text_cluster/Data/userdict.txt\")\n#\n# file_path = 'E:/WorkSpace/PycharmProject/Text_cluster/Data/Teacher_Data.txt'\n# files = codecs.open(file_path,'rb','utf-8').readlines()\n# corpus = []\n# Lens = []\n# # 读取预料 一行预料为一个文档,存于corpus列表中\n# for line in files:\n# corpus.append(line.strip())\n# Lens.append(len(line))\n# # print(max(Lens))\n# # print(min(Lens))\n#\n# if __name__ == '__main__':\n# for data in corpus:\n# if len(data)>5000:\n# print()"
},
{
"alpha_fraction": 0.6602497100830078,
"alphanum_fraction": 0.6878252029418945,
"avg_line_length": 38.20408248901367,
"blob_id": "df8af5e8d0a0963ddfff758ddd998da69f88b82d",
"content_id": "5c67d0cd54dd599d8a75fe1736c161d73d5e8be7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2140,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 49,
"path": "/word2vec_gensim.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# -*-coding: utf-8 -*-\n\nfrom gensim.models import word2vec\nimport multiprocessing\n\ndef train_wordVectors(sentences, embedding_size=128, window=5, min_count=5):\n '''\n :param sentences: sentences可以是LineSentence或者PathLineSentences读取的文件对象,也可以是\n The `sentences` iterable can be simply a list of lists of tokens,如lists=[['我','是','中国','人'],['我','的','家乡','在','广东']]\n :param embedding_size: 词嵌入大小\n :param window: 窗口\n :param min_count:Ignores all words with total frequency lower than this.\n :return: w2vModel\n '''\n w2vModel = word2vec.Word2Vec(sentences, size=embedding_size, window=window, min_count=min_count,\n workers=multiprocessing.cpu_count())\n return w2vModel\n\ndef save_wordVectors(w2vModel, word2vec_path):\n w2vModel.save(word2vec_path)\n w2vModel.wv.save_word2vec_format(word2vec_path + '.txt',binary=False)\n\ndef load_wordVectors(word2vec_path):\n w2vModel = word2vec.Word2Vec.load(word2vec_path)\n return w2vModel\n\nif __name__ == '__main__':\n # [1]若只有一个文件,使用LineSentence读取文件\n # segment_path='./data/segment/segment_0.txt'\n # sentences = word2vec.LineSentence(segment_path)\n\n # [1]若存在多文件,使用PathLineSentences读取文件列表\n segment_dir = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\keword_result'\n sentences = word2vec.PathLineSentences(segment_dir)\n\n # 简单的训练\n model = word2vec.Word2Vec(sentences, hs=1, min_count=1, window=3, size=100)\n print(model.wv.similarity('生物物理', '化学工程'))\n # print(model.wv.similarity('李达康'.encode('utf-8'), '王大路'.encode('utf-8')))\n\n # 一般训练,设置以下几个参数即可:\n word2vec_path = 'E:/WorkSpace/PycharmProject/Text_cluster/models/keyword_vec'\n model2 = train_wordVectors(sentences, embedding_size=128, window=5, min_count=5)\n\n save_wordVectors(model2, word2vec_path)\n\n model2 = load_wordVectors(word2vec_path)\n print(model2.wv.similarity('生物物理', '化学工程'))\n print(model2)\n\n"
},
{
"alpha_fraction": 0.57417893409729,
"alphanum_fraction": 0.5889014601707458,
"avg_line_length": 23.5,
"blob_id": "bebff9baf965ab66224cc467aa9fae3de7b97175",
"content_id": "bcd1e8ca7052630661a1cf0cbb346e7e71a2fce9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1063,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 36,
"path": "/Practice_demo/regex.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# encoding: UTF-8\nimport re\ndef main(str):\n # 将正则表达式编译成Pattern对象\n pattern = re.compile(r'hello.*\\!')\n # 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None\n match = pattern.match(str)\n if match:\n #使用Match获得分组信息\n print(match.group())\n # content = 'hello, liwei! how are you.'\n # pattern = re.compile('hello.*\\!')\n # match = re.match(pattern,content)\n # print(match.group())\ndef fenge():\n p = re.compile('\\d+')\n print(p.split('one1two2three3four4'))\ndef sousuo():\n p = re.compile('\\d+')\n #搜索string,以列表形式返回全部能匹配的字串\n print(p.findall('one1two2three3four4'))\ndef tihuan():\n p = re.compile(r'(\\w+) (\\w+)')\n s = 'i say, hello liwei'\n print(p.sub(r'\\2 \\1', s)) #将分组1替换为分组2\n\nif __name__ == \"__main__\":\n content = 'hello, liwei! How are you'\n main(content)\n\n # 分割字符串\n fenge()\n\n # 搜索string,以列表形式返回全部能匹配的字串\n sousuo()\n tihuan()\n\n"
},
{
"alpha_fraction": 0.5985769629478455,
"alphanum_fraction": 0.6083605289459229,
"avg_line_length": 39.154762268066406,
"blob_id": "781c69dc82a82dce178e7684d49e186670149f04",
"content_id": "4b859347226545aee984d1739b79d577a2107b4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3373,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 84,
"path": "/TestCNN_Classifier/data_trainning.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom tensorflow.contrib import learn\nfrom TestCNN_Classifier11 import data_helpers\nfrom TestCNN_Classifier.TextCNNClassifier import NN_config, CALC_config, TextCNNClassifier\n# Data Preparation\n# ==================================================\npositive_data_file = r\"E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\CNNdata\\rt-polaritydata\\rt-polarity.pos\"\nnegative_data_file = r\"E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\CNNdata\\rt-polaritydata\\rt-polarity.neg\"\ndev_sample_percentage = 0.1\n# Load data\nprint(\"Loading data...\")\nx_text, y = data_helpers.load_data_and_labels(positive_data_file, negative_data_file)\n\n# Build vocabulary\nmax_document_length = max([len(x.split(\" \")) for x in x_text])\nvocab_processor = learn.preprocessing.VocabularyProcessor(max_document_length)\nx = np.array(list(vocab_processor.fit_transform(x_text)))\n\nprint('vocabulary length is:',len(vocab_processor.vocabulary_))\n# Randomly shuffle data\nnp.random.seed(10)\nshuffle_indices = np.random.permutation(np.arange(len(y)))\nx_shuffled = x[shuffle_indices]\ny_shuffled = y[shuffle_indices]\n\n# Split train/test set\n# TODO: This is very crude, should use cross-validation\ndev_sample_index = -1 * int(dev_sample_percentage * float(len(y)))\nx_train, x_dev = x_shuffled[:dev_sample_index], x_shuffled[dev_sample_index:]\ny_train, y_dev = y_shuffled[:dev_sample_index], y_shuffled[dev_sample_index:]\nprint('The leangth of X_train is {}'.format(len(x_train)))\nprint('The length of x_dev is {}'.format(len(x_dev)))\n\n\n#------------------------------------------------------------------------------\n# ---------------- model processing ------------------------------------------\n#------------------------------------------------------------------------------\nnum_seqs = max_document_length\nnum_classes = 2\nnum_filters = 128\nfilter_steps = [5,6,7]\nembedding_size = 200\nvocab_size = len(vocab_processor.vocabulary_)\n\nlearning_rate = 0.001\nbatch_size = 128\nnum_epoches = 20\nl2_ratio = 0.0\n\ntrains = list(zip(x_train, y_train))\ndevs = list(zip(x_dev,y_dev))\n\nconfig_nn = NN_config(num_seqs = num_seqs,\n num_classes = num_classes,\n num_filters = num_filters,\n filter_steps = filter_steps,\n embedding_size= embedding_size,\n vocab_size = vocab_size)\nconfig_calc = CALC_config(learning_rate = learning_rate,\n batch_size = batch_size,\n num_epoches = num_epoches,\n l2_ratio = l2_ratio)\n\nprint('this is checking list:\\\\\\\\\\n',\n 'num_seqs:{}\\n'.format(num_seqs),\\\n 'num_classes:{} \\n'.format(num_classes),\\\n 'embedding_size:{}\\n'.format(embedding_size),\\\n 'num_filters:{}\\n'.format(num_filters),\\\n 'vocab_size:{}\\n'.format(vocab_size),\\\n 'filter_steps:',filter_steps)\nprint('this is check calc list:\\\\\\\\\\n',\n 'learning_rate :{}\\n'.format(learning_rate),\\\n 'num_epoches: {} \\n'.format(num_epoches),\\\n 'batch_size: {} \\n'.format(batch_size),\\\n 'l2_ratio : {} \\n'.format(l2_ratio))\n\n\ntext_model = TextCNNClassifier(config_nn,config_calc)\ntext_model.fit(trains)\naccuracy = text_model.predict_accuracy(devs,test=False)\nprint('the dev accuracy is :',accuracy)\n\npredictions = text_model.predict(x_dev)\n#print(predictions)\n"
},
{
"alpha_fraction": 0.6589387059211731,
"alphanum_fraction": 0.6743946671485901,
"avg_line_length": 22.349397659301758,
"blob_id": "59a7d4df4ed4e524a60565bf7571e9e189b4338a",
"content_id": "ada36979c167b9b6bafe57c308eacb77a19887c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2805,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 83,
"path": "/Practice_demo/jieba_practice2.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\nfrom __future__ import unicode_literals\nimport sys\n\nsys.path.append(\"../\")\n\nimport jieba\nimport jieba.posseg\nimport jieba.analyse\n\n# 分词\n\"\"\"\njieba.cut方法接受三个输入参数:\n需要分词的字符串\ncut_all参数用来控制是否采用全模式\nHMM参数用来控制是否使用HMM模式(马尔可夫模型)\n\njieba.cut_for_search方法接受两个参数:\n需要分词的字符串\n是否使用HMM模型\n\"\"\"\nseg_list = jieba.cut(\"主讲课程:1、研究生课程“管理学前沿2、研究生课程“管理学研究”3、本科生课程“公共与第三部门组织战略管理\", cut_all=True)\nprint(\"Full Mode:\", \"/ \".join(seg_list)) # 全模式\n\nseg_list = jieba.cut(\"我来到北京清华大学\", cut_all=False)\nprint(\"Default Mode:\", \"/ \".join(seg_list)) # 精确模式\n\nseg_list = jieba.cut(\"他来到了网易杭研大厦\") # 默认是精确模式\nprint(\", \".join(seg_list))\n\nseg_list = jieba.cut_for_search(\"小明硕士毕业于中国科学院计算所,后在日本京都大学深造\") # 搜索引擎模式\nprint(\", \".join(seg_list))\n\n\n# 添加词典\njieba.load_userdict(\"E:/WorkSpace/PycharmProject/NLP/Demo/dic.txt\") #文件必须为utf-8编码格式\nseg_list = jieba.cut(\"他是创新办主任,也是云计算方面的专家\") # 默认是精确模式\nprint(\", \".join(seg_list))\n\n\n# 调整词典\nprint('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))\n\njieba.suggest_freq(('中', '将'), True)\n\nprint('/'.join(jieba.cut('如果放到post中将出错。', HMM=False)))\n\nprint('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))\n\njieba.suggest_freq('台中', True)\n\nprint('/'.join(jieba.cut('「台中」正确应该不会被切开', HMM=False)))\n\n# 关键词提取\n\ns = '''\n此外,公司拟对全资子公司吉林欧亚置业有限公司增资4.3亿元,增资后,吉林欧亚置业注册\n资本由7000万元增加到5亿元。吉林欧亚置业主要经营范围为房地产开发及百货零售等业务。\n目前在建吉林欧亚城市商业综合体项目。2013年,实现营业收入0万元,实现净利润-139.13万元。\n'''\n#TF-IDF\nfor x, w in jieba.analyse.extract_tags(s, topK=20, withWeight=True):\n print('%s %s' % (x, w))\n\n# textrank\nfor x, w in jieba.analyse.textrank(s, withWeight=True):\n print('%s %s' % (x, w))\n\n# 词性标注\nwords = jieba.posseg.cut(\"我爱北京天安门\")\nfor word, flag in words:\n print('%s %s' % (word, flag))\n\n# Tokenize\nresult = jieba.tokenize(u'永和服装饰品有限公司')\nfor tk in result:\n print(\"word %s\\t\\t start: %d \\t\\t end:%d\" % (tk[0], tk[1], tk[2]))\n\nresult = jieba.tokenize(u'永和服装饰品有限公司', mode='search')\nfor tk in result:\n print(\"word %s\\t\\t start: %d \\t\\t end:%d\" % (tk[0], tk[1], tk[2]))\n\n\n\n"
},
{
"alpha_fraction": 0.7666174173355103,
"alphanum_fraction": 0.7695716619491577,
"avg_line_length": 31.238094329833984,
"blob_id": "14238739c5f4ade2ddd8cc9114d10d5218998392",
"content_id": "a9413a13cced672a0006c3efb3dad741e49c529e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 749,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 21,
"path": "/Test/Text_Classification.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "GB18030",
"text": "# 导入数据集预处理、特征工程和模型训练所需的库\nfrom sklearn import model_selection, preprocessing, linear_model, naive_bayes, metrics, svm\nfrom sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer\nfrom sklearn import decomposition, ensemble\n\nimport pandas, xgboost, numpy, textblob, string\nfrom keras.preprocessing import text, sequence\nfrom keras import layers, models, optimizers\n\n# 加载数据集\ndata = open('data/corpus').read()\nlabels, texts = [], []\nfor i, line in enumerate(data.split(\"\\n\")):\n content = line.split()\nlabels.append(content[0])\ntexts.append(content[1])\n\n# 创建一个dataframe,列名为text和label\ntrainDF = pandas.DataFrame()\ntrainDF['text'] = texts\ntrainDF['label'] = labels\n"
},
{
"alpha_fraction": 0.6215721964836121,
"alphanum_fraction": 0.6234003901481628,
"avg_line_length": 29.38888931274414,
"blob_id": "fded035a1700d1910f9aa992b2294cee4c532f57",
"content_id": "9ecadff52e710d6382508defb0440d6129588356",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 18,
"path": "/Test/stopwd_reduction.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "GB18030",
"text": "# 停用词表按照行进行存储,每一行只有一个词语\n# 将网络上收集到的停用词表去重\ndef stopwd_reduction(infilepath, outfilepath):\n infile = open(infilepath, 'r', encoding='utf-8')\n outfile = open(outfilepath, 'w')\n stopwordslist = []\n '''\n infile.read().split('\\n'):\n read函数读取文本内容为str格式,\n 再通过split函数对字符串进行切片,并返回分割后的字符串列表(list)\n '''\n for str in infile.read().split('\\n'):\n if str not in stopwordslist:\n stopwordslist.append(str)\n outfile.write(str + '\\n')\n\n\nstopwd_reduction('./test/stopwords.txt', './test/stopword.txt')\n"
},
{
"alpha_fraction": 0.4910614490509033,
"alphanum_fraction": 0.5363128781318665,
"avg_line_length": 20.841463088989258,
"blob_id": "eff025dcfdfa27d3e294300f8c33d9af68c59c58",
"content_id": "251669423947846014eade4a3418c372f783f96c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2088,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 82,
"path": "/Practice_demo/lianbiao.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# ListNode只定义了__init__这个函数,那这个类的实例化对象只能表示一个节点\n# 它虽然具有初始节点值,也有.next这个定义,但没有接下来其他类函数去定义节点关系\n# 那它就只能表示一个节点。\nclass ListNode:\n def __init__(self, x):\n self.val = x\n self.next = None\n\n\n#Solution类中的函数分别用递归和非递归的方法合并两张有序链表\nclass Solution:\n def mergeTwoLists1(self, l1, l2):\n \"\"\"\n 该函数用递归方法\n :type l1: ListNode\n :type l2: ListNode\n :rtype: ListNode\n \"\"\"\n if l1==None and l2==None:\n return None\n if l1==None:\n return l2\n if l2==None:\n return l1\n if l1.val<=l2.val:\n l1.next=self.mergeTwoLists1(l1.next,l2)\n return l1\n else:\n l2.next=self.mergeTwoLists1(l1,l2.next)\n return l2\n def mergeTwoLists2(self, l1, l2):\n \"\"\"\n 该函数用非递归方法\n :type l1: ListNode\n :type l2: ListNode\n :rtype: ListNode\n \"\"\"\n if l1 is None and l2 is None:\n return None\n new_list = ListNode(0)\n pre = new_list\n while l1 is not None and l2 is not None:\n if l1.val < l2.val:\n pre.next = l1\n l1 = l1.next\n else:\n pre.next = l2\n l2 = l2.next\n pre = pre.next\n if l1 is not None:\n pre.next = l1\n else:\n pre.next = l2\n return new_list.next\n\n#有序链表l1的定义\nhead1 = ListNode(2)\nn1 = ListNode(3)\nn2 = ListNode(4)\nn3 = ListNode(9)\nhead1.next = n1\nn1.next = n2\nn2.next = n3\n\n#有序链表l2的定义\nhead2 = ListNode(3)\nm1 = ListNode(5)\nm2 = ListNode(8)\nm3 = ListNode(10)\nhead2.next = m1\nm1.next = m2\nm2.next = m3\n\n\ns = Solution()\n#递归调用合并两张链表\nres = s.mergeTwoLists1(head1,head2)\n#也可以非递归调用\n#res = s.mergeTwoLists2(head1,head2)\nwhile res:\n print(res.val)\n res = res.next"
},
{
"alpha_fraction": 0.728483259677887,
"alphanum_fraction": 0.7430984377861023,
"avg_line_length": 47.125,
"blob_id": "33a4471bff459e4345698d87b18023fd68ea023e",
"content_id": "34065d8c4b4e3fcdb7cbd45daf1e48bd98a8ca43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3079,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 64,
"path": "/Practice_demo/text.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import gensim\nfrom sklearn.datasets import fetch_20newsgroups\nfrom gensim.utils import simple_preprocess\nfrom gensim.parsing.preprocessing import STOPWORDS\nfrom gensim.corpora import Dictionary\nimport os\nfrom pprint import pprint\nnews_dataset = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))\ndocuments = news_dataset.data\nprint(\"In the dataset there are\", len(documents), \"textual documents\")\nprint (\"And this is the first one:\\n\", documents[0])\n\ndef tokenize(text):\n return [token for token in simple_preprocess(text) if token not in STOPWORDS]\nprint(\"After the tokenizer, the previous document becomes:\\n\", tokenize(documents[0]))\n\n# Next step: tokenize all the documents and build a count dictionary, that contains the count of the tokens over the complete text corpus.\nprocessed_docs = [tokenize(doc) for doc in documents]\nword_count_dict = Dictionary(processed_docs)\nprint(\"In the corpus there are\", len(word_count_dict), \"unique tokens\")\n\nprint(\"\\n\",word_count_dict,\"\\n\")\n\nword_count_dict.filter_extremes(no_below=20, no_above=0.1) # word must appear >10 times, and no more than 20% documents\nprint(\"After filtering, in the corpus there are only\", len(word_count_dict), \"unique tokens\")\n\nbag_of_words_corpus = [word_count_dict.doc2bow(pdoc) for pdoc in processed_docs] # bow all document of corpus\n\nmodel_name = \"./model.lda\"\nif os.path.exists(model_name):\n lda_model = gensim.models.LdaModel.load(model_name)\n print(\"loaded from old\")\nelse:\n # preprocess()\n lda_model = gensim.models.LdaModel(bag_of_words_corpus, num_topics=100, id2word=word_count_dict, passes=5)#num_topics: the maximum numbers of topic that can provide\n lda_model.save(model_name)\n print(\"loaded from new\")\n\n# 1.\n# if you don't assign the target document, then\n# every running of lda_model.print_topics(k) gonna get top k topic_keyword from whole the corpora documents in the bag_of_words_corpus from 0-n.\n# and if given a single new document, it will only analyse this document, and output top k topic_keyword from this document.\n\npprint(lda_model.print_topics(30,6))#by default num_topics=10, no more than LdaModel's; by default num_words=10, no limitation\nprint(\"\\n\")\n# pprint(lda_model.print_topics(10))\n\n# 2.\n# when you assign a particular document for it to assign:\n# pprint(lda_model[bag_of_words_corpus[0]].print_topics(10))\nfor index, score in sorted(lda_model[bag_of_words_corpus[0]], key=lambda tup: -1 * tup[1]):\n print(\"Score: {}\\t Topic: {}\".format(score, lda_model.print_topic(index, 5)))\nprint\nprint(news_dataset.target_names[news_dataset.target[0]]) # bag_of_words_corpus align to news_dataset\nprint(\"\\n\")\n\n# 3.\n# process an unseed document\nunseen_document = \"In my spare time I either play badmington or drive my car\"\nprint(\"The unseen document is composed by the following text:\", unseen_document)\nprint\nbow_vector = word_count_dict.doc2bow(tokenize(unseen_document))\nfor index, score in sorted(lda_model[bow_vector], key=lambda tup: -1 * tup[1]):\n print(\"Score: {}\\t Topic: {}\".format(score, lda_model.print_topic(index, 7)))"
},
{
"alpha_fraction": 0.6082627177238464,
"alphanum_fraction": 0.6118643879890442,
"avg_line_length": 32.239437103271484,
"blob_id": "b62bb178bb2ef7d33218ee66d4ba27ce26b8422c",
"content_id": "6640f5e90dd55166eabc21887ff4e0780ea9e62a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5400,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 142,
"path": "/segment.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import jieba\nimport jieba.analyse\nimport os\nimport re\nimport codecs\nfrom string import digits\n'''\nread() 每次读取整个文件,它通常将读取到底文件内容放到一个字符串变量中,也就是说 .read() 生成文件内容是一个字符串类型。\nreadline()每次只读取文件的一行,通常也是读取到的一行内容放到一个字符串变量中,返回str类型。\nreadlines()每次按行读取整个文件内容,将读取到的内容放到一个列表中,返回list类型。\n'''\ndef getStopwords(path):\n \"\"\"\n 加载停用词\n :param path: txt形式的文件\n :return stopwords: 停用词列表\n \"\"\"\n print(\"正在加载停用词...\")\n stopwords = []\n with open(path, \"r\", encoding='utf-8-sig') as f:\n lines = f.readlines()\n for line in lines:\n stopwords.append(line.strip())\n return stopwords\n\ndef clearTXTNum(source_in_path, source_out_path):\n \"\"\"\n 去除文本中的数字\n :param source_in_path:\n :param source_out_path:\n \"\"\"\n print(\"正在去除文本中的数字...\")\n infile = open(source_in_path, 'r',encoding='utf-8')\n outfile = open(source_out_path, 'w',encoding='utf-8')\n for eachline in infile.readlines():\n remove_digits = str.maketrans('', '', digits)\n lines = eachline.translate(remove_digits)\n #lines.encode('utf-8')\n outfile.write(lines)\n\ndef segment_line(file_list,segment_out_dir,stopwords=[]):\n '''\n 字词分割,对每行进行字词分割\n :param file_list:\n :param segment_out_dir:\n :param stopwords:\n :return:\n '''\n print(\"正在进行分词...\")\n for i,file in enumerate(file_list):\n segment_out_name=os.path.join(segment_out_dir,'segment_{}.txt'.format(i))\n segment_file = open(segment_out_name, 'a', encoding='utf8')\n with open(file, encoding='utf8') as f:\n text = f.readlines()\n for sentence in text:\n # jieba.cut():参数sentence必须是str(unicode)类型\n sentence = list(jieba.cut(sentence))\n sentence = re.sub()\n sentence_segment = []\n for word in sentence:\n if word not in stopwords:\n sentence_segment.append(word)\n segment_file.write(\" \".join(sentence_segment))\n del text\n f.close()\n segment_file.close()\n\ndef segment_lines(source_in_dir, segment_out_dir, stopwords=[]):\n '''\n 字词分割,对整个文件内容进行字词分割\n :param file_list:\n :param segment_out_dir:\n :param stopwords:\n :return:\n '''\n print(\"正在进分词...\")\n file_list = os.listdir(source_in_dir)\n for file in file_list:\n source =os.path.join(source_in_dir,file)\n with open(source, 'rb') as f:\n document = f.read()\n # document_decode = document.decode('GBK')\n document_cut = jieba.cut(document)\n sentence_segment=[]\n for word in document_cut:\n if word not in stopwords:\n sentence_segment.append(word)\n result = ' '.join(sentence_segment)\n result = result.encode('utf-8')\n with open(segment_out_dir, 'wb') as f2:\n f2.write(result)\n\ndef get_keyword(path, keyword_path):\n \"\"\"\n 提取文档中每一行的关键词\n :param path:\n :param keyword_path:\n \"\"\"\n print(\"正在提取文档中每一行的关键词...\")\n # 引入提取关键词算法的抽取接口(TF-IDF、textrank)\n tfidf = jieba.analyse.extract_tags\n #textrank = jieba.analyse.textrank\n\n #基于TF-IDF算法进行关键词抽取\n contents = codecs.open(path, 'rb', encoding='utf-8').readlines()\n count = 1\n with codecs.open(keyword_path, 'wb', encoding='utf-8') as f:\n for content in contents:\n #tfidf的输入为str,得到的结果为一个list\n keyword = \" \".join(tfidf(content,topK=150,withWeight=False))\n if count == 1:\n f.write((keyword))\n else:\n f.write(('\\n' + keyword))\n count += 1\n f.close()\n\nif __name__ == '__main__':\n #文本清洗:去除数字\n source_in_path = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\other data\\Teacher_Data.txt'\n source_out_path = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\source\\Teachr_Data_delNum.txt'\n clearTXTNum(source_in_path, source_out_path)\n\n # 多线程分词,windows下暂时不支持\n #jieba.enable_parallel()\n #加载自定义词典\n print(\"正在加载自定义词典...\")\n userdict_path = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\other data\\userdict.txt'\n jieba.load_userdict(userdict_path)\n\n #加载停用词\n stopwords_path = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\other data\\stopwords.txt'\n stopwords = getStopwords(stopwords_path)\n\n #实现分词\n source_in_dir = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\source'\n segment_out_dir = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\segmen_result\\seg_result_new.txt'\n segment_lines(source_in_dir, segment_out_dir, stopwords)\n\n #提取分词结果中的关键词,使用TF-IDF\n keyword_path = r'E:\\WorkSpace\\PycharmProject\\Text_cluster\\Data\\keword_result\\keyword_result_new.txt'\n get_keyword(segment_out_dir, keyword_path)\n"
},
{
"alpha_fraction": 0.6248591542243958,
"alphanum_fraction": 0.6415696740150452,
"avg_line_length": 33.55194854736328,
"blob_id": "4270c3a18b7d9173698b8b73f656b2306975f5fa",
"content_id": "16c7cb302adcb9cf828440994d725ae56de8591a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6502,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 154,
"path": "/doc2vec_gensim.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport sys\nimport logging\nimport os\nfrom sklearn.cluster import KMeans\nfrom sklearn.externals import joblib\nimport gensim\nfrom gensim.models import Doc2Vec\n\ndef get_trainset(path):\n \"\"\"\n 加载预料,将其整理成规定的形式,使用到TaggedDocument模型\n :param keyword_path:\n :return:返回doc2vec规定的数据格式\n \"\"\"\n documents = []\n # 使用count当做每个句子的“标签”,标签和每个句子是一一对应的\n count = 0\n with open(path, 'r', encoding='utf-8') as f:\n docs = f.readlines()\n for doc in docs:\n words = doc.strip('\\n')\n # 这里documents里的每个元素是二元组,具体可以查看函数文档\n documents.append(gensim.models.doc2vec.TaggedDocument(words, [str(count)]))\n count += 1\n if count % 10000 == 0:\n logging.info('{} has loaded...'.format(count))\n return documents\n\ndef train_docVecs(documents_train, size=200, epoch_num=1):\n \"\"\"\n 训练文本,得到文本向量\n :param documents_train: 训练数据,必须要TaggedDocument格式\n :param size: 表示生成的向量纬度\n :param window: 表示训练的窗口大小,也就是当前词与预测词在一个句子中的最大距离是多少\n :param min_count:表示参与训练的最小词频,也就是对字典做截断,词频少于min_count次数的单词会被丢弃掉,默认值为5\n :param dm:表示训练的算法,默认为1。dm=0时,则使用DBOW\n :param alpha:分为start_alpha和end_alpha两个参数,表示初始的学习速率,在训练过程中会线性地递减到min_alpha\n :param max_vocab_size:设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。\n 每一千万个单词需要大约1GB的RAM。设置成None则没有限制。\n :param sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,官网给的解释 1e-5效果比较好。设置为0时是词最少的时候!\n :param workers:用于控制训练的并行数。\n :param total_examples: Count of sentences.\n :param total_words : Count of raw words in documents.\n :param negtive:\n :param epochs:迭代次数,默认继承了word2vec的5次\n :return: 返回的是训练好的模型。\n \"\"\"\n model = Doc2Vec(documents_train, min_count=1, window=3, size=size,\n sample=1e-3, negative=5, workers=4, epochs= epoch_num)\n model.train(documents_train, total_examples=model.corpus_count, epochs=300)\n return model\n\ndef save_docVecs(model, doc2vec_path):\n # 保存模型\n model.save(doc2vec_path)\n\ndef test_doc2vec(load_path):\n # 加载模型\n model = Doc2Vec.load(load_path)\n # 输出标签为‘10’句子的向量\n print(model.docvecs['10'])\n\ndef cluster(x_train,load_path, cluster_path2, kmean_model_path):\n \"\"\"\n k均值聚类\n :param x_train: 数据\n :param load_path: doc2vec模型路径\n :param cluster_path: 聚类结果输出的存放路径\n :param kmean_model_path: K均值聚类模型的存放路径\n :return: 返回类簇中心向量\n \"\"\"\n infered_vectors_list= []\n print(\"load doc2vec model...\")\n model_dm = Doc2Vec.load(load_path)\n print(\"load train vectors...\")\n i = 0\n for text, label in x_train:\n #得到每个文本对应的文档向量\n vector = model_dm.infer_vector(text)\n infered_vectors_list.append(vector)\n i += 1\n\n print(\"train kmean model...\")\n # 设定簇数\n kmean_model = KMeans(n_clusters=85)\n # 模型训练\n kmean_model.fit(infered_vectors_list)\n\n # 簇的中心向量\n cluster_centers = kmean_model.cluster_centers_\n # 保存模型,载入模型使用model = joblib.load(kmean_model_path)\n joblib.dump(kmean_model,kmean_model_path)\n # 用来评估簇的个数是否合适,距离越小说明簇分的越好。选取临界点的簇个数\n #print(kmean_model.inertia_)\n\n \"\"\"\n #每个样本所属的类簇,并将训练结果输出\n Labels = kmean_model.labels_\n with open(cluster_path1, 'w') as wf1:\n for i in range(4861):\n string = \"\"\n text = x_train[i][0]\n for word in text:\n string = string + word\n string = '该文本属于类簇'+ str(Labels[i]) + ':\\t' + string\n string = string + '\\n'\n wf1.write(string)\n \"\"\"\n # 通过训练的模型预测前1000个文本所属类簇标签\n labels = kmean_model.predict(infered_vectors_list[0:4851])\n with open(cluster_path2, 'w') as wf2:\n for i in range(4851):\n string = \"\"\n text = x_train[i][0]\n for word in text:\n string = string + word\n #string = string + '\\t'\n string = '该文本属于类簇'+ str(labels[i]) + ':\\t' + string\n string = string + '\\n'\n wf2.write(string)\n\n return cluster_centers\n\nif __name__ == '__main__':\n curPath = os.path.abspath(os.path.dirname(__file__))\n rootPath = os.path.split(curPath)[0]\n sys.path.append(rootPath)\n # 引入日志配置\n logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)\n\n #加载数据\n keyword_path = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\keword_result\\\\keyword_result.txt'\n source_path = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\source\\\\Teachr_Data_delNum.txt'\n segment_path = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\segmen_result\\\\seg_result.txt'\n #docus = get_trainset(keyword_path)\n #docus = get_trainset(segment_path)\n docus = get_trainset(source_path)\n\n #训练数据\n #doc_model= train_docVecs(docus)\n\n #训练并保存数据\n docs2vec_path = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\models\\\\segment_d2v.model'\n doc_model = train_docVecs(docus)\n save_docVecs(doc_model, docs2vec_path)\n\n #测试数据\n # test_doc2vec(docs2vec_path)\n #K均值聚类\n #cluster_path1 = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\cluster_result\\\\claffify_train.txt'\n cluster_path2 = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\cluster_result\\\\claffify_segment.txt'\n kmean_model_path = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\models\\\\segment_kmeans.model'\n cluster_centers = cluster(docus, docs2vec_path, cluster_path2, kmean_model_path)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5916473269462585,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 31.621212005615234,
"blob_id": "fae10bc28b9bd870c8e9220f4627fb73617288ff",
"content_id": "59b7b54373aa51c7a85f737e6d22970f72f2d0bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2405,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 66,
"path": "/MongoData.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import pymongo\nimport csv\nimport sys\nimport os\n\nclient = pymongo.MongoClient('localhost',27017)\nZJU_Teacher_Infomation= client['ZJU_Teacher_Infomation']\nTeacher_detail_Info = ZJU_Teacher_Infomation['Teacher_detail_Info']\n\ndef solve_largeCSVfile():\n \"\"\"\n 以下代码为解决csv文件中数据过大导致无法读取的问题\n \"\"\"\n maxInt = sys.maxsize\n decrement = True\n while decrement:\n decrement = False\n try:\n csv.field_size_limit(maxInt)\n except OverflowError:\n maxInt = int(maxInt / 10)\n decrement = True\ndef text_save(filename, data):\n \"\"\"\n 该函数主要实现list写到txt文件的操作\n :param fileneme: 文件路径/文件名\n :param data: list\n \"\"\"\n file = open(filename, 'w', encoding = 'utf-8')\n for i in range(len(data)):\n s = str(data[i]).replace('[', '').replace(']', '') #列表中特殊字符的处理\n s = s.replace(\"'\", '').replace(',', '').replace(\"\\n\",'').replace(\"null\",'')\n file.write(s)\n file.close()\ndef Text_Union():\n # 获取目标文件夹的路径\n filedir = \"E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\Teacher_Data2\\\\\"\n # 获取当前文件夹中的文件名称列表\n filenames = os.listdir(filedir)\n # 打开当前目录下的result.txt文件,如果没有则创建\n f = open('E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\Teacher_Data.txt', 'w', encoding='utf-8')\n # 先遍历文件名\n for filename in filenames:\n filepath = filedir + '/' + filename\n # 遍历单个文件,读取行数\n for line in open(filepath, 'r', encoding='utf-8'):\n f.writelines(line)\n f.write('\\n')\n # 关闭文件\n f.close()\nwith open(\"E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\Teacher_detail_Iofo.csv\",\"r\",encoding=\"utf-8\") as csvfile:\n solve_largeCSVfile()\n reader = csv.reader(csvfile)\n sum = 0\n Text_Name = []\n for line in reader:\n #print(f\"# line = {line}, typeOfLine = {type(line)}, lenOfLine = {len(line)}\")\n del line[0]\n file_name = \"E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\Teacher_Data2\\\\\" + str(line[0]) + \".txt\"\n Text_Name.append(line[0])\n text_save( file_name, line)\n sum += 1\n print(\"成功存储\"+ str(sum) + \"个TXT文件\")\n print(Text_Name)\n print(len(Text_Name))\nText_Union()\n\n\n"
},
{
"alpha_fraction": 0.5998160243034363,
"alphanum_fraction": 0.6421343088150024,
"avg_line_length": 36.517242431640625,
"blob_id": "1790dd620f55b26e014fa1e353ee4396a10a2706",
"content_id": "67ac04d6595a1548b7703a592f726c7aa271d6ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1149,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 29,
"path": "/Practice_demo/test.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# -*-coding: utf-8 -*-\n# import re\n# #pattern = re.compile('[^\\u4e00-\\u9fa5]')\n# pattern = re.compile('[^\\b\\d+(?:\\.\\d+)\\s+]')\n# name = '2018中111d国人1厉害qwertyuioplkjh5464gfdsazxcvbnm1231564648'\n# b = pattern.sub('',name)\n# print(b)\n# #去掉文本行里面的空格、\\t、数字(其他有要去除的也可以放到' \\t1234567890'里面)\n# print(list(filter(lambda x:x not in '0123456789',name)))\nimport jieba\nimport jieba.analyse\nimport os\nimport re\nimport codecs\n\n\ndef segment_lines(source_in_dir, segment_out_dir, stopwords=[]):\n file_list = os.listdir(source_in_dir)\n for file in file_list:\n source =os.path.join(source_in_dir,file)\n with open(source, 'rb') as f:\n document = f.read()\n document = filter(lambda ch: ch not in '0123456789', str(document))\n document = ''.join(list(document))\n with codecs.open(segment_out_dir, 'wb',encoding='utf-8') as f2:\n f2.write(document)\nsource_in_dir= 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\source'\nsegment_out_dir = 'E:\\\\WorkSpace\\\\PycharmProject\\\\Text_cluster\\\\Data\\\\Teacher_Data_cnum.txt'\nsegment_lines(source_in_dir, segment_out_dir, stopwords=[])"
},
{
"alpha_fraction": 0.6905737519264221,
"alphanum_fraction": 0.6987704634666443,
"avg_line_length": 39.66666793823242,
"blob_id": "9f250a0a601f8a9090dc06d8ff5774aca239f22a",
"content_id": "4c6b7ed932dc28362430d7efb1d5b4fd95acbc10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 12,
"path": "/Practice_demo/Tencent_AILab_ChineseEmbedding_use.py",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "import numpy as np\nwith open(r'E:\\WorkSpace\\PycharmProject\\NLP\\Tencent_AILab_ChineseEmbedding\\Tencent_AILab_ChineseEmbedding.txt','r',encoding='utf-8') as f:\n f.readline()#第一行为词汇数和向量维度,在这里不予展示\n f.readline()\n m=f.readline()#读取第三个词\n vecdic = dict()#构造字典\n vectorlist = m.split()#切分一行,分为词汇和词向量\n vector = list(map(lambda x:float(x),vectorlist[1:]))#对词向量进行处理\n vec = np.array(vector)#将列表转化为array\n vecdic[vectorlist[0]]=vec\n print(vectorlist[0])\n print(vecdic['的'])\n"
},
{
"alpha_fraction": 0.8648648858070374,
"alphanum_fraction": 0.8828828930854797,
"avg_line_length": 54.5,
"blob_id": "a1bdb47f6b9e5c5d8b38e69590aa22098a4eb6a2",
"content_id": "2d7d3e67312ba6b47614dadce67524965aada1e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 229,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 2,
"path": "/README.md",
"repo_name": "fengzilaolei/ZJU_Teacher_Cluster",
"src_encoding": "UTF-8",
"text": "# ZJU_Teacher_Cluster\n本项目主要将从浙大教师查询主页上的所有教师信息进行文本处理,包括从MongoDB上提取数据、分词、关键词提取、word2vec、doc2vec以及K-means聚类等相关操作。\n"
}
] | 17 |
SunatP/ITCS381_Multimedia
|
https://github.com/SunatP/ITCS381_Multimedia
|
d0f196caed36f083f082a441dda21a6fa9e5c6e4
|
3d1a894ced595d2ac3b0c43630f4dea528a7890e
|
21794b65df26406be2ed6f26f0a3912b4e2bd1a4
|
refs/heads/master
| 2023-05-11T15:21:21.167480 | 2021-01-06T06:10:00 | 2021-01-06T06:10:00 | 166,171,758 | 0 | 1 | null | 2019-01-17T06:21:10 | 2021-01-06T06:10:05 | 2023-05-01T20:15:32 |
Jupyter Notebook
|
[
{
"alpha_fraction": 0.6225779056549072,
"alphanum_fraction": 0.6520640254020691,
"avg_line_length": 25.399999618530273,
"blob_id": "50ad6984eac4ac17132b8f0f405d887b047cb69a",
"content_id": "293c59a4155e5a69e0cbf0689bd50d9fdad5caae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 45,
"path": "/Lab Teacher Worapan/fixed period in a video.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include\"opencv2/opencv.hpp\"\n#include<opencv2/highgui/highgui.hpp>\n#include<opencv2/videoio/videoio.hpp>\n#include<iostream>\n\nusing namespace std;\nusing namespace cv;\n\nint main() {\n\n\ttime_t start, end;\n\tVideoCapture cap(\"./20.avi\");\n\n\tif (!cap.isOpened()) {\n\t\tcout << \"Error opening video stream or file\" << endl;\n\t\treturn -1;\n\t}\n\tint frame_width = cap.get(cv::CAP_PROP_FRAME_WIDTH);\n\tint frame_height = cap.get(cv::CAP_PROP_FRAME_HEIGHT);\n\tVideoWriter video(\"20out.avi\", cv::CAP_PROP_FOURCC>>('M', 'J', 'P', 'G'), 30, Size(frame_width, frame_height), true);\n\ttime(&start);\n\n\tfor (;;) { // interval loop with time \n\n\t\tMat frame;\n\t\tcap >> frame;\n\t\tvideo.write(frame);\n\t\timshow(\"Frame\", frame);\n\t\tchar c = (char)waitKey(33);\n\t\tif (c == 27) break;\n\n\t\ttime(&end);\n\t\tdouble dif = difftime(end, start);\n\t\tprintf(\"Elasped time is %.2lf seconds. \\n\", dif);\n\t\tif (dif >= 18) // 18 second interval * 30 fps = 540 fps or 10 seconds output it's mean 5.4 frames per 1 second average should be 5.1 ~ 5.8 fps\n\t\t{ // dif in second not millisecond\n\t\t\tstd::cout << \"DONE\" << dif << std::endl; // standard output when complete\n\t\t\tbreak;\n\t\t}\n\n\t}\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.6501261591911316,
"alphanum_fraction": 0.6576955318450928,
"avg_line_length": 30.3157901763916,
"blob_id": "dc09c48866615ea1d5b49aea5314016be2e89c49",
"content_id": "ca0bab005eaa6330ae2770b21971705b5e226f9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1189,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 38,
"path": "/Lab Teacher Worapan/Accessing Image Data.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\n\tdouble total = 0;\n\tdouble mean;\n\tofstream fout(\"filename.txt\");\n\tMat img = imread(\"dog.jpg\", IMREAD_GRAYSCALE);\n\tfor (int y = 0; y < img.rows; y++) {\n\t\tfor (int x = 0; x < img.cols; x++) {\n\t\t\tint color = img.at<uchar>(cv::Point(x, y));\n\t\t\tprintf(\"Grey: %d\\n\", color);\n\t\t\ttotal += (img.rows+img.cols);\n\t\t\tfout << \"Gray Value is: \" << (int)color << endl; // don't need to cast integer value\n\t\t}\n\t}\n\t mean = (total / (img.rows * img.cols));\n\t fout << std::fixed << std::setprecision(2) << \"The average of Gray value is \" <<(double)mean << endl; // cast into double value\n\t fout.close();\n\tprintf(\"Average of Gray is : %.2f \\n\", mean);\n\tprintf(\"Calculate Complete\\n\");\n\tcout << \"Press Enter to Continue\";\n\tcin.ignore();\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.6516516804695129,
"alphanum_fraction": 0.672672688961029,
"avg_line_length": 14.857142448425293,
"blob_id": "a5b607d258bccbef5f5ce82c76c7ab2905bb0514",
"content_id": "9dac31bb04f8f6dce5750873021837f81ea1a244",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 21,
"path": "/Lab Teacher Worapan/Display img.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n\nusing namespace std;\nusing namespace cv;\n\n#define MODE 1\n\nint main()\n{\n\tif (MODE == 1)\n\t{\n\t\tMat img;\n\t\timg = imread(\"dog.jpg\", 1);\n\t\tnamedWindow(\"Display window\", WINDOW_AUTOSIZE);\n\t\timshow(\"Display Window\", img);\n\t\twaitKey(0);\n\t}\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6060130596160889,
"alphanum_fraction": 0.6326797604560852,
"avg_line_length": 23.837661743164062,
"blob_id": "83bf6e60a2356cf890124edb820aefbc6fd5fec9",
"content_id": "bbb2e1e5bf36963e93adbe8f637b255b91acf133",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3825,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 154,
"path": "/Lab Teacher Worapan/scratch.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\nusing namespace std;\nusing namespace cv;\n\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param);\nint mouse();\nint magnitude();\nint lab13();\n/**\n * @function main\n */\nint main()\n{\n\tcv::setBreakOnError(true);\n\tmagnitude();\n}\nint magnitude()\n{\n\n\tMat img = imread(\"dog.jpg\", IMREAD_COLOR);\n\tnamedWindow(\"Input\");\n\n\tMat sobelX, sobelY, abssobelX, abssobelY, imgrey;\n\tcv::Mat1f mag;\n\tcv::cvtColor(img, imgrey, COLOR_BGR2GRAY);\n\n\tcv::Sobel(imgrey, sobelX, CV_32F, 1, 0, 3);\n\tcv::convertScaleAbs(sobelX, abssobelX);\n\tnamedWindow(\"SobelX\");\n\tcv::imshow(\"SobelX\", abssobelX);\n\n\tcv::Sobel(imgrey, sobelY, CV_32F, 0, 1, 3);\n\tcv::convertScaleAbs(sobelY, abssobelY);\n\tnamedWindow(\"SobelY\");\n\tcv::imshow(\"SobelY\", abssobelY);\n\n\tmagnitude(sobelX, sobelY, mag);\n\timshow(\"Result\", mag);\n\n\tcv::waitKey(0);\n\n\treturn 0 ;\n}\n\n\nint lab13()\n{\n\tMat src, dst;\n\n\t/// Load image\n\tsrc = imread(\"dog.jpg\", IMREAD_COLOR);\n\n\tif (!src.data)\n\t{\n\t\treturn -1;\n\t}\n\n\t/// Separate the image in 3 places ( B, G and R )\n\tvector<Mat> bgr_planes;\n\tsplit(src, bgr_planes);\n\n\t/// Establish the number of bins\n\tint histSize = 256;\n\n\t/// Set the ranges ( for B,G,R) )\n\tfloat range[] = { 0, 256 };\n\tconst float* histRange = { range };\n\n\tbool uniform = true; bool accumulate = false;\n\n\tMat b_hist, g_hist, r_hist;\n\n\t/// Compute the histograms:\n\tcalcHist(&bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, &histRange, uniform, accumulate);\n\n\t// Draw the histograms for B, G and R\n\tint hist_w = 512; int hist_h = 400;\n\tint bin_w = cvRound((double)hist_w / histSize);\n\n\tMat histImage(hist_h, hist_w, CV_8UC3, Scalar(0, 0, 0));\n\n\t/// Normalize the result to [ 0, histImage.rows ]\n\tnormalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\n\t/// Draw for each channel\n\tfor (int i = 1; i < histSize; i++)\n\t{\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(b_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(b_hist.at<float>(i))),\n\t\t\tScalar(255, 0, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(g_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(g_hist.at<float>(i))),\n\t\t\tScalar(0, 255, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(r_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(r_hist.at<float>(i))),\n\t\t\tScalar(0, 0, 255), 2, 8, 0);\n\t}\n\n\t/// Display\n\tnamedWindow(\"calcHist Demo\", cv::WINDOW_AUTOSIZE);\n\timshow(\"calcHist Demo\", histImage);\n\n\twaitKey(0);\n\n\treturn 0;\n}\n\n\nint mouse()\n{\n\n\tMat img;\n\timg = imread(\"dog.jpg\", 1);\n\n\tnamedWindow(\"Example\");\n\tsetMouseCallback(\"Example\", mouse_callback);\n\n\timshow(\"Example\", img);\n\twaitKey(0);\n\treturn 0;\n\n}\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param)\n{\n\tif (event == EVENT_MOUSEMOVE)\n\t{\n\t\tcout << \"( X: \" << x << \", Y: \" << y << \")\" << endl;\n\t}\n\tif (event == EVENT_LBUTTONDOWN)\n\t{\n\t\tMat img;\n\t\timg = imread(\"dog.jpg\", 1);\n\t\tVec3b color = img.at<Vec3b>(cv::Point(x, y));\n\n\t\tcout << \"Left button of the mouse is clicked - position ( X:\" << x << \", Y: \" << y << \")\" << endl;\n\t\tprintf(\"Blue: %d, Green: %d, Red: %d \\n\", color[0], color[1], color[2]);\n\t}\n}\n"
},
{
"alpha_fraction": 0.6803278923034668,
"alphanum_fraction": 0.7704917788505554,
"avg_line_length": 11.199999809265137,
"blob_id": "1835ec4de0a8c3f4f1d9cd4b0f2e2436f08e2721",
"content_id": "a843c10ddd4ae1ad2c6da00290cfe0f38b103e9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 10,
"path": "/requirements.txt",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "sphinx-rtd-theme==0.2.4\nSphinx==1.6.7\ntravis-sphinx==1.4.3\nflask==1.0\njupyter\nnbconvert\npandoc\nnbsphinx\nIPython\nipykernel\n"
},
{
"alpha_fraction": 0.6032698750495911,
"alphanum_fraction": 0.6380380988121033,
"avg_line_length": 24.101299285888672,
"blob_id": "2d1c1710607240749f5ef51e2a065352e68c3c09",
"content_id": "8248cef0d878937999be4969135ef537e9a54edd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9664,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 385,
"path": "/Lab Teacher Worapan/6Lab_Left.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n/*\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tMat image = imread(\"dog.jpg\", 1);\n\tnamedWindow(\"Original Image\", 1);\n\timshow(\"Original Image\", image);\n\n\t// Split the image into different channels\n\tvector<Mat> rgbChannels(3);\n\tsplit(image, rgbChannels);\n\n\t// Show individual channels\n\tMat g, fin_img;\n\tg = Mat::zeros(Size(image.cols, image.rows), CV_8UC1);\n\n\t// Showing Red Channel\n\t// G and B channels are kept as zero matrix for visual perception\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(rgbChannels[2]);\n\n\t\t// Merge the three channels\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Red\", 1);\n\t\timshow(\"Red\", fin_img);\n\t}\n\n\t// Showing Green Channel\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(rgbChannels[1]);\n\t\tchannels.push_back(g);\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Green\", 1);\n\t\timshow(\"Green\", fin_img);\n\t}\n\n\t// Showing Blue Channel\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(rgbChannels[0]);\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(g);\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Blue\", 1);\n\t\timshow(\"Blue\", fin_img);\n\t}\n\tcv::waitKey(0);\n\n}*/\n\nusing namespace std;\nusing namespace cv;\n\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param);\nint mouse();\nint magnitude();\nint lab13();\nint histogram();\nint Lab14();\nint act4();\nvoid sobel();\n/**\n * @function main\n */\nint main()\n{\ncv:setBreakOnError(true);\n\t//mouse();\n\t//sobel();\n\t//lab13();\n\t//magnitude();\n\t//Lab14();\n\t//act4();\n}\nvoid sobel()\n{\n\tMat img;\n\timg = imread(\"dog.jpg\", 1);\n\tnamedWindow(\"Input\");\n\timshow(\"Input\", img);\n\n\tMat sobel_x, sobel_y;\n\tMat abs_sobel_x, abs_sobel_y;\n\n\tMat img_gray;\n\tcv::cvtColor(img, img_gray, cv::COLOR_BGR2GRAY);\n\n\t//Gradient X\n\tSobel(img_gray, sobel_x, CV_16S, 1, 0, 3);\n\tconvertScaleAbs(sobel_x, abs_sobel_x);\n\timshow(\"Sobel X\", abs_sobel_x);\n\n\t//Gradient Y\n\tSobel(img_gray, sobel_y, CV_16S, 0, 1, 3);\n\tconvertScaleAbs(sobel_y, abs_sobel_y);\n\timshow(\"Sobel Y\", abs_sobel_y);\n\n\tcv::waitKey(0);\n}\n\nint magnitude()\n{\n\n\tMat img = imread(\"dog.jpg\", IMREAD_COLOR);\n\tnamedWindow(\"Input\");\n\n\tMat sobelX, sobelY, abssobelX, abssobelY, imgrey;\n\tcv::Mat1f mag;\n\tcv::cvtColor(img, imgrey, COLOR_BGR2GRAY);\n\n\tcv::Sobel(imgrey, sobelX, CV_32F, 1, 0, 3);\n\tcv::convertScaleAbs(sobelX, abssobelX);\n\tnamedWindow(\"SobelX\");\n\tcv::imshow(\"SobelX\", abssobelX);\n\n\tcv::Sobel(imgrey, sobelY, CV_32F, 0, 1, 3);\n\tcv::convertScaleAbs(sobelY, abssobelY);\n\tnamedWindow(\"SobelY\");\n\tcv::imshow(\"SobelY\", abssobelY);\n\n\tmagnitude(sobelX, sobelY, mag);\n\timshow(\"Result\", mag);\n\n\tcv::waitKey(0);\n\n\treturn 0;\n}\n\n\nint lab13()\n{\n\tMat src, dst;\n\n\t/// Load image\n\tsrc = imread(\"dog.jpg\", IMREAD_COLOR);\n\n\tif (!src.data)\n\t{\n\t\treturn -1;\n\t}\n\n\t/// Separate the image in 3 places ( B, G and R )\n\tvector<Mat> bgr_planes;\n\tsplit(src, bgr_planes);\n\n\t/// Establish the number of bins\n\tint histSize = 256;\n\n\t/// Set the ranges ( for B,G,R) )\n\tfloat range[] = { 0, 256 };\n\tconst float* histRange = { range };\n\n\tbool uniform = true; bool accumulate = false;\n\n\tMat b_hist, g_hist, r_hist;\n\n\t/// Compute the histograms:\n\tcalcHist(&bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, &histRange, uniform, accumulate);\n\n\t// Draw the histograms for B, G and R\n\tint hist_w = 512; int hist_h = 400;\n\tint bin_w = cvRound((double)hist_w / histSize);\n\n\tMat histImage(hist_h, hist_w, CV_8UC3, Scalar(0, 0, 0));\n\n\t/// Normalize the result to [ 0, histImage.rows ]\n\tnormalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\n\t/// Draw for each channel\n\tfor (int i = 1; i < histSize; i++)\n\t{\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(b_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(b_hist.at<float>(i))),\n\t\t\tScalar(255, 0, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(g_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(g_hist.at<float>(i))),\n\t\t\tScalar(0, 255, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(r_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(r_hist.at<float>(i))),\n\t\t\tScalar(0, 0, 255), 2, 8, 0);\n\t}\n\n\t/// Display\n\tnamedWindow(\"calcHist Demo\", cv::WINDOW_AUTOSIZE);\n\timshow(\"calcHist Demo\", histImage);\n\n\twaitKey(0);\n\n\treturn 0;\n}\n\n\nint mouse()\n{\n\n\tMat img;\n\timg = imread(\"dog.jpg\", 1);\n\n\tnamedWindow(\"Example\");\n\tsetMouseCallback(\"Example\", mouse_callback);\n\n\timshow(\"Example\", img);\n\twaitKey(0);\n\treturn 0;\n\n}\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param)\n{\n\tif (event == EVENT_MOUSEMOVE)\n\t{\n\t\tcout << \"( X: \" << x << \", Y: \" << y << \")\" << endl;\n\t}\n\tif (event == EVENT_LBUTTONDOWN)\n\t{\n\t\tMat img;\n\t\timg = imread(\"dog.jpg\", 1);\n\t\tVec3b color = img.at<Vec3b>(cv::Point(x, y));\n\n\t\tcout << \"Left button of the mouse is clicked - position ( X:\" << x << \", Y: \" << y << \")\" << endl;\n\t\tprintf(\"Blue: %d, Green: %d, Red: %d \\n\", color[0], color[1], color[2]);\n\t}\n}\n\nint histogram()\n{\n\tMat src, dst;\n\n\t/// Load image\n\tsrc = imread(\"dog.jpg\", IMREAD_COLOR);\n\n\tif (!src.data)\n\t{\n\t\treturn -1;\n\t}\n\n\t/// Separate the image in 3 places ( B, G and R )\n\tvector<Mat> bgr_planes;\n\tsplit(src, bgr_planes);\n\n\t/// Establish the number of bins\n\tint histSize = 256;\n\n\t/// Set the ranges ( for B,G,R) )\n\tfloat range[] = { 0, 256 };\n\tconst float* histRange = { range };\n\n\tbool uniform = true; bool accumulate = false;\n\n\tMat b_hist, g_hist, r_hist;\n\n\t/// Compute the histograms:\n\tcalcHist(&bgr_planes[0], 1, 0, Mat(), b_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[1], 1, 0, Mat(), g_hist, 1, &histSize, &histRange, uniform, accumulate);\n\tcalcHist(&bgr_planes[2], 1, 0, Mat(), r_hist, 1, &histSize, &histRange, uniform, accumulate);\n\n\t// Draw the histograms for B, G and R\n\tint hist_w = 512; int hist_h = 400;\n\tint bin_w = cvRound((double)hist_w / histSize);\n\n\tMat histImage(hist_h, hist_w, CV_8UC3, Scalar(0, 0, 0));\n\n\t/// Normalize the result to [ 0, histImage.rows ]\n\tnormalize(b_hist, b_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(g_hist, g_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\tnormalize(r_hist, r_hist, 0, histImage.rows, NORM_MINMAX, -1, Mat());\n\n\t/// Draw for each channel\n\tfor (int i = 1; i < histSize; i++)\n\t{\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(b_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(b_hist.at<float>(i))),\n\t\t\tScalar(255, 0, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(g_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(g_hist.at<float>(i))),\n\t\t\tScalar(0, 255, 0), 2, 8, 0);\n\t\tline(histImage, Point(bin_w*(i - 1), hist_h - cvRound(r_hist.at<float>(i - 1))),\n\t\t\tPoint(bin_w*(i), hist_h - cvRound(r_hist.at<float>(i))),\n\t\t\tScalar(0, 0, 255), 2, 8, 0);\n\t}\n\n\t/// Display\n\tnamedWindow(\"calcHist Demo\", cv::WINDOW_AUTOSIZE);\n\timshow(\"calcHist Demo\", histImage);\n\n\twaitKey(0);\n\n\treturn 0;\n}\n\nint Lab14() {\n\tMat img1, hsv1;\n\tMat img2, hsv2;\n\n\timg1 = imread(\"dog.jpg\", IMREAD_COLOR);\n\timg2 = imread(\"dog11.jpg\", IMREAD_COLOR);\n\n\tcvtColor(img1, hsv1, cv::COLOR_BGR2HSV);\n\tcvtColor(img2, hsv2, COLOR_BGR2HSV);\n\n\tint h_bins = 50; int s_bins = 60;\n\tint histSize[] = { h_bins, s_bins };\n\n\tfloat h_ranges[] = { 0, 180 };\n\tfloat s_ranges[] = { 0, 256 };\n\n\tconst float* ranges[] = { h_ranges,s_ranges };\n\tint channels[] = { 0,1 };\n\n\tMatND hist1;\n\tMatND hist2;\n\n\tcalcHist(&hsv1, 1, channels, Mat(), hist1, 2, histSize, ranges, true, false);\n\tnormalize(hist1, hist1, 0, 1, NORM_MINMAX, -1, Mat());\n\tcalcHist(&hsv2, 1, channels, Mat(), hist2, 2, histSize, ranges, true, false);\n\tnormalize(hist2, hist2, 0, 1, NORM_MINMAX, -1, Mat());\n\tdouble sim = compareHist(hist1, hist2, cv::HISTCMP_CORREL);\n\tprintf(\"The correlation similarlity is %f\\n\", sim);\n\tprintf(\"\\n\");\n\tcin.ignore();\n\treturn 0;\n}\nint act4()\n{\nMat img1, hsv1;\nMat img2, hsv2;\nMat img3, hsv3;\n\nimg1 = imread(\"dog.jpg\", IMREAD_COLOR);\nimg2 = imread(\"dog_gray.jpg\", IMREAD_COLOR);\nimg3 = imread(\"dog11.jpg\", IMREAD_COLOR);\n\ncvtColor(img1, hsv1, COLOR_BGR2HSV);\ncvtColor(img2, hsv2, COLOR_BGR2HSV);\ncvtColor(img3, hsv3, COLOR_BGR2HSV);\n\nint h_bins = 50; int s_bins = 60;\nint histSize[] = { h_bins, s_bins };\n\nfloat h_ranges[] = { 0, 180 };\nfloat s_ranges[] = { 0, 256 };\n\nconst float* ranges[] = { h_ranges,s_ranges };\nint channels[] = { 0,1 };\n\nMatND hist1;\nMatND hist2;\nMatND hist3;\n\ncalcHist(&hsv1, 1, channels, Mat(), hist1, 2, histSize, ranges, true, false);\nnormalize(hist1, hist1, 0, 1, NORM_MINMAX, -1, Mat());\ncalcHist(&hsv2, 1, channels, Mat(), hist2, 2, histSize, ranges, true, false);\nnormalize(hist2, hist2, 0, 1, NORM_MINMAX, -1, Mat());\ncalcHist(&hsv3, 1, channels, Mat(), hist3, 2, histSize, ranges, true, false);\nnormalize(hist3, hist3, 0, 1, NORM_MINMAX, -1, Mat());\ndouble sim1 = compareHist(hist1, hist2, HISTCMP_CORREL);\ndouble sim2 = compareHist(hist1, hist3, HISTCMP_CORREL);\nprintf(\"The correlation similarlity 1 is %f\\n\", sim1);\nprintf(\"The correlation similarlity 2 is %f\\n\", sim2);\nprintf(\"\\n\");\ncin.ignore();\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.6871795058250427,
"alphanum_fraction": 0.696794867515564,
"avg_line_length": 22.65151596069336,
"blob_id": "bcdbedba7937169b92092ad37884abd89fa4af45",
"content_id": "12054699e86f1277dedddd34dbbd2c69c1cb9099",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1560,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 66,
"path": "/Lab Teacher Worapan/Split.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tMat image = imread(\"dog.jpg\", 1);\n\tnamedWindow(\"Original Image\", 1);\n\timshow(\"Original Image\", image);\n\n\t// Split the image into different channels\n\tvector<Mat> rgbChannels(3);\n\tsplit(image, rgbChannels);\n\n\t// Show individual channels\n\tMat g, fin_img;\n\tg = Mat::zeros(Size(image.cols, image.rows), CV_8UC1);\n\n\t// Showing Red Channel\n\t// G and B channels are kept as zero matrix for visual perception\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(rgbChannels[2]);\n\n\t\t// Merge the three channels\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Red\", 1);\n\t\timshow(\"Red\", fin_img);\n\t}\n\n\t// Showing Green Channel\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(rgbChannels[1]);\n\t\tchannels.push_back(g);\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Green\", 1);\n\t\timshow(\"Green\", fin_img);\n\t}\n\n\t// Showing Blue Channel\n\t{\n\t\tvector<Mat> channels;\n\t\tchannels.push_back(rgbChannels[0]);\n\t\tchannels.push_back(g);\n\t\tchannels.push_back(g);\n\t\tmerge(channels, fin_img);\n\t\tnamedWindow(\"Blue\", 1);\n\t\timshow(\"Blue\", fin_img);\n\t}\n\tcv::waitKey(0);\n\n}"
},
{
"alpha_fraction": 0.6345933675765991,
"alphanum_fraction": 0.650629997253418,
"avg_line_length": 19.325580596923828,
"blob_id": "7fb3c75898020a02a91717110a9aa96911ed2712",
"content_id": "2477facffaae7bfcfca31b21bf935064e82ed65d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 43,
"path": "/Lab Teacher Worapan/Write File AVI.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include \"opencv2/opencv.hpp\"\n#include<opencv2/highgui/highgui.hpp>\n#include<opencv2/videoio/videoio.hpp>\n#include <iostream>\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\n\tVideoCapture cap(\"./20.avi\");\n\n\n\tif (!cap.isOpened())\n\t{\n\t\tcout << \"Error opening video stream\" << endl;\n\t\treturn -1;\n\t}\n\tint frame_width = cap.get(cv::CAP_PROP_FRAME_WIDTH);\n\tint frame_height = cap.get(cv::CAP_PROP_FRAME_HEIGHT);\n\tVideoWriter video(\"20_out.avi\", cv::CAP_PROP_FOURCC>>('M', 'J', 'P', 'G'), 10, Size(frame_width, frame_height));\n\n\twhile (true)\n\t{\n\t\tMat frame;\n\t\tcap >> frame; // take new frame from camera\n\t\t//End of video\n\t\tif (frame.empty())\n\t\t\tbreak;\t\n\t\t\n\t\tvideo.write(frame);\n\t\t\n\t\timshow(\"Frame\", frame);\n\t\tchar c = (char)waitKey(1);\n\t\tif (c == 27)\n\t\t\tbreak;\n\t}\n\tcap.release();\n\tvideo.release();\n\tdestroyAllWindows();\n}"
},
{
"alpha_fraction": 0.6203007698059082,
"alphanum_fraction": 0.6353383660316467,
"avg_line_length": 37.70909118652344,
"blob_id": "1d982054732949a400bf9e6bd4af1ac667221da5",
"content_id": "7fdf1a3ab46ba9ab6aa00c701da6663e2d2f8da0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2128,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 55,
"path": "/Lab Teacher Worapan/Accessing Image Data (BGR).cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\n\tdouble total = 0;\n\tdouble totalb = 0;\n\tdouble totalg = 0;\n\tdouble totalr = 0;\n\tdouble meanb,meang,meanr;\n\tdouble mean;\n\tofstream fout(\"filename.txt\");\n\tMat img = imread(\"dog.jpg\", IMREAD_COLOR);\n\tfor (int y = 0; y < img.rows; y++) {\n\t\tfor (int x = 0; x < img.cols; x++) {\n\t\t\tVec3b color = img.at<Vec3b>(cv::Point(x, y));\n\t\t\tprintf(\"Blue: %d, Green: %d, Red: %d \\n \", color[0], color[1], color[2]);\n\t\t\ttotal += (img.rows + img.cols);\n\t\t\ttotalb += (color[0]);\n\t\t\ttotalg += (color[1]);\n\t\t\ttotalr += (color[2]);\n\t\t\tfout << \"Blue Value is: \" << (Vec3b)color[0] << \"Green Value is: \" << (Vec3b)color[1] << \"Red Value is: \"<< (Vec3b)color[2] << endl; // don't need to cast integer value\n\t\t}\n\t}\n\tmean = (total / (img.rows * img.cols));\n\tmeanb = (totalb / (img.rows * img.cols));\n\tmeang = (totalg / (img.rows * img.cols));\n\tmeanr = (totalr / (img.rows * img.cols));\n\tfout << std::fixed << std::setprecision(2) << \"The average of BGR value is \" << mean << endl; // cast into double value\n\tfout << std::fixed << std::setprecision(2) << \"The average of Blue value is \" << meanb << endl; // cast into double value\n\tfout << std::fixed << std::setprecision(2) << \"The average of Green value is \" << meang << endl; // cast into double value\n\tfout << std::fixed << std::setprecision(2) << \"The average of Red value is \" << meanr << endl; // cast into double value\n\n\tfout.close();\n\tprintf(\"Average of BGR is : %.2f \\n\", mean);\n\tprintf(\"Average of Blue Value is : %.2f \\n\", meanb);\n\tprintf(\"Average of Green Value is : %.2f \\n\", meang);\n\tprintf(\"Average of Red Value is : %.2f \\n\", meanr);\n\tprintf(\"Calculate Complete\\n\");\n\tcout << \"Press Enter to Continue\";\n\tcin.ignore();\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.532753586769104,
"alphanum_fraction": 0.5550971031188965,
"avg_line_length": 36.15802001953125,
"blob_id": "52e0b4a0804ce20332d05c2a7bc8cf3bb47e2c57",
"content_id": "7d65d35e0ee41990c82d6e2d3c0ed9567c5c413a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 15754,
"license_type": "no_license",
"max_line_length": 235,
"num_lines": 424,
"path": "/SeamCarving/Multimedia.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "/*\n\tCode By\n\tSunat P. 6088130\n\tBarameerak K. 6088156\n\tPoonkasem K. 6088071\n\n\tTeacher Assf. Prof. Dr. Worapan K.\n*/\n#include<stdio.h>\n#include<iostream>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include<opencv2/imgproc/imgproc.hpp>\n#include<stdlib.h>\n#include<math.h>\n\nusing namespace std;\nusing namespace cv;\n\n// Using Forward Seam Carving not Backward Seam Carving\nint main()\n{\n\t// Create Matrix img\n\tMat img = imread(\"test.jpg\");\n\tnamedWindow(\"Original\", WINDOW_AUTOSIZE); // Create Windows to display img\n\timshow(\"Original\", img);\n\tint c = cvWaitKey(0);\n\tSize sz = img.size(); // Create sz for specify width and height of image\n\tint height = sz.height;\n\tint width = sz.width;\n\tint bsstartpoint, next;\n\tint cl, cu, cr; // initialize value for CL , CU , CR\n\tMat FWDseamcrav; // Create Matrix to calculate value in new img\n\n\t// ESC or Escape = 27, A = 97 , D = 100 , S = 115 , W = 119 \n\twhile (c != 27)\n\t{\n\t\twhile (c != 97 && c != 100 && c != 115 && c != 119 && c != 27)\n\t\t{ // Wait until press WASD key\n\t\t\tc = cvWaitKey(0);\n\t\t}\n\t\tif (c == 97 || c == 100) { // A = 97 For Reduce width in vertical directional & D = 100 for Increase width in Vertical directional\n\t\t\t/* Code Here */\n\t\t\tcv::Mat gray_img; // Create Matrix name grey_img for convert color img to grey img\n\t\t\tcvtColor(img, gray_img, cv::COLOR_BGR2GRAY); // used cvtColor() or convertColor from original to grey img by using cv::COLOR_BGR2GRAY\n\t\t\tcv::Size csz = gray_img.size();\n\t\t\tcv::Mat M(csz.height, csz.width, CV_8U); // Create Matrix M\n\t\t\tcv::Mat K(csz.height, csz.width, CV_8U); // Create Matrix K\n\t\t\t\t\t\t\t\t\t\t // CV_8U is 8-bit unsigned integer matrix/image with 3 channels\n\t\t\tfor (int i = 0; i < gray_img.rows; i++) // Create 2 for loop for calculate Seam Carving by using Forward Seam Carving\n\t\t\t{\n\t\t\t\tfor (int j = 0; j < gray_img.cols; j++)\n\t\t\t\t{\n\t\t\t\t\tif (i == 0)\n\t\t\t\t\t{\n\t\t\t\t\t\tif (j == 0)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j, i))); // Calculate M matrix\n\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse if (j == gray_img.cols - 1)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j - 1, i))); // Calculate M matrix\n\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j - 1, i))); // Calculate M matrix\n\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\tif (j == 0)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j, i - 1)) + abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j, i))); // Calculate CU Position\n\t\t\t\t\t\t\tcr = M.at<uchar>(Point(j + 1, i)) + (abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j, i))) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j + 1, i)))); // Calcualte CR Position\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = min(cu, cr); // M matrix value is equal from calculate CU , CR by using min()\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse {\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 3; // Value of K Matrix will equal to 3\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse if (j == gray_img.cols - 1) {\n\t\t\t\t\t\t\tcl = M.at<uchar>(Point(j - 1, i - 1)) + (abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j - 1, i))) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j - 1, i)))); // Calculate CL Position\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j, i - 1)) + abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j - 1, i))); // Calculate CU Postion\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = min(cl, cu); // M matrix value is equal from calculate CL , CU by using min()\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 1; // Value of K Matrix will equal to 1\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcl = M.at<uchar>(Point(j - 1, i - 1)) + (abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j - 1, i))) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j - 1, i)))); // Calculate CL position\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j, i - 1)) + abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j - 1, i))); // Calculate CU position\n\t\t\t\t\t\t\tcr = M.at<uchar>(Point(j + 1, i - 1)) + (abs(gray_img.at<uchar>(Point(j + 1, i)) - gray_img.at<uchar>(Point(j - 1, i))) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j + 1, i)))); // Calculate CR position\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = min({ cl,cu,cr });\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // If M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse if (M.at<uchar>(Point(j, i)) == cr)\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 3; // Value of K Matrix will equal to 3\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 1; // Value of K Matrix will equal to 1\n\t\t\t\t\t\t\t}\n\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t//namedWindow(\"Energy Map\", WINDOW_AUTOSIZE);\n\t\t\t//imshow(\"Energy Map\", M); // Show Energy Map\n\n\t\t\t// Find the Best Seam in the Vertical direction\n\n\t\t\t// Start to find min value from last row to start find best seam\n\n\t\t\tint startbestseam = M.at<uchar>(Point(0, gray_img.rows - 1)); // Start from 0 gray_img cols and rows \n\t\t\tfor (int b = 0; b < gray_img.cols; b++)\n\t\t\t{\n\t\t\t\tif (M.at<uchar>(Point(b, gray_img.rows - 1)) < startbestseam) // if b value in M matrix is less than startbestseam \n\t\t\t\t{\n\t\t\t\t\tstartbestseam = M.at<uchar>(Point(b, gray_img.rows - 1)); // startbestseam value is equal to M matrix\n\t\t\t\t\tbsstartpoint = b; // Best seam point will equal to b value\n\t\t\t\t}\n\t\t\t}\n\t\t\tMat BSseam(csz.height, csz.width, CV_8U, Scalar(0, 0, 0)); // Create matrix name BSseam\n\t\t\tFWDseamcrav = BSseam.clone(); // FWDseamcarv matrix will equal to BSseam that clone value into new matrix\n\t\t\tnext = bsstartpoint;\n\t\t\tfor (int c = gray_img.rows - 1; c > 0; c--)\n\t\t\t{\n\t\t\t\tFWDseamcrav.at<uchar>(Point(next, c)) = 255; // FWDseamcarv set value to 255\n\t\t\t\tif (K.at<uchar>(Point(next, c)) == 1) // If K matrix value equal to 1\n\t\t\t\t{\n\t\t\t\t\tnext = next - 1;\n\t\t\t\t}\n\t\t\t\telse if (K.at<uchar>(Point(next, c)) == 2) // If K matrix value equal to 2\n\t\t\t\t{\n\t\t\t\t\tnext = next;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tnext = next + 1;\n\t\t\t\t}\n\t\t\t}\n\t\t\t//namedWindow(\"Best Seam\", WINDOW_AUTOSIZE);\n\t\t\t//imshow(\"Best Seam\", FWDseamcrav); // Show Best seam Output \n\t\t\tgray_img.release();\n\t\t\tM.release();\n\t\t\tK.release();\n\n\t\t}\n\t\tif (c == 115 || c == 119) // S Key for decrease height horizontal directional and W Key for increase height horizontal directical\n\t\t{\n\t\t\t/* CODE HERE */\n\t\t\tMat gray_img; // Create Matrix for gray img\n\t\t\tcvtColor(img, gray_img, COLOR_BGR2GRAY); // Convert normal color into gray color\n\t\t\tSize csz = gray_img.size(); // Declare size name csz \n\t\t\tMat M(csz.height, csz.width, CV_8U);\n\t\t\tMat K(csz.height, csz.width, CV_8U);\n\t\t\tfor (int j = 0; j < gray_img.cols; j++)\n\t\t\t{\n\t\t\t\tfor (int i = 0; i < gray_img.rows; i++)\n\t\t\t\t{\n\t\t\t\t\tif (j == 0)\n\t\t\t\t\t{\n\t\t\t\t\t\tif (i == gray_img.rows - 1)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i))); // Calculate M matrix\n\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse if (i == 0)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j, i + 1))); // Calculate M matrix\n\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i + 1))); // Calculate M matrix\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\tif (i == gray_img.rows - 1)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j - 1, i)) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i))); // Calculate value for CU\n\t\t\t\t\t\t\tcr = M.at<uchar>(Point(j - 1, i - 1)) + (abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i))) + abs(gray_img.at<uchar>(Point(j - 1, i)) - gray_img.at<uchar>(Point(j, i - 1)))); // Calculate value for CR\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // If M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 3; // Value of K Matrix will equal to 3\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse if (i == 0)\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcl = M.at<uchar>(Point(j - 1, i + 1)) + (abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j, i + 1))) + abs(gray_img.at<uchar>(Point(j - 1, i)) - gray_img.at<uchar>(Point(j, i + 1)))); // Calculate value for CL\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j - 1, i)) + abs(gray_img.at<uchar>(Point(j, i)) - gray_img.at<uchar>(Point(j, i + 1))); // Calculate value for CU\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = min({ cl,cu });\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // If M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 1; // Value of K Matrix will equal to 1\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\t\telse\n\t\t\t\t\t\t{\n\t\t\t\t\t\t\tcl = M.at<uchar>(Point(j - 1, i + 1)) + (abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i + 1))) + abs(gray_img.at<uchar>(Point(j - 1, i)) - gray_img.at<uchar>(Point(j, i + 1)))); // Calculate value for CL\n\t\t\t\t\t\t\tcu = M.at<uchar>(Point(j - 1, i)) + abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i + 1))); // Calculate value for CU\n\t\t\t\t\t\t\tcr = M.at<uchar>(Point(j - 1, i - 1)) + (abs(gray_img.at<uchar>(Point(j, i - 1)) - gray_img.at<uchar>(Point(j, i + 1))) + abs(gray_img.at<uchar>(Point(j - 1, i)) - gray_img.at<uchar>(Point(j, i - 1)))); // Calculate value for CR\n\t\t\t\t\t\t\tM.at<uchar>(Point(j, i)) = min({ cl,cu,cr });\n\t\t\t\t\t\t\tif (M.at<uchar>(Point(j, i)) == cu) // If M matrix value equal to CU\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 2; // Value of K Matrix will equal to 2\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse if (M.at<uchar>(Point(j, i)) == cr)\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 3; // Value of K Matrix will equal to 3\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t\telse\n\t\t\t\t\t\t\t{\n\t\t\t\t\t\t\t\tK.at<uchar>(Point(j, i)) = 1; // Value of K Matrix will equal to 1\n\t\t\t\t\t\t\t}\n\t\t\t\t\t\t}\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\t//namedWindow(\"Energy Map\", WINDOW_AUTOSIZE);\n\t\t\t//imshow(\"Energy Map\", M); // Show Energy Map\n\n\t\t\t// Find the best seam in the vertical direction\n\t\t\tint startbestseam = M.at<uchar>(Point(gray_img.cols - 1, 0));\n\t\t\tint bsstartpoint, next;\n\t\t\tbsstartpoint = 0;\n\t\t\tnext = 0;\n\t\t\tfor (int b = 0; b < gray_img.rows; b++)\n\t\t\t{\n\t\t\t\tif (M.at<uchar>(Point(gray_img.cols - 1, b)) < startbestseam)\n\t\t\t\t{\n\t\t\t\t\tstartbestseam = M.at<uchar>(Point(gray_img.cols - 1, b)); // startbestseam equal to M matrix\n\t\t\t\t\tbsstartpoint = b; // Set bsstartpoint equal to b \n\t\t\t\t}\n\t\t\t}\n\t\t\tMat FWDBSeam(csz.height, csz.width, CV_8U, Scalar(0, 0, 0)); // Create Matrix for calculate Forward seam carving\n\t\t\tFWDseamcrav = FWDBSeam.clone(); // Clone matrix FWDBSeam to FWDseamcrav\n\t\t\tnext = bsstartpoint; // Set next equal to bsstartpoint\n\t\t\tfor (int c = gray_img.cols - 1; c > 0; c--)\n\t\t\t{\n\t\t\t\tFWDseamcrav.at<uchar>(Point(c, next)) = 255; // Matrix FWDseamcrav set to 255\n\t\t\t\tif (K.at<uchar>(Point(c, next)) == 1)\n\t\t\t\t{\n\t\t\t\t\tnext = next + 1; // Increment value by plus 1\n\t\t\t\t}\n\t\t\t\telse if (K.at<uchar>(Point(c, next)) == 2)\n\t\t\t\t{\n\t\t\t\t\tnext = next; // No change value\n\t\t\t\t}\n\t\t\t\telse {\n\t\t\t\t\tnext = next - 1; // Decrement value by minus 1 \n\t\t\t\t}\n\t\t\t}\n\t\t\t//namedWindow(\"Best Seam\", WINDOW_AUTOSIZE);\n\t\t\t//imshow(\"Best Seam\", FWDseamcrav);\n\t\t\tgray_img.release();\n\t\t\tM.release();\n\t\t\tK.release();\n\t\t}\n\n\t\t// Insert or delete the best seam\n\t\tif (c == 97) // A key\n\t\t{\n\t\t\t// Reduce width or delete seam vertically\n\t\t\t// Copy the pixels into this image\n\t\t\tMat img_new(height, --width, CV_8UC3, Scalar(0, 0, 0)); // Create new Matrix for new img\n\t\t\tint del;\n\t\t\tfor (int i = 0; i < img_new.rows; i++)\n\t\t\t{\n\t\t\t\tdel = 0;\n\t\t\t\tfor (int j = 0; j < img_new.cols; j++)\n\t\t\t\t{\n\t\t\t\t\tif (FWDseamcrav.at<uchar>(Point(j, i)) == 255) // If FWDseamcrav is equal to 255\n\t\t\t\t\t{\n\t\t\t\t\t\tdel = 1; // Set del equal to 1\n\t\t\t\t\t}\n\t\t\t\t\tif (del == 1)\n\t\t\t\t\t{\n\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j + 1, i)); // Set img_new Matrix will increment value in Point j + 1 \n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i)); // img_new will equal to original img Matrix\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\t// Show the resized image\n\t\t\timshow(\"Output\", img_new);\n\t\t\t// Clone img new into img for next loop processing\n\t\t\timg.release();\n\t\t\timg = img_new.clone();\n\t\t\timg_new.release();\n\t\t}\n\t\tif (c == 100) // D\n\t\t{\n\t\t\t// Increase width or insert seam vertically\n\t\t\t// Copy the pixels into this image\n\t\t\tMat img_new(height, ++width, CV_8UC3, Scalar(0, 0, 0));\n\t\t\tint ins;\n\t\t\tfor (int i = 0; i < img_new.rows; i++)\n\t\t\t{\n\t\t\t\tins = 0;\n\t\t\t\tfor (int j = 0; j < img_new.cols - 1; j++)\n\t\t\t\t{\n\t\t\t\t\tif (ins == 1)\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j - 1, i)); // Set img_new Matrix will decrement value in Point j - 1 \n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i)); // img_new will equal to original img Matrix\n\t\t\t\t\t}\n\t\t\t\t\tif (FWDseamcrav.at<uchar>(Point(j, i)) == 255) // If FWDseamcrav is equal to 255\n\t\t\t\t\t{\n\t\t\t\t\t\tins = 1; // Set ins equal to 1\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\t// Show the resized image\n\t\t\timshow(\"Output\", img_new);\n\t\t\t// Clone img new into img for next loop processing\n\t\t\timg.release();\n\t\t\timg = img_new.clone();\n\t\t\timg_new.release();\n\t\t}\n\t\tif (c == 115)\n\t\t{\n\t\t\t// Reduce height or delete seam horizontal\n\t\t\t// Copy the pixels into this image\n\t\t\tMat img_new(--height, width, CV_8UC3, Scalar(0, 0, 0));\n\t\t\tint del;\n\t\t\tfor (int j = 0; j < img_new.cols; j++)\n\t\t\t{\n\t\t\t\tdel = 0;\n\t\t\t\tfor (int i = 0; i < img_new.rows; i++)\n\t\t\t\t{\n\t\t\t\t\tif (FWDseamcrav.at<uchar>(Point(j, i)) == 255) // If FWDseamcrav is equal to 255\n\t\t\t\t\t{\n\t\t\t\t\t\tdel = 1; // Set del equal to 1\n\t\t\t\t\t}\n\t\t\t\t\tif (del == 1)\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i + 1)); // Set img_new Matrix will increment value in Point i + 1 \n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i)); // img_new will equal to original img Matrix\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\t// Show the resized image\n\t\t\timshow(\"Output\", img_new);\n\t\t\t// Clone img)new into img for next loop processing\n\t\t\timg.release();\n\t\t\timg = img_new.clone();\n\t\t\timg_new.release();\n\t\t}\n\t\tif (c == 119)\n\t\t{\n\t\t\t// Increase height or insert seam horizontal\n\t\t\t// Copy the pixels into this image\n\t\t\tMat img_new(++height, width, CV_8UC3, Scalar(0, 0, 0));\n\t\t\tint ins;\n\t\t\tfor (int j = 0; j < img_new.cols; j++)\n\t\t\t{\n\t\t\t\tins = 0;\n\t\t\t\tfor (int i = 0; i < img_new.rows - 1; i++)\n\t\t\t\t{\n\t\t\t\t\tif (ins == 1)\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i - 1)); // Set img_new Matrix will decrement value in Point i + 1 \n\t\t\t\t\t}\n\t\t\t\t\telse\n\t\t\t\t\t{\n\t\t\t\t\t\timg_new.at<Vec3b>(Point(j, i)) = img.at<Vec3b>(Point(j, i)); // img_new will equal to original img Matrix\n\t\t\t\t\t}\n\t\t\t\t\tif (FWDseamcrav.at<uchar>(Point(j, i)) == 255)\n\t\t\t\t\t{\n\t\t\t\t\t\tins = 1;\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t\t// Show the resized image\n\t\t\timshow(\"Output\", img_new);\n\t\t\t// Clone img new into img for next loop processing\n\t\t\timg.release();\n\t\t\timg = img_new.clone();\n\t\t\timg_new.release();\n\t\t}\n\t\tif (c == 27)\n\t\t\tbreak;\n\t\tc = cvWaitKey(0);\n\t}\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.7364627718925476,
"alphanum_fraction": 0.7664589285850525,
"avg_line_length": 76.78787994384766,
"blob_id": "95e8ecd365823c2b71324665abf4aaedc34b1c19",
"content_id": "da2fe282d61abc15f8828f117f28b9bb8d3c8ee1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5134,
"license_type": "no_license",
"max_line_length": 556,
"num_lines": 66,
"path": "/Week2/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# Week 2 Pixel Point and Neighborhood Operations\n\n## Representation of Monochrome Image in programming\n - ## Grey Channel\n \n * each element (pixel) in Matrix (2D Array) represents the intensity of brightness in that pixel \n * 0 is equal to Black (0-Black)\n * 255 is equal to White (255-White)\n * **NOTE** **Monochrome:** Each pixel is stored as asingle bit (0 or 1) A 640 x 480 monochrome image requires 37.5 KB of storage.\n * **Grayscale:** Each pixel is usually storedas a byte (value between 0\nto 255)A 640 x 480 grayscale image requires over 300 KB of storage\n\n - ## RGB Channel \n \n * In the Red Channel, each element of the matrix (valued 0-255) represents an intensity of red color in that pixel, likewise in green and blue channels.\n - ## Color in per Channels\n \n## Objectives (Monochrome)\n \n## Objectives (Color) \n \n## Creating a negative of a grayscale image\n \n - A positive image is a normal image. A negative image is a total inversion, in which light areas appear dark and vice versa. A negative color image is additionally color-reversed with red areas appearing cyan, greens appearing magenta, and blues appearing yellow, and vice versa.\n - Film negatives usually have less contrast, but a wider dynamic range, than the final printed positive images. The contrast typically increases when they are printed onto photographic paper. When negative film images are brought into the digital realm, their contrast may be adjusted at the time of scanning or, more usually, during subsequent post-processing. \n\n \n\n## Bitwise operation Black and White Image\n## 1. BITWISE by using image\n\n ## 2. BITWISE by using image (Cont.)\n \n ## 3. Bitwise operation with image Threshold\n 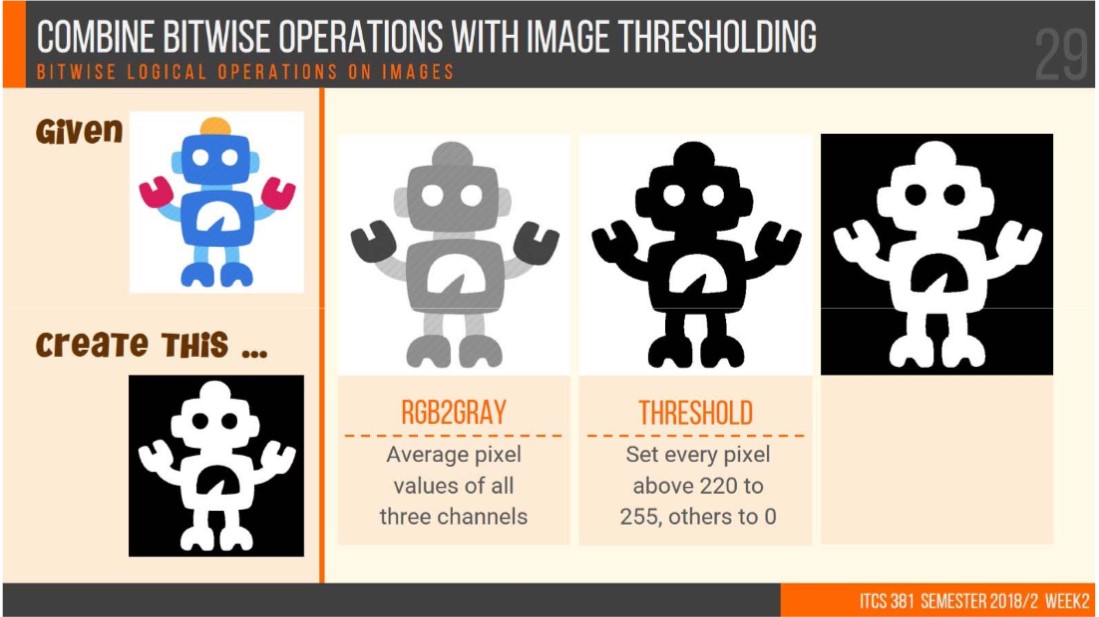\n\n## Pixel vs Neighborhood Processing\n 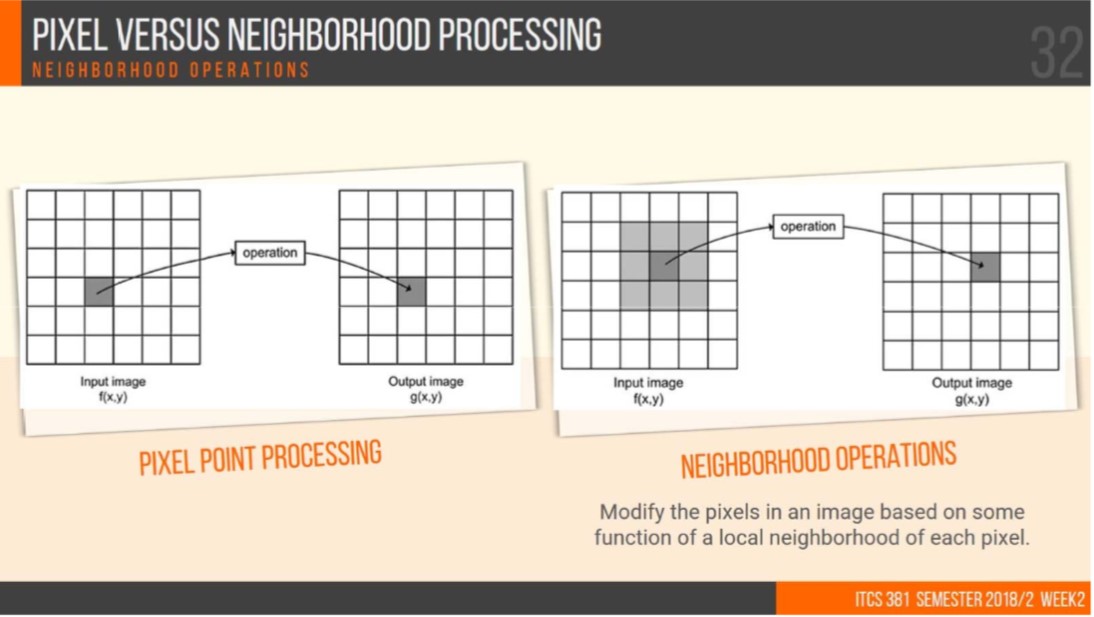\n - ## Neighborhood Processing \n \n \n **What is it ?** A sliding neighborhood operation is an operation that is performed a pixel at a time, with the value of any given pixel in the output image being determined by applying some algorithm to the values of the corresponding input pixel's neighborhood. A pixel's neighborhood is some set of pixels, defined by their locations relative to that pixel, which is called the center pixel. The neighborhood is a rectangular block, and as you move from one element to the next in an image matrix, the neighborhood block slides in the same direction. \n \n The following figure shows the neighborhood blocks for some of the elements in a 6-by-5 matrix with 2-by-3 sliding blocks. The center pixel for each neighborhood is marked with a dot.\n \n - **EXAMPLE**\n \n\nThe center pixel is the actual pixel in the input image being processed by the operation. If the neighborhood has an odd number of rows and columns, the center pixel is actually in the center of the neighborhood. If one of the dimensions has even length, the center pixel is just to the left of center or just above center. For example, in a 2-by-2 neighborhood, the center pixel is the upper left one.\n\nFor any m-by-n neighborhood, the center pixel is\n```\n floor(([m n]+1)/2) \n``` \n\nIn the 2-by-3 block shown in Example, the center pixel is (1,2), or, the pixel in the second column of the top row of the neighborhood.\n\nTo perform a sliding neighborhood operation:\n\n 1. Select a single pixel.\n 2. Determine the pixel's neighborhood.\n 3. Apply a function to the values of the pixels in the neighborhood. This function must return a scalar.\n 4. Find the pixel in the output image whose position corresponds to that of the center pixel in the input image. Set this output pixel to the value returned by the function.\n 5. Repeat steps 1 through 4 for each pixel in the input image.\n\nFor example, suppose Example represents an averaging operation. The function might sum the values of the six neighborhood pixels and then divide by 6. The result is the value of the output pixel.\n"
},
{
"alpha_fraction": 0.6047430634498596,
"alphanum_fraction": 0.6245059370994568,
"avg_line_length": 14.84375,
"blob_id": "382314f49e590ca3af7df31f0d8e86ce7d9d985b",
"content_id": "bd37ca373d2655e28f3bc37b895b1f4213ea05ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 32,
"path": "/Lab Teacher Worapan/Display video.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tVideoCapture cap(\"kimiwa.avi\");\n\tif (!cap.isOpened())\n\t{\n\t\treturn -1;\n\t}\n\twhile (1)\n\t{\n\t\tMat frame;\n\t\tcap >> frame; // take new frame from camera\n\t\t//End of video\n\t\tif (frame.empty())\n\t\t{\n\t\t\tbreak; \n\t\t}\n\t\timshow(\"Frame\", frame);\n\n\t\tchar c = (char)waitKey(25);\n\t\tif (c == 27) // 27 is ASCII for 'ESC' button\n\t\t\tbreak;\n\t}\n\tcap.release();\n\tdestroyAllWindows();\n}"
},
{
"alpha_fraction": 0.6510499119758606,
"alphanum_fraction": 0.6779912710189819,
"avg_line_length": 34.9323844909668,
"blob_id": "a960b12927f8071e5a3d4eed1520611091051876",
"content_id": "e012480c55d411d7a9ba0bc4a24335af17c0876b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16472,
"license_type": "no_license",
"max_line_length": 258,
"num_lines": 281,
"path": "/Project_Prototype/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# อธิบายไลบรารี่ที่ต้องใช้ในโปรเจค ITCS381_Multimedia\n\n```python\nimport cv2 # ไลบรารี่ OpenCV\nfrom matplotlib import pyplot as plt #import python plot graph\nimport matplotlib as mpl #import math library from python\nimport numpy as np\n```\n\n## OpenCV คืออะไร\n\n**OpenCV (Open source Computer Vision)** เป็นไลบรารีฟังก์ชันการเขียนโปรแกรม (Library of Programming Functions) โดยส่วนใหญ่จะมุ่งเป้าไปที่การแสดงผลด้วยคอมพิวเตอร์แบบเรียลไทม์ (Real-Time Computer Vision)\nOpenCV ยังสนับสนุนเฟรมเวิร์กการเรียนรู้เชิงลึก (Deep Learning Frameworks) ได้แก่ TensorFlow, Torch/PyTorch และ Caffe\n\n\n\n## การใช้ประโยชน์\n\nตัวอย่างการประยุกต์ใช้งาน OpenCV มีดังนี้\n\n - ชุดเครื่องมือคุณลักษณะ 2 มิติและ 3 มิติ (2D and 3D feature toolkits)\n - การประมาณระยะในขณะเคลื่อนที่ (Egomotion Estimation)\n - ระบบรู้จำใบหน้า (Facial recognition system)\n - การจดจำท่าทาง (Gesture recognition)\n - ปฏิสัมพันธ์ระหว่างมนุษย์และคอมพิวเตอร์ (Human-Computer interaction; HCI)\n\n## สามารถเขียนด้วยภาษาอะไรบ้าง\n\nOpenCV ถูกเขียนขึ้นด้วยภาษา C++ มีการรองรับ Python, Java และ MATLAB/OCTAVE — API สำหรับอินเทอร์เฟสเหล่านี้สามารถพบได้ในเอกสารออนไลน์ ซึ่งมีการรวมไว้หลากหลายภาษา เช่น C#, Perl, Ch, Haskell และ Ruby ได้รับการพัฒนาเพื่อส่งเสริมการนำมาใช้งานโดยผู้ใช้ที่เพิ่มขึ้น\n\n## มาเล่ากันถึงโค้ดและไลบรารี่ที่ต้องใช้ในโปรเจคกันดีกว่า\n\n```python\nim = cv2.imread('รูป.jpg',0)\n\n```\n **cv2.imread(img,value)**\n value สามารถแทนค่า 0 คือ **ภาพสีเทา(Grayscale)** หรือ 1 **สำหรับภาพสี(Color)** และ -1 สำหรับการโหลดภาพมาใช้ปกติ **(Normal import)**\n\n ```python\nprint(im.shape) #Get the dimension of an image height*width\n ```\n **print(ตัวแปร.shape)** คือการแสดงผลลัพธ์ของขนาดภาพ คือ **กว้าง x ยาว** โค้ดบรรทัดนี้เหมาะสำหรับการคำนวนเพื่อการแบ่ง ROI (Region of Interest) ในแต่ละช่องของรูป\n\n ```python\nim = cv2.imread('รูป.jpg',1)\nplt.imshow(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))\n ```\n\n **im = cv2.imread('รูป.jpg',1)** ถ้าเราใช้โค้ดนี้เพื่อเอารูปมาใช้ใน Jupyter Notebook รูปที่ได้จะมีสีสันที่ผิดปกติเนื่องจาก Jupyter Notebook นั้นใช้โหมดสีแบบ BGR เราจึงต้องเปลี่ยนโหมดสีนี้กลับเป็นสีปกติโดยใช้ Library **cv2.cvtColor(img,Colormode)**\n\n ```python\nim = cv2.imread('รูป.jpg',1)\nconvert = cv2.cvtColor(im,cv2.colormode)\nplt.imshow(convert)\n ```\n## โหมดสีที่ใช้ในโปรแจคแบบคร่าวๆ\n| โหมดสี(colormode) | ความหมาย |\n| :-------------: |:-------------:|\n|COLOR_BGR2GRAY|เปลี่ยนโหมดสีจาก BGR เป็น Gray|\n|COLOR_BGR2RGB|เปลี่ยนโหมดสีจาก BGR เป็น RGB|\n|COLOR_RGB2GRAY|เปลี่ยนโหมดสีจาก RGB เป็น Gray|\n|COLOR_RGB2BGR|เปลี่ยนโหมดสีจาก RGB เป็น BGR|\n|COLOR_GRAY2BGR|เปลี่ยนโหมดสีจาก Gray เป็น BGR|\n|COLOR_GRAY2RGB|เปลี่ยนโหมดสีจาก Gray เป็น RGB|\n\n## ทุกครั้งที่นำภาพมาใช้ใน Jupyter Notebook ต้องใช้ cv2.cvtColor ทุกครั้งหรือไม่\n\nถ้านำภาพมาใช้ปกติ เช่น การ Plot Graph หรือใช้ในบางฟังก์ชัน สีที่ออกมาจะเป็น RGB แบบปกติ แต่ เมื่อใช้ไลบรารี่ **CV2** ของ Python แล้ว ภาพที่นำมาใช้กับ **CV2** นั้นจะมีการเรียงสีแบบใหม่เป็น BGR (Blue-Green-Red) วิธีแก้ให้ใช้โค้ดนี้เพื่อแก้โหมดสีให้ถุกต้อง\n\n```python\ncv2.cvtColor(im,cv2.COLOR_BGR2RGB) # เปลี่ยนโหมดสีจาก BGR เป็น RGB\n```\n## เปลี่ยนภาพสีเป็นขาวดำ (BGR To Grayscale)\nภาพที่เรานำเข้ามาใช้ใน Jupyter Notebook นั้น โหมดสีที่ใช้นั้นปกติจะเป็น BGR ถ้าเราต้องการเปลี่ยนโหมดสีให้เป็น Grayscale ทำได้โดยใช้โค้ด ดังนี้\n```python\nim = cv2.cvtColor(imC, cv2.COLOR_BGR2GRAY)\n```\n\n\n\n## การเลือกแค่สีเดียวจาก BGR ในรูปแบบ Grayscale\n```python\nim = cv2.imread('รูป.jpg',0)\nim[:,:,0] # สีน้ำเงิน Blue Channel\nim[:,:,1] # สีเขียว Green Channel\nim[:,:,2] # สีแดง Red Channel\n# ให้เลือกสีใดสีหนึ่งจากนั้นให้ใช้โค้ด 2 บรรทัดล่าง เพื่อเปลี่ยนสีเป็น Grayscale\nconvertbgr2gray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) \nconvertgray2bgr = cv2.cvtColor(convertbgr2gray,cv2.COLOR_GRAY2BGR)\n```\n\n## การเลือกสองสีจาก BGR แล้วนำสองสีที่เลือกมาผสมกัน\n\n```python\nonecolorRR = im.copy()\nonecolorRR[:,:,0] = 0\nonecolorRR[:,:,0] = 0\naxes[0].imshow(cv2.cvtColor(onecolorDD,cv2.COLOR_RGB2BGR))\naxes[0].set_title(\"Blue-Green\", fontsize=32) # สีที่ได้จะเป็น สีน้ำเงิน-เขียว\naxes[0].axis('off')\n\nonecolorDD = im.copy()\nonecolorDD[:,:,2] = 0\nonecolorDD[:,:,2] = 0\naxes[1].imshow(cv2.cvtColor(onecolorRR,cv2.COLOR_RGB2BGR))\naxes[1].set_title(\"Green-Red\", fontsize=32) # สีที่ได้จะเป็น สีเขียว-แดง\naxes[1].axis('off')\n\nonecolorRGB = im.copy()\nonecolorRGB[:,:,1] = 0\nonecolorRGB[:,:,1] = 0\naxes[2].imshow(cv2.cvtColor(onecolorRGB,cv2.COLOR_RGB2BGR))\n\naxes[2].set_title(\"Red-Blue \", fontsize=32) # สีที่ได้จะเป็น สีแดง-น้ำเงิน\naxes[2].axis('off')\n```\n \n## การปรับแต่งสีรูปในโหมด Grayscale\n\n**เพิ่ม/ลดความสว่าง (Brightness/Darkness)** ให้กับรูป โดยการใช้\n```python\nweight = 100 # weight คือการเพิ่ม/ลด ค่าความสว่างให้กับภาพได้\nbrighter = cv2.add(im,weight) # ใช้ไลบรารี่ add จาก cv2 เพื่อเพิ่มความสว่างให้กับภาพ \n```\n**weight** ถ้าค่าที่ใช้เป็นลบ เช่น **-200** ภาพที่ใช้ **weight = -200** จะมืดลง แต่ถ้าใช้ **weight = 100** ภาพที่ได้จะมีความสว่างมากขึ้น\n\n**การทำภาพสีกลับ (invert Process)**\n\n```python\nnegative = cv2.subtract(255,im) # 255 คือ Value ที่ใช้ในการ Invert ค่าใน Histogram ส่งผลให้ภาพที่ได้มีลักษณะคล้ายกับเนกาทีฟ\n```\nการใช้ **cv2.subtract** คือการลดค่าแสง/สี ที่อยู่ในภาพให้ได้ตามความต้องการ\n\n**การเพิ่ม/ลดคอนทราสต์ (Increase/Decrease Contrast)** โดยการใช้\n\n```python\nhigher = cv2.multiply(4,im) # cv2.multiply คือการนำ value ไปคูณกับภาพที่ต้องการแสดงผล จะทำให้ภาพที่ได้มีคอนทราสต์มากยิ่งขึ้น\ncontrast = cv2.divide(im,8) # cv2.divide คือการนำ ภาพที่ต้องการแสดงผลไปหารด้วย Value จะทำให้ภาพที่ได้มีคอนทราสต์ลดลง\n```\n\n## การปรับแต่งรูปในโหมดสี RGB (ใช้ for loop)\n\nโดยทุกรูปที่ต้องการจะปรับแต่งนั้นต้องใช้โค้ดนี้เสมอ\n```python\n im = cv2.cvtColor(brighter,cv2.COLOR_BGR2RGB\n```\nเพราะเราการเปลี่ยนโหมดสีจาก BGR ให้อยู่โหมดปกติที่ตามนุษย์แบบเรามอง (RGB) จะสามารถแก้ไขภาพได้ง่ายขึ้น\n\n**ทำภาพสีให้สว่าง(Increase Brightness) โดยใช้ for loop**\n```python\nimport numpy as np\nweight = 100\n\nbrighter = np.ones(imC.shape,dtype='uint8') # for increase Brightness\nfor i in np.arange(0,3):\n brighter[:,:,i] = cv2.add(imC[:,:,i], weight)\n increase = cv2.cvtColor(brighter,cv2.COLOR_BGR2RGB)\n\ndarker = np.ones(imC.shape,dtype='uint8') # darker for decrease Brightness\nfor i in np.arange(0,3):\n darker[:,:,i] = cv2.add(imC[:,:,i], weight-200)\n```\n**for loop** นี้จะทำการเพิ่ม **Weight** ลงใน imC[:,:,i] ตั้งแต่ 0 - 3\n\n**การทำภาพเนกาทีฟ (Negative Process)**\n\n```python\nnegative = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n negative[:,:,i] = cv2.subtract(255,imC[:,:,i]) # 255 คือ Value ที่ใช้ในการ Invert ค่าใน Histogram ส่งผลให้ภาพที่ได้มีลักษณะคล้ายกับเนกาทีฟในโหมดสี \n```\n**เพิ่ม/ลดครอนทราสต์ให้กับภาพ (Increase/Decrease Contrast)**\n\n```python\nContrast = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n Contrast[:,:,i] = cv2.multiply(2,imC[:,:,i]) # Multiply ไว้ใช้สำหรับการเร่งคอนทราสต์\n\nlowercon = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n lowercon[:,:,i] = cv2.divide(imC[:,:,i],2) # Divide สำหรับการลดคอนทราสต์\n```\n\n## การใช้ ROI สำหรับตกแต่งรูปภาพเฉพาะพื้นที่ ที่เราสนใจ\nROI = Region of Interesting คือการเลือกจุดที่เราสนใจจากภาพนั้นๆและต้องการนำส่วนนั้นของภาพมาใช้ คล้ายกับการครอปภาพ เพื่อนำไปตัดแปะ วิธีการใช้มีดังนี้\n\n```python\ndef get_figsize(im):\n # What size does the figure need to be in inches to fit the image?\n dpi = plt.rcParams['figure.dpi']\n dim = im.shape\n figuresize = dim[1]/float(dpi), dim[0]/float(dpi)\n return(figuresize)\n```\n\n```python\ndef display_image_actual_size_single(im_data):\n figuresize = get_figsize(im_data)\n # Create a figure of the right size with one axes that takes up the full figure\n fig = plt.figure(figsize=figuresize)\n # Add the single axis to fit the image to the screen boundary\n ax = fig.add_axes([0, 0, 1, 1])\n ax.imshow(im_data, cmap='gray')\n ax.axis('off')\n plt.show()\n return(fig)\n```\n\n```python\nrows, cols, channels = fg.shape #get the width, the height, and the channels of fg\nroi = bg[0:0+rows, 2288:2500+cols] # เลือกบริเวณที่เราสนใจจากนั้นคำนวน พื้นที่ ที่ต้องการจะตัด โดยใส่ จุดเริ่มต้น:จุดสิ้นสุดลงไปใน เช่น bg[0:1000 , 200:1000] เป็นต้น\ndisplay_image_actual_size_single(roi) # เพื่อแสดงบริเวณที่ตัดรูปภาพออกมาใช้\nprint(fg.shape)\nprint(roi.shape)\n```\n\n## ใส่เอฟเฟคให้กับภาพ\n\n การใส่เอฟเฟคเช่น **Median Blur , Gaussian Blur , Average , etc.** สามารถทำได้โดยใช้ **CV2** เข้ามาช่วย\n\n **สิงที่ต้อง Import มาใช้**\n\n ```python\nimport cv2 #import OpenCV\nfrom matplotlib import pyplot as plt #import python plot graph\nimport matplotlib as mpl #import math library from python\nimport numpy as np\n ```\n\n ## ฟังก์ชั่นการใส่ Salt & Pepper ให้กับภาพ\n\n```python\ndef saltpepper_noise(image, prob):\n output = np.zeros(image.shape,np.uint8)\n thres = 1 - prob\n for i in range(image.shape[0]):\n for j in range(image.shape[1]):\n rdn = np.random.random()\n if rdn < prob:\n output[i][j] = 0\n elif rdn > thres:\n output[i][j] = 255\n else:\n output[i][j] = image[i][j]\n return output\n```\nวิธีการใช้ ให้สร้างตัวแปรขึ้นมา 1 ตัว แล้วบอก ตัวแปรตัวนี้ให้เท่ากับชื่อฟังก์ชันที่ต้องการใช้ เช่น\n\n```python\nimSP1 = saltpepper_noise(im,prob) #Add noise, 'prob' controls how much noise is added\n# แทน prob ด้วย ค่าที่ต้องการ แนะนำว่า 0.01 - 0.00750\n```\n ## ฟังก์ชั่นการใส่ Gaussian Blur ให้กับภาพ\n\n ```python\nBlurGauss = cv2.GaussianBlur(im, (15,15), 0)\n ```\n\n ## ฟังก์ชั่นการใช้ Box average ให้กับภาพ\n ```python\nblurBox = cv2.boxFilter(im, -1, (15,15))\n ```\n\n## การใช้ Sobel Edge Detector\n```\nsobeledgeH = cv2.Sobel(im, -1, 0, 1, ksize=5) #horizontal edges, changes in the y direction\nsobeledgeV = cv2.Sobel(im, -1, 1, 0, ksize=5) #vertical edges, changes in the x direction\nsobeledgeHV = cv2.Sobel(im, -1, 1, 1, ksize=5) #sobel edges, changes in the x direction\n```\n\n## การผสมฟังก์ชั่นการเบลอ\n```python\n# Median Filter on S&P\nimSP2 = saltpepper_noise(im,0.425) \nmedianFilteredimSP = cv2.medianBlur(imSP2,7) #Apply a median filter to of size ‘sz’\n\n# Gaussian on Filter S&P\nimblurSP4 = saltpepper_noise(im,0.0625) #Add noise, 'prob' controls how much noise is added\nBlurGauss2 = cv2.GaussianBlur(imblurSP4, (15,15), 0)\n```"
},
{
"alpha_fraction": 0.6445086598396301,
"alphanum_fraction": 0.6965317726135254,
"avg_line_length": 30.477272033691406,
"blob_id": "20587b56ca8ced13d332c4feb22e05911d5f4288",
"content_id": "be92cad6ba2fa5c4aef2f7b42e3e0808fcdf4ee3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1384,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 44,
"path": "/Lab Teacher Worapan/Drawing.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tString text = \" \";\n\tint FontFace = FONT_HERSHEY_SCRIPT_SIMPLEX;\n\tdouble FontScale = 2;\n\tint thickness = 3;\n\tMat img(600, 600, CV_8UC3, Scalar(0,0,255));\n\n\tint baseline = 0;\n\tSize textSize = getTextSize(text, FontFace, FontScale, thickness, &baseline);\n\n\tbaseline += thickness;\n\n\tPoint textOrg((img.cols - textSize.width) / 2, (img.rows + textSize.height) / 2);\n\n\tcv::rectangle(img, textOrg + Point(25, 100), textOrg + Point(textSize.width - textSize.height),Scalar(128,64,0), cv::FILLED);\n\tcv::circle(img, textOrg + Point(8, -25), 25,Scalar(64, 128, 0), cv::FILLED);\n\n\tcv::line(img, textOrg + Point(-50, -100), textOrg + Point(textSize.width - textSize.height), Scalar(128, 64, 0));\t\n\tcv::putText(img, text, textOrg, FontFace, FontScale, Scalar(0, 0, 255), 8);\n\n\tcv::line(img, textOrg + Point(85, 100), textOrg + Point(textSize.width - textSize.height), Scalar(128, 64, 0));\n\n\n\t\n\timshow(\"Example\", img);\n\n\tcv::waitKey(0);\n}"
},
{
"alpha_fraction": 0.670918345451355,
"alphanum_fraction": 0.6887755393981934,
"avg_line_length": 14.115385055541992,
"blob_id": "00a453a945054f3c85960f5ecda158b23f06fb0a",
"content_id": "bc5df407ba77ed4a4a9b37ae6c7a17ef57230a1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 26,
"path": "/Lab Teacher Worapan/ConvertColor.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tMat img = imread(\"dog.jpg\", 1);\n\timshow(\"Example-In\", img);\n\n\tMat gray;\n\tcvtColor(img, gray, COLOR_BGR2GRAY);\n\n\timshow(\"Example-Out\", gray);\n\timwrite(\"dog_gray.jpg\", gray);\n\tcv::waitKey(0);\n\n\treturn 0 ;\n\n\n\n}"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.6311047673225403,
"avg_line_length": 36.67856979370117,
"blob_id": "1ea27bb75482557d4422a1bf8f4ae33c88b12690",
"content_id": "2dd6c5e5d46b56d6e2d20ae68a5882a13ff302b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2329,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 56,
"path": "/Week6/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# Week 6 Non-uniform Image Scaling **Seam Carving**\n\n## Teached by Asst. Prof. Dr. Worapan Kusakunniran\n\n### Topic\n - Unform Scaling\n - Interpolation\n - Non-Uniform resizing\n - Backward Seam Carving\n - Forward Seam Carving\n - Sample Applications\n - Image Scaling\n - Interpolation is needed because of the finite size of pixels\n - Finite pixel doesn’t have real decimal index\n - Interpolation can obtain approximate value to fit in index based on proportional values between it\n - Suppose that we are scaling an image\n - Original image coordinate(x,y)\n - Scaled image coordinate(x′,y′)\n - When we want to fill-in color for each pixel at (x′,y′)in the scaled image, we will use color of pixel at (x,y)from the original image, where x,y=(x′/s,y′/s), s is scaling factor\n - xand y are often not integer, thus such pixel does not actually exist ->(x,y)are shown in the above figure as x, surrounding by 4 pixels P1,P2,P3,P4\n - Interpolation\n - Nearest neighbor\n - Bilinear interpolation\n - Bicubic interpolation\n- **Interpolation: Nearest Neighbor**\n - Nearest neighbor\n - Use value of pixel whose center is closest in the original image to real coordinates of ideal interpolated pixel (proportional round up)\n\n```C++\ntemplate<class PIXEL>\nvoid ScaleMinifyByTwo(PIXEL *Target, PIXEL *Source, int SrcWidth, int SrcHeight)\n{\n int x, y, x2, y2;\n int TgtWidth, TgtHeight;\n PIXEL p, q;\n\n TgtWidth = SrcWidth / 2;\n TgtHeight = SrcHeight / 2;\n for (y = 0; y < TgtHeight; y++) {\n y2 = 2 * y;\n for (x = 0; x < TgtWidth; x++) {\n x2 = 2 * x;\n p = average(Source[y2*SrcWidth + x2], Source[y2*SrcWidth + x2 + 1]);\n q = average(Source[(y2+1)*SrcWidth + x2], Source[(y2+1)*SrcWidth + x2 + 1]);\n Target[y*TgtWidth + x] = average(p, q);\n } /* for */\n } /* for */\n}\n```\n\n$$หาอัตราส่วนจากรูปแรก = x1*y1$$\n$$หาอัตราส่วนจากรูปที่สอง = x2*y2$$\n$$หา Sx โดย Sx = x2/x1 $$\n$$หา Sy โดย Sy = y2/y1 $$\n$$หา y' โดย y' = yตำแหน่งใหม่แต่ละช่อง/Sy$$\n$$หา x' โดย x' = xตำแหน่งใหม่แต่ละช่อง/Sx$$"
},
{
"alpha_fraction": 0.6328125,
"alphanum_fraction": 0.6414930820465088,
"avg_line_length": 23.53191566467285,
"blob_id": "92311a3aafbac893b62549fb352513edf001f463",
"content_id": "5927eac1c0b84d91210014f7090f97e49255dc7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1152,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 47,
"path": "/Lab Teacher Worapan/Mouse Interact.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\n\nusing namespace std;\nusing namespace cv;\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param);\n\nint main()\n{\n\n\tMat img;\n\timg = imread(\"dog.jpg\", 1);\n\n\tnamedWindow(\"Example\");\n\tsetMouseCallback(\"Example\", mouse_callback);\n\n\timshow(\"Example\", img);\n\twaitKey();\n\n}\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param)\n{\n\tif (event == EVENT_MOUSEMOVE)\n\t{\n\t\tcout << \"( X: \" << x << \", Y: \" << y << \")\" << endl;\n\t}\n\tif (event == EVENT_LBUTTONDOWN)\n\t{\n\t\tMat img;\n\t\timg = imread(\"dog.jpg\", 1);\n\t\tVec3b color = img.at<Vec3b>(cv::Point(x, y));\n\n\t\tcout << \"Left button of the mouse is clicked - position ( X:\" << x << \", Y: \" << y << \")\" << endl;\n\t\tprintf(\"Blue: %d, Green: %d, Red: %d \\n\", color[0], color[1], color[2]);\n\t}\n}"
},
{
"alpha_fraction": 0.6907630562782288,
"alphanum_fraction": 0.7281985282897949,
"avg_line_length": 35.31770706176758,
"blob_id": "492fa1679cb0e6551820b6bd218874d5ff3d9745",
"content_id": "26826501c94e7531f5c9c817c10232b96d80fb0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6972,
"license_type": "no_license",
"max_line_length": 427,
"num_lines": 192,
"path": "/Lab1/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# LAB 1: Grayscale and RGB Color Images\n\n## Working with Black & White Images\n### Read/write and display an image\nChoose your input image and save it to Lab1 directory. Choose an image that is different from the ones used as examples in class and choose one that is not the same as your friends. Be creative and have fun!\n\n```python\nimport cv2 #import OpenCV\nfrom matplotlib import pyplot as plt #import matplotlib\n```\nLoad an image in grayscale. OpenCV imread takes two parameters: the name of an image file, and a tag 1 for color, **0 for grayscale**, and **-1 for unchanged (load the image as is)**. Then we write it to file.\n\n```python\nim = cv2.imread('dog.jpg',0)\ncv2.imwrite('dog_bw.jpg',im)\n```\nTrue\n\nDisplay an image using matplotlib. The cmap argument indicates the colormap. Default is color; ours is grayscale.\n```python\nplt.imshow(im, cmap='gray')\nplt.show()\n```\n\n\n## Explore the properties of the image\n\n```python\nprint(im.shape) #Get the dimension of an image height*width\nprint(im.dtype) #Get the data type of an image\n```\n\n(640, 640) <br>\nuint8\n\n\nOur bird image is a 2D array of **640 rows** and **640 columns**, representing the height and width, respectively. Your image may be of different dimensions and that is okay. Each pixel value is stored in an **8-bit unsigned integer (uint8)** for **color/intensity scaling in the range of 0 to 255**.\n\nIn most image processing programming, images are stored in multi-dimensional arrays: 2D for grayscale and 3D for color. Operations on images are thus nothing more than mathematical functions performed on arrays and matrices. In Python, these are supported by the NumPy library. We show a couple examples below.\n```python\nimport numpy as np #import numpy library\nprint(np.min(im)) #Find the minimum pixel value in an image\nprint(np.max(im)) #Find the maimum pixel value in an image\n\n```\nOutput<br> 0 <br>\n251\n## Working with Color Images\n\n### BGR versus RGB channels\nFirst, we reload our bird image. This time, load it in color (using imread with flag=1). Then, display the color image.\n\n```python\nim = cv2.imread('dog.jpg',1)\nplt.imshow(im)\nplt.show()\n```\n\n\n\n```python\nplt.imshow(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))\nplt.show()\n```\n\n## Explore the information in each color channel\n\nNext, let's try to analze the information contained in each of the three channels individually. First, we separate the three color channels into three layers. These channels correspond to the third dimension of our image array. Since our image is BGR, the first layer (index 0) is blue, then green and red. Each layer can be displayed as a 2D grayscale image, whose intensity indicates the amount of the color a pixel contains.\n\n```python\nfig, axes = plt.subplots(2, 3, figsize=(30,20))\nplt.tight_layout()\n\naxes[0,0].imshow(cv2.cvtColor(im,cv2.COLOR_BGR2RGB))\naxes[0,0].set_title(\"Original\", fontsize=32)\naxes[0,0].axis('off')\naxes[0,1].imshow(im)\naxes[0,1].set_title(\"!!!Incorrect channels!!!\", fontsize=32)\naxes[0,1].axis('off')\naxes[0,2].imshow(cv2.cvtColor(im,cv2.COLOR_BGR2GRAY), cmap='gray')\naxes[0,2].set_title(\"8-Bit Grayscale\", fontsize=32)\naxes[0,2].axis('off')\n\naxes[1,0].imshow(im[:,:,0], cmap='gray')\naxes[1,0].set_title(\"Blue\", fontsize=32)\naxes[1,0].axis('off')\n\naxes[1,1].imshow(im[:,:,1], cmap='gray')\naxes[1,1].set_title(\"Green\", fontsize=32)\naxes[1,1].axis('off')\n\naxes[1,2].imshow(im[:,:,2], cmap='gray')\naxes[1,2].set_title(\"Red\", fontsize=32)\naxes[1,2].axis('off')\n\nplt.show()\nfig.savefig(\"Lab1Ex1.jpg\", bbox_inches='tight')\n```\n## Output should be like this\n\n\n\n## Coloring and mixing up the channels\n\nGive the blue channel the blue color. Create a copy of our image. Instead of extracting the blue as we did earlier, we leave it alone. We then set the other two channels to zero.\n\n```python\nonecolorR = im.copy()\nonecolorR[:,:,1] = 0\nonecolorR[:,:,2] = 0\nplt.imshow(cv2.cvtColor(onecolorR,cv2.COLOR_RGB2BGR)) # Add this line to show the true output\n``` \n\n## Color in BGR Blue and Black\n\n```python\nfig, axes = plt.subplots(1, 2, figsize=(30,20))\nplt.tight_layout()\n\naxes[1].imshow(cv2.cvtColor(onecolorR,cv2.COLOR_RGB2BGR))\naxes[0].set_title(\"Blue (in grayscale)\", fontsize=32)\naxes[0].axis('off')\naxes[0].imshow(cv2.cvtColor(onecolorR,cv2.COLOR_BGR2GRAY), cmap='gray')\naxes[1].set_title(\"Blue\", fontsize=32)\naxes[1].axis('off')\n\n\nplt.show()\nfig.savefig(\"Lab1Ex2.jpg\", bbox_inches='tight')\n```\n## Output should be like this\n\n\n\n\n**Exercise #2**: One-channel color image. Above, we have created one one-color image for the blue channel. Your task is to create the other two one-color images for the green and red channels. Then, display the three channels side-by-side. An example of an expected output is shown below.\n\n```python\nfig, axes = plt.subplots(1, 3, figsize=(30,20))\nplt.tight_layout()\n\naxes[2].imshow(cv2.cvtColor(onecolorB,cv2.COLOR_RGB2BGR))\naxes[0].set_title(\"Blue \", fontsize=32)\naxes[0].axis('off')\naxes[1].imshow(cv2.cvtColor(onecolorD,cv2.COLOR_RGB2BGR))\naxes[1].set_title(\"Green\", fontsize=32)\naxes[1].axis('off')\naxes[0].imshow(cv2.cvtColor(onecolorR,cv2.COLOR_RGB2BGR))\naxes[2].set_title(\"Red\", fontsize=32)\naxes[2].axis('off')\n\n\nplt.show()\nfig.savefig(\"Lab1Ex2.jpg\", bbox_inches='tight')\n```\n## Output should be like this\n\n\n\n\n**Exercise #3**: Two-channel color image. Pairing of the BGR channels. Create and display three two-channel color images; they are blue-green, green-red, and red-blue. An example of an expected output is shown below. Hint: to display one-color image, we set the other two channels to zeros. Thus, to display two-color image, which channel or channels should be set to zeros?\n```python\nfig, axes = plt.subplots(1, 3, figsize=(30,20))\nplt.tight_layout()\n\nonecolorRGB = im.copy()\nonecolorRGB[:,:,1] = 0\nonecolorRGB[:,:,1] = 0\naxes[2].imshow(cv2.cvtColor(onecolorRGB,cv2.COLOR_RGB2BGR))\n\naxes[2].set_title(\"Red-Blue \", fontsize=32)\naxes[2].axis('off')\nonecolorDD = im.copy()\nonecolorDD[:,:,2] = 0\nonecolorDD[:,:,2] = 0\naxes[1].imshow(cv2.cvtColor(onecolorRR,cv2.COLOR_RGB2BGR))\naxes[1].set_title(\"Green-Red\", fontsize=32)\naxes[1].axis('off')\n\nonecolorRR = im.copy()\nonecolorRR[:,:,0] = 0\nonecolorRR[:,:,0] = 0\naxes[0].imshow(cv2.cvtColor(onecolorDD,cv2.COLOR_RGB2BGR))\naxes[0].set_title(\"Blue-Green\", fontsize=32)\naxes[0].axis('off')\n\nplt.show()\nfig.savefig(\"Lab1Ex3.jpg\", bbox_inches='tight')\n```\n## Output should be like this\n\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.688524603843689,
"avg_line_length": 23.33333396911621,
"blob_id": "22a17662de96fd236a9ad9717f3f914cc98458d7",
"content_id": "384d8581c9a17ec13203fabe9c29d94d91b84923",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 30,
"path": "/Lab Teacher Worapan/Canny Edge Detection.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tnamedWindow(\"Example-In\");\n\tnamedWindow(\"Example-Out\");\n\n\tMat img = imread(\"dog.jpg\", 1);\n\timshow(\"Example-In\", img);\n\n\tMat img_blur, out; // Using Gaussian Tech. => blur , GBlur , MBlur , biBlur\n\tblur(img, img_blur, Size(5, 5));\n\n\tint lowthres = 20; /* Low Value for limit with 25% average value of img*/\n\tint highthres = 60; /* High Value for limit with 25% average value of img*/\n\tint kernel_size = 3; /* used for find image gradients */\n\tCanny(img_blur,out,lowthres,highthres,kernel_size);\n\n\timshow(\"Example-Out\", out);\n\n\tcv::waitKey(0);\n\n}\n\n\n"
},
{
"alpha_fraction": 0.704125165939331,
"alphanum_fraction": 0.7344238758087158,
"avg_line_length": 122.31578826904297,
"blob_id": "0462ceced563662d14b8d4b23bc1eb403623d9b0",
"content_id": "f1f8454458b7f63b75a092c76bb165c03d51ba5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11250,
"license_type": "no_license",
"max_line_length": 581,
"num_lines": 57,
"path": "/Week1/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# Week 1 Digitization and Bitmap Image\n---\n## Digital Image \n * A camera raw image file contains minimally processed data from the image sensor of either a digital camera, or motion picture film scanner, or other image scanner.\n * ไฟล์ RAW เป็นรูปแบบของไฟล์ที่เซนเซอร์กล้องของเราบันทึกข้อมูลภาพทุกส่วนเอาไว้ครับ การที่มันไม่ถูกย่อแบบ JPEG ทำให้เราได้ไฟล์ภาพที่คุณภาพสูงกว่า และสามารถเอามาแต่งต่อและแก้ไขได้โดยที่ภาพไม่เสียหายเหมือน JPEG ที่โดนบีบอัดคุณภาพไฟล์มาแล้ว(JPEG สามารถแต่งภาพได้แต่ไม่ดีเท่าไฟล์ RAW)\n \n \n\n---\n## Color Bit depth\n* รูปภาพของเราจะมีระดับของโทนแสงขาว-ดำอยู่ที่ไล่ตั้งแต่มืดตื๋อไปจนสว่างจ้า สิ่งนี้เราเรียกมันว่า bit-depth ไฟล์ JPEG (8 bit) มันไล่ได้256ระดับ ในขณะที่ไฟล์ RAW (12 bit, 14 bit) จะไล่ได้ 4,096 ระดับ ไปจนถึงเป็นหมื่นๆระดับ (ขึ้นอยู่กับความสามารถของเซนเซอร์จากกล้องถ่ายภาพ)\n* ในการใช้งานทั่วๆไป การไล่ได้256ระดับของ 8 bit ก็ถือว่าเหลือเฟือแล้ว แต่หากเราเอาภาพที่ไล่โทนได้แค่ 256 ระดับไปทำการแต่ง ภาพเรามีโอกาสที่จะเกิดความแตกต่างในการไล่โทนอย่างเห็นได้ชัด เห็นความไม่นุ่มนวล เพราะระดับการไล่โทนมันมีน้อยไป\n\n.jpg)\n\n----\n\n# Pixels from Image \n * พิกเซล (Pixel) นั้นมีความสำคัญต่อการสร้างภาพกราฟฟิกของคอมพิวเตอร์มาก เพราะทุกๆ ส่วนของภาพกราฟฟิก เช่น จุด เส้น แบบ ลายและสีของภาพ ล้วนเกิดจากพิกเซลทั้งสิ้น อย่างเช่น กล้องถ่ายรูปความละเอียด 5 ล้านพิกเซล นั้นหมายความว่าเมื่อถ่ายภาพที่ความละเอียดสูงสุด (ที่กล้องตัวนั้นๆ จะสามารถทำได้) ภาพนั้นจะได้เม็ด พิกเซล (Pixel) 5 ล้านเม็ด หากลองสังเกตไฟล์ภาพจากหน้าจอคอม หรือโทรศัพท์มือถือดีๆ เราจะมองเห็นภาพเหล่านั้นมีเม็ดสีสีเหลี่ยมเล็กๆ เรียงต่อกันอยู่ นั้นแหละคือ พิกเซล (Pixel) ดังนั้นจึงสามารถสรุปได้ว่า หากค่าพิกเซลสูงมากเท่าไหร่ภาพที่ได้ก็จะยิ่งมีความละเอียดสูงมากตามไปด้วย\n\n \n\n * อะไรคือ PPI\n * ค่า PPI หรือ Pixel Per Inch นั้นมักจะใช้บอกถึงความละเอียดภาพที่แสดงผลบนหน้าจอแสดงผลในแง่ของจำนวนเม็ดพิกเซลต่อพื้นที่แสดงผลขนาด 1 ตารางนิ้ว ยกตัวอย่างเช่น มือถือแบรนด์หนึ่งมีหน้าจอความละเอียด 440 PPI นั้นหมายความว่าในพื้นที่หน้าจอขนาด 1 ตารางนิ้วนั้น จะมีเม็ดพิกเซลเล็กๆ เรียงกันถึง 440 พิกเซลเลยทีเดียว หากเปรียบเป็นการปลูกข้าว ก็เท่ากับว่าในพื้นที่ 1 ตารางนิ้ว นั้นมีต้นข้าวปลูกอยู่ถึง 440 ต้นนั้นเอง\n 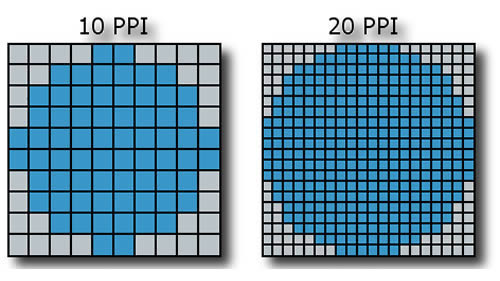\n * แล้ว DPI ล่ะคืออะไร\n * DPI ย่อมาจาก Dots Per Inch หรือหากอธิบายอย่างสั้นๆก็คือ หน่วยวัดความละเอียดของรูปภาพที่เราจำเป็นต้องเลือกใช้ในงานพิมพ์เพื่อคุณภาพงานพิมพ์ที่ดีที่สุด ซึ่งยิ่งจำนวนจุดมีมากเท่าไหร่ ความคมชัดของรูปภาพก็จะมีมากยิ่งขึ้น เพราะเนื่องจากเครื่องพิมพ์ไม่สามารถรักษาขนาด Dot ให้เท่ากับ Pixel ได้และการพิมพ์ลงบนกระดาษที่ต่างกันอาจไม่สามารถรับหมึกได้เท่ากันจึงส่งผลให้เกิดข้อแตกต่างกับควาวมความคมชัดของภาพ ยกตัวอย่างเช่น ภาพที่มีรายละเอียด 2500DPI ก็จะแสดงผลได้ละเอียดและชัดเจนมากกว่ารูปภาพที่มีความละเอียดเพียงแค่ 1100DPI เป็นต้น\n \n\n* สรุป \n * DPI คือการตั้งค่าการพิมพ์ที่สามารถทำได้บนเครื่องพิมพ์\n\n * PPI คือการตั้งค่าของภาพที่สามารถทำได้ในโปรแกรมสำหรับการพิมพ์\n\n## Calculate Image Size\n - **Example** Want to print 8 * 10 inch picture at 300 dpi \n - calculate total pixel\n 1. (width * dpi) * (height * dpi) = (8 * 300) * (10* 300) = 2400 * 3000 pixel\n\n## Compatible file type\n\n| Image Type | Byte per pixel | Possible color combination |Compatible File Type|\n| ------------- |:-------------:| -----:|-----:|\n| 1 bit Line art | 1/8 byte per pixel | 2 colors, 1 bit per pixel. One ink or white paper |TIF, PNG, GIF |\n| 8-bit Indexed Color | Up to 1 byte per pixel if 256 colors| 256 colors maximum.For graphics use today |TIF, PNG, GIF |\n| 8-bit Grayscale | 1 byte per pixel |\t256 shades of gray|JPG, TIF, PNG |\n| 16 bit Grayscale | 2 bytes per pixel |65636 shades of gray |TIF, PNG|\n| 24 bit RGB(8-bit mode) | 3 bytes per pixel (one byte each for R, G, B) | Computes 16.77 million colors max. 24 bits is the \"Norm\" for photo images, e.g., JPG |JPG, TIF, PNG |\n| 32 bit CMYK | 4 bytes per pixel, for Prepress |Cyan, Magneta, Yellow and Black ink, typically in halftones|TIF|\n| 48-bit RGB(16-bit mode) | 6 bytes per pixel | 2.81 trillion colors max. Except we don't have 16-bit display devices |TIF,PNG|\n\n## **Note**\n * **JPG** files are limited to only 24 bit RGB color or 8-bit grayscale. JPG is radically different than most, using a lossy compression which at extremes can be very small but also detrimental to image quality if we overdo it. A larger file with a better JPG Quality setting is the best photo image. Surely the most popular image file, most digital camera images and web page images are JPG. Many one hour photo printing shops only accept JPG files. Just do not overdo the size reduction. The largest high quality JPG image is still a rather small file, compared to others. \n * **GIF** files were designed by CompuServe for early 8-bit video monitors when small file size was important for speed of dial up modems, all before 24 bit color or JPG was popular (and now 24 bit color is very superior for photo images). Since the image resolution number (dpi) is Not used by video monitors, it is not stored in GIF files, therefore making GIF less suitable for printing purposes. GIF is at most one byte per pixel, and is intended for indexed color, such as graphics, but 8-bit grayscale will also fit. GIF uses lossless compression. \n * **PNG** files are versatile (multi-purpose). Two main modes: 8-bit PNG mode is intended for indexed color, comparable uses as GIF files (but with additions). Otherwise PNG can be 24 bit or 48-bit RGB color, or 8 or 16 bit grayscale, comparable to TIF for those. PNG uses lossless compression, often a bit smaller file than GIF or TIF LZW, but can be slightly slower to open and decompress.\n * **TIF** files are the most versatile in a few ways (image types RGB, CMYK prepress, YCbCr, Halftones, CIE L*a*b*), and surely we could say popular with the more serious users (but not compatible in web browsers). Generally used for lossless data, both photo and for scanned text document archival. LZW compression is used for photos, and documents usually use ITU G3 or G4 compression (including fax is TIFF format). Technically TIF allows designers to invent any new format in TIF format, but of course, then it is only compatible for their intended use with their software. \n * **Raw** files are 12 or 14 bits per pixel (less than 2 bytes per pixel), and are often also compressed. Raw images are not directly viewable (our monitors show RGB). We see a RGB conversion while processing raw (typically correcting white balance and maybe exposure), and then a RGB file is output, often a JPG file. If additional edit is needed later, we discard that JPG file as expendable, and use the raw process to add any additional edit, and output a good replacement JPG file. \n"
},
{
"alpha_fraction": 0.6844181418418884,
"alphanum_fraction": 0.7001972198486328,
"avg_line_length": 22.604650497436523,
"blob_id": "a8656131f608aa2327367ca5ffcff689beb32d94",
"content_id": "f701f9148bb22853c7f8f5db97d10c2c47013578",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1014,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 43,
"path": "/Lab Teacher Worapan/Gradient and Sobel Derivatives.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h> // Standard io\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n#include <iostream> // for output\n#include <cmath> // Calculate mathmatic\n#include<fstream> // Write file output\n#include <windows.h> // Add this header for waiting output before close automatically\n#include <iomanip> // add for decimal place\n#include <limits>\n\n\nusing namespace std;\nusing namespace cv;\n\nvoid mouse_callback(int event, int x, int y, int flag, void *param);\n\nint main()\n{\n\n\tMat img;\n\timg = imread(\"dog.jpg\", 1);\n\tnamedWindow(\"Input\");\n\timshow(\"Input\", img);\n\n\tMat sobel_x, sobel_y;\n\tMat abs_sobel_x, abs_sobel_y;\n\n\tMat img_gray;\n\tcv::cvtColor(img, img_gray, cv::COLOR_BGR2GRAY);\n\n\t//Gradient X\n\tSobel(img_gray,sobel_x,CV_16S,1,0,3);\n\tconvertScaleAbs(sobel_x,abs_sobel_x);\n\timshow(\"Sobel X\", abs_sobel_x);\n\n\t//Gradient Y\n\tSobel(img_gray, sobel_y, CV_16S, 0, 1, 3);\n\tconvertScaleAbs(sobel_y, abs_sobel_y);\n\timshow(\"Sobel Y\", abs_sobel_y);\n\n\tcv::waitKey(0);\n}"
},
{
"alpha_fraction": 0.6587982773780823,
"alphanum_fraction": 0.6781116127967834,
"avg_line_length": 18.33333396911621,
"blob_id": "591f1411d7c02eb274b40e566dd2912e2887757a",
"content_id": "1b568d0c4f2d58eb7f1313363977cda4cb8bbb58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 24,
"path": "/Lab Teacher Worapan/Smooth an image.cpp",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n#include<opencv2/core/core.hpp>\n#include<opencv2/highgui/highgui.hpp>\n#include \"opencv2/imgproc/imgproc.hpp\"\n\n\nusing namespace std;\nusing namespace cv;\n\nint main()\n{\n\tnamedWindow(\"Example-In\");\n\tnamedWindow(\"Example-Out\");\n\n\tMat img = imread(\"dog.jpg\", 1);\n\timshow(\"Example-In\", img);\n\n\tMat out; // Using Gaussian Tech. => blur , GBlur , MBlur , biBlur\n\tGaussianBlur(img, out, Size(7, 7), 0, 0);\n\timshow(\"Example-Out\", out);\n\n\tcv::waitKey(0);\n\n}\n\n\n"
},
{
"alpha_fraction": 0.6632987260818481,
"alphanum_fraction": 0.7044258117675781,
"avg_line_length": 40.09356689453125,
"blob_id": "3d1dfc8a0fa1092302b34fa7de2b06f891e7a688",
"content_id": "5dc90846677ecdc1f67bd3e5f349d8a0bea4cb5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7027,
"license_type": "no_license",
"max_line_length": 452,
"num_lines": 171,
"path": "/Lab2/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# LAB 2: Image Arithmetic Operations\n\n## Image Arithmetic for Grayscale Images \n\nPick a color image you like. Instead of loading an image in grayscale as we have done earlier, we will try reading it as is (without a flag). Expectedly, we obtain a BGR image. We then convert it to grayscale using **OpenCV cvtColor** function. Look familiar? This is the same function that we use to convert from BGR to RGB. The only difference is the transform specification: **cv2.COLOR_BGR2GRAY.** We display side-by-side the color and gray images.\n### Example of code\n```python\nimC = cv2.imread('dog.jpg') # any kind of picture can be use\nim = cv2.cvtColor(imC, cv2.COLOR_BGR2GRAY)\n```\n\n```python\nimC = cv2.imread('dog.jpg')\nim = cv2.cvtColor(imC, cv2.COLOR_BGR2GRAY)\nfig, axes = plt.subplots(1, 2, figsize=(30,20))\nplt.tight_layout()\n\naxes[0].imshow(cv2.cvtColor(imC,cv2.COLOR_BGR2RGB))\naxes[0].set_title(\"Original\", fontsize=32)\naxes[0].axis('off')\naxes[1].imshow(im,cmap='gray')\naxes[1].set_title(\"Gray\", fontsize=32)\naxes[1].axis('off')\n\n\nplt.show()\nfig.savefig(\"Lab2Ex1.jpg\", bbox_inches='tight')\n```\n### Output should be like this picture\n\n\n**Exercise #1**: In the following lines of code, we show you how to perform addition on a grayscale image, making it uniformly brighter. Refer to the lecture on how to do subtraction, multiplication, division, and image negative. Below, we show you our complete set of output, you do yours on your selected image. You will need to vary the weight (increase or decrease it), observe the results, and select the weight that best fitted your work.\n\n### Example code\n```python\nweight = 100 #Specify a constant to add/subtract to an image\nbrighter = cv2.add(im,weight) #Image addition, an image is uniformly brighter\n```\n### Example code to give the result 2 x 3 picture\n\n```python\nweight = 100 #Specify a constant to add/subtract to an image\nbrighter = cv2.add(im,weight) #Image addition, an image is uniformly brighter\nfig, axes = plt.subplots(2, 3, figsize=(30,20))\nplt.tight_layout()\n\naxes[0,0].imshow(im,cmap='gray')\naxes[0,0].set_title(\"Original\", fontsize=32)\naxes[0,0].axis('off')\naxes[0,1].imshow(brighter,cmap='gray')\naxes[0,1].set_title(\"Brighter\", fontsize=32)\naxes[0,1].axis('off')\nbrighter2 = cv2.add(im,weight-200) \naxes[0,2].imshow(brighter2,cmap='gray')\naxes[0,2].set_title(\"Darker\", fontsize=32)\naxes[0,2].axis('off')\nnegative = cv2.subtract(255,im) \naxes[1,0].imshow(negative,cmap='gray')\naxes[1,0].set_title(\"Negative\", fontsize=32)\naxes[1,0].axis('off')\nhigher = cv2.multiply(4,im) \naxes[1,1].imshow(higher,cmap='gray')\naxes[1,1].set_title(\"Higher Contrast\", fontsize=32)\naxes[1,1].axis('off')\ncontrast = cv2.divide(im,8) \naxes[1,2].imshow(contrast,cmap='gray')\naxes[1,2].set_title(\"Lower Contrast\", fontsize=32)\naxes[1,2].axis('off')\n\n\n\n\nplt.show()\nfig.savefig(\"Lab2Ex2.jpg\", bbox_inches='tight')\n\n```\n### Example should be like this\n\n\n## Image Arithmetic for Color Images\n\n\nNext, we apply the same five operations: brighter/darker, higher/lower contrast, and negative to a color image. Unlike grayscale, we now have three channels that we need to handle. The arithmetic is essentially the same as before but we repeat it three times for three channels. As an example, we pick another color image to work on and detail how to brighten it in two steps. The code and the result is shown below.\n\n 1. Use NumPy to create a placeholder for a new (brighter) image. This is a 3D array the same size and shape as the original image. Its data type is an 8-bit unsigned integer. All elements, i.e. pixel values, are set to 1.\n 2. Use for-loop to process the **three BGR channels.** Each iteration of the loop adds weight to the pixel values of each channel of an input image and store it into the respective channel of an output image.\n### Example Code\n```python\nweight = 100\nbrighter = np.ones(im.shape,dtype='uint8')\nfor i in np.arange(0,3):\n brighter[:,:,i] = cv2.add(im[:,:,i], weight)\n```\n\n\n### Code to process\n```python\nimport numpy as np # Don't forget to import numpy to use in np.arange\nweight = 100\nfig, axes = plt.subplots(1, 2, figsize=(30,20))\nplt.tight_layout()\n\naxes[0].imshow(cv2.cvtColor(imC,cv2.COLOR_BGR2RGB))\naxes[0].set_title(\"Original\", fontsize=32)\naxes[0].axis('off')\n\n\n\nbrighter = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n brighter[:,:,i] = cv2.add(imC[:,:,i], weight)\n axes[1].imshow(cv2.cvtColor(brighter,cv2.COLOR_BGR2RGB))\naxes[1].set_title(\"Brighter\", fontsize=32)\naxes[1].axis('off')\n \nfig.savefig(\"Lab2Ex3.jpg\", bbox_inches='tight')\n```\n\n### Output should be like this\n\n\n\n**Exercise 2** : follow the brighter example to perform darker, higher- and lower-contrast. Then, do a negative image. The code for negative operation is exactly the same as that use in grayscale, i.e. there is no need to explicitly perform arithmetic on each channel separately. Adjust the weights to fit your image so you can clearly see effects of all five operators. Display your results in a 2x3 grid as shown in an example below.\n\n```python\nfig, axes = plt.subplots(2, 3, figsize=(30,20))\nplt.tight_layout()\n\naxes[0,0].imshow(cv2.cvtColor(imC,cv2.COLOR_BGR2RGB))\naxes[0,0].set_title(\"Original\", fontsize=32)\naxes[0,0].axis('off')\n\nbrighter = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n brighter[:,:,i] = cv2.add(imC[:,:,i], weight)\n axes[0,1].imshow(cv2.cvtColor(brighter,cv2.COLOR_BGR2RGB))\naxes[0,1].set_title(\"Brighter\", fontsize=32)\naxes[0,1].axis('off')\n \ndarker = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n darker[:,:,i] = cv2.add(imC[:,:,i], weight-200)\n axes[0,2].imshow(cv2.cvtColor(darker,cv2.COLOR_BGR2RGB))\naxes[0,2].set_title(\"Darker\", fontsize=32)\naxes[0,2].axis('off') \n\nnegative = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n negative[:,:,i] = cv2.subtract(255,imC[:,:,i])\n axes[1,0].imshow(cv2.cvtColor(negative,cv2.COLOR_BGR2RGB))\naxes[1,0].set_title(\"Negative\", fontsize=32)\naxes[1,0].axis('off') \n \nContrast = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n Contrast[:,:,i] = cv2.multiply(2,imC[:,:,i])\n axes[1,1].imshow(cv2.cvtColor(Contrast,cv2.COLOR_BGR2RGB))\naxes[1,1].set_title(\"Higher Contrast\", fontsize=32)\naxes[1,1].axis('off') \n\nlowercon = np.ones(imC.shape,dtype='uint8')\nfor i in np.arange(0,3):\n lowercon[:,:,i] = cv2.divide(imC[:,:,i],2)\n axes[1,2].imshow(cv2.cvtColor(lowercon,cv2.COLOR_BGR2RGB))\naxes[1,2].set_title(\"Lower Contrst\", fontsize=32)\naxes[1,2].axis('off') \n \nfig.savefig(\"Lab2Ex4.jpg\", bbox_inches='tight')\n```\n### Output should be like this\n\n"
},
{
"alpha_fraction": 0.6309012770652771,
"alphanum_fraction": 0.7024320363998413,
"avg_line_length": 35.78947448730469,
"blob_id": "8cf23a74c2fc4a35ed4c2a1b4bc10e051352cb58",
"content_id": "f176bd3fd69fe74f0c9a18f931995b7aff6f17e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 19,
"path": "/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# ITCS381 Introduction to Multimedia Systems\n[](https://travis-ci.org/SunatP/ITCS381_Multimedia)\n# Grading Policy\n* Week 1 - 5 30% -|\n* Week 6 - 10 20% -> 65% \n* Week 11 - 15 15% -|\n* No Midterm Exam\n* Final Exam 35%\n----\n## Note Week 3 - 4\n- one individual Project 50%\n- Theoretical concepts Excercise 20%\n- Practical Skills 30%\n----\n### Update Class \n 1. Digitization and Bitmap Image (Week 1)\n * [Lecture 1](https://github.com/SunatP/ITCS381_Multimedia/tree/master/Week1)\n 2. Pixel Point and Neighborhood Operations (Week 2)\n * [Lecture 2](https://github.com/SunatP/ITCS381_Multimedia/tree/master/Week2)\n"
},
{
"alpha_fraction": 0.7010769844055176,
"alphanum_fraction": 0.7260540723800659,
"avg_line_length": 38.85844802856445,
"blob_id": "1b960ea1884e9c4443feec306403d8552a4a08ae",
"content_id": "f0ae976ad6d47abf9dfbc1bd90cea121ba45142f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 10884,
"license_type": "no_license",
"max_line_length": 430,
"num_lines": 219,
"path": "/Lab3/README.md",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "# LAB 3: Image Bitwise Logical Operators\n\n## Adding a Logo to an Image Using Bitwise Operators\n\nIn this lab exercise, we make use of user-defined functions in order to display the actual size of an image while fitting it to the screen boundaries. We provide two functions: one for displaying a single image and the other for displaying two images side-by-side. Here are the code and sample usages of these functions are presented below.\n## Add this line into Jupyter Notebook\n```python\nimport cv2 #import OpenCV\nfrom matplotlib import pyplot as plt #import python plot graph\nimport matplotlib as mpl #import math library from python\n\nbg = cv2.imread('bg.jpg')\nbg = cv2.cvtColor(bg,cv2.COLOR_BGR2RGB)\nfg = cv2.imread('fg.jpg')\nfg = cv2.cvtColor(fg,cv2.COLOR_BGR2RGB)\n```\n\n```python\ndef get_figsize(im):\n # What size does the figure need to be in inches to fit the image?\n dpi = plt.rcParams['figure.dpi']\n dim = im.shape\n figuresize = dim[1]/float(dpi), dim[0]/float(dpi)\n return(figuresize)\n```\n\n```python\ndef display_image_actual_size_single(im_data):\n figuresize = get_figsize(im_data)\n # Create a figure of the right size with one axes that takes up the full figure\n fig = plt.figure(figsize=figuresize)\n # Add the single axis to fit the image to the screen boundary\n ax = fig.add_axes([0, 0, 1, 1])\n ax.imshow(im_data, cmap='gray')\n ax.axis('off')\n plt.show()\n return(fig)\n```\n\n```python\ndef display_image_actual_size_double(im_data1,im_data2):\n # assuming that the two input images have the same dimension and shape\n # then, we calculate figsize from one of the two images\n figuresize = get_figsize(im_data1)\n # Create a figure of the right size that can accommodate two images side-by-side\n fig = plt.figure(figsize=(figuresize[0],figuresize[1]*2+.1))\n ax1 = fig.add_axes([0,0,1,1])\n ax1.imshow(im_data1, cmap='gray')\n ax1.axis('off')\n ax2 = fig.add_axes([1.1,0,1,1])\n ax2.imshow(im_data2, cmap='gray')\n ax2.axis('off')\n return(fig)\n```\n\n```python\nplt.imshow(bg)\n```\n## Output of BG should be like this\n\n\n\n## Load and display selected images\n\nFirst, let us look at our background and foreground images that we have chosen. Load them into your Python enviroment and display them. The code here illustrates how to use both of our user-defined image-display functions. Also, we show you two foreground cases (as noted above); you need only one.\n\n```python\nfig = display_image_actual_size_double(fg, bg)\n```\n## Output of BG and FG should be like this\n\n\n\n## Identify a region of interest on a background image\n\nDecide where on the background you want to put your foreground image. Cut from the background this region of interest (roi); it is of the same width, same height, and same color channels as the foreground image. For example, in our case here, we will put the logo at the bottom right of our poster. The logo's top-left corner will be at the coordinate (row=390, column=765) of the poster. Remember image axes? Row 0 is at the top.\n\n## Code\n```python\nrows, cols, channels = fg.shape #get the width, the height, and the channels of fg\nroi = bg[1000:1000+rows, 1800:1800+cols] #cut from bg the roi of the same dimesions as fg\nprint(fg.shape)\nprint(roi.shape)\nfig = display_image_actual_size_double(fg,roi)\nfig.savefig(\"Lab3Ex1.jpg\",bbox_inches='tight') #Save image output\n```\n## Output should be like this\n\n\n\n## Create a binary mask of a foreground\n\nFollowing the lecture where we create a black-and-white image of a robot, we first convert the foreground image to grayscale, named it fgGrayscale. Then, we threshold it using OpenCV threshold function (provided below). It returns two outputs, the thresholded image is the latter. The second variable thres is your threshold.\n\n```python\n# Example \nretval, mask = cv2.threshold(fgGrayscale, thres, 255, cv2.THRESH_BINARY)\n```\n## How to use it with code\n```python\nfgGrayscale = cv2.cvtColor(fg,cv2.COLOR_BGR2GRAY)\nretval, mask = cv2.threshold(fgGrayscale, 200, 255, cv2.THRESH_BINARY)\nfig = display_image_actual_size_double(fgGrayscale, mask)\nfig.savefig(\"Lab3Ex2.jpg\",bbox_inches='tight')\n```\n\n## Output should be like this\n\n\n\n## แล้วอะไรคือ **cv2.threshold**\nในตัวอย่างคือโค้ด ของ Python, **Threshold** ก็คือเกณฑ์ที่ใช้แบ่งสิ่งใดสิ่งหนึ่ง เช่น\nมีรถอยู่ 5 คัน ขับด้วยความเร็ว ดังนี้ 60, 156, 120, 80 และ 180 กม.ต่อชม. แล้วเราก็เถียงกับเพื่อนว่า คันไหนขับเร็ว คันไหนขับช้า เราเลยต้องมีเกณฑ์มาแบ่ง\nสมมติเราให้ รถที่ขับเร็วกว่า 90 กม.ต่อชม. เป็นรถที่ขับเร็ว เราเรียกค่านี้ว่า **Threshold Value**\n<br>\n\n**Threshold Value** คือ การนำภาพ 1 Channel (หรือ **Grayscale Image**) มาแปลงค่า intesity ของแต่ละ Pixel ให้เหลือเพียง 2 ค่า คือ 0(ดำ) กับ 255(ขาว) เราเรียกภาพที่มีค่า intensity เพียง 2 ค่า ว่า **\"Binary Image\"** โดยเราจะใช้ Threshold Value ในการแบ่งว่า Pixel ที่มี intensity XX ควรมีค่าเท่าไหร่ ดังนี้\n\n - pixel ที่มีค่า มากกว่าเท่ากับ Threshold Value มีค่าเท่ากับ 255 หรือสีขาว\n\n - pixel ที่มีค่า น้อยกว่า Threshold Value มีค่าเท่ากับ 0 หรือสีดำนั้นเอง\n\n**Pixel** ที่เป็นสีดำจะมีค่าเป็น **0** ส่วนสีขาวจะมีค่าเป็น **255** ซึ่งเพิ่งเท่านี้เรายังไม่สามารถลบ พื้นหลัง ออกได้เดี๋ยวคราวหน้าจะมาสอนสร้าง mask ไว้คุมตัวโคนันแล้วลบพื้นหลังทิ้ง \n\n```python\ncv2.threshold(Grayscale_img, threshold_value, max_value, style)\n\ncv2.threshold(img,thres,255,cv2.THRESH_BINARY)\n\n```\n\n|คำศัพท์|ความหมาย|\n|--|--|\n|Grayscale_img | ภาพขาวดำ ที่จริงมันก็คือ ภาพที่มี 1 Channel เราอาจจะไม่ต้องแปลงเป็น Grayscale แต่เอา Channel R, G หรือ B มาใช้เลยก็ได้ด้วยการใช้ Function cv2.split() |\n|threshold_value|Threshold value|\n|max_value| \tค่าสีที่ใช้แสดง เมื่อ Pixel นั้นมีค่ามากกว่า th_value เช่น ถ้าเราลดจาก 255 เป็น 200 ภาพผลลัพธ์ที่ได้จากสีขาวก็จะกลายเป็นสีออกเทาๆ|\n|style|ลักษณะผลลัพธ์ แบบที่เราใช้ก็เป็นแบบธรรมดา ถ้าเติม _INV ไปก็จะ invert สีผลลัพธ์ให้ตรงกันข้าม |\n\n**Style** มีทั้งหมด 5 แบบ ดังตัวอย่าง\n```python\ncv2.THRESHOLD_BINARY\n\ncv2.THRESHOLD_BINARY_INV \n\ncv2.THRESHOLD_TRUNC\n\ncv2.THRESHOLD_TOZERO\n\ncv2.THRESHOLD_TOZERO_INV\n```\n\n## Mask the foreground and the roi, then combine them\n\nThe next steps involves applying one or more bitwise operations, making use of the binary mask we have just created. We give you the expected output; it is your task to figure out the process. Below is an OpenCV command for 'and' operation. The syntax of other bitwise operations are the same (consult OpenCV library to learn more).\n\n\n```python \nmask_inv = cv2.bitwise_not(mask)\nresult = cv2.bitwise_and(fg, fg, mask = mask_inv)\nfig = display_image_actual_size_double(mask_inv,result)\nfig.savefig(\"Lab3Ex3.jpg\",bbox_inches='tight')\n```\n## Output should be like this \n\n\n\n## อะไรคือ **cv2.bitwise_not cv2.bitwise_and**\n```python\nresult = cv2.bitwise_and(fg, fg, mask = mask_inv)\n```\n**bitwise_and** คือการนำภาพระดับบิตที่ชื่อว่า fg มาทำการ AND กับ Mask ที่ชื่อว่า mask_inv โดยมีหลักการว่า 0 AND กับอะไรก็จะได้ 0\n```python\ninv=cv2.bitwise_not(mask)\n```\n**bitwise_not** คือการการสลับภาพ mask จาก 0 เป็น 1 จาก 1 เป็น 0 หรือ การสลับจากภาพขาวเป็นดำ จากดำเป็นขาว\n\n<br>\n\n**Exercise #4** : Mask the roi (deleting pixels that will be replaced by the logo). Display both the mask and the result.\n\n```python\nresult2 = cv2.bitwise_and(roi,roi,mask=mask)\nfig = display_image_actual_size_double(mask,result2)\nfig.savefig(\"Lab3Ex4.jpg\", bbox_inches='tight')\n```\n\n## Output should be like this \n\n\n\n\n**Exercise #5** : Combine foreground and roi (putting the logo onto the roi). Display and save your combined roi.\n\n```python\nresult3 = cv2.add(result,result2)\nfig = display_image_actual_size_single(result3)\nfig.savefig(\"Lab3Ex5.jpg\", bbox_inches='tight')\n```\n## Output should be like this \n\n\n\n## Put the processed roi back onto the original background image4\n\n\n**Exercise #6**: Put roi (now with the logo) back onto the original background. Display and save your result.\n\n## Add Logo to image\n\n```python\ndst = cv2.add(result2,result3)\nbg[0:rows, 0:cols ] = dst\nfig = display_image_actual_size_single(bg)\nfig.savefig(\"Lab3Ex6.jpg\", bbox_inches='tight')\n```\n\n## Output it's look like this\n\n"
},
{
"alpha_fraction": 0.6363636255264282,
"alphanum_fraction": 0.6499032974243164,
"avg_line_length": 31.3125,
"blob_id": "7eae9da31949265ddd0f57a10e451f325d802f17",
"content_id": "379d647e558b82e5d68b09710a7e9f88e4d74a96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 517,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 16,
"path": "/test_nb.py",
"repo_name": "SunatP/ITCS381_Multimedia",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport tempfile\nimport cv2\nfrom matplotlib import pyplot as plt\n\ndef _exec_notebook(path):\n with tempfile.NamedTemporaryFile(suffix=\".ipynb\") as fout:\n args = [\"jupyter\", \"nbconvert\", \"--to\", \"notebook\", \"--execute\",\n \"--ExecutePreprocessor.timeout=1000\",\n \"--output\", fout.name, path]\n subprocess.check_call(args)\n \nim = cv2.imread(r\"Lab1/dog.jpg\") \nplt.imshow(im, cmap='gray')\n\n_exec_notebook(\"./Project_Prototype/Project_MM_Prototype.ipynb\")\n"
}
] | 26 |
BobM-DS/Airline-customer-value-analysis
|
https://github.com/BobM-DS/Airline-customer-value-analysis
|
3620d4b8e51ef735f1e4b9338c4ad5601d679635
|
eb5c626a002a3df7a5e5ea2ef7f02dd3b8a2d57a
|
b516e91c867be1ae31ded7adcbc618985345c7b0
|
refs/heads/master
| 2021-10-09T09:41:38.069750 | 2018-12-25T13:37:19 | 2018-12-25T13:37:19 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6834625601768494,
"alphanum_fraction": 0.7054263353347778,
"avg_line_length": 26.64285659790039,
"blob_id": "8b73c1ca17410990be8fa0d2166f051d7d8d494a",
"content_id": "5cbbc26c1426a89e3624c30c4c5b8c2526a26124",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 774,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 28,
"path": "/code/standardization.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 28 05:19:38 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\n\ndata_file = '../data/Processed_data/standardization.csv'\ndata_output = '../data/Processed_data/model_input.csv'\ndata_statics = '../data/Processed_data/data_statics.csv'\ndata_mean_path = '../data/Processed_data/data_mean.csv'\ndata_std_path = '../data/Processed_data/data_std.csv'\n\n#get input DataFrame\ndata = pd.read_csv(data_file)\n\n#standardization procedure\ndata = (data - data.mean(axis=0)) / (data.std(axis=0))\ndata_mean = data.mean(axis=0)\ndata_std = data.std(axis=0)\ndata_mean.to_csv(data_mean_path)\ndata_std.to_csv(data_std_path)\n\ndata.columns = ['Z'+i for i in data.columns] #columns rename\n#data_record.to_csv(data_statics)\ndata.to_csv(data_output, index=False)\n"
},
{
"alpha_fraction": 0.742168664932251,
"alphanum_fraction": 0.759036123752594,
"avg_line_length": 25.774192810058594,
"blob_id": "49bee0937f8daa8a30b2b258699fe6e43e16f0de",
"content_id": "466947c2eeae85e29b2d3937f9f92957a52a062b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 830,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/code/Value_Predict.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 24 04:10:09 2018\n\n@author: bob\n\"\"\"\n#import py files\nimport Clientdata\nimport Kmeans\nimport K_means_cluster\nimport DefineLaber\n\n#run model:\ninput_file = '../data/Processed_data/model_input.csv' #get model_input \nK_means_model, centers, labels = Kmeans.kmeans()\n\n#display the detiles of the Cluster\nprint \"Details of Cluster\"\nK_means_cluster.resultOfCluster(centers, labels)\nprint \"Every Attr Feature\"\nK_means_cluster.plotEveryFeature(labels)\nprint \"Every Value Distribution\"\nK_means_cluster.labelPlot(labels, 5, centers)\n\n#get prepared for predicting the Value of Client \ninput_data = Clientdata.Get_input_data()\n\n#Predict\nclient_predict = K_means_model.predict(input_data)\nclient_laber = DefineLaber.Relaber(client_predict)\nprint \"This Client's Value is {}\\n\".format(client_laber)\n"
},
{
"alpha_fraction": 0.5408163070678711,
"alphanum_fraction": 0.5695732831954956,
"avg_line_length": 29.828571319580078,
"blob_id": "379ebfce4c4ad763006446fb96ea655bcbce6f79",
"content_id": "abdff4318b554705ffabcd96a695cacd5371e6e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1078,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 35,
"path": "/code/PlotEachCluster.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 24 03:36:51 2018\n\n@author: bob\n\"\"\"\nimport matplotlib.pyplot as plt\nimport numpy as np\n\ndef PlotCluster(data, laber):\n data = [round(i, 2) for i in data]\n \n ind = np.arange(5) # the x locations for the groups\n width = 0.7 # the width of the bars\n \n fig, ax = plt.subplots()\n rects1 = ax.bar(ind - width/2, data, width, yerr=(np.std(data)),\n color='SkyBlue')\n \n # Add some text for labels, title and custom x-axis tick labels, etc.\n title = 'Cluster' + '_' + str(laber)\n ax.set_title(title)\n ax.set_xticks(ind)\n ax.set_xticklabels(('Avg_C', 'Recent', 'Frequrent', 'Miles', 'Length'))\n ax.legend()\n \n offset = {'center': 0.5, 'right': 0.57, 'left': 0.43} # x_txt = x + w*off\n \n for rect in rects1:\n height = rect.get_height()\n ax.text(rect.get_x() + rect.get_width()*offset['center'], 1.01*height,\n '{}'.format(height), va='bottom')\n fig_path_name = '../data/result/' + str(laber)\n plt.savefig(fig_path_name)\n plt.show()"
},
{
"alpha_fraction": 0.6344537734985352,
"alphanum_fraction": 0.6736694574356079,
"avg_line_length": 31.5,
"blob_id": "f782d14ad9f812ea7f7be32a8c512d4640fb31b4",
"content_id": "ad846c0a8838270082dd827f5fedbb979d62d799",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 714,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 22,
"path": "/code/data_clean.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 28 00:31:11 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\n\ndata_file = '../data/Original_data/air_data.csv' #original data file\ncleaned_data = '../data/Processed_data/data_cleaned.xls' #result cleaned data file\n\ndata = pd.read_csv(data_file, encoding='utf-8')\n#remove the NaN value in data and return DataFrame\ndata[data['SUM_YR_1'].notnull() * data['SUM_YR_1'].notnull()]\n\nindex1 = data['SUM_YR_1'] != 0 #ticket's price isn't zero in first year\nindex2 = data['SUM_YR_2'] != 0 #ticket's price isn't zero in second year\nindex3 = (data['SEG_KM_SUM'] != 0) & (data['avg_discount'] != 0)\nresult = data[index1 | index2 | index3]\n\n#result.to_excel(cleaned_data, index=False)"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 23,
"blob_id": "0dc9951efad2a6befeaeae024d633f576bf5b4f3",
"content_id": "12eec4e57419871d27357576075534df5c306e28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# Airline-customer-value-analysis\nCluster Model\n"
},
{
"alpha_fraction": 0.6346801519393921,
"alphanum_fraction": 0.6599326729774475,
"avg_line_length": 22.799999237060547,
"blob_id": "794364ca18c6f6a4c868a02726c90cfe27379501",
"content_id": "61d669bc258fe979f7043c3726c7e471c617798b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/code/Kmeans.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 24 04:34:44 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\nfrom sklearn.cluster import KMeans\n\n#run Kmeans model\n#return model ,centers of each clusters and labels of the datasets\ndef kmeans():\n input_file = '../data/Processed_data/model_input.csv'\n \n k = 5 # set the number of clustering\n \n data = pd.read_csv(input_file)\n \n k_model = KMeans(n_clusters=k, n_jobs=7) \n k_model.fit(data)\n \n centers = k_model.cluster_centers_ #centery of clustering\n labels = k_model.labels_ #labels\n return k_model, centers, labels"
},
{
"alpha_fraction": 0.5746479034423828,
"alphanum_fraction": 0.6103286147117615,
"avg_line_length": 33.32258224487305,
"blob_id": "f74f778d835af607c95b78dfe43c23ba4e18b6c8",
"content_id": "4b52926ba86f599b421fc186cbb65f274d3a600d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 31,
"path": "/code/Clientdata.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 24 04:26:26 2018\n\n@author: bob\n\"\"\"\nimport numpy as np\nimport pandas as pd\n#get data prepared\n\n#get dataset's mean and std return both\ndef Get_Mean_Std():\n data_mean_path = '../data/Processed_data/data_mean.csv'\n data_std_path = '../data/Processed_data/data_std.csv'\n mean = pd.read_csv(data_mean_path, names=['attr', 'mean']).T.ix['mean'].values\n std = pd.read_csv(data_std_path, names=['attr', 'std']).T.ix['std'].values\n return mean, std\n\ndef Get_input_data():\n print \"Please input the Client's data\"\n Load_time = input(\"Load_time(0~200): \")\n Last_to_end = input(\"Last_to_end(0~1000): \")\n Flight_count = input(\"Flight_count(0~300): \")\n Seg_km_sum = input(\"Seg_km_sum(0~600000): \")\n Avg_discount = input(\"Avg_discount(0~1.5): \")\n \n mean, std = Get_Mean_Std()\n input_data = np.array([Load_time, Last_to_end, Flight_count, \\\n Seg_km_sum, Avg_discount])\n model_input = (input_data-mean) / (std)\n return np.array(model_input).reshape(1, -1)\n\n"
},
{
"alpha_fraction": 0.654321014881134,
"alphanum_fraction": 0.7078189253807068,
"avg_line_length": 21.090909957885742,
"blob_id": "35cf1b09bad3a3a5865d0aaa6faf7d39ff5f7ae3",
"content_id": "43a1414b464d9fc130232e6ae655e44504a17fc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 11,
"path": "/code/test.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Dec 23 22:17:09 2018\n\n@author: bob\n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\n\ndata = pd.read_csv('/home/bob/Desktop/fly_project/data/Processed_data/data_statics.csv')\n"
},
{
"alpha_fraction": 0.5522252321243286,
"alphanum_fraction": 0.573115348815918,
"avg_line_length": 24.627906799316406,
"blob_id": "2d97adc671dfe0f0a23100eb7c05aff3278eeca7",
"content_id": "cc9c832acc8a763b04d4df30f289ae4cbb1ecfcc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1101,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 43,
"path": "/code/plotEveryClassHist.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Apr 8 23:56:06 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport os\n\npath = '../data/categories'\nfilename_list = os.listdir(path)\n\ndef plotEachFeature():\n for feature in [u'L', u'R', u'F', u'M', u'C']:\n plot_data = []\n for name in filename_list:\n filename = path + '/' + name\n data = pd.read_csv(filename)\n plot_data.append(data[feature].mean())\n print plot_data\n #for i in range(len(plot_data)):\n # plot_data[i] = abs(plot_data[i])\n title = feature + '_class situation'\n plt.title(title)\n plt.bar([1,2,3,4,5], plot_data)\n plt.show()\n \n#def plotEachClass():\n\nfor name in filename_list:\n filename = path + '/' + name\n data = pd.read_csv(filename)\n plot_data = data.mean(axis=0).values.tolist()\n #print plot_data\n print data.columns\n #for i in range(len(plot_data)):\n # plot_data[i] = abs(plot_data[i])\n plt.title(name)\n plt.bar([1,2,3,4,5], plot_data)\n plt.show()"
},
{
"alpha_fraction": 0.5346320271492004,
"alphanum_fraction": 0.5757575631141663,
"avg_line_length": 21.047618865966797,
"blob_id": "09614e39c007b79e74c629a35d4f787bed40372a",
"content_id": "e318e59d4cd5026258d490b32cc961322ed0cbf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 21,
"path": "/code/DefineLaber.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Dec 25 21:24:28 2018\n\n@author: bob\n\"\"\"\n\ndef Relaber(predict_laber):\n predict = int(predict_laber)\n if predict == 0:\n laber = 'Important retention customer'\n if predict == 1:\n laber = 'Valuable customer'\n if predict == 2:\n laber = 'Worth developing'\n if predict == 3:\n laber = 'Normal'\n if predict == 4:\n laber = 'Low valuable'\n return laber"
},
{
"alpha_fraction": 0.5619596838951111,
"alphanum_fraction": 0.579971194267273,
"avg_line_length": 24.962265014648438,
"blob_id": "e60b50322abcbae6466c793125e7348c99877c1b",
"content_id": "65019054636da042a01b3b303bd4072b73756f8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1388,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 53,
"path": "/code/attr_specification.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 28 02:04:48 2018\n\n@author: bob\n\"\"\"\nimport pandas as pd\nimport datetime\nimport csv\n\ndata_file = '../data/Processed_data/data_cleaned.xls'\ndata_output = '../data/Processed_data/standardization.csv'\n\ndata = pd.read_excel(data_file, \n usecols=['FFP_DATE', 'LOAD_TIME', 'FLIGHT_COUNT', 'avg_discount',\n 'SEG_KM_SUM', 'LAST_TO_END'])\n\ndef change2datetime(time):\n time = time.split('/')\n time = [int(i) for i in time]\n return time\n\ndef month_differ(x, y):\n month_differ = abs((x.year - y.year) * 12 + (x.month - y.month) * 1)\n return month_differ \n\n#def month_number(data):\nresult = []\nfor index, row in data.iterrows():\n f = str(row['FFP_DATE'])\n l = str(row['LOAD_TIME'])\n ffp = change2datetime(f)\n load = change2datetime(l)\n ffp_month = datetime.datetime(ffp[0], ffp[1], ffp[2])\n load_month = datetime.datetime(load[0], load[1], load[2])\n \n L = month_differ(load_month, ffp_month)\n R = row['LAST_TO_END']\n F = row['FLIGHT_COUNT']\n M = row['SEG_KM_SUM']\n C = row['avg_discount']\n target = [L, R, F, M, C]\n result.append(target)\n #mon.append(month)\n#return mon\n\n#write to csv \n'''\nwith open(data_output, 'w') as f:\n writer = csv.writer(f)\n writer.writerow(['L', 'R', 'F', 'M', 'C'])\n writer.writerows(result)\n'''\n\n\n \n \n"
},
{
"alpha_fraction": 0.6754507422447205,
"alphanum_fraction": 0.694868266582489,
"avg_line_length": 27.8799991607666,
"blob_id": "70b4b00776b3f8837ab086cde744250abefaa855",
"content_id": "be75e01facc7f8d62fe4866fcbf742aeaf2c867d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 25,
"path": "/code/data_explore.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Mar 27 01:00:46 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\n\n#basci exploration on origin data\n#find maximum and minimum in missing data and return the number\n\n#the original data, index in the first row\ndata_file = '../data/Original_data/air_data.csv' \n#result of missing situation above\nresult_file = '../data/Processed_data/explore.csv' \n\n\ndata = pd.read_csv(data_file, encoding='utf-8')\nexplore = data.describe(percentiles=[], include='all').T\n#caculate the number of null by len(data) - 'count'\nexplore['null'] = len(data) - explore['count']\nexplore['null_per'] = explore['null'] / len(data)\nexplore = explore[['null', 'null_per', 'max', 'min']]\n#explore.to_csv(result_file)"
},
{
"alpha_fraction": 0.5203539729118347,
"alphanum_fraction": 0.6513274312019348,
"avg_line_length": 17.25806427001953,
"blob_id": "0c426ffe4696dbf13da18b37236a4b1d9b7d6e17",
"content_id": "ee41b5ee80e8e25f9cec8925c5c3108a6837488d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 31,
"path": "/origin_code/test.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Dec 25 21:11:25 2018\n\n@author: bob\n\"\"\"\n\n#-*- coding: utf-8 -*-\n\nimport numpy as np\nimport pandas as pd\nfrom sklearn.cluster import KMeans\n\ninputfile = '../data/temp/zscoreddata.xls' \nk = 5 \n\n\ndata = pd.read_excel(inputfile) #\n\n\nkmodel = KMeans(n_clusters = k, n_jobs = 4) #\nkmodel.fit(data) #\n\nkmodel.cluster_centers_\nkmodel.labels_ \nx = [1.0989423842,-0.9008699207,3.1202488347,3.8241744646,-0.2289724862]\nx_new = np.array(x).reshape(1, -1)\n\npre = kmodel.predict(x_new)\nprint pre"
},
{
"alpha_fraction": 0.5667770504951477,
"alphanum_fraction": 0.5805739760398865,
"avg_line_length": 32.850467681884766,
"blob_id": "ca8627e0ced2d4fce207d8fe2846527030dc795d",
"content_id": "fc8b68204eb7d6491785a21ddcbc92bd37dae8b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3628,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 107,
"path": "/code/K_means_cluster.py",
"repo_name": "BobM-DS/Airline-customer-value-analysis",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 28 05:34:39 2018\n\n@author: bob\n\"\"\"\n\nimport pandas as pd\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport csv\n\nimport PlotEachCluster\n\n#input_file = '../data/Processed_data/model_input.csv'\n#data = pd.read_csv(input_file)\n\n#create a table that describe the result of cluster\ndef resultOfCluster(center, labels): \n whole_info = []\n clu_class = list(set(labels))\n for i in range(0, 5):\n row = []\n row.append(clu_class[i])\n row.append(labels.tolist().count(i))\n for j in range(0, 5):\n row.append(center[i][j])\n whole_info.append(row)\n \n result_of_cluster = pd.DataFrame(np.array(whole_info), \n columns=['cluster_class',\n 'cluster_number',\n 'ZL',\n 'ZR',\n 'ZF',\n 'ZM',\n 'ZC'])\n result_of_cluster.set_index('cluster_class', inplace=True)\n print result_of_cluster\n #save file\n #result_of_cluster.to_excel('../data/Processed_data/ResultOfCluster.xls', index=False)\n #return result_of_cluster\n\n#return a dic contains all classes' values\ndef resultOfClass(labels):\n input_file = '../data/Processed_data/model_input.csv'\n data = pd.read_csv(input_file)\n class_dic = {}\n for i in range(0, len(set(labels))):\n class_dic[str(i)] = []\n index_arr = range(0, len(data))\n for index, label in zip(index_arr, labels):\n row = data.ix[index].values\n class_dic[str(label)].append(row)\n return class_dic\n\n#plot the each feature's situation\ndef plotEveryFeature(labels):\n class_dic = resultOfClass(labels)\n for feature in range(0, 5):# C, R, F, M, L\n plot_arr = []\n for class_number in range(0, 5): #for every Class \n arr = np.array(class_dic[str(class_number)])\n plot_arr.append(arr[:,feature].mean())\n #print plot_arr\n PlotEachCluster.PlotCluster(plot_arr, feature)\n \n#write each categories to file.csv; target path is ../data/categories/\ndef writeCategoryTofile(labels):\n class_dic = resultOfClass(labels)\n for cate in class_dic.keys():\n cate_info = class_dic[cate]\n cate_arr = np.array(cate_info)\n filepath = '../data/categaries/'\n filename = 'category_' + cate\n target = filepath + filename + '.csv'\n with open(target, 'w') as f:\n writer = csv.writer(f)\n writer.writerow(['L', 'R', 'F', 'M', 'C'])\n writer.writerows(cate_info)\n print \"Category is: \", cate, \n print \"Mean is: \", cate_arr.mean(axis=0)\n\n#plot the classes after clustering \n'''\nparameters:\ncolumns: dataset's columns\nk: numbers of cluster\ncenters: center of each class\n'''\ndef labelPlot(labels, k, centers):\n #k = 5 #numbers of data\n plot_data = centers\n color = ['b', 'g', 'r', 'c', 'y'] #set color\n \n angles = np.linspace(0, 2*np.pi, k, endpoint=False)\n plot_data = np.concatenate((plot_data, plot_data[:,[0]]), axis=1) \n angles = np.concatenate((angles, [angles[0]])) \n \n fig = plt.figure()\n ax = fig.add_subplot(111, polar=True) #set parameter Polar\n for i in range(len(plot_data)):\n ax.plot(angles, plot_data[i], 'o-', color = color[i], label = 'cate'+str(i), linewidth=2)# 画线\n ax.set_rgrids(np.arange(0.01, 3.5, 0.5), np.arange(-1, 2.5, 0.5), fontproperties=\"SimHei\")\n ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties=\"SimHei\")\n plt.legend(loc=3)\n plt.show()\n\n\n"
}
] | 14 |
wokka1/DualUniverseMarketCalc
|
https://github.com/wokka1/DualUniverseMarketCalc
|
8b4eb9c02ddc869577f6f14342a9961b70678a5e
|
c11bd4de54b4ae2d4d2cb9930b64627a6d7c8395
|
a3eb9fd079d0fb8268667aa21f2a065ac1d7b166
|
refs/heads/main
| 2023-01-25T02:05:22.456362 | 2020-12-06T20:03:12 | 2020-12-06T20:03:12 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.660183310508728,
"alphanum_fraction": 0.6618600487709045,
"avg_line_length": 39.297298431396484,
"blob_id": "6bfcd1871295a8313f0169cdca4a755251d889e6",
"content_id": "23c913f8c42c4d1df44ef8a00c6349ea67e6bb96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8946,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 222,
"path": "/src/GameItem.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "from src.TermColors import Colors, colorText\nfrom src.ItemData import ItemData\nfrom src.inputUtils import parseToInt, parseToFloat\nimport pprint\n\npp = pprint.PrettyPrinter(indent=2)\nprettyFormat = pp.pformat\n\n\nclass GameItemDataName:\n NAME = 'name'\n MARKET_SELL_PRICE = 'marketSellPrice'\n CRAFTING_COST = 'craftingCost'\n\n\nclass GameItem:\n \"\"\"Represents an item in the game. Holds values for it's market value and\n sub-components\"\"\"\n\n def __init__(self, name):\n self._data = {\n GameItemDataName.NAME: ItemData('Name', name),\n GameItemDataName.MARKET_SELL_PRICE: ItemData('Market Sell Price', None),\n GameItemDataName.CRAFTING_COST: ItemData('Crafting Components', {})\n }\n\n def getData(self, dataName):\n \"\"\"Gets the data associated with the given data name\"\"\"\n if dataName in self._data:\n return self._data[dataName]\n else:\n print('Property with name: ', dataName, ' was not found.')\n\n def setData(self, dataName, newData):\n \"\"\"Sets the data for the item with the given name\"\"\"\n if dataName in self._data:\n self._data[dataName].data = newData\n else:\n print('Property with name: ', dataName, ' was not found.')\n\n def addCraftingCost(self, itemName, quantity):\n craftingCost = self._data.craftingCost.data\n craftingCost[itemName] = quantity\n self._data.craftingCost.data = craftingCost\n\n def editPrompt(self, gameItems):\n dataKeyList = list(self._data.keys())\n doneEditing = False\n while (doneEditing is False):\n print('Enter a number from below to update its value')\n i = 1\n for key in dataKeyList:\n itemData = self._data[key]\n print(str(i) + '. ' + str(itemData.title) + ': ' + str(itemData.data))\n i += 1\n print(str(i) + '. Stop editing')\n choice = input('Enter a number from above: ')\n parsedChoice = parseToInt(choice, 1, dataKeyList.__len__() + 1)\n\n # If the choice was successfully parsed\n if (parsedChoice is not None):\n # If they chose to stop editing\n if (parsedChoice == dataKeyList.__len__() + 1):\n doneEditing = True\n else:\n self.editDataPrompt(dataKeyList[parsedChoice - 1])\n\n def editDataPrompt(self, dataName, gameItems=None):\n if (dataName == GameItemDataName.CRAFTING_COST):\n self.editCraftingCostPrompt()\n return\n elif(dataName == GameItemDataName.MARKET_SELL_PRICE):\n self.editMarketSellPricePrompt()\n return\n elif(dataName == GameItemDataName.NAME):\n newValue = input('Enter a new value for \"' +\n self._data[dataName].title + '\": ')\n self._data[dataName].data = newValue\n gameItems.changeItemName(newValue)\n print('Value successfully changed')\n\n def editMarketSellPricePrompt(self):\n correctValueEntered = False\n while (correctValueEntered is False):\n newValue = input('Enter a new value for \"' +\n self._data[GameItemDataName.MARKET_SELL_PRICE].title + '\": ')\n parsedValue = parseToFloat(newValue, min=0)\n if (parsedValue is not None):\n self._data[GameItemDataName.MARKET_SELL_PRICE].data = parsedValue\n correctValueEntered = True\n print('Value successfully changed')\n\n def editCraftingCostPrompt(self):\n doneEditing = False\n while(doneEditing is False):\n craftingItems = self._data[GameItemDataName.CRAFTING_COST].data\n print(colorText(prettyFormat(craftingItems), Colors.OKGREEN))\n print('Enter a command below to edit the crafting components')\n print(Colors.OKCYAN + 'add' + Colors.ENDC +\n ': Add a new crafting requirement to ' +\n colorText(self._data['name'].data, Colors.OKBLUE))\n print(Colors.OKCYAN + 'edit [itemName]' + Colors.ENDC +\n ': Edit the crafting requirement with the given ' +\n '\"itemName\"')\n print(Colors.OKCYAN + 'delete [itemName]' + Colors.ENDC +\n ' Delete the crafting requirement with the given' +\n ' \"itemName\"')\n print(Colors.OKCYAN + 'exit' + Colors.ENDC +\n ': Exit editing')\n inputStr = input('Enter command: ')\n if (inputStr == 'exit'):\n doneEditing = True\n elif (inputStr == 'add'):\n self.addCraftingItemPrompt()\n elif (inputStr.startswith('delete')):\n self.deleteCraftingItem(inputStr[7:])\n elif (inputStr.startswith('edit')):\n self.editCraftingItemPrompt(inputStr[5:])\n\n def addCraftingItemPrompt(self):\n name = input('Enter the name of the crafting component: ')\n parsedChoice = None\n while (parsedChoice == None):\n quantity = input('Enter the quantity of the crafting component: ')\n parsedChoice = parseToFloat(quantity, 0)\n if (parsedChoice is not None):\n craftingItems = self._data[GameItemDataName.CRAFTING_COST].data\n craftingItems[name] = parsedChoice\n self._data[GameItemDataName.CRAFTING_COST].data = craftingItems\n\n def editCraftingItemPrompt(self, craftItemName):\n selectionMade = False\n craftingDataItem = self._data[GameItemDataName.CRAFTING_COST]\n craftItemQuantity = craftingDataItem.data[craftItemName]\n while(selectionMade == False):\n print('Edit the name or the quantity?')\n print('name: ' + craftItemName)\n print('qty: ' + str(craftItemQuantity))\n selection = input('name, qty, or exit: ')\n if selection == 'exit':\n selectionMade = True\n return\n elif selection == 'qty':\n quantity = input('Enter the quantity of the crafting component: ')\n parsedQty = parseToFloat(quantity, 0)\n if (parsedQty is not None):\n craftingItems = craftingDataItem.data\n craftingItems[craftItemName] = parsedQty\n craftingDataItem.data = craftingItems\n selectionMade = True\n elif selection == 'name':\n newName = input('Enter the new name of the crafting component: ')\n craftingItems = craftingDataItem.data\n craftingItems[newName] = craftingItems[craftItemName]\n del craftingItems[craftItemName]\n craftingDataItem.data = craftingItems\n selectionMade = True\n\n def deleteCraftingItem(self, craftItemName):\n craftingItems = self._data[GameItemDataName.CRAFTING_COST].data\n if (craftItemName in craftingItems):\n del craftingItems[craftItemName]\n self._data[GameItemDataName.CRAFTING_COST].data = craftingItems\n else:\n print('Crafting item with name: \"' + craftItemName + '\" does not exist' +\n ' for \"' + self._data[GameItemDataName.NAME].data + '\"')\n\n def print(self, gameItems):\n \"\"\"Prints values for this game item to the console\"\"\"\n print(Colors.OKBLUE + self._data['name'].data + Colors.ENDC)\n for key in self._data:\n if key != GameItemDataName.NAME:\n itemData = self._data[key]\n itemValue = itemData.data\n itemTitle = itemData.title\n if type(itemValue) is float:\n itemValue = \"{:,}\".format(itemValue)\n elif type(itemValue) is dict:\n itemValue = str(prettyFormat(itemValue))\n print('\\t' + itemTitle + ': ', colorText(itemValue, Colors.OKGREEN))\n craftItems = self._data[GameItemDataName.CRAFTING_COST].data\n totalMarketCost = 0\n allCraftItemsFound = True\n for craftItemName, craftItemQty in craftItems.items():\n craftItemObj = gameItems.getItem(craftItemName)\n if (craftItemObj is not None):\n craftItemMarketCost = craftItemObj.getData(GameItemDataName.MARKET_SELL_PRICE).data\n if (craftItemMarketCost is not None):\n totalMarketCost += craftItemMarketCost * craftItemQty\n else:\n allCraftItemsFound = False\n else:\n allCraftItemsFound = False\n if (allCraftItemsFound):\n print('\\tCraft item total market cost: ' + \"{:,}\".format(totalMarketCost))\n else:\n print('\\tCraft item total market cost: ' + 'unknown because some ' +\n 'crafting items do not have a market value')\n\n def printTree(self, numIndent, gameItems, quantity):\n \"\"\"Prints a tree of this game item where the children are the components\n required to build this item, and their cost is their market price\n multiplied by the given quanitity.\"\"\"\n\n spaces = ''\n spaceRange = range(numIndent)\n for i in spaceRange:\n spaces += ' '\n name = self._data[GameItemDataName.NAME].data\n\n # Get the actual cost of the item and print it\n marketSellPrice = self._data[GameItemDataName.MARKET_SELL_PRICE].data\n if marketSellPrice is not None:\n actualCost = marketSellPrice * quantity\n print(spaces + colorText(name, Colors.OKBLUE) + \": \" + \"{:,.2f}\".format(actualCost))\n\n # Get the crafting requirements for this game item\n craftingItems = self._data[GameItemDataName.CRAFTING_COST].data\n for craftName, craftQty in craftingItems.items():\n gameItem = gameItems.getItem(craftName)\n if gameItem is not None:\n gameItem.printTree(numIndent + 1, gameItems, craftQty * quantity)\n"
},
{
"alpha_fraction": 0.7133333086967468,
"alphanum_fraction": 0.7200000286102295,
"avg_line_length": 16.346153259277344,
"blob_id": "497e7413aede41c5f064b8a3c9a18d665399b99f",
"content_id": "02a07c7938f3d39ffd1b387b8dde87553137b063",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 453,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 26,
"path": "/README.md",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "# Dual Universe Market Calc\n\n## Usage\n\nRun `sh run.sh` from a shell and it will startup everythign for you 😁\n\n## Dev Setup\n\nIf the `env` folder hasn't been created yet locally, run\n\n```sh\npython3 -m venv env\n```\n\nThen, once the folder has been created, run \n\n```\n. env/bin/activate\n```\n\nTo enter the virtual Python environment. Then you can install new dependencies with the following:\n\n```\npip3 install somePackage\npip3 freeze > requirements.txt\n```"
},
{
"alpha_fraction": 0.6526315808296204,
"alphanum_fraction": 0.6526315808296204,
"avg_line_length": 18,
"blob_id": "413d37da864fd4d532143c8410cad8af36705e55",
"content_id": "f0073ee5a8962179a33c0dfda0b59d596a4a8905",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 380,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 20,
"path": "/src/ItemData.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "class ItemData:\n def __init__(self, title, data):\n self._title = title\n self._data = data\n\n def getTitle(self):\n return self._title\n\n def setTitle(self, newTitle):\n self._title = newTitle\n\n title = property(getTitle, setTitle)\n\n def getData(self):\n return self._data\n\n def setData(self, newData):\n self._data = newData\n\n data = property(getData, setData)\n"
},
{
"alpha_fraction": 0.644444465637207,
"alphanum_fraction": 0.644444465637207,
"avg_line_length": 29,
"blob_id": "1e2f249a967b70ba9a98fad8f65361a1e1c57555",
"content_id": "3fe703bf81cb60a5a27313e23d19eecf9d74eef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/src/printFunctions.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "def printHelp():\n with open('txt/help.txt', 'r') as helpText:\n print(helpText.read())\n"
},
{
"alpha_fraction": 0.8108108043670654,
"alphanum_fraction": 0.8108108043670654,
"avg_line_length": 36,
"blob_id": "a4052976cd7b74f8afa239a6ea8510de5a956043",
"content_id": "19bba60f17f757b65fab2cdf2ed9eeadab826217",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 1,
"path": "/config.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "gameItemsFileName = 'gameItems.json'\n"
},
{
"alpha_fraction": 0.6763284802436829,
"alphanum_fraction": 0.6763284802436829,
"avg_line_length": 32.119998931884766,
"blob_id": "e67448aab9728512b0e8763dd50abb2240bb544c",
"content_id": "1bfbcfe85adb5a6fc7a8d0acda8fc710881ed602",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1656,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 50,
"path": "/src/inputUtils.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "def parseToInt(userInput, min=None, max=None):\n \"\"\"Parses the given string from the user and lets the user know if it is\n not a valid number. Returns None if the value is not parsable and the number\n if it is.\n\n If min is provided then it checks to make sure the value is at least that high\n or more. If max is provided then it checks to see if it is that value or \n less\"\"\"\n parsedChoice = None\n try:\n parsedChoice = int(userInput)\n except:\n print('\"' + userInput + '\" is not a number.')\n return None\n\n if min is not None and parsedChoice < min:\n print('\"' + userInput + '\" needs to be more than or equal to ' + str(min))\n return None\n\n if max is not None and parsedChoice > max:\n print('\"' + userInput + '\" needs to be less than or equal to ' + str(max))\n return None\n\n return parsedChoice\n\n\ndef parseToFloat(userInput, min=None, max=None):\n \"\"\"Parses the given string from the user and lets the user know if it is\n not a valid number. Returns None if the value is not parsable and the number\n if it is.\n\n If min is provided then it checks to make sure the value is at least that high\n or more. If max is provided then it checks to see if it is that value or \n less\"\"\"\n parsedChoice = None\n try:\n parsedChoice = float(userInput)\n except:\n print('\"' + userInput + '\" is not a number.')\n return None\n\n if min is not None and parsedChoice < min:\n print('\"' + userInput + '\" needs to be more than or equal to ' + str(min))\n return None\n\n if max is not None and parsedChoice > max:\n print('\"' + userInput + '\" needs to be less than or equal to ' + str(max))\n return None\n\n return parsedChoice\n"
},
{
"alpha_fraction": 0.6937269568443298,
"alphanum_fraction": 0.696494460105896,
"avg_line_length": 21.12244987487793,
"blob_id": "f27a1abda4711116c6deebaee7b4e08583855b4f",
"content_id": "eb43925e41f7adce3977bf2d452088ab931e58b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1084,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 49,
"path": "/main.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "from src.GameItems import GameItems\nfrom src.printFunctions import *\nimport json\nfrom os import path\nimport config\n\ngameItems = GameItems()\n\n\ndef addGameItem():\n name = input('Name of the game item: ')\n addResult = gameItems.addItem(name)\n if (addResult is not True):\n return\n print('Game item addition was successful')\n\n\ndef printItems():\n gameItems.printItems()\n\n\ndef printTree(name):\n gameItems.printTree(name)\n\n\ndef editGameItem(name):\n gameItem = gameItems.getItem(name)\n if (gameItem is None):\n print('Game item with name \"' + name + '\" was not found.')\n return\n gameItem.editPrompt(gameItems)\n gameItems.save()\n\n\nexitIndicated = False\nwhile exitIndicated is False:\n inputStr = input('What would you like to do? (\"help\" for commands): ')\n if inputStr == 'exit':\n exitIndicated = True\n elif inputStr == 'help':\n printHelp()\n elif inputStr == 'add':\n addGameItem()\n elif inputStr == 'print':\n printItems()\n elif inputStr.startswith('print tree'):\n printTree(inputStr[11:])\n elif inputStr.startswith('edit'):\n editGameItem(inputStr[5:])\n"
},
{
"alpha_fraction": 0.6686217188835144,
"alphanum_fraction": 0.670087993144989,
"avg_line_length": 24.259260177612305,
"blob_id": "f484d8a517edb8719aa8bcbf53f2f43c3f2c0842",
"content_id": "0ca5f43bd76f8262abaffb954f5b5aac997678e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1364,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 54,
"path": "/src/GameItems.py",
"repo_name": "wokka1/DualUniverseMarketCalc",
"src_encoding": "UTF-8",
"text": "import json\nfrom os import path\nfrom src.GameItem import GameItem\nimport jsonpickle\n\ngameItemsFileName = 'gameItems.json'\n\n\nclass GameItems:\n \"\"\"Holds the different game items and allows them to be interacted with.\"\"\"\n\n def __init__(self):\n if path.exists(gameItemsFileName):\n with open(gameItemsFileName) as json_file:\n self._gameItems = jsonpickle.decode(json_file.read())\n else:\n self._gameItems = []\n\n def addItem(self, name):\n if name in self._gameItems:\n print('The item with the name ' + name + ' already exists.')\n return False\n else:\n self._gameItems[name] = GameItem(name)\n self.save()\n\n return True\n\n def getItem(self, name):\n if name in self._gameItems:\n return self._gameItems[name]\n else:\n return None\n\n def changeItemName(self, oldName, newName):\n if oldName in self._gameItems:\n self._gameItems[newName] = self._gameItems[oldName]\n del self._gameItems[oldName]\n else:\n return None\n\n def getItems(self):\n return self._gameItems\n\n def printItems(self):\n for itemName in self._gameItems:\n self._gameItems[itemName].print(self)\n\n def printTree(self, itemName):\n self._gameItems[itemName].printTree(0, self, 1)\n\n def save(self):\n with open(gameItemsFileName, 'w') as json_file:\n json_file.write(jsonpickle.encode(self._gameItems))\n"
}
] | 8 |
acr92/googlectf_writeups
|
https://github.com/acr92/googlectf_writeups
|
69a9b7acd99cb7337c3d600c44301822a7097f8d
|
17241f2720295069d43c82f6831b2be70ef265a4
|
c97b51ab7583d96642f8a6fffd924c9e2ae84132
|
refs/heads/master
| 2022-01-24T03:24:52.214160 | 2016-05-01T16:56:56 | 2016-05-01T16:56:56 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7367458939552307,
"alphanum_fraction": 0.7385740280151367,
"avg_line_length": 33.1875,
"blob_id": "c839aff82c50ea19cc6a302ae96dcaa7da7b2d05",
"content_id": "9673e72a2f81da8ddcc7d82ecb369806d4ec6090",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 16,
"path": "/networking/opabina_regalis_ssl_stripping/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Opabina Regalis SSL Stripping\n\n## Challenge\n\nFollowing on from Opabina Regalis - Fetch Token, can you implement an SSL stripping attack?\n\n## Solution\n\nI just sent a few messages back and forth to get a feeling of the content. I saw that we\ngot a large HTML page back, and I decided to save that and open it in Firefox.\n\nFrom there I saw a URL to `/user/sign_in`.\n\nThen I modified the request to GET `/user/sign_in` instead of GET `/`, and I got the flag.\n\n*Token is*: `CTF{Why=were=the=apple=and=the=orange=all=alone..Because=the=banana=spli7}`\n"
},
{
"alpha_fraction": 0.6563535928726196,
"alphanum_fraction": 0.6740331649780273,
"avg_line_length": 18.255319595336914,
"blob_id": "f04a3d60dd06f322ebb96fd3a43260ca110d8dc4",
"content_id": "786b822ca4f44290bce41770f2cbf020787b4e41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 905,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 47,
"path": "/networking/opabina_regalis_ssl_stripping/exploit.py",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "from pwn import *\nimport struct\nimport binascii\nimport format_pb2\n\ncontext(arch='x86_64', os='linux')\n\nconn = remote('ssl-added-and-removed-here.ctfcompetition.com', 19121, ssl=True)\n\n\ndef read_msg():\n\tlength = u32(conn.recv(4))\n\tlog.debug(\"< (len): %d\" % length)\n\trequest = format_pb2.Exchange()\n\tdata = conn.recvn(length)\n\trequest.ParseFromString(data)\n\tlog.info(\"< %s\" % request)\n\treturn request\n\ndef send_msg(payload):\n\tlog.info(\"> %s\" % payload)\n\tdata = payload.SerializeToString()\n\toutput = p32(len(data)) + data\n\tconn.send(output)\n\n# Request to server\ni = read_msg()\ni.request.uri = \"/user/sign_in\"\nsend_msg(i)\n\n# Reply back to client\ni = read_msg()\n\nf = open(\"test_request.html\", \"wb\")\nf.write(i.reply.body)\nf.close()\n\ni.reply.body = i.reply.body.replace('https://elided','http://elided')\n\nf = open(\"test_reply.html\", \"wb\")\nf.write(i.reply.body)\nf.close()\n\nsend_msg(i)\n\ni = read_msg()\nsend_msg(i)\n"
},
{
"alpha_fraction": 0.7591093182563782,
"alphanum_fraction": 0.7591093182563782,
"avg_line_length": 29.875,
"blob_id": "bb27945c27d193019afb36e7c46c74e1b6106b21",
"content_id": "48760d8c1b9925f2def41a33f8ffab504916d06e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 16,
"path": "/networking/opabina_regalis_input_validation/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Opabina Regalis Input Validation\n\n## Challenge\n\nFollowing on from Opabina Regalis - Fetch Token and Opabina Regalis - \nDowngrade Attack - can you find an input validation request that would \nallow you to access otherwise protected resources?\n\n## Solution\n\nFor this I just re-used all the code from Opabina Regalis Downgrade Attack.\n\nI just had to change the URI to point to `/protected/token` instead of\n`/protected/secret`, and it was done.\n\n*Token is:* `CTF{-Why-dont-eggs-tell-jokes...Theyd-crack-each-other-up-}`\n"
},
{
"alpha_fraction": 0.6424988508224487,
"alphanum_fraction": 0.6662106513977051,
"avg_line_length": 24.5,
"blob_id": "bd72e2f414fad0138a65bb61ca189278e5a69663",
"content_id": "9f52d095a65d1f7cc885dbf7f248d508ffe9854c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2193,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 86,
"path": "/networking/opabina_regalis_downgrade_attack/exploit.py",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "from pwn import *\nimport sys\nimport struct\nimport binascii\nimport format_pb2\nimport md5\nimport re\nfrom itertools import permutations\n\ncontext(arch='x86_64', os='linux')\n\ndef m(i):\n\to = md5.new()\n\to.update(i)\n\treturn o.hexdigest()\n\ndef calc_pass(username, realm, password, method, uri, nonce, nc, cnonce, qop=\"auth\"):\n\tHA1 = m(username +\":\"+ realm +\":\"+ password)\n\tHA2 = m(method +\":\"+ uri)\n\tRESPONSE = m(HA1 +\":\"+ nonce + \":\" + nc +\":\" + cnonce + \":\" + qop + \":\" + HA2)\n\treturn RESPONSE\n\n\nconn = remote('ssl-added-and-removed-here.ctfcompetition.com', 20691, ssl=True)\n\ndef read_msg():\n\tlength = u32(conn.recv(4))\n\trequest = format_pb2.Exchange()\n\tdata = conn.recv(length)\n\trequest.ParseFromString(data)\n\tlog.info(\"< %s\" % request)\n\treturn request\n\ndef send_msg(payload):\n\tlog.warn(\"> %s\" % payload)\n\tdata = payload.SerializeToString()\n\toutput = p32(len(data)) + data\n\tconn.send(output)\n\n# Request\ni = read_msg()\nsend_msg(i)\n\n# Response (401 Unauthorized)\ni = read_msg()\nauth_header = i.reply.headers[1].value\n\nauth_header = re.search('Digest realm=\"(.*?)\",qop=\"auth\",nonce=\"(.*?)\",opaque=\"(.*?)\"', auth_header)\n\nrealm = auth_header.group(1)\nnonce = auth_header.group(2)\nopaque = auth_header.group(3)\nlog.info(\"got realm [%s] nonce [%s] opaque [%s]\" % (realm,nonce,opaque))\n\ni.reply.headers[1].value = \"Basic realm=\\\"%s\\\"\" % realm\nlog.info(\"overriding header %s\" % auth_header)\nsend_msg(i)\n\n# Request (w request info)\ni = read_msg()\n\nauth_header = i.request.headers[0].value[6:]\nauth_header = base64.b64decode(auth_header)\nlog.info(\"Got: %s\" % auth_header)\n\nupw = auth_header.split(':')\nusername = upw[0]\npassword = upw[1]\n\nlog.info(\"got username=[%s] password=[%s]\" % (username, password))\nuri = \"/protected/secret\"\nnc = \"00000001\"\ncnonce=\"0a4f113b\"\nresponse = calc_pass(username, realm, password, \"GET\", uri, nonce, nc, cnonce)\n\ni.request.uri = uri \n\nauth_header = 'Digest username=\"%s\",realm=\"%s\",nonce=\"%s\",uri=\"%s\",qop=auth,nc=%s,cnonce=\"%s\",response=\"%s\",opaque=\"%s\"' % (username,realm,nonce,uri,nc, cnonce, response,opaque)\n\nlog.info(\"overriding header %s\" % auth_header)\ni.request.headers[0].value = auth_header\nsend_msg(i)\n\n# Response (w token hopefully)\ni = read_msg()\nsend_msg(i)\n"
},
{
"alpha_fraction": 0.7694370150566101,
"alphanum_fraction": 0.7694370150566101,
"avg_line_length": 38.96428680419922,
"blob_id": "0880dcaeb0cce73caacdf2c9c809298dc8010240",
"content_id": "4c4786365d2df4632cc9325c0fd2a7c88185e34f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1119,
"license_type": "no_license",
"max_line_length": 278,
"num_lines": 28,
"path": "/networking/opabina_regalis_token_fetch/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Opabina Regalis Token Fetch\n\n## Challenge\nThere are a variety of client side machines that have access to certain websites we'd like to access. We have a system in place, called \"Opabina Regalis\" where we can intercept and modify HTTP requests on the fly. Can you implement some attacks to gain access to those websites?\n\nOpabina Regalis makes use of Protocol Buffers to send a short snippet of the HTTP request for modification.\n\n## Solution\n\nThe real challenge here is just getting protocol buffers running, and understanding how it works.\n\nI copied the protocol buffer definition provided into `format.proto`, ran:\n\n```\nprotoc -I=. --python_out=. format.proto\n```\n\nand got the definition.\n\nThen I created a simple framework, which I re-used for the next opabina regalis challenges.\n\nThe second part of the challenge is understanding what the task actually is...We're a\nMan-in-the-middle proxy between requests, and we can modify the requests however we'd like.\n\nWe simply change the `i.request.uri` from `/not-token` to `/token`, forward that to the server,\nand read the reply back.\n\n*Token is:* `CTF{WhyDidTheTomatoBlush...ItSawTheSaladDressing}`\n"
},
{
"alpha_fraction": 0.4691357910633087,
"alphanum_fraction": 0.4962962865829468,
"avg_line_length": 72.4000015258789,
"blob_id": "5e47faf2ea76b9bcb9b9313bb4e33dce4858eb39",
"content_id": "82621b6ebd64b81602639362463024d839adbde4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 5,
"path": "/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Writeups for Googles Capture The Flag (April 2016) \n \nThis repository contains write ups for the challenges that I managed to solve \nduring the [Google Capture The Flag](https://capturetheflag.withgoogle.com) \nchallenge from April 29th to May 1st 2016. \n"
},
{
"alpha_fraction": 0.7476475834846497,
"alphanum_fraction": 0.7660393714904785,
"avg_line_length": 53.372093200683594,
"blob_id": "952f73f7388272d52c025e5bed69147401c26e7b",
"content_id": "701928cc3d4e8f02060ba42693b70557e5abe448",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2338,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 43,
"path": "/networking/opabina_regalis_downgrade_attack/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Opabina Regalis Downgrade Attack\n\n## Challenge\nFollowing on from Opabina Regalis - Token Fetch, this challenge listens on ssl-added-and-removed-here.ctfcompetition.com:20691.\n\n## Solution\n\nThe client makes a request to the server to `/protected/not-secret`. We want to modify that to `/protected/secret`.\n\nWe get a reply from the server, where it gives us [HTTP Digest](https://en.wikipedia.org/wiki/Digest_access_authentication)\ninformation, and the client is expected to reply correctly to this.\n\nThe name of the challenge provides us with a hint that we need to downgrade the request, so we simply modify the reply\nfrom the server to reply with `Basic realm=\"In the realm of hackers\"` instead of the proper `Digest ...` message.\nWe then downgrade it from HTTP Digest authentication, to HTTP basic authentication.\n\nWhen we do this, we get back a message with the header: `Basic Z29vZ2xlLmN0ZjoxOTQ0MTU1NjgyLjY2NzgzNzcxNC4yMTE5MjUyMTk0`\n\nHTTP Basic authentication just uses `base64({username}:{password})` so we simply run base64 decode on the string, split\nit into the `username` and `password`, and store that for use later.\n\nThe next part is then to generate the proper message that we should send to the server to get our token. We need to\nsend this message using HTTP Digest authentication, since that's what the server expects.\n\nTo do this, we need to extract some information from the reply made earlier. From this message:\n\n```\nDigest realm=\\\"In the realm of hackers\\\",qop=\\\"auth\\\",nonce=\\\"72b8a80341ce2885\\\",opaque=\\\"72b8a80341ce2885\\\"\n```\n\nWe need to extract the `nonce` and `opaque` value. We will use this in a minute.\n\nTo generate a HTTP Digest response, we need `username`, `realm`, `password`, `method`, `uri`, `nonce`, `nc` and `cnonce`.\nSince `nc` and `cnonce` is chosen by us, they can be anything. `uri` we know to be `/protected/secret` so we\njust hardcode it to that. The rest of the variables we've obtained throughout the packets, and we're now ready\nto generate the response.\n\nWe override the request packet (the one we got earlier with Basic authentication info) to point to `/protected/secret` and\nwe generate a proper response. We then forward all of this to the server, and read the reply.\n\nThis should provide you with the token.\n\n*Token is:* `CTF{What:is:green:and:goes:to:summer:camp...A:brussel:scout}`\n"
},
{
"alpha_fraction": 0.7374749779701233,
"alphanum_fraction": 0.7515029907226562,
"avg_line_length": 37.38461685180664,
"blob_id": "4876a30705ddaa3e51f36abebca12109e0196c1f",
"content_id": "89de95a6e89a60123fb81a77d4b8af4a2538e83a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 13,
"path": "/networking/opabina_regalis_redirect/README.md",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "# Opabina Regalis - Redirect\n\n## Challenge\n\nFollowing on from Opabina Regalis - Token Fetch, can you get access to the `/protected/secret` URI?\n\n## Solution\n\nWhen we get the 401 Unauthorized reply from the server, instead of forwarding that, we modify it to a\n`302 REDIRECT`, add a `Location` header pointing to `/protected/secret`, send a few messages back\nand forth until finally we get the token.\n\n*Token is:* `CTF{Why,do,fungi,have,to,pay,double,bus,fares----because,they,take,up,7oo,Mushroom}`\n"
},
{
"alpha_fraction": 0.6712328791618347,
"alphanum_fraction": 0.6969178318977356,
"avg_line_length": 19.85714340209961,
"blob_id": "f4d432ddf9b815e31caba2ee406d5c69cee956c4",
"content_id": "300b0472675bb3d8acd4088463026b5c2a4b5542",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 28,
"path": "/networking/opabina_regalis_token_fetch/exploit.py",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "from pwn import *\nimport struct\nimport binascii\nimport format_pb2\n\ncontext(arch='x86_64', os='linux', log_level='debug')\n\nconn = remote('ssl-added-and-removed-here.ctfcompetition.com', 1876, ssl=True)\n\n\ndef read_msg():\n\tlength = u32(conn.recv(4))\n\trequest = format_pb2.Exchange()\n\tdata = conn.recv(length)\n\trequest.ParseFromString(data)\n\tlog.info(\"< %s\" % request)\n\treturn request\n\ndef send_msg(payload):\n\tlog.info(\"> %s\" % payload)\n\tdata = payload.SerializeToString()\n\toutput = p32(len(data)) + data\n\tconn.send(output)\n\ni = read_msg()\ni.request.uri = \"/token\"\nsend_msg(i)\nread_msg()\n"
},
{
"alpha_fraction": 0.6711899638175964,
"alphanum_fraction": 0.6920667886734009,
"avg_line_length": 16.740739822387695,
"blob_id": "2fe4770349e33eedbf4d2d5436f37ea7cd37ad99",
"content_id": "5d7a39e53768db2ab3411deffa3da8f8a3672a6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 958,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 54,
"path": "/networking/opabina_regalis_redirect/exploit.py",
"repo_name": "acr92/googlectf_writeups",
"src_encoding": "UTF-8",
"text": "from pwn import *\nimport sys\nimport struct\nimport binascii\nimport format_pb2\nimport md5\nimport re\n\ncontext(arch='x86_64', os='linux')\n\nconn = remote('ssl-added-and-removed-here.ctfcompetition.com', 13001, ssl=True)\n\ndef read_msg():\n\tlength = u32(conn.recv(4))\n\trequest = format_pb2.Exchange()\n\tdata = conn.recv(length)\n\trequest.ParseFromString(data)\n\tlog.info(\"< %s\" % request)\n\treturn request\n\ndef send_msg(payload):\n\tlog.info(\"> %s\" % payload)\n\tdata = payload.SerializeToString()\n\toutput = p32(len(data)) + data\n\tconn.send(output)\n\n# Request\ni = read_msg()\nsend_msg(i)\n\n# Response\ni = read_msg()\ni.reply.status = 302;\ndel i.reply.headers[:]\nlocation = i.reply.headers.add()\nlocation.key = \"Location\"\nlocation.value = \"/protected/secret\"\nsend_msg(i)\n\n# Request (w request info)\ni = read_msg()\ni.request.uri = \"/protected/secret\"\nsend_msg(i)\n\n# Response (w token hopefully)\ni = read_msg()\nsend_msg(i)\n\n\ni = read_msg()\nsend_msg(i)\n\ni = read_msg()\nsend_msg(i)\n"
}
] | 10 |
SammyPoot/ai-testing-harness
|
https://github.com/SammyPoot/ai-testing-harness
|
53a9ec6b64e190e5d10ff16085a89bf8fd08ea11
|
1ef5ed1512d043e649d8746bc44b9b7a9e156ee9
|
6fcdaed2ff59554dba83b8b2080b246968253cab
|
refs/heads/master
| 2022-02-03T02:20:49.694980 | 2019-06-25T13:25:10 | 2019-06-25T13:25:10 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3944039046764374,
"alphanum_fraction": 0.406326025724411,
"avg_line_length": 35.69643020629883,
"blob_id": "65a726a79d223614f98324c33044eec9c27994e0",
"content_id": "7a065364e05c150d5d48f57a2a75ed8b84a238b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4110,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 112,
"path": "/harness.py",
"repo_name": "SammyPoot/ai-testing-harness",
"src_encoding": "UTF-8",
"text": "import json\nfrom elasticsearch import Elasticsearch\n\nHOST = 'localhost'\nPORT = 9200\nUSER = 'user'\nSECRET = 'secret'\nSCHEME = 'https'\n\ndef make_query(input, classification_filter = false, range_km = false, lat = 50.705948, lon = -3.5091076):\n input_uc = input.upper\n classification_filter_uc = classification_filter.upper\n\n paf_filter = {'match': {'paf.buildingName': {'query': input_uc, 'fuzziness': '1'}}}\n\n nisra_filter = {'match': {'nisra.buildingName': {'query': input_uc, 'fuzziness': '1'}}}\n\n pao_filter = {\n 'match': {\n 'lpi.paoText': {\n 'query': input_uc,\n 'fuzziness': '1',\n 'minimum_should_match': '-45%'\n }\n }\n }\n\n if (classification_filter):\n classification_filter_filters = [{'terms': {'classificationCode': [classification_filter_uc]}}]\n else:\n classification_filter_filters = []\n\n if (range_km):\n geo_filters = [{'geo_distance': {'distance': range_km.to_string + 'km', 'lpi.location': [lon, lat]}}]\n else:\n geo_filters = []\n\n filters = classification_filter_filters + geo_filters\n\n welsh_split_synonyms_analyzer_outer = {\n 'query': input_uc,\n 'analyzer': 'welsh_split_synonyms_analyzer',\n 'boost': 1,\n 'minimum_should_match': '-40%',\n }\n\n input_uc_matcher = {'query': input_uc, 'boost': 0.2, 'fuzziness': '0'}\n\n query = {\n 'version': true,\n 'query': {\n 'dis_max': {\n 'tie_breaker': 1,\n 'queries': [\n {'bool': {\n 'should': [\n {'dis_max': {\n 'tie_breaker': 0,\n 'queries': [\n {'constant_score': {'filter': paf_filter, 'boost': 2.5}},\n {'constant_score': {'filter': nisra_filter, 'boost': 2.5}},\n {'constant_score': {'filter': pao_filter, 'boost': 2.5}},\n ]\n }}\n ],\n 'filter': filters,\n 'minimum_should_match': '-40%'\n }},\n {'bool': {\n 'must': [\n {'dis_max': {\n 'tie_breaker': 0,\n 'queries': [\n {'match': {'lpi.nagAll': welsh_split_synonyms_analyzer_outer}},\n {'match': {'nisra.nisraAll': welsh_split_synonyms_analyzer_outer}},\n {'match': {'paf.pafAll': welsh_split_synonyms_analyzer_outer}},\n ]\n }},\n ],\n 'should': [\n {'dis_max': {\n 'tie_breaker': 0,\n 'queries': [\n {'match': {'lpi.nagAll.bigram': input_uc_matcher}},\n {'match': {'nisra.nisraAll.bigram': input_uc_matcher}},\n {'match': {'paf.pafAll.bigram': input_uc_matcher}},\n ]\n }},\n ],\n 'filter': filters,\n 'boost': 0.075\n }},\n ]\n }\n },\n 'from': 0,\n 'size': 0,\n 'sort': [{'_score': {'order': 'desc'}}, {'uprn': {'order': 'asc'}}],\n 'track_scores': true\n }\n\n return query\n\ndef do_query(options):\n es = Elasticsearch([HOST], http_auth = (USER, SECRET), scheme = SCHEME, port = PORT)\n\n query = make_query(*options)\n print(json.dumps(query))\n results = es.search(index = 'test-index', body = query)\n print('Got %d Hits:' % results['hits']['total']['value'])\n for hit in results['hits']['hits']:\n print('%(timestamp)s %(author)s: %(text)s' % hit['_source'])\n"
},
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 20,
"blob_id": "ec57fd4666127be29c6d3995779367a6353c8eff",
"content_id": "033355597189acf39f1744085538959735f3e97e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 21,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/README.md",
"repo_name": "SammyPoot/ai-testing-harness",
"src_encoding": "UTF-8",
"text": "# ai-testing-harness\n"
}
] | 2 |
MengmengJi/Flask_demo
|
https://github.com/MengmengJi/Flask_demo
|
f5f56be02250ec1df988688822c486551a671270
|
43afef275df1b3725a66e1eecfab564cc5e9020c
|
3e2cce83e1c151fe776b031c32fcccb0a2a50d55
|
refs/heads/master
| 2021-09-05T18:10:16.910956 | 2018-01-30T05:29:40 | 2018-01-30T05:29:40 | 119,486,446 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5971351861953735,
"alphanum_fraction": 0.6401074528694153,
"avg_line_length": 30.05555534362793,
"blob_id": "24202bad54cabb4844890b5ea413e23634beb517",
"content_id": "801ef2357a3c795ff046a4d92817921f6f48371d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1279,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 36,
"path": "/demoapp.py",
"repo_name": "MengmengJi/Flask_demo",
"src_encoding": "UTF-8",
"text": "#-*-coding: utf-8-*-\nfrom flask import Flask\nfrom flask import render_template #jinja2\nfrom flask import request\nimport urllib2,urllib\n\napp = Flask(__name__)\n\n#向百度发起请求(爬虫模块)\ndef getHtml(wd,pn):\n #百度会判断是用机器还是浏览器访问的\n #添加头信息,告诉百度我使用浏览器访问的\n req = urllib2.Request('https://www.baidu.com/s?wd=%s&pn=%s' % (wd,pn))\n req.add_header('User-Agent','Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36')\n return urllib2.urlopen(req).read()\n\n#装饰器\[email protected]('/') #定义路由\ndef index():\n return render_template('index.html')\n #return render_template('demo1.html', name = 'aaa')\n #return render_template('demo1.html', names = ['qiangzi','xiaoming'])\n\[email protected]('/s')\ndef search():\n if request.method == 'GET':\n wd = request.args.get('wd')\n wd = urllib.quote(wd.encode('utf-8')) #urllib.quote只能解码utf-8,所以先编码\n pn = request.args.get('pn')\n return getHtml(wd,pn)\n else:\n return None\n \nif __name__ == '__main__':\n app.debug = True #开启调试模式\n app.run(host = '0.0.0.0', port = 5000) #所有IP可访问,指定端口8000"
}
] | 1 |
pro2s/fyTunnel
|
https://github.com/pro2s/fyTunnel
|
25e36b0243fc959d2e8529db099e9b568d36b7c9
|
64ca08a8a555985b266fadbcd5f5c0be13d1099c
|
48e1304fdb82ca680154dfcdd614ddae23b3ed0a
|
refs/heads/master
| 2021-01-21T04:50:52.581070 | 2016-07-06T16:48:56 | 2016-07-06T16:48:56 | 49,839,104 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4966000020503998,
"alphanum_fraction": 0.5001999735832214,
"avg_line_length": 34.128807067871094,
"blob_id": "f72084163f60c23d07550b49fb4c8f36ab441e4f",
"content_id": "fb2df8dbed62e04ec15859cfe3c09f1c8a0a6b75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15019,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 427,
"path": "/main.py",
"repo_name": "pro2s/fyTunnel",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport sys\nreload(sys)\nsys.setdefaultencoding(\"utf-8\")\nimport logging\nimport math\nimport codecs \nimport base64\nimport webapp2\nimport flickr_api\nimport urllib2\nimport urllib\nimport json\nimport re\nimport jinja2\nimport os\nimport datetime\nfrom flickr import FlickrAPI \nfrom webapp2_extras import sessions\nfrom google.appengine.api import urlfetch\nfrom google.appengine.api import urlfetch\nfrom google.appengine.api import memcache\nfrom google.appengine.ext import ndb\nfrom google.appengine.api import taskqueue\nfrom settings import * \n\n\nurlfetch.set_default_fetch_deadline(10)\n\n\nFYT_SLAVES = [\n'http://fyslave.appspot.com/sync/',\n'http://fyslave-1.appspot.com/sync/',\n'http://fyslave-2.appspot.com/sync/',\n'http://fyslave-3.appspot.com/sync/',\n]\n\n\nclass Settings(ndb.Model):\n name = ndb.StringProperty()\n value = ndb.StringProperty()\n \n @staticmethod\n def get(name):\n retval = Settings.get_by_id(name)\n if not retval:\n return None\n return retval.value\n \n @staticmethod\n def set(name, value):\n retval = Settings.get_by_id(name)\n if not retval:\n retval = Settings(id = name)\n retval.name = name\n retval.value = value\n retval.put()\n else:\n retval.value = value\n retval.put()\n \nclass Slave(ndb.Model):\n url = ndb.StringProperty()\n order = ndb.IntegerProperty()\n status = ndb.BooleanProperty(default = True)\n \nclass Album(ndb.Model):\n title = ndb.StringProperty()\n description = ndb.StringProperty()\n flikr_id = ndb.StringProperty()\n yaf_id = ndb.StringProperty()\n sync = ndb.BooleanProperty( default = False)\n \nclass Photo(ndb.Model):\n title = ndb.StringProperty()\n url = ndb.StringProperty()\n flikr_id = ndb.StringProperty()\n flikr_album_id = ndb.StringProperty()\n yaf_id = ndb.StringProperty()\n yaf_album_id = ndb.StringProperty()\n sync = ndb.BooleanProperty( default = False)\n\n\nJINJA_ENVIRONMENT = jinja2.Environment(\n loader=jinja2.FileSystemLoader([os.path.join(os.path.dirname(__file__),\"templates\"),],encoding='utf-8'),\n extensions=['jinja2.ext.autoescape'])\n\n\n\nMENU = [\n {\n \"id\":\"index\",\n \"name\":u\"Flickr\",\n \"url\":\"/\",\n },\n {\n \"id\":\"yaf\",\n \"name\":u\"Яндекс.фотки\",\n \"url\":\"/\",\n },\n {\n \"id\":\"trafik\",\n \"name\":u\"Трафик\",\n \"url\":\"/\",\n },\n]\n\nclass BaseHandler(webapp2.RequestHandler):\n def dispatch(self):\n # Get a session store for this request.\n self.session_store = sessions.get_store(request=self.request)\n try:\n # Dispatch the request.\n webapp2.RequestHandler.dispatch(self)\n finally:\n # Save all sessions.\n self.session_store.save_sessions(self.response)\n \n @webapp2.cached_property\n def session(self):\n # Returns a session using the default cookie key.\n return self.session_store.get_session()\n\n \nclass Clear(BaseHandler):\n def get(self):\t \n order = 0 \n for slave_url in FYT_SLAVES:\n s = Slave.get_or_insert(slave_url)\n s.url = slave_url\n s.status = True\n s.order = order\n s.put()\n order += 1\n self.response.write(\"OK\")\n\nclass Clean(BaseHandler): \n def get(self):\t \n id = self.request.get('id','')\n a = Album.get_by_id(id)\n if a is not None and not a.sync:\n ndb.delete_multi(\n Photo.query(Photo.flikr_album_id == id).fetch(keys_only=True)\n )\n self.response.write(\"OK\")\n \nclass PhotoSync(BaseHandler):\n def post(self): \n id = self.request.get('id')\n p = Photo.get_by_id(id)\n urlfetch.set_default_fetch_deadline(60)\n if p is not None:\n if not p.sync or p.yaf_id == '':\n data = \"\"\n \n result = urlfetch.fetch(p.url)\n data = result.content\n url = 'http://api-fotki.yandex.ru/api/users/protasov-s/album/'+ p.yaf_album_id +'/photos/?format=json'\n logging.info(url)\n result = urlfetch.fetch(url=url,\n payload=data,\n method=urlfetch.POST,\n headers={'Content-Length': len(data),'Content-Type': 'image/jpeg', 'Authorization':'OAuth ' + yaf_token})\n\n url = result.headers.get('Location')\n photo = json.loads(result.content)\n \n photo['title'] = p.flikr_id\n photo['summary'] = p.title\n photo_data = json.dumps(photo)\n # logging.info(photo_data)\n result = urlfetch.fetch(url=url,\n payload=photo_data,\n method=urlfetch.PUT,\n headers={'Accept': 'application/json','Content-Type': 'application/json; charset=utf-8; type=entry;', 'Authorization':'OAuth ' + yaf_token})\n if result.status_code == 200:\n p.yaf_id = photo['id']\n p.sync = True\n p.put()\n \n \n\n\nclass Sync(BaseHandler):\n def post(self):\n p_id = self.request.get('id')\n p_title = self.request.get('title')\n album_id = self.request.get('album_id')\n album_yaf = self.request.get('album_yaf').split(':')[-1]\n \n ph = Photo.get_by_id(p_id)\n if ph is None:\n f = FlickrAPI(api_key = F_API_KEY,\n api_secret= F_API_SECRET,\n oauth_token= F_TOKEN,\n oauth_token_secret= F_TOKEN_SECRET)\n \n sizes = f.get('flickr.photos.getSizes', params={'photo_id': p_id})\n if sizes['stat'] == 'ok':\n url_photo = sizes['sizes']['size'][-1]['source']\n logging.info(url_photo)\n \n ph = Photo(\n id = p_id, \n url = url_photo,\n title = p_title, \n flikr_id = p_id,\n flikr_album_id = album_id, \n yaf_id = '', \n yaf_album_id = album_yaf,\n )\n ph.put()\n if not ph.sync:\n # taskqueue.add(url='/psync/',queue_name='psync', params = {'id': p.id,})\n \n form_fields = {\n \"id\": ph.flikr_id,\n \"url\": ph.url,\n \"title\": ph.title,\n \"album_id\": ph.yaf_album_id,\n }\n form_data = urllib.urlencode(form_fields)\n slaves = Slave.query().order(Slave.order)\n slave_url = 'http://fyslave.appspot.com/sync/'\n for s in slaves:\n logging.info(s)\n if s.status: \n slave_url = s.url\n break\n logging.info(slave_url)\n result = urlfetch.fetch(url= slave_url,\n payload=form_data,\n method=urlfetch.POST,\n headers={'Content-Type': 'application/x-www-form-urlencoded'})\n \n def get(self):\t \n flickr_auth = flikr_token\n if flickr_auth is not None:\n a = flickr_api.auth.AuthHandler.fromdict(flickr_auth)\n flickr_api.set_auth_handler(a)\n u = flickr_api.test.login()\n id = self.request.get('id','')\n for item in u.getPhotosets():\n if item.id == id:\n a = Album.get_by_id(item.id)\n if a is not None and not a.sync:\n pages = (item.photos + 250) // 500\n if pages == 0: pages = 1 \n for page in range(pages):\n for p in item.getPhotos(page = page + 1):\n # p.id, p.title, album.id, album.yaf_id\n taskqueue.add(url='/sync/', params = {'id': p.id, 'title': p.title, 'album_id': item.id, 'album_yaf':a.yaf_id})\n self.response.write(a.title + '<br>')\n \n \nclass GetResult(BaseHandler):\n def post(self): \n id = self.request.get('id')\n status = self.request.get('status')\n yaf_id = self.request.get('yandex_id')\n slave_url = self.request.get('slave_url')\n logging.info(slave_url)\n if status == 'ok':\n p = Photo.get_by_id(id)\n if p is not None:\n p.yaf_id = yaf_id\n p.sync = True\n p.put()\n elif status == 'busy':\n s = Slave.get_by_id(slave_url)\n if s is not None:\n s.status = False\n s.put() \n \n \nclass GetVerifier(BaseHandler):\n def get(self):\t \n oauth_verifier = self.request.get('oauth_verifier')\n oauth_token = self.session.get('oauth_token')\n oauth_token_secret = self.session.get('oauth_token_secret')\n f = FlickrAPI(api_key=F_API_KEY,\n api_secret=F_API_SECRET,\n oauth_token=oauth_token,\n oauth_token_secret=oauth_token_secret)\n\n authorized_tokens = f.get_auth_tokens(oauth_verifier)\n\n Settings.set('F_TOKEN', authorized_tokens['oauth_token'])\n \n Settings.set('F_TOKEN_SECRET', authorized_tokens['oauth_token_secret'])\n self.redirect('/')\n \n\t\nclass MainHandler(BaseHandler):\n def get(self):\n url = ''\n ps = ''\n albums = {}\n y_albums = {}\n \n auth = False\n \n F_TOKEN = Settings.get('F_TOKEN')\n F_TOKEN_SECRET = Settings.get('F_TOKEN_SECRET')\n if F_TOKEN and F_TOKEN_SECRET:\n f = FlickrAPI(api_key = F_API_KEY,\n api_secret= F_API_SECRET,\n oauth_token= F_TOKEN,\n oauth_token_secret= F_TOKEN_SECRET)\n try:\n result = f.get('flickr.test.null')\n if result['stat'] == 'ok':\n auth = True\n except:\n auth = False\n \n if not auth:\n f = FlickrAPI(api_key=F_API_KEY,\n api_secret=F_API_SECRET,\n callback_url='http://fytunnel.appspot.com/callback/')\n #callback_url='http://localhost:10080/callback/')\n auth_props = f.get_authentication_tokens(perms = 'read')\n auth_url = auth_props['auth_url']\n\n #Store this token in a session or something for later use in the next step.\n self.session['oauth_token'] = auth_props['oauth_token']\n self.session['oauth_token_secret'] = auth_props['oauth_token_secret']\n self.redirect(auth_url)\n \n else:\n \n f = FlickrAPI(api_key = F_API_KEY,\n api_secret= F_API_SECRET,\n oauth_token= F_TOKEN,\n oauth_token_secret= F_TOKEN_SECRET)\n \n user = f.get('flickr.test.login')\n data = f.get('flickr.photosets.getList', params={'user_id': user['user']['id']})\n \n albums = {}\n if data['stat'] == 'ok':\n for item in data['photosets']['photoset']:\n id = item['id']\n albums[id] = {} \n albums[id]['id'] = id\n albums[id]['photos'] = item['photos']\n albums[id]['title'] = item['title']['_content']\n albums[id]['description'] = item['description']['_content']\n \n \n '''\n a = flickr_api.auth.AuthHandler.fromdict(flickr_auth)\n flickr_api.set_auth_handler(a)\n u = flickr_api.test.login()\n ps = u.getPhotosets()\n '''\n \n for id, item in albums.iteritems():\n a = Album.get_by_id(id)\n \n if a is None:\n a = Album(title = item['title'],description = item['description'], flikr_id = item['id'], yaf_id = '', id = id)\n a.put()\n if a.yaf_id == '':\n url = 'http://api-fotki.yandex.ru/api/users/protasov-s/albums/?format=json'\n data = json.dumps({'title':item['title'], 'summary':item['description'], 'password':item['id']})\n req = urllib2.Request(url, data, {'Accept': 'application/json','Content-Type': 'application/json; charset=utf-8; type=entry;', 'Authorization':'OAuth ' + yaf_token})\n f = urllib2.urlopen(req)\n data = json.load(f)\n a.yaf_id = data['id']\n a.put()\n f.close()\n if a.title != item['title'] or a.description != item['description']:\n a.title = item['title']\n a.description = item['description']\n \n url = 'http://api-fotki.yandex.ru/api/users/protasov-s/album/%s/?format=json' % a.yaf_id.split(':')[-1]\n result = urlfetch.fetch(url=url,headers={'Accept': 'application/json', 'Authorization':'OAuth ' + yaf_token})\n if result.status_code == 200:\n yalbum = json.loads(result.content)\n yalbum['title'] = item['title']\n yalbum['summary'] = item['description']\n \n yalbum_data = json.dumps(yalbum)\n \n result = urlfetch.fetch(url=url,\n payload=yalbum_data,\n method=urlfetch.PUT,\n headers={'Accept': 'application/json','Content-Type': 'application/json; charset=utf-8; type=entry;', 'Authorization':'OAuth ' + yaf_token})\n \n \n item['yaf_id'] = a.yaf_id\n \n url = 'http://api-fotki.yandex.ru/api/users/protasov-s/albums/published/'\n result = urlfetch.fetch(url=url, headers={'Accept': 'application/json', 'Authorization':'OAuth ' + yaf_token})\n data = json.loads(result.content)\n \n for a in data['entries']:\n y_albums[a['id']] = a\n \n template_values = {\n 'auth':auth,\n 'menu':MENU,\n 'active':'index',\n 'albums':albums,\n 'url':url,\n 'y_albums':y_albums\n }\n template = JINJA_ENVIRONMENT.get_template('index.tpl')\n html = template.render(template_values)\n self.response.write(html)\n\nconfig = {}\nconfig['webapp2_extras.sessions'] = {\n 'secret_key': 'some-secret-key',\n} \napp = webapp2.WSGIApplication([\n ('/', MainHandler),\n ('/callback/',GetVerifier),\n ('/clear/',Clear),\n ('/clean/',Clean),\n ('/sync/',Sync),\n ('/result/',GetResult),\n ('/psync/',PhotoSync),\n \n], debug=True,config=config)\n"
},
{
"alpha_fraction": 0.5384615659713745,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 19,
"blob_id": "9be38673abbb755511463263fe3c6dae2e5ec8ed",
"content_id": "ae004b5bfffe92ad7a0c8a0f779d5549da45455a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/flickr_api/flickr_keys.py",
"repo_name": "pro2s/fyTunnel",
"src_encoding": "UTF-8",
"text": "API_KEY = 'bbf62a7072bc4ed62f4a51803960b62f'\nAPI_SECRET = 'b66088c00d451317'"
},
{
"alpha_fraction": 0.5822094082832336,
"alphanum_fraction": 0.5993332266807556,
"avg_line_length": 24.287355422973633,
"blob_id": "755b0774f712e571d3b82415fdd020d80f8f1b45",
"content_id": "2d11af90977f339562dafde135ec821b26a734a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6599,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 261,
"path": "/static/js/ParseWiki.js",
"repo_name": "pro2s/fyTunnel",
"src_encoding": "UTF-8",
"text": "/*************************************************************************\n * ParseWiki.js - Copywrite (c) 2009 James Eggers\n * Released under the Common Development and Distribution License\n * For more information about the license, please visit\n * http://en.wikipedia.org/wiki/Common_Development_and_Distribution_License\n *************************************************************************/\n\n// Formatting\nvar boldPattern = /\\*(.*?)\\*/g;\nvar boldReplacement = \"<b>$1</b>\";\n\nvar italicsPattern = /__(.*?)__/g;\nvar italicsReplacement = \"<i>$1</i>\";\n\nvar underlinePattern = /\\+(.*?)\\+/g;\nvar underlineReplacement = \"<u>$1</u>\";\n\nvar heading1Pattern = /^!\\s(.*)$/;\nvar heading1Replacement = \"<h1>$1</h1>\";\n\nvar heading2Pattern = /^!{2}\\s(.*)$/;\nvar heading2Replacement = \"<h2>$1</h2>\";\n\nvar heading3Pattern = /^!{3}\\s(.*)$/;\nvar heading3Replacement = \"<h3>$1</h3>\";\n\nvar heading4Pattern = /^!{4}\\s(.*)$/;\nvar heading4Replacement = \"<h4>$1</h4>\";\n\nvar heading5Pattern = /^!{5}\\s(.*)$/;\nvar heading5Replacement = \"<h5>$1</h5>\";\n\nvar heading6Pattern = /^!{6}\\s(.*)$/;\nvar heading6Replacement = \"<h6>$1</h6>\";\n\n/// Horizontal Rule\nvar hrPattern = /^-{4}$/;\nvar hrReplacement = \"<hr />\";\n\n// Anchors/Internal Links\nvar anchorPattern = /\\[a:(.*?)\\]/;\nvar anchorReplacement = \"<a name=\\\"$1\\\"></a>\";\n\nvar goToPattern = /\\[goto:(.*?)\\|(.*?)\\]/;\nvar goToReplacement = \"<a href=\\\"#$1\\\">$2</a>\";\n\n// External Links\nvar urlPattern = /\\[url:(.*?)\\|(.*?)\\]/;\nvar urlReplacement = \"<a href=\\\"$1\\\">$2</a>\";\n\nvar lvlPattern = /\\[([1-9]|10)\\]/g;\nvar lvlReplacement = \"<img style=\\\"vertical-align: text-bottom;\\\" src=\\\"http://worldoftanks.ru/dcont/fb/news/special_pic/$1.png?MEDIA_PREFIX=/dcont/fb/\\\" alt=\\\"\\\" width=\\\"15\\\" height=\\\"15\\\">\";\n\nvar wgaPattern = /\\[wga:(.*?)\\]/g;\nvar wgaReplacement = \"<img style=\\\"vertical-align: text-bottom;\\\" src=\\\"https://worldoftanks.ru/dcont/fb/news/special_pic/$1.png\\\" alt=\\\"\\\" width=\\\"25\\\" height=\\\"25\\\">\";\n\nvar wgPattern = /\\[wg:(.*?)\\]/g;\nvar wgReplacement = \"<img style=\\\"vertical-align: text-bottom;\\\" src=\\\"http://worldoftanks.ru/dcont/fb/news/special_pic/$1.png?MEDIA_PREFIX=/dcont/fb/\\\" alt=\\\"\\\" width=\\\"15\\\" height=\\\"15\\\">\";\n\n\nvar unorderedListDepth = 0;\nvar orderedListDepth = 0;\nvar tableline = 0;\n\nfunction ParseWiki(inputData)\n{\n var output = \"\";\n var lines = inputData.split(\"\\n\");\n \n for (var i=0; i<lines.length; i++)\n {\n lines[i] = ReplaceBold(lines[i]);\n lines[i] = ReplaceItalics(lines[i]);\n lines[i] = ReplaceUnderline(lines[i]);\n lines[i] = ReplaceHeading1(lines[i]);\n lines[i] = ReplaceHeading2(lines[i]);\n lines[i] = ReplaceHeading3(lines[i]);\n lines[i] = ReplaceHeading4(lines[i]);\n lines[i] = ReplaceHeading5(lines[i]);\n lines[i] = ReplaceHeading6(lines[i]);\n lines[i] = ReplaceHorizontalRule(lines[i]);\n lines[i] = ReplaceLists(lines[i]);\n lines[i] = ReplaceTable(lines[i]);\n lines[i] = ReplaceBlankLines(lines[i]);\n lines[i] = ReplaceAnchor(lines[i]);\n lines[i] = ReplaceGoTo(lines[i]);\n lines[i] = ReplaceLink(lines[i]);\n lines[i] = ReplaceWGAction(lines[i]);\n lines[i] = ReplaceLvl(lines[i]);\n lines[i] = ReplaceWG(lines[i]);\n output += lines[i] + \"\\n\";\n } \n \n return output; \n}\n\nfunction ReplaceBold(data)\n{ \n return data.replace(boldPattern, boldReplacement);\n}\n\nfunction ReplaceItalics(data)\n{ \n return data.replace(italicsPattern, italicsReplacement);\n}\n\nfunction ReplaceUnderline(data)\n{ \n return data.replace(underlinePattern, underlineReplacement);\n}\n\nfunction ReplaceHeading1(data)\n{\n return data.replace(heading1Pattern, heading1Replacement);\n}\n\nfunction ReplaceHeading2(data)\n{\n return data.replace(heading2Pattern, heading2Replacement);\n}\n\nfunction ReplaceHeading3(data)\n{\n return data.replace(heading3Pattern, heading3Replacement);\n}\n\nfunction ReplaceHeading4(data)\n{\n return data.replace(heading4Pattern, heading4Replacement);\n}\n\nfunction ReplaceHeading5(data)\n{\n return data.replace(heading5Pattern, heading5Replacement);\n}\n\nfunction ReplaceHeading6(data)\n{\n return data.replace(heading6Pattern, heading6Replacement);\n}\n\nfunction ReplaceHorizontalRule(data)\n{\n return data.replace(hrPattern, hrReplacement);\n}\n\nfunction ReplaceAnchor(data)\n{\n return data.replace(anchorPattern, anchorReplacement);\n}\n\nfunction ReplaceGoTo(data)\n{\n return data.replace(goToPattern, goToReplacement);\n}\n\nfunction ReplaceLink(data)\n{\n return data.replace(urlPattern, urlReplacement);\n}\n\nfunction ReplaceWGAction(data)\n{\n\treturn data.replace(wgaPattern, wgaReplacement);\n}\n\nfunction ReplaceLvl(data)\n{\n return data.replace(lvlPattern, lvlReplacement);\n}\nfunction ReplaceWG(data)\n{\n return data.replace(wgPattern, wgReplacement);\n}\n\nfunction ReplaceLists(data)\n{\n var output = \"\";\n var unorderedPattern = /^\\*\\s(.*)$/;\n var orderedPattern = /^\\#\\s(.*)$/;\n \n if (unorderedListDepth > 0 && data.match(unorderedPattern) == null)\n {\n unorderedListDepth = unorderedListDepth - 1;\n output += \"</ul>\"; \n }\n \n if (orderedListDepth > 0 && data.match(orderedPattern) == null)\n {\n orderedListDepth = orderedListDepth - 1;\n output += \"</ol>\"; \n } \n \n if (unorderedListDepth == 0 && data.match(unorderedPattern) != null)\n {\n output += \"<ul>\";\n unorderedListDepth += 1;\n }\n \n if (unorderedListDepth > 0 && data.match(unorderedPattern) != null)\n {\n output = output + data.replace(unorderedPattern, \"<li>$1</li>\");\n } \n \n if (orderedListDepth == 0 && data.match(orderedPattern) != null)\n {\n output += \"<ol>\";\n orderedListDepth += 1;\n }\n \n if (orderedListDepth > 0 && data.match(orderedPattern) != null)\n {\n output = output + data.replace(orderedPattern, \"<li>$1</li>\");\n } \n \n if (output == \"</ul>\")\n {\n output += data;\n }\n \n if (output == \"</ol>\")\n {\n output += data;\n }\n \n if (output.length == 0)\n {\n output += data;\n }\n \n return output;\n}\nfunction ReplaceTable(data)\n{\n\tvar output = data;\n\tvar table = data.split(\"|\");\n\t//table.pop();\n\t//table.shift();\n\n\tif (table.length > 1) {\n\t\toutput = \"\";\n\t\tif (tableline == 0) output = \"<table>\";\n\t\ttableline++;\n\t\toutput += \"<tr>\" + table.join(\"</td><td>\") + \"</tr>\";\n\t} else if (tableline > 0) {\n\t\toutput=\"</table>\"+data;\n\t\ttableline = 0;\n\t}\n\t\n\treturn output;\n\t\n}\nfunction ReplaceBlankLines(data)\n{\n if (data.length == 0)\n {\n data = \"<br />\";\n }\n \n return data;\n}"
}
] | 3 |
theja-vanka/flask-cassandra
|
https://github.com/theja-vanka/flask-cassandra
|
a74fadf79504389910adc4532509d6b19ea848ef
|
1edfc07f24e4dfefceca28f79fc98490025d6141
|
38c44d2bc8a323046561e63f4413fcc278f145f1
|
refs/heads/master
| 2023-05-13T23:31:42.857135 | 2020-01-21T12:03:40 | 2020-01-21T12:03:40 | 235,256,541 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6821621656417847,
"alphanum_fraction": 0.6962162256240845,
"avg_line_length": 43.095237731933594,
"blob_id": "32f5ff66c0a8732cc5b021e730e5c8bc4a3a5bec",
"content_id": "6ccae300ceec62a819248288cde9ee2cf5476ac1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 21,
"path": "/helpers/cassandradb.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Dependencies for Cassandra\nfrom cassandra.cluster import Cluster, ExecutionProfile, EXEC_PROFILE_DEFAULT\nfrom cassandra.query import dict_factory\nfrom cassandra.auth import PlainTextAuthProvider\n\nclass CassandraSession:\n def __init__(self, hostip='104.211.214.233', keyspace='brand_dev'):\n self.hostip = hostip\n self.keyspace = keyspace\n self.profile = ExecutionProfile(request_timeout=6000,row_factory=dict_factory)\n self.auth_provider = PlainTextAuthProvider(username='cassandra', password='N4udsKzcujSx')\n self.cluster = Cluster(contact_points=[self.hostip],\n auth_provider=self.auth_provider,\n execution_profiles={EXEC_PROFILE_DEFAULT: self.profile})\n self.session = self.cluster.connect(self.keyspace)\n\n def __del__(self):\n self.session.shutdown()\n\n def __repr__(self):\n return f\"< Hostip : {self.hostip}, Keyspace : {self.keyspace} >\""
},
{
"alpha_fraction": 0.7368420958518982,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 35.61538314819336,
"blob_id": "af783288fd44f1cb951da671ee420ca92b3bd386",
"content_id": "f1a864869bb8e8c43e4ba8041b5ce008664195e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 13,
"path": "/models/cluster.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra Model Dependencies\nfrom cassandra.cqlengine import columns\nfrom cassandra.cqlengine.models import Model\n\n# CustomerMaster Model Class\nclass NewClusterMaster(Model):\n __table_name__ = 'new_cluster'\n __keyspace__ = 'brand_dev'\n customer_code = columns.Integer(primary_key=True)\n customer_name = columns.Text()\n latitude = columns.Double()\n longitude = columns.Double()\n customer_label = columns.Integer(primary_key=True, clustering_order=\"ASC\")"
},
{
"alpha_fraction": 0.5419103503227234,
"alphanum_fraction": 0.5916179418563843,
"avg_line_length": 37.03703689575195,
"blob_id": "5e0d82e886e9ba3e98be7e94eb697948c0a10ef9",
"content_id": "acc74e9579ebd0c6c8cfd88acf73ed142db38ae7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1026,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 27,
"path": "/helpers/haversine.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "from math import radians, cos, sin, asin, sqrt\n\nclass Haversine:\n def __init__(self, latitude1, longitude1, latitude2, longitude2):\n self.lat1 = latitude1\n self.lng1 = longitude1\n self.lat2 = latitude2\n self.lng2 = longitude2\n\n def __del__(self):\n self.lat1 = None\n self.lng1 = None\n self.lat2 = None\n self.lng2 = None\n\n def __repr__(self):\n return f\"< Latitude1 : {self.lat1}, Longitude1 : {self.lng1},Latitude2 : {self.lat2}, Longitude2 : {self.lng2} >\"\n \n def getDistance(self):\n self.lng1, self.lat1, self.lng2, self.lat2 = map(radians, [self.lng1, self.lat1, self.lng2, self.lat2])\n # haversine formula\n self.dlon = self.lng2 - self.lng1\n self.dlat = self.lat2 - self.lat1\n self.a = sin(self.dlat / 2)**2 + cos(self.lat1) * cos(self.lat2) * sin(self.dlon / 2)**2\n self.c = 2 * asin(sqrt(self.a))\n self.r = 6371 # Radius of earth in kilometers. Use 3956 for miles\n return self.c * self.r"
},
{
"alpha_fraction": 0.728205144405365,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 23.5,
"blob_id": "902906189c2ea52f3cfcdad3e702f9d5f129f567",
"content_id": "1e987b8ddb7a6475e9deab596afaa2285bfb6b56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 8,
"path": "/resources/hello.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource, reqparse\n\n# Customer Master API Scaffold\nclass HelloAPI(Resource):\n\n def get(self):\n return 'Flask up and running', 200"
},
{
"alpha_fraction": 0.6692506670951843,
"alphanum_fraction": 0.6778638958930969,
"avg_line_length": 39.068965911865234,
"blob_id": "71e161a553cd9566503c157c8d67eaba3d3315cc",
"content_id": "93be8dead3a88141b14d5dca7f281ab681effe12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1161,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 29,
"path": "/resources/cluster.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource, reqparse\nimport flask\n# Model dependencies\nfrom models.cluster import NewClusterMaster\nfrom helpers.cassandradb import CassandraSession\n\nclass NewClusterAPI(Resource):\n\n def get(self):\n # Return all clusters created by user\n result = [dict(row) for row in NewClusterMaster.objects().all()]\n return result, 200\n\nclass ClusterPropAPI(Resource):\n \n def get(self):\n data = {}\n data['clusterid'] = flask.request.args.get('clusterid')\n count = NewClusterMaster.objects().count() + 1 \n cassObj = CassandraSession()\n asyncquery = cassObj.session.execute_async('SELECT MAX(poi) FROM poi_frame ;')\n maxvalue = list(asyncquery.result())[0]['system.max(poi)']\n asyncquery = cassObj.session.execute_async('SELECT * FROM poi_frame WHERE customer_label ='+data['clusterid'])\n queryresult = list(asyncquery.result())\n returndict = {}\n returndict['probability'] = (maxvalue - queryresult[0]['poi']) / maxvalue\n returndict['customer_label'] = queryresult[0]['customer_label']\n return returndict, 200"
},
{
"alpha_fraction": 0.4710743725299835,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 19,
"blob_id": "859c330111e12031ea6780d65ab764e793dbba4a",
"content_id": "24444b1f9ceed9e815d658b766a3f361d9add97b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "cassandra-driver==3.21.0 \nFlask==1.1.1 \nFlask-Cors==3.0.8 \nFlask-JWT==0.3.2 \nFlask-RESTful==0.3.7 \ngunicorn==20.0.4 \n"
},
{
"alpha_fraction": 0.7298578023910522,
"alphanum_fraction": 0.7298578023910522,
"avg_line_length": 34.25,
"blob_id": "642dc49cba3bc39287706ca5484cdb85377b4c94",
"content_id": "9257aab24ec56db9204a4e18e8d02477879afc21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 12,
"path": "/models/items.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra Model Dependencies\nfrom cassandra.cqlengine import columns\nfrom cassandra.cqlengine.models import Model\n\n# CustomerMaster Model Class\nclass ItemMaster(Model):\n __table_name__ = 'item_master'\n __keyspace__ = 'brand_dev'\n item_code = columns.Integer(primary_key=True)\n item_name = columns.Text()\n item_label = columns.Integer(primary_key=True, clustering_order=\"ASC\")\n category = columns.Text()"
},
{
"alpha_fraction": 0.7352941036224365,
"alphanum_fraction": 0.7450980544090271,
"avg_line_length": 26.909090042114258,
"blob_id": "004cc22cb01ec8c166a28b05662cb63f83e44184",
"content_id": "730ae1f19c313da377815c4bf4542c8badd2ed9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 11,
"path": "/resources/items.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource, reqparse\nfrom models.items import ItemMaster\nimport collections\n\n# Customer Master API Scaffold\nclass ItemMasterAPI(Resource):\n\n def get(self):\n result = [dict(row) for row in ItemMaster.objects().all()]\n return result, 200"
},
{
"alpha_fraction": 0.7624258995056152,
"alphanum_fraction": 0.8144094944000244,
"avg_line_length": 46.69565200805664,
"blob_id": "15f5024ea60fdd8a128ef6de91d673ee44a46f9e",
"content_id": "3bae0dc294ec2048c2e07fe7b9f8747a2769aab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2193,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 46,
"path": "/app.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flask Dependencies\nfrom flask import Flask\nfrom flask_cors import CORS\nfrom flask_restful import Api\n\n# Controller Dependencies\nfrom resources.customer import CustomerMasterAPI\nfrom resources.customer import CustomerCreateAPI\nfrom resources.cluster import NewClusterAPI\nfrom resources.cluster import ClusterPropAPI\nfrom resources.items import ItemMasterAPI\nfrom resources.transaction import TransactionMasterPopularityAPI\nfrom resources.transaction import TransactionMasterSellerAPI\nfrom resources.hello import HelloAPI\nfrom resources.madhuram_items import ItemMadhuramMasterAPI\nfrom resources.madhuram_transaction import TransactionMadhuramMasterPopularityAPI\nfrom resources.madhuram_transaction import TransactionMadhuramMasterSellerAPI\n\n# Cassandra Session and Connection Dependencies\nfrom cassandra.cqlengine import connection\nfrom helpers.cassandradb import CassandraSession\n\n# Flask Constructors\napp = Flask(__name__)\nCORS(app)\napi = Api(app)\n\n# RESTFull End-points\napi.add_resource(HelloAPI,'/') #http://127.0.0.1:8080/\napi.add_resource(CustomerMasterAPI, '/getCustomers') #http://127.0.0.1:8080/getCustomers\napi.add_resource(CustomerCreateAPI, '/createCluster') #http://127.0.0.1:8080/createCluster\napi.add_resource(NewClusterAPI,'/getNewClusters') #http://127.0.0.1:8080/getNewClusters\napi.add_resource(ClusterPropAPI,'/getNewClusterprop') #http://127.0.0.1:8080/getNewClusterprop\napi.add_resource(ItemMasterAPI, '/getItems') #http://127.0.0.1:8080/getItems\napi.add_resource(TransactionMasterPopularityAPI, '/popularityModel') #http://127.0.0.1:8080/popularityModel\napi.add_resource(TransactionMasterSellerAPI, '/getSelling') #http://127.0.0.1:8080/getSelling\napi.add_resource(ItemMadhuramMasterAPI, '/getMadhuramItems') #http://127.0.0.1:8080/getMadhuramitems\napi.add_resource(TransactionMadhuramMasterPopularityAPI, '/popularityMadhuramModel') #http://127.0.0.1:8080/popularityMadhuramModel\napi.add_resource(TransactionMadhuramMasterSellerAPI, '/sellerMadhuramModel') #http://127.0.0.1:8080/sellerMadhuramModel\n\n\n# Main Function for app\nif __name__ == '__main__':\n cassObj = CassandraSession()\n connection.set_session(cassObj.session)\n app.run(host='0.0.0.0', debug=True)"
},
{
"alpha_fraction": 0.7121721506118774,
"alphanum_fraction": 0.7162071466445923,
"avg_line_length": 31.34782600402832,
"blob_id": "8bdd11d17815c069a6e6bf887a5f3c650f9dd3a4",
"content_id": "e253cb54b5057b2f47c99bce1172c674cf8fd3f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1487,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 46,
"path": "/scriptpoi.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Model Dependencies\nfrom models.customer import CustomerMaster\nfrom models.pointsofinterest import PointsOfInterestMaster\n\n# Cassandra Session and Connection Dependencies\nfrom cassandra.cqlengine import connection\nfrom helpers.cassandradb import CassandraSession\n\n# Cassandra Model Functions\nfrom models.poiframe import PointsOfInterestFrame\n\n# Helper functions\nimport collections\nfrom helpers.haversine import Haversine\n\ncassObj = CassandraSession()\nconnection.set_session(cassObj.session)\ncustomers = [dict(row) for row in CustomerMaster.objects().all()]\ninterest = [dict(row) for row in PointsOfInterestMaster.objects().all()]\n\ngrouped = collections.defaultdict(list)\nfor customer in customers:\n grouped[customer['customer_label']].append(customer)\nresult = []\nfor model, group in grouped.items():\n resultdict = {}\n resultdict['customer_label'] = model\n resultdict['customers'] = group\n result.append(resultdict)\n\njsondict = []\nfor cluster in result:\n temp = {}\n temp['customer_label'] = cluster['customer_label']\n temp['POI'] = 0\n for _ in cluster['customers']:\n latitude = _['latitude']\n longitude = _['longitude']\n for _2 in interest:\n dist = Haversine(latitude,longitude,_2['latitude'],_2['longitude']).getDistance()\n if dist <= 1:\n temp['POI'] += 1\n jsondict.append(temp)\n\nfor son in jsondict:\n result = PointsOfInterestFrame.create(customer_label=son['customer_label'], poi=son['POI'])"
},
{
"alpha_fraction": 0.7449856996536255,
"alphanum_fraction": 0.7449856996536255,
"avg_line_length": 33.5,
"blob_id": "73fb5e8003e308422729420e57156624b89f5c16",
"content_id": "714254240486c506ca68ae145ac231d81793f801",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 10,
"path": "/models/poiframe.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra Model Dependencies\nfrom cassandra.cqlengine import columns\nfrom cassandra.cqlengine.models import Model\n\n# CustomerMaster Model Class\nclass PointsOfInterestFrame(Model):\n __table_name__ = 'poi_frame'\n __keyspace__ = 'brand_dev'\n customer_label = columns.Integer(primary_key=True)\n poi = columns.Integer(primary_key=True)\n "
},
{
"alpha_fraction": 0.6423029899597168,
"alphanum_fraction": 0.6488362550735474,
"avg_line_length": 47.9900016784668,
"blob_id": "925399f9dee659fd97abc77c3fac55bfba1aecc3",
"content_id": "58ce787ab895604338a4f960b6321c93d7a72e43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4898,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 100,
"path": "/resources/madhuram_transaction.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource, reqparse\nimport flask\n\n# Model dependencies\nfrom models.madhuram_transaction import TransactionMadhuramMaster\nfrom models.items import ItemMaster\nfrom models.customer import CustomerMaster\n\n# For Aggregate / Helper Functions\nfrom helpers.cassandradb import CassandraSession\nfrom collections import Counter, defaultdict\nimport math\n\n# Customer Master API Scaffold\nclass TransactionMadhuramMasterPopularityAPI(Resource):\n\n def get(self):\n # To force a required parameter\n data = {}\n data['clusterid'] = flask.request.args.get('clusterid')\n # Async query started\n cassObj = CassandraSession()\n asyncquery = cassObj.session.execute_async(\"SELECT groupbyandsum(item_code, quantity) from transaction_madhuram_master\")\n # Get all customers in that cluster id\n customers = [dict(row) for row in CustomerMaster.objects.filter(customer_label=data['clusterid']).allow_filtering().all()]\n # Create list of items to be removed from query\n removeitemlist = []\n for customer in customers:\n for request in [dict(row)for row in TransactionMadhuramMaster.objects.distinct(['item_code','customer_code']).filter(customer_code=customer['customer_code']).allow_filtering().all()]:\n removeitemlist.append(request['item_code'])\n\n itemTransaction = dict(list(asyncquery.result())[0]['brand_dev.groupbyandsum(item_code, quantity)'])\n asyncquery1 = cassObj.session.execute_async('SELECT MAX(poi) FROM poi_frame ;')\n asyncquery2 = cassObj.session.execute_async('SELECT * FROM poi_frame WHERE customer_label ='+data['clusterid'])\n maxvalue = list(asyncquery1.result())[0]['system.max(poi)']\n queryresult = list(asyncquery2.result())\n currentPOI = queryresult[0]['poi']/maxvalue\n [itemTransaction.pop(key) for key in removeitemlist if key in itemTransaction]\n topItems = Counter(itemTransaction)\n topItems = topItems.most_common(20) \n result = []\n for i in topItems:\n _ = {}\n _temp = [dict(row) for row in ItemMaster.objects.filter(item_code=i[0]).all().allow_filtering()]\n _['item_name'] = _temp[0]['item_name']\n _['quantity'] = (i[1] * currentPOI) / 1200\n result.append(_)\n return result, 200\n\nclass TransactionMadhuramMasterSellerAPI(Resource):\n def get(self):\n # To force a required parameter\n data = {}\n data['clusterid'] = flask.request.args.get('clusterid')\n # Async query started\n cassObj = CassandraSession()\n asyncquery = cassObj.session.execute_async(\"SELECT groupbyandsum(item_code, quantity) from transaction_madhuram_master\")\n # Get all customers in that cluster id\n customers = [dict(row) for row in CustomerMaster.objects.filter(customer_label=data['clusterid']).allow_filtering().all()]\n # Create list of items to be removed from query\n sellingitemlist = []\n for customer in customers:\n for request in [dict(row)for row in TransactionMadhuramMaster.objects.distinct(['item_code','customer_code']).filter(customer_code=customer['customer_code']).allow_filtering().all()]:\n sellingitemlist.append(request['item_code'])\n itemTransaction = dict(list(asyncquery.result())[0]['brand_dev.groupbyandsum(item_code, quantity)'])\n items = {item: itemTransaction[item] for item in sellingitemlist}\n queryresult = []\n for k, v in items.items():\n _ = {}\n _temp = [dict(row) for row in ItemMaster.objects.filter(item_code=k).all().allow_filtering()]\n print(_temp)\n _temp2 = [dict(row) for row in TransactionMadhuramMaster.objects.filter(item_code=k).all().allow_filtering()]\n _['item_name'] = _temp[0]['item_name']\n _['category'] = _temp[0]['category']\n _['logquantity'] = math.log1p(v)\n _['quantity'] = v\n _['unitprice'] = round(_temp2[0]['item_rate'])\n queryresult.append(_)\n \n grouped = defaultdict(list)\n for item in queryresult:\n grouped[item['category']].append(item)\n result = []\n for model, group in grouped.items():\n resultdict = {}\n resultdict['category'] = model\n resultdict['items'] = group\n result.append(resultdict)\n return result, 200 \n\nclass TransactionMadhuramMasterCollaboratorAPI(Resource):\n def get(self):\n # To force a required parameter\n data = {}\n data['clusterid'] = flask.request.args.get('clusterid')\n # Async query started\n cassObj = CassandraSession()\n asyncquery = cassObj.session.execute_async(\"SELECT groupbyandsum(item_code, quantity) from transaction_master\")\n return \"Success\", 200"
},
{
"alpha_fraction": 0.6485879421234131,
"alphanum_fraction": 0.6575738191604614,
"avg_line_length": 43.52857208251953,
"blob_id": "2176872026dd3306a097f8872dbee0cd9c7ac4cd",
"content_id": "d7cffcb1132e213e0367db2f6d670034240e6c4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3116,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 70,
"path": "/resources/customer.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource\nimport flask\n\n# Model dependencies\nfrom models.customer import CustomerMaster\nfrom models.cluster import NewClusterMaster\nfrom models.pointsofinterest import PointsOfInterestMaster\nfrom models.poiframe import PointsOfInterestFrame\n\n# Helper Functions\nfrom helpers.cassandradb import CassandraSession\nfrom helpers.haversine import Haversine\nimport collections\nimport random\nimport string\n\n# Customer Master API Scaffold\nclass CustomerMasterAPI(Resource):\n\n def get(self):\n queryresult = [dict(row) for row in CustomerMaster.objects().all()]\n grouped = collections.defaultdict(list)\n for item in queryresult:\n grouped[item['customer_label']].append(item)\n result = []\n for model, group in grouped.items():\n resultdict = {}\n resultdict['customer_label'] = model\n resultdict['customers'] = group\n result.append(resultdict)\n return result, 200\n\nclass CustomerCreateAPI(Resource):\n\n def post(self):\n \n data = {}\n data['latitude'] = float(flask.request.form.get('latitude'))\n data['longitude'] = float(flask.request.form.get('longitude'))\n globalcount = 0\n queryresult = [dict(row) for row in PointsOfInterestMaster.objects().all()]\n for res in queryresult:\n haverdist = Haversine(res['latitude'], res['longitude'], data['latitude'], data['longitude']).getDistance()\n if haverdist < 1.0:\n globalcount += 1\n queryresult = [dict(row) for row in CustomerMaster.objects().all()]\n distmin = 999\n for res in queryresult:\n haverdist = Haversine(res['latitude'], res['longitude'], data['latitude'], data['longitude']).getDistance()\n if haverdist < distmin:\n distmin = haverdist\n if distmin <= 0.1:\n return \"Failure\", 400\n queryresult = [dict(row) for row in NewClusterMaster.objects().all()]\n for res in queryresult:\n haverdist = Haversine(res['latitude'], res['longitude'], data['latitude'], data['longitude']).getDistance()\n if haverdist < distmin:\n distmin = haverdist\n if distmin <= 0.1:\n return \"Failure\", 400\n count = NewClusterMaster.objects().count() + 1 \n cassObj = CassandraSession()\n asyncquery = cassObj.session.execute_async(\"SELECT MAX(customer_label) from customer_master ;\")\n inputlabel = list(asyncquery.result())[0]['system.max(customer_label)'] + count\n asyncquery = cassObj.session.execute_async(\"SELECT MAX(customer_code) from customer_master ;\")\n inputcode = list(asyncquery.result())[0]['system.max(customer_code)'] + count\n result = PointsOfInterestFrame.create(customer_label=inputlabel, poi=globalcount)\n result = NewClusterMaster.create(customer_label=inputlabel, customer_code=inputcode, customer_name=random.choice(string.ascii_letters[0:4]), latitude=data['latitude'], longitude=data['longitude'])\n return dict(result),200"
},
{
"alpha_fraction": 0.7397769689559937,
"alphanum_fraction": 0.7397769689559937,
"avg_line_length": 37.5,
"blob_id": "732083b274d3ecf04adab75146e41bb62d23b8a5",
"content_id": "710737dfeff588fb1ab2dbc7b091a77a05fa75e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 14,
"path": "/models/madhuram_transaction.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra Model Dependencies\nfrom cassandra.cqlengine import columns\nfrom cassandra.cqlengine.models import Model\n\n# CustomerMaster Model Class\nclass TransactionMadhuramMaster(Model):\n __table_name__ = 'transaction_madhuram_master'\n __keyspace__ = 'brand_dev'\n customer_code = columns.Integer(primary_key=True)\n item_code = columns.Integer(primary_key=True)\n item_name = columns.Text()\n item_rate = columns.Double()\n quantity = columns.Double(primary_key=True, clustering_order=\"DESC\")\n amount = columns.Double()"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 41.75,
"blob_id": "be7fd76b914cf1777100f1bd6b8f0daa1eb56ba8",
"content_id": "ff72671c70946e05a92b05f51bb5537b8446553b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 512,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 12,
"path": "/models/pointsofinterest.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra Model Dependencies\nfrom cassandra.cqlengine import columns\nfrom cassandra.cqlengine.models import Model\n\n# CustomerMaster Model Class\nclass PointsOfInterestMaster(Model):\n __table_name__ = 'points_of_interest'\n __keyspace__ = 'brand_dev'\n category = columns.Text(primary_key=True)\n latitude = columns.Double(primary_key=True, clustering_order=\"ASC\")\n longitude = columns.Double(primary_key=True, clustering_order=\"ASC\")\n name = columns.Text(primary_key=True, clustering_order=\"ASC\")"
},
{
"alpha_fraction": 0.7581120729446411,
"alphanum_fraction": 0.7669616341590881,
"avg_line_length": 29.909090042114258,
"blob_id": "f94d1d0557d9daa0ab039b021b1e7cf8cb9cf7e2",
"content_id": "43109cd27139d802dc3fb7ee538af9f3d402eb88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/resources/madhuram_items.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Flast RESTFull Dependencies\nfrom flask_restful import Resource, reqparse\nfrom models.madhuram_items import ItemMadhuramMaster\nimport collections\n\n# Customer Master API Scaffold\nclass ItemMadhuramMasterAPI(Resource):\n\n def get(self):\n result = [dict(row) for row in ItemMadhuramMaster.objects().all()]\n return result, 200"
},
{
"alpha_fraction": 0.859350860118866,
"alphanum_fraction": 0.859350860118866,
"avg_line_length": 28.454545974731445,
"blob_id": "6bbc0a72497f90262afe9275e2e33a7484030c4f",
"content_id": "b8e2952809f47a37830b084927a1545aa283819f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 22,
"path": "/scripts/sync.py",
"repo_name": "theja-vanka/flask-cassandra",
"src_encoding": "UTF-8",
"text": "# Cassandra dependencies\nfrom cassandra.cqlengine.management import sync_table\nfrom cassandra.cqlengine import connection\nfrom cassandra.auth import PlainTextAuthProvider\n\n# Cassandra Helpers\nfrom helpers.cassandradb import CassandraSession\n\n# Cassandra Data Models\nfrom models.customer import CustomerMaster\nfrom models.cluster import NewClusterMaster\nfrom models.items import ItemMaster\nfrom models.transaction import TransactionMaster\n\n# Session/connection creation\ncassObj = CassandraSession()\nconnection.set_session(cassObj.session)\n\nsync_table(CustomerMaster)\nsync_table(NewClusterMaster)\nsync_table(ItemMaster)\nsync_table(TransactionMaster)"
}
] | 17 |
kategomezny/IS211_Assignment4
|
https://github.com/kategomezny/IS211_Assignment4
|
4eb0b832a1a4fc3d6cfd92cebc1b4e04b91ad0ce
|
46e13b6cf862b121f225ce28082e4a2ce9fa1022
|
6d0413fd7d1c21770edf9a640f192f8b75254035
|
refs/heads/master
| 2020-03-30T08:20:18.042963 | 2018-09-30T21:17:46 | 2018-09-30T21:17:46 | 151,007,200 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5527927875518799,
"alphanum_fraction": 0.5787387490272522,
"avg_line_length": 34.126583099365234,
"blob_id": "ee2aba60fac5714a9d4c20db637f9f0fa540b5c6",
"content_id": "d5579588116a705e8fa53e15e4db3625c662c0e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2775,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 79,
"path": "/sort_compare.py",
"repo_name": "kategomezny/IS211_Assignment4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Sorting Algorithm Comparison\"\"\"\n\nimport timeit\nimport random\n\n\ndef creating_lists(list_lenght):\n \"\"\"Creates all the lists\"\"\" \n list=[]\n for i in range (list_lenght):\n list.append(random.randrange(0, 10000))\n return list\n \n\ndef insertion_sort(a_list):\n \"\"\"Sorting the list using the insertion sort method\"\"\"\n start = timeit.timeit()\n for index in range(1, len(a_list)):\n current_value = a_list[index]\n position = index\n while position > 0 and a_list[position - 1] > current_value:\n a_list[position] = a_list[position - 1]\n position = position - 1\n a_list[position] = current_value\n \n \n end = timeit.timeit()\n \n return a_list, end-start\n \n \ndef shell_sort(a_list):\n \"\"\"Sorting the list using the shell sort method\"\"\"\n start = timeit.timeit()\n sublist_count = len(a_list) // 2\n while sublist_count > 0:\n for start_position in range(sublist_count):\n gap_insertion_sort(a_list, start_position, sublist_count) \n \n sublist_count = sublist_count // 2\n end = timeit.timeit()\n return a_list, end-start\n \n\ndef gap_insertion_sort(a_list, start, gap):\n \"\"\"Defines the increments to be used in the shell sort\"\"\"\n for i in range(start + gap, len(a_list), gap):\n current_value = a_list[i]\n position = i\n while position >= gap and a_list[position - gap] >current_value:\n a_list[position] = a_list[position - gap]\n position = position - gap\n \n a_list[position] = current_value\n \n \ndef python_sort(a_list):\n \"\"\"calls sort() on the input list\"\"\"\n start = timeit.timeit()\n new_list = a_list.sort()\n end = timeit.timeit()\n return new_list, end-start\n \n\nif __name__ == \"__main__\": \n print (\"Time for a list of 500 items is: \" )\n print (\" insertion sort = \" + str(insertion_sort(creating_lists(500))[1]))\n print (\" shell sort = \" + str(shell_sort(creating_lists(500))[1]))\n print (\" python sort = \" + str(python_sort(creating_lists(500))[1]))\n print (\"Time for a list of 1,000 items is: \" )\n print (\" insertion sort = \" + str(insertion_sort(creating_lists(1000))[1]))\n print (\" shell sort = \" + str(shell_sort(creating_lists(1000))[1]))\n print (\" python sort = \" + str(python_sort(creating_lists(1000))[1]))\n print (\"Time for a list of 10,000 items is: \" )\n print (\" insertion sort = \" + str(insertion_sort(creating_lists(10000))[1]))\n print (\" shell sort = \" + str(shell_sort(creating_lists(10000))[1]))\n print (\" python sort = \" + str(python_sort(creating_lists(10000))[1]))\n"
},
{
"alpha_fraction": 0.5567081570625305,
"alphanum_fraction": 0.5880590081214905,
"avg_line_length": 32.114501953125,
"blob_id": "ec223bc2d17f2f06e211e8a94df32b23c32693d6",
"content_id": "a803d6bf22023d0a2092e0598b8055002e6be0e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4338,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 131,
"path": "/search_compare.py",
"repo_name": "kategomezny/IS211_Assignment4",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Search Algorithm Comparison\"\"\"\n\n\nimport random\nimport timeit\n\n\ndef main():\n \"\"\"prints how long each function takes, on average\"\"\" \n search_averages=creating_lists(500,100)\n print (\"----results for 100 lists of 500 items----\")\n print (\"Sequential Search took %10.7f seconds to run, on average\" % (search_averages[0]) )\n print (\"ordered sequential search took %10.7f seconds to run, on average\" % (search_averages[1]) )\n print (\"binary search iterative took %10.7f seconds to run, on average\" % (search_averages[2]) )\n print (\"binary search recursive took %10.7f seconds to run, on average\" % (search_averages[3]) )\n search_averages=creating_lists(1000,100)\n print (\"----results for 100 lists of 1,000 items----\")\n print (\"Sequential Search took %10.7f seconds to run, on average\" % (search_averages[0]) )\n print (\"ordered sequential search took %10.7f seconds to run, on average\" % (search_averages[1]) )\n print (\"binary search iterative took %10.7f seconds to run, on average\" % (search_averages[2]) )\n print (\"binary search recursive took %10.7f seconds to run, on average\" % (search_averages[3]) )\n search_averages=creating_lists(10000,100)\n print (\"----results for 100 lists of 10,000 items----\")\n print (\"Sequential Search took %10.7f seconds to run, on average\" % (search_averages[0]) )\n print (\"ordered sequential search took %10.7f seconds to run, on average\" % (search_averages[1]) )\n print (\"binary search iterative took %10.7f seconds to run, on average\" % (search_averages[2]) )\n print (\"binary search recursive took %10.7f seconds to run, on average\" % (search_averages[3]) )\n \ndef creating_lists(list_lenght,total_lists):\n \"\"\"Creates all the lists\"\"\"\n sum_time1 = 0\n sum_time2 = 0\n sum_time3 = 0\n sum_time4 = 0\n for i in range(total_lists): \n lists=[]\n for i in range (list_lenght):\n lists.append(random.randrange(0, 10000))\n \n sum_time1 =+ sequential_search(lists,-1)[1]\n sum_time2 =+ ordered_sequential_search(lists,-1)[1]\n lists.sort()\n sum_time3 =+ binary_search_iterative(lists,-1)[1]\n start = timeit.timeit()\n recursive_results=binary_search_recursive(lists,-1)\n end = timeit.timeit()\n sum_time4 =+ (end-start)\n \n return sum_time1/total_lists, sum_time2/total_lists, sum_time3/total_lists, sum_time4/total_lists\n\n \n#SEQUENTIAL_SEARCH sum_time1\ndef sequential_search(a_list, item):\n start = timeit.timeit()\n pos = 0\n found = False\n \n while pos < len(a_list) and not found:\n if a_list[pos] == item:\n found = True\n else:\n pos = pos+1\n \n end = timeit.timeit()\n \n \n return found, end-start\n\n\n#ORDERED SEQUENTIAL SEARCH sum_time2\ndef ordered_sequential_search(a_list,item):\n start = timeit.timeit()\n pos = 0\n found = False\n stop = False\n \n while pos < len(a_list) and not found and not stop:\n if a_list[pos] == item:\n found = True\n else: \n if a_list[pos] > item:\n stop = True\n else:\n pos = pos+1\n end = timeit.timeit()\n \n \n return found, end-start\n \n\n#BINARY SEARCH ITERATIVE sum_time3\ndef binary_search_iterative(a_list, item):\n start = timeit.timeit()\n first = 0\n last = len(a_list) - 1\n found = False\n \n while first <= last and not found:\n midpoint = (first + last) // 2\n if a_list[midpoint] == item:\n found = True\n elif item < a_list[midpoint]:\n last = midpoint - 1\n else:\n first = midpoint + 1\n \n end = timeit.timeit()\n \n \n return found, end-start\n\n\n#BINARY SEARCH RECURSIVE sum_time4\ndef binary_search_recursive(a_list, item):\n if len(a_list) == 0:\n return False\n else:\n midpoint = len(a_list) // 2\n if a_list[midpoint] == item:\n return True\n else:\n if item < a_list[midpoint]:\n return binary_search_recursive(a_list[:midpoint], item)\n else:\n return binary_search_recursive(a_list[midpoint + 1:], item)\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 2 |
NoelleTemple/yaw_control
|
https://github.com/NoelleTemple/yaw_control
|
07cd80dadefb44d2894c225893057dbbfc68b81f
|
b539a1017bf29b35316ad97b07a079d022b19f3f
|
6cd4d4060192ddb8d930d72a24db3778030bdc93
|
refs/heads/master
| 2020-08-03T11:28:19.532710 | 2019-09-30T21:18:27 | 2019-09-30T21:18:27 | 211,736,254 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6696637868881226,
"alphanum_fraction": 0.7001563906669617,
"avg_line_length": 29.452381134033203,
"blob_id": "26fef48c85a2ba3d08ab4c06e46ead4a89a719f0",
"content_id": "31b75ae1ac359c6e4bb8b2bf14a99241d5e7fe3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2558,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 84,
"path": "/yawcntl.py",
"repo_name": "NoelleTemple/yaw_control",
"src_encoding": "UTF-8",
"text": "import logging\nimport sys\nimport time\nimport RPi.GPIO as GPIO\nfrom servocntl_pkg import servo\nfrom Adafruit_BNO055 import BNO055\n\nsu=servo(description=\"change to desired heading\", boardpin = 35, frequency = 50)\nsu.setup()\n\nbno = BNO055.BNO055(address=0x29)\n\nif len(sys.argv) == 2 and sys.argv[1].lower() == '-v':\n\tlogging.basicConfig(level=logging.DEBUG)\n\nif not bno.begin():\n\traise RuntimeError('Failed to initialize BNO055! Is the sensor connected?')\n\nstatus, self_test, error = bno.get_system_status()\nprint('System status: {0}'.format(status))\nprint('Self test result (0x0F is normal): 0x{0:02X}'.format(self_test))\n\nif status == 0x01:\n\tprint('System error: {0}'.format(error))\n\tprint('See datasheet section 4.3.59 for the meaning.')\nprint('Reading BNO055 Heading. Press Cntl-C to quit...')\np=GPIO.PWM(su.boardpin, su.frequency)\np.start(0.5)\n\n#original heading\nog_heading, roll, pitch = bno.read_euler()\n#where do you want to go?\ndegrees = 60\n#clockwise if true, counter clockwise if false\ncw = true\n\nwhile True:\n\tGPIO.setwarnings(False)\n\theading, roll, pitch = bno.read_euler()\n\tsys, gyro, accel, mag = bno.get_calibration_status()\n\tprint('Heading = {0:0.2F}'.format(heading))\n\tif cw == true:\n\t\t#set servo all the way to the left\n\t\tdc = 2.5\n\t\tnew_heading = og_heading + degrees\n\t\tif new_heading > 360:\n\t\t\tdes_heading = new_heading-360\n\t\telse:\n\t\t\tdes_heading = new_heading\n\t\tx = True\n\t\twhile x == True:\n\t\t\tp.ChangeDutyCycle(dc)\n\t\t\ttime.sleep(0.25)\n\t\t\theading, roll, pitch = bno.read_euler()\n\t\t\tif heading < des_heading+5 && heading > des_heading-5:\n\t\t\t\tx=False\n\t\t\telse:\n\t\t\t\tdc=dc+1\n\t\t\t#need an exception if it doesn't catch it (when does it just pass,\n\t\t\t#could change step size and go back instead of looking for certain point\n\t\t\t#what happens if it just never reads where it's in those bounds?\n\t\tprint('duty cycle: {}'.format(dc))\n\telse:\n\t\tdc = 12.5\n\t\tnew_heading = og_heading-degress\n\t\tif new_heading < 0:\n\t\t\tdes_heading = new_heading + 360\n\t\telse:\n\t\t\tdes_heading = new_heading\n\t\tx = True\n\t\twhile x == True:\n\t\t\tp.ChangeDutyCycle(dc)\n\t\t\ttime.sleep(0.25)\n\t\t\theading, roll, pitch = bno.read_euler()\n\t\t\tif heading < des_heading+5 && heading > des_heading-5:\n\t\t\t\tx = False\n\t\t\telse:\n\t\t\t\tdc = dc-1\n\t\t\t#need that exception from earlier here.\nGPIO.cleanup()\n\n#also need an exception to address if des_heading is out of servo range (preferably without \n#moving the servos to the edges to find them-servo will go to one end, calculate other end with that value?\n#will be an approximation so give 10 degree buffer zone? (not the most accurate detection method)\n"
},
{
"alpha_fraction": 0.6754850149154663,
"alphanum_fraction": 0.7186948657035828,
"avg_line_length": 27.350000381469727,
"blob_id": "0950ad4372fc9c6de0c7d1e4fc54acc42678a3bb",
"content_id": "36e0259cb696c37c7112e12eb067da7ccb6e8efa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 40,
"path": "/heading_range.py",
"repo_name": "NoelleTemple/yaw_control",
"src_encoding": "UTF-8",
"text": "import logging\nimport sys\nimport time\nimport RPi.GPIO as GPIO\nfrom servocntl_pkg import servo\nfrom Adafruit_BNO055 import BNO055\n\nsu=servo(description=\"change to desired heading\", boardpin = 35, frequency = 50)\nsu.setup()\n\nbno = BNO055.BNO055(address=0x29)\n\nif len(sys.argv) == 2 and sys.argv[1].lower() == '-v':\n\tlogging.basicConfig(level=logging.DEBUG)\n\nif not bno.begin():\n\traise RuntimeError('Failed to initialize BNO055! Is the sensor connected?')\n\nstatus, self_test, error = bno.get_system_status()\nprint('System status: {0}'.format(status))\nprint('Self test result (0x0F is normal): 0x{0:02X}'.format(self_test))\n\nif status == 0x01:\n\tprint('System error: {0}'.format(error))\n\tprint('See datasheet section 4.3.59 for the meaning.')\nprint('Reading BNO055 Heading. Press Cntl-C to quit...')\np=GPIO.PWM(su.boardpin, su.frequency)\np.start(0)\ncnt=0\nwhile True:\n\tGPIO.setwarnings(False)\n\theading, roll, pitch = bno.read_euler()\n\tsys, gyro, accel, mag = bno.get_calibration_status()\n\tprint('Heading = {0:0.2F}'.format(heading))\n\tcnt=cnt+1\n\tp.ChangeDutyCycle(cnt)\n\tprint('Duty Cycle = {}'.format(cnt)) \n\ttime.sleep(1)\n\nGPIO.cleanup()\n"
},
{
"alpha_fraction": 0.46125155687332153,
"alphanum_fraction": 0.4948197305202484,
"avg_line_length": 30.608108520507812,
"blob_id": "2a0d7c79f9e9d3ecc12f4557cb322865fa7360d8",
"content_id": "7520094fda400f65d71389c4271d05d749ff9230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2413,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 74,
"path": "/controlServo.py",
"repo_name": "NoelleTemple/yaw_control",
"src_encoding": "UTF-8",
"text": "from servo_pi.servo import Servo\r\nfrom Adafruit_BNO055 import BNO055\r\nimport time\r\nimport sys\r\n\r\n\r\ndef main(argv):\r\n head_goal = float(argv[0])\r\n\r\n servo = Servo(35)\r\n\r\n bno = BNO055.BNO055(address=0x29)\r\n\r\n if not bno.begin():\r\n raise RuntimeError('Failed to initialize BNO055! Is the sensor connected?')\r\n\r\n status, self_test, error = bno.get_system_status()\r\n print('System status: {0}'.format(status))\r\n print('Self test result (0x0F is normal): 0x{0:02X}'.format(self_test))\r\n\r\n if status == 0x01:\r\n print('System error: {0}'.format(error))\r\n print('See datasheet section 4.3.59 for the meaning.')\r\n print('Reading BNO055 Heading. Press Cntl-C to quit...')\r\n\r\n pos = 90\r\n servo.set_position(pos)\r\n\r\n while True:\r\n cur_heading, _, _ = bno.read_euler()\r\n minval = abs((cur_heading - pos) % 360)\r\n maxval = abs((cur_heading + (180 - pos)) % 360)\r\n\r\n if minval < maxval:\r\n mode = 0x00\r\n else:\r\n mode = 0x01\r\n\r\n if ((cur_heading - 15) < head_goal) & ((cur_heading + 15) > head_goal):\r\n pos = pos\r\n print(\"goal achieved\")\r\n elif mode == 0x00:\r\n if head_goal > maxval or head_goal < minval:\r\n print(\"goal is out of range\")\r\n elif head_goal < cur_heading:\r\n pos -= 10\r\n elif head_goal > cur_heading:\r\n pos += 10\r\n else:\r\n if (head_goal > maxval) and (head_goal < minval):\r\n print(\"goal is out of range\")\r\n elif (head_goal < maxval) & (cur_heading < maxval):\r\n if (head_goal < cur_heading):\r\n pos -= 10\r\n elif (head_goal > cur_heading):\r\n pos += 10\r\n elif (head_goal > minval) & (cur_heading > minval):\r\n if (head_goal < cur_heading):\r\n pos -= 10\r\n elif (head_goal > cur_heading):\r\n pos += 10\r\n elif (head_goal < maxval) & (cur_heading > maxval):\r\n pos += 10\r\n elif (head_goal > minval) & (cur_heading < minval):\r\n pos -= 10\r\n else:\r\n\t\tpass\r\n\r\n servo.set_position(pos)\r\n time.sleep(.1)\r\n print(\"heading: {} head_goal: {}\".format(cur_heading, head_goal))\r\n\r\nif __name__ == \"__main__\":\r\n main(sys.argv[1:])\r\n"
}
] | 3 |
Ri-tik/SearchAnalysis
|
https://github.com/Ri-tik/SearchAnalysis
|
a309a5d9ad44f89b343bcd34859bd092c1ff821b
|
1c82e46cc78ade7fb711fade8638e592ae87bc0b
|
2938b238b54b674b682811c51a37a284b4e41422
|
refs/heads/main
| 2023-08-30T02:44:25.304641 | 2021-11-15T23:05:43 | 2021-11-15T23:05:43 | 393,941,389 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7816455960273743,
"alphanum_fraction": 0.7816455960273743,
"avg_line_length": 26.521739959716797,
"blob_id": "c23f50794a67ea94466b9bc531a47644410fbcd7",
"content_id": "8b737913442d38d34f3a2971caf96abdfe1da325",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 632,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 23,
"path": "/SearchAnalysis/Server/server.py",
"repo_name": "Ri-tik/SearchAnalysis",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template\n\nfrom SearchAnalysis.SearchAnalysis.spiders.CourseSearch import CourseSearchSpider\nfrom SearchAnalysis.SearchAnalysis.spiders.GoogleSearch import GooglesearchSpider\napp = Flask(__name__)\n\nimport scrapy,csv\nimport pip._vendor.requests as request\nfrom scrapy.http import TextResponse\nfrom scrapy.linkextractors import LinkExtractor\nimport SearchAnalysis.SearchAnalysis.items as SI\n\n\[email protected]('/')\ndef index():\n return render_template('index.html')\n\[email protected]('/my-link/')\ndef run(butn):\n if butn == \"Course\":\n return CourseSearchSpider\n else:\n return GooglesearchSpider"
},
{
"alpha_fraction": 0.7146596908569336,
"alphanum_fraction": 0.7146596908569336,
"avg_line_length": 27.296297073364258,
"blob_id": "c8f855f0e5f54be0a880a9edbb65cbdc2912a319",
"content_id": "7ef71c8a21d20952b0f4b38e296afe1ae639341e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 27,
"path": "/SearchAnalysis/SearchAnalysis/items.py",
"repo_name": "Ri-tik/SearchAnalysis",
"src_encoding": "UTF-8",
"text": "# Define here the models for your scraped items\n#\n# See documentation in:\n# https://docs.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass SearchanalysisItem(scrapy.Item):\n # define the fields for your item here like:\n # name = scrapy.Field()\n imdbRate=scrapy.Field()\n rottRate=scrapy.Field()\n imdbLink=scrapy.Field()\n rottLink=scrapy.Field()\n imdb_rating_no=scrapy.Field()\n imdb_rating_votes= scrapy.Field()\n imdb_reviews= scrapy.Field()\n im_detailed_reviews=scrapy.Field()\n\nclass CourseItem(scrapy.Item):\n course_Title=scrapy.Field()\n course_Ratings=scrapy.Field()\n course_TotalReviews=scrapy.Field()\n course_Provider=scrapy.Field()\n course_University=scrapy.Field()\n course_Description=scrapy.Field()\n"
},
{
"alpha_fraction": 0.648413896560669,
"alphanum_fraction": 0.6548338532447815,
"avg_line_length": 50.568626403808594,
"blob_id": "efb9393c140dceadbb94f4cf819ba9b058b9b8d3",
"content_id": "f219f1087ad1992c5fd9e5bd5396e9d23a6f8919",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2648,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 51,
"path": "/SearchAnalysis/SearchAnalysis/spiders/CourseSearch.py",
"repo_name": "Ri-tik/SearchAnalysis",
"src_encoding": "UTF-8",
"text": "import scrapy,csv\nimport pip._vendor.requests as request\nfrom scrapy.http import TextResponse\nfrom scrapy.linkextractors import LinkExtractor\nfrom ..items import CourseItem\n\ninp2 = input(\"Enter Course Name: \")\n#inp1 = \" \".join(inp1.split())+\" course\"\n\nclass CourseSearchSpider(scrapy.Spider):\n name = 'CourseSearch'\n #url1 = \"https://search.aol.com/aol/search?q={}\".format(inp1)\n courseInp = \"https://www.classcentral.com/search?q={}&sort=rating-up&lang=english\".format(inp2)\n #udemyInp = \"https://www.udemy.com/topic/{}/\".format(inp2)\n #udacityinp = \"https://www.udacity.com/courses/all?search={}&sort=highest'%20'rated\".format(inp2)\n start_urls = [courseInp]\n def parse(self, response):\n items = CourseItem()\n self.course_Title = response.css('.line-tight.margin-bottom-xxsmall::text').extract()\n self.course_Ratings = response.css(\"span::attr(aria-label)\").extract()[1::]\n self.course_TotalReviews = response.css(\".color-gray::text\").extract()\n self.course_Provide = response.css('.color-charcoal.margin-left-small::text').extract()\n self.course_University = response.css(\".block::attr(title)\").extract()\n self.course_Description = response.css(\".block.hover-no-underline::text\").extract()[-21:-6]\n #self.course_Link = response.css(\".rottenTomatoes a\").xpath(\"@href\").extract()[0]\n self.course_Links = response.css(\"a\").xpath(\"@href\").extract()\n self.course_Provider=[]\n for i in self.course_Provide:\n self.course_Provider.append(i.strip())\n \n items['course_Title']=self.course_Title\n items['course_Ratings']= self.course_Ratings\n items['course_TotalReviews']= self.course_TotalReviews\n items['course_Provider']= self.course_Provider\n items['course_University'] = self.course_University\n items['course_Description']= self.course_Description\n \n yield items\n\n fieldnames1 = ['Course Description','Course Provider','course_University','Course Ratings','Course Name','Total Reviews']\n with open('courseData','w') as f:\n writer = csv.DictWriter(f,fieldnames=fieldnames1)\n writer.writeheader()\n w=csv.writer(f)\n data = zip(items['course_Description'],items['course_Provider'],items['course_University'],items['course_Ratings'],items['course_Title'],items['course_TotalReviews'])\n w.writerows(data)\n \n print(\"Search Result Is Completed And Data Has Been Stored\")\n #def display(self):\n # print(\"IMDB Rating:\",self.imdbRate)\n #print(\"Rotten Rating:\",self.rottRate)\n\n \n "
},
{
"alpha_fraction": 0.6091635823249817,
"alphanum_fraction": 0.6165436506271362,
"avg_line_length": 41.24675369262695,
"blob_id": "964d174a51346f844df1bf3f40d4d590180985d7",
"content_id": "c230c047e155824b5ec741a2ab22994ae87874bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3252,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 77,
"path": "/SearchAnalysis/SearchAnalysis/spiders/GoogleSearch.py",
"repo_name": "Ri-tik/SearchAnalysis",
"src_encoding": "UTF-8",
"text": "import scrapy,csv\nimport pip._vendor.requests as request\nfrom scrapy.http import TextResponse\nfrom scrapy.linkextractors import LinkExtractor\n\n#from SearchAnalysis import SearchAnalysis\nfrom SearchAnalysis.items import SearchanalysisItem\n\ninp1 = input(\"Enter Show Name: \")\ninp1 = \"+\".join(inp1.split())+\"+imdb\"\nclass GooglesearchSpider(scrapy.Spider):\n name = 'GoogleSearch'\n url1 = \"https://search.aol.com/aol/search?q={}\".format(inp1)\n start_urls = [url1]\n def parse(self, response):\n items = SearchanalysisItem()\n self.imdbRate = response.css('.imdb::text').extract()[0]\n self.rottRate = response.css('.rottenTomatoes::text').extract()[0]\n self.imdbLink = response.css(\".imdb a\").xpath(\"@href\").extract()[0]\n self.rottLink = response.css(\".rottenTomatoes a\").xpath(\"@href\").extract()[0]\n self.links = response.css(\".lh-17::text\").extract()\n for i in self.links:\n if i.startswith(\"/title\"):\n self.imdbLink = \"https://www.imdb.com\"+i\n break\n rateUrl = self.imdbLink+'/ratings/'\n rateResp = request.get(rateUrl)\n reviewUrl = self.imdbLink+'/reviews'\n reviewResp = request.get(reviewUrl)\n\n self.im_rating_link = TextResponse(body=rateResp.content, url=rateUrl)\n self.im_rating_no = self.im_rating_link.css(\".rightAligned::text\").extract()\n self.im_rating_votes = self.im_rating_link.css(\"tr :nth-child(3) .leftAligned::text\").extract()\n\n self.im_review_link = TextResponse(body=reviewResp.content, url=reviewUrl)\n self.im_reviews = self.im_review_link.css(\".title::text\").extract()\n self.im_detailed_reviews = self.im_review_link.css(\".show-more__control::text\").extract()\n #self.im_detailReview = self.im_rating_link.css(\"\").extract() \n #self.display()\n \n items['imdbRate']=self.imdbRate\n items['rottRate']= self.rottRate\n items['imdbLink']= self.imdbLink\n items['rottLink']= self.rottLink\n items['imdb_rating_no']= self.im_rating_no\n items['imdb_rating_votes']= self.im_rating_votes\n items['imdb_reviews']= self.im_reviews\n items['im_detailed_reviews']=self.im_detailed_reviews\n \n yield items\n\n fieldnames1 = ['RatingNo','Votes']\n with open('ShowData','w') as f:\n writer = csv.DictWriter(f,fieldnames=fieldnames1)\n writer.writeheader()\n w=csv.writer(f)\n data = zip(items['imdb_rating_no'],items['imdb_rating_votes'])\n w.writerows(data)\n\n '''fieldnames2 = ['imdb_reviews']\n with open('ShowReviews','w') as f2:\n writer = csv.DictWriter(f2,fieldnames=fieldnames2)\n writer.writeheader()\n w=csv.writer(f2)\n data = items['imdb_reviews']\n w.writerows(data) '''\n\n with open(\"ShowReviews.txt\", \"w\") as f2:\n f2.write(\"Show Reviews \\n\")\n f2.writelines(items['imdb_reviews'])\n f2.writelines(items['im_detailed_reviews'])\n\n \n print(\"Search Result Is Completed And Data Has Been Stored\")\n #def display(self):\n # print(\"IMDB Rating:\",self.imdbRate)\n #print(\"Rotten Rating:\",self.rottRate)"
},
{
"alpha_fraction": 0.811188817024231,
"alphanum_fraction": 0.811188817024231,
"avg_line_length": 94.33333587646484,
"blob_id": "3c9dc43ba47051c269fa42838c5865990883f6cb",
"content_id": "c314c5b4267c7264065c313a5e488bdf4e7b71e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Ri-tik/SearchAnalysis",
"src_encoding": "UTF-8",
"text": "# SearchAnalysis\nSearch Engine web application for analysis on web search results on categories like Movies, Tv-Shows, Courses & Stocks.<br />\nAll information is extracted from web search, various analysis techniques are applied and presented as a search result in the web application.\n"
}
] | 5 |
tanvi1706/kattis-programming-tutor
|
https://github.com/tanvi1706/kattis-programming-tutor
|
5025052e575ef7375ff476bed87714492e9aee82
|
e66feb9a951877f99c401df60d24713bce73833a
|
337ddc920e0f1a6618511f60986435878b1b7b47
|
refs/heads/master
| 2023-05-28T21:24:40.916198 | 2021-06-04T02:50:15 | 2021-06-04T02:50:15 | 369,915,794 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5800604224205017,
"alphanum_fraction": 0.5891238451004028,
"avg_line_length": 21.066667556762695,
"blob_id": "cca0c35b33cd695c77a709d3f14a222f7f9726ba",
"content_id": "1e99a1891b6fd7301709fd62565e61e5ebdaa7d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 15,
"path": "/session-1/ABC.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "a,b,c = input().split(\" \")\nnumbers = [int(a), int(b), int(c)]\nnumbers.sort()\ndictionary = {\"A\": 0, \"B\": 0, \"C\": 0}\nst = \"ABC\"\nfor i in range(len(st)):\n dictionary[st[i]] = numbers[i]\nstring_input = input()\nresult = []\nfor ch in string_input:\n result.append(dictionary[ch])\nprint(' '.join(str(x) for x in result))\n\n\n# [email protected]\n"
},
{
"alpha_fraction": 0.44748857617378235,
"alphanum_fraction": 0.45890411734580994,
"avg_line_length": 18,
"blob_id": "bab4c2289de9f9f5a2516cdd60bdf457d6faf5f9",
"content_id": "66406f49de6f198accb56324da1ec6affeb7223e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 23,
"path": "/session-2/anotherBrick.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "h, w, n = input().split()\nh = int(h)\nw = int(w)\nn = int(n)\nheight = 0\nwidth = 0\ncompleted = False\nnumbers = [int(i) for i in input().split()]\nfor x in numbers:\n if height < h:\n width += x\n if width == w:\n height += 1\n width = 0\n elif width > w:\n height = h + 1\n if height == h:\n completed = True\n \nif completed:\n print(\"YES\")\nelse:\n print(\"NO\")\n\n"
},
{
"alpha_fraction": 0.5443196296691895,
"alphanum_fraction": 0.550561785697937,
"avg_line_length": 23.303030014038086,
"blob_id": "7e2e22f4a15f0b0bdd1374d22f3e297b0306ff9b",
"content_id": "10fc956c4179e8fcdca761a2cfb92b06d2ad4e3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 801,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 33,
"path": "/session-2/ptice.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "num = int(input())\nsequence = input()\ndictionary = { \"Adrian\": \"ABC\", \"Bruno\": \"BABC\", \"Goran\": \"CCAABB\" }\ncounts = {\"Adrian\": 0, \"Bruno\": 0, \"Goran\": 0}\nfor y in dictionary.keys():\n x = dictionary[y]\n len_x = len(x)\n for i in range(len(sequence)):\n if x[i % len_x] == sequence[i]:\n counts[y] += 1\n# if len(list(set(list(counts.values())))) == 1:\n# print(counts[\"Adrian\"])\n# for x in counts.keys():\n# print(x)\n# else:\n# name = max(counts, key=counts.get)\n# print(counts[name])\n# print(name)\n# print(counts.keys())\nmaximum = max(counts, key=counts.get)\nprint(counts[maximum])\nfor name in counts.keys():\n if counts[name] == counts[maximum]:\n print(name)\n\n\n\n\n\n# B A A C C\n#Adrain: A B C A B\n#Bruno: B A B C B\n# C C A A B"
},
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6263157725334167,
"avg_line_length": 14.75,
"blob_id": "c64660ea06282c16839432c5ed8fd5f2d9776d4d",
"content_id": "f31fb8294ca5db7ca786f940c85d1f1d594cb00d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 12,
"path": "/session-1/cold_puter.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def coldput(temperatures):\n\tcount = 0\n\tfor t in temperatures:\n\t\tif t < 0:\n\t\t\tcount += 1\n\treturn count\n\n\n\nnumber = int(input())\nx = [int(i) for i in list(input().split())]\nprint(coldput(x))\n\n"
},
{
"alpha_fraction": 0.4941634237766266,
"alphanum_fraction": 0.5408560037612915,
"avg_line_length": 16.200000762939453,
"blob_id": "cb7a43605ced5cd24a551dbb036e567064bd2a4f",
"content_id": "fe20e7f36a2fc8bf294d40fd6d6754aaea9b0a45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 257,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 15,
"path": "/session-1/quadrant_selection.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def select_quadrant_x_y(x,y):\n\tif x > 0 and y > 0:\n\t\tprint(\"1\")\n\telif x > 0 and y < 0:\n\t\tprint(\"4\")\n\telif x < 0 and y > 0:\n\t\tprint(\"2\")\n\telif x < 0 and y < 0:\n\t\tprint(\"3\")\n\telse:\n\t\tprint(\"invalid\")\n\nx = int(input())\ny = int(input())\nselect_quadrant_x_y(x,y)"
},
{
"alpha_fraction": 0.4736842215061188,
"alphanum_fraction": 0.49624061584472656,
"avg_line_length": 23.272727966308594,
"blob_id": "68aacfd1c5af1e97933276c3bf3a23feb5f43460",
"content_id": "0c7ff23661a42dd30c99b07ad2f990363f0f2880",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 11,
"path": "/aPrizeNoOneCanWin.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "n,x = map(int, input().split())\ngoods = sorted(map(int, input().split()))\nif n == 1:\n print('1')\nelif goods[-1] + goods[-2] <= x:\n print(n)\nelse:\n for i,cost in enumerate(goods):\n if cost + goods[i + 1] > x:\n print(i + 1)\n break"
},
{
"alpha_fraction": 0.46047157049179077,
"alphanum_fraction": 0.5339806079864502,
"avg_line_length": 23.89655113220215,
"blob_id": "494e68c33aa6819ea841aa8e8e630bf027fd78e3",
"content_id": "bd4a7193e6600f0ec38bb11b518e12bf8f49fc8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 29,
"path": "/session-1/Trik.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def triks(sequence, listing):\n\tfor c in sequence:\n\t\tif c == 'C':\n\t\t\tif listing[0] == 1 and listing[2] == 0:\n\t\t\t\tlisting[0] = 0\n\t\t\t\tlisting[2] = 1\n\t\t\telif listing[0] == 0 and listing[2] == 1:\n\t\t\t\tlisting[0] = 1\n\t\t\t\tlisting[2] = 0\n\t\tif c == 'A':\n\t\t\tif listing[0] == 1 and listing[1] == 0:\n\t\t\t\tlisting[0] = 0\n\t\t\t\tlisting[1] = 1\n\t\t\telif listing[0] == 0 and listing[1] == 1:\n\t\t\t\tlisting[0] = 1\n\t\t\t\tlisting[1] = 0\n\t\tif c == 'B':\n\t\t\tif listing[1] == 1 and listing[2] == 0:\n\t\t\t\tlisting[1] = 0\n\t\t\t\tlisting[2] = 1\n\t\t\telif listing[1] == 0 and listing[2] == 1:\n\t\t\t\tlisting[1] = 1\n\t\t\t\tlisting[2] = 0\n\tfor i in range(len(listing)):\n\t\tif listing[i] == 1:\n\t\t\treturn i + 1\nsequence = input()\nstart = [1, 0, 0]\nprint(triks(sequence,start))"
},
{
"alpha_fraction": 0.5016722679138184,
"alphanum_fraction": 0.5150501728057861,
"avg_line_length": 16.647058486938477,
"blob_id": "f3ffe294d61f07443149d9623cf8b6d78041ef36",
"content_id": "082874cd9ff59de40174ca2a6150605b2bef0d06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 299,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 17,
"path": "/anotherCandy.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "n = int(input())\n\nfor test in range(0, n):\n input()\n candies = 0\n children = (int(input()))\n\n for t in range(0, children):\n candy = int(input())\n candies += candy\n\n remainder = candies % children\n\n if remainder == 0:\n print('YES')\n else:\n print('NO')"
},
{
"alpha_fraction": 0.6037036776542664,
"alphanum_fraction": 0.6185185313224792,
"avg_line_length": 19.846153259277344,
"blob_id": "c8564e7a4e582b338d95dfdc6b401daf63cb8252",
"content_id": "a31ccfe85697988fbfaa1714d99e638e1473e334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 13,
"path": "/session-1/QALY.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def quality_of_life(quality_values):\n\tsumm = 0\n\tfor x in quality_values:\n\t\tsumm += x[0]*x[1]\n\n\treturn summ\nvalues = []\nl = []\nnumber = int(input())\nfor n in range(number):\n\tx,y = input().split(' ')\n\tl.append([float(x), float(y)])\nprint(format(quality_of_life(l), \".3f\"))"
},
{
"alpha_fraction": 0.5799086689949036,
"alphanum_fraction": 0.5981734991073608,
"avg_line_length": 28.266666412353516,
"blob_id": "6ba0689d7b3f6ef5b83b5a21004eb1670a63dc3a",
"content_id": "585d23bdac8b3b052596734a3c4618308ff4c74d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 15,
"path": "/session-2/Akcija.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def minimum_cost(numbers):\n minimum_sum = 0\n list_of_groups = [numbers[i:i+3] for i in range(0, len(numbers), 3)]\n for group in list_of_groups:\n if len(group) == 1:\n minimum_sum += group[0]\n else:\n minimum_sum += group[0] + group[1]\n return minimum_sum\nn = int(input())\nnumbers = []\nfor i in range(n):\n numbers.append(int(input()))\nnumbers.sort(reverse=True)\nprint(minimum_cost(numbers))"
},
{
"alpha_fraction": 0.6390977501869202,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 25.700000762939453,
"blob_id": "b29ceb74c0b480ba102a2f8ab836eb82ba4996aa",
"content_id": "dbf8e76b13fca2240b2fa4899644543686e8b37d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 10,
"path": "/session-2/soda_s.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "possess, empty, req = input().split()\nempty = int(possess) + int(empty)\nreq = int(req)\ntotal = 0\nwhile empty >= req:\n bottles = empty % req # the new bottles bought\n empty = empty // req # remaining bottles\n total += empty\n empty += bottles\nprint(total)"
},
{
"alpha_fraction": 0.5701219439506531,
"alphanum_fraction": 0.6173780560493469,
"avg_line_length": 40,
"blob_id": "12eccf0492ca1b0c6c1ea73aabfdaccba7cb77b5",
"content_id": "801f9c71be27c0546f3955b68dbe86032e9c3e75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 656,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 16,
"path": "/session-1/cannonball.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "\nimport math\ndef amazing_cannonball(v0, theeta, x1, h1, h2):\n t = x1 / (v0 * math.cos(math.radians(theeta)))\n vertical_distance = (v0 * t * math.sin(math.radians(theeta))) - ((9.81 * t * t)/2)\n if vertical_distance > h1+1 and vertical_distance < h2-1:\n return \"Safe\"\n else:\n return \"Not Safe\"\n # return vertical_distance\n\nn = int(input())\nfor i in range(n):\n v0, theeta, x1, h1, h2 = input().split(\" \")\n print(amazing_cannonball(float(v0), float(theeta), float(x1), float(h1), float(h2)))\n# v0, theeta, x1, h1, h2 = input().split(\" \")\n# print(amazing_cannonball(float(v0), float(theeta), float(x1), float(h1), float(h2)))"
},
{
"alpha_fraction": 0.5157894492149353,
"alphanum_fraction": 0.5157894492149353,
"avg_line_length": 18.200000762939453,
"blob_id": "f91ba1952e29f0adb3331323769d35d1807b6d27",
"content_id": "b17e746844665c764cdb263ae46ad5ae6ef0945c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 5,
"path": "/session-2/A_different_problem.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "x, y = input().split()\nx = int(x)\ny = int(y)\nprint(abs(x-y))\n# print(x - y if x > y else y - x)"
},
{
"alpha_fraction": 0.5721544623374939,
"alphanum_fraction": 0.5813007950782776,
"avg_line_length": 27.14285659790039,
"blob_id": "62fff88ec3f7460c4865308380d5bfb6479526d8",
"content_id": "437344844193ed0579118c03854b9ec257b87f82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 984,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 35,
"path": "/session-2/alien.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def to_decimal(number, system, base):\n exp = 0\n total = 0\n for char in number[::-1]:\n total += system[char] * base ** exp\n exp += 1\n return total\n\ndef from_decimal(number, system_list, base):\n div = number // base\n mod = number % base\n indices = [mod]\n number = div\n while number != 0:\n div = number // base\n mod = number % base\n number = div\n indices.append(mod)\n return ''.join([system_list[index] for index in indices[::-1]])\n \n\nT = int(input())\n\nfor i in range(T):\n alien_number, source_language, target_language = map(str, input().split())\n system = {}\n system_list = []\n source_base = 0\n for char in source_language:\n system[char] = source_base\n source_base += 1\n for char in target_language:\n system_list.append(char)\n decimal = to_decimal(alien_number, system, source_base)\n print(f'Case #{i+1}: {from_decimal(decimal, system_list, len(system_list))}')"
},
{
"alpha_fraction": 0.42234331369400024,
"alphanum_fraction": 0.4386920928955078,
"avg_line_length": 19.44444465637207,
"blob_id": "465cf1afde2d57d996f4829c2b2fb96dc2dee174",
"content_id": "d2a365752533744d0815963875d16d44a61b9b51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 18,
"path": "/session-2/ACMContest.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "contest = []\nlist_of_visited = []\nscore = 0\ncount = 0\nn = input()\nwhile n != \"-1\":\n x, y, z = n.split(\" \")\n x = int(x)\n if z == \"right\":\n score += x\n count += 1\n for i in list_of_visited:\n if i == y:\n score += 20\n elif z == \"wrong\":\n list_of_visited.append(y)\n n = input()\nprint(f\"{count} {score}\")"
},
{
"alpha_fraction": 0.3161993622779846,
"alphanum_fraction": 0.336448609828949,
"avg_line_length": 20.100000381469727,
"blob_id": "3711543ce42c52c1f83bca8fefbce1bbf07105ba",
"content_id": "6a7c2f5cf8b1a65b16ea78a64658d6e35e2fc84b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 30,
"path": "/substringQuery.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "string = input()\nn = int(input())\nfor i in range(n):\n x,t = input().split()\n t = int(t)\n count = 0\n j = 0\n s = string\n while j < len(s):\n if x in s:\n count += 1\n s = s[j + len(x) + 1:]\n j = j + len(x) + 1\n else:\n j += 1\n\n if count == t:\n print(j + 1)\n break\n if j == len(s) - 1:\n print(\"-1\")\n\n # for j,ch in enumerate(string):\n # if ch in x:\n # count += 1\n # if count == t:\n # print(j + 1)\n # break\n # if j == len(string) - 1:\n # print(\"-1\")\n \n"
},
{
"alpha_fraction": 0.49651971459388733,
"alphanum_fraction": 0.5104408264160156,
"avg_line_length": 22.94444465637207,
"blob_id": "012ea12f74ea54bc24481c1a9f970fc801c4f056",
"content_id": "be623c5a6ad934cd7b259fdc7d64508db1322eee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 18,
"path": "/session-2/speed_limit.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "n = int(input())\nlist_of_journey = []\nwhile n != -1:\n current_list = []\n for i in range(n):\n x, y = input().split()\n current_list.append([int(x), int(y)])\n list_of_journey.append(current_list)\n n = int(input())\n \n# print(list_of_journey)\nfor l in list_of_journey:\n curr = 0\n summ = 0\n for x in l:\n summ += x[0] * (x[1] - curr)\n curr = x[1]\n print(\"{} miles\".format(summ))\n"
},
{
"alpha_fraction": 0.5355086326599121,
"alphanum_fraction": 0.5834932923316956,
"avg_line_length": 22.590909957885742,
"blob_id": "a73518d8964cf88de9ae25a1366d0ca21d49777e",
"content_id": "c23fed90d1ed89ff31cf23720ce86867a66c4966",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 521,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 22,
"path": "/session-2/Alphabet_spam.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "\nsequence = input()\n\nlength = len(sequence)\nlower_count = 0\nupper_count = 0\nspecial_count = 0\nspace_count = 0 \n\nfor x in sequence:\n if x == \"_\":\n space_count += 1\n elif ord(x) >= 97 and ord(x) <= 122:\n lower_count += 1\n elif ord(x) >= 65 and ord(x) <= 90:\n upper_count += 1\n else:\n special_count += 1\n\nprint(\"{:.16f}\".format(space_count/length))\nprint(\"{:.16f}\".format(lower_count/length))\nprint(\"{:.16f}\".format(upper_count/length))\nprint(\"{:.16f}\".format(special_count/length))\n\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6161616444587708,
"avg_line_length": 32.33333206176758,
"blob_id": "e391f5ddb3e2ea283d960ee071170b2f4619792b",
"content_id": "f74d8b7f0f627ba4e6056d9104fc499d7de7fe8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 3,
"path": "/aaah.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "string1 = input()[:-1]\nstring2 = input()[:-1]\nprint('go' if len(string2) <= len(string1) else 'no')"
},
{
"alpha_fraction": 0.6057692170143127,
"alphanum_fraction": 0.6057692170143127,
"avg_line_length": 20,
"blob_id": "53c247ca0c6af7483faab4ce3f5504bd7273248b",
"content_id": "3ef7a1052cf48141525a3c461dd6774ba6bdad52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/session-1/jack.py",
"repo_name": "tanvi1706/kattis-programming-tutor",
"src_encoding": "UTF-8",
"text": "def function_u(n,t,m):\n\treturn n*t*m\n\nn,t,m = input().split(' ')\nprint(function_u(int(n),int(t),int(m)))"
}
] | 20 |
figafetta/UG9_B_71210728
|
https://github.com/figafetta/UG9_B_71210728
|
48ee69e0aa7b7dbb1620853798c3c5b839441b93
|
1f73044e0c9646e8bf41b7b945938a1bcd8e3302
|
f7b2c9698db4b20651fbf99ec3187446ed9aeff9
|
refs/heads/master
| 2023-08-30T07:28:36.179771 | 2021-11-12T04:01:33 | 2021-11-12T04:01:33 | 427,227,247 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6414762735366821,
"alphanum_fraction": 0.6625658869743347,
"avg_line_length": 42.769229888916016,
"blob_id": "0f9115e6fc80887b8d81d18212eba7aa4fb3896b",
"content_id": "b6e6a737c1b2297dfafcade8ba5c9122a7dfc7d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 13,
"path": "/2_B_71210728.py",
"repo_name": "figafetta/UG9_B_71210728",
"src_encoding": "UTF-8",
"text": "print (\"1. Test Case 1\")\nprint (\"2. Test Case 2\")\noption=int(input(\"Pilih Soal :\")) \nif option==1 :\n jari_jari = int(input(\"Masukan jari-jari alas tabung :\"))\n tinggi_tabung = int(input(\"Masukan tinggi tabung :\"))\n volume_tabung = 3.14*(jari_jari*jari_jari*tinggi_tabung)\n print (\"Volume Tabung: \", volume_tabung)\nelif option==2 :\n jari_jari = int(input(\"Masukan jari-jari alas tabung :\"))\n tinggi_tabung = int(input(\"Masukan tinggi tabung :\"))\n volume_tabung = 3.14*(jari_jari*jari_jari*tinggi_tabung)\n print (\"Volume Tabung: \", volume_tabung)\n"
},
{
"alpha_fraction": 0.4845360815525055,
"alphanum_fraction": 0.5628865957260132,
"avg_line_length": 31.399999618530273,
"blob_id": "8399fdc05725031f897f7d5e50b895be424aac12",
"content_id": "a0b31d5163d6d044ace6c8ecf8a3f92963e1821f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 485,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 15,
"path": "/3_B_71210728.py",
"repo_name": "figafetta/UG9_B_71210728",
"src_encoding": "UTF-8",
"text": "print (\"1. Test Case 1\")\nprint (\"2. Test Case 2\")\noption=int(input(\"Pilih Soal :\"))\nif option==1 :\n N1 = int(input(\"Nilai 1 :\"))\n N2 = int(input(\"Nilai 2 :\"))\n N3 = int(input(\"Nilai 3 :\"))\n Rata_rata = (N1+N2+N3)/3\n print (\"Rata-rata dari 78+80+50 adalah\", Rata_rata )\nelif option==2 :\n N1 = int(input(\"Nilai 1 :\"))\n N2 = int(input(\"Nilai 2 :\"))\n N3 = int(input(\"Nilai 3 :\"))\n Rata_rata = (N1+N2+N3)/3\n print (\"Rata-rata dari 45+85+99 adalah\", Rata_rata )"
},
{
"alpha_fraction": 0.581632673740387,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 23.75,
"blob_id": "7a6d37b21a0c68d4835022c030f1683fd7bac520",
"content_id": "4e0196227790fd5850902ca04331dba399ec1327",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/4_B_71210728.py",
"repo_name": "figafetta/UG9_B_71210728",
"src_encoding": "UTF-8",
"text": "print (\"1. Test Case 1\")\nprint (\"2. Test Case 2\")\noption=int(input(\"Pilih soal :\"))\nif option==1 :"
},
{
"alpha_fraction": 0.5907173156738281,
"alphanum_fraction": 0.6286919713020325,
"avg_line_length": 28.6875,
"blob_id": "84d66c68f898b2ef0c1ee4760fdb0a805db02a98",
"content_id": "f083f93fbcb4d24ef088987dfe6b784956a9c03a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 16,
"path": "/1_B_71210728.py",
"repo_name": "figafetta/UG9_B_71210728",
"src_encoding": "UTF-8",
"text": "from typing import Optional\n\n\nprint (\"1. Test Case 1\")\nprint (\"2. Test Case 2\")\noption=int(input(\"Pilih soal :\"))\nif option==1 :\n nama = input(\"Nama : \")\n ttl = input(\"Tempat tanggal lahir : \")\n print (\"Hallo! Milzyrin, Inyint\")\n print (\"Anda lahir di Bengkulu pada tanggal 30 Februari 2000\")\nelif option==2 :\n nama = input (\"Nama : \")\n ttl = input (\"Tempat tanggal lahir\")\n print (\"Halo! Tyuruk, Uzulun Umurusutsu\")\n print (\"Anda lahir di Jepang pada tanggal 31 November 1987\")"
}
] | 4 |
conatel-i-d/sm-api
|
https://github.com/conatel-i-d/sm-api
|
1c5d8843379b7751b507318e166dbcbbae61a92d
|
1a57e8303ae5f33ae4c8ac8247449fac5b0c848d
|
42477a508f27108f27d023638aec880c921f26a6
|
refs/heads/master
| 2022-09-27T03:49:30.102865 | 2020-07-21T18:07:38 | 2020-07-21T18:07:38 | 219,530,687 | 1 | 0 |
MIT
| 2019-11-04T15:14:13 | 2021-08-21T20:52:00 | 2022-09-16T18:12:56 |
Python
|
[
{
"alpha_fraction": 0.6372712254524231,
"alphanum_fraction": 0.6489184498786926,
"avg_line_length": 45.30769348144531,
"blob_id": "586266c1a77ae3e9a0cdc54de3d981d11efed3b0",
"content_id": "1dbf832ab5bfbad6df7dc7f763efee163f7327bf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 601,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 13,
"path": "/app/macs/find_test.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import json, os, pathlib\nfrom collections.abc import Iterable\n\nmac = \"229e\"\nkey = \"123\" # switch id\nwith open(os.path.join(pathlib.Path(__file__).parent.absolute(), 'mac_address_resp_example.json')) as json_file:\n show_mac_address_table_resp = json.load(json_file)\nfor nic_name,nic_value in show_mac_address_table_resp['msg'].items():\n if isinstance(nic_value, Iterable):\n if 'mac_entries' in nic_value:\n for curr_mac in nic_value['mac_entries']:\n if curr_mac['mac_address'].find(mac) >= 0:\n print(dict(switch_id=int(key), interface=nic_name))"
},
{
"alpha_fraction": 0.6105918884277344,
"alphanum_fraction": 0.6542056202888489,
"avg_line_length": 20.46666717529297,
"blob_id": "f94cb6f97846ef428300ba898c3989fb3d381ae7",
"content_id": "eb06587e946df26e239baba9f0befcaf2c1465e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 15,
"path": "/app/utils/b64.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import base64\n\ndef encode(text):\n if text == None:\n return None\n enc = base64.b64encode(text.encode('UTF-8'))\n enc_result = str(enc, 'UTF-8')\n return enc_result\n\ndef decode(text):\n if text == None:\n return None\n dec = base64.b64decode(text.encode('UTF-8'))\n dec_result = str(dec, 'UTF-8')\n return dec_result"
},
{
"alpha_fraction": 0.6678743958473206,
"alphanum_fraction": 0.6727052927017212,
"avg_line_length": 23.382352828979492,
"blob_id": "6f5aee98bca61e9db7e31267c7e6df0fcad8ce1b",
"content_id": "45c92eeafaef1a3189890d749a2a3184dbb290e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 828,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 34,
"path": "/app/config.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\n\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\nclass BaseConfig:\n TITLE = 'Api'\n VERSION = '0.0.1'\n CONFIG_NAME = 'base'\n DEBUG = False\n TESTING = False\n SQLALCHEMY_TRACK_MODIFICATIONS = False\n \nclass DevelopmentConfig(BaseConfig):\n CONFIG_NAME = 'dev'\n DEBUG = True\n SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URI')\n \nclass TestingConfig(BaseConfig):\n CONFIG_NAME = 'test'\n DEBUG = True\n TESTING = True\n SQLALCHEMY_DATABASE_URI = 'sqlite:///{0}/db/app-tetst.db'.format(basedir)\n \nclass ProductionConfig(BaseConfig):\n CONFIG_NAME = 'prod'\n SQLALCHEMY_DATABASE_URI = os.environ.get('DATABASE_URI')\n \nEXPORT_CONFIGS = [\n DevelopmentConfig,\n TestingConfig,\n ProductionConfig,\n]\n\nconfig_by_name = { cfg.CONFIG_NAME: cfg for cfg in EXPORT_CONFIGS }"
},
{
"alpha_fraction": 0.6700491905212402,
"alphanum_fraction": 0.6703566908836365,
"avg_line_length": 33.242103576660156,
"blob_id": "4df333c521013c0df7bc4ba11f7b3aa4f6c9aa62",
"content_id": "81c18a631c42d5088b764af763c0cc9271b56745",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3262,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 95,
"path": "/app/nics/controller.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\nimport json\nimport asyncio\n\nfrom flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\n\nfrom app.api_response import ApiResponse\nfrom app.utils.async_action import async_action\nfrom app.utils.authorization import authorize\nfrom app.utils.logger import log\nfrom app.utils.prime import prime_fetch\nfrom app.switch.service import SwitchService\nfrom .service import NicsService\n\nfrom app.errors import SwitchNotFound, JobTemplateNotFound, PlaybookTimeout, PlaybookFailure, ApiException\napi_description = \"\"\"\nRepresentación de las nics del switch.\n\"\"\"\n\n\napi = Namespace('Nics', description=api_description)\n\[email protected](\"/<int:switch_id>/nics\")\[email protected](\"switch_id\", \"Identificador único del Switch\")\nclass InterfaceResource(Resource):\n \"\"\"\n Interface Resource\n \"\"\"\n @log\n @async_action\n @authorize\n async def get(self, switch_id: int):\n \"\"\"\n Devuelve la lista de Interfaces\n \"\"\"\n # List jobs templates\n # '/api/v2/job_templates/'\n try:\n result = await NicsService.get_by_switch_id(switch_id)\n return ApiResponse(result)\n #return ApiResponse(RESULT)\n except SwitchNotFound:\n raise ApiException(f'No se encuentra un switch con el id:{switch_id}')\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la información de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')\n\[email protected](\"/<int:switch_id>/nics_prime\")\[email protected](\"switch_id\", \"Identificador único del Switch\")\nclass InterfaceResource(Resource):\n @log\n @async_action\n @authorize\n async def get(self, switch_id: int):\n \"\"\"\n Devuelve la lista de Interfaces obtenidas desde el CISCO PRIME\n \"\"\"\n try:\n result = await NicsService.get_from_prime_by_switch_id(switch_id)\n return ApiResponse(result) \n except SwitchNotFound:\n raise ApiException(f'En el Cisco Prime no se encuentra un switch con el id:{switch_id}')\n \n\[email protected](\"/<int:switch_id>/nics/reset\")\[email protected](\"switch_id\", \"Identificador único del Switch\")\nclass InterfaceResource(Resource):\n \"\"\"\n Interface Resource\n \"\"\"\n @log\n @async_action\n @authorize\n async def post(self, switch_id: int):\n \"\"\"\n Resetea la interface indicada\n \"\"\"\n try:\n nic_name = request.args.get('nic_name')\n result = await NicsService.reset_switch_nic(switch_id, nic_name)\n return ApiResponse(result)\n except SwitchNotFound:\n raise ApiException(f'No se encuentra un switch con el id:{switch_id}')\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')"
},
{
"alpha_fraction": 0.6931386590003967,
"alphanum_fraction": 0.6978102326393127,
"avg_line_length": 35.83871078491211,
"blob_id": "ae0528d971cfdfac626aaadd54283e78afaf1ca1",
"content_id": "736e88c971bc108aeee42cc4ad84d6df6e4f68cb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3425,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 93,
"path": "/app/utils/base_interfaces_test.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import inspect\nimport pytest\nfrom flask_restplus import Namespace\n\nfrom .base_interfaces import BaseInterfaces, marshmallow_fields, restplus_fields\n\nclass ChildInterfaces(BaseInterfaces):\n __name__ = 'Test'\n id = dict(\n m=marshmallow_fields.Int(attribute='id'),\n r=restplus_fields.Integer(description='Unique identifier', required=True, example=123),\n )\n firstName = dict(\n m=marshmallow_fields.String(attribute='first_name'),\n r=restplus_fields.String(description='User first name', required=False, example=\"Example\"),\n )\n admin = dict(\n m=marshmallow_fields.Bool(attribute='admin', default=False, required=True),\n r=restplus_fields.Boolean(description='User is Admin?', required=False, example=False, default=False)\n )\n create_model_keys = ['firstName', 'admin']\n update_model_keys = ['admin']\n\[email protected]\ndef api():\n return Namespace('Test', description=\"Test resources\")\n\[email protected]\ndef base(api):\n return BaseInterfaces(api)\n\[email protected]\ndef child(api):\n return ChildInterfaces(api)\n\ndef test_class_existance(base):\n assert base != None\n\ndef test_pick_exists(child):\n assert getattr(child, 'pick') != None\n\ndef test_pick_returns_list(child):\n actual = child.pick(['admin', 'firstName', 'id'])\n assert len(actual) == 3\n\ndef test_create_marshmallow_schema_exists(child):\n assert child.create_marshmallow_schema != None\n\ndef test_create_marshmallow_schema_result(child):\n assert inspect.isclass(child._schema) == True\n\ndef test_schema_is_valid(child):\n schema = child._schema()\n actual = schema.dump(dict(id='not an int')).data\n assert actual == dict(admin=False)\n actual = schema.dump(dict(id=1)).data\n assert actual == dict(id=1, admin=False)\n actual = schema.dump(dict(id=1, first_name='Example', admin=True)).data\n assert actual == dict(id=1, firstName='Example', admin=True)\n\ndef test_single_schema_works(child):\n actual = child.single_schema.dump(dict(id='not an int')).data\n assert actual == dict(admin=False)\n actual = child.single_schema.dump(dict(id=1)).data\n assert actual == dict(id=1, admin=False)\n actual = child.single_schema.dump(dict(id=1, first_name='Example', admin=True)).data\n assert actual == dict(id=1, firstName='Example', admin=True)\n\ndef test_many_schema_works(child):\n actual = child.many_schema.dump([dict(id='not an int')]).data\n assert actual == [dict(admin=False)]\n actual = child.many_schema.dump([dict(id=1)]).data\n assert actual == [dict(id=1, admin=False)]\n actual = child.many_schema.dump([dict(id=1, first_name='Example', admin=True)]).data\n assert actual == [dict(id=1, firstName='Example', admin=True)]\n\ndef test_create_model_is_valid(child):\n assert str(child.create_model) == 'Model(TestCreate,{admin,firstName})'\n\ndef test_update_model_is_valid(child):\n assert str(child.update_model) == 'Model(TestUpdate,{admin})'\n\ndef test_model_is_valid(child):\n assert str(child.model) == 'Model(Test,{admin,firstName,id})'\n\ndef test_single_response_model_is_valid(child):\n assert str(child.single_response_model) == 'Model(TestSingleResponse,{item})'\n\ndef test_many_response_model_is_valid(child):\n assert str(child.many_response_model) == 'Model(TestManyResponse,{items,count})'\n\ndef test_error_response_model_is_valid(child):\n assert str(child.error_response_model) == 'Model(TestErrorResponse,{message})'"
},
{
"alpha_fraction": 0.6330680847167969,
"alphanum_fraction": 0.6379310488700867,
"avg_line_length": 34.92063522338867,
"blob_id": "c1447089e274a8954400980e2427f30284a3f17f",
"content_id": "c38601e3f4f390b2515ddcc9ae460ad3a61c2c5b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2262,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 63,
"path": "/app/macs/service.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app import db\nfrom typing import List\n\nfrom app.utils.b64 import encode\nfrom collections.abc import Iterable\nimport os\nimport json\nimport sys\nfrom app.utils.prime import prime_fetch\nimport copy\nimport pathlib\n\nimport asyncio\nfrom app.jobs.service import JobService\nfrom app.switch.service import SwitchService\n\nfrom app.errors import ApiException\n\nENV = 'prod' if os.environ.get('ENV') == 'prod' else 'test'\nclass MacService:\n @staticmethod\n async def get(switch_id):\n switch = await SwitchService.get_by_id(switch_id)\n if switch == None:\n raise ApiException(f'No se encuentra el switch con el id {switch_id}', 404)\n extra_vars = dict()\n body = dict(limit=switch.name, extra_vars=extra_vars)\n return await JobService.run_job_template_by_name('show-mac-address-table', body)\n\n @staticmethod\n async def show_mac_addr_table(switch, macs_results):\n extra_vars = dict()\n body = dict(limit=switch[\"name\"], extra_vars=extra_vars)\n macs_results.append({ \n \"id\": switch[\"id\"],\n \"name\": switch[\"name\"],\n \"interfaces\": await JobService.run_job_template_by_name('show-mac-address-table', body)\n })\n return True\n\n @staticmethod\n async def find_by_mac(switches_ids):\n macs_results = []\n switches = []\n # Carga las macs de todos los switches pasados en switches_ids\n for sw_id in switches_ids:\n switch = await SwitchService.get_by_id(sw_id)\n if switch == None:\n raise ApiException(f'No se encuentra el switch con el id {sw_id}', 404)\n else:\n switches.append({ \"id\": sw_id, \"name\": switch.name})\n await asyncio.gather(*[MacService.show_mac_addr_table(sw, macs_results) for sw in switches])\n return macs_results\n \n\n @staticmethod\n async def cancel_find_by_mac(switches_ids):\n for sw_id in switches_ids:\n switch = await SwitchService.get_by_id(sw_id)\n if switch == None:\n raise ApiException(f'No se encuentra el switch con el id {sw_id}', 404)\n await JobService.cancel_jobs_by_template_name_and_host_name(f'{ENV}-show-mac-address-table', switch.name)\n return True"
},
{
"alpha_fraction": 0.6179104447364807,
"alphanum_fraction": 0.6268656849861145,
"avg_line_length": 23,
"blob_id": "9f06abfee8161a79caf95fa521435bac49b54b38",
"content_id": "c68d21786302b6308404a03bc5b7cd4afdefd3b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 14,
"path": "/app/__init__test.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import json\n\nfrom app.test.fixtures import app, client # noqa\n\n\ndef test_app_creates(app): # noqa\n assert app\n \ndef test_app_healthy(app, client): # noqa\n with client:\n resp = client.get('/healthz')\n data = json.loads(resp.data)\n assert resp.status_code == 200\n assert data['ok'] == True"
},
{
"alpha_fraction": 0.6690391302108765,
"alphanum_fraction": 0.6690391302108765,
"avg_line_length": 27.200000762939453,
"blob_id": "9ecbc3af24611838cc2cc9775485621c534bcc9c",
"content_id": "411780a0189f3052aa7979d9eabb6420b5ee63da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 281,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 10,
"path": "/app/api_flask.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask_restplus import Api\n\nfrom app.api_response import ApiResponse\n\n\nclass ApiFlask(Api):\n def make_response(self, rv, *args, **kwargs):\n if isinstance(rv, ApiResponse):\n return rv.to_response()\n return Api.make_response(self, rv, *args, **kwargs)"
},
{
"alpha_fraction": 0.6037735939025879,
"alphanum_fraction": 0.6682389974594116,
"avg_line_length": 20.931034088134766,
"blob_id": "d0bda0f2cb2b3d4fd59169545abbc2e093ece498",
"content_id": "6395e73143c277a80e80a0733eb9d69e5d42630f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 29,
"path": "/migrations/versions/2b60825ec877_create_jobs_table.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "\"\"\"create jobs table\n\nRevision ID: 2b60825ec877\nRevises: 7e633f4a3f96\nCreate Date: 2019-11-11 17:58:52.193982\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '2b60825ec877'\ndown_revision = '7e633f4a3f96'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n op.create_table(\n 'jobs',\n sa.Column('id', sa.Integer, primary_key=True),\n sa.Column('job_id', sa.Integer, nullable=False, unique=True),\n sa.Column('type', sa.String(255), nullable=False),\n sa.Column('result', sa.JSON, nullable=False)\n )\n\ndef downgrade():\n op.drop_table('switch')\n"
},
{
"alpha_fraction": 0.7456647157669067,
"alphanum_fraction": 0.7514451146125793,
"avg_line_length": 16.399999618530273,
"blob_id": "d4cde92d9f12ca8f1bc2abd4a555d410f427edca",
"content_id": "243447a4c98d44f6ae862d80e84adcb25849eac2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 173,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 10,
"path": "/Makefile",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": ".PHONY: test run migration\n\ntest:\n\tpytest --disable-warnings --maxfail 1\n\nrun:\n\tFLASK_APP=./app.py FLASK_DEBUG=True FLASK_ENV=dev flask run\n\nmigration:\n\talembic upgrade head"
},
{
"alpha_fraction": 0.6158798336982727,
"alphanum_fraction": 0.6201716661453247,
"avg_line_length": 16.22222137451172,
"blob_id": "b6b0cb599715232744c9cbc7c5f83623ed036759",
"content_id": "333e619aba5c2159dfe771eb9411ff591bcb91cf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 27,
"path": "/app/test/fixtures.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom app import create_app\nfrom app.api_flask import ApiFlask\n\[email protected]\ndef app():\n return create_app('test')[0]\n\[email protected]\ndef api():\n return create_app('test')[1]\n \[email protected]\ndef client(app):\n return app.test_client()\n\[email protected]\ndef db(app):\n from app import db\n \n with app.app_context():\n db.drop_all()\n db.create_all()\n yield db\n db.drop_all()\n db.session.commit()\n\n"
},
{
"alpha_fraction": 0.6205918192863464,
"alphanum_fraction": 0.6282934546470642,
"avg_line_length": 40.13333511352539,
"blob_id": "f20bcd3bcb1110a767c3aadefb613232619facd5",
"content_id": "1a0ca14eb6125fdae8595494af83c39dc54e3dd5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2471,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 60,
"path": "/app/switch/interfaces.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app.utils.base_interfaces import BaseInterfaces, marshmallow_fields, restplus_fields\n\nclass SwitchInterfaces(BaseInterfaces):\n __name__ = 'Switch'\n id = dict(\n m=marshmallow_fields.Int(attribute='id', dump_only=True),\n r=restplus_fields.Integer(description='Identificador único', required=True, example=123),\n )\n name = dict(\n m=marshmallow_fields.String(attribute='name'),\n r=restplus_fields.String(description='Nombre del Switch', required=True, example='sw-core-1'),\n )\n description = dict(\n m=marshmallow_fields.String(attribute='description'),\n r=restplus_fields.String(description='Descripción del Switch', required=False, example='Switch de core #1'),\n )\n model = dict(\n m=marshmallow_fields.String(attribute='model'),\n r=restplus_fields.String(\n description='Modelo del Switch',\n required=False,\n example='Cisco 2960x' \n )\n )\n ip = dict(\n m=marshmallow_fields.String(attribute='ip'),\n r=restplus_fields.String(\n description='Dirección IP para la administración del switch',\n required=True,\n example='192.168.1.1' \n )\n )\n ansible_user = dict(\n m=marshmallow_fields.String(attribute='ansible_user'),\n r=restplus_fields.String(\n description='Nombre del usuario para conectarse ssh',\n required=False,\n example='my_name' \n )\n )\n ansible_ssh_pass = dict(\n m=marshmallow_fields.String(attribute='ansible_ssh_pass'),\n r=restplus_fields.String(\n description='Password del usuario para conectarse ssh',\n required=False,\n example='my_pass' \n )\n )\n\n ansible_ssh_port = dict(\n m=marshmallow_fields.Int(attribute='ansible_ssh_port'),\n r=restplus_fields.Integer(description='Puerto pasa conectarse por ssh', required=False, example=22),\n )\n is_visible = dict(\n m=marshmallow_fields.Boolean(attribute='is_visible'),\n r=restplus_fields.Boolean(description='Determina si el switch es visible para el operador', required=False, example=False),\n )\n\n create_model_keys = ['name', 'description', 'model', 'ip', 'ansible_user', 'ansible_ssh_pass', 'ansible_ssh_port', 'is_visible' ]\n update_model_keys = ['name', 'description', 'model', 'ip', 'ansible_user', 'ansible_ssh_pass', 'ansible_ssh_port', 'is_visible' ]"
},
{
"alpha_fraction": 0.659217894077301,
"alphanum_fraction": 0.659217894077301,
"avg_line_length": 21.375,
"blob_id": "709a9b86ab36bb3a2267fcb277f0d4daaab2ce84",
"content_id": "e0ee951ab5ad2918d3837bf8abfeba6b03815545",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 8,
"path": "/app/utils/async_action.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import asyncio\nfrom functools import wraps\n\ndef async_action(f):\n @wraps(f)\n def wrapped(*args, **kwargs):\n return asyncio.run(f(*args, **kwargs))\n return wrapped\n"
},
{
"alpha_fraction": 0.6567567586898804,
"alphanum_fraction": 0.6729729771614075,
"avg_line_length": 35.10975646972656,
"blob_id": "cdbbcf2c0b0884e990207246a26a0e4f652f0a4d",
"content_id": "240d78b046d036efd74010544be289ca969a9c36",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2963,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 82,
"path": "/app/macs/controller.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os, sys\nfrom flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\nfrom app.utils.async_action import async_action\nfrom app.utils.logger import log\nfrom app.api_response import ApiResponse\nfrom app.errors import ApiException, JobTemplateNotFound, PlaybookFailure, PlaybookTimeout\nfrom .service import MacService\nfrom app.utils.authorization import authorize \nfrom app.utils.b64 import decode\n\napi_description = \"\"\"\nMethodos find y cancel_find para las macs de un switch o edificio.\n\"\"\"\n\napi = Namespace('Macs', description=api_description)\n\[email protected](\"/find\")\[email protected](400, 'Bad Request')\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass FindMacResource(Resource):\n @api.expect([str])\n @api.response(200, 'Interfaces donde se encontro la mac')\n @log\n @async_action\n @authorize\n async def post(self):\n \"\"\"\n Busca una mac o substring de la misma en la lista de swtiches recibidos en el body.\n \"\"\"\n json_data = request.get_json()\n if json_data is None:\n raise ApiException('JSON body is undefined')\n try:\n switches_ids = list(json_data[\"switchesToFindIds\"])\n resp = await MacService.find_by_mac(switches_ids)\n return ApiResponse(resp)\n except Exception as err:\n raise ApiException(f'Runtime python error. Error: {err}')\n\n\[email protected](\"/cancel_find_tasks\")\[email protected](400, 'Bad Request')\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass CancelFindMacResource(Resource):\n @api.expect([str])\n @api.response(201, 'Trabajos de buscar mac cancelados correctamente')\n @log\n @async_action\n @authorize\n async def post(self):\n \"\"\"\n Dados una lista de ids de swithces, busca los trabajos \"busqueda de mac\" pendientes en esos switches y los cancela.\n \"\"\"\n json_data = request.get_json()\n if json_data is None:\n raise ApiException('JSON body is undefined')\n switches_ids = list(json_data[\"switchesToFindIds\"])\n if switches_ids is None or len(switches_ids) == 0:\n raise ApiException(\"No se encontraron elementos en switches_ids y debe tener al menos uno para poder buscar por mac\")\n try:\n resp = await MacService.cancel_find_by_mac(switches_ids)\n return ApiResponse({}, 201)\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')"
},
{
"alpha_fraction": 0.7120419144630432,
"alphanum_fraction": 0.7312390804290771,
"avg_line_length": 16.33333396911621,
"blob_id": "c649f5309a016ee348c814749b0daab5ffb355ea",
"content_id": "863958f72e77e91f923e14c11c846ca7cde73749",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 573,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 33,
"path": "/Dockerfile",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "FROM python:3.7\n\nEXPOSE 80/tcp\nEXPOSE 9191/tcp\n\nRUN apt-get update\nRUN apt-get install -y --no-install-recommends \\\n libatlas-base-dev \\\n gfortran \\\n nginx \\\n supervisor\n\nRUN pip3 install uwsgi psycopg2\n\nWORKDIR /usr/src/app\nCOPY requirements.txt ./\nRUN pip3 install --no-cache-dir -r requirements.txt\n\nRUN useradd --no-create-home nginx\nRUN rm /etc/nginx/sites-enabled/default\nRUN rm -r /root/.cache\n\n\nCOPY nginx.conf /etc/nginx\nCOPY flask-nginx.conf /etc/nginx/conf.d/\nCOPY uwsgi.ini /etc/uwsgi/\nCOPY supervisord.conf /ect/\n\n\n\nCOPY . .\n\nCMD [\"/usr/bin/supervisord\"]\n\n"
},
{
"alpha_fraction": 0.608832836151123,
"alphanum_fraction": 0.6356467008590698,
"avg_line_length": 27.863636016845703,
"blob_id": "4924c50ca156acb98fa5638e0a47fa0991caa08e",
"content_id": "b3281c061612ab6266324e6e69ac01cedfa350f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 634,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 22,
"path": "/app/switch/model.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from sqlalchemy import Integer, Column, String, Boolean\nfrom app import db # noqa\n\n\nclass Switch(db.Model): # type: ignore\n \"\"\"Switch Model\"\"\"\n\n __tablename__ = \"switch\"\n\n id = Column(Integer(), primary_key=True)\n name = Column(String(255))\n description = Column(String(255))\n model = Column(String(255))\n ip = Column(String(15))\n ansible_user = Column(String(255))\n ansible_ssh_pass = Column(String(255))\n ansible_ssh_port = Column(Integer)\n is_visible = Column(Boolean)\n def update(self, changes):\n for key, val in changes.items():\n setattr(self, key, val)\n return self"
},
{
"alpha_fraction": 0.7495853900909424,
"alphanum_fraction": 0.7512437701225281,
"avg_line_length": 36.6875,
"blob_id": "e31a8a6a985f1ed2b12fb73644bfec35412469c2",
"content_id": "bf7c5264ef67e5ece55959266784c69f171e2ab5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "permissive",
"max_line_length": 153,
"num_lines": 16,
"path": "/app/utils/prime.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport aiohttp\nfrom aiohttp.client import ClientTimeout\nimport sys\n\nPRIME_API_URL = os.getenv('CISCO_PRIME_BASE_URL')\nAUTH = aiohttp.BasicAuth(os.getenv('CISCO_PRIME_USER'), os.getenv('CISCO_PRIME_PASSWORD'))\nTIMEOUT_SECONDS = 5\nTIMEOUT = ClientTimeout(total=TIMEOUT_SECONDS)\n\nasync def prime_fetch(endpoint):\n url = PRIME_API_URL + endpoint\n async with aiohttp.ClientSession(auth=AUTH, json_serialize=json.dumps, timeout=TIMEOUT, connector=aiohttp.TCPConnector(verify_ssl=False)) as session:\n async with session.get(url) as resp:\n return await resp.json()\n"
},
{
"alpha_fraction": 0.6839080452919006,
"alphanum_fraction": 0.6839080452919006,
"avg_line_length": 28.16666603088379,
"blob_id": "2a68f2e44ee93b8da569bc2e312c59e5118c35bb",
"content_id": "3a4393aa32654454696917b563b1f5df53359fa8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 6,
"path": "/app/macs/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "BASE_ROUTE = \"macs\"\n\ndef register_routes(api, app, root=\"api\"):\n from .controller import api as switch_api\n\n api.add_namespace(switch_api, path=f\"/{root}/{BASE_ROUTE}\")"
},
{
"alpha_fraction": 0.616350531578064,
"alphanum_fraction": 0.6274689435958862,
"avg_line_length": 34.39352035522461,
"blob_id": "047eb2f81fb949fd745110ac5c15e508fe0aebe5",
"content_id": "840d8ae323c0daf347b4937320a2c80c2d7c1d9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7663,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 216,
"path": "/app/switch/controller.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os, sys\nfrom flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\nfrom app.utils.async_action import async_action\n\nfrom app.api_response import ApiResponse\nfrom app.errors import ApiException, JobTemplateNotFound, PlaybookFailure, PlaybookTimeout, SwitchNotFound\nfrom .service import SwitchService\nfrom .model import Switch\nfrom .interfaces import SwitchInterfaces\n\nfrom app.utils.authorization import authorize\nfrom app.utils.logger import log\nfrom app.utils.b64 import decode\nfrom app.macs.service import MacService\n\napi_description = \"\"\"\nRepresentación de los switches de la empresa.\n\"\"\"\n\napi = Namespace('Switch', description=api_description)\ninterfaces = SwitchInterfaces(api)\n\[email protected](\"/\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass SwitchResource(Resource):\n \"\"\"\n Switch Resource\n \"\"\"\n @api.response(200, 'Lista de Switches', interfaces.many_response_model)\n @log\n @async_action\n @authorize\n async def get(self):\n \"\"\"\n Devuelve la lista de Switches\n \"\"\"\n try:\n entities = await SwitchService.get_all()\n return ApiResponse(interfaces.many_schema.dump(entities).data)\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')\n @api.expect(interfaces.create_model)\n @api.response(200, 'Nuevo Switch', interfaces.single_response_model)\n @log\n @authorize\n def post(self):\n \"\"\"\n Crea un nuevo Switch.\n \"\"\"\n json_data = request.get_json()\n if json_data is None:\n raise ApiException('JSON body is undefined')\n body = interfaces.single_schema.load(json_data).data\n Switch = SwitchService.create(body)\n return ApiResponse(interfaces.single_schema.dump(Switch).data)\n\n @api.expect(interfaces.update_model)\n @api.response(200, 'Switches Actualizados', interfaces.many_response_model)\n @log\n @authorize\n def put(self, id: int):\n \"\"\"\n Actualiza un batch de Switches por su ID.\n \"\"\"\n json_data = request.get_json()\n sw_updated = []\n for item in json_data:\n sw = interfaces.single_schema.load(request.json).data\n sw_updated.append(SwitchService.update(id, sw))\n return ApiResponse(interfaces.many_schema.dump(sw_updated).data)\n\[email protected](\"/<int:id>\")\[email protected](\"id\", \"Identificador único del Switch\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass SwitchIdResource(Resource):\n @api.response(200, 'Switch', interfaces.single_response_model)\n @log\n @async_action\n @authorize\n async def get(self, id: int):\n \"\"\"\n Obtiene un único Switch por ID.\n \"\"\"\n try:\n switch = await SwitchService.get_by_id(id)\n return ApiResponse(interfaces.single_schema.dump(switch).data)\n except SwitchNotFound:\n raise ApiException(f'No se encuentra un switch con el id:{id}')\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')\n\n\n @api.response(204, 'No Content')\n @log\n @authorize\n def delete(self, id: int) -> Response:\n \"\"\"\n Elimina un único Switch por ID.\n \"\"\"\n from flask import jsonify\n id = SwitchService.delete_by_id(id)\n return ApiResponse(None, 204)\n\n @api.expect(interfaces.update_model)\n @api.response(200, 'Switch Actualizado', interfaces.single_response_model)\n @log\n @authorize\n def put(self, id: int):\n \"\"\"\n Actualiza un único Switch por ID.\n \"\"\"\n try:\n body = interfaces.single_schema.load(request.json).data\n Switch = SwitchService.update(id, body)\n return ApiResponse(interfaces.single_schema.dump(Switch).data)\n except SwitchNotFound:\n raise ApiException(f'No se encuentra un switch con el id:{id}')\[email protected](\"/inventory\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass SwitchInventoryResource(Resource):\n \"\"\"\n Inventory switch Resource\n \"\"\"\n @api.response(200, 'Inventario con lista de swithces')\n @async_action\n async def get(self):\n \"\"\"\n Devuelve la lista de Switches\n \"\"\"\n try:\n entities = await SwitchService.get_all()\n ansible_switches_vars = {}\n for x in entities:\n ansible_switches_vars[x.name] = { \n \"ansible_host\": x.ip,\n \"ansible_become\": True,\n \"ansible_become_method\": \"enable\",\n \"ansible_connection\": \"network_cli\",\n \"ansible_network_os\": \"ios\",\n \"ansible_port\": x.ansible_ssh_port or 22,\n \"ansible_user\": decode(x.ansible_user),\n \"ansible_ssh_pass\": decode(x.ansible_ssh_pass)\n }\n ansible_switches_hostnames = map(lambda x : x.name, entities)\n sw_inv = {\n 'group': {\n 'hosts': list(ansible_switches_hostnames),\n },\n '_meta': {\n 'hostvars': ansible_switches_vars\n }\n }\n return ApiResponse(sw_inv)\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')\n\[email protected](\"/<int:id>/macs\")\[email protected](\"id\", \"Identificador único del Switch\")\nclass SwitchMacResource(Resource):\n \"\"\"\n Mac Resource\n \"\"\"\n @api.response(200, 'Lista de Interfaces con sus respectivas macs', interfaces.many_response_model)\n @log\n @async_action\n @authorize\n async def get(self, switch_id: int):\n \"\"\"\n Devuelve la lista de todaslas macs del switch\n \"\"\"\n try:\n resp = await MacService.get(switch_id)\n return ApiResponse(resp)\n except SwitchNotFound:\n raise ApiException(f'No se encuentra un switch con el id:{switch_id}')\n except JobTemplateNotFound:\n raise ApiException('No existe un playbook para obtener la infrmación de las interfaces')\n except PlaybookTimeout:\n raise ApiException('La ejecución de la tarea supero el tiempo del timeout')\n except PlaybookFailure:\n raise ApiException('Fallo la ejecución de la tarea')\n"
},
{
"alpha_fraction": 0.6204379796981812,
"alphanum_fraction": 0.6277372241020203,
"avg_line_length": 36.40909194946289,
"blob_id": "02ff26eba993b43fc373d6c0c0c41a8373c6a4c2",
"content_id": "ebb667838e6623bb24bd430728152a57b2e15ce3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 822,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 22,
"path": "/app/api_response.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import json, Response\nfrom marshmallow import fields, Schema\nfrom flask_restplus import fields as f\n\n\nclass ApiResponse(object):\n def __init__(self, value, status=200):\n self.value = value\n self.status = status\n\n def to_response(self):\n if self.value == None:\n return Response('', status=self.status, mimetype='application/json')\n if self.status >= 400:\n return Response(json.dumps(self.value), status=self.status, mimetype='application/json')\n data = {}\n if isinstance(self.value, dict):\n data['item'] = self.value\n if isinstance(self.value, list):\n data['items'] = self.value\n data['count'] = len(self.value)\n return Response(json.dumps(data), status=self.status, mimetype='application/json')"
},
{
"alpha_fraction": 0.6949999928474426,
"alphanum_fraction": 0.6949999928474426,
"avg_line_length": 24.125,
"blob_id": "3872137e440d1a6ab7746c0b3e788cb52ac42268",
"content_id": "dfd2d76ed789c8d3a3ab1b5b4e464e5c69e9d08f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 8,
"path": "/app/jobs/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from .model import Job\n\nBASE_ROUTE = \"jobs\"\n\ndef register_routes(api, app, root=\"api\"):\n from .controller import api as results_api\n\n api.add_namespace(results_api, path=f\"/{root}/{BASE_ROUTE}\")"
},
{
"alpha_fraction": 0.48564398288726807,
"alphanum_fraction": 0.6899097561836243,
"avg_line_length": 15.472972869873047,
"blob_id": "8c7334af3555d445e6566500db4286181a720018",
"content_id": "026005779264f635b28b615d2f3977a3a306c856",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1219,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 74,
"path": "/requirements.txt",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "aiohttp==3.6.2\nalembic==1.0.11\namqp==2.5.1\naniso8601==7.0.0\nastroid==2.2.5\nasync-timeout==3.0.1\nasyncio==3.4.3\natomicwrites==1.3.0\nattrs==19.1.0\nbcrypt==3.1.7\nbilliard==3.6.1.0\nboto==2.49.0\ncached-property==1.5.1\ncertifi==2019.9.11\ncffi==1.13.2\nchardet==3.0.4\nClick==7.0\ncryptography==2.8\ndocker==3.7.3\ndocker-compose==1.24.1\ndocker-pycreds==0.4.0\ndockerpty==0.4.1\ndocopt==0.6.2\necdsa==0.15\nFlask==1.1.1\nFlask-RESTful==0.3.7\nflask-restplus==0.12.1\nFlask-SQLAlchemy==2.4.0\nfuture==0.18.2\nidna==2.7\nimportlib-metadata==0.19\nisort==4.3.21\nitsdangerous==1.1.0\nJinja2==2.10.1\njsonschema==3.0.2\nkombu==4.6.5\nlazy-object-proxy==1.4.1\nMako==1.1.0\nMarkupSafe==1.1.1\nmarshmallow==2.19.5\nmccabe==0.6.1\nmore-itertools==7.2.0\nmultidict==4.5.2\nmypy-extensions==0.4.1\npackaging==19.1\nparamiko==2.6.0\npluggy==0.12.0\npy==1.8.0\npyasn1==0.4.8\npycparser==2.19\npylint==2.3.1\nPyNaCl==1.3.0\npyparsing==2.4.2\npyrsistent==0.15.4\npytest==5.0.1\npython-dateutil==2.8.0\npython-editor==1.0.4\npython-jose==3.0.1\npytz==2019.2\nPyYAML==5.1\nrequests==2.20.1\nrsa==4.0\nsix==1.12.0\nSQLAlchemy==1.3.6\ntexttable==0.9.1\ntyped-ast==1.4.0\nurllib3==1.24.3\nvine==1.3.0\nwcwidth==0.1.7\nwebsocket-client==0.56.0\nWerkzeug==0.15.5\nwrapt==1.11.2\nyarl==1.3.0\nzipp==0.5.2\n"
},
{
"alpha_fraction": 0.6788537502288818,
"alphanum_fraction": 0.6847826242446899,
"avg_line_length": 36.407405853271484,
"blob_id": "261afa60467d8de2dc8fd5bfbaf00b379aa3a294",
"content_id": "5d916bea8f8bd1edc9cdce62f384b5be99680758",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1012,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 27,
"path": "/app/utils/awx.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport aiohttp\nfrom aiohttp.client import ClientTimeout\n\n\nAWX_BASE_URL = 'http://web:8052'\nAUTH = aiohttp.BasicAuth(os.environ.get('AWX_USER'), os.environ.get('AWX_PASSWORD'))\nTIMEOUT_SECONDS = 60\nTIMEOUT = ClientTimeout(total=TIMEOUT_SECONDS)\n\nasync def awx_fetch(endpoint):\n url = AWX_BASE_URL + endpoint\n async with aiohttp.ClientSession(auth=AUTH, json_serialize=json.dumps, timeout=TIMEOUT) as session:\n async with session.get(url) as resp:\n return await resp.json()\n\nasync def awx_post(endpoint, data):\n url = AWX_BASE_URL + endpoint\n if data != None:\n async with aiohttp.ClientSession(auth=AUTH, json_serialize=json.dumps, timeout=TIMEOUT) as session:\n async with session.post(url=url, json=data) as resp:\n return await resp.json()\n else:\n async with aiohttp.ClientSession(auth=AUTH, timeout=TIMEOUT) as session:\n async with session.post(url=url) as resp:\n return await resp.text()\n\n\n"
},
{
"alpha_fraction": 0.6456539034843445,
"alphanum_fraction": 0.6601409316062927,
"avg_line_length": 49.09803771972656,
"blob_id": "506127b9580b5ba0ef6f487f4affd0d61de08485",
"content_id": "b5ba8fd971ab96329df10eb537b1c0af6bb2ea19",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2555,
"license_type": "permissive",
"max_line_length": 156,
"num_lines": 51,
"path": "/app/logs/interfaces.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app.utils.base_interfaces import BaseInterfaces, marshmallow_fields, restplus_fields\n\nclass LogInterfaces(BaseInterfaces):\n __name__ = 'Log'\n id = dict(\n m=marshmallow_fields.Int(attribute='id', dump_only=True),\n r=restplus_fields.Integer(description='Identificador único', required=True, example=123),\n )\n http_method = dict(\n m=marshmallow_fields.String(attribute='http_method'),\n r=restplus_fields.String(description='Tipo de metodo http', required=True, example='POST'),\n )\n http_url = dict(\n m=marshmallow_fields.String(attribute='http_url'),\n r=restplus_fields.String(description='url de destino', required=False, example='http://ejemplo.com/api/entidad/'),\n )\n payload = dict(\n m=marshmallow_fields.String(attribute='payload'),\n r=restplus_fields.String(\n description='Payload del Request',\n required=False,\n example='{ \"name\": \"Juan\"}' \n )\n )\n\n user_name = dict(\n m=marshmallow_fields.String(attribute='user_name'),\n r=restplus_fields.String(description='nombre de usuario', required=True, example='nombre de ejemplo'),\n )\n user_email = dict(\n m=marshmallow_fields.String(attribute='user_email'),\n r=restplus_fields.String(description='email de usuario', required=True, example='[email protected]'),\n )\n response_status_code = dict(\n m=marshmallow_fields.Int(attribute='response_status_code', dump_only=True),\n r=restplus_fields.Integer(description='Http status code de la respuesta', required=True, example=123),\n )\n message = dict(\n m=marshmallow_fields.String(attribute='message', dump_only=True),\n r=restplus_fields.String(description='Mensaje de la respuesta', required=True, example=123),\n )\n date_start = dict(\n m=marshmallow_fields.String(attribute='date_start'),\n r=restplus_fields.String(description='Datetime de inicio la consulta', required=True, example='2018-28-01 00:00:00'),\n )\n date_end = dict(\n m=marshmallow_fields.String(attribute='date_end'),\n r=restplus_fields.String(description='Datetime de finalizacion la consulta', required=True, example='2018-28-01 00:00:00'),\n )\n create_model_keys = [\"id\", \"http_method\", \"http_url\", \"payload\", \"user_name\", \"user_email\", \"response_status_code\", \"message\", \"date_start\", \"date_end\"]\n update_model_keys = [\"id\", \"http_method\", \"http_url\", \"payload\", \"user_name\", \"user_email\", \"response_status_code\", \"message\", \"date_start\", \"date_end\"]"
},
{
"alpha_fraction": 0.6048988103866577,
"alphanum_fraction": 0.6464323997497559,
"avg_line_length": 25.828571319580078,
"blob_id": "0d88e8150679b288749468727812e1cfcd840495",
"content_id": "8c6af2078ae53fabffac0d61f2a54e7bbc193bce",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 939,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 35,
"path": "/migrations/versions/7e633f4a3f96_switch.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "\"\"\"switch\n\nRevision ID: 7e633f4a3f96\nRevises: 44ce70d8983e\nCreate Date: 2019-10-25 15:45:26.106566\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '7e633f4a3f96'\ndown_revision = None\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n op.create_table(\n 'switch',\n sa.Column('id', sa.BIGINT, primary_key=True),\n sa.Column('name', sa.String(255), nullable=False),\n sa.Column('ip', sa.String(15), nullable=False),\n sa.Column('description', sa.String(255), nullable=True),\n sa.Column('model', sa.String(255), nullable=True),\n sa.Column('ansible_user', sa.String(255), nullable=True),\n sa.Column('ansible_ssh_pass', sa.String(255), nullable=True),\n sa.Column('ansible_ssh_port', sa.Integer, nullable=True),\n sa.Column('is_visible', sa.Boolean, default=True),\n )\n\n\ndef downgrade():\n op.drop_table('switch')\n"
},
{
"alpha_fraction": 0.5648252367973328,
"alphanum_fraction": 0.5648252367973328,
"avg_line_length": 21.200000762939453,
"blob_id": "499403e3a486f5f62d4293c0a7973a73a378d02c",
"content_id": "c913a49428643abcd983229834aef69f8e8cac49",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 887,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 40,
"path": "/app/logs/service.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app import db\nfrom typing import List\nfrom .model import Log\n\n\nclass LogService:\n @staticmethod\n def get_all() -> List[Log]:\n return Log.query.all()\n\n @staticmethod\n def get_by_id(id: int) -> Log:\n return Log.query.get(id)\n\n @staticmethod\n def update(id: int, body) -> Log:\n model = LogService.get_by_id(id)\n if model is None:\n return None\n model.update(body)\n db.session.commit()\n return model\n\n @staticmethod\n def delete_by_id(id: int) -> List[int]:\n model = Log.query.filter(Log.id == id).first()\n if not model:\n return []\n db.session.delete(model)\n db.session.commit()\n return [id]\n\n @staticmethod\n def create(new_attrs) -> Log:\n model = Log(**new_attrs)\n\n db.session.add(model)\n db.session.commit()\n\n return model"
},
{
"alpha_fraction": 0.5968688726425171,
"alphanum_fraction": 0.6516634225845337,
"avg_line_length": 27.38888931274414,
"blob_id": "31bb3c95357e3c3195bd3bab7fc9781bd0069d86",
"content_id": "380201cc59b75bd8901e58577cf4ad52666edd47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1022,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 36,
"path": "/migrations/versions/76c3cd4b5053_create_logs_table.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "\"\"\"create logs table\n\nRevision ID: 76c3cd4b5053\nRevises: a2708f0d3454\nCreate Date: 2019-11-22 11:15:30.644292\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '76c3cd4b5053'\ndown_revision = '2b60825ec877'\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n op.create_table(\n 'logs',\n sa.Column('id', sa.Integer, primary_key=True),\n sa.Column('http_method', sa.String(30), nullable=True),\n sa.Column('http_url', sa.String(255), nullable=True),\n sa.Column('payload', sa.String(1000), nullable=True),\n sa.Column('user_name', sa.String(255), nullable=False),\n sa.Column('user_email', sa.String(255), nullable=True),\n sa.Column('response_status_code', sa.Integer, nullable=True),\n sa.Column('message', sa.String(255), nullable=True),\n sa.Column('date_start', sa.DateTime, nullable=False),\n sa.Column('date_end', sa.DateTime, nullable=False)\n )\n\n\ndef downgrade():\n op.drop_table('logs')\n"
},
{
"alpha_fraction": 0.6040723919868469,
"alphanum_fraction": 0.610859751701355,
"avg_line_length": 23.61111068725586,
"blob_id": "9148dfc10f4f56c63008057202afd5ff73d0d23d",
"content_id": "58a50aa4bd307ad36279d557c06eec1e5c15cf26",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 18,
"path": "/app/jobs/model.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from sqlalchemy import Integer, Column, String, JSON\nfrom app import db # noqa\n\n\nclass Job(db.Model): # type: ignore\n \"\"\"Job Model\"\"\"\n\n __tablename__ = \"jobs\"\n\n id = Column(Integer(), primary_key=True)\n job_id = Column(Integer(), unique=True)\n type = Column(String(255))\n result = Column(JSON)\n\n def update(self, changes):\n for key, val in changes.items():\n setattr(self, key, val)\n return self"
},
{
"alpha_fraction": 0.6963993310928345,
"alphanum_fraction": 0.6996726393699646,
"avg_line_length": 38.32258224487305,
"blob_id": "63044cfc2bd285a08a29fc1140efdaba907f5936",
"content_id": "def9e513f5325229fa3bb697771ef72a0f8c1b0e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1222,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 31,
"path": "/app/api_response_test.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import Response\n\nfrom app.api_response import ApiResponse\n\ndef test_api_response_to_response_returns_a_response_object():\n expected = ApiResponse(value=None).to_response()\n assert isinstance(expected, Response)\n\ndef test_api_response_to_response_empty_value_mimetype():\n expected = ApiResponse(value=None).to_response()\n assert expected.mimetype == 'text/html'\n\ndef test_api_response_to_response_default_status():\n expected = ApiResponse(value=None).to_response()\n assert expected.status == '200 OK'\n\ndef test_api_response_to_response_value_mimetype():\n expected = ApiResponse(value={'ok': True}).to_response()\n assert expected.mimetype == 'application/json'\n\ndef test_api_response_to_response_empty_body():\n expected = ApiResponse(value=None).to_response()\n assert expected.data == b''\n\ndef test_api_response_to_response_single_value_body():\n expected = ApiResponse(value={'ok': True}).to_response()\n assert expected.data == b'{\"item\": {\"ok\": true}}'\n\ndef test_api_response_to_response_multiple_value_body():\n expected = ApiResponse(value=[{'ok': True}, {'ok': False}]).to_response()\n assert expected.data == b'{\"count\": 2, \"items\": [{\"ok\": true}, {\"ok\": false}]}'\n\n\n\n"
},
{
"alpha_fraction": 0.6995074152946472,
"alphanum_fraction": 0.6995074152946472,
"avg_line_length": 24.5,
"blob_id": "f789feda12152db42cb1b0ad53696a04fcb663ff",
"content_id": "683f4208fb325f9b30bc1d64b5047de85d3c06f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 8,
"path": "/app/switch/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from .model import Switch\n\nBASE_ROUTE = \"switch\"\n\ndef register_routes(api, app, root=\"api\"):\n from .controller import api as switch_api\n\n api.add_namespace(switch_api, path=f\"/{root}/{BASE_ROUTE}\")"
},
{
"alpha_fraction": 0.6739606261253357,
"alphanum_fraction": 0.6914660930633545,
"avg_line_length": 25.941177368164062,
"blob_id": "65d9aa1d90b0c78306ce6b5b8f699dd372a29483",
"content_id": "d239588d1a998fa2d641faad8a1c7648123c7d27",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 17,
"path": "/app.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom app import create_app\nfrom alembic.config import Config\nfrom alembic import command\n\nFLASK_ENV = os.environ.get('FLASK_ENV', 'test')\nFLASK_PORT = os.environ.get('FLASK_PORT', 5000)\n\nalembic_cfg = Config(\"./alembic.ini\")\nalembic_cfg.set_main_option('sqlalchemy.url', os.environ['DATABASE_URI'])\n\n(app, _) = create_app(FLASK_ENV)\n\nif __name__ == \"__main__\":\n command.upgrade(alembic_cfg, \"head\")\n app.run(host='0.0.0.0', port=FLASK_PORT)"
},
{
"alpha_fraction": 0.6251891255378723,
"alphanum_fraction": 0.625945508480072,
"avg_line_length": 37.33333206176758,
"blob_id": "237dc8ce984f06a48edb9a5183de702d43c45f2a",
"content_id": "f3e8e1b8873eb20dc333d4a3c5a7df228c54990a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2650,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 69,
"path": "/app/nics/service.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "\"\"\"\nNics service\n\nDesacopla el manejo del request/response HTTP de la lógica de la\naplicación.\n\"\"\"\nimport asyncio\nfrom app.switch.service import SwitchService\nfrom app.jobs.service import JobService\nfrom app.utils.prime import prime_fetch\nfrom app.errors import ApiException, SwitchNotFound\n\n\nclass NicsService:\n @staticmethod\n async def reset_switch_nic(switch_id, nic_name):\n switch = await SwitchService.get_by_id(switch_id)\n if switch == None:\n raise SwitchNotFound\n extra_vars = dict(interface_name=nic_name)\n body = dict(limit=switch.name, extra_vars=extra_vars)\n return await JobService.run_job_template_by_name('reset-interface', body)\n\n @staticmethod\n async def get_by_switch_id(switch_id):\n \"\"\"\n Devuelve la información de todas las interfaces a través\n del AWX, quien consulta directamente al switch.\n\n Args:\n switch_id (int): Identidad del switch\n \"\"\"\n switch = await SwitchService.get_by_id(switch_id)\n if switch == None:\n raise SwitchNotFound\n extra_vars = dict(something='awesome')\n body = dict(limit=switch.name, extra_vars=extra_vars)\n sw_result = await JobService.run_job_template_by_name('show-interfaces-information', body)\n try:\n result = dict()\n prime_result = await NicsService.get_from_prime_by_switch_id(switch_id)\n for key, value in sw_result.items():\n if key in prime_result:\n result[key] = { **prime_result[key], **value}\n else:\n result[key] = value\n return result\n except Exception as err:\n print(f'Switch no pertenece al prime. Error: {str(err)}', flush=True)\n return sw_result\n\n @staticmethod\n async def get_from_prime_by_switch_id(switch_id):\n \"\"\"\n Devuelve la información de todas las interfaces a través\n del la api del Cisco Prime, quien consulta directamente al switch.\n\n Args:\n switch_id (int): Identidad del switch\n \"\"\"\n result = dict()\n try:\n from_prime = await prime_fetch(f'/webacs/api/v4/data/InventoryDetails/{switch_id}.json')\n for interface in from_prime['queryResponse'][\"entity\"][0][\"inventoryDetailsDTO\"][\"ethernetInterfaces\"][\"ethernetInterface\"]:\n result[interface[\"name\"]] = interface\n return result\n except Exception as err:\n print(\"Error in get_from_prime: \" + str(err), flush=True)\n raise ApiException(\"Error al cargar nics del Cisco Prime. Error: \" + str(err))"
},
{
"alpha_fraction": 0.7539863586425781,
"alphanum_fraction": 0.7539863586425781,
"avg_line_length": 38.90909194946289,
"blob_id": "358e4c22e80d304eeda82ac3c4b1008e6cbd042f",
"content_id": "24ada0cebef57c30a5f9a2fc31b167804a4495de",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 11,
"path": "/app/routes.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "def register_routes(api, app, root=\"api\"):\n from app.switch import register_routes as attach_switch\n from app.nics import register_routes as attach_nics\n from app.macs import register_routes as attach_macs\n from app.jobs import register_routes as attach_jobs\n from app.logs import register_routes as attach_logs\n attach_switch(api, app)\n attach_nics(api, app)\n attach_macs(api, app)\n attach_jobs(api, app)\n attach_logs(api, app)\n"
},
{
"alpha_fraction": 0.6325459480285645,
"alphanum_fraction": 0.6561679840087891,
"avg_line_length": 29.520000457763672,
"blob_id": "ed3c40a72ce5d2921c53ca884eb6790f19a84feb",
"content_id": "b6a2c7cb14075d9529198db3676fb3f1b57904ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 762,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 25,
"path": "/app/logs/model.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom sqlalchemy import Integer, Column, String, JSON, DateTime\nfrom app import db # noqa\n\n\nclass Log(db.Model): # type: ignore\n \"\"\"Log Model\"\"\"\n\n __tablename__ = \"logs\"\n\n id = Column(Integer(), primary_key=True)\n http_method = Column(String(30))\n http_url = Column(String(255))\n payload = Column(String(1000))\n user_name = Column(String(255))\n user_email = Column(String(255))\n response_status_code = Column(Integer)\n message = Column(String(255))\n date_start = Column(DateTime(), default=datetime.datetime.utcnow)\n date_end = Column(DateTime(), default=datetime.datetime.utcnow)\n def update(self, changes):\n for key, val in changes.items():\n setattr(self, key, val)\n return self"
},
{
"alpha_fraction": 0.6688963174819946,
"alphanum_fraction": 0.6772575378417969,
"avg_line_length": 21.185184478759766,
"blob_id": "d6abbe7d0fcb0d28d27bc8755ba45d12d878f6b5",
"content_id": "c53c4f10709e6ded8c42d933f601a84f5124faa0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 27,
"path": "/app/example_async_use.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom utils.async_action import async_action\nfrom utils.fetch import fetch\nimport asyncio\nimport aiohttp\nimport time\nimport sys\n\napp = Flask(__name__)\n\[email protected]('/')\n@async_action\nasync def index():\n await asyncio.sleep(5)\n contador = 0\n async with aiohttp.ClientSession() as session:\n for i in range(10):\n html = await fetch(session, 'https://api.telemetry.conatest.click/clients')\n contador += 1\n return 'Hello world whit total: ' + str(contador)\n\[email protected]('/helloifr')\ndef hif():\n return 'Hello world whit total'\n\n\napp.run()"
},
{
"alpha_fraction": 0.46177491545677185,
"alphanum_fraction": 0.5050732493400574,
"avg_line_length": 32.904632568359375,
"blob_id": "f92eef0ed194ffee90c3496ee87ad74e99dd2fc7",
"content_id": "1d219d538ce03b52445f25bcdc24dcc509ac3163",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 49771,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 1468,
"path": "/app/nics/README.md",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "```python\nRESULT = {\n \"FastEthernet0/1\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con AP Prev&Lab <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 21,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4701\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/1\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/10\": {\n \"access_mode_vlan\": \"600 (VIRL_FLAT)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470a\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/10\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/11\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"--> Mgmt G0 4431 172.30.1.145 <--\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 3,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470b\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/11\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/12\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470c\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/12\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/13\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con RTR-GW 2921 <---\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 48,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 10028000,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470d\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/13\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"trunk\",\n \"operational_trunk_encapsulation\": \"dot1q\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 10045000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"25/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"25/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/14\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 612936,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con SW-Meraki <---\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 612936,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 411000,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470e\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/14\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"trunk\",\n \"operational_trunk_encapsulation\": \"dot1q\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 9658000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"24/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/15\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> GW LoRaWAN <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.470f\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/15\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/16\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"-->UCS-C200 Puerto 2<--\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4710\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/16\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/17\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"---> Conexion con GI 0/0/0 RTR-HQ <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4711\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/17\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/18\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"---> Conexion con GI 0/0/2 RTR-HQ <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4712\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/18\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/19\": {\n \"access_mode_vlan\": \"501 (Conexion_Conatel)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4713\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/19\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/2\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con AP PRUEBAS <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4702\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/2\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/20\": {\n \"access_mode_vlan\": \"2000 (VLAN2000)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4714\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/20\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/21\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 4000,\n \"interface_resets\": 4,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4715\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/21\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"trunk\",\n \"operational_trunk_encapsulation\": \"dot1q\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 6000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/22\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 3000,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4716\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/22\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"trunk\",\n \"operational_trunk_encapsulation\": \"dot1q\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 4000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/23\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4717\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/23\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/24\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con SW-L3-CPD <---\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 1000,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4718\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/24\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"trunk\",\n \"operational_trunk_encapsulation\": \"dot1q\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 8000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/3\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"dynamic auto\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con AP PRUEBAS <---\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4703\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/3\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"static access\",\n \"operational_trunk_encapsulation\": \"native\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/4\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"dynamic auto\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 8,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con AP PRUEBAS <---\",\n \"duplex\": \" Full-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 40,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 9604000,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4704\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/4\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"static access\",\n \"operational_trunk_encapsulation\": \"native\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 376000,\n \"overrun_errors\": 0,\n \"protocol\": \"up (connected) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"24/255\",\n \"speed\": \"100Mb/s\",\n \"state\": \"up\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/5\": {\n \"access_mode_vlan\": \"501 (Conexion_Conatel)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4705\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/5\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/6\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"---> Prueba WhatsUp Gold <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4706\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/6\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/7\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4707\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/7\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/8\": {\n \"access_mode_vlan\": \"10 (WAN)\",\n \"adminisrtative_mode\": \"static access\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4708\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/8\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"Off\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"FastEthernet0/9\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"dynamic auto\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"---> PRUEBA <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Fast Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4709\",\n \"media_type\": \"10/100BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"FastEthernet0/9\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"GigabitEthernet0/1\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"dynamic auto\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Gigabit Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4719\",\n \"media_type\": \"10/100/1000BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"GigabitEthernet0/1\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"GigabitEthernet0/2\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"dynamic auto\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 10000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 1000,\n \"description\": \"\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"Gigabit Ethernet\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.471a\",\n \"media_type\": \"10/100/1000BaseTX\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"GigabitEthernet0/2\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (notconnect) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"Port-channel1\": {\n \"access_mode_vlan\": \"1 (default)\",\n \"adminisrtative_mode\": \"trunk\",\n \"administrative_trunk_encapsulation\": \"dot1q\",\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 100000,\n \"collisions\": 0,\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 100,\n \"description\": \"---> Conexion con SW-CPD-CORE1 <---\",\n \"duplex\": \" Auto-duplex\",\n \"enabled_vlans\": \"ALL\",\n \"frame_errors\": 0,\n \"hw_type\": \"EtherChannel\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"auto\",\n \"mac_address\": \"88f0.7787.4716\",\n \"media_type\": \"unknown\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"Port-channel1\",\n \"native_vlan\": \"1 (default)\",\n \"native_vlan_tagging\": \"enabled\",\n \"operational_mode\": \"down\",\n \"operational_trunk_encapsulation\": \"\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"down (disabled) \",\n \"pruning_enabled_vlans\": \"2-1001\",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"Auto-speed\",\n \"state\": \"administratively down\",\n \"switchport\": \"Enabled\",\n \"trunk_negotiation\": \"On\",\n \"tx_load\": \"1/255\",\n \"voice_vlan\": \"none\"\n },\n \"Vlan1\": {\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 1000000,\n \"collisions\": \"\",\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 10,\n \"description\": \"\",\n \"duplex\": \"\",\n \"frame_errors\": 0,\n \"hw_type\": \"EtherSVI\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 2,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4740\",\n \"media_type\": \"\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"Vlan1\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"up \",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"\",\n \"state\": \"up\",\n \"tx_load\": \"1/255\"\n },\n \"Vlan10\": {\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 1000000,\n \"collisions\": \"\",\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 10,\n \"description\": \"---> VLAN PRUEBAS <---\",\n \"duplex\": \"\",\n \"frame_errors\": 0,\n \"hw_type\": \"EtherSVI\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 2,\n \"internet_address\": \"172.30.1.140/24\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4741\",\n \"media_type\": \"\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"Vlan10\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"up \",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"\",\n \"state\": \"up\",\n \"tx_load\": \"1/255\"\n },\n \"Vlan600\": {\n \"bandwdth_units\": \"Kbit\",\n \"bandwdth_value\": 1000000,\n \"collisions\": \"\",\n \"crc_errors\": 0,\n \"delay_units\": \"usec\",\n \"delay_value\": 10,\n \"description\": \"\",\n \"duplex\": \"\",\n \"frame_errors\": 0,\n \"hw_type\": \"EtherSVI\",\n \"ignored_errors\": 0,\n \"input_errors\": 0,\n \"input_rate_interval_units\": \"minute\",\n \"input_rate_interval_value\": 5,\n \"input_rate_units\": \"bits/sec\",\n \"input_rate_value\": 0,\n \"interface_resets\": 1,\n \"internet_address\": \"\",\n \"link_type\": \"\",\n \"mac_address\": \"88f0.7787.4742\",\n \"media_type\": \"\",\n \"mtu_units\": \"bytes\",\n \"mtu_value\": 1500,\n \"name\": \"Vlan600\",\n \"output_errors\": 0,\n \"output_rate_interval_units\": \"minute\",\n \"output_rate_interval_value\": 5,\n \"output_rate_units\": \"bits/sec\",\n \"output_rate_value\": 0,\n \"overrun_errors\": 0,\n \"protocol\": \"up \",\n \"reliability\": \"255/255\",\n \"rx_load\": \"1/255\",\n \"speed\": \"\",\n \"state\": \"up\",\n \"tx_load\": \"1/255\"\n }\n}\n```"
},
{
"alpha_fraction": 0.7467249035835266,
"alphanum_fraction": 0.7532750964164734,
"avg_line_length": 34.30769348144531,
"blob_id": "5b985e227be8138aa332a44a0927600bcd195203",
"content_id": "7e4fe9305e598b08d62c74dd0cb2950356333ecf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 13,
"path": "/app/api_flask_test.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import Response\n\nfrom app.api_flask import ApiFlask\nfrom app.api_response import ApiResponse\nfrom app.test.fixtures import api\n\n\ndef test_api_flask_make_response(api):\n #should convert the ApiResponse object to a `Response` by calling its `to_response` method.\n api_response = ApiResponse(value={'ok': True}, status=200)\n response = api.make_response(api_response)\n expected = isinstance(response, Response)\n assert expected == True"
},
{
"alpha_fraction": 0.6309217810630798,
"alphanum_fraction": 0.6507528424263,
"avg_line_length": 27.978723526000977,
"blob_id": "b2a0ffac967389a4aa7d81016375f6eba7892ac3",
"content_id": "6d292530c127a533f2adf9df9a107600d785ee59",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2728,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 94,
"path": "/app/jobs/controller.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\n\nfrom app.api_response import ApiResponse \nfrom app.errors import ApiException\n\nfrom .service import JobService\nfrom .model import Job\nfrom .interfaces import JobInterfaces\n\n\n\napi_description = \"\"\"\nRepresentación de los Jobs de la empresa.\n\"\"\"\n\napi = Namespace('Jobs', description=api_description)\ninterfaces = JobInterfaces(api)\n\[email protected](\"/\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass JobResource(Resource):\n \"\"\"\n Jobs Resource\n \"\"\"\n\n @api.response(200, 'Lista de Jobs', interfaces.many_response_model)\n def get(self):\n \"\"\"\n Devuelve la lista de Jobs\n \"\"\"\n entities = JobService.get_all()\n return ApiResponse(interfaces.many_schema.dump(entities).data)\n\n @api.expect(interfaces.create_model)\n @api.response(200, 'Nuevo Job', interfaces.single_response_model)\n def post(self):\n \"\"\"\n Crea un nuevo Job.\n \"\"\"\n json_data = request.get_json()\n if json_data is None:\n raise ApiException('JSON body is undefined')\n body = interfaces.single_schema.load(json_data).data\n Job = JobService.create(body)\n return ApiResponse(interfaces.single_schema.dump(Job).data)\n\n\[email protected](\"/<int:id>\")\[email protected](\"id\", \"Identificador único del Job\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass JobIdResource(Resource):\n @api.response(200, 'Job', interfaces.single_response_model)\n def get(self, id: int):\n \"\"\"\n Obtiene un único Job por ID.\n \"\"\"\n Job = JobService.get_by_id(id)\n return ApiResponse(interfaces.single_schema.dump(Job).data)\n\n @api.response(204, 'No Content')\n def delete(self, id: int) -> Response:\n \"\"\"\n Elimina un único Job por ID.\n \"\"\"\n from flask import jsonify\n\n id = JobService.delete_by_id(id)\n return ApiResponse(None, 204)\n\n @api.expect(interfaces.update_model)\n @api.response(200, 'Job Actualizado', interfaces.single_response_model)\n def put(self, id: int):\n \"\"\"\n Actualiza un único Job por ID.\n \"\"\"\n body = interfaces.single_schema.load(request.json).data\n Job = JobService.update(id, body)\n return ApiResponse(interfaces.single_schema.dump(Job).data)"
},
{
"alpha_fraction": 0.7188081741333008,
"alphanum_fraction": 0.7216014862060547,
"avg_line_length": 28.86111068725586,
"blob_id": "8c45a2d3c8c84698ee8d7f864ae166d93c84bcd5",
"content_id": "23f27633267b3b35febd4ff528cc975a4d2f1e08",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1076,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 36,
"path": "/app/errors.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from werkzeug.exceptions import HTTPException\n\nfrom app.api_response import ApiResponse\n\nclass ApiException(HTTPException):\n def __init__(self, message, status=400, code='UncaughtError'):\n self.message = message\n self.status = status\n self.code = code\n\n def to_response(self):\n return ApiResponse(dict(message=self.message, code=self.code), status=self.status).to_response()\n\ndef register_error_handlers(app):\n app.register_error_handler(ApiException, lambda err: err.to_response())\n\nclass JobTemplateNotFound(Exception):\n \"\"\"No existe el job_template\"\"\"\n\nclass PlaybookTimeout(Exception):\n \"\"\"La ejecución del playbook supero el tiempo del timeout\"\"\"\n\nclass PlaybookFailure(Exception):\n \"\"\"Fallo la ejecución del playbook\"\"\"\n\nclass ConnectToAwxFailure(Exception):\n \"\"\"Fallo al intentar conectarse con la api de AWX\"\"\"\n\nclass PlaybookCancelFailure(Exception):\n \"\"\"Fallo la intentar cancelar un job\"\"\"\n\nclass NicNotFound(Exception):\n \"\"\"No existe la nic\"\"\"\n\nclass SwitchNotFound(Exception):\n \"\"\"No existe el switch\"\"\""
},
{
"alpha_fraction": 0.6513222455978394,
"alphanum_fraction": 0.6581782698631287,
"avg_line_length": 45.45454406738281,
"blob_id": "763a96ccf432f8a3b6b6b4063f06556272a45448",
"content_id": "e2b0bb6982c4b390b419a7e6466e436cb43d4c20",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1022,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 22,
"path": "/app/jobs/interfaces.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app.utils.base_interfaces_test import BaseInterfaces, marshmallow_fields, restplus_fields\n\nclass JobInterfaces(BaseInterfaces):\n __name__ = 'Job'\n id = dict(\n m=marshmallow_fields.Int(attribute='id', dump_only=True),\n r=restplus_fields.Integer(description='Identificador único', required=True, example=123),\n )\n job_id = dict(\n m=marshmallow_fields.Int(attribute='job_id'),\n r=restplus_fields.Integer(description='Identificador del trabajo', required=True, example=123),\n )\n type = dict(\n m=marshmallow_fields.String(attribute='type'),\n r=restplus_fields.String(description='Tipo de resultado', required=True, example='interfaces'),\n )\n result = dict(\n m=marshmallow_fields.Dict(attribute='result'),\n r=restplus_fields.Raw(description='El resultado', required=False, example=\"{ interfaces: [ nic1: ..., nic: ...] }\"),\n )\n create_model_keys = [ 'id', 'type', 'job_id', 'result']\n update_model_keys = ['type', 'job_id', 'result']"
},
{
"alpha_fraction": 0.5867418646812439,
"alphanum_fraction": 0.5987306237220764,
"avg_line_length": 40.735294342041016,
"blob_id": "33d3ff47da201340c48ceea08045aed738d3eacd",
"content_id": "043a8130254a25d6fe21593ff295e1d6b7268761",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1422,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 34,
"path": "/app/nics/interfaces.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "# from app.utils.base_interfaces_test import BaseInterfaces, marshmallow_fields, restplus_fields\n\n# class SwitchInterfaces(BaseInterfaces):\n# __name__ = 'Switch'\n# id = dict(\n# m=marshmallow_fields.Int(attribute='id', dump_only=True),\n# r=restplus_fields.Integer(description='Identificador único', required=True, example=123),\n# )\n# name = dict(\n# m=marshmallow_fields.String(attribute='name'),\n# r=restplus_fields.String(description='Nombre del Switch', required=True, example='sw-core-1'),\n# )\n# description = dict(\n# m=marshmallow_fields.String(attribute='description'),\n# r=restplus_fields.String(description='Descripción del Switch', required=False, example='Switch de core #1'),\n# )\n# model = dict(\n# m=marshmallow_fields.String(attribute='model'),\n# r=restplus_fields.String(\n# description='Modelo del Switch',\n# required=False,\n# example='Cisco 2960x' \n# )\n# )\n# ip = dict(\n# m=marshmallow_fields.String(attribute='ip'),\n# r=restplus_fields.String(\n# description='Dirección IP para la administración del switch',\n# required=True,\n# example='192.168.1.1' \n# )\n# )\n# create_model_keys = ['name', 'description', 'model', 'ip']\n# update_model_keys = ['name', 'description', 'model', 'ip']"
},
{
"alpha_fraction": 0.652914822101593,
"alphanum_fraction": 0.6609865427017212,
"avg_line_length": 29.97222137451172,
"blob_id": "7d54a5546450922c0358cbb85e91ba234c1beb7a",
"content_id": "8fe2db719bbd2204eb02ad375ca00c21d5c43939",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1115,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 36,
"path": "/app/utils/authorization.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nimport json\n\nfrom jose import jwt\nfrom jose.exceptions import JWTError, ExpiredSignatureError, JWTClaimsError, JWKError\nfrom functools import wraps\nfrom flask import request, redirect\nfrom app.api_response import ApiResponse\nfrom app.errors import ApiException\n\n\n\nPUBLIC_KEY = f\"\"\"\n-----BEGIN PUBLIC KEY----- \n{os.environ.get('PUBLIC_KEY')}\n-----END PUBLIC KEY-----\n\"\"\"\n\ndef authorize(func):\n @wraps(func)\n def authorize_handler(*args, **kwargs):\n token = request.headers.get('Token')\n if not token:\n return ApiResponse({\"Error\": \"Token not found\"}, 400)\n try:\n jwt.decode(token, PUBLIC_KEY, algorithms=['RS256'], audience='dashboard',options={ \"leeway\": 120, \"verify_exp\": False })\n except JWTError as error:\n raise ApiException(error)\n except JWTClaimsError as error:\n raise ApiException(error)\n except ExpiredSignatureError as error:\n raise ApiException(error)\n except JWKError as error:\n raise ApiException(error)\n return func(*args, **kwargs)\n return authorize_handler\n"
},
{
"alpha_fraction": 0.5603360533714294,
"alphanum_fraction": 0.5641548037528992,
"avg_line_length": 40.35789489746094,
"blob_id": "31c3fd695789e3409a05acba2a10abc6cc8bc9ea",
"content_id": "ed64ca2b204d27e51b6e31c82acd715c0fbbc730",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3928,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 95,
"path": "/app/switch/service.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from app import db\nfrom typing import List\nfrom .model import Switch\nfrom app.utils.b64 import encode\nfrom app.errors import ApiException\nimport os\nimport json\nimport sys\nfrom app.utils.prime import prime_fetch\nimport copy\nimport pathlib\nimport asyncio\nfrom app.jobs.service import JobService\n\nclass SwitchService:\n @staticmethod\n async def get_all() -> List[Switch]:\n switches_from_prime = []\n try:\n ids_sw_in_db = list(map(lambda x: int(x[0]), db.session.query(Switch.id).all()))\n prime_data = await prime_fetch('/webacs/api/v4/data/Devices.json?.full=true&.maxResults=300&.firstResult=0')\n # with open(os.path.join(pathlib.Path(__file__).parent.absolute(), 'prime_devices_full.json')) as json_file:\n # prime_data = json.load(json_file)\n switches = prime_data['queryResponse']['entity']\n for switch in switches:\n switch_data = switch[\"devicesDTO\"]\n if not (int(switch_data[\"@id\"]) in ids_sw_in_db):\n SwitchService.create({\n \"id\": int(switch_data[\"@id\"]),\n \"name\": switch_data[\"deviceName\"],\n \"description\": \"software_type: {0}, software_version: {1}\".format(switch_data.get(\"softwareType\",\"unknown\"),switch_data.get(\"softwareVersion\",\"unknown\")),\n \"model\": switch_data[\"deviceType\"], \n \"ip\": switch_data[\"ipAddress\"],\n \"ansible_user\": encode(os.getenv(\"PRIME_SWITCHES_SSH_USER\")),\n \"ansible_ssh_pass\": encode(os.getenv(\"PRIME_SWITCHES_SSH_PASS\")),\n \"is_visible\": True\n })\n else:\n SwitchService.update(int(switch_data[\"@id\"]),{\n \"name\": switch_data[\"deviceName\"],\n \"description\": \"software_type: {0}, software_version: {1}\".format(switch_data.get(\"softwareType\",\"unknown\"),switch_data.get(\"softwareVersion\",\"unknown\")),\n \"model\": switch_data[\"deviceType\"], \n \"ip\": switch_data[\"ipAddress\"],\n \"ansible_user\": encode(os.getenv(\"PRIME_SWITCHES_SSH_USER\")),\n \"ansible_ssh_pass\": encode(os.getenv(\"PRIME_SWITCHES_SSH_PASS\"))\n })\n except Exception as err:\n print(\"Can't connect with prime to list switches, error: \", err, file=sys.stderr)\n return db.session.query(Switch).all()\n \n @staticmethod\n async def get_by_id(id: int) -> Switch:\n sws = await SwitchService.get_all()\n if len(sws) > 0:\n switch = list(filter(lambda x: x.id == int(id), sws))\n if len(switch) > 0:\n return switch[0]\n raise SwitchNotFound\n\n @staticmethod\n def update(id: int, body) -> Switch:\n model = Switch.query.get(id)\n if model is None:\n raise SwitchNotFound\n model.update(body)\n db.session.commit()\n return model\n\n @staticmethod\n def delete_by_id(id: int) -> List[int]:\n model = Switch.query.filter(Switch.id == id).first()\n if not model:\n return []\n db.session.delete(model)\n db.session.commit()\n return [id]\n\n @staticmethod\n def create(new_attrs) -> Switch:\n model = Switch(**new_attrs)\n db.session.add(model)\n db.session.commit()\n return model\n\n @staticmethod\n async def get_macs(switch_id, nic_name):\n switch = SwitchService.get_by_id(switch_id)\n if switch == None:\n raise SwitchNotFound\n extra_vars = dict(interface_name=nic_name)\n body = dict(limit=switch.name, extra_vars=extra_vars)\n return await JobService.run_job_template_by_name('get-mac-address-table', body)\n\nclass SwitchNotFound(Exception):\n \"\"\"No existe el switch\"\"\""
},
{
"alpha_fraction": 0.680232584476471,
"alphanum_fraction": 0.680232584476471,
"avg_line_length": 27.83333396911621,
"blob_id": "0d5e94fb452bd04027fda64e35710a54f872dba9",
"content_id": "828e297499bd2ef4613242f49add6f4888615682",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 172,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 6,
"path": "/app/nics/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "BASE_ROUTE = \"switch\"\n\ndef register_routes(api, app, root=\"api\"):\n from .controller import api as nics_api\n\n api.add_namespace(nics_api, path=f\"/{root}/{BASE_ROUTE}\")"
},
{
"alpha_fraction": 0.6349714994430542,
"alphanum_fraction": 0.6542022824287415,
"avg_line_length": 28.26041603088379,
"blob_id": "8b6089aa7e788cd2d62739707f9553cdfd075453",
"content_id": "9e52cf73960499a757dd33335831aaa0105a3e5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2813,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 96,
"path": "/app/logs/controller.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\n\nfrom app.api_response import ApiResponse\nfrom app.errors import ApiException\nfrom .service import LogService\nfrom .model import Log\nfrom .interfaces import LogInterfaces\n\nfrom app.utils.authorization import authorize\n\napi_description = \"\"\"\nRepresentación de los switches de la empresa.\n\"\"\"\n\napi = Namespace('Log', description=api_description)\ninterfaces = LogInterfaces(api)\n\[email protected](\"/\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass LogResource(Resource):\n \"\"\"\n Log Resource\n \"\"\"\n\n @api.response(200, 'Lista de Logs', interfaces.many_response_model)\n @authorize\n def get(self):\n \"\"\"\n Devuelve la lista de Logs\n \"\"\"\n entities = LogService.get_all()\n return ApiResponse(interfaces.many_schema.dump(entities).data)\n\n @api.expect(interfaces.create_model)\n @api.response(200, 'Nuevo Log', interfaces.single_response_model)\n @authorize\n def post(self):\n \"\"\"\n Crea un nuevo Log.\n \"\"\"\n json_data = request.get_json()\n if json_data is None:\n raise ApiException('JSON body is undefined')\n body = interfaces.single_schema.load(json_data).data\n Log = LogService.create(body)\n return ApiResponse(interfaces.single_schema.dump(Log).data)\n\n\[email protected](\"/<int:id>\")\[email protected](\"id\", \"Identificador único del Log\")\[email protected](400, 'Bad Request', interfaces.error_response_model)\[email protected](responses={\n 401: 'Unauthorized',\n 403: 'Forbidden',\n 500: 'Internal server error',\n 502: 'Bad Gateway',\n 503: 'Service Unavailable',\n})\nclass LogIdResource(Resource):\n @api.response(200, 'Log', interfaces.single_response_model)\n @authorize\n def get(self, id: int):\n \"\"\"\n Obtiene un único Log por ID.\n \"\"\"\n Log = LogService.get_by_id(id)\n return ApiResponse(interfaces.single_schema.dump(Log).data)\n\n @api.response(204, 'No Content')\n @authorize\n def delete(self, id: int) -> Response:\n \"\"\"\n Elimina un único Log por ID.\n \"\"\"\n id = LogService.delete_by_id(id)\n return ApiResponse(None, 204)\n\n @api.expect(interfaces.update_model)\n @api.response(200, 'Log Actualizado', interfaces.single_response_model)\n @authorize\n def put(self, id: int):\n \"\"\"\n Actualiza un único Log por ID.\n \"\"\"\n body = interfaces.single_schema.load(request.json).data\n Log = LogService.update(id, body)\n return ApiResponse(interfaces.single_schema.dump(Log).data)"
},
{
"alpha_fraction": 0.6336206793785095,
"alphanum_fraction": 0.7025862336158752,
"avg_line_length": 12.70588207244873,
"blob_id": "b7e2067cf5e9f73355c008520fec71fc6334bd68",
"content_id": "493594b374cffb4a6207b217743f12f51805f49c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 232,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 17,
"path": "/uwsgi.ini",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "[uwsgi]\nwsgi-file = uswgi.py\ncallable = app\nprocesses = 4\nthreads = 2\nstats = 127.0.0.1:9191\n\nuid = nginx\ngid = nginx\n\nmaster = true\nprocesses = 5\n\nsocket = /tmp/uwsgi.sock\nchmod-socket = 664\nchown-socket = nginx:nginx\nvacuum = true"
},
{
"alpha_fraction": 0.6987028121948242,
"alphanum_fraction": 0.7030881643295288,
"avg_line_length": 32.190940856933594,
"blob_id": "7bc9f1e1587e8406b792b235e0953cce8642813f",
"content_id": "04f877684b6c2666101785d22acc6fa556b657eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 27219,
"license_type": "permissive",
"max_line_length": 403,
"num_lines": 817,
"path": "/README.md",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "# `flask-blueprint`\n\nBlueprint para la creación de APIs con Flask\n\n## Indice\n\n- [Inspiración](#inspiration)\n- [Consideraciones](#considerations)\n- [Librerías](#libraries)\n- [Estructura](#structure)\n - [Convención de nombres](#naming_convention)\n - [`Model`](#model)\n - [`Interfaces`](#interfaces)\n - [`Service`](#service)\n - [`Controller`](#controller)\n - [Declaración de rutas](#route_declaration)\n- [API Response](#api_response)\n- [Paginación](#pagination)\n- [Orden](#order)\n- [Filtros](#filters)\n- [Busqueda](#search)\n- [Errors](#errors)\n- [Autenticación](#authentiaction)\n- [Authorización](#authorization)\n- [`create_app`](#create_app)\n- [Fixtures](#fixtures)\n- [Run `dev`](#run)\n- [Tests](#test)\n- [Swagger](#swagger)\n- [Migraciones](#migrations)\n - [Uso de `alembic`](#alembic_use)\n- [Puesta en producción](#production)\n - [Docker Compose](#production_docker_compose)\n - [Kubernetes](#production_kubernetes)\n - [AWS Lambda](#production_aws_lambda) \n\n## Inspiración<a name=\"inspiration\"></a>\n\nEste proyecto esta fuertemente inspirado por los siguientes recursos:\n\n- [Talk \"Flask for Fun and Profit\", Armin Ronacher, PyBay2016, YouTube](https://www.youtube.com/watch?v=1ByQhAM5c1I)\n - [Slides deck](https://speakerdeck.com/mitsuhiko/flask-for-fun-and-profit?slide=42)\n- [Blog \"Flask best practises\", AJ Pryor, http://alanpryorjr.com](http://alanpryorjr.com/2019-05-20-flask-api-example/)\n\n## Librerías<a name=\"libraries\"></a>\n\n- [`flask`](https://palletsprojects.com/p/flask/)\n- [`pytest`](https://docs.pytest.org/en/latest/)\n- [`marshmallow`](https://marshmallow.readthedocs.io/en/3.0/)\n- [`sqlalchemy`](https://www.sqlalchemy.org/)\n- [`flask-restplus`](https://flask-restplus.readthedocs.io/en/stable/)\n- [`alembic`](https://alembic.sqlalchemy.org)\n\n## Estructura<a name=\"structure\"></a>\n\nTodos los archivos que estén relacionados por un mismo topico, deben pertenecer al mismo modulo. No se crean carpetas de `controllers`, `models`, etc.\n\nLa unidad básica de una API es un `entity`, que corresponde a \"aquello sobre lo que queremos operar\". Cada `entity` debe contar con al menos las siguientes piezas:\n\n- `Model`: Representación de Python de la `entity`.\n- `Controller`: Orquesta las rutas, servicios y esquemas de la `entity`.\n- `Interfaces`: Serializa y deserializa los menajes para manipular las `entities`. También sirve para documentar las interfaces.\n- `Service`: Manipula `entities`. Por ejemplo, operaciones CRUD.\n\nLos archivos de prueba de cada entidad deben existir en conjunto con los archivos de la aplicación.\n\nLa estructura final será similar a la siguiente:\n\n```\n/entity\n __init__.py\n controller.py\n controller_test.py\n model.py\n model_test.py\n interfaces.py\n service.py\n service_test.py\n```\n\n### Convención de nombres<a name=\"naming_convention\"></a>\n\nEs importante notar que el nombre de la `entity` esta en singular. Esto es porque todos los lenguajes ya tienen una forma nativa de definir una lista de elementos, como un `array` o una `tupla`. Todos los demás recursos también se nombrarán en singular.\n\n¿Cuando no se seguira esta regla?\n\nCuando se tenga que nombrar una `entity` en un sistema que no cuente con una abstacción nativa de una lista. Por ejemplo:\n\n- En SQL cuando se quiere referenciar una tabla.\n- Al crear las rutas de una `entity`\n\n### `Model`<a name=\"model\"></a>\n\n_Representación de Python de la `entity`._\n\nUsualmente será una clase basada en `db.Model` de `sqlalchemy`. Sin embargo, este no tiene que ser el único caso.\n\n```python\nclass Entity(db.Model):\n \"\"\" Modelo de la entidad `Entity`. \"\"\"\n __tablename__ = 'entities'\n id = Column(Integer(), primary_key=True)\n name = Column(String(255))\n```\n\nComo mínmo, se debe hacer un `fixture` para probar la existencia del modelo.\n\n```python\nfrom pytest import fixture\nfrom .model import Entity\n\n@fixture\ndef entity() -> Entity:\n return Entity(\n id=1, name=\"Test Entitity\"\n )\n \ndef test_Entity_create(entity: Entity):\n assert entity\n```\n\n### `Interfaces`<a name=\"interfaces\"></a>\n\n_Serializa y deserializa los menajes para manipular las `entities`. También sirve para documentar las interfaces._\n\nUtilizaremos `marshmallow` para serializar y deserializar `entities`. En partícular, utilizaremos el objeto `Interfaces` para realizar los cambios de nombres correspondientes de nuestras variables. En JSON y JavaScript, se suele utilizar `camelCase` para definir el nombre de las variables, mientras que en Python se usa `snake_case`.\n\n```python\nfrom app.utils.base_interfaces_test import BaseInterfaces, marshmallow_fields, restplus_fields\n\nclass EntityInterfaces(BaseInterfaces):\n ''' Entity Schema '''\n __name__ = 'Entity'\n id = dict(\n m=marshmallow_fields.Int(attribute='id', dump_only=True),\n r=restplus_fields.Integer(description='Unique identifier', required=True, example=123),\n )\n name = dict(\n m=marshmallow_fields.String(attribute='name'),\n r=restplus_fields.String(description='Name of the entity', required=False, example='My entity'),\n )\n camelCase = dict(\n m=marshmallow_fields.String(attribute='snake_case'),\n r=restplus_fields.String(\n description='Example of how to convert from camelCase to snake_case',\n required=False,\n example='Something' \n )\n )\n create_model_keys = ['name', 'camelCase']\n update_model_keys = ['camelCase']\n```\n\nEl objeto `Interfaces` hereda de la clase `BaseInterfaces`, creada a medida para este proyecto. La dificultad que intenta suplir, es el de tener que montar los esquemas de `marshmallow` y los modelos de `flask-restful`, para manipular los mensajes JSON, y documentar las interfaces.\n\nEsta clase espera que se le configuren todos los atributos, con sus configuraciones de `marshmallow` y `flask-restful`, identificados dentro de un diccionario bajo las llaves `m`, y `r` respectivamente. Luego al momento de crear una instancia de esta clase, quedarán disponibles distintos modelos y esquemas para simplificar la serialización/deserialización de los datos, y simplificar su documentación.\n\nA continuación se presenta la definicón de dicha clase, y los atributos disponibles:\n\n```txt\nThis class simplifies the creation of `marshmallo` schemas, and \n`flask_restplus` models to document the API.\n\nArgs:\n api (flask_restplus.Namespace): `flask_restplus` Namespace instance.\n name (str, optional): Name of the entity.\n\nAttributes:\n _api (flask_restplus.Namespace): `flask_restplus` Namespace instance.\n __name__ (string): Name of the entity. Used as prefix for the model names.\n _shcema (marshmallow.Schema): Dynamically generated `marshmallow` :class:`Schema`.\n single_schema (marshmallow.Schema): `marshmallow` instance for a single entity.\n many_shcema (marshmallow.Schema): `marshmallow` instance for a list of entities.\n create_model_keys (:list:str): List of field names that creates the entity's create model.\n update_model_keys (:list:str): List of field names that creates the entity's update model.\n create_model (flask_restplus.Namespace.model): Entity's create model.\n update_model (flask_restplus.Namespace.model): Entity's update model.\n model (flask_resplus.Namespace.model): Entity's model.\n single_response_model (flask_restplus.Namespace.model): Single entity's response model.\n many_response_model (flask_restplus.Namespace.model): Multiple entity's response model.\n```\n\n_Las `Interfaces` no tienen por que contar con una suite de pruebas._\n\n### Services<a name=\"services\"></a>\n\n_Manipula `entities`. Por ejemplo, operaciones CRUD._\n\nOtras funciones de las cuales estan encargados los `Services` son:\n\n- Obtener información de una API.\n- Manipular data frames.\n- Obtener predicciones a partir de modelos de ML.\n- Etc.\n\nDeben estar encargados de todas las tareas relacionadas con el procesamiento de datos. Los servicios pueden depender de otros servicios. No así los `Models`. Esta es una distinción importante.\n\n```python\nfrom app import db\nfrom typing import List\n\nfrom .model import Entity\nfrom .interface import EntityInterface\n\n\nclass EntityService():\n @classmethod\n def get_all() -> List[Entity]:\n return Entity.query.all()\n \n @statimethod\n def get_by_id(id: int) -> Entity:\n return Entity.query.get(id)\n \n @staticmethod\n def update(id: int, attributes: EntityInterface) -> Entity:\n entity = Entity.query.get(id)\n entity.update(updates)\n db.session.commit()\n return entity\n \n @staticmethod\n def delete_by_id(id: int) -> List[int]:\n entity = Entity.query.filter(Entity.id == id).fist()\n if not entity:\n return []\n db.session.delete(entity)\n db.session.commit()\n return [id]\n \n @staticmethod\n def create(attributes: EntityInterface) -> Entity:\n entity = Entity(name=attributes['name'])\n db.session.add(entity)\n db.session.commit()\n return entity\n```\n\nLos `Services` deben contar con pruebas sobre todos sus metodos. Como interactuan con otros servicios usualmente es necesario realizar `mocks` de los mismos.\n\n```python\nfrom flas_sqlalchemy import SQLAlchemy\nfrom typing import List\n\nfrom app.test.fixtures import app, db # noqa\nfrom .model import Entity\nfrom .service import EntityService\nfrom .interface import EntityInterface\n\n\ndef test_get_all(db: SQLAlchemy): # noqa\n entity_1 = Entity(id=1, name='1')\n entity_2 = Entity(id=2, name='2')\n db.session.add(entity_1)\n db.session.add(entity_2)\n db.session.commit()\n results: List[Entity] = EntityService.get_all()\n assert len(results) == 2\n assert entity_1 in results and entity_2 in results\n \ndef test_update(db: SQLAlchemy): #noqa\n id = 1\n entity: Entity = Entity(id=id, name='1')\n db.session.add(entity_1)\n db.session.commit()\n attributes: EntityInterface = {'name': '2'}\n EntityService.update(1, updates)\n result: Entity = Entity.query.get(id)\n assert result.name == '2'\n \ndef test_delete_by_id(db: SQLAlchemy): #noqa\n entity_1 = Entity(id=1, name='1')\n entity_2 = Entity(id=2, name='2')\n db.session.add(entity_1)\n db.session.add(entity_2)\n db.session.commit()\n EntityService.delete_by_id(1)\n db.session.commit()\n results: List[Entity] = Entity.query.all()\n assert len(results) == 1\n assert entity_1 not in results and entity_2 in results\n \ndef test_create(db: SQLAlchemy): # noqa\n attributes: EntityInterface = {'name': '1'}\n EntityService.create(attributes)\n results: List[Entity] = Widget.query.all()\n assert len(results) == 1\n for key in attributes.keys():\n assert getattr(results[0], key) == attributes[key]\n```\n\n### Controller<a name=\"controller\"></a>\n\n_Orquesta las rutas, servicios y esquemas de la `entity`._\n\nAdemás, podemos utilizar `flask-restplus` para documentar la API con Swagger.\n\n```python\nfrom flask import request\nfrom flask_accepts import accepts, responds\nfrom flask_restplus import Namespace, Resource\nfrom flask.wrappers import Response\nfrom typing import List\n\nfrom .schema import EntitiySchema\nfrom .service import EntityService\nfrom .model import Entity\nfrom .interface import EntityInterface\n\napi = Namespace('Entity', description='Single namespace, single entity')\n\n\[email protected]('/')\nclass EntityResource(Resource):\n \"\"\" Entity Resource \"\"\"\n \n @responds(schema=EntitySchema, many=True)\n def get(self) -> List[Entity]:\n \"\"\" Get all entities \"\"\"\n return EntityService.get_all()\n \n @accepts(schema=EntitySchema, api=api)\n @responds(schema=EntitySchema)\n def post(self) -> Entity:\n \"\"\" Create a single Entity \"\"\"\n return EntityService.create(request.parsed_obj)\n \[email protected]('/<int:id>')\[email protected]('id', 'Entity ID')\nclass EntityIdResource(Resource):\n \"\"\" Entity ID Resource \"\"\"\n \n @responds(schema=EntitySchema)\n def get(self, id: int) -> Entity:\n \"\"\" Get a single Entity \"\"\"\n return EntityService.get_by_id(id)\n \n def delete(self, id: int) -> Response:\n \"\"\" Delete a single Entity \"\"\"\n from flask import jsonify\n id = WidgetService.delete_by_id(id)\n return jsonify({ 'status: 'success', 'id': id })\n \n @accepts(schema=EntitySchema, api=api)\n @responds(schema=EntitySchema)\n def put(self, id: int) -> Entity:\n \"\"\" Update a single Entity \"\"\"\n return EntityService.update(id, request.parsed_obj)\n```\n\n> `request.parsed_object` es creado por el docorador `accepts` de `flask_accepts`. El mismo consume el esquema, y se encarga de deserializar el cuerpo para convertirlo a un diccionario valido que podemos usar luego en nuestros `Services`.\n\nPara testear los controladores tendremos que construir un `mock` del `Service`. Esto es para mantener las priebas del `Controller` aisladas del `Service`.\n\n```python\nfrom unittest.mock import patch\nfrom flask.testing import FlaskClient\n\nfrom app.test.fixtures import client, app # noqa\nfrom .service import EntityService\nfrom .schema import EntitySchema\nfrom .model import Entity\nfrom .interface import EntityInterface\nfrom . import BASE_ROUTE\n\ndef make_entity(id: int = 123, name: str = 'Test Entity') -> Entity:\n return Entity(id=id, name=name)\n \nclass TestEntityResource:\n @patch.object(EntityService, 'get_all',\n lambda: [make_entity(123, name='Test Entity 1'),\n make_entity(124, name='Test Entity 2')])\n def test_get(self, client: FlaskClient): #noqa\n with client:\n results = client.get(f'/api/{BASE_ROUTE}', follow_redirects=True).get_json()\n expected = EntitySchema(many=True).dump(\n [make_entity(123, name='Test Entity 1'),\n make_entity(124, name='Test Entity 2')]\n ).data\n for r in results:\n assert r in expected\n```\n\n### Declaración de rutas <a name=\"route_declaration\"></a>\n\nLo último que queda definir es como se terminan registrando las rutas en la API. La siguiente forma muestra como hacerlo evitando problemas de importaciones circulares.\n\nDefinimos dentro de cada carpeta de entidad la configuración de las rutas en el archivo `./app/entity/__init__.py`.\n\n```python\nfrom .model import Entity #noqa\nfrom .schema import WidgetSchema # noqa\n\nBASE_ROUTE = 'entity'\n\ndef register_routes(api, app, root='api'):\n \"\"\" Registramos las rutas definidas en la `api` del `Controller` \"\"\"\n from .controller import api as entity_api\n api.add_namespace(entity_api, path=f'/{root}/{BASE_ROUTE}')\n```\n\nDesde otro archivo importaremos esta función, y la llamaremos con el objeto `api` y la aplicación de Flask global.\n\n## API Response<a name=\"api_response\"></a>\n\nPara simplificar la creación del cuerpo de la respuesta, se utilizara una clase llamada `ApiResponse` que deberá ser retornada por los metodos de los `Controllers`. La clase recibira el valor de la respuesta, y el codigo de respuesta. La misma creara luego, internamente, la estructura acorde para la respuesta.\n\nEsto simplificara las tareas de agregar links para la paginación, y para agregar relaciones entre entidades de forma centralizada.\n\n**¿Como hacemos para que `flask` pueda procesar esta clase?**\n\nSobrescribiendo el método `make_response` de `flask`. Este metodo es llamado previo a la construcción de la respuesta final hacia el cliente. Para poder sobrescribirlo, debemos crear una nueva clase que herede de `flask_restplus.Api`.\n\n```python\nfrom flask_restplus import Api\n\nfrom app.api_response import ApiResponse\n\n\nclass ApiFlask(Api):\n def make_response(self, rv, *args, **kwargs):\n if isinstance(rv, ApiResponse):\n return rv.to_response()\n return Api.make_response(self, rv, *args, **kwargs)\n```\n\nLuego, utilizaremos esta clase para crear nuestra aplicación de `flask`.\n\n## Paginación<a name=\"pagination\"></a>\n\nTODO\n\n## Orden<a name=\"order\"></a>\n\nTODO\n\n## Filtros<a name=\"filters\"></a>\n\nTODO\n\n## Busqueda<a name=\"search\"></a>\n\nTODO\n\n\n## Errors<a name=\"errors\"></a>\n\nPara los errores podemos hacer algo parecido. Los errores pueden contar con logica compartida, mismos codigos de error, o una misma estructura. Para simplificar como se emiten estos errores, los mismos se tirarán utilizando una clase especial llamada `ApiException`.\n\n```python\nfrom werkzeug.exceptions import HTTPException\n\nfrom app.api_response import ApiResponse\n\nclass ApiException(HTTPException):\n def __init__(self, message, code=400):\n self.message = message\n self.code = code\n\n def to_response(self):\n return ApiResponse({'message': self.message}, status=self.code)\n```\n\nLo que queda es indicarle a `flask` como reaccionar cunado se enfrenta con una excepción. Para eso utilizamos la función `register_error_handlers`.\n\n```python\ndef register_error_handlers(app):\n app.register_error_handler(ApiException, lambda err: err.to_response())\n```\n\nCuando `flask` detecte un error de tipo `ApiException`, correrá el código indicado en la función Lambda.\n\n**¿Como lo utilizamos?**\n\n```python\nfrom flask import request\nfrom flask_restplus import Namespace, Resource, fields\nfrom flask.wrappers import Response\n\nfrom app.api_response import ApiResponse\nfrom app.api_exception import ApiException\n\napi = Namespace('Math', description=\"Math resources\")\n\[email protected](\"/sum\")\nclass MathResource(Resource):\n \"\"\"Math sum resource\"\"\"\n\n @api.response(200, 'Sum result')\n def get(self) -> ApiResponse:\n \"\"\"Returns the sim result\"\"\"\n a = request.args('a', type=int)\n b = request.args('b', type=int)\n if a is None or b is None:\n raise ApiException('Numbers must be integers')\n return ApiResult({'result': a + b}) \n```\n\n## `create_app`<a name=\"create_app\"></a>\n\nPara poder testear correctamente la API, necesitamos una forma sencilla de crearla. Un patron utilizado en Flask es crear un metodo llamado `create_app` que cree la API, consumiendo una lista de configuraciones.\n\nDentro de `app/__init__.py` creamos el siguiente metodo:\n\n```python\nfrom flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_restplus import Api, Resource, fields\n\ndb = SQLAlchemy()\n\n\ndef create_app(env=None):\n from app.config import config_by_name\n from app.routes import register_routes\n # Creamos la aplicación de Flask\n app = Flask(__name__)\n config = config_by_name[env or \"test\"]\n app.config.from_object(config)\n # Creacmos el objeto `api`\n api_title = os.environ['APP_TITLE'] or config.TITLE\n api_version = os.environ('APP_VERSION') or config.VERSION\n api = Api(app, title=api_title, version=api_version)\n # Registramos las rutas\n register_routes(api, app)\n # Inicializamos la base de datos\n db.init_app(app)\n # Creamos una ruta para chequear la salud del sistema\n @app.route('/healthz')\n def healthz():\n \"\"\" Healthz endpoint \"\"\"\n return \"ok\"\n # Retornamos la aplicación de Flask\n return app\n```\n\nEn `./app/config.py` creamos los archivos de configuración para cada uno de nuestros ambientes (por lo menos `test` y `prod`).\n\n```python\nimport os\n\nbasedir = os.path.abspath(path.dirname(__file__))\n\nclass BaseConfig:\n TITLE = 'Api'\n VERSION = '0.0.1'\n CONFIG_NAME = 'base'\n DEBUG = False\n TESTING = False\n \nclass DevelopmentConfig(BaseConfig):\n CONFIG_NAME: 'dev'\n DEBUG = True\n SQLALCHEMY_DATABASE_URI = 'sqlite:///{0}/app-dev.db'.format(basedir)\n \nclass TestingConfig(BaseConfig):\n CONFIG_NAME = 'test'\n DEBUG = True\n TESTING = True\n SQLALCHEMY_DATABASE_URI = 'sqlite:///{0}/app-tetst.db'.format(basedir)\n \nclass ProductionConfig(BaseConfig):\n CONFIG_NAME = 'prod'\n SQLALCHEMY_DATABASE_URI = \"sqlite:///{0}/app-prod.db\".format(basedir)\n \nEXPORT_CONFIGS = [\n DevelopmentConfig,\n TestingConfig,\n ProductionConfig,\n]\n\nconfig_by_name = { cfg.CONFIG_NAME: cfg for cfg in EXPORT_CONFIGS }\n```\n\nLo único que queda definir es el metodo para importar las rutas `register_routes`, definido en el módulo `./app/routes.py`.\n\n```python\ndef register_routes(api, app, root=\"api\"):\n # Importamos el metodo `register_routes` de cada `entity` y lo renombramos\n from app.entity import register_routes as attach_entity\n # Registramos las rutas\n attach_entity(api, app)\n```\n\nUna de las ventajas del metodo `create_app` es que tambien podemos realizar pruebas sobre el.\n\n```python\nfrom app.test.fixtures import app, client # noqa\n\n\ndef test_app_creates(app): # noqa\n assert app\n \ndef test_app_healthy(app, client): # noqa\n with client:\n resp = client.get('/healthz')\n assert resp.status_code == 200\n assert resp.text == 'ok'\n```\n\n## Fixtures<a name=\"fixtures\"></a>\n\nLos `fixtures` existen para crear un ambiente base confiable y replicable por sobre el cual correr las pruebas. Los metodos de pruebas pueden recibir estos `fixtures` como argumentos al momento de ser llamados. Los mismos se registran utilizando el decorador `@pytset.fixture`. Por ejemplo, para nuestro caso conviene crear un `fixture` para la `app` y uno para la `db`:\n\n```python\nimport pytest\n\nfrom app import create_app\n\n\[email protected]\ndef app():\n return create_app('test')\n\[email protected]\ndef client(app):\n return app.test_client()\n\[email protected]\ndef db(app):\n from app import db\n \n with app.app_context():\n db.drop_all()\n db.create_all()\n yield db\n db.drop_all()\n db.session.commit()\n```\n\nSi los definimos en un módulo llamado `test`, despues solo tenemos que importarlos a nuestro archivo de pruebas, y utilizar los mismos nombres de los argumentos, que los utilizados al momento de construir el `fixture`. Si vemos el ejemplo del archivo de pruebas de `create_app` podemos ver como utilizarlos.\n\n## Run `dev`<a name=\"run\"></a>\n\nPara correr la aplicación en modo desarrollo utilizamos el siguiente comando:\n\n```bash\nFLASK_ENV=development flask run --port 8000\n```\n\n## Tests<a name=\"tests\"></a>\n\nPara correr las pruebas utilizaremos `pytest`. Desde la `cli` solo es necesario utilizar este comando:\n\n```\npytest\n```\n\nFlask provee una forma de testear la aplicación, al exponer la clase `Client` de `Werkzeug`, y manejando el contexto local por nosotros.\n\nLo más importante es contar con un `fixture` que represente al cliente.\n\nEn nuestro caso lo definimos de la siguiente manera.\n\n```python\nimport pytest\n\nfrom app import create_app\nfrom app.api_flask import ApiFlask\n\[email protected]\ndef app():\n return create_app('test')[0]\n\[email protected]\ndef client(app):\n return app.test_client()\n```\n\nAhora que contamos con el fixture, lo podemos utilizar dentro de nuestras pruebas.\n\n```python\ndef test_empty_db(client):\n \"\"\"Start with a blank database.\"\"\"\n \n rv = client.get('/')\n assert b'No enties here so far' in rv.data\n```\n\nPara probar `POST` requests, podemos pasarle el cuerpo en el argumento `json` del metodo `client.post()`.\n\n```python\ndef test_messages(client):\n \"\"\"Tests that messages work.\"\"\"\n\n rv = client.post('/add', json=dict(name='Something', purpose='awesome'))\n assert b'{\"name\": \"something\", \"purpose\": \"awesome\", \"id\": 1}' in rv\n```\n\nSi necesitamos realizar pruebas en base a información recibida en el contexto `request`, `g`, y `session`, podemos utilizar el metodo `test_request_context`, que se encuentra dentro del objeto `app`. El objeto `app` también lo definimos como un `fixture`.\n\n```python\ndef test_query_parameters(app, client):\n \"\"\"Test the name in the query parameters.\"\"\"\n\n with app.test_request_context('?name=John'):\n assert flask.request.path == '/'\n assert flask.request.args['name'] == 'John'\n```\n\n## Swagger<a name=swagger></a>\n\nAl utilizar `flask_restful` ya contamos con documentación en formato `swagger` que podemos visualizar desde la raiz de nuestra API. Osea, si servimos la `api` desde el puerto `8000`, podemos encontrar la documentación en `http://localhost:8000`.\n\nTambién podemos servir la el documento `swagger` en JSON agregando la siguiente ruta:\n\n```python\nfrom flask import Flask, jsonify\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_restplus import Api, Resource, fields\n\ndb = SQLAlchemy()\n\n\ndef create_app(env=None):\n # Dentro de `create_app` despues de definir la `api`\n @app.route('/swagger')\n def swagger():\n \"\"\" Swagger JSON docs \"\"\"\n return jsonify(api.__schema__)\n # ...\n```\n\n## Migraciones <a name=\"migrations\"></a>\n\nLas migraciones de la base de datos las haremos con [`alembic`](https://alembic.sqlalchemy.org)\n\nEs una herramienta para desarrollar migraciones de bases de datos desarrollado por el autor de SQLAlchemy. Con esta herramienta podremos:\n\n1. Emitir modificaciones en la base de datos.\n2. Construir `scripts` que indiquen una serie de `pasos` necesarios para actualizar o revertir el estado de una tabla.\n3. Permite la ejecución de `scripts` de forma secuencial.\n\n### Uso de `alembic`<a name=\"alembic_use\"></a>\n\nUna vez instalado `alembic` debemos crear la carpeta donde se incluiran todas las migraciones. Esto lo hacemos con el comando:\n\n```\nalembic init migrations\n```\n\nSe creara:\n\n1. Un archivo en la raiz llamado `alembic.ini`\n2. Una carpeta llamada `migrations` donde incluiremos nuestros `scripts`.\n\nDentro del archivo `alembic.ini` colocamos la ruta hacia la base de datos de `dev` modificando el valor de `sqlalchemy.url`.\n\nLas migraciones se crean dentro de revisiones. `Alembic` puede generar los archivos de revisiones por nosotros con el siguiente comando:\n\n```\nalembic revision -m \"create entity table\"\n```\n\nEl resultado será un nuevo archivo de migración dentro de `./migrations/versions/`. Dentro de este documento tendremos que modificar las declaraciones de las funciones `upgrade()` y `downgrade()`. Las mismas son ejecutadas cuando nos movemos en un, u otro sentido de las migraciones.\n\nEl siguiente es un ejemplo de como las podemos configurar para crear una nueva tabla:\n\n```python\ndef upgrade():\n op.create_table(\n 'entity',\n sa.Column('id', sa.Integer, primary_key=True),\n sa.Column('name', sa.String(255), nullable=False),\n sa.Column('purpose', sa.String(255), nullable=False),\n )\n\ndef downgrade():\n op.drop_table('entity')\n```\n\nAl finalizar, podemos aplicar nuestra nueva revisión con el comando:\n\n```\nalembic upgrade head\n```\n\nEsto aplicara todos los cambios definidos en la migración.\n\nExisten otros comandos útiles que `alembic` nos provee:\n\n- Para ver la migración actual\n ```\n alembic current --verbose\n ```\n- Para ver la historia de las migraciones\n ```\n alembic history --verbose\n ```\n- Para bajar a la versión anterior de la base\n ```\n alembic downgrade -1\n ```\n- Para subir a la versión siguiente\n ```\n alembic upgrade +1\n ```\n- Para hacer un roll-back de todas las migraciones\n ```\n alembic downgrade base\n ```\n\n## Puesta en producción<a name=\"production\"></a>\n \nTODO\n\n### Docker Compose <a name=\"production_docker_compose\"></a>\n\nTODO\n\n### Kubernetes <a name=\"production_kubernetes\"></a>\n\nTODO\n\n### AWS Lambda <a name=\"production_aws_lambda\"></a>\n\nTODO\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6855670213699341,
"alphanum_fraction": 0.6855670213699341,
"avg_line_length": 23.375,
"blob_id": "d93152ab931fcfc177493aebe7a7a8a40bc1673e",
"content_id": "c8db76e18f6e4643d2a3733917520ca1833eb42e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 8,
"path": "/app/logs/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from .model import Log\n\nBASE_ROUTE = \"logs\"\n\ndef register_routes(api, app, root=\"api\"):\n from .controller import api as logs_api\n\n api.add_namespace(logs_api, path=f\"/{root}/{BASE_ROUTE}\")"
},
{
"alpha_fraction": 0.5742381811141968,
"alphanum_fraction": 0.5768316388130188,
"avg_line_length": 31.58450698852539,
"blob_id": "66d686687d412083d6262cea953c38f8244abda4",
"content_id": "94201210ebe64474b3f8c4a19511d1323b991a2d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4628,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 142,
"path": "/app/jobs/service.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import asyncio\nimport os\nimport sys\nfrom time import time\n\nfrom app import db\nfrom app.errors import JobTemplateNotFound, PlaybookTimeout, PlaybookFailure, ConnectToAwxFailure, PlaybookCancelFailure\nfrom app.utils.awx import awx_fetch, awx_post\nfrom typing import List\nfrom .model import Job\n\n\nENV = 'prod' if os.environ.get('ENV') == 'prod' else 'dev'\nTIMEOUT_SECONDS = 120\n\n\nclass JobService:\n @staticmethod\n def get_all() -> List[Job]:\n return Job.query.all()\n\n @staticmethod\n def get_by_id(id: int) -> Job:\n result = Job.query.get(id)\n return result\n\n @staticmethod\n def get_by_job_id(id: int) -> Job:\n result = Job.query.filter(Job.job_id == id).first()\n return result\n @staticmethod\n def get(conditions) -> Job:\n return Job.query.filter_by(**conditions).first()\n\n @staticmethod\n def update(id: int, body) -> Job:\n model = JobService.get_by_id(id)\n if model is None:\n return None\n model.update(body)\n db.session.commit()\n return model\n\n @staticmethod\n def delete_by_id(id: int) -> List[int]:\n model = Job.query.filter(Job.id == id).first()\n if model is None:\n return []\n \n db.session.delete(model)\n db.session.commit()\n return [id]\n \n @staticmethod\n def delete_by_job_id(job_id: int) -> List[int]:\n model = Job.query.filter(Job.job_id == job_id).first()\n if model is None:\n return []\n db.session.delete(model)\n db.session.commit()\n return [job_id]\n\n @staticmethod\n def create(new_attrs) -> Job:\n model = Job(**new_attrs)\n db.session.add(model)\n db.session.commit()\n\n return model\n @staticmethod\n async def get_job_template_id_by_name(job_template_name):\n \"\"\"\n Obtiene el ID en el AWX correspondiente al job_template\n identificado por el nombre job_template_name.\n\n Args:\n job_template_name (str): Nombre del job_template\n \"\"\"\n response = await awx_fetch('/api/v2/job_templates/')\n job_template_name = f'{ENV}-{job_template_name}'\n job_templates = response.get('results', [])\n for job_template in job_templates:\n if job_template.get('name') == job_template_name:\n return job_template.get('id')\n @classmethod\n async def run_job_template_by_name(cls, job_template_name, body):\n \"\"\"\n Ejecuta una tarea en el AWX, hallada según su nombre\n\n Args:\n job_template_name (str): El nombre del job_template a ejecutar\n body (dict): Cuerpo de la tarea\n \"\"\"\n print(job_template_name, flush=True)\n job_template_id = await cls.get_job_template_id_by_name(job_template_name)\n if job_template_id is None:\n raise JobTemplateNotFound\n endpoint = f'/api/v2/job_templates/{job_template_id}/launch/'\n launch = await awx_post(endpoint, body)\n job_id = launch.get('job')\n timeout_start = time()\n while time() < timeout_start + TIMEOUT_SECONDS:\n job = await awx_fetch('/api/v2/jobs/' + str(job_id) + '/')\n status = job.get('status')\n if status == 'failed':\n raise PlaybookFailure\n elif status == 'successful':\n result = cls.get_by_job_id(job_id)\n if result is not None:\n cls.delete_by_job_id(job_id)\n return getattr(result, 'result')\n return\n await asyncio.sleep(1)\n raise PlaybookTimeout\n\n @classmethod\n async def get_jobs_from_awx(cls):\n \"\"\"\n Solicita a AWX y luego devuelve la lista de Jobs con sus respectivos estados\n\n Args:\n \"\"\"\n return await awx_fetch(\"/api/v2/jobs?order_by=-created&page_size=100\")\n\n @classmethod\n async def cancel_jobs_by_template_name_and_host_name(cls, job_template_name, limit_host_name):\n try:\n all_jobs = list((await JobService.get_jobs_from_awx())[\"results\"])\n except:\n raise ConnectToAwxFailure\n jobs_for_cancel = filter(\n lambda x:\n x[\"summary_fields\"][\"job_template\"][\"name\"] == job_template_name and\n x[\"limit\"] == limit_host_name and\n x[\"status\"] in [\"running\",\"pending\",\"waiting\"],\n all_jobs )\n for job in jobs_for_cancel:\n try:\n await awx_post(f'/api/v2/jobs/{job[\"id\"]}/cancel/', None)\n except:\n raise PlaybookCancelFailure\n return True\n"
},
{
"alpha_fraction": 0.6674713492393494,
"alphanum_fraction": 0.6674713492393494,
"avg_line_length": 30.264150619506836,
"blob_id": "575525bf33eb261c787812fb0c7e8694c2189e96",
"content_id": "2e434967bb1ce87c02df14b6c1692d1b79eb1fdc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1662,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 53,
"path": "/app/__init__.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import jsonify, Flask, render_template\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_restplus import Resource, apidoc\nfrom app.api_flask import ApiFlask\n\ndb = SQLAlchemy()\n\ndef create_app(env=None):\n from app.config import config_by_name\n from app.routes import register_routes\n from app.errors import register_error_handlers\n\n # Creamos la aplicación de Flask\n app = Flask(__name__, template_folder='./templates')\n config = config_by_name[env or \"test\"]\n app.config.from_object(config)\n\n # Creacmos el objeto `api`\n api_title = os.environ.get('APP_TITLE', config.TITLE)\n api_version = os.environ.get('APP_VERSION', config.VERSION)\n api_description = \"\"\"\n API del Conatel Switch Manager\n \"\"\"\n api = ApiFlask(app, \n title=api_title, \n version=api_version, \n description=api_description,\n license='MIT',\n licence_url='https://opensource.org/licenses/MIT',\n endpoint='',\n )\n # Registramos las rutas\n register_routes(api, app)\n # Registramos loa error_handlers\n register_error_handlers(app)\n # Inicializamos la base de datos\n db.init_app(app)\n\n # Configuración de página de documentación\n @api.documentation\n # pylint: disable=unused-variable\n def custom_ui():\n return render_template('api_docs.html')\n # return apidoc.ui_for(api)\n # Creamos una ruta para chequear la salud del sistema\n @app.route('/healthz')\n # pylint: disable=unused-variable\n def healthz(): \n \"\"\" Healthz endpoint \"\"\"\n return jsonify({\"ok\": True})\n # Retornamos la aplicación de Flask\n return app, api\n"
},
{
"alpha_fraction": 0.6291788220405579,
"alphanum_fraction": 0.6291788220405579,
"avg_line_length": 41.79861068725586,
"blob_id": "8ac5e400e6c2dfaadde63288ab8182429236beaf",
"content_id": "887386c39a930fc50f998ee58936f2309eb3f540",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6162,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 144,
"path": "/app/utils/base_interfaces.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "from marshmallow import fields as marshmallow_fields, Schema\nfrom flask_restplus import fields as restplus_fields\n\nclass BaseInterfaces(object):\n \"\"\"\n This class simplifies the creation of `marshmallo` schemas, and \n `flask_restplus` models to document the API.\n\n Args:\n api (flask_restplus.Namespace): `flask_restplus` Namespace instance.\n name (str, optional): Name of the entity.\n\n Attributes:\n _api (flask_restplus.Namespace): `flask_restplus` Namespace instance.\n __name__ (string): Name of the entity. Used as prefix for the model names.\n _shcema (marshmallow.Schema): Dynamically generated `marshmallow` :class:`Schema`.\n single_schema (marshmallow.Schema): `marshmallow` instance for a single entity.\n many_shcema (marshmallow.Schema): `marshmallow` instance for a list of entities.\n create_model_keys (:list:str): List of field names that creates the entity's create model.\n update_model_keys (:list:str): List of field names that creates the entity's update model.\n create_model (flask_restplus.Namespace.model): Entity's create model.\n update_model (flask_restplus.Namespace.model): Entity's update model.\n model (flask_resplus.Namespace.model): Entity's model.\n single_response_model (flask_restplus.Namespace.model): Single entity's response model.\n many_response_model (flask_restplus.Namespace.model): Multiple entity's response model.\n error_response_model (flask_restplus.Namespace.model): Error response model.\n \"\"\"\n\n def __init__(self, api, name=''):\n self._api = api\n self.__name__ = getattr(self, '__name__', None) or name\n self._schema = self.create_marshmallow_schema()\n self.single_schema = self._schema()\n self.many_schema = self._schema(many=True)\n self.create_model_keys = getattr(self, 'create_model_keys', None) or self.get_restplus_fields_keys()\n self.create_model = self._api.model(self.__name__ + 'Create', self.get_restplus_fields(self.create_model_keys))\n self.update_model_keys = getattr(self, 'update_model_keys', None) or self.create_model_keys\n self.update_model = self._api.model(self.__name__ + 'Update', self.get_restplus_fields(self.update_model_keys))\n self.model = self._api.model(self.__name__, self.get_restplus_fields(self.get_restplus_fields_keys()))\n self.single_response_model = self.create_single_response_model()\n self.many_response_model = self.create_many_response_model()\n self.error_response_model = self.create_error_response_model()\n\n def get_restplus_fields(self, keys):\n \"\"\"Returns a dictionary of `flask_restplus fields.\n\n Args:\n keys (:obj:`list` of :obj:`str`): List of fields to include\n\n Returns:\n A dictionary with its keys as the names of the wanted `flask_restplus``\n fields, and its values with their configuration.\n \"\"\"\n return {key: getattr(self, key).get('r') for key in self.get_restplus_fields_keys() if key in keys}\n\n def get_restplus_fields_keys(self):\n \"\"\"Gets the list of the `flask_restplus` configured fields.\n\n Returns:\n The list of `flask_restplus` fields.\n \"\"\"\n return [field for field in self.attributes() if\n type(getattr(self, field)) is dict\n and getattr(self, field).get('r') is not None\n ]\n\n def get_marshmallow_fields_keys(self):\n \"\"\"Gets the list of the `marshmallow` configured fields.\n\n Returns:\n The list of `marshmallow` fields.\n \"\"\"\n return [field for field in self.attributes() if\n type(getattr(self, field)) is dict\n and getattr(self, field).get('m') is not None\n ]\n\n def attributes(self):\n \"\"\"\n Returns a list with all the object attributes that are not\n callable or doesn't start with '__'.\n\n Returns:\n The list of attribute names.\n \"\"\"\n return [key for key in dir(self) if \n not key.startswith('__')\n and not key in ['schema']\n and not callable(getattr(self, key))\n ]\n\n def pick(self, keys):\n \"\"\"Returns a list of current attributes included in the `keys` list.\n\n Args:\n keys (:obj:`list` of :obj:`str`): List of attribute names.\n\n Returns:\n The list of attributes that match the ones on the `keys` list.\n \"\"\"\n values = [getattr(self, key) for key in self.attributes() if key in keys]\n return values\n \n def create_marshmallow_schema(self):\n \"\"\"\n Dynamically creates a `marshmallow.Schema` class given the object\n configured `marshmallow.fields`.\n\n Returns:\n A `marshmallow.Schema` class.\n \"\"\"\n fields_keys = self.get_marshmallow_fields_keys()\n return type(self.__name__ + 'MarshmallowSchema', (Schema,), {field_key: getattr(self, field_key).get('m') for field_key in fields_keys})\n\n def create_single_response_model(self):\n \"\"\"Creates the single response model.\n\n Returns:\n A `flask_resplus.Namespace.model` for a single entity's response body.\n \"\"\"\n return self._api.model(self.__name__ + 'SingleResponse', dict(\n item=restplus_fields.Nested(self.model),\n ))\n\n def create_many_response_model(self):\n \"\"\"Creates the single response model.\n\n Returns:\n A `flask_resplus.Namespace.model` for a multuple entity's response body.\n \"\"\"\n return self._api.model(self.__name__ + 'ManyResponse', dict(\n items=restplus_fields.List(restplus_fields.Nested(self.model)),\n count=restplus_fields.Integer\n ))\n\n def create_error_response_model(self):\n \"\"\"Creates the error response model\n \n Returns:\n A `flask_restplus.Namespace.model` for an error response\n \"\"\"\n return self._api.model(self.__name__ + 'ErrorResponse', dict(\n message=restplus_fields.String(description='Error message', example='Something went wrong'),\n ))"
},
{
"alpha_fraction": 0.7464285492897034,
"alphanum_fraction": 0.7464285492897034,
"avg_line_length": 24.545454025268555,
"blob_id": "c6db00ed6adc8b087e54b833bb18c4b369762da6",
"content_id": "57a45837540e52f6693abe19d29bba2b08d4549a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 280,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 11,
"path": "/uswgi.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom app import create_app\nfrom alembic.config import Config\nfrom alembic import command\n\nalembic_cfg = Config(\"./alembic.ini\")\nalembic_cfg.set_main_option('sqlalchemy.url', os.environ['DATABASE_URI'])\ncommand.upgrade(alembic_cfg, \"head\")\n\n(app, _) = create_app(\"prod\")"
},
{
"alpha_fraction": 0.5867282748222351,
"alphanum_fraction": 0.5921881794929504,
"avg_line_length": 33.50724792480469,
"blob_id": "e8c2efae15e616abe5e16ab01aa0ed2f24cdb95c",
"content_id": "8c9da3615568ea0e909efc77803ef8a2a495abdd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2381,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 69,
"path": "/app/utils/logger.py",
"repo_name": "conatel-i-d/sm-api",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nimport datetime\nfrom jose import jwt\nfrom jose.exceptions import JWTError, ExpiredSignatureError, JWTClaimsError, JWKError\nfrom functools import wraps\nfrom flask import request, redirect, Response, make_response\nfrom app.api_response import ApiResponse\nfrom app.errors import ApiException\nfrom app.logs.service import LogService\nPUBLIC_KEY = f\"\"\"\n-----BEGIN PUBLIC KEY----- \n{os.environ.get('PUBLIC_KEY')}\n-----END PUBLIC KEY-----\n\"\"\"\n\n\ndef log(func):\n @wraps(func)\n def log_handler(*args, **kwargs):\n token = request.headers.get('Token')\n if not token:\n return ApiResponse({\"Error\": \"Token not found\"}, 400)\n http_method = request.method\n http_url = request.url\n payload = json.dumps(request.get_json())\n\n token_dec = jwt.decode(token, PUBLIC_KEY, algorithms=['RS256'], audience='dashboard', options={\n \"verify_signature\": False,\n \"verify_aud\": False,\n \"verify_iat\": False,\n \"verify_exp\": False,\n \"verify_nbf\": False,\n \"verify_iss\": False,\n \"verify_sub\": False,\n \"verify_jti\": False,\n \"verify_at_hash\": False\n }) \n user_name = token_dec[\"name\"]\n user_email = token_dec[\"email\"]\n date_start = datetime.datetime.utcnow()\n try:\n response = func(*args, **kwargs)\n except ApiException as err:\n response = err\n except Exception as err:\n response = ApiException('Internal server error', 500, str(err))\n\n if isinstance(response, ApiResponse):\n response_status_code = response.status\n message = str(response.value or \"\")[0:250] + \"...\"\n elif isinstance(response, ApiException):\n message = response.message \n response_status_code = response.status\n response = ApiResponse(message, response_status_code)\n date_end = datetime.datetime.utcnow()\n LogService.create({\n \"http_method\": http_method,\n \"http_url\": http_url,\n \"payload\": payload,\n \"user_name\": user_name,\n \"user_email\": user_email,\n \"date_start\": date_start,\n \"response_status_code\": response_status_code,\n \"message\": message,\n \"date_end\": date_end\n })\n return response\n return log_handler\n"
}
] | 53 |
LittleCharmander/3d-medical-image-super-resolution
|
https://github.com/LittleCharmander/3d-medical-image-super-resolution
|
71f9cb23b2ce1812bff26158ac75ee49d5e73615
|
a2c5fab6a9609367da131054caa4c39e9872890f
|
75e25816223b7c9baa52c5fe10f83589d7c6df99
|
refs/heads/master
| 2022-04-10T01:33:19.895032 | 2020-03-26T03:06:18 | 2020-03-26T03:06:18 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6253297924995422,
"alphanum_fraction": 0.6411609649658203,
"avg_line_length": 33.45454406738281,
"blob_id": "5e2c9b13e7e9427d8d8979bbbba79aa397528236",
"content_id": "332afa066c389a679dad5a505a1b2286a2675239",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 11,
"path": "/inference_SRGAN.sh",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nCUDA_VISIBLE_DEVICES=1 python main.py \\\n --output_dir ./trails/results/ \\\n --summary_dir ./trails/result/log/ \\\n --mode inference \\\n --is_training False \\\n --task unet \\\n --input_dir_LR /home/share/ziyumeng/Yucheng/Data/LR_lipid_test \\\n --perceptual_mode MSE \\\n --pre_trained_model True \\\n --checkpoint ./trails/SRGAN/model-40000 \\\n"
},
{
"alpha_fraction": 0.5344827771186829,
"alphanum_fraction": 0.6021220088005066,
"avg_line_length": 30.41666603088379,
"blob_id": "e5fab820f813a991810717896097e2786b9d66b6",
"content_id": "127f609a72a967c7887415c931fac0b3993ca744",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 24,
"path": "/train_SRGAN.sh",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "CUDA_VISIBLE_DEVICES='1' python main.py \\\n --output_dir ./trails/SRGAN/ \\\n --summary_dir ./trails/SRGAN/log/ \\\n --mode train \\\n --is_training True \\\n --task SRGAN \\\n --batch_size 16 \\\n --crop_size 24 \\\n --input_dir_LR /home/share/ziyumeng/Yucheng/Data/HCP_lipid_slice/LR/ \\\n --input_dir_HR /home/share/ziyumeng/Yucheng/Data/HCP_lipid_slice/HR/ \\\n --perceptual_mode MSE \\\n --name_queue_capacity 4096 \\\n --image_queue_capacity 4096 \\\n --ratio 0.001 \\\n --learning_rate 0.0001 \\\n --decay_step 100000 \\\n --decay_rate 0.1 \\\n --stair True \\\n --beta 0.9 \\\n --max_iter 500000 \\\n --queue_thread 10 \\\n --vgg_scaling 0.0061 \\\n --pre_trained_model True \\\n --checkpoint ./trails/SRunet/model-300000\n"
},
{
"alpha_fraction": 0.5959714651107788,
"alphanum_fraction": 0.6105268001556396,
"avg_line_length": 40.842830657958984,
"blob_id": "1842d87047a5fc067c018f7315d8a855b714c263",
"content_id": "611e0bfc1b9e42f68048b93017bec28d15a92836",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21298,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 509,
"path": "/model.py",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport tensorflow as tf\nfrom lib.ops import *\nimport collections\nimport os\nimport math\nimport scipy.misc as sic\nimport numpy as np\n\n\n# Define the dataloader\ndef data_loader(FLAGS):\n with tf.device('/cpu:0'):\n # Define the returned data batches\n Data = collections.namedtuple('Data', 'paths_LR, paths_HR, inputs, targets, image_count, steps_per_epoch')\n\n #Check the input directory\n if (FLAGS.input_dir_LR == 'None') or (FLAGS.input_dir_HR == 'None'):\n raise ValueError('Input directory is not provided')\n\n if (not os.path.exists(FLAGS.input_dir_LR)) or (not os.path.exists(FLAGS.input_dir_HR)):\n raise ValueError('Input directory not found')\n\n image_list_LR = os.listdir(FLAGS.input_dir_LR)\n image_list_LR = [_ for _ in image_list_LR if _.endswith('.png')]\n if len(image_list_LR)==0:\n raise Exception('No png files in the input directory')\n\n image_list_LR_temp = sorted(image_list_LR)\n image_list_LR = [os.path.join(FLAGS.input_dir_LR, _) for _ in image_list_LR_temp]\n image_list_HR = [os.path.join(FLAGS.input_dir_HR, _) for _ in image_list_LR_temp]\n\n image_list_LR_tensor = tf.convert_to_tensor(image_list_LR, dtype=tf.string)\n image_list_HR_tensor = tf.convert_to_tensor(image_list_HR, dtype=tf.string)\n\n with tf.variable_scope('load_image'):\n output = tf.train.slice_input_producer([image_list_LR_tensor, image_list_HR_tensor],\n shuffle=False, capacity=FLAGS.name_queue_capacity)\n\n\n # Reading and decode the HR images\n reader = tf.WholeFileReader(name='image_reader')\n image_LR = tf.read_file(output[0])\n image_HR = tf.read_file(output[1])\n input_image_LR = tf.image.decode_png(image_LR, channels=1)\n input_image_HR = tf.image.decode_png(image_HR, channels=1)\n input_image_LR = tf.image.convert_image_dtype(input_image_LR, dtype=tf.float32)\n input_image_HR = tf.image.convert_image_dtype(input_image_HR, dtype=tf.float32)\n\n assertion = tf.assert_equal(tf.shape(input_image_LR)[2], 1, message=\"image should only have 1 channel\")\n with tf.control_dependencies([assertion]):\n if FLAGS.interpolation == True:\n input_image_LR = tf.image.resize_images(input_image_LR,[FLAGS.crop_size*2,FLAGS.crop_size*2])\n else:\n input_image_LR = tf.identity(input_image_LR)\n input_image_HR = tf.identity(input_image_HR)\n\n # Normalize the low resolution image to [0, 1], high resolution to [-1, 1]\n a_image = preprocessLR(input_image_LR)\n b_image = preprocess(input_image_HR)\n\n inputs, targets = [a_image, b_image]\n\n\n with tf.name_scope('data_preprocessing'):\n input_images = tf.identity(input_image_LR)\n target_images = tf.identity(input_image_HR)\n\n\n if FLAGS.interpolation == True:\n input_images.set_shape([FLAGS.crop_size*2, FLAGS.crop_size*2, 1])\n else:\n input_images.set_shape([FLAGS.crop_size, FLAGS.crop_size, 1])\n target_images.set_shape([FLAGS.crop_size*2, FLAGS.crop_size*2, 1])\n\n if FLAGS.mode == 'train':\n paths_LR_batch, paths_HR_batch, inputs_batch, targets_batch = tf.train.shuffle_batch([output[0], output[1], input_images, target_images],\n batch_size=FLAGS.batch_size, capacity=FLAGS.image_queue_capacity+4*FLAGS.batch_size,\n min_after_dequeue=FLAGS.image_queue_capacity, num_threads=FLAGS.queue_thread)\n else:\n paths_LR_batch, paths_HR_batch, inputs_batch, targets_batch = tf.train.batch([output[0], output[1], input_images, target_images],\n batch_size=FLAGS.batch_size, num_threads=FLAGS.queue_thread, allow_smaller_final_batch=True)\n\n steps_per_epoch = int(math.ceil(len(image_list_LR) / FLAGS.batch_size))\n if FLAGS.task == 'SRGAN' or FLAGS.task == 'unet':\n if FLAGS.interpolation == True:\n inputs_batch.set_shape([FLAGS.batch_size, FLAGS.crop_size*2, FLAGS.crop_size*2, 1])\n else:\n inputs_batch.set_shape([FLAGS.batch_size, FLAGS.crop_size, FLAGS.crop_size, 1])\n targets_batch.set_shape([FLAGS.batch_size, FLAGS.crop_size*2, FLAGS.crop_size*2, 1])\n\n return Data(\n paths_LR=paths_LR_batch,\n paths_HR=paths_HR_batch,\n inputs=inputs_batch,\n targets=targets_batch,\n image_count=len(image_list_LR),\n steps_per_epoch=steps_per_epoch\n )\n\n\n# The test data loader. Allow input image with different size\ndef test_data_loader(FLAGS):\n # Get the image name list\n if (FLAGS.input_dir_LR == 'None') or (FLAGS.input_dir_HR == 'None'):\n raise ValueError('Input directory is not provided')\n\n if (not os.path.exists(FLAGS.input_dir_LR)) or (not os.path.exists(FLAGS.input_dir_HR)):\n raise ValueError('Input directory not found')\n\n image_list_LR_temp = os.listdir(FLAGS.input_dir_LR)\n image_list_LR = [os.path.join(FLAGS.input_dir_LR, _) for _ in image_list_LR_temp if _.split('.')[-1] == 'png']\n image_list_HR = [os.path.join(FLAGS.input_dir_HR, _) for _ in image_list_LR_temp if _.split('.')[-1] == 'png']\n\n # Read in and preprocess the images\n# def preprocess_test(name, mode):\n# im = sic.imread(name, mode=\"RGB\").astype(np.float32)\n# # check grayscale image\n# if im.shape[-1] != 1:\n# h, w = im.shape\n# temp = np.empty((h, w, 1), dtype=np.uint8)\n# temp[:, :, :] = im[:, :, np.newaxis]\n# im = temp.copy()\n# if mode == 'LR':\n# im = im / np.max(im)\n# elif mode == 'HR':\n# im = im / np.max(im)\n# im = im * 2 - 1\n#\n# return im\n# Read in and preprocess the images\ndef preprocess_test(name, mode):\n im = sic.imread(name, mode=\"L\").astype(np.float32)/255\n im = im[:,:,np.newaxis]\n \n return im\n\n image_LR = [preprocess_test(_, 'LR') for _ in image_list_LR]\n image_HR = [preprocess_test(_, 'HR') for _ in image_list_HR]\n\n # Push path and image into a list\n Data = collections.namedtuple('Data', 'paths_LR, paths_HR, inputs, targets')\n\n return Data(\n paths_LR = image_list_LR,\n paths_HR = image_list_HR,\n inputs = image_LR,\n targets = image_HR\n )\n\n\n# The inference data loader. Allow input image with different size\ndef inference_data_loader(FLAGS):\n # Get the image name list\n if (FLAGS.input_dir_LR == 'None'):\n raise ValueError('Input directory is not provided')\n\n if not os.path.exists(FLAGS.input_dir_LR):\n raise ValueError('Input directory not found')\n\n image_list_LR_temp = os.listdir(FLAGS.input_dir_LR)\n image_list_LR = [os.path.join(FLAGS.input_dir_LR, _) for _ in image_list_LR_temp if _.split('.')[-1] == 'png']\n\n # Read in and preprocess the images\n def preprocess_test(name):\n im = sic.imread(name, mode=\"L\").astype(np.float32)/255\n print('im.shape=',im.shape)\n im = im[:,:,np.newaxis]\n #im = tf.image.resize_images(im,[FLAGS.crop_size*2,FLAGS.crop_size*2])\n\n # check grayscale image\n \n# if im.shape[-1] != 1:\n# h, w = im.shape\n# temp = np.empty((h, w, 1), dtype=np.uint8)\n# temp[:, :, :] = im[:, :, np.newaxis]\n# im = temp.copy()\n# h, w = im.shape\n# im = sic.imresize(im,(2*h,2*w),'cubic')\n# im = im / np.max(im)\n\n\n return im\n\n image_LR = [preprocess_test(_) for _ in image_list_LR]\n print('image_LR=',image_LR)\n # list to array to tensor\n image_LR = np.asarray(image_LR)\n print('image_LR(array) = ',image_LR.shape)\n image_LR = tf.image.resize_images(image_LR,[256*2,256*2])\n # tensor to array to list\n print('image_LR(tensor).shape=', image_LR.shape)\n with tf.Session() as sess:\n image_LR = image_LR.eval()\n image_LR = np.ndarray.tolist(image_LR)\n\n # Push path and image into a list\n Data = collections.namedtuple('Data', 'paths_LR, inputs')\n\n return Data(\n paths_LR=image_list_LR,\n inputs=image_LR\n )\n\n\n# Definition of the generator\nimport lib.ops as ops\ndef generator(gen_inputs, gen_output_channels, reuse=False, FLAGS=None):\n # Check the flag\n if FLAGS is None:\n raise ValueError('No FLAGS is provided for generator')\n\n # define u-net\n def unet(input, output_channel, scope):\n with slim.arg_scope([slim.conv2d, slim.conv2d_transpose, slim.max_pool2d, slim.avg_pool2d], stride=1, padding='SAME'):\n # slim.conv2d default relu activation\n # subsampling\n convl0 = slim.repeat(gen_inputs, 2, slim.conv2d, 64, [3, 3], scope='convl0')\n pool0 = slim.max_pool2d(convl0, [2, 2], scope='pool0')\n bn0 = slim.batch_norm(pool0, decay=0.9, epsilon=1e-5, scope=\"bn0\")\n\n convl1 = slim.repeat(bn0, 2, slim.conv2d, 128, [3, 3], scope='convl1')\n pool1 = slim.max_pool2d(convl1, [2, 2], scope='pool1')\n bn1 = slim.batch_norm(pool1, decay=0.9, epsilon=1e-5, scope=\"bn1\")\n\n # upsampling\n conv_t1 = slim.conv2d_transpose(bn1, 256, [2,2], scope='conv_t1')\n merge1 = tf.concat([conv_t1, convl1], 3)\n convl2 = slim.stack(merge1, slim.conv2d, [(256, [3, 3]),(128, [3,3])], scope='convl2')\n bn2 = slim.batch_norm(convl2, decay=0.9, epsilon=1e-5, scope='bn2')\n\n conv_t2 = slim.conv2d_transpose(bn2, 128, [2,2], scope='conv_t2')\n merge2 = tf.concat([conv_t2, convl0], 3)\n convl3 = slim.stack(merge2, slim.conv2d, [(128, [3,3]), (64, [3,3])], scope='convl3')\n bn3 = slim.batch_norm(convl3, decay=0.9, epsilon=1e-5, scope='bn3')\n\n # output layer scoreMap\n net = slim.conv2d(bn3, 1, [1,1], scope='scoreMap')\n return net\n\n\n # generator\n with tf.variable_scope('generator_unit', reuse=reuse):\n with tf.variable_scope('unet_output'):\n net = unet(gen_inputs, gen_output_channels, 'unet')\n\n #with tf.variable_scope('subpixelconv_stage1'):\n # net = ops.convol2(net, 3, 64, 1, scope='conv')\n # net = ops.pixelShuffler(net, scale=2)\n # net = ops.prelu_tf(net)\n\n #with tf.variable_scope('output_stage'):\n # net = ops.convol2(net, 9, gen_output_channels, 1, scope='conv')\n\n return net\n\n\n# Definition of the discriminator\ndef discriminator(dis_inputs, FLAGS=None):\n if FLAGS is None:\n raise ValueError('No FLAGS is provided for generator')\n\n # Define the discriminator block\n def discriminator_block(inputs, output_channel, kernel_size, stride, scope):\n with tf.variable_scope(scope):\n net = convol2(inputs, kernel_size, output_channel, stride, use_bias=False, scope='conv1')\n net = batchnorm(net, FLAGS.is_training)\n net = lrelu(net, 0.2)\n\n return net\n\n with tf.device('/gpu:0'):\n with tf.variable_scope('discriminator_unit'):\n # The input layer\n with tf.variable_scope('input_stage'):\n net = convol2(dis_inputs, 3, 64, 1, scope='conv')\n net = lrelu(net, 0.2)\n\n # The discriminator block part\n # block 1\n net = discriminator_block(net, 64, 3, 2, 'disblock_1')\n\n # block 2\n net = discriminator_block(net, 128, 3, 1, 'disblock_2')\n\n # block 3\n net = discriminator_block(net, 128, 3, 2, 'disblock_3')\n\n # block 4\n net = discriminator_block(net, 256, 3, 1, 'disblock_4')\n\n # block 5\n net = discriminator_block(net, 256, 3, 2, 'disblock_5')\n\n # block 6\n net = discriminator_block(net, 512, 3, 1, 'disblock_6')\n\n # block_7\n net = discriminator_block(net, 512, 3, 2, 'disblock_7')\n\n # The dense layer 1\n with tf.variable_scope('dense_layer_1'):\n net = slim.flatten(net)\n net = denselayer(net, 1024)\n net = lrelu(net, 0.2)\n\n # The dense layer 2\n with tf.variable_scope('dense_layer_2'):\n net = denselayer(net, 1)\n net = tf.nn.sigmoid(net)\n\n return net\n\n\n\n# Define the whole network architecture\ndef SRGAN(inputs, targets, FLAGS):\n # Define the container of the parameter\n Network = collections.namedtuple('Network', 'discrim_real_output, discrim_fake_output, discrim_loss, \\\n discrim_grads_and_vars, adversarial_loss, content_loss, gen_grads_and_vars, gen_output, train, global_step, \\\n learning_rate')\n\n # Build the generator part\n with tf.variable_scope('generator'):\n output_channel = targets.get_shape().as_list()[-1]\n gen_output = generator(inputs, output_channel, reuse=False, FLAGS=FLAGS)\n gen_output.set_shape([FLAGS.batch_size, FLAGS.crop_size*2, FLAGS.crop_size*2, 1])\n\n # Build the fake discriminator\n with tf.name_scope('fake_discriminator'):\n with tf.variable_scope('discriminator', reuse=False):\n discrim_fake_output = discriminator(gen_output, FLAGS=FLAGS)\n\n # Build the real discriminator\n with tf.name_scope('real_discriminator'):\n with tf.variable_scope('discriminator', reuse=True):\n discrim_real_output = discriminator(targets, FLAGS=FLAGS)\n\n\n # Use MSE loss directly\n if FLAGS.perceptual_mode == 'MSE':\n extracted_feature_gen = gen_output\n extracted_feature_target = targets\n\n else:\n raise NotImplementedError('Unknown perceptual type!!')\n\n # Calculating the generator loss\n with tf.variable_scope('generator_loss'):\n # Content loss\n with tf.variable_scope('content_loss'):\n # Compute the euclidean distance between the two features\n diff = extracted_feature_gen - extracted_feature_target\n if FLAGS.perceptual_mode == 'MSE':\n content_loss = tf.reduce_mean(tf.reduce_sum(tf.square(diff), axis=[3]))\n else:\n content_loss = FLAGS.vgg_scaling*tf.reduce_mean(tf.reduce_sum(tf.square(diff), axis=[3]))\n\n with tf.variable_scope('adversarial_loss'):\n adversarial_loss = tf.reduce_mean(-tf.log(discrim_fake_output + FLAGS.EPS))\n\n gen_loss = content_loss + (FLAGS.ratio)*adversarial_loss\n print(adversarial_loss.get_shape())\n print(content_loss.get_shape())\n\n # Calculating the discriminator loss\n with tf.variable_scope('discriminator_loss'):\n discrim_fake_loss = tf.log(1 - discrim_fake_output + FLAGS.EPS)\n discrim_real_loss = tf.log(discrim_real_output + FLAGS.EPS)\n\n discrim_loss = tf.reduce_mean(-(discrim_fake_loss + discrim_real_loss))\n\n # Define the learning rate and global step\n with tf.variable_scope('get_learning_rate_and_global_step'):\n global_step = tf.contrib.framework.get_or_create_global_step()\n learning_rate = tf.train.exponential_decay(FLAGS.learning_rate, global_step, FLAGS.decay_step, FLAGS.decay_rate, staircase=FLAGS.stair)\n incr_global_step = tf.assign(global_step, global_step + 1)\n\n with tf.variable_scope('dicriminator_train'):\n discrim_tvars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='discriminator')\n discrim_optimizer = tf.train.AdamOptimizer(learning_rate, beta1=FLAGS.beta)\n discrim_grads_and_vars = discrim_optimizer.compute_gradients(discrim_loss, discrim_tvars)\n discrim_train = discrim_optimizer.apply_gradients(discrim_grads_and_vars)\n\n with tf.variable_scope('generator_train'):\n # Need to wait discriminator to perform train step\n with tf.control_dependencies([discrim_train]+ tf.get_collection(tf.GraphKeys.UPDATE_OPS)):\n gen_tvars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='generator')\n gen_optimizer = tf.train.AdamOptimizer(learning_rate, beta1=FLAGS.beta)\n gen_grads_and_vars = gen_optimizer.compute_gradients(gen_loss, gen_tvars)\n gen_train = gen_optimizer.apply_gradients(gen_grads_and_vars)\n\n #[ToDo] If we do not use moving average on loss??\n exp_averager = tf.train.ExponentialMovingAverage(decay=0.99)\n update_loss = exp_averager.apply([discrim_loss, adversarial_loss, content_loss])\n\n return Network(\n discrim_real_output = discrim_real_output,\n discrim_fake_output = discrim_fake_output,\n discrim_loss = exp_averager.average(discrim_loss),\n discrim_grads_and_vars = discrim_grads_and_vars,\n adversarial_loss = exp_averager.average(adversarial_loss),\n content_loss = exp_averager.average(content_loss),\n gen_grads_and_vars = gen_grads_and_vars,\n gen_output = gen_output,\n train = tf.group(update_loss, incr_global_step, gen_train),\n global_step = global_step,\n learning_rate = learning_rate\n )\n\n\ndef unet(inputs, targets, FLAGS):\n # Define the container of the parameter\n Network = collections.namedtuple('Network', 'content_loss, gen_grads_and_vars, gen_output, train, global_step, \\\n learning_rate')\n\n # Build the generator part\n with tf.variable_scope('generator'):\n output_channel = targets.get_shape().as_list()[-1]\n gen_output = generator(inputs, output_channel, reuse=False, FLAGS=FLAGS)\n gen_output.set_shape([FLAGS.batch_size, FLAGS.crop_size * 2, FLAGS.crop_size * 2, 1])\n\n # Use the VGG54 feature\n if FLAGS.perceptual_mode == 'MSE':\n extracted_feature_gen = gen_output\n extracted_feature_target = targets\n\n else:\n raise NotImplementedError('Unknown perceptual type')\n\n # Calculating the generator loss\n with tf.variable_scope('generator_loss'):\n # Content loss\n with tf.variable_scope('content_loss'):\n # Compute the euclidean distance between the two features\n # check=tf.equal(extracted_feature_gen, extracted_feature_target)\n diff = extracted_feature_gen - extracted_feature_target\n if FLAGS.perceptual_mode == 'MSE':\n content_loss = tf.reduce_mean(tf.reduce_sum(tf.square(diff), axis=[3]))\n else:\n content_loss = FLAGS.vgg_scaling * tf.reduce_mean(tf.reduce_sum(tf.square(diff), axis=[3]))\n\n gen_loss = content_loss\n\n # Define the learning rate and global step\n with tf.variable_scope('get_learning_rate_and_global_step'):\n global_step = tf.contrib.framework.get_or_create_global_step()\n learning_rate = tf.train.exponential_decay(FLAGS.learning_rate, global_step, FLAGS.decay_step, FLAGS.decay_rate,\n staircase=FLAGS.stair)\n incr_global_step = tf.assign(global_step, global_step + 1)\n\n with tf.variable_scope('generator_train'):\n # Need to wait discriminator to perform train step\n with tf.control_dependencies(tf.get_collection(tf.GraphKeys.UPDATE_OPS)):\n gen_tvars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope='generator')\n gen_optimizer = tf.train.AdamOptimizer(learning_rate, beta1=FLAGS.beta)\n gen_grads_and_vars = gen_optimizer.compute_gradients(gen_loss, gen_tvars)\n gen_train = gen_optimizer.apply_gradients(gen_grads_and_vars)\n\n # [ToDo] If we do not use moving average on loss??\n exp_averager = tf.train.ExponentialMovingAverage(decay=0.99)\n update_loss = exp_averager.apply([content_loss])\n\n return Network(\n content_loss=exp_averager.average(content_loss),\n gen_grads_and_vars=gen_grads_and_vars,\n gen_output=gen_output,\n train=tf.group(update_loss, incr_global_step, gen_train),\n global_step=global_step,\n learning_rate=learning_rate\n )\n\n\ndef save_images(fetches, FLAGS, step=None):\n image_dir = os.path.join(FLAGS.output_dir, \"images\")\n if not os.path.exists(image_dir):\n os.makedirs(image_dir)\n\n filesets = []\n in_path = fetches['path_LR']\n name, _ = os.path.splitext(os.path.basename(str(in_path)))\n fileset = {\"name\": name, \"step\": step}\n\n if FLAGS.mode == 'inference':\n kind = \"outputs\"\n filename = name + \".png\"\n if step is not None:\n filename = \"%08d-%s\" % (step, filename)\n fileset[kind] = filename\n out_path = os.path.join(image_dir, filename)\n contents = fetches[kind][0]\n with open(out_path, \"wb\") as f:\n f.write(contents)\n filesets.append(fileset)\n else:\n for kind in [\"inputs\", \"outputs\", \"targets\"]:\n filename = name + \"-\" + kind + \".png\"\n if step is not None:\n filename = \"%08d-%s\" % (step, filename)\n fileset[kind] = filename\n out_path = os.path.join(image_dir, filename)\n contents = fetches[kind][0]\n with open(out_path, \"wb\") as f:\n f.write(contents)\n filesets.append(fileset)\n return filesets\n"
},
{
"alpha_fraction": 0.731356680393219,
"alphanum_fraction": 0.758310854434967,
"avg_line_length": 36.099998474121094,
"blob_id": "d9316a29479265875ccfc2c27287ba8c211a7853",
"content_id": "6eca4096ba317c0e7f1433d06b8f74d0224cdbe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 30,
"path": "/README.md",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "# MRI segmentation\nThis project aids researchers to get better segmentation results of MRI brain images. \nWe improve the segmentation results towards two criteria: \n\t1. the mask should be smooth and without noise \n\t2. there should be minimum misclassification \n(There might be minor bugs since the version is not the most up-to-date)\n\nThis project features two aspects:\n\n\t1. It is able to take 3d patches\n\t2. The user can choose between Resnet(deeper) and Unet(require less memory consumption)\n\nTraining data used in this project:\n\n\t1. 2 high-resolution (0.5*0.5*0.5mm) data acquired at the BIC center at Beckman Institute in UIUC, and HCP data (0.7*0.7*0.7mm with different fov)\n\t2. Use HR images as prior information, warp the HCP data to a HR space for artificial data\n\t3. The crude segmentation is done using SPM toolbox\n\n\nThis script is revised from:\nhttps://github.com/brade31919/SRGAN-tensorflow\n\n## Pictures\n### Unet strcture\n\n### Synthetic Data Generation Flowchart\n\n### Test result\n\n\n"
},
{
"alpha_fraction": 0.6141906976699829,
"alphanum_fraction": 0.6319290399551392,
"avg_line_length": 33.61538314819336,
"blob_id": "29a2667504f49bdb7618e370b1ded9aa137f4e31",
"content_id": "eefe7f08fa951776bdcccc0543079225bb4e9643",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 13,
"path": "/test_SRGAN.sh",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nCUDA_VISIBLE_DEVICES=0 python main.py \\\n --output_dir ./result/ \\\n --summary_dir ./result/log/ \\\n --mode test \\\n --is_training False \\\n --task unet \\\n --batch_size 16 \\\n --input_dir_LR /home/share/ziyumeng/Yucheng/Data/LR_lipid_test \\\n --input_dir_HR /home/share/ziyumeng/Yucheng/Data/LR_lipid_test \\\n --perceptual_mode MSE \\\n --pre_trained_model True \\\n --checkpoint ./trails/SRGAN/model-40000 \\\n\n"
},
{
"alpha_fraction": 0.5361111164093018,
"alphanum_fraction": 0.5986111164093018,
"avg_line_length": 29,
"blob_id": "872093ad2982a3eba490a37392118412fa16cea1",
"content_id": "9a252a2a41085ddac5e5fc772b953e05664f8a17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 24,
"path": "/train_SRunet.sh",
"repo_name": "LittleCharmander/3d-medical-image-super-resolution",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nCUDA_VISIBLE_DEVICES='4' python main.py \\\n --output_dir ./trails/SRunet/ \\\n --summary_dir ./trails/SRunet/log/ \\\n --mode train \\\n --is_training True \\\n --task unet \\\n --batch_size 4 \\\n --interpolation True \\\n --crop_size 256 \\\n --input_dir_LR /home/share/ziyumeng/Yucheng/Data/HCP_lipid_slice/LR/ \\\n --input_dir_HR /home/share/ziyumeng/Yucheng/Data/HCP_lipid_slice/HR/ \\\n --name_queue_capacity 4096 \\\n --image_queue_capacity 4096 \\\n --perceptual_mode MSE \\\n --queue_thread 12 \\\n --ratio 0.001 \\\n --learning_rate 0.0001 \\\n --decay_step 500000 \\\n --decay_rate 0.1 \\\n --stair True \\\n --beta 0.9 \\\n --max_iter 200000 \\\n --save_freq 20000\n"
}
] | 6 |
jameskamradtjr/libesocial
|
https://github.com/jameskamradtjr/libesocial
|
0743a008b29af14b0d5df0960d2726a73e5d088a
|
15b408ded59ea954c51bdb5635deab17188e4b36
|
df1c4081be6d41b55b861a51f08a083e226ce66e
|
refs/heads/master
| 2022-10-20T10:22:07.064416 | 2020-06-08T15:21:00 | 2020-06-08T15:21:00 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7064102292060852,
"alphanum_fraction": 0.7354700565338135,
"avg_line_length": 27.88888931274414,
"blob_id": "23ef256f3007963b0f0e8605864bb7e48231367f",
"content_id": "733f1fb4fb3ba81bcc56dbbd527ab1e715e6a828",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4746,
"license_type": "permissive",
"max_line_length": 239,
"num_lines": 162,
"path": "/README.md",
"repo_name": "jameskamradtjr/libesocial",
"src_encoding": "UTF-8",
"text": "# LIBeSocial\n\nBiblioteca em Python para lidar com os processos do [eSocial](https://portal.esocial.gov.br):\n\n- Validação dos XML's dos eventos;\n- Comunicação com o Webservices do eSocial para envio e consulta de lotes;\n- Assinatura dos XML's (e conexão com o webservices) com certificado tipo `A1`.\n\nApesar desta biblioteca ter sido desenvolvida para lidar especialmente com os eventos de SST (Saúde e Segurança do Trabalho), nada impede que ela possa ser utilizada para enviar/validar quaisquer dos eventos disponíveis no projeto eSocial.\n\nNo momento só é possível utilizar assinaturas do tipo `A1` em arquivos no formato `PKCS#12` (geralmente arquivos com extensão `.pfx` ou `.p12`).\n\n# Documentação\n\nUm manual de utilização está sendo feito em https://qualitaocupacional.com.br/libesocial/\n\n# Instalação\n\nPyPi:\n```\npip install libesocial\n```\n\nA versão mais recente diretamente do repositório:\n\n```\npip install https://github.com/qualitaocupacional/libesocial/archive/master.zip\n```\n\nOu você pode clonar este repositório:\n```\ngit clone https://github.com/qualitaocupacional/libesocial\n```\n\nEntrar na pasta do repositório recém clonado:\n```\n> cd libesocial\n> python setup.py install\n```\n# Uso básico\n\n**Montando um Lote e transmitindo para o eSocial**\n\n```python\nimport esocial.xml\nimport esocial.client\n\nide_empregador = {\n 'tpInsc': 1,\n 'nrInsc': '12345678901234' # CNPJ/CPF completo (com 14/11 dígitos)\n}\n\nesocial_ws = esocial.client.WSClient(\n pfx_file='caminho/para/o/arquivo/certificado/A1',\n pfx_passw='senha do arquivo de certificado',\n employer_id=ide_empregador,\n sender_id=ide_empregador\n)\n\nevento1_grupo1 = esocial.xml.load_fromfile('evento1.xml')\nevento2_grupo1 = esocial.xml.load_fromfile('evento2.xml')\n\n# Adicionando eventos ao lote\nesocial_ws.add_event(evento1_grupo1)\nesocial_ws.add_event(evento2_grupo1)\n\nresult = esocial_ws.send(group_id=1)\n\n# result vai ser um Element object\n#<Element {http://www.esocial.gov.br/schema/lote/eventos/envio/retornoEnvio/v1_1_0}eSocial at 0x>\nprint(esocial.xml.dump_tostring(result))\n```\n\nPor padrão, o webservice de envio/consulta de lotes é o de \"**Produção Restrita**\", para enviar para o ambiente de \"**Produção Empresas**\", onde as coisas são para valer:\n\n```python\nimport esocial.client\n\nesocial_ws = esocial.client.WSClient(\n pfx_file='caminho/para/o/arquivo/certificado/A1',\n pfx_passw='senha do arquivo de certificado',\n employer_id=ide_empregador,\n sender_id=ide_empregador,\n target='production'\n)\n\n...\n\n```\n\n\n**Assinando um evento**\n\n```python\nimport esocial.xml\nimport esocial.utils\n\ncert_data = esocial.utils.pkcs12_data('my_cert_file.pfx', 'my password')\nevt2220 = esocial.xml.load_fromfile('S2220.xml')\n\n# Signing using the signature algorithms from eSocial documentation\nevt2220_signed = esocial.xml.sign(evt2220, cert_data)\n\n```\n\n**Validando um evento**\n\n```python\nimport esocial.xml\n\nevt2220 = esocial.xml.load_fromfile('S2220.xml')\ntry:\n esocial.xml.XMLValidate(evt2220).validate()\nexcept AssertionError as e:\n print('O XML do evento S-2220 é inválido!')\n print(e)\n```\nou\n```python\nimport esocial.xml\n\nevt2220 = esocial.xml.load_fromfile('S2220.xml')\nxmlschema = esocial.xml.XMLValidate(evt2220)\nif xmlschema.isvalid():\n print('XML do evento é válido! :-D.')\nelse:\n print('O XML do evento S-2220 é inválido!')\n print(str(xmlschema.last_error))\n```\n\n**OBSERVAÇÃO**: Até o presente momento (*15/05/2018*), a [SignXML](https://github.com/XML-Security/signxml),\nversão **2.5.2** que está no [PyPi](https://pypi.org/project/signxml) não está alinhada com a versão mais\natual da [Cryptography](https://pypi.org/project/cryptography):\n\n```\n(...)/site-packages/signxml/__init__.py:370: CryptographyDeprecationWarning: signer and verifier have been deprecated. Please use sign and verify instead.\n signer = key.signer(padding=PKCS1v15(), algorithm=hash_alg)\n\n```\nIsso não atrapalha o funcionamento da **LIBeSocial**, mas é um aviso de que no futuro essa\nfunção não vai mais funcionar. Você pode instalar a mesma versão **2.5.2** da **SignXML** diretamente do\nrepositório oficial, onde esta *issue* já foi corrigida:\n```\npip install https://github.com/XML-Security/signxml/archive/master.zip\n```\n\n# Requisitos\n\nA LIBeSocial requer as seguintes bibliotecas Python:\n\n- **requests** >= 2.7.0\n- **lxml** >= 4.2.1\n- **zeep** >= 2.5.0\n- **pyOpenSSL** >= 17.5.0\n- **signxml** >= 2.5.2\n- **six** >= 1.11.0\n\n# Licença\n\nA LIBeSocial é um projeto de código aberto, desenvolvido pelo departamento de\nPesquisa e Desenvolvimento e Tecnologia da Informação da [Qualitá Segurança e Saúde Ocupacional](https://qualitaocupacional.com.br)\ne está licenciada pela [Apache License 2.0](http://www.apache.org/licenses/LICENSE-2.0).\n"
},
{
"alpha_fraction": 0.6024590134620667,
"alphanum_fraction": 0.6322652697563171,
"avg_line_length": 35.76712417602539,
"blob_id": "17f269638a8a140940a62248c64b456797e6ff9b",
"content_id": "653c9da9bb60638c2dfc2679c18cdf876d474a7f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2684,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 73,
"path": "/esocial/tests/test_xml.py",
"repo_name": "jameskamradtjr/libesocial",
"src_encoding": "UTF-8",
"text": "# Copyright 2018, Qualita Seguranca e Saude Ocupacional. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\nimport os\n\nimport esocial\n\nfrom unittest import TestCase\n\nfrom esocial import xml\nfrom esocial import client\nfrom esocial.utils import pkcs12_data\n\nhere = os.path.dirname(os.path.abspath(__file__))\nthere = os.path.dirname(os.path.abspath(esocial.__file__))\n\n\nclass TestXML(TestCase):\n\n def test_S2220_xml(self):\n evt2220 = xml.load_fromfile(os.path.join(here, 'xml', 'S-2220.xml'))\n isvalid = True\n try:\n xml.XMLValidate(evt2220).validate()\n except AssertionError:\n isvalid = False\n self.assertTrue(isvalid)\n\n def test_xml_sign(self):\n evt2220_not_signed = xml.load_fromfile(os.path.join(here, 'xml', 'S-2220_not_signed.xml'))\n xmlschema = xml.XMLValidate(evt2220_not_signed)\n isvalid = xmlschema.isvalid()\n self.assertFalse(isvalid, msg=str(xmlschema.last_error))\n # Test signing\n cert_data = pkcs12_data(\n cert_file=os.path.join(there, 'certs', 'libesocial-cert-test.pfx'),\n password='cert@test'\n )\n evt2220_signed = xml.sign(evt2220_not_signed, cert_data)\n xml.XMLValidate(evt2220_signed).validate()\n\n def test_xml_send_batch(self):\n evt2220 = xml.load_fromfile(os.path.join(here, 'xml', 'S-2220_not_signed.xml'))\n employer_id = {\n 'tpInsc': 2,\n 'nrInsc': '12345678901234'\n }\n ws = client.WSClient(\n pfx_file=os.path.join(there, 'certs', 'libesocial-cert-test.pfx'),\n pfx_passw='cert@test',\n employer_id=employer_id,\n sender_id=employer_id\n )\n ws.add_event(evt2220)\n batch_to_send = ws._make_send_envelop(1)\n ws.validate_envelop('send', batch_to_send)\n\n def test_xml_retrieve_batch(self):\n ws = client.WSClient()\n protocol_number = 'A.B.YYYYMM.NNNNNNNNNNNNNNNNNNN'\n batch_to_retrieve = ws._make_retrieve_envelop(protocol_number)\n ws.validate_envelop('retrieve', batch_to_retrieve)\n"
}
] | 2 |
kevinghst/ML-Spring-19
|
https://github.com/kevinghst/ML-Spring-19
|
d96f38721d054d6b5635427569ceaa0982d1e6b6
|
884066589300e8037ab177f83a76d9db5ef6e501
|
cb696c67562fe1a8df708405b79da832a3fdda77
|
refs/heads/master
| 2020-05-18T19:28:19.089695 | 2019-05-16T18:44:23 | 2019-05-16T18:44:23 | 184,609,313 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6685303449630737,
"alphanum_fraction": 0.6805111765861511,
"avg_line_length": 26.822221755981445,
"blob_id": "acce10b87afdf6a427103d3477e93e79e62a8e6c",
"content_id": "fee5131d469b00dddb54eafde921189b1b09970c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1252,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 45,
"path": "/c++ implementation/neural_network.h",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#ifndef ML_SPRING19_PROJECT_NEURAL_NETWORK_H\n#define ML_SPRING19_PROJECT_NEURAL_NETWORK_H\n\n#include <string>\n#include <vector>\n#include \"loss_function.h\"\n#include \"optimizer.h\"\n#include \"layer.h\"\n#include <xtensor/xarray.hpp>\n#include <xtensor/xio.hpp>\n#include <xtensor/xmath.hpp>\n\nusing namespace std;\n\nclass NeuralNetwork {\n string optimizer;\n Loss* loss_function;\n xt::xarray<double> errors; // 0 is training, 1 is validation\n //skipping progress bar\n //skipping validation data\n\npublic:\n int batch_size = 0;\n vector<Layer*> layers;\n\n NeuralNetwork(string optimizer, Loss *loss_function);\n// void set_trainable(bool);\n void add(Layer*);\n// double test_on_batch(xt::xarray<double>*, xt::xarray<double>*);\n double train_on_batch(xt::xarray<double>*, xt::xarray<double>*);\n// xt::xarray<double> fit(xt::xarray<double>*, xt::xarray<double>*, int, int);\n xt::xarray<double> _forward_pass(xt::xarray<double>*, bool);\n void _backward_pass(xt::xarray<double>*);\n xt::xarray<double> _jacobian();\n xt::xarray<double> _jacobian_opt();\n void summary(string);\n xt::xarray<double> predict(xt::xarray<double> *X);\n};\n\n\n#endif //ML_SPRING19_PROJECT_NEURAL_NETWORK_H\n"
},
{
"alpha_fraction": 0.5526074767112732,
"alphanum_fraction": 0.569990873336792,
"avg_line_length": 33.109375,
"blob_id": "f2c2f2db5585dfa0edcbf20065d68ed97104cc00",
"content_id": "5b0ab93ce03f398866cc490fbfb18cfea42396bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2186,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 64,
"path": "/python implementation/optimizers.py",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n# Optimizers for models that use gradient based methods for finding the \n# weights that minimizes the loss.\n# A great resource for understanding these methods: \n# http://sebastianruder.com/optimizing-gradient-descent/index.html\n\nclass Adam():\n def __init__(self, learning_rate=0.001, b1=0.9, b2=0.999):\n self.learning_rate = learning_rate\n self.eps = 1e-8\n self.m = None\n self.v = None\n # Decay rates\n self.b1 = b1\n self.b2 = b2\n\n def update(self, w, grad_wrt_w):\n # If not initialized\n if self.m is None:\n self.m = np.zeros(np.shape(grad_wrt_w))\n self.v = np.zeros(np.shape(grad_wrt_w))\n \n self.m = self.b1 * self.m + (1 - self.b1) * grad_wrt_w\n self.v = self.b2 * self.v + (1 - self.b2) * np.power(grad_wrt_w, 2)\n\n m_hat = self.m / (1 - self.b1)\n v_hat = self.v / (1 - self.b2)\n\n self.w_updt = self.learning_rate * m_hat / (np.sqrt(v_hat) + self.eps)\n\n return w - self.w_updt\n\nclass Adadelta():\n def __init__(self, rho=0.95, eps=1e-6):\n self.E_w_updt = None # Running average of squared parameter updates\n self.E_grad = None # Running average of the squared gradient of w\n self.w_updt = None # Parameter update\n self.eps = eps\n self.rho = rho\n\n def update(self, w, grad_wrt_w):\n # If not initialized\n if self.w_updt is None:\n self.w_updt = np.zeros(np.shape(w))\n self.E_w_updt = np.zeros(np.shape(w))\n self.E_grad = np.zeros(np.shape(grad_wrt_w))\n\n # Update average of gradients at w\n self.E_grad = self.rho * self.E_grad + (1 - self.rho) * np.power(grad_wrt_w, 2)\n \n RMS_delta_w = np.sqrt(self.E_w_updt + self.eps)\n RMS_grad = np.sqrt(self.E_grad + self.eps)\n\n # Adaptive learning rate\n adaptive_lr = RMS_delta_w / RMS_grad\n\n # Calculate the update\n self.w_updt = adaptive_lr * grad_wrt_w\n\n # Update the running average of w updates\n self.E_w_updt = self.rho * self.E_w_updt + (1 - self.rho) * np.power(self.w_updt, 2)\n\n return w - self.w_updt\n\n\n\n"
},
{
"alpha_fraction": 0.6593983173370361,
"alphanum_fraction": 0.6765596866607666,
"avg_line_length": 32.228187561035156,
"blob_id": "833db097c91efc76f9df3f1048c16407d9f5186f",
"content_id": "9992a87bc54da2dcdc603b136f2a45339f31b4a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 4953,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 149,
"path": "/c++ implementation/CMakeLists.txt",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.14)\nproject(ML_Spring19_Project)\n#set(CMAKE_INSTALL_PREFIX C:/Anaconda/pkgs/)\n\nset(CMAKE_CXX_STANDARD 14)\n\nset(xtl_DIR C:/Anaconda/pkgs/xtl-0.6.4-h1ad3211_0/Library/lib/cmake/xtl)\nset(xtensor_DIR C:/Anaconda/pkgs/xtensor-0.20.5-h1ad3211_0/Library/lib/cmake/xtensor)\nset(xtensor-blas_DIR C:/Anaconda/pkgs/xtensor-blas-0.16.1-hd41736c_0/Library/lib/cmake/xtensor-blas)\n#set(OpenBLAS_DIR C:/Anaconda/pkgs/openblas-0.3.6-h828a276_2/Library/share/cmake/OpenBLAS)\n\nfind_package(xtl REQUIRED CONFIG)\nfind_package(xtensor REQUIRED CONFIG)\nfind_package(xtensor-blas REQUIRED CONFIG)\n\nset(XTENSOR_INCLUDE_DIR ${xtensor_INCLUDE_DIRS})\nset(XBLAS_INCLUDE_DIR ${xtensor_blas_INCLUDE_DIRS})\n#message(STATUS \"xtensor : \" ${XTENSOR_INCLUDE_DIR})\n#message(STATUS \"xblas : \" ${XBLAS_INCLUDE_DIR})\n\n\nmessage(STATUS \"Forcing tests build type to Release\")\nset(CMAKE_BUILD_TYPE Release CACHE STRING \"Choose the type of build.\" FORCE)\n\ninclude(CheckCXXCompilerFlag)\n\nstring(TOUPPER \"${CMAKE_BUILD_TYPE}\" U_CMAKE_BUILD_TYPE)\n\ninclude(set_compiler_flag.cmake)\n\nif(CPP17)\n # User requested C++17, but compiler might not oblige.\n set_compiler_flag(\n _cxx_std_flag CXX\n \"-std=c++17\" # this should work with GNU, Intel, PGI\n \"/std:c++17\" # this should work with MSVC\n )\n if(_cxx_std_flag)\n message(STATUS \"Building with C++17\")\n endif()\nelse()\n set_compiler_flag(\n _cxx_std_flag CXX REQUIRED\n \"-std=c++14\" # this should work with GNU, Intel, PGI\n \"/std:c++14\" # this should work with MSVC\n )\n message(STATUS \"Building with C++14\")\nendif()\n\nif(NOT _cxx_std_flag)\n message(FATAL_ERROR \"xtensor-blas needs a C++14-compliant compiler.\")\nendif()\n\nif(CMAKE_CXX_COMPILER_ID MATCHES \"GNU\" OR (CMAKE_CXX_COMPILER_ID MATCHES \"Intel\" AND NOT WIN32))\n# set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${_cxx_std_flag} -march=native -Wunused-parameter -Wextra -Wreorder -Wconversion -Wsign-conversion\")\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${_cxx_std_flag} -march=native -Wextra -Wreorder\")\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} -Wold-style-cast\")\nelseif(CMAKE_CXX_COMPILER_ID MATCHES \"MSVC\")\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${_cxx_std_flag} /EHsc /MP /bigobj /wd4800\")\n set(CMAKE_EXE_LINKER_FLAGS /MANIFEST:NO)\n add_definitions(-D_CRT_SECURE_NO_WARNINGS)\n add_definitions(-D_SILENCE_TR1_NAMESPACE_DEPRECATION_WARNING)\nelseif(CMAKE_CXX_COMPILER_ID MATCHES \"Clang\")\n if(NOT WIN32)\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${_cxx_std_flag} -march=native -Wunused-parameter -Wextra -Wreorder -Wconversion -Wsign-conversion\")\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} -Wold-style-cast -Wunused-variable\")\n else() # We are using clang-cl\n set(CMAKE_CXX_FLAGS \"${CMAKE_CXX_FLAGS} ${_cxx_std_flag} /EHsc /MP /bigobj\")\n set(CMAKE_EXE_LINKER_FLAGS /MANIFEST:NO)\n add_definitions(-D_CRT_SECURE_NO_WARNINGS)\n add_definitions(-D_SILENCE_TR1_NAMESPACE_DEPRECATION_WARNING)\n endif()\nelse()\n message(FATAL_ERROR \"Unsupported compiler: ${CMAKE_CXX_COMPILER_ID}\")\nendif()\n\n\nadd_definitions(-DHAVE_CBLAS=1)\nOPTION(USE_OPENBLAS \"use OpenBLAS (requires suitable OpenBLASConfig.cmake)\" OFF)\nif(OpenBLAS_DIR)\n set(USE_OPENBLAS ON)\nendif()\nif(USE_OPENBLAS)\n find_package(OpenBLAS REQUIRED)\n set(BLAS_LIBRARIES ${OpenBLAS_LIBRARY})\nelse()\n# set(BLAS_DIR C:/Anaconda/pkgs/openblas-0.3.6-h828a276_2/Library/share/cmake/OpenBLAS)\n find_package(BLAS REQUIRED)\n find_package(LAPACK REQUIRED)\nendif()\n\nmessage(STATUS \"BLAS VENDOR: \" ${BLAS_VENDOR})\nmessage(STATUS \"BLAS LIBRARIES: \" ${BLAS_LIBRARIES})\n#message(STATUS \"LAPACK LIBRARIES: \" ${LAPACK_LIBRARIES})\n\n#set(BLAS_INCLUDE_DIR ${OpenBLAS_INCLUDE_DIRS})\n\ninclude_directories(.)\ninclude_directories(${xtl_INCLUDE_DIRS})\ninclude_directories(${XTENSOR_INCLUDE_DIR})\ninclude_directories(${XBLAS_INCLUDE_DIR})\n\nset(SOURCE_FILES\n optimizer.cpp\n loss_function.cpp\n activation_function.cpp\n layer.cpp\n neural_network.cpp\n autoencoder.cpp\n )\nset(HEADER_FILES\n optimizer.h\n loss_function.h\n activation_function.h\n layer.h\n neural_network.h\n )\n\nadd_library(NeuralNetwork SHARED\n ${HEADER_FILES}\n ${SOURCE_FILES}\n )\n\n#add_executable(autoencoder\n# autoencoder.cpp)\nadd_executable(autoencoder\n autoencoder.cpp\n ${HEADER_FILES}\n ${SOURCE_FILES}\n ${XTENSOR_BLAS_HEADERS}\n ${XTENSOR_HEADERS}\n )\n\n#target_include_directories(autoencoder PUBLIC\n# ${XTENSOR_INCLUDE_DIR}\n# ${XBLAS_INCLUDE_DIR}\n# )\nlink_libraries(xtensor-blas\n xtensor\n ${BLAS_LIBRARIES}\n ${LAPACK_LIBRARIES}\n )\ntarget_link_libraries(autoencoder\n NeuralNetwork\n# xtensor\n ${BLAS_LIBRARIES}\n ${LAPACK_LIBRARIES}\n# xtensor-blas\n )\n\n\n"
},
{
"alpha_fraction": 0.5392641425132751,
"alphanum_fraction": 0.563426673412323,
"avg_line_length": 28.868852615356445,
"blob_id": "a1e4fd3b9866d6f1d27c220269d574ab91357bd8",
"content_id": "9951cf6b94ceb8983d6cb81a321e6aeeddb82846",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1821,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 61,
"path": "/c++ implementation/optimizer.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#include \"optimizer.h\"\n\nusing namespace std;\n\nAdam::Adam(double learning_rate, double b1, double b2) {\n this->learning_rate = learning_rate;\n this->b1 = b1;\n this->b2 = b2;\n}\nAdam::Adam() {\n Adam(0.0002, 0.5, 0.999);\n}\nxt::xarray<double> Adam::update(xt::xarray<double> *w, xt::xarray<double> *grad_wrt_w) {\n if (!this->initialized) {\n this->initialized = true;\n this->m = xt::zeros<double>(w->shape());\n this->v = xt::zeros<double>(grad_wrt_w->shape());\n }\n this->m = this->m * this->b1 + *grad_wrt_w * (1 - this->b1);\n this->v = this->v * this->b2 + xt::pow(*grad_wrt_w, 2) * (1 - this->b2);\n\n auto m_hat = this->m / (1 - this->b1);\n auto v_hat = this->v / (1 - this->b2);\n auto w_updt = (m_hat * this->learning_rate) / (xt::sqrt(v_hat) + this->eps);\n\n return *w - w_updt;\n}\n\nAdadelta::Adadelta( double rho, double eps) {\n this->rho = rho;\n this->eps = eps;\n}\nAdadelta::Adadelta() {\n Adadelta(0.95, 1.0e-6);\n}\nxt::xarray<double> Adadelta::update(xt::xarray<double> *w, xt::xarray<double> *grad_wrt_w) {\n if (!this->initialized) {\n this->initialized = true;\n this->w_updt = xt::zeros<double>(w->shape());\n this->E_w_updt = xt::zeros<double>(w->shape());\n this->E_grad = xt::zeros<double>(grad_wrt_w->shape());\n }\n\n// update average gradients at w\n this->E_grad = this->E_grad * this->rho + xt::pow(*grad_wrt_w, 2) * (1 - this->rho);\n\n auto RMS_delta_w = xt::sqrt(this->E_w_updt + this->eps);\n auto RMS_grad = xt::sqrt(this->E_grad + this->eps);\n\n auto adaptive_lr = RMS_delta_w / RMS_grad;\n\n this->w_updt = adaptive_lr * *grad_wrt_w;\n\n this->E_w_updt = this->E_w_updt * this->rho + xt::pow(this->w_updt, 2) * (1 - this->rho);\n\n return *w - this->w_updt;\n}"
},
{
"alpha_fraction": 0.6743197441101074,
"alphanum_fraction": 0.6870748400688171,
"avg_line_length": 33.588233947753906,
"blob_id": "fbfd4d9be0048dffc14d502ae769945dea85d6d0",
"content_id": "92799f69447213ad2d4a28c30485f7a4e580d7a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1176,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 34,
"path": "/c++ implementation/loss_function.h",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#ifndef ML_SPRING19_PROJECT_LOSS_FUNCTION_H\n#define ML_SPRING19_PROJECT_LOSS_FUNCTION_H\n\n#include <xtensor/xarray.hpp>\n#include <xtensor/xio.hpp>\n#include <xtensor/xmath.hpp>\n#include <xtensor/xsort.hpp>\n\nusing namespace std;\n\nclass Loss {\npublic:\n virtual xt::xarray<double> loss(xt::xarray<double> *, xt::xarray<double> *)=0;\n virtual xt::xarray<double> gradient(xt::xarray<double> *, xt::xarray<double> *)=0;\n virtual xt::xarray<double> acc(xt::xarray<double> *, xt::xarray<double> *)=0;\n};\nclass SquareLoss: public Loss {\npublic:\n xt::xarray<double> loss(xt::xarray<double> *, xt::xarray<double> *) override;\n xt::xarray<double> gradient(xt::xarray<double> *, xt::xarray<double> *) override;\n xt::xarray<double> acc(xt::xarray<double> *, xt::xarray<double> *) override;\n};\nclass CrossEntropy: public Loss {\npublic:\n xt::xarray<double> loss(xt::xarray<double> *, xt::xarray<double> *) override;\n xt::xarray<double> gradient(xt::xarray<double> *, xt::xarray<double> *) override;\n xt::xarray<double> acc(xt::xarray<double> *, xt::xarray<double> *) override;\n};\n\n#endif //ML_SPRING19_PROJECT_LOSS_FUNCTION_H\n"
},
{
"alpha_fraction": 0.6830188632011414,
"alphanum_fraction": 0.6867924332618713,
"avg_line_length": 25.5,
"blob_id": "943b120885dc6ed754a364a30742526d21e85744",
"content_id": "437b10fb3b5da4191e4e3cf52629762b7851bd6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 10,
"path": "/python implementation/data_operation.py",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport math\nimport sys\nimport pdb\n\ndef accuracy_score(y_true, y_pred):\n \"\"\" Compare y_true to y_pred and return the accuracy \"\"\"\n accuracy = np.sum(y_true == y_pred, axis=0) / len(y_true)\n return accuracy\n"
},
{
"alpha_fraction": 0.5480931401252747,
"alphanum_fraction": 0.569692850112915,
"avg_line_length": 37.738563537597656,
"blob_id": "ff450e4f32ca25da13e6daedc7b381f91b5ea189",
"content_id": "a79b4aa61f72b1093584f277648c12b92c1020ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5926,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 153,
"path": "/c++ implementation/autoencoder.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n#include <iostream>\n#include <iomanip>\n#include <fstream>\n#include <xtensor/xarray.hpp>\n#include <xtensor/xcsv.hpp>\n#include <xtensor/xview.hpp>\n#include \"optimizer.h\"\n#include \"loss_function.h\"\n#include \"layer.h\"\n#include \"neural_network.h\"\n\nusing namespace std;\nusing namespace xt::placeholders;\n\n#define trace(input) do { if (1) { cout << input << endl; } } while(0)\n#define here() do { cout << \" here\" << endl; } while (0)\n#define there() do { cout << \" there\" << endl; } while (0)\n\nclass Autoencoder {\n int img_rows = 28;\n int img_cols = 28;\n int img_dim = img_rows * img_cols;\n int latent_dim = 16;\n\n string optimizer;\n Loss *loss_function;\n NeuralNetwork* autoencoder;\n\n xt::xarray<double> X, testX;\n\n NeuralNetwork build_encoder(string optimizer, Loss *loss_function) {\n NeuralNetwork encoder(optimizer, loss_function);\n auto *dense1 = new Dense(512, Shape(this->img_dim, 1), true, false);\n auto *act1 = new Activation(\"leaky_relu\");\n// auto *batch1 = new BatchNormalization(0.8);\n auto *dense2 = new Dense(256);\n auto *act2 = new Activation(\"leaky_relu\");\n// auto *batch2 = new BatchNormalization(0.8);\n auto *dense3 = new Dense(this->latent_dim, Shape(this->img_dim, 1), false, true);\n encoder.add(dense1);\n encoder.add(act1);\n// encoder->add(batch1);\n encoder.add(dense2);\n encoder.add(act2);\n// encoder->add(batch2);\n encoder.add(dense3);\n return encoder;\n }\n NeuralNetwork build_decoder(string optimizer, Loss *loss_function) {\n NeuralNetwork decoder(optimizer, loss_function);\n auto *dense1 = new Dense(256, Shape(this->latent_dim, 1));\n auto *act1 = new Activation(\"leaky_relu\");\n// auto * batch1 = new BatchNormalization(0.8);\n auto *dense2 = new Dense(512);\n auto *act2 = new Activation(\"leaky_relu\");\n// auto *batch2 = new BatchNormalization(0.8);\n auto *dense3 = new Dense(this->img_dim);\n auto *act3 = new Activation(\"tanh\");\n decoder.add(dense1);\n decoder.add(act1);\n// decoder.add(batch1);\n decoder.add(dense2);\n decoder.add(act2);\n// decoder.add(batch2);\n decoder.add(dense3);\n decoder.add(act3);\n return decoder;\n }\n void save_images(int epoch) {\n int rows = 5;\n auto index = xt::random::randint<int>({rows*rows,1}, 0, X.shape(0));\n xt::xarray<double> images = xt::view(X, xt::keep(index), xt::all());\n xt::xarray<double> gen_images = this->autoencoder->predict(&images);\n// gen_images.reshape({-1, this->img_rows, this->img_cols});\n gen_images = (gen_images * -127.5) + 127.5;\n// trace(gen_images);\n\n string file_name = \"../image_predictions/ae_\" + to_string(epoch) + \".pgm\";\n ofstream image_file(file_name, ofstream::out | ofstream::trunc);\n if (image_file.is_open()) {\n image_file << \"P2\\r\\n\";\n image_file << this->img_rows << \" \" << this->img_cols << \"\\r\\n\";\n image_file << \"255\\r\\n\";\n xt::xarray<double> image = xt::view(gen_images, xt::keep(0), xt::all());\n image.reshape({this->img_rows, this->img_cols});\n// for (int x=0; x<rows*rows)\n for (int i = 0; i< this->img_rows-1; i++) {\n for (int j = 0; j<this->img_cols-1; j++) {\n image_file << image(i,j) << \" \";\n }\n image_file << \"\\r\\n\";\n }\n image_file.close();\n }\n\n\n }\npublic:\n Autoencoder(xt::xarray<double> X, xt::xarray<double> testX) {\n this->X = X;\n this->testX = testX;\n this->loss_function = new SquareLoss();\n this->optimizer = \"adam\";\n NeuralNetwork encoder = this->build_encoder(this->optimizer, this->loss_function);\n NeuralNetwork decoder = this->build_decoder(this->optimizer, this->loss_function);\n autoencoder = new NeuralNetwork(this->optimizer, this->loss_function);\n autoencoder->layers.insert(autoencoder->layers.end(), encoder.layers.begin(), encoder.layers.end());\n autoencoder->layers.insert(autoencoder->layers.end(), decoder.layers.begin(), decoder.layers.end());\n// autoencoder->output_dim = this->img_dim;\n autoencoder->summary(\"Variational Autoencoder\");\n }\n\n void train(int n_epochs, int batch_size, int save_interval) {\n this->autoencoder->batch_size = batch_size;\n this->X = (this->X - 127.5) / 127.5;\n this->testX = (this->testX - 127.5) / 127.5;\n for (int epoch = 0; epoch<n_epochs; epoch++) {\n auto index = xt::random::randint<int>({batch_size,1}, 0, X.shape(0));\n xt::xarray<double> random_batch = xt::view(X, xt::keep(index), xt::all());\n auto loss = this->autoencoder->train_on_batch(&random_batch, &random_batch);\n cout << epoch << \" [D loss: \" << setprecision(6) << loss << \"]\"<<endl;\n if (epoch % save_interval == 0)\n this->save_images(epoch);\n }\n }\n\n};\n\n\nint main (int argc, char **argv) {\n trace(\"Loading MNIST data...\"<<endl);\n xt::xarray<double> train_data, test_data;\n ifstream train_file(\"../mnist_train.csv\");\n if (train_file.is_open()) {\n train_data = xt::load_csv<double>(train_file);\n train_file.close();\n }\n ifstream test_file(\"../mnist_test.csv\");\n if (test_file.is_open()) {\n test_data = xt::load_csv<double>(test_file);\n test_file.close();\n }\n xt::xarray<double> X = xt::view(train_data, xt::all(), xt::range(1,_));\n xt::xarray<double> testX = xt::view(test_data, xt::all(), xt::range(1,_));\n// trace(\"(\" << X.shape(0) << \",\" << X.shape(1) << \")\");\n// trace(\"(\" << testX.shape(0) << \",\" << testX.shape(1) << \")\");\n\n Autoencoder ae(X, testX);\n ae.train(2000, 50, 40);\n}"
},
{
"alpha_fraction": 0.782537043094635,
"alphanum_fraction": 0.782537043094635,
"avg_line_length": 74.75,
"blob_id": "50bc425e0c9c479f9ec01bcd27e78ad8ae41270f",
"content_id": "dc6497107f19059d3ea9f833010f8a54ad148e38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 8,
"path": "/README.md",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "# Optimizing Jacobian Computation for Autoencoders\n\nThis repo contains Python and C++ implementations for the standard and optimized versions of the algorithm used to compute the Jacobians of an autoencoder.\n\nThe methods **_jacobian()** and **_jacobian_opt()** in *neural_network.py/cpp* are the standard and optimized backpropagation algorithms respectively. The methods **jacob_backward_pass()** and **jacob_backward_opt_pass()** from *layers.py/cpp* \nare used to propagate the Jacobian across each layer object.\n\nThe underlying autoencoder infrastructure is based on Erik Lindernoren's *ML-From-Scratch* project.\n\n"
},
{
"alpha_fraction": 0.5759615302085876,
"alphanum_fraction": 0.5980769395828247,
"avg_line_length": 24.365854263305664,
"blob_id": "0105dddb38a23190f7650ad15f2becd70c7b0dc8",
"content_id": "4b1e8f1302378e399c51c8f82d0f37fd8e50ebef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1040,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 41,
"path": "/c++ implementation/activation_function.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/7/2019.\n//\n\n#include \"activation_function.h\"\n\nxt::xarray<double> Sigmoid::function(xt::xarray<double> *x) {\n return 1 / (1 + xt::exp(-*x));\n}\nxt::xarray<double> Sigmoid::gradient(xt::xarray<double> *x) {\n auto sig = this->function(x);\n return sig * (1 - sig);\n}\n\n\nxt::xarray<double> TanH::function(xt::xarray<double> *x) {\n return (2 / (1 + xt::exp(-2 * *x))) - 1;\n}\nxt::xarray<double> TanH::gradient(xt::xarray<double> *x) {\n auto tanh = this->function(x);\n return 1 - xt::pow(tanh, 2);\n}\n\n\n//LeakyReLU::LeakyReLU(double alpha) {\n// this->alpha = alpha;\n//}\nxt::xarray<double> LeakyReLU::function(xt::xarray<double> *x) {\n return xt::where(*x >= 0, *x, *x * this->alpha);\n}\nxt::xarray<double> LeakyReLU::gradient(xt::xarray<double> *x) {\n return xt::where(*x >= 0, 1, this->alpha);\n}\n\n\nxt::xarray<double> ReLU::function(xt::xarray<double> *x) {\n return xt::where(*x >= 0, *x, 0);\n}\nxt::xarray<double> ReLU::gradient(xt::xarray<double> *x) {\n return xt::where(*x >= 0, 1, 0);\n}\n"
},
{
"alpha_fraction": 0.6233479976654053,
"alphanum_fraction": 0.6321585774421692,
"avg_line_length": 29.266666412353516,
"blob_id": "9e404a40eb62bebeb9d730a573e26c350e514764",
"content_id": "825afb5b4da3ad150fb95c8a1cdd97a99626f90e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 15,
"path": "/python implementation/data_manipulation.py",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom itertools import combinations_with_replacement\nimport numpy as np\nimport math\nimport sys\n\ndef batch_iterator(X, y=None, batch_size=64):\n \"\"\" Simple batch generator \"\"\"\n n_samples = X.shape[0]\n for i in np.arange(0, n_samples, batch_size):\n begin, end = i, min(i+batch_size, n_samples)\n if y is not None:\n yield X[begin:end], y[begin:end]\n else:\n yield X[begin:end]\n"
},
{
"alpha_fraction": 0.5421220660209656,
"alphanum_fraction": 0.5514571666717529,
"avg_line_length": 40.56467056274414,
"blob_id": "54296095fc6f37729af44f93eb8b1a82f761582d",
"content_id": "5b6aeba04656f72e70452660f781a51efb49370d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 13176,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 317,
"path": "/c++ implementation/layer.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/4/2019.\n//\n\n#include <chrono>\n#include \"layer.h\"\n\n#define trace(input) do { if (1) { cout << input << endl; } } while(0)\n#define here() do { cout << \" here\" << endl; } while (0)\n#define there() do { cout << \" there\" << endl; } while (0)\n\nvoid Layer::set_input_shape(Shape input_shape) {\n this->input_shape = input_shape;\n}\nxt::xarray<double> Layer::dot(xt::xarray<double> *a, xt::xarray<double> *b) {\n// Use this definition if xtensor_blas doesn't compile\n xt::xarray<double> mult = xt::zeros<double>({a->shape(0), b->shape(1)});\n for (int i=0; i<a->shape(0); i++) {\n for (int j=0; j<b->shape(1); j++) {\n for (int k=1; k<a->shape(1); k++) {\n mult(i,j) += (*a)(i,k) * (*b)(k,j);\n }\n }\n }\n// xt::xarray<double> mult = xt::linalg::dot(*a, *b);\n return mult;\n}\n\nDense::Dense(int n_units, Shape input_shape, bool first_layer, bool latent_layer) {\n this->n_units = n_units;\n this->input_shape = input_shape;\n this->first_layer = first_layer;\n this->latent_layer = latent_layer;\n}\nDense::Dense(int n_units, Shape input_shape) {\n this->n_units = n_units;\n this->input_shape = input_shape;\n this->first_layer = false;\n this->latent_layer = false;\n}\nDense::Dense(int n_units) {\n this->n_units = n_units;\n this->input_shape = Shape(1, 1);\n this->first_layer = false;\n this->latent_layer = false;\n}\nvoid Dense::initialize(string optimizer) {\n this->trainable = true;\n double limit = 1.0 / sqrt(this->input_shape.first);\n this->W = xt::random::rand({this->input_shape.first, this->n_units}, -limit, limit);\n this->w0 = xt::zeros<double>({1, this->n_units});\n if (optimizer == \"adam\") {\n this->W_opt = new Adam();\n this->w0_opt = new Adam();\n } else if (optimizer == \"adadelta\"){\n this->W_opt = new Adadelta();\n this->w0_opt = new Adadelta();\n }\n}\nstring Dense::layer_name() {\n return this->name;\n}\nint Dense::parameters() {\n return this->W.shape(0) * this->W.shape(1) + this->w0.shape(0) * this->w0.shape(1);\n}\nxt::xarray<double> Dense::forward_pass(xt::xarray<double> *X, bool training) {\n this->layer_input = *X;\n// trace(\" X (\" << X->get_rows_number() << \",\" << X->get_columns_number() << \")\");\n// trace(\" W (\" << W.get_rows_number() << \",\" << W.get_columns_number() << \")\");\n// trace(\" w0(\" << w0.get_rows_number() << \",\" << w0.get_columns_number() << \")\");\n return this->dot(X, &this->W) + this->w0;\n}\nvoid Dense::backward_pass(xt::xarray<double> *accum_grad, int index) {\n xt::xarray<double> W = xt::transpose(this->W);\n if (this->trainable) {\n // calc gradients w.r.t. layer weights\n xt::xarray<double> input_transp = xt::transpose(this->layer_input);\n auto grad_W = this->dot(&input_transp, accum_grad);\n xt::xarray<double> grad_w0 = xt::sum(*accum_grad, 0);\n // update layer weights\n this->W = this->W_opt->update(&this->W, &grad_W);\n this->w0 = this->w0_opt->update(&this->w0, &grad_w0);\n }\n *accum_grad = this->dot(accum_grad, &W);\n}\nvoid Dense::jacob_backward_pass(xt::xarray<double> *accum_grad, int index) {\n xt::xarray<double> W = xt::transpose(this->W);\n// auto start = chrono::system_clock::now();\n if (index == 1) {\n // accum_grad = np.einsum('ij,jk->ijk', accum_grad, W.T)\n xt::xarray<double> temp = xt::zeros<double>({accum_grad->shape(0), accum_grad->shape(1), W.shape(1)});\n for (int i=0; i<accum_grad->shape(0); i++) {\n for (int j=0; j<accum_grad->shape(1); j++) {\n for (int k=0; k<W.shape(1); k++) {\n temp(i,j,k) = (*accum_grad)(i,j) * W(j,k);\n }\n }\n }\n *accum_grad = temp;\n } else {\n *accum_grad = this->dot(accum_grad, &W);\n }\n// auto end = chrono::system_clock::now();\n// trace(\" \" << index << \": \" << (chrono::duration<double>(end - start)).count());\n}\nvoid Dense::jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index) {\n xt::xarray<double> W = xt::transpose(this->W);\n// auto start = chrono::system_clock::now();\n if (this->latent_layer) {\n *accum_grad = this->dot(accum_grad, &W);\n } else {\n auto a_grad = *accum_grad;\n auto b_grad = this->dot(accum_grad, &W);\n if (this->first_layer){\n// *accum_grad = einsum('ijk,ikp->ijp', a_grad, b_grad);\n xt::xarray<double> temp = xt::zeros<double>({a_grad.shape(0), a_grad.shape(1), b_grad.shape(2)});\n for (int i=0; i<a_grad.shape(0); i++) {\n for (int j=0; j<a_grad.shape(1); j++) {\n for (int p=0; p<b_grad.shape(2); p++) {\n for (int k=0; k<b_grad.shape(1); k++) {\n temp(i,j,k) += a_grad(i,j,k) * b_grad(i,k,p);\n }\n }\n }\n }\n *accum_grad = temp;\n }\n }\n// auto end = chrono::system_clock::now();\n// trace(\" \" << index << \": \" << (chrono::duration<double>(end - start)).count());\n}\n\nShape Dense::output_shape() {\n return Shape (this->n_units, 1);\n}\n\n\nActivation::Activation(string function_name) {\n this->function_name = function_name;\n this ->trainable = true;\n this->first_layer = false;\n this->latent_layer = false;\n if (function_name == \"sigmoid\")\n this->activation_function = new Sigmoid();\n else if (function_name == \"tanh\")\n this->activation_function = new TanH();\n else if (function_name == \"leaky_relu\")\n this->activation_function = new LeakyReLU();\n}\nstring Activation::layer_name() {\n return this->name + \" (\" + this->function_name + \")\";\n}\nint Activation::parameters() {\n return 0;\n}\nxt::xarray<double> Activation::forward_pass(xt::xarray<double> *X, bool training) {\n this->layer_input = *X;\n return this->activation_function->function(X);\n}\n\nvoid Activation::backward_pass(xt::xarray<double> *accum_grad, int index) {\n *accum_grad = *accum_grad * this->activation_function->gradient(&layer_input);\n}\nvoid Activation::jacob_backward_pass(xt::xarray<double> *accum_grad, int index){\n// auto start = chrono::system_clock::now();\n\n auto act_grad = this->activation_function->gradient(&this->layer_input);\n if (index == 0) {\n *accum_grad = act_grad;\n } else {\n// *accum_grad = np.einsum('ijk,ik -> ijk', accum_grad, act_grad);\n xt::xarray<double> temp = xt::zeros<double>(accum_grad->shape());\n for (int i=0; i<accum_grad->shape(0); i++) {\n for (int j=0; j<accum_grad->shape(1); j++) {\n for (int k=0; k<accum_grad->shape(1); k++) {\n temp(i,j,k) = (*accum_grad)(i,j,k) * act_grad(i,k);\n }\n }\n }\n *accum_grad = temp;\n }\n// auto end = chrono::system_clock::now();\n// trace(\" \" << index << \": \" << (chrono::duration<double>(end - start)).count());\n}\nvoid Activation::jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index){\n// auto start = chrono::system_clock::now();\n auto a_grad = *accum_grad;\n auto b_grad = *accum_grad;\n auto act_grad = this->activation_function->gradient(&this->layer_input);\n act_grad = xt::diag(xt::flatten(act_grad));\n\n xt::xarray<double> temp;\n if (b_grad.dimension() == 2) {\n// temp = xt::linalg::tensordot(act_grad, xt::transpose(b_grad), {1}, {1});\n xt::xarray<double> transp = xt::transpose(b_grad);\n temp = this->dot(&act_grad, &transp);\n } else {\n// temp = np.einsum('ijk,ikp->ijp', b_grad, act_grad)\n temp = xt::zeros<double>({b_grad.shape(0), b_grad.shape(1), act_grad.shape(2)});\n for (int i=0; i<b_grad.shape(0); i++) {\n for (int j=0; j<b_grad.shape(1); j++) {\n for (int p=0; p<act_grad.shape(2); p++) {\n for (int k=0; k<act_grad.shape(1); k++) {\n temp(i,j,k) += b_grad(i,j,k) * act_grad(i,k,p);\n }\n }\n }\n }\n }\n\n// accum_grad = np.einsum('ijk,ikp->ijp', a_grad, temp)\n xt::xarray<double> temp2 = xt::zeros<double>({a_grad.shape(0), a_grad.shape(1), temp.shape(2)});\n for (int i=0; i<a_grad.shape(0); i++) {\n for (int j=0; j<a_grad.shape(1); j++) {\n for (int p=0; p<temp.shape(2); p++) {\n for (int k=0; k<temp.shape(1); k++) {\n temp2(i,j,k) += a_grad(i,j,k) * temp(i,k,p);\n }\n }\n }\n }\n *accum_grad = temp2;\n\n// auto end = chrono::system_clock::now();\n// trace(\" \" << index << \": \" << (chrono::duration<double>(end - start)).count());\n}\nShape Activation::output_shape() {\n return this->input_shape;\n}\nvoid Activation::initialize(string optimizer) {}\n\n\nBatchNormalization::BatchNormalization(double momentum) {\n this->momentum = momentum;\n this->epsilon = 0.01;\n this->trainable = true;\n this->initialized = false;\n}\nvoid BatchNormalization::initialize(string optimizer) {\n this->gamma = xt::ones<double>({this->input_shape.first, this->input_shape.second});\n this->beta = xt::zeros<double>({this->input_shape.first, this->input_shape.second});\n if (optimizer == \"adam\") {\n this->gamma_opt = new Adam();\n this->beta_opt = new Adam();\n } else if (optimizer == \"adadelta\"){\n this->gamma_opt = new Adadelta();\n this->beta_opt = new Adadelta();\n }\n}\nstring BatchNormalization::layer_name() {\n return this->name;\n}\nint BatchNormalization::parameters() {\n// return xt::prod(this->gamma.shape()) + xt::prod(this->beta.shape());\n return this->gamma.shape(0) * this->gamma.shape(1) + this->beta.shape(0) * this->beta.shape(1);\n}\nxt::xarray<double> BatchNormalization::forward_pass(xt::xarray<double> *X, bool training) {\n if (!this->initialized) {\n this->running_mean = xt::mean(*X, 0);\n this->running_var = xt::variance(*X, {0});\n this->initialized = true;\n }\n xt::xarray<double> mean, var;\n if (training && this->trainable) {\n mean = xt::mean(*X, 0);\n var = xt::variance(*X, {0});\n this->running_mean = this->running_mean * this->momentum + mean * (1 - this->momentum);\n this->running_var = this->running_var * this->momentum + var * (1 - this->momentum);\n } else {\n mean = this->running_mean;\n var = this->running_var;\n }\n // stats to save for backward pass\n this->X_centered = *X - mean; // element-wise xt::xarray minus row vector: each row of X gets the mean subtracted\n this->stddev_inv =1.0 / xt::sqrt(var + this->epsilon);\n// this->X_centered.print_preview();\n// var.print_unique();\n// this->stddev_inv.print_unique();\n\n auto X_norm = this->X_centered * this->stddev_inv;\n// X_norm.print_preview();\n// this->gamma.print_preview();\n// this->beta.print_preview();\n// trace(\" X_norm (\" << X_norm.get_rows_number() << \",\" << X_norm.get_columns_number() << \")\");\n// trace(\" gamma (\" << this->gamma.get_rows_number() << \",\" << this->gamma.get_columns_number() << \")\");\n// trace(\" beta (\" << this->beta.get_rows_number() << \",\" << this->beta.get_columns_number() << \")\");\n return this->gamma * X_norm + this->beta;\n}\nvoid BatchNormalization::backward_pass(xt::xarray<double> *accum_grad, int index) {\n auto gamma = this->gamma;\n\n if (this->trainable) {\n auto X_norm = this->X_centered * this->stddev_inv;\n xt::xarray<double> grad_gamma = xt::sum(*accum_grad * X_norm, 0);\n xt::xarray<double> grad_beta = xt::sum(*accum_grad, 0);\n// trace(\" accum_grad (\" << accum_grad->get_rows_number() << \",\" << accum_grad->get_columns_number() << \")\");\n// trace(\" X_norm (\" << X_norm.get_rows_number() << \",\" << X_norm.get_columns_number() << \")\");\n// trace(\" grad_gamma (\" << grad_gamma.get_rows_number() << \",\" << grad_gamma.get_columns_number() << \")\");\n// trace(\" gamma (\" << this->gamma.get_rows_number() << \",\" << this->gamma.get_columns_number() << \")\");\n this->gamma = this->gamma_opt->update(&this->gamma, &grad_gamma);\n this->beta = this ->beta_opt->update(&this->beta, &grad_beta);\n }\n int batch_size = accum_grad->shape(0);\n// trace(\" accum_grad (\" << accum_grad->get_rows_number() << \",\" << accum_grad->get_columns_number() << \")\");\n// trace(\" X_centered (\" << this->X_centered.get_rows_number() << \",\" << this->X_centered.get_columns_number() << \")\");\n *accum_grad = (1.0/batch_size) * gamma * this->stddev_inv * (\n (batch_size * *accum_grad)\n - xt::sum(*accum_grad, 0)\n - (this->X_centered * xt::pow(this->stddev_inv, 2) * xt::sum(*accum_grad * this->X_centered, 0))\n );\n// trace(\" accum_grad(\" << accum_grad->get_rows_number() << \",\" << accum_grad->get_columns_number() << \")\");\n}\nShape BatchNormalization::output_shape() {\n return this->input_shape;\n}\nvoid BatchNormalization::jacob_backward_pass(xt::xarray<double> *accum_grad, int index) {}\nvoid BatchNormalization::jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index) {}\n"
},
{
"alpha_fraction": 0.7042416930198669,
"alphanum_fraction": 0.7106333374977112,
"avg_line_length": 36.82417678833008,
"blob_id": "381ce0246f0fc3c6acc7d793640ac1caa51c145b",
"content_id": "ae688a1bc6bcfc4ccf43378c097e9fb569158672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3442,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 91,
"path": "/c++ implementation/layer.h",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/4/2019.\n//\n\n#ifndef ML_SPRING19_PROJECT_LAYER_H\n#define ML_SPRING19_PROJECT_LAYER_H\n\n#include <string>\n#include <xtensor/xarray.hpp>\n#include <xtensor/xio.hpp>\n#include <xtensor/xmath.hpp>\n#include <xtensor/xrandom.hpp>\n#include <xtensor/xmanipulation.hpp>\n#include <xtensor-blas/xlinalg.hpp>\n#include \"optimizer.h\"\n#include \"activation_function.h\"\n\nusing namespace std;\n\ntypedef pair<int, int> Shape;\n\nclass Layer {\npublic:\n Shape input_shape;\n bool trainable;\n bool first_layer, latent_layer;\n void set_input_shape(Shape);\n xt::xarray<double> dot(xt::xarray<double> *a, xt::xarray<double> *b);\n virtual string layer_name()=0;\n virtual int parameters()=0;\n virtual void initialize(string optimizer)=0;\n virtual xt::xarray<double> forward_pass(xt::xarray<double> *X, bool training)=0;\n virtual void backward_pass(xt::xarray<double> *accum_grad, int index)=0;\n virtual void jacob_backward_pass(xt::xarray<double> *accum_grad, int index)=0;\n virtual void jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index)=0;\n virtual Shape output_shape()=0;\n};\nclass Dense: public Layer {\n string name = \"Dense\";\n int n_units;\n xt::xarray<double> layer_input;\n xt::xarray<double> W, w0;\n Optimizer *W_opt, *w0_opt;\npublic:\n Dense(int n_units, Shape, bool first_layer, bool latent_layer);\n Dense(int n_units, Shape input_shape);\n explicit Dense(int n_units);\n string layer_name() override;\n int parameters() override;\n void initialize(string optimizer) override;\n xt::xarray<double> forward_pass(xt::xarray<double> *X, bool training) override;\n void backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index) override;\n Shape output_shape() override;\n};\nclass Activation: public Layer {\n string name = \"Activation\";\n string function_name;\n ActivationFunction* activation_function;\n xt::xarray<double> layer_input;\npublic:\n explicit Activation(string);\n string layer_name() override;\n int parameters() override;\n void initialize(string optimizer) override;\n xt::xarray<double> forward_pass(xt::xarray<double> *X, bool training) override;\n void backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index) override;\n Shape output_shape() override;\n};\nclass BatchNormalization: public Layer {\n string name = \"BatchNormalization\";\n bool initialized;\n double momentum, epsilon;\n xt::xarray<double> gamma, beta, X_centered, running_mean, running_var, stddev_inv;\n Optimizer *gamma_opt, *beta_opt;\npublic:\n explicit BatchNormalization(double);\n string layer_name() override;\n int parameters() override;\n void initialize(string optimizer) override;\n xt::xarray<double> forward_pass(xt::xarray<double> *X, bool training) override;\n void backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_pass(xt::xarray<double> *accum_grad, int index) override;\n void jacob_backward_opt_pass(xt::xarray<double> *accum_grad, int index) override;\n Shape output_shape() override;\n};\n\n#endif //ML_SPRING19_PROJECT_LAYER_H\n"
},
{
"alpha_fraction": 0.698400616645813,
"alphanum_fraction": 0.710586428642273,
"avg_line_length": 28.177778244018555,
"blob_id": "3b94c712a8e6230892bc88106364bba117191e91",
"content_id": "272417bcf2110fc77dc85cf50bc8fa65ef4e4806",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1313,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 45,
"path": "/c++ implementation/activation_function.h",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/7/2019.\n//\n\n#ifndef ML_SPRING19_PROJECT_ACTIVATION_FUNCTION_H\n#define ML_SPRING19_PROJECT_ACTIVATION_FUNCTION_H\n\n#include <xtensor/xarray.hpp>\n#include <xtensor/xio.hpp>\n#include <xtensor/xmath.hpp>\n\nusing namespace std;\n\nclass ActivationFunction {\npublic:\n virtual xt::xarray<double> function(xt::xarray <double> *x)=0;\n virtual xt::xarray<double> gradient(xt::xarray <double> *x)=0;\n};\nclass Sigmoid : public ActivationFunction {\npublic:\n xt::xarray<double> function(xt::xarray <double> *x) override;\n xt::xarray<double> gradient(xt::xarray <double> *x) override;\n};\nclass TanH : public ActivationFunction {\npublic:\n xt::xarray<double> function(xt::xarray <double> *x) override;\n xt::xarray<double> gradient(xt::xarray <double> *x) override;\n};\nclass LeakyReLU : public ActivationFunction {\nprivate:\n double alpha=0.2;\npublic:\n// LeakyReLU(double alpha);\n xt::xarray<double> function(xt::xarray <double> *x) override;\n xt::xarray<double> gradient(xt::xarray <double> *x) override;\n};\nclass ReLU : public ActivationFunction {\n\npublic:\n// LeakyReLU(double alpha);\n xt::xarray<double> function(xt::xarray <double> *x) override;\n xt::xarray<double> gradient(xt::xarray <double> *x) override;\n};\n\n#endif //ML_SPRING19_PROJECT_ACTIVATION_FUNCTION_H\n"
},
{
"alpha_fraction": 0.6578947305679321,
"alphanum_fraction": 0.6720647811889648,
"avg_line_length": 23.09756088256836,
"blob_id": "7b2e39bf5b7181218033bfc2fe44c7ef401d6416",
"content_id": "17e094d435701b3e4505937f932caca6e9c360f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 988,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 41,
"path": "/c++ implementation/optimizer.h",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#ifndef OPTIMIZER_H\n#define OPTIMIZER_H\n\n#include <xtensor/xarray.hpp>\n#include <xtensor/xio.hpp>\n#include <xtensor/xmath.hpp>\n#include <xtensor/xbuilder.hpp>\n\nusing namespace std;\n\nclass Optimizer {\npublic:\n virtual xt::xarray<double> update(xt::xarray<double> *w, xt::xarray<double> *grad_wrt_w)=0;\n};\n\nclass Adam: public Optimizer {\n double eps = 1.0e-8;\n double learning_rate, b1, b2;\n bool initialized = false;\n xt::xarray<double> m,v;\npublic:\n Adam();\n Adam(double learing_rate, double b1, double b2);\n xt::xarray<double> update(xt::xarray<double> *w, xt::xarray<double> *grad_wrt_w) override ;\n};\nclass Adadelta: public Optimizer {\n double eps, rho;\n bool initialized = false;\n xt::xarray<double> E_w_updt, E_grad, w_updt;\npublic:\n Adadelta();\n Adadelta(double rho, double eps);\n xt::xarray<double> update(xt::xarray<double> *w, xt::xarray<double> *grad_wrt_w) override ;\n};\n\n\n#endif //OPTIMIZER_H\n"
},
{
"alpha_fraction": 0.5517668724060059,
"alphanum_fraction": 0.5584315061569214,
"avg_line_length": 44.11888122558594,
"blob_id": "da3b64f494f117d6bc3b9bea5df40534609a79ad",
"content_id": "0a7e1be61b30dcb1b04948b7591aef341432c458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6452,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 143,
"path": "/c++ implementation/neural_network.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#include \"neural_network.h\"\n#include <string>\n#include <chrono>\n\n#define trace(input) do { if (1) { cout << input << endl; } } while(0)\n#define here() do { cout << \" here\" << endl; } while (0)\n#define there() do { cout << \" there\" << endl; } while (0)\n\n\nNeuralNetwork::NeuralNetwork(string optimizer, Loss* loss_function) {\n this->optimizer = optimizer;\n this->loss_function = loss_function;\n}\n//void NeuralNetwork::set_trainable(bool trainable) {\n// for (auto layer : this->layers) {\n// layer->trainable = trainable;\n// }\n//}\nvoid NeuralNetwork::add(Layer* layer) {\n if (!this->layers.empty()) {\n layer->set_input_shape(this->layers.back()->output_shape());\n }\n layer->initialize(this->optimizer);\n this->layers.push_back(layer);\n}\n//double NeuralNetwork::test_on_batch(xt::xarray<double>* X, xt::xarray<double>* y) {\n// xt::xarray<double> y_pred = this->_forward_pass(X, false);\n// auto loss = this->loss_function->loss(y, &y_pred);\n// //can add in acc if needed\n// return loss.calculate_mean().calculate_mean();\n//}\ndouble NeuralNetwork::train_on_batch(xt::xarray<double>* X, xt::xarray<double>* y) {\n// auto start = chrono::system_clock::now();\n xt::xarray<double> y_pred = this->_forward_pass(X, true);\n auto t1 = chrono::system_clock::now();\n// trace(\" fpass: \" << (chrono::duration<double>(t1 - start)).count());\n double loss = xt::mean(this->loss_function->loss(y, &y_pred))();\n auto t2 = chrono::system_clock::now();\n// trace(\" loss: \" << (chrono::duration<double>(t2 - t1)).count());\n auto loss_grad = this->loss_function->gradient(y, &y_pred);\n auto t3 = chrono::system_clock::now();\n// trace(\" lgrad: \" << (chrono::duration<double>(t3 - t2)).count());\n this->_backward_pass(&loss_grad);\n auto t4 = chrono::system_clock::now();\n// trace(\" bpass: \" << (chrono::duration<double>(t4 - t3)).count());\n //can add in acc if needed\n return loss;\n}\n//xt::xarray<double> NeuralNetwork::fit(xt::xarray<double>* X, xt::xarray<double>* y, int n_epochs, int batch_size) {\n// Vector<double> batch_error;\n// int n_samples = X->get_rows_number();\n// for (int j = 1; j<=n_epochs; j++) {\n// int i = 0;\n// do {\n// int end = min(i+batch_size-1, n_samples-1);\n// double loss = this->train_on_batch(X->get_subxt::xarray_rows(i, end),y->get_subxt::xarray_rows(i, end));\n// i = i+batch_size;\n// } while(i<n_samples);\n// }\n// return xt::xarray<double>();\n//}\nxt::xarray<double> NeuralNetwork::_forward_pass(xt::xarray<double>* X, bool training) {\n xt::xarray<double> layer_output = *X;\n int i = 0;\n for (auto layer : this->layers) {\n// trace(endl<<i++ << \": \" << layer->layer_name());\n// trace(\" in (\" << layer_output.get_rows_number() << \",\" << layer_output.get_columns_number() << \")\");\n// auto start = chrono::system_clock::now();\n layer_output = layer->forward_pass(&layer_output, training);\n// auto end = chrono::system_clock::now();\n// trace(\" \" << i++ << \": \" << layer->layer_name()<< \" \" << (chrono::duration<double>(end - start)).count());\n// trace(\" out(\" << layer_output.get_rows_number() << \",\" << layer_output.get_columns_number() << \")\");\n }\n return layer_output;\n}\nvoid NeuralNetwork::_backward_pass(xt::xarray<double>* loss_grad){\n int i = 0;\n for (auto it = this->layers.rbegin(); it != this->layers.rend(); it++) {\n// trace(i << \": \" << (*it)->layer_name());\n// trace(\" in (\" << loss_grad->get_rows_number() << \",\" << loss_grad->get_columns_number() << \")\");\n// auto start = chrono::system_clock::now();\n (*it)->backward_pass(loss_grad, i);\n// auto end = chrono::system_clock::now();\n// trace(\" \" << i << \": \" << (*it)->layer_name()<< \" \" << (chrono::duration<double>(end - start)).count());\n// trace(\" out(\" << loss_grad->get_rows_number() << \",\" << loss_grad->get_columns_number() << \")\");\n i++;\n }\n// this->_jacobian();\n// this->_jacobian_opt();\n}\nxt::xarray<double> NeuralNetwork::_jacobian() {\n xt::xarray<double> batch_loss_grad;\n int i = 0;\n trace(\" Jacobian\");\n for (auto it = this->layers.rbegin(); it != this->layers.rend(); it++) {\n auto start = chrono::system_clock::now();\n (*it)->jacob_backward_pass(&batch_loss_grad, i);\n auto end = chrono::system_clock::now();\n trace(\" \" << i++ << \": \" << (*it)->layer_name()<< \" \" << (chrono::duration<double>(end - start)).count());\n }\n return batch_loss_grad;\n}\nxt::xarray<double> NeuralNetwork::_jacobian_opt() {\n xt::xarray<double> batch_loss_grad;\n int i = 0;\n int num_layers = layers.size() - 1;\n trace(\" Optimal Jacobian\");\n while (!layers[num_layers - i]->latent_layer) {\n auto start = chrono::system_clock::now();\n layers[num_layers - i]->jacob_backward_pass(&batch_loss_grad, i);\n auto end = chrono::system_clock::now();\n trace(\" \" << i << \": \" << layers[num_layers - i]->layer_name()<< \" \" << (chrono::duration<double>(end - start)).count());\n i++;\n }\n while (i<num_layers) {\n auto start = chrono::system_clock::now();\n layers[num_layers - i]->jacob_backward_opt_pass(&batch_loss_grad, i);\n auto end = chrono::system_clock::now();\n trace(\" \" << i++ << \": \" << layers[num_layers - i]->layer_name()<< \" \" << (chrono::duration<double>(end - start)).count());\n i++;\n }\n return batch_loss_grad;\n}\nvoid NeuralNetwork::summary(string name) {\n cout << name << endl;\n cout << \"Input Shape: (\" << this->layers[0]->input_shape.first << \", \" << this->layers[0]->input_shape.second << \")\" << endl;\n cout << left << setw(27)<< \"| Layer type\" << setw(15) << \"| Parameters \" << setw(15) << \"| Output Shape\" << endl;\n int total_params = 0;\n for (auto layer : this->layers) {\n cout << left << \"| \" << layer->layer_name() << setw(25-layer->layer_name().size()) << \" \"\n << \"| \" << setw(13) << layer->parameters()\n << \"| \" << \"(\" << layer->output_shape().first << \",\" << layer->output_shape().second << \")\" << endl;\n total_params += layer->parameters();\n }\n cout << endl << \"Total Parameters: \" << total_params << endl << endl;\n}\nxt::xarray<double> NeuralNetwork::predict(xt::xarray<double> *X) {\n return this->_forward_pass(X, false);\n}\n"
},
{
"alpha_fraction": 0.5688679218292236,
"alphanum_fraction": 0.599056601524353,
"avg_line_length": 34.36666488647461,
"blob_id": "083de5fbec74c2f74cab1b02e1153e16c3677702",
"content_id": "5c5fe8598e80eba4d74ce6eec652c422de2b50b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1060,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 30,
"path": "/c++ implementation/loss_function.cpp",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "//\n// Created by Robbie on 5/3/2019.\n//\n\n#include \"loss_function.h\"\n\n\nxt::xarray<double> SquareLoss::loss(xt::xarray<double> *y, xt::xarray<double> *y_pred) {\n return xt::pow(*y - *y_pred, 2) * 0.5;\n}\nxt::xarray<double> SquareLoss::gradient(xt::xarray<double>* y, xt::xarray<double>* y_pred) {\n return -(*y - *y_pred);\n}\nxt::xarray<double> SquareLoss::acc(xt::xarray<double>* y, xt::xarray<double>* y_pred) {\n return 0;\n// return xt::xarray<double> (1,0);\n}\nxt::xarray<double> CrossEntropy::loss(xt::xarray<double>* y, xt::xarray<double>* y_pred) {\n auto p = xt::clip(*y_pred, 1.0e-15, 1.0 - 1.0e-15);\n return -1 * *y * xt::log(p) - (1 - *y) * xt::log(1.0 - p);\n}\nxt::xarray<double> CrossEntropy::gradient(xt::xarray<double>* y, xt::xarray<double>* y_pred) {\n return (*y - *y_pred) * -1.0;\n}\nxt::xarray<double> CrossEntropy::acc(xt::xarray<double>* y, xt::xarray<double>* y_pred) {\n auto y_true = xt::argmax(*y, 1);\n auto y_p = xt::argmax(*y_pred,1);\n// return xt::sum(y_true == y_p, 0) / xt::prod(y_true.shape());\n return 0;\n}"
},
{
"alpha_fraction": 0.5709797739982605,
"alphanum_fraction": 0.5795209407806396,
"avg_line_length": 33.528812408447266,
"blob_id": "334680d0355134baa1424f473b192e469fe8983e",
"content_id": "0a54c5ab6149afe2cd48f6e106ef1683c36f5e69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10186,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 295,
"path": "/python implementation/layers.py",
"repo_name": "kevinghst/ML-Spring-19",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function, division\nimport math\nimport numpy as np\nimport copy\nfrom activation_functions import Sigmoid, TanH, LeakyReLU, ReLU\nimport time\n\nclass Layer(object):\n\n def set_input_shape(self, shape):\n \"\"\" Sets the shape that the layer expects of the input in the forward\n pass method \"\"\"\n self.input_shape = shape\n\n def layer_name(self):\n \"\"\" The name of the layer. Used in model summary. \"\"\"\n return self.__class__.__name__\n\n def parameters(self):\n \"\"\" The number of trainable parameters used by the layer \"\"\"\n return 0\n\n def forward_pass(self, X, training):\n \"\"\" Propogates the signal forward in the network \"\"\"\n raise NotImplementedError()\n\n def backward_pass(self, accum_grad, idx):\n \"\"\" Propogates the accumulated gradient backwards in the network.\n If the has trainable weights then these weights are also tuned in this method.\n As input (accum_grad) it receives the gradient with respect to the output of the layer and\n returns the gradient with respect to the output of the previous layer. \"\"\"\n raise NotImplementedError()\n\n def output_shape(self):\n \"\"\" The shape of the output produced by forward_pass \"\"\"\n raise NotImplementedError()\n\n\nclass Dense(Layer):\n \"\"\"A fully-connected NN layer.\n Parameters:\n -----------\n n_units: int\n The number of neurons in the layer.\n input_shape: tuple\n The expected input shape of the layer. For dense layers a single digit specifying\n the number of features of the input. Must be specified if it is the first layer in\n the network.\n \"\"\"\n def __init__(self, n_units, input_shape=None, first_layer=False, latent_layer=False):\n self.layer_input = None\n self.input_shape = input_shape\n self.n_units = n_units\n self.trainable = True\n self.W = None\n self.w0 = None\n self.backprop_opt = False\n self.first_layer = first_layer\n self.latent_layer = latent_layer\n\n def initialize(self, optimizer):\n # Initialize the weights\n limit = 1 / math.sqrt(self.input_shape[0])\n self.W = np.random.uniform(-limit, limit, (self.input_shape[0], self.n_units))\n self.w0 = np.zeros((1, self.n_units))\n # Weight optimizers\n self.W_opt = copy.copy(optimizer)\n self.w0_opt = copy.copy(optimizer)\n\n def parameters(self):\n return np.prod(self.W.shape) + np.prod(self.w0.shape)\n\n def forward_pass(self, X, training=True):\n self.layer_input = X\n return X.dot(self.W) + self.w0\n\n def backward_pass(self, accum_grad, idx):\n # Save weights used during forwards pass\n W = self.W\n\n if self.trainable:\n # Calculate gradient w.r.t layer weights\n grad_w = self.layer_input.T.dot(accum_grad)\n grad_w0 = np.sum(accum_grad, axis=0, keepdims=True)\n\n # Update the layer weights\n self.W = self.W_opt.update(self.W, grad_w)\n self.w0 = self.w0_opt.update(self.w0, grad_w0)\n\n # Return accumulated gradient for next layer\n # Calculated based on the weights used during the forward pass\n accum_grad = accum_grad.dot(W.T)\n return accum_grad\n\n def jacob_backward_pass(self, accum_grad, idx):\n start = time.time()\n W = self.W\n if idx == 1:\n accum_grad = np.einsum('ij,jk->ijk', accum_grad, W.T)\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return accum_grad\n else:\n accum_grad = accum_grad.dot(W.T)\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return accum_grad\n\n def jacob_backward_opt_pass(self, past_grad, idx):\n start = time.time()\n W = self.W\n if self.latent_layer:\n accum_grad = past_grad.dot(W.T)\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return (past_grad, W)\n else:\n a_grad, b_grad = past_grad\n temp = b_grad.dot(W.T)\n accum_grad = np.einsum('ijk,ikp->ijp', a_grad, temp)\n\n if self.first_layer:\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return accum_grad\n else:\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return (a_grad, temp)\n\n def output_shape(self):\n return (self.n_units, )\n\n\nactivation_functions = {\n 'sigmoid': Sigmoid,\n 'leaky_relu': LeakyReLU,\n 'tanh': TanH,\n 'relu': ReLU\n}\n\nclass Activation(Layer):\n \"\"\"A layer that applies an activation operation to the input.\n\n Parameters:\n -----------\n name: string\n The name of the activation function that will be used.\n \"\"\"\n\n def __init__(self, name):\n self.activation_name = name\n self.activation_func = activation_functions[name]()\n self.trainable = True\n self.backprop_opt = False\n self.latent_layer = False\n\n def layer_name(self):\n return \"Activation (%s)\" % (self.activation_func.__class__.__name__)\n\n def forward_pass(self, X, training=True):\n self.layer_input = X\n return self.activation_func(X)\n\n def backward_pass(self, accum_grad, idx):\n return accum_grad * self.activation_func.gradient(self.layer_input)\n\n def jacob_backward_pass(self,accum_grad, idx):\n start = time.time()\n act_grad = self.activation_func.gradient(self.layer_input)\n if idx == 0:\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return act_grad\n else:\n arr = np.einsum('ijk,ik -> ijk',accum_grad, act_grad)\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return arr\n\n def jacob_backward_opt_pass(self, past_grad, idx):\n start = time.time()\n a_grad, b_grad = past_grad\n act_grad = self.activation_func.gradient(self.layer_input)\n act_grad = map(np.diagflat, act_grad)\n act_grad = np.array(list(act_grad))\n\n if len(b_grad.shape) == 2:\n temp = np.tensordot(act_grad,b_grad.T,axes=(1,1)).swapaxes(1,2)\n else:\n temp = np.einsum('ijk,ikp->ijp', b_grad, act_grad)\n\n accum_grad = np.einsum('ijk,ikp->ijp', a_grad, temp)\n\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return (a_grad, temp)\n\n def output_shape(self):\n return self.input_shape\n\n\nclass BatchNormalization(Layer):\n \"\"\"Batch normalization.\n \"\"\"\n def __init__(self, momentum=0.99):\n self.momentum = momentum\n self.trainable = True\n self.eps = 0.01\n self.running_mean = None\n self.running_var = None\n self.backprop_opt = False\n self.latent_layer = False\n\n def initialize(self, optimizer):\n # Initialize the parameters\n self.gamma = np.ones(self.input_shape)\n self.beta = np.zeros(self.input_shape)\n # parameter optimizers\n self.gamma_opt = copy.copy(optimizer)\n self.beta_opt = copy.copy(optimizer)\n\n def parameters(self):\n return np.prod(self.gamma.shape) + np.prod(self.beta.shape)\n\n def forward_pass(self, X, training=True):\n # Initialize running mean and variance if first run\n if self.running_mean is None:\n self.running_mean = np.mean(X, axis=0)\n self.running_var = np.var(X, axis=0)\n\n if training and self.trainable:\n mean = np.mean(X, axis=0)\n var = np.var(X, axis=0)\n self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * mean\n self.running_var = self.momentum * self.running_var + (1 - self.momentum) * var\n else:\n mean = self.running_mean\n var = self.running_var\n\n # Statistics saved for backward pass\n self.X_centered = X - mean\n self.stddev_inv = 1 / np.sqrt(var + self.eps)\n\n X_norm = self.X_centered * self.stddev_inv\n output = self.gamma * X_norm + self.beta\n\n return output\n\n def backward_pass(self, accum_grad, idx):\n # Save parameters used during the forward pass\n gamma = self.gamma\n\n # If the layer is trainable the parameters are updated\n if self.trainable:\n X_norm = self.X_centered * self.stddev_inv\n grad_gamma = np.sum(accum_grad * X_norm, axis=0)\n grad_beta = np.sum(accum_grad, axis=0)\n\n self.gamma = self.gamma_opt.update(self.gamma, grad_gamma)\n self.beta = self.beta_opt.update(self.beta, grad_beta)\n\n batch_size = accum_grad.shape[0]\n\n # The gradient of the loss with respect to the layer inputs (use weights and statistics from forward pass)\n accum_grad = (1 / batch_size) * gamma * self.stddev_inv * (\n batch_size * accum_grad - np.sum(accum_grad, axis=0) - self.X_centered * self.stddev_inv**2 * np.sum(accum_grad * self.X_centered, axis=0)\n )\n\n return accum_grad\n\n def jacob_backward_pass(self,accum_grad, idx):\n start = time.time()\n batch_size = accum_grad.shape[0]\n gamma = self.gamma\n expand_X_centered = np.apply_along_axis(np.tile, -1, self.X_centered, (accum_grad.shape[1],1))\n\n accum_grad = (1/batch_size) * gamma * self.stddev_inv * (\n batch_size * accum_grad - np.sum(accum_grad, axis=0) - expand_X_centered * self.stddev_inv**2 * np.sum(accum_grad * expand_X_centered, axis=0)\n )\n end = time.time()\n duration = (end-start) * 1000\n print(str(idx) + \":\" + str(duration))\n return accum_grad\n\n def output_shape(self):\n return self.input_shape\n"
}
] | 17 |
thelittlebug/autoplotter
|
https://github.com/thelittlebug/autoplotter
|
ac752f3c78e6e2f059a6a21d52a28afcbce967f7
|
d30d1d1a418066755540c2d5ef4dc4f6b162973f
|
d164c02be596263896c9e3f33a8c09cc7f5207df
|
refs/heads/master
| 2022-11-30T19:32:28.973277 | 2020-08-15T16:30:43 | 2020-08-15T16:30:43 | 287,770,879 | 0 | 0 | null | 2020-08-15T15:14:34 | 2020-08-15T11:54:21 | 2020-07-27T05:08:48 | null |
[
{
"alpha_fraction": 0.7169312238693237,
"alphanum_fraction": 0.7215608358383179,
"avg_line_length": 33.16279220581055,
"blob_id": "d1f5ec72d966478040745e0d85e5e9832ded4fd2",
"content_id": "6ec2d1b83982514efb8f710ca4c3aa21ac25724a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1512,
"license_type": "permissive",
"max_line_length": 189,
"num_lines": 43,
"path": "/README.md",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "# AutoPlotter\r\n\r\nautoplotter is a python package for GUI based exploratory data analysis. It is built on the top of dash.\r\n\r\n[](https://travis-ci.org/badges/badgerbadgerbadger)\r\n[](http://badges.mit-license.org)\r\n\r\n## Installation\r\n\r\nUse the package manager [pip](https://pip.pypa.io/en/stable/) to install autoplotter.\r\n\r\n```bash\r\npip install autoplotter\r\n```\r\n\r\n## Usage\r\n\r\n```python\r\nfrom autoplotter import run_app # Importing the autoplotter for GUI Based EDA\r\n\r\nimport plotly.express as px # Importing plotly express to load dataset\r\ndf = px.data.tips() # Getting the Restaurant data\r\n\r\nrun_app(df) # Calling the autoplotter.run_app\r\n```\r\n[](https://gifyu.com/image/QGyH)\r\n\r\n\r\n## Contributing\r\nPull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.\r\n\r\nPlease make sure to update tests as appropriate.\r\n\r\n## Support \r\n\r\n- Support me by following on <a href=\"https://github.com/ersaurabhverma\" target=\"_blank\">Github</a> and <a href=\"https://www.linkedin.com/in/vermasaurabh8010/\" target=\"_blank\">LinkedIn</a>.\r\n\r\n\r\n## License\r\n\r\n[](http://badges.mit-license.org)\r\n\r\n- **[MIT license](http://opensource.org/licenses/mit-license.php)**\r\n"
},
{
"alpha_fraction": 0.5797101259231567,
"alphanum_fraction": 0.5840579867362976,
"avg_line_length": 51.230770111083984,
"blob_id": "d08e47e544d0194236a5c46d5ce5cf9ef4bc6236",
"content_id": "bc49a3bb0256cec4278a1dedbfc7cecc546f67ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 690,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 13,
"path": "/autoplotter/navbar.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "import dash_bootstrap_components as dbc\r\nimport dash_html_components as html\r\ndef Navbar():\r\n navbar = dbc.NavbarSimple(color ='dark',dark=True,className=\"ml-auto flex-nowrap mt-3 mt-md-0\",\r\n children=[dbc.NavItem(dbc.NavLink(\"Data Exploration\", href=\"/data-exploration\",className=\"fas fa-chart-line\")),\r\n dbc.NavItem(dbc.NavLink(\"Plots\", href=\"/plot\",className=\"fas fa-chart-area\")),\r\n ],brand=\"Data\",brand_href=\"/home\",sticky=\"top\"\r\n )\r\n return navbar\r\n\r\ndef homepage_heading():\r\n heading=html.H4('Data Preview',style={'text-align':'center'})\r\n return heading"
},
{
"alpha_fraction": 0.5457659363746643,
"alphanum_fraction": 0.5494655966758728,
"avg_line_length": 48.30344772338867,
"blob_id": "c347c56fb7e2910635dc2b8384f7fba49d5d8021",
"content_id": "3c4d2f2ea19ea91da1dce0d2498afee3b030eeab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7298,
"license_type": "permissive",
"max_line_length": 246,
"num_lines": 145,
"path": "/autoplotter/app.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "import dash\r\nimport dash_core_components as dcc\r\nimport dash_html_components as html\r\nfrom dash.dependencies import Input, Output, State, MATCH, ALL\r\nimport dash_bootstrap_components as dbc\r\nfrom .plots import App, plot_graph, add_parameters, _params\r\nfrom .homepage import Homepage\r\nfrom jupyter_dash import JupyterDash\r\nimport pandas as pd\r\nimport logging\r\nimport plotly.graph_objects as go\r\nfrom .data_exploration import dataexploration, plot_distributions ,association,get_pps_array,get_corr_array\r\n\r\n# just set the width to 100% is enough ;) you cannot get the browser size with your old server side width checking\r\nWIDTH = \"100%\"\r\n\r\nadded_params_value=[]\r\nexternal_stylesheets = [dbc.themes.BOOTSTRAP,{\r\n 'href': 'https://use.fontawesome.com/releases/v5.8.1/css/all.css',\r\n 'rel': 'stylesheet',\r\n 'integrity': 'sha384-50oBUHEmvpQ+1lW4y57PTFmhCaXp0ML5d60M1M7uH2+nqUivzIebhndOJK28anvf',\r\n 'crossorigin': 'anonymous'\r\n}]\r\n\r\n\r\n\r\ndef run_app(df, host=\"0.0.0.0\", port=12345):\r\n app = JupyterDash(__name__, external_stylesheets=external_stylesheets,suppress_callback_exceptions=True)\r\n app.config.suppress_callback_exceptions = True\r\n app.layout = html.Div([\r\n dcc.Location(id = 'url', refresh = False),\r\n html.Div(id = 'page-content')])\r\n try:\r\n @app.callback(Output('page-content', 'children'),[Input('url', 'pathname')])\r\n def display_page(pathname):\r\n if pathname == '/plot':\r\n return App(df)\r\n elif pathname == '/data-exploration':\r\n return dataexploration(df)\r\n else:\r\n return Homepage(df)\r\n\r\n @app.callback(Output('hist_plot','children'),[Input('hist_col_dropdown','value'),Input('theme_dropdown','value')])\r\n def update_data_distribution(col_list,theme):\r\n children = plot_distributions(df,col_list,theme)\r\n return children\r\n \r\n @app.callback([Output('corr','children'),Output('heatmap','style')],\r\n [Input('col1','value'),Input('col2','value'),Input('show-more','n_clicks')])\r\n def update_association(col1,col2,n):\r\n heat_map_style={'display':'none'}\r\n try:\r\n corr_child=association(df,col1,col2)\r\n except (TypeError):\r\n corr_child=[html.P('Please select numeric columns', style={'color':'red'})]\r\n if n is not None:\r\n if n%2==1:\r\n heat_map_style=_params()\r\n\r\n return corr_child,heat_map_style\r\n\r\n @app.callback([Output('output_plots','children'),Output('add-parameter-drop','options'),Output('color_div','style'),\r\n Output('facet_col_div','style'),Output('margin_x_div','style'),Output('margin_y_div','style'),Output('trendline_div','style'),\r\n Output('size_div','style'),Output('animation_div','style'),Output('opacity_div','style'),Output('barmode_div','style'),\r\n Output('boxmode_div','style'),Output('q_div','style'),Output('points_div','style')],\r\n [Input('charttype','value'), Input('xaxis','value'), Input('yaxis','value'), Input('theme_dropdown','value'), \r\n Input('add-parameter-drop','value'),Input('color','value'),Input('facet_col','value'),Input('margin-x','value'),\r\n Input('margin-y','value'),Input('trendline','value'),Input('size','value'),Input('animation','value'),Input('opacity','value'),\r\n Input('barmode','value'), Input('boxmode','value'),Input('q','value'),Input('points','value')])\r\n def update_plots(chart_type,x,y,theme,added_params,color,facet_col,margin_x,margin_y,trendline,size,animation,opacity,barmode,boxmode,q,points):\r\n color_style = {'display': 'none'}\r\n facet_col_style = {'display': 'none'}\r\n margin_x_style = {'display': 'none'}\r\n margin_y_style = {'display': 'none'}\r\n trendline_style={'display':'none'}\r\n size_style = {'display':'none'}\r\n animation_style = {'display':'none'}\r\n opacity_style={'display': 'none'}\r\n barmode_style = {'display': 'none'}\r\n boxmode_style = {'display': 'none'}\r\n q_style={'display': 'none'}\r\n points_style={'display': 'none'}\r\n\r\n facet_col_val,color_val, margin_x_val,margin_y_val,trendline_val,size_val,animation_val,opacity_val,barmode_val,boxmode_val,q_val,points_val,notched_val=None,None,None,None,None,None,None,1,'relative','group','linear','outliers',False\r\n box_val=False\r\n log_x = False\r\n log_y = False\r\n for param in added_params:\r\n if param == 'log_x':\r\n log_x=True\r\n if param=='log_y':\r\n log_y=True\r\n if param=='color':\r\n color_style = _params()\r\n color_val=color\r\n if param=='facet_col':\r\n facet_col_style = _params()\r\n facet_col_val=facet_col\r\n if param == 'marginal_x':\r\n margin_x_style= _params()\r\n margin_x_val = margin_x\r\n if param == 'marginal_y':\r\n margin_y_style=_params()\r\n margin_y_val=margin_y\r\n if param=='trendline':\r\n trendline_style=_params()\r\n trendline_val=trendline\r\n if param=='size':\r\n size_style = _params()\r\n size_val=size\r\n if param == 'animation_frame':\r\n animation_style=_params()\r\n animation_val = animation\r\n if param == 'opacity':\r\n opacity_style=_params()\r\n opacity_val=opacity\r\n\r\n if param == 'barmode':\r\n barmode_style=_params()\r\n barmode_val=barmode\r\n\r\n if param == 'mode':\r\n boxmode_style=_params()\r\n boxmode_val=boxmode\r\n if param == 'quartilemethod':\r\n q_style=_params()\r\n q_val=q\r\n if param == 'points':\r\n points_style=_params()\r\n points_val=points\r\n if param == 'notched':\r\n notched_val=True\r\n if param == 'box':\r\n box_val=True\r\n options = add_parameters(chart_type)\r\n plot_children = plot_graph(plot_type=chart_type,df=df,x=x,y=y,theme=theme,color=color_val,facet_col=facet_col_val,\r\n marginal_x=margin_x_val,marginal_y=margin_y_val,trendline=trendline_val,log_x=log_x,log_y=log_y,size=size_val,\r\n animation_frame =animation_val,opacity=opacity_val,barmode=barmode_val,boxmode=boxmode_val,\r\n quartilemethod=q_val,points=points_val,notched=notched_val,box=box_val)\r\n \r\n return plot_children, options, color_style, facet_col_style , margin_x_style, margin_y_style, trendline_style , size_style ,animation_style, opacity_style, barmode_style, boxmode_style,q_style,points_style \r\n\r\n app.run_server(mode='inline',width=WIDTH,host=host,port=port)\r\n except:\r\n app.run_server(mode='inline',width=WIDTH,host=host,port=port)\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5957446694374084,
"alphanum_fraction": 0.5957446694374084,
"avg_line_length": 14.333333015441895,
"blob_id": "9add3f231a36b4638f91fcd34499963129ffd9d2",
"content_id": "9c7473b68f5ce3cbc134ac91a4610ad6d1968235",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 3,
"path": "/autoplotter/__init__.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "from .app import run_app\r\n\r\n__ALL__=['run_app']"
},
{
"alpha_fraction": 0.6024385094642639,
"alphanum_fraction": 0.6092604398727417,
"avg_line_length": 54.679012298583984,
"blob_id": "ca8aac20a7def8be3aa06fd3c3a2194539df7ff6",
"content_id": "dab0c2522647b3482c97aabf16a93f7d4b37fe99",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13779,
"license_type": "permissive",
"max_line_length": 269,
"num_lines": 243,
"path": "/autoplotter/plots.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "### Graphing\r\nimport plotly.graph_objects as go\r\nimport plotly.express as px\r\n### Dash\r\nimport dash\r\nimport dash_core_components as dcc\r\nimport dash_html_components as html\r\nimport dash_bootstrap_components as dbc\r\nfrom dash.dependencies import Output, Input\r\n\r\n## Navbar\r\nfrom .navbar import Navbar\r\nfrom .data_exploration import plotly_templates\r\nimport logging\r\n\r\n#px.scatter.__code__.co_varnames\r\nadded_param_label_style={'padding':'0 0 0 10px','font-weight': 'bold'}\r\n\r\ndef add_parameters(plot_type):\r\n scatter=['color','size','facet_col','animation_frame','opacity',\r\n 'marginal_x','marginal_y','trendline','log_x','log_y']\r\n parallel_categories=['dimensions','color']\r\n parallel_coordinates=['dimensions','color']\r\n line=['color','facet_col','animation_frame','log_x','log_y']\r\n area=['color','facet_col','animation_frame','log_x','log_y']\r\n density_contour=['z','color','facet_col','animation_frame','marginal_x','marginal_y','log_x','log_y']\r\n density_heatmap=['z','facet_col','animation_frame','marginal_x','marginal_y','log_x','log_y']\r\n bar=['color','facet_col','animation_frame','opacity','barmode','log_x','log_y']\r\n histogram=['color','facet_col','animation_frame','opacity','barmode','log_x','log_y']\r\n box=['color','facet_col','quartilemethod','points','animation_frame','mode','log_x','log_y','notched']\r\n violin=['color','facet_col','animation_frame','mode','points','log_x','log_y','box']\r\n if plot_type=='line':\r\n return [{'label': i,'value' : i} for i in line]\r\n elif plot_type=='scatter':\r\n return [{'label': i,'value' : i} for i in scatter]\r\n elif plot_type=='parallel_categories':\r\n return [{'label': i,'value' : i} for i in parallel_categories]\r\n elif plot_type=='parallel_coordinates':\r\n return [{'label': i,'value' : i} for i in parallel_coordinates]\r\n elif plot_type=='area':\r\n return [{'label': i,'value' : i} for i in area]\r\n elif plot_type=='density_contour':\r\n return [{'label': i,'value' : i} for i in density_contour]\r\n elif plot_type=='density_heatmap':\r\n return [{'label': i,'value' : i} for i in density_heatmap]\r\n elif plot_type=='bar':\r\n return [{'label': i,'value' : i} for i in bar]\r\n elif plot_type=='histogram':\r\n return [{'label': i,'value' : i} for i in histogram]\r\n elif plot_type=='box':\r\n return [{'label': i,'value' : i} for i in box]\r\n elif plot_type=='violin':\r\n return [{'label': i,'value' : i} for i in violin]\r\n else:\r\n return []\r\n\r\n\r\n\r\ndef x_dropdown(df):\r\n dropdown=html.Div(children=[html.Label('X Axis'),dcc.Dropdown(id='xaxis', placeholder='Select X axis',\r\n options=[\r\n {'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns\r\n \r\n ],value=None,multi=False)]) \r\n return dropdown\r\n\r\ndef y_dropdown(df):\r\n dropdown=html.Div(children=[html.Label('Y Axis'),dcc.Dropdown(id='yaxis', placeholder='Select Y axis',\r\n options=[\r\n {'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns\r\n \r\n ],value=None,multi=True)]) \r\n return dropdown\r\n\r\nnav = Navbar()\r\nheader = html.H3(\r\n 'Select the name of an Illinois city to see its population!'\r\n)\r\n\r\n\r\ndef all_plots():\r\n plots=['scatter','line','area','bar','histogram','box','violin']\r\n all_plots_dropdown = html.Div(\r\n children=[html.Label('Choose Plot Type '),\r\n dcc.Dropdown(id='charttype',options=[{'label':chart,'value':chart} for chart in plots], value='scatter',placeholder='Select a chart type')])\r\n return all_plots_dropdown\r\n\r\ndef axes(df):\r\n axis=html.Div(children=[html.Div(children=[x_dropdown(df)],style={'width': '50%', 'display': 'inline-block'}),\r\n html.Div(children=[y_dropdown(df)],style={'width': '50%', 'float': 'right', 'display': 'inline-block'})])\r\n return axis \r\n\r\ndef App(df): \r\n output = html.Div(id = 'output_plots',children=[]) \r\n charts=html.Div(children=[html.Div(children=[all_plots()] ,\r\n style={'width': '25%', 'display': 'inline-block','margin': '0 0 0 10px'}),\r\n html.Div(children=[plotly_templates()],\r\n style={'width': '20%', 'display': 'inline-block','margin': '0 10px 0 0'}),\r\n html.Div(children=[axes(df)],\r\n style={'width': '50%', 'float': 'right', 'display': 'inline-block','margin': '0 10px 10px 0'})])\r\n add_parameters_dropdown=html.Div(children=[html.Label('Choose a Parameter'),\r\n dcc.Dropdown(id='add-parameter-drop',options=[],placeholder='Add Params..',value=[],multi=True)])\r\n \r\n \r\n color_div=html.Div(style={'display': 'none'},id='color_div',children=[html.Div(html.Label('Color '),\r\n style=added_param_label_style),html.Div(dcc.Dropdown(id='color', placeholder='Color Column',\r\n options=[{'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns],\r\n value=None,multi=False) ,style={})])\r\n\r\n size_div=html.Div(style={'display': 'none'},id='size_div',children=[html.Div(html.Label('Size'),\r\n style=added_param_label_style),html.Div(dcc.Dropdown(id='size', placeholder='Size',\r\n options=[{'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns],\r\n value=None,multi=False) ,style={})])\r\n \r\n \r\n facet_col_div = html.Div(style={'display': 'none'},id='facet_col_div',children=[html.Div(html.Label('Facet Column'),\r\n style=added_param_label_style),html.Div(dcc.Dropdown(id='facet_col', placeholder='Facet Column',\r\n options=[{'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns],\r\n value=None,multi=False),style={})])\r\n \r\n \r\n margin_x_div = html.Div(style={'display': 'None'},id='margin_x_div',children=[html.Div(html.Label('Margin X'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='margin-x',\r\n options=[{'label': i, 'value': i} for i in ('rug', 'box', 'violin', 'histogram')],\r\n value=None,labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n\r\n \r\n margin_y_div = html.Div(style={'display': 'none'},id='margin_y_div',children=[html.Div(html.Label('Margin Y'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='margin-y',\r\n options=[{'label': i, 'value': i} for i in ('rug', 'box', 'violin', 'histogram')],\r\n value=None,labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n \r\n\r\n trendline_div = html.Div(style={'display': 'None'},id='trendline_div',children=[html.Div(html.Label('Trendline'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='trendline',\r\n options=[{'label': 'Ordinary Least Square', 'value': 'ols'},\r\n {'label': 'Locally Weighted Scatterplot Smoothing line ', 'value': 'lowess'}],value=None,\r\n labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}))])\r\n\r\n\r\n animation_div=html.Div(style={'display': 'none'},id='animation_div',children=[html.Div(html.Label('Animated Frame '),\r\n style=added_param_label_style),html.Div(dcc.Dropdown(id='animation', placeholder='Animated Frame Column',\r\n options=[{'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns],\r\n value=None,multi=False) ,style={})])\r\n\r\n opacity_div=html.Div(style={'display': 'none'},id='opacity_div',children=[html.Div(html.Label('Opacity Value'),\r\n style=added_param_label_style),html.Div(dcc.Slider(id='opacity',min=0,max=1,step=0.1,value=1,)) ])\r\n\r\n \r\n barmode_div = html.Div(style={'display': 'None'},id='barmode_div',children=[html.Div(html.Label('Bar Mode'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='barmode',\r\n options=[{'label': i, 'value': i} for i in ('group', 'overlay', 'relative' )],\r\n value='relative',labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n \r\n boxmode_div = html.Div(style={'display': 'None'},id='boxmode_div',children=[html.Div(html.Label('Box Mode'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='boxmode',\r\n options=[{'label': i, 'value': i} for i in ('group', 'overlay' )],\r\n value='group',labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n \r\n q_div = html.Div(style={'display': 'None'},id='q_div',children=[html.Div(html.Label('Quartile Method'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='q',\r\n options=[{'label': i, 'value': i} for i in ('linear', 'inclusive','exclusive' )],\r\n value='linear',labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n\r\n points_div = html.Div(style={'display': 'None'},id='points_div',children=[html.Div(html.Label('Points'),\r\n style=added_param_label_style),html.Div(dcc.RadioItems(id='points',\r\n options=[{'label': i, 'value': i} for i in ('outliers', 'suspectedoutliers', 'all' )],\r\n value='outliers',labelStyle={'display': 'inline-block'},inputStyle={'margin':'10px 10px 10px 10px'}) ,style={})])\r\n\r\n \r\n layout = html.Div([nav,charts,add_parameters_dropdown,color_div,size_div,trendline_div,facet_col_div, \r\n margin_x_div ,margin_y_div,animation_div,opacity_div,barmode_div,q_div,boxmode_div,points_div,output])\r\n return layout\r\n\r\ndef plot_graph(plot_type,df,x,y,theme,color=None,facet_col=None,marginal_x=None,marginal_y=None,trendline=None,log_x=None,log_y=None,size=None,animation_frame=None,opacity=1,barmode='relative',boxmode=None,quartilemethod=None,points='outliers',notched=False,box=False):\r\n try:\r\n out=[]\r\n if plot_type == 'bar':\r\n fig=px.bar(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,opacity=opacity,animation_frame=animation_frame,barmode=barmode)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)])) \r\n return out\r\n elif plot_type == 'line':\r\n fig=px.line(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,animation_frame=animation_frame)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='area':\r\n fig=px.area(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,animation_frame=animation_frame)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='box':\r\n fig=px.box(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,animation_frame=animation_frame,boxmode=boxmode,points=points,notched=notched)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n fig.update_traces(quartilemethod=quartilemethod,boxmean='sd')\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='violin':\r\n fig=px.violin(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,animation_frame=animation_frame,violinmode=boxmode,points=points,box=box)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n fig.update_traces(meanline_visible=True)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='histogram':\r\n fig=px.histogram(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,log_x=log_x,log_y=log_y,opacity=opacity,animation_frame=animation_frame)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='parallel_categories':\r\n fig=px.parallel_categories(data_frame=df,template=theme,color=color,)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n elif plot_type=='parallel_coordinates':\r\n try:\r\n fig=px.parallel_coordinates(data_frame=df,template=theme,color=color)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n except (ValueError) as e:\r\n logging.warning(e)\r\n else:\r\n fig=px.scatter(data_frame=df,x=x,y=y,template=theme,color=color,facet_col=facet_col,marginal_x=marginal_x,marginal_y=marginal_y,trendline=trendline,log_x=log_x,log_y=log_y,size=size,opacity=opacity,animation_frame=animation_frame)\r\n fig.update_xaxes(showgrid=False)\r\n fig.update_yaxes(showgrid=False)\r\n out.append(html.Div(children=[dcc.Graph(figure=fig)]))\r\n return out\r\n except (TypeError,ValueError) as e:\r\n logging.warning(e)\r\n\r\n\r\n\r\ndef _params():\r\n return {'display':'block'}\r\n \r\n"
},
{
"alpha_fraction": 0.5875851511955261,
"alphanum_fraction": 0.6084784269332886,
"avg_line_length": 42.628379821777344,
"blob_id": "9f4061828e0cb0fc3be86f6d0ea989b688b7eab7",
"content_id": "81d0a22b548a49378ce009f6ad69ca1b7f2fe448",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6605,
"license_type": "permissive",
"max_line_length": 206,
"num_lines": 148,
"path": "/autoplotter/data_exploration.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "import dash_html_components as html\r\nimport dash_core_components as dcc\r\nimport dash_bootstrap_components as dbc\r\nfrom .navbar import Navbar\r\nimport plotly.express as px\r\nimport plotly.graph_objects as go\r\nimport ppscore as pps\r\nimport numpy as np\r\n\r\nnav=Navbar()\r\n\r\ndef get_radios(): \r\n button=html.Div(dcc.RadioItems(id='asso_type',options=[\r\n {'label': 'Predictive Power Score', 'value': 'Predictive Power Score'},\r\n {'label': 'Correlation', 'value': 'Correlation'}],value='Predictive Power Score',labelStyle={'display': 'inline-block','margin':'0 10px 0 10px'},inputStyle={'margin':'10px 10px 10px 10px'}))\r\n return button\r\n \r\n\r\ndef plotly_templates():\r\n themes=['ggplot2', 'seaborn', 'simple_white', 'plotly',\r\n 'plotly_white', 'plotly_dark', 'presentation', 'xgridoff',\r\n 'ygridoff', 'gridon', 'none']\r\n template_dropdown=html.Div(children=[html.Label('Select a theme'),dcc.Dropdown(id='theme_dropdown',placeholder='Select Theme',options=[\r\n {'label': i, 'value': i} for i in themes],value='plotly_dark')])\r\n return template_dropdown\r\n\r\ndef get_missing_valaues(df,col):\r\n n=df[col].notna().sum()\r\n values=(n/df.shape[0])*100\r\n return values,n\r\n\r\n\r\ntabs_styles = {\r\n 'height': '44px',\r\n 'position': 'static', \r\n 'top': '0px'\r\n \r\n \r\n}\r\ntab_style = {\r\n 'borderBottom': '1px solid #d6d6d6',\r\n 'padding': '6px',\r\n 'fontWeight': 'bold',\r\n \r\n}\r\n\r\ntab_selected_style = {\r\n 'borderTop': '1px solid #d6d6d6',\r\n 'borderBottom': '1px solid #d6d6d6',\r\n 'backgroundColor': '#FF6347',\r\n 'color': 'white',\r\n 'padding': '6px'\r\n}\r\n\r\ndef columns_dropdown(df):\r\n dropdown=html.Div(children=[html.Label('Select the columns'),dcc.Dropdown(id='hist_col_dropdown', placeholder='Select Columns',\r\n options=[\r\n {'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns\r\n \r\n ],value=[df.columns[0]],multi=True)]) \r\n\r\n return dropdown\r\n\r\ndef plot_distributions(df,cols,theme):\r\n out_plots=[]\r\n for col in cols:\r\n if df[col].dtype=='object':\r\n figure=px.histogram(df, x=col, color_discrete_sequence=['tomato'],template=theme,hover_data=df.columns)\r\n figure.update_xaxes(showgrid=False)\r\n figure.update_yaxes(showgrid=False)\r\n figure.update_layout(title_text=f'Histogram of {col}')\r\n value,n=get_missing_valaues(df,col)\r\n progress=dbc.Progress(style={\"height\": \"20px\",\"margin\":\"10px 20px 10px 20px\"},children=[dbc.Progress(f\"{df.shape[0]-n} missing values\",\r\n value=value, color=\"success\", bar=True), \r\n dbc.Progress(style={\"height\": \"20px\"},value=100-value,color=\"danger\", bar=True)],multi=True,)\r\n out_plots.append(html.Div(children=[progress,dcc.Graph(figure=figure)]))\r\n else:\r\n figure=px.histogram(df, x=col, color_discrete_sequence=['tomato'],template=theme,marginal=\"box\",hover_data=df.columns)\r\n figure.update_xaxes(showgrid=False)\r\n figure.update_yaxes(showgrid=False)\r\n figure.update_layout(title_text=f'Histogram of {col}')\r\n value,n=get_missing_valaues(df,col)\r\n progress=dbc.Progress(style={\"height\": \"20px\",\"margin\":\"10px 20px 10px 20px\"},children=[dbc.Progress(f\"{df.shape[0]-n} missing values\",\r\n value=value, color=\"success\", bar=True), \r\n dbc.Progress(value=100-value,\r\n color=\"danger\", bar=True)],multi=True)\r\n out_plots.append(html.Div(children=[progress,dcc.Graph(figure=figure)]))\r\n return out_plots\r\n\r\n\r\ndef association(df,col1,col2):\r\n if col1 is not None and col2 is not None:\r\n return [html.Label(f' Correlation between {col1} and {col2} = {df[col1].corr(df[col2])}',style={'margin':'10px 0 0 10px'})]\r\n\r\n\r\n\r\ndef get_corr_array(df):\r\n return df.corr()\r\n\r\ndef get_pps_array(df):\r\n ps=[]\r\n for i,col1 in enumerate(df.columns):\r\n ps.append([])\r\n for col2 in df.columns:\r\n ps[i].append(pps.score(df,col1,col2)['ppscore'])\r\n return np.array(ps)\r\n\r\ndef dataexploration(df):\r\n # Graphs\r\n distributions_plots=html.Div(id='hist_plot',children=[])\r\n corr_arr=get_corr_array(df)\r\n corr_fig=go.Figure(data=go.Heatmap(z=corr_arr, x=corr_arr.index,y=corr_arr.columns))\r\n corr_fig.update_layout(title='Heat Map for Correlation')\r\n\r\n association_structure=html.Div(children=[html.Div('Correlation'),\r\n\r\n\r\n html.Div([dcc.Dropdown(id='col1',options=[{ 'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns \r\n \r\n if df[col].dtype!='object'])], style={'width': '48%', 'display': 'inline-block','margin': '10px 0 10px 10px'} ),\r\n\r\n html.Div([dcc.Dropdown(id='col2',options=[{ 'label': f\"{col} ( {df[col].dtype} )\", 'value': col} for col in df.columns \r\n \r\n if df[col].dtype!='object'])], style={'width': '48%', 'float': 'right', 'display': 'inline-block','margin': '10px 10px 10px 0'} ),\r\n\r\n html.Div(id='corr',children=[],style={'dislay':'block'}),\r\n dbc.Button(\"Show/Hide\", outline=True, color=\"success\", className=\"mr-1\",id='show-more',style={'margin': '10px 10px 10px 10px'}),\r\n html.Div(style={'display':'none'},id='heatmap',children=[html.Div([dcc.Graph(figure=corr_fig)],id='heatmap-figure')])\r\n \r\n \r\n ])\r\n\r\n\r\n\r\n stats_analysis=html.Div([html.P(f' DataFrame shape = {df.shape}'),dbc.Table.from_dataframe(df.describe().reset_index(), striped=True, bordered=True, hover=True,dark=True)])\r\n \r\n # Tab layout\r\n data_exploration_structure=html.Div(children=[html.Div(children=[columns_dropdown(df)],style={'width': '65%', 'display': 'inline-block','margin': '0 0 10px 10px'}),\r\n html.Div(children=[plotly_templates()],style={'width': '30%', 'float': 'right', 'display': 'inline-block','margin': '0 10px 10px 0'})])\r\n tabs=html.Div(children=[nav,dcc.Tabs(id='tabs', value='tab-1', children=[\r\n dcc.Tab(style=tab_style, selected_style=tab_selected_style,label='Data Distributions', value='tab-1',\r\n children=[data_exploration_structure,distributions_plots]),\r\n dcc.Tab(style=tab_style, selected_style=tab_selected_style,label='Statistical Analysis', value='tab-2',\r\n children=[stats_analysis]),\r\n dcc.Tab(style=tab_style, selected_style=tab_selected_style,label='Association', value='tab-3',\r\n children=[association_structure])\r\n ], style=tabs_styles)])\r\n return tabs\r\n"
},
{
"alpha_fraction": 0.5937172770500183,
"alphanum_fraction": 0.6188481450080872,
"avg_line_length": 25.171428680419922,
"blob_id": "44b0ae4b4c9bbb395b2a5b23db967ca646ea3b99",
"content_id": "dfb0c597fc68c7c492118e3a0f08aaa6e5b39b64",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 955,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 35,
"path": "/autoplotter/homepage.py",
"repo_name": "thelittlebug/autoplotter",
"src_encoding": "UTF-8",
"text": "import dash\r\nimport dash_bootstrap_components as dbc\r\nimport dash_core_components as dcc\r\nimport dash_html_components as html\r\nfrom .navbar import Navbar, homepage_heading\r\nimport dash_table as dt\r\nimport pandas as pd\r\n\r\nnav = Navbar()\r\nheadline=homepage_heading()\r\n\r\n\r\ndef data_preview(df):\r\n data_body=html.Div(dt.DataTable(data=df.to_dict('records'),columns=[{'id': c, 'name': c} for c in df.columns],\r\n filter_action=\"native\",sort_action=\"native\",sort_mode=\"multi\",page_size= 20,\r\n style_cell={'textAlign': 'center','padding': '5px', 'fontWeight': 'italic','backgroundColor': 'rgb(100, 100, 100)',\r\n 'color': 'white'},\r\n style_header={\r\n 'backgroundColor': '#FF6347',\r\n 'fontWeight': 'bold'\r\n },\r\n \r\n ),style={'margin':'20px 20px 20px 30px'},\r\n )\r\n return data_body\r\n\r\ndef Homepage(df):\r\n \r\n layout = html.Div([\r\n \r\n nav,\r\n headline,\r\n data_preview(df)\r\n ])\r\n return layout\r\n\r\n\r\n"
}
] | 7 |
Farazzaidi22/CG_lab02
|
https://github.com/Farazzaidi22/CG_lab02
|
60ad271a84814b7fba921f035b06c9ba31e8d048
|
570f111f25d09fc1695b2473be51e1199428ea9a
|
ab0d78fb91e58688083af463163d763b922efe52
|
refs/heads/master
| 2020-08-02T13:53:39.173503 | 2019-09-27T18:13:16 | 2019-09-27T18:13:16 | 211,377,052 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6394686698913574,
"alphanum_fraction": 0.669829249382019,
"avg_line_length": 24.14285659790039,
"blob_id": "5a0ad7fd9b31e446bc072bf8a4bae992016dcc27",
"content_id": "f98b61cef1322bac5df37dfd5052d57ba8bd28f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 527,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 21,
"path": "/clickhandler.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "import time\nfrom tkinter import *\n\nroot = Tk()\n\nphoto_ball = PhotoImage(file ='C:\\\\Users\\\\Faraz_0hm6\\\\OneDrive\\\\Desktop\\\\basketball.png')\n\ndef pic():\n canvas = Canvas(root,width =200, height =200, bg= 'white')\n canvas.pack()\n canvas.create_image(0,0, image= photo_ball, anchor= NW)\n \nLabel(root, text = 'Press start to display image', font =('Verdana', 15)).pack(side = TOP, pady = 10)\n\nframe = Frame(root)\nbutton1 = Button(frame, text=\"Play\", command = pic)\nbutton1.pack(side = LEFT)\n\nframe.pack()\n\nroot.mainloop()"
},
{
"alpha_fraction": 0.6883333325386047,
"alphanum_fraction": 0.6983333230018616,
"avg_line_length": 26.31818199157715,
"blob_id": "6fab589cd9887b7f8cf46e3d1cd290e5b427d709",
"content_id": "88ed07cec02680646cd45f4edef542ae08997f48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 600,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 22,
"path": "/filehandler.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom PIL import Image, ImageTk\nfrom tkinter import filedialog\nroot = Tk()\n\n\ndef openThisPc():\n path=filedialog.askopenfilename(filetypes=[(\"Image File\",'.png')])\n im = Image.open(path)\n tkimage = ImageTk.PhotoImage(im)\n myvar=Label(root,image = tkimage)\n myvar.image = tkimage\n myvar.pack()\n\nLabel(root, text = 'Press Select image to choose an image from your pc', font =('Verdana', 15)).pack(side = TOP, pady = 10)\nframe = Frame(root)\nbutton1 = Button(frame, text=\"Select image\", command = openThisPc)\nbutton1.pack(side = LEFT)\n\nframe.pack()\n \nroot.mainloop()"
},
{
"alpha_fraction": 0.6412556171417236,
"alphanum_fraction": 0.6905829310417175,
"avg_line_length": 16.230770111083984,
"blob_id": "d0b506f342d3169652b43639ff0a19bd535a3c38",
"content_id": "13ef1b41e1c09c169abdf5438f04e621d290232f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 13,
"path": "/Image_histogram.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2 as cv\nfrom matplotlib import pyplot as plt\n\nimg = cv.imread(\"lena.jpg\", 1)\n\nhist = cv.calcHist([img], [0], None, [256], [0,256])\nplt.plot(hist)\n\nplt.show()\n\ncv.waitKey(0)\ncv.destroyAllWindows()"
},
{
"alpha_fraction": 0.6858237385749817,
"alphanum_fraction": 0.7241379022598267,
"avg_line_length": 33.79999923706055,
"blob_id": "3a573374d54edf3e15138f7a8ffc4189bbb49c29",
"content_id": "0b4d11b7899b1223edbfe13e2fab17eeae4e1e74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 522,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 15,
"path": "/opencv_basic.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "import cv2\n\n#to display img in the form of a 2D matrix\n#image address bhi dal skte hain direct (eg:- C:\\\\Users\\\\Faraz_0hm6\\\\OneDrive\\\\Desktop\\\\basketball.png)\nimg = cv2.imread(\"lena.jpg\", -1) # 0= grayscale, 1= RGB, -1= alpha shaders\nprint(img)\n\ncv2.imshow(\"image\", img) #to display image\n\n#how long window should be displayed (in nano seconds i.e 5 sec = 5000)\ncv2.waitKey(0) # just like Waitforseconds in unity func (0 is for running it infinitly)\ncv2.destroyAllWindows()\n\n#to copy an image\ncv2.imwrite(\"lena.jpg\", img)\n"
},
{
"alpha_fraction": 0.603960394859314,
"alphanum_fraction": 0.6386138796806335,
"avg_line_length": 13.5,
"blob_id": "5e1f1c7f2b808e0f3dac59378a5e25da043a82b3",
"content_id": "59522474a5354c0c0eba9cd3e0082c5a8ae339e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 14,
"path": "/CH.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "from tkinter import *\n\nroot = Tk()\n\ncan = Canvas(root, width = 100, height = 400, bg= 'blue')\n\ndef printt(event):\n print(event.x, event.y)\n\ncan.bind(\"<Button-1>\", printt)\n\ncan.pack()\n\nroot.mainloop()"
},
{
"alpha_fraction": 0.6023916006088257,
"alphanum_fraction": 0.6801195740699768,
"avg_line_length": 20.612903594970703,
"blob_id": "5c3db748af8f46ed2921b79889d8e4106c7b4f46",
"content_id": "bbc10216bdf2b195d2e4d98b3caf5efd9f48e351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 31,
"path": "/image_histo_rgb.py",
"repo_name": "Farazzaidi22/CG_lab02",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2 as cv\nfrom matplotlib import pyplot as plt\n\n#uint8 is an unsigned 8-bit integer that can represent values 0..255\n#numpy uint8 will wrap. For example, 235+30 = 9\n#img = np.zeros((200,200), np.uint8)\n\nimg =cv.imread(\"lena.jpg\")\n\ncv.imshow(\"img\", img)\n\n#splitting img in RGB \nb,r,g = cv.split(img)\n\ncv.imshow(\"b\", b)\ncv.imshow(\"g\", g)\ncv.imshow(\"r\", r)\n\n#hist(array, no of pixels, range of those pixels)\n#ravel is used for flattening a 2D array into 1D\nplt.hist(img.ravel(), 256, [0,256]) \n\nplt.hist(b.ravel(), 256, [0,256])\nplt.hist(g.ravel(), 256, [0,256])\nplt.hist(r.ravel(), 256, [0,256])\n\nplt.show()\n\ncv.waitKey(0)\ncv.destroyAllWindows()"
}
] | 6 |
nandarahul/interview-challenges
|
https://github.com/nandarahul/interview-challenges
|
21a2a85361b682441be9869739074ccf321a4895
|
dc7deecc0fdc8c80af531dc10443941ccbe45857
|
a7afd0427d220c46c4c334e5560a8ef45602cb8c
|
refs/heads/master
| 2022-12-12T09:55:04.972182 | 2017-11-15T07:58:29 | 2017-11-15T07:58:29 | 91,556,768 | 0 | 0 | null | 2017-05-17T09:10:49 | 2017-05-17T09:15:12 | 2022-12-08T00:39:43 |
Python
|
[
{
"alpha_fraction": 0.5283582210540771,
"alphanum_fraction": 0.5522388219833374,
"avg_line_length": 16,
"blob_id": "c431568a9d2c89ff7ee4faae0360cd80e608d2b5",
"content_id": "053b425c7f61138fc32d765318a7d7599bee06a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 59,
"path": "/isBalanced.cpp",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\nusing namespace std;\n\nbool isBalanced(string str){\n\tint openB=0;\n\tfor(int i=0;i < str.length();i++){\n\t\tif(str[i]=='(')\n\t\t\topenB++;\n\t\t\n\t\telse if(str[i] == ')')\n\t\t\topenB--;\n\t\t\tif(openB < 0)\n\t\t\t\treturn false;\n\t}\n\tif(openB)\n\t\treturn false;\n\treturn true;\n}\nint fib(int n){\n\tswitch(n){\n\t\tdefault:\n\t\t\treturn fib(n-1) + fib(n-2);\n\t\tcase 1:;\n\t\tcase 2:;\n\t}\n\treturn 1;\n}\nclass A{\n\tpublic:\n\tint u,l;\n\tA(int i) : u(i+1), l(i){}\n};\nint main(){\n\tint v = 5;\n\tint x = v/0;\n}\nint min(int a, int b){\n\treturn a<b?a:b;\n}\nint shortestPalindrome(string s) {\n\tint n = s.size();\n\tint **table = new int* [n];\n\tfor(int i=0;i<n;i++)\n\t\ttable[i] = new int[n];\n\tfor(int i=0;i<n;i++)\n\t\tfor(int j=0;j<n;j++)\n\t\ttable[i][j]=0;\n\tfor(int length=1;length<n;length++){\n\t\tfor(int start=0;start<n;start++){\n\t\t\tend = start+length;\n\t\t\tif(s[start] == s[end])\n\t\t\t\ttable[start][end] = table[start+1][end-1];\n\t\t\telse\n\t\t\t\ttable[start][end] = min(table[l][h-1], table[l+1][h]) + 1;\n\t\t}\n\t}\n\treturn table[0][n-1];\n}\n\n\n"
},
{
"alpha_fraction": 0.6586538553237915,
"alphanum_fraction": 0.6586538553237915,
"avg_line_length": 25.125,
"blob_id": "270544d5c6170df570a800f9c5a93beb54c59d14",
"content_id": "05c077f1d9cfda292d5055215e25daf4ec4a9ddc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 8,
"path": "/CSVEvaluator/models/evaluator.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "from csvfile import CSVFile\n\nclass Evaluator(object):\n def __init__(self, csv_path, csv_format):\n self.CSVObj = CSVFile(csv_path, csv_format)\n\n def evaluate(self):\n self.CSVObj.read_line()"
},
{
"alpha_fraction": 0.5244338512420654,
"alphanum_fraction": 0.5452920198440552,
"avg_line_length": 24.78461456298828,
"blob_id": "577b6e858793e9e906a06a68c7119c618d501227",
"content_id": "df0fe02db224351dabf90aa48cdbbcf085aa0453",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1678,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 65,
"path": "/try.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef method1():\n x = sys.stdin.readlines()\n for l in x:\n print l[:-1]\n\ndef method2():\n line = sys.stdin.readline()\n while line:\n line=line[:-1] if line[-1] == '\\n' else line\n print line\n line = sys.stdin.readline()\n if not line:\n print \"ehh\"\n print type(line)\n\ndef check_valid_hour(hour):\n return 0 <= hour <= 23\n\ndef check_valid_minute(minute):\n return 0 <= minute <= 59\n\ndef traverse(arr, preOrder):\n if not arr:\n return\n min_index = arr.index(min(arr))\n preOrder.append(arr[min_index])\n traverse(arr[:min_index], preOrder)\n traverse(arr[min_index+1:], preOrder)\n\ndef getPreOrder(arr):\n preOrder = []\n traverse(arr, preOrder)\n return preOrder\n\nif __name__ == \"__main__\":\n print getPreOrder([8,2,7,1,9,3,20])\n\n\ndef solution(A, B, C, D):\n # write your code in Python 2.7\n numbers = [A, B, C, D]\n two_digits = []\n for i, x in enumerate(numbers):\n for j, y in enumerate(numbers):\n if i == j:\n continue\n two_digits.append(x*10 + y)\n two_digits.sort(reverse=True)\n two_digits = ['0'+str(tg) if tg < 10 else str(tg) for tg in two_digits]\n numbers = [str(n) for n in numbers]\n print numbers\n for x in two_digits:\n if check_valid_hour(int(x)):\n for y in two_digits:\n ncopy = numbers[:]\n ncopy.remove(x[0])\n ncopy.remove(x[1])\n if y[0] in ncopy and y[1] in ncopy and check_valid_minute(int(y)):\n hour, minute = x, y\n return hour+\":\"+minute\n return \"NOT POSSIBLE\"\n\n#print solution(4,0,0,2)\n\n\n"
},
{
"alpha_fraction": 0.4817749559879303,
"alphanum_fraction": 0.5293185710906982,
"avg_line_length": 31.947368621826172,
"blob_id": "f6ef2ca57731d86e24b0825100693dbbd7fc9a7f",
"content_id": "f784c3a2ba79b930751326a54d286f0f0a8be9c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 631,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 19,
"path": "/printEncoding.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\n\ndef print_encoding(str, encoding):\n if len(encoding) == 0:\n print str\n return\n if not int(encoding[0]):\n print \"INVALID Encoding\"\n return\n if len(encoding) >= 2:\n if encoding[1] == '0':\n if int(encoding[:2]) > 26:\n print \"Invalid Encoding\"\n return\n print_encoding(str+chr(96+int(encoding[:2])), encoding[2:])\n return\n if int(encoding[:2]) <= 26:\n print_encoding(str+chr(96+int(encoding[:2])), encoding[2:])\n print_encoding(str+chr(96+int(encoding[0])), encoding[1:])\n\nprint_encoding(\"\", '4140111')\n\n\n\n"
},
{
"alpha_fraction": 0.5560867786407471,
"alphanum_fraction": 0.5913938879966736,
"avg_line_length": 34.78947448730469,
"blob_id": "75604a1aac0d22220e45b8f639634e15b1d03715",
"content_id": "fff0aaf502df112d46f26e8fbc2b4dee2cda92e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2719,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 76,
"path": "/Swiggy/navigation_alerts.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "from geopy.distance import vincenty\nimport math\n\"\"\"\nUsing geopy-1.11.0 library for computing lat-long distances\n\"\"\"\n\n\ndef compute_distance(lat_long1, lat_long2):\n return vincenty(lat_long1, lat_long2).kilometers\n\n\ndef read_csv_file(file_name):\n navigation_points = []\n with open(file_name) as f:\n for line in f:\n line = line.split(',')\n if line[0] and line[1]:\n navigation_points.append((float(line[0]), float(line[1])))\n\n return navigation_points\n\ndef get_direction(first, second, third):\n try:\n #slope1 = (second[1]-first[1])/(second[0]-first[0])\n #slope2 = (third[1]-second[1])/(third[0]-second[0])\n #angle = math.degrees(math.atan(slope2) - math.atan(slope1))\n\n vector1 = (second[0]-first[0], second[1]-first[1])\n vector2 = (third[0]-second[0], third[1]-second[1])\n angle = math.degrees(vector1[0]*vector2[1] - vector1[1]*vector2[0])\n if vector1 == (0,0) or vector2 == (0,0):\n return \"\"\n if angle > 0:\n direction = \"Left\"\n elif angle < 0:\n direction = \"Right\"\n else:\n direction = \"Take U turn\"\n angle = abs(angle)\n if angle < 30:\n direction += \"Slight \"\n elif angle > 140:\n direction = \"Take U turn towards\" + direction\n return direction\n except:\n return \"No turn\"\n \"\"\"\n a = math.sqrt((second[0]-first[0])**2 + (second[1]-first[1])**2)\n b = math.sqrt((second[0]-third[0])**2 + (second[1]-third[1])**2)\n c = math.sqrt((third[0]-first[0])**2 + (third[1]-first[1])**2)\n angle = math.acos((a**2 + b**2 - c**2) / (2*a*b) )\n return angle\"\"\"\n\n\ndef get_navigation_instructions(navigation_points, speed, timestamp):\n if navigation_points:\n if len(navigation_points) == 1:\n print timestamp, \": Reached Destination\"\n return\n distance_meters = compute_distance(navigation_points[0], navigation_points[1])*1000\n print timestamp, \"minutes: Go straight for %d meters.\\n\" % distance_meters\n time_minutes = distance_meters*60/(speed*1000)\n timestamp += time_minutes\n if len(navigation_points) > 2 and distance_meters:\n #print \"Angle\",\n print str(timestamp)+\" minutes\", get_direction(navigation_points[0], navigation_points[1], navigation_points[2])\n\n get_navigation_instructions(navigation_points[1:], speed, timestamp)\n else:\n print \"No navigation points specified!\"\n\nif __name__ == \"__main__\":\n file_name = \"lat_long.csv\"\n speed = input(\"Enter the speed: \")\n navigation_points = read_csv_file(file_name)\n get_navigation_instructions(navigation_points, speed, 0)"
},
{
"alpha_fraction": 0.46136364340782166,
"alphanum_fraction": 0.48181816935539246,
"avg_line_length": 24.823530197143555,
"blob_id": "e2d7229a4f3769f4c25abfb2afad6d62c3e41d78",
"content_id": "2e8540f1dc1d009758f26ca6f1cb50a74381cf91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 440,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 17,
"path": "/interview_bit.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\ndef maxSubArray(self, A):\n n = len(A)\n print A\n sum_mat = []\n maxN = A[0]\n for i, a in enumerate(A):\n sum_mat.append([0]*n)\n sum_mat[i][i] = a\n maxN = a if a > maxN else maxN\n\n for i in range(n):\n for j in range(i, n):\n sum_mat[i][j] = sum_mat[i][j-1] + A[j]\n maxN = sum_mat[i][j] if sum_mat[i][j] > maxN else maxN\n return maxN\n\nprint maxSubArray(1, (1, -2, 3, 4, 5))\n"
},
{
"alpha_fraction": 0.5475631356239319,
"alphanum_fraction": 0.5543159246444702,
"avg_line_length": 34.1134033203125,
"blob_id": "08ac70fee71dd258f12a1582bd11de63a42d311e",
"content_id": "dde0b16a2d43acb5b21a14db48a7861da23cc94d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3406,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 97,
"path": "/running_median.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#!/bin/python\nimport sys\n\n\nclass Heap:\n def __init__(self, max_heap=True):\n self.heap_list = [0]\n self.max_heap = max_heap\n\n def get_length(self):\n return len(self.heap_list)-1\n\n def get_maxmin(self):\n if len(self.heap_list) == 1:\n raise exception(\"Heap is Empty\")\n return self.heap_list[1]\n\n def extract_maxmin(self):\n if len(self.heap_list) == 1:\n raise exception(\"Heap is Empty\")\n result = self.heap_list[1]\n self.heap_list[1] = self.heap_list[-1]\n self.heap_list = self.heap_list[:-1]\n self.heapify_down(index=1)\n return result\n\n def heapify_up(self, index):\n if index < 1 or index >= len(self.heap_list):\n raise exception(\"invalid index passed\")\n parent = index/2\n if parent < 1:\n return\n toswap = (self.max_heap and self.heap_list[index] > self.heap_list[parent]) or (not self.max_heap and\n self.heap_list[index] < self.heap_list[parent])\n if toswap:\n self.heap_list[index], self.heap_list[parent] = self.heap_list[parent], self.heap_list[index]\n self.heapify_up(parent)\n\n def heapify_down(self, index):\n if index < 1 or index >= len(self.heap_list):\n raise exception(\"invalid index passed\")\n left, right = 2*index, 2*index + 1\n original = index\n\n if left < len(self.heap_list):\n if self.max_heap and self.heap_list[left] > self.heap_list[index]:\n original = left\n elif not self.max_heap and self.heap_list[left] < self.heap_list[index]:\n original = left\n if right < len(self.heap_list):\n if self.max_heap and self.heap_list[right] > self.heap_list[original]:\n original = right\n elif not self.max_heap and self.heap_list[right] < self.heap_list[original]:\n original = right\n if original != index:\n self.heap_list[original], self.heap_list[index] = self.heap_list[index], self.heap_list[original]\n self.heapify_down(original)\n\n def insert(self, num):\n self.heap_list.append(num)\n self.heapify_up(index=len(self.heap_list)-1)\n\n\nclass MedianRunner:\n def __init__(self):\n self.L = Heap(max_heap=True)\n self.R = Heap(max_heap=False)\n\n def getMedian(self):\n if self.L.get_length() == self.R.get_length():\n return (float)(self.L.get_maxmin() + self.R.get_maxmin())/2\n elif self.L.get_length() > self.R.get_length():\n return self.L.get_maxmin()\n return self.R.get_maxmin()\n\n def insert(self, num):\n if self.L.get_length() == 0 or num < self.L.get_maxmin():\n self.L.insert(num)\n else:\n self.R.insert(num)\n if self.L.get_length() - self.R.get_length() > 1:\n t = self.L.extract_maxmin()\n self.R.insert(t)\n #print t, self.L.get_length(), self.R.get_length(), self.L.get_maxmin(), self.R.get_maxmin()\n\n elif self.R.get_length() - self.L.get_length() > 1:\n t = self.R.extract_maxmin()\n self.L.insert(t)\n\nn = int(raw_input().strip())\na = []\nMR = MedianRunner()\nfor a_i in xrange(n):\n a_t = int(raw_input().strip())\n MR.insert(a_t)\n print \"%.1f\" % MR.getMedian()\n a.append(a_t)\n"
},
{
"alpha_fraction": 0.5161579847335815,
"alphanum_fraction": 0.5403949618339539,
"avg_line_length": 21.280000686645508,
"blob_id": "f2f149fdcd47a4d44d71aaf6c42a96fb63aa6736",
"content_id": "abb6aa89ebb0390671f5ea46fa94666e9a6c2d78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 50,
"path": "/soroco.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "import sys\nmin_cost = sys.maxint\n\n\ndef do_stuff(visited):\n # print \"hello\"\n global A, min_cost\n B = []\n for v in visited:\n B.append(A[v[0]][v[1]])\n B.sort()\n mid = len(B)/2\n if len(B) % 2:\n median = B[mid]\n else:\n median = int((B[mid-1]+B[mid])/2)\n ans = 0\n for b in B:\n ans += abs(b-median)\n print B\n if ans < min_cost:\n print B\n min_cost = ans\n\nimport copy\ndef depth_first(source, mvisited):\n # print \"j\"\n global N, M\n visited = copy.copy(mvisited)\n if source[0] in (-1, N) or source[1] in (-1, M) or source in visited:\n # print \"FUK\"\n return\n visited.add(source)\n if source == (N-1, M-1):\n do_stuff(visited)\n return\n depth_first((source[0]+1, source[1]), visited)\n depth_first((source[0]-1, source[1]), visited)\n depth_first((source[0], source[1]+1), visited)\n depth_first((source[0], source[1]-1), visited)\n\n\nN, M = map(int, raw_input().split())\nA = []\nfor _ in range(N):\n row = map(int, raw_input().split())\n A.append(row)\n\ndepth_first((0,0), set([]))\nprint min_cost\n"
},
{
"alpha_fraction": 0.5254722237586975,
"alphanum_fraction": 0.5506582856178284,
"avg_line_length": 21.921052932739258,
"blob_id": "6410cb179db8c6f21b7c2a26f660740f5cb93d02",
"content_id": "d328ae7c1a005615256696a1981f5732f7405d5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1747,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 76,
"path": "/bookingChallenge.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "import sys\nline = sys.stdin.readline()\nsq, rect, other = 0, 0, 0\nwhile line:\n otherFound = False\n #line=line[:-1] if line[-1] == '\\n' else line\n sides = line.split()\n sides = [int(s) for s in sides]\n\n for s1 in sides:\n if s1 <= 0:\n otherFound = True\n other += 1\n break\n if not otherFound:\n if sides[0]==sides[1]==sides[2]==sides[3]:\n sq += 1\n elif sides[0]==sides[2] and sides[1]==sides[3]:\n rect += 1\n else:\n other += 1\n line = sys.stdin.readline()\nprint sq, rect, other\n\n***********************************\nimport sys\nwords = sys.stdin.readline()\nM = int(raw_input())\nmydict = {}\nfor _ in range(2*M):\n id = int(raw_input())\n count = 0\n review = sys.stdin.readline()\n review = line[:-1] if line[-1] == '\\n' else review\n review = review.split()\n review = [r.strip(\",.\") for r in review]\n for wr in review:\n if wr in words:\n count+=1\n mydict[id] = mydict.get(id, 0) + count\n\nimport operator\nsorted_x = sorted(mydict.items(), key=operator.itemgetter(1), reverse=True)\nfor sx in sorted_x:\n sys.stdout.write(sx[0])\nsys.stdout.flush()\n\nimport sys\nnumbers = sys.stdin.readline()\nnumbers = numbers[-1]\nnumbers = numbers.split()\nnumbers = [int(n) for n in numbers]\nresult = [numbers[0]]\nprev = numbers[0]\nfor x in numbers[1:]:\n diff = x - prev\n if diff > 127 or diff < -127:\n result.append(-128)\n result.append(diff)\n prev = x\nfor r in result:\n print r,\n\nS = int(raw_input())\nM = int(raw_input())\nmydict = {}\nfound = False\nfor _ in range(M):\n x = int(raw_input())\n if S-x in mydict:\n found = True\n mydict[x] = 1\nif found:\n print 1\nelse:\n print 0\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.4836527705192566,
"alphanum_fraction": 0.5107102394104004,
"avg_line_length": 17.5,
"blob_id": "09c3a883cc472ef2b34bc395d57ac8ae254a8517",
"content_id": "d756bc743d2477238643b12420d12c091a732fdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 887,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 48,
"path": "/oneTreebo.cpp",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <unordered_set>\nusing namespace std;\n\nint main(){\n\tint M, K, TS, current_node;\n\tcin>>M;\n\tint *graph = new int[M+1];\n\tfor (int i=1;i<M+1;i++){\n\t\tscanf(\"%d\", &graph[i]);\n\t}\n\tbool *ts = new bool[M+1];\n\tgraph[0] = 0;\n\tcin>>K;\n\tfor(;K>0;K--){\n\t\tint q1, q2;\n\t\tscanf(\"%d %d\", &q1, &q2);\n\t\tif(q1 == 1){\n\t\t\t//unordered_set<int> traversedSet;\n\t\t\t//TS = 0;\n\t\t\tfor (int i=1;i<M+1;i++)\n\t\t\t\tts[i] = false;\n\n\t\t\tcurrent_node = q2;\n\t\t\twhile(true){\n\t\t\t\tif(graph[current_node] == 0){\n\t\t\t\t\tprintf(\"%d\\n\", current_node);\n\t\t\t\t\tbreak;\n\t\t\t\t}\n\t\t\t\tif(ts[graph[current_node]]){\n\t\t\t\t\tprintf(\"LOOP\\n\");\n\t\t\t\t\tbreak;\n\t\t\t\t}\n\t\t\t\t// if(TS & 1<<graph[current_node]){\n\t\t\t\t// \tprintf(\"LOOP\\n\");\n\t\t\t\t// \tbreak;\n\t\t\t\t// }\n\t\t\t\t// TS = TS | 1<<current_node;\n\t\t\t\tts[current_node] = true;\n\t\t\t\tcurrent_node = graph[current_node];\n\t\t\t}\n\t\t}\n\t\telse if(q1 == 2){\n\t\t\tgraph[q2] = 0;\n\t\t}\n\t}\n}"
},
{
"alpha_fraction": 0.5159362554550171,
"alphanum_fraction": 0.5298804640769958,
"avg_line_length": 26.135135650634766,
"blob_id": "03b1c87eae22b476bc6a6fc15537e3e8ee95e829",
"content_id": "2770927198b3e2b8d8ea2b3059a638f8796ec5fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1004,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 37,
"path": "/RivigoTree.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "import sys\n\ndef traverse(tree, root_index, u, l, descendantSeen):\n if root_index == u:\n descendantSeen = True\n if l == 0:\n if descendantSeen:\n return tree[root_index][0]\n else:\n return 0\n score_sum = 0\n for child_index in tree[root_index][1]:\n score_sum += traverse(tree, child_index, u, l-1, descendantSeen)\n return score_sum\n\ndef compute_score_sum(tree, u, l):\n if l <= 0:\n return 0\n return traverse(tree, 1, u, l-1, False)\n\nT = int(raw_input())\nwhile T:\n T -= 1\n N, Q = raw_input().split()\n N, Q = int(N), int(Q)\n tree = [[0, []]]\n scores = sys.stdin.readline().split()\n for i, s in enumerate(scores):\n tree.append([int(s), []])\n for _ in range(N-1):\n i, j = sys.stdin.readline().split()\n i, j = int(i), int(j)\n tree[i][1].append(j)\n for _ in range(Q):\n u, l = sys.stdin.readline().split()\n u, l = int(u), int(l)\n print compute_score_sum(tree, u, l)\n"
},
{
"alpha_fraction": 0.752173900604248,
"alphanum_fraction": 0.752173900604248,
"avg_line_length": 31.571428298950195,
"blob_id": "9ffac6830bc47bc2efb7c7843d617152f5242ab2",
"content_id": "4a647e55d66089a52a4c21f49c25d02de0ed1ca9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 230,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 7,
"path": "/CSVEvaluator 2/start.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "take csv file path as input()\n\nformat as input()\ncreate csvfile object\n\ncreate evaluator object -- take csvfile as input(), rules class to be created and pass as input\nevaluator.evaluate() --- creates objects for expressions --\n\n\n"
},
{
"alpha_fraction": 0.5388679504394531,
"alphanum_fraction": 0.5592452883720398,
"avg_line_length": 25.420000076293945,
"blob_id": "b449dec6e5f7866b7871f534d4d6e4cee659ba03",
"content_id": "ccec36f628002a852ef9fbb1341f71529a6086da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1325,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 50,
"path": "/mparser.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\nimport sys\nIE = \"INVALID EXPRESSION\"\n# Expression will be a list\n# This function will return a number\ndef create_expression(mlist):\n while '*' in mlist:\n pos = mlist.index('*')\n mlist = mlist[:pos-1] + [mlist[pos-1:pos+2]] + mlist[pos+2:]\n return mlist\n\n\ndef evaluate(expression):\n if len(expression) == 1:\n try:\n return int(expression[0])\n except:\n return IE\n if len(expression) == 3:\n if expression[1] == '*':\n return evaluate(expression[0]) * evaluate(expression[2])\n if expression[1] == '+':\n return evaluate(expression[0]) + evaluate(expression[2])\n if expression[1] == '-':\n return evaluate(expression[0]) - evaluate(expression[2])\n if expression[1] == '/':\n return evaluate(expression[0]) / evaluate(expression[2])\n\n\nline = sys.stdin.readline()\nlines = []\nwhile line:\n line = line[:-1]\n line = [l.strip() for l in line.split(',')]\n lines.append(line)\n line = sys.stdin.readline()\n\nif '_' in lines[0] or '_' in lines[-1] or len(lines) %2 ==0:\n print IE\n sys.exit()\n\nif len(lines) == 1:\n exp = create_expression(lines[0])\n print evaluate(exp)\n\nelse:\n ex = []\n for l, i in enumerate(lines):\n if i %2 :\n l[]\n create_expression()\n\n\n\n"
},
{
"alpha_fraction": 0.4672057628631592,
"alphanum_fraction": 0.4851751923561096,
"avg_line_length": 23.688888549804688,
"blob_id": "0f9d184d10f278776c56b982b90fc57acebac0bd",
"content_id": "223ce9533eb22771f48bd29ed47a6fb70e6a29dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 45,
"path": "/geeks4geeks/reverse.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "def reverse_special(mystrr):\n mystr = list(mystrr)\n print mystr\n i, j = 0, len(mystr)-1\n while i < j:\n special = False\n if mystr[i].lower() < 'a' or mystr[i].lower() > 'z':\n i += 1\n special = True\n if mystr[j].lower() < 'a' or mystr[j].lower() > 'z':\n j -= 1\n special = True\n if not special:\n mystr[i], mystr[j] = mystr[j], mystr[i]\n i += 1\n j -= 1\n mystrr = ''.join(s for s in mystr)\n return mystrr\n\ncount = 0\ndef permute(mystr, pos):\n if isinstance(mystr, str):\n mystr = list(mystr)\n for i in range(pos, len(mystr)):\n newstr = mystr\n newstr[i], newstr[pos] = newstr[pos], newstr[i]\n permute(newstr, pos+1)\n newstr[i], newstr[pos] = newstr[pos], newstr[i]\n\n if pos == len(mystr) - 1:\n global count\n count += 1\n print ''.join(mystr)\n\ndef test(k):\n k[0] = 11111\n\nif __name__ == \"__main__\":\n #print reverse_special(\"Ab,c,de!$\")\n #permute('rahul', 0)\n #print count\n #k = [1,2]\n k = 5\n test(k)\n print k\n\n\n"
},
{
"alpha_fraction": 0.4040403962135315,
"alphanum_fraction": 0.45252525806427,
"avg_line_length": 23.700000762939453,
"blob_id": "4796a3a51fa7c04638148cbff238bbda42e23ee2",
"content_id": "962dc92c2e0ba1f0a2036d5cac1e23263de1f39a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 20,
"path": "/merge_sorted_arrays.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\ndef merge_sorted(a, b):\n ai, bi = 0, 0\n sorted_list = []\n while ai < len(a) and bi < len(b):\n if a[ai] < b[bi]:\n sorted_list.append(a[ai])\n ai += 1\n else:\n sorted_list.append(b[bi])\n bi += 1\n while ai < len(a):\n sorted_list.append(a[ai])\n ai += 1\n while bi < len(b):\n sorted_list.append(b[bi])\n bi += 1\n\n return sorted_list\n\nprint merge_sorted([3, 4, 6, 10, 11, 15], [1, 5, 8, 12, 14, 19])\n"
},
{
"alpha_fraction": 0.5029069781303406,
"alphanum_fraction": 0.5174418687820435,
"avg_line_length": 26.520000457763672,
"blob_id": "364110c57127daec76fbe467086b7b0aa725961d",
"content_id": "19db4340681ef42fba37209db3cad76ee1478499",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 688,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 25,
"path": "/treebo1.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "import sys\n\nM = int(raw_input())\ngraph = sys.stdin.readline().split()\ngraph = [int(g) for g in graph]\ngraph = [0] + graph\nK = int(raw_input())\nwhile K:\n K -= 1\n query = sys.stdin.readline().split()\n query = [int(q) for q in query]\n if query[0] == 1:\n traversedSet = set([])\n current_node = query[1]\n while True:\n if graph[current_node] == 0:\n print current_node\n break\n if graph[current_node] in traversedSet:\n print \"LOOP\"\n break\n traversedSet.add(current_node)\n current_node = graph[current_node]\n elif query[0] == 2:\n graph[query[1]] = 0\n"
},
{
"alpha_fraction": 0.4750656187534332,
"alphanum_fraction": 0.5065616965293884,
"avg_line_length": 25.701753616333008,
"blob_id": "c70b7335975c0abea7f9d9d483729600e6bbc615",
"content_id": "595a056a8db09977fc0b527a8c630d0c9c1ed1e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 57,
"path": "/bs.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\nimport sys\nline = sys.stdin.readline()\n\nfilter_start = False\nall_requests, filters, request = [], [], []\nrequest_count = 0\nwhile line:\n if line == \"\\n\":\n line = sys.stdin.readline()\n continue\n line = line[:-1]\n if line.startswith(\"Started\"):\n all_requests.append(request)\n request = []\n if line == \"***************###############***************\":\n all_requests.append(request)\n filter_start=True\n line = sys.stdin.readline()\n line = line[:-1]\n if filter_start:\n filters.append(line)\n else:\n request.append(line)\n line = sys.stdin.readline()\n\nall_requests = all_requests[1:]\nresult = [0, 0, 0, 0, 0]\n\nfor nrequest in all_requests:\n # Filter 1\n words = nrequest[0].split()\n if words[1] == filters[0]:\n result[0] += 1\n # Filter 2\n if words[2].strip('\"') == filters[1]:\n result[1] += 1\n #Filter 3\n if words[4] == filters[2]:\n result[2] += 1\n #Filter 4\n words = nrequest[1].split()\n if words[0] == \"Processing\":\n if len(words) == 5:\n if words[4] == filters[3]:\n result[3] += 1\n elif words[4] == \"HTML\" and (filters[3] == \"null\" or filters[3] == \"blank\"):\n result[3] += 1\n elif len(words) == 4 and filters[3] in [\"null\",\"blank\",\"HTML\"]:\n result[3] += 1\n #Filter 5\n if nrequest[-1].startswith(\"Completed\"):\n if filters[4] in nrequest[-1]:\n result[4] += 1\n\n\nfor r in result:\n print r\n\n"
},
{
"alpha_fraction": 0.5637226104736328,
"alphanum_fraction": 0.5832839608192444,
"avg_line_length": 25.375,
"blob_id": "cf18293e29bb340f329f5f55c926e52275628ccb",
"content_id": "2402c1d46791b83d4a48034576965fa64bf2374d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 64,
"path": "/countIslands.cpp",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <queue>\n#include <utility>\nusing namespace std;\n\nint BFS(int** &Mat, int i, int j, int m, int n, int LABEL){\n\tif(Mat[i][j] == LABEL || Mat[i][j] == 0)\n\t\treturn 0;\n\tqueue<pair<int,int> > Q;\n\tpair<int,int> P(i,j);\n\tQ.push(P);\n\tMat[i][j] = LABEL;\n\twhile(!Q.empty()){\n\t\tpair<int,int> F = Q.front();\n\t\tif(F.first < m-1 && Mat[F.first + 1][F.second]!=0 && Mat[F.first + 1][F.second]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first+1, F.second);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.second < n-1 && Mat[F.first][F.second+1]!=0 && Mat[F.first][F.second + 1]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first, F.second+1);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.first > 0 && Mat[F.first - 1][F.second]!=0 && Mat[F.first - 1][F.second]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first-1, F.second);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.second > 0 && Mat[F.first][F.second-1] != 0 && Mat[F.first][F.second - 1] != LABEL){\n\t\t\tpair<int,int> neighbour(F.first, F.second-1);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tQ.pop();\n\t}\n\treturn 1;\n\n}\n\nint countIslands(int** &Mat, int m, int n){\n\tif(m<=0 || n<=0)\n\t\treturn 0;\n\tint count = 0, LABEL= -1;\n\tfor(int i=0;i<m;i++)\n\t\tfor(int j=0;j<n;j++)\n\t\t\tcount += BFS(Mat, i, j, m ,n, LABEL);\n\n\treturn count;\n}\n\nint main(int argc, char const *argv[])\n{\n\tint **Mat, m, n;\n\tcin>>m>>n;\n\tMat = new int*[m];\n\tfor(int i=0;i<m;i++)\n\t\tMat[i] = new int[n];\n\tfor(int i=0;i<m;i++){\n\t\tfor(int j=0;j<n;j++)\n\t\t\tcin>>Mat[i][j];\n\t}\n\tcout<<\"No. of Islands:\"<<countIslands(Mat, m, n)<<\"\\n\";\n}"
},
{
"alpha_fraction": 0.6057276129722595,
"alphanum_fraction": 0.6247086524963379,
"avg_line_length": 35.180721282958984,
"blob_id": "e64ae37678d47c1471a6166ffb65f16857695fa6",
"content_id": "0f580f2582880e563b912394b51f1e2f946b24d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3003,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 83,
"path": "/hubspot/hubspot_main.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\"\"\"\nAuthor: Rahul Nanda\n9th October 2017\n\n*** Python 2.7 ***\n\"\"\"\n\nimport requests\nimport sys\nimport json\nimport datetime\nGET_URL = \"https://candidate.hubteam.com/candidateTest/v2/partners?userKey=e418b67ecc80abceb128933bb27c\"\nPOST_URL = \"https://candidate.hubteam.com/candidateTest/v2/results?userKey=e418b67ecc80abceb128933bb27c\"\n\n\ndef get_info():\n r = requests.get(GET_URL)\n if r.status_code != 200:\n print (\"Initial call to the API: [%s] returned status code:[%d]. Please fix this. Exiting now..\" % (URL, r.status_code))\n sys.exit()\n return r.json()\n\n\ndef send_data(data):\n r = requests.post(POST_URL, data=json.dumps(data))\n print r.status_code\n print r.text\n\n\n# Specific to a country\ndef compute_country_event_info(country_name, country_partner_list):\n date_email_dict = {}\n for partner in country_partner_list:\n for date_str in partner[\"availableDates\"]:\n if date_str in date_email_dict:\n date_email_dict[date_str].append(partner[\"email\"])\n else:\n date_email_dict[date_str] = [partner[\"email\"]]\n date_count_list = []\n for date_str in date_email_dict:\n date_parse_list = map(int, date_str.split('-'))\n date_obj = datetime.date(date_parse_list[0], date_parse_list[1], date_parse_list[2])\n date_count_list.append((date_obj, date_email_dict[date_str]))\n\n date_count_list = sorted(date_count_list, key=lambda dc: dc[0])\n max_attendees_count, max_date_obj, max_attendees_emails = 0, None, []\n for i in xrange(len(date_count_list)-1):\n time_difference = date_count_list[i+1][0] - date_count_list[i][0]\n if time_difference.days == 1:\n both_days_attendees = set(date_count_list[i][1]).intersection(set(date_count_list[i+1][1]))\n if len(both_days_attendees) > max_attendees_count:\n max_attendees_count = len(both_days_attendees)\n max_attendees_emails = list(both_days_attendees)\n max_date_obj = date_count_list[i][0]\n\n start_date_str = None\n if max_attendees_count > 0:\n start_date_str = max_date_obj.isoformat()\n\n country_event_info = {\"attendeeCount\": max_attendees_count,\n \"attendees\": sorted(max_attendees_emails),\n \"name\": country_name,\n \"startDate\": start_date_str}\n\n #print country_event_info\n return country_event_info\n\n\nif __name__ == \"__main__\":\n data = get_info()\n country_dict = {}\n for partner in data[\"partners\"]:\n if partner[\"country\"] in country_dict:\n country_dict[partner[\"country\"]].append(partner)\n else:\n country_dict[partner[\"country\"]] = [partner]\n\n final_result = {\"countries\":[]}\n for country_name in country_dict:\n country_event_info = compute_country_event_info(country_name, country_dict[country_name])\n final_result[\"countries\"].append(country_event_info)\n print final_result\n send_data(final_result)\n"
},
{
"alpha_fraction": 0.5392912030220032,
"alphanum_fraction": 0.553158700466156,
"avg_line_length": 20.66666603088379,
"blob_id": "42302b6b9587f6c26152b36e3a7483b9ff4804d4",
"content_id": "13f18badfb6eaafeded50dda62250b7248cd0383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 649,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 30,
"path": "/codility.cpp",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <fstream>\nusing namespace std;\nint max(int a, int b){\n\tif (a>=b)\n\t\treturn a;\n\treturn b;\n}\nint traverse(tree* T, char direction){\n\tif(T == NULL)\n\t\treturn 0;\n\tif (direction == 'L') {\n\t\tif (T->r != NULL)\n\t\t\treturn max(traverse(T->r, 'R') + 1, traverse(T->l, 'L'));\n\t\treturn traverse(T->l, 'L');\n\t}\n\telse if (direction == 'R'){\n\t\tif (T->l != NULL)\n\t\t\treturn max(traverse(T->l, 'L') +1 , traverse(T->r, 'R'));\n\t\treturn traverse(T->r, 'R');\n\t}\n}\n\nint solution(tree * T) {\n // write your code in C++14 (g++ 6.2.0)\n \tif (T == NULL)\n \t\treturn 0;\n \treturn max(traverse(T->l, 'L'), traverse(T->r, 'R')); \n}"
},
{
"alpha_fraction": 0.5569853186607361,
"alphanum_fraction": 0.57421875,
"avg_line_length": 22.91758155822754,
"blob_id": "fcbe7c93ce3b0b90365318a73a44de481f6daed9",
"content_id": "1936b2de198779768b02f2e83fd39e9bed4bbecb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4352,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 182,
"path": "/arrays.cpp",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <fstream>\nusing namespace std;\n\n\n//Find the sum of the absolute difference of every pair of elements in a sorted array of numbers.\n#include <queue>\n#include <utility>\n\nint BFS(int** &Mat, int i, int j, int m, int n, int LABEL){\n\tif(Mat[i][j] == LABEL || Mat[i][j] == 0)\n\t\treturn 0;\n\tqueue<pair<int,int> > Q;\n\tpair<int,int> P(i,j);\n\tQ.push(P);\n\tMat[i][j] = LABEL;\n\twhile(!Q.empty()){\n\t\tpair<int,int> F = Q.front();\n\t\tif(F.first < m-1 && Mat[F.first + 1][F.second]!=0 && Mat[F.first + 1][F.second]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first+1, F.second);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.second < n-1 && Mat[F.first][F.second+1]!=0 && Mat[F.first][F.second + 1]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first, F.second+1);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.first > 0 && Mat[F.first - 1][F.second]!=0 && Mat[F.first - 1][F.second]!=LABEL){\n\t\t\tpair<int,int> neighbour(F.first-1, F.second);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tif(F.second > 0 && Mat[F.first][F.second-1] != 0 && Mat[F.first][F.second - 1] != LABEL){\n\t\t\tpair<int,int> neighbour(F.first, F.second-1);\n\t\t\tQ.push(neighbour);\n\t\t\tMat[neighbour.first][neighbour.second] = LABEL;\n\t\t}\n\t\tQ.pop();\n\t}\n\treturn 1;\n\n}\n\nint countIslands(int** &Mat, int m, int n){\n\tif(m<=0 || n<=0)\n\t\treturn 0;\n\tint count = 0, LABEL= -1;\n\tfor(int i=0;i<m;i++)\n\t\tfor(int j=0;j<n;j++){\n\t\t\t//cout<<i<<\" \"<<j<<\" \"<<Mat[i][j]<<\" \";\n\t\t\tint b = BFS(Mat, i, j, m ,n, LABEL);\n\t\t\t//cout<<\"BFS:\"<<b<<\"\\n\";\n\t\t\tcount += b;}\n\n\treturn count;\n}\n\n\n\nint sumAbsDiff(vector<int> data){\n\tint sum = 0;\n\tfor(int i=0;i<data.size();i++)\n\t\tsum += i*data[i] - (data.size()-i-1)*data[i];\n\treturn sum;\n}\nvoid callSumAbsDiff(){\n\tint m[] = {1,3,5};\n\tstd::vector<int> v(m, m+3);\n\tint q = v.front();\n\tcout<<q<<\"\\n\";\n\tcout<<sumAbsDiff(v)<<\"\\n\";\n}\n\nint binarySearch(vector<int> &A, int low, int high, int val){\n\tif(low > high) return -1;\n\tint mid = (low+high)/2;\n\tif(A[mid]==val) return mid;\n\tif(A[low]<=val && A[mid-1]>=val)\n\t\treturn binarySearch(A, low, mid-1, val);\n\treturn binarySearch(A, mid+1, high, val);\n}\n\nint checkSortedSubArray(std::vector<int> &A, int low, int high){\n\tif(low > high) return false;\n\treturn A[low] <= A[high];\n}\n\nint searchRotatedSortedArray(vector<int> &A, int low, int high, int val){\n\tif(low > high) return -1;\n\tint mid = (low+high)/2;\n\tif(A[mid]==val) return mid;\n\tif(checkSortedSubArray(A, low, mid-1))\n\t\tif(A[low]<=val && val<=A[mid-1])\n\t\t\treturn binarySearch(A, low, mid-1, val);\n\t\telse\n\t\t\treturn searchRotatedSortedArray(A, mid+1, high, val);\n\telse if(checkSortedSubArray(A, mid+1, high))\n\t\tif(A[mid+1]<=val && val<=A[high])\n\t\t\treturn binarySearch(A, mid+1, high, val);\n\t\telse\n\t\t\treturn searchRotatedSortedArray(A, low, mid-1, val);\n\treturn -1;\n\n}\n\nvoid swap(int &a, int &b){\n\tint temp = a;\n\ta = b;\n\tb = temp;\n}\nint partition(vector<int> &A, int low, int high){\n\tint pivotIndex = high;\n\tint i=low;\n\tfor(int j=low;j<=high-1;j++){\n\t\tif(A[j]<A[pivotIndex]){\n\t\t\tswap(A[i], A[j]);\n\t\t\ti++;\n\t\t}\n\t}\n\tswap(A[i], A[pivotIndex]);\n\treturn i;\n}\n\nvoid quickSort(vector<int> &A, int low, int high){\n\tif(low < high){\n\t\tint pivotIndex = partition(A, low, high);\n\t\tquickSort(A, low, pivotIndex-1);\n\t\tquickSort(A, pivotIndex+1, high);\n\t}\n}\n\n\nint longestPalindrome(int n, string s) {\n bool ** table = new bool* [n];\n for(int i=0;i<n;i++)\n \ttable[i] = new bool[n];\n int maxLength = 1;\n for(int i=0;i<n;i++)\n \ttable[i][i] = true;\n for(int i=0;i<n-1;i++){\n \tif(s[i] == s[i+1]){\n \t\ttable[i][i+1] = true;\n \t\tmaxLength = 2;\n \t}\n }\n for(int length=3;length<=n;length++){\n \tfor(int i=0;i < n-length-1;i++){\n \t\tint j = i+length-1;\n \t\tif(table[i+1][j-1] && s[i] == s[j]){\n \t\t\ttable[i][j] = true;\n \t\t\tif(length>maxLength)\n \t\t\t\tmaxLength = length;\n \t\t}\n \t\telse\n \t\t\ttable[i][j] = false;\n \t}\n }\n\n return maxLength;\n}\n\n\nint main(int argc, char const *argv[])\n{\n\t// int **Mat, m, n;\n\t// cin>>m>>n;\n\t// Mat = new int*[m];\n\t// for(int i=0;i<m;i++)\n\t// \tMat[i] = new int[n];\n\t// for(int i=0;i<m;i++){\n\t// \tfor(int j=0;j<n;j++)\n\t// \t\tcin>>Mat[i][j];\n\t// \t//cout<<\"\\n\";\n\t// }\n\t// cout<<\"No. of Islands:\"<<countIslands(Mat, m, n)<<\"\\n\";\n\tstring s = \"aabbefbbaa\";\n\tcout<<longestPalindrome(10, s);\n\t\n\n}"
},
{
"alpha_fraction": 0.5853107571601868,
"alphanum_fraction": 0.5853107571601868,
"avg_line_length": 20,
"blob_id": "ff1e9349b8d20282082ff8057590fdde0277e146",
"content_id": "27f57e82a0d97d474ff3724c9bec9c4ee6a126c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 42,
"path": "/CSVEvaluator 2/models/expression.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\nclass Exression(object):\n def __init__(self):\n self.name = None\n\n\nclass Equation(Exression):\n def __init__(self, string):\n if not self.check_valid(string):\n raise Exception(\"Invalid Equation\")\n self.string = string\n self.valid_operators = []\n self.valid_operands = []\n\n def check_valid(self, string):\n pass\n\n def evaluate_left_to_right(self):\n pass\n\n def evaluate_right_to_left(self):\n pass\n\nclass URL(Exression):\n def __init__(self, string):\n self.string = string\n\n def check_valid(self):\n pass\n\n def evaluate_http_status_code(self):\n pass\n\nclass SetExpression(Exression):\n def __init__(self, string, operator):\n self.string = string\n self.operator = operator\n\n def check_valid(self):\n pass\n\n def evaluate_intersection(self):\n pass\n\n\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 23.769229888916016,
"blob_id": "57dad44b09be6d748a201b8e483f6d926e9fd081",
"content_id": "c09bd47d3e9d643eda2f403d0e5f703ef44b06b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 13,
"path": "/CSVEvaluator 2/models/csvfile.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\nclass CSVFile(object):\n def __init__(self, path, file_format):\n self.file_format = file\n self.contents = None\n self.path = path\n\n def check_valid(self):\n pass\n\n def read_line(self, path):\n # self.contents will be updated\n # self.check_valid() will be called\n pass"
},
{
"alpha_fraction": 0.6288659572601318,
"alphanum_fraction": 0.6391752362251282,
"avg_line_length": 15.333333015441895,
"blob_id": "1d181f8e72b6763ac03ea5167459455c7d885656",
"content_id": "a64cc49e98621db64c7e77d762f1a11d4c790a53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 6,
"path": "/chemical_formula.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "def convert(chem_formula):\n\n for c in reversed(chem_formula):\n print c,\n\nconvert(\"CH4\")"
},
{
"alpha_fraction": 0.5750386118888855,
"alphanum_fraction": 0.5880948901176453,
"avg_line_length": 37.90163803100586,
"blob_id": "0e54b25df89889a069f5d19259227ac0daaea9a2",
"content_id": "406c1a59a3b1339c51ff512b65720688d3e43496",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7123,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 183,
"path": "/hulu/hangman.py",
"repo_name": "nandarahul/interview-challenges",
"src_encoding": "UTF-8",
"text": "\"\"\"\nAuthor: Rahul Nanda\nSeptember 29, 2017\n\"\"\"\n\nimport requests\nimport sys\nimport re\nimport time\nemailID = \"\"\nURL = \"http://gallows.hulu.com/play?code=\"+emailID\n\n\ndef get_wordlist_filename(word_length):\n if 1 <= word_length <= 4:\n return \"google-10000-english-usa-no-swears-short.txt\"\n if 5 <= word_length <= 8:\n return \"google-10000-english-usa-no-swears-medium.txt\"\n return \"google-10000-english-usa-no-swears-long.txt\"\n\n\ndef first_service_call():\n r = requests.get(URL)\n if r.status_code != 200:\n print (\"Initial call to the API: [%s] returned status code:[%d]. Please fix this. Exiting now..\" % (URL, r.status_code))\n sys.exit()\n return r.json()\n\n\ndef LAST_RESORT_pick_alphabet_not_picked_yet(letters_guessed):\n \"\"\"\n This function is called only when we are unable to find any of the unknown words in the\n dictionary files.\n This list is taken from https://www.math.cornell.edu/~mec/2003-2004/cryptography/subs/frequencies.html\n \"\"\"\n sequence = ['e', 't', 'a', 'o', 'i', 'n', 's', 'r', 'h', 'd', 'l', 'u', 'c', 'm', 'f', 'y', 'w',\n 'g', 'p', 'b', 'v', 'k', 'x', 'q', 'j', 'z']\n for alpha in sequence:\n if alpha not in letters_guessed:\n return alpha\n return None\n\n\ndef process_unknown_word(unknown_word, letters_guessed, search_in_complete_dict=False):\n if search_in_complete_dict:\n wordlist_filename = \"complete_dict.txt\"\n else:\n wordlist_filename = get_wordlist_filename(len(unknown_word))\n wordlist_file_object = open(wordlist_filename, \"r\")\n alpha_string = \"a-z\" if len(letters_guessed) == 0 else '^' + ''.join(letters_guessed)\n\n regex_word = \"^\" + unknown_word.replace(\"_\", \"[%s]\" % alpha_string) + \"$\"\n total_matched_words, position_count = 0, {}\n for i in xrange(len(unknown_word)):\n if unknown_word[i] == '_':\n position_count[i] = {}\n rank = 1\n for dictionary_word in wordlist_file_object:\n dictionary_word = dictionary_word.strip('\\n')\n\n if len(dictionary_word) != len(unknown_word):\n continue\n regex_match_result = re.search(regex_word, dictionary_word, re.IGNORECASE)\n if regex_match_result is not None:\n total_matched_words += 1\n #print dictionary_word\n for i in xrange(len(unknown_word)):\n if unknown_word[i] != '_':\n continue\n # print dictionary_word[i]\n if not dictionary_word[i].isalpha():\n continue\n if dictionary_word[i].lower() in position_count[i]:\n position_count[i][dictionary_word[i].lower()][0] += 1\n position_count[i][dictionary_word[i].lower()][1] += rank\n else:\n position_count[i][dictionary_word[i].lower()] = [1, rank]\n rank += 1\n\n wordlist_file_object.close()\n return position_count, total_matched_words\n\n\ndef generate_guess(current_state, letters_guessed):\n state_words = current_state.split()\n probability_sum = [[chr(ord('a')+i), 0, 0] for i in xrange(26)]\n \"\"\"\n Now search for the unknown words in the 10,000 wordlist file.\n \"\"\"\n for unknown_word in state_words:\n # print position_count\n if '_' not in unknown_word:\n continue\n position_count, total_matched_words = process_unknown_word(unknown_word, letters_guessed)\n #print position_count, total_matched_words\n for pos in position_count:\n for alphabet in position_count[pos]:\n probability_sum[ord(alphabet) - ord('a')][1] += \\\n (position_count[pos][alphabet][0] / (1.0 * total_matched_words))\n probability_sum[ord(alphabet) - ord('a')][2] += position_count[pos][alphabet][1]\n\n probability_sum = sorted(probability_sum, key=lambda ps:ps[1], reverse=True)\n max_probability_val = probability_sum[0][1]\n\n if max_probability_val == 0:\n \"\"\"\n this means that no unknown word was found in the 10,000 wordlist files. Now, we should\n search for the unknown words in the complete dictionary file.\"\"\"\n for unknown_word in state_words:\n # print position_count\n position_count, total_matched_words = process_unknown_word(unknown_word, letters_guessed,\n search_in_complete_dict=True)\n\n for pos in position_count:\n for alphabet in position_count[pos]:\n probability_sum[ord(alphabet) - ord('a')][1] += \\\n (position_count[pos][alphabet][0] / (1.0 * total_matched_words))\n probability_sum[ord(alphabet) - ord('a')][2] += position_count[pos][alphabet][1]\n\n probability_sum = sorted(probability_sum, key=lambda ps: ps[1], reverse=True)\n max_probability_val = probability_sum[0][1]\n\n\n top_alphabets = []\n for ps in probability_sum:\n if ps[1] == max_probability_val:\n top_alphabets.append(ps)\n # Sort same probability alphabets by the rank in the word frequency dictionary\n top_alphabets = sorted(top_alphabets, key=lambda ta: ta[2])\n\n if max_probability_val == 0:\n \"\"\"\n Damn! Still couldn't find the unknown word(s) in the dictionary. Now we just pick alphabets\n in the order of higher probability of occurrence according to the English Text.\n \"\"\"\n return LAST_RESORT_pick_alphabet_not_picked_yet(letters_guessed)\n\n #print probability_sum\n #print top_alphabets[0]\n return top_alphabets[0][0]\n\n\ndef play_hangman():\n\n first_call_dict = first_service_call()\n print first_call_dict\n token, status, current_state = first_call_dict['token'], first_call_dict['status'], first_call_dict['state']\n remaining_guesses = first_call_dict['remaining_guesses']\n letters_guessed = []\n while status == \"ALIVE\":\n # Let's Begin!\n print current_state\n print \"Status: %s Remaining_Guesses: %d\" % (status, remaining_guesses)\n guess_alphabet = generate_guess(current_state, letters_guessed)\n print \"Guess Alphabet: %s\" % guess_alphabet\n\n url_suffix = \"&token=%s&guess=%s\" % (token, guess_alphabet)\n api_result_dict = requests.get(URL+url_suffix).json()\n letters_guessed.append(guess_alphabet)\n status, current_state, remaining_guesses = api_result_dict['status'], api_result_dict['state'], \\\n api_result_dict['remaining_guesses']\n\n print current_state\n if status == \"FREE\":\n print \"FREE !!!!!! :))\"\n return True\n else:\n print \"DEAD :((\"\n return False\n\n\nif __name__ == \"__main__\":\n print \"Year 2046. Welcome! Let's play Hangman.\"\n free_count, dead_count = 0, 0\n while True:\n print \"\\n\\n******* Starting new game ********\"\n result = play_hangman()\n if result:\n free_count += 1\n else:\n dead_count += 1\n print \"Free Count: %d, Dead Count: %d\" % (free_count, dead_count)\n #time.sleep(5)\n\n\n\n\n"
}
] | 25 |
yang-bohn/my_spider
|
https://github.com/yang-bohn/my_spider
|
581513f55827c7ba942f533e571de5c290cec8c6
|
9bd3ecc33fe5ef2f99c335fd6f3dbfdb45df06be
|
485fb5b8c7180351eb4796945480d5f744d6671e
|
refs/heads/master
| 2021-01-02T14:23:11.062164 | 2020-02-11T02:40:42 | 2020-02-11T02:40:42 | 239,660,148 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5728715658187866,
"alphanum_fraction": 0.5930736064910889,
"avg_line_length": 21.100000381469727,
"blob_id": "74da7c4deb224c7f16ff0b26a5a82f8fc8fd2975",
"content_id": "b66d45f9d0f57d1a05c0812c69c0b253bd54d50d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 30,
"path": "/图片爬虫.py",
"repo_name": "yang-bohn/my_spider",
"src_encoding": "UTF-8",
"text": "encoding='utf-8'\r\nimport urllib.parse\r\nimport json\r\nimport requests\r\nimport jsonpath\r\n\r\n# 爬虫的基本思路\r\n\r\n# ***分析网站***\r\n# 1.url\r\nurl='https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}'\r\nwd = '美女'\r\nlabel = urllib.parse.quote(wd)\r\nprint(label)\r\n\r\n#2.模拟浏览器请求资源\r\nnum = 0\r\nfor index in range(0,2400,24):\r\n url = url.format(label,index)\r\n we_data = requests.get(url).text\r\n #3。解析网页,提取数据\r\n html = json.loads(we_data)\r\n photo = jsonpath.jsonpath(html,'$..path')\r\n print(photo)\r\n # 4.保存数据\r\n for i in photo:\r\n a = requests.get(i)\r\n with open(f'C:\\\\Users\\\\yangbowen\\\\Desktop\\\\tupian\\\\{num}.jpg','wb') as f:\r\n f.write(a.content)\r\n num+=1\r\n"
},
{
"alpha_fraction": 0.6183485984802246,
"alphanum_fraction": 0.6385321021080017,
"avg_line_length": 20.79166603088379,
"blob_id": "385fe856242f514fd5ff624a566e540cd42d5d4e",
"content_id": "7fbb080b01f95d47766c51551d65f505e6587d53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 24,
"path": "/疫情爬虫.py",
"repo_name": "yang-bohn/my_spider",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\r\n\r\n\r\nimport json\r\nimport requests\r\n\r\n\r\n#1.获取目标网址\r\nurl = \"https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5\"\r\n#2.模拟浏览器实现访问url\r\ndata = json.loads(requests.get(url).json()['data'])\r\n#3.从网页源代码中提取数据\r\nchina=data['areaTree'][0]['children']\r\n\r\n\r\n\r\ndata1=[]\r\nfor i in range(len(china)):\r\n data1.append([china[i]['name'],china[i]['total']['confirm'],china[i]['total']['dead'],china[i]['total']['heal']])\r\n\r\n\r\nimport pandas\r\ndata=pandas.DataFrame(data1,columns=['地区','确诊','死亡','治愈'])\r\ndata.to_excel(\"data1.xlsx\",index=False)"
},
{
"alpha_fraction": 0.4444444477558136,
"alphanum_fraction": 0.4444444477558136,
"avg_line_length": 3.5,
"blob_id": "352d32341ca5ff76c8bac0a4c973abda38838149",
"content_id": "d7e86726cc9db9e0ecb1d4618459c193bc1174e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 4,
"num_lines": 2,
"path": "/README.md",
"repo_name": "yang-bohn/my_spider",
"src_encoding": "UTF-8",
"text": "# -\n我的爬虫\n"
}
] | 3 |
cosmiczeus/dustytucker
|
https://github.com/cosmiczeus/dustytucker
|
e072571d2c030430107b3f1898f02abed9d59019
|
b4d35514d22045d5d684c3f9c1d87a359c94f9c0
|
877c3aac0da810f033ad00dd87067e804f08a295
|
refs/heads/master
| 2019-04-03T00:04:17.455600 | 2016-09-07T02:23:05 | 2016-09-07T02:23:05 | 66,993,400 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 25.85714340209961,
"blob_id": "da632376d99828c9d4aca24b217f84cb70845de8",
"content_id": "7535cd4014eac5296d01d1eefd99577ebcf255e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 7,
"path": "/urls.py",
"repo_name": "cosmiczeus/dustytucker",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import include, url\nfrom django.contrib import admin\n\nurlpatterns = [\n url(r'^dustytucker/', include('dustytucker.urls')),\n url(r'^admin/', admin.site.urls),\n]"
},
{
"alpha_fraction": 0.5496240854263306,
"alphanum_fraction": 0.5609022378921509,
"avg_line_length": 30.66666603088379,
"blob_id": "b456c8a4b730cfb1a4496bce1b1388ede12ea8f3",
"content_id": "3338f90d5a199e5cd0fd9371d0b9a1e5b3017046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1330,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 42,
"path": "/dustytucker/tour/migrations/0001_initial.py",
"repo_name": "cosmiczeus/dustytucker",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9 on 2016-09-06 03:34\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Location',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ],\n ),\n migrations.CreateModel(\n name='TourDate',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('date', models.DateTimeField()),\n ],\n ),\n migrations.CreateModel(\n name='Venue',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('location', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='tour.Location')),\n ],\n ),\n migrations.AddField(\n model_name='tourdate',\n name='venue',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='tour.Venue'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 32,
"blob_id": "219a4974bbd98392e1e402f8f6e7f7466a563e44",
"content_id": "3d99866ac939405d71b05b149fd00a9dca920efd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 4,
"path": "/dustytucker/views.py",
"repo_name": "cosmiczeus/dustytucker",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse\n\ndef home(request):\n return HttpResponse(\"Hello, world. You're at the Dusty Tucker index.\")\n"
},
{
"alpha_fraction": 0.7466216087341309,
"alphanum_fraction": 0.7516891956329346,
"avg_line_length": 24.69565200805664,
"blob_id": "bf68b85a449779d6a1c919f617341849f1d6f267",
"content_id": "2cb3e603c9744a946622b4ac45915e4d4049e601",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 23,
"path": "/dustytucker/tour/models.py",
"repo_name": "cosmiczeus/dustytucker",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.db import models\nfrom django.db.models import Model, DateTimeField\nfrom django.db.models.expressions import DateTime\nfrom django.db.models.fields.related import ForeignKey\nfrom django.forms import CharField\n\n\nclass Location(Model):\n city = CharField()\n state = CharField()\n\n\nclass Venue(Model):\n name = CharField(max_length=100)\n location = ForeignKey(Location, on_delete=models.CASCADE)\n\n\nclass TourDate(Model):\n date = DateTimeField()\n venue = ForeignKey(Venue, on_delete=models.CASCADE)\n description = CharField()\n\n"
}
] | 4 |
argonauts-zz/argonauts---public
|
https://github.com/argonauts-zz/argonauts---public
|
be47e715eb3575aabbc39a6f87f76d25d1aa6a6e
|
cb18fcfde3791892ae894c954600ffd9df41f616
|
733bbec25a0e7c57a605ec99065ce722bb0cbde7
|
refs/heads/master
| 2021-05-26T16:52:39.953213 | 2012-12-06T19:33:53 | 2012-12-06T19:33:53 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5855314135551453,
"alphanum_fraction": 0.6035785675048828,
"avg_line_length": 33.07368469238281,
"blob_id": "fc81494dd369761c2e65459ad8cc10b6bf199489",
"content_id": "29e222896f0f25f9f44f508cfba97ca5f094c654",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6483,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 190,
"path": "/project/metrics/python/argoissues.py",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "'''\nCreated on Jun 9, 2012\n\n@author: mjlenzo\n'''\nfrom collections import OrderedDict\nimport getpass\nfrom github import Github\nfrom github import Repository\nfrom github import Organization\nfrom github import Issue\nfrom datetime import *\nfrom pytz import timezone\n\nfrom matplotlib.dates import MONDAY\nfrom matplotlib.backends.backend_pdf import PdfPages\nimport numpy as np\nfrom pylab import \\\n figure, WeekdayLocator, DayLocator, DateFormatter, date2num, rcParams\n\nrcParams['xtick.major.pad']='15'\n\nTICK_MONDAY = WeekdayLocator(MONDAY)\nTICK_ALLDAYS = DayLocator()\nFMT_MAJOR = DateFormatter('%b-%d')\nFMT_MINOR = DateFormatter('%d')\n\ndefects = ['Req. Defect', 'Arch. Defect', 'Design Defect', 'Code Defect']\neastern = timezone('US/Eastern')\nutc = timezone('UTC')\nenoc = None\nargo = None\ngit = None\nissues = []\n\ndef init(userName, password):\n git = Github(userName, password)\n for org in git.get_user().get_orgs():\n if org.name == \"EnerNOC, Inc.\":\n enoc = org\n argo = enoc.get_repo('argo')\n for issue in argo.get_issues(state=\"Open\"):\n issues.append(issue)\n for issue in argo.get_issues(state=\"Closed\"):\n issues.append(issue)\n \n\ndef getIssues(startDate, endDate, tag=None):\n startDate = startDate + \"/00:00:00\"\n endDate = endDate + \"/23:59:59\"\n active_issues = OrderedDict()\n start_loc = eastern.localize(datetime.strptime(startDate,'%m-%d-%y/%H:%M:%S')) \n end_loc = eastern.localize(datetime.strptime(endDate,'%m-%d-%y/%H:%M:%S')) \n \n end_utc = end_loc.astimezone(utc)\n start_utc = start_loc.astimezone(utc)\n \n while start_utc <= end_utc:\n interval_start_utc = start_utc\n interval_end_utc = interval_start_utc + timedelta(hours=23,minutes=59, seconds=59)\n #print \"from \" + str(interval_start_utc.astimezone(eastern)) + \" to \" + str(interval_end_utc.astimezone(eastern))\n issue_list = []\n for issue in issues:\n created_at_utc = utc.localize(issue.created_at)\n closed_at_utc = None if issue.closed_at is None\\\n else utc.localize(issue.closed_at)\n labelList = [label.name for label in issue.labels\\\n if label.name == tag]\n if tag == None:\n labelList.append(\"all\")\n if len(labelList) > 0 and created_at_utc <= interval_end_utc:\n if closed_at_utc is None or closed_at_utc <= interval_end_utc:\n issue_list.append(issue)\n #print issue.title + \" created:\" + str(created_at_utc.astimezone(eastern)) + \" \" + issue.state \n start_utc += timedelta(days=1)\n key = datetime.strftime(interval_start_utc.astimezone(eastern),'%m-%d-%y')\n active_issues[key] = issue_list \n return active_issues\n\ndef format_date_plot(plotList, includeMinor=True):\n for ax in plotList:\n ax.yaxis.grid(True, 'major')\n ax.xaxis.grid(True, 'minor')\n ax.xaxis.set_major_locator(TICK_MONDAY)\n ax.xaxis.set_major_formatter(FMT_MAJOR)\n ax.xaxis.set_minor_locator(TICK_ALLDAYS)\n if includeMinor:\n ax.xaxis.set_minor_formatter(FMT_MINOR)\n\n ax.tick_params(which='both', width=2)\n ax.tick_params(which='major', length=4)\n ax.legend(loc='best')\n\ndef graphIssues(issueRegister, title):\n series_dates = [date2num(datetime.strptime(k,'%m-%d-%y'))\\\n for k in issueRegister.keys()]\n series_NumOpen = []\n series_NumClosed = []\n series_NumRemain = []\n for k in issueRegister.keys():\n numOpen = 0\n numClosed = 0\n for issue in issueRegister[k]:\n numOpen = numOpen + 1 \n if issue.state == 'closed':\n numClosed = numClosed + 1\n series_NumOpen.append(numOpen)\n series_NumClosed.append(numClosed)\n series_NumRemain.append(numOpen - numClosed)\n \n # Create figure\n fig = figure(num=None, \\\n figsize=(12, 8), \\\n dpi=80, \\\n facecolor='w',\\\n edgecolor='k')\n ax1 = fig.add_subplot(1,1,1)\n ax1.set_title(title)\n ax1.plot_date(series_dates, series_NumOpen, \\\n label = 'Issues Opened', \\\n color='red', ls='-', marker='o')\n ax1.plot_date(series_dates, series_NumClosed, \\\n label = 'Issues Closed', \\\n color ='black', ls='-', marker='x')\n ax1.bar(series_dates, series_NumRemain, 0.4 ,label='Remaining', color='grey')\n \n # Format plot areas\n format_date_plot([ax1])\n fig.autofmt_xdate()\n return fig\n \ndef graphContainment(issueRegister, title):\n \"\"\"\n Phase Containment Effectiveness:\n - Requirements Analysis\n - Architecture Design\n - ADEW/Prototyping/Experimentation\n - Detailed Design\n - Detailed Design Review\n - Implementation\n - Unit/Integration Testing\n - Architectural Verification\n \"\"\"\n series_reqPhase = []\n series_archPhase = []\n series_ADEWPhase = []\n series_expPhase = []\n series_designPhase = []\n series_reviewPhase = []\n series_implPhase = []\n series_testPhase = []\n series_verificationPhase = []\n \n for k in issueRegister.keys():\n reqPhase = 0\n archPhase = 0\n ADEWPhase = 0\n expPhase = 0\n designPhase = 0\n reviewPhase = 0\n implPhase = 0\n testPhase = 0\n verificationPhase = 0\n for issue in issueRegister[k]:\n labelList = [label.name for label in issue.labels]\n if 'Req. Defect' in labelList:\n reqPhase = reqPhase + 1\n elif 'Arch. Defect' in labelList:\n archPhase = archPhase + 1\n \n \ndef save_to_pdf(figureList, filename):\n pp = PdfPages(filename)\n for figure in figureList:\n figure.savefig(pp, format='pdf')\n pp.close()\n\nif __name__ == '__main__':\n userName = getpass.getpass(\"Username:\")\n password = getpass.getpass(\"Password:\")\n init(userName, password)\n all = getIssues('05-22-12','06-18-12')\n arch = getIssues('05-22-12','06-18-12', \"Arch. Defect\")\n design = getIssues('05-22-12','06-18-12', \"Design Defect\")\n code = getIssues('05-22-12','06-18-12', \"Code Defect\")\n fig1 = graphIssues(arch, 'Arch. Defects')\n fig2 = graphIssues(design, 'Design Defects')\n fig3 = graphIssues(code, 'Code Defects')\n #fig4 = graphContainment(all, 'Phase Containment')\n save_to_pdf([fig1,fig2,fig3], \"out.pdf\")\n \n "
},
{
"alpha_fraction": 0.5844426155090332,
"alphanum_fraction": 0.5910981893539429,
"avg_line_length": 32.38888931274414,
"blob_id": "771822ff25ff173174df599bdf0df87d2c6524bd",
"content_id": "02e75c4c3c3200ac83167bed045d7b6cffbf82e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2404,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 72,
"path": "/project/metrics/toggl/validate_toggl.py",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "from datetime import *\nfrom collections import OrderedDict\nimport csv\nimport sys\nimport os\n\n# Index constants for CSV records\nDSC = 5\nTAG = 12\nDUR = 11\n\ndef isValid (entry, validTasks):\n \"\"\"\n This function checks a time entry for a valid task name \n matching a valid tag. Returns true if valid, false if not.\n entry: A list row from a CSV file representing a time entry\n tasks: A list of valid task,tag pairs \n \"\"\"\n desc = entry[DSC].strip().lower()\n tag = entry[TAG].strip().lower()\n for task in validTasks:\n if desc == task[0] and tag == task[1]:\n return True\n return False\n\ndef validate (timeLog, taskList):\n \"\"\"\n This function validates a time log file against a set of\n valid tags and tasks, generating two output files:\n bad_timelog - a CSV file containing all bad time entries\n report_timelog - a CSV file containing any processed metrics\n timeLog: The CSV time log file to validate\n taskList: The text file contaning valid task, tag pairs\n \"\"\"\n # Create valid task list from taskList file\n valid = [line.strip() for line in open(taskList)]\n valid = [[v.strip().lower() for v in t.split(',')] for t in valid]\n\n # Create container to hold aggregate time data by WP entry\n WPs = OrderedDict([(k[0], datetime.strptime(\"00:00:00\",\"%H:%M:%S\"))\\\n for k in valid])\n \n # Create container to hold bad time data\n ERs = []\n\n # Parse time data\n with open (timeLog, 'rb') as f:\n reader = csv.reader(f, delimiter=',')\n for r in reader:\n if isValid(r, valid):\n dur = datetime.strptime(r[DUR],\"%H:%M:%S\")\n WPs[r[DSC].strip().lower()] += timedelta( \\\n minutes=dur.minute, \\\n seconds=dur.second, \\\n hours=dur.hour)\n else:\n ERs.append(r)\n \n # Write bad time data out to a csv file\n (head, tail) = os.path.split(timeLog)\n with open(head + \"/bad_\" + tail, 'wb') as f:\n writer = csv.writer(f)\n writer.writerows(ERs)\n \n # Write a time report out to a csv file\n with open(head + \"/report_\" + tail, 'wb') as f:\n report = [[k.upper(),v.strftime(\"%H:%M:%S\")] for k,v in WPs.iteritems()]\n writer = csv.writer(f)\n writer.writerows(report)\n\nif __name__ == '__main__':\n validate(sys.argv[1], sys.argv[2])\n"
},
{
"alpha_fraction": 0.5214592218399048,
"alphanum_fraction": 0.5630901455879211,
"avg_line_length": 36.1010627746582,
"blob_id": "e67200f078450fe85c752e95239045adc143450f",
"content_id": "4e149b84cabcac3f838bd9f5b585b42f8ad80f60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6990,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 188,
"path": "/project/metrics/python/toggler.py",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/python\n\nfrom matplotlib.dates import SUNDAY\nfrom matplotlib.backends.backend_pdf import PdfPages\nimport numpy as np\nfrom pylab import \\\n figure, WeekdayLocator, DayLocator, DateFormatter, date2num, rcParams\nfrom pytoggl.api import *\n\nrcParams['xtick.major.pad']='15'\n\nTICK_SUNDAYS = WeekdayLocator(SUNDAY)\nTICK_ALLDAYS = DayLocator()\nFMT_MAJOR = DateFormatter('%b-%d')\nFMT_MINOR = DateFormatter('%d')\n\ndef graphUtilization(series, seriesIndex, includeMinor=True):\n # Get x-axis intervals\n dates = [date2num(datetime.strptime(k,'%m/%d/%y')) \\\n for k in series.keys() if series[k]['Total'] > 0.0]\n user = APIConfig().getSeries()[seriesIndex]\n # Create figure\n fig = figure(num=None, \\\n figsize=(12, 8), \\\n dpi=80, \\\n facecolor='w',\\\n edgecolor='k')\n fig.suptitle(user, fontsize=20)\n\n ax = fig.add_subplot(1,1,1)\n intervalData = \\\n [series[k][user + \"_util\"]\\\n for k in series.keys() if series[k]['Total'] > 0.0]\n ax.bar(dates, intervalData, 0.8 ,label='Utilization', color='k')\n ax.axhline(y=1.0/APIConfig().NUM_USERS, \\\n label='Target', \\\n color='k', ls='--', lw=2, marker=None)\n \n ax.set_title('Utilization (avg = {0:.2f})'.format(\\\n sum(intervalData)/len(intervalData)))\n format_date_plot([ax], includeMinor)\n fig.autofmt_xdate()\n return fig\n\ndef graphSeries(series, seriesIndex, totalHours, includeMinor=True):\n\n # Get x-axis intervals\n dates_all = [date2num(datetime.strptime(k,'%m/%d/%y'))\\\n for k in series.keys()]\n dates_cut = [date2num(datetime.strptime(k,'%m/%d/%y')) \\\n for k in series.keys() if series[k]['Total'] > 0.0]\n user = APIConfig().getSeries()[seriesIndex]\n xmax = dates_all[-1]\n xmin = dates_all[0]\n\n # Create figure\n fig = figure(num=None, \\\n figsize=(12, 8), \\\n dpi=80, \\\n facecolor='w',\\\n edgecolor='k')\n fig.suptitle(user, fontsize=20)\n\n # SUBPLOT 1\n # Graph user's time data for each interval\n intervalData_all = [series[k][user]\\\n for k in series.keys()]\n intervalData_cut = [series[k][user]\\\n for k in series.keys()\\\n if series[k]['Total'] > 0.0]\n\n target = totalHours/len(intervalData_all)\n ax1 = fig.add_subplot(2,1,1)\n ax1_hrs = ax1.bar(dates_cut, intervalData_cut, 0.4 ,label='Worked', color='b')\n #ax1_hrs = ax1.plot_date(dates_cut, intervalData_cut, \\\n # label = 'Worked', \\\n # color='b', ls='-', marker='o')\n ax1_bar = ax1.axhline(y=target,\\\n label=\"Target ({0:.2f} hrs)\".format(target),\\\n color='k', ls='--', lw=2, marker=None)\n ax1.set_title(\"Hours Worked ({0:.2f} hrs)\"\\\n .format(sum(intervalData_all)))\n ax1.set_ylabel('Person hours')\n ax1.set_xlim(xmin, xmax)\n \n # SUBPLOT 2\n # Graph user's burndown\n burn = totalHours\n burnData = []\n for d in intervalData_cut:\n burn = (burn - d)\n burnData.append(burn)\n ax2 = fig.add_subplot(2,1,2)\n ax2.plot_date([dates_all[0],dates_all[-1]], \\\n [totalHours - totalHours/len(series), 0], \\\n label='Target',\\\n color=\"k\", ls='--', lw=2, marker=None)\n ax2.plot_date(dates_cut, burnData, \\\n label='Burndown', \\\n color='b', ls='-', marker=None)\n ax2_fit = np.polyfit(dates_cut, burnData, 1)\n ax2_trend = np.poly1d(ax2_fit)\n ax2_remain = ax2_trend(dates_all[-1])\n ax2_zero = datetime.fromordinal(ax2_trend.r).strftime('%b-%d')\n ax2.plot_date(dates_all,ax2_trend(dates_all), \\\n label='Trend: ' + ax2_zero, \\\n color=\"r\", ls='--', lw=2, marker=None)\n ax2.set_ylim(0)\n\n ax2.set_title('Resource Trajectory ({0:.2f} hrs)'.format(ax2_remain))\n ax2.set_ylabel('Person hours')\n\n # Format plot areas\n format_date_plot([ax1,ax2], includeMinor)\n fig.autofmt_xdate()\n return fig\n\ndef save_to_pdf(figureList, filename):\n pp = PdfPages(filename)\n for figure in figureList:\n figure.savefig(pp, format='pdf')\n pp.close()\n\ndef format_date_plot(plotList, includeMinor=True):\n for ax in plotList:\n ax.yaxis.grid(True, 'major')\n ax.xaxis.grid(True, 'minor')\n ax.xaxis.set_major_locator(TICK_SUNDAYS)\n ax.xaxis.set_major_formatter(FMT_MAJOR)\n ax.xaxis.set_minor_locator(TICK_ALLDAYS)\n if includeMinor:\n ax.xaxis.set_minor_formatter(FMT_MINOR)\n\n ax.tick_params(which='both', width=2)\n ax.tick_params(which='major', length=4)\n ax.legend(loc='best')\n\ndef create_report(log,\\\n startDate,\\\n endDate,\\\n out,\\\n reportType='daily',\n includeMinor=True):\n\n if log.getSize() == 0:\n print \"No Data for {0} to {1}\".format(startDate, endDate)\n return\n\n interval = 1 # one day\n if reportType == 'weekly':\n interval = 7 # seven days\n data = log.getDataSeriesByInterval(startDate, endDate, interval)\n \n userEffort = APIConfig().EFFORT_PER_WEEK/(8.0-interval) * len(data.keys())\n totalEffort = APIConfig().NUM_USERS * userEffort\n\n fig_list = []\n # Total\n fig_list.append( graphSeries(data, 0, totalEffort, includeMinor))\n # Users\n for i in range(1, len(APIConfig().getSeries())):\n f = graphSeries(data, i, userEffort, includeMinor)\n fig_list.append(f)\n #f = graphUtilization(data, i, includeMinor)\n #fig_list.append(f)\n save_to_pdf(fig_list, out)\n\nif __name__ == '__main__':\n report_iterations = False\n report_spring = False\n log = TimeLog.ParseCSVFile('../csv/toggl.csv')\n if report_iterations:\n create_report(log, '05-06-12', '05-12-12', 'springeosp.pdf')\n create_report(log, '04-15-12', '05-05-12', 'iteration10.pdf')\n create_report(log, '04-01-12', '04-14-12', 'iteration9.pdf')\n create_report(log, '03-18-12', '03-31-12', 'iteration8.pdf')\n create_report(log, '03-04-12', '03-17-12', 'iteration7.pdf')\n create_report(log, '02-12-12', '03-03-12', 'iteration6.pdf')\n create_report(log, '01-15-12', '02-11-12', 'iteration5.pdf')\n if report_spring:\n create_report(log, '01-15-12', '05-12-12',\\\n 'spring12.pdf', 'weekly', False)\n #create_report(log, '05-20-12', '05-26-12','week1.pdf')\n #create_report(log, '05-27-12', '06-02-12','week2.pdf')\n #create_report(log, '06-03-12', '06-09-12','week3.pdf')\n create_report(log, '06-10-12', '06-16-12','week4.pdf')\n #create_report(log, '05-22-12', '05-28-12','iteration12.pdf')\n #create_report(log, '05-29-12', '06-04-12','iteration13.pdf')\n \n \n \n"
},
{
"alpha_fraction": 0.5229325294494629,
"alphanum_fraction": 0.5293841361999512,
"avg_line_length": 30.63568687438965,
"blob_id": "47f11de53e91ea900431164c299d235d4bc16eb2",
"content_id": "6dc3658fbba93f5b6c5363d46a74fc90fef3609c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8525,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 269,
"path": "/project/metrics/python/pytoggl/api.py",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "from collections import OrderedDict\nfrom datetime import *\nfrom pytoggl.config import APIConfig\nimport requests, json\nimport csv\n\n\"\"\"\nAPI TO-DO\n1. Config file specifies users, API keys\n2. Get time data for each user\n3. Generate metrics for each user\n4. Generate aggregate metrics\n\"\"\"\n\n\"\"\" CSV File Indicies \"\"\"\nCSV_USER = 0\nCSV_EMAIL = 1\nCSV_CLIENT = 2\nCSV_PROJECT = 3\nCSV_DESCRIPTION = 5\nCSV_STARTDATE = 7\nCSV_STARTTIME = 8\nCSV_ENDDATE = 9\nCSV_ENDTIME = 10\nCSV_DURATION = 11\nCSV_TAGS = 12\n\ndef rreplace(s, old, new, occurrence):\n li = s.rsplit(old, occurrence)\n return new.join(li)\n\nclass TimeEntry:\n def __init__(self):\n self.user = \"\" # API and CSV\n self.description = \"\" # API and CSV\n self.startDate = \"\" # API and CSV\n self.endDate = \"\" # API and CSV\n self.startTime = \"\" # API and CSV\n self.endTime = \"\" # API and CSV\n self.duration = \"\" # API and CSV\n self.tags = [] # API and CSV\n self.start = \"\" # API ONLY\n self.stop = \"\" # API ONLY\n\n def firstTag(self):\n if len(self.tags) == 0:\n return 'Uncategorized'\n return self.tags[0]\n\n def hasTag(self, tagName):\n return (tagName in self.tags)\n\n @classmethod\n def ParseLine(cls,line):\n \"\"\"\n ParseLine:\n Parses a time entry from a CSV file\n Returns a TimeEntry\n \"\"\"\n try:\n t = TimeEntry()\n t.user = line[CSV_USER].strip()\n\n t.description = line[CSV_DESCRIPTION].strip()\n\n t.startTime = line[CSV_STARTTIME].strip()[0:8] # Cut GMT-offset\n t.startTime = datetime.strptime(t.startTime, '%H:%M:%S')\n\n t.startDate = line[CSV_STARTDATE].strip()\n t.startDate = datetime.strptime(t.startDate, '%Y-%m-%d')\n \n t.endTime = line[CSV_ENDTIME].strip()[0:8] # Cut GMT-offset\n t.endTime = datetime.strptime(t.endTime, '%H:%M:%S')\n\n t.endDate = line[CSV_ENDDATE].strip()\n t.endDate = datetime.strptime(t.endDate, '%Y-%m-%d')\n\n t.duration = line[CSV_DURATION].strip()\n t.duration = datetime.strptime(t.duration,'%H:%M:%S')\n t.duration = timedelta( \\\n minutes=t.duration.minute, \\\n seconds=t.duration.second, \\\n hours=t.duration.hour)\n t.tags = line[CSV_TAGS].split(',')\n return t\n except:\n return None\n \n @classmethod\n def ParseJSONEntry(cls, user, struct):\n try:\n t = TimeEntry()\n t.user = user\n # TODO t.startTime\n # TODO t.startDate\n # TODO t.endTime\n # TODO t.endDate\n # TODO t.duration\n t.description = struct['description']\n t.start = struct['start']\n t.stop = struct['stop']\n t.tags = struct['tag_names']\n return t\n except:\n return None\n\nclass TimeLog:\n def __init__(self):\n self.entries = []\n\n def append(self, entry):\n self.entries.append(entry)\n\n def getSize(self):\n return len(self.entries)\n\n def getDataSeriesByInterval(self,startdate,enddate,interval=7):\n result = OrderedDict()\n series = []\n users = []\n date = datetime.strptime(startdate,'%m-%d-%y') \n \n # Find all users in database\n for entry in self.entries:\n if entry.user not in series:\n users.append(entry.user)\n series.append(entry.user)\n series.append(entry.user + \"_util\")\n series.append(entry.user + \"_debt\")\n series.append('Total')\n series.append('Running Average')\n # Create result dictionary by week\n while date <= datetime.strptime(enddate,'%m-%d-%y'):\n begin = date\n date += timedelta(days=interval)\n end = date - timedelta(days=1)\n seriesInstance = {k:timedelta(seconds=0) for k in series}\n for entry in self.entries:\n if entry.startDate >= begin and entry.startDate <= end:\n seriesInstance[entry.user] += entry.duration\n seriesInstance['Total'] += entry.duration\n self.convertToHours(seriesInstance)\n key = datetime.strftime(end,'%m/%d/%y')\n result[key] = seriesInstance\n # Calculate running average and utilization\n runningSum = 0.0\n counter = 0\n for k in result.keys():\n counter = counter + 1\n runningSum += result[k]['Total']\n result[k]['Running Average'] = (runningSum/counter)\n for u in users:\n if result[k]['Total'] != 0.0:\n result[k][u + \"_util\"] = \\\n result[k][u]/result[k]['Total']\n return result\n\n def getTimesByTask(self, filters=None):\n result = {}\n for entry in self.entries:\n key = None\n if type(filters) is list:\n for f in filters:\n if entry.description.lower().count(f.lower()) > 0:\n key = entry.description.lower()\n break\n else:\n key = entry.description.lower()\n if key != None and key in result:\n result[key] += entry.duration\n elif key != None:\n result[key] = entry.duration\n self.convertToHours(result)\n return result\n\n def getTimesByTag(self):\n result = {}\n for entry in self.entries:\n key = entry.firstTag()\n if key in result:\n result[key] += entry.duration\n else:\n result[key] = entry.duration\n self.convertToHours(result)\n return result\n\n def getTimesByUser(self):\n result = {}\n for entry in self.entries:\n key = entry.user\n if key in result:\n result[key] += entry.duration\n else:\n result[key] = entry.duration\n self.convertToHours(result)\n return result\n\n def convertToHours(self, struct):\n iterator = None\n if type(struct) is dict:\n iterator = struct.keys()\n elif type(struct) is list:\n iterator = range(0,len(struct))\n for key in iterator:\n struct[key] = struct[key].seconds/3600.0 \\\n + struct[key].days * 24\n\n @classmethod\n def ParseCSVFile(cls, fileLocation):\n result = TimeLog()\n with open (fileLocation, 'rb') as f:\n reader = csv.reader(f, delimiter=',')\n for line in reader:\n obj = TimeEntry.ParseLine(line)\n if obj != None:\n result.append(obj)\n return result\n \n @classmethod\n def ParseResponse(cls, struct, result):\n if result == None:\n result = []\n for i in struct:\n result.append(TimeEntry.ParseEntry(i))\n\ndef print_dict(dictionary, indent=4):\n print json.dumps(dictionary, indent=indent)\n\ndef api(key, params=None):\n apiCall = \"\"\n if params:\n apiCall = APIConfig().API_PREFIX + key + \".json?\" + params\n else:\n apiCall = APIConfig().API_PREFIX + key + \".json\"\n return apiCall\n\ndef session(headers=None):\n if headers:\n return requests.session(auth=APIConfig().MY_AUTH, headers=headers)\n else:\n return requests.session(auth=APIConfig().MY_AUTH)\n\ndef jsonquery(key):\n with session() as r:\n response = r.get(api(key))\n content = response.content\n if response.ok:\n data = json.loads(content)[\"data\"]\n if type(data) is list:\n data.reverse()\n return data\n else:\n exit(\"Error: Verify credentials in ~/.toggl\")\n\ndef jsonqueryInterval(key, startdate, enddate):\n midnight = \"00:00:00\"\n almostMidnight = \"23:59:59\"\n params = \"start_date=\"+startdate+\"T\"+midnight+\"&end_date=\"\\\n +enddate+\"T\"+almostMidnight\n with session() as r:\n response = r.get(api(key, params))\n content = response.content\n if response.ok:\n data = json.loads(content)[\"data\"]\n if type(data) is list:\n data.reverse()\n return data\n else:\n exit(\"Error: Verify credentials in ~/.toggl\")\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7124463319778442,
"alphanum_fraction": 0.7124463319778442,
"avg_line_length": 22.299999237060547,
"blob_id": "90c8445997ff8b8138f97ac1c1af339b304e77e9",
"content_id": "85b5eaa75997db98850c531166dfb91b2e1bc830",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 10,
"path": "/project/metrics/toggl/Makefile",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "CSVFILES=$(wildcard reports/*.csv)\nVALID=valid.txt\n\nclean:\n\techo \"Make: Cleaning reports directory\"\n\t(rm reports/bad_*)\n\t(rm reports/report_*)\ncheck: $(CSVFILES)\n\techo \"Make: Checking time data\"\n\tpython validate_toggl.py $^ $(VALID) "
},
{
"alpha_fraction": 0.49764519929885864,
"alphanum_fraction": 0.4997383654117584,
"avg_line_length": 32.47368240356445,
"blob_id": "fa3cd9603995d7a725a0eeb96c76e9adf0b532dd",
"content_id": "5b80f0a321e793ce643557d0ad711da9b730cfab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1911,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 57,
"path": "/project/metrics/python/pytoggl/config.py",
"repo_name": "argonauts-zz/argonauts---public",
"src_encoding": "UTF-8",
"text": "import os, time, getpass, ConfigParser\nfrom pprint import pprint\n\nclass User:\n def __init__(self, key, name, api_key, api_pwd):\n self.Name = name\n self.Key = api_key\n self.Password = api_pwd\n \n def getAuth(self):\n return (self.api_key, self.api_pwd)\n \n\nclass APIConfig(object):\n _instance = None\n \n def __new__(cls, *args, **kwargs):\n if not cls._instance:\n cls._instance = \\\n super(APIConfig, cls).__new__(cls, *args, **kwargs)\n return cls._instance\n \n def getSeries(self):\n series = []\n series.append('Total')\n [series.append(user.Name) for user in self.USERS]\n return series\n\n def __init__(self):\n self.API_PREFIX = \"https://www.toggl.com/api/v6/\"\n self.USERS = []\n self.EFFORT_PER_WEEK = 42\n self.NUM_USERS = 5\n \n try:\n home = os.path.expanduser(\"~\")\n togglFile = os.path.join(home, \".toggl\")\n config = ConfigParser.RawConfigParser(allow_no_value=True)\n config.read(togglFile)\n \n config_series = {k:v for k,v in config.items(\"series\")}\n config_keys = {k:v for k,v in config.items(\"api_keys\")}\n config_pwds = {k:v for k,v in config.items(\"api_pwds\")}\n \n if len(config_series.keys()) != self.NUM_USERS\\\n or len(config_keys.keys()) != self.NUM_USERS\\\n or len(config_pwds.keys()) != self.NUM_USERS:\n print \"Invalid Configuration file\"\n return\n \n self.USERS = [User(k,\\\n config_series[k],\\\n config_keys[k],\\\n config_pwds[k]) for k in config_series.keys()]\n \n except ConfigParser.Error:\n print \"Error reading ~/.toggl\"\n\n\n\n"
}
] | 6 |
signoreankit/PythonLearn
|
https://github.com/signoreankit/PythonLearn
|
bd7dc66c2b71ff3526bafe5068c92f61b2cc5a52
|
ace0a43529bce1294521211044f96bbc73a7a1af
|
3f64d368a5b3cca816cb5e65b8d0059b81c2cca5
|
refs/heads/master
| 2020-03-27T08:29:35.469577 | 2018-08-29T08:07:04 | 2018-08-29T08:07:04 | 146,260,206 | 0 | 0 | null | 2018-08-27T07:10:38 | 2018-08-29T06:18:28 | 2018-08-29T08:07:04 |
Python
|
[
{
"alpha_fraction": 0.6412556171417236,
"alphanum_fraction": 0.6567015647888184,
"avg_line_length": 31.901639938354492,
"blob_id": "e611fce7a3c67f5124eb75a1fc06e082c1108fd9",
"content_id": "e9d6b4dbc92ebe7fd28626be4136d4f85561386d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2007,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 61,
"path": "/listpractise.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "my_list = [1,2,3]\nprint(my_list)\n\nmy_list = ['Ankit', '23', 'Empty']\nprint(my_list)\n\n# Length of a list - how many objects is in it?\nlist_length = len(my_list)\nprint(f'Length of the list is {list_length}') # f-string style\nprint('This is how my list looks: {l}'.format(l=my_list)) # .format() style\n\n# List indexing\nprint(f'object at index 3 is: {my_list[2]}')\n\n# List slicing\nprint(f'Last 2 objects of list are: {my_list[1::]}')\n\n# List reverse\nmy_list_reverse = my_list[::-1]\nprint('Reverse of my_list={l} is my_list_reverse={r}'.format(l=my_list, r=my_list_reverse))\n\n#List Concatenation\nlist_A = ['Hey', 'Wassup', ',']\nlist_B = [\"It's\", 'been', 'a', 'while']\n\nlist_Concat = list_A + list_B\n\nprint(f'List A = {list_A}\\nList B = {list_B}\\nList [A+B] = {list_Concat}')\n\n# List Mutability\nlist_Concat[1] = list_Concat[1].upper()\nprint('List_Concat can change! = {}'.format(list_Concat))\n\n# List Append: At the end of the list, and it only takes one argument\nlist_Concat.append(['.','Talkin\\'','\\'bout', 'is', 'not', 'my', 'style']) #appending a list to a list [[]]\nprint('Appending a list at the end of a list: ',list_Concat)\n\n# List pop, Removing an object or element from the list: By default removes the last item\npopped_item = list_Concat.pop()\nprint('The popped item is %s and the List after popped item is %s' % (popped_item, list_Concat))\n\n# Removing List item based on index\npopped_item2 = list_Concat.pop(2)\nprint('Popped item is \\'%s\\' which was at index 2 and now our list looks like this: %s' % (popped_item2, list_Concat))\n\n# List sorting using sort() method\nlist_char = ['f', 't', 'e', 'a', 's', 'p', 'o', 'r', 't', 's']\nlist_num = [2,4,6,78,9,0,1,1,1,1,4,67,8]\n\nlist_char.sort()\nlist_num.sort()\nprint(f'Sorted list_char is: {list_char}')\nprint(f'Sorted list_num is: {list_num}')\n\n# Reverse a list using reverse()\n\nlist_char.reverse()\nprint('Reverse of sorted char list is: {sc}'.format(sc = list_char))\n\nlist_num.reverse()\nprint('Reverse of sorted char list is: {sn}'.format(sn = list_num))\n"
},
{
"alpha_fraction": 0.6187050342559814,
"alphanum_fraction": 0.6582733988761902,
"avg_line_length": 28.3157901763916,
"blob_id": "6fca13066743f2dffe8d51ced7843dea0664cb18",
"content_id": "b87b4567f792ca1a4015112d8404a50ddd6a60b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 19,
"path": "/set.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "#Sets - Unordered collections of unique elements\n\n# To Define Set\nset_1 = set()\n\n# To add element to a set\nset_1.add('Ankit')\nset_1.add('Ankit') # It wont take duplicate items. Try it!\nset_1.add('Dell Xps 15')\nset_1.add('Python 3.6')\nset_1.add('Machine Learning')\n\nprint(\"Set_1: \", set_1)\n\n\n# Casting a list with duplicate items into Set - To get only unique values, It can be unordered.\nlist_toCast = [1, 1, 1, 3, 3, 3, 3, 2, 2, 2, 2, 2]\nnew_set = set(list_toCast)\nprint('Our list is: {l}\\nOur set from that list is: {s}'.format(l = list_toCast, s = new_set))"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.8152173757553101,
"avg_line_length": 29.66666603088379,
"blob_id": "ef2c0015ae6bbca2bf5492e8b510e3ecbba6d556",
"content_id": "b743c0af825271f52fcb67dd899d9975122a123c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 3,
"path": "/README.md",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "# PythonLearn\nThis repository contains my python learning code.\nFrom Date: 27th August 2018\n"
},
{
"alpha_fraction": 0.7042253613471985,
"alphanum_fraction": 0.7183098793029785,
"avg_line_length": 29.428571701049805,
"blob_id": "ed4280800f164dd35b8bbf2f1c9399e085555b5d",
"content_id": "cb0c0e8311c20c7990123664c64bd7f68f2b6883",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 35,
"path": "/stringman2.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "strObj = \"Hello, we'll be having more fun\"\n\n# UPPERCASE\nprint(strObj.upper())\n\n# lowercase\nprint(strObj.lower())\n\n# String are immutable\n# strObj[1] = 'l' is not possible\n# TypeError: 'str' object does not support item assignment\n\nstrObj2 = \". Welcome to Python Programming Language.\"\n\n# Concatenation\nstrObj3 = strObj+strObj2\nprint(strObj3)\n\nstrObj3 = strObj3 + \" Bye For Now.\"\nprint(strObj3)\nprint(strObj3.upper) # Here er didn't call the method upper(), so python will simply tell us what 'upper' is\nprint(strObj.upper()) # This is right way to call\n\n# Split Method - Split the string into an array or List in python.\nlistObj = strObj3.split() # By default, it'll split the string based on white space, or we can give any other delimeter\n # as an argument based on which the string will get split.\nprint(listObj)\n\nlistObj2 = strObj3.split('.')\nprint(listObj2)\n\n#String interpolation - When concating a string with a string variable(holding a String OfCourse!)\nstrVar = \"May the force \"\nstrVar2 = strVar + \"be with you!\"\nprint(strVar2)\n"
},
{
"alpha_fraction": 0.6456558704376221,
"alphanum_fraction": 0.6916524767875671,
"avg_line_length": 38.13333511352539,
"blob_id": "8352fea8e7548fbdba7fd2465ed992699af8fbce",
"content_id": "57ee7a239f4f7996dae3fe7075144d91c79f31b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1174,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 30,
"path": "/stringformat.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "# String Formatting using print method\n\n# 1 - The .format() method\nprint('Hello, my name is {}') # Output: Hello, my name is {}\nprint('Hello my name is {}'.format('Ankit')) # Output: Hello, my name is Ankit\n\n# More Examples\nprint('Hello, my name is {} {}'.format('Ankit', 'Srivastava'))\nprint('This {1} is full of {0}.'.format('mysteries', 'universe')) # strings can be inserted at index position\n# index 1 and index 0 in format method arguments: {1} = universe, {2} = mysteries\n\n# More Ways -- to use keywords\nprint('{t} song, What does {t} {f} say, is {a}.'.format(t='the', a = 'awesome', f='fox'))\n\n#Floor Formating\n\nfloatNum = 1723534534.434343435353535553\nprint('The Float num is {f:1.2f}'.format(f = floatNum)) # {value:width.precisionf}\n\n\n# 2 - The f-string format, new in python 3.6, something like js es6 template string format\n\nvarName = \"Bottle\"\nvarAge = 98.987654332\n\nprint(f'This {varName} is {varAge:1.2f} years old.') #add 'f' in the beginning and in curly braces directly use the variables\n\n# Traditional way of using %(percentage symbol) operator in string formatting\n\nprint('This %s is used to contain water which is %d years old' % (varName, varAge))\n"
},
{
"alpha_fraction": 0.6798507571220398,
"alphanum_fraction": 0.7029850482940674,
"avg_line_length": 27.53191566467285,
"blob_id": "a281e3312cb8b283ffccd8e6658de801fa8012ce",
"content_id": "580b7dd207d2ba7029f23f3c6d1bf0b41d3fca4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1340,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 47,
"path": "/stringman1.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "strObj = \"Hello, this is a string\"\n\n# Finding length of the string, SPACES are included as a part of the string.\nprint('String Length:', len(strObj))\n\n# Finding index value in a string. --INDEXING\nprint('Index 17 holds the character \\''+strObj[17]+'\\'')\n\n# Getting the last character in a string.\nprint('Last character in strObj is ', strObj[-1])\n\n# Slicing the part of the string. -- SLICING\n\"\"\" [start:stop:jump]\n start: Index from where we want to start the slice\n stop: Index we'll go up to (but not including it)\n jump: It is the size of the jump to take, 1:no jump\"\"\"\nprint('Slice1:', strObj[0:5:1])\n\n# Slicing the whole string with jump value 2\nprint('JUMP = 2', strObj[::2])\n\n# Slicing using negative indexes, From back to front\nprint('Slice2:', strObj[-1:-7:-1])\n\n# Does slice return anything? Yes, a string\nretString = strObj[0:-1:2]\nprint('Slice return is: ', retString)\n\n\n# type of the slice return\nprint('Type of retString is:', type(retString))\n\n# Does all of the above changes original strObj\nprint('StrObj is: ', strObj) # No Change!\nprint('StrObj type is: ', type(strObj))\n\n# PYTHON TRICK TO REVERSE A STRING\n\nsimpleString = \"Meditation\"\n\n# WAY 1\nreverseString1 = simpleString[-1::-1]\nprint('Reverse String1:', reverseString1)\n\n# WAY 2\nreverseString2 = simpleString[::-1]\nprint('Reverse String2:', reverseString2)"
},
{
"alpha_fraction": 0.6111513376235962,
"alphanum_fraction": 0.6451846361160278,
"avg_line_length": 34.35897445678711,
"blob_id": "7c24b1df0919b0e1c0d12921865da684f6787f53",
"content_id": "3e08847dba427b393ddd64401ad4fe2ecde9050c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1381,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 39,
"path": "/tuplespractise.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "# Tuples are just like lists except they are immutable\n# They are mainly used for data integrity - cuz we can't reassign values to tuple\ntuples_1 = (1, 'Ankit', [1,2,3,45,5], {'a': 1, 'b': 2})\nprint(f'tuples_1: {tuples_1}')\n\n# Length of the tuple\nprint('Length of the tuples_1 tuple is %s' %(len(tuples_1)))\n\n# Tuple Indexing\nprint('value at index 3 is {}'.format(tuples_1[3]))\n\n# Tuple slicing\nprint('Some slicing in tuples_1: {}'.format(tuples_1[1::]))\n\n# Reverse Tuple trick\nprint(f'Reverse of tuples_1 is: {tuples_1[::-1]}')\n\n# Getting the count of any tuple value\na = 'Ankit'\ntuple_toCount = (1, 1, 1, 1, 1, a, a, a, a, a, 'c', 'c')\nprint(f'Count of \\'Ankit\\' is: {tuple_toCount.count(\"Ankit\")}')\nprint(f'Count of \\'Variable a\\' is: {tuple_toCount.count(a)}')\n\n# Getting the index of any value in\ntuple_toCount = (1, 1, 1, 1, 1, a, a, a, a, a, 'c', 'c')\nprint('Index of a in tuple_toCount is: {}'.format(tuple_toCount.index(a)))\n\n# Differnce between list and tuple (immutability)\n\n# List - Mutable\nlist_imm = [1, 2, 3, 4, 5, 6]\nlist_imm[2] = 'x' # Reassigning value at any index is possible\nprint('List_imm: %s' % list_imm)\n\n# Tuples - Immutable\n\"\"\" tuple_imm = (1, 2, 3, 4, 5, 6)\n tuple_imm[2] = 'x' # Reassigning value at any index is not possible\n print('tuple_imm: {}'.format(tuple_imm)\"\"\"\n# Will throw an error: 'tuple' object does not support item assignment\n\n\n"
},
{
"alpha_fraction": 0.6036484241485596,
"alphanum_fraction": 0.6525704860687256,
"avg_line_length": 34.411766052246094,
"blob_id": "871ec9f9347d98594856f3710a413dd0435c6fbf",
"content_id": "b95f3a2cf81e096eb2de672bb46eb14e1cb3caea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 34,
"path": "/dictionarypractise.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "# Dictionary: Holds objects in key:value pair.\n\ndict_1 = {'apple': '23', 'mango': '40', 'kiwi': '75', 'strawberry': '67'}\nprint(f'Our first dictionary: {dict_1}')\n\n# Accessing value by key name\nprint('The price for 3 kiwis is {k} rupees.'.format(k=dict_1['kiwi']))\n\n# Dictionaries can hold lists and other dictionaries as values.\nlist_2 = [23, 33, 45.33, 77]\ndict_2 = {'yonex badminton': '2300', 'list_1':['a', 'v', 'c' ,'i'], 'list_2': list_2, 'dict_inner': {'a':1, 'b':2, 'c':3}}\n\nprint(f'Our dict_2 looks like: {dict_2}')\n\n# Accessing values from dict_2\nprint('Accessing list_1: %s' %(dict_2['list_1']))\nprint('Accessing 2nd index from list_1: {}'.format(dict_2['list_1'][2]))\nprint(f'Accessing dicton_inner from dict_2: {dict_2[\"dict_inner\"]}')\nprint(f'Accessing specific dict_inner value in dict_2: {dict_2[\"dict_inner\"][\"b\"]}')\nprint(f'Uppercase list index 2: {dict_2[\"list_1\"][2].upper()}')\n\n# Accessing keys, values and items in dictionaries\n\n#Keys\ndict_keys = dict_2.keys()\nprint(f'dict_2 keys: {dict_keys}')\n\n#Values\ndict_values = dict_2.values()\nprint(f'dict_2 values: {dict_values}')\n\n#Items: keys and values both\ndict_items = dict_2.items()\nprint('dict_2 items: {i}'.format(i = dict_items))\n\n\n"
},
{
"alpha_fraction": 0.6551724076271057,
"alphanum_fraction": 0.6914700269699097,
"avg_line_length": 21.040000915527344,
"blob_id": "3c8df58e0135bd806acd5735d66bf42e718cd49d",
"content_id": "818f1a9fc842e57ad754f409c9eee40af1462aff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 551,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 25,
"path": "/numbers.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "\"\"\"\n Integer - Whole numbers, eg: 0, 43,77 etc.\n Floating point numbers - Numbers with a decimal\n\"\"\"\n\n# Addition\nprint('Addition', 2+2)\n\n# Subtraction\nprint('Subtraction', 3-2)\n\n# Division\nprint('Division', 3/4)\n\n# Multiplication\nprint('Multiplication', 5*7)\n\n# Modulo or Mod operator - returns the remained after the division\nprint('Modulo', 97 % 5)\n\n# Exponent - a**b represents a to the power b\nprint('Exponent', 2 ** 4)\n\n# Floor Division - Returns the left side of the decimal or simple integer if no decimal\nprint('Floor Division', 9 // 2)\n"
},
{
"alpha_fraction": 0.5777778029441833,
"alphanum_fraction": 0.644444465637207,
"avg_line_length": 14.333333015441895,
"blob_id": "561bc39ff14355cda377ed3b99f13a52ccbe0d42",
"content_id": "cf24c288e057aef3a161786b3234048446cd079d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 3,
"path": "/rough.py",
"repo_name": "signoreankit/PythonLearn",
"src_encoding": "UTF-8",
"text": "strs = \"Ankit is my name\"\n\nprint(strs[0:4:1])"
}
] | 10 |
marinetech/SDM
|
https://github.com/marinetech/SDM
|
96c61b2d54eb269efa8c77b6a0b5226cba3322fa
|
c2e326b698cd73a50e90dc90cb93a7897c068999
|
83fa19a26096c660e30de82bdfeefe9018afbb92
|
refs/heads/master
| 2021-01-11T14:17:31.484420 | 2017-03-20T14:02:43 | 2017-03-20T14:02:43 | 81,309,358 | 1 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6105263233184814,
"avg_line_length": 18,
"blob_id": "b01687ca22c20a1c525a4b049eb8e6842c9f8870",
"content_id": "22b1221161ee9479b980f82425c7e3575d8b656f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 95,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 5,
"path": "/example5/tx/Makefile",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "all:\n\tgcc -W -Wall -o sdm-client-tx sdm-client-tx.c -lm\n\nclean:\n\trm -f sdm-client-tx *~ .*.sw?\n"
},
{
"alpha_fraction": 0.711422860622406,
"alphanum_fraction": 0.7294589281082153,
"avg_line_length": 16.785715103149414,
"blob_id": "0f6b6e75a2c6064a847d3e79ac0dbb1eb111d574",
"content_id": "1362f5c404ec9830654674a365be112886869a0b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 499,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 28,
"path": "/runEnv.sh",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\necho Creating /tmp/tx\ntouch /tmp/rx.txt\necho \"\" > /tmp/rx.txt\n\necho Constants :\ncat Constants.py\n\necho Generating tx\npython txgen.py\n\necho sizes\nwc /tmp/tx\nwc /tmp/rx.txt\n\necho Opening erlang terminal\ngnome-terminal -e \"./evins/_rel/evins/bin/evins console\"\n\nsleep 5\n\necho Opening modems terminals\ngnome-terminal -e \"nc localhost 7001\"\ngnome-terminal -e \"nc localhost 7002\"\n\necho Opening receive file monitor\ngnome-terminal -e \"tail -f /tmp/rx.txt\"\necho \"/tmp/rx.txt :\" >> /tmp/rx.txt\n\n"
},
{
"alpha_fraction": 0.5071665048599243,
"alphanum_fraction": 0.6328555941581726,
"avg_line_length": 27.34375,
"blob_id": "bf2239c48cfbf8283c386ee117c29e365e53fdee",
"content_id": "42f78576b93d57a6c0861bdf8cbda0ddce5e2d27",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 907,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 32,
"path": "/Constants.py",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "fs = 62500 \t# Sample frequency 48-72 = 250K ; 7-17 = 62.5K\nns = fs/10\t# Number of samples in sec out of sf\nfstart = 7000 \t# frequency start for the chirp / signal frequency for the sin\nfend = 17000\t# frequency end for the chirp\nfc = 20000\np = 1\t\t# the slope of the chirp\nbaseAmp = 30000 \t# minimal amplitude for the signal\nmaxAmp = 30000 \t# max amplitude for the signal\ndeltaAmp = 1000 \t# delta between each amplitude step\nnumberOfChirps = 5\nisSin = False \t# True = sinwave , False = Chirp\nextraWait = fs * 0 # basic chirp = 1 sec ; \n\n# 48-72 modem special settings\nd4872 = {'fs':'250000',\n\t'ns':'25000',\n\t'fstart':'48000',\n\t'fend':'72000'\n\t}\n\n# 7-17 modem special settings\nd717 = {'fs':'62500',\n\t'ns':'6250',\n\t'fstart':'7000',\n\t'fend':'17000'\n\t}\n##########################\n# - Constants !!!! do not change under this line\n##########################\n\nnref = 1024\t# refrence number of samples\nrefAmp = 32000\n"
},
{
"alpha_fraction": 0.6041666865348816,
"alphanum_fraction": 0.6041666865348816,
"avg_line_length": 18.200000762939453,
"blob_id": "8050495200523f2ff5eac54dfb9f9680fa31e5aa",
"content_id": "fae135292e5f3879b844eb549da17344e3fd121b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 96,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 5,
"path": "/example5/rx/Makefile",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "all: \n\tgcc -W -Wall -o sdm-client-rx sdm-client-rx.c -lm\n\nclean:\n\trm -f sdm-client-rx *~ .*.sw?\n"
},
{
"alpha_fraction": 0.5735294222831726,
"alphanum_fraction": 0.6102941036224365,
"avg_line_length": 23,
"blob_id": "11644075b64a8b87fba409e96081929f749d1e0f",
"content_id": "f2d504e8d3d557ee2053b1d5caa0247f3589c61c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 816,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 34,
"path": "/singen.py",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport math, wave, array\nfrom random import randint\nimport Constants as c\n\ndef createTX(expAmp = c.a):\n\tprint (\"Generate amplitude : \" + str(expAmp))\n\tfor m in range (0,2):\n\t\tprint(\"chirp num :\" + str(m))\n\t\tfor j in range(c.fs):\n\t\t\tbeta = (c.fend-c.fstart) * (math.pow((c.ns/c.fs), (-1 * c.p)))\n\t\t\ti = j / c.fs\n\t\t\tsample = expAmp * math.cos(math.pi * 2 * c.fstart * i)\n\t\t\t#print(str(int(sample)))\n\t\t\tf.write(str(int(sample)))\n\t\t\tf.write(\"\\n\")\n\tprint(\"chirp num : quite\")\n\tfor j in range(c.fs):\n\t\tbeta = (c.fend-c.fstart) * (math.pow((c.ns/c.fs), (-1 * c.p)))\n\t\ti = j / c.fs\n\t\tsample = 0\n\t\t#print(str(int(sample)))\n\t\tf.write(str(int(sample)))\n\t\tf.write(\"\\n\")\n\n\nf = open('/tmp/tx','w')\ncreateTX(10)\ncreateTX(100)\ncreateTX(1000)\ncreateTX(10000)\ncreateTX(20000)\ncreateTX(30000)\nf.close()\n"
},
{
"alpha_fraction": 0.5772825479507446,
"alphanum_fraction": 0.5887850522994995,
"avg_line_length": 26.27450942993164,
"blob_id": "65ccbaa197826412fb649adb124a4d4d837eec80",
"content_id": "8eac9fe9a3eed26215e88fbab70c1aa4ef2424be",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1391,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 51,
"path": "/txgen.py",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport math, wave, array\nfrom random import randint\nimport Constants as c\n\ndef createREF():\n\tfor j in range(c.nref):\n\t\tbeta = (c.fend-c.fstart) * (math.pow((c.nref/c.fs), (-1 * c.p)))\n\t\ti = j / c.fs\n\t\tsample = c.refAmp * math.cos(math.pi * 2 * (beta / (1+c.p) * math.pow(i , (1 + c.p)) + c.fstart * i))\n\t\t#print(str(int(sample)))\n\t\tf.write(str(int(sample)))\n\t\tf.write(\"\\n\")\n\n\n\ndef createTX(expAmp = 0):\n\tprint (\"Generate amplitude : \" + str(expAmp))\n\tfor m in range (0,c.numberOfChirps):\n\t\tprint(\"chirp num :\" + str(m))\n\t\tfor j in range(c.ns):\n\t\t\tbeta = (c.fend-c.fstart) * (math.pow((c.ns/c.fs), (-1 * c.p)))\n\t\t\ti = j / c.fs\n\t\t\tchirp = expAmp * math.cos(math.pi * 2 * (beta / (1+c.p) * math.pow(i , (1 + c.p)) + c.fstart * i))\n\t\t\tsin = expAmp * math.cos(math.pi * 2 * c.fstart * i)\n\t\t\tsample = sin if c.isSin else chirp\n\t\t\t#print(str(int(sample)))\n\t\t\tf.write(str(int(sample)))\n\t\t\tf.write(\"\\n\")\n#\t\tfor k in range(0,c.fs-c.ns + c.extraWait):\n#\t\t\tsample = 0\n#\t\t\t#print(str(int(sample)))\n#\t\t\tf.write(str(int(sample)))\n#\t\t\tf.write(\"\\n\")\n\n\nf = open('/tmp/ref','w')\nprint(\"creating /tmp/ref\")\ncreateREF()\nf.close()\nf = open('/tmp/tx','w')\nprint(\"Creating /tmp/tx\")\ncreateREF()\n#for k in range(0,cfs-c.ns):\n#\tsample = 0\n#\t#print(str(int(sample)))\n#\tf.write(str(int(sample)))\n#\tf.write(\"\\n\")\nfor r in range(c.baseAmp,c.maxAmp + 1 ,c.deltaAmp):\n\tcreateTX(r)\nf.close()\n"
},
{
"alpha_fraction": 0.5248931646347046,
"alphanum_fraction": 0.5621070861816406,
"avg_line_length": 30.314960479736328,
"blob_id": "cac63166be9584bc052e180a1d581636b03bf60b",
"content_id": "4ef2aa6935691d008eba874b0db06b5053b667b8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7954,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 254,
"path": "/example5/rx/sdm-client-rx.c",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n#include <sys/types.h>\n#include <sys/socket.h>\n#include <netinet/in.h>\n#include <netdb.h> \n#include <err.h> \n#include <arpa/inet.h> /* inet_addr() */\n#include <math.h>\n#include <limits.h> /* SHRT_MAX */\n#include <endian.h>\n\n#define BUFSIZE 1024\n#define NSAMPLES 1024\n#define SAMPLERATE 250000\n\n/* SDM PHY commands in binary form */\n/*\t\t\t | SDM prefix | cmd | param | length | */\nunsigned char cmd_config[] = {0x80 ,0x00 ,0x7f ,0xff ,0x00 ,0x00 ,0x00 ,0x00 ,0x04 ,0x5e ,0x01 ,0x03 ,0x00 ,0x00 ,0x00 ,0x00};\nunsigned char cmd_rx[] = {0x80 ,0x00 ,0x7f ,0xff ,0x00 ,0x00 ,0x00 ,0x00 ,0x02 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00};\nunsigned char cmd_ref[] = {0x80 ,0x00 ,0x7f ,0xff ,0x00 ,0x00 ,0x00 ,0x00 ,0x03 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00};\nunsigned char cmd_stop[] = {0x80 ,0x00 ,0x7f ,0xff ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00 ,0x00};\n\nunsigned char buf[BUFSIZE] = {0};\n\n/* function executing data/command exchange with the SDM PHY via the socket */\nvoid sdm_cmd(int sockfd, unsigned char *cmd, ssize_t len)\n{\n int i, n;\n\n printf(\"snd: \");\n for (i = 0; i < len; i++) {\n printf(\"%02x \", cmd[i]);\n if (i && (i + 1) % 16 == 0)\n printf(\" \");\n if (i && (i + 1) % 32 == 0)\n printf(\"\\n \");\n }\n printf(\"\\n\");\n\n n = write(sockfd, cmd, len);\n if (n < 0) \n err(1, \"write(): \");\n\n if (n != len)\n errx(1, \"n != len: %d != %ld\\n\", n , len);\n\n n = read(sockfd, buf, BUFSIZE);\n if (n < 0) \n err(1, \"read(): \");\n\n printf(\"rcv: \");\n for (i = 0; i < n; i++) {\n\t printf(\"%02x \", buf[i]);\n if (i && (i + 1) % 16 == 0) {\n printf(\"\\n\");\n if (i != n - 1)\n printf(\" \");\n }\n }\n printf(\"\\n\");\n}\n\n/* function generating sweep signal (as signal reference) */\nint chirp_sig(int nsamples, float amplitude, float fstart, float fend, float phi_start, signed short int *vchirp)\n{\n int i;\n \n fstart = fstart/SAMPLERATE;\n fend = fend/SAMPLERATE;\n if (nsamples <= 0 || amplitude < 0 || fstart < 0 || fend < 0 || vchirp == NULL)\n\t return -1;\n\n if (fstart < fend)\n for (i = 0; i < nsamples; i++)\n\t vchirp[i] = amplitude * cos(2.*M_PI*fstart*i + 2.*M_PI*(fend-fstart)/2./(nsamples-1)*i*i + phi_start) * SHRT_MAX;\n else\n for (i = 0; i < nsamples; i++)\n vchirp[i] = amplitude * cos(2.*M_PI*fstart*i - 2.*M_PI*(fstart-fend)/2./(nsamples-1)*i*i + phi_start) * SHRT_MAX;\n\n return nsamples;\n}\n\n/* function emptying the buffer of the SDM PHY*/\nvoid flush_data(int sockfd)\n{\n fd_set rfds;\n struct timeval tv;\n int ret;\n\n for (;;) {\n FD_ZERO(&rfds);\n FD_SET(sockfd, &rfds);\n\n tv.tv_sec = 1;\n tv.tv_usec = 0;\n ret = select(sockfd + 1, &rfds, NULL, NULL, &tv);\n \n if (ret == -1)\t{\n\t\twarn(\"Select() \");\n \t\treturn;\n\t}\n if (!ret) {\n warn(\"Select() \");\n break;\n\t}\n ret = read(sockfd, buf, BUFSIZE);\n printf (\"flush %d bytes\\n\", ret);\n }\n}\n\n/* function reading received signal from the SDM PHY */\nint read_data(int sockfd, unsigned char *readsig, int size)\n{\n fd_set rfds;\n struct timeval tv;\n int ret, n = 0;\n int i = 0;\n\n for (;;) {\n FD_ZERO(&rfds);\n FD_SET(sockfd, &rfds);\n\n tv.tv_sec = 10;\n tv.tv_usec = 0;\n ret = select(sockfd + 1, &rfds, NULL, NULL, &tv);\n if (ret == -1)\t{\n\t\twarn(\"Select()\");\n\t\treturn -1;\n\t}\n if (!ret) {\n\t return n;\n\t}\n\n ret = read(sockfd, readsig + n, size - n);\n if (ret == -1)\t{\n\t\twarn(\"Read()\");\n \t\treturn -1;\n\t}\n\n printf(\"read() %d\\n\", ret);\n \tfor (i = 0; i < ret; i++) {\n \t\tprintf(\"%02x \", readsig[n+i]);\n\t\tif (i && (i + 1) % 16 == 0) {\n\t \t\tprintf(\"\\n\");\n\t \t\tif (i != n - 1)\n\t\t\t\tprintf(\" \");\n\t\t}\n \t}\n\tn += ret;\n\tif (n >= size)\n\t\treturn n;\n }\n return 0;\n}\n\n/* function creating the socket, connecting the socket, configuring the PHY and reading from the SDM PHY buffer (reading received signal) */\nint main(int argc, char *argv[])\n{\n int sockfd, portno, i;\n struct sockaddr_in serveraddr;\n char *ip;\n float amplitude = 1; // reference signal amplitude\n float fstart = 20000; // start frequence of the reference signal \n float fend = 30000; // end frequency of the sweep signal \n float phi_start = 0; // beginning phase of the sweep signal \n int retn, retnsread;\n int mp = 15; // number of reference signal lengths - length of the buffer for read rx signal from the socket \n signed short int vchirp[NSAMPLES];\n signed short int readsig[mp*NSAMPLES];\n unsigned char ref_buf[sizeof(cmd_ref) + sizeof(vchirp)];\n unsigned char cmd_rx_buf[sizeof(cmd_rx)];\n int nsread = mp*NSAMPLES;\n FILE *fp;\n\n/* check command line arguments */\n if (argc != 3)\n errx(0 ,\"usage: %s <IP> <port>\\n\", argv[0]);\n ip = argv[1];\n portno = atoi(argv[2]);\n\n/* socket: create the socket */\n sockfd = socket(AF_INET, SOCK_STREAM, 0);\n if (sockfd < 0) \n err(1, \"socket(): \");\n memset((char *)&serveraddr, 0, sizeof(serveraddr));\n serveraddr.sin_addr.s_addr = inet_addr(ip);\n serveraddr.sin_family = AF_INET;\n serveraddr.sin_port = htons(portno);\n\n/* connect: create a connection with the SDM PHY */\n if (connect(sockfd, (struct sockaddr *)&serveraddr, sizeof(serveraddr)) < 0) \n err(1, \"connect(): \");\n\n/* empty the SDM PHY buffer*/\n flush_data(sockfd);\n\n/* send the command line \"cmd_stop\" to initialize the SDM PHY */\n printf(\"SDM command 'stop' send and reply:\\n\");\n sdm_cmd(sockfd, cmd_stop, sizeof(cmd_stop));\n printf(\"\\n\");\n\n/* send the command line \"cmd_config\" to configure the SDM PHY */\n printf(\"SDM command 'config' send and reply:\\n\");\n sdm_cmd(sockfd, cmd_config, sizeof(cmd_config));\n printf(\"\\n\");\n\n/* generate the reference signal (needed for SDM PHY detector) */\n printf(\"Generated reference signal :\\n\");\n retn = chirp_sig(NSAMPLES, amplitude, fstart, fend, phi_start, vchirp);\n if (retn <= 0)\n\t errx(1, \"chirp_sig() return %d\\n\", retn);\n retn = htobe32(retn);\n printf (\"%08x\\n\", retn);\n printf (\"\\n\");\n \n sleep(3);\n\n/* fill out the field 'len' with the length of the reference signal (always 1024 samples; in user applications: use zero padding if necessary) */\n/* fill out the field 'data' with the reference signal, and send the command line \"cmd_ref\" to the SDM PHY */\n printf(\"SDM command 'ref':\\n\");\n memcpy(ref_buf, cmd_ref, sizeof(cmd_ref));\n memcpy(ref_buf + sizeof(cmd_ref) - 5, &retn, sizeof(retn));\n memcpy(ref_buf + sizeof(cmd_ref), &vchirp, sizeof(vchirp));\n sdm_cmd(sockfd, ref_buf, sizeof(ref_buf));\n printf(\"\\n\");\n\n/* send the command line \"cmd_rx\" to the SDM PHY for initiating rx mode */\n printf(\"SDM command 'rx':\\n\"); \n memcpy(cmd_rx_buf, cmd_rx, sizeof(cmd_rx));\n memcpy(cmd_rx_buf + sizeof(cmd_rx_buf) - 7, &nsread, sizeof(nsread));\n sdm_cmd(sockfd, cmd_rx_buf, sizeof(cmd_rx_buf));\n \n/* reading from the socket of the SDm PHY: after detecting a matching signal the SDM PHY returns via the socket the received */\n/* signal samples (the samples comming after the detected matching signal) */\n retnsread = read_data(sockfd, (char *)readsig, sizeof(readsig));\n printf (\"read %d bytes\\n\", retnsread);\n\n fp = fopen(\"sig_rx.txt\",\"w+\");\n for (i = 0; i < mp*NSAMPLES; i++)\n\t fprintf(fp,\"%d\\n\",readsig[i]);\n fclose(fp); \n\n/* send the command line \"cmd_stop\" to the SDM PHY */\n printf(\"SDM command 'stop' send and reply:\\n\");\n sdm_cmd(sockfd, cmd_stop, sizeof(cmd_stop));\n printf(\"\\n\");\n \n close(sockfd);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5447807312011719,
"alphanum_fraction": 0.5528103709220886,
"avg_line_length": 28.436363220214844,
"blob_id": "a170bd45e783fe11a26f7cb61e4b374c61efb290",
"content_id": "940eebdb08bacbef998cc87dbe9f3a35d21d6a79",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1619,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 55,
"path": "/example5/tx/readlinetest.c",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n\nchar **strsplit(const char* str, const char* delim, size_t* numtokens) {\n // copy the original string so that we don't overwrite parts of it\n // (don't do this if you don't need to keep the old line,\n // as this is less efficient)\n char *s = strdup(str);\n // these three variables are part of a very common idiom to\n // implement a dynamically-growing array\n size_t tokens_alloc = 1;\n size_t tokens_used = 0;\n char **tokens = calloc(tokens_alloc, sizeof(char*));\n char *token, *strtok_ctx;\n for (token = strtok_r(s, delim, &strtok_ctx);\n token != NULL;\n token = strtok_r(NULL, delim, &strtok_ctx)) {\n // check if we need to allocate more space for tokens\n if (tokens_used == tokens_alloc) {\n tokens_alloc *= 2;\n tokens = realloc(tokens, tokens_alloc * sizeof(char*));\n }\n tokens[tokens_used++] = strdup(token);\n }\n // cleanup\n if (tokens_used == 0) {\n free(tokens);\n tokens = NULL;\n } else {\n tokens = realloc(tokens, tokens_used * sizeof(char*));\n }\n *numtokens = tokens_used;\n free(s);\n return tokens;\n}\n\nint main() {\n char line[1024];\n FILE *fp;\n char **tokens;\n size_t numtokens;\n fp = fopen(\"exp.txt\",\"r\");\n if (fp) {\n fgets(line,1024,fp);\n tokens = strsplit(line, \",\", &numtokens);\n \n for (size_t i = 0; i < numtokens; i++) {\n printf(\" token: \\\"%s\\\"\\n\", tokens[i]);\n }\n fclose(fp);\n } else {\n printf(\"fail - no file\\n\");\n }\n }\n"
},
{
"alpha_fraction": 0.7064220309257507,
"alphanum_fraction": 0.7064220309257507,
"avg_line_length": 11.823529243469238,
"blob_id": "a5fac2f56629159ff2014c48f8374412d66e7f8d",
"content_id": "3a0c00044b44142fe13d7dbe4880386897a4c227",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 218,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 17,
"path": "/README.md",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "# SDM\nEvologics software defined modem\n\n# Installation\n```\ngit clone https://github.com/marinetech/SDM.git\ncd SDM\ngit submodule update --init --recursive\ncd evins\nmake\n```\n\n# Run\n```\nchmod +x runenv.sh\n./runenv.sh\n```\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.581818163394928,
"avg_line_length": 28.615385055541992,
"blob_id": "6fdeaa9cb076771ea2fdaa4c213cc884b29209fe",
"content_id": "f263e4bec18b91dc039df8a0b7b24a8da492ea28",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 13,
"path": "/refgen.py",
"repo_name": "marinetech/SDM",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport math, wave, array\nimport Constants as c\n\nf = open('/tmp/ref','w')\nfor j in range(c.nref):\n\tbeta = (c.fend-c.fstart) * (math.pow((c.nref/c.fs), (-1 * c.p)))\n\ti = j / c.fs\n\tsample = c.a * math.cos(math.pi * 2 * (beta / (1+c.p) * math.pow(i , (1 + c.p)) + c.fstart * i))\n\t#print(str(int(sample)))\n\tf.write(str(int(sample)))\n\tf.write(\"\\n\")\nf.close()\n"
}
] | 10 |
mauludinr/Text-Mining---Term-Weighting
|
https://github.com/mauludinr/Text-Mining---Term-Weighting
|
1c198ba6fad876ed0049de6d7d5281d90ae9684e
|
841903793fe5bc3b83475608cd3f436e58523160
|
62d901ad07c72d8df61b62937da58392fc4514db
|
refs/heads/master
| 2020-04-04T10:11:27.730928 | 2018-10-04T15:26:45 | 2018-10-04T15:26:45 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7561983466148376,
"alphanum_fraction": 0.7570247650146484,
"avg_line_length": 28.299999237060547,
"blob_id": "18ec955eaaa5748d754b2d05a26d51204053f9ef",
"content_id": "e0823feba3fee3e8d7308a55dc1791b1f941f4cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 40,
"path": "/Main.py",
"repo_name": "mauludinr/Text-Mining---Term-Weighting",
"src_encoding": "UTF-8",
"text": "import Preprocessing as pre\r\nimport TermWeighting as termW\r\nfrom Output import Output\r\n\r\nsource = open(\"source.txt\", \"r\")\r\nsource = source.read()\r\noutput = Output()\r\n\r\ndocuments = pre.tokenization(source)\r\noutput.write_pre(documents, \"tokenization\")\r\n\r\ndocuments = pre.filtering(documents)\r\noutput.write_pre(documents, \"filtering\")\r\n\r\ndocuments = pre.stemming(documents)\r\noutput.write_pre(documents, \"stemming\")\r\n\r\nterms = pre.termFromDocuments(documents)\r\n\r\noutput.column_number = 0\r\n\r\nbinaryWeight = termW.binaryTermWeighting(terms, documents)\r\noutput.write_term_weight(terms, binaryWeight, \"Binary term frequency\")\r\n\r\nrawWeight = termW.rawTermWeighting(terms, documents)\r\noutput.write_term_weight(terms, rawWeight, \"Raw term frequency\")\r\n\r\nlogWeight = termW.logTermWeighting(terms, documents)\r\noutput.write_term_weight(terms, logWeight, \"Log term frequency\")\r\n\r\ndf = termW.documentFrequency(terms, documents)\r\noutput.write_doc_frequency(df, \"Document frequencies\")\r\n\r\nidf = termW.inverseDocumentFrequency(df, documents)\r\noutput.write_doc_frequency(idf, \"Inverse Document Frequencies\")\r\n\r\ntf_idf = termW.tf_idf(logWeight, idf)\r\noutput.write_term_weight(terms, tf_idf, \"tf * idf\")\r\n\r\noutput.save(\"result.xls\")"
}
] | 1 |
NurullahGundogdu/Algorithm_Projects
|
https://github.com/NurullahGundogdu/Algorithm_Projects
|
6e9e22ce61162a06f6e07ee71897da44d550baa6
|
57685a8634d305f6a9a93b0296f42b07dfd21723
|
2c90fe61c98b5cbd2e64a7419eae2a792bbe43a1
|
refs/heads/master
| 2020-12-23T09:02:03.218706 | 2020-02-05T17:08:12 | 2020-02-05T17:08:12 | 237,105,234 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3956011235713959,
"alphanum_fraction": 0.43468567728996277,
"avg_line_length": 22.86170196533203,
"blob_id": "275a857568d4658aa899a8200f4f1a412f57fcaa",
"content_id": "106d6e24192f4fd56d3494fcbf80301425bad6ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6729,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 282,
"path": "/Project_1/project_1.py",
"repo_name": "NurullahGundogdu/Algorithm_Projects",
"src_encoding": "UTF-8",
"text": "####################### Part1 #######################\n\ndef black_white_boxes(boxes,first_index,last_index):\n\n if first_index % 2 == 1:\n boxes[first_index],boxes[last_index] = boxes[last_index],boxes[first_index]\n \n if first_index < last_index:\n boxes = black_white_boxes(boxes,first_index + 1, last_index - 1)\n \n return boxes\n \n####################### Part2 #######################\n\n\ndef fakeCoin(coins): \n\n temp = 0\n\n arr1 = []\n arr2 = []\n\n if len(coins) % 2 == 1:\n size = (int) (len(coins) / 2)\n\n arr1 = coins[:size]\n\n arr2 = coins[size + 1:]\n\n if sum(arr1) == sum(arr2):\n\n return coins[size]\n\n else :\n\n size = (int) (len(coins) / 2)\n\n arr1 = coins[:size]\n\n arr2 = coins[size:]\n\n\n if sum(arr1) < sum(arr2):\n\n if len(arr1) == 1:\n\n return arr1[0]\n\n temp = fakeCoin(arr1)\n\n else :\n\n if len(arr2) == 1:\n return arr2[0]\n\n temp = fakeCoin(arr2)\n\n return temp\n \n\n\n####################### Part3 #######################\n\n\ndef partition(arr,low,high,num): \n \n i = ( low-1 ) \n pivot = arr[high] \n \n for j in range(low , high): \n \n if arr[j] < pivot: \n num += 1\n i = i+1 \n arr[i],arr[j] = arr[j],arr[i] \n \n arr[i+1],arr[high] = arr[high],arr[i+1] \n num += 1\n return ( i+1 ), num \n \n\ndef quickSort(arr,low,high,num): \n\n if low < high: \n\n pi, num = partition(arr,low,high,num) \n \n num = quickSort(arr, low, pi-1,num) \n num = quickSort(arr, pi+1, high,num) \n \n return num\n\ndef insertionSort(arr,num): \n \n for i in range(1, len(arr)): \n \n current = arr[i] \n\n position = i-1\n\n while position >= 0 and current < arr[position] : \n num += 1 \n arr[position+1] = arr[position] \n position -= 1\n\n arr[position+1] = current \n\n return num\n\n\n####################### Part4 #######################\n\ndef quickSelect(arr):\n\n if len(arr) % 2 == 1:\n return quickSelect_helper(arr, len(arr) // 2)\n else:\n return (quickSelect_helper(arr, len(arr) // 2 - 1) + quickSelect_helper(arr, len(arr) // 2)) // 2\n\n\n\ndef quickSelect_helper(arr, half_of_size):\n\n if len(arr) != 0:\n \n pivot = arr[half_of_size]\n \n Left_Side_Of_List = []\n\n Right_Side_Of_List = []\n\n for i in arr:\n if i < pivot:\n Left_Side_Of_List.append(i)\n \n elif i > pivot:\n Right_Side_Of_List.append(i)\n \n size_of_left = len(Left_Side_Of_List)\n\n pivot_num = len(arr) - size_of_left - len(Right_Side_Of_List)\n\n if half_of_size >= size_of_left and half_of_size < size_of_left + pivot_num:\n return pivot\n elif size_of_left > half_of_size:\n return quickSelect_helper(Left_Side_Of_List, half_of_size)\n else:\n return quickSelect_helper(Right_Side_Of_List, half_of_size - size_of_left - pivot_num)\n\n####################### Part5 #######################\n\n\ndef Optimal_SubArray(arr, index, subarr, temp, sum_B): \n \n if index == len(arr): \n if len(subarr) != 0: \n if sum(subarr) >= sum_B: \n if sum(subarr) <= sum(temp) and len(subarr) <= len(temp):\n temp = subarr\n \n else: \n \n temp = Optimal_SubArray(arr, index + 1, subarr, temp, sum_B) \n \n temp = Optimal_SubArray(arr, index + 1, subarr+[arr[index]], temp, sum_B) \n \n return temp;\n\n\n\n####################### Driver function #######################\n\n\ndef main():\n\n ####################### Part1 #######################\n\n boxes = [\"black\", \"black\", \"black\", \"black\", \"black\", \"black\", \"black\", \"black\", \"black\", \"black\",\n \"white\", \"white\", \"white\", \"white\", \"white\", \"white\", \"white\", \"white\", \"white\", \"white\"] \n\n print (\"---------------Part1---------------\\n\")\n \n print (\"Input : \", boxes, \"\\n\")\n\n boxes = black_white_boxes(boxes,0,len(boxes)-1) \n \n print (\"Output : \", boxes, \"\\n\")\n\n\n ####################### Part2 #######################\n\n print (\"---------------Part2---------------\\n\")\n\n arr = [1, 1, 1, 0, 1, 1, 1, 1, 1, 1] \n\n print (\"Input : \", arr, \"\\n\")\n \n print (\"Fake Coin : \", fakeCoin(arr), \"\\n\")\n\n\n ####################### Part3 #######################\n\n print (\"---------------Part3---------------\\n\")\n\n arr = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]\n arr2 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n arr3 = [2, 4, 9, 1, 10, 8, 3, 6, 5, 7]\n\n arr4 = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]\n arr5 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]\n arr6 = [2, 4, 9, 1, 10, 8, 3, 6, 5, 7]\n\n print (\"Quick Sort:\") \n print (\"Unsorted array : \", arr)\n print (\"Swap num : \",quickSort(arr,0,len(arr)-1,0))\n print (\"Sorted array : \",arr,\"\\n\") \n\n \n print (\"Insertion Sort:\") \n print (\"Unsorted array : \", arr4) \n print (\"Swap num : \",insertionSort(arr4,0))\n print (\"Sorted array : \",arr4,\"\\n\") \n\n\n print (\"Quick Sort:\") \n print (\"Unsorted array : \", arr2) \n print (\"Swap num : \",quickSort(arr2,0,len(arr2)-1,0)) \n print (\"Sorted array : \",arr2,\"\\n\") \n\n\n print (\"Insertion Sort:\") \n print (\"Unsorted array : \", arr5) \n print (\"Swap num : \",insertionSort(arr5,0))\n print (\"Sorted array : \",arr5,\"\\n\") \n\n\n print (\"Quick Sort:\") \n print (\"Unsorted array : \", arr3)\n print (\"Swap num : \",quickSort(arr,0,len(arr3)-1,0)) \n print (\"Sorted array : \",arr3,\"\\n\") \n\n \n print (\"Insertion Sort:\") \n print (\"Unsorted array : \", arr6) \n print (\"Swap num : \",insertionSort(arr6,0))\n print (\"Sorted array : \",arr6,\"\\n\") \n\n\n\n ####################### Part4 #######################\n\n print (\"---------------Part4---------------\\n\")\n\n arr = [10, 7, 8, 9, 1, 5, 20, 41, 12,11,31,2,21,90] \n\n arr2 = [1,2,3,4,5,6,7,8,9,10]\n\n arr3 = [13,12,11,10,9,8,7,6,5,4,3,2,1,0]\n\n arr4 =[1,1,1,1,1,1,1,1,1,1,1,1,1,1]\n print (\"Input : \", arr, \"\\n\")\n\n #print (\"Median : \", quickSelect(arr, len(arr) // 2), \"\\n\")\n print (\"Median : \", quickSelect(arr3), \"\\n\")\n\n\n ####################### Part5 #######################\n\n print (\"---------------Part5---------------\\n\")\n \n arr = [2, 4, 7, 5, 22, 11] \n print (\"Input : \", arr, \"\\n\")\n\n sum_B = (int) ((min(arr) + max(arr)) * (len(arr) / 4))\n\n print (\"SUM(B) : \", sum_B, \"\\n\")\n\n print (\"Optimal sub-array : \", Optimal_SubArray(arr, 0, [], arr, sum_B), \"\\n\")\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.3863281309604645,
"alphanum_fraction": 0.42509764432907104,
"avg_line_length": 19.039138793945312,
"blob_id": "8dc31d4d83b64a0a5c6bbc4a67f54d8f07aa0701",
"content_id": "61b3e60b3764cccf9a1a6e6a41c2cea4f7a4c5a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10240,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 511,
"path": "/Project_3/Project.py",
"repo_name": "NurullahGundogdu/Algorithm_Projects",
"src_encoding": "UTF-8",
"text": "class Part1:\n\n\tdef total_cost(self, NY, SF, n, M):\n\n\t\ttemp_NY = [0] * n\n\t\ttemp_SF = [0] * n\n\n\t\tfor i in range(n):\n\n\t\t\ttemp_NY[i] = NY[i] + min(temp_NY[i - 1], M + temp_SF[i - 1])\n\t\t\ttemp_SF[i] = SF[i] + min(temp_SF[i - 1], M + temp_NY[i - 1])\n\n\n\t\treturn min(temp_SF[n - 1],temp_NY[n- 1])\n\n\nclass Part2:\n\tdef printMaxActivities(self, s, f):\n\n\n\t\tf,s = zip(*sorted(zip(f,s)))\n\n\t\tprint(\"Start : \", s)\n\t\tprint(\"Finish : \", f)\n\n\t\tn = len(f)\n\t\tprint (\"Optimal list of sessions : \" , end = \" \")\n\n\t\ti = 0\n\t\tprint (i, end = \" \")\n\n\t\tfor j in range(n):\n\t\t\tif s[j] >= f[i]:\n\t\t\t\tprint (j, end = \" \")\n\t\t\t\ti = j\n\n\t\tprint()\n\n\nclass Part3:\n\n\tdef Subset_zero(self,index, sum_of_subarr, arr, size_of_arr, visit, dp, temp):\n\n\t\tif (index == size_of_arr) : \n\t\t\tif (sum_of_subarr == 0) : \n\t\t\t\tprint(temp)\n\t\t\t\treturn -1\n\t\t\telse : \n\t\t\t\treturn 0 \n\n\t\tif (visit[index][sum_of_subarr + size_of_arr]) : \n\t\t\treturn dp[index][sum_of_subarr + size_of_arr]\n\n\t\tvisit[index][sum_of_subarr + size_of_arr] = 1; \n\n\t\ttemp.append(arr[index])\n\n\t\tdp[index][sum_of_subarr + size_of_arr ] = self.Subset_zero(index + 1, sum_of_subarr + arr[index], arr, size_of_arr, visit, dp, temp) \n\t\t\n\t\ttemp.remove(arr[index])\n\n\t\tif dp[index][sum_of_subarr + size_of_arr ] == -1:\n\t\t\treturn -1\n\n\t\tdp[index][sum_of_subarr + size_of_arr ] += self.Subset_zero(index + 1, sum_of_subarr, arr, size_of_arr, visit, dp, temp)\n\n\t\treturn dp[index][sum_of_subarr + size_of_arr]\n\n\n\n\nclass Part4:\n\n\t\n\tdef getMin(self, word_1, word_2, mistmatch, gap, match):\n\t \n\t number_1 = 0\n\t number_2 = 0\n\t gapNum = 0\n\t mistmatchNum = 0\n\t matchNum = 0\n\t \n\t arr = []\n\n\t for row in range(len(word_1) + len(word_2) + 1):\n\t arr += [[0] * (len(word_1) + len(word_2) + 1)]\n\n\t for i in range(len(word_1) + len(word_2)):\n\t arr[i][0] = i * gap\n\t arr[0][i] = i * gap\n\t \n\t for i in range(1,len(word_1) + 1):\n\t for j in range(1, len(word_2) + 1):\n\t if word_1[i-1] == word_2[j-1]:\n\t arr[i][j] = arr[i-1][j-1]\n\t else:\n\t arr[i][j] = min(arr[i-1][j-1] + mistmatch,\n\t arr[i-1][j] + gap,\n\t arr[i][j-1] + gap)\n\t \n\t sum_len = len(word_1) + len(word_2)\n\n\t i = len(word_1)\n\t j = len(word_2)\n\t \n\t position_1 = sum_len\n\t position_2 = sum_len\n\t \n\n\t answer_1 = [0] * (sum_len + 1)\n\t answer_2 = [0] * (sum_len + 1)\n\t \n\t while not (i == 0 or j == 0):\n\t \n\t if word_1[i-1] == word_2[j-1]:\n\t \n\t answer_1[position_1] = ord(word_1[i-1])\n\t answer_2[position_2] = ord(word_2[j-1])\n\t \n\t position_1 -= 1\n\t position_2 -= 1\n\t \n\t i -= 1\n\t j -= 1 \n\t \n\t number_1 += 1\n\t number_2 += 1\n\t matchNum += 1\n\n\t elif arr[i-1][j-1] + mistmatch == arr[i][j]:\n\t \n\t answer_1[position_1] = ord(word_1[i-1])\n\t answer_2[position_2] = ord(word_2[j-1])\n\t \n\t position_1 -= 1\n\t position_2 -= 1\n\t \n\t i -= 1\n\t j -= 1 \n\t \n\t number_1 += 1\n\t number_2 += 1\n\t mistmatchNum += 1\n\n\t elif arr[i-1][j] + gap == arr[i][j]:\n\t \n\t answer_1[position_1] = ord(word_1[i-1])\n\t answer_2[position_2] = ord('_')\n\t \n\t position_2 -= 1\n\t position_1 -= 1\n\t \n\t i -= 1 \n\t number_1 += 1\n\t \n\t if j < len(word_2):\n\t number_2 += 1\n\t gapNum += 1\n\t \n\t elif arr[i][j-1] + gap == arr[i][j]:\n\t \n\t answer_1[position_1] = ord('_')\n\t answer_2[position_2] = ord(word_2[j-1])\n\t \n\t position_1 -= 1\n\t position_2 -= 1\n\t \n\t j -= 1\n\t number_2 += 1\n\t \n\t if i < len(word_1):\n\t number_1 += 1\n\t gapNum += 1\n\t \n\t while position_2 > 0:\n\t \n\t if j > 0:\n\t j -= 1\n\t answer_2[position_2] = ord(word_2[j])\n\t \n\t number_1 += 1\n\t number_2 += 1\n\t gapNum += 1\n\t \n\t else:\n\t answer_2[position_2] = ord('_')\n\t \n\t position_2 -= 1\n\t \n\t while position_1 > 0:\n\t \n\t if i > 0:\n\t i -= 1\n\t answer_1[position_1] = ord(word_1[i])\n\t \n\t number_1 += 1\n\t number_2 += 1\n\t gapNum += 1\n\t \n\t else:\n\t answer_1[position_1] = ord('_')\n\n\t position_1 -= 1\n\t \n\t temp = 1\n\n\t for i in range(sum_len,0,-1):\n\t if chr(answer_2[i]) == '_' and chr(answer_1[i]) == '_':\n\t temp = i + 1\n\t break\n\n\t cost = matchNum * match + gapNum * -gap + mistmatchNum * -mistmatch\n\n\t return answer_1[temp:temp+number_1], answer_2[temp:temp+number_2], cost\n\n\n\nclass Part5:\n\tdef min_number_op(self,arr):\n\n\t\tsum_of_arr = 0\n\t\top = 0\n\n\t\ttemp_neg = []\n\t\ttemp_pos = []\n\n\t\tfor i in range(len(arr)):\n\n\t\t\tif arr[i] < 0:\n\t\t\t\ttemp_neg.append(arr[i])\n\t\t\telse:\n\t\t\t\ttemp_pos.append(arr[i])\n\n\n\t\ttemp_neg.sort(reverse= True)\n\t\ttemp_pos.sort()\n\n\t\ti = 0\n\t\tj = 0\n\n\t\twhile i < len(temp_neg) and j < len(temp_pos):\n\n\t\t\tif temp_pos[j] > (0 - temp_neg[i]):\n\n\t\t\t\tif i != 0 or j != 0:\n\n\t\t\t\t\tif sum_of_arr < 0:\n\t\t\t\t\t\top += (-1) * (temp_neg[i] + sum_of_arr)\n\t\t\t\t\telse:\n\t\t\t\t\t\top += sum_of_arr - temp_neg[i]\n\n\t\t\t\tsum_of_arr += temp_neg[i]\n\t\t\t\ti += 1\n\n\t\t\telse:\n\n\t\t\t\tif i != 0 or j != 0:\n\n\t\t\t\t\tif sum_of_arr < 0:\n\t\t\t\t\t\top += temp_pos[j] - sum_of_arr\n\t\t\t\t\telse:\n\t\t\t\t\t\top += sum_of_arr + temp_pos[j]\n\n\t\t\t\tsum_of_arr += temp_pos[j]\n\t\t\t\tj += 1\n\n\t\tif i < len(temp_neg):\n\t\t\twhile i < len(temp_neg):\n\n\t\t\t\tif i != 0 or j != 0:\n\n\t\t\t\t\tif sum_of_arr < 0:\n\t\t\t\t\t\top += (-1) * (temp_neg[i] + sum_of_arr)\n\t\t\t\t\telse:\n\t\t\t\t\t\top += sum_of_arr - temp_neg[i]\n\n\t\t\t\tsum_of_arr += temp_neg[i]\n\t\t\t\ti += 1\n\n\t\telse:\n\n\t\t\twhile j < len(temp_pos):\n\n\t\t\t\tif i != 0 or j != 0:\n\n\t\t\t\t\tif sum_of_arr < 0:\n\t\t\t\t\t\top += temp_pos[j] - sum_of_arr\n\t\t\t\t\telse:\n\t\t\t\t\t\top += sum_of_arr + temp_pos[j]\n\n\t\t\t\tsum_of_arr += temp_pos[j]\n\t\t\t\tj += 1\n\n\n\t\treturn sum_of_arr, op\n\n\ndef main():\n\n####################################### Part 1 #######################################\n\n\tprint(\"####################################### Part 1 #######################################\\n\")\n\n\tNY = [1, 3, 20, 30]\n\tSF = [50, 20, 2, 4]\n\n\tn = 4\n\tM = 10\n\n\tpart1 = Part1()\n\n\tprint (\"Example 1:\")\n\tprint(\"List 1 : \", NY)\n\tprint(\"List 2 : \", SF)\n\tprint(\"M value : \", M)\n\tprint(\"Cost of an optimal plan : \", part1.total_cost(NY,SF, n, M))\n\tprint()\n\n\tNY = [1, 100, 1, 100, 1, 100]\n\tSF = [100, 1, 100, 1, 100, 1]\n\n\tn = 6\n\tM = 15\n\n\tprint(\"Example 2:\")\n\tprint (\"List 1 : \",NY)\n\tprint (\"List 2 : \",SF)\n\tprint (\"M value : \",M)\n\tprint(\"Cost of an optimal plan : \", part1.total_cost(NY, SF, n, M))\n\tprint(\"\\n\")\n\n\t\n\n####################################### Part 2 #######################################\n\n\t\n\tprint(\"####################################### Part 2 #######################################\\n\")\n\n\n\tpart2 = Part2()\n\n\ts = [1, 3, 0, 5, 8, 5]\n\tf = [2, 4, 6, 7, 9, 9]\n\n\n\tprint(\"Example 1:\")\n\n\tpart2.printMaxActivities(s, f)\n\n\tprint()\n\n\ts = [1, 2, 5, 3, 1, 0]\n\tf = [9, 3, 7, 4, 2, 6]\n\n\n\tprint(\"Example 2:\")\n\tpart2.printMaxActivities(s, f)\n\n\n\tprint(\"\\n\")\n\t\n\n####################################### Part 3 #######################################\n\t\n\tprint(\"####################################### Part 3 #######################################\\n\")\n\n\tprint (\"Example 1:\")\n\n\tpart3 = Part3()\n\n\n\tarr = [-2,3,-3,5,4]\n\tvisit = []\n\ttemp = []\n\tdp = []\n\t\n\tmaxSum = 1000\n\n\n\n\tfor row in range(len(arr)): dp += [[0] * maxSum]\n\n\tfor row in range(len(arr)): visit += [[0] * maxSum]\n\n\tprint(\"Array : \")\n\tprint (arr)\n\n\tprint(\"Subarray : \")\n\tpart3.Subset_zero(0, 0, arr, len(arr), visit, dp, temp)\n\t\n\tprint()\n\n\tprint (\"Example 2:\")\n\n\tarr = [-1, 6, 4, 2, 3, -7, -5]\n\tvisit = []\n\ttemp = []\n\tdp = []\n\n\tfor row in range(len(arr)): dp += [[0] * maxSum]\n\n\tfor row in range(len(arr)): visit += [[0] * maxSum]\n\tprint(\"Array : \")\n\tprint (arr)\n\tprint(\"Subarray : \")\n\tpart3.Subset_zero(0, 0, arr, len(arr), visit, dp, temp)\n\n\tprint()\n\n\tprint(\"\\n\")\n\n####################################### Part 4 #######################################\n\n\tprint(\"####################################### Part 4 #######################################\\n\")\n\n\n\tpart4 = Part4()\n\n\tprint (\"Example 1:\")\n\n\tword1 = \"ALIGNMENT\"\n\tword2 = \"SLIME\"\n\n\tmisMatchPenalty = 2\n\tgapPenalty = 1\n\tmatch = 2\n\n\tprint(\"First word : ALIGNMENT\")\n\tprint(\"Second word : SLIME\")\n\tprint(\"Match score : \", 2)\n\tprint(\"Mistmatch score : \", -2)\n\tprint(\"Gap score : \", -1)\n\n\tarr1, arr2, cost = part4.getMin(word1, word2, misMatchPenalty, gapPenalty, match)\n\n\tprint(\"\\nOutput : \")\n\n\tfor i in range(len(arr1)):\n\t print(chr(arr1[i]),end=\" \")\n\n\tprint()\n\t \n\tfor i in range(len(arr2)):\n\t\tprint(chr(arr2[i]),end=\" \")\n\n\tprint (\"\\n\\nCost : \", cost)\n\n\tprint(\"\\nExample 2:\")\n\n\n\tprint(\"First word : Nurullah\")\n\tprint(\"Second word : urah\")\n\tprint(\"Match score : \", 2)\n\tprint(\"Mistmatch score : \", -2)\n\tprint(\"Gap score : \", -1)\n\t\n\tword1 = \"Nurullah\"\n\tword2 = \"urah\"\n\n\tarr1, arr2, cost = part4.getMin(word1, word2, misMatchPenalty, gapPenalty, match)\n\n\tprint(\"\\nOutput : \")\n\n\tfor i in range(len(arr1)):\n\t print(chr(arr1[i]),end=\" \")\n\n\tprint()\n\t \n\tfor i in range(len(arr2)):\n\t\tprint(chr(arr2[i]),end=\" \")\n\n\n\tprint()\n\tprint (\"\\nCost : \", cost)\n\n\tprint(\"\\n\")\n\n\n####################################### Part 5 #######################################\n\n\t\n\n\tprint(\"####################################### Part 5 #######################################\\n\")\n\n\tarr = [5, -3, 4,2,-6,-10,1]\n\n\tpart5 = Part5()\n\n\n\tprint(\"Example 1:\")\n\tprint(\"List : \", arr)\n\n\ts, op = part5.min_number_op(arr)\n\n\tprint(\"Sum of the array : \",s)\n\tprint(\"Number of operations : \",op)\n\tprint()\n\n\tarr = [6,8,19,2,5,7,8]\n\n\tprint (\"Example 2:\")\n\tprint(\"List : \", arr)\n\ts, op = part5.min_number_op(arr)\n\n\tprint(\"Sum of the array : \", s)\n\tprint(\"Number of operations : \", op)\n\n\t\n\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.3852981925010681,
"alphanum_fraction": 0.436269074678421,
"avg_line_length": 27.782434463500977,
"blob_id": "2bc24307b25240c8be42a6cfcb8949dcf9410fb1",
"content_id": "d28d79ad81656cda25cd944a9304132427fcda9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14420,
"license_type": "no_license",
"max_line_length": 224,
"num_lines": 501,
"path": "/Project_2/hw4.py",
"repo_name": "NurullahGundogdu/Algorithm_Projects",
"src_encoding": "UTF-8",
"text": "############################# PART 1 #############################\n\nclass Part1:\n class b:\n\n def convert_special_array(self,arr):\n\n temp = []\n\n change_num = 0\n\n for i in range(len(arr) - 1):\n new = []\n for j in range(len(arr[i]) - 1):\n val = (arr[i][j] + arr[i + 1][j + 1]) - (arr[i][j + 1] + arr[i + 1][j])\n new.append(val)\n\n if val > 0:\n change_num += 1\n\n temp.append(new)\n\n if change_num == 0:\n return arr, 2\n\n num = 0\n\n for i in range(len(temp)):\n for j in range(len(temp[i])):\n if temp[i][j] > 0:\n if self.__helper(temp[i][j], i, j, arr):\n if num == 0:\n num += 1\n else:\n return arr, 0\n else:\n return arr, 0\n\n return arr, 1\n\n\n def __helper(self, value, i, j, arr):\n\n if self.__check(arr, i, j, value * (-1)):\n arr[i][j] -= value\n return True\n\n if self.__check(arr, i, j + 1, value):\n arr[i][j + 1] += value\n return True\n\n if self.__check(arr, i + 1, j, value):\n arr[i + 1][j] += value\n return True\n\n if self.__check(arr, i + 1, j + 1, value * (-1)):\n arr[i + 1][j + 1] -= value\n return True\n\n\n return False\n\n\n def __check(self, arr, i, j, value):\n\n if i - 1 >= 0 and j - 1 >= 0: #sol ust capraz\n if ( arr[i - 1][j - 1] + (arr[i][j] + value) ) - ( arr[i - 1][j] + arr[i + 1][j - 1] ) > 0:\n return False\n\n if i + 1 < len(arr) and j + 1 < len(arr[0]): #sag alt capraz\n if ( arr[i + 1][j + 1] + (arr[i][j] + value) ) - ( arr[i + 1][j] + arr[i][j + 1] ) > 0:\n return False\n\n if i + 1 < len(arr) and j - 1 >= 0: # sol alt capraz\n if ( arr[i + 1][j - 1] + (arr[i][j] + value) ) - ( arr[i][j - 1] + arr[i + 1][j - 1] ) < 0:\n return False\n\n if i - 1 >= 0 and j + 1 < len(arr[0]): #sag ust capraz\n if ( arr[i - 1][j + 1] + (arr[i][j] + value) ) - ( arr[i - 1][j] + arr[i][j + 1] ) < 0:\n return False\n\n return True\n \n\n class c:\n\n def find_leftmost_min(self, special_arr):\n\n index = []\n\n for i in range(len(special_arr)):\n index.append(i)\n\n if len(special_arr) == 1:\n self.__find_row_leftmost_min(special_arr,index,[0])\n return index\n\n odd = len(special_arr) % 2\n\n even_rows, even_index = self.__find_even_and_odd_rows(special_arr[:len(special_arr) - 1], index[:len(index) - 1], [], [], 0, odd)\n odd_rows, odd_index = self.__find_even_and_odd_rows(special_arr, index, [], [], 1, odd)\n\n self.__find_row_leftmost_min(even_rows, index, even_index)\n self.__find_row_leftmost_min(odd_rows, index, odd_index)\n\n return index\n\n\n def __find_row_leftmost_min(self, special_arr, left_mosts, index):\n\n if len(special_arr) == 0:\n return left_mosts\n\n leftMost = special_arr[0][0]\n\n for i in range(len(special_arr[0])):\n if leftMost > special_arr[0][i]:\n leftMost = special_arr[0][i]\n\n left_mosts[index[0]] = leftMost\n\n self.__find_row_leftmost_min(special_arr[1:], left_mosts ,index[1:])\n\n\n def __find_even_and_odd_rows(self, special_arr, index, even_odd_row, ind, type, odd):\n\n if len(special_arr) - (type + 1) >= 0:\n even_odd_row.append(special_arr[len(special_arr) - 1])\n ind.append(index[len(index) - 1])\n self.__find_even_and_odd_rows(special_arr[:-2], index[:-2], even_odd_row, ind, type, odd)\n\n if type == 1 and odd == 1 and len(special_arr) - (type + 1) == -1:\n even_odd_row.append(special_arr[len(special_arr) - 1])\n ind.append(index[len(index) - 1])\n\n return even_odd_row, ind\n\n############################# PART 2 #############################\n\nclass Part2:\n\n def kth_element(self, arr1, arr2, k, arr1_index, arr2_index):\n if arr1_index == len(arr1):\n return arr2[arr2_index + k - 1]\n\n if arr2_index == len(arr2):\n return arr1[arr1_index + k - 1]\n\n if (k == 0) or (k > (len(arr1) - arr1_index) + (len(arr2) - arr2_index)):\n return -1\n\n if k == 1:\n return arr1[arr1_index] if (arr1[arr1_index] < arr2[arr2_index]) else arr2[arr2_index]\n\n size = k // 2\n\n if size - 1 >= len(arr1) - arr1_index:\n return arr2[arr2_index + (k - (len(arr1) - arr1_index) - 1)] if arr1[len(arr1) - 1] < arr2[arr2_index + size - 1] else self.kth_element(arr1, arr2, k - size, arr1_index, arr2_index + size)\n\n if size - 1 >= len(arr2) - arr2_index:\n return arr1[arr1_index + (k - (len(arr2) - arr2_index) - 1)] if arr2[len(arr2) - 1] < arr1[arr1_index + size - 1] else self.kth_element(arr1, arr2, k - size, arr1_index + size, arr2_index)\n\n else:\n return self.kth_element(arr1, arr2, k - size, arr1_index + size, arr2_index) if arr1[size + arr1_index - 1] < arr2[size + arr2_index - 1] else self.kth_element(arr1, arr2, k - size, arr1_index, arr2_index + size)\n\n############################# PART 3 #############################\n\n\nclass Part3:\n\n\n def find_contiguous_subset(self, arr):\n if not arr:\n return None\n\n start, end = self.__helper(arr, 0, len(arr) - 1)\n\n return arr[start:end + 1]\n\n\n def __helper(self, arr, start, end):\n\n if start == end:\n return (start, end)\n\n middle = (start + end) // 2\n\n left = self.__helper(arr, start, middle)\n\n right = self.__helper(arr, middle + 1, end)\n\n return self.__combine(arr, left, right)\n\n\n def __combine(self, arr, left, right):\n\n sum_of_left = sum(arr[left[0]:left[1] + 1])\n\n sum_of_right = sum(arr[right[0]:right[1] + 1])\n\n if (right[0] - left[1]) == 1:\n\n sum_left_right = sum_of_left + sum_of_right\n\n if sum_of_right <= sum_left_right and sum_of_left <= sum_left_right:\n return (left[0], right[1])\n else:\n\n sum_range = sum(arr[left[0]:right[1] + 1])\n\n if sum_of_right <= sum_range and sum_of_left <= sum_range:\n return (left[0], right[1])\n\n return right if sum_of_left < sum_of_right else left\n\n\n############################# PART 4 #############################\n\n\nclass Part4:\n\n def __helper(self,graph, color_of_vertex, position, color, vertex_num):\n\n if color_of_vertex[position] != -1 and color_of_vertex[position] != color:\n return False\n\n color_of_vertex[position] = color\n\n isbipartite = True\n\n for i in range(0, vertex_num):\n\n if graph[position][i] == 1:\n\n if color_of_vertex[i] == -1:\n isbipartite &= self.__helper(graph, color_of_vertex, i, 1 - color, vertex_num)\n\n if color_of_vertex[i] != -1 and color_of_vertex[i] != 1 - color:\n return False\n\n if isbipartite == False:\n return False\n\n return True\n\n\n def isBipartite(self, graph, vertex_num):\n color_of_vertex = [-1] * vertex_num\n\n return self.__helper(graph, color_of_vertex, 0, 1, vertex_num)\n\n\n############################# PART 5 #############################\nclass Part5:\n\n def best_day_buy(self, C, P):\n\n index = []\n\n for i in range(1, len(C) + 1):\n index.append(i)\n\n units, best_day, no_gain = self.__best_day_buy_helper(C, P, index, [])\n\n print(\"The best day to buy goods is the \" + str(best_day) + \" th day.\")\n print(\"Selling day is the \" + str(best_day + 1) + \" th day.\")\n print(\"Maximum possible gain is \" + str(units) + \".\\n\")\n\n if len(no_gain) > 0:\n print(\"Days without earnings : \")\n for i in range(len(no_gain) - 1):\n print(no_gain[i])\n\n\n def __best_day_buy_helper(self,C, P, index, no_gain):\n\n if len(C) == 1 or len(P) == 1: #if arrays size equal to 1 return price - cost and day\n if P[0] - C[0] <= 0: #if there is no gain in that day print to screen no gain in that day\n no_gain.append(\"In the \"+ str(index[0] + 1)+\" th day there is no make money.\")\n\n return P[0] - C[0], index[0], no_gain\n\n elif len(C) == 0 or len(P) == 0:\n return 0, 0, no_gain #if arrays size equal to 0 return 0\n\n left_C = C[: len(C) // 2]\n right_C = C[len(C) // 2:] #arrays are divided two parts\n\n left_P = P[: len(P) // 2]\n right_P = P[len(P) // 2:]\n\n left_indexes = index[: len(index) // 2]\n right_indexes = index[len(index) // 2:]\n\n leftBest, indleft, no_gain = self.__best_day_buy_helper(left_C, left_P, left_indexes, no_gain) #call function for left part\n rightBest, indright, no_gain = self.__best_day_buy_helper(right_C, right_P, right_indexes, no_gain) #call function for right part\n\n\n if leftBest > rightBest: #return gain which is bigger than others\n return leftBest, indleft, no_gain\n else:\n return rightBest, indright, no_gain\n\n\nclass Example:\n\n def part_1(self, arr):\n\n print(\"Input array : \")\n\n for i in range(len(arr)):\n print(arr[i])\n\n\n part1 = Part1()\n c = part1.c().find_leftmost_min(arr)\n\n b, num = part1.b().convert_special_array(arr)\n\n\n\n if num == 1:\n print(\"\\nInput array is converted to special array.\")\n print(\"Output : \")\n for i in range(len(b)):\n print(b[i])\n elif num == 2:\n print(\"\\nInput array is already special array.\")\n else:\n print(\"\\nInput array can't be special array.\")\n\n\n print(\"\\nLeft most elements of input array : \", c, \"\\n\")\n\n def part_2(self, arr1, arr2, k):\n\n part2 = Part2()\n\n print(\"First array : \", arr1)\n print(\"Second array : \", arr2)\n print(k, \"th element : \", part2.kth_element(arr1, arr2, k, 0, 0), \"\\n\")\n\n def part_3(self, arr):\n\n part3 = Part3()\n\n largest_sublist = part3.find_contiguous_subset(arr)\n print(\"Input array : \", arr)\n print(\"The largest contiguous subset for largest sum= \", largest_sublist, \", Sum =\", sum(largest_sublist), \"\\n\")\n\n def part_4(self, graph, vertex_num):\n\n part4 = Part4()\n\n print(\"Input graph : \")\n for i in range(len(graph)):\n print(graph[i])\n\n if part4.isBipartite(graph, vertex_num):\n print(\"\\nYes, it is bipartite.\\n\")\n else:\n print(\"\\nNo, it isn't bipartite.\\n\")\n\n def part_5(self, C, P):\n\n print(\"Cost: \", C)\n print(\"Price: \", P, \"\\n\")\n\n part5 = Part5()\n\n part5.best_day_buy(C, P)\n\n print(\"\\n\")\n\n\n\ndef main():\n\n example =Example()\n\n ############################# PART 1 #############################\n\n print(\"------------------------ PART 1 ------------------------\\n\")\n\n arr = [[37, 23, 22, 32],\n [21, 6, 7, 10],\n [53, 34, 30, 31],\n [32, 13, 9, 6],\n [43, 21, 15, 8]]\n\n\n arr2 = [[10, 17, 13, 28, 23],\n [17, 22, 16, 29, 23],\n [24, 28, 22, 34, 24],\n [11, 13, 6, 17, 7],\n [45, 44, 32, 37, 23],\n [36, 33, 19, 21, 6],\n [75, 66, 51, 53, 34]]\n\n\n arr3 = [[37, 21, 53, 32, 43],\n [23, 6, 34, 13, 21],\n [22, 7, 30, 9, 15],\n [32, 10, 31, 6, 8],\n [15, 15, 30, 9, 15],\n [47, 7, 30, 9, 15]]\n\n example.part_1(arr)\n example.part_1(arr2)\n example.part_1(arr3)\n\n\n\n ############################# PART 2 #############################\n\n print(\"------------------------ PART 2 ------------------------\\n\")\n\n\n arr1 = [2, 3, 6, 7, 9]\n arr2 = [1, 4, 8, 10]\n k1 = 5\n\n arr3 = [0, 2, 9, 13, 17, 25, 61]\n arr4 = [2, 3, 4, 8, 10, 11]\n k2 = 8\n\n arr5 = [0, 1, 5, 9, 18, 23, 54]\n arr6 = [4, 6, 7, 22, 123]\n k3 = 7\n\n\n example.part_2(arr1, arr2, k1)\n example.part_2(arr3, arr4, k2)\n example.part_2(arr5, arr6, k3)\n\n\n ############################# PART 3 #############################\n\n print(\"------------------------ PART 3 ------------------------\\n\")\n\n arr = [5, -6, 6, 7, -6, 7, -4, 3]\n arr1 = [15, -6, -6, 12, 0, 7, -5, 3, 14]\n arr2 = [1, 2, -5, 10, -13, 12, 7, 1]\n\n example.part_3(arr)\n example.part_3(arr1)\n example.part_3(arr2)\n\n ############################# PART 4 #############################\n\n print(\"------------------------ PART 4 ------------------------\\n\")\n\n graph1 = [[0, 1, 0, 1],\n [1, 0, 1, 0],\n [0, 1, 0, 1],\n [1, 0, 1, 0]]\n\n vertex_num_1 = 4\n\n graph2 = [[1, 0, 1, 0],\n [0, 1, 0, 1],\n [1, 0, 1, 0],\n [0, 1, 0, 1]]\n\n vertex_num_2 = 4\n\n\n graph3 = [[0, 1, 0, 0, 0, 1],\n [1, 0, 1, 0, 0, 0],\n [0, 1, 0, 1, 0, 0],\n [0, 0, 1, 0, 1, 0],\n [0, 0, 0, 1, 0, 1],\n [1, 0, 0, 0, 1, 0]]\n\n vertex_num_3 = 6\n\n example.part_4(graph1, vertex_num_1)\n example.part_4(graph2, vertex_num_2)\n example.part_4(graph3, vertex_num_3)\n\n ############################# PART 5 #############################\n\n print(\"------------------------ PART 5 ------------------------\\n\")\n\n C = [5, 11, 2, 21, 5, 7, 8, 12, 13]\n P = [7, 9, 5, 21, 7, 13, 10, 14, 20]\n\n C1 = [15, 11, 22, 21, 5, 30, 18, 2, 3]\n P1 = [7, 9, 5, 21, 7, 13, 10, 14, 20]\n\n C2 = [2, 19, 12, 11, 5, 17, 18, 12, 31]\n P2 = [7, 9, 5, 21, 7, 13, 10, 14, 20]\n\n example.part_5(C, P)\n example.part_5(C1, P1)\n example.part_5(C2, P2)\n\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 3 |
xiqicpt/python-SKCOM-tool
|
https://github.com/xiqicpt/python-SKCOM-tool
|
42a56937df38e58e0b0360e377ccb47f99f1f886
|
40d47a13cfd3eca777c93cad1ee8622660a5df06
|
3fdaeab7b089e54fd683871f9ea79d290df9cb93
|
refs/heads/master
| 2023-05-07T07:05:58.084759 | 2020-03-26T07:37:59 | 2020-03-26T07:37:59 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5461874604225159,
"alphanum_fraction": 0.5848169326782227,
"avg_line_length": 34.7283935546875,
"blob_id": "f97023826b8bce28a981fd33d420be6226792e62",
"content_id": "90f2f2ea81655059604e3e2ef676c0ce0ff6bbf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3021,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 81,
"path": "/F.py",
"repo_name": "xiqicpt/python-SKCOM-tool",
"src_encoding": "UTF-8",
"text": "import win32api\r\nimport win32con\r\nimport os\r\n#\r\ndefaultVersion = \"2.13.20.0\"\r\ninfoDict = {}\r\nID = infoDict\r\n#\r\ndef getOSBit():\r\n import platform\r\n if platform.architecture()[0] == \"64bit\": return \"x64\"\r\n else: \"x84\"\r\ndef checkVersion(COM_path):\r\n if not os.path.isfile(COM_path): \r\n COM_path = \"不存在\"\r\n LastestVersion, LastestVersionName = \"不存在\", \"不存在\"\r\n else:\r\n LastestVersionName = win32api.GetFileVersionInfo(COM_path, '\\\\StringFileInfo\\\\040904b0\\\\ProductName')\r\n LastestVersion = win32api.GetFileVersionInfo(COM_path, '\\\\StringFileInfo\\\\040904b0\\\\FileVersion')\r\n return COM_path, LastestVersionName, LastestVersion\r\ndef getRegCOMPath():\r\n try:\r\n return win32api.RegQueryValue(win32con.HKEY_LOCAL_MACHINE, r\"SOFTWARE\\Classes\\WOW6432Node\\TypeLib\\{75AAD71C-8F4F-4F1F-9AEE-3D41A8C9BA5E}\\1.0\\0\\win32\")\r\n except:\r\n pass\r\n return \"不存在\" \r\ndef getCCModuleCOMPath():\r\n import comtypes.client as cc \r\n ModulePyName = \"_75AAD71C_8F4F_4F1F_9AEE_3D41A8C9BA5E_0_1_0.py\"\r\n ModulePyPath = \"\\\\\".join([cc.gen_dir,ModulePyName])\r\n if not os.path.isfile(ModulePyPath): return \"不存在\"\r\n with open(ModulePyPath, 'r') as f:\r\n f.readline(1000)\r\n data = f.readline(1000)\r\n f.close()\r\n return data[16:-2].replace(\"\\\\\\\\\",\"\\\\\")\r\ndef delCCModule(): \r\n def delFile(path, name):\r\n for fileName in os.listdir(path)[:]:\r\n if fileName.find(name) != -1: \r\n filePath = \"\\\\\".join([path, fileName])\r\n print(\"刪除\", filePath)\r\n os.remove(filePath)\r\n elif len(fileName.split(\".\")) == 1:\r\n filePath = \"\\\\\".join([path, fileName])\r\n delFile(filePath, name)\r\n import comtypes.client as cc \r\n delFile(cc.gen_dir, \"_75AAD71C_8F4F_4F1F_9AEE_3D41A8C9BA5E_0_1_0\")\r\ndef reset():\r\n infoDict['OSBit'] = getOSBit()\r\n infoDict['LastestCOM'] = {}\r\n COM_dir = \"\\\\\".join([os.path.split(__file__)[0], \"元件\", infoDict['OSBit']])\r\n if not os.path.isdir(COM_dir): infoDict['LastestCOM']['dir'] =\"不存在\"\r\n else: infoDict['LastestCOM']['dir'] = COM_dir\r\n\r\n COM_Names = ['LastestCOM', 'regCOM', 'CCCOM']\r\n COM_Paths = []\r\n COM_Paths.append(\"\\\\\".join([COM_dir, \"SKCOM.dll\"]))\r\n COM_Paths.append(getRegCOMPath())\r\n COM_Paths.append(getCCModuleCOMPath())\r\n \r\n for COM_Name, COM_Path in zip(COM_Names, COM_Paths):\r\n path, name, version = checkVersion(COM_Path) \r\n if COM_Name not in infoDict: infoDict[COM_Name] = {}\r\n infoDict[COM_Name]['path'] = path\r\n infoDict[COM_Name]['name'] = name\r\n infoDict[COM_Name]['version'] = version\r\n\r\nreset()\r\n#\r\n\r\n\r\nif __name__ == \"__main__\": \r\n for key in infoDict:\r\n print(key)\r\n if type(infoDict[key]) is dict:\r\n for item in infoDict[key]:\r\n print(item, infoDict[key][item])\r\n else:\r\n print(infoDict[key])\r\n print(\"-\"*20)\r\n\r\n"
},
{
"alpha_fraction": 0.5721969604492188,
"alphanum_fraction": 0.5736449956893921,
"avg_line_length": 43.622642517089844,
"blob_id": "16fc0bd362f24643bea96a682b9912c40ab4f363",
"content_id": "d65e75cdf420563745c6afb875c191fb8b3a68f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5774,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 106,
"path": "/群益SKCOM工具.py",
"repo_name": "xiqicpt/python-SKCOM-tool",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom PyQt5.uic import loadUi\r\nfrom PyQt5.QtWidgets import QApplication,QDialog, QMessageBox\r\nfrom F import *\r\n\r\nclass SKCOMUpdater(QDialog):\r\n def __init__(self):\r\n super(SKCOMUpdater,self).__init__()\r\n loadUi(r'interface.ui',self)\r\n self.resetLabel()\r\n self.Refresh.clicked.connect(self.resetLabel)\r\n self.Check.clicked.connect(self.Check_clicked)\r\n\r\n def resetLabel(self):\r\n reset()\r\n self.OSBit.setText(ID['OSBit'])\r\n self.lastestVersion.setText(ID['LastestCOM']['version'])\r\n self.lastestVersionName.setText(ID['LastestCOM']['name'])\r\n self.lastestVersionPath.setText(ID['LastestCOM']['path']) \r\n self.regVersion.setText(ID['regCOM']['version'])\r\n self.regVersionName.setText(ID['regCOM']['name'])\r\n self.regVersionPath.setText(ID['regCOM']['path']) \r\n self.moduleVersion.setText(ID['CCCOM']['version'])\r\n self.moduleVersionName.setText(ID['CCCOM']['name'])\r\n self.moduleVersionPath.setText(ID['CCCOM']['path']) \r\n \r\n pass\r\n\r\n def Check_clicked(self):\r\n \"\"\"\r\n 檢查三者版本的差異,並顯示提示視窗\r\n \"\"\"\r\n LCV = ID['LastestCOM']['version']\r\n RCV = ID['regCOM']['version']\r\n MCV = ID['CCCOM']['version']\r\n if LCV != defaultVersion:\r\n title = \"資料夾內的COM元件不是最新版本\"\r\n content = \"\\n\".join([\"資料夾內的COM元件 {:}\".format(LCV), \"不是最新版本 {:}\".format(defaultVersion), \"請下載最新群益API的COM替換\"])\r\n showMegBox(self, \"critical\", title, content)\r\n elif LCV == \"不存在\":\r\n title = \"找不到資料夾內的COM元件\"\r\n content = \"\\n\".join([\"找不到資料夾內的COM元件\", \"請重新下載本程式\"])\r\n showMegBox(self, \"critical\", title, content)\r\n elif RCV == \"不存在\":\r\n title = \"尚未註冊或找不到COM元件\"\r\n content = \"\\n\".join([\"尚未註冊或找不到COM元件\", \"請使用「系統管理員身分執行」元件中的「install.bat」以註冊COM元件\"])\r\n showMegBox(self, \"critical\", title, content)\r\n elif LCV != RCV:\r\n title = \"COM註冊版本不是最新版本\"\r\n content = \"\\n\".join([\"COM註冊版本不是最新版本\", \"請使用「系統管理員身分執行」元件中的「Uninstall.bat」「install.bat」以重新註冊COM元件\"])\r\n showMegBox(self, \"critical\", title, content)\r\n elif ID['LastestCOM']['name'] != ID['regCOM']['name']:\r\n title = \"COM註冊版本位元不是正確位元\"\r\n content = \"\\n\".join([\"COM註冊版本位元不是正確位元\", \"請使用「系統管理員身分執行」元件中的「Uninstall.bat」「install.bat」以重新註冊COM元件\"])\r\n showMegBox(self, \"critical\", title, content)\r\n elif ID['CCCOM']['name'] != ID['regCOM']['name']:\r\n title = \"COM註冊版本位元與ComtypesClient模型使用的COM不同\"\r\n content = \"\\n\".join([\"COM註冊版本位元與ComtypesClient模型使用的COM不同\", \"請重新註冊COM元件或再次檢查所使用的COM版本\"])\r\n showMegBox(self, \"critical\", title, content)\r\n title = \"重新生成ComtypesClient模型\"\r\n content = \"\\n\".join([\"重新生成ComtypesClient模型?\", \"若版本有差異,可能會導致群益API無法正常使用!\"])\r\n if showMegBox(self, \"info\", title, content, YesNo = True): \r\n delCCModule() \r\n import comtypes.client as cc\r\n cc.GetModule(ID['LastestCOM']['path'])\r\n elif RCV != MCV and MCV != \"不存在\":\r\n title = \"COM註冊版本與ComtypesClient模型版本不同\"\r\n content = \"\\n\".join([\"COM註冊版本與ComtypesClient模型版本不同\", \"請檢查是否程式使用的COM是否為最新版本\"])\r\n showMegBox(self, \"critical\", title, content)\r\n title = \"刪除舊版本的ComtypesClient模型\"\r\n content = \"\\n\".join([\"是否需要刪除舊版本的ComtypesClient模型?\", \"若版本有差異,可能會導致群益API無法正常使用!\"])\r\n if showMegBox(self, \"info\", title, content, YesNo = True): delCCModule() \r\n # info 等級\r\n elif MCV == \"不存在\":\r\n title = \"尚未生成新版COM的py模組\"\r\n content = \"\\n\".join([\"尚未生成新版COM模組\", \"可以正常執行群益API\"])\r\n showMegBox(self, \"info\", title, content)\r\n title = \"從更新器中產生新版COM的py模組\"\r\n content = \"\\n\".join([\"是否從更新器中產生新版COM的py模組?\"])\r\n if showMegBox(self, \"info\", title, content, YesNo = True): \r\n import comtypes.client as cc\r\n cc.GetModule(ID['LastestCOM']['path'])\r\n else:\r\n title = \"沒有任何異常\"\r\n content = \"\\n\".join([\"沒有檢查到任何錯誤\"]) \r\n showMegBox(self, \"info\", title, content)\r\n\r\n self.resetLabel()\r\n\r\n\r\ndef showMegBox(parent, level, title, content, YesNo = False):\r\n if not YesNo:\r\n if level == \"critical\":\r\n QMessageBox.critical(parent, title, content, QMessageBox.Yes)\r\n else:\r\n QMessageBox.information(parent, title, content, QMessageBox.Yes)\r\n else:\r\n reply = QMessageBox.information(parent, title, content, QMessageBox.Yes|QMessageBox.No, QMessageBox.No)\r\n if reply == 16384: return True\r\n else: return False\r\n\r\nif __name__ == '__main__':\r\n App = QApplication(sys.argv)\r\n Window = SKCOMUpdater()\r\n Window.show()\r\n sys.exit(App.exec_())"
},
{
"alpha_fraction": 0.7468879818916321,
"alphanum_fraction": 0.7800830006599426,
"avg_line_length": 14.0625,
"blob_id": "4782cbf0725f211aa6d3f548e08bfddaa6e8ac3f",
"content_id": "3e7065a4b2cc15dc21006e72ba884a4fa3f5e3f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 16,
"path": "/README.md",
"repo_name": "xiqicpt/python-SKCOM-tool",
"src_encoding": "UTF-8",
"text": "# SKCOM-tool\npython 群益API SKCOM工具\n版本(API):2.13.20\n\n檢查三格位置的SKCOM.dll版本差異與位置:\n1.當前的COM元件\n2.系統已註冊的COM元件\n3.comtypes client所用的COM元件\n\n並且給予相對應的建議動作。\n方便查詢出目前電腦上所使用的版本。\n\n**「三個位置的SKCOM都是最新版本就沒有問題。」**\n\n若不需要GUI,執行「F.py」,查看輸出即可。<br>\n新增 tkinter 版,可以單獨執行。\n"
},
{
"alpha_fraction": 0.5721344947814941,
"alphanum_fraction": 0.6029890179634094,
"avg_line_length": 39.69346618652344,
"blob_id": "4b9f646caa24e34fcaedb383c8c5e22bae5138ce",
"content_id": "b1fdb5acff7ee959e7d27ba8252dc1a19455bdf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9489,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 199,
"path": "/tk.py",
"repo_name": "xiqicpt/python-SKCOM-tool",
"src_encoding": "UTF-8",
"text": "\r\n# 基本功能\r\nimport win32api\r\nimport win32con\r\nimport os\r\nfrom win32api import GetFileVersionInfo\r\nfrom win32api import RegQueryValue\r\nfrom win32con import HKEY_LOCAL_MACHINE\r\nfrom os import listdir, remove\r\nfrom os.path import isfile, isdir\r\nfrom os.path import split as OSPATH_split\r\nfrom comtypes.client import gen_dir, GetModule\r\n#\r\ndefaultVersion = \"2.13.20.0\"\r\ninfoDict = {}\r\nID = infoDict\r\n#\r\ndef getOSBit():\r\n from platform import architecture\r\n if architecture()[0] == \"64bit\": return \"x64\"\r\n else: \"x84\"\r\ndef checkVersion(COM_path):\r\n if not isfile(COM_path): \r\n COM_path = \"不存在\"\r\n LastestVersion, LastestVersionName = \"不存在\", \"不存在\"\r\n else:\r\n LastestVersionName = GetFileVersionInfo(COM_path, '\\\\StringFileInfo\\\\040904b0\\\\ProductName')\r\n LastestVersion = GetFileVersionInfo(COM_path, '\\\\StringFileInfo\\\\040904b0\\\\FileVersion')\r\n return COM_path, LastestVersionName, LastestVersion\r\ndef getRegCOMPath():\r\n try:\r\n return RegQueryValue(HKEY_LOCAL_MACHINE, r\"SOFTWARE\\Classes\\WOW6432Node\\TypeLib\\{75AAD71C-8F4F-4F1F-9AEE-3D41A8C9BA5E}\\1.0\\0\\win32\")\r\n except:\r\n pass\r\n return \"不存在\" \r\ndef getCCModuleCOMPath():\r\n ModulePyName = \"_75AAD71C_8F4F_4F1F_9AEE_3D41A8C9BA5E_0_1_0.py\"\r\n ModulePyPath = \"\\\\\".join([gen_dir,ModulePyName])\r\n if not isfile(ModulePyPath): return \"不存在\"\r\n with open(ModulePyPath, 'r') as f:\r\n f.readline(1000)\r\n data = f.readline(1000)\r\n f.close()\r\n return data[16:-2].replace(\"\\\\\\\\\",\"\\\\\")\r\ndef delCCModule(): \r\n def delFile(path, name):\r\n for fileName in listdir(path)[:]:\r\n if fileName.find(name) != -1: \r\n filePath = \"\\\\\".join([path, fileName])\r\n print(\"刪除\", filePath)\r\n remove(filePath)\r\n elif len(fileName.split(\".\")) == 1:\r\n filePath = \"\\\\\".join([path, fileName])\r\n delFile(filePath, name)\r\n delFile(gen_dir, \"_75AAD71C_8F4F_4F1F_9AEE_3D41A8C9BA5E_0_1_0\")\r\ndef reset():\r\n infoDict['OSBit'] = getOSBit()\r\n infoDict['LastestCOM'] = {}\r\n COM_dir = \"\\\\\".join([OSPATH_split(__file__)[0], \"元件\", infoDict['OSBit']])\r\n if not isdir(COM_dir): infoDict['LastestCOM']['dir'] =\"不存在\"\r\n else: infoDict['LastestCOM']['dir'] = COM_dir\r\n\r\n COM_Names = ['LastestCOM', 'regCOM', 'CCCOM']\r\n COM_Paths = []\r\n COM_Paths.append(\"\\\\\".join([COM_dir, \"SKCOM.dll\"]))\r\n COM_Paths.append(getRegCOMPath())\r\n COM_Paths.append(getCCModuleCOMPath())\r\n \r\n for COM_Name, COM_Path in zip(COM_Names, COM_Paths):\r\n path, name, version = checkVersion(COM_Path) \r\n if COM_Name not in infoDict: infoDict[COM_Name] = {}\r\n infoDict[COM_Name]['path'] = path\r\n infoDict[COM_Name]['name'] = name\r\n infoDict[COM_Name]['version'] = version\r\nreset()\r\n\r\n# 視窗\r\n\r\nfrom tkinter import Label, Button, Tk\r\nfrom tkinter import messagebox\r\ndef tool_init(parent, font=('標楷體', 10)):\r\n parent.l0 = Label(parent, text=\"目前\", font=font)\r\n parent.l1 = Label(parent, text=\"系統位元:\", font=font)\r\n parent.l2 = Label(parent, text=\"目前版本:\", font=font)\r\n parent.l3 = Label(parent, text=\"目前名稱:\", font=font)\r\n parent.l4 = Label(parent, text=\"目前位置:\", font=font)\r\n\r\n parent.l0.place({'x':30, 'y':14})\r\n parent.l1.place({'x':30, 'y':10+30})\r\n parent.l2.place({'x':30, 'y':34+30})\r\n parent.l3.place({'x':30, 'y':58+30})\r\n parent.l4.place({'x':30, 'y':82+30})\r\n\r\n parent.l1r = Label(parent, text=\"註冊\", font=font)\r\n parent.l2r = Label(parent, text=\"目前版本:\", font=font)\r\n parent.l3r = Label(parent, text=\"目前名稱:\", font=font)\r\n parent.l4r = Label(parent, text=\"目前位置:\", font=font)\r\n\r\n parent.l1r.place({'x':30, 'y':10+142})\r\n parent.l2r.place({'x':30, 'y':34+142})\r\n parent.l3r.place({'x':30, 'y':58+142})\r\n parent.l4r.place({'x':30, 'y':82+142})\r\n\r\n parent.l1m = Label(parent, text=\"Comtypes Client\", font=font)\r\n parent.l2m = Label(parent, text=\"目前版本:\", font=font)\r\n parent.l3m = Label(parent, text=\"目前名稱:\", font=font)\r\n parent.l4m = Label(parent, text=\"目前位置:\", font=font)\r\n\r\n parent.l1m.place({'x':30, 'y':10+254})\r\n parent.l2m.place({'x':30, 'y':34+254})\r\n parent.l3m.place({'x':30, 'y':58+254})\r\n parent.l4m.place({'x':30, 'y':82+254})\r\n\r\n parent.Check = Button(parent, text = \"檢查狀況\")\r\n parent.Check[\"command\"] = lambda: Check_clicked(tool)\r\n parent.Check.place({'x':30+200, 'y':400})\r\n parent.Refresh = Button(parent, text = \"更新標籤\")\r\n parent.Refresh[\"command\"] = lambda: Refresh_clicked(tool)\r\n parent.Refresh.place({'x':100+200, 'y':400})\r\n\r\n Refresh_clicked(parent)\r\ndef Refresh_clicked(parent):\r\n reset()\r\n parent.l1['text'] = \"系統位元:\" + ID['OSBit']\r\n parent.l2['text'] = \"目前版本:\" + ID['LastestCOM']['version']\r\n parent.l3['text'] = \"目前名稱:\" + ID['LastestCOM']['name']\r\n parent.l4['text'] = \"目前位置:\" + ID['LastestCOM']['path']\r\n\r\n parent.l2r['text'] = \"目前版本:\" + ID['regCOM']['version']\r\n parent.l3r['text'] = \"目前名稱:\" + ID['regCOM']['name']\r\n parent.l4r['text'] = \"目前位置:\" + ID['regCOM']['path']\r\n\r\n parent.l2m['text'] = \"目前版本:\" + ID['CCCOM']['version']\r\n parent.l3m['text'] = \"目前名稱:\" + ID['CCCOM']['name']\r\n parent.l4m['text'] = \"目前位置:\" + ID['CCCOM']['path'] \r\ndef Check_clicked(parent):\r\n \"\"\"\r\n 檢查三者版本的差異,並顯示提示視窗\r\n \"\"\"\r\n LCV = ID['LastestCOM']['version']\r\n RCV = ID['regCOM']['version']\r\n MCV = ID['CCCOM']['version']\r\n if LCV != defaultVersion:\r\n title = \"資料夾內的COM元件不是最新版本\"\r\n content = \"\\n\".join([\"資料夾內的COM元件 {:}\".format(LCV), \"不是最新版本 {:}\".format(defaultVersion), \"請下載最新群益API的COM替換\"])\r\n messagebox.showerror(title=title, message=content)\r\n elif LCV == \"不存在\":\r\n title = \"找不到資料夾內的COM元件\"\r\n content = \"\\n\".join([\"找不到資料夾內的COM元件\", \"請重新下載本程式\"])\r\n messagebox.showerror(title=title, message=content)\r\n elif RCV == \"不存在\":\r\n title = \"尚未註冊或找不到COM元件\"\r\n content = \"\\n\".join([\"尚未註冊或找不到COM元件\", \"請使用「系統管理員身分執行」元件中的「install.bat」以註冊COM元件\"])\r\n messagebox.showerror(title=title, message=content)\r\n elif LCV != RCV:\r\n title = \"COM註冊版本不是最新版本\"\r\n content = \"\\n\".join([\"COM註冊版本不是最新版本\", \"請使用「系統管理員身分執行」元件中的「Uninstall.bat」「install.bat」以重新註冊COM元件\"])\r\n messagebox.showerror(title=title, message=content)\r\n elif ID['LastestCOM']['name'] != ID['regCOM']['name']:\r\n title = \"COM註冊版本位元不是正確位元\"\r\n content = \"\\n\".join([\"COM註冊版本位元不是正確位元\", \"請使用「系統管理員身分執行」元件中的「Uninstall.bat」「install.bat」以重新註冊COM元件\"])\r\n messagebox.showerror(title=title, message=content)\r\n elif ID['CCCOM']['name'] != ID['regCOM']['name'] and ID['CCCOM']['name'] != \"不存在\" :\r\n title = \"COM註冊版本位元與ComtypesClient模型使用的COM不同\"\r\n content = \"\\n\".join([\"COM註冊版本位元與ComtypesClient模型使用的COM不同\", \"請重新註冊COM元件或再次檢查所使用的COM版本\"])\r\n messagebox.showerror(title=title, message=content)\r\n title = \"重新生成ComtypesClient模型\"\r\n content = \"\\n\".join([\"重新生成ComtypesClient模型?\", \"若版本有差異,可能會導致群益API無法正常使用!\"])\r\n if messagebox.askokcancel(title=title, message=content): \r\n delCCModule() \r\n GetModule(ID['LastestCOM']['path'])\r\n elif RCV != MCV and MCV != \"不存在\":\r\n title = \"COM註冊版本與ComtypesClient模型版本不同\"\r\n content = \"\\n\".join([\"COM註冊版本與ComtypesClient模型版本不同\", \"請檢查是否程式使用的COM是否為最新版本\"])\r\n messagebox.showerror(title=title, message=content)\r\n title = \"刪除舊版本的ComtypesClient模型\" \r\n content = \"\\n\".join([\"是否需要刪除舊版本的ComtypesClient模型?\", \"若版本有差異,可能會導致群益API無法正常使用!\"])\r\n if messagebox.askokcancel(title=title, message=content): delCCModule() \r\n # info 等級\r\n elif MCV == \"不存在\":\r\n title = \"尚未生成新版COM的py模組\"\r\n content = \"\\n\".join([\"尚未生成新版COM模組\", \"可以正常執行群益API\"])\r\n messagebox.showinfo(title=title, message=content)\r\n title = \"從更新器中產生新版COM的py模組\"\r\n content = \"\\n\".join([\"是否從更新器中產生新版COM的py模組?\"])\r\n if messagebox.askokcancel(title=title, message=content): \r\n GetModule(ID['LastestCOM']['path'])\r\n else:\r\n title = \"沒有任何異常\"\r\n content = \"\\n\".join([\"沒有檢查到任何錯誤\"]) \r\n messagebox.showinfo(title=title, message=content)\r\n\r\n Refresh_clicked(parent)\r\n\r\nif __name__ == '__main__':\r\n tool = Tk()\r\n tool.title(\"SKCOM-tool\") \r\n tool.geometry('640x480')\r\n tool_init(tool)\r\n tool.mainloop()"
}
] | 4 |
LOVE-Yourself/bookFBS
|
https://github.com/LOVE-Yourself/bookFBS
|
cba4e8ec4819b5018611edbfba1e5cd8c4dbb78c
|
37aa580133e7f4bd1a86c0b274f7699a3ecfc666
|
d9bcf0f6f95304d37cb9145019787b2277ff0a7e
|
refs/heads/master
| 2021-05-13T12:39:23.312136 | 2018-01-08T13:32:18 | 2018-01-08T13:32:18 | 116,680,675 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6687116622924805,
"alphanum_fraction": 0.6717791557312012,
"avg_line_length": 19.25,
"blob_id": "508543ccd604f00de5bdbb9fe3bdf04e2c5d36dd",
"content_id": "437829c1f02d64688fca36a01cf1df54f1a13f23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 326,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 16,
"path": "/bookObject/items.py",
"repo_name": "LOVE-Yourself/bookFBS",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Define here the models for your scraped items\n#\n# See documentation in:\n# http://doc.scrapy.org/en/latest/topics/items.html\n\nimport scrapy\n\n\nclass BookobjectItem(scrapy.Item):\n\n book_name = scrapy.Field()\n book_img = scrapy.Field()\n author = scrapy.Field()\n book_info = scrapy.Field()\n\n\n"
},
{
"alpha_fraction": 0.6154155135154724,
"alphanum_fraction": 0.6230429410934448,
"avg_line_length": 45.092594146728516,
"blob_id": "e9b7bc6eac3e1123ea0534b935a63fa944622ce9",
"content_id": "d90c0459c9edb8863d81d4f1dda8354b646f8f76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2525,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 54,
"path": "/bookObject/spiders/read.py",
"repo_name": "LOVE-Yourself/bookFBS",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport scrapy\nfrom scrapy.linkextractors import LinkExtractor\nfrom scrapy.spiders import CrawlSpider, Rule\nfrom bookObject.items import BookobjectItem\nfrom scrapy_redis.spiders import RedisCrawlSpider\nimport errno\nclass ReadSpider(RedisCrawlSpider):\n name = 'read'\n allowed_domains = ['www.dushu.com']\n #start_urls = ['https://www.dushu.com/']\n redis_key = 'read:start_urls'\n rules = (\n Rule(LinkExtractor(allow=r'/book/\\d{4}\\.html'),follow=True,callback='parse_page'),#设为true才能继续提取\n Rule(LinkExtractor(allow=r'/book/\\d+_\\d+\\.html'),follow=True,callback='parse_page'),\n )\n\n def parse_item(self, response):\n\n bookitem = BookobjectItem()\n\n bookitem['book_name'] = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/h3/a//text()').extract_first()\n bookitem['book_img'] = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/div/a/img/@src').extract_first()\n\n book_info = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/p[2]')\n bookitem['book_info'] = book_info.xpath(\"string(.)\").extract_first()\n bookitem['author'] =response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/p[1]//text()').extract_first()\n yield bookitem\n\n def parse_page(self, response):\n\n bookitem = BookobjectItem()\n\n bookitem['book_name'] = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/h3/a//text()').extract_first()\n url_info = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/h3/a/@href').extract_first()\n\n new_url = 'http://www.dushu.com'+url_info\n print('----------->', new_url)\n bookitem['book_img'] = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/div/a/img/@src').extract_first()\n\n book_info = response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/p[2]')\n #bookitem['book_info'] = book_info.xpath(\"string(.)\").extract_first()\n bookitem['author'] =response.xpath('//div[@class=\"bookslist\"]/ul/li[1]/div/p[1]//text()').extract_first()\n #try :\n yield scrapy.Request(url=new_url,meta={'item':bookitem},callback=self.parser_info)\n # except:\n # print('该网址失效了!!!')\n\n def parser_info(self,response):\n\n item = response.meta['item']\n item['book_info'] = response.xpath('//div[@class=\"book-summary\"][1]/div[@class=\"border margin-top padding-large\"]/div[@class=\"text txtsummary\"]//text()').extract_first()\n print('------>',item['book_info'])\n yield item\n\n\n"
}
] | 2 |
ricardoramos88/wooldridge
|
https://github.com/ricardoramos88/wooldridge
|
020d59088afaa5f701b3ae94afe78e1acf7d36e3
|
9c6ceb2be681acdd3568b60fc1d7fad74a64fc8a
|
496847b071abff39f2c1b3f8f25b38d456477bb9
|
refs/heads/master
| 2023-05-09T23:51:30.999046 | 2021-06-10T06:15:25 | 2021-06-10T06:15:25 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.669829249382019,
"alphanum_fraction": 0.6736242771148682,
"avg_line_length": 31.9375,
"blob_id": "2c26c5a4f6611f1c462dd7d8197cd1abd9b88fec",
"content_id": "7f72e3dc219ab06ef0c5c2479e7cdfb18e56afd6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1054,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "ricardoramos88/wooldridge",
"src_encoding": "UTF-8",
"text": "import glob\nimport os\nimport sys\nfrom setuptools import find_packages, setup\n\n\nadditional_files = []\nfor filename in glob.iglob('./wooldridge/**', recursive=True):\n if '.csv.bz' in filename:\n additional_files.append(filename.replace('./wooldridge/', ''))\n\nfor filename in glob.iglob('./wooldridge/**', recursive=True):\n if '.txt' in filename:\n additional_files.append(filename.replace('./wooldridge/', ''))\n\nsetup(\n name='wooldridge',\n version='0.4.4',\n author='Tetsu Haruyama',\n author_email='[email protected]',\n packages=find_packages(),\n package_dir={'wooldridge': './wooldridge'},\n include_package_data=True,\n package_data={'wooldridge': additional_files},\n install_requires=['pandas'],\n url='https://github.com/spring-haru/wooldridge',\n license='LICENSE',\n description='Data sets from Introductory Econometrics: A Modern Approach (6th ed, J.M. Wooldridge)',\n long_description=open('README.md').read(),\n long_description_content_type='text/markdown',\n keywords=['data', 'wooldridge', 'econometrics']\n)\n"
},
{
"alpha_fraction": 0.739329993724823,
"alphanum_fraction": 0.7457549571990967,
"avg_line_length": 35.31666564941406,
"blob_id": "c7ce86948edfa492744b31aadef105066069970e",
"content_id": "a9d93d9fd4f695e1f56ed62a5fea0e6282d10f3b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2199,
"license_type": "permissive",
"max_line_length": 303,
"num_lines": 60,
"path": "/README.md",
"repo_name": "ricardoramos88/wooldridge",
"src_encoding": "UTF-8",
"text": "[](https://pypi.python.org/pypi/wooldridge/)\n[](https://github.com/spring-haru/wooldridge/actions?query=workflow%codeql-analysis)\n[](https://pepy.tech/project/wooldridge)\n\n# Wooldridge Meets Python\n### Data sets from _Introductory Econometrics: A Modern Approach_ (7th ed, J.M. Wooldridge)\n\n## Description\nA Python package which contains 111 data sets from one of the most famous **econometrics** textbooks for undergraduates.\n\nIt is extensively used in [Pythonで学ぶ入門計量経済学](https://py4etrics.github.io) (Japanese). Its Google-translated version (in the language of your choice) is also available in [Learning Introductory Econometrics with Python](https://translate.google.com/translate?sl=auto&tl=en&u=https://py4etrics.github.io).\n\nIt is also used in [Using Python for Introductory Econometrics](http://www.upfie.net), which is a sister book [Using R for Introductory Econometrics](http://www.urfie.net).\n\n## How to Use\nFirst things first.\n```\nimport wooldridge\n```\nTo load a data set named `<dataset>`:\n```\nwooldridge.data('<dataset>')\n```\nIt returns pandas `DataFrame`. Note that `<dataset>` is entered in strings. For example, to load a data set `mroz` into `df`:\n```\ndf = wooldridge.data('mroz')\n```\nTo show the description (e.g. variable definitions and sources) of a data set:\n```\nwooldridge.data('mroz', description=True)\n```\nTo show the list of 111 data sets contained in the package\n```\nwooldridge.data()\n```\n\n## How to Install\n```\npip install wooldridge\n```\nor\n```\ngit clone https://github.com/spring-haru/wooldridge.git\npip install .\n```\n\n## Note\nThe function `dataWoo()` introduced in the previous versions also works:\n```\nfrom wooldridge import *\n\ndf = dataWoo('<dataset>')\n\ndataWoo('<dataset>', description=True)\n\ndataWoo()\n```\n\n#### Reference\nJ.M. Wooldridge (2019) _Introductory Econometrics: A Modern Approach_, Cengage Learning, 7th edition.\n"
},
{
"alpha_fraction": 0.5760368704795837,
"alphanum_fraction": 0.6082949042320251,
"avg_line_length": 18.727272033691406,
"blob_id": "d724b573df3ab4a587f59ada0b67c1a2fdb0b1b0",
"content_id": "32ca9492793f7d67deb9974b59198b84beaf2a7c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 217,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 11,
"path": "/wooldridge/__init__.py",
"repo_name": "ricardoramos88/wooldridge",
"src_encoding": "UTF-8",
"text": "\"\"\"\nGithub page: https://github.com/spring-haru/wooldridge\n\"\"\"\n\nfrom .load_data import *\n\n__all__ = ['data', 'dataWoo']\n\n__author__ = 'Tetsu Haruyama'\n__version__ = '0.4.4'\n__copyright__ = 'Copyright (c) 2021 Tetsu Haruyama'\n"
},
{
"alpha_fraction": 0.5344900488853455,
"alphanum_fraction": 0.5666525363922119,
"avg_line_length": 43.58490753173828,
"blob_id": "02526f3c6f8b1d21ce4448db8f4c3b27599e0b79",
"content_id": "713527447107805e02a31285cc0d06842fd247e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2363,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 53,
"path": "/wooldridge/load_data.py",
"repo_name": "ricardoramos88/wooldridge",
"src_encoding": "UTF-8",
"text": "from os.path import abspath, join, split\nimport pandas as pd\n\n\ndef get_path(f):\n return split(abspath(f))[0]\n\n\nlst = \"\"\"\\\n J.M. Wooldridge (2016) Introductory Econometrics: A Modern Approach,\n Cengage Learning, 6th edition.\n\n 401k 401ksubs admnrev affairs airfare\n alcohol apple approval athlet1 athlet2\n attend audit barium beauty benefits\n beveridge big9salary bwght bwght2 campus\n card catholic cement census2000 ceosal1\n ceosal2 charity consump corn countymurders\n cps78_85 cps91 crime1 crime2 crime3\n crime4 discrim driving earns econmath\n elem94_95 engin expendshares ezanders ezunem\n fair fertil1 fertil2 fertil3 fish\n fringe gpa1 gpa2 gpa3 happiness\n hprice1 hprice2 hprice3 hseinv htv\n infmrt injury intdef intqrt inven\n jtrain jtrain2 jtrain3 kielmc lawsch85\n loanapp lowbrth mathpnl meap00_01 meap01\n meap93 meapsingle minwage mlb1 mroz\n murder nbasal nyse okun openness\n pension phillips pntsprd prison prminwge\n rdchem rdtelec recid rental return\n saving sleep75 slp75_81 smoke traffic1\n traffic2 twoyear volat vote1 vote2\n voucher wage1 wage2 wagepan wageprc\n wine\"\"\"\n\ndef data(name=None, description=False):\n if (name != None) & (description == False):\n return pd.read_csv(join(get_path(__file__), \"datasets/\" + name + \".csv.bz2\"), compression=\"bz2\")\n elif (name != None) & (description == True):\n with open(join(get_path(__file__), 'description/' + name + '.txt'), 'r', encoding=\"utf-8\") as f:\n print(f.read())\n elif name == None:\n print(lst)\n\ndef dataWoo(name=None, description=False):\n if (name != None) & (description == False):\n return pd.read_csv(join(get_path(__file__), \"datasets/\" + name + \".csv.bz2\"), compression=\"bz2\")\n elif (name != None) & (description == True):\n with open(join(get_path(__file__), 'description/' + name + '.txt'), 'r', encoding=\"utf-8\") as f:\n print(f.read())\n elif name == None:\n print(lst)\n"
},
{
"alpha_fraction": 0.7146596908569336,
"alphanum_fraction": 0.7395287752151489,
"avg_line_length": 62.66666793823242,
"blob_id": "afd3cc03b3d65c2cf6a1cc42341d001af0fc9231",
"content_id": "f9303be39accd88b46f32e229d6975139d5d2352",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 764,
"license_type": "permissive",
"max_line_length": 218,
"num_lines": 12,
"path": "/raw_data/explanations.md",
"repo_name": "ricardoramos88/wooldridge",
"src_encoding": "UTF-8",
"text": "#### data_R\n* `.RData` and `.r` files are obtained from [here](http://academic.cengage.com/resource_uploads/downloads/130527010X_514733.zip).\n\n#### data_csv\n* Created from data files from `.RData` and `.r` files in the `data_R` folder. [pyreadr](https://github.com/ofajardo/pyreadr) is used for `.RData`. Regarding the `.r` files, just replace the file extension with `.csv`.\n\n#### data_info\n* Extrated from `.RData` which combines data and data description.\n\n#### data_source\n* `source_5e.txt` is borrowed from [here](https://github.com/JustinMShea/wooldridge/blob/master/data-raw/WooldridgeDataSetHandbook_5eUTF.txt)\n* `source_6e.txt` is also taken from [here](https://github.com/JustinMShea/wooldridge/blob/master/data-raw/WooldridgeDataSetHandbook_6eUTF.txt)\n"
}
] | 5 |
dpksh77/AAVAAZ
|
https://github.com/dpksh77/AAVAAZ
|
5c12efcc382d0229af4edc0f1837a395c06b6321
|
3db70207114fefd2e41cdc3f2a58113b2fd5673f
|
6823dced847630f724f4caecbcc7ed38bad9a83f
|
refs/heads/master
| 2020-12-05T00:56:41.750659 | 2020-01-20T18:08:00 | 2020-01-20T18:08:00 | 224,176,703 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7906976938247681,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 20.5,
"blob_id": "8b91e76a1e45ee5fddcc34b8d72116080b29a519",
"content_id": "46b8d843f994e4b0fa969a9d005c3160cf2d7f0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 2,
"path": "/README.md",
"repo_name": "dpksh77/AAVAAZ",
"src_encoding": "UTF-8",
"text": "# AAVAAZ\nIt is a social networking website\n"
},
{
"alpha_fraction": 0.7553191781044006,
"alphanum_fraction": 0.7553191781044006,
"avg_line_length": 17.799999237060547,
"blob_id": "c14f4dd750e3895f41675cf0ef1b51707bcf8c99",
"content_id": "c5ae5ef468335643e8da6cdc83dc0c0f92897152",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/AAVAAZ/AAVAAZ_APP/apps.py",
"repo_name": "dpksh77/AAVAAZ",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass AavaazAppConfig(AppConfig):\n name = 'AAVAAZ_APP'\n"
}
] | 2 |
Sharathpavan007/fabrictest
|
https://github.com/Sharathpavan007/fabrictest
|
8cd32ecd5ecabc45aff45968c7151ded1b5b7167
|
fe0c782b7ef5681743e5c78656fb7f5fc1698611
|
2c80e23c43b0ca08be4aaacc0f6326aac2cee09b
|
refs/heads/master
| 2021-01-20T10:28:45.671118 | 2017-05-05T08:53:23 | 2017-05-05T08:53:23 | 90,355,630 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.701886773109436,
"alphanum_fraction": 0.7207547426223755,
"avg_line_length": 43,
"blob_id": "30cd9a1df91225fd84c3631a2478aef1233ad134",
"content_id": "508acea3e31d3b40902986360298a850adb8f873",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 6,
"path": "/fabfile.py",
"repo_name": "Sharathpavan007/fabrictest",
"src_encoding": "UTF-8",
"text": "from fabric.api import local\n\ndef test1():\n\tlocal(\"cd /home/devops/fabric/fabrictest && touch file1 file2 file3\")\n\tlocal(\"cd /home/devops/fabric/fabrictest && git add . && git commit -m test1\")\n\tlocal(\"cd /home/devops/fabric/fabrictest && git push origin master\")\n\n"
}
] | 1 |
orichamaru/Final_Blockchain_Course_Project
|
https://github.com/orichamaru/Final_Blockchain_Course_Project
|
172f1cdb073f9b2540286d67613a72541777bf59
|
eae023442d11760c100a560493f0cce2e2ef6825
|
a112a99c357060f449d4a3b751f24e130d439328
|
refs/heads/main
| 2023-06-04T08:37:50.446028 | 2021-06-19T07:14:25 | 2021-06-19T07:14:25 | 358,647,888 | 0 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.585418164730072,
"alphanum_fraction": 0.5882773399353027,
"avg_line_length": 24.907407760620117,
"blob_id": "3fbecc6ff57c09c4d0f4649e80356641d2e10a8e",
"content_id": "16fa5c859adef775ba9e7a5ddf9f6d6ddeac3931",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1399,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 54,
"path": "/generate_wallet.py",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "from Crypto.PublicKey import RSA\nfrom Crypto import Random\nimport binascii\n\n\nclass Wallet:\n\n def __init__(self, name=''):\n self.public_key = ''\n self.private_key = ''\n self.name = name\n\n def generate_keys(self):\n random_generator = Random.new().read\n key = RSA.generate(1024, random_generator)\n private, public = key, key.publickey()\n\n self.private_key = binascii.hexlify(\n private.exportKey(format='DER')).decode('ascii')\n self.public_key = binascii.hexlify(\n public.exportKey(format='DER')).decode('ascii')\n\n def get_keys(self):\n\n self.generate_keys()\n\n private = open(self.name + \"_private.txt\", \"w\")\n public = open(self.name + \"_public.txt\", \"w\")\n\n private.write(self.private_key)\n private.close()\n\n public.write(self.public_key)\n public.close()\n\n def import_key(self):\n\n private = open(self.name + \"_private.txt\", \"r\")\n self.private_key = private.readline()\n\n public = open(self.name + \"_public.txt\", \"r\")\n self.public_key = public.readline()\n\n def generate_recipient_key(self, name):\n\n public_key = open(name + \"_public.txt\", \"r\")\n recipient_public_key = public_key.readline()\n\n return recipient_public_key\n\n\nif __name__ == \"__main__\":\n name = input(\"Enter Your name\\n\")\n Wallet(name).get_keys()\n"
},
{
"alpha_fraction": 0.7589552402496338,
"alphanum_fraction": 0.7746268510818481,
"avg_line_length": 43.63333511352539,
"blob_id": "59650ccb5d12f681aa3db1cea57838f55ef50444",
"content_id": "0082bfb83c15058fd37ceca3c63b66413f2f2dfa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2680,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 60,
"path": "/README.md",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "# Final Blockchain_Course_Project\n\n## Implementation of Cryptocurrency using Blockchain from scratch\n\n### Steps for installation\n\n1. Clone this project using terminal or zip it.\n2. Open folder containing this project and run terminal\n\n\n### Assumptions\n\n1. All users intially are provided with 50 tokens.\n2. All nodes in network are hard nodes i.e they will can make transaction as well as mine a block.\n3. Transaction fees rate is 5% will be dedcuted from your account and will be credited to miner account upon successful addition of block into network.\n4. For now upon addition of 2 transaction in transaction book, everyone starts mining.\n\n\n\n\n### Steps for Generation Key Pair to become valid user of network \n\n1. For transaction you need to have wallet i.e private and public key pair , to generated key pair run below command and enter your name\n '''\n python3 generate_wallet.py\n ''' \n2. Your key pairs are saved in your wallet with your name\n3. Now you have your key pair , then you are ready to make transaction in blockchain network :smile:\n\n\n### Steps for getting connected to blockchain network\n\n#### Creating blockchain network for first time\n1. If network isn't created , then first run python3 client.py , add your port number and for first time connection(i.e for first node) enter -1.\n2. Above step creates blockchain network.\n\n#### Getting connected to existing blockchain network\n1. Run ''' python3 client.py ''' , enter your port number.\n2. For getting connected to network enter port number of any node which is connected in network.\n\n\n\n### Operations available \n\nAfter getting connected to network you will be prompted with following options\n1. Create transaction\n2. Getting information of last block of network\n3. Getting list of available transaction\n4. Getting information about your wallet\n\n\n\n### Steps for making transaction blockchain network\n\n1. After pressing 1, you will be asked for your name to fetch your wallet credentials.(Enter same name which you have typed while wallet generation).\n2. Then you, will be asked for reciever's name, enter his/her name.\n3. After that you will be asked for transaction amount,\n4. If all entries are legitimate, then your transaction will be recored in transaction book of every miner.\n5. As soon as number of transactions are sufficient in transaction book , then upon successfull mining you will be notified accordingly.\n6. Hurray your transaction is successfully added in network now :smile:\n\n\n"
},
{
"alpha_fraction": 0.5925076603889465,
"alphanum_fraction": 0.5970947742462158,
"avg_line_length": 30.329341888427734,
"blob_id": "8fe425fa9f87bfd8a68db04fe04131a470fa84d2",
"content_id": "b677358c42927caf696aaade201d5ea11411ae57",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5232,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 167,
"path": "/blockchain_network.py",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "from Crypto.PublicKey import RSA\nfrom Crypto.Signature import PKCS1_v1_5\nfrom Crypto.Hash import SHA\nimport binascii\nimport hashlib\nimport json\nfrom block import Block\nimport time\n\nDIFFICULTY = 5\ntime_limit = 10 # seconds\n\n\nclass Blockchain:\n COMMISSION = 'commision'\n\n def __init__(self):\n self.peers = []\n self.transactions = []\n self.chain = []\n self.isStopped = False\n self.maxTransactionTimeStamp = -1\n self.create_genesis_block()\n\n # Create Genesis Block\n def create_genesis_block(self):\n genesis_block = Block(DIFFICULTY)\n self.chain.append(genesis_block)\n\n # Adding peer\n def addPeers(self, obj):\n if isinstance(obj, list):\n for k in obj:\n if isinstance(k, int) and k not in self.peers:\n self.peers.append(k)\n\n elif isinstance(obj, int) and obj not in self.peers:\n self.peers.append(obj)\n return True\n\n def removePeer(self, obj):\n self.peers.remove(obj)\n\n def replaceChain(self, chain):\n if self.verify_chain(chain):\n self.chain = chain\n self.maxTransactionTimeStamp = -1\n for block in self.chain:\n for t in block.transactions:\n self.maxTransactionTimeStamp = max(\n self.maxTransactionTimeStamp, t['timestamp'])\n\n def verify_chain(self, chain):\n # verifyication of new chain should be done here\n return True\n\n def get_balance(self, pubKey):\n balance = 0\n for block in self.chain:\n for t in block.transactions:\n if t['sender_public_key'] == pubKey:\n balance = balance - t['amount']\n if t['recipient_public_key'] == pubKey:\n balance = balance + t['amount']\n return balance\n\n # Return last block\n\n def last_block_chain(self):\n return self.chain[-1]\n\n # Proof of work\n def proof_of_work(self, block):\n last_block = self.last_block_chain()\n difficulty = DIFFICULTY\n\n if last_block.index != 0:\n if last_block.minedAt - last_block.timestamp < time_limit:\n difficulty = last_block.difficulty + 1\n elif last_block.minedAt - last_block.timestamp > time_limit:\n difficulty = last_block.difficulty - 1\n else:\n difficulty = last_block.difficulty\n\n # block - block which needs to be added\n block.difficulty = difficulty\n block.nonce = 0\n while not self.is_block_valid(block) and self.isStopped == False:\n block.nonce += 1\n\n if self.isStopped == False:\n block.minedAt = time.time()\n\n # Calculate hash of block\n def calculate_hash_of_block(self, block):\n\n string_format_block = json.dumps(block.get_block_data(),\n sort_keys=True).encode()\n return hashlib.sha256(string_format_block).hexdigest()\n\n # Add transaction to blockchain network\n def verify_transaction(self, transaction, digital_signature):\n\n sender_public_key = transaction['sender_public_key']\n\n # If any other check you want to perform -----------------\n\n if digital_signature == self.COMMISSION:\n return True\n\n if (self.verify_signature(sender_public_key, transaction,\n digital_signature)):\n return True\n else:\n return False\n\n # Verifying transaction singature\n def verify_signature(self, sender_public_key, transaction,\n digital_signature):\n\n public_key = RSA.importKey(binascii.unhexlify(sender_public_key))\n verifier = PKCS1_v1_5.new(public_key)\n message = SHA.new(str(transaction).encode('utf8'))\n\n return verifier.verify(message, binascii.unhexlify(digital_signature))\n\n # Checking validity of block to be added\n def is_block_valid(self, block):\n\n # Calculate hash of block items\n\n block_hash = self.calculate_hash_of_block(block)\n\n return block_hash[:block.difficulty] == '0' * block.difficulty\n\n # Add block to blockchain network\n def add_block(self, block):\n self.chain.append(block)\n\n for t in block.transactions:\n self.maxTransactionTimeStamp = max(self.maxTransactionTimeStamp,\n t['timestamp'])\n\n # Mining of block\n def mine(self, transactions, minerId, timestamp):\n\n prev_block = self.last_block_chain()\n prev_hash = self.calculate_hash_of_block(prev_block)\n\n # Creating new block\n new_block = Block(DIFFICULTY)\n\n new_block.minerId = minerId\n new_block.index = prev_block.index + 1\n new_block.previous_hash = prev_hash\n\n # Coinbase transaction is also included\n # new_block.transactions = self.get_reward(self.available_transactions) ## need to implement\n\n new_block.transactions = transactions\n new_block.timestamp = timestamp\n\n # Nonce is correctily calculated\n self.proof_of_work(new_block)\n\n # This valid block will be added to block chain\n return new_block\n"
},
{
"alpha_fraction": 0.5463300943374634,
"alphanum_fraction": 0.5502135753631592,
"avg_line_length": 29.581947326660156,
"blob_id": "ac00f3d920e7c773e1368b9bb25105869173f1f6",
"content_id": "846b972886e6b34c0379aecdba8d9f5ff75fb364",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12875,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 421,
"path": "/client.py",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "import select\nimport socket\nimport pickle\nimport threading\nimport time\nfrom transaction import Transaction\nfrom blockchain_network import Blockchain\nfrom generate_wallet import Wallet\n\n# global blockchain object\nglobal_chain_object = Blockchain()\n\nthread = None\n\nTIMEOUT = 30 # seconds\n\nCHAINREQUEST = -3\nPEERREQUEST = -2\nNEWPEER = -1\n\nBLOCK = 1\nTRSANSACTION = 2\n\nINTITIAL_BALANCE = 50\nMYPORT = -1\n\nCOMMISSION_RATE = 5/100 # percentage\nCOMMISSION = Blockchain.COMMISSION\n\nTRANSACTION_PER_BLOCK = 2\n\npub_key = None\n\n\ndef sendData(port, message, type):\n global global_chain_object\n try:\n clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n clientSocket.connect((\"localhost\", port))\n dic = {'type': type, 'message': message}\n clientSocket.send(pickle.dumps(dic))\n clientSocket.close()\n except Exception as e:\n global_chain_object.removePeer(port)\n print(e)\n\n\ndef recvall(sock):\n BUFF_SIZE = 4096 # 4 KiB\n data = b''\n while True:\n part = sock.recv(BUFF_SIZE)\n data += part\n if len(part) < BUFF_SIZE:\n # either 0 or end of data\n break\n return data\n\n\ndef extractMessage(data):\n dic = pickle.loads(data)\n return dic['type'], dic['message']\n\n\ndef broadcast(message, type):\n global global_chain_object\n for port in global_chain_object.peers:\n if port != MYPORT:\n sendData(port, message, type)\n\n\ndef askPeers(firstPeer):\n global global_chain_object\n\n clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n try:\n clientSocket.connect((\"localhost\", firstPeer))\n\n dic = {'type': PEERREQUEST, \"message\": MYPORT}\n clientSocket.send(pickle.dumps(dic))\n\n data = recvall(clientSocket)\n clientSocket.close()\n\n _, message = extractMessage(data)\n\n global_chain_object.addPeers(message)\n\n except Exception as e:\n clientSocket.close()\n print(e)\n\n\ndef askChain(peer):\n global global_chain_object\n\n clientSocket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n try:\n clientSocket.connect((\"localhost\", peer))\n\n dic = {'type': CHAINREQUEST, \"message\": MYPORT}\n clientSocket.send(pickle.dumps(dic))\n\n data = recvall(clientSocket)\n clientSocket.close()\n\n _, message = extractMessage(data)\n\n global_chain_object.replaceChain(message)\n\n except Exception as e:\n clientSocket.close()\n print(e)\n\n\ndef generateMinerWallet():\n global pub_key\n\n wallet = Wallet(str(MYPORT))\n wallet.get_keys()\n\n pub_key = wallet.public_key\n\n\ndef publish(answer):\n print(\"\\nSolved Problem\\n\")\n\n T = threading.Thread(target=broadcast, args=(\n {'block': answer, 'port': MYPORT}, BLOCK,))\n T.setDaemon(True)\n T.start()\n\n\ndef counterDoubleSpend(dic, transaction):\n global global_chain_object\n if transaction['sender_public_key'] in dic:\n dic[transaction['sender_public_key']] = dic[transaction['sender_public_key']\n ] - (1+COMMISSION_RATE)*transaction['amount']\n else:\n dic[transaction['sender_public_key']] = - (1+COMMISSION_RATE)*transaction['amount'] + \\\n global_chain_object.get_balance(\n transaction['sender_public_key']) + INTITIAL_BALANCE\n\n return dic[transaction['sender_public_key']] >= 0\n\n\ndef compare(item):\n return item['timestamp']\n\n\ndef worker():\n global global_chain_object\n global thread\n global pub_key\n\n global_chain_object.transactions.sort(key=compare)\n\n while len(global_chain_object.transactions) >= 2 and (not global_chain_object.isStopped):\n\n toDrop = None\n\n with threading.Lock():\n timestamp = time.time()\n transactions = []\n dic = {}\n\n if(global_chain_object.transactions[0]['timestamp'] > global_chain_object.transactions[1]['timestamp']):\n temp = global_chain_object.transactions[0]\n global_chain_object.transactions[0] = global_chain_object.transactions[1]\n global_chain_object.transactions[1] = temp\n\n for i in range(TRANSACTION_PER_BLOCK):\n problem = global_chain_object.transactions[i]\n\n new_transaction = Transaction(\n problem['amount'] * COMMISSION_RATE, problem['sender_public_key'], pub_key, timestamp)\n new_transaction.signature = COMMISSION\n\n if not new_transaction.verifyIt(global_chain_object):\n print(\"\\nError in Commission\\n\")\n Transaction.printIt(new_transaction)\n toDrop = problem\n break\n\n if not counterDoubleSpend(dic, problem):\n print(\"\\nInsuficient balance\\n\")\n Transaction.printIt(problem)\n toDrop = problem\n break\n\n if(problem['timestamp'] < global_chain_object.maxTransactionTimeStamp):\n print(\"timestamp is less then \" +\n str(global_chain_object.maxTransactionTimeStamp))\n Transaction.printIt(problem)\n toDrop = problem\n break\n\n transactions.append(problem)\n transactions.append(new_transaction.get_transaction_bill())\n\n if toDrop != None:\n global_chain_object.transactions.remove(toDrop)\n else:\n for k in transactions:\n if k in global_chain_object.transactions:\n global_chain_object.transactions.remove(k)\n\n if toDrop != None:\n continue\n\n new_block = global_chain_object.mine(transactions, MYPORT, timestamp)\n\n # block verifyication and insertion shuld not be done parallely\n\n with threading.Lock():\n if global_chain_object.isStopped:\n return\n else:\n # Appending new block to global blockchain\n global_chain_object.add_block(new_block)\n # publishing new block\n publish(new_block)\n\n\ndef startThread():\n global thread\n global global_chain_object\n\n global_chain_object.isStopped = True\n\n if thread != None:\n thread.join()\n\n thread = None\n\n # Atleast having two transactions in pool\n if len(global_chain_object.transactions) >= 2:\n global_chain_object.isStopped = False\n thread = threading.Thread(target=worker)\n thread.setDaemon(True)\n thread.start()\n\n\ndef stopThread():\n global global_chain_object\n global thread\n global_chain_object.isStopped = True\n\n\ndef handle_new_transaction(new_transaction):\n global global_chain_object\n global thread\n\n # self verifying\n if(new_transaction.verifyIt(global_chain_object)):\n with threading.Lock():\n global_chain_object.transactions.append(\n new_transaction.get_transaction_bill())\n startThread()\n return True\n\n return False\n\n\ndef handle_new_block(new_block, port):\n global global_chain_object\n\n # block checking or insertion shuld otbe done parallely\n with threading.Lock():\n prev_block = global_chain_object.last_block_chain()\n prev_hash = global_chain_object.calculate_hash_of_block(\n prev_block)\n\n if(prev_block.index + 1 == new_block.index and prev_hash == new_block.previous_hash):\n stopThread()\n global_chain_object.add_block(new_block)\n\n print('\\n Valid Block is Mined By another miner \\n')\n new_block.printIt()\n\n elif prev_block.index + 2 == new_block.index:\n askChain(port)\n\n startThread() # this start thread function should not be kept under the lock\n\n\nMYPORT = (int)(input(\"enter the alloted port number\\n\"))\nserver = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n\nserver_address = ('localhost', MYPORT)\nprint(\"binding up on port\")\nserver.bind(server_address)\nserver.listen(10)\n\n\nfirstPeer = (int)(\n input(\"enter the port number of first peer or -1 if iam the first\\n\"))\n\nif firstPeer != -1:\n global_chain_object.addPeers(firstPeer)\n askPeers(firstPeer)\n askChain(firstPeer)\n\ngenerateMinerWallet()\n\nprint('\\nPrint 1 for transaction , 2 for last block, 3 for available transactions, 4 to get balance')\n\nRUN = True\nwhile RUN:\n try:\n r, _, _ = select.select([server, 0], [], [], TIMEOUT)\n\n for fd in r:\n if fd == -1:\n print(\"Something Goes Wrong\")\n RUN = False\n break\n\n if fd == 0:\n try:\n x = int(input())\n\n # Transaction\n if(x == 1):\n timestamp = time.time()\n\n sender_name = input(\n 'Enter your name (Make sure your key pairs exists)\\n')\n\n # Instantiating Wallet and Fetching Credentials\n wallet = Wallet(sender_name)\n wallet.import_key()\n sender_public_key = wallet.public_key\n sender_private_key = wallet.private_key\n print('\\nKeys successfully imported\\n')\n\n amount = int(input('\\nEnter amount\\n'))\n\n recipient_name = input(\n '\\nEnter recipient name (Make sure key pair exists)\\n')\n recipient_public_key = wallet.generate_recipient_key(\n recipient_name)\n print('\\n Recipient Address Successfully fetched \\n')\n\n new_transaction = Transaction(\n amount, sender_public_key, recipient_public_key, timestamp)\n new_transaction.sign_transaction(sender_private_key)\n\n if handle_new_transaction(new_transaction):\n\n # broadcasting to all nodes\n broadcast(new_transaction, TRSANSACTION)\n\n print('\\nTransaction Successfully Added and Broadcasted\\n')\n else:\n print('\\nWrong Transaction\\n')\n\n # Get Last Block of Chain\n if(x == 2):\n print('\\nLast Block of Chain is \\n')\n global_chain_object.last_block_chain().printIt()\n\n # Available Transactions\n if(x == 3):\n if(len(global_chain_object.transactions) == 0):\n print('\\nNo due transactions are left\\n')\n else:\n for t in global_chain_object.transactions:\n Transaction.printIt(t)\n\n if x == 4:\n wallet = Wallet()\n name = input('\\nEnter your name\\n')\n public_key = wallet.generate_recipient_key(name)\n print(\n \"\\nBalance \"+str(global_chain_object.get_balance(public_key) + INTITIAL_BALANCE)+'\\n')\n \n except Exception as e:\n print(e)\n\n else:\n try:\n connection, client_address = server.accept()\n\n data = recvall(connection)\n type, message = extractMessage(data)\n\n if type == PEERREQUEST:\n dic = {\"type\": \"none\",\n \"message\": global_chain_object.peers}\n connection.send(pickle.dumps(dic))\n\n if global_chain_object.addPeers(message):\n broadcast(message, NEWPEER)\n\n elif type == CHAINREQUEST:\n dic = {\"type\": \"none\",\n \"message\": global_chain_object.chain}\n connection.send(pickle.dumps(dic))\n\n elif type == NEWPEER:\n global_chain_object.addPeers(message)\n\n elif type == TRSANSACTION:\n if handle_new_transaction(message):\n print(\n '\\nRecieved new transaction... added to the pool\\n')\n\n elif type == BLOCK:\n connection.close() # its important\n handle_new_block(message['block'], message['port'])\n\n connection.close()\n except Exception as e:\n connection.close()\n print(e)\n\n except Exception as e:\n server.close()\n print(e)\n RUN = False\n"
},
{
"alpha_fraction": 0.5137681365013123,
"alphanum_fraction": 0.5297101736068726,
"avg_line_length": 29.66666603088379,
"blob_id": "0f4c34992e788bee1069d74e4fdea33af0b33017",
"content_id": "43ad3d02f745bff984f824b1270c134be146b941",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1380,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 45,
"path": "/block.py",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "from transaction import Transaction\n\n\nclass Block:\n def __init__(self,\n difficulty,\n minerId=-1,\n index=0,\n previous_hash=None,\n timestamp=1618473245.5043766,\n nonce=0):\n self.index = index\n self.previous_hash = previous_hash\n self.timestamp = timestamp\n self.transactions = []\n self.nonce = nonce\n self.minerId = minerId\n self.minedAt = timestamp\n self.difficulty = difficulty\n\n # Get block datagithub\n def get_block_data(self):\n data = {\n 'index': self.index,\n 'previous_hash': self.previous_hash,\n 'timestamp': self.timestamp,\n 'transactions': self.transactions,\n 'nonce': self.nonce,\n 'minerId': self.minerId,\n 'difficulty': self.difficulty\n }\n return data\n\n def printIt(self):\n print('index : ', self.index)\n print('miner id : ', self.minerId)\n print('diificulty : ', self.difficulty)\n if self.previous_hash != None:\n print('previous_hash : ', self.previous_hash[-50:])\n print('timestamp : ', self.timestamp)\n print('transactions : ')\n for t in self.transactions:\n Transaction.printIt(t)\n print('nonce : ', self.nonce)\n print()\n"
},
{
"alpha_fraction": 0.6088435649871826,
"alphanum_fraction": 0.615160346031189,
"avg_line_length": 35.75,
"blob_id": "2809f900f2bfb9b59135073e6a4e21f47a45f052",
"content_id": "11661034a4e1cb444b9862d5b67a97d31ccf6d94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2058,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 56,
"path": "/transaction.py",
"repo_name": "orichamaru/Final_Blockchain_Course_Project",
"src_encoding": "UTF-8",
"text": "from collections import OrderedDict\nfrom Crypto.PublicKey import RSA\nfrom Crypto.Signature import PKCS1_v1_5\nfrom Crypto.Hash import SHA\nimport binascii\nimport time\n\n# this class required to work on to make transactions more significant\nclass Transaction:\n\n def __init__(self, amount=0, sender_public_key=None, recipient_public_key=None, timestamp=time.time()):\n self.amount = amount\n self.sender_public_key = sender_public_key\n self.recipient_public_key = recipient_public_key\n self.timestamp = timestamp\n self.signautre = None\n\n def get_transaction_bill(self):\n return OrderedDict({'sender_public_key': self.sender_public_key,\n 'recipient_public_key': self.recipient_public_key,\n 'amount': self.amount,\n 'timestamp': self.timestamp\n })\n\n def sign_transaction(self, sender_private_key):\n\n private_key = RSA.importKey(\n binascii.unhexlify(sender_private_key))\n signer = PKCS1_v1_5.new(private_key)\n message = SHA.new(str(self.get_transaction_bill()).encode('utf8'))\n self.signature = binascii.hexlify(signer.sign(message)).decode('ascii')\n\n def verifyIt(self, blockchain):\n\n if(self.sender_public_key != None\n and self.signature != None\n and self.amount > 0\n and self.recipient_public_key != None):\n\n response = blockchain.verify_transaction(\n self.get_transaction_bill(), self.signature)\n\n return response\n else:\n return False\n\n @staticmethod\n def printIt(transaction):\n if isinstance(transaction, Transaction):\n transaction = transaction.get_transaction_bill()\n\n print('amount : ', transaction['amount'])\n print('sender : ', transaction['sender_public_key'][-50:])\n print('reciever : ', transaction['recipient_public_key'][-50:])\n print('timestamp : ', transaction['timestamp'])\n print()\n"
}
] | 6 |
jellythefish/some_random_works
|
https://github.com/jellythefish/some_random_works
|
97fadac3d53934ef2560d8515f05da9b5aa18264
|
f7a1293ab95822db3b2f4faccbd2d74140db62df
|
b426ed401cb903b22ff86758776c0b5312edd84c
|
refs/heads/master
| 2022-02-10T11:26:15.484538 | 2022-01-24T12:44:33 | 2022-01-24T12:44:33 | 169,105,239 | 2 | 0 | null | 2019-02-04T16:03:15 | 2022-01-22T14:23:46 | 2022-01-24T12:44:35 |
Python
|
[
{
"alpha_fraction": 0.6593155860900879,
"alphanum_fraction": 0.6646387577056885,
"avg_line_length": 38.878787994384766,
"blob_id": "9b9f935662a15ab5c40cbed791cfb6a98ba51f01",
"content_id": "a6145d7ffd5e511468811cb520e1a72b8f2e5924",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1319,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 33,
"path": "/ya_market_min-price_parser/scripts/parse.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const HTMLParser = require('node-html-parser');\nconst requestPage = require('./requestPage');\nconst { PRICES_RANGE_CLASSNAME, OUT_OF_STOCK_CLASSNAME, SINGLE_PRICE_CLASSNAME } = require('../constants/constants');\n\nasync function parse(URL, proxyList) {\n let response = null;\n let index = 0;\n do {\n index = Math.round(-0.5 + Math.random() * proxyList.length); // random proxy index from 0 to the last in the array\n response = await requestPage(URL, proxyList[index]);\n } while (!response.success)\n\n const { pageContent } = response;\n const parsedResponse = HTMLParser.parse(pageContent);\n\n const goodName = parsedResponse.querySelector('title').text.split(' — ')[0];\n const outOfStock = parsedResponse.querySelector(`.${OUT_OF_STOCK_CLASSNAME}`);\n if (outOfStock) {\n return { name: goodName, url: URL, onStock: outOfStock.text };\n }\n\n const priceRange = parsedResponse.querySelector(`.${PRICES_RANGE_CLASSNAME}`);\n let minPrice = '';\n if (priceRange) {\n minPrice = priceRange.text.split(' — ')[0];\n } else {\n priceBlock = parsedResponse.querySelector(`.${SINGLE_PRICE_CLASSNAME}`);\n minPrice = priceBlock.querySelectorAll('span')[1].text;\n } \n return { name: goodName, url: URL, minPrice: minPrice };\n}\n\nmodule.exports = parse;"
},
{
"alpha_fraction": 0.6515723466873169,
"alphanum_fraction": 0.6817610263824463,
"avg_line_length": 43.78873062133789,
"blob_id": "5270f122e6195d7ea5ae5b0ef97eba6f3deb69f7",
"content_id": "eed3ed371b9b785e5b4ffc0f5e49975ad8f17672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3208,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 71,
"path": "/wallpapers_changer/design.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'C:\\Users\\Svyatoslav Krasnov\\PycharmProjects\\unsplashWallpapers\\design.ui'\n#\n# Created by: PyQt5 UI code generator 5.13.2\n#\n# WARNING! All changes made in this file will be lost!\n\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\n\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(469, 263)\n MainWindow.setStyleSheet(\"\")\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setStyleSheet(\"background-image: url(\\\"background_image/21.jpg\\\") 0 0 0 0 stretch stretch;\\n\"\n\"border-width: 0px;\")\n self.centralwidget.setObjectName(\"centralwidget\")\n self.pushButton = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton.setGeometry(QtCore.QRect(80, 90, 301, 61))\n font = QtGui.QFont()\n font.setFamily(\"Perpetua\")\n font.setPointSize(16)\n font.setBold(False)\n font.setWeight(50)\n self.pushButton.setFont(font)\n self.pushButton.setIconSize(QtCore.QSize(32, 32))\n self.pushButton.setCheckable(False)\n self.pushButton.setObjectName(\"pushButton\")\n self.lineEdit = QtWidgets.QLineEdit(self.centralwidget)\n self.lineEdit.setGeometry(QtCore.QRect(30, 40, 331, 21))\n self.lineEdit.setObjectName(\"lineEdit\")\n self.label = QtWidgets.QLabel(self.centralwidget)\n self.label.setGeometry(QtCore.QRect(30, 10, 111, 16))\n font = QtGui.QFont()\n font.setPointSize(12)\n self.label.setFont(font)\n self.label.setObjectName(\"label\")\n self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)\n self.pushButton_2.setGeometry(QtCore.QRect(370, 40, 71, 21))\n self.pushButton_2.setObjectName(\"pushButton_2\")\n self.label_2 = QtWidgets.QLabel(self.centralwidget)\n self.label_2.setGeometry(QtCore.QRect(10, 160, 451, 61))\n font = QtGui.QFont()\n font.setPointSize(9)\n self.label_2.setFont(font)\n self.label_2.setStyleSheet(\"\")\n self.label_2.setText(\"\")\n self.label_2.setObjectName(\"label_2\")\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 469, 21))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"MainWindow\"))\n self.pushButton.setText(_translate(\"MainWindow\", \"Сохранить обои\"))\n self.lineEdit.setText(_translate(\"MainWindow\", \"C:\\\\Users\\\\Svyatoslav Krasnov\\\\Pictures\\\\unsplash_images\"))\n self.label.setText(_translate(\"MainWindow\", \"Путь к папке:\"))\n self.pushButton_2.setText(_translate(\"MainWindow\", \"Обзор\"))\n"
},
{
"alpha_fraction": 0.5804877877235413,
"alphanum_fraction": 0.5817072987556458,
"avg_line_length": 29.407407760620117,
"blob_id": "ab56ebf852b81c1df36e158d4d60854dbfd7f24e",
"content_id": "385ad4ddc890407e8159731b9658a3ced654d9c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 820,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 27,
"path": "/ya_market_min-price_parser/scripts/requestPage.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const puppeteer = require('puppeteer');\nconst responseValidated = require('./responseValidated');\n \nasync function requestPage(URL, proxy) {\n let browser, page = null;\n try { \n browser = await puppeteer.launch({\n headless: false,\n args: [`--proxy-server=${proxy}`]\n });\n page = await browser.newPage();\n await page.setDefaultNavigationTimeout(0); \n await page.goto(URL);\n const pageContent = await page.content(); // html code\n browser.close();\n if (!responseValidated(pageContent)) {\n return { success: false };\n }\n return { success: true, pageContent }\n } catch (err) {\n browser.close();\n console.error(err.message);\n return { success: false };\n }\n}\n\nmodule.exports = requestPage;"
},
{
"alpha_fraction": 0.6779661178588867,
"alphanum_fraction": 0.694915235042572,
"avg_line_length": 58,
"blob_id": "7d7d03aa6047111fde73a1c1b4ebbd20cb34acd5",
"content_id": "0e0decfabea18236f0e8fe060c935d31c40af8cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 1,
"path": "/traektoria_database_parser/to_fix.md",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "1.Progress bar of dots not working in compiled .exe ... :(\n"
},
{
"alpha_fraction": 0.7695035338401794,
"alphanum_fraction": 0.7695035338401794,
"avg_line_length": 46.16666793823242,
"blob_id": "6ffe90f2f0aca4dda3cd251707f33f2c879ca49b",
"content_id": "b52c98c82a1cf69de6894b01ec252b09a3672dfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 6,
"path": "/ya_market_min-price_parser/scripts/index.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const initializeProxyList = require('./initializeProxyList');\nconst parse = require('./parse');\nconst requestPage = require('./requestPage');\nconst responseValidated = require('./responseValidated');\n\nmodule.exports = { initializeProxyList, parse, requestPage, responseValidated };"
},
{
"alpha_fraction": 0.6941279768943787,
"alphanum_fraction": 0.7107800245285034,
"avg_line_length": 19.35714340209961,
"blob_id": "d901df5b43851a79ca60f2a5e3edca19f0f332cb",
"content_id": "337af30e424fd8928c768031e2979a71c1145947",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1609,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 56,
"path": "/ya_market_min-price_parser/README.md",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "# Парсер Яндекс Маркета\n\nПриложение, отражающее минимальную цену товара на Я.Маркете.\n\n*Work in progress...*\n\n(Beta):\n\n## Установка\n\n1. Клонируйте репозиторий на свой компюьтер и перейдите в папку с парсером:\n\n```bash\ngit clone https://github.com/jellythefish/some_random_works/\ncd ya_market_min-price_parser\n```\n\n\t2. Установите зависимости\n\n```bash\nnpm i\n```\n\n## Запуск и тестирование\n\n1. В config.js в поле URL нужно указать ссылку на конкретный товар на Я.Маркете:\n\n```javascript\nconst PROXY_FILENAME = 'proxy-list.txt';\n// ######################## URL RIGHT HERE \nconst URL = 'https://market.yandex.ru/product--ochki-virtualnoi-realnosti-dlia-smartfona-samsung-gear-vr-sm-r322/14177537?lr=213&onstock=1';\n// ########################\n\nmodule.exports = { PROXY_FILENAME, URL };\n```\n\n2. Для запуска парсера наберите в консоли\n\n```bash\nnpm run start\n```\n\n\n\nЧтобы протестировать парсер, наберите в консоли\n\n```bash\nnpm run test\n```\n\nПарсер пройдет по нескольким товарам разных категорий: одно предложение, одна цена, товара нет в наличии, много предложений.\n\n## ToDo\n\n+ Интегрировать с телеграм ботом\n+ Интегрировать апи на рандомный прокси\n\n"
},
{
"alpha_fraction": 0.6746100783348083,
"alphanum_fraction": 0.6759098768234253,
"avg_line_length": 28.97402572631836,
"blob_id": "62c701fdd052216521950031638493fe5fee5c37",
"content_id": "68a73e8f1901ebe4d5457a3c60614c60cb012624",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2308,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 77,
"path": "/mkv_merger/merge_mkvs.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport argparse\nfrom pathlib import Path\nimport os\nimport logging\nimport subprocess\nimport sys\nfrom dataclasses import dataclass\n\nlogging.basicConfig()\nlogging.root.setLevel(logging.DEBUG)\n\nSOUND_FOLDER_NAME = \"RUS Sound\"\nSUBS_FOLDER_NAME = \"RUS Subs\"\nVIDEO_FOLDER_NAME = \"Videos\"\nBINARY_PATH = Path(\"C:\\Program Files\\MKVToolNix\\mkvmerge.exe\")\n\n\n@dataclass \nclass FileName:\n sound: str\n sub: str\n video: str\n\n\ndef merge(input_path, input, output_path):\n cmd = [\n BINARY_PATH, \"--output\", output_path/input.video, \"-A\", \n input_path/VIDEO_FOLDER_NAME/input.video, \n input_path/SOUND_FOLDER_NAME/input.sound, \n input_path/SUBS_FOLDER_NAME/input.sub\n ]\n process = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n for c in iter(lambda: process.stdout.read(1), b''): \n sys.stdout.buffer.write(c)\n\n\ndef main():\n parser = argparse.ArgumentParser(description='MKVMerger')\n parser.add_argument('input_path', type=str, help='path with needed folders')\n parser.add_argument('output_path', type=str, help='path to merged mkvs')\n\n args = parser.parse_args()\n\n input_path, output_path = Path(args.input_path), Path(args.output_path)\n\n input_folders = os.listdir(input_path)\n assert SOUND_FOLDER_NAME in input_folders\n assert SUBS_FOLDER_NAME in input_folders\n assert VIDEO_FOLDER_NAME in input_folders\n\n sound_files = os.listdir(input_path/SOUND_FOLDER_NAME)\n sub_files = os.listdir(input_path/SUBS_FOLDER_NAME)\n video_files = os.listdir(input_path/VIDEO_FOLDER_NAME)\n\n assert len(sound_files) == len(sub_files) == len(video_files)\n\n sound_files = sorted([elem for elem in sound_files])\n sub_files = sorted([elem for elem in sub_files])\n video_files = sorted([elem for elem in video_files])\n\n if not os.path.exists(output_path):\n logging.info(\"Output directory {} does not exist, creating...\".format(output_path))\n os.makedirs(output_path)\n\n inputs = [\n FileName(sound, sub, video) \n for sound, sub, video in zip(sound_files, sub_files, video_files)\n ]\n for idx, input in enumerate(inputs):\n merge(input_path, input, output_path)\n logging.info(\"{} out of {} is completed\".format(idx + 1, len(inputs)))\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.642777144908905,
"alphanum_fraction": 0.6483762860298157,
"avg_line_length": 29.79310417175293,
"blob_id": "d7572ebbcdc90b7ab32d70950d67f38ae493bdbd",
"content_id": "6b4a1974cfe066b3b19751fda9220a809197da8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 29,
"path": "/mkv_merger/plex_rename.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n# renames videos according to Plex Media Server naming rules\n\nimport argparse\nfrom pathlib import Path\nimport os\n\ndef main():\n parser = argparse.ArgumentParser(description='renamer')\n parser.add_argument('new_name', type=str, help='name of a movie/tv show/etc...')\n parser.add_argument('season_number', type=str, help='number of a season')\n parser.add_argument('input_path', type=str, help='path with data')\n\n args = parser.parse_args()\n\n input_path = Path(args.input_path)\n video_files = os.listdir(input_path)\n \n video_files = sorted(video_files)\n \n for n, video in enumerate(video_files):\n ext = video.split(\".\")[-1]\n new_name = \"{} s{}e{}.{}\".format(args.new_name, str(args.season_number).zfill(2), str(n + 1).zfill(2), ext)\n os.rename(input_path/video, input_path/new_name)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.7259259223937988,
"alphanum_fraction": 0.7407407164573669,
"avg_line_length": 44,
"blob_id": "4af199356dbf63a63a6c5d1a52ccbc732e88fd5e",
"content_id": "8ae3cacaad8e913d83eaaa90141663c0d6f7d64a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 6,
"path": "/README.md",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "# some_random_works\nMy projects that somehow helped me to automatize routine actions.\n\nHi, not a pro (already pro =)) user on github, YET. So, to introduce myself here is my pic, i hope you like my smile <3\n\n\n"
},
{
"alpha_fraction": 0.7302052974700928,
"alphanum_fraction": 0.7536656856536865,
"avg_line_length": 47.85714340209961,
"blob_id": "d55fb1fab7f4ab7d61193d2145657a35fadd7652",
"content_id": "e065bb31d7bd0db149ff53cab47bcd0685434a26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 343,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 7,
"path": "/ya_market_min-price_parser/constants/constants.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const FORBIDDEN_TITLE = '403';\nconst CAPTCHA_IS_NEEDED_TITLE = 'Ой!';\nconst PRICES_RANGE_CLASSNAME = '_1S8ob0AgBK';\nconst OUT_OF_STOCK_CLASSNAME = 'Ca_h1ZgLxJ';\nconst SINGLE_PRICE_CLASSNAME = '_3NaXxl-HYN';\n\nmodule.exports = { FORBIDDEN_TITLE, CAPTCHA_IS_NEEDED_TITLE, PRICES_RANGE_CLASSNAME, OUT_OF_STOCK_CLASSNAME, SINGLE_PRICE_CLASSNAME }"
},
{
"alpha_fraction": 0.5958747267723083,
"alphanum_fraction": 0.5989304780960083,
"avg_line_length": 34.863014221191406,
"blob_id": "182476791d1a5bdfeb153074c05e1475bd0530a6",
"content_id": "09bdafa2d2c70f6bb51b0728b6cb8e1ea94cab5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2631,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 73,
"path": "/wallpapers_changer/save_wallpaper.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "import sys\nfrom PyQt5 import QtWidgets\nimport design\nimport os\nfrom pathlib import Path\nfrom shutil import copyfile\n\nclass ExampleApp(QtWidgets.QMainWindow, design.Ui_MainWindow):\n def __init__(self):\n super().__init__()\n self.setupUi(self)\n self.pushButton.clicked.connect(self.save_image)\n self.pushButton_2.clicked.connect(self.browse_folder)\n\n self.lineEdit.setText(str(Path(\"C:\\\\Users\\\\Slava\\\\Pictures\\\\unsplash_images\")))\n self.default_directory = str(Path(\"C:\\\\Users\\\\Slava\\\\Pictures\\\\unsplash_images\"))\n self.directory = self.default_directory\n self.next_image_name = self.get_next_image_name(os.listdir(self.default_directory))\n self.setWindowTitle(\"Wallpaper Saver\")\n\n def browse_folder(self):\n self.directory = str(Path(QtWidgets.QFileDialog.getExistingDirectory(self, \"Выберите папку\")))\n\n if self.directory == \".\":\n self.directory = self.default_directory\n\n self.lineEdit.setText(self.directory)\n\n def save_image(self):\n self.label_2.setText(\"...\")\n file_list = os.listdir(self.directory)\n self.next_image_name = self.get_next_image_name(file_list)\n tmp_image_path = Path(\"C:\\\\Users\\\\Slava\\\\AppData\\\\Roaming\\\\Microsoft\\\\Windows\\\\Themes\\\\CachedFiles\")\n ready = False\n files = \"\"\n while not ready or not files:\n try:\n files = os.listdir(tmp_image_path)\n ready = True\n except:\n print(\"Folder is still not loaded\")\n filepath_destination = self.lineEdit.text() + str(Path(f\"\\\\{self.next_image_name}\"))\n try:\n filename = files[0]\n ready = True\n filepath_source = Path(f\"{tmp_image_path}\\\\{filename}\")\n copyfile(filepath_source, filepath_destination)\n self.label_2.setText(f\"OK!\\nImage was saved as:\\n{filepath_destination}\")\n print(f\"Image was saved to {filepath_destination}\")\n except Exception as e:\n print(f\"Error: there are no files in the directory, also {e}\")\n\n def get_next_image_name(self, file_list):\n max = 0\n for file in file_list:\n filename = file.split(\".\")[0]\n try:\n if int(filename) > max:\n max = int(filename)\n except:\n print(f\"Error: filename of '{file}' cannot be casted to int.\")\n return str(max + 1) + \".jpg\"\n\n\ndef main():\n app = QtWidgets.QApplication(sys.argv)\n window = ExampleApp() \n window.show()\n app.exec_()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.62867271900177,
"alphanum_fraction": 0.6357649564743042,
"avg_line_length": 34.25,
"blob_id": "7faf3c14cfc94ce2dc5b0343e57afb0a2d27e616",
"content_id": "d42dd9c2b8eb45f00adaa96fd69a39a8139ae09d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1993,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 56,
"path": "/traektoria_database_parser/traektoria_parser.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "import requests\nfrom lxml import html\nfrom math import ceil\n\n\ndef our_parsed_page(url):\n response = requests.get(url)\n parsed_page = html.fromstring(response.content)\n return parsed_page\n\n\ndef listofpages(url):\n manypages = bool(parsed_page.xpath('//div[@class=\"showmemorelabel\"]/a/text()'))\n listofpages = []\n if manypages:\n url2 = parsed_page.xpath('//div[@class=\"showmemorelabel\"]/a/@href')\n url_wo_slashes = url.replace('/', '', 2)\n rooturl = url[:url_wo_slashes.index('/') + 2]\n newurl = rooturl + str(url2[0])\n\n howmanyshow = parsed_page.xpath('//span[@class=\"howmanyshown_count\"]/text()')\n howmanyshow = int(howmanyshow[0])\n allitems = parsed_page.xpath('//div[@class=\"howmanyshown\"]/text()')\n allitems = allitems[0]\n for elem in allitems:\n if not elem.isdigit():\n allitems = allitems.replace(elem, '')\n allitems = int(allitems)\n numberofpages = ceil(allitems / howmanyshow)\n listofpages = [newurl[:-1] + str(x) for x in range(1, numberofpages + 1)]\n else:\n listofpages.append(url)\n return listofpages\n\n\nurl = input(\"Введите URL: \").strip()\nparsed_page = our_parsed_page(url)\ndatabase = []\n\nfor page in listofpages(url):\n print('.', end='')\n parsed_page = our_parsed_page(page)\n category = parsed_page.xpath('//div[@class=\"p_info_name\"]/span[@itemprop=\"category\"]/text()')\n name = parsed_page.xpath('//div[@class=\"p_info_name\"]/span[@itemprop=\"name\"]/text()')\n price = parsed_page.xpath('//div[@class=\"price\"]/meta[@itemprop=\"price\"]/@content')\n database_of_page = list(zip(category, name, price))\n database.extend(database_of_page)\n\noutfile = open('database.txt', 'w', encoding='utf-8')\nfor elem in database:\n print(elem[0], elem[1], elem[2], file=outfile)\nprint('Итого товаров:', len(database), file=outfile)\noutfile.close()\nprint('')\nprint('OK\\nWrited to database.txt')\ninput(\"Press Enter to exit\")\n"
},
{
"alpha_fraction": 0.6716980934143066,
"alphanum_fraction": 0.7169811129570007,
"avg_line_length": 40.842105865478516,
"blob_id": "97a0f73aff2691b62418ecc604c227ec0037f4e9",
"content_id": "dc6881114293360af85b99cda4c8b7e3a3bbf3d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 795,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 19,
"path": "/traektoria_database_parser/README.md",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "# HOW TO\nThis is a python script to import database of all goods with their prices in any category.\n 1. Visit https://www.traektoria.ru/.\n 2. Choose any category of goods like snowboards, skateboards, etc...\n \n 3. Copy the url of chosen category.\n 4. Run traektoria_parser.py script.\n 5. Enter the copied URL and press ENTER.\n 6. The result will be placed in database.txt in one folder with .py script.\n \n P.S. the database.txt consists of several columns divided with tab:\n - Category;\n - Name of the Good;\n - Price;\n - The total amount of goods in chosen category in the end of the list.\n \n Yep... :) For the love of any kind of boarding.\n \n \n"
},
{
"alpha_fraction": 0.7036724090576172,
"alphanum_fraction": 0.7467285990715027,
"avg_line_length": 31.452054977416992,
"blob_id": "b70734ba5138007f348eeaa7e2cee8ab1731b14e",
"content_id": "83f1aa5a80a87ad5bbd2e1b5b2b83d6cf49b353d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2369,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 73,
"path": "/setup_boinc.sh",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n################# Setup Boinc server (Ubuntu 20.04)\n\n# 1) Install deps\nsudo add-apt-repository 'deb http://archive.ubuntu.com/ubuntu bionic main'\nsudo add-apt-repository ppa:ondrej/php-5\nsudo apt update\nsudo apt-get install git build-essential apache2 libapache2-mod-php5.6 php5.6 \\\n mariadb-server php5.6-gd php5.6-cli php5.6-mysql php5.6-xml php5.6-curl python-mysqldb \\\n libtool automake autoconf pkg-config libmysql++-dev libssl-dev \\\n libcurl4-openssl-dev\n\n\n# 2) Add user boincadm for a separate project\nsudo adduser boincadm\nsudo usermod -a -G boincadm www-data\nsudo chmod -R 711 /home/boincadm\n\n# 3) Configure MySQL server\nsudo mysql -h localhost -u root -p\nCREATE USER 'boincadm'@'localhost' IDENTIFIED BY '<PASSWORD>';\nGRANT ALL ON *.* TO 'boincadm'@'localhost';\nFLUSH PRIVILEGES;\nsudo systemctl enable mariadb.service\n\n# 4) Configure Apache2 TODO: configure later\nsudo systemctl enable apache2\nsudo a2enmod cgi\nsudo systemctl restart apache2\n# echo \"DefaultType application/octet-stream\" >> /etc/apache2/apache2.conf # FOR PROBLEMS WITH SIGNATURES\n# echo \"LimitXMLRequestBody 134217728\" >> /etc/apache2/apache2.conf # FOR LARGE FILES\n\n# 5) Build from sources\nsu boincadm\ncd ~\ngit clone https://github.com/BOINC/boinc.git boinc-src\ncd ~/boinc-src\n./_autosetup\n./configure --disable-client --disable-manager \\\n--with-jpeg-dir --with-png-dir --with-mysqli --with-curl --with-gd --with-zlib\nmake\n\n# 6) Make and configure a project\ncd ~/boinc-src/tools/\n./make_project --delete_prev_inst --drop_db_first --url_base http://<SERVER_EXTERNAL_IP> \\\n--db_passwd <DB_PASSWORD> --test_app cplan\n\ncd ~/projects/cplan/\nchmod 02770 upload\nchmod 02770 html/cache\nchmod 02770 html/inc\nchmod 02770 html/languages\nchmod 02770 html/languages/compiled\nchmod 02770 html/user_profile\n\nsudo ln -s /home/boincadm/projects/cplan/cplan.httpd.conf /etc/apache2/sites-enabled\n# generate a username/password file for your administrative web interface using\nhtpasswd -cb ~/projects/cplan/html/ops/.htpasswd boincadm <PASSWORD>\n\n# run crontab -e, and add an entry to run the project's cron script\ncrontab -e\n0,5,10,15,20,25,30,35,40,45,50,55 * * * * /home/boincadm/cplan/bin/start --cron\n/home/boincadm/projects/cplan/bin/start --cron\n\ncd ~/boinc-src/tools/\n./check_project -p ~/projects/cplan\n\n# 7) Run project\ncd ~/projects/cplan/bin\n./xadd\n./update_versions\n./start\n"
},
{
"alpha_fraction": 0.644385039806366,
"alphanum_fraction": 0.644385039806366,
"avg_line_length": 23.933332443237305,
"blob_id": "c67c4daf5a63833a4c4e5b406dc4030601eb03d8",
"content_id": "ccfad3a54f2dedf7a520fe50c5e47624965df01f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 15,
"path": "/ya_market_min-price_parser/index.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const { initializeProxyList, parse } = require('./scripts');\nconst { URL } = require('./config');\nconst process = require('process');\n\nlet proxyList = [];\ntry {\n proxyList = initializeProxyList();\n} catch(e) {\n console.error(\"Error occured while parsing the proxy list: \", e.stack);\n}\n\nparse(URL, proxyList).then(res => {\n console.log(res);\n process.exit();\n});\n"
},
{
"alpha_fraction": 0.6919642686843872,
"alphanum_fraction": 0.7589285969734192,
"avg_line_length": 55.25,
"blob_id": "6f8e14c7bc6935d3232a77d1f55b1abb3f67a783",
"content_id": "4ad40649bb424c47cff3d6c377c562742896bbff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 4,
"path": "/ya_market_min-price_parser/config.js",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "const PROXY_FILENAME = 'proxy-list.txt';\nconst URL = 'https://market.yandex.ru/product--ochki-virtualnoi-realnosti-dlia-smartfona-samsung-gear-vr-sm-r322/14177537?lr=213&onstock=1';\n\nmodule.exports = { PROXY_FILENAME, URL };"
},
{
"alpha_fraction": 0.6308355927467346,
"alphanum_fraction": 0.6371126174926758,
"avg_line_length": 25.278350830078125,
"blob_id": "b87ddd92f2746d01b7490906c2dc19dd6cecb53f",
"content_id": "2cb2361f1a350b5b78c6a39e95b337eb2c8dd37f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2549,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 97,
"path": "/wallpapers_changer/set_wallpaper.py",
"repo_name": "jellythefish/some_random_works",
"src_encoding": "UTF-8",
"text": "import requests\nimport ctypes\nimport pathlib\nimport urllib.request\nimport time\nimport logging.config\nimport logging\nimport os\nimport sys\nfrom pathlib import Path\n\n\n# Constants\nPROJECT_DIRECTORY = os.path.abspath(os.path.expanduser(os.path.dirname(sys.argv[0])))\n\nAPI = \"https://api.unsplash.com\"\nTOKEN = \"\"\nTMP_IMAGE_PATH = pathlib.Path(\"C:/Users/Slava/Pictures/unsplash_images/tmp.jpg\")\nDICTLOGCONFIG = {\n \"version\": 1,\n \"handlers\": {\n \"fileHandler\": {\n \"class\": \"logging.FileHandler\",\n \"formatter\": \"myFormatter\",\n \"filename\": Path(f\"{PROJECT_DIRECTORY}\\\\logs.log\")\n }\n },\n \"loggers\": {\n \"set_wallpaper.py\": {\n \"handlers\": [\"fileHandler\"],\n \"level\": \"INFO\",\n }\n },\n \"formatters\": {\n \"myFormatter\": {\n \"format\": \"%(asctime)s - %(name)s - %(levelname)s - %(message)s\"\n }\n }\n}\nlogging.config.dictConfig(DICTLOGCONFIG)\n\n# Variables\nrandom_image_method = \"photos/random\"\nimage_orientation = \"orientation=landscape\"\nauth = f\"client_id={TOKEN}\"\nlogger = logging.getLogger(\"set_wallpaper.py\")\n\n\n# Functions\ndef set_wallpaper(image_path):\n SPI_SETDESKWALLPAPER = 20\n ctypes.windll.user32.SystemParametersInfoW(SPI_SETDESKWALLPAPER, 0, str(image_path), 0x2)\n time.sleep(3)\n\n\ndef download_image(image_url):\n urllib.request.urlretrieve(image_url, TMP_IMAGE_PATH)\n\n\ndef delete_tmp_image(image_path):\n os.remove(image_path)\n\n\ndef main():\n # Calls\n logger.info(\"Sending get request...\")\n try:\n response = requests.get(f\"{API}/{random_image_method}/?{image_orientation}&{auth}\")\n json_response = response.json()\n except Exception as e:\n logger.error(f\"{e}\\n\")\n raise SystemExit(1)\n\n if response.status_code != 200:\n logger.error(f'Response status code - {response.status_code}: {json_response[\"errors\"]}\\n')\n raise SystemExit(1)\n else:\n logger.info(f'Response status code - {response.status_code}: OK')\n\n image_url = json_response[\"urls\"][\"raw\"]\n logger.info(\"Downloading the background image...\")\n try:\n download_image(image_url)\n except Exception as e:\n logger.error(f\"Failed downloading the background image, {e}\\n\")\n raise SystemExit(1)\n\n logger.info(\"Image downloaded\")\n logger.info(\"Setting wallpaper...\")\n set_wallpaper(TMP_IMAGE_PATH)\n logger.info(\"Wallpaper has been set\")\n delete_tmp_image(TMP_IMAGE_PATH)\n logger.info(\"TMP image has been deleted\\n\")\n\n\nif __name__ == \"__main__\":\n main()\n"
}
] | 17 |
gs27/Twitter-Sentiment-Analysis
|
https://github.com/gs27/Twitter-Sentiment-Analysis
|
ab670114180f4646ed26029ff1fe857a50b49102
|
cbb7d5dbd4c9c898c871b7e2d6dc7a4a5b473a2c
|
0fdf43245a837aa940e94cc7706900c7ca9fe696
|
refs/heads/master
| 2021-05-11T07:09:54.994667 | 2016-09-19T02:11:13 | 2016-09-19T02:11:13 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4311732351779938,
"alphanum_fraction": 0.44853875041007996,
"avg_line_length": 31.356164932250977,
"blob_id": "3f7f6c61761513b689f0975839a8cf821d368e53",
"content_id": "e83981e368819053d10a7b23b5e91c9a5024136e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2361,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 73,
"path": "/algorithims/Baseline.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, time\nclass Baseline(object):\n \n cache = {}\n \n def __init__(self):\n start_time = time.time()\n corpus = open(\"data/SentiWordNet_reformatted.csv\")\n rows = csv.reader(corpus)\n \n for row in rows:\n self.cache[row[0].lower()] = [float(row[1]), float(row[2])]\n # print \"Baseline initialization time: \" + str(time.time() - start_time)\n\n def formatThing(self, arr, name):\n if(len(arr) == 0):\n return name + \": []\"\n else:\n string = arr[0][0] + \"(\"+arr[0][1]+\",\"+arr[0][2]+\")\"\n for i, item in enumerate(arr):\n if i == 0:\n continue\n string += \",\" + arr[i][0] + \"(\"+arr[i][1]+\",\"+arr[i][2]+\")\"\n return name + \": [\" + string + \"]\"\n\n def grade(self, text):\n if \"?\" in text:\n print \"Text is a question\"\n words = [word.lower() for word in text.split(\" \")]\n corpus = open(\"data/SentiWordNet_reformatted.csv\")\n rows = csv.reader(corpus)\n pos = []\n neg = []\n neu = []\n score = [0,0]\n for row in rows:\n if row[0].lower() in words:\n if float(row[1]) == float(row[2]):\n neu.append(row)\n elif float(row[1]) > float(row[2]):\n pos.append(row)\n else:\n neg.append(row)\n score[0] += float(row[1])\n score[1] += float(row[2])\n\n print self.formatThing(pos, \"positive\")\n print self.formatThing(neg, \"negative\")\n print self.formatThing(neu, \"neutral\")\n print \"Final Score: [\" + str(score[0]) + \" vs. \" + str(score[1]) + \"]\"\n \n if score[0] > score[1]:\n return \"Text is Positive!\"\n elif score[0] < score[1]:\n return \"Text is Negative...\"\n else:\n return \"Text is Neutral.\"\n\n def test(self, text):\n if \"?\" in text:\n return \"question\"\n \n words = [word.lower() for word in text.split(\" \")]\n score = [0,0]\n for word in words:\n grade = self.cache.get(word, [0,0])\n score[0] += grade[0]\n score[1] += grade[1]\n \n if score[0] > score[1]:\n return \"positive\"\n else:\n return \"negative\""
},
{
"alpha_fraction": 0.4674822986125946,
"alphanum_fraction": 0.4842240810394287,
"avg_line_length": 24.47541046142578,
"blob_id": "a3db9ae77503a8ace857dff41e3126bae6876f45",
"content_id": "a43989fb589ea9678c614cc9743a20e42a430de4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1553,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 61,
"path": "/data/helperScripts/duplicates.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv\n\ndata = []\n\ndef find_duplicates(f):\n seen = set()\n # for line in f:\n # line_lower = line.lower()\n # if line_lower in seen:\n # print(line)\n # else:\n # seen.add(line_lower)\n words = csv.reader(f)\n count = 0\n\n for word in words:\n if word[1].lower() in seen:\n print(word[1])\n count += 1\n else:\n seen.add(word[1].lower())\n print count\n\ndef truncate(f, n):\n '''Truncates a float f to n decimal places without rounding'''\n if len(str(f).split('.')[1]) < n:\n return f\n s = '{}'.format(f)\n if 'e' in s or 'E' in s:\n return '{0:.{1}f}'.format(f, n)\n i, p, d = s.partition('.')\n return '.'.join([i, (d+'0'*n)[:n]])\n\ndef fix_duplicates(f):\n current = \"\"\n rows = csv.reader(f)\n pos = 0.0\n neg = 0.0\n count = 0\n for row in rows:\n if row[0].lower() == current:\n pos += float(row[1])\n neg += float(row[2])\n count += 1\n else:\n if current != \"\":\n data.append([current, truncate(pos/count, 4), truncate(neg/count, 4), truncate(1 - (pos/count + neg/count), 4)])\n current = row[0].lower()\n pos = float(row[1])\n neg = float(row[2])\n count = 1\n corpus = open('../SentiWordNet_reformatted.csv', 'wb')\n wr = csv.writer(corpus, delimiter=',')\n wr.writerows(data)\n corpus.close()\n\n\n\nif __name__ == '__main__':\n with open('data/testData.csv', 'r') as f:\n find_duplicates(f)"
},
{
"alpha_fraction": 0.5004945397377014,
"alphanum_fraction": 0.5390702486038208,
"avg_line_length": 29.17910385131836,
"blob_id": "74995f65bf1dd223a31883ea6be8425027f7d9b2",
"content_id": "da154148290bf104b1d9c00f9dee3e08f6916ec5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2022,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 67,
"path": "/data/helperScripts/combineCorpus.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv\n\nposC = csv.reader(open('data/raw/corpuses/poscorpus_raw.csv', 'rU'))\nnegC = csv.reader(open('data/raw/corpuses/negcorpus_raw.csv', 'rU'))\nqusC = csv.reader(open('data/raw/corpuses/quscorpus_raw.csv', 'rU'))\nactC = csv.reader(open('data/raw/corpuses/activecorpus_raw.csv', 'rU'))\ntestO = csv.reader(open('data/testDataOld.csv', 'rU'))\nsenC = csv.reader(open('data/testData/sentiment140/testdata.manual.2009.06.14.csv', 'rU'))\n\ndata = {}\n\nfor corpus in [posC, negC, qusC]:\n for row in corpus:\n if row[1].endswith(\"E+17\"):\n continue\n if row[0] == \"positive\":\n data[row[1].lower()] = [0, row[1]]\n elif row[0] == \"negative\":\n data[row[1].lower()] = [1, row[1]]\n elif row[0] == \"neutral\":\n data[row[1].lower()] = [2, row[1]]\n elif row[0] == \"question\":\n data[row[1].lower()] = [3, row[1]]\n\nwr = csv.writer(open('data/corpus.csv', 'wb'), delimiter=',')\nwr.writerows(data.values())\ndata = {}\nduplicate = 0\ncount = 0\nfor row in actC:\n count += 1\n if row[1].endswith(\"E+17\"):\n continue\n if row[0] == \"positive\":\n data[row[1].lower()] = [0, row[1]]\n elif row[0] == \"negative\":\n data[row[1].lower()] = [1, row[1]]\n elif row[0] == \"neutral\":\n data[row[1].lower()] = [2, row[1]]\n elif row[0] == \"question\":\n data[row[1].lower()] = [3, row[1]]\n\nprint len(data)\nprint duplicate\nprint count\nfor row in senC:\n if row[5].endswith(\"E+17\"):\n continue\n if row[0] == \"4\":\n data[row[5].lower()] = [0, row[5]]\n elif row[0] == \"0\":\n data[row[5].lower()] = [1, row[5]]\n elif row[0] == \"2\":\n data[row[5].lower()] = [2, row[5]]\n else:\n print \"Weird thing found: \" + row[0]\nprint len(data)\n\nfor row in testO:\n if row[0] == \"3\":\n if row[1].lower() in data:\n data[row[1].lower()] = [3, row[1]]\n else:\n print row[1]\n\nwr = csv.writer(open('data/testData.csv', 'w'), delimiter=',')\nwr.writerows(data.values())\n"
},
{
"alpha_fraction": 0.5099778175354004,
"alphanum_fraction": 0.5227272510528564,
"avg_line_length": 30.66666603088379,
"blob_id": "07f6ee46588806348a5e59c5e6b6a594a54945f0",
"content_id": "38ac60b111fb815d68c0a3d06bd2b962a922be79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1804,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 57,
"path": "/data/helperScripts/gettextfromid.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import os, csv, oauth2, json, codecs\n\ndef getLines():\n f = open('corpus.csv', 'r')\n count = 0\n line = \"\"\n lines = []\n try:\n reader = csv.reader(f)\n for row in reader:\n if count >= 100:\n lines.append(line)\n count = -1\n line = \"\"\n elif row[2] != \"\":\n if count == 0:\n line += row[2]\n else: \n line += (\",\" + row[2]) \n count += 1\n finally:\n lines.append(line)\n f.close()\n print(\"total of \" + str(len(lines)) + \" lines, \" + str(count) + \" on the last line\")\n return lines\n\ndef oauth_req(url, key, secret, http_method=\"GET\", post_body=\"\", http_headers=None):\n consumer = oauth2.Consumer(key=\"xxx\", secret=\"xxx\")\n token = oauth2.Token(key=key, secret=secret)\n client = oauth2.Client(consumer, token)\n resp, content = client.request(url, method=http_method, body=post_body, headers=http_headers )\n return content\n\ndef main():\n lines = getLines()\n raw = codecs.open('rawdata.txt', encoding='utf-8')\n f = open('corpus.csv','r')\n filedata = f.read().decode('utf-8')\n f.close()\n for line in lines:\n line = line.decode('utf-8')\n result = oauth_req(\"https://api.twitter.com/1.1/statuses/lookup.json?id=\"+line, 'xxx', 'xxx' )\n tweets = json.loads(result)\n \n #there has got to be a better way to do this\n for tweet in tweets:\n id = tweet['id_str'].decode('utf-8')\n text = tweet['text'].encode('unicode_escape').decode('utf-8')\n filedata = filedata.replace(id,text).decode('utf-8')\n\n f = open('corpusnew.csv','w')\n f.write(filedata.encode('utf-8'))\n f.close()\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.4834996163845062,
"alphanum_fraction": 0.49731388688087463,
"avg_line_length": 44.73684310913086,
"blob_id": "fb3330bc94afc1992eff4500467b56b8c44cae81",
"content_id": "ae5d8dcc7ab9f6c1d97e4eea3c44a4a2af46c942",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2606,
"license_type": "no_license",
"max_line_length": 239,
"num_lines": 57,
"path": "/data/helperScripts/sanitizeData.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, re\nfrom collections import OrderedDict\n\nposC = csv.reader(open('data/raw/corpuses/poscorpus_raw.csv', 'rU'))\nnegC = csv.reader(open('data/raw/corpuses/negcorpus_raw.csv', 'rU'))\nqusC = csv.reader(open('data/raw/corpuses/quscorpus_raw.csv', 'rU'))\n\nfix = {\n '\\\\u2019': \"'\",\n '\\\\\\u2026': \"...\",\n '\\\\u201c': '\"',\n '\\\\u201d': \"'\",\n '\\\\\\\\n': ' ',# '\\\\n' => ' '\n '<': '<',\n '>': '>',\n '&': '&',\n}\n\ndef clean(text):\n for k, v in fix.iteritems():\n text = text.replace(k,v)\n text = text.replace(k[1:],v)\n #order is important\n text = text.lower().replace(\"rt \", \"\")#make lowercase and remove rts\n text = re.sub(r'(\\\\\\\\u[0-9a-z]+)|(\\\\u[0-9a-z]+)', '', text)#replace emojis \\U23u8ufygcik ... note U lowercase\n text = re.sub(r'([0-9]+)', '', text)#remove numbers\n text = re.sub(r'(http[s]?:\\/\\/[^ \\n]+)', '', text)#replace URLs\n text = re.sub(r'(@[0-9a-z_]+)', '_tempuser_', text)\n text = text.replace(\"_tempuser_: \", \"\")#from the rts\n text = text.replace(\"_tempuser_\", \"\")\n text = text.replace('...', ' ')\n text = re.sub(r'([.,\\\"\\*\\&\\-\\^\\+])', '', text)#remove periods, commas, quotes, asterisks, ampersand\n text = re.sub(r'(.)\\1+', r'\\1\\1', text)#max 2 repeats (haaaappppppyyyyyyy => haappyy)\n text = text.replace(\"<3\" , \":)\").replace(\":]\",\":)\").replace(\";]\", \":)\").replace(\":))\", \":)\").replace(\": )\", \":)\").replace(\";)\", \":)\").replace(\":d\", \":)\").replace(\":-)\", \":)\").replace(\"=)\", \":)\").replace(\":P\", \":)\")\n text = text.replace(\"</3\", \":(\").replace(\":[\",\":(\").replace(\";[\", \":(\").replace(\":((\", \":(\").replace(\": (\", \":(\").replace(\";(\", \":(\").replace(\"d:\", \":(\").replace(\":-(\", \":(\").replace(\"=(\", \":(\").replace(\"=/\", \":(\").replace(\"=\\\\\", \":(\")\n text = re.sub(r'(?<!:)\\)(?!:)', '', text)#remove '(' or ')' if not ':(' or '):'\n text = re.sub(r'([\\\\\\/])', ' ', text)#replace '\\' or '/' with ' '\n text = text.replace(\"!\", \" !\")#makes exclamation marks their own word\n text = text.replace(\"?\", \" ?\")#makes question marks their own word\n text = text.replace(\"#\", \"\")#makes hashtags just word\n text = re.sub(' +',' ',text)#remove multiple consecutive spaces\n if text[0] == \" \":\n text = text[1:]\n return text\n\ndef softClean():\n for corpus, abv in {posC: 'pos', negC: 'neg', qusC: 'qus',}.iteritems():\n data = []\n for row in corpus:\n data.append([row[0], clean(row[1]).rstrip()])\n f = open('data/clean/' + abv + 'corpus.csv', 'wb')\n wr = csv.writer(f)\n wr.writerows(data)\n print \"done\"\n\nif __name__ == '__main__':\n print softClean()"
},
{
"alpha_fraction": 0.434965044260025,
"alphanum_fraction": 0.4545454680919647,
"avg_line_length": 36.657894134521484,
"blob_id": "13f9829f40f58eaad8d7256ef746fd473d93c946",
"content_id": "e16035c22b3e2358bbaf2b8b5c8784dd6a613c63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1430,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 38,
"path": "/data/helperScripts/approveData.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import os, csv, random\n\ndata = []\n\ndef main():\n temp = open('data/testDataOld.csv', 'rU')\n corpus = open('data/testData.csv', 'ab')\n tweets = csv.reader(temp)\n for tweet in tweets:\n if \"?\" in tweet[1]:\n try:\n print tweet[1].encode('unicode_escape').decode('utf-8')\n cmd = raw_input(\"(1=question, 2=keep, 3=discard, 4=break): \")\n if cmd == \"1\":\n data.append([3, tweet[1]])\n elif cmd == \"2\":\n data.append([tweet[0], tweet[1]])\n elif cmd == \"4\":\n break\n except Exception as e:\n break #will print and shit\n \n # if len(tweet[1]) > 50 and random.random() < 0.3333:\n # text = tweet[1].replace(\":))\", \"\").replace(\":)\", \"\").replace(\":P\", \"\").replace(\":-)\", \"\").replace(\": )\", \"\").replace(\":D\", \"\").replace(\"=)\", \"\").replace(\":(\", \"\").replace(\":-(\", \"\").replace(\": (\", \"\")\n # data.append(['positive', text.encode('unicode_escape').decode('utf-8') + \"\\n\"])\n # else:\n # data.append(['positive', tweet[1].encode('unicode_escape').decode('utf-8') + \"\\n\"])\n else:\n data.append([tweet[0], tweet[1]])\n\n wr = csv.writer(corpus, delimiter=',')\n wr.writerows(data)\n corpus.close()\n temp.close()\n print \"DONE\"\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5541125535964966,
"alphanum_fraction": 0.7939394116401672,
"avg_line_length": 47.125,
"blob_id": "212c63a629fdd8d38b241dbf300f314d6fbd9608",
"content_id": "e9bf9364febc33d89e3447e47160201bb1b33283",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1155,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 24,
"path": "/README.md",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "algorithim|initialization and training time|accuracy|average testing time\n---|---|---|---\nBaseline|0.249 sec|64.65%|3.02e-05 sec\nNLTK Naive Bayes|285.913 sec|79.42%|3.0158 sec\nSelf-implemented Naive Bayes|0.751 sec|84.03%|0.00276 sec\nmore|to|come|soon\n\n```\nBaseline initialization time: 0.274383068085\nNLTK Naive Bayes initialization and training time: 303.465944052\nMy Naive Bayes implementation's initialization and training time: 0.773118019104\n\nNaiveBayes score 4966.0 correct and 944.0 incorrect. Total percentage: 84.03% correct!\nBaseline score 3821.0 correct and 2089.0 incorrect. Total percentage: 64.65% correct!\nNLTK score 4694.0 correct and 1216.0 incorrect. Total percentage: 79.42% correct!\n\nNaiveBayes percision is 0.981035163967 recall is 0.911861917003\nBaseline percision is 0.887778810409 recall is 0.774579363471\nNLTK percision is 0.989668985874 recall is 0.84561340299\n\nTesting time statistics for NaiveBayes: {Total: 60.7811512947, Average: 0.0034281529213}\nTesting time statistics for Baseline: {Total: 0.715081214905, Average: 4.03317098085e-05}\nTesting time statistics for NLTK: {Total: 922.855100155, Average: 0.0520504850623}\n```\n"
},
{
"alpha_fraction": 0.49504950642585754,
"alphanum_fraction": 0.5099009871482849,
"avg_line_length": 21.55555534362793,
"blob_id": "a823325d2ed2b540f284771a4b9ff0fb941fd056",
"content_id": "65494fd78afacaf3a79ccc82ca46648492774bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/data/helperScripts/testStuff.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import re\n\ndef testRegex(str):\n while str != \"quit\":\n print re.sub(r'(.)\\1+', r'\\1\\1', str)\n str = raw_input('string: ')\n\nif __name__ == '__main__':\n testRegex(raw_input('string: '))"
},
{
"alpha_fraction": 0.4466131031513214,
"alphanum_fraction": 0.48105624318122864,
"avg_line_length": 28.049999237060547,
"blob_id": "b3a1e969bfec12438f9f357bbad98cf79dcf59a7",
"content_id": "0d5bb9b48480d69caece62956ebb2296edfbe6fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1742,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 60,
"path": "/data/helperScripts/fixfuckups.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv\nposC = csv.reader(open('data/clean/poscorpus.csv', 'rU'))\nnegC = csv.reader(open('data/clean/negcorpus.csv', 'rU'))\nqusC = csv.reader(open('data/clean/quscorpus.csv', 'rU'))\n\ndef toomanycells():\n actC = csv.reader(open('data/raw/corpuses/activecorpus_raw.csv', 'rU'))\n count = 0\n data = []\n for row in actC:\n if len(row) > 2:\n text = \"\"\n for i, val in enumerate(row):\n if i != 0:\n text = text + row[i]\n data.append([row[0], text])\n count += 1\n elif not \"E+17\" in row[1]:\n data.append([row[0], row[1]])\n wr = csv.writer(open('data/raw/corpuses/activecorpus_raw.csv', 'wb'))\n wr.writerows(data)\n print count\n\ndef lookOverQuestions():\n testD = csv.reader(open('data/testData.csv', 'rU'))\n data = []\n count = 0\n for row in testD:\n if row[0] == \"3\" and not \"?\" in row[1]:\n print row[1]\n count += 1\n # cmd = raw_input(\"??: \")\n # if cmd == \"1\":\n # data.append([9, row[1]])\n # else:\n # data.append([row[0], row[1]])\n # else:\n # data.append([row[0], row[1]])\n # wr = csv.writer(open('data/testData.csv', 'wb'))\n # wr.writerows(data)\n print count\n\ndef find7525line():\n total = [5386.0,5243.0,5295.0]\n corpusC = 0\n for corpus in[posC, negC, qusC]:\n # total = 0.0\n # for row in corpus:\n # total += 1.0\n # print total\n cur = 0.0\n for row in corpus:\n cur += 1.0\n if cur / total[corpusC] > 0.75:\n print row[1]\n break\n corpusC += 1\n\nif __name__ == \"__main__\":\n find7525line()"
},
{
"alpha_fraction": 0.514126718044281,
"alphanum_fraction": 0.5667808055877686,
"avg_line_length": 43.94230651855469,
"blob_id": "4c1d36b0b83691d0aeae4062505ae710209ab819",
"content_id": "664d349287e402e05cef79b0f9e93390223bf56a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2336,
"license_type": "no_license",
"max_line_length": 262,
"num_lines": 52,
"path": "/data/helperScripts/getData.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import os, oauth2, json, csv, random\n\ndef oauth_req(url, key, secret, http_method=\"GET\", post_body=\"\", http_headers=None):\n consumer = oauth2.Consumer(key=\"xxx\", secret=\"xxx\")\n token = oauth2.Token(key=key, secret=secret)\n client = oauth2.Client(consumer, token)\n resp, content = client.request(url, method=http_method, body=post_body, headers=http_headers )\n return content\n\n\ndef main():\n max_id = \"753730647579963392\"\n mydata = []\n count = 0\n while count < 100000:\n corpus = open('quscorpus.csv', 'ab')\n result = oauth_req(\"https://api.twitter.com/1.1/search/tweets.json?max_id=\"+max_id+\"&q=%40apple%20OR%20%40microsoft%20OR%20tech%20OR%20virtual%20OR%20business%20OR%20election%20OR%20bank%20lang%3Aen%20%3F\", 'xxx-xxx', 'xxx' )\n data = json.loads(result)\n if not 'statues' in data:\n print result\n tweets = data['statuses']\n # print data\n id = \"\"\n for tweet in tweets:\n # corpus.write(tweet['id_str']+',\"'+tweet['text'].encode('unicode_escape').decode('utf-8').replace('\"','\"\"')+'\"' + \"\\n\")\n if len(tweet['text']) > 50 and random.random() < 0.75:\n text = tweet['text'].encode('unicode_escape').decode('utf-8').replace(\":))\", \"\").replace(\":)\", \"\").replace(\":P\", \"\").replace(\":-)\", \"\").replace(\": )\", \"\").replace(\":D\", \"\").replace(\"=)\", \"\").replace(\":(\", \"\").replace(\":-(\", \"\").replace(\": (\", \"\")\n mydata.append(['question', text.encode('unicode_escape').decode('utf-8')])\n else:\n mydata.append(['question', tweet['text'].encode('unicode_escape').decode('utf-8')])\n count+=1\n id = tweet['id_str']\n\n print json.dumps(data['search_metadata'])\n print \"---v\"\n print \"\\n\\n\\n\"\n print \"id: \"+id\n try:\n max_id = data['search_metadata']['next_results'].replace(\"?max_id=\",\"\").replace(\"&q=who%20OR%20what%20OR%20where%20OR%20when%20OR%20why%20OR%20how%20OR%20if%20OR%20are%20OR%20do%20OR%20should%20OR%20guess%20lang%3Aen%20%3F&include_entities=1\", \"\")\n except Exception as e:\n max_id = str(int(id)-1)\n print max_id\n wr = csv.writer(corpus, delimiter=',')\n wr.writerows(mydata)\n corpus.close()\n mydata = []\n\n \n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.42532050609588623,
"alphanum_fraction": 0.446153849363327,
"avg_line_length": 43.58571243286133,
"blob_id": "311170f12c8f1305b25b8d125570ee567d3fe67a",
"content_id": "13c1e8349f4b00e67e377e232fe0b24ccfbbab0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3120,
"license_type": "no_license",
"max_line_length": 183,
"num_lines": 70,
"path": "/main.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, time\nfrom algorithims.Baseline import Baseline\nfrom algorithims.NaiveBayes import NaiveBayes\nfrom algorithims.NLTK import NLTK\nfrom data.helperScripts.sanitizeData import clean\n\ndef main():\n text = raw_input(\"Enter text to grade: \")\n print \"~~~~~~~~~~~~~~~~~~~~~~~~~~~~{Baseline}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\" \n print Baseline().grade(text)\n print \"~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\"\n print \"~~~~~~~~~~~~~~~~~~~~~~~~~~~{Naive Bayes}~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\"\n print NaiveBayes().grade(text)\n print \"~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\"\n\ndef test():\n # \"Baseline\":[0.0,0.0], \"NLTK\":[0.0,0.0], \n scores = {}\n percision = {}\n recall = {}\n testingTime = {}\n algos = {\"Baseline\":Baseline(), \"NLTK\":NLTK(), \"NaiveBayes\":NaiveBayes()}\n count = 0\n with open('data/testData.csv', 'rU') as corpus:\n rows = csv.reader(corpus)\n for row in rows:\n for name, algo in algos.items():\n if not name in scores:\n scores[name] = [0.0,0.0]\n percision[name] = {}\n recall[name] = {}\n testingTime[name] = 0.0\n for senti in [\"positive\", \"negative\", \"question\"]:\n percision[name][senti] = [0.0,0.0]\n recall[name][senti] = [0.0,0.0]\n count += 1\n start_time = time.time()\n hyp = algo.test(clean(row[1]))\n testingTime[name] += time.time() - start_time\n if hyp == row[0]:\n scores[name][0] += 1\n scores[name][1] += 1\n percision[name][hyp][0] += 1\n percision[name][hyp][1] += 1\n recall[name][hyp][0] += 1\n recall[name][hyp][1] += 1\n else:\n # print clean(row[1])\n # print hyp + \" vs. \" + row[0]\n scores[name][1] += 1\n for senti in [\"positive\", \"negative\", \"question\"]:\n if hyp == senti and row[0] != senti:\n percision[name][senti][1] += 1\n if hyp != senti and row[0] == senti:\n recall[name][senti][1] += 1\n\n print \"\\n\\n\"\n for name, scs in scores.items():\n print name + \" score \" + str(scs[0]) + \" correct and \" + str(scs[1]) + \" incorrect. Total percentage:\", scs[0]/scs[1]*100, \"% correct!\"\n print \"\\n\\n\"\n for name, scs in scores.items():\n print \"For\", name\n for senti in [\"positive\", \"negative\", \"question\"]:\n print \"sentiment\", senti + \":\", \"percision\", percision[name][senti][0]/percision[name][senti][1]*100, \"% and recall\", recall[name][senti][0]/recall[name][senti][1]*100,\"%\"\n print \"\\n\\n\"\n for name, scs in scores.items():\n print \"Testing time statistics for \"+name+\": {Total: \" + str(testingTime[name]) + \", Average: \" + str(testingTime[name]/count) + \"}\"\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5682888627052307,
"alphanum_fraction": 0.5965462923049927,
"avg_line_length": 29.380952835083008,
"blob_id": "9e7bac6208e782f8063bee016191979630767820",
"content_id": "a5071bba3abd89dc0981ac842b5fdc2f7f54d520",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 21,
"path": "/data/helperScripts/generateStopwords.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, re\n\n# {'positive': 5388}\n# {'negative': 5251}\n# {'question': 5295}\nposC = csv.reader(open('data/raw/corpuses/poscorpus_raw.csv', 'rU'))\nnegC = csv.reader(open('data/raw/corpuses/negcorpus_raw.csv', 'rU'))\nqusC = csv.reader(open('data/raw/corpuses/quscorpus_raw.csv', 'rU'))\n\nwords = {}\n\nfor corpus in [posC, negC, qusC]:\n for row in corpus:\n wordList = re.sub(\"[^\\w]\", \" \", row[1]).split()\n for word in wordList:\n words[word.lower()] = words.get(word.lower(), 0) + 1\n d_view = [ (v,k) for k,v in words.iteritems() ]\n d_view.sort(reverse=True)\n print d_view[:100]\n words = {}\n break"
},
{
"alpha_fraction": 0.6035734415054321,
"alphanum_fraction": 0.6091569066047668,
"avg_line_length": 36.33333206176758,
"blob_id": "63bbe873c6be4156efe66eb97d8870a9f9117cf3",
"content_id": "82ece1d0e9c20cafbb2f2277d9f93d1a2bd3117f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1791,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 48,
"path": "/algorithims/NLTK.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, nltk, time\nfrom data.helperScripts.sanitizeData import clean\n\nposC = csv.reader(open('data/clean/poscorpus.csv', 'rU'))\nnegC = csv.reader(open('data/clean/negcorpus.csv', 'rU'))\nqusC = csv.reader(open('data/clean/quscorpus.csv', 'rU'))\n\nclass NLTK():\n vocab = []\n trainingTweets = []\n NBClassifier = None\n\n def __init__(self):\n start_time = time.time()\n for corpus in[posC, negC, qusC]:\n count = 0\n for row in corpus:\n row[0] = row[0].lower()\n row[1] = clean(row[1].lower())\n self.trainingTweets.append( (self.getFeatureVector(row[1]), row[0]) )\n count += 1\n training_set = nltk.classify.util.apply_features(self.extract_features_complete, self.trainingTweets)\n self.NBClassifier = nltk.NaiveBayesClassifier.train(training_set)\n print \"NLTK Naive Bayes initialization and training time: \" + str(time.time() - start_time)\n\n def test(self, tweet):\n return self.NBClassifier.classify(self.extract_features_complete(self.getFeatureVector(tweet)))\n\n def getFeatureVector(self, tweet):\n featureVector = []\n tweet = clean(tweet)\n words = tweet.split(\" \")\n for w in words:\n featureVector.append(w.lower())\n if w.lower() not in self.vocab:\n self.vocab.append(w.lower())\n return featureVector\n\n def extract_features_complete(self, tweet):\n tweet_words = set(tweet)\n features = {}\n for word in self.vocab:\n features['contains(%s)' % word] = (word in tweet_words)\n return features\n \n def __exit__(self, exc_type, exc_value, traceback):\n print \"EXIT CALLLEDDDD\"\n print NBClassifier.show_most_informative_features(10)"
},
{
"alpha_fraction": 0.5338948965072632,
"alphanum_fraction": 0.5427196025848389,
"avg_line_length": 38.57936477661133,
"blob_id": "346aa42403910304dbf4214c2f47a0aca145f352",
"content_id": "af7d854d871b9c0efd06d47fac6fdfe4502295fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4986,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 126,
"path": "/algorithims/NaiveBayes.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "import csv, json, math, time\nfrom data.helperScripts.sanitizeData import clean\n\nposC = csv.reader(open('data/clean/poscorpus.csv', 'rU'))\nnegC = csv.reader(open('data/clean/negcorpus.csv', 'rU'))\nqusC = csv.reader(open('data/clean/quscorpus.csv', 'rU'))\n\nclass NaiveBayes(object):\n \n Bags = {}\n Vocab = {}\n CatSeen = {}\n\n def __init__(self):\n start_time = time.time()\n #load bags\n for corpus in[posC, negC, qusC]:\n for row in corpus:\n row[0] = row[0].lower()\n row[1] = clean(row[1].lower())\n\n if row[0] not in self.CatSeen:\n self.CatSeen[row[0]] = 0.0\n self.CatSeen[row[0]] += 1.0\n\n if row[0] not in self.Bags:\n self.Bags[row[0]] = {}\n\n for word, count in self.getWordCounts(row[1].split(\" \")).items():\n self.Bags[row[0]][word.lower()] = self.Bags[row[0]].get(word.lower(), 0.0) + count\n if word.lower() not in self.Vocab:\n self.Vocab[word.lower()] = 0.0\n self.Vocab[word.lower()] += count\n # print \"My Naive Bayes implementation's initialization and training time: \" + str(time.time() - start_time)\n\n\n def getWordCounts(self, words):\n wc = {}\n for word in words:\n wc[word] = wc.get(word, 0.0) + 1.0\n return wc\n\n def test(self, text):\n TotalLogScores = {\n \"positive\":0.0,\n \"negative\":0.0,\n \"question\":0.0,\n }\n TotalCatSeen = sum(self.CatSeen.values())\n PriorLogCatScore = {\n \"positive\":math.log(self.CatSeen[\"positive\"]/TotalCatSeen),\n \"negative\":math.log(self.CatSeen[\"negative\"]/TotalCatSeen),\n \"question\":math.log(self.CatSeen[\"question\"]/TotalCatSeen),\n }\n\n for word, count in self.getWordCounts(text.split(\" \")).items():\n if not word in self.Vocab: #or word in stopwords list\n continue\n \n p_word = self.Vocab[word] / sum(self.Vocab.values())\n scores = {}\n for cat in TotalLogScores:\n scores[cat] = self.Bags[cat].get(word, 0.0)/sum(self.Bags[cat].values())\n \n for cat, score in scores.items():\n if score > 0:\n TotalLogScores[cat] += math.log(count * score/p_word)\n\n Epsilon = 0\n\n TotalScores = {}\n for cat, logScore in TotalLogScores.items():\n TotalScores[cat] = math.exp(logScore)\n\n if TotalScores[\"question\"] > ( TotalScores[\"positive\"] + Epsilon ) and TotalScores[\"question\"] > ( TotalScores[\"negative\"] + Epsilon ):\n return \"question\"\n elif TotalScores[\"positive\"] > ( TotalScores[\"negative\"] + Epsilon ):# and TotalScores[\"positive\"] > ( TotalScores[\"question\"] + Epsilon ):\n return \"positive\"\n elif TotalScores[\"negative\"] > ( TotalScores[\"positive\"] + Epsilon ) and TotalScores[\"negative\"] > ( TotalScores[\"question\"] + Epsilon ):\n return \"negative\"\n else:\n return max(TotalScores, key=TotalScores.get)\n\n def grade(self, text):\n TotalLogScores = {\n \"positive\":0.0,\n \"negative\":0.0,\n \"question\":0.0,\n }\n TotalCatSeen = sum(self.CatSeen.values())\n PriorLogCatScore = {\n \"positive\":math.log(self.CatSeen[\"positive\"]/TotalCatSeen),\n \"negative\":math.log(self.CatSeen[\"negative\"]/TotalCatSeen),\n \"question\":math.log(self.CatSeen[\"question\"]/TotalCatSeen),\n }\n\n for word, count in self.getWordCounts(text.split(\" \")).items():\n if not word in self.Vocab: #or word in stopwords list\n continue\n \n p_word = self.Vocab[word] / sum(self.Vocab.values())\n scores = {}\n for cat in TotalLogScores:\n scores[cat] = self.Bags[cat].get(word, 0.0)/sum(self.Bags[cat].values())\n \n for cat, score in scores.items():\n if score > 0:\n TotalLogScores[cat] += math.log(count * score/p_word)\n\n Epsilon = 0\n\n TotalScores = {}\n for cat, logScore in TotalLogScores.items():\n TotalScores[cat] = math.exp(logScore)\n\n if TotalScores[\"question\"] > ( TotalScores[\"positive\"] + Epsilon ) and TotalScores[\"question\"] > ( TotalScores[\"negative\"] + Epsilon ):\n return \"Text is a Question...\"\n elif TotalScores[\"positive\"] > ( TotalScores[\"negative\"] + Epsilon ):# and TotalScores[\"positive\"] > ( TotalScores[\"question\"] + Epsilon ):\n return \"Text is positive\"\n elif TotalScores[\"negative\"] > ( TotalScores[\"positive\"] + Epsilon ) and TotalScores[\"negative\"] > ( TotalScores[\"question\"] + Epsilon ):\n return \"Text is negative\"\n else:\n return \"Text is neutral\"\n\nif __name__ == '__main__':\n n = NaiveBayes()"
},
{
"alpha_fraction": 0.5178571343421936,
"alphanum_fraction": 0.5446428656578064,
"avg_line_length": 27.04166603088379,
"blob_id": "a12b4d58b35832438b93d4acca3b3f1e3cdaa233",
"content_id": "c5884b377039b7981d194b27b6e1b8b3b2c6de0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 24,
"path": "/data/helperScripts/SWN_RF.py",
"repo_name": "gs27/Twitter-Sentiment-Analysis",
"src_encoding": "UTF-8",
"text": "#SentiWordNet Reformat\nimport os, csv\n\ndef get_words(row):\n words_ids = row[4].split(\" \")\n words = [w.split(\"#\")[0] for w in words_ids]\n return words\n\ndef main():\n SWN = open('raw/SentiWordNet_3.0.0_20130122.txt', 'r')\n data = []\n for line in SWN:\n if not line.startswith(\"#\"):\n row = line.split(\"\\t\")\n words = get_words(row)\n for word in words:\n data.append([word, row[2], row[3], 1 - (float(row[2]) + float(row[3]))])\n corpus = open('SentiWordNet_reformatted.csv', 'wb')\n wr = csv.writer(corpus, delimiter=',')\n wr.writerows(data)\n corpus.close()\n\nif __name__ == \"__main__\":\n main()"
}
] | 15 |
jmatthew133/Rock_Paper_Scissors
|
https://github.com/jmatthew133/Rock_Paper_Scissors
|
a9630198faba8035fadff743e1d436ce73d7d6d2
|
cd227e63e87a80417fa63d982fd1ce66487e9915
|
49e30a6987db446aa35e97f27288cc90183dbad5
|
refs/heads/master
| 2021-01-01T18:22:22.343503 | 2015-07-27T21:37:57 | 2015-07-27T21:37:57 | 39,799,162 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4922928810119629,
"alphanum_fraction": 0.4971098303794861,
"avg_line_length": 27.054054260253906,
"blob_id": "7f6ba815c9ec5b12a0a77bdfcff9f8600775e88e",
"content_id": "83b359720ae38bd6a495f62d3448efe83b1d9b02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2076,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 74,
"path": "/RockPaperScissors.py",
"repo_name": "jmatthew133/Rock_Paper_Scissors",
"src_encoding": "UTF-8",
"text": "# Rock Paper Scissors in Python\nfrom random import randint\n\ndef rock_paper_scissors():\n\n print \"Let's play Rock Paper Scissors!\"\n playing = True\n user_score = 0\n comp_score = 0\n ties = 0\n\n while playing == True:\n move = get_input()\n if move == \"rock\":\n print \"You played rock\"\n play = \"y\"\n elif move == \"paper\":\n print \"You played paper\"\n play = \"y\"\n elif move == \"scissors\":\n print \"You played scissors\"\n play = \"y\"\n elif move == \"quit\":\n print \"Quitting game, Goodbye\"\n playing = False\n play = \"n\"\n else:\n print \"Command not recognized, try again\"\n play = \"n\"\n\n if play == \"y\":\n comp_move = get_comp_move()\n print \"The computer played %s\" % comp_move\n result = check_hand(move, comp_move)\n if result == \"t\":\n print \"Tie Game!\"\n ties += 1\n elif result == \"w\":\n print \"You win!\"\n user_score += 1\n elif result == \"l\":\n print \"You lose :(\"\n comp_score += 1\n\n print \"You: %d, Computer: %d, Ties: %d\\n\" %(user_score, comp_score, ties)\n\n# Grabs input from the user\ndef get_input():\n txt = input(\"Please enter 'rock', 'paper', 'scissors', or 'quit'\")\n txt.lower()\n return txt\n\n# Generates random move from the computer\ndef get_comp_move():\n num = randint(1, 3)\n if num == 1:\n move = \"rock\"\n elif num == 2:\n move = \"paper\"\n else:\n move = \"scissors\"\n return move\n\n# Checks hands, returns w, l or t\ndef check_hand(you, comp):\n if you == comp:\n return \"t\"\n elif (you == \"rock\" and comp == \"scissors\") or (you == \"paper\" and comp == \"rock\") or (you == \"scissors\" and comp == \"paper\"):\n return \"w\"\n elif (you == \"rock\" and comp == \"paper\") or (you == \"paper\" and comp == \"scissors\") or (you == \"scissors\" and comp == \"rock\"):\n return \"l\"\n\n\nrock_paper_scissors()\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 31,
"blob_id": "b1e6f3635a12f0d881ccaa4514cc882819fc9ff7",
"content_id": "29b9c9cd4b4b71e072b6eeff71557c0b0da54f40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 2,
"path": "/README.md",
"repo_name": "jmatthew133/Rock_Paper_Scissors",
"src_encoding": "UTF-8",
"text": "# Rock_Paper_Scissors\nSimple Rock Paper Scissors game in python\n"
}
] | 2 |
rvaros/Donor-Charity-Machine-Learning-Project
|
https://github.com/rvaros/Donor-Charity-Machine-Learning-Project
|
075e00cf32a4a7ed8aac65e31a2648e1e6886aef
|
467168613f6e3e58ac3e1424abc6eb0ad8926aef
|
29802847f1ab58c12f29367b4c52277828ed4209
|
refs/heads/master
| 2020-05-03T10:37:53.037246 | 2019-04-29T18:04:50 | 2019-04-29T18:04:50 | 178,583,998 | 2 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6497461795806885,
"alphanum_fraction": 0.6578680276870728,
"avg_line_length": 26.38888931274414,
"blob_id": "370b60b189523c14f8388e002e7a2a8e7b46c33c",
"content_id": "199766a2d417a07249df8ff6f1a5f0f5f558d36b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 985,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 36,
"path": "/app.py",
"repo_name": "rvaros/Donor-Charity-Machine-Learning-Project",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nimport flask\nimport pickle\nfrom flask import Flask, render_template, request\n\napp=Flask(__name__)\n\[email protected]('/')\ndef index():\n return flask.render_template('index.html')\n\n\ndef ValuePredictor(result_list):\n print (result_list)\n result = np.array(result_list).reshape(1,-1)\n loaded_model = pickle.load(open(\"tree_classifier.pkl\",\"rb\"))\n predict = loaded_model.predict(result)\n return predict[0]\n\[email protected]('/predict',methods = ['POST'])\ndef predict():\n if request.method == 'POST':\n result_list = request.form.to_dict()\n result_list=list(result_list.values())\n result_list = list(map(int, result_list))\n predict = ValuePredictor(result_list)\n\n if int(predict)==1:\n prediction='Potential Donor Identified'\n else:\n prediction='Not a Potential Donor'\n return render_template(\"predict.html\",prediction=prediction)\n\nif __name__ == '__main__':\n app.run(port=5000, debug=True)"
}
] | 1 |
CalPolyResDev/checkin_parking_project
|
https://github.com/CalPolyResDev/checkin_parking_project
|
6ee4bbf3b4ec050461c42edd66d5aff43c867a03
|
cbfc7f04f4e0f32fda452bc2fcee5903f5b057fe
|
3455dab30194e2919653aab98368b9b4b41c7817
|
refs/heads/master
| 2021-03-24T13:28:02.059385 | 2017-08-02T00:29:46 | 2017-08-02T00:29:46 | 88,289,647 | 2 | 0 | null | 2017-04-14T17:45:35 | 2017-07-19T21:16:20 | 2017-07-29T04:08:57 |
Python
|
[
{
"alpha_fraction": 0.7434077262878418,
"alphanum_fraction": 0.7434077262878418,
"avg_line_length": 40.08333206176758,
"blob_id": "a1b04de51593dfcbc0cca6b06e599e5806687daf",
"content_id": "9d546f33ad1942e5484bf6091958177a510fee0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 986,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 24,
"path": "/checkin_parking/apps/administration/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.urls\n :synopsis: Checkin Parking Reservation Administration URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf.urls import url\nfrom django.contrib.auth.decorators import login_required\n\nfrom ...urls import administrative_access\nfrom .ajax import purge\nfrom .views import AdminSettingsUpdateView, PurgeView, PDFMapUploadView, BecomeStudentView\n\napp_name = 'administration'\n\nurlpatterns = [\n url(r'^$', login_required(administrative_access(AdminSettingsUpdateView.as_view())), name='settings'),\n url(r'^purge/$', login_required(administrative_access(PurgeView.as_view())), name='purge'),\n url(r'^ajax/run_purge/$', login_required(administrative_access(purge)), name='run_purge'),\n url(r'^maps/$', login_required(administrative_access(PDFMapUploadView.as_view())), name='update_maps'),\n url(r'^become_student/$', login_required(administrative_access(BecomeStudentView.as_view())), name=\"become_student\")\n]\n"
},
{
"alpha_fraction": 0.6763636469841003,
"alphanum_fraction": 0.6763636469841003,
"avg_line_length": 27.44827651977539,
"blob_id": "cf9ce633efe69c595f7d8027772abd79053b7959",
"content_id": "8779d74a55d841aab823118cbedb1023e533edba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 29,
"path": "/checkin_parking/apps/core/managers.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.managers\n :synopsis: Checkin Parking Reservation Core Managers.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.db.models.manager import Manager\n\n\nclass DefaultRelatedManager(Manager):\n use_for_related_fields = True\n\n def __init__(self, select_related=None, prefetch_related=None):\n self._select_related = select_related\n self._prefetch_related = prefetch_related\n super(DefaultRelatedManager, self).__init__()\n\n def get_queryset(self):\n queryset = super(DefaultRelatedManager, self).get_queryset()\n\n if self._select_related:\n queryset = queryset.select_related(*self._select_related)\n\n if self._prefetch_related:\n queryset = queryset.prefetch_related(*self._prefetch_related)\n\n return queryset\n"
},
{
"alpha_fraction": 0.5266990065574646,
"alphanum_fraction": 0.6043689250946045,
"avg_line_length": 20.6842098236084,
"blob_id": "eb92aa6bd61a356b2572629ff561da6aacc791e3",
"content_id": "357737c501b789328b6b884d119506d2debd8f3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 412,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 19,
"path": "/checkin_parking/apps/reservations/migrations/0009_remove_reservationslot_out_of_state.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2017-08-01 16:13\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('reservations', '0008_auto_20170723_2350'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='reservationslot',\n name='out_of_state',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6829853057861328,
"alphanum_fraction": 0.6891475319862366,
"avg_line_length": 34.621952056884766,
"blob_id": "02b4a57fbe9254f636410c231db2251e2643c686",
"content_id": "4958f6e11e2c7b169b8a50f500495ca54331a5f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2921,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 82,
"path": "/checkin_parking/apps/core/views.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.views\n :synopsis: Checkin Parking Reservation Core Views.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom collections import defaultdict\nfrom datetime import date as datetime_date, datetime, timedelta\nimport logging\nfrom operator import attrgetter, itemgetter\n\nfrom django.conf import settings\nfrom django.template.context import RequestContext\nfrom django.views.generic import TemplateView\n\nfrom ..administration.models import AdminSettings\nfrom ..reservations.models import ReservationSlot\n\nlogger = logging.getLogger(__name__)\n\n\nclass IndexView(TemplateView):\n template_name = \"core/index.djhtml\"\n\n def get_context_data(self, **kwargs):\n context = super(TemplateView, self).get_context_data(**kwargs)\n\n move_in_slot_dict = defaultdict(list)\n\n reservation_date_dict = defaultdict(list)\n reservation_slots = ReservationSlot.objects.filter(resident__isnull=True).distinct().select_related('timeslot', 'zone', 'zone__community')\n\n timeslot_length = AdminSettings.objects.get_settings().timeslot_length\n\n for reservation in reservation_slots:\n reservation_date_dict[reservation.timeslot.date].append(reservation)\n\n for date, reservation_slots in reservation_date_dict.items():\n reservation_slots.sort(key=attrgetter(\"timeslot.time\"))\n\n delta = datetime.combine(datetime_date.today(), reservation_slots[-1].timeslot.time)\n\n first_reservation = reservation_slots[0]\n\n move_in_slot_dict[first_reservation.class_level].append({\n \"date\": date,\n \"time_range\": first_reservation.timeslot.time.strftime(settings.PYTHON_TIME_FORMAT) + \" - \" + delta.strftime(settings.PYTHON_TIME_FORMAT),\n \"community\": first_reservation.zone.community.name,\n \"assisted_move_in\": first_reservation.timeslot.assisted_move_in,\n \"buildings\": ', '.join(first_reservation.zone.buildings.values_list('name', flat=True)),\n })\n\n for community, reservation_slots in move_in_slot_dict.items():\n reservation_slots.sort(key=itemgetter('date'))\n\n context[\"move_in_slot_dict\"] = dict(move_in_slot_dict) # Reason for conversion: https://code.djangoproject.com/ticket/16335\n\n return context\n\n\ndef handler500(request):\n \"\"\"500 error handler which includes ``request`` in the context.\"\"\"\n\n from django.template import loader\n from django.http import HttpResponseServerError\n\n template = loader.get_template('500.djhtml')\n context = RequestContext(request)\n\n try:\n raise\n except Exception as exc:\n exception_text = str(exc)\n if exception_text.startswith(\"['\"):\n exception_text = exception_text[2:-2]\n context['exception_text'] = exception_text\n\n logger.exception(exc)\n\n return HttpResponseServerError(template.render(context))\n"
},
{
"alpha_fraction": 0.6208791136741638,
"alphanum_fraction": 0.6416361331939697,
"avg_line_length": 34.60869598388672,
"blob_id": "6a7282de088adfd1453d3809e65896e1648e5909",
"content_id": "0c116b1f3eddf1794d2f6968e5553c0bb7c4b9e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1638,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 46,
"path": "/checkin_parking/apps/statistics/utils.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.statistics.utils\n :synopsis: Checkin Parking Statistics Utils\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\n\nfrom datetime import datetime\nfrom operator import itemgetter\nfrom statistics import mean\n\nfrom ..administration.models import AdminSettings\n\n\ndef add_overnight_points(data_points):\n '''Inserts points at beginning and end of day so overnight shows as having 0 reservations'''\n if len(data_points) > 2:\n points_to_add = []\n timeslot_length = AdminSettings.objects.get_settings().timeslot_length * 60 * 1000\n for index in range(1, len(data_points)):\n if data_points[index][0] - data_points[index - 1][0] > timeslot_length:\n points_to_add.append((index, data_points[index - 1][0] + timeslot_length, data_points[index][0] - 1))\n\n for point in sorted(points_to_add, key=itemgetter(0), reverse=True):\n data_points.insert(point[0], (point[2], 0))\n data_points.insert(point[0], (point[1], 0))\n\n\ndef generate_series(series_name, data_points, display_type):\n return {\n 'avg': mean([point[1] for point in data_points]) if data_points else 0,\n 'min': min(data_points, key=itemgetter(1))[1] if data_points else 0,\n 'max': max(data_points, key=itemgetter(1))[1] if data_points else 0,\n 'last': data_points[-1][1] if data_points else 0,\n 'name': series_name,\n 'data': data_points,\n 'type': display_type,\n }\n\n\ndef modify_query_for_date(query, kwargs):\n if kwargs['date']:\n query = query.filter(date=datetime.strptime(kwargs['date'], '%Y-%m-%d'))\n\n return query\n"
},
{
"alpha_fraction": 0.6266490817070007,
"alphanum_fraction": 0.6530343294143677,
"avg_line_length": 38.894737243652344,
"blob_id": "00484f29325ccac41ce7b2a4229e22cff62b8ab9",
"content_id": "ad8d15f73245b852c1db9162abc1445e84fbe0c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 758,
"license_type": "no_license",
"max_line_length": 387,
"num_lines": 19,
"path": "/checkin_parking/apps/reservations/migrations/0003_auto_20150907_1935.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('reservations', '0002_auto_20150907_1735'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='reservationslot',\n name='class_level',\n field=models.CharField(max_length=30, default=6, choices=[('Freshman', 'Freshman'), ('Transfer', 'Transfer'), ('Continuing', 'Continuing'), ('Freshman/Transfer', 'Freshman/Transfer'), ('Freshman/Continuing', 'Freshman/Continuing'), ('Transfer/Continuing', 'Transfer/Continuing'), ('Freshman/Transfer/Continuing', 'Freshman/Transfer/Continuing')], verbose_name='Class Level'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5492957830429077,
"alphanum_fraction": 0.6136820912361145,
"avg_line_length": 23.850000381469727,
"blob_id": "0578e8b200edaf5535acb945ca6dfdc20b6184a6",
"content_id": "d797ca4ba58c927dadf98bb857b1c01c0f527279",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 20,
"path": "/checkin_parking/apps/reservations/migrations/0004_reservationslot_out_of_state.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-02 22:37\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('reservations', '0003_auto_20150907_1935'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='reservationslot',\n name='out_of_state',\n field=models.BooleanField(default=False, verbose_name='In State?'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.3595890402793884,
"alphanum_fraction": 0.3595890402793884,
"avg_line_length": 33.35293960571289,
"blob_id": "ec597692c0d181b391b8b4629018bc3bacbd3b24",
"content_id": "593cfe77450d2d8408f177c7d26f3fa1e8c2ee2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 17,
"path": "/checkin_parking/settings/production.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "from .base import * # noqa\n\nDEBUG = False\n\n# ======================================================================================================== #\n# Session/Security Configuration #\n# ======================================================================================================== #\n\n# Cookie Settings\nSESSION_COOKIE_NAME = 'CPRKSessionID'\nSESSION_COOKIE_SECURE = True\nCSRF_COOKIE_SECURE = True\n\nALLOWED_HOSTS = [\n '.checkin.housing.calpoly.edu',\n '.staging.checkin.housing.calpoly.edu',\n]\n"
},
{
"alpha_fraction": 0.728863000869751,
"alphanum_fraction": 0.728863000869751,
"avg_line_length": 26.440000534057617,
"blob_id": "c136ff0c158ca9445ecabef382ff8e919b2cea08",
"content_id": "3f604df2f84b210c48cb480df918cc8c10406aae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 25,
"path": "/checkin_parking/apps/reservations/admin.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.admin\n :synopsis: Checkin Parking Reservation Reservation Admin Configuration.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import TimeSlot, ReservationSlot\n\n\nclass TimeSlotAdmin(admin.ModelAdmin):\n list_display = ['datetime', 'assisted_move_in', 'term_code']\n list_filter = ['assisted_move_in', 'term_code']\n\n\nclass ReservationSlotAdmin(admin.ModelAdmin):\n list_display = ['class_level', 'timeslot', 'zone', 'resident']\n list_filter = ['zone', 'class_level', 'timeslot']\n\n\nadmin.site.register(TimeSlot, TimeSlotAdmin)\nadmin.site.register(ReservationSlot, ReservationSlotAdmin)\n"
},
{
"alpha_fraction": 0.7118099927902222,
"alphanum_fraction": 0.7124518752098083,
"avg_line_length": 38.9487190246582,
"blob_id": "959a44381a1550e5881afc8ed261dc1df68b6cf9",
"content_id": "2c3aeca6159103f3a884cf189e5a8c18cf8f980e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3116,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 78,
"path": "/checkin_parking/apps/reservations/models.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.checkin_sessions.models\n :synopsis: Checkin Parking Reservation Models.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom datetime import datetime, timedelta\n\nfrom django.conf import settings\nfrom django.db.models.base import Model\nfrom django.db.models.deletion import SET_NULL\nfrom django.db.models.fields import CharField, DateField, TimeField, PositiveSmallIntegerField, BooleanField, DateTimeField, NullBooleanField\nfrom django.db.models.fields.related import ForeignKey, OneToOneField\nfrom django.utils.functional import cached_property\n\nfrom rmsconnector.constants import FRESHMAN, TRANSFER, CONTINUING\n\nfrom ..administration.models import AdminSettings\nfrom ..core.managers import DefaultRelatedManager\nfrom ..core.models import CheckinParkingUser\nfrom ..zones.models import Zone\n\n\nCLASS_LEVELS = [FRESHMAN, TRANSFER, CONTINUING,\n FRESHMAN + '/' + TRANSFER, FRESHMAN + '/' + CONTINUING, TRANSFER + '/' + CONTINUING,\n FRESHMAN + '/' + TRANSFER + '/' + CONTINUING]\nCLASS_LEVEL_CHOICES = [(class_level, class_level) for class_level in CLASS_LEVELS]\n\n\nclass TimeSlot(Model):\n \"\"\"A slot of time.\"\"\"\n\n date = DateField(verbose_name=\"Date\")\n time = TimeField(verbose_name=\"Time\")\n assisted_move_in = BooleanField(default=False, verbose_name=\"Assisted Move In?\")\n term_code = PositiveSmallIntegerField(verbose_name=\"Term Code\")\n\n @cached_property\n def datetime(self):\n combined = datetime.combine(self.date, self.time)\n return datetime.strftime(combined, settings.PYTHON_DATETIME_FORMAT)\n\n @cached_property\n def datetime_obj(self):\n combined = datetime.combine(self.date, self.time)\n return combined\n\n @cached_property\n def end_time(self):\n return (datetime.combine(datetime.today(), self.time) + timedelta(minutes=AdminSettings.objects.get_settings().timeslot_length)).time()\n\n @cached_property\n def end_datetime_obj(self):\n combined = datetime.combine(self.date, self.time)\n combined += timedelta(minutes=AdminSettings.objects.get_settings().timeslot_length)\n return combined\n\n def __str__(self):\n return self.datetime + \" (\" + str(self.term_code) + \")\"\n\n\nclass ReservationSlot(Model):\n \"\"\" A parking session.\"\"\"\n\n class_level = CharField(max_length=30, default=CLASS_LEVELS.index(FRESHMAN + '/' + TRANSFER + '/' + CONTINUING), choices=CLASS_LEVEL_CHOICES, verbose_name=\"Class Level\")\n timeslot = ForeignKey(TimeSlot, related_name=\"reservationslots\", verbose_name=\"Time Slot\")\n zone = ForeignKey(Zone, related_name=\"reservationslots\", verbose_name=\"Zone\")\n resident = OneToOneField(CheckinParkingUser, null=True, blank=True, related_name=\"reservationslot\", verbose_name=\"Resident\", on_delete=SET_NULL)\n\n objects = DefaultRelatedManager(select_related=[\"timeslot\", \"zone\", \"resident\"])\n\n last_scanned = DateTimeField(null=True, blank=True)\n last_scanned_on_time = NullBooleanField()\n\n def __str__(self):\n return str(self.timeslot) + \" - \" + str(self.zone) + \": \" + (str(self.resident) if self.resident else \"Open\")\n"
},
{
"alpha_fraction": 0.6586345434188843,
"alphanum_fraction": 0.6629015803337097,
"avg_line_length": 38.2512321472168,
"blob_id": "4ac9c0b9fe253c1bad44312496225fcb9fa4e4d3",
"content_id": "fddc76790e38c920a73972520e18a2157177f2ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7968,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 203,
"path": "/checkin_parking/apps/reservations/views.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.views\n :synopsis: Checkin Parking Reservation Reservation Views.\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\n\nfrom datetime import date as datetime_date, datetime, timedelta\n\nfrom django.core.exceptions import FieldError, ValidationError\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.db import transaction\nfrom django.http.response import HttpResponse, HttpResponseRedirect\nfrom django.views.generic.base import TemplateView\nfrom django.views.generic.detail import DetailView\nfrom django.views.generic.edit import FormView\nfrom django.views.generic.list import ListView\n\nfrom checkin_parking.apps.reservations.utils import generate_verification_url\n\nfrom ..administration.models import AdminSettings\nfrom .forms import GenerateReservationsForm\nfrom .models import TimeSlot, ReservationSlot\nfrom .utils import generate_pdf_file\n\n\nclass GenerateReservationSlotsView(FormView):\n template_name = \"reservations/generate_reservation_slots.djhtml\"\n form_class = GenerateReservationsForm\n success_url = reverse_lazy('reservations:list_time_slots')\n\n def form_valid(self, form):\n date = form.cleaned_data[\"date\"]\n start_time = form.cleaned_data[\"start_time\"]\n end_time = form.cleaned_data[\"end_time\"]\n class_level = form.cleaned_data[\"class_level\"]\n assisted_move_in = form.cleaned_data[\"assisted_move_in\"]\n zones = form.cleaned_data[\"zones\"]\n\n admin_settings = AdminSettings.objects.get_settings()\n end_datetime = datetime.combine(datetime_date.today(), end_time)\n\n delta = end_datetime - datetime.combine(datetime_date.today(), start_time)\n\n with transaction.atomic():\n # Split the time span into admin_settings.timeslot_length chunks\n while delta.total_seconds() > 0:\n timeslot = TimeSlot()\n timeslot.date = date\n timeslot.time = start_time\n timeslot.assisted_move_in = assisted_move_in\n timeslot.term_code = admin_settings.term_code\n timeslot.save()\n\n # For each zone, create zone.capacity reservation slots\n for zone in zones:\n for index in range(zone.capacity):\n reservationslot = ReservationSlot()\n reservationslot.class_level = class_level\n reservationslot.timeslot = timeslot\n reservationslot.zone = zone\n reservationslot.save()\n\n start_time = (datetime.combine(datetime_date.today(), start_time) + timedelta(minutes=admin_settings.timeslot_length)).time()\n delta = end_datetime - datetime.combine(datetime_date.today(), start_time)\n\n return super(GenerateReservationSlotsView, self).form_valid(form)\n\n\nclass TimeSlotListView(ListView):\n template_name = \"reservations/list_time_slots.djhtml\"\n model = TimeSlot\n\n\nclass ParkingPassVerificationView(TemplateView):\n template_name = 'reservations/parking_pass_verification.djhtml'\n\n def get_context_data(self, **kwargs):\n context = super(ParkingPassVerificationView, self).get_context_data(**kwargs)\n\n reservation_id = kwargs['reservation_id']\n user_id = int(kwargs['user_id'])\n valid_pass = True\n context['scanned_on_time'] = False\n context['scanned_early'] = False\n context['num_minutes_early'] = 0\n \n try:\n reservation_slot = ReservationSlot.objects.get(id=reservation_id)\n\n if not reservation_slot.resident or reservation_slot.resident.id != user_id:\n valid_pass = False\n except ReservationSlot.DoesNotExist:\n valid_pass = False\n\n context['parking_pass_valid'] = valid_pass\n\n if valid_pass:\n reservation_slot.last_scanned = datetime.now()\n timeslot = reservation_slot.timeslot\n if timeslot.datetime_obj <= datetime.now() and timeslot.end_datetime_obj >= datetime.now():\n reservation_slot.last_scanned_on_time = True\n context['scanned_on_time'] = True\n else:\n reservation_slot.last_scanned_on_time = False\n if timeslot.datetime_obj < datetime.now():\n context['scanned_early'] = True\n time_delta = datetime.now() - timeslot.datetime_obj\n context['num_minutes_early'] = int(round(time_delta.seconds / 60))\n reservation_slot.save()\n\n return context\n\n\nclass ParkingPassPDFView(TemplateView):\n template_name = 'reservations/parking_pass.rml'\n\n def get_context_data(self, **kwargs):\n context = super(ParkingPassPDFView, self).get_context_data(**kwargs)\n\n try:\n reservation_slot = ReservationSlot.objects.get(id=self.request.user.reservationslot.id)\n except ReservationSlot.DoesNotExist:\n raise ValidationError('You do not have a parking reservation on file. If you believe this is in error, call ResNet at (805) 756-5600.')\n\n context['reservation_slot'] = reservation_slot\n\n return context\n\n def render_to_response(self, context, **response_kwargs):\n pdf_data = generate_pdf_file(context['reservation_slot'], generate_verification_url(context['reservation_slot'], self.request))\n\n response = HttpResponse()\n response['Content-Type'] = 'application/pdf'\n response['Content-Disposition'] = 'filename=parkingpass.pdf'\n\n response.write(pdf_data)\n\n return response\n\n\nclass ReserveView(ListView):\n template_name = 'reservations/reserve.djhtml'\n model = TimeSlot\n\n def get_queryset(self, **kwargs):\n building = self.request.user.building\n term_type = self.request.user.term_type\n\n if not term_type:\n raise FieldError('Could not retrieve class level. Please call ResNet at (805) 756-5600.')\n\n base_queryset = TimeSlot.objects.filter(reservationslots__resident=None, reservationslots__class_level__contains=term_type)\n\n # Show all open zone slots\n queryset = base_queryset.filter(reservationslots__zone__buildings__name__contains=\"All\")\n\n # Show building specific slots as well\n if building:\n queryset = queryset | base_queryset.filter(reservationslots__zone__buildings=building)\n\n queryset = queryset.order_by('date', 'time')\n\n if 'change_reservation' in kwargs:\n return queryset.exclude(reservationslots__resident=self.request.user).distinct()\n else:\n return queryset.distinct()\n\n def render_to_response(self, context, **response_kwargs):\n if 'change_reservation' not in context:\n try:\n ReservationSlot.objects.get(id=self.request.user.reservationslot.id)\n return HttpResponseRedirect(reverse_lazy('reservations:view_reservation'))\n except:\n pass\n\n return super(ReserveView, self).render_to_response(context, **response_kwargs)\n\n\nclass ViewReservationView(DetailView):\n template_name = 'reservations/reservation_view.djhtml'\n model = ReservationSlot\n\n def get_object(self, queryset=None):\n try:\n reservation_slot = ReservationSlot.objects.get(id=self.request.user.reservationslot.id)\n except ReservationSlot.DoesNotExist:\n raise ValidationError('You do not have a parking reservation on file. If you believe this is in error, call ResNet at (805) 756-5600.')\n\n return reservation_slot\n\n\nclass ChangeReservationView(ReserveView):\n\n def get_context_data(self, **kwargs):\n context = super(ChangeReservationView, self).get_context_data(**kwargs)\n context['change_reservation'] = True\n return context\n\n def get_queryset(self, **kwargs):\n kwargs['change_reservation'] = True\n return super(ChangeReservationView, self).get_queryset(**kwargs)\n"
},
{
"alpha_fraction": 0.6861166954040527,
"alphanum_fraction": 0.6894701719284058,
"avg_line_length": 34.5,
"blob_id": "a226fd47b5a6c45dd590e09d1b3a8d601044fc74",
"content_id": "fe1843a3079910b975cba96fc5cc95e5d5506be0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1491,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 42,
"path": "/checkin_parking/apps/administration/models.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.models\n :synopsis: Checkin Parking Reservation Administration Models.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\nfrom datetime import date, datetime\n\n\nfrom django.db.models.base import Model\nfrom django.db.models.fields import PositiveSmallIntegerField, CharField, DateField\nfrom django.utils import timezone\n\nfrom rmsconnector.utils import get_current_term\n\nfrom .managers import AdminSettingsManager\nfrom django.utils.functional import cached_property\n\n\nclass AdminSettings(Model):\n \"\"\"Administrative settings.\"\"\"\n APPLICATION_TERMS_CHOICES = [('FA', 'Fall'),\n ('WI', 'Winter'),\n ('SP', 'Spring'),\n ('SU', 'Summer')]\n\n term_code = PositiveSmallIntegerField(default=get_current_term(), verbose_name='Term Code')\n application_term = CharField(default=APPLICATION_TERMS_CHOICES[0][0], choices=APPLICATION_TERMS_CHOICES, max_length=2)\n application_year = PositiveSmallIntegerField(default=datetime.now().year)\n timeslot_length = PositiveSmallIntegerField(default=40, verbose_name='Time Slot Length (in Minutes)')\n reservation_close_day = DateField(default=timezone.now)\n\n objects = AdminSettingsManager()\n\n @cached_property\n def reservation_open(self):\n return date.today() <= self.reservation_close_day\n\n class Meta:\n verbose_name = \"Admin Settings\"\n verbose_name_plural = \"Admin Settings\"\n"
},
{
"alpha_fraction": 0.5799458026885986,
"alphanum_fraction": 0.6124660968780518,
"avg_line_length": 28.520000457763672,
"blob_id": "33e32e2a3bbc94c641a398ffa5654396fc9e8aa3",
"content_id": "b37a691276c2198d492d7ad343269951267f389f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 25,
"path": "/checkin_parking/apps/core/migrations/0004_auto_20160518_1654.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-05-18 16:54\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0003_checkinparkinguser_term_type'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='checkinparkinguser',\n name='building',\n field=models.CharField(blank=True, max_length=30, null=True, verbose_name='Building'),\n ),\n migrations.AlterField(\n model_name='checkinparkinguser',\n name='term_type',\n field=models.CharField(blank=True, max_length=15, null=True, verbose_name='Class Level'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7114864587783813,
"alphanum_fraction": 0.712837815284729,
"avg_line_length": 31.173913955688477,
"blob_id": "e4da97e4bda04fd06dfa46c7cd009fd68108f0da",
"content_id": "c4d1c5ebea2a114607505d8d4dc5925b51570636",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1480,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 46,
"path": "/checkin_parking/apps/reservations/utils.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.utils\n :synopsis: Checkin Parking Reservation Reservations Utils.\n\n.. moduleauthor:: Thomas E. Willson <[email protected]>\n\n\"\"\"\n\nfrom pathlib import Path\n\nfrom django.core.urlresolvers import reverse\nfrom django.template.context import Context\nfrom django.template.loader import get_template\nimport trml2pdf\n\nfrom ...settings.base import MEDIA_ROOT\nfrom ..administration.models import AdminSettings\n\n\ndef generate_verification_url(reservation_slot, request):\n return request.build_absolute_uri(reverse('reservations:verify_parking_pass',\n kwargs={'reservation_id': reservation_slot.id, 'user_id': reservation_slot.resident.id}))\n\n\ndef generate_pdf_file(reservation_slot, verification_url):\n context = {}\n\n parking = {\n 'date': reservation_slot.timeslot.date,\n 'start': reservation_slot.timeslot.time,\n 'end': reservation_slot.timeslot.end_time,\n 'zone': reservation_slot.zone.name,\n }\n\n context['resident'] = reservation_slot.resident\n context['cal_poly_logo_path'] = Path(MEDIA_ROOT).joinpath('pdf_assets/cp_sa_uh_logo.jpg')\n context['parking'] = parking\n context['qr_code_url'] = verification_url\n context['timeslot_length'] = AdminSettings.objects.get_settings().timeslot_length\n\n template = get_template('reservations/parking_pass.rml')\n\n source_xml = template.render(Context(context))\n pdf_data = trml2pdf.parseString(source_xml)\n\n return pdf_data\n"
},
{
"alpha_fraction": 0.6903089880943298,
"alphanum_fraction": 0.6959269642829895,
"avg_line_length": 26.921567916870117,
"blob_id": "82a87f7a1845d36af0da771054cf69eb61d3fae8",
"content_id": "653d75aa14177a7803f081084877371ae2d16cbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1424,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 51,
"path": "/checkin_parking/apps/zones/models.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.zones.models\n :synopsis: Checkin Parking Reservation Zone Models.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.db.models.base import Model\nfrom django.db.models.fields import PositiveSmallIntegerField, CharField\nfrom django.db.models.fields.related import ForeignKey, ManyToManyField\nfrom django.utils.functional import cached_property\n\n\nclass Community(Model):\n \"\"\"Housing Community.\"\"\"\n\n name = CharField(max_length=30, verbose_name=\"Community Name\")\n\n def __str__(self):\n return self.name\n\n\nclass Building(Model):\n \"\"\"Housing Building.\"\"\"\n\n name = CharField(max_length=30, verbose_name=\"Building Name\")\n community = ForeignKey(Community, verbose_name=\"Community\", related_name=\"buildings\")\n\n def __str__(self):\n return self.name\n\n\nclass Zone(Model):\n \"\"\"A Parking zone.\"\"\"\n\n name = CharField(max_length=30, unique=True, verbose_name=\"Name\")\n community = ForeignKey(Community, verbose_name=\"Community\")\n buildings = ManyToManyField(Building, verbose_name=\"Building(s)\")\n capacity = PositiveSmallIntegerField(default=30, verbose_name=\"Capacity\")\n\n @property\n def formatted_building_list(self):\n return \", \".join(self.building_list)\n\n @cached_property\n def building_list(self):\n return [building.name for building in self.buildings.all().order_by(\"name\")]\n\n def __str__(self):\n return self.name\n"
},
{
"alpha_fraction": 0.6152427792549133,
"alphanum_fraction": 0.6156525015830994,
"avg_line_length": 46.85293960571289,
"blob_id": "3340a96a18f759c7e9f2510f637c40c26ab5b52e",
"content_id": "15670a5c576e6c0ef675b7729538c35b64674a54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4881,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 102,
"path": "/checkin_parking/apps/core/backends.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.backends\n :synopsis: Checkin Parking Reservation Core Authentication Backends.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nimport logging\n\nfrom django.conf import settings\nfrom django.core.exceptions import ObjectDoesNotExist, ValidationError\nfrom django_cas_ng.backends import CASBackend\nfrom ldap3 import Server, Connection, ObjectDef, AttrDef, Reader\nfrom ldap_groups.groups import ADGroup\nfrom rmsconnector.utils import Resident\n\nfrom ..administration.models import AdminSettings\nfrom ..zones.models import Building\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass CASLDAPBackend(CASBackend):\n \"\"\"CAS authentication backend with LDAP attribute retrieval.\"\"\"\n\n def authenticate(self, ticket, service, request):\n \"\"\"Verifies CAS ticket and gets or creates User object\"\"\"\n\n user = super(CASLDAPBackend, self).authenticate(ticket, service, request)\n\n # Populate user attributes\n if user:\n try:\n server = Server(settings.LDAP_GROUPS_SERVER_URI)\n connection = Connection(server=server, auto_bind=True, user=settings.LDAP_GROUPS_BIND_DN, password=settings.LDAP_GROUPS_BIND_PASSWORD, raise_exceptions=True)\n connection.start_tls()\n\n account_def = ObjectDef('user')\n account_def.add(AttrDef('userPrincipalName'))\n account_def.add(AttrDef('displayName'))\n account_def.add(AttrDef('givenName'))\n account_def.add(AttrDef('sn'))\n account_def.add(AttrDef('mail'))\n\n account_reader = Reader(connection=connection, object_def=account_def, query=\"userPrincipalName: {principal_name}\".format(principal_name=user.username), base=settings.LDAP_GROUPS_BASE_DN)\n account_reader.search_subtree()\n\n user_info = account_reader.entries[0]\n except Exception as msg:\n logger.exception(msg)\n else:\n principal_name = str(user_info[\"userPrincipalName\"])\n\n staff_list = [member[\"userPrincipalName\"] for member in ADGroup(settings.LDAP_ADMIN_GROUP).get_tree_members()]\n scanner_list = [member[\"userPrincipalName\"] for member in ADGroup(settings.LDAP_SCANNER_GROUP).get_tree_members()]\n developer_list = [member[\"userPrincipalName\"] for member in ADGroup(settings.LDAP_DEVELOPER_GROUP).get_tree_members()]\n\n # Add admin flag\n if principal_name in staff_list:\n user.is_admin = True\n\n # Add QR scanner flag (stats will be saved)\n if principal_name in scanner_list:\n user.is_scanner = True\n\n # Add superuser flags\n if principal_name in developer_list:\n user.is_staff = True\n user.is_superuser = True\n\n # Ensure that non-admins who log in are future residents\n if not user.is_admin and not user.is_scanner and not user.is_superuser:\n admin_settings = AdminSettings.objects.get_settings()\n\n try:\n resident = Resident(principal_name=principal_name, term_code=admin_settings.term_code)\n except ObjectDoesNotExist:\n raise ValidationError(\"University Housing has no record of {principal_name}.\".format(principal_name=principal_name))\n else:\n if not resident.has_current_and_valid_application(application_term=admin_settings.application_term, application_year=admin_settings.application_year):\n raise ValidationError(\"{principal_name} does not have a valid housing application.\".format(principal_name=principal_name))\n\n try:\n user.building = Building.objects.get(name=resident.address_dict['building'].replace('_', ' '), community__name=resident.address_dict['community']) if resident.address_dict['building'] else None\n except ObjectDoesNotExist:\n user.building = None\n logger.warning('Could not retrieve building: ' + str(resident.address_dict['building']) + ' with community ' + str(resident.address_dict['community']))\n\n user.term_type = resident.application_term_type(application_term=admin_settings.application_term, application_year=admin_settings.application_year)\n else:\n user.building = None\n user.term_type = None\n\n user.full_name = user_info[\"displayName\"]\n user.first_name = user_info[\"givenName\"]\n user.last_name = user_info[\"sn\"]\n user.email = user_info[\"mail\"]\n user.save()\n\n return user\n"
},
{
"alpha_fraction": 0.742090106010437,
"alphanum_fraction": 0.7425695061683655,
"avg_line_length": 41.57143020629883,
"blob_id": "6cd85679a532376a95b8be6e1a40d13a6dd02b8e",
"content_id": "41527469dd4de9933d3de270991ece69d3ffa9ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2086,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 49,
"path": "/checkin_parking/apps/administration/forms.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.forms\n :synopsis: Checkin Parking Reservation Administration Forms.\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\n\nimport os\n\nfrom clever_selects.forms import ChainedChoicesForm\nfrom clever_selects.form_fields import ChainedModelChoiceField\nfrom django.core.exceptions import ValidationError\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.forms import Form\nfrom django.forms.fields import FileField, ChoiceField, BooleanField, DateField\nfrom django.forms.models import ModelChoiceField\n\nfrom rmsconnector.constants import FRESHMAN, TRANSFER, CONTINUING\n\nfrom ..zones.models import Building, Community\n\n\nCLASS_LEVELS = [FRESHMAN, TRANSFER, CONTINUING]\nCLASS_LEVEL_CHOICES = [(class_level, class_level) for class_level in CLASS_LEVELS]\n\n\nclass PDFMapForm(Form):\n co_pcv_map = FileField(label='Poly Canyon Village Continuing Student Parking Info', required=False)\n trans_pcv_map = FileField(label='Poly Canyon Village Transfer Student Parking Info', required=False)\n pcv_loop = FileField(label='Poly Canyon Village Loop Navigation Info', required=False)\n co_cerro_map = FileField(label='Cerro Vista Continuing Student Parking Info', required=False)\n fresh_trans_cerro_map = FileField(label='Cerro Vista Freshman/Transfer Student Parking Info', required=False)\n\n def clean(self):\n cleaned_data = super(PDFMapForm, self).clean()\n for filedata in cleaned_data:\n if cleaned_data[filedata]:\n filename = cleaned_data[filedata].name\n ext = os.path.splitext(filename)[1].lower()\n if ext != '.pdf':\n raise ValidationError(\"One or more of the files are not PDF documents.\")\n return cleaned_data\n\n\nclass BecomeStudentForm(ChainedChoicesForm):\n community = ModelChoiceField(queryset=Community.objects.all(), required=False)\n building = ChainedModelChoiceField('community', reverse_lazy('zones:chained_building'), Building, required=False)\n term_type = ChoiceField(label='Class Level', choices=CLASS_LEVEL_CHOICES)\n"
},
{
"alpha_fraction": 0.5477178692817688,
"alphanum_fraction": 0.6141079068183899,
"avg_line_length": 23.100000381469727,
"blob_id": "6e296f9903b4020f578eaa7d27b683fd86bb95c5",
"content_id": "cd286d310f18b6fc72442a8fc6aea1bcd719941a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 482,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 20,
"path": "/checkin_parking/apps/reservations/migrations/0006_auto_20160912_1549.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-09-12 15:49\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('reservations', '0005_auto_20160912_1136'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='reservationslot',\n name='last_scanned',\n field=models.DateTimeField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7681159377098083,
"alphanum_fraction": 0.770531415939331,
"avg_line_length": 23.352941513061523,
"blob_id": "5b24c75443b9744c6fcbac6fcb878606dead698b",
"content_id": "5356b873f4803d2bae071b93fd7be411f4257446",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 17,
"path": "/checkin_parking/wsgi.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nfrom .manage import activate_env\n\nactivate_env()\n\nimport django # noqa\nfrom django.core.handlers.wsgi import WSGIHandler # noqa\nfrom raven.contrib.django.raven_compat.middleware.wsgi import Sentry # noqa\n\ndjango.setup()\n\n# Import any functions with uWSGI decorators here:\nfrom .apps.reservations import tasks # noqa\nfrom .apps.core import tasks # noqa\n\napplication = Sentry(WSGIHandler())\n"
},
{
"alpha_fraction": 0.6812307834625244,
"alphanum_fraction": 0.6812307834625244,
"avg_line_length": 36.79069900512695,
"blob_id": "47dcea430bcec4b624fba9ab142e7e8149cd9717",
"content_id": "5a18b3a8a2845e1f017abf177f082f948082a8f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1625,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 43,
"path": "/checkin_parking/apps/zones/forms.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.zones.forms\n :synopsis: Checkin Parking Reservation Zone Forms.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom clever_selects.form_fields import ModelChoiceField, ChainedModelMultipleChoiceField\nfrom clever_selects.forms import ChainedChoicesModelForm\nfrom django.core.urlresolvers import reverse_lazy\n\nfrom .models import Zone, Community, Building\n\n\nclass ZoneForm(ChainedChoicesModelForm):\n community = ModelChoiceField(queryset=Community.objects.all())\n buildings = ChainedModelMultipleChoiceField('community', reverse_lazy('zones:chained_building'), Building)\n\n def __init__(self, *args, **kwargs):\n super(ZoneForm, self).__init__(*args, **kwargs)\n\n self.fields[\"name\"].error_messages['required'] = 'A zone name is required.'\n self.fields[\"capacity\"].error_messages['required'] = 'A capacity is required.'\n self.fields[\"community\"].error_messages['required'] = 'A community is required.'\n self.fields[\"buildings\"].error_messages['required'] = 'At least one building must be selected.'\n\n if self.instance and self.instance.id:\n self.fields[\"capacity\"].widget.attrs['readonly'] = True\n self.fields[\"community\"].widget.attrs['autocomplete'] = \"off\"\n self.fields[\"buildings\"].help_text = \"\"\n\n def clean_capacity(self):\n capacity = self.cleaned_data.get(\"capacity\", None)\n\n if self.instance and self.instance.id:\n return self.instance.capacity\n else:\n return capacity\n\n class Meta:\n model = Zone\n fields = ['name', 'capacity', 'community', 'buildings']\n"
},
{
"alpha_fraction": 0.6925160884857178,
"alphanum_fraction": 0.6959024667739868,
"avg_line_length": 33.33720779418945,
"blob_id": "a4dcc9e616723350018b435b0c492341de6f7284",
"content_id": "f57237aefd4fe33690caacd2f6b983bbc71ae483",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2953,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 86,
"path": "/checkin_parking/apps/core/models.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.models\n :synopsis: Checkin Parking Reservation Core Models.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf import settings\nfrom django.contrib.auth.models import AbstractBaseUser, UserManager, PermissionsMixin\nfrom django.core.mail import send_mail\nfrom django.db.models.fields import CharField, EmailField, BooleanField, NullBooleanField\nfrom django.db.models.fields.related import ForeignKey\nfrom django.utils import timezone\nfrom django.utils.functional import cached_property\n\nfrom ..zones.models import Building\n\n\nclass CheckinParkingUserManager(UserManager):\n\n def _create_user(self, username, email, password, is_staff, is_superuser, **extra_fields):\n now = timezone.now()\n\n if not username:\n raise ValueError('The given username must be set.')\n\n email = self.normalize_email(email)\n username = self.normalize_email(username)\n\n user = self.model(username=username, email=email, is_staff=is_staff, is_active=True, is_superuser=is_superuser, last_login=now, **extra_fields)\n user.set_password(\"!\")\n user.save(using=self._db)\n\n return user\n\n\nclass CheckinParkingUser(AbstractBaseUser, PermissionsMixin):\n \"\"\"Checkin Parking Reservation User Model\"\"\"\n\n username = EmailField(unique=True, verbose_name='Principal Name')\n first_name = CharField(max_length=30, blank=True, verbose_name='First Name')\n last_name = CharField(max_length=30, blank=True, verbose_name='Last Name')\n full_name = CharField(max_length=30, blank=True, verbose_name='Full Name')\n email = EmailField(blank=True, verbose_name='Email Address')\n building = ForeignKey(Building, null=True, blank=True, related_name='residents')\n term_type = CharField(max_length=15, null=True, blank=True, verbose_name='Class Level')\n\n is_active = BooleanField(default=True)\n is_staff = BooleanField(default=False)\n is_admin = BooleanField(default=False)\n is_scanner = BooleanField(default=False)\n\n USERNAME_FIELD = 'username'\n objects = CheckinParkingUserManager()\n\n class Meta:\n verbose_name = 'Checkin Parking Reservation User'\n\n def get_full_name(self):\n return self.full_name\n\n def get_short_name(self):\n return self.first_name\n\n @cached_property\n def dn(self):\n return \"CN=\" + self.username.split(\"@\", 1)[0] + \",\" + settings.LDAP_GROUPS_USER_BASE_DN\n\n @cached_property\n def is_freshman(self):\n return True if self.term_type == 'Freshman' else False\n\n @cached_property\n def is_continuing(self):\n return True if self.term_type == 'Continuing' else False\n\n @cached_property\n def is_transfer(self):\n return True if self.term_type == 'Transfer' else False\n\n def email_user(self, subject, message, from_email=None):\n \"\"\"Sends an email to this user.\"\"\"\n\n if self.email:\n send_mail(subject, message, from_email, [self.email])\n"
},
{
"alpha_fraction": 0.6788496375083923,
"alphanum_fraction": 0.680647075176239,
"avg_line_length": 33.06122589111328,
"blob_id": "5a3ba49abc23c9f272e7e1ea2caa50fc923cc95c",
"content_id": "0f401c5878f510a8557ff5f9c2e8e51182bcc648",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1669,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 49,
"path": "/checkin_parking/apps/administration/utils.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.utils\n :synopsis: Checkin Parking Reservation Administration Utilities.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom collections import namedtuple\n\nfrom django.db import connection, connections, transaction\n\nfrom ..zones.models import Building, Community\n\n\ndef namedtuplefetchall(cursor):\n \"\"\"\n Return all rows from a cursor as a namedtuple.\n https://docs.djangoproject.com/en/1.9/topics/db/sql/#executing-custom-sql-directly\n \"\"\"\n\n desc = cursor.description\n nt_result = namedtuple('Result', [col[0] for col in desc])\n return [nt_result(*row) for row in cursor.fetchall()]\n\n\ndef sync_zone_data():\n with transaction.atomic():\n # Purge Building and Community Data\n Building.objects.all().delete()\n Community.objects.all().delete()\n\n # Grab buildings and communities from master and copy to slave\n with connections[\"uhin\"].cursor() as uhin_cursor:\n uhin_cursor.execute(\"SELECT * from core_community\")\n communities = namedtuplefetchall(uhin_cursor)\n\n for community in communities:\n Community.objects.create(id=community.id, name=community.name)\n\n uhin_cursor.execute(\"SELECT * from core_building\")\n buildings = namedtuplefetchall(uhin_cursor)\n\n for building in buildings:\n Building.objects.create(id=building.id, name=building.name, community=Community.objects.get(id=building.community_id))\n\n # Add the open zone Feature\n open_community = Community.objects.create(name=\"All\")\n Building.objects.create(name=\"All\", community=open_community)\n"
},
{
"alpha_fraction": 0.5553956627845764,
"alphanum_fraction": 0.6129496693611145,
"avg_line_length": 26.799999237060547,
"blob_id": "b340b826234bf390008d71ffa319b4de5876a672",
"content_id": "976484eebebeb60326ac6c447cb63c4615e0fb07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 25,
"path": "/checkin_parking/apps/administration/migrations/0007_auto_20170721_0026.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2017-07-21 00:26\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('administration', '0006_auto_20160912_1133'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='adminsettings',\n name='application_year',\n field=models.PositiveSmallIntegerField(default=2017),\n ),\n migrations.AlterField(\n model_name='adminsettings',\n name='term_code',\n field=models.PositiveSmallIntegerField(default='2176', verbose_name='Term Code'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6987477540969849,
"alphanum_fraction": 0.6987477540969849,
"avg_line_length": 31.126436233520508,
"blob_id": "cdb296f9d4f65ae7d22334a57064f5195cc118a3",
"content_id": "81c0a6e826dc54f3e12bab803fd119b5dcd86dc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2795,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 87,
"path": "/checkin_parking/apps/reservations/ajax.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.ajax\n :synopsis: Checkin Parking Reservation Reservation AJAX Methods.\n\n.. moduleauthor:: Thomas E. Willson <[email protected]>\n\n\"\"\"\nfrom datetime import datetime\n\nfrom django.core.exceptions import ValidationError\nfrom django.db import transaction\nfrom django.views.decorators.http import require_POST\nfrom django_ajax.decorators import ajax\n\nfrom .models import ReservationSlot, TimeSlot\nfrom .tasks import send_confirmation_email\n\n\n@ajax\n@require_POST\ndef reserve_slot(request):\n slot_id = request.POST['slot_id']\n change_reservation = request.POST.get('change_reservation', False)\n\n try:\n ReservationSlot.objects.get(resident=request.user)\n if not change_reservation:\n raise ValidationError('You have already reserved a slot. Please refresh this page.')\n except ReservationSlot.DoesNotExist:\n if change_reservation:\n raise ValidationError('Cannot change reservation as none exists. Please refresh this page.')\n\n base_queryset = ReservationSlot.objects.filter(timeslot__id=slot_id, resident=None)\n\n # Show all open zone slots\n queryset = base_queryset.filter(zone__buildings__name__contains=\"All\")\n\n # Show building specific slots as well\n if request.user.building:\n queryset = queryset | base_queryset.filter(zone__buildings=request.user.building, zone__buildings__community=request.user.building.community)\n\n success = False\n with transaction.atomic():\n if change_reservation:\n existing_slot = ReservationSlot.objects.get(resident=request.user)\n existing_slot.resident = None\n existing_slot.save()\n queryset.select_for_update()\n if queryset.exists():\n slot = queryset.first()\n slot.resident = request.user\n slot.save()\n send_confirmation_email(slot, request)\n success = True\n\n data = {'success': success}\n\n return data\n\n\n@ajax\n@require_POST\ndef cancel_reservation(request):\n try:\n reservation_slot = ReservationSlot.objects.get(resident=request.user)\n except ReservationSlot.DoesNotExist:\n return {'success': False}\n\n reservation_slot.resident = None\n reservation_slot.save()\n\n return {'success': True}\n\n\n@ajax\n@require_POST\ndef delete_timeslot(request):\n try:\n time_slot = TimeSlot.objects.get(id=request.POST['timeslot_id'])\n except ReservationSlot.DoesNotExist:\n return {'success': False}\n\n if time_slot.reservationslots.exclude(resident__isnull=True).exists() and datetime.combine(time_slot.date, time_slot.time) < datetime.now():\n return {'success': False, 'reservation_count': time_slot.reservationslots.exclude(resident__isnull=True).count()}\n\n time_slot.delete()\n return {'success': True}\n"
},
{
"alpha_fraction": 0.7097792029380798,
"alphanum_fraction": 0.7139852643013,
"avg_line_length": 32.96428680419922,
"blob_id": "e20a1d871ec75508854928a8734bb5797fd12ebb",
"content_id": "7f199960c2ec98af4aff1d1fe875f0364e652ca7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 951,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 28,
"path": "/checkin_parking/apps/core/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.urls\n :synopsis: Checkin Parking Reservation Core URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf import settings\nfrom django.conf.urls import url\nfrom django.contrib.staticfiles.templatetags.staticfiles import static\n# from django.views.decorators.cache import cache_page\nfrom django.views.generic.base import RedirectView\nfrom django_cas_ng.views import login as auth_login, logout as auth_logout\n# from django_js_reverse.views import urls_js\n\nfrom .views import IndexView\n\napp_name = 'core'\n\nurlpatterns = [\n url(r'^$', IndexView.as_view(), name='home'),\n url(r'^login/$', auth_login, name='login'),\n url(r'^logout/$', auth_logout, name='logout', kwargs={'next_page': settings.CAS_LOGOUT_URL}),\n url(r'^favicon\\.ico$', RedirectView.as_view(url=static('images/icons/favicon.ico')), name='favicon'),\n\n # url(r'^jsreverse/$', cache_page(3600)(urls_js), name='js_reverse'),\n]\n"
},
{
"alpha_fraction": 0.7076768279075623,
"alphanum_fraction": 0.7170633673667908,
"avg_line_length": 34.511905670166016,
"blob_id": "6a3d88ff670ef64c538a93685d191cefe49d044e",
"content_id": "c76ef8e5423cbd3f406d1ea30e2cd009486b33db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2983,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 84,
"path": "/checkin_parking/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.urls\n :synopsis: Checkin Parking Reservation URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\n\nimport logging\n\nfrom django.conf import settings\nfrom django.conf.urls import include, url\nfrom django.conf.urls.static import static as static_url\nfrom django.contrib import admin\nfrom django.contrib.auth.decorators import user_passes_test\nfrom django.contrib.auth.models import Group as group_unregistered\nfrom django.core.exceptions import PermissionDenied\nfrom django.views.decorators.cache import cache_page\nfrom django.views.defaults import permission_denied, page_not_found\nfrom django.views.generic import TemplateView\n\nfrom django_js_reverse.views import urls_js\n\nfrom .apps.core.views import handler500\nfrom .settings.base import MAIN_APP_NAME\n\n\ndef permissions_check(test_func, raise_exception=True):\n \"\"\"\n Decorator for views that checks whether a user has permission to view the\n requested page, redirecting to the log-in page if neccesary.\n If the raise_exception parameter is given the PermissionDenied exception\n is raised.\n\n :param test_func: A callable test that takes a User object and returns true if the test passes.\n :type test_func: callable\n :param raise_exception: Determines whether or not to throw an exception when permissions test fails.\n :type raise_exception: bool\n\n \"\"\"\n\n def check_perms(user):\n # First check if the user has the permission (even anon users)\n if test_func(user):\n return True\n # In case the 403 handler should be called raise the exception\n if raise_exception:\n raise PermissionDenied\n # As the last resort, show the login form\n return False\n return user_passes_test(check_perms)\n\nadministrative_access = permissions_check((lambda user: user.is_admin))\nscanner_access = permissions_check((lambda user: user.is_scanner or user.is_admin))\n\nadmin.autodiscover()\nadmin.site.unregister(group_unregistered)\n\nlogger = logging.getLogger(__name__)\n\nhandler500 = handler500\n\n\nurlpatterns = [\n url(r'^admin/', TemplateView.as_view(template_name=\"honeypot.djhtml\"), name=\"honeypot\"), # admin site urls, honeypot\n url(r'^flugzeug/', include(admin.site.urls)), # admin site urls, masked\n url(r'^reservations/', include(MAIN_APP_NAME + '.apps.reservations.urls')),\n url(r'^zones/', include(MAIN_APP_NAME + '.apps.zones.urls')),\n url(r'^statistics/', include(MAIN_APP_NAME + '.apps.statistics.urls')),\n url(r'^settings/', include(MAIN_APP_NAME + '.apps.administration.urls')),\n url(r'^jsreverse/$', cache_page(3600)(urls_js), name='js_reverse'),\n url(r'^', include(MAIN_APP_NAME + '.apps.core.urls')),\n]\n\n# Raise errors on purpose\nurlpatterns += [\n url(r'^500/$', handler500),\n url(r'^403/$', permission_denied),\n url(r'^404/$', page_not_found),\n]\n\nif settings.DEBUG:\n urlpatterns += static_url(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\n"
},
{
"alpha_fraction": 0.5579567551612854,
"alphanum_fraction": 0.6208251714706421,
"avg_line_length": 24.450000762939453,
"blob_id": "fac9cce43a0830e8cf4cbb91d4103c823e6d431a",
"content_id": "ba8f0cabe2a6ce90e4d334d49ddf9b3bd67cc149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 20,
"path": "/checkin_parking/apps/reservations/migrations/0007_reservationslot_assisted_move_in.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2017-07-21 00:26\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('reservations', '0006_auto_20160912_1549'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='reservationslot',\n name='assisted_move_in',\n field=models.BooleanField(default=False, verbose_name='Assisted Move In?'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5176358222961426,
"alphanum_fraction": 0.5243088603019714,
"avg_line_length": 33.983333587646484,
"blob_id": "bcacdf08448d6d246f3936b6c98082a108c12306",
"content_id": "435abffec3331a5ae7280f3c4f4fce6ea4dbecd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2098,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 60,
"path": "/checkin_parking/static/js/statistics.js",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "// Python-Style string formatting\n// Source: http://stackoverflow.com/a/18234317\nif (!String.prototype.format) {\n String.prototype.format = function() {\n var str = this.toString();\n if (!arguments.length)\n return str;\n var args = typeof arguments[0],\n args = ((\"string\" == args || \"number\" == args) ? arguments : arguments[0]);\n for (arg in args)\n str = str.replace(RegExp(\"\\\\{\" + arg + \"\\\\}\", \"gi\"), args[arg]);\n return str;\n }\n}\n\nfunction refreshCharts() {\n var urlArgs = {\n date: $('#use-custom-date').prop('checked') ? $('#custom-display-date').val() : '',\n show_remaining: $('#show-remaining').prop('checked') ? 'True' : 'False'\n };\n\n displayChart('#zone_chart', DjangoReverse['statistics:zone_chart_data'](urlArgs));\n displayChart('#class_level_chart', DjangoReverse['statistics:class_level_chart_data'](urlArgs));\n displayChart('#residency_chart', DjangoReverse['statistics:residency_chart_data'](urlArgs));\n displayChart('#qr_chart', DjangoReverse['statistics:qr_chart_data'](urlArgs));\n displayChart('#off_time_chart', DjangoReverse['statistics:off_time_chart_data'](urlArgs));\n}\n\n\nfunction displayChart(jquerySelector, datasourceURL) {\n $(jquerySelector).html('<p style=\"text-align: center;\">Loading... <img style=\"height: 10px; width: 10px;\" src=\"' + spinnerURL + '\"></img></p>');\n \n $.get(datasourceURL, function(response) { \n $(jquerySelector).html('');\n $(jquerySelector).highcharts({\n chart: {\n type: 'spline',\n backgroundColor: null,\n },\n title: {\n text: null\n },\n xAxis: {\n type: 'datetime',\n title: {\n text: null\n }\n },\n yAxis: {\n title: {\n text: 'Reservation Count'\n }\n },\n credits: {\n enabled: false\n },\n series: response.data,\n });\n });\n}"
},
{
"alpha_fraction": 0.5897920727729797,
"alphanum_fraction": 0.6351606845855713,
"avg_line_length": 25.450000762939453,
"blob_id": "edb67a12ee8ca03f725dd861dcf6b9fe06fdbe19",
"content_id": "45a0fa5cafdcb9a412f1637c02c4217461583b63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 20,
"path": "/checkin_parking/apps/administration/migrations/0006_auto_20160912_1133.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-09-12 11:33\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('administration', '0005_remove_adminsettings_reservation_open'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='adminsettings',\n name='term_code',\n field=models.PositiveSmallIntegerField(default='2178', verbose_name='Term Code'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7190082669258118,
"alphanum_fraction": 0.7190082669258118,
"avg_line_length": 20.352941513061523,
"blob_id": "c3af82914edacc11e6e291c964cb880897ac5ba5",
"content_id": "28a315293b14b5fbeec599668cef13a86a35c886",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 17,
"path": "/checkin_parking/apps/zones/admin.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.zones.admin\n :synopsis: Checkin Parking Reservation Zone Admin Configuration.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import Zone\n\n\nclass ZoneAdmin(admin.ModelAdmin):\n list_display = ['name', 'community', 'building_list', 'capacity']\n\nadmin.site.register(Zone, ZoneAdmin)\n"
},
{
"alpha_fraction": 0.7248061895370483,
"alphanum_fraction": 0.7248061895370483,
"avg_line_length": 24.799999237060547,
"blob_id": "e9defbb1af34fd6f85db83bb065d3101d4afc5ac",
"content_id": "d297e68fd3b1f87b0e6c5f72643384510940f8cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 20,
"path": "/checkin_parking/apps/core/admin.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.admin\n :synopsis: Checkin Parking Reservation Core Admin Configuration.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import CheckinParkingUser\n\n\nclass CheckinParkingUserAdmin(admin.ModelAdmin):\n list_display = ['username', 'first_name', 'last_name', 'is_admin', 'is_superuser']\n list_filter = ['is_admin', 'is_superuser']\n search_fields = ['username']\n\n\nadmin.site.register(CheckinParkingUser, CheckinParkingUserAdmin)\n"
},
{
"alpha_fraction": 0.5764254927635193,
"alphanum_fraction": 0.5793004035949707,
"avg_line_length": 39.13461685180664,
"blob_id": "9bb24fdece56e0c758b29f18bcbef68723198275",
"content_id": "9ff271cf22db15825c25b18ee15b84901cecd2fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2087,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 52,
"path": "/checkin_parking/apps/reservations/migrations/0001_initial.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\nimport django.db.models.deletion\nfrom django.conf import settings\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('zones', '__first__'),\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ]\n\n operations = [\n migrations.CreateModel(\n name='ReservationSlot',\n fields=[\n ('id', models.AutoField(verbose_name='ID', auto_created=True, primary_key=True, serialize=False)),\n ('class_level', models.PositiveSmallIntegerField(verbose_name='Class Level', default=3, choices=[(0, 'Freshman'), (1, 'Transfer'), (2, 'Continuing'), (3, 'All')])),\n ('resident', models.OneToOneField(to=settings.AUTH_USER_MODEL, null=True, related_name='reservationslot', blank=True, verbose_name='Resident', on_delete=django.db.models.deletion.SET_NULL)),\n ],\n options={\n },\n bases=(models.Model,),\n ),\n migrations.CreateModel(\n name='TimeSlot',\n fields=[\n ('id', models.AutoField(verbose_name='ID', auto_created=True, primary_key=True, serialize=False)),\n ('date', models.DateField(verbose_name='Date')),\n ('time', models.TimeField(verbose_name='Time')),\n ('term', models.PositiveSmallIntegerField(verbose_name='Term Code')),\n ],\n options={\n },\n bases=(models.Model,),\n ),\n migrations.AddField(\n model_name='reservationslot',\n name='timeslot',\n field=models.ForeignKey(related_name='reservationslots', verbose_name='Time Slot', to='reservations.TimeSlot'),\n preserve_default=True,\n ),\n migrations.AddField(\n model_name='reservationslot',\n name='zone',\n field=models.ForeignKey(related_name='reservationslots', verbose_name='Zone', to='zones.Zone'),\n preserve_default=True,\n ),\n ]\n"
},
{
"alpha_fraction": 0.6806495189666748,
"alphanum_fraction": 0.6806495189666748,
"avg_line_length": 24.482759475708008,
"blob_id": "2fb6e5c9e2f577df989d33ccca5acf0140e2fae1",
"content_id": "6bddaa0629ddccd9ff31aa5d8531c0ff70907791",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 739,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 29,
"path": "/checkin_parking/apps/administration/ajax.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.ajax\n :synopsis: Checkin Parking Reservation Administration Ajax.\n\n.. moduleauthor:: Thomas E. Willson <[email protected]>\n\n\"\"\"\nfrom django.views.decorators.http import require_POST\nfrom django_ajax.decorators import ajax\n\nfrom ..reservations.models import ReservationSlot, TimeSlot\n\n\n@ajax\n@require_POST\ndef purge(request):\n if request.POST['confirmation']:\n reservation_count = ReservationSlot.objects.count()\n timeslot_count = TimeSlot.objects.count()\n\n ReservationSlot.objects.all().delete()\n TimeSlot.objects.all().delete()\n\n data = {\n 'reservation_count': reservation_count,\n 'timeslot_count': timeslot_count,\n }\n\n return data\n"
},
{
"alpha_fraction": 0.6216843724250793,
"alphanum_fraction": 0.6253315806388855,
"avg_line_length": 39.03982162475586,
"blob_id": "1d8a222e4f37158dc0c91a83ccee9b450d9d9feb",
"content_id": "734ad1cd3f4cea8a2910cfc77fd906de33a0d4a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9048,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 226,
"path": "/checkin_parking/apps/statistics/views.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.statistics.views\n :synopsis: Checkin Parking Statistics Views\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\nfrom datetime import datetime, timezone\nimport csv\nimport io\n\nfrom django.http.response import HttpResponse\nfrom django.views.generic.base import TemplateView\nfrom django_datatables_view.mixins import JSONResponseView\n\nfrom ..administration.forms import CLASS_LEVELS\nfrom ..reservations.models import ReservationSlot, TimeSlot\nfrom ..zones.models import Zone\nfrom .utils import add_overnight_points, generate_series, modify_query_for_date\n\n\nclass CSVStatisticsView(TemplateView):\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n file = io.StringIO()\n field_names = ['date', 'time', 'zone', 'resident_first_name', 'resident_last_name', 'resident_full_name',\n 'resident_username', 'resident_class_level']\n writer = csv.DictWriter(file, field_names)\n writer.writeheader()\n\n for reservation_slot in ReservationSlot.objects.filter(resident__isnull=False).select_related('zone', 'resident', 'timeslot'):\n entry = {\n 'date': reservation_slot.timeslot.date,\n 'time': reservation_slot.timeslot.time,\n 'zone': reservation_slot.zone.name,\n 'resident_first_name': reservation_slot.resident.first_name,\n 'resident_last_name': reservation_slot.resident.last_name,\n 'resident_full_name': reservation_slot.resident.full_name,\n 'resident_username': reservation_slot.resident.username,\n 'resident_class_level': reservation_slot.resident.term_type,\n }\n\n writer.writerow(entry)\n\n context['csv_data'] = file.getvalue()\n\n return context\n\n def render_to_response(self, context, **response_kwargs):\n csv_data = context['csv_data']\n\n response = HttpResponse()\n response['Content-Type'] = 'text/csv'\n response['Content-Disposition'] = 'attachment;filename=MoveInReservationStats' + str(datetime.now()) + '.csv'\n\n response.write(csv_data)\n\n return response\n\n\nclass StatisticsPage(TemplateView):\n template_name = 'statistics/statistics.djhtml'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n\n reservations_filled = ReservationSlot.objects.filter(resident__isnull=False).count()\n total_reservation_slots = ReservationSlot.objects.all().count()\n\n reservation_slots_scanned_off_time = ReservationSlot.objects.filter(resident__isnull=False, last_scanned_on_time=False)\n qrstats_num_scanned_off_time_early = 0\n qrstats_num_scanned_off_time_late = 0\n \n for off_time_scan in reservation_slots_scanned_off_time:\n if off_time_scan.timeslot.datetime_obj < off_time_scan.last_scanned:\n qrstats_num_scanned_off_time_early += 1\n else:\n qrstats_num_scanned_off_time_late += 1\n\n overall_stats = [\n ('Reservations', reservations_filled),\n ('Freshman Reservations', ReservationSlot.objects.filter(resident__term_type='Freshman').count()),\n ('Continuing Reservations', ReservationSlot.objects.filter(resident__term_type='Continuing').count()),\n ('Transfer Reservations', ReservationSlot.objects.filter(resident__term_type='Transfer').count()),\n ('% Full', '{:.2%}'.format(reservations_filled / total_reservation_slots)),\n ('QRStats Scanned', ReservationSlot.objects.filter(resident__isnull=False, last_scanned__isnull=False).count()),\n ('QRStats Scanned On-Time', ReservationSlot.objects.filter(resident__isnull=False, last_scanned_on_time=True).count()),\n ('QRStats Scanned Off-Time', ReservationSlot.objects.filter(resident__isnull=False, last_scanned_on_time=False).count()),\n ('QRStats Scanned Off-Time & Early', qrstats_num_scanned_off_time_early),\n ('QRStats Scanned Off-Time & Late', qrstats_num_scanned_off_time_late),\n ]\n\n context['overall_stats'] = overall_stats\n\n return context\n\n\nclass ZoneChartData(JSONResponseView):\n\n def get_context_data(self, **kwargs):\n resident_null = True if kwargs['show_remaining'] == 'True' else False\n\n context = {}\n series = []\n\n for zone in Zone.objects.all():\n data_points = []\n\n for timeslot in modify_query_for_date(TimeSlot.objects.filter(reservationslots__zone=zone).distinct().order_by('date', 'time'), kwargs):\n data_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n timeslot.reservationslots.filter(resident__isnull=resident_null).count(),\n ])\n\n add_overnight_points(data_points)\n\n series.append(generate_series(zone.name, data_points, 'area'))\n\n context['data'] = series\n\n return context\n\n\nclass ClassLevelChartData(JSONResponseView):\n\n def get_context_data(self, **kwargs):\n resident_null = True if kwargs['show_remaining'] == 'True' else False\n\n context = {}\n series = []\n\n for class_level in CLASS_LEVELS:\n data_points = []\n timeslot_kwargs = {}\n reservationslot_kwargs = {'resident__isnull': resident_null}\n\n if not resident_null:\n timeslot_kwargs['reservationslots__resident__term_type'] = class_level\n reservationslot_kwargs['resident__term_type'] = class_level\n else:\n timeslot_kwargs['reservationslots__class_level__contains'] = class_level\n\n for timeslot in modify_query_for_date(TimeSlot.objects.filter(**timeslot_kwargs).distinct().order_by('date', 'time'), kwargs):\n data_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n timeslot.reservationslots.filter(**reservationslot_kwargs).distinct().count(),\n ])\n\n add_overnight_points(data_points)\n\n series.append(generate_series(class_level, data_points, 'area'))\n\n context['data'] = series\n\n return context\n \nclass QRChartData(JSONResponseView):\n\n def get_context_data(self, **kwargs):\n resident_null = True if kwargs['show_remaining'] == 'True' else False\n\n context = {}\n\n on_time_points = []\n off_time_points = []\n\n for timeslot in modify_query_for_date(TimeSlot.objects.all().order_by('date', 'time'), kwargs):\n on_time_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n timeslot.reservationslots.filter(resident__isnull=resident_null, last_scanned_on_time=True).count(),\n ])\n\n off_time_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n timeslot.reservationslots.filter(resident__isnull=resident_null, last_scanned_on_time=False).count(),\n ])\n\n series = [\n generate_series('On-Time Scans', on_time_points, 'area'),\n generate_series('Off-Time Scans', off_time_points, 'area'),\n ]\n\n context['data'] = series\n\n return context\n\nclass OffTimeData(JSONResponseView):\n\n def get_context_data(self, **kwargs):\n resident_null = True if kwargs['show_remaining'] == 'True' else False\n\n context = {}\n \n early_points = []\n late_points = []\n\n for timeslot in modify_query_for_date(TimeSlot.objects.all().order_by('date', 'time'), kwargs): \n reservation_slots_scanned_off_time = timeslot.reservationslots.filter(resident__isnull=resident_null, last_scanned_on_time=False)\n qrstats_num_scanned_off_time_early = 0\n qrstats_num_scanned_off_time_late = 0\n for off_time_scan in reservation_slots_scanned_off_time:\n if off_time_scan.timeslot.datetime_obj < off_time_scan.last_scanned:\n qrstats_num_scanned_off_time_early += 1\n else:\n qrstats_num_scanned_off_time_late += 1\n\n early_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n qrstats_num_scanned_off_time_early,\n ])\n\n late_points.append([\n datetime.combine(timeslot.date, timeslot.time).replace(tzinfo=timezone.utc).timestamp() * 1000,\n qrstats_num_scanned_off_time_late,\n ])\n\n series = [\n generate_series('Scanned before timeslot', early_points, 'area'),\n generate_series('Scanned after timeslot', late_points, 'area'),\n ]\n\n context['data'] = series\n\n return context"
},
{
"alpha_fraction": 0.7115902900695801,
"alphanum_fraction": 0.7628032565116882,
"avg_line_length": 25.5,
"blob_id": "e01225231d3d356af8f94c48f65b930e0042ec9e",
"content_id": "f564e8d57db74fde66172a0c84ba92f791a540be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 42,
"path": "/conf/uwsgi.ini",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "[uwsgi]\n# variables\nprojecthome = /var/www\nworkonhome = /var/virtualenvs\nreponame = checkin_parking_project\nprojectname = checkin_parking\nprojectdomain = checkin.housing.calpoly.edu\nbase = %(projecthome)/%(projectdomain)/%(reponame)\n\n# config\nprotocol = uwsgi\nplugins = python35, sentry\nvirtualenv = %(workonhome)/%(reponame)\nchdir = %(base)\nmodule = %(projectname).wsgi\nsocket = /run/uwsgi/%(projectdomain).socket\nchmod-socket = 777\npidfile = /run/uwsgi/%(projectdomain).pid\nuid = checkin_parking\ngid = checkin_parking\nlogto = %(base)/log/uwsgi.log\nvacuum = true\nmax-requests = 5000\nbuffer-size = 16384\nspooler = %(base)/spoolertasks\nmaster = true\nprocesses = 10\n\nmemory-report\nstats = %(base)/stats_socket\n\n# sentry\nalarm = sentry_alarm sentry:dsn=https://32b39ea7c1544a46959ec8b71669557f:[email protected]/7,logger=uwsgi.sentry\nlog-alarm = sentry_alarm .*DANGER cache.*\nalarm-listen-queue = sentry_alarm\nalarm-segfault = sentry_alarm\n\n# env\nenv = HTTPS=on\nenv = PROJECT_HOME=%(projecthome)\nenv = WORKON_HOME=%(workonhome)\nenv = DJANGO_SETTINGS_MODULE=settings.production\n"
},
{
"alpha_fraction": 0.7051281929016113,
"alphanum_fraction": 0.7051281929016113,
"avg_line_length": 20.272727966308594,
"blob_id": "29cd6097e29aa667b45b0b34d3e5f5b2f4b95296",
"content_id": "dca31a8fddaf54baa9a7e8c48d6dbd7bd0f97ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 11,
"path": "/checkin_parking/apps/administration/management/commands/sync_zone_data.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "from django.core.management.base import BaseCommand\n\nfrom ...utils import sync_zone_data\n\n\nclass Command(BaseCommand):\n\n help = \"Sync Building and Community Tables\"\n\n def handle(self, *args, **options):\n sync_zone_data()\n"
},
{
"alpha_fraction": 0.6744319796562195,
"alphanum_fraction": 0.6744319796562195,
"avg_line_length": 34.845359802246094,
"blob_id": "7276f113b73952c19586ac80ff21d81e3772d2b9",
"content_id": "e2e9b2716f197c3f8758401f67a69e2ca73ccd0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3477,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 97,
"path": "/checkin_parking/apps/administration/views.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.views\n :synopsis: Checkin Parking Reservation Administration Views.\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\n\nfrom pathlib import Path\n\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.views.generic.base import TemplateView\nfrom django.views.generic.edit import FormView, UpdateView\n\nfrom clever_selects.views import ChainedSelectFormViewMixin\n\nfrom ...settings.base import MEDIA_ROOT\nfrom ..reservations.models import TimeSlot, ReservationSlot\nfrom .forms import PDFMapForm, BecomeStudentForm\nfrom .models import AdminSettings\n\n\nclass AdminSettingsUpdateView(UpdateView):\n template_name = 'administration/admin_settings.djhtml'\n model = AdminSettings\n fields = ['term_code', 'timeslot_length', 'application_term', 'application_year', 'reservation_close_day']\n success_url = reverse_lazy('administration:settings')\n\n def get_object(self, queryset=None):\n return AdminSettings.objects.get_settings()\n\n def form_valid(self, form):\n if any(field in form.changed_data for field in ['term_code', 'timeslot_length']) and (TimeSlot.objects.count() or ReservationSlot.objects.count()):\n form.add_error(None, 'All reservations and time slots must be purged before changing the ' + ' or '.join([field.replace('_', ' ') for field in form.changed_data]) + '.')\n return super(AdminSettingsUpdateView, self).form_invalid(form)\n\n return super(AdminSettingsUpdateView, self).form_valid(form)\n\n\nclass PurgeView(TemplateView):\n template_name = 'administration/purge.djhtml'\n\n def get_context_data(self, **kwargs):\n context = super(PurgeView, self).get_context_data(**kwargs)\n\n context['reservation_count'] = ReservationSlot.objects.count()\n context['timeslot_count'] = TimeSlot.objects.count()\n\n return context\n\n\nclass PDFMapUploadView(FormView):\n template_name = \"administration/map_upload.djhtml\"\n form_class = PDFMapForm\n success_url = reverse_lazy('administration:update_maps')\n\n def form_valid(self, form):\n upload_dir = 'documents'\n upload_full_path = Path(MEDIA_ROOT).joinpath(upload_dir)\n\n try:\n upload_full_path.mkdir(parents=True)\n except FileExistsError:\n pass\n\n filenames = {\n 'co_pcv_map': 'co_pcv_parking_info.pdf',\n 'trans_pcv_map': 'trans_pcv_parking_info.pdf',\n 'pcv_loop': 'pcv_loop_nav_info.pdf',\n 'co_cerro_map': 'co_cerro_parking_info.pdf',\n 'fresh_trans_cerro_map': 'fresh_trans_cerro_parking_info.pdf'\n }\n\n for key, filename in filenames.items():\n if key in self.request.FILES:\n upload = self.request.FILES[key]\n filedata = b''.join(upload.chunks())\n\n dest = open(str(upload_full_path.joinpath(filename)), 'wb')\n dest.write(filedata)\n dest.close()\n\n return super(FormView, self).form_valid(form)\n\n\nclass BecomeStudentView(ChainedSelectFormViewMixin, FormView):\n template_name = \"administration/become_student.djhtml\"\n form_class = BecomeStudentForm\n success_url = reverse_lazy('administration:become_student')\n\n def form_valid(self, form):\n user = self.request.user\n user.building = form.cleaned_data['building']\n user.term_type = form.cleaned_data['term_type']\n user.save()\n\n return super(BecomeStudentView, self).form_valid(form)\n"
},
{
"alpha_fraction": 0.5950248837471008,
"alphanum_fraction": 0.5980099439620972,
"avg_line_length": 34.89285659790039,
"blob_id": "1034f4b16a07d07af13b78f695193e29a1f186a6",
"content_id": "edefaff897563ec88b03430ea3aa0832ac752f6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 28,
"path": "/checkin_parking/apps/administration/migrations/0001_initial.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\nimport rmsconnector.utils\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='AdminSettings',\n fields=[\n ('id', models.AutoField(verbose_name='ID', serialize=False, primary_key=True, auto_created=True)),\n ('reservation_open', models.BooleanField(verbose_name='Reservation Open', default=True)),\n ('term_code', models.PositiveSmallIntegerField(verbose_name='Term Code', default=rmsconnector.utils.get_current_term)),\n ('timeslot_length', models.PositiveSmallIntegerField(verbose_name='Time Slot Length (in Minutes)', default=40)),\n ],\n options={\n 'verbose_name': 'Admin Settings',\n 'verbose_name_plural': 'Admin Settings',\n },\n bases=(models.Model,),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6947176456451416,
"alphanum_fraction": 0.6958105564117432,
"avg_line_length": 46.32758712768555,
"blob_id": "581c9fe90cc775ea05500618f717b8ad0738a1f8",
"content_id": "e33bdb85a2c8d2f88feecd43720a8466adc065bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2745,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 58,
"path": "/checkin_parking/apps/reservations/forms.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.forms\n :synopsis: Checkin Parking Reservation Reservation Forms.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom datetime import datetime, date\n\nfrom django.core.exceptions import ValidationError\nfrom django.forms.fields import DateField, TimeField, ChoiceField, BooleanField\nfrom django.forms.forms import Form\nfrom django.forms.models import ModelMultipleChoiceField\n\nfrom ..administration.models import AdminSettings\nfrom ..zones.models import Zone\nfrom .models import CLASS_LEVEL_CHOICES, CLASS_LEVELS\n\n\nclass GenerateReservationsForm(Form):\n date = DateField(label=\"Date\")\n start_time = TimeField(label='Start Time', input_formats=['%H:%M'], error_messages={'required': 'A start time is required'})\n end_time = TimeField(label='End Time', input_formats=['%H:%M'], error_messages={'required': 'An end time is required'})\n class_level = ChoiceField(label='Class Level', choices=CLASS_LEVEL_CHOICES, initial=CLASS_LEVELS.index(\"Freshman/Transfer/Continuing\"), error_messages={'required': 'A class level is required'})\n assisted_move_in = BooleanField(label='Assisted move in?', required=False)\n zones = ModelMultipleChoiceField(queryset=Zone.objects.all(), error_messages={'required': 'At least one zone must be selected. If there are no zones from which to choose, please create one.'})\n\n error_messages = {\n 'time_conflict': \"The start time must be before the end time.\",\n 'interval_conflict': \"The time window must be greater than the set timeslot length ({length} Minutes)\",\n }\n\n def __init__(self, *args, **kwargs):\n super(GenerateReservationsForm, self).__init__(*args, **kwargs)\n\n self.fields[\"class_level\"].widget.attrs['autocomplete'] = \"off\"\n self.fields[\"zones\"].help_text = \"\"\n\n def clean(self):\n cleaned_data = super(GenerateReservationsForm, self).clean()\n start_time = cleaned_data.get(\"start_time\")\n end_time = cleaned_data.get(\"end_time\")\n\n if start_time and end_time:\n time_delta = datetime.combine(date.today(), end_time) - datetime.combine(date.today(), start_time)\n\n # Check to make sure start_time is before end_time\n if time_delta.total_seconds() < 0:\n raise ValidationError(self.error_messages['time_conflict'], code=\"code\")\n\n timeslot_length = AdminSettings.objects.get_settings().timeslot_length\n\n # Check to make sure the minute interval isn't bigger than the time slot\n if timeslot_length > time_delta.total_seconds() / 60:\n raise ValidationError(self.error_messages['interval_conflict'].format(length=timeslot_length), code=\"interval_conflict\")\n\n return cleaned_data\n"
},
{
"alpha_fraction": 0.5656192302703857,
"alphanum_fraction": 0.6321626901626587,
"avg_line_length": 21.54166603088379,
"blob_id": "46eabc0cbee746f263ede74bbef50bcba7614f54",
"content_id": "c33ad1facae141521662f7abc43ead4e9d5623f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 541,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 24,
"path": "/checkin_parking/apps/core/migrations/0005_auto_20160704_1557.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-04 15:56\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\ndef delete_users(apps, schema_editor):\n apps.get_model('core', 'CheckinParkingUser').objects.all().delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0004_auto_20160518_1654'),\n ('zones', '0001_initial'),\n ]\n\n operations = [\n migrations.RunPython(\n delete_users\n ),\n ]\n"
},
{
"alpha_fraction": 0.7125416398048401,
"alphanum_fraction": 0.7125416398048401,
"avg_line_length": 25.5,
"blob_id": "988dc9546ada93221300c37572bf03e6088fca53",
"content_id": "473636f21c2d88c48de9237ee8edadcbb59a914b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 901,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 34,
"path": "/checkin_parking/apps/core/context_processors.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.context_processors\n :synopsis: Checkin Parking Reservation Core Context Processors.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom ..administration.models import AdminSettings\n\n\ndef reservation_status(request):\n \"\"\"Adds the reservation status to the context.\"\"\"\n\n extra_context = {}\n\n admin_settings = AdminSettings.objects.get_settings()\n\n extra_context[\"reservation_open\"] = admin_settings.reservation_open\n extra_context[\"timeslot_length\"] = admin_settings.timeslot_length\n extra_context[\"reservation_close_day\"] = admin_settings.reservation_close_day\n\n return extra_context\n\n\ndef display_name(request):\n \"\"\"Adds the user's display name to each context request.\"\"\"\n\n extra_context = {}\n\n if request.user.is_authenticated():\n extra_context['user_display_name'] = request.user.get_full_name()\n\n return extra_context\n"
},
{
"alpha_fraction": 0.5524920225143433,
"alphanum_fraction": 0.5832449793815613,
"avg_line_length": 30.433332443237305,
"blob_id": "057613b27811a7d669fa83c38f0966f947b69bf2",
"content_id": "88edfcf9488d87bff939e3395a369b8849d4c532",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 943,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 30,
"path": "/checkin_parking/apps/administration/migrations/0002_auto_20160702_1309.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-02 13:09\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('administration', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='adminsettings',\n name='application_term',\n field=models.CharField(choices=[('FA', 'Fall'), ('WI', 'Winter'), ('SP', 'Spring'), ('SU', 'Summer')], default='FA', max_length=2),\n ),\n migrations.AddField(\n model_name='adminsettings',\n name='application_year',\n field=models.PositiveSmallIntegerField(default=2016),\n ),\n migrations.AlterField(\n model_name='adminsettings',\n name='term_code',\n field=models.PositiveSmallIntegerField(default='2166', verbose_name='Term Code'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.7194552421569824,
"alphanum_fraction": 0.7194552421569824,
"avg_line_length": 37.35820770263672,
"blob_id": "4996586a76dcdfa1197c029424c55cc671d5afe5",
"content_id": "910adf051c8ccacf139061095502db78234f9b39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2570,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 67,
"path": "/checkin_parking/apps/reservations/tasks.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.tasks\n :synopsis: Checkin Parking Reservation Reservations Tasks.\n\n.. moduleauthor:: Thomas E. Willson <[email protected]>\n\n\"\"\"\n\nfrom django.core import mail\nfrom django.core.mail import EmailMessage\nfrom django.utils import formats\n\nfrom ..administration.models import AdminSettings\nfrom .utils import generate_verification_url, generate_pdf_file\n\n\n# Emulate spool decorator in order to not cause an error when running locally.\n# The extra layer of wrapping is necessary to properly handle decorator arguments.\ntry:\n from uwsgidecorators import spool\nexcept:\n def spool(**kwargs):\n def wrap(f):\n def wrapped_f(*args):\n f(*args)\n wrapped_f.spool = f\n return wrapped_f\n return wrap\n\n\ndef send_confirmation_email(reservation_slot, request):\n verification_url = generate_verification_url(reservation_slot, request)\n send_confirmation_email_spooler.spool(reservation_slot, verification_url)\n\n\n@spool(pass_arguments=True)\ndef send_confirmation_email_spooler(reservation_slot, verification_url): # Needs uri_prefix to generate absolute url. Requests can't be pickled.\n with mail.get_connection() as connection:\n message = EmailMessage()\n message.connection = connection\n message.subject = 'Your Mustang Move-in Pass'\n message.from_email = 'University Housing <[email protected]>'\n message.to = [reservation_slot.resident.email]\n message.reply_to = ['University Housing <[email protected]>']\n message.attach('Mustang Move-in Pass.pdf', generate_pdf_file(reservation_slot, verification_url), 'application/pdf')\n message.body = 'Hello ' + reservation_slot.resident.full_name + \"\"\",\n\nYour Cal Poly Fall move-in arrival time has been successfully reserved and your Mustang Move-in Pass is attached.\n\nMy Reservation:\n\nDate: \"\"\" + formats.date_format(reservation_slot.timeslot.date) + \"\"\"\nStart Time: \"\"\" + formats.time_format(reservation_slot.timeslot.time) + \"\"\"\nEnd Time: \"\"\" + formats.time_format(reservation_slot.timeslot.end_time) + \"\"\"\nZone: \"\"\" + reservation_slot.zone.name + \"\"\"\n\nPlease arrive on your designated day and time. This will help ensure a convenient move-in experience.\n\nIf you need to edit your reservation, go to: http://checkin.housing.calpoly.edu. You can edit your reservation until \"\"\" + formats.date_format(AdminSettings.objects.get_settings().reservation_close_day) + \"\"\".\n\nPlease finalize your travel plans based on your final reservation.\n\nGo Mustangs!\nUniversity Housing\nCal Poly\n\"\"\"\n message.send()\n"
},
{
"alpha_fraction": 0.7382978796958923,
"alphanum_fraction": 0.7382978796958923,
"avg_line_length": 52.71428680419922,
"blob_id": "ddde80b3596d4998515ca64d2fa1bdb85119669f",
"content_id": "3af99cc2c34c21fef09ec5079ab7294d660d9f9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1880,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 35,
"path": "/checkin_parking/apps/reservations/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.reservations.urls\n :synopsis: Checkin Parking Reservation Reservations URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf.urls import url\nfrom django.contrib.auth.decorators import login_required\n\nfrom ...urls import administrative_access, scanner_access\nfrom ..core.views import IndexView\nfrom .ajax import reserve_slot, cancel_reservation, delete_timeslot\nfrom .views import GenerateReservationSlotsView, ParkingPassPDFView, ParkingPassVerificationView, ReserveView, ViewReservationView, ChangeReservationView, TimeSlotListView\n\n\napp_name = 'reservations'\n\nurlpatterns = [\n url(r'^slots/generate/$', login_required(administrative_access(GenerateReservationSlotsView.as_view())), name='generate_reservation_slots'),\n\n url(r'^slots/list/$', login_required(administrative_access(TimeSlotListView.as_view())), name='list_time_slots'),\n url(r'^slots/(?P<id>\\d+)/$', login_required(administrative_access(IndexView.as_view())), name='update_time_slot'), # What?\n url(r'^ajax/delete_time_slot/$', login_required(administrative_access(delete_timeslot)), name='delete_time_slot'),\n\n url(r'^reserve/$', login_required(ReserveView.as_view()), name='reserve'),\n url(r'^ajax/reserve_slot/$', login_required(reserve_slot), name='reserve_slot'),\n url(r'^view/$', login_required(ViewReservationView.as_view()), name='view_reservation'),\n url(r'^change/$', login_required(ChangeReservationView.as_view()), name='change_reservation'),\n url(r'^ajax/cancel/$', login_required(cancel_reservation), name='cancel_reservation'),\n\n url(r'^parking-pass/generate/$', login_required(ParkingPassPDFView.as_view()), name='generate_parking_pass'),\n url(r'^parking-pass/verify/(?P<reservation_id>\\d+)/(?P<user_id>\\d+)/$', login_required(scanner_access(ParkingPassVerificationView.as_view())), name='verify_parking_pass'),\n]\n"
},
{
"alpha_fraction": 0.49338316917419434,
"alphanum_fraction": 0.4983331561088562,
"avg_line_length": 35.79925537109375,
"blob_id": "2762df4d442c944d32aa9f8cee619d5855f86b0f",
"content_id": "36d3cad2d0196c919767b80ae8c0a67ada322e1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9899,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 269,
"path": "/checkin_parking/settings/base.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\n\nimport dj_database_url\nimport raven\n\nfrom checkin_parking.manage import get_env_variable\n\n# ======================================================================================================== #\n# General Settings #\n# ======================================================================================================== #\n\n# Local time zone for this installation. Choices can be found here:\nTIME_ZONE = 'America/Los_Angeles'\n\n# Language code for this installation.\nLANGUAGE_CODE = 'en-us'\n\nDATE_FORMAT = 'l, F d, Y'\n\nTIME_FORMAT = 'h:i a'\nPYTHON_TIME_FORMAT = '%I:%M%p'\n\nDATETIME_FORMAT = 'l, F d, Y h:i a'\nPYTHON_DATETIME_FORMAT = '%A, %B %d, %Y %I:%M%p' # Format: Monday, January 01, 2012 08:00am'\n\nDEFAULT_CHARSET = 'utf-8'\n\n# If you set this to False, Django will make some optimizations so as not\n# to load the internationalization machinery.\nUSE_I18N = False\n\n# If you set this to False, Django will not format dates, numbers and\n# calendars according to the current locale\nUSE_L10N = False\n\nTEST_RUNNER = 'django.test.runner.DiscoverRunner'\n\nMAIN_APP_NAME = 'checkin_parking'\n\nROOT_URLCONF = MAIN_APP_NAME + '.urls'\n\n# ======================================================================================================== #\n# Database Configuration #\n# ======================================================================================================== #\n\nDATABASES = {\n 'default': dj_database_url.config(default=get_env_variable('CHECKIN_PARKING_DB_DEFAULT_DATABASE_URL')),\n 'uhin': dj_database_url.config(default=get_env_variable('RESNET_INTERNAL_DB_DEFAULT_DATABASE_URL')),\n 'rms': {\n 'ENGINE': 'django.db.backends.oracle',\n 'NAME': 'mercprd.db.calpoly.edu:1521/mercprd',\n 'USER': get_env_variable('CHECKIN_PARKING_DB_RMS_USERNAME'),\n 'PASSWORD': get_env_variable('CHECKIN_PARKING_DB_RMS_PASSWORD'),\n },\n}\n\nDATABASE_ROUTERS = (\n 'rmsconnector.routers.RMSRouter',\n)\n\n# ======================================================================================================== #\n# E-Mail Configuration #\n# ======================================================================================================== #\n\n# Incoming email settings\nINCOMING_EMAIL = {\n 'IMAP4': {\n 'HOST': 'outlook.office365.com',\n 'PORT': 993,\n 'USE_SSL': True,\n 'USER': get_env_variable('CHECKIN_PARKING_EMAIL_USERNAME'),\n 'PASSWORD': get_env_variable('CHECKIN_PARKING_EMAIL_PASSWORD'),\n },\n}\n\nEMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend'\nEMAIL_HOST = 'outlook.office365.com'\nEMAIL_PORT = 25 # The port to use. Default values: 25, 587\nEMAIL_USE_TLS = True\nEMAIL_HOST_USER = INCOMING_EMAIL['IMAP4']['USER']\nEMAIL_HOST_PASSWORD = INCOMING_EMAIL['IMAP4']['PASSWORD']\n\n# Set the server's email address (for sending emails only)\nSERVER_EMAIL = 'ResDev Mail Relay Server <[email protected]>'\nDEFAULT_FROM_EMAIL = SERVER_EMAIL\n\n\n# ======================================================================================================== #\n# Authentication Configuration #\n# ======================================================================================================== #\n\nLOGIN_URL = '/login/'\n\nLOGIN_REDIRECT_URL = '/login/'\n\nAUTHENTICATION_BACKENDS = (\n 'django.contrib.auth.backends.ModelBackend',\n MAIN_APP_NAME + '.apps.core.backends.CASLDAPBackend',\n)\n\nAUTH_USER_MODEL = 'core.CheckinParkingUser'\n\nCAS_ADMIN_PREFIX = \"flugzeug/\"\nCAS_LOGOUT_COMPLETELY = False\nCAS_LOGIN_MSG = None\nCAS_LOGGED_MSG = None\n\nCAS_SERVER_URL = \"https://my.calpoly.edu/cas/\"\nCAS_LOGOUT_URL = \"https://my.calpoly.edu/cas/casClientLogout.jsp?logoutApp=University%20Housing%20Checkin%20Parking%20Reservation\"\n\n\n# ======================================================================================================== #\n# LDAP Groups Configuration #\n# ======================================================================================================== #\n\nLDAP_GROUPS_SERVER_URI = 'ldap://ad.calpoly.edu'\nLDAP_GROUPS_BASE_DN = 'DC=ad,DC=calpoly,DC=edu'\nLDAP_GROUPS_USER_BASE_DN = 'OU=People,OU=Enterprise,OU=Accounts,' + LDAP_GROUPS_BASE_DN\n\nLDAP_GROUPS_USER_SEARCH_BASE_DN = 'OU=Enterprise,OU=Accounts,' + LDAP_GROUPS_BASE_DN\nLDAP_GROUPS_GROUP_SEARCH_BASE_DN = 'OU=Groups,' + LDAP_GROUPS_BASE_DN\n\nLDAP_GROUPS_BIND_DN = get_env_variable('CHECKIN_PARKING_LDAP_USER_DN')\nLDAP_GROUPS_BIND_PASSWORD = get_env_variable('CHECKIN_PARKING_LDAP_PASSWORD')\n\nLDAP_GROUPS_USER_LOOKUP_ATTRIBUTE = 'userPrincipalName'\nLDAP_GROUPS_GROUP_LOOKUP_ATTRIBUTE = 'name'\nLDAP_GROUPS_ATTRIBUTE_LIST = ['displayName', LDAP_GROUPS_USER_LOOKUP_ATTRIBUTE]\n\nLDAP_ADMIN_GROUP = 'CN=checkinparking,OU=Websites,OU=UH,OU=Manual,OU=Groups,' + LDAP_GROUPS_BASE_DN\nLDAP_SCANNER_GROUP = 'CN=checkinparkingscanner,OU=Websites,OU=UH,OU=Manual,OU=Groups,' + LDAP_GROUPS_BASE_DN\nLDAP_DEVELOPER_GROUP = 'CN=UH-RN-DevTeam,OU=Technology,OU=UH,OU=Manual,OU=Groups,' + LDAP_GROUPS_BASE_DN\n\n\n# ======================================================================================================== #\n# Session/Security Configuration #\n# ======================================================================================================== #\n\nSESSION_COOKIE_HTTPONLY = True\nSESSION_EXPIRE_AT_BROWSER_CLOSE = True\n\nSECRET_KEY = get_env_variable('CHECKIN_PARKING_SECRET_KEY')\n\n# ======================================================================================================== #\n# File/Application Handling Configuration #\n# ======================================================================================================== #\n\nPROJECT_DIR = Path(__file__).parents[2]\n\nMEDIA_ROOT = str(PROJECT_DIR.joinpath(\"media\").resolve())\nMEDIA_URL = '/media/'\n\nSTATIC_ROOT = str(PROJECT_DIR.joinpath(\"static\").resolve())\n\nSTATIC_URL = '/static/'\n\nSTATICFILES_DIRS = [\n str(PROJECT_DIR.joinpath(MAIN_APP_NAME, \"static\").resolve()),\n]\n\nSTATICFILES_FINDERS = [\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n]\n\n# Django-JS-Reverse Variable Name\nJS_REVERSE_JS_VAR_NAME = 'DjangoReverse'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [\n str(PROJECT_DIR.joinpath(MAIN_APP_NAME, \"templates\").resolve()),\n ],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.debug',\n 'django.core.context_processors.media',\n 'django.core.context_processors.static',\n 'django.core.context_processors.request',\n MAIN_APP_NAME + '.apps.core.context_processors.display_name',\n MAIN_APP_NAME + '.apps.core.context_processors.reservation_status',\n ],\n },\n },\n]\n\nCRISPY_TEMPLATE_PACK = 'bootstrap3'\n\nMIDDLEWARE_CLASSES = [\n 'django.middleware.common.CommonMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'raven.contrib.django.raven_compat.middleware.SentryResponseErrorIdMiddleware',\n]\n\nINSTALLED_APPS = [\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.admin',\n 'django.contrib.staticfiles',\n 'django_cas_ng',\n 'raven.contrib.django.raven_compat',\n 'django_ajax',\n 'clever_selects',\n 'django_js_reverse',\n 'rmsconnector',\n MAIN_APP_NAME + '.apps.administration',\n MAIN_APP_NAME + '.apps.core',\n MAIN_APP_NAME + '.apps.reservations',\n MAIN_APP_NAME + '.apps.statistics',\n MAIN_APP_NAME + '.apps.zones',\n]\n\n# ======================================================================================================== #\n# Logging Configuration #\n# ======================================================================================================== #\n\nRAVEN_CONFIG = {\n 'dsn': get_env_variable('CHECKIN_PARKING_SENTRY_DSN'),\n 'release': raven.fetch_git_sha(str(PROJECT_DIR.resolve())),\n}\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': True,\n 'root': {\n 'level': 'INFO',\n 'handlers': ['sentry'],\n },\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s %(process)d %(thread)d %(message)s'\n },\n },\n 'handlers': {\n 'sentry': {\n 'level': 'INFO',\n 'class': 'raven.contrib.django.raven_compat.handlers.SentryHandler',\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'formatter': 'verbose'\n }\n },\n 'loggers': {\n 'django.db.backends': {\n 'level': 'ERROR',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'raven': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n 'sentry.errors': {\n 'level': 'DEBUG',\n 'handlers': ['console'],\n 'propagate': False,\n },\n },\n}\n"
},
{
"alpha_fraction": 0.7088515162467957,
"alphanum_fraction": 0.7147037386894226,
"avg_line_length": 51.57692337036133,
"blob_id": "5013da81924773be8bd3fe81f6b09f0673c75047",
"content_id": "69e1407c97c81fd78238920fa4a66fea382b59d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 26,
"path": "/checkin_parking/apps/statistics/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.statistics.urls\n :synopsis: Checkin Parking Reservation Statistics URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf.urls import url\nfrom django.contrib.auth.decorators import login_required\n\nfrom ...urls import administrative_access\nfrom .views import CSVStatisticsView, StatisticsPage, ZoneChartData, ClassLevelChartData, QRChartData, OffTimeData\n\n\napp_name = 'statistics'\n\nurlpatterns = [\n url(r'^$', login_required(administrative_access(StatisticsPage.as_view())), name='index'),\n url(r'^csv/$', login_required(administrative_access(CSVStatisticsView.as_view())), name='csv'),\n url(r'^zone_chart_data/(?P<date>[a-zA-Z0-9-]*)/(?P<show_remaining>True|False)/$', login_required(administrative_access(ZoneChartData.as_view())), name='zone_chart_data'),\n url(r'^class_level_chart_data/(?P<date>[a-zA-Z0-9-]*)/(?P<show_remaining>True|False)//$', login_required(administrative_access(ClassLevelChartData.as_view())), name='class_level_chart_data'),\n url(r'^qr_chart_data/(?P<date>[a-zA-Z0-9-]*)/(?P<show_remaining>True|False)//$', login_required(administrative_access(QRChartData.as_view())), name='qr_chart_data'),\n url(r'^off_time_chart_data/(?P<date>[a-zA-Z0-9-]*)/(?P<show_remaining>True|False)//$', login_required(administrative_access(OffTimeData.as_view())), name='off_time_chart_data'),\n\n]\n"
},
{
"alpha_fraction": 0.7612903118133545,
"alphanum_fraction": 0.7612903118133545,
"avg_line_length": 24.83333396911621,
"blob_id": "a6718d5ab8361d0c0f11ccdca1512cdf0cb6109e",
"content_id": "b7e367778476740079096d6442542126d2af23b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 465,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 18,
"path": "/checkin_parking/apps/administration/admin.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.administration.admin\n :synopsis: Checkin Parking Reservation Administration Admin Configuration.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.contrib import admin\n\nfrom .models import AdminSettings\n\n\nclass AdminSettingsManager(admin.ModelAdmin):\n list_display = [\"reservation_open\", \"term_code\", \"timeslot_length\", \"application_year\", \"application_term\"]\n\n\nadmin.site.register(AdminSettings, AdminSettingsManager)\n"
},
{
"alpha_fraction": 0.7093023061752319,
"alphanum_fraction": 0.7093023061752319,
"avg_line_length": 19.975608825683594,
"blob_id": "4d75a10bc4293b89ad49f068688734c34db8bb47",
"content_id": "fc93aeb2a95ce5e232229a1470b4e38c042d8a15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 860,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 41,
"path": "/checkin_parking/apps/zones/ajax.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.zones.ajax\n :synopsis: Checkin Parking Reservation Zone AJAX Methods.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nimport logging\n\nfrom clever_selects.views import ChainedSelectChoicesView\nfrom django.views.decorators.http import require_POST\nfrom django_ajax.decorators import ajax\n\nfrom .models import Building, Zone\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass BuildingChainedAjaxView(ChainedSelectChoicesView):\n\n def get_child_set(self):\n return Building.objects.filter(community__id=self.parent_value).order_by('name')\n\n\n@ajax\n@require_POST\ndef delete_zone(request):\n \"\"\" Deletes a zone.\n\n :param zone_id: The id of the zone to delete.\n :type zone_id: int\n\n \"\"\"\n\n # Pull post parameters\n zone_id = request.POST[\"zone_id\"]\n Zone.objects.get(id=zone_id).delete()\n\n return {\"success\": True}\n"
},
{
"alpha_fraction": 0.5792452692985535,
"alphanum_fraction": 0.6396226286888123,
"avg_line_length": 24.238094329833984,
"blob_id": "4b7055542fd05d1c87b4c9812bfe2dbed151a782",
"content_id": "d4d2661b227091d2707bfa3aa889e837e961572a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 530,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 21,
"path": "/checkin_parking/apps/administration/migrations/0003_adminsettings_reservation_close_day.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-10 10:16\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('administration', '0002_auto_20160702_1309'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='adminsettings',\n name='reservation_close_day',\n field=models.DateTimeField(default=django.utils.timezone.now),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6957746744155884,
"alphanum_fraction": 0.6985915303230286,
"avg_line_length": 21.1875,
"blob_id": "3bb3ec1ecd081b258e5659399881e1cd51db744e",
"content_id": "c9d3bee87ce2c631b1cf5776ac9b48828bcaf82e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 16,
"path": "/checkin_parking/apps/administration/managers.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.managers\n :synopsis: Checkin Parking Reservation Core Managers.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.db.models.manager import Manager\n\n\nclass AdminSettingsManager(Manager):\n\n def get_settings(self):\n settings, created = self.get_queryset().get_or_create(id=1)\n return settings\n"
},
{
"alpha_fraction": 0.5353588461875916,
"alphanum_fraction": 0.5400733351707458,
"avg_line_length": 35.71154022216797,
"blob_id": "5a056f894fb6b096a73db39abab7fc62d8dfe8d1",
"content_id": "8fda6a4c8d3eb950a862a5b5c71b5f662c05fed8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1909,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 52,
"path": "/checkin_parking/apps/zones/migrations/0001_initial.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import unicode_literals\n\nfrom django.db import models, migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Building',\n fields=[\n ('id', models.AutoField(verbose_name='ID', auto_created=True, primary_key=True, serialize=False)),\n ('name', models.CharField(verbose_name='Building Name', max_length=30)),\n ],\n options={\n },\n bases=(models.Model,),\n ),\n migrations.CreateModel(\n name='Community',\n fields=[\n ('id', models.AutoField(verbose_name='ID', auto_created=True, primary_key=True, serialize=False)),\n ('name', models.CharField(verbose_name='Community Name', max_length=30)),\n ],\n options={\n },\n bases=(models.Model,),\n ),\n migrations.CreateModel(\n name='Zone',\n fields=[\n ('id', models.AutoField(verbose_name='ID', auto_created=True, primary_key=True, serialize=False)),\n ('name', models.CharField(verbose_name='Name', max_length=30, unique=True)),\n ('capacity', models.PositiveSmallIntegerField(verbose_name='Capacity', default=30)),\n ('buildings', models.ManyToManyField(verbose_name='Building(s)', to='zones.Building')),\n ('community', models.ForeignKey(verbose_name='Community', to='zones.Community')),\n ],\n options={\n },\n bases=(models.Model,),\n ),\n migrations.AddField(\n model_name='building',\n name='community',\n field=models.ForeignKey(related_name='buildings', verbose_name='Community', to='zones.Community'),\n preserve_default=True,\n ),\n ]\n"
},
{
"alpha_fraction": 0.7306122183799744,
"alphanum_fraction": 0.7306122183799744,
"avg_line_length": 39.83333206176758,
"blob_id": "e59b3c3c0e11c3a3fd44fb78ac324549316ab866",
"content_id": "5ed2811a29229270d1e78c136470f98da6efa736",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 980,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 24,
"path": "/checkin_parking/apps/zones/urls.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.zones.urls\n :synopsis: Checkin Parking Reservation Zone URLs.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.conf.urls import url\nfrom django.contrib.auth.decorators import login_required\n\nfrom ...urls import administrative_access\nfrom .ajax import BuildingChainedAjaxView, delete_zone\nfrom .views import ZoneListView, ZoneCreateView, ZoneUpdateView\n\napp_name = 'zones'\n\nurlpatterns = [\n url(r'^list/$', login_required(administrative_access(ZoneListView.as_view())), name='list_zones'),\n url(r'^create/$', login_required(administrative_access(ZoneCreateView.as_view())), name='create_zone'),\n url(r'^update/(?P<id>\\d+)/$', login_required(administrative_access(ZoneUpdateView.as_view())), name='update_zone'),\n url(r'^ajax/delete/$', login_required(administrative_access(delete_zone)), name='delete_zone'),\n url(r'^ajax/update_buildings/$', login_required(BuildingChainedAjaxView.as_view()), name='chained_building'),\n]\n"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.724750280380249,
"avg_line_length": 31.178571701049805,
"blob_id": "e991b735136d97e37256dea2c3bd44d3976386e5",
"content_id": "8aa035c5d064839151b8e45ab1e36db255fa432b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 901,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 28,
"path": "/checkin_parking/apps/core/tasks.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.core.tasks\n :synopsis: Checkin Parking Core Tasks\n\n.. moduleauthor:: Thomas Willson <[email protected]>\n\n\"\"\"\nfrom concurrent.futures import ThreadPoolExecutor\n\nfrom rmsconnector.utils import Resident\nfrom uwsgidecorators import cron\n\nfrom ..administration.models import AdminSettings\nfrom ..zones.models import Building\nfrom .models import CheckinParkingUser\n\n\n@cron(0, 2, -1, -1, -1)\ndef update_users_buildings():\n def update_user_building(user):\n address_dict = Resident(principal_name=user.email, term_code=AdminSettings.objects.get_settings().term_code)\n\n if address_dict['building']:\n user.building = Building.objects.get(name=address_dict['building'], community__name=address_dict['community'])\n user.save()\n\n with ThreadPoolExecutor(max_workers=20) as pool:\n pool.map(update_user_building, CheckinParkingUser.objects.all())\n"
},
{
"alpha_fraction": 0.6115819215774536,
"alphanum_fraction": 0.6567796468734741,
"avg_line_length": 27.31999969482422,
"blob_id": "88ae335cfee121477709793748d75e6613a7f016",
"content_id": "7dc6b0bf6272c95564a1f19d5ce6ae2f7cb4cca9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 25,
"path": "/checkin_parking/apps/core/migrations/0006_auto_20160704_1556.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-04 15:56\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\ndef delete_users(apps, schema_editor):\n apps.get_model('core', 'CheckinParkingUser').objects.all().delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0005_auto_20160704_1557'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='checkinparkinguser',\n name='building',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, related_name='residents', to='zones.Building'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5336538553237915,
"alphanum_fraction": 0.6105769276618958,
"avg_line_length": 20.894737243652344,
"blob_id": "87e56aaa74a3494c0c51afffddcca8624931766b",
"content_id": "b75501d99026f45c63a63ca6622cdb4567831f27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 19,
"path": "/checkin_parking/apps/administration/migrations/0005_remove_adminsettings_reservation_open.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n# Generated by Django 1.9.6 on 2016-07-10 12:15\nfrom __future__ import unicode_literals\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('administration', '0004_auto_20160710_1018'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='adminsettings',\n name='reservation_open',\n ),\n ]\n"
},
{
"alpha_fraction": 0.7444561719894409,
"alphanum_fraction": 0.7444561719894409,
"avg_line_length": 25.30555534362793,
"blob_id": "d0c8b1c7bcfd70fd04740448c2e536cba678db6f",
"content_id": "8fc286a91e988a422e6e43cd4411ff1c8a65eef3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 36,
"path": "/checkin_parking/apps/zones/views.py",
"repo_name": "CalPolyResDev/checkin_parking_project",
"src_encoding": "UTF-8",
"text": "\"\"\"\n.. module:: checkin_parking.apps.zones.views\n :synopsis: Checkin Parking Reservation Zone Views.\n\n.. moduleauthor:: Alex Kavanaugh <[email protected]>\n\n\"\"\"\n\nfrom django.core.urlresolvers import reverse_lazy\nfrom django.views.generic.edit import CreateView, UpdateView\nfrom django.views.generic.list import ListView\n\nfrom clever_selects.views import ChainedSelectFormViewMixin\n\nfrom .forms import ZoneForm\nfrom .models import Zone\n\n\nclass ZoneListView(ListView):\n template_name = \"zones/list_zones.djhtml\"\n model = Zone\n\n\nclass ZoneCreateView(ChainedSelectFormViewMixin, CreateView):\n template_name = \"zones/create_zone.djhtml\"\n form_class = ZoneForm\n model = Zone\n success_url = reverse_lazy('zones:list_zones')\n\n\nclass ZoneUpdateView(ChainedSelectFormViewMixin, UpdateView):\n pk_url_kwarg = 'id'\n template_name = \"zones/update_zone.djhtml\"\n form_class = ZoneForm\n model = Zone\n success_url = reverse_lazy('zones:list_zones')\n"
}
] | 56 |
Alabaster456/Text-Adventure
|
https://github.com/Alabaster456/Text-Adventure
|
7012c4393bc2923dc8b0441e6f309c4d7ddc1ba9
|
fd6cb69d57acc450503b7c230f66c77b90f200f0
|
f966438df369386c356b601d3623b8ad10f148d0
|
refs/heads/master
| 2016-09-06T17:05:20.956609 | 2014-06-09T22:50:46 | 2014-06-09T22:50:46 | 20,624,645 | 0 | 1 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7561983466148376,
"alphanum_fraction": 0.7661157250404358,
"avg_line_length": 99.83333587646484,
"blob_id": "2bcba3df3824c1659fcceb96e466da062ae27b70",
"content_id": "eff01a6fd0dd33abb20edc46ba537066cb349927",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 443,
"num_lines": 12,
"path": "/README.md",
"repo_name": "Alabaster456/Text-Adventure",
"src_encoding": "UTF-8",
"text": "Text-Adventure\n==============\n\nUpdate that was on Codecademy\n--\nI currently have the repository pulled up as well as you guys added to it, so you can either fork it or participate in the main branch (which is my file) when you please. Please keep the code in a neat order though, because we don't want it to be unorganized and hard to distinguish variables from functions, etc. If you look at the file, you'll see a good demonstration as to what I mean.\n\n[](https://gitter.im/Alabaster456/Text-Adventure)\n\nWe will be using Gitter (a chat application) that allows us to communicate freely through real-time, so I'll add you to that as well. It's automatically linked to your GitHub account, so no registration is required. The purpose of using Gitter is to keep track of our code and compare whenever we brainstorm some ideas, so please chat in the room actively. I don't expect you to be in it everyday (24/7), but when you're participating? Yes. :)\n\nWhether it's a online editor or one that you downloaded, please make sure that it's Python 2.7.2. Codecademy also uses this version. It's not the latest version, but it's more preferred.\n"
},
{
"alpha_fraction": 0.5065104365348816,
"alphanum_fraction": 0.5091145634651184,
"avg_line_length": 35.57143020629883,
"blob_id": "ea5013d967ba6603f7aa170b8cf4de6d508f4969",
"content_id": "42cf5035a5da76766a2969fc99549b5d47e1aae5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 768,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 21,
"path": "/game.py",
"repo_name": "Alabaster456/Text-Adventure",
"src_encoding": "UTF-8",
"text": "#VARIABLE AREA \nuserHP = 50 #user's health\ndead = False #Checks to see if the user is alive or not.\ninventory = [\"\", \"\", \"\"] #Items the user can hold (could expand the list)\n\n\n#Start of the game - put it in the console to see how it looks! \nprint(\"-----------------------------\")\nprint(\"|| Welcome to Pyth-Adventure! ||\") \nprint(\"-----------------------------\")\n\n\nprint (\"------- ---------\") \nprint(\"| | | |\")\nprint(\"| Play | OR | Tutorial |\") \nprint(\" ------ ----------\")\nquestion = raw_input(\"If you want to begin playing, type play. If you want to read about the tutorial, type tutorial!\").upper()\nif question == \"PLAY\":\n print(\"Okay! Let's begin!\")\nelif question == \"TUTORIAL\":\n print(\"GOOD!\")\n"
}
] | 2 |
ONSdigital/ips_services
|
https://github.com/ONSdigital/ips_services
|
a6aa1dab622c88af6985c20ec8b9512016682a06
|
46df3d0686caeed94a272e0a5e162af3a72b7950
|
c61a2dd1df3d9e71e82aa43c9edffc18b9516cf4
|
refs/heads/develop
| 2022-08-08T16:04:18.476093 | 2021-06-03T13:04:34 | 2021-06-03T13:04:34 | 179,675,512 | 0 | 3 | null | 2019-04-05T12:15:21 | 2022-06-17T12:46:02 | 2022-08-01T16:52:52 |
Python
|
[
{
"alpha_fraction": 0.6526479721069336,
"alphanum_fraction": 0.6718587875366211,
"avg_line_length": 27.74626922607422,
"blob_id": "8a7754b200902336616d7cdca86559637cfbb870",
"content_id": "748188bf396aada10cd49976d113f539416c3f99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1926,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 67,
"path": "/tests/test_load_survey.py",
"repo_name": "ONSdigital/ips_services",
"src_encoding": "UTF-8",
"text": "import time\nimport uuid\n\nimport falcon\nimport ips.persistence.persistence as db\nfrom ips.util.services_logging import log\n\nfrom ips.persistence.import_survey import SURVEY_SUBSAMPLE\nfrom ips.services.dataimport.import_survey import import_survey\n\nimport pytest\n\nsurvey_data = \"data/import_data/dec/surveydata.csv\"\n\nrun_id = str(uuid.uuid4())\nstart_time = time.time()\ndelete_survey_subsample = db.delete_from_table(SURVEY_SUBSAMPLE)\n\n\n# noinspection PyUnusedLocal\ndef setup_module(module):\n log.info(\"Module level start time: {}\".format(start_time))\n\n\ndef test_invalid_quarter():\n # valid month, data not matching valid year\n with open(survey_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError):\n import_survey(run_id, file.read(), 'Q5', '2017')\n\n\ndef test_month1():\n with open(survey_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError):\n import_survey(run_id, file.read(), '25', '2009')\n\n\ndef test_month2():\n # matching year, invalid month\n with open(survey_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError):\n import_survey(run_id, file.read(), '11', '2017')\n\n\ndef test_year():\n # valid month, data not matching valid year\n with open(survey_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError):\n import_survey(run_id, file.read(), '12', '2009')\n\n\ndef test_valid_quarter():\n # valid month, data not matching valid year\n with open(survey_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError):\n import_survey(run_id, file.read(), 'Q4', '2017')\n\n\ndef test_valid_import():\n with open(survey_data, 'rb') as file:\n import_survey(run_id, file.read(), '12', '2017')\n\n\n# noinspection PyUnusedLocal\ndef teardown_module(module):\n log.info(\"Duration: {}\".format(time.strftime(\"%H:%M:%S\", time.gmtime(time.time() - start_time))))\n delete_survey_subsample(run_id=run_id)\n"
},
{
"alpha_fraction": 0.6002852916717529,
"alphanum_fraction": 0.6011412143707275,
"avg_line_length": 25.553030014038086,
"blob_id": "b62bc89e0f54b0e0eb5599739a490d956a9c4c77",
"content_id": "1a1a115b22316a561361b0f6798dc5f1f44f198d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3505,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 132,
"path": "/ips/persistence/run_management.py",
"repo_name": "ONSdigital/ips_services",
"src_encoding": "UTF-8",
"text": "import ips.persistence.persistence as db\nimport ips.services.run_management as status\nfrom ips.util.services_logging import log\n\nRUN_STEPS = 'RUN_STEPS'\nRUN_MANAGEMENT = 'RUN'\nPROCESS_VARIABLES = 'PROCESS_VARIABLE_PY'\n\n\ndef clear_existing_status():\n db.execute_sql()(\n f\"UPDATE {RUN_MANAGEMENT} SET RUN_STATUS = {status.FAILED} WHERE RUN_STATUS={status.IN_PROGRESS} \"\n )\n\n\ndef create_run(run_id: str, run_status: int) -> None:\n db.execute_sql()(\n f\"UPDATE {RUN_MANAGEMENT} SET RUN_STATUS = {run_status} WHERE RUN_ID='{run_id}' \"\n )\n\n\ndef process_variables_exist(run_id: str) -> bool:\n row = db.execute_sql()(\n f\"SELECT RUN_ID FROM {PROCESS_VARIABLES} WHERE RUN_ID='{run_id}' \"\n ).fetchone()\n\n if row is None:\n return False\n\n return True\n\n\ndef is_existing_run(run_id: str) -> bool:\n row = db.execute_sql()(\n f\"SELECT RUN_ID FROM {RUN_MANAGEMENT} WHERE RUN_ID='{run_id}' \"\n ).fetchone()\n\n if row is None:\n return False\n\n return True\n\n\ndef set_status(run_id: str, run_status: int, step: str = None) -> None:\n if step is None:\n db.execute_sql()(\n f\"UPDATE {RUN_MANAGEMENT} SET RUN_STATUS = {run_status} WHERE RUN_ID='{run_id}' \"\n )\n else:\n db.execute_sql()(\n f\"UPDATE {RUN_MANAGEMENT} SET RUN_STATUS = {run_status}, STEP='{step}' WHERE RUN_ID='{run_id}' \"\n )\n\n\ndef set_step_status(run_id: str, step_status: int, step: str = None) -> None:\n if step is not None:\n db.execute_sql()(\n f\"UPDATE {RUN_STEPS} SET STEP_STATUS = {step_status} WHERE RUN_ID='{run_id}' AND STEP_NUMBER = '{step}'\"\n )\n\n\ndef reset_steps(run_id: str) -> None:\n db.execute_sql()(\n f\"UPDATE {RUN_STEPS} SET STEP_STATUS = 0 WHERE RUN_ID='{run_id}'\"\n )\n\n\ndef cancel_steps(run_id: str) -> None:\n db.execute_sql()(\n f\"UPDATE {RUN_STEPS} SET STEP_STATUS = 4 WHERE RUN_ID='{run_id}' AND STEP_STATUS = 0\"\n )\n\n\ndef get_step_status(run_id: str, step: str) -> int:\n row = db.execute_sql()(\n f\"SELECT STEP_STATUS FROM {RUN_STEPS} WHERE RUN_ID='{run_id}' AND STEP_NUMBER = '{step}'\"\n ).fetchone()\n\n if row is None:\n return status.NOT_STARTED\n return row['STEP_STATUS']\n\n\ndef get_run_status(run_id: str) -> int:\n row = db.execute_sql()(\n f\"SELECT RUN_STATUS FROM {RUN_MANAGEMENT} WHERE RUN_ID='{run_id}' \"\n ).fetchone()\n\n if row is None:\n return status.NOT_STARTED\n return row['RUN_STATUS']\n\n\ndef get_step(run_id: str) -> str:\n row = db.execute_sql()(\n f\"SELECT STEP FROM {RUN_MANAGEMENT} WHERE RUN_ID='{run_id}' \"\n ).fetchone()\n\n if row is None:\n return \"Step not Started\"\n\n return row['STEP']\n\n\ndef get_percentage_done(run_id: str) -> int:\n row = db.execute_sql()(\n f\"SELECT PERCENT FROM {RUN_MANAGEMENT} WHERE RUN_ID='{run_id}' \"\n ).fetchone()\n\n if row is None:\n return status.NOT_STARTED\n\n return row['PERCENT']\n\n\ndef set_percentage_done(run_id: str, percent: int) -> None:\n db.execute_sql()(\n f\"UPDATE {RUN_MANAGEMENT} SET PERCENT = {percent} WHERE RUN_ID='{run_id}' \"\n )\n\n\ndef insert_issue(run_id: str, step_num: int, response_code: int, msg: str):\n db.execute_sql()(\n f\"INSERT INTO RESPONSE (RUN_ID, STEP_NUMBER, RESPONSE_CODE, MESSAGE) \"\n f\"VALUES ('{run_id}', {step_num}, {response_code}, '{msg}')\"\n )\n\n\ndef reset_issues(run_id: str):\n db.execute_sql()(\n f\"DELETE FROM RESPONSE WHERE RUN_ID = '{run_id}'\"\n )\n"
},
{
"alpha_fraction": 0.6178553104400635,
"alphanum_fraction": 0.6335356831550598,
"avg_line_length": 34.94545364379883,
"blob_id": "8f51248682487f1a03f263bda638f95706e6f93c",
"content_id": "8672306519924e9030b303b35c2a0aa3e0cb3908",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3954,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 110,
"path": "/tests/test_load_traffic.py",
"repo_name": "ONSdigital/ips_services",
"src_encoding": "UTF-8",
"text": "import time\nimport uuid\nimport falcon\n\nimport ips.persistence.sql as db\nfrom ips.util.services_logging import log\nfrom ips.services.dataimport.import_traffic import import_air, import_sea, import_tunnel\nfrom ips.persistence.import_traffic import TRAFFIC_TABLE\n\nimport pytest\n\ntunnel_data = \"data/import_data/dec/Tunnel Traffic Dec 2017.csv\"\nsea_data = \"data/import_data/dec/Sea Traffic Dec 2017.csv\"\nair_data = \"data/import_data/dec/Air Sheet Dec 2017 VBA.csv\"\n\nrun_id = str(uuid.uuid4())\nstart_time = time.time()\n\n\n# noinspection PyUnusedLocal\ndef setup_module(module):\n log.info(\"Module level start time: {}\".format(start_time))\n\n\ndef test_month1():\n month = '25'\n year = '2009'\n with open(tunnel_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_tunnel(run_id, file.read(), month, year)\n with open(sea_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_sea(run_id, file.read(), month, year)\n with open(air_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_air(run_id, file.read(), month, year)\n\n\ndef test_month2():\n # matching year, invalid month\n month = '11'\n year = '2017'\n with open(tunnel_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_tunnel(run_id, file.read(), month, year)\n with open(sea_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_sea(run_id, file.read(), month, year)\n with open(air_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_air(run_id, file.read(), month, year)\n\n\ndef test_year1():\n # valid month, data not matching valid year\n month = '12'\n year = '2009'\n with open(tunnel_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_tunnel(run_id, file.read(), month, year)\n with open(sea_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_sea(run_id, file.read(), month, year)\n with open(air_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_air(run_id, file.read(), month, year)\n\n\ndef test_invalid_quarter():\n # valid month, data not matching valid year\n month = 'Q5'\n year = '2009'\n with open(tunnel_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_tunnel(run_id, file.read(), month, year)\n with open(sea_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_sea(run_id, file.read(), month, year)\n with open(air_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_air(run_id, file.read(), month, year)\n\ndef test_valid_quarter():\n # valid month, data not matching valid year\n month = 'Q4'\n year = '2017'\n with open(tunnel_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_tunnel(run_id, file.read(), month, year)\n with open(sea_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_sea(run_id, file.read(), month, year)\n with open(air_data, 'rb') as file:\n with pytest.raises(falcon.HTTPError) as e_info:\n import_air(run_id, file.read(), month, year)\n\n\ndef test_valid_import():\n with open(tunnel_data, 'rb') as file:\n import_tunnel(run_id, file.read(), '12', '2017')\n with open(sea_data, 'rb') as file:\n import_sea(run_id, file.read(), '12', '2017')\n with open(air_data, 'rb') as file:\n import_air(run_id, file.read(), '12', '2017')\n\n\n# noinspection PyUnusedLocal\ndef teardown_module(module):\n log.info(\"Duration: {}\".format(time.strftime(\"%H:%M:%S\", time.gmtime(time.time() - start_time))))\n db.delete_from_table(TRAFFIC_TABLE, 'RUN_ID', '=', run_id)\n"
}
] | 3 |
egavett/CS473Algorithms
|
https://github.com/egavett/CS473Algorithms
|
3a14d55b6a210222ed1106c888e1952e38998359
|
fdf0cca6ccf56c2cfdcd2a869e367d6ced099ada
|
769470c8f41273786f42fd1d76bf955dacdb4885
|
refs/heads/master
| 2021-08-23T00:53:46.114649 | 2017-12-02T00:29:07 | 2017-12-02T00:29:07 | 108,437,070 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5279546976089478,
"alphanum_fraction": 0.5421090126037598,
"avg_line_length": 28.45833396911621,
"blob_id": "24b5c5d44d0d40f652ddc5d97b838b4582b5aacd",
"content_id": "ac2987e4b431fd29689d0ccfb9c5b9458a76935a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1413,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 48,
"path": "/3Sum/rosalind_3sum.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef three_sum(array):\n indices = collections.defaultdict(lambda:-1) # the problem asks for the original indices, but we need to sort the array\n for i in range(len(array)): # the dictionary will allow the retreval of the indices after the n^2 algorith finds three values\n indices[array[i]] = i\n\n n = len(array)\n array.sort()\n for i in range(0, n-2):\n a = array[i]\n start = i+1\n end = n-1\n while start < end:\n b = array[start]\n c = array[end]\n if a+b+c == 0:\n # return indices\n output = []\n output.append(indices[a]+1)\n output.append(indices[b]+1)\n output.append(indices[c]+1)\n output.sort()\n return \" \".join(str(x) for x in output)\n elif a+b+c > 0:\n end = end -1\n else:\n start = start + 1\n return \"-1\" # no triplet found\n\n\nfilein = open('rosalind_3sum.txt')\ndata = filein.read()\nfilein.close()\n\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\narrayCount = int(linesin[0][0])\n\nfileout = open(\"rosalind_3sum_output.txt\", \"w\")\n\nfor x in range(1, arrayCount+1):\n array = [int(x) for x in linesin[x]]\n output = three_sum(array)\n\n print(output)\n fileout.write(\"{}\\n\".format(output))\n\nfileout.close()"
},
{
"alpha_fraction": 0.5987260937690735,
"alphanum_fraction": 0.6100495457649231,
"avg_line_length": 26.72549057006836,
"blob_id": "54c31c7c4c04aec3f21c2ca77a4290950d3a10c3",
"content_id": "17aaab9229261d56191c73a022268021d77d5eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1413,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 51,
"path": "/BellmanFord/rosalind_bf.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\nimport math\n\ndef weighted_directed_graph( verticies, edges) :\n verticies = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n weights = collections.defaultdict(int)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n weights[(edge[0], edge[1])] = edge[2]\n return [verticies, d_graph, weights]\n\ndef bellman_ford(vertices, edges, weights):\n distances = collections.defaultdict(int)\n for vertex in vertices:\n distances[vertex] = math.inf\n distances[1] = 0\n \n for _ in range(len(vertices)-1):\n for u in edges.keys():\n for v in edges[u]:\n w = weights[(u, v)]\n if distances[u] + w < distances[v]:\n distances[v] = distances[u] + w\n \n return distances\n\n\nfilein = open('rosalind_bf.txt')\ndata = filein.read()\n\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\nvertexCount = int(linesin[0][0])\nlinesin.pop(0)\nedges = [(int(edge[0]), int(edge[1]), int(edge[2])) for edge in linesin]\nV, E, W = weighted_directed_graph(vertexCount, edges)\n\ndistances = bellman_ford(V, E, W)\n\noutput = \"\"\nfor v in distances.keys():\n if distances[v] == math.inf:\n output += \"x\"\n else:\n output += str(distances[v])\n output += \" \"\nprint(output)\n\nfileout = open(\"rosalind_bf_output.txt\", \"w\")\nfileout.write(output)\nfileout.close()"
},
{
"alpha_fraction": 0.5313680768013,
"alphanum_fraction": 0.5464852452278137,
"avg_line_length": 24.941177368164062,
"blob_id": "2aea9477b0a467f8219f2bd476f39b747d649e53",
"content_id": "2ffd95459d0917c551fc72ef309499ed344ab782",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1323,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 51,
"path": "/SPOJ/SPOJ_BICOLOR.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef undirected_graph( verticies, edges) :\n V = [ v for v in range (1, verticies +1) ]\n und_graph = collections.defaultdict(set)\n for edge in edges :\n und_graph[ edge[0]].add(edge[1])\n und_graph[ edge[1]].add(edge[0])\n return [V, und_graph]\n\ndef DFS(G):\n color = 1\n colors = collections.defaultdict(lambda:0, {})\n \n isBicolor = True\n vertices, neighbors = G\n\n def dfs(v, color):\n colors[v] = color\n\n for w in neighbors[v]:\n if colors[w] == 0:\n color = colors[v] + 1\n dfs(w, color)\n else:\n if (colors[v]%2) == (colors[w]%2):\n global isBicolor\n isBicolor = False\n \n dfs(0, color)\n global isBicolor\n return isBicolor\n\ndef bicolor_depth_first( vertices, edges):\n V, E = undirected_graph(vertices, edges)\n isBicolor = DFS((V, E))\n return isBicolor\n\nwhile int(input()) != 0:\n edgeCount = int(input())\n linesin = []\n for edge in range(0, edgeCount):\n linesin.append( str(input()).strip().split() )\n\n edges = [ [ int(edge[0]), int(edge[1]) ] for edge in linesin ]\n\n output = bicolor_depth_first(edges[0][0], edges[0:])\n if output:\n print(\"BICOLORABLE\")\n else:\n print(\"NOT BICOLORABLE\")\n"
},
{
"alpha_fraction": 0.4134615361690521,
"alphanum_fraction": 0.5096153616905212,
"avg_line_length": 16.33333396911621,
"blob_id": "3abab43ec6c9ee6bcc5b8666e3187ebafe92b4ac",
"content_id": "2a4e7761427f039b4722ab0868fd2fc686e528da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 6,
"path": "/IntroductionProblems/rosalind_ini3.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "str = \"wMq7cgPAxVaranusjVFP0o3ldSIyuKrin1acYuc9ZzSghHFQj2eTO16mbsLmyTbD9lF2wh5fQKGTOMerNSqR7ZQucaxLOiOeRZ4pictahnLNGn5xO9Fc9Rzu2SFdRoDka2VZmPwNKen3X4vMAp7uYYxwE5tHUXh.\"\n\na, b, c, d = 9, 15, 99, 103\n\nnewString = str[a:b+1] + \" \" + str[c:d+1]\nprint(newString)\n"
},
{
"alpha_fraction": 0.5395683646202087,
"alphanum_fraction": 0.5503597259521484,
"avg_line_length": 11.636363983154297,
"blob_id": "8cf4cfe484d7d099e57013853b61cc55265be57a",
"content_id": "1e82f82420400a3a717f6ad3ff9ab64a89443cd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 22,
"path": "/IntroductionProblems/SPOJ_TEST.cpp",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stdio.h>\nusing namespace std;\n \nint main() {\n\t// your code goes here\n\t\n\tbool found = false;\n\tint value;\n\t\n\twhile (!found) {\n\t\tscanf(\"%d\", &value); \n\t\t\n\t\tif (value == 42) {\n\t\t\tfound = true;\n\t\t} else {\n\t\t\tcout << value << endl;\n\t\t}\n\t}\n\t\n\treturn 0;\n} "
},
{
"alpha_fraction": 0.5910730361938477,
"alphanum_fraction": 0.6000901460647583,
"avg_line_length": 28.197368621826172,
"blob_id": "e504d1cc90b8afe3077a66536eab0023ab79ee5f",
"content_id": "8b0bbc18096ec931929adada1131440312650932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2218,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 76,
"path": "/StronglyConnectedComponents/rosalind_scc.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "# Implementation of Tarjan's strongly connected components algorithm\n# Based off of pseudocode from: https://en.wikipedia.org/wiki/Tarjan's_strongly_connected_components_algorithm\n\nimport collections\n\nclass Vertex: \n def __init__(self, value):\n self.value = value\n self.index = -1 # The order in which the vertices are visited; -1 = undefined\n self.lowLink = -1 # -1 = undefined\n self.onStack = False\n\ndef directed_graph(verticies, edges) :\n V = collections.defaultdict(Vertex)\n for v in range(1, verticies+1):\n V[v] = Vertex(v)\n\n d_graph = collections.defaultdict(set)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n\n return [V, d_graph]\n\ndef strongly_connected_component( graph ):\n components = []\n vertices, edges = graph \n global index\n index = 0\n stack = []\n\n def SCC(v):\n global index\n vertices[v].index = index\n vertices[v].lowLink = index\n index = index + 1\n\n stack.append(v)\n vertices[v].onStack = True\n\n for w in edges[v]:\n if vertices[w].index == -1:\n SCC(w)\n vertices[v].lowLink = min(vertices[v].lowLink, vertices[w].lowLink)\n elif vertices[w].onStack: # deterimine if the vertex is in the current compenent\n vertices[v].lowLink = min(vertices[v].lowLink, vertices[w].index)\n \n if vertices[v].lowLink == vertices[v].index:\n compenent = set()\n w = -1\n while v != w:\n w = stack.pop()\n vertices[w].onStack = False\n compenent.add(w)\n components.append(compenent)\n\n vertices.keys()\n for v in range(1, len(vertices.keys())+1):\n if vertices[v].index == -1:\n SCC(v)\n\n return components\n\nfilein = open(\"rosalind_scc.txt\")\ndata = filein.read()\nfilein.close()\n\nlinesin = [sublist.strip().split() for sublist in data.splitlines()]\nvertex_count = int(linesin[0][0])\nlinesin.pop(0) #remove the first line\n\nedges = [[int(edge[0]), int(edge[1])] for edge in linesin]\nd_graph = directed_graph(vertex_count, edges)\n\ncomponents = strongly_connected_component(d_graph)\n\nprint(len(components))"
},
{
"alpha_fraction": 0.527999997138977,
"alphanum_fraction": 0.5413333177566528,
"avg_line_length": 33.09090805053711,
"blob_id": "1e59f8ec3b3c9801ad7a6652e405f1c3ba8052f4",
"content_id": "d45f60d799080bbbe0f967303d06f781559cb4e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 11,
"path": "/DegreeArray/rosalind_deg.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "with open('rosalind_deg.txt') as text:\n points, lines = [int(x) for x in next(text).split(\" \")] # read first line\n vertices = [0] * points\n for line in text:\n a, b = [int(x) for x in line.split(\" \")]\n vertices[a-1] += 1\n vertices[b-1] += 1\n output = \"\"\n for vertex in vertices:\n output = output + str(vertex) + \" \"\n print output\n"
},
{
"alpha_fraction": 0.6101036071777344,
"alphanum_fraction": 0.6230570077896118,
"avg_line_length": 22.42424201965332,
"blob_id": "3341351b632576e216b4f5cd1c0f8586c6c45c55",
"content_id": "6dd584867a8761c4f92049023d98109c85cd67b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 772,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 33,
"path": "/2Sum/rosalind_2sum.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\n# time complexity: n\n# space complexity: n\ndef two_sum(array): \n visited = collections.defaultdict(lambda:-1)\n for i in range(len(array)):\n nextValue = array[i]\n if -nextValue in visited.keys():\n return \"{} {}\".format(visited[-nextValue]+1, i+1)\n else:\n visited[nextValue] = i\n return \"-1\"\n\n \n\nfilein = open('rosalind_2sum.txt')\ndata = filein.read()\nfilein.close()\n\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\narrayCount = int(linesin[0][0])\n\nfileout = open(\"rosalind_2sum_output.txt\", \"w\")\n\nfor x in range(1, arrayCount+1):\n array = [int(x) for x in linesin[x]]\n output = two_sum(array)\n\n print(output)\n fileout.write(\"{}\\n\".format(output))\n\nfileout.close()"
},
{
"alpha_fraction": 0.5969479084014893,
"alphanum_fraction": 0.6095152497291565,
"avg_line_length": 27.58974266052246,
"blob_id": "d126b4c809dd61b6dab16b01648e8bb0532eece3",
"content_id": "e842a35931fbb82e382b44aecc766a5c1ae05389",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 39,
"path": "/BinarySearch/rosalind_bins.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import math\n\ndef bs_recursive(array, low, high, target):\n if low > high:\n return -1\n middle = (high+low)/2\n if array[middle] == target:\n return middle+1\n elif array[middle] > target:\n return bs(array, low, middle-1, target)\n else:\n return bs(array, middle+1, high, target)\n\ndef bs(array, low, high, target):\n while low <= high:\n middle = int(math.floor((low+high)/2))\n if array[middle] == target:\n return middle + 1\n elif target < array[middle]:\n high = middle - 1\n else:\n low = middle + 1\n return -1\n\ndef binary_search(array, target):\n return bs(array, 0, len(array)-1, target)\n\nfilein = open(\"rosalind_bins.txt\")\ndata = filein.readlines()\nsorted_array = [int(value) for value in data[2].strip().split()]\nvalues = [int(value) for value in data[3].strip().split()]\nfilein.close()\n\noutput = [ binary_search(sorted_array, value) for value in values ]\nprint(\" \".join(str(x) for x in output))\n\nfileout = open(\"rosalind_bins_output.txt\", \"w\")\nfileout.write(\" \".join(str(x) for x in output))\nfileout.close()"
},
{
"alpha_fraction": 0.5298507213592529,
"alphanum_fraction": 0.5597015023231506,
"avg_line_length": 32.5,
"blob_id": "5c95ca6973997058c445e89b4d3848ec21e63c49",
"content_id": "1981e668d56e7623139507dff889ea958e18a1b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 4,
"path": "/IntroductionProblems/rosalind_ini5.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "with open('rosalind_ini5.txt') as text:\n for count, line in enumerate(text, 1):\n if count % 2 == 1:\n print(line)\n"
},
{
"alpha_fraction": 0.5623229742050171,
"alphanum_fraction": 0.5786119103431702,
"avg_line_length": 27.260000228881836,
"blob_id": "6e15ed6899fc327067f18c3437059618c01d7ab5",
"content_id": "53f748bae783da233ee70eeedde6f5e73eb5b034",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1412,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 50,
"path": "/BreadthFirstSearch/rosalind_bfs.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef undirected_graph( verticies, edges) :\n V = [ v for v in range (1, verticies +1) ]\n und_graph = collections.defaultdict(set)\n for edge in edges :\n und_graph[ edge[0]].add(edge[1])\n und_graph[ edge[1]].add(edge[0])\n return [V, und_graph]\n\ndef directed_graph( verticies, edges) :\n V = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n return [V, d_graph]\n\ndef BFS(G) :\n depths = collections.defaultdict( lambda:-1, {} )\n vertices, neighbors = G\n\n def bfs(v) :\n queue = [v]\n depths[v] = 0\n while queue :\n v = queue.pop(0)\n for w in neighbors[v] :\n if depths[w] == -1 :\n depths[w] = depths[v] + 1\n queue.append(w)\n bfs(1)\n return depths\n\ndef breadth_first_search( vertices, edges ):\n V, E = directed_graph(vertices, edges)\n depths = BFS( (V,E) )\n str_depths = [str(depths[vertex]) for vertex in range(1, vertices+1)]\n return str_depths\n\nfilein = open(\"rosalind_bfs.txt\")\ndata = filein.read()\n\nlinesin = [ line.strip().split() for line in data.splitlines() ]\nfor p in linesin: print(p)\nedges = [ [ int(edge[0]), int(edge[1]) ] for edge in linesin ]\n\nfilein.close()\n\noutput = breadth_first_search(edges[0][0], edges[1:])\nprint(\" \".join(output))"
},
{
"alpha_fraction": 0.6611161231994629,
"alphanum_fraction": 0.6642664074897766,
"avg_line_length": 28.639999389648438,
"blob_id": "01bae6810d7e693cdeaede6ce12ec6be0cea20f2",
"content_id": "959e858c0c978641b4d8bfabecc030029cf61f1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 75,
"path": "/LongestSubsequences/rosalind_lgis.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def lgis(array):\n subsequenceLength = []\n reference = []\n bestEnd = 0\n\n for nextIndex in range(len(array)):\n subsequenceLength.append(1)\n reference.append(None)\n\n for oldIndex in range(nextIndex):\n length = subsequenceLength[oldIndex]+1\n if array[oldIndex] < array[nextIndex] and length > subsequenceLength[nextIndex]:\n subsequenceLength[nextIndex] = length\n reference[nextIndex] = oldIndex\n\n if subsequenceLength[nextIndex] > subsequenceLength[bestEnd]:\n bestEnd = nextIndex\n\n # use the indices to build the actual subsequence\n subsequence = []\n currentReference = bestEnd\n while currentReference is not None:\n subsequence.append(array[currentReference])\n currentReference = reference[currentReference]\n subsequence.reverse()\n\n return subsequence\n\ndef lgds(array):\n subsequenceLength = []\n reference = []\n bestEnd = 0\n\n for nextIndex in range(len(array)):\n subsequenceLength.append(1)\n reference.append(None)\n\n for oldIndex in range(nextIndex):\n length = subsequenceLength[oldIndex]+1\n if array[oldIndex] > array[nextIndex] and length > subsequenceLength[nextIndex]:\n subsequenceLength[nextIndex] = length\n reference[nextIndex] = oldIndex\n\n if subsequenceLength[nextIndex] > subsequenceLength[bestEnd]:\n bestEnd = nextIndex\n\n # use the indices to build the actual subsequence\n subsequence = []\n currentReference = bestEnd\n while currentReference is not None:\n subsequence.append(array[currentReference])\n currentReference = reference[currentReference]\n subsequence.reverse()\n\n return subsequence\n\n\nfilein = open(\"rosalind_lgis.txt\")\ndata = filein.readlines()\nfilein.close()\ninputArray = [int(value) for value in data[1].strip().split()]\n\nfileout = open(\"rosalind_lgis_output.txt\", \"w\")\n\noutput = lgis(inputArray)\nprint \" \".join(str(x) for x in output)\nfileout.write(\" \".join(str(x) for x in output))\n\nfileout.write(\"\\n\")\n\noutput = lgds(inputArray)\nprint \" \".join(str(x) for x in output)\nfileout.write(\" \".join(str(x) for x in output))\n\nfileout.close()"
},
{
"alpha_fraction": 0.6365348696708679,
"alphanum_fraction": 0.6534839868545532,
"avg_line_length": 34.46666717529297,
"blob_id": "1fbd60f06c9c5089c5e60083a8b60b7d016735e0",
"content_id": "07830e6f73e2c14172d1e682e5974acce443a896",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 15,
"path": "/DynamicProgramming/SPOJ_FARIDA.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def maxCoins(array):\n maxArray = [0, array[0]]\n\n for index in range(2, len(array)+1):\n newMax = max(array[index-1] + maxArray[index-2], maxArray[index-1])\n maxArray.append(newMax)\n return maxArray[-1]\n\nnumberOfCases = int(input())\nfor i in range(numberOfCases):\n ingoreThis = int(input()) #parsing works without needed to know the length of the array\n inputStrings = list(map(int, input().split()))\n\n inputArray = [int(x) for x in inputStrings]\n print(\"Case %d: %d\" % (i+1, maxCoins(inputArray)))"
},
{
"alpha_fraction": 0.5807860493659973,
"alphanum_fraction": 0.5938864350318909,
"avg_line_length": 31.73214340209961,
"blob_id": "4e1462cddbb42978afdc36d66a976c5322ad9ff2",
"content_id": "71424c0b9c4a5a920a581bbfcf5967033256315a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1832,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 56,
"path": "/Dijkstra/rosalind_dij.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\nimport math\n\ndef weighted_directed_graph( verticies, edges) :\n verticies = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n weights = collections.defaultdict(int)\n for edge in edges :\n d_graph[edge[0]].add(edge[1])\n weights[(edge[0], edge[1])] = edge[2]\n return [verticies, d_graph, weights]\n\ndef dijkstra(vertices, edges, weights):\n q = []\n for vertex in vertices:\n weight = math.inf\n if vertex == 1:\n weight = 0\n q.append((weight, vertex)) \n distances = collections.defaultdict(lambda: -1)\n visited = set()\n\n while q:\n q.sort(key=lambda x: x[0]) # sort based on the weights\n w, u = q.pop(0)\n if w == math.inf: w = -1\n distances[u] = w # save v's final distance\n visited.add(u)\n\n for i in range(len(q)):\n v = q[i]\n if v[1] in edges[u] and v[1] not in visited: # if the vertices we haven't visited are adjacent to the next vertex\n weight = weights[u, v[1]]\n if w + weight < v[0]:\n newVertex = (w + weight, v[1]) # tuples are immutable, so create a new tuple to hold the new weight\n q[i] = newVertex\n return distances\n\n\n\nfilein = open('rosalind_dij.txt')\ndata = filein.read()\n\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\nvertexCount = int(linesin[0][0])\nlinesin.pop(0)\nedges = [(int(edge[0]), int(edge[1]), int(edge[2])) for edge in linesin]\nV, E, W = weighted_directed_graph(vertexCount, edges)\n\ndistances = dijkstra(V, E, W)\n\noutput = [distances[x] for x in sorted(distances.keys())]\nprint(\" \".join(str(x) for x in output))\nfileout = open(\"rosalind_dij_output.txt\", \"w\")\nfileout.write(\" \".join(str(x) for x in output))\nfileout.close()"
},
{
"alpha_fraction": 0.5819464325904846,
"alphanum_fraction": 0.589844822883606,
"avg_line_length": 29.30769157409668,
"blob_id": "914df2344e37f37c15894f5048b52ceecaab3814",
"content_id": "f679c25788946c1a9b9edc0017cec9ca09f3c2fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3545,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 117,
"path": "/2Sat/rosalind_2sat.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\nimport sys\n\nclass Vertex: \n def __init__(self, value):\n self.value = value\n self.index = -1 # The order in which the vertices are visited; -1 = undefined\n self.lowLink = -1 # -1 = undefined\n self.onStack = False\n\ndef implication_graph(verticies, edges) :\n V = collections.defaultdict(Vertex)\n for v in range(1, verticies+1):\n V[v] = Vertex(v)\n V[-v] = Vertex(-v)\n\n imp_graph = collections.defaultdict(set)\n for edge in edges:\n imp_graph[-edge[0]].add(edge[1])\n imp_graph[-edge[1]].add(edge[0])\n return [V, imp_graph]\n\ndef strongly_connected_component(vertices, edges):\n components = [] \n global index\n index = 0\n stack = []\n\n def SCC(v):\n global index\n vertices[v].index = index\n vertices[v].lowLink = index\n index = index + 1\n\n stack.append(v)\n vertices[v].onStack = True\n\n for w in edges[v]:\n if vertices[w].index == -1:\n SCC(w)\n vertices[v].lowLink = min(vertices[v].lowLink, vertices[w].lowLink)\n elif vertices[w].onStack: # deterimine if the vertex is in the current compenent\n vertices[v].lowLink = min(vertices[v].lowLink, vertices[w].index)\n \n if vertices[v].lowLink == vertices[v].index:\n compenent = []\n w = -1\n while v != w:\n w = stack.pop()\n vertices[w].onStack = False\n compenent.append(w)\n components.append(compenent)\n\n vertices.keys()\n for v in vertices.keys():\n if vertices[v].index == -1:\n SCC(v)\n \n return components\n\ndef two_sat(graph, vertexCount):\n vertices, edges = graph\n components = strongly_connected_component(vertices, edges) # get the stongly connected components of the implication graph\n\n for component in components:\n vertices = list(component)\n for v in vertices:\n if -v in vertices: # if a vertex and its implication are in the graph, return 0\n return 0, [] # in an array to match the format of the positive response\n \n # test passed, assign values\n assignments = collections.defaultdict(lambda:None)\n for component in components:\n for vertex in component:\n if assignments[vertex] == None:\n assignments[vertex] = True\n assignments[-vertex] = False\n\n # form the output\n output = []\n for v in range(1, vertexCount+1):\n if assignments[v]:\n output.append(v)\n else:\n output.append(-v)\n\n return 1, output\n\nsys.setrecursionlimit(1500)\nfilein = open(\"rosalind_2sat.txt\")\ngraphCount = int(filein.readline())\nfileout = open(\"rosalind_2sat_output.txt\", \"w\")\n\nfor i in range(graphCount):\n filein.readline() #skip whitespace\n \n #get data about graph\n nextLine = filein.readline()\n v, e = nextLine.strip().split()\n vertexCount, edgeCount = int(v), int(e)\n\n # get graph data\n data = []\n for _ in range(edgeCount):\n data.append(filein.readline())\n linesin = [ sublist.strip().split() for sublist in data ]\n edges = [(int(edge[0]), int(edge[1])) for edge in linesin]\n imp_graph = implication_graph(vertexCount, edges)\n\n result, output = two_sat(imp_graph, vertexCount)\n output_string = \"{} {}\".format(result, \" \".join(str(x) for x in output))\n \n print(output_string)\n fileout.write(\"{}\\n\".format(output_string))\n\nfilein.close()\nfileout.close()"
},
{
"alpha_fraction": 0.5928767323493958,
"alphanum_fraction": 0.6016438603401184,
"avg_line_length": 25.463768005371094,
"blob_id": "8b95d29f932678c680535bf216ce7a7b123205e7",
"content_id": "22db1e60edcd724b85313d684f2c99f3eea0149b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1825,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 69,
"path": "/ShortestPathDAG/rosalind_sdag.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\nimport math\n\ndef weighted_directed_graph( verticies, edges) :\n verticies = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n weights = collections.defaultdict(int)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n weights[(edge[0], edge[1])] = edge[2]\n return [verticies, d_graph, weights]\n\ndef DFS(G):\n visited = collections.defaultdict(lambda:False, {})\n vertices, neighbors = G\n stack = []\n\n def dfs(v):\n visited[v] = True\n\n for w in neighbors[v]:\n if visited[w] == False:\n dfs(w)\n stack.insert(0, v)\n\n for v in vertices:\n if visited[v] == False:\n dfs(v)\n return stack\n\ndef shortest_path(vertices, edges, weights):\n sortedVertices = DFS((vertices, edges)) # sort topologically using depth first sort\n\n distances = collections.defaultdict(int)\n for vertex in vertices:\n distances[vertex] = math.inf\n distances[1] = 0\n \n for u in sortedVertices:\n for v in edges[u]:\n w = weights[(u, v)]\n if distances[u] + w < distances[v]:\n distances[v] = distances[u] + w\n\n return distances\n\nfilein = open('rosalind_sdag.txt')\ndata = filein.read()\n\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\nvertexCount = int(linesin[0][0])\nlinesin.pop(0)\nedges = [(int(edge[0]), int(edge[1]), int(edge[2])) for edge in linesin]\nV, E, W = weighted_directed_graph(vertexCount, edges)\n\ndistances = shortest_path(V, E, W)\n\noutput = \"\"\nfor v in distances.keys():\n if distances[v] == math.inf:\n output += \"x\"\n else:\n output += str(distances[v])\n output += \" \"\nprint(output)\n\nfileout = open(\"rosalind_sdag_output.txt\", \"w\")\nfileout.write(output)\nfileout.close()"
},
{
"alpha_fraction": 0.5723541975021362,
"alphanum_fraction": 0.5826134085655212,
"avg_line_length": 29.799999237060547,
"blob_id": "bbd41df5b5c755192c1ba6a2d099fc380c265812",
"content_id": "7c6a777099bda04877678f4af450c6b44a0742c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1852,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 60,
"path": "/NegativeWeightCycle/rosalind_nwc.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\nimport math\n\ndef weighted_directed_graph( verticies, edges) :\n verticies = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n weights = collections.defaultdict(int)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n weights[(edge[0], edge[1])] = edge[2]\n return [verticies, d_graph, weights]\n\ndef bellman_ford(vertices, edges, weights):\n distances = collections.defaultdict(int)\n for vertex in vertices:\n distances[vertex] = math.inf\n distances[1] = 0\n \n for _ in range(len(vertices)-1):\n for u in edges.keys():\n for v in edges[u]:\n w = weights[(u, v)]\n if distances[u] + w < distances[v]:\n distances[v] = distances[u] + w\n \n #check for negative weight cycles \n for u in edges.keys():\n for v in edges[u]:\n w = weights[(u, v)]\n if distances[u] + w < distances[v]:\n print(\"Result: 1\")\n return \"1\" # nwc found: return 1 \n print(\"Result: -1\")\n return \"-1\" #no nwc: return -1\n\nfilein = open('rosalind_nwc.txt')\ngraphCount = int(filein.readline())\noutput = []\n\nfor i in range(graphCount):\n print(\"Begin instance\", i)\n nextLine = filein.readline()\n v, e = nextLine.strip().split()\n vertexCount, edgeCount = int(v), int(e)\n\n data = []\n for _ in range(edgeCount):\n data.append(filein.readline())\n linesin = [ sublist.strip().split() for sublist in data ]\n \n edges = [(int(edge[0]), int(edge[1]), int(edge[2])) for edge in linesin]\n V, E, W = weighted_directed_graph(vertexCount, edges)\n\n output.append(bellman_ford(V, E, W))\n\nprint(\" \".join(x for x in output))\n\nfileout = open(\"rosalind_nwc_output.txt\", \"w\")\nfileout.write(\" \".join(x for x in output))\nfileout.close()\n "
},
{
"alpha_fraction": 0.5361701846122742,
"alphanum_fraction": 0.5404255390167236,
"avg_line_length": 22.549999237060547,
"blob_id": "3b34adf5c1990db9ff189bf62cc4ecd974202e6e",
"content_id": "bdbe449a2f51ea52dce44b5cda5786a7e3a73a13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 20,
"path": "/SPOJ/SPOJ_PHONELST.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import sys\n\nc = raw_input()\ncaseCount = int(c)\nfor case in range(0, caseCount):\n numbers = []\n flag = False\n i = raw_input()\n inputCount = int(i)\n for j in range(0, inputCount):\n v = raw_input()\n value = str(v)\n for number in numbers:\n if number.startswith(value) or value.startswith(number):\n flag = True\n numbers.append(value)\n if flag == False:\n print('NO')\n else:\n print('YES')"
},
{
"alpha_fraction": 0.5486111044883728,
"alphanum_fraction": 0.5694444179534912,
"avg_line_length": 21.153846740722656,
"blob_id": "156dc08baa44a0813cf6ce856f5eccd11207ceaa",
"content_id": "9a46bd2a4dc2fd8f072d89be9f5016774bc74ff4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 13,
"path": "/Fibonacci/rosalind_fibo.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def fibonnaci(count):\n if count == 0 :\n return 0\n elif count == 1 :\n return 1\n else :\n return fibonnaci(count - 1) + fibonnaci(count - 2)\n\nwith open('rosalind_fibo.txt') as text:\n for line in text:\n number = int(line)\n\n print(fibonnaci(number))\n"
},
{
"alpha_fraction": 0.5680628418922424,
"alphanum_fraction": 0.6020942330360413,
"avg_line_length": 27.259260177612305,
"blob_id": "08a516672e3fe66ab168a04fb9351f71e5dba8d0",
"content_id": "638ae3c48d4d00ea6777af02c67c81f8a7cea1b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/MergingArrays/rosalind_mer.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def mergeArrays(array1, array2):\n output = []\n\n while array1 or array2:\n if not array1:\n output.extend(array2.pop(0) for x in array2)\n elif not array2:\n output.extend(array1.pop(0) for x in array1)\n else:\n if array1[0] < array2[0]:\n output.append(array1.pop(0))\n else:\n output.append(array2.pop(0))\n return output\n\nfilein = open(\"rosalind_mer.txt\")\ndata = filein.readlines()\nfilein.close()\narray1 = [int(value) for value in data[1].strip().split()]\narray2 = [int(value) for value in data[3].strip().split()]\noutput = mergeArrays(array1, array2)\n\nfileout = open(\"rosalind_mer_output.txt\", \"w\")\n\nfileout.write(\" \".join(str(x) for x in output))\n\nfileout.close()\n\n"
},
{
"alpha_fraction": 0.6492537260055542,
"alphanum_fraction": 0.6585820913314819,
"avg_line_length": 25.850000381469727,
"blob_id": "551377dfa0f9523e3a98a72dc1b9e6ffa0701634",
"content_id": "fa0df786a3d50ea580e7ebd8b4a7cd0e6951fdae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 536,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 20,
"path": "/MajorityElement/rosalind_maj.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef majority_element(array):\n threshold = len(array)/2\n occurrences = collections.defaultdict( lambda:0, {})\n for value in array:\n occurrences[value] +=1\n if occurrences[value] > threshold:\n return value\n return -1\n\nfilein = open(\"rosalind_maj.txt\")\ndata = filein.readlines()[1:]\nfilein.close()\n\noutput = []\nfor line in data:\n input_array = [int(value) for value in line.strip().split()]\n output.append(majority_element(input_array))\nprint(\" \".join(str(x) for x in output))"
},
{
"alpha_fraction": 0.581250011920929,
"alphanum_fraction": 0.6052083373069763,
"avg_line_length": 26.457143783569336,
"blob_id": "2928d3216a7f5949b6c6b1760da757e388ef2947",
"content_id": "49360020053e9c6499348e8703784931b938f535",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 960,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 35,
"path": "/MergeSort/rosalind_ms.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def mergeArrays(array1, array2):\n output = []\n\n while array1 or array2:\n if not array1:\n output.extend(array2.pop(0) for x in array2)\n elif not array2:\n output.extend(array1.pop(0) for x in array1)\n else:\n if array1[0] < array2[0]:\n output.append(array1.pop(0))\n else:\n output.append(array2.pop(0))\n return output\n\ndef mergeSort(array):\n #base case\n if len(array) <= 1:\n return array\n middle = len(array) // 2\n left = mergeSort(array[:middle])\n right = mergeSort(array[middle:])\n return mergeArrays(left, right)\n\nfilein = open(\"rosalind_ms.txt\")\ndata = filein.readlines()\nfilein.close()\ninputArray = [int(value) for value in data[1].strip().split()]\n\noutput = mergeSort(inputArray)\nprint \" \".join(str(x) for x in output)\n\nfileout = open(\"rosalind_ms_output.txt\", \"w\")\nfileout.write(\" \".join(str(x) for x in output))\nfileout.close()"
},
{
"alpha_fraction": 0.3786407709121704,
"alphanum_fraction": 0.49514561891555786,
"avg_line_length": 12,
"blob_id": "cb9c4c78ac6234cbffed5306f30f803bd82ab0e4",
"content_id": "7010b5931d0015789095daf190d045ac8c3e644c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 8,
"path": "/IntroductionProblems/rosalind_ini4.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "a = 4930\nb = 9031\ntotal = 0\n\nfor x in range(a, b+1):\n if x % 2 == 1:\n total += x\nprint(total)"
},
{
"alpha_fraction": 0.5952970385551453,
"alphanum_fraction": 0.6076732873916626,
"avg_line_length": 22.794116973876953,
"blob_id": "0eed3b2b6ff66c07a1c4f4d5e7e3cdaad32ef1cf",
"content_id": "ade9081c4b96354849acd4c13f6965fe5b3878cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 808,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 34,
"path": "/MortalFibonacciRabbits/rosalind_fibd.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef mortal_fibonacci(months, lifespan):\n dp = collections.defaultdict(lambda: -1, {})\n dp[0], dp[1] = 0, 1\n rabbits = 0\n \n def fibonacci(month):\n if (dp[month] != -1):\n return dp[month]\n else: \n newRabbits = fibonacci(month-1) + fibonacci(month-2)\n dp[month] = newRabbits\n if month-lifespan >= 0:\n newRabbits -= fibonacci(month-lifespan)\n return newRabbits\n\n rabbits = fibonacci(months)\n return rabbits\n\n\n\nfilein = open(\"rosalind_fibd.txt\")\ndata = filein.read()\nfilein.close()\nm, l = data.split(\" \")\nmonths, lifespan = int(m), int(l)\n\noutput = mortal_fibonacci(months, lifespan)\nprint output\n\nfileout = open(\"rosalind_fibd_output.txt\", \"w\")\nfileout.write(str(output))\nfileout.close()"
},
{
"alpha_fraction": 0.6293532252311707,
"alphanum_fraction": 0.6384742856025696,
"avg_line_length": 24.680850982666016,
"blob_id": "a62b1edc77f7f37ca54dc25ebf40af3bc7fc2b6c",
"content_id": "466d345f1d498702094a74252f5642823a81dc6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 47,
"path": "/ConnectedComponent/rosalind_cc.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\nmark = set()\n\ndef depth_first_search( graph):\n components = 0\n for vertex in graph.keys():\n if vertex not in mark:\n # new component\n #print(\"found new component\")\n components += 1\n dfs(vertex, graph)\n return components\n\ndef dfs(vertex, graph):\n #print(\"new iteration: {}\".format(vertex))\n mark.add(vertex)\n leaves = graph[vertex]\n for leaf in leaves:\n if leaf not in mark:\n dfs(leaf, graph)\n\ndef undirected_graph( edges ) :\n und_graph = collections.defaultdict(set)\n for edge in edges :\n und_graph[edge[0]].add(edge[1])\n und_graph[edge[1]].add(edge[0])\n return und_graph\n\n\n\nfilein = open(\"rosalind_cc.txt\")\ndata = filein.read()\n\n#note: the following does not add nodes with no connections to the graph\nlinesin = [ sublist.strip().split() for sublist in data.splitlines() ]\n\n#remove the first line\nvertex_count = int(linesin[0][0])\nlinesin.pop(0)\n\nedges = [ [ int(edge[0]), int(edge[1]) ] for edge in linesin ]\nund_graph = undirected_graph( edges )\ncount = depth_first_search(und_graph)\n\n# account for the missing vertices\nprint(count + vertex_count - len(und_graph.keys()))"
},
{
"alpha_fraction": 0.5621547102928162,
"alphanum_fraction": 0.5704419612884521,
"avg_line_length": 23.149999618530273,
"blob_id": "b1fbded399200e22057c5c932eb8d95d6e966590",
"content_id": "b46877385d82327063d609f70ef51184bb5f9f7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1448,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 60,
"path": "/DirectedAcyclicGraph/rosalind_dag.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "import collections\n\ndef directed_graph( verticies, edges) :\n V = [ v for v in range (1, verticies +1) ]\n d_graph = collections.defaultdict(set)\n for edge in edges :\n d_graph[ edge[0]].add(edge[1])\n return [V, d_graph]\n\ndef DFS(G):\n visited = collections.defaultdict(lambda:False, {})\n vertices, neighbors = G\n stack = []\n is_acyclic = 1\n\n def dfs(v):\n visited[v] = True\n stack.append(v)\n for w in neighbors[v]:\n if visited[w] == False:\n dfs(w)\n else:\n if w in stack:\n global is_acyclic\n is_acyclic = -1\n stack.remove(v)\n\n for v in vertices:\n if visited[v] == False:\n dfs(v)\n global is_acyclic\n return is_acyclic\n\ndef acyclicity_test(vertices, edges):\n V, E = directed_graph(vertices, edges)\n return DFS((V,E))\n\ndef start_test(linesin):\n edges = [ [ int(edge[0]), int(edge[1]) ] for edge in linesin ]\n output.append(acyclicity_test(edges[0][0], edges[1:]))\n del edges[:]\n del linesin[:]\n\nfilein = open(\"rosalind_dag.txt\")\ndata = filein.read()[4:]\n\nlinesin = []\noutput = []\nfor line in data.splitlines():\n\n if not line.strip():\n start_test(linesin)\n else: \n linesin.append(line.strip().split())\n# algorithm does not detect empty line at the end of the file\nstart_test(linesin)\n\nprint(\" \".join(str(x) for x in output))\n\nfilein.close()"
},
{
"alpha_fraction": 0.5267665982246399,
"alphanum_fraction": 0.5438972115516663,
"avg_line_length": 25,
"blob_id": "97336831497c5e280281cf009e5534bced9b4447",
"content_id": "9ca6b5d914e0101340283108923d9a0904588b57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 18,
"path": "/InsertionSort/rosalind_ins.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def insertion_sort( values ):\n swaps = 0\n for i in range(1, len(values)):\n k = i\n while k > 0 and values[k] < values[k-1]:\n temp = values[k]\n values[k] = values[k-1]\n values[k-1] = temp\n\n k -= 1\n swaps += 1\n return swaps\n\nfilein = open(\"rosalind_ins.txt\")\ncount = int(next(filein))\nunsortedArray = [int(x) for x in next(filein).split(\" \")]\nswaps = insertion_sort(unsortedArray)\nprint swaps"
},
{
"alpha_fraction": 0.5938023328781128,
"alphanum_fraction": 0.6088777184486389,
"avg_line_length": 36.28125,
"blob_id": "947bf5653926fa5a04a11397a038d1123f2ff73a",
"content_id": "008547ff16d6f3d7b1d1c6e3205449dcb443b072",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1194,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 32,
"path": "/DynamicProgramming/SPOJ_PARTY.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def maxParty(partyCount, budget, parties):\n table = [[-1 for _ in range(0, budget+1)] for _ in range(0, numItems+1)] \n\n def mp(currentParty, budgetLeft):\n if table[currentParty][budgetLeft] < 0:\n if budgetLeft < parties[currentParty][0]:\n table[currentParty][budgetLeft] = mp(currentParty-1, budgetLeft)\n else:\n table[currentParty][budgetLeft] = max(mp(currentParty-1, budgetLeft), \n parties[currentParty][1] + mp(currentParty-1, budgetLeft - parties[currentParty][0]))\n return table[currentParty][budgetLeft]\n\n return mp(partyCount, budget)\n\ndef getNewCase():\n newCase = raw_input().strip().split()\n budget, partyCount = int(newCase[0]), int(newCase[1])\n return budget, partyCount\n\n\nbudget, partyCount = getNewCase()\nwhile partyCount != 0:\n parties = []\n for _ in range(0, partyCount):\n party = raw_input().strip().split()\n parties.append((int(party[0]), int(party[1])))\n #input() # skip emptyline\n print \"parties: {}\".format(parties)\n\n print maxParty(partyCount, budget, parties)\n \n budget, partyCount = getNewCase()\n\n"
},
{
"alpha_fraction": 0.5144278407096863,
"alphanum_fraction": 0.5223880410194397,
"avg_line_length": 19.53061294555664,
"blob_id": "f04e595148beea2e90b7ad4f127ee167187d9d28",
"content_id": "325d3d0d2dd3ccb07e4e1a14208524fe29f8ef27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1005,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 49,
"path": "/QuickSort/rosalind_qs.py",
"repo_name": "egavett/CS473Algorithms",
"src_encoding": "UTF-8",
"text": "def partition(array, left, right):\n def swap(i, j):\n temp = array[i]\n array[i] = array[j]\n array[j] = temp\n\n pivot = array[left]\n i = left + 1\n j = right\n\n done = False\n while not done:\n while i <= j and array[i] <= pivot:\n i += 1\n while i <= j and array[j] >= pivot:\n j -= 1\n\n if i > j:\n done = True\n else:\n swap(i,j)\n swap(left,j)\n \n return j\n \n\ndef quickSort(array):\n def QS(left, right):\n if left < right:\n s = partition(array, left, right)\n QS(left, s-1)\n QS(s+1, right)\n\n QS(0, len(array)-1)\n return array\n\n\n\nfilein = open(\"rosalind_qs.txt\")\ndata = filein.readlines()\nfilein.close()\ninputArray = [int(value) for value in data[1].strip().split()]\n\noutput = quickSort(inputArray)\nprint \" \".join(str(x) for x in output)\n\nfileout = open(\"rosalind_qs_output.txt\", \"w\")\nfileout.write(\" \".join(str(x) for x in output))\nfileout.close()"
}
] | 29 |
abulyaev/BoxDrive
|
https://github.com/abulyaev/BoxDrive
|
245f1c01d3c8a85a616cb2d154ffba575b614bd6
|
9fec2f3871a9d548466e9471d46b62ca441472b4
|
b42ade89b99c7877b1054e8b5e200e82c6ed1239
|
refs/heads/master
| 2023-05-30T16:56:49.651475 | 2021-06-30T18:51:08 | 2021-06-30T18:51:08 | 338,405,551 | 3 | 0 |
MIT
| 2021-02-12T18:53:27 | 2021-03-03T21:02:20 | 2021-03-03T21:04:41 |
Python
|
[
{
"alpha_fraction": 0.7433264851570129,
"alphanum_fraction": 0.7494866251945496,
"avg_line_length": 17.69230842590332,
"blob_id": "7df5bac156576cc09eed517922201cca1da937b6",
"content_id": "a8cabf16ccc2e452b0298bd9cd9b62b99503817f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 487,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 26,
"path": "/README.md",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# BoxDrive\n\nPython/Django\n\nFile Sharing service with auth and file encryption.\n\nDjango Project located in site.\n\nTo run django server: \n```\npython.exe manage.py runserver\n```\n\nTo apply changes to DB models:\n```\npython.exe manage.py makemigrations\n```\n\n```\npython.exe manage.py sqlmigrate boxdriveapp <number from migrations folder>\n```\n\n```\npython.exe manage.py migrate\n```\nHow to create a pull request to this repository: https://opensource.com/article/19/7/create-pull-request-github\n\n"
},
{
"alpha_fraction": 0.8279569745063782,
"alphanum_fraction": 0.8279569745063782,
"avg_line_length": 17.799999237060547,
"blob_id": "8232c5b9cf8e595d62558580f99652176cb1db63",
"content_id": "da44e88fcf4e90d847cbd55c3a6ea49d609926a4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 93,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 5,
"path": "/site/boxdrivesite/boxdriveapp/admin.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Document\n\n\nadmin.site.register(Document)"
},
{
"alpha_fraction": 0.4878048896789551,
"alphanum_fraction": 0.5718157291412354,
"avg_line_length": 19.5,
"blob_id": "2d759f941a655769ec7e00b46fabe8e6d4910b2b",
"content_id": "9c9526bc5bb77e7e172550eab11a4c5b36e3b797",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 18,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0005_rename_user_document_cur_user.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-13 22:54\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveapp', '0004_auto_20210613_1656'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='document',\n old_name='user',\n new_name='cur_user',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5944444537162781,
"alphanum_fraction": 0.6370370388031006,
"avg_line_length": 26,
"blob_id": "e03d4fa2b846cf034a9fcb2d9be174385caed84c",
"content_id": "c10774cb540f529f2dc9317ffa5b5bbef01213cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 540,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 20,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0007_alter_document_cur_user.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-14 13:30\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveusersreg', '0001_initial'),\n ('boxdriveapp', '0006_alter_document_cur_user'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='document',\n name='cur_user',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='boxdriveusersreg.profile'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6331360936164856,
"alphanum_fraction": 0.6331360936164856,
"avg_line_length": 50.4782600402832,
"blob_id": "77c2197e340e57b70f4834d0cc90efcb56f175e9",
"content_id": "ffe9a3ce9be7662b7f14152f1c061486bcbf974b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1183,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 23,
"path": "/site/boxdrivesite/boxdriveapp/urls.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\n\nurlpatterns = [\n #path('', PostListView.as_view(), name='boxdrive-home'),\n #path('about/', views.about, name='boxdrive-about'),\n\n #path('file/new/', PostCreateView.as_view(), name='post-create'),\n #path('file/<int:pk>/', PostDetailView.as_view(), name='post-detail'),\n #path('file/<int:pk>/update/', PostUpdateView.as_view(), name='post-update'),\n #path('file/<int:pk>/delete/', PostDeleteView.as_view(), name='post-delete'),\n # path('', views.home, name='boxdrive-home'),\n\n #############################################\n path('', views.DocumentListView.as_view(), name='boxdrive-home'),\n path('about/', views.about, name='boxdrive-about'),\n path('file/<str:cur_user>/upload_file/', views.DocumentUploadView.as_view(), name='upload_file'),\n #path('delete/<int:document_id>/', views.DocumentDeleteView.as_view(), name='post-delete'),\n path('delete/<int:pk>/', views.DocumentDeleteView.as_view(), name='post-delete'),\n path('file/<int:pk>/', views.DocumentDetailView.as_view(), name='post-detail'),\n path('download/<str:pk>/', views.DocumentDownloadView.as_view(), name='post-download'),\n]"
},
{
"alpha_fraction": 0.6775000095367432,
"alphanum_fraction": 0.6790000200271606,
"avg_line_length": 32.34166717529297,
"blob_id": "538acb235b8b99898ee9558804d50985d7f20d56",
"content_id": "afd25a79302780ef199f61e3035fd5565e3b0566",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4037,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 120,
"path": "/site/boxdrivesite/boxdriveapp/views.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "import os\n#import magic\n#import mimetypes\nfrom django.shortcuts import render, redirect, get_object_or_404, get_list_or_404\nfrom django.views.generic import (\n ListView,\n DetailView,\n CreateView,\n UpdateView,\n DeleteView\n)\nfrom encrypted_files.uploadhandler import EncryptedFileUploadHandler\nfrom django.urls import reverse\n\nfrom . models import Document\nfrom django.contrib.auth.models import User\nfrom boxdriveusersreg.models import Profile\nfrom boxdrivesite.settings import MEDIA_ROOT\nfrom django.contrib import messages\nfrom django.contrib.auth.mixins import LoginRequiredMixin, UserPassesTestMixin\n\nfrom django.core.files.uploadhandler import MemoryFileUploadHandler, TemporaryFileUploadHandler\nfrom django.views.generic.edit import CreateView\nfrom django.utils.decorators import method_decorator\nfrom django.views.decorators.csrf import csrf_exempt, csrf_protect\nfrom encrypted_files.base import EncryptedFile\nfrom django.http import HttpResponse\n\n\ndef about(request):\n return render(request, 'boxdriveapp/about.html')\n\n\n##################################################################\nclass DocumentListView(LoginRequiredMixin, ListView):\n model = Document\n template_name = 'boxdriveapp/home.html'\n context_object_name = 'documents'\n\n # функция для фильтрации документов по юзеру \n def get_queryset(self, *args, **kwargs):\n return Document.objects.filter(cur_user=self.request.user.profile).order_by('-upload_time')\n\n\nclass DocumentDetailView(DetailView):\n model = Document\n\n\nclass DocumentCreateView(LoginRequiredMixin, CreateView):\n model = Document\n fields = ['title', 'file_field']\n\n def form_valid(self, form):\n form.instance.user = self.request.user\n return super().form_valid(form)\n\n\nclass DocumentUploadView(UpdateView):\n def get(self, request, cur_user, *args, **kwargs):\n return render(request, 'boxdriveapp/upload_file.html', {'cur_user': cur_user,})\n\n def post(self, request, cur_user):\n filename = request.FILES['filename']\n title = request.POST['title']\n\n user_obj = Profile.objects.get(user__username=cur_user)\n upload_doc = Document(cur_user=user_obj, title=title, file_field=filename)\n upload_doc.save()\n messages.success(request, 'Your Post has been uploaded successfully.')\n return render(request, 'boxdriveapp/upload_file.html')\n\n\nclass DocumentDeleteView(LoginRequiredMixin, DeleteView):\n model = Document\n\n def get(self, request, pk):\n object = self.get_object()\n if object is not None:\n # TODO: actually remove file from fs\n object.delete()\n messages.success(request, 'Your post has been deleted successfully.')\n return redirect('boxdrive-home')\n else:\n messages.success(request, \"Something went wrong. Couldn't delete file.\")\n\n#################################################################\n\n\n@method_decorator(csrf_exempt, 'dispatch')\nclass CreateEncryptedFile(CreateView):\n model = Document\n fields = [\"file\"]\n\n def post(self, request, *args, **kwargs):\n request.upload_handlers = [\n EncryptedFileUploadHandler(request=request),\n MemoryFileUploadHandler(request=request),\n TemporaryFileUploadHandler(request=request)\n ] \n return self._post(request)\n\n @method_decorator(csrf_protect)\n def _post(self, request):\n form = self.get_form()\n if form.is_valid():\n return self.form_valid(form)\n else:\n return self.form_invalid(form)\n\ndef decrypted(request,pk):\n f = Document.objects.get(pk=pk).file_field\n ef = EncryptedFile(f)\n return HttpResponse(ef.read()), f\n\nclass DocumentDownloadView(UpdateView):\n def get(self, request, pk):\n response , f = decrypted(request, pk)\n response['Content-Disposition'] = 'attachment; filename={file}'.format(file=f)\n response['Content-Type'] = \"text\\plain\"\n return response"
},
{
"alpha_fraction": 0.5641329884529114,
"alphanum_fraction": 0.5688835978507996,
"avg_line_length": 32.720001220703125,
"blob_id": "f87ebdecc4029570146c9f8f004bc1e2ae11afce",
"content_id": "e8ff137f9e078d546ffe7f6cde6eae2f5cc8c828",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 842,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 25,
"path": "/site/boxdrivesite/boxdriveapp/templates/boxdriveapp/upload_file.html",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "{% extends 'boxdriveapp/base.html' %}\n\n{% load crispy_forms_tags %}\n{% block content %}\n\n<div class=\"container my-4 alert alert-success\">\n <div class=\"container\">\n <form action=\"{% url 'upload_file' user.username %}\" method=\"post\" enctype=\"multipart/form-data\">\n {% csrf_token %}\n <br>\n <div class=\"form-group\">\n <input type=\"file\" name=\"filename\" id=\"filechoose\" required>\n </div>\n\n <div class=\"form-group\">\n <label for=\"exampleFormControlInput1\" class=\"display-4\">Title</label>\n <input type=\"text\" class=\"form-control\" name=\"title\" id=\"exampleFormControlInput1\" required>\n </div>\n\n <input type=\"submit\" value=\"Upload\" class=\"btn btn-outline-primary\">\n </form>\n </div>\n</div>\n\n{% endblock content %}"
},
{
"alpha_fraction": 0.726047933101654,
"alphanum_fraction": 0.7305389046669006,
"avg_line_length": 32.45000076293945,
"blob_id": "e4d2ecac44c323b68ad0b2103a04224d1feb600c",
"content_id": "6d259c48157dcf52dbcbac8660bba8dd50d69719",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 668,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 20,
"path": "/site/boxdrivesite/boxdriveapp/models.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom boxdriveusersreg.models import Profile\nfrom django.urls import reverse\n\n\n# TODO: Here we need to discuss about fields\nclass Document(models.Model):\n objects = models.Manager()\n cur_user = models.ForeignKey(Profile, on_delete=models.CASCADE)\n title = models.CharField(max_length=128)\n file_field = models.FileField(upload_to='documents/')\n upload_time = models.DateTimeField(auto_now_add=True)\n\n def __str__(self):\n return self.title\n\n def get_absolute_url(self):\n return reverse('document-detail', kwargs={'pk': self.pk})"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 20.125,
"blob_id": "862615ec0720d30a2dc7b9cb5e8793020f26a00e",
"content_id": "cdb881f0ad7337418624f0f55d0f676faa74ab35",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 8,
"path": "/site/boxdrivesite/boxdriveusersreg/apps.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass BoxdriveusersregConfig(AppConfig):\n name = 'boxdriveusersreg'\n\n def ready(self):\n import boxdriveusersreg.signals"
},
{
"alpha_fraction": 0.5192307829856873,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 19.22222137451172,
"blob_id": "a35219065d8ac08cf824a496fbc0e079ae7f7cf3",
"content_id": "8d3d293d95f9c25f7ac6735fcdfed3fd351b83f0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 18,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0002_alter_post_fileurl.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-12 13:36\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveapp', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='post',\n name='fileUrl',\n field=models.URLField(),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6646706461906433,
"alphanum_fraction": 0.6646706461906433,
"avg_line_length": 9.5,
"blob_id": "7a53c382427c0df4f348f30085eb1bf2147ccda6",
"content_id": "3201f995a8cf0b5991d44353ffe876dbd9b58d3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 167,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 16,
"path": "/site/boxdrivesite/README.md",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "#This is main Django folder\n```\npip install django\n```\n\n```\npip install django-crispy-forms\n```\n\n```\npip install Pillow\n```\n\n```\npip install django-encrypted-files\n```"
},
{
"alpha_fraction": 0.7731958627700806,
"alphanum_fraction": 0.7731958627700806,
"avg_line_length": 18.399999618530273,
"blob_id": "c36d4cad9ba278dca6914c46ae89b0ae0f410990",
"content_id": "b62cc383a284ee12ad44b452838d553aa00c94d3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 5,
"path": "/site/boxdrivesite/boxdriveapp/apps.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass BoxdriveappConfig(AppConfig):\n name = 'boxdriveapp'\n"
},
{
"alpha_fraction": 0.5130168199539185,
"alphanum_fraction": 0.5467075109481812,
"avg_line_length": 23.185184478759766,
"blob_id": "6fd74d0a4d2a64ade8230df141cab2e3a1eed6db",
"content_id": "98e0fe19d259ca1b0c1dd0c647e408952d26232a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 653,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 27,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0004_auto_20210613_1656.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-13 16:56\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveapp', '0003_document'),\n ]\n\n operations = [\n migrations.RemoveField(\n model_name='document',\n name='desc',\n ),\n migrations.AlterField(\n model_name='document',\n name='file_field',\n field=models.FileField(upload_to='documents/'),\n ),\n migrations.AlterField(\n model_name='document',\n name='title',\n field=models.CharField(max_length=128),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5905511975288391,
"alphanum_fraction": 0.6279527544975281,
"avg_line_length": 24.399999618530273,
"blob_id": "94dc36d38a3f91e413050b53ffdb5e0b8ecd3b2b",
"content_id": "ddd24d24131c5585d0f626275d2a5ae9186fb8f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 20,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0008_document_upload_time.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.6 on 2021-06-14 14:51\n\nfrom django.db import migrations, models\nimport django.utils.timezone\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveapp', '0007_alter_document_cur_user'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='document',\n name='upload_time',\n field=models.DateTimeField(auto_now_add=True, default=django.utils.timezone.now),\n preserve_default=False,\n ),\n ]\n"
},
{
"alpha_fraction": 0.5566149950027466,
"alphanum_fraction": 0.587604284286499,
"avg_line_length": 32.560001373291016,
"blob_id": "a78b47af60909532925d3b3ab5f9eef3f043c8fb",
"content_id": "9d25349a499c1d755ec53aba2a3dc9f82a80fe59",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 839,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 25,
"path": "/site/boxdrivesite/boxdriveapp/migrations/0003_document.py",
"repo_name": "abulyaev/BoxDrive",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-13 03:06\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('boxdriveusersreg', '0001_initial'),\n ('boxdriveapp', '0002_alter_post_fileurl'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Document',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=200)),\n ('file_field', models.FileField(upload_to='uploads/')),\n ('desc', models.TextField()),\n ('user', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='boxdriveusersreg.profile')),\n ],\n ),\n ]\n"
}
] | 15 |
IYuriy/Prometheus
|
https://github.com/IYuriy/Prometheus
|
caf4cae6f69e31f04b09dff21aadf7141400c156
|
17307700a1bf7813a3871148195369a7e274d1aa
|
24a6cb7699f6d2c8de7bc70afabdf87d67b00f1f
|
refs/heads/master
| 2021-01-09T06:32:54.346160 | 2017-02-05T16:42:59 | 2017-02-05T16:42:59 | 80,999,548 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5154015421867371,
"alphanum_fraction": 0.5187018513679504,
"avg_line_length": 29.299999237060547,
"blob_id": "10204ccb94dcf571fd132a78c6955704267a4ab0",
"content_id": "39470c273964e8822e289d4433c30ce92f27f2ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2478,
"license_type": "no_license",
"max_line_length": 516,
"num_lines": 60,
"path": "/Prometheus/lect6_2.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію encode_morze(text),\nяка приймає 1 аргумент -- рядок,\nта повертає рядок, який містить діаграму сигналу, що відповідає переданому тексту, закодованому міжнародним кодом Морзе для англійського алфавіту. Розділові та інші знаки, що не входять до латинського алфавіту, ігнорувати. Регістром літер нехтувати.\n\nДля передачі повідомлення за одиницю часу приймається тривалість однієї крапки. Тривалість тире дорівнює трьом крапкам. Пауза між елементами одного знака -- одна крапка, між знаками в слові -- 3 крапки, між словами -- 7 крапок. Словом вважати послідовність символів, обмежена пробілами. Результуюча \"діаграма\" демонструє наявність сигналу в кожний проміжок часу: на і-й позиції знаходиться \"^\", якщо в цей момент передається сигнал, і \"_\", якщо сигналу немає. Зайві паузи в кінці повідомлення на \"діаграмі\" відсутні.\n\"\"\"\ndef encode_morze(text):\n\tmorse_code = {\n \"A\" : \".-\", \n \"B\" : \"-...\", \n \"C\" : \"-.-.\", \n \"D\" : \"-..\", \n \"E\" : \".\", \n \"F\" : \"..-.\", \n \"G\" : \"--.\", \n \"H\" : \"....\", \n \"I\" : \"..\", \n \"J\" : \".---\", \n \"K\" : \"-.-\", \n \"L\" : \".-..\", \n \"M\" : \"--\", \n \"N\" : \"-.\", \n \"O\" : \"---\", \n \"P\" : \".--.\", \n \"Q\" : \"--.-\", \n \"R\" : \".-.\", \n \"S\" : \"...\", \n \"T\" : \"-\", \n \"U\" : \"..-\", \n \"V\" : \"...-\", \n \"W\" : \".--\", \n \"X\" : \"-..-\", \n \"Y\" : \"-.--\", \n \"Z\" : \"--..\",\n\t\" \" : \"_\"\n\t\t}\n\tmorse_simbol = {\n\t\t\".\" : \"^\",\n\t\t\"-\" : \"^^^\",\n\t\t\" \" : \"_\",\n\t\t\"_\" : \"_\",\n\t\t\"___\" : \"_____\"\n\t\t\t}\n\tp = ''\n\tencode = ''\n\tmorze_list = morse_code.keys()\n\tsimbol = morse_simbol.keys()\n\ttext_morze = text.upper()\n\tfor i in text_morze:\n\t\tif i in morze_list:\t\n\t\t\tp = p + \"_\" + morse_code[i]\n\tp = p[1: ]\n\tfor j in p:\n\t\tif j in simbol:\n\t\t\tencode = encode + \"_\" + morse_simbol[j]\n\tencode = encode[1: ]\n\treturn encode\n"
},
{
"alpha_fraction": 0.7192058563232422,
"alphanum_fraction": 0.724473237991333,
"avg_line_length": 37.17460250854492,
"blob_id": "b843e5b5bdce5aae492f110ecef7644d6b2f75f3",
"content_id": "6273f0736ce69aff344f29341c830acdf58b10e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3510,
"license_type": "no_license",
"max_line_length": 354,
"num_lines": 63,
"path": "/Prometheus/control_module1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nДешифрувати повідомлення, зашифроване шифром Бекона\r\n\r\nДля кодування повідомлень Френсіс Бекон запропонував кожну літеру тексту замінювати на групу з п'яти символів «А» або «B» (назвемо їх \"ab-групами\"). Для співставлення літер і кодуючих ab-груп в даному завданні використовується ключ-ланцюжок aaaaabbbbbabbbaabbababbaaababaab, в якому порядковий номер літери відповідає порядковому номеру початку ab-групи.\r\n\r\nНаприклад: літера \"а\" - перша літера алфавіту; для визначення її коду беремо 5 символів з ключа, починаючи з першого: aaaaa. Літера \"c\" - третя в алфавіті, отже для визначення її коду беремо 5 символів з ключа, починаючи з третього: aaabb.\r\n\r\nТаким чином, оригінальне повідомлення перетворюється на послідовність ab-груп і може далі бути накладене на будь-який текст відповідної довжини: А позначається нижнім регістром, В - верхнім.\r\n\r\nНаприклад, початкове повідомлення - Prometheus.\r\n\r\n1. Кодуємо його через ab-послідовності:\r\np = abbab\r\nr = babab\r\no = aabba\r\nm = bbaab\r\ne = abbbb\r\nt = babba\r\nh = bbbab\r\ne = abbbb\r\nu = abbaa\r\ns = ababb\r\nРезультат: abbab babab aabba bbaab abbbb babba bbbab abbbb abbaa ababb\r\n\r\n2. Підбираємо текст приблизно такої ж довжини, в якому сховаємо наше повідомлення: Welcome to the Hotel California Such a lovely place Such a lovely place\r\n\r\n3. Для зручності розбиваємо його на групи по 5 символів і відкидаємо зайву частину (щоб при декодуванні не отримувалися зайві п'ятірки). Співставимо ab-рядок і текст-сховище для порівняння:\r\nabbab babab aabba bbaab abbbb babba bbbab abbbb abbaa ababb\r\nWelco metot heHot elCal iforn iaSuc halov elypl aceSu chalo vely\r\n\r\n4. Змінюємо регістр символів, кодуючи A та B:\r\nabbab babab aabba bbaab abbbb babba bbbab abbbb abbaa ababb\r\nwELcO MeToT heHOt ELcaL iFORN IaSUc HALoV eLYPL aCEsu cHaLO vely\r\n\r\n5. Повертаємо початкові пробіли на місце:\r\nwELcOMe To The HOtEL caLiFORNIa SUcH A LoVeLY PLaCE sucH a LOvely\r\n\r\nДля дешифрування повідомлення необхідно виконати зворотні дії.\r\n\"\"\"\r\nimport sys\r\nimport re\r\n\r\na = sys.argv[1]\r\nkey = 'aaaaabbbbbabbbaabbababbaaababaab'\r\nalphabet = 'abcdefghijklmnopqrstuvwxyz'\r\nk = a.replace(\" \", \"\")\r\nstep = 5\r\nm = t = \"\"\r\n\r\nfor i in range(0, len(k), step):\r\n\tif (i + step) <= len(k):\r\n\t\tp = m + \" \" + k[i:i+step] \r\n\t\tm = p\r\nj = re.sub(r'[a-z]', 'a', p.lstrip())\r\np = re.sub(r'[A-Z]', 'b', j)\r\nn = p.replace(\" \", \"\")\r\n\r\nfor r in range(0, len(n), step):\r\n\td = t + \" \" + alphabet[key.index(n[r:r+step])]\r\n\tt = d\r\nprint d.replace(\" \", \"\")\r\n"
},
{
"alpha_fraction": 0.7017405033111572,
"alphanum_fraction": 0.7231012582778931,
"avg_line_length": 32.18421173095703,
"blob_id": "30c71d0d788670ec4d6c7d6b2f781b75fd85d0e5",
"content_id": "cf6d453383e69d4533035513054939360bcb8a8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1709,
"license_type": "no_license",
"max_line_length": 283,
"num_lines": 38,
"path": "/Prometheus/lect8_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити класс CombStr для представлення рядка символів.\n\nЗабезпечити наступні методи класу:\n\n конструктор, який приймає 1 аргумент -- рядок string.\n метод count_substrings(length), який приймає 1 аргумент -- невід'ємне ціле число length, та повертає ціле число -- кількість всіх різних підрядків довжиною length, що містяться в рядку string.\n\nТести із некоректними даними не проводяться.\n\nПослідовність символів substring вважається підрядком рядка string, якщо її можна отримати зі string шляхом відкидання символів з початку та/або з кінця рядка. Наприклад 'asd' є підрядком 'asdfg', а 'fgh' -- ні. Вважати, що порожніх підрядків не буває, тому для length=0 повертати 0.\n\"\"\"\nclass CombStr(object):\n\n\tdef __init__(self, string):\n\t\tself.string = string\n\n\tdef count_substrings(self, length):\n\t\tif type(length) is not int or length == 0:\n\t\t\treturn 0\n\n\t\tsubstr = set()\n\t\tstart, end = 0, length\n\n\t\twhile end <= len(self.string):\n\t\t\tsubstr.add(self.string[start : end])\n\t\t\tstart += 1\n\t\t\tend += 1\n\t\treturn len(substr)\n\ns0 = CombStr('qqqqqqweqqq%')\nprint s0.count_substrings(0) # 0\nprint s0.count_substrings(1) # 4\nprint s0.count_substrings(2) # 5\nprint s0.count_substrings(5) # 7\nprint s0.count_substrings(15) # 0\t\t\t\n"
},
{
"alpha_fraction": 0.7099447250366211,
"alphanum_fraction": 0.7209944725036621,
"avg_line_length": 41.588233947753906,
"blob_id": "21d71c328e433124701784ad531d491a0c99fdc5",
"content_id": "da3fd86f48260adb6cbcad409d7d4b28948b877f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1099,
"license_type": "no_license",
"max_line_length": 325,
"num_lines": 17,
"path": "/Prometheus/lect5_3.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію super_fibonacci(n, m),\nяка приймає 2 аргументи -- додатні цілі числа n та m (0 < n, m <= 35),\nта повертає число -- n-й елемент послідовності супер-Фібоначчі порядку m.\n\nНагадуємо, що послідовність Фібоначчі -- це послідовність чисел, в якій кожний елемент дорівнює сумі двох попередніх. Послідовністю супер-Фібоначчі порядку m будемо вважати таку послідовність чисел, в якій кожний елемент дорівнює сумі m попередніх. Перші m елементів (з порядковими номерами від 1 до m) вважатимемо одиницями.\n\"\"\"\ndef super_fibonacci(n, m):\n\tfib_num = []\n\tfor i in range(n):\n\t\tif i >= m:\n\t\t\tfib_num.append(sum(fib_num[-m:]))\n\t\telse:\n\t\t\tfib_num.append(1)\n\treturn fib_num[n - 1]\n"
},
{
"alpha_fraction": 0.6395891904830933,
"alphanum_fraction": 0.6601307392120361,
"avg_line_length": 25.09756088256836,
"blob_id": "2c75e17bf048b67df0ded6cc8c3e93e070ecdf30",
"content_id": "cdc38636246c8ab154ea3ee731f140f92b0bb1f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1335,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 41,
"path": "/Prometheus/lect7_4.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію create_calendar_page(month,year), яка приймає 2 аргументи -- цілі числа -- місяць (нумерація починається з 1) і рік,\nта повертає оператором return 1 рядок, який містить сторінку календаря на цей місяць.\n\nЯкщо місяць та рік не задані, використати сьогоднішні значення.\nЗайві пробіли в кінці під-рядків або всього рядка, як і зайві порожні рядки недопустимі.\n\n\"\"\"\n\n\nimport calendar\n\nclass LabCalendar(calendar.TextCalendar):\n\n\tdef formatday(self, day, weekday, width):\n\t\tif day == 0:\n\t\t\ts = ''\n\t\telse:\n\t\t\ts = '%02i' % day\n\t\treturn s.center(width)\n\n\tdef formatmonth(self, year, month, w=0, l=0):\n\t\tw = max(2, w)\n\t\tl = max(1, l)\n\t\ts = '-' * 20 +'\\n' * l\n\t\ts += self.formatweekheader(w).upper().rstrip()\n\t\ts += '\\n' * l\n\t\ts += '-' * 20\n\t\ts += '\\n' * l\n\t\tfor week in self.monthdays2calendar(year, month):\n\t\t\ts += self.formatweek(week, w).rstrip()\n\t\t\ts += '\\n' * l\n\t\treturn s\n\t\t\t\ndef create_calendar_page(month, year):\n\tcal = LabCalendar()\n\treturn cal.formatmonth(year, month)\n\nprint create_calendar_page(12, 1993)\n\n"
},
{
"alpha_fraction": 0.7348178029060364,
"alphanum_fraction": 0.73886638879776,
"avg_line_length": 39.16666793823242,
"blob_id": "d45b287a069ca87fc8636ec7f90bb3163cef9bd2",
"content_id": "b774f45196b0e577de079cb5e59a31f39c13b05d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 209,
"num_lines": 12,
"path": "/Prometheus/lect4_2.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nВхідні дані: довільна, відмінна від нуля, кількість значень - аргументів командного рядка. Значеннями-аргументами можуть бути числа або рядки, які складаються з цифр та літер латинського алфавіту без пробілів.\r\n\r\nРезультат роботи: рядок, що складається з отриманих значень в зворотньому порядку, записаних через пробіл. Пробіл в кінці рядка відсутній.\r\n\"\"\"\r\nimport sys\r\nraw = sys.argv[1: ]\r\nraw.reverse()\r\nraw = \" \".join(raw).rstrip()\r\nprint raw\r\n"
},
{
"alpha_fraction": 0.7315978407859802,
"alphanum_fraction": 0.7378814816474915,
"avg_line_length": 45.41666793823242,
"blob_id": "dfc1dae189c253b20999ae5be9780c587b3e2cb9",
"content_id": "876e6b17e653aef657b1a33f21f92a444da97561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1670,
"license_type": "no_license",
"max_line_length": 438,
"num_lines": 24,
"path": "/Prometheus/lect5_4.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію file_search(folder, filename),\nяка приймає 2 аргументи -- список folder та рядок filename,\nта повертає рядок -- повний шлях до файлу або папки filename в структурі folder.\n\nФайлова структура folder задається наступним чином:\n\nСписок -- це папка з файлами, його 0-й елемент містить назву папки, а всі інші можуть представляти або файли в цій папці (1 файл = 1 рядок-елемент списку), або вкладені папки, які так само представляються списками. Як і в файловій системі вашого комп'ютера, шлях до файлу складається з імен всіх папок, в яких він міститься, в порядку вкладеності (починаючи з зовнішньої і до папки, в якій безпосередньо знаходиться файл), розділених \"/\".\n\nВважати, що імена всіх файлів є унікальними. Повернути логічне значення False, якщо файл не знайдено.\n\"\"\"\ndef file_search(folder, filename):\n\tpath = False\t\n\tif filename in folder:\n\t\tpath = folder[0] + '/' + filename\n\telse:\n\t\tfor sub_folder in folder:\n\t\t\tif type(sub_folder) is list:\n\t\t\t\tsub = file_search(sub_folder, filename)\n\t\t\t\tif sub:\n\t\t\t\t\tpath = folder[0] + '/' + sub\n\treturn path\n"
},
{
"alpha_fraction": 0.6566882133483887,
"alphanum_fraction": 0.6982200741767883,
"avg_line_length": 48.439998626708984,
"blob_id": "83b38727858b31fa2ff5dffbf0f50c1d93b42744",
"content_id": "18c30deeacc9d04f4c194fedf31b67576858fbab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5309,
"license_type": "no_license",
"max_line_length": 777,
"num_lines": 75,
"path": "/Prometheus/lect7_2.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити класс Student для представлення відомостей про успішність слухача курсу Prometheus. Об'єкт класу має містити поля для збереження імені студента та балів, отриманих ним за виконання практичних завдань і фінального екзамена.\n\nЗабезпечити наступні методи класу:\n\n конструктор, який приймає рядок -- ім'я студента -- та словник, що містить налаштування курсу у наступному форматі:\n conf = {\n 'exam_max': 30, # кількість балів, доступна за здачу екзамена\n 'lab_max': 7, # кількість балів, доступна за виконання 1 практичної роботи\n 'lab_num': 10, # кількість практичних робіт в курсі\n 'k': 0.61, # частка балів від максимума, яку необхідно набрати для отримання сертифікату\n }.\n \n\tметод make_lab(m,n), який приймає 2 аргументи та повертає посилання на поточний об'єкт. Тут m -- кількість балів набрана за виконання завдання (ціле або дійсне число), а n -- ціле невід'ємне число, порядковий номер завдання (лаби нумеруються від 0 до lab_num-1). При повторній здачі завдання зараховується остання оцінка. Якщо n не задане, мається на увазі здача першого невиконаного практичного завдання. Врахувати, що під час тестування система іноді дає збої, тому за виконання завдання може бути нараховано більше балів ніж це можливо за правилами курсу, що не повинно впливати на рейтинг студента. Крім того в системі можуть міститися додаткові завдання, чиї номери виходять за межі 0..lab_num -- звичайно, бали за них не повинні зараховуватися для отримання сертифікату.\n \n\tметод make_exam(m), який приймає 1 аргумент -- ціле або дійсне число, оцінку за фінальний екзамен, та повертає посилання на поточний об'єкт. Як і у випадку з практичними завданнями, оцінка за екзамен в результаті помилки іноді може перевищувати максимально допустиму.\n \n\tметод is_certified(), який повертає тьюпл, що містить дійсне число (суму балів студента за проходження курсу), та логічне значення True або False в залежності від того, чи достатньо цих балів для отримання сертифікату.\n\nТак як курс є доступним онлайн і не має дедлайнів на здачу робіт, студент може виконувати роботи в довільному порядку. Вважати, що кількість спроб на виконання кожного з завдань необмежена.\n\n\"\"\"\n\nclass Student(object):\n\n\tdef __init__(self, name, conf):\n\t\tself.name = name\n\t\tself.conf = conf\n\t\tlab = [0 for lab in range(self.conf['lab_num'])]\n\t\tself.lab = lab\n\t\tself.exam = 0.0\n\n\tdef make_lab(self, m, n = None):\n\t\tif n == None:\n\t\t\tn = self.lab.index(0)\n\t\tif (n >= 0) and (n <= self.conf['lab_num']):\n\t\t\tif m <= self.conf['lab_max']:\n\t\t\t\tself.lab[n] = m\n\t\t\telse:\n\t\t\t\tself.lab[n] = self.conf['lab_max']\n\t\treturn self\n\n\tdef make_exam(self, m):\n\t\tif m <= self.conf['exam_max']:\n\t\t\tself.exam = m\n\t\telse:\n\t\t\tself.exam = self.conf['exam_max']\n\t\treturn self\n\n\tdef is_certified(self):\n\t\tmax_bals = self.conf['lab_max'] * self.conf['lab_num'] + self.conf['exam_max']\n\t\tmin_bals = max_bals * self.conf['k']\n\t\tsum_bals = sum(self.lab) + self.exam\n\t\treturn (sum_bals, sum_bals >= min_bals)\n\t\t\nconf = {\n'exam_max': 30,\n'lab_max': 7,\n'lab_num': 10,\n'k': 0.61,\n}\noleg = Student('Oleg', conf)\noleg.make_lab(1) # labs: 1 0 0 0 0 0 0 0 0 0, exam: 0\noleg.make_lab(8,0) # labs: 7 0 0 0 0 0 0 0 0 0, exam: 0\noleg.make_lab(1) # labs: 7 1 0 0 0 0 0 0 0 0, exam: 0\noleg.make_lab(10,7) # labs: 7 1 0 0 0 0 0 7 0 0, exam: 0\noleg.make_lab(4,1) # labs: 7 4 0 0 0 0 0 7 0 0, exam: 0\noleg.make_lab(5) # labs: 7 4 5 0 0 0 0 7 0 0, exam: 0\noleg.make_lab(6.5) # labs: 7 4 5 6.5 0 0 0 7 0 0, exam: 0\noleg.make_exam(32) # labs: 7 4 5 6.5 0 0 0 7 0 0, exam: 30\nprint oleg.is_certified() # (59.5, False)\noleg.make_lab(7,1) # labs: 7 7 5 6.5 0 0 0 7 0 0, exam: 30\nprint oleg.is_certified() # (62.5, True)\n"
},
{
"alpha_fraction": 0.6032329201698303,
"alphanum_fraction": 0.6443791389465332,
"avg_line_length": 31.975608825683594,
"blob_id": "7e7d64fb45fbf72d3df10ed42e55a7dccb028da4",
"content_id": "09af73fe171d784cc6ded17d6f7991d7683f3639",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1702,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 41,
"path": "/Prometheus/lect8_3.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію bouquets(narcissus_price, tulip_price, rose_price, summ),\nяка приймає 4 аргументи -- додатні дійсні числа (ціни за один нарцис, тюльпан та троянду, і суму грошей у кишені головного героя),\nта повертає ціле число -- кількість варіантів букетів, які можна скласти з цих видів квітів, таких щоб вартість кожного букету не перевищувала summ.\n\nНе забути, що букети з парною (загальною) кількістю квітів живим дівчатам не дарують. Тести із некоректними даними не проводяться.\n\"\"\"\ndef bouquets(narcissus_price, tulip_price, rose_price, summ):\n\n\tbouquet = [narcissus_price, tulip_price, rose_price]\n\tbouquet.sort(None, None, True)\n\ta, b, c = bouquet[0], bouquet[1], bouquet[2]\n\n\tcount = 0\n\n\tfor i in range(int(summ // a + 1)):\n\t\t if a * i <= summ:\n\t\t\tfor j in range(int((summ - a * i) // b + 1)):\n\t\t\t\tif a * i + b * j <= sum:\n\t\t\t\t\tfor k in range(int((summ - a * i - b * j) // c + 1)):\n\t\t\t\t\t\tif (i + j + k) % 2:\n\t\t\t\t\t\t\tcount += 1\n\treturn count\n\ndef test(got, expected):\n\tif got == expected:\n\t\tprefix = ' OK'\n\telse:\n\t\tprefix = ' X'\n\tprint '%s :prefix, got: %s, expected: %s' % (prefix, repr(got), repr(expected))\n\ndef main():\n\ttest(bouquets(1,1,1,5), 34)\n\ttest(bouquets(2,3,4,10), 12)\n\ttest(bouquets(2,3,4,100), 4019)\n\ttest(bouquets(200,300,400,100000), 3524556)\n\nif __name__ == '__main__':\n\tmain()\n\t\t\t\t\t\t\t\n\n"
},
{
"alpha_fraction": 0.27074283361434937,
"alphanum_fraction": 0.44693171977996826,
"avg_line_length": 23.941667556762695,
"blob_id": "7e4a63846128771e65a6306373db1b57e2945fa7",
"content_id": "d03283c15a69eeb5bc6abac622aecc2e56afde05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8979,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 360,
"path": "/Prometheus/exam.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "def print_maze(maze, x, y):\n\tfor i in range(len(maze)):\n\t\ts = ''\n\t\tfor j in range(len(maze)):\n\t\t\tif i == x and j == y:\n\t\t\t\ts += 'X'\n\t\t\telif maze[i][j] == 1:\n\t\t\t\ts += '#'\n\t\t\telse:\n\t\t\t\ts += '.'\n\t\tprint s\n\tprint ' '\n\nclass MazeRunner(object):\n \n\tdef __init__(self, maze, start, finish):\n\t\tself.__maze = maze\n\t\tself.__rotation = (1,0)\n\t\tself.__x = start[0]\n\t\tself.__y = start[1]\n\t\tself.__finish = finish\n\n\tdef go(self):\n\t\tx = self.__x + self.__rotation[0]\n\t\ty = self.__y + self.__rotation[1]\n\n\t\tif x > len(self.__maze)-1 \\\n\t\t\tor y > len(self.__maze)-1 \\\n\t\t\tor x < 0 or y < 0 \\\n\t\t\tor self.__maze[x][y] == 1:\n\t\t\treturn False\n\t\tself.__x = x\n\t\tself.__y = y\n\t\tprint_maze(self.__maze, self.__x, self.__y)\n\t\treturn True\n \n\tdef turn_right(self):\n\t\tleft_rotation = {\n\t\t\t(0,1) : (1,0),\n\t\t\t(1,0) : (0,-1),\n\t\t\t(0,-1) : (-1,0),\n\t\t\t(-1,0) : (0,1),\n\t\t}\n\t\tself.__rotation = left_rotation[self.__rotation]\n\t\treturn self\n \n\tdef turn_left(self):\n\t\tright_rotation = {\n\t\t\t(1,0) : (0,1),\n\t\t\t(0,-1) : (1,0),\n\t\t\t(-1,0) : (0,-1),\n\t\t\t(0,1) : (-1,0),\n\t\t}\n\t\tself.__rotation = right_rotation[self.__rotation]\n\t\treturn self\n \n\tdef found(self):\n\t\treturn self.__x == self.__finish[0] and self.__y == self.__finish[1]\n\n\ndef maze_controller(self):\n\timport random\n\tcounter = 0\n\twhile not self.found() and counter < 100000:\n\t\tself.go()\n\t\tcounter += 1\n\t\tx = random.choice([0, 1])\n\t\tif x == 0:\n\t\t\tself.turn_right()\n\t\telse:\n\t\t\tself.turn_left()\n\n\nmaze_example1 = {\n 'm': [\n [0,1,0,0,0],\n [0,1,1,1,1],\n [0,0,0,0,0],\n [1,1,1,1,0],\n [0,0,0,1,0],\n ],\n 's': (0,0),\n 'f': (4,4)\n}\nmaze_runner = MazeRunner(maze_example1['m'], maze_example1['s'], maze_example1['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 1'\n\nmaze_example2 = {\n 'm': [\n [0,0,0,0,0,0,0,1],\n [0,1,1,1,1,1,1,1],\n [0,0,0,0,0,0,0,0],\n [1,1,1,1,0,1,0,1],\n [0,0,0,0,0,1,0,1],\n [0,1,0,1,1,1,1,1],\n [1,1,0,0,0,0,0,0],\n [0,0,0,1,1,1,1,0],\n ],\n 's': (7,7),\n 'f': (0,0)\n}\nmaze_runner = MazeRunner(maze_example2['m'], maze_example2['s'], maze_example2['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 2'\n\nmaze_example3 = {\n 'm': [\n [0,0,0,0,0,0,0,0,0,0,0],\n [1,0,1,1,1,0,1,1,1,0,1],\n [1,0,1,0,0,0,0,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,1,1,0,1,0,1],\n [1,0,1,0,0,0,0,0,1,0,1],\n ],\n 's': (0,5),\n 'f': (10,5)\n}\nmaze_runner = MazeRunner(maze_example3['m'], maze_example3['s'], maze_example3['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 3'\n\nmaze_example4 = {\n 'm': [\n [0,0,0,0,1,0,1,0,0,0,0],\n [0,1,1,1,1,0,1,1,1,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,1,0,1,1,1,1,1,0,1,0],\n [1,1,0,1,0,0,0,1,0,1,1],\n [0,1,0,1,0,1,0,1,0,1,0],\n [0,1,0,0,0,1,0,0,0,1,0],\n [0,1,0,1,1,1,1,1,0,1,0],\n [0,1,0,0,0,0,0,0,0,1,0],\n [0,1,1,1,1,0,1,1,1,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n ],\n 's': (0,5),\n 'f': (4,5)\n}\nmaze_runner = MazeRunner(maze_example4['m'], maze_example4['s'], maze_example4['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 4'\n\nmaze_example6 = {\n 'm': [\n [1,0,1,0,1],\n [1,1,1,1,1],\n [0,0,0,0,0],\n [1,1,1,1,1],\n [1,0,1,0,1],\n ],\n 's': (2,0),\n 'f': (2,4)\n}\nmaze_runner = MazeRunner(maze_example6['m'], maze_example6['s'], maze_example6['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 6'\n\nmaze_example7 = {\n 'm': [\n [0,0,0,0,0,0,0,0],\n [0,1,1,1,1,1,1,0],\n [0,1,1,0,0,0,1,0],\n [0,1,0,0,1,0,1,0],\n [0,1,1,1,1,0,1,0],\n [0,0,0,0,0,0,1,0],\n [1,1,1,1,1,1,1,0],\n [0,0,0,0,0,0,0,0],\n ],\n 's': (3, 2),\n 'f': (7, 0)\n}\nmaze_runner = MazeRunner(maze_example7['m'], maze_example7['s'], maze_example7['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 7'\n\nmaze_example8 = {\n 'm': [\n [1,0,1,0,1],\n [1,0,1,0,1],\n [1,0,1,0,1],\n [1,0,0,0,1],\n [1,1,1,1,1],\n ],\n 's': (0,1),\n 'f': (0,3)\n}\nmaze_runner = MazeRunner(maze_example8['m'], maze_example8['s'], maze_example8['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 8'\n\nmaze_example10 = {\n 'm': [\n [1,0,0,0,1,0,0,1],\n [1,0,1,0,1,1,0,1],\n [1,0,1,0,0,0,0,1],\n [1,1,1,1,1,0,1,1],\n [1,0,0,0,0,0,0,1],\n [1,1,1,0,1,1,1,1],\n [1,0,0,0,0,0,0,0],\n [1,0,1,0,1,0,1,0],\n ],\n 's': (0, 3),\n 'f': (7, 5)\n}\nmaze_runner = MazeRunner(maze_example10['m'], maze_example10['s'], maze_example10['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 10'\n\nmaze_example5 = {\n 'm': [\n [0,0,0,1,1,0,1,1,0,0,0],\n [0,1,0,0,0,0,0,0,0,1,0],\n [0,1,0,1,1,1,1,1,0,1,0],\n [0,0,0,1,0,0,0,1,0,0,0],\n [0,0,1,1,0,0,0,1,1,0,0],\n [0,0,1,0,0,0,0,0,1,0,0],\n [0,0,1,0,1,0,1,0,1,0,0],\n [0,0,1,0,0,0,0,0,1,0,0],\n [0,0,1,1,1,0,1,1,1,0,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,0,1,0,1,0,1,0,1,0,0],\n ],\n 's': (0,5),\n 'f': (4,5)\n}\nmaze_runner = MazeRunner(maze_example5['m'], maze_example5['s'], maze_example5['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 5'\n\nmaze_example9 = {\n 'm': [\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,1,1,0,1,1,1,1,1,1,0],\n [0,1,0,0,1,0,1,0,1,0,0],\n [0,1,0,1,1,0,1,0,1,1,1],\n [0,1,0,0,1,0,1,0,0,0,0],\n [0,1,1,0,1,0,1,0,1,1,0],\n [0,1,0,0,1,0,1,0,1,0,0],\n [0,1,0,1,1,0,1,0,1,0,1],\n [0,1,0,0,1,0,1,0,1,0,0],\n [0,1,1,1,1,0,1,1,1,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n ],\n 's': (0, 5),\n 'f': (2, 5)\n}\nmaze_runner = MazeRunner(maze_example9['m'], maze_example9['s'], maze_example9['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 9'\n\nmaze_example11 = {\n 'm': [\n [0,0,0,1,0,0,0,0,0,0,0],\n [0,1,0,1,0,1,1,1,1,1,0],\n [0,1,0,1,0,1,0,0,0,1,0],\n [0,1,0,0,0,1,0,1,1,1,0],\n [0,1,1,1,1,1,0,1,0,0,0],\n [0,1,0,0,1,1,0,1,1,1,0],\n [0,1,0,0,0,0,0,0,0,1,0],\n [0,1,1,1,1,1,1,1,0,1,0],\n [0,0,0,1,0,0,0,1,0,1,0],\n [0,0,0,1,0,1,0,1,0,1,0],\n [0,0,0,0,0,1,0,0,0,0,0],\n ],\n 's': (4, 8),\n 'f': (9, 1)\n}\nmaze_runner = MazeRunner(maze_example11['m'], maze_example11['s'], maze_example11['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 11'\n\nmaze_example12 = {\n 'm': [\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,1,1,1,1,1,1,1,1,1,0],\n [0,1,0,0,0,0,0,0,0,1,0],\n [0,1,0,1,1,1,1,1,0,1,0],\n [0,1,0,1,0,0,0,1,0,1,0],\n [0,1,0,1,0,1,0,1,0,1,0],\n [0,1,0,1,0,1,0,1,0,1,0],\n [0,1,0,1,1,1,0,1,0,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,1,1,1,1,1,1,1,1,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n ],\n 's': (6, 4),\n 'f': (10, 5)\n}\nmaze_runner = MazeRunner(maze_example12['m'], maze_example12['s'], maze_example12['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 12'\n\nmaze_example13 = {\n 'm': [\n [0,1,0,0,0,0,0,0,0,0,0],\n [0,1,0,1,1,1,1,1,1,1,1],\n [0,1,0,0,0,0,0,0,0,0,0],\n [0,1,0,1,1,1,1,1,0,1,0],\n [0,1,0,0,0,0,0,1,0,1,0],\n [0,1,1,1,1,1,0,1,0,1,0],\n [0,0,0,0,0,0,0,1,0,1,0],\n [0,1,0,1,1,1,0,1,0,1,0],\n [0,1,0,0,0,0,0,1,0,1,0],\n [0,1,1,1,1,1,1,1,0,1,0],\n [0,0,0,0,0,0,0,0,0,1,0],\n ],\n 's': (10, 5),\n 'f': (6, 4)\n}\nmaze_runner = MazeRunner(maze_example13['m'], maze_example13['s'], maze_example13['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 13'\n\nmaze_example14 = {\n 'm': [\n [1,0,1,1,1,0,1,1,1,0,1],\n [0,0,0,0,0,0,0,0,0,0,0],\n [1,0,1,1,1,0,1,1,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,0,0,1,1,1,0,0,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,0,1,0,1,0,1,0,1],\n [1,0,1,1,1,0,1,1,1,0,1],\n [0,0,0,0,0,0,0,0,0,0,0],\n [1,0,1,1,1,0,1,1,1,0,1],\n ],\n 's': (10, 1),\n 'f': (7, 7)\n}\nmaze_runner = MazeRunner(maze_example14['m'], maze_example14['s'], maze_example14['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 14'\n\nmaze_example15 = {\n 'm': [\n [0,0,0,0,0,1,0,0,0,0,0],\n [0,0,0,1,0,1,0,1,0,0,0],\n [0,0,0,0,0,1,0,0,0,0,0],\n [0,1,0,0,0,1,0,0,0,1,0],\n [0,0,0,0,0,0,0,0,0,0,0],\n [1,1,1,1,0,1,0,1,1,1,1],\n [0,0,0,0,0,0,0,0,0,0,0],\n [0,1,0,0,0,1,0,0,0,1,0],\n [0,0,0,0,0,1,0,0,0,0,0],\n [0,0,0,1,0,1,0,1,0,0,0],\n [0,0,0,0,0,1,0,0,0,0,0],\n ],\n 's': (1, 1),\n 'f': (9, 9)\n}\nmaze_runner = MazeRunner(maze_example15['m'], maze_example15['s'], maze_example15['f'])\nmaze_controller(maze_runner)\nprint maze_runner.found(), 'Var 15'\n"
},
{
"alpha_fraction": 0.7044117450714111,
"alphanum_fraction": 0.7117646932601929,
"avg_line_length": 43.33333206176758,
"blob_id": "937ba15403f2cb5feef36025c98044f7c0951843",
"content_id": "19571848898269032ff8c356e399b54452b76b31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1056,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 15,
"path": "/Prometheus/lect4_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nВхідні дані: рядок, передається в програму як аргумент командного рядка. Може містити пробіли, літери латинського алфавіту в будь-якому регістрі та цифри. Для передачі одним значенням рядок, що містить пробіли, береться в подвійні лапки.\r\n\r\nРезультат роботи: рядок \"YES\", якщо отриманий рядок є паліндромом, або \"NO\" - якщо ні. Рядок вважається паліндромом, якщо він однаково читається як зліва направо, так і справа наліво. Відмінністю регістрів та пробілами знехтувати.\r\n\"\"\"\r\nimport sys\r\nimport re\r\nraw = sys.argv[1]\r\nraw = re.sub('[^a-z0-9\\-\\_]','',raw.strip(' ').lower())\r\nif raw == raw[::-1]:\r\n\tprint \"YES\"\r\nelse:\r\n\tprint \"NO\"\r\n"
},
{
"alpha_fraction": 0.6472019553184509,
"alphanum_fraction": 0.7177615761756897,
"avg_line_length": 37.53125,
"blob_id": "3e38e49e3b223582b6d7c7e8d56b07e085824bf5",
"content_id": "01f518397ddd231168c77f830bd00fefbad20adb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 265,
"num_lines": 32,
"path": "/Prometheus/lect7_3.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити класс SuperStr, який наслідує функціональність стандартного типу str і містить 2 нових методи:\n\n метод is_repeatance(s), який приймає 1 аргумент s та повертає True або False в залежності від того, чи може бути поточний рядок бути отриманий цілою кількістю повторів рядка s. Повернути False, якщо s не є рядком. Вважати, що порожній рядок не містить повторів.\n \n\tметод is_palindrom(), який повертає True або False в залежності від того, чи є рядок паліндромом. Регістрами символів нехтувати. Порожній рядок вважати паліндромом.\n\n\"\"\"\nclass SuperStr(str):\n\n\tdef is_repeatance(self, s):\n\t\tif type(s) is not str or s == '' or self == '':\n\t\t\treturn False\n\t\treturn self.replace(s, '') == ''\n\t\n\tdef is_palindrom(self):\n\t\treturn self.lower() == self.lower()[::-1]\t\t\n\t\ns = SuperStr('123123123123')\nprint s.is_repeatance('123') # True\nprint s.is_repeatance('123123') # True\nprint s.is_repeatance('123123123123') # True\nprint s.is_repeatance('12312') # False\nprint s.is_repeatance(123) # False\nprint s.is_palindrom() # False\nprint s # 123123123123 (рядок)\nprint int(s) # 123123123123 (ціле число)\nprint s + 'qwe' # 123123123123qwe\np = SuperStr('123_321')\nprint p.is_palindrom() # True\n"
},
{
"alpha_fraction": 0.6943899393081665,
"alphanum_fraction": 0.7194978594779968,
"avg_line_length": 43.71929931640625,
"blob_id": "a68204a598efc3937d39a245c4b59ab3469811e5",
"content_id": "1b2100ef30772d9130bd9137c2a49ea888df7bb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3550,
"license_type": "no_license",
"max_line_length": 261,
"num_lines": 57,
"path": "/Prometheus/lect7_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити класс Sphere для представлення сфери у тривимірному просторі.\n\nЗабезпечити наступні методи класу:\n\n- конструктор, який приймає 4 дійсних числа: радіус, та 3 координати центру кулі. Якщо конструктор викликається без аргументів, створити об'єкт сфери \n із одиничним радіусом та центром у початку координат. Якщо конструктор викликається з 1 аргументом, створити об'єкт сфери з відповідним радіусом та центром у початку координат.\n\n- метод get_volume(), який повертає дійсне число -- об'єм кулі, обмеженої поточною сферою.\n- метод get_square(), який повертає дійсне число -- площу зовнішньої поверхні сфери.\n- метод get_radius(), який повертає дійсне число -- радіус сфери.\n- метод get_center(), який повертає тьюпл із 3 дійсними числами -- координатами центра сфери в тому ж порядку, в яком вони задаються в конструкторі.\n- метод set_radius(r), який приймає 1 аргумент -- дійсне число, та змінює радіус поточної сфери, нічого не повертаючи.\n- метод set_center(x,y,z), який приймає 3 аргументи -- дійсних числа, та змінює координати центра сфери, нічого не повертаючи. Координати задаються в тому ж порядку, що і в конструкторі.\n- метод is_point_inside(x,y,z), який приймає 3 аргументи -- дійсних числа -- координати деякої точки в просторі (в тому ж порядку, що і в конструкторі), та повертає логічне значення True або False в залежності від того, чи знаходиться ця точка всередині сфери.\n\n\"\"\"\n\nimport math\n\nclass Sphere(object):\n\n\tdef __init__(self, radius = 1, x_local = 0.0, y_local = 0.0, z_local = 0.0):\n\t\tself.set_radius(radius)\n\t\tself.set_center(x_local, y_local, z_local)\n\n\tdef get_volume(self):\n\t\treturn 4 * math.pi * math.pow(self.radius, 3)/3\n\t\n\tdef get_square(self):\n\t\treturn 4 * math.pi * math.pow(self.radius, 2)\n\t\n\tdef get_radius(self):\n\t\treturn self.radius \n\t\n\tdef get_center(self):\n\t\treturn (self.x_local, self.y_local, self.z_local)\n\n\tdef set_radius(self, radius):\n\t\tself.radius = radius\n\t\n\tdef set_center(self, x_local, y_local, z_local):\n\t\tself.x_local = x_local\n\t\tself.y_local = y_local\n\t\tself.z_local = z_local\n\tdef is_point_inside(self, a, b, c):\n\t\treturn math.pow(self.radius, 2) >= math.pow((self.x_local - a), 2) + math.pow((self.y_local - b), 2) + math.pow((self.z_local - c), 2)\n\ns0 = Sphere(0.5) # test sphere creation with radius and default center\nprint s0.get_center() # (0.0, 0.0, 0.0)\nprint s0.get_volume() # 0.523598775598\nprint s0.is_point_inside(0, -1.5, 0) # False\ns0.set_radius(1.6)\nprint s0.is_point_inside(0, -1.5, 0) # True\nprint s0.get_radius() # 1.6\n"
},
{
"alpha_fraction": 0.6417636275291443,
"alphanum_fraction": 0.6785058379173279,
"avg_line_length": 35.28888702392578,
"blob_id": "6b78dec263c9a30bf7f8eb1e524b734fd5b712aa",
"content_id": "bbb2a10fc934ca222e52765614f5fc53f8a3fadb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2278,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 45,
"path": "/Prometheus/lect6_3.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nРозробити функцію saddle_point(matrix),\nяка приймає 1 аргумент -- прямокутну матрицю цілих чисел, задану у вигляді списка списків,\nта повертає тьюпл із координатами \"сідлової точки\" переданої матриці або логічну константу False, якщо такої точки не існує.\n\nСідловою точкою вважається такий елемент матриці, який є мінімальним (строго менше за інші) у своєму рядку та максимальним (строго більше за інші) у своєму стовпці, наприклад:\nматриця:\n1 2 3\n0 2 1\n\"1\" в лівому верхньому кутку (за координатами (0;0)) є сідловою точкою матриці.\n\nВважати, що передані дані є коректними, тобто матриця не містить інших значень крім цілих чисел, а всі вкладені списки мають однакову довжину. Результуючий тьюпл містить два числа -- порядкові номери сідлової точки в рядку (індекс його списка у зовнішньому списку) та в стовпці (індекс у внутрішньому списку).\n\"\"\"\n\ndef saddle_point(matrix):\t\n\tif len(matrix) == 1:\n\t\treturn (0, 0)\n\tfor i in range(len(matrix)):\n\t\tflag = True\n\t\tmin_raw = min(matrix[i])\n\t\tif matrix[i].count(min_raw) == 1:\n\t\t\tk = matrix[i].index(min_raw)\n\t\t\tfor j in range(len(matrix)):\n\t\t\t\tif min_raw <= matrix[j][k] and j != i:\n\t\t\t\t\tflag = False\n\t\t\tif flag:\n\t\t\t\treturn (i, k)\n\treturn False\ndef test(got, expected):\n\tif got == expected:\n\t\tprefix = ' OK '\n\telse:\n\t\tprefix = ' X '\n\tprint '%s got: %s expected: %s' % (prefix, repr(got), repr(expected))\n\ndef main():\n\ttest(saddle_point([[1,2,3],[3,2,1]]), False)\n\ttest(saddle_point([[8,3,0,1,2,3,4,8,1,2,3],[3,2,1,2,3,9,4,7,9,2,3],[7,6,0,1,3,5,2,3,4,1,1]]), (1, 2))\n\ttest(saddle_point([[21]]), (0, 0))\n\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.5784810185432434,
"alphanum_fraction": 0.6253164410591125,
"avg_line_length": 33.34782791137695,
"blob_id": "70acd7f5c6a82b06688f7b46fa897d88337164ec",
"content_id": "34cc749d219bd65915e118472dc6af3ad6dd30d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1044,
"license_type": "no_license",
"max_line_length": 243,
"num_lines": 23,
"path": "/Prometheus/lect6_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію count_holes(n),\nяка приймає 1 аргумент -- ціле число або рядок, який містить ціле число,\nта повертає ціле число -- кількість \"отворів\" у десятковому записі цього числа друкованими цифрами (вважати, що у \"4\" та у \"0\" по одному отвору), або рядок ERROR, якщо переданий аргумент не задовольняє вимогам: є дійсним або взагалі не числом.\n\"\"\"\ndef count_holes(n):\n\tdict_num = {'-': 0, '0': 1, '1': 0, '2': 0, '3': 0, '4': 1, '5': 0, '6': 1, '7': 0, '8': 2, '9': 1}\n\tstr_num = '-0123456789'\n\tcounter = 0\n\tif len(str(n)) != 0:\n\t\tfor k in str(n):\n\t\t\tif k not in str_num:\n\t\t\t\treturn 'ERROR'\t\n\t\ta = str(int(n))\n\t\tfor i in a:\n\t\t\tcounter = counter + dict_num[i]\n\telse: \n\t\treturn 'ERROR'\n\tif type(n) == float:\n\t\treturn 'ERROR'\n\treturn counter\n"
},
{
"alpha_fraction": 0.5247108340263367,
"alphanum_fraction": 0.6424816250801086,
"avg_line_length": 58.4375,
"blob_id": "a350649f7eb9cdfe7e9327f80d81f33a6ccd3203",
"content_id": "28c1c46e3f040d97b5091c72eb661a8a967a7afa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1275,
"license_type": "no_license",
"max_line_length": 271,
"num_lines": 16,
"path": "/Prometheus/lect8_4.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію make_sudoku(size),\nяка приймає 1 аргумент -- додатнє ціле число (1 <= size <= 42),\nта повертає список списків -- квадратну матрицю, що представляє судоку розмірності size.\n\nСудоку розмірності X являє собою квадратну матрицю розмірністю X**2 на X**2, розбиту на X**2 квадратів розмірністю X на X, заповнену цілими числами таким чином, щоб кожна вертикаль, кожна горизонталь та кожний квадрат містили всі числа від 1 до X**2 включно без повторів.\n\"\"\"\n\ndef make_sudoku(size):\n\treturn [[((i * size + i / size + j) % (size * size) + 1) for j in range(size * size)] for i in range(size * size)]\n\nprint make_sudoku(1) # [[1]]\nprint make_sudoku(2) # [[1,2,3,4],[3,4,1,2],[2,1,4,3],[4,3,2,1]]\nprint make_sudoku(3) # [[3,5,8,1,2,7,6,4,9],[6,7,4,5,8,9,3,2,1],[2,1,9,3,4,6,5,7,8],[9,8,6,7,1,4,2,5,3],[4,3,1,2,6,5,8,9,7],[7,2,5,9,3,8,1,6,4],[1,6,3,4,7,2,9,8,5],[8,9,7,6,5,1,4,3,2],[5,4,2,8,9,3,7,1,6]]\n"
},
{
"alpha_fraction": 0.49514561891555786,
"alphanum_fraction": 0.541262149810791,
"avg_line_length": 25.46666717529297,
"blob_id": "82935f663424682a8f9c11498e7e6fda5e8b6cf1",
"content_id": "c27b25f37546853efde197552e9a491d099b69e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 15,
"path": "/Prometheus/lect2_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nВхідні дані: 3 дійсних числа -- аргументи командного рядка.\r\n\r\nВихідні дані: результат обчислення формули\r\nf = (1/(c * (2 * math.pi)**0.5)) * math.exp(-((a - b)**2)/(2 * (c**2)))\r\n\"\"\"\r\nimport math\r\nimport sys \r\na = float(sys.argv[1])\r\nb = float(sys.argv[2])\r\nc = float(sys.argv[3])\r\nf = (1/(c * (2 * math.pi)**0.5)) * math.exp(-((a - b)**2)/(2 * (c**2)))\r\nprint f\r\n"
},
{
"alpha_fraction": 0.6434599161148071,
"alphanum_fraction": 0.6540084481239319,
"avg_line_length": 27.625,
"blob_id": "9bf858b809fea9849cda605051227ac6802b1e27",
"content_id": "e6297373491bf9eacd3c46c74836058cab8c8567",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 638,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 16,
"path": "/Prometheus/lect3_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nВхідні дані: 3 дійсних числа a, b, c. Передаються в програму як аргументи командного рядка.\r\n\r\nРезультат роботи: рядок \"triangle\", якщо можуть існувати відрізки з такою довжиною та з них можна скласти трикутник, або \"not triangle\" -- якщо ні.\r\n\"\"\"\r\nimport sys\r\na = float(sys.argv[1])\r\nb = float(sys.argv[2])\r\nc = float(sys.argv[3])\r\n\r\nif a + b > c and a + c > b and c + b > a:\r\n\tprint \"triangle\"\r\nelse:\r\n\tprint \"not triangle\"\r\n"
},
{
"alpha_fraction": 0.5568660497665405,
"alphanum_fraction": 0.6276326775550842,
"avg_line_length": 26.95121955871582,
"blob_id": "5d692ce4f7fdad827549e9813ad23da02a78df4b",
"content_id": "3c974302ca347e62071c176d576058853e4387e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1615,
"license_type": "no_license",
"max_line_length": 291,
"num_lines": 41,
"path": "/Prometheus/lect4_4.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nЗавдання передбачає пошук \"щасливих\" квитків. \"Щасливим\" називається такий тролейбусний квиток, в якому сума перших трьох цифр дорівнює сумі останніх трьох. Наприклад 030111 (0+3+0 = 1+1+1), 902326 (9+0+2 = 3+2+6), 001100 (0+0+1 = 1+0+0).\r\n\r\nВхідні дані: два цілих невід'ємних числа (0<=a1<=a2<=999999) - аргументи командного рядка.\r\n\r\nРезультат роботи: кількість \"щасливих квитків\", чиї номери лежать на проміжку від a1 до a2 включно. Якщо число на проміжку має менше 6 розрядів, вважати, що на його початку дописуються нулі у необхідній кількості, як це і відбувається при нумерації квитків. Виводити номери квитків не треба.\r\n\"\"\"\r\nimport sys\r\na1 = int(sys.argv[1])\r\na2 = int(sys.argv[2])\r\n\r\nif a1 < 0:\r\n\tprint a1, \":must be not less 0!\"\r\nif a2 < 0:\r\n\tprint a2, \":must be not less 0!\"\r\n\r\nk = \"%06d\" % a1\r\nl = \"%06d\" % a2\r\nsumm = 0\r\nsu = 0\r\nj = 0\r\n\r\nwhile a1 <= a2:\r\n\tk = \"%06d\" % a1\r\n\t#print k\r\n\tfor i in range(len(k)/2):\r\n\t\tsumm = int(k[i]) + summ\r\n\t#print k, sum\r\n\tfor m in range(len(k)/2):\r\n\t\tm = m + 1\r\n\t\tsu = int(k[-m]) + su\r\n\t#print k, sum, su\r\n\tif summ == su:\r\n\t\tj = j + 1\r\n\t\t#print k,\r\n\tsumm = 0\r\n\tsu = 0\r\n\ta1 = a1 + 1\r\nprint j\r\n"
},
{
"alpha_fraction": 0.6061801314353943,
"alphanum_fraction": 0.6640368103981018,
"avg_line_length": 28.25,
"blob_id": "fb6a11f3c747fd6093f353874d1162ad121a5401",
"content_id": "832f27dd39f1efd4f398760b1db4909cd19af7e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2003,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 52,
"path": "/Prometheus/control_module2.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію convert_n_to_m(x, n, m),\nяка приймає 3 аргументи -- ціле число (в системі числення з основою n) або рядок x, що представляє таке число, та цілі числа n та m (1 <= n, m <= 36),\nта повертає рядок -- представлення числа х у системі числення m.\n\nУ випадку, якщо аргумент х не є числом або рядком, або не може бути представленням цілого невід'ємного числа в системі числення з основою n, повернути логічну константу False.\n\nВ системах числення з основою більше десяти для позначення розрядів із значенням більше 9 використовувати літери латинського алфавіту у верхньому регістрі від A до Z. У вхідному x можуть використовуватися обидва регістри.\n\n\"\"\"\ndef convert_n_to_m(x, n, m):\n\tdigits = '0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'\n\tnumber = ''\n\n\tif (type(x) in [int, long]) and (x >= 0):\n\t\tx = str(x)\n\n\ttry:\n\t\tx = int(x, n)\n\texcept:\n\t\treturn False\n\n\tif x == 0:\n\t\treturn 0\n\tif m == 1:\n\t\treturn '0' * x\n\n\twhile x:\n\t\tnumber = digits[x % m] + number\n\t\tx = x / m\n\n\treturn number\n\ndef test(got, expected):\n\tif got == expected:\n\t\tprefix = ' OK '\n\telse:\n\t\tprefix = ' X '\n\tprint '%s got: %s expected: %s' % (prefix, repr(got), repr(expected))\n\ndef main():\n\ttest(convert_n_to_m([123], 4, 3), False)\n\ttest(convert_n_to_m(\"0123\", 5, 6), '102')\n\ttest(convert_n_to_m(\"123\", 3, 5), False)\n\ttest(convert_n_to_m(123, 4, 1), '000000000000000000000000000')\n\ttest(convert_n_to_m(-123.0, 11, 16), False)\n\ttest(convert_n_to_m(\"A1Z\", 36, 16), '32E7')\n\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.6744930744171143,
"alphanum_fraction": 0.6819637417793274,
"avg_line_length": 29.233333587646484,
"blob_id": "501fa6aa3810c7e91ca3ada86ec227f85406811b",
"content_id": "98ee72161e7f9de4ce3360742ebc4e97bfb6a5b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1454,
"license_type": "no_license",
"max_line_length": 318,
"num_lines": 30,
"path": "/Prometheus/lect4_3.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\r\n#-*- coding: utf-8 -*-\r\n\"\"\"\r\nВхідні дані: рядок, що складається з відкриваючих та закриваючих круглих дужок - аргумент командного рядка. Для передачі в якості рядка послідовність береться в подвійні лапки.\r\n\r\nРезультат роботи: рядок \"YES\", якщо вхідний рядок містить правильну дужкову послідовність; або рядок \"NO\", якщо послідовність є неправильною. Дужкова послідовність вважається правильною, якщо всі дужки можна розбити попарно \"відкриваюча\"-\"закриваюча\", при чому в кожній парі закриваюча дужка слідує після відкриваючої.\r\n\r\nПояснення для математиків:\r\n\"\" (порожній рядок) - правильна дужкова послідовність (ПДП)\r\n\"(ПДП)\" - також ПДП\r\n\"ПДППДП\" (дві ПДП записані поряд) - також ПДП\r\n\"\"\"\r\nimport sys\r\nimport re\r\nrow = sys.argv[1]\r\nk = 0\r\nn = 0\r\nif row[0] == ')':\r\n\tprint \"NO\"\r\nelse:\r\n\tfor i in row:\r\n\t\tif i == ')':\r\n\t\t\tk = k +1\r\n\t\t\r\n\t\telif i == '(':\r\n\t\t\tn = n + 1\r\n\tif k == n:\r\n\t\tprint \"YES\"\r\n\telse:\r\n\t\tprint \"NO\"\r\n"
},
{
"alpha_fraction": 0.7153392434120178,
"alphanum_fraction": 0.7182890772819519,
"avg_line_length": 36.61111068725586,
"blob_id": "62bf4c04aa18e84fa3736b2c76e75885f6027449",
"content_id": "d8991b41a5c6561b6d3d6c63e643babf3721af89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 273,
"num_lines": 18,
"path": "/Prometheus/lect5_1.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію clean_list(list_to_clean),\nяка приймає 1 аргумент -- список будь-яких значень (рядків, цілих та дійсних чисел) довільної довжини,\nта повертає список, який складається з тих самих значень, але не містить повторів елементів. Це значить, що у випадку наявності значення в початковому списку в кількох екземплярах перший \"екземпляр\" значення залишається на своєму місці, а другий, третій та ін. видаляються.\n\"\"\"\n\ndef clean_list(list_to_clean):\n\tresult = []\n\tfor i in list_to_clean:\n\t\tflag = False \n\t\tfor j in result:\n\t\t\tif i == j and str(i)== str(j):\n\t\t\t\tflag = True\n\t\tif not flag:\n\t\t\tresult.append(i)\t\t\n\treturn result\n\n"
},
{
"alpha_fraction": 0.4743589758872986,
"alphanum_fraction": 0.5128205418586731,
"avg_line_length": 20.428571701049805,
"blob_id": "f72ff19c4f937bc96354b44c2e2c41433cc21541",
"content_id": "2c3ddf978ca6baebac02cec23c97f7c26a06f444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 156,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 7,
"path": "/Prometheus/first_program.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "import math\r\nimport sys\r\na = float(sys.argv[1])\r\nb = float(sys.argv[2])\r\nb != 0\r\nx = (((a * b)**0.5)/ (math.exp(a) * b)) + a * math.exp((2 * a)/b)\r\nprint x "
},
{
"alpha_fraction": 0.5964125394821167,
"alphanum_fraction": 0.605381190776825,
"avg_line_length": 18.39130401611328,
"blob_id": "3ee61cb62277f9e6db425e3d188decc10ec19e61",
"content_id": "cd42537e4c0f30a6072011251ec3a2cd619c2235",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 23,
"path": "/Prometheus/lect5_2.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію counter(a, b),\nяка приймає 2 аргументи -- цілі невід'ємні числа a та b,\nта повертає число -- кількість різних цифр числа b, які містяться у числі а.\n\"\"\"\n\ndef counter(a, b):\n\tk = 0\n\tb_list = []\n\ta_list = []\n\tfor i in str(b):\n\t\tb_list.append(i)\n\tfor j in str(a):\n\t\ta_list.append(j)\n\t\n\n\tfor num_a in set(a_list):\n\t\tfor num_b in set(b_list):\n\t\t\tif num_a == num_b:\n\t\t\t\tk = k + 1\n\treturn k\n"
},
{
"alpha_fraction": 0.672831654548645,
"alphanum_fraction": 0.6766581535339355,
"avg_line_length": 34.6136360168457,
"blob_id": "10ad75933d4fc29649092af66286df1594b6ed61",
"content_id": "9703bf56855c04ae4d966d369c3a9224317b368f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2016,
"license_type": "no_license",
"max_line_length": 281,
"num_lines": 44,
"path": "/Prometheus/lect6_4.py",
"repo_name": "IYuriy/Prometheus",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#-*- coding: utf-8 -*-\n\"\"\"\nРозробити функцію find_most_frequent(text),\nяка приймає 1 аргумент -- текст довільної довжини, який може містити літери латинського алфавіту, пробіли та розділові знаки (,.:;!?-);\nта повертає список слів (у нижньому регістрі), які зустрічаються в тексті найчастіше.\n\nСлова, записані через дефіс, вважати двома словами (наприклад, \"hand-made\"). Слова у різних відмінках, числах та з іншими перетвореннями (наприклад, \"page\" та \"pages\") вважаються різними словами. Регістр слів -- навпаки, не має значення: слова \"page\" та \"Page\" вважаються 1 словом.\n\nЯкщо слів, які зустрічаються найчастіше, декілька -- вивести їх в алфавітному порядку.\n\"\"\"\nimport re\n\ndef find_most_frequent(text):\n\tdict_find = {}\n\tlist_find = []\n\ttext = re.sub('[%s]' % ',.:;!?-', ' ', text.lower()).split()\n\n\tfor word in text:\n\t\tdict_find.setdefault(word, 0)\n\t\tdict_find[word] += 1\n\n\tif len(dict_find) == 0:\n\t\treturn []\n\tmax_id = max(value for key, value in dict_find.items())\n\n\tfor word, count in dict_find.items():\n\t\tif count == max_id:\n\t\t\tlist_find.append(word)\n\treturn list_find\n\ndef test(got, expected):\n\tif got == expected:\n\t\tprefix = ' OK '\n\telse:\n\t\tprefix = ' X '\n\tprint '%s got: %s expected: %s' % (prefix, repr(got), repr(expected))\n\ndef main():\n\ttest(find_most_frequent('Hello,Hello, my dear!'), ['hello'])\n\ttest(find_most_frequent('to understand recursion you need first to understand recursion...'), ['recursion', 'to', 'understand'])\n\ttest(find_most_frequent('Mom! Mom! Are you sleeping?!!!'), ['mom'])\nif __name__ == '__main__':\n\tmain()\t\n"
}
] | 25 |
BrockDSL/econ-data-cruncher
|
https://github.com/BrockDSL/econ-data-cruncher
|
ec2f60d0519abf56a00a4877a694627cd5090dd7
|
63e1676570685f1614e6dc72d8647062d3ad13fe
|
89cd26267c4b8ff3764248746780f1160f5d5cbc
|
refs/heads/master
| 2020-09-04T16:50:48.108417 | 2019-11-27T21:01:01 | 2019-11-27T21:01:01 | 219,820,606 | 1 | 3 | null | 2019-11-05T18:14:36 | 2019-11-15T18:30:26 | 2019-11-15T19:16:52 |
Python
|
[
{
"alpha_fraction": 0.597028374671936,
"alphanum_fraction": 0.6060333251953125,
"avg_line_length": 31.66176414489746,
"blob_id": "b3d60b9e7c463921782178f3aa714de90da59035",
"content_id": "f271cb4063d1dbb07fe68eface3e706e2efdf709",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2221,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 68,
"path": "/CouchDB-1.2/CouchDB-1.2/setup.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright (C) 2007-2009 Christopher Lenz\n# All rights reserved.\n#\n# This software is licensed as described in the file COPYING, which\n# you should have received as part of this distribution.\n\nimport sys\ntry:\n from setuptools import setup\n has_setuptools = True\nexcept ImportError:\n from distutils.core import setup\n has_setuptools = False\n\n\n# Build setuptools-specific options (if installed).\nif not has_setuptools:\n print(\"WARNING: setuptools/distribute not available. Console scripts will not be installed.\")\n setuptools_options = {}\nelse:\n setuptools_options = {\n 'entry_points': {\n 'console_scripts': [\n 'couchpy = couchdb.view:main',\n 'couchdb-dump = couchdb.tools.dump:main',\n 'couchdb-load = couchdb.tools.load:main',\n 'couchdb-replicate = couchdb.tools.replicate:main',\n 'couchdb-load-design-doc = couchdb.loader:main',\n ],\n },\n 'install_requires': [],\n 'test_suite': 'couchdb.tests.__main__.suite',\n 'zip_safe': True,\n }\n\n\nsetup(\n name = 'CouchDB',\n version = '1.2',\n description = 'Python library for working with CouchDB',\n long_description = \\\n\"\"\"This is a Python library for CouchDB. It provides a convenient high level\ninterface for the CouchDB server.\"\"\",\n author = 'Christopher Lenz',\n author_email = '[email protected]',\n maintainer = 'Dirkjan Ochtman',\n maintainer_email = '[email protected]',\n license = 'BSD',\n url = 'https://github.com/djc/couchdb-python/',\n classifiers = [\n 'Development Status :: 6 - Mature',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Topic :: Database :: Front-Ends',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n packages = ['couchdb', 'couchdb.tools', 'couchdb.tests'],\n **setuptools_options\n)\n"
},
{
"alpha_fraction": 0.5528517365455627,
"alphanum_fraction": 0.5543726086616516,
"avg_line_length": 29.10344886779785,
"blob_id": "d200ce62263a948ffb637716cb92f0535168bad5",
"content_id": "720c24ad8d7ab6bbed2da206a4ad3310be2e6d52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2630,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 87,
"path": "/edc_003_auth_affil_best_guess.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Attempts to normalize Author affiliation data by grepping\n# puts results in Author_Affliations_Best_Guess\n#\n#\n#\n\nimport couchdb\nimport re\n\ncount = 0\n\n#Magic grep function that will attempt to create a standard affiliation name\ndef best_guess(dirty_affil):\n\n bg = dirty_affil\n\n\n\n if (re.search(\" University of (.+?)[,.]\",bg)):\n bg = re.search(\" University of (.+?)[,.]\",bg)\n bg = bg.group(0)\n if (re.search(\"(.+?) University[,. ]\",bg)):\n bg = re.search(\"(.+?) University[,. ]\",bg)\n bg = bg.group(0)\n\n if(re.search(\"and\",bg)):\n return bg\n\n #Remove Dept Affils\n bg = re.sub(\"Department of Economics, \",\"\",bg)\n bg = re.sub(\"Dept of Economics, \",\"\",bg)\n bg = re.sub(\"Department of Finance, \",\"\",bg)\n bg = re.sub(\"Department of Statistics, \",\"\", bg)\n bg = re.sub(\"Department of Telecommunications\", \"\",bg)\n bg = re.sub(\"Dept. of Economics, \",\"\",bg)\n bg = re.sub(\"Economics Department, \",\"\",bg)\n bg = re.sub(\"Department of Mathematics, \",\"\",bg)\n bg = re.sub(\"Faculty of Economics, \",\"\",bg)\n bg = re.sub(\"Departments of Mathematics and Statistics, \",\"\",bg)\n\n #trim leading & trailing , ' ' . if still there\n bg = re.sub(\",$\",\"\",bg)\n bg = re.sub(\" $\",\"\",bg)\n bg = re.sub(\"^,\",\"\",bg)\n bg = re.sub(\"^ \",\"\",bg)\n #remove \" that were already in the affil statement\n bg = re.sub(\"\\\"\",\"\",bg)\n #bg = re.sub(\"^.\",\"\",bg)\n #bg = re.sub(\".$\",\"\",bg)\n\n return bg.strip()\n\n\n\nif __name__ == \"__main__\":\n\n couch = couchdb.Server()\n db = couch['econ_data_working']\n map_fun = '''function(doc) {\n if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n emit(doc.id, {ACCESSION : doc.id, AUTHORS_CLEAN : doc.Authors_Clean, ISSN : doc.ISSN, DATE : doc.Source_Clean, AFFILS : doc.Author_Affiliations_Clean, AFFIL_RAW : doc.Author_Affiliations, AUTHORS_RAW : doc.Authors});\n }'''\n\n print \"Working on best guesses...\"\n results = db.query(map_fun)\n for r in results:\n print \".\"\n art_obj = r[\"value\"]\n accession = art_obj['ACCESSION']\n date = art_obj['DATE']\n affil_raw = art_obj['AFFIL_RAW']\n affil_clean = art_obj['AFFILS']\n autho_raw = art_obj['AUTHORS_RAW']\n issn = art_obj['ISSN']\n bglist = list()\n for df in affil_clean:\n if re.search(\"and\",df):\n count += 1\n bglist.append(best_guess(df))\n doc = db[r.id]\n doc['Author_Affliations_Best_Guess'] = bglist\n db.save(doc) \n # print bglist\n \n print \".fin\"\n print count\n\n \n"
},
{
"alpha_fraction": 0.6865671873092651,
"alphanum_fraction": 0.6865671873092651,
"avg_line_length": 21.33333396911621,
"blob_id": "3694df0484c31f3477b5e8fd0853aa7338036340",
"content_id": "8c87bb98aa77ea05d3798edbeaccc605af9379f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 3,
"path": "/logs/log_directories.md",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n##Log File Descriptions##\n\n### See Settings.py.orig for details ##"
},
{
"alpha_fraction": 0.7348993420600891,
"alphanum_fraction": 0.744966447353363,
"avg_line_length": 13.899999618530273,
"blob_id": "4827535c8b3816bcac7c0b69ebcfd48b2b68ac94",
"content_id": "bcd4e08ca8f536cfed757bbbcda91eb23b0e00e5",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 298,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 20,
"path": "/CouchDB-1.2/CouchDB-1.2/Makefile",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": ".PHONY: test doc upload-doc\n\ntest:\n\ttox\n\ntest2:\n\tPYTHONPATH=. python -m couchdb.tests\n\ntest3:\n\tPYTHONPATH=. python3 -m couchdb.tests\n\ndoc:\n\tpython setup.py build_sphinx\n\nupload-doc: doc\n\tpython setup.py upload_sphinx\n\ncoverage:\n\tPYTHONPATH=. coverage run couchdb/tests/__main__.py\n\tcoverage report\n"
},
{
"alpha_fraction": 0.533687949180603,
"alphanum_fraction": 0.5390070676803589,
"avg_line_length": 24.613636016845703,
"blob_id": "f4829c361182d5a2191ded3661716a542369058e",
"content_id": "21cbfb80c68075b75fdfd2412be3ba01f7313714",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1128,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 44,
"path": "/edc_004_002_3_abstracts.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Read CouchDB entires and spit out abs data\n#\n#\n#\n#\n\nimport couchdb\nimport re\n\nabs_list = open(\"data/md_built/abs_list.csv\",\"w\")\ncouch = couchdb.Server()\ndb = couch['econ_data']\nmap_fun = '''function(doc) {\n if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n emit(doc.id, {ACCESSION : doc.id, ISSN : doc.ISSN, ABSTRACT: doc.Abstract});\n}'''\n\ncount = 0\n\nresults = db.query(map_fun)\nfor r in results:\n count += 1\n art_obj = r[\"value\"]\n accession = art_obj['ACCESSION']\n issn = art_obj['ISSN']\n\n #DEBUG\n #line_out = str(r.id) + \",\" + str(accession[0])+\",\"+str(issn[0])+\",\"\n\n line_out = str(accession[0])+\",\"+str(issn[0])+\",\"\n \n if 'ABSTRACT' in art_obj.keys():\n ab_total = ' '.join(art_obj['ABSTRACT'])\n ab_total = re.sub('<[^<]+?>', '', ab_total)\n ab_total = re.sub('\\n','',ab_total)\n ab_total = re.sub('\\\"','\\\"\"',ab_total)\n ab_total = re.sub(',','\"\",',ab_total)\n line_out += \"\\\"\" + ab_total + \"\\\"\"\n else:\n line_out += \"\\\"NO_ABSTRACT\\\"\"\n \n abs_list.write(line_out+\"\\n\")\n abs_list.flush()\n"
},
{
"alpha_fraction": 0.7521008253097534,
"alphanum_fraction": 0.7521008253097534,
"avg_line_length": 33,
"blob_id": "c56a5ed40e5724fb158f23d9eb863a2a6745a6c9",
"content_id": "bc064d6335792b44d299fc878ef69e869a21482c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 7,
"path": "/data/data_directories.md",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n##Data Directory info##\n-TOC_in, to harvest specific AN\n-TOC_out, processed files\n-AN_in, specific AN's ready for the db\n-AN_out, after AN has been put in db\n-cache, scratch directory\n-md_built, Various final outputs will be plopped here"
},
{
"alpha_fraction": 0.582608699798584,
"alphanum_fraction": 0.6217391490936279,
"avg_line_length": 34.38461685180664,
"blob_id": "32ffea2fe25deaad46d3ee0339787cb1b04d6802",
"content_id": "357f853fd8d5bd0233fb4cd44eaa392b119fac23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3220,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 91,
"path": "/edc_001_process_downloads.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "#\n# Step 1 in Z\n#\n#\nfrom settings import *\nfrom requests_html import HTMLSession\nfrom bs4 import BeautifulSoup\nimport os,sys\nimport shutil\nimport urllib.request\nimport urllib.error\nfrom array import array\nfrom bs4 import BeautifulSoup\nfrom types import *\nfrom random import randint\nfrom time import time\n\nhtml_data_in = DATA_BASE+TOC_IN\nhtml_data_out = DATA_BASE+TOC_OUT\ndata_in = DATA_BASE+AN_IN\nerror_dir = DATA_BASE+TOC_ERROR\n\nsession = HTMLSession()\n\nfront_Link = \"https://proxy.library.brocku.ca/login?url=http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=\"\nback_Link = \"&site=ehost-live&scope=site\"\n\nuagents = ['Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1468.0 Safari/537.36',\n 'Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)',\n 'Mozilla/5.0 (Windows NT 6.1; rv:22.0) Gecko/20130405 Firefox/22.0',\n 'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.0) Opera 12.14',\n 'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52',\n 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36',\n 'Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)',\n 'Mozilla/4.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/5.0)']\n\nlog_file = open(LOG_BASE+TOC_PROCESS+\"log.txt\",\"a\")\n\n\ncan_files = os.listdir(html_data_in+\"/\")\nfor html_c in can_files:\n val_count = 0\n with open(html_data_in+\"/\"+html_c,encoding=\"utf8\") as fp:\n soupAN = BeautifulSoup(fp,'lxml')\n #soupAN = BeautifulSoup(open(html_data_in+\"/\"+html_c))\n ans = []\n #build list of ANs found in html candidate document\n for s in soupAN.findAll('cite'):\n ans.append(s.text[4:])\n #ans.sort()\n print(ans)\n \n print (\"\\nProcessing...\\n\"+html_c+\"\\n\"+ans[0],\" : \",len(ans))\n #do the downloading\n tss = time()\n for an_index in ans:\n #ua_string = uagents[randint(0,len(uagents)-1)]\n #headers = {'User-agent': ua_string }\n #print(E_URL+str(an_index))\n link = front_Link + str(an_index) + back_Link\n print(link)\n \n req = session.get(link)\n req.html.render()\n print(req.html.html)\n\n #below code is at a standstill, as we are having trouble scraping the screen from ebscohost\n #see https://github.com/BrockDSL/econ-data-cruncher/issues/4\n '''\n soupMD = BeautifulSoup(html_result,'lxml')\n brick = soupMD.find('dl')\n print(brick)\n val_count += 1\n ofile = open(data_in+\"/\"+str(an_index)+\".htm\",\"w\")\n ofile.write(brick.prettify().encode('utf8'))\n ofile.flush()\n ofile.close()\n time_delta = time() - tss\n print(\"Downloaded in: \"+str(time_delta)+\" sec\")\n report = \"\\n\"+html_c+\" : \"+\"Start AN: \"+str(ans[0])+\" offset of \"+str(len(ans))+\" records downloaded in \"+str(time_delta)\n log_file.write(report)\n log_file.flush()\n try:\n shutil.move(html_data_in+\"/\"+html_c,html_data_out)\n except:\n print (html_data_in+\"/\"+html_c+\" has already been processed\")\n shutil.move(html_data_in+\"/\"+html_c,error_dir)\n\nlog_file.close()\nprint (\"\\nfin\")\n'''\n"
},
{
"alpha_fraction": 0.49971893429756165,
"alphanum_fraction": 0.5092748999595642,
"avg_line_length": 27.677419662475586,
"blob_id": "890af99e46fd5b3879e762defeaae95f09869a79",
"content_id": "64123f2727f65288e22b78f38b37effa9ed3bb5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1779,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 62,
"path": "/edc_004_002_4_subjects.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Read CouchDB entires as JSON and spit out CSV\n#\n#\n#\n#\n\nimport couchdb\nimport re\n\n#final_list = open(\"complete_data_easy.csv\",\"w\")\nsub_list = open(\"data/md_built/subject_list.csv\",\"w\")\ncouch = couchdb.Server()\ndb = couch['econ_data']\nmap_fun = '''function(doc) {\n if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n emit(doc.id, {ACCESSION : doc.id, ISSN : doc.ISSN, SUBJECT: doc.Subject_Terms_Clean});\n}'''\n\ncount = 0\n\nresults = db.query(map_fun)\nfor r in results:\n count += 1\n art_obj = r[\"value\"]\n accession = art_obj['ACCESSION']\n issn = art_obj['ISSN']\n\n line_out = str(accession[0])+\",\"+str(issn[0])\n if 'SUBJECT' in art_obj.keys():\n for s in art_obj['SUBJECT']:\n sub_list.write(line_out + \",\" + s + \"\\n\")\n else:\n sub_list.write(line_out + \", NO_SUBJECTS\\n\")\n \n #sub_list.write(line_out+\"\\n\")\n sub_list.flush()\n\n## for af in affil_clean:\n## print count,\" ::: \",str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(af)+'\\\"'\n## final_list.write(str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(af)+'\\\"\\n')\n## final_list.flush()\n## count +=1\n\n#final_list.close()\n\n\n \n## if (not re.search(r'<sup>',a_moving[au])):\n## au_vals = re.sub(r'<sup>','',a_moving[au+1])\n## au_vals = re.sub(r'</sup>','',au_vals)\n## au_vals = re.sub(r'\\n','',au_vals).strip()\n## if (a_moving[au] == \"NA\"):\n## print a_moving[max(0,au-1)],\"NA\"\n## else:\n## for e in au_vals.split(','):\n## print a_moving[au],af_list[int(e)]\n \n \n \n\n # print str(accession[0]),str(issn[0]),str(date[0]),'\\\"'+a+'\\\"'\n"
},
{
"alpha_fraction": 0.4974924921989441,
"alphanum_fraction": 0.5060180425643921,
"avg_line_length": 26.68055534362793,
"blob_id": "e6f580db9d0f42245cddd6e89d8608bf16a69602",
"content_id": "27fe12bf3badc0525e944d1fb0f4c476f9ddf625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1994,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 72,
"path": "/edc_004_001_afill_dump.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Read CouchDB entires as JSON and spit out CSV\n#\n#\n#\n#\n\nimport couchdb\nimport re\n\n\nauthor_list = open(\"data/md_built/author_list.csv\",\"w\")\ncouch = couchdb.Server()\ndb = couch['econ_data_working']\nmap_fun = '''function(doc) {\n if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n emit(doc.id, {ACCESSION : doc.id, ISSN : doc.ISSN, AUTHOR_AFFILIATIONS_BEST_GUESS : doc.Author_Affliations_Best_Guess});\n}'''\n\ncount = 0\nprint \"Working on author/affiliation metadata...\"\nresults = db.query(map_fun)\nfor r in results:\n print \".\"\n count += 1\n art_obj = r[\"value\"]\n accession = art_obj['ACCESSION']\n issn = art_obj['ISSN']\n\n line_out = \"\\\"\"+str(accession[0])+\"\\\",\\\"\"+str(issn[0])+\"\\\"\"\n\n for a in art_obj['AUTHOR_AFFILIATIONS_BEST_GUESS']:\n atemp = re.sub(\"\\\"\",\"\",a)\n f_line = line_out + \",\\\"\" + atemp + \"\\\"\\n\"\n author_list.write(f_line)\n author_list.flush()\n\n \n## if 'SUBJECT' in art_obj.keys():\n## for s in art_obj['SUBJECT']:\n## line_out += s + \",\"\n## else:\n## line_out += \", NO_SUBJECTS\"\n \n\n\n## for af in affil_clean:\n## print count,\" ::: \",str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(af)+'\\\"'\n## final_list.write(str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(af)+'\\\"\\n')\n## final_list.flush()\n## count +=1\n\n#final_list.close()\n\n\n \n## if (not re.search(r'<sup>',a_moving[au])):\n## au_vals = re.sub(r'<sup>','',a_moving[au+1])\n## au_vals = re.sub(r'</sup>','',au_vals)\n## au_vals = re.sub(r'\\n','',au_vals).strip()\n## if (a_moving[au] == \"NA\"):\n## print a_moving[max(0,au-1)],\"NA\"\n## else:\n## for e in au_vals.split(','):\n## print a_moving[au],af_list[int(e)]\n \n \n \n\n # print str(accession[0]),str(issn[0]),str(date[0]),'\\\"'+a+'\\\"'\n\nprint \".fin\\n\"\n"
},
{
"alpha_fraction": 0.661773681640625,
"alphanum_fraction": 0.6672782897949219,
"avg_line_length": 25.370967864990234,
"blob_id": "4217fb0394bef23746e072a53b3d44925643cb92",
"content_id": "d66e260028e4e60f21b4d75a8eea1b67deab03e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1635,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/settings.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "# Base URL for DB product\nE_URL = \"http://search.ebscohost.com/login.aspx?direct=true&db=bth&AN=\"\n\n#COUCH CONFIGS\n\nimport os,sys\n\n#ensure you python install settings.py inside couchdb\nsys.path.append(r'.\\CouchDB-1.2\\CouchDB-1.2') #append your file path to CouchDB\n\nimport couchdb\n\n\n#see dylan/tim/anyone for access\n\nCDB_USER = \"----\"\nCDB_PASSWORD = \"----\"\n\nCDB_HOST = \"http://\"+CDB_USER+\":\"+CDB_PASSWORD+\"@rtod.library.brocku.ca:32771/\"\nCDB_NAME = \"econ_data_test\"\n\ncouch = couchdb.Server(CDB_HOST)\n\ndbname = CDB_NAME\nif dbname in couch:\n db = couch[dbname]\nelse:\n db = couch.create(dbname)\n\n\n#Data File locations\nDATA_BASE = \"data/\"\n\nTOC_IN = \"TOC_in/\"\nTOC_OUT = \"TOC_out/\"\nTOC_ERROR = \"TOC_error/\"\n\nAN_IN = \"AN_in/\"\nAN_OUT = \"AN_out/\"\nAN_ERROR = \"AN_error/\"\n\n#Log File locations\nLOG_BASE = \"logs/\"\nTOC_PROCESS = \"toc_process/\"\nAN_PROCESS = \"an_process/\"\n\n\n# run once to create all directories need\nif __name__ == \"__main__\":\n print(\"Creating directories...\")\n import os\n cwd = os.getcwd()\n os.makedirs(os.path.join(cwd,DATA_BASE), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,TOC_IN), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,TOC_OUT), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,TOC_ERROR), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,AN_IN), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,AN_OUT), exist_ok = True)\n os.makedirs(os.path.join(cwd,DATA_BASE,AN_ERROR), exist_ok = True)\n os.makedirs(os.path.join(cwd,LOG_BASE,TOC_PROCESS), exist_ok = True)\n os.makedirs(os.path.join(cwd,LOG_BASE,AN_PROCESS), exist_ok = True)\n print(\"done\")\n"
},
{
"alpha_fraction": 0.6850574612617493,
"alphanum_fraction": 0.6942528486251831,
"avg_line_length": 35.16666793823242,
"blob_id": "1f76c7506651c0eedaa9bd77752268c2e9e1850a",
"content_id": "fcce2376387407611db9cdc9f2b9babebec29f28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 12,
"path": "/edc_004_002_2_affil_best_guess_addition.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\nimport csv\nfrom edc_003_auth_affil_best_guess import best_guess\n\nprint \"adding column of 'best guesses' of affiliation data\"\nf = csv.reader(open('data/md_built/complete_data.csv','rb'))\ncsvfile = open (\"data/md_built/data_with_best_guess.csv\",\"wb\")\no = csv.writer(csvfile , delimiter=',',quotechar='\\\"',quoting=csv.QUOTE_ALL)\nfor dline in f:\n print \".\"\n dline.append(best_guess(dline[4]))\n o.writerow(dline) \nprint \".fin\"\n"
},
{
"alpha_fraction": 0.765467643737793,
"alphanum_fraction": 0.768345296382904,
"avg_line_length": 29.173913955688477,
"blob_id": "3cdf3f187600c17b4bafb4e7ecf69493b01bd16d",
"content_id": "11a2ec58f4fcbd0d9babc9ff36fe532e933ed458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 695,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 23,
"path": "/Readme.md",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n## Econ Data Cruncher ##\n\nMade with Python\nInstall pre-reqs with *setup_linux*\n\n## Required ##\n- [Beautiful Soup](http://www.crummy.com/software/BeautifulSoup/#Download)\n- [CouchDB](https://couchdb.apache.org/)\n- [Couchpy](https://pypi.python.org/pypi/couchpy/0.2dev)\n\nNote: update settings.py with relevant authentication information on local cloned repository\n\n\n## HOWTO connect to DB ##\nupdate the connection settings with proper username and password\n\n\n## HOWTO install CouchDB locally ##\nnavigate to couchdb folder that contains settings.py\n\nrun 'python settings.py install'\n\nremember to update your sys path to the folder that you installed CouchDB to inside the python file you're using\n"
},
{
"alpha_fraction": 0.5455216765403748,
"alphanum_fraction": 0.5479822754859924,
"avg_line_length": 28.442028045654297,
"blob_id": "9e7c9ff2cf0b3d6ea4bc8608cf6dc89c8846618a",
"content_id": "4cd69acb199b40f0aed4b7812294287f92419814",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4064,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 138,
"path": "/edc_002_process_ans.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Parses AN HTML & Dumps into Couch\n# \n#\n#\n\nimport json\nimport re\nimport numbers\nimport urllib\nimport urllib2\nimport couchdb\nimport types\nimport os,sys\nimport shutil\nfrom settings import *\nfrom bs4 import BeautifulSoup\n\n\ndata_in_dir = DATA_BASE+AN_IN\ndata_out_dir = DATA_BASE+AN_OUT\ndata_er_dir = DATA_BASE+AN_ERROR\nlog_file = open(LOG_BASE+AN_PROCESS+\"log.txt\",\"a\")\n\n\ntry:\n os.mkdir(data_out_dir)\n os.mkdir(data_er_dir)\nexcept:\n print \"Folders already exist\"\n\ncouch = couchdb.Server()\n\ntry:\n db = couch.create(CDB_NAME)\nexcept:\n db = couch[CDB_NAME]\n \ncan_files = os.listdir(data_in_dir+\"/\")\nfor meta_c in can_files:\n mid = dict()\n soup = BeautifulSoup(open(data_in_dir+\"/\"+meta_c))\n #print \"\\n\"+meta_c\n \n for s in soup.find_all(\"dt\"):\n elements = list()\n m_name = s.text.strip(' :\\n')\n m_name = re.sub(r' ','_',m_name)\n for t in s.find_next(\"dd\"):\n if (str(t.encode('utf8').decode('ascii','ignore')).strip() != \"\"):\n elements.append(str(t.encode('utf8').decode('ascii','ignore')).strip())\n mid[m_name] = elements\n\n #get the non numerials out\n if(mid.has_key('Accession_Number')):\n temp_acc = re.sub(r'<[^>]*?>', '', str(mid['Accession_Number']).encode('utf8').decode('ascii','ignore'))\n temp_acc = re.sub(r'\\\\n', '', temp_acc)\n temp_acc = re.sub(r' ','', temp_acc)\n temp_acc = re.sub(r'\\[\\'','',temp_acc)\n temp_acc = re.sub(r'\\'\\]','',temp_acc)\n temp_el = list()\n temp_el.append(str(temp_acc).encode('utf8').decode('ascii','ignore').strip())\n mid['id'] = temp_el\n\n #Remove HTML elements from title\n if(mid.has_key('Title')):\n temp_title = re.sub(r'<[^>]*?>', '', str(mid['Title']).encode('utf8').decode('ascii','ignore'))\n temp_title = re.sub(r'\\\\n','', temp_title)\n temp_title = re.sub(r'\\[\\'','',temp_title)\n temp_title = re.sub(r'\\'\\]','',temp_title)\n temp_title = temp_title.strip()\n temp_el = list()\n temp_el.append(str(temp_title).encode('utf8').decode('ascii','ignore').strip(\" \"))\n mid['Title_Clean'] = temp_el\n\n #Remove <br /> from various fields\n if(mid.has_key('Subject_Terms')):\n temp_el = list()\n for sub in mid['Subject_Terms']:\n if (sub != \"<br/>\"):\n temp_el.append(sub)\n mid['Subject_Terms_Clean'] = temp_el\n \n if(mid.has_key('Authors')):\n temp_el = list()\n for sub in mid['Authors']:\n if (sub != \"<br/>\"):\n temp_el.append(sub)\n del mid['Authors']\n mid['Authors'] = temp_el\n \n if(mid.has_key('Author_Affiliations')):\n temp_el = list()\n for sub in mid['Author_Affiliations']:\n if (sub != \"<br/>\"):\n temp_el.append(sub)\n del mid['Author_Affiliations']\n mid['Author_Affiliations'] = temp_el\n\n\n #Create clean versions of lists\n if(mid.has_key('Author_Affiliations')):\n temp_el = list()\n for sub in mid['Author_Affiliations']:\n if not(re.match('^<sup>',sub)):\n temp_el.append(sub)\n mid['Author_Affiliations_Clean'] = temp_el\n\n #Create short version of Source\n if(mid.has_key('Source')):\n splits = str(mid['Source']).split(',')\n final = splits[0].split(\".\")\n temp_el = list()\n temp_el.append(final[1].strip())\n mid['Source_Clean'] = temp_el\n \n try:\n response = db.save(mid)\n except:\n report = meta_c + \":: couldn't save to couch\\n\"\n print report\n log_file.write(report)\n log_file.flush()\n shutil.move(data_in_dir+\"/\"+meta_c,data_er_dir)\n continue\n \n report = meta_c + \":: \"+str(response)+\"\\n\"\n print report\n log_file.write(report)\n log_file.flush()\n try:\n shutil.move(data_in_dir+\"/\"+meta_c,data_out_dir)\n except:\n print data_in_dir+\"/\"+meta_c+\" has already been processed\"\n shutil.move(data_in_dir+\"/\"+meta_c,data_er_dir)\n\nlog_file.close()\nprint \"\\nfin\"\n"
},
{
"alpha_fraction": 0.7763158082962036,
"alphanum_fraction": 0.7763158082962036,
"avg_line_length": 14.199999809265137,
"blob_id": "7cea5deb363a8aece55534e1a50e9f97a4f0e534",
"content_id": "2440583759b47d8dacea126de734eabf9bc0c14f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 152,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 10,
"path": "/make_dirs",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nmkdir data\nmkdir data/TOC_in\nmkdir data/TOC_out\nmkdir data/AN_in\nmkdir data/AN_out\n\nmkdir logs\nmkdir logs/toc_process\nmkdir logs/an_process\n"
},
{
"alpha_fraction": 0.489112913608551,
"alphanum_fraction": 0.49919354915618896,
"avg_line_length": 32.73469543457031,
"blob_id": "0a385f460cf18ec67ce2010e8f84eb3f4aa921cb",
"content_id": "8747f45cd9cf19c5562991ba0e3fea1cefd33df8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4960,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 147,
"path": "/edc_004_002_1_author_affil_raw.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "\n#\n# Read CouchDB entires as JSON and spit out CSV\n#\n#\n#\n#\n\nimport couchdb\nimport re\n\ntotal_w_na = 0\nfinal_list = open(\"data/md_built/complete_data.csv\",\"w\")\nbreak_list = open(\"data/md_built/break_list_author_affil.csv\",\"w\")\ncouch = couchdb.Server()\ndb = couch['econ_data']\nmap_fun = '''function(doc) {\n if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n emit(doc.id, {ACCESSION : doc.id, ISSN : doc.ISSN, DATE : doc.Source_Clean, AFFIL_RAW : doc.Author_Affiliations_Clean, AFFILS : doc.Author_Affiliations, AUTHORS_RAW : doc.Authors});\n}'''\n\n#Original\n##map_fun = '''function(doc) {\n## if (doc.Document_Type == \"Article\" && doc.Authors != null && doc.Author_Affiliations != null)\n## emit(doc.id, {ACCESSION : doc.id, ISSN : doc.ISSN, DATE : doc.Source_Clean, AFFILS : doc.Author_Affiliations_Clean, AFFIL_RAW : doc.Author_Affiliations, AUTHORS_RAW : doc.Authors});\n##}'''\n\n\nresults = db.query(map_fun)\nprint \"Computing List of matched Authors & Affiliations...\"\nfor r in results:\n print \".\"\n art_obj = r[\"value\"]\n accession = art_obj['ACCESSION']\n date = art_obj['DATE']\n affil_raw = art_obj['AFFIL_RAW']\n autho_raw = art_obj['AUTHORS_RAW']\n issn = art_obj['ISSN']\n\n au_left = dict()\n af_list = dict()\n\n for af in range(0,len(affil_raw)):\n caf = re.sub(r'<[^>]*?>','',affil_raw[af])\n caf = re.sub(r'\\n', '', caf)\n try:\n af_list[int(caf.strip())] = affil_raw[af+1]\n except:\n pass\n\n\n\n\n a_moving = []\n\n for ak in autho_raw:\n if (not re.search(r'<cite>',ak)):\n a_moving.append(ak)\n\n\n count = 0\n stopper = False\n while(stopper == False):\n try:\n a_moving[count+1]\n #print \"IT :::\",a_moving,\"count\",count,\n if (re.search(r'NA',a_moving[count])):\n break\n elif (not re.search(r'<sup>',a_moving[count+1])and not re.search(r'NA',a_moving[count+1])):\n total_w_na += 1\n a_moving.insert(count+1,\"NA\")\n count += 2\n except:\n stopper = True\n\n\n #Last element in author list needs to be a sup, indicating affiliations, if not NA\n if (not re.search(r'<sup>',a_moving[-1])):\n a_moving.append(\"NA\")\n\n## count = 0\n## stopper = False\n## while(stopper == False):\n## print \"IT :::\",a_moving,\"count\",count,\"a_moving\",a_moving[count+1]\n## if (count == (len(a_moving))):\n## if(not re.search(r'<sub>',a_moving[count])):\n## print \"1\"\n## a_moving.append(\"NA\")\n## stopper = True\n## break\n## elif (re.search(r'NA',a_moving[count])):\n## print \"2\"\n## count += 1\n## continue\n## elif (not re.search(r'<sup>',a_moving[count+1])):\n## print \"3\"\n## a_moving.insert(count+1,\"NA\")\n## else:\n## count += 1\n## \n \n## for a_index in range(0,len(a_moving)):\n## if (a_index == len(a_moving) - 1):\n## break\n## if (a_index % 2 == 0 and not re.search(r'<sup>',a_moving[a_index+1])):\n## a_moving.insert(a_index+1,\"NA\")\n\n \n for au in range(0,len(a_moving)):\n if (au == len(a_moving) -1):\n break\n if(a_moving[au + 1] == \"NA\"):\n #Spit out\n #print str(accession[0])+','+str(issn[0])+','+str(date[0]),',\\\"'+str(a_moving[au])+'\\\",\\\"No Affiliation\\\"\\n'\n final_list.write(str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(a_moving[au])+'\\\",\\\"No Affiliation\\\"\\n')\n final_list.flush()\n elif(au % 2 == 0):\n au_vals = re.sub(r'<sup>','',a_moving[au+1])\n au_vals = re.sub(r'</sup>','',au_vals)\n au_vals = re.sub(r'\\n','',au_vals).strip()\n for e in au_vals.split(','):\n #print str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(a_moving[au])+'\\\"',',\\\"'+af_list[int(e)]+'\\\"\\n'\n try:\n final_list.write(str(accession[0])+','+str(issn[0])+','+str(date[0])+',\\\"'+str(a_moving[au])+'\\\",\\\"'+af_list[int(e)]+'\\\"\\n')\n except:\n break_list.write(r['id']+\"\\n\")\n final_list.flush()\n break_list.flush()\nfinal_list.close()\nbreak_list.close()\nprint \".fin\"\nprint \"Total articles with NA components \",total_w_na\n\n \n## if (not re.search(r'<sup>',a_moving[au])):\n## au_vals = re.sub(r'<sup>','',a_moving[au+1])\n## au_vals = re.sub(r'</sup>','',au_vals)\n## au_vals = re.sub(r'\\n','',au_vals).strip()\n## if (a_moving[au] == \"NA\"):\n## print a_moving[max(0,au-1)],\"NA\"\n## else:\n## for e in au_vals.split(','):\n## print a_moving[au],af_list[int(e)]\n \n \n \n\n # print str(accession[0]),str(issn[0]),str(date[0]),'\\\"'+a+'\\\"'\n"
},
{
"alpha_fraction": 0.647335410118103,
"alphanum_fraction": 0.6802507638931274,
"avg_line_length": 17.764705657958984,
"blob_id": "01e11aadd103ca457850a90da18461d8f9a14451",
"content_id": "6569e70d12aa758c1d346cc8769df02f8203eb23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 638,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 34,
"path": "/test_conn.py",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Nov 5 12:28:22 2019\n@author: dsouvage\n\"\"\"\n\nimport settings\n\n\nimport os,sys\n\n\n#ensure you python install settings.py inside couchdb\nsys.path.append(r'\\OneDrive - Brock University\\CitationProject\\econ-data-cruncher\\CouchDB-1.2\\CouchDB-1.2') #append your file path to CouchDB\n\n\nimport couchdb\n\n\n\n\nCDB_USER = \"------\"\nCDB_PASSWORD = \"-------\"\n\nCDB_HOST = \"https://\"+CDB_USER+\":\"+CDB_PASSWORD+\"@rtod.library.brocku.ca:32771/econ_data/working\"\nCDB_NAME = \"econ_data_working\"\n\ncouch = couchdb.Server(CDB_HOST)\n\ntry:\n db = couch.create(CDB_NAME)\n print(\"Connection successful\")\nexcept:\n db = couch[CDB_NAME]\n"
},
{
"alpha_fraction": 0.7398265600204468,
"alphanum_fraction": 0.7458305358886719,
"avg_line_length": 44.42424392700195,
"blob_id": "a711a7b19abd1155a424bd29edb23c44f2c0d83e",
"content_id": "41d8bdda816aae83a347cf846ee6803462bdf62d",
"detected_licenses": [
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1499,
"license_type": "permissive",
"max_line_length": 163,
"num_lines": 33,
"path": "/CouchDB-1.2/CouchDB-1.2/README.rst",
"repo_name": "BrockDSL/econ-data-cruncher",
"src_encoding": "UTF-8",
"text": "CouchDB-Python Library\n======================\n\n.. image:: https://travis-ci.org/djc/couchdb-python.svg\n :target: https://travis-ci.org/djc/couchdb-python\n\nA Python library for working with CouchDB. `Downloads`_ are available via `PyPI`_.\nOur `documentation`_ is also hosted there. We have a `mailing list`_.\n\nThis package currently encompasses four primary modules:\n\n* ``couchdb.client``: the basic client library\n* ``couchdb.design``: management of design documents\n* ``couchdb.mapping``: a higher-level API for mapping between CouchDB documents and Python objects\n* ``couchdb.view``: a CouchDB view server that allows writing view functions in Python\n\nIt also provides a couple of command-line tools:\n\n* ``couchdb-dump``: writes a snapshot of a CouchDB database (including documents, attachments, and design documents) to MIME multipart file\n* ``couchdb-load``: reads a MIME multipart file as generated by couchdb-dump and loads all the documents, attachments, and design documents into a CouchDB database\n* ``couchdb-replicate``: can be used as an update-notification script to trigger replication between databases when data is changed\n\nPrerequisites:\n\n* Python 2.7, 3.4 or later\n* CouchDB 0.10.x or later (0.9.x should probably work, as well)\n\n``simplejson`` will be used if installed.\n\n.. _Downloads: http://pypi.python.org/pypi/CouchDB\n.. _PyPI: http://pypi.python.org/\n.. _documentation: http://packages.python.org/CouchDB/\n.. _mailing list: http://groups.google.com/group/couchdb-python\n"
}
] | 17 |
JerryBinder/Arduino-Time
|
https://github.com/JerryBinder/Arduino-Time
|
34a86d5ad0b5bc43a63979c91c7227e3adace8a9
|
e39864275594a17a596debdd61ed3b5abc9bc8eb
|
9f02dbd7083101b04e03993c51aab73322b258c9
|
refs/heads/master
| 2018-12-18T22:03:34.474321 | 2018-09-14T23:10:21 | 2018-09-14T23:10:21 | 73,765,897 | 0 | 0 | null | 2016-11-15T02:01:15 | 2018-09-14T23:10:23 | 2018-09-14T23:29:10 |
C++
|
[
{
"alpha_fraction": 0.7798507213592529,
"alphanum_fraction": 0.7910447716712952,
"avg_line_length": 37.28571319580078,
"blob_id": "b6308ffcd472255ec2a6e3fa4fe20680c073e10f",
"content_id": "98cafa29c3d64003455bb87d759fab1524390c37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 536,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 14,
"path": "/README.md",
"repo_name": "JerryBinder/Arduino-Time",
"src_encoding": "UTF-8",
"text": "# Time\nMade with Isaac Figueroa.\n\nProof of concept for an Arduino device featuring the following:\n\n* Settable clock\n * Python script to set Arduino's clock through a USB connection to a PC\n* Stopwatch\n* LED mood light, which gradually cycles from bright cold light at midday to cool, dim light at night.\n* Time display can be set to different bases, such as hexidecimal.\n\nFor more information, check out the project's presentation slideshow:\n\nhttps://docs.google.com/presentation/d/1KrbM9JQbbZiO5QuJvHQMmM7-p94z-rmzHsKcqhOngYw/edit?usp=sharing\n"
},
{
"alpha_fraction": 0.6797945499420166,
"alphanum_fraction": 0.6969178318977356,
"avg_line_length": 20.538461685180664,
"blob_id": "c087bff9e45eaf3d5433d0203c8f5c4013c4beb1",
"content_id": "b6f1d9c387a395a027c8a70a7271fa1c1413ea4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 26,
"path": "/time.py",
"repo_name": "JerryBinder/Arduino-Time",
"src_encoding": "UTF-8",
"text": "import time\r\nimport serial.tools.list_ports\r\nimport serial\r\nimport signal # For trapping ctrl-c or SIGINT\r\nimport sys # For exiting program with exit code\r\n\r\ndef SIGINT_handler(signal, frame):\r\n\tprint('Quitting program!')\r\n\tser.close()\r\n\tsys.exit(0)\r\n\r\nsignal.signal(signal.SIGINT, SIGINT_handler)\r\n\r\nprint(\"Running time.py...\")\r\n\r\nsignal.signal(signal.SIGINT, SIGINT_handler)\r\n\r\nser=serial.Serial(\"COM3\",baudrate=9600,timeout=10)\r\n\r\nwhile(1):\r\n\tmycmd=ser.read()\r\n\tif (len(mycmd)>0):\r\n\t\tepoch=int(time.time())\r\n\t\tser.write(str(epoch).encode())\r\n\t\tser.write(b'\\n')\r\n\t\tprint(str(epoch))"
},
{
"alpha_fraction": 0.49284064769744873,
"alphanum_fraction": 0.5250577330589294,
"avg_line_length": 19.435644149780273,
"blob_id": "3e9dc5c75562660c770a07beaddf51cd6a173b3f",
"content_id": "dc657a1d853144d778e75442c151618dc10c5c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8660,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 404,
"path": "/clock.ino",
"repo_name": "JerryBinder/Arduino-Time",
"src_encoding": "UTF-8",
"text": "#include <Time.h>\r\n#include <TimeLib.h>\r\n#include <LiquidCrystal.h>\r\n\r\n#define TIME_MSG_LEN 11 // time sync to PC is HEADER and unix time_t as ten ascii digits\r\n#define TIME_HEADER 255 // Header tag for serial time sync message\r\n\r\nLiquidCrystal lcd(12, 11, 5, 4, 3, 2);\r\n\r\nconst int buttonBluePin = 7;\r\nconst int buttonOrangePin = 1;\r\nconst int buttonRedPin = 8;\r\nconst int redPin = 10;\r\nconst int yellowPin = 9;\r\nconst int whitePin = 6;\r\nconst long interval = 1000;\r\n\r\nconst bool debug = false; // displays button high/low states on second line\r\n\r\n // Buttons are named after the color of the wire connecting them to digital ports\r\nbool buttonOrangeState;\r\nbool buttonBlueState;\r\nbool buttonRedState;\r\nint clockMode; // used to switch between clock modes\r\nint elapsedSec; // current time saved in stopwatch\r\nint elapsedMin;\r\nunsigned long currentMillis;\r\nunsigned long previousMillis;\r\nbool running;\r\nint selectedTime; // determines whether hour (0), minute (1), or second (2) will be changed\r\n \r\nvoid setup() {\r\n // initialize the pushbutton pin as an input:\r\n pinMode(buttonBluePin, INPUT);\r\n pinMode(buttonOrangePin, INPUT);\r\n pinMode(buttonRedPin, INPUT);\r\n lcd.begin(16, 2);\r\n Serial.begin(9600);\r\n\r\n buttonOrangeState = 0;\r\n buttonBlueState = 0;\r\n buttonRedState = 0;\r\n clockMode = 0;\r\n elapsedSec = 0;\r\n elapsedMin = 0;\r\n currentMillis = 0;\r\n previousMillis = 0;\r\n running = 0;\r\n selectedTime = 0;\r\n\r\n setTime(12,00,00,12,11,2012); //can be set by clockMode 5\r\n\r\n //final setTime and getting time from USB should probably be here in setup\r\n}\r\n \r\nvoid loop() {\r\n // Clear LCD for new data\r\n lcd.setCursor(0,1);\r\n lcd.clear();\r\n lcd.setCursor(0,0);\r\n lcd.clear();\r\n\r\n setLedColors();\r\n \r\n // Get current state of the buttons\r\n buttonOrangeState = digitalRead(buttonOrangePin);\r\n buttonBlueState = digitalRead(buttonBluePin);\r\n buttonRedState = digitalRead(buttonRedPin);\r\n\r\n if(buttonBlueState == LOW)\r\n clockMode++;\r\n if(clockMode > 5)\r\n clockMode = 0;\r\n\r\n if(running && buttonOrangeState == LOW && clockMode != 5) {\r\n running = false;\r\n } \r\n else if(!running && buttonOrangeState == LOW && clockMode != 5) {\r\n running = true;\r\n }\r\n \r\n if(elapsedSec > 0 || elapsedMin > 0)\r\n {\r\n if(clockMode != 5 && buttonRedState == LOW)\r\n {\r\n elapsedSec = 0;\r\n running = false;\r\n }\r\n }\r\n \r\n\r\n switch(clockMode)\r\n {\r\n case 0: // military\r\n {\r\n lcd.print(hour());\r\n lcd.print(':');\r\n lcd.print(minute());\r\n lcd.print(':');\r\n lcd.print(second());\r\n if(elapsedSec > 0)\r\n {\r\n lcd.setCursor(0,1);\r\n if(running)\r\n lcd.print(\"Running: \");\r\n else\r\n lcd.print(\"Paused: \");\r\n lcd.print(elapsedMin);\r\n lcd.print(':');\r\n lcd.print(elapsedSec);\r\n }\r\n break;\r\n }\r\n case 1: // AM/PM\r\n {\r\n lcd.print(hourFormat12());\r\n lcd.print(':');\r\n lcd.print(minute());\r\n lcd.print(':');\r\n lcd.print(second());\r\n if(isAM())\r\n lcd.print(\" AM\");\r\n else\r\n lcd.print(\" PM\");\r\n if(elapsedSec > 0)\r\n {\r\n lcd.setCursor(0,1);\r\n if(running)\r\n lcd.print(\"Running: \");\r\n else\r\n lcd.print(\"Paused: \");\r\n lcd.print(elapsedMin);\r\n lcd.print(':');\r\n lcd.print(elapsedSec);\r\n }\r\n break;\r\n }\r\n case 2: // binary\r\n {\r\n lcd.print(hour(), BIN);\r\n lcd.print(':');\r\n lcd.print(minute(), BIN);\r\n lcd.print(':');\r\n lcd.setCursor(0,1);\r\n lcd.print(second(), BIN);\r\n break;\r\n }\r\n case 3: // hex\r\n {\r\n lcd.print(hour(), HEX);\r\n lcd.print(':');\r\n lcd.print(minute(), HEX);\r\n lcd.print(':');\r\n lcd.print(second(), HEX);\r\n if(elapsedSec > 0)\r\n {\r\n lcd.setCursor(0,1);\r\n if(running)\r\n lcd.print(\"Running: \");\r\n else\r\n lcd.print(\"Paused: \");\r\n lcd.print(elapsedMin);\r\n lcd.print(':');\r\n lcd.print(elapsedSec);\r\n }\r\n break;\r\n }\r\n case 4: // stopwatch\r\n {\r\n stopwatch();\r\n break;\r\n }\r\n case 5: // clock set\r\n {\r\n clockSet();\r\n break;\r\n }\r\n }\r\n\r\n // Increment stopwatch even if it's not being displayed, as long as running=true\r\n if(running && (millis() - previousMillis >= interval))\r\n {\r\n previousMillis = millis();\r\n elapsedSec++;\r\n }\r\n if(elapsedSec > 60)\r\n {\r\n elapsedSec = 0;\r\n elapsedMin++;\r\n }\r\n\r\n if(debug && clockMode < 2)\r\n {\r\n lcd.setCursor(0, 1);\r\n lcd.print(buttonBlueState);\r\n lcd.print(\" \");\r\n lcd.print(buttonOrangeState);\r\n lcd.print(\" \");\r\n lcd.print(buttonRedState);\r\n lcd.print(\" \");\r\n lcd.print(running);\r\n }\r\n\r\n if(running && (millis() - previousMillis >= interval))\r\n {\r\n previousMillis = millis();\r\n elapsedSec++;\r\n }\r\n \r\n if(clockMode == 5)\r\n delay(250);\r\n else\r\n delay(1000);\r\n}\r\n\r\n// Sets LED colors based on current hour\r\nvoid setLedColors()\r\n{\r\n switch(hour())\r\n {\r\n case 23:\r\n case 1:\r\n {\r\n analogWrite(redPin, 255); \r\n analogWrite(yellowPin, 145); \r\n analogWrite(whitePin, 0);\r\n break;\r\n }\r\n case 22:\r\n case 2:\r\n {\r\n analogWrite(redPin, 255); \r\n analogWrite(yellowPin, 165); \r\n analogWrite(whitePin, 0);\r\n break;\r\n }\r\n case 21:\r\n case 3:\r\n {\r\n analogWrite(redPin, 235); \r\n analogWrite(yellowPin, 185); \r\n analogWrite(whitePin, 0);\r\n break;\r\n }\r\n case 20:\r\n case 4:\r\n {\r\n analogWrite(redPin, 200); \r\n analogWrite(yellowPin, 215); \r\n analogWrite(whitePin, 0);\r\n break;\r\n }\r\n case 19:\r\n case 5:\r\n {\r\n analogWrite(redPin, 180); \r\n analogWrite(yellowPin, 235); \r\n analogWrite(whitePin, 100);\r\n break;\r\n }\r\n case 18:\r\n case 6:\r\n {\r\n analogWrite(redPin, 140); \r\n analogWrite(yellowPin, 255); \r\n analogWrite(whitePin, 125);\r\n break;\r\n }\r\n case 17:\r\n case 7:\r\n {\r\n analogWrite(redPin, 100); \r\n analogWrite(yellowPin, 235); \r\n analogWrite(whitePin, 160);\r\n break;\r\n }\r\n case 16:\r\n case 8:\r\n {\r\n analogWrite(redPin, 50); \r\n analogWrite(yellowPin, 215); \r\n analogWrite(whitePin, 200);\r\n break;\r\n }\r\n case 15:\r\n case 9:\r\n {\r\n analogWrite(redPin, 0); \r\n analogWrite(yellowPin, 195); \r\n analogWrite(whitePin, 220);\r\n break;\r\n }\r\n case 14:\r\n case 10:\r\n {\r\n analogWrite(redPin, 0); \r\n analogWrite(yellowPin, 175); \r\n analogWrite(whitePin, 240);\r\n break;\r\n }\r\n case 13:\r\n case 11:\r\n {\r\n analogWrite(redPin, 0); \r\n analogWrite(yellowPin, 155); \r\n analogWrite(whitePin, 255);\r\n break;\r\n }\r\n case 12:\r\n {\r\n analogWrite(redPin, 0); \r\n analogWrite(yellowPin, 135); \r\n analogWrite(whitePin, 255);\r\n break;\r\n }\r\n }\r\n}\r\n\r\nvoid stopwatch()\r\n{\r\n if(elapsedSec == 0 && elapsedMin == 0)\r\n lcd.print(\"0:0\");\r\n else\r\n {\r\n lcd.print(elapsedMin);\r\n lcd.print(':');\r\n lcd.print(elapsedSec);\r\n }\r\n\r\n if(elapsedSec== 0 && !running)\r\n {\r\n lcd.setCursor(0,1);\r\n lcd.print(\"Press to start.\");\r\n }\r\n\r\n if(elapsedSec > 0 && running)\r\n {\r\n lcd.setCursor(0,1);\r\n lcd.print(\"Running\");\r\n }\r\n\r\n if(elapsedSec > 0 && !running)\r\n {\r\n if(second() % 2 == 0)\r\n {\r\n lcd.setCursor(0,1);\r\n lcd.print(\"Paused\");\r\n }\r\n }\r\n}\r\n\r\nvoid clockSet()\r\n{\r\n if(buttonOrangeState == LOW)\r\n selectedTime++;\r\n if(selectedTime > 2)\r\n selectedTime = 0;\r\n \r\n switch(selectedTime)\r\n {\r\n case 0: // set hour\r\n {\r\n if(buttonRedState == LOW){\r\n setTime((hour()+1),minute(),second(),1,1,1970);\r\n }\r\n lcd.print(hour());\r\n lcd.print(':');\r\n lcd.print(minute());\r\n lcd.print(':');\r\n lcd.print(second());\r\n lcd.setCursor(0,1);\r\n lcd.print(\"^hour\");\r\n break;\r\n }\r\n case 1: // set minute\r\n {\r\n lcd.print(hour());\r\n lcd.print(':');\r\n if(buttonRedState == LOW){\r\n setTime(hour(),(minute()+1),second(),1,1,1970);\r\n }\r\n lcd.print(minute());\r\n lcd.print(':');\r\n lcd.print(second());\r\n lcd.setCursor(0,1);\r\n lcd.print(\" ^minute\");\r\n break;\r\n }\r\n case 2: // set second\r\n {\r\n lcd.print(hour());\r\n lcd.print(':');\r\n lcd.print(minute());\r\n lcd.print(':');\r\n if(buttonRedState == LOW){\r\n setTime(hour(),minute(),(second()+1),1,1,1970);\r\n }\r\n lcd.print(second());\r\n lcd.setCursor(0,1);\r\n lcd.print(\" ^second\");\r\n break;\r\n }\r\n }\r\n}\r\n"
}
] | 3 |
ai-are-better-than-humans/myFirstCProject
|
https://github.com/ai-are-better-than-humans/myFirstCProject
|
cbd2a1205d48fcb6ac21563e33751602263ee4e0
|
7e1c2990632b79bcbce67facc9ee6638a30528bc
|
087aa8b498d3bbccd61e225d59dae989036fa134
|
refs/heads/main
| 2023-01-08T14:16:52.645938 | 2020-11-09T16:03:26 | 2020-11-09T16:03:26 | 310,743,444 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6204690933227539,
"alphanum_fraction": 0.631130039691925,
"avg_line_length": 25.58823585510254,
"blob_id": "186802c00cfb8e78c2dee4abe2c871033d34ca0f",
"content_id": "514e73f317b163155b5d97320b70ffa64049622f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 17,
"path": "/ImageView.py",
"repo_name": "ai-are-better-than-humans/myFirstCProject",
"src_encoding": "UTF-8",
"text": "from matplotlib.pyplot import imshow, show\r\nimport numpy as np\r\n\r\n\r\nf = open(r\"<Desktop Location>\\Desktop\\img_temp\\pixels.txt\", \"r\")\r\nf2 = open(r\"<Desktop Location>\\Desktop\\img_temp\\info.txt\", \"r\")\r\n\r\nnewvals = [int(x) for x in f.readline().split(',') if x != '\\n']\r\ninfo = [int(x) for x in f2.readline().split(',') if x != '\\n']\r\n\r\nwidth = info[0]\r\nheight = info[1]\r\nbpx = info[2]\r\n\r\nnewvals = np.array(newvals).reshape((height, width, bpx))\r\nimshow(newvals)\r\nshow()\r\n"
},
{
"alpha_fraction": 0.5645105838775635,
"alphanum_fraction": 0.581061840057373,
"avg_line_length": 33.53403091430664,
"blob_id": "f12f88db8eddf39ce4997958e58ca750babbd40e",
"content_id": "9e0d82088efb2c39a39d682ea814ea2b45f070b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 20361,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 573,
"path": "/ImageWrite.c",
"repo_name": "ai-are-better-than-humans/myFirstCProject",
"src_encoding": "UTF-8",
"text": "//TODO: make errors more descriptive, add more restrictions to png data formatting, optimize code for speed, make code portable?? idrk lmao\r\n\r\n\r\n/*\r\nReferences:\r\n wikipedia.org/wiki/Portable_Network_Graphics\r\n libpng.org/pub/png\r\n w3.org/TR/PNG\r\n zlib.net\r\n\r\n\r\nBit of background info:\r\n-------------------------\r\nPNG's are composed of a 8-byte signature, and then multiple chunks.\r\nthe names of these chunks tell you what type of information they're carrying\r\n\r\nChunks have different types. There's critical and ancillary chunks.\r\ncritical chunks are the important ones, they contain stuff like the end of the file and actual pixel information.\r\nancillary chunks can be useful, but aren't required for the PNG to work.\r\n\r\nThese Chunks are made up of four parts:\r\n- A 4-byte value that represents the length of the information it has\r\n- A 4-byte value that represents the type of chunk\r\n- The actual information of the chunk, with a length determined by the first section\r\n- And a 4-byte CRC which is used to check if the data was corrupted\r\n\r\nThere are four Critical Chunk types:\r\n-IEND: Appears at end of file and holds no information.\r\n-IHDR: Appears at start of file and holds useful information, such as dimensions\r\n-IDAT: Holds pixel values, usually near end of file\r\n-PLTE: In some cases, the IDAT chunk wont hold ACTUAL rgb values; instead, it'll hold numbers which correspond to an index of a list of colors. The PLTE chunk is that list.\r\n\r\n\r\nDeeper Dive:\r\n-----------------\r\nThe IHDR Chunk contains ALOT of juicy information. Heres its structure:\r\n-A 4-byte value indicating the pictures width\r\n-A 4-byte value indicating the pictures height\r\n-A 1-byte value indicating the 'bit depth',\r\n *(essentially how many bits it takes to get represent one color channel)\r\n-A 1-byte value indicating the color type.\r\n *(Possible types are 3 - Indexed (uses PLTE), 0 - Grayscale, 4 - Grayscale with transparency, 2 - RGB, and 6 - RGB with transparency)\r\n-A 1-byte value indicating the compression method,\r\n *(as of now the only available option is deflate/inflate)\r\n-A 1-byte value indicating the filter method.\r\n *(Again, theres only available option, called Adaptive filtering)\r\n-A 1-byte value indicating the Interlace method.\r\n *(Interlacing allows the image to be transmitted over your shitty wifi better by sending information in passes, but does not affect the actual order of pixel values)\r\n\r\n ***(If you were to Write to a PNG, simply reverse this process)\r\nIn Order to actually GET the picture from a PNG, you need to:\r\n 1. Combine the data from all the IDAT chunks (there can be multiple)\r\n\r\n 2. Use the uncompress() function on the IDAT chunks to get the values we're going to work with\r\n\r\n 3. With these values, you'll need to preform 'Adaptive filtering'.\r\n With this, at the start of each row of the PNG, there is a filter byte. The value of this byte determines how the values in its row are filtered:\r\n\r\n > If the bytes value is 0, the current pixel is unchanged.\r\n > If the bytes value is 1, the current pixel is equal to the current pixel minus the previous one.\r\n > If the bytes value is 2, the current pixel is equal to the current pixel minus the one above it.\r\n > If the bytes value is 3, the current pixel is equal to the current pixel minus the average of the previous and above pixels\r\n > If the bytes value is 4, the current pixel is equal to the current pixel minus the result of the 'Paeth function' when given the left, above, and upper-left pixels.\r\n\r\n 4. Finally, if your image uses the PLTE chunk, replace all the numbers with their corresponding index.\r\n Otherwise, you should be left with values ordering top-left to bottom-right, with each value representing one color channel.\r\n If you group these numbers by color channels per pixel, you should have groups with x amount of values, each representing one pixel.\r\n*/\r\n\r\n\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n#include \"zlib.h\"\r\n\r\n\r\n#define bytesToInt(a, b, c, d) ((a) << 24 | (b) << 16 | (c) << 8 | (d))\r\n#define compType(a, b) ((a)[0]==(b)[0] && (a)[1]==(b)[1] && (a)[2]==(b)[2] && (a)[3]==(b)[3])\r\n\r\n// List of Critical Chunk Types\r\nconst unsigned char IEND_CHUNK[4] = {'I', 'E', 'N', 'D'};\r\nconst unsigned char IDAT_CHUNK[4] = {'I', 'D', 'A', 'T'};\r\nconst unsigned char IHDR_CHUNK[4] = {'I', 'H', 'D', 'R'};\r\nconst unsigned char PLTE_CHUNK[4] = {'P', 'L', 'T', 'E'};\r\n\r\n// List of Ancillary Chunk Types\r\nconst unsigned char BKGD_CHUNK[4] = {'b', 'K', 'G', 'D'};\r\nconst unsigned char CHRM_CHUNK[4] = {'c', 'H', 'R', 'M'};\r\nconst unsigned char DSIG_CHUNK[4] = {'d', 'S', 'I', 'G'};\r\nconst unsigned char EXIF_CHUNK[4] = {'e', 'X', 'I', 'f'};\r\nconst unsigned char GAMA_CHUNK[4] = {'g', 'A', 'M', 'A'};\r\nconst unsigned char HIST_CHUNK[4] = {'h', 'I', 'S', 'T'};\r\nconst unsigned char ICCP_CHUNK[4] = {'i', 'C', 'C', 'P'};\r\nconst unsigned char ITXT_CHUNK[4] = {'i', 'T', 'X', 't'};\r\nconst unsigned char PHYS_CHUNK[4] = {'p', 'H', 'Y', 's'};\r\nconst unsigned char SBIT_CHUNK[4] = {'s', 'B', 'I', 'T'};\r\nconst unsigned char SPLT_CHUNK[4] = {'s', 'P', 'L', 'T'};\r\nconst unsigned char SRGB_CHUNK[4] = {'s', 'R', 'G', 'B'};\r\nconst unsigned char STER_CHUNK[4] = {'s', 'T', 'E', 'R'};\r\nconst unsigned char TEXT_CHUNK[4] = {'t', 'E', 'X', 't'};\r\nconst unsigned char TIME_CHUNK[4] = {'t', 'I', 'M', 'E'};\r\nconst unsigned char TRNS_CHUNK[4] = {'t', 'R', 'N', 'S'};\r\nconst unsigned char ZTXT_CHUNK[4] = {'z', 'T', 'X', 't'};\r\n\r\n// An Example Of A Valid PNG Header\r\nconst unsigned char SIGNATURE[8] = {0x89, 0x50, 0x4E, 0x47, 0x0D, 0x0A, 0x1A, 0x0A};\r\n// An Array Which Acts As A Lookup Table For The Error Detection Process\r\nunsigned long CRC_TABLE[256];\r\n// Used To See If We Still Need To Compute The CRC Table, Since Its Quicker Than Having It Predefined\r\nstatic int CRC_TABLE_COMPUTED = 0;\r\n\r\n\r\ntypedef struct Pix {\r\n int RGBA[4];\r\n} Pix;\r\ntypedef struct PLTE {\r\n Pix* indexes;\r\n int indexCount;\r\n} PLTE;\r\ntypedef struct Chunk {\r\n int length;\r\n unsigned char type[4];\r\n unsigned char *data;\r\n unsigned char crc[4];\r\n} Chunk;\r\ntypedef struct IHDR {\r\n int width;\r\n int height;\r\n int bitd;\r\n int colort;\r\n int compm;\r\n int filterm;\r\n int interlacem;\r\n int channels;\r\n} IHDR;\r\ntypedef struct PNG {\r\n Chunk* chunks;\r\n int chunkCount;\r\n\r\n unsigned char* bytes;\r\n long int byteCount;\r\n\r\n IHDR iheader;\r\n PLTE palette;\r\n Pix* pixels;\r\n} PNG;\r\n\r\n\r\nPNG getPNGFromPath(char*);\r\nPLTE getPaletteFromChunks(Chunk*, int);\r\nChunk* getChunksFromBytes(unsigned char*);\r\n\r\nint hasValidCRC(Chunk*);\r\nint getChunkCount(unsigned char*);\r\nint hasValidBitDepth(int, int);\r\nint hasValidSignature(unsigned char*);\r\n\r\nvoid freePNG(PNG);\r\nvoid makeCRCTable(void);\r\nvoid throwError(char*, int, int);\r\nvoid getBytesFromPath(char*, long int*, unsigned char**);\r\n\r\nunsigned char* getImgFromChunks(Chunk*, IHDR);\r\nunsigned long CRC32(unsigned long, unsigned char*, int);\r\nPix* getPixelsFromImg(unsigned char*, IHDR, PLTE);\r\n\r\n\r\n// An example of a program which takes a PNG, and writes its channels, width, height, and pixel information to two files\r\nint main(int argc, char* argv[])\r\n{\r\n int output_text = 1; // Debugging variable\r\n PNG fpng = getPNGFromPath(argv[1]);\r\n\r\n if(output_text){\r\n printf(\"\\n\\nthere are %d chunks\\n\", fpng.chunkCount);\r\n printf(\"width: %d - height: %d\\n\", fpng.iheader.width, fpng.iheader.height);\r\n printf(\"color channels: %d\\n\", fpng.iheader.channels);\r\n printf(\"bit depth: %d\\n\", fpng.iheader.bitd);\r\n\r\n if(fpng.palette.indexCount != 0){\r\n printf(\"palette: \");\r\n for(int j = 0; j < fpng.palette.indexCount; j++){\r\n printf(\"(%d,%d,%d) \", fpng.palette.indexes[j].RGBA[0], fpng.palette.indexes[j].RGBA[1], fpng.palette.indexes[j].RGBA[2]);\r\n }\r\n printf(\"\\n\");\r\n }\r\n printf(\"\\n#-#-#-#-#-#-#-#-#-#-#\\n\");\r\n\r\n for(int i = 0; i < fpng.chunkCount; i++){\r\n printf(\"value of type: %.4s\\n\", fpng.chunks[i].type);\r\n printf(\"value of data: %.4s\\n\", fpng.chunks[i].data);\r\n printf(\"value of length: %d\\n\", fpng.chunks[i].length);\r\n printf(\"value of crc: %.4s\\n\\n\", fpng.chunks[i].crc);\r\n printf(i != fpng.chunkCount-1 ? \"--------------------\\n\" : \"\\n\");\r\n }\r\n }\r\n\r\n FILE *fp = fopen(\"C:\\\\Users\\\\mlfre\\\\OneDrive\\\\Desktop\\\\img_temp\\\\pixels.txt\", \"w\");\r\n throwError(\"ERROR: could not open pixels.txt\\n\\n\", fp == NULL, EXIT_FAILURE);\r\n\r\n for(int i = 0; i < fpng.iheader.width*fpng.iheader.height; i++){\r\n\r\n if(fpng.palette.indexCount == 0){\r\n for(int k = 0; k < fpng.iheader.channels; k++){\r\n fprintf(fp, \"%d,\", fpng.pixels[i].RGBA[k]);\r\n }\r\n }\r\n else{\r\n fprintf(fp, \"%d,\", fpng.pixels[i].RGBA[0]);\r\n fprintf(fp, \"%d,\", fpng.pixels[i].RGBA[1]);\r\n fprintf(fp, \"%d,\", fpng.pixels[i].RGBA[2]);\r\n }\r\n }\r\n fprintf(fp, \"\\n\");\r\n\r\n FILE *fp2 = fopen(\"C:\\\\Users\\\\mlfre\\\\OneDrive\\\\Desktop\\\\img_temp\\\\info.txt\", \"w\");\r\n throwError(\"ERROR: could not open info.txt\\n\\n\", fp2 == NULL, EXIT_FAILURE);\r\n\r\n fprintf(fp2, \"%d,\", fpng.iheader.width);\r\n fprintf(fp2, \"%d,\", fpng.iheader.height);\r\n if(fpng.palette.indexCount == 0) fprintf(fp2, \"%d\\n\", fpng.iheader.channels);\r\n else fprintf(fp2, \"3\");\r\n\r\n fclose(fp);\r\n fclose(fp2);\r\n\r\n freePNG(fpng);\r\n return 0;\r\n}\r\n\r\nint getChunkCount(unsigned char* bytes)\r\n{\r\n int count = 0;\r\n int length = 0;\r\n int next_seg = 7;\r\n unsigned char type[4] = {0, 0, 0, 0};\r\n\r\n while(!compType(type, IEND_CHUNK)){\r\n length = bytesToInt(bytes[next_seg+1], bytes[next_seg+2],\r\n bytes[next_seg+3], bytes[next_seg+4]);\r\n\r\n type[0] = bytes[next_seg+5];\r\n type[1] = bytes[next_seg+6];\r\n type[2] = bytes[next_seg+7];\r\n type[3] = bytes[next_seg+8];\r\n\r\n next_seg+=length+12;\r\n count++;\r\n\r\n }\r\n\r\n return count;\r\n}\r\n\r\nvoid throwError(char* message, int condition, int status)\r\n{\r\n if(condition){\r\n fprintf(stderr, message);\r\n exit(status);\r\n }\r\n}\r\n\r\nvoid freePNG(PNG fpng)\r\n{\r\n free(fpng.bytes);\r\n for(int i = 0; i < fpng.chunkCount; i++) free(fpng.chunks[i].data);\r\n free(fpng.chunks);\r\n free(fpng.palette.indexes);\r\n free(fpng.pixels);\r\n}\r\n\r\nvoid getBytesFromPath(char* path, long int* length, unsigned char** dest)\r\n{\r\n FILE *fp = fopen(path, \"rb\");\r\n throwError(\"ERROR: could not open file\\n\\n\", fp == NULL, EXIT_FAILURE);\r\n\r\n fseek(fp, 0, SEEK_END);\r\n *length = ftell(fp);\r\n\r\n rewind(fp);\r\n *dest = (unsigned char *)malloc(*length+1);\r\n fread(*dest, *length, 1, fp);\r\n fclose(fp);\r\n\r\n}\r\n\r\nPNG getPNGFromPath(char* path)\r\n{\r\n PNG new_png;\r\n int channels[7] = {1, 0, 3, 1, 2, 0, 4};\r\n\r\n getBytesFromPath(path, &new_png.byteCount, &new_png.bytes);\r\n new_png.chunkCount = getChunkCount(new_png.bytes);\r\n new_png.chunks = getChunksFromBytes(new_png.bytes);\r\n\r\n new_png.iheader.width = bytesToInt(new_png.chunks[0].data[0], new_png.chunks[0].data[1],\r\n new_png.chunks[0].data[2], new_png.chunks[0].data[3]);\r\n new_png.iheader.height = bytesToInt(new_png.chunks[0].data[4], new_png.chunks[0].data[5],\r\n new_png.chunks[0].data[6], new_png.chunks[0].data[7]);\r\n\r\n new_png.iheader.bitd = new_png.chunks[0].data[8];\r\n new_png.iheader.colort = new_png.chunks[0].data[9];\r\n new_png.iheader.compm = new_png.chunks[0].data[10];\r\n\r\n new_png.iheader.filterm = new_png.chunks[0].data[11];\r\n new_png.iheader.interlacem = new_png.chunks[0].data[12];\r\n new_png.iheader.channels = channels[new_png.iheader.colort];\r\n\r\n throwError(\"ERROR: PNG has an invalid bit depth\\n\\n\", !hasValidBitDepth(new_png.iheader.bitd, new_png.iheader.colort), EXIT_FAILURE);\r\n throwError(\"ERROR: PNG has an invalid CRC\\n\\n\", !hasValidCRC(new_png.chunks), EXIT_FAILURE);\r\n throwError(\"ERROR: PNG has an invalid signature\\n\\n\", !hasValidSignature(new_png.bytes), EXIT_FAILURE);\r\n\r\n new_png.palette = getPaletteFromChunks(new_png.chunks, new_png.chunkCount);\r\n unsigned char* temp = getImgFromChunks(new_png.chunks, new_png.iheader);\r\n new_png.pixels = getPixelsFromImg(temp, new_png.iheader, new_png.palette);\r\n\r\n free(temp);\r\n return new_png;\r\n}\r\n\r\nChunk* getChunksFromBytes(unsigned char* bytes)\r\n{\r\n int next_seg = 7;\r\n int chunks = 0;\r\n Chunk* chunk_array = (Chunk*) malloc(sizeof(Chunk)*getChunkCount(bytes));\r\n\r\n while(!compType(chunk_array[chunks-1].type, IEND_CHUNK)){\r\n chunk_array[chunks].length = bytesToInt(bytes[next_seg+1], bytes[next_seg+2],\r\n bytes[next_seg+3], bytes[next_seg+4]);\r\n\r\n chunk_array[chunks].type[0] = bytes[next_seg+5];\r\n chunk_array[chunks].type[1] = bytes[next_seg+6];\r\n chunk_array[chunks].type[2] = bytes[next_seg+7];\r\n chunk_array[chunks].type[3] = bytes[next_seg+8];\r\n\r\n chunk_array[chunks].data = calloc(chunk_array[chunks].length, 1);\r\n\r\n if(chunk_array[chunks].length > 0){\r\n for(int cnt = 0; cnt < chunk_array[chunks].length; cnt++){\r\n chunk_array[chunks].data[cnt] = bytes[next_seg+9+cnt];\r\n }\r\n }\r\n\r\n chunk_array[chunks].crc[0] = bytes[next_seg+chunk_array[chunks].length+9];\r\n chunk_array[chunks].crc[1] = bytes[next_seg+chunk_array[chunks].length+10];\r\n chunk_array[chunks].crc[2] = bytes[next_seg+chunk_array[chunks].length+11];\r\n chunk_array[chunks].crc[3] = bytes[next_seg+chunk_array[chunks].length+12];\r\n\r\n next_seg+=chunk_array[chunks].length+12;\r\n chunks++;\r\n\r\n }\r\n\r\n return chunk_array;\r\n}\r\n\r\nvoid makeCRCTable(void){\r\n unsigned long c;\r\n\r\n for (int n = 0; n < 256; n++) {\r\n c = (unsigned long) n;\r\n\r\n for (int k = 0; k < 8; k++) {\r\n c = c & 1 ? 0xedb88320L ^ (c >> 1) : c >> 1;\r\n }\r\n CRC_TABLE[n] = c;\r\n }\r\n}\r\n\r\nunsigned long CRC32(unsigned long crc, unsigned char *buf, int len){\r\n unsigned long c = crc ^ 0xffffffffL;\r\n\r\n if(!CRC_TABLE_COMPUTED){\r\n makeCRCTable();\r\n CRC_TABLE_COMPUTED = 1;\r\n }\r\n\r\n for (int n = 0; n < len; n++) {\r\n c = CRC_TABLE[(c ^ buf[n]) & 0xff] ^ (c >> 8);\r\n }\r\n\r\n return c ^ 0xffffffffL;\r\n}\r\n\r\n\r\nint hasValidSignature(unsigned char* bytes)\r\n{\r\n int equal = 1;\r\n for(int i = 0; i < 8; i++) equal = bytes[i] == SIGNATURE[i] ? equal : 0;\r\n return equal;\r\n}\r\n\r\nint hasValidBitDepth(int bitd, int colort)\r\n{\r\n if (bitd == 8) return 1;\r\n switch(colort){\r\n case 0:\r\n return bitd == 1 || bitd == 2 || bitd == 4 || bitd == 16;\r\n case 3:\r\n return bitd == 1 || bitd == 2 || bitd == 4;\r\n case 2:\r\n case 4:\r\n case 6:\r\n return bitd == 16;\r\n default:\r\n return 0;\r\n }\r\n}\r\n\r\nint hasValidCRC(Chunk* chunks)\r\n{\r\n int count = 0;\r\n\r\n unsigned long type_crc;\r\n unsigned long chunk_crc;\r\n unsigned long actual_crc;\r\n\r\n while(!compType(chunks[count].type, IEND_CHUNK))\r\n {\r\n type_crc = CRC32(0L, chunks[count].type, 4);\r\n chunk_crc = CRC32(type_crc, chunks[count].data, chunks[count].length);\r\n actual_crc = bytesToInt(chunks[count].crc[0], chunks[count].crc[1],\r\n chunks[count].crc[2], chunks[count].crc[3]);\r\n\r\n if(actual_crc != chunk_crc) return 0;\r\n\r\n count++;\r\n }\r\n\r\n return 1;\r\n}\r\n\r\nPLTE getPaletteFromChunks(Chunk* chunks, int chunkCount)\r\n{\r\n PLTE img_palette;\r\n\r\n for(int chk = 0; chk < chunkCount; chk++){\r\n if(compType(chunks[chk].type, PLTE_CHUNK)){\r\n\r\n img_palette.indexCount = chunks[chk].length/3;\r\n img_palette.indexes = (Pix*) malloc(sizeof(Pix)*img_palette.indexCount);\r\n\r\n for(int i = 0; i < img_palette.indexCount; i++){\r\n img_palette.indexes[i].RGBA[0] = chunks[chk].data[(i*3)];\r\n img_palette.indexes[i].RGBA[1] = chunks[chk].data[(i*3)+1];\r\n img_palette.indexes[i].RGBA[2] = chunks[chk].data[(i*3)+2];\r\n img_palette.indexes[i].RGBA[3] = 0;\r\n }\r\n break;\r\n }\r\n\r\n else if(compType(chunks[chk].type, IEND_CHUNK)){\r\n img_palette.indexes = NULL;\r\n img_palette.indexCount = 0;\r\n }\r\n }\r\n\r\n return img_palette;\r\n}\r\n\r\nunsigned char* getImgFromChunks(Chunk* chunks, IHDR img_info)\r\n{\r\n int count = 0;\r\n int type_count = 0;\r\n int idat_count = 0;\r\n uLongf compressed_size = 0;\r\n uLongf uncompressed_size = img_info.height*(1+((img_info.bitd*img_info.channels*img_info.width+7)>>3));\r\n unsigned char* compressed_idat;\r\n unsigned char* uncompressed_idat = (unsigned char*) malloc(uncompressed_size);\r\n\r\n\r\n while(1){\r\n if (compType(chunks[count].type, IDAT_CHUNK)){\r\n for(; compType(chunks[count+idat_count].type, IDAT_CHUNK); idat_count++){\r\n compressed_size += chunks[count+idat_count].length;\r\n }\r\n\r\n compressed_idat = (unsigned char*) malloc(compressed_size);\r\n for(int j = 0; j < idat_count; j++){\r\n for(int i = 0; i < chunks[count+j].length; i++){\r\n compressed_idat[type_count] = chunks[count+j].data[i];\r\n type_count++;\r\n }\r\n }\r\n break;\r\n }\r\n count++;\r\n }\r\n\r\n int ret = uncompress(uncompressed_idat, &uncompressed_size, compressed_idat, compressed_size);\r\n free(compressed_idat);\r\n\r\n return ret == 0 ? uncompressed_idat : '\\0';\r\n}\r\n\r\nint PaethPredictor(int a, int b, int c)\r\n{\r\n int pa = abs(b - c);\r\n int pb = abs(a - c);\r\n int pc = abs(a + b - (2*c));\r\n\r\n if(pa <= pb && pa <= pc) return a;\r\n else if(pb <= pc) return b;\r\n return c;\r\n}\r\n\r\nPix* getPixelsFromImg(unsigned char* img, IHDR img_info, PLTE color_indexes)\r\n{\r\n int stride = ((img_info.bitd * img_info.channels * img_info.width + 7) >> 3);\r\n int* pixels = (int*) malloc(sizeof(int)*img_info.height*stride);\r\n Pix* rgba_pixels = (Pix*) malloc(sizeof(Pix)*img_info.width*img_info.height);\r\n\r\n int i = 0;\r\n int current_pixel = 0;\r\n int filter_type;\r\n\r\n int filt_a;\r\n int filt_b;\r\n int filt_c;\r\n\r\n int bpp = stride/img_info.width;\r\n\r\n for(int r = 0; r < img_info.height; r++){\r\n filter_type = img[i];\r\n i++;\r\n for(int c = 0; c < stride; c++){\r\n\r\n filt_a = c >= bpp ? pixels[r * stride + c - bpp] : 0;\r\n filt_b = r > 0 ? pixels[(r - 1) * stride + c] : 0;\r\n filt_c = r > 0 && c >= bpp ? pixels[(r - 1) * stride + c - bpp] : 0;\r\n\r\n switch(filter_type){\r\n case 0:\r\n pixels[current_pixel] = img[i] & 0xff;\r\n break;\r\n case 1:\r\n pixels[current_pixel] = (img[i] + filt_a) & 0xff;\r\n break;\r\n case 2:\r\n pixels[current_pixel] = (img[i] + filt_b) & 0xff;\r\n break;\r\n case 3:\r\n pixels[current_pixel] = (img[i] + filt_a + filt_c) & 0xff;\r\n break;\r\n case 4:\r\n pixels[current_pixel] = (img[i] + PaethPredictor(filt_a, filt_b, filt_c)) & 0xff;\r\n break;\r\n }\r\n current_pixel++;\r\n i++;\r\n }\r\n }\r\n\r\n for(int pixl = 0; pixl < img_info.width*img_info.height; pixl++){\r\n rgba_pixels[pixl].RGBA[0] = 0;\r\n rgba_pixels[pixl].RGBA[1] = 0;\r\n rgba_pixels[pixl].RGBA[2] = 0;\r\n rgba_pixels[pixl].RGBA[3] = 0;\r\n\r\n if(color_indexes.indexCount == 0){\r\n for(int chnl = 0; chnl < img_info.channels; chnl++){\r\n rgba_pixels[pixl].RGBA[chnl] = pixels[(pixl*img_info.channels)+chnl];\r\n }\r\n }\r\n else{\r\n rgba_pixels[pixl].RGBA[0] = color_indexes.indexes[pixels[pixl]].RGBA[0];\r\n rgba_pixels[pixl].RGBA[1] = color_indexes.indexes[pixels[pixl]].RGBA[1];\r\n rgba_pixels[pixl].RGBA[2] = color_indexes.indexes[pixels[pixl]].RGBA[2];\r\n }\r\n }\r\n\r\n free(pixels);\r\n return rgba_pixels;\r\n}\r\n"
},
{
"alpha_fraction": 0.8045112490653992,
"alphanum_fraction": 0.8045112490653992,
"avg_line_length": 65.5,
"blob_id": "1e00f154a30289a8560f97a5f1a3e431daccfde3",
"content_id": "28b2133b3a59fd3175c36bb9450970350db8a03e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ai-are-better-than-humans/myFirstCProject",
"src_encoding": "UTF-8",
"text": "# myFirstCProject\njust a simple c program to read png information. You can find out more about how this is preformed in ImageWrite.c\n"
}
] | 3 |
tianjingying/Calculator
|
https://github.com/tianjingying/Calculator
|
f84ca7050af5db71843b0525ef5778276d0fd7cd
|
7ce9339381442f1ad114893e0c03c5bd007e11b5
|
545a5aac1592471900a05a78aaa85deb593ca82e
|
refs/heads/master
| 2021-01-18T23:55:51.694743 | 2017-04-12T16:14:03 | 2017-04-12T16:14:03 | 87,133,431 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.3859960436820984,
"alphanum_fraction": 0.4100591838359833,
"avg_line_length": 27.615819931030273,
"blob_id": "992c4e08a4abc505f65207e7d0ea19fcce188aa0",
"content_id": "0ffe4de4a513913aa77bf0c3d2a2dbcfee6320d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5420,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 177,
"path": "/cal.py",
"repo_name": "tianjingying/Calculator",
"src_encoding": "UTF-8",
"text": "import re\n\ndef init_action(expression):\n \"\"\"\n # 初始化表达式\n :param expression: \"-1-20*-3\"\n :return: res ['-1', '-', '20', '*', '-3']\n \"\"\"\n res = []\n tag = False\n char = \"\"\n for i in expression:\n if i.isdigit():\n tag = True\n char += i\n else:\n # 不是数字,就是符号\n if tag:\n #遇到符号,且之前有数字\n if i == \".\":\n # 解决遇到小数的情况\n char += i\n else:\n res.append(char)\n char = \"\"\n res.append(i)\n tag = False\n else:\n #遇到符号,之前没数字\n if i == \"-\":\n char = i\n else:\n res.append(i)\n pass\n if len(char) > 0:\n res.append(char)\n return res\n\ndef delete_space(expression):\n res = \"\"\n for i in expression:\n if i == \" \":\n continue\n res += i\n pass\n return res\n\ndef priority(exp , opt_list):\n \"\"\"\n 判断优先级\n :param exp: 当前符号\n :param opt_list: 符号栈\n :return:\">\" 当前符号优先级大于栈顶元素优先级\n \"<\" 当前符号优先级小于栈顶元素优先级\n \"=\" : 当前符号优先级等于栈顶元素优先级\n \"\"\"\n laval1 = [\"+\",\"-\"]\n laval2 = [\"*\",\"/\"]\n if exp in laval1:\n if opt_list[-1] in laval1:\n # 都是 + — 同一优先级\n return \"=\"\n else:\n return \"<\"\n if exp in laval2:\n if opt_list[-1] in laval2 :\n return \"=\"\n elif opt_list[-1] in laval1:\n return \">\"\n\n\ndef compute(num1, opt, num2 ):\n \"\"\"\n 计算\n :param num1: 第一操作数\n :param opt: 运算符\n :param num2: 第二操作数\n :return:\n \"\"\"\n if opt == \"+\":\n return num1 + num2\n elif opt == \"-\" :\n return num1 - num2\n elif opt == \"*\":\n return num1 * num2\n elif opt == \"/\" :\n return num1 / num2\n else:\n return None\n\ndef calculate(exp_list):\n number_list = []\n opt_list = []\n symbol_list = [\"+\",\"-\",\"*\",\"/\",\"(\",\")\"]\n tag = False\n for exp in exp_list:\n if exp not in symbol_list:\n #是数字\n exp = float(exp)\n if not tag:\n number_list.append(exp)\n else:\n tag = False\n num2 = exp\n num1 = number_list.pop()\n opt = opt_list.pop()\n result = compute(num1, opt, num2)\n # print(\"result111 : %s\"%result)\n # print(\"num1 : %s\" % num1)\n # print(\"opt : %s\" % opt)\n # print(\"num2 : %s\" % num2)\n number_list.append(result)\n else:\n # 是符号\n if len(opt_list) == 0 :\n opt_list.append(exp)\n else:\n if priority(exp , opt_list) == \"=\" or priority(exp , opt_list) == \"<\":\n # 可以计算\n num1 = 0\n num2 = 0\n opt = opt_list.pop()\n if len(number_list) >= 2:\n num2 = number_list.pop()\n num1 = number_list.pop()\n result = compute(num1, opt, num2 )\n # print(\"result : %s\"%result)\n number_list.append(result)\n opt_list.append(exp)\n else:\n print(\"输入的表达式有误,不能运算\")\n return None\n elif priority(exp , opt_list) == \">\":\n tag = True\n opt_list.append(exp)\n\n # print(\"number_list : %s\"%number_list)\n # print(\"opt_list : %s\" % opt_list)\n if len(number_list) == 2 and len(opt_list) == 1:\n pass\n num2 = number_list.pop()\n num1 = number_list.pop()\n opt = opt_list.pop()\n return compute(num1, opt, num2)\n else:\n print(\"输入的表达式有误,不能运算\")\n return None\n\nif __name__ == \"__main__\":\n # expression = \"1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568/14 )) - (-4*3)/ (16-3*2) )\"\n # expression = \"-1 + 2-3 + 4 + 5+8\"\n # expression = \"2*2+3*4-22*6+4\"\n # expression = \"2*2+(3*(4-22)*6)*2+(4+5)-4\"\n while True:\n expression = input(\"请输入表达式: \").strip()\n expression = delete_space(expression)\n # print(\"expression : %s\"%expression)\n while True:\n match = re.search(r'\\([^()]+\\)',expression)\n if not match:\n break\n else:\n exp = match.group()\n exp_list = init_action(exp[1:-1])\n # print(\"exp_list : %s\"%exp_list)\n cal_result = calculate(exp_list)\n # print(\"cal_result:%s\"%cal_result)\n tmp = expression.replace(exp,str(cal_result))\n expression = tmp\n # print(\"expression: %s\"%expression)\n\n # print(\"expression--22 : %s\"%expression)\n\n exp_list = init_action(expression)\n # print(\"exp_list : %s\"%exp_list)\n cal_result = calculate(exp_list)\n print(\"计算结果:%s\"%cal_result)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6109510064125061,
"alphanum_fraction": 0.6743515729904175,
"avg_line_length": 12.760000228881836,
"blob_id": "f0e7ff216ea8b794cd4cd6c495ddf4a39cb01e77",
"content_id": "bdb52572a4567e2e9989d1d89a6fdcc20c0dcd56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 25,
"path": "/readme.md",
"repo_name": "tianjingying/Calculator",
"src_encoding": "UTF-8",
"text": "#menu\n##1.Employee_information[介绍]\n>模拟计算器开发\n\n##2.need environment[环境需求]\n`Python版本 >= Python3.0`\n\n##3.move[移植问题]\n 暂时不存在移植问题\n\n##4.menu.py 1.0 feature[特性]\n>*实现加减乘除及拓号优先级解析增\n\n\n##5.important .py[重要的Python文件]\n>*\tcal.py\n\n\n##6.how to[怎么执行]\n>* python3 cal.py , 运行程序后按照界面的提示操作\n\n##7.参见本目录中的 \"flowsheet.jpg\"文件\n\n##8.博客地址:\n\thttp://5506100.blog.51cto.com/\n\t\n\t"
}
] | 2 |
MGabr/evaluate-glint-word2vec
|
https://github.com/MGabr/evaluate-glint-word2vec
|
141424a61decff3e9fa6ba6899973ba6d828ad85
|
88a55895d797083e26a56b1c65e34fd93697f6f3
|
3614ecdd23dfd43d2d35b9bf6b3799fef032265d
|
refs/heads/master
| 2020-04-10T19:49:04.556039 | 2019-04-14T21:39:31 | 2019-04-14T21:39:31 | 161,248,215 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6891460418701172,
"alphanum_fraction": 0.6943336129188538,
"avg_line_length": 38.15625,
"blob_id": "b424e32353db688d724925d7f5e888948fc56357",
"content_id": "43c7c5d18a219f7540b7d14ef8f688196d39210a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2506,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 64,
"path": "/extras/get_corpus_stats.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom argparse import ArgumentParser, ArgumentDefaultsHelpFormatter\n\nfrom operator import add\n\nfrom pyspark.ml.feature import StopWordsRemover\nfrom pyspark.sql import SparkSession\nfrom pyspark.sql.types import Row\n\n\nparser = ArgumentParser(description=\"Get the counts of the top words.\", formatter_class=ArgumentDefaultsHelpFormatter)\nparser.add_argument(\"txtPath\", help=\"The path of the text file\")\nparser.add_argument(\"--stop-word-lang\", help=\"The language to use for removing stop words. \"\n \"Empty string means no stop word removal\", default=\"\")\nparser.add_argument(\"--stop-word-file\", help=\"The (additional) stop word file to use for removing stop words. \"\n \"Empty string means no stop word removal with file\", default=\"\")\nparser.add_argument(\"--min-count\", help=\"The minimum number of times a token must appear\", default=5, type=int)\nparser.add_argument(\"--top-count\", help=\"The number of top words to get the frequency for\", default=50, type=int)\nargs = parser.parse_args()\n\n\nspark = SparkSession.builder \\\n .appName(\"get frequent words\") \\\n .config(\"spark.sql.catalogImplementation\", \"in-memory\") \\\n .getOrCreate()\nsc = spark.sparkContext\n\n\nif args.stop_word_lang or args.stop_word_file:\n sentences = sc.textFile(args.txtPath).map(lambda row: Row(sentence_raw=row.split(\" \"))).toDF()\n stopWords = []\n if args.stop_word_lang:\n stopWords += StopWordsRemover.loadDefaultStopWords(args.stop_word_lang)\n if args.stop_word_file:\n stopWords += sc.textFile(args.stop_word_file).collect()\n remover = StopWordsRemover(inputCol=\"sentence_raw\", outputCol=\"sentence\", stopWords=stopWords)\n sentences = remover.transform(sentences)\nelse:\n sentences = sc.textFile(args.txtPath).map(lambda row: Row(sentence=row.split(\" \"))).toDF()\n\n\nwords = sentences.rdd.map(lambda row: row.sentence).flatMap(lambda x: x)\n\nwordCounts = words.map(lambda w: (w, 1)) \\\n .reduceByKey(add) \\\n .filter(lambda w: w[1] >= args.min_count) \\\n\nvocabCount = wordCounts.count()\n\nwordCount = wordCounts.reduce(lambda x, y: (\"\", x[1] + y[1]))[1]\n\nwordCounts = wordCounts.collect()\nwordCounts.sort(key=lambda x: x[1], reverse=True)\ntopWordCounts = wordCounts[:args.top_count]\n\n\nsc.stop()\n\n\nprint(\"Vocabulary size: \" + str(vocabCount))\nprint(\"Words in corpus: \" + str(wordCount))\nfor wordCount in topWordCounts:\n print(str(wordCount[0].encode(\"utf-8\")) + \": \" + str(wordCount[1]))\n"
},
{
"alpha_fraction": 0.7449392676353455,
"alphanum_fraction": 0.7449392676353455,
"avg_line_length": 31.933332443237305,
"blob_id": "be2816fcd9445bbf6cf208b89067a5c4b82083cf",
"content_id": "6826f637dc44720b6b74fa9b29a01cace417f68c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 15,
"path": "/get_texts.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "from argparse import ArgumentParser\n\nfrom gensim.corpora import WikiCorpus\n\n\nparser = ArgumentParser(description=\"Convert a wikipedia dump into a txt file.\")\nparser.add_argument(\"wikiPath\", help=\"The path of the wikipedia dump\")\nparser.add_argument(\"outputPath\", help=\"The output path\")\nargs = parser.parse_args()\n\n\nwith open(args.outputPath, 'w') as output:\n\twiki = WikiCorpus(args.wikiPath, lemmatize=False, dictionary={})\n\tfor text in wiki.get_texts():\n\t\toutput.write(\" \".join(text) + \"\\n\")\n"
},
{
"alpha_fraction": 0.7180094718933105,
"alphanum_fraction": 0.7180094718933105,
"avg_line_length": 39.19047546386719,
"blob_id": "194fb74172d9856c0460caa5b4ddeea83aaa7f05",
"content_id": "81a41ae9f8b5b80dda23bee673f3feb33fc91073",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 21,
"path": "/get_article_texts.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "import wikipedia\n\nfrom argparse import ArgumentParser, ArgumentDefaultsHelpFormatter\n\n\nparser = ArgumentParser(description=\"Get wikipedia articles as a txt file.\",\n formatter_class=ArgumentDefaultsHelpFormatter)\nparser.add_argument(\"articlesPath\", help=\"The path of the txt file with wikipedia article titles\")\nparser.add_argument(\"outputPath\", help=\"The output path\")\nparser.add_argument(\"--lang\", help=\"The language of the wikipedia articles\", default=\"en\")\nargs = parser.parse_args()\n\n\nwikipedia.set_lang(args.lang)\nwikipedia.set_rate_limiting(True)\nwith open(args.outputPath, 'w') as output:\n with open(args.articlesPath, 'r') as articlesfile:\n for article in articlesfile:\n article = article.replace(\"\\n\", \"\").replace(\" \", \"_\")\n\n output.write(wikipedia.page(article).content.lower())\n"
},
{
"alpha_fraction": 0.7714365124702454,
"alphanum_fraction": 0.7861915230751038,
"avg_line_length": 54.27692413330078,
"blob_id": "dd17484a704cdc55710e2ca0506b1b109d84e35d",
"content_id": "11bcb5b519bbe164ac03513eec9b7d45441219e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3592,
"license_type": "no_license",
"max_line_length": 271,
"num_lines": 65,
"path": "/README.md",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "# Glint-Word2Vec Evaluation\n\nScripts for comparing the default Spark ML implementation of Word2Vec or the Gensim implementation\nwith a custom implementation of Word2Vec using the Glint parameter server with specialized \noperations for efficient distributed Word2Vec computation.\n\nThe [project report](https://github.com/MGabr/evaluate-glint-word2vec/blob/master/project_report.pdf) sums up experiments performed.\n\n## Usage\n\n### Evaluation sets\n\nThe models are evaluated on the SimLex 999 and wordsim 353 evaluation sets.\nThe original english sets are provided as well as german sets from \nhttps://github.com/iraleviant/eval-multilingual-simlex.\n\nFurther word analogies to evaluate and visualize via PCA will need to be specified as csv file. \nAn example is ``example_country_capitals_de.csv`` which consists of german country-capital \nrelations. The country-capital relations from the original Word2Vec paper are also provided.\n\n### Data sets\n\nAs dataset to train Word2Vec on you can download a wikipedia dump and then extract it \nto a text file with ``get_texts.py``. For testing, a subset of articles from a wikipedia \ndump can be created with ``get_analogy_texts.py``. Another possibility is getting \nspecific wikipedia articles with ``get_articles_texts.py``. The articles to get will need\nto be specified as txt file. An example is ``example_country_capitals_de_articles.txt``.\nAnother option is using the script ``demo-download-big-model-v1.sh`` as used in the original\nword2vec open source implementation.\n\n### Training and evaluating\n\nFor the training and evaluation you will need the ``glint-word2vec-assembly-1.0.jar`` \nand the python binding file ``ml_glintword2vec.py`` as zip from \nhttps://github.com/MGabr/glint-word2vec. These will have to be specified as ``--jars`` \nand ``--py-files`` options of ``spark-submit``.\n\n``train_word2vec.py`` can then be used to train a Glint, Gensim or standard Spark ML model and \n``evaluate_word2vec.py`` to evaluate and visualize word analogies using a model.\n\nIn most cases you will want to remove stop words before training a model to avoid \nexploding gradients. This can be done with the ``--stop-word-lang`` and \n``--stop-word-file`` options.\n\n### Example\n\nAn example for evaluating Glint Word2Vec with default settings (150 partitions, 5 parameter servers)\non a german wikipedia dump on the original Word2Vec country-capitals analogies is the following.\n\n```bash\npython3 get_texts.py dewiki-latest-pages-articles.xml.bz2 dewiki-latest-pages-articles.txt\nspark-submit --num-executors 5 --executor-cores 30 --jars glint-word2vec-assembly-1.0.jar --py-files ml_glintword2vec.zip train_word2vec.py dewiki-latest-pages-articles.txt dewiki-latest-pages-articles.model glint --stop-word-lang de --stop-word-file stopwords/dewiki.txt\nspark-submit --num-executors 5 --executor-cores 1 --jars glint-word2vec-assembly-1.0.jar --py-files ml_glintword2vec.zip evaluate_word2vec.py evaluation/country_capitals_de.csv de dewiki-latest-pages-articles.model glint country_capitals_de.png\n```\n\nTo evaluate Glint Word2Vec with parameter servers running in a separate Spark application you have to \nstart them beforehand with a command like\n\n```bash\nspark-submit --num-executors 5 --executor-cores 20 --class glint.Main glint-word2vec-assembly-1.0.jar spark\n```\n\nAfterwards ``--parameter-server-host`` followed by the host of the parameter server master \n(visible in the output of the Spark application) has to be added as argument to ``train_word2vec.py``.\nThe separate parameter servers Spark application will also be terminated after training is finished."
},
{
"alpha_fraction": 0.7084547877311707,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 32.46341323852539,
"blob_id": "c5221a41c3c73cfeb2b97a0096fabade059f756e",
"content_id": "d10f9b628d28e329e528dafea134bd25590328b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1372,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 41,
"path": "/get_analogy_texts.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "from argparse import ArgumentParser, ArgumentDefaultsHelpFormatter\nimport csv\n\nfrom gensim.corpora import WikiCorpus\n\n\nparser = ArgumentParser(description=\"Get a number of articles containing analogy words from a wikipedia dump.\",\n\t\t\t\t\t\tformatter_class=ArgumentDefaultsHelpFormatter)\nparser.add_argument(\"csvPath\", help=\"The path to the csv containing the word analogies which should be contained\")\nparser.add_argument(\"wikiPath\", help=\"The path of the wikipedia dump\")\nparser.add_argument(\"outputPath\", help=\"The output path\")\nparser.add_argument(\"--n-articles\", help=\"The number of articles\", type=int, default=1000)\nargs = parser.parse_args()\n\n\nif args.wikiPath.endswith(\".txt\"):\n\tinp = open(args.wikiPath, \"r\")\n\twiki_file = False\nelse:\n\twiki = WikiCorpus(args.wikiPath, lemmatize=False, dictionary={})\n\tinp = wiki.get_texts()\n\twiki_file = True\n\ntry:\n\twith open(args.csvPath) as csvfile:\n\t\tword_analogies = [row for row in csv.reader(csvfile, delimiter=\",\")]\n\t\tremaining_n_articles = args.n_articles\n\t\twith open(args.outputPath, \"w\") as out:\n\t\t\tfor text in inp:\n\t\t\t\tfor word_analogy in word_analogies:\n\t\t\t\t\tif word_analogy[0] in text and word_analogy[1] in text:\n\t\t\t\t\t\tif wiki_file:\n\t\t\t\t\t\t\tout.write(\" \".join(text) + \"\\n\")\n\t\t\t\t\t\telse:\n\t\t\t\t\t\t\tout.write(text)\n\t\t\t\t\t\tremaining_n_articles -= 1\n\t\t\t\t\t\tbreak\n\t\t\t\tif remaining_n_articles == 0:\n\t\t\t\t\tbreak\nfinally:\n\tinp.close()\n"
},
{
"alpha_fraction": 0.7971014380455017,
"alphanum_fraction": 0.8405796885490417,
"avg_line_length": 7.75,
"blob_id": "d6a59df2767ee5db16a50b976a912572453e7fbc",
"content_id": "07162b3e32004c93048ed2464fc736be12f9020b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "gensim\nmatplotlib\nsklearn\npyspark==2.3.2\nwikipedia\nscipy\nnumpy\ngensim"
},
{
"alpha_fraction": 0.7196487188339233,
"alphanum_fraction": 0.7291200160980225,
"avg_line_length": 35.068321228027344,
"blob_id": "79050152c47aa3f8564150af18179ae57cc5f42c",
"content_id": "69c1bc6f559f534d0380492006568755cc52128e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5807,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 161,
"path": "/train_word2vec.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom argparse import ArgumentParser, ArgumentDefaultsHelpFormatter\nfrom time import time\n\nfrom pyspark.ml.feature import Word2Vec, StopWordsRemover\nfrom pyspark.sql import SparkSession\nfrom pyspark.sql.types import Row\n\n\nparser = ArgumentParser(description=\"Train a word2vec model.\", formatter_class=ArgumentDefaultsHelpFormatter)\nparser.add_argument(\"txtPath\", help=\"The path of the text file to use for training\")\nparser.add_argument(\"modelPath\", help=\"The path to save the trained model to\")\nparser.add_argument(\"modelType\", help=\"The type of model to train\", choices=(\"glint\", \"ml\", \"gensim\"))\n\nparser.add_argument(\"--step-size\",\n\t\t\t\t\thelp=\"The step size / learning rate. For glint model type too large values might result in \"\n\t\t\t\t\t\t \"exploding gradients and NaN vectors\", default=0.01875, type=float)\nparser.add_argument(\"--vector-size\", help=\"The vector size\", default=100, type=int)\nparser.add_argument(\"--window-size\", help=\"The window size\", default=5, type=int)\n\nparser.add_argument(\"--num-partitions\",\n\t\t\t\t\thelp=\"The number of partitions. Should equal num-executors * executor-cores\", default=150, type=int)\n\nparser.add_argument(\"--stop-word-lang\",\n\t\t\t\t\thelp=\"The language to use for removing default stop words. \"\n\t\t\t\t\t\t \"Empty string means no default stop word removal. \", default=\"\")\nparser.add_argument(\"--stop-word-file\",\n\t\t\t\t\thelp=\"The (additional) stop word file to use for removing stop words. \"\n\t\t\t\t\t\t \"Empty string means no stop word removal with file. \", default=\"\")\n\nparser.add_argument(\"--num-parameter-servers\",\n\t\t\t\t\thelp=\"The number of parameter servers to use. Set to 1 for local mode testing. \"\n\t\t\t\t\t\t \"Only relevant for glint model type\", default=5, type=int)\nparser.add_argument(\"--parameter-server-host\",\n\t\t\t\t\thelp=\"The host master host of the running parameter servers. \"\n\t\t\t\t\t\t \"If this is not set a standalone parameter server cluster is started in this Spark application. \"\n\t\t\t\t\t\t \"Only relevant for glint model type\", default=\"\")\nparser.add_argument(\"--batch-size\",\n\t\t\t\t\thelp=\"The mini-batch size. Too large values might result in exploding gradients and NaN vectors. \"\n\t\t\t\t\t\t \"Only relevant for glint model type\", default=10, type=int)\nparser.add_argument(\"--unigram-table-size\",\n\t\t\t\t\thelp=\"The size of the unigram table. Set to a lower value if there is not enough memory locally. \"\n\t\t\t\t\t\t \"Only relevant for glint model type\", default=100000000, type=int)\n\nargs = parser.parse_args()\n\n\ndef train_spark():\n\tfrom ml_glintword2vec import ServerSideGlintWord2Vec\n\n\t# initialize spark session with required settings\n\tspark = SparkSession.builder \\\n\t\t.appName(\"train word2vec\") \\\n\t\t.config(\"spark.driver.maxResultSize\", \"0\") \\\n\t\t.config(\"spark.kryoserializer.buffer.max\", \"2047m\") \\\n\t\t.config(\"spark.rpc.message.maxSize\", \"2047\") \\\n\t\t.config(\"spark.sql.catalogImplementation\", \"in-memory\") \\\n\t\t.config(\"spark.dynamicAllocation.enabled\", \"false\") \\\n\t\t.getOrCreate()\n\n\tsc = spark.sparkContext\n\n\t# choose model\n\tif args.modelType == \"glint\":\n\t\tword2vec = ServerSideGlintWord2Vec(\n\t\t\tseed=1,\n\t\t\tnumPartitions=args.num_partitions,\n\t\t\tinputCol=\"sentence\",\n\t\t\toutputCol=\"model\",\n\t\t\tstepSize=args.step_size,\n\t\t\tvectorSize=args.vector_size,\n\t\t\twindowSize=args.window_size,\n\t\t\tnumParameterServers=args.num_parameter_servers,\n\t\t\tparameterServerHost=args.parameter_server_host,\n\t\t\tunigramTableSize=args.unigram_table_size,\n\t\t\tbatchSize=args.batch_size\n\t\t)\n\telse:\n\t\tword2vec = Word2Vec(\n\t\t\tseed=1,\n\t\t\tnumPartitions=args.num_partitions,\n\t\t\tinputCol=\"sentence\",\n\t\t\toutputCol=\"model\",\n\t\t\tstepSize=args.step_size,\n\t\t\tvectorSize=args.vector_size,\n\t\t\twindowSize=args.window_size\n\t\t)\n\n\t# remove stop words and shuffle if specified\n\tif args.stop_word_lang or args.stop_word_file:\n\t\tsentences = sc.textFile(args.txtPath).map(lambda row: Row(sentence_raw=row.split(\" \"))).toDF()\n\t\tstopwords = []\n\t\tif args.stop_word_lang:\n\t\t\tstopwords += StopWordsRemover.loadDefaultStopWords(args.stop_word_lang)\n\t\tif args.stop_word_file:\n\t\t\tstopwords += sc.textFile(args.stop_word_file).collect()\n\t\tremover = StopWordsRemover(inputCol=\"sentence_raw\", outputCol=\"sentence\", stopWords=stopwords)\n\t\tsentences = remover.transform(sentences)\n\telse:\n\t\tsentences = sc.textFile(args.txtPath).map(lambda row: Row(sentence=row.split(\" \"))).toDF()\n\n\t# train and save model\n\tmodel = word2vec.fit(sentences)\n\tmodel.save(args.modelPath)\n\n\t# shutdown parameter server Spark application\n\tif args.modelType == \"glint\":\n\t\tmodel.stop(terminateOtherClients=True)\n\n\t# shutdown Spark application\n\tsc.stop()\n\n\ndef train_gensim():\n\tfrom gensim.corpora import TextCorpus\n\tfrom gensim.corpora.textcorpus import lower_to_unicode\n\tfrom gensim.models import Word2Vec as GensimWord2Vec\n\n\tstart = time()\n\n\tstopwords = []\n\tif args.stop_word_lang:\n\t\t# starting spark only for this...\n\t\tspark = SparkSession.builder.appName(\"load stop words\").getOrCreate()\n\t\tstopwords += StopWordsRemover.loadDefaultStopWords(args.stop_word_lang)\n\t\tspark.sparkContext.stop()\n\tif args.stop_word_file:\n\t\twith open(args.stop_word_file) as stop_word_file:\n\t\t\tstopwords += [word.strip(\"\\n\") for word in stop_word_file.readlines()]\n\n\tdef remove_stopwords(tokens):\n\t\treturn [token for token in tokens if token not in stopwords]\n\n\tcorpus = TextCorpus(\n\t\targs.txtPath,\n\t\tdictionary={None: None},\n\t\tcharacter_filters=[lower_to_unicode],\n\t\ttoken_filters=[remove_stopwords]\n\t)\n\n\tmodel = GensimWord2Vec(\n\t\tseed=1,\n\t\talpha=args.step_size,\n\t\tsize=args.vector_size,\n\t\twindow=args.window_size,\n\t\tsample=1e-6,\n sg=1\n\t)\n\tmodel.build_vocab(corpus.get_texts())\n\tmodel.train(corpus.get_texts(), total_examples=model.corpus_count, epochs=model.epochs)\n\tmodel.save(args.modelPath)\n\n\tend = time()\n\tprint(\"Gensim training took {} seconds\".format(end - start))\n\n\nif args.modelType == \"glint\" or args.modelType == \"ml\":\n\ttrain_spark()\nelse:\n\ttrain_gensim()\n"
},
{
"alpha_fraction": 0.6348734498023987,
"alphanum_fraction": 0.6584706902503967,
"avg_line_length": 38.93885040283203,
"blob_id": "a8eb06b39d42798c7ed5e4f73acc381445cf8a7d",
"content_id": "cfa0b2a7daed68335f3957f5443e055cc63e4be3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11103,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 278,
"path": "/evaluate_word2vec.py",
"repo_name": "MGabr/evaluate-glint-word2vec",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom argparse import ArgumentParser\nimport codecs\n\nfrom gensim.models import Word2Vec as GensimWord2Vec\nimport matplotlib\n\nmatplotlib.use('agg')\n\nfrom matplotlib import pyplot\nfrom numpy import dot, any, zeros\nfrom numpy.linalg import norm\nfrom pyspark.ml.feature import Word2VecModel\nfrom pyspark.sql import SparkSession\nfrom pyspark.sql.functions import udf, lower, col\nfrom pyspark.sql.types import StructType, StructField, StringType, ArrayType\nfrom sklearn.decomposition import PCA\nfrom scipy.stats import spearmanr\n\n\ndef words_and_vecs_from_csv(spark, model, csv_filename):\n if spark:\n schema = StructType([StructField(\"word1\", StringType(), False), StructField(\"word2\", StringType(), False)])\n df = spark.read.csv(csv_filename, header=False, schema=schema)\n df = df.select(lower(col(\"word1\")).alias(\"word1\"), lower(col(\"word2\")).alias(\"word2\"))\n\n rows = df.collect()\n words1 = [row.word1 for row in rows]\n words2 = [row.word2 for row in rows]\n\n as_array = udf(lambda s: [s], ArrayType(StringType(), False))\n df = df.withColumn(\"word1\", as_array(\"word1\")).withColumn(\"word2\", as_array(\"word2\"))\n wordvecs1 = [row.model for row in model.transform(df.withColumnRenamed(\"word1\", \"sentence\")).collect()]\n wordvecs2 = [row.model for row in model.transform(df.withColumnRenamed(\"word2\", \"sentence\")).collect()]\n else:\n words1 = []\n words2 = []\n with open(csv_filename, \"r\") as csv_file:\n for line in csv_file:\n row = line.strip(\"\\n\").split(\",\")\n words1.append(row[0])\n words2.append(row[1])\n\n wordvecs1 = [model.wv[word1] if word1 in model.wv else zeros(model.wv.vector_size) for word1 in words1]\n wordvecs2 = [model.wv[word2] if word2 in model.wv else zeros(model.wv.vector_size) for word2 in words2]\n\n return words1, words2, wordvecs1, wordvecs2\n\n\ndef wordvecs_from_tsv(spark, model, tsv_filename):\n if spark:\n df = spark.read.option(\"sep\", \"\\t\").csv(tsv_filename, header=True)\n df = df.select(lower(col(\"word1\")).alias(\"word1\"), lower(col(\"word2\")).alias(\"word2\"))\n\n as_array = udf(lambda s: [s], ArrayType(StringType(), False))\n df = df.withColumn(\"word1\", as_array(\"word1\")).withColumn(\"word2\", as_array(\"word2\"))\n\n wordvecs1 = {row.sentence[0]: row.model for row\n in model.transform(df.withColumnRenamed(\"word1\", \"sentence\")).collect()}\n wordvecs2 = {row.sentence[0]: row.model for row\n in model.transform(df.withColumnRenamed(\"word2\", \"sentence\")).collect()}\n\n wordvecs = {}\n wordvecs.update(wordvecs1)\n wordvecs.update(wordvecs2)\n # remove words with zero vectors\n wordvecs = {word: vector for (word, vector) in wordvecs.items() if any(vector)}\n else:\n wordvecs = {}\n with open(tsv_filename, \"r\") as tsv_file:\n for line in tsv_file:\n row = line.split(\"\\t\")\n word1 = row[0].lower()\n word2 = row[1].lower()\n if word1 in model.wv and word2 in model.wv:\n wordvecs[word1] = model.wv[word1]\n wordvecs[word2] = model.wv[word2]\n\n return wordvecs\n\n\ndef wordvecs_from_simlex(spark, model, language):\n return wordvecs_from_tsv(spark, model, \"evaluation/simlex-\" + language + \".txt\")\n\n\ndef wordvecs_from_wordsim353(spark, model, language):\n return wordvecs_from_tsv(spark, model, \"evaluation/wordsim353-\" + language + \".txt\")\n\n\ndef word_synonyms(words1, model):\n if hasattr(model, 'findSynonyms'):\n return [[(row.asDict()[\"word\"], row.asDict()[\"similarity\"])\n for row in model.findSynonyms(word1, 5).head(5)] for word1 in words1]\n else:\n return [model.most_similar([word1], topn=5) for word1 in words1 if word1 in model.wv]\n\n\ndef print_word_synonyms(words1, predicted_synonyms):\n for predicted_synonym, word1 in zip(predicted_synonyms, words1):\n words = [word.encode(\"utf-8\") for word, _ in predicted_synonym]\n similarities = [round(similarity, 4) for _, similarity in predicted_synonym]\n print(\"Predicted synonyms {} for {} with similarity {}\".format(words, word1.encode(\"utf-8\"), similarities))\n\n\ndef word_analogies(wordvecs1, wordvecs2, words1, words2):\n word2_minus_word1_vec = wordvecs2[0] - wordvecs1[0]\n if hasattr(model, 'findSynonyms'):\n return [[(row.asDict()[\"word\"], row.asDict()[\"similarity\"])\n for row in model.findSynonyms(word2_minus_word1_vec + wordvec1, 5).head(5)] for wordvec1 in wordvecs1]\n else:\n base_word1 = words1[0] if words1[0] in model.wv else zeros(model.wv.vector_size)\n base_word2 = words2[0] if words2[0] in model.wv else zeros(model.wv.vector_size)\n return [model.most_similar(positive=[base_word2, word1], negative=[base_word1], topn=5)\n for word1, word2 in zip(words1, words2) if word1 in model.wv and word2 in model.wv]\n\n\ndef print_word_analogies(words1, words2, predicted_words2):\n num_correct = 0\n for word1, word2, predicted_word2 in zip(words1, words2, predicted_words2):\n words = [word.encode(\"utf-8\") for word, _ in predicted_word2]\n similarities = [round(similarity, 4) for _, similarity in predicted_word2]\n print(\"Predicted analogies {} for {} with similarity {}\".format(words, word1.encode(\"utf-8\"), similarities))\n if words[0] == word2.encode(\"utf-8\"):\n num_correct += 1\n print(\"Predicted {} of {} analogies correctly\".format(num_correct, len(words1)))\n\n\ndef plot_word_analogies(words1, words2, wordvecs1, wordvecs2, save_plot_filename=None):\n words = words1 + words2\n vecs = wordvecs1 + wordvecs2\n\n # perform PCA\n pca = PCA(n_components=2)\n pca_vecs = pca.fit_transform(vecs)\n\n # plot words\n pyplot.scatter(pca_vecs[:, 0], pca_vecs[:, 1])\n for word1, word2 in zip(range(len(words1)), range(len(words1), 2 * len(words1))):\n pyplot.plot(pca_vecs[[word1, word2], 0], pca_vecs[[word1, word2], 1], linestyle=\"dashed\", color=\"gray\")\n for i, word in enumerate(words):\n pyplot.annotate(word, xy=(pca_vecs[i, 0], pca_vecs[i, 1]))\n\n # save or show plot\n if save_plot_filename:\n pyplot.savefig(save_plot_filename)\n else:\n pyplot.show()\n pyplot.clf()\n\n\ndef distance(v1, v2):\n \"\"\"\n Returns the cosine distance between two vectors.\n \"\"\"\n return 1 - dot(v1, v2) / ( norm(v1) * norm(v2) )\n\n\ndef correlation_and_coverage(word_vectors, language, source):\n \"\"\"\n This method computes the Spearman's rho correlation (with p-value) of the supplied word vectors.\n \"\"\"\n pair_list = []\n if source == \"simlex\":\n fread_simlex=codecs.open(\"evaluation/simlex-\" + language + \".txt\", 'r', 'utf-8')\n else:\n fread_simlex=codecs.open(\"evaluation/wordsim353-\" + language + \".txt\", 'r', 'utf-8')\n\n line_number = 0\n for line in fread_simlex:\n\n if line_number > 0:\n tokens = line.split()\n word_i = tokens[0].lower()\n word_j = tokens[1].lower()\n score = float(tokens[2])\n\n if word_i in word_vectors and word_j in word_vectors:\n pair_list.append( ((word_i, word_j), score) )\n else:\n pass\n line_number += 1\n\n pair_list.sort(key=lambda x: - x[1])\n\n coverage = len(pair_list)\n\n extracted_list = []\n extracted_scores = {}\n\n for (x,y) in pair_list:\n\n (word_i, word_j) = x\n current_distance = distance(word_vectors[word_i], word_vectors[word_j])\n extracted_scores[(word_i, word_j)] = current_distance\n extracted_list.append(((word_i, word_j), current_distance))\n\n extracted_list.sort(key=lambda x: x[1])\n\n spearman_original_list = []\n spearman_target_list = []\n\n for position_1, (word_pair, score_1) in enumerate(pair_list):\n score_2 = extracted_scores[word_pair]\n position_2 = extracted_list.index((word_pair, score_2))\n spearman_original_list.append(position_1)\n spearman_target_list.append(position_2)\n\n spearman_rho = spearmanr(spearman_original_list, spearman_target_list)\n\n return round(spearman_rho[0], 3), coverage\n\n\ndef print_simlex_correlation(word_vectors, language):\n score, coverage = correlation_and_coverage(word_vectors, language, \"simlex\")\n print(\"SimLex-999 score and coverage: {}, {}\".format(score, coverage))\n\n\ndef print_wordsim353_correlation(word_vectors, language):\n score, coverage = correlation_and_coverage(word_vectors, language, \"wordsim353\")\n print(\"WordSim overall score and coverage: {}, {}\".format(score, coverage))\n\n\nparser = ArgumentParser(description=\"Evaluate and visualize word analogies like countries to capitals of a ServerSideGlintWord2Vec model.\")\nparser.add_argument(\"csvPath\", help=\"The path to the csv containing the word analogies to predict\")\nparser.add_argument(\"language\", help=\"The language of the simlex and wordsim353 evaluation set to use\", choices=(\"de\", \"en\"))\nparser.add_argument(\"modelPath\", help=\"The path of the directory containing the trained model\")\nparser.add_argument(\"modelType\", help=\"The type of model to train\", choices=(\"glint\", \"ml\", \"gensim\"))\nparser.add_argument(\"visualizationPath\", help=\"The path to save the visualization to\")\nargs = parser.parse_args()\n\n\nif args.modelType == \"glint\" or args.modelType == \"ml\":\n # initialize spark session with required settings\n spark = SparkSession.builder \\\n .appName(\"evaluate word2vec\") \\\n .config(\"spark.driver.maxResultSize\", \"0\") \\\n .config(\"spark.kryoserializer.buffer.max\", \"2047m\") \\\n .config(\"spark.rpc.message.maxSize\", \"2047\") \\\n .config(\"spark.sql.catalogImplementation\", \"in-memory\") \\\n .config(\"spark.dynamicAllocation.enabled\", \"false\") \\\n .getOrCreate()\n\n sc = spark.sparkContext\nelse:\n spark = None\n sc = None\n\n# load model\nif args.modelType == \"glint\":\n from ml_glintword2vec import ServerSideGlintWord2VecModel\n model = ServerSideGlintWord2VecModel.load(args.modelPath)\nelif args.modelType == \"ml\":\n model = Word2VecModel.load(args.modelPath)\nelse:\n model = GensimWord2Vec.load(args.modelPath)\n\n# get required vectors with model\nwords1, words2, wordvecs1, wordvecs2 = words_and_vecs_from_csv(spark, model, args.csvPath)\nsimlex_wordvecs = wordvecs_from_simlex(spark, model, args.language)\nws353_wordvecs = wordvecs_from_wordsim353(spark, model, args.language)\npredicted_synonyms = word_synonyms(words1, model)\npredicted_words2 = word_analogies(wordvecs1, wordvecs2, words1, words2)\n\n# stop model\nif args.modelType == \"glint\":\n model.stop()\n\n# shutdown Spark application\nif sc:\n sc.stop()\n\n# evaluate and print results\nprint_word_synonyms(words1, predicted_synonyms)\nprint_word_analogies(words1, words2, predicted_words2)\nplot_word_analogies(words1, words2, wordvecs1, wordvecs2, save_plot_filename=args.visualizationPath)\nprint_simlex_correlation(simlex_wordvecs, args.language)\nprint_wordsim353_correlation(ws353_wordvecs, args.language)\n"
}
] | 8 |
cansadadeserfeliz/console-drawing-tool
|
https://github.com/cansadadeserfeliz/console-drawing-tool
|
65324a6f72115372b8dc8db24e3cf6680821c79f
|
4ebb8ead60084a41f845519f3cc601d6bf91e713
|
2564e597eb5dfb56b69c97cddfa469e6659d573d
|
refs/heads/master
| 2023-06-22T10:47:31.425773 | 2021-07-23T02:22:25 | 2021-07-23T02:22:25 | 388,544,641 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6186094284057617,
"alphanum_fraction": 0.6564416885375977,
"avg_line_length": 21.744186401367188,
"blob_id": "2dcab2412567f15f53e0671b0fe6f9d3e8637aac",
"content_id": "80a22087bf7d353bf25728d7a64b92a6d11f49ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 978,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 43,
"path": "/tests/conftest.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom drawing import Canvas\nfrom drawing import CreateLineCommand\nfrom drawing import CreateRectangleCommand\n\n\[email protected]\ndef canvas():\n return Canvas('C 20 4')\n\n\[email protected]\ndef filled_canvas(canvas):\n CreateLineCommand('L 1 2 6 2').draw(canvas)\n CreateLineCommand('L 6 3 6 4').draw(canvas)\n CreateRectangleCommand('R 16 1 20 3').draw(canvas)\n return canvas\n\n\ndef _write_to_file(filename, file_content):\n with open(filename, 'w') as writer:\n writer.write(file_content)\n\n\[email protected]\ndef input_file(tmpdir):\n input_file_content = \\\n 'C 20 4\\n' \\\n 'L 1 2 6 2\\n' \\\n 'L 6 3 6 4\\n' \\\n 'R 16 1 20 3\\n' \\\n 'B 10 3 o'\n input_file = tmpdir.join('input.txt')\n _write_to_file(input_file.strpath, input_file_content)\n return input_file\n\n\[email protected]\ndef output_file(tmpdir):\n output_file = tmpdir.join('output.txt')\n _write_to_file(output_file.strpath, '')\n return output_file\n"
},
{
"alpha_fraction": 0.4495515823364258,
"alphanum_fraction": 0.47421523928642273,
"avg_line_length": 31.436363220214844,
"blob_id": "a16faa34c2763ee244e43eb01aea2bde02e21953",
"content_id": "538087d78d6a0e3a07df1dfbe94cdd3fdba9a287",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3568,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 110,
"path": "/tests/test_main.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom main import read_input, draw_canvas_into_file\nfrom drawing import Canvas\nfrom drawing.exceptions import CommandNotFound, FileFormatError\n\nfrom .conftest import _write_to_file\n\n\ndef test_successfully_draw_in_file(input_file, output_file):\n canvas, commands = read_input(filename=input_file.strpath)\n\n assert canvas is not None\n assert isinstance(canvas, Canvas)\n assert canvas.w == 20\n assert canvas.h == 4\n assert len(commands) == 4\n\n draw_canvas_into_file(canvas, commands, filename=output_file.strpath)\n\n expected_output_file_content = \\\n '----------------------\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '----------------------\\n' \\\n '----------------------\\n' \\\n '| |\\n' \\\n '|xxxxxx |\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '----------------------\\n' \\\n '----------------------\\n' \\\n '| |\\n' \\\n '|xxxxxx |\\n' \\\n '| x |\\n' \\\n '| x |\\n' \\\n '----------------------\\n' \\\n '----------------------\\n' \\\n '| xxxxx|\\n' \\\n '|xxxxxx x x|\\n' \\\n '| x xxxxx|\\n' \\\n '| x |\\n' \\\n '----------------------\\n' \\\n '----------------------\\n' \\\n '|oooooooooooooooxxxxx|\\n' \\\n '|xxxxxxooooooooox x|\\n' \\\n '| xoooooooooxxxxx|\\n' \\\n '| xoooooooooooooo|\\n' \\\n '----------------------\\n'\n assert output_file.read() == expected_output_file_content\n\n\ndef test_read_input_fails_without_create_canvas_command(input_file):\n input_file_content = \\\n 'L 1 2 6 2\\n' \\\n 'L 6 3 6 4\\n' \\\n 'R 16 1 20 3\\n' \\\n 'B 10 3 o'\n _write_to_file(input_file.strpath, input_file_content)\n\n with pytest.raises(CommandNotFound) as excinfo:\n read_input(filename=input_file.strpath)\n assert excinfo.value.message == '\"Create Canvas\" command is not provided.'\n\n\ndef test_read_input_fails_with_repeated_create_canvas_command(input_file):\n input_file_content = \\\n 'C 20 4\\n' \\\n 'L 1 2 6 2\\n' \\\n 'L 6 3 6 4\\n' \\\n 'C 30 10\\n' \\\n 'R 16 1 20 3\\n' \\\n 'B 10 3 o'\n _write_to_file(input_file.strpath, input_file_content)\n\n with pytest.raises(FileFormatError) as excinfo:\n read_input(filename=input_file.strpath)\n assert excinfo.value.message == '\"Create Canvas\" command appears more than once.'\n\n\ndef test_read_input_fails_with_empty_lines(input_file):\n input_file_content = \\\n 'C 20 4\\n' \\\n 'L 1 2 6 2\\n' \\\n 'L 6 3 6 4\\n' \\\n ' \\n' \\\n 'R 16 1 20 3\\n' \\\n 'B 10 3 o'\n _write_to_file(input_file.strpath, input_file_content)\n\n with pytest.raises(FileFormatError) as excinfo:\n read_input(filename=input_file.strpath)\n assert excinfo.value.message == 'Input file cannot contain empty lines.'\n\n\ndef test_read_input_fails_with_unknown_command(input_file):\n input_file_content = \\\n 'C 20 4\\n' \\\n 'L 1 2 6 2\\n' \\\n 'L 6 3 6 4\\n' \\\n 'X 1 2 3\\n' \\\n 'R 16 1 20 3\\n' \\\n 'B 10 3 o'\n _write_to_file(input_file.strpath, input_file_content)\n\n with pytest.raises(CommandNotFound) as excinfo:\n read_input(filename=input_file.strpath)\n assert excinfo.value.message == 'Unknown command: \"X\".'\n"
},
{
"alpha_fraction": 0.47671785950660706,
"alphanum_fraction": 0.5055373907089233,
"avg_line_length": 30.911645889282227,
"blob_id": "6e8e901392cceaae4f6c956f7082a962638d42d4",
"content_id": "1a20a0df0321b9ba978af959970e8a30f7fc1c64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7946,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 249,
"path": "/tests/test_drawing.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom drawing import (\n Canvas,\n CreateLineCommand,\n CreateRectangleCommand,\n BucketFillCommand,\n)\nfrom drawing.exceptions import (\n CommandValidationError,\n DrawingError,\n)\n\n\nclass TestCommandCreation:\n\n def test_create_canvas(self):\n canvas = Canvas('C 20 4')\n\n assert canvas.w == 20\n assert canvas.h == 4\n\n @pytest.mark.parametrize('command_line', [\n 'C',\n 'C 20',\n 'X',\n 'X 20 4',\n 'C x 4',\n 'C 20 x',\n 'C x 4',\n 'C -1 4',\n 'C 20 -1',\n 'C 20 4 11',\n ])\n def test_fails_to_create_canvas_with_invalid_input(self, command_line):\n with pytest.raises(CommandValidationError):\n Canvas(command_line)\n\n def test_create_line_command(self):\n command = CreateLineCommand('L 1 2 6 2')\n\n assert command.x1 == 1\n assert command.y1 == 2\n assert command.x2 == 6\n assert command.y2 == 2\n\n @pytest.mark.parametrize('command_line', [\n 'L',\n 'X',\n 'L 1',\n 'L 1 2 6',\n 'L 1 2 6 2 6',\n 'L x 2 6 2',\n 'L 1 x 6 2',\n 'L 1 2 x 2',\n 'L 1 2 6 x',\n 'L -1 2 6 2',\n 'L 1 -2 6 2',\n 'L 1 2 -6 2',\n 'L 1 2 6 -2',\n ])\n def test_fails_to_create_line_command_with_invalid_input(self, command_line):\n with pytest.raises(CommandValidationError):\n CreateLineCommand(command_line)\n\n @pytest.mark.parametrize('command_line', [\n 'L 1 2 6 4',\n 'L 5 3 6 4',\n ])\n def test_fails_to_create_not_vertical_or_horizontal_line_command(self, command_line):\n with pytest.raises(CommandValidationError) as excinfo:\n CreateLineCommand(command_line)\n assert excinfo.value.message == 'Currently only horizontal or vertical lines are supported.'\n\n def test_create_rectangle_command(self):\n command = CreateRectangleCommand('R 1 2 6 2')\n\n assert command.x1 == 1\n assert command.y1 == 2\n assert command.x2 == 6\n assert command.y2 == 2\n\n @pytest.mark.parametrize('command_line, error_message', [\n ('R', ''),\n ('X', ''),\n ('R 1', ''),\n ('R 1 2 6', ''),\n ('R 1 2 6 2 6', ''),\n ('R x 2 6 2', ''),\n ('R 1 x 6 2', ''),\n ('R 1 2 x 2', ''),\n ('R 1 2 6 x', ''),\n ('R -1 2 6 2', ''),\n ('R 1 -2 6 2', ''),\n ('R 1 2 -6 2', ''),\n ('R 1 2 6 -2', ''),\n ('R 1 3 6 2', '(x1,y1) should be an upper left corner and (x2,y2) - lower right corner.'),\n ('R 7 2 6 2', '(x1,y1) should be an upper left corner and (x2,y2) - lower right corner.'),\n ])\n def test_fails_to_create_rectangle_command_with_invalid_input(self, command_line, error_message):\n with pytest.raises(CommandValidationError) as excinfo:\n CreateRectangleCommand(command_line)\n assert excinfo.value.message == error_message\n\n def test_bucket_fill_command(self):\n command = BucketFillCommand('B 10 3 o')\n\n assert command.x == 10\n assert command.y == 3\n assert command.c == 'o'\n\n @pytest.mark.parametrize('command_line', [\n 'B',\n 'X',\n 'B 10',\n 'B 10 3',\n 'B 10 3 o 1',\n 'B x 3 o',\n 'B 10 x o',\n 'B -1 3 o',\n 'B 10 -1 o',\n 'B 10 3 oo',\n ])\n def test_fails_to_bucket_fill_command_with_invalid_input(self, command_line):\n with pytest.raises(CommandValidationError):\n BucketFillCommand(command_line)\n\n\nclass TestDrawLine:\n\n def test_successfully_draw_vertical_line(self, canvas):\n command = CreateLineCommand('L 1 2 6 2')\n command.draw(canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '| |\\n' \\\n '|xxxxxx |\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '----------------------\\n'\n assert canvas.matrix_to_str() == expected_matrix\n\n @pytest.mark.parametrize('command_line', [\n 'L 1 2 21 2',\n 'L 6 3 6 5',\n ])\n def test_fails_if_line_does_not_match_canvas_area(self, command_line, canvas):\n command = CreateLineCommand(command_line)\n\n with pytest.raises(DrawingError) as excinfo:\n command.draw(canvas)\n assert excinfo.value.message == 'Cannot draw outside of the canvas boundaries.'\n\n def test_successfully_draw_horizontal_line(self, canvas):\n command = CreateLineCommand('L 6 3 6 4')\n command.draw(canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '| |\\n' \\\n '| |\\n' \\\n '| x |\\n' \\\n '| x |\\n' \\\n '----------------------\\n'\n assert canvas.matrix_to_str() == expected_matrix\n\n\nclass TestDrawRectangle:\n\n def test_successfully_draw_rectangle(self, canvas):\n command = CreateRectangleCommand('R 16 1 20 3')\n command.draw(canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '| xxxxx|\\n' \\\n '| x x|\\n' \\\n '| xxxxx|\\n' \\\n '| |\\n' \\\n '----------------------\\n'\n assert canvas.matrix_to_str() == expected_matrix\n\n @pytest.mark.parametrize('command_line', [\n 'R 16 1 20 5',\n 'R 16 1 21 3',\n ])\n def test_fails_if_rectangle_does_not_match_canvas_area(self, command_line, canvas):\n command = CreateRectangleCommand(command_line)\n\n with pytest.raises(DrawingError) as excinfo:\n command.draw(canvas)\n assert excinfo.value.message == 'Cannot draw outside of the canvas boundaries.'\n\n\nclass TestBucketFill:\n def test_successfully_fill_bucket(self, filled_canvas):\n BucketFillCommand('B 10 3 o').draw(filled_canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '|oooooooooooooooxxxxx|\\n' \\\n '|xxxxxxooooooooox x|\\n' \\\n '| xoooooooooxxxxx|\\n' \\\n '| xoooooooooooooo|\\n' \\\n '----------------------\\n'\n assert filled_canvas.matrix_to_str() == expected_matrix\n\n BucketFillCommand('B 17 2 s').draw(filled_canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '|oooooooooooooooxxxxx|\\n' \\\n '|xxxxxxoooooooooxsssx|\\n' \\\n '| xoooooooooxxxxx|\\n' \\\n '| xoooooooooooooo|\\n' \\\n '----------------------\\n'\n assert filled_canvas.matrix_to_str() == expected_matrix\n\n BucketFillCommand('B 5 3 k').draw(filled_canvas)\n\n expected_matrix = \\\n '----------------------\\n' \\\n '|oooooooooooooooxxxxx|\\n' \\\n '|xxxxxxoooooooooxsssx|\\n' \\\n '|kkkkkxoooooooooxxxxx|\\n' \\\n '|kkkkkxoooooooooooooo|\\n' \\\n '----------------------\\n'\n assert filled_canvas.matrix_to_str() == expected_matrix\n\n @pytest.mark.parametrize('command_line', [\n 'B 17 2 o', # Already filled with 's'\n 'B 6 2 o', # Already filled with 'x'\n ])\n def test_fails_when_target_is_not_empty(self, command_line, filled_canvas):\n BucketFillCommand('B 17 2 s').draw(filled_canvas)\n\n with pytest.raises(DrawingError) as excinfo:\n BucketFillCommand(command_line).draw(filled_canvas)\n assert excinfo.value.message == 'Target area is already filled.'\n\n @pytest.mark.parametrize('command_line', [\n 'B 21 2 o',\n 'B 6 5 o',\n ])\n def test_fails_if_point_is_outside_canvas_area(self, command_line, canvas):\n with pytest.raises(DrawingError) as excinfo:\n BucketFillCommand(command_line).draw(canvas)\n assert excinfo.value.message == 'Cannot draw outside of the canvas boundaries.'\n"
},
{
"alpha_fraction": 0.6293103694915771,
"alphanum_fraction": 0.6293103694915771,
"avg_line_length": 21.30769157409668,
"blob_id": "4ed4450459c9af3be3d012c61e798c7dbf62a5a3",
"content_id": "107cde483d6f792caf7d5dba51e07495bf47b5aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 580,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 26,
"path": "/drawing/exceptions.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "class CommandNotFound(Exception):\n \"\"\"Unknown command.\"\"\"\n\n def __init__(self, message=''):\n self.message = message\n\n\nclass FileFormatError(Exception):\n \"\"\"Invalid file format.\"\"\"\n\n def __init__(self, message=''):\n self.message = message\n\n\nclass CommandValidationError(Exception):\n \"\"\"Command syntax or parameters are invalid.\"\"\"\n\n def __init__(self, message=''):\n self.message = message\n\n\nclass DrawingError(Exception):\n \"\"\"Command syntax or parameters are invalid.\"\"\"\n\n def __init__(self, message=''):\n self.message = message\n"
},
{
"alpha_fraction": 0.733021080493927,
"alphanum_fraction": 0.7423887848854065,
"avg_line_length": 27.93220329284668,
"blob_id": "f39bf894c430c68c20b952ce87957b338afd4c04",
"content_id": "bcfd5b66edfe3287ad842eff20ac274f6b72125b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1708,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 59,
"path": "/README.md",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "\n[](https://travis-ci.com/cansadadeserfeliz/console-drawing-tool)\n[](https://codecov.io/github/cansadadeserfeliz/console-drawing-tool?branch=master)\n\n\n# Coding challenge\n\n## Drawing tool\n\nYou're given the task of writing a simple drawing tool. In a nutshell, the program reads the\n`input.txt`, executes a set of commands from the file, step by step, and produces\n`output.txt`.\n\nAt this time, the functionality of the program is quite limited but this might change in the future.\nAt the moment, the program should support the following set of commands:\n\n### Create Canvas\n\n`C w h`\n\nShould create a new canvas of width `w` and height `h`.\n\n### Create Line\n\n`L x1 y1 x2 y2`\n\nShould create a new line from `(x1,y1)` to `(x2,y2)`. Currently\nonly horizontal or vertical lines are supported. Horizontal and vertical\nlines will be drawn using the `'x'` character.\n\n### Create Rectangle\n\n`R x1 y1 x2 y2`\n\nShould create a new rectangle, whose upper left\ncorner is `(x1,y1)` and lower right corner is `(x2,y2)`. Horizontal and vertical\nlines will be drawn using the `'x'` character.\n\n### Bucket Fill\n\n`B x y c`\n\nShould fill the entire area connected to `(x,y)` with \"colour\" `c`.\nThe behaviour of this is the same as that of the \"bucket fill\" tool in paint\nprograms.\n\nPlease take into account that you can only draw if a canvas has been created.\n\n# Installation\n\n pip install -r requirements.txt\n cp sample_input.txt input.txt\n\n# Run the script\n\n python main.py\n\n# Run unit tests\n\n pytest\n"
},
{
"alpha_fraction": 0.6734693646430969,
"alphanum_fraction": 0.6734693646430969,
"avg_line_length": 18.600000381469727,
"blob_id": "3f73c0f84eca77f5d98a122acb3ab369aea820ba",
"content_id": "b62a81557f18c7c3b80305d765ee47a6faf7eaee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 5,
"path": "/config.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "INPUT_FILENAME = 'input.txt'\nOUTPUT_FILENAME = 'output.txt'\n\nMARKER_COLOR = 'x'\nEMPTY_COLOR = ' '\n"
},
{
"alpha_fraction": 0.483735054731369,
"alphanum_fraction": 0.5081745982170105,
"avg_line_length": 26.985849380493164,
"blob_id": "02f2e177048e6ee38e8caacc49b929f8ccc2ac3b",
"content_id": "7daf664280cee2cb7f1fce7b0a9311e15de65488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5933,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 212,
"path": "/drawing/__init__.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "import re\n\nfrom config import (\n MARKER_COLOR,\n EMPTY_COLOR,\n)\nfrom .exceptions import CommandValidationError\nfrom .exceptions import DrawingError\n\n\nclass Canvas:\n pattern = r'^C (?P<w>[1-9]\\d*) (?P<h>[1-9]\\d*)$'\n\n def __init__(self, line):\n result = re.match(self.pattern, line)\n if result is None:\n raise CommandValidationError()\n result_dict = result.groupdict()\n\n self.w = int(result_dict['w'])\n self.h = int(result_dict['h'])\n\n # Create an empty canvas matrix\n y_border = ['-'] * (self.w + 2)\n self.matrix = [y_border]\n for _ in range(self.h):\n self.matrix.append(['|'] + [EMPTY_COLOR] * self.w + ['|'])\n self.matrix.append(y_border)\n\n def apply_command(self, command):\n assert isinstance(command, Command)\n command.draw(self)\n\n def matrix_to_str(self):\n output = ''\n for line in self.matrix:\n output += ''.join(line) + '\\n'\n return output\n\n\nclass Command:\n pattern = None\n command_line = None\n\n def parse_command_line(self):\n result = re.match(self.pattern, self.command_line)\n if result is None:\n raise CommandValidationError()\n return result.groupdict()\n\n @staticmethod\n def validate(data):\n raise NotImplementedError\n\n\nclass CreateLineCommand(Command):\n pattern = r'^L (?P<x1>[1-9]\\d*) (?P<y1>[1-9]\\d*) (?P<x2>[1-9]\\d*) (?P<y2>[1-9]\\d*)$'\n\n def __init__(self, line):\n self.command_line = line\n data = self.parse_command_line()\n cleaned_data = self.validate(data)\n\n self.x1 = cleaned_data['x1']\n self.y1 = cleaned_data['y1']\n self.x2 = cleaned_data['x2']\n self.y2 = cleaned_data['y2']\n\n @staticmethod\n def validate(data):\n x1 = int(data['x1'])\n y1 = int(data['y1'])\n x2 = int(data['x2'])\n y2 = int(data['y2'])\n\n if x1 != x2 and y1 != y2:\n raise CommandValidationError('Currently only horizontal or vertical lines are supported.')\n\n return {\n 'x1': x1,\n 'y1': y1,\n 'x2': x2,\n 'y2': y2,\n }\n\n def draw(self, canvas):\n # Validate canvas boundaries\n if any([\n self.x1 < 1,\n self.x2 < 1,\n self.x1 < 1,\n self.y2 < 1,\n self.x1 > canvas.w,\n self.x2 > canvas.w,\n self.y1 > canvas.h,\n self.y2 > canvas.h,\n ]):\n raise DrawingError('Cannot draw outside of the canvas boundaries.')\n\n if self.x1 == self.x2:\n x = self.x1\n # Draw vertical lines\n for y in range(self.y1, self.y2 + 1):\n canvas.matrix[y][x] = MARKER_COLOR\n elif self.y1 == self.y2:\n y = self.y1\n # Draw horizontal lines\n for x in range(self.x1, self.x2 + 1):\n canvas.matrix[y][x] = MARKER_COLOR\n\n\nclass CreateRectangleCommand(Command):\n pattern = r'^R (?P<x1>[1-9]\\d*) (?P<y1>[1-9]\\d*) (?P<x2>[1-9]\\d*) (?P<y2>[1-9]\\d*)$'\n\n def __init__(self, line):\n self.command_line = line\n data = self.parse_command_line()\n cleaned_data = self.validate(data)\n\n self.x1 = cleaned_data['x1']\n self.y1 = cleaned_data['y1']\n self.x2 = cleaned_data['x2']\n self.y2 = cleaned_data['y2']\n\n @staticmethod\n def validate(data):\n x1 = int(data['x1'])\n y1 = int(data['y1'])\n x2 = int(data['x2'])\n y2 = int(data['y2'])\n\n if x1 > x2 or y1 > y2:\n raise CommandValidationError('(x1,y1) should be an upper left corner and (x2,y2) - lower right corner.')\n\n return {\n 'x1': x1,\n 'y1': y1,\n 'x2': x2,\n 'y2': y2,\n }\n\n def draw(self, canvas):\n # Validate canvas boundaries\n if any([\n self.x1 < 1,\n self.x2 < 1,\n self.x1 < 1,\n self.y2 < 1,\n self.x1 > canvas.w,\n self.x2 > canvas.w,\n self.y1 > canvas.h,\n self.y2 > canvas.h,\n ]):\n raise DrawingError('Cannot draw outside of the canvas boundaries.')\n\n # Draw horizontal lines\n for x in range(self.x1, self.x2 + 1):\n canvas.matrix[self.y1][x] = MARKER_COLOR\n canvas.matrix[self.y2][x] = MARKER_COLOR\n # Draw vertical lines\n for y in range(self.y1, self.y2 + 1):\n canvas.matrix[y][self.x1] = MARKER_COLOR\n canvas.matrix[y][self.x2] = MARKER_COLOR\n\n\nclass BucketFillCommand(Command):\n pattern = r'^B (?P<x>[1-9]\\d*) (?P<y>[1-9]\\d*) (?P<c>\\w)$'\n\n def __init__(self, line):\n self.command_line = line\n data = self.parse_command_line()\n cleaned_data = self.validate(data)\n\n self.x = cleaned_data['x']\n self.y = cleaned_data['y']\n self.c = cleaned_data['c']\n\n @staticmethod\n def validate(data):\n x = int(data['x'])\n y = int(data['y'])\n c = data['c']\n\n return {\n 'x': x,\n 'y': y,\n 'c': c,\n }\n\n def fill_recursive(self, canvas, x, y):\n if canvas.matrix[y][x] != EMPTY_COLOR:\n return\n canvas.matrix[y][x] = self.c\n self.fill_recursive(canvas, x, y + 1)\n self.fill_recursive(canvas, x, y - 1)\n self.fill_recursive(canvas, x + 1, y)\n self.fill_recursive(canvas, x - 1, y)\n\n def draw(self, canvas):\n # Validate canvas boundaries\n if any([\n self.x < 1,\n self.y < 1,\n self.x > canvas.w,\n self.y > canvas.h,\n ]):\n raise DrawingError('Cannot draw outside of the canvas boundaries.')\n\n if canvas.matrix[self.y][self.x] != EMPTY_COLOR:\n raise DrawingError('Target area is already filled.')\n\n self.fill_recursive(canvas, self.x, self.y)\n"
},
{
"alpha_fraction": 0.6594982147216797,
"alphanum_fraction": 0.6612903475761414,
"avg_line_length": 28.36842155456543,
"blob_id": "8d2cf431f4849a3bf25aeb70cb58f51c018807f8",
"content_id": "837c391e41ff28e62a63d646897dd1e8d8af1650",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1674,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 57,
"path": "/main.py",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "from drawing import (\n Canvas,\n CreateLineCommand,\n CreateRectangleCommand,\n BucketFillCommand,\n)\nfrom drawing.exceptions import CommandNotFound, FileFormatError\nfrom config import (\n INPUT_FILENAME,\n OUTPUT_FILENAME,\n)\n\nCOMMAND_MAPPER = {\n 'L': CreateLineCommand,\n 'R': CreateRectangleCommand,\n 'B': BucketFillCommand,\n}\n\n\ndef draw_canvas_into_file(canvas, commands, filename=OUTPUT_FILENAME):\n with open(filename, 'w') as writer:\n writer.write(canvas.matrix_to_str())\n\n for command in commands:\n canvas.apply_command(command)\n writer.write(canvas.matrix_to_str())\n\n\ndef read_input(filename=INPUT_FILENAME):\n command_lines = list(open(filename).readlines())\n\n assert len(command_lines) > 0, 'Input file is empty.'\n\n create_canvas_command_line = command_lines.pop(0)\n if not create_canvas_command_line.startswith('C'):\n raise CommandNotFound('\"Create Canvas\" command is not provided.')\n canvas = Canvas(create_canvas_command_line)\n\n commands = []\n\n for line in command_lines:\n if line.startswith('C'):\n raise FileFormatError('\"Create Canvas\" command appears more than once.')\n if not line.strip():\n raise FileFormatError('Input file cannot contain empty lines.')\n command_name = line[0]\n try:\n command_class = COMMAND_MAPPER[command_name]\n except KeyError:\n raise CommandNotFound(f'Unknown command: \"{command_name}\".')\n commands.append(command_class(line))\n return canvas, commands\n\n\nif __name__ == '__main__':\n canvas, commands = read_input()\n draw_canvas_into_file(canvas, commands)\n"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.5333333611488342,
"avg_line_length": 14,
"blob_id": "3d0c589b6d39ff480e9f89eb5d32de983e4e247f",
"content_id": "f045c71886a741570b3c264541a4ee07c40ed4b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/pytest.ini",
"repo_name": "cansadadeserfeliz/console-drawing-tool",
"src_encoding": "UTF-8",
"text": "[pytest]\naddopts =\n --cov=./\n --cov-report html\n --no-cov-on-fail\n"
}
] | 9 |
HPKR/HPKR.github.io
|
https://github.com/HPKR/HPKR.github.io
|
84fa81c7407952341e337c26c56c21c07766bdea
|
f4ac79d6d21bd6be31586fb230c76454d672b1d8
|
a5b2320374551afe3e63e17bc564f79eeaa1537d
|
refs/heads/main
| 2023-05-25T08:59:01.977425 | 2021-06-06T00:15:52 | 2021-06-06T00:15:52 | 374,174,574 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6382978558540344,
"alphanum_fraction": 0.7234042286872864,
"avg_line_length": 45,
"blob_id": "a4c4c1e75fac037fb7f4388afe02706614b476c6",
"content_id": "ba4f48a1f875d92921cc4fa3e6a6f26430d7ba50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/README.md",
"repo_name": "HPKR/HPKR.github.io",
"src_encoding": "UTF-8",
"text": "\n<h2>https://hardeepkaur17.herokuapp.com/</h2>\n"
},
{
"alpha_fraction": 0.5059382319450378,
"alphanum_fraction": 0.5938242077827454,
"avg_line_length": 22.38888931274414,
"blob_id": "d5f8970051d06dc93e3d3abb73e6f586607a0a21",
"content_id": "4aaafeabebe1143084172cc03f2a679b6bce83fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 18,
"path": "/jobs/migrations/0004_auto_20210530_1420.py",
"repo_name": "HPKR/HPKR.github.io",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.1 on 2021-05-30 18:20\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('jobs', '0003_auto_20210530_1344'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='job',\n name='image',\n field=models.ImageField(height_field=100, upload_to='images/', width_field=100),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4545454680919647,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 15.666666984558105,
"blob_id": "5e072f106a96169b498e0d823628fd8466491ec6",
"content_id": "08d92d2085cc2c3f3d7281948362a4138ecf0bf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "HPKR/HPKR.github.io",
"src_encoding": "UTF-8",
"text": "django==3.1.2\nboto3==1.17.88\npillow==8.0.0\ndjango-storages==1.11.1\ngunicorn==20.1.0\npsycopg2==2.8.6"
}
] | 3 |
pauloricardos/testeback
|
https://github.com/pauloricardos/testeback
|
775e746ea1e55a4e8a7b5a183f4ae930e64e48d8
|
09a8f5d6e46a0222486bee9b6364ec8d2aefdd4b
|
fd21ed6a3862197ffa126078592bcd7000e5caad
|
refs/heads/master
| 2020-04-30T17:56:21.433558 | 2019-03-23T01:35:55 | 2019-03-23T01:35:55 | 176,993,162 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5479452013969421,
"alphanum_fraction": 0.6104109883308411,
"avg_line_length": 24.30555534362793,
"blob_id": "34166262944967a814b76ece0d1a4c58a1b0a58b",
"content_id": "c685cce6e6c81e524c184aaebc0ee19d8de2324c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1825,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 72,
"path": "/connection.py",
"repo_name": "pauloricardos/testeback",
"src_encoding": "UTF-8",
"text": "import pymysql \n\nhost = \"localhost\"\nuser = \"root\"\npassword = \"123456\"\ndb = \"batch\"\nport = 3306\n\ncon = pymysql.connect(host, user, password, db, port)\nc = con.cursor()\n\ndef select(fields, tables, where=None):\n\n global c \n\n query = \"SELECT \" + fields + \" FROM \" + tables\n if (where):\n query = query + \"WHERE \" + where\n\n c.execute(query)\n return c.fetchall()\n\ndef insert(values, table, fields=None):\n \n global c, con\n\n query2 = \"DELETE FROM \" + table\n c.execute(query2)\n\n query = \"INSERT INTO \" + table\n if (fields):\n query = query + \" (\" + fields + \") \"\n query = query + \" VALUES \" + \", \".join([\"(\"+ v +\")\" for v in values])\n\n c.execute(query)\n con.commit()\n\n \nvalues = [\n \"'1499', '86871053000101', 'Pedro', 'Actived', '1200'\", \n \"'1500', '22588938000107', 'Maria', 'Actived', '1280'\",\n \"'1501', '68077847000108', 'Joao', 'Is not actived', '1600'\",\n \"'1502', '00701438000105', 'Rodrigo', 'Actived', '500'\"]\n\ninsert(values, \"tb_customer_account\", fields=\"id_customer, cpf_cnpj, nm_customer, is_active, vl_total\")\nprint(select(\"*\", \"tb_customer_account\"))\n\n\ndef orderBySalary(table):\n \n global c\n \n salaries = select(\"vl_total\", table)\n print(salaries)\norderBySalary(\"tb_customer_account\")\n\n# select avg(vl_total) from tb_customer_account where id_customer >= 1500 and vl_total > 560;\n# select vl_total from tb_customer_account where id_customer >= 1500 and vl_total > 560;\n# select count(*) from tb_customer_account where id_customer >= 1500 and vl_total > 560;\n# select * from tb_customer_account\n\ndef average(fields, table):\n\n global c\n\n numbers = []\n for vl_total in table:\n numbers.append(\"vl_total\")\n listSum = sum(numbers)\n print (listSum)\n\naverage(\"vl_total\", \"tb_customer_account\") "
},
{
"alpha_fraction": 0.6780487895011902,
"alphanum_fraction": 0.704878032207489,
"avg_line_length": 36.3636360168457,
"blob_id": "70518566c5f68ec35724176a094804a2bb0ef106",
"content_id": "bb64a24a2fc18b281031ddc9dc29dc8ababf9f88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 11,
"path": "/customerAccount.sql",
"repo_name": "pauloricardos/testeback",
"src_encoding": "UTF-8",
"text": "create table if not exists tb_customer_account (\n id_customer int unsigned not null auto_increment,\n cpf_cnpj varchar(14) not null,\n nm_customer varchar(45) not null,\n is_active ENUM('Actived', 'Is not actived') not null,\n vl_total int unsigned not null,\n unique key (id_customer),\n primary key (cpf_cnpj)\n)\n\nselect avg(vl_total) from tb_customer_account where id > 1500 and vl_total > 560"
}
] | 2 |
JoaRiski/DockerMinimalPython
|
https://github.com/JoaRiski/DockerMinimalPython
|
7047e748391b59b1ab8ee462d1304e18c1f36d8e
|
98fa7ea3504c241d181abaed6c77322c14695ee3
|
39a764c565295a86f06ef47ce8e71889efa9523b
|
refs/heads/master
| 2020-05-20T22:40:49.120892 | 2019-05-09T11:36:00 | 2019-05-09T11:36:00 | 185,787,139 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8149999976158142,
"alphanum_fraction": 0.8149999976158142,
"avg_line_length": 39,
"blob_id": "04c2dc54d9ecc139039538c092de8291accb3eab",
"content_id": "5e5052490327df5b03103860ff3923000fa900b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 5,
"path": "/README.md",
"repo_name": "JoaRiski/DockerMinimalPython",
"src_encoding": "UTF-8",
"text": "# Docker Minimal Python\n\nThis repository is an exmaple of how to build a minimal python container by\nbuilding the python code into a statically linked binary and adding that to\nthe scratch container.\n"
},
{
"alpha_fraction": 0.7001827955245972,
"alphanum_fraction": 0.703839123249054,
"avg_line_length": 23.863636016845703,
"blob_id": "ee341b0039a23835dd68ca8dab78aaaa3d375ef4",
"content_id": "97176fac9686cb6d2eb7fc53e874d4c21f17870f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 22,
"path": "/Dockerfile",
"repo_name": "JoaRiski/DockerMinimalPython",
"src_encoding": "UTF-8",
"text": "FROM python:3.7 AS builder\n\nRUN apt-get update && apt-get install patchelf -y\n\nWORKDIR /build\n\nCOPY ./app/requirements.txt /build/requirements.txt\nRUN pip install -U pip PyInstaller staticx --no-cache-dir && \\\n pip install -r requirements.txt --no-cache-dir\n\nCOPY ./app /build\nRUN python -OO -m PyInstaller main.py \\\n --distpath /build \\\n --noconfirm \\\n --onefile\nRUN mkdir /dist && staticx /build/main /dist/main\nRUN mkdir /empty\n\nFROM scratch\nCOPY --from=builder /dist /app/.\nCOPY --from=builder /empty /tmp\nENTRYPOINT [\"/app/main\"]\n"
},
{
"alpha_fraction": 0.5709969997406006,
"alphanum_fraction": 0.6102719306945801,
"avg_line_length": 26.58333396911621,
"blob_id": "d2fe513dc311db87d7722cb17a65322b5df618fd",
"content_id": "a74ca6e335373ac3ca7b792fb8cd49abffdc9c82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 12,
"path": "/app/main.py",
"repo_name": "JoaRiski/DockerMinimalPython",
"src_encoding": "UTF-8",
"text": "import requests\n\n\ndef main():\n print(requests.get(\"http://192.168.11.4:5000/\"))\n # There's no DNS resolution so we can't pull a joke from this API :(\n # print(requests.get(\"https://api.chucknorris.io/jokes/random\").json().get(\"value\", \"No joke found, sorry :(\"))\n\n\nif __name__ == \"__main__\":\n print(\"Test\")\n main()\n"
}
] | 3 |
GabrielSirtoriCorrea/Sexta-Feira-Mark_6
|
https://github.com/GabrielSirtoriCorrea/Sexta-Feira-Mark_6
|
28196105c7ed1918d8f950ddafd4965e24fbec5b
|
52ba612e41de36e44f1f7f0751fc08595c6cecef
|
829fdc8ba2ff7f8d53dd538dfed9a3aefc4fdd96
|
refs/heads/master
| 2023-04-05T18:31:12.969916 | 2021-04-30T01:16:14 | 2021-04-30T01:16:14 | 268,164,565 | 7 | 1 |
MIT
| 2020-05-30T21:44:53 | 2021-03-17T18:55:04 | 2021-04-30T01:12:09 |
Java
|
[
{
"alpha_fraction": 0.5708782076835632,
"alphanum_fraction": 0.5848875045776367,
"avg_line_length": 33.400604248046875,
"blob_id": "e3233fcb5fd0aa3a3001e3b3784d49a305268ec9",
"content_id": "ce7e8d7c8db175c63df1d351bdd65675079abbd4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 11421,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 332,
"path": "/App/app/src/main/java/com/gazeboindustries/friday/ServerConnection.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.gazeboindustries.friday;\n\nimport android.os.AsyncTask;\n\nimport org.json.JSONArray;\nimport org.json.JSONException;\nimport org.json.JSONObject;\n\nimport java.io.BufferedReader;\nimport java.io.IOException;\nimport java.io.InputStreamReader;\nimport java.io.PrintWriter;\nimport java.net.Socket;\nimport java.util.ArrayList;\n\nimport static java.lang.Thread.sleep;\n\npublic class ServerConnection extends AsyncTask<JSONObject, Integer, ArrayList<JSONArray>> {\n //private String IP = \"gazeboindustries.hopto.org\";\n private String IP = \"192.168.0.5\";\n private int port = 5000;\n private Socket socket;\n private PrintWriter out;\n private BufferedReader in;\n private JSONObject jsonRequest;\n private JSONObject jsonResponse;\n private String data;\n private ArrayList<JSONArray> list = null;\n private JSONArray arrayResponse;\n private char[] buffer;\n private boolean msgStatus = false;\n\n\n @Override\n protected ArrayList<JSONArray> doInBackground(JSONObject... params) {\n try {\n if(params[0].get(\"request\").equals(\"getDevicesStatus\")) {\n this.socket = new Socket(IP, port);\n this.out = new PrintWriter(this.socket.getOutputStream(), true);\n this.in = new BufferedReader(new InputStreamReader(this.socket.getInputStream()));\n\n this.out.println(params[0]);\n\n this.msgStatus = true;\n\n try {\n sleep(125);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n this.buffer = new char[this.socket.getReceiveBufferSize()];\n\n this.in.read(this.buffer);\n\n this.data = new String(this.buffer);\n\n this.jsonResponse = new JSONObject(this.data);\n\n System.out.println(this.jsonResponse);\n\n this.socket.close();\n this.out.close();\n this.in.close();\n\n }else{\n this.socket = new Socket(IP, port);\n this.out = new PrintWriter(this.socket.getOutputStream(), true);\n this.in = new BufferedReader(new InputStreamReader(this.socket.getInputStream()));\n\n this.out.println(params[0]);\n\n this.msgStatus = true;\n\n try {\n sleep(125);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n this.buffer = new char[this.socket.getReceiveBufferSize()];\n\n this.in.read(this.buffer);\n\n this.data = new String(this.buffer);\n\n this.jsonResponse = new JSONObject(this.data);\n\n System.out.println(this.jsonResponse);\n\n this.list = new ArrayList<>();\n\n for (int c = 0; c < jsonResponse.length(); c++) {\n this.arrayResponse = (JSONArray) this.jsonResponse.get(Integer.toString(c));\n this.list.add(arrayResponse);\n }\n\n this.socket.close();\n this.out.close();\n this.in.close();\n }\n\n } catch (IOException | JSONException e) {\n System.out.println(\"DEU ERRO\");\n e.printStackTrace();\n }\n return null;\n }\n\n public boolean getMsgStatus(){\n return this.msgStatus;\n }\n\n public JSONObject sendJSONRequest(JSONObject request){\n try {\n execute(request);\n while(this.jsonResponse == null){\n sleep(100);\n }\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n return this.jsonResponse;\n\n }\n\n public ArrayList<JSONArray> sendRequest(JSONObject request){\n try {\n execute(request);\n while(this.list == null){\n sleep(100);\n }\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n return this.list;\n\n }\n\n public JSONObject prepareAddInteraction(String request, String key1, String key2, String key3, String res1, String res2, String res3, String command){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"keyWord1\", key1);\n this.jsonRequest.put(\"keyWord2\", key2);\n this.jsonRequest.put(\"keyWord3\", key3);\n this.jsonRequest.put(\"response1\", res1);\n this.jsonRequest.put(\"response2\", res2);\n this.jsonRequest.put(\"response3\", res3);\n this.jsonRequest.put(\"command\", command);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareAddDevice(String request, String device, String desc, int actions){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"device\", device);\n this.jsonRequest.put(\"description\", desc);\n this.jsonRequest.put(\"actions\", actions);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareAddHomework(String request, String type, String subject, String homework, String delivery, String desc){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"type\", type);\n this.jsonRequest.put(\"subject\", subject);\n this.jsonRequest.put(\"homeWork\", homework);\n this.jsonRequest.put(\"delivery\", delivery);\n this.jsonRequest.put(\"description\", desc);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareAddProject(String request, String type, String project){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"type\", type);\n this.jsonRequest.put(\"project\", project);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareRequest(String request){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareUpdateInteraction(String request, int updateId, String key1, String key2, String key3, String res1, String res2, String res3, String command){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"updateId\", updateId);\n this.jsonRequest.put(\"keyWord1\", key1);\n this.jsonRequest.put(\"keyWord2\", key2);\n this.jsonRequest.put(\"keyWord3\", key3);\n this.jsonRequest.put(\"response1\", res1);\n this.jsonRequest.put(\"response2\", res2);\n this.jsonRequest.put(\"response3\", res3);\n this.jsonRequest.put(\"command\", command);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareUpdateDevice(String request, String deleteName, int updateId, String device, String desc, int actions){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"deleteName\", deleteName);\n this.jsonRequest.put(\"updateId\", updateId);\n this.jsonRequest.put(\"device\", device);\n this.jsonRequest.put(\"description\", desc);\n this.jsonRequest.put(\"actions\", actions);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareUpdateHomework(String request, int updateId, String type, String subject, String homework, String delivery, String desc){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"updateId\", updateId);\n this.jsonRequest.put(\"type\", type);\n this.jsonRequest.put(\"subject\", subject);\n this.jsonRequest.put(\"homeWork\", homework);\n this.jsonRequest.put(\"delivery\", delivery);\n this.jsonRequest.put(\"description\", desc);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareUpdateProject(String request, int updateId, String type, String project){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"updateId\", updateId);\n this.jsonRequest.put(\"type\", type);\n this.jsonRequest.put(\"project\", project);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareDelete(String request, int deleteId){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"deleteId\", deleteId);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareDelete(String request, int deleteId, String name){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"deleteId\", deleteId);\n this.jsonRequest.put(\"deleteName\", name);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareSetDevice(String device, int action, String url){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", \"setDevicesStatus\");\n this.jsonRequest.put(\"receiverID\", device);\n this.jsonRequest.put(\"action\", action);\n this.jsonRequest.put(\"url\", url);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.6823821067810059,
"alphanum_fraction": 0.6873449087142944,
"avg_line_length": 32.66666793823242,
"blob_id": "a90b68453c4e0b1a721c91e4594e7ed85e13c3ba",
"content_id": "79dc70a85da2b0f3339ba9c035a556524ea67425",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 12,
"path": "/Sexta-Feira(A.I.)/BackgroundListening.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "from Functions import ServerConnection, setRequestJson\nimport os\n\nconnection = ServerConnection()\n\nwhile True:\n response = connection.send(setRequestJson('getDevicesStatus', 'Server', 0, '.com'))\n\n if response['Friday']['action'] == 1: \n os.startfile(os.getcwd().replace('Sexta-Feira(A.I.)', '') + 'Sexta-FeiraInterface/dist/Sexta-FeiraInterface.jar')\n print('Started')\n break"
},
{
"alpha_fraction": 0.6245854496955872,
"alphanum_fraction": 0.6330209970474243,
"avg_line_length": 46.41679382324219,
"blob_id": "e2451caf03bfd829d78acd352ae595d5a003cfb9",
"content_id": "591806a73763ca6ad701e4fb20939bce6d6f9962",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31359,
"license_type": "permissive",
"max_line_length": 217,
"num_lines": 655,
"path": "/README.md",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "# Sexta-Feira MARK 6\n Sexta-Feira, é uma assistente virtual desenvolvida para auxiliar o usuário nas tarefas\ndo dia-a-dia, podendo mostrar imagens, realizar pesquisas na internet etc.\n\n No início, o projeto contia as seguintes ideias:\n\n - Uma assistente virtual para auxiliar nas atividades do dia-a-dia com uma interface de interação com usuário\n - Um banco de dados para o armazenamento de dados necessários\n - Um sistema de Internet das coisas (IoT) na qual seria possivel fazer comunicação entre dispositivos\n - Um aplicativo para o acesso a todas as informações do banco de dados\n\n Tendo as ideias em mente o projeto foi separado em 4 subsistemas:\n\n - Banco de dados \n - Servidor\n - Sexta-feira\n - App\n \n## Banco de dados\n O banco de dados foi criado com o MySQL, ele é responsável por armazenar todos os dados do sistema.\n\n### Tabelas\n - Interactions - Responsável por armazenar todas as conversas e comandos com a Sexta-Feira (Assistente virtual)\n - Projects - Responsável por armazenar projetos pessoais\n - HomeWorkManagement - Responsável por armazenar tarefas escolares\n - Device - Responsável por armazenar os dispositivos conectados ao servidor\n\n### Estrutura\n\n Interactions | Projects | HomeWorkManagement | Device |\n---------------- | --------------- | ----------------------- | ---------------------- |\n KeyWordID | ProjectID | HomeWorkID | DeviceID |\n KeyWord1 | ProjectType | HomeWorkType | DeviceName |\n KeyWord2 | Project | HomeWorkSubject | DeviceDescription |\n KeyWord3 | | HomeWork | DeviceActions |\n response1 | | HomeWorkDelivery | |\n response2 | | HomeWorkDescription | |\n response3 | | | |\n Command | | | |\n\n## Servidor\n O servidor, é responsavel pela comunicação entre os subsistemas, ele tem acesso ao banco de dados e envia as\ninformações conforme as requisições. Para a conexão entre o servidor e seus clientes, foi utilizado socket, \ncom o protocolo TCP/IP para comunicação\n\n### Estrutura do servidor\n Para criarmos a estrutura base do servidor, utilizamos a bibiloteca socketserver, assim, podemos criar uma \nclasse extendida de **socketserver.BaseRequestHandler** para o gerenciamento de vários clientes ao mesmo tempo, ]\nseparados por Threads. \n\n\n ```class ClientManage(socketserver.BaseRequestHandler):\n def handle(self):\n dataBaseConnection = DataBaseConnection()\n\n dateTimeNow= datetime.now()\n print(f'Connected by {self.client_address} at {dateTimeNow.hour}:{dateTimeNow.minute} ')\n\n while True:\n data = self.request.recv(5800).decode()\n print(data)\n\n try:\n if data:\n clientRequest = json.loads(data)\n\n except:\n print('error')\n\n server = socketserver.ThreadingTCPServer((host, port), ClientManage)\n server.serve_forever()\n\n```\n\n### Comunicação banco de dados\n Para a comunicação com o banco de dados MySQL, utilizamos a biblioteca mysqlConnector. Para instala-la,\nutilizamos o PIP.\n\n ```pip install mysql-connector-python```\n\n Após a instalação da biblioteca, foi criada uma classe para o gerenciamento do banco de dados. No método\nconstrutor, iniciamos a conexão com o banco e definimos o cursor. Em seguida, foram criados os métodos: get(),\nupdate(), delete() e insert() para cada tabela.\n\n ```\n import mysql.connector as mysqlConnector\n from datetime import datetime\n\n class DataBaseConnection:\n def __init__(self):\n self.dataBaseConnector = mysqlConnector.connect(host='localhost', user='root', password='Gazao015', \n database='sextafeiradatabase')\n\n self.dataBaseCursor = self.dataBaseConnector.cursor()\n\n def getInteractions(self):\n self.dataBaseCursor.execute('SELECT * FROM Interactions')\n return self.dataBaseCursor.fetchall()\n\n def insertHomeWork(self, Type, subject, homeWork, delivery, desc):\n self.dataBaseCursor.execute('INSERT INTO HomeWorkManagement(HomeWorkType, HomeWorkSubject, HomeWork, HomeWorkDelivery, HomeWorkDescription) VALUES (%s,%s,%s,%s,%s)', (Type, subject, homeWork, delivery, desc))\n self.dataBaseConnector.commit()\n\n def updateDevice(self, updateId, name, desc, actions):\n self.dataBaseCursor.execute(f\"UPDATE Device SET DeviceName = '{name}', DeviceDescription = '{desc}', DeviceActions = '{actions}' WHERE DeviceID = '{updateId}' \")\n self.dataBaseConnector.commit()\n\n def deleteProject(self, deleteID):\n self.dataBaseCursor.execute('DELETE FROM Projects WHERE ProjectID = %d' % (deleteID))\n self.dataBaseConnector.commit()\n\n (...)\n ```\n\n\n## Sexta-Feira\n A Sexta-Feira é a assistente virtual. Ela é separada em 2 partes Interface e Sexta-Feira\n\n### Sexta-Feira (A.I.)\n Sexta-Feira é o cérebro de tudo, ela é responsável pelo reconhecimento de voz do usuário, conexão com o \nservidor etc.\n\n Para termos um assistente virtual funcional, nós temos de ter uma atenção especial para o reconhecimento de \nvoz. É ele o responsável por garantir a interação do usuário com o software, se não temos um bom reconhecimento, o software não é eficiente.\n\n Tendo isso em mente, foi inventada uma estratégia para o melhor reconhecimento. O uso de **PALAVRAS CHAVE**,\n**RESPOSTAS** e **COMANDOS**. Esses três termos, formam uma **INTERAÇÃO** que o usuário pode.\nter com o software.\n\n No banco de dados estão armazenadas todas as interações, quando o software é iniciado ele se conecta com o\nservidor, e pede todas as interações e armazena em uma lista para serem tradas. \n\n Após o programa receber as interações do servidor, ele entra em um loop de repetição na qual este fica \nescutando o microfone do usuário a espera de um audio.\n\n Ao escutar algo do microfone, o software pega as interações contidas na lista, e faz um loop até que\ntodas as **Palavras chave** de uma interação estejam na frase. Quando isso acontece, o software responde \natravés de **Sínteze de voz** uma das respostas contidas nessa interação, escolhida de forma aleatória. \n\n Existe também a possibilidade do software executar um comando, nesse caso, o comando contido na interação,\né o **Nome do método a ser executado**, todos esses métodos estão no arquivo **COMMANDS.PY**, esse método é chamado\natravés de um outro método chamado **CallCommands**, executado no arquivo principal **SEXTA-FEIRA.PY**.\n\n\n #### Reconhecimento de voz\n Para fazermos o reconhecimento de voz, utilizamos a biblioteca **SpeechRecognition**, podemos instala-la \n com o pip.\n\n ```pip install SpeechRecognition```\n\n Todo o processo de reconhecimento de voz, é executado no método **Recognition()** e chamado no arquivo\n principal **Sexta-Feira(A.i.)**\n\n ```def Recognition():\n recognizer = sr.Recognizer() #Instanciamos o objeto da classe principal \n\n try:\n with sr.Microphone() as source: # Definimos o microfone\n recognizer.adjust_for_ambient_noise(source) # Regulamos o ruído do microfone\n\n print('Say:')\n\n sound = recognizer.listen(source) # Escutamos o microfone\n speech = recognizer.recognize_google(sound, language='pt').lower() # Recebemos o reconhecimento\n print('You said: ', speech)\n\n return ' ' + speech + ' ' # Retornamos a frase dita\n except:\n return ''\n ```\n\n #### Sínteze de voz\n Outra parte importante para garantirmos a boa interação do usuário com o software é a **SÍNTEZE DE VOZ**. Ela\n é responsável por responder ao usuário utilizando o **Narrador do Windows**, assim dando \n a impressão para o usuário que ele está falando com alguém real.\n\n Para realizar a sínteze de voz, utilizamos a biblioteca **pyttsx3**, e instalamos ela novamente com o pip\n\n ```pip install pyttsx3```\n\n Para que o software não interrompa sua execução para \"falar\" as respostas, importamos a classe**Threading** já contida no Python,\n essa bibiloteca contém a classe **Thread**, que nos permite criar processos paralelos dentro do mesmo programa, então foi criada \n uma classe **Speaker**, subclasse de Thread, dentro do método **Run()** da classe, escrevemos o código a ser executado de forma \n paralela, depois iniciamos a Thread instanciando um objeto da classe Speaker, e executamos o método **start()**.\n\n ```class Speaker(Thread):\n def __init__(self, text):\n Thread.__init__(self)\n self.text = text\n\n def run(self):\n speaker = pyttsx3.init('sapi5')\n speaker.say(self.text)\n speaker.runAndWait()\n\n def speak(text):\n speak = Speaker(text)\n speak.start()\n\n ```\n\n #### Comunicação com servidor\n Para fazermos a conexão com servidor utilizamos a biblioteca **Socket** ja contida no python, e utilizamos o\n protocolo TCP/IP para comunicação.\n\n A conexão com o servidor é estabelecida através da classe **ServerConnection**, que inicializa a conexão no\n seu método construtor e envia e recebe as informações pelo método **send()**.\n\n ``` class ServerConnection:\n def __init__(self):\n try:\n file = open('E:/Sexta-Feira-Mark_6/Configurations.json', 'r') \n configs = json.load(file)['FridayConfigs'] #Pegamos o ip do servidor no arquivo Configurations.json\n\n self.connection = socket(AF_INET, SOCK_STREAM, 0) #Definimos o protocolo TCP/IP\n self.connection.connect((configs['ServerHost'], configs['Port'] )) # Conectamos com o servidor\n except:\n print('ERRO AO CONECTAR-SE COM O SERVIDOR') \n \n def send(self, message):\n self.connection.send(message.encode()) #Enviamos os dados\n\n return json.loads(self.connection.recv(5800).decode('utf-8')) # retorna a resposta enviada pelo servidor\n\n ```\n\n Os dados enviados ao servidor, são enviados em forma de estrutura de dados **JSON**. Para formatarmos os\n dados nessa estrutura, utilizamos o método **setRequestJson()**, e depois enviamos pelo socket.\n\n ```def setRequestJson(request, receiverID, action, url):\n requestJson = json.dumps({\n 'header': 'gazeboindustries09082004',\n 'receiverID': receiverID,\n 'request': request,\n 'action': action,\n 'url': url\n \n })\n\n return requestJson\n ```\n\n #### Comunicação com a Interface\n Para que possamos mostrar imagens e dados na interface, precisamos criar um método para a comunicação entre\n a **Sexta-Feira(A.I.)** e a **Interface** fazendo com que elas trabalhem em conjunto. Com isso em mente, foi criado o \n arquivo **FridayComunication.json**, ele é o responsável por fazer a troca de informações entre a **Sexta-Feira** e a \n **Interface**. \n\n No entanto, para termos uma comunicação em tempo real, precisamos reescrever este arquivo várias vezes. Então\n foi criado o método **setFridayComunication()**, ele é o responsável por reescrever esse arquivo json quando alguma\n comunicação for necessária\n\n ``` def setFridayComunication(action, content, url):\n filePath = 'E:/Sexta-Feira-Mark_6/Sexta-FeiraInterface/src/com/friday/FridayComunication.json'\n readFile = open(filePath, 'r') # Abrimos o arquivo em formato leitura\n newJson = json.load(readFile) # Colocamos os dados em um dicionário\n\n print(newJson)\n\n newJson['action'] = action\n newJson['content'] = content # Sobreescrevemos os dados\n newJson['url'] = url\n\n writeFile = open(filePath, 'w') # Abrimos o arquivo novamente, agora em formato de escrita\n json.dump(newJson, writeFile, indent=4) # Escrevemos o dicionário com os novos dados\n ``` \n\n Todos esses métodos estão contidos no arquivo **Functions.py**\n\n\n### Interface\n A Interface é responsável por mostrar imagens, tabelas e dados para a melhor visualização e compreensão \ndo usuário conforme o pedido da Sexta-feira(A.I.). Ela foi construída em JAVA, e utilizando o JavaFX para\na criação do layout. \n\n #### Layout\n \n \n \n\n \n\n #### Comunicação com Sexta-Feira(A.I.)\n Para que possamos ler os dados contidos no **FridayComunication.json** e comunicarmos com Sexta-Feira(A.I.),\n foi criada a classe **FridayComunication.JAVA**, ela é responsável por ler o arquivo json, e retornar os dados\n necessários através do método **readJsonFile()**.\n \n ```public class FridayComunication {\n private static JSONObject jsonObject;\n private static JSONParser parser; # Declaração dos atributos necessários\n\n public static JSONObject readJsonFile() {\n parser = new JSONParser(); # Instanciando objeto da classe JSONParser para lermos o arquivo\n\n try {\n jsonObject = (JSONObject) parser.parse(new FileReader(\"E:\\\\Sexta-Feira-Mark_6\\\\SextaFeiraInterface\\\\src\\\\com\\\\friday\\\\FridayComunication.json\")); \n } catch (ParseException | IOException e) {\n e.printStackTrace();\n }\n\n return jsonObject; # Retornando os dados em um JSONObject\n }\n } \n \n ```\n\n Agora que ja temos os dados necessários, podemos saber qual ação devemos tomar, e essa informação está no campo **Action** do JSONObject, \n sendo assim, no SceneController, classe que controla os itens don layout, podemos fazer o **Switch()** desse dado e executar a os comandos \n correspondentes, se existir algum dado que deve ser passado da Sexta-Feira(A.I.) para a Interface, colocamos isso no campo **Content** do \n Json, ou no caso de uma imagem, colocamos o caminho para o arquivo no campo **Url** do Json.Fazemos tudo isso no método **connectionLoop()**.\n\n ```private void connectionLoop() {\n response = FridayComunication.readJsonFile();\n action = Integer.parseInt(response.get(\"action\").toString());\n\n switch (action) {\n case 0:\n tableView.setVisible(false);\n imageView.setVisible(false);\n break;\n\n case 1:\n \n if (!tableView.getColumns().contains(commandColumn)) {\n imageView.setVisible(false);\n setTableData();\n\n addInteractionsColumns();\n\n }\n\n break;\n\n case 2:\n if (!tableView.getColumns().contains(homeWorkColumn)) {\n imageView.setVisible(false);\n setTableData();\n addHomeWorksColumns();\n }\n break;\n\n case 3:\n if (!tableView.getColumns().contains(projectColumn)) {\n imageView.setVisible(false);\n setTableData();\n addProjectsColumns();\n }\n break;\n\n case 4:\n\n if (!tableView.getColumns().contains(DeviceColumn)) {\n imageView.setVisible(false);\n setTableData();\n\n addDevicesColumns();\n\n\n }\n break;\n\n case 5:\n tableView.setVisible(false);\n\n imagePath = response.get(\"url\").toString();\n System.out.println(imagePath);\n imageFile = new File(imagePath);\n image = new Image(imageFile.toURI().toString());\n imageView.setImage(image);\n imageView.setVisible(true);\n\n\n default:\n break;\n }\n }\n \n ```\n\n Pronto. Agora ja conseguimos ler os dados e fazer as ações pedidas, porém, precisamos que tudo isso seja\n executado continuamente, em um **loop infinito**. Para isso configuramos um EventHandler, criamos um keyFrame\n para fazermos um loop desse Event, e depois colocamos isso no TimeLine.\n\n ```public void initialize(URL url, ResourceBundle rb) {\n\n EventHandler handler = new EventHandler() { \n\n @Override\n public void handle(Event event) {\n setClock();\n connectionLoop();\n }\n\n };\n\n KeyFrame frame = new KeyFrame(Duration.millis(1000), handler);\n Timeline timeline = new Timeline();\n timeline.getKeyFrames().add(frame);\n timeline.setCycleCount(Timeline.INDEFINITE);\n timeline.play();\n\n }\n \n ``` \n\n## App\n O app é responsável pela interação total do usuário com o banco de dados através do servidor, é nele em que o \nusuário pode adicionar interações, tarefas, atualizar um projeto, excluir um device etc.\n\n Para a construção do App, foi utilizado o Android Studio com o JAVA como linguagem de programação, além de xml\npara a construção dos layouts. \n\n ### Permições \n Antes de começar a criar os layouts e as classes JAVA, primeiro precisamos definir as permições que o nosso app precisa ter \n para acessarmos alguns recursos do dispositivo, no nosso caso, precisamos da permição de acesso a internet, para que possamos \n fazer a conexão com o servidor.\n\n <uses-permission android:name=\"android.permission.ACCESS_NETWORK_STATE\" />\n <uses-permission android:name=\"android.permission.INTERNET\" />\n\n ### Layouts\n Para a criação desse projeto, foi escolhido a utilização do recurso **Bottom navigation** para uma melhor\n experiência do usuário, em decorrência disso, foi utilizado **FRAGMENTS** para a construção dos layouts, assim,\n não precisamos colocar o Bottom navigation em todas as activities e apenas na MainActivity.\n \n \n \n \n \n \n \n \n \n \n \n \n \n \n\n ### Comunicação com servidor\n A comunicação com o servidor, foi feita novamente com **Socket** e protocolo TCP/IP. Foi criada a classe ServerConnection para o\n gerenciamento da conexão. É importante ressaltar, que ao utilizarmos sockets no **Android**, temos que obrigatoriamente tornarmos a \n nossa classe ServerConnection uma **Subclasse** de **AsyncTask**, para que possamos fazer os request em **BACKGROUND** através do \n método **doInBackground()** descendente da classe AsyncTask.\n\n ```public class ServerConnection extends AsyncTask<JSONObject, Integer, ArrayList<JSONArray>> {\n private String IP = \"gazeboindustries.hopto.org\"; // Utilizando um DNS\n private int port = 5000;\n private Socket socket;\n private PrintWriter out;\n private BufferedReader in;\n private JSONObject jsonRequest;\n private JSONObject jsonResponse;\n private String data;\n private ArrayList<JSONArray> list = null;\n private JSONArray arrayResponse;\n private char[] buffer;\n private boolean msgStatus = false;\n\n\n @Override\n protected ArrayList<JSONArray> doInBackground(JSONObject... params) {\n try {\n if(params[0].get(\"request\").equals(\"getDevicesStatus\")) {\n this.socket = new Socket(IP, port);\n this.out = new PrintWriter(this.socket.getOutputStream(), true);\n this.in = new BufferedReader(new InputStreamReader(this.socket.getInputStream()));\n\n this.out.println(params[0]);\n\n this.msgStatus = true;\n\n try {\n sleep(125);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n this.buffer = new char[this.socket.getReceiveBufferSize()];\n\n this.in.read(this.buffer);\n\n this.data = new String(this.buffer);\n\n this.jsonResponse = new JSONObject(this.data);\n\n System.out.println(this.jsonResponse);\n\n this.socket.close();\n this.out.close();\n this.in.close();\n\n }else{\n this.socket = new Socket(IP, port);\n this.out = new PrintWriter(this.socket.getOutputStream(), true);\n this.in = new BufferedReader(new InputStreamReader(this.socket.getInputStream()));\n\n this.out.println(params[0]);\n\n this.msgStatus = true;\n\n try {\n sleep(125);\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n this.buffer = new char[this.socket.getReceiveBufferSize()];\n\n this.in.read(this.buffer);\n\n this.data = new String(this.buffer);\n\n this.jsonResponse = new JSONObject(this.data);\n\n System.out.println(this.jsonResponse);\n\n this.list = new ArrayList<>();\n\n for (int c = 0; c < jsonResponse.length(); c++) {\n this.arrayResponse = (JSONArray) this.jsonResponse.get(Integer.toString(c));\n this.list.add(arrayResponse);\n }\n\n this.socket.close();\n this.out.close();\n this.in.close();\n }\n\n } catch (IOException | JSONException e) {\n System.out.println(\"DEU ERRO\");\n e.printStackTrace();\n }\n return null;\n } \n\n ```\n\n Apesar de ser de simples implementação, a classe AsyncTask nos atrapalha um pouco na hora de retornarmos os valores recebidos,\n então, para deixarmos mais simples o trabalho, criamos o método sendRequest(), que executa o método doInBackground() e nos retorna \n os valores recebidos. Desse modo, precisamos apenas instanciar o objeto da classe ServerConnection e chamarmos o método sendRequest.\n\n ```public ArrayList<JSONArray> sendRequest(JSONObject request){\n try {\n execute(request);\n while(this.list == null){\n sleep(100);\n }\n } catch (InterruptedException e) {\n e.printStackTrace();\n }\n\n return this.list;\n\n }\n ```\n Após isso, toda a parte de comunicação com o servidor e envio de requests já está feita, agora precisamosdefinir o que será enviado,\n nesse caso, utilizamos **JSON** para colocarmos as nossas informações em uma estrutura e criamos os métodos **prepareRequest()** para\n cada tipo de estrutura, assim, podemos passar os dados como parâmetro, receber o request ja prepará-lo, e depois enviá-lo. \n\n ```public JSONObject prepareRequest(String request){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n \n public JSONObject prepareAddInteraction(String request, String key1, String key2, String key3, String res1, \n String res2, String res3, String command){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"keyWord1\", key1);\n this.jsonRequest.put(\"keyWord2\", key2);\n this.jsonRequest.put(\"keyWord3\", key3);\n this.jsonRequest.put(\"response1\", res1);\n this.jsonRequest.put(\"response2\", res2);\n this.jsonRequest.put(\"response3\", res3);\n this.jsonRequest.put(\"command\", command);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n public JSONObject prepareUpdateDevice(String request, String deleteName, int updateId, String device, \n String desc, int actions){\n try {\n this.jsonRequest = new JSONObject();\n this.jsonRequest.put(\"header\", \"gazeboindustries09082004\");\n this.jsonRequest.put(\"request\", request);\n this.jsonRequest.put(\"deleteName\", deleteName);\n this.jsonRequest.put(\"updateId\", updateId);\n this.jsonRequest.put(\"device\", device);\n this.jsonRequest.put(\"description\", desc);\n this.jsonRequest.put(\"actions\", actions);\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n return jsonRequest;\n }\n\n (...)\n ``` \n\n ### Activity principal\n Pelo fato da Activity principal ser a única no nosso app, ela tem a responsabilidade de comportar todos os\n fragments, através do FrameLayout, e o bottom Navigation. Quando ela é iniciada, procura pelo fragment\n principal da aplicação, que, nesse caso, é o HomeFragment.\n\n ### Fragments\n Os fragments, apesar de serem diferentes de uma activity, também precisam obrigatóriamente de uma classe\n JAVA de controle para cada fragment. Tendo isso em mente, foi necessário criar uma estrutura de pastas para \n melhor organização do projeto, permitindo assim uma melhor compreensão. Então foi criada a seguinte estrutura:\n\n \n\n Como o objetivo desse App é **Editar os dados do Banco de Dados**, precisamos ter a possibilidade de \n inserir, atualizar, excluir e visualizar os dados das 4 tabelas (Interactions, Device, Projects, \n HomeWorkManagement). Para que isso seja possível foram criados 3 tipos de fragments para cada tabela.\n\n - Fragment Principal: Esse fragment, é iniciado quando o respectivo ícone no Bottom navigation for\n clicado. Ele é responsável por **Mostrar** os dados contidos na tabela através de um ListView\n\n - View Fragment: Esse fragment é iniciado quando um determinado item do ListView for clicado. Ele mostra com\n mais detalhes a tupla da tabela, é ele o responsável por **Editar** ou **Excluir** a tupla.\n\n - Add Fragment: Esse fragment é iniciado quando o botão **Adicionar** localizado no Fragment principal é \n clicado. Ele é responsável por adicionar uma nova tupla no banco de dados.\n\n Agora já temos cada fragment com sua responsabilidade. E ja temos o controle total do banco de dados pelo app.\n\n\n# Considerações finais\n Após 3 meses trabalhando nesse projeto, finalmente cheguei em uma versão que me agrada. Porém considero longe \n da versão final. Ainda existem implementações que devem ser feitas, como por exemplo, o Acesso da localização\n do telefone através do app, além de adicionar mais interações, comandos e devices.\n\n# Me faça uma doação!\n Gostou do projeto? Me faça uma doação! Assim você me incentiva a aprender mais e criar novos projetos :D\n\n Você pode utilizar o App do seu banco para ler o QR Code abaixo, ou se preferir, utilizar minha chave pix:\n \n :point_down::point_down:\n \n 0caf9f55-45dd-43a3-865c-70d005770ef7\n\n \n\n"
},
{
"alpha_fraction": 0.6387582421302795,
"alphanum_fraction": 0.6396989822387695,
"avg_line_length": 24.309524536132812,
"blob_id": "93e95017c3fb2d81248d3a42aeb4cd21f5cd2b4e",
"content_id": "5930a42620fc8ea3c959b8619912afabba8b3da2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1063,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 42,
"path": "/Sexta-FeiraInterface/src/com/friday/SextaFeiraInterface.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage com.friday;\n\nimport javafx.application.Application;\nimport javafx.fxml.FXMLLoader;\nimport javafx.scene.Parent;\nimport javafx.scene.Scene;\nimport javafx.stage.Stage;\n\n/**\n *\n * @author Gazebo\n */\npublic class SextaFeiraInterface extends Application {\n \n @Override\n public void start(Stage stage) throws Exception {\n //Runtime.getRuntime().exec(\"cmd.exe /c start \\\\Sexta-Feira-Mark_6\\\\Sexta-Feira(A.I.)\\\\Sexta-Feira(A.I.).py\");\n \n Parent root = FXMLLoader.load(getClass().getResource(\"Scene.fxml\"));\n \n Scene scene = new Scene(root);\n \n stage.setTitle(\"Sexta-Feira\");\n stage.setScene(scene);\n stage.show();\n \n stage.setFullScreen(true);\n }\n\n /**\n * @param args the command line arguments\n */\n public static void main(String[] args) {\n launch(args);\n }\n \n}\n"
},
{
"alpha_fraction": 0.6851805448532104,
"alphanum_fraction": 0.6943960189819336,
"avg_line_length": 51.828948974609375,
"blob_id": "c188ec58eec1df3f279aa4fdf2ac5ef5e5b5ec54",
"content_id": "9f373ae1dd00b49459204be6c7c79669ffd1bb10",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4015,
"license_type": "permissive",
"max_line_length": 251,
"num_lines": 76,
"path": "/Server/DataBase.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import mysql.connector as mysqlConnector\nfrom datetime import datetime\nimport sqlite3\n\nclass DataBaseConnection:\n def __init__(self):\n self.dataBaseConnector = mysqlConnector.connect(host='localhost', user='root', password='Gazao015', \n database='sextafeiradatabase')\n\n self.dataBaseCursor = self.dataBaseConnector.cursor()\n\n def getInteractions(self):\n self.dataBaseCursor.execute('SELECT * FROM Interactions')\n return self.dataBaseCursor.fetchall()\n\n def getHomeWorks(self):\n self.dataBaseCursor.execute('SELECT * FROM HomeWorkManagement')\n return self.dataBaseCursor.fetchall()\n\n def getProjects(self):\n self.dataBaseCursor.execute('SELECT * FROM Projects')\n return self.dataBaseCursor.fetchall()\n\n def getDevices(self):\n self.dataBaseCursor.execute('SELECT * FROM Device')\n return self.dataBaseCursor.fetchall()\n\n def insertInteraction(self, key1, key2, key3, res1, res2, res3, command):\n self.dataBaseCursor.execute('INSERT INTO Interactions(KeyWord1, KeyWord2, KeyWord3, Response1, Response2, Response3, Command) VALUES (%s,%s,%s,%s,%s,%s,%s)', (key1, key2, key3, res1, res2, res3, command))\n self.dataBaseConnector.commit()\n\n def insertHomeWork(self, Type, subject, homeWork, delivery, desc):\n self.dataBaseCursor.execute('INSERT INTO HomeWorkManagement(HomeWorkType, HomeWorkSubject, HomeWork, HomeWorkDelivery, HomeWorkDescription) VALUES (%s,%s,%s,%s,%s)', (Type, subject, homeWork, delivery, desc))\n self.dataBaseConnector.commit()\n\n def insertProject(self, type, name):\n self.dataBaseCursor.execute('INSERT INTO Projects(ProjectType, ProjectName) VALUES (%s,%s)', (type, name))\n self.dataBaseConnector.commit()\n\n def insertDevice(self, name, desc, actions):\n self.dataBaseCursor.execute('INSERT INTO Device(DeviceName, DeviceDescription, DeviceActions) VALUES (%s,%s,%s)', (name, desc, actions))\n self.dataBaseConnector.commit()\n\n\n def updateInteraction(self, updateId, key1, key2, key3, res1, res2, res3, command):\n self.dataBaseCursor.execute(f\"UPDATE Interactions set KeyWord1 = '{key1}', KeyWord2 = '{key2}', KeyWord3 = '{key3}', Response1 = '{res1}', Response2 = '{res2}', Response3 = '{res3}', Command = '{command}' WHERE InteractionId = '{updateId}' \")\n self.dataBaseConnector.commit()\n\n def updateHomeWork(self, updateId, type, subject, homeWork, delivery, desc):\n self.dataBaseCursor.execute(f\"UPDATE HomeWorkManagement set HomeWorkType = '{type}', HomeWorkSubject = '{subject}', HomeWork = '{homeWork}', HomeWorkDelivery = '{delivery}', HomeWorkDescription = '{desc}' WHERE HomeWorkID ='{updateId}' \")\n self.dataBaseConnector.commit()\n\n def updateProject(self, updateId, type, name):\n self.dataBaseCursor.execute(f\"UPDATE Projects SET ProjectName='{name}', ProjectType='{type}' WHERE ProjectID='{updateId}' \")\n self.dataBaseConnector.commit()\n\n def updateDevice(self, updateId, name, desc, actions):\n self.dataBaseCursor.execute(f\"UPDATE Device SET DeviceName = '{name}', DeviceDescription = '{desc}', DeviceActions = '{actions}' WHERE DeviceID = '{updateId}' \")\n self.dataBaseConnector.commit()\n\n\n def deleteInteraction(self, deleteID):\n self.dataBaseCursor.execute('DELETE FROM Interactions WHERE InteractionID = %d' % (deleteID))\n self.dataBaseConnector.commit()\n\n def deleteDevice(self, deleteID):\n self.dataBaseCursor.execute('DELETE FROM Device WHERE DeviceID = %d' % (deleteID))\n self.dataBaseConnector.commit()\n\n def deleteHomeWork(self, deleteID):\n self.dataBaseCursor.execute('DELETE FROM HomeWorkManagement WHERE HomeWorkID = %d' % (deleteID))\n self.dataBaseConnector.commit()\n\n def deleteProject(self, deleteID):\n self.dataBaseCursor.execute('DELETE FROM Projects WHERE ProjectID = %d' % (deleteID))\n self.dataBaseConnector.commit()\n"
},
{
"alpha_fraction": 0.6731863617897034,
"alphanum_fraction": 0.6731863617897034,
"avg_line_length": 35.0512809753418,
"blob_id": "cfe648aeceaf980f27800f0c9efc6f3010f78180",
"content_id": "0b1ebb530e141c6f5d5aef8906e5dc0e04f95081",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2813,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 78,
"path": "/App/app/src/main/java/com/gazeboindustries/friday/Fragments/SkillsFragments/HomeworkFragments/AddHomeWorkFragment.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.gazeboindustries.friday.Fragments.SkillsFragments.HomeworkFragments;\n\nimport android.os.Bundle;\nimport android.view.LayoutInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.Toast;\n\nimport androidx.annotation.NonNull;\nimport androidx.annotation.Nullable;\nimport androidx.fragment.app.Fragment;\n\nimport com.gazeboindustries.friday.R;\nimport com.gazeboindustries.friday.ServerConnection;\n\nimport java.text.ParseException;\nimport java.text.SimpleDateFormat;\nimport java.util.Date;\n\npublic class AddHomeWorkFragment extends Fragment {\n private Button btnAddHomeWork;\n private EditText type;\n private EditText subject;\n private EditText homeWork;\n private EditText delivery;\n private EditText desc;\n\n private ServerConnection connection;\n private SimpleDateFormat sdf;\n private SimpleDateFormat dateOutput;\n private Date dateFormated;\n\n @Nullable\n @Override\n public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n sdf = new SimpleDateFormat(\"dd/MM/yyyy\");\n dateOutput = new SimpleDateFormat(\"yyyy-MM-dd\");\n\n View view = inflater.inflate(R.layout.fragment_addhomework, container, false);\n\n btnAddHomeWork = view.findViewById(R.id.btnAddHomeWork);\n\n type = view.findViewById(R.id.txtHomeWorkType);\n subject = view.findViewById(R.id.txtHomeWorkSubject);\n homeWork = view.findViewById(R.id.txtHomeWork);\n delivery = view.findViewById(R.id.txtHomeWorkDelivery);\n desc = view.findViewById(R.id.txtHomeWorkDescription);\n\n btnAddHomeWork.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n connection = new ServerConnection();\n\n try {\n dateFormated = sdf.parse(delivery.getText().toString());\n\n connection.sendRequest(connection.prepareAddHomework(\"insertHomeWork\", type.getText().toString(), subject.getText().toString(),\n homeWork.getText().toString(), dateOutput.format(dateFormated), desc.getText().toString()));\n\n if(connection.getMsgStatus()){\n Toast.makeText(view.getContext(), \"Tarefa enviada\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(view.getContext(), \"Erro ao enviar a tarefa\", Toast.LENGTH_SHORT).show();\n }\n\n } catch (ParseException e) {\n Toast.makeText(view.getContext(), \"Insira um formato válido\", Toast.LENGTH_SHORT).show();\n }\n\n }\n });\n\n\n return view;\n}\n}\n"
},
{
"alpha_fraction": 0.7012700438499451,
"alphanum_fraction": 0.7012700438499451,
"avg_line_length": 33.1698112487793,
"blob_id": "8d5749cf83690e23fdc2a0252ac1ff81074c2b3e",
"content_id": "1b06c24ab3c2c80bc3b605313d713f2ad0b3e1b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1811,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 53,
"path": "/App/app/src/main/java/com/gazeboindustries/friday/Fragments/SkillsFragments/ProjectsFragments/AddProjectFragment.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.gazeboindustries.friday.Fragments.SkillsFragments.ProjectsFragments;\n\nimport android.os.Bundle;\nimport android.view.LayoutInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.Toast;\n\nimport androidx.annotation.NonNull;\nimport androidx.annotation.Nullable;\nimport androidx.fragment.app.Fragment;\n\nimport com.gazeboindustries.friday.R;\nimport com.gazeboindustries.friday.ServerConnection;\n\npublic class AddProjectFragment extends Fragment {\n private Button btnAddProject;\n private EditText type;\n private EditText project;\n\n private ServerConnection connection;\n\n @Nullable\n @Override\n public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n View view = inflater.inflate(R.layout.fragment_addproject, container, false);\n\n btnAddProject = view.findViewById(R.id.btnAddProject);\n project = view.findViewById(R.id.txtAddNameProject);\n type = view.findViewById(R.id.txtAddTypeProject);\n\n btnAddProject.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n connection = new ServerConnection();\n\n connection.sendRequest(connection.prepareAddProject(\"insertProject\", type.getText().toString(), project.getText().toString()));\n\n if(connection.getMsgStatus()){\n Toast.makeText(view.getContext(), \"Projeto adicionado\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(view.getContext(), \"Erro ao adicionar projeto\", Toast.LENGTH_SHORT).show();\n }\n\n }\n });\n\n\n return view;\n }\n}\n"
},
{
"alpha_fraction": 0.5596407651901245,
"alphanum_fraction": 0.5683413147926331,
"avg_line_length": 29.427350997924805,
"blob_id": "4bd65d8ae90295343f3c8444f5f141ba813a5f4a",
"content_id": "a97111d4ef617f9854dc3daa5464316e20cbb5e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3563,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 117,
"path": "/Sexta-Feira(A.I.)/Functions.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import speech_recognition as sr \nimport pyttsx3, random, json\nfrom unicodedata import normalize\nfrom socket import socket, AF_INET, SOCK_STREAM\nfrom datetime import datetime\nfrom threading import Thread\n\ndef Recognition():\n recognizer = sr.Recognizer()\n\n try:\n with sr.Microphone() as source:\n recognizer.adjust_for_ambient_noise(source)\n\n print('Say:')\n\n sound = recognizer.listen(source)\n speech = recognizer.recognize_google(sound, language='pt').lower()\n print('You said: ', speech)\n\n return ' ' + speech + ' '\n except:\n return ''\n\nclass Speaker(Thread):\n def __init__(self, text):\n Thread.__init__(self)\n self.text = text\n\n def run(self):\n speaker = pyttsx3.init('sapi5')\n speaker.say(self.text)\n speaker.runAndWait()\n\ndef speak(text):\n speak = Speaker(text)\n speak.start()\n\ndef responseSelector():\n return random.randint(4, 6)\n\ndef languageUnderstanding(phrase):\n phraseFilter = [' o ', ' a ', ' os ', ' as ', ' um ', ' uma ', ' uns ', ' umas ', ' ante ', ' apos ',\n ' ate ', ' com ',' contra ', ' de ' ,\n ' desde ', ' entre ', ' para ', ' perante ', ' por ', ' sem ', ' sob ', ' sobre ',\n ' como ', ' e ', ' ainda ', ' tambem ', ' contudo ', ' entretanto ', ' mas ', ' entanto ',\n ' porem ', ' todavia ', ' assim ', ' entao ', ' logo ', ' pois ', ' porque ', ' por ',\n ' que ', ' para ', ' no ',' na ']\n\n phraseFiltered = normalize('NFKD', phrase).encode('ASCII', 'ignore').decode('ASCII')\n \n for word in phraseFilter:\n if word in phraseFiltered:\n phraseFiltered = phraseFiltered.replace(word, ' ')\n\n print('Filtered:', phraseFiltered)\n return phraseFiltered\n\ndef setRequestJson(request, receiverID, action, url):\n requestJson = json.dumps({\n 'header': 'gazeboindustries09082004',\n 'receiverID': receiverID,\n 'request': request,\n 'action': action,\n 'url': url\n \n })\n\n return requestJson\n\ndef setup():\n setFridayComunication(0, None, \".com\")\n\n server = ServerConnection()\n\n interactions = list(server.send(setRequestJson('getInteractions', 'server', 1, \".com\")).items())\n\n hour = int(datetime.now().hour)\n if 5 <= hour <= 11:\n speak('Bom dia chefe!')\n elif 12 <= hour <= 17:\n speak('Boa tarde chefe!')\n else:\n speak('Boa noite chefe!')\n\n\n return [server, interactions]\n\nclass ServerConnection:\n def __init__(self):\n try:\n file = open('/Sexta-Feira-Mark_6/Configurations.json', 'r')\n configs = json.load(file)['FridayConfigs']\n\n self.connection = socket(AF_INET, SOCK_STREAM, 0)\n self.connection.connect((configs['ServerHost'], configs['Port'] ))\n except:\n print('ERRO AO CONECTAR-SE COM O SERVIDOR') \n \n def send(self, message):\n self.connection.send(message.encode())\n\n return json.loads(self.connection.recv(5800).decode('utf-8'))\n\ndef setFridayComunication(action, content, url):\n filePath = 'E:/Sexta-Feira-Mark_6/Sexta-FeiraInterface/src/com/friday/FridayComunication.json'\n readFile = open(filePath, 'r')\n newJson = json.load(readFile)\n\n print(newJson)\n\n newJson['action'] = action\n newJson['content'] = content\n newJson['url'] = url\n\n writeFile = open(filePath, 'w')\n json.dump(newJson, writeFile, indent=4)\n\n\n\n"
},
{
"alpha_fraction": 0.6283354163169861,
"alphanum_fraction": 0.6317822337150574,
"avg_line_length": 37.2386360168457,
"blob_id": "4757dd11bf90695784ea58a58942f38aaaf3261a",
"content_id": "eacbb84c0aa094afa97e719c2e7f431d6f437cff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 16839,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 440,
"path": "/Sexta-FeiraInterface/src/com/friday/SceneController.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.friday;\n\nimport java.io.File;\nimport java.lang.reflect.Array;\nimport java.net.URL;\nimport java.text.ParseException;\nimport java.text.SimpleDateFormat;\nimport java.util.Arrays;\nimport java.util.Calendar;\nimport java.util.GregorianCalendar;\nimport java.util.Locale;\nimport java.util.List;\nimport java.util.ResourceBundle;\n\nimport org.json.simple.JSONArray;\nimport org.json.simple.JSONObject;\nimport org.omg.CORBA.portable.IDLEntity;\n\nimport javafx.event.ActionEvent;\nimport javafx.event.Event;\nimport javafx.fxml.FXML;\nimport javafx.fxml.Initializable;\nimport javafx.scene.control.Label;\nimport javafx.animation.KeyFrame;\nimport javafx.animation.Timeline;\nimport javafx.collections.ObservableList;\nimport javafx.util.Duration;\nimport javafx.event.EventHandler;\nimport javafx.scene.image.ImageView;\nimport javafx.scene.control.TableView;\nimport javafx.scene.control.TableColumn;\nimport javafx.scene.control.cell.PropertyValueFactory;\nimport javafx.collections.FXCollections;\nimport javafx.scene.image.Image;\nimport javafx.scene.control.TableColumn.CellDataFeatures;\nimport javafx.beans.value.ObservableValue;\nimport javafx.beans.property.ReadOnlyObjectWrapper;\nimport javafx.util.Callback;\n\npublic class SceneController implements Initializable {\n\n @FXML\n private Label lblTime;\n @FXML\n private Label lblDayMonth;\n @FXML\n private Label lblWeekDay;\n @FXML\n private ImageView imageView;\n @FXML\n private TableView<JSONArray> tableView;\n\n private TableColumn idColumn = new TableColumn<JSONArray, Integer>(\"ID\");\n\n private TableColumn keyWord1Column = new TableColumn<JSONArray, String>(\"Palavra chave 1\");\n private TableColumn keyWord2Column = new TableColumn<JSONArray, String>(\"Palavra chave 2\");\n private TableColumn keyWord3Column = new TableColumn<JSONArray, String>(\"Palavra chave 3\");\n private TableColumn response1Column = new TableColumn<JSONArray, String>(\"Resposta 1\");\n private TableColumn response2Column = new TableColumn<JSONArray, String>(\"Resposta 2\");\n private TableColumn response3Column = new TableColumn<JSONArray, String>(\"Resposta 3\");\n private TableColumn commandColumn = new TableColumn<JSONArray, String>(\"Comando\");\n\n private TableColumn homeWorkTypeColumn = new TableColumn<JSONArray, String>(\"Tipo\");\n private TableColumn homeWorkSubjectColumn = new TableColumn<JSONArray, String>(\"Matéria\");\n private TableColumn homeWorkColumn = new TableColumn<JSONArray, String>(\"Tarefa\");\n private TableColumn homeWorkDeliveryColumn = new TableColumn<JSONArray, String>(\"Entrega\");\n private TableColumn homeWorkDescColumn = new TableColumn<JSONArray, String>(\"Descrição\");\n\n private TableColumn projectColumn = new TableColumn<JSONArray, String>(\"Projeto\");\n private TableColumn projectTypeColumn = new TableColumn<JSONArray, String>(\"Tipo\");\n\n private TableColumn DeviceColumn = new TableColumn<JSONArray, String>(\"Device\");\n private TableColumn DeviceDescColumn = new TableColumn<JSONArray, String>(\"Descrição\");\n private TableColumn DeviceActionsColumn = new TableColumn<JSONArray, String>(\"Número de ações\");\n \n JSONArray arrayResponse;\n JSONObject response;\n String imagePath;\n int action;\n File imageFile;\n Image image;\n ObservableList<JSONArray> tableViewData = FXCollections.observableArrayList();\n\n Locale locale;\n Calendar calendar;\n GregorianCalendar gregCalendar;\n SimpleDateFormat dateFormat;\n SimpleDateFormat hourFormat;\n String date;\n String hour;\n String weekDay;\n\n @Override\n public void initialize(URL url, ResourceBundle rb) {\n\n EventHandler handler = new EventHandler() {\n\n @Override\n public void handle(Event event) {\n setClock();\n connectionLoop();\n }\n\n };\n\n KeyFrame frame = new KeyFrame(Duration.millis(1000), handler);\n Timeline timeline = new Timeline();\n timeline.getKeyFrames().add(frame);\n timeline.setCycleCount(Timeline.INDEFINITE);\n timeline.play();\n\n }\n\n private void connectionLoop() {\n response = FridayComunication.readJsonFile();\n action = Integer.parseInt(response.get(\"action\").toString());\n\n switch (action) {\n case 0:\n tableView.setVisible(false);\n imageView.setVisible(false);\n break;\n\n case 1:\n \n if (!tableView.getColumns().contains(commandColumn)) {\n imageView.setVisible(false);\n setTableData();\n\n addInteractionsColumns();\n\n }\n\n break;\n\n case 2:\n if (!tableView.getColumns().contains(homeWorkColumn)) {\n imageView.setVisible(false);\n setTableData();\n addHomeWorksColumns();\n }\n break;\n\n case 3:\n if (!tableView.getColumns().contains(projectColumn)) {\n imageView.setVisible(false);\n setTableData();\n addProjectsColumns();\n }\n break;\n\n case 4:\n\n if (!tableView.getColumns().contains(DeviceColumn)) {\n imageView.setVisible(false);\n setTableData();\n\n addDevicesColumns();\n\n\n }\n break;\n\n case 5:\n tableView.setVisible(false);\n\n imagePath = response.get(\"url\").toString();\n System.out.println(imagePath);\n imageFile = new File(imagePath);\n image = new Image(imageFile.toURI().toString());\n imageView.setImage(image);\n imageView.setVisible(true);\n\n\n default:\n break;\n }\n }\n\n private void addInteractionsColumns() {\n tableView.getColumns().clear();\n\n idColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, Integer>, ObservableValue<Integer>>() {\n @Override\n public ObservableValue<Integer> call(CellDataFeatures<JSONArray, Integer> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(0));\n }\n });\n\n keyWord1Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(1));\n }\n });\n\n keyWord2Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(2));\n }\n });\n\n keyWord3Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(3));\n }\n });\n\n response1Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(4));\n }\n });\n\n response2Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(5));\n }\n });\n\n response3Column.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(6));\n }\n });\n\n commandColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(7));\n }\n });\n\n tableView.getColumns().addAll(idColumn, keyWord1Column, keyWord2Column, keyWord3Column, response1Column,\n response2Column, response3Column, commandColumn);\n\n tableView.setVisible(true);\n }\n\n private void addHomeWorksColumns() {\n tableView.getColumns().clear();\n\n idColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, Integer>, ObservableValue<Integer>>() {\n @Override\n public ObservableValue<Integer> call(CellDataFeatures<JSONArray, Integer> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(0));\n }\n });\n\n homeWorkTypeColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(1));\n }\n });\n\n homeWorkSubjectColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(2));\n }\n });\n\n homeWorkColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(3));\n }\n });\n\n homeWorkDeliveryColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(4));\n }\n });\n\n homeWorkDescColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(5));\n }\n });\n\n tableView.getColumns().addAll(idColumn, homeWorkTypeColumn, homeWorkSubjectColumn, homeWorkColumn,\n homeWorkDeliveryColumn, homeWorkDescColumn);\n\n tableView.setVisible(true);\n }\n\n private void addProjectsColumns() {\n tableView.getColumns().clear();\n\n projectTypeColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(1));\n }\n });\n\n projectColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(2));\n }\n });\n\n idColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, Integer>, ObservableValue<Integer>>() {\n @Override\n public ObservableValue<Integer> call(CellDataFeatures<JSONArray, Integer> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(0));\n }\n });\n\n tableView.getColumns().addAll(idColumn, projectTypeColumn, projectColumn);\n\n tableView.setVisible(true);\n }\n\n private void addDevicesColumns() {\n tableView.getColumns().clear();\n\n idColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, Integer>, ObservableValue<Integer>>() {\n @Override\n public ObservableValue<Integer> call(CellDataFeatures<JSONArray, Integer> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(0));\n }\n });\n\n \n DeviceColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(1));\n }\n });\n\n\n\n DeviceDescColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(2));\n }\n });\n\n DeviceActionsColumn.setCellValueFactory(new Callback<CellDataFeatures<JSONArray, String>, ObservableValue<String>>() {\n @Override\n public ObservableValue<String> call(CellDataFeatures<JSONArray, String> param) {\n // TODO Auto-generated method stub\n return new ReadOnlyObjectWrapper(param.getValue().get(3));\n }\n });\n\n tableView.getColumns().addAll(idColumn, DeviceColumn, DeviceDescColumn, DeviceActionsColumn);\n\n tableView.setVisible(true);\n }\n\n private void setTableData(){\n tableView.getItems().clear();\n\n response = (JSONObject) FridayComunication.readJsonFile().get(\"content\");\n System.out.println(response);\n\n for (int c = 0; c < response.size(); c++) {\n arrayResponse = (JSONArray) response.get(Integer.toString(c));\n tableViewData.add(arrayResponse);\n System.out.println(arrayResponse);\n }\n tableView.setItems(tableViewData);\n System.out.println(\"TableView dados >>> \" + tableView.getItems());\n }\n\n private void setClock() {\n\n try {\n locale = new Locale(\"pt\", \"BR\");\n gregCalendar = new GregorianCalendar();\n dateFormat = new SimpleDateFormat(\"dd'/'MM'/'yyyy\", locale);\n hourFormat = new SimpleDateFormat(\"HH':'mm\", locale);\n\n calendar = gregCalendar.getInstance();\n\n date = dateFormat.format(calendar.getTime());\n hour = hourFormat.format(calendar.getTime());\n\n calendar.setTime(dateFormat.parse(date));\n\n weekDay = Integer.toString(calendar.get(Calendar.DAY_OF_WEEK)) + \"ª Feira\";\n\n if(weekDay.equals(\"7ª Feira\")){\n weekDay = \"Sábado\";\n \n }else{\n if(weekDay.equals(\"1ª Feira\")){\n weekDay = \"Domingo\";\n }\n } \n\n lblWeekDay.setText(weekDay);\n lblDayMonth.setText(date);\n lblTime.setText(hour);\n\n } catch (ParseException e) {\n // TODO Auto-generated catch block\n e.printStackTrace();\n }\n\n\n\n\n }\n\n}\n\n\n"
},
{
"alpha_fraction": 0.6707317233085632,
"alphanum_fraction": 0.6788617968559265,
"avg_line_length": 26.44444465637207,
"blob_id": "bc11f517f5a03ed6e647fedc35b3faaafc4df1e7",
"content_id": "e4f5bcbe4f0e22e98297e16b6b912fbe94f89209",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 246,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 9,
"path": "/Server/Configurations.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import json\n\ndef serverConfigs():\n file = open('E:/Sexta-Feira-Mark_6/Configurations.json', 'r')\n return json.load(file)['ServerConfigs']\n\ndef setConfigs(list):\n file = open('Configurations.json', 'w')\n json.dump(list, file, indent=4)"
},
{
"alpha_fraction": 0.6895833611488342,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 35.846153259277344,
"blob_id": "2c706c7206d386378f7d1f2108832c8d79a38fb5",
"content_id": "3fa8e97bffd3802581ff899d8e2d2f4167e24c7f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 480,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 13,
"path": "/Sexta-Feira(A.I.)/Sexta-Feira(A.I.).py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import Functions\nfrom Commands import callCommand\n\nconnection, interactions = Functions.setup()\n\nwhile True: \n speech = Functions.languageUnderstanding(Functions.Recognition())\n \n for interaction in interactions:\n if interaction[1][1] in speech and interaction[1][2] in speech and interaction[1][3] in speech:\n callCommand(interaction[1][7], speech, connection)\n Functions.speak(interaction[1][Functions.responseSelector()])\n break\n\n"
},
{
"alpha_fraction": 0.6879756450653076,
"alphanum_fraction": 0.6879756450653076,
"avg_line_length": 26.375,
"blob_id": "7e1a5ec653e86ba245842562e5e60c84c790c20c",
"content_id": "087a40e06a69686d2477bbd2df2220371892ccad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 657,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 24,
"path": "/Sexta-FeiraInterface/src/com/friday/FridayComunication.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "\npackage com.friday;\n\nimport java.io.FileReader;\nimport java.io.IOException;\nimport org.json.simple.JSONObject;\nimport org.json.simple.parser.JSONParser;\nimport org.json.simple.parser.ParseException;\n\npublic class FridayComunication {\n private static JSONObject jsonObject;\n private static JSONParser parser;\n\n public static JSONObject readJsonFile() {\n parser = new JSONParser();\n\n try {\n jsonObject = (JSONObject) parser.parse(new FileReader(\".\\\\src\\\\com\\\\friday\\\\FridayComunication.json\"));\n } catch (ParseException | IOException e) {\n e.printStackTrace();\n }\n\n return jsonObject;\n }\n}"
},
{
"alpha_fraction": 0.6089458465576172,
"alphanum_fraction": 0.6116599440574646,
"avg_line_length": 39.39912414550781,
"blob_id": "f631acb17787d10d3135622dac7d9251fb550471",
"content_id": "e8e25310e505a550401429f5808f7d874451f931",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 9212,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 228,
"path": "/App/app/src/main/java/com/gazeboindustries/friday/Fragments/DevicesFragments/ViewDevicesFragment.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.gazeboindustries.friday.Fragments.DevicesFragments;\n\nimport android.annotation.SuppressLint;\nimport android.app.AlertDialog;\nimport android.content.DialogInterface;\nimport android.content.Intent;\nimport android.graphics.drawable.Drawable;\nimport android.os.Bundle;\nimport android.view.LayoutInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.Toast;\n\nimport androidx.annotation.NonNull;\nimport androidx.annotation.Nullable;\nimport androidx.fragment.app.Fragment;\n\nimport com.gazeboindustries.friday.R;\nimport com.gazeboindustries.friday.ServerConnection;\n\nimport org.json.JSONException;\nimport org.json.JSONObject;\n\npublic class ViewDevicesFragment extends Fragment {\n private Intent intent;\n private EditText txtDevice;\n private EditText txtDescription;\n private EditText txtActions;\n\n private Button btnEditSend;\n private Button btnDeleteCancel;\n private Button btnAction;\n private Button btnOnOff;\n\n private Drawable cancelIcon;\n private Drawable saveIcon;\n\n private Drawable editIcon;\n private Drawable removeIcon;\n\n private int deviceAction;\n private int ID;\n\n private ServerConnection connection;\n\n private AlertDialog.Builder removeAlert;\n private AlertDialog removeDialog;\n\n private JSONObject status;\n private JSONObject deviceStatus;\n\n\n @SuppressLint(\"SetTextI18n\")\n @Nullable\n @Override\n public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n View view = inflater.inflate(R.layout.fragment_viewdevice, container, false);\n\n connection = new ServerConnection();\n\n txtDevice = view.findViewById(R.id.txtViewDevice);\n txtDescription = view.findViewById(R.id.txtViewDeviceDescription);\n txtActions = view.findViewById(R.id.txtViewDeviceActions);\n btnEditSend = view.findViewById(R.id.btnEditDevice);\n btnDeleteCancel = view.findViewById(R.id.btnRemoveDevice);\n btnAction = view.findViewById(R.id.btnActionDevice);\n btnOnOff = view.findViewById(R.id.btnOnOffDevice);\n\n intent = getActivity().getIntent();\n\n ID = intent.getIntExtra(\"ID\", 0);\n txtDevice.setText(intent.getStringExtra(\"Device\"));\n txtDescription.setText(intent.getStringExtra(\"Description\"));\n txtActions.setText(Integer.toString(intent.getIntExtra(\"Actions\", 0)));\n\n try {\n status = (JSONObject) connection.sendJSONRequest(connection.prepareRequest(\"getDevicesStatus\"));\n deviceStatus = (JSONObject) status.get(txtDevice.getText().toString());\n System.out.println(deviceStatus.toString());\n deviceAction = deviceStatus.getInt(\"action\");\n if(deviceAction != 0){\n btnOnOff.setText(\"Desligar\");\n }\n\n } catch (JSONException e) {\n e.printStackTrace();\n }\n\n removeAlert = new AlertDialog.Builder(view.getContext());\n removeAlert.setMessage(\"Deseja remover o device?\");\n removeAlert.setCancelable(false);\n\n removeAlert.setNegativeButton(\"Cancelar\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n Toast.makeText(getContext(), \"Cancelado\", Toast.LENGTH_SHORT).show();\n }\n });\n\n removeAlert.setPositiveButton(\"Excluir\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n connection = null;\n connection = new ServerConnection();\n connection.sendRequest(connection.prepareDelete(\"deleteDevice\", ID, txtDevice.getText().toString()));\n\n if(connection.getMsgStatus()) {\n Toast.makeText(getContext(), \"Excluído\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(getContext(), \"Erro ao remover device\", Toast.LENGTH_SHORT).show();\n }\n }\n });\n\n btnEditSend.setOnClickListener(new View.OnClickListener() {\n @SuppressLint(\"SetTextI18n\")\n @Override\n public void onClick(View view) {\n if(btnEditSend.getText().equals(\"Editar\")){\n txtDevice.setEnabled(true);\n txtDescription.setEnabled(true);\n txtActions.setEnabled(true);\n\n btnDeleteCancel.setText(\"Cancelar\");\n btnEditSend.setText(\"Salvar\");\n\n cancelIcon = getResources().getDrawable(R.drawable.ic_clear_black_24dp);\n saveIcon = getResources().getDrawable(R.drawable.ic_save_black_24dp);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(saveIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(cancelIcon, null, null, null);\n\n }else{\n connection = null;\n connection = new ServerConnection();\n connection.sendRequest(connection.prepareUpdateDevice(\"updateDevice\",intent.getStringExtra(\"Device\"), ID, txtDevice.getText().toString(), txtDescription.getText().toString(),\n Integer.parseInt(txtActions.getText().toString())));\n\n txtDevice.setEnabled(false);\n txtDescription.setEnabled(false);\n txtActions.setEnabled(false);\n\n btnDeleteCancel.setText(\"Excluir\");\n btnEditSend.setText(\"Editar\");\n\n editIcon = getResources().getDrawable(R.drawable.ic_edit_black_24dp);\n removeIcon = getResources().getDrawable(R.drawable.ic_delete_black_24dp);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(editIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(removeIcon, null, null, null);\n\n intent.putExtra(\"ID\", ID);\n intent.putExtra(\"Device\", txtDevice.getText().toString());\n intent.putExtra(\"Description\", txtDescription.getText().toString());\n intent.putExtra(\"Actions\", Integer.parseInt(txtActions.getText().toString()));\n\n if(connection.getMsgStatus()){\n Toast.makeText(getContext(), \"Salvo\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(getContext(), \"Erro ao salvar o device\", Toast.LENGTH_SHORT).show();\n }\n }\n }\n });\n\n btnDeleteCancel.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n if(btnDeleteCancel.getText().equals(\"Excluir\")){\n removeDialog = removeAlert.create();\n removeDialog.show();\n }else{\n txtDevice.setEnabled(false);\n txtDescription.setEnabled(false);\n\n btnDeleteCancel.setText(\"Excluir\");\n btnEditSend.setText(\"Editar\");\n\n editIcon = getResources().getDrawable(R.drawable.ic_edit_black_24dp);\n removeIcon = getResources().getDrawable(R.drawable.ic_delete_black_24dp);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(editIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(removeIcon, null, null, null);\n\n txtDevice.setText(intent.getStringExtra(\"Device\"));\n txtDescription.setText(intent.getStringExtra(\"Description\"));\n txtDescription.setText(intent.getIntExtra(\"Actions\", 0));\n\n }\n }\n });\n\n btnOnOff.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n connection = null;\n connection = new ServerConnection();\n\n if(btnOnOff.getText().equals(\"Ligar\")){\n connection.sendRequest(connection.prepareSetDevice(txtDevice.getText().toString(), 1, \".com\"));\n deviceAction = 1;\n btnOnOff.setText(\"Desligar\");\n }else{\n connection.sendRequest(connection.prepareSetDevice(txtDevice.getText().toString(), 0, \".com\"));\n deviceAction = 0;\n btnOnOff.setText(\"Ligar\");\n\n }\n }\n });\n\n btnAction.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n connection = null;\n connection = new ServerConnection();\n if(deviceAction != 0){\n deviceAction++;\n connection.sendRequest(connection.prepareSetDevice(txtDevice.getText().toString(), deviceAction, \".com\"));\n }\n }\n });\n\n return view;\n }\n}\n"
},
{
"alpha_fraction": 0.6189455986022949,
"alphanum_fraction": 0.6202546954154968,
"avg_line_length": 40.5990104675293,
"blob_id": "5f31d6816d53b53a4e3f6d3c5407f28defb578d7",
"content_id": "84cc04aa8522b19b2e9469c4282dfaee026988a7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8407,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 202,
"path": "/App/app/src/main/java/com/gazeboindustries/friday/Fragments/SkillsFragments/HomeworkFragments/ViewHomeWorkFragment.java",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "package com.gazeboindustries.friday.Fragments.SkillsFragments.HomeworkFragments;\n\nimport android.annotation.SuppressLint;\nimport android.app.AlertDialog;\nimport android.content.DialogInterface;\nimport android.content.Intent;\nimport android.graphics.drawable.Drawable;\nimport android.os.Bundle;\nimport android.view.LayoutInflater;\nimport android.view.View;\nimport android.view.ViewGroup;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.Toast;\n\nimport androidx.annotation.NonNull;\nimport androidx.annotation.Nullable;\nimport androidx.fragment.app.Fragment;\n\nimport com.gazeboindustries.friday.R;\nimport com.gazeboindustries.friday.ServerConnection;\n\nimport java.text.ParseException;\nimport java.text.SimpleDateFormat;\nimport java.util.Date;\n\npublic class ViewHomeWorkFragment extends Fragment {\n private Intent intent;\n private EditText txtType;\n private EditText txtSubject;\n private EditText txtHomeWork;\n private EditText txtDelivery;\n private EditText txtDescription;\n\n private Button btnEditSend;\n private Button btnDeleteCancel;\n\n private Drawable saveIcon;\n private Drawable cancelIcon;\n\n private Drawable editIcon;\n private Drawable removeIcon;\n\n private SimpleDateFormat sdf;\n private SimpleDateFormat dateOutput;\n private Date dateFormated;\n\n private ServerConnection connection;\n private int ID;\n\n private AlertDialog.Builder removeAlert;\n private AlertDialog removeDialog;\n\n @Nullable\n @Override\n public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {\n View view = inflater.inflate(R.layout.fragment_viewhomework, container, false);\n\n connection = new ServerConnection();\n\n sdf = new SimpleDateFormat(\"dd/MM/yyyy\");\n dateOutput = new SimpleDateFormat(\"yyyy-MM-dd\");\n\n\n txtType = view.findViewById(R.id.txtViewHomeWorkType);\n txtSubject = view.findViewById(R.id.txtViewHomeWorkSubject);\n txtHomeWork = view.findViewById(R.id.txtViewHomeWork);\n txtDelivery = view.findViewById(R.id.txtViewHomeWorkDelivery);\n txtDescription = view.findViewById(R.id.txtViewHomeWorkDescription);\n\n intent = getActivity().getIntent();\n\n btnEditSend = view.findViewById(R.id.btnEditHomeWork);\n btnDeleteCancel = view.findViewById(R.id.btnRemoveHomeWork);\n\n ID = intent.getIntExtra(\"ID\", 0);\n txtType.setText(intent.getStringExtra(\"Type\"));\n txtSubject.setText(intent.getStringExtra(\"Subject\"));\n txtHomeWork.setText(intent.getStringExtra(\"HomeWork\"));\n txtDelivery.setText(intent.getStringExtra(\"Delivery\"));\n txtDescription.setText(intent.getStringExtra(\"Description\"));\n\n removeAlert = new AlertDialog.Builder(view.getContext());\n removeAlert.setMessage(\"Deseja remover a interação?\");\n removeAlert.setCancelable(false);\n\n removeAlert.setNegativeButton(\"Cancelar\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n Toast.makeText(getContext(), \"Cancelado\", Toast.LENGTH_SHORT).show();\n }\n });\n\n removeAlert.setPositiveButton(\"Excluir\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n connection.sendRequest(connection.prepareDelete(\"deleteHomeWork\", ID));\n\n if(connection.getMsgStatus()) {\n Toast.makeText(getContext(), \"Excluído\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(getContext(), \"Erro ao remover tarefa\", Toast.LENGTH_SHORT).show();\n }\n }\n });\n\n btnEditSend.setOnClickListener(new View.OnClickListener() {\n @SuppressLint(\"SetTextI18n\")\n @Override\n public void onClick(View view) {\n if(btnEditSend.getText().equals(\"Editar\")){\n txtType.setEnabled(true);\n txtSubject.setEnabled(true);\n txtHomeWork.setEnabled(true);\n txtDelivery.setEnabled(true);\n txtDescription.setEnabled(true);\n\n btnDeleteCancel.setText(\"Cancelar\");\n btnEditSend.setText(\"Salvar\");\n\n cancelIcon = getResources().getDrawable(R.drawable.ic_clear_black_24dp);\n saveIcon = getResources().getDrawable(R.drawable.ic_save_black_24dp);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(saveIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(cancelIcon, null, null, null);\n\n }else{\n try {\n dateFormated = sdf.parse(txtDelivery.getText().toString());\n\n connection.sendRequest(connection.prepareUpdateHomework(\"updateHomeWork\", ID, txtType.getText().toString(), txtSubject.getText().toString(),\n txtHomeWork.getText().toString(), dateOutput.format(dateFormated), txtDescription.getText().toString()));\n\n\n txtType.setEnabled(false);\n txtSubject.setEnabled(false);\n txtHomeWork.setEnabled(false);\n txtDelivery.setEnabled(false);\n txtDescription.setEnabled(false);\n\n btnDeleteCancel.setText(\"Excluir\");\n btnEditSend.setText(\"Editar\");\n\n editIcon = getResources().getDrawable(R.drawable.ic_edit_black_24dp);\n removeIcon = getResources().getDrawable(R.drawable.ic_delete_black_24dp);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(editIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(removeIcon, null, null, null);\n intent.putExtra(\"ID\", ID);\n intent.putExtra(\"Type\", txtType.getText().toString());\n intent.putExtra(\"Subject\", txtSubject.getText().toString());\n intent.putExtra(\"HomeWork\", txtHomeWork.getText().toString());\n intent.putExtra(\"Delivery\", txtDelivery.getText().toString());\n intent.putExtra(\"Description\", txtDescription.getText().toString());\n\n } catch (ParseException e ) {\n Toast.makeText(view.getContext(), \"Insira um formato válido\", Toast.LENGTH_SHORT).show();\n }\n\n\n if(connection.getMsgStatus()){\n Toast.makeText(getContext(), \"Salvo\", Toast.LENGTH_SHORT).show();\n }else{\n Toast.makeText(getContext(), \"Erro ao salvar a tarefa\", Toast.LENGTH_SHORT).show();\n }\n }\n }\n });\n\n btnDeleteCancel.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n if(btnDeleteCancel.getText().equals(\"Excluir\")){\n removeDialog = removeAlert.create();\n removeDialog.show();\n\n }else{\n\n txtType.setText(intent.getStringExtra(\"Type\"));\n txtSubject.setText(intent.getStringExtra(\"Subject\"));\n txtHomeWork.setText(intent.getStringExtra(\"HomeWork\"));\n txtDelivery.setText(intent.getStringExtra(\"Delivery\"));\n txtDescription.setText(intent.getStringExtra(\"Description\"));\n\n txtType.setEnabled(false);\n txtSubject.setEnabled(false);\n txtHomeWork.setEnabled(false);\n txtDelivery.setEnabled(false);\n txtDescription.setEnabled(false);\n\n btnEditSend.setCompoundDrawablesWithIntrinsicBounds(editIcon, null, null, null);\n btnDeleteCancel.setCompoundDrawablesWithIntrinsicBounds(removeIcon, null, null, null);\n\n btnDeleteCancel.setText(\"Excluir\");\n btnEditSend.setText(\"Editar\");\n }\n }\n });\n\n return view;\n }\n}\n"
},
{
"alpha_fraction": 0.47926267981529236,
"alphanum_fraction": 0.4826483726501465,
"avg_line_length": 42.9421501159668,
"blob_id": "00bd926e28caf82efd52cc45c072d109648d3163",
"content_id": "d0dad33dfac7586890b5c21a40c19dd7a114976e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10633,
"license_type": "permissive",
"max_line_length": 348,
"num_lines": 242,
"path": "/Server/Server.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import socketserver, json, time, os\nfrom datetime import *\nfrom DataBase import DataBaseConnection\nfrom Configurations import serverConfigs, setConfigs\n\nconfigs = serverConfigs()\n\nhost = configs['Host']\nport = configs['Port']\n\nprint('---SERVER STARTED---')\n\ndef convertList(dataBaseList): \n indexes = list()\n\n for deviceIndex in range(0, len(dataBaseList)):\n indexes.append(str(deviceIndex))\n\n dictionary = dict(zip(indexes, dataBaseList))\n\n print(dictionary)\n return dictionary\n\ndef convertHeader(header):\n headerList = list()\n\n for index in range(0, len(header)):\n headerList.append(header[index][0])\n\n dictionary = dict(zip(['Header'], [headerList]))\n\n return dictionary\n\ndef getDevicesStatus():\n file = open('./Server/DevicesStatus.json', 'r')\n return json.load(file)\n \ndef setDevicesStatus(receiverID, action, url):\n readFile = open('./Server/DevicesStatus.json', 'r')\n \n newJson = json.load(readFile)\n\n print(newJson)\n\n newJson[receiverID]['action'] = action\n newJson[receiverID]['url'] = url\n\n writeFile = open('./Server/DevicesStatus.json', 'w')\n json.dump(newJson, writeFile, indent=4)\n\nclass ClientManage(socketserver.BaseRequestHandler):\n def handle(self):\n dataBaseConnection = DataBaseConnection()\n\n dateTimeNow= datetime.now()\n print(f'Connected by {self.client_address} at {dateTimeNow.hour}:{dateTimeNow.minute} ')\n\n while True:\n data = self.request.recv(5800).decode()\n print(data)\n\n try:\n if data:\n clientRequest = json.loads(data)\n\n if clientRequest['header'] == 'gazeboindustries09082004':\n \n if clientRequest['request'] == 'startFriday':\n setDevicesStatus('Friday', 1, '.com')\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'getDevices':\n device = convertList(dataBaseConnection.getDevices())\n\n self.request.send(json.dumps(device).encode())\n\n elif clientRequest['request'] == 'getInteractions':\n interactions = convertList(dataBaseConnection.getInteractions())\n\n self.request.send(json.dumps(interactions).encode())\n\n elif clientRequest['request'] == 'getProjects':\n projects = convertList(dataBaseConnection.getProjects())\n self.request.send(json.dumps(projects).encode())\n\n elif clientRequest['request'] == 'getHomeWorks':\n listHomeWorks = list()\n dataBaseHomeWorks = dataBaseConnection.getHomeWorks()\n\n for homeWork in dataBaseHomeWorks:\n homeWork = list(homeWork)\n date = datetime.strftime(homeWork[4], '%d/%m/%Y')\n homeWork[4] = date\n\n listHomeWorks.append(homeWork)\n\n homeWorkconverted = convertList(listHomeWorks)\n\n self.request.send(json.dumps(homeWorkconverted).encode())\n\n elif clientRequest['request'] == 'getDevicesStatus':\n print('Enviado')\n self.request.send(json.dumps(getDevicesStatus()).encode())\n\n elif clientRequest['request'] == 'setDevicesStatus':\n setDevicesStatus(clientRequest['receiverID'], clientRequest['action'], clientRequest['url'])\n self.request.send(json.dumps(getDevicesStatus()).encode())\n \n elif clientRequest['request'] == 'insertInteraction':\n print('adding')\n\n dataBaseConnection.insertInteraction(clientRequest['keyWord1'], \n clientRequest['keyWord2'],\n clientRequest['keyWord3'],\n clientRequest['response1'],\n clientRequest['response2'],\n clientRequest['response3'],\n clientRequest['command'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'insertDevice':\n dataBaseConnection.insertDevice(clientRequest['device'], \n clientRequest['description'],\n clientRequest['actions'])\n\n readFile = open('./Server/DevicesStatus.json', 'r')\n \n newJson = json.load(readFile)\n\n print(newJson)\n\n newJson[clientRequest['device']] = {'action': 0, 'url': '.com'}\n writeFile = open('./Server/DevicesStatus.json', 'w')\n json.dump(newJson, writeFile, indent=4)\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'insertHomeWork':\n print('adding')\n dataBaseConnection.insertHomeWork(clientRequest['type'], \n clientRequest['subject'],\n clientRequest['homeWork'],\n clientRequest['delivery'],\n clientRequest['description'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'insertProject':\n dataBaseConnection.insertProject(clientRequest['type'], clientRequest['project'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'deleteInteraction':\n print('Deleting')\n dataBaseConnection.deleteInteraction(clientRequest['deleteId'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'deleteDevice':\n dataBaseConnection.deleteDevice(clientRequest['deleteId'])\n\n readFile = open('./Server/DevicesStatus.json', 'r')\n \n newJson = json.load(readFile)\n\n print(newJson)\n\n del newJson[clientRequest['deleteName']]\n\n writeFile = open('./Server/DevicesStatus.json', 'w')\n json.dump(newJson, writeFile, indent=4)\n \n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'deleteHomeWork':\n dataBaseConnection.deleteHomeWork(clientRequest['deleteId'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'deleteProject':\n dataBaseConnection.deleteProject(clientRequest['deleteId'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'updateProject':\n dataBaseConnection.updateProject(clientRequest['updateId'], \n clientRequest['type'],\n clientRequest['project'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'updateDevice':\n dataBaseConnection.updateDevice(clientRequest['updateId'], \n clientRequest['device'],\n clientRequest['description'],\n clientRequest['actions'])\n\n readFile = open('./Server/DevicesStatus.json', 'r')\n \n newJson = json.load(readFile)\n\n print(newJson)\n\n del newJson[clientRequest['deleteName']]\n\n newJson[clientRequest['device']] = {'action': 0, 'url': '.com'}\n\n writeFile = open('./Server/DevicesStatus.json', 'w')\n json.dump(newJson, writeFile, indent=4)\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'updateHomeWork':\n dataBaseConnection.updateHomeWork(clientRequest['updateId'], \n clientRequest['type'],\n clientRequest['subject'],\n clientRequest['homeWork'],\n clientRequest['delivery'],\n clientRequest['description'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n\n elif clientRequest['request'] == 'updateInteraction':\n dataBaseConnection.updateInteraction(clientRequest['updateId'], \n clientRequest['keyWord1'],\n clientRequest['keyWord2'],\n clientRequest['keyWord3'],\n clientRequest['response1'],\n clientRequest['response2'],\n clientRequest['response3'],\n clientRequest['command'])\n\n self.request.send(json.dumps({'requestStatus': True}).encode())\n else:\n break\n\n except:\n print('error')\n\nserver = socketserver.ThreadingTCPServer((host, port), ClientManage)\nserver.serve_forever()"
},
{
"alpha_fraction": 0.7541613578796387,
"alphanum_fraction": 0.760136604309082,
"avg_line_length": 40.82143020629883,
"blob_id": "6c51bdea0d6f8eaa51840c4e9113f1063d5cfab1",
"content_id": "dfc4ef12033295df476869912908a51981dd1eb1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2349,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 56,
"path": "/Sexta-Feira(A.I.)/Commands.py",
"repo_name": "GabrielSirtoriCorrea/Sexta-Feira-Mark_6",
"src_encoding": "UTF-8",
"text": "import Functions, os\nfrom datetime import datetime\n\ndef getDirectory(path):\n return os.getcwd().replace('Sexta-FeiraInterface', '') + path\n\ndef callCommand(command, speech, connection):\n commands = globals()\n\n try:\n commands[command](speech, connection)\n except:\n print('No command corresponding')\n\ndef dateTime(speech, connection):\n Functions.speak(f'Agora são {datetime.now().hour} horas e {datetime.now().minute} minutos ')\n\ndef updateFriday(speech, connection):\n os.system('git fetch')\n Functions.speak('Estou instalado as atualizações e reiniciarei o computador')\n os.system('shutdown /r')\n os.system('git reset --hard origin/master')\n\ndef sendCloseToInterface(speech, connection):\n Functions.setFridayComunication(0, None, \".com\")\n \ndef sendInteractionsToInterface(speech, connection):\n response = connection.send(Functions.setRequestJson('getInteractions', 'Interface', 1, '.com'))\n Functions.setFridayComunication(1, response, \".com\")\n\ndef sendHomeWorksToInterface(speech, connection):\n response = connection.send(Functions.setRequestJson('getHomeWorks', 'Interface', 2, '.com'))\n Functions.setFridayComunication(2, response, \".com\")\n\ndef sendProjectsToInterface(speech, connection):\n response = connection.send(Functions.setRequestJson('getProjects', 'Interface', 3, '.com'))\n Functions.setFridayComunication(3, response, \".com\")\n\ndef sendDevicesToInterface(speech, connection):\n response = connection.send(Functions.setRequestJson('getDevices', 'Interface', 4, '.com'))\n Functions.setFridayComunication(4, response, \".com\")\n\ndef sendPeriodicTableToInterface(speech, connection):\n Functions.setFridayComunication(5, None, getDirectory('Images\\TabelaPeriodica.jpg'))\n\ndef sendPoliticalBrazilToInterface(speech, connection):\n Functions.setFridayComunication(5, None, getDirectory('Images\\Brasil Político.jpg'))\n\ndef sendEletronicDestToInterface(speech, connection):\n Functions.setFridayComunication(5, None, getDirectory('Images\\diagrama-de-pauling.jpg'))\n\ndef sendAnglesTableToInterface(speech, connection):\n Functions.setFridayComunication(5, None, getDirectory('Images\\TabelaSenoCossenoTangente.png'))\n\ndef sendFisicEquationsToInterface(speech, connection):\n Functions.setFridayComunication(5, None, getDirectory('Images\\Equações Dinamica.png'))\n\n"
}
] | 16 |
nemanja97/xkcd-downloader
|
https://github.com/nemanja97/xkcd-downloader
|
f0b19edcddd85d23a7e8bd0a0a128269be20426d
|
5e39fb33380f914ec52d1ad25033b35ec093a6a7
|
be1f4b4a596acb4779525c8a2050cb6f5202cfde
|
refs/heads/master
| 2021-04-06T11:18:26.464730 | 2018-03-11T11:56:37 | 2018-03-11T11:56:37 | 124,751,398 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6140414476394653,
"alphanum_fraction": 0.6304110288619995,
"avg_line_length": 29.898876190185547,
"blob_id": "d62f980f61050c364d47df5ac10a37974a922835",
"content_id": "699460ff30392cf2d6eb02f936ca008ceba45e8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2749,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 89,
"path": "/xkcd-multithreaded.py",
"repo_name": "nemanja97/xkcd-downloader",
"src_encoding": "UTF-8",
"text": "#! python3\n# xkcd-multitreaded.py - A multi threaded web scrapper that locally stores all of the xkcd comics\n\nimport requests\nimport bs4\nimport os\nimport threading\n\n\ndef site_scrap(page, index):\n # Establishes connections to 100 pages given an index\n # Some pages contain 404 statuses -> xkcd.com/404 as a joke\n # If such a page is reached, just continue going\n i = index * 100\n end = i + 100\n while i < end:\n try:\n i += 1\n contents = page_connect(page + r\"/\" + str(i))\n print(\"Downloading >> \" + page + r\"/\" + str(i))\n save_comic(get_comic(contents), i)\n except requests.exceptions.HTTPError:\n pass\n except Exception:\n pass\n\n\ndef page_connect(page):\n # Attempts to connect to a page and returns a bs4 object\n resource = requests.get(page)\n resource.raise_for_status()\n soup = bs4.BeautifulSoup(resource.text, \"html.parser\")\n return soup\n\n\ndef get_comic(soup):\n # Given a bs4 object, locates the comic and returns that content\n comicElement = soup.select(\"#comic img\")\n if comicElement == []:\n raise Exception(\"Could not find comic image.\")\n else:\n comicUrl = \"http:\" + comicElement[0].get('src')\n resource = requests.get(comicUrl)\n resource.raise_for_status()\n return resource\n\n\ndef save_comic(resource, counter):\n # Saves the comic as an image, chunk by chunk into a file\n imageFile = open(os.path.join('xkcd-multithreaded', 'xkcd-comic[' + str(counter) + '].png'), 'wb')\n for chunk in resource.iter_content(100000):\n imageFile.write(chunk)\n imageFile.close()\n\n\ndef get_counter():\n # Returns how many hundred comics there are\n # Starts from xkcd comic 1900 and goes up from there\n # When it reaches a 404 page, returns\n max_counter = 19\n while True:\n try:\n c = requests.get(url + r\"/\" + str(max_counter * 100))\n if c.status_code == 404:\n return max_counter\n max_counter += 1\n except requests.exceptions.HTTPError:\n break\n except Exception:\n break\n\n\nif __name__ == \"__main__\":\n # Makes the directory to download into and determines the number of threads needing to be created\n url = \"http://xkcd.com\"\n os.makedirs('xkcd-multithreaded', exist_ok=True)\n max_counter = get_counter()\n\n downloadThreads = []\n for index in range(0, max_counter):\n downloadThread = threading.Thread(target=site_scrap, args=(url, index))\n downloadThreads.append(downloadThread)\n\n for downloadThread in downloadThreads:\n downloadThread.start()\n\n for downloadThread in downloadThreads:\n downloadThread.join()\n print(\"Finished.\")"
},
{
"alpha_fraction": 0.7376425862312317,
"alphanum_fraction": 0.7604562640190125,
"avg_line_length": 36.57143020629883,
"blob_id": "90e3a215d6eb56abb4e585d062d01bbb1dfc3826",
"content_id": "dd317f501a0e70429408e8717d9e4737a31e8691",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 7,
"path": "/README.md",
"repo_name": "nemanja97/xkcd-downloader",
"src_encoding": "UTF-8",
"text": "<h1 align=\"center\">xkcd-downloader</h1>\n\n<p>A python made xkcd website scrapper. Quickly download all the comics, by using multithreading to download files in parallel.</p>\n\n<h3> Requirements </h3>\n\n- [beautifulsoup4](https://pypi.python.org/pypi/beautifulsoup4)\n"
}
] | 2 |
BjDaMaster/SnakePython
|
https://github.com/BjDaMaster/SnakePython
|
c67555ac2c9f8c2443a0e3bb632a2e04ece35bc8
|
4e59cc50b36425f40dfcf04f8a0ef148c00ccc9e
|
c52efa8e20af50005c79b1b29601a4ff6d7777f0
|
refs/heads/master
| 2020-04-01T22:04:37.283492 | 2018-10-18T21:30:21 | 2018-10-18T21:30:21 | 153,690,281 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5098722577095032,
"alphanum_fraction": 0.5586527585983276,
"avg_line_length": 27.13725471496582,
"blob_id": "57c295c9fd3d4318e16825ed273771ccda2719f4",
"content_id": "54062dcb2c22ae423be906f9cacb5353ca75a5fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4305,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 153,
"path": "/Snake.py",
"repo_name": "BjDaMaster/SnakePython",
"src_encoding": "UTF-8",
"text": "import pygame\nimport sys\nimport random\nimport time\n\npygame.init()\n\n\nclass Snake():\n def __init__(self):\n self.position = [100, 50]\n self.body = [[100, 50], [90, 50], [80, 50]]\n self.direction = \"RIGHT\"\n\n def changeDirTo(self, dir):\n if dir == \"RIGHT\" and not self.direction == \"LEFT\":\n self.direction = \"RIGHT\"\n elif dir == \"LEFT\" and not self.direction == \"RIGHT\":\n self.direction = \"LEFT\"\n elif dir == \"UP\" and not self.direction == \"DOWN\":\n self.direction = \"UP\"\n elif dir == \"DOWN\" and not self.direction == \"UP\":\n self.direction = \"DOWN\"\n\n def move(self, foodPos):\n if self.direction == \"RIGHT\":\n self.position[0] = self.position[0] + 10\n elif self.direction == \"LEFT\":\n self.position[0] = self.position[0] - 10\n elif self.direction == \"UP\":\n self.position[1] = self.position[1] - 10\n elif self.direction == \"DOWN\":\n self.position[1] = self.position[1] + 10\n self.body.insert(0, list(self.position))\n\n if self.position == foodPos:\n return 1\n else:\n self.body.pop()\n return 0\n\n def move_Right(self):\n self.position[0] = self.position[0] + 10\n\n def move_Left(self):\n self.position[0] = self.position[0] - 10\n\n def move_Up(self):\n self.position[0] = self.position[1] - 10\n\n def move_Down(self):\n self.position[0] = self.position[1] + 10\n\n def checkCollision(self):\n if self.position[0] > 490 or self.position[0] < 10:\n return 1\n elif self.position[1] > 500 or self.position[1] < 10:\n return 1\n for bodyPart in self.body[1:]:\n if self.position == bodyPart:\n return 1\n return 0\n\n def getHeadPosition(self):\n return self.position\n\n def getBody(self):\n return self.body\n\n\nclass FoodSpawn():\n def __init__(self):\n self.position = [random.randint(4, 46)*10, random.randint(4, 46)*10]\n self.isFoodOnScreen = True\n\n def spawnFood(self):\n if not self.isFoodOnScreen:\n self.position = [random.randrange(\n 4, 46)*10, random.randrange(4, 46)*10]\n self.isFoodOnScreen = True\n return self.position\n\n def setFoodOnScreen(self, b):\n self.isFoodOnScreen = b\n\n\nwindow = pygame.display.set_mode((500 + 20, 500 + 20))\npygame.display.set_caption(\"Snake Game\")\nfps = pygame.time.Clock()\n\nscore = 0\n\nsnake = Snake()\nfoodSpawner = FoodSpawn()\n\n\ndef gameOver():\n font = pygame.font.SysFont('Candara', 30)\n score_text = font.render(\n \"Congrats you got %s points!\" % score, 4, (255, 0, 0))\n window.blit(score_text, (100, 250))\n pygame.display.flip()\n time.sleep(3)\n pygame.quit()\n sys.exit()\n\n\nwhile True:\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n gameOver()\n\n pressed = pygame.key.get_pressed()\n\n if pressed[pygame.K_RIGHT]:\n snake.changeDirTo('RIGHT')\n elif pressed[pygame.K_LEFT]:\n snake.changeDirTo('LEFT')\n elif pressed[pygame.K_UP]:\n snake.changeDirTo('UP')\n elif pressed[pygame.K_DOWN]:\n snake.changeDirTo('DOWN')\n elif pressed[pygame.K_ESCAPE]:\n gameOver()\n\n foodPos = foodSpawner.spawnFood()\n if(snake.move(foodPos) == 1):\n score += 1\n foodSpawner.setFoodOnScreen(False)\n\n window.fill(pygame.Color(225, 225, 225))\n for x in range(0, 510, 10):\n pygame.draw.rect(window, (0, 0, 225), [x, 0, 10, 10])\n pygame.draw.rect(window, (0, 0, 225), [x, 510, 10, 10])\n\n for x in range(0, 510, 10):\n pygame.draw.rect(window, (0, 0, 225), [0, x, 10, 10])\n pygame.draw.rect(window, (0, 0, 225), [510, x, 10, 10])\n\n for pos in snake.getBody():\n pygame.draw.rect(window, pygame.Color(0, 225, 0),\n pygame.Rect(pos[0], pos[1], 10, 10))\n pygame.draw.rect(window, pygame.Color(225, 0, 0),\n pygame.Rect(foodPos[0], foodPos[1], 10, 10))\n\n if(snake.checkCollision() == 1):\n gameOver()\n\n pygame.display.set_caption(\"Snake | Score: %s\" % score)\n pygame.display.flip()\n fps.tick(20)\n\npygame.quit()\n"
}
] | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.